| Service | Microsoft Docs article | Related commit history on GitHub | Change details |
|---|---|---|---|
| active-directory-b2c | Analytics With Application Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/active-directory-b2c/analytics-with-application-insights.md | zone_pivot_groups: b2c-policy-type ::: zone pivot="b2c-custom-policy" -In Azure Active Directory B2C (Azure AD B2C), you can send event data directly to [Application Insights](../azure-monitor/app/app-insights-overview.md) by using the instrumentation key provided to Azure AD B2C. With an Application Insights technical profile, you can get detailed and customized event logs for your user journeys to: +In Azure Active Directory B2C (Azure AD B2C), you can send event data directly to [Application Insights](/azure/azure-monitor/app/app-insights-overview) by using the instrumentation key provided to Azure AD B2C. With an Application Insights technical profile, you can get detailed and customized event logs for your user journeys to: - Gain insights on user behavior. - Troubleshoot your own policies in development or in production. To disable Application Insights logs, change the `DisableTelemetry` metadata to ## Next steps -Learn how to [create custom KPI dashboards using Azure Application Insights](../azure-monitor/app/overview-dashboard.md#create-custom-kpi-dashboards-using-application-insights). +Learn how to [create custom KPI dashboards using Azure Application Insights](/azure/azure-monitor/app/overview-dashboard#create-custom-kpi-dashboards-using-application-insights). ::: zone-end |
| active-directory-b2c | Azure Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/active-directory-b2c/azure-monitor.md | Use Azure Monitor to route Azure Active Directory B2C (Azure AD B2C) sign in and You can route log events to: - An Azure [storage account](../storage/blobs/storage-blobs-introduction.md).-- A [Log Analytics workspace](../azure-monitor/essentials/resource-logs.md#send-to-log-analytics-workspace) (to analyze data, create dashboards, and alert on specific events).+- A [Log Analytics workspace](/azure/azure-monitor/essentials/resource-logs#send-to-log-analytics-workspace) (to analyze data, create dashboards, and alert on specific events). - An Azure [event hub](../event-hubs/event-hubs-about.md) (and integrate with your Splunk and Sumo Logic instances).  To enable _Diagnostic settings_ in Microsoft Entra ID within your Azure AD B2C t > [!TIP] > Azure Lighthouse is typically used to manage resources for multiple customers. However, it can also be used to manage resources **within an enterprise that has multiple Microsoft Entra tenants of its own**, which is what we are doing here, except that we are only delegating the management of single resource group. -After you complete the steps in this article, you'll have created a new resource group (here called _azure-ad-b2c-monitor_) and have access to that same resource group that contains the [Log Analytics workspace](../azure-monitor/logs/quick-create-workspace.md) in your **Azure AD B2C** portal. You'll also be able to transfer the logs from Azure AD B2C to your Log Analytics workspace. +After you complete the steps in this article, you'll have created a new resource group (here called _azure-ad-b2c-monitor_) and have access to that same resource group that contains the [Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace) in your **Azure AD B2C** portal. You'll also be able to transfer the logs from Azure AD B2C to your Log Analytics workspace. During this deployment, you'll authorize a user or group in your Azure AD B2C directory to configure the Log Analytics workspace instance within the tenant that contains your Azure subscription. To create the authorization, you deploy an [Azure Resource Manager](../azure-resource-manager/index.yml) template to the subscription that contains the Log Analytics workspace. A **Log Analytics workspace** is a unique environment for Azure Monitor log data 1. Sign in to the [Azure portal](https://portal.azure.com). 1. If you have access to multiple tenants, select the **Settings** icon in the top menu to switch to your Microsoft Entra ID tenant from the **Directories + subscriptions** menu.-1. [Create a Log Analytics workspace](../azure-monitor/logs/quick-create-workspace.md). This example uses a Log Analytics workspace named _AzureAdB2C_, in a resource group named _azure-ad-b2c-monitor_. +1. [Create a Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace). This example uses a Log Analytics workspace named _AzureAdB2C_, in a resource group named _azure-ad-b2c-monitor_. ## 3. Delegate resource management After you've deployed the template and waited a few minutes for the resource pro Diagnostic settings define where logs and metrics for a resource should be sent. Possible destinations are: -- [Azure storage account](../azure-monitor/essentials/resource-logs.md#send-to-azure-storage)-- [Event hubs](../azure-monitor/essentials/resource-logs.md#send-to-azure-event-hubs) solutions-- [Log Analytics workspace](../azure-monitor/essentials/resource-logs.md#send-to-log-analytics-workspace)+- [Azure storage account](/azure/azure-monitor/essentials/resource-logs#send-to-azure-storage) +- [Event hubs](/azure/azure-monitor/essentials/resource-logs#send-to-azure-event-hubs) solutions +- [Log Analytics workspace](/azure/azure-monitor/essentials/resource-logs#send-to-log-analytics-workspace) In this example, we use the Log Analytics workspace to create a dashboard. To configure monitoring settings for Azure AD B2C activity logs: 1. Select **Save**. > [!NOTE]-> It can take up to 15 minutes after an event is emitted for it to [appear in a Log Analytics workspace](../azure-monitor/logs/data-ingestion-time.md). Also, learn more about [Active Directory reporting latencies](../active-directory/reports-monitoring/reference-azure-ad-sla-performance.md), which can impact the staleness of data and play an important role in reporting. +> It can take up to 15 minutes after an event is emitted for it to [appear in a Log Analytics workspace](/azure/azure-monitor/logs/data-ingestion-time). Also, learn more about [Active Directory reporting latencies](../active-directory/reports-monitoring/reference-azure-ad-sla-performance.md), which can impact the staleness of data and play an important role in reporting. If you see the error message, _To set up Diagnostic settings to use Azure Monitor for your Azure AD B2C directory, you need to set up delegated resource management_, make sure you sign in with a user who is a member of the [security group](#32-select-a-security-group) and [select your subscription](#4-select-your-subscription). Now you can configure your Log Analytics workspace to visualize your data and co ### 6.1 Create a Query -Log queries help you to fully use the value of the data collected in Azure Monitor Logs. A powerful query language allows you to join data from multiple tables, aggregate large sets of data, and perform complex operations with minimal code. Virtually any question can be answered and analysis performed as long as the supporting data has been collected, and you understand how to construct the right query. For more information, see [Get started with log queries in Azure Monitor](../azure-monitor/logs/get-started-queries.md). +Log queries help you to fully use the value of the data collected in Azure Monitor Logs. A powerful query language allows you to join data from multiple tables, aggregate large sets of data, and perform complex operations with minimal code. Virtually any question can be answered and analysis performed as long as the supporting data has been collected, and you understand how to construct the right query. For more information, see [Get started with log queries in Azure Monitor](/azure/azure-monitor/logs/get-started-queries). 1. Sign in to the [Azure portal](https://portal.azure.com). 1. If you have access to multiple tenants, select the **Settings** icon in the top menu to switch to your Microsoft Entra ID tenant from the **Directories + subscriptions** menu. For more samples, see the Azure AD B2C [SIEM GitHub repo](https://aka.ms/b2csiem ### 6.2 Create a Workbook -Workbooks provide a flexible canvas for data analysis and the creation of rich visual reports within the Azure portal. They allow you to tap into multiple data sources from across Azure, and combine them into unified interactive experiences. For more information, see [Azure Monitor Workbooks](../azure-monitor/visualize/workbooks-overview.md). +Workbooks provide a flexible canvas for data analysis and the creation of rich visual reports within the Azure portal. They allow you to tap into multiple data sources from across Azure, and combine them into unified interactive experiences. For more information, see [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview). Follow the instructions below to create a new workbook using a JSON Gallery Template. This workbook provides a **User Insights** and **Authentication** dashboard for Azure AD B2C tenant. The workbook will display reports in the form of a dashboard. ## Create alerts -Alerts are created by alert rules in Azure Monitor and can automatically run saved queries or custom log searches at regular intervals. You can create alerts based on specific performance metrics or when certain events occur. You can also create alerts on absence of an event, or when a number of events occur within a particular time window. For example, alerts can be used to notify you when average number of sign-ins exceeds a certain threshold. For more information, see [Create alerts](../azure-monitor/alerts/alerts-create-new-alert-rule.md). +Alerts are created by alert rules in Azure Monitor and can automatically run saved queries or custom log searches at regular intervals. You can create alerts based on specific performance metrics or when certain events occur. You can also create alerts on absence of an event, or when a number of events occur within a particular time window. For example, alerts can be used to notify you when average number of sign-ins exceeds a certain threshold. For more information, see [Create alerts](/azure/azure-monitor/alerts/alerts-create-new-alert-rule). -Use the following instructions to create a new Azure Alert, which will send an [email notification](../azure-monitor/alerts/action-groups.md) whenever there's a 25% drop in the **Total Requests** compared to previous period. Alert will run every 5 minutes and look for the drop in the last hour compared to the hour before it. The alerts are created using Kusto query language. +Use the following instructions to create a new Azure Alert, which will send an [email notification](/azure/azure-monitor/alerts/action-groups) whenever there's a 25% drop in the **Total Requests** compared to previous period. Alert will run every 5 minutes and look for the drop in the last hour compared to the hour before it. The alerts are created using Kusto query language. 1. Sign in to the [Azure portal](https://portal.azure.com). 1. If you have access to multiple tenants, select the **Settings** icon in the top menu to switch to your Microsoft Entra ID tenant from the **Directories + subscriptions** menu. After the alert is created, go to **Log Analytics workspace** and select **Alert ### Configure action groups -Azure Monitor and Service Health alerts use action groups to notify users that an alert has been triggered. You can include sending a voice call, SMS, email; or triggering various types of automated actions. Follow the guidance [Create and manage action groups in the Azure portal](../azure-monitor/alerts/action-groups.md) +Azure Monitor and Service Health alerts use action groups to notify users that an alert has been triggered. You can include sending a voice call, SMS, email; or triggering various types of automated actions. Follow the guidance [Create and manage action groups in the Azure portal](/azure/azure-monitor/alerts/action-groups) Here's an example of an alert notification email. Here's an example of an alert notification email. To onboard multiple Azure AD B2C tenant logs to the same Log Analytics Workspace (or Azure storage account, or event hub), you'll need separate deployments with different **Msp Offer Name** values. Make sure your Log Analytics workspace is in the same resource group as the one you configured in [Create or choose resource group](#1-create-or-choose-resource-group). -When working with multiple Log Analytics workspaces, use [Cross Workspace Query](../azure-monitor/logs/cross-workspace-query.md) to create queries that work across multiple workspaces. For example, the following query performs a join of two Audit logs from different tenants based on the same Category (for example, Authentication): +When working with multiple Log Analytics workspaces, use [Cross Workspace Query](/azure/azure-monitor/logs/cross-workspace-query) to create queries that work across multiple workspaces. For example, the following query performs a join of two Audit logs from different tenants based on the same Category (for example, Authentication): ```kusto workspace("AD-B2C-TENANT1").AuditLogs workspace("AD-B2C-TENANT1").AuditLogs ## Change the data retention period -Azure Monitor Logs are designed to scale and support collecting, indexing, and storing massive amounts of data per day from any source in your enterprise or deployed in Azure. By default, logs are retained for 30 days, but retention duration can be increased to up to two years. Learn how to [manage usage and costs with Azure Monitor Logs](../azure-monitor/logs/cost-logs.md). After you select the pricing tier, you can [Change the data retention period](../azure-monitor/logs/data-retention-configure.md). +Azure Monitor Logs are designed to scale and support collecting, indexing, and storing massive amounts of data per day from any source in your enterprise or deployed in Azure. By default, logs are retained for 30 days, but retention duration can be increased to up to two years. Learn how to [manage usage and costs with Azure Monitor Logs](/azure/azure-monitor/logs/cost-logs). After you select the pricing tier, you can [Change the data retention period](/azure/azure-monitor/logs/data-retention-configure). ## Disable monitoring data collection To stop collecting logs to your Log Analytics workspace, delete the diagnostic s 1. Sign in to the [Azure portal](https://portal.azure.com). 1. If you have access to multiple tenants, select the **Settings** icon in the top menu to switch to your Microsoft Entra ID tenant from the **Directories + subscriptions** menu. 1. Choose the resource group that contains the Log Analytics workspace. This example uses a resource group named _azure-ad-b2c-monitor_ and a Log Analytics workspace named `AzureAdB2C`.-1. [Delete the Logs Analytics workspace](../azure-monitor/logs/delete-workspace.md). +1. [Delete the Logs Analytics workspace](/azure/azure-monitor/logs/delete-workspace). 1. Select the **Delete** button to delete the resource group. ## Next steps - Find more samples in the Azure AD B2C [SIEM gallery](https://aka.ms/b2csiem). -- For more information about adding and configuring diagnostic settings in Azure Monitor, see [Tutorial: Collect and analyze resource logs from an Azure resource](../azure-monitor/essentials/monitor-azure-resource.md).+- For more information about adding and configuring diagnostic settings in Azure Monitor, see [Tutorial: Collect and analyze resource logs from an Azure resource](/azure/azure-monitor/essentials/monitor-azure-resource). - For information about streaming Microsoft Entra logs to an event hub, see [Tutorial: Stream Microsoft Entra logs to an Azure event hub](../active-directory/reports-monitoring/tutorial-azure-monitor-stream-logs-to-event-hub.md). |
| active-directory-b2c | Partner Whoiam | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/active-directory-b2c/partner-whoiam.md | The following diagram shows the implementation architecture. * [App Service](https://azure.microsoft.com/services/app-service/): Host the BRIMS API and admin portal services * [Microsoft Entra ID](https://azure.microsoft.com/services/active-directory/): Authenticate administrative users for the portal * [Azure Cosmos DB](https://azure.microsoft.com/services/cosmos-db/): Store and retrieve settings- * [Application Insights overview](../azure-monitor/app/app-insights-overview.md) (optional): Sign in to the API and the portal + * [Application Insights overview](/azure/azure-monitor/app/app-insights-overview) (optional): Sign in to the API and the portal 3. Deploy the BRIMS API and the BRIMS administration portal in your Azure environment. 4. Follow the documentation to configure your app. Use BRIMS for user identity verification. Azure AD B2C custom policy samples are in the BRIMS sign-up documentation. |
| active-directory-b2c | Technicalprofiles | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/active-directory-b2c/technicalprofiles.md | A *technical profile* provides a framework with a built-in mechanism to communic A technical profile enables these types of scenarios: -- [Application Insights](analytics-with-application-insights.md): Sends event data to [Application Insights](../azure-monitor/app/app-insights-overview.md).+- [Application Insights](analytics-with-application-insights.md): Sends event data to [Application Insights](/azure/azure-monitor/app/app-insights-overview). - [Microsoft Entra ID](active-directory-technical-profile.md): Provides support for the Azure AD B2C user management. - [Microsoft Entra multifactor authentication](multi-factor-auth-technical-profile.md): Provides support for verifying a phone number by using Microsoft Entra multifactor authentication. - [Claims transformation](claims-transformation-technical-profile.md): Calls output claims transformations to manipulate claims values, validate claims, or set default values for a set of output claims. |
| active-directory-b2c | Troubleshoot With Application Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/active-directory-b2c/troubleshoot-with-application-insights.md | Here's a list of queries you can use to see the logs: The entries may be long. Export to CSV for a closer look. -For more information about querying, see [Overview of log queries in Azure Monitor](../azure-monitor/logs/log-query-overview.md). +For more information about querying, see [Overview of log queries in Azure Monitor](/azure/azure-monitor/logs/log-query-overview). ## See the logs in VS Code extension |
| active-directory-b2c | Whats New Docs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/active-directory-b2c/whats-new-docs.md | Title: "What's new in Azure Active Directory business-to-customer (B2C)" description: "New and updated documentation for the Azure Active Directory business-to-customer (B2C)." Previously updated : 07/31/2024 Last updated : 09/11/2024 +## August 2024 ++This month, we changed Twitter to X in numerous articles and code samples. ++### Updated articles ++- [Tutorial: Configure Keyless with Azure Active Directory B2C](partner-keyless.md) - Editorial updates + ## July 2024 ### Updated articles Welcome to what's new in Azure Active Directory B2C documentation. This article ### Updated articles - [Define an OAuth2 custom error technical profile in an Azure Active Directory B2C custom policy](oauth2-error-technical-profile.md) - Error code updates-- [Configure authentication in a sample Python web app by using Azure AD B2C](configure-authentication-sample-python-web-app.md) - Python version update---## May 2024 --### New articles --- [Configure Transmit Security with Azure Active Directory B2C for risk detection and prevention](partner-transmit-security.md)--### Updated articles --- [Set up sign-up and sign-in with a LinkedIn account using Azure Active Directory B2C](identity-provider-linkedin.md) - Updated LinkedIn instructions-- [Page layout versions](page-layout.md) - Updated page layout versions-+- [Configure authentication in a sample Python web app by using Azure AD B2C](configure-authentication-sample-python-web-app.md) - Python version updates |
| advisor | Advisor Alerts Arm | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-alerts-arm.md | - Title: Create Advisor alerts for new recommendations by using Resource Manager template -description: Learn how to set up an alert for new recommendations from Azure Advisor by using an Azure Resource Manager template (ARM template). -- Previously updated : 06/29/2020---# Quickstart: Create Advisor alerts on new recommendations by using an ARM template --This article shows you how to set up an alert for new recommendations from Azure Advisor by using an Azure Resource Manager template (ARM template). ---Whenever Advisor detects a new recommendation for one of your resources, an event is stored in an [Azure activity log](../azure-monitor/essentials/platform-logs-overview.md). You can set up alerts for these events from Advisor by using a recommendation-specific alerts creation experience. You can select a subscription and optionally a resource group to specify the resources that you want to receive alerts on. --You can also determine the types of recommendations by using these properties: --- Category-- Impact level-- Recommendation type--You can also configure the action that takes place when an alert is triggered by: --- Selecting an existing action group.-- Creating a new action group.--To learn more about action groups, see [Create and manage action groups](../azure-monitor/alerts/action-groups.md). --> [!NOTE] -> Advisor alerts are currently only available for High Availability, Performance, and Cost recommendations. Security recommendations aren't supported. --## Prerequisites --- If you don't have an Azure subscription, create a [free account](https://azure.microsoft.com/free/?WT.mc_id=A261C142F) before you begin.-- To run the commands from your local computer, install the Azure CLI or the Azure PowerShell modules. For more information, see [Install the Azure CLI](/cli/azure/install-azure-cli) and [Install Azure PowerShell](/powershell/azure/install-azure-powershell).--## Review the template --The following template creates an action group with an email target and enables all service health notifications for the target subscription. Save this template as *CreateAdvisorAlert.json*. --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "actionGroups_name": { - "defaultValue": "advisorAlert", - "type": "string" - }, - "activityLogAlerts_name": { - "defaultValue": "AdvisorAlertsTest", - "type": "string" - }, - "emailAddress": { - "defaultValue": "<email address>", - "type": "string" - } - }, - "variables": { - "alertScope": "[concat('/','subscriptions','/',subscription().subscriptionId)]" - }, - "resources": [ - { - "comments": "Action Group", - "type": "microsoft.insights/actionGroups", - "apiVersion": "2019-06-01", - "name": "[parameters('actionGroups_name')]", - "location": "Global", - "scale": null, - "dependsOn": [], - "tags": {}, - "properties": { - "groupShortName": "[parameters('actionGroups_name')]", - "enabled": true, - "emailReceivers": [ - { - "name": "[parameters('actionGroups_name')]", - "emailAddress": "[parameters('emailAddress')]" - } - ], - "smsReceivers": [], - "webhookReceivers": [] - } - }, - { - "comments": "Azure Advisor Activity Log Alert", - "type": "microsoft.insights/activityLogAlerts", - "apiVersion": "2017-04-01", - "name": "[parameters('activityLogAlerts_name')]", - "location": "Global", - "scale": null, - "tags": {}, - "properties": { - "scopes": [ - "[variables('alertScope')]" - ], - "condition": { - "allOf": [ - { - "field": "category", - "equals": "Recommendation" - }, - { - "field": "properties.recommendationCategory", - "equals": "Cost" - }, - { - "field": "properties.recommendationImpact", - "equals": "Medium" - }, - { - "field": "operationName", - "equals": "Microsoft.Advisor/recommendations/available/action" - } - ] - }, - "actions": { - "actionGroups": [ - { - "actionGroupId": "[resourceId('microsoft.insights/actionGroups', parameters('actionGroups_name'))]", - "webhookProperties": {} - } - ] - }, - "enabled": true, - "description": "" - }, - "dependsOn": [ - "[resourceId('microsoft.insights/actionGroups', parameters('actionGroups_name'))]" - ] - } - ] -} -``` --The template defines two resources: --- [Microsoft.Insights/actionGroups](/azure/templates/microsoft.insights/actiongroups)-- [Microsoft.Insights/activityLogAlerts](/azure/templates/microsoft.insights/activityLogAlerts)--## Deploy the template --Deploy the template by using any standard method for [deploying an ARM template](../azure-resource-manager/templates/deploy-portal.md), such as the following examples that use the CLI and PowerShell. Replace the sample values for `ResourceGroup`, and `emailAddress` with appropriate values for your environment. The workspace name must be unique among all Azure subscriptions. --# [CLI](#tab/CLI) --```azurecli -az login -az deployment group create --name CreateAdvisorAlert --resource-group my-resource-group --template-file CreateAdvisorAlert.json --parameters emailAddress='user@contoso.com' -``` --# [PowerShell](#tab/PowerShell) --```powershell -Connect-AzAccount -Select-AzSubscription -SubscriptionName my-subscription -New-AzResourceGroupDeployment -Name CreateAdvisorAlert -ResourceGroupName my-resource-group -TemplateFile CreateAdvisorAlert.json -emailAddress user@contoso.com -``` ----## Validate the deployment --Verify that the workspace was created by using one of the following commands. Replace the sample values for **Resource Group** with the value that you used in the previous example. --# [CLI](#tab/CLI) --```azurecli -az monitor activity-log alert show --resource-group my-resource-group --name AdvisorAlertsTest -``` --# [PowerShell](#tab/PowerShell) --```powershell -Get-AzActivityLogAlert -ResourceGroupName my-resource-group -Name AdvisorAlertsTest -``` ----## Clean up resources --If you plan to continue working with subsequent quickstarts and tutorials, you might want to leave these resources in place. When you no longer need the resources, delete the resource group, which deletes the alert rule and the related resources. To delete the resource group by using the CLI or PowerShell: --# [CLI](#tab/CLI) --```azurecli -az group delete --name my-resource-group -``` --# [PowerShell](#tab/PowerShell) --```powershell -Remove-AzResourceGroup -Name my-resource-group -``` ----## Related content --- Get an [overview of activity log alerts](../azure-monitor/alerts/alerts-overview.md) and learn how to receive alerts.-- Learn more about [action groups](../azure-monitor/alerts/action-groups.md). |
| advisor | Advisor Alerts Bicep | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-alerts-bicep.md | - Title: Create Advisor alerts for new recommendations by using Bicep -description: Learn how to set up an alert for new recommendations from Azure Advisor by using Bicep. -- Previously updated : 04/26/2022---# Quickstart: Create Advisor alerts on new recommendations by using Bicep --This article shows you how to set up an alert for new recommendations from Azure Advisor by using Bicep. ---Whenever Advisor detects a new recommendation for one of your resources, an event is stored in an [Azure activity log](../azure-monitor/essentials/platform-logs-overview.md). You can set up alerts for these events from Advisor by using a recommendation-specific alerts creation experience. You can select a subscription and optionally select a resource group to specify the resources that you want to receive alerts on. --You can also determine the types of recommendations by using these properties: --- Category-- Impact level-- Recommendation type--You can also configure the action that takes place when an alert is triggered by: --- Selecting an existing action group.-- Creating a new action group.--To learn more about action groups, see [Create and manage action groups](../azure-monitor/alerts/action-groups.md). --> [!NOTE] -> Advisor alerts are currently only available for High Availability, Performance, and Cost recommendations. Security recommendations aren't supported. --## Prerequisites --- If you don't have an Azure subscription, create a [free account](https://azure.microsoft.com/free/?WT.mc_id=A261C142F) before you begin.-- To run the commands from your local computer, install the Azure CLI or the Azure PowerShell modules. For more information, see [Install the Azure CLI](/cli/azure/install-azure-cli) and [Install Azure PowerShell](/powershell/azure/install-azure-powershell).--## Review the Bicep file --The Bicep file used in this quickstart is from [Azure Quickstart Templates](https://azure.microsoft.com/resources/templates/insights-alertrules-servicehealth/). ---The Bicep file defines two resources: --- [Microsoft.Insights/actionGroups](/azure/templates/microsoft.insights/actiongroups)-- [Microsoft.Insights/activityLogAlerts](/azure/templates/microsoft.insights/activityLogAlerts)--## Deploy the Bicep file --1. Save the Bicep file as `main.bicep` to your local computer. -1. Deploy the Bicep file by using either the Azure CLI or Azure PowerShell. -- # [CLI](#tab/CLI) -- ```azurecli - az group create --name exampleRG --location eastus - az deployment group create --resource-group exampleRG --template-file main.bicep --parameters alertName=<alert-name> - ``` -- # [PowerShell](#tab/PowerShell) -- ```azurepowershell - New-AzResourceGroup -Name exampleRG -Location eastus - New-AzResourceGroupDeployment -ResourceGroupName exampleRG -TemplateFile ./main.bicep -alertName "<alert-name>" - ``` -- -- > [!NOTE] - > Replace \<alert-name\> with the name of the alert. -- When the deployment finishes, you should see a message that indicates the deployment succeeded. --## Validate the deployment --Use the Azure portal, the Azure CLI, or Azure PowerShell to list the deployed resources in the resource group. --# [CLI](#tab/CLI) --```azurecli-interactive -az resource list --resource-group exampleRG -``` --# [PowerShell](#tab/PowerShell) --```azurepowershell-interactive -Get-AzResource -ResourceGroupName exampleRG -``` ----## Clean up resources --When you no longer need the resources, use the Azure portal, the Azure CLI, or Azure PowerShell to delete the resource group. --# [CLI](#tab/CLI) --```azurecli-interactive -az group delete --name exampleRG -``` --# [PowerShell](#tab/PowerShell) --```azurepowershell-interactive -Remove-AzResourceGroup -Name exampleRG -``` ----## Related content --- Get an [overview of activity log alerts](../azure-monitor/alerts/alerts-overview.md) and learn how to receive alerts.-- Learn more about [action groups](../azure-monitor/alerts/action-groups.md). |
| advisor | Advisor Alerts Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-alerts-portal.md | - Title: Create Advisor alerts for new recommendations using Azure portal -description: Create Azure Advisor alerts for new recommendations by using the Azure portal. - Previously updated : 09/09/2019---# Create Azure Advisor alerts on new recommendations by using the Azure portal --This article shows you how to set up an alert for new recommendations from Azure Advisor by using the Azure portal. --Whenever Advisor detects a new recommendation for one of your resources, an event is stored in the [Azure activity log](../azure-monitor/essentials/platform-logs-overview.md). You can set up alerts for these events from Advisor by using a recommendation-specific alerts creation experience. You can select a subscription and optionally a resource group to specify the resources that you want to receive alerts on. --You can also determine the types of recommendations by using these properties: --* Category -* Impact level -* Recommendation type --You can also configure the action that takes place when an alert is triggered by: --* Selecting an existing action group. -* Creating a new action group. --To learn more about action groups, see [Create and manage action groups](../azure-monitor/alerts/action-groups.md). --> [!NOTE] -> Advisor alerts are currently only available for High Availability, Performance, and Cost recommendations. Security recommendations aren't supported. --## Create an alert rule --Follow these steps to create an alert rule. --1. In the [Azure portal](https://portal.azure.com), select **Advisor**. --  --1. In the **Monitoring** section on the left menu, select **Alerts**. --  --1. Select **New Advisor Alert**. --  --1. In the **Scope** section, select the subscription and optionally the resource group that you want to be alerted on. --  --1. In the condition section, select the method you want to use for configuring your alert. If you want to alert for all recommendations for a certain category or impact level, select **Category and impact level**. If you want to alert for all recommendations of a certain type, select **Recommendation type**. --  --1. Depending on the **Configured by** option that you select, you can specify the criteria. If you want all recommendations, leave the remaining fields blank. --  --1. In the action groups section, choose **Select existing** to use an action group that you already created or select **Create new** to set up a new [action group](../azure-monitor/alerts/action-groups.md). --  --1. In the alert details section, give your alert a name and short description. If you want your alert to be enabled, leave the **Enable rule upon creation** selection set to **Yes**. Then select the resource group to save your alert to. This setting won't affect the targeting scope of the recommendation. -- :::image type="content" source="./media/advisor-alerts/create8.png" alt-text="Screenshot that shows the alert details section."::: --## Configure recommendation alerts to use a webhook --This section shows you how to configure Advisor alerts to send recommendation data through webhooks to your existing systems. --You can set up alerts to be notified when you have a new Advisor recommendation on one of your resources. These alerts can notify you through email or text message. They can also be used to integrate with your existing systems through a webhook. --### Use the Advisor recommendation alert payload --If you want to integrate Advisor alerts into your own systems by using a webhook, you need to parse the JSON payload that's sent from the notification. --When you set up your action group for this alert, you select if you want to use the common alert schema. If you select the common alert schema, your payload looks like this example: --```json -{ - "schemaId":"azureMonitorCommonAlertSchema", - "data":{ - "essentials":{ - "alertId":"/subscriptions/<subid>/providers/Microsoft.AlertsManagement/alerts/<alerted>", - "alertRule":"Webhhook-test", - "severity":"Sev4", - "signalType":"Activity Log", - "monitorCondition":"Fired", - "monitoringService":"Activity Log - Recommendation", - "alertTargetIDs":[ - "/subscriptions/<subid>/resourcegroups/<resource group name>/providers/microsoft.dbformariadb/servers/<resource name>" - ], - "originAlertId":"001d8b40-5d41-4310-afd7-d65c9d4428ed", - "firedDateTime":"2019-07-17T23:00:57.3858656Z", - "description":"A new recommendation is available.", - "essentialsVersion":"1.0", - "alertContextVersion":"1.0" - }, - "alertContext":{ - "channels":"Operation", - "claims":"{\"http://schemas.xmlsoap.org/ws/2005/05/identity/claims/emailaddress\":\"Microsoft.Advisor\"}", - "caller":"Microsoft.Advisor", - "correlationId":"8554b847-2a72-48ef-9776-600aca3c3aab", - "eventSource":"Recommendation", - "eventTimestamp":"2019-07-17T22:28:54.1566942+00:00", - "httpRequest":"{\"clientIpAddress\":\"0.0.0.0\"}", - "eventDataId":"001d8b40-5d41-4310-afd7-d65c9d4428ed", - "level":"Informational", - "operationName":"Microsoft.Advisor/recommendations/available/action", - "properties":{ - "recommendationSchemaVersion":"1.0", - "recommendationCategory":"Performance", - "recommendationImpact":"Medium", - "recommendationName":"Increase the MariaDB server vCores", - "recommendationResourceLink":"https://portal.azure.com/#blade/Microsoft_Azure_Expert/RecommendationListBlade/source/ActivityLog/recommendationTypeId/a5f888e3-8cf4-4491-b2ba-b120e14eb7ce/resourceId/%2Fsubscriptions%<subscription id>%2FresourceGroups%2<resource group name>%2Fproviders%2FMicrosoft.DBforMariaDB%2Fservers%2F<resource name>", - "recommendationType":"a5f888e3-8cf4-4491-b2ba-b120e14eb7ce" - }, - "status":"Active", - "subStatus":"", - "submissionTimestamp":"2019-07-17T22:28:54.1566942+00:00" - } - } -} - ``` --If you don't use the common schema, your payload looks like the following example: --```json -{ - "schemaId":"Microsoft.Insights/activityLogs", - "data":{ - "status":"Activated", - "context":{ - "activityLog":{ - "channels":"Operation", - "claims":"{\"http://schemas.xmlsoap.org/ws/2005/05/identity/claims/emailaddress\":\"Microsoft.Advisor\"}", - "caller":"Microsoft.Advisor", - "correlationId":"3ea7320f-c002-4062-adb8-96d3bd92a5f4", - "description":"A new recommendation is available.", - "eventSource":"Recommendation", - "eventTimestamp":"2019-07-17T20:36:39.3966926+00:00", - "httpRequest":"{\"clientIpAddress\":\"0.0.0.0\"}", - "eventDataId":"a12b8e59-0b1d-4003-bfdc-3d8152922e59", - "level":"Informational", - "operationName":"Microsoft.Advisor/recommendations/available/action", - "properties":{ - "recommendationSchemaVersion":"1.0", - "recommendationCategory":"Performance", - "recommendationImpact":"Medium", - "recommendationName":"Increase the MariaDB server vCores", - "recommendationResourceLink":"https://portal.azure.com/#blade/Microsoft_Azure_Expert/RecommendationListBlade/source/ActivityLog/recommendationTypeId/a5f888e3-8cf4-4491-b2ba-b120e14eb7ce/resourceId/%2Fsubscriptions%2F<subscription id>%2FresourceGroups%2F<resource group name>%2Fproviders%2FMicrosoft.DBforMariaDB%2Fservers%2F<resource name>", - "recommendationType":"a5f888e3-8cf4-4491-b2ba-b120e14eb7ce" - }, - "resourceId":"/subscriptions/<subscription id>/resourcegroups/<resource group name>/providers/microsoft.dbformariadb/servers/<resource name>", - "resourceGroupName":"<resource group name>", - "resourceProviderName":"MICROSOFT.DBFORMARIADB", - "status":"Active", - "subStatus":"", - "subscriptionId":"<subscription id>", - "submissionTimestamp":"2019-07-17T20:36:39.3966926+00:00", - "resourceType":"MICROSOFT.DBFORMARIADB/SERVERS" - } - }, - "properties":{ - - } - } -} -``` --In either schema, you can identify Advisor recommendation events by looking for `eventSource` is `Recommendation` and `operationName` is `Microsoft.Advisor/recommendations/available/action`. --Some of the other important fields that you might want to use are: --* `alertTargetIDs` (in the common schema) or `resourceId` (legacy schema) -* `recommendationType` -* `recommendationName` -* `recommendationCategory` -* `recommendationImpact` -* `recommendationResourceLink` --## Manage your alerts --From Advisor, you can edit, delete, or disable and enable your recommendations alerts. --1. In the [Azure portal](https://portal.azure.com), select **Advisor**. -- :::image type="content" source="./media/advisor-alerts/create1.png" alt-text="Screenshot that shows the Azure portal menu with Advisor selected."::: --1. In the **Monitoring** section on the left menu, select **Alerts**. -- :::image type="content" source="./media/advisor-alerts/create2.png" alt-text="Screenshot that shows the Azure portal menu with Alerts selected."::: --1. To edit an alert, select the alert name to open the alert and edit the fields you want to edit. --1. To delete, enable, or disable an alert, select the ellipsis at the end of the row. Then select the action you want to take. --## Related content --- Get an [overview of activity log alerts](../azure-monitor/alerts/alerts-overview.md) and learn how to receive alerts.-- Learn more about [action groups](../azure-monitor/alerts/action-groups.md). |
| advisor | Advisor Assessments | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-assessments.md | - Title: Use Well Architected Framework assessments in Azure Advisor -description: Azure Advisor offers Well Architected Framework assessments (curated and focused Advisor optimization reports) through the Assessments entry in the left menu of the Azure Advisor Portal. -- Previously updated : 08/22/2024--#customer intent: As an Advisor user, I want WAF assessments so that I can better understand recommendations. ----# Use Azure WAF assessments --Microsoft now offers Well Architected Framework (WAF) Assessment recommendations related to Azure resources based on the five pillars of WAF to Azure Advisor customers. You can take assessments on, and receive recommendations directly within, the Advisor platform. --> [!NOTE] -> Only the Assessments initiated via Advisor and the corresponding recommendations are visible on Advisor for the selected subscription and/or workload. --## What are Azure WAF assessments? --The Azure Well-Architected Framework, WAF, is a design scheme that helps you understand the pros and cons of cloud system options and can improve the quality of a workload. To learn more, see [Azure Well- Architected Framework](/azure/well-architected/). --Microsoft WAF Assessments help you work through a scenario of questions and recommendations that result in a curated guidance report that is actionable and informative. Assessments take time but it's time well-spent. Azure Advisor WAF Assessments help you identify gaps in your workloads across five pillars: Reliability, Cost, Operational Excellence, Performance, and Security via a set of curated questions on your workload. Assessments need you to work through a scenario of questions on your workloads and then provide recommendations that are actionable and informative. For the preview launch, we enabled the following two assessments via Advisor: --* [Mission Critical | Well-Architected Review](/assessments/23513bdb-e8a2-4f0b-8b6b-191ee1f52d34/) --* [Azure Well-Architected Review](/assessments/azure-architecture-review/) --To see all Microsoft assessment choices, go to the [Learn platform > Assessments](/assessments/). --## Prerequisites ---## Access Azure Advisor WAF assessments --1. Sign in to the [Azure portal](https://portal.azure.com/) and select [**Advisor**](https://aka.ms/azureadvisordashboard) from any page. The **Advisor** score dashboard page opens. --1. Select **Assessments** in the left navigation menu. The **Assessments** page opens with a list of completed or in progress assessments. ---## Create Azure Advisor WAF assessments --1. Select **New assessment**. An input area opens. -1. Provide the input parameters: - * **Subscription**: Choose from the list of available subscriptions in the dropdown Advisor. Once chosen, the system looks for workloads configured for that subscription. Not all subscriptions are available for the WAF Assessments preview. - * **Workload** (optional): If you have workloads configured for that subscription, you can view them in the list and select one. - * **Assessment type**: In the preview launch, we enabled two types of assessments: - * [Azure Well-Architected Review](/assessments/azure-architecture-review/) - * [Mission Critical | Well-Architected Review](/assessments/23513bdb-e8a2-4f0b-8b6b-191ee1f52d34/) - * **Assessment name**: A unique name for the assessment. Typing in the name activates the **Review and Create** option at the top of the page and the **Next** button at the bottom of the page. To find an existing assessment, go to the main **Assessments** page. - Select **Next**. A page opens that shows all of the existing assessments with the same subscription and workload (if any), and status of each similar assessment, both *Completed* and *In progress*. -1. You can choose to: - * View the recommendations generated for a completed recommendation. - * Resume an assessment you initiated earlier by selecting **Create**. If you do so, you're redirected to **Learn** platform, select **Continue** to resume creating the assessment. You can't resume an *In-progress* assessment created by someone else. - * Review the recommendations of a completed assessment created by someone from your organization. - * Create the new assessment. -If you arrow back a page, or use the **Review and create** tab, the new assessment options form is reset to a page with tiles showing similar, existing, assessments.\ -From there, you can proceed by selecting **Create** (at page bottom), or **Click here to start a new assessment** (at page top), or select **Previous** to return to the **Start new assessment** (you lose your workload type and assessment name choices).\ -If you select **Create** or **Click here to start a new assessment**, the **Learn > Assessments** question pages open to the **Assessment overview** page. The **Progress** bar shows how many questions are part of this assessment. The **Milestones** table includes the assessment by default, as the initial milestone. Adding milestones can help you keep track of progress as you implement the assessment recommendations. To learn more about milestones, see [Microsoft Assessments - Milestones](https://techcommunity.microsoft.com/t5/core-infrastructure-and-security/microsoft-assessments-milestones/ba-p/3975841). -1. To begin the assessment creation process, select **Continue**. The assessment begins. The steps change depending on the chosen assessment type. -1. If you chose **Mission Critical** when creating the assessment, skip to step 7.\ -If you chose **Azure Well-Architected Review** as the assessment type: The page shown in the following image opens. On that page, select a workload type. Each workload type results in a list of approximately 60 questions based on the key recommendations provided in the pillars of the Well-Architected Framework. To know more about workload types, see [Well-Architected Branches for Assessing Workload-Types - Microsoft Community Hub](https://techcommunity.microsoft.com/t5/azure-architecture-blog/well-architected-branches-for-assessing-workload-types/ba-p/3267234). - * **Core Well-Architected Review**: To learn more, see [Azure Well-Architected Review](/assessments/azure-architecture-review/). - * **Azure Machine Learning**: To learn more, see [Assessing your machine learning workloads](/shows/azure-enablement/assessing-your-machine-learning-workloads). - * **Internet of Things**: Use the following content to help implement the recommendations: - * [Reliability](/azure/well-architected/iot/iot-reliability): Complete the reliability questions for IoT workloads in the Azure Well-Architected Review. - * [Security](/azure/well-architected/iot/iot-security): Complete the security questions for IoT workloads in the Azure Well-Architected Review. - * **SAP On Azure (Preview)**: For detailed information on the different types of storage and their capability and usability with SAP workloads and SAP components, see [Azure Storage types for SAP workload](/azure/sap/workloads/planning-guide-storage). - * **Azure Stack Hub (Preview)**: Evaluates the performance efficiency of your workloads running on Azure Stack Hub. To learn more, see [Manage workloads that run on Azure Stack Hub](/azure/cloud-adoption-framework/scenarios/azure-stack/manage).\ -When ready, select **Next**. The WAF Configuration options page opens. -1. For **Azure Well-Architected** assessment types only:\ - Select a Core Pillar of WAF to be used in the assessment. To learn more about well architected pillars, see [Introducing the Microsoft Azure Well-Architected Framework](https://azure.microsoft.com/blog/introducing-the-microsoft-azure-wellarchitected-framework/). When ready, select **Next**. -1. The assessment begins, the number of questions vary based on the selected assessment type. The following screenshot is an example only.\ - Your answers to the questions are essential to the quality of the assessment recommendations. Respond to the different question and continue clicking on **Next** until you reach a page with **View guidance**. -1. Select **View guidance** to navigate to the results page, example shown in the following screenshot.\ - The assessment recommendations are available in Azure Advisor after a maximum of 8 hours of after completion. You can also download the recommendations immediately. --**Key Points**: --* Assessments are tailored to your selected workload type, such as IoT, SAP, data services, machine learning, etc., which you choose during the assessment. The Azure Well-Architected Framework provides a suite of actionable guidance that you can use to improve your workloads in the areas that matter most to your business. The framework is designed to help you evaluate your workloads against the latest set of Azure best practices. --* Assessments for a subscription and workload can be taken repeatedly; however, while creating a new assessment, you're notified if there's an existing assessment already created for the same subscription and workload. --* Assessments marked as *Completed* can't be edited. --## View Azure Advisor WAF assessment recommendations --There are multiple avenues to access the recommendations, but you must have the correct permissions. --To learn more about permissions, see [Permissions in Azure Advisor](/azure/advisor/permissions). To find out what subscriptions you have permissions for, and what level of permissions, see [List Azure role assignments using the Azure portal](/azure/role-based-access-control/role-assignments-list-portal#list-owners-of-a-subscription). If you have Contributor permissions, you can view the recommendations for assessments created by other users and the assessments that you created. --1. Open the **Assessments** main page and then any completed assessment. The recommendations list page for that assessment opens. -1. You can sort the recommendations based on **Priority**, **Recommendation**, and **Category**. You can also use **Actions** > **Group** to group the recommendations by category or priority. --> [!NOTE] -> Assessment recommendations have no immediate impact on your existing Advisor score. --## Manage Azure Advisor WAF assessment recommendations --You can manage WAF assessment recommendations, setting recommendation status for what needs action and what can be postponed or dismissed. You can also track recommendations via the different recommendation statuses. --Managing Advisor WAF assessment recommendations is slightly different than managing regular Advisor recommendations. ---* On the **Not started** tab, with new recommendations, you can set initial status changes. For example, mark a recommendation as *In progress*: If you accept a recommendation and start working on it, select **Mark as in progress**, which moves it to the **In progress** tab. ---* On the **In progress** tab, you can take action on a recommendation by selecting **Mark as completed** or **Dismiss**. If you select **Dismiss**, you must provide a reason as shown in the following screenshot. ---* You can accept or dismiss or set status on multiple recommendations at a time using the checkbox control. The action you take moves the selected recommendations to the tab for that action. For example, if you mark recommendations as *In progress*, they're moved to the **In progress** tab. ---* You can reset a recommendations status. If you reset the status, it returns to the **Not started** status. ---* You can postpone a recommendation. If you do so, pick a time length for the postponement. Postponed recommendations move to the **Postponed or dismissed** tab. ---## Act on and complete Azure Advisor WAF assessments --Operations experts review and act on recommendations marked as *In progress*. --Once the recommendation is, or multiple recommendations are, selected with **Mark as completed** selected, in the **In progress** tab, those recommendations are moved to the **Completed** tab. ---## Azure Advisor WAF assessments FAQs --Some common questions and answers. --**Q**. Can I edit previously taken assessments?\ -**A**. In the current program, assessments can't be edited once completed. --**Q**. Why am I not getting any recommendations?\ -**A**. If you didn't answer all of the assessment questions and skipped to **View guidance**, you might not get any recommendations generated. The other reason might be that the Learn platform hasn't generated any recommendations for the assessment. --**Q**. Can I view recommendations for the assessments not taken by me?\ -**A**. Subscription role-based access control (RBAC) limits access to recommendations and assessments in Advisor. You can see recommendations for all completed assessments only if you have Reader/Contributor access to the subscription under which assessment is created. --**Q**. Can I take multiple assessments for a subscription?\ -**A**. There's no limit on the number of assessments that can be taken for a subscription. However, while creating a new assessment, you're notified if an existing assessment of the same type is already created for the same subscription/workload. --**Q**. How do assessment-based recommendations affect my Advisor score?\ -**A**. We're working on a score strategy that includes the resolution of assessment-based recommendations as well. --**Q**. I completed my assessment, but I don't see the recommendations and the assessment shows "In progress," why?\ -**A**. Currently, it could take up to a maximum of eight hours, for the recommendations to sync into Advisor after we complete the assessment in the Learn platform. We're working on fixing it. --**Q**. An error occurred while trying to retrieve the list.\ -**A**. This error occurs when you don't have Contributor or Reader access to any subscription. Work with your administrator to get access. --**Q**. Assessment type drop down is disabled for a subscription.\ -**A**. This error occurs when you don't have Contributor access on the subscription selected. Work with your administrator to get access or select a different subscription. --**Q**. Unable to log in to learn ΓÇô "Your account is not registered to Microsoft Learn which is required before you can start assessment."\ -**A**. In the current release, we only support accounts whose home tenant is same as the tenant in which the subscription lies. As a workaround, ask your administrator to create a new account in the tenant of the subscription and use that account to register on Learn platform. To know more about tenant profiles and home tenant, check [Accounts & tenant profiles (Android)](/entra/identity-platform/accounts-overview). --**Q**. Unable to log in to learn ΓÇô "Looks like you are using an External/Guest Account which is not supported."\ -**A**. In the current release, we only support accounts whose home tenant is same as the tenant in which the subscription lies. As a workaround, ask your administrator to create a new account in the tenant of the subscription and use that account to register on Learn platform. To know more about tenant profiles and home tenant, check [Accounts & tenant profiles (Android)](/entra/identity-platform/accounts-overview). --## Related content --* [Complete an Azure Well-Architected Review assessment](/azure/well-architected/cross-cutting-guides/implementing-recommendations) -* [Tailored Well-Architected Assessments for your workloads](https://techcommunity.microsoft.com/t5/azure-governance-and-management/tailored-well-architected-assessments-for-your-workloads/ba-p/2914022) -* [Azure Machine Learning](/assessments/eec33ce4-4ef0-4bd2-9f69-1956e50465d4/) |
| advisor | Advisor Azure Resource Graph | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-azure-resource-graph.md | - Title: Advisor data in Azure Resource Graph -description: Make queries for Advisor data in Azure Resource Graph - Previously updated : 03/12/2020---# Query for Advisor data in Resource Graph Explorer (Azure Resource Graph) --Advisor resources are now onboarded to [Azure Resource Graph](https://azure.microsoft.com/features/resource-graph/). This lays foundation to many at-scale customer scenarios for Advisor recommendations. Few scenarios that were not possible before to do at scale and now can be achieved using Resource Graph are: -* Gives capability to perform complex query for all your subscriptions in Azure portal -* Recommendations summarized by category types (like reliability, performance) and impact types (high, medium, low) -* All recommendations for a particular recommendation type -* Impacted resource count by recommendation category -- ---## Advisor resource types in Azure Graph --Available Advisor resource types in [Resource Graph](../governance/resource-graph/index.yml): -There are 3 resource types available for querying under Advisor resources. Here is the list of the resources that are now available for querying in Resource Graph. -* Microsoft.Advisor/configurations -* Microsoft.Advisor/recommendations -* Microsoft.Advisor/suppressions --These resource types are listed under a new table named as AdvisorResources, which you can also query in the Resource Graph Explorer in Azure portal. ---## Next steps --For more information about Advisor recommendations, see: -* [Introduction to Azure Advisor](advisor-overview.md) -* [Get started with Advisor](advisor-get-started.md) -* [Advisor cost recommendations](advisor-cost-recommendations.md) -* [Advisor reliability recommendations](advisor-high-availability-recommendations.md) -* [Advisor performance recommendations](advisor-performance-recommendations.md) -* [Advisor security recommendations](advisor-security-recommendations.md) -* [Advisor operational excellence recommendations](advisor-operational-excellence-recommendations.md) -* [Advisor REST API](/rest/api/advisor/) |
| advisor | Advisor Cost Optimization Workbook | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-cost-optimization-workbook.md | - Title: Understand and optimize your Azure costs with the new Azure Cost Optimization workbook. -description: Understand and optimize your Azure costs with the new Azure Cost Optimization workbook. - Previously updated : 12/28/2023------# Understand and optimize your Azure costs using the Cost Optimization workbook -The Azure Cost Optimization workbook is designed to provide an overview and help you optimize costs of your Azure environment. It offers a set of cost-relevant insights and recommendations aligned with the Well-Architected Framework Cost Optimization pillar. --## Overview -The Azure Cost Optimization workbook serves as a centralized hub for some of the most commonly used tools that can help you drive utilization and efficiency goals. It offers a range of recommendations, including Azure Advisor cost recommendations, identification of idle resources, and management of improperly deallocated Virtual Machines. Additionally, it provides recommendations for applying Azure Reservations and Savings Plan for Compute and insights into using Azure Hybrid Benefit options. The workbook template is available in Azure Advisor gallery. --Here’s how to get started: --1. Navigate to [Workbooks gallery](https://aka.ms/advisorworkbooks) in Azure Advisor. -1. Open **Cost Optimization (Preview)** workbook template. --The workbook is organized into different tabs and subtabs, each focusing on a specific area to help you reduce the cost of your Azure environment. --* Overview -* Rate Optimization -- * Azure Hybrid Benefit - * Azure Reservations - * Azure Savings Plan for Compute --* Usage Optimization -- * Compute - * Storage - * Networking - * Other popular Azure services --Each tab supports the following capabilities: -* **Filters** - use subscription, resource group, and tag filters to focus on a specific workload. -* **Export** - export the recommendations to share the insights and collaborate with your team more effectively. -* **Quick Fix** - apply the recommended optimization directly from the workbook page, streamlining the optimization process. ---> [!NOTE] -> The workbook serves as guidance and doesn't guarantee cost reduction. ---### Welcome -The home page of the workbook highlights the goal and prerequisites. It also provides a way to submit feedback and raise issues. --### Resource overview -This image shows the resources distribution per region. Here, you should review where most of the resources are located and understand if there's data being transferred to other regions and if this behavior is expected, since data transfer costs might apply. It's important to notice that the cost of an Azure service can vary between locations based on on-demand and local infrastructure costs and replication costs. --### Security Recommendations --The Security Recommendations query focuses on reviewing the Azure Advisor security recommendations. -Potentially, you could enhance the security of your workloads by reinvesting some of the cost savings identified from the workbook assessment. --### Reliability recommendations --The Reliability Recommendations query focuses on reviewing the Azure Advisor reliability recommendations. -Potentially, you could enhance the reliability of your workloads by reinvesting some of the cost savings identified from the workbook assessment. --## Rate Optimization --The Rate Optimization tab focuses on reviewing potential savings related to the rate optimization of your Azure services. ---### Azure Hybrid Benefit --Azure Hybrid Benefit represents an excellent opportunity to save on Virtual Machines (VMs) operating system costs. Using the workbook, you can identify the opportunities to use the Azure Hybrid Benefit for VM/VMSS (Windows and Linux), SQL (SQL Server VMs, SQL DB and SQL MI), and Azure Stack HCI (VMs and AKS). --> [!NOTE] -> If you select a Dev/Test subscription in the scope of the workbook, then you should already have discounts on Windows and SQL licenses. So, any recommendations shown on the page don’t apply to the subscription. --#### Windows VM/VMSS --Azure Hybrid Benefit represents an excellent opportunity to save on Virtual Machines OS costs. -If you have Software Assurance, you can enable the [Azure Hybrid Benefit](/azure/virtual-machines/windows/hybrid-use-benefit-licensing). You can see potential savings using [Azure Hybrid Benefit Calculator](https://azure.microsoft.com/pricing/hybrid-benefit/#calculator). --> [!NOTE] -> The query has a Quick Fix column that helps you to apply Azure Hybrid Benefit to Windows VMs. --#### Linux VM/VMSS --[Azure Hybrid Benefit for Linux](/azure/virtual-machines/linux/azure-hybrid-benefit-linux) is a licensing benefit that helps you to significantly reduce the costs of running your Red Hat Enterprise Linux (RHEL) and SUSE Linux Enterprise Server (SLES) virtual machines (VMs) in the cloud. --#### SQL --Azure Hybrid Benefit represents an excellent opportunity to save costs on SQL instances. -If you have Software Assurance, you can enable [SQL Hybrid Benefit](/azure/azure-sql/azure-hybrid-benefit). -You can see potential savings using [Azure Hybrid Benefit Calculator](https://azure.microsoft.com/pricing/hybrid-benefit/#calculator). --#### Azure Stack HCI --Azure Hybrid Benefit represents an excellent opportunity to save costs on Azure Stack HCI. If you have Software Assurance, you can enable [Azure Stack HCI Hybrid Benefit](/azure-stack/hci/concepts/azure-hybrid-benefit-hci). --### Azure Reservations --Review Azure Reservations cost saving opportunities. Use filters for subscriptions, a look back period (7, 30 or 60 days), a term (1 year or 3 years), and a resource type. Learn more about [What are Azure Reservations?](../cost-management-billing/reservations/save-compute-costs-reservations.md) and how much you can [save with Reservations](https://azure.microsoft.com/pricing/reservations). --### Azure savings plan for compute --Review Azure savings plan for compute cost saving opportunities. Use filters for subscriptions, a look back period (7, 30 or 60 days), and a term (1 year or 3 years). Learn more about [What is Azure savings plans for compute?](https://azure.microsoft.com/pricing/offers/savings-plan-compute) and how much you can [save with Savings Plan for Compute](https://azure.microsoft.com/pricing/offers/savings-plan-compute). --## Usage Optimization --The Usage Optimization tab focuses on reviewing potential savings related to usage optimization of your Azure services. ---### Compute --The following queries show compute resources that you can optimize to save money. --#### Virtual Machines in a Stopped State --This query identifies Virtual Machines that aren't properly deallocated. If a virtual machine’s status is Stopped rather than Stopped (Deallocated), you're still billed for the resource as the hardware remains allocated for you. Learn more about [States and billing status of Azure Virtual Machines](/azure/virtual-machines/states-billing). --#### Deallocated virtual machines --A virtual machine in a deallocated state is not only powered off, but the underlying host infrastructure is also released, resulting in no charges for the allocated resources while the VM is in this state. However, some Azure resources such as disks and networking continue to incur charges. --#### Virtual Machine Scale Sets --This query focuses on cost optimization opportunities specific to Virtual Machine Scale Sets. It provides recommendations such as: --* Consider using Azure Spot VMs for workloads that can handle interruptions, early terminations, or evictions. For example, workloads such as batch processing jobs, development and testing environments, and large compute workloads may be good candidates for scheduling on a spot node pool. -* Spot priority mix: Azure provides the flexibility of running a mix of uninterruptible standard VMs and interruptible Spot VMs for Virtual Machine Scale Set deployments. You can use the Spot Priority Mix using Flexible orchestration to easily balance between high-capacity availability and lower infrastructure costs according to workload requirements. --#### Advisor Recommendations -Review the Advisor recommendations for Compute. Some of the recommendations available in this tile could be "Optimize virtual machine spend by resizing or shutting down underutilized instances", or "Buy reserved virtual machine instances to save money over pay-as-you-go costs." --### Storage --The following queries show storage resources that you can optimize to save money. --#### Storage accounts which are not v2 --The Storage accounts which are not v2 query focuses on identifying the storage accounts which are configured as v1. There are several reasons to justify upgrading to v2, such as: --* Ability to enable Storage Lifecycle Management; -* Storage Reserved Instances; -* Access tiers - you can transition data from a hotter access tier to a cooler access tier if there's no access for a period. --Upgrading a v1 storage account to a general-purpose v2 account is free. You can specify the desired account tier during the upgrade process. If an account tier isn't specified on the upgrade, the default account tier of the upgraded account will be Hot. However, changing the storage access tier after the upgrade may result in changes to your bill, so we recommend that you specify the new account tier during an upgrade. --#### Unattached Managed Disks --The Unattached Managed Disks query helps you to identify unattached managed disks. Unattached disks represent a cost in the subscription. The query automatically ignores disks used by Azure Site Recovery. Use the information to identify and remove any unattached disks that are no longer needed. --> [!NOTE] -> The query has a Quick Fix column that helps you to remove the disk if not needed. --#### Disk Snapshots with + 30 Days --The Disk Snapshots with + 30 Days query identifies snapshots that are older than 30 days. Identifying and managing outdated snapshots can help you optimize storage costs and ensure efficient use of your Azure environment. --#### Snapshots using premium storage --To save 60% of cost, we recommend storing your snapshots in Standard Storage, regardless of the storage type of the parent disk. It's the default option for Managed Disks snapshots. Migrate your snapshot from Premium to Standard Storage. --#### Snapshots with deleted source disk --The Snapshots with deleted source disk query identifies snapshots where the source disk has been deleted. --#### Idle Backup --Review protected items backup activity to determine if there are items not backed up in the last 90 days. This could either mean that the underlying resource that's being backed up doesn't exist anymore or there's some issue with the resource that's preventing backups from being taken reliably. --#### Backup storage redundancy settings --By default, when you configure backup for resources, geo-redundant storage (GRS) replication is applied to these backups. While this is the recommended storage replication option as it creates more redundancy for your critical data, you can choose to protect items using locally-redundant storage (LRS) if that meets your backup availability needs for dev-test workloads. Using LRS instead of GRS halves the cost of your backup storage. --#### Advisor Recommendations --Review the Advisor recommendations for Storage. Some of the recommendations available in this tile could be "Blob storage reserved capacity", or "Use lifecycle management". --### Networking --The following queries show networking resources that you can optimize to save money. --#### Azure Firewall Premium --The Azure Firewall Premium query identifies Azure Firewalls with Premium SKU and evaluates whether the associated policy incorporates premium-only features or not. If a Premium SKU Firewall lacks a policy with premium features, such as TLS or intrusion detection, it is shown on the page. For more information about Azure Firewall SKUs, see [SKU comparison table](../firewall/choose-firewall-sku.md). --#### Azure Firewall instances per region --Optimize the use of Azure Firewall by having a central instance of Azure Firewall in the hub virtual network or Virtual WAN secure hub. Share the same firewall across many spoke virtual networks that are connected to the same hub from the same region. Ensure there's no unexpected cross-region traffic as part of the hub-spoke topology, nor multiple Azure firewall instances deployed to the same region. To learn more about Azure Firewall design principles, check [Azure Well-Architected Framework review - Azure Firewall](/azure/well-architected/service-guides/azure-firewall#cost-optimization). --#### Application Gateway with empty backend pool --Review the Application Gateways with empty backend pools. -App gateways are considered idle if there isn't any backend pool with targets. --#### Load Balancer with empty backend pool --Review the Standard Load Balancers with empty backend pools. Load Balancers are considered idle if there isn’t any backend pool with targets. --#### Unattached Public IPs --Review the orphan Public IP Addresses. The query also shows Public IP addresses attached to idle network interface cards (NIC). --#### Virtual Network Gateways --Review idle Virtual Network Gateways that have no connections defined, as they may represent additional cost. --#### Advisor Recommendations --Review the Advisor recommendations for Networking. Some of the recommendations available in this tile could be "Reduce costs by deleting or reconfiguring idle virtual network gateways", or "Reduce costs by eliminating unprovisioned ExpressRoute circuits." --### Top 10 services --The following queries show other popular Azure resources that you can optimize to save money. --#### Web Apps --Review the App Service list. --* Review the Stopped App Services as they will be charged. --* Consider upgrading from the V2 SKU to the V3 SKU. The V3 SKU is cheaper than similar V2 SKU and allows [Reserved Instances and Savings plan for compute](https://azure.microsoft.com/pricing/details/app-service/windows/). --* Determine the right reserved instance size before you buy - Before you buy a reservation, you should determine the size of the Premium v3 reserved instance that you need. The following sections help you determine the right Premium v3 reserved instance size. --* Use Autoscale appropriately - Autoscale can be used to provision resources for when they're needed or on demand, which allows you to minimize costs when your environment is idle. --#### Azure Kubernetes Clusters (AKS) --Review the AKS list. Some of the cost optimization opportunities are: --* Enable cluster autoscaler to automatically adjust the number of agent nodes in response to resource constraints. -* Consider using Azure Spot VMs for workloads that can handle interruptions, early terminations, or evictions. For example, workloads such as batch processing jobs, development and testing environments, and large compute workloads may be good candidates for scheduling on a spot node pool. -* Utilize the Horizontal pod autoscaler to adjust the number of pods in a deployment depending on CPU utilization or other select metrics. -* Use the Start/Stop feature in Azure Kubernetes Services (AKS). -* Use appropriate VM SKU per node pool and reserved instances where long-term capacity is expected. --#### Azure Synapse --Review the Azure Synapse workspaces that don't have any SQL pools attached to them. --#### Monitoring --Review [Azure Monitor - Best Practices](../azure-monitor/best-practices-cost.md) for design checklists and configuration recommendations related to Azure Monitor Logs, Azure resources, Alerts, Virtual machines, Containers, and Application Insights. --**Log Analytics** --Review costs related to data ingestion on Log Analytics. The following advice could be of help in cost optimization: --* Adopt commitment tiers where applicable. -* Adopt Azure Monitor Logs dedicated cluster if a single workspace does not ingest enough data as per the minimum commitment tier (100 GB/day) or if it is possible to aggregate ingestion costs from more than one workspace in the same region. -* Convert the free tier based workspace to Pay-as-you-go model and add them to an Azure Monitor Logs dedicated cluster where possible. --🖱️ Select one or more Log Analytics workspaces to review the daily ingestion trend for the past 30 days and understand its usage. --**Azure Advisor Cost recommendations** --Review the Advisor recommendations for Log Analytics. Some of the recommendations available in this tile could be *Consider removing unused restored tables* or *Consider configuring the low-cost Basic logs plan on selected tables*. --For more information, see: -* [Well-Architected cost optimization design principles](/azure/well-architected/cost/principles) -* [Cloud Adoption Framework manage cloud costs](/azure/cloud-adoption-framework/get-started/manage-costs) -* [Azure FinOps principles](/azure/cost-management-billing/finops/overview-finops) -* [Azure Advisor cost recommendations](advisor-reference-cost-recommendations.md) |
| advisor | Advisor Cost Recommendations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-cost-recommendations.md | - Title: Reduce service costs using Azure Advisor -description: Use Azure Advisor to optimize the cost of your Azure deployments. - Previously updated : 11/08/2023----# Reduce service costs by using Azure Advisor --Azure Advisor helps you optimize and reduce your overall Azure spend by identifying idle and underutilized resources. You can get cost recommendations from the **Cost** tab on the Advisor dashboard. --1. Sign in to the [**Azure portal**](https://portal.azure.com). --1. Search for and select [**Advisor**](https://aka.ms/azureadvisordashboard) from any page. --1. On the **Advisor** dashboard, select the **Cost** tab. --## Optimize virtual machine (VM) or virtual machine scale set (VMSS) spend by resizing or shutting down underutilized instances --Although certain application scenarios can result in low utilization by design, you can often save money by managing the size and number of your virtual machines or virtual machine scale sets. --Advisor uses machine-learning algorithms to identify low utilization and to identify the ideal recommendation to ensure optimal usage of virtual machines and virtual machine scale sets. The recommended actions are shut down or resize, specific to the resource being evaluated. --### Shutdown recommendations --Advisor identifies resources that weren't used at all over the last seven days and makes a recommendation to shut them down. --* Recommendation criteria include **CPU** and **Outbound Network utilization** metrics. **Memory** isn't considered since we found that **CPU** and **Outbound Network utilization** are sufficient. --* The last seven days of utilization data are analyzed. You can change your lookback period in the configurations. The available lookback periods are 7, 14, 21, 30, 60, and 90 days. After you change the lookback period, it might take up to 48 hours for the recommendations to be updated. --* Metrics are sampled every 30 seconds, aggregated to 1 min and then further aggregated to 30 mins (we take the max of average values while aggregating to 30 mins). On virtual machine scale sets, the metrics from individual virtual machines are aggregated using the average of the metrics across instances. --* A shutdown recommendation is created if: - * P95 of the maximum value of CPU utilization summed across all cores is less than 3% - * P100 of average CPU in last 3 days (sum over all cores) <= 2% - * Outbound Network utilization is less than 2% over a seven-day period --### Resize SKU recommendations --Advisor recommends resizing virtual machines when it's possible to fit the current load on a more appropriate SKU, which is less expensive (based on retail rates). On virtual machine scale sets, Advisor recommends resizing when it's possible to fit the current load on a more appropriate cheaper SKU, or a lower number of instances of the same SKU. --* Recommendation criteria include **CPU**, **Memory**, and **Outbound Network utilization**. --* The last 7 days of utilization data are analyzed. You can change your lookback period in the configurations. The available lookback periods are 7, 14, 21, 30, 60, and 90 days. After you change the lookback period, it might take up to 48 hours for the recommendations to be updated. --* Metrics are sampled every 30 seconds, aggregated to 1 minute, and then further aggregated to 30 minutes (taking the max of average values while aggregating to 30 minutes). On virtual machine scale sets, the metrics from individual virtual machines are aggregated using the average of the metrics for instance count recommendations, and aggregated using the max of the metrics for SKU change recommendations. --* An appropriate SKU (for virtual machines) or instance count (for virtual machine scale set resources) is determined based on the following criteria: - * Performance of the workloads on the new SKU won't be impacted. - * Target for user-facing workloads: - * P95 of CPU and Outbound Network utilization at 40% or lower on the recommended SKU - * P100 of Memory utilization at 60% or lower on the recommended SKU - * Target for non user-facing workloads: - * P95 of the CPU and Outbound Network utilization at 80% or lower on the new SKU - * P100 of Memory utilization at 80% or lower on the new SKU - * The new SKU, if applicable, has the same Accelerated Networking and Premium Storage capabilities - * The new SKU, if applicable, is supported in the current region of the Virtual Machine with the recommendation - * The new SKU, if applicable, is less expensive - * Instance count recommendations also take into account if the virtual machine scale set is being managed by Service Fabric or AKS. For service fabric managed resources, recommendations take into account reliability and durability tiers. -* Advisor determines if a workload is user-facing by analyzing its CPU utilization characteristics. The approach is based on findings by Microsoft Research. You can find more details here: [Prediction-Based Power Oversubscription in Cloud Platforms - Microsoft Research](https://www.microsoft.com/research/publication/prediction-based-power-oversubscription-in-cloud-platforms/). --* Based on the best fit and the cheapest costs with no performance impacts, Advisor not only recommends smaller SKUs in the same family (for example D3v2 to D2v2), but also SKUs in a newer version (for example D3v2 to D2v3), or a different family (for example D3v2 to E3v2). --* For virtual machine scale set resources, Advisor prioritizes instance count recommendations over SKU change recommendations because instance count changes are easily actionable, resulting in faster savings. --### Burstable recommendations --We evaluate if workloads are eligible to run on specialized SKUs called **Burstable SKUs** that support variable workload performance requirements and are less expensive than general purpose SKUs. Learn more about burstable SKUs here: [B-series burstable - Azure Virtual Machines](/azure/virtual-machines/sizes-b-series-burstable). --A burstable SKU recommendation is made if: --* The average **CPU utilization** is less than a burstable SKUs' baseline performance - * If the P95 of CPU is less than two times the burstable SKUs' baseline performance - * If the current SKU doesn't have accelerated networking enabled, since burstable SKUs don't support accelerated networking yet - * If we determine that the Burstable SKU credits are sufficient to support the average CPU utilization over 7 days. You can change your lookback period in the configurations. --The resulting recommendation suggests that a user should resize their current virtual machine or virtual machine scale set to a burstable SKU with the same number of cores. This suggestion is made so a user can take advantage of lower cost and also the fact that the workload has low average utilization but high spikes in cases, which can be best served by the B-series SKU. --Advisor shows the estimated cost savings for either recommended action: resize or shut down. For resize, Advisor provides current and target SKU/instance count information. -To be more selective about the actioning on underutilized virtual machines or virtual machine scale sets, you can adjust the CPU utilization rule by subscription. --In some cases recommendations can't be adopted or might not be applicable, such as some of these common scenarios (there might be other cases): --* Virtual machine or virtual machine scale set has been provisioned to accommodate upcoming traffic --* Virtual machine or virtual machine scale set uses other resources not considered by the resize algorithm, such as metrics other than CPU, Memory and Network --* Specific testing being done on the current SKU, even if not utilized efficiently --* Need to keep virtual machine or virtual machine scale set SKUs homogeneous --* Virtual machine or virtual machine scale set being utilized for disaster recovery purposes --In such cases, simply use the Dismiss/Postpone options associated with the recommendation. --### Limitations --* The savings associated with the recommendations are based on retail rates and don't take into account any temporary or long-term discounts that might apply to your account. As a result, the listed savings might be higher than actually possible. --* The recommendations don't take into account the presence of Reserved Instances (RI) / Savings plan purchases. As a result, the listed savings might be higher than actually possible. In some cases, for example in the case of cross-series recommendations, depending on the types of SKUs that reserved instances have been purchased for, the costs might increase when the optimization recommendations are followed. We caution you to consider your RI/Savings plan purchases when you act on the right-size recommendations. --We're constantly working on improving these recommendations. Feel free to share feedback on [Advisor Forum](https://aka.ms/advisorfeedback). --## Configure VM/VMSS recommendations --You can adjust Advisor virtual machine (VM) and Virtual Machine Scale Sets recommendations. Specifically, you can set up a filter for each subscription to only show recommendations for machines with certain CPU utilization. This setting will filter recommendations but will not change how they are generated. --> [!NOTE] -> If you don't have the required permissions, the option is disabled in the user interface. For information on permissions, see [Permissions in Azure Advisor](permissions.md). --To adjust Advisor VM/Virtual Machine Scale Sets right sizing rules, follow these steps: --1. From any Azure Advisor page, click **Configuration** in the left navigation pane. The Advisor Configuration page opens with the **Resources** tab selected, by default. --1. Select the **VM/Virtual Machine Scale Sets right sizing** tab. --1. Select the subscriptions you’d like to set up a filter for average CPU utilization, and then click **Edit**. --1. Select the desired average CPU utilization value and click **Apply**. It can take up to 24 hours for the new settings to be reflected in recommendations. -- :::image type="content" source="media/advisor-get-started/advisor-configure-rules.png" alt-text="Screenshot of Azure Advisor configuration option for VM/Virtual Machine Scale Sets sizing rules." lightbox="media/advisor-get-started/advisor-configure-rules.png"::: --## Next steps --To learn more about Advisor recommendations, see: --* [Advisor cost recommendations (full list)](advisor-reference-cost-recommendations.md) -* [Introduction to Advisor](advisor-overview.md) -* [Advisor score](azure-advisor-score.md) |
| advisor | Advisor Get Started | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-get-started.md | - Title: Azure Advisor portal basics -description: Learn how to get started with Azure Advisor through the Azure portal, get and manage recommendations, and configure Advisor settings. -- Previously updated : 03/07/2024----# Azure Advisor portal basics --Learn how to access Azure Advisor through the Azure portal, get and manage recommendations, and configure Advisor settings. --> [!NOTE] -> Advisor runs in the background to find newly created resources. It can take up to 24 hours to provide recommendations on those resources. --## Open Advisor --To access Advisor, sign in to the [Azure portal](https://portal.azure.com). Then select the [Advisor](https://aka.ms/azureadvisordashboard) icon at the top of the page or use the search bar at the top to search for Advisor. You can also use the left pane and select **Advisor**. The Advisor **Overview** page opens by default. --## View the Advisor dashboard --On the Advisor **Overview** page, you see personalized and actionable recommendations. ---* The links at the top offer options for **Feedback**, downloading recommendations as comma-separated value (CSV) files or PDFs, and a link to Advisor **Workbooks**. -* The filter buttons underneath them focus the recommendations. -* The tiles represent the different recommendation categories and include your current score in each category. -* **Get started** takes you to options for direct access to Advisor workbooks, recommendations, and the Azure Well-Architected Framework main page. --### Filter and access recommendations --The tiles on the Advisor **Overview** page show the different categories of recommendations for all the subscriptions to which you have access, by default. --To filter the display, use the buttons at the top of the page: --* **Subscription**: Select **All** for Advisor recommendations on all subscriptions. Alternatively, select specific subscriptions. Apply changes by clicking outside of the button. -* **Recommendation Status**: **Active** (the default, recommendations not postponed or dismissed), **Postponed** or **Dismissed**. Apply changes by clicking outside of the button. -* **Resource Group**: Select **All** (the default) or specific resource groups. Apply changes by clicking outside of the button. -* **Type**: Select **All** (the default) or specific resources. Apply changes by clicking outside of the button. -* For more advanced filtering, select **Add filter**. --To display a specific list of recommendations, select a category tile. ---Each tile provides information about the recommendations for that category: --* Your overall score for the category. -* The total number of recommendations for the category, and the specific number per impact. -* The number of impacted resources by the recommendations. --For detailed graphics and information on your Advisor score, see [Optimize Azure workloads by using Advisor score](/azure/advisor/azure-advisor-score). --### Get recommendation details and solution options --You can view recommendation details, such as the recommended actions and affected resources. You can also see the solution options, including postponing or dismissing a recommendation. --1. To review details of a recommendation, including the affected resources, open the recommendation list for a category. Then select **Description** or **Impacted resources** for a specific recommendation. The following screenshot shows a Reliability recommendation details page. -- :::image type="content" source="./media/advisor-get-started/advisor-score-reliability-recommendation-page.png" alt-text="Screenshot that shows an Advisor Reliability Recommendation details example." lightbox="./media/advisor-get-started/advisor-score-reliability-recommendation-page.png"::: --1. To see action details, select a **Recommended actions** link. The Azure page where you can act opens. Alternatively, open a page to the affected resources to take the recommended action (the two pages might be the same). - - To help you understand the recommendation before you act, select **Learn more** on the **Recommended action** page or at the top of the **Recommendation details** page. --1. You can postpone the recommendation. -- :::image type="content" source="./media/advisor-get-started/advisor-recommendation-postpone.png" alt-text="Screenshot that shows an Advisor recommendation postpone option." lightbox="./media/advisor-get-started/advisor-recommendation-postpone.png"::: -- You can't dismiss the recommendation without certain privileges. For information on permissions, see [Permissions in Azure Advisor](permissions.md). --### Download recommendations --To download your recommendations, select **Download as CSV** or **Download as PDF** on the action bar at the top of any recommendation list or details page. The download option respects any filters you applied to Advisor. If you select the download option while viewing a specific recommendation category or recommendation, the downloaded summary only includes information for that category or recommendation. --## Configure recommendations --You can exclude subscriptions or resources, such as test resources, from Advisor recommendations and configure Advisor to generate recommendations only for specific subscriptions and resource groups. --> [!NOTE] -> To change subscriptions or Advisor compute rules, you must be a subscription owner. If you don't have the required permissions, the option is disabled in the user interface. For information on permissions, see [Permissions in Azure Advisor](permissions.md). For details on right-sizing VMs, see [Reduce service costs by using Azure Advisor](advisor-cost-recommendations.md). --From any Azure Advisor page, select **Configuration** in the left pane. The Advisor configuration page opens with the **Resources** tab selected, by default. --Use the **Resources** tab to select or unselect subscriptions for Advisor recommendations. When you're ready, select **Apply**. The page refreshes. ---Use the **VM/VMSS right sizing** tab to adjust Advisor virtual machine (VM) and virtual machine scale sets (VMSS) recommendations. Specifically, you can set up a filter for each subscription to only show recommendations for machines with certain CPU utilization. This setting filters recommendations by machine, but it doesn't change how they're generated. Follow these steps: --1. Select the subscriptions for which you want to set up a filter for average CPU utilization. Then select **Edit**. Not all subscriptions can be edited for VM/VMSS right sizing, and certain privileges are required. For more information on permissions, see [Permissions in Azure Advisor](permissions.md). --1. Select the average CPU utilization value you want and select **Apply**. It can take up to 24 hours for the new settings to be reflected in recommendations. -- :::image type="content" source="./media/advisor-get-started/advisor-configure-rules.png" alt-text="Screenshot that shows an Advisor configuration option for VM/VMSS sizing rules." lightbox="./media/advisor-get-started/advisor-configure-rules.png"::: --## Related content --To learn more about Advisor, see: --- [Introduction to Azure Advisor](advisor-overview.md)-- [Advisor cost recommendations](advisor-cost-recommendations.md)-- [Advisor security recommendations](advisor-security-recommendations.md)-- [Advisor reliability recommendations](advisor-high-availability-recommendations.md)-- [Advisor operational excellence recommendations](advisor-operational-excellence-recommendations.md)-- [Advisor performance recommendations](advisor-performance-recommendations.md) |
| advisor | Advisor How To Calculate Total Cost Savings | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-how-to-calculate-total-cost-savings.md | - Title: Calculate cost savings in Azure Advisor- Previously updated : 09/05/2024 -description: Export cost savings in Azure Advisor and calculate the aggregated potential yearly savings by using the cost savings amount for each recommendation. ---# Calculate cost savings --This article provides guidance on how to calculate total cost savings in Azure Advisor. --## Understand cost savings --Azure Advisor provides recommendations for resizing/shutting down underutilized resources, purchasing compute reserved instances, and savings plans for compute. --These recommendations contain one or more calls-to-action and forecasted savings from following the recommendations. Recommendations should be followed in a specific order: rightsizing/shutdown, followed by reservation purchases, and finally, the savings plan purchase. This sequence allows each step to impact the subsequent ones positively. --For example, rightsizing or shutting down resources reduces on-demand costs immediately. This change in your usage pattern essentially invalidates your existing reservation and savings plan recommendations, as they were based on your pre-rightsizing usage and costs. Updated reservation and savings plan recommendations (and their forecasted savings) should appear within three days. --The forecasted savings from reservations and savings plans are based on actual rates and usage, while the forecasted savings from rightsizing/shutdown are based on retail rates. The actual savings may vary depending on the usage patterns and rates. Assuming there are no material changes to your usage patterns, your actual savings from reservations and savings plan should be in line with the forecasts. Savings from rightsizing/shutdown vary based on your actual rates. This is important if you intend to track cost savings forecasts from Azure Advisor. --## Export cost savings for recommendations --To calculate aggregated potential yearly savings, follow these steps: --1. Sign in to the [**Azure portal**](https://portal.azure.com). --1. Search for and select [**Advisor**](https://aka.ms/azureadvisordashboard) from any page.\ -The Advisor **Overview** page opens. --1. Export cost recommendations by navigating to the **Cost** tab on the left navigation menu and choosing **Download as CSV**. --1. Use the cost savings amount for each recommendation to calculate aggregated potential yearly savings. -- [](./media/advisor-how-to-calculate-total-cost-savings.png#lightbox) --> [!NOTE] -> Different types of cost savings recommendations are generated using overlapping datasets (for example, VM rightsizing/shutdown, VM reservations and savings plan recommendations all consider on-demand VM usage). As a result, resource changes (e.g., VM shutdowns) or reservation/savings plan purchases will impact on-demand usage, and the resulting recommendations and associated savings forecast. |
| advisor | Advisor How To Improve Reliability | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-how-to-improve-reliability.md | - Title: Improve reliability of your business-critical applications using Azure Advisor recommendations and the reliability workbook. -description: Use Azure Advisor to evaluate the reliability posture of your business-critical applications, assess risks and plan improvements. - Previously updated : 05/19/2023----# Improve the reliability of your business-critical applications using Azure Advisor --Azure Advisor helps you assess and improve the reliability of your business-critical applications. --## Reliability recommendations --You can get reliability recommendations on the **Reliability** tab on the Advisor dashboard. --1. Sign in to the [**Azure portal**](https://portal.azure.com). --1. Search for and select [**Advisor**](https://aka.ms/azureadvisordashboard) from any page. --1. On the **Advisor** dashboard, select the **Reliability** tab. --## Reliability workbook --You can evaluate the reliability of posture of your applications, assess risks and plan improvements using the new Reliability workbook template, which is available in Azure Advisor. --1. Sign in to the [**Azure portal**](https://portal.azure.com). --1. Search for and select [**Advisor**](https://aka.ms/azureadvisordashboard) from any page. --1. Select **Workbooks** item in the left menu. --1. Open **Reliability** workbook template. ---Reliability considerations for individual Azure services are provided in the [resiliency checklist for Azure services](/azure/architecture/checklist/resiliency-per-service). --> [!NOTE] -> The workbook is to be used as a guidance only and does not represent a guarantee for service level. --### Navigating the workbook --Workbook offers a set of filters that you can use to scope recommendation for a specific application. --* Subscription -* Resource Group -* Environment -* Tags --The workbook uses tags with names Environment, environment, Env, env and common keywords (prod, dev, qa, uat, sit, test) as part of resource name to show environment for a specific resource. If there are no tags or naming conventions detected, the environment filter is displayed as 'undefined'. The 'undefined' value is shown only within the workbook and is not used anywhere else. --Use **SLA** and **Help** controls to show additional information: --* Show SLA - Displays the service SLA. -* Show Help - Displays best practice configurations to increase the reliability of the resource deployment. --The workbook offers best practices for Azure services including: -* **Compute**: Virtual Machines, Virtual Machine Scale Sets -* **Containers**: Azure Kubernetes service -* **Databases**: SQL Database, Synapse SQL Pool, Cosmos DB, Azure Database for MySQL, PostgreSQL, Azure Cache for Redis -* **Integration**: Azure API Management -* **Networking**: Azure Firewall, Azure Front Door & CDN, Application Gateway, Load Balancer, Public IP, VPN & Express Route Gateway -* **Storage**: Storage Account -* **Web**: App Service Plan, App Service, Function App -* **Azure Site Recovery** -* **Service Alerts** --To share the findings with your team, you can export data for each of the services or share the workbook link with them. -To customize the workbook, save the template into your subscription and click Edit button in top menu. --> [!NOTE] -> To assess your workload using the tenets found in the Microsoft Azure Well-Architected Framework, see the [Microsoft Azure Well-Architected Review](/assessments/?id=azure-architecture-review&mode=pre-assessment). --## Next steps --For more information about Advisor recommendations, see: -* [Reliability recommendations](advisor-reference-reliability-recommendations.md) -* [Introduction to Advisor](advisor-overview.md) -* [Get started with Advisor](advisor-get-started.md) -- |
| advisor | Advisor How To Performance Resize High Usage Vm Recommendations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-how-to-performance-resize-high-usage-vm-recommendations.md | - Title: Improve the performance of highly used VMs using Azure Advisor -description: Use Azure Advisor to improve the performance of your Azure virtual machines with consistent high utilization. - Previously updated : 10/27/2022---# Improve the performance of highly used VMs using Azure Advisor --Azure Advisor helps you improve the speed and responsiveness of your business-critical applications. You can get performance recommendations from the **Performance** tab on the Advisor dashboard. --1. Sign in to the [**Azure portal**](https://portal.azure.com). --1. Search for and select [**Advisor**](https://aka.ms/azureadvisordashboard) from any page. --1. On the **Advisor** dashboard, select the **Performance** tab. --## Optimize virtual machine (VM) performance by right-sizing highly utilized instances --You can improve the quality of your workload and prevent many performance-related issues (i.e., throttling, high latency) by regularly assessing your [performance efficiency](/azure/architecture/framework/scalability/overview). Performance efficiency is defined by the [Azure Well-Architected Framework](/azure/architecture/framework/) as the ability of your workload to adapt to changes in load. Performance efficiency is one of the five pillars of architectural excellence on Azure. --Unless by design, we recommend keeping your application's usage well below your virtual machine's size limits, so it can better operate and easily accommodate changes. --Advisor aggregates various metrics over a minimum of 7 days, identifies virtual machines with consistent high utilization across those metrics, and finds better sizes (SKUs) for improved performance. Finally, Advisor examines capacity signals in Azure to frequently refresh the recommended SKUs, ensuring that they are available for deployment in the region. --### Resize SKU recommendations --Advisor recommends resizing virtual machines when use is consistently high (above predefined thresholds) given the running virtual machine's size limits. --- The recommendation algorithm evaluates **CPU**, **Memory**, **VM Cached IOPS Consumed Percentage**, and **VM Uncached Bandwidth Consumed Percentage** usage metrics-- The observation period is the past 7 days from the day of the recommendation-- Metrics are sampled every 30 seconds, aggregated to 1 minute and then further aggregated to 30 minutes (taking the average of 1-minute average values while aggregating to 30 minutes)-- A SKU upgrade for virtual machines is decided given the following criteria: - - For each metric, we create a new feature from the P50 (median) of its 30-mins averages aggregated over the observation period. Therefore, a virtual machine is identified as a candidate for a resize if: - * _Both_ `CPU` and `Memory` features are >= *90%* of the current SKU's limits - * Otherwise, _either_ - * The `VM Cached IOPS` feature is >= to *95%* of the current SKU's limits, and the current SKU's max local disk IOPS is >= to its network disk IOPS. _or_ - * the `VM Uncached Bandwidth` feature is >= *95%* of the current SKU's limits, and the current SKU's max network disk throttle limits are >= to its local disk throttle units -- We ensure the following:- - The current workload utilization will be better on the new SKU's given that it has higher limits and better performance guarantees - - The new SKU has the same Accelerated Networking and Premium Storage capabilities - - The new SKU is supported and ready for deployment in the same region as the running virtual machine ---In some cases, recommendations can't be adopted or might not be applicable, such as some of these common scenarios (there may be other cases): -- The virtual machine is short-lived-- The current virtual machine has already been provisioned to accommodate upcoming traffic-- Specific testing being done using the current SKU, even if not utilized efficiently-- There's a need to keep the virtual machine as-is--In such cases, simply use the Dismiss/Postpone options associated with the recommendation. --We're constantly working on improving these recommendations. Feel free to share feedback on [Advisor Forum](https://aka.ms/advisorfeedback). --## Next steps --To learn more about Advisor recommendations and best practices, see: -* [Get started with Advisor](advisor-get-started.md) -* [Introduction to Advisor](advisor-overview.md) -* [Advisor score](azure-advisor-score.md) -* [Advisor performance recommendations](advisor-reference-performance-recommendations.md) -* [Advisor cost recommendations (full list)](advisor-reference-cost-recommendations.md) -* [Advisor reliability recommendations](advisor-reference-reliability-recommendations.md) -* [Advisor security recommendations](advisor-security-recommendations.md) -* [Advisor operational excellence recommendations](advisor-reference-operational-excellence-recommendations.md) -* [The Microsoft Azure Well-Architected Framework](/azure/architecture/framework/) |
| advisor | Advisor How To Plan Migration Workloads Service Retirement | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-how-to-plan-migration-workloads-service-retirement.md | - Title: Prepare migration of your workloads impacted by service retirements. -description: Use Azure Advisor to plan the migration of the workloads impacted by service retirements. - Previously updated : 05/19/2023----# Prepare migration of your workloads impacted by service retirement --Azure Advisor helps you assess and improve the continuity of your business-critical applications. It's important to be aware of upcoming Azure services and feature retirements to understand their impact on your workloads and plan migration. --## Service Retirement workbook --The Service Retirement workbook provides a single centralized resource level view of service retirements. It helps you assess impact, evaluate options, and plan for migration from retiring services and features. The workbook template is available in Azure Advisor gallery. -Here's how to get started: --1. Navigate to [Workbooks gallery](https://aka.ms/advisorworkbooks) in Azure Advisor -1. Open **Service Retirement (Preview)** workbook template. -1. Select a service from the list to display a detailed view of impacted resources. --The workbook shows a list and a map view of service retirements that impact your resources. For each of the services, there's a planned retirement date, number of impacted resources and migration instructions including recommended alternative service. --* Use subscription, resource group and location filters to focus on a specific workload. -* Use sorting to find services, which are retiring soon and have the biggest impact on your workloads. -* Share the report with your team to help them plan migration using export function. ----> [!NOTE] -> The workbook contains information about a subset of services and features that are in the retirement lifecycle. While we continue to add more services to this workbook, you can view the lifecycle status of all Azure services by visiting [Azure updates](https://azure.microsoft.com/updates/?updateType=retirements). - -For more information, see: -* [Azure Service Health](../service-health/overview.md) -* [Azure updates](https://azure.microsoft.com/updates/?updateType=retirements) -* [Introduction to Advisor](advisor-overview.md) |
| advisor | Advisor Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-overview.md | - Title: Introduction to Azure Advisor -description: Learn how to use Azure Advisor to optimize your Azure deployments and get answers to frequently asked questions. - Previously updated : 07/08/2024---# Introduction to Azure Advisor --Learn about the key capabilities of Azure Advisor and get answers to frequently asked questions. --## What is Advisor? -Advisor is a digital cloud assistant that helps you follow best practices to optimize your Azure deployments. It analyzes your resource configuration and usage telemetry and then recommends solutions that can help you improve the cost effectiveness, performance, reliability, and security of your Azure resources. --With Advisor, you can: --* Get proactive, actionable, and personalized best practices recommendations. -* Improve the performance, security, and reliability of your resources, as you identify opportunities to reduce your overall Azure spend. -* Get recommendations with proposed actions inline. --You can access Advisor through the [Azure portal](https://aka.ms/azureadvisordashboard). Sign in to the [portal](https://portal.azure.com), locate **Advisor** on the navigation pane, or search for it on the **All services** menu. --The Advisor dashboard displays personalized recommendations for all your subscriptions. The recommendations are divided into five categories: --* **Reliability**: To ensure and improve the continuity of your business-critical applications. For more information, see [Advisor reliability recommendations](advisor-reference-reliability-recommendations.md). -* **Security**: To detect threats and vulnerabilities that might lead to security breaches. For more information, see [Advisor security recommendations](advisor-security-recommendations.md). -* **Performance**: To improve the speed of your applications. For more information, see [Advisor performance recommendations](advisor-reference-performance-recommendations.md). -* **Cost**: To optimize and reduce your overall Azure spending. For more information, see [Advisor cost recommendations](advisor-reference-cost-recommendations.md). -* **Operational excellence**: To help you achieve process and workflow efficiency, resource manageability, and deployment best practices. For more information, see [Advisor operational excellence recommendations](advisor-reference-operational-excellence-recommendations.md). --You can apply filters to display recommendations for specific subscriptions and resource types. ---Select a category to display the list of recommendations for that category. Select a recommendation to learn more about it. You can also learn about actions that you can perform to take advantage of an opportunity or resolve an issue. ---Select the recommended action for a recommendation to implement the recommendation. A simple interface opens that enables you to implement the recommendation. It also might refer you to documentation that assists you with implementation. After you implement a recommendation, it can take up to a day for Advisor to recognize the action. --If you don't intend to take immediate action on a recommendation, you can postpone it for a specified time period. You can also dismiss it. If you don't want to receive recommendations for a specific subscription or resource group, you can configure Advisor to only generate recommendations for specified subscriptions and resource groups. --## Frequently asked questions --Here are answers to common questions about Advisor. --### How do I access Advisor? -You can access Advisor through the [Azure portal](https://aka.ms/azureadvisordashboard). Sign in to the [portal](https://portal.azure.com), locate **Advisor** on the navigation pane, or search for it on the **All services** menu. --### What permissions do I need to access Advisor? --You can access Advisor recommendations as the Owner, Contributor, or Reader of a subscription, resource group, or resource. --### What resources does Advisor provide recommendations for? --Advisor provides recommendations for the following --- Azure API Management-- Azure Application Gateway-- Azure App Service-- Availability sets-- Azure Cache-- Azure Database for MySQL-- Azure Database for PostgreSQL-- Azure Farmbeats-- Azure Stack ACI-- Azure public IP addresses-- Azure Synapse Analytics-- Central server-- Azure Cognitive Services-- Azure Cosmos DB-- Azure Data Explorer-- Azure Data Factory-- Databricks Workspace-- Azure ExpressRoute-- Azure Front Door-- Azure HDInsight cluster-- Azure IoT Hub-- Azure Key Vault-- Azure Kubernetes Service-- Log Analytics-- Azure Cache for Redis server-- SQL Server-- Azure Storage account-- Azure Traffic Manager profile-- Azure Virtual Machines-- Azure Virtual Machine Scale Sets-- Azure Virtual Network gateway--Advisor also includes your recommendations from [Microsoft Defender for Cloud](/azure/defender-for-cloud/defender-for-cloud-introduction), which might include recommendations for other resource types. --### Can I postpone or dismiss a recommendation? --To postpone or dismiss a recommendation, select **Postpone** or **Dismiss**. The recommendation is moved to the **Postponed/Dismissed** tab on the recommendation list page. --## Related content --To learn more about Advisor recommendations, see: --* [Get started with Advisor](advisor-get-started.md) -* [Advisor score](azure-advisor-score.md) -* [Advisor reliability recommendations](advisor-reference-reliability-recommendations.md) -* [Advisor security recommendations](advisor-security-recommendations.md) -* [Advisor performance recommendations](advisor-reference-performance-recommendations.md) -* [Advisor cost recommendations](advisor-reference-cost-recommendations.md) -* [Advisor operational excellence recommendations](advisor-reference-operational-excellence-recommendations.md) |
| advisor | Advisor Quick Fix | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-quick-fix.md | - Title: Quick Fix remediation for Advisor recommendations -description: Perform bulk remediation using Quick Fix in Advisor - Previously updated : 03/13/2020---# Quick Fix remediation for Advisor -**Quick Fix** enables a faster and easier way of remediation for recommendation on multiple resources. It provides capability for bulk remediations for resources and helps you optimize your subscriptions faster with remediation at scale for your resources. -The feature is available for certain recommendations only, via Azure portal. ---## Steps to use 'Quick Fix' --1. From the list of recommendations that have the **Quick Fix** label, click on the recommendation. -- :::image type="content" source="./media/quick-fix-1.png" alt-text="{Screenshot of Azure Advisor showing Quick Fix labels in the recommendations.}"::: - - *Prices in the image are for example purposes only* --2. On the Recommendation details page, you'll see list of resources for which you have this recommendation. Select all the resources you want to remediate for the recommendation. -- :::image type="content" source="./media/quick-fix-2.png" alt-text="Screenshot of the Impacted resources window with list items and the Quick Fix button highlighted."::: - - *Prices in the image are for example purposes only* --3. Once you have selected the resources, click on the **Quick Fix** button to bulk remediate. -- > [!NOTE] - > Some of the listed resources might be disabled, because you don't have the appropriate permissions to modify them. - - > [!NOTE] - > If there are other implications, in addition to benefits mentioned in Advisor, you will be communicated in the experience to help you take informed remediation decisions. - -4. You will get a notification for the remediation completion. You will see an error if there are resources which are not remediated and resources in the selected mode in the resource list view. ---## Next steps --For more information about Advisor recommendations, see: -* [Introduction to Azure Advisor](advisor-overview.md) -* [Get started with Advisor](advisor-get-started.md) -* [Advisor Cost recommendations](advisor-cost-recommendations.md) -* [Advisor Performance recommendations](advisor-performance-recommendations.md) -* [Advisor Security recommendations](advisor-security-recommendations.md) -* [Advisor Operational Excellence recommendations](advisor-operational-excellence-recommendations.md) -* [Advisor REST API](/rest/api/advisor/) |
| advisor | Advisor Recommendations Digest | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-recommendations-digest.md | - Title: Recommendation digest for Azure Advisor -description: Get periodic summary for your active recommendations - Previously updated : 03/16/2020---# Configure periodic summary for recommendations --Advisor **recommendation digests** provide an easy and proactive way to stay on top of your active recommendations, across different categories. The feature provides the ability to configure periodic notifications for the summary of all your active recommendations, across different categories. You can choose your desired channel for notifications like email, sms or others, using action groups. -This article shows you how to set-up a **recommendation digests** for your Advisor recommendations. ---## Setting-up your recommendation digest --The **recommendation digest** creation experience helps you configure the summary. You can select below parameters for configurations: -1. Category: We have recommendation categories like cost, high availability, performance and operational excellence. The capability is not available for security recommendations yet. -2. Frequency of digest: Frequency for the summary notifications can be weekly, bi-weekly and monthly. -3. Action group: You can either select an existing action group or create a new action group. To learn more about action groups, see [create and manage action groups](../azure-monitor/alerts/action-groups.md). -4. Language for the digest -5. Recommendation digest name: You can use a user-friendly string to better track and monitor the digests. --## Steps to create recommendation digest in Azure portal --Here are the steps to create **recommendation digest:** -* **Step 1:** In the Azure portal, go to **Advisor** and under **Monitoring** section, select **Recommendation digest** --  --* **Step 2:** Select **New recommendation digest** from the top bar as below: --  --* **Step 3:** In the **scope** section, select the **subscription** for your digest --  --* **Step 4:** In the **condition** section, select the configurations like **category**, **frequency** and **language** --  --* **Step 5:** In the **action group** section, select the **action group** for the digest. You can learn more here - [Create and manage action groups](../azure-monitor/alerts/action-groups.md) --  --* **Step 6:** In this final section for **digest details**, you can assign name and state to your recommendation digest. Press **create recommendation digest** to complete the set-up. -  --## Next steps --For more information about Advisor recommendations, see: -* [Introduction to Azure Advisor](advisor-overview.md) -* [Get started with Advisor](advisor-get-started.md) -* [Advisor Cost recommendations](advisor-cost-recommendations.md) -* [Advisor Performance recommendations](advisor-performance-recommendations.md) -* [Advisor Security recommendations](advisor-security-recommendations.md) -* [Advisor Operational Excellence recommendations](advisor-operational-excellence-recommendations.md) -* [Advisor REST API](/rest/api/advisor/) |
| advisor | Advisor Reference Cost Recommendations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-reference-cost-recommendations.md | - Title: Cost recommendations -description: Full list of available cost recommendations in Advisor. - Previously updated : 10/15/2023---# Cost recommendations --Azure Advisor helps you optimize and reduce your overall Azure spend by identifying idle and underutilized resources. You can get cost recommendations from the **Cost** tab on the Advisor dashboard. --1. Sign in to the [**Azure portal**](https://portal.azure.com). --1. Search for and select [**Advisor**](https://aka.ms/azureadvisordashboard) from any page. --1. On the **Advisor** dashboard, select the **Cost** tab. -----## AI Services --### Potential Cost Savings on this Document Intelligence Resource --We observed that your Document Intelligence (formerly Form Recognizer) resource had enough usage in the past 30 days for you to consider using a Commitment tier. --Learn more about [Cognitive Service - AzureAdvisorFRCommitment (Potential Cost Savings on this Computer Vision Resource)](https://azure.microsoft.com/pricing/details/cognitive-services/computer-vision/). --### Potential Cost Savings on this Computer Vision Resource --We observed that your Computer Vision resource had enough READ usage in the past 30 days for you to consider using a Commitment tier. --Learn more about [Cognitive Service - AzureAdvisorCVReadCommitment (Potential Cost Savings on this Computer Vision Resource)](https://azure.microsoft.com/pricing/details/cognitive-services/computer-vision/). --### Potential Cost Savings on this Speech Service Resource --We observed that your Speech Service resource had enough usage in the past 30 days for you to consider using a Commitment tier. --Learn more about [Cognitive Service - AzureAdvisorSpeechCommitment (Azure AI Document Intelligence pricing)](https://azure.microsoft.com/pricing/details/ai-document-intelligence/). --### Potential Cost Savings on this Translator Resource --We observed that your Translator resource had enough usage in the past 30 days for you to consider using a Commitment tier. --Learn more about [Cognitive Service - AzureAdvisorTranslatorCommitment (Potential Cost Savings on this Translator Resource)](https://azure.microsoft.com/pricing/details/cognitive-services/translator/). --### Potential Cost Savings on this LUIS Resource --We observed that your LUIS resource had enough usage in the past 30 days for you to consider using a Commitment tier. --Learn more about [Cognitive Service - AzureAdvisorLUISCommitment (Potential Cost Savings on this LUIS Resource)](https://azure.microsoft.com/pricing/details/cognitive-services/language-understanding-intelligent-services/). --### Potential Cost Savings on this Language Service Resource --We observed that your Language Service resource had enough usage in the past 30 days for you to consider using a Commitment tier. --Learn more about [Cognitive Service - AzureAdvisorTextAnalyticsCommitment (Potential Cost Savings on this Language Service Resource)](https://azure.microsoft.com/pricing/details/cognitive-services/language-service/). --### Enable Autoscaling for Azure Databricks Clusters --Autoscaling makes it easier to achieve high cluster utilization, because you don’t need to provision the cluster to match a workload. When you're using autoscaling, workloads can run faster and overall costs can be reduced compared to a static cluster. --Learn more about [Databricks Workspace - DatabricksEnableAutoscaling (Enable Autoscaling for Azure Databricks Clusters)](/azure/databricks/archive/compute/configure). ----## Analytics --### Unused, stopped, Data Explorer resources --This recommendation surfaces all stopped Data Explorer resources that have been stopped for at least 60 days. Consider deleting the resources. --Learn more about [Data explorer resource - ADX stopped resource (Unused stopped Data Explorer resources)](https://aka.ms/adxunusedstoppedcluster). --### Unused/Empty Data Explorer resources --This recommendation surfaces all Data Explorer resources provisioned more than 10 days from the last update, and found either empty or with no activity. Consider deleting the resources. --Learn more about [Data explorer resource - ADX Unused resource (Unused/Empty Data Explorer resources)](https://aka.ms/adxemptycluster). --### Right-size Data Explorer resources for optimal cost --One or more of these issues were detected: Low data capacity, CPU utilization, or memory utilization. Scale down and/or scale in the resource to the recommended configuration shown. --Learn more about [Data explorer resource - Right-size for cost (Right-size Data Explorer resources for optimal cost)](https://aka.ms/adxskusize). --### Reduce Data Explorer table cache policy to optimize costs --Reducing the table cache policy frees up Data Explorer cluster nodes with low CPU utilization, memory, and a high cache size configuration. --Learn more about [Data explorer resource - ReduceCacheForAzureDataExplorerTables (Reduce Data Explorer table cache policy to optimize costs)](https://aka.ms/adxcachepolicy). --### Unused running Data Explorer resources --This recommendation surfaces all running Data Explorer resources with no user activity. Consider stopping the resources. --Learn more about [Data explorer resource - StopUnusedClusters (Unused running Data Explorer resources)](/azure/data-explorer/azure-advisor#azure-data-explorer-unused-cluster). --### Cleanup unused storage in Data Explorer resources --Over time, internal extents merge operations can accumulate redundant and unused storage artifacts that remain beyond the data retention period. While this unreferenced data doesn’t negatively impact the performance, it can lead to more storage use and larger costs than necessary. This recommendation surfaces Data Explorer resources that have unused storage artifacts. We recommended that you run the cleanup command to detect and delete unused storage artifacts and reduce cost. Recoverability will be reset to the cleanup time and not available on data that was created before running the cleanup. --Learn more about [Data explorer resource - RunCleanupCommandForAzureDataExplorer (Cleanup unused storage in Data Explorer resources)](https://aka.ms/adxcleanextentcontainers). --### Enable optimized autoscale for Data Explorer resources --Looks like your resource could have automatically scaled to reduce costs (based on the usage patterns, cache utilization, ingestion utilization, and CPU). To optimize costs and performance, we recommend enabling optimized autoscale. To make sure you don't exceed your planned budget, add a maximum instance count when you enable optimized autoscale. --Learn more about [Data explorer resource - EnableOptimizedAutoscaleAzureDataExplorer (Enable optimized autoscale for Data Explorer resources)](https://aka.ms/adxoptimizedautoscale). --### Change Data Explorer clusters to a more cost effective and better performing SKU --You have resources operating under a nonoptimal SKU. We recommend migrating to a more cost effective and better performing SKU. This SKU should reduce your costs and improve overall performance. We have calculated the required instance count that meets both the CPU and cache of your cluster. --Learn more about [Data explorer resource - SkuChangeForAzureDataExplorer (Change Data Explorer clusters to a more cost effective and better performing SKU)](https://aka.ms/clusterChooseSku). --### Consider Changing Pricing Tier --Based on your current usage volume, investigate changing your pricing (Commitment) tier to receive a discount and reduce costs. --Learn more about [Log Analytics workspace - considerChangingPricingTier (Consider Changing Pricing Tier)](/azure/azure-monitor/logs/change-pricing-tier). --### Consider configuring the low-cost Basic logs plan on selected tables --We have identified ingestion of more than 1 GB per month to tables that are eligible for the low cost Basic log data plan. The Basic log plan gives you search capabilities for debugging and troubleshooting at a lower cost. --Learn more about [Log Analytics workspace - EnableBasicLogs (Consider configuring the low-cost Basic logs plan on selected tables)](https://aka.ms/basiclogs). --### Consider removing unused restored tables --You have one or more tables with restored data active in your workspace. If you're no longer using a restored data, delete the table to avoid unnecessary charges. --Learn more about [Log Analytics workspace - DeleteRestoredTables (Consider removing unused restored tables)](https://aka.ms/LogAnalyticsRestore). --### Consider enabling autopause on Spark compute --Autopause releases and shuts down unused Compute resources after a set idle period of inactivity. --Learn more about [Synapse workspace - EnableSynapseSparkComputeAutoPauseGuidance (Consider enabling autopause feature on spark compute.)](https://aka.ms/EnableSynapseSparkComputeAutoPauseGuidance). --### Consider enabling autoscale on Spark compute --Autoscale automatically scales the number of nodes in a cluster instance up and down. During the creation of a new Spark pool, you can set a minimum and maximum number of nodes when autoscale is selected. Autoscale then monitors the resource requirements of the load and scales the number of nodes up or down. There's no extra charge for this feature. --Learn more about [Synapse workspace - EnableSynapseSparkComputeAutoScaleGuidance (Consider enabling autoscale feature on spark compute.)](https://aka.ms/EnableSynapseSparkComputeAutoScaleGuidance). ----## Compute --### Standard SSD disks billing caps. --Customers running high IO workloads in Standard HDDs can upgrade to Standard SSDs and benefit from better performance and SLA and now experience a limit on the maximum number of billed transactions. --Learn more about [Understand Azure Disk Storage billing](/azure/virtual-machines/disks-understand-billing). --### Underutilized Disks Identified --You have disks that are utilized less than 10%, right-size to save cost. --Learn more about [Managed disks: Find and delete unattached disks](/azure/virtual-machines/disks-find-unattached-portal). --### You have disks that haven't been attached to a VM for more than 30 days. Evaluate if you still need the disk. --We've observed that you have disks that haven't been attached to a VM for more than 30 days. Evaluate if you still need the disk. If you decide to delete the disk, recovery isn't possible. We recommend that you create a snapshot before deletion or ensure the data in the disk is no longer required. --Learn more about [Disk - DeleteOrDowngradeUnattachedDisks (You have disks that haven't been attached to a VM for more than 30 days. Evaluate if you still need the disk.)](https://aka.ms/unattacheddisks). --### Right-size or shutdown underutilized virtual machine scale sets --We've analyzed the usage patterns of your virtual machine scale sets over the past seven days and identified virtual machine scale sets with low usage. While certain scenarios can result in low utilization by design, you can often save money by managing the size and number of virtual machine scale sets. --Learn more about [Virtual machine scale set - LowUsageVmss (Right-size or shutdown underutilized virtual machine scale sets)](https://aka.ms/aa_lowusagerec_vmss_learnmore). --> [!TIP] -> If you're unsure whether you can shut down an idle resource without causing chaos, you can first restrict access to the resource. Make sure the resource's role is restricted, too. Leave the resource up for a few weeks, and if nobody has connected to it or has complained, chances are the resource can be shut down safely. --### Use Virtual Machines with Ephemeral OS Disk enabled to save cost and get better performance --With Ephemeral OS Disk, You get these benefits: Save on storage cost for OS disk. Get lower read/write latency to OS disk. Faster VM Reimage operation by resetting OS (and Temporary disk) to its original state. It's preferable to use Ephemeral OS Disk for short-lived IaaS VMs or VMs with stateless workloads. --Learn more about [Subscription - EphemeralOsDisk (Use Virtual Machines with Ephemeral OS Disk enabled to save cost and get better performance)](/azure/virtual-machines/windows/ephemeral-os-disks). -----## Databases --### Right-size underutilized MariaDB servers --Our internal telemetry shows that your MariaDB database server resources have been underutilized for an extended period of time over the last seven days. Low resource utilization results in unwanted expenditure that can be fixed without significant performance impact. To reduce your costs and efficiently manage your resources, we recommend reducing the compute size (vCores) by half. --Learn more about [MariaDB server - OrcasMariaDbCpuRightSize (Right-size underutilized MariaDB servers)](https://aka.ms/mariadbpricing). --### Right-size underutilized MySQL servers --Our internal telemetry shows that your MySQL database server resources have been underutilized for an extended period of time over the last seven days. Low resource utilization results in unwanted expenditure that can be fixed without significant performance impact. To reduce your costs and efficiently manage your resources, we recommend reducing the compute size (vCores) by half. --Learn more about [MySQL server - OrcasMySQLCpuRightSize (Right-size underutilized MySQL servers)](https://aka.ms/mysqlpricing). --### Right-size underutilized PostgreSQL servers --Our internal telemetry shows that your PostgreSQL database server resources have been underutilized for an extended period of time over the last seven days. Low resource utilization results in unwanted expenditure that can be fixed without significant performance impact. To reduce your costs and efficiently manage your resources, we recommend reducing the compute size (vCores) by half. --Learn more about [PostgreSQL server - OrcasPostgreSqlCpuRightSize (Right-size underutilized PostgreSQL servers)](https://aka.ms/postgresqlpricing). --### Review the configuration of your Azure Cosmos DB free tier account --Your Azure Cosmos DB free tier account currently contains resources with a total provisioned throughput exceeding 1,000 Request Units per second (RU/s). Because the free tier only covers the first 1000 RU/s of throughput provisioned across your account, any throughput beyond 1000 RU/s is billed at the regular pricing. As a result, we anticipate that you're charged for the throughput currently provisioned on your Azure Cosmos DB account. --Learn more about [Azure Cosmos DB account - CosmosDBFreeTierOverage (Review the configuration of your Azure Cosmos DB free tier account)](/azure/cosmos-db/understand-your-bill#azure-free-tier). --### Consider taking action on your idle Azure Cosmos DB containers --We haven't detected any activity over the past 30 days on one or more of your Azure Cosmos DB containers. Consider lowering their throughput, or deleting them if you don't plan on using them. --Learn more about [Azure Cosmos DB account - CosmosDBIdleContainers (Consider taking action on your idle Azure Cosmos DB containers)](/azure/cosmos-db/how-to-provision-container-throughput). --### Enable autoscale on your Azure Cosmos DB database or container --Based on your usage in the past seven days, you can save by enabling autoscale. For each hour, we compared the RU/s provisioned to the actual utilization of the RU/s (what autoscale would have scaled to) and calculated the cost savings across the time period. Autoscale helps optimize your cost by scaling down RU/s when not in use. --Learn more about [Azure Cosmos DB account - CosmosDBAutoscaleRecommendations (Enable autoscale on your Azure Cosmos DB database or container)](/azure/cosmos-db/provision-throughput-autoscale). --### Configure manual throughput instead of autoscale on your Azure Cosmos DB database or container --Based on your usage in the past seven days, you can save by using manual throughput instead of autoscale. Manual throughput is more cost-effective when average utilization of your max throughput (RU/s) is greater than 66% or less than or equal to 10%. --Learn more about [Azure Cosmos DB account - CosmosDBMigrateToManualThroughputFromAutoscale (Configure manual throughput instead of autoscale on your Azure Cosmos DB database or container)](/azure/cosmos-db/how-to-choose-offer). -----## Management and Governance --### Azure Monitor --For Azure Monitor cost optimization suggestions, see [Optimize costs in Azure Monitor](../azure-monitor/best-practices-cost.md). --### Purchasing a savings plan for compute could unlock lower prices --We analyzed your compute usage over the last 30 days and recommend adding a savings plan to increase your savings. The savings plan unlocks lower prices on select compute services when you commit to spend a fixed hourly amount for 1 or 3 years. As you use select compute services globally, your usage is covered by the plan at reduced prices. During the times when your usage is above your hourly commitment, you’ll simply be billed at your regular pay-as-you-go prices. With savings automatically applying across compute usage globally, you’ll continue saving even as your usage needs change over time. Savings plan are more suited for dynamic workloads while accommodating for planned or unplanned changes while reservations are more suited for stable, predictable workloads with no planned changes. Saving estimates are calculated for individual subscriptions and the usage pattern observed over last 30 days. Shared scope savings plans are available in purchase experience and can further increase savings. --Learn more about [Subscription - SavingsPlan (Purchasing a savings plan for compute could unlock lower prices)](https://aka.ms/savingsplan-compute). ------## Networking --### Delete ExpressRoute circuits in the provider status of Not Provisioned --We noticed that your ExpressRoute circuit is in the provider status of Not Provisioned for more than one month. This circuit is currently billed hourly to your subscription. Delete the circuit if you aren't planning to provision the circuit with your connectivity provider. --Learn more about [ExpressRoute circuit - ExpressRouteCircuit (Delete ExpressRoute circuits in the provider status of Not Provisioned)](https://aka.ms/expressroute). --### Repurpose or delete idle virtual network gateways --We noticed that your virtual network gateway has been idle for over 90 days. This gateway is being billed hourly. Reconfigure this gateway, or delete it if you don't intend to use it anymore. --Learn more about [Virtual network gateway - IdleVNetGateway (Repurpose or delete idle virtual network gateways)](https://aka.ms/aa_idlevpngateway_learnmore). --### Consider migrating to Front Door Standard/Premium --Your Front Door Classic tier contains a large number of domains or routing rules, which adds extra charges. Front Door Standard or Premium tiers don't charge per additional domain or routing rule. Consider migrating to save costs. --Learn more about [Front Door pricing](https://aka.ms/afd-pricing). --### Consider using multiple endpoints under one single Front Door Standard/Premium profile --We detected your subscription contains multiple Front Door Standard/Premium profiles with a small number of endpoints on them. You can save costs in base fees by using multiple endpoints within one profile. You can use a maximum of 10 endpoints with Standard tier and 25 endpoints with Premium tier. --Learn more about [Front Door endpoints](https://aka.ms/afd-endpoints). --## Reserved instances --### Buy virtual machine reserved instances to save money over pay-as-you-go costs --Reserved instances can provide a significant discount over pay-as-you-go prices. With reserved instances, you can prepurchase the base costs for your virtual machines. Discounts automatically apply to new or existing VMs that have the same size and region as your reserved instance. We analyzed your usage over the last 30 days and recommend money-saving reserved instances. --Learn more about [Virtual machine - ReservedInstance (Buy virtual machine reserved instances to save money over pay-as-you-go costs)](https://aka.ms/reservedinstances). --### Consider App Service reserved instances to save over your on-demand costs --We analyzed your App Service usage pattern over the selected term, look-back period, and recommend a Reserved Instance purchase that maximizes your savings. With reserved instances, you can prepurchase hourly usage for the App Service plan and save over your Pay-as-you-go costs. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions based on usage pattern over selected Term, look-back period. --Learn more about [Subscription - AppServiceReservedCapacity (Consider App Service reserved instances to save over your on-demand costs)](https://aka.ms/rirecommendations). --### Consider Azure Cosmos DB reserved instances to save over your pay-as-you-go costs --We analyzed your Azure Cosmos DB usage pattern over last 30 days and calculate a Reserved Instance purchase that maximizes your savings. With reserved instances, you can prepurchase Azure Cosmos DB hourly usage and save over your pay-as-you-go costs. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and usage pattern over last 30 days. Shared scope recommendations are available in reservation purchase experience and can increase savings even more. --Learn more about [Subscription - CosmosDBReservedCapacity (Consider Azure Cosmos DB reserved instances to save over your pay-as-you-go costs)](https://aka.ms/rirecommendations). --### Consider virtual machine reserved instances to save over your on-demand costs --Reserved instances can provide a significant discount over on-demand prices. With reserved instances, you can prepurchase the base costs for your virtual machines. Discounts automatically apply to new or existing VMs that have the same size and region as your reserved instance. We analyzed your usage over the selected Term, look-back period, and recommend money-saving reserved instances. --Learn more about [Subscription - ReservedInstance (Consider virtual machine reserved instances to save over your on-demand costs)](https://aka.ms/rirecommendations). --### Consider Cosmos DB reserved instances to save over your pay-as-you-go costs --We analyzed your Cosmos DB usage pattern over selected Term, look-back period and calculate a Reserved Instance purchase that maximizes your savings. With reserved instances, you can prepurchase Cosmos DB hourly usage and save over your pay-as-you-go costs. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and usage pattern over the selected Term, look-back period. Shared scope recommendations are available in reservation purchase experience and can increase savings even more. --Learn more about [Subscription - CosmosDBReservedCapacity (Consider Cosmos DB reserved instances to save over your pay-as-you-go costs)](https://aka.ms/rirecommendations). --### Consider SQL PaaS DB reserved instances to save over your pay-as-you-go costs --We analyzed your SQL PaaS usage pattern over last 30 days and recommend a Reserved Instance purchase that maximizes your savings. With reserved instances, you can prepurchase hourly usage for your SQL PaaS deployments and save over your SQL PaaS compute costs. SQL license is charged separately and is not discounted by the reservation. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and the usage pattern observed over last 30 days. Shared scope recommendations are available in reservation purchase experience and can increase savings further. --Learn more about [Subscription - SQLReservedCapacity (Consider SQL PaaS DB reserved instances to save over your pay-as-you-go costs)](https://aka.ms/rirecommendations). --### Consider App Service stamp fee reserved instances to save over your on-demand costs --We analyzed your App Service isolated environment stamp fees usage pattern over last 30 days and recommend a Reserved Instance purchase to maximize your savings. With reserved instances, you can prepurchase hourly usage for the isolated environment stamp fee and save over your pay-as-you-go costs. Reserved instances only apply to the stamp fee and not to the App Service instances. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions based on usage pattern over last 30 days. --Learn more about [Subscription - AppServiceReservedCapacity (Consider App Service stamp fee reserved instances to save over your on-demand costs)](https://aka.ms/rirecommendations). --### Consider Database for MariaDB reserved instances to save over your pay-as-you-go costs --We analyzed your Azure Database for MariaDB usage pattern over last 30 days and recommend a Reserved Instance purchase that maximizes your savings. With reserved instances, you can prepurchase MariaDB hourly usage and save over your compute costs. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and the usage pattern over last 30 days. Shared scope recommendations are available in reservation purchase experience and can increase savings further. --Learn more about [Subscription - MariaDBSQLReservedCapacity (Consider Database for MariaDB reserved instances to save over your pay-as-you-go costs)](https://aka.ms/rirecommendations). --### Consider Database for MySQL reserved instances to save over your pay-as-you-go costs --We analyzed your MySQL Database usage pattern over last 30 days and recommend reserved instances purchase that maximizes your savings. With reserved instances, you can prepurchase MySQL hourly usage and save over your compute costs. Reserved instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and the usage pattern over last 30 days. Shared scope recommendations are available in reservation purchase experience and can increase savings further. --Learn more about [Subscription - MySQLReservedCapacity (Consider Database for MySQL reserved instances to save over your pay-as-you-go costs)](https://aka.ms/rirecommendations). --### Consider Database for PostgreSQL reserved instances to save over your pay-as-you-go costs --We analyzed your Database for PostgreSQL usage pattern over last 30 days and recommend a Reserved Instance purchase that maximizes your savings. With reserved instances, you can prepurchase PostgreSQL Database hourly usage and save over your on-demand costs. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and the usage pattern over last 30 days. Shared scope recommendations are available in reservation purchase experience and can increase savings further. --Learn more about [Subscription - PostgreSQLReservedCapacity (Consider Database for PostgreSQL reserved instances to save over your pay-as-you-go costs)](https://aka.ms/rirecommendations). --### Consider Cache for Redis reserved instances to save over your pay-as-you-go costs --We analyzed your Cache for Redis usage pattern over last 30 days and calculated a Reserved Instance purchase that maximizes your savings. With reserved instances, you can prepurchase Cache for Redis hourly usage and save over your current on-demand costs. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and the usage pattern observed over last 30 days. Shared scope recommendations are available in reservation purchase experience and can increase savings further. --Learn more about [Subscription - RedisCacheReservedCapacity (Consider Cache for Redis reserved instances to save over your pay-as-you-go costs)](https://aka.ms/rirecommendations). --### Consider Azure Synapse Analytics (formerly SQL DW) reserved instances to save over your pay-as-you-go costs --We analyze your Azure Synapse Analytics usage pattern over last 30 days and recommend a Reserved Instance purchase that maximizes your savings. With reserved instances, you can prepurchase Synapse Analytics hourly usage and save over your on-demand costs. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and the usage pattern observed over last 30 days. Shared scope recommendations are available in reservation purchase experience and can increase savings further. --Learn more about [Subscription - SQLDWReservedCapacity (Consider Azure Synapse Analytics (formerly SQL DW) reserved instances to save over your pay-as-you-go costs)](https://aka.ms/rirecommendations). --### (Preview) Consider Blob storage reserved instances to save on Blob v2 and Data Lake storage Gen2 costs --We analyzed your Azure Blob and Data Lake storage usage over last 30 days and calculated a Reserved Instance purchase that would maximize your savings. With reserved instances, you can prepurchase hourly usage and save over your current on-demand costs. Blob storage reserved instances applies only to data stored on Azure Blob (GPv2) and Azure Data Lake Storage (Gen 2). Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and the usage pattern observed over last 30 days. Shared scope recommendations are available in reservation purchase experience and can increase savings further. --Learn more about [Subscription - BlobReservedCapacity ((Preview) Consider Blob storage reserved instances to save on Blob v2 and Data Lake storage Gen2 costs)](https://aka.ms/rirecommendations). --### Consider Azure Dedicated Host reserved instances to save over your on-demand costs --We analyzed your Azure Dedicated Host usage over last 30 days and calculated a Reserved Instance purchase that would maximize your savings. With reserved instances, you can prepurchase hourly usage and save over your current on-demand costs. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and the usage pattern observed over last 30 days. Shared scope recommendations are available in reservation purchase experience and can increase savings further. --Learn more about [Subscription - AzureDedicatedHostReservedCapacity (Consider Azure Dedicated Host reserved instances to save over your on-demand costs)](https://aka.ms/rirecommendations). --### Consider Data Factory reserved instances to save over your on-demand costs --We analyzed your Data Factory usage over last 30 days and calculated a Reserved Instance purchase that would maximize your savings. With reserved instances, you can prepurchase hourly usage and save over your current on-demand costs. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and the usage pattern observed over last 30 days. Shared scope recommendations are available in reservation purchase experience and can increase savings further. --Learn more about [Subscription - DataFactorybReservedCapacity (Consider Data Factory reserved instances to save over your on-demand costs)](https://aka.ms/rirecommendations). --### Consider Azure Data Explorer reserved instances to save over your on-demand costs --We analyzed your Azure Data Explorer usage over last 30 days and calculated a Reserved Instance purchase that would maximize your savings. With reserved instances, you can prepurchase hourly usage and save over your current on-demand costs. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and the usage pattern observed over last 30 days. Shared scope recommendations are available in reservation purchase experience and can increase savings further. --Learn more about [Subscription - AzureDataExplorerReservedCapacity (Consider Azure Data Explorer reserved instances to save over your on-demand costs)](https://aka.ms/rirecommendations). --### Consider Azure Files reserved instances to save over your on-demand costs --We analyzed your Azure Files usage over last 30 days and calculated a Reserved Instance purchase that would maximize your savings. With reserved instances, you can prepurchase hourly usage and save over your current on-demand costs. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and the usage pattern observed over last 30 days. Shared scope recommendations are available in reservation purchase experience and can increase savings further. --Learn more about [Subscription - AzureFilesReservedCapacity (Consider Azure Files reserved instances to save over your on-demand costs)](https://aka.ms/rirecommendations). --### Consider Azure VMware Solution reserved instances to save over your on-demand costs --We analyzed your Azure VMware Solution usage over last 30 days and calculated a Reserved Instance purchase that would maximize your savings. With reserved instances, you can prepurchase hourly usage and save over your current on-demand costs. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and the usage pattern observed over last 30 days. Shared scope recommendations are available in reservation purchase experience and can increase savings further. --Learn more about [Subscription - AzureVMwareSolutionReservedCapacity (Consider Azure VMware Solution reserved instances to save over your on-demand costs)](https://aka.ms/rirecommendations). --### Consider NetApp Storage reserved instances to save over your on-demand costs --We analyzed your NetApp Storage usage over last 30 days and calculated a Reserved Instance purchase that would maximize your savings. With reserved instances, you can prepurchase hourly usage and save over your current on-demand costs. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and the usage pattern observed over last 30 days. Shared scope recommendations are available in reservation purchase experience and can increase savings further. --Learn more about [Subscription - NetAppStorageReservedCapacity (Optimize costs for Azure Files with Reservations)](/azure/storage/files/files-reserve-capacity). --### Consider Azure Managed Disk reserved instances to save over your on-demand costs --We analyzed your Azure Managed Disk usage over last 30 days and calculated a Reserved Instance purchase that would maximize your savings. With reserved instances, you can prepurchase hourly usage and save over your current on-demand costs. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and the usage pattern observed over last 30 days. Shared scope recommendations are available in reservation purchase experience and can increase savings further. --Learn more about [Subscription - AzureManagedDiskReservedCapacity (Consider Azure Managed Disk reserved instances to save over your on-demand costs)](https://aka.ms/rirecommendations). --### Consider Red Hat reserved instances to save over your on-demand costs --We analyzed your Red Hat usage over last 30 days and calculated a Reserved Instance purchase that would maximize your savings. With reserved instances, you can prepurchase hourly usage and save over your current on-demand costs. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and the usage pattern observed over last 30 days. Shared scope recommendations are available in reservation purchase experience and can increase savings further. --Learn more about [Subscription - RedHatReservedCapacity (Consider Red Hat reserved instances to save over your on-demand costs)](https://aka.ms/rirecommendations). --### Consider RedHat OSA reserved instances to save over your on-demand costs --We analyzed your RedHat Open Source Assurance (OSA) usage over last 30 days and calculated a Reserved Instance purchase that would maximize your savings. With reserved instances, you can prepurchase hourly usage and save over your current on-demand costs. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and the usage pattern observed over last 30 days. Shared scope recommendations are available in reservation purchase experience and can increase savings further. --Learn more about [Subscription - RedHatOsaReservedCapacity (Consider RedHat OSA reserved instances to save over your on-demand costs)](https://aka.ms/rirecommendations). --### Consider SapHana reserved instances to save over your on-demand costs --We analyzed your SapHana usage over last 30 days and calculated a Reserved Instance purchase that would maximize your savings. With reserved instances, you can prepurchase hourly usage and save over your current on-demand costs. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and the usage pattern observed over last 30 days. Shared scope recommendations are available in reservation purchase experience and can increase savings further. --Learn more about [Subscription - SapHanaReservedCapacity (Consider SapHana reserved instances to save over your on-demand costs)](https://aka.ms/rirecommendations). --### Consider SuseLinux reserved instances to save over your on-demand costs --We analyzed your SuseLinux usage over last 30 days and calculated a Reserved Instance purchase that would maximize your savings. With reserved instances, you can prepurchase hourly usage and save over your current on-demand costs. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and the usage pattern observed over last 30 days. Shared scope recommendations are available in reservation purchase experience and can increase savings further. --Learn more about [Subscription - SuseLinuxReservedCapacity (Consider SuseLinux reserved instances to save over your on-demand costs)](https://aka.ms/rirecommendations). --### Consider VMware Cloud Simple reserved instances --We analyzed your VMware Cloud Simple usage over last 30 days and calculated a Reserved Instance purchase that would maximize your savings. With reserved instances, you can prepurchase hourly usage and save over your current on-demand costs. Reserved Instance is a billing benefit and automatically applies to new or existing deployments. Saving estimates are calculated for individual subscriptions and the usage pattern observed over last 30 days. Shared scope recommendations are available in reservation purchase experience and can increase savings further. --Learn more about [Subscription - VMwareCloudSimpleReservedCapacity (Consider VMware Cloud Simple reserved instances )](https://aka.ms/rirecommendations). --### Configure automatic renewal for your expiring reservation --The reserved instances listed are expiring soon or recently expired. Your resources will continue to operate normally, however, you'll be billed at the on-demand rates going forward. To optimize your costs, configure automatic renewal for these reservations or purchase a replacement manually. --Learn more about [Reservation - ReservedInstancePurchaseNew (Configure automatic renewal for your expiring reservation)](https://aka.ms/reservedinstances). --### Purchasing a savings plan for compute could unlock lower prices --We analyzed your compute usage over the last 30 days and recommend adding a savings plan to increase your savings. The savings plan unlocks lower prices on select compute services when you commit to spend a fixed hourly amount for one or three years. As you use select compute services globally, your usage is covered by the plan at reduced prices. During the times when your usage is above your hourly commitment, you’ll be billed at your regular pay-as-you-go prices. With savings automatically applying across compute usage globally, you’ll continue saving even as your usage needs change over time. Savings plan are more suited for dynamic workloads while accommodating for planned or unplanned changes while reservations are more suited for stable, predictable workloads with no planned changes. Saving estimates are calculated for individual subscriptions and the usage pattern observed over last 30 days. Shared scope savings plans are available in purchase experience and can further increase savings. --Learn more about [Subscription - SavingsPlan (Purchasing a savings plan for compute could unlock lower prices)](https://aka.ms/savingsplan-compute). --### Consider Cosmos DB reserved instances to save over your pay-as-you-go costs --We analyzed your Cosmos DB usage pattern over selected Term, look-back period and calculate a Reserved Instance purchase that maximizes your savings. With reserved instances you can pre-purchase Cosmos DB hourly usage and save over your pay-as-you-go costs. Reserved Instance is a billing benefit and will automatically apply to new or existing deployments. Saving estimates are calculated for individual subscriptions and usage pattern over selected Term, look-back period. Shared scope recommendations are available in reservation purchase experience and can increase savings even more. --Learn more about [Subscription - CosmosDBReservedCapacity (Consider Cosmos DB reserved instances to save over your pay-as-you-go costs)](https://aka.ms/rirecommendations). -----## Storage --### Use Standard Storage to store Managed Disks snapshots --To save 60% of cost, store your snapshots in Standard Storage, regardless of the storage type of the parent disk. It is the default option for Managed Disks snapshots. Migrate your snapshot from Premium to Standard Storage. Refer to Managed Disks pricing details. --Learn more about [Managed Disk Snapshot - ManagedDiskSnapshot (Use Standard Storage to store Managed Disks snapshots)](https://aka.ms/aa_manageddisksnapshot_learnmore). --### Revisit retention policy for classic log data in storage accounts --Large classic log data is detected on your storage accounts. You're billed on capacity of data stored in storage accounts including classic logs. Check the retention policy of classic logs and update with necessary period to retain less log data. This would reduce unnecessary classic log data and save your billing cost from less capacity. --Learn more about [Storage Account - XstoreLargeClassicLog (Revisit retention policy for classic log data in storage accounts)](/azure/storage/common/manage-storage-analytics-logs#modify-retention-policy). --### Based on your high transactions/TB ratio, premium storage might be more cost effective --Your transactions/TB ratio might be high. Exact number would depend on transaction mix and region but anywhere over 30 or 35 TPB/TB are good candidates to evaluate a move to Premium storage. --Learn more about [Storage Account - MoveToPremiumStorage (Based on your high transactions/TB ratio, there is a possibility that premium storage might be more cost effective in addition to being performant for your scenario. More details on pricing for premium and standard accounts can be found here)](https://aka.ms/azureblobstoragepricing). --### Use differential or incremental backup for database workloads --For SQL/HANA DBs in Azure VMs being backed up to Azure, using daily differential with weekly full backup is often more cost-effective than daily fully backups. For HANA, Azure Backup also supports incremental backup that is even more cost effective. --Learn more about [Recovery Services vault - Optimize costs of database backup (Use differential or incremental backup for database workloads)](https://aka.ms/DBBackupCostOptimization). -----## Web --### Right-size underutilized App Service plans --We've analyzed the usage patterns of your App Service plan over the past seven days and identified low CPU usage. While certain scenarios can result in low utilization by design, you can save money by choosing a less expensive SKU while retaining the same features. --> [!NOTE] -> - Currently, this recommendation only works for App Service plans running on Windows on a SKU that allows you to downscale to less expensive tiers without losing any features, like from P3v2 to P2v2 or from P2v2 to P1v2. -> - CPU bursts that last only a few minutes might not be correctly detected. Perform a careful analysis in your App Service plan metrics blade before downscaling your SKU. --Learn more about [App Service plans](../app-service/overview-hosting-plans.md). --### Unused/Empty App Service plans --Your App Service plan does not have any running applications associated with it. Consider deleting the resource to reduce expenses, or add new applications under it to utilize its capabilities. - -Learn more about [App Service plans](../app-service/overview-hosting-plans.md). ------## Next steps --Learn more about [Cost Optimization - Microsoft Azure Well Architected Framework](/azure/architecture/framework/cost/overview) |
| advisor | Advisor Reference Operational Excellence Recommendations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-reference-operational-excellence-recommendations.md | - Title: Operational excellence recommendations -description: Operational excellence recommendations - Previously updated : 10/05/2023---# Operational excellence recommendations --Operational excellence recommendations in Azure Advisor can help you with: -- Process and workflow efficiency.-- Resource manageability.-- Deployment best practices. --You can get these recommendations on the **Operational Excellence** tab of the Advisor dashboard. --1. Sign in to the [**Azure portal**](https://portal.azure.com). --1. Search for and select [**Advisor**](https://aka.ms/azureadvisordashboard) from any page. --1. On the **Advisor** dashboard, select the **Operational Excellence** tab. ---## AI + machine learning --### Upgrade to the latest version of the Immersive Reader SDK --We have identified resources under this subscription using outdated versions of the Immersive Reader SDK. The latest version of the Immersive Reader SDK provides you with updated security, performance, and an expanded set of features for customizing and enhancing your integration experience. --Learn more about [Azure AI Immersive Reader](/azure/ai-services/immersive-reader/). --### Upgrade to the latest version of the Immersive Reader SDK --We have identified resources under this subscription using outdated versions of the Immersive Reader SDK. The latest version of the Immersive Reader SDK provides you with updated security, performance and an expanded set of features for customizing and enhancing your integration experience. --Learn more about [Cognitive Service - ImmersiveReaderSDKRecommendation (Upgrade to the latest version of the Immersive Reader SDK)](https://aka.ms/ImmersiveReaderAzureAdvisorSDKLearnMore). ----## Analytics --### Reduce the cache policy on your Data Explorer tables --Reduce the table cache policy to match the usage patterns (query lookback period) --Learn more about [Data explorer resource - ReduceCacheForAzureDataExplorerTablesOperationalExcellence (Reduce the cache policy on your Data Explorer tables)](https://aka.ms/adxcachepolicy). -----## Compute --### Update your outdated Azure Spring Apps SDK to the latest version --We have identified API calls from an outdated Azure Spring Apps SDK. We recommend upgrading to the latest version for the latest fixes, performance improvements, and new feature capabilities. --Learn more about the [Azure Spring Apps service](../spring-apps/index.yml). --### Update Azure Spring Apps API Version --We have identified API calls from outdated Azure Spring Apps API for resources under this subscription. We recommend switching to the latest Azure Spring Apps API version. You need to update your existing code to use the latest API version. Also, you need to upgrade your Azure SDK and Azure CLI to the latest version, which ensures you receive the latest features and performance improvements. --Learn more about the [Azure Spring Apps service](../spring-apps/index.yml). --### New HCX version is available for upgrade --Your HCX version isn't latest. New HCX version is available for upgrade. Updating a VMware HCX system installs the latest features, problem fixes, and security patches. --Learn more about [AVS Private cloud - HCXVersion (New HCX version is available for upgrade)](https://aka.ms/vmware/hcxdoc). --### Recreate your pool to get the latest node agent features and fixes --Your pool has an old node agent. Consider recreating your pool to get the latest node agent updates and bug fixes. --Learn more about [Batch account - OldPool (Recreate your pool to get the latest node agent features and fixes)](https://aka.ms/batch_oldpool_learnmore). --### Delete and recreate your pool to remove a deprecated internal component --Your pool is using a deprecated internal component. Delete and recreate your pool for improved stability and performance. --Learn more about [Batch account - RecreatePool (Delete and recreate your pool to remove a deprecated internal component)](https://aka.ms/batch_deprecatedcomponent_learnmore). --### Upgrade to the latest API version to ensure your Batch account remains operational --In the past 14 days, you have invoked a Batch management or service API version that is scheduled for deprecation. Upgrade to the latest API version to ensure your Batch account remains operational. --Learn more about [Batch account - UpgradeAPI (Upgrade to the latest API version to ensure your Batch account remains operational.)](https://aka.ms/batch_deprecatedapi_learnmore). --### Delete and recreate your pool using a different VM size --Your pool is using A8-A11 VMs, which are set to be retired in March 2021. Delete your pool and recreate it with a different VM size. --Learn more about [Batch account - RemoveA8_A11Pools (Delete and recreate your pool using a different VM size)](https://aka.ms/batch_a8_a11_retirement_learnmore). --### Recreate your pool with a new image --Your pool is using an image with an imminent expiration date. Recreate the pool with a new image to avoid potential interruptions. A list of newer images is available via the ListSupportedImages API. --Learn more about [Batch account - EolImage (Recreate your pool with a new image)](https://aka.ms/batch_expiring_image_learn_more). --### Increase the number of compute resources you can deploy by 10 vCPU --If quota limits are exceeded, new VM deployments are blocked until quota is increased. Increase your quota now to enable deployment of more resources. Learn More --Learn more about [Virtual machine - IncreaseQuotaExperiment (Increase the number of compute resources you can deploy by 10 vCPU)](https://aka.ms/SubscriptionServiceLimits). --### Add Azure Monitor to your virtual machine (VM) labeled as production --Azure Monitor for VMs monitors your Azure virtual machines (VM) and Virtual Machine Scale Sets at scale. It analyzes the performance and health of your Windows and Linux VMs, and it monitors their processes and dependencies on other resources and external processes. It includes support for monitoring performance and application dependencies for VMs that are hosted on-premises or in another cloud provider. --Learn more about [Virtual machine - AddMonitorProdVM (Add Azure Monitor to your virtual machine (VM) labeled as production)](/azure/azure-monitor/insights/vminsights-overview). --### Excessive NTP client traffic caused by frequent DNS lookups and NTP sync for new servers, which happens often on some global NTP servers --Excessive NTP client traffic caused by frequent DNS lookups and NTP sync for new servers, which happens often on some global NTP servers. Frequent DNS lookups and NTP sync can be viewed as malicious traffic and blocked by the DDOS service in the Azure environment --Learn more about [Virtual machine - GetVmlistFortigateNtpIssue (Excessive NTP client traffic caused by frequent DNS lookups and NTP sync for new servers, which happens often on some global NTP servers.)](https://docs.fortinet.com/document/fortigate/6.2.3/fortios-release-notes/236526/known-issues). --### An Azure environment update has been rolled out that might affect your Checkpoint Firewall --The image version of the Checkpoint firewall installed might have been affected by the recent Azure environment update. A kernel panic resulting in a reboot to factory defaults can occur in certain circumstances. --Learn more about [Virtual machine - NvaCheckpointNicServicing (An Azure environment update has been rolled out that might affect your Checkpoint Firewall.)](https://supportcenter.checkpoint.com/supportcenter/portal). --### The iControl REST interface has an unauthenticated remote command execution vulnerability --An unauthenticated remote command execution vulnerability allows for unauthenticated attackers with network access to the iControl REST interface, through the BIG-IP management interface and self IP addresses, to execute arbitrary system commands, create or delete files, and disable services. This vulnerability can only be exploited through the control plane and can't be exploited through the data plane. Exploitation can lead to complete system compromise. The BIG-IP system in Appliance mode is also vulnerable --Learn more about [Virtual machine - GetF5vulnK03009991 (The iControl REST interface has an unauthenticated remote command execution vulnerability.)](https://support.f5.com/csp/article/K03009991). --### NVA Accelerated Networking enabled but potentially not working --Desired state for Accelerated Networking is set to ΓÇÿtrueΓÇÖ for one or more interfaces on your VM, but actual state for accelerated networking isn't enabled. --Learn more about [Virtual machine - GetVmListANDisabled (NVA Accelerated Networking enabled but potentially not working.)](../virtual-network/create-vm-accelerated-networking-cli.md). --### Virtual machines with Citrix Application Delivery Controller (ADC) and accelerated networking enabled might disconnect during maintenance operation --We have identified that you're running a Network virtual Appliance (NVA) called Citrix Application Delivery Controller (ADC), and the NVA has accelerated networking enabled. The Virtual machine that this NVA is deployed on might experience connectivity issues during a platform maintenance operation. It is recommended that you follow the article provided by the vendor: https://aka.ms/Citrix_CTX331516 --Learn more about [Virtual machine - GetCitrixVFRevokeError (Virtual machines with Citrix Application Delivery Controller (ADC) and accelerated networking enabled might disconnect during maintenance operation)](https://aka.ms/Citrix_CTX331516). --### Update your outdated Azure Spring Cloud SDK to the latest version --We have identified API calls from an outdated Azure Spring Cloud SDK. We recommend upgrading to the latest version for the latest fixes, performance improvements, and new feature capabilities. --Learn more about [Spring Cloud Service - SpringCloudUpgradeOutdatedSDK (Update your outdated Azure Spring Cloud SDK to the latest version)](/azure/spring-cloud). --### Update Azure Spring Cloud API Version --We have identified API calls from outdated Azure Spring Cloud API for resources under this subscription. We recommend switching to the latest Spring Cloud API version. You need to update your existing code to use the latest API version. Also, you need to upgrade your Azure SDK and Azure CLI to the latest version, which ensures you receive the latest features and performance improvements. --Learn more about [Spring Cloud Service - UpgradeAzureSpringCloudAPI (Update Azure Spring Cloud API Version)](/azure/spring-cloud). ------## Containers --### The api version you use for Microsoft.App is deprecated, use latest api version --The api version you use for Microsoft.App is deprecated, use latest api version --Learn more about [Microsoft App Container App - UseLatestApiVersion (The api version you use for Microsoft.App is deprecated, use latest api version)](https://aka.ms/containerappsapiversion). --### Update cluster's service principal --This cluster's service principal is expired and the cluster isn't healthy until the service principal is updated --Learn more about [Kubernetes service - UpdateServicePrincipal (Update cluster's service principal)](/azure/aks/update-credentials). --### Monitoring addon workspace is deleted --Monitoring addon workspace is deleted. Correct issues to set up monitoring addon. --Learn more about [Kubernetes service - MonitoringAddonWorkspaceIsDeleted (Monitoring addon workspace is deleted)](https://aka.ms/aks-disable-monitoring-addon). --### Deprecated Kubernetes API in 1.16 is found --Deprecated Kubernetes API in 1.16 is found. Avoid using deprecated API. --Learn more about [Kubernetes service - DeprecatedKubernetesAPIIn116IsFound (Deprecated Kubernetes API in 1.16 is found)](https://aka.ms/aks-deprecated-k8s-api-1.16). --### Enable the Cluster Autoscaler --This cluster has not enabled AKS Cluster Autoscaler, and it can't adapt to changing load conditions unless you have other ways to autoscale your cluster --Learn more about [Kubernetes service - EnableClusterAutoscaler (Enable the Cluster Autoscaler)](/azure/aks/cluster-autoscaler). --### The AKS node pool subnet is full --Some of the subnets for this cluster's node pools are full and can't take any more worker nodes. Using the Azure CNI plugin requires to reserve IP addresses for each node and all the pods for the node at node provisioning time. If there isn't enough IP address space in the subnet, no worker nodes can be deployed. Additionally, the AKS cluster can't be upgraded if the node subnet is full. --Learn more about [Kubernetes service - NodeSubnetIsFull (The AKS node pool subnet is full)](/azure/aks/create-node-pools#add-a-node-pool-with-a-unique-subnet). --### Expired ETCD cert --Expired ETCD cert, update. --Learn more about [Kubernetes service - ExpiredETCDCertPre03012022 (Expired ETCD cert)](https://aka.ms/AKSUpdateCredentials). --### Disable the Application Routing Addon --This cluster has Pod Security Policies enabled, which are going to be deprecated in favor of Azure Policy for AKS --Learn more about [Kubernetes service - UseAzurePolicyForKubernetes (Disable the Application Routing Addon)](/azure/aks/use-pod-security-on-azure-policy). --### Use Ephemeral OS disk --This cluster isn't using ephemeral OS disks which can provide lower read/write latency, along with faster node scaling and cluster upgrades --Learn more about [Kubernetes service - UseEphemeralOSdisk (Use Ephemeral OS disk)](/azure/aks/concepts-storage#ephemeral-os-disk). --### Outdated Azure Linux (Mariner) OS SKUs Found --Found outdated Azure Linux (Mariner) OS SKUs. 'CBL-Mariner' SKU isn't supported. 'Mariner' SKU is equivalent to 'AzureLinux', but it's advisable to switch to 'AzureLinux' SKU for future updates and support, as 'AzureLinux' is the Generally Available version. --Learn more about [Kubernetes service - ClustersWithDeprecatedMarinerSKU (Outdated Azure Linux (Mariner) OS SKUs Found)](https://aka.ms/AzureLinuxOSSKU). --### Free and Standard tiers for AKS control plane management --This cluster has not enabled the Standard tier that includes the Uptime SLA by default, and is limited to an SLO of 99.5%. --Learn more about [Kubernetes service - Free and Standard Tier](/azure/aks/free-standard-pricing-tiers). --### Deprecated Kubernetes API in 1.22 has been found --Deprecated Kubernetes API in 1.22 has been found. Avoid using deprecated APIs. --Learn more about [Kubernetes service - DeprecatedKubernetesAPIIn122IsFound (Deprecated Kubernetes API in 1.22 has been found)](https://aka.ms/aks-deprecated-k8s-api-1.22). ----## Databases --### Azure SQL IaaS Agent must be installed in full mode --Full mode installs the SQL IaaS Agent to the VM to deliver full functionality. Use it for managing a SQL Server VM with a single instance. There is no cost associated with using the full manageability mode. System administrator permissions are required. Note that installing or upgrading to full mode is an online operation, there is no restart required. --Learn more about [SQL virtual machine - UpgradeToFullMode (SQL IaaS Agent must be installed in full mode)](/azure/azure-sql/virtual-machines/windows/sql-server-iaas-agent-extension-automate-management). --### Install SQL best practices assessment on your SQL VM --SQL best practices assessment provides a mechanism to evaluate the configuration of your Azure SQL VM for best practices like indexes, deprecated features, trace flag usage, statistics, etc. Assessment results are uploaded to your Log Analytics workspace using Azure Monitoring Agent (AMA). --Learn more about [SQL virtual machine - SqlAssessmentAdvisorRec (Install SQL best practices assessment on your SQL VM)](/azure/azure-sql/virtual-machines/windows/sql-assessment-for-sql-vm). --### Migrate Azure Cosmos DB attachments to Azure Blob Storage --We noticed that your Azure Cosmos DB collection is using the legacy attachments feature. We recommend migrating attachments to Azure Blob Storage to improve the resiliency and scalability of your blob data. --Learn more about [Azure Cosmos DB account - CosmosDBAttachments (Migrate Azure Cosmos DB attachments to Azure Blob Storage)](/azure/cosmos-db/attachments#migrating-attachments-to-azure-blob-storage). --### Improve resiliency by migrating your Azure Cosmos DB accounts to continuous backup --Your Azure Cosmos DB accounts are configured with periodic backup. Continuous backup with point-in-time restore is now available on these accounts. With continuous backup, you can restore your data to any point in time within the past 30 days. Continuous backup might also be more cost-effective as a single copy of your data is retained. --Learn more about [Azure Cosmos DB account - CosmosDBMigrateToContinuousBackup (Improve resiliency by migrating your Azure Cosmos DB accounts to continuous backup)](/azure/cosmos-db/continuous-backup-restore-introduction). --### Enable partition merge to configure an optimal database partition layout --Your account has collections that could benefit from enabling partition merge. Minimizing the number of partitions reduces rate limiting and resolve storage fragmentation problems. Containers are likely to benefit from this if the RU/s per physical partition is < 3000 RUs and storage is < 20 GB. --Learn more about [Cosmos DB account - CosmosDBPartitionMerge (Enable partition merge to configure an optimal database partition layout)](/azure/cosmos-db/merge?tabs=azure-powershell). ----### Your Azure Database for MySQL - Flexible Server is vulnerable using weak, deprecated TLSv1 or TLSv1.1 protocols --To support modern security standards, MySQL community edition discontinued the support for communication over Transport Layer Security (TLS) 1.0 and 1.1 protocols. Microsoft also stopped supporting connections over TLSv1 and TLSv1.1 to Azure Database for MySQL - Flexible server to comply with the modern security standards. We recommend you upgrade your client driver to support TLSv1.2. --Learn more about [Azure Database for MySQL flexible server - OrcasMeruMySqlTlsDeprecation (Your Azure Database for MySQL - Flexible Server is vulnerable using weak, deprecated TLSv1 or TLSv1.1 protocols)](https://aka.ms/encrypted_connection_deprecated_protocols). --### Optimize or partition tables in your database which has huge tablespace size --The maximum supported tablespace size in Azure Database for MySQL -Flexible server is 4TB. To effectively manage large tables, we recommended that you optimize the table or implement partitioning, which helps distribute the data across multiple files and prevent reaching the hard limit of 4TB in the tablespace. --Learn more about [Azure Database for MySQL flexible server - MySqlFlexibleServerSingleTablespace4TBLimit2bf9 (Optimize or partition tables in your database which has huge tablespace size)](https://techcommunity.microsoft.com/t5/azure-database-for-mysql-blog/how-to-reclaim-storage-space-with-azure-database-for-mysql/ba-p/3615876). --### Enable storage autogrow for MySQL Flexible Server --Storage auto-growth prevents a server from running out of storage and becoming read-only. --Learn more about [Azure Database for MySQL flexible server - MySqlFlexibleServerStorageAutogrow43b64 (Enable storage autogrow for MySQL Flexible Server)](/azure/mysql/flexible-server/concepts-service-tiers-storage#storage-auto-grow). --### Apply resource delete lock --Lock your MySQL Flexible Server to protect from accidental user deletions and modifications --Learn more about [Azure Database for MySQL flexible server - MySqlFlexibleServerResourceLockbe19e (Apply resource delete lock)](/azure/azure-resource-manager/management/lock-resources). --### Add firewall rules for MySQL Flexible Server --Add firewall rules to protect your server from unauthorized access --Learn more about [Azure Database for MySQL flexible server - MySqlFlexibleServerNoFirewallRule6e523 (Add firewall rules for MySQL Flexible Server)](/azure/mysql/flexible-server/how-to-manage-firewall-portal). ---### Injecting a cache into a virtual network (VNet) imposes complex requirements on your network configuration, which is a common source of incidents affecting customer applications --Injecting a cache into a virtual network (VNet) imposes complex requirements on your network configuration. It's difficult to configure the network accurately and avoid affecting cache functionality. It's easy to break the cache accidentally while making configuration changes for other network resources, which is a common source of incidents affecting customer applications --Learn more about [Redis Cache Server - PrivateLink (Injecting a cache into a virtual network (VNet) imposes complex requirements on your network configuration. This is a common source of incidents affecting customer applications)](https://aka.ms/VnetToPrivateLink). --### Support for TLS versions 1.0 and 1.1 is retiring on September 30, 2024 --Support for TLS 1.0/1.1 is retiring on September 30, 2024. Configure your cache to use TLS 1.2 only and your application to use TLS 1.2 or later. See https://aka.ms/TLSVersions for more information. --Learn more about [Redis Cache Server - TLSVersion (Support for TLS versions 1.0 and 1.1 is retiring on September 30, 2024.)](https://aka.ms/TLSVersions). --### TLS versions 1.0 and 1.1 are known to be susceptible to security attacks, and have other Common Vulnerabilities and Exposures (CVE) weaknesses --TLS versions 1.0 and 1.1 are known to be susceptible to security attacks, and have other Common Vulnerabilities and Exposures (CVE) weaknesses. We highly recommend that you configure your cache to use TLS 1.2 only and your application to use TLS 1.2 or later. See https://aka.ms/TLSVersions for more information. --Learn more about [Redis Cache Server - TLSVersion (TLS versions 1.0 and 1.1 are known to be susceptible to security attacks, and have other Common Vulnerabilities and Exposures (CVE) weaknesses.)](https://aka.ms/TLSVersions). --### Cloud service caches are being retired in August 2024, migrate before then to avoid any problems --This instance of Azure Cache for Redis has a dependency on Cloud Services (classic) which is being retired in August 2024. Follow the instructions found in the following link to migrate to an instance without this dependency. If you need to upgrade your cache to Redis 6 note that upgrading a cache with a dependency on cloud services isn't supported. You must migrate your cache instance to Virtual Machine Scale Set before upgrading. For more information, see the following link. Note: If you have completed your migration away from Cloud Services, allow up to 24 hours for this recommendation to be removed --Learn more about [Redis Cache Server - MigrateFromCloudService (Cloud service caches are being retired in August 2024, migrate before then to avoid any problems)](/azure/azure-cache-for-redis/cache-faq#caches-with-a-dependency-on-cloud-services-%28classic%29). --### Redis persistence allows you to persist data stored in a cache so you can reload data from an event that caused data loss. --Redis persistence allows you to persist data stored in Redis. You can also take snapshots and back up the data. If there's a hardware failure, the persisted data is automatically loaded in your cache instance. Data loss is possible if a failure occurs where Cache nodes are down. --Learn more about [Redis Cache Server - Persistence (Redis persistence allows you to persist data stored in a cache so you can reload data from an event that caused data loss.)](https://aka.ms/redis/persistence). --### Using persistence with soft delete enabled can increase storage costs. --Check to see if your storage account has soft delete enabled before using the data persistence feature. Using data persistence with soft delete causes very high storage costs. For more information, see the following link. --Learn more about [Redis Cache Server - PersistenceSoftEnable (Using persistence with soft delete enabled can increase storage costs.)](https://aka.ms/redis/persistence). --### You might benefit from using an Enterprise tier cache instance --This instance of Azure Cache for Redis is using one or more advanced features from the list - more than 6 shards, geo-replication, zone-redundancy or persistence. Consider switching to an Enterprise tier cache to get the most out of your Redis experience. Enterprise tier caches offer higher availability, better performance and more powerful features like active geo-replication. --Learn more about [Redis Cache Server - ConsiderUsingRedisEnterprise (You might benefit from using an Enterprise tier cache instance)](https://aka.ms/redisenterpriseupgrade). ------## Integration --### Use Azure AD-based authentication for more fine-grained control and simplified management --You can use Azure AD-based authentication, instead of gateway tokens, which allows you to use standard procedures to create, assign and manage permissions and control expiry times. Additionally, you gain fine-grained control across gateway deployments and easily revoke access in case of a breach. --Learn more about [Api Management - ShgwUseAdAuth (Use Azure AD-based authentication for more fine-grained control and simplified management)](https://aka.ms/apim/shgw/how-to/use-ad-auth). --### Validate JWT policy is being used with security keys that have insecure key size for validating Json Web Token (JWT). --Validate JWT policy is being used with security keys that have insecure key size for validating Json Web Token (JWT). We recommend using longer key sizes to improve security for JWT-based authentication & authorization. --Learn more about [Api Management - validate-jwt-with-insecure-key-size (Validate JWT policy is being used with security keys that have insecure key size for validating Json Web Token (JWT).)](). --### Use self-hosted gateway v2 --We have identified one or more instances of your self-hosted gateway(s) that are using a deprecated version of the self-hosted gateway (v0.x and/or v1.x). --Learn more about [Api Management - shgw-legacy-image-usage (Use self-hosted gateway v2)](https://aka.ms/apim/shgw/migration/v2). --### Use Configuration API v2 for self-hosted gateways --We have identified one or more instances of your self-hosted gateway(s) that are using the deprecated Configuration API v1. --Learn more about [Api Management - shgw-config-api-v1-usage (Use Configuration API v2 for self-hosted gateways)](https://aka.ms/apim/shgw/migration/v2). --### Only allow tracing on subscriptions intended for debugging purposes. Sharing subscription keys with tracing allowed with unauthorized users could lead to disclosure of sensitive information contained in tracing logs such as keys, access tokens, passwords, internal hostnames, and IP addresses. --Traces generated by Azure API Management service might contain sensitive information that is intended for service owner and must not be exposed to clients using the service. Using tracing enabled subscription keys in production or automated scenarios creates a risk of sensitive information exposure if client making call to the service requests a trace. --Learn more about [Api Management - heavy-tracing-usage (Only allow tracing on subscriptions intended for debugging purposes. Sharing subscription keys with tracing allowed with unauthorized users could lead to disclosure of sensitive information contained in tracing logs such as keys, access tokens, passwords, internal hostnames, and IP addresses.)](/azure/api-management/api-management-howto-api-inspector). --### Self-hosted gateway instances were identified that use gateway tokens that expire soon --At least one deployed self-hosted gateway instance was identified that uses a gateway token that expires in the next seven days. To ensure that it can connect to the control-plane, generate a new gateway token and update your deployed self-hosted gateways (does not impact data-plane traffic). --Learn more about [Api Management - ShgwGatewayTokenNearExpiry (Self-hosted gateway instance(s) were identified that use gateway tokens that expire soon)](). ---## Internet of Things --### IoT Hub Fallback Route Disabled --We have detected that the Fallback Route on your IoT Hub has been disabled. When the Fallback Route is disabled messages stop flowing to the default endpoint. If you're no longer able to ingest telemetry downstream consider re-enabling the Fallback Route. --Learn more about [IoT hub - IoTHubFallbackDisabledAdvisor (IoT Hub Fallback Route Disabled)](/azure/iot-hub/iot-hub-devguide-messages-d2c#fallback-route). -----## Management and governance --### Upgrade to Start/Stop VMs v2 --The new version of Start/Stop VMs v2 (preview) provides a decentralized low-cost automation option for customers who want to optimize their VM costs. It offers all of the same functionality as the original version available with Azure Automation, but it is designed to take advantage of newer technology in Azure. --Learn more about [Automation account - SSV1_Upgrade (Upgrade to Start/Stop VMs v2)](https://aka.ms/startstopv2docs). --### Repair your log alert rule --We have detected that one or more of your alert rules have invalid queries specified in their condition section. Log alert rules are created in Azure Monitor and are used to run analytics queries at specified intervals. The results of the query determine if an alert needs to be triggered. Analytics queries might become invalid overtime due to changes in referenced resources, tables, or commands. We recommend that you correct the query in the alert rule to prevent it from getting auto-disabled and ensure monitoring coverage of your resources in Azure. --Learn more about [Alert Rule - ScheduledQueryRulesLogAlert (Repair your log alert rule)](https://aka.ms/aa_logalerts_queryrepair). --### Log alert rule was disabled --The alert rule was disabled by Azure Monitor as it was causing service issues. To enable the alert rule, contact support. --Learn more about [Alert Rule - ScheduledQueryRulesRp (Log alert rule was disabled)](https://aka.ms/aa_logalerts_queryrepair). --### Update Azure Managed Grafana SDK Version --We have identified that an older SDK version has been used to manage or access your Grafana workspace. To get access to all the latest functionality, it is recommended that you switch to use the latest SDK version. --Learn more about [Grafana Dashboard - UpdateAzureManagedGrafanaSDK (Update Azure Managed Grafana SDK Version)](https://aka.ms/GrafanaPortalLearnMore). --### Switch to Azure Monitor based alerts for backup --Switch to Azure Monitor based alerts for backup to leverage various benefits, such as - standardized, at-scale alert management experiences offered by Azure, ability to route alerts to different notification channels of choice, and greater flexibility in alert configuration. --Learn more about [Recovery Services vault - SwitchToAzureMonitorAlerts (Switch to Azure Monitor based alerts for backup)](https://aka.ms/AzMonAlertsBackup). -----## Networking --### Resolve Certificate Update issue for your Application Gateway --We have detected that one or more of your Application Gateways is unable to fetch the latest version certificate present in your Key Vault. If it is intended to use a particular version of the certificate, ignore this message. --Learn more about [Application gateway - AppGwAdvisorRecommendationForCertificateUpdateErrors (Resolve Certificate Update issue for your Application Gateway)](). --### Resolve Azure Key Vault issue for your Application Gateway --We've detected that one or more of your Application Gateways is unable to obtain a certificate due to misconfigured Key Vault. You must fix this configuration immediately to avoid operational issues with your gateway. --Learn more about [Application gateway - AppGwAdvisorRecommendationForKeyVaultErrors (Resolve Azure Key Vault issue for your Application Gateway)](https://aka.ms/agkverror). --### Application Gateway does not have enough capacity to scale out --We've detected that your Application Gateway subnet does not have enough capacity for allowing scale-out during high traffic conditions, which can cause downtime. --Learn more about [Application gateway - AppgwRestrictedSubnetSpace (Application Gateway does not have enough capacity to scale out)](https://aka.ms/application-gateway-faq). --### Enable Traffic Analytics to view insights into traffic patterns across Azure resources --Traffic Analytics is a cloud-based solution that provides visibility into user and application activity in Azure. Traffic analytics analyzes Network Watcher network security group (NSG) flow logs to provide insights into traffic flow. With traffic analytics, you can view top talkers across Azure and non Azure deployments, investigate open ports, protocols and malicious flows in your environment and optimize your network deployment for performance. You can process flow logs at 10 mins and 60 mins processing intervals, giving you faster analytics on your traffic. --Learn more about [Network Security Group - NSGFlowLogsenableTA (Enable Traffic Analytics to view insights into traffic patterns across Azure resources)](https://aka.ms/aa_enableta_learnmore). --### Set up staging environments in Azure App Service --Deploy an app to a slot first and then swap it into production to ensure that all instances of the slot are warmed up before being swapped and eliminate downtime. The traffic redirection is seamless, no requests are dropped because of swap operations. --Learn more about [Subscription - AzureApplicationService (Set up staging environments in Azure App Service)](../app-service/deploy-staging-slots.md). --### Enforce 'Add or replace a tag on resources' using Azure Policy --Azure Policy is a service in Azure that you use to create, assign, and manage policies that enforce different rules and effects over your resources. Enforce a policy that adds or replaces the specified tag and value when any resource is created or updated. Existing resources can be remediated by triggering a remediation task, which does not modify tags on resource groups. --Learn more about [Subscription - AddTagPolicy (Enforce 'Add or replace a tag on resources' using Azure Policy)](../governance/policy/overview.md). --### Enforce 'Allowed locations' using Azure Policy --Azure Policy is a service in Azure that you use to create, assign, and manage policies that enforce different rules and effects over your resources. Enforce a policy that enables you to restrict the locations your organization can specify when deploying resources. Use the policy to enforce your geo-compliance requirements. --Learn more about [Subscription - AllowedLocationsPolicy (Enforce 'Allowed locations' using Azure Policy)](../governance/policy/overview.md). --### Enforce 'Audit VMs that do not use managed disks' using Azure Policy --Azure Policy is a service in Azure that you use to create, assign, and manage policies that enforce different rules and effects over your resources. Enforce a policy that audits VMs that do not use managed disks. --Learn more about [Subscription - AuditForManagedDisksPolicy (Enforce 'Audit VMs that do not use managed disks' using Azure Policy)](../governance/policy/overview.md). --### Enforce 'Allowed virtual machine SKUs' using Azure Policy --Azure Policy is a service in Azure that you use to create, assign, and manage policies that enforce different rules and effects over your resources. Enforce a policy that enables you to specify a set of virtual machine SKUs that your organization can deploy. --Learn more about [Subscription - AllowedVirtualMachineSkuPolicy (Enforce 'Allowed virtual machine SKUs' using Azure Policy)](../governance/policy/overview.md). --### Enforce 'Inherit a tag from the resource group' using Azure Policy --Azure Policy is a service in Azure that you use to create, assign, and manage policies that enforce different rules and effects over your resources. Enforce a policy that adds or replaces the specified tag and value from the parent resource group when any resource is created or updated. Existing resources can be remediated by triggering a remediation task. --Learn more about [Subscription - InheritTagPolicy (Enforce 'Inherit a tag from the resource group' using Azure Policy)](../governance/policy/overview.md). --### Use Azure Lighthouse to simply and securely manage customer subscriptions at scale --Using Azure Lighthouse improves security and reduces unnecessary access to your customer tenants by enabling more granular permissions for your users. It also allows for greater scalability, as your users can work across multiple customer subscriptions using a single login in your tenant. --Learn more about [Subscription - OnboardCSPSubscriptionsToLighthouse (Use Azure Lighthouse to simply and securely manage customer subscriptions at scale)](../lighthouse/concepts/cloud-solution-provider.md). --### Subscription with more than 10 VNets must be managed using AVNM --Subscription with more than 10 VNets must be managed using AVNM. Azure Virtual Network Manager is a management service that enables you to group, configure, deploy, and manage virtual networks globally across subscriptions. --Learn more about [Subscription - ManageVNetsUsingAVNM (Subscription with more than 10 VNets must be managed using AVNM)](/azure/virtual-network-manager/). --### VNet with more than 5 peerings must be managed using AVNM connectivity configuration --VNet with more than 5 peerings must be managed using AVNM connectivity configuration. Azure Virtual Network Manager is a management service that enables you to group, configure, deploy, and manage virtual networks globally across subscriptions. --Learn more about [Virtual network - ManagePeeringsUsingAVNM (VNet with more than 5 peerings must be managed using AVNM connectivity configuration)](). --### Upgrade NSG flow logs to VNet flow logs --Virtual Network flow log allows you to record IP traffic flowing in a virtual network. It provides several benefits over Network Security Group flow log like simplified enablement, enhanced coverage, accuracy, performance and observability of Virtual Network Manager rules and encryption status. --Learn more about [Resource - UpgradeNSGToVnetFlowLog (Upgrade NSG flow logs to VNet flow logs)](https://aka.ms/vnetflowlogspreviewdocs). --### Migrate Azure Front Door (classic) to Standard/Premium tier --On 31 March 2027, Azure Front Door (classic) will be retired for the public cloud, and youΓÇÖll need to migrate to Front Door Standard or Premium by that date. --Beginning 1 April 2025, youΓÇÖll no longer be able to create new Front Door (classic) resources via the Azure portal, Terraform, or any command line tools. However, you can continue to make modifications to existing resources until Front Door (classic) is fully retired. --Azure Front Door Standard and Premium combine the capabilities of static and dynamic content delivery with turnkey security, enhanced DevOps experiences, simplified pricing, and better Azure integrations --Learn more about [Azure Front Door (classic) will be retired on 31 March 2027](https://azure.microsoft.com/updates/azure-front-door-classic-will-be-retired-on-31-march-2027/). ----## SAP for Azure --### Ensure the HANA DB VM type supports the HANA scenario in your SAP workload --Correct VM type needs to be selected for the specific HANA Scenario. The HANA scenarios can be 'OLAP', 'OLTP', 'OLAP: Scaleup' and 'OLTP: Scaleup'. See SAP note 1928533 for the correct VM type for your SAP workload. The correct VM type helps ensure better performance and support for your SAP systems --Learn more about [Database Instance - HanaDBSupport (Ensure the HANA DB VM type supports the HANA scenario in your SAP workload)](https://launchpad.support.sap.com/#/notes/1928533). --### Ensure the Operating system in App VM is supported in combination with DB type in your SAP workload --Operating system in the VMs in your SAP workload need to be supported for the DB type selected. See SAP note 1928533 for the correct OS-DB combinations for the ASCS, Database and Application VMs to ensure better performance and support for your SAP systems --Learn more about [App Server Instance - AppOSDBSupport (Ensure the Operating system in App VM is supported in combination with DB type in your SAP workload)](https://launchpad.support.sap.com/#/notes/1928533). --### Set the parameter net.ipv4.tcp_keepalive_time to '300' in the Application VM OS in SAP workloads --In the Application VM OS, edit the /etc/sysctl.conf file and add net.ipv4.tcp_keepalive_time = 300 to enable faster reconnection after an ASCS failover. This setting is recommended for all Application VM OS in SAP workloads in order. --Learn more about [App Server Instance - AppIPV4TCPKeepAlive (Set the parameter net.ipv4.tcp_keepalive_time to '300' in the Application VM OS in SAP workloads)](https://launchpad.support.sap.com/#/notes/1410736). --### Ensure the Operating system in DB VM is supported for the DB type in your SAP workload --Operating system in the VMs in your SAP workload need to be supported for the DB type selected. See SAP note 1928533 for the correct OS-DB combinations for the ASCS, Database and Application VMs to ensure better performance and support for your SAP systems --Learn more about [Database Instance - DBOSDBSupport (Ensure the Operating system in DB VM is supported for the DB type in your SAP workload)](https://launchpad.support.sap.com/#/notes/1928533). --### Set the parameter net.ipv4.tcp_retries2 to '15' in the Application VM OS in SAP workloads --In the Application VM OS, edit the /etc/sysctl.conf file and add net.ipv4.tcp_retries2 = 15 to enable faster reconnection after an ASCS failover. This is recommended for all Application VM OS in SAP workloads. --Learn more about [App Server Instance - AppIpv4Retries2 (Set the parameter net.ipv4.tcp_retries2 to '15' in the Application VM OS in SAP workloads)](https://www.suse.com/support/kb/doc/?id=000019722#:~:text=To%20check%20for%20current%20values%20of%20certain%20TCP%20tuning). --### See the parameter net.ipv4.tcp_keepalive_probes to '9' in the Application VM OS in SAP workloads --In the Application VM OS, edit the /etc/sysctl.conf file and add net.ipv4.tcp_keepalive_probes = 9 to enable faster reconnection after an ASCS failover. This setting is recommended for all Application VM OS in SAP workloads. --Learn more about [App Server Instance - AppIPV4Probes (See the parameter net.ipv4.tcp_keepalive_probes to '9' in the Application VM OS in SAP workloads)](/azure/virtual-machines/workloads/sap/high-availability-guide). --### Set the parameter net.ipv4.tcp_tw_recycle to '0' in the Application VM OS in SAP workloads --In the Application VM OS, edit the /etc/sysctl.conf file and add net.ipv4.tcp_tw_recycle = 0 to enable faster reconnection after an ASCS failover. This setting is recommended for all Application VM OS in SAP workloads. --Learn more about [App Server Instance - AppIpv4Recycle (Set the parameter net.ipv4.tcp_tw_recycle to '0' in the Application VM OS in SAP workloads)](https://www.suse.com/support/kb/doc/?id=000019722#:~:text=To%20check%20for%20current%20values%20of%20certain%20TCP%20tuning). --### Ensure the Operating system in ASCS VM is supported in combination with DB type in your SAP workload --Operating system in the VMs in your SAP workload need to be supported for the DB type selected. See SAP note 1928533 for the correct OS-DB combinations for the ASCS, Database and Application VMs. The correct OS-DB combinations help ensure better performance and support for your SAP systems --Learn more about [Central Server Instance - ASCSOSDBSupport (Ensure the Operating system in ASCS VM is supported in combination with DB type in your SAP workload)](https://launchpad.support.sap.com/#/notes/1928533). --### Azure Center for SAP recommendation: All VMs in SAP system must be certified for SAP --Azure Center for SAP solutions recommendation: All VMs in SAP system must be certified for SAP. --Learn more about [App Server Instance - VM_0001 (Azure Center for SAP recommendation: All VMs in SAP system must be certified for SAP)](https://launchpad.support.sap.com/#/notes/1928533). --### Set the parameter net.ipv4.tcp_retries1 to '3' in the Application VM OS in SAP workloads --In the Application VM OS, edit the /etc/sysctl.conf file and add net.ipv4.tcp_retries1 = 3 to enable faster reconnection after an ASCS failover. This setting is recommended for all Application VM OS in SAP workloads. --Learn more about [App Server Instance - AppIpv4Retries1 (Set the parameter net.ipv4.tcp_retries1 to '3' in the Application VM OS in SAP workloads)](https://www.suse.com/support/kb/doc/?id=000019722#:~:text=To%20check%20for%20current%20values%20of%20certain%20TCP%20tuning). --### Set the parameter net.ipv4.tcp_tw_reuse to '0' in the Application VM OS in SAP workloads --In the Application VM OS, edit the /etc/sysctl.conf file and add net.ipv4.tcp_tw_reuse = 0 to enable faster reconnection after an ASCS failover. This setting is recommended for all Application VM OS in SAP workloads. --Learn more about [App Server Instance - AppIpv4TcpReuse (Set the parameter net.ipv4.tcp_tw_reuse to '0' in the Application VM OS in SAP workloads)](https://www.suse.com/support/kb/doc/?id=000019722#:~:text=To%20check%20for%20current%20values%20of%20certain%20TCP%20tuning). --### Set the parameter net.ipv4.tcp_keepalive_intvl to '75' in the Application VM OS in SAP workloads --In the Application VM OS, edit the /etc/sysctl.conf file and add net.ipv4.tcp_keepalive_intvl = 75 to enable faster reconnection after an ASCS failover. This setting is recommended for all Application VM OS in SAP workloads. --Learn more about [App Server Instance - AppIPV4intvl (Set the parameter net.ipv4.tcp_keepalive_intvl to '75' in the Application VM OS in SAP workloads)](/azure/virtual-machines/workloads/sap/high-availability-guide). -----### Ensure Accelerated Networking is enabled on all NICs for improved performance of SAP workloads --Network latency between App VMs and DB VMs for SAP workloads is required to be 0.7ms or less. If accelerated networking isn't enabled, network latency can increase beyond the threshold of 0.7ms --Learn more about [Database Instance - NIC_0001_DB (Ensure Accelerated Networking is enabled on all NICs for improved performance of SAP workloads)](https://launchpad.support.sap.com/#/notes/1928533). --### Ensure Accelerated Networking is enabled on all NICs for improved performance of SAP workloads --Network latency between App VMs and DB VMs for SAP workloads is required to be 0.7ms or less. If accelerated networking isn't enabled, network latency can increase beyond the threshold of 0.7ms --Learn more about [App Server Instance - NIC_0001 (Ensure Accelerated Networking is enabled on all NICs for improved performance of SAP workloads)](https://launchpad.support.sap.com/#/notes/1928533). -----### Azure Center for SAP recommendation: Ensure Accelerated networking is enabled on all interfaces --Azure Center for SAP solutions recommendation: Ensure Accelerated networking is enabled on all interfaces. --Learn more about [Database Instance - NIC_0001_DB (Azure Center for SAP recommendation: Ensure Accelerated networking is enabled on all interfaces)](https://launchpad.support.sap.com/#/notes/1928533). --### Azure Center for SAP recommendation: Ensure Accelerated networking is enabled on all interfaces --Azure Center for SAP solutions recommendation: Ensure Accelerated networking is enabled on all interfaces. --Learn more about [App Server Instance - NIC_0001 (Azure Center for SAP recommendation: Ensure Accelerated networking is enabled on all interfaces)](https://launchpad.support.sap.com/#/notes/1928533). --### Azure Center for SAP recommendation: Ensure Accelerated networking is enabled on all interfaces --Azure Center for SAP solutions recommendation: Ensure Accelerated networking is enabled on all interfaces. --Learn more about [Central Server Instance - NIC_0001_ASCS (Azure Center for SAP recommendation: Ensure Accelerated networking is enabled on all interfaces)](https://launchpad.support.sap.com/#/notes/1928533). --### Azure Center for SAP recommendation: All VMs in SAP system must be certified for SAP --Azure Center for SAP solutions recommendation: All VMs in SAP system must be certified for SAP. --Learn more about [Central Server Instance - VM_0001_ASCS (Azure Center for SAP recommendation: All VMs in SAP system must be certified for SAP)](https://launchpad.support.sap.com/#/notes/1928533). --### Azure Center for SAP recommendation: All VMs in SAP system must be certified for SAP --Azure Center for SAP solutions recommendation: All VMs in SAP system must be certified for SAP. --Learn more about [Database Instance - VM_0001_DB (Azure Center for SAP recommendation: All VMs in SAP system must be certified for SAP)](https://launchpad.support.sap.com/#/notes/1928533). --### Disable fstrim in SLES OS to avoid XFS metadata corruption in SAP workloads --fstrim scans the filesystem and sends 'UNMAP' commands for each unused block it finds; useful in thin-provisioned system if the system is over-provisioned. Running SAP HANA on an over-provisioned storage array isn't recommended. Active fstrim can cause XFS metadata corruption See SAP note: 2205917 --Learn more about [App Server Instance - GetFsTrimForApp (Disable fstrim in SLES OS to avoid XFS metadata corruption in SAP workloads)](https://www.suse.com/support/kb/doc/?id=000019447). --### Disable fstrim in SLES OS to avoid XFS metadata corruption in SAP workloads --fstrim scans the filesystem and sends 'UNMAP' commands for each unused block it finds; useful in thin-provisioned system if the system is over-provisioned. Running SAP HANA on an over-provisioned storage array isn't recommended. Active fstrim can cause XFS metadata corruption See SAP note: 2205917 --Learn more about [Central Server Instance - GetFsTrimForAscs (Disable fstrim in SLES OS to avoid XFS metadata corruption in SAP workloads)](https://www.suse.com/support/kb/doc/?id=000019447). --### Disable fstrim in SLES OS to avoid XFS metadata corruption in SAP workloads --fstrim scans the filesystem and sends 'UNMAP' commands for each unused block it finds; useful in thin-provisioned system if the system is over-provisioned. Running SAP HANA on an over-provisioned storage array isn't recommended. Active fstrim can cause XFS metadata corruption See SAP note: 2205917 --Learn more about [Database Instance - GetFsTrimForDb (Disable fstrim in SLES OS to avoid XFS metadata corruption in SAP workloads)](https://www.suse.com/support/kb/doc/?id=000019447). --### For better performance and support, ensure HANA data filesystem type is supported for HANA DB --For different volumes of SAP HANA, where asynchronous I/O is used, SAP only supports filesystems validated as part of an SAP HANA appliance certification. Using an unsupported filesystem might lead to various operational issues, e.g. hanging recovery and index server crashes. See SAP note 2972496. --Learn more about [Database Instance - HanaDataFileSystemSupported (For better performance and support, ensure HANA data filesystem type is supported for HANA DB)](https://launchpad.support.sap.com/#/notes/2972496). --### For better performance and support, ensure HANA shared filesystem type is supported for HANA DB --For different volumes of SAP HANA, where asynchronous I/O is used, SAP only supports filesystems validated as part of an SAP HANA appliance certification. Using an unsupported filesystem might lead to various operational issues, e.g. hanging recovery and index server crashes. See SAP note 2972496. --Learn more about [Database Instance - HanaSharedFileSystem (For better performance and support, ensure HANA shared filesystem type is supported for HANA DB)](https://launchpad.support.sap.com/#/notes/2972496). ---### For better performance and support, ensure HANA log filesystem type is supported for HANA DB --For different volumes of SAP HANA, where asynchronous I/O is used, SAP only supports filesystems validated as part of an SAP HANA appliance certification. Using an unsupported filesystem might lead to various operational issues, e.g. hanging recovery and index server crashes. See SAP note 2972496. --Learn more about [Database Instance - HanaLogFileSystemSupported (For better performance and support, ensure HANA log filesystem type is supported for HANA DB)](https://launchpad.support.sap.com/#/notes/2972496). --### Azure Center for SAP recommendation: Ensure all NICs for a system are attached to the same VNET --Azure Center for SAP recommendation: Ensure all NICs for a system must be attached to the same VNET. --Learn more about [App Server Instance - AllVmsHaveSameVnetApp (Azure Center for SAP recommendation: Ensure all NICs for a system are attached to the same VNET)](/azure/virtual-machines/workloads/sap/sap-deployment-checklist#:~:text=this%20article.-,Networking,-.). --### Azure Center for SAP recommendation: Swap space on HANA systems must be 2GB --Azure Center for SAP solutions recommendation: Swap space on HANA systems must be 2GB. --Learn more about [Database Instance - SwapSpaceForSap (Azure Center for SAP recommendation: Swap space on HANA systems must be 2GB)](https://launchpad.support.sap.com/#/notes/1999997). --### Azure Center for SAP recommendation: Ensure all NICs for a system are attached to the same VNET --Azure Center for SAP recommendation: Ensure all NICs for a system must be attached to the same VNET. --Learn more about [Central Server Instance - AllVmsHaveSameVnetAscs (Azure Center for SAP recommendation: Ensure all NICs for a system are attached to the same VNET)](/azure/virtual-machines/workloads/sap/sap-deployment-checklist#:~:text=this%20article.-,Networking,-.). --### Azure Center for SAP recommendation: Ensure all NICs for a system are attached to the same VNET --Azure Center for SAP recommendation: Ensure all NICs for a system must be attached to the same VNET. --Learn more about [Database Instance - AllVmsHaveSameVnetDb (Azure Center for SAP recommendation: Ensure all NICs for a system are attached to the same VNET)](/azure/virtual-machines/workloads/sap/sap-deployment-checklist#:~:text=this%20article.-,Networking,-.). --### Azure Center for SAP recommendation: Ensure network configuration is optimized for HANA and OS --Azure Center for SAP solutions recommendation: Ensure network configuration is optimized for HANA and OS. --Learn more about [Database Instance - NetworkConfigForSap (Azure Center for SAP recommendation: Ensure network configuration is optimized for HANA and OS)](https://launchpad.support.sap.com/#/notes/2382421). ----## Storage --### Create a backup of HSM --Create a periodic HSM backup to prevent data loss and have ability to recover the HSM in case of a disaster. --Learn more about [Managed HSM Service - CreateHSMBackup (Create a backup of HSM)](/azure/key-vault/managed-hsm/best-practices#create-backups). --### Application Volume Group SDK Recommendation --The minimum API version for Azure NetApp Files application volume group feature must be 2022-01-01. We recommend using 2022-03-01 when possible to fully leverage the API. --Learn more about [Volume - Application Volume Group SDK version recommendation (Application Volume Group SDK Recommendation)](https://aka.ms/anf-sdkversion). --### Availability Zone Volumes SDK Recommendation --The minimum SDK version of 2022-05-01 is recommended for the Azure NetApp Files Availability zone volume placement feature, to enable deployment of new Azure NetApp Files volumes in the Azure availability zone (AZ) that you specify. --Learn more about [Volume - Azure NetApp Files AZ Volume SDK version recommendation (Availability Zone Volumes SDK Recommendation)](https://aka.ms/anf-sdkversion). --### Cross Zone Replication SDK recommendation --The minimum SDK version of 2022-05-01 is recommended for the Azure NetApp Files Cross Zone Replication feature, to enable you to replicate volumes across availability zones within the same region. --Learn more about [Volume - Azure NetApp Files Cross Zone Replication SDK recommendation](https://aka.ms/anf-sdkversion). --### Volume Encryption using Customer Managed Keys with Azure Key Vault SDK Recommendation --The minimum API version for Azure NetApp Files Customer Managed Keys with Azure Key Vault feature is 2022-05-01. --Learn more about [Volume - CMK with AKV SDK Recommendation (Volume Encryption using Customer Managed Keys with Azure Key Vault SDK Recommendation)](). --### Cool Access SDK Recommendation --The minimum SDK version of 2022-03-01 is recommended for Standard service level with cool access feature to enable moving inactive data to an Azure storage account (the cool tier) and free up storage that resides within Azure NetApp Files volumes, resulting in overall cost savings. --Learn more about [Capacity Pool - Azure NetApp Files Cool Access SDK version recommendation (Cool Access SDK Recommendation)](https://aka.ms/anf-sdkversion). --### Large Volumes SDK Recommendation --The minimum SDK version of 2022-xx-xx is recommended for automation of large volume creation, resizing and deletion. --Learn more about [Volume - Large Volumes SDK Recommendation](/azure/azure-netapp-files/azure-netapp-files-resource-limits). --### Prevent hitting subscription limit for maximum storage accounts --A region can support a maximum of 250 storage accounts per subscription. You have either already reached or are about to reach that limit. If you reach that limit, you're unable to create any more storage accounts in that subscription/region combination. Evaluate the recommended action below to avoid hitting the limit. --Learn more about [Storage Account - StorageAccountScaleTarget (Prevent hitting subscription limit for maximum storage accounts)](https://aka.ms/subscalelimit). --### Update to newer releases of the Storage Java v12 SDK for better reliability. --We noticed that one or more of your applications use an older version of the Azure Storage Java v12 SDK to write data to Azure Storage. Unfortunately, the version of the SDK being used has a critical issue that uploads incorrect data during retries (for example, in case of HTTP 500 errors), resulting in an invalid object being written. The issue is fixed in newer releases of the Java v12 SDK. --Learn more about [Storage Account - UpdateStorageJavaSDK (Update to newer releases of the Storage Java v12 SDK for better reliability.)](/azure/developer/java/sdk/?view=azure-java-stable&preserve-view=true). ------## Virtual desktop infrastructure --### Permissions missing for start VM on connect --We have determined you enabled start VM on connect but didn't grant the Azure Virtual Desktop the rights to power manage VMs in your subscription. As a result your users connecting to host pools won't receive a remote desktop session. Review feature documentation for requirements. --Learn more about [Host Pool - AVDStartVMonConnect (Permissions missing for start VM on connect)](https://aka.ms/AVDStartVMRequirement). --### No validation environment enabled --We have determined that you do not have a validation environment enabled in current subscription. When creating your host pools, you have selected "No" for "Validation environment" in the properties tab. Having at least one host pool with a validation environment enabled ensures the business continuity through Azure Virtual Desktop service deployments with early detection of potential issues. --Learn more about [Host Pool - ValidationEnvHostPools (No validation environment enabled)](../virtual-desktop/create-validation-host-pool.md). --### Not enough production environments enabled --We have determined that too many of your host pools have Validation Environment enabled. In order for Validation Environments to best serve their purpose, you must have at least one, but never more than half of your host pools in Validation Environment. By having a healthy balance between your host pools with Validation Environment enabled and those with it disabled, you're best able to utilize the benefits of the multistage deployments that Azure Virtual Desktop offers with certain updates. To fix this issue, open your host pool's properties and select "No" next to the "Validation Environment" setting. --Learn more about [Host Pool - ProductionEnvHostPools (Not enough production environments enabled)](../virtual-desktop/create-host-pools-powershell.md). -----## Web --### Set up staging environments in Azure App Service --Deploy an app to a slot first and then swap it into production to ensure that all instances of the slot are warmed up before being swapped and eliminate downtime. The traffic redirection is seamless, no requests are dropped because of swap operations. --Learn more about [App service - AzureAppService-StagingEnv (Set up staging environments in Azure App Service)](../app-service/deploy-staging-slots.md). --### Update Service Connector API Version --We have identified API calls from outdated Service Connector API for resources under this subscription. We recommend switching to the latest Service Connector API version. You need to update your existing code or tools to use the latest API version. --Learn more about [App service - UpgradeServiceConnectorAPI (Update Service Connector API Version)](/azure/service-connector). --### Update Service Connector SDK to the latest version --We have identified API calls from an outdated Service Connector SDK. We recommend upgrading to the latest version for the latest fixes, performance improvements, and new feature capabilities. --Learn more about [App service - UpgradeServiceConnectorSDK (Update Service Connector SDK to the latest version)](/azure/service-connector). -------## Next steps --Learn more about [Operational Excellence - Microsoft Azure Well Architected Framework](/azure/architecture/framework/devops/overview) |
| advisor | Advisor Reference Performance Recommendations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-reference-performance-recommendations.md | - Title: Performance recommendations -description: Full list of available performance recommendations in Advisor. - Previously updated : 6/24/2024---# Performance recommendations --The performance recommendations in Azure Advisor can help improve the speed and responsiveness of your business-critical applications. You can get performance recommendations from Advisor on the **Performance** tab of the Advisor dashboard. --1. Sign in to the [**Azure portal**](https://portal.azure.com). --1. Search for and select [**Advisor**](https://aka.ms/azureadvisordashboard) from any page. --1. On the **Advisor** dashboard, select the **Performance** tab. ---## AI + machine learning --### 429 Throttling Detected on this resource --We observed that there have been 1,000 or more 429 throttling errors on this resource in a one day timeframe. Consider enabling autoscale to better handle higher call volumes and reduce the number of 429 errors. --Learn more about [Azure AI services autoscale](/azure/ai-services/autoscale?tabs=portal). --### Text Analytics Model Version Deprecation --Upgrade the model version to a newer model version or latest to utilize the latest and highest quality models. --Learn more about [Cognitive Service - TAUpgradeToLatestModelVersion (Text Analytics Model Version Deprecation)](https://aka.ms/language-model-lifecycle). --### Text Analytics Model Version Deprecation --Upgrade the model version to a newer model version or latest to utilize the latest and highest quality models. --Learn more about [Cognitive Service - TAUpgradeModelVersiontoLatest (Text Analytics Model Version Deprecation)](https://aka.ms/language-model-lifecycle). --### Upgrade to the latest Cognitive Service Text Analytics API version --Upgrade to the latest API version to get the best results in terms of model quality, performance and service availability. Also there are new features available as new endpoints starting from V3.0 such as personal data recognition, entity recognition and entity linking available as separate endpoints. In terms of changes in preview endpoints, we have Opinion Mining in SA endpoint, redacted text property in personal data endpoint --Learn more about [Cognitive Service - UpgradeToLatestAPI (Upgrade to the latest Cognitive Service Text Analytics API version)](/azure/cognitive-services/text-analytics/how-tos/text-analytics-how-to-call-api). --### Upgrade to the latest API version of Azure Cognitive Service for Language --Upgrade to the latest API version to get the best results in terms of model quality, performance and service availability. --Learn more about [Cognitive Service - UpgradeToLatestAPILanguage (Upgrade to the latest API version of Azure Cognitive Service for Language)](https://aka.ms/language-api). --### Upgrade to the latest Cognitive Service Text Analytics SDK version --Upgrade to the latest SDK version to get the best results in terms of model quality, performance and service availability. Also there are new features available as new endpoints starting from V3.0 such as personal data recognition, entity recognition and entity linking available as separate endpoints. In terms of changes in preview endpoints, we have Opinion Mining in SA endpoint, redacted text property in personal data endpoint --Learn more about [Cognitive Service - UpgradeToLatestSDK (Upgrade to the latest Cognitive Service Text Analytics SDK version)](/azure/cognitive-services/text-analytics/quickstarts/text-analytics-sdk?tabs=version-3-1&pivots=programming-language-csharp). --### Upgrade to the latest Cognitive Service Language SDK version --Upgrade to the latest SDK version to get the best results in terms of model quality, performance and service availability. --Learn more about [Cognitive Service - UpgradeToLatestSDKLanguage (Upgrade to the latest Cognitive Service Language SDK version)](https://aka.ms/language-api). --### Upgrade to the latest Azure AI Language SDK version --Upgrade to the latest SDK version to get the best results in terms of model quality, performance and service availability. Also there are new features available as new endpoints starting from V3.0 such as personal data recognition, entity recognition and entity linking available as separate endpoints. In terms of changes in preview endpoints, we have Opinion Mining in SA endpoint, redacted text property in personal data endpoint. --Learn more about [Azure AI Language](/azure/ai-services/language-service/language-detection/overview). -----## Analytics --### Right-size Data Explorer resources for optimal performance. --This recommendation surfaces all Data Explorer resources that exceed the recommended data capacity (80%). The recommended action to improve the performance is to scale to the recommended configuration shown. --Learn more about [Data explorer resource - Right-size ADX resource (Right-size Data Explorer resources for optimal performance.)](https://aka.ms/adxskuperformance). --### Review table cache policies for Data Explorer tables --This recommendation surfaces Data Explorer tables with a high number of queries that look back beyond the configured cache period (policy) - you see the top 10 tables by query percentage that access out-of-cache data. The recommended action to improve the performance: Limit queries on this table to the minimal necessary time range (within the defined policy). Alternatively, if data from the entire time range is required, increase the cache period to the recommended value. --Learn more about [Data explorer resource - UpdateCachePoliciesForAdxTables (Review table cache policies for Data Explorer tables)](https://aka.ms/adxcachepolicy). --### Reduce Data Explorer table cache policy for better performance --Reducing the table cache policy frees up unused data from the resource's cache and improves performance. --Learn more about [Data explorer resource - ReduceCacheForAzureDataExplorerTablesToImprovePerformance (Reduce Data Explorer table cache policy for better performance)](https://aka.ms/adxcachepolicy). --### Increase the cache in the cache policy --Based on your actual usage during the last month, update the cache policy to increase the hot cache for the table. The retention period must always be larger than the cache period. If you increase the cache and the retention period is lower than the cache period, update the retention policy. The analysis is based only on user queries that scanned data. --Learn more about [Data explorer resource - IncreaseCacheForAzureDataExplorerTablesToImprovePerformance (Increase the cache in the cache policy)](https://aka.ms/adxcachepolicy). --### Enable Optimized Autoscale for Data Explorer resources --Looks like your resource could have automatically scaled to improve performance (based on your actual usage during the last week, cache utilization, ingestion utilization, CPU, and streaming ingests utilization). To optimize costs and performance, we recommend enabling Optimized Autoscale. --Learn more about [Data explorer resource - PerformanceEnableOptimizedAutoscaleAzureDataExplorer (Enable Optimized Autoscale for Data Explorer resources)](https://aka.ms/adxoptimizedautoscale). --### Reads happen on most recent data --More than 75% of your read requests are landing on the memstore, indicating that the reads are primarily on recent data. Recent data reads suggest that even if a flush happens on the memstore, the recent file needs to be accessed and put in the cache. --Learn more about [HDInsight cluster - HBaseMemstoreReadPercentage (Reads happen on most recent data)](../hdinsight/hbase/apache-hbase-advisor.md). --### Consider using Accelerated Writes feature in your HBase cluster to improve cluster performance. --You're seeing this advisor recommendation because HDInsight team's system log shows that in the past seven days, your cluster has encountered the following scenarios: --1. High WAL sync time latency --2. High write request count (at least 3 one hour windows of over 1000 avg_write_requests/second/node) --These conditions are indicators that your cluster is suffering from high write latencies, which can be due to heavy workload on your cluster. --To improve the performance of your cluster, consider utilizing the Accelerated Writes feature provided by Azure HDInsight HBase. The Accelerated Writes feature for HDInsight Apache HBase clusters attaches premium SSD-managed disks to every RegionServer (worker node) instead of using cloud storage. As a result, it provides low write-latency and better resiliency for your applications. --To read more on this feature, visit link: --Learn more about [HDInsight cluster - AccWriteCandidate (Consider using Accelerated Writes feature in your HBase cluster to improve cluster performance.)](../hdinsight/hbase/apache-hbase-accelerated-writes.md). --### More than 75% of your queries are full scan queries --More than 75% of the scan queries on your cluster are doing a full region/table scan. Modify your scan queries to avoid full region or table scans. --Learn more about [HDInsight cluster - ScanQueryTuningcandidate (More than 75% of your queries are full scan queries.)](../hdinsight/hbase/apache-hbase-advisor.md). --### Check your region counts as you have blocking updates --Region counts needs to be adjusted to avoid updates getting blocked. It might require a scale up of the cluster by adding new nodes. --Learn more about [HDInsight cluster - RegionCountCandidate (Check your region counts as you have blocking updates.)](../hdinsight/hbase/apache-hbase-advisor.md). --### Consider increasing the flusher threads --The flush queue size in your region servers is more than 100 or there are updates getting blocked frequently. Tuning of the flush handler is recommended. --Learn more about [HDInsight cluster - FlushQueueCandidate (Consider increasing the flusher threads)](../hdinsight/hbase/apache-hbase-advisor.md). --### Consider increasing your compaction threads for compactions to complete faster --The compaction queue in your region servers is more than 2000 suggesting that more data requires compaction. Slower compactions can affect read performance as the number of files to read are more. More files without compaction can also affect the heap usage related to how files interact with Azure file system. --Learn more about [HDInsight cluster - CompactionQueueCandidate (Consider increasing your compaction threads for compactions to complete faster)](/azure/hdinsight/hbase/apache-hbase-advisor). --### Tables with Clustered Columnstore Indexes (CCI) with less than 60 million rows --Clustered columnstore tables are organized in data into segments. Having high segment quality is critical to achieving optimal query performance on a columnstore table. You can measure segment quality by the number of rows in a compressed row group. --Learn more about [Synapse workspace - SynapseCCIGuidance (Tables with Clustered Columnstore Indexes (CCI) with less than 60 million rows)](https://aka.ms/AzureSynapseCCIGuidance). --### Update SynapseManagementClient SDK Version --New SynapseManagementClient is using .NET SDK 4.0 or above. --Learn more about [Synapse workspace - UpgradeSynapseManagementClientSDK (Update SynapseManagementClient SDK Version)](https://aka.ms/UpgradeSynapseManagementClientSDK). ----## Compute --### vSAN capacity utilization has crossed critical threshold --Your vSAN capacity utilization has reached 75%. The cluster utilization is required to remain below the 75% critical threshold for SLA compliance. Add new nodes to the vSphere cluster to increase capacity or delete VMs to reduce consumption or adjust VM workloads --Learn more about [Azure VMware Solution private cloud - vSANCapacity (vSAN capacity utilization has crossed critical threshold)](../azure-vmware/architecture-private-clouds.md). --### Update Automanage to the latest API Version --We have identified SDK calls from outdated API for resources under this subscription. We recommend switching to the latest SDK versions to ensure you receive the latest features and performance improvements. --Learn more about [Virtual machine - UpdateToLatestApi (Update Automanage to the latest API Version)](/azure/automanage/reference-sdk). --### Improve user experience and connectivity by deploying VMs closer to userΓÇÖs location. --We have determined that your VMs are located in a region different or far from where your users are connecting with Azure Virtual Desktop. Distant user regions might lead to prolonged connection response times and affect overall user experience. --Learn more about [Virtual machine - RegionProximitySessionHosts (Improve user experience and connectivity by deploying VMs closer to userΓÇÖs location.)](../virtual-desktop/connection-latency.md). --### Use Managed disks to prevent disk I/O throttling --Your virtual machine disks belong to a storage account that has reached its scalability target, and is susceptible to I/O throttling. To protect your virtual machine from performance degradation and to simplify storage management, use Managed Disks. --Learn more about [Virtual machine - ManagedDisksStorageAccount (Use Managed disks to prevent disk I/O throttling)](https://aka.ms/aa_avset_manageddisk_learnmore). --### Convert Managed Disks from Standard HDD to Premium SSD for performance --We have noticed your Standard HDD disk is approaching performance targets. Azure premium SSDs deliver high-performance and low-latency disk support for virtual machines with IO-intensive workloads. Give your disk performance a boost by upgrading your Standard HDD disk to Premium SSD disk. Upgrading requires a VM reboot, which takes three to five minutes. --Learn more about [Disk - MDHDDtoPremiumForPerformance (Convert Managed Disks from Standard HDD to Premium SSD for performance)](/azure/virtual-machines/windows/disks-types#premium-ssd). --### Enable Accelerated Networking to improve network performance and latency --We have detected that Accelerated Networking isn't enabled on VM resources in your existing deployment that might be capable of supporting this feature. If your VM OS image supports Accelerated Networking as detailed in the documentation, make sure to enable this free feature on these VMs to maximize the performance and latency of your networking workloads in cloud --Learn more about [Virtual machine - AccelNetConfiguration (Enable Accelerated Networking to improve network performance and latency)](../virtual-network/create-vm-accelerated-networking-cli.md#enable-accelerated-networking-on-existing-vms). --### Use SSD Disks for your production workloads --We noticed that you're using SSD disks while also using Standard HDD disks on the same VM. Standard HDD managed disks are recommended for dev-test and backup; we recommend you use Premium SSDs or Standard SSDs for production. Premium SSDs deliver high-performance and low-latency disk support for virtual machines with IO-intensive workloads. Standard SSDs provide consistent and lower latency. Upgrade your disk configuration today for improved latency, reliability, and availability. Upgrading requires a VM reboot, which takes three to five minutes. --Learn more about [Virtual machine - MixedDiskTypeToSSDPublic (Use SSD Disks for your production workloads)](/azure/virtual-machines/windows/disks-types#disk-comparison). --### Match production Virtual Machines with Production Disk for consistent performance and better latency --Production virtual machines need production disks if you want to get the best performance. We see that you're running a production level virtual machine, however, you're using a low performing disk with standard HDD. Upgrading disks that are attached to your production disks, either Standard SSD or Premium SSD, benefits you with a more consistent experience and improvements in latency. --Learn more about [Virtual machine - MatchProdVMProdDisks (Match production Virtual Machines with Production Disk for consistent performance and better latency)](/azure/virtual-machines/windows/disks-types#disk-comparison). --### Accelerated Networking might require stopping and starting the VM --We have detected that Accelerated Networking isn't engaged on VM resources in your existing deployment even though the feature has been requested. In rare cases like this, it might be necessary to stop and start your VM, at your convenience, to re-engage AccelNet. --Learn more about [Virtual machine - AccelNetDisengaged (Accelerated Networking might require stopping and starting the VM)](../virtual-network/create-vm-accelerated-networking-cli.md#enable-accelerated-networking-on-existing-vms). --### Take advantage of Ultra Disk low latency for your log disks and improve your database workload performance --Ultra disk is available in the same region as your database workload. Ultra disk offers high throughput, high IOPS, and consistent low latency disk storage for your database workloads: For Oracle DBs, you can now use either 4k or 512E sector sizes with Ultra disk depending on your Oracle DB version. For SQL server, using Ultra disk for your log disk might offer more performance for your database. See instructions here for migrating your log disk to Ultra disk. --Learn more about [Virtual machine - AzureStorageVmUltraDisk (Take advantage of Ultra Disk low latency for your log disks and improve your database workload performance.)](/azure/virtual-machines/disks-enable-ultra-ssd?tabs=azure-portal). --### Upgrade the size of your most active virtual machines to prevent resource exhaustion and improve performance --We analyzed data for the past seven days and identified virtual machines (VMs) with high utilization across different metrics (that is, CPU, Memory, and VM IO). Those VMs might experience performance issues since they're nearing or at their SKU's limits. Consider upgrading their SKU to improve performance. --Learn more about [Virtual machine - UpgradeSizeHighVMUtilV0 (Upgrade the size of your most active virtual machines to prevent resource exhaustion and improve performance)](https://aka.ms/aa_resizehighusagevmrec_learnmore). -----## Containers --### Unsupported Kubernetes version is detected --Unsupported Kubernetes version is detected. Ensure Kubernetes cluster runs with a supported version. --Learn more about [Kubernetes service - UnsupportedKubernetesVersionIsDetected (Unsupported Kubernetes version is detected)](https://aka.ms/aks-supported-versions). --### Unsupported Kubernetes version is detected --Unsupported Kubernetes version is detected. Ensure Kubernetes cluster runs with a supported version. --Learn more about [HDInsight Cluster Pool - UnsupportedHiloAKSVersionIsDetected (Unsupported Kubernetes version is detected)](https://aka.ms/aks-supported-versions). --### Clusters with a single node pool --We recommended that you add one or more node pools instead of using a single node pool. Multiple pools help to isolate critical system pods from your application to prevent misconfigured or rogue application pods from accidentally killing system pods. --Learn more about [Kubernetes service - ClustersWithASingleNodePool (Clusters with a Single Node Pool)](/azure/aks/use-system-pools?tabs=azure-cli#system-and-user-node-pools). --### Update Fleet API to the latest version --We have identified SDK calls from outdated Fleet API for resources under your subscription. We recommend switching to the latest SDK version, which ensures you receive the latest features and performance improvements. --Learn more about [Kubernetes fleet manager | PREVIEW - UpdateToLatestFleetApi (Update Fleet API to the latest Version)](/azure/kubernetes-fleet/update-orchestration). -----## Databases --### Configure your Azure Cosmos DB query page size (MaxItemCount) to -1 --You're using the query page size of 100 for queries for your Azure Cosmos DB container. We recommend using a page size of -1 for faster scans. --Learn more about [Azure Cosmos DB account - CosmosDBQueryPageSize (Configure your Azure Cosmos DB query page size (MaxItemCount) to -1)](/azure/cosmos-db/sql-api-query-metrics#max-item-count). --### Add composite indexes to your Azure Cosmos DB container --Your Azure Cosmos DB containers are running ORDER BY queries incurring high Request Unit (RU) charges. It's recommended to add composite indexes to your containers' indexing policy to improve the RU consumption and decrease the latency of these queries. --Learn more about [Azure Cosmos DB account - CosmosDBOrderByHighRUCharge (Add composite indexes to your Azure Cosmos DB container)](/azure/cosmos-db/index-policy#composite-indexes). --### Optimize your Azure Cosmos DB indexing policy to only index what's needed --Your Azure Cosmos DB containers are using the default indexing policy, which indexes every property in your documents. Because you're storing large documents, a high number of properties get indexed, resulting in high Request Unit consumption and poor write latency. To optimize write performance, we recommend overriding the default indexing policy to only index the properties used in your queries. --Learn more about [Azure Cosmos DB account - CosmosDBDefaultIndexingWithManyPaths (Optimize your Azure Cosmos DB indexing policy to only index what's needed)](/azure/cosmos-db/index-policy). --### Use hierarchical partition keys for optimal data distribution --Your account has a custom setting that allows the logical partition size in a container to exceed the limit of 20 GB. The Azure Cosmos DB team applied this setting as a temporary measure to give you time to rearchitect your application with a different partition key. It isn't recommended as a long-term solution, as SLA guarantees aren't honored when the limit is increased. You can now use hierarchical partition keys (preview) to rearchitect your application. The feature allows you to exceed the 20-GB limit by setting up to three partition keys, ideal for multitenant scenarios or workloads that use synthetic keys. --Learn more about [Azure Cosmos DB account - CosmosDBHierarchicalPartitionKey (Use hierarchical partition keys for optimal data distribution)](https://devblogs.microsoft.com/cosmosdb/hierarchical-partition-keys-private-preview/). --### Configure your Azure Cosmos DB applications to use Direct connectivity in the SDK --We noticed that your Azure Cosmos DB applications are using Gateway mode via the Azure Cosmos DB .NET or Java SDKs. We recommend switching to Direct connectivity for lower latency and higher scalability. --Learn more about [Azure Cosmos DB account - CosmosDBGatewayMode (Configure your Azure Cosmos DB applications to use Direct connectivity in the SDK)](/azure/cosmos-db/performance-tips#networking). --### Enhance Performance by Scaling Up for Optimal Resource Utilization --Maximizing the efficiency of your system's resources is crucial for maintaining top-notch performance. Our system closely monitors CPU usage, and when it crosses the 90% threshold over a 12-hour period, a proactive alert is triggered. This alert not only informs Azure Cosmos DB for MongoDB vCore users of the elevated CPU consumption but also provides valuable guidance on scaling up to a higher tier. By upgrading to a more robust tier, you can unlock improved performance and ensure your system operates at its peak potential. --Learn more about [Scaling and configuring Your Azure Cosmos DB for MongoDB vCore cluster](/azure/cosmos-db/mongodb/vcore/how-to-scale-cluster). --### PerformanceBoostervCore --When CPU usage surpasses 90% within a 12-hour timeframe, users are notified about the high usage. Additionally it advises them to scale up to a higher tier to get a better performance. --Learn more about [Cosmos DB account - ScaleUpvCoreRecommendation (PerformanceBoostervCore)](/azure/cosmos-db/mongodb/vcore/how-to-scale-cluster). ---### Scale the storage limit for MariaDB server --Our system shows that the server might be constrained because it's approaching limits for the currently provisioned storage values. Approaching the storage limits might result in degraded performance or the server moved to read-only mode. To ensure continued performance, we recommend increasing the provisioned storage amount or turning ON the "Auto-Growth" feature for automatic storage increases --Learn more about [MariaDB server - OrcasMariaDbStorageLimit (Scale the storage limit for MariaDB server)](https://aka.ms/mariadbstoragelimits). --### Increase the MariaDB server vCores --Our system shows that the CPU has been running under high utilization for an extended time period over the last seven days. High CPU utilization might lead to slow query performance. To improve performance, we recommend moving to a larger compute size. --Learn more about [MariaDB server - OrcasMariaDbCpuOverload (Increase the MariaDB server vCores)](https://aka.ms/mariadbpricing). --### Scale the MariaDB server to higher SKU --Our system shows that the server might be unable to support the connection requests because of the maximum supported connections for the given SKU, which might result in a large number of failed connections requests which adversely affect the performance. To improve performance, we recommend moving to higher memory SKU by increasing vCore or switching to Memory-Optimized SKUs. --Learn more about [MariaDB server - OrcasMariaDbConcurrentConnection (Scale the MariaDB server to higher SKU)](https://aka.ms/mariadbconnectionlimits). --### Move your MariaDB server to Memory Optimized SKU --Our system shows that there is high churn in the buffer pool for this server which can result in slower query performance and increased IOPS. To improve performance, review your workload queries to identify opportunities to minimize memory consumed. If no such opportunity found, then we recommend moving to higher SKU with more memory or increase storage size to get more IOPS. --Learn more about [MariaDB server - OrcasMariaDbMemoryCache (Move your MariaDB server to Memory Optimized SKU)](https://aka.ms/mariadbpricing). --### Increase the reliability of audit logs --Our system shows that the server's audit logs might have been lost over the past day. Lost audit logs can occur when your server is experiencing a CPU-heavy workload, or a server generates a large number of audit logs over a short time period. We recommend only logging the necessary events required for your audit purposes using the following server parameters: audit_log_events, audit_log_exclude_users, audit_log_include_users. If the CPU usage on your server is high due to your workload, we recommend increasing the server's vCores to improve performance. --Learn more about [MariaDB server - OrcasMariaDBAuditLog (Increase the reliability of audit logs)](https://aka.ms/mariadb-audit-logs). --### Scale the storage limit for MySQL server --Our system shows that the server might be constrained because it is approaching limits for the currently provisioned storage values. Approaching the storage limits might result in degraded performance or in the server being moved to read-only mode. To ensure continued performance, we recommend increasing the provisioned storage amount or turning ON the "Auto-Growth" feature for automatic storage increases --Learn more about [MySQL server - OrcasMySQLStorageLimit (Scale the storage limit for MySQL server)](https://aka.ms/mysqlstoragelimits). --### Scale the MySQL server to higher SKU --Our system shows that the server might be unable to support the connection requests because of the maximum supported connections for the given SKU, which might result in a large number of failed connections requests that adversely affect the performance. To improve performance, we recommend moving to a higher memory SKU by increasing vCore or switching to Memory-Optimized SKUs. --Learn more about [MySQL server - OrcasMySQLConcurrentConnection (Scale the MySQL server to higher SKU)](https://aka.ms/mysqlconnectionlimits). --### Increase the MySQL server vCores --Our system shows that the CPU has been running under high utilization for an extended time period over the last seven days. High CPU utilization might lead to slow query performance. To improve performance, we recommend moving to a larger compute size. --Learn more about [MySQL server - OrcasMySQLCpuOverload (Increase the MySQL server vCores)](https://aka.ms/mysqlpricing). --### Move your MySQL server to Memory Optimized SKU --Our system shows that there is high churn in the buffer pool for this server which can result in slower query performance and increased IOPS. To improve performance, review your workload queries to identify opportunities to minimize memory consumed. If no such opportunity found, then we recommend moving to higher SKU with more memory or increase storage size to get more IOPS. --Learn more about [MySQL server - OrcasMySQLMemoryCache (Move your MySQL server to Memory Optimized SKU)](https://aka.ms/mysqlpricing). --### Add a MySQL Read Replica server --Our system shows that you might have a read intensive workload running, which results in resource contention for this server. Resource contention might lead to slow query performance for the server. To improve performance, we recommend you add a read replica, and offload some of your read workloads to the replica. --Learn more about [MySQL server - OrcasMySQLReadReplica (Add a MySQL Read Replica server)](https://aka.ms/mysqlreadreplica). --### Improve MySQL connection management --Our system shows that your application connecting to MySQL server might be managing connections poorly, which might result in unnecessary resource consumption and overall higher application latency. To improve connection management, we recommend that you reduce the number of short-lived connections and eliminate unnecessary idle connections. You can do this by configuring a server side connection-pooler, such as ProxySQL. --Learn more about [MySQL server - OrcasMySQLConnectionPooling (Improve MySQL connection management)](https://aka.ms/azure_mysql_connection_pooling). --### Increase the reliability of audit logs --Our system shows that the server's audit logs might have been lost over the past day. This can occur when your server is experiencing a CPU heavy workload or a server generates a large number of audit logs over a short time period. We recommend only logging the necessary events required for your audit purposes using the following server parameters: audit_log_events, audit_log_exclude_users, audit_log_include_users. If the CPU usage on your server is high due to your workload, we recommend increasing the server's vCores to improve performance. --Learn more about [MySQL server - OrcasMySQLAuditLog (Increase the reliability of audit logs)](https://aka.ms/mysql-audit-logs). --### Improve performance by optimizing MySQL temporary-table sizing --Our system shows that your MySQL server might be incurring unnecessary I/O overhead due to low temporary-table parameter settings. This might result in unnecessary disk-based transactions and reduced performance. We recommend that you increase the 'tmp_table_size' and 'max_heap_table_size' parameter values to reduce the number of disk-based transactions. --Learn more about [MySQL server - OrcasMySqlTmpTables (Improve performance by optimizing MySQL temporary-table sizing)](https://aka.ms/azure_mysql_tmp_table). --### Improve MySQL connection latency --Our system shows that your application connecting to MySQL server might be managing connections poorly. This might result in higher application latency. To improve connection latency, we recommend that you enable connection redirection. This can be done by enabling the connection redirection feature of the PHP driver. --Learn more about [MySQL server - OrcasMySQLConnectionRedirection (Improve MySQL connection latency)](https://aka.ms/azure_mysql_connection_redirection). --### Increase the storage limit for MySQL Flexible Server --Our system shows that the server might be constrained because it is approaching limits for the currently provisioned storage values. Approaching the storage limits might result in degraded performance or in the server being moved to read-only mode. To ensure continued performance, we recommend increasing the provisioned storage amount. --Learn more about [Azure Database for MySQL flexible server - OrcasMeruMySqlStorageUpsell (Increase the storage limit for MySQL Flexible Server)](https://aka.ms/azure_mysql_flexible_server_storage). --### Scale the MySQL Flexible Server to a higher SKU --Our system shows that your Flexible Server is exceeding the connection limits associated with your current SKU. A large number of failed connection requests might adversely affect server performance. To improve performance, we recommend increasing the number of vCores or switching to a higher SKU. --Learn more about [Azure Database for MySQL flexible server - OrcasMeruMysqlConnectionUpsell (Scale the MySQL Flexible Server to a higher SKU)](https://aka.ms/azure_mysql_flexible_server_storage). --### Increase the MySQL Flexible Server vCores. --Our system shows that the CPU has been running under high utilization for an extended time period over the last seven days. High CPU utilization might lead to slow query performance. To improve performance, we recommend moving to a larger compute size. --Learn more about [Azure Database for MySQL flexible server - OrcasMeruMysqlCpuUpcell (Increase the MySQL Flexible Server vCores.)](https://aka.ms/azure_mysql_flexible_server_pricing). --### Improve performance by optimizing MySQL temporary-table sizing. --Our system shows that your MySQL server might be incurring unnecessary I/O overhead due to low temporary-table parameter settings. Unnecessary I/O overhead might result in unnecessary disk-based transactions and reduced performance. We recommend that you increase the 'tmp_table_size' and 'max_heap_table_size' parameter values to reduce the number of disk-based transactions. --Learn more about [Azure Database for MySQL flexible server - OrcasMeruMysqlTmpTable (Improve performance by optimizing MySQL temporary-table sizing.)](https://dev.mysql.com/doc/refman/8.0/en/internal-temporary-tables.html#internal-temporary-tables-engines). --### Move your MySQL server to Memory Optimized SKU --Our system shows that there is high memory usage for this server that can result in slower query performance and increased IOPS. To improve performance, review your workload queries to identify opportunities to minimize memory consumed. If no such opportunity found, then we recommend moving to higher SKU with more memory or increase storage size to get more IOPS. --Learn more about [Azure Database for MySQL flexible server - OrcasMeruMysqlMemoryUpsell (Move your MySQL server to Memory Optimized SKU)](https://aka.ms/azure_mysql_flexible_server_storage). --### Add a MySQL Read Replica server --Our system shows that you might have a read intensive workload running, which results in resource contention for this server. This might lead to slow query performance for the server. To improve performance, we recommend you add a read replica, and offload some of your read workloads to the replica. --Learn more about [Azure Database for MySQL flexible server - OrcasMeruMysqlReadReplicaUpsell (Add a MySQL Read Replica server)](https://aka.ms/flexible-server-mysql-read-replicas). --### Increase the work_mem to avoid excessive disk spilling from sort and hash --Our system shows that the configuration work_mem is too small for your PostgreSQL server which is resulting in disk spilling and degraded query performance. To improve this, we recommend increasing the work_mem limit for the server, which helps to reduce the scenarios when the sort or hash happens on disk and improves the overall query performance. --Learn more about [PostgreSQL server - OrcasPostgreSqlWorkMem (Increase the work_mem to avoid excessive disk spilling from sort and hash)](https://aka.ms/runtimeconfiguration). --### Boost your workload performance by 30% with the new Ev5 compute hardware --With the new Ev5 compute hardware, you can boost workload performance by 30% with higher concurrency and better throughput. Navigate to the Compute+Storage option on the Azure portal and switch to Ev5 compute at no extra cost. Ev5 compute provides best performance among other VM series in terms of QPS and latency. --Learn more about [Azure Database for MySQL flexible server - OrcasMeruMySqlComputeSeriesUpgradeEv5 (Boost your workload performance by 30% with the new Ev5 compute hardware)](https://techcommunity.microsoft.com/t5/azure-database-for-mysql-blog/boost-azure-mysql-business-critical-flexible-server-performance/ba-p/3603698). --### Increase the storage limit for Hyperscale (Citus) server group --Our system shows that one or more nodes in the server group might be constrained because they are approaching limits for the currently provisioned storage values. This might result in degraded performance or in the server being moved to read-only mode. To ensure continued performance, we recommend increasing the provisioned disk space. --Learn more about [PostgreSQL server - OrcasPostgreSqlCitusStorageLimitHyperscaleCitus (Increase the storage limit for Hyperscale (Citus) server group)](/azure/postgresql/howto-hyperscale-scale-grow#increase-storage-on-nodes). --### Increase the PostgreSQL server vCores --Over 7 days, CPU usage was at least one of the following: Above 90% for 2 or more hours, above 50% for 50% of the time, at max usage for 20% of the time. High CPU utilization can lead to slow query performance. To improve performance, we recommend moving your server to a larger SKU with higher compute. -Learn more about [Azure Database for PostgreSQL flexible server - Upscale Server SKU for PostgreSQL on Azure Database](/azure/postgresql/flexible-server/concepts-compute). --### Optimize log_statement settings for PostgreSQL on Azure Database --Our system shows that you have log_statement enabled, for better performance set it to NONE --Learn more about [Azure Database for PostgreSQL flexible server - Optimize log_statement settings for PostgreSQL on Azure Database](/azure/postgresql/flexible-server/concepts-logging). --### Optimize log_duration settings for PostgreSQL on Azure Database --You may experience potential performance degradation due to logging settings. To optimize these settings, set the log_duration server parameter to OFF. --Learn more about [Learn more about Azure Database for PostgreSQL flexible server - Optimize log_duration settings for PostgreSQL on Azure Database](/azure/postgresql/flexible-server/concepts-logging). --### Optimize log_min_duration settings for PostgreSQL on Azure Database --Your log_min_duration server parameter is set to less than 60,000 ms (1 minute), which can lead to potential performance degradation. You can optimize logging settings by setting the log_min_duration_statement parameter to -1. --Learn more about [Azure Database for PostgreSQL flexible server - Optimize log_min_duration settings for PostgreSQL on Azure Database](/azure/postgresql/flexible-server/concepts-logging). --### Optimize log_error_verbosity settings for PostgreSQL on Azure Database --Your server has been configured to output VERBOSE error logs. This can be useful for troubleshooting your database, but it can also result in reduced database performance. To improve performance, we recommend changing the log_error_verbosity server parameter to the DEFAULT setting. --Learn more about [Learn more about Azure Database for PostgreSQL flexible server - Optimize log_error_verbosity settings for PostgreSQL on Azure Database](/azure/postgresql/flexible-server/concepts-logging). --### Identify if checkpoints are happening too often to improve PostgreSQL - Flexible Server performance --Your sever is encountering checkpoints frequently. To resolve the issue, we recommend increasing your max_wal_size server parameter. --Learn more about [Azure Database for PostgreSQL flexible server ΓÇô Increase max_wal_size](/azure/postgresql/flexible-server/server-parameters-table-write-ahead-logcheckpoints?pivots=postgresql-16#max_wal_size). --### Identify inactive Logical Replication Slots to improve PostgreSQL - Flexible Server performance --Your server may have inactive logical replication slots which can result in degraded server performance and availability. We recommend deleting inactive replication slots or consuming the changes from the slots so the Log Sequence Number (LSN) advances to closer to the current LSN of the server. --Learn more about [Azure Database for PostgreSQL flexible server ΓÇô Unused/inactive Logical Replication Slots](/azure/postgresql/flexible-server/how-to-autovacuum-tuning#unused-replication-slots). --### Identify long-running transactions to improve PostgreSQL - Flexible Server performance --There are transactions running for more than 24 hours. Review the High CPU Usage-> Long Running Transactions section in the troubleshooting guides to identify and mitigate the issue. --Learn more about [Azure Database for PostgreSQL flexible server ΓÇô Long Running transactions using Troubleshooting guides](/azure/postgresql/flexible-server/how-to-troubleshooting-guides). --### Identify Orphaned Prepared transactions to improve PostgreSQL - Flexible Server performance --There are orphaned prepared transactions. Rollback/Commit the prepared transaction. The recommendations are shared in Autovacuum Blockers -> Autovacuum Blockers section in the troubleshooting guides. --Learn more about [Azure Database for PostgreSQL flexible server ΓÇô Orphaned Prepared transactions using Troubleshooting guides](/azure/postgresql/flexible-server/how-to-troubleshooting-guides). --### Identify Transaction Wraparound to improve PostgreSQL - Flexible Server performance --The server has crossed the 50% wraparound limit, having 1 billion transactions. Refer to the recommendations shared in the Autovacuum Blockers -> Emergency AutoVacuum and Wraparound section of the troubleshooting guides. --Learn more about [Azure Database for PostgreSQL flexible server ΓÇô Transaction Wraparound using Troubleshooting guides](/azure/postgresql/flexible-server/how-to-troubleshooting-guides). --### Identify High Bloat Ratio to improve PostgreSQL - Flexible Server performance --The server has a bloat_ratio (dead tuples/ (live tuples + dead tuples) > 80%). Refer to the recommendations shared in the Autovacuum Monitoring section of the troubleshooting guides. --Learn more about [Azure Database for PostgreSQL flexible server ΓÇô High Bloat Ratio using Troubleshooting guides](/azure/postgresql/flexible-server/how-to-troubleshooting-guides). --### Increase the storage limit for Hyperscale (Citus) server group --Our system shows that one or more nodes in the server group might be constrained because they are approaching limits for the currently provisioned storage values. This might result in degraded performance or in the server being moved to read-only mode. To ensure continued performance, we recommend increasing the provisioned disk space. --Learn more about [Hyperscale (Citus) server group - MarlinStorageLimitRecommendation (Increase the storage limit for Hyperscale (Citus) server group)](/azure/postgresql/howto-hyperscale-scale-grow#increase-storage-on-nodes). --### Migrate your database from SSPG to FSPG --Consider our new offering, Azure Database for PostgreSQL Flexible Server, which provides richer capabilities such as zone resilient HA, predictable performance, maximum control, custom maintenance window, cost optimization controls, and simplified developer experience. --Learn more about [Azure Database for PostgreSQL flexible server - OrcasPostgreSqlMeruMigration (Migrate your database from SSPG to FSPG)](/azure/postgresql/how-to-upgrade-using-dump-and-restore). --### Improve your Cache and application performance when running with high network bandwidth --Cache instances perform best when not running under high network bandwidth that might cause unresponsiveness, data loss, or unavailability. Apply best practices to reduce network bandwidth or scale to a different size or SKU with more capacity. --Learn more about [Redis Cache Server - RedisCacheNetworkBandwidth (Improve your Cache and application performance when running with high network bandwidth)](https://aka.ms/redis/recommendations/bandwidth). --### Improve your Cache and application performance when running with many connected clients --Cache instances perform best when not running under high network bandwidth that might cause unresponsiveness, data loss, or unavailability. Apply best practices to reduce the server load or scale to a different size or SKU with more capacity. --Learn more about [Redis Cache Server - RedisCacheConnectedClients (Improve your Cache and application performance when running with many connected clients)](https://aka.ms/redis/recommendations/connections). --### Improve your Cache and application performance when running with many connected clients --Cache instances perform best when not running under high network bandwidth that might cause unresponsiveness, data loss, or unavailability. Apply best practices to reduce the server load or scale to a different size or SKU with more capacity. --Learn more about [Redis Cache Server - RedisCacheConnectedClientsHigh (Improve your Cache and application performance when running with many connected clients)](https://aka.ms/redis/recommendations/connections). --### Improve your Cache and application performance when running with high server load --Cache instances perform best when not running under high network bandwidth that might cause unresponsiveness, data loss, or unavailability. Apply best practices to reduce the server load or scale to a different size or SKU with more capacity. --Learn more about [Redis Cache Server - RedisCacheServerLoad (Improve your Cache and application performance when running with high server load)](https://aka.ms/redis/recommendations/cpu). --### Improve your Cache and application performance when running with high server load --Cache instances perform best when not running under high network bandwidth that might cause unresponsiveness, data loss, or unavailability. Apply best practices to reduce the server load or scale to a different size or SKU with more capacity. --Learn more about [Redis Cache Server - RedisCacheServerLoadHigh (Improve your Cache and application performance when running with high server load)](https://aka.ms/redis/recommendations/cpu). --### Improve your Cache and application performance when running with high memory pressure --Cache instances perform best when not running under high network bandwidth that might cause unresponsiveness, data loss, or unavailability. Apply best practices to reduce used memory or scale to a different size or SKU with more capacity. --Learn more about [Redis Cache Server - RedisCacheUsedMemory (Improve your Cache and application performance when running with high memory pressure)](https://aka.ms/redis/recommendations/memory). --### Improve your Cache and application performance when memory rss usage is high. --Cache instances perform best when not running under high network bandwidth that might cause unresponsiveness, data loss, or unavailability. Apply best practices to reduce used memory or scale to a different size or SKU with more capacity. --Learn more about [Redis Cache Server - RedisCacheUsedMemoryRSS (Improve your Cache and application performance when memory rss usage is high.)](https://aka.ms/redis/recommendations/memory). --### Cache instances perform best when the host machines where client application runs is able to keep up with responses from the cache --Cache instances perform best when the host machines where the client application runs, is able to keep up with responses from the cache. If client host machine is running hot on memory, CPU, or network bandwidth, the cache responses don't reach your application fast enough and can result in higher latency. --Learn more about [Redis Cache Server - UnresponsiveClient (Cache instances perform best when the host machines where client application runs is able to keep up with responses from the cache.)](/azure/azure-cache-for-redis/cache-troubleshoot-client). ---## DevOps --### Update to the latest AMS API Version --We have identified calls to an Azure Media Services (AMS) API version that is not recommended. We recommend switching to the latest AMS API version to ensure uninterrupted access to AMS, latest features, and performance improvements. --Learn more about [Monitor - UpdateToLatestAMSApiVersion (Update to the latest AMS API Version)](https://aka.ms/AMSAdvisor). --### Upgrade to the latest Workloads SDK version --Upgrade to the latest Workloads SDK version to get the best results in terms of model quality, performance and service availability. --Learn more about [Monitor - UpgradeToLatestAMSSdkVersion (Upgrade to the latest Workloads SDK version)](https://aka.ms/AMSAdvisor). ----## Integration --### Upgrade your API Management resource to an alternative version --Your subscription is running on versions that have been scheduled for deprecation. On 30 September 2023, all API versions for the Azure API Management service prior to 2021-08-01 retire and API calls fail. Upgrade to newer version to prevent disruption to your services. --Learn more about [Api Management - apimgmtdeprecation (Upgrade your API Management resource to an alternative version)](https://azure.microsoft.com/updates/api-versions-being-retired-for-azure-api-management/). ------## Mobile --### Use recommended version of Chat SDK --Azure Communication Services Chat SDK can be used to add rich, real-time chat to your applications. Update to the recommended version of Chat SDK to ensure the latest fixes and features. --Learn more about [Communication service - UpgradeChatSdk (Use recommended version of Chat SDK)](../communication-services/concepts/chat/sdk-features.md). --### Use recommended version of Resource Manager SDK --Resource Manager SDK can be used to create and manage Azure Communication Services resources. Update to the recommended version of Resource Manager SDK to ensure the latest fixes and features. --Learn more about [Communication service - UpgradeResourceManagerSdk (Use recommended version of Resource Manager SDK)](../communication-services/quickstarts/create-communication-resource.md?pivots=platform-net&tabs=windows). --### Use recommended version of Identity SDK --Azure Communication Services Identity SDK can be used to manage identities, users, and access tokens. Update to the recommended version of Identity SDK to ensure the latest fixes and features. --Learn more about [Communication service - UpgradeIdentitySdk (Use recommended version of Identity SDK)](../communication-services/concepts/sdk-options.md). --### Use recommended version of SMS SDK --Azure Communication Services SMS SDK can be used to send and receive SMS messages. Update to the recommended version of SMS SDK to ensure the latest fixes and features. --Learn more about [Communication service - UpgradeSmsSdk (Use recommended version of SMS SDK)](/azure/communication-services/concepts/telephony-sms/sdk-features). --### Use recommended version of Phone Numbers SDK --Azure Communication Services Phone Numbers SDK can be used to acquire and manage phone numbers. Update to the recommended version of Phone Numbers SDK to ensure the latest fixes and features. --Learn more about [Communication service - UpgradePhoneNumbersSdk (Use recommended version of Phone Numbers SDK)](../communication-services/concepts/sdk-options.md). --### Use recommended version of Calling SDK --Azure Communication Services Calling SDK can be used to enable voice, video, screen-sharing, and other real-time communication. Update to the recommended version of Calling SDK to ensure the latest fixes and features. --Learn more about [Communication service - UpgradeCallingSdk (Use recommended version of Calling SDK)](../communication-services/concepts/voice-video-calling/calling-sdk-features.md). --### Use recommended version of Call Automation SDK --Azure Communication Services Call Automation SDK can be used to make and manage calls, play audio, and configure recording. Update to the recommended version of Call Automation SDK to ensure the latest fixes and features. --Learn more about [Communication service - UpgradeServerCallingSdk (Use recommended version of Call Automation SDK)](../communication-services/concepts/voice-video-calling/call-automation-apis.md). --### Use recommended version of Network Traversal SDK --Azure Communication Services Network Traversal SDK can be used to access TURN servers for low-level data transport. Update to the recommended version of Network Traversal SDK to ensure the latest fixes and features. --Learn more about [Communication service - UpgradeTurnSdk (Use recommended version of Network Traversal SDK)](../communication-services/concepts/sdk-options.md). --### Use recommended version of Rooms SDK --Azure Communication Services Rooms SDK can be used to control who can join a call, when they can meet, and how they can collaborate. Update to the recommended version of Rooms SDK to ensure the latest fixes and features. A non-recommended version was detected in the last 48-60 hours. --Learn more about [Communication service - UpgradeRoomsSdk (Use recommended version of Rooms SDK)](/azure/communication-services/concepts/rooms/room-concept). -----## Networking --### Upgrade SDK version recommendation --The latest version of Azure Front Door Standard and Premium Client Library or SDK contains fixes to issues reported by customers and proactively identified through our QA process. The latest version also carries reliability and performance optimization in addition to new features that can improve your overall experience using Azure Front Door Standard and Premium. --Learn more about [Front Door Profile - UpgradeCDNToLatestSDKLanguage (Upgrade SDK version recommendation)](https://aka.ms/afd/tiercomparison). --### Upgrade SDK version recommendation --The latest version of Azure Traffic Collector SDK contains fixes to issues proactively identified through our QA process, supports the latest resource model & has reliability and performance optimization that can improve your overall experience of using ATC. --Learn more about [Azure Traffic Collector - UpgradeATCToLatestSDKLanguage (Upgrade SDK version recommendation)](/azure/expressroute/traffic-collector). --### Upgrade your ExpressRoute circuit bandwidth to accommodate your bandwidth needs --You have been using over 90% of your procured circuit bandwidth recently. If you exceed your allocated bandwidth, you experience an increase in dropped packets sent over ExpressRoute. Upgrade your circuit bandwidth to maintain performance if your bandwidth needs remain this high. --Learn more about [ExpressRoute circuit - UpgradeERCircuitBandwidth (Upgrade your ExpressRoute circuit bandwidth to accommodate your bandwidth needs)](../expressroute/about-upgrade-circuit-bandwidth.md). --### Experience more predictable, consistent latency with a private connection to Azure --Improve the performance, privacy, and reliability of your business-critical apps by extending your on-premises networks to Azure with Azure ExpressRoute. Establish private ExpressRoute connections directly from your WAN, through a cloud exchange facility, or through POP and IPVPN connections. --Learn more about [Subscription - AzureExpressRoute (Experience more predictable, consistent latency with a private connection to Azure)](/azure/expressroute/expressroute-howto-circuit-portal-resource-manager). --### Upgrade Workloads API to the latest version (Azure Center for SAP solutions API) --We have identified calls to an outdated Workloads API version for resources under this resource group. We recommend switching to the latest Workloads API version to ensure uninterrupted access to latest features and performance improvements in Azure Center for SAP solutions. If there are multiple Virtual Instances for SAP solutions (VIS) shown in the recommendation, ensure you update the API version for all VIS resources. --Learn more about [Subscription - UpdateToLatestWaasApiVersionAtSub (Upgrade Workloads API to the latest version (Azure Center for SAP solutions API))](https://go.microsoft.com/fwlink/?linkid=2228001). --### Upgrade Workloads SDK to the latest version (Azure Center for SAP solutions SDK) --We have identified calls to an outdated Workloads SDK version from resources in this Resource Group. Upgrade to the latest Workloads SDK version to get the latest features and the best results in terms of model quality, performance and service availability for Azure Center for SAP solutions. If there are multiple Virtual Instances for SAP solutions (VIS) shown in the recommendation, ensure you update the SDK version for all VIS resources. --Learn more about [Subscription - UpgradeToLatestWaasSdkVersionAtSub (Upgrade Workloads SDK to the latest version (Azure Center for SAP solutions SDK))](https://go.microsoft.com/fwlink/?linkid=2228000). --### Configure DNS Time to Live to 60 seconds --Time to Live (TTL) affects how recent the response a client gets when it makes a request to Azure Traffic Manager. Reducing the TTL value means that the client is routed to a functioning endpoint more quickly, in the case of a failover. Configure your TTL to 60 seconds to route traffic to a health endpoint as quickly as possible. --Learn more about [Traffic Manager profile - ProfileTTL (Configure DNS Time to Live to 60 seconds)](https://aka.ms/Um3xr5). --### Configure DNS Time to Live to 20 seconds --Time to Live (TTL) affects how recent the response a client gets when it makes a request to Azure Traffic Manager. Reducing the TTL value means that the client is routed to a functioning endpoint more quickly, in the case of a failover. Configure your TTL to 20 seconds to route traffic to a health endpoint as quickly as possible. --Learn more about [Traffic Manager profile - FastFailOverTTL (Configure DNS Time to Live to 20 seconds)](https://aka.ms/Ngfw4r). --### Configure DNS Time to Live to 60 seconds --Time to Live (TTL) affects how recent the response a client gets when it makes a request to Azure Traffic Manager. Reducing the TTL value means that the client is routed to a functioning endpoint more quickly, in the case of a failover. Configure your TTL to 60 seconds to route traffic to a health endpoint as quickly as possible. --Learn more about [Traffic Manager profile - ProfileTTL (Configure DNS Time to Live to 60 seconds)](https://aka.ms/Um3xr5). --### Consider increasing the size of your virtual network Gateway SKU to address consistently high CPU use --Under high traffic load, the VPN gateway might drop packets due to high CPU. --Learn more about [Virtual network gateway - HighCPUVNetGateway (Consider increasing the size of your virtual network (VNet) Gateway SKU to address consistently high CPU use)](https://aka.ms/HighCPUP2SVNetGateway). --### Consider increasing the size of your virtual network Gateway SKU to address high P2S use --Each gateway SKU can only support a specified count of concurrent P2S connections. Your connection count is close to your gateway limit, so more connection attempts might fail. --Learn more about [Virtual network gateway - HighP2SConnectionsVNetGateway (Consider increasing the size of your VNet Gateway SKU to address high P2S use)](https://aka.ms/HighP2SConnectionsVNetGateway). --### Make sure you have enough instances in your Application Gateway to support your traffic --Your Application Gateway has been running on high utilization recently and under heavy load you might experience traffic loss or increase in latency. It is important that you scale your Application Gateway accordingly and add a buffer so that you're prepared for any traffic surges or spikes and minimize the effect that it might have in your QoS. Application Gateway v1 SKU (Standard/WAF) supports manual scaling and v2 SKU (Standard_v2/WAF_v2) supports manual and autoscaling. With manual scaling, increase your instance count. If autoscaling is enabled, make sure your maximum instance count is set to a higher value so Application Gateway can scale out as the traffic increases. --Learn more about [Application gateway - HotAppGateway (Make sure you have enough instances in your Application Gateway to support your traffic)](https://aka.ms/hotappgw). -------## SAP for Azure --### To avoid soft-lockup in Mellanox driver, reduce the can_queue value in the App VM OS in SAP workloads --To avoid sporadic soft-lockup in Mellanox driver, reduce the can_queue value in the OS. The value cannot be set directly. Add the following kernel boot line options to achieve the same effect:'hv_storvsc.storvsc_ringbuffer_size=131072 hv_storvsc.storvsc_vcpus_per_sub_channel=1024' --Learn more about [App Server Instance - AppSoftLockup (To avoid soft-lockup in Mellanox driver, reduce the can_queue value in the App VM OS in SAP workloads)](https://www.suse.com/support/kb/doc/?id=000020248). --### To avoid soft-lockup in Mellanox driver, reduce the can_queue value in the ASCS VM OS in SAP workloads --To avoid sporadic soft-lockup in Mellanox driver, reduce the can_queue value in the OS. The value cannot be set directly. Add the following kernel boot line options to achieve the same effect:'hv_storvsc.storvsc_ringbuffer_size=131072 hv_storvsc.storvsc_vcpus_per_sub_channel=1024' --Learn more about [Central Server Instance - AscsoftLockup (To avoid soft-lockup in Mellanox driver, reduce the can_queue value in the ASCS VM OS in SAP workloads)](https://www.suse.com/support/kb/doc/?id=000020248). --### To avoid soft-lockup in Mellanox driver, reduce the can_queue value in the DB VM OS in SAP workloads --To avoid sporadic soft-lockup in Mellanox driver, reduce the can_queue value in the OS. The value cannot be set directly. Add the following kernel boot line options to achieve the same effect:'hv_storvsc.storvsc_ringbuffer_size=131072 hv_storvsc.storvsc_vcpus_per_sub_channel=1024' --Learn more about [Database Instance - DBSoftLockup (To avoid soft-lockup in Mellanox driver, reduce the can_queue value in the DB VM OS in SAP workloads)](https://www.suse.com/support/kb/doc/?id=000020248). --### For improved file system performance in HANA DB with ANF, optimize tcp_wmem OS parameter --The parameter net.ipv4.tcp_wmem specifies minimum, default, and maximum send buffer sizes that are used for a TCP socket. Set the parameter as per SAP note: 302436 to certify HANA DB to run with ANF and improve file system performance. The maximum value must not exceed net.core.wmem_max parameter. --Learn more about [Database Instance - WriteBuffersAllocated (For improved file system performance in HANA DB with ANF, optimize tcp_wmem OS parameter)](https://launchpad.support.sap.com/#/notes/3024346). --### For improved file system performance in HANA DB with ANF, optimize tcp_rmem OS parameter --The parameter net.ipv4.tcp_rmem specifies minimum, default, and maximum receive buffer sizes used for a TCP socket. Set the parameter as per SAP note 3024346 to certify HANA DB to run with ANF and improve file system performance. The maximum value must not exceed net.core.rmem_max parameter. --Learn more about [Database Instance - OptimiseReadTcp (For improved file system performance in HANA DB with ANF, optimize tcp_rmem OS parameter)](https://launchpad.support.sap.com/#/notes/3024346). --### For improved file system performance in HANA DB with ANF, optimize wmem_max OS parameter --In HANA DB with ANF storage type, the maximum write socket buffer, defined by the parameter net.core.wmem_max must be set large enough to handle outgoing network packets. The net.core.wmem_max configuration certifies HANA DB to run with ANF and improves file system performance. See SAP note: 3024346. --Learn more about [Database Instance - MaxWriteBuffer (For improved file system performance in HANA DB with ANF, optimize wmem_max OS parameter)](https://launchpad.support.sap.com/#/notes/3024346). --### For improved file system performance in HANA DB with ANF, optimize tcp_rmem OS parameter --The parameter net.ipv4.tcp_rmem specifies minimum, default, and maximum receive buffer sizes used for a TCP socket. Set the parameter as per SAP note 3024346 to certify HANA DB to run with ANF and improve file system performance. The maximum value must not exceed net.core.rmem_max parameter. --Learn more about [Database Instance - OptimizeReadTcp (For improved file system performance in HANA DB with ANF, optimize tcp_rmem OS parameter)](https://launchpad.support.sap.com/#/notes/3024346). --### For improved file system performance in HANA DB with ANF, optimize rmem_max OS parameter --In HANA DB with ANF storage type, the maximum read socket buffer, defined by the parameter, net.core.rmem_max must be set large enough to handle incoming network packets. The net.core.rmem_max configuration certifies HANA DB to run with ANF and improves file system performance. See SAP note: 3024346. --Learn more about [Database Instance - MaxReadBuffer (For improved file system performance in HANA DB with ANF, optimize rmem_max OS parameter)](https://launchpad.support.sap.com/#/notes/3024346). --### For improved file system performance in HANA DB with ANF, set receiver backlog queue size to 300000 --The parameter net.core.netdev_max_backlog specifies the size of the receiver backlog queue, used if a network interface receives packets faster than the kernel can process. Set the parameter as per SAP note: 3024346. The net.core.netdev_max_backlog configuration certifies HANA DB to run with ANF and improves file system performance. --Learn more about [Database Instance - BacklogQueueSize (For improved file system performance in HANA DB with ANF, set receiver backlog queue size to 300000)](https://launchpad.support.sap.com/#/notes/3024346). --### To improve file system performance in HANA DB with ANF, enable the TCP window scaling OS parameter --Enable the TCP window scaling parameter as per SAP note: 302436. The TCP window scaling configuration certifies HANA DB to run with ANF and improves file system performance in HANA DB with ANF in SAP workloads. --Learn more about [Database Instance - EnableTCPWindowScaling (To improve file system performance in HANA DB with ANF, enable the TCP window scaling OS parameter )](https://launchpad.support.sap.com/#/notes/3024346). --### For improved file system performance in HANA DB with ANF, disable IPv6 protocol in OS --Disable IPv6 as per recommendation for SAP on Azure for HANA DB with ANF to improve file system performance. --Learn more about [Database Instance - DisableIPv6Protocol (For improved file system performance in HANA DB with ANF, disable IPv6 protocol in OS)](/azure/virtual-machines/workloads/sap/sap-hana-scale-out-standby-netapp-files-suse). --### To improve file system performance in HANA DB with ANF, disable parameter for slow start after idle --The parameter net.ipv4.tcp_slow_start_after_idle disables the need to scale-up incrementally the TCP window size for TCP connections that were idle for some time. By setting this parameter to zero as per SAP note: 302436, the maximum speed is used from beginning for previously idle TCP connections. --Learn more about [Database Instance - ParameterSlowStart (To improve file system performance in HANA DB with ANF, disable parameter for slow start after idle)](https://launchpad.support.sap.com/#/notes/3024346). --### For improved file system performance in HANA DB with ANF optimize tcp_max_syn_backlog OS parameter --To prevent the kernel from using SYN cookies in a situation where lots of connection requests are sent in a short timeframe and to prevent a warning about a potential SYN flooding attack in the system log, the size of the SYN backlog must be set to a reasonably high value. See SAP note 2382421. --Learn more about [Database Instance - TCPMaxSynBacklog (For improved file system performance in HANA DB with ANF optimize tcp_max_syn_backlog OS parameter)](/azure/virtual-machines/workloads/sap/sap-hana-scale-out-standby-netapp-files-suse). --### For improved file system performance in HANA DB with ANF, enable the tcp_sack OS parameter --Enable the tcp_sack parameter as per SAP note: 302436. The tcp_sack configuration certifies HANA DB to run with ANF and improves file system performance in HANA DB with ANF in SAP workloads. --Learn more about [Database Instance - TCPSackParameter (For improved file system performance in HANA DB with ANF, enable the tcp_sack OS parameter)](https://launchpad.support.sap.com/#/notes/3024346). --### In high-availability scenario for HANA DB with ANF, disable the tcp_timestamps OS parameter --Disable the tcp_timestamps parameter as per SAP note: 302436. The tcp_timestamps configuration certifies HANA DB to run with ANF and improves file system performance in high-availability scenarios for HANA DB with ANF in SAP workloads --Learn more about [Database Instance - DisableTCPTimestamps (In high-availability scenario for HANA DB with ANF, disable the tcp_timestamps OS parameter)](https://launchpad.support.sap.com/#/notes/3024346). --### For improved file system performance in HANA DB with ANF, enable the tcp_timestamps OS parameter --Enable the tcp_timestamps parameter as per SAP note: 302436. The tcp_timestamps configuration certifies HANA DB to run with ANF and improves file system performance in HANA DB with ANF in SAP workloads. --Learn more about [Database Instance - EnableTCPTimestamps (For improved file system performance in HANA DB with ANF, enable the tcp_timestamps OS parameter)](https://launchpad.support.sap.com/#/notes/3024346). --### To improve file system performance in HANA DB with ANF, enable auto-tuning TCP receive buffer size --The parameter net.ipv4.tcp_moderate_rcvbuf enables TCP to perform buffer auto-tuning, to automatically size the buffer (no greater than tcp_rmem to match the size required by the path for full throughput. Enable this parameter as per SAP note: 302436 for improved file system performance. --Learn more about [Database Instance - EnableAutoTuning (To improve file system performance in HANA DB with ANF, enable auto-tuning TCP receive buffer size)](https://launchpad.support.sap.com/#/notes/3024346). --### For improved file system performance in HANA DB with ANF, optimize net.ipv4.ip_local_port_range --As HANA uses a considerable number of connections for the internal communication, it makes sense to have as many client ports available as possible for this purpose. Set the OS parameter, net.ipv4.ip_local_port_range parameter as per SAP note 2382421 to ensure optimal internal HANA communication. --Learn more about [Database Instance - IPV4LocalPortRange (For improved file system performance in HANA DB with ANF, optimize net.ipv4.ip_local_port_range)](https://launchpad.support.sap.com/#/notes/2382421). --### To improve file system performance in HANA DB with ANF, optimize sunrpc.tcp_slot_table_entries --Set the parameter sunrpc.tcp_slot_table_entries to 128 as per recommendation for improved file system performance in HANA DB with ANF in SAP workloads. --Learn more about [Database Instance - TCPSlotTableEntries (To improve file system performance in HANA DB with ANF, optimize sunrpc.tcp_slot_table_entries)](/azure/virtual-machines/workloads/sap/sap-hana-scale-out-standby-netapp-files-suse). --### All disks in LVM for /hana/data volume must be of the same type to ensure high performance in HANA DB --If multiple disk types are selected in the /hana/data volume, performance of HANA DB in SAP workloads might get restricted. Ensure all HANA Data volume disks are of the same type and are configured as per recommendation for SAP on Azure. --Learn more about [Database Instance - HanaDataDiskTypeSame (All disks in LVM for /hana/data volume must be of the same type to ensure high performance in HANA DB)](/azure/virtual-machines/workloads/sap/hana-vm-operations-storage). --### Stripe size for /hana/data must be 256 kb for improved performance of HANA DB in SAP workloads --If you're using LVM or mdadm to build stripe sets across several Azure premium disks, you need to define stripe sizes. Based on experience with recentLinux versions, Azure recommends using stripe size of 256 kb for /hana/data filesystem for better performance of HANA DB. --Learn more about [Database Instance - HanaDataStripeSize (Stripe size for /hana/data must be 256 kb for improved performance of HANA DB in SAP workloads)](/azure/virtual-machines/workloads/sap/hana-vm-operations-storage). --### To improve file system performance in HANA DB with ANF, optimize the parameter vm.swappiness --Set the OS parameter vm.swappiness to 10 as per recommendation for improved file system performance in HANA DB with ANF in SAP workloads. --Learn more about [Database Instance - VmSwappiness (To improve file system performance in HANA DB with ANF, optimize the parameter vm.swappiness)](/azure/virtual-machines/workloads/sap/sap-hana-scale-out-standby-netapp-files-suse). --### To improve file system performance in HANA DB with ANF, disable net.ipv4.conf.all.rp_filter --Disable the reverse path filter linux OS parameter, net.ipv4.conf.all.rp_filter as per recommendation for improved file system performance in HANA DB with ANF in SAP workloads. --Learn more about [Database Instance - DisableIPV4Conf (To improve file system performance in HANA DB with ANF, disable net.ipv4.conf.all.rp_filter)](/azure/virtual-machines/workloads/sap/sap-hana-scale-out-standby-netapp-files-suse). --### If using Ultradisk, the IOPS for /hana/data volume must be >=7000 for better HANA DB performance --IOPS of at least 7000 in /hana/data volume is recommended for SAP workloads when using Ultradisk. Select the disk type for /hana/data volume as per this requirement to ensure high performance of the DB. --Learn more about [Database Instance - HanaDataIOPS (If using Ultradisk, the IOPS for /hana/data volume must be >=7000 for better HANA DB performance)](/azure/virtual-machines/workloads/sap/hana-vm-operations-storage#azure-ultra-disk-storage-configuration-for-sap-hana). --### To improve file system performance in HANA DB with ANF, change parameter tcp_max_slot_table_entries --Set the OS parameter tcp_max_slot_table_entries to 128 as per SAP note: 302436 for improved file transfer performance in HANA DB with ANF in SAP workloads. --Learn more about [Database Instance - OptimizeTCPMaxSlotTableEntries (To improve file system performance in HANA DB with ANF, change parameter tcp_max_slot_table_entries)](/azure/virtual-machines/workloads/sap/sap-hana-scale-out-standby-netapp-files-suse#:~:text=Create%20configuration%20file%20/etc/sysctl.d/ms%2Daz.conf%20with%20Microsoft%20for%20Azure%20configuration%20settings). --### Ensure the read performance of /hana/data volume is >=400 MB/sec for better performance in HANA DB --Read activity of at least 400 MB/sec for /hana/data for 16 MB and 64 MB I/O sizes is recommended for SAP workloads on Azure. Select the disk type for /hana/data as per this requirement to ensure high performance of the DB and to meet minimum storage requirements for SAP HANA. --Learn more about [Database Instance - HanaDataVolumePerformance (Ensure the read performance of /hana/data volume is >=400 MB/sec for better performance in HANA DB)](/azure/virtual-machines/workloads/sap/hana-vm-operations-storage#:~:text=Read%20activity%20of%20at%20least%20400%20MB/sec%20for%20/hana/data). --### Read/write performance of /hana/log volume must be >=250 MB/sec for better performance in HANA DB --Read/Write activity of at least 250 MB/sec for /hana/log for 1 MB I/O size is recommended for SAP workloads on Azure. Select the disk type for /hana/log volume as per this requirement to ensure high performance of the DB and to meet minimum storage requirements for SAP HANA. --Learn more about [Database Instance - HanaLogReadWriteVolume (Read/write performance of /hana/log volume must be >=250 MB/sec for better performance in HANA DB)](/azure/virtual-machines/workloads/sap/hana-vm-operations-storage#:~:text=Read/write%20on%20/hana/log%20of%20250%20MB/sec%20with%201%20MB%20I/O%20sizes). --### If using Ultradisk, the IOPS for /hana/log volume must be >=2000 for better performance in HANA DB --IOPS of at least 2000 in /hana/log volume is recommended for SAP workloads when using Ultradisk. Select the disk type for /hana/log volume as per this requirement to ensure high performance of the DB. --Learn more about [Database Instance - HanaLogIOPS (If using Ultradisk, the IOPS for /hana/log volume must be >=2000 for better performance in HANA DB)](/azure/virtual-machines/workloads/sap/hana-vm-operations-storage#azure-ultra-disk-storage-configuration-for-sap-hana:~:text=1%20x%20P6-,Azure%20Ultra%20disk%20storage%20configuration%20for%20SAP%20HANA,-Another%20Azure%20storage). --### All disks in LVM for /hana/log volume must be of the same type to ensure high performance in HANA DB --If multiple disk types are selected in the /hana/log volume, performance of HANA DB in SAP workloads might get restricted. Ensure all HANA Data volume disks are of the same type and are configured as per recommendation for SAP on Azure. --Learn more about [Database Instance - HanaDiskLogVolumeSameType (All disks in LVM for /hana/log volume must be of the same type to ensure high performance in HANA DB)](/azure/virtual-machines/workloads/sap/hana-vm-operations-storage#:~:text=For%20the%20/hana/log%20volume.%20the%20configuration%20would%20look%20like). --### Enable Write Accelerator on /hana/log volume with Premium disk for improved write latency in HANA DB --Azure Write Accelerator is a functionality for Azure M-Series VMs. It improves I/O latency of writes against the Azure premium storage. For SAP HANA, Write Accelerator is to be used against the /hana/log volume only. --Learn more about [Database Instance - WriteAcceleratorEnabled (Enable Write Accelerator on /hana/log volume with Premium disk for improved write latency in HANA DB)](/azure/virtual-machines/workloads/sap/hana-vm-operations-storage#:~:text=different%20SAP%20applications.-,Solutions%20with%20premium%20storage%20and%20Azure%20Write%20Accelerator%20for%20Azure%20M%2DSeries%20virtual%20machines,-Azure%20Write%20Accelerator). --### Stripe size for /hana/log must be 64 kb for improved performance of HANA DB in SAP workloads --If you're using LVM or mdadm to build stripe sets across several Azure premium disks, you need to define stripe sizes. To get enough throughput with larger I/O sizes, Azure recommends using stripe size of 64 kb for /hana/log filesystem for better performance of HANA DB. --Learn more about [Database Instance - HanaLogStripeSize (Stripe size for /hana/log must be 64 kb for improved performance of HANA DB in SAP workloads)](/azure/virtual-machines/workloads/sap/hana-vm-operations-storage#:~:text=As%20stripe%20sizes%20the%20recommendation%20is%20to%20use). ------## Security --### Update Attestation API Version --We have identified API calls from outdated an Attestation API for resources under this subscription. We recommend switching to the latest Attestation API versions. You need to update your existing code to use the latest API version. Using the latest API version ensures you receive the latest features and performance improvements. --Learn more about [Attestation provider - UpgradeAttestationAPI (Update Attestation API Version)](/rest/api/attestation). --### Update Key Vault SDK Version --New Key Vault Client Libraries are split to keys, secrets, and certificates SDKs, which are integrated with recommended Azure Identity library to provide seamless authentication to Key Vault across all languages and environments. It also contains several performance fixes to issues reported by customers and proactively identified through our QA process. If Key Vault is integrated with Azure Storage, Disk or other Azure services that can use old Key Vault SDK and when all your current custom applications are using .NET SDK 4.0 or above, dismiss the recommendation. --Learn more about [Key vault - UpgradeKeyVaultSDK (Update Key Vault SDK Version)](/azure/key-vault/general/client-libraries). --### Update Key Vault SDK Version --New Key Vault Client Libraries are split to keys, secrets, and certificates SDKs, which are integrated with recommended Azure Identity library to provide seamless authentication to Key Vault across all languages and environments. It also contains several performance fixes to issues reported by customers and proactively identified through our QA process. --> [!IMPORTANT] -> Be aware that you can only remediate recommendation for custom applications you have access to. Recommendations can be shown due to integration with other Azure services like Storage, Disk encryption, which are in process to update to new version of our SDK. If you use .NET 4.0 in all your applications, dismiss the recommendation. --Learn more about [Managed HSM Service - UpgradeKeyVaultMHSMSDK (Update Key Vault SDK Version)](/azure/key-vault/general/client-libraries). -----## Storage --### Use "Put Blob" for blobs smaller than 256 MB --When writing a block blob that is 256 MB or less (64 MB for requests using REST versions before 2016-05-31), you can upload it in its entirety with a single write operation using "Put Blob". Based on your aggregated metrics, we believe your storage account's write operations can be optimized. --Learn more about [Storage Account - StorageCallPutBlob (Use \""Put Blob\"" for blobs smaller than 256 MB)](https://aka.ms/understandblockblobs). --### Increase provisioned size of premium file share to avoid throttling of requests --Your requests for premium file share are throttled as the I/O operations per second (IOPS) or throughput limits for the file share have reached. To protect your requests from being throttled, increase the size of the premium file share. --Learn more about [Storage Account - AzureStorageAdvisorAvoidThrottlingPremiumFiles (Increase provisioned size of premium file share to avoid throttling of requests)](). --### Create statistics on table columns --We have detected that you're missing table statistics that might be impacting query performance. The query optimizer uses statistics to estimate the cardinality or number of rows in the query result which enables the query optimizer to create a high quality query plan. --Learn more about [SQL data warehouse - CreateTableStatisticsSqlDW (Create statistics on table columns)](https://aka.ms/learnmorestatistics). --### Remove data skew to increase query performance --We have detected distribution data skew greater than 15%, which can cause costly performance bottlenecks. --Learn more about [SQL data warehouse - DataSkewSqlDW (Remove data skew to increase query performance)](https://aka.ms/learnmoredataskew). --### Update statistics on table columns --We have detected that you don't have up-to-date table statistics, which might be impacting query performance. The query optimizer uses up-to-date statistics to estimate the cardinality or number of rows in the query result that enables the query optimizer to create a high quality query plan. --Learn more about [SQL data warehouse - UpdateTableStatisticsSqlDW (Update statistics on table columns)](https://aka.ms/learnmorestatistics). --### Scale up to optimize cache utilization with SQL Data Warehouse --We have detected that you had high cache used percentage with low hit percentage, indicating a high cache eviction rate that can affect the performance of your workload. --Learn more about [SQL data warehouse - SqlDwIncreaseCacheCapacity (Scale up to optimize cache utilization with SQL Data Warehouse)](https://aka.ms/learnmoreadaptivecache). --### Scale up or update resource class to reduce tempdb contention with SQL Data Warehouse --We have detected that you had high tempdb utilization that can affect the performance of your workload. --Learn more about [SQL data warehouse - SqlDwReduceTempdbContention (Scale up or update resource class to reduce tempdb contention with SQL Data Warehouse)](https://aka.ms/learnmoretempdb). --### Convert tables to replicated tables with SQL Data Warehouse --We have detected that you might benefit from using replicated tables. Replicated tables avoid costly data movement operations and significantly increase the performance of your workload. --Learn more about [SQL data warehouse - SqlDwReplicateTable (Convert tables to replicated tables with SQL Data Warehouse)](https://aka.ms/learnmorereplicatedtables). --### Split staged files in the storage account to increase load performance --We have detected that you can increase load throughput by splitting your compressed files that are staged in your storage account. A good rule of thumb is to split compressed files into 60 or more to maximize the parallelism of your load. --Learn more about [SQL data warehouse - FileSplittingGuidance (Split staged files in the storage account to increase load performance)](https://aka.ms/learnmorefilesplit). --### Increase batch size when loading to maximize load throughput, data compression, and query performance --We have detected that you can increase load performance and throughput by increasing the batch size when loading into your database. Consider using the COPY statement. If you're unable to use the COPY statement, consider increasing the batch size when using loading utilities such as the SQLBulkCopy API or BCP - a good rule of thumb is a batch size between 100K to 1M rows. --Learn more about [SQL data warehouse - LoadBatchSizeGuidance (Increase batch size when loading to maximize load throughput, data compression, and query performance)](https://aka.ms/learnmoreincreasebatchsize). --### Co-locate the storage account within the same region to minimize latency when loading --We have detected that you're loading from a region that is different from your SQL pool. Consider loading from a storage account that is within the same region as your SQL pool to minimize latency when loading data. --Learn more about [SQL data warehouse - ColocateStorageAccount (Co-locate the storage account within the same region to minimize latency when loading)](https://aka.ms/learnmorestoragecolocation). --### Upgrade your Storage Client Library to the latest version for better reliability and performance --The latest version of Storage Client Library/ SDK contains fixes to issues reported by customers and proactively identified through our QA process. The latest version also carries reliability and performance optimization in addition to new features that can improve your overall experience using Azure Storage. --Learn more about [Storage Account - UpdateStorageSDK (Upgrade your Storage Client Library to the latest version for better reliability and performance)](https://aka.ms/learnmorestoragecolocation). --### Upgrade your Storage Client Library to the latest version for better reliability and performance --The latest version of Storage Client Library/ SDK contains fixes to issues reported by customers and proactively identified through our QA process. The latest version also carries reliability and performance optimization in addition to new features that can improve your overall experience using Azure Storage. --Learn more about [Storage Account - UpdateStorageDataMovementSDK (Upgrade your Storage Client Library to the latest version for better reliability and performance)](https://aka.ms/AA5wtca). --### Upgrade to Standard SSD Disks for consistent and improved performance --Because you're running IaaS virtual machine workloads on Standard HDD managed disks, be aware that a Standard SSD disk option is now available for all Azure VM types. Standard SSD disks are a cost-effective storage option optimized for enterprise workloads that need consistent performance. Upgrade your disk configuration today for improved latency, reliability, and availability. Upgrading requires a VM reboot, which takes three to five minutes. --Learn more about [Storage Account - StandardSSDForNonPremVM (Upgrade to Standard SSD Disks for consistent and improved performance)](/azure/virtual-machines/windows/disks-types#standard-ssd). --### Use premium performance block blob storage --One or more of your storage accounts has a high transaction rate per GB of block blob data stored. Use premium performance block blob storage instead of standard performance storage for your workloads that require fast storage response times and/or high transaction rates and potentially save on storage costs. --Learn more about [Storage Account - PremiumBlobStorageAccount (Use premium performance block blob storage)](https://aka.ms/usePremiumBlob). --### Convert Unmanaged Disks from Standard HDD to Premium SSD for performance --We have noticed your Unmanaged HDD Disk is approaching performance targets. Azure premium SSDs deliver high-performance and low-latency disk support for virtual machines with IO-intensive workloads. Give your disk performance a boost by upgrading your Standard HDD disk to Premium SSD disk. Upgrading requires a VM reboot, which takes three to five minutes. --Learn more about [Storage Account - UMDHDDtoPremiumForPerformance (Convert Unmanaged Disks from Standard HDD to Premium SSD for performance)](/azure/virtual-machines/windows/disks-types#premium-ssd). --### Distribute data in server group to distribute workload among nodes --It looks like the data is not distributed in this server group but stays on the coordinator. For full Hyperscale (Citus) benefits, distribute data on worker nodes in the server group. --Learn more about [Hyperscale (Citus) server group - OrcasPostgreSqlCitusDistributeData (Distribute data in server group to distribute workload among nodes)](https://go.microsoft.com/fwlink/?linkid=2135201). --### Rebalance data in Hyperscale (Citus) server group to distribute workload among worker nodes more evenly --It looks like the data is not well balanced between worker nodes in this Hyperscale (Citus) server group. In order to use each worker node of the Hyperscale (Citus) server group effectively rebalance data in the server group. --Learn more about [Hyperscale (Citus) server group - OrcasPostgreSqlCitusRebalanceData (Rebalance data in Hyperscale (Citus) server group to distribute workload among worker nodes more evenly)](https://go.microsoft.com/fwlink/?linkid=2148869). -----## Virtual desktop infrastructure --### Improve user experience and connectivity by deploying VMs closer to userΓÇÖs location --We have determined that your VMs are located in a region different or far from where your users are connecting with Azure Virtual Desktop, which might lead to prolonged connection response times and affect overall user experience. When you create VMs for your host pools, try to use a region closer to the user. Having close proximity ensures continuing satisfaction with the Azure Virtual Desktop service and a better overall quality of experience. --Learn more about [Host Pool - RegionProximityHostPools (Improve user experience and connectivity by deploying VMs closer to userΓÇÖs location.)](../virtual-desktop/connection-latency.md). --### Change the max session limit for your depth first load balanced host pool to improve VM performance --Depth first load balancing uses the max session limit to determine the maximum number of users that can have concurrent sessions on a single session host. If the max session limit is too high, all user sessions are directed to the same session host and this might cause performance and reliability issues. Therefore, when setting a host pool to have depth first load balancing, also set an appropriate max session limit according to the configuration of your deployment and capacity of your VMs. To fix this, open your host pool's properties and change the value next to the "Max session limit" setting. --Learn more about [Host Pool - ChangeMaxSessionLimitForDepthFirstHostPool (Change the max session limit for your depth first load balanced host pool to improve VM performance )](../virtual-desktop/configure-host-pool-load-balancing.md). -----## Web --### Move your App Service Plan to PremiumV2 for better performance --Your app served more than 1000 requests per day for the past 3 days. Your app might benefit from the higher performance infrastructure available with the Premium V2 App Service tier. The Premium V2 tier features Dv2-series VMs with faster processors, SSD storage, and doubled memory-to-core ratio when compared to the previous instances. Learn more about upgrading to Premium V2 from our documentation. --Learn more about [App service - AppServiceMoveToPremiumV2 (Move your App Service Plan to PremiumV2 for better performance)](https://aka.ms/ant-premiumv2). --### Check outbound connections from your App Service resource --Your app has opened too many TCP/IP socket connections. Exceeding ephemeral TCP/IP port connection limits can cause unexpected connectivity issues for your apps. --Learn more about [App service - AppServiceOutboundConnections (Check outbound connections from your App Service resource)](https://aka.ms/antbc-socket). -----## Next steps --Learn more about [Performance Efficiency - Microsoft Azure Well Architected Framework](/azure/architecture/framework/scalability/overview) |
| advisor | Advisor Reference Reliability Recommendations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-reference-reliability-recommendations.md | - Title: Reliability recommendations -description: Full list of available reliability recommendations in Advisor. --- Previously updated : 09/03/2024---# Reliability recommendations --Azure Advisor helps you ensure and improve the continuity of your business-critical applications. You can get reliability recommendations on the **Reliability** tab on the Advisor dashboard. --1. Sign in to the [**Azure portal**](https://portal.azure.com). --1. Search for and select [**Advisor**](https://aka.ms/azureadvisordashboard) from any page. --1. On the **Advisor** dashboard, select the **Reliability** tab. ---## AgFood Platform -<!--77f976ab-59e3-474d-ba04-32a7d41c9cb1_begin--> -#### Upgrade to the latest ADMA DotNet SDK version - -We identified calls to an ADMA DotNet SDK version that is scheduled for deprecation. To ensure uninterrupted access to ADMA, latest features, and performance improvements, switch to the latest SDK version. - -**Potential benefits**: Ensure uninterrupted access to ADMA - -For More information, see [What is Azure Data Manager for Agriculture?](https://aka.ms/FarmBeatsPaaSAzureAdvisorFAQ) --<!--77f976ab-59e3-474d-ba04-32a7d41c9cb1_end--> --<!--1233e513-ac1c-402d-be94-7133dc37cac6_begin--> -#### Upgrade to the latest ADMA Java SDK version - -We have identified calls to a ADMA Java Sdk version that is scheduled for deprecation. We recommend switching to the latest Sdk version to ensure uninterrupted access to ADMA, latest features, and performance improvements. - -**Potential benefits**: Ensure uninterrupted access to ADMA - -For More information, see [What is Azure Data Manager for Agriculture?](https://aka.ms/FarmBeatsPaaSAzureAdvisorFAQ) --<!--1233e513-ac1c-402d-be94-7133dc37cac6_end--> - --<!--c4ec2fa1-19f4-491f-9311-ca023ee32c38_begin--> -#### Upgrade to the latest ADMA Python SDK version - -We identified calls to an ADMA Python SDK version that is scheduled for deprecation. To ensure uninterrupted access to ADMA, latest features, and performance improvements, switch to the latest SDK version. - -**Potential benefits**: Ensure uninterrupted access to ADMA - -For More information, see [What is Azure Data Manager for Agriculture?](https://aka.ms/FarmBeatsPaaSAzureAdvisorFAQ) --<!--c4ec2fa1-19f4-491f-9311-ca023ee32c38_end--> - --<!--9e49a43a-dbe2-477d-9d34-a4f209617fdb_begin--> -#### Upgrade to the latest ADMA JavaScript SDK version - -We identified calls to an ADMA JavaScript SDK version that is scheduled for deprecation. To ensure uninterrupted access to ADMA, latest features, and performance improvements, switch to the latest SDK version. - -**Potential benefits**: Ensure uninterrupted access to ADMA - -For More information, see [What is Azure Data Manager for Agriculture?](https://aka.ms/FarmBeatsPaaSAzureAdvisorFAQ) --<!--9e49a43a-dbe2-477d-9d34-a4f209617fdb_end--> - -<!--microsoft_agfoodplatform_end> -## API Management -<!--3dd24a8c-af06-49c3-9a04-fb5721d7a9bb_begin--> -#### Migrate API Management service to stv2 platform - -Support for API Management instances hosted on the stv1 platform will be retired by 31 August 2024. Migrate to stv2 based platform before that to avoid service disruption. - -**Potential benefits**: Improve service stability and leverage new platform features - -For More information, see [API Management stv1 platform retirement - Global Azure cloud (August 2024)](/azure/api-management/breaking-changes/stv1-platform-retirement-august-2024) --<!--3dd24a8c-af06-49c3-9a04-fb5721d7a9bb_end--> --<!--8962964c-a6d6-4c3d-918a-2777f7fbdca7_begin--> -#### Hostname certificate rotation failed - -The API Management service failing to refresh the hostname certificate from the Key Vault can lead to the service using a stale certificate and runtime API traffic being blocked. Ensure that the certificate exists in the Key Vault, and the API Management service identity is granted secret read access. - -**Potential benefits**: Ensure service availability - -For More information, see [Configure a custom domain name for your Azure API Management instance](https://aka.ms/apimdocs/customdomain) --<!--8962964c-a6d6-4c3d-918a-2777f7fbdca7_end--> - --<!--6124b23c-0d97-4098-9009-79e8c56cbf8c_begin--> -#### The legacy portal was deprecated 3 years ago and retired in October 2023. However, we are seeing active usage of the portal which may cause service disruption soon when we disable it. - -We highly recommend that you migrate to the new developer portal as soon as possible to continue enjoying our services and take advantage of the new features and improvements. - -**Potential benefits**: Ensure business continuity - -For More information, see [Migrate to the new developer portal](/previous-versions/azure/api-management/developer-portal-deprecated-migration) --<!--6124b23c-0d97-4098-9009-79e8c56cbf8c_end--> - --<!--53fd1359-ace2-4712-911c-1fc420dd23e8_begin--> -#### Dependency network status check failed - -Azure API Management service dependency not available. Please, check virtual network configuration. - -**Potential benefits**: Improve service stability - -For More information, see [Deploy your Azure API Management instance to a virtual network - external mode](https://aka.ms/apim-vnet-common-issues) --<!--53fd1359-ace2-4712-911c-1fc420dd23e8_end--> - --<!--b7316772-5c8f-421f-bed0-d86b0f128e25_begin--> -#### SSL/TLS renegotiation blocked - -SSL/TLS renegotiation attempt blocked; secure communication might fail. To support client certificate authentication scenarios, enable 'Negotiate client certificate' on listed hostnames. For browser-based clients, this option might result in a certificate prompt being presented to the client. - -**Potential benefits**: Ensure service availability - -For More information, see [How to secure APIs using client certificate authentication in API Management](/azure/api-management/api-management-howto-mutual-certificates-for-clients) --<!--b7316772-5c8f-421f-bed0-d86b0f128e25_end--> - --<!--2e4d65a3-1e77-4759-bcaa-13009484a97e_begin--> -#### Deploy an Azure API Management instance to multiple Azure regions for increased service availability - -Azure API Management supports multi-region deployment, which enables API publishers to add regional API gateways to an existing API Management instance. Multi-region deployment helps reduce request latency perceived by geographically distributed API consumers and improves service availability. - -**Potential benefits**: Increased resilience against regional failures - -For More information, see [Deploy an Azure API Management instance to multiple Azure regions](/azure/api-management/api-management-howto-deploy-multi-region) --<!--2e4d65a3-1e77-4759-bcaa-13009484a97e_end--> - --<!--f4c48f42-74f2-41bf-bf99-14e2f9ea9ac9_begin--> -#### Enable and configure autoscale for API Management instance on production workloads. - -API Management instance in production service tiers can be scaled by adding and removing units. The autoscaling feature can dynamically adjust the units of an API Management instance to accommodate a change in load without manual intervention. - -**Potential benefits**: Increase scalability and optimize cost. - -For More information, see [Automatically scale an Azure API Management instance](https://aka.ms/apimautoscale) --<!--f4c48f42-74f2-41bf-bf99-14e2f9ea9ac9_end--> - -<!--microsoft_apimanagement_end> -## App Service -<!--1294987d-c97d-41d0-8fd8-cb6eab52d87b_begin--> -#### Scale out your App Service plan to avoid CPU exhaustion - -High CPU utilization can lead to runtime issues with applications. Your application exceeded 90% CPU over the last couple of days. To reduce CPU usage and avoid runtime issues, scale out the application. - -**Potential benefits**: Keep your app healthy - -For More information, see [Best practices for Azure App Service](https://aka.ms/antbc-cpu) --<!--1294987d-c97d-41d0-8fd8-cb6eab52d87b_end--> --<!--a85f5f1c-c01f-4926-84ec-700b7624af8c_begin--> -#### Check your app's service health issues - -We have a recommendation related to your app's service health. Open the Azure Portal, go to the app, click the Diagnose and Solve to see more details. - -**Potential benefits**: Keep your app healthy - -For More information, see [Best practices for Azure App Service](/azure/app-service/app-service-best-practices) --<!--a85f5f1c-c01f-4926-84ec-700b7624af8c_end--> - --<!--b30897cc-2c2e-4677-a2a1-107ae982ff49_begin--> -#### Fix the backup database settings of your App Service resource - -When an application has an invalid database configuration, its backups fail. For details, see your application's backup history on your app management page. - -**Potential benefits**: Ensure business continuity - -For More information, see [Best practices for Azure App Service](https://aka.ms/antbc) --<!--b30897cc-2c2e-4677-a2a1-107ae982ff49_end--> - --<!--80efd6cb-dcee-491b-83a4-7956e9e058d5_begin--> -#### Fix the backup storage settings of your App Service resource - -When an application has invalid storage settings, its backups fail. For details, see your application's backup history on your app management page. - -**Potential benefits**: Ensure business continuity - -For More information, see [Best practices for Azure App Service](https://aka.ms/antbc) --<!--80efd6cb-dcee-491b-83a4-7956e9e058d5_end--> - --<!--66d3137a-c4da-4c8a-b6b8-e03f5dfba66e_begin--> -#### Scale up your App Service plan SKU to avoid memory problems - -The App Service Plan containing your application exceeded 85% memory allocation. High memory consumption can lead to runtime issues your applications. Find the problem application and scale it up to a higher plan with more memory resources. - -**Potential benefits**: Keep your app healthy - -For More information, see [Best practices for Azure App Service](https://aka.ms/antbc-memory) --<!--66d3137a-c4da-4c8a-b6b8-e03f5dfba66e_end--> - --<!--45cfc38d-3ffd-4088-bb15-e4d0e1e160fe_begin--> -#### Scale out your App Service plan - -Consider scaling out your App Service Plan to at least two instances to avoid cold start delays and service interruptions during routine maintenance. - -**Potential benefits**: Optimize user experience and availability - -For More information, see [https://aka.ms/appsvcnuminstances](https://aka.ms/appsvcnuminstances) --<!--45cfc38d-3ffd-4088-bb15-e4d0e1e160fe_end--> - --<!--3e35f804-52cb-4ebf-84d5-d15b3ab85dfc_begin--> -#### Fix application code, a worker process crashed due to an unhandled exception - -A worker process in your application crashed due to an unhandled exception. To identify the root cause, collect memory dumps and call stack information at the time of the crash. - -**Potential benefits**: Keep your app healthy and highly available - -For More information, see [https://aka.ms/appsvcproactivecrashmonitoring](https://aka.ms/appsvcproactivecrashmonitoring) --<!--3e35f804-52cb-4ebf-84d5-d15b3ab85dfc_end--> - --<!--78c5ab69-858a-43ca-a5ac-4ca6f9cdc30d_begin--> -#### Upgrade your App Service to a Standard plan to avoid request rejects - -When an application is part of a shared App Service plan and meets its quota multiple times, incoming requests might be rejected. Your web application canΓÇÖt accept incoming requests after meeting a quota. To remove the quota, upgrade to a Standard plan. - -**Potential benefits**: Keep your app healthy - -For More information, see [Azure App Service plan overview](https://aka.ms/ant-asp) --<!--78c5ab69-858a-43ca-a5ac-4ca6f9cdc30d_end--> - --<!--59a83512-d885-4f09-8e4f-c796c71c686e_begin--> -#### Move your App Service resource to Standard or higher and use deployment slots - -When an application is deployed multiple times in a week, problems might occur. You deployed your application multiple times last week. To help you reduce deployment impact to your production web application, move your App Service resource to the Standard (or higher) plan, and use deployment slots. - -**Potential benefits**: Keep your app healthy while updating - -For More information, see [Set up staging environments in Azure App Service](https://aka.ms/ant-staging) --<!--59a83512-d885-4f09-8e4f-c796c71c686e_end--> - --<!--dc3edeee-f0ab-44ae-b612-605a0a739612_begin--> -#### Consider upgrading the hosting plan of the Static Web App(s) in this subscription to Standard SKU. - -The combined bandwidth used by all the Free SKU Static Web Apps in this subscription is exceeding the monthly limit of 100GB. Consider upgrading these applications to Standard SKU to avoid throttling. - -**Potential benefits**: Higher availability for the apps by avoiding throttling. - -For More information, see [Pricing ΓÇô Static Web Apps ](https://azure.microsoft.com/pricing/details/app-service/static/) --<!--dc3edeee-f0ab-44ae-b612-605a0a739612_end--> - --<!--0dc165fd-69bf-468a-aa04-a69377b6feb0_begin--> -#### Use deployment slots for your App Service resource - -When an application is deployed multiple times in a week, problems might occur. You deployed your application multiple times over the last week. To help you manage changes and help reduce deployment impact to your production web application, use deployment slots. - -**Potential benefits**: Keep your app healthy while updating - -For More information, see [Set up staging environments in Azure App Service](https://aka.ms/ant-staging) --<!--0dc165fd-69bf-468a-aa04-a69377b6feb0_end--> - --<!--6d732ac5-82e0-4a66-887e-eccee79a2063_begin--> -#### CX Observer Personalized Recommendation - -CX Observer Personalized Recommendation - -**Potential benefits**: NA - - --<!--6d732ac5-82e0-4a66-887e-eccee79a2063_end--> - --<!--8be322ab-e38b-4391-a5f3-421f2270d825_begin--> -#### Consider changing your application architecture to 64-bit - -Your App Service is configured as 32-bit, and its memory consumption is approaching the limit of 2 GB. If your application supports, consider recompiling your application and changing the App Service configuration to 64-bit instead. - -**Potential benefits**: Improve your application reliability - -For More information, see [Application performance FAQs for Web Apps in Azure](https://aka.ms/appsvc32bit) --<!--8be322ab-e38b-4391-a5f3-421f2270d825_end--> - -<!--microsoft_web_end> -## App Service Certificates -<!--a2385343-200c-4eba-bbe2-9252d3f1d6ea_begin--> -#### Domain verification required to issue your App Service Certificate - -You have an App Service Certificate that's currently in a Pending Issuance status and requires domain verification. Failure to validate domain ownership will result in an unsuccessful certificate issuance. Domain verification isn't automated for App Service Certificates and will require action. If you've recently verified domain ownership and have been issued a certificate, you may disregard this message. - -**Potential benefits**: Ensure successful issuance of App Service Certificate. - -For More information, see [Add and manage TLS/SSL certificates in Azure App Service](https://aka.ms/ASCDomainVerificationRequired) --<!--a2385343-200c-4eba-bbe2-9252d3f1d6ea_end--> -<!--microsoft_certificateregistration_end> -## Application Gateway -<!--6a2b1e70-bd4c-4163-86de-5243d7ac05ee_begin--> -#### Upgrade your SKU or add more instances - -Deploying two or more medium or large sized instances ensures business continuity (fault tolerance) during outages caused by planned or unplanned maintenance. - -**Potential benefits**: Ensure business continuity through application gateway resilience - -For More information, see [Multi-region load balancing - Azure Reference Architectures ](https://aka.ms/aa_gatewayrec_learnmore) --<!--6a2b1e70-bd4c-4163-86de-5243d7ac05ee_end--> --<!--52a9d0a7-efe1-4512-9716-394abd4e0ab1_begin--> -#### Avoid hostname override to ensure site integrity - -Avoid overriding the hostname when configuring Application Gateway. Having a domain on the frontend of Application Gateway different than the one used to access the backend, can lead to broken cookies or redirect URLs. Make sure the backend is able to deal with the domain difference, or update the Application Gateway configuration so the hostname doesn't need to be overwritten towards the backend. When used with App Service, attach a custom domain name to the Web App and avoid use of the *.azurewebsites.net host name towards the backend. Note that a different frontend domain isn't a problem in all situations, and certain categories of backends like REST APIs, are less sensitive in general. - -**Potential benefits**: Ensure site integrity and avoid broken cookies or redirect urls through a resilient Application Gateway configuration. - -For More information, see [Troubleshoot App Service issues in Application Gateway](https://aka.ms/appgw-advisor-usecustomdomain) --<!--52a9d0a7-efe1-4512-9716-394abd4e0ab1_end--> - --<!--17454550-1543-4068-bdaf-f3ed7cdd3d86_begin--> -#### Implement ExpressRoute Monitor on Network Performance Monitor - -When ExpressRoute circuit isn't monitored by ExpressRoute Monitor on Network Performance, you miss notifications of loss, latency, and performance of on-premises to Azure resources, and Azure to on-premises resources. For end-to-end monitoring, implement ExpressRoute Monitor on Network Performance. - -**Potential benefits**: Improve time-to-detect and time-to-mitigate issues in your network and provide insights on your network path via ExpressRoute - -For More information, see [Configure Network Performance Monitor for ExpressRoute (deprecated)](/azure/expressroute/how-to-npm) --<!--17454550-1543-4068-bdaf-f3ed7cdd3d86_end--> - --<!--70f87e66-9b2d-4bfa-ae38-1d7d74837689_begin--> -#### Implement multiple ExpressRoute circuits in your Virtual Network for cross premises resiliency - -When an ExpressRoute gateway only has one ExpressRoute circuit associated to it, resiliency issues might occur. To ensure peering location redundancy and resiliency, connect one or more additional circuits to your gateway. - -**Potential benefits**: Improve resiliency in case of ExpressRoute peering location failure - -For More information, see [Designing for high availability with ExpressRoute](/azure/expressroute/designing-for-high-availability-with-expressroute) --<!--70f87e66-9b2d-4bfa-ae38-1d7d74837689_end--> - --<!--6cd70072-c45c-4716-bf7b-b35c18e46e72_begin--> -#### Add at least one more endpoint to the profile, preferably in another Azure region - -Profiles need more than one endpoint to ensure availability if one of the endpoints fails. We also recommend that endpoints be in different regions. - -**Potential benefits**: Improve resiliency by allowing failover - -For More information, see [Traffic Manager endpoints](https://aka.ms/AA1o0x4) --<!--6cd70072-c45c-4716-bf7b-b35c18e46e72_end--> - --<!--0bbe0a49-3c63-49d3-ab4a-aa24198f03f7_begin--> -#### Add an endpoint configured to "All (World)" - -For geographic routing, traffic is routed to endpoints in defined regions. When a region fails, there is no pre-defined failover. Having an endpoint where the Regional Grouping is configured to "All (World)" for geographic profiles avoids traffic black holing and guarantees service availablity. - -**Potential benefits**: Improve resiliency by avoiding traffic black holes - -For More information, see [Add, disable, enable, delete, or move endpoints](https://aka.ms/Rf7vc5) --<!--0bbe0a49-3c63-49d3-ab4a-aa24198f03f7_end--> - --<!--0db76759-6d22-4262-93f0-2f989ba2b58e_begin--> -#### Add or move one endpoint to another Azure region - -All endpoints associated to this proximity profile are in the same region. Users from other regions may experience long latency when attempting to connect. Adding or moving an endpoint to another region will improve overall performance for proximity routing and provide better availability if all endpoints in one region fail. - -**Potential benefits**: Improve resiliency by allowing failover to another region - -For More information, see [Configure the performance traffic routing method](https://aka.ms/Ldkkdb) --<!--0db76759-6d22-4262-93f0-2f989ba2b58e_end--> - --<!--e070c4bf-afaf-413e-bc00-e476b89c5f3d_begin--> -#### Move to production gateway SKUs from Basic gateways - -The Basic VPN SKU is for development or testing scenarios. If you're using the VPN gateway for production, move to a production SKU, which offers higher numbers of tunnels, Border Gateway Protocol (BGP), active-active configuration, custom IPsec/IKE policy, and increased stability and availability. - -**Potential benefits**: Additional available features and higher stability and availability - -For More information, see [About VPN Gateway configuration settings](https://aka.ms/aa_basicvpngateway_learnmore) --<!--e070c4bf-afaf-413e-bc00-e476b89c5f3d_end--> - --<!--c249dc0e-9a17-423e-838a-d72719e8c5dd_begin--> -#### Enable Active-Active gateways for redundancy - -In active-active configuration, both instances of the VPN gateway establish site-to-site (S2S) VPN tunnels to your on-premise VPN device. When a planned maintenance or unplanned event happens to one gateway instance, traffic is automatically switched over to the other active IPsec tunnel. - -**Potential benefits**: Ensure business continuity through connection resilience - -For More information, see [Design highly available gateway connectivity for cross-premises and VNet-to-VNet connections](https://aka.ms/aa_vpnha_learnmore) --<!--c249dc0e-9a17-423e-838a-d72719e8c5dd_end--> - --<!--1c7fc5ab-f776-4aee-8236-ab478519f68f_begin--> -#### Disable health probes when there is only one origin in an origin group - -If you only have a single origin, Front Door always routes traffic to that origin even if its health probe reports an unhealthy status. The status of the health probe doesn't do anything to change Front Door's behavior. In this scenario, health probes don't provide a benefit. - -**Potential benefits**: Ensure service availability by reducing unnecessary health probe traffic - -For More information, see [Best practices for Front Door](https://aka.ms/afd-disable-health-probes) --<!--1c7fc5ab-f776-4aee-8236-ab478519f68f_end--> - --<!--5185d64e-46fd-4ed2-8633-6d81f5e3ca59_begin--> -#### Use managed TLS certificates - -When Front Door manages your TLS certificates, it reduces your operational costs, and helps you to avoid costly outages caused by forgetting to renew a certificate. Front Door automatically issues and rotates the managed TLS certificates. - -**Potential benefits**: Ensure service availability by having Front Door manage and rotate your certificates - -For More information, see [Best practices for Front Door](https://aka.ms/afd-use-managed-tls) --<!--5185d64e-46fd-4ed2-8633-6d81f5e3ca59_end--> - --<!--56f0c458-521d-4b8b-a704-c0a099483d19_begin--> -#### Use NAT gateway for outbound connectivity - -Prevent connectivity failures due to source network address translation (SNAT) port exhaustion by using NAT gateway for outbound traffic from your virtual networks. NAT gateway scales dynamically and provides secure connections for traffic headed to the internet. - -**Potential benefits**: Prevent outbound connection failures with NAT gateway - -For More information, see [Use Source Network Address Translation (SNAT) for outbound connections](/azure/load-balancer/load-balancer-outbound-connections#2-associate-a-nat-gateway-to-the-subnet) --<!--56f0c458-521d-4b8b-a704-c0a099483d19_end--> - --<!--5c488377-be3e-4365-92e8-09d1e8d9038c_begin--> -#### Deploy your Application Gateway across Availability Zones - -Achieve zone redundancy by deploying Application Gateway across Availability Zones. Zone redundancy boosts resilience by enabling Application Gateway to survive various outages, which ensures continuity even if one zone is affected, and enhances overall reliability. - -**Potential benefits**: Resiliency of Application Gateways is considerably increased when using Availability Zones. - -For More information, see [Scaling Application Gateway v2 and WAF v2](https://aka.ms/appgw/az) --<!--5c488377-be3e-4365-92e8-09d1e8d9038c_end--> - --<!--6cc8be07-8c03-4bd7-ad9b-c2985b261e01_begin--> -#### Update VNet permission of Application Gateway users - -To improve security and provide a more consistent experience across Azure, all users must pass a permission check to create or update an Application Gateway in a Virtual Network. The users or service principals minimum permission required is Microsoft.Network/virtualNetworks/subnets/join/action. - -**Potential benefits**: Avoid disruptions in management of Application Gateway resource - -For More information, see [Application Gateway infrastructure configuration](https://aka.ms/agsubnetjoin) --<!--6cc8be07-8c03-4bd7-ad9b-c2985b261e01_end--> - --<!--79f543f9-60e6-4ef6-ae42-2095f6149cba_begin--> -#### Use the same domain name on Front Door and your origin - -When you rewrite the Host header, request cookies and URL redirections might break. When you use platforms like Azure App Service, features like session affinity and authentication and authorization might not work correctly. Make sure to validate whether your application is going to work correctly. - -**Potential benefits**: Ensure application integrity by preserving original host name - -For More information, see [Best practices for Front Door](https://aka.ms/afd-same-domain-origin) --<!--79f543f9-60e6-4ef6-ae42-2095f6149cba_end--> - --<!--8d61a7d4-5405-4f43-81e3-8c6239b844a6_begin--> -#### Implement Site Resiliency for ExpressRoute - -To ensure maximum resiliency, Microsoft recommends that you connect to two ExpressRoute circuits in two peering locations. The goal of Maximum Resiliency is to enhance availability and ensure the highest level of resilience for critical workloads. - -**Potential benefits**: Maximum Resiliency in ExpressRoute is designed to ensure there isnΓÇÖt a single point of failure within the Microsoft network path. This is achieved by offering dual (2) circuits across two different locations for site diversity in ExpressRoute. The goal of Maximum Resiliency is to enhance availability and ensure the highest level of resilience for critical workloads. - -For More information, see [Design and architect Azure ExpressRoute for resiliency](https://aka.ms/ersiteresiliency) --<!--8d61a7d4-5405-4f43-81e3-8c6239b844a6_end--> - --<!--c9af1ef6-55bc-48af-bfe4-2c80490159f8_begin--> -#### Implement Zone Redundant ExpressRoute Gateways - -Implement zone-redundant Virtual Network Gateway in Azure Availability Zones. This brings resiliency, scalability, and higher availability to your Virtual Network Gateways. - -**Potential benefits**: Provides zonal resiliency and redundancy for ExpressRoute - -For More information, see [Create a zone-redundant virtual network gateway in availability zones](/azure/vpn-gateway/create-zone-redundant-vnet-gateway) --<!--c9af1ef6-55bc-48af-bfe4-2c80490159f8_end--> - --<!--c9c9750b-9ddb-436f-b19a-9c725539a0b5_begin--> -#### Ensure autoscaling is used for increased performance and resiliency - -When configuring the Application Gateway, it's recommended to provision autoscaling to scale in and out in response to changes in demand. This helps to minimize the effects of a single failing component. - -**Potential benefits**: Increase performance and resiliency. - -For More information, see [Scaling Application Gateway v2 and WAF v2](/azure/application-gateway/application-gateway-autoscaling-zone-redundant) --<!--c9c9750b-9ddb-436f-b19a-9c725539a0b5_end--> - -<!--microsoft_network_end> -## Application Gateway for Containers -<!--db83b3d4-96e5-4cfe-b736-b3280cadd163_begin--> -#### Migrate to supported version of AGC - -The version of Application Gateway for Containers was provisioned with a preview version and isn't supported for production. Ensure you provision a new gateway using the latest API version. - -**Potential benefits**: Ensure supportability and resiliency for production workloads - -For More information, see [What is Application Gateway for Containers?](https://aka.ms/appgwcontainers/docs) --<!--db83b3d4-96e5-4cfe-b736-b3280cadd163_end--> -<!--microsoft_servicenetworking_end> -## Azure AI Search -<!--97b38421-f88c-4db0-b397-b2d81eff6630_begin--> -#### Create a Standard search service (2GB) - -When you exceed your storage quota, indexing operations stop working. You're close to exceeding your storage quota of 2GB. If you need more storage, create a Standard search service or add extra partitions. - -**Potential benefits**: capability to handle more data - -For More information, see [https://aka.ms/azs/search-limits-quotas-capacity](https://aka.ms/azs/search-limits-quotas-capacity) --<!--97b38421-f88c-4db0-b397-b2d81eff6630_end--> --<!--8d31f25f-31a9-4267-b817-20ee44f88069_begin--> -#### Create a Standard search service (50MB) - -When you exceed your storage quota, indexing operations stop working. You're close to exceeding your storage quota of 50MB. To maintain operations, create a Basic or Standard search service. - -**Potential benefits**: capability to handle more data - -For More information, see [https://aka.ms/azs/search-limits-quotas-capacity](https://aka.ms/azs/search-limits-quotas-capacity) --<!--8d31f25f-31a9-4267-b817-20ee44f88069_end--> - --<!--b3efb46f-6d30-4201-98de-6492c1f8f10d_begin--> -#### Avoid exceeding your available storage quota by adding more partitions - -When you exceed your storage quota, you can still query, but indexing operations stop working. You're close to exceeding your available storage quota. If you need more storage, add extra partitions. - -**Potential benefits**: Able to index additional data - -For More information, see [https://aka.ms/azs/search-limits-quotas-capacity](https://aka.ms/azs/search-limits-quotas-capacity) --<!--b3efb46f-6d30-4201-98de-6492c1f8f10d_end--> - -<!--microsoft_search_end> -## Azure Arc-enabled Kubernetes -<!--6d55ea5b-6e80-4313-9b80-83d384667eaa_begin--> -#### Upgrade to the latest agent version of Azure Arc-enabled Kubernetes - -For the best Azure Arc enabled Kubernetes experience, improved stability and new functionality, upgrade to the latest agent version. - -**Potential benefits**: Arc-enabled K8s latest agent version - -For More information, see [Upgrade Azure Arc-enabled Kubernetes agents](https://aka.ms/ArcK8sAgentUpgradeDocs) --<!--6d55ea5b-6e80-4313-9b80-83d384667eaa_end--> -<!--microsoft_kubernetes_end> -## Azure Arc-enabled Kubernetes Configuration -<!--4bc7a00b-edbb-4963-8800-1b0f8897fecf_begin--> -#### Upgrade Microsoft Flux extension to the newest major version - -The Microsoft Flux extension has a major version release. Plan for a manual upgrade to the latest major version for Microsoft Flux for all Azure Arc-enabled Kubernetes and Azure Kubernetes Service (AKS) clusters within 6 months for continued support and new functionality. - -**Potential benefits**: Continued support and new functionality - -For More information, see [Available extensions for Azure Arc-enabled Kubernetes clusters](https://aka.ms/fluxreleasenotes) --<!--4bc7a00b-edbb-4963-8800-1b0f8897fecf_end--> --<!--79cfad72-9b6d-4215-922d-7df77e1ea3bb_begin--> -#### Upcoming Breaking Changes for Microsoft Flux Extension - -The Microsoft Flux extension frequently receives updates for security and stability. The upcoming update, in line with the OSS Flux Project, will modify the HelmRelease and HelmChart APIs by removing deprecated fields. To avoid disruption to your workloads, necessary action is needed. - -**Potential benefits**: Improved stability, security, and new functionality - -For More information, see [Available extensions for Azure Arc-enabled Kubernetes clusters](https://aka.ms/fluxreleasenotes) --<!--79cfad72-9b6d-4215-922d-7df77e1ea3bb_end--> - --<!--c8e3b516-a0d5-4c64-8a7a-71cfd068d5e8_begin--> -#### Upgrade Microsoft Flux extension to a supported version - -Current version of Microsoft Flux on one or more Azure Arc enabled clusters and Azure Kubernetes clusters is out of support. To get security patches, bug fixes and Microsoft support, upgrade to a supported version. - -**Potential benefits**: Get security patches, bug fixes and Microsoft support - -For More information, see [Available extensions for Azure Arc-enabled Kubernetes clusters](https://aka.ms/fluxreleasenotes) --<!--c8e3b516-a0d5-4c64-8a7a-71cfd068d5e8_end--> - -<!--microsoft_kubernetesconfiguration_end> -## Azure Arc-enabled servers -<!--9d5717d2-4708-4e3f-bdda-93b3e6f1715b_begin--> -#### Upgrade to the latest version of the Azure Connected Machine agent - -The Azure Connected Machine agent is updated regularly with bug fixes, stability enhancements, and new functionality. For the best Azure Arc experience, upgrade your agent to the latest version. - -**Potential benefits**: Improved stability and new functionality - -For More information, see [Managing and maintaining the Connected Machine agent](/azure/azure-arc/servers/manage-agent) --<!--9d5717d2-4708-4e3f-bdda-93b3e6f1715b_end--> -<!--microsoft_hybridcompute_end> -## Azure Cache for Redis -<!--7c380315-6ad9-4fb2-8930-a8aeb1d6241b_begin--> -#### Increase fragmentation memory reservation - -Fragmentation and memory pressure can cause availability incidents. To help in reduce cache failures when running under high memory pressure, increase reservation of memory for fragmentation through the maxfragmentationmemory-reserved setting available in the Advanced Settings options. - -**Potential benefits**: Avoid availability incidents when your cache has high memory fragmentation - -For More information, see [How to configure Azure Cache for Redis](https://aka.ms/redis/recommendations/memory-policies) --<!--7c380315-6ad9-4fb2-8930-a8aeb1d6241b_end--> --<!--c9e4a27c-79e6-4e4c-904f-b6612b6cd892_begin--> -#### Configure geo-replication for Cache for Redis instances to increase durability of applications - -Geo-Replication enables disaster recovery for cached data, even in the unlikely event of a widespread regional failure. This can be essential for mission-critical applications. We recommend that you configure passive geo-replication for Premium Azure Cache for Redis instances. - -**Potential benefits**: Geo-Replication enables disaster recovery for cached data. - -For More information, see [Configure passive geo-replication for Premium Azure Cache for Redis instances](https://aka.ms/redispremiumgeoreplication) --<!--c9e4a27c-79e6-4e4c-904f-b6612b6cd892_end--> - -<!--microsoft_cache_end> -## Azure Container Apps -<!--c692e862-953b-49fe-9c51-e5d2792c1cc1_begin--> -#### Re-create your your Container Apps environment to avoid DNS issues - -There's a potential networking issue with your Container Apps environments that might cause DNS issues. We recommend that you create a new Container Apps environment, re-create your Container Apps in the new environment, and delete the old Container Apps environment. - -**Potential benefits**: Avoid DNS failures in your Container Apps Environment. - -For More information, see [Quickstart: Deploy your first container app using the Azure portal](https://aka.ms/createcontainerapp) --<!--c692e862-953b-49fe-9c51-e5d2792c1cc1_end--> --<!--b9ce2d2e-554b-4391-8ebc-91c570602b04_begin--> -#### Renew custom domain certificate - -The custom domain certificate you uploaded is near expiration. To prevent possible service downtime, renew your certificate and upload the new certificate for your container apps. - -**Potential benefits**: Your service wont fail because of expired certificate. - -For More information, see [Custom domain names and bring your own certificates in Azure Container Apps](https://aka.ms/containerappcustomdomaincert) --<!--b9ce2d2e-554b-4391-8ebc-91c570602b04_end--> - --<!--fa6c0880-da2e-42fd-9cb3-e1267ec5b5c2_begin--> -#### An issue has been detected that is preventing the renewal of your Managed Certificate. - -We detected the managed certificate used by the Container App has failed to auto renew. Follow the documentation link to make sure that the DNS settings of your custom domain are correct. - -**Potential benefits**: Avoid downtime due to an expired certificate. - -For More information, see [Custom domain names and free managed certificates in Azure Container Apps](https://aka.ms/containerapps/managed-certificates) --<!--fa6c0880-da2e-42fd-9cb3-e1267ec5b5c2_end--> - --<!--9be5f344-6fa5-4abc-a1f2-61ae6192a075_begin--> -#### Increase the minimal replica count for your containerized application - -The minimal replica count set for your Azure Container App containerized application might be too low, which can cause resilience, scalability, and load balancing issues. For better availability, consider increasing the minimal replica count. - -**Potential benefits**: Better availability for your container app. - -For More information, see [Set scaling rules in Azure Container Apps](https://aka.ms/containerappscalingrules) --<!--9be5f344-6fa5-4abc-a1f2-61ae6192a075_end--> - -<!--microsoft_app_end> -## Azure Cosmos DB -<!--5e4e9f04-9201-4fd9-8af6-a9539d13d8ec_begin--> -#### Configure Azure Cosmos DB containers with a partition key - -When Azure Cosmos DB nonpartitioned collections reach their provisioned storage quota, you lose the ability to add data. Your Cosmos DB nonpartitioned collections are approaching their provisioned storage quota. Migrate these collections to new collections with a partition key definition so they can automatically be scaled out by the service. - -**Potential benefits**: Scale your containers seamlessly with increase in storage or request rates without running into any limits - -For More information, see [Partitioning and horizontal scaling in Azure Cosmos DB](/azure/cosmos-db/partitioning-overview#choose-partitionkey) --<!--5e4e9f04-9201-4fd9-8af6-a9539d13d8ec_end--> --<!--bdb595a4-e148-41f9-98e8-68ec92d1932e_begin--> -#### Use static Cosmos DB client instances in your code and cache the names of databases and collections - -A high number of metadata operations on an account can result in rate limiting. Metadata operations have a system-reserved request unit (RU) limit. Avoid rate limiting from metadata operations by using static Cosmos DB client instances in your code and caching the names of databases and collections. - -**Potential benefits**: Optimize your RU usage and avoid rate limiting - -For More information, see [Performance tips for Azure Cosmos DB and .NET SDK v2](/azure/cosmos-db/performance-tips) --<!--bdb595a4-e148-41f9-98e8-68ec92d1932e_end--> - --<!--44a0a07f-23a2-49df-b8dc-a1b14c7c6a9d_begin--> -#### Check linked Azure Key Vault hosting your encryption key - -When an Azure Cosmos DB account can't access its linked Azure Key Vault hosting the encyrption key, data access and security issues might happen. Your Azure Key Vault's configuration is preventing your Cosmos DB account from contacting the key vault to access your managed encryption keys. If you recently performed a key rotation, ensure that the previous key, or key version, remains enabled and available until Cosmos DB completes the rotation. The previous key or key version can be disabled after 24 hours, or after the Azure Key Vault audit logs don't show any activity from Azure Cosmos DB on that key or key version. - -**Potential benefits**: Update your configurations to continue using customer-managed keys and access your data - -For More information, see [Configure customer-managed keys for your Azure Cosmos DB account with Azure Key Vault](/azure/cosmos-db/how-to-setup-cmk) --<!--44a0a07f-23a2-49df-b8dc-a1b14c7c6a9d_end--> - --<!--213974c8-ed9c-459f-9398-7cdaa3c28856_begin--> -#### Configure consistent indexing mode on Azure Cosmos DB containers - -Azure Cosmos containers configured with the Lazy indexing mode update asynchronously, which improves write performance, but can impact query freshness. Your container is configured with the Lazy indexing mode. If query freshness is critical, use Consistent Indexing Mode for immediate index updates. - -**Potential benefits**: Improve query result consistency and reliability - -For More information, see [Manage indexing policies in Azure Cosmos DB](/azure/cosmos-db/how-to-manage-indexing-policy) --<!--213974c8-ed9c-459f-9398-7cdaa3c28856_end--> - --<!--bc9e5110-a220-4ab9-8bc9-53f92d3eef70_begin--> -#### Hotfix - Upgrade to 2.6.14 version of the Async Java SDK v2 or to Java SDK v4 - -There's a critical bug in version 2.6.13 (and lower) of the Azure Cosmos DB Async Java SDK v2 causing errors when a Global logical sequence number (LSN) greater than the Max Integer value is reached. The error happens transparently to you by the service after a large volume of transactions occur in the lifetime of an Azure Cosmos DB container. Note: While this is a critical hotfix for the Async Java SDK v2, we still highly recommend you migrate to the [Java SDK v4](/azure/cosmos-db/sql/sql-api-sdk-java-v4). - -**Potential benefits**: If action isnΓÇÖt taken, all create, read, update, and delete operations may begin to fail with NumberFormatException - -For More information, see [Azure Cosmos DB Async Java SDK for API for NoSQL (legacy): Release notes and resources](/azure/cosmos-db/sql/sql-api-sdk-async-java) --<!--bc9e5110-a220-4ab9-8bc9-53f92d3eef70_end--> - --<!--38942ae5-3154-4e0b-98d9-23aa061c334b_begin--> -#### Critical issue - Upgrade to the current recommended version of the Java SDK v4 - -There's a critical bug in version 4.15 and lower of the Azure Cosmos DB Java SDK v4 causing errors when a Global logical sequence number (LSN) greater than the Max Integer value is reached. This happens transparently to you by the service after a large volume of transactions occur in the lifetime of an Azure Cosmos DB container. Avoid this problem by upgrading to the current recommended version of the Java SDK v4 - -**Potential benefits**: If action isnΓÇÖt taken, all create, read, update, and delete operations may begin to fail with NumberFormatException - -For More information, see [Azure Cosmos DB Java SDK v4 for API for NoSQL: release notes and resources](/azure/cosmos-db/sql/sql-api-sdk-java-v4) --<!--38942ae5-3154-4e0b-98d9-23aa061c334b_end--> - --<!--123039b5-0fda-4744-9a17-d6b5d5d122b2_begin--> -#### Use the new 3.6+ endpoint to connect to your upgraded Azure Cosmos DB's API for MongoDB account - -Some of your applications are connecting to your upgraded Azure Cosmos DB's API for MongoDB account using the legacy 3.2 endpoint - [accountname].documents.azure.com. Use the new endpoint - [accountname].mongo.cosmos.azure.com (or its equivalent in sovereign, government, or restricted clouds). - -**Potential benefits**: Take advantage of the latest features in version 3.6+ of Azure Cosmos DB's API for MongoDB - -For More information, see [Azure Cosmos DB for MongoDB (4.0 server version): supported features and syntax](/azure/cosmos-db/mongodb-feature-support-40) --<!--123039b5-0fda-4744-9a17-d6b5d5d122b2_end--> - --<!--0da795d9-26d2-4f02-a019-0ec383363c88_begin--> -#### Upgrade your Azure Cosmos DB API for MongoDB account to v4.2 to save on query/storage costs and utilize new features - -Your Azure Cosmos DB API for MongoDB account is eligible to upgrade to version 4.2. Upgrading to v4.2 can reduce your storage costs by up to 55% and your query costs by up to 45% by leveraging a new storage format. Numerous additional features such as multi-document transactions are also included in v4.2. - -**Potential benefits**: Improved reliability, query/storage efficiency, performance, and new feature capabilities - -For More information, see [Upgrade the API version of your Azure Cosmos DB for MongoDB account](/azure/cosmos-db/mongodb-version-upgrade) --<!--0da795d9-26d2-4f02-a019-0ec383363c88_end--> - --<!--ec6fe20c-08d6-43da-ac18-84ac83756a88_begin--> -#### Enable Server Side Retry (SSR) on your Azure Cosmos DB's API for MongoDB account - -When an account is throwing a TooManyRequests error with the 16500 error code, enabling Server Side Retry (SSR) can help mitigate the issue. - -**Potential benefits**: Prevent throttling and improve your query reliability and performance - - --<!--ec6fe20c-08d6-43da-ac18-84ac83756a88_end--> - --<!--b57f7a29-dcc8-43de-86fa-18d3f9d3764d_begin--> -#### Add a second region to your production workloads on Azure Cosmos DB - -Production workloads on Azure Cosmos DB run in a single region might have availability issues, this appears to be the case with some of your Cosmos DB accounts. Increase their availability by configuring them to span at least two Azure regions. NOTE: Additional regions incur additional costs. - -**Potential benefits**: Improve the availability of your production workloads - -For More information, see [High availability (Reliability) in Azure Cosmos DB for NoSQL](/azure/cosmos-db/high-availability) --<!--b57f7a29-dcc8-43de-86fa-18d3f9d3764d_end--> - --<!--51a4e6bd-5a95-4a41-8309-40f5640fdb8b_begin--> -#### Upgrade old Azure Cosmos DB SDK to the latest version - -An Azure Cosmos DB account using an old version of the SDK lacks the latest fixes and improvements. Your Azure Cosmos DB account is using an old version of the SDK. For the latest fixes, performance improvements, and new feature capabilities, upgrade to the latest version. - -**Potential benefits**: Improved reliability, performance, and new feature capabilities - -For More information, see [Azure Cosmos DB documentation](/azure/cosmos-db/) --<!--51a4e6bd-5a95-4a41-8309-40f5640fdb8b_end--> - --<!--60a55165-9ccd-4536-81f6-e8dc6246d3d2_begin--> -#### Upgrade outdated Azure Cosmos DB SDK to the latest version - -An Azure Cosmos DB account using an old version of the SDK lacks the latest fixes and improvements. Your Azure Cosmos DB account is using an outdated version of the SDK. We recommend upgrading to the latest version for the latest fixes, performance improvements, and new feature capabilities. - -**Potential benefits**: Improved reliability, performance, and new feature capabilities - -For More information, see [Azure Cosmos DB documentation](/azure/cosmos-db/) --<!--60a55165-9ccd-4536-81f6-e8dc6246d3d2_end--> - --<!--5de9f2e6-087e-40da-863a-34b7943beed4_begin--> -#### Enable service managed failover for Cosmos DB account - -Enable service managed failover for Cosmos DB account to ensure high availability of the account. Service managed failover automatically switches the write region to the secondary region in case of a primary region outage. This ensures that the application continues to function without any downtime. - -**Potential benefits**: Azure's Service-Managed Failover feature enhances system availability by automating failover processes, reducing downtime, and improving resilience. - -For More information, see [High availability (Reliability) in Azure Cosmos DB for NoSQL](/azure/cosmos-db/high-availability) --<!--5de9f2e6-087e-40da-863a-34b7943beed4_end--> - --<!--64fbcac1-f652-4b6f-8170-2f97ffeb5631_begin--> -#### Enable HA for your Production workload - -Many clusters with consistent workloads do not have high availability (HA) enabled. It's recommended to activate HA from the Scale page in the Azure Portal to prevent database downtime in case of unexpected node failures and to qualify for SLA guarantees. - -**Potential benefits**: Activate HA to avoid database downtime in case of an unexpected node failure - -For More information, see [Scaling and configuring Your Azure Cosmos DB for MongoDB vCore cluster](https://aka.ms/enableHAformongovcore) --<!--64fbcac1-f652-4b6f-8170-2f97ffeb5631_end--> - --<!--8034b205-167a-4fd5-a133-0c8cb166103c_begin--> -#### Enable zone redundancy for multi-region Cosmos DB accounts - -This recommendation suggests enabling zone redundancy for multi-region Cosmos DB accounts to improve high availability and reduce the risk of data loss in case of a regional outage. - -**Potential benefits**: Improved high availability and reduced risk of data loss - -For More information, see [High availability (Reliability) in Azure Cosmos DB for NoSQL](/azure/cosmos-db/high-availability#replica-outages) --<!--8034b205-167a-4fd5-a133-0c8cb166103c_end--> - --<!--92056ca3-8fab-43d1-bebf-f9c377ef20e9_begin--> -#### Add at least one data center in another Azure region - -Your Azure Managed Instance for Apache Cassandra cluster is designated as a production cluster but is currently deployed in a single Azure region. For production clusters, we recommend adding at least one more data center in another Azure region to guard against disaster recovery scenarios. - -**Potential benefits**: Ensure applications have another region in case of disaster recovery - -For More information, see [Best practices for high availability and disaster recovery](/azure/managed-instance-apache-cassandra/resilient-applications) --<!--92056ca3-8fab-43d1-bebf-f9c377ef20e9_end--> - --<!--a030f8ab-4dd4-4751-822b-f231a0df5f5a_begin--> -#### Avoid being rate limited for Control Plane operation - -We found high number of Control Plane operations on your account through resource provider. Request that exceeds the documented limits at sustained levels over consecutive 5-minute periods may experience request being throttling as well failed or incomplete operation on Azure Cosmos DB resources. - -**Potential benefits**: Optimize control plane operation and avoid operation failure due to rate limiting - -For More information, see [Azure Cosmos DB service quotas](https://docs.microsoft.com/azure/cosmos-db/concepts-limits#control-plane) --<!--a030f8ab-4dd4-4751-822b-f231a0df5f5a_end--> - -<!--microsoft_documentdb_end> -## Azure Data Explorer -<!--fa2649e9-e1a5-4d07-9b26-51c080d9a9ba_begin--> -#### Resolve virtual network issues - -Service failed to install or resume due to virtual network (VNet) issues. To resolve this issue, follow the steps in the troubleshooting guide. - -**Potential benefits**: Improve reliability, availability, performance, and new feature capabilities - -For More information, see [Troubleshoot access, ingestion, and operation of your Azure Data Explorer cluster in your virtual network](/azure/data-explorer/vnet-deploy-troubleshoot) --<!--fa2649e9-e1a5-4d07-9b26-51c080d9a9ba_end--> --<!--f2bcadd1-713b-4acc-9810-4170a5d01dea_begin--> -#### Add subnet delegation for 'Microsoft.Kusto/clusters' - -If a subnet isnΓÇÖt delegated, the associated Azure service wonΓÇÖt be able to operate within it. Your subnet doesnΓÇÖt have the required delegation. Delegate your subnet for 'Microsoft.Kusto/clusters'. - -**Potential benefits**: Improve reliability, availability, performance, and new feature capabilities - -For More information, see [What is subnet delegation?](/azure/virtual-network/subnet-delegation-overview) --<!--f2bcadd1-713b-4acc-9810-4170a5d01dea_end--> - -<!--microsoft_kusto_end> -## Azure Database for MySQL -<!--cf388b0c-2847-4ba9-8b07-54c6b23f60fb_begin--> -#### High Availability - Add primary key to the table that currently doesn't have one. - -Our internal monitoring system has identified significant replication lag on the High Availability standby server. This lag is primarily caused by the standby server replaying relay logs on a table that lacks a primary key. To address this issue and adhere to best practices, it's recommended to add primary keys to all tables. Once this is done, proceed to disable and then re-enable High Availability to mitigate the problem. - -**Potential benefits**: By implementing this approach, the standby server will be shielded from the adverse effects of high replication lag caused by the absence of a primary key on any table. This approach can contribute to reduced failover times, ultimately supporting the goal of maintaining business continuity. - -For More information, see [Troubleshoot replication latency in Azure Database for MySQL - Flexible Server](/azure/mysql/how-to-troubleshoot-replication-latency#no-primary-key-or-unique-key-on-a-table) --<!--cf388b0c-2847-4ba9-8b07-54c6b23f60fb_end--> --<!--fb41cc05-7ac3-4b0e-a773-a39b5c1ca9e4_begin--> -#### Replication - Add a primary key to the table that currently doesn't have one - -Our internal monitoring observed significant replication lag on your replica server because the replica server is replaying relay logs on a table that lacks a primary key. To ensure that the replica server can effectively synchronize with the primary and keep up with changes, add primary keys to the tables in the primary server and then recreate the replica server. - -**Potential benefits**: By implementing this approach, the replica server will achieve a state of close synchronization with the primary server. - -For More information, see [Troubleshoot replication latency in Azure Database for MySQL - Flexible Server](/azure/mysql/how-to-troubleshoot-replication-latency#no-primary-key-or-unique-key-on-a-table) --<!--fb41cc05-7ac3-4b0e-a773-a39b5c1ca9e4_end--> - -<!--microsoft_dbformysql_end> -## Azure Database for PostgreSQL -<!--33f26810-57d0-4612-85ff-a83ee9be884a_begin--> -#### Remove inactive logical replication slots (important) - -Inactive logical replication slots can result in degraded server performance and unavailability due to write ahead log (WAL) file retention and buildup of snapshot files. Your Azure Database for PostgreSQL flexible server might have inactive logical replication slots. THIS NEEDS IMMEDIATE ATTENTION. Either delete the inactive replication slots, or start consuming the changes from these slots, so that the slots' Log Sequence Number (LSN) advances and is close to the current LSN of the server. - -**Potential benefits**: Improve PostgreSQL availability by removing inactive logical replication slots - -For More information, see [Logical replication and logical decoding in Azure Database for PostgreSQL - Flexible Server](https://aka.ms/azure_postgresql_flexible_server_logical_decoding) --<!--33f26810-57d0-4612-85ff-a83ee9be884a_end--> --<!--6f33a917-418c-4608-b34f-4ff0e7be8637_begin--> -#### Remove inactive logical replication slots - -When an Orcas PostgreSQL flexible server has inactive logical replication slots, degraded server performance and unavailability due to write ahead log (WAL) file retention and buildup of snapshot files might occur. THIS NEEDS IMMEDIATE ATTENTION. Either delete the inactive replication slots, or start consuming the changes from these slots, so that the slots' Log Sequence Number (LSN) advances and is close to the current LSN of the server. - -**Potential benefits**: Improve PostgreSQL availability by removing inactive logical replication slots - -For More information, see [Logical decoding](https://aka.ms/azure_postgresql_logical_decoding) --<!--6f33a917-418c-4608-b34f-4ff0e7be8637_end--> - --<!--5295ed8a-f7a1-48d3-b4a9-e5e472cf1685_begin--> -#### Configure geo redundant backup storage - -Configure GRS to ensure that your database meets its availability and durability targets even in the face of failures or disasters. - -**Potential benefits**: Ensures recovery from regional failure or disaster. - -For More information, see [Backup and restore in Azure Database for PostgreSQL - Flexible Server](https://aka.ms/PGGeoBackup) --<!--5295ed8a-f7a1-48d3-b4a9-e5e472cf1685_end--> - --<!--eb241cd1-4bdc-4800-945b-4c9c8eeb6f07_begin--> -#### Define custom maintenance windows to occur during low-peak hours - -When specifying preferences for the maintenance schedule, you can pick a day of the week and a time window. If you don't specify, the system will pick times between 11pm and 7am in your server's region time. Pick a day and time where usage is low. - -**Potential benefits**: Configure maintenance window enables avoiding maintenance during system peak. - -For More information, see [Scheduled maintenance in Azure Database for PostgreSQL - Flexible Server](https://aka.ms/PGCustomMaintenanceWindow) --<!--eb241cd1-4bdc-4800-945b-4c9c8eeb6f07_end--> - -<!--microsoft_dbforpostgresql_end> -## Azure IoT Hub -<!--51b1fad8-4838-426f-9871-107bc089677b_begin--> -#### Upgrade Microsoft Edge device runtime to a supported version for IoT Hub - -When Edge devices use outdated versions, performance degradation might occur. We recommend you upgrade to the latest supported version of the Azure IoT Edge runtime. - -**Potential benefits**: Ensure business continuity with latest supported version for your Edge devices - -For More information, see [Update IoT Edge](https://aka.ms/IOTEdgeSDKCheck) --<!--51b1fad8-4838-426f-9871-107bc089677b_end--> --<!--d448c687-b808-4143-bbdc-02c35478198a_begin--> -#### Upgrade device client SDK to a supported version for IotHub - -When devices use an outdated SDK, performance degradation can occur. Some or all of your devices are using an outdated SDK. We recommend you upgrade to a supported SDK version. - -**Potential benefits**: Ensure business continuity with supported SDK for your devices - -For More information, see [Azure IoT Hub SDKs](https://aka.ms/iothubsdk) --<!--d448c687-b808-4143-bbdc-02c35478198a_end--> - --<!--8d7efd88-c891-46be-9287-0aec2fabd51c_begin--> -#### IoT Hub Potential Device Storm Detected - -This is when two or more devices are trying to connect to the IoT Hub using the same device ID credentials. When the second device (B) connects, it causes the first one (A) to become disconnected. Then (A) attempts to reconnect again, which causes (B) to get disconnected. - -**Potential benefits**: Improve connectivity of your devices - -For More information, see [Understand and resolve Azure IoT Hub errors](https://aka.ms/IotHubDeviceStorm) --<!--8d7efd88-c891-46be-9287-0aec2fabd51c_end--> - --<!--d1ff97b9-44cd-4acf-a9d3-3af500bd79d6_begin--> -#### Upgrade Device Update for IoT Hub SDK to a supported version - -When a Device Update for IoT Hub instance uses an outdated version of the SDK, it doesn't get the latest upgrades. For the latest fixes, performance improvements, and new feature capabilities, upgrade to the latest Device Update for IoT Hub SDK version. - -**Potential benefits**: Ensure business continuity with supported SDK - -For More information, see [What is Device Update for IoT Hub?](/azure/iot-hub-device-update/understand-device-update) --<!--d1ff97b9-44cd-4acf-a9d3-3af500bd79d6_end--> - --<!--e4bda6ac-032c-44e0-9b40-e0522796a6d2_begin--> -#### Add IoT Hub units or increase SKU level - -When an IoT Hub exceeds its daily message quota, operation and cost problems might occur. To ensure smooth operation in the future, add units or increase the SKU level. - -**Potential benefits**: The IoT Hub can receive messages again. - -For More information, see [Understand and resolve Azure IoT Hub errors](/azure/iot-hub/troubleshoot-error-codes#403002-iothubquotaexceeded) --<!--e4bda6ac-032c-44e0-9b40-e0522796a6d2_end--> - -<!--microsoft_devices_end> -## Azure Kubernetes Service (AKS) -<!--70829b1a-272b-4728-b418-8f1a56432d33_begin--> -#### Enable Autoscaling for your system node pools - -To ensure your system pods are scheduled even during times of high load, enable autoscaling on your system node pool. - -**Potential benefits**: Enabling Autoscaler for system node pool ensures system pods are scheduled and cluster can function. - -For More information, see [Use the cluster autoscaler in Azure Kubernetes Service (AKS)](/azure/aks/cluster-autoscaler?tabs=azure-cli#before-you-begin) --<!--70829b1a-272b-4728-b418-8f1a56432d33_end--> --<!--a9228ae7-4386-41be-b527-acd59fad3c79_begin--> -#### Have at least 2 nodes in your system node pool - -Ensure your system node pools have at least 2 nodes for reliability of your system pods. With a single node, your cluster can fail in the event of a node or hardware failure. - -**Potential benefits**: Having 2 nodes ensures resiliency against node failures. - -For More information, see [Manage system node pools in Azure Kubernetes Service (AKS)](/azure/aks/use-system-pools?tabs=azure-cli#system-and-user-node-pools) --<!--a9228ae7-4386-41be-b527-acd59fad3c79_end--> - --<!--f31832f1-7e87-499d-a52a-120f610aba98_begin--> -#### Create a dedicated system node pool - -A cluster without a dedicated system node pool is less reliable. We recommend you dedicate system node pools to only serve critical system pods, preventing resource starvation between system and competing user pods. Enforce this behavior with the CriticalAddonsOnly=true:NoSchedule taint on the pool. - -**Potential benefits**: Ensures cluster reliability by preventing resource scarcity for core system pods - -For More information, see [Manage system node pools in Azure Kubernetes Service (AKS)](/azure/aks/use-system-pools?tabs=azure-cli#before-you-begin) --<!--f31832f1-7e87-499d-a52a-120f610aba98_end--> - --<!--fac2ad84-1421-4dd3-8477-9d6e605392b4_begin--> -#### Ensure B-series Virtual Machine's (VMs) aren't used in production environments - -When a cluster has one or more node pools using a non-recommended burstable VM SKU, full vCPU capability 100% is unguaranteed. Ensure B-series VM's aren't used in production environments. - -**Potential benefits**: Best practice for consistent performance - -For More information, see [B-series burstable virtual machine sizes](/azure/virtual-machines/sizes-b-series-burstable) --<!--fac2ad84-1421-4dd3-8477-9d6e605392b4_end--> - -<!--microsoft_containerservice_end> -## Azure NetApp Files -<!--2e795f35-fce6-48dc-a5ac-6860cb9a0442_begin--> -#### Configure AD DS Site for Azure Netapp Files AD Connector - -If Azure NetApp Files can't reach assigned AD DS site domain controllers, the domain controller discovery process queries all domain controllers. Unreachable domain controllers may be used, causing issues with volume creation, client queries, authentication, and AD connection modifications. - -**Potential benefits**: Optimize DNS Connectivity with Azure Netapp Files - -For More information, see [Understand guidelines for Active Directory Domain Services site design and planning for Azure NetApp Files](https://aka.ms/anfsitescoping) --<!--2e795f35-fce6-48dc-a5ac-6860cb9a0442_end--> --<!--4e112555-7dc0-4f33-85e7-18398ac41345_begin--> -#### Ensure Roles assigned to Microsoft.NetApp Delegated Subnet has Subnet Read Permissions - -Roles that are required for the management of Azure NetApp Files resources, must have "Microsoft.network/virtualNetworks/subnets/read" permissions on the subnet that is delegated to Microsoft.NetApp If the role, whether Custom or Built-In doesn't have this permission, then Volume Creations will fail - -**Potential benefits**: Prevent volume creation failures by ensuring subnet/read permissions - - --<!--4e112555-7dc0-4f33-85e7-18398ac41345_end--> - --<!--8754f0ed-c82a-497e-be31-c9d701c976e1_begin--> -#### Review SAP configuration for timeout values used with Azure NetApp Files - -High availability of SAP while used with Azure NetApp Files relies on setting proper timeout values to prevent disruption to your application. Review the 'Learn more' link to ensure your configuration meets the timeout values as noted in the documentation. - -**Potential benefits**: Improve resiliency of SAP Application on ANF - -For More information, see [Use Azure to host and run SAP workload scenarios](/azure/sap/workloads/get-started) --<!--8754f0ed-c82a-497e-be31-c9d701c976e1_end--> - --<!--cda11061-35a8-4ca3-aa03-b242dcdf7319_begin--> -#### Implement disaster recovery strategies for your Azure NetApp Files resources - -To avoid data or functionality loss during a regional or zonal disaster, implement common disaster recovery techniques such as cross region replication or cross zone replication for your Azure NetApp Files volumes. - -**Potential benefits**: Manage disaster recovery easily with Azure NetApp Files replication features - -For More information, see [Understand data protection and disaster recovery options in Azure NetApp Files](https://aka.ms/anfcrr) --<!--cda11061-35a8-4ca3-aa03-b242dcdf7319_end--> - --<!--e4bebd74-387a-4a74-b757-475d2d1b4e3e_begin--> -#### Azure Netapp Files - Enable Continuous Availability for SMB Volumes - -For Continuous Availability, we recommend enabling Server Message Block (SMB) volume for your Azure Netapp Files. - -**Potential benefits**: Prevent application disruptions by enabling Continuous Availability for SMB volumes - -For More information, see [Enable Continuous Availability on existing SMB volumes](https://aka.ms/anfdoc-continuous-availability) --<!--e4bebd74-387a-4a74-b757-475d2d1b4e3e_end--> - -<!--microsoft_netapp_end> -## Azure Site Recovery -<!--3ebfaf53-4d8c-4e67-a948-017bbbf59de6_begin--> -#### Enable soft delete for your Recovery Services vaults - -Soft delete helps you retain your backup data in the Recovery Services vault for an additional duration after deletion, giving you an opportunity to retrieve it before it's permanently deleted. - -**Potential benefits**: Helps recovery of backup data in cases of accidental deletion - -For More information, see [Soft delete for Azure Backup](/azure/backup/backup-azure-security-feature-cloud) --<!--3ebfaf53-4d8c-4e67-a948-017bbbf59de6_end--> --<!--9b1308f1-4c25-4347-a061-7cc5cd6a44ab_begin--> -#### Enable Cross Region Restore for your recovery Services Vault - -Cross Region Restore (CRR) allows you to restore Azure VMs in a secondary region (an Azure paired region), helping with disaster recovery. - -**Potential benefits**: As one of the restore options, Cross Region Restore (CRR) allows you to restore Azure VMs in a secondary region, which is an Azure paired region. - -For More information, see [How to restore Azure VM data in Azure portal](/azure/backup/backup-azure-arm-restore-vms#cross-region-restore) --<!--9b1308f1-4c25-4347-a061-7cc5cd6a44ab_end--> - -<!--microsoft_recoveryservices_end> -## Azure Spring Apps -<!--39d862c8-445c-40c6-ba59-0e86134df606_begin--> -#### Upgrade Application Configuration Service to Gen 2 - -We notice you are still using Application Configuration Service Gen1 which will be end of support by April 2024. Application Configuration Service Gen2 provides better performance compared to Gen1 and the upgrade from Gen1 to Gen2 is zero downtime so we recommend to upgrade as soon as possible. - -**Potential benefits**: Higher stability and availability - -For More information, see [Use Application Configuration Service for Tanzu](https://aka.ms/AsaAcsUpgradeToGen2) --<!--39d862c8-445c-40c6-ba59-0e86134df606_end--> -<!--microsoft_appplatform_end> -## Azure SQL Database -<!--2ea11bcb-dfd0-48dc-96f0-beba578b989a_begin--> -#### Enable cross region disaster recovery for SQL Database - -Enable cross region disaster recovery for Azure SQL Database for business continuity in the event of regional outage. - -**Potential benefits**: Enabling disaster recovery creates a continuously synchronized readable secondary database for a primary database. - -For More information, see [Overview of business continuity with Azure SQL Database](https://aka.ms/sqldb_dr_overview) --<!--2ea11bcb-dfd0-48dc-96f0-beba578b989a_end--> --<!--807e58d0-e385-41ad-987b-4a4b3e3fb563_begin--> -#### Enable zone redundancy for Azure SQL Database to achieve high availability and resiliency. - -To achieve high availability and resiliency, enable zone redundancy for the SQL database or elastic pool to use availability zones and ensure the database or elastic pool is resilient to zonal failures. - -**Potential benefits**: Enabling zone redundancy ensures Azure SQL Database is resilient to zonal hardware and software failures and the recovery is transparent to applications. - -For More information, see [Availability through redundancy - Azure SQL Database](/azure/azure-sql/database/high-availability-sla?view=azuresql&tabs=azure-powershell#zone-redundant-availability) --<!--807e58d0-e385-41ad-987b-4a4b3e3fb563_end--> - -<!--microsoft_sql_end> -## Azure Stack HCI -<!--09e56b5a-9a00-47a7-82dd-9bd9569eb6ed_begin--> -#### Upgrade to the latest version of AKS enabled by Arc - -Upgrade to the latest version of API/SDK of AKS enabled by Azure Arc for new functionality and improved stability. - -**Potential benefits**: The latest version of AKS enabled by Azure Arc with new functionality and improved stability. - -For More information, see [https://azure.github.io/azure-sdk/releases/latest/https://docsupdatetracker.net/index.html](https://azure.github.io/azure-sdk/releases/latest/https://docsupdatetracker.net/index.html) --<!--09e56b5a-9a00-47a7-82dd-9bd9569eb6ed_end--> --<!--2ac72093-309f-41ec-bf9d-55e9fc490563_begin--> -#### Upgrade to the latest version of AKS enabled by Arc - -Upgrade to the latest version of API/SDK of AKS enabled by Azure Arc for new functionality and improved stability. - -**Potential benefits**: The latest version of AKS enabled by Azure Arc with new functionality and improved stability. - -For More information, see [https://azure.github.io/azure-sdk/releases/latest/https://docsupdatetracker.net/index.html](https://azure.github.io/azure-sdk/releases/latest/https://docsupdatetracker.net/index.html) --<!--2ac72093-309f-41ec-bf9d-55e9fc490563_end--> - -<!--microsoft_azurestackhci_end> -## Classic deployment model storage -<!--fd04ff97-d3b3-470a-9544-dfea3a5708db_begin--> -#### Action required: Migrate classic storage accounts by 8/30/2024. - -Migrate your classic storage accounts to Azure Resource Manager to ensure business continuity. Azure Resource Manager will provide all of the same functionality plus a consistent management layer, resource grouping, and access to new features and updates. - -**Potential benefits**: Ensure the ability to manage your data by migrating your classic storage account(s) - - --<!--fd04ff97-d3b3-470a-9544-dfea3a5708db_end--> -<!--microsoft_classicstorage_end> -## Classic deployment model virtual machine -<!--13ff4efb-6c84-4684-8838-52c123e3e3a2_begin--> -#### Migrate off Cloud Services (classic) before 31 August 2024 - -Cloud Services (classic) is retiring. To avoid any loss of data or business continuity, migrate off before 31 Aug 2024. - -**Potential benefits**: Continuity of your service - -For More information, see [Migrate Azure Cloud Services (classic) to Azure Cloud Services (extended support)](https://aka.ms/ExternalRetirementEmailMay2022) --<!--13ff4efb-6c84-4684-8838-52c123e3e3a2_end--> -<!--microsoft_classiccompute_end> -## Cognitive Services -<!--13fed411-54aa-4923-b830-23b51539d79d_begin--> -#### Upgrade your application to use the latest API version from Azure OpenAI - -An Azure OpenAI resource with an older API version lacks the latest features and functionalities. We recommend that you use the latest REST API version. - -**Potential benefits**: Our new API versions contain the latest and greatest features and capabilities. - -For More information, see [Azure OpenAI Service REST API reference](/azure/cognitive-services/openai/reference) --<!--13fed411-54aa-4923-b830-23b51539d79d_end--> --<!--3f83aee8-222d-445c-9a46-2af5fe5b4777_begin--> -#### Quota exceeded for this resource, wait or upgrade to unblock - -If the quota for your resource is exceeded your resource becomes blocked. You can wait for the quota to automatically get replenished soon, or, to use the resource again now, upgrade it to a paid SKU. - -**Potential benefits**: If you upgrade to a paid SKU you can use the resource again today. - -For More information, see [Plan and manage costs for Azure AI Studio](/azure/cognitive-services/plan-manage-costs#pay-as-you-go) --<!--3f83aee8-222d-445c-9a46-2af5fe5b4777_end--> - -<!--microsoft_cognitiveservices_end> -## Container Registry -<!--af0cdbce-c610-499b-9bd7-b169cdb1bb2e_begin--> -#### Use Premium tier for critical production workloads - -Premium registries provide the highest amount of included storage, concurrent operations and network bandwidth, enabling high-volume scenarios. The Premium tier also adds features such as geo-replication, availability zone support, content-trust, customer-managed keys and private endpoints. - -**Potential benefits**: The Premium tier provides the highest amount of performance, scale and resiliency options - -For More information, see [Azure Container Registry service tiers](https://aka.ms/AAqwyv6) --<!--af0cdbce-c610-499b-9bd7-b169cdb1bb2e_end--> --<!--dcfa2602-227e-4b6c-a60d-7b1f6514e690_begin--> -#### Ensure Geo-replication is enabled for resilience - -Geo-replication enables workloads to use a single image, tag and registry name across regions, provides network-close registry access, reduced data transfer costs and regional Registry resilience if a regional outage occurs. This feature is only available in the Premium service tier. - -**Potential benefits**: Improved resilience and pull performance, simplified registry management and reduced data transfer costs - -For More information, see [Geo-replication in Azure Container Registry](https://aka.ms/AAqwx90) --<!--dcfa2602-227e-4b6c-a60d-7b1f6514e690_end--> - -<!--microsoft_containerregistry_end> -## Content Delivery Network -<!--ceecfd41-89b3-4c64-afe6-984c9cc03126_begin--> -#### Azure CDN From Edgio, Managed Certificate Renewal Unsuccessful. Additional Validation Required. - -Azure CDN from Edgio employs CNAME delegation to renew certificates with DigiCert for managed certificate renewals. It's essential that Custom Domains resolve to an azureedge.net endpoint for the automatic renewal process with DigiCert to be successful. Ensure your Custom Domain's CNAME and CAA records are configured correctly. Should you require further assistance, please submit a support case to Azure to re-attempt the renewal request. - -**Potential benefits**: Ensure service availability. - - --<!--ceecfd41-89b3-4c64-afe6-984c9cc03126_end--> --<!--4e1c2077-7c73-4ace-b4aa-f11b36c28290_begin--> -#### Renew the expired Azure Front Door customer certificate to avoid service disruption - -When customer certificates for Azure Front Door Standard and Premium profiles expire, you might have service disruptions. To avoid service disruption, renew the certificate before it expires. - -**Potential benefits**: Ensure service availability. - -For More information, see [Configure HTTPS on an Azure Front Door custom domain by using the Azure portal](/azure/frontdoor/standard-premium/how-to-configure-https-custom-domain#use-your-own-certificate) --<!--4e1c2077-7c73-4ace-b4aa-f11b36c28290_end--> - --<!--bfe85fd2-ee53-4c35-8781-7790da2107e1_begin--> -#### Re-validate domain ownership for the Azure Front Door managed certificate renewal - -Azure Front Door (AFD) can't automatically renew the managed certificate because the domain isn't CNAME mapped to AFD endpoint. For the managed certificate to be automatically renewed, revalidate domain ownership. - -**Potential benefits**: undefined - -For More information, see [Configure a custom domain on Azure Front Door by using the Azure portal](/azure/frontdoor/standard-premium/how-to-add-custom-domain#domain-validation-state) --<!--bfe85fd2-ee53-4c35-8781-7790da2107e1_end--> - --<!--2c057605-4707-4d3e-bbb0-a7fe9b6a626b_begin--> -#### Switch Secret version to 'Latest' for the Azure Front Door customer certificate - -Configure the Azure Front Door (AFD) customer certificate secret to 'Latest' for the AFD to refer to the latest secret version in Azure Key Vault, allowing the secret can be automatically rotated. - -**Potential benefits**: LatestΓÇÖ version can be automatically rotated. - -For More information, see [Configure HTTPS on an Azure Front Door custom domain by using the Azure portal](/azure/frontdoor/standard-premium/how-to-configure-https-custom-domain#certificate-renewal-and-changing-certificate-types) --<!--2c057605-4707-4d3e-bbb0-a7fe9b6a626b_end--> - --<!--9411bc9f-d181-497c-b519-4154ae04fb00_begin--> -#### Validate domain ownership by adding DNS TXT record to DNS provider - -Validate domain ownership by adding the DNS TXT record to your DNS provider. Validating domain ownership through TXT records enhances security and ensures proper control over your domain. - -**Potential benefits**: Ensure service availability. - -For More information, see [Configure a custom domain on Azure Front Door by using the Azure portal](/azure/frontdoor/standard-premium/how-to-add-custom-domain#domain-validation-state) --<!--9411bc9f-d181-497c-b519-4154ae04fb00_end--> - -<!--microsoft_cdn_end> -## Data Factory -<!--617ee02c-be69-441e-8294-dee5a237efff_begin--> -#### Implement BCDR strategy for cross region redundancy in Azure Data Factory - -Implementing BCDR strategy improves high availability and reduced risk of data loss - -**Potential benefits**: Improves high availability and reduced risk of data loss - -For More information, see [BCDR for Azure Data Factory and Azure Synapse Analytics pipelines - Azure Architecture Center ](https://aka.ms/AArn7ln) --<!--617ee02c-be69-441e-8294-dee5a237efff_end--> --<!--939b97dc-fdca-4324-ba36-6ea7e1ab399b_begin--> -#### Enable auto upgrade on your SHIR - -Auto-upgrade of Self-hosted Integration runtime has been disabled. Know that you aren't getting the latest changes and bug fixes on the Self-Hosted Integration runtime. Review them to enable the SHIR auto upgrade - -**Potential benefits**: To get the latest changes and bug fixes on the Self-Hosted Integration runtime - -For More information, see [Self-hosted integration runtime auto-update and expire notification](https://aka.ms/shirexpirynotification) --<!--939b97dc-fdca-4324-ba36-6ea7e1ab399b_end--> - -<!--microsoft_datafactory_end> -## Fluid Relay -<!--a5e8a0f8-2c84-407a-b3d8-f371d684363b_begin--> -#### Azure Fluid Relay client library should be upgraded - -If the Azure Fluid Relay service is invoked with an old client library, it might cause appplication problems. To ensure your application remains operational, upgrade your Azure Fluid Relay client library to the latest version. Upgrading provides the most up-to-date functionality, and enhancements in performance and stability. - -**Potential benefits**: Improved reliability - -For More information, see [Version compatibility with Fluid Framework releases](/azure/azure-fluid-relay/concepts/version-compatibility) --<!--a5e8a0f8-2c84-407a-b3d8-f371d684363b_end--> -<!--microsoft_fluidrelay_end> -## HDInsight -<!--69740e3e-5b96-4b0e-b9b8-4d7573e3611c_begin--> -#### Apply critical updates by dropping and recreating your HDInsight clusters (certificate rotation round 2) - -The HDInsight service attempted to apply a critical certificate update on your running clusters. However, due to some custom configuration changes, we're unable to apply the updates on all clusters. To prevent those clusters from becoming unhealthy and unusable, drop and recreate your clusters. - -**Potential benefits**: Ensure cluster health and stability - -For More information, see [Set up clusters in HDInsight with Apache Hadoop, Apache Spark, Apache Kafka, and more](/azure/hdinsight/hdinsight-hadoop-provision-linux-clusters) --<!--69740e3e-5b96-4b0e-b9b8-4d7573e3611c_end--> --<!--24acd95e-fc9f-490c-b32d-edc6d747d0bc_begin--> -#### Non-ESP ABFS clusters [Cluster Permissions for Word Readable] - -Plan to introduce a change in non-ESP ABFS clusters, which restricts non-Hadoop group users from running Hadoop commands for storage operations. This change is to improve cluster security posture. Customers need to plan for the updates before September 30, 2023. - -**Potential benefits**: This change is to improve cluster security posture - -For More information, see [Azure HDInsight release notes](https://aka.ms/hdireleasenotes) --<!--24acd95e-fc9f-490c-b32d-edc6d747d0bc_end--> - --<!--35e3a19f-16e7-4bb1-a7b8-49e02a35af2e_begin--> -#### Restart brokers on your Kafka Cluster Disks - -When data disks used by Kafka brokers in HDInsight clusters are almost full, the Apache Kafka broker process can't start and fails. To mitigate, find the retention time for every topic, back up the files that are older, and restart the brokers. - -**Potential benefits**: Avoid Kafka broker issues - -For More information, see [Scenario: Brokers are unhealthy or can't restart due to disk space full issue](https://aka.ms/kafka-troubleshoot-full-disk) --<!--35e3a19f-16e7-4bb1-a7b8-49e02a35af2e_end--> - --<!--41a248ef-50d4-4c48-81fb-13196f957210_begin--> -#### Cluster Name length update - -The max length of cluster name will be changed to 45 from 59 characters, to improve the security posture of clusters. This change will be implemented by September 30th, 2023. - -**Potential benefits**: Security posture improvement for HDInsight - -For More information, see [Azure HDInsight release notes](/azure/hdinsight/hdinsight-release-notes) --<!--41a248ef-50d4-4c48-81fb-13196f957210_end--> - --<!--8f163c95-0029-4139-952a-42bd0d773b93_begin--> -#### Upgrade your cluster to the the latest HDInsight image - -A cluster created one year ago doesn't have the latest image upgrades. Your cluster was created 1 year ago. As part of the best practices, we recommend you use the latest HDInsight images for the best open source updates, Azure updates, and security fixes. The recommended maximum duration for cluster upgrades is less than six months. - -**Potential benefits**: Get the latest fixes and features - -For More information, see [Consider the below points before starting to create a cluster.](/azure/hdinsight/hdinsight-overview-before-you-start#keep-your-clusters-up-to-date) --<!--8f163c95-0029-4139-952a-42bd0d773b93_end--> - --<!--97355d8e-59ae-43ff-9214-d4acf728467a_begin--> -#### Upgrade your HDInsight Cluster - -A cluster not using the latest image doesn't have the latest upgrades. Your cluster isn't using the latest image. We recommend you use the latest versions of HDInsight images for the best of open source updates, Azure updates, and security fixes. HDInsight releases happen every 30 to 60 days. - -**Potential benefits**: Get the latest fixes and features - -For More information, see [Azure HDInsight release notes](/azure/hdinsight/hdinsight-release-notes) --<!--97355d8e-59ae-43ff-9214-d4acf728467a_end--> - --<!--b3bf9f14-c83e-4dd3-8f5c-a6be746be173_begin--> -#### Gateway or virtual machine not reachable - -We have detected a Network prob failure, it indicates unreachable gateway or a virtual machine. Verify all cluster hostsΓÇÖ availability. Restart virtual machine to recover. If you need further assistance, don't hesitate to contact Azure support for help. - -**Potential benefits**: Improved availability - - --<!--b3bf9f14-c83e-4dd3-8f5c-a6be746be173_end--> - --<!--e4635832-0ab1-48b1-a386-c791197189e6_begin--> -#### VM agent is 9.9.9.9. Upgrade the cluster. - -Our records indicate that one or more of your clusters are using images dated February 2022 or older (image versions 2202xxxxxx or older). -There is a potential reliability issue on HDInsight clusters that use images dated February 2022 or older.Consider rebuilding your clusters with latest image. - -**Potential benefits**: Improved Reliability in Scaling and Network connectivity - - --<!--e4635832-0ab1-48b1-a386-c791197189e6_end--> - -<!--microsoft_hdinsight_end> -## Media Services -<!--b7c9fd99-a979-40b4-ab48-b1dfab6bb41a_begin--> -#### Increase Media Services quotas or limits - -When a media account hits its quota limits, disruption of service might occur. To avoid any disruption of service, review current usage of assets, content key policies, and stream policies and increase quota limits for the entities that are close to hitting the limit. You can request quota limits be increased by opening a ticket and adding relevant details. TIP: Don't create additional Azure Media accounts in an attempt to obtain higher limits. - -**Potential benefits**: Avoid any disruption to service due to customer exceeding quota limits. - -For More information, see [Azure Media Services quotas and limits](https://aka.ms/ams-quota-recommendation/) --<!--b7c9fd99-a979-40b4-ab48-b1dfab6bb41a_end--> -<!--microsoft_media_end> -## Service Bus -<!--29765e2c-5286-4039-963f-f8231e56cc3e_begin--> -#### Use Service Bus premium tier for improved resilience - -When running critical applications, the Service Bus premium tier offers better resource isolation at the CPU and memory level, enhancing availability. It also supports Geo-disaster recovery feature enabling easier recovery from regional disasters without having to change application configurations. - -**Potential benefits**: Service Bus premium tier offers better resiliency with CPU and memory resource isolation as well as Geo-disaster recovery - -For More information, see [Service Bus premium messaging tier](https://aka.ms/asb-premium) --<!--29765e2c-5286-4039-963f-f8231e56cc3e_end--> --<!--68e62f5c-4ed1-4b78-a2a0-4d9a4cebf106_begin--> -#### Use Service Bus autoscaling feature in the premium tier for improved resilience - -When running critical applications, enabling the auto scale feature allows you to have enough capacity to handle the load on your application. Having the right amount of resources running can reduce throttling and provide a better user experience. - -**Potential benefits**: Enabling autoscale prevents users from capacity constraints - -For More information, see [Automatically update messaging units of an Azure Service Bus namespace](https://aka.ms/asb-autoscale) --<!--68e62f5c-4ed1-4b78-a2a0-4d9a4cebf106_end--> - -<!--microsoft_servicebus_end> -## SQL Server on Azure Virtual Machines -<!--77f01e65-e57f-40ee-a0e9-e18c007d4d4c_begin--> -#### Enable Azure backup for SQL on your virtual machines - -For the benefits of zero-infrastructure backup, point-in-time restore, and central management with SQL AG integration, enable backups for SQL databases on your virtual machines using Azure backup. - -**Potential benefits**: SQL aware backups with no-infra for backup, centralized management, AG integration and point-in-time restore - -For More information, see [About SQL Server Backup in Azure VMs](/azure/backup/backup-azure-sql-database) --<!--77f01e65-e57f-40ee-a0e9-e18c007d4d4c_end--> -<!--microsoft_sqlvirtualmachine_end> -## Storage -<!--d42d751d-682d-48f0-bc24-bb15b61ac4b8_begin--> -#### Use Managed Disks for storage accounts reaching capacity limit - -When Premium SSD unmanaged disks in storage accounts are about to reach their Premium Storage capacity limit, failures might occur. To avoid failures when this limit is reached, migrate to Managed Disks that don't have an account capacity limit. This migration can be done through the portal in less than 5 minutes. - -**Potential benefits**: Avoid scale issues when account reaches capacity limit - -For More information, see [Scalability and performance targets for standard storage accounts](https://aka.ms/premium_blob_quota) --<!--d42d751d-682d-48f0-bc24-bb15b61ac4b8_end--> --<!--8ef907f4-f8e3-4bf1-962d-27e005a7d82d_begin--> -#### Configure blob backup - -Azure blob backup helps protect data from accidental or malicious deletion. We recommend that you configure blob backup. - -**Potential benefits**: Protect data from accidental or malicious deletion - -For More information, see [Overview of Azure Blob backup](/azure/backup/blob-backup-overview) --<!--8ef907f4-f8e3-4bf1-962d-27e005a7d82d_end--> - -<!--microsoft_storage_end> -## Subscriptions -<!--9e91a63f-faaf-46f2-ac7c-ddfcedf13366_begin--> -#### Turn on Azure Backup to get simple, reliable, and cost-effective protection for your data - -Keep your information and applications safe with robust, one click backup from Azure. Activate Azure Backup to get cost-effective protection for a wide range of workloads including VMs, SQL databases, applications, and file shares. - -**Potential benefits**: Ensure your business-critical applications stay protected - -For More information, see [Azure Backup Documentation - Azure Backup ](/azure/backup/) --<!--9e91a63f-faaf-46f2-ac7c-ddfcedf13366_end--> --<!--242639fd-cd73-4be2-8f55-70478db8d1a5_begin--> -#### Create an Azure Service Health alert - -Azure Service Health alerts keep you informed about issues and advisories in four areas (Service issues, Planned maintenance, Security and Health advisories). These alerts are personalized to notify you about disruptions or potential impacts on your chosen Azure regions and services. - -**Potential benefits**: Stay informed about issues and advisories across 4 areas (Service issues, Planned maintenance, Security advisories and Health advisories) - -For More information, see [Create activity log alerts on service notifications using the Azure portal](https://aka.ms/aa_servicehealthalert_action) --<!--242639fd-cd73-4be2-8f55-70478db8d1a5_end--> - -<!--microsoft_subscriptions_end> -## Virtual Machines -<!--02cfb5ef-a0c1-4633-9854-031fbda09946_begin--> -#### Improve data reliability by using Managed Disks - -Virtual machines in an Availability Set with disks that share either storage accounts or storage scale units aren't resilient to single storage scale unit failures during outages. Migrate to Azure Managed Disks to ensure that the disks of different VMs in the Availability Set are sufficiently isolated to avoid a single point of failure. - -**Potential benefits**: Ensure business continuity through data resilience - -For More information, see [https://aka.ms/aa_avset_manageddisk_learnmore](https://aka.ms/aa_avset_manageddisk_learnmore) --<!--02cfb5ef-a0c1-4633-9854-031fbda09946_end--> --<!--ed651749-cd37-4fd5-9897-01b416926745_begin--> -#### Enable virtual machine replication to protect your applications from regional outage - -Virtual machines are resilient to regional outages when replication to another region is enabled. To reduce adverse business impact during an Azure region outage, we recommend enabling replication of all business-critical virtual machines. - -**Potential benefits**: Ensure business continuity in case of any Azure region outage - -For More information, see [Quickstart: Set up disaster recovery to a secondary Azure region for an Azure VM](https://aka.ms/azure-site-recovery-dr-azure-vms) --<!--ed651749-cd37-4fd5-9897-01b416926745_end--> - --<!--bcfeb92b-fe93-4cea-adc6-e747055518e9_begin--> -#### Update your outbound connectivity protocol to Service Tags for Azure Site Recovery - -IP address-based allowlisting is a vulnerable way to control outbound connectivity for firewalls, Service Tags are a good alternative. We highly recommend the use of Service Tags, to allow connectivity to Azure Site Recovery services for the machines. - -**Potential benefits**: Ensures better security, stability and resiliency than hard coded IP Addresses - -For More information, see [About networking in Azure VM disaster recovery](https://aka.ms/azure-site-recovery-using-service-tags) --<!--bcfeb92b-fe93-4cea-adc6-e747055518e9_end--> - --<!--58d6648d-32e8-4346-827c-4f288dd8ca24_begin--> -#### Upgrade the standard disks attached to your premium-capable VM to premium disks - -Using Standard SSD disks with premium VMs may lead to suboptimal performance and latency issues. We recommend that you consider upgrading the standard disks to premium disks. For any Single Instance Virtual Machine using premium storage for all Operating System Disks and Data Disks, we guarantee Virtual Machine Connectivity of at least 99.9%. When choosing to upgrade, there are two factors to consider. The first factor is that upgrading requires a VM reboot and that takes 3-5 minutes to complete. The second is if the VMs in the list are mission-critical production VMs, evaluate the improved availability against the cost of premium disks. - -**Potential benefits**: Improved availability with single VM SLA available only when all disks are premium - -For More information, see [Azure managed disk types](https://aka.ms/aa_storagestandardtopremium_learnmore) --<!--58d6648d-32e8-4346-827c-4f288dd8ca24_end--> - --<!--57ecb3cd-f2b4-4cad-8b3a-232cca527a0b_begin--> -#### Upgrade VM from Premium Unmanaged Disks to Managed Disks at no additional cost - -Azure Managed Disks provide higher resiliency, simplified service management, higher scale target and more choices among several disk types. Your VM is using premium unmanaged disks that can be migrated to managed disks at no additional cost through the portal in less than 5 minutes. - -**Potential benefits**: Leverage higher resiliency and other benefits of Managed Disks - -For More information, see [Introduction to Azure managed disks](https://aka.ms/md_overview) --<!--57ecb3cd-f2b4-4cad-8b3a-232cca527a0b_end--> - --<!--11f04d70-5bb3-4065-b717-1f11b2e050a8_begin--> -#### Upgrade your deprecated Virtual Machine image to a newer image - -Virtual Machines (VMs) in your subscription are running on images scheduled for deprecation. Once the image is deprecated, new VMs can't be created from the deprecated image. To prevent disruption to your workloads, upgrade to a newer image. (VMRunningDeprecatedImage) - -**Potential benefits**: Minimize any potential disruptions to your VM workloads - -For More information, see [Deprecated Azure Marketplace images - Azure Virtual Machines ](https://aka.ms/DeprecatedImagesFAQ) --<!--11f04d70-5bb3-4065-b717-1f11b2e050a8_end--> - --<!--937d85a4-11b2-4e13-a6b5-9e15e3d74d7b_begin--> -#### Upgrade to a newer offer of Virtual Machine image - -Virtual Machines (VMs) in your subscription are running on images scheduled for deprecation. Once the image is deprecated, new VMs can't be created from the deprecated image. To prevent disruption to your workloads, upgrade to a newer image. (VMRunningDeprecatedOfferLevelImage) - -**Potential benefits**: Minimize any potential disruptions to your VM workloads - -For More information, see [Deprecated Azure Marketplace images - Azure Virtual Machines ](https://aka.ms/DeprecatedImagesFAQ) --<!--937d85a4-11b2-4e13-a6b5-9e15e3d74d7b_end--> - --<!--681acf17-11c3-4bdd-8f71-da563c79094c_begin--> -#### Upgrade to a newer SKU of Virtual Machine image - -Virtual Machines (VMs) in your subscription are running on images scheduled for deprecation. Once the image is deprecated, new VMs can't be created from the deprecated image. To prevent disruption to your workloads, upgrade to a newer image. - -**Potential benefits**: Minimize any potential disruptions to your VM workloads - -For More information, see [Deprecated Azure Marketplace images - Azure Virtual Machines ](https://aka.ms/DeprecatedImagesFAQ) --<!--681acf17-11c3-4bdd-8f71-da563c79094c_end--> - --<!--3b739bd1-c193-4bb6-a953-1362ee3b03b2_begin--> -#### Upgrade your Virtual Machine Scale Set to alternative image version - -VMSS in your subscription are running on images that have been scheduled for deprecation. Once the image is deprecated, your Virtual Machine Scale Set workloads would no longer scale out. Upgrade to newer version of the image to prevent disruption to your workload. - -**Potential benefits**: Minimize any potential disruptions to your Virtual Machine Scale Set workloads - -For More information, see [Deprecated Azure Marketplace images - Azure Virtual Machines ](https://aka.ms/DeprecatedImagesFAQ) --<!--3b739bd1-c193-4bb6-a953-1362ee3b03b2_end--> - --<!--3d18d7cd-bdec-4c68-9160-16a677d0f86a_begin--> -#### Upgrade your Virtual Machine Scale Set to alternative image offer - -VMSS in your subscription are running on images that have been scheduled for deprecation. Once the image is deprecated, your Virtual Machine Scale Set workloads would no longer scale out. To prevent disruption to your workload, upgrade to newer offer of the image. - -**Potential benefits**: Minimize any potential disruptions to your Virtual Machine Scale Set workloads - -For More information, see [Deprecated Azure Marketplace images - Azure Virtual Machines ](https://aka.ms/DeprecatedImagesFAQ) --<!--3d18d7cd-bdec-4c68-9160-16a677d0f86a_end--> - --<!--44abb62e-7789-4f2f-8001-fa9624cb3eb3_begin--> -#### Upgrade your Virtual Machine Scale Set to alternative image SKU - -VMSS in your subscription are running on images that have been scheduled for deprecation. Once the image is deprecated, your Virtual Machine Scale Set workloads would no longer scale out. To prevent disruption to your workload, upgrade to newer SKU of the image. - -**Potential benefits**: Minimize any potential disruptions to your Virtual Machine Scale Set workloads - -For More information, see [Deprecated Azure Marketplace images - Azure Virtual Machines ](https://aka.ms/DeprecatedImagesFAQ) --<!--44abb62e-7789-4f2f-8001-fa9624cb3eb3_end--> - --<!--53e0a3cb-3569-474a-8d7b-7fd06a8ec227_begin--> -#### Provide access to mandatory URLs missing for your Azure Virtual Desktop environment - -For a session host to deploy and register to Windows Virtual Desktop (WVD) properly, you need a set of URLs in the 'allowed list' in case your VM runs in a restricted environment. For specific URLs missing from your allowed list, search your application event log for event 3702. - -**Potential benefits**: Ensure successful deployment and session host functionality when using Windows Virtual Desktop service - -For More information, see [Required FQDNs and endpoints for Azure Virtual Desktop](/azure/virtual-desktop/safe-url-list) --<!--53e0a3cb-3569-474a-8d7b-7fd06a8ec227_end--> - --<!--00e4ac6c-afa3-4578-a021-5f15e18850a2_begin--> -#### Align location of resource and resource group - -To reduce the impact of region outages, co-locate your resources with their resource group in the same region. This way, Azure Resource Manager stores metadata related to all resources within the group in one region. By co-locating, you reduce the chance of being affected by region unavailability. - -**Potential benefits**: Reduce write failures due to region outages - -For More information, see [What is Azure Resource Manager?](/azure/azure-resource-manager/management/overview#resource-group-location-alignment) --<!--00e4ac6c-afa3-4578-a021-5f15e18850a2_end--> - --<!--066a047a-9ace-45f4-ac50-6325840a6b00_begin--> -#### Use Availability zones for better resiliency and availability - -Availability Zones (AZ) in Azure help protect your applications and data from datacenter failures. Each AZ is made up of one or more datacenters equipped with independent power, cooling, and networking. By designing solutions to use zonal VMs, you can isolate your VMs from failure in any other zone. - -**Potential benefits**: Usage of zonal VMs protect your apps from zonal outage in any other zones. - -For More information, see [What are availability zones?](/azure/reliability/availability-zones-overview) --<!--066a047a-9ace-45f4-ac50-6325840a6b00_end--> - --<!--3b587048-b04b-4f81-aaed-e43793652b0f_begin--> -#### Enable Azure Virtual Machine Scale Set (VMSS) application health monitoring - -Configuring Virtual Machine Scale Set application health monitoring using the Application Health extension or load balancer health probes enables the Azure platform to improve the resiliency of your application by responding to changes in application health. - -**Potential benefits**: Increase resiliency by exposing application health to Azure - -For More information, see [Using Application Health extension with Virtual Machine Scale Sets](https://aka.ms/vmss-app-health-monitoring) --<!--3b587048-b04b-4f81-aaed-e43793652b0f_end--> - --<!--651c7925-17a3-42e5-85cd-73bd095cf27f_begin--> -#### Enable Backups on your Virtual Machines - -Secure your data by enabling backups for your virtual machines. - -**Potential benefits**: Protection of your Virtual Machines - -For More information, see [What is the Azure Backup service?](/azure/backup/backup-overview) --<!--651c7925-17a3-42e5-85cd-73bd095cf27f_end--> - --<!--b4d988a9-85e6-4179-b69c-549bdd8a55bb_begin--> -#### Enable automatic repair policy on Azure Virtual Machine Scale Sets (VMSS) - -Enabling automatic instance repairs helps achieve high availability by maintaining a set of healthy instances. If an unhealthy instance is found by the Application Health extension or load balancer health probe, automatic instance repairs attempt to recover the instance by triggering repair actions. - -**Potential benefits**: Increase resiliency by automating repair of failed instances - -For More information, see [Automatic instance repairs for Azure Virtual Machine Scale Sets](https://aka.ms/vmss-automatic-repair) --<!--b4d988a9-85e6-4179-b69c-549bdd8a55bb_end--> - --<!--ce8bb934-ce5c-44b3-a94c-1836fa7a269a_begin--> -#### Configure Virtual Machine Scale Set automated scaling by metrics - -Optimize resource utilization, reduce costs, and enhance application performance with custom autoscale based on a metric. Automatically add Virtual Machine instances based on real-time metrics such as CPU, memory, and disk operations. Ensure high availability while maintaining cost-efficiency. - -**Potential benefits**: Ensures high availability while maintaining cost-efficiency - -For More information, see [Overview of autoscale with Azure Virtual Machine Scale Sets](https://aka.ms/VMSSCustomAutoscaleMetric) --<!--ce8bb934-ce5c-44b3-a94c-1836fa7a269a_end--> - --<!--d4102c0f-ebe3-4b22-8fe0-e488866a87af_begin--> -#### Use Azure Disks with Zone Redundant Storage (ZRS) for higher resiliency and availability - -Azure Disks with ZRS provide synchronous replication of data across three Availability Zones in a region, making the disk tolerant to zonal failures without disruptions to applications. For higher resiliency and availability, migrate disks from LRS to ZRS. - -**Potential benefits**: By designing your applications to use ZRS Disks, your data is replicated across 3 Availability Zones, making your disk resilient to a zonal outage - -For More information, see [Convert a disk from LRS to ZRS](https://aka.ms/migratedisksfromLRStoZRS) --<!--d4102c0f-ebe3-4b22-8fe0-e488866a87af_end--> - -<!--microsoft_compute_end> -## Workloads -<!--3ca22452-0f8f-4701-a313-a2d83334e3cc_begin--> -#### Configure an Always On availability group for Multi-purpose SQL servers (MPSQL) - -MPSQL servers with an Always On availability group have better availability. Your MPSQL servers aren't configured as part of an Always On availability group in the shared infrastructure in your Epic system. Always On availability groups improve database availability and resource use. - -**Potential benefits**: Improved Database availability and resource use - -For More information, see [What is an Always On availability group?](/sql/database-engine/availability-groups/windows/overview-of-always-on-availability-groups-sql-server?view=sql-server-ver16#Benefits) --<!--3ca22452-0f8f-4701-a313-a2d83334e3cc_end--> --<!--f3d23f88-aee2-4b5a-bfd6-65b22bd70fc0_begin--> -#### Configure Local host cache on Citrix VDI servers to ensure seamless connection brokering operations - -We have observed that your Citrix VDI servers aren't configured Local host Cache. Local Host Cache (LHC) is a feature in Citrix Virtual Apps and Desktops that allows connection brokering operations to continue when an outage occurs.LHC engages when the site database is inaccessible for 90 seconds. - -**Potential benefits**: Seamless connection brokering operations - - --<!--f3d23f88-aee2-4b5a-bfd6-65b22bd70fc0_end--> - --<!--dfa50c39-104a-418b-873a-c145fe521c9b_begin--> -#### Deploy Hyperspace Web servers as part of a Virtual Machine Scale Set Flex configured for 3 zones - -We have observed that your Hyperspace Web servers in the Virtual Machine Scale Set Flex set up aren't spread across 3 zones in the selected region. For services like Hyperspace Web in Epic systems that require high availability and large scale, it's recommended that servers are deployed as part of Virtual Machine Scale Set Flex and spread across 3 zones. With Flexible orchestration, Azure provides a unified experience across the Azure VM ecosystem - -**Potential benefits**: High availability and on-demand large scale for Hyperspace web servers in Epic DB - -For More information, see [Create a Virtual Machine Scale Set that uses Availability Zones](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-use-availability-zones?tabs=cli-1%2Cportal-2) --<!--dfa50c39-104a-418b-873a-c145fe521c9b_end--> - --<!--45c2994f-a01d-4024-843e-a2a84dae48b4_begin--> -#### Set the Idle timeout in Azure Load Balancer to 30 minutes for ASCS HA setup in SAP workloads - -To prevent load balancer timeout, make sure that all Azure Load Balancing Rules have: 'Idle timeout (minutes)' set to the maximum value of 30 minutes. Open the load balancer, select 'load balancing rules' and add or edit the rule to enable the setting. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability#:~:text=To%20set%20up%20standard%20load%20balancer%2C%20follow%20these%20configuration%20steps) --<!--45c2994f-a01d-4024-843e-a2a84dae48b4_end--> - --<!--aec9b9fb-145f-4af8-94f3-7fdc69762b72_begin--> -#### Enable Floating IP in the Azure Load balancer for ASCS HA setup in SAP workloads - -For port resuse and better high availability, enable floating IP in the load balancing rules for the Azure Load Balancer for HA set up of ASCS instance in SAP workloads. Open the load balancer, select 'load balancing rules' and add or edit the rule to enable. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability#:~:text=To%20set%20up%20standard%20load%20balancer%2C%20follow%20these%20configuration%20steps) --<!--aec9b9fb-145f-4af8-94f3-7fdc69762b72_end--> - --<!--c3811f93-a1a5-4a84-8fba-dd700043cc42_begin--> -#### Enable HA ports in the Azure Load Balancer for ASCS HA setup in SAP workloads - -For port resuse and better high availability, enable HA ports in the load balancing rules for HA set up of ASCS instance in SAP workloads. Open the load balancer, select 'load balancing rules' and add or edit the rule to enable. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability#:~:text=To%20set%20up%20standard%20load%20balancer%2C%20follow%20these%20configuration%20steps) --<!--c3811f93-a1a5-4a84-8fba-dd700043cc42_end--> - --<!--27899d14-ac62-41f4-a65d-e6c2a5af101b_begin--> -#### Disable TCP timestamps on VMs placed behind Azure Load Balancer in ASCS HA setup in SAP workloads - -Disable TCP timestamps on VMs placed behind AzurEnabling TCP timestamps will cause the health probes to fail due to TCP packets being dropped by the VM's guest OS TCP stack causing the load balancer to mark the endpoint as down - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [https://launchpad.support.sap.com/#/notes/2382421](https://launchpad.support.sap.com/#/notes/2382421) --<!--27899d14-ac62-41f4-a65d-e6c2a5af101b_end--> - --<!--1c1deb1c-ae1b-49a7-88d3-201285ad63b6_begin--> -#### Set the Idle timeout in Azure Load Balancer to 30 minutes for HANA DB HA setup in SAP workloads - -To prevent load balancer timeout, ensure that all Azure Load Balancing Rules 'Idle timeout (minutes)' parameter is set to the maximum value of 30 minutes. Open the load balancer, select 'load balancing rules' and add or edit the rule to enable the recommended settings. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability#:~:text=To%20set%20up%20standard%20load%20balancer%2C%20follow%20these%20configuration%20steps) --<!--1c1deb1c-ae1b-49a7-88d3-201285ad63b6_end--> - --<!--cca36756-d938-4f3a-aebf-75358c7c0622_begin--> -#### Enable Floating IP in the Azure Load balancer for HANA DB HA setup in SAP workloads - -For more flexible routing, enable floating IP in the load balancing rules for the Azure Load Balancer for HA set up of HANA DB instance in SAP workloads. Open the load balancer, select 'load balancing rules' and add or edit the rule to enable the recommended settings. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability#:~:text=To%20set%20up%20standard%20load%20balancer%2C%20follow%20these%20configuration%20steps) --<!--cca36756-d938-4f3a-aebf-75358c7c0622_end--> - --<!--a5ac35c2-a299-4864-bfeb-09d2348bda68_begin--> -#### Enable HA ports in the Azure Load Balancer for HANA DB HA setup in SAP workloads - -For enhanced scalability, enable HA ports in the Load balancing rules for HA set up of HANA DB instance in SAP workloads. Open the load balancer, select 'load balancing rules' and add or edit the rule to enable the recommended settings. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability#:~:text=To%20set%20up%20standard%20load%20balancer%2C%20follow%20these%20configuration%20steps) --<!--a5ac35c2-a299-4864-bfeb-09d2348bda68_end--> - --<!--760ba688-69ea-431b-afeb-13683a03f0c2_begin--> -#### Disable TCP timestamps on VMs placed behind Azure Load Balancer in HANA DB HA setup in SAP workloads - -Disable TCP timestamps on VMs placed behind Azure Load Balancer. Enabling TCP timestamps causes the health probes to fail due to TCP packets dropped by the VM's guest OS TCP stack causing the load balancer to mark the endpoint as down. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [Azure Load Balancer health probes](/azure/load-balancer/load-balancer-custom-probe-overview#:~:text=Don%27t%20enable%20TCP,must%20be%20disabled) --<!--760ba688-69ea-431b-afeb-13683a03f0c2_end--> - --<!--28a00e1e-d0ad-452f-ad58-95e6c584e594_begin--> -#### Ensure that stonith is enabled for the Pacemaker configuration in ASCS HA setup in SAP workloads - -In a Pacemaker cluster, the implementation of node level fencing is done using a STONITH (Shoot The Other Node in the Head) resource. To help manage failed nodes, ensure that 'stonith-enable' is set to 'true' in the HA cluster configuration. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability of SAP HANA on Azure VMs on Red Hat Enterprise Linux](/azure/virtual-machines/workloads/sap/sap-hana-high-availability-rhel) --<!--28a00e1e-d0ad-452f-ad58-95e6c584e594_end--> - --<!--deede7ea-68c5-4fb9-8f08-5e706f88ac67_begin--> -#### Set the corosync token in Pacemaker cluster to 30000 for ASCS HA setup in SAP workloads (RHEL) - -The corosync token setting determines the timeout that is used directly, or as a base, for real token timeout calculation in HA clusters. To allow memory-preserving maintenance, set the corosync token to 30000 for SAP on Azure. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability of SAP HANA on Azure VMs on Red Hat Enterprise Linux](/azure/virtual-machines/workloads/sap/sap-hana-high-availability-rhel) --<!--deede7ea-68c5-4fb9-8f08-5e706f88ac67_end--> - --<!--35ef8bba-923e-44f3-8f06-691deb679468_begin--> -#### Set the expected votes parameter to '2' in Pacemaker cofiguration in ASCS HA setup in SAP workloads (RHEL) - -For a two node HA cluster, set the quorum 'expected-votes' parameter to '2' as recommended for SAP on Azure to ensure a proper quorum, resilience, and data consistency. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability of SAP HANA on Azure VMs on Red Hat Enterprise Linux](/azure/virtual-machines/workloads/sap/sap-hana-high-availability-rhel) --<!--35ef8bba-923e-44f3-8f06-691deb679468_end--> - --<!--0fffcdb4-87db-44f2-956f-dc9638248659_begin--> -#### Enable the 'concurrent-fencing' parameter in Pacemaker cofiguration in ASCS HA setup in SAP workloads (ConcurrentFencingHAASCSRH) - -Concurrent fencing enables the fencing operations to be performed in parallel, which enhances high availability (HA), prevents split-brain scenarios, and contributes to a robust SAP deployment. Set this parameter to 'true' in the Pacemaker cluster configuration for ASCS HA setup. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability of SAP HANA on Azure VMs on Red Hat Enterprise Linux](/azure/virtual-machines/workloads/sap/sap-hana-high-availability-rhel) --<!--0fffcdb4-87db-44f2-956f-dc9638248659_end--> - --<!--6921340e-baa1-424f-80d5-c07bbac3cf7c_begin--> -#### Ensure that stonith is enabled for the cluster configuration in ASCS HA setup in SAP workloads - -In a Pacemaker cluster, the implementation of node level fencing is done using a STONITH (Shoot The Other Node in the Head) resource. To help manage failed nodes, ensure that 'stonith-enable' is set to 'true' in the HA cluster configuration. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--6921340e-baa1-424f-80d5-c07bbac3cf7c_end--> - --<!--4eb10096-942e-402d-b4a6-e4e271c87a02_begin--> -#### Set the stonith timeout to 144 for the cluster configuration in ASCS HA setup in SAP workloads - -The ΓÇÿstonith-timeoutΓÇÖ specifies how long the cluster waits for a STONITH action to complete. Setting it to '144' seconds allows more time for fencing actions to complete. We recommend this setting for HA clusters for SAP on Azure. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--4eb10096-942e-402d-b4a6-e4e271c87a02_end--> - --<!--9f30eb2b-6a6f-4fa8-89dc-85a395c31233_begin--> -#### Set the corosync token in Pacemaker cluster to 30000 for ASCS HA setup in SAP workloads (SUSE) - -The corosync token setting determines the timeout that is used directly, or as a base, for real token timeout calculation in HA clusters. To allow memory-preserving maintenance, set the corosync token to '30000' for SAP on Azure. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--9f30eb2b-6a6f-4fa8-89dc-85a395c31233_end--> - --<!--f32b8f89-fb3c-4030-bd4a-0a16247db408_begin--> -#### Set 'token_retransmits_before_loss_const' to 10 in Pacemaker cluster in ASCS HA setup in SAP workloads - -The corosync token_retransmits_before_loss_const determines how many token retransmits are attempted before timeout in HA clusters. For stability and reliability, set the 'totem.token_retransmits_before_loss_const' to '10' for ASCS HA setup. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--f32b8f89-fb3c-4030-bd4a-0a16247db408_end--> - --<!--fed84141-4942-49b3-8b0c-73a8b352f754_begin--> -#### The 'corosync join' timeout specifies in milliseconds how long to wait for join messages in the membership protocol so when a new node joins the cluster, it has time to synchronize its state with existing nodes. Set to '60' in Pacemaker cluster configuration for ASCS HA setup. - - - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--fed84141-4942-49b3-8b0c-73a8b352f754_end--> - --<!--73227428-640d-4410-aec4-bac229a2b7bd_begin--> -#### Set the 'corosync consensus' in Pacemaker cluster to '36000' for ASCS HA setup in SAP workloads - -The corosync 'consensus' parameter specifies in milliseconds how long to wait for consensus before starting a round of membership in the cluster configuration. Set 'consensus' in the Pacemaker cluster configuration for ASCS HA setup to 1.2 times the corosync token for reliable failover behavior. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--73227428-640d-4410-aec4-bac229a2b7bd_end--> - --<!--14a889a6-374f-4bd4-8add-f644e3fe277d_begin--> -#### Set the 'corosync max_messages' in Pacemaker cluster to '20' for ASCS HA setup in SAP workloads - -The corosync 'max_messages' constant specifies the maximum number of messages that one processor can send on receipt of the token. Set it to 20 times the corosync token parameter in the Pacemaker cluster configuration to allow efficient communication without overwhelming the network. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--14a889a6-374f-4bd4-8add-f644e3fe277d_end--> - --<!--89a9ddd9-f9bf-47e4-b5f7-a0a4edfa0cdb_begin--> -#### Set 'expected votes' to '2' in the cluster configuration in ASCS HA setup in SAP workloads (SUSE) - -For a two node HA cluster, set the quorum 'expected_votes' parameter to 2 as recommended for SAP on Azure to ensure a proper quorum, resilience, and data consistency. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--89a9ddd9-f9bf-47e4-b5f7-a0a4edfa0cdb_end--> - --<!--2030a15b-ff0b-47c3-b934-60072ccda75e_begin--> -#### Set the two_node parameter to 1 in the cluster cofiguration in ASCS HA setup in SAP workloads - -For a two node HA cluster, set the quorum parameter 'two_node' to 1 as recommended for SAP on Azure. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--2030a15b-ff0b-47c3-b934-60072ccda75e_end--> - --<!--dc19b2c9-0770-4929-8f63-81c07fe7b6f3_begin--> -#### Enable 'concurrent-fencing' in Pacemaker ASCS HA setup in SAP workloads (ConcurrentFencingHAASCSSLE) - -Concurrent fencing enables the fencing operations to be performed in parallel, which enhances HA, prevents split-brain scenarios, and contributes to a robust SAP deployment. Set this parameter to 'true' in the Pacemaker cluster configuration for ASCS HA setup. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--dc19b2c9-0770-4929-8f63-81c07fe7b6f3_end--> - --<!--cb56170a-0ecb-420a-b2c9-5c4878a0132a_begin--> -#### Ensure the number of 'fence_azure_arm' instances is one in Pacemaker in HA enabled SAP workloads - -If you're using Azure fence agent for fencing with either managed identity or service principal, ensure that there's one instance of fence_azure_arm (an I/O fencing agent for Azure Resource Manager) in the Pacemaker configuration for ASCS HA setup for high availability. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--cb56170a-0ecb-420a-b2c9-5c4878a0132a_end--> - --<!--05747c68-715f-4c8f-b027-f57a931cc07a_begin--> -#### Set stonith-timeout to 900 in Pacemaker configuration with Azure fence agent for ASCS HA setup - -For reliable function of the Pacemaker for ASCS HA set the 'stonith-timeout' to 900. This setting is applicable if you're using the Azure fence agent for fencing with either managed identity or service principal. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--05747c68-715f-4c8f-b027-f57a931cc07a_end--> - --<!--88261a1a-6a32-4fb6-8bbd-fcd60fdfcab6_begin--> -#### Create the softdog config file in Pacemaker configuration for ASCS HA setup in SAP workloads - -The softdog timer is loaded as a kernel module in linux OS. This timer triggers a system reset if it detects that the system has hung. Ensure that the softdog configuation file is created in the Pacemaker cluster forASCS HA set up - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--88261a1a-6a32-4fb6-8bbd-fcd60fdfcab6_end--> - --<!--3730bc11-c81c-43eb-896a-8fce0bac139d_begin--> -#### Ensure the softdog module is loaded in for Pacemaler in ASCS HA setup in SAP workloads - -The softdog timer is loaded as a kernel module in linux OS. This timer triggers a system reset if it detects that the system has hung. First ensure that you created the softdog configuration file, then load the softdog module in the Pacemaker configuration for ASCS HA setup - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--3730bc11-c81c-43eb-896a-8fce0bac139d_end--> - --<!--255e9f7b-db3a-4a67-b87e-6fdc36ea070d_begin--> -#### Set PREFER_SITE_TAKEOVER parameter to 'true' in the Pacemaker configuration for HANA DB HA setup - -The PREFER_SITE_TAKEOVER parameter in SAP HANA defines if the HANA system replication (SR) resource agent prefers to takeover the secondary instance instead of restarting the failed primary locally. For reliable function of HANA DB high availability (HA) setup, set PREFER_SITE_TAKEOVER to 'true'. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability of SAP HANA on Azure VMs on Red Hat Enterprise Linux](/azure/virtual-machines/workloads/sap/sap-hana-high-availability-rhel) --<!--255e9f7b-db3a-4a67-b87e-6fdc36ea070d_end--> - --<!--4594198b-b114-4865-8ed8-be06db945408_begin--> -#### Enable stonith in the cluster cofiguration in HA enabled SAP workloads for VMs with Redhat OS - -In a Pacemaker cluster, the implementation of node level fencing is done using STONITH (Shoot The Other Node in the Head) resource. To help manage failed nodes, ensure that 'stonith-enable' is set to 'true' in the HA cluster configuration of your SAP workload. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability of SAP HANA on Azure VMs on Red Hat Enterprise Linux](/azure/virtual-machines/workloads/sap/sap-hana-high-availability-rhel) --<!--4594198b-b114-4865-8ed8-be06db945408_end--> - --<!--604f3822-6a28-47db-b31c-4b0dbe317625_begin--> -#### Set the corosync token in Pacemaker cluster to 30000 for HA enabled HANA DB for VM with RHEL OS - -The corosync token setting determines the timeout that is used directly, or as a base, for real token timeout calculation in HA clusters. To allow memory-preserving maintenance, set the corosync token to 30000 for SAP on Azure with Redhat OS. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability of SAP HANA on Azure VMs on Red Hat Enterprise Linux](/azure/virtual-machines/workloads/sap/sap-hana-high-availability-rhel) --<!--604f3822-6a28-47db-b31c-4b0dbe317625_end--> - --<!--937a1997-fc2d-4a3a-a9f6-e858a80921fd_begin--> -#### Set the expected votes parameter to '2' in HA enabled SAP workloads (RHEL) - -For a two node HA cluster, set the quorum votes to '2' as recommended for SAP on Azure to ensure a proper quorum, resilience, and data consistency. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability of SAP HANA on Azure VMs on Red Hat Enterprise Linux](/azure/virtual-machines/workloads/sap/sap-hana-high-availability-rhel) --<!--937a1997-fc2d-4a3a-a9f6-e858a80921fd_end--> - --<!--6cc63594-c89f-4535-b878-cdd13659cfc5_begin--> -#### Enable the 'concurrent-fencing' parameter in the Pacemaker cofiguration for HANA DB HA setup - -Concurrent fencing enables the fencing operations to be performed in parallel, which enhances high availability (HA), prevents split-brain scenarios, and contributes to a robust SAP deployment. Set this parameter to 'true' in the Pacemaker cluster configuration for HANA DB HA setup. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability of SAP HANA on Azure VMs on Red Hat Enterprise Linux](/azure/virtual-machines/workloads/sap/sap-hana-high-availability-rhel) --<!--6cc63594-c89f-4535-b878-cdd13659cfc5_end--> - --<!--230fddab-0864-4c5e-bb27-037bec7c46c6_begin--> -#### Set parameter PREFER_SITE_TAKEOVER to 'true' in the cluster cofiguration in HA enabled SAP workloads - -The PREFER_SITE_TAKEOVER parameter in SAP HANA topology defines if the HANA SR resource agent prefers to takeover the secondary instance instead of restarting the failed primary locally. For reliable function of HANA DB HA setup, set it to 'true'. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--230fddab-0864-4c5e-bb27-037bec7c46c6_end--> - --<!--210d0895-074c-4cc7-88de-b0a9e00820c6_begin--> -#### Enable stonith in the cluster configuration in HA enabled SAP workloads for VMs with SUSE OS - -In a Pacemaker cluster, the implementation of node level fencing is done using STONITH (Shoot The Other Node in the Head) resource. To help manage failed nodes, ensure that 'stonith-enable' is set to 'true' in the HA cluster configuration. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--210d0895-074c-4cc7-88de-b0a9e00820c6_end--> - --<!--64e5e17e-640e-430f-987a-721f133dbd5c_begin--> -#### Set the stonith timeout to 144 for the cluster configuration in HA enabled SAP workloads - -The ΓÇÿstonith-timeoutΓÇÖ specifies how long the cluster waits for a STONITH action to complete. Setting it to '144' seconds allows more time for fencing actions to complete. We recommend this setting for HA clusters for SAP on Azure. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--64e5e17e-640e-430f-987a-721f133dbd5c_end--> - --<!--a563e3ad-b6b5-4ec2-a444-c4e30800b8cf_begin--> -#### Set the corosync token in Pacemaker cluster to 30000 for HA enabled HANA DB for VM with SUSE OS - -The corosync token setting determines the timeout that is used directly, or as a base, for real token timeout calculation in HA clusters. To allow memory-preserving maintenance, set the corosync token to 30000 for HA enabled HANA DB for VM with SUSE OS. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--a563e3ad-b6b5-4ec2-a444-c4e30800b8cf_end--> - --<!--99681175-0124-44de-93ae-edc08f9dc0a8_begin--> -#### Set 'token_retransmits_before_loss_const' to 10 in Pacemaker cluster in HA enabled SAP workloads - -The corosync token_retransmits_before_loss_const determines how many token retransmits are attempted before timeout in HA clusters. Set the totem.token_retransmits_before_loss_const to 10 as recommended for HANA DB HA setup. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--99681175-0124-44de-93ae-edc08f9dc0a8_end--> - --<!--b8ac170f-433e-4d9c-8b75-f7070a2a5c92_begin--> -#### Set the 'corosync join' in Pacemaker cluster to 60 for HA enabled HANA DB in SAP workloads - -The 'corosync join' timeout specifies in milliseconds how long to wait for join messages in the membership protocol so when a new node joins the cluster, it has time to synchronize its state with existing nodes. Set to '60' in Pacemaker cluster configuration for HANA DB HA setup. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--b8ac170f-433e-4d9c-8b75-f7070a2a5c92_end--> - --<!--63e27ad9-1804-405a-97eb-d784686ffbe3_begin--> -#### Set the 'corosync consensus' in Pacemaker cluster to 36000 for HA enabled HANA DB in SAP workloads - -The corosync 'consensus' parameter specifies in milliseconds how long to wait for consensus before starting a new round of membership in the cluster. For reliable failover behavior, set 'consensus' in the Pacemaker cluster configuration for HANA DB HA setup to 1.2 times the corosync token. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--63e27ad9-1804-405a-97eb-d784686ffbe3_end--> - --<!--7ce9ff70-f684-47a2-b26f-781f80b1bccc_begin--> -#### Set the 'corosync max_messages' in Pacemaker cluster to 20 for HA enabled HANA DB in SAP workloads - -The corosync 'max_messages' constant specifies the maximum number of messages that one processor can send on receipt of the token. To allow efficient communication without overwhelming the network, set it to 20 times the corosync token parameter in the Pacemaker cluster configuration. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--7ce9ff70-f684-47a2-b26f-781f80b1bccc_end--> - --<!--37240e75-9493-433a-8671-2e2582584875_begin--> -#### Set the expected votes parameter to 2 in HA enabled SAP workloads (SUSE) - -Set the expected votes parameter to '2' in the cluster configuration in HA enabled SAP workloads to ensure a proper quorum, resilience, and data consistency. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--37240e75-9493-433a-8671-2e2582584875_end--> - --<!--41cd63e2-69a4-4a4f-bb69-1d3f832001f9_begin--> -#### Set the two_node parameter to 1 in the cluster configuration in HA enabled SAP workloads - -For a two node HA cluster, set the quorum parameter 'two_node' to 1 as recommended for SAP on Azure. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--41cd63e2-69a4-4a4f-bb69-1d3f832001f9_end--> - --<!--d763b894-7641-4c5d-9bc3-6f2515a6eb67_begin--> -#### Enable the 'concurrent-fencing' parameter in the cluster configuration in HA enabled SAP workloads - -Concurrent fencing enables the fencing operations to be performed in parallel, which enhances HA, prevents split-brain scenarios, and contributes to a robust SAP deployment. Set this parameter to 'true' in HA enabled SAP workloads. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--d763b894-7641-4c5d-9bc3-6f2515a6eb67_end--> - --<!--1f4b5e87-69e9-470a-8245-f337fd0d5528_begin--> -#### Ensure there is one instance of fence_azure_arm in the Pacemaker configuration for HANA DB HA setup - -If you're using Azure fence agent for fencing with either managed identity or service principal, ensure that one instance of fence_azure_arm (an I/O fencing agent for Azure Resource Manager) is in the Pacemaker configuration for HANA DB HA setup for high availability. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--1f4b5e87-69e9-470a-8245-f337fd0d5528_end--> - --<!--943f7572-1884-4120-808d-ac2a3e70e33a_begin--> -#### Set stonith-timeout to 900 in Pacemaker configuration with Azure fence agent for HANA DB HA setup - -If you're using the Azure fence agent for fencing with either managed identity or service principal, ensure reliable function of the Pacemaker for HANA DB HA setup, by setting the 'stonith-timeout' to 900. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--943f7572-1884-4120-808d-ac2a3e70e33a_end--> - --<!--63233341-73a2-4180-b57f-6f83395161b9_begin--> -#### Ensure that the softdog config file is in the Pacemaker configuration for HANA DB in SAP workloads - -The softdog timer is loaded as a kernel module in Linux OS. This timer triggers a system reset if it detects that the system is hung. Ensure that the softdog configuration file is created in the Pacemaker cluster for HANA DB HA setup. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--63233341-73a2-4180-b57f-6f83395161b9_end--> - --<!--b27248cd-67dc-4824-b162-4563adaa6d70_begin--> -#### Ensure the softdog module is loaded in Pacemaker in ASCS HA setup in SAP workloads - -The softdog timer is loaded as a kernel module in Linux OS. This timer triggers a system reset if it detects that the system is hung. First ensure that you created the softdog configuration file, then load the softdog module in the Pacemaker configuration for HANA DB HA setup. - -**Potential benefits**: Reliability of HA setup in SAP workloads - -For More information, see [High availability for SAP HANA on Azure VMs on SUSE Linux Enterprise Server](/azure/virtual-machines/workloads/sap/sap-hana-high-availability) --<!--b27248cd-67dc-4824-b162-4563adaa6d70_end--> - -<!--microsoft_workloads_end> -<!--articleBody--> - - - -## Next steps --Learn more about [Reliability - Microsoft Azure Well Architected Framework](/azure/architecture/framework/resiliency/overview) |
| advisor | Advisor Release Notes | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-release-notes.md | - Title: What's new in Azure Advisor -description: Learn about what's new and what's changed in Azure Advisor with information from release notes, videos, and blog posts. - Previously updated : 05/03/2024---# What's new in Azure Advisor? --You can learn about what's new in Azure Advisor with the items in this article. These items might be release notes, videos, blog posts, and other types of information. Bookmark this page to stay up to date with the service. --## April 2024 --### Azure Advisor will no longer display aggregated potential yearly savings beginning September 30, 2024 --In the Azure portal, Advisor currently shows potential aggregated cost savings under the label **Potential yearly savings based on retail pricing** on pages where cost recommendations appear. This aggregated savings estimate will be removed from the Azure portal on September 30, 2024. You can still evaluate potential yearly savings tailored to your specific needs by following the steps in [Calculate cost savings](/azure/advisor/advisor-how-to-calculate-total-cost-savings). All individual recommendations and their associated potential savings will remain available. --#### Recommended action --If you want to continue calculating aggregated potential yearly savings, follow [these steps](/azure/advisor/advisor-how-to-calculate-total-cost-savings). Individual recommendations might show savings that overlap with the savings shown in other recommendations, although you might not be able to benefit from them concurrently. For example, you can benefit from savings plans or from reservations for virtual machines (VMs), but not typically from both on the same VMs. --### Public preview: Resiliency review on Azure Advisor --Recommendations from Azure Well-Architected Framework (WAF) Reliability reviews in Advisor help you focus on the most important recommendations to ensure that your workloads remain resilient. As part of the review, personalized and prioritized recommendations from Microsoft Cloud Solution Architects are presented to you and your team. You can triage recommendations (accept or reject), manage their lifecycle on Advisor, and work with your Microsoft account team to track resolution. You can reach out to your account team to request a WAF Reliability assessment to successfully optimize workload resiliency and reliability by implementing curated recommendations and track its lifecycle on Advisor. --To learn more, see [Azure Advisor Resiliency reviews](/azure/advisor/advisor-resiliency-reviews). --## March 2024 --### Well-Architected Framework (WAF) assessments and recommendations --The WAF assessment provides a curated view of a workload's architecture. Now you can take the WAF assessment and manage recommendations on Advisor to improve resiliency, security, cost, operational excellence, and performance efficiency. As a part of this release, we're announcing two key WAF assessments: [Mission-Critical | Well-Architected Review](/assessments/23513bdb-e8a2-4f0b-8b6b-191ee1f52d34/) and [Azure Well-Architected Review](/assessments/azure-architecture-review/). --To get started, see [Use Azure WAF assessments](/azure/advisor/advisor-assessments). --## November 2023 --### ZRS recommendations for Azure disks --Advisor now has zone-redundant storage (ZRS) recommendations for Azure managed disks. Disks with ZRS provide synchronous replication of data across three availability zones in a region, enabling disks to tolerate zonal failures without causing disruptions to your application. By adopting this recommendation, you can now design your solutions to utilize ZRS disks. Access these recommendations through the Advisor portal and APIs. --To learn more, see [Use Azure disks with zone-redundant storage for higher resiliency and availability](/azure/advisor/advisor-reference-reliability-recommendations#use-azure-disks-with-zone-redundant-storage-for-higher-resiliency-and-availability). --## October 2023 --### New version of the Service Retirement workbook --Advisor now has a new version of the Service Retirement workbook that includes three major changes: --* Ten new services are onboarded to the workbook. The retirement workbook now covers 40 services. -* Seven services that completed their retirement lifecycle are off-boarded. -* User experience and navigation are improved. --List of the newly added --| Service | Retiring feature | -|--|-| -| Azure Monitor | Classic alerts for Azure US Government cloud and Azure China 21Vianet | -| Azure Stack Edge | IoT Edge on Kubernetes | -| Azure Migrate | Classic | -| Application Insights | Troubleshooting guides retirement | -| Azure Maps | Gen1 price tier | -| Application Insights | Single URL ping test | -| Azure API for FHIR | Azure API for FHIR | -| Azure Health Data Services | SMART on FHIR proxy | -| Azure Database for MariaDB | Entire service | -| Azure Cache for Redis | Support for TLS 1.0 and 1.1 | --List of the removed --| Service | Retiring feature | -|--|-| -| Azure Virtual Machines | Classic IaaS | -| Azure Cache for Redis | Version 4.x | -| Virtual Machines | NV and NV_Promo series | -| Virtual Machines | NC-series | -| Virtual Machines | NC V2 series | -| Virtual Machines | ND-Series | -| Virtual Machines | Azure Dedicated Host SKUs (Dsv3-Type1, Esv3-Type1, Dsv3-Type2, and Esv3-Type2) | --User experience improvements: --* **Resource details grid**: Now, the resource details are readily available by default. Previously, they were only visible after selecting a service. -* **Resource link**: The **Resource** link now opens in a context pane. Previously, it opened on the same tab. --To learn more, see [Prepare migration of your workloads affected by service retirement](/azure/advisor/advisor-how-to-plan-migration-workloads-service-retirement). --### Service Health Alert recommendations --Advisor now provides Azure Service Health alert recommendations for subscriptions that don't have Service Health alerts configured. The link redirects you to the **Service Health** page. There, you can create and customize alerts based on the class of service health notification, affected subscriptions, services, and regions. --Service Health alerts keep you informed about issues and advisories in four areas: Service issues, Planned maintenance, Security advisories, and Health advisories. The alerts can be crucial for incident preparedness. --To learn more, see [Service Health portal classic experience overview](/azure/service-health/service-health-overview). --## August 2023 --### Improved VM resiliency with availability zone recommendations --Advisor now provides availability zone recommendations. By adopting these recommendations, you can design your solutions to utilize zonal VMs, ensuring the isolation of your VMs from potential failures in other zones. With zonal deployment, you can expect enhanced resiliency in your workload by avoiding downtime and business interruptions. --To learn more, see [Use availability zones for better resiliency and availability](/azure/advisor/advisor-reference-reliability-recommendations#use-availability-zones-for-better-resiliency-and-availability). --## July 2023 --### Workload-based recommendations management --Advisor now offers the capability of grouping or filtering recommendations by workload. The feature is available to selected customers based on their support contract. --If you're interested in workload-based recommendations, reach out to your account team for more information. --### Cost Optimization workbook template --The Azure Cost Optimization workbook serves as a centralized hub for some of the most-used tools that can help you drive utilization and efficiency goals. It offers a range of recommendations, including Advisor cost recommendations, identification of idle resources, and management of improperly deallocated VMs. It also provides insights into using Azure Hybrid Benefit options for Windows, Linux, and SQL databases. --To learn more, see [Understand and optimize your Azure costs by using the Cost Optimization workbook](/azure/advisor/advisor-cost-optimization-workbook). --## June 2023 --### Recommendation reminders for an upcoming event --Advisor now offers new recommendation reminders to help you proactively manage and improve the resilience and health of your workloads before an important event. Customers in the [Azure Event Management (AEM) program](https://www.microsoft.com/unifiedsupport/enhanced-solutions) are now reminded about outstanding recommendations for their subscriptions and resources that are critical for the event. --The event notifications are displayed when you visit Advisor or manage resources critical for an upcoming event. The reminders are displayed for events happening within the next 12 months and only for the subscriptions linked to an event. The notification includes a call to action to review outstanding recommendations for reliability, security, performance, and operational excellence. --## May 2023 --### New: Reliability workbook template --Advisor now has a Reliability workbook template. The new workbook helps you identify areas of improvement by checking configuration of selected Azure resources by using the [resiliency checklist](/azure/architecture/checklist/resiliency-per-service) and documented best practices. You can use filters, subscriptions, resource groups, and tags to focus on resources that you care about most. Use the workbook recommendations to: --* Optimize your workload. -* Prepare for an important event. -* Mitigate risks after an outage. --To learn more, see [Optimize your resources for reliability](https://aka.ms/advisor_improve_reliability). --To assess the reliability of your workload by using the tenets found in theΓÇ»[Azure WAF](/azure/architecture/framework/), see theΓÇ»[Azure Well-Architected Framework review](/assessments/?id=azure-architecture-review&mode=pre-assessment). --### Data in Azure Resource Graph is now available in Azure China and US Government clouds --Advisor data is now available in Azure Resource Graph in the Azure China and US Government clouds. Resource Graph is useful for customers who can now get recommendations for all their subscriptions at once and build custom views of Advisor recommendation data. For example, you can: --* Review your recommendations summarized by impact and category. -* See all recommendations for a recommendation type. -* View affected resource counts by recommendation category. --To learn more, see [Query for Advisor data in Resource Graph Explorer (Azure Resource Graph)](https://aka.ms/advisorarg). --### Service Retirement workbook --Advisor now provides a Service Retirement workbook. It's important to be aware of the upcoming Azure service and feature retirements to understand their effect on your workloads and plan migration. The [Service Retirement workbook](https://portal.azure.com/#view/Microsoft_Azure_Expert/AdvisorMenuBlade/~/workbooks) provides a single centralized resource-level view of service retirements. It helps you assess impact, evaluate options, and plan migration. -The workbook includes 35 services and features that are planned for retirement. You can view planned retirement dates and the list and map of affected resources. You also get information to take the necessary actions. --To learn more, see [Prepare migration of your workloads impacted by service retirements](advisor-how-to-plan-migration-workloads-service-retirement.md). --## April 2023 --### Postpone/dismiss a recommendation for multiple resources --Advisor now provides the option to postpone or dismiss a recommendation for multiple resources at once. After you open a recommendations details page with a list of recommendations and associated resources, select the relevant resources and choose **Postpone** or **Dismiss** in the command bar at the top of the page. --To learn more, see [Dismiss and postpone recommendations](/azure/advisor/view-recommendations#dismissing-and-postponing-recommendations). --### VM/virtual machine scale set right-sizing recommendations with custom lookback period --You can now improve the relevance of recommendations to make them more actionable to achieve more cost savings. --The right-sizing recommendations help optimize costs by identifying idle or underutilized VMs based on their CPU, memory, and network activity over the default lookback period of seven days. Now, with this latest update, you can adjust the default lookback period to get recommendations based on 14, 21, 30, 60, or even 90 days of use. The configuration can be applied at the subscription level. This capability is especially useful when the workloads have biweekly or monthly peaks (such as with payroll applications). --To learn more, see [Optimize VM or virtual machine scale set spend by resizing or shutting down underutilized instances](advisor-cost-recommendations.md#optimize-virtual-machine-vm-or-virtual-machine-scale-set-vmss-spend-by-resizing-or-shutting-down-underutilized-instances). --## March 2023 --### Advanced filtering capabilities --Advisor now provides more filtering capabilities. You can filter recommendations by resource group, resource type, impact, and workload. --## November 2022 --### New cost recommendations for virtual machine scale sets --Advisor now offers cost-optimization recommendations for virtual machine scale sets. They include shutdown recommendations for resources that we detect aren't used at all. They also include SKU change or instance count reduction recommendations for resources that we detect are underutilized. An example recommendation is for resources where we think customers are paying for more than what they might need based on the workloads running on the resources. --To learn more, see [ -Optimize VM or virtual machine scale set spend by resizing or shutting down underutilized instances](/azure/advisor/advisor-cost-recommendations#optimize-virtual-machine-vm-or-virtual-machine-scale-set-vmss-spend-by-resizing-or-shutting-down-underutilized-instances). --## June 2022 --### Advisor support for Azure Database for MySQL - Flexible Server --Advisor provides a personalized list of best practices for optimizing your Azure Database for MySQL - Flexible Server instance. The feature analyzes your resource configuration and usage. It then recommends solutions to help you improve the cost effectiveness, performance, reliability, and security of your resources. With Advisor, you can find recommendations based on transport layer security (TLS) configuration, CPU, and storage usage to prevent resource exhaustion. --To learn more, see [Azure Advisor for MySQL](/azure/mysql/single-server/concepts-azure-advisor-recommendations). --## May 2022 --### Unlimited number of subscriptions --It's easier now to get an overview of optimization opportunities available to your organization. There's no need to spend time and effort to apply filters and process subscriptions in batches. --To learn more, see [Get started with Azure Advisor](advisor-get-started.md). --### Tag filtering --You can now get Advisor recommendations scoped to a business unit, workload, or team. To filter recommendations and calculate scores, use tags that you already assigned to Azure resources, resource groups, and subscriptions. Apply tag filters to: --* Identify cost-saving opportunities by business units. -* Compare scores for workloads to optimize critical ones first. --To learn more, see [Filter Advisor recommendations by using tags](advisor-tag-filtering.md). --## January 2022 --The [Shut down/Resize your VMs](advisor-cost-recommendations.md#optimize-virtual-machine-vm-or-virtual-machine-scale-set-vmss-spend-by-resizing-or-shutting-down-underutilized-instances) recommendation was enhanced to increase quality, robustness, and applicability. --Improvements include: --- Cross-SKU family series resize recommendations are now available. -- Cross-version resize recommendations are now available. In general, newer versions of SKU families are more optimized, provide more features, and have better performance/cost ratios than older versions.-- Updated recommendation criteria include other SKU characteristics for better actionability. Examples are accelerated networking support, premium storage support, availability in a region, and inclusion in an availability set.---To learn more, read the [How-to guide](advisor-cost-recommendations.md#optimize-virtual-machine-vm-or-virtual-machine-scale-set-vmss-spend-by-resizing-or-shutting-down-underutilized-instances). |
| advisor | Advisor Resiliency Reviews | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-resiliency-reviews.md | - Title: Azure Advisor resiliency reviews -description: Optimize resource resiliency with custom recommendation reviews. -- Previously updated : 08/22/2024----# Azure Advisor Resiliency Reviews --Azure Advisor Resiliency Reviews help you focus on the most important recommendations to optimize your cloud deployments and improve resiliency. Review recommendations are tailored to the needs of your workload and include custom ones curated by your account team using Azure best practices and prioritized automated recommendations. --You can find resiliency reviews in [Azure Advisor](https://aka.ms/azureadvisordashboard), which serves as your single-entry point for Microsoft best practices. --In this article, you learn how to enable and access resiliency reviews prepared for you, triage, manage, implement, and track recommendations' lifecycles. --## Terminology --* *Triage recommendations* means to accept or reject a recommendation. -* *Manage recommendation lifecycle* means to mark a recommendation as completed, postponed or dismissed, in progress, or not started. You can only manage a recommendation is in the *Accepted* state. --## How it works --After you request a review, Microsoft Cloud Solution Architect engineers perform extensive analysis, curate the list of prioritized recommendations, and publish a resiliency review. You triage the recommendations and implement them. Your Microsoft account team works with you to facilitate the process. --The following table defines the responsible parties for Advisor actions: --| **Responsibility** | **Description** | -||::| -|Request a resiliency review|Customer via your Customer Success Account Manager or aligned Cloud Solution Architect.| -|Analyze workload configuration, perform the review via the Well Architected Reliability Assessment and prepare recommendations|Microsoft account team. Team members include Account Managers, Engineers, and Cloud Solution Architects. | -|Triage recommendations to accept or reject them.|Customer. Triage is done by team members who have authority to make decisions about workload optimization priorities.| -|Manage recommendations' lifecycle.|Customer. Setting the status of accepted recommendation as completed, postponed or dismissed, in progress, or not started.| -|Implement recommendations that were accepted|Customer. Implementation is done by engineers who are responsible for managing resources and their configuration.| -|Facilitate implementation|Microsoft account team via your support contract.| --## Enable reviews --Resiliency reviews are available to customers with Unified or Premier Support contracts via a Well Architected Reliability Assessment. To initiate a review, reach out to your Customer Success Account Manager. You can find their contacts in [Services Hub](https://serviceshub.microsoft.com/). --Your Microsoft account team works with you to collect information about the workload. They need to know which subscriptions are used for the workload, and which subscriptions they should use to publish the review and recommendations. You need to work with the owner of this subscription to configure permissions for your team. --## View and triage recommendations --To view or triage recommendations, or to manage recommendations' lifecycles, requires specific role permissions. For definitions, see [Terminology](#terminology). ---### Access reviews --You can find resiliency reviews created by your account team in the left navigation pane under the **Manage** > **Reviews (Preview)** menu in Azure Advisor. --If there's a new review available to you, you see a notification banner on top of the Advisor pages. A **New** review is one with all recommendations in the *Pending* state. --1. Open the Azure portal and navigate to [Advisor](https://aka.ms/azureadvisordashboard). -Select **Manage** > **Reviews (Preview)** in the left navigation pane. A list of reviews opens. At the top of the page, you see the number of **Total Reviews** and review **Recommendations**, and a graph of **Reviews by status**. -1. Use search, filters, and sorting to find the review you need. You can filter reviews by one of the **Status equals** states shown next, or choose *All* (the default) to see all reviews. If you donΓÇÖt see a review for your subscription, make sure the review subscription is included in the global portal filter. You might need to update the filter to see the reviews for a subscription. -- * *New*: No recommendations are triaged (accepted or rejected) - * *In progress*: Some recommendations aren't triaged - * *Triaged*: All recommendations are triaged - * *Completed*: All accepted-state recommendations are implemented, postponed, or dismissed ---At the top of the reviews page, use **Feedback** to tell us about your experience. Use the **Refresh** button to refresh the page as needed. --> [!NOTE] -> If you have no reviews, the **Reviews** menu item in the left navigation is hidden. --### Review recommendations --The triage process includes reviewing recommendations and making decisions on which to implement. Use *Accept* and *Reject* actions to capture your decision. Accepted recommendations are available to your engineering team under the Advisor **Reliability** menu item. ---1. From the **Reviews** page, select a review name to open the recommendations list page. For new reviews, recommendations are in *Pending* state. -1. Take a note of recommendations priority. **Priority** is defined by your account team to help you decide which recommendations should be implemented first. -1. Select a recommendation *Title* or the *Impacted subscriptions* view link to get detailed information. A pane opens with details ΓÇô description, potential benefits, and notes from your account team along with the list of impacted subscriptions. -1. If all recommendations for that review are triaged, none appear in the **Pending** view; select the **Accepted** or **Rejected** tabs to view those recommendations. --### Recommendation priority --The priority of a recommendation is based on the impact and urgency of the suggested improvements. Your account team sets recommendation priority. --* *Critical*: The most important recommendations that can have a significant impact on your Azure resources. They should be addressed as soon as possible to avoid potential issues such as security breaches, data loss, or service outages. -* *High*: The recommendations that can improve the performance, reliability, or cost efficiency of your Azure resources. They should be addressed in a timely manner to optimize your Azure deployments. -* *Medium*: The recommendations that can enhance the operational excellence or user experience of your Azure resources. They should be considered and implemented if they align with your business goals and requirements. -* *Low*: The recommendations that can provide extra benefits or insights for your Azure resources. They should be reviewed and implemented if they're relevant and feasible for your scenario. -* *Informational*: The recommendations that can help you learn more about the features and capabilities of Azure. They don't require any action, but they can help you discover new ways to use Azure. --### Accept recommendations --You must accept recommendations for your engineering team to start implementation. When a review recommendation is accepted, it becomes available under the Advisor **Reliability** page where it can be acted on. --From a review recommendations details page: --1. You can accept a single recommendation by clicking **Accept**. -1. You can accept multiple recommendations at a time by selecting them using the checkbox control and clicking **Accept**. -1. Accepted recommendations are moved to the **Accepted** tab and become visible to your engineering team under **Recommendations** > **Reliability**. -1. If you accepted a recommendation by mistake, use **Reset** to move it back to the pending state. --### Reject recommendations --1. You can reject a recommendation if you disagree with it. -1. You must select a reason when you reject a recommendation. Select one of the reasons from the list of available options. -1. The rejected recommendation is moved to the **Rejected** tab. Rejected recommendations aren't visible for your engineering team under **Recommendations** > **Reliability**. -1. You can reject multiple recommendations at a time using the checkbox control, and the same reason for rejection is applied to all selected recommendations. If you need to select a different reason, reject one recommendation at a time. -1. If you reject a recommendation by mistake, select **Reset** to move it back to the pending state and tab. --> [!NOTE] -> The reason for the rejection is visible to your account team. It helps them understand workload context and your business priorities better. Additionally, Microsoft uses this information to improve the quality of recommendations. --## Implement recommendations --Once review recommendations are triaged, all recommendations with *Accepted* status become available on the Advisor **Reliability** page with links to the resources needing action. Typically, an engineer on your team implements the recommendations by going to the resource page and making the recommended change. --For definitions on recommendation states, see [Terminology](#terminology). --### Prerequisites to implement recommendations --For details on permissions to act on recommendations, see [Permissions in Azure Advisor - Azure Advisor | Microsoft Learn](/azure/advisor/permissions). --### Access accepted review recommendations --To view *Accepted* review recommendations, go to **Recommendations** > **Reliability** in the left navigation to open the **Reliability** page at the **Reviews** tab, by default. --The recommendations are grouped by type: --* **Reviews**: These recommendations are part of a review for a selected workload. -* **Automated**: These recommendations are the standard Advisor recommendations for the selected subscriptions. --> [!NOTE] -> If none of your resiliency review recommendations are in the *Accepted* state, the **Reviews** tab is hidden. ---You can filter the recommendations by subscription, priority, and workload, as well as sort the recommendation list. --You can sort recommendations using column headers - *Priority* (Critical, High, Medium, Low, Informational), *Description*, *Impacted resources*, *Review name*, *Potential benefits*, or *Last updated* date. --### View recommendation details --Select a recommendation description to open a details page. Your account team adds the *Description*, *Potential benefits*, and *Notes* when the review is prepared. ---The options in the **Reliability** recommendations detail differ from those in the **Reviews** recommendations detail. Here, a team developer can open the *Impacted subscriptions* link and take direct action. --For details on recommendation priority, see [Recommendation priority](#recommendation-priority). --### Manage recommendation lifecycle --Recommendation status is a valuable indicator for determining what actions need to be taken. --* Once you begin to implement a recommendation, mark it as *In progress*. -* Once the recommendation is implemented, the recommended action is taken, update the status to *Completed*. When all recommendations in a review are marked as *Completed*, the review is marked as *Completed* on the **Review** page. -* You can also postpone the recommendation for action later. -* You can dismiss a recommendation if you don't plan to implement it. If you dismiss the recommendation, you must give a reason, just as you must give a reason if you reject a recommendation in a review. ---## Review maintenance --Your Microsoft account team engineers keep track of the results of your actions on resiliency reviews and continue to refine the recommendation reviews accordingly. --## Next steps --To learn more about Advisor reliability recommendations, see: --[Improve the reliability of your business-critical applications using Azure Advisor](/azure/advisor/advisor-how-to-improve-reliability). --[Reliability recommendations](/azure/advisor/advisor-reference-reliability-recommendations). |
| advisor | Advisor Security Recommendations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-security-recommendations.md | - Title: Make resources more secure with Azure Advisor -description: Use Azure Advisor to help improve the security of your Azure deployments. - Previously updated : 01/29/2019--# Make resources more secure with Azure Advisor --Azure Advisor provides you with a consistent, consolidated view of recommendations for all your Azure resources. It integrates with Microsoft Defender for Cloud to bring you security recommendations. You can get security recommendations from the **Security** tab on the Advisor dashboard. --Defender for Cloud helps you prevent, detect, and respond to threats with increased visibility into and control over the security of your Azure resources. It periodically analyzes the security state of your Azure resources. When Defender for Cloud identifies potential security vulnerabilities, it creates recommendations. The recommendations guide you through the process of configuring the controls you need. --For more information about security recommendations, see [Review your security recommendations in Microsoft Defender for Cloud](/azure/defender-for-cloud/review-security-recommendations). --## How to access Security recommendations in Azure Advisor --1. Sign in to the [Azure portal](https://portal.azure.com), and then open [Advisor](https://aka.ms/azureadvisordashboard). --2. On the Advisor dashboard, click the **Security** tab. --## Next steps --To learn more about Advisor recommendations, see: -* [Introduction to Advisor](advisor-overview.md) -* [Get started with Advisor](advisor-get-started.md) -* [Advisor cost recommendations](advisor-reference-cost-recommendations.md) -* [Advisor performance recommendations](advisor-reference-performance-recommendations.md) -* [Advisor reliability recommendations](advisor-reference-reliability-recommendations.md) -* [Advisor operational excellence recommendations](advisor-reference-operational-excellence-recommendations.md) -* [Advisor REST API](/rest/api/advisor/) |
| advisor | Advisor Sovereign Clouds | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-sovereign-clouds.md | - Title: Sovereign cloud feature variations -description: List of feature variations and usage limitations for Advisor in sovereign clouds. - Previously updated : 09/19/2022---# Azure Advisor in sovereign clouds --Azure sovereign clouds enable you to build and digitally transform workloads in the cloud while meeting your security, compliance, and policy requirements. --## Azure Government (United States) --The following Azure Advisor recommendation **features aren't currently available** in Azure Government: --### Cost --- (Preview) Consider App Service stamp fee reserved capacity to save over your on-demand costs.-- (Preview) Consider Azure Data Explorer reserved capacity to save over your pay-as-you-go costs.-- (Preview) Consider Azure Synapse Analytics (formerly SQL DW) reserved capacity to save over your pay-as-you-go costs.-- (Preview) Consider Blob storage reserved capacity to save on Blob v2 and Data Lake Storage Gen2 costs.-- (Preview) Consider Blob storage reserved instance to save on Blob v2 and Data Lake Storage Gen2 costs.-- (Preview) Consider Cache for Redis reserved capacity to save over your pay-as-you-go costs.-- (Preview) Consider Azure Cosmos DB reserved capacity to save over your pay-as-you-go costs.-- (Preview) Consider Database for MariaDB reserved capacity to save over your pay-as-you-go costs.-- (Preview) Consider Database for MySQL reserved capacity to save over your pay-as-you-go costs.-- (Preview) Consider Database for PostgreSQL reserved capacity to save over your pay-as-you-go costs.-- (Preview) Consider SQL DB reserved capacity to save over your pay-as-you-go costs.-- (Preview) Consider SQL PaaS DB reserved capacity to save over your pay-as-you-go costs.-- Consider App Service stamp fee reserved instance to save over your on-demand costs.-- Consider Azure Synapse Analytics (formerly SQL DW) reserved instance to save over your pay-as-you-go costs.-- Consider Cache for Redis reserved instance to save over your pay-as-you-go costs.-- Consider Azure Cosmos DB reserved instance to save over your pay-as-you-go costs.-- Consider Database for MariaDB reserved instance to save over your pay-as-you-go costs.-- Consider Database for MySQL reserved instance to save over your pay-as-you-go costs.-- Consider Database for PostgreSQL reserved instance to save over your pay-as-you-go costs.-- Consider SQL PaaS DB reserved instance to save over your pay-as-you-go costs.--### Operational --- Add Azure Monitor to your virtual machine (VM) labeled as production.-- Delete and recreate your pool using a VM size that will soon be retired.-- Enable Traffic Analytics to view insights into traffic patterns across Azure resources.-- Enforce 'Add or replace a tag on resources' using Azure Policy.-- Enforce 'Allowed locations' using Azure Policy.-- Enforce 'Allowed virtual machine SKUs' using Azure Policy.-- Enforce 'Audit VMs that don't use managed disks' using Azure Policy.-- Enforce 'Inherit a tag from the resource group' using Azure Policy.-- Update Azure Spring Cloud API Version.-- Update your outdated Azure Spring Cloud SDK to the latest version.-- Upgrade to the latest version of the Immersive Reader SDK.--### Performance --- Accelerated Networking may require stopping and starting the VM.-- Arista Networks vEOS Router may experience high CPU utilization, reduced throughput and high latency.-- Barracuda Networks NextGen Firewall may experience high CPU utilization, reduced throughput and high latency.-- Cisco Cloud Services Router 1000V may experience high CPU utilization, reduced throughput and high latency.-- Consider increasing the size of your NVA to address persistent high CPU.-- Distribute data in server group to distribute workload among nodes.-- More than 75% of your queries are full scan queries.-- NetApp Cloud Volumes ONTAP may experience high CPU utilization, reduced throughput and high latency.-- Palo Alto Networks VM-Series Firewall may experience high CPU utilization, reduced throughput and high latency.-- Reads happen on most recent data.-- Rebalance data in Hyperscale (Citus) server group to distribute workload among worker nodes more evenly.-- Update Attestation API Version.-- Update Key Vault SDK Version.-- Update to the latest version of your Arista VEOS product for Accelerated Networking support.-- Update to the latest version of your Barracuda NG Firewall product for Accelerated Networking support.-- Update to the latest version of your Check Point product for Accelerated Networking support.-- Update to the latest version of your Cisco Cloud Services Router 1000V product for Accelerated Networking support.-- Update to the latest version of your F5 BigIp product for Accelerated Networking support.-- Update to the latest version of your NetApp product for Accelerated Networking support.-- Update to the latest version of your Palo Alto Firewall product for Accelerated Networking support.-- Upgrade your ExpressRoute circuit bandwidth to accommodate your bandwidth needs.-- Use SSD Disks for your production workloads.-- vSAN capacity utilization has crossed critical threshold.--### Reliability --- Avoid hostname override to ensure site integrity.-- Check Point Virtual Machine may lose Network Connectivity.-- Drop and recreate your HDInsight clusters to apply critical updates.-- Upgrade device client SDK to a supported version for IotHub.-- Upgrade to the latest version of the Azure Connected Machine agent.--## Right size calculations --The calculation for recommending that you should right-size or shut down underutilized virtual machines in Azure Government is as follows: --- Advisor monitors your virtual machine usage for seven days and identifies low-utilization virtual machines.-- Virtual machines are considered low utilization if their CPU utilization is 5% or less and their network utilization is less than 2%, or if the current workload can be accommodated by a smaller virtual machine size.--If you want to be more aggressive at identifying underutilized virtual machines, you can adjust the CPU utilization rule on a per subscription basis. --## Next steps --For more information about Advisor recommendations, see: --- [Introduction to Azure Advisor](./advisor-overview.md)-- [Reliability recommendations](./advisor-high-availability-recommendations.md)-- [Performance recommendations](./advisor-reference-performance-recommendations.md)-- [Cost recommendations](./advisor-reference-cost-recommendations.md)-- [Operational excellence recommendations](./advisor-reference-operational-excellence-recommendations.md) |
| advisor | Advisor Tag Filtering | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/advisor-tag-filtering.md | - Title: Review optimization opportunities by workload, environment or team -description: Review optimization opportunities by workload, environment or team -- Previously updated : 05/25/2022---# Review optimization opportunities by workload, environment or team --You can now get Advisor recommendations and scores scoped to a workload, environment, or team using resource tag filters. Filter recommendations and calculate scores using tags you have already assigned to Azure resources, resource groups and subscriptions. Use tag filters to: --* Identify cost saving opportunities by team -* Compare scores for workloads to optimize the critical ones first --> [!TIP] -> For more information on how to use resource tags to organize and govern your Azure resources, please see the [Cloud Adoption FrameworkΓÇÖs guidance](/azure/cloud-adoption-framework/ready/azure-best-practices/resource-tagging) and [Build a cloud governance strategy on Azure](/training/modules/build-cloud-governance-strategy-azure/). --## How to filter recommendations using tags --1. Sign in to the [Azure portal](https://portal.azure.com/). -1. Search for and select [Advisor](https://aka.ms/azureadvisordashboard) from any page. -1. On the Advisor dashboard, click on the **Add Filter** button. -1. Select the tag in the **Filter** field and value(s). -1. Click **Apply**. Summary tiles will be updated to reflect the filter. -1. Click on any of the categories to review recommendations. - - [](./media/tags/overview-tag-filters.png#lightbox) - - -## How to calculate scores using resource tags --1. Sign in to the [Azure portal](https://portal.azure.com/). -1. Search for and select [Advisor](https://aka.ms/azureadvisordashboard) from any page. -1. Select **Advisor score (preview)** from the navigation menu on the left. -1. Click on the **Add Filter** button. -1. Select the tag in the **Filter** field and value(s). -1. Click **Apply**. Advisor score will be updated to only include resources impacted by the filter. -1. Click on any of the categories to review recommendations. - - [](./media/tags/score-tag-filters.png#lightbox) --> [!NOTE] -> Not all capabilities are available when tag filters are used. For example, tag filters are not supported for security score and score history. --## Next steps --To learn more about tagging, see: -- [Define your tagging strategy - Cloud Adoption Framework](/azure/cloud-adoption-framework/ready/azure-best-practices/resource-tagging)-- [Tag resources, resource groups, and subscriptions for logical organization - Azure Resource Manager](/azure/azure-resource-manager/management/tag-resources?tabs=json) |
| advisor | Azure Advisor Score | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/azure-advisor-score.md | - Title: Use Advisor score -description: Use Azure Advisor score to measure optimization progress. - Previously updated : 07/12/2024----# Use Advisor score --This article shows you how to use Azure Advisor score to measure optimization progress. --## Introduction to score --Advisor provides best-practice recommendations for your workloads. These recommendations are personalized and actionable to help you: --* Improve the posture of your workloads and optimize your Azure deployments. -* Proactively prevent top issues by following best practices. -* Assess your Azure workloads against the five pillars of the [Azure Well-Architected Framework](/azure/architecture/framework/). --As a core feature of Advisor, Advisor score can help you achieve these goals effectively and efficiently. --To get the most out of Azure, it's crucial to understand where you are in your workload optimization journey. You need to know which services or resources are consumed well and which are not. Further, you want to know how to prioritize your actions, based on recommendations, to maximize the outcome. --It's also important to track and report the progress you're making in this optimization journey. With Advisor score, you can easily do all these things with the new gamification experience. --As your personalized cloud consultant, Advisor continually assesses your usage telemetry and resource configuration to check for industry best practices. Advisor then aggregates its findings into a single score. With this score, you can tell at a glance if you're taking the necessary steps to build reliable, secure, and cost-efficient solutions. --The Advisor score consists of an overall score, which can be further broken down into five category scores. One score for each category of Advisor represents the five pillars of the Well-Architected Framework. --You can track the progress you make over time by viewing your overall score and category score with daily, weekly, and monthly trends. You can also set benchmarks to help you achieve your goals. --## Use Advisor score in the portal --1. Sign in to the [Azure portal](https://portal.azure.com). --1. Search for and select [**Advisor**](https://aka.ms/azureadvisordashboard) from any page. --1. Select **Advisor score** on the left pane to open the score page. ---## Interpret an Advisor score --Advisor displays your overall Advisor score and a breakdown for Advisor categories, in percentages. A score of 100% in any category means all your resources assessed by Advisor follow the best practices that Advisor recommends. On the other end of the spectrum, a score of 0% means that none of your resources assessed by Advisor follow Advisor's recommendations. Using these score grains, you can easily achieve the following flow: --* **Advisor score** helps you baseline how your workload or subscriptions are doing based on an Advisor score. You can also see the historical trends to understand what your trend is. -* **Score by category** for each recommendation tells you which outstanding recommendations improve your score the most. These values reflect both the weight of the recommendation and the predicted ease of implementation. These factors help to make sure you can get the most value with your time. They also help you with prioritization. -* **Category score impact** for each recommendation helps you prioritize your remediation actions for each category. --The contribution of each recommendation to your category score is shown clearly on the **Advisor score** page in the Azure portal. You can increase each category score by the percentage point listed in the **Potential score increase** column. This value reflects both the weight of the recommendation within the category and the predicted ease of implementation to address the potentially easiest tasks. Focusing on the recommendations with the greatest score impact helps you make the most progress with time. -- --If any Advisor recommendations aren't relevant for an individual resource, you can postpone or dismiss those recommendations. They're excluded from the score calculation with the next refresh. Advisor also uses this input as feedback to improve the model. --## How is an Advisor score calculated? --Advisor displays your category scores and your overall Advisor score as percentages. A score of 100% in any category means all your resources, *assessed by Advisor*, follow the best practices that Advisor recommends. On the other end of the spectrum, a score of 0% means that none of your resources, assessed by Advisor, follows Advisor recommendations. --**Each of the five categories has a highest potential score of 100.** Your overall Advisor score is calculated as a sum of each applicable category score, divided by the sum of the highest potential score from all applicable categories. In most cases, this means adding up five Advisor scores for each category and dividing by 500. But *each category score is calculated only if you use resources that are assessed by Advisor*. --### Advisor score calculation example --* **Single subscription score:** This example is the simple mean of all Advisor category scores for your subscription. If the Advisor category scores are **Cost** = 73, **Reliability** = 85, **Operational excellence** = 77, and **Performance** = 100, the Advisor score would be (73 + 85 + 77 + 100)/(4x100) = 0.84% or 84%. -* **Multiple subscriptions score:** When multiple subscriptions are selected, the overall Advisor score is calculated as an average of aggregated category scores. Each category score is calculated by using the individual subscription score and the subscription consumption-based weight. The overall score is calculated as the sum of aggregated category scores divided by the sum of the highest potential scores. --### Scoring methodology --The calculation of the Advisor score can be summarized in four steps: --1. Advisor calculates the *retail cost of impacted resources*. These resources are the ones in your subscriptions that have at least one recommendation in Advisor. -1. Advisor calculates the *retail cost of assessed resources*. These resources are the ones monitored by Advisor, whether they have any recommendations or not. -1. For each recommendation type, Advisor calculates the *healthy resource ratio*. This ratio is the retail cost of impacted resources divided by the retail cost of assessed resources. -1. Advisor applies three other weights to the healthy resource ratio in each category: -- * Recommendations with greater impact are weighted heavier than recommendations with lower impact. - * Resources with long-standing recommendations count more against your score. - * Resources that you postpone or dismiss in Advisor are removed from your score calculation entirely. --Advisor applies this model at an Advisor category level to give an Advisor score for each category. **Security** uses a [secure score](/azure/defender-for-cloud/secure-score-security-controls) model. A simple average produces the final Advisor score. --## Frequently asked questions (FAQs) --Here are answers to common questions about Advisor score. --### How often is my score refreshed? --Your score is refreshed at least once per day. --### Why did my score change? --Your score can change if you remediate impacted resources by adopting the best practices that Advisor recommends. If you or anyone with permissions on your subscription has modified or created new resources, you might also see fluctuations in your score. Your score is based on a ratio of the cost-impacted resources relative to the total cost of all resources. --### I implemented a recommendation but my score didn't change. Why didn't the score increase? --The score doesn't reflect adopted recommendations right away. It takes at least 24 hours for the score to change after the recommendation is remediated. --### Why do some recommendations have the empty "-" value in the category score impact column? --Advisor doesn't immediately include new recommendations or recommendations with recent changes in the scoring model. After a short evaluation period, typically a few weeks, they're included in the score. --### Why is the cost score impact greater for some recommendations even if they have lower potential savings? --Your **Cost** score reflects both your potential savings from underutilized resources and the predicted ease of implementing those recommendations. For example, extra weight is applied to impacted resources that have been idle for a long time, even if the potential savings are lower. --### What does it mean when I see "Coming soon" in the score impact column? --This message means that the recommendation is new, and we're working on bringing it to the Advisor score model. After this new recommendation is considered in a score calculation, you'll see the score impact value for your recommendation. --### What if a recommendation isn't relevant? --If you dismiss a recommendation from Advisor, it's excluded from the calculation of your score. Dismissing recommendations also helps Advisor improve the quality of recommendations. --### Why don't I have a score for one or more categories or subscriptions? --Advisor generates a score only for the categories and subscriptions that have resources that are assessed by Advisor. --### How does Advisor calculate the retail cost of resources on a subscription? --Advisor uses the pay-as-you-go rates published on [Azure pricing](https://azure.microsoft.com/pricing/). These rates don't reflect any applicable discounts. The rates are then multiplied by the quantity of usage on the last day the resource was allocated. Omitting discounts from the calculation of the resource cost makes Advisor scores comparable across subscriptions, tenants, and enrollments where discounts might vary. --### Do I need to view the recommendations in Advisor to get points for my score? --No. Your score reflects whether you adopt best practices that Advisor recommends, even if you adopt those best practices proactively and never view your recommendations in Advisor. --### Does the scoring methodology differentiate between production and dev-test workloads? --No, not for now. But you can dismiss recommendations on individual resources if those resources are used for development and test and the recommendations don't apply. --### Can I compare scores between a subscription with 100 resources and a subscription with 100,000 resources? --The scoring methodology is designed to control for the number of resources on a subscription and service mix. Subscriptions with fewer resources can have higher or lower scores than subscriptions with more resources. --### Does my score depend on how much I spend on Azure? --No. Your score isn't necessarily a reflection of how much you spend. Unnecessary spending results in a lower **Cost** score. --## Related content --For more information about Advisor recommendations, see: --* [Introduction to Advisor](advisor-overview.md) -* [Get started with Advisor](advisor-get-started.md) -* [Advisor cost recommendations](advisor-cost-recommendations.md) -* [Advisor performance recommendations](advisor-performance-recommendations.md) -* [Advisor security recommendations](advisor-security-recommendations.md) -* [Advisor operational excellence recommendations](advisor-operational-excellence-recommendations.md) |
| advisor | Permissions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/permissions.md | - Title: Roles and permissions -description: Learn about Advisor permissions, how to manage access to Advisor recommendations and reviews. - Previously updated : 08/22/2024---# Roles and permissions --Learn how to manage access to recommendations and reviews for your organization. --## Roles and associated access --Advisor uses the built-in roles provided by Azure role-based access control (Azure RBAC). --Review the following section to learn more about each role and the associated access. --### Roles to view, dismiss, and postpone recommendations --| Role | View recommendations | Dismiss and postpone recommendations | -|:|: |: | -| Subscription Reader | X | | -| Subscription Contributor | X | X | -| Subscription Owner | X | X | -| Resource group Reader | X | | -| Resource group Contributor | X | X | -| Resource group Owner | X | X | -| Resource Reader | X | | -| Resource Contributor | X | X | -| Resource Owner | X | X | --### Roles to edit rules and configurations --| Role | Edit rules | Edit subscription configuration | Edit resource group configuration | -|:|: |: |: | -| Subscription Contributor | X | X | X | -| Subscription Owner | X | X | X | -| Resource group Contributor | | | X | -| Resource group Owner | | | X | --> [!NOTE] -> You must have access to the resource associated with the recommendation to view a recommendation. --To learn more about built-in roles, see [Azure built-in roles](/azure/role-based-access-control/built-in-roles "Azure built-in roles | Azure RBAC | Microsoft Learn"). To learn more about Azure role-based access control (Azure RBAC), see [What is Azure role-based access control (Azure RBAC)?](/azure/role-based-access-control/overview "What is Azure role-based access control (Azure RBAC)? | Azure RBAC | Microsoft Learn"). ----## Available actions to build custom roles --If your organization requires roles that don't match the Azure built-in roles, create your own custom role. A custom role works like a built-in role and allow you to assign it to users, groups, and service principals at management group, subscription, and resource group scopes. Use the following actions to create your custom role. --| Action | Details | -|: |: | -| `Microsoft.Advisor/generateRecommendations/action` | Create a Recommendation. | -| `Microsoft.Advisor/register/action` | Register with the Provider. | -| `Microsoft.Advisor/unregister/action` | Unregister with the Provider. | -| `Microsoft.Advisor/advisorScore/read` | Gets Advisor score. | -| `Microsoft.Advisor/configurations/read` | Read Configurations. | -| `Microsoft.Advisor/configurations/write` | Create or update Configuration. | -| `Microsoft.Advisor/generateRecommendations/read` | Get status of `generateRecommendations` action. | -| `Microsoft.Advisor/metadata/read` | Read Metadata. | -| `Microsoft.Advisor/operations/read` | Get operations. | -| `Microsoft.Advisor/recommendations/read` | Read recommendations. | -| `Microsoft.Advisor/recommendations/write` | Create recommendations. | -| `Microsoft.Advisor/recommendations/available/action` | New recommendation is available. | -| `Microsoft.Advisor/recommendations/suppressions/read` | Read Suppressions. | -| `Microsoft.Advisor/recommendations/suppressions/write` | Create or update Suppressions. | -| `Microsoft.Advisor/recommendations/suppressions/delete` | Delete Suppression. | -| `Microsoft.Advisor/suppressions/read` | Read Suppressions. | -| `Microsoft.Advisor/suppressions/write` | Create or update Suppressions. | -| `Microsoft.Advisor/suppressions/delete` | Delete Suppression. | -| `Microsoft.Advisor/assessmentTypes/read` | Reads `AssessmentTypes`. | -| `Microsoft.Advisor/assessments/read` | Reads Assessments. | -| `Microsoft.Advisor/assessments/write` | Create Assessments. | -| `Microsoft.Advisor/resiliencyReviews/read` | Reads `resiliencyReviews`. | -| `Microsoft.Advisor/triageRecommendations/read` | Reads `triageRecommendations`. | -| `Microsoft.Advisor/triageRecommendations/approve/action` | Approves `triageRecommendations`. | -| `Microsoft.Advisor/triageRecommendations/reject/action` | Rejects `triageRecommendations`. | -| `Microsoft.Advisor/triageRecommendations/reset/action` | Resets `triageRecommendations`. | -| `Microsoft.Advisor/workloads/read` | Reads workloads. | --> [!NOTE] -> For example, you must have a sufficient permission level for a virtual machine (VM) to view recommendations associated with the VM. --To learn more about custom roles, see [Azure custom roles](/azure/role-based-access-control/custom-roles "Azure custom roles | Azure RBAC | Microsoft Learn"). --## Permissions and unavailable actions --If your permission level is too low, your access to the associated action is blocked. Review common problems in the following section. --### Configure subscription or resource group is blocked --When you try to configure a subscription or resource group, the option to include or exclude is blocked. The blocked status indicates that your permission level for that resource group or subscription is insufficient. To learn how to change your permission level, see [Tutorial: Grant a user access to Azure resources using the Azure portal](/azure/role-based-access-control/quickstart-assign-role-user-portal "Tutorial: Grant a user access to Azure resources using the Azure portal | Azure RBAC | Microsoft Learn"). --### Postpone or dismiss is allowed, but sends an error --When you try to postpone or dismiss a recommendation, you receive an error. The error indicates that your permission level is insufficient. You must have a sufficient permission level to dismiss recommendations. --> [!TIP] -> After you dismiss a recommendation, you must manually reactivate it before it is added in your list of recommendations. If you dismiss a recommendation, you may miss important advice that optimizes your Azure deployment. --To postpone or dismiss a recommendation, verify that your permission level for the resource associated with the recommendation is set to Contributor or better. To learn how to change your permission level, see [Tutorial: Grant a user access to Azure resources using the Azure portal](/azure/role-based-access-control/quickstart-assign-role-user-portal "Tutorial: Grant a user access to Azure resources using the Azure portal | Azure RBAC | Microsoft Learn"). --## Related content --This article provided an overview of how Advisor uses Azure role-based access control (Azure RBAC) to control user permissions and how to resolve common problems. To learn more about Advisor, see the following articles. --* [Introduction to Azure Advisor](./advisor-overview.md "Introduction to Azure Advisor | Azure Advisor | Microsoft Learn") --* [Azure Advisor portal basics](./advisor-get-started.md "Azure Advisor portal basics | Azure Advisor | Microsoft Learn") |
| advisor | Resource Graph Samples | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/resource-graph-samples.md | - Title: Azure Resource Graph sample queries for Azure Advisor -description: Sample Azure Resource Graph queries for Azure Advisor showing use of resource types and tables to access Azure Advisor related resources and properties. Previously updated : 07/07/2022----# Azure Resource Graph sample queries for Azure Advisor --This page is a collection of [Azure Resource Graph](../governance/resource-graph/overview.md) sample queries for Azure Advisor. --## Sample queries ---## Next steps --- Learn more about the [query language](../governance/resource-graph/concepts/query-language.md).-- Learn more about how to [explore resources](../governance/resource-graph/concepts/explore-resources.md). |
| advisor | View Recommendations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/advisor/view-recommendations.md | - Title: Configure Azure Advisor recommendations view -description: View and filter Azure Advisor recommendations to reduce noise. - Previously updated : 01/02/2024---# Configure the Azure Advisor recommendations view --Azure Advisor provides recommendations to help you optimize your Azure deployments. Within Advisor, you have access to a few features that help you narrow down your recommendations to only the ones that matter to you. --## Configure subscriptions and resource groups --Advisor gives you the ability to select subscriptions and resource groups that matter to you and your organization. You only see recommendations for the subscriptions and resource groups that you select. By default, all are selected. Configuration settings apply to the subscription or resource group, so the same settings apply to everyone that has access to that subscription or resource group. Configuration settings can be changed in the Azure portal or programmatically. --To make changes in the Azure portal: --1. Open [Azure Advisor](https://aka.ms/azureadvisordashboard) in the Azure portal. --1. Select **Configuration** from the menu. -- :::image type="content" source="./media/view-recommendations/configuration.png" alt-text="Screenshot of Azure Advisor showing the Configuration pane."::: --1. Select the checkbox in the **Include** column for any subscriptions or resource groups to receive Advisor recommendations. If the box is disabled, you might not have permission to make a configuration change on that subscription or resource group. Learn more about [permissions in Azure Advisor](permissions.md). --1. Select **Apply** at the bottom after you make a change. --## Filter your view in the Azure portal --Configuration settings remain active until changed. If you want to limit the view of recommendations for a single viewing, you can use the dropdown lists provided at the top of the Advisor pane. You can filter recommendations by subscription, resource group, workload, resource type, recommendation status, and impact. These filters are available for **Overview**, **Score**, **Cost**, **Security**, **Reliability**, **Operational excellence**, **Performance**, and **All recommendations** pages. -- :::image type="content" source="./media/view-recommendations/filtering.png" alt-text="Screenshot of Advisor showing filtering options."::: --> [!NOTE] -> Contact your account team to add new workloads to the workload filter or edit workload names. --## Dismiss and postpone recommendations --Advisor allows you to dismiss or postpone recommendations on a single resource. If you dismiss a recommendation, you don't see it again unless you manually activate it. However, postponing a recommendation allows you to specify a duration after which the recommendation is automatically activated again. Postponing can be done in the Azure portal or programmatically. --### Postpone a single recommendation in the Azure portal --1. Open [Azure Advisor](https://aka.ms/azureadvisordashboard) in the Azure portal. -1. Select a recommendation category to view your recommendations. -1. Select a recommendation from the list of recommendations. -1. Select **Postpone** or **Dismiss** for the recommendation you want to postpone or dismiss. -- :::image type="content" source="./media/view-recommendations/postpone-dismiss.png" alt-text="Screenshot that shows the Use Managed Disks page with the Select column and Postpone and Dismiss actions for a single recommendation highlighted."::: --### Postpone or dismiss multiple recommendations in the Azure portal --1. Open [Azure Advisor](https://aka.ms/azureadvisordashboard) in the Azure portal. -1. Select a recommendation category to view your recommendations. -1. Select a recommendation from the list of recommendations. -1. Select the checkbox at the left of the row for all resources you want to postpone or dismiss the recommendation. -1. Select **Postpone** or **Dismiss** in the upper-left corner of the table. -- :::image type="content" source="./media/view-recommendations/postpone-dismiss-multiple.png" alt-text="Screenshot that shows the Use Managed Disks page with the Select column and Postpone and Dismiss actions in the table highlighted."::: --> [!NOTE] -> You need Contributor or Owner permission to dismiss or postpone a recommendation. Learn more about permissions in Advisor. --If the selection boxes are disabled, recommendations might still be loading. Wait for all recommendations to load before you try to postpone or dismiss. --### Reactivate a postponed or dismissed recommendation --You can activate a recommendation that was postponed or dismissed. This action can be done in the Azure portal or programmatically. In the Azure portal: --1. Open [Advisor](https://aka.ms/azureadvisordashboard) in the Azure portal. --1. Change the filter on the **Overview** pane to **Postponed**. Advisor then displays postponed or dismissed recommendations. -- :::image type="content" source="./media/view-recommendations/activate-postponed.png" alt-text="Screenshot that shows the Advisor pane with the Postponed dropdown menu selected."::: --1. Select a category to see **Postponed** and **Dismissed** recommendations. --1. Select a recommendation from the list of recommendations. This action opens recommendations with the **Postponed & Dismissed** tab already selected to show the resources for which this recommendation was postponed or dismissed. --1. Select **Activate** at the end of the row. The recommendation is now active for that resource and removed from the table. The recommendation is visible on the **Active** tab. -- :::image type="content" source="./media/view-recommendations/activate-postponed-2.png" alt-text="Screenshot that shows the Enable Soft Delete pane with the Postponed & Dismissed tab and the Activate action highlighted."::: --## Related content --This article explains how you can view recommendations that matter to you in Advisor. To learn more about Advisor, see: --- [What is Azure Advisor?](advisor-overview.md)-- [Get started with Advisor](advisor-get-started.md)-- [Permissions in Azure Advisor](permissions.md) |
| api-management | Api Management Gateways Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/api-management-gateways-overview.md | For details about monitoring options, see [Observability in Azure API Management | [Request tracing](api-management-howto-api-inspector.md) | ✔️ | ❌<sup>4</sup> | ✔️ | ✔️ | ❌ | <sup>1</sup> The v2 tiers support Azure Monitor-based analytics.<br/>-<sup>2</sup> Gateway uses [Azure Application Insight's built-in memory buffer](./../azure-monitor/app/telemetry-channels.md#built-in-telemetry-channels) and does not provide delivery guarantees.<br/> +<sup>2</sup> Gateway uses [Azure Application Insight's built-in memory buffer](/azure/azure-monitor/app/telemetry-channels#built-in-telemetry-channels) and does not provide delivery guarantees.<br/> <sup>3</sup> The self-hosted gateway currently doesn't send resource logs (diagnostic logs) to Azure Monitor. Optionally [send metrics](how-to-configure-cloud-metrics-logs.md) to Azure Monitor, or [configure and persist logs locally](how-to-configure-local-metrics-logs.md) where the self-hosted gateway is deployed.<br/> <sup>4</sup> Tracing is currently unavailable in the v2 tiers. |
| api-management | Api Management Howto App Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/api-management-howto-app-insights.md | You can easily integrate Azure Application Insights with Azure API Management. A > In an API Management [workspace](workspaces-overview.md), a workspace owner can independently integrate Application Insights and enable Application Insights logging for the workspace's APIs. The general guidance to integrate a workspace with Application Insights is similar to the guidance for an API Management instance; however, configuration is scoped to the workspace only. Currently, you must integrate Application Insights in a workspace by configuring a connection string (recommended) or an instrumentation key. > [!WARNING]-> When using our [self-hosted gateway](self-hosted-gateway-overview.md), we do not guarantee all telemetry will be pushed to Azure Application Insights given it relies on [Application Insights' in-memory buffering](./../azure-monitor/app/telemetry-channels.md#built-in-telemetry-channels). +> When using our [self-hosted gateway](self-hosted-gateway-overview.md), we do not guarantee all telemetry will be pushed to Azure Application Insights given it relies on [Application Insights' in-memory buffering](/azure/azure-monitor/app/telemetry-channels#built-in-telemetry-channels). ## Prerequisites * You need an Azure API Management instance. [Create one](get-started-create-service-instance.md) first. -* To use Application Insights, [create an instance of the Application Insights service](/previous-versions/azure/azure-monitor/app/create-new-resource). To create an instance using the Azure portal, see [Workspace-based Application Insights resources](../azure-monitor/app/create-workspace-resource.md). +* To use Application Insights, [create an instance of the Application Insights service](/previous-versions/azure/azure-monitor/app/create-new-resource). To create an instance using the Azure portal, see [Workspace-based Application Insights resources](/azure/azure-monitor/app/create-workspace-resource). > [!NOTE] > The Application Insights resource **can be** in a different subscription or even a different tenant than the API Management resource. The following are high level steps for this scenario. You can create a connection between Application Insights and your API Management using the Azure portal, the REST API, or related Azure tools. API Management configures a *logger* resource for the connection. > [!IMPORTANT]- > Currently, in the portal, API Management only supports connections to Application Insights using an Application Insights instrumentation key. For enhanced security, we recommend using an Application Insights connection string with an API Management managed identity. To configure connection string with managed identity credentials, use the [REST API](#create-a-connection-using-the-rest-api-bicep-or-arm-template) or related tools as shown in a later section of this article. [Learn more](../azure-monitor/app/sdk-connection-string.md) about Application Insights connection strings. + > Currently, in the portal, API Management only supports connections to Application Insights using an Application Insights instrumentation key. For enhanced security, we recommend using an Application Insights connection string with an API Management managed identity. To configure connection string with managed identity credentials, use the [REST API](#create-a-connection-using-the-rest-api-bicep-or-arm-template) or related tools as shown in a later section of this article. [Learn more](/azure/azure-monitor/app/sdk-connection-string) about Application Insights connection strings. > > [!NOTE] Application Insights receives: | *Trace* | If you configure a [trace](trace-policy.md) policy. <br /> The `severity` setting in the `trace` policy must be equal to or greater than the `verbosity` setting in the Application Insights logging. | > [!NOTE]-> See [Application Insights limits](../azure-monitor/service-limits.md#application-insights) for information about the maximum size and number of metrics and events per Application Insights instance. +> See [Application Insights limits](/azure/azure-monitor/service-limits#application-insights) for information about the maximum size and number of metrics and events per Application Insights instance. ## Emit custom metrics-You can emit [custom metrics](../azure-monitor/essentials/metrics-custom-overview.md) to Application Insights from your API Management instance. API Management emits custom metrics using policies such as [emit-metric](emit-metric-policy.md) and [azure-openai-emit-token-metric](azure-openai-emit-token-metric-policy.md). The following section uses the `emit-metric` policy as an example. +You can emit [custom metrics](/azure/azure-monitor/essentials/metrics-custom-overview) to Application Insights from your API Management instance. API Management emits custom metrics using policies such as [emit-metric](emit-metric-policy.md) and [azure-openai-emit-token-metric](azure-openai-emit-token-metric-policy.md). The following section uses the `emit-metric` policy as an example. > [!NOTE]-> Custom metrics are a [preview feature](../azure-monitor/essentials/metrics-custom-overview.md) of Azure Monitor and subject to [limitations](../azure-monitor/essentials/metrics-custom-overview.md#design-limitations-and-considerations). +> Custom metrics are a [preview feature](/azure/azure-monitor/essentials/metrics-custom-overview) of Azure Monitor and subject to [limitations](/azure/azure-monitor/essentials/metrics-custom-overview#design-limitations-and-considerations). To emit custom metrics, perform the following configuration steps. To emit custom metrics, perform the following configuration steps. ### Limits for custom metrics -Azure Monitor imposes [usage limits](../azure-monitor/essentials/metrics-custom-overview.md#quotas-and-limits) for custom metrics that may affect your ability to emit metrics from API Management. For example, Azure Monitor currently sets a limit of 10 dimension keys per metric, and a limit of 50,000 total active time series per region in a subscription (within a 12 hour period). +Azure Monitor imposes [usage limits](/azure/azure-monitor/essentials/metrics-custom-overview#quotas-and-limits) for custom metrics that may affect your ability to emit metrics from API Management. For example, Azure Monitor currently sets a limit of 10 dimension keys per metric, and a limit of 50,000 total active time series per region in a subscription (within a 12 hour period). These limits have the following implications for configuring custom metrics in API Management: Addressing the issue of telemetry data flow from API Management to Application I ## Related content -+ Learn more about [Azure Application Insights](../azure-monitor/app/app-insights-overview.md). ++ Learn more about [Azure Application Insights](/azure/azure-monitor/app/app-insights-overview). + Consider [logging with Azure Event Hubs](api-management-howto-log-event-hubs.md). + Learn about visualizing data from Application Insights using [Azure Managed Grafana](visualize-using-managed-grafana-dashboard.md) |
| api-management | Api Management Howto Autoscale | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/api-management-howto-autoscale.md | -An Azure API Management service instance can scale automatically based on a set of rules. This behavior can be enabled and configured through [Azure Monitor autoscale](../azure-monitor/autoscale/autoscale-overview.md#supported-services-for-autoscale). +An Azure API Management service instance can scale automatically based on a set of rules. This behavior can be enabled and configured through [Azure Monitor autoscale](/azure/azure-monitor/autoscale/autoscale-overview#supported-services-for-autoscale). The article walks through the process of configuring autoscale and suggests optimal configuration of autoscale rules. |
| api-management | Api Management Howto Use Azure Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/api-management-howto-use-azure-monitor.md | In this tutorial, you learn how to: ## View metrics of your APIs -API Management emits [metrics](../azure-monitor/essentials/data-platform-metrics.md) every minute, giving you near real-time visibility into the state and health of your APIs. The following are the most frequently used metrics. For a list of all available metrics, see [supported metrics](../azure-monitor/essentials/metrics-supported.md#microsoftapimanagementservice). +API Management emits [metrics](/azure/azure-monitor/essentials/data-platform-metrics) every minute, giving you near real-time visibility into the state and health of your APIs. The following are the most frequently used metrics. For a list of all available metrics, see [supported metrics](/azure/azure-monitor/essentials/metrics-supported#microsoftapimanagementservice). * **Capacity** - helps you make decisions about upgrading/downgrading your API Management services. The metric is emitted per minute and reflects the estimated gateway capacity at the time of reporting. The metric ranges from 0-100 calculated based on gateway resources such as CPU and memory utilization and other factors. To access metrics: ## Set up an alert rule -You can receive [alerts](../azure-monitor/alerts/alerts-metric-overview.md) based on metrics and activity logs. In Azure Monitor, [configure an alert rule](../azure-monitor/alerts/alerts-create-new-alert-rule.md) to perform an action when it triggers. Common actions include: +You can receive [alerts](/azure/azure-monitor/alerts/alerts-metric-overview) based on metrics and activity logs. In Azure Monitor, [configure an alert rule](/azure/azure-monitor/alerts/alerts-create-new-alert-rule) to perform an action when it triggers. Common actions include: * Send an email notification * Call a webhook To configure an example alert rule based on a request metric: :::image type="content" source="media/api-management-howto-use-azure-monitor/threshold-1.png" alt-text="Screenshot of configuring alert logic in the portal."::: -1. On the **Actions** tab, select or create one or more *action groups* to notify users about the alert and take an action. For example, create a new action group to send a notification email to `admin@contoso.com`. For detailed steps, see [Create and manage action groups in the Azure portal](../azure-monitor/alerts/action-groups.md). +1. On the **Actions** tab, select or create one or more *action groups* to notify users about the alert and take an action. For example, create a new action group to send a notification email to `admin@contoso.com`. For detailed steps, see [Create and manage action groups in the Azure portal](/azure/azure-monitor/alerts/action-groups). :::image type="content" source="media/api-management-howto-use-azure-monitor/action-details.png" alt-text="Screenshot of configuring notifications for new action group in the portal."::: To configure resource logs: You have several options about where to send the logs and metrics. For example, archive resource logs along with metrics to a storage account, stream them to an event hub, or send them to a Log Analytics workspace. > [!TIP]- > If you select a Log Analytics workspace, you can choose to store the data in the resource-specific ApiManagementGatewayLogs table or store in the general AzureDiagnostics table. We recommend using the resource-specific table for log destinations that support it. [Learn more](../azure-monitor/essentials/resource-logs.md#send-to-log-analytics-workspace) + > If you select a Log Analytics workspace, you can choose to store the data in the resource-specific ApiManagementGatewayLogs table or store in the general AzureDiagnostics table. We recommend using the resource-specific table for log destinations that support it. [Learn more](/azure/azure-monitor/essentials/resource-logs#send-to-log-analytics-workspace) 1. After configuring details for the log destination or destinations, select **Save**. > [!NOTE] > Adding a diagnostic setting object might result in a failure if the [MinApiVersion property](/dotnet/api/microsoft.azure.management.apimanagement.models.apiversionconstraint.minapiversion) of your API Management service is set to any API version higher than 2022-09-01-preview. -For more information, see [Create diagnostic settings to send platform logs and metrics to different destinations](../azure-monitor/essentials/diagnostic-settings.md). +For more information, see [Create diagnostic settings to send platform logs and metrics to different destinations](/azure/azure-monitor/essentials/diagnostic-settings). ## View diagnostic data in Azure Monitor To view the data: :::image type="content" source="media/api-management-howto-use-azure-monitor/logs-menu-item.png" alt-text="Screenshot of Logs item in Monitoring menu in the portal."::: -1. Run queries to view the data. Several [sample queries](../azure-monitor/logs/queries.md) are provided, or run your own. For example, the following query retrieves the most recent 24 hours of data from the ApiManagementGatewayLogs table: +1. Run queries to view the data. Several [sample queries](/azure/azure-monitor/logs/queries) are provided, or run your own. For example, the following query retrieves the most recent 24 hours of data from the ApiManagementGatewayLogs table: ```kusto ApiManagementGatewayLogs To view the data: For more information about using resource logs for API Management, see: -* [Log Analytics tutorial](../azure-monitor/logs/log-analytics-tutorial.md), or try the [Log Analytics demo environment](https://ms.portal.azure.com/#view/Microsoft_OperationsManagementSuite_Workspace/LogsDemo.ReactView). +* [Log Analytics tutorial](/azure/azure-monitor/logs/log-analytics-tutorial), or try the [Log Analytics demo environment](https://ms.portal.azure.com/#view/Microsoft_OperationsManagementSuite_Workspace/LogsDemo.ReactView). -* [Overview of log queries in Azure Monitor](../azure-monitor/logs/log-query-overview.md). +* [Overview of log queries in Azure Monitor](/azure/azure-monitor/logs/log-query-overview). * [API Management resource log schema reference](gateway-log-schema-reference.md). |
| api-management | Metrics Retirement Aug 2023 | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/breaking-changes/metrics-retirement-aug-2023.md | The five legacy metrics will no longer be available after 31 August 2023. Update any tools that use the five legacy metrics to use equivalent functionality that is provided through the Requests metric filtered on one or more dimensions. For example, filter Requests on the **GatewayResponseCode** or **GatewayResponseCodeCategory** dimension. > [!NOTE]-> Configure filters on the Requests metric to meet your monitoring and alerting needs. For available dimensions, see [Azure Monitor metrics for API Management](../../azure-monitor/essentials/metrics-supported.md#microsoftapimanagementservice). +> Configure filters on the Requests metric to meet your monitoring and alerting needs. For available dimensions, see [Azure Monitor metrics for API Management](/azure/azure-monitor/essentials/metrics-supported#microsoftapimanagementservice). |Legacy metric |Example replacement with Requests metric| |
| api-management | Developer Portal Audit Log Schema Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/developer-portal-audit-log-schema-reference.md | The following fields are logged for each request to the developer portal. ## Related content * [ApiManagementGatewayLogs schema reference](gateway-log-schema-reference.md)-* Learn more about [Common and service-specific schema for Azure Resource Logs](../azure-monitor/essentials/resource-logs-schema.md) +* Learn more about [Common and service-specific schema for Azure Resource Logs](/azure/azure-monitor/essentials/resource-logs-schema) |
| api-management | Developer Portal Enable Usage Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/developer-portal-enable-usage-logs.md | To configure a diagnostic setting for developer portal usage logs: 1. **Diagnostic setting name**: Enter a descriptive name. 1. **Category groups**: Optionally make a selection for your scenario. 1. Under **Categories**: Select **Logs related to Developer Portal usage**. Optionally select other categories as needed.- 1. Under **Destination details**, select one or more options and specify details for the destination. For example, archive logs to a storage account or stream them to an event hub. [Learn more](../azure-monitor/essentials/diagnostic-settings.md) + 1. Under **Destination details**, select one or more options and specify details for the destination. For example, archive logs to a storage account or stream them to an event hub. [Learn more](/azure/azure-monitor/essentials/diagnostic-settings) 1. Select **Save**. ## View diagnostic log data If you send logs to a storage account, you can access the data in the Azure port ## Related content -* [Overview of log queries in Azure Monitor](../azure-monitor/logs/log-query-overview.md). +* [Overview of log queries in Azure Monitor](/azure/azure-monitor/logs/log-query-overview). * [Developer portal audit log schema reference](developer-portal-audit-log-schema-reference.md). |
| api-management | Diagnostic Logs Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/diagnostic-logs-reference.md | This reference describes settings for API diagnostics logging from an API Manage | Always log errors | boolean | If this setting is enabled, all failures are logged, regardless of the **Sampling** setting. | Log client IP address | boolean | If this setting is enabled, the client IP address for API requests is logged. | | Verbosity | | Specifies the verbosity of the logs and whether custom traces that are configured in [trace](trace-policy.md) policies are logged. <br/><br/>* Error - failed requests, and custom traces of severity `error`<br/>* Information - failed and successful requests, and custom traces of severity `error` and `information`<br/> * Verbose - failed and successful requests, and custom traces of severity `error`, `information`, and `verbose`<br/><br/>Default: Information | -| Correlation protocol | | Specifies the protocol used to correlate telemetry sent by multiple components to Application Insights. Default: Legacy <br/><br/>For information, see [Telemetry correlation in Application Insights](../azure-monitor/app/distributed-tracing-telemetry-correlation.md). | +| Correlation protocol | | Specifies the protocol used to correlate telemetry sent by multiple components to Application Insights. Default: Legacy <br/><br/>For information, see [Telemetry correlation in Application Insights](/azure/azure-monitor/app/distributed-tracing-telemetry-correlation). | | Headers to log | list | Specifies the headers that are logged for requests and responses. Default: no headers are logged. | | Number of payload (body) bytes to log| integer | Specifies the number of initial bytes of the frontend or backend request or response body that are logged. Maximum: 8,192. Default: 0 | | Frontend Request | | Specifies whether and how *frontend requests* (requests incoming to the API Management gateway) are logged.<br/><br/> If this setting is enabled, specify **Headers to log**, **Number of payload bytes to log**, or both. | |
| api-management | Emit Metric Policy | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/emit-metric-policy.md | -> * Custom metrics are a [preview feature](../azure-monitor/essentials/metrics-custom-overview.md) of Azure Monitor and subject to [limitations](../azure-monitor/essentials/metrics-custom-overview.md#design-limitations-and-considerations). +> * Custom metrics are a [preview feature](/azure/azure-monitor/essentials/metrics-custom-overview) of Azure Monitor and subject to [limitations](/azure/azure-monitor/essentials/metrics-custom-overview#design-limitations-and-considerations). > * For more information about the API Management data added to Application Insights, see [How to integrate Azure API Management with Azure Application Insights](./api-management-howto-app-insights.md#what-data-is-added-to-application-insights). [!INCLUDE [api-management-policy-generic-alert](../../includes/api-management-policy-generic-alert.md)] |
| api-management | Gateway Log Schema Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/gateway-log-schema-reference.md | -This article provides a schema reference for the Azure API Management GatewayLogs resource log. Log entries also include fields in the [top-level common schema](../azure-monitor/essentials/resource-logs-schema.md#top-level-common-schema). +This article provides a schema reference for the Azure API Management GatewayLogs resource log. Log entries also include fields in the [top-level common schema](/azure/azure-monitor/essentials/resource-logs-schema#top-level-common-schema). To enable collection of the resource log in API Management, see [Monitor published APIs](api-management-howto-use-azure-monitor.md#resource-logs). The following properties are logged for each API request. ## Next steps * For information about monitoring APIs in API Management, see [Monitor published APIs](api-management-howto-use-azure-monitor.md)-* Learn more about [Common and service-specific schema for Azure Resource Logs](../azure-monitor/essentials/resource-logs-schema.md) +* Learn more about [Common and service-specific schema for Azure Resource Logs](/azure/azure-monitor/essentials/resource-logs-schema) * [DeveloperPortalAuditLogs schema reference](developer-portal-audit-log-schema-reference.md) |
| api-management | How To Configure Cloud Metrics Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/how-to-configure-cloud-metrics-logs.md | The self-hosted gateway currently emits the following metrics through Azure Moni The self-hosted gateway currently does not send [diagnostic logs](./api-management-howto-use-azure-monitor.md#activity-logs) to the cloud. However, it is possible to [configure and persist logs locally](how-to-configure-local-metrics-logs.md) where the self-hosted gateway is deployed. -If a gateway is deployed in [Azure Kubernetes Service](https://azure.microsoft.com/services/kubernetes-service/), you can enable [Azure Monitor for containers](../azure-monitor/containers/container-insights-overview.md) to collect logs from your containers and view them in Log Analytics. +If a gateway is deployed in [Azure Kubernetes Service](https://azure.microsoft.com/services/kubernetes-service/), you can enable [Azure Monitor for containers](/azure/azure-monitor/containers/container-insights-overview) to collect logs from your containers and view them in Log Analytics. ## Next steps |
| api-management | How To Configure Local Metrics Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/how-to-configure-local-metrics-logs.md | The self-hosted gateway outputs logs to `stdout` and `stderr` by default. You ca kubectl logs <pod-name> ``` -If your self-hosted gateway is deployed in Azure Kubernetes Service, you can enable [Azure Monitor for containers](../azure-monitor/containers/container-insights-overview.md) to collect `stdout` and `stderr` from your workloads and view the logs in Log Analytics. +If your self-hosted gateway is deployed in Azure Kubernetes Service, you can enable [Azure Monitor for containers](/azure/azure-monitor/containers/container-insights-overview) to collect `stdout` and `stderr` from your workloads and view the logs in Log Analytics. The self-hosted gateway also supports many protocols including `localsyslog`, `rfc5424`, and `journal`. The following table summarizes all the options supported. spec: When configuring to use local syslog on Azure Kubernetes Service, you can choose two ways to explore the logs: -- Use [Syslog collection with Container Insights](./../azure-monitor/containers/container-insights-syslog.md)+- Use [Syslog collection with Container Insights](/azure/azure-monitor/containers/container-insights-syslog) - Connect & explore logs on the worker nodes #### Consuming logs from worker nodes |
| api-management | How To Deploy Self Hosted Gateway Azure Arc | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/how-to-deploy-self-hosted-gateway-azure-arc.md | To enable monitoring of the self-hosted gateway, configure the following Log Ana > [!NOTE] > If you haven't enabled Log Analytics: -> 1. Walk through the [Create a Log Analytics workspace](../azure-monitor/logs/quick-create-workspace.md) quickstart. -> 1. Learn where to find the [Log Analytics agent settings](../azure-monitor/agents/log-analytics-agent.md). +> 1. Walk through the [Create a Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace) quickstart. +> 1. Learn where to find the [Log Analytics agent settings](/azure/azure-monitor/agents/log-analytics-agent). ## Next Steps |
| api-management | How To Self Hosted Gateway On Kubernetes In Production | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/how-to-self-hosted-gateway-on-kubernetes-in-production.md | Starting with version 2.1.5 or above, the self-hosted gateway provides observabi ## Local logs and metrics The self-hosted gateway sends telemetry to [Azure Monitor](api-management-howto-use-azure-monitor.md) and [Azure Application Insights](api-management-howto-app-insights.md) according to configuration settings in the associated API Management service. When [connectivity to Azure](self-hosted-gateway-overview.md#connectivity-to-azure) is temporarily lost, the flow of telemetry to Azure is interrupted and the data is lost for the duration of the outage. -Consider using [Azure Monitor Container Insights](./../azure-monitor/containers/container-insights-overview.md) to monitor your containers or [setting up local monitoring](how-to-configure-local-metrics-logs.md) to ensure the ability to observe API traffic and prevent telemetry loss during Azure connectivity outages. +Consider using [Azure Monitor Container Insights](/azure/azure-monitor/containers/container-insights-overview) to monitor your containers or [setting up local monitoring](how-to-configure-local-metrics-logs.md) to ensure the ability to observe API traffic and prevent telemetry loss during Azure connectivity outages. ## Namespace Kubernetes [namespaces](https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/) help with dividing a single cluster among multiple teams, projects, or applications. Namespaces provide a scope for resources and names. They can be associated with a resource quota and access control policies. |
| api-management | Howto Use Analytics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/howto-use-analytics.md | Azure API Management provides analytics for your APIs so that you can analyze th ## About API analytics -* API Management provides analytics using an [Azure Monitor-based dashboard](../azure-monitor/visualize/workbooks-overview.md). The dashboard aggregates data in an Azure Log Analytics workspace. +* API Management provides analytics using an [Azure Monitor-based dashboard](/azure/azure-monitor/visualize/workbooks-overview). The dashboard aggregates data in an Azure Log Analytics workspace. * In the classic API Management service tiers, your API Management instance also includes *legacy built-in analytics* in the Azure portal, and analytics data can be accessed using the API Management REST API. Closely similar data is shown in the Azure Monitor-based dashboard and built-in analytics. If you need to configure one, the following are brief steps to send gateway logs 1. In the left-hand menu, under **Monitoring**, select **Diagnostic settings** > **+ Add diagnostic setting**. 1. Enter a descriptive name for the diagnostic setting. 1. In **Logs**, select **Logs related to ApiManagement Gateway**.-1. In **Destination details**, select **Send to Log Analytics** and select a Log Analytics workspace in the same or a different subscription. If you need to create a workspace, see [Create a Log Analytics workspace](../azure-monitor/logs/quick-create-workspace.md). +1. In **Destination details**, select **Send to Log Analytics** and select a Log Analytics workspace in the same or a different subscription. If you need to create a workspace, see [Create a Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace). 1. Make sure **Resource specific** is selected as the destination table. 1. Select **Save**. |
| api-management | Mitigate Owasp Api Threats | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/mitigate-owasp-api-threats.md | More information about this threat: [API10:2019 Insufficient logging and monito * Monitor API traffic with [Azure Monitor](api-management-howto-use-azure-monitor.md). -* Log to [Application Insights](api-management-howto-app-insights.md) for debugging purposes. Correlate [transactions in Application Insights](../azure-monitor/app/search-and-transaction-diagnostics.md?tabs=transaction-diagnostics) between API Management and the backend API to [trace them end-to-end](../azure-monitor/app/correlation.md). +* Log to [Application Insights](api-management-howto-app-insights.md) for debugging purposes. Correlate [transactions in Application Insights](/azure/azure-monitor/app/search-and-transaction-diagnostics?tabs=transaction-diagnostics) between API Management and the backend API to [trace them end-to-end](/azure/azure-monitor/app/correlation). * If needed, forward custom events to [Event Hubs](api-management-howto-log-event-hubs.md). More information about this threat: [API10:2019 Insufficient logging and monito * Use the Azure Activity log for tracking activity in the service. -* Use custom events in [Azure Application Insights](../azure-monitor/app/api-custom-events-metrics.md) and [Azure Monitor](../azure-monitor/app/custom-data-correlation.md) as needed. +* Use custom events in [Azure Application Insights](/azure/azure-monitor/app/api-custom-events-metrics) and [Azure Monitor](/azure/azure-monitor/app/custom-data-correlation) as needed. * Configure [OpenTelemetry](how-to-deploy-self-hosted-gateway-kubernetes-opentelemetry.md#introduction-to-opentelemetry) for [self-hosted gateways](self-hosted-gateway-overview.md) on Kubernetes. |
| api-management | Self Hosted Gateway Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/self-hosted-gateway-overview.md | To operate properly, each self-hosted gateway needs outbound connectivity on por | Hostname of Azure Table Storage account | ✔️ | Optional<sup>2</sup> | Account associated with instance (`<table-storage-account-name>.table.core.windows.net`) | | Endpoints for Azure Resource Manager | ✔️ | Optional<sup>3</sup> | Required endpoints are `management.azure.com`. | | Endpoints for Microsoft Entra integration | ✔️ | Optional<sup>4</sup> | Required endpoints are `<region>.login.microsoft.com` and `login.microsoftonline.com`. |-| Endpoints for [Azure Application Insights integration](api-management-howto-app-insights.md) | Optional<sup>5</sup> | Optional<sup>5</sup> | Minimal required endpoints are:<ul><li>`rt.services.visualstudio.com:443`</li><li>`dc.services.visualstudio.com:443`</li><li>`{region}.livediagnostics.monitor.azure.com:443`</li></ul>Learn more in [Azure Monitor docs](../azure-monitor/ip-addresses.md#outgoing-ports) | +| Endpoints for [Azure Application Insights integration](api-management-howto-app-insights.md) | Optional<sup>5</sup> | Optional<sup>5</sup> | Minimal required endpoints are:<ul><li>`rt.services.visualstudio.com:443`</li><li>`dc.services.visualstudio.com:443`</li><li>`{region}.livediagnostics.monitor.azure.com:443`</li></ul>Learn more in [Azure Monitor docs](/azure/azure-monitor/ip-addresses#outgoing-ports) | | Endpoints for [Event Hubs integration](api-management-howto-log-event-hubs.md) | Optional<sup>5</sup> | Optional<sup>5</sup> | Learn more in [Azure Event Hubs docs](../event-hubs/network-security.md) | | Endpoints for [external cache integration](api-management-howto-cache-external.md) | Optional<sup>5</sup> | Optional<sup>5</sup> | This requirement depends on the external cache that is being used | |
| api-management | Trace Policy | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/trace-policy.md | +- The policy creates a [Trace](/azure/azure-monitor/app/data-model-complete#trace) telemetry in Application Insights, when [Application Insights integration](./api-management-howto-app-insights.md) is enabled and the `severity` specified in the policy is equal to or greater than the `verbosity` specified in the [diagnostic setting](./diagnostic-logs-reference.md). - The policy adds a property in the log entry when [resource logs](./api-management-howto-use-azure-monitor.md#resource-logs) are enabled and the severity level specified in the policy is at or higher than the verbosity level specified in the [diagnostic setting](./diagnostic-logs-reference.md). - The policy is not affected by Application Insights sampling. All invocations of the policy will be logged. The `trace` policy adds a custom trace into the request tracing output in the te |Name|Description|Required| |-|--|--| | message | A string or expression to be logged. Policy expressions are allowed. | Yes |-| metadata | Adds a custom property to the Application Insights [Trace](../azure-monitor/app/data-model-complete.md#trace) telemetry. | No | +| metadata | Adds a custom property to the Application Insights [Trace](/azure/azure-monitor/app/data-model-complete#trace) telemetry. | No | ### metadata attributes |
| api-management | Troubleshoot Response Timeout And Errors | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/troubleshoot-response-timeout-and-errors.md | Client applications calling APIs through your API Management (APIM) service may * Intermittent HTTP 500 errors * Timeout error messages -These symptoms manifest as instances of `BackendConnectionFailure` in your [Azure Monitor resource logs](../azure-monitor/essentials/resource-logs.md). +These symptoms manifest as instances of `BackendConnectionFailure` in your [Azure Monitor resource logs](/azure/azure-monitor/essentials/resource-logs). ## Cause |
| api-management | Validate Service Updates | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/validate-service-updates.md | As a first step, ensure that you know about service updates that are expected or * API Management updates are announced on the [API Management GitHub repo](https://github.com/Azure/API-Management/releases). We recommend that you subscribe to receive notifications from this repository to know when update rollouts begin. -* Monitor service updates that are taking place in your API Management instance by using the Azure [Activity log](../azure-monitor/essentials/activity-log.md). The "Scheduled maintenance" event is emitted when an update begins. +* Monitor service updates that are taking place in your API Management instance by using the Azure [Activity log](/azure/azure-monitor/essentials/activity-log). The "Scheduled maintenance" event is emitted when an update begins. :::image type="content" source="media/validate-service-updates/scheduled-maintenance.png" alt-text="Scheduled maintenance event in Activity log"::: - To receive notifications automatically, [set up an alert](../azure-monitor/alerts/alerts-activity-log.md) on the Activity log. + To receive notifications automatically, [set up an alert](/azure/azure-monitor/alerts/alerts-activity-log) on the Activity log. * Updates roll out to regions in the following phases: Azure EUAP regions, followed by West Central US, followed by remaining regions in several later phases. The sequence of regions updated in the later deployment phases differs from service to service. You can expect at least 24 hours between each phase of the production rollout. |
| api-management | Virtual Network Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/virtual-network-reference.md | When an API Management service instance is hosted in a VNet, the ports in the fo | * / 443 | Outbound | TCP | VirtualNetwork / AzureKeyVault | **Access to Azure Key Vault** | External & Internal | | * / 5671, 5672, 443 | Outbound | TCP | VirtualNetwork / EventHub | Dependency for [Log to Azure Event Hubs policy](api-management-howto-log-event-hubs.md) and [Azure Monitor](api-management-howto-use-azure-monitor.md) (optional) | External & Internal | | * / 445 | Outbound | TCP | VirtualNetwork / Storage | Dependency on Azure File Share for [GIT](api-management-configuration-repository-git.md) (optional) | External & Internal |-| * / 1886, 443 | Outbound | TCP | VirtualNetwork / AzureMonitor | **Publish [Diagnostics Logs and Metrics](api-management-howto-use-azure-monitor.md), [Resource Health](../service-health/resource-health-overview.md), and [Application Insights](api-management-howto-app-insights.md)** | External & Internal | +| * / 1886, 443 | Outbound | TCP | VirtualNetwork / AzureMonitor | **Publish [Diagnostics Logs and Metrics](api-management-howto-use-azure-monitor.md), [Resource Health](/azure/service-health/resource-health-overview), and [Application Insights](api-management-howto-app-insights.md)** | External & Internal | | * / 6380 | Inbound & Outbound | TCP | VirtualNetwork / VirtualNetwork | Access external Azure Cache for Redis service for [caching](api-management-caching-policies.md) policies between machines (optional) | External & Internal | | * / 6381 - 6383 | Inbound & Outbound | TCP | VirtualNetwork / VirtualNetwork | Access internal Azure Cache for Redis service for [caching](api-management-caching-policies.md) policies between machines (optional) | External & Internal | | * / 4290 | Inbound & Outbound | UDP | VirtualNetwork / VirtualNetwork | Sync Counters for [Rate Limit](rate-limit-policy.md) policies between machines (optional) | External & Internal | When an API Management service instance is hosted in a VNet, the ports in the fo | * / 5671, 5672, 443 | Outbound | TCP | VirtualNetwork / Azure Event Hubs | Dependency for [Log to Azure Event Hubs policy](api-management-howto-log-event-hubs.md) and monitoring agent (optional)| External & Internal | | * / 445 | Outbound | TCP | VirtualNetwork / Storage | Dependency on Azure File Share for [GIT](api-management-configuration-repository-git.md) (optional) | External & Internal | | * / 443, 12000 | Outbound | TCP | VirtualNetwork / AzureCloud | Health and Monitoring Extension & Dependency on Event Grid (if events notification activated) (optional) | External & Internal |-| * / 1886, 443 | Outbound | TCP | VirtualNetwork / AzureMonitor | **Publish [Diagnostics Logs and Metrics](api-management-howto-use-azure-monitor.md), [Resource Health](../service-health/resource-health-overview.md), and [Application Insights](api-management-howto-app-insights.md)** | External & Internal | +| * / 1886, 443 | Outbound | TCP | VirtualNetwork / AzureMonitor | **Publish [Diagnostics Logs and Metrics](api-management-howto-use-azure-monitor.md), [Resource Health](/azure/service-health/resource-health-overview), and [Application Insights](api-management-howto-app-insights.md)** | External & Internal | | * / 6380 | Inbound & Outbound | TCP | VirtualNetwork / VirtualNetwork | Access external Azure Cache for Redis service for [caching](api-management-caching-policies.md) policies between machines (optional) | External & Internal | | * / 6381 - 6383 | Inbound & Outbound | TCP | VirtualNetwork / VirtualNetwork | Access internal Azure Cache for Redis service for [caching](api-management-caching-policies.md) policies between machines (optional) | External & Internal | | * / 4290 | Inbound & Outbound | UDP | VirtualNetwork / VirtualNetwork | Sync Counters for [Rate Limit](rate-limit-policy.md) policies between machines (optional) | External & Internal | Enable publishing the [developer portal](api-management-howto-developer-portal.m You're not required to allow inbound requests from service tag `AzureLoadBalancer` for the Developer SKU, since only one compute unit is deployed behind it. However, inbound connectivity from `AzureLoadBalancer` becomes **critical** when scaling to a higher SKU, such as Premium, because failure of the health probe from load balancer then blocks all inbound access to the control plane and data plane. ## Application Insights - If you enabled [Azure Application Insights](api-management-howto-app-insights.md) monitoring on API Management, allow outbound connectivity to the [telemetry endpoint](../azure-monitor/ip-addresses.md#outgoing-ports) from the VNet. + If you enabled [Azure Application Insights](api-management-howto-app-insights.md) monitoring on API Management, allow outbound connectivity to the [telemetry endpoint](/azure/azure-monitor/ip-addresses#outgoing-ports) from the VNet. ## KMS endpoint |
| api-management | Visualize Using Managed Grafana Dashboard | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/api-management/visualize-using-managed-grafana-dashboard.md | Review the default visualizations on the dashboard, which will appear similar to ## Next steps * For more information about managing your Grafana dashboard, see the [Grafana docs](https://grafana.com/docs/grafana/v9.0/dashboards/).-* Easily pin log queries and charts from the Azure portal to your Managed Grafana dashboard. For more information, see [Monitor your Azure services in Grafana](../azure-monitor/visualize/grafana-plugin.md#pin-charts-from-the-azure-portal-to-azure-managed-grafana). +* Easily pin log queries and charts from the Azure portal to your Managed Grafana dashboard. For more information, see [Monitor your Azure services in Grafana](/azure/azure-monitor/visualize/grafana-plugin#pin-charts-from-the-azure-portal-to-azure-managed-grafana). |
| app-service | App Service Configure Premium Tier | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/app-service-configure-premium-tier.md | New-AzAppServicePlan -ResourceGroupName <resource_group_name> ` ## More resources * [Scale up an app in Azure](manage-scale-up.md)-* [Scale instance count manually or automatically](../azure-monitor/autoscale/autoscale-get-started.md) +* [Scale instance count manually or automatically](/azure/azure-monitor/autoscale/autoscale-get-started) * [Tutorial: Run a load test to identify performance bottlenecks in a web app](../load-testing/tutorial-identify-bottlenecks-azure-portal.md) |
| app-service | App Service Key Vault References | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/app-service-key-vault-references.md | As part of creating the app, attempted mounting of the content share could fail ### Considerations for Application Insights instrumentation -Apps can use the `APPINSIGHTS_INSTRUMENTATIONKEY` or `APPLICATIONINSIGHTS_CONNECTION_STRING` application settings to integrate with [Application Insights](../azure-monitor/app/app-insights-overview.md). The portal experiences for App Service and Azure Functions also use these settings to surface telemetry data from the resource. If these values are referenced from Key Vault, these experiences aren't available, and you instead need to work directly with the Application Insights resource to view the telemetry. However, these values are [not considered secrets](../azure-monitor/app/sdk-connection-string.md#is-the-connection-string-a-secret), so you might alternatively consider configuring them directly instead of using key vault references. +Apps can use the `APPINSIGHTS_INSTRUMENTATIONKEY` or `APPLICATIONINSIGHTS_CONNECTION_STRING` application settings to integrate with [Application Insights](/azure/azure-monitor/app/app-insights-overview). The portal experiences for App Service and Azure Functions also use these settings to surface telemetry data from the resource. If these values are referenced from Key Vault, these experiences aren't available, and you instead need to work directly with the Application Insights resource to view the telemetry. However, these values are [not considered secrets](/azure/azure-monitor/app/sdk-connection-string#is-the-connection-string-a-secret), so you might alternatively consider configuring them directly instead of using key vault references. ### Azure Resource Manager deployment |
| app-service | App Service Plan Manage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/app-service-plan-manage.md | You can find **Clone App** in the **Development Tools** section of the menu. To scale up an App Service plan's pricing tier, see [Scale up an app in Azure](manage-scale-up.md). -To scale out an app's instance count, see [Scale instance count manually or automatically](../azure-monitor/autoscale/autoscale-get-started.md). +To scale out an app's instance count, see [Scale instance count manually or automatically](/azure/azure-monitor/autoscale/autoscale-get-started). <a name="delete"></a> |
| app-service | App Service Web Nodejs Best Practices And Troubleshoot Guide | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/app-service-web-nodejs-best-practices-and-troubleshoot-guide.md | let keepaliveAgent = new Agent({ #### My node application is consuming too much CPU -You may receive a recommendation from Azure App Service on your portal about high cpu consumption. You can also set up monitors to watch for certain [metrics](web-sites-monitor.md). When checking the CPU usage on the [Azure portal Dashboard](../azure-monitor/essentials/metrics-charts.md), check the MAX values for CPU so you donΓÇÖt miss the peak values. +You may receive a recommendation from Azure App Service on your portal about high cpu consumption. You can also set up monitors to watch for certain [metrics](web-sites-monitor.md). When checking the CPU usage on the [Azure portal Dashboard](/azure/azure-monitor/essentials/metrics-charts), check the MAX values for CPU so you donΓÇÖt miss the peak values. If you believe your application is consuming too much CPU and you cannot explain why, you can profile your node application to find out. #### Profiling your node application on Azure App Service with V8-Profiler You can see that 95% of the time was consumed by the WriteConsoleLog function. T ### My node application is consuming too much memory -If your application is consuming too much memory, you see a notice from Azure App Service on your portal about high memory consumption. You can set up monitors to watch for certain [metrics](web-sites-monitor.md). When checking the memory usage on the [Azure portal Dashboard](../azure-monitor/essentials/metrics-charts.md), be sure to check the MAX values for memory so you donΓÇÖt miss the peak values. +If your application is consuming too much memory, you see a notice from Azure App Service on your portal about high memory consumption. You can set up monitors to watch for certain [metrics](web-sites-monitor.md). When checking the memory usage on the [Azure portal Dashboard](/azure/azure-monitor/essentials/metrics-charts), be sure to check the MAX values for memory so you donΓÇÖt miss the peak values. #### Leak detection and Heap Diff for Node.js |
| app-service | Configure Language Java Apm | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/configure-language-java-apm.md | This article shows how to connect Java applications deployed on Azure App Servic ## Configure Application Insights -Azure Monitor Application Insights is a cloud native application monitoring service that enables customers to observe failures, bottlenecks, and usage patterns to improve application performance and reduce mean time to resolution (MTTR). With a few clicks or CLI commands, you can enable monitoring for your Node.js or Java apps, autocollecting logs, metrics, and distributed traces, eliminating the need for including an SDK in your app. For more information about the available app settings for configuring the agent, see the [Application Insights documentation](../azure-monitor/app/java-standalone-config.md). +Azure Monitor Application Insights is a cloud native application monitoring service that enables customers to observe failures, bottlenecks, and usage patterns to improve application performance and reduce mean time to resolution (MTTR). With a few clicks or CLI commands, you can enable monitoring for your Node.js or Java apps, autocollecting logs, metrics, and distributed traces, eliminating the need for including an SDK in your app. For more information about the available app settings for configuring the agent, see the [Application Insights documentation](/azure/azure-monitor/app/java-standalone-config). # [Azure portal](#tab/portal) |
| app-service | Configure Language Nodejs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/configure-language-nodejs.md | When deploying Node.js apps on Azure App Service for Linux, you may need to hand ## Monitor with Application Insights -Application Insights allows you to monitor your application's performance, exceptions, and usage without making any code changes. To attach the App Insights agent, go to your web app in the Portal and select **Application Insights** under **Settings**, then select **Turn on Application Insights**. Next, select an existing App Insights resource or create a new one. Finally, select **Apply** at the bottom. To instrument your web app using PowerShell, please see [these instructions](../azure-monitor/app/azure-web-apps-nodejs.md#enable-through-powershell) +Application Insights allows you to monitor your application's performance, exceptions, and usage without making any code changes. To attach the App Insights agent, go to your web app in the Portal and select **Application Insights** under **Settings**, then select **Turn on Application Insights**. Next, select an existing App Insights resource or create a new one. Finally, select **Apply** at the bottom. To instrument your web app using PowerShell, please see [these instructions](/azure/azure-monitor/app/azure-web-apps-nodejs#enable-through-powershell) -This agent will monitor your server-side Node.js application. To monitor your client-side JavaScript, [add the JavaScript SDK to your project](../azure-monitor/app/javascript.md). +This agent will monitor your server-side Node.js application. To monitor your client-side JavaScript, [add the JavaScript SDK to your project](/azure/azure-monitor/app/javascript). -For more information, see the [Application Insights extension release notes](../azure-monitor/app/web-app-extension-release-notes.md). +For more information, see the [Application Insights extension release notes](/azure/azure-monitor/app/web-app-extension-release-notes). ::: zone-end |
| app-service | Deploy Staging Slots | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/deploy-staging-slots.md | If you have any problems, see [Troubleshoot swaps](#troubleshoot-swaps). ## Monitor a swap -If the [swap operation](#AboutConfiguration) takes a long time to complete, you can get information on the swap operation in the [activity log](../azure-monitor/essentials/platform-logs-overview.md). +If the [swap operation](#AboutConfiguration) takes a long time to complete, you can get information on the swap operation in the [activity log](/azure/azure-monitor/essentials/platform-logs-overview). # [Azure portal](#tab/portal) |
| app-service | Firewall Integration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/environment/firewall-integration.md | Azure Firewall can send logs to Azure Storage, Event Hubs, or Azure Monitor logs AzureDiagnostics | where msg_s contains "Deny" | where TimeGenerated >= ago(1h) ``` -Integrating your Azure Firewall with Azure Monitor logs is useful when first getting an application working when you aren't aware of all of the application dependencies. You can learn more about Azure Monitor logs from [Analyze log data in Azure Monitor](../../azure-monitor/logs/log-query-overview.md). +Integrating your Azure Firewall with Azure Monitor logs is useful when first getting an application working when you aren't aware of all of the application dependencies. You can learn more about Azure Monitor logs from [Analyze log data in Azure Monitor](/azure/azure-monitor/logs/log-query-overview). <a name="dependencies"></a> ## Configuring third-party firewall with your ASE |
| app-service | How To Upgrade Preference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/environment/how-to-upgrade-preference.md | When an upgrade is available, Azure adds a planned maintenance event in the Serv You can configure alerts to send a message to your email address and/or SMS phone number when an event is generated in Azure Monitor. You can also set up a trigger for your custom Azure Function or Logic App, which allows you to automatically take action on your resources. This action could be to automatically divert the traffic from your App Service Environment in one region that is upgraded to an App Service Environment in another region. Then, you can automatically change the traffic back to normal when an upgrade completes. -To configure alerts for upgrade notifications, select the **Add service health alert** at the top of the dashboard. Learn more about [Azure Monitor Alerts](../../azure-monitor/alerts/alerts-overview.md). This how-to article guides you through [configuring alerts for service health events](../../service-health/alerts-activity-log-service-notifications-portal.md). Finally, you can follow this how-to guide to learn [how to create actions groups](../../azure-monitor/alerts/action-groups.md) that trigger based on the alert. +To configure alerts for upgrade notifications, select the **Add service health alert** at the top of the dashboard. Learn more about [Azure Monitor Alerts](/azure/azure-monitor/alerts/alerts-overview). This how-to article guides you through [configuring alerts for service health events](/azure/service-health/alerts-activity-log-service-notifications-portal). Finally, you can follow this how-to guide to learn [how to create actions groups](/azure/azure-monitor/alerts/action-groups) that trigger based on the alert. ### Send test notifications |
| app-service | Using An Ase | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/environment/using-an-ase.md | As a customer, you should monitor the App Service plans and the individual apps Through Azure portal and CLI, you can configure the scale ratio of your frontend servers between 5 and 15 (default 15) App Service plan instances per frontend server. An App Service Environment will always have a minimum of two frontend servers. You can also increase the size of the frontend servers. -The [metrics scope](../../azure-monitor/essentials/metrics-supported.md#microsoftwebhostingenvironmentsmultirolepools) used to monitor the platform infrastructure is called `Microsoft.Web/hostingEnvironments/multiRolePools`. +The [metrics scope](/azure/azure-monitor/essentials/metrics-supported#microsoftwebhostingenvironmentsmultirolepools) used to monitor the platform infrastructure is called `Microsoft.Web/hostingEnvironments/multiRolePools`. You'll see a scope called `Microsoft.Web/hostingEnvironments/workerPools`. The metrics here are only applicable to App Service Environment v1. If you integrate with Log Analytics, you can see the logs by selecting **Logs** **Creating an alert** -To create an alert against your logs, follow the instructions in [Create, view, and manage log alerts using Azure Monitor](../../azure-monitor/alerts/alerts-log.md). In brief: +To create an alert against your logs, follow the instructions in [Create, view, and manage log alerts using Azure Monitor](/azure/azure-monitor/alerts/alerts-log). In brief: * Open the Alerts page in your ASE portal * Select **New alert rule** For more specific examples, use: az find "az appservice ase" [AppDeploy]: ../deploy-local-git.md [ASEWAF]: ./integrate-with-application-gateway.md [AppGW]: ../../web-application-firewall/ag/ag-overview.md-[logalerts]: ../../azure-monitor/alerts/alerts-log.md +[logalerts]: /azure/azure-monitor/alerts/alerts-log |
| app-service | Using | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/environment/using.md | If you integrate with Azure Monitor Logs, you can see the logs by selecting **Lo ### Create an alert -To create an alert against your logs, follow the instructions in [Create, view, and manage log alerts by using Azure Monitor](../../azure-monitor/alerts/alerts-log.md). In brief: +To create an alert against your logs, follow the instructions in [Create, view, and manage log alerts by using Azure Monitor](/azure/azure-monitor/alerts/alerts-log). In brief: 1. Open the **Alerts** page in your App Service Environment portal. 1. Select **New alert rule**. To delete: [AppDeploy]: ../deploy-local-git.md [ASEWAF]: ./integrate-with-application-gateway.md [AppGW]: ../../web-application-firewall/ag/ag-overview.md-[logalerts]: ../../azure-monitor/alerts/alerts-log.md +[logalerts]: /azure/azure-monitor/alerts/alerts-log |
| app-service | Language Support Policy | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/language-support-policy.md | App Service follows community support timelines for the lifecycle of the runtime End-of-support dates for runtime versions are determined independently by their respective stacks and are outside the control of App Service. App Service sends reminder notifications to subscription owners for upcoming end-of-support runtime versions when they become available for each language. -Roles that receive notifications include account administrators, service administrators, and coadministrators. Contributors, readers, or other roles don't directly receive notifications unless they opt in to receive notification emails, using [Service Health Alerts](../service-health/alerts-activity-log-service-notifications-portal.md). +Roles that receive notifications include account administrators, service administrators, and coadministrators. Contributors, readers, or other roles don't directly receive notifications unless they opt in to receive notification emails, using [Service Health Alerts](/azure/service-health/alerts-activity-log-service-notifications-portal). ## Timelines for language runtime version support |
| app-service | Manage Automatic Scaling | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/manage-automatic-scaling.md | -Automatic scaling is a new scale-out option that automatically handles scaling decisions for your web apps and App Service Plans. It's different from the pre-existing **[Azure autoscale](../azure-monitor/autoscale/autoscale-overview.md)**, which lets you define scaling rules based on schedules and resources. With automatic scaling, you can adjust scaling settings to improve your app's performance and avoid cold start issues. The platform prewarms instances to act as a buffer when scaling out, ensuring smooth performance transitions. You're charged per second for every instance, including prewarmed instances. +Automatic scaling is a new scale-out option that automatically handles scaling decisions for your web apps and App Service Plans. It's different from the pre-existing **[Azure autoscale](/azure/azure-monitor/autoscale/autoscale-overview)**, which lets you define scaling rules based on schedules and resources. With automatic scaling, you can adjust scaling settings to improve your app's performance and avoid cold start issues. The platform prewarms instances to act as a buffer when scaling out, ensuring smooth performance transitions. You're charged per second for every instance, including prewarmed instances. A comparison of scale-out and scale in options available on App Service: To disable ARR Affinity cookies: select your App Service app, and under **Settin ## More resources -* [Get started with autoscale in Azure](../azure-monitor/autoscale/autoscale-get-started.md) +* [Get started with autoscale in Azure](/azure/azure-monitor/autoscale/autoscale-get-started) * [Configure PremiumV3 tier for App Service](app-service-configure-premium-tier.md) * [Scale up server capacity](manage-scale-up.md) * [High-density hosting](manage-scale-per-app.md) |
| app-service | Manage Backup | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/manage-backup.md | The following table shows which app configurations are restored when you choose |[Managed identities](overview-managed-identity.md)| No | |[Custom domains](app-service-web-tutorial-custom-domain.md)| No | |[TLS/SSL](configure-ssl-bindings.md)| No |-|[Scale out](../azure-monitor/autoscale/autoscale-get-started.md?toc=/azure/app-service/toc.json)| No | +|[Scale out](/azure/azure-monitor/autoscale/autoscale-get-started?toc=/azure/app-service/toc.json)| No | |[Diagnostics with Azure Monitor](troubleshoot-diagnostic-logs.md#send-logs-to-azure-monitor)| No |-|[Alerts and metrics](../azure-monitor/alerts/alerts-classic-portal.md)| No | -|Backup| No | +|[Alerts and Metrics](/azure/azure-monitor/alerts/alerts-classic-portal)| No | +|[Backup](manage-backup.md)| No | |Associated [deployment slots](deploy-staging-slots.md)| No | |Any linked database that [custom backup](#whats-included-in-a-custom-backup) supports| No | |
| app-service | Manage Create Arc Environment | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/manage-create-arc-environment.md | az extension add --upgrade --yes --name appservice-kube ## Create a Log Analytics workspace -While a [Log Analytic workspace](../azure-monitor/logs/quick-create-workspace.md) is not required to run App Service in Azure Arc, it's how developers can get application logs for their apps that are running in the Azure Arc-enabled Kubernetes cluster. +While a [Log Analytic workspace](/azure/azure-monitor/logs/quick-create-workspace) is not required to run App Service in Azure Arc, it's how developers can get application logs for their apps that are running in the Azure Arc-enabled Kubernetes cluster. 1. For simplicity, create the workspace now. |
| app-service | Manage Scale Up | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/manage-scale-up.md | This article shows you how to scale your app in Azure App Service. There are two * [Scale out](https://en.wikipedia.org/wiki/Scalability#Horizontal_and_vertical_scaling): Increase the number of VM instances that run your app. Basic, Standard and Premium service plans scale out to as many as 3, 10 and 30 instances respectively. [App Service Environments](environment/intro.md) in **Isolated** tier further increases your scale-out count to 100 instances. For more information about scaling out, see- [Scale instance count manually or automatically](../azure-monitor/autoscale/autoscale-get-started.md). There, you find out how + [Scale instance count manually or automatically](/azure/azure-monitor/autoscale/autoscale-get-started). There, you find out how to use autoscaling, which is to scale instance count automatically based on predefined rules and schedules. >[!IMPORTANT] For a table of service limits, quotas, and constraints, and supported features i ## More resources -* [Scale instance count manually or automatically](../azure-monitor/autoscale/autoscale-get-started.md) +* [Scale instance count manually or automatically](/azure/azure-monitor/autoscale/autoscale-get-started) * [Configure Premium V3 tier for App Service](app-service-configure-premium-tier.md) * [Tutorial: Run a load test to identify performance bottlenecks in a web app](../load-testing/tutorial-identify-bottlenecks-azure-portal.md) <!-- LINKS --> |
| app-service | Overview Arc Integration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/overview-arc-integration.md | All applications deployed with Azure App Service on Kubernetes with Azure Arc ar ### What logs are collected? -Logs for both system components and your applications are written to standard output. Both log types can be collected for analysis using standard Kubernetes tools. You can also configure the App Service cluster extension with a [Log Analytics workspace](../azure-monitor/logs/log-analytics-overview.md), and it sends all logs to that workspace. +Logs for both system components and your applications are written to standard output. Both log types can be collected for analysis using standard Kubernetes tools. You can also configure the App Service cluster extension with a [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-overview), and it sends all logs to that workspace. By default, logs from system components are sent to the Azure team. Application logs aren't sent. You can prevent these logs from being transferred by setting `logProcessor.enabled=false` as an extension configuration setting. This configuration setting will also disable forwarding of application to your Log Analytics workspace. Disabling the log processor might impact time needed for any support cases, and you will be asked to collect logs from standard output through some other means. |
| app-service | Overview Diagnostics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/overview-diagnostics.md | To review tailored best practice recommendations, check out the Resiliency Score ### Investigate application code issues (only for Windows app) -Because many app issues are related to issues in your application code, App Service diagnostics integrates with [Application Insights](../azure-monitor/app/app-insights-overview.md) to highlight exceptions and dependency issues to correlate with the selected downtime. Application Insights has to be enabled separately. +Because many app issues are related to issues in your application code, App Service diagnostics integrates with [Application Insights](/azure/azure-monitor/app/app-insights-overview) to highlight exceptions and dependency issues to correlate with the selected downtime. Application Insights has to be enabled separately.  |
| app-service | Overview Hosting Plans | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/overview-hosting-plans.md | When you create an app in App Service, it's part of an App Service plan. When th In this way, the App Service plan is the scale unit of the App Service apps. If the plan is configured to run five VM instances, then all apps in the plan run on all five instances. If the plan is configured for autoscaling, then all apps in the plan are scaled out together based on the autoscale settings. -For information on scaling out an app, see [Scale instance count manually or automatically](../azure-monitor/autoscale/autoscale-get-started.md). +For information on scaling out an app, see [Scale instance count manually or automatically](/azure/azure-monitor/autoscale/autoscale-get-started). <a name="cost"></a> |
| app-service | Overview Manage Costs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/overview-manage-costs.md | Depending on which feature you use in App Service, the following cost-accruing r - **Isolated tier** A [Virtual Network](../virtual-network/index.yml) is required for an App Service environment and is charged separately. - **Backup** A [Storage account](../storage/index.yml) is required to make backups and is charged separately.-- **Diagnostic logs** You can select [Storage account](../storage/index.yml) as the logging option, or integrate with [Azure Log Analytics](../azure-monitor/logs/log-analytics-tutorial.md). These services are charged separately.+- **Diagnostic logs** You can select [Storage account](../storage/index.yml) as the logging option, or integrate with [Azure Log Analytics](/azure/azure-monitor/logs/log-analytics-tutorial). These services are charged separately. - **App Service certificates** Certificates you purchase in Azure must be maintained in [Azure Key Vault](/azure/key-vault/), which is charged separately. ### Costs that might accrue after resource deletion Production workloads come with the recommendation of the dedicated **Standard** > [!NOTE] > **Premium V3** supports both Windows containers and Linux containers. -Once you choose the pricing tier you want, you should minimize the idle instances. In a scale-out deployment, you can waste money on underutilized compute instances. You should [configure autoscaling](../azure-monitor/autoscale/autoscale-get-started.md), available in **Standard** tier and higher. By creating scale-out schedules, as well as metric-based scale-out rules, you only pay for the instances you really need at any given time. +Once you choose the pricing tier you want, you should minimize the idle instances. In a scale-out deployment, you can waste money on underutilized compute instances. You should [configure autoscaling](/azure/azure-monitor/autoscale/autoscale-get-started), available in **Standard** tier and higher. By creating scale-out schedules, as well as metric-based scale-out rules, you only pay for the instances you really need at any given time. ### Azure Reservations |
| app-service | Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/overview.md | Azure App Service is a fully managed platform as a service (PaaS) offering for d * **Managed production environment** - App Service automatically [patches and maintains the OS and language frameworks](overview-patch-os-runtime.md) for you. Spend time writing great apps and let Azure worry about the platform. * **Containerization and Docker** - Dockerize your app and host a custom Windows or Linux container in App Service. Run sidecar containers of your choice. Migrate your Docker skills directly to App Service. * **DevOps optimization** - Set up [continuous integration and deployment](deploy-continuous-deployment.md) with Azure DevOps, GitHub, BitBucket, Docker Hub, or Azure Container Registry. Promote updates through [test and staging environments](deploy-staging-slots.md). Manage your apps in App Service by using [Azure PowerShell](/powershell/azure/) or the [cross-platform command-line interface (CLI)](/cli/azure/install-azure-cli).-* **Global scale with high availability** - Scale [up](manage-scale-up.md) or [out](../azure-monitor/autoscale/autoscale-get-started.md) manually or automatically. Host your apps anywhere in Microsoft's global datacenter infrastructure, and the App Service [SLA](https://azure.microsoft.com/support/legal/sla/app-service/) promises high availability. +* **Global scale with high availability** - Scale [up](manage-scale-up.md) or [out](/azure/azure-monitor/autoscale/autoscale-get-started) manually or automatically. Host your apps anywhere in Microsoft's global datacenter infrastructure, and the App Service [SLA](https://azure.microsoft.com/support/legal/sla/app-service/) promises high availability. * **Connections to SaaS platforms and on-premises data** - Choose from [many hundreds of connectors](/connectors/connector-reference/connector-reference-logicapps-connectors) for enterprise systems (such as SAP), SaaS services (such as Salesforce), and internet services (such as Facebook). Access on-premises data using [Hybrid Connections](app-service-hybrid-connections.md) and [Azure Virtual Networks](./overview-vnet-integration.md). * **Security and compliance** - App Service is [ISO, SOC, and PCI compliant](https://www.microsoft.com/trust-center). Create [IP address restrictions](app-service-ip-restrictions.md) and [managed service identities](overview-managed-identity.md). [Prevent subdomain takeovers](reference-dangling-subdomain-prevention.md). * **Authentication** - [Authenticate users](overview-authentication-authorization.md) using the built-in authentication component. Authenticate users with [Microsoft Entra ID](configure-authentication-provider-aad.md), [Google](configure-authentication-provider-google.md), [Facebook](configure-authentication-provider-facebook.md), [X](configure-authentication-provider-twitter.md), or [Microsoft account](configure-authentication-provider-microsoft.md). |
| app-service | Quickstart Arc | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/quickstart-arc.md | The application logs for all the apps hosted in your Kubernetes cluster are logg **Log_s** contains application logs for a given App Service and **AppName_s** contains the App Service app name. In addition to logs you write via your application code, the Log_s column also contains logs on container startup, shutdown, and Function Apps. -You can learn more about log queries in [getting started with Kusto](../azure-monitor/logs/get-started-queries.md). +You can learn more about log queries in [getting started with Kusto](/azure/azure-monitor/logs/get-started-queries). ## (Optional) Deploy a custom container |
| app-service | Troubleshoot Diagnostic Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/troubleshoot-diagnostic-logs.md | When stored in the App Service file system, logs are subject to the available st > [!NOTE] > App Service provides a dedicated, interactive diagnostics tool to help you troubleshoot your application. For more information, see [Azure App Service diagnostics overview](overview-diagnostics.md). >-> In addition, you can use other Azure services, such as [Azure Monitor](../azure-monitor/app/azure-web-apps.md), to improve the logging and monitoring capabilities of your app. +> In addition, you can use other Azure services to improve the logging and monitoring capabilities of your app, such as [Azure Monitor](/azure/azure-monitor/app/azure-web-apps). > ## Enable application logging (Windows) For a list of supported log types and their descriptions, see [Supported resourc ## Networking considerations -For Diagnostic Settings restrictions, refer to the [official Diagnostic Settings documentation regarding destination limits](../azure-monitor/essentials/diagnostic-settings.md#destination-limitations). +For Diagnostic Settings restrictions, refer to the [official Diagnostic Settings documentation regarding destination limits](/azure/azure-monitor/essentials/diagnostic-settings#destination-limitations). ## <a name="nextsteps"></a> Next steps-* [Query logs with Azure Monitor](../azure-monitor/logs/log-query-overview.md) -* [How to Monitor Azure App Service](monitor-app-service.md) +* [Query logs with Azure Monitor](/azure/azure-monitor/logs/log-query-overview) +* [How to Monitor Azure App Service](web-sites-monitor.md) * [Troubleshooting Azure App Service in Visual Studio](troubleshoot-dotnet-visual-studio.md) * [Tutorial: Run a load test to identify performance bottlenecks in a web app](../load-testing/tutorial-identify-bottlenecks-azure-portal.md) |
| app-service | Troubleshoot Http 502 Http 503 | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/troubleshoot-http-502-http-503.md | Troubleshooting can be divided into three distinct tasks, in sequential order: ### 1. Observe and monitor application behavior #### Track Service health-Microsoft Azure publicizes each time there is a service interruption or performance degradation. You can track the health of the service on the [Azure Portal](https://portal.azure.com/). For more information, see [Track service health](../service-health/service-notifications.md). +Microsoft Azure publicizes each time there is a service interruption or performance degradation. You can track the health of the service on the [Azure Portal](https://portal.azure.com/). For more information, see [Track service health](/azure/service-health/service-notifications). #### Monitor your app This option enables you to find out if your application is having any issues. In your appΓÇÖs blade, click the **Requests and errors** tile. The **Metric** blade will show you all the metrics you can add. Some of the metrics that you might want to monitor for your app are For more information, see: * [Monitor apps in Azure App Service](web-sites-monitor.md)-* [Receive alert notifications](../azure-monitor/alerts/alerts-overview.md) +* [Receive alert notifications](/azure/azure-monitor/alerts/alerts-overview) <a name="collect"></a> |
| app-service | Troubleshoot Performance Degradation | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/troubleshoot-performance-degradation.md | Troubleshooting can be divided into three distinct tasks, in sequential order: ### 1. Observe and monitor application behavior #### Track Service health-Microsoft Azure publicizes each time there is a service interruption or performance degradation. You can track the health of the service on the [Azure portal](https://portal.azure.com/). For more information, see [Track service health](../service-health/service-notifications.md). +Microsoft Azure publicizes each time there is a service interruption or performance degradation. You can track the health of the service on the [Azure portal](https://portal.azure.com/). For more information, see [Track service health](/azure/service-health/service-notifications). #### Monitor your app This option enables you to find out if your application is having any issues. In your appΓÇÖs blade, click the **Requests and errors** tile. The **Metric** blade shows you all the metrics you can add. Some of the metrics that you might want to monitor for your app are For more information, see: * [Monitor apps in Azure App Service](web-sites-monitor.md)-* [Receive alert notifications](../azure-monitor/alerts/alerts-overview.md) +* [Receive alert notifications](/azure/azure-monitor/alerts/alerts-overview) #### Monitor web endpoint status If you are running your app in the **Standard** pricing tier, App Service lets you monitor two endpoints from three geographic locations. Each App Service app provides an extensible management end point that allows you - Source code editors like [Azure DevOps](https://www.visualstudio.com/products/what-is-visual-studio-online-vs.aspx). - Management tools for connected resources such as a MySQL database connected to an app. -[Azure Application Insights](https://azure.microsoft.com/services/application-insights/) is a performance monitoring site extension that's also available. To use Application Insights, you rebuild your code with an SDK. You can also install an extension that provides access to additional data. The SDK lets you write code to monitor the usage and performance of your app in more detail. For more information, see [Monitor performance in web applications](../azure-monitor/app/app-insights-overview.md). +[Azure Application Insights](https://azure.microsoft.com/services/application-insights/) is a performance monitoring site extension that's also available. To use Application Insights, you rebuild your code with an SDK. You can also install an extension that provides access to additional data. The SDK lets you write code to monitor the usage and performance of your app in more detail. For more information, see [Monitor performance in web applications](/azure/azure-monitor/app/app-insights-overview). <a name="collect"></a> You can enable the Application Insights Profiler to start capturing detailed per Application Insights Profiler provides statistics on response time for each web call and traces that indicates which line of code caused the slow responses. Sometimes the App Service app is slow because certain code is not written in a performant way. Examples include sequential code that can be run in parallel and undesired database lock contentions. Removing these bottlenecks in the code increases the app's performance, but they are hard to detect without setting up elaborate traces and logs. The traces collected by Application Insights Profiler helps identifying the lines of code that slows down the application and overcome this challenge for App Service apps. - For more information, see [Profiling live apps in Azure App Service with Application Insights](../azure-monitor/app/profiler.md). + For more information, see [Profiling live apps in Azure App Service with Application Insights](/azure/azure-monitor/app/profiler). ##### Use Remote Profiling In Azure App Service, web apps, API apps, mobile back ends, and WebJobs can be remotely profiled. Choose this option if you have access to the app resource and you know how to reproduce the issue, or if you know the exact time interval the performance issue happens. |
| app-service | Tutorial Custom Container Sidecar | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/tutorial-custom-container-sidecar.md | First you create the resources that the tutorial uses (for more information, see > - A resource group > - A [container registry](../container-registry/container-registry-intro.md) with two images deployed: > - An Nginx image with the OpenTelemetry module.- > - An OpenTelemetry collector image, configured to export to [Azure Monitor](../azure-monitor/overview.md). - > - A [log analytics workspace](../azure-monitor/logs/log-analytics-overview.md) - > - An [Application Insights](../azure-monitor/app/app-insights-overview.md) component + > - An OpenTelemetry collector image, configured to export to [Azure Monitor](/azure/azure-monitor/overview). + > - A [log analytics workspace](/azure/azure-monitor/logs/log-analytics-overview) + > - An [Application Insights](/azure/azure-monitor/app/app-insights-overview) component ## 2. Create a sidecar-enabled app |
| app-service | Tutorial Dotnetcore Sqldb App | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/tutorial-dotnetcore-sqldb-app.md | In the AZD output, find the link to stream App Service logs and navigate to it i Stream App Service logs at: https://portal.azure.com/#@/resource/subscriptions/<subscription-guid>/resourceGroups/<group-name>/providers/Microsoft.Web/sites/<app-name>/logStream </pre> -Learn more about logging in .NET apps in the series on [Enable Azure Monitor OpenTelemetry for .NET, Node.js, Python and Java applications](../azure-monitor/app/opentelemetry-enable.md?tabs=aspnetcore). +Learn more about logging in .NET apps in the series on [Enable Azure Monitor OpenTelemetry for .NET, Node.js, Python and Java applications](/azure/azure-monitor/app/opentelemetry-enable?tabs=aspnetcore). Having issues? Check the [Troubleshooting section](#troubleshooting). |
| app-service | Tutorial Java Spring Cosmosdb | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/tutorial-java-spring-cosmosdb.md | Azure App Service captures all messages output to the console to help you diagno :::column-end::: :::row-end::: -Learn more about logging in Java apps in the series on [Enable Azure Monitor OpenTelemetry for .NET, Node.js, Python and Java applications](../azure-monitor/app/opentelemetry-enable.md?tabs=java). +Learn more about logging in Java apps in the series on [Enable Azure Monitor OpenTelemetry for .NET, Node.js, Python and Java applications](/azure/azure-monitor/app/opentelemetry-enable?tabs=java). Having issues? Check the [Troubleshooting section](#troubleshooting). In the AZD output, find the link to stream App Service logs and navigate to it i Stream App Service logs at: https://portal.azure.com/#@/resource/subscriptions/<subscription-guid>/resourceGroups/<group-name>/providers/Microsoft.Web/sites/<app-name>/logStream </pre> -Learn more about logging in Java apps in the series on [Enable Azure Monitor OpenTelemetry for .NET, Node.js, Python and Java applications](../azure-monitor/app/opentelemetry-enable.md?tabs=java). +Learn more about logging in Java apps in the series on [Enable Azure Monitor OpenTelemetry for .NET, Node.js, Python and Java applications](/azure/azure-monitor/app/opentelemetry-enable?tabs=java). Having issues? Check the [Troubleshooting section](#troubleshooting). |
| app-service | Tutorial Java Tomcat Connect Managed Identity Postgresql Database | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/tutorial-java-tomcat-connect-managed-identity-postgresql-database.md | ms.devlang: java Last updated 06/04/2024 -+ |
| app-service | Tutorial Java Tomcat Mysql App | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/tutorial-java-tomcat-mysql-app.md | Azure App Service captures all messages output to the console to help you diagno :::column-end::: :::row-end::: -Learn more about logging in Java apps in the series on [Enable Azure Monitor OpenTelemetry for .NET, Node.js, Python and Java applications](../azure-monitor/app/opentelemetry-enable.md?tabs=java). +Learn more about logging in Java apps in the series on [Enable Azure Monitor OpenTelemetry for .NET, Node.js, Python and Java applications](/azure/azure-monitor/app/opentelemetry-enable?tabs=java). Having issues? Check the [Troubleshooting section](#troubleshooting). In the AZD output, find the link to stream App Service logs and navigate to it i Stream App Service logs at: https://portal.azure.com/#@/resource/subscriptions/<subscription-guid>/resourceGroups/<group-name>/providers/Microsoft.Web/sites/<app-name>/logStream </pre> -Learn more about logging in Java apps in the series on [Enable Azure Monitor OpenTelemetry for .NET, Node.js, Python and Java applications](../azure-monitor/app/opentelemetry-enable.md?tabs=java). +Learn more about logging in Java apps in the series on [Enable Azure Monitor OpenTelemetry for .NET, Node.js, Python and Java applications](/azure/azure-monitor/app/opentelemetry-enable?tabs=java). Having issues? Check the [Troubleshooting section](#troubleshooting). |
| app-service | Tutorial Troubleshoot Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/tutorial-troubleshoot-monitor.md | Last updated 06/29/2023 # Tutorial: Troubleshoot an App Service app with Azure Monitor -This tutorial shows how to troubleshoot an [App Service](overview.md) app using [Azure Monitor](../azure-monitor/overview.md). The sample app includes code meant to exhaust memory and cause HTTP 500 errors, so you can diagnose and fix the problem using Azure Monitor. When you're finished, you have a sample app running on App Service on Linux integrated with [Azure Monitor](../azure-monitor/overview.md). +This tutorial shows how to troubleshoot an [App Service](overview.md) app using [Azure Monitor](/azure/azure-monitor/overview). The sample app includes code meant to exhaust memory and cause HTTP 500 errors, so you can diagnose and fix the problem using Azure Monitor. When you're finished, you have a sample app running on App Service on Linux integrated with [Azure Monitor](/azure/azure-monitor/overview). -[Azure Monitor](../azure-monitor/overview.md) maximizes the availability and performance of your applications and services by delivering a comprehensive solution for collecting, analyzing, and acting on telemetry from your cloud and on-premises environments. +[Azure Monitor](/azure/azure-monitor/overview) maximizes the availability and performance of your applications and services by delivering a comprehensive solution for collecting, analyzing, and acting on telemetry from your cloud and on-premises environments. In this tutorial, you learn how to: Diagnostic settings can be used to collect metrics for certain Azure services in You run the following commands to create diagnostic settings for AppServiceConsoleLogs (standard output/error) and AppServiceHTTPLogs (web server logs). Replace _\<app-name>_ and _\<workspace-name>_ with your values. > [!NOTE]-> The first two commands, `resourceID` and `workspaceID`, are variables to be used in the [az monitor diagnostic-settings create](/cli/azure/monitor/diagnostic-settings#az-monitor-diagnostic-settings-create) command. See [Create diagnostic settings using Azure CLI](../azure-monitor/essentials/create-diagnostic-settings.md?tabs=cli) for more information on this command. +> The first two commands, `resourceID` and `workspaceID`, are variables to be used in the [az monitor diagnostic-settings create](/cli/azure/monitor/diagnostic-settings#az-monitor-diagnostic-settings-create) command. See [Create diagnostic settings using Azure CLI](/azure/azure-monitor/essentials/create-diagnostic-settings?tabs=cli) for more information on this command. > ```azurecli In the Azure portal, select your Log Analytics workspace. ### Log queries -Log queries help you to fully apply the value of the data collected in Azure Monitor Logs. You use log queries to identify the logs in both AppServiceHTTPLogs and AppServiceConsoleLogs. See the [log query overview](../azure-monitor/logs/log-query-overview.md) for more information on log queries. +Log queries help you to fully apply the value of the data collected in Azure Monitor Logs. You use log queries to identify the logs in both AppServiceHTTPLogs and AppServiceConsoleLogs. See the [log query overview](/azure/azure-monitor/logs/log-query-overview) for more information on log queries. ### View AppServiceHTTPLogs with log query What you learned: > * Used log queries to identify and troubleshoot web app errors ## <a name="nextsteps"></a> Next steps-* [Query logs with Azure Monitor](../azure-monitor/logs/log-query-overview.md) +* [Query logs with Azure Monitor](/azure/azure-monitor/logs/log-query-overview) * [Troubleshooting Azure App Service in Visual Studio](troubleshoot-dotnet-visual-studio.md) * [Analyze app Logs in HDInsight](/azure/hdinsight/hdinsight-hadoop-oms-log-analytics-tutorial) * [Tutorial: Run a load test to identify performance bottlenecks in a web app](../load-testing/tutorial-identify-bottlenecks-azure-portal.md) |
| app-service | Web Sites Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/web-sites-monitor.md | There are two metrics that reflect CPU usage: **CPU percentage**: Useful for apps hosted in Basic, Standard, and Premium plans, because they can be scaled out. CPU percentage is a good indication of the overall usage across all instances. ## Metrics granularity and retention policy-Metrics for an app and app service plan are logged and aggregated by the service and [retained according to these rules](../azure-monitor/essentials/data-platform-metrics.md#retention-of-metrics). +Metrics for an app and app service plan are logged and aggregated by the service and [retained according to these rules](/azure/azure-monitor/essentials/data-platform-metrics#retention-of-metrics). ## Monitoring quotas and metrics in the Azure portal To review the status of the various quotas and metrics that affect an app, go to the [Azure portal](https://portal.azure.com). You can access metrics directly from the resource **Overview** page. Here you'll Clicking on any of those charts will take you to the metrics view where you can create custom charts, query different metrics and much more. -To learn more about metrics, see [Monitor service metrics](../azure-monitor/data-platform.md). +To learn more about metrics, see [Monitor service metrics](/azure/azure-monitor/data-platform). ## Alerts and autoscale Metrics for an app or an App Service plan can be hooked up to alerts. For more i App Service apps hosted in Basic or higher App Service plans support autoscale. With autoscale, you can configure rules that monitor the App Service plan metrics. Rules can increase or decrease the instance count, which can provide additional resources as needed. Rules can also help you save money when the app is over-provisioned. -For more information about autoscale, see [How to scale](../azure-monitor/autoscale/autoscale-get-started.md) and [Best practices for Azure Monitor autoscaling](../azure-monitor/autoscale/autoscale-best-practices.md). +For more information about autoscale, see [How to scale](/azure/azure-monitor/autoscale/autoscale-get-started) and [Best practices for Azure Monitor autoscaling](/azure/azure-monitor/autoscale/autoscale-best-practices). [fzilla]:https://go.microsoft.com/fwlink/?LinkId=247914 [vmsizes]:https://go.microsoft.com/fwlink/?LinkID=309169 |
| app-service | Webjobs Sdk Get Started | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/webjobs-sdk-get-started.md | The connection string is now set in your app in Azure. ## Enable Application Insights logging -When the WebJob runs in Azure, you can't monitor function execution by viewing console output. To be able to monitor your WebJob, you should create an associated [Application Insights](../azure-monitor/app/app-insights-overview.md) instance when you publish your project. +When the WebJob runs in Azure, you can't monitor function execution by viewing console output. To be able to monitor your WebJob, you should create an associated [Application Insights](/azure/azure-monitor/app/app-insights-overview) instance when you publish your project. ### Create an Application Insights instance When the WebJob runs in Azure, you can't monitor function execution by viewing c 1. Under **Settings**, choose **Configuration** and verify that a new `APPINSIGHTS_INSTRUMENTATIONKEY` was created. This key is used to connect your WebJob instance to Application Insights. -To take advantage of [Application Insights](../azure-monitor/app/app-insights-overview.md) logging, you need to update your logging code as well. +To take advantage of [Application Insights](/azure/azure-monitor/app/app-insights-overview) logging, you need to update your logging code as well. ### Install the Application Insights extension |
| app-service | Webjobs Sdk How To | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-service/webjobs-sdk-how-to.md | config.LoggerFactory = new LoggerFactory() ### Custom telemetry for Application Insights -The process for implementing custom telemetry for [Application Insights](../azure-monitor/app/app-insights-overview.md) depends on the SDK version. To learn how to configure Application Insights, see [Add Application Insights logging](webjobs-sdk-get-started.md#enable-application-insights-logging). +The process for implementing custom telemetry for [Application Insights](/azure/azure-monitor/app/app-insights-overview) depends on the SDK version. To learn how to configure Application Insights, see [Add Application Insights logging](webjobs-sdk-get-started.md#enable-application-insights-logging). #### Version 3.*x* static async Task Main() } ``` -When the [`TelemetryConfiguration`] is constructed, all registered types of [`ITelemetryInitializer`] are included. To learn more, see [Application Insights API for custom events and metrics](../azure-monitor/app/api-custom-events-metrics.md). +When the [`TelemetryConfiguration`] is constructed, all registered types of [`ITelemetryInitializer`] are included. To learn more, see [Application Insights API for custom events and metrics](/azure/azure-monitor/app/api-custom-events-metrics). In version 3.*x*, you no longer have to flush the [`TelemetryClient`] when the host stops. The .NET Core dependency injection system automatically disposes of the registered `ApplicationInsightsLoggerProvider`, which flushes the [`TelemetryClient`]. private class CustomTelemetryClientFactory : DefaultTelemetryClientFactory } ``` -The `SamplingPercentageEstimatorSettings` object configures [adaptive sampling](../azure-monitor/app/sampling.md). This means that in certain high-volume scenarios, Applications Insights sends a selected subset of telemetry data to the server. +The `SamplingPercentageEstimatorSettings` object configures [adaptive sampling](/azure/azure-monitor/app/sampling). This means that in certain high-volume scenarios, Applications Insights sends a selected subset of telemetry data to the server. After you create the telemetry factory, you pass it in to the Application Insights logging provider: |
| app-spaces | How To Manage Components | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/app-spaces/how-to-manage-components.md | The **Deployment** section in App Spaces provides a detailed log of all deployme ## Logs App Spaces provides robust logging capabilities for static app components, which can be filtered over a range of time periods from the last hour to the last 30 days. You can enable logs through the **Log Settings** button, which offers different configuration options. The **Auto** setting automatically collects logs for HTTP requests, global errors, and usage analytics. For more customized tracking, you can choose the **Manual with npm packages** option to set up custom event tracking with IntelliSense. Alternatively, the **Manual with React and Angular plug-ins** option allows you to configure connection strings to define where to send telemetry data by replacing the placeholder `YOUR_CONNECTION_STRING` with the actual connection string. These flexible logging options ensure comprehensive monitoring and analysis tailored to specific needs. -Select **Open in advanced queries** to go to the [Log Analytics workspace](../azure-monitor/logs/log-analytics-workspace-overview.md). +Select **Open in advanced queries** to go to the [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-workspace-overview). For Application Insights, see [Enable a framework extension for Application Insights JavaScript SDK](https://go.microsoft.com/fwlink/?linkid=2269911). ::: zone-end ::: zone pivot="app" ## Logs -Select system logs to check service-level events, or console logs to debug code. For more information, see [Use queries in Log Analytics](../azure-monitor/logs/queries.md). +Select system logs to check service-level events, or console logs to debug code. For more information, see [Use queries in Log Analytics](/azure/azure-monitor/logs/queries). -Select **Open in advanced queries** to go to the [Log Analytics workspace](../azure-monitor/logs/log-analytics-workspace-overview.md). +Select **Open in advanced queries** to go to the [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-workspace-overview). ::: zone-end ::: zone pivot="database" ::: zone-end |
| application-gateway | Application Gateway Diagnostics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/application-gateway/application-gateway-diagnostics.md | Other storage locations: - **Azure Event Hubs**: Event hubs are a great option for integrating with other security information and event management (SIEM) tools to get alerts on your resources. - **Azure Monitor partner integrations**. -Learn more about the Azure Monitor's [diagnostic settings destinations](../azure-monitor/essentials/diagnostic-settings.md?WT.mc_id=Portal-Microsoft_Azure_Monitoring&tabs=portal#destinations) . +Learn more about the Azure Monitor's [diagnostic settings destinations](/azure/azure-monitor/essentials/diagnostic-settings?WT.mc_id=Portal-Microsoft_Azure_Monitoring&tabs=portal#destinations) . ## Enable logging through PowerShell |
| application-gateway | Application Gateway Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/application-gateway/application-gateway-metrics.md | -Application Gateway publishes data points to [Azure Monitor](../azure-monitor/overview.md) for the performance of your Application Gateway and backend instances. These data points are called metrics, and are numerical values in an ordered set of time-series data. Metrics describe some aspect of your application gateway at a particular time. If there are requests flowing through the Application Gateway, it measures and sends its metrics in 60-second intervals. If there are no requests flowing through the Application Gateway or no data for a metric, the metric isn't reported. For more information, see [Azure Monitor metrics](../azure-monitor/essentials/data-platform-metrics.md). +Application Gateway publishes data points to [Azure Monitor](/azure/azure-monitor/overview) for the performance of your Application Gateway and backend instances. These data points are called metrics, and are numerical values in an ordered set of time-series data. Metrics describe some aspect of your application gateway at a particular time. If there are requests flowing through the Application Gateway, it measures and sends its metrics in 60-second intervals. If there are no requests flowing through the Application Gateway or no data for a metric, the metric isn't reported. For more information, see [Azure Monitor metrics](/azure/azure-monitor/essentials/data-platform-metrics). <a name="metrics-supported-by-application-gateway-v1-sku"></a> In the following image, you see an example with three metrics displayed for the :::image type="content" source="media/application-gateway-diagnostics/figure5.png" alt-text="Screenshot shows the Metric view of three metrics." lightbox="media/application-gateway-diagnostics/figure5-lb.png"::: -To see a current list of metrics, see [Supported metrics with Azure Monitor](../azure-monitor/essentials/metrics-supported.md). +To see a current list of metrics, see [Supported metrics with Azure Monitor](/azure/azure-monitor/essentials/metrics-supported). ### Alert rules on metrics A list of alerts appears after you create a metric alert. It provides an overvie ![List of alerts and rules][9] -To learn more about alert notifications, see [Receive alert notifications](../azure-monitor/alerts/alerts-overview.md). +To learn more about alert notifications, see [Receive alert notifications](/azure/azure-monitor/alerts/alerts-overview). -To understand more about webhooks and how you can use them with alerts, visit [Configure a webhook on an Azure metric alert](../azure-monitor/alerts/alerts-webhooks.md). +To understand more about webhooks and how you can use them with alerts, visit [Configure a webhook on an Azure metric alert](/azure/azure-monitor/alerts/alerts-webhooks). ## Next steps |
| application-gateway | Configure Alerts With Templates | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/application-gateway/configure-alerts-with-templates.md | Last updated 06/17/2024 Azure Monitor alerts proactively notify you when important conditions are found in your monitoring data. They allow you to identify and address issues in your system before your customers notice them. For more information about Azure Monitor Alerts for Application Gateway, see [Monitoring Azure Application Gateway](monitor-application-gateway.md#alerts). -The templates for alerts described here are defined generically for settings like Severity, Aggregation Granularity, Frequency of Evaluation, Condition Type, and so on. You can modify the settings after deployment to meet your needs. See [detailed information about configuring a metric alert rule](../azure-monitor/alerts/alerts-create-new-alert-rule.md) for more information. +The templates for alerts described here are defined generically for settings like Severity, Aggregation Granularity, Frequency of Evaluation, Condition Type, and so on. You can modify the settings after deployment to meet your needs. See [detailed information about configuring a metric alert rule](/azure/azure-monitor/alerts/alerts-create-new-alert-rule) for more information. -The templates for metric-based alerts use the **Dynamic threshold** value with [high sensitivity](../azure-monitor/alerts/alerts-dynamic-thresholds.md#known-issues-with-dynamic-threshold-sensitivity). You can choose to adjust these settings based on your needs. +The templates for metric-based alerts use the **Dynamic threshold** value with [high sensitivity](/azure/azure-monitor/alerts/alerts-dynamic-thresholds#known-issues-with-dynamic-threshold-sensitivity). You can choose to adjust these settings based on your needs. -The following ARM templates are available to configure Azure Monitor alerts for Application Gateway. For the procedure to use these templates, see [Create a new alert rule using an ARM template](../azure-monitor/alerts/alerts-create-rule-cli-powershell-arm.md#create-a-new-alert-rule-using-an-arm-template). +The following ARM templates are available to configure Azure Monitor alerts for Application Gateway. For the procedure to use these templates, see [Create a new alert rule using an ARM template](/azure/azure-monitor/alerts/alerts-create-rule-cli-powershell-arm#create-a-new-alert-rule-using-an-arm-template). - Alert for Backend Response Status as 5xx The following ARM templates are available to configure Azure Monitor alerts for - See [Monitoring Application Gateway data reference](monitor-application-gateway-reference.md) for a reference of the metrics, logs, and other important values created by Application Gateway. -- See [Monitoring Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md) for details on monitoring Azure resources.+- See [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) for details on monitoring Azure resources. |
| application-gateway | Application Gateway For Containers Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/application-gateway/for-containers/application-gateway-for-containers-metrics.md | -Application Gateway for Containers publishes data points to [Azure Monitor](../../azure-monitor/overview.md) for the performance of your Application Gateway for Containers and backend instances. These data points are called metrics, and are numerical values in an ordered set of time-series data. Metrics describe some aspect of your application gateway at a particular time. If there are requests flowing through the Application Gateway, it measures and sends its metrics in 60-second intervals. If there are no requests flowing through the Application Gateway or no data for a metric, the metric isn't reported. For more information, see [Azure Monitor metrics](../../azure-monitor/essentials/data-platform-metrics.md). +Application Gateway for Containers publishes data points to [Azure Monitor](/azure/azure-monitor/overview) for the performance of your Application Gateway for Containers and backend instances. These data points are called metrics, and are numerical values in an ordered set of time-series data. Metrics describe some aspect of your application gateway at a particular time. If there are requests flowing through the Application Gateway, it measures and sends its metrics in 60-second intervals. If there are no requests flowing through the Application Gateway or no data for a metric, the metric isn't reported. For more information, see [Azure Monitor metrics](/azure/azure-monitor/essentials/data-platform-metrics). ## Metrics supported by Application Gateway for Containers |
| application-gateway | Diagnostics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/application-gateway/for-containers/diagnostics.md | You can monitor Azure Application Gateway for Containers resources in the follow ## Diagnostic logs -You can use different types of logs in Azure to manage and troubleshoot Application Gateway for Containers. You can access some of these logs through the portal. All logs can be extracted from Azure Blob storage and viewed in different tools, such as [Azure Monitor logs](../../azure-monitor/logs/data-platform-logs.md), Excel, and Power BI. You can learn more about the different types of logs from the following list: +You can use different types of logs in Azure to manage and troubleshoot Application Gateway for Containers. You can access some of these logs through the portal. All logs can be extracted from Azure Blob storage and viewed in different tools, such as [Azure Monitor logs](/azure/azure-monitor/logs/data-platform-logs), Excel, and Power BI. You can learn more about the different types of logs from the following list: -* **Activity log**: You can use [Azure activity logs](../../azure-monitor/essentials/activity-log.md) (formerly known as operational logs and audit logs) to view all operations that are submitted to your Azure subscription, and their status. Activity log entries are collected by default, and you can view them in the Azure portal. +* **Activity log**: You can use [Azure activity logs](/azure/azure-monitor/essentials/activity-log) (formerly known as operational logs and audit logs) to view all operations that are submitted to your Azure subscription, and their status. Activity log entries are collected by default, and you can view them in the Azure portal. * **Access log**: You can use this log to view Application Gateway for Containers access patterns and analyze important information. This includes the caller's IP, requested URL, response latency, return code, and bytes in and out. An access log is collected every 60 seconds. The data may be stored in a storage account that is specified at time of enable logging. ### Configure access log New-AzDiagnosticSetting -Name 'AppGWForContainersLogs' -ResourceId "/subscriptio > [!Note] > After initially enabling diagnostic logs, it may take up to one hour before logs are available at your selected destination. -For more information and Azure Monitor deployment tutorials, see [Diagnostic settings in Azure Monitor](../../azure-monitor/essentials/diagnostic-settings.md). +For more information and Azure Monitor deployment tutorials, see [Diagnostic settings in Azure Monitor](/azure/azure-monitor/essentials/diagnostic-settings). ### Access log format |
| application-gateway | Prometheus Grafana | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/application-gateway/for-containers/prometheus-grafana.md | You can monitor Azure Application Gateway for Containers resources in the follow [](./media/prometheus-grafana/design-arch.png#lightbox) ## Learn About the Services-- [What is Azure Managed Prometheus?](../../azure-monitor/essentials/prometheus-metrics-overview.md)+- [What is Azure Managed Prometheus?](/azure/azure-monitor/essentials/prometheus-metrics-overview) - Why use Prometheus: Azure Prometheus offers native integration and management capabilities, simplifying the setup and management of monitoring infrastructure. - [What is Azure Managed Grafana?](../../managed-grafan) - Why use Grafana: Azure Managed Grafana lets you bring together all your telemetry data into one place and Built-in support for Azure Monitor and Azure Data Explorer using Microsoft Entra identities.-- [What is Azure Log Analytics Workspace?](../../azure-monitor/logs/log-analytics-workspace-overview.md)+- [What is Azure Log Analytics Workspace?](/azure/azure-monitor/logs/log-analytics-workspace-overview) - Why use Log Analytics Workspace: Log Analytics workspace scales with your business needs, handling large volumes of log data efficiently and detects and diagnose issues quickly. ## Prerequisites We created the resources and now we combine all resources and configure promethe ## Enable diagnostic logs for Application Gateway for Containers Activity logging is automatically enabled for every Resource Manager resource. For Access Logs, you must enable access logging to start collecting the data available through those logs. To enable logging, you may configure diagnostic settings in Azure Monitor. -1. [Create a log analytics workspace](../../azure-monitor/logs/quick-create-workspace.md). +1. [Create a log analytics workspace](/azure/azure-monitor/logs/quick-create-workspace). 2. Send logs from Application Gateway for Containers to log analytics workspace: 1. Enter **Application Gateway for Containers** in the search box. Select your active Application Gateway for Container resource. 2. Search and select Diagnostic Setting under Monitoring. Add diagnostic setting. |
| application-gateway | Siem Integration With Sentinel | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/application-gateway/for-containers/siem-integration-with-sentinel.md | In this QuickStart guide, you set up: ## Learn About The Services - [What is Azure Sentinel?](../../sentinel/overview.md) - Why use Sentinel: Sentinel offers security content that is pre-packaged in SIEM solutions, allowing you to monitor, analyze, investigate, notify, and integrate with many platforms and products, including Log Analytics Workspace.-- [What is Azure Log Analytics Workspace?](../../azure-monitor/logs/log-analytics-workspace-overview.md)+- [What is Azure Log Analytics Workspace?](/azure/azure-monitor/logs/log-analytics-workspace-overview) - Why use Log Analytics Workspace: Log Analytics workspace scales with your business needs, handling large volumes of log data efficiently and detects and diagnose issues quickly. ## Prerequisites |
| application-gateway | High Traffic Support | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/application-gateway/high-traffic-support.md | You can use Application Gateway with Web Application Firewall (WAF) for a scalab It's important that you scale your Application Gateway according to your traffic and with a bit of a buffer so that you're prepared for any traffic surges or spikes and minimizing the impact that it may have in your QoS. The following suggestions help you set up Application Gateway with WAF to handle extra traffic. -Please check the [metrics documentation](./application-gateway-metrics.md) for the complete list of metrics offered by Application Gateway. See [visualize metrics](./application-gateway-metrics.md#metrics-visualization) in the Azure portal and the [Azure monitor documentation](../azure-monitor/alerts/alerts-metric.md) on how to set alerts for metrics. +Please check the [metrics documentation](./application-gateway-metrics.md) for the complete list of metrics offered by Application Gateway. See [visualize metrics](./application-gateway-metrics.md#metrics-visualization) in the Azure portal and the [Azure monitor documentation](/azure/azure-monitor/alerts/alerts-metric) on how to set alerts for metrics. For details and recommendations on performance efficiency for Application Gateway, see [Azure Well-Architected Framework review - Azure Application Gateway v2](/azure/well-architected/services/networking/azure-application-gateway#performance-efficiency). Check your Compute Unit metric for the past one month. Compute unit metric is a ## Monitoring and alerting -To get notified of any traffic or utilization anomalies, you can set up alerts on certain metrics. See [metrics documentation](./application-gateway-metrics.md) for the complete list of metrics offered by Application Gateway. See [visualize metrics](./application-gateway-metrics.md#metrics-visualization) in the Azure portal and the [Azure monitor documentation](../azure-monitor/alerts/alerts-metric.md) on how to set alerts for metrics. +To get notified of any traffic or utilization anomalies, you can set up alerts on certain metrics. See [metrics documentation](./application-gateway-metrics.md) for the complete list of metrics offered by Application Gateway. See [visualize metrics](./application-gateway-metrics.md#metrics-visualization) in the Azure portal and the [Azure monitor documentation](/azure/azure-monitor/alerts/alerts-metric) on how to set alerts for metrics. To configure alerts using ARM templates, see [Configure Azure Monitor alerts for Application Gateway](configure-alerts-with-templates.md). |
| application-gateway | Key Vault Certs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/application-gateway/key-vault-certs.md | Azure Application Gateway doesn't just poll for the renewed certificate version 4. You find a recommendation titled **Resolve Azure Key Vault issue for your Application Gateway**, if your gateway is experiencing this issue. Ensure the correct subscription is selected from the drop-down options above. 5. Select it to view the error details, the associated key vault resource and the [troubleshooting guide](../application-gateway/application-gateway-key-vault-common-errors.md) to fix your exact issue. -By identifying such an event through Azure Advisor or Resource Health, you can quickly resolve any configuration problems with your Key Vault. We strongly recommend you take advantage of [Azure Advisor](../advisor/advisor-alerts-portal.md) and [Resource Health](../service-health/resource-health-alert-monitor-guide.md) alerts to stay informed when a problem is detected. +By identifying such an event through Azure Advisor or Resource Health, you can quickly resolve any configuration problems with your Key Vault. We strongly recommend you take advantage of [Azure Advisor](/azure/advisor/advisor-alerts-portal) and [Resource Health](/azure/service-health/resource-health-alert-monitor-guide) alerts to stay informed when a problem is detected. For Advisor alert, use "Resolve Azure Key Vault issue for your Application Gateway" in the recommendation type shown:</br>  |
| application-gateway | Log Analytics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/application-gateway/log-analytics.md | -Once your Application Gateway WAF is operational, you can enable logs to inspect what is happening with each request. Firewall logs give insight to what the WAF is evaluating, matching, and blocking. With Log Analytics, you can examine the data inside the firewall logs to give even more insights. For more information about log queries, see [Overview of log queries in Azure Monitor](../azure-monitor/logs/log-query-overview.md). +Once your Application Gateway WAF is operational, you can enable logs to inspect what is happening with each request. Firewall logs give insight to what the WAF is evaluating, matching, and blocking. With Log Analytics, you can examine the data inside the firewall logs to give even more insights. For more information about log queries, see [Overview of log queries in Azure Monitor](/azure/azure-monitor/logs/log-query-overview). ## Prerequisites * An Azure account with an active subscription is required. If you don't already have an account, you can [create an account for free](https://azure.microsoft.com/free/?WT.mc_id=A261C142F). * An Azure Web Application Firewall with logs enabled. For more information, see [Azure Web Application Firewall on Azure Application Gateway](../web-application-firewall/ag/ag-overview.md).-* A Log Analytics workspace. For more information about creating a Log Analytics workspace, see [Create a Log Analytics workspace in the Azure portal](../azure-monitor/logs/quick-create-workspace.md). +* A Log Analytics workspace. For more information about creating a Log Analytics workspace, see [Create a Log Analytics workspace in the Azure portal](/azure/azure-monitor/logs/quick-create-workspace). ## Import WAF logs |
| application-gateway | Monitor Application Gateway Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/application-gateway/monitor-application-gateway-reference.md | Application Gateway's Layer 4 proxy provides log data through access logs. These You can use Azure activity logs to view all operations that are submitted to your Azure subscription, and their status. Activity log entries are collected by default. You can view them in the Azure portal. Azure activity logs were formerly known as *operational logs* and *audit logs*. -Azure generates activity logs by default. The logs are preserved for 90 days in the Azure event logs store. Learn more about these logs by reading the [View events and activity log](../azure-monitor/essentials/activity-log.md) article. +Azure generates activity logs by default. The logs are preserved for 90 days in the Azure event logs store. Learn more about these logs by reading the [View events and activity log](/azure/azure-monitor/essentials/activity-log) article. ## Related content |
| application-gateway | Monitor Application Gateway | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/application-gateway/monitor-application-gateway.md | For Application Gateway, resource-specific mode creates three tables: :::image type="content" source="./media/application-gateway-diagnostics/resource-specific.png" alt-text="Screenshot of the resource ID for application gateway in the portal." lightbox="./media/application-gateway-diagnostics/resource-specific.png"::: -**Workspace Transformations:** Opting for the Resource specific option allows you to filter and modify your data before [workspace transformations](../azure-monitor/essentials/data-collection-transformations-workspace.md) ingests it. This approach provides granular control, allowing you to focus on the most relevant information from the logs there by reducing data costs and enhancing security. +**Workspace Transformations:** Opting for the Resource specific option allows you to filter and modify your data before [workspace transformations](/azure/azure-monitor/essentials/data-collection-transformations-workspace) ingests it. This approach provides granular control, allowing you to focus on the most relevant information from the logs there by reducing data costs and enhancing security. -For detailed instructions on setting up workspace transformations, see [Tutorial: Add a workspace transformation to Azure Monitor Logs by using the Azure portal](../azure-monitor/logs/tutorial-workspace-transformations-portal.md). +For detailed instructions on setting up workspace transformations, see [Tutorial: Add a workspace transformation to Azure Monitor Logs by using the Azure portal](/azure/azure-monitor/logs/tutorial-workspace-transformations-portal). [!INCLUDE [horz-monitor-platform-metrics](~/reusable-content/ce-skilling/azure/includes/azure-monitor/horizontals/horz-monitor-platform-metrics.md)] Application Gateway v1 |Metric|Response status (4xx, 5xx) crosses threshold|When Application Gateway response status is 4xx or 5xx. There could be occasional 4xx or 5xx response seen due to transient issues. You should observe the gateway in production to determine static threshold or use dynamic threshold for the alert.| |Metric|Failed requests crosses threshold|When failed requests metric crosses a threshold. You should observe the gateway in production to determine static threshold or use dynamic threshold for the alert.| -Azure Monitor alerts proactively notify you when important conditions are found in your monitoring data. They allow you to identify and address issues in your system before your customers notice them. You can set alerts on [metrics](../azure-monitor/alerts/alerts-metric-overview.md), [logs](../azure-monitor/alerts/alerts-unified-log.md), and the [activity log](../azure-monitor/alerts/activity-log-alerts.md). Different types of alerts have benefits and drawbacks. +Azure Monitor alerts proactively notify you when important conditions are found in your monitoring data. They allow you to identify and address issues in your system before your customers notice them. You can set alerts on [metrics](/azure/azure-monitor/alerts/alerts-metric-overview), [logs](/azure/azure-monitor/alerts/alerts-unified-log), and the [activity log](/azure/azure-monitor/alerts/activity-log-alerts). Different types of alerts have benefits and drawbacks. -If you're creating or running an application that uses Application Gateway, [Azure Monitor Application Insights](../azure-monitor/app/app-insights-overview.md) can offer other types of alerts. +If you're creating or running an application that uses Application Gateway, [Azure Monitor Application Insights](/azure/azure-monitor/app/app-insights-overview) can offer other types of alerts. [!INCLUDE [horz-monitor-advisor-recommendations](~/reusable-content/ce-skilling/azure/includes/azure-monitor/horizontals/horz-monitor-advisor-recommendations.md)] |
| application-gateway | Overview V2 | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/application-gateway/overview-v2.md | The v2 SKU includes the following enhancements: Application Gateway v2 is available under two SKUs: - **Basic** (preview): The Basic SKU is designed for applications that have lower traffic and SLA requirements, and don't need advanced traffic management features. For information on how to register for the public preview of Application Gateway Basic SKU, see [Register for the preview](#register-for-the-preview).-- **Standard_v2 SKU**: The Standard_v2 SKU is designed for running production workloads and high traffic. It also includes auto scale that can automatically adjust the number of instances to match your traffic needs. +- **Standard_v2 SKU**: The Standard_v2 SKU is designed for running production workloads and high traffic. It also includes [autoscaling](high-traffic-support.md#autoscaling-for-application-gateway-v2-sku-standard_v2waf_v2-sku), which can automatically adjust the number of instances to match your traffic needs. The following table displays a comparison between Basic and Standard_v2. | Feature | Capabilities | Basic SKU (preview)| Standard SKU | | :: | : | :: | :: | | Reliability | SLA | 99.9 | 99.95 |-| Functionality - basic | HTTP/HTTP2/HTTPS<br>Websocket<br>Public/Private IP<br>Cookie Affinity<br>Path-based affinity<br>Wildcard<br>Multisite<br>KeyVault<br>AKS (via AGIC)<br>Zone<br>Header rewrite | ✓<br>✓<br>✓<br>✓<br>✓<br>✓<br>✓<br>✓<br>✓<br>✓<br>✓ | ✓<br>✓<br>✓<br>✓<br>✓<br>✓<br>✓<br>✓<br>✓<br>✓<br>✓ | -| Functionality - advanced | URL rewrite<br>mTLS<br>Private Link<br>Private-only<sup>1</sup><br>TCP/TLS Proxy | | ✓<br>✓<br>✓<br>✓<br>✓ | +| Functionality - basic | HTTP/HTTP2/HTTPS<br>Websocket<br>Public/Private IP<br>Cookie Affinity<br>Path-based affinity<br>Wildcard<br>Multisite<br>KeyVault<br>Zone<br>Header rewrite | ✓<br>✓<br>✓<br>✓<br>✓<br>✓<br>✓<br>✓<br>✓<br>✓<br>✓ | ✓<br>✓<br>✓<br>✓<br>✓<br>✓<br>✓<br>✓<br>✓<br>✓<br>✓| +| Functionality - advanced | AKS (via AGIC)<br>URL rewrite<br>mTLS<br>Private Link<br>Private-only<sup>1</sup><br>TCP/TLS Proxy | | ✓<br>✓<br>✓<br>✓<br>✓<br>✓ | | Scale | Max. connections per second<br>Number of listeners<br>Number of backend pools<br>Number of backend servers per pool<br>Number of rules | 200<sup>1</sup><br>5<br>5<br>5<br>5 | 62500<sup>1</sup><br>100<br>100<br>1200<br>400 | | Capacity Unit | Connections per second per compute unit<br>Throughput<br>Persistent new connections | 10<br>2.22 Mbps<br>2500 | 50<br>2.22 Mbps<br>2500 | Unregister-AzProviderFeature -FeatureName AllowApplicationGatewayBasicSku -Provi Depending on your requirements and environment, you can create a test Application Gateway using either the Azure portal, Azure PowerShell, or Azure CLI. -- - [Tutorial: Create an application gateway that improves web application access](tutorial-autoscale-ps.md) - [Learn module: Introduction to Azure Application Gateway](/training/modules/intro-to-azure-application-gateway) |
| application-gateway | Parameter Based Path Selection Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/application-gateway/parameter-based-path-selection-portal.md | + + Title: Route traffic using parameter based path selection in portal - Azure Application Gateway +description: Learn how to use the Azure portal to configure an Azure Application Gateway to choose the backend pool based on the value of a header, part of URL, or query string in the request. ++++ Last updated : 09/10/2024++++# Perform parameter based path selection with Azure Application Gateway - Azure portal ++This article describes how to use the Azure portal to configure an [Application Gateway v2 SKU](./application-gateway-autoscaling-zone-redundant.md) instance to perform parameter based path selection by combining the capabilities of URL Rewrite with path-based routing. ++If you don't have an Azure subscription, create a [free account](https://azure.microsoft.com/free/?WT.mc_id=A261C142F) before you begin. ++## Before you begin ++You need to have an Application Gateway v2 SKU instance to complete the steps in this article. URL rewrite and rewriting headers aren't supported in the v1 SKU. If you don't have the v2 SKU, create an [Application Gateway v2 SKU](./tutorial-autoscale-ps.md) instance before you begin. +++## Sign in to Azure ++Sign in to the [Azure portal](https://portal.azure.com/) with your Azure account. ++## Configure parameter based path selection ++For this example, you have a shopping website and the product category is passed as query string in the URL, and you want to route the request to backend based on the query string, then: ++**Step 1:** Create a path-map as shown in the following image: +++**Step 2 (a):** Create a rewrite set which has 3 rewrite rules: ++* The first rule has a condition that checks the *query_string* variable for *category=shoes* and has an action that rewrites the URL path to /*listing1* and has **Reevaluate path map** enabled ++* The second rule has a condition that checks the *query_string* variable for *category=bags* and has an action that rewrites the URL path to /*listing2* and has **Reevaluate path map** enabled ++* The third rule has a condition that checks the *query_string* variable for *category=accessories* and has an action that rewrites the URL path to /*listing3* and has **Reevaluate path map** enabled ++ :::image type="content" source="./media/rewrite-http-headers-url/url-scenario1-2.png" alt-text="A screenshot of URL rewrite scenario 1-2."::: ++ +**Step 2 (b):** Associate this rewrite set with the default path of the previous path-based rule: +++If the user requests *contoso.com/listing?category=any*, then it's matched with the default path since none of the path patterns in the path map (/listing1, /listing2, /listing3) are matched. Since you associated the previous rewrite set with this path, this rewrite set is evaluated. Because the query string doesn't match the condition in any of the 3 rewrite rules in this rewrite set, no rewrite action takes place. Therefore, the request is routed unchanged to the backend associated with the default path (which is *GenericList*). ++If the user requests *contoso.com/listing?category=shoes*, then the default path is matched. However, in this case, the condition in the first rule matches. Therefore, the action associated with the condition is executed, which rewrites the URL path to /*listing1* and reevaluates the path-map. When the path-map is reevaluated, the request matches the path associated with pattern */listing1* and the request is routed to the backend associated with this pattern (ShoesListBackendPool). ++> [!NOTE] +> This scenario can be extended to any header or cookie value, URL path, query string or server variables based on the conditions defined and essentially enables you to route requests based on those conditions. ++## Next steps ++To learn more about how to set up some common use cases, see [common header rewrite scenarios](./rewrite-http-headers-url.md). |
| application-gateway | Resource Health Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/application-gateway/resource-health-overview.md | -[Azure Resource Health](../service-health/resource-health-overview.md) helps you diagnose and get support when an Azure service problem affects your resources. It informs you about the current and past health of your resources. And it provides technical support to help you mitigate problems. +[Azure Resource Health](/azure/service-health/resource-health-overview) helps you diagnose and get support when an Azure service problem affects your resources. It informs you about the current and past health of your resources. And it provides technical support to help you mitigate problems. For Application Gateway, Resource Health relies on signals emitted by the gateway to assess whether it's healthy or not. If the gateway is unhealthy, Resource Health analyzes additional information to determine the source of the problem. It also identifies actions that Microsoft is taking or what you can do to fix the problem. -For additional details on how health is assessed, review the full list of resource types and health checks in [Azure Resource Health](../service-health/resource-health-checks-resource-types.md#microsoftnetworkapplicationgateways). +For additional details on how health is assessed, review the full list of resource types and health checks in [Azure Resource Health](/azure/service-health/resource-health-checks-resource-types#microsoftnetworkapplicationgateways). The health status for Application Gateway is displayed as one of the following statuses: |
| application-gateway | Rewrite Http Headers Url | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/application-gateway/rewrite-http-headers-url.md | description: This article provides an overview of rewriting HTTP headers and URL Previously updated : 09/06/2024 Last updated : 09/10/2024 Here are the steps for replacing the hostname: 1. Create a rewrite rule with a condition that evaluates if the location header in the response contains azurewebsites.net. Enter the pattern `(https?):\/\/.*azurewebsites\.net(.*)$`. 2. Perform an action to rewrite the location header so that it has the application gateway's hostname. Do this by entering `{http_resp_Location_1}://contoso.com{http_resp_Location_2}` as the header value. Alternatively, you can also use the server variable `host` to set the hostname to match the original request. - +  #### Implement security HTTP headers to prevent vulnerabilities You can evaluate an HTTP request or response header for the presence of a header #### Parameter based path selection -To accomplish scenarios where you want to choose the backend pool based on the value of a header, part of the URL, or query string in the request, you can use the combination of URL Rewrite capability and path-based routing. For example, if you have a shopping website and the product category is passed as query string in the URL, and you want to route the request to backend based on the query string, then: +To accomplish scenarios where you want to choose the backend pool based on the value of a header, part of the URL, or query string in the request, you can use a combination of URL Rewrite capability and path-based routing. -**Step1:** Create a path-map as shown in the image below +To do this, create a rewrite set with a condition that checks for a specific parameter (query string, header, etc.) and then performs an action where it changes the URL path (ensure **Reevaluate path map** is enabled). The rewrite set must then be associated to a path based rule. The path based rule must contain the same URL paths specified in the rewrite set and their corresponding backend pool. +Thus, the rewrite set allows users to check for a specific parameter and assign it a new path, and the path based rule allows users to assign backend pools to those paths. As long as "Reevaluate path map" is enabled, traffic routs based on the path specified in the rewrite set. -**Step 2 (a):** Create a rewrite set which has 3 rewrite rules: +For a use case example using query strings, see [Route traffic using parameter based path selection in portal](parameter-based-path-selection-portal.md). -* The first rule has a condition that checks the *query_string* variable for *category=shoes* and has an action that rewrites the URL path to /*listing1* and has **Reevaluate path map** enabled --* The second rule has a condition that checks the *query_string* variable for *category=bags* and has an action that rewrites the URL path to /*listing2* and has **Reevaluate path map** enabled --* The third rule has a condition that checks the *query_string* variable for *category=accessories* and has an action that rewrites the URL path to /*listing3* and has **Reevaluate path map** enabled --- --**Step 2 (b):** Associate this rewrite set with the default path of the above path-based rule ---If the user requests *contoso.com/listing?category=any*, then it's matched with the default path since none of the path patterns in the path map (/listing1, /listing2, /listing3) are matched. Since you associated the previous rewrite set with this path, this rewrite set is evaluated. Because the query string won't match the condition in any of the 3 rewrite rules in this rewrite set, no rewrite action takes place. Therefore, the request is routed unchanged to the backend associated with the default path (which is *GenericList*). --If the user requests *contoso.com/listing?category=shoes*, then the default path is matched. However, in this case the condition in the first rule matches. Therefore, the action associated with the condition is executed, which rewrites the URL path to /*listing1* and reevaluates the path-map. When the path-map is reevaluated, the request matches the path associated with pattern */listing1* and the request is routed to the backend associated with this pattern (ShoesListBackendPool). --> [!NOTE] -> This scenario can be extended to any header or cookie value, URL path, query string or server variables based on the conditions defined and essentially enables you to route requests based on those conditions. #### Rewrite query string parameters based on the URL |
| automanage | Arm Deploy | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automanage/arm-deploy.md | Last updated 12/10/2021 # Onboard a machine to Automanage with an Azure Resource Manager (ARM) template > [!CAUTION]-> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](https://learn.microsoft.com/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://ms.portal.azure.com/). +> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://portal.azure.com/). ## Overview Follow the steps to onboard a machine to Automanage Best Practices using an ARM template. |
| automanage | Automanage Account | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automanage/automanage-account.md | Last updated 12/10/2021 # Automanage Accounts > [!CAUTION]-> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](https://learn.microsoft.com/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://ms.portal.azure.com/). +> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://portal.azure.com/). The Automanage account is the identity that is used by the Automanage service to perform its automated operations. |
| automanage | Automanage Arc | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automanage/automanage-arc.md | Last updated 05/12/2022 # Azure Automanage for Machines Best Practices - Azure Arc-enabled servers > [!CAUTION]-> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](https://learn.microsoft.com/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://ms.portal.azure.com/). +> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://portal.azure.com/). > [!CAUTION] > This article references CentOS, a Linux distribution that is End Of Life (EOL) status. Please consider your use and planning accordingly. For more information, see the [CentOS End Of Life guidance](/azure/virtual-machines/workloads/centos/centos-end-of-life). Automanage supports the following operating systems for Azure Arc-enabled server | Service | Description | Configuration Profile<sup>1</sup> | | | | |-| [Machines Insights Monitoring](../azure-monitor/vm/vminsights-overview.md) | Azure Monitor for machines monitors the performance and health of your virtual machines, including their running processes and dependencies on other resources. | Production | +| [Machines Insights Monitoring](/azure/azure-monitor/vm/vminsights-overview) | Azure Monitor for machines monitors the performance and health of your virtual machines, including their running processes and dependencies on other resources. | Production | | [Update Management](../automation/update-management/overview.md) | You can use Update Management in Azure Automation to manage operating system updates for your machines. You can quickly assess the status of available updates on all agent machines and manage the process of installing required updates for servers. | Production, Dev/Test | | [Microsoft Antimalware](../security/fundamentals/antimalware.md) | Microsoft Antimalware for Azure is a free real-time protection that helps identify and remove viruses, spyware, and other malicious software. It generates alerts when known malicious or unwanted software tries to install itself or run on your Azure systems. **Note:** Microsoft Antimalware requires that there be no other antimalware software installed, or it may fail to work. This is also only supported for Windows Server 2016 and above. | Production, Dev/Test | | [Change Tracking & Inventory](../automation/change-tracking/overview.md) | Change Tracking and Inventory combines change tracking and inventory functions to allow you to track virtual machine and server infrastructure changes. The service supports change tracking across services, daemons software, registry, and files in your environment to help you diagnose unwanted changes and raise alerts. Inventory support allows you to query in-guest resources for visibility into installed applications and other configuration items. | Production, Dev/Test | | [Machine Configuration](../governance/machine-configuration/overview.md) | Machine Configuration policy is used to monitor the configuration and report on the compliance of the machine. The Automanage service will install the Azure security baseline using the Guest Configuration extension. For Arc machines, the machine configuration service will install the baseline in audit-only mode. You will be able to see where your VM is out of compliance with the baseline, but noncompliance won't be automatically remediated. | Production, Dev/Test | | [Azure Automation Account](../automation/automation-create-standalone-account.md) | Azure Automation supports management throughout the lifecycle of your infrastructure and applications. | Production, Dev/Test |-| [Log Analytics Workspace](../azure-monitor/logs/log-analytics-overview.md) | Azure Monitor stores log data in a Log Analytics workspace, which is an Azure resource and a container where data is collected, aggregated, and serves as an administrative boundary. | Production, Dev/Test | +| [Log Analytics Workspace](/azure/azure-monitor/logs/log-analytics-overview) | Azure Monitor stores log data in a Log Analytics workspace, which is an Azure resource and a container where data is collected, aggregated, and serves as an administrative boundary. | Production, Dev/Test | <sup>1</sup> The [configuration profile](overview-configuration-profiles.md) selection is available when you are enabling Automanage. You can also create your own custom profile with the set of Azure services and settings that you need. |
| automanage | Automanage Linux | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automanage/automanage-linux.md | -> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](https://learn.microsoft.com/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://ms.portal.azure.com/). +> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://portal.azure.com/). > [!CAUTION] > This article references CentOS, a Linux distribution that is End Of Life (EOL) status. Please consider your use and planning accordingly. For more information, see the [CentOS End Of Life guidance](/azure/virtual-machines/workloads/centos/centos-end-of-life). Automanage supports the following Linux distributions and versions: | Service | Description | Configuration Profile Supported<sup>1</sup> | | | -- | - |-| [Machines Insights Monitoring](../azure-monitor/vm/vminsights-overview.md) | Azure Monitor for machines monitors the performance and health of your virtual machines, including their running processes and dependencies on other resources. Learn [more](../azure-monitor/vm/vminsights-overview.md). | Production | +| [Machines Insights Monitoring](/azure/azure-monitor/vm/vminsights-overview) | Azure Monitor for machines monitors the performance and health of your virtual machines, including their running processes and dependencies on other resources. Learn [more](/azure/azure-monitor/vm/vminsights-overview). | Production | | [Backup](../backup/backup-overview.md) | Azure Backup provides independent and isolated backups to guard against unintended destruction of the data on your VMs. Learn [more](../backup/backup-azure-vms-introduction.md). Charges are based on the number and size of VMs being protected. Learn [more](https://azure.microsoft.com/pricing/details/backup/). | Production | | [Microsoft Defender for Cloud](../security-center/security-center-introduction.md) | Microsoft Defender for Cloud is a unified infrastructure security management system that strengthens the security posture of your data centers, and provides advanced threat protection across your hybrid workloads in the cloud. Learn [more](../security-center/security-center-introduction.md). Automanage will configure the subscription where your VM resides to the free-tier offering of Microsoft Defender for Cloud (Enhanced security off). If your subscription is already onboarded to Microsoft Defender for Cloud, then Automanage will not reconfigure it. | Production, Dev/Test | | [Update Management](../automation/update-management/overview.md) | You can use Update Management in Azure Automation to manage operating system updates for your machines. You can quickly assess the status of available updates on all agent machines and manage the process of installing required updates for servers. Learn [more](../automation/update-management/overview.md). | Production, Dev/Test | Automanage supports the following Linux distributions and versions: | [Machine configuration](../governance/machine-configuration/overview.md) | Machine configuration is used to monitor the configuration and report on the compliance of the machine. The Automanage service will install the Azure Linux baseline using the guest configuration extension. For Linux machines, the machine configuration service will install the baseline in audit-only mode. You will be able to see where your VM is out of compliance with the baseline, but noncompliance won't be automatically remediated. Learn [more](../governance/machine-configuration/overview.md). | Production, Dev/Test | | [Boot Diagnostics](/azure/virtual-machines/boot-diagnostics) | Boot diagnostics is a debugging feature for Azure virtual machines (VM) that allows diagnosis of VM boot failures. Boot diagnostics enables a user to observe the state of their VM as it is booting up by collecting serial log information and screenshots. This will only be enabled for machines that are using managed disks. | Production, Dev/Test | | [Azure Automation Account](../automation/automation-create-standalone-account.md) | Azure Automation supports management throughout the lifecycle of your infrastructure and applications. Learn [more](../automation/automation-intro.md). | Production, Dev/Test |-| [Log Analytics Workspace](../azure-monitor/logs/log-analytics-workspace-overview.md) | Azure Monitor stores log data in a Log Analytics workspace, which is an Azure resource and a container where data is collected, aggregated, and serves as an administrative boundary. Learn [more](../azure-monitor/logs/workspace-design.md). | Production, Dev/Test | +| [Log Analytics Workspace](/azure/azure-monitor/logs/log-analytics-workspace-overview) | Azure Monitor stores log data in a Log Analytics workspace, which is an Azure resource and a container where data is collected, aggregated, and serves as an administrative boundary. Learn [more](/azure/azure-monitor/logs/workspace-design). | Production, Dev/Test | <sup>1</sup> The configuration profile selection is available when you are enabling Automanage. Learn [more](overview-configuration-profiles.md). You can also create your own custom profile with the set of Azure services and settings that you need. |
| automanage | Automanage Smb Over Quic | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automanage/automanage-smb-over-quic.md | -> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](https://learn.microsoft.com/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://ms.portal.azure.com/). +> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://portal.azure.com/). SMB over QUIC offers an "SMB VPN" for telecommuters, mobile device users, and branch offices, providing secure, reliable connectivity to edge file servers over untrusted networks like the Internet. To learn more about SMB over QUIC and how to configure SMB over QUIC, see [SMB over QUIC](/windows-server/storage/file-server/smb-over-quic). |
| automanage | Automanage Upgrade | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automanage/automanage-upgrade.md | -> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](https://learn.microsoft.com/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://ms.portal.azure.com/). +> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://portal.azure.com/). Automanage machine best practices released the generally available API version. The API now supports creating custom profiles where you can pick and choose the services and settings you want to apply to your machines. This article describes the differences in the versions and how to upgrade. |
| automanage | Automanage Windows Server | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automanage/automanage-windows-server.md | -> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](https://learn.microsoft.com/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://ms.portal.azure.com/). +> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://portal.azure.com/). These Azure services are automatically onboarded for you when you use Automanage Machine Best Practices on a Windows Server VM. They are essential to our best practices white paper, which you can find in our [Cloud Adoption Framework](/azure/cloud-adoption-framework/manage/azure-server-management). Automanage supports the following Windows versions: | Service | Description | Configuration Profile<sup>1</sup> | | - | | |-| [Machines Insights Monitoring](../azure-monitor/vm/vminsights-overview.md) | Azure Monitor for Machines monitors the performance and health of your virtual machines, including their running processes and dependencies on other resources. | Production | +| [Machines Insights Monitoring](/azure/azure-monitor/vm/vminsights-overview) | Azure Monitor for Machines monitors the performance and health of your virtual machines, including their running processes and dependencies on other resources. | Production | | [Backup](../backup/backup-overview.md) | Azure Backup provides independent and isolated backups to guard against unintended destruction of the data on your machines. Charges are based on the number and size of VMs being protected. | Production | | [Microsoft Defender for Cloud](/azure/defender-for-cloud/defender-for-cloud-introduction) | Microsoft Defender for Cloud is a unified infrastructure security management system that strengthens the security posture of your data centers, and provides advanced threat protection across your hybrid workloads in the cloud. Automanage will configure the subscription where your VM resides to the free-tier offering of Microsoft Defender for Cloud (Enhanced security off). If your subscription is already onboarded to Microsoft Defender for Cloud, then Automanage will not reconfigure it. | Production, Dev/Test | | [Microsoft Antimalware](../security/fundamentals/antimalware.md) | Microsoft Antimalware for Azure is a free real-time protection that helps identify and remove viruses, spyware, and other malicious software. It generates alerts when known malicious or unwanted software tries to install itself or run on your Azure systems. **Note:** Microsoft Antimalware requires that there be no other antimalware software installed, or it may fail to work. | Production, Dev/Test | Automanage supports the following Windows versions: | [Boot Diagnostics](/azure/virtual-machines/boot-diagnostics) | Boot diagnostics is a debugging feature for Azure virtual machines (VM) that allows diagnosis of VM boot failures. Boot diagnostics enables a user to observe the state of their VM as it is booting up by collecting serial log information and screenshots. This will only be enabled for machines that are using managed disks. | Production, Dev/Test | | [Windows Admin Center](/windows-server/manage/windows-admin-center/azure/manage-vm) | Use Windows Admin Center (preview) in the Azure portal to manage the Windows Server operating system inside an Azure VM. This is only supported for machines using Windows Server 2016 or higher. Automanage configures Windows Admin Center over a Private IP address. If you wish to connect with Windows Admin Center over a Public IP address, please open an inbound port rule for port 6516. Automanage onboards Windows Admin Center for the Dev/Test profile by default. Use the preferences to enable or disable Windows Admin Center for the Production and Dev/Test environments. | Production, Dev/Test | | [Azure Automation Account](../automation/automation-create-standalone-account.md) | Azure Automation supports management throughout the lifecycle of your infrastructure and applications. | Production, Dev/Test |-| [Log Analytics Workspace](../azure-monitor/logs/log-analytics-overview.md) | Azure Monitor stores log data in a Log Analytics workspace, which is an Azure resource and a container where data is collected, aggregated, and serves as an administrative boundary. | Production, Dev/Test | +| [Log Analytics Workspace](/azure/azure-monitor/logs/log-analytics-overview) | Azure Monitor stores log data in a Log Analytics workspace, which is an Azure resource and a container where data is collected, aggregated, and serves as an administrative boundary. | Production, Dev/Test | <sup>1</sup> The [configuration profile](overview-configuration-profiles.md) selection is available when you are enabling Automanage. You can also create your own custom profile with the set of Azure services and settings that you need. |
| automanage | How To Disable Automanage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automanage/how-to-disable-automanage.md | -> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](https://learn.microsoft.com/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://ms.portal.azure.com/). +> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://portal.azure.com/). You may decide one day to disable Automanage on certain VMs. For instance, your machine is running some super sensitive secure workload and you need to lock it down even further than Azure would have done naturally, so you need to configure the machine outside of Azure best practices. |
| automanage | Move Automanaged Configuration Profile | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automanage/move-automanaged-configuration-profile.md | -> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](https://learn.microsoft.com/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://ms.portal.azure.com/). +> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://portal.azure.com/). This article describes how to migrate an Automanage Configuration Profile to a different region. You might want to move your Configuration Profiles to another region for many reasons. For example, to take advantage of a new Azure region, to meet internal policy and governance requirements, or in response to capacity planning requirements. You may want to deploy Azure Automanage to some VMs that are in a new region. Some regions may require that you use Automanage Configuration Profiles that are local to that region. |
| automanage | Move Automanaged Vms | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automanage/move-automanaged-vms.md | -> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](https://learn.microsoft.com/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://ms.portal.azure.com/). +> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://portal.azure.com/). This article describes how to keep Automanage enabled on a virtual machine (VM) when you move it to a different region. You might want to move your virtual machines to another region for a number of reasons. For example, to take advantage of a new Azure region, to meet internal policy and governance requirements, or in response to capacity planning requirements. Those VMs that you move may be currently Automanaged, and you may want them to remain Automanaged after your move. |
| automanage | Overview About | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automanage/overview-about.md | -> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](https://learn.microsoft.com/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://ms.portal.azure.com/). +> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://portal.azure.com/). This article covers information about Azure Automanage machine best practices, which have the following benefits: |
| automanage | Overview Azure Disk Encryption | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automanage/overview-azure-disk-encryption.md | -> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](https://learn.microsoft.com/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://ms.portal.azure.com/). +> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://portal.azure.com/). Automanage is compatible with VMs that have Azure Disk Encryption (ADE) enabled. |
| automanage | Overview Configuration Profiles | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automanage/overview-configuration-profiles.md | -> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](https://learn.microsoft.com/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://ms.portal.azure.com/). +> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://portal.azure.com/). When you are enabling Automanage for your machine, a configuration profile is required. Configuration profiles are the foundation of this service. They define which services we onboard your machines to and to some extent what the configuration of those services would be. |
| automanage | Overview Vm Status | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automanage/overview-vm-status.md | -> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](https://learn.microsoft.com/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://ms.portal.azure.com/). +> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://portal.azure.com/). In the Azure portal, go to the **Automanage machine best practices** page which lists all of your automanage machines. Here you will see the overall status of each machine. |
| automanage | Quick Create Virtual Machines Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automanage/quick-create-virtual-machines-portal.md | -> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](https://learn.microsoft.com/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://ms.portal.azure.com/). +> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://portal.azure.com/). Get started with Azure Automanage for virtual machines by using the Azure portal to enable automanagement on a new or existing virtual machine. |
| automanage | Repair Automanage Account | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automanage/repair-automanage-account.md | -> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](https://learn.microsoft.com/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://ms.portal.azure.com/). +> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://portal.azure.com/). > [!IMPORTANT] > This article is only relevant for machines that were onboarded to the earlier version of Automanage (API version 2020-06-30-preview). The status for these machines will be **Needs upgrade**. |
| automanage | Virtual Machines Best Practices | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automanage/virtual-machines-best-practices.md | -> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](https://learn.microsoft.com/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://ms.portal.azure.com/). +> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://portal.azure.com/). These Azure services are automatically onboarded for you when you use Automanage. They are essential to our best practices white paper, which you can find in our [Cloud Adoption Framework](/azure/cloud-adoption-framework/manage/azure-server-management). For all of these services, we will auto-onboard, auto-configure, monitor for dri | Service | Description | Profiles Supported<sup>1</sup> | Preferences supported<sup>1</sup> | | - | | | |-| VM Insights Monitoring | Azure Monitor for VMs monitors the performance and health of your virtual machines, including their running processes and dependencies on other resources. Learn [more](../azure-monitor/vm/vminsights-overview.md). | Azure VM Best Practices ΓÇô Production | No | +| VM Insights Monitoring | Azure Monitor for VMs monitors the performance and health of your virtual machines, including their running processes and dependencies on other resources. Learn [more](/azure/azure-monitor/vm/vminsights-overview). | Azure VM Best Practices ΓÇô Production | No | | Backup | Azure Backup provides independent and isolated backups to guard against unintended destruction of the data on your VMs. Learn [more](../backup/backup-azure-vms-introduction.md). Charges are based on the number and size of VMs being protected. Learn [more](https://azure.microsoft.com/pricing/details/backup/). | Azure VM Best Practices ΓÇô Production | Yes | | Microsoft Defender for Cloud | Microsoft Defender for Cloud is a unified infrastructure security management system that strengthens the security posture of your data centers, and provides advanced threat protection across your hybrid workloads in the cloud. Learn [more](/azure/defender-for-cloud/defender-for-cloud-introduction). Automanage will configure the subscription where your VM resides to the free-tier offering of Microsoft Defender for Cloud. If your subscription is already onboarded to Microsoft Defender for Cloud, then automanaged will not reconfigure it. | Azure VM Best Practices ΓÇô Production, Azure VM Best Practices ΓÇô Dev/Test | No | | Microsoft Antimalware | Microsoft Antimalware for Azure is a free real-time protection that helps identify and remove viruses, spyware, and other malicious software. It generates alerts when known malicious or unwanted software tries to install itself or run on your Azure systems. Learn [more](../security/fundamentals/antimalware.md). | Azure VM Best Practices ΓÇô Production, Azure VM Best Practices ΓÇô Dev/Test | Yes | For all of these services, we will auto-onboard, auto-configure, monitor for dri | Change Tracking & Inventory | Change Tracking and Inventory combines change tracking and inventory functions to allow you to track virtual machine and server infrastructure changes. The service supports change tracking across services, daemons software, registry, and files in your environment to help you diagnose unwanted changes and raise alerts. Inventory support allows you to query in-guest resources for visibility into installed applications and other configuration items. Learn [more](../automation/change-tracking/overview.md). | Azure VM Best Practices ΓÇô Production, Azure VM Best Practices ΓÇô Dev/Test | No | | Guest configuration | Guest configuration is used to monitor the configuration and report on the compliance of the machine. The Automanage service will install the [Windows security baselines](/windows/security/threat-protection/windows-security-baselines) using the guest configuration extension. Learn [more](../governance/machine-configuration/overview.md). | Azure VM Best Practices ΓÇô Production, Azure VM Best Practices ΓÇô Dev/Test | No | | Azure Automation Account | Azure Automation supports management throughout the lifecycle of your infrastructure and applications. Learn [more](../automation/automation-intro.md). | Azure VM Best Practices ΓÇô Production, Azure VM Best Practices ΓÇô Dev/Test | No |-| Log Analytics Workspace | Azure Monitor stores log data in a Log Analytics workspace, which is an Azure resource and a container where data is collected, aggregated, and serves as an administrative boundary. Learn [more](../azure-monitor/logs/log-analytics-workspace-overview.md). | Azure VM Best Practices ΓÇô Production, Azure VM Best Practices ΓÇô Dev/Test | No | +| Log Analytics Workspace | Azure Monitor stores log data in a Log Analytics workspace, which is an Azure resource and a container where data is collected, aggregated, and serves as an administrative boundary. Learn [more](/azure/azure-monitor/logs/log-analytics-workspace-overview). | Azure VM Best Practices ΓÇô Production, Azure VM Best Practices ΓÇô Dev/Test | No | <sup>1</sup> Configuration profiles are available when you are enabling Automanage. Learn [more](overview-about.md). You can also adjust the default settings of the configuration profile and set your own preferences within the best practices constraints. |
| automanage | Virtual Machines Custom Profile | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automanage/virtual-machines-custom-profile.md | -> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](https://learn.microsoft.com/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://ms.portal.azure.com/). +> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://portal.azure.com/). Azure Automanage for Virtual Machines includes default best practice profiles that can't be edited. However, if you need more flexibility, you can pick and choose the set of services and settings by creating a custom profile. |
| automanage | Virtual Machines Policy Enable | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automanage/virtual-machines-policy-enable.md | -> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](https://learn.microsoft.com/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://ms.portal.azure.com/). +> On 31 August 2024, both Automation Update Management and the Log Analytics agent it uses will be retired. Migrate to Azure Update Manager before that. Refer to guidance on migrating to Azure Update Manager [here](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager?WT.mc_id=Portal-Microsoft_Azure_Automation). [Migrate Now](https://portal.azure.com/). If you want to enable Automanage for lots of VMs, you can do that using a built-in [Azure Policy](..\governance\azure-management.md). This article will walk you through finding the right policy and how to assign it in order to enable Automanage in the Azure portal. |
| automation | Automation Alert Metric | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/automation-alert-metric.md | -In this article, you learn how to create a [metric alert](../azure-monitor/alerts/alerts-metric-overview.md) based on runbook completion status. +In this article, you learn how to create a [metric alert](/azure/azure-monitor/alerts/alerts-metric-overview) based on runbook completion status. ## Sign in to Azure Alerts allow you to define a condition to monitor for and an action to take when ### Define the action to take -1. Under **Action group**, select **Specify action group**. An action group is a group of actions that you can use across more than one alert. These can include but aren't limited to, email notifications, runbooks, webhooks, and many more. To learn more about action groups and steps to create one that sends an email notification, see [Create and manage action groups](../azure-monitor/alerts/action-groups.md). +1. Under **Action group**, select **Specify action group**. An action group is a group of actions that you can use across more than one alert. These can include but aren't limited to, email notifications, runbooks, webhooks, and many more. To learn more about action groups and steps to create one that sends an email notification, see [Create and manage action groups](/azure/azure-monitor/alerts/action-groups). ### Define alert details |
| automation | Automation Create Alert Triggered Runbook | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/automation-create-alert-triggered-runbook.md | -You can use [Azure Monitor](../azure-monitor/overview.md) to monitor base-level metrics and logs for most services in Azure. You can call Azure Automation runbooks by using [action groups](../azure-monitor/alerts/action-groups.md) to automate tasks based on alerts. This article shows you how to configure and run a runbook by using alerts. +You can use [Azure Monitor](/azure/azure-monitor/overview) to monitor base-level metrics and logs for most services in Azure. You can call Azure Automation runbooks by using [action groups](/azure/azure-monitor/alerts/action-groups) to automate tasks based on alerts. This article shows you how to configure and run a runbook by using alerts. ## Prerequisites You can use automation runbooks with three alert types: * Near-real-time metric alerts > [!NOTE]-> The common alert schema standardizes the consumption experience for alert notifications in Azure. Historically, the three alert types in Azure (metric, log, and activity log) have had their own email templates, webhook schemas, etc. To learn more, see [Common alert schema](../azure-monitor/alerts/alerts-common-schema.md). +> The common alert schema standardizes the consumption experience for alert notifications in Azure. Historically, the three alert types in Azure (metric, log, and activity log) have had their own email templates, webhook schemas, etc. To learn more, see [Common alert schema](/azure/azure-monitor/alerts/alerts-common-schema). When an alert calls a runbook, the actual call is an HTTP POST request to the webhook. The body of the POST request contains a JSON-formated object that has useful properties that are related to the alert. The following table lists links to the payload schema for each alert type: |Alert |Description|Payload schema | ||||-|[Common alert](../azure-monitor/alerts/alerts-common-schema.md)|The common alert schema that standardizes the consumption experience for alert notifications in Azure today.|Common alert payload schema.| -|[Activity log alert](../azure-monitor/alerts/activity-log-alerts.md) |Sends a notification when any new event in the Azure activity log matches specific conditions. For example, when a `Delete VM` operation occurs in **myProductionResourceGroup** or when a new Azure Service Health event with an Active status appears.| [Activity log alert payload schema](../azure-monitor/alerts/activity-log-alerts-webhook.md) | -|[Near real-time metric alert](../azure-monitor/alerts/alerts-metric-near-real-time.md) | Sends a notification faster than metric alerts when one or more platform-level metrics meet specified conditions. For example, when the value for **CPU %** on a VM is greater than 90, and the value for **Network In** is greater than 500 MB for the past 5 minutes.| [Near real-time metric alert payload schema](../azure-monitor/alerts/alerts-webhooks.md#payload-schema) | +|[Common alert](/azure/azure-monitor/alerts/alerts-common-schema)|The common alert schema that standardizes the consumption experience for alert notifications in Azure today.|Common alert payload schema.| +|[Activity log alert](/azure/azure-monitor/alerts/activity-log-alerts) |Sends a notification when any new event in the Azure activity log matches specific conditions. For example, when a `Delete VM` operation occurs in **myProductionResourceGroup** or when a new Azure Service Health event with an Active status appears.| [Activity log alert payload schema](/azure/azure-monitor/alerts/activity-log-alerts-webhook) | +|[Near real-time metric alert](/azure/azure-monitor/alerts/alerts-metric-near-real-time) | Sends a notification faster than metric alerts when one or more platform-level metrics meet specified conditions. For example, when the value for **CPU %** on a VM is greater than 90, and the value for **Network In** is greater than 500 MB for the past 5 minutes.| [Near real-time metric alert payload schema](/azure/azure-monitor/alerts/alerts-webhooks#payload-schema) | Because the data that's provided by each type of alert is different, each alert type is handled differently. In the next section, you learn how to create a runbook to handle different types of alerts. Alerts use action groups, which are collections of actions that are triggered by 1. Under **Alert rule details**, for the **Alert rule name** text box. -1. Select **Create alert rule**. You can use the action group in the [activity log alerts](../azure-monitor/alerts/activity-log-alerts.md) and [near real-time alerts](../azure-monitor/alerts/alerts-overview.md) that you create. +1. Select **Create alert rule**. You can use the action group in the [activity log alerts](/azure/azure-monitor/alerts/activity-log-alerts) and [near real-time alerts](/azure/azure-monitor/alerts/alerts-overview) that you create. ## Verification Azure Automation provides scripts for common Azure VM management operations like ## Next steps * Discover different ways to start a runbook, see [Start a runbook](./start-runbooks.md).-* Create an activity log alert, see [Create activity log alerts](../azure-monitor/alerts/activity-log-alerts.md). -* Learn how to create a near real-time alert, see [Create an alert rule in the Azure portal](../azure-monitor/alerts/alerts-metric.md?toc=/azure/azure-monitor/toc.json). +* Create an activity log alert, see [Create activity log alerts](/azure/azure-monitor/alerts/activity-log-alerts). +* Learn how to create a near real-time alert, see [Create an alert rule in the Azure portal](/azure/azure-monitor/alerts/alerts-metric?toc=/azure/azure-monitor/toc.json). |
| automation | Automation Dsc Diagnostics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/automation-dsc-diagnostics.md | -Azure Automation State Configuration retains node status data for 30 days. You can send node status data to [Azure Monitor Logs](../azure-monitor/logs/data-platform-logs.md) if you prefer to retain this data for a longer period. Compliance status is visible in the Azure portal or with PowerShell, for nodes and for individual DSC resources in node configurations. +Azure Automation State Configuration retains node status data for 30 days. You can send node status data to [Azure Monitor Logs](/azure/azure-monitor/logs/data-platform-logs) if you prefer to retain this data for a longer period. Compliance status is visible in the Azure portal or with PowerShell, for nodes and for individual DSC resources in node configurations. Azure Monitor Logs provides greater operational visibility to your Automation State Configuration data and can help address incidents more quickly. With Azure Monitor Logs you can: To start sending your Automation State Configuration reports to Azure Monitor Lo * The PowerShell [Az Module](/powershell/azure/new-azureps-module-az) installed. Ensure you have the latest version. If necessary, run `Update-Module -Name Az`. - An Azure Automation account. For more information, see [An introduction to Azure Automation](automation-intro.md).-- A Log Analytics workspace. For more information, see [Azure Monitor Logs overview](../azure-monitor/logs/data-platform-logs.md).+- A Log Analytics workspace. For more information, see [Azure Monitor Logs overview](/azure/azure-monitor/logs/data-platform-logs). - At least one Azure Automation State Configuration node. For more information, see [Onboarding machines for management by Azure Automation State Configuration](automation-dsc-onboarding.md). - The [xDscDiagnostics](https://www.powershellgallery.com/packages/xDscDiagnostics/2.7.0.0) module, version 2.7.0.0 or greater. For installation steps, see [Troubleshoot Azure Automation Desired State Configuration](./troubleshoot/desired-state-configuration.md). Filtering details: - Filter on `DscResourceStatusData` to return operations for each DSC resource called in the node configuration applied to that resource. - Filter on `DscResourceStatusData` to return error information for any DSC resources that fail. -To learn more about constructing log queries to find data, see [Overview of log queries in Azure Monitor](../azure-monitor/logs/log-query-overview.md). +To learn more about constructing log queries to find data, see [Overview of log queries in Azure Monitor](/azure/azure-monitor/logs/log-query-overview). ### Send an email when a State Configuration compliance check fails To learn more about constructing log queries to find data, see [Overview of log If you have set up logs from more than one Automation account or subscription to your workspace, you can group your alerts by subscription and Automation account. Derive the Automation account name from the `Resource` property in the log search results of the `DscNodeStatusData`. -1. Review [Create, view, and manage metric alerts using Azure Monitor](../azure-monitor/alerts/alerts-metric.md) to complete the remaining steps. +1. Review [Create, view, and manage metric alerts using Azure Monitor](/azure/azure-monitor/alerts/alerts-metric) to complete the remaining steps. ### Find failed DSC resources across all nodes Azure Automation diagnostics create two categories of records in Azure Monitor L - For a PowerShell cmdlet reference, see [Az.Automation](/powershell/module/az.automation). - For pricing information, see [Azure Automation State Configuration pricing](https://azure.microsoft.com/pricing/details/automation/). - To see an example of using Azure Automation State Configuration in a continuous deployment pipeline, see [Set up continuous deployment with Chocolatey](automation-dsc-cd-chocolatey.md).-- To learn more about how to construct different search queries and review the Automation State Configuration logs with Azure Monitor Logs, see [Log searches in Azure Monitor Logs](../azure-monitor/logs/log-query-overview.md).-- To learn more about Azure Monitor Logs and data collection sources, see [Collecting Azure storage data in Azure Monitor Logs overview](../azure-monitor/essentials/resource-logs.md#send-to-log-analytics-workspace).+- To learn more about how to construct different search queries and review the Automation State Configuration logs with Azure Monitor Logs, see [Log searches in Azure Monitor Logs](/azure/azure-monitor/logs/log-query-overview). +- To learn more about Azure Monitor Logs and data collection sources, see [Collecting Azure storage data in Azure Monitor Logs overview](/azure/azure-monitor/essentials/resource-logs#send-to-log-analytics-workspace). |
| automation | Automation Hybrid Runbook Worker | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/automation-hybrid-runbook-worker.md | Azure Automation provides native integration of the Hybrid Runbook Worker role t | Platform | Description | ||| |**Extension-based (V2)** |Installed using the [Hybrid Runbook Worker VM extension](./extension-based-hybrid-runbook-worker-install.md), without any dependency on the Log Analytics agent reporting to an Azure Monitor Log Analytics workspace. **This is the recommended platform**.|-|**Agent-based (V1)** |Installed after the [Log Analytics agent](../azure-monitor/agents/log-analytics-agent.md) reporting to an Azure Monitor [Log Analytics workspace](../azure-monitor/logs/log-analytics-workspace-overview.md) is completed.| +|**Agent-based (V1)** |Installed after the [Log Analytics agent](/azure/azure-monitor/agents/log-analytics-agent) reporting to an Azure Monitor [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-workspace-overview) is completed.| :::image type="content" source="./media/automation-hybrid-runbook-worker/hybrid-worker-group-platform-inline.png" alt-text="Screenshot of hybrid worker group showing platform field." lightbox="./media/automation-hybrid-runbook-worker/hybrid-worker-group-platform-expanded.png"::: There are two types of Runbook Workers - system and user. The following table de |**System** |Supports a set of hidden runbooks used by the Update Management feature that are designed to install user-specified updates on Windows and Linux machines.<br> This type of Hybrid Runbook Worker isn't a member of a Hybrid Runbook Worker group, and therefore doesn't run runbooks that target a Runbook Worker group. | |**User** |Supports user-defined runbooks intended to run directly on the Windows and Linux machines. | -Agent-based (V1) Hybrid Runbook Workers rely on the [Log Analytics agent](../azure-monitor/agents/log-analytics-agent.md) reporting to an Azure Monitor [Log Analytics workspace](../azure-monitor/logs/log-analytics-workspace-overview.md). The workspace isn't only to collect monitoring data from the machine, but also to download the components required to install the agent-based Hybrid Runbook Worker. +Agent-based (V1) Hybrid Runbook Workers rely on the [Log Analytics agent](/azure/azure-monitor/agents/log-analytics-agent) reporting to an Azure Monitor [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-workspace-overview). The workspace isn't only to collect monitoring data from the machine, but also to download the components required to install the agent-based Hybrid Runbook Worker. When Azure Automation [Update Management](./update-management/overview.md) is enabled, any machine connected to your Log Analytics workspace is automatically configured as a system Hybrid Runbook Worker. To configure it as a user Windows Hybrid Runbook Worker, see [Deploy an agent-based Windows Hybrid Runbook Worker in Automation](automation-windows-hrw-install.md) and for Linux, see [Deploy an agent-based Linux Hybrid Runbook Worker in Automation](./automation-linux-hrw-install.md). If you use a proxy server for communication between Azure Automation and machine ### Firewall use -If you use a firewall to restrict access to the Internet, you must configure the firewall to permit access. If using the Log Analytics gateway as a proxy, ensure that it's configured for Hybrid Runbook Workers. See [Configure the Log Analytics gateway for Automation Hybrid Runbook Workers](../azure-monitor/agents/gateway.md). +If you use a firewall to restrict access to the Internet, you must configure the firewall to permit access. If using the Log Analytics gateway as a proxy, ensure that it's configured for Hybrid Runbook Workers. See [Configure the Log Analytics gateway for Automation Hybrid Runbook Workers](/azure/azure-monitor/agents/gateway). ### Service tags |
| automation | Automation Linux Hrw Install | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/automation-linux-hrw-install.md | Before you start, make sure that you've the following. ### A Log Analytics workspace -The Hybrid Runbook Worker role depends on an Azure Monitor Log Analytics workspace to install and configure the role. You can create it through [Azure Resource Manager](../azure-monitor/logs/resource-manager-workspace.md#create-a-log-analytics-workspace), through [PowerShell](../azure-monitor/logs/powershell-workspace-configuration.md?toc=%2fpowershell%2fmodule%2ftoc.json), or in the [Azure portal](../azure-monitor/logs/quick-create-workspace.md). +The Hybrid Runbook Worker role depends on an Azure Monitor Log Analytics workspace to install and configure the role. You can create it through [Azure Resource Manager](/azure/azure-monitor/logs/resource-manager-workspace#create-a-log-analytics-workspace), through [PowerShell](/azure/azure-monitor/logs/powershell-workspace-configuration?toc=%2fpowershell%2fmodule%2ftoc.json), or in the [Azure portal](/azure/azure-monitor/logs/quick-create-workspace). -If you don't have an Azure Monitor Log Analytics workspace, review the [Azure Monitor Log design guidance](../azure-monitor/logs/workspace-design.md) before you create the workspace. +If you don't have an Azure Monitor Log Analytics workspace, review the [Azure Monitor Log design guidance](/azure/azure-monitor/logs/workspace-design) before you create the workspace. ### Log Analytics agent -The Hybrid Runbook Worker role requires the [Log Analytics agent](../azure-monitor/agents/log-analytics-agent.md) for the supported Linux operating system. For servers or machines hosted outside of Azure, you can install the Log Analytics agent using [Azure Arc-enabled servers](../azure-arc/servers/overview.md). The agent is installed with certain service accounts that execute commands requiring root permissions. For more information, see [Service accounts](./automation-hrw-run-runbooks.md#service-accounts). +The Hybrid Runbook Worker role requires the [Log Analytics agent](/azure/azure-monitor/agents/log-analytics-agent) for the supported Linux operating system. For servers or machines hosted outside of Azure, you can install the Log Analytics agent using [Azure Arc-enabled servers](../azure-arc/servers/overview.md). The agent is installed with certain service accounts that execute commands requiring root permissions. For more information, see [Service accounts](./automation-hrw-run-runbooks.md#service-accounts). ### Supported Linux operating systems |
| automation | Automation Manage Send Joblogs Log Analytics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/automation-manage-send-joblogs-log-analytics.md | Azure Automation can send runbook job status and job streams to your Log Analyti - Use customized views and search queries to visualize your runbook results, runbook job status, and other related key indicators or metrics through an [Azure dashboard](../azure-portal/azure-portal-dashboards.md). - Get the audit logs related to Automation accounts, runbooks, and other asset create, modify and delete operations. -Using Azure Monitor logs, you can consolidate logs from different resources in the same workspace where it can be analyzed with [queries](../azure-monitor/logs/log-query-overview.md) to quickly retrieve, consolidate, and analyze the collected data. You can create and test queries using [Log Analytics](../azure-monitor/logs/log-query-overview.md) in the Azure portal and then either directly analyze the data using these tools or save queries for use with [visualization](../azure-monitor/best-practices-analysis.md) or [alert rules](../azure-monitor/alerts/alerts-overview.md). +Using Azure Monitor logs, you can consolidate logs from different resources in the same workspace where it can be analyzed with [queries](/azure/azure-monitor/logs/log-query-overview) to quickly retrieve, consolidate, and analyze the collected data. You can create and test queries using [Log Analytics](/azure/azure-monitor/logs/log-query-overview) in the Azure portal and then either directly analyze the data using these tools or save queries for use with [visualization](/azure/azure-monitor/best-practices-analysis) or [alert rules](/azure/azure-monitor/alerts/alerts-overview). -Azure Monitor uses a version of the [Kusto query language (KQL)](/azure/kusto/query/) used by Azure Data Explorer that is suitable for simple log queries. It also includes advanced functionality such as aggregations, joins, and smart analytics. You can quickly learn the query language using [multiple lessons](../azure-monitor/logs/get-started-queries.md). +Azure Monitor uses a version of the [Kusto query language (KQL)](/azure/kusto/query/) used by Azure Data Explorer that is suitable for simple log queries. It also includes advanced functionality such as aggregations, joins, and smart analytics. You can quickly learn the query language using [multiple lessons](/azure/azure-monitor/logs/get-started-queries). ## Azure Automation diagnostic settings You can configure diagnostic settings in the Azure portal from the menu for the :::image type="content" source="media/automation-manage-send-joblogs-log-analytics/destination-details-options-inline.png" alt-text="Screenshot showing selections in destination details section." lightbox="media/automation-manage-send-joblogs-log-analytics/destination-details-options-expanded.png"::: - - **Log Analytics** : Enter the Subscription ID and workspace name. If you don't have a workspace, you must [create one before proceeding](../azure-monitor/logs/quick-create-workspace.md). + - **Log Analytics** : Enter the Subscription ID and workspace name. If you don't have a workspace, you must [create one before proceeding](/azure/azure-monitor/logs/quick-create-workspace). - **Event Hubs**: Specify the following criteria: - Subscription: The same subscription as that of the Event Hub. You can configure diagnostic settings in the Azure portal from the menu for the 1. Click **Save**. -After a few moments, the new setting appears in your list of settings for this resource, and logs are streamed to the specified destinations as new event data is generated. There can be 15 minutes time difference between the event emitted and its appearance in [Log Analytics workspace](../azure-monitor/logs/data-ingestion-time.md). +After a few moments, the new setting appears in your list of settings for this resource, and logs are streamed to the specified destinations as new event data is generated. There can be 15 minutes time difference between the event emitted and its appearance in [Log Analytics workspace](/azure/azure-monitor/logs/data-ingestion-time). ## Query the logs To create an alert rule, create a log search for the runbook job records that sh ```kusto AzureDiagnostics | where ResourceProvider == "MICROSOFT.AUTOMATION" and Category == "JobLogs" and (ResultType == "Failed" or ResultType == "Suspended") | summarize AggregatedValue = count() by RunbookName_s ```- 1. To open the **Create alert rule** screen, click **+New alert rule** on the top of the page. For more information on the options to configure the alerts, see [Log alerts in Azure](../azure-monitor/alerts/alerts-log.md#create-a-new-log-alert-rule-in-the-azure-portal) + 1. To open the **Create alert rule** screen, click **+New alert rule** on the top of the page. For more information on the options to configure the alerts, see [Log alerts in Azure](/azure/azure-monitor/alerts/alerts-log#create-a-new-log-alert-rule-in-the-azure-portal) ## Azure Automation diagnostic audit logs You can now send audit logs also to the Azure Monitor workspace. This allows ent ## Difference between activity logs and audit logs -Activity log is aΓÇ»[platform log](../azure-monitor/essentials/platform-logs-overview.md)in Azure that provides insight into subscription-level events. The activity log for Automation account includes information about when an automation resource is modified or created or deleted. However, it does not capture the name or ID of the resource. +Activity log is aΓÇ»[platform log](/azure/azure-monitor/essentials/platform-logs-overview)in Azure that provides insight into subscription-level events. The activity log for Automation account includes information about when an automation resource is modified or created or deleted. However, it does not capture the name or ID of the resource. Audit logs for Automation accounts capture the name and ID of the resource such as automation variable, credential, connection and so on, along with the type of the operation performed for the resource and Azure Automation would scrub some details like client IP data conforming to the GDPR compliance. AzureDiagnostics ## Next steps -* To learn how to construct search queries and review the Automation job logs with Azure Monitor logs, see [Log searches in Azure Monitor logs](../azure-monitor/logs/log-query-overview.md). +* To learn how to construct search queries and review the Automation job logs with Azure Monitor logs, see [Log searches in Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview). * To understand creation and retrieval of output and error messages from runbooks, see [Monitor runbook output](automation-runbook-output-and-messages.md). * To learn more about runbook execution, how to monitor runbook jobs, and other technical details, see [Runbook execution in Azure Automation](automation-runbook-execution.md).-* To learn more about Azure Monitor logs and data collection sources, see [Collecting Azure storage data in Azure Monitor logs overview](../azure-monitor/essentials/resource-logs.md#send-to-log-analytics-workspace). -* For help troubleshooting Log Analytics, see [Troubleshooting why Log Analytics is no longer collecting data](../azure-monitor/logs/data-collection-troubleshoot.md). +* To learn more about Azure Monitor logs and data collection sources, see [Collecting Azure storage data in Azure Monitor logs overview](/azure/azure-monitor/essentials/resource-logs#send-to-log-analytics-workspace). +* For help troubleshooting Log Analytics, see [Troubleshooting why Log Analytics is no longer collecting data](/azure/azure-monitor/logs/data-collection-troubleshoot). |
| automation | Automation Managing Data | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/automation-managing-data.md | To ensure the security of data in transit to Azure Automation, we strongly encou Older versions of TLS/Secure Sockets Layer (SSL) have been found to be vulnerable and while they still currently work to allow backwards compatibility, they are **not recommended**. We do not recommend explicitly setting your agent to only use TLS 1.2 unless its necessary, as it can break platform level security features that allow you to automatically detect and take advantage of newer more secure protocols as they become available, such as TLS 1.3. -For information about TLS support with the Log Analytics agent for Windows and Linux, which is a dependency for the Hybrid Runbook Worker role, see [Log Analytics agent overview - TLS](../azure-monitor/agents/log-analytics-agent.md#tls-protocol). +For information about TLS support with the Log Analytics agent for Windows and Linux, which is a dependency for the Hybrid Runbook Worker role, see [Log Analytics agent overview - TLS](/azure/azure-monitor/agents/log-analytics-agent#tls-protocol). ### Upgrade TLS protocol for Hybrid Workers and Webhook calls |
| automation | Automation Network Configuration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/automation-network-configuration.md | The following port and URLs are required for the Hybrid Runbook Worker, and for ### Network planning for Hybrid Runbook Worker -For either a system or user Hybrid Runbook Worker to connect to and register with Azure Automation, it must have access to the port number and URLs described in this section. The worker must also have access to the [ports and URLs required for the Log Analytics agent](../azure-monitor/agents/log-analytics-agent.md) to connect to the Azure Monitor Log Analytics workspace. +For either a system or user Hybrid Runbook Worker to connect to and register with Azure Automation, it must have access to the port number and URLs described in this section. The worker must also have access to the [ports and URLs required for the Log Analytics agent](/azure/azure-monitor/agents/log-analytics-agent) to connect to the Azure Monitor Log Analytics workspace. If you have an Automation account that's defined for a specific region, you can restrict Hybrid Runbook Worker communication to that regional datacenter. Review the [DNS records used by Azure Automation](how-to/automation-region-dns-records.md) for the required DNS records. |
| automation | Automation Runbook Execution | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/automation-runbook-execution.md | A runbook requires appropriate [credentials](shared-resources/credentials.md) to ## Azure Monitor -Azure Automation makes use of [Azure Monitor](../azure-monitor/overview.md) for monitoring its machine operations. The operations require a Log Analytics workspace and a [Log Analytics agent](../azure-monitor/agents/log-analytics-agent.md). +Azure Automation makes use of [Azure Monitor](/azure/azure-monitor/overview) for monitoring its machine operations. The operations require a Log Analytics workspace and a [Log Analytics agent](/azure/azure-monitor/agents/log-analytics-agent). ### Log Analytics agent for Windows -The [Log Analytics agent for Windows](../azure-monitor/agents/agent-windows.md) works with Azure Monitor to manage Windows VMs and physical computers. The machines can be running either in Azure or in a non-Azure environment, such as a local datacenter. +The [Log Analytics agent for Windows](/azure/azure-monitor/agents/agent-windows) works with Azure Monitor to manage Windows VMs and physical computers. The machines can be running either in Azure or in a non-Azure environment, such as a local datacenter. >[!NOTE] >The Log Analytics agent for Windows was previously known as the Microsoft Monitoring Agent (MMA). ### Log Analytics agent for Linux -The [Log Analytics agent for Linux](../azure-monitor/agents/agent-linux.md) works similarly to the agent for Windows, but connects Linux computers to Azure Monitor. The agent is installed with certain service accounts that execute commands requiring root permissions. For more information, see [Service accounts](./automation-hrw-run-runbooks.md#service-accounts). +The [Log Analytics agent for Linux](/azure/azure-monitor/agents/agent-linux) works similarly to the agent for Windows, but connects Linux computers to Azure Monitor. The agent is installed with certain service accounts that execute commands requiring root permissions. For more information, see [Service accounts](./automation-hrw-run-runbooks.md#service-accounts). The Log Analytics agent log is located at `/var/opt/microsoft/omsagent/log/omsagent.log`. |
| automation | Automation Tutorial Installed Software | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/automation-tutorial-installed-software.md | First you need to enable Change tracking and Inventory for this tutorial. If you 1. Navigate to your Automation account and select **Inventory** or **Change tracking** under **Configuration Management**. -2. Choose the [Log Analytics](../azure-monitor/logs/log-query-overview.md) workspace. This workspace collects data that is generated by features such as Change Tracking and Inventory. The workspace provides a single location to review and analyze data from multiple sources. +2. Choose the [Log Analytics](/azure/azure-monitor/logs/log-query-overview) workspace. This workspace collects data that is generated by features such as Change Tracking and Inventory. The workspace provides a single location to review and analyze data from multiple sources. [!INCLUDE [azure-monitor-log-analytics-rebrand](~/reusable-content/ce-skilling/azure/includes/azure-monitor-log-analytics-rebrand.md)] After the feature is enabled, information about installed software and changes o To enable non-Azure machines for the feature: -1. Install the [Log Analytics agent for Windows](../azure-monitor/agents/agent-windows.md) or [Log Analytics agent for Linux](automation-linux-hrw-install.md), depending on your operating system. +1. Install the [Log Analytics agent for Windows](/azure/azure-monitor/agents/agent-windows) or [Log Analytics agent for Linux](automation-linux-hrw-install.md), depending on your operating system. 2. Navigate to your Automation account and go to **Inventory** or **Change tracking** under **Configuration Management**. ConfigurationData | summarize arg_max(TimeGenerated, *) by SoftwareName, Computer ``` -To learn more about running and searching log files in Azure Monitor logs, see [Azure Monitor logs](../azure-monitor/logs/log-query-overview.md). +To learn more about running and searching log files in Azure Monitor logs, see [Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview). ## See the software inventory for a single machine |
| automation | Automation Windows Hrw Install | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/automation-windows-hrw-install.md | Before you start, make sure that you have the following. ### A Log Analytics workspace -The Hybrid Runbook Worker role depends on an Azure Monitor Log Analytics workspace to install and configure the role. You can create it through [Azure Resource Manager](../azure-monitor/logs/resource-manager-workspace.md#create-a-log-analytics-workspace), through [PowerShell](../azure-monitor/logs/powershell-workspace-configuration.md?toc=%2fpowershell%2fmodule%2ftoc.json), or in the [Azure portal](../azure-monitor/logs/quick-create-workspace.md). +The Hybrid Runbook Worker role depends on an Azure Monitor Log Analytics workspace to install and configure the role. You can create it through [Azure Resource Manager](/azure/azure-monitor/logs/resource-manager-workspace#create-a-log-analytics-workspace), through [PowerShell](/azure/azure-monitor/logs/powershell-workspace-configuration?toc=%2fpowershell%2fmodule%2ftoc.json), or in the [Azure portal](/azure/azure-monitor/logs/quick-create-workspace). -If you don't have an Azure Monitor Log Analytics workspace, review the [Azure Monitor Log design guidance](../azure-monitor/logs/workspace-design.md) before you create the workspace. +If you don't have an Azure Monitor Log Analytics workspace, review the [Azure Monitor Log design guidance](/azure/azure-monitor/logs/workspace-design) before you create the workspace. ### Log Analytics agent -The Hybrid Runbook Worker role requires the [Log Analytics agent](../azure-monitor/agents/log-analytics-agent.md) for the supported Windows operating system. For servers or machines hosted outside of Azure, you can install the Log Analytics agent using [Azure Arc-enabled servers](../azure-arc/servers/overview.md). +The Hybrid Runbook Worker role requires the [Log Analytics agent](/azure/azure-monitor/agents/log-analytics-agent) for the supported Windows operating system. For servers or machines hosted outside of Azure, you can install the Log Analytics agent using [Azure Arc-enabled servers](../azure-arc/servers/overview.md). ### Supported Windows operating system The *Azure Automation* folder has a sub-folder with the version number as the na ## Update Log Analytics agent to latest version -Azure Automation [Agent-based User Hybrid Runbook Worker](automation-hybrid-runbook-worker.md) (V1) requires the [Log Analytics agent](../azure-monitor/agents/log-analytics-agent.md) (also known as MMA agent) during the installation of the Hybrid Worker. We recommend you to update the Log Analytics agent to the latest version to reduce security vulnerabilities and benefit from bug fixes. +Azure Automation [Agent-based User Hybrid Runbook Worker](automation-hybrid-runbook-worker.md) (V1) requires the [Log Analytics agent](/azure/azure-monitor/agents/log-analytics-agent) (also known as MMA agent) during the installation of the Hybrid Worker. We recommend you to update the Log Analytics agent to the latest version to reduce security vulnerabilities and benefit from bug fixes. Log Analytics agent versions prior to [10.20.18053 (bundle) and 1.0.18053.0 (extension)](/azure/virtual-machines/extensions/oms-windows#agent-and-vm-extension-version) use an older method of certificate handling, and hence it is **not recommended**. Hybrid Workers on the outdated agents will not be able to connect to Azure, and Azure Automation jobs executed by these Hybrid Workers will stop. You must update the Log Analytics agent to the latest version by following the below steps: 1. Check the current version of the Log Analytics agent for your Windows Hybrid Worker: Go to the installation path - *C:\ProgramFiles\Microsoft Monitoring Agent\Agent* and right-click *HealthService.exe* to check **Properties**. The field **Product version** provides the version number of the Log Analytics agent.-2. If your Log Analytics agent version is prior to [10.20.18053 (bundle) and 1.0.18053.0 (extension)](/azure/virtual-machines/extensions/oms-windows#agent-and-vm-extension-version), upgrade to the latest version of the Windows Log Analytics agent, following these [guidelines](../azure-monitor/agents/agent-manage.md). +2. If your Log Analytics agent version is prior to [10.20.18053 (bundle) and 1.0.18053.0 (extension)](/azure/virtual-machines/extensions/oms-windows#agent-and-vm-extension-version), upgrade to the latest version of the Windows Log Analytics agent, following these [guidelines](/azure/azure-monitor/agents/agent-manage). > [!NOTE] > Any Azure Automation jobs running on the Hybrid Worker during the upgrade process might stop. Ensure that there arenΓÇÖt any jobs running or scheduled during the Log Analytics agent upgrade. |
| automation | Configure Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/change-tracking/configure-alerts.md | -If you're not familiar with Azure Monitor alerts, see [Overview of alerts in Microsoft Azure](../../azure-monitor/alerts/alerts-overview.md) before you start. To learn more about alerts that use log queries, see [Log alerts in Azure Monitor](../../azure-monitor/alerts/alerts-unified-log.md). +If you're not familiar with Azure Monitor alerts, see [Overview of alerts in Microsoft Azure](/azure/azure-monitor/alerts/alerts-overview) before you start. To learn more about alerts that use log queries, see [Log alerts in Azure Monitor](/azure/azure-monitor/alerts/alerts-unified-log). ## Create alert Let's use this example to discuss the steps for creating alerts on a change. 5. After the alert logic is set, assign action groups to perform actions in response to triggering of the alert. In this case, we're setting up emails to be sent and an IT Service Management (ITSM) ticket to be created. -Follow the steps below to set up alerts to let you know the status of an update deployment. If you are new to Azure alerts, see [Azure Alerts overview](../../azure-monitor/alerts/alerts-overview.md). +Follow the steps below to set up alerts to let you know the status of an update deployment. If you are new to Azure alerts, see [Azure Alerts overview](/azure/azure-monitor/alerts/alerts-overview). ## Configure action groups for your alerts -Once you have your alerts configured, you can set up an action group, which is a group of actions to use across multiple alerts. The actions can include email notifications, runbooks, webhooks, and much more. To learn more about action groups, see [Create and manage action groups](../../azure-monitor/alerts/action-groups.md). +Once you have your alerts configured, you can set up an action group, which is a group of actions to use across multiple alerts. The actions can include email notifications, runbooks, webhooks, and much more. To learn more about action groups, see [Create and manage action groups](/azure/azure-monitor/alerts/action-groups). 1. Select an alert and then select **Create New** under **Action Groups**. Once you have your alerts configured, you can set up an action group, which is a ## Next steps -* Learn more about [alerts in Azure Monitor](../../azure-monitor/alerts/alerts-overview.md). +* Learn more about [alerts in Azure Monitor](/azure/azure-monitor/alerts/alerts-overview). -* Learn about [log queries](../../azure-monitor/logs/log-query-overview.md) to retrieve and analyze data from a Log Analytics workspace. +* Learn about [log queries](/azure/azure-monitor/logs/log-query-overview) to retrieve and analyze data from a Log Analytics workspace. -* [Analyze usage in Log Analytics workspace](../../azure-monitor/logs/analyze-usage.md) describes how to analyze and alert on your data usage. +* [Analyze usage in Log Analytics workspace](/azure/azure-monitor/logs/analyze-usage) describes how to analyze and alert on your data usage. |
| automation | Enable From Automation Account | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/change-tracking/enable-from-automation-account.md | Machines not in Azure need to be added manually. We recommend installing the Log 1. From your Automation account select **Inventory** or **Change tracking** under **Configuration Management**. -2. Click **Add non-Azure machine**. This action opens up a new browser window with [instructions to install and configure the Log Analytics agent for Windows](../../azure-monitor/agents/log-analytics-agent.md) so that the machine can begin reporting Change Tracking and Inventory operations. If you're enabling a machine that's currently managed by Operations Manager, a new agent isn't required and the workspace information is entered into the existing agent. +2. Click **Add non-Azure machine**. This action opens up a new browser window with [instructions to install and configure the Log Analytics agent for Windows](/azure/azure-monitor/agents/log-analytics-agent) so that the machine can begin reporting Change Tracking and Inventory operations. If you're enabling a machine that's currently managed by Operations Manager, a new agent isn't required and the workspace information is entered into the existing agent. ## Enable machines in the workspace |
| automation | Enable From Runbook | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/change-tracking/enable-from-runbook.md | This method uses two runbooks: * Azure subscription. If you don't have one yet, you can [activate your MSDN subscriber benefits](https://azure.microsoft.com/pricing/member-offers/msdn-benefits-details/) or sign up for a [free account](https://azure.microsoft.com/free/?WT.mc_id=A261C142F). * [Automation account](../automation-security-overview.md) to manage machines.-* [Log Analytics workspace](../../azure-monitor/logs/log-analytics-workspace-overview.md) +* [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-workspace-overview) * A [virtual machine](/azure/virtual-machines/windows/quick-create-portal). * Two Automation assets, which are used by the **Enable-AutomationSolution** runbook. This runbook, if it doesn't already exist in your Automation account, is automatically imported by the **Enable-MultipleSolution** runbook during its first run. * *LASolutionSubscriptionId*: Subscription ID of where the Log Analytics workspace is located. |
| automation | Manage Change Tracking Monitoring Agent | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/change-tracking/manage-change-tracking-monitoring-agent.md | To manage tracking and inventory, ensure that you enable Change tracking with AM 1. Use the filter to view all the DCRs that are configured to the specific LA workspace level. >[!NOTE]- >The settings that you configure are applicable to all the VMs that are attached to a specific DCR. For more information about DCR, see [Data collection rules in Azure Monitor](../../azure-monitor/essentials/data-collection-rule-overview.md). + >The settings that you configure are applicable to all the VMs that are attached to a specific DCR. For more information about DCR, see [Data collection rules in Azure Monitor](/azure/azure-monitor/essentials/data-collection-rule-overview). 1. Select **Add** to configure new file settings |
| automation | Manage Change Tracking | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/change-tracking/manage-change-tracking.md | You can do various searches against the Azure Monitor logs for change records. W ## Next steps * For information about scope configurations, see [Limit Change Tracking and Inventory deployment scope](manage-scope-configurations.md).-* If you need to search logs stored in Azure Monitor Logs, see [Log searches in Azure Monitor Logs](../../azure-monitor/logs/log-query-overview.md). +* If you need to search logs stored in Azure Monitor Logs, see [Log searches in Azure Monitor Logs](/azure/azure-monitor/logs/log-query-overview). * If finished with deployments, see [Remove Change Tracking and Inventory](remove-feature.md). * To delete your VMs from Change Tracking and Inventory, see [Remove VMs from Change Tracking and Inventory](remove-vms-from-change-tracking.md). * To troubleshoot feature errors, see [Troubleshoot Change Tracking and Inventory issues](../troubleshoot/change-tracking.md). |
| automation | Overview Monitoring Agent | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/change-tracking/overview-monitoring-agent.md | This article explains on the latest version of change tracking support using Azu ## Key benefits -- **Compatibility with the unified monitoring agent** - Compatible with the [Azure Monitor Agent](../../azure-monitor/agents/agents-overview.md) that enhances security, reliability, and facilitates multi-homing experience to store data.+- **Compatibility with the unified monitoring agent** - Compatible with the [Azure Monitor Agent](/azure/azure-monitor/agents/agents-overview) that enhances security, reliability, and facilitates multi-homing experience to store data. - **Compatibility with tracking tool**- Compatible with the Change tracking (CT) extension deployed through the Azure Policy on the client's virtual machine. You can switch to Azure Monitor Agent (AMA), and then the CT extension pushes the software, files, and registry to AMA.-- **Multi-homing experience** ΓÇô Provides standardization of management from one central workspace. You can [transition from Log Analytics (LA) to AMA](../../azure-monitor/agents/azure-monitor-agent-migration.md) so that all VMs point to a single workspace for data collection and maintenance.-- **Rules management** ΓÇô Uses [Data Collection Rules](../../azure-monitor/essentials/data-collection-rule-overview.md) to configure or customize various aspects of data collection. For example, you can change the frequency of file collection.+- **Multi-homing experience** ΓÇô Provides standardization of management from one central workspace. You can [transition from Log Analytics (LA) to AMA](/azure/azure-monitor/agents/azure-monitor-agent-migration) so that all VMs point to a single workspace for data collection and maintenance. +- **Rules management** ΓÇô Uses [Data Collection Rules](/azure/azure-monitor/essentials/data-collection-rule-overview) to configure or customize various aspects of data collection. For example, you can change the frequency of file collection. ## Current limitations The following table shows the tracked item limits per machine for change trackin ## Supported operating systems -Change Tracking and Inventory is supported on all operating systems that meet Azure Monitor agent requirements. See [supported operating systems](../../azure-monitor/agents/agents-overview.md#supported-operating-systems) for a list of the Windows and Linux operating system versions that are currently supported by the Azure Monitor agent. +Change Tracking and Inventory is supported on all operating systems that meet Azure Monitor agent requirements. See [supported operating systems](/azure/azure-monitor/agents/agents-overview#supported-operating-systems) for a list of the Windows and Linux operating system versions that are currently supported by the Azure Monitor agent. To understand client requirements for TLS, see [TLS for Azure Automation](../automation-managing-data.md#tls-for-azure-automation). |
| automation | Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/change-tracking/overview.md | -> - **File Integrity Monitoring**: Microsoft Defender for Servers Plan 2 will offer a new File Integrity Monitoring (FIM) solution powered by Microsoft Defender for Endpoint (MDE) integration. Microsoft Defender for Cloud recommends disabling FIM over MMA by November 2024 and onboarding your environment to the new FIM version based on Defender for Endpoint. File Integrity Monitoring based on Log Analytics Agent (MMA) is supported till November 2024. [Learn more](https://learn.microsoft.com/azure/defender-for-cloud/prepare-deprecation-log-analytics-mma-agent#migration-from-fim-over-log-analytics-agent-mma). +> - **File Integrity Monitoring**: Microsoft Defender for Servers Plan 2 will offer a new File Integrity Monitoring (FIM) solution powered by Microsoft Defender for Endpoint (MDE) integration. Microsoft Defender for Cloud recommends disabling FIM over MMA by November 2024 and onboarding your environment to the new FIM version based on Defender for Endpoint. File Integrity Monitoring based on Log Analytics Agent (MMA) is supported till November 2024. [Learn more](/azure/defender-for-cloud/prepare-deprecation-log-analytics-mma-agent#migration-from-fim-over-log-analytics-agent-mma). This article introduces you to Change Tracking and Inventory in Azure Automation. This feature tracks changes in virtual machines hosted in Azure, on-premises, and other cloud environments to help you pinpoint operational and environmental issues with software managed by the Distribution Package Manager. Items that are tracked by Change Tracking and Inventory include: Change Tracking and Inventory is used by Microsoft Defender [Microsoft Defender Enabling all features included in Change Tracking and Inventory might cause additional charges. Before proceeding, review [Automation Pricing](https://azure.microsoft.com/pricing/details/automation/) and [Azure Monitor Pricing](https://azure.microsoft.com/pricing/details/monitor/). -Change Tracking and Inventory forwards data to Azure Monitor Logs, and this collected data is stored in a Log Analytics workspace. The File Integrity Monitoring (FIM) feature is available only when **Microsoft Defender for servers** is enabled. See Microsoft Defender for Cloud [Pricing](../../security-center/security-center-pricing.md) to learn more. FIM uploads data to the same Log Analytics workspace as the one created to store data from Change Tracking and Inventory. We recommend that you monitor your linked Log Analytics workspace to keep track of your exact usage. For more information about analyzing Azure Monitor Logs data usage, see [Analyze usage in Log Analytics workspace](../../azure-monitor/logs/analyze-usage.md). +Change Tracking and Inventory forwards data to Azure Monitor Logs, and this collected data is stored in a Log Analytics workspace. The File Integrity Monitoring (FIM) feature is available only when **Microsoft Defender for servers** is enabled. See Microsoft Defender for Cloud [Pricing](../../security-center/security-center-pricing.md) to learn more. FIM uploads data to the same Log Analytics workspace as the one created to store data from Change Tracking and Inventory. We recommend that you monitor your linked Log Analytics workspace to keep track of your exact usage. For more information about analyzing Azure Monitor Logs data usage, see [Analyze usage in Log Analytics workspace](/azure/azure-monitor/logs/analyze-usage). -Machines connected to the Log Analytics workspace use the [Log Analytics agent](../../azure-monitor/agents/log-analytics-agent.md) to collect data about changes to installed software, Windows services, Windows registry and files, and Linux daemons on monitored servers. When data is available, the agent sends it to Azure Monitor Logs for processing. Azure Monitor Logs applies logic to the received data, records it, and makes it available for analysis. +Machines connected to the Log Analytics workspace use the [Log Analytics agent](/azure/azure-monitor/agents/log-analytics-agent) to collect data about changes to installed software, Windows services, Windows registry and files, and Linux daemons on monitored servers. When data is available, the agent sends it to Azure Monitor Logs for processing. Azure Monitor Logs applies logic to the received data, records it, and makes it available for analysis. > [!NOTE] > Change Tracking and Inventory requires linking a Log Analytics workspace to your Automation account. For a definitive list of supported regions, see [Azure Workspace mappings](../how-to/region-mappings.md). The region mappings don't affect the ability to manage VMs in a separate region from your Automation account. For limits that apply to Change Tracking and Inventory, see [Azure Automation se ## Supported operating systems -Change Tracking and Inventory is supported on all operating systems that meet Log Analytics agent requirements. See [supported operating systems](../../azure-monitor/agents/agents-overview.md#supported-operating-systems) for a list of the Windows and Linux operating system versions that are currently supported by the Log Analytics agent. +Change Tracking and Inventory is supported on all operating systems that meet Log Analytics agent requirements. See [supported operating systems](/azure/azure-monitor/agents/agents-overview#supported-operating-systems) for a list of the Windows and Linux operating system versions that are currently supported by the Log Analytics agent. To understand client requirements for TLS 1.2 or higher, see [TLS for Azure Automation](../automation-managing-data.md#tls-for-azure-automation). The following table shows the tracked item limits per machine for Change Trackin |Services|250| |Daemons|250| -The average Log Analytics data usage for a machine using Change Tracking and Inventory is approximately 40 MB per month, depending on your environment. With the Usage and Estimated Costs feature of the Log Analytics workspace, you can view the data ingested by Change Tracking and Inventory in a usage chart. Use this data view to evaluate your data usage and determine how it affects your bill. See [Understand your usage and estimate costs](../../azure-monitor/cost-usage.md#usage-and-estimated-costs). +The average Log Analytics data usage for a machine using Change Tracking and Inventory is approximately 40 MB per month, depending on your environment. With the Usage and Estimated Costs feature of the Log Analytics workspace, you can view the data ingested by Change Tracking and Inventory in a usage chart. Use this data view to evaluate your data usage and determine how it affects your bill. See [Understand your usage and estimate costs](/azure/azure-monitor/cost-usage#usage-and-estimated-costs). ### Windows services data A key capability of Change Tracking and Inventory is alerting on changes to the ## Update Log Analytics agent to latest version -For Change Tracking & Inventory, machines use the [Log Analytics agent](../../azure-monitor/agents/log-analytics-agent.md) to collect data about changes to installed software, Windows services, Windows registry and files, and Linux daemons on monitored servers. Soon, Azure will no longer accept connections from older versions of the Windows Log Analytics (LA) agent, also known as the Windows Microsoft Monitoring Agent (MMA), that uses an older method for certificate handling. We recommend to upgrade your agent to the latest version as soon as possible. +For Change Tracking & Inventory, machines use the [Log Analytics agent](/azure/azure-monitor/agents/log-analytics-agent) to collect data about changes to installed software, Windows services, Windows registry and files, and Linux daemons on monitored servers. Soon, Azure will no longer accept connections from older versions of the Windows Log Analytics (LA) agent, also known as the Windows Microsoft Monitoring Agent (MMA), that uses an older method for certificate handling. We recommend to upgrade your agent to the latest version as soon as possible. [Agents that are on version - 10.20.18053 (bundle) and 1.0.18053.0 (extension)](/azure/virtual-machines/extensions/oms-windows#agent-and-vm-extension-version) or newer aren't affected in response to this change. If you’re on an agent prior to that, your agent will be unable to connect, and the Change Tracking & Inventory pipeline & downstream activities can stop. You can check the current LA agent version in HeartBeat table within your LA Workspace. -Ensure to upgrade to the latest version of the Windows Log Analytics agent (MMA) following these [guidelines](../../azure-monitor/agents/agent-manage.md). +Ensure to upgrade to the latest version of the Windows Log Analytics agent (MMA) following these [guidelines](/azure/azure-monitor/agents/agent-manage). ## Next steps |
| automation | Extension Based Hybrid Runbook Worker Install | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/extension-based-hybrid-runbook-worker-install.md | You can delete the Hybrid Runbook Worker from the portal. 1. Select **Delete**. - You'll be presented with a warning in a dialog box **Delete Hybrid worker** that the selected hybrid worker would be deleted permanently. Select **Delete**. This operation will delete the extension for the **Extension based (V2)** worker or remove the **Agent based (V1)** entry from the portal. However, it leaves the stale hybrid worker on the VM. To manually uninstall the agent, see [Uninstall agent](../azure-monitor/agents/agent-manage.md#uninstall-agent). + You'll be presented with a warning in a dialog box **Delete Hybrid worker** that the selected hybrid worker would be deleted permanently. Select **Delete**. This operation will delete the extension for the **Extension based (V2)** worker or remove the **Agent based (V1)** entry from the portal. However, it leaves the stale hybrid worker on the VM. To manually uninstall the agent, see [Uninstall agent](/azure/azure-monitor/agents/agent-manage#uninstall-agent). :::image type="content" source="./media/extension-based-hybrid-runbook-worker-install/delete-machine-from-group.png" alt-text="Screenshot showing to delete virtual machine from existing group."::: To check the version of the extension-based Hybrid Runbook Worker: ## Monitor performance of Hybrid Workers using VM insights -Using [VM insights](../azure-monitor/vm/vminsights-overview.md), you can monitor the performance of Azure VMs and Arc-enabled Servers deployed as Hybrid Runbook workers. Among multiple elements that are considered during performances, the VM insights monitors the key operating system performance indicators related to processor, memory, network adapter, and disk utilization. -- For Azure VMs, see [How to chart performance with VM insights](../azure-monitor/vm/vminsights-performance.md).+Using [VM insights](/azure/azure-monitor/vm/vminsights-overview), you can monitor the performance of Azure VMs and Arc-enabled Servers deployed as Hybrid Runbook workers. Among multiple elements that are considered during performances, the VM insights monitors the key operating system performance indicators related to processor, memory, network adapter, and disk utilization. +- For Azure VMs, see [How to chart performance with VM insights](/azure/azure-monitor/vm/vminsights-performance). - For Arc-enabled servers, see [Tutorial: Monitor a hybrid machine with VM insights](../azure-arc/servers/learn/tutorial-enable-vm-insights.md). ## Next steps |
| automation | Automation Region Dns Records | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/how-to/automation-region-dns-records.md | The [Azure Automation](../automation-intro.md) service uses many DNS (Domain Nam * Webhooks >[!NOTE]->Linux Hybrid Runbook Worker registration will fail with the new records unless it is version 1.6.10.2 or higher. You must upgrade to a newer version of the [Log Analytics agent for Linux](../../azure-monitor/agents/agent-linux.md) in order for the machine to receive an updated version of the worker role and use these new records. Existing machines will continue working without any issues. +>Linux Hybrid Runbook Worker registration will fail with the new records unless it is version 1.6.10.2 or higher. You must upgrade to a newer version of the [Log Analytics agent for Linux](/azure/azure-monitor/agents/agent-linux) in order for the machine to receive an updated version of the worker role and use these new records. Existing machines will continue working without any issues. ## DNS records per region |
| automation | Private Link Security | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/how-to/private-link-security.md | With Private Link you can: - Connect privately to Azure Monitor Log Analytics workspace without opening any public network access. >[!NOTE]- >A separate private endpoint for your Log Analytics workspace is required if your Automation account is linked to a Log Analytics workspace to forward job data, and when you have enabled features such as Update Management, Change Tracking and Inventory, State Configuration, or Start/Stop VMs during off-hours. For more information about Private Link for Azure Monitor, see [Use Azure Private Link to securely connect networks to Azure Monitor](../../azure-monitor/logs/private-link-security.md). + >A separate private endpoint for your Log Analytics workspace is required if your Automation account is linked to a Log Analytics workspace to forward job data, and when you have enabled features such as Update Management, Change Tracking and Inventory, State Configuration, or Start/Stop VMs during off-hours. For more information about Private Link for Azure Monitor, see [Use Azure Private Link to securely connect networks to Azure Monitor](/azure/azure-monitor/logs/private-link-security). - Ensure your Automation data is only accessed through authorized private networks. - Prevent data exfiltration from your private networks by defining your Azure Automation resource that connects through your private endpoint. For more information, see [Key Benefits of Private Link](../../private-link/pri ## Limitations - In the current implementation of Private Link, Automation account cloud jobs cannot access Azure resources that are secured using private endpoint. For example, Azure Key Vault, Azure SQL, Azure Storage account, etc. To workaround this, use a [Hybrid Runbook Worker](../automation-hybrid-runbook-worker.md) instead. Hence, on-premises VMs are supported to run Hybrid Runbook Workers against an Automation Account with Private Link enabled.-- You need to use the latest version of the [Log Analytics agent](../../azure-monitor/agents/log-analytics-agent.md) for Windows or Linux.-- The [Log Analytics Gateway](../../azure-monitor/agents/gateway.md) does not support Private Link.+- You need to use the latest version of the [Log Analytics agent](/azure/azure-monitor/agents/log-analytics-agent) for Windows or Linux. +- The [Log Analytics Gateway](/azure/azure-monitor/agents/gateway) does not support Private Link. - Azure alert (metric, log, and activity log) can't be used to trigger an Automation webhook when the Automation account is configured with **Public access** set to **Disable**. ## How it works To understand & configure Update Management review [About Update Management](../ If you want your machines configured for Update management to connect to Automation & Log Analytics workspace in a secure manner over Private Link channel, you have to enable Private Link for the Log Analytics workspace linked to the Automation Account configured with Private Link. -You can control how a Log Analytics workspace can be reached from outside of the Private Link scopes by following the steps described in [Configure Log Analytics](../../azure-monitor/logs/private-link-configure.md#configure-access-to-your-resources). If you set **Allow public network access for ingestion** to **No**, then machines outside of the connected scopes cannot upload data to this workspace. If you set **Allow public network access for queries** to **No**, then machines outside of the scopes cannot access data in this workspace. +You can control how a Log Analytics workspace can be reached from outside of the Private Link scopes by following the steps described in [Configure Log Analytics](/azure/azure-monitor/logs/private-link-configure#configure-access-to-your-resources). If you set **Allow public network access for ingestion** to **No**, then machines outside of the connected scopes cannot upload data to this workspace. If you set **Allow public network access for queries** to **No**, then machines outside of the scopes cannot access data in this workspace. Use **DSCAndHybridWorker** target sub-resource to enable Private Link for user & system hybrid workers. |
| automation | Migrate Existing Agent Based Hybrid Worker To Extension Based Workers | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/migrate-existing-agent-based-hybrid-worker-to-extension-based-workers.md | +- **Agent based hybrid runbook worker** (V1) - The Agent-based hybrid runbook worker depends on theΓÇ»[Log Analytics Agent](/azure/azure-monitor/agents/log-analytics-agent). - **Extension based hybrid runbook worker** (V2) - The Extension-based hybrid runbook worker provides native integration of the hybrid runbook worker role through the Virtual machine (VM) extension framework.ΓÇ» The process of executing runbooks on Hybrid Runbook Workers remains the same for both. |
| automation | Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/overview.md | Azure Automation supports management throughout the lifecycle of your infrastruc Depending on your requirements, one or more of the following Azure services integrate with or complement Azure Automation to help fulfill them: * [Azure Arc-enabled servers](../azure-arc/servers/overview.md) enables simplified onboarding of hybrid machines to Update Management, Change Tracking and Inventory, and the Hybrid Runbook Worker role.-* [Azure Alerts action groups](../azure-monitor/alerts/action-groups.md) can initiate an Automation runbook when an alert is raised. -* [Azure Monitor](../azure-monitor/overview.md) to collect metrics and log data from your Automation account for further analysis and take action on the telemetry. Automation features such as Update Management and Change Tracking and Inventory rely on the Log Analytics workspace to deliver elements of their functionality. +* [Azure Alerts action groups](/azure/azure-monitor/alerts/action-groups) can initiate an Automation runbook when an alert is raised. +* [Azure Monitor](/azure/azure-monitor/overview) to collect metrics and log data from your Automation account for further analysis and take action on the telemetry. Automation features such as Update Management and Change Tracking and Inventory rely on the Log Analytics workspace to deliver elements of their functionality. * [Azure Policy](../governance/policy/samples/built-in-policies.md) includes initiative definitions to help establish and maintain compliance with different security standards for your Automation account. * [Azure Site Recovery](../site-recovery/site-recovery-runbook-automation.md) can use Azure Automation runbooks to automate recovery plans. |
| automation | Quickstart Create Automation Account Template | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/quickstart-create-automation-account-template.md | If you don't have an Azure subscription, create a [free account](https://azure.m If you're new to Azure Automation and Azure Monitor, it's important that you understand the configuration details. The understanding can help you avoid errors when you try to create, configure, and use a Log Analytics workspace linked to your new Automation account. -* Review [additional details](../azure-monitor/logs/resource-manager-workspace.md#create-a-log-analytics-workspace) to fully understand workspace configuration options, such as access control mode, pricing tier, retention, and capacity reservation level. +* Review [additional details](/azure/azure-monitor/logs/resource-manager-workspace#create-a-log-analytics-workspace) to fully understand workspace configuration options, such as access control mode, pricing tier, retention, and capacity reservation level. * Review [workspace mappings](how-to/region-mappings.md) to specify the supported regions inline or in a parameter file. Only certain regions are supported for linking a Log Analytics workspace and an Automation account in your subscription. -* If you're new to Azure Monitor Logs and haven't deployed a workspace already, review the [workspace design guidance](../azure-monitor/logs/workspace-design.md). This document will help you learn about access control, and help you understand the recommended design implementation strategies for your organization. +* If you're new to Azure Monitor Logs and haven't deployed a workspace already, review the [workspace design guidance](/azure/azure-monitor/logs/workspace-design). This document will help you learn about access control, and help you understand the recommended design implementation strategies for your organization. ## Review the template |
| automation | Start Runbooks | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/start-runbooks.md | The following table helps you determine the method to start a runbook in Azure A | [Windows PowerShell](/powershell/module/az.automation/start-azautomationrunbook) |<li>Call from command line with Windows PowerShell cmdlets.<br> <li>Can be included in automated feature with multiple steps.<br> <li>Request is authenticated with certificate or OAuth user principal / service principal.<br> <li>Provide simple and complex parameter values.<br> <li>Track job state.<br> <li>Client required to support PowerShell cmdlets. | | [Azure Automation API](/rest/api/automation/) |<li>Most flexible method but also most complex.<br> <li>Call from any custom code that can make HTTP requests.<br> <li>Request authenticated with certificate, or Oauth user principal / service principal.<br> <li>Provide simple and complex parameter values. *If you're calling a Python runbook using the API, the JSON payload must be serialized.*<br> <li>Track job state. | | [Webhooks](automation-webhooks.md) |<li>Start runbook from single HTTP request.<br> <li>Authenticated with security token in URL.<br> <li>Client can't override parameter values specified when webhook created. Runbook can define single parameter that is populated with the HTTP request details.<br> <li>No ability to track job state through webhook URL. |-| [Respond to Azure Alert](../azure-monitor/alerts/alerts-overview.md) |<li>Start a runbook in response to Azure alert.<br> <li>Configure webhook for runbook and link to alert.<br> <li>Authenticated with security token in URL. | +| [Respond to Azure Alert](/azure/azure-monitor/alerts/alerts-overview) |<li>Start a runbook in response to Azure alert.<br> <li>Configure webhook for runbook and link to alert.<br> <li>Authenticated with security token in URL. | | [Schedule](./shared-resources/schedules.md) |<li>Automatically start runbook on hourly, daily, weekly, or monthly schedule.<br> <li>Manipulate schedule through Azure portal, PowerShell cmdlets, or Azure API.<br> <li>Provide parameter values to be used with schedule. | | [From Another Runbook](automation-child-runbooks.md) |<li>Use a runbook as an activity in another runbook.<br> <li>Useful for functionality used by multiple runbooks.<br> <li>Provide parameter values to child runbook and use output in parent runbook. | |
| automation | Change Tracking | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/troubleshoot/change-tracking.md | The machine has already been deployed to another workspace for Change Tracking. ### Resolution -1. Make sure that your machine is reporting to the correct workspace. For guidance on how to verify this, see [Verify agent connectivity to Azure Monitor](../../azure-monitor/agents/agent-windows.md#verify-agent-connectivity-to-azure-monitor). Also make sure that this workspace is linked to your Azure Automation account. To confirm, go to your Automation account and select **Linked workspace** under **Related Resources**. +1. Make sure that your machine is reporting to the correct workspace. For guidance on how to verify this, see [Verify agent connectivity to Azure Monitor](/azure/azure-monitor/agents/agent-windows#verify-agent-connectivity-to-azure-monitor). Also make sure that this workspace is linked to your Azure Automation account. To confirm, go to your Automation account and select **Linked workspace** under **Related Resources**. 1. Make sure that the machines show up in the Log Analytics workspace linked to your Automation account. Run the following query in the Log Analytics workspace. Heartbeat | summarize by Computer, Solutions ``` -If you don't see your machine in query results, it hasn't recently checked in. There's probably a local configuration issue and you should reinstall the agent. For information about installation and configuration, see [Collect log data with the Log Analytics agent](../../azure-monitor/agents/log-analytics-agent.md). +If you don't see your machine in query results, it hasn't recently checked in. There's probably a local configuration issue and you should reinstall the agent. For information about installation and configuration, see [Collect log data with the Log Analytics agent](/azure/azure-monitor/agents/log-analytics-agent). If your machine shows up in the query results, verify the scope configuration. See [Targeting monitoring solutions in Azure Monitor](/previous-versions/azure/azure-monitor/insights/solution-targeting). -For more troubleshooting of this issue, see [Issue: You are not seeing any Linux data](../../azure-monitor/agents/agent-linux-troubleshoot.md#issue-you-arent-seeing-any-linux-data). +For more troubleshooting of this issue, see [Issue: You are not seeing any Linux data](/azure/azure-monitor/agents/agent-linux-troubleshoot#issue-you-arent-seeing-any-linux-data). ##### Log Analytics agent for Linux not configured correctly |
| automation | Extension Based Hybrid Runbook Worker | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/troubleshoot/extension-based-hybrid-runbook-worker.md | This error can occur due to the following reasons: #### Resolution - Ensure that the machine exists, and Hybrid Runbook Worker extension is installed on it. The Hybrid Worker should be healthy and should give a heartbeat. Troubleshoot any network issues by checking the Microsoft-SMA event logs on the Workers in the Hybrid Runbook Worker Group that tried to run this job. -- You can also monitor [HybridWorkerPing](../../azure-monitor/essentials/metrics-supported.md#microsoftautomationautomationaccounts) metric that provides the number of pings from a Hybrid Worker and can help to check ping-related issues. +- You can also monitor [HybridWorkerPing](/azure/azure-monitor/essentials/metrics-supported#microsoftautomationautomationaccounts) metric that provides the number of pings from a Hybrid Worker and can help to check ping-related issues. ### Scenario: Job was suspended as it exceeded the job limit for a Hybrid Worker Jobs might get suspended due to any of the following reasons: #### Resolution - If the job limit for a Hybrid Worker exceeds four jobs per 30 seconds, you can add more Hybrid Workers to the Hybrid Worker group for high availability and load balancing. You can also schedule jobs so they do not exceed the limit of four jobs per 30 seconds. The processing time of the jobs queue depends on the Hybrid worker hardware profile and load. Ensure that the Hybrid Worker is healthy and gives a heartbeat. - Troubleshoot any network issues by checking the Microsoft-SMA event logs on the Workers in the Hybrid Runbook Worker Group that tried to run this job. -- You can also monitor the [HybridWorkerPing](../../azure-monitor/essentials/metrics-supported.md#microsoftautomationautomationaccounts) metric that provides the number of pings from a Hybrid Worker and can help to check ping-related issues. +- You can also monitor the [HybridWorkerPing](/azure/azure-monitor/essentials/metrics-supported#microsoftautomationautomationaccounts) metric that provides the number of pings from a Hybrid Worker and can help to check ping-related issues. ### Scenario: Hybrid Worker deployment fails with Private Link error |
| automation | Hybrid Runbook Worker | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/troubleshoot/hybrid-runbook-worker.md | The Hybrid Runbook Worker jobs failed to refresh when communicating through a Lo #### Resolution -Verify the Log Analytics Gateway server is online and is accessible from the machine hosting the Hybrid Runbook Worker role. For additional troubleshooting information, see [Troubleshoot Log Analytics Gateway](../../azure-monitor/agents/gateway.md#troubleshooting). +Verify the Log Analytics Gateway server is online and is accessible from the machine hosting the Hybrid Runbook Worker role. For additional troubleshooting information, see [Troubleshoot Log Analytics Gateway](/azure/azure-monitor/agents/gateway#troubleshooting). ### Scenario: Job failed to start as the Hybrid Worker was not available when the scheduled job started This error can occur due to the following reasons: #### Resolution - Ensure that the machine exists, and Hybrid Runbook Worker extension is installed on it. The Hybrid Worker should be healthy and should give a heartbeat. Troubleshoot any network issues by checking the Microsoft-SMA event logs on the Workers in the Hybrid Runbook Worker Group that tried to run this job.-- You can also monitor [HybridWorkerPing](../../azure-monitor/essentials/metrics-supported.md#microsoftautomationautomationaccounts) metric that provides the number of pings from a Hybrid Worker and can help to check ping-related issues.+- You can also monitor [HybridWorkerPing](/azure/azure-monitor/essentials/metrics-supported#microsoftautomationautomationaccounts) metric that provides the number of pings from a Hybrid Worker and can help to check ping-related issues. ### Scenario: Job was suspended as it exceeded the job limit for a Hybrid Worker Jobs might get suspended due to any of the following reasons: #### Resolution - If the job limit for a Hybrid Worker exceeds four jobs per 30 seconds, you can add more Hybrid Workers to the Hybrid Worker group for high availability and load balancing. You can also schedule jobs so they do not exceed the limit of four jobs per 30 seconds. The processing time of the jobs queue depends on the Hybrid worker hardware profile and load. Ensure that the Hybrid Worker is healthy and gives a heartbeat. - Troubleshoot any network issues by checking the Microsoft-SMA event logs on the Workers in the Hybrid Runbook Worker Group that tried to run this job.-- You can also monitor the [HybridWorkerPing](../../azure-monitor/essentials/metrics-supported.md#microsoftautomationautomationaccounts) metric that provides the number of pings from a Hybrid Worker and can help to check ping-related issues.+- You can also monitor the [HybridWorkerPing](/azure/azure-monitor/essentials/metrics-supported#microsoftautomationautomationaccounts) metric that provides the number of pings from a Hybrid Worker and can help to check ping-related issues. The following issues are possible causes: #### Resolution ##### Mistyped workspace ID or key-To verify if the agent's workspace ID or workspace key was mistyped, see [Adding or removing a workspace - Windows agent](../../azure-monitor/agents/agent-manage.md#windows-agent) for the Windows agent or [Adding or removing a workspace - Linux agent](../../azure-monitor/agents/agent-manage.md#linux-agent) for the Linux agent. Make sure to select the full string from the Azure portal, and copy and paste it carefully. +To verify if the agent's workspace ID or workspace key was mistyped, see [Adding or removing a workspace - Windows agent](/azure/azure-monitor/agents/agent-manage#windows-agent) for the Windows agent or [Adding or removing a workspace - Linux agent](/azure/azure-monitor/agents/agent-manage#linux-agent) for the Linux agent. Make sure to select the full string from the Azure portal, and copy and paste it carefully. ##### Configuration not downloaded You might also need to update the date or time zone of your computer. If you sel ##### Log Analytics gateway not configured -Follow the steps mentioned [here](../../azure-monitor/agents/gateway.md#configure-for-automation-hybrid-runbook-workers) to add Hybrid Runbook Worker endpoints to the Log Analytics Gateway. +Follow the steps mentioned [here](/azure/azure-monitor/agents/gateway#configure-for-automation-hybrid-runbook-workers) to add Hybrid Runbook Worker endpoints to the Log Analytics Gateway. ### <a name="set-azstorageblobcontent-execution-fails"></a>Scenario: Set-AzStorageBlobContent fails on a Hybrid Runbook Worker Place this file in the same folder as the executable file `OrchestratorSandbox.e ## Linux -The Linux Hybrid Runbook Worker depends on the [Log Analytics agent for Linux](../../azure-monitor/agents/log-analytics-agent.md) to communicate with your Automation account to register the worker, receive runbook jobs, and report status. If registration of the worker fails, here are some possible causes for the error. +The Linux Hybrid Runbook Worker depends on the [Log Analytics agent for Linux](/azure/azure-monitor/agents/log-analytics-agent) to communicate with your Automation account to register the worker, receive runbook jobs, and report status. If registration of the worker fails, here are some possible causes for the error. ### <a name="prompt-for-password"></a>Scenario: Linux Hybrid Runbook Worker receives prompt for a password when signing a runbook wget https://raw.githubusercontent.com/Microsoft/OMS-Agent-for-Linux/master/inst ## Windows -The Windows Hybrid Runbook Worker depends on the [Log Analytics agent for Windows](../../azure-monitor/agents/log-analytics-agent.md) to communicate with your Automation account to register the worker, receive runbook jobs, and report status. If registration of the worker fails, this section includes some possible reasons. +The Windows Hybrid Runbook Worker depends on the [Log Analytics agent for Windows](/azure/azure-monitor/agents/log-analytics-agent) to communicate with your Automation account to register the worker, receive runbook jobs, and report status. If registration of the worker fails, this section includes some possible reasons. ### <a name="mma-not-running"></a>Scenario: The Log Analytics agent for Windows isn't running This issue can be caused by your proxy or network firewall blocking communicatio #### Resolution -Logs are stored locally on each hybrid worker at C:\ProgramData\Microsoft\System Center\Orchestrator\7.2\SMA\Sandboxes. You can verify if there are any warning or error events in the **Application and Services Logs\Microsoft-SMA\Operations** and **Application and Services Logs\Operations Manager** event logs. These logs indicate a connectivity or other type of issue that affects the enabling of the role to Azure Automation, or an issue encountered under normal operations. For more help troubleshooting issues with the Log Analytics agent, see [Troubleshoot issues with the Log Analytics Windows agent](../../azure-monitor/agents/agent-windows-troubleshoot.md). +Logs are stored locally on each hybrid worker at C:\ProgramData\Microsoft\System Center\Orchestrator\7.2\SMA\Sandboxes. You can verify if there are any warning or error events in the **Application and Services Logs\Microsoft-SMA\Operations** and **Application and Services Logs\Operations Manager** event logs. These logs indicate a connectivity or other type of issue that affects the enabling of the role to Azure Automation, or an issue encountered under normal operations. For more help troubleshooting issues with the Log Analytics agent, see [Troubleshoot issues with the Log Analytics Windows agent](/azure/azure-monitor/agents/agent-windows-troubleshoot). Hybrid workers send [Runbook output and messages](../automation-runbook-output-and-messages.md) to Azure Automation in the same way that runbook jobs running in the cloud send output and messages. You can enable the Verbose and Progress streams just as you do for runbooks. |
| automation | Onboarding | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/troubleshoot/onboarding.md | Failed to configure automation account for diagnostic logging #### Cause -This error can be caused if the pricing tier doesn't match the subscription's billing model. For more information, see [Monitoring usage and estimated costs in Azure Monitor](../../azure-monitor/cost-usage.md#usage-and-estimated-costs). +This error can be caused if the pricing tier doesn't match the subscription's billing model. For more information, see [Monitoring usage and estimated costs in Azure Monitor](/azure/azure-monitor/cost-usage#usage-and-estimated-costs). #### Resolution |
| automation | Update Agent Issues Linux | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/troubleshoot/update-agent-issues-linux.md | If the asset tag is different than 7783-7084-3265-9085-8269-3286-77, then reboot ### Monitoring Agent -To fix this, install Azure Log Analytics Linux agent and ensure it communicates the required endpoints. For more information, see [Install Log Analytics agent on Linux computers](../../azure-monitor/agents/agent-linux.md). +To fix this, install Azure Log Analytics Linux agent and ensure it communicates the required endpoints. For more information, see [Install Log Analytics agent on Linux computers](/azure/azure-monitor/agents/agent-linux). This task checks if the folder is present - process_name="omsagent" ps aux | grep %s | grep -v grep" % (process_name)" ``` -For more information, see [Troubleshoot issues with the Log Analytics agent for Linux](../../azure-monitor/agents/agent-linux-troubleshoot.md) +For more information, see [Troubleshoot issues with the Log Analytics agent for Linux](/azure/azure-monitor/agents/agent-linux-troubleshoot) ### Multihoming This check determines if the agent is reporting to multiple workspaces. Update Management doesn't support multihoming. -To fix this issue, purge the OMS Agent completely and reinstall it with the [workspace linked with Update management](../../azure-monitor/agents/agent-linux-troubleshoot.md#purge-and-reinstall-the-linux-agent) +To fix this issue, purge the OMS Agent completely and reinstall it with the [workspace linked with Update management](/azure/azure-monitor/agents/agent-linux-troubleshoot#purge-and-reinstall-the-linux-agent) Validate that there are no more multihoming by checking the directories under this path: |
| automation | Update Agent Issues | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/troubleshoot/update-agent-issues.md | To fix, you need to download and install [Windows Management Framework 5.1](http This check determines whether you're using TLS 1.2 to encrypt your communications. TLS 1.0 is no longer supported by the platform. Use TLS 1.2 to communicate with Update Management. -To fix, follow the steps to [Enable TLS 1.2](../../azure-monitor/agents/agent-windows.md#configure-agent-to-use-tls-12) +To fix, follow the steps to [Enable TLS 1.2](/azure/azure-monitor/agents/agent-windows#configure-agent-to-use-tls-12) ## Monitoring agent service health checks To validate, check event id *15003 (HW start event) OR 15004 (hw stopped event) Raise a support ticket if the issue is not fixed still. ### VMs linked workspace-See [Network requirements](../../azure-monitor/agents/agent-windows-troubleshoot.md#connectivity-issues). +See [Network requirements](/azure/azure-monitor/agents/agent-windows-troubleshoot#connectivity-issues). To validate: Check VMs connected workspace or Heartbeat table of corresponding log analytics. Invoke-RestMethod -Headers @{"Metadata"="true"} -Method GET -Uri http://169.254. This check determines if the Log Analytics agent for Windows (`healthservice`) is running on the machine. To learn more about troubleshooting the service, see [The Log Analytics agent for Windows isn't running](hybrid-runbook-worker.md#mma-not-running). -To reinstall the Log Analytics agent for Windows, see [Install the agent for Windows](../../azure-monitor/agents/agent-windows.md). +To reinstall the Log Analytics agent for Windows, see [Install the agent for Windows](/azure/azure-monitor/agents/agent-windows). ### Monitoring agent service events |
| automation | Update Management | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/troubleshoot/update-management.md | This issue can be caused by local configuration issues or by improperly configur 1. Run the troubleshooter for [Windows](update-agent-issues.md#troubleshoot-offline) or [Linux](update-agent-issues-linux.md#troubleshoot-offline), depending on the OS. -2. Make sure that your machine is reporting to the correct workspace. For guidance on how to verify this aspect, see [Verify agent connectivity to Azure Monitor](../../azure-monitor/agents/agent-windows.md#verify-agent-connectivity-to-azure-monitor). Also make sure that this workspace is linked to your Azure Automation account. To confirm, go to your Automation account and select **Linked workspace** under **Related Resources**. +2. Make sure that your machine is reporting to the correct workspace. For guidance on how to verify this aspect, see [Verify agent connectivity to Azure Monitor](/azure/azure-monitor/agents/agent-windows#verify-agent-connectivity-to-azure-monitor). Also make sure that this workspace is linked to your Azure Automation account. To confirm, go to your Automation account and select **Linked workspace** under **Related Resources**. 3. Make sure that the machines show up in the Log Analytics workspace linked to your Automation account. Run the following query in the Log Analytics workspace. This issue can be caused by local configuration issues or by improperly configur | summarize by Computer, Solutions ``` - If you don't see your machine in the query results, it hasn't recently checked in. There's probably a local configuration issue and you should [reinstall the agent](../../azure-monitor/agents/agent-windows.md). + If you don't see your machine in the query results, it hasn't recently checked in. There's probably a local configuration issue and you should [reinstall the agent](/azure/azure-monitor/agents/agent-windows). If your machine is listed in the query results, verify under the **Solutions** property that **updates** is listed. This verifies it is registered with Update Management. If it is not, check for scope configuration problems. The [scope configuration](../update-management/scope-configuration.md) determines which machines are configured for Update Management. To configure the scope configuration for the target the machine, see [Enable machines in the workspace](../update-management/enable-from-automation-account.md#enable-machines-in-the-workspace). |
| automation | Configure Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/update-management/configure-alerts.md | Alerts in Azure proactively notify you of results from runbook jobs, service hea ## Available metrics -Azure Automation creates two distinct platform metrics related to Update Management that are collected and forwarded to Azure Monitor. These metric are available for analysis using [Metrics Explorer](../../azure-monitor/essentials/metrics-charts.md) and for alerting using a [metrics alert rule](../../azure-monitor/alerts/alerts-metric.md). +Azure Automation creates two distinct platform metrics related to Update Management that are collected and forwarded to Azure Monitor. These metric are available for analysis using [Metrics Explorer](/azure/azure-monitor/essentials/metrics-charts) and for alerting using a [metrics alert rule](/azure/azure-monitor/alerts/alerts-metric). The two metrics emitted are: When used for alerts, both metrics support dimensions that carry additional info ## Create alert -Follow the steps below to set up alerts to let you know the status of an update deployment. If you are new to Azure alerts, see [Azure Alerts overview](../../azure-monitor/alerts/alerts-overview.md). +Follow the steps below to set up alerts to let you know the status of an update deployment. If you are new to Azure alerts, see [Azure Alerts overview](/azure/azure-monitor/alerts/alerts-overview). 1. In your Automation account, select **Alerts** under **Monitoring**, and then select **New alert rule**. Follow the steps below to set up alerts to let you know the status of an update ## Configure action groups for your alerts -Once you have your alerts configured, you can set up an action group, which is a group of actions to use across multiple alerts. The actions can include email notifications, runbooks, webhooks, and much more. To learn more about action groups, see [Create and manage action groups](../../azure-monitor/alerts/action-groups.md). +Once you have your alerts configured, you can set up an action group, which is a group of actions to use across multiple alerts. The actions can include email notifications, runbooks, webhooks, and much more. To learn more about action groups, see [Create and manage action groups](/azure/azure-monitor/alerts/action-groups). 1. Select an alert and then select **Add action groups** under **Actions**. This will display the **Select an action group to attach to this alert rule** pane. Once you have your alerts configured, you can set up an action group, which is a ## Next steps -* Learn more about [alerts in Azure Monitor](../../azure-monitor/alerts/alerts-overview.md). +* Learn more about [alerts in Azure Monitor](/azure/azure-monitor/alerts/alerts-overview). -* Learn about [log queries](../../azure-monitor/logs/log-query-overview.md) to retrieve and analyze data from a Log Analytics workspace. +* Learn about [log queries](/azure/azure-monitor/logs/log-query-overview) to retrieve and analyze data from a Log Analytics workspace. -* [Azure Monitor best practices - Cost management](../../azure-monitor/best-practices-cost.md) describes how to control your costs by changing your data retention period, and how to analyze and alert on your data usage. +* [Azure Monitor best practices - Cost management](/azure/azure-monitor/best-practices-cost) describes how to control your costs by changing your data retention period, and how to analyze and alert on your data usage. |
| automation | Configure Groups | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/update-management/configure-groups.md | To preview the results of your dynamic group query, click **Preview**. The previ ## Define dynamic groups for non-Azure machines -A dynamic group for non-Azure machines uses saved searches, also called computer groups. To learn how to create a saved search, see [Creating a computer group](../../azure-monitor/logs/computer-groups.md#creating-a-computer-group). Once your saved search is created, you can select it from the list of saved searches in **Update management** in the Azure portal. Click **Preview** to preview the computers in the saved search. +A dynamic group for non-Azure machines uses saved searches, also called computer groups. To learn how to create a saved search, see [Creating a computer group](/azure/azure-monitor/logs/computer-groups#creating-a-computer-group). Once your saved search is created, you can select it from the list of saved searches in **Update management** in the Azure portal. Click **Preview** to preview the computers in the saved search.  > [!NOTE]-> A saved search that [queries data stored across multiple Log Analytics workspaces](../../azure-monitor/logs/cross-workspace-query.md) is not supported. +> A saved search that [queries data stored across multiple Log Analytics workspaces](/azure/azure-monitor/logs/cross-workspace-query) is not supported. ## Next steps |
| automation | Deploy Updates | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/update-management/deploy-updates.md | To schedule a new update deployment, perform the following steps. Depending on t > [!IMPORTANT] > When building a dynamic group of Azure VMs, Update Management only supports a maximum of 500 queries that combines subscriptions or resource groups in the scope of the group. -6. In the **Machines to update** region, select a saved search, an imported group, or pick **Machines** from the dropdown menu and select individual machines. With this option, you can see the readiness of the Log Analytics agent for each machine. To learn about the different methods of creating computer groups in Azure Monitor logs, see [Computer groups in Azure Monitor logs](../../azure-monitor/logs/computer-groups.md). You can include up to a maximum of 1000 machines in a scheduled update deployment. +6. In the **Machines to update** region, select a saved search, an imported group, or pick **Machines** from the dropdown menu and select individual machines. With this option, you can see the readiness of the Log Analytics agent for each machine. To learn about the different methods of creating computer groups in Azure Monitor logs, see [Computer groups in Azure Monitor logs](/azure/azure-monitor/logs/computer-groups). You can include up to a maximum of 1000 machines in a scheduled update deployment. > [!NOTE] > This option is not available if you selected an Azure VM or Azure Arc-enabled server. The machine is automatically targeted for the scheduled deployment. |
| automation | Enable From Automation Account | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/update-management/enable-from-automation-account.md | This article describes how you can use your Automation account to enable the [Up * Azure subscription. If you don't have one yet, you can [activate your MSDN subscriber benefits](https://azure.microsoft.com/pricing/member-offers/msdn-benefits-details/) or sign up for a [free account](https://azure.microsoft.com/free/?WT.mc_id=A261C142F). * [Automation account](../automation-security-overview.md) to manage machines.-* An [Azure virtual machine](/azure/virtual-machines/windows/quick-create-portal), or VM or server registered with Azure Arc-enabled servers. Non-Azure VMs or servers need to have the [Log Analytics agent](../../azure-monitor/agents/log-analytics-agent.md) for Windows or Linux installed and reporting to the workspace linked to the Automation account where Update Management is enabled. We recommend installing the Log Analytics agent for Windows or Linux by first connecting your machine to [Azure Arc-enabled servers](../../azure-arc/servers/overview.md), and then use Azure Policy to assign the [Deploy Log Analytics agent to *Linux* or *Windows* Azure Arc machines](../../governance/policy/samples/built-in-policies.md#monitoring) built-in policy. Alternatively, if you plan to monitor the machines with Azure Monitor for VMs, instead use the [Enable Azure Monitor for VMs](../../governance/policy/samples/built-in-initiatives.md#monitoring) initiative. +* An [Azure virtual machine](/azure/virtual-machines/windows/quick-create-portal), or VM or server registered with Azure Arc-enabled servers. Non-Azure VMs or servers need to have the [Log Analytics agent](/azure/azure-monitor/agents/log-analytics-agent) for Windows or Linux installed and reporting to the workspace linked to the Automation account where Update Management is enabled. We recommend installing the Log Analytics agent for Windows or Linux by first connecting your machine to [Azure Arc-enabled servers](../../azure-arc/servers/overview.md), and then use Azure Policy to assign the [Deploy Log Analytics agent to *Linux* or *Windows* Azure Arc machines](../../governance/policy/samples/built-in-policies.md#monitoring) built-in policy. Alternatively, if you plan to monitor the machines with Azure Monitor for VMs, instead use the [Enable Azure Monitor for VMs](../../governance/policy/samples/built-in-initiatives.md#monitoring) initiative. ## Sign in to Azure For machines or servers hosted outside of Azure, including the ones registered w 1. From your Automation account, select **Update management** under **Update management**. -2. Select **Add non-Azure machine**. This action opens a new browser window with [instructions to install and configure the Log Analytics agent for Windows](../../azure-monitor/agents/log-analytics-agent.md) so that the machine can begin reporting to Update Management. If you're enabling a machine that's currently managed by Operations Manager, a new agent isn't required. The workspace information is added to the agents configuration. +2. Select **Add non-Azure machine**. This action opens a new browser window with [instructions to install and configure the Log Analytics agent for Windows](/azure/azure-monitor/agents/log-analytics-agent) so that the machine can begin reporting to Update Management. If you're enabling a machine that's currently managed by Operations Manager, a new agent isn't required. The workspace information is added to the agents configuration. ## Enable machines in the workspace |
| automation | Enable From Runbook | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/update-management/enable-from-runbook.md | This method uses two runbooks: * Azure subscription. If you don't have one yet, you can [activate your MSDN subscriber benefits](https://azure.microsoft.com/pricing/member-offers/msdn-benefits-details/) or sign up for a [free account](https://azure.microsoft.com/free/?WT.mc_id=A261C142F). * [Automation account](../automation-security-overview.md) to manage machines.-* [Log Analytics workspace](../../azure-monitor/logs/log-analytics-workspace-overview.md) +* [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-workspace-overview) * A [virtual machine](/azure/virtual-machines/windows/quick-create-portal). * Two Automation assets, which are used by the **Enable-AutomationSolution** runbook. This runbook, if it doesn't already exist in your Automation account, is automatically imported by the **Enable-MultipleSolution** runbook during its first run. * *LASolutionSubscriptionId*: Subscription ID of where the Log Analytics workspace is located. |
| automation | Enable From Template | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/update-management/enable-from-template.md | The JSON template specifies a default value for the other parameters that would If you're new to Azure Automation and Azure Monitor, it's important that you understand the following configuration details. They can help you avoid errors when you try to create, configure, and use a Log Analytics workspace linked to your new Automation account. -* Review [additional details](../../azure-monitor/logs/resource-manager-workspace.md#create-a-log-analytics-workspace) to fully understand workspace configuration options, such as access control mode, pricing tier, retention, and capacity reservation level. +* Review [additional details](/azure/azure-monitor/logs/resource-manager-workspace#create-a-log-analytics-workspace) to fully understand workspace configuration options, such as access control mode, pricing tier, retention, and capacity reservation level. * Review [workspace mappings](../how-to/region-mappings.md) to specify the supported regions inline or in a parameter file. Only certain regions are supported for linking a Log Analytics workspace and an Automation account in your subscription. -* If you're new to Azure Monitor logs and have not deployed a workspace already, you should review the [workspace design guidance](../../azure-monitor/logs/workspace-design.md). It will help you to learn about access control, and understand the design implementation strategies we recommend for your organization. +* If you're new to Azure Monitor logs and have not deployed a workspace already, you should review the [workspace design guidance](/azure/azure-monitor/logs/workspace-design). It will help you to learn about access control, and understand the design implementation strategies we recommend for your organization. ## Deploy template |
| automation | Mecmintegration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/update-management/mecmintegration.md | You can report and update managed Windows servers by creating and pre-staging so * You must have [Azure Automation Update Management](overview.md) added to your Automation account. * Windows servers currently managed by your Microsoft Configuration Manager environment also need to report to the Log Analytics workspace that also has Update Management enabled.-* This feature is enabled in Microsoft Configuration Manager current branch version 1606 and higher. To integrate your Microsoft Configuration Manager central administration site or a standalone primary site with Azure Monitor logs and import collections, review [Connect Configuration Manager to Azure Monitor logs](../../azure-monitor/logs/collect-sccm.md). +* This feature is enabled in Microsoft Configuration Manager current branch version 1606 and higher. To integrate your Microsoft Configuration Manager central administration site or a standalone primary site with Azure Monitor logs and import collections, review [Connect Configuration Manager to Azure Monitor logs](/azure/azure-monitor/logs/collect-sccm). * Windows agents must either be configured to communicate with a Windows Server Update Services (WSUS) server or have access to Microsoft Update if they don't receive security updates from Microsoft Configuration Manager. How you manage clients hosted in Azure IaaS with your existing Microsoft Configuration Manager environment primarily depends on the connection you have between Azure datacenters and your infrastructure. This connection affects any design changes you may need to make to your Microsoft Configuration Manager infrastructure and related cost to support those necessary changes. To understand what planning considerations you need to evaluate before proceeding, review [Configuration Manager on Azure - Frequently Asked Questions](/configmgr/core/understand/configuration-manager-on-azure#networking). |
| automation | Operating System Requirements | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/update-management/operating-system-requirements.md | The section describes operating system-specific requirements. For additional gui Windows Update agents must be configured to communicate with a Windows Server Update Services (WSUS) server, or they require access to Microsoft Update. For hybrid machines, we recommend installing the Log Analytics agent for Windows by first connecting your machine to [Azure Arc-enabled servers](../../azure-arc/servers/overview.md), and then use Azure Policy to assign the [Deploy Log Analytics agent to Microsoft Azure Arc machines](../../governance/policy/samples/built-in-policies.md#monitoring) built-in policy definition. Alternatively, if you plan to monitor the machines with VM insights, instead use the [Enable Enable VM insights](../../governance/policy/samples/built-in-initiatives.md#monitoring) initiative. -You can use Update Management with Microsoft Configuration Manager. To learn more about integration scenarios, see [Integrate Update Management with Windows Configuration Manager](mecmintegration.md). The [Log Analytics agent for Windows](../../azure-monitor/agents/agent-windows.md) is required for Windows servers managed by sites in your Configuration Manager environment. +You can use Update Management with Microsoft Configuration Manager. To learn more about integration scenarios, see [Integrate Update Management with Windows Configuration Manager](mecmintegration.md). The [Log Analytics agent for Windows](/azure/azure-monitor/agents/agent-windows) is required for Windows servers managed by sites in your Configuration Manager environment. By default, Windows VMs that are deployed from Azure Marketplace are set to receive automatic updates from Windows Update Service. This behavior doesn't change when you add Windows VMs to your workspace. If you don't actively manage updates by using Update Management, the default behavior (to automatically apply updates) applies. |
| automation | Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/update-management/overview.md | If the Windows Update Agent (WUA) on the Windows machine is configured to report You can deploy and install software updates on machines that require the updates by creating a scheduled deployment. Updates classified as *Optional* aren't included in the deployment scope for Windows machines. Only required updates are included in the deployment scope. -The scheduled deployment defines which target machines receive the applicable updates. It does so either by explicitly specifying certain machines or by selecting a [computer group](../../azure-monitor/logs/computer-groups.md) that's based on log searches of a specific set of machines (or based on an [Azure query](query-logs.md) that dynamically selects Azure VMs based on specified criteria). These groups differ from [scope configuration](/previous-versions/azure/azure-monitor/insights/solution-targeting), which is used to control the targeting of machines that receive the configuration to enable Update Management. This prevents them from performing and reporting update compliance, and install approved required updates. +The scheduled deployment defines which target machines receive the applicable updates. It does so either by explicitly specifying certain machines or by selecting a [computer group](/azure/azure-monitor/logs/computer-groups) that's based on log searches of a specific set of machines (or based on an [Azure query](query-logs.md) that dynamically selects Azure VMs based on specified criteria). These groups differ from [scope configuration](/previous-versions/azure/azure-monitor/insights/solution-targeting), which is used to control the targeting of machines that receive the configuration to enable Update Management. This prevents them from performing and reporting update compliance, and install approved required updates. While defining a deployment, you also specify a schedule to approve and set a time period during which updates can be installed. This period is called the maintenance window. A 10-minute span of the maintenance window is reserved for reboots, assuming one is needed and you selected the appropriate reboot option. If patching takes longer than expected and there's less than 10 minutes in the maintenance window, a reboot won't occur. Azure Automation Update Management depends on the following external dependencie ### Management packs -The following management packs are installed on the machines managed by Update Management. If your Operations Manager management group is [connected to a Log Analytics workspace](../../azure-monitor/agents/om-agents.md), the management packs are installed in the Operations Manager management group. You don't need to configure or manage these management packs. +The following management packs are installed on the machines managed by Update Management. If your Operations Manager management group is [connected to a Log Analytics workspace](/azure/azure-monitor/agents/om-agents), the management packs are installed in the Operations Manager management group. You don't need to configure or manage these management packs. * Microsoft System Center Advisor Update Assessment Intelligence Pack (Microsoft.IntelligencePacks.UpdateAssessment) * Microsoft.IntelligencePack.UpdateAssessment.Configuration (Microsoft.IntelligencePack.UpdateAssessment.Configuration) The following management packs are installed on the machines managed by Update M > [!NOTE] > If you have an Operations Manager 1807 or 2019 management group connected to a Log Analytics workspace with agents configured in the management group to collect log data, you need to override the parameter `IsAutoRegistrationEnabled` and set it to `True` in the **Microsoft.IntelligencePacks.AzureAutomation.HybridAgent.Init** rule. -For more information about updates to management packs, see [Connect Operations Manager to Azure Monitor logs](../../azure-monitor/agents/om-agents.md). +For more information about updates to management packs, see [Connect Operations Manager to Azure Monitor logs](/azure/azure-monitor/agents/om-agents). > [!NOTE] > For Update Management to fully manage machines with the Log Analytics agent, you must update to the Log Analytics agent for Windows or the Log Analytics agent for Linux. To learn how to update the agent, see [How to upgrade an Operations Manager agent](/system-center/scom/deploy-upgrade-agents). In environments that use Operations Manager, you must be running System Center Operations Manager 2012 R2 UR 14 or later. Update Management scans managed machines for data using the following rules. It * Each Linux machine - Update Management does a scan every hour. -The average data usage by Azure Monitor logs for a machine using Update Management is approximately 25 MB per month. This value is only an approximation and is subject to change, depending on your environment. We recommend that you monitor your environment to keep track of your exact usage. For more information about analyzing Azure Monitor Logs data usage, see [Azure Monitor Logs pricing details](../../azure-monitor/logs/cost-logs.md). +The average data usage by Azure Monitor logs for a machine using Update Management is approximately 25 MB per month. This value is only an approximation and is subject to change, depending on your environment. We recommend that you monitor your environment to keep track of your exact usage. For more information about analyzing Azure Monitor Logs data usage, see [Azure Monitor Logs pricing details](/azure/azure-monitor/logs/cost-logs). ## Update classifications Update Management relies on the locally configured update repository to update s ## Update Windows Log Analytics agent to latest version -Update Management requires [Log Analytics agent](../../azure-monitor/agents/log-analytics-agent.md)  for its functioning. We recommend you to update Windows Log Analytics agent (also known as Windows Microsoft Monitoring Agent (MMA)) to the latest version to reduce security vulnerabilities and benefit from bug fixes. Log Analytics agent versions prior to [10.20.18053 (bundle) and 1.0.18053.0 (extension)](/azure/virtual-machines/extensions/oms-windows#agent-and-vm-extension-version) use an older method of certificate handling and hence it is not recommended. Older Windows Log Analytics agents would not be able to connect to Azure and Update Management would stop working on them. +Update Management requires [Log Analytics agent](/azure/azure-monitor/agents/log-analytics-agent)  for its functioning. We recommend you to update Windows Log Analytics agent (also known as Windows Microsoft Monitoring Agent (MMA)) to the latest version to reduce security vulnerabilities and benefit from bug fixes. Log Analytics agent versions prior to [10.20.18053 (bundle) and 1.0.18053.0 (extension)](/azure/virtual-machines/extensions/oms-windows#agent-and-vm-extension-version) use an older method of certificate handling and hence it is not recommended. Older Windows Log Analytics agents would not be able to connect to Azure and Update Management would stop working on them. You must update Log Analytics agent to the latest version, by following below steps:  1. Check the current version of Log Analytics agent for your machine:  Go to the installation path - *C:\ProgramFiles\Microsoft Monitoring Agent\Agent* and right-click on *HealthService.exe* to check **Properties**. In the **Details** tab, the field **Product version** provides version number of the Log Analytics agent. -1. If your Log Analytics agent version is prior to [10.20.18053 (bundle) and 1.0.18053.0 (extension)](/azure/virtual-machines/extensions/oms-windows#agent-and-vm-extension-version), upgrade to the latest version of the Windows Log Analytics agent, following these [guidelines](../../azure-monitor/agents/agent-manage.md).  +1. If your Log Analytics agent version is prior to [10.20.18053 (bundle) and 1.0.18053.0 (extension)](/azure/virtual-machines/extensions/oms-windows#agent-and-vm-extension-version), upgrade to the latest version of the Windows Log Analytics agent, following these [guidelines](/azure/azure-monitor/agents/agent-manage).  >[!NOTE] > During the upgrade process, update management schedules might fail. Ensure to do this when there is no planned schedule. |
| automation | Plan Deployment | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/update-management/plan-deployment.md | Update Management is an Azure Automation feature, and therefore requires an Auto Update Management depends on a Log Analytics workspace in Azure Monitor to store assessment and update status log data collected from managed machines. Integration with Log Analytics also enables detailed analysis and alerting in Azure Monitor. You can use an existing workspace in your subscription, or create a new one dedicated only for Update Management. -If you are new to Azure Monitor Logs and the Log Analytics workspace, you should review the [Design a Log Analytics workspace](../../azure-monitor/logs/workspace-design.md) deployment guide. +If you are new to Azure Monitor Logs and the Log Analytics workspace, you should review the [Design a Log Analytics workspace](/azure/azure-monitor/logs/workspace-design) deployment guide. ## Step 3: Supported operating systems Update Management supports specific versions of the Windows Server and Linux ope ## Step 4: Log Analytics agent -The [Log Analytics agent](../../azure-monitor/agents/log-analytics-agent.md) for Windows and Linux is required to support Update Management. The agent is used for both data collection, and the Automation system Hybrid Runbook Worker role to support Update Management runbooks used to manage the assessment and update deployments on the machine. +The [Log Analytics agent](/azure/azure-monitor/agents/log-analytics-agent) for Windows and Linux is required to support Update Management. The agent is used for both data collection, and the Automation system Hybrid Runbook Worker role to support Update Management runbooks used to manage the assessment and update deployments on the machine. On Azure VMs, if the Log Analytics agent isn't already installed, when you enable Update Management for the VM it is automatically installed using the Log Analytics VM extension for [Windows](/azure/virtual-machines/extensions/oms-windows) or [Linux](/azure/virtual-machines/extensions/oms-linux). The agent is configured to report to the Log Analytics workspace linked to the Automation account Update Management is enabled in. -Non-Azure VMs or servers need to have the Log Analytics agent for Windows or Linux installed and reporting to the linked workspace. We recommend installing the Log Analytics agent for Windows or Linux by first connecting your machine to [Azure Arc-enabled servers](../../azure-arc/servers/overview.md), and then use Azure Policy to assign the [Deploy Log Analytics agent to Linux or Windows Azure Arc machines](../../governance/policy/samples/built-in-policies.md#monitoring) built-in policy definition. Alternatively, if you plan to monitor the machines with [VM insights](../../azure-monitor/vm/vminsights-overview.md), instead use the [Enable Azure Monitor for VMs](../../governance/policy/samples/built-in-initiatives.md#monitoring) initiative. +Non-Azure VMs or servers need to have the Log Analytics agent for Windows or Linux installed and reporting to the linked workspace. We recommend installing the Log Analytics agent for Windows or Linux by first connecting your machine to [Azure Arc-enabled servers](../../azure-arc/servers/overview.md), and then use Azure Policy to assign the [Deploy Log Analytics agent to Linux or Windows Azure Arc machines](../../governance/policy/samples/built-in-policies.md#monitoring) built-in policy definition. Alternatively, if you plan to monitor the machines with [VM insights](/azure/azure-monitor/vm/vminsights-overview), instead use the [Enable Azure Monitor for VMs](../../governance/policy/samples/built-in-initiatives.md#monitoring) initiative. If you're enabling a machine that's currently managed by Operations Manager, a new agent isn't required. The workspace information is added to the agents configuration when you connect the management group to the Log Analytics workspace. For Windows machines, you must also allow traffic to any endpoints required by W For Red Hat Linux machines, see [IPs for the RHUI content delivery servers](/azure/virtual-machines/workloads/redhat/redhat-rhui#the-ips-for-the-rhui-content-delivery-servers) for required endpoints. For other Linux distributions, see your provider documentation. -If your IT security policies do not allow machines on the network to connect to the internet, you can set up a [Log Analytics gateway](../../azure-monitor/agents/gateway.md) and then configure the machine to connect through the gateway to Azure Automation and Azure Monitor. +If your IT security policies do not allow machines on the network to connect to the internet, you can set up a [Log Analytics gateway](/azure/azure-monitor/agents/gateway) and then configure the machine to connect through the gateway to Azure Automation and Azure Monitor. ## Step 6: Permissions Update Management allows you to target updates to a dynamic group representing A * Locations * Tags -For non-Azure machines, a dynamic group uses saved searches, also called [computer groups](../../azure-monitor/logs/computer-groups.md). Update deployments scoped to a group of machines is only visible from the Automation account in the Update Management **Deployment schedules** option, not from a specific Azure VM. +For non-Azure machines, a dynamic group uses saved searches, also called [computer groups](/azure/azure-monitor/logs/computer-groups). Update deployments scoped to a group of machines is only visible from the Automation account in the Update Management **Deployment schedules** option, not from a specific Azure VM. Alternatively, updates can be managed only for a selected Azure VM. Update deployments scoped to the specific machine are visible from both the machine and from the Automation account in Update Management **Deployment schedules** option. |
| automation | Query Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/automation/update-management/query-logs.md | On a Windows computer, you can review the following information to verify agent 1. Open the Windows Event Log. Go to **Application and Services Logs\Operations Manager** and search for Event ID 3000 and Event ID 5002 from the source **Service Connector**. These events indicate that the computer has registered with the Log Analytics workspace and is receiving configuration. -If the agent can't communicate with Azure Monitor logs and the agent is configured to communicate with the internet through a firewall or proxy server, confirm the firewall or proxy server is properly configured. To learn how to verify the firewall or proxy server is properly configured, see [Network configuration for Windows agent](../../azure-monitor/agents/agent-windows.md) or [Network configuration for Linux agent](../../azure-monitor/vm/monitor-virtual-machine.md). +If the agent can't communicate with Azure Monitor logs and the agent is configured to communicate with the internet through a firewall or proxy server, confirm the firewall or proxy server is properly configured. To learn how to verify the firewall or proxy server is properly configured, see [Network configuration for Windows agent](/azure/azure-monitor/agents/agent-windows) or [Network configuration for Linux agent](/azure/azure-monitor/vm/monitor-virtual-machine). > [!NOTE] > If your Linux systems are configured to communicate with a proxy or Log Analytics Gateway and you're enabling Update Management, update the `proxy.conf` permissions to grant the omiuser group read permission on the file by using the following commands: If the agent can't communicate with Azure Monitor logs and the agent is configur Newly added Linux agents show a status of **Updated** after an assessment has been performed. This process can take up to 6 hours. -To confirm that an Operations Manager management group is communicating with Azure Monitor logs, see [Validate Operations Manager integration with Azure Monitor logs](../../azure-monitor/agents/om-agents.md#validate-operations-manager-integration-with-azure-monitor). +To confirm that an Operations Manager management group is communicating with Azure Monitor logs, see [Validate Operations Manager integration with Azure Monitor logs](/azure/azure-monitor/agents/om-agents#validate-operations-manager-integration-with-azure-monitor). ### Single Azure VM Assessment queries (Windows) Update ## Next steps -* For details of Azure Monitor logs, see [Azure Monitor logs](../../azure-monitor/logs/log-query-overview.md). +* For details of Azure Monitor logs, see [Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview). * For help with alerts, see [Configure alerts](configure-alerts.md). |
| azure-app-configuration | Howto Geo Replication | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-app-configuration/howto-geo-replication.md | -This article covers replication of Azure App Configuration stores. You'll learn about how to create, use and delete a replica in your configuration store. +This article covers replication of Azure App Configuration stores. You learn about how to create, use, and delete a replica in your configuration store. To learn more about the concept of geo-replication, see [Geo-replication in Azure App Configuration](./concept-geo-replication.md). To delete a replica in the portal, follow the steps below. ## Automatic replica discovery -The App Configuration providers can automatically discover any additional replicas from a given App Configuration endpoint and attempt to connect to them. This feature allows you to benefit from geo-replication without having to change your code or redeploy your application. This means you can enable geo-replication or add extra replicas even after your application has been deployed. +The App Configuration providers can automatically discover any replicas from a given App Configuration endpoint and attempt to connect to them. This feature allows you to benefit from geo-replication without having to change your code or redeploy your application. This means you can enable geo-replication or add extra replicas even after your application has been deployed. Automatic replica discovery is enabled by default, but you can refer to the following sample code to disable it (not recommended). spec: > [!NOTE] > The automatic replica discovery and failover support is available if you use version **1.3.0** or later of [Azure App Configuration Kubernetes Provider](./quickstart-azure-kubernetes-service.md). +### [Python](#tab/python) ++Specify the `replica_discovery_enabled` property when loading the configuration store and set it to `False`. +++```python +config = load(endpoint=endpoint, credential=credential, replica_discovery_enabled=False) +``` ++> [!NOTE] +> The automatic replica discovery support is available if you use version **1.3.0** or later. + ## Scale and failover with replicas Each replica you create has its dedicated endpoint. If your application resides in multiple geo-locations, you can update each deployment of your application in a location to connect to the replica closer to that location, which helps minimize the network latency between your application and App Configuration. Since each replica has its separate request quota, this setup also helps the scalability of your application while it grows to a multi-region distributed service. -When geo-replication is enabled, and if one replica isn't accessible, you can let your application failover to another replica for improved resiliency. App Configuration providers have built-in failover support through user provided replicas as well as additional automatically discovered replicas. You can provide a list of your replica endpoints in the order of the most preferred to the least preferred endpoint. When the current endpoint isn't accessible, the provider will fail over to a less preferred endpoint, but it will try to connect to the more preferred endpoints from time to time. If all user provided replicas are not accessible, the automatically discovered replicas will be randomly selected and used. When a more preferred endpoint becomes available, the provider will switch to it for future requests. +When geo-replication is enabled, and if one replica isn't accessible, you can let your application failover to another replica for improved resiliency. App Configuration providers have built-in failover support through user provided replicas and/or additional automatically discovered replicas. You can provide a list of your replica endpoints in the order of the most preferred to the least preferred endpoint. When the current endpoint isn't accessible, the provider will fail over to a less preferred endpoint, but it tries to connect to the more preferred endpoints from time to time. If all user provided replicas aren't accessible, the automatically discovered replicas will be randomly selected and used. When a more preferred endpoint becomes available, the provider will switch to it for future requests. Assuming you have an application using Azure App Configuration, you can update it as the following sample code to take advantage of the failover feature. You can either provide a list of endpoints for Microsoft Entra authentication or a list of connection strings for access key-based authentication. spring.cloud.azure.appconfiguration.stores[0].connection-strings[1]="${SECOND_RE ### [Kubernetes](#tab/kubernetes) -The Azure App Configuration Kubernetes Provider supports failover with automatically discovered replicas by default, as long as automatic replica discovery is not disabled. It does not support or require user-provided replicas. +The Azure App Configuration Kubernetes Provider supports failover with automatically discovered replicas by default, as long as automatic replica discovery isn't disabled. It doesn't support or require user-provided replicas. ++### [Python](#tab/python) ++The Azure App Configuration Python Provider supports failover with automatically discovered replicas by default, as long as automatic replica discovery isn't disabled. It doesn't support or require user-provided replicas. configurationBuilder.AddAzureAppConfiguration(options => ### [Java Spring](#tab/spring) -This feature is not yet supported in the Azure App Configuration Java Spring Provider. +This feature isn't yet supported in the Azure App Configuration Java Spring Provider. ### [Kubernetes](#tab/kubernetes) -This feature is not yet supported in the Azure App Configuration Kubernetes Provider. +This feature isn't yet supported in the Azure App Configuration Kubernetes Provider. ++### [Python](#tab/python) ++This feature isn't yet supported in the Azure App Configuration Python Provider. |
| azure-app-configuration | Monitor App Configuration Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-app-configuration/monitor-app-configuration-reference.md | -Resource Provider and Type: [App Configuration Platform Metrics](../azure-monitor/essentials/metrics-supported.md#microsoftappconfigurationconfigurationstores) +Resource Provider and Type: [App Configuration Platform Metrics](/azure/azure-monitor/essentials/metrics-supported#microsoftappconfigurationconfigurationstores) | Metric | Unit | Description | |-|--| -- | Resource Provider and Type: [App Configuration Platform Metrics](../azure-monito | Replication Latency | Milliseconds | Represents the average time it takes for a replica to be consistent with current state. | | Snapshot Storage Size | Count | Represents the total storage usage of configuration snapshot(s) in bytes. | -For more information, see a list of [all platform metrics supported in Azure Monitor](../azure-monitor/essentials/metrics-supported.md). +For more information, see a list of [all platform metrics supported in Azure Monitor](/azure/azure-monitor/essentials/metrics-supported). ## Metric Dimensions App Configuration has the following dimensions associated with its metr | Replication Latency | The **Endpoint** of the replica that data was replicated to is included as a dimension. | | Snapshot Storage Size | This metric does not have any dimensions. | - For more information on what metric dimensions are, see [Multi-dimensional metrics](../azure-monitor/essentials/data-platform-metrics.md#multi-dimensional-metrics). + For more information on what metric dimensions are, see [Multi-dimensional metrics](/azure/azure-monitor/essentials/data-platform-metrics#multi-dimensional-metrics). ## Resource logs This section lists the category types of resource log collected for App Configuration.  | Resource log type | Further information| |-|--|-| HttpRequest | [App Configuration Resource Log Category Information](../azure-monitor/essentials/resource-logs-categories.md) | +| HttpRequest | [App Configuration Resource Log Category Information](/azure/azure-monitor/essentials/resource-logs-categories) | -For more information, see a list of [all resource logs category types supported in Azure Monitor](../azure-monitor/essentials/resource-logs-schema.md). +For more information, see a list of [all resource logs category types supported in Azure Monitor](/azure/azure-monitor/essentials/resource-logs-schema).   ## Azure Monitor Logs tables App Configuration uses the [AACHttpRequest Table](/azure/azure-monitor/refere ## See Also * See [Monitoring Azure App Configuration](monitor-app-configuration.md) for a description of monitoring Azure App Configuration.-* See [Monitoring Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md) for details on monitoring Azure resources. +* See [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) for details on monitoring Azure resources. |
| azure-app-configuration | Monitor App Configuration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-app-configuration/monitor-app-configuration.md | Last updated 05/05/2021 # Monitoring App Configuration When you have critical applications and business processes relying on Azure resources, you want to monitor those resources for their availability, performance, and operation. -This article describes the monitoring data generated by App Configuration. App Configuration uses [Azure Monitor](../azure-monitor/overview.md). If you are unfamiliar with the features of Azure Monitor common to all Azure services that use it, read [Monitoring Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md). +This article describes the monitoring data generated by App Configuration. App Configuration uses [Azure Monitor](/azure/azure-monitor/overview). If you are unfamiliar with the features of Azure Monitor common to all Azure services that use it, read [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource). ## Monitoring overview page in the Azure portal The **Overview** page in the Azure portal includes a brief view of the resource usage, such as the total number of requests, number of throttled requests, and request duration per configuration store. This information is useful, but only displays a small amount of the monitoring data available. Some of this monitoring data is collected automatically and is available for analysis as soon as you create the resource. You can enable additional types of data collection with some configuration. The **Overview** page in the Azure portal includes a brief view of the resource >  ## Monitoring data -App Configuration collects the same kinds of monitoring data as other Azure resources that are described in [Monitoring data from Azure resources](../azure-monitor/essentials/monitor-azure-resource.md#monitoring-data). See [Monitoring App Configuration data reference](./monitor-app-configuration-reference.md) for detailed information on the metrics and logs metrics created by App Configuration. +App Configuration collects the same kinds of monitoring data as other Azure resources that are described in [Monitoring data from Azure resources](/azure/azure-monitor/essentials/monitor-azure-resource#monitoring-data). See [Monitoring App Configuration data reference](./monitor-app-configuration-reference.md) for detailed information on the metrics and logs metrics created by App Configuration. ## Collection and routing Platform metrics and the activity log are collected and stored automatically, but can be routed to other locations by using a diagnostic setting. -Resource Logs are not collected and stored until you create a diagnostic setting and route them to one or more locations. For example, to view logs and metrics for a configuration store in near real-time in Azure Monitor, collect the resource logs in a Log Analytics workspace. If you do not already have one, create a [Log Analytics Workspace](../azure-monitor/logs/quick-create-workspace.md) and follow these steps to create and enable a diagnostic setting. +Resource Logs are not collected and stored until you create a diagnostic setting and route them to one or more locations. For example, to view logs and metrics for a configuration store in near real-time in Azure Monitor, collect the resource logs in a Log Analytics workspace. If you do not already have one, create a [Log Analytics Workspace](/azure/azure-monitor/logs/quick-create-workspace) and follow these steps to create and enable a diagnostic setting. #### [Portal](#tab/portal) Resource Logs are not collected and stored until you create a diagnostic setting Get-AzureRmDiagnosticSetting -ResourceId <app-configuration-resource-id> ``` -For more information on creating a diagnostic setting using the Azure portal, CLI, or PowerShell, see [create a diagnostic setting to collect platform logs and metrics in Azure](../azure-monitor/essentials/diagnostic-settings.md). +For more information on creating a diagnostic setting using the Azure portal, CLI, or PowerShell, see [create a diagnostic setting to collect platform logs and metrics in Azure](/azure/azure-monitor/essentials/diagnostic-settings). When you create a diagnostic setting, you specify which categories of logs to collect. For further information on the categories of logs for App Configuration, reference [App Configuration monitoring data reference](./monitor-app-configuration-reference.md#resourcelogs). ## Analyzing metrics -You can analyze metrics for App Configuration with metrics from other Azure services using metrics explorer by opening **Metrics** from the **Azure Monitor** menu. See [Analyze metrics with Azure Monitor metrics explorer](../azure-monitor/essentials/analyze-metrics.md) for details on using this tool. For App Configuration, the following metrics are collected: +You can analyze metrics for App Configuration with metrics from other Azure services using metrics explorer by opening **Metrics** from the **Azure Monitor** menu. See [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics) for details on using this tool. For App Configuration, the following metrics are collected: * Http Incoming Request Count * Http Incoming Request Duration In the portal, navigate to the **Metrics** section and select the **Metric Names > [!div class="mx-imgBorder"] >  -For a list of the platform metrics collected for App Configuration, see [Monitoring App Configuration data reference metrics](./monitor-app-configuration-reference.md#metrics). For reference, you can also see a list of [all resource metrics supported in Azure Monitor](../azure-monitor/essentials/metrics-supported.md). +For a list of the platform metrics collected for App Configuration, see [Monitoring App Configuration data reference metrics](./monitor-app-configuration-reference.md#metrics). For reference, you can also see a list of [all resource metrics supported in Azure Monitor](/azure/azure-monitor/essentials/metrics-supported). ## Analyzing logs-Data in Azure Monitor Logs is stored in tables where each table has its own set of unique properties. The common schema is outlined in [Azure Monitor resource log schema](../azure-monitor/essentials/resource-logs-schema.md#top-level-common-schema). +Data in Azure Monitor Logs is stored in tables where each table has its own set of unique properties. The common schema is outlined in [Azure Monitor resource log schema](/azure/azure-monitor/essentials/resource-logs-schema#top-level-common-schema). -The [Activity log](../azure-monitor/essentials/activity-log.md) is a platform log in Azure that provides insight into subscription-level events. You can view it independently or route it to Azure Monitor Logs, where you can do much more complex queries using Log Analytics. +The [Activity log](/azure/azure-monitor/essentials/activity-log) is a platform log in Azure that provides insight into subscription-level events. You can view it independently or route it to Azure Monitor Logs, where you can do much more complex queries using Log Analytics. For a list of the types of resource logs collected for App Configuration, see [Monitoring App Configuration data reference](./monitor-app-configuration-reference.md#resourcelogs). For a list of the tables used by Azure Monitor Logs and queryable by Log Analytics, see [Monitoring App Configuration data reference](./monitor-app-configuration-reference.md#azuremonitorlogstables) >[!IMPORTANT] Following are sample queries that you can use to help you monitor your App Confi ## Alerts -Azure Monitor alerts proactively notify you when important conditions are found in your monitoring data. They allow you to identify and address issues in your system before your customers notice them. You can set alerts on [metrics](../azure-monitor/alerts/alerts-metric-overview.md), [logs](../azure-monitor/alerts/alerts-unified-log.md), and the [activity log](../azure-monitor/alerts/activity-log-alerts.md). Different types of alerts have benefits and drawbacks. +Azure Monitor alerts proactively notify you when important conditions are found in your monitoring data. They allow you to identify and address issues in your system before your customers notice them. You can set alerts on [metrics](/azure/azure-monitor/alerts/alerts-metric-overview), [logs](/azure/azure-monitor/alerts/alerts-unified-log), and the [activity log](/azure/azure-monitor/alerts/activity-log-alerts). Different types of alerts have benefits and drawbacks. The following table lists common and recommended alert rules for App Configuration. | Alert type | Condition | Description  | The following table lists common and recommended alert rules for App C * See [Monitoring App Configuration data reference](./monitor-app-configuration-reference.md) for a reference of the metrics, logs, and other important values created by App Configuration. -* See [Monitoring Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md) for details on monitoring Azure resources. +* See [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) for details on monitoring Azure resources. |
| azure-app-configuration | Quickstart Azure Kubernetes Service | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-app-configuration/quickstart-azure-kubernetes-service.md | Add following key-values to the App Configuration store and leave **Label** and --namespace azappconfig-system \ --create-namespace ```-+ > [!TIP] > The App Configuration Kubernetes Provider is also available as an AKS extension. This integration allows for seamless installation and management via the Azure CLI, ARM templates, or Bicep templates. Utilizing the AKS extension facilitates automatic minor/patch version updates, ensuring your system is always up-to-date. For detailed installation instructions, please refer to the [Azure App Configuration extension for Azure Kubernetes Service](/azure/aks/azure-app-configuration). Add following key-values to the App Configuration store and leave **Label** and key: mysettings.json auth: workloadIdentity:- managedIdentityClientId: <your-managed-identity-client-id> + serviceAccountName: <your-service-account-name> ``` - Replace the value of the `endpoint` field with the endpoint of your Azure App Configuration store. Follow the steps in [use workload identity](./reference-kubernetes-provider.md#use-workload-identity) and update the `auth` section with the client ID of the user-assigned managed identity you created. + Replace the value of the `endpoint` field with the endpoint of your Azure App Configuration store. Proceed to the next step to update the `auth` section with your authentication information. > [!NOTE] > `AzureAppConfigurationProvider` is a declarative API object. It defines the desired state of the ConfigMap created from the data in your App Configuration store with the following behavior: Add following key-values to the App Configuration store and leave **Label** and > - The ConfigMap will be reset based on the present data in your App Configuration store if it's deleted or modified by any other means. > - The ConfigMap will be deleted if the App Configuration Kubernetes Provider is uninstalled. +1. Follow the [instructions to use the workload identity](./reference-kubernetes-provider.md#use-workload-identity) to authenticate with your App Configuration store. Update the *appConfigurationProvider.yaml* file by replacing the `serviceAccountName` field with the name of the service account you created. For more information on other authentication methods, refer to the examples in the [Authentication](./reference-kubernetes-provider.md#authentication) section. + 1. Update the *deployment.yaml* file in the *Deployment* directory to use the ConfigMap `configmap-created-by-appconfig-provider` as a mounted data volume. It is important to ensure that the `volumeMounts.mountPath` matches the `WORKDIR` specified in your *Dockerfile* and the *config* directory created before. ```yaml Ensure that you specify the correct key-value selectors to match the expected da You can customize the installation by providing additional Helm values when installing the Azure App Configuration Kubernetes Provider. For example, you can set the log level, configure the provider to run on a specific node, or disable the workload identity. Refer to the [installation guide](./reference-kubernetes-provider.md#installation) for more information. +#### Why am I unable to authenticate with Azure App Configuration using workload identity after upgrading the provider to version 2.0.0? ++Starting with version 2.0.0, a user-provided service account is required for authenticating with Azure App Configuration [using workload identity](./reference-kubernetes-provider.md#use-workload-identity). This change enhances security through namespace isolation. Previously, a Kubernetes providerΓÇÖs service account was used for all namespaces. For updated instructions, see the documentation on using workload identity. If you need time to migrate when upgrading to version 2.0.0, you can temporarily set `workloadIdentity.globalServiceAccountEnabled=true` during provider installation. Please note that support for using the providerΓÇÖs service account will be deprecated in a future release. + ## Clean up resources Uninstall the App Configuration Kubernetes Provider from your AKS cluster if you want to keep the AKS cluster. |
| azure-app-configuration | Reference Kubernetes Provider | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-app-configuration/reference-kubernetes-provider.md | -The following reference outlines the properties supported by the Azure App Configuration Kubernetes Provider `v1.3.0`. See [release notes](https://github.com/Azure/AppConfiguration/blob/main/releaseNotes/KubernetesProvider.md) for more information on the change. +The following reference outlines the properties supported by the Azure App Configuration Kubernetes Provider `v2.0.0`. See [release notes](https://github.com/Azure/AppConfiguration/blob/main/releaseNotes/KubernetesProvider.md) for more information on the change. ## Properties The `spec.auth` property isn't required if the connection string of your App Con |workloadIdentity|The settings for using workload identity.|false|object| |managedIdentityClientId|The client ID of user-assigned managed identity of virtual machine scale set.|false|string| -The `spec.auth.workloadIdentity` property has the following child properties. One of them must be specified. +The `spec.auth.workloadIdentity` property has the following child property. |Name|Description|Required|Type| |||||-|managedIdentityClientId|The client ID of the user-assigned managed identity associated with the workload identity.|alternative|string| -|managedIdentityClientIdReference|The client ID of the user-assigned managed identity can be obtained from a ConfigMap. The ConfigMap must be in the same namespace as the Kubernetes provider.|alternative|object| --The `spec.auth.workloadIdentity.managedIdentityClientIdReference` property has the following child properties. --|Name|Description|Required|Type| -||||| -|configMap|The name of the ConfigMap where the client ID of a user-assigned managed identity can be found.|true|string| -|key|The key name that holds the value for the client ID of a user-assigned managed identity.|true|string| +|serviceAccountName|The name of the service account associated with the workload identity.|true|string| The `spec.configuration` has the following child properties. If the `spec.secret.auth` property isn't set, the system-assigned managed identi |Name|Description|Required|Type| ||||| |servicePrincipalReference|The name of the Kubernetes Secret that contains the credentials of a service principal used for authentication with Key Vaults that don't have individual authentication methods specified.|false|string|-|workloadIdentity|The settings of the workload identity used for authentication with Key Vaults that don't have individual authentication methods specified. It has the same child properties as `spec.auth.workloadIdentity`.|false|object| +|workloadIdentity|The settings of the workload identity used for authentication with Key Vaults that don't have individual authentication methods specified. It has the same child property as `spec.auth.workloadIdentity`.|false|object| |managedIdentityClientId|The client ID of a user-assigned managed identity of virtual machine scale set used for authentication with Key Vaults that don't have individual authentication methods specified.|false|string| |keyVaults|The authentication methods for individual Key Vaults.|false|object array| The authentication method of each *Key Vault* can be specified with the followin ||||| |uri|The URI of a Key Vault.|true|string| |servicePrincipalReference|The name of the Kubernetes Secret that contains the credentials of a service principal used for authentication with a Key Vault.|false|string|-|workloadIdentity|The settings of the workload identity used for authentication with a Key Vault. It has the same child properties as `spec.auth.workloadIdentity`.|false|object| +|workloadIdentity|The settings of the workload identity used for authentication with a Key Vault. It has the same child property as `spec.auth.workloadIdentity`.|false|object| |managedIdentityClientId|The client ID of a user-assigned managed identity of virtual machine scale set used for authentication with a Key Vault.|false|string| The `spec.secret.refresh` property has the following child properties. The `spec.featureFlag.refresh` property has the following child properties. ## Installation Use the following `helm install` command to install the Azure App Configuration Kubernetes Provider. See [helm-values.yaml](https://github.com/Azure/AppConfiguration-KubernetesProvider/blob/main/deploy/parameter/helm-values.yaml) for the complete list of parameters and their default values. You can override the default values by passing the `--set` flag to the command.- + ```bash helm install azureappconfiguration.kubernetesprovider \ oci://mcr.microsoft.com/azure-app-configuration/helmchart/kubernetes-provider \ helm install azureappconfiguration.kubernetesprovider \ By default, autoscaling is disabled. However, if you have multiple `AzureAppConfigurationProvider` resources to produce multiple ConfigMaps/Secrets, you can enable horizontal pod autoscaling by setting `autoscaling.enabled` to `true`. +```bash +helm install azureappconfiguration.kubernetesprovider \ + oci://mcr.microsoft.com/azure-app-configuration/helmchart/kubernetes-provider \ + --namespace azappconfig-system \ + --create-namespace + --set autoscaling.enabled=true +``` ++## Data collection ++The software may collect information about you and your use of the software and send it to Microsoft. Microsoft may use this information to provide services and improve our products and services. You may turn off the telemetry by setting the `requestTracing.enabled=false` while installing the Azure App Configuration Kubernetes Provider. There are also some features in the software that may enable you and Microsoft to collect data from users of your applications. If you use these features, you must comply with applicable law, including providing appropriate notices to users of your applications together with a copy of MicrosoftΓÇÖs privacy statement. Our privacy statement is located at https://go.microsoft.com/fwlink/?LinkID=824704. You can learn more about data collection and use in the help documentation and our privacy statement. Your use of the software operates as your consent to these practices. + ## Examples ### Authentication By default, autoscaling is disabled. However, if you have multiple `AzureAppConf 1. [Get the OIDC issuer URL](/azure/aks/workload-identity-deploy-cluster#retrieve-the-oidc-issuer-url) of the AKS cluster. -1. [Create a user-assigned managed identity](/azure/active-directory/managed-identities-azure-resources/how-manage-user-assigned-managed-identities#create-a-user-assigned-managed-identity) and note down its client ID after creation. +1. [Create a user-assigned managed identity](/azure/active-directory/managed-identities-azure-resources/how-manage-user-assigned-managed-identities#create-a-user-assigned-managed-identity) and note down its client ID, tenant ID, name, and resource group. -1. Create the federated identity credential between the managed identity, OIDC issuer, and subject using the Azure CLI. +1. [Grant the user-assigned managed identity **App Configuration Data Reader** role](/azure/azure-app-configuration/concept-enable-rbac#assign-azure-roles-for-access-rights) in Azure App Configuration. + +1. Create a service account by adding a YAML file (e.g., *serviceAccount.yaml*) with the following content to the directory containing your AKS deployment files. The service account will be created when you apply all your deployment changes to your AKS cluster (e.g., using `kubectl apply`). Replace `<your-managed-identity-client-id>` with the client ID and `<your-managed-identity-tenant-id>` with the tenant ID of the user-assigned managed identity that has just been created. Replace `<your-service-account-name>` with your preferred name. - ``` azurecli - az identity federated-credential create --name "${FEDERATED_IDENTITY_CREDENTIAL_NAME}" --identity-name "${USER_ASSIGNED_IDENTITY_NAME}" --resource-group "${RESOURCE_GROUP}" --issuer "${AKS_OIDC_ISSUER}" --subject system:serviceaccount:azappconfig-system:az-appconfig-k8s-provider --audience api://AzureADTokenExchange - ``` + ``` yaml + apiVersion: v1 + kind: ServiceAccount + metadata: + name: <your-service-account-name> + annotations: + azure.workload.identity/client-id: <your-managed-identity-client-id> + azure.workload.identity/tenant-id: <your-managed-identity-tenant-id> + ``` -1. [Grant the user-assigned managed identity **App Configuration Data Reader** role](/azure/active-directory/managed-identities-azure-resources/qs-configure-portal-windows-vmss#user-assigned-managed-identity) in Azure App Configuration. +1. Create a federated identity credential for the user-assigned managed identity using the Azure CLI. Replace `<user-assigned-identity-name>` with the name and `<resource-group>` with the resource group of the newly created user-assigned managed identity. Replace `<aks-oidc-issuer>` with the OIDC issuer URL of the AKS cluster. Replace `<your-service-account-name>` with the name of the newly created service account. Replace `<federated-identity-credential-name>` with your preferred name for the federated identity credential. ++ ``` azurecli + az identity federated-credential create --name "<federated-identity-credential-name>" --identity-name "<user-assigned-identity-name>" --resource-group "<resource-group>" --issuer "<aks-oidc-issuer>" --subject system:serviceaccount:default:<your-service-account-name> --audience api://AzureADTokenExchange + ``` ++ Note that the subject of the federated identity credential should follow this format: `system:serviceaccount:<service-account-namespace>:<service-account-name>`. -1. Set the `spec.auth.workloadIdentity.managedIdentityClientId` property to the client ID of the user-assigned managed identity in the following sample `AzureAppConfigurationProvider` resource and deploy it to the AKS cluster. +1. Set the `spec.auth.workloadIdentity.serviceAccountName` property to the name of the service account in the following sample `AzureAppConfigurationProvider` resource. Be sure that the `AzureAppConfigurationProvider` resource and the service account are in the same namespace. ``` yaml apiVersion: azconfig.io/v1 By default, autoscaling is disabled. However, if you have multiple `AzureAppConf configMapName: configmap-created-by-appconfig-provider auth: workloadIdentity:- managedIdentityClientId: <your-managed-identity-client-id> + serviceAccountName: <your-service-account-name> ``` #### Use connection string |
| azure-app-configuration | Run Experiments Aspnet Core | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-app-configuration/run-experiments-aspnet-core.md | To run an experiment, you first need to connect a workspace-based Application In :::image type="content" source="./media/run-experiments-aspnet-core/select-application-insights.png" alt-text="Screenshot of the Azure portal, adding an Application Insights to a store." lightbox="./media/run-experiments-aspnet-core/select-application-insights.png"::: -1. Select the Application Insights resource you want to use as the telemetry provider for your variant feature flags and application, and select **Save**. If you don't have an Application Insights resource, create one by selecting **Create new**. For more information about how to proceed, go to [Create a worskpace-based resource](../azure-monitor/app/create-workspace-resource.md#create-a-workspace-based-resource). Then, back in **Application Insights (preview)**, reload the list of available Application Insights resources and select your new Application Insights resource. +1. Select the Application Insights resource you want to use as the telemetry provider for your variant feature flags and application, and select **Save**. If you don't have an Application Insights resource, create one by selecting **Create new**. For more information about how to proceed, go to [Create a worskpace-based resource](/azure/azure-monitor/app/create-workspace-resource#create-a-workspace-based-resource). Then, back in **Application Insights (preview)**, reload the list of available Application Insights resources and select your new Application Insights resource. 1. A notification indicates that the Application Insights resource was updated successfully for the App Configuration store. ## Connect a Split Experimentation Workspace (preview) to your store Any edit to a variant feature flag generates a new version of the experimentatio > To get experimentation results, you need at least 30 events per variant, but we suggest you have more that the minimum sampling size to make sure that your experimentation is producing reliable results. > [!NOTE]-> Application Insights sampling is enabled by default and it may impact your experimentation results. For this tutorial, you are recommended to turn off sampling in Application Insights. Learn more about [Sampling in Application Insights](../azure-monitor/app/sampling-classic-api.md). +> Application Insights sampling is enabled by default and it may impact your experimentation results. For this tutorial, you are recommended to turn off sampling in Application Insights. Learn more about [Sampling in Application Insights](/azure/azure-monitor/app/sampling-classic-api). ## Next step |
| azure-arc | Upload Metrics And Logs To Azure Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/data/upload-metrics-and-logs-to-azure-monitor.md | Upload the usage only once per day. When usage information is exported and uploa > [!NOTE] > Note that usage data is automatically uploaded for Azure Arc data controller deployed in **direct** connected mode. -For uploading metrics, Azure monitor only accepts the last 30 minutes of data ([Learn more](../../azure-monitor/essentials/metrics-store-custom-rest-api.md#troubleshooting)). The guidance for uploading metrics is to upload the metrics immediately after creating the export file so you can view the entire data set in Azure portal. For instance, if you exported the metrics at 2:00 PM and ran the upload command at 2:50 PM. Since Azure Monitor only accepts data for the last 30 minutes, you may not see any data in the portal. +For uploading metrics, Azure monitor only accepts the last 30 minutes of data ([Learn more](/azure/azure-monitor/essentials/metrics-store-custom-rest-api#troubleshooting)). The guidance for uploading metrics is to upload the metrics immediately after creating the export file so you can view the entire data set in Azure portal. For instance, if you exported the metrics at 2:00 PM and ran the upload command at 2:50 PM. Since Azure Monitor only accepts data for the last 30 minutes, you may not see any data in the portal. ## Related content |
| azure-arc | Upload Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/data/upload-metrics.md | To upload metrics for SQL Managed Instance enabled by Azure Arc and Azure Arc-en >[!NOTE] >Wait for at least 30 mins after the Azure Arc-enabled data instances are created for the first upload. >- >Make sure `upload` the metrics right away after `export` as Azure Monitor only accepts metrics for the last 30 minutes. [Learn more](../../azure-monitor/essentials/metrics-store-custom-rest-api.md#troubleshooting). + >Make sure `upload` the metrics right away after `export` as Azure Monitor only accepts metrics for the last 30 minutes. [Learn more](/azure/azure-monitor/essentials/metrics-store-custom-rest-api#troubleshooting). If you see any errors indicating "Failure to get metrics" during export, check if data collection is set to `true` by running the following command: Create, read, update, and delete (CRUD) operations on Azure Arc-enabled data ser Upload the usage only once per day. When usage information is exported and uploaded multiple times within the same 24 hour period, only the resource inventory is updated in Azure portal but not the resource usage. -For uploading metrics, Azure monitor only accepts the last 30 minutes of data ([Learn more](../../azure-monitor/essentials/metrics-store-custom-rest-api.md#troubleshooting)). The guidance for uploading metrics is to upload the metrics immediately after creating the export file so you can view the entire data set in Azure portal. For instance, if you exported the metrics at 2:00 PM and ran the upload command at 2:50 PM. Since Azure Monitor only accepts data for the last 30 minutes, you may not see any data in the portal. +For uploading metrics, Azure monitor only accepts the last 30 minutes of data ([Learn more](/azure/azure-monitor/essentials/metrics-store-custom-rest-api#troubleshooting)). The guidance for uploading metrics is to upload the metrics immediately after creating the export file so you can view the entire data set in Azure portal. For instance, if you exported the metrics at 2:00 PM and ran the upload command at 2:50 PM. Since Azure Monitor only accepts data for the last 30 minutes, you may not see any data in the portal. ## Related content |
| azure-arc | Extensions Release | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/kubernetes/extensions-release.md | The following extensions are currently available for use with Arc-enabled Kubern Azure Monitor Container Insights provides visibility into the performance of workloads deployed on the Kubernetes cluster. Use this extension to collect memory and CPU utilization metrics from controllers, nodes, and containers. -For more information, see [Azure Monitor Container Insights for Azure Arc-enabled Kubernetes clusters](../../azure-monitor/containers/container-insights-enable-arc-enabled-clusters.md?toc=/azure/azure-arc/kubernetes/toc.json&bc=/azure/azure-arc/kubernetes/breadcrumb/toc.json). +For more information, see [Azure Monitor Container Insights for Azure Arc-enabled Kubernetes clusters](/azure/azure-monitor/containers/container-insights-enable-arc-enabled-clusters?toc=/azure/azure-arc/kubernetes/toc.json&bc=/azure/azure-arc/kubernetes/breadcrumb/toc.json). ## Azure Policy |
| azure-arc | Kubernetes Resource View | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/kubernetes/kubernetes-resource-view.md | After you edit the YAML, select **Review + save**, confirm the changes, and then ## Next steps -- Learn how to [deploy Azure Monitor for containers](../../azure-monitor/containers/container-insights-enable-arc-enabled-clusters.md?toc=/azure/azure-arc/kubernetes/toc.json) for more in-depth information about nodes and containers on your clusters.+- Learn how to [deploy Azure Monitor for containers](/azure/azure-monitor/containers/container-insights-enable-arc-enabled-clusters?toc=/azure/azure-arc/kubernetes/toc.json) for more in-depth information about nodes and containers on your clusters. - Learn about [identity and access options for Azure Arc-enabled Kubernetes](identity-access-overview.md). |
| azure-arc | Monitor Gitops Flux 2 | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/kubernetes/monitor-gitops-flux-2.md | resource fluxRuleGroup 'Microsoft.AlertsManagement/prometheusRuleGroups@2023-03- ## Next steps - Review our tutorial on [using GitOps with Flux v2 to manage configuration and application deployment](tutorial-use-gitops-flux2.md).-- Learn about [Azure Monitor Container Insights](../../azure-monitor/containers/container-insights-enable-arc-enabled-clusters.md?toc=/azure/azure-arc/kubernetes/toc.json&bc=/azure/azure-arc/kubernetes/breadcrumb/toc.json).+- Learn about [Azure Monitor Container Insights](/azure/azure-monitor/containers/container-insights-enable-arc-enabled-clusters?toc=/azure/azure-arc/kubernetes/toc.json&bc=/azure/azure-arc/kubernetes/breadcrumb/toc.json). |
| azure-arc | Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/kubernetes/overview.md | Once your Kubernetes clusters are connected to Azure, at scale you can: * Configure clusters and deploy applications using [GitOps-based configuration management](tutorial-use-gitops-connected-cluster.md). -* View and monitor your clusters using [Azure Monitor for containers](../../azure-monitor/containers/container-insights-enable-arc-enabled-clusters.md?toc=/azure/azure-arc/kubernetes/toc.json). +* View and monitor your clusters using [Azure Monitor for containers](/azure/azure-monitor/containers/container-insights-enable-arc-enabled-clusters?toc=/azure/azure-arc/kubernetes/toc.json). * Enforce threat protection using [Microsoft Defender for Kubernetes](/azure/defender-for-cloud/defender-for-kubernetes-azure-arc?toc=/azure/azure-arc/kubernetes/toc.json). |
| azure-arc | Private Link | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/kubernetes/private-link.md | For more information, see [Key benefits of Azure Private Link](../../private-lin Azure Arc Private Link Scope connects private endpoints (and the virtual networks they're contained in) to an Azure resource, in this case Azure Arc-enabled Kubernetes clusters. When you enable any one of the Arc-enabled Kubernetes cluster supported extensions, such as Azure Monitor, then connection to other Azure resources may be required for these scenarios. For example, in the case of Azure Monitor, the logs collected from the cluster are sent to Log Analytics workspace. -Connectivity to the other Azure resources from an Arc-enabled Kubernetes cluster listed earlier requires configuring Private Link for each service. For an example, see [Private Link for Azure Monitor](../../azure-monitor/logs/private-link-security.md). +Connectivity to the other Azure resources from an Arc-enabled Kubernetes cluster listed earlier requires configuring Private Link for each service. For an example, see [Private Link for Azure Monitor](/azure/azure-monitor/logs/private-link-security). ## Current limitations Consider these current limitations when planning your Private Link setup. On Azure Arc-enabled Kubernetes clusters configured with private links, the following extensions support end-to-end connectivity through private links. Refer to the guidance linked to each cluster extension for additional configuration steps and details on support for private links. * [Azure GitOps](conceptual-gitops-flux2.md)-* [Azure Monitor](../../azure-monitor/logs/private-link-security.md) +* [Azure Monitor](/azure/azure-monitor/logs/private-link-security) ## Planning your Private Link setup If you run into problems, the following suggestions may help: * Learn more about [Azure Private Endpoint](../../private-link/private-link-overview.md). * Learn how to [troubleshoot Azure Private Endpoint connectivity problems](../../private-link/troubleshoot-private-endpoint-connectivity.md).-* Learn how to [configure Private Link for Azure Monitor](../../azure-monitor/logs/private-link-security.md). +* Learn how to [configure Private Link for Azure Monitor](/azure/azure-monitor/logs/private-link-security). |
| azure-arc | Tutorial Arc Enabled Open Service Mesh | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/kubernetes/tutorial-arc-enabled-open-service-mesh.md | Follow these steps to allow Azure Monitor to scrape Prometheus endpoints for col osm metrics enable --namespace <namespace2> ``` -3. Install the Azure Monitor extension using the guidance available [here](../../azure-monitor/containers/container-insights-enable-arc-enabled-clusters.md?toc=/azure/azure-arc/kubernetes/toc.json). +3. Install the Azure Monitor extension using the guidance available [here](/azure/azure-monitor/containers/container-insights-enable-arc-enabled-clusters?toc=/azure/azure-arc/kubernetes/toc.json). 4. Create a Configmap in the `kube-system` namespace that enables Azure Monitor to monitor your namespaces. For example, create a `container-azm-ms-osmconfig.yaml` with the following to monitor `<namespace1>` and `<namespace2>`: |
| azure-arc | Use Azure Policy Flux 2 | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/kubernetes/use-azure-policy-flux-2.md | If you have a scenario that differs from the built-in policies, you can overcome ## Next steps -* [Set up Azure Monitor for Containers with Azure Arc-enabled Kubernetes clusters](../../azure-monitor/containers/container-insights-enable-arc-enabled-clusters.md). +* [Set up Azure Monitor for Containers with Azure Arc-enabled Kubernetes clusters](/azure/azure-monitor/containers/container-insights-enable-arc-enabled-clusters). * Learn more about [deploying applications using GitOps with Flux v2](tutorial-use-gitops-flux2.md). |
| azure-arc | Use Azure Policy | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/kubernetes/use-azure-policy.md | For existing clusters, you may need to manually run a remediation task. This tas ## Next steps -[Set up Azure Monitor for Containers with Azure Arc-enabled Kubernetes clusters](../../azure-monitor/containers/container-insights-enable-arc-enabled-clusters.md). +[Set up Azure Monitor for Containers with Azure Arc-enabled Kubernetes clusters](/azure/azure-monitor/containers/container-insights-enable-arc-enabled-clusters). |
| azure-arc | Security Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/resource-bridge/security-overview.md | Azure Arc resource bridge stores resource information in Azure Cosmos DB. As des ## Security audit logs -The [activity log](../../azure-monitor/essentials/activity-log-insights.md) is an Azure platform log that provides insight into subscription-level events. This includes tracking when the Azure Arc resource bridge is modified, deleted, or added. You can [view the activity log](../../azure-monitor/essentials/activity-log-insights.md#view-the-activity-log) in the Azure portal or retrieve entries with PowerShell and Azure CLI. By default, activity log events are [retained for 90 days](../../azure-monitor/essentials/activity-log-insights.md#retention-period) and then deleted. +The [activity log](/azure/azure-monitor/essentials/activity-log-insights) is an Azure platform log that provides insight into subscription-level events. This includes tracking when the Azure Arc resource bridge is modified, deleted, or added. You can [view the activity log](/azure/azure-monitor/essentials/activity-log-insights#view-the-activity-log) in the Azure portal or retrieve entries with PowerShell and Azure CLI. By default, activity log events are [retained for 90 days](/azure/azure-monitor/essentials/activity-log-insights#retention-period) and then deleted. ## Next steps |
| azure-arc | Agent Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/agent-overview.md | The Azure Connected Machine agent package contains several logical components bu * The Extension agent manages VM extensions, including install, uninstall, and upgrade. Azure downloads extensions and copies them to the `%SystemDrive%\%ProgramFiles%\AzureConnectedMachineAgent\ExtensionService\downloads` folder on Windows, and to `/opt/GC_Ext/downloads` on Linux. On Windows, the extension installs to the following path `%SystemDrive%\Packages\Plugins\<extension>`, and on Linux the extension installs to `/var/lib/waagent/<extension>`. >[!NOTE]-> The [Azure Monitor agent (AMA)](../../azure-monitor/agents/azure-monitor-agent-overview.md) is a separate agent that collects monitoring data, and it does not replace the Connected Machine agent; the AMA only replaces the Log Analytics agent, Diagnostics extension, and Telegraf agent for both Windows and Linux machines. +> The [Azure Monitor agent (AMA)](/azure/azure-monitor/agents/azure-monitor-agent-overview) is a separate agent that collects monitoring data, and it does not replace the Connected Machine agent; the AMA only replaces the Log Analytics agent, Diagnostics extension, and Telegraf agent for both Windows and Linux machines. ### Azure Arc Proxy |
| azure-arc | Concept Log Analytics Extension Deployment | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/concept-log-analytics-extension-deployment.md | Azure Monitor supports multiple methods to install the Azure Monitor agent and c The Azure Monitor agent is required if you want to: -* Monitor the operating system and any workloads running on the machine or server using [VM insights](../../azure-monitor/vm/vminsights-overview.md) -* Analyze and alert using [Azure Monitor](../../azure-monitor/overview.md) +* Monitor the operating system and any workloads running on the machine or server using [VM insights](/azure/azure-monitor/vm/vminsights-overview) +* Analyze and alert using [Azure Monitor](/azure/azure-monitor/overview) * Perform security monitoring in Azure by using [Microsoft Defender for Cloud](/azure/defender-for-cloud/defender-for-cloud-introduction) or [Microsoft Sentinel](../../sentinel/overview.md) * Collect inventory and track changes by using [Azure Automation Change Tracking and Inventory](../../automation/change-tracking/overview.md) The Azure Monitor agent is required if you want to: > Azure Monitor agent logs are stored locally and are updated after temporary disconnection of an Arc-enabled machine. > -This article reviews the deployment methods for the Azure Monitor agent VM extension, across multiple production physical servers or virtual machines in your environment, to help you determine which works best for your organization. If you are interested in the new Azure Monitor agent and want to see a detailed comparison, see [Azure Monitor agents overview](../../azure-monitor/agents/agents-overview.md). +This article reviews the deployment methods for the Azure Monitor agent VM extension, across multiple production physical servers or virtual machines in your environment, to help you determine which works best for your organization. If you are interested in the new Azure Monitor agent and want to see a detailed comparison, see [Azure Monitor agents overview](/azure/azure-monitor/agents/agents-overview). ## Installation options This method supports managing the installation, management, and removal of VM ex You can use Azure Policy to deploy the Azure Monitor agent VM extension at-scale to machines in your environment, and maintain configuration compliance. This is accomplished by using either the [**Configure Linux Arc-enabled machines to run Azure Monitor Agent**](https://portal.azure.com/#view/Microsoft_Azure_Policy/PolicyDetailBlade/definitionId/%2Fproviders%2FMicrosoft.Authorization%2FpolicyDefinitions%2F845857af-0333-4c5d-bbbc-6076697da122) or the [**Configure Windows Arc-enabled machines to run Azure Monitor Agent**](https://portal.azure.com/#view/Microsoft_Azure_Policy/PolicyDetailBlade/definitionId/%2Fproviders%2FMicrosoft.Authorization%2FpolicyDefinitions%2F94f686d6-9a24-4e19-91f1-de937dc171a4) policy definition. -Azure Policy includes several prebuilt definitions related to Azure Monitor. For a complete list of the built-in policies in the **Monitoring** category, see [Azure Policy built-in definitions for Azure Monitor](../../azure-monitor/policy-reference.md). +Azure Policy includes several prebuilt definitions related to Azure Monitor. For a complete list of the built-in policies in the **Monitoring** category, see [Azure Policy built-in definitions for Azure Monitor](/azure/azure-monitor/policy-reference). #### Advantages The Azure Monitor agent VM extension can be installed using the Azure portal. Se * To start collecting security-related events with Microsoft Sentinel, see [onboard to Microsoft Sentinel](scenario-onboard-azure-sentinel.md), or to collect with Microsoft Defender for Cloud, see [onboard to Microsoft Defender for Cloud](../../security-center/quickstart-onboard-machines.md). -* Read the VM insights [Monitor performance](../../azure-monitor/vm/vminsights-performance.md) and [Map dependencies](../../azure-monitor/vm/vminsights-maps.md) articles to see how well your machine is performing and view discovered application components. +* Read the VM insights [Monitor performance](/azure/azure-monitor/vm/vminsights-performance) and [Map dependencies](/azure/azure-monitor/vm/vminsights-maps) articles to see how well your machine is performing and view discovered application components. |
| azure-arc | Deploy Ama Policy | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/deploy-ama-policy.md | Data Collection Rules define the data collection process in Azure Monitor. They 1. From your browser, go to the [Azure portal](https://portal.azure.com). 1. Navigate to the **Monitor | Overview** page. Under **Settings**, select **Data Collection Rules**.- A list of existing DCRs displays. You can filter this at the top of the window. If you need to create a new DCR, see [Data collection rules in Azure Monitor](../../azure-monitor/essentials/data-collection-rule-overview.md) for more information. + A list of existing DCRs displays. You can filter this at the top of the window. If you need to create a new DCR, see [Data collection rules in Azure Monitor](/azure/azure-monitor/essentials/data-collection-rule-overview) for more information. 1. Select the DCR to apply to your ARM template to view its overview. In order for Azure Policy to check if AMA is installed on your Arc-enabled, you' ## Additional resources -* [Azure Monitor overview](../../azure-monitor/overview.md) +* [Azure Monitor overview](/azure/azure-monitor/overview) * [Tutorial: Monitor a hybrid machine with VM insights](learn/tutorial-enable-vm-insights.md) |
| azure-arc | Tutorial Assign Policy Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/learn/tutorial-assign-policy-portal.md | To remove the assignment created, follow these steps: ## Next steps -In this tutorial, you assigned a policy definition to a scope and evaluated its compliance report. The policy definition validates that all the resources in the scope are compliant and identifies which ones aren't. Now you are ready to monitor your Azure Arc-enabled servers machine by enabling [VM insights](../../../azure-monitor/vm/vminsights-overview.md). +In this tutorial, you assigned a policy definition to a scope and evaluated its compliance report. The policy definition validates that all the resources in the scope are compliant and identifies which ones aren't. Now you are ready to monitor your Azure Arc-enabled servers machine by enabling [VM insights](/azure/azure-monitor/vm/vminsights-overview). To learn how to monitor and view the performance, running process and their dependencies from your machine, continue to the tutorial: |
| azure-arc | Tutorial Enable Vm Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/learn/tutorial-enable-vm-insights.md | Last updated 04/25/2022 # Tutorial: Monitor a hybrid machine with VM insights -[Azure Monitor](../../../azure-monitor/overview.md) can collect data directly from your hybrid machines into a Log Analytics workspace for detailed analysis and correlation. Typically, this would require installing the [Log Analytics agent](../../../azure-monitor/agents/log-analytics-agent.md) on the machine using a script, manually, or an automated method following your configuration management standards. Now, Azure Arc-enabled servers can install the Log Analytics and Dependency agent [VM extension](../manage-vm-extensions.md) for Windows and Linux, enabling [VM insights](../../../azure-monitor/vm/vminsights-overview.md) to collect data from your non-Azure VMs. +[Azure Monitor](/azure/azure-monitor/overview) can collect data directly from your hybrid machines into a Log Analytics workspace for detailed analysis and correlation. Typically, this would require installing the [Log Analytics agent](/azure/azure-monitor/agents/log-analytics-agent) on the machine using a script, manually, or an automated method following your configuration management standards. Now, Azure Arc-enabled servers can install the Log Analytics and Dependency agent [VM extension](../manage-vm-extensions.md) for Windows and Linux, enabling [VM insights](/azure/azure-monitor/vm/vminsights-overview) to collect data from your non-Azure VMs. <!This tutorial shows you how to configure and collect data from your Linux or Windows machines by enabling VM insights following a simplified set of steps, which streamlines the experience and takes a shorter amount of time.> In this tutorial, you will learn how to: * VM extension functionality is available only in the list of [supported regions](../overview.md#supported-regions). -* See [Supported operating systems](../../../azure-monitor/vm/vminsights-enable-overview.md#supported-operating-systems) to ensure that the servers operating system you're enabling is supported by VM insights. +* See [Supported operating systems](/azure/azure-monitor/vm/vminsights-enable-overview#supported-operating-systems) to ensure that the servers operating system you're enabling is supported by VM insights. -* Review firewall requirements for the Log Analytics agent provided in the [Log Analytics agent overview](../../../azure-monitor/agents/log-analytics-agent.md#network-requirements). The VM insights Map Dependency agent doesn't transmit any data itself, and it doesn't require any changes to firewalls or ports. +* Review firewall requirements for the Log Analytics agent provided in the [Log Analytics agent overview](/azure/azure-monitor/agents/log-analytics-agent#network-requirements). The VM insights Map Dependency agent doesn't transmit any data itself, and it doesn't require any changes to firewalls or ports. <!## Sign in to Azure portal Sign in to the [Azure portal](https://portal.azure.com).> To learn more about Azure Monitor, see the following article: > [!div class="nextstepaction"]-> [Azure Monitor overview](../../../azure-monitor/overview.md) +> [Azure Monitor overview](/azure/azure-monitor/overview) |
| azure-arc | Manage Agent | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/manage-agent.md | Links to the current and previous releases of the Windows agents are available b ## Upgrade the agent -The Azure Connected Machine agent is updated regularly to address bug fixes, stability enhancements, and new functionality. [Azure Advisor](../../advisor/advisor-overview.md) identifies resources that aren't using the latest version of the machine agent and recommends that you upgrade to the latest version. It notifies you when you select the Azure Arc-enabled server by presenting a banner on the **Overview** page or when you access Advisor through the Azure portal. +The Azure Connected Machine agent is updated regularly to address bug fixes, stability enhancements, and new functionality. [Azure Advisor](/azure/advisor/advisor-overview) identifies resources that aren't using the latest version of the machine agent and recommends that you upgrade to the latest version. It notifies you when you select the Azure Arc-enabled server by presenting a banner on the **Overview** page or when you access Advisor through the Azure portal. The Azure Connected Machine agent for Windows and Linux can be upgraded to the latest release manually or automatically depending on your requirements. Installing, upgrading, or uninstalling the Azure Connected Machine Agent doesn't require you to restart your server. To configure the agent to communicate to the service through a proxy server or t As of agent version 1.13, proxy settings can be configured using the `azcmagent config` command or system environment variables. If a proxy server is specified in both the agent configuration and system environment variables, the agent configuration will take precedence and become the effective setting. Use `azcmagent show` to view the effective proxy configuration for the agent. > [!NOTE]-> Azure Arc-enabled servers doesn't support using proxy servers that require authentication, TLS (HTTPS) connections, or a [Log Analytics gateway](../../azure-monitor/agents/gateway.md) as a proxy for the Connected Machine agent. +> Azure Arc-enabled servers doesn't support using proxy servers that require authentication, TLS (HTTPS) connections, or a [Log Analytics gateway](/azure/azure-monitor/agents/gateway) as a proxy for the Connected Machine agent. ### Agent-specific proxy configuration If you're already using environment variables to configure the proxy server for ## Alerting for Azure Arc-enabled server disconnection -The Connected Machine agent [sends a regular heartbeat message](overview.md#agent-status) to the service every five minutes. If an Arc-enabled server stops sending heartbeats to Azure for longer than 15 minutes, it can mean that it's offline, the network connection has been blocked, or the agent isn't running. Develop a plan for how youΓÇÖll respond and investigate these incidents, including setting up [Resource Health alerts](../..//service-health/resource-health-alert-monitor-guide.md) to get notified when such incidents occur. +The Connected Machine agent [sends a regular heartbeat message](overview.md#agent-status) to the service every five minutes. If an Arc-enabled server stops sending heartbeats to Azure for longer than 15 minutes, it can mean that it's offline, the network connection has been blocked, or the agent isn't running. Develop a plan for how youΓÇÖll respond and investigate these incidents, including setting up [Resource Health alerts](/azure/service-health/resource-health-alert-monitor-guide) to get notified when such incidents occur. ## Next steps The Connected Machine agent [sends a regular heartbeat message](overview.md#agen * Review the [Planning and deployment guide](plan-at-scale-deployment.md) to plan for deploying Azure Arc-enabled servers at any scale and implement centralized management and monitoring. -* Learn how to manage your machine using [Azure Policy](../../governance/policy/overview.md), for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verifying the machine is reporting to the expected Log Analytics workspace, enable monitoring with [VM insights](../../azure-monitor/vm/vminsights-enable-policy.md), and much more. +* Learn how to manage your machine using [Azure Policy](../../governance/policy/overview.md), for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verifying the machine is reporting to the expected Log Analytics workspace, enable monitoring with [VM insights](/azure/azure-monitor/vm/vminsights-enable-policy), and much more. |
| azure-arc | Manage Howto Migrate | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/manage-howto-migrate.md | To migrate an Azure Arc-enabled server from one Azure region to another, you hav * Troubleshooting information can be found in the [Troubleshoot Connected Machine agent guide](troubleshoot-agent-onboard.md). -* Learn how to manage your machine using [Azure Policy](../../governance/policy/overview.md), for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verifying the machine is reporting to the expected Log Analytics workspace, enable monitoring with [VM insights](../../azure-monitor/vm/vminsights-enable-policy.md) policy, and much more. +* Learn how to manage your machine using [Azure Policy](../../governance/policy/overview.md), for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verifying the machine is reporting to the expected Log Analytics workspace, enable monitoring with [VM insights](/azure/azure-monitor/vm/vminsights-enable-policy) policy, and much more. |
| azure-arc | Manage Vm Extensions Cli | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/manage-vm-extensions-cli.md | For the `--extension-targets` parameter, you need to specify the extension and t To upgrade the Log Analytics agent extension for Windows that has a newer version available, run the following command: ```azurecli-az connectedmachine upgrade-extension --machine-name "myMachineName" --resource-group "myResourceGroup" --extension-targets '{\"Microsoft.EnterpriseCloud.Monitoring.MicrosoftMonitoringAgent\":{\"targetVersion\":\"1.0.18053.0\"}}' +az connectedmachine upgrade-extension --machine-name "myMachineName" --resource-group "myResourceGroup" --extension-targets '{"Microsoft.EnterpriseCloud.Monitoring.MicrosoftMonitoringAgent":{"targetVersion":"1.0.18053.0"}}' ``` You can review the version of installed VM extensions at any time by running the command [az connectedmachine extension list](/cli/azure/connectedmachine/extension#az-connectedmachine-extension-list). The `typeHandlerVersion` property value represents the version of the extension. |
| azure-arc | Manage Vm Extensions Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/manage-vm-extensions-portal.md | VM extensions can be applied to your Azure Arc-enabled server-managed machine vi  - To complete the installation, you are required to provide the workspace ID and primary key. If you are not familiar with how to find this information, see [obtain workspace ID and key](../../azure-monitor/agents/agent-windows.md#workspace-id-and-key). + To complete the installation, you are required to provide the workspace ID and primary key. If you are not familiar with how to find this information, see [obtain workspace ID and key](/azure/azure-monitor/agents/agent-windows#workspace-id-and-key). 5. After confirming the required information provided, select **Review + Create**. A summary of the deployment is displayed and you can review the status of the deployment. |
| azure-arc | Manage Vm Extensions Template | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/manage-vm-extensions-template.md | The Custom Script extension configuration specifies things like script location ## Deploy the Dependency agent extension -To use the Azure Monitor Dependency agent extension, the following sample is provided to run on Windows and Linux. If you are unfamiliar with the Dependency agent, see [Overview of Azure Monitor agents](../../azure-monitor/vm/vminsights-dependency-agent-maintenance.md). +To use the Azure Monitor Dependency agent extension, the following sample is provided to run on Windows and Linux. If you are unfamiliar with the Dependency agent, see [Overview of Azure Monitor agents](/azure/azure-monitor/vm/vminsights-dependency-agent-maintenance). ### Template file for Linux |
| azure-arc | Manage Vm Extensions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/manage-vm-extensions.md | Azure Arc-enabled servers enables you to deploy, remove, and update Azure VM ext Azure Arc-enabled servers VM extension support provides the following key benefits: -- Collect log data for analysis with [Logs in Azure Monitor](../../azure-monitor/logs/data-platform-logs.md) by enabling the Azure Monitor agent VM extension. Log data analysis makes it useful for doing complex analysis across log data from different kinds of sources.+- Collect log data for analysis with [Logs in Azure Monitor](/azure/azure-monitor/logs/data-platform-logs) by enabling the Azure Monitor agent VM extension. Log data analysis makes it useful for doing complex analysis across log data from different kinds of sources. -- With [VM insights](../../azure-monitor/vm/vminsights-overview.md), it analyzes the performance of your Windows and Linux VMs, and monitors their processes and dependencies on other resources and external processes. This is achieved through enabling both the Azure Monitor agent and Dependency agent VM extensions.+- With [VM insights](/azure/azure-monitor/vm/vminsights-overview), it analyzes the performance of your Windows and Linux VMs, and monitors their processes and dependencies on other resources and external processes. This is achieved through enabling both the Azure Monitor agent and Dependency agent VM extensions. - Download and execute scripts on hybrid connected machines using the Custom Script Extension. This extension is useful for post deployment configuration, software installation, or any other configuration or management tasks. Arc-enabled servers support moving machines with one or more VM extensions insta |Custom Script extension |Microsoft.Compute | CustomScriptExtension |[Windows Custom Script Extension](/azure/virtual-machines/extensions/custom-script-windows)| |Azure Monitor for VMs (insights) |Microsoft.Azure.Monitoring.DependencyAgent |DependencyAgentWindows | [Dependency agent virtual machine extension for Windows](/azure/virtual-machines/extensions/agent-dependency-windows)| |Azure Key Vault Certificate Sync | Microsoft.Azure.Key.Vault |KeyVaultForWindows | [Key Vault virtual machine extension for Windows](/azure/virtual-machines/extensions/key-vault-windows) |-|Azure Monitor Agent |Microsoft.Azure.Monitor |AzureMonitorWindowsAgent |[Install the Azure Monitor agent](../../azure-monitor/agents/azure-monitor-agent-manage.md) | +|Azure Monitor Agent |Microsoft.Azure.Monitor |AzureMonitorWindowsAgent |[Install the Azure Monitor agent](/azure/azure-monitor/agents/azure-monitor-agent-manage) | |Azure Automation Hybrid Runbook Worker extension |Microsoft.Compute |HybridWorkerForWindows |[Deploy an extension-based User Hybrid Runbook Worker](../../automation/extension-based-hybrid-runbook-worker-install.md) to execute runbooks locally | |Azure Extension for SQL Server |Microsoft.AzureData |WindowsAgent.SqlServer |[Install Azure extension for SQL Server](/sql/sql-server/azure-arc/connect#initiate-the-connection-from-azure) to initiate SQL Server connection to Azure | |Windows Admin Center (preview) |Microsoft.AdminCenter |AdminCenter |[Manage Azure Arc-enabled Servers using Windows Admin Center in Azure](/windows-server/manage/windows-admin-center/azure/manage-arc-hybrid-machines) | Arc-enabled servers support moving machines with one or more VM extensions insta |Custom Script extension |Microsoft.Azure.Extensions |CustomScript |[Linux Custom Script Extension Version 2](/azure/virtual-machines/extensions/custom-script-linux) | |Azure Monitor for VMs (insights) |Microsoft.Azure.Monitoring.DependencyAgent |DependencyAgentLinux |[Dependency agent virtual machine extension for Linux](/azure/virtual-machines/extensions/agent-dependency-linux) | |Azure Key Vault Certificate Sync | Microsoft.Azure.Key.Vault |KeyVaultForLinux | [Key Vault virtual machine extension for Linux](/azure/virtual-machines/extensions/key-vault-linux) |-|Azure Monitor Agent |Microsoft.Azure.Monitor |AzureMonitorLinuxAgent |[Install the Azure Monitor agent](../../azure-monitor/agents/azure-monitor-agent-manage.md) | +|Azure Monitor Agent |Microsoft.Azure.Monitor |AzureMonitorLinuxAgent |[Install the Azure Monitor agent](/azure/azure-monitor/agents/azure-monitor-agent-manage) | |Azure Automation Hybrid Runbook Worker extension |Microsoft.Compute |HybridWorkerForLinux |[Deploy an extension-based User Hybrid Runbook Worker](../../automation/extension-based-hybrid-runbook-worker-install.md) to execute runbooks locally| |Linux OS Update Extension |Microsoft.SoftwareUpdateManagement |LinuxOsUpdateExtension |[Overview of Azure Update Manager](/azure/update-manager/overview?tabs=azure-vms)| |Linux Patch Extension |Microsoft.CPlat.Core |LinuxPatchExtension |[Automatic Guest Patching for Azure Virtual Machines and Scale Sets](/azure/virtual-machines/automatic-vm-guest-patching)| |
| azure-arc | Migrate Legacy Agents | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/migrate-legacy-agents.md | Azure Monitor Agent (AMA) replaces the Log Analytics agent (also known as Micros Azure Arc is a bridge, extending not only Azure Monitor but the breadth of Azure management capabilities across Microsoft Defender, Azure Policy, and Azure Update Manager to non-Azure environments. Through the lightweight Connected Machine agent, Azure Arc projects non-Azure servers into the Azure control plane, providing a consistent management experience across Azure VMs and non-Azure servers. -This article focuses on considerations when migrating from legacy Log Analytics agents in non-Azure environments. For core migration guidance, see [Migrate to Azure Monitor Agent from Log Analytics agent](../../azure-monitor/agents/azure-monitor-agent-migration.md). +This article focuses on considerations when migrating from legacy Log Analytics agents in non-Azure environments. For core migration guidance, see [Migrate to Azure Monitor Agent from Log Analytics agent](/azure/azure-monitor/agents/azure-monitor-agent-migration). ## Advantages of Azure Arc |
| azure-arc | Onboard Ansible Playbooks | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/onboard-ansible-playbooks.md | After you have successfully installed the agent and configured it to connect to - Review the [Planning and deployment guide](plan-at-scale-deployment.md) to plan for deploying Azure Arc-enabled servers at any scale and implement centralized management and monitoring. - Review connection troubleshooting information in the [Troubleshoot Connected Machine agent guide](troubleshoot-agent-onboard.md).-- Learn how to manage your machine using [Azure Policy](../../governance/policy/overview.md) for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verifying that the machine is reporting to the expected Log Analytics workspace, enabling monitoring with [VM insights](../../azure-monitor/vm/vminsights-enable-policy.md), and much more.+- Learn how to manage your machine using [Azure Policy](../../governance/policy/overview.md) for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verifying that the machine is reporting to the expected Log Analytics workspace, enabling monitoring with [VM insights](/azure/azure-monitor/vm/vminsights-enable-policy), and much more. |
| azure-arc | Onboard Configuration Manager Custom Task | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/onboard-configuration-manager-custom-task.md | To verify that the machines have been successfully connected to Azure Arc, verif - Review the [Planning and deployment guide](plan-at-scale-deployment.md) to plan for deploying Azure Arc-enabled servers at any scale and implement centralized management and monitoring. - Review connection troubleshooting information in the [Troubleshoot Connected Machine agent guide](troubleshoot-agent-onboard.md).-- Learn how to manage your machine using [Azure Policy](../../governance/policy/overview.md) for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verifying that the machine is reporting to the expected Log Analytics workspace, enabling monitoring with [VM insights](../../azure-monitor/vm/vminsights-enable-policy.md), and much more.+- Learn how to manage your machine using [Azure Policy](../../governance/policy/overview.md) for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verifying that the machine is reporting to the expected Log Analytics workspace, enabling monitoring with [VM insights](/azure/azure-monitor/vm/vminsights-enable-policy), and much more. |
| azure-arc | Onboard Configuration Manager Powershell | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/onboard-configuration-manager-powershell.md | The script status monitoring will indicate whether the script has successfully i - Review the [Planning and deployment guide](plan-at-scale-deployment.md) to plan for deploying Azure Arc-enabled servers at any scale and implement centralized management and monitoring. - Review connection troubleshooting information in the [Troubleshoot Connected Machine agent guide](troubleshoot-agent-onboard.md).-- Learn how to manage your machine using [Azure Policy](../../governance/policy/overview.md) for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verifying that the machine is reporting to the expected Log Analytics workspace, enabling monitoring with [VM insights](../../azure-monitor/vm/vminsights-enable-policy.md), and much more.+- Learn how to manage your machine using [Azure Policy](../../governance/policy/overview.md) for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verifying that the machine is reporting to the expected Log Analytics workspace, enabling monitoring with [VM insights](/azure/azure-monitor/vm/vminsights-enable-policy), and much more. |
| azure-arc | Onboard Group Policy Powershell | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/onboard-group-policy-powershell.md | After you have successfully installed the agent and configured it to connect to * Review the [Planning and deployment guide](plan-at-scale-deployment.md) to plan for deploying Azure Arc-enabled servers at any scale and implement centralized management and monitoring. * Review connection troubleshooting information in the [Troubleshoot Connected Machine agent guide](troubleshoot-agent-onboard.md).-* Learn how to manage your machine using [Azure Policy](../../governance/policy/overview.md) for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verifying that the machine is reporting to the expected Log Analytics workspace, enabling monitoring with [VM insights](../../azure-monitor/vm/vminsights-enable-policy.md), and much more. +* Learn how to manage your machine using [Azure Policy](../../governance/policy/overview.md) for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verifying that the machine is reporting to the expected Log Analytics workspace, enabling monitoring with [VM insights](/azure/azure-monitor/vm/vminsights-enable-policy), and much more. * Learn more about [Group Policy](/troubleshoot/windows-server/group-policy/group-policy-overview). |
| azure-arc | Onboard Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/onboard-portal.md | After you install the agent and configure it to connect to Azure Arc-enabled ser - Review the [Planning and deployment guide](plan-at-scale-deployment.md) to plan for deploying Azure Arc-enabled servers at any scale and implement centralized management and monitoring. -- Learn how to manage your machine using [Azure Policy](../../governance/policy/overview.md), for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verify the machine is reporting to the expected Log Analytics workspace, enable monitoring with [VM insights](../../azure-monitor/vm/vminsights-enable-policy.md), and much more.+- Learn how to manage your machine using [Azure Policy](../../governance/policy/overview.md), for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verify the machine is reporting to the expected Log Analytics workspace, enable monitoring with [VM insights](/azure/azure-monitor/vm/vminsights-enable-policy), and much more. |
| azure-arc | Onboard Powershell | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/onboard-powershell.md | After you install and configure the agent to register with Azure Arc-enabled ser * Review the [Planning and deployment guide](plan-at-scale-deployment.md) to plan for deploying Azure Arc-enabled servers at any scale and implement centralized management and monitoring. -* Learn how to manage your machine by using [Azure Policy](../../governance/policy/overview.md). You can use VM [guest configuration](../../governance/machine-configuration/overview.md), verify that the machine is reporting to the expected Log Analytics workspace, and enable monitoring with [VM insights](../../azure-monitor/vm/vminsights-enable-policy.md). +* Learn how to manage your machine by using [Azure Policy](../../governance/policy/overview.md). You can use VM [guest configuration](../../governance/machine-configuration/overview.md), verify that the machine is reporting to the expected Log Analytics workspace, and enable monitoring with [VM insights](/azure/azure-monitor/vm/vminsights-enable-policy). |
| azure-arc | Onboard Service Principal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/onboard-service-principal.md | After you install the agent and configure it to connect to Azure Arc-enabled ser - Review the [Planning and deployment guide](plan-at-scale-deployment.md) to plan for deploying Azure Arc-enabled servers at any scale and implement centralized management and monitoring. - Learn how to [troubleshoot agent connection issues](troubleshoot-agent-onboard.md).-- Learn how to manage your machines using [Azure Policy](../../governance/policy/overview.md) for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verifying that machines are reporting to the expected Log Analytics workspace, monitoring with [VM insights](../../azure-monitor/vm/vminsights-enable-policy.md), and more.+- Learn how to manage your machines using [Azure Policy](../../governance/policy/overview.md) for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verifying that machines are reporting to the expected Log Analytics workspace, monitoring with [VM insights](/azure/azure-monitor/vm/vminsights-enable-policy), and more. |
| azure-arc | Onboard Update Management Machines | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/onboard-update-management-machines.md | After the agent is installed and configured to connect to Azure Arc-enabled serv - Review the [Planning and deployment guide](plan-at-scale-deployment.md) to plan for deploying Azure Arc-enabled servers at any scale and implement centralized management and monitoring. -- Learn how to manage your machine using [Azure Policy](../../governance/policy/overview.md), for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verify the machine is reporting to the expected Log Analytics workspace, enable monitoring with [VM insights](../../azure-monitor/vm/vminsights-enable-policy.md), and much more.+- Learn how to manage your machine using [Azure Policy](../../governance/policy/overview.md), for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verify the machine is reporting to the expected Log Analytics workspace, enable monitoring with [VM insights](/azure/azure-monitor/vm/vminsights-enable-policy), and much more. |
| azure-arc | Onboard Windows Admin Center | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/onboard-windows-admin-center.md | After you install the agent and configure it to connect to Azure Arc-enabled ser * Review the [Planning and deployment guide](plan-at-scale-deployment.md) to plan for deploying Azure Arc-enabled servers at any scale and implement centralized management and monitoring. -* Learn how to manage your machine using [Azure Policy](../../governance/policy/overview.md), for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verifying the machine is reporting to the expected Log Analytics workspace, enable monitoring with [VM insights](../../azure-monitor/vm/vminsights-enable-policy.md), and much more. +* Learn how to manage your machine using [Azure Policy](../../governance/policy/overview.md), for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verifying the machine is reporting to the expected Log Analytics workspace, enable monitoring with [VM insights](/azure/azure-monitor/vm/vminsights-enable-policy), and much more. |
| azure-arc | Onboard Windows Server | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/onboard-windows-server.md | To uninstall Azure Arc Setup from a Windows Server 2025 machine from the command * Review the [Planning and deployment guide](plan-at-scale-deployment.md) to plan for deploying Azure Arc-enabled servers at any scale and implement centralized management and monitoring. -* Learn how to manage your machine using [Azure Policy](../../governance/policy/overview.md), for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verifying the machine is reporting to the expected Log Analytics workspace, enable monitoring with [VM insights](../../azure-monitor/vm/vminsights-enable-policy.md), and much more. +* Learn how to manage your machine using [Azure Policy](../../governance/policy/overview.md), for such things as VM [guest configuration](../../governance/machine-configuration/overview.md), verifying the machine is reporting to the expected Log Analytics workspace, enable monitoring with [VM insights](/azure/azure-monitor/vm/vminsights-enable-policy), and much more. |
| azure-arc | Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/overview.md | Azure Arc-enabled servers lets you manage Windows and Linux physical servers and When a hybrid machine is connected to Azure, it becomes a connected machine and is treated as a resource in Azure. Each connected machine has a Resource ID enabling the machine to be included in a resource group. -To connect hybrid machines to Azure, you install the [Azure Connected Machine agent](agent-overview.md) on each machine. This agent doesn't replace the Azure [Azure Monitor Agent](../../azure-monitor/agents/azure-monitor-agent-overview.md). The Azure Monitor Agent for Windows and Linux is required in order to: +To connect hybrid machines to Azure, you install the [Azure Connected Machine agent](agent-overview.md) on each machine. This agent doesn't replace the Azure [Azure Monitor Agent](/azure/azure-monitor/agents/azure-monitor-agent-overview). The Azure Monitor Agent for Windows and Linux is required in order to: * Proactively monitor the OS and workloads running on the machine * Manage it using Automation runbooks or solutions like Update Management When you connect your machine to Azure Arc-enabled servers, you can perform many * Use [Update Management](../../automation/update-management/overview.md) to manage operating system updates for your Windows and Linux servers. Automate onboarding and configuration of a set of Azure services when you use [Azure Automanage (preview)](../../automanage/automanage-arc.md). * Perform post-deployment configuration and automation tasks using supported [Arc-enabled servers VM extensions](manage-vm-extensions.md) for your non-Azure Windows or Linux machine. * **Monitor**:- * Monitor operating system performance and discover application components to monitor processes and dependencies with other resources using [VM insights](../../azure-monitor/vm/vminsights-overview.md). - * Collect other log data, such as performance data and events, from the operating system or workloads running on the machine with the [Azure Monitor Agent](../../azure-monitor/agents/azure-monitor-agent-overview.md). This data is stored in a [Log Analytics workspace](../../azure-monitor/logs/log-analytics-workspace-overview.md). + * Monitor operating system performance and discover application components to monitor processes and dependencies with other resources using [VM insights](/azure/azure-monitor/vm/vminsights-overview). + * Collect other log data, such as performance data and events, from the operating system or workloads running on the machine with the [Azure Monitor Agent](/azure/azure-monitor/agents/azure-monitor-agent-overview). This data is stored in a [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-workspace-overview). > [!NOTE] > At this time, enabling Azure Automation Update Management directly from an Azure Arc-enabled server is not supported. See [Enable Update Management from your Automation account](../../automation/update-management/enable-from-automation-account.md) to understand requirements and [how to enable Update Management for non-Azure VMs](../../automation/update-management/enable-from-automation-account.md#enable-non-azure-vms). -Log data collected and stored in a Log Analytics workspace from the hybrid machine contains properties specific to the machine, such as a Resource ID, to support [resource-context](../../azure-monitor/logs/manage-access.md#access-mode) log access. +Log data collected and stored in a Log Analytics workspace from the hybrid machine contains properties specific to the machine, such as a Resource ID, to support [resource-context](/azure/azure-monitor/logs/manage-access#access-mode) log access. Watch this video to learn more about Azure monitoring, security, and update services across hybrid and multicloud environments. |
| azure-arc | Plan At Scale Deployment | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/plan-at-scale-deployment.md | In this phase, system engineers or administrators enable the core features in th |--|-|| | [Create a resource group](../../azure-resource-manager/management/manage-resource-groups-portal.md#create-resource-groups) | A dedicated resource group to include only Azure Arc-enabled servers and centralize management and monitoring of these resources. | One hour | | Apply [Tags](../../azure-resource-manager/management/tag-resources.md) to help organize machines. | Evaluate and develop an IT-aligned [tagging strategy](/azure/cloud-adoption-framework/decision-guides/resource-tagging/) that can help reduce the complexity of managing your Azure Arc-enabled servers and simplify making management decisions. | One day |-| Design and deploy [Azure Monitor Logs](../../azure-monitor/logs/data-platform-logs.md) | Evaluate [design and deployment considerations](../../azure-monitor/logs/workspace-design.md) to determine if your organization should use an existing or implement another Log Analytics workspace to store collected log data from hybrid servers and machines.<sup>1</sup> | One day | +| Design and deploy [Azure Monitor Logs](/azure/azure-monitor/logs/data-platform-logs) | Evaluate [design and deployment considerations](/azure/azure-monitor/logs/workspace-design) to determine if your organization should use an existing or implement another Log Analytics workspace to store collected log data from hybrid servers and machines.<sup>1</sup> | One day | | [Develop an Azure Policy](../../governance/policy/overview.md) governance plan | Determine how you will implement governance of hybrid servers and machines at the subscription or resource group scope with Azure Policy. | One day | | Configure [Role based access control (RBAC)](../../role-based-access-control/overview.md) | Develop an access plan to control who has access to manage Azure Arc-enabled servers and ability to view their data from other Azure services and solutions. | One day |-| Identify machines with Log Analytics agent already installed | Run the following log query in [Log Analytics](../../azure-monitor/logs/log-analytics-overview.md) to support conversion of existing Log Analytics agent deployments to extension-managed agent:<br> Heartbeat <br> | summarize arg_max(TimeGenerated, OSType, ResourceId, ComputerEnvironment) by Computer <br> | where ComputerEnvironment == "Non-Azure" and isempty(ResourceId) <br> | project Computer, OSType | One hour | +| Identify machines with Log Analytics agent already installed | Run the following log query in [Log Analytics](/azure/azure-monitor/logs/log-analytics-overview) to support conversion of existing Log Analytics agent deployments to extension-managed agent:<br> Heartbeat <br> | summarize arg_max(TimeGenerated, OSType, ResourceId, ComputerEnvironment) by Computer <br> | where ComputerEnvironment == "Non-Azure" and isempty(ResourceId) <br> | project Computer, OSType | One hour | <sup>1</sup> When evaluating your Log Analytics workspace design, consider integration with Azure Automation in support of its Update Management and Change Tracking and Inventory feature, as well as Microsoft Defender for Cloud and Microsoft Sentinel. If your organization already has an Automation account and enabled its management features linked with a Log Analytics workspace, evaluate whether you can centralize and streamline management operations, as well as minimize cost, by using those existing resources versus creating a duplicate account, workspace, etc. Phase 3 is when administrators or system engineers can enable automation of manu |Task |Detail |Estimated duration | |--|-||-|Create a Resource Health alert |If a server stops sending heartbeats to Azure for longer than 15 minutes, it can mean that it is offline, the network connection has been blocked, or the agent is not running. Develop a plan for how youΓÇÖll respond and investigate these incidents and use [Resource Health alerts](../..//service-health/resource-health-alert-monitor-guide.md) to get notified when they start.<br><br> Specify the following when configuring the alert:<br> **Resource type** = **Azure Arc-enabled servers**<br> **Current resource status** = **Unavailable**<br> **Previous resource status** = **Available** | One hour | -|Create an Azure Advisor alert | For the best experience and most recent security and bug fixes, we recommend keeping the Azure Connected Machine agent up to date. Out-of-date agents will be identified with an [Azure Advisor alert](../../advisor/advisor-alerts-portal.md).<br><br> Specify the following when configuring the alert:<br> **Recommendation type** = **Upgrade to the latest version of the Azure Connected Machine agent** | One hour | -|[Assign Azure policies](../../governance/policy/assign-policy-portal.md) to your subscription or resource group scope |Assign the **Enable Azure Monitor for VMs** [policy](../../azure-monitor/vm/vminsights-enable-policy.md) (and others that meet your needs) to the subscription or resource group scope. Azure Policy allows you to assign policy definitions that install the required agents for VM insights across your environment.| Varies | +|Create a Resource Health alert |If a server stops sending heartbeats to Azure for longer than 15 minutes, it can mean that it is offline, the network connection has been blocked, or the agent is not running. Develop a plan for how youΓÇÖll respond and investigate these incidents and use [Resource Health alerts](/azure/service-health/resource-health-alert-monitor-guide) to get notified when they start.<br><br> Specify the following when configuring the alert:<br> **Resource type** = **Azure Arc-enabled servers**<br> **Current resource status** = **Unavailable**<br> **Previous resource status** = **Available** | One hour | +|Create an Azure Advisor alert | For the best experience and most recent security and bug fixes, we recommend keeping the Azure Connected Machine agent up to date. Out-of-date agents will be identified with an [Azure Advisor alert](/azure/advisor/advisor-alerts-portal).<br><br> Specify the following when configuring the alert:<br> **Recommendation type** = **Upgrade to the latest version of the Azure Connected Machine agent** | One hour | +|[Assign Azure policies](../../governance/policy/assign-policy-portal.md) to your subscription or resource group scope |Assign the **Enable Azure Monitor for VMs** [policy](/azure/azure-monitor/vm/vminsights-enable-policy) (and others that meet your needs) to the subscription or resource group scope. Azure Policy allows you to assign policy definitions that install the required agents for VM insights across your environment.| Varies | |Enable [Azure Update Manager](/azure/update-manager/) for your Azure Arc-enabled servers. |Configure Azure Update Manager on your Arc-enabled servers to manage system updates for your Windows and Linux virtual machines. You can choose to [deploy updates on-demand](/azure/update-manager/deploy-updates?tabs=install-single-overview%2Cinstall-scale-overview) or [apply updates using custom schedule](/azure/update-manager/scheduled-patching?tabs=schedule-updates-single-machine%2Cschedule-updates-scale-overview%2Cwindows-maintenance). | 5 minutes | ## Next steps |
| azure-arc | Private Link Security | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/private-link-security.md | Azure Arc Private Link Scope connects private endpoints (and the virtual network Connectivity to any other Azure resource from an Azure Arc-enabled server requires configuring Private Link for each service, which is optional, but recommended. Azure Private Link requires separate configuration per service. -For more information about configuring Private Link for the Azure services listed earlier, see the [Azure Automation](../../automation/how-to/private-link-security.md), [Azure Monitor](../../azure-monitor/logs/private-link-security.md), [Azure Key Vault](/azure/key-vault/general/private-link-service), or [Azure Blob storage](../../private-link/tutorial-private-endpoint-storage-portal.md) articles. +For more information about configuring Private Link for the Azure services listed earlier, see the [Azure Automation](../../automation/how-to/private-link-security.md), [Azure Monitor](/azure/azure-monitor/logs/private-link-security), [Azure Key Vault](/azure/key-vault/general/private-link-service), or [Azure Blob storage](../../private-link/tutorial-private-endpoint-storage-portal.md) articles. > [!IMPORTANT] > Azure Private Link is now generally available. Both Private Endpoint and Private Link service (service behind standard load balancer) are generally available. Different Azure PaaS onboard to Azure Private Link following different schedules. See [Private Link availability](../../private-link/availability.md) for an updated status of Azure PaaS on Private Link. For known limitations, see [Private Endpoint](../../private-link/private-endpoint-overview.md#limitations) and [Private Link Service](../../private-link/private-link-service-overview.md#limitations). It might take up to 15 minutes for the Private Link Scope to accept connections * If you are experiencing issues with your Azure Private Endpoint connectivity setup, see [Troubleshoot Azure Private Endpoint connectivity problems](../../private-link/troubleshoot-private-endpoint-connectivity.md). -* See the following to configure Private Link for [Azure Automation](../../automation/how-to/private-link-security.md), [Azure Monitor](../../azure-monitor/logs/private-link-security.md), [Azure Key Vault](/azure/key-vault/general/private-link-service), or [Azure Blob storage](../../private-link/tutorial-private-endpoint-storage-portal.md). +* See the following to configure Private Link for [Azure Automation](../../automation/how-to/private-link-security.md), [Azure Monitor](/azure/azure-monitor/logs/private-link-security), [Azure Key Vault](/azure/key-vault/general/private-link-service), or [Azure Blob storage](../../private-link/tutorial-private-endpoint-storage-portal.md). |
| azure-arc | Scenario Migrate To Azure | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/scenario-migrate-to-azure.md | With Azure PowerShell, use the [Get-AzConnectedMachineExtension](/powershell/mod With the Azure CLI, use the [az connectedmachine extension list](/cli/azure/connectedmachine/extension#az-connectedmachine-extension-list) command with the `--machine-name` and `--resource-group` parameters. By default, the output of Azure CLI commands is in JSON (JavaScript Object Notation). To change the default output to a list or table, for example, use [az configure --output](/cli/azure/reference-index). You can also add `--output` to any command for a one time change in output format. -After identifying which VM extensions are deployed, you can remove them using the [Azure portal](manage-vm-extensions-portal.md), using the [Azure PowerShell](manage-vm-extensions-powershell.md), or using the [Azure CLI](manage-vm-extensions-cli.md). If the Log Analytics VM extension or Dependency agent VM extension was deployed using Azure Policy and the [VM insights initiative](../../azure-monitor/vm/vminsights-enable-policy.md), it is necessary to [create an exclusion](../../governance/policy/tutorials/create-and-manage.md#remove-a-non-compliant-or-denied-resource-from-the-scope-with-an-exclusion) to prevent re-evaluation and deployment of the extensions on the Azure Arc-enabled server before the migration is complete. +After identifying which VM extensions are deployed, you can remove them using the [Azure portal](manage-vm-extensions-portal.md), using the [Azure PowerShell](manage-vm-extensions-powershell.md), or using the [Azure CLI](manage-vm-extensions-cli.md). If the Log Analytics VM extension or Dependency agent VM extension was deployed using Azure Policy and the [VM insights initiative](/azure/azure-monitor/vm/vminsights-enable-policy), it is necessary to [create an exclusion](../../governance/policy/tutorials/create-and-manage.md#remove-a-non-compliant-or-denied-resource-from-the-scope-with-an-exclusion) to prevent re-evaluation and deployment of the extensions on the Azure Arc-enabled server before the migration is complete. ## Step 2: Review access rights After migration and completion of all post-migration configuration steps, you ca To resume using audit settings inside a machine with guest configuration policy definitions, see [Enable guest configuration](../../governance/machine-configuration/overview.md). -If the Log Analytics VM extension or Dependency agent VM extension was deployed using Azure Policy and the [VM insights initiative](../../azure-monitor/vm/vminsights-enable-policy.md), remove the [exclusion](../../governance/policy/tutorials/create-and-manage.md#remove-a-non-compliant-or-denied-resource-from-the-scope-with-an-exclusion) you created earlier. To use Azure Policy to enable Azure virtual machines, see [Deploy Azure Monitor at scale using Azure Policy](../../azure-monitor/best-practices.md). +If the Log Analytics VM extension or Dependency agent VM extension was deployed using Azure Policy and the [VM insights initiative](/azure/azure-monitor/vm/vminsights-enable-policy), remove the [exclusion](../../governance/policy/tutorials/create-and-manage.md#remove-a-non-compliant-or-denied-resource-from-the-scope-with-an-exclusion) you created earlier. To use Azure Policy to enable Azure virtual machines, see [Deploy Azure Monitor at scale using Azure Policy](/azure/azure-monitor/best-practices). ## Next steps |
| azure-arc | Scenario Onboard Azure Sentinel | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/scenario-onboard-azure-sentinel.md | This article is intended to help you onboard your Azure Arc-enabled server to [M Before you start, make sure that you've met the following requirements: -- A [Log Analytics workspace](../../azure-monitor/logs/data-platform-logs.md). For more information about Log Analytics workspaces, see [Designing your Azure Monitor Logs deployment](../../azure-monitor/logs/workspace-design.md).+- A [Log Analytics workspace](/azure/azure-monitor/logs/data-platform-logs). For more information about Log Analytics workspaces, see [Designing your Azure Monitor Logs deployment](/azure/azure-monitor/logs/workspace-design). - Microsoft Sentinel [enabled in your subscription](../../sentinel/quickstart-onboard.md). |
| azure-arc | Troubleshoot Vm Extensions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/servers/troubleshoot-vm-extensions.md | The following troubleshooting steps apply to all VM extensions. - The Log Analytics agent version 1.13.9 (corresponding extension version is 1.13.15) is not correctly marking uploaded data with the resource ID of the Azure Arc-enabled server. Although logs are being sent to the service, when you try to view the data from the selected enabled server after selecting **Logs** or **Insights**, no data is returned. You can view its data by running queries from Azure Monitor Logs or from Azure Monitor for VMs, which are scoped to the workspace. -- Some distributions are not currently supported by the Log Analytics agent for Linux. The agent requires additional dependencies to be installed, including Python 2. Review the support matrix and prerequisites [here](../../azure-monitor/agents/agents-overview.md#supported-operating-systems).+- Some distributions are not currently supported by the Log Analytics agent for Linux. The agent requires additional dependencies to be installed, including Python 2. Review the support matrix and prerequisites [here](/azure/azure-monitor/agents/agents-overview#supported-operating-systems). - Error code 52 in the status message indicates a missing dependency. Check the output and logs for more information about which dependency is missing. |
| azure-arc | How To Configure Monitor Site | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/site-manager/how-to-configure-monitor-site.md | Last updated 04/18/2024 Azure Arc sites provide a centralized view to monitor groups of resources, but don't provide monitoring capabilities for the site overall. Instead, customers can set up alerts and monitoring for supported resources within a site. Once alerts are set up and triggered depending on the alert criteria, Azure Arc site manager (preview) makes the resource alert status visible within the site pages. -If you aren't familiar with Azure Monitor, learn more about how to [monitor Azure resources with Azure Monitor](../../azure-monitor/essentials/monitor-azure-resource.md). +If you aren't familiar with Azure Monitor, learn more about how to [monitor Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource). ## Prerequisites If you aren't familiar with Azure Monitor, learn more about how to [monitor Azur ## Configure alerts for sites in Azure Arc -This section provides basic steps for configuring alerts for sites in Azure Arc. For more detailed information about Azure Monitor, see [Create or edit an alert rule](../../azure-monitor/alerts/alerts-create-metric-alert-rule.yml). +This section provides basic steps for configuring alerts for sites in Azure Arc. For more detailed information about Azure Monitor, see [Create or edit an alert rule](/azure/azure-monitor/alerts/alerts-create-metric-alert-rule). To configure alerts for sites in Azure Arc, follow the below steps. |
| azure-arc | Agent Overview Scvmm | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/system-center-virtual-machine-manager/agent-overview-scvmm.md | The Azure Connected Machine agent package contains several logical components bu * The Extension agent manages VM extensions, including install, uninstall, and upgrade. Azure downloads extensions and copies them to the `%SystemDrive%\%ProgramFiles%\AzureConnectedMachineAgent\ExtensionService\downloads` folder on Windows, and to `/opt/GC_Ext/downloads` on Linux. On Windows, the extension installs to the following path `%SystemDrive%\Packages\Plugins\<extension>`, and on Linux the extension installs to `/var/lib/waagent/<extension>`. >[!NOTE]-> The [Azure Monitor agent (AMA)](../../azure-monitor/agents/azure-monitor-agent-overview.md) is a separate agent that collects monitoring data, and it does not replace the Connected Machine agent; the AMA only replaces the Log Analytics agent, Diagnostics extension, and Telegraf agent for both Windows and Linux machines. +> The [Azure Monitor agent (AMA)](/azure/azure-monitor/agents/azure-monitor-agent-overview) is a separate agent that collects monitoring data, and it does not replace the Connected Machine agent; the AMA only replaces the Log Analytics agent, Diagnostics extension, and Telegraf agent for both Windows and Linux machines. ## Agent resources |
| azure-arc | Azure Arc Agent | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-arc/vmware-vsphere/azure-arc-agent.md | The Azure Connected Machine agent package contains several logical components bu * The Extension agent manages VM extensions, including install, uninstall, and upgrade. Azure downloads extensions and copies them to the `%SystemDrive%\%ProgramFiles%\AzureConnectedMachineAgent\ExtensionService\downloads` folder on Windows, and to `/opt/GC_Ext/downloads` on Linux. On Windows, the extension installs to the path `%SystemDrive%\Packages\Plugins\<extension>`, and on Linux the extension installs to `/var/lib/waagent/<extension>`. >[!NOTE]-> The [Azure Monitor agent (AMA)](../../azure-monitor/agents/azure-monitor-agent-overview.md) is a separate agent that collects monitoring data, and it does not replace the Connected Machine agent; the AMA only replaces the Log Analytics agent, Diagnostics extension, and Telegraf agent for both Windows and Linux machines. +> The [Azure Monitor agent (AMA)](/azure/azure-monitor/agents/azure-monitor-agent-overview) is a separate agent that collects monitoring data, and it does not replace the Connected Machine agent; the AMA only replaces the Log Analytics agent, Diagnostics extension, and Telegraf agent for both Windows and Linux machines. ## Agent resources |
| azure-cache-for-redis | Cache Azure Active Directory For Authentication | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-cache-for-redis/cache-azure-active-directory-for-authentication.md | The following table includes links to code samples. They demonstrate how to conn - Configure private links or firewall rules to protect your cache from a denial of service attack. - Ensure that your client application sends a new Microsoft Entra token at least three minutes before token expiry to avoid connection disruption.-- When you call the Redis server `AUTH` command periodically, consider adding a jitter so that the `AUTH` commands are staggered. In this way, your Redis server doesn't receive too many `AUTH` commands at the same time.+- When you call the Redis server `AUTH` command periodically, consider adding a random delay so that the `AUTH` commands are staggered. In this way, your Redis server doesn't receive too many `AUTH` commands at the same time. ## Related content |
| azure-cache-for-redis | Cache How To Import Export Data | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-cache-for-redis/cache-how-to-import-export-data.md | Use import to bring Redis compatible RDB files from any Redis server running in :::image type="content" source="./media/cache-how-to-import-export-data/cache-import-blobs.png" alt-text="Screenshot showing the Import button to select to begin the import."::: - You can monitor the progress of the import operation by following the notifications from the Azure portal, or by viewing the events in the [activity log](../azure-monitor/essentials/activity-log.md). + You can monitor the progress of the import operation by following the notifications from the Azure portal, or by viewing the events in the [activity log](/azure/azure-monitor/essentials/activity-log). > [!IMPORTANT] > Activity log support is not yet available in the Enterprise tiers. Export allows you to export the data stored in Azure Cache for Redis to Redis co :::image type="content" source="./media/cache-how-to-import-export-data/cache-export-data.png" alt-text="Screenshot showing a blob name prefix and an Export button."::: - You can monitor the progress of the export operation by following the notifications from the Azure portal, or by viewing the events in the [audit log](../azure-monitor/essentials/activity-log.md). + You can monitor the progress of the export operation by following the notifications from the Azure portal, or by viewing the events in the [audit log](/azure/azure-monitor/essentials/activity-log). :::image type="content" source="./media/cache-how-to-import-export-data/cache-export-data-export-complete.png" alt-text="Screenshot showing the export progress in the notifications area."::: |
| azure-cache-for-redis | Cache Monitor Diagnostic Settings | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-cache-for-redis/cache-monitor-diagnostic-settings.md | ms.devlang: azurecli # Monitor Azure Cache for Redis data using diagnostic settings -Diagnostic settings in Azure are used to collect resource logs. An Azure resource emits resource logs and provides rich, frequent data about the operation of that resource. These logs are captured per request and are also referred to as "data plane logs". See [diagnostic settings in Azure Monitor](../azure-monitor/essentials/diagnostic-settings.md) for a recommended overview of the functionality in Azure. The content of these logs varies by resource type. In Azure Cache for Redis, two options are available to log: +Diagnostic settings in Azure are used to collect resource logs. An Azure resource emits resource logs and provides rich, frequent data about the operation of that resource. These logs are captured per request and are also referred to as "data plane logs". See [diagnostic settings in Azure Monitor](/azure/azure-monitor/essentials/diagnostic-settings) for a recommended overview of the functionality in Azure. The content of these logs varies by resource type. In Azure Cache for Redis, two options are available to log: - **Cache Metrics** (that is "AllMetrics") used to [log metrics from Azure Monitor](/azure/azure-monitor/essentials/diagnostic-settings?tabs=portal) - **Connection Logs** logs connections to the cache for security and diagnostic purposes. The connection logs produced look similar among the tiers, but have some differe ### Basic, Standard, and Premium tiers - Because connection logs in these tiers consist of point-in-time snapshots taken every 10 seconds, connections that are established and removed in-between 10-second intervals aren't logged. - Authentication events aren't logged.-- All diagnostic settings may take up to [90 minutes](../azure-monitor/essentials/diagnostic-settings.md#time-before-telemetry-gets-to-destination) to start flowing to your selected destination. +- All diagnostic settings may take up to [90 minutes](/azure/azure-monitor/essentials/diagnostic-settings#time-before-telemetry-gets-to-destination) to start flowing to your selected destination. - Enabling connection logs can cause a small performance degradation to the cache instance. - Only the _Analytics Logs_ pricing plan is supported when streaming logs to Azure Log Analytics. For more information, see [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/). The connection logs produced look similar among the tiers, but have some differe - Disconnection logs aren't yet fully stable and events may be missed. - Because connection logs on the Enterprise tiers are event-based, be careful of your retention policies. For instance, if retention is set to 10 days, and a connection event occurred 15 days ago, that connection might still exist, but the log for that connection isn't retained. - If using [active geo-replication](cache-how-to-active-geo-replication.md), logging must be configured for each cache instance in the geo-replication group individually.-- All diagnostic settings may take up to [90 minutes](../azure-monitor/essentials/diagnostic-settings.md#time-before-telemetry-gets-to-destination) to start flowing to your selected destination. +- All diagnostic settings may take up to [90 minutes](/azure/azure-monitor/essentials/diagnostic-settings#time-before-telemetry-gets-to-destination) to start flowing to your selected destination. - Enabling connection logs may cause a small performance degradation to the cache instance. > [!NOTE] The connection logs produced look similar among the tiers, but have some differe > > [!IMPORTANT]-> When selecting logs, you can chose either the specific _Category_ or _Category groups_, which are predefined groupings of logs across Azure services. When you use _Category groups_, [you can no longer configure the retention settings](../azure-monitor/essentials/diagnostic-settings.md#resource-logs). If you need to determine retention duration for your connection logs, select the item in the _Categories_ section instead. +> When selecting logs, you can chose either the specific _Category_ or _Category groups_, which are predefined groupings of logs across Azure services. When you use _Category groups_, [you can no longer configure the retention settings](/azure/azure-monitor/essentials/diagnostic-settings#resource-logs). If you need to determine retention duration for your connection logs, select the item in the _Categories_ section instead. > ## Log Destinations The connection logs produced look similar among the tiers, but have some differe You can turn on diagnostic settings for Azure Cache for Redis instances and send resource logs to the following destinations: - **Log Analytics workspace** - doesn't need to be in the same region as the resource being monitored.-- **Storage account** - must be in the same region as the cache. [Premium storage accounts are not supported](../azure-monitor/essentials/diagnostic-settings.md#destination-limitations) as a destination, however. +- **Storage account** - must be in the same region as the cache. [Premium storage accounts are not supported](/azure/azure-monitor/essentials/diagnostic-settings#destination-limitations) as a destination, however. - **Event hub** - diagnostic settings can't access event hub resources when virtual networks are enabled. Enable the **Allow trusted Microsoft services to bypass this firewall?** setting in event hubs to grant access to your event hub resources. The event hub must be in the same region as the cache. - **Partner Solution** - a list of potential partner logging solutions can be found [here](../partner-solutions/partners.md) -For more information on diagnostic requirements, see [diagnostic settings](../azure-monitor/essentials/diagnostic-settings.md?tabs=CMD). +For more information on diagnostic requirements, see [diagnostic settings](/azure/azure-monitor/essentials/diagnostic-settings?tabs=CMD). You're charged normal data rates for storage account and event hub usage when you send diagnostic logs to either destination. You're billed under Azure Monitor not Azure Cache for Redis. When sending logs to **Log Analytics**, you're only charged for Log Analytics data ingestion. And the log for a disconnection event looks like this: ## Next steps -For detailed information about how to create a diagnostic setting by using the Azure portal, CLI, or PowerShell, see [create diagnostic setting to collect platform logs and metrics in Azure](../azure-monitor/essentials/diagnostic-settings.md) article. +For detailed information about how to create a diagnostic setting by using the Azure portal, CLI, or PowerShell, see [create diagnostic setting to collect platform logs and metrics in Azure](/azure/azure-monitor/essentials/diagnostic-settings) article. |
| azure-cache-for-redis | Cache Moving Resources | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-cache-for-redis/cache-moving-resources.md | To move your cache instance to another region, you'll need to create [a second p ### Verify -You can monitor the progress of the import operation by following the notifications from the Azure portal, or by viewing the events in the [audit log](../azure-monitor/essentials/activity-log.md). +You can monitor the progress of the import operation by following the notifications from the Azure portal, or by viewing the events in the [audit log](/azure/azure-monitor/essentials/activity-log). ### Clean up source resources |
| azure-cache-for-redis | Monitor Cache | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-cache-for-redis/monitor-cache.md | In contrast, for clustered caches, use the metrics with the suffix `Instance Bas ### Log Analytics queries > [!NOTE]-> For a tutorial on how to use Azure Log Analytics, see [Overview of Log Analytics in Azure Monitor](../azure-monitor/logs/log-analytics-overview.md). Remember that it may take up to 90 minutes before logs show up in Log Analtyics. +> For a tutorial on how to use Azure Log Analytics, see [Overview of Log Analytics in Azure Monitor](/azure/azure-monitor/logs/log-analytics-overview). Remember that it may take up to 90 minutes before logs show up in Log Analtyics. Here are some basic queries to use as models. |
| azure-functions | Analyze Telemetry Data | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/analyze-telemetry-data.md | Last updated 10/14/2020 Azure Functions integrates with Application Insights to better enable you to monitor your function apps. Application Insights collects telemetry data generated by your function app, including information your app writes to logs. Application Insights integration is typically enabled when your function app is created. If your function app doesn't have the instrumentation key set, you must first [enable Application Insights integration](configure-monitoring.md#enable-application-insights-integration). -By default, the data collected from your function app is stored in Application Insights. In the [Azure portal](https://portal.azure.com), Application Insights provides an extensive set of visualizations of your telemetry data. You can drill into error logs and query events and metrics. This article provides basic examples of how to view and query your collected data. To learn more about exploring your function app data in Application Insights, see [What is Application Insights?](../azure-monitor/app/app-insights-overview.md). +By default, the data collected from your function app is stored in Application Insights. In the [Azure portal](https://portal.azure.com), Application Insights provides an extensive set of visualizations of your telemetry data. You can drill into error logs and query events and metrics. This article provides basic examples of how to view and query your collected data. To learn more about exploring your function app data in Application Insights, see [What is Application Insights?](/azure/azure-monitor/app/app-insights-overview). -To be able to view Application Insights data from a function app, you must have at least Contributor role permissions on the function app. You also need to have the [Monitoring Reader permission](../azure-monitor/roles-permissions-security.md#monitoring-reader) on the Application Insights instance. You have these permissions by default for any function app and Application Insights instance that you create. +To be able to view Application Insights data from a function app, you must have at least Contributor role permissions on the function app. You also need to have the [Monitoring Reader permission](/azure/azure-monitor/roles-permissions-security#monitoring-reader) on the Application Insights instance. You have these permissions by default for any function app and Application Insights instance that you create. To learn more about data retention and potential storage costs, see [Data collection, retention, and storage in Application Insights](/previous-versions/azure/azure-monitor/app/data-retention-privacy). With [Application Insights integration enabled](configure-monitoring.md#enable-a  > [!NOTE]- > It can take up to five minutes for the list to appear while the telemetry client batches data for transmission to the server. The delay doesn't apply to the [Live Metrics Stream](../azure-monitor/app/live-stream.md). That service connects to the Functions host when you load the page, so logs are streamed directly to the page. + > It can take up to five minutes for the list to appear while the telemetry client batches data for transmission to the server. The delay doesn't apply to the [Live Metrics Stream](/azure/azure-monitor/app/live-stream). That service connects to the Functions host when you load the page, so logs are streamed directly to the page. 1. To see the logs for a particular function invocation, select the **Date (UTC)** column link for that invocation. The logging output for that invocation appears in a new page. To open Application Insights from a function app in the [Azure portal](https://p  -For information about how to use Application Insights, see the [Application Insights documentation](../azure-monitor/app/app-insights-overview.md). This section shows some examples of how to view data in Application Insights. If you're already familiar with Application Insights, you can go directly to [the sections about how to configure and customize the telemetry data](configure-monitoring.md#configure-log-levels). +For information about how to use Application Insights, see the [Application Insights documentation](/azure/azure-monitor/app/app-insights-overview). This section shows some examples of how to view data in Application Insights. If you're already familiar with Application Insights, you can go directly to [the sections about how to configure and customize the telemetry data](configure-monitoring.md#configure-log-levels).  The following areas of Application Insights can be helpful when evaluating the b | Investigate | Description | | - | -- |-| **[Failures](../azure-monitor/app/asp-net-exceptions.md)** | Create charts and alerts based on function failures and server exceptions. The **Operation Name** is the function name. Failures in dependencies aren't shown unless you implement custom telemetry for dependencies. | -| **[Performance](../azure-monitor/app/performance-counters.md)** | Analyze performance issues by viewing resource utilization and throughput per **Cloud role instances**. This performance data can be useful for debugging scenarios where functions are bogging down your underlying resources. | -| **[Metrics](../azure-monitor/essentials/metrics-charts.md)** | Create charts and alerts that are based on metrics. Metrics include the number of function invocations, execution time, and success rates. | -| **[Live Metrics](../azure-monitor/app/live-stream.md)** | View metrics data as it's created in near real time. | +| **[Failures](/azure/azure-monitor/app/asp-net-exceptions)** | Create charts and alerts based on function failures and server exceptions. The **Operation Name** is the function name. Failures in dependencies aren't shown unless you implement custom telemetry for dependencies. | +| **[Performance](/azure/azure-monitor/app/performance-counters)** | Analyze performance issues by viewing resource utilization and throughput per **Cloud role instances**. This performance data can be useful for debugging scenarios where functions are bogging down your underlying resources. | +| **[Metrics](/azure/azure-monitor/essentials/metrics-charts)** | Create charts and alerts that are based on metrics. Metrics include the number of function invocations, execution time, and success rates. | +| **[Live Metrics](/azure/azure-monitor/app/live-stream)** | View metrics data as it's created in near real time. | ## Query telemetry data -[Application Insights Analytics](../azure-monitor/logs/log-query-overview.md) gives you access to all telemetry data in the form of tables in a database. Analytics provides a query language for extracting, manipulating, and visualizing the data. +[Application Insights Analytics](/azure/azure-monitor/logs/log-query-overview) gives you access to all telemetry data in the form of tables in a database. Analytics provides a query language for extracting, manipulating, and visualizing the data. Choose **Logs** to explore or query for logged events. |
| azure-functions | Configure Monitoring | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/configure-monitoring.md | -You can use Application Insights without any custom configuration. However, the default configuration can result in high volumes of data. If you're using a Visual Studio Azure subscription, you might hit your data cap for Application Insights. For information about Application Insights costs, see [Application Insights billing](../azure-monitor/logs/cost-logs.md#application-insights-billing). For more information, see [Solutions with high-volume of telemetry](#solutions-with-high-volume-of-telemetry). +You can use Application Insights without any custom configuration. However, the default configuration can result in high volumes of data. If you're using a Visual Studio Azure subscription, you might hit your data cap for Application Insights. For information about Application Insights costs, see [Application Insights billing](/azure/azure-monitor/logs/cost-logs#application-insights-billing). For more information, see [Solutions with high-volume of telemetry](#solutions-with-high-volume-of-telemetry). In this article, you learn how to configure and customize the data that your functions send to Application Insights. You can set common logging configurations in the *[host.json]* file. By default, these settings also govern custom logs emitted by your code. However, in some cases this behavior can be disabled in favor of options that give you more control over logging. For more information, see [Custom application logs](#custom-application-logs). The following table summarizes the configuration options available for each stac | .NET (isolated model) | Default (send custom logs to the Functions host): `host.json`<br/>To send logs directly to Application Insights, see: [Configure Application Insights in the HostBuilder](./dotnet-isolated-process-guide.md#application-insights) | | Node.JS | `host.json` | | Python | `host.json` |-| Java | Default (send custom logs to the Functions host): `host.json`<br/>To send logs directly to Application Insights, see: [Configure the Application Insights Java agent](../azure-monitor/app/monitor-functions.md#distributed-tracing-for-java-applications) | +| Java | Default (send custom logs to the Functions host): `host.json`<br/>To send logs directly to Application Insights, see: [Configure the Application Insights Java agent](/azure/azure-monitor/app/monitor-functions#distributed-tracing-for-java-applications) | | PowerShell | `host.json` | When you configure custom application logs to be sent directly, the host no longer emits them, and `host.json` no longer controls their behavior. Similarly, the options exposed by each stack apply only to custom logs, and they don't change the behavior of the other runtime logs described in this article. In this case, to control the behavior of all logs, you might need to make changes in both configurations. As noted in the previous section, the runtime aggregates data about function exe ## Configure sampling -Application Insights has a [sampling](../azure-monitor/app/sampling.md) feature that can protect you from producing too much telemetry data on completed executions at times of peak load. When the rate of incoming executions exceeds a specified threshold, Application Insights starts to randomly ignore some of the incoming executions. The default setting for maximum number of executions per second is 20 (five in version 1.x). You can configure sampling in [*host.json*](./functions-host-json.md#applicationinsights). Here's an example: +Application Insights has a [sampling](/azure/azure-monitor/app/sampling) feature that can protect you from producing too much telemetry data on completed executions at times of peak load. When the rate of incoming executions exceeds a specified threshold, Application Insights starts to randomly ignore some of the incoming executions. The default setting for maximum number of executions per second is 20 (five in version 1.x). You can configure sampling in [*host.json*](./functions-host-json.md#applicationinsights). Here's an example: ### [v2.x+](#tab/v2) You can exclude certain types of telemetry from sampling. In this example, data -If your project uses a dependency on the Application Insights SDK to do manual telemetry tracking, you might experience unusual behavior if your sampling configuration differs from the sampling configuration in your function app. In such cases, use the same sampling configuration as the function app. For more information, see [Sampling in Application Insights](../azure-monitor/app/sampling.md). +If your project uses a dependency on the Application Insights SDK to do manual telemetry tracking, you might experience unusual behavior if your sampling configuration differs from the sampling configuration in your function app. In such cases, use the same sampling configuration as the function app. For more information, see [Sampling in Application Insights](/azure/azure-monitor/app/sampling). ## Enable SQL query collection Application Insights automatically collects data on dependencies for HTTP reques } ``` -For more information, see [Advanced SQL tracking to get full SQL query](../azure-monitor/app/asp-net-dependencies.md#advanced-sql-tracking-to-get-full-sql-query). +For more information, see [Advanced SQL tracking to get full SQL query](/azure/azure-monitor/app/asp-net-dependencies#advanced-sql-tracking-to-get-full-sql-query). ## Configure scale controller logs For a function app to send data to Application Insights, it needs to connect to | Setting name | Description | | - | - |-| **[`APPLICATIONINSIGHTS_CONNECTION_STRING`](functions-app-settings.md#applicationinsights_connection_string)** | This setting is recommended and is required when your Application Insights instance runs in a sovereign cloud. The connection string supports other [new capabilities](../azure-monitor/app/migrate-from-instrumentation-keys-to-connection-strings.md#new-capabilities). | +| **[`APPLICATIONINSIGHTS_CONNECTION_STRING`](functions-app-settings.md#applicationinsights_connection_string)** | This setting is recommended and is required when your Application Insights instance runs in a sovereign cloud. The connection string supports other [new capabilities](/azure/azure-monitor/app/migrate-from-instrumentation-keys-to-connection-strings#new-capabilities). | | **[`APPINSIGHTS_INSTRUMENTATIONKEY`](functions-app-settings.md#appinsights_instrumentationkey)** | Legacy setting, which Application Insights has deprecated in favor of the connection string setting. | When you create your function app in the [Azure portal](./functions-get-started.md) from the command line by using [Azure Functions Core Tools](./create-first-function-cli-csharp.md) or [Visual Studio Code](./create-first-function-vs-code-csharp.md), Application Insights integration is enabled by default. The Application Insights resource has the same name as your function app, and is created either in the same region or in the nearest region. You can use the [`APPLICATIONINSIGHTS_AUTHENTICATION_STRING`](./functions-app-se >[!NOTE] >There's no Entra authentication support for local development. -The value contains either `Authorization=AAD` for a system-assigned managed identity or `ClientId=<YOUR_CLIENT_ID>;Authorization=AAD` for a user-assigned managed identity. The managed identity must already be available to the function app, with an assigned role equivalent to [Monitoring Metrics Publisher](/azure/role-based-access-control/built-in-roles/monitor#monitoring-metrics-publisher). For more information, see [Microsoft Entra authentication for Application Insights](../azure-monitor/app/azure-ad-authentication.md). +The value contains either `Authorization=AAD` for a system-assigned managed identity or `ClientId=<YOUR_CLIENT_ID>;Authorization=AAD` for a user-assigned managed identity. The managed identity must already be available to the function app, with an assigned role equivalent to [Monitoring Metrics Publisher](/azure/role-based-access-control/built-in-roles/monitor#monitoring-metrics-publisher). For more information, see [Microsoft Entra authentication for Application Insights](/azure/azure-monitor/app/azure-ad-authentication). The [`APPLICATIONINSIGHTS_CONNECTION_STRING`](functions-app-settings.md#applicationinsights_connection_string) setting is still required. Function apps are an essential part of solutions that can cause high volumes of The generated telemetry can be consumed in real-time dashboards, alerting, detailed diagnostics, and so on. Depending on how the generated telemetry is consumed, you need to define a strategy to reduce the volume of data generated. This strategy allows you to properly monitor, operate, and diagnose your function apps in production. Consider the following options: -+ **Use sampling**: As mentioned [previously](#configure-sampling), sampling helps to dramatically reduce the volume of telemetry events ingested while maintaining a statistically correct analysis. It could happen that even using sampling you still get a high volume of telemetry. Inspect the options that [adaptive sampling](../azure-monitor/app/sampling.md#configuring-adaptive-sampling-for-aspnet-applications) provides to you. For example, set the `maxTelemetryItemsPerSecond` to a value that balances the volume generated with your monitoring needs. Keep in mind that the telemetry sampling is applied per host executing your function app. ++ **Use sampling**: As mentioned [previously](#configure-sampling), sampling helps to dramatically reduce the volume of telemetry events ingested while maintaining a statistically correct analysis. It could happen that even using sampling you still get a high volume of telemetry. Inspect the options that [adaptive sampling](/azure/azure-monitor/app/sampling#configuring-adaptive-sampling-for-aspnet-applications) provides to you. For example, set the `maxTelemetryItemsPerSecond` to a value that balances the volume generated with your monitoring needs. Keep in mind that the telemetry sampling is applied per host executing your function app. + **Default log level**: Use `Warning` or `Error` as the default value for all telemetry categories. Later, you can decide which [categories](#configure-categories) you want to set at the `Information` level, so that you can monitor and diagnose your functions properly. For more information about monitoring, see: + [Monitor Azure Functions](functions-monitoring.md) + [Analyze Azure Functions telemetry data in Application Insights](analyze-telemetry-data.md)-+ [Application Insights overview](../azure-monitor/app/app-insights-overview.md) ++ [Application Insights overview](/azure/azure-monitor/app/app-insights-overview) [host.json]: functions-host-json.md |
| azure-functions | Create First Function Vs Code Python | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/create-first-function-vs-code-python.md | Title: Create a Python function using Visual Studio Code - Azure Functions description: Learn how to create a Python function, then publish the local project to serverless hosting in Azure Functions using the Azure Functions extension in Visual Studio Code. Previously updated : 06/03/2024 Last updated : 09/10/2024 ms.devlang: python ai-usage: ai-assisted In this section, you use Visual Studio Code to create a local Azure Functions pr 1. In Visual Studio Code, press <kbd>F1</kbd> to open the command palette and search for and run the command `Azure Functions: Create New Project...`. -2. Choose the directory location for your project workspace and choose **Select**. You should either create a new folder or choose an empty folder for the project workspace. Don't choose a project folder that is already part of a workspace. +1. Choose the directory location for your project workspace and choose **Select**. You should either create a new folder or choose an empty folder for the project workspace. Don't choose a project folder that is already part of a workspace. -3. Provide the following information at the prompts: +1. Provide the following information at the prompts: |Prompt|Selection| |--|--| In this section, you use Visual Studio Code to create a local Azure Functions pr |**Authorization level**| Choose `ANONYMOUS`, which lets anyone call your function endpoint. For more information, see [Authorization level](functions-bindings-http-webhook-trigger.md#http-auth).| |**Select how you would like to open your project** | Choose `Open in current window`.| -4. Visual Studio Code uses the provided information and generates an Azure Functions project with an HTTP trigger. You can view the local project files in the Explorer. The generated `function_app.py` project file contains your functions. -<! Remove these last steps after the next Core Tools version is released (4.28.0)> -5. Open the local.settings.json project file and verify that the `AzureWebJobsFeatureFlags` setting has a value of `EnableWorkerIndexing`. This is required for Functions to interpret your project correctly as the Python v2 model when running locally. +1. Visual Studio Code uses the provided information and generates an Azure Functions project with an HTTP trigger. You can view the local project files in the Explorer. The generated `function_app.py` project file contains your functions. -6. In the local.settings.json file, update the `AzureWebJobsStorage` setting as in the following example: +1. In the local.settings.json file, update the `AzureWebJobsStorage` setting as in the following example: ```json "AzureWebJobsStorage": "UseDevelopmentStorage=true", ```-- This tells the local Functions host to use the storage emulator for the storage connection currently required by the Python v2 model. When you publish your project to Azure, you need to instead use the default storage account. If you're instead using an Azure Storage account, set your storage account connection string here. + + This tells the local Functions host to use the storage emulator for the storage connection required by the Python v2 model. When you publish your project to Azure, this setting uses the default storage account instead. If you're using an Azure Storage account during local development, set your storage account connection string here. ## Start the emulator 1. In Visual Studio Code, press <kbd>F1</kbd> to open the command palette. In the command palette, search for and select `Azurite: Start`. -1. Check the bottom bar and verify that Azurite emulation services are running. If so, you can now run your function locally. +1. Check the bottom bar and verify that Azurite emulation services are running. If so, you can now run your function locally. [!INCLUDE [functions-run-function-test-local-vs-code](../../includes/functions-run-function-test-local-vs-code.md)] |
| azure-functions | Dedicated Plan | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/dedicated-plan.md | Even with Always On enabled, the execution timeout for individual functions is c ## Scaling -Using an App Service plan, you can manually scale out by adding more VM instances. You can also enable autoscale, though autoscale will be slower than the elastic scale of the Premium plan. For more information, see [Scale instance count manually or automatically](../azure-monitor/autoscale/autoscale-get-started.md?toc=%2fazure%2fapp-service%2ftoc.json). You can also scale up by choosing a different App Service plan. For more information, see [Scale up an app in Azure](../app-service/manage-scale-up.md). +Using an App Service plan, you can manually scale out by adding more VM instances. You can also enable autoscale, though autoscale will be slower than the elastic scale of the Premium plan. For more information, see [Scale instance count manually or automatically](/azure/azure-monitor/autoscale/autoscale-get-started?toc=%2fazure%2fapp-service%2ftoc.json). You can also scale up by choosing a different App Service plan. For more information, see [Scale up an app in Azure](../app-service/manage-scale-up.md). > [!NOTE] > When running JavaScript (Node.js) functions on an App Service plan, you should choose a plan that has fewer vCPUs. For more information, see [Choose single-core App Service plans](functions-reference-node.md#choose-single-vcpu-app-service-plans). |
| azure-functions | Dotnet Isolated Process Guide | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/dotnet-isolated-process-guide.md | var host = new HostBuilder() ### Application Insights -You can configure your isolated process application to emit logs directly to [Application Insights](../azure-monitor/app/app-insights-overview.md?tabs=net). This behavior replaces the default behavior of [relaying logs through the host](./configure-monitoring.md#custom-application-logs), and is recommended because it gives you control over how those logs are emitted. +You can configure your isolated process application to emit logs directly to [Application Insights](/azure/azure-monitor/app/app-insights-overview?tabs=net). This behavior replaces the default behavior of [relaying logs through the host](./configure-monitoring.md#custom-application-logs), and is recommended because it gives you control over how those logs are emitted. #### Install packages var host = new HostBuilder() host.Run(); ``` -The call to `ConfigureFunctionsApplicationInsights()` adds an `ITelemetryModule`, which listens to a Functions-defined `ActivitySource`. This creates the dependency telemetry required to support distributed tracing. To learn more about `AddApplicationInsightsTelemetryWorkerService()` and how to use it, see [Application Insights for Worker Service applications](../azure-monitor/app/worker-service.md). +The call to `ConfigureFunctionsApplicationInsights()` adds an `ITelemetryModule`, which listens to a Functions-defined `ActivitySource`. This creates the dependency telemetry required to support distributed tracing. To learn more about `AddApplicationInsightsTelemetryWorkerService()` and how to use it, see [Application Insights for Worker Service applications](/azure/azure-monitor/app/worker-service). #### Managing log levels |
| azure-functions | Durable Functions Best Practice Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/durable/durable-functions-best-practice-reference.md | There are several tools available to help you diagnose problems. ### Durable Functions and Durable Task Framework Logs #### Durable Functions Extension-The Durable extension emits tracking events that allow you to trace the end-to-end execution of an orchestration. These tracking events can be found and queried using the [Application Insights Analytics](../../azure-monitor/logs/log-query-overview.md) tool in the Azure portal. The verbosity of tracking data emitted can be configured in the `logger` (Functions 1.x) or `logging` (Functions 2.0) section of the host.json file. See [configuration details](durable-functions-diagnostics.md#functions-10). +The Durable extension emits tracking events that allow you to trace the end-to-end execution of an orchestration. These tracking events can be found and queried using the [Application Insights Analytics](/azure/azure-monitor/logs/log-query-overview) tool in the Azure portal. The verbosity of tracking data emitted can be configured in the `logger` (Functions 1.x) or `logging` (Functions 2.0) section of the host.json file. See [configuration details](durable-functions-diagnostics.md#functions-10). #### Durable Task Framework Starting in v2.3.0 of the Durable extension, logs emitted by the underlying Durable Task Framework (DTFx) are also available for collection. See [details on how to enable these logs](durable-functions-diagnostics.md#durable-task-framework-logging). |
| azure-functions | Durable Functions Diagnostics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/durable/durable-functions-diagnostics.md | There are several options for diagnosing issues with [Durable Functions](durable ## Application Insights -[Application Insights](../../azure-monitor/app/app-insights-overview.md) is the recommended way to do diagnostics and monitoring in Azure Functions. The same applies to Durable Functions. For an overview of how to leverage Application Insights in your function app, see [Monitor Azure Functions](../functions-monitoring.md). +[Application Insights](/azure/azure-monitor/app/app-insights-overview) is the recommended way to do diagnostics and monitoring in Azure Functions. The same applies to Durable Functions. For an overview of how to leverage Application Insights in your function app, see [Monitor Azure Functions](../functions-monitoring.md). -The Azure Functions Durable Extension also emits *tracking events* that allow you to trace the end-to-end execution of an orchestration. These tracking events can be found and queried using the [Application Insights Analytics](../../azure-monitor/logs/log-query-overview.md) tool in the Azure portal. +The Azure Functions Durable Extension also emits *tracking events* that allow you to trace the end-to-end execution of an orchestration. These tracking events can be found and queried using the [Application Insights Analytics](/azure/azure-monitor/logs/log-query-overview) tool in the Azure portal. ### Tracking data |
| azure-functions | Functions App Settings | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/functions-app-settings.md | Don't use both `APPINSIGHTS_INSTRUMENTATIONKEY` and `APPLICATIONINSIGHTS_CONNECT ## APPLICATIONINSIGHTS_AUTHENTICATION_STRING -Enables access to Application Insights by using Microsoft Entra authentication. Use this setting when you must connect to your Application Insights workspace by using Microsoft Entra authentication. For more information, see [Microsoft Entra authentication for Application Insights](../azure-monitor/app/azure-ad-authentication.md). +Enables access to Application Insights by using Microsoft Entra authentication. Use this setting when you must connect to your Application Insights workspace by using Microsoft Entra authentication. For more information, see [Microsoft Entra authentication for Application Insights](/azure/azure-monitor/app/azure-ad-authentication). When you use `APPLICATIONINSIGHTS_AUTHENTICATION_STRING`, the specific value that you set depends on the type of managed identity: The connection string for Application Insights. Don't use both `APPINSIGHTS_INST + When your function app requires the added customizations supported by using the connection string. + When your Application Insights instance runs in a sovereign cloud, which requires a custom endpoint. -For more information, see [Connection strings](../azure-monitor/app/sdk-connection-string.md). +For more information, see [Connection strings](/azure/azure-monitor/app/sdk-connection-string). |Key|Sample value| ||| |
| azure-functions | Functions Compare Logic Apps Ms Flow Webjobs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/functions-compare-logic-apps-ms-flow-webjobs.md | You can mix and match services when you build an orchestration, such as calling | **Development** | Code-first (imperative) | Designer-first (declarative) | | **Connectivity** | [About a dozen built-in binding types](functions-triggers-bindings.md#supported-bindings), write code for custom bindings | [Large collection of connectors](/connectors/connector-reference/connector-reference-logicapps-connectors), [Enterprise Integration Pack for B2B scenarios](../logic-apps/logic-apps-enterprise-integration-overview.md), [build custom connectors](/connectors/custom-connectors/) | | **Actions** | Each activity is an Azure function; write code for activity functions |[Large collection of ready-made actions](/connectors/connector-reference/connector-reference-logicapps-connectors)|-| **Monitoring** | [Azure Application Insights](../azure-monitor/app/app-insights-overview.md) | [Azure portal](../logic-apps/quickstart-create-example-consumption-workflow.md), [Azure Monitor Logs](../logic-apps/monitor-workflows-collect-diagnostic-data.md), [Microsoft Defender for Cloud](../logic-apps/healthy-unhealthy-resource.md) | +| **Monitoring** | [Azure Application Insights](/azure/azure-monitor/app/app-insights-overview) | [Azure portal](../logic-apps/quickstart-create-example-consumption-workflow.md), [Azure Monitor Logs](../logic-apps/monitor-workflows-collect-diagnostic-data.md), [Microsoft Defender for Cloud](../logic-apps/healthy-unhealthy-resource.md) | | **Management** | [REST API](durable/durable-functions-http-api.md), [Visual Studio](/visualstudio/azure/vs-azure-tools-resources-managing-with-cloud-explorer) | [Azure portal](../logic-apps/quickstart-create-example-consumption-workflow.md), [REST API](/rest/api/logic/), [PowerShell](/powershell/module/az.logicapp), [Visual Studio](../logic-apps/manage-logic-apps-with-visual-studio.md) | | **Execution context** | Can run [locally](./functions-kubernetes-keda.md) or in the cloud | Runs in Azure, locally, or on premises. For more information, see [What is Azure Logic Apps](../logic-apps/logic-apps-overview.md#resource-environment-differences). | |
| azure-functions | Functions Consumption Costs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/functions-consumption-costs.md | When estimating the overall costs of your function app and related services, use | Related cost | Description | | | -- | | **Storage account** | Each function app requires that you have an associated General Purpose [Azure Storage account](../storage/common/storage-introduction.md#types-of-storage-accounts), which is [billed separately](https://azure.microsoft.com/pricing/details/storage/). This account is used internally by the Functions runtime, but you can also use it for Storage triggers and bindings. If you don't have a storage account, one is created for you when the function app is created. To learn more, see [Storage account requirements](storage-considerations.md#storage-account-requirements).|-| **Application Insights** | Functions relies on [Application Insights](../azure-monitor/app/app-insights-overview.md) to provide a high-performance monitoring experience for your function apps. While not required, you should [enable Application Insights integration](configure-monitoring.md#enable-application-insights-integration). A free grant of telemetry data is included every month. To learn more, see [the Azure Monitor pricing page](https://azure.microsoft.com/pricing/details/monitor/). | +| **Application Insights** | Functions relies on [Application Insights](/azure/azure-monitor/app/app-insights-overview) to provide a high-performance monitoring experience for your function apps. While not required, you should [enable Application Insights integration](configure-monitoring.md#enable-application-insights-integration). A free grant of telemetry data is included every month. To learn more, see [the Azure Monitor pricing page](https://azure.microsoft.com/pricing/details/monitor/). | | **Network bandwidth** | You can incur costs for data transfer depending on the direction and scenario of the data movement. To learn more, see [Bandwidth pricing details](https://azure.microsoft.com/pricing/details/bandwidth/). | ## Behaviors affecting execution time Function execution units are a combination of execution time and your memory usa If you haven't already done so, [enable Application Insights in your function app](configure-monitoring.md#enable-application-insights-integration). With this integration enabled, you can [query this telemetry data in the portal](analyze-telemetry-data.md#query-telemetry-data). -You can use either [Azure Monitor metrics explorer](../azure-monitor/essentials/metrics-getting-started.md) in the [Azure portal] or REST APIs to get Monitor Metrics data. +You can use either [Azure Monitor metrics explorer](/azure/azure-monitor/essentials/metrics-getting-started) in the [Azure portal] or REST APIs to get Monitor Metrics data. [!INCLUDE [functions-consumption-metrics-queries](../../includes/functions-consumption-metrics-queries.md)] |
| azure-functions | Functions Dotnet Class Library | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/functions-dotnet-class-library.md | Install-Package Microsoft.Azure.WebJobs.Logging.ApplicationInsights -Version <VE In this command, replace `<VERSION>` with a version of this package that supports your installed version of [Microsoft.Azure.WebJobs](https://www.nuget.org/packages/Microsoft.Azure.WebJobs/). -The following C# examples uses the [custom telemetry API](../azure-monitor/app/api-custom-events-metrics.md). The example is for a .NET class library, but the Application Insights code is the same for C# script. +The following C# examples uses the [custom telemetry API](/azure/azure-monitor/app/api-custom-events-metrics). The example is for a .NET class library, but the Application Insights code is the same for C# script. # [v4.x](#tab/v4) namespace functionapp0915 } ``` -In this example, the custom metric data gets aggregated by the host before being sent to the customMetrics table. To learn more, see the [GetMetric](../azure-monitor/app/api-custom-events-metrics.md#getmetric) documentation in Application Insights. +In this example, the custom metric data gets aggregated by the host before being sent to the customMetrics table. To learn more, see the [GetMetric](/azure/azure-monitor/app/api-custom-events-metrics#getmetric) documentation in Application Insights. When running locally, you must add the `APPINSIGHTS_INSTRUMENTATIONKEY` setting, with the Application Insights key, to the [local.settings.json](functions-develop-local.md#local-settings-file) file. |
| azure-functions | Functions Host Json | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/functions-host-json.md | For the complete JSON structure, see the earlier [example host.json file](#sampl ### applicationInsights.samplingSettings -For more information about these settings, see [Sampling in Application Insights](../azure-monitor/app/sampling.md). +For more information about these settings, see [Sampling in Application Insights](/azure/azure-monitor/app/sampling). |Property | Default | Description | | | | | For more information about these settings, see [Sampling in Application Insights |Property | Default | Description | | | | | -| enableSqlCommandTextInstrumentation | false | Enables collection of the full text of SQL queries, which is disabled by default. For more information on collecting SQL query text, see [Advanced SQL tracking to get full SQL query](../azure-monitor/app/asp-net-dependencies.md#advanced-sql-tracking-to-get-full-sql-query). | +| enableSqlCommandTextInstrumentation | false | Enables collection of the full text of SQL queries, which is disabled by default. For more information on collecting SQL query text, see [Advanced SQL tracking to get full SQL query](/azure/azure-monitor/app/asp-net-dependencies#advanced-sql-tracking-to-get-full-sql-query). | ### applicationInsights.snapshotConfiguration -For more information on snapshots, see [Debug snapshots on exceptions in .NET apps](../azure-monitor/app/snapshot-debugger.md) and [Troubleshoot problems enabling Application Insights Snapshot Debugger or viewing snapshots](/troubleshoot/azure/azure-monitor/app-insights/snapshot-debugger-troubleshoot). +For more information on snapshots, see [Debug snapshots on exceptions in .NET apps](/azure/azure-monitor/app/snapshot-debugger) and [Troubleshoot problems enabling Application Insights Snapshot Debugger or viewing snapshots](/troubleshoot/azure/azure-monitor/app-insights/snapshot-debugger-troubleshoot). |Property | Default | Description | | | | | |
| azure-functions | Functions Identity Based Connections Tutorial | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/functions-identity-based-connections-tutorial.md | Congratulations! You've successfully created your function app to reference the Whenever your app would need to add a reference to a secret, you would just need to define a new application setting pointing to the value stored in Key Vault. For more information, see [Key Vault references for Azure Functions](../app-service/app-service-key-vault-references.md?toc=%2Fazure%2Fazure-functions%2Ftoc.json). > [!TIP]-> The [Application Insights connection string](../azure-monitor/app/sdk-connection-string.md) and its included instrumentation key are not considered secrets and can be retrieved from App Insights using [Reader](../role-based-access-control/built-in-roles.md#reader) permissions. You do not need to move them into Key Vault, although you certainly can. +> The [Application Insights connection string](/azure/azure-monitor/app/sdk-connection-string) and its included instrumentation key are not considered secrets and can be retrieved from App Insights using [Reader](../role-based-access-control/built-in-roles.md#reader) permissions. You do not need to move them into Key Vault, although you certainly can. ## Use managed identity for AzureWebJobsStorage |
| azure-functions | Functions Infrastructure As Code | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/functions-infrastructure-as-code.md | When you deploy multiple resources in a single Bicep file or ARM template, the o ## Prerequisites + The examples are designed to execute in the context of an existing resource group.-+ Both Application Insights and storage logs require you to have an existing [Azure Log Analytics workspace](../azure-monitor/logs/log-analytics-overview.md). Workspaces can be shared between services, and as a rule of thumb you should create a workspace in each geographic region to improve performance. For an example of how to create a Log Analytics workspace, see [Create a Log Analytics workspace](../azure-monitor/logs/quick-create-workspace.md?tabs=azure-resource-manager#create-a-workspace). You can find the fully qualified workspace resource ID in a workspace page in the [Azure portal](https://portal.azure.com) under **Settings** > **Properties** > **Resource ID**. ++ Both Application Insights and storage logs require you to have an existing [Azure Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-overview). Workspaces can be shared between services, and as a rule of thumb you should create a workspace in each geographic region to improve performance. For an example of how to create a Log Analytics workspace, see [Create a Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace?tabs=azure-resource-manager#create-a-workspace). You can find the fully qualified workspace resource ID in a workspace page in the [Azure portal](https://portal.azure.com) under **Settings** > **Properties** > **Resource ID**. ::: zone pivot="container-apps" + This article assumes that you have already created a [managed environment](../container-apps/environment.md) in Azure Container Apps. You need both the name and the ID of the managed environment to create a function app hosted on Container Apps. ::: zone-end This same workspace can be used for the Application Insights resource defined la ## Create Application Insights -You should be using Application Insights for monitoring your function app executions. Application Insights now requires an Azure Log Analytics workspace, which can be shared. These examples assume you're using an existing workspace and have the fully qualified resource ID for the workspace. For more information, see [Azure Log Analytics workspace](../azure-monitor/logs/log-analytics-overview.md). +You should be using Application Insights for monitoring your function app executions. Application Insights now requires an Azure Log Analytics workspace, which can be shared. These examples assume you're using an existing workspace and have the fully qualified resource ID for the workspace. For more information, see [Azure Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-overview). In this example section, the Application Insights resource is defined with the type `Microsoft.Insights/components` and the kind `web`: |
| azure-functions | Functions Monitoring | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/functions-monitoring.md | -[Azure Functions](functions-overview.md) offers built-in integration with [Azure Application Insights](../azure-monitor/app/app-insights-overview.md) to monitor functions executions. This article provides an overview of the monitoring capabilities provided by Azure for monitoring Azure Functions. +[Azure Functions](functions-overview.md) offers built-in integration with [Azure Application Insights](/azure/azure-monitor/app/app-insights-overview) to monitor functions executions. This article provides an overview of the monitoring capabilities provided by Azure for monitoring Azure Functions. -Application Insights collects log, performance, and error data. By automatically detecting performance anomalies and featuring powerful analytics tools, you can more easily diagnose issues and better understand how your functions are used. These tools are designed to help you continuously improve performance and usability of your functions. You can even use Application Insights during local function app project development. For more information, see [What is Application Insights?](../azure-monitor/app/app-insights-overview.md). +Application Insights collects log, performance, and error data. By automatically detecting performance anomalies and featuring powerful analytics tools, you can more easily diagnose issues and better understand how your functions are used. These tools are designed to help you continuously improve performance and usability of your functions. You can even use Application Insights during local function app project development. For more information, see [What is Application Insights?](/azure/azure-monitor/app/app-insights-overview). As Application Insights instrumentation is built into Azure Functions, you need a valid instrumentation key to connect your function app to an Application Insights resource. The instrumentation key is added to your application settings as you create your function app resource in Azure. If your function app doesn't already have this key, you can [set it manually](configure-monitoring.md#enable-application-insights-integration). You can also monitor the function app itself by using Azure Monitor. To learn mo You can try out Application Insights integration with Azure Functions for free featuring a daily limit to how much data is processed for free. -If you enable Applications Insights during development, you might hit this limit during testing. Azure provides portal and email notifications when you're approaching your daily limit. If you miss those alerts and hit the limit, new logs won't appear in Application Insights queries. Be aware of the limit to avoid unnecessary troubleshooting time. For more information, see [Application Insights billing](../azure-monitor/logs/cost-logs.md#application-insights-billing). +If you enable Applications Insights during development, you might hit this limit during testing. Azure provides portal and email notifications when you're approaching your daily limit. If you miss those alerts and hit the limit, new logs won't appear in Application Insights queries. Be aware of the limit to avoid unnecessary troubleshooting time. For more information, see [Application Insights billing](/azure/azure-monitor/logs/cost-logs#application-insights-billing). > [!IMPORTANT]-> Application Insights has a [sampling](../azure-monitor/app/sampling.md) feature that can protect you from producing too much telemetry data on completed executions at times of peak load. Sampling is enabled by default. If you appear to be missing data, you might need to adjust the sampling settings to fit your particular monitoring scenario. To learn more, see [Configure sampling](configure-monitoring.md#configure-sampling). +> Application Insights has a [sampling](/azure/azure-monitor/app/sampling) feature that can protect you from producing too much telemetry data on completed executions at times of peak load. Sampling is enabled by default. If you appear to be missing data, you might need to adjust the sampling settings to fit your particular monitoring scenario. To learn more, see [Configure sampling](configure-monitoring.md#configure-sampling). -The full list of Application Insights features available to your function app is detailed in [Application Insights for Azure Functions supported features](../azure-monitor/app/azure-functions-supported-features.md). +The full list of Application Insights features available to your function app is detailed in [Application Insights for Azure Functions supported features](/azure/azure-monitor/app/azure-functions-supported-features). ## Application Insights integration Starting with version 2.x of Functions, Application Insights automatically colle + Azure Service Bus + Azure Storage services (Blob, Queue, and Table) -HTTP requests and database calls using `SqlClient` are also captured. For the complete list of dependencies supported by Application Insights, see [automatically tracked dependencies](../azure-monitor/app/asp-net-dependencies.md#automatically-tracked-dependencies). +HTTP requests and database calls using `SqlClient` are also captured. For the complete list of dependencies supported by Application Insights, see [automatically tracked dependencies](/azure/azure-monitor/app/asp-net-dependencies#automatically-tracked-dependencies). Application Insights generates an _application map_ of collected dependency data. The following is an example of an application map of an HTTP trigger function with a Queue storage output binding. There are two ways to view a stream of the log data being generated by your func * **Built-in log streaming**: the App Service platform lets you view a stream of your application log files. This stream is equivalent to the output seen when you debug your functions during [local development](functions-develop-local.md) and when you use the **Test** tab in the portal. All log-based information is displayed. For more information, see [Stream logs](../app-service/troubleshoot-diagnostic-logs.md#stream-logs). This streaming method supports only a single instance, and can't be used with an app running on Linux in a Consumption plan. -* **Live Metrics Stream**: when your function app is [connected to Application Insights](configure-monitoring.md#enable-application-insights-integration), you can view log data and other metrics in near real time in the Azure portal using [Live Metrics Stream](../azure-monitor/app/live-stream.md). Use this method when monitoring functions running on multiple-instances or on Linux in a Consumption plan. This method uses [sampled data](configure-monitoring.md#configure-sampling). +* **Live Metrics Stream**: when your function app is [connected to Application Insights](configure-monitoring.md#enable-application-insights-integration), you can view log data and other metrics in near real time in the Azure portal using [Live Metrics Stream](/azure/azure-monitor/app/live-stream). Use this method when monitoring functions running on multiple-instances or on Linux in a Consumption plan. This method uses [sampled data](configure-monitoring.md#configure-sampling). Log streams can be viewed both in the portal and in most local development environments. To learn how to enable log streams, see [Enable streaming execution logs in Azure Functions](streaming-logs.md). To enable this feature, you add an application setting named `SCALE_CONTROLLER_L ## Azure Monitor metrics -In addition to log-based telemetry data collected by Application Insights, you can also get data about how the function app is running from [Azure Monitor Metrics](../azure-monitor/essentials/data-platform-metrics.md). To learn more, see [Monitoring with Azure Monitor](monitor-functions.md). +In addition to log-based telemetry data collected by Application Insights, you can also get data about how the function app is running from [Azure Monitor Metrics](/azure/azure-monitor/essentials/data-platform-metrics). To learn more, see [Monitoring with Azure Monitor](monitor-functions.md). ## Report issues To report an issue with Application Insights integration in Functions, or to mak For more information, see the following resources: -* [Application Insights](../azure-monitor/app/app-insights-overview.md) +* [Application Insights](/azure/azure-monitor/app/app-insights-overview) * [ASP.NET Core logging](/aspnet/core/fundamentals/logging/) |
| azure-functions | Functions Reference Node | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/functions-reference-node.md | This section describes several impactful patterns for Node.js apps that we recom ### Choose single-vCPU App Service plans -When you create a function app that uses the App Service plan, we recommend that you select a single-vCPU plan rather than a plan with multiple vCPUs. Today, Functions runs Node.js functions more efficiently on single-vCPU VMs, and using larger VMs doesn't produce the expected performance improvements. When necessary, you can manually scale out by adding more single-vCPU VM instances, or you can enable autoscale. For more information, see [Scale instance count manually or automatically](../azure-monitor/autoscale/autoscale-get-started.md?toc=/azure/app-service/toc.json). +When you create a function app that uses the App Service plan, we recommend that you select a single-vCPU plan rather than a plan with multiple vCPUs. Today, Functions runs Node.js functions more efficiently on single-vCPU VMs, and using larger VMs doesn't produce the expected performance improvements. When necessary, you can manually scale out by adding more single-vCPU VM instances, or you can enable autoscale. For more information, see [Scale instance count manually or automatically](/azure/azure-monitor/autoscale/autoscale-get-started?toc=/azure/app-service/toc.json). <a name="cold-start"></a> |
| azure-functions | Functions Reference Python | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/functions-reference-python.md | As an example, the following code demonstrates how to define a Blob Storage inpu "Values": { "FUNCTIONS_WORKER_RUNTIME": "python", "STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",- "AzureWebJobsStorage": "<azure-storage-connection-string>", - "AzureWebJobsFeatureFlags": "EnableWorkerIndexing" + "AzureWebJobsStorage": "<azure-storage-connection-string>" } } ``` def main(req: func.HttpRequest) -> func.HttpResponse: logging.info(f'My app setting value:{my_app_setting_value}') ``` -For local development, application settings are [maintained in the *local.settings.json* file](functions-develop-local.md#local-settings-file). --When you're using the new programming model, enable the following app setting in the *local.settings.json* file, as shown here: --```json -"AzureWebJobsFeatureFlags": "EnableWorkerIndexing" -``` --When you're deploying the function, this setting isn't created automatically. You must explicitly create this setting in your function app in Azure for it to run by using the v2 model. -+For local development, application settings are [maintained in the *local.settings.json* file](functions-develop-local.md#local-settings-file). ::: zone-end ## Python version |
| azure-functions | Security Concepts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/security-concepts.md | As with any application or service, the goal is to run your function app with th Functions supports built-in [Azure role-based access control (Azure RBAC)](../role-based-access-control/overview.md). Azure roles supported by Functions are [Contributor](../role-based-access-control/built-in-roles.md#contributor), [Owner](../role-based-access-control/built-in-roles.md#owner), and [Reader](../role-based-access-control/built-in-roles.md#owner). -Permissions are effective at the function app level. The Contributor role is required to perform most function app-level tasks. You also need the Contributor role along with the [Monitoring Reader permission](../azure-monitor/roles-permissions-security.md#monitoring-reader) to be able to view log data in Application Insights. Only the Owner role can delete a function app. +Permissions are effective at the function app level. The Contributor role is required to perform most function app-level tasks. You also need the Contributor role along with the [Monitoring Reader permission](/azure/azure-monitor/roles-permissions-security#monitoring-reader) to be able to view log data in Application Insights. Only the Owner role can delete a function app. #### Organize functions by privilege |
| azure-functions | Deploy | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/start-stop-vms/deploy.md | The following metric alert properties in the request body support customization: - AutoStop_TimeAggregationOperator - AutoStop_TimeWindow -To learn more about how Azure Monitor metric alerts work and how to configure them see [Metric alerts in Azure Monitor](../../azure-monitor/alerts/alerts-metric-overview.md). +To learn more about how Azure Monitor metric alerts work and how to configure them see [Metric alerts in Azure Monitor](/azure/azure-monitor/alerts/alerts-metric-overview). 1. From the list of Logic apps, to configure auto stop, select **ststv2_vms_AutoStop**. |
| azure-functions | Manage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/start-stop-vms/manage.md | -Start/Stop VMs v2 includes a [dashboard](../../azure-monitor/best-practices-analysis.md#azure-dashboards) to help you understand the management scope and recent operations against your VMs. It is a quick and easy way to verify the status of each operation thatΓÇÖs performed on your Azure VMs. The visualization in each tile is based on a Log query and to see the query, select the **Open in logs blade** option in the right-hand corner of the tile. This opens the [Log Analytics](../../azure-monitor/logs/log-analytics-overview.md#start-log-analytics) tool in the Azure portal, and from here you can evaluate the query and modify to support your needs, such as custom [log alerts](../../azure-monitor/alerts/alerts-log.md), a custom [workbook](../../azure-monitor/visualize/workbooks-overview.md), etc. +Start/Stop VMs v2 includes a [dashboard](/azure/azure-monitor/best-practices-analysis#azure-dashboards) to help you understand the management scope and recent operations against your VMs. It is a quick and easy way to verify the status of each operation thatΓÇÖs performed on your Azure VMs. The visualization in each tile is based on a Log query and to see the query, select the **Open in logs blade** option in the right-hand corner of the tile. This opens the [Log Analytics](/azure/azure-monitor/logs/log-analytics-overview#start-log-analytics) tool in the Azure portal, and from here you can evaluate the query and modify to support your needs, such as custom [log alerts](/azure/azure-monitor/alerts/alerts-log), a custom [workbook](/azure/azure-monitor/visualize/workbooks-overview), etc. The log data each tile in the dashboard displays is refreshed every hour, with a manual refresh option on demand by clicking the **Refresh** icon on a given visualization, or by refreshing the full dashboard. -To learn about working with a log-based dashboard, see the following [tutorial](../../azure-monitor/visualize/tutorial-logs-dashboards.md). +To learn about working with a log-based dashboard, see the following [tutorial](/azure/azure-monitor/visualize/tutorial-logs-dashboards). ## Configure email notifications To change email notifications after Start/Stop VMs v2 is deployed, you can modif :::image type="content" source="media/manage/email-notification-type-example.png" alt-text="Screenshot of the Email/SMS/Push/Voice page showing an example email address updated."::: - To learn more about action groups, see [action groups](../../azure-monitor/alerts/action-groups.md) + To learn more about action groups, see [action groups](/azure/azure-monitor/alerts/action-groups) The following screenshot is an example email that is sent when the feature shuts down virtual machines. |
| azure-functions | Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/start-stop-vms/overview.md | Last updated 09/23/2022 # Start/Stop VMs v2 overview -The Start/Stop VMs v2 feature starts or stops Azure Virtual Machines instances across multiple subscriptions. It starts or stops virtual machines on user-defined schedules, provides insights through [Azure Application Insights](../../azure-monitor/app/app-insights-overview.md), and send optional notifications by using [action groups](../../azure-monitor/alerts/action-groups.md). For most scenarios, Start/Stop VMs can manage virtual machines deployed and managed both by Azure Resource Manager and by Azure Service Manager (classic), which is [deprecated](/azure/virtual-machines/classic-vm-deprecation). +The Start/Stop VMs v2 feature starts or stops Azure Virtual Machines instances across multiple subscriptions. It starts or stops virtual machines on user-defined schedules, provides insights through [Azure Application Insights](/azure/azure-monitor/app/app-insights-overview), and send optional notifications by using [action groups](/azure/azure-monitor/alerts/action-groups). For most scenarios, Start/Stop VMs can manage virtual machines deployed and managed both by Azure Resource Manager and by Azure Service Manager (classic), which is [deprecated](/azure/virtual-machines/classic-vm-deprecation). This new version of Start/Stop VMs v2 provides a decentralized low-cost automation option for customers who want to optimize their VM costs. It offers all of the same functionality as the original version that was available with Azure Automation, but it's designed to take advantage of newer technology in Azure. The Start/Stop VMs v2 relies on multiple Azure services and it will be charged based on the service that are deployed and consumed. |
| azure-functions | Storage Considerations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/storage-considerations.md | You shouldn't apply [lifecycle management policies](../storage/blobs/lifecycle-m Because function code and keys might be persisted in the storage account, logging of activity against the storage account is a good way to monitor for unauthorized access. Azure Monitor resource logs can be used to track events against the storage data plane. See [Monitoring Azure Storage](../storage/blobs/monitor-blob-storage.md) for details on how to configure and examine these logs. -The [Azure Monitor activity log](../azure-monitor/essentials/activity-log.md) shows control plane events, including the [listKeys operation]. However, you should also configure resource logs for the storage account to track subsequent use of keys or other identity-based data plane operations. You should have at least the [StorageWrite log category](../storage/blobs/monitor-blob-storage.md#collection-and-routing) enabled to be able to identify modifications to the data outside of normal Functions operations. +The [Azure Monitor activity log](/azure/azure-monitor/essentials/activity-log) shows control plane events, including the [listKeys operation]. However, you should also configure resource logs for the storage account to track subsequent use of keys or other identity-based data plane operations. You should have at least the [StorageWrite log category](../storage/blobs/monitor-blob-storage.md#collection-and-routing) enabled to be able to identify modifications to the data outside of normal Functions operations. To limit the potential impact of any broadly scoped storage permissions, consider using a nonstorage destination for these logs, such as Log Analytics. For more information, see [Monitoring Azure Blob Storage](../storage/blobs/monitor-blob-storage.md). |
| azure-functions | Streaming Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-functions/streaming-logs.md | There are two ways to view a stream of log files being generated by your functio * **Built-in log streaming**: the App Service platform lets you view a stream of your application log files. This is equivalent to the output seen when you debug your functions during [local development](functions-develop-local.md) and when you use the **Test** tab in the portal. All log-based information is displayed. For more information, see [Stream logs](../app-service/troubleshoot-diagnostic-logs.md#stream-logs). This streaming method supports only a single instance, and can't be used with an app running on Linux in a Consumption plan. When your function is scaled to multiple instances, data from other instances isn't shown using this method. -* **Live Metrics Stream**: when your function app is [connected to Application Insights](configure-monitoring.md#enable-application-insights-integration), you can view log data and other metrics in near real-time in the Azure portal using [Live Metrics Stream](../azure-monitor/app/live-stream.md). Use this method when monitoring functions running on multiple-instances and supports all plan types. This method uses [sampled data](configure-monitoring.md#configure-sampling). +* **Live Metrics Stream**: when your function app is [connected to Application Insights](configure-monitoring.md#enable-application-insights-integration), you can view log data and other metrics in near real-time in the Azure portal using [Live Metrics Stream](/azure/azure-monitor/app/live-stream). Use this method when monitoring functions running on multiple-instances and supports all plan types. This method uses [sampled data](configure-monitoring.md#configure-sampling). Log streams can be viewed both in the portal and in most local development environments. func azure functionapp logstream <FunctionAppName> ``` >[!NOTE] ->Because built-in log streaming isn't yet enabled for function apps running on Linux in a Consumption plan, you need to instead enable the [Live Metrics Stream](../azure-monitor/app/live-stream.md) to view the logs in near-real time. +>Because built-in log streaming isn't yet enabled for function apps running on Linux in a Consumption plan, you need to instead enable the [Live Metrics Stream](/azure/azure-monitor/app/live-stream) to view the logs in near-real time. Use this command to display the Live Metrics Stream in a new browser window. |
| azure-government | Azure Secure Isolation Guidance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-government/azure-secure-isolation-guidance.md | Moreover, all Azure traffic traveling within a region or between regions is [enc > You should review Azure **[best practices for the protection of data in transit](../security/fundamentals/data-encryption-best-practices.md#protect-data-in-transit)** to help ensure that all data in transit is encrypted. For key Azure PaaS storage services (for example, Azure SQL Database, Azure SQL Managed Instance, and Azure Synapse Analytics), data encryption in transit is **[enforced by default](/azure/azure-sql/database/security-overview#transport-layer-security-encryption-in-transit)**. ### Third-party network virtual appliances-Azure provides you with many features to help you achieve your security and isolation goals, including [Microsoft Defender for Cloud](/azure/defender-for-cloud/defender-for-cloud-introduction), [Azure Monitor](../azure-monitor/overview.md), [Azure Firewall](../firewall/overview.md), [VPN Gateway](../vpn-gateway/vpn-gateway-about-vpngateways.md), [network security groups](../virtual-network/network-security-groups-overview.md), [Application Gateway](../application-gateway/overview.md), [Azure DDoS Protection](../ddos-protection/ddos-protection-overview.md), [Network Watcher](../network-watcher/network-watcher-monitoring-overview.md), [Microsoft Sentinel](../sentinel/overview.md), and [Azure Policy](../governance/policy/overview.md). In addition to the built-in capabilities that Azure provides, you can use third-party [network virtual appliances](https://azure.microsoft.com/solutions/network-appliances/) to accommodate your specific network isolation requirements while at the same time applying existing in-house skills. Azure supports many appliances, including offerings from F5, Palo Alto Networks, Cisco, Check Point, Barracuda, Citrix, Fortinet, and many others. Network appliances support network functionality and services in the form of VMs in your virtual networks and deployments. +Azure provides you with many features to help you achieve your security and isolation goals, including [Microsoft Defender for Cloud](/azure/defender-for-cloud/defender-for-cloud-introduction), [Azure Monitor](/azure/azure-monitor/overview), [Azure Firewall](../firewall/overview.md), [VPN Gateway](../vpn-gateway/vpn-gateway-about-vpngateways.md), [network security groups](../virtual-network/network-security-groups-overview.md), [Application Gateway](../application-gateway/overview.md), [Azure DDoS Protection](../ddos-protection/ddos-protection-overview.md), [Network Watcher](../network-watcher/network-watcher-monitoring-overview.md), [Microsoft Sentinel](../sentinel/overview.md), and [Azure Policy](../governance/policy/overview.md). In addition to the built-in capabilities that Azure provides, you can use third-party [network virtual appliances](https://azure.microsoft.com/solutions/network-appliances/) to accommodate your specific network isolation requirements while at the same time applying existing in-house skills. Azure supports many appliances, including offerings from F5, Palo Alto Networks, Cisco, Check Point, Barracuda, Citrix, Fortinet, and many others. Network appliances support network functionality and services in the form of VMs in your virtual networks and deployments. The cumulative effect of network isolation restrictions is that each cloud service acts as though it were on an isolated network where VMs within the cloud service can communicate with one another, identifying one another by their source IP addresses with confidence that no other parties can impersonate their peer VMs. They can also be configured to accept incoming connections from the Internet over specific ports and protocols and to ensure that all network traffic leaving your virtual networks is always encrypted. |
| azure-government | Compare Azure Government Global Azure | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-government/compare-azure-government-global-azure.md | Table below lists API endpoints in Azure vs. Azure Government for accessing and ||Notification Hubs|servicebus.windows.net|servicebus.usgovcloudapi.net|| |**Management and governance**|Azure Automation|azure-automation.net|azure-automation.us|| ||Azure Monitor|mms.microsoft.com|oms.microsoft.us|Log Analytics workspace portal|-|||ods.opinsights.azure.com|ods.opinsights.azure.us|[Data collector API](../azure-monitor/logs/data-collector-api.md)| +|||ods.opinsights.azure.com|ods.opinsights.azure.us|[Data collector API](/azure/azure-monitor/logs/data-collector-api)| |||oms.opinsights.azure.com|oms.opinsights.azure.us|| |||portal.loganalytics.io|portal.loganalytics.us|| |||api.loganalytics.io|api.loganalytics.us|| The following Automation **features aren't currently available** in Azure Govern - Automation analytics solution -### [Azure Advisor](../advisor/index.yml) +### [Azure Advisor](/azure/advisor/) -For feature variations and limitations, see [Azure Advisor in sovereign clouds](../advisor/advisor-sovereign-clouds.md). +For feature variations and limitations, see [Azure Advisor in sovereign clouds](/azure/advisor/advisor-sovereign-clouds). ### [Azure Lighthouse](../lighthouse/index.yml) The following Azure Lighthouse **features aren't currently available** in Azure The following document contains information about Azure Managed Grafana feature availability in Azure Government: [Azure Managed Grafana: Feature availability in sovereign clouds](../managed-grafan?#feature-availability-in-sovereign-clouds). -### [Azure Monitor](../azure-monitor/index.yml) +### [Azure Monitor](/azure/azure-monitor/) Azure Monitor enables the same features in both Azure and Azure Government. The following options are available for previous versions of System Center Opera - Integrating System Center Operations Manager 2016 with Azure Government requires an updated Advisor management pack that is included with Update Rollup 2 or later. - System Center Operations Manager 2012 R2 requires an updated Advisor management pack included with Update Rollup 3 or later. -For more information, see [Connect Operations Manager to Azure Monitor](../azure-monitor/agents/om-agents.md). +For more information, see [Connect Operations Manager to Azure Monitor](/azure/azure-monitor/agents/om-agents). **Frequently asked questions** For more information, see [Connect Operations Manager to Azure Monitor](../azure - Can I switch between Azure and Azure Government workspaces from the Operations Management Suite portal? - No. The portals for Azure and Azure Government are separate and don't share information. -#### [Application Insights](../azure-monitor/app/app-insights-overview.md) +#### [Application Insights](/azure/azure-monitor/app/app-insights-overview) Application Insights (part of Azure Monitor) enables the same features in both Azure and Azure Government. This section describes the supplemental configuration that is required to use Application Insights in Azure Government. -**Visual Studio** ΓÇô In Azure Government, you can enable monitoring on your ASP.NET, ASP.NET Core, Java, and Node.js based applications running on Azure App Service. For more information, see [Application monitoring for Azure App Service overview](../azure-monitor/app/azure-web-apps.md). In Visual Studio, go to Tools|Options|Accounts|Registered Azure Clouds|Add New Azure Cloud and select Azure US Government as the Discovery endpoint. After that, adding an account in File|Account Settings will prompt you for which cloud you want to add from. +**Visual Studio** ΓÇô In Azure Government, you can enable monitoring on your ASP.NET, ASP.NET Core, Java, and Node.js based applications running on Azure App Service. For more information, see [Application monitoring for Azure App Service overview](/azure/azure-monitor/app/azure-web-apps). In Visual Studio, go to Tools|Options|Accounts|Registered Azure Clouds|Add New Azure Cloud and select Azure US Government as the Discovery endpoint. After that, adding an account in File|Account Settings will prompt you for which cloud you want to add from. **SDK endpoint modifications** ΓÇô In order to send data from Application Insights to an Azure Government region, you'll need to modify the default endpoint addresses that are used by the Application Insights SDKs. Each SDK requires slightly different modifications, as described in [Application Insights overriding default endpoints](/previous-versions/azure/azure-monitor/app/create-new-resource#override-default-endpoints). -**Firewall exceptions** ΓÇô Application Insights uses several IP addresses. You might need to know these addresses if the app that you're monitoring is hosted behind a firewall. For more information, see [IP addresses used by Azure Monitor](../azure-monitor/ip-addresses.md) from where you can download Azure Government IP addresses. +**Firewall exceptions** ΓÇô Application Insights uses several IP addresses. You might need to know these addresses if the app that you're monitoring is hosted behind a firewall. For more information, see [IP addresses used by Azure Monitor](/azure/azure-monitor/ip-addresses) from where you can download Azure Government IP addresses. >[!NOTE] >Although these addresses are static, it's possible that we'll need to change them from time to time. All Application Insights traffic represents outbound traffic except for availability monitoring and webhooks, which require inbound firewall rules. |
| azure-government | Azure Services In Fedramp Auditscope | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-government/compliance/azure-services-in-fedramp-auditscope.md | This article provides a detailed list of Azure, Dynamics 365, Microsoft 365, and | Service | FedRAMP High | DoD IL2 | | - |::|:-:|-| [Advisor](../../advisor/index.yml) | ✅ | ✅ | +| [Advisor](/azure/advisor/) | ✅ | ✅ | | [AI Builder](/ai-builder/) | ✅ | ✅ | | [Analysis Services](../../analysis-services/index.yml) | ✅ | ✅ | | [API Management](../../api-management/index.yml) | ✅ | ✅ | This article provides a detailed list of Azure, Dynamics 365, Microsoft 365, and | [Azure Managed Grafana](../../managed-grafana/index.yml) | ✅ | ✅ | | [Azure Marketplace portal](https://azuremarketplace.microsoft.com/) | ✅ | ✅ | | [Azure Maps](../../azure-maps/index.yml) | ✅ | ✅ |-| [Azure Monitor](../../azure-monitor/index.yml) (incl. [Application Insights](../../azure-monitor/app/app-insights-overview.md), [Log Analytics](../../azure-monitor/logs/data-platform-logs.md), and [Application Change Analysis](../../azure-monitor/app/change-analysis.md)) | ✅ | ✅ | +| [Azure Monitor](/azure/azure-monitor/) (incl. [Application Insights](/azure/azure-monitor/app/app-insights-overview), [Log Analytics](/azure/azure-monitor/logs/data-platform-logs), and [Application Change Analysis](/azure/azure-monitor/app/change-analysis)) | ✅ | ✅ | | [Azure NetApp Files](../../azure-netapp-files/index.yml) | ✅ | ✅ | | **Service** | **FedRAMP High** | **DoD IL2** | | [Azure OpenAI](/azure/ai-services/openai/) | ✅ | ✅ | This article provides a detailed list of Azure, Dynamics 365, Microsoft 365, and | [Scheduler](../../scheduler/index.yml) (replaced by [Logic Apps](../../logic-apps/index.yml)) | ✅ | ✅ | | [Service Bus](../../service-bus-messaging/index.yml) | ✅ | ✅ | | [Service Fabric](/azure/service-fabric/) | ✅ | ✅ |-| [Service Health](../../service-health/index.yml) | ✅ | ✅ | +| [Service Health](/azure/service-health/) | ✅ | ✅ | | [SignalR Service](../../azure-signalr/index.yml) | ✅ | ✅ | | **Service** | **FedRAMP High** | **DoD IL2** | | [Site Recovery](../../site-recovery/index.yml) | ✅ | ✅ | This article provides a detailed list of Azure, Dynamics 365, Microsoft 365, and | Service | FedRAMP High | DoD IL2 | DoD IL4 | DoD IL5 | DoD IL6 | | - |::|:-:|:-:|:-:|:-:|-| [Advisor](../../advisor/index.yml) | ✅ | ✅ | ✅ | ✅ | ✅ | +| [Advisor](/azure/advisor/) | ✅ | ✅ | ✅ | ✅ | ✅ | | [AI Builder](/ai-builder/) | ✅ | ✅ | ✅ | ✅| | | [Analysis Services](../../analysis-services/index.yml) | ✅ | ✅ | ✅ | ✅ | | | [API Management](../../api-management/index.yml) | ✅ | ✅ | ✅ | ✅ | ✅ | This article provides a detailed list of Azure, Dynamics 365, Microsoft 365, and | [Azure Kubernetes Service (AKS)](/azure/aks/) | ✅ | ✅ | ✅ | ✅ | ✅ | | [Azure Managed Grafana](../../managed-grafana/index.yml) | ✅ | ✅ | | | | | [Azure Maps](../../azure-maps/index.yml) | ✅ | ✅ | ✅ | ✅ | |-| [Azure Monitor](../../azure-monitor/index.yml) (incl. [Application Insights](../../azure-monitor/app/app-insights-overview.md) and [Log Analytics](../../azure-monitor/logs/data-platform-logs.md)) | ✅ | ✅ | ✅ | ✅ | ✅ | +| [Azure Monitor](/azure/azure-monitor/) (incl. [Application Insights](/azure/azure-monitor/app/app-insights-overview) and [Log Analytics](/azure/azure-monitor/logs/data-platform-logs)) | ✅ | ✅ | ✅ | ✅ | ✅ | | [Azure NetApp Files](../../azure-netapp-files/index.yml) | ✅ | ✅ | ✅ | ✅ | | | [Azure OpenAI](/azure/ai-services/openai/) | ✅ | ✅ | ✅ | ✅ | | | [Azure Policy](../../governance/policy/index.yml) | ✅ | ✅ | ✅ | ✅ | ✅ | This article provides a detailed list of Azure, Dynamics 365, Microsoft 365, and | [Service Bus](../../service-bus-messaging/index.yml) | ✅ | ✅ | ✅ | ✅ | ✅ | | [Service Fabric](/azure/service-fabric/) | ✅ | ✅ | ✅ | ✅ | ✅ | | **Service** | **FedRAMP High** | **DoD IL2** | **DoD IL4** | **DoD IL5** | **DoD IL6** |-| [Service Health](../../service-health/index.yml) | ✅ | ✅ | ✅ | ✅ | | +| [Service Health](/azure/service-health/) | ✅ | ✅ | ✅ | ✅ | | | [SignalR Service](../../azure-signalr/index.yml) | ✅ | ✅ | ✅ | ✅ | ✅ | | [Site Recovery](../../site-recovery/index.yml) | ✅ | ✅ | ✅ | ✅ | | | [SQL Database](/azure/azure-sql/database/sql-database-paas-overview) | ✅ | ✅ | ✅ | ✅ | ✅ | |
| azure-government | Secure Azure Computing Architecture | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-government/compliance/secure-azure-computing-architecture.md | As mentioned earlier, you can build the SACA reference by using a variety of app - There are Azure services that can meet requirements for log analytics, host-based protection, and IDS functionality. It's possible that some services arenΓÇÖt generally available in Microsoft Azure DoD regions. In this case, you might need to use third-party tools if these Azure services canΓÇÖt meet your requirements. Look at the tools you're comfortable with and the feasibility of using Azure native tooling. - We recommend that you use as many Azure native tools as possible. They're built with cloud security in mind and seamlessly integrate with the rest of the Azure platform. Use the Azure native tools in the following list to meet various SCCA requirements: - - [Azure Monitor](../../azure-monitor/overview.md) + - [Azure Monitor](/azure/azure-monitor/overview) - [Microsoft Defender for Cloud](/azure/defender-for-cloud/defender-for-cloud-introduction) - [Network Watcher](../../network-watcher/network-watcher-monitoring-overview.md) - [Azure Key Vault](/azure/key-vault/general/overview) |
| azure-government | Documentation Government Impact Level 5 | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-government/documentation-government-impact-level-5.md | For Management and governance services availability in Azure Government, see [Pr - You can store your managed application definition in a storage account that you provide when you create the application. Doing so allows you to manage its location and access for your regulatory needs, including [storage encryption with customer-managed keys](#storage-encryption-with-key-vault-managed-keys). For more information, see [Bring your own storage](../azure-resource-manager/managed-applications/publish-service-catalog-bring-your-own-storage.md). -### [Azure Monitor](../azure-monitor/index.yml) +### [Azure Monitor](/azure/azure-monitor/) -- By default, all data and saved queries are encrypted at rest using Microsoft-managed keys. Configure encryption at rest of your data in Azure Monitor [using customer-managed keys in Azure Key Vault](../azure-monitor/logs/customer-managed-keys.md).+- By default, all data and saved queries are encrypted at rest using Microsoft-managed keys. Configure encryption at rest of your data in Azure Monitor [using customer-managed keys in Azure Key Vault](/azure/azure-monitor/logs/customer-managed-keys). -#### [Log Analytics](../azure-monitor/logs/data-platform-logs.md) +#### [Log Analytics](/azure/azure-monitor/logs/data-platform-logs) -Log Analytics, which is a feature of Azure Monitor, is intended to be used for monitoring the health and status of services and infrastructure. The monitoring data and logs primarily store [logs and metrics](../azure-monitor/logs/data-security.md#data-retention) that are service generated. When used in this primary capacity, Log Analytics supports Impact Level 5 workloads in Azure Government with no extra configuration required. +Log Analytics, which is a feature of Azure Monitor, is intended to be used for monitoring the health and status of services and infrastructure. The monitoring data and logs primarily store [logs and metrics](/azure/azure-monitor/logs/data-security#data-retention) that are service generated. When used in this primary capacity, Log Analytics supports Impact Level 5 workloads in Azure Government with no extra configuration required. -Log Analytics may also be used to ingest extra customer-provided logs. These logs may include data ingested as part of operating Microsoft Defender for Cloud or Microsoft Sentinel. If the ingested logs or the queries written against these logs are categorized as IL5 data, then you should configure customer-managed keys (CMK) for your Log Analytics workspaces and Application Insights components. Once configured, any data sent to your workspaces or components is encrypted with your Azure Key Vault key. For more information, see [Azure Monitor customer-managed keys](../azure-monitor/logs/customer-managed-keys.md). +Log Analytics may also be used to ingest extra customer-provided logs. These logs may include data ingested as part of operating Microsoft Defender for Cloud or Microsoft Sentinel. If the ingested logs or the queries written against these logs are categorized as IL5 data, then you should configure customer-managed keys (CMK) for your Log Analytics workspaces and Application Insights components. Once configured, any data sent to your workspaces or components is encrypted with your Azure Key Vault key. For more information, see [Azure Monitor customer-managed keys](/azure/azure-monitor/logs/customer-managed-keys). ### [Azure Site Recovery](../site-recovery/index.yml) |
| azure-government | Documentation Government Manage Oms | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-government/documentation-government-manage-oms.md | The first step in integrating your cloud assets with Azure Monitor logs is insta You can connect Azure VMs to Azure Monitor logs directly through the Azure portal. For instructions, see [New ways to enable Azure Monitor logs on your Azure VMs](https://blogs.technet.microsoft.com/momteam/2016/02/10/new-ways-to-enable-log-analytics-oms-on-your-azure-vms/). -You can also connect them programmatically or configure the Azure Monitor virtual machine extension right into your Azure Resource Manager templates. See the instructions for Windows-based machines at [Connect Windows computers to Azure Monitor logs](../azure-monitor/agents/agent-windows.md) and for Linux-based machines at [Connect Linux computers to Azure Monitor logs](../azure-monitor/vm/monitor-virtual-machine.md). +You can also connect them programmatically or configure the Azure Monitor virtual machine extension right into your Azure Resource Manager templates. See the instructions for Windows-based machines at [Connect Windows computers to Azure Monitor logs](/azure/azure-monitor/agents/agent-windows) and for Linux-based machines at [Connect Linux computers to Azure Monitor logs](/azure/azure-monitor/vm/monitor-virtual-machine). ## Onboarding storage accounts and Operations Manager to Azure Monitor logs Azure Monitor logs can also connect to your storage account and/or existing System Center Operations Manager deployments to offer you operations management in hybrid scenarios (across cloud providers or in cloud/on-premises infrastructures). Azure Monitor logs also supports collecting logging information from other monit  <p align="center">Figure 3: Azure Resource Manager templates for Azure VMs with Azure Monitor VM extension</p> -Information about setting up Azure Monitor logs with your existing Operations Manager implementation on-premises can be found in [Connect Operations Manager to Azure Monitor logs](../azure-monitor/agents/om-agents.md). +Information about setting up Azure Monitor logs with your existing Operations Manager implementation on-premises can be found in [Connect Operations Manager to Azure Monitor logs](/azure/azure-monitor/agents/om-agents). ## Applying intelligence through management solutions Now that you have various sources for logging data, you have to make sense of all this data. |
| azure-government | Documentation Government Overview Wwps | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-government/documentation-government-overview-wwps.md | For top secret data, you can deploy Azure Stack Hub, which can operate disconnec Listed below are key enabling technologies and services that you may find helpful when deploying confidential data and workloads on Azure: -- All recommended technologies used for Unclassified data, especially services such as [Virtual Network](../virtual-network/virtual-networks-overview.md) (VNet), [Microsoft Defender for Cloud](/azure/defender-for-cloud/), and [Azure Monitor](../azure-monitor/index.yml).+- All recommended technologies used for Unclassified data, especially services such as [Virtual Network](../virtual-network/virtual-networks-overview.md) (VNet), [Microsoft Defender for Cloud](/azure/defender-for-cloud/), and [Azure Monitor](/azure/azure-monitor/). - Public IP addresses are disabled allowing only traffic through private connections, including [ExpressRoute](../expressroute/index.yml) and [Virtual Private Network (VPN)](../vpn-gateway/index.yml) gateway. - Data encryption is recommended with customer-managed keys (CMK) in [Azure Key Vault](/azure/key-vault/) backed by multi-tenant hardware security modules (HSMs) that have [FIPS 140 validation](/azure/key-vault/keys/about-keys#compliance). - Only services that support [VNet integration](../virtual-network/virtual-network-for-azure-services.md) options are enabled. Azure VNet enables you to place Azure resources in a non-internet routable network, which can then be connected to your on-premises network using VPN technologies. VNet integration gives web apps access to resources in the virtual network. |
| azure-government | Documentation Government Plan Security | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-government/documentation-government-plan-security.md | To assist you with Microsoft Defender for Cloud usage, Microsoft has published e - [How Microsoft Defender for Cloud helps detect attacks against your Linux machines](https://azure.microsoft.com/blog/how-azure-security-center-helps-detect-attacks-against-your-linux-machines/) - [Use Microsoft Defender for Cloud to detect when compromised Linux machines attack](https://azure.microsoft.com/blog/leverage-azure-security-center-to-detect-when-compromised-linux-machines-attack/) -**[Azure Monitor](../azure-monitor/overview.md)** helps you maximize the availability and performance of applications by delivering a comprehensive solution for collecting, analyzing, and acting on telemetry from both cloud and on-premises environments. It helps you understand how your applications are performing, and proactively identifies issues affecting deployed applications and resources they depend on. Azure Monitor integrates the capabilities of [Log Analytics](../azure-monitor/logs/data-platform-logs.md) and [Application Insights](../azure-monitor/app/app-insights-overview.md) that were previously branded as standalone services. +**[Azure Monitor](/azure/azure-monitor/overview)** helps you maximize the availability and performance of applications by delivering a comprehensive solution for collecting, analyzing, and acting on telemetry from both cloud and on-premises environments. It helps you understand how your applications are performing, and proactively identifies issues affecting deployed applications and resources they depend on. Azure Monitor integrates the capabilities of [Log Analytics](/azure/azure-monitor/logs/data-platform-logs) and [Application Insights](/azure/azure-monitor/app/app-insights-overview) that were previously branded as standalone services. Azure Monitor collects data from each of the following tiers: With Azure Monitor, you can get a 360-degree view of your applications, infrastr - **Investigate** threats with AI and hunt suspicious activities at scale, tapping into decades of cybersecurity work at Microsoft. - **Respond** to incidents rapidly with built-in orchestration and automation of common tasks. -**[Azure Advisor](../advisor/advisor-overview.md)** helps you follow best practices to optimize your Azure deployments. It analyzes resource configurations and usage telemetry and then recommends solutions that can help you improve the cost effectiveness, performance, high availability, and security of Azure resources. +**[Azure Advisor](/azure/advisor/advisor-overview)** helps you follow best practices to optimize your Azure deployments. It analyzes resource configurations and usage telemetry and then recommends solutions that can help you improve the cost effectiveness, performance, high availability, and security of Azure resources. ## Next steps |
| azure-large-instances | Faq | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-large-instances/faq.md | We always recommend customers to configure alerts for service health notificatio This monitoring and alerting mechanism is different than traditional mechanisms. It's recommended for customers to set up Service Health alerts to their preferred communication channels for service issues, planned maintenance, or other changes that occur around Azure Large Instances. Not setting this up could cause issues with your Azure Large Instances that might go undetected for a long time and cause downtime if not addressed at the right time. -[Receive activity log alerts on Azure service notifications using Azure portal](./../service-health/alerts-activity-log-service-notifications-portal.md) +[Receive activity log alerts on Azure service notifications using Azure portal](/azure/service-health/alerts-activity-log-service-notifications-portal) ## Based on my business priority, can I request a change in the ΓÇ£PlannedΓÇ¥ maintenance schedule for Azure Large Instances - if I must? Microsoft sends a health notification service for both planned and unplanned events. |
| azure-maps | Tutorial Create Store Locator | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-maps/tutorial-create-store-locator.md | The following screenshot shows the general layout of the Contoso Coffee store lo To maximize the usefulness of this store locator, we include a responsive layout that adjusts when a user's screen width is smaller than 700 pixels wide. A responsive layout makes it easy to use the store locator on a small screen, like on a mobile device. Here's a screenshot showing a sample of the small-screen layout: <a id="create a data-set"></a> If you open the text file in Notepad, it looks similar to the following text: Your workspace folder should now look like the following screenshot: - :::image type="content" source="./media/tutorial-create-store-locator/store-locator-workspace.png" alt-text="Screenshot of the images folder in the Contoso Coffee directory."::: + :::image type="content" source="./media/tutorial-create-store-locator/store-locator-workspace.png" lightbox="./media/tutorial-create-store-locator/store-locator-workspace.png" alt-text="Screenshot of the images folder in the Contoso Coffee directory."::: ## Create the HTML |
| azure-maps | Tutorial Prioritized Routes | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-maps/tutorial-prioritized-routes.md | The following steps show you how to create and display the Map control in a web </html> ``` - Some things to know about the above HTML: + Some things to know about the HTML: * The HTML header includes CSS and JavaScript resource files hosted by the Azure Map Control library.- * The `onload` event in the body of the page calls the `GetMap` function when the body of the page has loaded. + * The `onload` event in the body of the page calls the `GetMap` function when the body of the page finishes loading. * The `GetMap` function contains the inline JavaScript code used to access the Azure Maps API. 3. Next, add the following JavaScript code to the `GetMap` function, just beneath the code added in the last step. This code creates a map control and initializes it using your Azure Maps subscription keys that you provide. Make sure and replace the string `<Your Azure Maps Subscription Key>` with the Azure Maps subscription key that you copied from your Maps account. The following steps show you how to create and display the Map control in a web }); ``` - Some things to know about the above JavaScript: + Some things to know about the JavaScript: * This code is the core of the `GetMap` function, which initializes the Map Control API for your Azure Maps account. * [atlas] is the namespace that contains the Azure Maps API and related visual components. The following steps show you how to create and display the Map control in a web 4. Save the file and open it in your browser. The browser displays a basic map by calling `atlas.Map` using your Azure Maps subscription key. - :::image type="content" source="./media/tutorial-prioritized-routes/basic-map.png" alt-text="A screenshot that shows the most basic map you can make by calling the atlas Map API, using your Azure Maps subscription key."::: + :::image type="content" source="./media/tutorial-prioritized-routes/basic-map.png" lightbox="./media/tutorial-prioritized-routes/basic-map.png" alt-text="A screenshot that shows the most basic map you can make by calling the atlas Map API, using your Azure Maps subscription key."::: ## Render real-time traffic data on a map The following steps show you how to create and display the Map control in a web }); ``` - Some things to know about the above JavaScript: + Some things to know about the JavaScript: * This code implements the Map control's `ready` event handler. The rest of the code in this tutorial is placed inside the `ready` event handler. * In the map `ready` event handler, the traffic flow setting on the map is set to `relative`, which is the speed of the road relative to free-flow. In this tutorial, two routes are calculated on the map. The first route is calcu ``` - Some things to know about the above JavaScript: + Some things to know about the JavaScript: * In the Map control's `ready` event handler, a data source is created to store the route from start to finish. * [Expressions] are used to retrieve the line width and color from properties on the route line feature.- * To ensure that the route line doesn't cover up the road labels, we've passed a second parameter with the value of `'labels'`. + * To ensure that the route line doesn't cover up the road labels, pass a second parameter with the value of `'labels'`. - Next, a symbol layer is created and attached to the data source. This layer specifies how the start and end points are rendered. Expressions have been added to retrieve the icon image and text label information from properties on each point object. To learn more about expressions, see [Data-driven style expressions]. + Next, a symbol layer is created and attached to the data source. This layer specifies how the start and end points are rendered. Expressions are added to retrieve the icon image and text label information from properties on each point object. To learn more about expressions, see [Data-driven style expressions]. 2. Next, set the start point as a fictitious company in Seattle called *Fabrikam*, and the end point as a Microsoft office. In the Map control's `ready` event handler, append the following code. In this tutorial, two routes are calculated on the map. The first route is calcu ``` - About the above JavaScript: + About the JavaScript: * This code creates two [GeoJSON Point objects] to represent start and end points, which are then added to the data source. * The last block of code sets the camera view using the latitude and longitude of the start and end points. This section shows you how to use the Azure Maps Route service to get directions }); ``` - About the above JavaScript: + About the JavaScript: * This code queries the Azure Maps routing service through the [Azure Maps Route Directions API] method. * The route line is then created from the coordinates of each turn and added to the data source. |
| azure-maps | Tutorial Route Location | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-maps/tutorial-route-location.md | The following steps show you how to create and display the Map control in a web </html> ``` - Some things to know about the above HTML: + Some things to know about the HTML: * The HTML header includes CSS and JavaScript resource files hosted by the Azure Map Control library.- * The `onload` event in the body of the page calls the `GetMap` function when the body of the page has loaded. - * The `GetMap` function contains the inline JavaScript code used to access the Azure Maps APIs. It's added in the next step. + * The `onload` event in the body of the page calls the `GetMap` function when the body of the page finishes loading. + * The `GetMap` function contains the inline JavaScript code used to access the Azure Maps APIs. This function is added in the next step. 3. Next, add the following JavaScript code to the `GetMap` function, just beneath the code added in the last step. This code creates a map control and initializes it using your Azure Maps subscription keys that you provide. Make sure and replace the string `<Your Azure Maps Key>` with the Azure Maps primary key that you copied from your Maps account. The following steps show you how to create and display the Map control in a web }); ``` - Some things to know about the above JavaScript: + Some things to know about the JavaScript: * This is the core of the `GetMap` function, which initializes the Map Control API for your Azure Maps account key. * [atlas] is the namespace that contains the Azure Maps API and related visual components. In this tutorial, the route is rendered using a line layer. The start and end po }); ``` - Some things to know about the above JavaScript: + Some things to know about the JavaScript: * This code implements the Map control's `ready` event handler. The rest of the code in this tutorial is placed inside the `ready` event handler. * In the map control's `ready` event handler, a data source is created to store the route from start to end point. * To define how the route line is rendered, a line layer is created and attached to the data source. To ensure that the route line doesn't cover up the road labels, pass a second parameter with the value of `'labels'`. - Next, a symbol layer is created and attached to the data source. This layer specifies how the start and end points are rendered. Expressions have been added to retrieve the icon image and text label information from properties on each point object. To learn more about expressions, see [Data-driven style expressions]. + Next, a symbol layer is created and attached to the data source. This layer specifies how the start and end points are rendered. Expressions were added to retrieve the icon image and text label information from properties on each point object. To learn more about expressions, see [Data-driven style expressions]. 2. Next, set the start point at Microsoft, and the end point at a gas station in Seattle. Start and points are created by appending the following code in the Map control's `ready` event handler: In this tutorial, the route is rendered using a line layer. The start and end po }); ``` - Some things to know about the above JavaScript: + Some things to know about the JavaScript: * This code creates two [GeoJSON Point objects] to represent start and end points, which are then added to the data source. * The last block of code sets the camera view using the latitude and longitude of the start and end points. This section shows you how to use the Azure Maps Route Directions API to get rou }); ``` - Some things to know about the above JavaScript: + Some things to know about the JavaScript: * This code constructs the route from the start to end point. * The `url` queries the Azure Maps Route service API to calculate route directions. |
| azure-monitor | Agent Data Sources | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/agent-data-sources.md | - Title: Log Analytics agent data sources in Azure Monitor -description: Data sources define the log data that Azure Monitor collects from agents and other connected sources. This article describes how Azure Monitor uses data sources, explains how to configure them, and summarizes the different data sources available. --- Previously updated : 10/19/2023-----# Log Analytics agent data sources in Azure Monitor --The data that Azure Monitor collects from virtual machines with the legacy [Log Analytics](./log-analytics-agent.md) agent is defined by the data sources that you configure in the [Log Analytics workspace](../logs/data-platform-logs.md). Each data source creates records of a particular type. Each type has its own set of properties. ----> [!IMPORTANT] -> The data sources described in this article apply only to virtual machines running the Log Analytics agent. --## Summary of data sources --The following table lists the agent data sources that are currently available with the Log Analytics agent. Each agent data source links to an article that provides information for that data source. It also provides information on their method and frequency of collection. --| Data source | Platform | Log Analytics agent | Operations Manager agent | Azure Storage | Operations Manager required? | Operations Manager agent data sent via management group | Collection frequency | -| | | | | | | | | -| [Custom logs](data-sources-custom-logs.md) | Windows |• | | | | | On arrival. | -| [Custom logs](data-sources-custom-logs.md) | Linux |• | | | | | On arrival. | -| [IIS logs](data-sources-iis-logs.md) | Windows |• |• |• | | |Depends on the Log File Rollover setting. | -| [Performance counters](data-sources-performance-counters.md) | Windows |• |• | | | |As scheduled, minimum of 10 seconds. | -| [Performance counters](data-sources-performance-counters.md) | Linux |• | | | | |As scheduled, minimum of 10 seconds. | -| [Syslog](data-sources-syslog.md) | Linux |• | | | | |From Azure Storage is 10 minutes. From agent is on arrival. | -| [Windows Event logs](data-sources-windows-events.md) |Windows |• |• |• | |• | On arrival. | --## Configure data sources --To configure data sources for Log Analytics agents, go to the **Log Analytics workspaces** menu in the Azure portal and select a workspace. Select **Legacy agents management**. Select the tab for the data source you want to configure. Use the links in the preceding table to access documentation for each data source and information on their configuration. --Any configuration is delivered to all agents connected to that workspace. You can't exclude any connected agents from this configuration. ---## Data collection --Data source configurations are delivered to agents that are directly connected to Azure Monitor within a few minutes. The specified data is collected from the agent and delivered directly to Azure Monitor at intervals specific to each data source. See the documentation for each data source for these specifics. --For System Center Operations Manager agents in a connected management group, data source configurations are translated into management packs and delivered to the management group every 5 minutes by default. The agent downloads the management pack like any other and collects the specified data. Depending on the data source, the data will either be sent to a management server, which forwards the data to the Azure Monitor, or the agent will send the data to Azure Monitor without going through the management server. --For more information, see [Data collection in Azure Monitor](../essentials/data-collection.md). You can read about details of connecting Operations Manager and Azure Monitor and modifying the frequency that configuration is delivered at [Configure integration with System Center Operations Manager](./om-agents.md). --If the agent is unable to connect to Azure Monitor or Operations Manager, it will continue to collect data that it will deliver when it establishes a connection. Data can be lost if the amount of data reaches the maximum cache size for the client, or if the agent can't establish a connection within 24 hours. --## Log records --All log data collected by Azure Monitor is stored in the workspace as records. Records collected by different data sources will have their own set of properties and be identified by their **Type** property. See the documentation for each data source and solution for details on each record type. --## Next steps --* Learn about [monitoring solutions](/previous-versions/azure/azure-monitor/insights/solutions) that add functionality to Azure Monitor and also collect data into the workspace. -* Learn about [log queries](../logs/log-query-overview.md) to analyze the data collected from data sources and monitoring solutions. -* Configure [alerts](../alerts/alerts-overview.md) to proactively notify you of critical data collected from data sources and monitoring solutions. |
| azure-monitor | Agent Linux Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/agent-linux-troubleshoot.md | - Title: Troubleshoot Azure Log Analytics Linux Agent | Microsoft Docs -description: Describe the symptoms, causes, and resolution for the most common issues with the Log Analytics agent for Linux in Azure Monitor. ---- Previously updated : 06/02/2024----# Troubleshoot issues with the Log Analytics agent for Linux --This article provides help in troubleshooting errors you might experience with the Log Analytics agent for Linux in Azure Monitor. --> [!CAUTION] -> This article references CentOS, a Linux distribution that is End Of Life (EOL) status. Please consider your use and planning accordingly. For more information, see the [CentOS End Of Life guidance](/azure/virtual-machines/workloads/centos/centos-end-of-life). --## Log Analytics Troubleshooting Tool --The Log Analytics agent for Linux Troubleshooting Tool is a script designed to help find and diagnose issues with the Log Analytics agent. It's automatically included with the agent upon installation. Running the tool should be the first step in diagnosing an issue. --### Use the Troubleshooting Tool --To run the Troubleshooting Tool, paste the following command into a terminal window on a machine with the Log Analytics agent: --`sudo /opt/microsoft/omsagent/bin/troubleshooter` --### Manual installation --The Troubleshooting Tool is automatically included when the Log Analytics agent is installed. If installation fails in any way, you can also install the tool manually: --1. Ensure that the [GNU Project Debugger (GDB)](https://www.gnu.org/software/gdb/) is installed on the machine because the troubleshooter relies on it. -1. Copy the troubleshooter bundle onto your machine: `wget https://raw.github.com/microsoft/OMS-Agent-for-Linux/master/source/code/troubleshooter/omsagent_tst.tar.gz` -1. Unpack the bundle: `tar -xzvf omsagent_tst.tar.gz` -1. Run the manual installation: `sudo ./install_tst` --### Scenarios covered --The Troubleshooting Tool checks the following scenarios: --- The agent is unhealthy; the heartbeat doesn't work properly.-- The agent doesn't start or can't connect to Log Analytics.-- The agent Syslog isn't working.-- The agent has high CPU or memory usage.-- The agent has installation issues.-- The agent custom logs aren't working.-- Agent logs can't be collected.--For more information, see the [Troubleshooting Tool documentation on GitHub](https://github.com/microsoft/OMS-Agent-for-Linux/blob/master/docs/Troubleshooting-Tool.md). -- > [!NOTE] - > Run the Log Collector tool when you experience an issue. Having the logs initially will help our support team troubleshoot your issue faster. --## Purge and reinstall the Linux agent --A clean reinstall of the agent fixes most issues. This task might be the first suggestion from our support team to get the agent into an uncorrupted state. Running the Troubleshooting Tool and Log Collector tool and attempting a clean reinstall helps to solve issues more quickly. --1. Download the purge script: -- `$ wget https://raw.githubusercontent.com/microsoft/OMS-Agent-for-Linux/master/tools/purge_omsagent.sh` -1. Run the purge script (with sudo permissions): -- `$ sudo sh purge_omsagent.sh` --## Important log locations and the Log Collector tool -- File | Path - - | -- - Log Analytics agent for Linux log file | `/var/opt/microsoft/omsagent/<workspace id>/log/omsagent.log` - Log Analytics agent configuration log file | `/var/opt/microsoft/omsconfig/omsconfig.log` -- We recommend that you use the Log Collector tool to retrieve important logs for troubleshooting or before you submit a GitHub issue. For more information about the tool and how to run it, see [OMS Linux Agent Log Collector](https://github.com/Microsoft/OMS-Agent-for-Linux/blob/master/tools/LogCollector/OMS_Linux_Agent_Log_Collector.md). --## Important configuration files -- Category | File location - -- | -- - Syslog | `/etc/syslog-ng/syslog-ng.conf` or `/etc/rsyslog.conf` or `/etc/rsyslog.d/95-omsagent.conf` - Performance, Nagios, Zabbix, Log Analytics output and general agent | `/etc/opt/microsoft/omsagent/<workspace id>/conf/omsagent.conf` - Extra configurations | `/etc/opt/microsoft/omsagent/<workspace id>/conf/omsagent.d/*.conf` -- > [!NOTE] - > Editing configuration files for performance counters and Syslog is overwritten if the collection is configured from the [agent's configuration](../agents/agent-data-sources.md#configure-data-sources) in the Azure portal for your workspace. To disable configuration for all agents, disable collection from **Legacy agents management**. For a single agent, run the following script: -> -> `sudo /opt/microsoft/omsconfig/Scripts/OMS_MetaConfigHelper.py --disable && sudo rm /etc/opt/omi/conf/omsconfig/configuration/Current.mof* /etc/opt/omi/conf/omsconfig/configuration/Pending.mof*` --## Installation error codes --| Error code | Meaning | -| | | -| NOT_DEFINED | Because the necessary dependencies aren't installed, the auoms auditd plug-in won't be installed. Installation of auoms failed. Install package auditd. | -| 2 | Invalid option provided to the shell bundle. Run `sudo sh ./omsagent-*.universal*.sh --help` for usage. | -| 3 | No option provided to the shell bundle. Run `sudo sh ./omsagent-*.universal*.sh --help` for usage. | -| 4 | Invalid package type *or* invalid proxy settings. The omsagent-*rpm*.sh packages can only be installed on RPM-based systems. The omsagent-*deb*.sh packages can only be installed on Debian-based systems. We recommend that you use the universal installer from the [latest release](agent-linux.md#agent-install-package). Also review to verify your proxy settings. | -| 5 | The shell bundle must be executed as root *or* there was a 403 error returned during onboarding. Run your command by using `sudo`. | -| 6 | Invalid package architecture *or* there was a 200 error returned during onboarding. The omsagent-\*x64.sh packages can only be installed on 64-bit systems. The omsagent-\*x86.sh packages can only be installed on 32-bit systems. Download the correct package for your architecture from the [latest release](https://github.com/Microsoft/OMS-Agent-for-Linux/releases/latest). | -| 17 | Installation of OMS package failed. Look through the command output for the root failure. | -| 18 | Installation of OMSConfig package failed. Look through the command output for the root failure. | -| 19 | Installation of OMI package failed. Look through the command output for the root failure. | -| 20 | Installation of SCX package failed. Look through the command output for the root failure. | -| 21 | Installation of Provider kits failed. Look through the command output for the root failure. | -| 22 | Installation of bundled package failed. Look through the command output for the root failure | -| 23 | SCX or OMI package already installed. Use `--upgrade` instead of `--install` to install the shell bundle. | -| 30 | Internal bundle error. File a [GitHub issue](https://github.com/Microsoft/OMS-Agent-for-Linux/issues) with details from the output. | -| 55 | Unsupported openssl version *or* can't connect to Azure Monitor *or* dpkg is locked *or* missing curl program. | -| 61 | Missing Python ctypes library. Install the Python ctypes library or package (python-ctypes). | -| 62 | Missing tar program. Install tar. | -| 63 | Missing sed program. Install sed. | -| 64 | Missing curl program. Install curl. | -| 65 | Missing gpg program. Install gpg. | --## Onboarding error codes --| Error code | Meaning | -| | | -| 2 | Invalid option provided to the omsadmin script. Run `sudo sh /opt/microsoft/omsagent/bin/omsadmin.sh -h` for usage. | -| 3 | Invalid configuration provided to the omsadmin script. Run `sudo sh /opt/microsoft/omsagent/bin/omsadmin.sh -h` for usage. | -| 4 | Invalid proxy provided to the omsadmin script. Verify the proxy and see our [documentation for using an HTTP proxy](./log-analytics-agent.md#firewall-requirements). | -| 5 | 403 HTTP error received from Azure Monitor. See the full output of the omsadmin script for details. | -| 6 | Non-200 HTTP error received from Azure Monitor. See the full output of the omsadmin script for details. | -| 7 | Unable to connect to Azure Monitor. See the full output of the omsadmin script for details. | -| 8 | Error onboarding to Log Analytics workspace. See the full output of the omsadmin script for details. | -| 30 | Internal script error. File a [GitHub issue](https://github.com/Microsoft/OMS-Agent-for-Linux/issues) with details from the output. | -| 31 | Error generating agent ID. File a [GitHub issue](https://github.com/Microsoft/OMS-Agent-for-Linux/issues) with details from the output. | -| 32 | Error generating certificates. See the full output of the omsadmin script for details. | -| 33 | Error generating metaconfiguration for omsconfig. File a [GitHub issue](https://github.com/Microsoft/OMS-Agent-for-Linux/issues) with details from the output. | -| 34 | Metaconfiguration generation script not present. Retry onboarding with `sudo sh /opt/microsoft/omsagent/bin/omsadmin.sh -w <Workspace ID> -s <Workspace Key>`. | --## Enable debug logging --### OMS output plug-in debug -- FluentD allows for plug-in-specific logging levels that allow you to specify different log levels for inputs and outputs. To specify a different log level for OMS output, edit the general agent configuration at `/etc/opt/microsoft/omsagent/<workspace id>/conf/omsagent.conf`. -- In the OMS output plug-in, before the end of the configuration file, change the `log_level` property from `info` to `debug`: --``` -<match oms.** docker.**> - type out_oms - log_level debug - num_threads 5 - buffer_chunk_limit 5m - buffer_type file - buffer_path /var/opt/microsoft/omsagent/<workspace id>/state/out_oms*.buffer - buffer_queue_limit 10 - flush_interval 20s - retry_limit 10 - retry_wait 30s -</match> -``` --Debug logging allows you to see batched uploads to Azure Monitor separated by type, number of data items, and time taken to send. --Here's an example debug-enabled log: --``` -Success sending oms.nagios x 1 in 0.14s -Success sending oms.omi x 4 in 0.52s -Success sending oms.syslog.authpriv.info x 1 in 0.91s -``` --### Verbose output --Instead of using the OMS output plug-in, you can output data items directly to `stdout`, which is visible in the Log Analytics agent for Linux log file. --In the Log Analytics general agent configuration file at `/etc/opt/microsoft/omsagent/<workspace id>/conf/omsagent.conf`, comment out the OMS output plug-in by adding a `#` in front of each line: --``` -#<match oms.** docker.**> -# type out_oms -# log_level info -# num_threads 5 -# buffer_chunk_limit 5m -# buffer_type file -# buffer_path /var/opt/microsoft/omsagent/<workspace id>/state/out_oms*.buffer -# buffer_queue_limit 10 -# flush_interval 20s -# retry_limit 10 -# retry_wait 30s -#</match> -``` --Below the output plug-in, uncomment the following section by removing the `#` in front of each line: --``` -<match **> - type stdout -</match> -``` --## Issue: Unable to connect through proxy to Azure Monitor --### Probable causes --* The proxy specified during onboarding was incorrect. -* The Azure Monitor and Azure Automation service endpoints aren't included in the approved list in your datacenter. --### Resolution --1. Reonboard to Azure Monitor with the Log Analytics agent for Linux by using the following command with the option `-v` enabled. It allows verbose output of the agent connecting through the proxy to Azure Monitor: -`/opt/microsoft/omsagent/bin/omsadmin.sh -w <Workspace ID> -s <Workspace Key> -p <Proxy Conf> -v` --1. Review the section [Update proxy settings](agent-manage.md#update-proxy-settings) to verify you've properly configured the agent to communicate through a proxy server. --1. Double-check that the endpoints outlined in the Azure Monitor [network firewall requirements](./log-analytics-agent.md#firewall-requirements) list are added to an allowlist correctly. If you use Azure Automation, the necessary network configuration steps are also linked above. --## Issue: You receive a 403 error when trying to onboard --### Probable causes --* Date and time are incorrect on the Linux server. -* The workspace ID and workspace key aren't correct. --### Resolution --1. Check the time on your Linux server with the command date. If the time is +/- 15 minutes from the current time, onboarding fails. To correct this situation, update the date and/or time zone of your Linux server. -1. Verify that you've installed the latest version of the Log Analytics agent for Linux. The newest version now notifies you if time skew is causing the onboarding failure. -1. Reonboard by using the correct workspace ID and workspace key in the installation instructions earlier in this article. --## Issue: You see a 500 and 404 error in the log file right after onboarding --This is a known issue that occurs on the first upload of Linux data into a Log Analytics workspace. This issue doesn't affect data being sent or service experience. --## Issue: You see omiagent using 100% CPU --### Probable causes --A regression in nss-pem package [v1.0.3-5.el7](https://pkgs.org/download/nss-pem) caused a severe performance issue. We've been seeing this issue come up a lot in Redhat/CentOS 7.x distributions. To learn more about this issue, see [1667121 Performance regression in libcurl](https://bugzilla.redhat.com/show_bug.cgi?id=1667121). --Performance-related bugs don't happen all the time, and they're difficult to reproduce. If you experience such an issue with omiagent, use the script `omiHighCPUDiagnostics.sh`, which will collect the stack trace of the omiagent when it exceeds a certain threshold. --1. Download the script: <br/> -`wget https://raw.githubusercontent.com/microsoft/OMS-Agent-for-Linux/master/tools/LogCollector/source/omiHighCPUDiagnostics.sh` --1. Run diagnostics for 24 hours with 30% CPU threshold: <br/> -`bash omiHighCPUDiagnostics.sh --runtime-in-min 1440 --cpu-threshold 30` --1. Callstack will be dumped in the omiagent_trace file. If you notice many curl and NSS function calls, follow these resolution steps. --### Resolution --1. Upgrade the nss-pem package to [v1.0.3-5.el7_6.1](https://pkgs.org/download/nss-pem): <br/> -`sudo yum upgrade nss-pem` --1. If nss-pem isn't available for upgrade, which mostly happens on CentOS, downgrade curl to 7.29.0-46. If you run "yum update" by mistake, curl will be upgraded to 7.29.0-51 and the issue will happen again: <br/> -`sudo yum downgrade curl libcurl` --1. Restart OMI: <br/> -`sudo scxadmin -restart` --## Issue: You're not seeing forwarded Syslog messages --### Probable causes --* The configuration applied to the Linux server doesn't allow collection of the sent facilities or log levels. -* Syslog isn't being forwarded correctly to the Linux server. -* The number of messages being forwarded per second is too great for the base configuration of the Log Analytics agent for Linux to handle. --### Resolution --* Verify the configuration in the Log Analytics workspace for Syslog has all the facilities and the correct log levels. Review [configure Syslog collection in the Azure portal](data-sources-syslog.md#configure-syslog-in-the-azure-portal). -* Verify the native Syslog messaging daemons (`rsyslog`, `syslog-ng`) can receive the forwarded messages. -* Check firewall settings on the Syslog server to ensure that messages aren't being blocked. -* Simulate a Syslog message to Log Analytics by using a `logger` command: <br/> - `logger -p local0.err "This is my test message"` --## Issue: You're receiving Errno address already in use in omsagent log file --You see `[error]: unexpected error error_class=Errno::EADDRINUSE error=#<Errno::EADDRINUSE: Address already in use - bind(2) for "127.0.0.1" port 25224>` in omsagent.log. --### Probable causes --This error indicates that the Linux diagnostic extension (LAD) is installed side by side with the Log Analytics Linux VM extension. It's using the same port for Syslog data collection as omsagent. --### Resolution --1. As root, execute the following commands. Note that 25224 is an example, and it's possible that in your environment you see a different port number used by LAD. -- ``` - /opt/microsoft/omsagent/bin/configure_syslog.sh configure LAD 25229 -- sed -i -e 's/25224/25229/' /etc/opt/microsoft/omsagent/LAD/conf/omsagent.d/syslog.conf - ``` -- You then need to edit the correct `rsyslogd` or `syslog_ng` config file and change the LAD-related configuration to write to port 25229. --1. If the VM is running `rsyslogd`, the file to be modified is `/etc/rsyslog.d/95-omsagent.conf` (if it exists, else `/etc/rsyslog`). If the VM is running `syslog_ng`, the file to be modified is `/etc/syslog-ng/syslog-ng.conf`. -1. Restart omsagent `sudo /opt/microsoft/omsagent/bin/service_control restart`. -1. Restart the Syslog service. --## Issue: You're unable to uninstall omsagent using the purge option --### Probable causes --* The Linux diagnostic extension is installed. -* The Linux diagnostic extension was installed and uninstalled, but you still see an error about omsagent being used by mdsd and it can't be removed. --### Resolution --1. Uninstall the Linux diagnostic extension. -1. Remove Linux diagnostic extension files from the machine if they're present in the following location: `/var/lib/waagent/Microsoft.Azure.Diagnostics.LinuxDiagnostic-<version>/` and `/var/opt/microsoft/omsagent/LAD/`. --## Issue: You can't see any Nagios data --### Probable causes --* The omsagent user doesn't have permissions to read from the Nagios log file. -* The Nagios source and filter haven't been uncommented from the omsagent.conf file. --### Resolution --1. Add the omsagent user to read from the Nagios file by following these [instructions](https://github.com/Microsoft/OMS-Agent-for-Linux/blob/master/docs/OMS-Agent-for-Linux.md#nagios-alerts). -1. In the Log Analytics agent for Linux general configuration file at `/etc/opt/microsoft/omsagent/<workspace id>/conf/omsagent.conf`, ensure that *both* the Nagios source and filter are uncommented. -- ``` - <source> - type tail - path /var/log/nagios/nagios.log - format none - tag oms.nagios - </source> -- <filter oms.nagios> - type filter_nagios_log - </filter> - ``` --## Issue: You aren't seeing any Linux data --### Probable causes --* Onboarding to Azure Monitor failed. -* Connection to Azure Monitor is blocked. -* Virtual machine was rebooted. -* OMI package was manually upgraded to a newer version compared to what was installed by the Log Analytics agent for Linux package. -* OMI is frozen, blocking the OMS agent. -* DSC resource logs *class not found* error in `omsconfig.log` log file. -* Log Analytics agent for data is backed up. -* DSC logs *Current configuration doesn't exist. Execute Start-DscConfiguration command with -Path parameter to specify a configuration file and create a current configuration first.* in `omsconfig.log` log file, but no log message exists about `PerformRequiredConfigurationChecks` operations. --### Resolution --1. Install all dependencies like the auditd package. -1. Check if onboarding to Azure Monitor was successful by checking if the following file exists: `/etc/opt/microsoft/omsagent/<workspace id>/conf/omsadmin.conf`. If it wasn't, reonboard by using the omsadmin.sh command-line [instructions](https://github.com/Microsoft/OMS-Agent-for-Linux/blob/master/docs/OMS-Agent-for-Linux.md#onboarding-using-the-command-line). -1. If you're using a proxy, check the preceding proxy troubleshooting steps. -1. In some Azure distribution systems, the omid OMI server daemon doesn't start after the virtual machine is rebooted. If this is the case, you won't see Audit, ChangeTracking, or UpdateManagement solution-related data. The workaround is to manually start the OMI server by running `sudo /opt/omi/bin/service_control restart`. -1. After the OMI package is manually upgraded to a newer version, it must be manually restarted for the Log Analytics agent to continue functioning. This step is required for some distros where the OMI server doesn't automatically start after it's upgraded. Run `sudo /opt/omi/bin/service_control restart` to restart the OMI. -- In some situations, the OMI can become frozen. The OMS agent might enter a blocked state waiting for the OMI, which blocks all data collection. The OMS agent process will be running but there will be no activity, which is evidenced by no new log lines (such as sent heartbeats) present in `omsagent.log`. Restart the OMI with `sudo /opt/omi/bin/service_control restart` to recover the agent. -1. If you see a DSC resource *class not found* error in omsconfig.log, run `sudo /opt/omi/bin/service_control restart`. -1. In some cases, when the Log Analytics agent for Linux can't talk to Azure Monitor, data on the agent is backed up to the full buffer size of 50 MB. The agent should be restarted by running the following command: `/opt/microsoft/omsagent/bin/service_control restart`. -- > [!NOTE] - > This issue is fixed in agent version 1.1.0-28 or later. - > -- * If the `omsconfig.log` log file doesn't indicate that `PerformRequiredConfigurationChecks` operations are running periodically on the system, there might be a problem with the cron job/service. Make sure the cron job exists under `/etc/cron.d/OMSConsistencyInvoker`. If needed, run the following commands to create the cron job: -- ``` - mkdir -p /etc/cron.d/ - echo "*/15 * * * * omsagent /opt/omi/bin/OMSConsistencyInvoker > 2>&1" | sudo tee /etc/cron.d/OMSConsistencyInvoker - ``` -- * Also, make sure the cron service is running. You can use `service cron status` with Debian, Ubuntu, and SUSE or `service crond status` with RHEL, CentOS, and Oracle Linux to check the status of this service. If the service doesn't exist, you can install the binaries and start the service by using the following instructions: -- **Ubuntu/Debian** -- ``` - # To Install the service binaries - sudo apt-get install -y cron - # To start the service - sudo service cron start - ``` -- **SUSE** -- ``` - # To Install the service binaries - sudo zypper in cron -y - # To start the service - sudo systemctl enable cron - sudo systemctl start cron - ``` -- **RHEL/CentOS** -- ``` - # To Install the service binaries - sudo yum install -y crond - # To start the service - sudo service crond start - ``` -- **Oracle Linux** -- ``` - # To Install the service binaries - sudo yum install -y cronie - # To start the service - sudo service crond start - ``` --## Issue: When you configure collection from the portal for Syslog or Linux performance counters, the settings aren't applied --### Probable causes --* The Log Analytics agent for Linux hasn't picked up the latest configuration. -* The changed settings in the portal weren't applied. --### Resolution --**Background:** `omsconfig` is the Log Analytics agent for Linux configuration agent that looks for new portal-side configuration every five minutes. This configuration is then applied to the Log Analytics agent for Linux configuration files located at /etc/opt/microsoft/omsagent/conf/omsagent.conf. --In some cases, the Log Analytics agent for Linux configuration agent might not be able to communicate with the portal configuration service. This scenario results in the latest configuration not being applied. --1. Check that the `omsconfig` agent is installed by running `dpkg --list omsconfig` or `rpm -qi omsconfig`. If it isn't installed, reinstall the latest version of the Log Analytics agent for Linux. --1. Check that the `omsconfig` agent can communicate with Azure Monitor by running the following command: `sudo su omsagent -c 'python /opt/microsoft/omsconfig/Scripts/GetDscConfiguration.py'`. This command returns the configuration that the agent receives from the service, including Syslog settings, Linux performance counters, and custom logs. If this command fails, run the following command: `sudo su omsagent -c 'python /opt/microsoft/omsconfig/Scripts/PerformRequiredConfigurationChecks.py'`. This command forces the omsconfig agent to talk to Azure Monitor and retrieve the latest configuration. --## Issue: You aren't seeing any custom log data --### Probable causes --* Onboarding to Azure Monitor failed. -* The setting **Apply the following configuration to my Linux Servers** hasn't been selected. -* `omsconfig` hasn't picked up the latest custom log configuration from the service. -* The Log Analytics agent for Linux user `omsagent` is unable to access the custom log due to permissions or not being found. You might see the following errors: - * `[DATETIME] [warn]: file not found. Continuing without tailing it.` - * `[DATETIME] [error]: file not accessible by omsagent.` -* Known issue with race condition fixed in Log Analytics agent for Linux version 1.1.0-217. --### Resolution --1. Verify onboarding to Azure Monitor was successful by checking if the following file exists: `/etc/opt/microsoft/omsagent/<workspace id>/conf/omsadmin.conf`. If not, either: -- 1. Reonboard by using the omsadmin.sh command line [instructions](https://github.com/Microsoft/OMS-Agent-for-Linux/blob/master/docs/OMS-Agent-for-Linux.md#onboarding-using-the-command-line). - 1. Under **Advanced Settings** in the Azure portal, ensure that the setting **Apply the following configuration to my Linux Servers** is enabled. --1. Check that the `omsconfig` agent can communicate with Azure Monitor by running the following command: `sudo su omsagent -c 'python /opt/microsoft/omsconfig/Scripts/GetDscConfiguration.py'`. This command returns the configuration that the agent receives from the service, including Syslog settings, Linux performance counters, and custom logs. If this command fails, run the following command: `sudo su omsagent -c 'python /opt/microsoft/omsconfig/Scripts/PerformRequiredConfigurationChecks.py'`. This command forces the `omsconfig` agent to talk to Azure Monitor and retrieve the latest configuration. --**Background:** Instead of the Log Analytics agent for Linux running as a privileged user - `root`, the agent runs as the `omsagent` user. In most cases, explicit permission must be granted to this user for certain files to be read. To grant permission to `omsagent` user, run the following commands: --1. Add the `omsagent` user to the specific group: `sudo usermod -a -G <GROUPNAME> <USERNAME>`. -1. Grant universal read access to the required file: `sudo chmod -R ugo+rx <FILE DIRECTORY>`. --There's a known issue with a race condition with the Log Analytics agent for Linux version earlier than 1.1.0-217. After you update to the latest agent, run the following command to get the latest version of the output plug-in: `sudo cp /etc/opt/microsoft/omsagent/sysconf/omsagent.conf /etc/opt/microsoft/omsagent/<workspace id>/conf/omsagent.conf`. --## Issue: You're trying to reonboard to a new workspace --When you try to reonboard an agent to a new workspace, the Log Analytics agent configuration needs to be cleaned up before reonboarding. To clean up old configuration from the agent, run the shell bundle with `--purge`: --``` -sudo sh ./omsagent-*.universal.x64.sh --purge -``` --Or --``` -sudo sh ./onboard_agent.sh --purge -``` --You can continue to reonboard after you use the `--purge` option. --## Issue: Log Analytics agent extension in the Azure portal is marked with a failed state: Provisioning failed --### Probable causes --* The Log Analytics agent has been removed from the operating system. -* The Log Analytics agent service is down, disabled, or not configured. --### Resolution --1. Remove the extension from the Azure portal. -1. Install the agent by following the [instructions](../vm/monitor-virtual-machine.md). -1. Restart the agent by running the following command: <br/> `sudo /opt/microsoft/omsagent/bin/service_control restart`. -1. Wait several minutes until the provisioning state changes to **Provisioning succeeded**. --## Issue: The Log Analytics agent upgrade on-demand --### Probable causes --The Log Analytics agent packages on the host are outdated. --### Resolution --1. Check for the latest release on [this GitHub page](https://github.com/Microsoft/OMS-Agent-for-Linux/releases/). -1. Download the installation script (1.4.2-124 is an example version): -- ``` - wget https://github.com/Microsoft/OMS-Agent-for-Linux/releases/download/OMSAgent_GA_v1.4.2-124/omsagent-1.4.2-124.universal.x64.sh - ``` --1. Upgrade packages by executing `sudo sh ./omsagent-*.universal.x64.sh --upgrade`. --## Issue: Installation is failing and says Python2 can't support ctypes, even though Python3 is being used --### Probable causes --For this known issue, if the VM's language isn't English, a check will fail when verifying which version of Python is being used. This issue leads to the agent always assuming Python2 is being used and failing if there's no Python2. --### Resolution --Change the VM's environmental language to English: --``` -export LANG=en_US.UTF-8 -``` |
| azure-monitor | Agent Linux | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/agent-linux.md | - Title: Install Log Analytics agent on Linux computers -description: This article describes how to connect Linux computers hosted in other clouds or on-premises to Azure Monitor with the Log Analytics agent for Linux. -- Previously updated : 06/01/2023------# Install the Log Analytics agent on Linux computers --> [!CAUTION] -> This article references CentOS, a Linux distribution that is End Of Life (EOL) status. Please consider your use and planning accordingly. For more information, see the [CentOS End Of Life guidance](/azure/virtual-machines/workloads/centos/centos-end-of-life). -This article provides details on installing the Log Analytics agent on Linux computers hosted in other clouds or on-premises. ---The [installation methods described in this article](#install-the-agent) are: --* Install the agent for Linux by using a wrapper-script hosted on GitHub. We recommend this method to install and upgrade the agent when the computer has connectivity with the internet, either directly or through a proxy server. -* Manually download and install the agent. This step is required when the Linux computer doesn't have access to the internet and will be communicating with Azure Monitor or Azure Automation through the [Log Analytics gateway](./gateway.md). --For more efficient options that you can use for Azure virtual machines, see [Installation options](./log-analytics-agent.md#installation-options). --## Requirements --The following sections outline the requirements for installation. --### Supported operating systems --For a list of Linux distributions supported by the Log Analytics agent, see [Overview of Azure Monitor agents](agents-overview.md#supported-operating-systems). --OpenSSL 1.1.0 is only supported on x86_x64 platforms (64-bit). OpenSSL earlier than 1.x isn't supported on any platform. -->[!NOTE] ->The Log Analytics Linux agent doesn't run in containers. To monitor containers, use the [Container Monitoring solution](/previous-versions/azure/azure-monitor/containers/containers) for Docker hosts or [Container insights](../containers/container-insights-overview.md) for Kubernetes. --Starting with versions released after August 2018, we're making the following changes to our support model: --* Only the server versions are supported, not the client versions. -* Focus support on any of the [Azure Linux Endorsed distros](/azure/virtual-machines/linux/endorsed-distros). There might be some delay between a new distro/version being Azure Linux Endorsed and it being supported for the Log Analytics Linux agent. -* All minor releases are supported for each major version listed. -* Versions that have passed their manufacturer's end-of-support date aren't supported. -* Only support VM images. Containers aren't supported, even those derived from official distro publishers' images. -* New versions of AMI aren't supported. -* Only versions that run OpenSSL 1.x by default are supported. -->[!NOTE] ->If you're using a distro or version that isn't currently supported and doesn't align to our support model, we recommend that you fork this repo. Acknowledge that Microsoft support won't provide assistance with forked agent versions. --### Python requirement --Starting from agent version 1.13.27, the Linux agent will support both Python 2 and 3. We always recommend that you use the latest agent. --If you're using an older version of the agent, you must have the virtual machine use Python 2 by default. If your virtual machine is using a distro that doesn't include Python 2 by default, then you must install it. The following sample commands will install Python 2 on different distros: --- **Red Hat, CentOS, Oracle**:-- ```bash - sudo yum install -y python2 - ``` -- **Ubuntu, Debian**:-- ```bash - sudo apt-get update - sudo apt-get install -y python2 - ``` -- **SUSE**:-- ```bash - sudo zypper install -y python2 - ``` --Again, only if you're using an older version of the agent, the python2 executable must be aliased to *python*. Use the following method to set this alias: --1. Run the following command to remove any existing aliases: -- ```bash - sudo update-alternatives --remove-all python - ``` --1. Run the following command to create the alias: -- ```bash - sudo update-alternatives --install /usr/bin/python python /usr/bin/python2 - ``` --### Supported Linux hardening -The OMS Agent has limited customization and hardening support for Linux. --The following tools are currently supported: -- SELinux (Marketplace images for CentOS and RHEL with their default settings)-- FIPS (Marketplace images for CentOS and RHEL 6/7 with their default settings)--The following tools aren't supported: -- CIS-- SELinux (custom hardening like MLS)--CIS, FIPS, and SELinux hardening support is planned for [Azure Monitor Agent](./azure-monitor-agent-overview.md). Further hardening and customization methods aren't supported or planned for OMS Agent. For instance, OS images like GitHub Enterprise Server, which include customizations such as limitations to user account privileges, aren't supported. --### Agent prerequisites --The following table highlights the packages required for [supported Linux distros](#supported-operating-systems) on which the agent will be installed. --|Required package |Description |Minimum version | -|--||-| -|Glibc | GNU C library | 2.5-12| -|Openssl | OpenSSL libraries | 1.0.x or 1.1.x | -|Curl | cURL web client | 7.15.5 | -|Python | | 2.7 or 3.6-3.11| -|Python-ctypes | | -|PAM | Pluggable authentication modules | | -->[!NOTE] ->Either rsyslog or syslog-ng is required to collect syslog messages. The default syslog daemon on version 5 of Red Hat Enterprise Linux, CentOS, and Oracle Linux version (sysklog) isn't supported for syslog event collection. To collect syslog data from this version of these distributions, the rsyslog daemon should be installed and configured to replace sysklog. --### Network requirements -For the network requirements for the Linux agent, see [Log Analytics agent overview](./log-analytics-agent.md#network-requirements). --### Workspace ID and key --Regardless of the installation method used, you need the workspace ID and key for the Log Analytics workspace that the agent will connect to. Select the workspace from the **Log Analytics workspaces** menu in the Azure portal. Under the **Settings** section, select **Agents**. --->[!NOTE] ->While regenerating the Log Analytics Workspace shared keys is possible, the intention for this is **not** to immediately restrict access to any agents currently using those keys. Agents use the key to generate a certificate that expires after three months. Regenerating the shared keys will only prevent agents from renewing their certificates, not continuing to use those certificates until they expire. --## Agent install package --The Log Analytics agent for Linux is composed of multiple packages. The release file contains the following packages, which are available by running the shell bundle with the `--extract` parameter: --Package | Version | Description | -- | ---omsagent | 1.16.0 | The Log Analytics agent for Linux. -omsconfig | 1.2.0 | Configuration agent for the Log Analytics agent. -omi | 1.7.1 | Open Management Infrastructure (OMI), a lightweight CIM Server. *OMI requires root access to run a cron job necessary for the functioning of the service*. -scx | 1.7.1 | OMI CIM providers for operating system performance metrics. -apache-cimprov | 1.0.1 | Apache HTTP Server performance monitoring provider for OMI. Only installed if Apache HTTP Server is detected. -mysql-cimprov | 1.0.1 | MySQL Server performance monitoring provider for OMI. Only installed if MySQL/MariaDB server is detected. -docker-cimprov | 1.0.0 | Docker provider for OMI. Only installed if Docker is detected. --### Agent installation details ---Installing the Log Analytics agent for Linux packages also applies the following systemwide configuration changes. Uninstalling the omsagent package removes these artifacts. --* A non-privileged user named `omsagent` is created. The daemon runs under this credential. -* A sudoers *include* file is created in `/etc/sudoers.d/omsagent`. This file authorizes `omsagent` to restart the syslog and omsagent daemons. If sudo *include* directives aren't supported in the installed version of sudo, these entries will be written to `/etc/sudoers`. -* The syslog configuration is modified to forward a subset of events to the agent. For more information, see [Configure Syslog data collection](data-sources-syslog.md). --On a monitored Linux computer, the agent is listed as `omsagent`. `omsconfig` is the Log Analytics agent for the Linux configuration agent that looks for new portal-side configuration every 5 minutes. The new and updated configuration is applied to the agent configuration files located at `/etc/opt/microsoft/omsagent/conf/omsagent.conf`. --## Install the agent ---### [Wrapper script](#tab/wrapper-script) --The following steps configure setup of the agent for Log Analytics in Azure and Azure Government cloud. A wrapper script is used for Linux computers that can communicate directly or through a proxy server to download the agent hosted on GitHub and install the agent. --If your Linux computer needs to communicate through a proxy server to Log Analytics, this configuration can be specified on the command line by including `-p [protocol://][user:password@]proxyhost[:port]`. The `protocol` property accepts `http` or `https`. The `proxyhost` property accepts a fully qualified domain name or IP address of the proxy server. --For example: `https://proxy01.contoso.com:30443` --If authentication is required in either case, specify the username and password. For example: `https://user01:password@proxy01.contoso.com:30443` --1. To configure the Linux computer to connect to a Log Analytics workspace, run the following command that provides the workspace ID and primary key. The following command downloads the agent, validates its checksum, and installs it. -- ``` - wget https://raw.githubusercontent.com/Microsoft/OMS-Agent-for-Linux/master/installer/scripts/onboard_agent.sh && sh onboard_agent.sh -w <YOUR WORKSPACE ID> -s <YOUR WORKSPACE PRIMARY KEY> - ``` -- The following command includes the `-p` proxy parameter and example syntax when authentication is required by your proxy server: -- ``` - wget https://raw.githubusercontent.com/Microsoft/OMS-Agent-for-Linux/master/installer/scripts/onboard_agent.sh && sh onboard_agent.sh -p [protocol://]<proxy user>:<proxy password>@<proxyhost>[:port] -w <YOUR WORKSPACE ID> -s <YOUR WORKSPACE PRIMARY KEY> - ``` --1. To configure the Linux computer to connect to a Log Analytics workspace in Azure Government cloud, run the following command that provides the workspace ID and primary key copied earlier. The following command downloads the agent, validates its checksum, and installs it. -- ``` - wget https://raw.githubusercontent.com/Microsoft/OMS-Agent-for-Linux/master/installer/scripts/onboard_agent.sh && sh onboard_agent.sh -w <YOUR WORKSPACE ID> -s <YOUR WORKSPACE PRIMARY KEY> -d opinsights.azure.us - ``` -- The following command includes the `-p` proxy parameter and example syntax when authentication is required by your proxy server: -- ``` - wget https://raw.githubusercontent.com/Microsoft/OMS-Agent-for-Linux/master/installer/scripts/onboard_agent.sh && sh onboard_agent.sh -p [protocol://]<proxy user>:<proxy password>@<proxyhost>[:port] -w <YOUR WORKSPACE ID> -s <YOUR WORKSPACE PRIMARY KEY> -d opinsights.azure.us - ``` -1. Restart the agent by running the following command: -- ``` - sudo /opt/microsoft/omsagent/bin/service_control restart [<workspace id>] - ``` --### [Shell](#tab/shell) --The Log Analytics agent for Linux is provided in a self-extracting and installable shell script bundle. This bundle contains Debian and RPM packages for each of the agent components and can be installed directly or extracted to retrieve the individual packages. One bundle is provided for x64 and one for x86 architectures. --> [!NOTE] -> For Azure VMs, we recommend that you install the agent on them by using the [Azure Log Analytics VM extension](/azure/virtual-machines/extensions/oms-linux) for Linux. --1. [Download](https://github.com/microsoft/OMS-Agent-for-Linux#azure-install-guide) and transfer the appropriate bundle (x64 or x86) to your Linux VM or physical computer by using scp/sftp. --1. Install the bundle by using the `--install` argument. To onboard to a Log Analytics workspace during installation, provide the `-w <WorkspaceID>` and `-s <workspaceKey>` parameters copied earlier. -- >[!NOTE] - > Use the `--upgrade` argument if any dependent packages, such as omi, scx, omsconfig, or their older versions, are installed. This would be the case if the System Center Operations Manager agent for Linux is already installed. -- ``` - sudo sh ./omsagent-*.universal.x64.sh --install -w <workspace id> -s <shared key> --skip-docker-provider-install - ``` -- > [!NOTE] - > The preceding command uses the optional `--skip-docker-provider-install` flag to disable the Container Monitoring data collection because the [Container Monitoring solution](/previous-versions/azure/azure-monitor/containers/containers) is being retired. --1. To configure the Linux agent to install and connect to a Log Analytics workspace through a Log Analytics gateway, run the following command. It provides the proxy, workspace ID, and workspace key parameters. This configuration can be specified on the command line by including `-p [protocol://][user:password@]proxyhost[:port]`. The `proxyhost` property accepts a fully qualified domain name or IP address of the Log Analytics gateway server. -- ``` - sudo sh ./omsagent-*.universal.x64.sh --upgrade -p https://<proxy address>:<proxy port> -w <workspace id> -s <shared key> - ``` -- If authentication is required, specify the username and password. For example: -- ``` - sudo sh ./omsagent-*.universal.x64.sh --upgrade -p https://<proxy user>:<proxy password>@<proxy address>:<proxy port> -w <workspace id> -s <shared key> - ``` --1. To configure the Linux computer to connect to a Log Analytics workspace in Azure Government or Microsoft Azure operated by 21Vianet cloud, run the following command that provides the workspace ID and primary key copied earlier, substituting `opinsights.azure.us` or `opinsights.azure.cn` respectively for the domain name: -- ``` - sudo sh ./omsagent-*.universal.x64.sh --upgrade -w <workspace id> -s <shared key> -d <domain name> - ``` --To install the agent packages and configure the agent to report to a specific Log Analytics workspace at a later time, run: --``` -sudo sh ./omsagent-*.universal.x64.sh --upgrade -``` --To extract the agent packages from the bundle without installing the agent, run: --``` -sudo sh ./omsagent-*.universal.x64.sh --extract -``` -----## Upgrade from a previous release --Upgrading from a previous version, starting with version 1.0.0-47, is supported in each release. Perform the installation with the `--upgrade` parameter to upgrade all components of the agent to the latest version. --> [!NOTE] -> The warning message "docker provider package installation skipped" appears during the upgrade because the `--skip-docker-provider-install` flag is set. If you're installing over an existing `omsagent` installation and want to remove the docker provider, purge the existing installation first. Then install by using the `--skip-docker-provider-install` flag. --## Cache information -Data from the Log Analytics agent for Linux is cached on the local machine at *%STATE_DIR_WS%/out_oms_common*.buffer* before it's sent to Azure Monitor. Custom log data is buffered in *%STATE_DIR_WS%/out_oms_blob*.buffer*. The path might be different for some [solutions and data types](https://github.com/microsoft/OMS-Agent-for-Linux/search?utf8=%E2%9C%93&q=+buffer_path&type=). --The agent attempts to upload every 20 seconds. If it fails, it waits an exponentially increasing length of time until it succeeds. For example, it waits 30 seconds before the second attempt, 60 seconds before the third, 120 seconds, and so on, up to a maximum of 16 minutes between retries until it successfully connects again. The agent retries up to six times for a given chunk of data before discarding and moving to the next one. This process continues until the agent can successfully upload again. For this reason, the data might be buffered up to approximately 30 minutes before it's discarded. --The default cache size is 10 MB but can be modified in the [omsagent.conf file](https://github.com/microsoft/OMS-Agent-for-Linux/blob/e2239a0714ae5ab5feddcc48aa7a4c4f971417d4/installer/conf/omsagent.conf). --## Next steps --- Review [Managing and maintaining the Log Analytics agent for Windows and Linux](agent-manage.md) to learn about how to reconfigure, upgrade, or remove the agent from the virtual machine.-- Review [Troubleshooting the Linux agent](agent-linux-troubleshoot.md) if you encounter issues while you're installing or managing the agent.-- Review [Agent data sources](./agent-data-sources.md) to learn about data source configuration.- |
| azure-monitor | Agent Manage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/agent-manage.md | - Title: Manage the Azure Log Analytics agent -description: This article describes the different management tasks that you'll typically perform during the lifecycle of the Log Analytics Windows or Linux agent deployed on a machine. ---- Previously updated : 07/06/2023----# Manage and maintain the Log Analytics agent for Windows and Linux --After initial deployment of the Log Analytics Windows or Linux agent in Azure Monitor, you might need to reconfigure the agent, upgrade it, or remove it from the computer if it has reached the retirement stage in its lifecycle. You can easily manage these routine maintenance tasks manually or through automation, which reduces both operational error and expenses. ---## Upgrade the agent --Upgrade to the latest release of the Log Analytics agent for Windows and Linux manually or automatically based on your deployment scenario and the environment the VM is running in. --| Environment | Installation method | Upgrade method | -|--|-|-| -| Azure VM | Log Analytics agent VM extension for Windows/Linux | The agent is automatically upgraded [after the VM model changes](/azure/virtual-machines/extensions/features-linux#how-agents-and-extensions-are-updated), unless you configured your Azure Resource Manager template to opt out by setting the property `autoUpgradeMinorVersion` to **false**. Once deployed, however, the extension won't upgrade minor versions unless redeployed, even with this property set to **true**. Only the Linux agent supports automatic update post deployment with `enableAutomaticUpgrade` property (see [Enable Auto-update for the Linux agent](#enable-auto-update-for-the-linux-agent)). Major version upgrade is always manual (see [VirtualMachineExtensionInner.AutoUpgradeMinorVersion Property](/dotnet/api/microsoft.azure.management.compute.fluent.models.virtualmachineextensioninner.autoupgrademinorversion)). | -| Custom Azure VM images | Manual installation of Log Analytics agent for Windows/Linux | Updating VMs to the newest version of the agent must be performed from the command line running the Windows installer package or Linux self-extracting and installable shell script bundle.| -| Non-Azure VMs | Manual installation of Log Analytics agent for Windows/Linux | Updating VMs to the newest version of the agent must be performed from the command line running the Windows installer package or Linux self-extracting and installable shell script bundle. | --### Upgrade the Windows agent --To update the agent on a Windows VM to the latest version not installed by using the Log Analytics VM extension, you either run from the command prompt, script, or other automation solution or use the **MMASetup-\<platform\>.msi Setup Wizard**. --To download the latest version of the Windows agent from your Log Analytics workspace: --1. Sign in to the [Azure portal](https://portal.azure.com). --1. In the Azure portal, select **All services**. In the list of resources, enter **Log Analytics**. As you begin typing, the list filters based on your input. Select **Log Analytics workspaces**. --1. In your list of Log Analytics workspaces, select the workspace. --1. In your Log Analytics workspace, select the **Agents** tile and then select **Windows Servers**. --1. On the **Windows Servers** screen, select the appropriate **Download Windows Agent** version to download depending on the processor architecture of the Windows operating system. -->[!NOTE] ->During the upgrade of the Log Analytics agent for Windows, it doesn't support configuring or reconfiguring a workspace to report to. To configure the agent, follow one of the supported methods listed under [Add or remove a workspace](#add-or-remove-a-workspace). -> --#### Upgrade using the Setup Wizard --1. Sign on to the computer with an account that has administrative rights. --1. Execute **MMASetup-\<platform\>.exe** to start the **Setup Wizard**. --1. On the first page of the **Setup Wizard**, select **Next**. --1. In the **Microsoft Monitoring Agent Setup** dialog, select **I agree** to accept the license agreement. --1. In the **Microsoft Monitoring Agent Setup** dialog, select **Upgrade**. The status page displays the progress of the upgrade. --1. When the **Microsoft Monitoring Agent configuration completed successfully** page appears, select **Finish**. --#### Upgrade from the command line --1. Sign on to the computer with an account that has administrative rights. --1. To extract the agent installation files, run `MMASetup-<platform>.exe /c` from an elevated command prompt, and it will prompt you for the path to extract files to. Alternatively, you can specify the path by passing the arguments `MMASetup-<platform>.exe /c /t:<Full Path>`. --1. Run the following command, where D:\ is the location for the upgrade log file: -- ```dos - setup.exe /qn /l*v D:\logs\AgentUpgrade.log AcceptEndUserLicenseAgreement=1 - ``` --### Upgrade the Linux agent --Upgrade from prior versions (>1.0.0-47) is supported. Performing the installation with the `--upgrade` command will upgrade all components of the agent to the latest version. --Run the following command to upgrade the agent: --`sudo sh ./omsagent-*.universal.x64.sh --upgrade` --### Enable auto-update for the Linux agent --We recommend that you enable [Automatic Extension Upgrade](/azure/virtual-machines/automatic-extension-upgrade) by using these commands to update the agent automatically. --# [PowerShell](#tab/PowerShellLinux) --```powershell -Set-AzVMExtension \ - -ResourceGroupName myResourceGroup \ - -VMName myVM \ - -ExtensionName OmsAgentForLinux \ - -ExtensionType OmsAgentForLinux \ - -Publisher Microsoft.EnterpriseCloud.Monitoring \ - -TypeHandlerVersion latestVersion \ - -ProtectedSettingString '{"workspaceKey":"myWorkspaceKey"}' \ - -SettingString '{"workspaceId":"myWorkspaceId","skipDockerProviderInstall": true}' \ - -EnableAutomaticUpgrade $true -``` --# [Azure CLI](#tab/CLILinux) --```powershell -az vm extension set \ - --resource-group myResourceGroup \ - --vm-name myVM \ - --name OmsAgentForLinux \ - --publisher Microsoft.EnterpriseCloud.Monitoring \ - --protected-settings '{"workspaceKey":"myWorkspaceKey"}' \ - --settings '{"workspaceId":"myWorkspaceId","skipDockerProviderInstall": true}' \ - --version latestVersion \ - --enable-auto-upgrade true -``` ---## Add or remove a workspace --Add or remove a workspace using the Windows agent or the Linux agent. --### Windows agent --The steps in this section are necessary not only when you want to reconfigure the Windows agent to report to a different workspace or remove a workspace from its configuration, but also when you want to configure the agent to report to more than one workspace. (This practice is commonly referred to as multihoming.) Configuring the Windows agent to report to multiple workspaces can only be performed after initial setup of the agent and by using the methods described in this section. --#### Update settings from Control Panel --1. Sign on to the computer with an account that has administrative rights. --1. Open Control Panel. --1. Select **Microsoft Monitoring Agent** and then select the **Azure Log Analytics** tab. --1. If you're removing a workspace, select it and then select **Remove**. Repeat this step for any other workspace you want the agent to stop reporting to. --1. If you're adding a workspace, select **Add**. In the **Add a Log Analytics Workspace** dialog, paste the workspace ID and workspace key (primary key). If the computer should report to a Log Analytics workspace in Azure Government cloud, select **Azure US Government** from the **Azure Cloud** dropdown list. --1. Select **OK** to save your changes. --#### Remove a workspace using PowerShell --```powershell -$workspaceId = "<Your workspace Id>" -$mma = New-Object -ComObject 'AgentConfigManager.MgmtSvcCfg' -$mma.RemoveCloudWorkspace($workspaceId) -$mma.ReloadConfiguration() -``` --#### Add a workspace in Azure commercial using PowerShell --```powershell -$workspaceId = "<Your workspace Id>" -$workspaceKey = "<Your workspace Key>" -$mma = New-Object -ComObject 'AgentConfigManager.MgmtSvcCfg' -$mma.AddCloudWorkspace($workspaceId, $workspaceKey) -$mma.ReloadConfiguration() -``` --#### Add a workspace in Azure for US Government using PowerShell --```powershell -$workspaceId = "<Your workspace Id>" -$workspaceKey = "<Your workspace Key>" -$mma = New-Object -ComObject 'AgentConfigManager.MgmtSvcCfg' -$mma.AddCloudWorkspace($workspaceId, $workspaceKey, 1) -$mma.ReloadConfiguration() -``` -->[!NOTE] ->If you've used the command line or script previously to install or configure the agent, `EnableAzureOperationalInsights` was replaced by `AddCloudWorkspace` and `RemoveCloudWorkspace`. -> --### Linux agent --The following steps demonstrate how to reconfigure the Linux agent if you decide to register it with a different workspace or to remove a workspace from its configuration. --1. To verify the agent is registered to a workspace, run the following command: -- `/opt/microsoft/omsagent/bin/omsadmin.sh -l` -- It should return a status similar to the following example: -- `Primary Workspace: <workspaceId> Status: Onboarded(OMSAgent Running)` -- It's important that the status also shows the agent is running. Otherwise, the following steps to reconfigure the agent won't finish successfully. --1. If the agent is already registered with a workspace, remove the registered workspace by running the following command. Otherwise, if it isn't registered, proceed to the next step. -- `/opt/microsoft/omsagent/bin/omsadmin.sh -X` --1. To register with a different workspace, run the following command: -- `/opt/microsoft/omsagent/bin/omsadmin.sh -w <workspace id> -s <shared key> [-d <top level domain>]` - -1. To verify your changes took effect, run the following command: -- `/opt/microsoft/omsagent/bin/omsadmin.sh -l` -- It should return a status similar to the following example: -- `Primary Workspace: <workspaceId> Status: Onboarded(OMSAgent Running)` --The agent service doesn't need to be restarted for the changes to take effect. --## Update proxy settings --Log Analytics Agent (MMA) doesn't use the system proxy settings. As a result, you have to pass proxy settings while you install MMA. These settings will be stored under MMA configuration (registry) on the VM. To configure the agent to communicate to the service through a proxy server or [Log Analytics gateway](./gateway.md) after deployment, use one of the following methods to complete this task. --### Windows agent --Use a Windows agent. --#### Update settings using Control Panel --1. Sign on to the computer with an account that has administrative rights. --1. Open Control Panel. --1. Select **Microsoft Monitoring Agent** and then select the **Proxy Settings** tab. --1. Select **Use a proxy server** and provide the URL and port number of the proxy server or gateway. If your proxy server or Log Analytics gateway requires authentication, enter the username and password to authenticate and then select **OK**. --#### Update settings using PowerShell --Copy the following sample PowerShell code, update it with information specific to your environment, and save it with a PS1 file name extension. Run the script on each computer that connects directly to the Log Analytics workspace in Azure Monitor. --```powershell -param($ProxyDomainName="https://proxy.contoso.com:30443", $cred=(Get-Credential)) --# First we get the Health Service configuration object. We need to determine if we -#have the right update rollup with the API we need. If not, no need to run the rest of the script. -$healthServiceSettings = New-Object -ComObject 'AgentConfigManager.MgmtSvcCfg' --$proxyMethod = $healthServiceSettings | Get-Member -Name 'SetProxyInfo' --if (!$proxyMethod) -{ - Write-Output 'Health Service proxy API not present, will not update settings.' - return -} --Write-Output "Clearing proxy settings." -$healthServiceSettings.SetProxyInfo('', '', '') --$ProxyUserName = $cred.username --Write-Output "Setting proxy to $ProxyDomainName with proxy username $ProxyUserName." -$healthServiceSettings.SetProxyInfo($ProxyDomainName, $ProxyUserName, $cred.GetNetworkCredential().password) -``` --### Linux agent --Perform the following steps if your Linux computers need to communicate through a proxy server or Log Analytics gateway. The proxy configuration value has the following syntax: `[protocol://][user:password@]proxyhost[:port]`. The `proxyhost` property accepts a fully qualified domain name or IP address of the proxy server. --1. Edit the file `/etc/opt/microsoft/omsagent/proxy.conf` by running the following commands and change the values to your specific settings: -- ``` - proxyconf="https://proxyuser:proxypassword@proxyserver01:30443" - sudo echo $proxyconf >>/etc/opt/microsoft/omsagent/proxy.conf - sudo chown omsagent:omiusers /etc/opt/microsoft/omsagent/proxy.conf - ``` --1. Restart the agent by running the following command: -- ``` - sudo /opt/microsoft/omsagent/bin/service_control restart [<workspace id>] - ``` -- If you see `cURL failed to perform on this base url` in the log, you can try removing `'\n'` in `proxy.conf` EOF to resolve the failure: -- ``` - od -c /etc/opt/microsoft/omsagent/proxy.conf - cat /etc/opt/microsoft/omsagent/proxy.conf | tr -d '\n' > /etc/opt/microsoft/omsagent/proxy2.conf - rm /etc/opt/microsoft/omsagent/proxy.conf - mv /etc/opt/microsoft/omsagent/proxy2.conf /etc/opt/microsoft/omsagent/proxy.conf - sudo chown omsagent:omiusers /etc/opt/microsoft/omsagent/proxy.conf - sudo /opt/microsoft/omsagent/bin/service_control restart [<workspace id>] - ``` --## Uninstall agent --Use one of the following procedures to uninstall the Windows or Linux agent by using the command line or **Setup Wizard**. --### Windows agent --Use the Windows agent. --#### Uninstall from Control Panel --1. Sign on to the computer with an account that has administrative rights. --1. In Control Panel, select **Programs and Features**. --1. In **Programs and Features**, select **Microsoft Monitoring Agent** > **Uninstall** > **Yes**. -->[!NOTE] ->The **Agent Setup Wizard** can also be run by double-clicking `MMASetup-\<platform\>.exe`, which is available for download from a workspace in the Azure portal. --#### Uninstall from the command line --The downloaded file for the agent is a self-contained installation package created with IExpress. The setup program for the agent and supporting files are contained in the package and must be extracted to properly uninstall by using the command line shown in the following example. --1. Sign on to the computer with an account that has administrative rights. --1. To extract the agent installation files, from an elevated command prompt run `extract MMASetup-<platform>.exe` and it will prompt you for the path to extract files to. Alternatively, you can specify the path by passing the arguments `extract MMASetup-<platform>.exe /c:<Path> /t:<Path>`. For more information on the command-line switches supported by IExpress, see [Command-line switches for IExpress](https://www.betaarchive.com/wiki/index.php?title=Microsoft_KB_Archive/197147) and then update the example to suit your needs. --1. At the prompt, enter `%WinDir%\System32\msiexec.exe /x <Path>:\MOMAgent.msi /qb`. --### Linux agent --To remove the agent, run the following command on the Linux computer. The `--purge` argument completely removes the agent and its configuration. -- `wget https://raw.githubusercontent.com/Microsoft/OMS-Agent-for-Linux/master/installer/scripts/onboard_agent.sh && sh onboard_agent.sh --purge` --## Configure agent to report to an Operations Manager management group --Use the Windows agent. --### Windows agent --Perform the following steps to configure the Log Analytics agent for Windows to report to a System Center Operations Manager management group. ---1. Sign on to the computer with an account that has administrative rights. --1. Open Control Panel. --1. Select **Microsoft Monitoring Agent** and then select the **Operations Manager** tab. --1. If your Operations Manager servers have integration with Active Directory, select **Automatically update management group assignments from AD DS**. --1. Select **Add** to open the **Add a Management Group** dialog. --1. In the **Management group name** field, enter the name of your management group. --1. In the **Primary management server** field, enter the computer name of the primary management server. --1. In the **Management server port** field, enter the TCP port number. --1. Under **Agent Action Account**, choose either the local system account or a local domain account. --1. Select **OK** to close the **Add a Management Group** dialog. Then select **OK** to close the **Microsoft Monitoring Agent Properties** dialog. --### Linux agent --Perform the following steps to configure the Log Analytics agent for Linux to report to a System Center Operations Manager management group. ---1. Edit the file `/etc/opt/omi/conf/omiserver.conf`. --1. Ensure that the line beginning with `httpsport=` defines the port 1270, such as, `httpsport=1270`. --1. Restart the OMI server by using the following command: -- `sudo /opt/omi/bin/service_control restart` --## Frequently asked questions --This section provides answers to common questions. --### How do I stop the Log Analytics agent from communicating with Azure Monitor? --For agents connected to Log Analytics directly, open Control Panel and select **Microsoft Monitoring Agent**. Under the **Azure Log Analytics (OMS)** tab, remove all workspaces listed. In System Center Operations Manager, remove the computer from the Log Analytics managed computers list. Operations Manager updates the configuration of the agent to no longer report to Log Analytics. --## Next steps --- Review [Troubleshooting the Linux agent](agent-linux-troubleshoot.md) if you encounter issues while you install or manage the Linux agent.-- Review [Troubleshooting the Windows agent](agent-windows-troubleshoot.md) if you encounter issues while you install or manage the Windows agent. |
| azure-monitor | Agent Windows Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/agent-windows-troubleshoot.md | - Title: Troubleshoot issues with the Log Analytics agent for Windows -description: Describe the symptoms, causes, and resolution for the most common issues with the Log Analytics agent for Windows in Azure Monitor. -- Previously updated : 06/01/2023----# Troubleshoot issues with the Log Analytics agent for Windows --This article provides help in troubleshooting errors you might experience with the Log Analytics agent for Windows in Azure Monitor and suggests possible solutions to resolve them. --## Log Analytics Troubleshooting Tool --The Log Analytics agent for Windows Troubleshooting Tool is a collection of PowerShell scripts designed to help find and diagnose issues with the Log Analytics agent. It's automatically included with the agent upon installation. Running the tool should be the first step in diagnosing an issue. --### Use the Troubleshooting Tool --1. Open the PowerShell prompt as administrator on the machine where the Log Analytics agent is installed. -1. Go to the directory where the tool is located: -- `cd "C:\Program Files\Microsoft Monitoring Agent\Agent\Troubleshooter"` -1. Execute the main script by using this command: -- `.\GetAgentInfo.ps1` -1. Select a troubleshooting scenario. -1. Follow instructions on the console. Note that trace logs steps require manual intervention to stop log collection. Based on the reproducibility of the issue, wait for the time duration and select "s" to stop log collection and proceed to the next step. -- The location of the results file is logged upon completion and a new explorer window highlighting it is opened. --### Installation --The Troubleshooting Tool is automatically included upon installation of the Log Analytics Agent build 10.20.18053.0 and onward. --### Scenarios covered --The Troubleshooting Tool checks the following scenarios: --- The agent isn't reporting data or heartbeat data is missing.-- The agent extension deployment is failing.-- The agent is crashing.-- The agent is consuming high CPU or memory.-- Installation and uninstallation experience failures.-- Custom logs have issues.-- OMS Gateway has issues.-- Performance counters have issues.-- Agent logs can't be collected.-->[!NOTE] ->Run the Troubleshooting Tool when you experience an issue. Having the logs initially will help our support team troubleshoot your issue faster. --## Important troubleshooting sources -- To assist with troubleshooting issues related to the Log Analytics agent for Windows, the agent logs events to the Windows Event Log, specifically under *Application and Services\Operations Manager*. --## Connectivity issues --If the agent is communicating through a proxy server or firewall, restrictions might be in place that prevent communication from the source computer and the Azure Monitor service. If communication is blocked because of misconfiguration, registration with a workspace might fail while attempting to install the agent or configure the agent post-setup to report to another workspace. Agent communication might fail after successful registration. This section describes the methods to troubleshoot this type of issue with the Windows agent. --Double-check that the firewall or proxy is configured to allow the following ports and URLs described in the following table. Also confirm that HTTP inspection isn't enabled for web traffic. It can prevent a secure TLS channel between the agent and Azure Monitor. --|Agent resource|Ports |Direction |Bypass HTTPS inspection| -|||--|--| -|*.ods.opinsights.azure.com |Port 443 |Outbound|Yes | -|*.oms.opinsights.azure.com |Port 443 |Outbound|Yes | -|*.blob.core.windows.net |Port 443 |Outbound|Yes | -|*.agentsvc.azure-automation.net |Port 443 |Outbound|Yes | --For firewall information required for Azure Government, see [Azure Government management](../../azure-government/compare-azure-government-global-azure.md#azure-monitor). If you plan to use the Azure Automation Hybrid Runbook Worker to connect to and register with the Automation service to use runbooks or management solutions in your environment, it must have access to the port number and the URLs described in [Configure your network for the Hybrid Runbook Worker](../../automation/automation-hybrid-runbook-worker.md#network-planning). --There are several ways you can verify if the agent is successfully communicating with Azure Monitor: --- Enable the [Azure Log Analytics Agent Health assessment](../insights/solution-agenthealth.md) in the workspace. From the Agent Health dashboard, view the **Count of unresponsive agents** column to quickly see if the agent is listed.-- Run the following query to confirm the agent is sending a heartbeat to the workspace it's configured to report to. Replace `<ComputerName>` with the actual name of the machine.-- ``` - Heartbeat - | where Computer like "<ComputerName>" - | summarize arg_max(TimeGenerated, * ) by Computer - ``` -- If the computer is successfully communicating with the service, the query should return a result. If the query didn't return a result, first verify the agent is configured to report to the correct workspace. If it's configured correctly, proceed to step 3 and search the Windows Event Log to identify if the agent is logging the issue that might be preventing it from communicating with Azure Monitor. --- Another method to identify a connectivity issue is by running the **TestCloudConnectivity** tool. The tool is installed by default with the agent in the folder *%SystemRoot%\Program Files\Microsoft Monitoring Agent\Agent*. From an elevated command prompt, go to the folder and run the tool. The tool returns the results and highlights where the test failed. For example, perhaps it was related to a particular port or URL that was blocked.-- :::image type="content" source="./media/agent-windows-troubleshoot/output-testcloudconnection-tool-01.png" lightbox="./media/agent-windows-troubleshoot/output-testcloudconnection-tool-01.png" alt-text="Screenshot that shows TestCloudConnection tool execution results."::: --- Filter the *Operations Manager* event log by **Event sources** *Health Service Modules*, *HealthService*, and *Service Connector* and filter by **Event Level** *Warning* and *Error* to confirm if it has written events from the following table. If they are, review the resolution steps included for each possible event.-- |Event ID |Source |Description |Resolution | - ||-||--| - |2133 & 2129 |Health Service |Connection to the service from the agent failed. |This error can occur when the agent can't communicate directly or through a firewall or proxy server to the Azure Monitor service. Verify agent proxy settings or that the network firewall or proxy allows TCP traffic from the computer to the service.| - |2138 |Health Service Modules |Proxy requires authentication. |Configure the agent proxy settings and specify the username/password required to authenticate with the proxy server. | - |2129 |Health Service Modules |Failed connection. Failed TLS negotiation. |Check your network adapter TCP/IP settings and agent proxy settings.| - |2127 |Health Service Modules |Failure sending data received error code. |If it only happens periodically during the day, it could be a random anomaly that can be ignored. Monitor to understand how often it happens. If it happens often throughout the day, first check your network configuration and proxy settings. If the description includes HTTP error code 404 and it's the first time that the agent tries to send data to the service, it will include a 500 error with an inner 404 error code. The 404 error code means "not found," which indicates that the storage area for the new workspace is still being provisioned. On the next retry, data will successfully write to the workspace as expected. An HTTP error 403 might indicate a permission or credentials issue. More information is included with the 403 error to help troubleshoot the issue.| - |4000 |Service Connector |DNS name resolution failed. |The machine couldn't resolve the internet address used when it sent data to the service. This issue might be DNS resolver settings on your machine, incorrect proxy settings, or a temporary DNS issue with your provider. If it happens periodically, it could be caused by a transient network-related issue.| - |4001 |Service Connector |Connection to the service failed. |This error can occur when the agent can't communicate directly or through a firewall or proxy server to the Azure Monitor service. Verify agent proxy settings or that the network firewall or proxy allows TCP traffic from the computer to the service.| - |4002 |Service Connector |The service returned HTTP status code 403 in response to a query. Check with the service administrator for the health of the service. The query will be retried later. |This error is written during the agent's initial registration phase. You'll see a URL similar to *https://\<workspaceID>.oms.opinsights.azure.com/AgentService.svc/AgentTopologyRequest*. A 403 error code means "forbidden" and can be caused by a mistyped Workspace ID or key. The date and time might also be incorrect on the computer. If the time is +/- 15 minutes from current time, onboarding fails. To correct this issue, update the date and/or time of your Windows computer.| --## Data collection issues --After the agent is installed and reports to its configured workspace or workspaces, it might stop receiving configuration and collecting or forwarding performance, logs, or other data to the service depending on what's enabled and targeting the computer. You need to determine: --- Is it a particular data type or all data that's not available in the workspace?-- Is the data type specified by a solution or specified as part of the workspace data collection configuration?-- How many computers are affected? Is it a single computer or multiple computers reporting to the workspace?-- Was it working and did it stop at a particular time of day, or has it never been collected?-- Is the log search query you're using syntactically correct?-- Has the agent ever received its configuration from Azure Monitor?--The first step in troubleshooting is to determine if the computer is sending a heartbeat event. --``` -Heartbeat - | where Computer like "<ComputerName>" - | summarize arg_max(TimeGenerated, * ) by Computer -``` --If the query returns results, you need to determine if a particular data type isn't collected and forwarded to the service. This issue could be caused by the agent not receiving updated configuration from the service or some other symptom that prevents the agent from operating normally. Perform the following steps to further troubleshoot. --1. Open an elevated command prompt on the computer and restart the agent service by entering `net stop healthservice && net start healthservice`. -1. Open the *Operations Manager* event log and search for **event IDs** *7023, 7024, 7025, 7028*, and *1210* from **Event source** *HealthService*. These events indicate the agent is successfully receiving configuration from Azure Monitor and they're actively monitoring the computer. The event description for event ID 1210 will also specify on the last line all of the solutions and Insights that are included in the scope of monitoring on the agent. -- :::image type="content" source="./media/agent-windows-troubleshoot/event-id-1210-healthservice-01.png" lightbox="./media/agent-windows-troubleshoot/event-id-1210-healthservice-01.png" alt-text="Screenshot that shows an Event ID 1210 description."::: --1. Wait several minutes. If you don't see the expected data in the query results or visualization, depending on if you're viewing the data from a solution or Insight, from the *Operations Manager* event log, search for **Event sources** *HealthService* and *Health Service Modules*. Filter by **Event Level** *Warning* and *Error* to confirm if it has written events from the following table. -- |Event ID |Source |Description |Resolution | - ||-||--| - |8000 |HealthService |This event will specify if a workflow related to performance, event, or other data type collected is unable to forward to the service for ingestion to the workspace. | Event ID 2136 from source HealthService is written together with this event and can indicate the agent is unable to communicate with the service. Possible reasons might be misconfiguration of the proxy and authentication settings, network outage, or the network firewall or proxy doesn't allow TCP traffic from the computer to the service.| - |10102 and 10103 |Health Service Modules |Workflow couldn't resolve the data source. |This issue can occur if the specified performance counter or instance doesn't exist on the computer or is incorrectly defined in the workspace data settings. If this is a user-specified [performance counter](data-sources-performance-counters.md#configure-performance-counters), verify the information specified follows the correct format and exists on the target computers. | - |26002 |Health Service Modules |Workflow couldn't resolve the data source. |This issue can occur if the specified Windows event log doesn't exist on the computer. This error can be safely ignored if the computer isn't expected to have this event log registered. Otherwise, if this is a user-specified [event log](data-sources-windows-events.md#configure-windows-event-logs), verify the information specified is correct. | - -## Pinned Certificate Issues with Older Microsoft Monitoring Agents - Breaking Change --*Root CA Change Overview* --As of 30 June 2023, Log Analytics back-end will no longer be accepting connections from MMA that reference an outdate root certificate. These MMAs are older versions prior to the Winter 2020 release (Log Analytics Agent) and prior to SCOM 2019 UR3 (SCOM). Any version, Bundle: 10.20.18053 / Extension: 1.0.18053.0, or greater will not have any issues, as well as any version above SCOM 2019 UR3. Any agent older than that will break and no longer be working and uploading to Log Analytics. --*What exactly is changing?* --As part of an ongoing security effort across various Azure services, Azure Log Analytics will be officially switching from the Baltimore CyberTrust CA Root to the [DigiCert Global G2 CA Root](https://www.digicert.com/kb/digicert-root-certificates.htm). This change will impact TLS communications with Log Analytics if the new DigiCert Global G2 CA Root certificate is missing from the OS, or the application is referencing the old Baltimore Root CA. **What this means is that Log Analytics will no longer accept connections from MMA that use this old root CA after it's retired.** --*Solution products* --You may have received the breaking change notification even if you have not personally installed the Microsoft Monitoring Agent. That is because various Azure products leverage the Microsoft Monitoring Agent. If youΓÇÖre using one of these products, you may be affected as they leverage the Windows Log Analytics Agent. For those products with links below there may be specific instructions that will require you to upgrade to the latest agent. --- VM Insights-- [System Center Operations Manager (SCOM)](/system-center/scom/deploy-upgrade-agents)-- [System Center Service Manager (SCSM)](/system-center/scsm/upgrade-service-manager)-- [Microsoft Defender for Server](/microsoft-365/security/defender-endpoint/update-agent-mma-windows)-- [Microsoft Defender for Endpoint](/microsoft-365/security/defender-endpoint/update-agent-mma-windows)-- Azure Sentinel-- [Azure Automation Agent-based Hybrid Worker](../../automation/automation-windows-hrw-install.md#update-log-analytics-agent-to-latest-version)-- [Azure Automation Change Tracking and Inventory](../../automation/change-tracking/overview.md?tabs=python-2#update-log-analytics-agent-to-latest-version)-- [Azure Automation Update Management](../../automation/update-management/overview.md#update-windows-log-analytics-agent-to-latest-version)---*Identifying and Remidiating Breaking Agents* --For deployments with a limited number of agents, we highly recommend you upgrading your agent per node via [these management instructions](https://aka.ms/MMA-Upgrade). --For deployments with multiple nodes, we've written a script that will detect any affected breaking MMAs per subscription and then subsequently upgrade them to the latest version. These scripts need to be run sequentially, starting with UpdateMMA.ps1 then UpgradeMMA.ps1. Depending on the machine, the script may take a while. PowerShell 7 or greater is needed to run to avoid a timeout. --*UpdateMMA.ps1* -This script will go through VMs in your subscriptions, check for existing MMAs installed and then generate a .csv file of agents that need to be upgraded. --*UpgradeMMA.ps1* -This script will use the .CSV file generated in UpdateMMA.ps1 to upgrade all breaking MMAs. --Both of these scripts may take a while to complete. --# [UpdateMMA](#tab/UpdateMMA) --```powershell -# UpdateMMA.ps1 -# This script is to be run per subscription, the customer has to set the az subscription before running this within the terminal scope. -# This script uses parallel processing, modify the $parallelThrottleLimit parameter to either increase or decrease the number of parallel processes -# PS> .\UpdateMMA.ps1 GetInventory -# The above command will generate a csv file with the details of VM's and VMSS that require MMA upgrade. -# The customer can modify the csv by adding/removing rows if needed -# Update the MMA by running the script again and passing the csv file as parameter as shown below: -# PS> .\UpdateMMA.ps1 Upgrade -# If you don't want to check the inventory, then run the script wiht an additional -no-inventory-check -# PS> .\UpdateMMA.ps1 GetInventory & .\UpdateMMA.ps1 Upgrade ---# This version of the script requires Powershell version >= 7 in order to improve performance via ForEach-Object -Parallel -# https://docs.microsoft.com/powershell/scripting/whats-new/migrating-from-windows-powershell-51-to-powershell-7?view=powershell-7.1 -if ($PSVersionTable.PSVersion.Major -lt 7) -{ - Write-Host "This script requires Powershell version 7 or newer to run. Please see https://docs.microsoft.com/powershell/scripting/whats-new/migrating-from-windows-powershell-51-to-powershell-7?view=powershell-7.1." - exit 1 -} --$parallelThrottleLimit = 16 -$mmaFixVersion = [version]"10.20.18053.0" --function GetVmsWithMMAInstalled -{ - param( - $fileName - ) -- $vmList = az vm list --show-details --query "[?powerState=='VM running'].{ResourceGroup:resourceGroup, VmName:name}" | ConvertFrom-Json - - if(!$vmList) - { - Write-Host "Cannot get the VM list, this script can only detect the running VM's" - return - } -- $vmsCount = $vmList.Length - - $vmParallelThrottleLimit = $parallelThrottleLimit - if ($vmsCount -lt $vmParallelThrottleLimit) - { - $vmParallelThrottleLimit = $vmsCount - } -- if($vmsCount -eq 1) - { - $vmGroups += ,($vmList[0]) - } - else - { - # split the vm's into batches to do parallel processing - for ($i = 0; $i -lt $vmsCount; $i += $vmParallelThrottleLimit) - { - $vmGroups += , ($vmList[$i..($i + $vmParallelThrottleLimit - 1)]) - } - } -- Write-Host "Detected $vmsCount Vm's running in this subscription." - $hash = [hashtable]::Synchronized(@{}) - $hash.One = 1 -- $vmGroups | Foreach-Object -ThrottleLimit $parallelThrottleLimit -Parallel { - $len = $using:vmsCount - $hash = $using:hash - $_ | ForEach-Object { - $percent = 100 * $hash.One++ / $len - Write-Progress -Activity "Getting VM Inventory" -PercentComplete $percent - $vmName = $_.VmName - $resourceGroup = $_.ResourceGroup - $responseJson = az vm run-command invoke --command-id RunPowerShellScript --name $vmName -g $resourceGroup --scripts '@UpgradeMMA.ps1' --parameters "functionName=GetMMAVersion" --output json | ConvertFrom-Json - if($responseJson) - { - $mmaVersion = $responseJson.Value[0].message - if ($mmaVersion) - { - $extensionName = az vm extension list -g $resourceGroup --vm-name $vmName --query "[?name == 'MicrosoftMonitoringAgent'].name" | ConvertFrom-Json - if ($extensionName) - { - $installType = "Extension" - } - else - { - $installType = "Installer" - } - $csvObj = New-Object -TypeName PSObject -Property @{ - 'Name' = $vmName - 'Resource_Group' = $resourceGroup - 'Resource_Type' = "VM" - 'Install_Type' = $installType - 'Version' = $mmaVersion - "Instance_Id" = "" - } - $csvObj | Export-Csv $using:fileName -Append -Force - } - } - } - } -} --function GetVmssWithMMAInstalled -{ - param( - $fileName - ) -- # get the vmss list which are successfully provisioned - $vmssList = az vmss list --query "[?provisioningState=='Succeeded'].{ResourceGroup:resourceGroup, VmssName:name}" | ConvertFrom-Json -- $vmssCount = $vmssList.Length - Write-Host "Detected $vmssCount Vmss running in this subscription." - $hash = [hashtable]::Synchronized(@{}) - $hash.One = 1 -- $vmssList | Foreach-Object -ThrottleLimit $parallelThrottleLimit -Parallel { - $len = $using:vmssCount - $hash = $using:hash - $percent = 100 * $hash.One++ / $len - Write-Progress -Activity "Getting VMSS Inventory" -PercentComplete $percent - $vmssName = $_.VmssName - $resourceGroup = $_.ResourceGroup -- # get running vmss instance ids - $vmssInstanceIds = az vmss list-instances --resource-group $resourceGroup --name $vmssName --expand instanceView --query "[?instanceView.statuses[1].displayStatus=='VM running'].instanceId" | ConvertFrom-Json - if ($vmssInstanceIds.Length -gt 0) - { - $isMMAExtensionInstalled = az vmss extension list -g $resourceGroup --vmss-name $vmssName --query "[?name == 'MicrosoftMonitoringAgent'].name" | ConvertFrom-Json - if ($isMMAExtensionInstalled ) - { - # check an instance in vmss, if it needs an MMA upgrade. Since the extension is installed at VMSS level, checking for bad version in 1 instance should be fine. - $responseJson = az vmss run-command invoke --command-id RunPowerShellScript --name $vmssName -g $resourceGroup --instance-id $vmssInstanceIds[0] --scripts '@UpgradeMMA.ps1' --parameters "functionName=GetMMAVersion" --output json | ConvertFrom-Json - $mmaVersion = $responseJson.Value[0].message - if ($mmaVersion) - { - $csvObj = New-Object -TypeName PSObject -Property @{ - 'Name' = $vmssName - 'Resource_Group' = $resourceGroup - 'Resource_Type' = "VMSS" - 'Install_Type' = "Extension" - 'Version' = $mmaVersion - "Instance_Id" = "" - } - $csvObj | Export-Csv $using:fileName -Append -Force - } - } - else - { - foreach ($instanceId in $vmssInstanceIds) - { - $responseJson = az vmss run-command invoke --command-id RunPowerShellScript --name $vmssName -g $resourceGroup --instance-id $instanceId --scripts '@UpgradeMMA.ps1' --parameters "functionName=GetMMAVersion" --output json | ConvertFrom-Json - $mmaVersion = $responseJson.Value[0].message - if ($mmaVersion) - { - $csvObj = New-Object -TypeName PSObject -Property @{ - 'Name' = $vmssName - 'Resource_Group' = $resourceGroup - 'Resource_Type' = "VMSS" - 'Install_Type' = "Installer" - 'Version' = $mmaVersion - "Instance_Id" = $instanceId - } - $csvObj | Export-Csv $using:fileName -Append -Force - } - } - } - } - } -} --function Upgrade -{ - param( - $fileName = "MMAInventory.csv" - ) - Import-Csv $fileName | ForEach-Object -ThrottleLimit $parallelThrottleLimit -Parallel { - $mmaVersion = [version]$_.Version - if($mmaVersion -lt $using:mmaFixVersion) - { - if ($_.Install_Type -eq "Extension") - { - if ($_.Resource_Type -eq "VMSS") - { - # if the extension is installed with a custom name, provide the name using the flag: --extension-instance-name <extension name> - az vmss extension set --name MicrosoftMonitoringAgent --publisher Microsoft.EnterpriseCloud.Monitoring --force-update --vmss-name $_.Name --resource-group $_.Resource_Group --no-wait --output none - } - else - { - # if the extension is installed with a custom name, provide the name using the flag: --extension-instance-name <extension name> - az vm extension set --name MicrosoftMonitoringAgent --publisher Microsoft.EnterpriseCloud.Monitoring --force-update --vm-name $_.Name --resource-group $_.Resource_Group --no-wait --output none - } - } - else { - if ($_.Resource_Type -eq "VMSS") - { - az vmss run-command invoke --command-id RunPowerShellScript --name $_.Name -g $_.Resource_Group --instance-id $_.Instance_Id --scripts '@UpgradeMMA.ps1' --parameters "functionName=UpgradeMMA" --output none - } - else - { - az vm run-command invoke --command-id RunPowerShellScript --name $_.Name -g $_.Resource_Group --scripts '@UpgradeMMA.ps1' --parameters "functionName=UpgradeMMA" --output none - } - } - } - } -} --function GetInventory -{ - param( - $fileName = "MMAInventory.csv" - ) -- # create a new file - New-Item -Name $fileName -ItemType File -Force - GetVmsWithMMAInstalled $fileName - GetVmssWithMMAInstalled $fileName -} --switch ($args.Count) -{ - 0 { - Write-Host "The arguments provided are incorrect." - Write-Host "To get the Inventory: Run the script as: PS> .\UpdateMMA.ps1 GetInventory" - Write-Host "To update MMA from Inventory: Run the script as: PS> .\UpdateMMA.ps1 Upgrade" - Write-Host "To do the both steps together: PS> .\UpdateMMA.ps1 GetInventory & .\UpdateMMA.ps1 Upgrade" - } - 1 { - $funcname = $args[0] - Invoke-Expression "& $funcname" - } - 2 { - $funcname = $args[0] - $funcargs = $args[1] - Invoke-Expression "& $funcname $funcargs" - } -} -``` --# [UpgradeMMA](#tab/UpgradeMMA) --```powershell -#UpgradeMMA.ps1 --param( - $functionName -) --$mmaLatestVersion32bitDownloadUrl = "https://go.microsoft.com/fwlink/?LinkId=828604" -$mmaLatestVersion64bitDownloadUrl = "https://go.microsoft.com/fwlink/?LinkId=828603" -$mmaName = 'Microsoft Monitoring Agent' -$mmaFixVersion = [version]"10.20.18053.0" -$regPath = 'HKLM:\Software\Microsoft\Windows\CurrentVersion\Uninstall\*' --function GetMMAVersion -{ - $mmaVersion = (Get-ItemProperty $regPath | Where-Object { $_.DisplayName -eq $mmaName }).DisplayVersion - return $mmaVersion -} --function MMAUpgradeRequirementCheck -{ - $mmaVersion = [version](GetMMAVersion) - if ($mmaVersion -and ($mmaVersion -lt $mmaFixVersion)) - { - return $TRUE - } - return $FALSE -} --function GetMMAUpgradeUrl -{ - $osArchitecture = (Get-WmiObject Win32_OperatingSystem).OSArchitecture - if ($osArchitecture -eq "64-bit") - { - $newMMADownloadUrl = $mmaLatestVersion64bitDownloadUrl - } - else - { - $newMMADownloadUrl = $mmaLatestVersion32bitDownloadUrl - } - - return $newMMADownloadUrl -} --function UpgradeMMA -{ - $mmaUpgradeRequired = MMAUpgradeRequirementCheck - if ($mmaUpgradeRequired) - { - $mmaDownloadUrl = GetMMAUpgradeUrl - if ($mmaDownloadUrl) - { - $downloadedFile = "MMASetup.exe" - # Download mma exe files - Invoke-WebRequest "$mmaDownloadUrl" -OutFile $downloadedFile - if(Test-Path $PSScriptRoot\MMA) - { - Remove-Item $PSScriptRoot\MMA -Recurse -Force - } - # Extract MMA exe file - Start-Process -Wait -NoNewWindow -FilePath "$PSScriptRoot\$downloadedFile" -ArgumentList "/c /t:$PSScriptRoot\MMA" - # Run Setup.exe - Start-Process -Wait -NoNewWindow -FilePath "MMA\Setup.exe" -ArgumentList "/qn /l*v AgentUpgrade.log AcceptEndUserLicenseAgreement=1" - } - } -} --if ($functionName -eq "GetMMAVersion") -{ - GetMMAVersion -} -elseif ($functionName -eq "UpgradeMMA" ) -{ - UpgradeMMA -} -else -{ - return "Wrong parameters" -} -``` |
| azure-monitor | Agent Windows | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/agent-windows.md | - Title: Install Log Analytics agent on Windows computers -description: This article describes how to connect Windows computers hosted in other clouds or on-premises to Azure Monitor with the Log Analytics agent for Windows. - Previously updated : 06/01/2023------# Install Log Analytics agent on Windows computers --This article provides information on how to install the Log Analytics agent on Windows computers by using the following methods: --* Manual installation using the setup wizard or command line. -* Azure Automation Desired State Configuration (DSC). --The installation methods described in this article are typically used for virtual machines on-premises or in other clouds. For more efficient options that you can use for Azure virtual machines, see [Installation options](./log-analytics-agent.md#installation-options). ---> [!NOTE] -> Installing the Log Analytics agent typically won't require you to restart the machine. --## Requirements --### Supported operating systems --For a list of Windows versions supported by the Log Analytics agent, see [Overview of Azure Monitor agents](agents-overview.md#supported-operating-systems). --### SHA-2 code signing support requirement --The Windows agent began to exclusively use SHA-2 signing on August 17, 2020. This change affected customers using the Log Analytics agent on a legacy OS as part of any Azure service, such as Azure Monitor, Azure Automation, Azure Update Management, Azure Change Tracking, Microsoft Defender for Cloud, Microsoft Sentinel, and Windows Defender Advanced Threat Protection. --The change doesn't require any customer action unless you're running the agent on a legacy OS version, such as Windows 7, Windows Server 2008 R2, and Windows Server 2008. Customers running on a legacy OS version were required to take the following actions on their machines before August 17, 2020, or their agents stopped sending data to their Log Analytics workspaces: --1. Install the latest service pack for your OS. The required service pack versions are: -- - Windows 7 SP1 - - Windows Server 2008 SP2 - - Windows Server 2008 R2 SP1 --1. Install the SHA-2 signing Windows updates for your OS as described in [2019 SHA-2 code signing support requirement for Windows and WSUS](https://support.microsoft.com/help/4472027/2019-sha-2-code-signing-support-requirement-for-windows-and-wsus). -1. Update to the latest version of the Windows agent (version 10.20.18067). -1. We recommend that you configure the agent to [use TLS 1.2](agent-windows.md#configure-agent-to-use-tls-12). --### Network requirements -See [Log Analytics agent overview](./log-analytics-agent.md#network-requirements) for the network requirements for the Windows agent. - -### Configure Agent to use TLS 1.2 -[TLS 1.2](/windows-server/security/tls/tls-registry-settings#tls-12) protocol ensures the security of data in transit for communication between the Windows agent and the Log Analytics service. If you're installing on an [operating system without TLS enabled by default](../logs/data-security.md#sending-data-securely-using-tls), then you should configure TLS 1.2 using the steps below. --1. Locate the following registry subkey: **HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols**. -1. Create a subkey under **Protocols** for TLS 1.2: **HKLM\System\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.2**. -1. Create a **Client** subkey under the TLS 1.2 protocol version subkey you created earlier. For example, **HKLM\System\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.2\Client**. -1. Create the following DWORD values under **HKLM\System\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.2\Client**: -- * **Enabled** [Value = 1] - * **DisabledByDefault** [Value = 0] --Configure .NET Framework 4.6 or later to support secure cryptography because by default it's disabled. The [strong cryptography](/dotnet/framework/network-programming/tls#schusestrongcrypto) uses more secure network protocols like TLS 1.2 and blocks protocols that aren't secure. --1. Locate the following registry subkey: **HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\\.NETFramework\v4.0.30319**. -1. Create the DWORD value **SchUseStrongCrypto** under this subkey with a value of **1**. -1. Locate the following registry subkey: **HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Microsoft\\.NETFramework\v4.0.30319**. -1. Create the DWORD value **SchUseStrongCrypto** under this subkey with a value of **1**. -1. Restart the system for the settings to take effect. --### Workspace ID and key --Regardless of the installation method used, you'll require the workspace ID and key for the Log Analytics workspace that the agent will connect to. Select the workspace from the **Log Analytics workspaces** menu in the Azure portal. Then in the **Settings** section, select **Agents**. ---> [!NOTE] -> You can't configure the agent to report to more than one workspace during initial setup. [Add or remove a workspace](agent-manage.md#add-or-remove-a-workspace) after installation by updating the settings from Control Panel or PowerShell. -->[!NOTE] ->While regenerating the Log Analytics Workspace shared keys is possible, the intention for this is **not** to immediately restrict access to any agents currently using those keys. Agents use the key to generate a certificate that expires after three months. Regenerating the shared keys will only prevent agents from renewing their certificates, not continuing to use those certificates until they expire. --## Install the agent ---### [Setup wizard](#tab/setup-wizard) --The following steps install and configure the Log Analytics agent in Azure and Azure Government cloud by using the setup wizard for the agent on your computer. If you want to learn how to configure the agent to also report to a System Center Operations Manager management group, see [deploy the Operations Manager agent with the Agent Setup Wizard](/system-center/scom/manage-deploy-windows-agent-manually#to-deploy-the-operations-manager-agent-with-the-agent-setup-wizard). --1. In your Log Analytics workspace, from the **Windows Servers** page you navigated to earlier, select the appropriate **Download Windows Agent** version to download depending on the processor architecture of the Windows operating system. -2. Run Setup to install the agent on your computer. -2. On the **Welcome** page, click **Next**. -3. On the **License Terms** page, read the license and then click **I Agree**. -4. On the **Destination Folder** page, change or keep the default installation folder and then click **Next**. -5. On the **Agent Setup Options** page, choose to connect the agent to Azure Log Analytics and then click **Next**. -6. On the **Azure Log Analytics** page, perform the following: - 1. Paste the **Workspace ID** and **Workspace Key (Primary Key)** that you copied earlier. If the computer should report to a Log Analytics workspace in Azure Government cloud, select **Azure US Government** from the **Azure Cloud** drop-down list. - 2. If the computer needs to communicate through a proxy server to the Log Analytics service, click **Advanced** and provide the URL and port number of the proxy server. If your proxy server requires authentication, type the username and password to authenticate with the proxy server and then click **Next**. -7. Click **Next** once you have completed providing the necessary configuration settings. - <!-- convertborder later --> - :::image type="content" source="media/agent-windows/log-analytics-mma-setup-laworkspace.png" lightbox="media/agent-windows/log-analytics-mma-setup-laworkspace.png" alt-text="paste Workspace ID and Primary Key" border="false":::<br><br> -8. On the **Ready to Install** page, review your choices and then click **Install**. -9. On the **Configuration completed successfully** page, click **Finish**. --When complete, the **Microsoft Monitoring Agent** appears in **Control Panel**. To confirm it is reporting to Log Analytics, review [Verify agent connectivity to Log Analytics](#verify-agent-connectivity-to-azure-monitor). --### [Command Line](#tab/command-line) --The downloaded file for the agent is a self-contained installation package. The setup program for the agent and supporting files are contained in the package and need to be extracted in order to properly install using the command line shown in the following examples. -->[!NOTE] ->If you want to upgrade an agent, you need to use the Log Analytics scripting API. For more information, see [Managing and maintaining the Log Analytics agent for Windows and Linux](agent-manage.md). --The following table highlights the specific parameters supported by setup for the agent, including when deployed by using Automation DSC. --|MMA-specific options |Notes | -||--| -| NOAPM=1 | Optional parameter. Installs the agent without .NET Application Performance Monitoring.| -|ADD_OPINSIGHTS_WORKSPACE | 1 = Configure the agent to report to a workspace. | -|OPINSIGHTS_WORKSPACE_ID | Workspace ID (guid) for the workspace to add. | -|OPINSIGHTS_WORKSPACE_KEY | Workspace key used to initially authenticate with the workspace. | -|OPINSIGHTS_WORKSPACE_AZURE_CLOUD_TYPE | Specify the cloud environment where the workspace is located. <br> 0 = Azure commercial cloud (default). <br> 1 = Azure Government. <br> 2 = Azure operated by 21Vianet cloud. | -|OPINSIGHTS_PROXY_URL | URI for the proxy to use. Example: OPINSIGHTS_PROXY_URL=IPAddress:Port or OPINSIGHTS_PROXY_URL=FQDN:Port | -|OPINSIGHTS_PROXY_USERNAME | Username to access an authenticated proxy. | -|OPINSIGHTS_PROXY_PASSWORD | Password to access an authenticated proxy. | --1. To extract the agent installation files, from an elevated command prompt, run `MMASetup-<platform>.exe /c`. You're prompted for the path to extract files to. Alternatively, you can specify the path by passing the arguments `MMASetup-<platform>.exe /c /t:<Full Path>`. -1. To silently install the agent and configure it to report to a workspace in Azure commercial cloud, from the folder you extracted the setup files to, enter: -- ```shell - setup.exe /qn NOAPM=1 ADD_OPINSIGHTS_WORKSPACE=1 OPINSIGHTS_WORKSPACE_AZURE_CLOUD_TYPE=0 OPINSIGHTS_WORKSPACE_ID="<your workspace ID>" OPINSIGHTS_WORKSPACE_KEY="<your workspace key>" AcceptEndUserLicenseAgreement=1 - ``` -- Or to configure the agent to report to Azure US Government cloud, enter: -- ```shell - setup.exe /qn NOAPM=1 ADD_OPINSIGHTS_WORKSPACE=1 OPINSIGHTS_WORKSPACE_AZURE_CLOUD_TYPE=1 OPINSIGHTS_WORKSPACE_ID="<your workspace ID>" OPINSIGHTS_WORKSPACE_KEY="<your workspace key>" AcceptEndUserLicenseAgreement=1 - ``` - - Or to configure the agent to report to Microsoft Azure operated by 21Vianet cloud, enter: -- ```shell - setup.exe /qn NOAPM=1 ADD_OPINSIGHTS_WORKSPACE=1 OPINSIGHTS_WORKSPACE_AZURE_CLOUD_TYPE=2 OPINSIGHTS_WORKSPACE_ID="<your workspace ID>" OPINSIGHTS_WORKSPACE_KEY="<your workspace key>" AcceptEndUserLicenseAgreement=1 - ``` -- >[!NOTE] - >The string values for the parameters *OPINSIGHTS_WORKSPACE_ID* and *OPINSIGHTS_WORKSPACE_KEY* need to be enclosed in double quotation marks to instruct Windows Installer to interpret as valid options for the package. --#### [Azure Automation](#tab/azure-automation) --You can use the following script example to install the agent using Azure Automation DSC. If you do not have an Automation account, see [Get started with Azure Automation](../../automation/index.yml) to understand requirements and steps for creating an Automation account required before using Automation DSC. If you are not familiar with Automation DSC, review [Getting started with Automation DSC](../../automation/automation-dsc-getting-started.md). --The following example installs the 64-bit agent, identified by the `URI` value. You can also use the 32-bit version by replacing the URI value. The URIs for both versions are: --- **Windows 64-bit agent:** https://go.microsoft.com/fwlink/?LinkId=828603-- **Windows 32-bit agent:** https://go.microsoft.com/fwlink/?LinkId=828604-->[!NOTE] ->This procedure and script example does not support upgrading the agent already deployed to a Windows computer. --The 32-bit and 64-bit versions of the agent package have different product codes and new versions released also have a unique value. The product code is a GUID that is the principal identification of an application or product and is represented by the Windows Installer **ProductCode** property. The `ProductId` value in the **MMAgent.ps1** script has to match the product code from the 32-bit or 64-bit agent installer package. --To retrieve the product code from the agent install package directly, you can use Orca.exe from the [Windows SDK Components for Windows Installer Developers](/windows/win32/msi/platform-sdk-components-for-windows-installer-developers), which is a component of the Windows Software Development Kit, or using PowerShell following an [example script](https://www.scconfigmgr.com/2014/08/22/how-to-get-msi-file-information-with-powershell/) written by a Microsoft Valuable Professional (MVP). For either approach, you first need to extract the **MOMagent.msi** file from the MMASetup installation package, as explained in the first step of the instructions for installing the agent using the command line. --1. Import the xPSDesiredStateConfiguration DSC Module from [https://www.powershellgallery.com/packages/xPSDesiredStateConfiguration](https://www.powershellgallery.com/packages/xPSDesiredStateConfiguration) into Azure Automation. -2. Create Azure Automation variable assets for *OPSINSIGHTS_WS_ID* and *OPSINSIGHTS_WS_KEY*. Set *OPSINSIGHTS_WS_ID* to your Log Analytics workspace ID and set *OPSINSIGHTS_WS_KEY* to the primary key of your workspace. -3. Copy the script and save it as MMAgent.ps1. -- ```powershell - Configuration MMAgent - { - $OIPackageLocalPath = "C:\Deploy\MMASetup-AMD64.exe" - $OPSINSIGHTS_WS_ID = Get-AutomationVariable -Name "OPSINSIGHTS_WS_ID" - $OPSINSIGHTS_WS_KEY = Get-AutomationVariable -Name "OPSINSIGHTS_WS_KEY" - - Import-DscResource -ModuleName xPSDesiredStateConfiguration - Import-DscResource -ModuleName PSDesiredStateConfiguration - - Node OMSnode { - Service OIService - { - Name = "HealthService" - State = "Running" - DependsOn = "[Package]OI" - } - - xRemoteFile OIPackage { - Uri = "https://go.microsoft.com/fwlink/?LinkId=828603" - DestinationPath = $OIPackageLocalPath - } - - Package OI { - Ensure = "Present" - Path = $OIPackageLocalPath - Name = "Microsoft Monitoring Agent" - ProductId = "8A7F2C51-4C7D-4BFD-9014-91D11F24AAE2" - Arguments = '/C:"setup.exe /qn NOAPM=1 ADD_OPINSIGHTS_WORKSPACE=1 OPINSIGHTS_WORKSPACE_ID=' + $OPSINSIGHTS_WS_ID + ' OPINSIGHTS_WORKSPACE_KEY=' + $OPSINSIGHTS_WS_KEY + ' AcceptEndUserLicenseAgreement=1"' - DependsOn = "[xRemoteFile]OIPackage" - } - } - } - - ``` --1. Update the `ProductId` value in the script with the product code extracted from the latest version of the agent installation package by using the methods recommended earlier. -1. [Import the MMAgent.ps1 configuration script](../../automation/automation-dsc-getting-started.md#import-a-configuration-into-azure-automation) into your Automation account. -1. [Assign a Windows computer or node](../../automation/automation-dsc-getting-started.md#enable-an-azure-resource-manager-vm-for-management-with-state-configuration) to the configuration. Within 15 minutes, the node checks its configuration and the agent is pushed to the node. -----## Verify agent connectivity to Azure Monitor --After installation of the agent is finished, you can verify that it's successfully connected and reporting in two ways. --From **System and Security** in **Control Panel**, find the item **Microsoft Monitoring Agent**. Select it, and on the **Azure Log Analytics** tab, the agent should display a message stating *The Microsoft Monitoring Agent has successfully connected to the Microsoft Operations Management Suite service.* -<!-- convertborder later --> --You can also perform a log query in the Azure portal: --1. In the Azure portal, search for and select **Monitor**. -1. Select **Logs** on the menu. -1. On the **Logs** pane, in the query field, enter: -- ``` - Heartbeat - | where Category == "Direct Agent" - | where TimeGenerated > ago(30m) - ``` --In the search results that are returned, you should see heartbeat records for the computer that indicate it's connected and reporting to the service. --## Cache information --Data from the Log Analytics agent is cached on the local machine at *C:\Program Files\Microsoft Monitoring Agent\Agent\Health Service State* before it's sent to Azure Monitor. The agent attempts to upload every 20 seconds. If it fails, it will wait an exponentially increasing length of time until it succeeds. It will wait 30 seconds before the second attempt, 60 seconds before the next, 120 seconds, and so on to a maximum of 8.5 hours between retries until it successfully connects again. This wait time is slightly randomized to avoid all agents simultaneously attempting connection. Oldest data is discarded when the maximum buffer is reached. --The default cache size is 50 MB, but it can be configured between a minimum of 5 MB and maximum of 1.5 GB. It's stored in the registry key *HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\HealthService\Parameters\Persistence Cache Maximum*. The value represents the number of pages, with 8 KB per page. --## Next steps --- Review [Managing and maintaining the Log Analytics agent for Windows and Linux](agent-manage.md) to learn about how to reconfigure, upgrade, or remove the agent from the virtual machine.-- Review [Troubleshooting the Windows agent](agent-windows-troubleshoot.md) if you encounter issues while you install or manage the agent.- |
| azure-monitor | Azure Monitor Agent Custom Text Log Migration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-custom-text-log-migration.md | - Title: Migrate from custom text log version 1 to DCR agent custom text logs. -description: Steps that you must perform when migrating from custom text log v1 to DCR based AMA custom text logs. - Previously updated : 05/09/2023---# Migrate from MMA custom text table to AMA DCR based custom text table -This article describes the steps to migrate a [MMA Custom text log](data-sources-custom-logs.md) table so you can use it as a destination for a new [AMA custom text logs](data-collection-log-text.md) DCR. If you're creating a new AMA custom text table, then this article doesn't pertain to you. ---> [!Warning] -> Your MMA agents won't be able to write to existing custom tables after migration. If your AMA agent writes to an existing custom table, it is implicitly migrated. ---## Background -You must configure MMA custom text logs to support new DCR features that allow AMA agents to write to it. Take the following actions: -- Your table is reconfigured to enable all DCR-based custom logs features.-- Your AMA agents can write data to any column in the table. -- Your MMA Custom text log will lose the ability to write to the custom log.-To continue to write you custom data from both MMA and AMA each must have its own custom table. Your data queries in LA that process your data must join the two tables until the migration is complete at which point you can remove the join. - -## Migration -You should follow the steps only if the following criteria are true: -- You created the original table using the Custom Log Wizard.-- You're going to preserve the existing data in the table.-- You do not need MMA agents to send data to the existing table-- You're going to exclusively write new data using and [AMA custom text log DCR](data-collection-log-text.md) and possibly configure an [ingestion time transformation](azure-monitor-agent-transformation.md).--## Procedure -1. Configure your data collection rule (DCR) following procedures at [collect text logs with Azure Monitor Agent](data-collection-log-text.md) -2. Issue the following API call against your existing custom logs table to enable ingestion from Data Collection Rule and manage your table from the portal UI. This call is idempotent and future calls have no effect. Migration is one-way, you can't migrate the table back to MMA. --```rest -POST -https://management.azure.com/subscriptions/{subscriptionId}/resourcegroups/{resourceGroupName}/providers/Microsoft.OperationalInsights/workspaces/{workspaceName}/tables/{tableName}/migrate?api-version=2021-12-01-preview -``` -3. Discontinue MMA custom text log collection and start using the AMA custom text log. --## Next steps -- [Walk through a tutorial sending custom logs using the Azure portal.](data-collection-log-text.md)-- [Create an ingestion time transform for your custom text data](azure-monitor-agent-transformation.md) |
| azure-monitor | Azure Monitor Agent Data Collection | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-data-collection.md | - Title: Collect data with Azure Monitor Agent -description: Describes how to collect data from virtual machines, Virtual Machine Scale Sets, and Arc-enabled on-premises servers using Azure Monitor Agent. - Previously updated : 07/10/2024-------# Collect data with Azure Monitor Agent --[Azure Monitor agent (AMA)](azure-monitor-agent-overview.md) is used to collect data from Azure virtual machines, Virtual Machine scale sets, and Arc-enabled servers. [Data collection rules (DCR)](../essentials/data-collection-rule-overview.md) define the data to collect from the agent and where that data should be sent. This article describes how to use the Azure portal to create a DCR to collect different types of data and install the agent on any machines that require it. --If you're new to Azure Monitor or have basic data collection requirements, then you may be able to meet all of your requirements using the Azure portal and the guidance in this article. If you want to take advantage of additional DCR features such as [transformations](../essentials/data-collection-transformations.md), then you may need to create a DCR using other methods or edit it after creating it in the portal. You can also use different methods to manage DCRs and create associations if you want to deploy using CLI, PowerShell, ARM templates, or Azure Policy. --> [!NOTE] -> To send data across tenants, you must first enable [Azure Lighthouse](../../lighthouse/overview.md). ---> [!WARNING] -> The following cases may collect duplicate data which may result in additional charges. -> -> - Creating multiple DCRs with the same data source and associating them to the same agent. Ensure that you're filtering data in the DCRs such that each collects unique data. -> - Creating a DCR that collects security logs and enabling Sentinel for the same agents. In this case, you may collect the same events in the Event table and the SecurityEvent table. -> - Using both the Azure Monitor agent and the legacy Log Analytics agent on the same machine. Limit duplicate events to only the time when you transition from one agent to the other. --## Data sources --The table below lists the types of data you can currently collect with the Azure Monitor Agent and where you can send that data. The link for each is to an article describing the details of how to configure that data source. Follow this article to create the DCR and assign it to resources, and then follow the linked article to configure the data source. --| Data source | Description | Client OS | Destinations | -|:|:|:|:| -| [Windows events](./data-collection-windows-events.md) | Information sent to the Windows event logging system, including sysmon events. | Windows | Log Analytics workspace | -| [Performance counters](./data-collection-performance.md) | Numerical values measuring performance of different aspects of operating system and workloads. | Windows<br>Linux | Azure Monitor Metrics (Preview)<br>Log Analytics workspace | -| [Syslog](./data-collection-syslog.md) | Information sent to the Linux event logging system. | Linux | Log Analytics workspace | -| [Text log](./data-collection-log-text.md) | Information sent to a text log file on a local disk. | Windows<br>Linux | Log Analytics workspace -| [JSON log](./data-collection-log-json.md) | Information sent to a JSON log file on a local disk. | Windows<br>Linux | Log Analytics workspace | -| [IIS logs](./data-collection-iis.md) | Internet Information Service (IIS) logs from to the local disk of Windows machines | Windows | Log Analytics workspace | ---> [!NOTE] -> Azure Monitor Agent also supports Azure service [SQL Best Practices Assessment](/sql/sql-server/azure-arc/assess/) which is currently Generally available. For more information, refer [Configure best practices assessment using Azure Monitor Agent](/sql/sql-server/azure-arc/assess#enable-best-practices-assessment). --## Prerequisites --- [Permissions to create Data Collection Rule objects](../essentials/data-collection-rule-create-edit.md#permissions) in the workspace.-- See the article describing each data source for any additional prerequisites.--## Overview -When you create a DCR in the Azure portal, you're walked through a series of pages to provide the information needed to collect data from the machines you specify. The following table describes the information you need to provide on each page. --| Section | Description | -|:|:| -| Resources | Machines that will use the DCR. When you add a machine to the DCR, it creates a [data collection rule association (DCRA)](../essentials/data-collection-rule-overview.md#data-collection-rule-associations-dcra) between the machine and the DCR. You can edit the DCR to add or remove machines after it's created. | -| Data source | The type of data to collect from the machine. The list of available data sources are listed above in [Data sources](#data-sources). Each data source has its own configuration settings and potentially prerequisites, so see the individual article for each for details. | -| Destination | Destination where the data collected from the data source should be sent. If you have multiple data sources in the DCR, they can be sent to separate destinations, and data from a single data source may be sent to multiple destinations. See the article for each data source for more details about their destination such as the table in the Log Analytics workspace. | ---## Create data collection rule --> [!IMPORTANT] -> Create your data collection rule in the same region as your destination Log Analytics workspace or Azure Monitor workspace. You can associate the data collection rule to machines or containers from any subscription or resource group in the tenant. To send data across tenants, you must first enable [Azure Lighthouse](../../lighthouse/overview.md). ---On the **Monitor** menu in the Azure portal, select **Data Collection Rules** > **Create** to open the DCR creation page. ---The **Basic** page includes basic information about the DCR. ---| Setting | Description | -|:|:| -| Rule Name | Name for the DCR. This should be something descriptive that helps you identify the rule. | -| Subscription | Subscription to store the DCR. This does not need to be the same subscription as the virtual machines. | -| Resource group | Resource group to store the DCR. This does not need to be the same resource group as the virtual machines. | -| Region | Region to store the DCR. This must be the same region as any Log Analytics workspace or Azure Monitor workspace used in a destination of the DCR. If you have workspaces in different regions, then create multiple DCRs associated with the same set of machines. | -| Platform Type | Specifies the type of data sources that will be available for the DCR, either **Windows** or **Linux**. **None** allows for both. <sup>1</sup> | -| Data Collection Endpoint | Specifies the data collection endpoint (DCE) used to collect data. This is only required if you're using Azure Monitor Private Links. This DCE must be in the same region as the DCR. For more information, see [How to set up data collection endpoints based on your deployment](../essentials/data-collection-endpoint-overview.md). | --<sup>1</sup> This option sets the `kind` attribute in the DCR. There are other values that can be set for this attribute, but they are not available in the portal. ---## Add resources -The **Resources** page allows you to add resources that will be associated with the DCR. Click **+ Add resources** to select resources. The Azure Monitor agent will automatically be installed on any resources that don't already have it. --> [!IMPORTANT] -> The portal enables system-assigned managed identity on the target resources, along with existing user-assigned identities, if there are any. For existing applications, unless you specify the user-assigned identity in the request, the machine defaults to using system-assigned identity instead. ---- If the machine you're monitoring is not in the same region as your destination Log Analytics workspace and you're collecting data types that require a DCE, select **Enable Data Collection Endpoints** and select an endpoint in the region of each monitored machine. If the monitored machine is in the same region as your destination Log Analytics workspace, or if you don't require a DCE, don't select a data collection endpoint on the **Resources** tab. - --## Add data sources -The **Collect and deliver** page allows you to add and configure data sources for the DCR and a destination for each. --| Screen element | Description | -|:|:| -| **Data source** | Select a **Data source type** and define related fields based on the data source type you select. See the articles linked in [Data sources](#data-sources) above for details on configuring each type of data source. | -| **Destination** | Add one or more destinations for each data source. You can select multiple destinations of the same or different types. For instance, you can select multiple Log Analytics workspaces, which is also known as multihoming. See the details for each data type for the different destinations they support. | --A DCR can contain multiple different data sources up to a limit of 10 data sources in a single DCR. You can combine different data sources in the same DCR, but you will typically want to create different DCRs for different data collection scenarios. See [Best practices for data collection rule creation and management in Azure Monitor](../essentials/data-collection-rule-best-practices.md) for recommendations on how to organize your DCRs. --> [!NOTE] -> It can take up to 5 minutes for data to be sent to the destinations when you create a data collection rule using the data collection rule wizard. --## Verify operation -Once you've created a DCR and associated it with a machine, you can verify that the agent is operational and that data is being collected by running queries in the Log Analytics workspace. --### Verify agent operation -Verify that the agent is operational and communicating properly by running the following query in Log Analytics to check if there are any records in the [Heartbeat](/azure/azure-monitor/reference/tables/heartbeat) table. A record should be sent to this table from each agent every minute. --``` kusto -Heartbeat -| where TimeGenerated > ago(24h) -| where Computer has "<computer name>" -| project TimeGenerated, Category, Version -| order by TimeGenerated desc -``` --### Verify that records are being received -It will take a few minutes for the agent to be installed and start running any new or modified DCRs. You can then verify that records are being received from each of your data sources by checking the table that each writes to in the Log Analytics workspace. For example, the following query checks for Windows events in the [Event](/azure/azure-monitor/reference/tables/event) table. --``` kusto -Event -| where TimeGenerated > ago(48h) -| order by TimeGenerated desc -``` --## Troubleshooting -Go through the following steps if you aren't collecting data that you're expecting. --- Verify that the agent is installed and running on the machine.-- See the **Troubleshooting** section of the article for the data source you're having trouble with.-- See [Monitor and troubleshoot DCR data collection in Azure Monitor](../essentials/data-collection-monitor.md) to enable monitoring for the DCR.- - View metrics to determine if data is being collected and whether any rows are being dropped. - - View logs to identify errors in the data collection. --## Next steps --- [Collect text logs by using Azure Monitor Agent](data-collection-log-text.md).-- Learn more about [Azure Monitor Agent](azure-monitor-agent-overview.md).-- Learn more about [data collection rules](../essentials/data-collection-rule-overview.md). |
| azure-monitor | Azure Monitor Agent Data Field Differences | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-data-field-differences.md | - Title: Data field differences between MMA and AMA -description: Documents that field lever data changes made in the migration. ---- Previously updated : 06/21/2024-Customer intent: As an azure administrator, I want to understand which Log Analytics Workspace queries I may need to update after AMA migration. ---# AMA agent data field differences from MMA --[Azure Monitor Agent (AMA)](./agents-overview.md) replaces the Log Analytics agent, also known as Microsoft Monitor Agent (MMA) and OMS, for Windows and Linux machines, in Azure and non-Azure environments, on-premises and other clouds. The agent introduces a simplified, flexible method of configuring data collection using [Data Collection Rules (DCRs)](../essentials/data-collection-rule-overview.md). The article provides information on the data fields that change when collected by AMA, which is critical information for you to migrate your LAW queries. --Each of the data changes was carefully considered and the rational for each change is provided in the table. If you encounter a data field that isn't in the tables file a support request. Your help keeping the tables current and complete is appreciated. --## Log analytics workspace tables --### W3CIISLog table for Internet Information Services (IIS) --This table collects log data from the Internet Information Service on Window systems. --| LAW Field | Difference | Reason | Additional Information | -|--||--|| -| sSiteName | Not be populated | depends on customer data collection configuration | The MMA agent could turn on collection by default, but by principle is restricted from making configuration changes in other services.<p>Enable the `Service Name (s-sitename)` field in W3C logging of IIS. See [Select W3C Fields to Log](/iis/manage/provisioning-and-managing-iis/configure-logging-in-iis#select-w3c-fields-to-log).| -| Fileuri | No longer populated | not required for MMA parity | MMA doesn't collect this field. This field was only populated for IIS logs collected from Azure Cloud Services through the Azure Diagnostics Extension. | --### Windows event table --This table collects Events from the Windows Event log. There are two other tables that are used to store Windows events, the SecurityEvent and Event tables. --| LAW Field | Difference | Reason | Additional Information | -|--||--|| -| UserName | MMA enriches the event with the username before sending the event for ingestion. AMA doesn't do the same enrichment. | The AMA enrichment isn't implemented yet. | AMA principles dictate that the event data should remain unchanged by default. Adding and enriched field adds possible processing errors and extra costs for storage. In this case, the customer demand for the field is very high and work is underway to add the username. | --### Perf table for performance counters --The perf table collects performance counters from Windows and Linux agents. It offers valuable insights into the performance of hardware components, operating systems, and applications. The following table shows key differences in how data is reported between OMS and Azure Monitor Agent (AMA). --| LAW Field | Difference | Reason | Additional Information | -|--||--|| -| InstanceName | Reported as **_Total** by OMS<br>Reported as **total** by AMA | | Where `ObjectName` is **"Logical Disk"** and `CounterName` is **"% Used Space"**, the `InstanceName` value is reported as **_Total** for records ingested by the OMS agent, and as **total** for records ingested by the Azure Monitor Agent (AMA).\* | -| CounterValue | Is rounded to the nearest whole number by OMS but not rounded by AMA | | Where `ObjectName` is **"Logical Disk"** and `CounterName` is **"% Used Space"**, the `CounterValue` value is rounded to the nearest whole number for records ingested by the OMS agent but not rounded for records ingested by the Azure Monitor Agent (AMA).\* | --\* Doesn't apply to records ingested by the Microsoft Monitoring Agent (MMA) on Windows. ---## Next steps --* [Azure Monitor Agent migration helper workbook](./azure-monitor-agent-migration-helper-workbook.md) -* [DCR Config Generator](./azure-monitor-agent-migration-data-collection-rule-generator.md) - |
| azure-monitor | Azure Monitor Agent Extension Versions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-extension-versions.md | - Title: Azure Monitor Agent extension versions -description: This article describes the version details for the Azure Monitor Agent virtual machine extension. - Previously updated : 08/12/2024-------# Azure Monitor Agent extension versions --> [!CAUTION] -> This article references CentOS, a Linux distribution that is End Of Life (EOL) status. Please consider your use and planning accordingly. For more information, see the [CentOS End Of Life guidance](/azure/virtual-machines/workloads/centos/centos-end-of-life). --This article describes the version details for the Azure Monitor Agent virtual machine extension. This extension deploys the agent on virtual machines, scale sets, and Arc-enabled servers (on-premises servers with Azure Arc agent installed). --We strongly recommended to always update to the latest version, or opt in to the [Automatic Extension Update](/azure/virtual-machines/automatic-extension-upgrade) feature. A version is not automatically rolled out until it meets a high quality bar which can take as long as 5 weeks after the initial release. --[//]: # "DON'T change the format (column schema, etc.) of the table without consulting glinuxagent alias. The [Azure Monitor Linux Agent Troubleshooting Tool](https://github.com/Azure/azure-linux-extensions/blob/master/AzureMonitorAgent/ama_tst/AMA-Troubleshooting-Tool.md) parses the table at runtime to determine the latest version of AMA; altering the format could degrade some of the functions of the tool." --## Version details -| Release Date | Release notes | Windows | Linux | -|:|:|:|:| -| August 2024 | **Windows**<ul><li>Added columns to the SecurityEvent table: Keywords, Opcode, Correlation, ProcessId, ThreadId, EventRecordId.</li><li>AMA: Support AMA Client Installer support for W365 Azure Virtual Desktop (AVD) tenants/partners.</li></ul>**Linux Features**<ul><li>Enable Dynamic Linking of OpenSSL 1.1 in all regions</li><li>Add Computer field to Custom Logs</li><li>Add EventHub upload support for Custom Logs </li><li>Reliability improvement for upload task scheduling</li><li>Added support for SUSE15 SP5, and AWS 3 distributions</li></ul>**Linux Fixes**<ul><li>Fix Direct upload to storage for perf counters when no other destination is configured. You don't see perf counters If storage was the only configured destination for perf counters, they wouldn't see perf counters in their blob or table.</li><li>Fluent-Bit updated to version 3.0.7. This fixes the issue with Fluent-Bit creating junk files in the root directory on process shutdown.</li><li>Fix proxy for system-wide proxy using http(s)_proxy env var </li><li>Support for syslog hostnames that are up to 255characters</li><li>Stop sending rows longer than 1MB. This exceeds ingestion limits and destabilizes the agent. Now the row is gracefully dropped and a diagnostic message is written.</li><li>Set max disk space used for rsyslog spooling to 1GB. There was no limit before which could lead to high memory usage.</li><li>Use random available TCP port when there is a port conflict with AMA port 28230 and 28330 . This resolved issues where port 28230 and 28330 were already in uses by the customer which prevented data upload to Azure.</li><li>Fix to AMACoreAgent crash in certain architectures affecting custom log collection</li></ul>| 1.29 | 1.32.6 | -| June 2024 |**Windows**<ul><li>Fix encoding issues with Resource ID field.</li><li>AMA: Support new ingestion endpoint for GovSG environment.</li><li>Upgrade AzureSecurityPack version to 4.33.0.1.</li><li>Upgrade Metrics Extension version to 2.2024.517.533.</li><li>Upgrade Health Extension version to 2024.528.1.</li></ul>**Linux**<ul><li>Coming Soon</li></ul>| 1.28.2 | | -| May 2024 |**Windows**<ul><li>Upgraded Fluent-bit version to 3.0.5. This Fix resolves as security issue in fluent-bit (NVD - CVE-2024-4323 (nist.gov)</li><li>Disabled Fluent-bit logging that caused disk exhaustion issues for some customers. Example error is Fluentbit log with "[C:\projects\fluent-bit-2e87g\src\flb_scheduler.c:72 errno=0] No error" fills up the entire disk of the server.</li><li>Fixed AMA extension getting stuck in deletion state on some VMs that are using Arc. This fix improves reliability.</li><li>Fixed AMA not using system proxy, this issue is a bug introduced in 1.26.0. The issue was caused by a new feature that uses the Arc agent’s proxy settings. When the system proxy as set as None the proxy was broken in 1.26.</li><li>Fixed Windows Firewall Logs log file rollover issues</li></ul>| 1.27.0 | | -| April 2024 |**Windows**<ul><li>In preparation for the May 17 public preview of Firewall Logs, the agent completed the addition of a profile filter for Domain, Public, and Private Logs. </li><li>AMA running on an Arc enabled server will default to using the Arc proxy settings if available.</li><li>The AMA VM extension proxy settings override the Arc defaults.</li><li>Bug fix in MSI installer: Symptom - If there are spaces in the fluent-bit config path, AMA wasn't recognizing the path properly. AMA now adds quotes to configuration path in fluent-bit.</li><li>Bug fix for Container Insights: Symptom - custom resource ID weren't being honored.</li><li>Security issue fix: skip the deletion of files and directory whose path contains a redirection (via Junction point, Hard links, Mount point, OB Symlinks etc.).</li><li>Updating MetricExtension package to 2.2024.328.1744.</li></ul>**Linux**<ul><li>AMA 1.30 now available in Arc.</li><li>New distribution support Debian 12, RHEL CIS L2.</li><li>Fix for mdsd version 1.30.3 in persistence mode, which converted positive integers to float/double values ("3.0", "4.0") to type ulong which broke Azure stream analytics.</li></ul>| 1.26.0 | 1.31.1 | -| March 2024 | **Known Issues - ** a change in 1.25.0 to the encoding of resource IDs in the request headers to the ingestion end point has disrupted SQL ATP. This is causing failures in alert notifications to the Microsoft Detection Center (MDC) and potentially affecting billing events. Symptom is not seeing expected alerts related to SQL security threats. 1.25.0 didn't release to all data centers and it wasn't identified for auto update in any data center. Customers that did upgrade to 1.25.0 should roll back to 1.24.0<br><br>**Windows**<ul><li>**Breaking Change from Public Preview to GA** Due to customer feedback, automatic parsing of JSON into column in your custom table in Log Analytic was added. You must take action to migrate your JSON DCR created before this release to prevent data loss. This fix is the last before the release of the JSON Log type in Public Preview.</li><li>Fix AMA when resource ID contains non-ascii chars, which is common when using some languages other than English. Errors would follow this pattern: … [HealthServiceCommon] [] [Error] … WinHttpAddRequestHeaders(x-ms-AzureResourceId: /subscriptions/{your subscription #} /resourceGroups/???????/providers/ … PostDataItems" failed with code 87(ERROR_INVALID_PARAMETER) </li></ul>**Linux**<ul><li>The AMA agent now supports Debian 12 and RHEL9 CIS L2 distribution.</li></ul>| 1.25.0 | 1.31.0 | -| February 2024 | **Known Issues**<ul><li>Occasional crash during startup in Arm64 VMs. The fix is in 1.30.3</li></uL>**Windows**<ul><li>Fix memory leak in Internet Information Service (IIS) log collection</li><li>Fix JSON parsing with Unicode characters for some ingestion endpoints</li><li>Allow Client installer to run on Azure Virtual Desktop (AVD) DevBox partner</li><li>Enable Transport Layer Security (TLS) 1.3 on supported Windows versions</li><li>Update MetricsExtension package to 2.2024.202.2043</li></ul>**Linux**<ul><li>Features<ul><li>Add EventTime to syslog for parity with OMS agent</li><li>Add more Common Event Format (CEF) format support</li><li>Add CPU quotas for Azure Monitor Agent (AMA)</li></ul><li>Fixes<ul><li>Handle truncation of large messages in syslog due to Transmission Control Protocol (TCP) framing issue</li><li>Set NO_PROXY for Instance Metadata Service (IMDS) endpoint in AMA Python wrapper</li><li>Fix a crash in syslog parsing</li><li>Add reasonable limits for metadata retries from IMDS</li><li>No longer reset /var/log/azure folder permissions</li></ul></ul> | 1.24.0 | 1.30.3<br>1.30.2 | -| January 2024 |**Known Issues**<ul><li>1.29.5 doesn't install on Arc-enabled servers because the agent extension code size is beyond the deployment limit set by Arc. **This issue was fixed in 1.29.6**</li></ul>**Windows**<ul><li>Added support for Transport Layer Security (TLS) 1.3</li><li>Reverted a change to enable multiple IIS subscriptions to use same filter. Feature is redeployed once memory leak is fixed</li><li>Improved Event Trace for Windows (ETW) event throughput rate</li></ul>**Linux**<ul><li>Fix error messages logged, intended for mdsd.err, that instead went to mdsd.warn in 1.29.4 only. Likely error messages: "Exception while uploading to Gig-LA: ...", "Exception while uploading to ODS: ...", "Failed to upload to ODS: ..."</li><li>Reduced noise generated by AMAs' use of semanage when SELinux is enabled</li><li>Handle time parsing in syslog to handle Daylight Savings Time (DST) and leap day</li></ul> | 1.23.0 | 1.29.5, 1.29.6 | -| December 2023 |**Known Issues**<ul><li>1.29.4 doesn't install on Arc-enabled servers because the agent extension code size is beyond the deployment limit set by Arc. Fix is coming in 1.29.6</li><li>Multiple IIS subscriptions cause a memory leak. feature reverted in 1.23.0</ul>**Windows** <ul><li>Prevent CPU spikes by not using bookmark when resetting an Event Log subscription</li><li>Added missing Fluent Bit executable to AMA client setup for Custom Log support</li><li>Updated to latest AzureCredentialsManagementService and DsmsCredentialsManagement package</li><li>Update ME to v2.2023.1027.1417</li></ul>**Linux**<ul><li>Support for TLS v1.3</li><li>Support for nopri in Syslog</li><li>Ability to set disk quota from Data Collection Rule (DCR) Agent Settings</li><li>Add Arm64 Ubuntu 22 support</li><li>**Fixes**<ul><li>SysLog</li><ul><li>Parse syslog Palo Alto CEF with multiple space characters following the hostname</li><li>Fix an issue with incorrectly parsing messages containing two '\n' chars in a row</li><li>Improved support for non-RFC compliant devices</li><li>Support Infoblox device messages containing both hostname and IP headers</li></ul><li>Fix AMA crash in Read Hat Enterprise Linux (RHEL) 7.2</li><li>Remove dependency on "which" command</li><li>Fix port conflicts due to AMA using 13000 </li><li>Reliability and Performance improvements</li></ul></li></ul>| 1.22.0 | 1.29.4| -| October 2023| **Windows** <ul><li>Minimize CPU spikes when resetting an Event Log subscription</li><li>Enable multiple IIS subscriptions to use same filter</li><li>Clean up files and folders for inactive tenants in multitenant mode</li><li>AMA installer doesn't install unnecessary certs</li><li>AMA emits Telemetry table locally</li><li>Update Metric Extension to v2.2023.721.1630</li><li>Update AzureSecurityPack to v4.29.0.4</li><li>Update AzureWatson to v1.0.99</li></ul>**Linux**<ul><li> Add support for Process metrics counters for Log Analytics upload and Azure Monitor Metrics</li><li>Use rsyslog omfwd TCP for improved syslog reliability</li><li>Support Palo Alto CEF logs where hostname is followed by two spaces</li><li>Bug and reliability improvements</li></ul> |1.21.0|1.28.11| -| September 2023| **Windows** <ul><li>Fix issue with high CPU usage due to excessive Windows Event Logs subscription reset</li><li>Reduce Fluent Bit resource usage by limiting tracked files older than three days and limiting logging to errors only</li><li>Fix race condition where resource_id is unavailable when agent is restarted</li><li>Fix race-condition when vm-extension provision agent (also known as GuestAgent) is issuing a disable-vm-extension command to AMA</li><li>Update MetricExtension version to 2.2023.721.1630</li><li>Update Troubleshooter to v1.5.14 </li></ul>|1.20.0| None | -| August 2023| **Windows** <ul><li>AMA: Allow prefixes in the tag names to handle regression</li><li>Updating package version for AzSecPack 4.28 release</li></ui>|1.19.0| None | -| July 2023| **Windows** <ul><li>Fix crash when Event Log subscription callback throws errors.<li>MetricExtension updated to 2.2023.609.2051</li></ui> |1.18.0|None| -| June 2023| **Windows** <ul><li>Add new FilePath column to custom logs table. You must manually add the column to your custom table</li><li>Config setting to disable custom IMDS endpoint in Tenant.json file</li><li>Fluent Bit binaries signed with Microsoft customer Code Sign cert</li><li>Minimize number of retries on calls to refresh tokens</li><li>Don't overwrite resource ID with empty string</li><li>AzSecPack updated to version 4.27</li><li>AzureProfiler and AzurePerfCollector updated to version 1.0.0.990</li><li>MetricsExtension updated to version 2.2023.513.10</li><li>Troubleshooter updated to version 1.5.0</li></ul>**Linux** <ul><li>To identify forwarder/collector machine, add new column CollectorHostName to syslog table </li><li>Link OpenSSL dynamically</li><li>**Fixes**<ul><li>Allow uploads soon after AMA startup</li><li>To avoid thread pool scheduling issues, run LocalSink Garbage Collector on a dedicated thread </li><li>Fix upgrade restart of disabled services</li><li>Handle Linux Hardening where sudo on root is blocked</li><li>CEF processing fixes for noncompliant Request For Comment (RFC) 5424 logs</li><li>Adaptive Security Appliance (ASA) tenant can fail to start up due to config-cache directory permissions</li><li>Fix auth proxy in AMA</li><li>Fix to remove null characters in agentlauncher.log after log rotation</li><li>Fix for authenticated proxy(1.27.3)</li><li>Fix regression in Virtual Machine (VM) Insights(1.27.4)</ul></li></ul>|1.17.0 |1.27.4| -| May 2023 | **Windows** <ul><li>Enable Large Event support for all regions</li><li>Update to TroubleShooter 1.4.0</li><li>Fixed issue when Event Log subscription became invalid and wouldn't resubscribe</li><li>AMA: Fixed issue with Large Event sending too large data. Also affecting Custom Log</li></ul> **Linux** <ul><li>Support for CIS and SELinux [hardening](./agents-overview.md)</li><li>Include Ubuntu 22.04 (Jammy Jellyfish) in azure-mdsd package publishing</li><li>Move storage SDK patch to build container</li><li>Add system Telegraf counters to AMA</li><li>Drop msgpack and syslog data if not configured in active configuration</li><li>Limit the events sent to Public ingestion pipeline</li><li>**Fixes** <ul><li>Fix mdsd crash in init when in persistent mode </li><li>To avoid a race condition, remove FdClosers from ProtocolListeners </li><li>Fix sed regex special character escaping issue in rpm macro for CentOS 7.3 (Maipo)</li><li>Fix latency and future timestamp issue</li><li>Install AMA syslog configs only if customer is opted in for syslog in DCR</li><li>Fix heartbeat time check</li><li>Skip unnecessary cleanup in fatal signal handler</li><li>Fix case where fast-forwarding may cause intervals to be skipped</li><li>Fix comma separated custom log paths with fluent</li><li>Fix to prevent events folder growing too large and filling the disk</li><li>Hotfix (1.26.3) for Syslog</li></ul></li><ul> | 1.16.0.0 | 1.26.2-1.26.5<sup>Hotfix</sup>| -| Apr 2023 | **Windows** <ul><li>AMA: Enable Large Event support based on Region</li><li>AMA: Upgrade to Fluent Bit version 2.0.9</li><li>Update Troubleshooter to 1.3.1</li><li>Update ME version to 2.2023.331.1521</li><li>Updating package version for AzSecPack 4.26 release</li></ul>|1.15.0|None| -| Mar 2023 | **Windows** <ul><li>Text file collection improvements to handle high rate logging and continuous tailing of longer lines</li><li>VM Insights fixes for collecting metrics from non-English OS</li></ul> | 1.14.0.0 | None | -| Feb 2023 | <ul><li>**Linux (hotfix)** Resolved potential data loss due to "Bad file descriptor" errors seen in the mdsd error log with previous version. Upgrade to hotfix version</li><li>**Windows** Reliability improvements in Fluent Bit buffering to handle larger text files</li></ul> | 1.13.1 | 1.25.2<sup>Hotfix</sup> | -| Jan 2023 | **Linux** <ul><li>RHEL 9 and Amazon Linux 2 support</li><li>Update to OpenSSL 1.1.1s and require TLS 1.2 or higher</li><li>Performance improvements</li><li>Improvements in Garbage Collection for persisted disk cache and handling corrupted cache files better</li><li>**Fixes** <ul><li>Set agent service memory limit for CentOS/RedHat 7 distros. Resolved MemoryMax parsing error</li><li>Fixed modifying rsyslog system-wide log format caused by installer on RedHat/CentOS 7.3</li><li>Fixed permissions to config directory</li><li>Installation reliability improvements</li><li>Fixed permissions on default file so rpm verification doesn't fail</li><li>Added traceFlags setting to enable trace logs for agent</li></ul></li></ul> **Windows** <ul><li>Fixed issue related to incorrect *EventLevel* and *Task* values for Log Analytics *Event* table, to match Windows Event Viewer values</li><li>Added missing columns for IIS logs - *TimeGenerated, Time, Date, Computer, SourceSystem, AMA, W3SVC, SiteName*</li><li>Reliability improvements for metrics collection</li><li>Fixed machine restart issues on for Arc-enabled servers related to repeated calls to HIMDS service</li></ul> | 1.12.0 | 1.25.1 | -| Nov-Dec 2022 | <ul><li>Support for air-gapped clouds added for [Windows Microsoft Standard Installer (MSI) installer for clients](./azure-monitor-agent-windows-client.md) </li><li>Reliability improvements for using AMA with Custom Metrics destination</li><li>Performance and internal logging improvements</li></ul> | 1.11.0 | None | -| Oct 2022 | **Windows** <ul><li>Increased reliability of data uploads</li><li>Data quality improvements</li></ul> **Linux** <ul><li>Support for `http_proxy` and `https_proxy` environment variables for [network proxy configurations](./azure-monitor-agent-network-configuration.md#proxy-configuration) for the agent</li><li>[Text logs](./data-collection-log-text.md) <ul><li>Network proxy support enabled</li><li>Fixed missing `_ResourceId`</li><li>Increased maximum line size support to 1 MB</li></ul></li><li>Support ingestion of syslog events whose timestamp is in the future</li><li>Performance improvements</li><li>Fixed `diskio` metrics instance name dimension to use the disk mount paths instead of the device names</li><li>Fixed world writable file issue to lock down write access to certain agent logs and configuration files stored locally on the machine</li></ul> | 1.10.0.0 | 1.24.2 | -| Sep 2022 | Reliability improvements | 1.9.0 | None | -| August 2022 | **Common updates** <ul><li>Improved resiliency: Default lookback (retry) time updated to last three days (72 hours) up from 60 minutes, for agent to collect data post interruption. Look back time is subject to default offline cache size of 10 Gb</li><li>Fixes the preview custom text log feature that was incorrectly removing the *TimeGenerated* field from the raw data of each event. All events are now additionally stamped with agent (local) upload time</li><li>Reliability and supportability improvements</li></ul> **Windows** <ul><li>Fixed datetime format to UTC</li><li>Fix to use default location for firewall log collection, if not provided</li><li>Reliability and supportability improvements</li></ul> **Linux** <ul><li>Support for OpenSuse 15, Debian 11 Arm64</li><li>Support for coexistence of Azure Monitor agent with legacy Azure Diagnostic extension for Linux (LAD)</li><li>Increased max-size of User Datagram Protocol (UDP) payload for Telegraf output to prevent dimension truncation</li><li>Prevent unconfigured upload to Azure Monitor Metrics destination</li><li>Fix for disk metrics wherein *instance name* dimension uses the disk mount paths instead of the device names, to provide parity with legacy agent</li><li>Fixed *disk free MB* metric to report megabytes instead of bytes</li></ul> | 1.8.0 | 1.22.2 | -| July 2022 | Fix for mismatch event timestamps for Sentinel Windows Event Forwarding | 1.7.0 | None | -| June 2022 | Bug fixes with user assigned identity support, and reliability improvements | 1.6.0 | None | -| May 2022 | <ul><li>Fixed issue where agent stops functioning due to faulty XPath query. With this version, only query related Windows events fail, other data types continue to be collected</li><li>Collection of Windows network troubleshooting logs added to 'CollectAMAlogs.ps1' tool</li><li>Linux support for Debian 11 distro</li><li>Fixed issue to list mount paths instead of device names for Linux disk metrics</li></ul> | 1.5.0.0 | 1.21.0 | -| April 2022 | <ul><li>Private IP information added in Log Analytics <i>Heartbeat</i> table for Windows and Linux</li><li>Fixed bugs in Windows IIS log collection (preview) <ul><li>Updated IIS site column name to match backend Kusto Query Language (KQL) transform</li><li>Added delay to IIS upload task to account for IIS buffering</li></ul></li><li>Fixed Linux CEF syslog forwarding for Sentinel</li><li>Removed 'error' message for Azure MSI token retrieval failure on Arc to show as 'Info' instead</li><li>Support added for Ubuntu 22.04, RHEL 8.5, 8.6, AlmaLinux and RockyLinux distros</li></ul> | 1.4.1<sup>Hotfix</sup> | 1.19.3 | -| March 2022 | <ul><li>Fixed timestamp and XML format bugs in Windows Event logs</li><li>Full Windows OS information in Log Analytics Heartbeat table</li><li>Fixed Linux performance counters to collect instance values instead of 'total' only</li></ul> | 1.3.0 | 1.17.5.0 | -| February 2022 | <ul><li>Bug fixes for the AMA Client installer</li><li>Versioning fix to reflect appropriate Windows major/minor/hotfix versions</li><li>Internal test improvement on Linux</li></ul> | 1.2.0 | 1.15.3 | -| January 2022 | <ul><li>Syslog RFC compliance for Linux</li><li>Fixed issue for Linux perf counters not flowing on restart</li><li>Fixed installation failure on Windows Server 2008 R2 SP1</li></ul> | 1.1.5.1<sup>Hotfix</sup> | 1.15.2.0<sup>Hotfix</sup> | -| December 2021 | <ul><li>Fixed issues impacting Linux Arc-enabled servers</li><li>'Heartbeat' table > 'Category' column reports "Azure Monitor Agent" in Log Analytics for Windows</li></ul> | 1.1.4 | 1.14.7.0<sup>2</sup> | -| September 2021 | <ul><li>Fixed issue causing data loss on restarting the agent</li><li>Fixed issue for Arc Windows servers</li></ul> | 1.1.3.2<sup>Hotfix</sup> | 1.12.2.0 <sup>1</sup> | -| August 2021 | Fixed issue allowing Azure Monitor Metrics as the only destination | 1.1.2.0 | 1.10.9.0<sup>Hotfix</sup> | -| July 2021 | <ul><li>Support for direct proxies</li><li>Support for Log Analytics gateway</li></ul> [Learn more](https://azure.microsoft.com/updates/general-availability-azure-monitor-agent-and-data-collection-rules-now-support-direct-proxies-and-log-analytics-gateway/) | 1.1.1 | 1.10.5.0 | -| June 2021 | General availability announced. <ul><li>All features except metrics destination now generally available</li><li>Production quality, security, and compliance</li><li>Availability in all public regions</li><li>Performance and scale improvements for higher EPS</li></ul> [Learn more](https://azure.microsoft.com/updates/azure-monitor-agent-and-data-collection-rules-now-generally-available/) | 1.0.12 | 1.9.1.0 | --<sup>Hotfix</sup> Don't use AMA Linux versions v1.10.7, v1.15.1, v1.25.2 and AMA Windows v1.1.3.1, v1.1.5.0. Use the hotfix versions.<br/> -<sup>1</sup> Known issue: No data collected from Linux Arc-enabled servers.<br/> -<sup>2</sup> Known issue: Linux performance counters data stops flowing on restarting or rebooting the machines. --## Next steps --- [Install and manage the extension](./azure-monitor-agent-manage.md).-- [Create a data collection rule](./azure-monitor-agent-data-collection.md) to collect data from the agent and send it to Azure Monitor. |
| azure-monitor | Azure Monitor Agent Health | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-health.md | - Title: View Azure Monitor Agent Health -description: Experience to view agent health at scale and troubleshoot issues related to data collection via agents --- Previously updated : 5/13/2024----# Azure Monitor Agent Health -Use the **Azure Monitor Agent Health** workbook in the Azure portal for a summary of the details and health of agents deployed across your organization. This workbook provides you with the following: --- Distribution of your agents across environments and resource types -- Health trend and details of agents including their last heartbeat-- Agent processes footprint for both processor and memory for a selected agent-- Summary of data collection rules and their associated agents---Access the workbook from **Workbooks** in the **Monitor** menu in the Azure portal, or by clicking [here](https://ms.portal.azure.com/#blade/AppInsightsExtension/UsageNotebookBlade/ComponentId/Azure%20Monitor/ConfigurationId/community-Workbooks%2FAzure%20Monitor%20-%20Agents%2FAMA%20Health/Type/workbook/WorkbookTemplateName/AMA%20Health%20(Preview)). Try it out and [share your feedback](mailto:obs-agent-pms@microsoft.com) with us. ---- |
| azure-monitor | Azure Monitor Agent Manage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-manage.md | - Title: Install and manage Azure Monitor Agent -description: Options for installing and managing Azure Monitor Agent on Azure virtual machines and Azure Arc-enabled servers. --- Previously updated : 07/15/2024------# Install and manage Azure Monitor Agent --This article details the different methods to install, uninstall, update, and configure [Azure Monitor Agent](azure-monitor-agent-overview.md) on Azure virtual machines, scale sets, and Azure Arc-enabled servers. --> [!IMPORTANT] -> Azure Monitor Agent requires at least one data collection rule (DCR) to begin collecting data after it's installed on the client machine. Depending on the installation method you use, a DCR may or may not be created automatically. If not, then you need to configure data collection following the guidance at [Collect data with Azure Monitor Agent](./azure-monitor-agent-data-collection.md). --## Prerequisites --See the following articles for prerequisites and other requirements for Azure Monitor Agent: --* [Azure Monitor Agent supported operating systems and environments](./azure-monitor-agent-supported-operating-systems.md) -* [Azure Monitor Agent requirements](./azure-monitor-agent-requirements.md) -* [Azure Monitor Agent network configuration](./azure-monitor-agent-network-configuration.md) --> [!IMPORTANT] -> Installing, upgrading, or uninstalling Azure Monitor Agent won't require a machine restart. --## Installation options --The following table lists the different options for installing Azure Monitor Agent on Azure VMs and Azure Arc-enabled servers. The [Azure Arc agent](../../azure-arc/servers/deployment-options.md) must be installed on any machines not in Azure before Azure Monitor Agent can be installed. --| Installation method | Description | -|:|:| -| VM extension | Use any of the methods below to use the Azure extension framework to install the agent. This method does not create a DCR, so you must create at least one and associate it with the agent before data collection will begin. | -| [Create a DCR](./azure-monitor-agent-data-collection.md) | When you create a DCR in the Azure portal, Azure Monitor Agent is installed on any machines that are added as resources for the DCR. The agent will begin collecting data defined in the DCR immediately. -| [VM insights](../vm/vminsights-enable-overview.md) | When you enable VM insights on a machine, Azure Monitor Agent is installed, and a DCR is created that collects a predefined set of data. You shouldn't modify this DCR, but you can create additional DCRs to collect other data. | -| [Container insights](../containers/kubernetes-monitoring-enable.md#container-insights) | When you enable Container insights on a Kubernetes cluster, a containerized version of Azure Monitor Agent is installed in the cluster, and a DCR is created that immediately begins collecting data. You can modify this DCR using guidance at [Configure data collection and cost optimization in Container insights using data collection rule](../containers/container-insights-data-collection-dcr.md). -| [Client installer](./azure-monitor-agent-windows-client.md) | Installs the agent by using a Windows MSI installer for Windows 10 and Windows 11 clients. | -| [Azure Policy](./azure-monitor-agent-policy.md) | Use Azure Policy to automatically install the agent on Azure virtual machines and Azure Arc-enabled servers and automatically associate them with required DCRs. | --> [!NOTE] -> To send data across tenants, you must first enable [Azure Lighthouse](../../lighthouse/overview.md). -> Cloning a machine with Azure Monitor Agent installed is not supported. The best practice for these situations is to use [Azure Policy](../../azure-arc/servers/deploy-ama-policy.md) or an Infrastructure as a code tool to deploy AMA at scale. --## Install agent extension --This section provides details on installing Azure Monitor Agent using the VM extension. --### [Portal](#tab/azure-portal) -Use the guidance at [Collect data with Azure Monitor Agent](./azure-monitor-agent-data-collection.md) to install the agent using the Azure portal and create a DCR to collect data. --### [PowerShell](#tab/azure-powershell) --You can install Azure Monitor Agent on Azure virtual machines and on Azure Arc-enabled servers by using the PowerShell command for adding a virtual machine extension. --### Azure virtual machines --Use the following PowerShell commands to install Azure Monitor Agent on Azure virtual machines. Choose the appropriate command based on your chosen authentication method. --* Windows - ```powershell - ## User-assigned managed identity - Set-AzVMExtension -Name AzureMonitorWindowsAgent -ExtensionType AzureMonitorWindowsAgent -Publisher Microsoft.Azure.Monitor -ResourceGroupName <resource-group-name> -VMName <virtual-machine-name> -Location <location> -TypeHandlerVersion <version-number> -EnableAutomaticUpgrade $true -SettingString '{"authentication":{"managedIdentity":{"identifier-name":"mi_res_id","identifier-value":"/subscriptions/<my-subscription-id>/resourceGroups/<my-resource-group>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<my-user-assigned-identity>"}}}' - - ## System-assigned managed identity - Set-AzVMExtension -Name AzureMonitorWindowsAgent -ExtensionType AzureMonitorWindowsAgent -Publisher Microsoft.Azure.Monitor -ResourceGroupName <resource-group-name> -VMName <virtual-machine-name> -Location <location> -TypeHandlerVersion <version-number> -EnableAutomaticUpgrade $true - ``` --* Linux - ```powershell - ## User-assigned managed identity - Set-AzVMExtension -Name AzureMonitorLinuxAgent -ExtensionType AzureMonitorLinuxAgent -Publisher Microsoft.Azure.Monitor -ResourceGroupName <resource-group-name> -VMName <virtual-machine-name> -Location <location> -TypeHandlerVersion <version-number> -EnableAutomaticUpgrade $true -SettingString '{"authentication":{"managedIdentity":{"identifier-name":"mi_res_id","identifier-value":/subscriptions/<my-subscription-id>/resourceGroups/<my-resource-group>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<my-user-assigned-identity>"}}}' - - ## System-assigned managed identity - Set-AzVMExtension -Name AzureMonitorLinuxAgent -ExtensionType AzureMonitorLinuxAgent -Publisher Microsoft.Azure.Monitor -ResourceGroupName <resource-group-name> -VMName <virtual-machine-name> -Location <location> -TypeHandlerVersion <version-number> -EnableAutomaticUpgrade $true - ``` --### Azure virtual machines scale set --Use the [Add-AzVmssExtension](/powershell/module/az.compute/add-azvmssextension) PowerShell cmdlet to install Azure Monitor Agent on Azure virtual machines scale sets. --### Azure Arc-enabled servers --Use the following PowerShell commands to install Azure Monitor Agent on Azure Arc-enabled servers. --* Windows - ```powershell - New-AzConnectedMachineExtension -Name AzureMonitorWindowsAgent -ExtensionType AzureMonitorWindowsAgent -Publisher Microsoft.Azure.Monitor -ResourceGroupName <resource-group-name> -MachineName <arc-server-name> -Location <arc-server-location> -EnableAutomaticUpgrade - ``` --* Linux - ```powershell - New-AzConnectedMachineExtension -Name AzureMonitorLinuxAgent -ExtensionType AzureMonitorLinuxAgent -Publisher Microsoft.Azure.Monitor -ResourceGroupName <resource-group-name> -MachineName <arc-server-name> -Location <arc-server-location> -EnableAutomaticUpgrade - ``` --#### [Azure CLI](#tab/azure-cli) --You can install Azure Monitor Agent on Azure virtual machines and on Azure Arc-enabled servers by using the Azure CLI command for adding a virtual machine extension. --### Azure virtual machines --Use the following CLI commands to install Azure Monitor Agent on Azure virtual machines. Choose the appropriate command based on your chosen authentication method. --#### User-assigned managed identity --* Windows - ```azurecli - az vm extension set --name AzureMonitorWindowsAgent --publisher Microsoft.Azure.Monitor --ids <vm-resource-id> --enable-auto-upgrade true --settings '{"authentication":{"managedIdentity":{"identifier-name":"mi_res_id","identifier-value":"/subscriptions/<my-subscription-id>/resourceGroups/<my-resource-group>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<my-user-assigned-identity>"}}}' - ``` --* Linux - ```azurecli - az vm extension set --name AzureMonitorLinuxAgent --publisher Microsoft.Azure.Monitor --ids <vm-resource-id> --enable-auto-upgrade true --settings '{"authentication":{"managedIdentity":{"identifier-name":"mi_res_id","identifier-value":"/subscriptions/<my-subscription-id>/resourceGroups/<my-resource-group>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<my-user-assigned-identity>"}}}' - ``` --#### System-assigned managed identity --* Windows - ```azurecli - az vm extension set --name AzureMonitorWindowsAgent --publisher Microsoft.Azure.Monitor --ids <vm-resource-id> --enable-auto-upgrade true - ``` --* Linux - ```azurecli - az vm extension set --name AzureMonitorLinuxAgent --publisher Microsoft.Azure.Monitor --ids <vm-resource-id> --enable-auto-upgrade true - ``` --### Azure virtual machines scale set --Use the [az vmss extension set](/cli/azure/vmss/extension) CLI cmdlet to install Azure Monitor Agent on Azure virtual machines scale sets. --### Azure Arc-enabled servers --Use the following CLI commands to install Azure Monitor Agent on Azure Arc-enabled servers. --* Windows - ```azurecli - az connectedmachine extension create --name AzureMonitorWindowsAgent --publisher Microsoft.Azure.Monitor --type AzureMonitorWindowsAgent --machine-name <arc-server-name> --resource-group <resource-group-name> --location <arc-server-location> --enable-auto-upgrade true - ``` --* Linux - ```azurecli - az connectedmachine extension create --name AzureMonitorLinuxAgent --publisher Microsoft.Azure.Monitor --type AzureMonitorLinuxAgent --machine-name <arc-server-name> --resource-group <resource-group-name> --location <arc-server-location> --enable-auto-upgrade true - ``` --#### [Resource Manager template](#tab/azure-resource-manager) --You can use Resource Manager templates to install Azure Monitor Agent on Azure virtual machines and on Azure Arc-enabled servers and to create an association with data collection rules. You must create any data collection rule prior to creating the association. --Get sample templates for installing the agent and creating the association from the following resources: --* [Template to install Azure Monitor Agent (Azure and Azure Arc)](../agents/resource-manager-agent.md#azure-monitor-agent) -* [Template to create association with data collection rule](../essentials/data-collection-rule-create-edit.md?tabs=arm#create-a-dcr) --Install the templates by using [any deployment method for Resource Manager templates](../../azure-resource-manager/templates/deploy-powershell.md), such as the following commands. --* PowerShell - ```powershell - New-AzResourceGroupDeployment -ResourceGroupName "<resource-group-name>" -TemplateFile "<template-filename.json>" -TemplateParameterFile "<parameter-filename.json>" - ``` --* Azure CLI - ```azurecli - az deployment group create --resource-group "<resource-group-name>" --template-file "<path-to-template>" --parameters "@<parameter-filename.json>" - ``` ----## Uninstall --#### [Portal](#tab/azure-portal) --To uninstall Azure Monitor Agent by using the Azure portal, go to your virtual machine, scale set, or Azure Arc-enabled server. Select the **Extensions** tab and select **AzureMonitorWindowsAgent** or **AzureMonitorLinuxAgent**. In the dialog that opens, select **Uninstall**. --#### [PowerShell](#tab/azure-powershell) --### Uninstall on Azure virtual machines --Use the following PowerShell commands to uninstall Azure Monitor Agent on Azure virtual machines. --* Windows - ```powershell - Remove-AzVMExtension -Name AzureMonitorWindowsAgent -ResourceGroupName <resource-group-name> -VMName <virtual-machine-name> - ``` --* Linux - ```powershell - Remove-AzVMExtension -Name AzureMonitorLinuxAgent -ResourceGroupName <resource-group-name> -VMName <virtual-machine-name> - ``` --### Uninstall on Azure virtual machines scale set --Use the [Remove-AzVmssExtension](/powershell/module/az.compute/remove-azvmssextension) PowerShell cmdlet to uninstall Azure Monitor Agent on Azure virtual machines scale sets. --### Uninstall on Azure Arc-enabled servers --Use the following PowerShell commands to uninstall Azure Monitor Agent on Azure Arc-enabled servers. --* Windows - ```powershell - Remove-AzConnectedMachineExtension -MachineName <arc-server-name> -ResourceGroupName <resource-group-name> -Name AzureMonitorWindowsAgent - ``` --* Linux - ```powershell - Remove-AzConnectedMachineExtension -MachineName <arc-server-name> -ResourceGroupName <resource-group-name> -Name AzureMonitorLinuxAgent - ``` --#### [Azure CLI](#tab/azure-cli) --### Uninstall on Azure virtual machines --Use the following CLI commands to uninstall Azure Monitor Agent on Azure virtual machines. --* Windows - ```azurecli - az vm extension delete --resource-group <resource-group-name> --vm-name <virtual-machine-name> --name AzureMonitorWindowsAgent - ``` --* Linux - ```azurecli - az vm extension delete --resource-group <resource-group-name> --vm-name <virtual-machine-name> --name AzureMonitorLinuxAgent - ``` --### Uninstall on Azure virtual machines scale set --Use the [az vmss extension delete](/cli/azure/vmss/extension) CLI cmdlet to uninstall Azure Monitor Agent on Azure virtual machines scale sets. --### Uninstall on Azure Arc-enabled servers --Use the following CLI commands to uninstall Azure Monitor Agent on Azure Arc-enabled servers. --* Windows - ```azurecli - az connectedmachine extension delete --name AzureMonitorWindowsAgent --machine-name <arc-server-name> --resource-group <resource-group-name> - ``` --* Linux - ```azurecli - az connectedmachine extension delete --name AzureMonitorLinuxAgent --machine-name <arc-server-name> --resource-group <resource-group-name> - ``` --#### [Resource Manager template](#tab/azure-resource-manager) --N/A ----## Update --> [!NOTE] -> The recommendation is to enable [Automatic Extension Upgrade](/azure/virtual-machines/automatic-extension-upgrade) to update installed extensions to the stable version across all regions. A version is not automatically rolled out until it meets a high quality bar which can take as long as 5 weeks after the initial release. Upgrades are issued in batches, so you may see some of your virtual machines, scale-sets or Arc-enabled servers get upgraded before others. If you need to upgrade an extension immediately, you may use the manual instructions below. --#### [Portal](#tab/azure-portal) --To perform a one-time update of the agent, you must first uninstall the existing agent version. Then install the new version as described. --We recommend that you enable automatic update of the agent by enabling the [Automatic Extension Upgrade](/azure/virtual-machines/automatic-extension-upgrade) feature. Go to your virtual machine or scale set, select the **Extensions** tab and select **AzureMonitorWindowsAgent** or **AzureMonitorLinuxAgent**. In the dialog that opens, select **Enable automatic upgrade**. --#### [PowerShell](#tab/azure-powershell) --### Update on Azure virtual machines --To perform a one-time update of the agent, you must first uninstall the existing agent version, then install the new version as described. --We recommend that you enable automatic update of the agent by enabling the [Automatic Extension Upgrade](/azure/virtual-machines/automatic-extension-upgrade) feature by using the following PowerShell commands. --* Windows - ```powershell - Set-AzVMExtension -ExtensionName AzureMonitorWindowsAgent -ResourceGroupName <resource-group-name> -VMName <virtual-machine-name> -Publisher Microsoft.Azure.Monitor -ExtensionType AzureMonitorWindowsAgent -TypeHandlerVersion <version-number> -Location <location> -EnableAutomaticUpgrade $true - ``` --* Linux - ```powershell - Set-AzVMExtension -ExtensionName AzureMonitorLinuxAgent -ResourceGroupName <resource-group-name> -VMName <virtual-machine-name> -Publisher Microsoft.Azure.Monitor -ExtensionType AzureMonitorLinuxAgent -TypeHandlerVersion <version-number> -Location <location> -EnableAutomaticUpgrade $true - ``` --### Update on Azure Arc-enabled servers --To perform a one-time upgrade of the agent, use the following PowerShell commands. --* Windows - ```powershell - $target = @{"Microsoft.Azure.Monitor.AzureMonitorWindowsAgent" = @{"targetVersion"=<target-version-number>}} - Update-AzConnectedExtension -ResourceGroupName $env.ResourceGroupName -MachineName <arc-server-name> -ExtensionTarget $target - ``` --* Linux - ```powershell - $target = @{"Microsoft.Azure.Monitor.AzureMonitorLinuxAgent" = @{"targetVersion"=<target-version-number>}} - Update-AzConnectedExtension -ResourceGroupName $env.ResourceGroupName -MachineName <arc-server-name> -ExtensionTarget $target - ``` --We recommend that you enable automatic update of the agent by enabling the [Automatic Extension Upgrade](../../azure-arc/servers/manage-automatic-vm-extension-upgrade.md#manage-automatic-extension-upgrade) feature by using the following PowerShell commands. --* Windows - ```powershell - Update-AzConnectedMachineExtension -ResourceGroup <resource-group-name> -MachineName <arc-server-name> -Name AzureMonitorWindowsAgent -EnableAutomaticUpgrade - ``` --* Linux - ```powershell - Update-AzConnectedMachineExtension -ResourceGroup <resource-group-name> -MachineName <arc-server-name> -Name AzureMonitorLinuxAgent -EnableAutomaticUpgrade - ``` --#### [Azure CLI](#tab/azure-cli) --### Update on Azure virtual machines --To perform a one-time update of the agent, you must first uninstall the existing agent version, then install the new version as described. - -We recommend that you enable automatic update of the agent by enabling the [Automatic Extension Upgrade](/azure/virtual-machines/automatic-extension-upgrade) feature by using the following CLI commands. --* Windows - ```azurecli - az vm extension set --name AzureMonitorWindowsAgent --publisher Microsoft.Azure.Monitor --vm-name <virtual-machine-name> --resource-group <resource-group-name> --enable-auto-upgrade true - ``` --* Linux - ```azurecli - az vm extension set --name AzureMonitorLinuxAgent --publisher Microsoft.Azure.Monitor --vm-name <virtual-machine-name> --resource-group <resource-group-name> --enable-auto-upgrade true - ``` --### Update on Azure Arc-enabled servers --To perform a one-time upgrade of the agent, use the following CLI commands. --* Windows - ```azurecli - az connectedmachine upgrade-extension --extension-targets "{\"Microsoft.Azure.Monitor.AzureMonitorWindowsAgent\":{\"targetVersion\":\"<target-version-number>\"}}" --machine-name <arc-server-name> --resource-group <resource-group-name> - ``` --* Linux - ```azurecli - az connectedmachine upgrade-extension --extension-targets "{\"Microsoft.Azure.Monitor.AzureMonitorLinuxAgent\":{\"targetVersion\":\"<target-version-number>\"}}" --machine-name <arc-server-name> --resource-group <resource-group-name> - ``` - - We recommend that you enable automatic update of the agent by enabling the [Automatic Extension Upgrade](../../azure-arc/servers/manage-automatic-vm-extension-upgrade.md#manage-automatic-extension-upgrade) feature by using the following PowerShell commands. --* Windows - ```azurecli - az connectedmachine extension update --name AzureMonitorWindowsAgent --machine-name <arc-server-name> --resource-group <resource-group-name> --enable-auto-upgrade true - ``` --* Linux - ```azurecli - az connectedmachine extension update --name AzureMonitorLinuxAgent --machine-name <arc-server-name> --resource-group <resource-group-name> --enable-auto-upgrade true - ``` --#### [Resource Manager template](#tab/azure-resource-manager) --N/A ----## Configure (Preview) --[Data Collection Rules (DCRs)](../essentials/data-collection-rule-overview.md) serve as a management tool for Azure Monitor Agent (AMA) on your machine. The AgentSettings DCR can be used to configure AMA parameters like `DisQuotaInMb`, ensuring your agent is tailored to your specific monitoring needs. --> [!NOTE] -> Important considerations to keep in mind when working with the AgentSettings DCR: -> -> * The AgentSettings DCR can only be configured via template deployment. -> * AgentSettings is always it's own DCR and can't be added an existing one. -> * For proper functionality, both the machine and the AgentSettings DCR must be located in the same region. --### Supported parameters --The AgentSettings DCR currently supports configuring the following parameters: --| Parameter | Description | Valid values | -| | -- | -- | -| `MaxDiskQuotaInMB` | Defines the amount of disk space used by the Azure Monitor Agent log files and cache. | 1000-50000 (in MB) | -| `TimeReceivedForForwardedEvents` | Changes WEF column in the Sentinel WEF table to use TimeReceived instead of TimeGenerated data | 0 or 1 | --### Setting up AgentSettings DCR --#### [Portal](#tab/azure-portal) --Currently not supported. --#### [PowerShell](#tab/azure-powershell) --N/A --#### [Azure CLI](#tab/azure-cli) --N/A --#### [Resource Manager template](#tab/azure-resource-manager) --1. **Prepare the environment:** -- [Install AMA](#installation-options) on your VM. --1. **Create a DCR:** -- This example sets the maximum amount of disk space used by AMA cache to 5000 MB. -- ```json - { - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": {}, - "resources": [ - { - "type": "Microsoft.Insights/dataCollectionRules", - "name": "dcr-contoso-01", - "apiVersion": "2023-03-11", - "properties": - { - "description": "A simple agent settings", - "agentSettings": - { - "logs": [ - { - "name": "MaxDiskQuotaInMB", - "value": "5000" - } - ] - } - }, - "kind": "AgentSettings", - "location": "eastus" - } - ] - } - ``` - -1. **Associate the DCR with your machine:** -- Use these ARM template and parameter files: -- **ARM template file** - - ```json - { - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "type": "string", - "metadata": { - "description": "The name of the virtual machine." - } - }, - "associationName": { - "type": "string", - "metadata": { - "description": "The name of the association." - } - }, - "dataCollectionRuleId": { - "type": "string", - "metadata": { - "description": "The resource ID of the data collection rule." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/dataCollectionRuleAssociations", - "apiVersion": "2021-09-01-preview", - "scope": "[format('Microsoft.Compute/virtualMachines/{0}', parameters('vmName'))]", - "name": "[parameters('associationName')]", - "properties": { - "description": "Association of data collection rule. Deleting this association will break the data collection for this virtual machine.", - "dataCollectionRuleId": "[parameters('dataCollectionRuleId')]" - } - } - ] - } - ``` - - **Parameter file** - - ```json - { - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "value": "my-azure-vm" - }, - "associationName": { - "value": "my-windows-vm-my-dcr" - }, - "dataCollectionRuleId": { - "value": "/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/my-resource-group/providers/microsoft.insights/datacollectionrules/my-dcr" - } - } - } - ``` --1. **Activate the settings:** -- Restart AMA to apply changes. ----## Next steps --[Create a data collection rule](./azure-monitor-agent-data-collection.md) to collect data from the agent and send it to Azure Monitor. |
| azure-monitor | Azure Monitor Agent Migration Data Collection Rule Generator | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-migration-data-collection-rule-generator.md | - Title: Workspace configuration to DCR config generator -description: Using the Workspace configuration to DCR config generator to help migrate from MMA to AMA agents ---- Previously updated : 06/16/2024--# Customer intent: As an azure administrator, I want to understand how to use the workspace configuration to DCR config generator. ----# Convert workspace configuration to DCR configurations --Whereas Log Analytics Agent inherits its configuration from Log Analytics workspaces, the Azure Monitor Agent relies on data collection rules (DCRs) for configuration --The workspace configuration to DCR config generator is a PowerShell that reads the configuration from your workspace produce multiple DCR ARM templates, based on the MMA configurations present on the workspace. --## Prerequisites -- PowerShell version 7.1.3 or higher is recommended (minimum version 5.1)-- Az PowerShell module to pull workspace agent configuration information Az PowerShell module. To install the Az PowerShell module, see [Install Azure PowerShell on Windows](/powershell/azure/install-azps-windows)-- Read/Write access to the specified workspace resource--## Installation and execution --Download the [PowerShell script](https://github.com/microsoft/AzureMonitorCommunity/tree/master/Azure%20Services/Azure%20Monitor/Agents/Migration%20Tools/DCR%20Config%20Generator) from Git Hub. ---The script retrieves the configuration of the legacy agent configurations from the workspace and generates DCR ARM templates for each supported DCR type in the specified output folder. More than one template may be created, one for each DCR type. --For multiple workspaces with data collections configured, you must run the script for each workspace. IIS logs the script also creates an additional data collection role as part of that configuration. ---When the script completes, it prompts you to test the deployment of the template in your environment. Choose to either let it deploy the template for you, or store the template specified output folder --> [!NOTE] -> The script does not associate the DCRs with the workspace. You must create your own data collection rule associations (DCRAs), to associate the DCRs with the relevant servers. This allows you to control the deployment of the DCRs to the servers and test the DCRs on a sample of servers before deploying at scale. ---To run script, copy the following command and replace the parameters with your values: --```powershell - .\WorkspaceConfigToDCRMigrationTool.ps1 -SubscriptionId $subId -ResourceGroupName $rgName -WorkspaceName $workspaceName -DCRName $dcrName -OutputFolder $outputFolderPath -``` --### Script parameters ---| Name | Required | Description | -| -- |::|:--:| -| `SubscriptionId` | YES | The subscription ID of the workspace | -| `ResourceGroupName` | YES | The resource Group of the workspace | -| `WorkspaceName` | YES | The name of the workspace (Azure resource IDs are case insensitive) | -| `DCRName` | YES | The base name used for each one the outputs DCRs | -| `OutputFolder` | NO | The output folder path. If not provided, the working directory path is used | ---### Outputs: -- Currently supported DCR types: - - - **Windows** contains `WindowsPerfCounters` and `WindowsEventLogs` data sources only - - **Linux** contains `LinuxPerfCounters` and `Syslog` data sources only - - **Custom Logs** contains `logFiles` data sources only - - **IIS Logs** contains `iisLogs` data sources only - - **DependencyAgent** extension - - **Extensions** contains `extensions` data sources only along with any associated perfCounters data sources - - `VMInsights` --## Deployment --For information on deploying the DCRs, see [Data collection rules in Azure Monitor](/azure/azure-monitor/essentials/data-collection-rule-overview) and [Create and edit data collection rules (DCRs) in Azure Monitor](/azure/azure-monitor/essentials/data-collection-rule-create-edit) --> [!Warning] -> You shouldnΓÇÖt use an existing custom log table used by MMA agents. Your MMA agents won't be able to write to the table once the first AMA agent writes to the table. You should create a new table for AMA to use to prevent MMA data loss. --## Next steps --- [Azure Monitor Agent Migration Helper workbook](azure-monitor-agent-migration-helper-workbook.md)-- [Data collection rule structure](../essentials/data-collection-rule-structure.md) -- [Sample data collection rules (DCRs)](../essentials/data-collection-rule-samples.md) for sample DCRs for different data collection scenarios.-- [Azure Monitor service limits](../service-limits.md#data-collection-rules) for limits that apply to each DCR. |
| azure-monitor | Azure Monitor Agent Migration Helper Workbook | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-migration-helper-workbook.md | - Title: Azure Monitor Agent Migration Helper workbook -description: Plan your migration from the Log Analytics Agent to the Azure Monitor Agent using the Azure Monitor Agent Migration Helper workbook. ---- Previously updated : 09/03/2024--# Customer intent: As an azure administrator, I want to understand how the Azure Monitor Agent Migration Helper workbook can help me in migrating from the MMA agent to the AMA agent. ----# Azure Monitor Agent Migration Helper workbook --Azure Monitor Agent Migration Helper workbook is a workbook-based Azure Monitor solution that helps you discover what to migrate and track progress as you move from Log Analytics Agent to Azure Monitor Agent. Use this single pane of glass view to expedite and track the status of your agent migration journey. The helper now supports multiple subscriptions, and includes automatic migration recommendations based on your usage. --## Using the AMA workbook --To open the workbook: -1. Navigate to the **Monitor** page in the Azure portal, and select **Workbooks**. -1. In the **Workbooks** pane, scroll down to the **AMA Migration Helper** workbook, and select it. ---The workbook opens on the **Subscriptions Overview** tab. -This page provides a high-level view of the resources in your subscriptions, which agents are deployed, and the migration status. Use this page to keep track of the migration status of your resources across your subscriptions. --On the subscriptions overview tab, the workbook automatically detects the following resources: -- Subscriptions -- Workspaces-- Azure Virtual Machines-- Virtual Machine Scale Sets-- Arc-enabled servers-- Hybrid machines without Arc where the legacy agent is deployed--Each item has a tab that provides a detailed view of the resources in that category. -- :::image type="content" source="./media/azure-monitor-agent-migration-helper-workbook/subscriptions-overview.png" lightbox="./media/azure-monitor-agent-migration-helper-workbook/subscriptions-overview.png" alt-text="A screenshot showing subscriptions overview tab."::: --The Migration status table appears at the bottom of the page. --The table includes the following columns: -- Subscription-- Resource Type-- Resource count-- How many resources have both agents deployed-- How many resources have only the Log Analytics Agent deployed-- How many resources have only the Azure Monitor Agent deployed-- Migration status--The table can be exported to Excel to allow you to work offline or share the data. --The following image shows the migration status table with the following statuses: --- Not Started: Resources that don't have any Azure Monitor Agents deployed.-- In progress: Resources that have both agents deployed.-- Completed: Resources that have only the Azure Monitor Agent deployed.--- :::image type="content" source="./media/azure-monitor-agent-migration-helper-workbook/migration-status.png" lightbox="./media/azure-monitor-agent-migration-helper-workbook/migration-status.png" alt-text="A screenshot showing the migration status table."::: --### Azure Virtual Machines, Azure Virtual Machine Scale Sets, and Arc-enabled servers tabs --The Azure Virtual Machines and Scale Sets tabs provides a detailed view of the Azure Virtual Machines, Virtual Machine Scale Sets and Arc-enabled serves in your subscriptions. These machines are listed regardless of the workspace to which they send telemetry. -The table provides a view of the migration status is per machine showing which agents are deployed, the last time a heartbeat was sent to one of your workspaces, and the migration status. -- :::image type="content" source="./media/azure-monitor-agent-migration-helper-workbook/azure-virtual-machines-tab.png" lightbox="./media/azure-monitor-agent-migration-helper-workbook/azure-virtual-machines-tab.png" alt-text="A screenshot showing the Azure Virtual Machines migration status tab."::: --### Hybrid machines without Arc --The Hybrid machines without Arc tab provide a detailed view of the hybrid machines in your subscriptions that aren't Arc-enables but have the legacy agent deployed. The table includes the Log Analytics workspace that the machine sends telemetry to, the last time the machine sent a heartbeat to the workspace -- :::image type="content" source="./media/azure-monitor-agent-migration-helper-workbook/hybrid-machines-tab.png" lightbox="./media/azure-monitor-agent-migration-helper-workbook/hybrid-machines-tab.png" alt-text="A screenshot showing the Hybrid machines without Arc migration status tab."::: ---### Workspaces --The **Workspace** tab provides a detailed view of the workspaces in your subscriptions. Choose a specific workspace to view using the dropdown above the table. The dropdown at the top of the page doesn't filter the table. --On the **Agents** tab, the table shows how many resources of each type are sending telemetry to the workspace, which agent is configured and the migration status. -- :::image type="content" source="./media/azure-monitor-agent-migration-helper-workbook/workspace-agents-tab.png" lightbox="./media/azure-monitor-agent-migration-helper-workbook/workspace-agents-tab.png" alt-text="A screenshot showing the workspace agents tab."::: --The **Solutions** tab shows the legacy solutions that have been deployed into the workspace and the recommended migration steps are for that specific solution. Select the recommendation for more information. The last time data any kind of logs or telemetry was received from teach solution is listed. ---You can also see this information in the **Legacy solutions** tab on your Log Analytics workspace page. --### Automation update management --The AMA migration Helper workbook provides you with guidance on which of your machines are using the update Management solution and how to migrate them. --The **Azure Automation Update Management** tab provides a detailed view of the machines in your subscriptions that are using the Update Management solution. It detects your automation accounts linked to your workspace, shows the machines that may require migration, their status, and the ability to migrate them. --Select **Migrate Now** to go to the Azure Update Manager migration tool(Preview). --For more information, see [Move from Automation Update Management to Azure Update Manager](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager) ----## Workspace Auditing workbook --The Azure Monitor Workspace Auditing workbook is another workbook tool to help you understand your workspaces. -This workbook collects all of your Log Analytics workspaces and shows you the following for each workspace: -1. All data sources that are sending data to the workspace. -1. The agents that are sending heartbeats to the workspace. -1. The resources that are sending data to the workspace. -1. Any Application Insights resources that are sending data to the workspace. --To use the Azure Monitor Workspace Auditing workbook, follow the steps below --1. Copy the workbook JSON from the [GitHub repository](https://github.com/microsoft/AzureMonitorCommunity/blob/master/Azure%20Services/Log%20Analytics%20workspaces/Workbooks/Workspace%20Audit.json). -1. In the Azure portal, navigate to the **Azure Monitor** page, and select **Workbooks**. -1. Select **+ New**. -1. Select the Advanced editor **</>** -1. Select **Gallery Template**. -1. Replace the text with the JSON from the GitHub repository. -1. Select **Apply**. ---The **Data Collection** tab shows the data sources that have been collected into this workspace over th last seven days. The table includes the data source, whether it's billable and the volume of data ingested, and the last time data was received from that data source. ---The following tabs are also available in the workbook: -- **Agents**: Lists the agents that are sending heartbeats to the workspace. -- **Azure Resources**: Lists the resources that are sending data to the workspace. -- **Application Insights**: The Application Insights resources that are sending data to the workspace. |
| azure-monitor | Azure Monitor Agent Migration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-migration.md | - Title: Migrate to Azure Monitor Agent from Log Analytics agent -description: Guidance for migrating to Azure Monitor Agent from MMA ---- Previously updated : 08/13/2024--# Customer intent: As an azure administrator, I want to understand the process of migrating from the MMA agent to the AMA agent. ----# Migrate to Azure Monitor Agent from Log Analytics agent --[Azure Monitor Agent (AMA)](./agents-overview.md) replaces the Log Analytics agent, also known as Microsoft Monitor Agent (MMA) and OMS, for Windows and Linux machines, in Azure and non-Azure environments, on-premises and other clouds. The agent introduces a simplified, flexible method of configuring data collection using [Data Collection Rules (DCRs)](../essentials/data-collection-rule-overview.md). This article provides guidance on how to implement a successful migration from the Log Analytics agent to Azure Monitor Agent. --Migration is a complex task. Start planning your migration to Azure Monitor Agent using the information in this article as a guide. --> [!IMPORTANT] -> The Log Analytics agent will be [retired on **August 31, 2024**](https://azure.microsoft.com/updates/were-retiring-the-log-analytics-agent-in-azure-monitor-on-31-august-2024/). The depreciation does not apply to MMA agent connected exclusively to an On-Prem SCOM installation. -> -> You can expect the following when you use the MMA or OMS agent after August 31, 2024. -> - **Data upload:** Cloud ingestion services will gradually reduce support for MMA agents, which may result in decreased support and potential compatibility issues for MMA agents over time. Ingestion for MMA will be unchanged until February 1 2025. -> - **Installation:** The ability to install the legacy agents will be removed from the Azure Portal and installation policies for legacy agents will be removed. You can still install the MMA agents extension as well as perform offline installations. -> - **Customer Support:** You will not be able to get support for legacy agent issues. -> - **OS Support:** Support for new Linux or Windows distros, including service packs, won't be added after the deprecation of the legacy agents. -> - Log Analytics Agent can coexist with Azure Monitor Agent. Expect to see duplicate data if both agents are collecting the same data. --  --## Benefits -Using Azure Monitor agent, you get immediate benefits as shown below: ---- **Cost savings** by [using data collection rules](./azure-monitor-agent-data-collection.md):- - Enables targeted and granular data collection for a machine or subset(s) of machines, as compared to the "all or nothing" approach of legacy agents. - - Allows filtering rules and data transformations to reduce the overall data volume being uploaded, thus lowering ingestion and storage costs significantly. -- **Security and Performance**- - Enhanced security through Managed Identity and Microsoft Entra tokens (for clients). - - Higher event throughput that is 25% better than the legacy Log Analytics (MMA/OMS) agents. -- **Simpler management** including efficient troubleshooting:- - Supports data uploads to multiple destinations (multiple Log Analytics workspaces, i.e. *multihoming* on Windows and Linux) including cross-region and cross-tenant data collection (using Azure LightHouse). - - Centralized agent configuration "in the cloud" for enterprise scale throughout the data collection lifecycle, from onboarding to deployment to updates and changes over time. - - Any change in configuration is rolled out to all agents automatically, without requiring a client side deployment. - - Greater transparency and control of more capabilities and services, such as Microsoft Sentinel, Defender for Cloud, and VM Insights. -- **A single agent** that serves all data collection needs across [supported](./azure-monitor-agent-supported-operating-systems.md) servers and client devices. A single agent is the goal, although Azure Monitor Agent is currently converging with the Log Analytics agents.--## Before you begin --- Review the [prerequisites](/azure/azure-monitor/agents/azure-monitor-agent-manage#prerequisites) for installing Azure Monitor Agent.-To monitor non-Azure and on-premises servers, you must install the Azure Arc agent. The Arc agent makes your on-premises servers visible to Azure as a resource it can target. You don't incur any additional cost for installing the Azure Arc agent. --- Verify that Azure Monitor Agent can address all of your needs. Azure Monitor Agent is General Availability (GA) for data collection and is used for data collection by various Azure Monitor features and other Azure services.-- Verify that you have the necessary permissions to install the Azure Monitor Agent. You must have the necessary permissions to install the agent on the machines you want to monitor. For more information, see [Permissions required to install the Azure Monitor Agent](/azure/azure-monitor/agents/azure-monitor-agent-manage#permissions-required-to-install-the-azure-monitor-agent).--## High level guidance --Use the following guidance to plan and execute your migration: --- Understand your agents and how many you have to migrate.-- Understand how you're using your workspaces.-- Understand which solutions, insights, and data collections that are configured.-- Configure your data collections and validate the collections.-- Understand additional dependencies and services.-- Remove the legacy agents.--The **Azure Monitor Agent Migration Helper** workbook is a workbook-based Azure Monitor solution that can help you at each of the steps outlined above. This guide references the workbook and other tools at each stage of the migration process. For more information, see [Azure Monitor Agent Migration Helper workbook](./azure-monitor-agent-migration-helper-workbook.md). --## Understand your agents --Use the [DCR generator](./azure-monitor-agent-migration-data-collection-rule-generator.md) to convert your legacy agent configuration into [data collection rules](../essentials/data-collection-rule-overview.md) automatically.<sup>1</sup> -To help understand your agents, review the following questions: --|**Question**|**Actions**| -||| -|**How many agents do you have to migrate ?**|Understand the number of agents you have to migrate.| -|**Do you have any agents that are deployed outside of Azure?** <p>Are these agents deployed in your own data center or in another cloud environment? | For servers that are outside of Azure, you must first deploy the Azure ARC Connected Machine Agent. For more information, see [Overview of Azure Connected Machine agent](/azure/azure-arc/servers/agent-overview).| -|**Are you using System Center Operations Manager (SCOM) ?**<p> What your intended plan for SCOM going forward?|If you're planning on continuing to use SCOM, start evaluating SCOM Managed Instance. For more information, see [SCOM Managed Instance](/system-center/scom/operations-manager-managed-instance-overview).| -|**How are you deploying your agents today?**| If you're using any automated methods to deploy the legacy agent, consider when to stop those automated deployments for new servers, and start focusing on deploying the new agent. Stopping automated deployment for new servers helps ensure that you don't keep adding to your migration effort and lets you focus on the existing inventory of agents to migrate. --The Azure Monitor Agent Migration Helper Workbook can help you understand how many agents you have to migrate. For more information, see [Azure Monitor Agent migration helper workbook- Agents](./azure-monitor-agent-migration-helper-workbook.md#using-the-ama-workbook).| ---## Understand your workspaces, solutions, insights, and data collections --Before migration, understand how your Log Analytics workspaces are being used. Check if they're all in use and which agents are sending their telemetry to which workspaces. Many workspaces get created over time, and it can become unclear which workspaces are actually in use, which workspaces are being used to collect telemetry, and from which servers. Migration is a good opportunity to clean up and consolidate your workspaces. --When looking at your workspaces, note which solutions are configured. This information is important to understand what data you're collecting and how you're using it. --The Azure Monitor Agent Migration Helper Workbook can help you understand which workspaces you have, and the solutions implemented in each workspace, and when you last used the solution. Each solution has a migration recommendation. For more information, see [Azure Monitor Agent migration helper workbook- Workspaces](./azure-monitor-agent-migration-helper-workbook.md#workspaces) --You can also use the Azure Monitor Workspace Auditing workbook to help you understand your workspaces. To use the Azure Monitor Workspace Auditing workbook, copy the workbook from the [GitHub repository](https://github.com/microsoft/AzureMonitorCommunity/blob/master/Azure%20Services/Log%20Analytics%20workspaces/Workbooks/Workspace%20Audit.json) and import it into your Log Analytics workspace. --This workbook collects all of your Log Analytics workspaces and shows you the following for each workspace: -- All data sources that are sending data to the workspace.-- The agents that are sending heartbeats to the workspace. -- The resources that are sending data to the workspace.-- Any Application Insights resources that are sending data to the workspace.--For more information, see [Azure Monitor Workspace Auditing workbook](./azure-monitor-agent-migration-helper-workbook.md#workspace-auditing-workbook). ---## Configure your data collections and validate the collections --When configuring your data collections, consider the following steps: --- Identify a pilot group of servers that you can use for this process. Use the pilot servers to validate the data before you deploy at scale.--- Use the DCR Config Generator to transform the data collections that are configured in the workspace and deploy them as data collection rules back into your environment. For more information on the DCR Config Generator, see [DCR Config Generator](./azure-monitor-agent-migration-data-collection-rule-generator.md).-- Migrate VM Insights or Azure Monitor for Virtual Machines to the Azure Monitor Agent. Validate the migrated data collections for the pilot group of servers compared with what was collected before migration. To avoid double ingestion, you can disable data collection from legacy agents during the testing phase without uninstalling the agents yet, by removing the workspace configurations for legacy agents. For more information, see [Log Analytics agent data sources in Azure Monitor](/azure/azure-monitor/agents/agent-data-sources#configure-data-sources)--- Validate the new data to ensure there are no gaps. Compare the data ingested by legacy agent data to Azure Monitor Agent. Use KQL to compare equivalent data from each agent based on agent type.--- Plan deployment at scale using Azure policy. Use built-in policies to deploy extensions and DCR associations at scale. Using policy also ensures automatic deployment of extensions and DCR associations for new machines. For more information on deploying at scale, see [Manage Azure Monitor Agent - Use Azure policies](/azure/azure-monitor/agents/azure-monitor-agent-manage#use-azure-policy).----## Understand additional dependencies and services --Before migration it's important to understand how your other services are impacted. --|Service|Impact| -||| -|Update Management|If you're using Update Management under Azure Automation, you must migrate to Azure Update Manager.<p> Azure Update Manager has its own agent and is decoupled from the Azure Monitor agent.<p>Update Management will be deprecated at the end of August 2024. We recommend migrating to Azure Update Manager.<p>For more information, see [Move from Automation Update Management to Azure Update Manager](/azure/update-manager/guidance-migration-automation-update-management-azure-update-manager).<p>The AMA migration Helper workbook shows you which of your machines are using the update Management solution today and how to migrate them. For more information, see [Azure Monitor Agent migration helper workbook- Update management](./azure-monitor-agent-migration-helper-workbook.md#automation-update-management).| -|Change Tracking and Inventory|If you're using Change Tracking and Inventory, you must migrate to Azure Automation.<p>Change Tracking and Inventory are also part of Azure Automation. While Azure Monitor Agent has a change tracking and inventory solution, you must create a data collection rule. For more information, see [Manage change tracking and inventory using Azure Monitoring Agent](/azure/automation/change-tracking/manage-change-tracking-monitoring-agent).| -|Defender for cloud|If you're using Defender for Cloud for your service or Defender for servers and you have P2 enabled or plan to enable P2 for your servers, change your agent deployment in Defender for Cloud from the legacy agent deployment to agent-less scanning.<p>If you're using Defender for Cloud to collect security events, create a custom data collection rule to collect those events.| -|Microsoft Sentinel|If you're using Microsoft Sentinel, the solutions that were using the legacy agent have been converted to Azure Monitor Agent based solutions, and can be updated.| --## Remove the legacy agents --As part of your migration planning, plan to remove the legacy agent once migration is complete to avoid duplication of data collection. --If you don't need to retain the MMA on any of your machines, use the MMA Discovery and Removal tool to remove the agent at scale. For more information on the MMA Discovery and Removal tool, see [MMA Discovery and Removal tool](/azure/azure-monitor/agents/azure-monitor-agent-mma-removal-tool?tabs=single-tenant%2Cdiscovery). --If however you're using System Center Operations Manager (SCOM), keep the MMA agent deployed to the machines that you'll continue managing with System Center Operations Manager. --A SCOM Admin Management Pack exists and can help you remove the workspace configurations at scale while retaining the SCOM Management Group configuration. For more information on the SCOM Admin Management Pack, see [SCOM Admin Management Pack](https://github.com/thekevinholman/SCOM.Management). ---## Known Migration Issues -- IIS Logs: When IIS log collection is enabled, AMA might not populate the `sSiteName` column of the `W3CIISLog` table. This field gets collected by default when IIS log collection is enabled for the legacy agent. If you need to collect the `sSiteName` field using AMA, enable the `Service Name (s-sitename)` field in W3C logging of IIS. For steps to enable this field, see [Select W3C Fields to Log](/iis/manage/provisioning-and-managing-iis/configure-logging-in-iis#select-w3c-fields-to-log).-- SQL Assessment Solution: This is now part of SQL best practice assessment. The deployment policies require one Log Analytics Workspace per subscription, which isn't the best practice recommended by the AMA team.-- Microsoft Defender for cloud: is moving to an agent-less solution. Some features will not be ready by the deprecation date. Customers should stay on MMA for machines that use File Integrity Monitoring (FIM), Endpoint protection discovery recommendations, OS Misconfigurations (Azure Security Benchmark (ASB) recommendations) and Adaptive Application controls.-- Update management is moving to an agent-less solution but will not be ready by the MMA depreciation date. Customers that use Update Management should stay on MMA until the new service Automated Update Manager is ready.----## Next steps --- [Azure Monitor Agent migration helper workbook](./azure-monitor-agent-migration-helper-workbook.md)-- [DCR Config Generator](./azure-monitor-agent-migration-data-collection-rule-generator.md)-- [MMA Discovery and Removal tool](/azure/azure-monitor/agents/azure-monitor-agent-mma-removal-tool?tabs=single-tenant%2Cdiscovery) |
| azure-monitor | Azure Monitor Agent Mma Removal Tool | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-mma-removal-tool.md | - Title: MMA Discovery and Removal Utility -description: This article describes a PowerShell script to remove the legacy agent from systems that migrated to the Azure Monitor Agent. ---- Previously updated : 07/30/2024--# Customer intent: As an Azure account administrator, I want to use the available Azure Monitor tools to migrate from the Log Analytics Agent to the Azure Monitor Agent and track the status of the migration in my account. --# MMA/OMS Discovery and Removal Utility --After you migrate your machines to the Azure Monitor Agent (AMA), remove the legacy Log Analytics Agent depending on your operating systems, to avoid duplication of logs. The legacy Discovery and Removal Utility can remove the extensions from Azure Virtual Machines (VMs), Azure Virtual Machine Scale Sets (VMSSs), and Azure Arc servers from a single subscription. --The utility works in two steps: --1. *Discovery*: The utility creates an inventory of all machines that have a legacy agent installed in a simple CSV file. We recommend that you don't create any new VMs while the utility is running. --2. *Removal*: The utility removes the legacy agent from machines listed in the CSV file. You should edit the list of machine in the CSV file to ensure that only machines you want the agent removed from are present. -->!Note -> The removal does not work on MMA agents that were installed using the MSI installer. It only works on the VM extensions. -> --## Prerequisites -Do all the setup steps on an Internet connected machine. You need: --- Windows 10 or later, or Windows Server 2019 or later.-- [PowerShell 7.0 or later.](/powershell/scripting/install/installing-powershell?view=powershell-7.4&preserve-view=true), which enables parallel execution that speeds the process up.-- Azcli must be installed to communicate with the [Azure Graph API.](/cli/azure/install-azure-cli-windows?tabs=azure-cli). -1. Open PowerShell as administrator: -2. Run the command: `Invoke-WebRequest -Uri https://aka.ms/installazurecliwindows -OutFile AzureCLI.msi`. -3. Run the command: `Start-Process msiexec.exe -Wait -ArgumentList '/I AzureCLI.msi /quiet'`. -4. The latest version of Azure CLI will download and install. ---## Step 1 Login and set subscription -The tool works one subscription at a time. You must log in and set the subscription to do the removal. Open a PowerShell command prompt as administrator and login. --``` PowerShell -az login - ``` -Next you must set your subscription. --``` PowerShell -Az account set --subscription {subscription_id or ΓÇ£subscription_nameΓÇ¥} - ``` -## Step 2 Copy the script --You use the following script for agent removal. Open a file in your local directory named LogAnalyticsAgentUninstallUtilityScript.ps1 and copy the script into the file. - ``` PowerShell -# This is per subscription, the customer has to set the az subscription before running this. -# az login -# az account set --subscription <subscription_id/subscription_name> -# This script uses parallel processing, modify the $parallelThrottleLimit parameter to either increase or decrease the number of parallel processes -# PS> .\LogAnalyticsAgentUninstallUtilityScript.ps1 GetInventory -# The above command will generate a csv file with the details of Vm's and Vmss and Arc servers that has log analyice Agent extension installed. -# The customer can modify the the csv by adding/removing rows if needed -# Remove the log analytics agent by running the script again as shown below: -# PS> .\LogAnalyticsAgentUninstallUtilityScript.ps1 UninstallExtension --# This version of the script requires Powershell version >= 7 in order to improve performance via ForEach-Object -Parallel -# https://docs.microsoft.com/en-us/powershell/scripting/whats-new/migrating-from-windows-powershell-51-to-powershell-7?view=powershell-7.1 -if ($PSVersionTable.PSVersion.Major -lt 7) -{ - Write-Host "This script requires Powershell version 7 or newer to run. Please see https://docs.microsoft.com/en-us/powershell/scripting/whats-new/migrating-from-windows-powershell-51-to-powershell-7?view=powershell-7.1." - exit 1 -} --$parallelThrottleLimit = 16 --function GetArcServersWithLogAnalyticsAgentExtensionInstalled { - param ( - $fileName - ) - - $serverList = az connectedmachine list --query "[].{ResourceId:id, ResourceGroup:resourceGroup, ServerName:name}" | ConvertFrom-Json - if(!$serverList) - { - Write-Host "Cannot get the Arc server list" - return - } -- $serversCount = $serverList.Length - $vmParallelThrottleLimit = $parallelThrottleLimit - if ($serversCount -lt $vmParallelThrottleLimit) - { - $serverParallelThrottleLimit = $serversCount - } -- $serverGroups = @() -- if($serversCount -eq 1) - { - $serverGroups += ,($serverList[0]) - } - else - { - # split the list into batches to do parallel processing - for ($i = 0; $i -lt $serversCount; $i += $vmParallelThrottleLimit) - { - $serverGroups += , ($serverList[$i..($i + $serverParallelThrottleLimit - 1)]) - } - } -- Write-Host "Detected $serversCount Arc servers in this subscription." - $hash = [hashtable]::Synchronized(@{}) - $hash.One = 1 -- $serverGroups | Foreach-Object -ThrottleLimit $parallelThrottleLimit -Parallel { - $len = $using:serversCount - $hash = $using:hash - $_ | ForEach-Object { - $percent = 100 * $hash.One++ / $len - Write-Progress -Activity "Getting Arc server extensions Inventory" -PercentComplete $percent - $serverName = $_.ServerName - $resourceGroup = $_.ResourceGroup - $resourceId = $_.ResourceId - Write-Debug "Getting extensions for Arc server: $serverName" - $extensions = az connectedmachine extension list -g $resourceGroup --machine-name $serverName --query "[?contains(['MicrosoftMonitoringAgent', 'OmsAgentForLinux', 'AzureMonitorLinuxAgent', 'AzureMonitorWindowsAgent'], properties.type)].{type: properties.type, name: name}" | ConvertFrom-Json -- if (!$extensions) { - return - } - $extensionMap = @{} - foreach ($ext in $extensions) { - $extensionMap[$ext.type] = $ext.name - } - if ($extensionMap.ContainsKey("MicrosoftMonitoringAgent")) { - $extensionName = $extensionMap["MicrosoftMonitoringAgent"] - } - elseif ($extensionMap.ContainsKey("OmsAgentForLinux")) { - $extensionName = $extensionMap["OmsAgentForLinux"] - } - if ($extensionName) { - $amaExtensionInstalled = "False" - if ($extensionMap.ContainsKey("AzureMonitorWindowsAgent") -or $extensionMap.ContainsKey("AzureMonitorLinuxAgent")) { - $amaExtensionInstalled = "True" - } - $csvObj = New-Object -TypeName PSObject -Property @{ - 'ResourceId' = $resourceId - 'Name' = $serverName - 'Resource_Group' = $resourceGroup - 'Resource_Type' = "ArcServer" - 'Install_Type' = "Extension" - 'Extension_Name' = $extensionName - 'AMA_Extension_Installed' = $amaExtensionInstalled - } - $csvObj | Export-Csv $using:fileName -Append -Force | Out-Null - } - # az cli sometime cannot handle many requests at same time, so delaying next request by 2 milliseconds - Start-Sleep -Milliseconds 2 - } - } -} --function GetVmsWithLogAnalyticsAgentExtensionInstalled -{ - param( - $fileName - ) - - $vmList = az vm list --query "[].{ResourceId:id, ResourceGroup:resourceGroup, VmName:name}" | ConvertFrom-Json - - if(!$vmList) - { - Write-Host "Cannot get the VM list" - return - } -- $vmsCount = $vmList.Length - $vmParallelThrottleLimit = $parallelThrottleLimit - if ($vmsCount -lt $vmParallelThrottleLimit) - { - $vmParallelThrottleLimit = $vmsCount - } -- if($vmsCount -eq 1) - { - $vmGroups += ,($vmList[0]) - } - else - { - # split the vm's into batches to do parallel processing - for ($i = 0; $i -lt $vmsCount; $i += $vmParallelThrottleLimit) - { - $vmGroups += , ($vmList[$i..($i + $vmParallelThrottleLimit - 1)]) - } - } -- Write-Host "Detected $vmsCount Vm's in this subscription." - $hash = [hashtable]::Synchronized(@{}) - $hash.One = 1 -- $vmGroups | Foreach-Object -ThrottleLimit $parallelThrottleLimit -Parallel { - $len = $using:vmsCount - $hash = $using:hash - $_ | ForEach-Object { - $percent = 100 * $hash.One++ / $len - Write-Progress -Activity "Getting VM extensions Inventory" -PercentComplete $percent - $resourceId = $_.ResourceId - $vmName = $_.VmName - $resourceGroup = $_.ResourceGroup - Write-Debug "Getting extensions for VM: $vmName" - $extensions = az vm extension list -g $resourceGroup --vm-name $vmName --query "[?contains(['MicrosoftMonitoringAgent', 'OmsAgentForLinux', 'AzureMonitorLinuxAgent', 'AzureMonitorWindowsAgent'], typePropertiesType)].{type: typePropertiesType, name: name}" | ConvertFrom-Json - - if (!$extensions) { - return - } - $extensionMap = @{} - foreach ($ext in $extensions) { - $extensionMap[$ext.type] = $ext.name - } - if ($extensionMap.ContainsKey("MicrosoftMonitoringAgent")) { - $extensionName = $extensionMap["MicrosoftMonitoringAgent"] - } - elseif ($extensionMap.ContainsKey("OmsAgentForLinux")) { - $extensionName = $extensionMap["OmsAgentForLinux"] - } - if ($extensionName) { - $amaExtensionInstalled = "False" - if ($extensionMap.ContainsKey("AzureMonitorWindowsAgent") -or $extensionMap.ContainsKey("AzureMonitorLinuxAgent")) { - $amaExtensionInstalled = "True" - } - $csvObj = New-Object -TypeName PSObject -Property @{ - 'ResourceId' = $resourceId - 'Name' = $vmName - 'Resource_Group' = $resourceGroup - 'Resource_Type' = "VM" - 'Install_Type' = "Extension" - 'Extension_Name' = $extensionName - 'AMA_Extension_Installed' = $amaExtensionInstalled - } - $csvObj | Export-Csv $using:fileName -Append -Force | Out-Null - } - # az cli sometime cannot handle many requests at same time, so delaying next request by 2 milliseconds - Start-Sleep -Milliseconds 2 - } - } -} --function GetVmssWithLogAnalyticsAgentExtensionInstalled -{ - param( - $fileName - ) -- # get the vmss list which are successfully provisioned - $vmssList = az vmss list --query "[?provisioningState=='Succeeded'].{ResourceId:id, ResourceGroup:resourceGroup, VmssName:name}" | ConvertFrom-Json -- $vmssCount = $vmssList.Length - Write-Host "Detected $vmssCount Vmss in this subscription." - $hash = [hashtable]::Synchronized(@{}) - $hash.One = 1 -- $vmssList | Foreach-Object -ThrottleLimit $parallelThrottleLimit -Parallel { - $len = $using:vmssCount - $hash = $using:hash - $percent = 100 * $hash.One++ / $len - Write-Progress -Activity "Getting VMSS extensions Inventory" -PercentComplete $percent - $resourceId = $_.ResourceId - $vmssName = $_.VmssName - $resourceGroup = $_.ResourceGroup - Write-Debug "Getting extensions for VMSS: $vmssName" - $extensions = az vmss extension list -g $resourceGroup --vmss-name $vmssName --query "[?contains(['MicrosoftMonitoringAgent', 'OmsAgentForLinux', 'AzureMonitorLinuxAgent', 'AzureMonitorWindowsAgent'], typePropertiesType)].{type: typePropertiesType, name: name}" | ConvertFrom-Json - - if (!$extensions) { - return - } - $extensionMap = @{} - foreach ($ext in $extensions) { - $extensionMap[$ext.type] = $ext.name - } - if ($extensionMap.ContainsKey("MicrosoftMonitoringAgent")) { - $extensionName = $extensionMap["MicrosoftMonitoringAgent"] - } - elseif ($extensionMap.ContainsKey("OmsAgentForLinux")) { - $extensionName = $extensionMap["OmsAgentForLinux"] - } - if ($extensionName) { - $amaExtensionInstalled = "False" - if ($extensionMap.ContainsKey("AzureMonitorWindowsAgent") -or $extensionMap.ContainsKey("AzureMonitorLinuxAgent")) { - $amaExtensionInstalled = "True" - } - $csvObj = New-Object -TypeName PSObject -Property @{ - 'ResourceId' = $resourceId - 'Name' = $vmssName - 'Resource_Group' = $resourceGroup - 'Resource_Type' = "VMSS" - 'Install_Type' = "Extension" - 'Extension_Name' = $extensionName - 'AMA_Extension_Installed' = $amaExtensionInstalled - } - $csvObj | Export-Csv $using:fileName -Append -Force | Out-Null - } - # az cli sometime cannot handle many requests at same time, so delaying next request by 2 milliseconds - Start-Sleep -Milliseconds 2 - } -} --function GetInventory -{ - param( - $fileName = "LogAnalyticsAgentExtensionInventory.csv" - ) -- # create a new file - New-Item -Name $fileName -ItemType File -Force -- Start-Transcript -Path $logFileName -Append - GetVmsWithLogAnalyticsAgentExtensionInstalled $fileName - GetVmssWithLogAnalyticsAgentExtensionInstalled $fileName - GetArcServersWithLogAnalyticsAgentExtensionInstalled $fileName - Stop-Transcript -} --function UninstallExtension -{ - param( - $fileName = "LogAnalyticsAgentExtensionInventory.csv" - ) - Start-Transcript -Path $logFileName -Append - Import-Csv $fileName | ForEach-Object -ThrottleLimit $parallelThrottleLimit -Parallel { - if ($_.Install_Type -eq "Extension") - { - $extensionName = $_.Extension_Name - $resourceName = $_.Name - Write-Debug "Uninstalling extension: $extensionName from $resourceName" - if ($_.Resource_Type -eq "VMSS") - { - # if the extension is installed with a custom name, provide the name using the flag: --extension-instance-name <extension name> - az vmss extension delete --name $extensionName --vmss-name $resourceName --resource-group $_.Resource_Group --output none --no-wait - } - elseif($_.Resource_Type -eq "VM") - { - # if the extension is installed with a custom name, provide the name using the flag: --extension-instance-name <extension name> - az vm extension delete --name $extensionName --vm-name $resourceName --resource-group $_.Resource_Group --output none --no-wait - } - elseif($_.Resource_Type -eq "ArcServer") - { - az connectedmachine extension delete --name $extensionName --machine-name $resourceName --resource-group $_.Resource_Group --no-wait --output none --yes -y - } - # az cli sometime cannot handle many requests at same time, so delaying next delete request by 2 milliseconds - Start-Sleep -Milliseconds 2 - } - } - Stop-Transcript -} --$logFileName = "LogAnalyticsAgentUninstallUtilityScriptLog.log" --switch ($args.Count) -{ - 0 { - Write-Host "The arguments provided are incorrect." - Write-Host "To get the Inventory: Run the script as: PS> .\LogAnalyticsAgentUninstallUtilityScript.ps1 GetInventory" - Write-Host "To uninstall Log Analytics Agent from Inventory: Run the script as: PS> .\LogAnalyticsAgentUninstallUtilityScript.ps1 UninstallExtension" - } - 1 { - if (-Not (Test-Path $logFileName)) { - New-Item -Path $logFileName -ItemType File - } - $funcname = $args[0] - Invoke-Expression "& $funcname" - } - 2 { - if (-Not (Test-Path $logFileName)) { - New-Item -Path $logFileName -ItemType File - } - $funcname = $args[0] - $funcargs = $args[1] - Invoke-Expression "& $funcname $funcargs" - } -} -- ``` --## Step 3 Gets the inventory -You collect a list of all legacy agents on all VM, VMSSs and Arc enabled server in the subscription. You run the script you downloaded an inventory of legacy agents in your subscription. - ``` PowerShell - .\LogAnalyticsAgentUninstallUtilityScript.ps1 GetInventory - ``` -The script reports the total VM, VMSSs, or Arc enables servers seen in the subscription. It takes several minutes to run. You see a progress bar in the console window. Once complete, you're able to see a CSV file called "LogAnalyticsAgentExtensionInventory.csv in the local directory with the following format. --| Resource_ID | Name | Resource_Group | Resource_Type | Install_Type | Extension_Name | AMA_Extension_Installed | -|||||||| -| 012cb5cf-e1a8-49ee-a484-d40673167c9c | Linux-ama-e2e-debian9 | Linux-AMA-E2E | VM | Extension | OmsAgentForLinux | True | -| 8acae35a-454f-4869-bf4f-658189d98516 | test2012-r2-da | test2012-r2-daAMA-ADMIN | VM | Extension | MicrosoftMonitorAgent | False | --## Step 4 Uninstalls the inventory -This script iterates through the list of VM, Virtual Machine Scale Sets, and Arc enabled servers and uninstalls the legacy agent. You can't remove the agent if it isn't running. - ``` PowerShell - .\LogAnalyticsAgentUninstallUtilityScript.ps1 UninstallExtension - ``` -Once the script is complete you'll be able to see the removal status for your VM, Virtual Machine Scale Sets, and Arc enabled servers in the "LogAnalyticsAgentExtensionInventory.csv file. - |
| azure-monitor | Azure Monitor Agent Network Configuration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-network-configuration.md | - Title: Azure Monitor network configuration -description: Define network settings and enable network isolation for Azure Monitor Agent. - Previously updated : 07/10/2024-----# Azure Monitor agent network configuration -Azure Monitor Agent supports connecting by using direct proxies, Log Analytics gateway, and private links. This article explains how to define network settings and enable network isolation for Azure Monitor Agent. ----## Virtual network service tags --The [Azure virtual network service tags](../../virtual-network/service-tags-overview.md) must be enabled on the virtual network for the virtual machine. Both *AzureMonitor* and *AzureResourceManager* tags are required. --Azure Virtual network service tags can be used to define network access controls on [network security groups](../../virtual-network/network-security-groups-overview.md#security-rules), [Azure Firewall](../../firewall/service-tags.md), and user-defined routes. Use service tags in place of specific IP addresses when you create security rules and routes. For scenarios where Azure virtual network service tags cannot be used, the Firewall requirements are given below. -->[!NOTE] -> Data collection endpoint public IP addresses are not part of the above mentioned network service tags. If you have custom logs or IIS log data collection rules, consider allowing the data collection endpoint's public IP addresses for these scenarios to work until these scenarios are supported by network service tags. --## Firewall endpoints -The following table provides the endpoints that firewalls need to provide access to for different clouds. Each is an outbound connection to port 443. --> [!IMPORTANT] -> For all endpoints, HTTPS inspection must be disabled. --|Endpoint |Purpose | Example | -|:--|:--|:--| -| `global.handler.control.monitor.azure.com` |Access control service - | -| `<virtual-machine-region-name>`.handler.control.monitor.azure.com |Fetch data collection rules for specific machine | westus2.handler.control.monitor.azure.com | -|`<log-analytics-workspace-id>`.ods.opinsights.azure.com |Ingest logs data | 1234a123-aa1a-123a-aaa1-a1a345aa6789.ods.opinsights.azure.com -| management.azure.com | Only needed if sending time series data (metrics) to Azure Monitor [Custom metrics](../essentials/metrics-custom-overview.md) database | - | -| `<virtual-machine-region-name>`.monitoring.azure.com | Only needed if sending time series data (metrics) to Azure Monitor [Custom metrics](../essentials/metrics-custom-overview.md) database | westus2.monitoring.azure.com | -| `<data-collection-endpoint>.<virtual-machine-region-name>`.ingest.monitor.azure.com | Only needed if sending data to Log Analytics [custom logs](./data-collection-text-log.md) table | 275test-01li.eastus2euap-1.canary.ingest.monitor.azure.com | --Replace the suffix in the endpoints with the suffix in the following table for different clouds. --| Cloud | Suffix | -|:|:| -| Azure Commercial | .com | -| Azure Government | .us | -| Microsoft Azure operated by 21Vianet | .cn | --->[!NOTE] -> If you use private links on the agent, you must **only** add the [private data collection endpoints (DCEs)](../essentials/data-collection-endpoint-overview.md#components-of-a-dce). The agent does not use the non-private endpoints listed above when using private links/data collection endpoints. -> The Azure Monitor Metrics (custom metrics) preview isn't available in Azure Government and Azure operated by 21Vianet clouds. --> [!NOTE] -> When using AMA with AMPLS, all of your Data Collection Rules much use Data Collection Endpoints. Those DCE's must be added to the AMPLS configuration using [private link](../logs/private-link-configure.md#connect-azure-monitor-resources) --## Proxy configuration --The Azure Monitor Agent extensions for Windows and Linux can communicate either through a proxy server or a [Log Analytics gateway](./gateway.md) to Azure Monitor by using the HTTPS protocol. Use it for Azure virtual machines, Azure virtual machine scale sets, and Azure Arc for servers. Use the extensions settings for configuration as described in the following steps. Both anonymous and basic authentication by using a username and password are supported. --> [!IMPORTANT] -> Proxy configuration isn't supported for [Azure Monitor Metrics (public preview)](../essentials/metrics-custom-overview.md) as a destination. If you're sending metrics to this destination, it will use the public internet without any proxy. --> [!NOTE] -> Setting Linux system proxy via environment variables such as `http_proxy` and `https_proxy` is only supported using Azure Monitor Agent for Linux version 1.24.2 and above. For the ARM template, if you have proxy configuration please follow the ARM template example below declaring the proxy setting inside the ARM template. Additionally, a user can set "global" environment variables that get picked up by all systemd services [via the DefaultEnvironment variable in /etc/systemd/system.conf](https://www.man7.org/linux/man-pages/man5/systemd-system.conf.5.html). ---Use PowerShell commands in the following examples depending on your environment and configuration.: --# [Windows VM](#tab/PowerShellWindows) --**No proxy** --```powershell -$settingsString = '{"proxy":{"mode":"none"}}'; -Set-AzVMExtension -ExtensionName AzureMonitorWindowsAgent -ExtensionType AzureMonitorWindowsAgent -Publisher Microsoft.Azure.Monitor -ResourceGroupName <resource-group-name> -VMName <virtual-machine-name> -Location <location> -SettingString $settingsString -``` --**Proxy with no authentication** --```powershell -$settingsString = '{"proxy":{"mode":"application","address":"http://[address]:[port]","auth": "false"}}'; -Set-AzVMExtension -ExtensionName AzureMonitorWindowsAgent -ExtensionType AzureMonitorWindowsAgent -Publisher Microsoft.Azure.Monitor -ResourceGroupName <resource-group-name> -VMName <virtual-machine-name> -Location <location> -SettingString $settingsString -``` --**Proxy with authentication** --```powershell -$settingsString = '{"proxy":{"mode":"application","address":"http://[address]:[port]","auth": "true"}}'; -$protectedSettingsString = '{"proxy":{"username":"[username]","password": "[password]"}}'; -Set-AzVMExtension -ExtensionName AzureMonitorWindowsAgent -ExtensionType AzureMonitorWindowsAgent -Publisher Microsoft.Azure.Monitor -ResourceGroupName <resource-group-name> -VMName <virtual-machine-name> -Location <location> -SettingString $settingsString -ProtectedSettingString $protectedSettingsString -``` ---# [Linux VM](#tab/PowerShellLinux) --**No proxy** --```powershell -$settingsString = '{"proxy":{"mode":"none"}}'; -Set-AzVMExtension -ExtensionName AzureMonitorLinuxAgent -ExtensionType AzureMonitorLinuxAgent -Publisher Microsoft.Azure.Monitor -ResourceGroupName <resource-group-name> -VMName <virtual-machine-name> -Location <location> -SettingString $settingsString -``` --**Proxy with no authentication** --```powershell -$settingsString = '{"proxy":{"mode":"application","address":"http://[address]:[port]","auth": "false"}}'; -Set-AzVMExtension -ExtensionName AzureMonitorLinuxAgent -ExtensionType AzureMonitorLinuxAgent -Publisher Microsoft.Azure.Monitor -ResourceGroupName <resource-group-name> -VMName <virtual-machine-name> -Location <location> -SettingString $settingsString -``` --**Proxy with authentication** --```powershell -$settingsString = '{"proxy":{"mode":"application","address":"http://[address]:[port]","auth": "true"}}'; -$protectedSettingsString = '{"proxy":{"username":"[username]","password": "[password]"}}'; -Set-AzVMExtension -ExtensionName AzureMonitorLinuxAgent -ExtensionType AzureMonitorLinuxAgent -Publisher Microsoft.Azure.Monitor -ResourceGroupName <resource-group-name> -VMName <virtual-machine-name> -Location <location> -SettingString $settingsString -ProtectedSettingString $protectedSettingsString -``` ---# [Windows Arc-enabled server](#tab/PowerShellWindowsArc) --**No proxy** --```powershell -$settings = @{"proxy" = @{mode = "none"}} -New-AzConnectedMachineExtension -Name AzureMonitorWindowsAgent -ExtensionType AzureMonitorWindowsAgent -Publisher Microsoft.Azure.Monitor -ResourceGroupName <resource-group-name> -MachineName <arc-server-name> -Location <arc-server-location> -Setting $settings -``` --**Proxy with no authentication** --```powershell -$settings = @{"proxy" = @{mode = "application"; address = "http://[address]:[port]"; auth = "false"}} -New-AzConnectedMachineExtension -Name AzureMonitorWindowsAgent -ExtensionType AzureMonitorWindowsAgent -Publisher Microsoft.Azure.Monitor -ResourceGroupName <resource-group-name> -MachineName <arc-server-name> -Location <arc-server-location> -Setting $settings -``` --**Proxy with authentication** --```powershell -$settings = @{"proxy" = @{mode = "application"; address = "http://[address]:[port]"; auth = "true"}} -$protectedSettings = @{"proxy" = @{username = "[username]"; password = "[password]"}} -New-AzConnectedMachineExtension -Name AzureMonitorWindowsAgent -ExtensionType AzureMonitorWindowsAgent -Publisher Microsoft.Azure.Monitor -ResourceGroupName <resource-group-name> -MachineName <arc-server-name> -Location <arc-server-location> -Setting $settings -ProtectedSetting $protectedSettings -``` --# [Linux Arc-enabled server](#tab/PowerShellLinuxArc) --**No proxy** --```powershell -$settings = @{"proxy" = @{mode = "none"}} -New-AzConnectedMachineExtension -Name AzureMonitorLinuxAgent -ExtensionType AzureMonitorLinuxAgent -Publisher Microsoft.Azure.Monitor -ResourceGroupName <resource-group-name> -MachineName <arc-server-name> -Location <arc-server-location> -Setting $settings -``` --**Proxy with no authentication** --```powershell -$settings = @{"proxy" = @{mode = "application"; address = "http://[address]:[port]"; auth = "false"}} -New-AzConnectedMachineExtension -Name AzureMonitorLinuxAgent -ExtensionType AzureMonitorLinuxAgent -Publisher Microsoft.Azure.Monitor -ResourceGroupName <resource-group-name> -MachineName <arc-server-name> -Location <arc-server-location> -Setting $settings -``` --**Proxy with authentication** --```powershell -$settings = @{"proxy" = @{mode = "application"; address = "http://[address]:[port]"; auth = "true"}} -$protectedSettings = @{"proxy" = @{username = "[username]"; password = "[password]"}} -New-AzConnectedMachineExtension -Name AzureMonitorLinuxAgent -ExtensionType AzureMonitorLinuxAgent -Publisher Microsoft.Azure.Monitor -ResourceGroupName <resource-group-name> -MachineName <arc-server-name> -Location <arc-server-location> -Setting $settings -ProtectedSetting $protectedSettings -``` -----# [ARM Policy Template example](#tab/ArmPolicy) --```powershell -{ - "properties": { - "displayName": "Configure Windows Arc-enabled machines to run Azure Monitor Agent", - "policyType": "BuiltIn", - "mode": "Indexed", - "description": "Automate the deployment of Azure Monitor Agent extension on your Windows Arc-enabled machines for collecting telemetry data from the guest OS. This policy will install the extension if the OS and region are supported and system-assigned managed identity is enabled, and skip install otherwise. Learn more: https://aka.ms/AMAOverview.", - "metadata": { - "version": "2.3.0", - "category": "Monitoring" - }, - "parameters": { - "effect": { - "type": "String", - "metadata": { - "displayName": "Effect", - "description": "Enable or disable the execution of the policy." - }, - "allowedValues": [ - "DeployIfNotExists", - "Disabled" - ], - "defaultValue": "DeployIfNotExists" - } - }, - "policyRule": { - "if": { - "allOf": [ - { - "field": "type", - "equals": "Microsoft.HybridCompute/machines" - }, - { - "field": "Microsoft.HybridCompute/machines/osName", - "equals": "Windows" - }, - { - "field": "location", - "in": [ - "australiacentral", - "australiaeast", - "australiasoutheast", - "brazilsouth", - "canadacentral", - "canadaeast", - "centralindia", - "centralus", - "eastasia", - "eastus", - "eastus2", - "eastus2euap", - "francecentral", - "germanywestcentral", - "japaneast", - "japanwest", - "jioindiawest", - "koreacentral", - "koreasouth", - "northcentralus", - "northeurope", - "norwayeast", - "southafricanorth", - "southcentralus", - "southeastasia", - "southindia", - "swedencentral", - "switzerlandnorth", - "uaenorth", - "uksouth", - "ukwest", - "westcentralus", - "westeurope", - "westindia", - "westus", - "westus2", - "westus3" - ] - } - ] - }, - "then": { - "effect": "[parameters('effect')]", - "details": { - "type": "Microsoft.HybridCompute/machines/extensions", - "roleDefinitionIds": [ - "/providers/Microsoft.Authorization/roleDefinitions/cd570a14-e51a-42ad-bac8-bafd67325302" - ], - "existenceCondition": { - "allOf": [ - { - "field": "Microsoft.HybridCompute/machines/extensions/type", - "equals": "AzureMonitorWindowsAgent" - }, - { - "field": "Microsoft.HybridCompute/machines/extensions/publisher", - "equals": "Microsoft.Azure.Monitor" - }, - { - "field": "Microsoft.HybridCompute/machines/extensions/provisioningState", - "equals": "Succeeded" - } - ] - }, - "deployment": { - "properties": { - "mode": "incremental", - "template": { - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "type": "string" - }, - "location": { - "type": "string" - } - }, - "variables": { - "extensionName": "AzureMonitorWindowsAgent", - "extensionPublisher": "Microsoft.Azure.Monitor", - "extensionType": "AzureMonitorWindowsAgent" - }, - "resources": [ - { - "name": "[concat(parameters('vmName'), '/', variables('extensionName'))]", - "type": "Microsoft.HybridCompute/machines/extensions", - "location": "[parameters('location')]", - "apiVersion": "2021-05-20", - "properties": { - "publisher": "[variables('extensionPublisher')]", - "type": "[variables('extensionType')]", - "autoUpgradeMinorVersion": true, - "enableAutomaticUpgrade": true, - "settings": { - "proxy": { - "auth": "false", - "mode": "application", - "address": "http://XXX.XXX.XXX.XXX" - } - }, - "protectedsettings": { } - } - } - ] - }, - "parameters": { - "vmName": { - "value": "[field('name')]" - }, - "location": { - "value": "[field('location')]" - } - } - } - } - } - } - } - }, - "id": "/providers/Microsoft.Authorization/policyDefinitions/94f686d6-9a24-4e19-91f1-de937dc171a4", - "type": "Microsoft.Authorization/policyDefinitions", - "name": "94f686d6-9a24-4e19-91f1-de937dc171a4" -} -``` ----## Log Analytics gateway configuration --1. Follow the guidance above to configure proxy settings on the agent and provide the IP address and port number that correspond to the gateway server. If you've deployed multiple gateway servers behind a load balancer, the agent proxy configuration is the virtual IP address of the load balancer instead. -1. Add the **configuration endpoint URL** to fetch data collection rules to the allowlist for the gateway - `Add-OMSGatewayAllowedHost -Host global.handler.control.monitor.azure.com` - `Add-OMSGatewayAllowedHost -Host <gateway-server-region-name>.handler.control.monitor.azure.com`. - (If you're using private links on the agent, you must also add the [data collection endpoints](../essentials/data-collection-endpoint-overview.md#components-of-a-dce).) -1. Add the **data ingestion endpoint URL** to the allowlist for the gateway - `Add-OMSGatewayAllowedHost -Host <log-analytics-workspace-id>.ods.opinsights.azure.com`. -1. Restart the **OMS Gateway** service to apply the changes - `Stop-Service -Name <gateway-name>` and - `Start-Service -Name <gateway-name>`. --## Next steps --- [Add endpoint to AMPLS resource](../logs/private-link-configure.md#connect-azure-monitor-resources). |
| azure-monitor | Azure Monitor Agent Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-overview.md | - Title: Azure Monitor Agent overview -description: Overview of the Azure Monitor Agent, which collects monitoring data from the guest operating system of virtual machines. --- Previously updated : 07/10/2024----# Customer intent: As an IT manager, I want to understand the capabilities of Azure Monitor Agent to determine whether I can use the agent to collect the data I need from the operating systems of my virtual machines. ----# Azure Monitor Agent overview --Azure Monitor Agent (AMA) collects monitoring data from the guest operating system of Azure and hybrid virtual machines and delivers it to Azure Monitor for use by features, insights, and other services such as [Microsoft Sentinel](../../sentintel/../sentinel/overview.md) and [Microsoft Defender for Cloud](/azure/defender-for-cloud/defender-for-cloud-introduction). This article provides an overview of Azure Monitor Agent's capabilities and supported use cases. --See a short video introduction to Azure Monitor agent, which includes a demo of how to deploy the agent from the Azure portal: [ITOps Talk: Azure Monitor Agent](https://www.youtube.com/watch?v=f8bIrFU8tCs) --> [!NOTE] -> Azure Monitor Agent replaces the [Legacy Agent](./log-analytics-agent.md) for Azure Monitor. The Log Analytics agent is on a **deprecation path** and won't be supported after **August 31, 2024**. Any new data centers brought online after January 1 2024 will not support the Log Analytics agent. If you use the Log Analytics agent to ingest data to Azure Monitor, [migrate to the new Azure Monitor agent](./azure-monitor-agent-migration.md) prior to that date. --## Installation -The Azure Monitor agent is one method of [data collection for Azure Monitor](../data-sources.md). It's installed on virtual machines running in Azure, in other clouds, or on-premises where it has access to local logs and performance data. Without the agent, you could only collect data from the host machine since you would have no access to the client operating system and running processes. --The agent can be installed using different methods as described in [Install and manage Azure Monitor Agent](./azure-monitor-agent-manage.md). You can install the agent on a single machine or at scale using Azure Policy or other tools. In some cases, the agent will be automatically installed when you enable a feature that requires it, such as Microsoft Sentinel. --## Data collection -All data collected by the Azure Monitor agent is done with a [data collection rule (DCR)](../essentials/data-collection-rule-overview.md) where you define the following: --- Data type being collected.-- Transforming the data, including filtering, aggregating, and shaping.-- Destination for collected data.--A single DCR can contain multiple data sources of different types. Depending on your requirements, you can choose whether to include several data sources in a few DCRs or create separate DCRs for each data source. This allows you to centrally define the logic for different data collection scenarios and apply them to different sets of machines. See [Best practices for data collection rule creation and management in Azure Monitor](../essentials/data-collection-rule-best-practices.md) for recommendations on how to organize your DCRs. --The DCR is applied to a particular agent by creating a [data collection rule association (DCRA)](../essentials/data-collection-rule-overview.md#data-collection-rule-associations-dcra) between the DCR and the agent. One DCR can be associated with multiple agents, and each agent can be associated with multiple DCRs. When an agent is installed, it connects to Azure Monitor to retrieve any DCRs that are associated with it. The agent periodically checks back with Azure Monitor to determine if there are any changes to existing DCRs or associations with new ones. ---## Costs --There's no cost for the Azure Monitor Agent, but you might incur charges for the data ingested and stored. For information on Log Analytics data collection and retention and for customer metrics, see [Azure Monitor Logs cost calculations and options](../logs/cost-logs.md) and [Analyze usage in a Log Analytics workspace](../logs/analyze-usage.md). ---## Supported regions --Azure Monitor Agent is available in all public regions, Azure Government and China clouds, for generally available features. It's not yet supported in air-gapped clouds. For more information, see [Product availability by region](https://azure.microsoft.com/global-infrastructure/services/?products=monitor&rar=true®ions=all). ---## Supported services and features --The following tables identify the different environments and features that are currently supported by Azure Monitor agent in addition to those supported by the legacy agent. This information will assist you in determining whether Azure Monitor agent can support your current requirements. See [Migrate to Azure Monitor Agent from Log Analytics agent](../agents/azure-monitor-agent-migration.md) for guidance on migrating specific features. ---### Windows agents --| Category | Area | Azure Monitor Agent | Legacy Agent | -|:|:|:|:| -| **Environments supported** | | | | -| | Azure | Γ£ô | Γ£ô | -| | Other cloud (Azure Arc) | Γ£ô | Γ£ô | -| | On-premises (Azure Arc) | Γ£ô | Γ£ô | -| | Windows Client OS | Γ£ô | | -| **Data collected** | | | | -| | Event Logs | Γ£ô | Γ£ô | -| | Performance | Γ£ô | Γ£ô | -| | File based logs | Γ£ô | Γ£ô | -| | IIS logs | Γ£ô | Γ£ô | -| **Data sent to** | | | | -| | Azure Monitor Logs | Γ£ô | Γ£ô | -| **Services and features supported** | | | | -| | Microsoft Sentinel | Γ£ô ([View scope](./azure-monitor-agent-migration.md#understand-additional-dependencies-and-services)) | Γ£ô | -| | VM Insights | Γ£ô | Γ£ô | -| | Microsoft Defender for Cloud - Only uses MDE agent | | | -| | Automation Update Management - Moved to Azure Update Manager | Γ£ô | Γ£ô | -| | Azure Stack HCI | Γ£ô | | -| | Update Manager - no longer uses agents | | | -| | Change Tracking | Γ£ô | Γ£ô | -| | SQL Best Practices Assessment | Γ£ô | | --### Linux agents --| Category | Area | Azure Monitor Agent | Legacy Agent | -|:|:|:|:| -| **Environments supported** | | | | -| | Azure | Γ£ô | Γ£ô | -| | Other cloud (Azure Arc) | Γ£ô | Γ£ô | -| | On-premises (Azure Arc) | Γ£ô | Γ£ô | -| **Data collected** | | | -| | Syslog | Γ£ô | Γ£ô | -| | Performance | Γ£ô | Γ£ô | -| | File based logs | Γ£ô | | -| **Data sent to** | | | | -| | Azure Monitor Logs | Γ£ô | Γ£ô | -| **Services and features supported** | | | | -| | Microsoft Sentinel | Γ£ô ([View scope](./azure-monitor-agent-migration.md#understand-additional-dependencies-and-services)) | Γ£ô | -| | VM Insights | Γ£ô | Γ£ô | -| | Microsoft Defender for Cloud - Only use MDE agent | | | -| | Automation Update Management - Moved to Azure Update Manager | Γ£ô | Γ£ô | -| | Update Manager - no longer uses agents | | | -| | Change Tracking | Γ£ô | Γ£ô | ---## Supported data sources -See [Collect data with Azure Monitor Agent](./azure-monitor-agent-data-collection.md) for a list of the data sources that can be collected by the Azure Monitor Agent and details on how to configure each. --## Next steps --- [Install the Azure Monitor Agent](azure-monitor-agent-manage.md) on Windows and Linux virtual machines.-- [Create a data collection rule](./azure-monitor-agent-data-collection.md) to collect data from the agent and send it to Azure Monitor. |
| azure-monitor | Azure Monitor Agent Performance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-performance.md | - Title: Performance Benchmark for forwarding Gateway using Azure Monitor Agent -description: Performance data for the AMA running in a gateway scenario --- Previously updated : 4/07/2023-- -# Customer intent: As a deployment engineer, I can scope the resources required to scale my gateway data colletors the use the Azure Monitor Agent. ---# Azure Monitor Agent Performance Benchmark --The agent can handle many thousands of events per second in the gateway event forwarding scenario. The exact throughput rate depends on various factors such as the size of each event, the specific data type, and physical hardware resources. This article describes the Microsoft internal benchmark used for testing the agent throughput of 10k Syslog events in the forwarder scenario. The benchmark results should provide a guide to size the resources that you need in your environment. --> [!NOTE] -> The results in this article are informational about the performance of AMA in the forwarding scenario only and do not constitute any service agreement on the part of Microsoft. --## Best practices for agent as a forwarder. --- Each AMA is limited to ingesting 20k EPS, and drops any data that exceeds the limits.-- The forwarder should be on a dedicated system to eliminate potential interference from other workloads. -- The forwarder system should be monitored for CPU, memory, and disk utilization to prevent overloads from causing data loss. -- Where possible use a load balancer and redundant forwarder systems to improve reliability and scalability. -- For other considerations for forwarders, see the Log Analytics Gateway documentation. --## Agent Performance --The benchmark is run in a controlled environment to get repeatable, accurate, and statistically significant results. The resources consumed by the agent are measured under a load of 10,000 simulated Syslog events per second. The simulated load is run on the same physical hardware that the agent under test is on. Test trials are run for seven days. For each trial, performance metrics are sampled every second to collect CPU, memory, and network maximum and average usage. This approach provides the right information to help you estimate the resources needed for your environment. --> [!NOTE] -> The results do not measure the end-to-end throughput ingested by a Log Analytics Workspace (or other telemetry sinks), as there may be end-to-end variability due to network and backend pipeline performance. --The benchmarks are run on an Azure VM Standard_F8s_v2 system using AMA Linux version 1.25.2 and 10 GB of disk space for the event cache. --- vCPUΓÇÖs: 8 with HyperThreading (800% CPU is possible) -- Memory: 16 GiB -- Temp Storage: 64 GiB -- Max Disk IOPS: 6400 -- Network: 12500 Mbp Max on all 4 physical NICs ----## Results --| Perf Metric | Ave (Max) Med | -|:|::| -| CPU % | 51 (262) | -| Mem RSS MB | 276 (1,017) | -| Network KBps | 338 (18,033) | ---## Frequently asked questions --This section provides answers to common questions. --### How much data is sent per agent? --The amount of data sent per agent depends on: --* The solutions you've enabled. -* The number of logs and performance counters being collected. -* The volume of data in the logs. --See [Analyze usage in a Log Analytics workspace](../logs/analyze-usage.md). --For computers that are able to run the WireData agent, use the following query to see how much data is being sent: --```kusto -WireData -| where ProcessName == "C:\\Program Files\\Microsoft Monitoring Agent\\Agent\\MonitoringHost.exe" -| where Direction == "Outbound" -| summarize sum(TotalBytes) by Computer -``` --### How much network bandwidth is used by the Microsoft Monitoring Agent when it sends data to Azure Monitor? --Bandwidth is a function of the amount of data sent. Data is compressed as it's sent over the network. --## Next steps --- [Connect computers without internet access by using the Log Analytics gateway in Azure Monitor](gateway.md)-- [Install the Azure Monitor Agent](azure-monitor-agent-manage.md) on Windows and Linux virtual machines.-- [Create a data collection rule](azure-monitor-agent-data-collection.md) to collect data from the agent and send it to Azure Monitor. |
| azure-monitor | Azure Monitor Agent Policy | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-policy.md | - Title: Use Azure Policy to install and manage the Azure Monitor agent -description: Options for managing Azure Monitor Agent on Azure virtual machines and Azure Arc-enabled servers. --- Previously updated : 7/10/2024------# Use Azure Policy to install and manage the Azure Monitor agent --Using [Azure Policy](../../governance/policy/overview.md), you can have the Azure Monitor agent automatically installed on your existing and new virtual machines and have the appropriate DCRs automatically associated with them. This article describes the built-in policies and initiatives that you can leverage for this functionality and features of Azure Monitor to assist in managing them. --Use the following policies and policy initiatives to automatically install the agent and associate it with a data collection rule every time you create a virtual machine, scale set, or Azure Arc-enabled server. --> [!NOTE] -> Azure Monitor has a preview [data collection rule DCR](../essentials/data-collection-rule-overview.md) experience that simplifies creating assignments for policies and initiatives that use DCRs. This includes initiatives that install the Azure Monitor agent. You may choose to use that experience to create assignments for the initiatives described in this article. See [Manage data collection rules (DCRs) and associations in Azure Monitor](../essentials/data-collection-rule-view.md#azure-policy) for more information. --## Prerequisites -Before you proceed, review [prerequisites for agent installation](azure-monitor-agent-manage.md#prerequisites). --> [!NOTE] -> As per Microsoft Identity best practices, policies for installing Azure Monitor Agent on virtual machines and scale sets rely on user-assigned managed identity. This option is the more scalable and resilient managed identity for these resources. -> For Azure Arc-enabled servers, policies rely on system-assigned managed identity as the only supported option today. ---## Built-in policies --You can choose to use the individual policies from the preceding policy initiative to perform a single action at scale. For example, if you only want to automatically install the agent, use the second agent installation policy from the initiative, as shown. -----## Built-in policy initiatives - --There are built-in policy initiatives for Windows and Linux virtual machines, scale sets that provide at-scale onboarding using Azure Monitor agents end-to-end -- [Deploy Windows Azure Monitor Agent with user-assigned managed identity-based auth and associate with Data Collection Rule](https://ms.portal.azure.com/#view/Microsoft_Azure_Policy/InitiativeDetailBlade/id/%2Fproviders%2FMicrosoft.Authorization%2FpolicySetDefinitions%2F0d1b56c6-6d1f-4a5d-8695-b15efbea6b49/scopes~/%5B%22%2Fsubscriptions%2Fae71ef11-a03f-4b4f-a0e6-ef144727c711%22%5D)-- [Deploy Linux Azure Monitor Agent with user-assigned managed identity-based auth and associate with Data Collection Rule](https://ms.portal.azure.com/#view/Microsoft_Azure_Policy/InitiativeDetailBlade/id/%2Fproviders%2FMicrosoft.Authorization%2FpolicySetDefinitions%2Fbabf8e94-780b-4b4d-abaa-4830136a8725/scopes~/%5B%22%2Fsubscriptions%2Fae71ef11-a03f-4b4f-a0e6-ef144727c711%22%5D) --> [!NOTE] -> The policy definitions only include the list of Windows and Linux versions that Microsoft supports. To add a custom image, use the `Additional Virtual Machine Images` parameter. --These initiatives above comprise individual policies that: --- (Optional) Create and assign built-in user-assigned managed identity, per subscription, per region. [Learn more](../../active-directory/managed-identities-azure-resources/how-to-assign-managed-identity-via-azure-policy.md#policy-definition-and-details).- - `Bring Your Own User-Assigned Identity`: If set to `false`, it creates the built-in user-assigned managed identity in the predefined resource group and assigns it to all the machines that the policy is applied to. Location of the resource group can be configured in the `Built-In-Identity-RG Location` parameter. - If set to `true`, you can instead use an existing user-assigned identity that is automatically assigned to all the machines that the policy is applied to. -- Install Azure Monitor Agent extension on the machine, and configure it to use user-assigned identity as specified by the following parameters.- - `Bring Your Own User-Assigned Managed Identity`: If set to `false`, it configures the agent to use the built-in user-assigned managed identity created by the preceding policy. If set to `true`, it configures the agent to use an existing user-assigned identity. - - `User-Assigned Managed Identity Name`: If you use your own identity (selected `true`), specify the name of the identity that's assigned to the machines. - - `User-Assigned Managed Identity Resource Group`: If you use your own identity (selected `true`), specify the resource group where the identity exists. - - `Additional Virtual Machine Images`: Pass additional VM image names that you want to apply the policy to, if not already included. - - `Built-In-Identity-RG Location`: If you use built-in user-assigned managed identity, specify the location where the identity and the resource group should be created. This parameter is only used when `Bring Your Own User-Assigned Managed Identity` parameter is set to `false`. -- Create and deploy the association to link the machine to specified data collection rule.- - `Data Collection Rule Resource Id`: The Azure Resource Manager resourceId of the rule you want to associate via this policy to all machines the policy is applied to. -- :::image type="content" source="media/azure-monitor-agent-install/built-in-ama-dcr-initiatives.png" lightbox="media/azure-monitor-agent-install/built-in-ama-dcr-initiatives.png" alt-text="Partial screenshot from the Azure Policy Definitions page that shows two built-in policy initiatives for configuring Azure Monitor Agent."::: --### Known issues --- Managed Identity default behavior. [Learn more](../../active-directory/managed-identities-azure-resources/managed-identities-faq.md#what-identity-will-imds-default-to-if-dont-specify-the-identity-in-the-request).-- Possible race condition with using built-in user-assigned identity creation policy. [Learn more](../../active-directory/managed-identities-azure-resources/how-to-assign-managed-identity-via-azure-policy.md#known-issues).-- Assigning policy to resource groups. If the assignment scope of the policy is a resource group and not a subscription, the identity used by policy assignment (different from the user-assigned identity used by agent) must be manually granted [these roles](../../active-directory/managed-identities-azure-resources/how-to-assign-managed-identity-via-azure-policy.md#required-authorization) prior to assignment/remediation. Failing to do this step will result in *deployment failures*.-- Other [Managed Identity limitations](../../active-directory/managed-identities-azure-resources/managed-identities-faq.md#limitations).----## Remediation --The initiatives or policies will apply to each virtual machine as it's created. A [remediation task](../../governance/policy/how-to/remediate-resources.md) deploys the policy definitions in the initiative to existing resources, so you can configure Azure Monitor Agent for any resources that were already created. --When you create the assignment by using the Azure portal, you have the option of creating a remediation task at the same time. For information on the remediation, see [Remediate non-compliant resources with Azure Policy](../../governance/policy/how-to/remediate-resources.md). -<!-- convertborder later --> ----## Next steps --[Create a data collection rule](./azure-monitor-agent-send-data-to-event-hubs-and-storage.md) to collect data from the agent and send it to Azure Monitor. |
| azure-monitor | Azure Monitor Agent Private Link | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-private-link.md | - Title: Enable network isolation for Azure Monitor Agent by using Private Link -description: Enable network isolation for Azure Monitor Agent. - Previously updated : 5/1/2023------# Enable network isolation for Azure Monitor Agent by using Private Link --By default, Azure Monitor Agent connects to a public endpoint to connect to your Azure Monitor environment. This article explains how to enable network isolation for your agents by using [Azure Private Link](../../private-link/private-link-overview.md). --## Prerequisites --- A [data collection rule](../essentials/data-collection-rule-create-edit.md), which defines the data Azure Monitor Agent collects and the destination to which the agent sends data. --## Link your data collection endpoints to your Azure Monitor Private Link Scope --1. [Create a data collection endpoint](../essentials/data-collection-endpoint-overview.md#create-a-data-collection-endpoint) for each of your regions for agents to connect to instead of using the public endpoint. An agent can only connect to a data collection endpoint in the same region. If you have agents in multiple regions, create a data collection endpoint in each one. --1. [Configure your private link](../logs/private-link-configure.md). You'll use the private link to connect your data collection endpoint to a set of Azure Monitor resources that define the boundaries of your monitoring network. This set is called an Azure Monitor Private Link Scope. --1. [Add the data collection endpoints to your Azure Monitor Private Link Scope](../logs/private-link-configure.md#connect-azure-monitor-resources) resource. This process adds the data collection endpoints to your private DNS zone (see [how to validate](../logs/private-link-configure.md#review-and-validate-your-private-link-setup)) and allows communication via private links. You can do this task from the AMPLS resource or on an existing data collection endpoint resource's **Network isolation** tab. -- > [!IMPORTANT] - > Other Azure Monitor resources like the Log Analytics workspaces configured in your data collection rules that you want to send data to must be part of this same AMPLS resource. - - For your data collection endpoints, ensure the **Accept access from public networks not connected through a Private Link Scope** option is set to **No** on the **Network Isolation** tab of your endpoint resource in the Azure portal. This setting ensures that public internet access is disabled and network communication only happens via private links. - - :::image type="content" source="media/azure-monitor-agent-dce/data-collection-endpoint-network-isolation.png" lightbox="media/azure-monitor-agent-dce/data-collection-endpoint-network-isolation.png" alt-text="Screenshot that shows configuring data collection endpoint network isolation." border="false"::: - -1. Associate the data collection endpoints to the target resources by editing the data collection rule in the Azure portal. On the **Resources** tab, select **Enable Data Collection Endpoints**. Select a data collection endpoint for each virtual machine. See [Configure data collection for Azure Monitor Agent](../agents/azure-monitor-agent-data-collection.md). - - :::image type="content" source="media/azure-monitor-agent-dce/data-collection-rule-virtual-machines-with-endpoint.png" lightbox="media/azure-monitor-agent-dce/data-collection-rule-virtual-machines-with-endpoint.png" alt-text="Screenshot that shows configuring data collection endpoints for an agent." border="false"::: ---## Next steps --- Learn more about [Best practices for monitoring virtual machines in Azure Monitor](../best-practices-vm.md). |
| azure-monitor | Azure Monitor Agent Requirements | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-requirements.md | - Title: Azure Monitor agent requirements -description: Requirements for Azure Monitor Agent on Azure virtual machines and Azure Arc-enabled servers and prerequisites for installation. --- Previously updated : 7/18/2023------# Azure Monitor agent requirements -This article provides requirements and prerequisites for the Azure Monitor agent. Refer to the details in this article before you follow the guidance to install the agent in [Install and manage Azure Monitor Agent](./azure-monitor-agent-manage.md). --## Virtual machine extension details --Azure Monitor Agent is implemented as an [Azure VM extension](/azure/virtual-machines/extensions/overview) with the details in the following table. You can install it by using any of the methods to install virtual machine extensions. For version information, see [Azure Monitor agent extension versions](./azure-monitor-agent-extension-versions.md). --| Property | Windows | Linux | -|:|:|:| -| Publisher | Microsoft.Azure.Monitor | Microsoft.Azure.Monitor | -| Type | AzureMonitorWindowsAgent | AzureMonitorLinuxAgent | -| TypeHandlerVersion | See [Azure Monitor agent extension versions](./azure-monitor-agent-extension-versions.md) | [Azure Monitor agent extension versions](./azure-monitor-agent-extension-versions.md) | ---## Permissions - For methods other than using the Azure portal, you must have the following role assignments to install the agent: -- | Built-in role | Scopes | Reason | - |:|:|:| - | <ul><li>[Virtual Machine Contributor](../../role-based-access-control/built-in-roles.md#virtual-machine-contributor)</li><li>[Azure Connected Machine Resource Administrator](../../role-based-access-control/built-in-roles.md#azure-connected-machine-resource-administrator)</li></ul> | <ul><li>Virtual machines, scale sets,</li><li>Azure Arc-enabled servers</li></ul> | To deploy the agent | - | Any role that includes the action *Microsoft.Resources/deployments/** (for example, [Log Analytics Contributor](../../role-based-access-control/built-in-roles.md#log-analytics-contributor) | <ul><li>Subscription and/or</li><li>Resource group and/or </li></ul> | To deploy agent extension via Azure Resource Manager templates (also used by Azure Policy) | --[Managed identity](../../active-directory/managed-identities-azure-resources/overview.md) must be enabled on Azure virtual machines. Both user-assigned and system-assigned managed identities are supported. --- **User-assigned**: This managed identity should be used for large-scale deployments and can be configured with [built-in Azure policies](./azure-monitor-agent-policy.md). You can create a user-assigned managed identity once and share it across multiple VMs making it more scalable than a system-assigned managed identity. If you use a user-assigned managed identity, you must pass the managed identity details to Azure Monitor Agent via extension settings:-- ```json - { - "authentication": { - "managedIdentity": { - "identifier-name": "mi_res_id" or "object_id" or "client_id", - "identifier-value": "<resource-id-of-uai>" or "<guid-object-or-client-id>" - } - } - } - ``` -You should use `mi_res_id` as the `identifier-name`. The following sample commands only show usage with `mi_res_id` for the sake of brevity. For more information on `mi_res_id`, `object_id`, and `client_id`, see the [Managed identity documentation](../../active-directory/managed-identities-azure-resources/how-to-use-vm-token.md#get-a-token-using-http). -- **System-assigned**: This managed identity is suited for initial testing or small deployments. When used at scale, for all VMs in a subscription for example, it results in a substantial number of identities created and deleted in Microsoft Entra ID. To avoid this churn of identities, use user-assigned managed identities instead. --> [!IMPORTANT] -> System-assigned managed identity is the only supported authentication For Azure Arc-enabled servers and is enabled automatically as soon as you install the Azure Arc agent. ---## Disk space - Required disk space can vary significantly depending on how an agent is configured or if the agent is unable to communicate with the destinations and must cache data. By default the agent requires 10Gb of disk space to run. The following table provides guidance for capacity planning: --| Purpose | Environment | Path | Suggested Space | -|:|:|:|:| -| Download and install packages | Linux | /var/lib/waagent/Microsoft.Azure.Monitor.AzureMonitorLinuxAgent-{Version}/ | 500 MB | -| Download and install packages | Windows | C:\Packages\Plugins\Microsoft.Azure.Monitor.AzureMonitorWindowsAgent | 500 MB| -| Extension Logs | Linux (Azure VM) | /var/log/azure/Microsoft.Azure.Monitor.AzureMonitorLinuxAgent/ | 100 MB | -| Extension Logs | Linux (Azure Arc) | /var/lib/GuestConfig/extension_logs/Microsoft.Azure.Monitor.AzureMonitorLinuxAgent-{version}/ | 100 MB | -| Extension Logs | Windows (Azure VM) | C:\WindowsAzure\Logs\Plugins\Microsoft.Azure.Monitor.AzureMonitorWindowsAgent | 100 MB | -| Extension Logs | Windows (Azure Arc) | C:\ProgramData\GuestConfig\extension_logs\Microsoft.Azure.Monitor.AzureMonitorWindowsAgent | 100 MB | -| Agent Cache | Linux | /etc/opt/microsoft/azuremonitoragent, /var/opt/microsoft/azuremonitoragent | 500 MB | -| Agent Cache | Windows (Azure VM) | C:\WindowsAzure\Resources\AMADataStore.{DataStoreName} | 10.5 GB | -| Agent Cache | Windows (Azure Arc) | C:\Resources\Directory\AMADataStore. {DataStoreName} | 10.5 GB | -| Event Cache | Linux | /var/opt/microsoft/azuremonitoragent/events | 10 GB | -| Event Cache | Linux | /var/lib/rsyslog | 1 GB | ---## Next steps --[Create a data collection rule](azure-monitor-agent-data-collection.md) to collect data from the agent and send it to Azure Monitor. |
| azure-monitor | Azure Monitor Agent Send Data To Event Hubs And Storage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-send-data-to-event-hubs-and-storage.md | - Title: Send data to Event Hubs and Storage (Preview) -description: This article describes how to use Azure Monitor Agent to upload data to Azure Storage and Event Hubs. --- Previously updated : 10/09/2023----# Send data to Event Hubs and Storage (Preview) --This article describes how to use the Azure Monitor Agent (AMA) to upload data to Azure Storage and Event Hubs. This feature is in preview. --The Azure Monitor Agent is the new, consolidated telemetry agent for collecting data from IaaS resources like virtual machines. By using the upload capability in this preview, you can upload the logs<sup>[1](#FN1)</sup> you send to Log Analytics workspaces to Event Hubs and Storage. Both data destinations use data collection rules to configure collection setup for the agents. --> [!NOTE] -> This functionality replaces the Windows diagnostics extension (WAD) and Linux diagnostics extension (LAD). For more information, see [Compare Azure Monitor Agent to legacy agents](./agents-overview.md#compare-to-legacy-agents). --**Footnotes** --<a name="FN1">1</a>: Not all data types are supported; refer to [What's supported](#whats-supported) for specifics. --## What's supported --### Data types --- Windows:- - Windows Event Logs ΓÇô to eventhub and storage - - Perf counters ΓÇô eventhub and storage - - IIS logs ΓÇô to storage blob - - Custom logs ΓÇô to storage blob --- Linux:- - Syslog ΓÇô to eventhub and storage - - Perf counters ΓÇô to eventhub and storage - - Custom Logs / Log files ΓÇô to storage --### Operating systems --- Environments that are supported by the Azure Monitoring Agent on Windows and Linux-- This feature is only supported and planned to be supported for Azure VMs. There are no plans to bring this to on-premises or Azure Arc scenarios.--## What's not supported --### Data types --- Windows:- - ETW Logs - - Windows Crash Dumps (not planned nor will be supported) - - Application Logs (not planned nor will be supported) - - .NET event source logs (not planned nor will be supported) --## Prerequisites --A managed identity (either system or user) associated with the resources below. We highly recommend using [user-assigned managed identity](../../active-directory/managed-identities-azure-resources/how-manage-user-assigned-managed-identities.md) for better scalability and performance. --- [Storage account](../../storage/common/storage-account-create.md)-- [Event Hubs namespace and event hub](../../event-hubs/event-hubs-create.md)-- [Virtual machine](/azure/virtual-machines/overview)--## Create a data collection rule --Create a data collection rule for collecting events and sending to storage and event hub. --1. In the Azure portal's search box, type in *template* and then select **Deploy a custom template**. -- :::image type="content" source="../logs/media/tutorial-workspace-transformations-api/deploy-custom-template.png" lightbox="../logs/media/tutorial-workspace-transformations-api/deploy-custom-template.png" alt-text="Screenshot that shows the Azure portal with template entered in the search box and Deploy a custom template highlighted in the search results."::: --1. Select **Build your own template in the editor**. -- :::image type="content" source="../logs/media/tutorial-workspace-transformations-api/build-custom-template.png" lightbox="../logs/media/tutorial-workspace-transformations-api/build-custom-template.png" alt-text="Screenshot that shows portal screen to build template in the editor."::: --1. Paste this Azure Resource Manager template into the editor: -- ### [Windows](#tab/windows) -- ```json - { - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "location": { - "type": "string", - "defaultValue": "[resourceGroup().location]", - "metadata": { - "description": "Location for all resources." - } - }, - "dataCollectionRulesName": { - "defaultValue": "[concat(resourceGroup().name, 'DCR')]", - "type": "String" - }, - "storageAccountName": { - "defaultValue": "[concat(resourceGroup().name, 'sa')]", - "type": "String" - }, - "eventHubNamespaceName": { - "defaultValue": "[concat(resourceGroup().name, 'eh')]", - "type": "String" - }, - "eventHubInstanceName": { - "defaultValue": "[concat(resourceGroup().name, 'ehins')]", - "type": "String" - } - }, - "resources": [ - { - "type": "Microsoft.Insights/dataCollectionRules", - "apiVersion": "2022-06-01", - "name": "[parameters('dataCollectionRulesName')]", - "location": "[parameters('location')]", - "kind": "AgentDirectToStore", - "properties": { - "dataSources": { - "performanceCounters": [ - { - "streams": [ - "Microsoft-Perf" - ], - "samplingFrequencyInSeconds": 10, - "counterSpecifiers": [ - "\\Process(_Total)\\Working Set - Private", - "\\Memory\\% Committed Bytes In Use", - "\\LogicalDisk(_Total)\\% Free Space", - "\\Network Interface(*)\\Bytes Total/sec" - ], - "name": "perfCounterDataSource10" - } - ], - "windowsEventLogs": [ - { - "streams": [ - "Microsoft-Event" - ], - "xPathQueries": [ - "Application!*[System[(Level=2)]]", - "System!*[System[(Level=2)]]" - ], - "name": "eventLogsDataSource" - } - ], - "iisLogs": [ - { - "streams": [ - "Microsoft-W3CIISLog" - ], - "logDirectories": [ - "C:\\inetpub\\logs\\LogFiles\\W3SVC1\\" - ], - "name": "myIisLogsDataSource" - } - ], - "logFiles": [ - { - "streams": [ - "Custom-Text-logs" - ], - "filePatterns": [ - "C:\\JavaLogs\\*.log" - ], - "format": "text", - "settings": { - "text": { - "recordStartTimestampFormat": "ISO 8601" - } - }, - "name": "myTextLogs" - } - ] - }, - "destinations": { - "eventHubsDirect": [ - { - "eventHubResourceId": "[resourceId('Microsoft.EventHub/namespaces/eventhubs', parameters('eventHubNamespaceName'), parameters('eventHubInstanceName'))]", - "name": "myEh1" - } - ], - "storageBlobsDirect": [ - { - "storageAccountResourceId": "[resourceId('Microsoft.Storage/storageAccounts/', parameters('storageAccountName'))]", - "name": "blobNamedPerf", - "containerName": "PerfBlob" - }, - { - "storageAccountResourceId": "[resourceId('Microsoft.Storage/storageAccounts/', parameters('storageAccountName'))]", - "name": "blobNamedWin", - "containerName": "WinEventBlob" - }, - { - "storageAccountResourceId": "[resourceId('Microsoft.Storage/storageAccounts/', parameters('storageAccountName'))]", - "name": "blobNamedIIS", - "containerName": "IISBlob" - }, - { - "storageAccountResourceId": "[resourceId('Microsoft.Storage/storageAccounts/', parameters('storageAccountName'))]", - "name": "blobNamedTextLogs", - "containerName": "TxtLogBlob" - } - ], - "storageTablesDirect": [ - { - "storageAccountResourceId": "[resourceId('Microsoft.Storage/storageAccounts/', parameters('storageAccountName'))]", - "name": "tableNamedPerf", - "tableName": "PerfTable" - }, - { - "storageAccountResourceId": "[resourceId('Microsoft.Storage/storageAccounts/', parameters('storageAccountName'))]", - "name": "tableNamedWin", - "tableName": "WinTable" - }, - { - "storageAccountResourceId": "[resourceId('Microsoft.Storage/storageAccounts/', parameters('storageAccountName'))]", - "name": "tableUnnamed" - } - ] - }, - "dataFlows": [ - { - "streams": [ - "Microsoft-Perf" - ], - "destinations": [ - "myEh1", - "blobNamedPerf", - "tableNamedPerf", - "tableUnnamed" - ] - }, - { - "streams": [ - "Microsoft-Event" - ], - "destinations": [ - "myEh1", - "blobNamedWin", - "tableNamedWin", - "tableUnnamed" - ] - }, - { - "streams": [ - "Microsoft-W3CIISLog" - ], - "destinations": [ - "blobNamedIIS" - ] - }, - { - "streams": [ - "Custom-Text-logs" - ], - "destinations": [ - "blobNamedTextLogs" - ] - } - ] - } - } - ] - } - ``` -- ### [Linux](#tab/linux) -- ```json - { - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "location": { - "type": "string", - "defaultValue": "[resourceGroup().location]", - "metadata": { - "description": "Location for all resources." - } - }, - "dataCollectionRulesName": { - "defaultValue": "[concat(resourceGroup().name, 'DCR')]", - "type": "String" - }, - "storageAccountName": { - "defaultValue": "[concat(resourceGroup().name, 'sa')]", - "type": "String" - }, - "eventHubNamespaceName": { - "defaultValue": "[concat(resourceGroup().name, 'eh')]", - "type": "String" - }, - "eventHubInstanceName": { - "defaultValue": "[concat(resourceGroup().name, 'ehins')]", - "type": "String" - } - }, - "resources": [ - { - "type": "Microsoft.Insights/dataCollectionRules", - "apiVersion": "2022-06-01", - "name": "[parameters('dataCollectionRulesName')]", - "location": "[parameters('location')]", - "kind": "AgentDirectToStore", - "properties": { - "dataSources": { - "performanceCounters": [ - { - "streams": [ - "Microsoft-Perf" - ], - "samplingFrequencyInSeconds": 10, - "counterSpecifiers": [ - "Processor(*)\\% Processor Time", - "Processor(*)\\% Idle Time", - "Processor(*)\\% User Time", - "Processor(*)\\% Nice Time", - "Processor(*)\\% Privileged Time", - "Processor(*)\\% IO Wait Time", - "Processor(*)\\% Interrupt Time", - "Processor(*)\\% DPC Time", - "Memory(*)\\Available MBytes Memory", - "Memory(*)\\% Available Memory", - "Memory(*)\\Used Memory MBytes", - "Memory(*)\\% Used Memory", - "Memory(*)\\Pages/sec", - "Memory(*)\\Page Reads/sec", - "Memory(*)\\Page Writes/sec", - "Memory(*)\\Available MBytes Swap", - "Memory(*)\\% Available Swap Space", - "Memory(*)\\Used MBytes Swap Space", - "Memory(*)\\% Used Swap Space", - "Logical Disk(*)\\% Free Inodes", - "Logical Disk(*)\\% Used Inodes", - "Logical Disk(*)\\Free Megabytes", - "Logical Disk(*)\\% Free Space", - "Logical Disk(*)\\% Used Space", - "Logical Disk(*)\\Logical Disk Bytes/sec", - "Logical Disk(*)\\Disk Read Bytes/sec", - "Logical Disk(*)\\Disk Write Bytes/sec", - "Logical Disk(*)\\Disk Transfers/sec", - "Logical Disk(*)\\Disk Reads/sec", - "Logical Disk(*)\\Disk Writes/sec", - "Network(*)\\Total Bytes Transmitted", - "Network(*)\\Total Bytes Received", - "Network(*)\\Total Bytes", - "Network(*)\\Total Packets Transmitted", - "Network(*)\\Total Packets Received", - "Network(*)\\Total Rx Errors", - "Network(*)\\Total Tx Errors", - "Network(*)\\Total Collisions" - ], - "name": "perfCounterDataSource10" - } - ], - "syslog": [ - { - "streams": [ - "Microsoft-Syslog" - ], - "facilityNames": [ - "auth", - "authpriv", - "cron", - "daemon", - "mark", - "kern", - "local0", - "local1", - "local2", - "local3", - "local4", - "local5", - "local6", - "local7", - "lpr", - "mail", - "news", - "syslog", - "user", - "uucp" - ], - "logLevels": [ - "Debug", - "Info", - "Notice", - "Warning", - "Error", - "Critical", - "Alert", - "Emergency" - ], - "name": "syslogDataSource" - } - ], - "logFiles": [ - { - "streams": [ - "Custom-Text-logs" - ], - "filePatterns": [ - "/var/log/messages" - ], - "format": "text", - "settings": { - "text": { - "recordStartTimestampFormat": "ISO 8601" - } - }, - "name": "myTextLogs" - } - ] - }, - "destinations": { - "eventHubsDirect": [ - { - "eventHubResourceId": "[resourceId('Microsoft.EventHub/namespaces/eventhubs', parameters('eventHubNamespaceName'), parameters('eventHubInstanceName'))]", - "name": "myEh1" - } - ], - "storageBlobsDirect": [ - { - "storageAccountResourceId": "[resourceId('Microsoft.Storage/storageAccounts/', parameters('storageAccountName'))]", - "name": "blobNamedPerf", - "containerName": "PerfBlob" - }, - { - "storageAccountResourceId": "[resourceId('Microsoft.Storage/storageAccounts/', parameters('storageAccountName'))]", - "name": "blobNamedLinux", - "containerName": "SyslogBlob" - }, - { - "storageAccountResourceId": "[resourceId('Microsoft.Storage/storageAccounts/', parameters('storageAccountName'))]", - "name": "blobNamedTextLogs", - "containerName": "TxtLogBlob" - } - ], - "storageTablesDirect": [ - { - "storageAccountResourceId": "[resourceId('Microsoft.Storage/storageAccounts/', parameters('storageAccountName'))]", - "name": "tableNamedPerf", - "tableName": "PerfTable" - }, - { - "storageAccountResourceId": "[resourceId('Microsoft.Storage/storageAccounts/', parameters('storageAccountName'))]", - "name": "tableNamedLinux", - "tableName": "LinuxTable" - }, - { - "storageAccountResourceId": "[resourceId('Microsoft.Storage/storageAccounts/', parameters('storageAccountName'))]", - "name": "tableUnnamed" - } - ] - }, - "dataFlows": [ - { - "streams": [ - "Microsoft-Perf" - ], - "destinations": [ - "myEh1", - "blobNamedPerf", - "tableNamedPerf", - "tableUnnamed" - ] - }, - { - "streams": [ - "Microsoft-Syslog" - ], - "destinations": [ - "myEh1", - "blobNamedLinux", - "tableNamedLinux", - "tableUnnamed" - ] - }, - { - "streams": [ - "Custom-Text-logs" - ], - "destinations": [ - "blobNamedTextLogs" - ] - } - ] - } - } - ] - } - ``` -- --1. Update the following values in the Azure Resource Manager template. See the example Azure Resource Manager template for a sample. -- **Event hub** -- | Value | Description | - |:|:| - | `dataSources` | Define it per your requirements. The supported types for direct upload to Event Hubs for Windows are `performanceCounters` and `windowsEventLogs` and for Linux, they're `performanceCounters` and `syslog`. | - | `destinations` | Use `eventHubsDirect` for direct upload to the event hub. | - | `eventHubResourceId` | Resource ID of the event hub instance.<br><br>NOTE: It isn't the event hub namespace resource ID. | - | `dataFlows` | Under `dataFlows`, include destination name. | -- **Storage table** -- | Value | Description | - |:|:| - | `dataSources` | Define it per your requirements. The supported types for direct upload to storage Table for Windows are `performanceCounters`, `windowsEventLogs` and for Linux, they're `performanceCounters` and `syslog`. | - | `destinations` | Use `storageTablesDirect` for direct upload to table storage. | - | `storageAccountResourceId` | Resource ID of the storage account. | - | `tableName` | The name of the Table where JSON blob with event data is uploaded to. | - | `dataFlows` | Under `dataFlows`, include destination name. | -- **Storage blob** -- | Value | Description | - |:|:| - | `dataSources` | Define it per your requirements. The supported types for direct upload to storage blob for Windows are `performanceCounters`, `windowsEventLogs`, `iisLogs`, `logFiles` and for Linux, they're `performanceCounters`, `syslog` and `logFiles`. | - | `destinations` | Use `storageBlobsDirect` for direct upload to blob storage. | - | `storageAccountResourceId` | The resource ID of the storage account. | - | `containerName` | The name of the container where JSON blob with event data is uploaded to. | - | `dataFlows` | Under `dataFlows`, include destination name. | --1. Select **Save**. --## Create DCR association and deploy Azure Monitor Agent --Use custom template deployment to create the DCR association and AMA deployment. --1. In the Azure portal's search box, type in *template* and then select **Deploy a custom template**. -- :::image type="content" source="../logs/media/tutorial-workspace-transformations-api/deploy-custom-template.png" lightbox="../logs/media/tutorial-workspace-transformations-api/deploy-custom-template.png" alt-text="Screenshot that shows the Azure portal with template entered in the search box and Deploy a custom template highlighted in the search results."::: --1. Select **Build your own template in the editor**. -- :::image type="content" source="../logs/media/tutorial-workspace-transformations-api/build-custom-template.png" lightbox="../logs/media/tutorial-workspace-transformations-api/build-custom-template.png" alt-text="Screenshot that shows portal screen to build template in the editor."::: --1. Paste this Azure Resource Manager template into the editor. -- ### [Windows](#tab/windows-1) -- ```json - { - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "defaultValue": "[concat(resourceGroup().name, 'vm')]", - "type": "String" - }, - "location": { - "type": "string", - "defaultValue": "[resourceGroup().location]", - "metadata": { - "description": "Location for all resources." - } - }, - "dataCollectionRulesName": { - "defaultValue": "[concat(resourceGroup().name, 'DCR')]", - "type": "String", - "metadata": { - "description": "Data Collection Rule Name" - } - }, - "dcraName": { - "type": "string", - "defaultValue": "[concat(uniquestring(resourceGroup().id), 'DCRLink')]", - "metadata": { - "description": "Name of the association." - } - }, - "identityName": { - "type": "string", - "defaultValue": "[concat(resourceGroup().name, 'UAI')]", - "metadata": { - "description": "Managed Identity" - } - } - }, - "resources": [ - { - "type": "Microsoft.Compute/virtualMachines/providers/dataCollectionRuleAssociations", - "name": "[concat(parameters('vmName'),'/microsoft.insights/', parameters('dcraName'))]", - "apiVersion": "2021-04-01", - "properties": { - "description": "Association of data collection rule. Deleting this association will break the data collection for this virtual machine.", - "dataCollectionRuleId": "[resourceID('Microsoft.Insights/dataCollectionRules',parameters('dataCollectionRulesName'))]" - } - }, - { - "type": "Microsoft.Compute/virtualMachines/extensions", - "name": "[concat(parameters('vmName'), '/AMAExtension')]", - "apiVersion": "2020-06-01", - "location": "[parameters('location')]", - "dependsOn": [ - "[resourceId('Microsoft.Compute/virtualMachines/providers/dataCollectionRuleAssociations', parameters('vmName'), 'Microsoft.Insights', parameters('dcraName'))]" - ], - "properties": { - "publisher": "Microsoft.Azure.Monitor", - "type": "AzureMonitorWindowsAgent", - "typeHandlerVersion": "1.0", - "autoUpgradeMinorVersion": true, - "settings": { - "authentication": { - "managedIdentity": { - "identifier-name": "mi_res_id", - "identifier-value": "[resourceID('Microsoft.ManagedIdentity/userAssignedIdentities/',parameters('identityName'))]" - } - } - } - } - } - ] - } - ``` -- ### [Linux](#tab/linux-1) -- ```json - { - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "defaultValue": "[concat(resourceGroup().name, 'vm')]", - "type": "String" - }, - "location": { - "type": "string", - "defaultValue": "[resourceGroup().location]", - "metadata": { - "description": "Location for all resources." - } - }, - "dataCollectionRulesName": { - "defaultValue": "[concat(resourceGroup().name, 'DCR')]", - "type": "String", - "metadata": { - "description": "Data Collection Rule Name" - } - }, - "dcraName": { - "type": "string", - "defaultValue": "[concat(uniquestring(resourceGroup().id), 'DCRLink')]", - "metadata": { - "description": "Name of the association." - } - }, - "identityName": { - "type": "string", - "defaultValue": "[concat(resourceGroup().name, 'UAI')]", - "metadata": { - "description": "Managed Identity" - } - } - }, - "resources": [ - { - "type": "Microsoft.Compute/virtualMachines/providers/dataCollectionRuleAssociations", - "name": "[concat(parameters('vmName'),'/microsoft.insights/', parameters('dcraName'))]", - "apiVersion": "2021-04-01", - "properties": { - "description": "Association of data collection rule. Deleting this association will break the data collection for this virtual machine.", - "dataCollectionRuleId": "[resourceID('Microsoft.Insights/dataCollectionRules',parameters('dataCollectionRulesName'))]" - } - }, - { - "type": "Microsoft.Compute/virtualMachines/extensions", - "name": "[concat(parameters('vmName'), '/AMAExtension')]", - "apiVersion": "2020-06-01", - "location": "[parameters('location')]", - "dependsOn": [ - "[resourceId('Microsoft.Compute/virtualMachines/providers/dataCollectionRuleAssociations', parameters('vmName'), 'Microsoft.Insights', parameters('dcraName'))]" - ], - "properties": { - "publisher": "Microsoft.Azure.Monitor", - "type": "AzureMonitorLinuxAgent", - "typeHandlerVersion": "1.0", - "autoUpgradeMinorVersion": true, - "settings": { - "authentication": { - "managedIdentity": { - "identifier-name": "mi_res_id", - "identifier-value": "[resourceID('Microsoft.ManagedIdentity/userAssignedIdentities/',parameters('identityName'))]" - } - } - } - } - } - ] - } - ``` - - -1. Select **Save**. --## Troubleshooting --Use the following section to troubleshoot sending data to Event Hubs and Storage. --### Data not found in storage account blob storage --- Check that the built-in role `Storage Blob Data Contributor` is assigned with managed identity on the storage account.-- Check that the managed identity is assigned to the VM.-- Check that the AMA settings have managed identity parameter.--### Data not found in storage account table storage --- Check that the built-in role `Storage Table Data Contributor` is assigned with managed identity on the storage account.-- Check that the managed identity is assigned to the VM.-- Check that the AMA settings have managed identity parameter.--### Data not flowing to event hub --- Check that the built-in role `Azure Event Hubs Data Sender` is assigned with managed identity on the event hub instance.-- Check that the managed identity is assigned to the VM.-- Check that the AMA settings have managed identity parameter.--## AMA and WAD/LAD Convergence --### Will the Azure Monitoring Agent support data upload to Application Insights? --No, this support isn't a part of the roadmap. Application Insights are now powered by Log Analytics Workspaces. --### Will the Azure Monitoring Agent support Windows Crash Dumps as a data type to upload? --No, this support isn't a part of the roadmap. The Azure Monitoring Agent is meant for telemetry logs and not large file types. --### Does this mean the Linux (LAD) and Windows (WAD) Diagnostic Extensions are no longer supported/retired? --No, not until Azure formally announces the deprecation of these agents, which would start a three-year clock until they're no longer supported. --### How to configure AMA for event hubs and storage data destinations --Today the configuration experience is by using the DCR API. --### Will you still be actively developing on WAD and LAD? --WAD and LAD will only be getting security/patches going forward. Most engineering funding has gone to the Azure Monitoring Agent. We highly recommend migrating to the Azure Monitoring Agent to benefit from all its awesome capabilities. --## See also --- For more information on creating a data collection rule, see [Collect data from virtual machines using Azure Monitor Agent](./azure-monitor-agent-data-collection.md). |
| azure-monitor | Azure Monitor Agent Supported Operating Systems | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-supported-operating-systems.md | - Title: Azure Monitor Agent supported operating systems -description: Identifies the operating systems supported by Azure Monitor Agent and legacy agents. --- Previously updated : 07/24/2024----# Customer intent: As an IT manager, I want to understand the capabilities of Azure Monitor Agent to determine whether I can use the agent to collect the data I need from the operating systems of my virtual machines. ----# Azure Monitor Agent supported operating systems and environments -This article lists the operating systems supported by [Azure Monitor Agent](./azure-monitor-agent-overview.md) and [legacy agents](./log-analytics-agent.md). See [Install and manage Azure Monitor Agent](./azure-monitor-agent-manage.md) for details on installing the agent. --> [!NOTE] -> All operating systems listed are assumed to be x64. x86 isn't supported for any operating system. --## Windows operating systems --| Operating system | Azure Monitor agent | Legacy agent| -|:|::|:: -| Windows Server 2022 | Γ£ô | Γ£ô | -| Windows Server 2022 Core | Γ£ô | | -| Windows Server 2019 | Γ£ô | Γ£ô | -| Windows Server 2019 Core | Γ£ô | | -| Windows Server 2016 | Γ£ô | Γ£ô | -| Windows Server 2016 Core | Γ£ô | | -| Windows Server 2012 R2 | Γ£ô | Γ£ô | -| Windows Server 2012 | Γ£ô | Γ£ô | -| Windows 11 Client and Pro | Γ£ô<sup>1</sup>, <sup>2</sup> | | -| Windows 11 Enterprise<br>(including multi-session) | Γ£ô | | -| Windows 10 1803 (RS4) and higher | Γ£ô<sup>1</sup> | | -| Windows 10 Enterprise<br>(including multi-session) and Pro<br>(Server scenarios only) | Γ£ô | Γ£ô | -| Azure Stack HCI | Γ£ô | Γ£ô | -| Windows IoT Enterprise | Γ£ô | | --<sup>1</sup> Requires Azure Monitor agent [client installer](./azure-monitor-agent-windows-client.md).<br> -<sup>2</sup> Also supported on Arm64-based machines. --## Linux operating systems --> [!CAUTION] -> CentOS is a Linux distribution that is nearing End Of Life (EOL) status. Please consider your use and planning accordingly. For more information, see the [CentOS End Of Life guidance](/azure/virtual-machines/workloads/centos/centos-end-of-life). --| Operating system | Azure Monitor agent <sup>1</sup> | Legacy Agent <sup>1</sup> | -|:|::|::| -| AlmaLinux 9 | Γ£ô<sup>2</sup> | Γ£ô | -| AlmaLinux 8 | Γ£ô<sup>2</sup> | Γ£ô | -| Amazon Linux 2017.09 | | Γ£ô | -| Amazon Linux 2 | Γ£ô | Γ£ô | -| Azure Linux | Γ£ô | | -| CentOS Linux 8 | Γ£ô | Γ£ô | -| CentOS Linux 7 | Γ£ô<sup>2</sup> | Γ£ô | -| CBL-Mariner 2.0 | Γ£ô<sup>2,3</sup> | | -| Debian 12 | Γ£ô | | -| Debian 11 | Γ£ô<sup>2</sup> | Γ£ô | -| Debian 10 | Γ£ô | Γ£ô | -| Debian 9 | Γ£ô | Γ£ô | -| Debian 8 | | Γ£ô | -| OpenSUSE 15 | Γ£ô | Γ£ô | -| Oracle Linux 9 | Γ£ô | | -| Oracle Linux 8 | Γ£ô | Γ£ô | -| Oracle Linux 7 | Γ£ô | Γ£ô | -| Oracle Linux 6.4+ | | | -| Red Hat Enterprise Linux Server 9+ | Γ£ô | Γ£ô | -| Red Hat Enterprise Linux Server 8.6+ | Γ£ô<sup>2</sup> | Γ£ô | -| Red Hat Enterprise Linux Server 8.0-8.5 | Γ£ô | Γ£ô | -| Red Hat Enterprise Linux Server 7 | Γ£ô | Γ£ô | -| Red Hat Enterprise Linux Server 6.7+ | | | -| Rocky Linux 9 | Γ£ô | Γ£ô | -| Rocky Linux 8 | Γ£ô | Γ£ô | -| SUSE Linux Enterprise Server 15 SP5 | Γ£ô<sup>2</sup> | Γ£ô | -| SUSE Linux Enterprise Server 15 SP4 | Γ£ô<sup>2</sup> | Γ£ô | -| SUSE Linux Enterprise Server 15 SP3 | Γ£ô | Γ£ô | -| SUSE Linux Enterprise Server 15 SP2 | Γ£ô | Γ£ô | -| SUSE Linux Enterprise Server 15 SP1 | Γ£ô | Γ£ô | -| SUSE Linux Enterprise Server 15 | Γ£ô | Γ£ô | -| SUSE Linux Enterprise Server 12 | Γ£ô | Γ£ô | -| Ubuntu 22.04 LTS | Γ£ô | Γ£ô | -| Ubuntu 20.04 LTS | Γ£ô<sup>2</sup> | Γ£ô | -| Ubuntu 18.04 LTS | Γ£ô<sup>2</sup> | Γ£ô | -| Ubuntu 16.04 LTS | Γ£ô | Γ£ô | -| Ubuntu 14.04 LTS | | Γ£ô | --<sup>1</sup> Requires Python (2 or 3) to be installed on the machine.<br> -<sup>2</sup> Also supported on Arm64-based machines.<br> -<sup>3</sup> Does not include the required least 4GB of disk space by default. See note below. --> [!NOTE] -> Machines and appliances that run heavily customized or stripped-down versions of the above distributions and hosted solutions that disallow customization by the user are not supported. Azure Monitor and legacy agents rely on various packages and other baseline functionality that is often removed from such systems, and their installation may require some environmental modifications considered to be disallowed by the appliance vendor. For example, [GitHub Enterprise Server](https://docs.github.com/en/enterprise-server/admin/overview/about-github-enterprise-server) is not supported due to heavy customization as well as [documented, license-level disallowance](https://docs.github.com/en/enterprise-server/admin/overview/system-overview#operating-system-software-and-patches) of operating system modification. --> [!NOTE] -> CBL-Mariner 2.0's disk size is by default about 1GB to provide storage savings, compared to other Azure VMs that are about 30GB. The Azure Monitor Agent requires at least 4GB disk size in order to install and run successfully. See [CBL-Mariner's documentation](https://eng.ms/docs/products/mariner-linux/gettingstarted/azurevm/azurevm#disk-size) for more information and instructions on how to increase disk size before installing the agent. --## Hardening standards -Azure Monitoring Agent supports most industry-standard hardening standards and is continuously tested and certified against these standards every release. All Azure Monitor Agent scenarios are designed from the ground up with security in mind. --### Windows hardening -Azure Monitoring Agent supports all standard Windows hardening standards, including STIG and FIPs, and is FedRamp compliant under Azure Monitor. --### Linux hardening -The Azure Monitoring Agent for Linux supports various hardening standards for Linux operating systems and distros. Every release of the agent is tested and certified against the supported hardening standards using images that are publicly available on the Azure Marketplace and published by CIS. Only the settings and hardening that are applied to those images are supported. If you apply additional customizations on your own golden images, and those settings are not covered by the CIS images, it will be considered a non-supported scenario. --> [!NOTE] -> Only the Azure Monitoring Agent for Linux will support these hardening standards. They are not supported by the legacy Log Analytics Agent or the Diagnostics Extension. --Currently supported hardening standards: -- SELinux-- CIS level 1 and 2<sup>1</sup>-- STIG-- FIPs-- FedRamp--| Operating system | Azure Monitor agent <sup>1</sup> | Legacy Agent<sup>1</sup> | -|:|::|::|::| -| CentOS Linux 7 | Γ£ô | | -| Debian 10 | Γ£ô | | -| Ubuntu 18 | Γ£ô | | -| Ubuntu 20 | Γ£ô | | -| Red Hat Enterprise Linux Server 7 | Γ£ô | | -| Red Hat Enterprise Linux Server 8 | Γ£ô | | --<sup>1</sup> Supports only the above distros and version ---## On-premises and other clouds -Azure Monitor agent is supported on machines in other clouds and on-premises with [Azure Arc-enabled servers](../../azure-arc/servers/overview.md). Azure Monitor agent authenticates to your workspace with managed identity, which is created when you install the [Connected Machine agent](../../azure-arc/servers/agent-overview.md), which is part of Azure Arc. The legacy Log Analytics agent authenticated using the workspace ID and key, so it didn't need Azure Arc. Managed identity is a more secure and manageable authentication solution. --The Azure Arc agent is only used as an installation mechanism and does not add any cost or resource consumption. There are paid options for Azure Arc, but these aren't required for the Azure Monitor agent. ----## Next steps --- [Install the Azure Monitor Agent](azure-monitor-agent-manage.md) on Windows and Linux virtual machines.-- [Identify requirements and prerequisites](azure-monitor-agent-requirements.md) for Azure Monitor Agent installation. |
| azure-monitor | Azure Monitor Agent Transformation | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-transformation.md | - Title: Transform text logs during ingestion in Azure Monitor Logs -description: Write a KQL query that transforms text log data and add the transformation to a data collection rule in Azure Monitor Logs. - Previously updated : 07/19/2023-----# Tutorial: Transform text logs during ingestion in Azure Monitor Logs --Ingestion-time transformations let you filter or modify incoming data before it's stored in a Log Analytics workspace. This article explains how to write a KQL query that transforms text log data and add the transformation to a data collection rule. --The procedure described here assumes you've already ingested some data from a text file, as described in [Collect text logs with Azure Monitor Agent](../agents/data-collection-text-log.md). In this tutorial, you'll: --1. Write a KQL query to transform ingested data. -1. Modify the target table schema. -1. Add the transformation to your data collection rule. -1. Verify that the transformation works correctly. --## Prerequisites --To complete this procedure, you need: --- Log Analytics workspace where you have at least [contributor rights](../logs/manage-access.md#azure-rbac).-- [Data collection rule](../essentials/data-collection-rule-overview.md), [data collection endpoint](../essentials/data-collection-endpoint-overview.md#create-a-data-collection-endpoint), and [custom table](../logs/create-custom-table.md#create-a-custom-table), as described in [Collect text logs with Azure Monitor Agent](../agents/data-collection-text-log.md). -- A VM, Virtual Machine Scale Set, or Arc-enabled on-premises server that writes logs to a text file.- Text file requirements: - - Store on the local drive of the machine on which Azure Monitor Agent is running. - - Delineate with an end of line. - - Use ASCII or UTF-8 encoding. Other formats such as UTF-16 aren't supported. - - Don't allow circular logging, log rotation where the file is overwritten with new entries, or renaming where a file is moved and a new file with the same name is opened. ---## Write a KQL query to transform ingested data --1. View the data in the target custom table in Log Analytics: - 1. In the Azure portal, select **Log Analytics workspaces** > your Log Analytics workspace > **Logs**. - 1. Run a basic query the custom logs table to view table data. -1. Use the query window to write and test a query that transforms the raw data in your table. -- For information about the KQL operators that transformations support, see [Structure of transformation in Azure Monitor](../essentials/data-collection-transformations-structure.md#kql-limitations). - - > [!Note] - > The only columns that are available to apply transforms against are TimeGenerated and RawData. Other columns are added to the table automatically after the transformation and are not available at the time of transformation. - > The _ResourceId column can't be used in the transformation. -- **Example** - - The sample uses [basic KQL operators](/azure/data-explorer/kql-quick-reference) to parse the data in the `RawData` column into three new columns, called `Time Ingested`, `RecordNumber`, and `RandomContent`: - - - The `extend` operator adds new columns. - - The `project` operator formats the output to match the columns of the target table schema: -- ```kusto - MyTable_CL - | extend d=todynamic(RawData) - | project TimeGenerated,TimeIngested=tostring(d.Time), - RecordNumber=tostring(d.RecordNumber), - RandomContent=tostring(d.RandomContent), - RawData - ``` - > [!NOTE] - > Querying table data in this way doesn't actually modify the data in the table. Azure Monitor applies the transformation in the [data ingestion pipeline](../essentials/data-collection-transformations.md) after you [add your transformation query to the data collection rule](#apply-the-transformation-to-your-data-collection-rule). --1. Format the query into a single line and replace the table name in the first line of the query with the word `source`. - - For example: -- ```kusto - source | extend d=todynamic(RawData) | project TimeGenerated,TimeIngested=tostring(d.Time),RecordNumber=tostring(d.RecordNumber), RandomContent=tostring(d.RandomContent), RawData - ``` --1. Copy the formatted query so you can paste it into the data collection rule configuration. --## Modify the custom table to include the new columns --[Add or delete columns in your custom table](../logs/create-custom-table.md#add-or-delete-a-custom-column), based on your transformation query. --The example transformation query above adds three new columns of type `string`: -- `TimeIngested`-- `RecordNumber`-- `RandomContent`--To support this transformation, add these three new columns to your custom table. ---## Apply the transformation to your data collection rule --1. On the **Monitor** menu, select **Data Collection Rules** > your data collection rule. -1. Select **Data sources** > your data source. -1. Paste the formatted transformation query in the **Transform** field on the **Data source** tab of the **Add data source** screen. -1. Select **Save**. -- :::image type="content" source="media/azure-monitor-agent-transformation/add-transformation-to-data-collection-rule.png" alt-text="Screenshot of the Add data sources pane with the Transform field highlighted." lightbox="media/azure-monitor-agent-transformation/add-transformation-to-data-collection-rule.png"::: --## Check that the transformation works --View the data in the target custom table and check that data is being ingested correctly into the modified table: -1. In the Azure portal, select **Log Analytics workspaces** > your Log Analytics workspace > **Logs**. -1. Run a basic query the custom logs table to view table data. ---## Next steps --Learn more about: -- [Data collection transformations](../essentials/data-collection-rule-structure.md).-- [Data collection rules](../essentials/data-collection-rule-overview.md). -- [Data collection endpoints](../essentials/data-collection-endpoint-overview.md). -- |
| azure-monitor | Azure Monitor Agent Troubleshoot Linux Vm Rsyslog | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-troubleshoot-linux-vm-rsyslog.md | - Title: Syslog troubleshooting on Azure Monitor Agent for Linux -description: Guidance for troubleshooting rsyslog issues on Linux virtual machines, scale sets with Azure Monitor Agent, and data collection rules. --- Previously updated : 5/31/2023----# Syslog troubleshooting guide for Azure Monitor Agent for Linux --> [!CAUTION] -> This article references CentOS, a Linux distribution that is End Of Life (EOL) status. Please consider your use and planning accordingly. For more information, see the [CentOS End Of Life guidance](/azure/virtual-machines/workloads/centos/centos-end-of-life). --Overview of Azure Monitor Agent for Linux Syslog collection and supported RFC standards: --- Azure Monitor Agent installs an output configuration for the system Syslog daemon during the installation process. The configuration file specifies the way events flow between the Syslog daemon and Azure Monitor Agent.-- For `rsyslog` (most Linux distributions), the configuration file is `/etc/rsyslog.d/10-azuremonitoragent-omfwd.conf`. For `syslog-ng`, the configuration file is `/etc/syslog-ng/conf.d/azuremonitoragent-tcp.conf`.-- Azure Monitor Agent listens to a TCP port to receive events from `rsyslog` / `syslog-ng`. The port for this communication is logged at `/etc/opt/microsoft/azuremonitoragent/config-cache/syslog.port`.- > [!NOTE] - > Before Azure Monitor Agent version 1.28, it used a Unix domain socket instead of TCP port to receive events from rsyslog. `omfwd` output module in `rsyslog` offers spooling and retry mechanisms for improved reliability. -- The Syslog daemon uses queues when Azure Monitor Agent ingestion is delayed or when Azure Monitor Agent isn't reachable.-- Azure Monitor Agent ingests Syslog events via the previously mentioned socket and filters them based on facility or severity combination from data collection rule (DCR) configuration in `/etc/opt/microsoft/azuremonitoragent/config-cache/configchunks/`. Any `facility` or `severity` not present in the DCR is dropped.-- Azure Monitor Agent attempts to parse events in accordance with **RFC3164** and **RFC5424**. It also knows how to parse the message formats listed in [this website](./azure-monitor-agent-overview.md#supported-services-and-features).-- Azure Monitor Agent identifies the destination endpoint for Syslog events from the DCR configuration and attempts to upload the events.- > [!NOTE] - > Azure Monitor Agent uses local persistency by default. All events received from `rsyslog` or `syslog-ng` are queued in `/var/opt/microsoft/azuremonitoragent/events` if they fail to be uploaded. --## Issues --You might encounter the following issues. --### Rsyslog data isn't uploaded because of a full disk space issue on Azure Monitor Agent for Linux --The next sections describe the issue. --#### Symptom -**Syslog data is not uploading**: When you inspect the error logs at `/var/opt/microsoft/azuremonitoragent/log/mdsd.err`, you see entries about *Error while inserting item to Local persistent store…No space left on device* similar to the following snippet: --``` -2021-11-23T18:15:10.9712760Z: Error while inserting item to Local persistent store syslog.error: IO error: No space left on device: While appending to file: /var/opt/microsoft/azuremonitoragent/events/syslog.error/000555.log: No space left on device -``` --#### Cause -Azure Monitor Agent for Linux buffers events to `/var/opt/microsoft/azuremonitoragent/events` prior to ingestion. On a default Azure Monitor Agent for Linux installation, this directory takes ~650 MB of disk space at idle. The size on disk increases when it's under sustained logging load. It gets cleaned up about every 60 seconds and reduces back to ~650 MB when the load returns to idle. --#### Confirm the issue of a full disk -The `df` command shows almost no space available on `/dev/sda1`, as shown in the following output. Note that you should examine the line item that correlates to the log directory (for example, `/var/log` or `/var` or `/`). --```bash - df -h -``` -```output -Filesystem Size Used Avail Use% Mounted on -udev 63G 0 63G 0% /dev -tmpfs 13G 720K 13G 1% /run -/dev/sda1 29G 29G 481M 99% / -tmpfs 63G 0 63G 0% /dev/shm -tmpfs 5.0M 0 5.0M 0% /run/lock -tmpfs 63G 0 63G 0% /sys/fs/cgroup -/dev/sda15 105M 4.4M 100M 5% /boot/efi -/dev/sdb1 251G 61M 239G 1% /mnt -tmpfs 13G 0 13G 0% /run/user/1000 -``` --You can use the `du` command to inspect the disk to determine which files are causing the disk to be full. For example: --```bash - cd /var/log - du -h syslog* -``` -```output -6.7G syslog -18G syslog.1 -``` --In some cases, `du` might not report any large files or directories. It might be possible that a [file marked as (deleted) is taking up the space](https://unix.stackexchange.com/questions/182077/best-way-to-free-disk-space-from-deleted-files-that-are-held-open). This issue can happen when some other process has attempted to delete a file, but a process with the file is still open. You can use the `lsof` command to check for such files. In the following example, we see that `/var/log/syslog` is marked as deleted but it takes up 3.6 GB of disk space. It hasn't been deleted because a process with PID 1484 still has the file open. --```bash - sudo lsof +L1 -``` --```output -COMMAND PID USER FD TYPE DEVICE SIZE/OFF NLINK NODE NAME -none 849 root txt REG 0,1 8632 0 16764 / (deleted) -rsyslogd 1484 syslog 14w REG 8,1 3601566564 0 35280 /var/log/syslog (deleted) -``` --### Rsyslog default configuration logs all facilities to /var/log/ -On some popular distros (for example, Ubuntu 18.04 LTS), rsyslog ships with a default configuration file (`/etc/rsyslog.d/50-default.conf`), which logs events from nearly all facilities to disk at `/var/log/syslog`. RedHat/CentOS family Syslog events are stored under `/var/log/` but in a different file: `/var/log/messages`. --Azure Monitor Agent doesn't rely on Syslog events being logged to `/var/log/`. Instead, it configures the rsyslog service to forward events over a TCP port directly to the `azuremonitoragent` service process (mdsd). --#### Fix: Remove high-volume facilities from /etc/rsyslog.d/50-default.conf -If you're sending a high log volume through rsyslog and your system is set up to log events for these facilities, consider modifying the default rsyslog config to avoid logging and storing them under `/var/log/`. The events for this facility would still be forwarded to Azure Monitor Agent because rsyslog uses a different configuration for forwarding placed in `/etc/rsyslog.d/10-azuremonitoragent-omfwd.conf`. --1. For example, to remove `local4` events from being logged at `/var/log/syslog` or `/var/log/messages`, change this line in `/etc/rsyslog.d/50-default.conf` from this snippet: -- ```config - *.*;auth,authpriv.none -/var/log/syslog - ``` -- To this snippet (add `local4.none;`): -- ```config - *.*;local4.none;auth,authpriv.none -/var/log/syslog - ``` --1. `sudo systemctl restart rsyslog` - |
| azure-monitor | Azure Monitor Agent Troubleshoot Linux Vm | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-troubleshoot-linux-vm.md | - Title: Troubleshoot the Azure Monitor agent on Linux virtual machines and scale sets -description: Guidance for troubleshooting issues on Linux virtual machines, scale sets with Azure Monitor agent and Data Collection Rules. --- Previously updated : 5/31/2023-----# Troubleshooting guidance for the Azure Monitor agent on Linux virtual machines and scale sets ---## Basic troubleshooting steps -Follow the steps below to troubleshoot the latest version of the Azure Monitor agent running on your Linux virtual machine: --1. **Carefully review the [prerequisites here](./azure-monitor-agent-manage.md#prerequisites).** --2. **Verify that the extension was successfully installed and provisioned, which installs the agent binaries on your machine**: - 1. Open Azure portal > select your virtual machine > Open **Settings** : **Extensions + applications** from the pane on the left > 'AzureMonitorLinuxAgent'should show up with Status: 'Provisioning succeeded' - 2. If you don't see the extension listed, check if machine can reach Azure and find the extension to install using the command below: - ```azurecli - az vm extension image list-versions --location <machine-region> --name AzureMonitorLinuxAgent --publisher Microsoft.Azure.Monitor - ``` - 3. Wait for 10-15 minutes as extension maybe in transitioning status. If it still doesn't show up as above, [uninstall and install the extension](./azure-monitor-agent-manage.md) again. - 4. Check if you see any errors in extension logs located at `/var/log/azure/Microsoft.Azure.Monitor.AzureMonitorLinuxAgent/` on your machine --3. **Verify that the agent is running**: - 1. Check if the agent is emitting heartbeat logs to Log Analytics workspace using the query below. Skip if 'Custom Metrics' is the only destination in the DCR: - ```Kusto - Heartbeat | where Category == "Azure Monitor Agent" and Computer == "<computer-name>" | take 10 - ``` - 2. Check if the agent service is running - ``` - systemctl status azuremonitoragent - ``` - 3. Check if you see any errors in core agent logs located at `/var/opt/microsoft/azuremonitoragent/log/mdsd.*` on your machine - -4. **Verify that the DCR exists and is associated with the virtual machine:** - 1. If using Log Analytics workspace as destination, verify that DCR exists in the same physical region as the Log Analytics workspace. - 2. Open Azure portal > select your data collection rule > Open **Configuration** : **Resources** from the pane on the left > You should see the virtual machine listed here. - 3. If not listed, click 'Add' and select your virtual machine from the resource picker. Repeat across all DCRs. --5. **Verify that agent was able to download the associated DCR(s) from AMCS service:** - 1. Check if you see the latest DCR downloaded at this location `/etc/opt/microsoft/azuremonitoragent/config-cache/configchunks/` ---## Issues collecting Syslog -For more information on how to troubleshoot syslog issues with Azure Monitor Agent, see [here](azure-monitor-agent-troubleshoot-linux-vm-rsyslog.md). --- The quality of service (QoS) file `/var/opt/microsoft/azuremonitoragent/log/mdsd.qos` provides CSV-format 15-minute aggregations of the processed events and contains the information on the amount of the processed syslog events in the given timeframe. **This file is useful in tracking Syslog event ingestion drops**.-- For example, the below fragment shows that in the 15 minutes preceding 2022-02-28T19:55:23.5432920Z, the agent received 77 syslog events with facility daemon and level info and sent 77 of said events to the upload task. Additionally, the agent upload task received 77 and successfully uploaded all 77 of these daemon.info messages. -- ``` - #Time: 2022-02-28T19:55:23.5432920Z - #Fields: Operation,Object,TotalCount,SuccessCount,Retries,AverageDuration,AverageSize,AverageDelay,TotalSize,TotalRowsRead,TotalRowsSent - ... - MaRunTaskLocal,daemon.debug,15,15,0,60000,0,0,0,0,0 - MaRunTaskLocal,daemon.info,15,15,0,60000,46.2,0,693,77,77 - MaRunTaskLocal,daemon.notice,15,15,0,60000,0,0,0,0,0 - MaRunTaskLocal,daemon.warning,15,15,0,60000,0,0,0,0,0 - MaRunTaskLocal,daemon.error,15,15,0,60000,0,0,0,0,0 - MaRunTaskLocal,daemon.critical,15,15,0,60000,0,0,0,0,0 - MaRunTaskLocal,daemon.alert,15,15,0,60000,0,0,0,0,0 - MaRunTaskLocal,daemon.emergency,15,15,0,60000,0,0,0,0,0 - ... - MaODSRequest,https://e73fd5e3-ea2b-4637-8da0-5c8144b670c8_LogManagement,15,15,0,455067,476.467,0,7147,77,77 - ``` --**Troubleshooting steps** -1. Review the [generic Linux AMA troubleshooting steps](#basic-troubleshooting-steps) first. If agent is emitting heartbeats, proceed to step 2. -2. The parsed configuration is stored at `/etc/opt/microsoft/azuremonitoragent/config-cache/configchunks/`. Check that Syslog collection is defined and the log destinations are the same as constructed in DCR UI / DCR JSON. - 1. If yes, proceed to step 3. If not, the issue is in the configuration workflow. - 2. Investigate `mdsd.err`,`mdsd.warn`, `mdsd.info` files under `/var/opt/microsoft/azuremonitoragent/log` for possible configuration errors. --3. Validate the layout of the Syslog collection workflow to ensure all necessary pieces are in place and accessible: - 1. For `rsyslog` users, ensure the `/etc/rsyslog.d/10-azuremonitoragent.conf` file is present, isn't empty, and is accessible by the `rsyslog` daemon (syslog user). - 1. Check your rsyslog configuration at `/etc/rsyslog.conf` and `/etc/rsyslog.d/*` to see if you have any inputs bound to a non-default ruleset, as messages from these inputs won't be forwarded to Azure Monitor Agent. For instance, messages from an input configured with a non-default ruleset like `input(type="imtcp" port="514" `**`ruleset="myruleset"`**`)` won't be forward. - 2. For `syslog-ng` users, ensure the `/etc/syslog-ng/conf.d/azuremonitoragent.conf` file is present, isn't empty, and is accessible by the `syslog-ng` daemon (syslog user). - 3. Ensure the file `/run/azuremonitoragent/default_syslog.socket` exists and is accessible by `rsyslog` or `syslog-ng` respectively. - 5. Check that syslog daemon queue isn't overflowing, causing the upload to fail, by referring the guidance here: [Rsyslog data not uploaded due to Full Disk space issue on AMA Linux Agent](./azure-monitor-agent-troubleshoot-linux-vm-rsyslog.md) -4. To debug syslog events ingestion further, you can append trace flag **-T 0x2002** at the end of **MDSD_OPTIONS** in the file `/etc/default/azuremonitoragent`, and restart the agent: - ``` - export MDSD_OPTIONS="-A -c /etc/opt/microsoft/azuremonitoragent/mdsd.xml -d -r $MDSD_ROLE_PREFIX -S $MDSD_SPOOL_DIRECTORY/eh -L $MDSD_SPOOL_DIRECTORY/events -e $MDSD_LOG_DIR/mdsd.err -w $MDSD_LOG_DIR/mdsd.warn -o $MDSD_LOG_DIR/mdsd.info -T 0x2002" - ``` -5. After the issue is reproduced with the trace flag on, you'll find more debug information in `/var/opt/microsoft/azuremonitoragent/log/mdsd.info`. Inspect the file for the possible cause of syslog collection issue, such as parsing / processing / configuration / upload errors. - > [!WARNING] - > Ensure to remove trace flag setting **-T 0x2002** after the debugging session, since it generates many trace statements that could fill up the disk more quickly or make visually parsing the log file difficult. --## Troubleshooting issues on Arc-enabled server -If after checking basic troubleshooting steps you don't see the Azure Monitor Agent emitting logs or find **'Failed to get MSI token from IMDS endpoint'** errors in `/var/opt/microsoft/azuremonitoragent/log/mdsd.err` log file, it's likely `syslog` user isn't a member of the group `himds`. Add `syslog` user to `himds` user group if the user isn't a member of this group. Create user `syslog` and the group `syslog`, if necessary, and make sure that the user is in that group. For more information check out Azure Arc-enabled server authentication requirements [here](../../azure-arc/servers/managed-identity-authentication.md). |
| azure-monitor | Azure Monitor Agent Troubleshoot Windows Arc | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-troubleshoot-windows-arc.md | - Title: Troubleshoot the Azure Monitor agent on Windows Arc-enabled server -description: Guidance for troubleshooting issues on Windows Arc-enabled server with Azure Monitor agent and Data Collection Rules. - Previously updated : 7/19/2023------# Troubleshooting guidance for the Azure Monitor agent on Windows Arc-enabled server ---## Basic troubleshooting steps (installation, agent not running, configuration issues) -Follow the steps below to troubleshoot the latest version of the Azure Monitor agent running on your Windows Arc-enabled server: --1. **Carefully review the [prerequisites here](./azure-monitor-agent-manage.md#prerequisites).** --2. **Verify that the extension was successfully installed and provisioned, which installs the agent binaries on your machine**: - 1. Open Azure portal > select your Arc-enabled server > Open **Settings** : **Extensions** from the pane on the left > 'AzureMonitorWindowsAgent'should show up with Status: 'Succeeded' - 2. If not, check if the Arc agent (Connected Machine Agent) is able to connect to Azure and the extension service is running. - ```azurecli - azcmagent show - ``` - You should see the below output: - ``` - Resource Name : <server name> - [...] - Dependent Service Status - Agent Service (himds) : running - GC Service (gcarcservice) : running - Extension Service (extensionservice) : running - ``` - 3. Wait for 10-15 minutes as extension maybe in transitioning status. If it still doesn't show up, [uninstall and install the extension](./azure-monitor-agent-manage.md) again and repeat the verification to see the extension show up. - 4. If not, check if you see any errors in extension logs located at `C:\ProgramData\GuestConfig\extension_logs\Microsoft.Azure.Monitor.AzureMonitorWindowsAgent` on your machine --3. **Verify that the agent is running**: - 1. Check if the agent is emitting heartbeat logs to Log Analytics workspace using the query below. Skip if 'Custom Metrics' is the only destination in the DCR: - ```Kusto - Heartbeat | where Category == "Azure Monitor Agent" and Computer == "<computer-name>" | take 10 - ``` - 2. If not, open Task Manager and check if 'MonAgentCore.exe' process is running. If it is, wait for 5 minutes for heartbeat to show up. - 3. If not, check if you see any errors in core agent logs located at `C:\Resources\Directory\AMADataStore\Configuration` on your machine - -4. **Verify that the DCR exists and is associated with the Arc-enabled server:** - 1. If using Log Analytics workspace as destination, verify that DCR exists in the same physical region as the Log Analytics workspace. - 2. On your Arc-enabled server, verify the existence of the file `C:\Resources\Directory\AMADataStore\mcs\mcsconfig.latest.xml`. If this file doesn't exist, the Arc-enabled server may not be associated with a DCR. - 3. Open Azure portal > select your data collection rule > Open **Configuration** : **Resources** from the pane on the left > You should see the Arc-enabled server listed here - 4. If not listed, click 'Add' and select your Arc-enabled server from the resource picker. Repeat across all DCRs. --5. **Verify that agent was able to download the associated DCR(s) from AMCS service:** - 1. Check if you see the latest DCR downloaded at this location `C:\Resources\Directory\AMADataStore\mcs\configchunks` --## Issues collecting Performance counters -1. Check that your DCR JSON contains a section for 'performanceCounters'. If not, fix your DCR. See [how to create DCR](./azure-monitor-agent-data-collection.md) or [sample DCR](./data-collection-rule-sample-agent.md). -2. Check that the file `C:\Resources\Directory\AMADataStore\mcs\mcsconfig.lkg.xml` exists. -3. Open the file and check if it contains `CounterSet` nodes as shown in the example below: - ```xml - <CounterSet storeType="Local" duration="PT1M" - eventName="c9302257006473204344_16355538690556228697" - sampleRateInSeconds="15" format="Factored"> - <Counter>\Processor(_Total)\% Processor Time</Counter> - <Counter>\Memory\Committed Bytes</Counter> - <Counter>\LogicalDisk(_Total)\Free Megabytes</Counter> - <Counter>\PhysicalDisk(_Total)\Avg. Disk Queue Length</Counter> - </CounterSet> - ``` ---### Issues using 'Custom Metrics' as destination -1. Carefully review the [prerequisites here](./azure-monitor-agent-manage.md#prerequisites). -2. Ensure that the associated DCR is correctly authored to collect performance counters and send them to Azure Monitor metrics. You should see this section in your DCR: - ```json - "destinations": { - "azureMonitorMetrics": { - "name":"myAmMetricsDest" - } - } - ``` - -3. Run PowerShell command: - ```powershell - Get-WmiObject Win32_Process -Filter "name = 'MetricsExtension.Native.exe'" | select Name,ExecutablePath,CommandLine | Format-List - ``` - - Verify that the *CommandLine* parameter in the output contains the argument "-TokenSource MSI" -4. Verify `C:\Resources\Directory\AMADataStore\mcs\AuthToken-MSI.json` file is present. -5. Verify `C:\Resources\Directory\AMADataStore\mcs\CUSTOMMETRIC_<subscription>_<region>_MonitoringAccount_Configuration.json` file is present. -6. Collect logs by running the command `C:\Packages\Plugins\Microsoft.Azure.Monitor.AzureMonitorWindowsAgent\<version-number>\Monitoring\Agent\table2csv.exe C:\Resources\Directory\AMADataStore\Tables\MaMetricsExtensionEtw.tsf` - 1. The command will generate the file 'MaMetricsExtensionEtw.csv' - 2. Open it and look for any Level 2 errors and try to fix them. --## Issues collecting Windows event logs -1. Check that your DCR JSON contains a section for 'windowsEventLogs'. If not, fix your DCR. See [how to create DCR](./azure-monitor-agent-data-collection.md) or [sample DCR](./data-collection-rule-sample-agent.md). -2. Check that the file `C:\Resources\Directory\AMADataStore\mcs\mcsconfig.lkg.xml` exists. -3. Open the file and check if it contains `Subscription` nodes as shown in the example below: - ```xml - <Subscription eventName="c9302257006473204344_14882095577508259570" - query="System!*[System[(Level = 1 or Level = 2 or Level = 3)]]"> - <Column name="ProviderGuid" type="mt:wstr" defaultAssignment="00000000-0000-0000-0000-000000000000"> - <Value>/Event/System/Provider/@Guid</Value> - </Column> - ... - - </Column> - </Subscription> - ``` |
| azure-monitor | Azure Monitor Agent Troubleshoot Windows Vm | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-troubleshoot-windows-vm.md | - Title: Troubleshoot the Azure Monitor agent on Windows virtual machines and scale sets -description: Guidance for troubleshooting issues on Windows virtual machines, scale sets with Azure Monitor agent and Data Collection Rules. - Previously updated : 01/23/2024-----# Troubleshooting guidance for the Azure Monitor agent on Windows virtual machines and scale sets ---## Basic troubleshooting steps (installation, agent not running, configuration issues) -Follow the steps below to troubleshoot the latest version of the Azure Monitor agent running on your Windows virtual machine: --1. **Carefully review the [prerequisites here](./azure-monitor-agent-manage.md#prerequisites).** --2. **Verify that the extension was successfully installed and provisioned, which installs the agent binaries on your machine**: - 1. Open Azure portal > select your virtual machine > Open **Settings** : **Extensions + applications** from the pane on the left > 'AzureMonitorWindowsAgent'should show up with Status: 'Provisioning succeeded' - 2. If not, check if machine can reach Azure and find the extension to install using the command below: - ```azurecli - az vm extension image list-versions --location <machine-region> --name AzureMonitorWindowsAgent --publisher Microsoft.Azure.Monitor - ``` - 3. Wait for 10-15 minutes as extension maybe in transitioning status. If it still doesn't show up, [uninstall and install the extension](./azure-monitor-agent-manage.md) again and repeat the verification to see the extension show up. - 4. If not, check if you see any errors in extension logs located at `C:\WindowsAzure\Logs\Plugins\Microsoft.Azure.Monitor.AzureMonitorWindowsAgent` on your machine - -3. **Verify that the agent is running**: - 1. Check if the agent is emitting heartbeat logs to Log Analytics workspace using the query below. Skip if 'Custom Metrics' is the only destination in the DCR: - ```Kusto - Heartbeat | where Category == "Azure Monitor Agent" and Computer == "<computer-name>" | take 10 - ``` - 2. If not, open Task Manager and check if 'MonAgentCore.exe' process is running. If it is, wait for 5 minutes for heartbeat to show up. - 3. If not, check if you see any errors in core agent logs located at `C:\WindowsAzure\Resources\AMADataStore.<virtual-machine-name>\Configuration` on your machine - -4. **Verify that the DCR exists and is associated with the virtual machine:** - 1. If using Log Analytics workspace as destination, verify that DCR exists in the same physical region as the Log Analytics workspace. - 2. On your virtual machine, verify the existence of the file `C:\WindowsAzure\Resources\AMADataStore.<virtual-machine-name>\mcs\mcsconfig.latest.xml`. If this file doesn't exist: - - The virtual machine may not be associated with a DCR. See step 3 - - The virtual machine may not have Managed Identity enabled. [See here](../../active-directory/managed-identities-azure-resources/qs-configure-portal-windows-vm.md#enable-system-assigned-managed-identity-during-creation-of-a-vm) on how to enable. - - IMDS service isn't running/accessible from the virtual machine. [Check if you can access IMDS from the machine](/azure/virtual-machines/windows/instance-metadata-service?tabs=windows). - - AMA can't access IMDS. Check if you see IMDS errors in `C:\WindowsAzure\Resources\AMADataStore.<virtual-machine-name>\Tables\MAEventTable.tsf` file. - 3. Open Azure portal > select your data collection rule > Open **Configuration** : **Resources** from the pane on the left > You should see the virtual machine listed here - 4. If not listed, click 'Add' and select your virtual machine from the resource picker. Repeat across all DCRs. --5. **Verify that agent was able to download the associated DCR(s) from AMCS service:** - 1. Check if you see the latest DCR downloaded at this location `C:\WindowsAzure\Resources\AMADataStore.<virtual-machine-name>\mcs\configchunks` - -## Issues collecting Performance counters -1. Check that your DCR JSON contains a section for 'performanceCounters'. If not, fix your DCR. See [how to create DCR](./azure-monitor-agent-data-collection.md) or [sample DCR](./data-collection-rule-sample-agent.md). -2. Check that the file `C:\WindowsAzure\Resources\AMADataStore.<virtual-machine-name>\mcs\mcsconfig.lkg.xml` exists. -3. Open the file and check if it contains `CounterSet` nodes as shown in the example below: - ```xml - <CounterSet storeType="Local" duration="PT1M" - eventName="c9302257006473204344_16355538690556228697" - sampleRateInSeconds="15" format="Factored"> - <Counter>\Processor(_Total)\% Processor Time</Counter> - <Counter>\Memory\Committed Bytes</Counter> - <Counter>\LogicalDisk(_Total)\Free Megabytes</Counter> - <Counter>\PhysicalDisk(_Total)\Avg. Disk Queue Length</Counter> - </CounterSet> - ``` ---### Issues using 'Custom Metrics' as destination -1. Carefully review the [prerequisites here](./azure-monitor-agent-manage.md#prerequisites). -2. Ensure that the associated DCR is correctly authored to collect performance counters and send them to Azure Monitor metrics. You should see this section in your DCR: - ```json - "destinations": { - "azureMonitorMetrics": { - "name":"myAmMetricsDest" - } - } - ``` -3. Run PowerShell command: - ```powershell - Get-WmiObject Win32_Process -Filter "name = 'MetricsExtension.Native.exe'" | select Name,ExecutablePath,CommandLine | Format-List - ``` - Verify that the *CommandLine* parameter in the output contains the argument "-TokenSource MSI" -4. Verify `C:\WindowsAzure\Resources\AMADataStore.<virtual-machine-name>\mcs\AuthToken-MSI.json` file is present. -5. Verify `C:\WindowsAzure\Resources\AMADataStore.<virtual-machine-name>\mcs\CUSTOMMETRIC_<subscription>_<region>_MonitoringAccount_Configuration.json` file is present. -6. Collect logs by running the command `C:\Packages\Plugins\Microsoft.Azure.Monitor.AzureMonitorWindowsAgent\<version-number>\Monitoring\Agent\table2csv.exe C:\WindowsAzure\Resources\AMADataStore.<virtual-machine-name>\Tables\MaMetricsExtensionEtw.tsf` - 1. The command will generate the file 'MaMetricsExtensionEtw.csv' - 2. Open it and look for any Level 2 errors and try to fix them. --## Issues collecting Windows event logs -1. Check that your DCR JSON contains a section for 'windowsEventLogs'. If not, fix your DCR. See [how to create DCR](./azure-monitor-agent-data-collection.md) or [sample DCR](./data-collection-rule-sample-agent.md). -2. Check that the file `C:\WindowsAzure\Resources\AMADataStore.<virtual-machine-name>\mcs\mcsconfig.lkg.xml` exists. -3. Open the file and check if it contains `Subscription` nodes as shown in the example below: - ```xml - <Subscription eventName="c9302257006473204344_14882095577508259570" - query="System!*[System[(Level = 1 or Level = 2 or Level = 3)]]"> - <Column name="ProviderGuid" type="mt:wstr" defaultAssignment="00000000-0000-0000-0000-000000000000"> - <Value>/Event/System/Provider/@Guid</Value> - </Column> - ... - - </Column> - </Subscription> - ``` |
| azure-monitor | Azure Monitor Agent Windows Client | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/azure-monitor-agent-windows-client.md | - Title: Set up the Azure Monitor agent on Windows client devices -description: This article describes the instructions to install the agent on Windows 10, 11 client OS devices, configure data collection, manage and troubleshoot the agent. - Previously updated : 7/19/2023-----# Install Azure Monitor agent on Windows client devices using the client installer --Use the client installer to install Azure Monitor Agent on Windows client devices and send monitoring data to your Log Analytics workspace. -The [Azure Monitor Agent extension](./azure-monitor-agent-requirements.md#virtual-machine-extension-details) and the installer install the **same underlying agent** and use data collection rules to configure data collection. This article explains how to install Azure Monitor Agent on Windows client devices using the client installer and how to associate data collection rules to your Windows client devices. ---> [!NOTE] -> This article provides specific guidance for installing the Azure Monitor agent on Windows client devices, subject to the [limitations](#limitations). For standard installation and management guidance for the agent, refer [the agent extension management guidance here](./azure-monitor-agent-manage.md) --### Comparison with virtual machine extension -Here is a comparison between client installer and VM extension for Azure Monitor Agent: --| Functional component | For VMs/servers via extension | For clients via installer| -|:|:|:| -| Agent installation method | Via VM extension | Via client installer | -| Agent installed | Azure Monitor Agent | Same | -| Authentication | Using Managed Identity | Using Microsoft Entra device token | -| Central configuration | Via Data collection rules | Same | -| Associating config rules to agents | DCRs associates directly to individual VM resources | DCRs associate to a monitored object (MO), which maps to all devices within the Microsoft Entra tenant | -| Data upload to Log Analytics | Via Log Analytics endpoints | Same | -| Feature support | All features documented [here](./azure-monitor-agent-overview.md) | Features dependent on AMA agent extension that don't require more extensions. This includes support for Sentinel Windows Event filtering | -| [Networking options](./azure-monitor-agent-network-configuration.md) | Proxy support, Private link support | Proxy support only | ---## Supported device types --| Device type | Supported? | Installation method | Additional information | -|:|:|:|:| -| Windows 10, 11 desktops, workstations | Yes | Client installer | Installs the agent using a Windows MSI installer | -| Windows 10, 11 laptops | Yes | Client installer | Installs the agent using a Windows MSI installer. The installs works on laptops but the agent is **not optimized yet** for battery, network consumption | -| Virtual machines, scale sets | No | [Virtual machine extension](./azure-monitor-agent-requirements.md#virtual-machine-extension-details) | Installs the agent using Azure extension framework | -| On-premises servers | No | [Virtual machine extension](./azure-monitor-agent-requirements.md#virtual-machine-extension-details) (with Azure Arc agent) | Installs the agent using Azure extension framework, provided for on-premises by installing Arc agent | --## Prerequisites -- The machine must be running Windows client OS version 10 RS4 or higher.-- To download the installer, the machine should have [C++ Redistributable version 2015)](/cpp/windows/latest-supported-vc-redist?view=msvc-170&preserve-view=true) or higher-- The machine must be domain joined to a Microsoft Entra tenant (AADj or Hybrid AADj machines), which enables the agent to fetch Microsoft Entra device tokens used to authenticate and fetch data collection rules from Azure.-- You might need tenant admin permissions on the Microsoft Entra tenant.-- The device must have access to the following HTTPS endpoints:- - global.handler.control.monitor.azure.com - - `<virtual-machine-region-name>`.handler.control.monitor.azure.com (example: westus.handler.control.azure.com) - - `<log-analytics-workspace-id>`.ods.opinsights.azure.com (example: 12345a01-b1cd-1234-e1f2-1234567g8h99.ods.opinsights.azure.com) - (If using private links on the agent, you must also add the [data collection endpoints](../essentials/data-collection-endpoint-overview.md#components-of-a-dce)) -- A data collection rule you want to associate with the devices. If it doesn't exist already, [create a data collection rule](./azure-monitor-agent-data-collection.md). **Do not associate the rule to any resources yet**.-- Before using any PowerShell cmdlet, ensure cmdlet related PowerShell module is installed and imported.---## Limitations ---## Install the agent -1. Download the Windows MSI installer for the agent using [this link](https://go.microsoft.com/fwlink/?linkid=2192409). You can also download it from **Monitor** > **Data Collection Rules** > **Create** experience on Azure portal (shown in the following screenshot): - <!-- convertborder later --> - :::image type="content" source="media/azure-monitor-agent-windows-client/azure-monitor-agent-client-installer-portal.png" lightbox="media/azure-monitor-agent-windows-client/azure-monitor-agent-client-installer-portal.png" alt-text="Diagram shows download agent link on Azure portal." border="false"::: -1. Open an elevated admin command prompt window and change directory to the location where you downloaded the installer. -1. To install with **default settings**, run the following command: - ```cli - msiexec /i AzureMonitorAgentClientSetup.msi /qn - ``` -1. To install with custom file paths, [network proxy settings](./azure-monitor-agent-network-configuration.md, or on a Non-Public Cloud use the following command with the values from the following table: -- ```cli - msiexec /i AzureMonitorAgentClientSetup.msi /qn DATASTOREDIR="C:\example\folder" - ``` -- | Parameter | Description | - |:|:| - | INSTALLDIR | Directory path where the agent binaries are installed | - | DATASTOREDIR | Directory path where the agent stores its operational logs and data | - | PROXYUSE | Must be set to "true" to use proxy | - | PROXYADDRESS | Set to Proxy Address. PROXYUSE must be set to "true" to be correctly applied | - | PROXYUSEAUTH | Set to "true" if proxy requires authentication | - | PROXYUSERNAME | Set to Proxy username. PROXYUSE and PROXYUSEAUTH must be set to "true" | - | PROXYPASSWORD | Set to Proxy password. PROXYUSE and PROXYUSEAUTH must be set to "true" | - | CLOUDENV | Set to Cloud. "Azure Commercial", "Azure China", "Azure US Gov", "Azure USNat", or "Azure USSec ---1. Verify successful installation: - - Open **Control Panel** -> **Programs and Features** OR **Settings** -> **Apps** -> **Apps & Features** and ensure you see ‘Azure Monitor Agent’ listed - - Open **Services** and confirm ‘Azure Monitor Agent’ is listed and shows as **Running**. -1. Proceed to create the monitored object that you'll associate data collection rules to, for the agent to actually start operating. --> [!NOTE] -> The agent installed with the client installer currently doesn't support updating local agent settings once it is installed. Uninstall and reinstall AMA to update above settings. ---## Create and associate a monitored object -You need to create a monitored object (MO), which represents the Microsoft Entra tenant within Azure Resource Manager (ARM). This ARM entity is what Data Collection Rules are then associated with. **Azure associates a monitored object to all Windows client machines in the same Microsoft Entra tenant**. --Currently this association is only **limited** to the Microsoft Entra tenant scope, which means configuration applied to the Microsoft Entra tenant will be applied to all devices that are part of the tenant and running the agent installed via the client installer. Agents installed as virtual machine extension will not be impacted by this. -The following image demonstrates how this works: -<!-- convertborder later --> --Then, proceed with the following instructions to create and associate them to a monitored object, using REST APIs or PowerShell commands. --### Permissions required -Since MO is a tenant level resource, the scope of the permission would be higher than a subscription scope. Therefore, an Azure tenant admin might be needed to perform this step. [Follow these steps to elevate Microsoft Entra tenant admin as Azure Tenant Admin](../../role-based-access-control/elevate-access-global-admin.md). It gives the Microsoft Entra admin 'owner' permissions at the root scope. This is needed for all methods described in the following section. --### Using REST APIs --#### 1. Assign the Monitored Objects Contributor role to the operator --This step grants the ability to create and link a monitored object to a user or group. --**Request URI** -```HTTP -PUT https://management.azure.com/providers/microsoft.insights/providers/microsoft.authorization/roleassignments/{roleAssignmentGUID}?api-version=2021-04-01-preview -``` -**URI Parameters** --| Name | In | Type | Description | -|:|:|:|:|:| -| `roleAssignmentGUID` | path | string | Provide any valid guid (you can generate one using https://guidgenerator.com/) | --**Headers** -- Authorization: ARM Bearer Token (using ‘Get-AzAccessToken’ or other method)-- Content-Type: Application/json--**Request Body** -```JSON -{ - "properties": - { - "roleDefinitionId":"/providers/Microsoft.Authorization/roleDefinitions/56be40e24db14ccf93c37e44c597135b", - "principalId":"aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa" - } -} -``` --**Body parameters** --| Name | Description | -|:|:| -| roleDefinitionId | Fixed value: Role definition ID of the Monitored Objects Contributor role: `/providers/Microsoft.Authorization/roleDefinitions/56be40e24db14ccf93c37e44c597135b` | -| principalId | Provide the `Object Id` of the identity of the user to which the role needs to be assigned. It might be the user who elevated at the beginning of step 1, or another user or group who will perform later steps. | --After this step is complete, **reauthenticate** your session and **reacquire** your ARM bearer token. --#### 2. Create monitored object -This step creates the monitored object for the Microsoft Entra tenant scope. It's used to represent client devices that are signed with that Microsoft Entra tenant identity. --**Permissions required**: Anyone who has 'Monitored Object Contributor' at an appropriate scope can perform this operation, as assigned in step 1. --**Request URI** -```HTTP -PUT https://management.azure.com/providers/Microsoft.Insights/monitoredObjects/{AADTenantId}?api-version=2021-09-01-preview -``` -**URI Parameters** --| Name | In | Type | Description | -|:|:|:|:|:| -| `AADTenantId` | path | string | ID of the Microsoft Entra tenant that the device(s) belong to. The MO is created with the same ID | --**Headers** -- Authorization: ARM Bearer Token-- Content-Type: Application/json--**Request Body** -```JSON -{ - "properties": - { - "location":"eastus" - } -} -``` -**Body parameters** --| Name | Description | -|:|:| -| `location` | The Azure region where the MO object would be stored. It should be the **same region** where you created the Data Collection Rule. This region is the location where agent communications would happen. | ---#### 3. Associate DCR to monitored object -Now we associate the Data Collection Rules (DCR) to the monitored object by creating Data Collection Rule Associations. --**Permissions required**: Anyone who has ‘Monitored Object Contributor’ at an appropriate scope can perform this operation, as assigned in step 1. --**Request URI** -```HTTP -PUT https://management.azure.com/{MOResourceId}/providers/microsoft.insights/datacollectionruleassociations/{associationName}?api-version=2021-09-01-preview -``` -**Sample Request URI** -```HTTP -PUT https://management.azure.com/providers/Microsoft.Insights/monitoredObjects/{AADTenantId}/providers/microsoft.insights/datacollectionruleassociations/{associationName}?api-version=2021-09-01-preview -``` --**URI Parameters** --| Name | In | Type | Description | -|:|:|:|:|:| -| ``MOResourceId` | path | string | Full resource ID of the MO created in step 2. Example: 'providers/Microsoft.Insights/monitoredObjects/{AADTenantId}' | --**Headers** -- Authorization: ARM Bearer Token-- Content-Type: Application/json--**Request Body** -```JSON -{ - "properties": - { - "dataCollectionRuleId": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Insights/dataCollectionRules/{DCRName}" - } -} -``` -**Body parameters** --| Name | Description | -|:|:| -| `dataCollectionRuleID` | The resource ID of an existing Data Collection Rule that you created in the **same region** as the monitored object. | --#### 4. List associations to the monitored object -If you need to view the associations, you can list them for the monitored object. --**Permissions required**: Anyone who has ‘Reader’ at an appropriate scope can perform this operation, similar to that assigned in step 1. --**Request URI** -```HTTP -GET https://management.azure.com/{MOResourceId}/providers/microsoft.insights/datacollectionruleassociations/?api-version=2021-09-01-preview -``` -**Sample Request URI** -```HTTP -GET https://management.azure.com/providers/Microsoft.Insights/monitoredObjects/{AADTenantId}/providers/microsoft.insights/datacollectionruleassociations/?api-version=2021-09-01-preview -``` --```JSON -{ - "value": [ - { - "id": "/subscriptions/703362b3-f278-4e4b-9179-c76eaf41ffc2/resourceGroups/myResourceGroup/providers/Microsoft.Compute/virtualMachines/myVm/providers/Microsoft.Insights/dataCollectionRuleAssociations/myRuleAssociation", - "name": "myRuleAssociation", - "type": "Microsoft.Insights/dataCollectionRuleAssociations", - "properties": { - "dataCollectionRuleId": "/subscriptions/703362b3-f278-4e4b-9179-c76eaf41ffc2/resourceGroups/myResourceGroup/providers/Microsoft.Insights/dataCollectionRules/myCollectionRule", - "provisioningState": "Succeeded" - }, - "systemData": { - "createdBy": "user1", - "createdByType": "User", - "createdAt": "2021-04-01T12:34:56.1234567Z", - "lastModifiedBy": "user2", - "lastModifiedByType": "User", - "lastModifiedAt": "2021-04-02T12:34:56.1234567Z" - }, - "etag": "070057da-0000-0000-0000-5ba70d6c0000" - } - ], - "nextLink": null -} -``` --#### 5. Disassociate DCR from the monitored object -If you need to remove an association of a Data Collection Rule (DCR) to the monitored object. --**Permissions required**: Anyone who has ‘Monitored Object Contributor’ at an appropriate scope can perform this operation, as assigned in step 1. --**Request URI** -```HTTP -DELETE https://management.azure.com/{MOResourceId}/providers/microsoft.insights/datacollectionruleassociations/{associationName}?api-version=2021-09-01-preview -``` -**Sample Request URI** -```HTTP -DELETE https://management.azure.com/providers/Microsoft.Insights/monitoredObjects/{AADTenantId}/providers/microsoft.insights/datacollectionruleassociations/{associationName}?api-version=2021-09-01-preview -``` --**URI Parameters** --| Name | In | Type | Description | -||||| -| `MOResourceId` | path | string | Full resource ID of the MO created in step 2. Example: 'providers/Microsoft.Insights/monitoredObjects/{AADTenantId}' | -| `associationName` | path | string | The name of the association. The name is case insensitive. Example: 'assoc01' | --**Headers** -- Authorization: ARM Bearer Token-- Content-Type: Application/json---### Using PowerShell for onboarding -```PowerShell -$TenantID = "xxxxxxxxx-xxxx-xxx" #Your Tenant ID -$SubscriptionID = "xxxxxx-xxxx-xxxxx" #Your Subscription ID -$ResourceGroup = "rg-yourResourceGroup" #Your resourcegroup --#If cmdlet below produces an error stating 'Interactive authentication is not supported in this session, please run cmdlet 'Connect-AzAccount -UseDeviceAuthentication -#uncomment next to -UseDeviceAuthentication below -Connect-AzAccount -Tenant $TenantID #-UseDeviceAuthentication --#Select the subscription -Select-AzSubscription -SubscriptionId $SubscriptionID --#Grant Access to User at root scope "/" -$user = Get-AzADUser -SignedIn --New-AzRoleAssignment -Scope '/' -RoleDefinitionName 'Owner' -ObjectId $user.Id --#Create Auth Token -$auth = Get-AzAccessToken --$AuthenticationHeader = @{ - "Content-Type" = "application/json" - "Authorization" = "Bearer " + $auth.Token - } ---#1. Assign the Monitored Object Contributor role to the operator -$newguid = (New-Guid).Guid -$UserObjectID = $user.Id --$body = @" -{ - "properties": { - "roleDefinitionId":"/providers/Microsoft.Authorization/roleDefinitions/56be40e24db14ccf93c37e44c597135b", - "principalId": `"$UserObjectID`" - } -} -"@ --$requestURL = "https://management.azure.com/providers/microsoft.insights/providers/microsoft.authorization/roleassignments/$newguid`?api-version=2021-04-01-preview" ---Invoke-RestMethod -Uri $requestURL -Headers $AuthenticationHeader -Method PUT -Body $body ---########################## --#2. Create a monitored object --# "location" property value under the "body" section should be the Azure region where the MO object would be stored. It should be the "same region" where you created the Data Collection Rule. This is the location of the region from where agent communications would happen. -$Location = "eastus" #Use your own location -$requestURL = "https://management.azure.com/providers/Microsoft.Insights/monitoredObjects/$TenantID`?api-version=2021-09-01-preview" -$body = @" -{ - "properties":{ - "location":`"$Location`" - } -} -"@ --$Respond = Invoke-RestMethod -Uri $requestURL -Headers $AuthenticationHeader -Method PUT -Body $body -Verbose -$RespondID = $Respond.id --########################## --#3. Associate DCR to monitored object -#See reference documentation https://learn.microsoft.com/en-us/rest/api/monitor/data-collection-rule-associations/create?tabs=HTTP -$associationName = "assoc01" #You can define your custom associationname, must change the association name to a unique name, if you want to associate multiple DCR to monitored object -$DCRName = "dcr-WindowsClientOS" #Your Data collection rule name --$requestURL = "https://management.azure.com$RespondId/providers/microsoft.insights/datacollectionruleassociations/$associationName`?api-version=2021-09-01-preview" -$body = @" - { - "properties": { - "dataCollectionRuleId": "/subscriptions/$SubscriptionID/resourceGroups/$ResourceGroup/providers/Microsoft.Insights/dataCollectionRules/$DCRName" - } - } --"@ --Invoke-RestMethod -Uri $requestURL -Headers $AuthenticationHeader -Method PUT -Body $body --#(Optional example). Associate another DCR to monitored object. Remove comments around text below to use. -#See reference documentation https://learn.microsoft.com/en-us/rest/api/monitor/data-collection-rule-associations/create?tabs=HTTP -<# -$associationName = "assoc02" #You must change the association name to a unique name, if you want to associate multiple DCR to monitored object -$DCRName = "dcr-PAW-WindowsClientOS" #Your Data collection rule name --$requestURL = "https://management.azure.com$RespondId/providers/microsoft.insights/datacollectionruleassociations/$associationName`?api-version=2021-09-01-preview" -$body = @" - { - "properties": { - "dataCollectionRuleId": "/subscriptions/$SubscriptionID/resourceGroups/$ResourceGroup/providers/Microsoft.Insights/dataCollectionRules/$DCRName" - } - } --"@ --Invoke-RestMethod -Uri $requestURL -Headers $AuthenticationHeader -Method PUT -Body $body --#4. (Optional) Get all the associatation. -$requestURL = "https://management.azure.com$RespondId/providers/microsoft.insights/datacollectionruleassociations?api-version=2021-09-01-preview" -(Invoke-RestMethod -Uri $requestURL -Headers $AuthenticationHeader -Method get).value -#> --``` -## Verify successful setup -Check the ‘Heartbeat’ table (and other tables you configured in the rules) in the Log Analytics workspace that you specified as a destination in the data collection rule(s). -The `SourceComputerId`, `Computer`, `ComputerIP` columns should all reflect the client device information respectively, and the `Category` column should say 'Azure Monitor Agent'. See the following example: -<!-- convertborder later --> --### Using PowerShell for offboarding -```PowerShell -#This will remove the monitor object -$TenantID = "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" #Your Tenant ID --Connect-AzAccount -Tenant $TenantID --#Create Auth Token -$auth = Get-AzAccessToken --$AuthenticationHeader = @{ - "Content-Type" = "application/json" - "Authorization" = "Bearer " + $auth.Token -} --#Get monitored object -$requestURL = "https://management.azure.com/providers/Microsoft.Insights/monitoredObjects/$TenantID`?api-version=2021-09-01-preview" -$MonitoredObject = Invoke-RestMethod -Uri $requestURL -Headers $AuthenticationHeader -Method Get --#Get data collection rule associations to monitored object -$requestURL = "https://management.azure.com$($MonitoredObject.id)/providers/microsoft.insights/datacollectionruleassociations?api-version=2021-09-01-preview" -$MonitoredObjectAssociations = Invoke-RestMethod -Uri $requestURL -Headers $AuthenticationHeader -Method Get --#Disassociate from all Data Collection Rule -foreach ($Association in $MonitoredObjectAssociations.value){ - $requestURL = "https://management.azure.com$($Association.id)?api-version=2022-06-01" - Invoke-RestMethod -Uri $requestURL -Headers $AuthenticationHeader -Method Delete -} --#Delete monitored object -$requestURL = "https://management.azure.com/providers/Microsoft.Insights/monitoredObjects/$TenantID`?api-version=2021-09-01-preview" -Invoke-AzRestMethod -Uri $requestURL -Method Delete --``` ---## Manage the agent --### Check the agent version -You can use any of the following options to check the installed version of the agent: -- Open **Control Panel** > **Programs and Features** > **Azure Monitor Agent** and see the 'Version' listed-- Open **Settings** > **Apps** > **Apps and Features** > **Azure Monitor Agent** and see the 'Version' listed--### Uninstall the agent -You can use any of the following options to check the installed version of the agent: -- Open **Control Panel** > **Programs and Features** > **Azure Monitor Agent** and click 'Uninstall'-- Open **Settings** > **Apps** > **Apps and Features** > **Azure Monitor Agent** and click 'Uninstall'--If you face issues during 'Uninstall', refer to the [troubleshooting guidance](#troubleshoot). --### Update the agent -In order to update the version, install the new version you wish to update to. ---## Troubleshoot -### View agent diagnostic logs -1. Rerun the installation with logging turned on and specify the log file name: - `Msiexec /I AzureMonitorAgentClientSetup.msi /L*V <log file name>` -2. Runtime logs are collected automatically either at the default location `C:\Resources\Azure Monitor Agent\` or at the file path mentioned during installation. - - If you can't locate the path, the exact location can be found on the registry as `AMADataRootDirPath` on `HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\AzureMonitorAgent`. -3. The 'ServiceLogs' folder contains log from AMA Windows Service, which launches and manages AMA processes -4. 'AzureMonitorAgent.MonitoringDataStore' contains data/logs from AMA processes. --### Common installation issues --#### Missing DLL -- Error message: "There's a problem with this Windows Installer package. A DLL required for this installer to complete could not be run. …"-- Ensure you have installed [C++ Redistributable (>2015)](/cpp/windows/latest-supported-vc-redist?view=msvc-170&preserve-view=true) before installing AMA:--<a name='not-aad-joined'></a> --#### Not Microsoft Entra joined -Error message: "Tenant and device IDs retrieval failed" -1. Run the command `dsregcmd /status`. This should produce the output as `AzureAdJoined : YES` in the 'Device State' section. If not, join the device with a Microsoft Entra tenant and try installation again. --#### Silent install from command prompt fails -Make sure to start the installer on administrator command prompt. Silent install can only be initiated from the administrator command prompt. --#### Uninstallation fails due to the uninstaller being unable to stop the service -- If There's an option to try again, do try it again-- If retry from uninstaller doesn't work, cancel the uninstall and stop Azure Monitor Agent service from Services (Desktop Application)-- Retry uninstall-#### Force uninstall manually when uninstaller doesn't work -- Stop Azure Monitor Agent service. Then try uninstalling again. If it fails, then proceed with the following steps-- Delete AMA service with "sc delete AzureMonitorAgent" from admin cmd-- Download [this tool](https://support.microsoft.com/topic/fix-problems-that-block-programs-from-being-installed-or-removed-cca7d1b6-65a9-3d98-426b-e9f927e1eb4d) and uninstall AMA-- Delete AMA binaries. They're stored in `Program Files\Azure Monitor Agent` by default-- Delete AMA data/logs. They're stored in `C:\Resources\Azure Monitor Agent` by default-- Open Registry. Check `HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Azure Monitor Agent`. If it exists, delete the key.--### Post installation/Operational issues -Once the agent is installed successfully (i.e. you see the agent service running but don't see data as expected), you can follow standard troubleshooting steps listed here for [Windows VM](./azure-monitor-agent-troubleshoot-windows-vm.md) and [Windows Arc-enabled server](azure-monitor-agent-troubleshoot-windows-arc.md) respectively. --## Frequently asked questions --This section provides answers to common questions. --### Is Azure Arc required for Microsoft Entra joined machines? --No. Microsoft Entra joined (or Microsoft Entra hybrid joined) machines running Windows 10 or 11 (client OS) **do not require Azure Arc** to be installed. Instead, you can use the Windows MSI installer for Azure Monitor Agent. --## Questions and feedback -Take this [quick survey](https://forms.microsoft.com/r/CBhWuT1rmM) or share your feedback/questions regarding the client installer. |
| azure-monitor | Data Collection Iis | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/data-collection-iis.md | - Title: Collect IIS logs with Azure Monitor Agent -description: Configure collection of Internet Information Services (IIS) logs on virtual machines with Azure Monitor Agent. - Previously updated : 07/12/2024-------# Collect IIS logs with Azure Monitor Agent -**IIS Logs** is one of the data sources used in a [data collection rule (DCR)](../essentials/data-collection-rule-create-edit.md). Details for the creation of the DCR are provided in [Collect data with Azure Monitor Agent](./azure-monitor-agent-data-collection.md). This article provides additional details for the Windows events data source type. --Internet Information Services (IIS) stores user activity in log files that can be collected by Azure Monitor agent and sent to a Log Analytics workspace. ---## Prerequisites --- [Log Analytics workspace](../logs/log-analytics-workspace-overview.md) where you have at least [contributor rights](../logs/manage-access.md#azure-rbac). Windows events are sent to the [Event](/azure/azure-monitor/reference/tables/event) table.-- A data collection endpoint (DCE) if you plan to use Azure Monitor Private Links. The data collection endpoint must be in the same region as the Log Analytics workspace. See [How to set up data collection endpoints based on your deployment](../essentials/data-collection-endpoint-overview.md#how-to-set-up-data-collection-endpoints-based-on-your-deployment) for details.-- Either a new or existing DCR described in [Collect data with Azure Monitor Agent](./azure-monitor-agent-data-collection.md).--## Configure collection of IIS logs on client -Before you can collect IIS logs from the machine, you must ensure that IIS logging has been enabled and is configured correctly. --- The IIS log file must be in W3C format and stored on the local drive of the machine running the agent. -- Each entry in the log file must be delineated with an end of line. -- The log file must not use circular logging,, which overwrites old entries.-- The log file must not use renaming, where a file is moved and a new file with the same name is opened. --The default location for IIS log files is **C:\\inetpub\\logs\\LogFiles\\W3SVC1**. Verify that log files are being written to this location or check your IIS configuration to identify an alternate location. Check the timestamps of the log files to ensure that they're recent. ----## Configure IIS log data source --Create a data collection rule, as described in [Collect data with Azure Monitor Agent](./azure-monitor-agent-data-collection.md). In the **Collect and deliver** step, select **IIS Logs** from the **Data source type** dropdown. You only need to specify a file pattern to identify the directory where the log files are located if they are stored in a different location than configured in IIS. In most cases, you can leave this value blank. ---## Destinations --IIS log data can be sent to the following locations. --| Destination | Table / Namespace | -|:|:| -| Log Analytics workspace | [W3CIISLog](/azure/azure-monitor/reference/tables/w3ciislog) | - ---### Sample IIS log queries --- **Count the IIS log entries by URL for the host www.contoso.com.**- - ```kusto - W3CIISLog - | where csHost=="www.contoso.com" - | summarize count() by csUriStem - ``` --- **Review the total bytes received by each IIS machine.**-- ```kusto - W3CIISLog - | summarize sum(csBytes) by Computer - ``` --- **Identify any records with a return status of 500.**- - ```kusto - W3CIISLog - | where scStatus==500 - | summarize AggregatedValue = count() by Computer, bin(TimeGenerated, 15m) - ``` ---> [!NOTE] -> The X-Forwarded-For custom field is not supported at this time. If this is a critical field, you can collect the IIS logs as a custom text log. --## Troubleshooting -Go through the following steps if you aren't collecting data from the JSON log that you're expecting. --- Verify that IIS logs are being created in the location you specified.-- Verify that IIS logs are configured to be W3C formatted.-- See [Verify operation](./azure-monitor-agent-data-collection.md#verify-operation) to verify whether the agent is operational and data is being received.---## Next steps --Learn more about: --- [Azure Monitor Agent](azure-monitor-agent-overview.md).-- [Data collection rules](../essentials/data-collection-rule-overview.md).-- [Best practices for cost management in Azure Monitor](../best-practices-cost.md). |
| azure-monitor | Data Collection Log Json | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/data-collection-log-json.md | - Title: Collect logs from a JSON file with Azure Monitor Agent -description: Configure a data collection rule to collect log data from a JSON file on a virtual machine using Azure Monitor Agent. - Previously updated : 08/28/2024------# Collect logs from a JSON file with Azure Monitor Agent -**Custom JSON Logs** is one of the data sources used in a [data collection rule (DCR)](../essentials/data-collection-rule-create-edit.md). Details for the creation of the DCR are provided in [Collect data with Azure Monitor Agent](./azure-monitor-agent-data-collection.md). This article provides additional details for the text and JSON logs type. --Many applications and services will log information to a JSON files instead of standard logging services such as Windows Event log or Syslog. This data can be collected with [Azure Monitor Agent](azure-monitor-agent-overview.md) and stored in a Log Analytics workspace with data collected from other sources. --## Prerequisites --- Log Analytics workspace where you have at least [contributor rights](../logs/manage-access.md#azure-rbac).-- A data collection endpoint (DCE) in the same region as the Log Analytics workspace. See [How to set up data collection endpoints based on your deployment](../essentials/data-collection-endpoint-overview.md#how-to-set-up-data-collection-endpoints-based-on-your-deployment) for details.-- Either a new or existing DCR described in [Collect data with Azure Monitor Agent](./azure-monitor-agent-data-collection.md).--## Basic operation -The following diagram shows the basic operation of collecting log data from a json file. --1. The agent watches for any log files that match a specified name pattern on the local disk. -2. Each entry in the log is collected and sent to Azure Monitor. The incoming stream defined by the user is used to parse the log data into columns. -3. A default transformation is used if the schema of the incoming stream matches the schema of the target table. ----## JSON file requirements and best practices -The file that the Azure Monitor Agent is monitoring must meet the following requirements: --- The file must be stored on the local drive of the machine with the Azure Monitor Agent in the directory that is being monitored.-- Each record must be delineated with an end of line. -- The file must use ASCII or UTF-8 encoding. Other formats such as UTF-16 aren't supported.-- New records should be appended to the end of the file and not overwrite old records. Overwriting will cause data loss.-- JSON text must be contained in a single row. The JSON body format is not supported. See sample below.- --Adhere to the following recommendations to ensure that you don't experience data loss or performance issues: - --- Create a new log file every day so that you can easily clean up old files.-- Continuously clean up log files in the monitored directory. Tracking many log files can drive up agent CPU and Memory usage. Wait for at least 2 days to allow ample time for all logs to be processed.-- Don't rename a file that matches the file scan pattern to another name that also matches the file scan pattern. This will cause duplicate data to be ingested. -- Don't rename or copy large log files that match the file scan pattern into the monitored directory. If you must, do not exceed 50MB per minute.----## Custom table -Before you can collect log data from a JSON file, you must create a custom table in your Log Analytics workspace to receive the data. The table schema must match the columns in the incoming stream, or you must add a transformation to ensure that the output schema matches the table. --> [!WARNING] -> You shouldn't use an existing custom table used by Log Analytics agent. The legacy agents won't be able to write to the table once the first Azure Monitor agent writes to it. Create a new table for Azure Monitor agent to use to prevent Log Analytics agent data loss. -> --For example, you can use the following PowerShell script to create a custom table with multiple columns. --```powershell -$tableParams = @' -{ - "properties": { - "schema": { - "name": "{TableName}_CL", - "columns": [ - { - "name": "TimeGenerated", - "type": "DateTime" - }, - { - "name": "MyStringColumn", - "type": "string" - }, - { - "name": "MyIntegerColumn", - "type": "int" - }, - { - "name": "MyRealColumn", - "type": "real" - }, - { - "name": "MyBooleanColumn", - "type": "bool" - }, - { - "name": "FilePath", - "type": "string" - }, - { - "name": "Computer", - "type": "string" - } - ] - } - } -} -'@ --Invoke-AzRestMethod -Path "/subscriptions/{subscription}/resourcegroups/{resourcegroup}/providers/microsoft.operationalinsights/workspaces/{WorkspaceName}/tables/{TableName}_CL?api-version=2021-12-01-preview" -Method PUT -payload $tableParams -``` ---## Create a data collection rule for a JSON file --> [!NOTE] -> The agent based JSON custom file ingestion is currently in preview and does not have a complete UI experience in the portal yet. While you can create the DCR using the portal, you must modify it to define the columns in the incoming stream. This section includes details on creating the DCR using an ARM template. --### Incoming stream schema --> [!NOTE] -> Multiline support that uses an [ISO 8601](https://wikipedia.org/wiki/ISO_8601) time stamp to delimited events is expected mid-October 2024 --JSON files include a property name with each value, and the incoming stream in the DCR needs to include a column matching the name of each property. You need to modify the `columns` section of the ARM template with the columns from your log. -- The following table describes optional columns that you can include in addition to the columns defining the data in your log file. -- | Column | Type | Description | -|:|:|:| -| `TimeGenerated` | datetime | The time the record was generated. This value will be automatically populated with the time the record is added to the Log Analytics workspace if it's not included in the incoming stream. | -| `FilePath` | string | If you add this column to the incoming stream in the DCR, it will be populated with the path to the log file. This column is not created automatically and can't be added using the portal. You must manually modify the DCR created by the portal or create the DCR using another method where you can explicitly define the incoming stream. | -| `Computer` | string | If you add this column to the incoming stream in the DCR, it will be populated with the name of the computer with the log file. This column is not created automatically and can't be added using the portal. You must manually modify the DCR created by the portal or create the DCR using another method where you can explicitly define the incoming stream. | --### Transformation -The [transformation](../essentials/data-collection-transformations.md) potentially modifies the incoming stream to filter records or to modify the schema to match the target table. If the schema of the incoming stream is the same as the target table, then you can use the default transformation of `source`. If not, then modify the `transformKql` section of tee ARM template with a KQL query that returns the required schema. --### ARM template --Use the following ARM template to create a DCR for collecting text log files, making the changes described in the previous sections. The following table describes the parameters that require values when you deploy the template. --| Setting | Description | -|:|:| -| Data collection rule name | Unique name for the DCR. | -| Data collection endpoint resource ID | Resource ID of the data collection endpoint (DCE). | -| Location | Region for the DCR. Must be the same location as the Log Analytics workspace. | -| File patterns | Identifies the location and name of log files on the local disk. Use a wildcard for filenames that vary, for example when a new file is created each day with a new name. You can enter multiple file patterns separated by commas (AMA version 1.26 or higher required for multiple file patterns on Linux).<br><br>Examples:<br>- C:\Logs\MyLog.json<br>- C:\Logs\MyLog*.json<br>- C:\App01\AppLog.json, C:\App02\AppLog.json<br>- /var/mylog.json<br>- /var/mylog*.json | -| Table name | Name of the destination table in your Log Analytics Workspace. | -| Workspace resource ID | Resource ID of the Log Analytics workspace with the target table. | --> [!IMPORTANT] -> When you create the DCR using an ARM template, you still must associate the DCR with the agents that will use it. You can edit the DCR in the Azure portal and select the agents as described in [Add resources](./azure-monitor-agent-data-collection.md#add-resources) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "dataCollectionRuleName": { - "type": "string", - "metadata": { - "description": "Unique name for the DCR. " - } - }, - "dataCollectionEndpointResourceId": { - "type": "string", - "metadata": { - "description": "Resource ID of the data collection endpoint (DCE)." - } - }, - "location": { - "type": "string", - "metadata": { - "description": "Region for the DCR. Must be the same location as the Log Analytics workspace. " - } - }, - "filePatterns": { - "type": "string", - "metadata": { - "description": "Path on the local disk for the log file to collect. May include wildcards.Enter multiple file patterns separated by commas (AMA version 1.26 or higher required for multiple file patterns on Linux)." - } - }, - "tableName": { - "type": "string", - "metadata": { - "description": "Name of destination table in your Log Analytics workspace. " - } - }, - "workspaceResourceId": { - "type": "string", - "metadata": { - "description": "Resource ID of the Log Analytics workspace with the target table." - } - } - }, - "variables": { - "tableOutputStream": "[concat('Custom-', parameters('tableName'))]" - }, - "resources": [ - { - "type": "Microsoft.Insights/dataCollectionRules", - "apiVersion": "2022-06-01", - "name": "[parameters('dataCollectionRuleName')]", - "location": "[parameters('location')]", - "properties": { - "dataCollectionEndpointId": "[parameters('dataCollectionEndpointResourceId')]", - "streamDeclarations": { - "Custom-Json-stream": { - "columns": [ - { - "name": "TimeGenerated", - "type": "datetime" - }, - { - "name": "FilePath", - "type": "string" - }, - { - "name": "MyStringColumn", - "type": "string" - }, - { - "name": "MyIntegerColumn", - "type": "int" - }, - { - "name": "MyRealColumn", - "type": "real" - }, - { - "name": "MyBooleanColumn", - "type": "boolean" - } - ] - } - }, - "dataSources": { - "logFiles": [ - { - "streams": [ - "Custom-Json-stream" - ], - "filePatterns": [ - "[parameters('filePatterns')]" - ], - "format": "json", - "name": "Custom-Json-stream" - } - ] - }, - "destinations": { - "logAnalytics": [ - { - "workspaceResourceId": "[parameters('workspaceResourceId')]", - "name": "workspace" - } - ] - }, - "dataFlows": [ - { - "streams": [ - "Custom-Json-stream" - ], - "destinations": [ - "workspace" - ], - "transformKql": "source", - "outputStream": "[variables('tableOutputStream')]" - } - ] - } - } - ] -} -``` ---## Troubleshooting -Go through the following steps if you aren't collecting data from the JSON log that you're expecting. --- Verify that data is being written to the log file being collected.-- Verify that the name and location of the log file matches the file pattern you specified.-- Verify that the schema of the incoming stream in the DCR matches the schema in the log file.-- Verify that the schema of the target table matches the incoming stream or that you have a transformation that will convert the incoming stream to the correct schema.-- See [Verify operation](./azure-monitor-agent-data-collection.md#verify-operation) to verify whether the agent is operational and data is being received.-----## Next steps --Learn more about: --- [Azure Monitor Agent](azure-monitor-agent-overview.md).-- [Data collection rules](../essentials/data-collection-rule-overview.md).-- [Best practices for cost management in Azure Monitor](../best-practices-cost.md). |
| azure-monitor | Data Collection Log Text | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/data-collection-log-text.md | - Title: Collect logs from a text file with Azure Monitor Agent -description: Configure a data collection rule to collect log data from a text file on a virtual machine using Azure Monitor Agent. - Previously updated : 08/28/2024------# Collect logs from a text file with Azure Monitor Agent -**Custom Text Logs** is one of the data sources used in a [data collection rule (DCR)](../essentials/data-collection-rule-create-edit.md). Details for the creation of the DCR are provided in [Collect data with Azure Monitor Agent](./azure-monitor-agent-data-collection.md). This article provides additional details for the text logs type. --Many applications and services will log information to text files instead of standard logging services such as Windows Event log or Syslog. This data can be collected with [Azure Monitor Agent](azure-monitor-agent-overview.md) and stored in a Log Analytics workspace with data collected from other sources. --## Prerequisites --- Log Analytics workspace where you have at least [contributor rights](../logs/manage-access.md#azure-rbac).-- A data collection endpoint (DCE) in the same region as the Log Analytics workspace. See [How to set up data collection endpoints based on your deployment](../essentials/data-collection-endpoint-overview.md#how-to-set-up-data-collection-endpoints-based-on-your-deployment) for details.-- Either a new or existing DCR described in [Collect data with Azure Monitor Agent](./azure-monitor-agent-data-collection.md).--## Basic operation --The following diagram shows the basic operation of collecting log data from a text file. --1. The agent watches for any log files that match a specified name pattern on the local disk. -2. Each entry in the log is collected and sent to Azure Monitor. The incoming stream includes the entire log entry in a single column. -3. If the default transformation is used, the entire log entry is sent to a single column in the target table. -4. If a custom transformation is used, the log entry can be parsed into multiple columns in the target table. -----## Text file requirements and best practices -The file that the Azure Monitor Agent is monitoring must meet the following requirements: --- The file must be stored on the local drive of the machine with the Azure Monitor Agent in the directory that is being monitored.-- Each record must be delineated with an end of line. -- The file must use ASCII or UTF-8 encoding. Other formats such as UTF-16 aren't supported.-- New records should be appended to the end of the file and not overwrite old records. Overwriting will cause data loss.--Adhere to the following recommendations to ensure that you don't experience data loss or performance issues: - -- Create a new log file every day so that you can easily clean up old files.-- Continuously clean up log files in the monitored directory. Tracking many log files can drive up agent CPU and Memory usage. Wait for at least 2 days to allow ample time for all logs to be processed.-- Don't rename a file that matches the file scan pattern to another name that also matches the file scan pattern. This will cause duplicate data to be ingested. -- Don't rename or copy large log files that match the file scan pattern into the monitored directory. If you must, do not exceed 50MB per minute.---## Incoming stream --> [!NOTE] -> Multiline support that uses an [ISO 8601](https://wikipedia.org/wiki/ISO_8601) time stamp to delimited events is expected mid-October 2024 --The incoming stream of data includes the columns in the following table. --| Column | Type | Description | -|:|:|:| -| `TimeGenerated` | datetime | The time the record was generated. This value will be automatically populated with the time the record is added to the Log Analytics workspace. You can override this value using a transformation to set `TimeGenerated` to another value. | -| `RawData` | string | The entire log entry in a single column. You can use a transformation if you want to break down this data into multiple columns before sending to the table. | -| `FilePath` | string | If you add this column to the incoming stream in the DCR, it will be populated with the path to the log file. This column is not created automatically and can't be added using the portal. You must manually modify the DCR created by the portal or create the DCR using another method where you can explicitly define the incoming stream. | -| `Computer` | string | If you add this column to the incoming stream in the DCR, it will be populated with the name of the computer with the log file. This column is not created automatically and can't be added using the portal. You must manually modify the DCR created by the portal or create the DCR using another method where you can explicitly define the incoming stream. | ---## Custom table -Before you can collect log data from a text file, you must create a custom table in your Log Analytics workspace to receive the data. The table schema must match the data you are collecting, or you must add a transformation to ensure that the output schema matches the table. --> [!Warning] -> You shouldnΓÇÖt use an existing custom log table used by MMA agents. Your MMA agents won't be able to write to the table once the first AMA agent writes to the table. You should create a new table for AMA to use to prevent MMA data loss. ---For example, you can use the following PowerShell script to create a custom table with `RawData`, `FilePath`, and `Computer`. You wouldn't need a transformation for this table because the schema matches the default schema of the incoming stream. ---```powershell -$tableParams = @' -{ - "properties": { - "schema": { - "name": "{TableName}_CL", - "columns": [ - { - "name": "TimeGenerated", - "type": "DateTime" - }, - { - "name": "RawData", - "type": "String" - }, - { - "name": "FilePath", - "type": "String" - }, - { - "name": "Computer", - "type": "String" - } - ] - } - } -} -'@ --Invoke-AzRestMethod -Path "/subscriptions/{subscription}/resourcegroups/{resourcegroup}/providers/microsoft.operationalinsights/workspaces/{WorkspaceName}/tables/{TableName}_CL?api-version=2021-12-01-preview" -Method PUT -payload $tableParams -``` ---## Create a data collection rule for a text file --### [Portal](#tab/portal) --Create a data collection rule, as described in [Collect data with Azure Monitor Agent](./azure-monitor-agent-data-collection.md). In the **Collect and deliver** step, select **Custom Text Logs** from the **Data source type** dropdown. - --| Setting | Description | -|:|:| -| File pattern | Identifies the location and name of log files on the local disk. Use a wildcard for filenames that vary, for example when a new file is created each day with a new name. You can enter multiple file patterns separated by commas.<br><br>Examples:<br>- C:\Logs\MyLog.txt<br>- C:\Logs\MyLog*.txt<br>- C:\App01\AppLog.txt, C:\App02\AppLog.txt<br>- /var/mylog.log<br>- /var/mylog*.log | -| Table name | Name of the destination table in your Log Analytics Workspace. | -| Record delimiter | Not currently used but reserved for future potential use allowing delimiters other than the currently supported end of line (`/r/n`). | -| Transform | [Ingestion-time transformation](../essentials/data-collection-transformations.md) to filter records or to format the incoming data for the destination table. Use `source` to leave the incoming data unchanged. | -- --### [Resource Manager template](#tab/arm) --Use the following ARM template to create or modify a DCR for collecting text log files. In addition to the parameter values, you may need to modify the following values in the template: --- `columns`: Remove the `FilePath` column if you don't want to collect it.-- `transformKql`: Modify the default transformation if you want to modify or filter the incoming stream, for example to parse the log entry into multiple columns. The output schema of the transformation must match the schema of the target table.--> [!IMPORTANT] -> If you create the DCR using an ARM template, you still must associate the DCR with the agents that will use it. You can edit the DCR in the Azure portal and select the agents as described in [Add resources](./azure-monitor-agent-data-collection.md#add-resources) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "dataCollectionRuleName": { - "type": "string", - "metadata": { - "description": "Unique name for the DCR. " - } - }, - "dataCollectionEndpointResourceId": { - "type": "string", - "metadata": { - "description": "Resource ID of the data collection endpoint (DCE)." - } - }, - "location": { - "type": "string", - "metadata": { - "description": "Region for the DCR. Must be the same location as the Log Analytics workspace. " - } - }, - "filePatterns": { - "type": "string", - "metadata": { - "description": "Path on the local disk for the log file to collect. May include wildcards.Enter multiple file patterns separated by commas (AMA version 1.26 or higher required for multiple file patterns on Linux)." - } - }, - "tableName": { - "type": "string", - "metadata": { - "description": "Name of destination table in your Log Analytics workspace. " - } - }, - "workspaceResourceId": { - "type": "string", - "metadata": { - "description": "Resource ID of the Log Analytics workspace with the target table." - } - } - }, - "variables": { - "tableOutputStream": "[concat('Custom-', parameters('tableName'))]" - }, - "resources": [ - { - "type": "Microsoft.Insights/dataCollectionRules", - "name": "[parameters('dataCollectionRuleName')]", - "location": "[parameters('location')]", - "apiVersion": "2022-06-01", - "properties": { - "dataCollectionEndpointId": "[parameters('dataCollectionEndpointResourceId')]", - "streamDeclarations": { - "Custom-Text-stream": { - "columns": [ - { - "name": "TimeGenerated", - "type": "datetime" - }, - { - "name": "RawData", - "type": "string" - }, - { - "name": "FilePath", - "type": "string" - }, - { - "name": "Computer", - "type": "string" - } - ] - } - }, - "dataSources": { - "logFiles": [ - { - "streams": [ - "Custom-Text-stream" - ], - "filePatterns": [ - "[parameters('filePatterns')]" - ], - "format": "text", - "name": "Custom-Text-dataSource" - } - ] - }, - "destinations": { - "logAnalytics": [ - { - "workspaceResourceId": "[parameters('workspaceResourceId')]", - "name": "workspace" - } - ] - }, - "dataFlows": [ - { - "streams": [ - "Custom-Text-dataSource" - ], - "destinations": [ - "workspace" - ], - "transformKql": "source", - "outputStream": "[variables('tableOutputStream')]" - } - ] - } - } - ] -} -``` ----## Delimited log files -Many text log files have entries that are delimited by a character such as a comma. To parse this data into separate columns, use a transformation with the [split function](/azure/data-explorer/kusto/query/split-function). --For example, consider a text file with the following comma-delimited data. These fields could be described as: `Time`, `Code`, `Severity`,`Module`, and `Message`. --```plaintext -2024-06-21 19:17:34,1423,Error,Sales,Unable to connect to pricing service. -2024-06-21 19:18:23,1420,Information,Sales,Pricing service connection established. -2024-06-21 21:45:13,2011,Warning,Procurement,Module failed and was restarted. -2024-06-21 23:53:31,4100,Information,Data,Nightly backup complete. -``` --The following transformation parses the data into separate columns. Because `split` returns dynamic data, you must use functions such as `tostring` and `toint` to convert the data to the correct scalar type. You also need to provide a name for each entry that matches the column name in the target table. Note that this example provides a `TimeGenerated` value. If this was not provided, the ingestion time would be used. --```kusto -source | project d = split(RawData,",") | project TimeGenerated=todatetime(d[0]), Code=toint(d[1]), Severity=tostring(d[2]), Module=tostring(d[3]), Message=tostring(d[4]) -``` ---Retrieving this data with a log query would return the following results. ----## Troubleshooting -Go through the following steps if you aren't collecting data from the text log that you're expecting. --- Verify that data is being written to the log file being collected.-- Verify that the name and location of the log file matches the file pattern you specified.-- Verify that the schema of the target table matches the incoming stream or that you have a transformation that will convert the incoming stream to the correct schema.-- See [Verify operation](./azure-monitor-agent-data-collection.md#verify-operation) to verify whether the agent is operational and data is being received.--## Next steps --Learn more about: --- [Azure Monitor Agent](azure-monitor-agent-overview.md)-- [Data collection rules](../essentials/data-collection-rule-overview.md)-- [Best practices for cost management in Azure Monitor](../best-practices-cost.md) |
| azure-monitor | Data Collection Performance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/data-collection-performance.md | - Title: Collect performance counters with Azure Monitor Agent -description: Describes how to collect performance counters from virtual machines, Virtual Machine Scale Sets, and Arc-enabled on-premises servers using Azure Monitor Agent. - Previously updated : 07/12/2024-------# Collect performance counters with Azure Monitor Agent --**Performance counters** is one of the data sources used in a [data collection rule (DCR)](../essentials/data-collection-rule-create-edit.md). Details for the creation of the DCR are provided in [Collect data with Azure Monitor Agent](./azure-monitor-agent-data-collection.md). This article provides more details for the Windows events data source type. --Performance counters provide insight into the performance of hardware components, operating systems, and applications. [Azure Monitor Agent](azure-monitor-agent-overview.md) can collect performance counters from Windows and Linux machines at frequent intervals for near real time analysis. --## Prerequisites --* If you're going to send performance data to a [Log Analytics workspace](../logs/log-analytics-workspace-overview.md), then you must have one created where you have at least [contributor rights](../logs/manage-access.md#azure-rbac). -* Either a new or existing DCR described in [Collect data with Azure Monitor Agent](./azure-monitor-agent-data-collection.md). --## Configure performance counters data source --Create a data collection rule, as described in [Collect data with Azure Monitor Agent](./azure-monitor-agent-data-collection.md). In the **Collect and deliver** step, select **Performance Counters** from the **Data source type** dropdown. --For performance counters, select from a predefined set of objects and their sampling rate. - --Select **Custom** to specify an [XPath](https://www.w3schools.com/xml/xpath_syntax.asp) to collect any performance counters not available by default. Use the format `\PerfObject(ParentInstance/ObjectInstance#InstanceIndex)\Counter`. If the counter name contains an ampersand (&), replace it with `&`. For example, `\Memory\Free & Zero Page List Bytes`. You can view the default counters for examples. -- -> [!NOTE] -> At this time, Microsoft.HybridCompute ([Azure Arc-enabled servers](../../azure-arc/servers/overview.md)) resources can't be viewed in [Metrics Explorer](../essentials/metrics-getting-started.md) (the Azure portal UX), but they can be acquired via the Metrics REST API (Metric Namespaces - List, Metric Definitions - List, and Metrics - List). --## Destinations --Performance counters data can be sent to the following locations. --| Destination | Table / Namespace | -|:|:| -| Log Analytics workspace | Perf (see [Azure Monitor Logs reference](/azure/azure-monitor/reference/tables/perf#columns)) | -| Azure Monitor Metrics | Windows: Virtual Machine Guest<br>Linux: azure.vm.linux.guestmetrics | - -> [!NOTE] -> On Linux, using Azure Monitor Metrics as the only destination is supported in v1.10.9.0 or higher. ---## Log queries with performance records --The following queries are examples to retrieve performance records. --#### All performance data from a particular computer --```query -Perf -| where Computer == "MyComputer" -``` --#### Average CPU utilization across all computers --```query -Perf -| where ObjectName == "Processor" and CounterName == "% Processor Time" and InstanceName == "_Total" -| summarize AVGCPU = avg(CounterValue) by Computer -``` --#### Hourly average, minimum, maximum, and 75-percentile CPU usage for a specific computer --```query -Perf -| where CounterName == "% Processor Time" and InstanceName == "_Total" and Computer == "MyComputer" -| summarize ["min(CounterValue)"] = min(CounterValue), ["avg(CounterValue)"] = avg(CounterValue), ["percentile75(CounterValue)"] = percentile(CounterValue, 75), ["max(CounterValue)"] = max(CounterValue) by bin(TimeGenerated, 1h), Computer -``` --> [!NOTE] -> Additional query examples are available at [Queries for the Perf table](/azure/azure-monitor/reference/queries/perf). --## Next steps --* [Collect text logs by using Azure Monitor Agent](data-collection-text-log.md). -* Learn more about [Azure Monitor Agent](azure-monitor-agent-overview.md). -* Learn more about [data collection rules](../essentials/data-collection-rule-overview.md). |
| azure-monitor | Data Collection Snmp Data | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/data-collection-snmp-data.md | - Title: Collect SNMP trap data with Azure Monitor Agent -description: Learn how to collect SNMP trap data and send the data to Azure Monitor Logs using Azure Monitor Agent. - Previously updated : 07/12/2024-----# Collect SNMP trap data with Azure Monitor Agent --Simple Network Management Protocol (SNMP) is a widely deployed management protocol for monitoring and configuring Linux devices and appliances. This article describes how to collect SNMP trap data and send it to a Log Analytics workspace using Azure Monitor Agent. - -You can collect SNMP data in two ways: --- **Polls** - The managing system polls an SNMP agent to gather values for specific properties. Polls are most often used for stateful health detection and collecting performance metrics.-- **Traps** - An SNMP agent forwards events or notifications to a managing system. Traps are most often used as event notifications.--Azure Monitor agent can't collect SNMP data directly, but you can send this data to one of the following data sources that Azure Monitor agent can collect: --- Syslog. The data is stored in the `Syslog` table with your other syslog data collected by Azure Monitor agent.-- Text file. The data is stored in a custom table that you create. Using a transformation, you can parse the data and store it in a structured format.---## Prerequisites ---- A Log Analytics workspace where you have at least [contributor rights](../logs/manage-access.md#azure-rbac).--- Management Information Base (MIB) files for the devices you are monitoring.- - SNMP identifies monitored properties using Object Identifier (OID) values, which are defined and described in vendor-provided MIB files. The device vendor typically provides MIB files. If you don't have the MIB files, you can find the files for many vendors on third-party websites. Some vendors maintain a single MIB for all devices, while others have hundreds of MIB files. -- Place all MIB files for each device that sends SNMP traps in `/usr/share/snmp/mibs`, the default directory for MIB files. This enables logging SNMP trap fields with meaningful names instead of OIDs. To load an MIB file correctly, snmptrapd must load all dependent MIBs. Be sure to check the snmptrapd log file after loading MIBs to ensure that there are no missing dependencies in parsing your MIB files. --- A Linux server with an SNMP trap receiver.-- This article uses **snmptrapd**, an SNMP trap receiver from the [Net-SNMP](https://www.net-snmp.org/) agent, which most Linux distributions provide. However, there are many other SNMP trap receiver services you can use. It's important that the SNMP trap receiver you use can load MIB files for your environment, so that the properties in the SNMP trap message have meaningful names instead of OIDs. -- The snmptrapd configuration procedure may vary between Linux distributions. For more information on snmptrapd configuration, including guidance on configuring for SNMP v3 authentication, see the [Net-SNMP documentation](https://www.net-snmp.org/docs/man/snmptrapd.conf.html). -- - -## Set up the trap receiver log options and format ---To set up the snmptrapd trap receiver on a Red Hat Enterprise Linux 7 or Oracle Linux 7 server: --1. Install and enable snmptrapd: -- ```bash - #Install the SNMP agent - sudo yum install net-snmp - #Enable the service - sudo systemctl enable snmptrapd - #Allow UDP 162 through the firewall - sudo firewall-cmd --zone=public --add-port=162/udp --permanent - ``` --1. Authorize community strings (SNMP v1 and v2 authentication strings) and define the format for the traps written to the log file: - - 1. Open `snmptrapd.conf`: - - ```bash - sudo vi /etc/snmp/snmptrapd.conf - ``` -- 1. Add these lines to your `snmptrapd.conf` file: - - ```bash - # Allow all traps for all OIDs, from all sources, with a community string of public - authCommunity log,execute,net public - # Format logs for collection by Azure Monitor Agent - format2 snmptrap %a %B %y/%m/%l %h:%j:%k %N %W %q %T %W %v \n - ``` -- > [!NOTE] - > snmptrapd logs both traps and daemon messages - for example, service stop and start - to the same log file. In the example above, weΓÇÖve defined the log format to start with the word ΓÇ£snmptrapΓÇ¥ to make it easy to filter snmptraps from the log later on. --## Configure the trap receiver to send trap data to syslog or text file --- -To edit the output behavior configuration of snmptrapd: --1. Open the `/etc/snmp/snmptrapd.conf` file: - - ```bash - sudo vi /etc/sysconfig/snmptrapd - ``` --2. Configure the output destination such as in the following example configuration: -- ```bash - # snmptrapd command line options - # '-f' is implicitly added by snmptrapd systemd unit file - # OPTIONS="-Lsd" - OPTIONS="-m ALL -Ls2 -Lf /var/log/snmptrapd" - ``` - - The options in this example configuration are: - - - `-m ALL` - Load all MIB files in the default directory. - - `-Ls2` - Output traps to syslog, to the Local2 facility. - - `-Lf /var/log/snmptrapd` - Log traps to the `/var/log/snmptrapd` file. - -> [!NOTE] -> See Net-SNMP documentation for more information about [how to set output options](https://www.net-snmp.org/docs/man/snmpcmd.html) and [how to set formatting options](https://www.net-snmp.org/docs/man/snmptrapd.html). --## Collect SNMP traps using Azure Monitor Agent --Depending on where you sent SNMP events, use the guidance at one of the following to collect the data with Azure Monitor Agent: --- [Collect Syslog events with Azure Monitor Agent](./data-collection-syslog.md)-- [Collect logs from a text file with Azure Monitor Agent](./data-collection-log-text.md)---## Next steps --Learn more about: --- [Azure Monitor Agent](azure-monitor-agent-overview.md).-- [Data collection rules](../essentials/data-collection-rule-overview.md).-- [Best practices for cost management in Azure Monitor](../best-practices-cost.md). |
| azure-monitor | Data Collection Syslog | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/data-collection-syslog.md | - Title: Collect Syslog events with Azure Monitor Agent -description: Configure collection of Syslog events by using a data collection rule on virtual machines with Azure Monitor Agent. -- Previously updated : 07/12/2024----# Collect Syslog events with Azure Monitor Agent --**Syslog events** is one of the data sources used in a [data collection rule (DCR)](../essentials/data-collection-rule-create-edit.md). Details for the creation of the DCR are provided in [Collect data with Azure Monitor Agent](./azure-monitor-agent-data-collection.md). This article provides additional details for the Syslog events data source type. --Syslog is an event logging protocol that's common to Linux. You can use the Syslog daemon that's built into Linux devices and appliances to collect local events of the types you specify. Applications send messages that are either stored on the local machine or delivered to a Syslog collector. --> [!TIP] -> To collect data from devices that don't allow local installation of Azure Monitor Agent, [configure a dedicated Linux-based log forwarder](../../sentinel/forward-syslog-monitor-agent.md). --## Prerequisites --- [Log Analytics workspace](../logs/log-analytics-workspace-overview.md) where you have at least [contributor rights](../logs/manage-access.md#azure-rbac). Syslog events are sent to the [Syslog](/azure/azure-monitor/reference/tables/event) table.-- Either a new or existing DCR described in [Collect data with Azure Monitor Agent](./azure-monitor-agent-data-collection.md).--## Configure collection of Syslog data --In the **Collect and deliver** step of the DCR, select **Linux Syslog** from the **Data source type** dropdown. --The following facilities are supported with the Syslog collector: --| Priority Index Number | Priority Name | -|:|:| -| {none} | No Pri | -| 0 | Kern | -| 1 | user | -| 2 | mail | -| 3 | daemon | -| 4 | auth | -| 5 | syslog | -| 6 | lpr | -| 7 | news | -| 8 | uucp | -| 9 | cron | -| 10 | authpriv | -| 11 | ftp | -| 12 | ntp | -| 13 | audit | -| 14 | alert | -| 15 | clock | -| 16 | local0 | -| 17 | local1 | -| 18 | local2 | -| 19 | local3 | -| 20 | local4 | -| 21 | local5 | -| 22 | local6 | -| 23 | local7 | ---By default, the agent will collect all events that are sent by the Syslog configuration. Change the **Minimum log level** for each facility to limit data collection. Select **NONE** to collect no events for a particular facility. --## Destinations --Syslog data can be sent to the following locations. --| Destination | Table / Namespace | -|:|:| -| Log Analytics workspace | [Syslog](/azure/azure-monitor/reference/tables/syslog) | - --> [!NOTE] -> Azure Monitor Linux Agent versions 1.15.2 and higher support syslog RFC formats including Cisco Meraki, Cisco ASA, Cisco FTD, Sophos XG, Juniper Networks, Corelight Zeek, CipherTrust, NXLog, McAfee, and Common Event Format (CEF). ---## Configure Syslog on the Linux agent -When Azure Monitor Agent is installed on a Linux machine, it installs a default Syslog configuration file that defines the facility and severity of the messages that are collected if Syslog is enabled in a DCR. The configuration file is different depending on the Syslog daemon that the client has installed. --### Rsyslog -On many Linux distributions, the rsyslogd daemon is responsible for consuming, storing, and routing log messages sent by using the Linux Syslog API. Azure Monitor Agent uses the TCP forward output module (`omfwd`) in rsyslog to forward log messages. --The Azure Monitor Agent installation includes default config files located in `/etc/opt/microsoft/azuremonitoragent/syslog/rsyslogconf/`. When Syslog is added to a DCR, this configuration is installed under the `etc/rsyslog.d` system directory and rsyslog is automatically restarted for the changes to take effect. --> [!NOTE] -> On rsyslog-based systems, Azure Monitor Linux Agent adds forwarding rules to the default ruleset defined in the rsyslog configuration. If multiple rulesets are used, inputs bound to non-default ruleset(s) are **not** forwarded to Azure Monitor Agent. For more information about multiple rulesets in rsyslog, see the [official documentation](https://www.rsyslog.com/doc/master/concepts/multi_ruleset.html). --Following is the default configuration which collects Syslog messages sent from the local agent for all facilities with all log levels. --``` -$ cat /etc/rsyslog.d/10-azuremonitoragent-omfwd.conf -# Azure Monitor Agent configuration: forward logs to azuremonitoragent --template(name="AMA_RSYSLOG_TraditionalForwardFormat" type="string" string="<%PRI%>%TIMESTAMP% %HOSTNAME% %syslogtag%%msg:::sp-if-no-1st-sp%%msg%") -# queue.workerThreads sets the maximum worker threads, it will scale back to 0 if there is no activity -# Forwarding all events through TCP port -*.* action(type="omfwd" -template="AMA_RSYSLOG_TraditionalForwardFormat" -queue.type="LinkedList" -queue.filename="omfwd-azuremonitoragent" -queue.maxFileSize="32m" -action.resumeRetryCount="-1" -action.resumeInterval="5" -action.reportSuspension="on" -action.reportSuspensionContinuation="on" -queue.size="25000" -queue.workerThreads="100" -queue.dequeueBatchSize="2048" -queue.saveonshutdown="on" -target="127.0.0.1" Port="28330" Protocol="tcp") -``` --The following configuration is used when you use SELinux and decide to use Unix sockets. --``` -$ cat /etc/rsyslog.d/10-azuremonitoragent.conf -# Azure Monitor Agent configuration: forward logs to azuremonitoragent -$OMUxSockSocket /run/azuremonitoragent/default_syslog.socket -template(name="AMA_RSYSLOG_TraditionalForwardFormat" type="string" string="<%PRI%>%TIMESTAMP% %HOSTNAME% %syslogtag%%msg:::sp-if-no-1st-sp%%msg%") -$OMUxSockDefaultTemplate AMA_RSYSLOG_TraditionalForwardFormat -# Forwarding all events through Unix Domain Socket -*.* :omuxsock: -``` --``` -$ cat /etc/rsyslog.d/05-azuremonitoragent-loadomuxsock.conf -# Azure Monitor Agent configuration: load rsyslog forwarding module. -$ModLoad omuxsock -``` --On some legacy systems, you may see rsyslog log formatting issues when a traditional forwarding format is used to send Syslog events to Azure Monitor Agent. For these systems, Azure Monitor Agent automatically places a legacy forwarder template instead: --`template(name="AMA_RSYSLOG_TraditionalForwardFormat" type="string" string="%TIMESTAMP% %HOSTNAME% %syslogtag%%msg:::sp-if-no-1st-sp%%msg%\n")` --### Syslog-ng --The Azure Monitor Agent installation includes default config files located in `/etc/opt/microsoft/azuremonitoragent/syslog/syslog-ngconf/azuremonitoragent-tcp.conf`. When Syslog is added to a DCR, this configuration is installed under the `/etc/syslog-ng/conf.d/azuremonitoragent-tcp.conf` system directory and syslog-ng is automatically restarted for the changes to take effect. --The default contents are shown in the following example. This example collects Syslog messages sent from the local agent for all facilities and all severities. -``` -$ cat /etc/syslog-ng/conf.d/azuremonitoragent-tcp.conf -# Azure MDSD configuration: syslog forwarding config for mdsd agent -options {}; --# during install time, we detect if s_src exist, if it does then we -# replace it by appropriate source name like in redhat 's_sys' -# Forwrding using tcp -destination d_azure_mdsd { - network("127.0.0.1" - port(28330) - log-fifo-size(25000)); -}; --log { - source(s_src); # will be automatically parsed from /etc/syslog-ng/syslog-ng.conf - destination(d_azure_mdsd); - flags(flow-control); -}; -``` -The following configuration is used when you use SELinux and decide to use Unix sockets. -``` -$ cat /etc/syslog-ng/conf.d/azuremonitoragent.conf -# Azure MDSD configuration: syslog forwarding config for mdsd agent options {}; -# during install time, we detect if s_src exist, if it does then we -# replace it by appropriate source name like in redhat 's_sys' -# Forwrding using unix domain socket -destination d_azure_mdsd { - unix-dgram("/run/azuremonitoragent/default_syslog.socket" - flags(no_multi_line) ); -}; - -log { - source(s_src); # will be automatically parsed from /etc/syslog-ng/syslog-ng.conf - destination(d_azure_mdsd); -}; -``` -->[!Note] -> Azure Monitor supports collection of messages sent by rsyslog or syslog-ng, where rsyslog is the default daemon. The default Syslog daemon on version 5 of Red Hat Enterprise Linux and Oracle Linux version (sysklog) isn't supported for Syslog event collection. To collect Syslog data from this version of these distributions, the rsyslog daemon should be installed and configured to replace sysklog. --If you edit the Syslog configuration, you must restart the Syslog daemon for the changes to take effect. ---## Supported facilities --The following facilities are supported with the Syslog collector: --| Pri index | Pri Name | -|:|:| -| 0 | None | -| 1 | Kern | -| 2 | user | -| 3 | mail | -| 4 | daemon | -| 4 | auth | -| 5 | syslog | -| 6 | lpr | -| 7 | news | -| 8 | uucp | -| 9 | ftp | -| 10 | ntp | -| 11 | audit | -| 12 | alert | -| 13 | mark | -| 14 | local0 | -| 15 | local1 | -| 16 | local2 | -| 17 | local3 | -| 18 | local4 | -| 19 | local5 | -| 20 | local6 | -| 21 | local7 | --## Syslog record properties --Syslog records have a type of **Syslog** and have the properties shown in the following table. --| Property | Description | -|: |: | -| Computer |Computer that the event was collected from. | -| Facility |Defines the part of the system that generated the message. | -| HostIP |IP address of the system sending the message. | -| HostName |Name of the system sending the message. | -| SeverityLevel |Severity level of the event. | -| SyslogMessage |Text of the message. | -| ProcessID |ID of the process that generated the message. | -| EventTime |Date and time that the event was generated. | --## Sample Syslog log queries --The following table provides different examples of log queries that retrieve Syslog records. --- **All Syslogs**-- ``` kusto - Syslog - ``` --- **All Syslog records with severity of error**-- ``` kusto - Syslog - | where SeverityLevel == "error" - ``` --- **All Syslog records with auth facility type**-- ``` kusto - Syslog - | where facility == "auth" - ``` --- **Count of Syslog records by facility**-- ``` kusto - Syslog - | summarize AggregatedValue = count() by facility - ``` --## Troubleshooting -Go through the following steps if you aren't collecting data from the JSON log that you're expecting. --- Verify that data is being written to Syslog.-- See [Verify operation](./azure-monitor-agent-data-collection.md#verify-operation) to verify whether the agent is operational and data is being received.--## Next steps --Learn more about: --- [Azure Monitor Agent](azure-monitor-agent-overview.md)-- [Data collection rules](../essentials/data-collection-rule-overview.md)-- [Best practices for cost management in Azure Monitor](../best-practices-cost.md) |
| azure-monitor | Data Collection Windows Events | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/data-collection-windows-events.md | - Title: Collect Windows events from virtual machines with Azure Monitor Agent -description: Describes how to collect Windows events counters from virtual machines, Virtual Machine Scale Sets, and Arc-enabled on-premises servers using Azure Monitor Agent. - Previously updated : 07/12/2024-------# Collect Windows events with Azure Monitor Agent -**Windows events** is one of the data sources used in a [data collection rule (DCR)](../essentials/data-collection-rule-create-edit.md). Details for the creation of the DCR are provided in [Collect data with Azure Monitor Agent](./azure-monitor-agent-data-collection.md). This article provides additional details for the Windows events data source type. --Windows event logs are one of the most common data sources for Windows machines with [Azure Monitor Agent](azure-monitor-agent-overview.md) since it's a common source of health and information for the Windows operating system and applications running on it. You can collect events from standard logs, such as System and Application, and any custom logs created by applications you need to monitor. --## Prerequisites --- [Log Analytics workspace](../logs/log-analytics-workspace-overview.md) where you have at least [contributor rights](../logs/manage-access.md#azure-rbac). Windows events are sent to the [Event](/azure/azure-monitor/reference/tables/event) table.-- Either a new or existing DCR described in [Collect data with Azure Monitor Agent](./azure-monitor-agent-data-collection.md).--## Configure Windows event data source --In the **Collect and deliver** step of the DCR, select **Windows Event Logs** from the **Data source type** dropdown. Select from a set of logs and severity levels to collect. ---Select **Custom** to [filter events by using XPath queries](#filter-events-using-xpath-queries). You can then specify an [XPath](https://www.w3schools.com/xml/xpath_syntax.asp) to collect any specific values. ---## Security events -There are two methods you can use to collect security events with Azure Monitor agent: --- Select the security event log in your DCR just like the System and Application logs. These events are sent to the [Event](/azure/azure-monitor/reference/tables/Event) table in your Log Analytics workspace with other events. -- Enable Microsoft Sentinel on the workspace which also uses Azure Monitor agent to collect events. Security events are sent to the [SecurityEvent](/azure/azure-monitor/reference/tables/SecurityEvent).--## Filter events using XPath queries --You're charged for any data you collect in a Log Analytics workspace. Therefore, you should only collect the event data you need. The basic configuration in the Azure portal provides you with a limited ability to filter out events. To specify more filters, use custom configuration and specify an XPath that filters out the events you don't need. --XPath entries are written in the form `LogName!XPathQuery`. For example, you might want to return only events from the Application event log with an event ID of 1035. The `XPathQuery` for these events would be `*[System[EventID=1035]]`. Because you want to retrieve the events from the Application event log, the XPath is `Application!*[System[EventID=1035]]` ---### Extract XPath queries from Windows Event Viewer --In Windows, you can use Event Viewer to extract XPath queries as shown in the following screenshots. --When you paste the XPath query into the field on the **Add data source** screen, as shown in step 5, you must append the log type category followed by an exclamation point (!). ----> [!TIP] -> You can use the PowerShell cmdlet `Get-WinEvent` with the `FilterXPath` parameter to test the validity of an XPath query locally on your machine first. For more information, see the tip provided in the [Windows agent-based connections](../../sentinel/connect-services-windows-based.md) instructions. The [`Get-WinEvent`](/powershell/module/microsoft.powershell.diagnostics/get-winevent) PowerShell cmdlet supports up to 23 expressions. Azure Monitor data collection rules support up to 20. The following script shows an example: -> -> ```powershell -> $XPath = '*[System[EventID=1035]]' -> Get-WinEvent -LogName 'Application' -FilterXPath $XPath -> ``` -> -> - In the preceding cmdlet, the value of the `-LogName` parameter is the initial part of the XPath query until the exclamation point (!). The rest of the XPath query goes into the `$XPath` parameter. -> - If the script returns events, the query is valid. -> - If you receive the message "No events were found that match the specified selection criteria," the query might be valid but there are no matching events on the local machine. -> - If you receive the message "The specified query is invalid," the query syntax is invalid. --Examples of using a custom XPath to filter events: --| Description | XPath | -|:|:| -| Collect only System events with Event ID = 4648 | `System!*[System[EventID=4648]]` -| Collect Security Log events with Event ID = 4648 and a process name of consent.exe | `Security!*[System[(EventID=4648)]] and *[EventData[Data[@Name='ProcessName']='C:\Windows\System32\consent.exe']]` | -| Collect all Critical, Error, Warning, and Information events from the System event log except for Event ID = 6 (Driver loaded) | `System!*[System[(Level=1 or Level=2 or Level=3) and (EventID != 6)]]` | -| Collect all success and failure Security events except for Event ID 4624 (Successful logon) | `Security!*[System[(band(Keywords,13510798882111488)) and (EventID != 4624)]]` | --> [!NOTE] -> For a list of limitations in the XPath supported by Windows event log, see [XPath 1.0 limitations](/windows/win32/wes/consuming-events#xpath-10-limitations). For example, you can use the "position", "Band", and "timediff" functions within the query but other functions like "starts-with" and "contains" are not currently supported. ---## Destinations -Windows event data can be sent to the following locations. --| Destination | Table / Namespace | -|:|:| -| Log Analytics workspace | [Event](/azure/azure-monitor/reference/tables/event) | - ----## Next steps --- [Collect text logs by using Azure Monitor Agent](data-collection-text-log.md).-- Learn more about [Azure Monitor Agent](azure-monitor-agent-overview.md).-- Learn more about [data collection rules](../essentials/data-collection-rule-overview.md). |
| azure-monitor | Data Sources Collectd | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/data-sources-collectd.md | - Title: Collect data from CollectD in Azure Monitor | Microsoft Docs -description: CollectD is an open source Linux daemon that periodically collects data from applications and system level information. This article provides information on collecting data from CollectD in Azure Monitor. -- Previously updated : 06/01/2023----# Collect data from CollectD on Linux agents in Azure Monitor -[CollectD](https://collectd.org/) is an open source Linux daemon that periodically collects performance metrics from applications and system level information. Example applications include the Java Virtual Machine (JVM), MySQL Server, and Nginx. This article provides information on collecting performance data from CollectD in Azure Monitor using the Log Analytics agent. ---A full list of available plugins can be found at [Table of Plugins](https://collectd.org/wiki/index.php/Table_of_Plugins). ---The following CollectD configuration is included in the Log Analytics agent for Linux to route CollectD data to the Log Analytics agent for Linux. ---```xml -LoadPlugin write_http --<Plugin write_http> - <Node "oms"> - URL "127.0.0.1:26000/oms.collectd" - Format "JSON" - StoreRates true - </Node> -</Plugin> -``` --Additionally, if using an versions of collectD before 5.5 use the following configuration instead. --```xml -LoadPlugin write_http --<Plugin write_http> - <URL "127.0.0.1:26000/oms.collectd"> - Format "JSON" - StoreRates true - </URL> -</Plugin> -``` --The CollectD configuration uses the default`write_http` plugin to send performance metric data over port 26000 to Log Analytics agent for Linux. --> [!NOTE] -> This port can be configured to a custom-defined port if needed. --The Log Analytics agent for Linux also listens on port 26000 for CollectD metrics and then converts them to Azure Monitor schema metrics. The following is the Log Analytics agent for Linux configuration `collectd.conf`. --```xml -<source> - type http - port 26000 - bind 127.0.0.1 -</source> --<filter oms.collectd> - type filter_collectd -</filter> -``` --> [!NOTE] -> CollectD by default is set to read values at a 10-second [interval](https://collectd.org/wiki/index.php/Interval). As this directly affects the volume of data sent to Azure Monitor Logs, you might need to tune this interval within the CollectD configuration to strike a good balance between the monitoring requirements and associated costs and usage for Azure Monitor Logs. --## Versions supported -- Azure Monitor currently supports CollectD version 4.8 and above.-- Log Analytics agent for Linux v1.1.0-217 or above is required for CollectD metric collection.---## Configuration -The following are basic steps to configure collection of CollectD data in Azure Monitor. --1. Configure CollectD to send data to the Log Analytics agent for Linux using the write_http plugin. -2. Configure the Log Analytics agent for Linux to listen for the CollectD data on the appropriate port. -3. Restart CollectD and Log Analytics agent for Linux. --### Configure CollectD to forward data --1. To route CollectD data to the Log Analytics agent for Linux, `oms.conf` needs to be added to CollectD's configuration directory. The destination of this file depends on the Linux distro of your machine. -- If your CollectD config directory is located in /etc/collectd.d/: -- ```console - sudo cp /etc/opt/microsoft/omsagent/sysconf/omsagent.d/oms.conf /etc/collectd.d/oms.conf - ``` -- If your CollectD config directory is located in /etc/collectd/collectd.conf.d/: -- ```console - sudo cp /etc/opt/microsoft/omsagent/sysconf/omsagent.d/oms.conf /etc/collectd/collectd.conf.d/oms.conf - ``` -- >[!NOTE] - >For CollectD versions before 5.5 you will have to modify the tags in `oms.conf` as shown above. - > --2. Copy collectd.conf to the desired workspace's omsagent configuration directory. -- ```console - sudo cp /etc/opt/microsoft/omsagent/sysconf/omsagent.d/collectd.conf /etc/opt/microsoft/omsagent/<workspace id>/conf/omsagent.d/ - sudo chown omsagent:omiusers /etc/opt/microsoft/omsagent/<workspace id>/conf/omsagent.d/collectd.conf - ``` --3. Restart CollectD and Log Analytics agent for Linux with the following commands. -- ```console - sudo service collectd restart - sudo /opt/microsoft/omsagent/bin/service_control restart - ``` --## CollectD metrics to Azure Monitor schema conversion -To maintain a familiar model between infrastructure metrics already collected by Log Analytics agent for Linux and the new metrics collected by CollectD the following schema mapping is used: --| CollectD Metric field | Azure Monitor field | -|:--|:--| -| `host` | Computer | -| `plugin` | None | -| `plugin_instance` | Instance Name<br>If **plugin_instance** is *null* then InstanceName="*_Total*" | -| `type` | ObjectName | -| `type_instance` | CounterName<br>If **type_instance** is *null* then CounterName=**blank** | -| `dsnames[]` | CounterName | -| `dstypes` | None | -| `values[]` | CounterValue | --## Next steps -* Learn about [log queries](../logs/log-query-overview.md) to analyze the data collected from data sources and solutions. -* Use [Custom Fields](../logs/custom-fields.md) to parse data from syslog records into individual fields. |
| azure-monitor | Data Sources Custom Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/data-sources-custom-logs.md | - Title: Collect text logs with the Log Analytics agent in Azure Monitor -description: Azure Monitor can collect events from text files on both Windows and Linux computers. This article describes how to define a new custom log and details of the records they create in Azure Monitor. ---- Previously updated : 05/03/2023----# Collect text logs with the Log Analytics agent in Azure Monitor --The Custom Logs data source for the Log Analytics agent in Azure Monitor allows you to collect events from text files on both Windows and Linux computers. Many applications log information to text files instead of standard logging services, such as Windows Event log or Syslog. After the data is collected, you can either parse it into individual fields in your queries or extract it during collection to individual fields. -->[!IMPORTANT] -> This article describes how to collect a text log with the Log Analytics agent. If you're using the Azure Monitor agent, then see [Collect text logs with Azure Monitor Agent](data-collection-text-log.md). ----The log files to be collected must match the following criteria: --- The log must either have a single entry per line or use a timestamp matching one of the following formats at the start of each entry:-- YYYY-MM-DD HH:MM:SS<br>M/D/YYYY HH:MM:SS AM/PM<br>Mon DD, YYYY HH:MM:SS<br />yyMMdd HH:mm:ss<br />ddMMyy HH:mm:ss<br />MMM d hh:mm:ss<br />dd/MMM/yyyy:HH:mm:ss zzz<br />yyyy-MM-ddTHH:mm:ssK --- The log file must not allow circular logging. This behavior is log rotation where the file is overwritten with new entries or the file is renamed and the same file name is reused for continued logging.-- The log file must use ASCII or UTF-8 encoding. Other formats such as UTF-16 aren't supported.-- For Linux, time zone conversion isn't supported for time stamps in the logs.-- As a best practice, the log file should include the date and time that it was created to prevent log rotation overwriting or renaming.-->[!NOTE] -> If there are duplicate entries in the log file, Azure Monitor will collect them. The query results that are generated will be inconsistent. The filter results will show more events than the result count. You must validate the log to determine if the application that creates it is causing this behavior. Address the issue, if possible, before you create the custom log collection definition. --A Log Analytics workspace supports the following limits: --* Only 500 custom logs can be created. -* A table only supports up to 500 columns. -* The maximum number of characters for the column name is 500. -->[!IMPORTANT] ->Custom log collection requires that the application writing the log file flushes the log content to the disk periodically. This is because the custom log collection relies on filesystem change notifications for the log file being tracked. --## Define a custom log table --Use the following procedure to define a custom log table. Scroll to the end of this article for a walkthrough of a sample of adding a custom log. --### Open the Custom Log wizard --The Custom Log wizard runs in the Azure portal and allows you to define a new custom log to collect. --1. In the Azure portal, select **Log Analytics workspaces** > your workspace > **Tables**. -1. Select **Create** and then **New custom log (MMA-based)**. -- By default, all configuration changes are automatically pushed to all agents. For Linux agents, a configuration file is sent to the Fluentd data collector. ---### Upload and parse a sample log --To start, upload a sample of the custom log. The wizard will parse and display the entries in this file for you to validate. Azure Monitor will use the delimiter that you specify to identify each record. --**New Line** is the default delimiter and is used for log files that have a single entry per line. If the line starts with a date and time in one of the available formats, you can specify a **Timestamp** delimiter, which supports entries that span more than one line. --If a timestamp delimiter is used, the TimeGenerated property of each record stored in Azure Monitor will be populated with the date and time specified for that entry in the log file. If a new line delimiter is used, TimeGenerated is populated with the date and time when Azure Monitor collected the entry. --1. Select **Browse** and browse to a sample file. This button might be labeled **Choose File** in some browsers. -1. Select **Next**. -- The Custom Log wizard uploads the file and lists the records that it identifies. --1. Change the delimiter that's used to identify a new record. Select the delimiter that best identifies the records in your log file. -1. Select **Next**. --### Add log collection paths --You must define one or more paths on the agent where it can locate the custom log. You can either provide a specific path and name for the log file or you can specify a path with a wildcard for the name. This step supports applications that create a new file each day or when one file reaches a certain size. You can also provide multiple paths for a single log file. --For example, an application might create a log file each day with the date included in the name as in log20100316.txt. A pattern for such a log might be *log\*.txt*, which would apply to any log file following the application's naming scheme. --The following table provides examples of valid patterns to specify different log files. --| Description | Path | -|: |: | -| All files in *C:\Logs* with .txt extension on the Windows agent |C:\Logs\\\*.txt | -| All files in *C:\Logs* with a name starting with log and a .txt extension on the Windows agent |C:\Logs\log\*.txt | -| All files in */var/log/audit* with .txt extension on the Linux agent |/var/log/audit/*.txt | -| All files in */var/log/audit* with a name starting with log and a .txt extension on the Linux agent |/var/log/audit/log\*.txt | --1. Select Windows or Linux to specify which path format you're adding. -1. Enter the path and select the **+** button. -1. Repeat the process for any more paths. --### Provide a name and description for the log --The name that you specify will be used for the log type as described. It will always end with _CL to distinguish it as a custom log. --1. Enter a name for the log. The **\_CL** suffix is automatically provided. -1. Add an optional **Description**. -1. Select **Next** to save the custom log definition. --### Validate that the custom logs are being collected --It might take up to an hour for the initial data from a new custom log to appear in Azure Monitor. Azure Monitor will start collecting entries from the logs found in the path you specified from the point that you defined the custom log. It won't retain the entries that you uploaded during the custom log creation. It will collect already existing entries in the log files that it locates. --After Azure Monitor starts collecting from the custom log, its records will be available with a log query. Use the name that you gave the custom log as the **Type** in your query. --> [!NOTE] -> If the RawData property is missing from the query, you might need to close and reopen your browser. --### Parse the custom log entries --The entire log entry will be stored in a single property called **RawData**. You'll most likely want to separate the different pieces of information in each entry into individual properties for each record. For options on parsing **RawData** into multiple properties, see [Parse text data in Azure Monitor](../logs/parse-text.md). --## Delete a custom log table --See [Delete a table](../logs/create-custom-table.md#delete-a-table). --## Data collection --Azure Monitor collects new entries from each custom log approximately every 5 minutes. The agent records its place in each log file that it collects from. If the agent goes offline for a period of time, Azure Monitor collects entries from where it last left off, even if those entries were created while the agent was offline. --The entire contents of the log entry are written to a single property called **RawData**. For methods to parse each imported log entry into multiple properties, see [Parse text data in Azure Monitor](../logs/parse-text.md). --## Custom log record properties --Custom log records have a type with the log name that you provide and the properties in the following table. --| Property | Description | -|: |: | -| TimeGenerated |Date and time that the record was collected by Azure Monitor. If the log uses a time-based delimiter, this is the time collected from the entry. | -| SourceSystem |Type of agent the record was collected from. <br> OpsManager ΓÇô Windows agent, either direct connect or System Center Operations Manager <br> Linux ΓÇô All Linux agents | -| RawData |Full text of the collected entry. You'll most likely want to [parse this data into individual properties](../logs/parse-text.md). | -| ManagementGroupName |Name of the management group for System Center Operations Manager agents. For other agents, this name is AOI-\<workspace ID\>. | --## Sample walkthrough of adding a custom log --The following section walks through an example of creating a custom log. The sample log being collected has a single entry on each line starting with a date and time and then comma-delimited fields for code, status, and message. Several sample entries are shown. --```output -2019-08-27 01:34:36 207,Success,Client 05a26a97-272a-4bc9-8f64-269d154b0e39 connected -2019-08-27 01:33:33 208,Warning,Client ec53d95c-1c88-41ae-8174-92104212de5d disconnected -2019-08-27 01:35:44 209,Success,Transaction 10d65890-b003-48f8-9cfc-9c74b51189c8 succeeded -2019-08-27 01:38:22 302,Error,Application could not connect to database -2019-08-27 01:31:34 303,Error,Application lost connection to database -``` --### Upload and parse a sample log --We provide one of the log files and can see the events that it will be collecting. In this case, **New line** is a sufficient delimiter. If a single entry in the log could span multiple lines though, a timestamp delimiter would need to be used. ---### Add log collection paths --The log files will be located in *C:\MyApp\Logs*. A new file will be created each day with a name that includes the date in the pattern *appYYYYMMDD.log*. A sufficient pattern for this log would be *C:\MyApp\Logs\\\*.log*. ---### Provide a name and description for the log --We use a name of *MyApp_CL* and type in a **Description**. ---### Validate that the custom logs are being collected --We use a simple query of *MyApp_CL* to return all records from the collected log. -<!-- convertborder later --> --## Alternatives to custom logs --While custom logs are useful if your data fits the criteria listed, there are cases where you need another strategy: --- The data doesn't fit the required structure, such as having the timestamp in a different format.-- The log file doesn't adhere to requirements such as file encoding or an unsupported folder structure.-- The data requires preprocessing or filtering before collection.--In the cases where your data can't be collected with custom logs, consider the following alternate strategies: --- Use a custom script or other method to write data to [Windows Events](data-sources-windows-events.md) or [Syslog](data-sources-syslog.md), which are collected by Azure Monitor.-- Send the data directly to Azure Monitor by using [HTTP Data Collector API](../logs/data-collector-api.md).--## Next steps --* See [Parse text data in Azure Monitor](../logs/parse-text.md) for methods to parse each imported log entry into multiple properties. -* Learn about [log queries](../logs/log-query-overview.md) to analyze the data collected from data sources and solutions. |
| azure-monitor | Data Sources Event Tracing Windows | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/data-sources-event-tracing-windows.md | - Title: Collecting Event Tracing for Windows (ETW) Events for analysis Azure Monitor Logs -description: Learn how to collect Event Tracing for Windows (ETW) for analysis in Azure Monitor Logs. ---- Previously updated : 05/31/2023-ms. reviewer: shseth --# Collecting Event Tracing for Windows (ETW) Events for analysis Azure Monitor Logs --*Event Tracing for Windows (ETW)* provides a mechanism for instrumentation of user-mode applications and kernel-mode drivers. The Log Analytics agent is used to [collect Windows events](./data-sources-windows-events.md) written to the Administrative and Operational [ETW channels](/windows/win32/wes/eventmanifestschema-channeltype-complextype). However, it is occasionally necessary to capture and analyze other events, such as those written to the Analytic channel. ---## Event flow --To successfully collect [manifest-based ETW events](/windows/win32/etw/about-event-tracing#types-of-providers) for analysis in Azure Monitor Logs, you must use the [Azure diagnostics extension](./diagnostics-extension-overview.md) for Windows (WAD). In this scenario, the diagnostics extension acts as the ETW consumer, writing events to Azure Storage (tables) as an intermediate store. Here it will be stored in a table named **WADETWEventTable**. Log Analytics then collects the table data from Azure storage, presenting it as a table named **ETWEvent**. ---## Configuring ETW Log collection --### Step 1: Locate the correct ETW provider --Use either of the following commands to enumerate the ETW providers on a source Windows System. --Command line: --``` -logman query providers -``` --PowerShell: -``` -Get-NetEventProvider -ShowInstalled | Select-Object Name, Guid -``` -Optionally, you may choose to pipe this PowerShell output to Out-Gridview to aid navigation. --Record the ETW provider name and GUID that aligns to the Analytic or Debug log that is presented in the Event Viewer, or to the module you intend to collect event data for. --### Step 2: Diagnostics extension --Ensure the *Windows diagnostics extension* is [installed](./diagnostics-extension-windows-install.md#install-with-azure-portal) on all source systems. --### Step 3: Configure ETW log collection --1. From the pane on the left, navigate to the **Diagnostic Settings** for the virtual machine --2. Select the **Logs** tab. --3. Scroll down and enable the **Event tracing for Windows (ETW) events** option --4. Set the provider GUID or provider class based on the provider you are configuring collection for --5. Set the [**Log Level**](/windows/win32/etw/configuring-and-starting-an-event-tracing-session) as appropriate --6. Click the ellipsis adjacent to the supplied provider, and click **Configure** --7. Ensure the **Default destination table** is set to **etweventtable** --8. Set a [**Keyword filter**](/windows/win32/wes/defining-keywords-used-to-classify-types-of-events) if required --9. Save the provider and log settings --Once matching events are generated, you should start to see the ETW events appearing in the **WADetweventtable** table in Azure Storage. You can use Azure Storage Explorer to confirm this. --### Step 4: Configure Log Analytics storage account collection --Follow [these instructions](./diagnostics-extension-logs.md#collect-logs-from-azure-storage) to collect the logs from Azure Storage. Once configured, the ETW event data should appear in Log Analytics under the **ETWEvent** table. --## Next steps -- Use [custom fields](../logs/custom-fields.md) to create structure in your ETW events-- Learn about [log queries](../logs/log-query-overview.md) to analyze the data collected from data sources and solutions. |
| azure-monitor | Data Sources Firewall Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/data-sources-firewall-logs.md | - Title: Collect Firewall logs with Azure Monitor Agent -description: Configure collection of Windows Firewall logs on virtual machines with Azure Monitor Agent. - Previously updated : 6/1/2023-------# Collect firewall logs with Azure Monitor Agent -Windows Firewall is a Microsoft Windows application that filters information coming to your system from the Internet and blocks potentially harmful programs. Windows Firewall logs are generated on both client and server operating systems. These logs provide valuable information about network traffic, including dropped packets and successful connections. Parsing Windows Firewall log files can be done using methods like Windows Event Forwarding (WEF) or forwarding logs to a SIEM product like Azure Sentinel. You can turn it on or off by following these steps on any Windows system: -1. Select Start, then open Settings. -1. Under Update & Security, select Windows Security, Firewall & network protection. -1. Select a network profile: domain, private, or public. -1. Under Microsoft Defender Firewall, switch the setting to On or Off. --## Prerequisites -To complete this procedure, you need: -- Log Analytics workspace where you have at least [contributor rights](../logs/manage-access.md#azure-rbac).-- [Data collection endpoint](../essentials/data-collection-endpoint-overview.md#create-a-data-collection-endpoint).-- [Permissions to create Data Collection Rule objects](../essentials/data-collection-rule-overview.md) in the workspace.-- A Virtual Machine, Virtual Machine Scale Set, or Arc-enabled on-premises machine that is running firewall. --## Add Firewall table to Log Analytics Workspace -Unlike other tables that are created by default in LAW, the Windows Firewall table must be manually created. Search for the Security and Audit solution and create it. See screenshot below. If the table isn't present you'll get a DCR deployment error stating that the table isn't present in LAW. The schema for the firewall table that gets created is located here: [Windows Firewall Schema](/azure/azure-monitor/reference/tables/windowsfirewall) --[  ](./media/data-collection-firewall-log/security-and-audit-solution.png#lightbox) --## Create a data collection rule to collect firewall logs -The [data collection rule](../essentials/data-collection-rule-overview.md) defines: -- Which source log files Azure Monitor Agent scans for new events.-- How Azure Monitor transforms events during ingestion.-- The destination Log Analytics workspace and table to which Azure Monitor sends the data.--You can define a data collection rule to send data from multiple machines to a Log Analytics workspaces, including workspace in a different region or tenant. Create the data collection rule in the *same region* as your Analytics workspace. --> [!NOTE] -> To send data across tenants, you must first enable [Azure Lighthouse](../../lighthouse/overview.md). --To create the data collection rule in the Azure portal: -1. On the **Monitor** menu, select **Data Collection Rules**. -1. Select **Create** to create a new data collection rule and associations. -- [  ](media/data-collection-firewall-log/data-collection-rules-updated.png#lightbox) - -1. Enter a **Rule name** and specify a **Subscription**, **Resource Group**, **Region**, and **Platform Type**: - - **Region** specifies where the DCR will be created. The virtual machines and their associations can be in any subscription or resource group in the tenant. - - **Platform Type** specifies the type of resources this rule can apply to. The **Custom** option allows for both Windows and Linux types. - -**Data Collection End Point** select a previously created data [collection end point](../essentials/data-collection-endpoint-overview.md). - - [  ](media/data-collection-firewall-log/data-collection-rule-basics-updated.png#lightbox) -1. On the **Resources** tab: Select **+ Add resources** and associate resources with the data collection rule. Resources can be Virtual Machines, Virtual Machine Scale Sets, and Azure Arc for servers. The Azure portal installs Azure Monitor Agent on resources that don't already have it installed. --> [!IMPORTANT] -> The portal enables system-assigned managed identity on the target resources, along with existing user-assigned -> identities, if there are any. For existing applications, unless you specify the user-assigned identity in the -> request, the machine defaults to using system-assigned identity instead. If you need network isolation using private -> links, select existing endpoints from the same region for the respective resources or [create a new endpoint](../essentials/data-collection-endpoint-overview.md). --1. On the **Collect and deliver** tab, select **Add data source** to add a data source and set a destination. -1. Select **Firewall Logs**. -- [ ](media/data-collection-firewall-log/firewall-data-collection-rule.png#lightbox) --1. On the **Destination** tab, add a destination for the data source. -- [  ](media/data-collection-firewall-log/data-collection-rule-destination.png#lightbox) --1. Select **Review + create** to review the details of the data collection rule and association with the set of virtual machines. -1. Select **Create** to create the data collection rule. --> [!NOTE] -> It can take up to 5 minutes for data to be sent to the destinations after you create the data collection rule. ---### Sample log queries --Count the firewall log entries by URL for the host www.contoso.com. - -```kusto -WindowsFirewall -| take 10 -``` --[  ](media/data-collection-firewall-log/law-query-results.png#lightbox) --## Troubleshoot -Use the following steps to troubleshoot the collection of firewall logs. --### Run Azure Monitor Agent troubleshooter -To test your configuration and share logs with Microsoft [use the Azure Monitor Agent Troubleshooter](use-azure-monitor-agent-troubleshooter.md). --### Check if any firewall logs have been received -Start by checking if any records have been collected for your firewall logs by running the following query in Log Analytics. If the query doesn't return records, check the other sections for possible causes. This query looks for entries in the last two days, but you can modify for another time range. --``` kusto -WindowsFirewall -| where TimeGenerated > ago(48h) -| order by TimeGenerated desc -``` --### Verify that firewall logs are being created -Look at the timestamps of the log files and open the latest to see that latest timestamps are present in the log files. The default location for firewall log files is C:\windows\system32\logfiles\firewall\pfirewall.log. --[  ](media/data-collection-firewall-log/firewall-files-on-disk.png#lightbox) --To turn on logging follow these steps. -1. gpedit {follow the picture}ΓÇï -2. netsh advfirewall>set allprofiles logging allowedconnections enableΓÇï -3. netsh advfirewall>set allprofiles logging droppedconnections enableΓÇï --[  ](media/data-collection-firewall-log/turn-on-firewall-logging.png#lightbox) --## Next steps -Learn more about: -- [Azure Monitor Agent](azure-monitor-agent-overview.md).-- [Data collection rules](../essentials/data-collection-rule-overview.md).-- [Data collection endpoints](../essentials/data-collection-endpoint-overview.md) |
| azure-monitor | Data Sources Iis Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/data-sources-iis-logs.md | - Title: Collect IIS logs with the Log Analytics agent in Azure Monitor -description: This article describes how to configure collection of IIS log files that store user activity and the details of the records they create in Azure Monitor. - Previously updated : 06/01/2023-----# Collect IIS logs with the Log Analytics agent in Azure Monitor -Internet Information Services (IIS) stores user activity in log files that can be collected by the Log Analytics agent and stored in [Azure Monitor Logs](../data-platform.md). ---> [!IMPORTANT] -> This article covers collecting IIS logs with the [Log Analytics agent](./log-analytics-agent.md), which **will be deprecated by August 2024**. Be sure to [migrate to Azure Monitor Agent](./azure-monitor-agent-manage.md) before August 2024 to continue ingesting data. See [Collect text logs with Azure Monitor Agent (preview)](../agents/data-collection-text-log.md) for details on collecting IIS logs with [Azure Monitor Agent](azure-monitor-agent-overview.md). --## Configure IIS logs -Azure Monitor collects entries from log files created by IIS, so you must [configure IIS for logging](/previous-versions/orphan-topics/ws.11/hh831775(v=ws.11)). --Azure Monitor only supports IIS log files stored in W3C format and doesn't support custom fields or IIS Advanced Logging. It doesn't collect logs in NCSA or IIS native format. --Configure IIS logs in Azure Monitor from the [Agent configuration menu](../agents/agent-data-sources.md#configure-data-sources) for the Log Analytics agent. No configuration is required other than selecting **Collect W3C format IIS log files**. --## Data collection -Azure Monitor collects IIS log entries from each agent each time the log timestamp changes. The log is read every 5 minutes. If for any reason IIS doesn't update the timestamp before the rollover time when a new file is created, entries will be collected following creation of the new file. --The frequency of new file creation is controlled by the **Log File Rollover Schedule** setting for the IIS site. The setting is once a day by default. If the setting is **Hourly**, Azure Monitor collects the log each hour. If the setting is **Daily**, Azure Monitor collects the log every 24 hours. --> [!IMPORTANT] -> We recommend that you set **Log File Rollover Schedule** to **Hourly**. If it's set to **Daily**, you might experience spikes in your data because it will be collected only once per day. --## IIS log record properties -IIS log records have a type of **W3CIISLog** and have the properties shown in the following table: --| Property | Description | -|: |: | -| Computer |Name of the computer that the event was collected from. | -| cIP |IP address of the client. | -| csMethod |Method of the request, such as GET or POST. | -| csReferer |Site that the user followed a link from to the current site. | -| csUserAgent |Browser type of the client. | -| csUserName |Name of the authenticated user that accessed the server. Anonymous users are indicated by a hyphen. | -| csUriStem |Target of the request, such as a webpage. | -| csUriQuery |Query, if any, that the client was trying to perform. | -| ManagementGroupName |Name of the management group for Operations Manager agents. For other agents, this name is AOI-\<workspace ID\>. | -| RemoteIPCountry |Country/region of the IP address of the client. | -| RemoteIPLatitude |Latitude of the client IP address. | -| RemoteIPLongitude |Longitude of the client IP address. | -| scStatus |HTTP status code. | -| scSubStatus |Substatus error code. | -| scWin32Status |Windows status code. | -| sIP |IP address of the web server. | -| SourceSystem |OpsMgr. | -| sPort |Port on the server the client connected to. | -| sSiteName |Name of the IIS site. | -| TimeGenerated |Date and time the entry was logged. | -| TimeTaken |Length of time to process the request in milliseconds. | -| csHost | Host name. | -| csBytes | Number of bytes that the server received. | --## Log queries with IIS logs -Different examples of log queries that retrieve IIS log records are shown in the following table: --| Query | Description | -|: |: | -| W3CIISLog |All IIS log records. | -| W3CIISLog | where scStatus==500 |All IIS log records with a return status of 500. | -| W3CIISLog | summarize count() by cIP |Count of IIS log entries by client IP address. | -| W3CIISLog | where csHost=="www\.contoso.com" | summarize count() by csUriStem |Count of IIS log entries by URL for the host www\.contoso.com. | -| W3CIISLog | summarize sum(csBytes) by Computer | take 500000 |Total bytes received by each IIS computer. | --## Next steps -* Configure Azure Monitor to collect other [data sources](../agents/agent-data-sources.md) for analysis. -* Learn about [log queries](../logs/log-query-overview.md) to analyze the data collected from data sources and solutions. |
| azure-monitor | Data Sources Json | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/data-sources-json.md | - Title: Collecting custom JSON data sources with the Log Analytics agent for Linux in Azure Monitor -description: Custom JSON data sources can be collected into Azure Monitor using the Log Analytics Agent for Linux. These custom data sources can be simple scripts returning JSON such as curl or one of FluentD's 300+ plugins. This article describes the configuration required for this data collection. -- Previously updated : 06/01/2023----# Collecting custom JSON data sources with the Log Analytics agent for Linux in Azure Monitor --Custom JSON data sources can be collected into [Azure Monitor](../data-platform.md) using the Log Analytics agent for Linux. These custom data sources can be simple scripts returning JSON such as [curl](https://curl.haxx.se/) or one of [FluentD's 300+ plugins](https://www.fluentd.org/plugins/all). This article describes the configuration required for this data collection. ---> [!NOTE] -> Log Analytics agent for Linux v1.1.0-217+ is required for Custom JSON Data. -> This collection flow only works with MMA. Consider moving to the AMA agent and using the additional collection features available there -> --## Configuration --### Configure input plugin --To collect JSON data in Azure Monitor, add `oms.api.` to the start of a FluentD tag in an input plugin. --For example, following is a separate configuration file `exec-json.conf` in `/etc/opt/microsoft/omsagent/<workspace id>/conf/omsagent.d/`. This uses the FluentD plugin `exec` to run a curl command every 30 seconds. The output from this command is collected by the JSON output plugin. --```xml -<source> - type exec - command 'curl localhost/json.output' - format json - tag oms.api.httpresponse - run_interval 30s -</source> --<match oms.api.httpresponse> - type out_oms_api - log_level info -- buffer_chunk_limit 5m - buffer_type file - buffer_path /var/opt/microsoft/omsagent/<workspace id>/state/out_oms_api_httpresponse*.buffer - buffer_queue_limit 10 - flush_interval 20s - retry_limit 10 - retry_wait 30s -</match> -``` --The configuration file added under `/etc/opt/microsoft/omsagent/<workspace id>/conf/omsagent.d/` will require to have its ownership changed with the following command. --`sudo chown omsagent:omiusers /etc/opt/microsoft/omsagent/conf/omsagent.d/exec-json.conf` --### Configure output plugin -Add the following output plugin configuration to the main configuration in `/etc/opt/microsoft/omsagent/<workspace id>/conf/omsagent.conf` or as a separate configuration file placed in `/etc/opt/microsoft/omsagent/<workspace id>/conf/omsagent.d/` --```xml -<match oms.api.**> - type out_oms_api - log_level info -- buffer_chunk_limit 5m - buffer_type file - buffer_path /var/opt/microsoft/omsagent/<workspace id>/state/out_oms_api*.buffer - buffer_queue_limit 10 - flush_interval 20s - retry_limit 10 - retry_wait 30s -</match> -``` --### Restart Log Analytics agent for Linux -Restart the Log Analytics agent for Linux service with the following command. --```console -sudo /opt/microsoft/omsagent/bin/service_control restart -``` --## Output -The data will be collected in Azure Monitor with a record type of `<FLUENTD_TAG>_CL`. --For example, the custom tag `tag oms.api.tomcat` in Azure Monitor with a record type of `tomcat_CL`. You could retrieve all records of this type with the following log query. --```console -Type=tomcat_CL -``` --Nested JSON data sources are supported, but are indexed based off of parent field. For example, the following JSON data is returned from a log query as `tag_s : "[{ "a":"1", "b":"2" }]`. --```json -{ - "tag": [{ - "a":"1", - "b":"2" - }] -} -``` ---## Next steps -* Learn about [log queries](../logs/log-query-overview.md) to analyze the data collected from data sources and solutions. |
| azure-monitor | Data Sources Linux Applications | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/data-sources-linux-applications.md | - Title: Collect Linux application performance in Azure Monitor | Microsoft Docs -description: This article provides details for configuring the Log Analytics agent for Linux to collect performance counters for MySQL and Apache HTTP Server. -- Previously updated : 06/01/2023----# Collect performance counters for Linux applications in Azure Monitor --This article provides details for configuring the [Log Analytics agent for Linux](https://github.com/Microsoft/OMS-Agent-for-Linux) to collect performance counters for specific applications into Azure Monitor. The applications included in this article are: --- [MySQL](#mysql)-- [Apache HTTP Server](#apache-http-server)----## MySQL -If MySQL Server or MariaDB Server is detected on the computer when the Log Analytics agent is installed, a performance monitoring provider for MySQL Server will be automatically installed. This provider connects to the local MySQL/MariaDB server to expose performance statistics. MySQL user credentials must be configured so that the provider can access the MySQL Server. --### Configure MySQL credentials -The MySQL OMI provider requires a preconfigured MySQL user and installed MySQL client libraries in order to query the performance and health information from the MySQL instance. These credentials are stored in an authentication file that's stored on the Linux agent. The authentication file specifies what bind-address and port the MySQL instance is listening on and what credentials to use to gather metrics. --During installation of the Log Analytics agent for Linux the MySQL OMI provider will scan MySQL my.cnf configuration files (default locations) for bind-address and port and partially set the MySQL OMI authentication file. --The MySQL authentication file is stored at `/var/opt/microsoft/mysql-cimprov/auth/omsagent/mysql-auth`. ---### Authentication file format -Following is the format for the MySQL OMI authentication file --> [Port]=[Bind-Address], [username], [Base64 encoded Password] -> (Port)=(Bind-Address), (username), (Base64 encoded Password) -> (Port)=(Bind-Address), (username), (Base64 encoded Password) -> AutoUpdate=[true|false] --The entries in the authentication file are described in the following table. --| Property | Description | -|:--|:--| -| Port | Represents the current port the MySQL instance is listening on. Port 0 specifies that the properties following are used for default instance. | -| Bind-Address| Current MySQL bind-address. | -| username| MySQL user used to use to monitor the MySQL server instance. | -| Base64 encoded Password| Password of the MySQL monitoring user encoded in Base64. | -| AutoUpdate| Specifies whether to rescan for changes in the my.cnf file and overwrite the MySQL OMI Authentication file when the MySQL OMI Provider is upgraded. | --### Default instance -The MySQL OMI authentication file can define a default instance and port number to make managing multiple MySQL instances on one Linux host easier. The default instance is denoted by an instance with port 0. All additional instances will inherit properties set from the default instance unless they specify different values. For example, if MySQL instance listening on port ΓÇÿ3308ΓÇÖ is added, the default instanceΓÇÖs bind-address, username, and Base64 encoded password will be used to try and monitor the instance listening on 3308. If the instance on 3308 is bound to another address and uses the same MySQL username and password pair only the bind-address is needed, and the other properties will be inherited. --The following table has example instance settings --| Description | File | -|:--|:--| -| Default instance and instance with port 3308. | `0=127.0.0.1, myuser, cnBwdA==`<br>`3308=, ,`<br>`AutoUpdate=true` | -| Default instance and instance with port 3308 and different user name and password. | `0=127.0.0.1, myuser, cnBwdA==`<br>`3308=127.0.1.1, myuser2,cGluaGVhZA==`<br>`AutoUpdate=true` | ---### MySQL OMI Authentication File Program -Included with the installation of the MySQL OMI provider is a MySQL OMI authentication file program which can be used to edit the MySQL OMI Authentication file. The authentication file program can be found at the following location. --`/opt/microsoft/mysql-cimprov/bin/mycimprovauth` --> [!NOTE] -> The credentials file must be readable by the omsagent account. Running the mycimprovauth command as omsgent is recommended. --The following table provides details on the syntax for using mycimprovauth. --| Operation | Example | Description -|:--|:--|:--| -| autoupdate *false or true* | mycimprovauth autoupdate false | Sets whether or not the authentication file will be automatically updated on restart or update. | -| default *bind-address username password* | mycimprovauth default 127.0.0.1 root pwd | Sets the default instance in the MySQL OMI authentication file.<br>The password field should be entered in plain text - the password in the MySQL OMI authentication file will be Base 64 encoded. | -| delete *default or port_num* | mycimprovauth 3308 | Deletes the specified instance by either default or by port number. | -| help | mycimprov help | Prints out a list of commands to use. | -| print | mycimprov print | Prints out an easy to read MySQL OMI authentication file. | -| update port_num *bind-address username password* | mycimprov update 3307 127.0.0.1 root pwd | Updates the specified instance or adds the instance if it does not exist. | --The following example commands define a default user account for the MySQL server on localhost. The password field should be entered in plain text - the password in the MySQL OMI authentication file will be Base 64 encoded --```console -sudo su omsagent -c '/opt/microsoft/mysql-cimprov/bin/mycimprovauth default 127.0.0.1 <username> <password>' -sudo /opt/omi/bin/service_control restart -``` --### Database Permissions Required for MySQL Performance Counters -The MySQL User requires access to the following queries to collect MySQL Server performance data. --```sql -SHOW GLOBAL STATUS; -SHOW GLOBAL VARIABLES: -``` --The MySQL user also requires SELECT access to the following default tables. --- information_schema-- mysql. --These privileges can be granted by running the following grant commands. --```sql -GRANT SELECT ON information_schema.* TO ΓÇÿmonuserΓÇÖ@ΓÇÖlocalhostΓÇÖ; -GRANT SELECT ON mysql.* TO ΓÇÿmonuserΓÇÖ@ΓÇÖlocalhostΓÇÖ; -``` --> [!NOTE] -> To grant permissions to a MySQL monitoring user the granting user must have the ΓÇÿGRANT optionΓÇÖ privilege as well as the privilege being granted. --### Define performance counters --Once you configure the Log Analytics agent for Linux to send data to Azure Monitor, you must configure the performance counters to collect. Use the procedure in [Windows and Linux performance data sources in Azure Monitor](data-sources-performance-counters.md) with the counters in the following table. --| Object Name | Counter Name | -|:--|:--| -| MySQL Database | Disk Space in Bytes | -| MySQL Database | Tables | -| MySQL Server | Aborted Connection Pct | -| MySQL Server | Connection Use Pct | -| MySQL Server | Disk Space Use in Bytes | -| MySQL Server | Full Table Scan Pct | -| MySQL Server | InnoDB Buffer Pool Hit Pct | -| MySQL Server | InnoDB Buffer Pool Use Pct | -| MySQL Server | InnoDB Buffer Pool Use Pct | -| MySQL Server | Key Cache Hit Pct | -| MySQL Server | Key Cache Use Pct | -| MySQL Server | Key Cache Write Pct | -| MySQL Server | Query Cache Hit Pct | -| MySQL Server | Query Cache Prunes Pct | -| MySQL Server | Query Cache Use Pct | -| MySQL Server | Table Cache Hit Pct | -| MySQL Server | Table Cache Use Pct | -| MySQL Server | Table Lock Contention Pct | --## Apache HTTP Server -If Apache HTTP Server is detected on the computer when the omsagent bundle is installed, a performance monitoring provider for Apache HTTP Server will be automatically installed. This provider relies on an Apache module that must be loaded into the Apache HTTP Server in order to access performance data. The module can be loaded with the following command: --```console -sudo /opt/microsoft/apache-cimprov/bin/apache_config.sh -c -``` --To unload the Apache monitoring module, run the following command: --```console -sudo /opt/microsoft/apache-cimprov/bin/apache_config.sh -u -``` --### Define performance counters --Once you configure the Log Analytics agent for Linux to send data to Azure Monitor, you must configure the performance counters to collect. Use the procedure in [Windows and Linux performance data sources in Azure Monitor](data-sources-performance-counters.md) with the counters in the following table. --| Object Name | Counter Name | -|:--|:--| -| Apache HTTP Server | Busy Workers | -| Apache HTTP Server | Idle Workers | -| Apache HTTP Server | Pct Busy Workers | -| Apache HTTP Server | Total Pct CPU | -| Apache Virtual Host | Errors per Minute - Client | -| Apache Virtual Host | Errors per Minute - Server | -| Apache Virtual Host | KB per Request | -| Apache Virtual Host | Requests KB per Second | -| Apache Virtual Host | Requests per Second | ----## Next steps -* [Collect performance counters](data-sources-performance-counters.md) from Linux agents. -* Learn about [log queries](../logs/log-query-overview.md) to analyze the data collected from data sources and solutions. |
| azure-monitor | Data Sources Performance Counters | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/data-sources-performance-counters.md | - Title: Collect Windows and Linux performance data sources with the Log Analytics agent in Azure Monitor -description: Learn how to configure collection of performance counters for Windows and Linux agents, how they're stored in the workspace, and how to analyze them. ---- Previously updated : 10/19/2023---# Collect Windows and Linux performance data sources with the Log Analytics agent -Performance counters in Windows and Linux provide insight into the performance of hardware components, operating systems, and applications. Azure Monitor can collect performance counters from Log Analytics agents at frequent intervals for near real time analysis. Azure Monitor can also aggregate performance data for longer-term analysis and reporting. ----## Configure performance counters -Configure performance counters from the [Legacy agents management menu](../agents/agent-data-sources.md#configure-data-sources) for the Log Analytics workspace. --When you first configure Windows or Linux performance counters for a new workspace, you're given the option to quickly create several common counters. They're listed with a checkbox next to each. Ensure that any counters you want to initially create are selected and then select **Add the selected performance counters**. --For Windows performance counters, you can choose a specific instance for each performance counter. For Linux performance counters, the instance of each counter that you choose applies to all child counters of the parent counter. The following table shows the common instances available to both Windows and Linux performance counters. --| Instance name | Description | -| | | -| \_Total |Total of all the instances | -| \* |All instances | -| (/|/var) |Matches instances named / or /var | --### Windows performance counters ---Follow this procedure to add a new Windows performance counter to collect. V2 Windows performance counters aren't supported. --1. Select **Add performance counter**. -1. Enter the name of the counter in the text box in the format *object(instance)\counter*. When you start typing, a matching list of common counters appears. You can either select a counter from the list or enter one of your own. You can also return all instances for a particular counter by specifying *object\counter*. -- When SQL Server performance counters are collected from named instances, all named instance counters start with *MSSQL$* followed by the name of the instance. For example, to collect the Log Cache Hit Ratio counter for all databases from the Database performance object for named SQL instance INST2, specify `MSSQL$INST2:Databases(*)\Log Cache Hit Ratio`. --1. When you add a counter, it uses the default of 10 seconds for its **Sample Interval**. Change this default value to a higher value of up to 1,800 seconds (30 minutes) if you want to reduce the storage requirements of the collected performance data. -1. After you're finished adding counters, select **Apply** at the top of the screen to save the configuration. --### Linux performance counters ---Follow this procedure to add a new Linux performance counter to collect. --1. Select **Add performance counter**. -1. Enter the name of the counter in the text box in the format *object(instance)\counter*. When you start typing, a matching list of common counters appears. You can either select a counter from the list or enter one of your own. -1. All counters for an object use the same **Sample Interval**. The default is 10 seconds. Change this default value to a higher value of up to 1,800 seconds (30 minutes) if you want to reduce the storage requirements of the collected performance data. -1. After you're finished adding counters, select **Apply** at the top of the screen to save the configuration. --#### Configure Linux performance counters in a configuration file -Instead of configuring Linux performance counters by using the Azure portal, you have the option of editing configuration files on the Linux agent. Performance metrics to collect are controlled by the configuration in */etc/opt/microsoft/omsagent/\<workspace id\>/conf/omsagent.conf*. --Each object, or category, of performance metrics to collect should be defined in the configuration file as a single `<source>` element. The syntax follows the pattern here: --```xml -<source> - type oms_omi - object_name "Processor" - instance_regex ".*" - counter_name_regex ".*" - interval 30s -</source> -``` --The parameters in this element are described in the following table. --| Parameters | Description | -|:--|:--| -| object\_name | Object name for the collection. | -| instance\_regex | A *regular expression* that defines which instances to collect. The value `.*` specifies all instances. To collect processor metrics for only the \_Total instance, you could specify `_Total`. To collect process metrics for only the crond or sshd instances, you could specify `(crond\|sshd)`. | -| counter\_name\_regex | A *regular expression* that defines which counters (for the object) to collect. To collect all counters for the object, specify `.*`. To collect only swap space counters for the memory object, for example, you could specify `.+Swap.+` | -| interval | Frequency at which the object's counters are collected. | --The following table lists the objects and counters that you can specify in the configuration file. More counters are available for certain applications. For more information, see [Collect performance counters for Linux applications in Azure Monitor](data-sources-linux-applications.md). --| Object name | Counter name | -|:--|:--| -| Logical Disk | % Free Inodes | -| Logical Disk | % Free Space | -| Logical Disk | % Used Inodes | -| Logical Disk | % Used Space | -| Logical Disk | Disk Read Bytes/sec | -| Logical Disk | Disk Reads/sec | -| Logical Disk | Disk Transfers/sec | -| Logical Disk | Disk Write Bytes/sec | -| Logical Disk | Disk Writes/sec | -| Logical Disk | Free Megabytes | -| Logical Disk | Logical Disk Bytes/sec | -| Memory | % Available Memory | -| Memory | % Available Swap Space | -| Memory | % Used Memory | -| Memory | % Used Swap Space | -| Memory | Available MBytes Memory | -| Memory | Available MBytes Swap | -| Memory | Page Reads/sec | -| Memory | Page Writes/sec | -| Memory | Pages/sec | -| Memory | Used MBytes Swap Space | -| Memory | Used Memory MBytes | -| Network | Total Bytes Transmitted | -| Network | Total Bytes Received | -| Network | Total Bytes | -| Network | Total Packets Transmitted | -| Network | Total Packets Received | -| Network | Total Rx Errors | -| Network | Total Tx Errors | -| Network | Total Collisions | -| Physical Disk | Avg. Disk sec/Read | -| Physical Disk | Avg. Disk sec/Transfer | -| Physical Disk | Avg. Disk sec/Write | -| Physical Disk | Physical Disk Bytes/sec | -| Process | Pct Privileged Time | -| Process | Pct User Time | -| Process | Used Memory kBytes | -| Process | Virtual Shared Memory | -| Processor | % DPC Time | -| Processor | % Idle Time | -| Processor | % Interrupt Time | -| Processor | % IO Wait Time | -| Processor | % Nice Time | -| Processor | % Privileged Time | -| Processor | % Processor Time | -| Processor | % User Time | -| System | Free Physical Memory | -| System | Free Space in Paging Files | -| System | Free Virtual Memory | -| System | Processes | -| System | Size Stored In Paging Files | -| System | Uptime | -| System | Users | --The following configuration is the default for performance metrics: --```xml -<source> - type oms_omi - object_name "Physical Disk" - instance_regex ".*" - counter_name_regex ".*" - interval 5m -</source> --<source> - type oms_omi - object_name "Logical Disk" - instance_regex ".*" - counter_name_regex ".*" - interval 5m -</source> --<source> - type oms_omi - object_name "Processor" - instance_regex ".*" - counter_name_regex ".*" - interval 30s -</source> --<source> - type oms_omi - object_name "Memory" - instance_regex ".*" - counter_name_regex ".*" - interval 30s -</source> -``` --## Data collection -Azure Monitor collects all specified performance counters at their specified sample interval on all agents that have that counter installed. The data isn't aggregated. The raw data is available in all log query views for the duration specified by your Log Analytics workspace. --## Performance record properties -Performance records have a type of **Perf** and have the properties listed in the following table. --| Property | Description | -|: |: | -| Computer |Computer that the event was collected from. | -| CounterName |Name of the performance counter. | -| CounterPath |Full path of the counter in the form \\\\\<Computer>\\object(instance)\\counter. | -| CounterValue |Numeric value of the counter. | -| InstanceName |Name of the event instance. Empty if no instance. | -| ObjectName |Name of the performance object. | -| SourceSystem |Type of agent the data was collected from: <br><br>OpsManager ΓÇô Windows agent, either direct connect or SCOM <br> Linux ΓÇô All Linux agents <br> AzureStorage ΓÇô Azure Diagnostics | -| TimeGenerated |Date and time the data was sampled. | --## Sizing estimates - A rough estimate for collection of a particular counter at 10-second intervals is about 1 MB per day per instance. You can estimate the storage requirements of a particular counter with the following formula: --> 1 MB x (number of counters) x (number of agents) x (number of instances) --## Log queries with performance records -The following table provides different examples of log queries that retrieve performance records. --| Query | Description | -|: |: | -| Perf |All performance data | -| Perf | where Computer == "MyComputer" |All performance data from a particular computer | -| Perf | where CounterName == "Current Disk Queue Length" |All performance data for a particular counter | -| Perf | where ObjectName == "Processor" and CounterName == "% Processor Time" and InstanceName == "_Total" | summarize AVGCPU = avg(CounterValue) by Computer |Average CPU utilization across all computers | -| Perf | where CounterName == "% Processor Time" | summarize AggregatedValue = max(CounterValue) by Computer |Maximum CPU utilization across all computers | -| Perf | where ObjectName == "LogicalDisk" and CounterName == "Current Disk Queue Length" and Computer == "MyComputerName" | summarize AggregatedValue = avg(CounterValue) by InstanceName |Average current disk queue length across all the instances of a given computer | -| Perf | where CounterName == "Disk Transfers/sec" | summarize AggregatedValue = percentile(CounterValue, 95) by Computer |95th percentile of disk transfers/sec across all computers | -| Perf | where CounterName == "% Processor Time" and InstanceName == "_Total" | summarize AggregatedValue = avg(CounterValue) by bin(TimeGenerated, 1h), Computer |Hourly average of CPU usage across all computers | -| Perf | where Computer == "MyComputer" and CounterName startswith_cs "%" and InstanceName == "_Total" | summarize AggregatedValue = percentile(CounterValue, 70) by bin(TimeGenerated, 1h), CounterName | Hourly 70th percentile of every percent counter for a particular computer | -| Perf | where CounterName == "% Processor Time" and InstanceName == "_Total" and Computer == "MyComputer" | summarize ["min(CounterValue)"] = min(CounterValue), ["avg(CounterValue)"] = avg(CounterValue), ["percentile75(CounterValue)"] = percentile(CounterValue, 75), ["max(CounterValue)"] = max(CounterValue) by bin(TimeGenerated, 1h), Computer |Hourly average, minimum, maximum, and 75-percentile CPU usage for a specific computer | -| Perf | where ObjectName == "MSSQL$INST2:Databases" and InstanceName == "master" | All performance data from the database performance object for the master database from the named SQL Server instance INST2 --## Next steps -* [Collect performance counters from Linux applications](data-sources-linux-applications.md), including MySQL and Apache HTTP Server. -* Learn about [log queries](../logs/log-query-overview.md) to analyze the data collected from data sources and solutions. -* Export collected data to [Power BI](../logs/log-powerbi.md) for more visualizations and analysis. |
| azure-monitor | Data Sources Syslog | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/data-sources-syslog.md | - Title: Collect Syslog data sources with the Log Analytics agent in Azure Monitor -description: Syslog is an event logging protocol that's common to Linux. This article describes how to configure collection of Syslog messages in Log Analytics and details the records they create. -- Previously updated : 07/06/2023----# Collect Syslog data sources with the Log Analytics agent --> [!CAUTION] -> This article references CentOS, a Linux distribution that is End Of Life (EOL) status. Please consider your use and planning accordingly. For more information, see the [CentOS End Of Life guidance](/azure/virtual-machines/workloads/centos/centos-end-of-life). --Syslog is an event logging protocol that's common to Linux. Applications send messages that might be stored on the local machine or delivered to a Syslog collector. When the Log Analytics agent for Linux is installed, it configures the local Syslog daemon to forward messages to the agent. The agent then sends the messages to Azure Monitor where a corresponding record is created. ---> [!NOTE] -> Azure Monitor supports collection of messages sent by rsyslog or syslog-ng, where rsyslog is the default daemon. The default Syslog daemon on version 5 of Red Hat Enterprise Linux, CentOS, and Oracle Linux version (sysklog) isn't supported for Syslog event collection. To collect Syslog data from this version of these distributions, the [rsyslog daemon](http://rsyslog.com) should be installed and configured to replace sysklog. ---The following facilities are supported with the Syslog collector: --* kern -* user -* mail -* daemon -* auth -* syslog -* lpr -* news -* uucp -* cron -* authpriv -* ftp -* local0-local7 --For any other facility, [configure a Custom Logs data source](data-sources-custom-logs.md) in Azure Monitor. --## Configure Syslog --The Log Analytics agent for Linux will only collect events with the facilities and severities that are specified in its configuration. You can configure Syslog through the Azure portal or by managing configuration files on your Linux agents. --### Configure Syslog in the Azure portal --Configure Syslog from the [Agent configuration menu](../agents/agent-data-sources.md#configure-data-sources) for the Log Analytics workspace. This configuration is delivered to the configuration file on each Linux agent. --You can add a new facility by selecting **Add facility**. For each facility, only messages with the selected severities will be collected. Select the severities for the particular facility that you want to collect. You can't provide any other criteria to filter messages. ---By default, all configuration changes are automatically pushed to all agents. If you want to configure Syslog manually on each Linux agent, clear the **Apply below configuration to my machines** checkbox. --### Configure Syslog on Linux agent --When the [Log Analytics agent is installed on a Linux client](../vm/monitor-virtual-machine.md), it installs a default Syslog configuration file that defines the facility and severity of the messages that are collected. You can modify this file to change the configuration. The configuration file is different depending on the Syslog daemon that the client has installed. --> [!NOTE] -> If you edit the Syslog configuration, you must restart the Syslog daemon for the changes to take effect. -> -> --#### rsyslog --The configuration file for rsyslog is located at `/etc/rsyslog.d/95-omsagent.conf`. Its default contents are shown in the following example. This example collects Syslog messages sent from the local agent for all facilities with a level of warning or higher. --```config -kern.warning @127.0.0.1:25224 -user.warning @127.0.0.1:25224 -daemon.warning @127.0.0.1:25224 -auth.warning @127.0.0.1:25224 -syslog.warning @127.0.0.1:25224 -uucp.warning @127.0.0.1:25224 -authpriv.warning @127.0.0.1:25224 -ftp.warning @127.0.0.1:25224 -cron.warning @127.0.0.1:25224 -local0.warning @127.0.0.1:25224 -local1.warning @127.0.0.1:25224 -local2.warning @127.0.0.1:25224 -local3.warning @127.0.0.1:25224 -local4.warning @127.0.0.1:25224 -local5.warning @127.0.0.1:25224 -local6.warning @127.0.0.1:25224 -local7.warning @127.0.0.1:25224 -``` --You can remove a facility by removing its section of the configuration file. You can limit the severities that are collected for a particular facility by modifying that facility's entry. For example, to limit the user facility to messages with a severity of error or higher, you would modify that line of the configuration file to the following example: --```config -user.error @127.0.0.1:25224 -``` --#### syslog-ng --The configuration file for syslog-ng is located at `/etc/syslog-ng/syslog-ng.conf`. Its default contents are shown in this example. This example collects Syslog messages sent from the local agent for all facilities and all severities. --```config -# -# Warnings (except iptables) in one file: -# -destination warn { file("/var/log/warn" fsync(yes)); }; -log { source(src); filter(f_warn); destination(warn); }; --#OMS_Destination -destination d_oms { udp("127.0.0.1" port(25224)); }; --#OMS_facility = auth -filter f_auth_oms { level(alert,crit,debug,emerg,err,info,notice,warning) and facility(auth); }; -log { source(src); filter(f_auth_oms); destination(d_oms); }; --#OMS_facility = authpriv -filter f_authpriv_oms { level(alert,crit,debug,emerg,err,info,notice,warning) and facility(authpriv); }; -log { source(src); filter(f_authpriv_oms); destination(d_oms); }; --#OMS_facility = cron -filter f_cron_oms { level(alert,crit,debug,emerg,err,info,notice,warning) and facility(cron); }; -log { source(src); filter(f_cron_oms); destination(d_oms); }; --#OMS_facility = daemon -filter f_daemon_oms { level(alert,crit,debug,emerg,err,info,notice,warning) and facility(daemon); }; -log { source(src); filter(f_daemon_oms); destination(d_oms); }; --#OMS_facility = kern -filter f_kern_oms { level(alert,crit,debug,emerg,err,info,notice,warning) and facility(kern); }; -log { source(src); filter(f_kern_oms); destination(d_oms); }; --#OMS_facility = local0 -filter f_local0_oms { level(alert,crit,debug,emerg,err,info,notice,warning) and facility(local0); }; -log { source(src); filter(f_local0_oms); destination(d_oms); }; --#OMS_facility = local1 -filter f_local1_oms { level(alert,crit,debug,emerg,err,info,notice,warning) and facility(local1); }; -log { source(src); filter(f_local1_oms); destination(d_oms); }; --#OMS_facility = mail -filter f_mail_oms { level(alert,crit,debug,emerg,err,info,notice,warning) and facility(mail); }; -log { source(src); filter(f_mail_oms); destination(d_oms); }; --#OMS_facility = syslog -filter f_syslog_oms { level(alert,crit,debug,emerg,err,info,notice,warning) and facility(syslog); }; -log { source(src); filter(f_syslog_oms); destination(d_oms); }; --#OMS_facility = user -filter f_user_oms { level(alert,crit,debug,emerg,err,info,notice,warning) and facility(user); }; -log { source(src); filter(f_user_oms); destination(d_oms); }; -``` --You can remove a facility by removing its section of the configuration file. You can limit the severities that are collected for a particular facility by removing them from its list. For example, to limit the user facility to alert only critical messages, you would modify that section of the configuration file as shown in the following example: --```config -#OMS_facility = user -filter f_user_oms { level(alert,crit) and facility(user); }; -log { source(src); filter(f_user_oms); destination(d_oms); }; -``` --### Collect data from other Syslog ports --The Log Analytics agent listens for Syslog messages on the local client on port 25224. When the agent is installed, a default Syslog configuration is applied and found in the following location: --* **Rsyslog**: `/etc/rsyslog.d/95-omsagent.conf` -* **Syslog-ng**: `/etc/syslog-ng/syslog-ng.conf` --You can change the port number by creating two configuration files: a FluentD config file and a rsyslog-or-syslog-ng file depending on the Syslog daemon you have installed. --* The FluentD config file should be a new file located in `/etc/opt/microsoft/omsagent/conf/omsagent.d` and replace the value in the `port` entry with your custom port number. -- ```xml - <source> - type syslog - port %SYSLOG_PORT% - bind 127.0.0.1 - protocol_type udp - tag oms.syslog - </source> - <filter oms.syslog.**> - type filter_syslog - ``` --* For rsyslog, you should create a new configuration file located in `/etc/rsyslog.d/` and replace the value `%SYSLOG_PORT%` with your custom port number. -- > [!NOTE] - > If you modify this value in the configuration file `95-omsagent.conf`, it will be overwritten when the agent applies a default configuration. - > -- ```config - # OMS Syslog collection for workspace %WORKSPACE_ID% - kern.warning @127.0.0.1:%SYSLOG_PORT% - user.warning @127.0.0.1:%SYSLOG_PORT% - daemon.warning @127.0.0.1:%SYSLOG_PORT% - auth.warning @127.0.0.1:%SYSLOG_PORT% - ``` --* The syslog-ng config should be modified by copying the example configuration shown next and adding the custom modified settings to the end of the `syslog-ng.conf` configuration file located in `/etc/syslog-ng/`. Do *not* use the default label `%WORKSPACE_ID%_oms` or `%WORKSPACE_ID_OMS`. Define a custom label to help distinguish your changes. -- > [!NOTE] - > If you modify the default values in the configuration file, they'll be overwritten when the agent applies a default configuration. - > -- ```config - filter f_custom_filter { level(warning) and facility(auth; }; - destination d_custom_dest { udp("127.0.0.1" port(%SYSLOG_PORT%)); }; - log { source(s_src); filter(f_custom_filter); destination(d_custom_dest); }; - ``` --After you finish the changes, restart the Syslog and the Log Analytics agent service to ensure the configuration changes take effect. --## Syslog record properties --Syslog records have a type of **Syslog** and have the properties shown in the following table. --| Property | Description | -|: |: | -| Computer |Computer that the event was collected from. | -| Facility |Defines the part of the system that generated the message. | -| HostIP |IP address of the system sending the message. | -| HostName |Name of the system sending the message. | -| SeverityLevel |Severity level of the event. | -| SyslogMessage |Text of the message. | -| ProcessID |ID of the process that generated the message. | -| EventTime |Date and time that the event was generated. | --## Log queries with Syslog records --The following table provides different examples of log queries that retrieve Syslog records. --| Query | Description | -|: |: | -| Syslog |All Syslogs | -| Syslog | where SeverityLevel == "error" |All Syslog records with severity of error | -| Syslog | summarize AggregatedValue = count() by Computer |Count of Syslog records by computer | -| Syslog | summarize AggregatedValue = count() by Facility |Count of Syslog records by facility | --## Next steps --* Learn about [log queries](../logs/log-query-overview.md) to analyze the data collected from data sources and solutions. -* Use [custom fields](../logs/custom-fields.md) to parse data from Syslog records into individual fields. -* [Configure Linux agents](../vm/monitor-virtual-machine.md) to collect other types of data. |
| azure-monitor | Data Sources Windows Events | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/data-sources-windows-events.md | - Title: Collect Windows event log data sources with Log Analytics agent in Azure Monitor -description: The article describes how to configure the collection of Windows event logs by Azure Monitor and details of the records they create. - Previously updated : 07/06/2023-----# Collect Windows event log data sources with Log Analytics agent --Windows event logs are one of the most common [data sources](../agents/agent-data-sources.md) for Log Analytics agents on Windows virtual machines because many applications write to the Windows event log. You can collect events from standard logs, such as System and Application, and any custom logs created by applications you need to monitor. ----## Configure Windows event logs --Configure Windows event logs from the [Legacy agents management menu](../agents/agent-data-sources.md#configure-data-sources) for the Log Analytics workspace. --Azure Monitor only collects events from Windows event logs that are specified in the settings. You can add an event log by entering the name of the log and selecting **+**. For each log, only the events with the selected severities are collected. Check the severities for the particular log that you want to collect. You can't provide any other criteria to filter events. --As you enter the name of an event log, Azure Monitor provides suggestions of common event log names. If the log you want to add doesn't appear in the list, you can still add it by entering the full name of the log. You can find the full name of the log by using event viewer. In event viewer, open the **Properties** page for the log and copy the string from the **Full Name** field. ---> [!IMPORTANT] -> You can't configure collection of security events from the workspace by using the Log Analytics agent. You must use [Microsoft Defender for Cloud](../../security-center/security-center-enable-data-collection.md) or [Microsoft Sentinel](../../sentinel/connect-windows-security-events.md) to collect security events. The [Azure Monitor agent](azure-monitor-agent-overview.md) can also be used to collect security events. --Critical events from the Windows event log will have a severity of "Error" in Azure Monitor Logs. --## Data collection --Azure Monitor collects each event that matches a selected severity from a monitored event log as the event is created. The agent records its place in each event log that it collects from. If the agent goes offline for a while, it collects events from where it last left off, even if those events were created while the agent was offline. There's a potential for these events to not be collected if the event log wraps with uncollected events being overwritten while the agent is offline. -->[!NOTE] ->Azure Monitor doesn't collect audit events created by SQL Server from source *MSSQLSERVER* with event ID 18453 that contains keywords *Classic* or *Audit Success* and keyword *0xa0000000000000*. -> --## Windows event records properties --Windows event records have a type of event and have the properties in the following table: --| Property | Description | -|: |: | -| Computer |Name of the computer that the event was collected from. | -| EventCategory |Category of the event. | -| EventData |All event data in raw format. | -| EventID |Number of the event. | -| EventLevel |Severity of the event in numeric form. | -| EventLevelName |Severity of the event in text form. | -| EventLog |Name of the event log that the event was collected from. | -| ParameterXml |Event parameter values in XML format. | -| ManagementGroupName |Name of the management group for System Center Operations Manager agents. For other agents, this value is `AOI-<workspace ID>`. | -| RenderedDescription |Event description with parameter values. | -| Source |Source of the event. | -| SourceSystem |Type of agent the event was collected from. <br> OpsManager ΓÇô Windows agent, either direct connect or Operations Manager managed. <br> Linux ΓÇô All Linux agents. <br> AzureStorage ΓÇô Azure Diagnostics. | -| TimeGenerated |Date and time the event was created in Windows. | -| UserName |User name of the account that logged the event. | --## Log queries with Windows events --The following table provides different examples of log queries that retrieve Windows event records. --| Query | Description | -|:|:| -| Event |All Windows events. | -| Event | where EventLevelName == "Error" |All Windows events with severity of error. | -| Event | summarize count() by Source |Count of Windows events by source. | -| Event | where EventLevelName == "Error" | summarize count() by Source |Count of Windows error events by source. | --## Next steps --* Configure Log Analytics to collect other [data sources](../agents/agent-data-sources.md) for analysis. -* Learn about [log queries](../logs/log-query-overview.md) to analyze the data collected from data sources and solutions. -* Configure [collection of performance counters](data-sources-performance-counters.md) from your Windows agents. |
| azure-monitor | Diagnostics Extension Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/diagnostics-extension-logs.md | - Title: Use Blob Storage for IIS and Table Storage for events in Azure Monitor | Microsoft Docs -description: Azure Monitor can read the logs for Azure services that write diagnostics to Azure Table Storage or IIS logs written to Azure Blob Storage. --- Previously updated : 07/19/2023-----# Send data from Azure Diagnostics extension to Azure Monitor Logs --Azure Diagnostics extension is an [agent in Azure Monitor](../agents/agents-overview.md) that collects monitoring data from the guest operating system of Azure compute resources including virtual machines. This article describes how to collect data collected by the diagnostics extension from Azure Storage to Azure Monitor Logs. --> [!NOTE] -> The Log Analytics agent in Azure Monitor is typically the preferred method to collect data from the guest operating system into Azure Monitor Logs. For a comparison of the agents, see [Overview of the Azure Monitor agents](../agents/agents-overview.md). --## Supported data types --Azure Diagnostics extension stores data in an Azure Storage account. For Azure Monitor Logs to collect this data, it must be in the following locations: --| Log type | Resource type | Location | -| | | | -| IIS logs |Virtual machines <br> Web roles <br> Worker roles |wad-iis-logfiles (Azure Blob Storage) | -| Syslog |Virtual machines |LinuxsyslogVer2v0 (Azure Table Storage) | -| Azure Service Fabric Operational Events |Service Fabric nodes |WADServiceFabricSystemEventTable | -| Service Fabric Reliable Actor Events |Service Fabric nodes |WADServiceFabricReliableActorEventTable | -| Service Fabric Reliable Service Events |Service Fabric nodes |WADServiceFabricReliableServiceEventTable | -| Windows Event logs |Service Fabric nodes <br> Virtual machines <br> Web roles <br> Worker roles |WADWindowsEventLogsTable (Table Storage) | -| Windows ETW logs |Service Fabric nodes <br> Virtual machines <br> Web roles <br> Worker roles |WADETWEventTable (Table Storage) | --## Data types not supported --The following data types aren't supported: --- Performance data from the guest operating system-- IIS logs from Azure websites--## Enable Azure Diagnostics extension --For information on how to install and configure the diagnostics extension, see [Install and configure Azure Diagnostics extension for Windows (WAD)](../agents/diagnostics-extension-windows-install.md) or [Use Azure Diagnostics extension for Linux to monitor metrics and logs](/azure/virtual-machines/extensions/diagnostics-linux). You can specify the storage account and configure collection of the data that you want to forward to Azure Monitor Logs. --## Collect logs from Azure Storage --To enable collection of diagnostics extension data from an Azure Storage account: --1. In the Azure portal, go to **Log Analytics Workspaces** and select your workspace. -1. Select **Legacy storage account logs** in the **Classic** section of the menu. -1. Select **Add**. -1. Select the **Storage account** that contains the data to collect. -1. Select the **Data Type** you want to collect. -1. The value for **Source** is automatically populated based on the data type. -1. Select **OK** to save the configuration. -1. Repeat for more data types. --In approximately 30 minutes, you'll see data from the storage account in the Log Analytics workspace. You'll only see data that's written to storage after the configuration is applied. The workspace doesn't read the preexisting data from the storage account. --> [!NOTE] -> The portal doesn't validate that the source exists in the storage account or if new data is being written. --## Next steps --* [Collect logs and metrics for Azure services](../essentials/resource-logs.md#send-to-log-analytics-workspace) for supported Azure services. -* [Enable solutions](/previous-versions/azure/azure-monitor/insights/solutions) to provide insight into the data. -* [Use search queries](../logs/log-query-overview.md) to analyze the data. |
| azure-monitor | Diagnostics Extension Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/diagnostics-extension-overview.md | - Title: Azure Diagnostics extension overview -description: Use Azure Diagnostics for debugging, measuring performance, monitoring, and performing traffic analysis in cloud services, virtual machines, and service fabric. - Previously updated : 07/06/2023-----# Azure Diagnostics extension overview --Azure Diagnostics extension is an [agent in Azure Monitor](../agents/agents-overview.md) that collects monitoring data from the guest operating system of Azure compute resources including virtual machines. This article provides an overview of Azure Diagnostics extension, the specific functionality that it supports, and options for installation and configuration. --> [!NOTE] -> Azure Diagnostics extension is one of the agents available to collect monitoring data from the guest operating system of compute resources. For a description of the different agents and guidance on selecting the appropriate agents for your requirements, see [Overview of the Azure Monitor agents](../agents/agents-overview.md). --## Primary scenarios --Use Azure Diagnostics extension if you need to: --* Send data to Azure Storage for archiving or to analyze it with tools such as [Azure Storage Explorer](../../vs-azure-tools-storage-manage-with-storage-explorer.md). -* Send data to [Azure Monitor Metrics](../essentials/data-platform-metrics.md) to analyze it with [metrics explorer](../essentials/metrics-getting-started.md) and to take advantage of features such as near-real-time [metric alerts](../alerts/alerts-metric-overview.md) and [autoscale](../autoscale/autoscale-overview.md) (Windows only). -* Send data to third-party tools by using [Azure Event Hubs](./diagnostics-extension-stream-event-hubs.md). -* Collect [boot diagnostics](/troubleshoot/azure/virtual-machines/boot-diagnostics) to investigate VM boot issues. --Limitations of Azure Diagnostics extension: --* It can only be used with Azure resources. -* It has limited ability to send data to Azure Monitor Logs. --## Comparison to Log Analytics agent --The Log Analytics agent in Azure Monitor can also be used to collect monitoring data from the guest operating system of virtual machines. You can choose to use either or both depending on your requirements. For a comparison of the Azure Monitor agents, see [Overview of the Azure Monitor agents](../agents/agents-overview.md). --The key differences to consider are: --* Azure Diagnostics Extension can be used only with Azure virtual machines. The Log Analytics agent can be used with virtual machines in Azure, other clouds, and on-premises. -* Azure Diagnostics extension sends data to Azure Storage, [Azure Monitor Metrics](../essentials/data-platform-metrics.md) (Windows only) and Azure Event Hubs. The Log Analytics agent collects data to [Azure Monitor Logs](../logs/data-platform-logs.md). -* The Log Analytics agent is required for retired [solutions](/previous-versions/azure/azure-monitor/insights/solutions), [VM insights](../vm/vminsights-overview.md), and other services such as [Microsoft Defender for Cloud](../../security-center/index.yml). --## Costs --There's no cost for Azure Diagnostics extension, but you might incur charges for the data ingested. Check [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/) for the destination where you're collecting data. --## Data collected --The following tables list the data that can be collected by the Windows and Linux diagnostics extension. --### Windows diagnostics extension (WAD) --| Data source | Description | -||-| -| Windows event logs | Events from Windows event log. | -| Performance counters | Numerical values measuring performance of different aspects of operating system and workloads. | -| IIS logs | Usage information for IIS websites running on the guest operating system. | -| Application logs | Trace messages written by your application. | -| .NET EventSource logs | Code writing events using the .NET [EventSource](/dotnet/api/system.diagnostics.tracing.eventsource) class. | -| [Manifest-based ETW logs](/windows/desktop/etw/about-event-tracing) | Event tracing for Windows events generated by any process. | -| Crash dumps (logs) | Information about the state of the process if an application crashes. | -| File-based logs | Logs created by your application or service. | -| Agent diagnostic logs | Information about Azure Diagnostics itself. | --### Linux diagnostics extension (LAD) --| Data source | Description | -|-|--| -| Syslog | Events sent to the Linux event logging system | -| Performance counters | Numerical values measuring performance of different aspects of operating system and workloads | -| Log files | Entries sent to a file-based log | --## Data destinations --The Azure Diagnostics extension for both Windows and Linux always collects data into an Azure Storage account. For a list of specific tables and blobs where this data is collected, see [Install and configure Azure Diagnostics extension for Windows](diagnostics-extension-windows-install.md) and [Use Azure Diagnostics extension for Linux to monitor metrics and logs](/azure/virtual-machines/extensions/diagnostics-linux). --Configure one or more *data sinks* to send data to other destinations. The following sections list the sinks available for the Windows and Linux diagnostics extension. --### Windows diagnostics extension (WAD) --| Destination | Description | -|:-|:--| -| Azure Monitor Metrics | Collect performance data to Azure Monitor Metrics. See [Send Guest OS metrics to the Azure Monitor metric database](../essentials/collect-custom-metrics-guestos-resource-manager-vm.md). | -| Event hubs | Use Azure Event Hubs to send data outside of Azure. See [Streaming Azure Diagnostics data to Azure Event Hubs](diagnostics-extension-stream-event-hubs.md). | -| Azure Storage blobs | Write data to blobs in Azure Storage in addition to tables. | -| Application Insights | Collect data from applications running in your VM to Application Insights to integrate with other application monitoring. See [Send diagnostic data to Application Insights](diagnostics-extension-to-application-insights.md). | --You can also collect WAD data from storage into a Log Analytics workspace to analyze it with Azure Monitor Logs, although the Log Analytics agent is typically used for this functionality. It can send data directly to a Log Analytics workspace and supports solutions and insights that provide more functionality. See [Collect Azure diagnostic logs from Azure Storage](diagnostics-extension-logs.md). --### Linux diagnostics extension (LAD) --LAD writes data to tables in Azure Storage. It supports the sinks in the following table. --| Destination | Description | -|:-|:| -| Event hubs | Use Azure Event Hubs to send data outside of Azure. | -| Azure Storage blobs | Write data to blobs in Azure Storage in addition to tables. | -| Azure Monitor Metrics | Install the Telegraf agent in addition to LAD. See [Collect custom metrics for a Linux VM with the InfluxData Telegraf agent](../essentials/collect-custom-metrics-linux-telegraf.md). | --## Installation and configuration --The diagnostics extension is implemented as a [virtual machine extension](/azure/virtual-machines/extensions/overview) in Azure, so it supports the same installation options using Azure Resource Manager templates, PowerShell, and the Azure CLI. For information on installing and maintaining virtual machine extensions, see [Virtual machine extensions and features for Windows](/azure/virtual-machines/extensions/features-windows) and [Virtual machine extensions and features for Linux](/azure/virtual-machines/extensions/features-linux). --You can also install and configure both the Windows and Linux diagnostics extension in the Azure portal under **Diagnostic settings** in the **Monitoring** section of the virtual machine's menu. --See the following articles for information on installing and configuring the diagnostics extension for Windows and Linux: --* [Install and configure Azure Diagnostics extension for Windows](diagnostics-extension-windows-install.md) -* [Use Linux diagnostics extension to monitor metrics and logs](/azure/virtual-machines/extensions/diagnostics-linux) --## Supported operating systems --The following tables list the operating systems that are supported by WAD and LAD. See the documentation for each agent for unique considerations and for the installation process. See Telegraf documentation for its supported operating systems. All operating systems are assumed to be x64. x86 is not supported for any operating system. --### Windows --| Operating system | Support | -|:|:-:| -| Windows Server 2022 | ❌ | -| Windows Server 2022 Core | ❌ | -| Windows Server 2019 | ✅ | -| Windows Server 2019 Core | ❌ | -| Windows Server 2016 | ✅ | -| Windows Server 2016 Core | ✅ | -| Windows Server 2012 R2 | ✅ | -| Windows Server 2012 | ✅ | -| Windows 11 Client & Pro | ❌ | -| Windows 11 Enterprise (including multi-session) | ❌ | -| Windows 10 1803 (RS4) and higher | ❌ | -| Windows 10 Enterprise (including multi-session) and Pro (Server scenarios only) | ✅ | --### Linux --| Operating system | Support | -|:-|:-:| -| CentOS Linux 9 | ❌ | -| CentOS Linux 8 | ❌ | -| CentOS Linux 7 | ✅ | -| Debian 12 | ❌ | -| Debian 11 | ❌ | -| Debian 10 | ❌ | -| Debian 9 | ✅ | -| Debian 8 | ❌ | -| Oracle Linux 9 | ❌ | -| Oracle Linux 8 | ❌ | -| Oracle Linux 7 | ✅ | -| Oracle Linux 6.4+ | ✅ | -| Red Hat Enterprise Linux Server 9 | ❌ | -| Red Hat Enterprise Linux Server 8\* | ✅ | -| Red Hat Enterprise Linux Server 7 | ✅ | -| SUSE Linux Enterprise Server 15 | ❌ | -| SUSE Linux Enterprise Server 12 | ✅ | -| Ubuntu 22.04 LTS | ❌ | -| Ubuntu 20.04 LTS | ✅ | -| Ubuntu 18.04 LTS | ✅ | -| Ubuntu 16.04 LTS | ✅ | -| Ubuntu 14.04 LTS | ✅ | --\* Requires Python 2 to be installed on the machine and aliased to the python command. --## Other documentation --See the following articles for more information. --### Azure Cloud Services (classic) web and worker roles --* [Introduction to Azure Cloud Services monitoring](../../cloud-services/cloud-services-how-to-monitor.md) -* [Enabling Azure Diagnostics in Azure Cloud Services](../../cloud-services/cloud-services-dotnet-diagnostics.md) -* [Application Insights for Azure Cloud Services](../app/azure-web-apps-net-core.md) -* [Trace the flow of an Azure Cloud Services application with Azure Diagnostics](../../cloud-services/cloud-services-dotnet-diagnostics-trace-flow.md) --### Azure Service Fabric --[Monitor and diagnose services in a local machine development setup](/azure/service-fabric/service-fabric-diagnostics-how-to-monitor-and-diagnose-services-locally) --## Next steps --* Learn to [use performance counters in Azure Diagnostics](../../cloud-services/diagnostics-performance-counters.md). -* If you have trouble with diagnostics starting or finding your data in Azure Storage tables, see [Troubleshooting Azure Diagnostics](diagnostics-extension-troubleshooting.md). |
| azure-monitor | Diagnostics Extension Schema Windows | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/diagnostics-extension-schema-windows.md | - Title: Windows diagnostics extension schema -description: Configuration schema reference for Windows diagnostics extension (WAD) in Azure Monitor. --- Previously updated : 07/12/2022-----# Windows diagnostics extension schema -Azure Diagnostics extension is an agent in Azure Monitor that collects monitoring data from the guest operating system and workloads of Azure compute resources. This article details the schema used for configuration of the diagnostics extension on Windows virtual machines and other compute resources. --> [!NOTE] -> The schema in this article is valid for versions 1.3 and newer (Azure SDK 2.4 and newer). Newer configuration sections are commented to show in what version they were added. Version 1.0 and 1.2 of the schema have been archived and no longer available. --## Public configuration file schema --Download the public configuration file schema definition by executing the following PowerShell command: --```powershell -(Get-AzureServiceAvailableExtension -ExtensionName 'PaaSDiagnostics' -ProviderNamespace 'Microsoft.Azure.Diagnostics').PublicConfigurationSchema | Out-File –Encoding utf8 -FilePath 'C:\temp\WadConfig.xsd' -``` ---## Common Attribute Types - **scheduledTransferPeriod** attribute appears in several elements. It is the interval between scheduled transfers to storage rounded up to the nearest minute. The value is an [XML “Duration Data Type.”](https://www.w3schools.com/xml/schema_dtypes_date.asp) ---## DiagnosticsConfiguration Element - *Tree: Root - DiagnosticsConfiguration* --Added in version 1.3. --The top-level element of the diagnostics configuration file. --**Attribute** xmlns - The XML namespace for the diagnostics configuration file is: -`http://schemas.microsoft.com/ServiceHosting/2010/10/DiagnosticsConfiguration` ---|Child Elements|Description| -|--|--| -|**PublicConfig**|Required. See description elsewhere on this page.| -|**PrivateConfig**|Optional. See description elsewhere on this page.| -|**IsEnabled**|Boolean. See description elsewhere on this page.| --## PublicConfig Element - *Tree: Root - DiagnosticsConfiguration - PublicConfig* -- Describes the public diagnostics configuration. --|Child Elements|Description| -|--|--| -|**WadCfg**|Required. See description elsewhere on this page.| -|**StorageAccount**|The name of the Azure Storage account to store the data in. May also be specified as a parameter when executing the Set-AzureServiceDiagnosticsExtension cmdlet.| -|**StorageType**|Can be *Table*, *Blob*, or *TableAndBlob*. Table is default. When TableAndBlob is chosen, diagnostic data is written twice -- once to each type.| -|**LocalResourceDirectory**|The directory on the virtual machine where the Monitoring Agent stores event data. If not, set, the default directory is used:<br /><br /> For a Worker/web role: `C:\Resources\<guid>\directory\<guid>.<RoleName.DiagnosticStore\`<br /><br /> For a Virtual Machine: `C:\WindowsAzure\Logs\Plugins\Microsoft.Azure.Diagnostics.IaaSDiagnostics\<WADVersion>\WAD<WADVersion>`<br /><br /> Required attributes are:<br /><br /> - **path** - The directory on the system to be used by Azure Diagnostics.<br /><br /> - **expandEnvironment** - Controls whether environment variables are expanded in the path name.| --## WadCFG Element - *Tree: Root - DiagnosticsConfiguration - PublicConfig - WadCFG* -- Identifies and configures the telemetry data to be collected. ---## DiagnosticMonitorConfiguration Element - *Tree: Root - DiagnosticsConfiguration - PublicConfig - WadCFG - DiagnosticMonitorConfiguration* -- Required --|Attributes|Description| -|-|--| -| **overallQuotaInMB** | The maximum amount of local disk space that may be consumed by the various types of diagnostic data collected by Azure Diagnostics. The default setting is 4096 MB.<br /> -|**useProxyServer** | Configure Azure Diagnostics to use the proxy server settings as set in Internet Explorer settings.| -|**sinks** | Added in 1.5. Optional. Points to a sink location to also send diagnostic data for all child elements that support sinks. Sink example is Application Insights or Event Hubs. Note you need to add the *resourceId* property under the *Metrics* element if you want events uploaded to Event Hubs to have a resource ID. | ---<br /> <br /> --|Child Elements|Description| -|--|--| -|**CrashDumps**|See description elsewhere on this page.| -|**DiagnosticInfrastructureLogs**|Enable collection of logs generated by Azure Diagnostics. The diagnostic infrastructure logs are useful for troubleshooting the diagnostics system itself. Optional attributes are:<br /><br /> - **scheduledTransferLogLevelFilter** - Configures the minimum severity level of the logs collected.<br /><br /> - **scheduledTransferPeriod** - The interval between scheduled transfers to storage rounded up to the nearest minute. The value is an [XML “Duration Data Type.”](https://www.w3schools.com/xml/schema_dtypes_date.asp) | -|**Directories**|See description elsewhere on this page.| -|**EtwProviders**|See description elsewhere on this page.| -|**Metrics**|See description elsewhere on this page.| -|**PerformanceCounters**|See description elsewhere on this page.| -|**WindowsEventLog**|See description elsewhere on this page.| -|**DockerSources**|See description elsewhere on this page. | ----## CrashDumps Element - *Tree: Root - DiagnosticsConfiguration - PublicConfig - WadCFG - DiagnosticMonitorConfiguration - CrashDumps* -- Enable the collection of crash dumps. --|Attributes|Description| -|-|--| -|**containerName**|Optional. The name of the blob container in your Azure Storage account to be used to store crash dumps.| -|**crashDumpType**|Optional. Configures Azure Diagnostics to collect mini or full crash dumps.| -|**directoryQuotaPercentage**|Optional. Configures the percentage of **overallQuotaInMB** to be reserved for crash dumps on the VM.| --|Child Elements|Description| -|--|--| -|**CrashDumpConfiguration**|Required. Defines configuration values for each process.<br /><br /> The following attribute is also required:<br /><br /> **processName** - The name of the process you want Azure Diagnostics to collect a crash dump for.| --## Directories Element - *Tree: Root - DiagnosticsConfiguration - PublicConfig - WadCFG - DiagnosticMonitorConfiguration - Directories* -- Enables the collection of the contents of a directory, IIS failed access request logs and/or IIS logs. -- Optional **scheduledTransferPeriod** attribute. See explanation earlier. --|Child Elements|Description| -|--|--| -|**IISLogs**|Including this element in the configuration enables the collection of IIS logs:<br /><br /> **containerName** - The name of the blob container in your Azure Storage account to be used to store the IIS logs.| -|**FailedRequestLogs**|Including this element in the configuration enables collection of logs about failed requests to an IIS site or application. You must also enable tracing options under **system.WebServer** in **Web.config**.| -|**DataSources**|A list of directories to monitor.| -----## DataSources Element - *Tree: Root - DiagnosticsConfiguration - PublicConfig - WadCFG - DiagnosticMonitorConfiguration - Directories - DataSources* -- A list of directories to monitor. --|Child Elements|Description| -|--|--| -|**DirectoryConfiguration**|Required. Required attribute:<br /><br /> **containerName** - The name of the blob container in your Azure Storage account that to be used to store the log files.| ------## DirectoryConfiguration Element - *Tree: Root - DiagnosticsConfiguration - PublicConfig - WadCFG - DiagnosticMonitorConfiguration - Directories - DataSources - DirectoryConfiguration* -- May include either the **Absolute** or **LocalResource** element but not both. --|Child Elements|Description| -|--|--| -|**Absolute**|The absolute path to the directory to monitor. The following attributes are required:<br /><br /> - **Path** - The absolute path to the directory to monitor.<br /><br /> - **expandEnvironment** - Configures whether environment variables in Path are expanded.| -|**LocalResource**|The path relative to a local resource to monitor. Required attributes are:<br /><br /> - **Name** - The local resource that contains the directory to monitor<br /><br /> - **relativePath** - The path relative to Name that contains the directory to monitor| ----## EtwProviders Element - *Tree: Root - DiagnosticsConfiguration - PublicConfig - WadCFG - DiagnosticMonitorConfiguration - EtwProviders* -- Configures collection of ETW events from EventSource and/or ETW Manifest based providers. --|Child Elements|Description| -|--|--| -|**EtwEventSourceProviderConfiguration**|Configures collection of events generated from [EventSource Class](/dotnet/api/system.diagnostics.tracing.eventsource). Required attribute:<br /><br /> **provider** - The class name of the EventSource event.<br /><br /> Optional attributes are:<br /><br /> - **scheduledTransferLogLevelFilter** - The minimum severity level to transfer to your storage account.<br /><br /> - **scheduledTransferPeriod** - The interval between scheduled transfers to storage rounded up to the nearest minute. The value is an [XML “Duration Data Type.”](https://www.w3schools.com/xml/schema_dtypes_date.asp) | -|**EtwManifestProviderConfiguration**|Required attribute:<br /><br /> **provider** - The GUID of the event provider<br /><br /> Optional attributes are:<br /><br /> - **scheduledTransferLogLevelFilter** - The minimum severity level to transfer to your storage account.<br /><br /> - **scheduledTransferPeriod** - The interval between scheduled transfers to storage rounded up to the nearest minute. The value is an [XML “Duration Data Type.”](https://www.w3schools.com/xml/schema_dtypes_date.asp) | ----## EtwEventSourceProviderConfiguration Element - *Tree: Root - DiagnosticsConfiguration - PublicConfig - WadCFG - DiagnosticMonitorConfiguration - EtwProviders- EtwEventSourceProviderConfiguration* -- Configures collection of events generated from [EventSource Class](/dotnet/api/system.diagnostics.tracing.eventsource). --|Child Elements|Description| -|--|--| -|**DefaultEvents**|Optional attribute:<br/><br/> **eventDestination** - The name of the table to store the events in| -|**Event**|Required attribute:<br /><br /> **id** - The id of the event.<br /><br /> Optional attribute:<br /><br /> **eventDestination** - The name of the table to store the events in| ----## EtwManifestProviderConfiguration Element - *Tree: Root - DiagnosticsConfiguration - PublicConfig - WadCFG - DiagnosticMonitorConfiguration - EtwProviders - EtwManifestProviderConfiguration* --|Child Elements|Description| -|--|--| -|**DefaultEvents**|Optional attribute:<br /><br /> **eventDestination** - The name of the table to store the events in| -|**Event**|Required attribute:<br /><br /> **id** - The id of the event.<br /><br /> Optional attribute:<br /><br /> **eventDestination** - The name of the table to store the events in| ----## Metrics Element - *Tree: Root - DiagnosticsConfiguration - PublicConfig - WadCFG - DiagnosticMonitorConfiguration - Metrics* -- Enables you to generate a performance counter table that is optimized for fast queries. Each performance counter that is defined in the **PerformanceCounters** element is stored in the Metrics table in addition to the Performance Counter table. -- The **resourceId** attribute is required. The resource ID of the Virtual Machine or Virtual Machine Scale Set you are deploying Azure Diagnostics to. Get the **resourceID** from the [Azure portal](https://portal.azure.com). Select **Browse** -> **Resource Groups** -> **<Name\>**. Click the **Properties** tile and copy the value from the **ID** field. This resourceID property is used for both sending custom metrics and for adding a resourceID property to data sent to Event Hubs. Note you need to add the *resourceId* property under the *Metrics* element if you want events uploaded to Event Hubs to have a resource ID. --|Child Elements|Description| -|--|--| -|**MetricAggregation**|Required attribute:<br /><br /> **scheduledTransferPeriod** - The interval between scheduled transfers to storage rounded up to the nearest minute. The value is an [XML “Duration Data Type.”](https://www.w3schools.com/xml/schema_dtypes_date.asp) | ----## PerformanceCounters Element - *Tree: Root - DiagnosticsConfiguration - PublicConfig - WadCFG - DiagnosticMonitorConfiguration - PerformanceCounters* -- Enables the collection of performance counters. -- Optional attribute: -- Optional **scheduledTransferPeriod** attribute. See explanation earlier. --|Child Element|Description| -|-|--| -|**PerformanceCounterConfiguration**|The following attributes are required:<br /><br /> - **counterSpecifier** - The name of the performance counter. For example, `\Processor(_Total)\% Processor Time`. To get a list of performance counters on your host, run the command `typeperf`.<br /><br /> - **sampleRate** - How often the counter should be sampled.<br /><br /> Optional attribute:<br /><br /> **unit** - The unit of measure of the counter. Values are available at [UnitType Class](/dotnet/api/microsoft.azure.management.sql.models.unittype) | -|**sinks** | Added in 1.5. Optional. Points to a sink location to also send diagnostic data. For example, Azure Monitor or Event Hubs. Note you need to add the *resourceId* property under the *Metrics* element if you want events uploaded to Event Hubs to have a resource ID.| -----## WindowsEventLog Element - *Tree: Root - DiagnosticsConfiguration - PublicConfig - WadCFG - DiagnosticMonitorConfiguration - WindowsEventLog* -- Enables the collection of Windows Event Logs. -- Optional **scheduledTransferPeriod** attribute. See explanation earlier. --|Child Element|Description| -|-|--| -|**DataSource**|The Windows Event logs to collect. Required attribute:<br /><br /> **name** - The XPath query describing the Windows events to be collected. For example:<br /><br /> `Application!*[System[(Level <=3)]], System!*[System[(Level <=3)]], System!*[System[Provider[@Name='Microsoft Antimalware']]], Security!*[System[(Level <= 3)]`<br /><br /> To collect all events, specify "*" | -|**sinks** | Added in 1.5. Optional. Points to a sink location to also send diagnostic data for all child elements that support sinks. Sink example is Application Insights or Event Hubs.| ---## Logs Element - *Tree: Root - DiagnosticsConfiguration - PublicConfig - WadCFG - DiagnosticMonitorConfiguration - Logs* -- Present in version 1.0 and 1.1. Missing in 1.2. Added back in 1.3. -- Defines the buffer configuration for basic Azure logs. --|Attribute|Type|Description| -||-|--| -|**bufferQuotaInMB**|**unsignedInt**|Optional. Specifies the maximum amount of file system storage that is available for the specified data.<br /><br /> The default is 0.| -|**scheduledTransferLogLevelFilter**|**string**|Optional. Specifies the minimum severity level for log entries that are transferred. The default value is **Undefined**, which transfers all logs. Other possible values (in order of most to least information) are **Verbose**, **Information**, **Warning**, **Error**, and **Critical**.| -|**scheduledTransferPeriod**|**duration**|Optional. Specifies the interval between scheduled transfers of data, rounded up to the nearest minute.<br /><br /> The default is PT0S.| -|**sinks** |**string**| Added in 1.5. Optional. Points to a sink location to also send diagnostic data. For example, Application Insights or Event Hubs. Note you need to add the *resourceId* property under the *Metrics* element if you want events uploaded to Event Hubs to have a resource ID.| --## DockerSources - *Tree: Root - DiagnosticsConfiguration - PublicConfig - WadCFG - DiagnosticMonitorConfiguration - DockerSources* -- Added in 1.9. --|Element Name|Description| -||--| -|**Stats**|Tells the system to collect stats for Docker containers| --## SinksConfig Element - *Tree: Root - DiagnosticsConfiguration - PublicConfig - WadCFG - SinksConfig* -- A list of locations to send diagnostics data to and the configuration associated with those locations. --|Element Name|Description| -||--| -|**Sink**|See description elsewhere on this page.| --## Sink Element - *Tree: Root - DiagnosticsConfiguration - PublicConfig - WadCFG - SinksConfig - Sink* -- Added in version 1.5. -- Defines locations to send diagnostic data to. For example, the Application Insights service. --|Attribute|Type|Description| -||-|--| -|**name**|string|A string identifying the sinkname.| --|Element|Type|Description| -|-|-|--| -|**Application Insights**|string|Used only when sending data to Application Insights. Contain the Instrumentation Key for an active Application Insights account that you have access to.| -|**Channels**|string|One for each additional filtering that stream that you| --## Channels Element - *Tree: Root - DiagnosticsConfiguration - PublicConfig - WadCFG - SinksConfig - Sink - Channels* -- Added in version 1.5. -- Defines filters for streams of log data passing through a sink. --|Element|Type|Description| -|-|-|--| -|**Channel**|string|See description elsewhere on this page.| --## Channel Element - *Tree: Root - DiagnosticsConfiguration - PublicConfig - WadCFG - SinksConfig - Sink - Channels - Channel* -- Added in version 1.5. -- Defines locations to send diagnostic data to. For example, the Application Insights service. --|Attributes|Type|Description| -|-|-|--| -|**logLevel**|**string**|Specifies the minimum severity level for log entries that are transferred. The default value is **Undefined**, which transfers all logs. Other possible values (in order of most to least information) are **Verbose**, **Information**, **Warning**, **Error**, and **Critical**.| -|**name**|**string**|A unique name of the channel to refer to| ---## PrivateConfig Element - *Tree: Root - DiagnosticsConfiguration - PrivateConfig* -- Added in version 1.3. -- Optional -- Stores the private details of the storage account (name, key, and endpoint). This information is sent to the virtual machine, but cannot be retrieved from it. --|Child Elements|Description| -|--|--| -|**StorageAccount**|The storage account to use. The following attributes are required<br /><br /> - **name** - The name of the storage account.<br /><br /> - **key** - The key to the storage account.<br /><br /> - **endpoint** - The endpoint to access the storage account. <br /><br /> -**sasToken** (added 1.8.1)- You can specify an SAS token instead of a storage account key in the private config. If provided, the storage account key is ignored. <br />Requirements for the SAS Token: <br />- Supports account SAS token only <br />- *b*, *t* service types are required. <br /> - *a*, *c*, *u*, *w* permissions are required. <br /> - *c*, *o* resource types are required. <br /> - Supports the HTTPS protocol only <br /> - Start and expiry time must be valid.| ---## IsEnabled Element - *Tree: Root - DiagnosticsConfiguration - IsEnabled* -- Boolean. Use `true` to enable the diagnostics or `false` to disable the diagnostics. --## Example configuration - Following is a complete sample configuration for Windows diagnostics extension shown in both JSON and XML. -- -### JSON --The *PublicConfig* and *PrivateConfig* are separated because in most JSON usage cases, they are passed as different variables. These cases include Resource Manager templates, PowerShell, and Visual Studio. --> [!NOTE] -> The public config Azure Monitor sink definition has two properties, *resourceId* and *region*. These are only required for Classic VMs and Classic Cloud services. The *region* property should not be used for other resources, the *resourceId* property is used on ARM VMs to populate the resourceID field in logs uploaded to Event Hubs. --```json -"PublicConfig" { - "WadCfg": { - "DiagnosticMonitorConfiguration": { - "overallQuotaInMB": 10000, - "DiagnosticInfrastructureLogs": { - "scheduledTransferLogLevelFilter": "Error" - }, - "PerformanceCounters": { - "scheduledTransferPeriod": "PT1M", - "sinks": "AzureMonitorSink", - "PerformanceCounterConfiguration": [ - { - "counterSpecifier": "\\Processor(_Total)\\% Processor Time", - "sampleRate": "PT1M", - "unit": "percent" - } - ] - }, - "Directories": { - "scheduledTransferPeriod": "PT5M", - "IISLogs": { - "containerName": "iislogs" - }, - "FailedRequestLogs": { - "containerName": "iisfailed" - }, - "DataSources": [ - { - "containerName": "mynewprocess", - "Absolute": { - "path": "C:\\MyNewProcess", - "expandEnvironment": false - } - }, - { - "containerName": "badapp", - "Absolute": { - "path": "%SYSTEMDRIVE%\\BadApp", - "expandEnvironment": true - } - }, - { - "containerName": "goodapp", - "LocalResource": { - "relativePath": "..\\PeanutButter", - "name": "Skippy" - } - } - ] - }, - "EtwProviders": { - "sinks": "", - "EtwEventSourceProviderConfiguration": [ - { - "scheduledTransferPeriod": "PT5M", - "provider": "MyProviderClass", - "Event": [ - { - "id": 0 - }, - { - "id": 1, - "eventDestination": "errorTable" - } - ], - "DefaultEvents": { - } - } - ], - "EtwManifestProviderConfiguration": [ - { - "scheduledTransferPeriod": "PT2M", - "scheduledTransferLogLevelFilter": "Information", - "provider": "5974b00b-84c2-44bc-9e58-3a2451b4e3ad", - "Event": [ - { - "id": 0 - } - ], - "DefaultEvents": { - } - } - ] - }, - "WindowsEventLog": { - "scheduledTransferPeriod": "PT5M", - "DataSource": [ - { - "name": "System!*[System[Provider[@Name='Microsoft Antimalware']]]" - }, - { - "name": "System!*[System[Provider[@Name='NTFS'] and (EventID=55)]]" - }, - { - "name": "System!*[System[Provider[@Name='disk'] and (EventID=7 or EventID=52 or EventID=55)]]" - } - ] - }, - "Logs": { - "scheduledTransferPeriod": "PT1M", - "scheduledTransferLogLevelFilter": "Verbose", - "sinks": "ApplicationInsights.AppLogs" - }, - "CrashDumps": { - "directoryQuotaPercentage": 30, - "dumpType": "Mini", - "containerName": "wad-crashdumps", - "CrashDumpConfiguration": [ - { - "processName": "mynewprocess.exe" - }, - { - "processName": "badapp.exe" - } - ] - } - }, - "SinksConfig": { - "Sink": [ - { - "name": "AzureMonitorSink", - "AzureMonitor": - { - "ResourceId": "{insert resourceId if a classic VM or cloud service, else property not needed}", - "Region": "{insert Azure region of resource if a classic VM or cloud service, else property not needed}" - } - }, - { - "name": "ApplicationInsights", - "ApplicationInsights": "{Insert InstrumentationKey}", - "Channels": { - "Channel": [ - { - "logLevel": "Error", - "name": "Errors" - }, - { - "logLevel": "Verbose", - "name": "AppLogs" - } - ] - } - }, - { - "name": "EventHub", - "EventHub": { - "Url": "https://myeventhub-ns.servicebus.windows.net/diageventhub", - "SharedAccessKeyName": "SendRule", - "usePublisherId": false - } - }, - { - "name": "secondaryEventHub", - "EventHub": { - "Url": "https://myeventhub-ns.servicebus.windows.net/secondarydiageventhub", - "SharedAccessKeyName": "SendRule", - "usePublisherId": false - } - }, - { - "name": "secondaryStorageAccount", - "StorageAccount": { - "name": "secondarydiagstorageaccount", - "endpoint": "https://core.windows.net" - } - } - ] - } - }, - "StorageAccount": "diagstorageaccount", - "StorageType": "TableAndBlob" -} -``` --> [!NOTE] -> The private config Azure Monitor sink definition has two properties, *PrincipalId* and *Secret*. These are only required for Classic VMs and Classic Cloud services. These properties should not be used for other resources. ---```json -"PrivateConfig" { - "storageAccountName": "diagstorageaccount", - "storageAccountKey": "{base64 encoded key}", - "storageAccountEndPoint": "https://core.windows.net", - "storageAccountSasToken": "{sas token}", - "EventHub": { - "Url": "https://myeventhub-ns.servicebus.windows.net/diageventhub", - "SharedAccessKeyName": "SendRule", - "SharedAccessKey": "{base64 encoded key}" - }, - "AzureMonitorAccount": { - "ServicePrincipalMeta": { - "PrincipalId": "{Insert service principal client Id}", - "Secret": "{Insert service principal client secret}" - } - }, - "SecondaryStorageAccounts": { - "StorageAccount": [ - { - "name": "secondarydiagstorageaccount", - "key": "{base64 encoded key}", - "endpoint": "https://core.windows.net", - "sasToken": "{sas token}" - } - ] - }, - "SecondaryEventHubs": { - "EventHub": [ - { - "Url": "https://myeventhub-ns.servicebus.windows.net/secondarydiageventhub", - "SharedAccessKeyName": "SendRule", - "SharedAccessKey": "{base64 encoded key}" - } - ] - } -} --``` --### XML --```xml -<?xml version="1.0" encoding="utf-8"?> -<DiagnosticsConfiguration xmlns="http://schemas.microsoft.com/ServiceHosting/2010/10/DiagnosticsConfiguration"> - <PublicConfig> - <WadCfg> - <DiagnosticMonitorConfiguration overallQuotaInMB="10000"> -- <PerformanceCounters scheduledTransferPeriod="PT1M" sinks="AzureMonitorSink"> - <PerformanceCounterConfiguration counterSpecifier="\Processor(_Total)\% Processor Time" sampleRate="PT1M" unit="percent" /> - </PerformanceCounters> -- <Directories scheduledTransferPeriod="PT5M"> - <IISLogs containerName="iislogs" /> - <FailedRequestLogs containerName="iisfailed" /> -- <DataSources> - <DirectoryConfiguration containerName="mynewprocess"> - <Absolute path="C:\MyNewProcess" expandEnvironment="false" /> - </DirectoryConfiguration> - <DirectoryConfiguration containerName="badapp"> - <Absolute path="%SYSTEMDRIVE%\BadApp" expandEnvironment="true" /> - </DirectoryConfiguration> - <DirectoryConfiguration containerName="goodapp"> - <LocalResource name="Skippy" relativePath="..\PeanutButter"/> - </DirectoryConfiguration> - </DataSources> -- </Directories> -- <EtwProviders> - <EtwEventSourceProviderConfiguration - provider="MyProviderClass" - scheduledTransferPeriod="PT5M"> - <Event id="0"/> - <Event id="1" eventDestination="errorTable"/> - <DefaultEvents /> - </EtwEventSourceProviderConfiguration> - <EtwManifestProviderConfiguration provider="5974b00b-84c2-44bc-9e58-3a2451b4e3ad" scheduledTransferLogLevelFilter="Information" scheduledTransferPeriod="PT2M"> - <Event id="0"/> - <DefaultEvents eventDestination="defaultTable"/> - </EtwManifestProviderConfiguration> - </EtwProviders> -- <WindowsEventLog scheduledTransferPeriod="PT5M"> - <DataSource name="System!*[System[Provider[@Name='Microsoft Antimalware']]]"/> - <DataSource name="System!*[System[Provider[@Name='NTFS'] and (EventID=55)]]" /> - <DataSource name="System!*[System[Provider[@Name='disk'] and (EventID=7 or EventID=52 or EventID=55)]]" /> - </WindowsEventLog> -- <Logs bufferQuotaInMB="1024" - scheduledTransferPeriod="PT1M" - scheduledTransferLogLevelFilter="Verbose" - sinks="ApplicationInsights.AppLogs"/> <!-- sinks attribute added in 1.5 --> -- <CrashDumps containerName="wad-crashdumps" directoryQuotaPercentage="30" dumpType="Mini"> - <CrashDumpConfiguration processName="mynewprocess.exe" /> - <CrashDumpConfiguration processName="badapp.exe"/> - </CrashDumps> -- <DockerSources> <!-- Added in 1.9 --> - <Stats enabled="true" sampleRate="PT1M" scheduledTransferPeriod="PT1M" /> - </DockerSources> -- </DiagnosticMonitorConfiguration> -- <SinksConfig> <!-- Added in 1.5 --> - <Sink name="AzureMonitorSink"> - <AzureMonitor> <!-- Added in 1.11 --> - <resourceId>{insert resourceId}</ResourceId> <!-- Parameter only needed for classic VMs and Classic Cloud Services, exclude VMSS and Resource Manager VMs--> - <Region>{insert Azure region of resource}</Region> <!-- Parameter only needed for classic VMs and Classic Cloud Services, exclude VMSS and Resource Manager VMs --> - </AzureMonitor> - </Sink> - <Sink name="ApplicationInsights"> - <ApplicationInsights>{Insert InstrumentationKey}</ApplicationInsights> - <Channels> - <Channel logLevel="Error" name="Errors" /> - <Channel logLevel="Verbose" name="AppLogs" /> - </Channels> - </Sink> - <Sink name="EventHub"> <!-- Added in 1.7 --> - <EventHub Url="https://myeventhub-ns.servicebus.windows.net/diageventhub" SharedAccessKeyName="SendRule" usePublisherId="false" /> - </Sink> - <Sink name="secondaryEventHub"> <!-- Added in 1.7 --> - <EventHub Url="https://myeventhub-ns.servicebus.windows.net/secondarydiageventhub" SharedAccessKeyName="SendRule" usePublisherId="false" /> - </Sink> - <Sink name="secondaryStorageAccount"> <!-- Added in 1.7 --> - <StorageAccount name="secondarydiagstorageaccount" endpoint="https://core.windows.net" /> - </Sink> - </SinksConfig> -- </WadCfg> --  <StorageAccount>diagstorageaccount</StorageAccount> -  <StorageType>TableAndBlob</StorageType> <!-- Added in 1.8 --> - </PublicConfig> -- <PrivateConfig> <!-- Added in 1.3 --> - <StorageAccount name="" key="" endpoint="" sasToken="{sas token}" /> <!-- sasToken in Private config added in 1.8.1 --> - <EventHub Url="https://myeventhub-ns.servicebus.windows.net/diageventhub" SharedAccessKeyName="SendRule" SharedAccessKey="{base64 encoded key}" /> -- <AzureMonitorAccount> - <ServicePrincipalMeta> <!-- Added in 1.11; only needed for classic VMs and Classic cloud services --> - <PrincipalId>{Insert service principal clientId}</PrincipalId> - <Secret>{Insert service principal client secret}</Secret> - </ServicePrincipalMeta> - </AzureMonitorAccount> -- <SecondaryStorageAccounts> - <StorageAccount name="secondarydiagstorageaccount" key="{base64 encoded key}" endpoint="https://core.windows.net" sasToken="{sas token}" /> - </SecondaryStorageAccounts> -- <SecondaryEventHubs> - <EventHub Url="https://myeventhub-ns.servicebus.windows.net/secondarydiageventhub" SharedAccessKeyName="SendRule" SharedAccessKey="{base64 encoded key}" /> - </SecondaryEventHubs> -- </PrivateConfig> - <IsEnabled>true</IsEnabled> -</DiagnosticsConfiguration> --``` -> [!NOTE] -> The public config Azure Monitor sink definition has two properties, resourceId and region. These are only required for Classic VMs and Classic Cloud services. These properties should not be used for Resource Manager Virtual Machines or Virtual Machine Scale sets. -> There is also an additional Private Config element for the Azure Monitor sink, that passes in a Principal Id and Secret. This is only required for Classic VMs and Classic Cloud Services. For Resource Manager VMs and VMSS the Azure Monitor definition in the private config element can be excluded. -> |
| azure-monitor | Diagnostics Extension Stream Event Hubs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/diagnostics-extension-stream-event-hubs.md | - Title: Send data from Windows Azure diagnostics extension to Azure Event Hubs -description: Configure diagnostics extension in Azure Monitor to send data to Azure Event Hub so you can forward it to locations outside of Azure. --- Previously updated : 07/19/2023----# Send data from Windows Azure diagnostics extension to Azure Event Hubs -Azure diagnostics extension is an agent in Azure Monitor that collects monitoring data from the guest operating system and workloads of Azure virtual machines and other compute resources. This article describes how to send data from the Windows Azure Diagnostic (WAD) extension to [Azure Event Hubs](https://azure.microsoft.com/services/event-hubs/) so you can forward to locations outside of Azure. --## Supported data --The data collected from the guest operating system that can be sent to Event Hubs includes the following. Other data sources collected by WAD, including IIS Logs and crash dumps, cannot be sent to Event Hubs. --* Event Tracing for Windows (ETW) events -* Performance counters -* Windows event logs, including application logs in the Windows event log -* Azure Diagnostics infrastructure logs --## Prerequisites --* Windows diagnostics extension 1.6 or higher. See [Azure Diagnostics extension configuration schema versions and history](diagnostics-extension-versions.md) for a version history and [Azure Diagnostics extension overview](diagnostics-extension-overview.md) for supported resources. -* Event Hubs namespace must always be provisioned. See [Get started with Event Hubs](../../event-hubs/event-hubs-dotnet-standard-getstarted-send.md) for details. -* Event hub must be at least Standard tier. Basic tier is not supported. ---## Configuration schema -See [Install and configure Windows Azure diagnostics extension (WAD)](diagnostics-extension-windows-install.md) for different options for enabling and configuring the diagnostics extension and [Azure Diagnostics configuration schema](diagnostics-extension-schema-windows.md) for a reference of the configuration schema. The rest of this article will describe how to use this configuration to send data to an event hub. --Azure Diagnostics always sends logs and metrics to an Azure Storage account. You can configure one or more *data sinks* that send data to additional locations. Each sink is defined in the [SinksConfig element](diagnostics-extension-schema-windows.md#sinksconfig-element) of the public configuration with sensitive information in the private configuration. This configuration for event hubs uses the values in the following table. --| Property | Description | -|:|:| -| Name | Descriptive name for the sink. Used in the configuration to specify which data sources to send to the sink. | -| Url | Url of the event hub in the form \<event-hubs-namespace\>.servicebus.windows.net/\<event-hub-name\>. | -| SharedAccessKeyName | Name of a shared access policy for the event hub that has at least **Send** authority. | -| SharedAccessKey | Primary or secondary key from the shared access policy for the event hub. | --Example public and private configurations are shown below. This is a minimal configuration with a single performance counter and event log to illustrate how to configure and use the event hub data sink. See [Azure Diagnostics configuration schema](diagnostics-extension-schema-windows.md) for a more complex example. --### Public configuration --```JSON -{ - "WadCfg": { - "DiagnosticMonitorConfiguration": { - "overallQuotaInMB": 5120, - "PerformanceCounters": { - "scheduledTransferPeriod": "PT1M", - "sinks": "myEventHub", - "PerformanceCounterConfiguration": [ - { - "counterSpecifier": "\\Processor(_Total)\\% Processor Time", - "sampleRate": "PT3M" - } - ] - }, - "WindowsEventLog": { - "scheduledTransferPeriod": "PT1M", - "sinks": "myEventHub", - "DataSource": [ - { - "name": "Application!*[System[(Level=1 or Level=2 or Level=3)]]" - } - ] - } - }, - "SinksConfig": { - "Sink": [ - { - "name": "myEventHub", - "EventHub": { - "Url": "https://diags-mycompany-ns.servicebus.windows.net/diageventhub", - "SharedAccessKeyName": "SendRule" - } - } - ] - } - }, - "StorageAccount": "mystorageaccount", -} -``` ---### Private configuration --```JSON -{ - "storageAccountName": "mystorageaccount", - "storageAccountKey": "{base64 encoded key}", - "storageAccountEndPoint": "https://core.windows.net", - "EventHub": { - "Url": "https://diags-mycompany-ns.servicebus.windows.net/diageventhub", - "SharedAccessKeyName": "SendRule", - "SharedAccessKey": "{base64 encoded key}" - } -} -``` ----## Configuration options -To send data to a data sink, you specify the **sinks** attribute on the data source's node. Where you place the **sinks** attribute determines the scope of the assignment. In the following example, the **sinks** attribute is defined to the **PerformanceCounters** node which will cause all child performance counters to be sent to the event hub. --```JSON -"PerformanceCounters": { - "scheduledTransferPeriod": "PT1M", - "sinks": "MyEventHub", - "PerformanceCounterConfiguration": [ - { - "counterSpecifier": "\\Processor(_Total)\\% Processor Time", - "sampleRate": "PT3M" - }, - { - "counterSpecifier": "\\Memory\\Available MBytes", - "sampleRate": "PT3M" - }, - { - "counterSpecifier": "\\Web Service(_Total)\\ISAPI Extension Requests/sec", - "sampleRate": "PT3M" - } - ] -} -``` ---In the following example, the **sinks** attribute is applied directly to three counters which will cause only those performance counters to be sent to the event hub. --```JSON -"PerformanceCounters": { - "scheduledTransferPeriod": "PT1M", - "PerformanceCounterConfiguration": [ - { - "counterSpecifier": "\\Processor(_Total)\\% Processor Time", - "sampleRate": "PT3M", - "sinks": "MyEventHub" - }, - { - "counterSpecifier": "\\Memory\\Available MBytes", - "sampleRate": "PT3M" - }, - { - "counterSpecifier": "\\Web Service(_Total)\\ISAPI Extension Requests/sec", - "sampleRate": "PT3M" - }, - { - "counterSpecifier": "\\ASP.NET\\Requests Rejected", - "sampleRate": "PT3M", - "sinks": "MyEventHub" - }, - { - "counterSpecifier": "\\ASP.NET\\Requests Queued", - "sampleRate": "PT3M", - "sinks": "MyEventHub" - } - ] -} -``` --## Validating configuration -You can use a variety of methods to validate that data is being sent to the event hub. One straightforward method is to use Event Hubs capture as described in [Capture events through Azure Event Hubs in Azure Blob Storage or Azure Data Lake Storage](../../event-hubs/event-hubs-capture-overview.md). ---## Troubleshoot Event Hubs sinks --- Look at the Azure Storage table **WADDiagnosticInfrastructureLogsTable** which contains logs and errors for Azure Diagnostics itself. One option is to use a tool such as [Azure Storage Explorer](https://www.storageexplorer.com) to connect to this storage account, view this table, and add a query for TimeStamp in the last 24 hours. You can use the tool to export a .csv file and open it in an application such as Microsoft Excel. Excel makes it easy to search for calling-card strings, such as **EventHubs**, to see what error is reported. --- Check that your event hub is successfully provisioned. All connection info in the **PrivateConfig** section of the configuration must match the values of your resource as seen in the portal. Make sure that you have a SAS policy defined (*SendRule* in the example) in the portal and that *Send* permission is granted. --## Next steps --* [Event Hubs overview](../../event-hubs/event-hubs-about.md) -* [Create an event hub](../../event-hubs/event-hubs-create.md) -* [Event Hubs FAQ](../../event-hubs/event-hubs-faq.yml) --<!-- Images. --> -[0]: ../../event-hubs/media/event-hubs-streaming-azure-diags-data/dashboard.png --- |
| azure-monitor | Diagnostics Extension To Application Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/diagnostics-extension-to-application-insights.md | - Title: Send Azure Diagnostics data to Application Insights -description: Update the Azure Diagnostics public configuration to send data to Application Insights. - Previously updated : 06/01/2023-----# Send Cloud Service, Virtual Machine, or Service Fabric diagnostic data to Application Insights -Cloud services, Virtual Machines, Virtual Machine Scale Sets and Service Fabric all use the Azure Diagnostics extension to collect data. Azure diagnostics sends data to Azure Storage tables. However, you can also pipe all or a subset of the data to other locations using Azure Diagnostics extension 1.5 or later. --This article describes how to send data from the Azure Diagnostics extension to Application Insights. --## Diagnostics configuration explained -The Azure diagnostics extension 1.5 introduced sinks, which are additional locations where you can send diagnostic data. --Example configuration of a sink for Application Insights: --```xml -<SinksConfig> - <Sink name="ApplicationInsights"> - <ApplicationInsights>{Insert InstrumentationKey}</ApplicationInsights> - <Channels> - <Channel logLevel="Error" name="MyTopDiagData" /> - <Channel logLevel="Verbose" name="MyLogData" /> - </Channels> - </Sink> -</SinksConfig> -``` -```JSON -"SinksConfig": { - "Sink": [ - { - "name": "ApplicationInsights", - "ApplicationInsights": "{Insert InstrumentationKey}", - "Channels": { - "Channel": [ - { - "logLevel": "Error", - "name": "MyTopDiagData" - }, - { - "logLevel": "Error", - "name": "MyLogData" - } - ] - } - } - ] -} -``` -- The **Sink** *name* attribute is a string value that uniquely identifies the sink.--- The **ApplicationInsights** element specifies instrumentation key of the Application insights resource where the Azure diagnostics data is sent.- - If you don't have an existing Application Insights resource, see [Create a new Application Insights resource](/previous-versions/azure/azure-monitor/app/create-new-resource) for more information on creating a resource and getting the instrumentation key. - - If you are developing a Cloud Service with Azure SDK 2.8 and later, this instrumentation key is automatically populated. The value is based on the **APPINSIGHTS_INSTRUMENTATIONKEY** service configuration setting when packaging the Cloud Service project. See [Use Application Insights with Cloud Services](../app/azure-web-apps-net-core.md). --- The **Channels** element contains one or more **Channel** elements.- - The *name* attribute uniquely refers to that channel. - - The *loglevel* attribute lets you specify the log level that the channel allows. The available log levels in order of most to least information are: - - Verbose - - Information - - Warning - - Error - - Critical --A channel acts like a filter and allows you to select specific log levels to send to the target sink. For example, you could collect verbose logs and send them to storage, but send only Errors to the sink. --The following graphic shows this relationship. -<!-- convertborder later --> --The following graphic summarizes the configuration values and how they work. You can include multiple sinks in the configuration at different levels in the hierarchy. The sink at the top level acts as a global setting and the one specified at the individual element acts like an override to that global setting. ---## Complete sink configuration example -Here is a complete example of the public configuration file that -1. sends all errors to Application Insights (specified at the **DiagnosticMonitorConfiguration** node) -2. also sends Verbose level logs for the Application Logs (specified at the **Logs** node). --```xml -<WadCfg> - <DiagnosticMonitorConfiguration overallQuotaInMB="4096" - sinks="ApplicationInsights.MyTopDiagData"> <!-- All info below sent to this channel --> - <DiagnosticInfrastructureLogs /> - <PerformanceCounters> - <PerformanceCounterConfiguration counterSpecifier="\Processor(_Total)\% Processor Time" sampleRate="PT3M" /> - <PerformanceCounterConfiguration counterSpecifier="\Memory\Available MBytes" sampleRate="PT3M" /> - </PerformanceCounters> - <WindowsEventLog scheduledTransferPeriod="PT1M"> - <DataSource name="Application!*" /> - </WindowsEventLog> - <Logs scheduledTransferPeriod="PT1M" scheduledTransferLogLevelFilter="Verbose" - sinks="ApplicationInsights.MyLogData"/> <!-- This specific info sent to this channel --> - </DiagnosticMonitorConfiguration> --<SinksConfig> - <Sink name="ApplicationInsights"> - <ApplicationInsights>{Insert InstrumentationKey}</ApplicationInsights> - <Channels> - <Channel logLevel="Error" name="MyTopDiagData" /> - <Channel logLevel="Verbose" name="MyLogData" /> - </Channels> - </Sink> - </SinksConfig> -</WadCfg> -``` -```JSON -"WadCfg": { - "DiagnosticMonitorConfiguration": { - "overallQuotaInMB": 4096, - "sinks": "ApplicationInsights.MyTopDiagData", "_comment": "All info below sent to this channel", - "DiagnosticInfrastructureLogs": { - }, - "PerformanceCounters": { - "PerformanceCounterConfiguration": [ - { - "counterSpecifier": "\\Processor(_Total)\\% Processor Time", - "sampleRate": "PT3M" - }, - { - "counterSpecifier": "\\Memory\\Available MBytes", - "sampleRate": "PT3M" - } - ] - }, - "WindowsEventLog": { - "scheduledTransferPeriod": "PT1M", - "DataSource": [ - { - "name": "Application!*" - } - ] - }, - "Logs": { - "scheduledTransferPeriod": "PT1M", - "scheduledTransferLogLevelFilter": "Verbose", - "sinks": "ApplicationInsights.MyLogData", "_comment": "This specific info sent to this channel" - } - }, - "SinksConfig": { - "Sink": [ - { - "name": "ApplicationInsights", - "ApplicationInsights": "{Insert InstrumentationKey}", - "Channels": { - "Channel": [ - { - "logLevel": "Error", - "name": "MyTopDiagData" - }, - { - "logLevel": "Verbose", - "name": "MyLogData" - } - ] - } - } - ] - } -} -``` -In the previous configuration, the following lines have the following meanings: --### Send all the data that is being collected by Azure diagnostics --```xml -<DiagnosticMonitorConfiguration overallQuotaInMB="4096" sinks="ApplicationInsights"> -``` --```json -"DiagnosticMonitorConfiguration": { - "overallQuotaInMB": 4096, - "sinks": "ApplicationInsights", -} -``` --### Send only error logs to the Application Insights sink --```xml -<DiagnosticMonitorConfiguration overallQuotaInMB="4096" sinks="ApplicationInsights.MyTopDiagdata"> -``` --```json -"DiagnosticMonitorConfiguration": { - "overallQuotaInMB": 4096, - "sinks": "ApplicationInsights.MyTopDiagData", -} -``` --### Send Verbose application logs to Application Insights --```xml -<Logs scheduledTransferPeriod="PT1M" scheduledTransferLogLevelFilter="Verbose" sinks="ApplicationInsights.MyLogData"/> -``` -```JSON -"DiagnosticMonitorConfiguration": { - "overallQuotaInMB": 4096, - "sinks": "ApplicationInsights.MyLogData", -} -``` --## Limitations --- **Channels only log type and not performance counters.** If you specify a channel with a performance counter element, it is ignored.-- **The log level for a channel cannot exceed the log level for what is being collected by Azure diagnostics.** For example, you cannot collect Application Log errors in the Logs element and try to send Verbose logs to the Application Insight sink. The *scheduledTransferLogLevelFilter* attribute must always collect equal or more logs than the logs you are trying to send to a sink.-- **You cannot send blob data collected by Azure diagnostics extension to Application Insights.** For example, anything specified under the *Directories* node. For Crash Dumps the actual crash dump is sent to blob storage and only a notification that the crash dump was generated is sent to Application Insights.--## Next Steps -* Learn how to [view your Azure diagnostics information](../app/azure-web-apps-net-core.md) in Application Insights. -* Use [PowerShell](../../cloud-services/cloud-services-diagnostics-powershell.md) to enable the Azure diagnostics extension for your application. -* Use [Visual Studio](/visualstudio/azure/vs-azure-tools-diagnostics-for-cloud-services-and-virtual-machines) to enable the Azure diagnostics extension for your application - |
| azure-monitor | Diagnostics Extension Troubleshooting | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/diagnostics-extension-troubleshooting.md | - Title: Troubleshooting Azure Diagnostics extension -description: Troubleshoot problems when you use Azure Diagnostics in Azure Virtual Machines, Azure Service Fabric, or Azure Cloud Services. - Previously updated : 06/01/2023-----# Azure Diagnostics troubleshooting -This article describes troubleshooting information that's relevant to using Azure Diagnostics. For more information about Diagnostics, see [Azure Diagnostics overview](diagnostics-extension-overview.md). --## Logical components --The components are: --- **Diagnostics Plug-in Launcher (DiagnosticsPluginLauncher.exe)**: Launches the Diagnostics extension. It serves as the entry-point process.-- **Diagnostics Plug-in (DiagnosticsPlugin.exe)**: Configures, launches, and manages the lifetime of the monitoring agent. It's the main process that's launched by the launcher.-- **Monitoring Agent (MonAgent\*.exe processes)**: Monitors, collects, and transfers the diagnostics data.--## Log/artifact paths -The following paths lead to some important logs and artifacts. We refer to this information throughout this article. --### Azure Cloud Services -| Artifact | Path | -| | | -| Azure Diagnostics configuration file | %SystemDrive%\Packages\Plugins\Microsoft.Azure.Diagnostics.PaaSDiagnostics\<version>\Config.txt | -| Log files | C:\Logs\Plugins\Microsoft.Azure.Diagnostics.PaaSDiagnostics\<version>\ | -| Local store for diagnostics data | C:\Resources\Directory\<CloudServiceDeploymentID>.\<RoleName>.DiagnosticStore\WAD0107\Tables | -| Monitoring agent configuration file | C:\Resources\Directory\<CloudServiceDeploymentID>.\<RoleName>.DiagnosticStore\WAD0107\Configuration\MaConfig.xml | -| Azure Diagnostics extension package | %SystemDrive%\Packages\Plugins\Microsoft.Azure.Diagnostics.PaaSDiagnostics\<version> | -| Log collection utility path | %SystemDrive%\Packages\GuestAgent\ | -| MonAgentHost log file| C:\Resources\Directory\<CloudServiceDeploymentID>.\<RoleName>.DiagnosticStore\WAD0107\Configuration\MonAgentHost.<seq_num>.log | --### Virtual machines -| Artifact | Path | -| | | -| Azure Diagnostics configuration file | C:\Packages\Plugins\Microsoft.Azure.Diagnostics.IaaSDiagnostics\<version>\RuntimeSettings | -| Log files | C:\WindowsAzure\Logs\Plugins\Microsoft.Azure.Diagnostics.IaaSDiagnostics\<DiagnosticsVersion>\ | -| Local store for diagnostics data | C:\WindowsAzure\Logs\Plugins\Microsoft.Azure.Diagnostics.IaaSDiagnostics\<DiagnosticsVersion>\WAD0107\Tables | -| Monitoring agent configuration file | C:\WindowsAzure\Logs\Plugins\Microsoft.Azure.Diagnostics.IaaSDiagnostics\<DiagnosticsVersion>\WAD0107\Configuration\MaConfig.xml | -| Status file | C:\Packages\Plugins\Microsoft.Azure.Diagnostics.IaaSDiagnostics\<version>\Status | -| Azure Diagnostics extension package | C:\Packages\Plugins\Microsoft.Azure.Diagnostics.IaaSDiagnostics\<DiagnosticsVersion>| -| Log collection utility path | C:\WindowsAzure\Logs\WaAppAgent.log | -| MonAgentHost log file | C:\WindowsAzure\Logs\Plugins\Microsoft.Azure.Diagnostics.IaaSDiagnostics\<DiagnosticsVersion>\WAD0107\Configuration\MonAgentHost.<seq_num>.log | --## Metric data doesn't appear in the Azure portal -Diagnostics provides metric data that can be displayed in the Azure portal. If you have problems seeing the data in the portal, check the `WADMetrics\*` table in the Diagnostics storage account to see if the corresponding metric records are there and ensure that the [resource provider](../../azure-resource-manager/management/resource-providers-and-types.md) Microsoft.Insights is registered. --Here, the `PartitionKey` of the table is the resource ID, virtual machine, or virtual machine scale set. `RowKey` is the metric name. It's also known as the performance counter name. --If the resource ID is incorrect, check **Diagnostics Configuration** > **Metrics** > **ResourceId** to see if the resource ID is set correctly. --If there's no data for the specific metric, check **Diagnostics Configuration** > **PerformanceCounter** to see if the metric (performance counter) is included. We enable the following counters by default: -- \Processor(_Total)\% Processor Time-- \Memory\Available Bytes-- \ASP.NET Applications(__Total__)\Requests/Sec-- \ASP.NET Applications(__Total__)\Errors Total/Sec-- \ASP.NET\Requests Queued-- \ASP.NET\Requests Rejected-- \Processor(w3wp)\% Processor Time-- \Process(w3wp)\Private Bytes-- \Process(WaIISHost)\% Processor Time-- \Process(WaIISHost)\Private Bytes-- \Process(WaWorkerHost)\% Processor Time-- \Process(WaWorkerHost)\Private Bytes-- \Memory\Page Faults/sec-- \.NET CLR Memory(_Global_)\% Time in GC-- \LogicalDisk(C:)\Disk Write Bytes/sec-- \LogicalDisk(C:)\Disk Read Bytes/sec-- \LogicalDisk(D:)\Disk Write Bytes/sec-- \LogicalDisk(D:)\Disk Read Bytes/sec--If the configuration is set correctly but you still can't see the metric data, use the following guidelines to help you troubleshoot. --## Azure Diagnostics doesn't start -For information about why Diagnostics failed to start, see the *DiagnosticsPluginLauncher.log* and *DiagnosticsPlugin.log* files in the log files location that was provided earlier. --If these logs indicate `Monitoring Agent not reporting success after launch`, it means there was a failure launching *MonAgentHost.exe*. Look at the logs in the location that's indicated for the `MonAgentHost` log file in the previous "Virtual machines" section. --The last line of the log files contains the exit code. --``` -DiagnosticsPluginLauncher.exe Information: 0 : [4/16/2016 6:24:15 AM] DiagnosticPlugin exited with code 0 -``` --If you find a **negative** exit code, see the [exit code table](#azure-diagnostics-plug-in-exit-codes) in the [References section](#references). --## Diagnostics data isn't logged to Azure Storage -Determine if none of the data appears or if some of the data appears. --### Diagnostics infrastructure logs -Diagnostics logs all errors in the Diagnostics infrastructure logs. Make sure you've enabled the [capture of Diagnostics infrastructure logs in your configuration](#check-diagnostics-extension-configuration). Then you can quickly look for any relevant errors that appear in the `DiagnosticInfrastructureLogsTable` table in your configured storage account. --### No data appears -The most common reason that event data doesn't appear at all is that the storage account information is defined incorrectly. --Solution: Correct your Diagnostics configuration and reinstall Diagnostics. --If the storage account is configured correctly, remote access into the machine and verify that *DiagnosticsPlugin.exe* and *MonAgentCore.exe* are running. If they aren't running, follow the steps in [Azure Diagnostics doesn't start](#azure-diagnostics-doesnt-start). --If the processes are running, go to [Is data getting captured locally?](#is-data-getting-captured-locally) and follow the instructions there. --If there's still a problem, try to: --1. Uninstall the agent. -1. Remove the directory *C:\WindowsAzure\Logs\Plugins\Microsoft.Azure.Diagnostics.IaaSDiagnostics*. -1. Install the agent again. --### Part of the data is missing -If you're getting some data but not all, it means that the data collection/transfer pipeline is set correctly. Follow the subsections here to narrow down the issue. --#### Is the collection configured? -The Diagnostics configuration contains instructions for a particular type of data to be collected. [Review your configuration](#check-diagnostics-extension-configuration) to verify that you're only looking for data that you've configured for the collection. --#### Is the host generating data? -- **Performance counters**: Open `perfmon` and check the counter.-- **Trace logs**: Remote access into the VM and add a `TextWriterTraceListener` to the app's config file. To set up the text listener, see [Create and initialize trace listeners](https://msdn.microsoft.com/library/sk36c28t.aspx). Make sure the `<trace>` element has `<trace autoflush="true">`. If you don't see trace logs being generated, see the section "More about missing trace logs."-- **Event Tracing for Windows (ETW) traces**: Remote access into the VM and install the PerfView tool. In PerfView, run **File** > **User Command** > **Listen etwprovder1** > **etwprovider2**, and so on. The **Listen** command is case sensitive, and there can't be spaces between the comma-separated list of ETW providers. If the command fails to run, select **Log** at the bottom right of the PerfView tool to see what attempted to run and what the result was. Assuming the input is correct, a new window opens. In a few seconds, you'll see ETW traces.-- **Event logs**: Remote access into the VM. Open Event Viewer and make sure that the events exist.--#### Is data getting captured locally? -Next, make sure the data is getting captured locally. The data is locally stored in *.tsf files in the local store for diagnostics data. Different kinds of logs get collected in different .tsf files. The names are similar to the table names in Azure Storage. --For example, performance counters get collected in *PerformanceCountersTable.tsf*. Event logs get collected in *WindowsEventLogsTable.tsf*. Use the instructions in the [Local log extraction](#local-log-extraction) section to open the local collection files and verify that you see them getting collected on disk. --If you don't see logs getting collected locally, and have already verified that the host is generating data, you likely have a configuration issue. Review your configuration carefully. --Also, review the configuration that was generated for *MonitoringAgent MaConfig.xml*. Verify that there's a section that describes the relevant log source. Then verify that it isn't lost in translation between the Diagnostics configuration and the monitoring agent configuration. --#### Is data getting transferred? -If you've verified that the data is getting captured locally but you still don't see it in your storage account, follow these steps: --- Verify that you've provided a correct storage account and that you haven't rolled over keys for the given storage account. For Azure Cloud Services, sometimes users don't update `useDevelopmentStorage=true`.-- Verify that the provided storage account is correct. Make sure you don't have network restrictions that prevent the components from reaching public storage endpoints. One way to do that is to remote access into the machine and try to write something to the same storage account yourself.-- Finally, you can look at what failures are being reported by the monitoring agent. The monitoring agent writes its logs in *maeventtable.tsf*, which is located in the local store for diagnostics data. Follow the instructions in the [Local log extraction](#local-log-extraction) section to open this file. Then try to determine if there are `errors` that indicate failures reading to local files writing to storage.--### Capture and archive logs -If you're thinking about contacting support, the first thing they might ask you is to collect logs from your machine. You can save time by doing that yourself. Run the `CollectGuestLogs.exe` utility at the Log collection utility path. It generates a .zip file with all relevant Azure logs in the same folder. --## Diagnostics data tables not found -The tables in Azure Storage that hold ETW events are named by using the following code: --```csharp - if (String.IsNullOrEmpty(eventDestination)) { - if (e == "DefaultEvents") - tableName = "WADDefault" + MD5(provider); - else - tableName = "WADEvent" + MD5(provider) + eventId; - } - else - tableName = "WAD" + eventDestination; -``` --Here's an example: --```xml - <EtwEventSourceProviderConfiguration provider="prov1"> - <Event id="1" /> - <Event id="2" eventDestination="dest1" /> - <DefaultEvents /> - </EtwEventSourceProviderConfiguration> - <EtwEventSourceProviderConfiguration provider="prov2"> - <DefaultEvents eventDestination="dest2" /> - </EtwEventSourceProviderConfiguration> -``` -```JSON -"EtwEventSourceProviderConfiguration": [ - { - "provider": "prov1", - "Event": [ - { - "id": 1 - }, - { - "id": 2, - "eventDestination": "dest1" - } - ], - "DefaultEvents": { - "eventDestination": "DefaultEventDestination", - "sinks": "" - } - }, - { - "provider": "prov2", - "DefaultEvents": { - "eventDestination": "dest2" - } - } -] -``` -This code generates four tables: --| Event | Table name | -| | | -| provider="prov1" <Event id="1" /> |WADEvent+MD5("prov1")+"1" | -| provider="prov1" <Event id="2" eventDestination="dest1" /> |WADdest1 | -| provider="prov1" <DefaultEvents /> |WADDefault+MD5("prov1") | -| provider="prov2" <DefaultEvents eventDestination="dest2" /> |WADdest2 | --## References --Check out the following references --### Check Diagnostics extension configuration -The easiest way to check your extension configuration is to go to [Azure Resource Explorer](https://resources.azure.com). Then go to the virtual machine or cloud service where the Diagnostics extension (IaaSDiagnostics / PaaDiagnostics) is. --Alternatively, remote desktop into the machine and look at the Diagnostics configuration file that's described in the Log artifacts path section. --In either case, search for **Microsoft.Azure.Diagnostics** and the **xmlCfg** or **WadCfg** field. --If you're searching on a virtual machine and the **WadCfg** field is present, it means the config is in JSON format. If the **xmlCfg** field is present, it means the config is in XML and is base64 encoded. You need to [decode it](https://www.bing.com/search?q=base64+decoder) to see the XML that was loaded by Diagnostics. --For the cloud service role, if you pick the configuration from disk, the data is base64 encoded. You'll need to [decode it](https://www.bing.com/search?q=base64+decoder) to see the XML that was loaded by Diagnostics. --### Azure Diagnostics plug-in exit codes -The plug-in returns the following exit codes: --| Exit code | Description | -| | | -| 0 |Success. | -| -1 |Generic error. | -| -2 |Unable to load the rcf file.<p>This internal error should only happen if the guest agent plug-in launcher is manually invoked incorrectly on the VM. | -| -3 |Can't load the Diagnostics configuration file.<p><p>Solution: Caused by a configuration file not passing schema validation. The solution is to provide a configuration file that complies with the schema. | -| -4 |Another instance of the monitoring agent Diagnostics is already using the local resource directory.<p><p>Solution: Specify a different value for **LocalResourceDirectory**. | -| -6 |The guest agent plug-in launcher attempted to launch Diagnostics with an invalid command line.<p><p>This internal error should only happen if the guest agent plug-in launcher is manually invoked incorrectly on the VM. | -| -10 |The Diagnostics plug-in exited with an unhandled exception. | -| -11 |The guest agent was unable to create the process responsible for launching and monitoring the monitoring agent.<p><p>Solution: Verify that sufficient system resources are available to launch new processes.<p> | -| -101 |Invalid arguments when calling the Diagnostics plug-in.<p><p>This internal error should only happen if the guest agent plug-in launcher is manually invoked incorrectly on the VM. | -| -102 |The plug-in process is unable to initialize itself.<p><p>Solution: Verify that sufficient system resources are available to launch new processes. | -| -103 |The plug-in process is unable to initialize itself. Specifically, it's unable to create the logger object.<p><p>Solution: Verify that sufficient system resources are available to launch new processes. | -| -104 |Unable to load the rcf file provided by the guest agent.<p><p>This internal error should only happen if the guest agent plug-in launcher is manually invoked incorrectly on the VM. | -| -105 |The Diagnostics plug-in can't open the Diagnostics configuration file.<p><p>This internal error should only happen if the Diagnostics plug-in is manually invoked incorrectly on the VM. | -| -106 |Can't read the Diagnostics configuration file.<p><p>Caused by a configuration file not passing schema validation. <br><br>Solution: Provide a configuration file that complies with the schema. For more information, see [Check Diagnostics extension configuration](#check-diagnostics-extension-configuration). | -| -107 |The resource directory pass to the monitoring agent is invalid.<p><p>This internal error should only happen if the monitoring agent is manually invoked incorrectly on the VM.</p> | -| -108 |Unable to convert the Diagnostics configuration file into the monitoring agent configuration file.<p><p>This internal error should only happen if the Diagnostics plug-in is manually invoked with an invalid configuration file. | -| -110 |General Diagnostics configuration error.<p><p>This internal error should only happen if the Diagnostics plug-in is manually invoked with an invalid configuration file. | -| -111 |Unable to start the monitoring agent.<p><p>Solution: Verify that sufficient system resources are available. | -| -112 |General error. | --### Local log extraction -The monitoring agent collects logs and artifacts as `.tsf` files. The `.tsf` file isn't readable but you can convert it into a `.csv` as follows: --``` -<Azure diagnostics extension package>\Monitor\x64\table2csv.exe <relevantLogFile>.tsf -``` -A new file called `<relevantLogFile>.csv` is created in the same path as the corresponding `.tsf` file. --> [!NOTE] -> You only need to run this utility against the main `.tsf` file (for example, `PerformanceCountersTable.tsf`). The accompanying files (for example, `PerformanceCountersTables_\*\*001.tsf`, `PerformanceCountersTables_\*\*002.tsf`) are automatically processed. --### More about missing trace logs --> [!NOTE] -> The following information applies mostly to Azure Cloud Services unless you've configured the `DiagnosticsMonitorTraceListener` on an application that's running on your infrastructure as a service (IaaS) VM. --- Make sure the **DiagnosticMonitorTraceListener** is configured in the web.config or app.config. It's configured by default in cloud service projects. However, some customers comment it out, which causes the trace statements to not be collected by Diagnostics.-- If logs aren't getting written from the **OnStart** or **Run** method, make sure the **DiagnosticMonitorTraceListener** is in the app.config. By default, it's in the web.config, but that only applies to code running within *w3wp.exe*. So you need it in app.config to capture traces that are running in *WaIISHost.exe*.-- Make sure you're using **Diagnostics.Trace.TraceXXX** instead of **Diagnostics.Debug.WriteXXX.** The Debug statements are removed from a release build.-- Make sure the compiled code actually has the **Diagnostics.Trace lines**. Use Reflector, ildasm, or ILSpy to verify. **Diagnostics.Trace** commands are removed from the compiled binary unless you use the TRACE conditional compilation symbol. This common problem occurs when you're using MSBuild to build a project.--## Known issues and mitigations --The following known issues have mitigations. --### .NET 4.5 dependency --The Azure Diagnostics extension for Windows has a runtime dependency on .NET Framework 4.5 or later. At the time of writing, all machines that are provisioned for Azure Cloud Services, and all official images that are based on Azure VMs, have .NET 4.5 or later installed. --It's still possible to encounter a situation where you try to run the Azure Diagnostics extension for Windows on a machine that doesn't have .NET 4.5 or later. This situation happens when you create your machine from an old image or snapshot, or when you bring your own custom disk. --This issue generally manifests as an exit code **255** when you run *DiagnosticsPluginLauncher.exe.* Failure happens because of the following unhandled exception: -``` -System.IO.FileLoadException: Could not load file or assembly 'System.Threading.Tasks, Version=1.5.11.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a' or one of its dependencies -``` --**Mitigation:** Install .NET 4.5 or later on your machine. --### Performance counters data is available in storage but doesn't show in the portal --The portal experience in the VMs shows certain performance counters by default. If you don't see the performance counters, and you know that the data is getting generated because it's available in storage, be sure to check: --- Whether the data in storage has counter names in English. If the counter names aren't in English, the portal metric chart won't recognize it. - - **Mitigation**: Change the machine's language to English for system accounts. To do this, select **Control Panel** > **Region** > **Administrative** > **Copy Settings**. Next, clear **Welcome screen and system accounts** so that the custom language isn't applied to the system account. --- If you're using wildcards (\*) in your performance counter names, the portal can't correlate the configured and collected counter when the performance counters are sent to the Azure Storage sink. - - **Mitigation**: To make sure you can use wildcards and have the portal expand the (\*), route your performance counters to the Azure Monitor sink. |
| azure-monitor | Diagnostics Extension Versions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/diagnostics-extension-versions.md | - Title: Windows Azure Diagnostics (WAD) extension configuration schema version history -description: Relevant to collecting perf counters in Azure Virtual Machines, VM Scale Sets, Service Fabric, and Cloud Services. --- Previously updated : 07/12/2022-----# Windows Azure Diagnostics (WAD) extension configuration schema versions and history --This article provides the version history of the [Azure Diagnostics extension for Windows (WAD)](diagnostics-extension-overview.md) schema versions shipped as part of the Microsoft Azure SDK. ---## Azure SDK and diagnostics versions shipping chart --|Azure SDK version | Diagnostics extension version | Model| -||-|| -|1.x |1.0 |plug-in| -|2.0 - 2.4 |1.0 |plug-in| -|2.5 |1.2 |extension| -|2.6 |1.3 |"| -|2.7 |1.4 |"| -|2.8 |1.5 |"| -|2.9 |1.6 |"| -|2.96 |1.7 |"| -|2.96 |1.8 |"| -|2.96 |1.8.1 |"| -|2.96 |1.9 |"| -|2.96 |1.11 |"| -|2.96 |1.21 |"| --- Azure Diagnostics version 1.0 first shipped in a plug-in model -- meaning that when you installed the Azure SDK, you got the version of Azure diagnostics shipped with it. -- Starting with SDK 2.5 (diagnostics version 1.2), Azure diagnostics went to an extension model. The tools to utilize new features were only available in newer Azure SDKs, but any service using Azure diagnostics would pick up the latest shipping version directly from Azure. For example, anyone still using SDK 2.5 would be loading the latest version shown in the previous table, regardless if they are using the newer features. --## Schemas index -Different versions of Azure diagnostics use different configuration schemas. Schema 1.0 and 1.2 have been deprecated. For more information on version 1.3 and later, see [Diagnostics 1.3 and later Configuration Schema](diagnostics-extension-schema-windows.md) --## Version history --### Diagnostics extension 1.11 -Added support for the Azure Monitor sink. This sink is only applicable to performance counters. Enables sending performance counters collected on your VM, VMSS, or cloud service to Azure Monitor as custom metrics. The Azure Monitor sink supports: -* Retrieving all performance counters sent to Azure Monitor via the [Azure Monitor metrics APIs.](/rest/api/monitor/metrics/list) -* Alerting on all performance counters sent to Azure Monitor via the new [unified alerts experience](../alerts/alerts-overview.md) in Azure Monitor -* Treating wildcard operator in performance counters as the "Instance" dimension on your metric. For example if you collected the "LogicalDisk(\*)/DiskWrites/sec" counter you would be able to filter and split on the "Instance" dimension to plot or alert on the Disk Writes/sec for each Logical Disk (C:, D:, etc.) --Define Azure Monitor as a new sink in your diagnostics extension configuration -```json -"SinksConfig": { - "Sink": [ - { - "name": "AzureMonitorSink", - "AzureMonitor": {} - }, - ] -} -``` --```xml -<SinksConfig> - <Sink name="AzureMonitorSink"> - <AzureMonitor/> - </Sink> -</SinksConfig> -``` -> [!NOTE] -> Configuring the Azure Monitor sink for Classic VMs and Classic CLoud Service requires more parameters to be defined in the Diagnostics extension's private config. -> -> For more details please reference the [detailed diagnostics extension schema documentation.](diagnostics-extension-schema-windows.md) --Next, you can configure your performance counters to be routed to the Azure Monitor Sink. -```json -"PerformanceCounters": { - "scheduledTransferPeriod": "PT1M", - "sinks": "AzureMonitorSink", - "PerformanceCounterConfiguration": [ - { - "counterSpecifier": "\\Processor(_Total)\\% Processor Time", - "sampleRate": "PT1M", - "unit": "percent" - } - ] -}, -``` -```xml -<PerformanceCounters scheduledTransferPeriod="PT1M", sinks="AzureMonitorSink"> - <PerformanceCounterConfiguration counterSpecifier="\Processor(_Total)\% Processor Time" sampleRate="PT1M" unit="percent" /> -</PerformanceCounters> -``` --### Diagnostics extension 1.9 -Added Docker support. ---### Diagnostics extension 1.8.1 -Can specify a SAS token instead of a storage account key in the private config. If a SAS token is provided, the storage account key is ignored. ---```json -{ - "storageAccountName": "diagstorageaccount", - "storageAccountEndPoint": "https://core.windows.net", - "storageAccountSasToken": "{sas token}", - "SecondaryStorageAccounts": { - "StorageAccount": [ - { - "name": "secondarydiagstorageaccount", - "endpoint": "https://core.windows.net", - "sasToken": "{sas token}" - } - ] - } -} -``` --```xml -<PrivateConfig> - <StorageAccount name="diagstorageaccount" endpoint="https://core.windows.net" sasToken="{sas token}" /> - <SecondaryStorageAccounts> - <StorageAccount name="secondarydiagstorageaccount" endpoint="https://core.windows.net" sasToken="{sas token}" /> - </SecondaryStorageAccounts> -</PrivateConfig> -``` ---### Diagnostics extension 1.8 -Added Storage Type to PublicConfig. StorageType can be *Table*, *Blob*, *TableAndBlob*. *Table* is the default. ---```json -{ - "WadCfg": { - }, - "StorageAccount": "diagstorageaccount", - "StorageType": "TableAndBlob" -} -``` --```xml -<PublicConfig> - <WadCfg /> - <StorageAccount>diagstorageaccount</StorageAccount> - <StorageType>TableAndBlob</StorageType> -</PublicConfig> -``` ---### Diagnostics extension 1.7 -Added the ability to route to EventHub. --### Diagnostics extension 1.5 -Added the sinks element and the ability to send diagnostics data to [Application Insights](../app/azure-web-apps-net-core.md) making it easier to diagnose issues across your application as well as the system and infrastructure level. --### Azure SDK 2.6 and diagnostics extension 1.3 -For Cloud Service projects in Visual Studio, the following changes were made. (These changes also apply to later versions of Azure SDK.) --* The local emulator now supports diagnostics. This change means you can collect diagnostics data and ensure your application is creating the right traces while you're developing and testing in Visual Studio. The connection string `UseDevelopmentStorage=true` enables diagnostics data collection while you're running your cloud service project in Visual Studio by using the Azure Storage Emulator. All diagnostics data is collected in the (Development Storage) storage account. -* The diagnostics storage account connection string (Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString) is stored once again in the service configuration (.cscfg) file. In Azure SDK 2.5 the diagnostics storage account was specified in the diagnostics.wadcfgx file. --There are some notable differences between how the connection string worked in Azure SDK 2.4 and earlier and how it works in Azure SDK 2.6 and later. --* In Azure SDK 2.4 and earlier, the connection string was used at runtime by the diagnostics plugin to get the storage account information for transferring diagnostics logs. -* In Azure SDK 2.6 and later, Visual Studio uses the diagnostics connection string to configure the diagnostics extension with the appropriate storage account information during publishing. The connection string lets you define different storage accounts for different service configurations that Visual Studio will use when publishing. However, because the diagnostics plugin is no longer available (after Azure SDK 2.5), the .cscfg file by itself can't enable the Diagnostics Extension. You have to enable the extension separately through tools such as Visual Studio or PowerShell. -* To simplify the process of configuring the diagnostics extension with PowerShell, the package output from Visual Studio also contains the public configuration XML for the diagnostics extension for each role. Visual Studio uses the diagnostics connection string to populate the storage account information present in the public configuration. The public config files are created in the Extensions folder and follow the pattern `PaaSDiagnostics.<RoleName>.PubConfig.xml`. Any PowerShell based deployments can use this pattern to map each configuration to a Role. -* The connection string in the .cscfg file is also used by the Azure portal to access the diagnostics data so it can appear in the **Monitoring** tab. The connection string is needed to configure the service to show verbose monitoring data in the portal. --#### Migrating projects to Azure SDK 2.6 and later -When migrating from Azure SDK 2.5 to Azure SDK 2.6 or later, if you had a diagnostics storage account specified in the .wadcfgx file, then it will stay there. To take advantage of the flexibility of using different storage accounts for different storage configurations, you'll have to manually add the connection string to your project. If you're migrating a project from Azure SDK 2.4 or earlier to Azure SDK 2.6, then the diagnostics connection strings are preserved. However, note the changes in how connection strings are treated in Azure SDK 2.6 as specified in the previous section. --#### How Visual Studio determines the diagnostics storage account -* If a diagnostics connection string is specified in the .cscfg file, Visual Studio uses it to configure the diagnostics extension when publishing, and when generating the public configuration xml files during packaging. -* If no diagnostics connection string is specified in the .cscfg file, then Visual Studio falls back to using the storage account specified in the .wadcfgx file to configure the diagnostics extension when publishing, and generating the public configuration xml files when packaging. -* The diagnostics connection string in the .cscfg file takes precedence over the storage account in the .wadcfgx file. If a diagnostics connection string is specified in the .cscfg file, then Visual Studio uses that and ignores the storage account in .wadcfgx. --#### What does the "Update development storage connection strings…" checkbox do? -The checkbox for **Update development storage connection strings for Diagnostics and Caching with Microsoft Azure storage account credentials when publishing to Microsoft Azure** gives you a convenient way to update any development storage account connection strings with the Azure storage account specified during publishing. --For example, suppose you select this checkbox and the diagnostics connection string specifies `UseDevelopmentStorage=true`. When you publish the project to Azure, Visual Studio will automatically update the diagnostics connection string with the storage account you specified in the Publish wizard. However, if a real storage account was specified as the diagnostics connection string, then that account is used instead. --### Diagnostics functionality differences between Azure SDK 2.4 and earlier and Azure SDK 2.5 and later -If you're upgrading your project from Azure SDK 2.4 to Azure SDK 2.5 or later, you should bear in mind the following diagnostics functionality differences. --* **Configuration APIs are deprecated** – Programmatic configuration of diagnostics is available in Azure SDK 2.4 or earlier versions, but is deprecated in Azure SDK 2.5 and later. If your diagnostics configuration is currently defined in code, you'll need to reconfigure those settings from scratch in the migrated project in order for diagnostics to keep working. The diagnostics configuration file for Azure SDK 2.4 is diagnostics.wadcfg, and diagnostics.wadcfgx for Azure SDK 2.5 and later. -* **Diagnostics for cloud service applications can only be configured at the role level, not at the instance level.** -* **Every time you deploy your app, the diagnostics configuration is updated** – This can cause parity issues if you change your diagnostics configuration from Server Explorer and then redeploy your app. -* **In Azure SDK 2.5 and later, crash dumps are configured in the diagnostics configuration file, not in code** – If you have crash dumps configured in code, you'll have to manually transfer the configuration from code to the configuration file, because the crash dumps aren't transferred during the migration to Azure SDK 2.6. |
| azure-monitor | Diagnostics Extension Windows Install | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/diagnostics-extension-windows-install.md | - Title: Install and configure the Azure Diagnostics extension for Windows (WAD) -description: Learn about installing and configuring the Azure Diagnostics extension for Windows and how the data is stored in an Azure Storage account. --- Previously updated : 07/19/2023-----# Install and configure the Azure Diagnostics extension for Windows (WAD) --The [Azure Diagnostics extension](diagnostics-extension-overview.md) is an agent in Azure Monitor that collects monitoring data from the guest operating system and workloads of Azure virtual machines and other compute resources. This article provides information on how to install and configure the Azure Diagnostics extension for Windows and describes how the data is stored in an Azure Storage account. --The diagnostics extension is implemented as a [virtual machine extension](/azure/virtual-machines/extensions/overview) in Azure. It supports the same installation options by using Azure Resource Manager templates, PowerShell, and the Azure CLI. For information on how to install and maintain virtual machine extensions, see [Virtual machine extensions and features for Windows](/azure/virtual-machines/extensions/features-windows). --## Overview --When you configure the Azure Diagnostics extension for Windows, you must specify a storage account where all specified data will be sent. You can optionally add one or more *data sinks* to send the data to different locations: --- **Azure Monitor sink**: Send guest performance data to Azure Monitor Metrics.-- **Azure Event Hub sink**: Send guest performance and log data to event hubs to forward outside of Azure. This sink can't be configured in the Azure portal.--## Install with Azure portal --You can install and configure the diagnostics extension on an individual virtual machine in the Azure portal. You'll work with an interface as opposed to working directly with the configuration. When you enable the diagnostics extension, it will automatically use a default configuration with the most common performance counters and events. You can modify this default configuration according to your specific requirements. --> [!NOTE] -> The following steps describe the most common settings for the diagnostics extension. For more information on all the configuration options, see [Windows diagnostics extension schema](diagnostics-extension-schema-windows.md). --1. Open the menu for a virtual machine in the Azure portal. --1. Select **Diagnostic settings** in the **Monitoring** section of the VM menu. --1. Select **Enable guest-level monitoring** if the diagnostics extension hasn't already been enabled. - <!-- convertborder later --> - :::image type="content" source="media/diagnostics-extension-windows-install/enable-monitoring.png" lightbox="media/diagnostics-extension-windows-install/enable-monitoring.png" alt-text="Screenshot that shows enabling monitoring." border="false"::: --1. A new Azure Storage account will be created for the VM. The name will be based on the name of the resource group for the VM. A default set of guest performance counters and logs will be selected. - <!-- convertborder later --> - :::image type="content" source="media/diagnostics-extension-windows-install/diagnostic-settings.png" lightbox="media/diagnostics-extension-windows-install/diagnostic-settings.png" alt-text="Screenshot that shows Diagnostic settings." border="false"::: --1. On the **Performance counters** tab, select the guest metrics you want to collect from this virtual machine. Use the **Custom** setting for more advanced selection. - <!-- convertborder later --> - :::image type="content" source="media/diagnostics-extension-windows-install/performance-counters.png" lightbox="media/diagnostics-extension-windows-install/performance-counters.png" alt-text="Screenshot that shows Performance counters." border="false"::: --1. On the **Logs** tab, select the logs to collect from the virtual machine. Logs can be sent to storage or event hubs, but not to Azure Monitor. Use the [Log Analytics agent](../agents/log-analytics-agent.md) to collect guest logs to Azure Monitor. - <!-- convertborder later --> - :::image type="content" source="media/diagnostics-extension-windows-install/logs.png" lightbox="media/diagnostics-extension-windows-install/logs.png" alt-text="Screenshot that shows the Logs tab with different logs selected for a virtual machine." border="false"::: --1. On the **Crash dumps** tab, specify any processes to collect memory dumps after a crash. The data will be written to the storage account for the diagnostic setting. You can optionally specify a blob container. - <!-- convertborder later --> - :::image type="content" source="media/diagnostics-extension-windows-install/crash-dumps.png" lightbox="media/diagnostics-extension-windows-install/crash-dumps.png" alt-text="Screenshot that shows the Crash dumps tab." border="false"::: --1. On the **Sinks** tab, specify whether to send the data to locations other than Azure storage. If you select **Azure Monitor**, guest performance data will be sent to Azure Monitor Metrics. You can't configure the event hubs sink by using the Azure portal. - <!-- convertborder later --> - :::image type="content" source="media/diagnostics-extension-windows-install/sinks.png" lightbox="media/diagnostics-extension-windows-install/sinks.png" alt-text="Screenshot that shows the Sinks tab with the Send diagnostic data to Azure Monitor option enabled." border="false"::: - - If you haven't enabled a system-assigned identity configured for your virtual machine, you might see the following warning when you save a configuration with the Azure Monitor sink. Select the banner to enable the system-assigned identity. - <!-- convertborder later --> - :::image type="content" source="media/diagnostics-extension-windows-install/managed-entity.png" lightbox="media/diagnostics-extension-windows-install/managed-entity.png" alt-text="Screenshot that shows the managed identity warning." border="false"::: --1. On the **Agent** tab, you can change the storage account, set the disk quota, and specify whether to collect diagnostic infrastructure logs. - <!-- convertborder later --> - :::image type="content" source="media/diagnostics-extension-windows-install/agent.png" lightbox="media/diagnostics-extension-windows-install/agent.png" alt-text="Screenshot that shows the Agent tab with the option to set the storage account." border="false"::: --1. Select **Save** to save the configuration. --> [!NOTE] -> The configuration for the diagnostics extension can be formatted in either JSON or XML, but any configuration done in the Azure portal will always be stored as JSON. If you use XML with another configuration method and then change your configuration with the Azure portal, the settings will be changed to JSON. Also, there's no option to set up the retention period for these logs. --## Resource Manager template --For information on how to deploy the diagnostics extension with Azure Resource Manager templates, see [Use monitoring and diagnostics with a Windows VM and Azure Resource Manager templates](/azure/virtual-machines/extensions/diagnostics-template). --## Azure CLI deployment --The Azure CLI can be used to deploy the Azure Diagnostics extension to an existing virtual machine by using [az vm extension set](/cli/azure/vm/extension#az-vm-extension-set) as in the following example: --```azurecli -az vm extension set \ - --resource-group myResourceGroup \ - --vm-name myVM \ - --name IaaSDiagnostics \ - --publisher Microsoft.Azure.Diagnostics \ - --protected-settings protected-settings.json \ - --settings public-settings.json -``` --The protected settings are defined in the [PrivateConfig element](diagnostics-extension-schema-windows.md#privateconfig-element) of the configuration schema. The following minimal example of a protected settings file defines the storage account. For complete details of the private settings, see [Example configuration](diagnostics-extension-schema-windows.md#privateconfig-element). --```JSON -{ - "storageAccountName": "mystorageaccount", - "storageAccountKey": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx", - "storageAccountEndPoint": "https://core.windows.net" -} -``` --The public settings are defined in the [Public element](diagnostics-extension-schema-windows.md#publicconfig-element) of the configuration schema. The following minimal example of a public settings file enables collection of diagnostic infrastructure logs, a single performance counter, and a single event log. For complete details of the public settings, see [Example configuration](diagnostics-extension-schema-windows.md#publicconfig-element). --```JSON -{ - "StorageAccount": "mystorageaccount", - "WadCfg": { - "DiagnosticMonitorConfiguration": { - "overallQuotaInMB": 5120, - "PerformanceCounters": { - "scheduledTransferPeriod": "PT1M", - "PerformanceCounterConfiguration": [ - { - "counterSpecifier": "\\Processor Information(_Total)\\% Processor Time", - "unit": "Percent", - "sampleRate": "PT60S" - } - ] - }, - "WindowsEventLog": { - "scheduledTransferPeriod": "PT1M", - "DataSource": [ - { - "name": "Application!*[System[(Level=1 or Level=2 or Level=3)]]" - } - ] - } - } - } -} -``` --## PowerShell deployment --PowerShell can be used to deploy the Azure Diagnostics extension to an existing virtual machine by using [Set-AzVMDiagnosticsExtension](/powershell/module/servicemanagement/azure/set-azurevmdiagnosticsextension), as in the following example: --```powershell -Set-AzVMDiagnosticsExtension -ResourceGroupName "myvmresourcegroup" ` - -VMName "myvm" ` - -DiagnosticsConfigurationPath "DiagnosticsConfiguration.json" -``` --The private settings are defined in the [PrivateConfig element](diagnostics-extension-schema-windows.md#privateconfig-element). The public settings are defined in the [Public element](diagnostics-extension-schema-windows.md#publicconfig-element) of the configuration schema. You can also choose to specify the details of the storage account as parameters of the `Set-AzVMDiagnosticsExtension` cmdlet rather than including them in the private settings. --The following minimal example of a configuration file enables collection of diagnostic infrastructure logs, a single performance counter, and a single event log. For complete details of the private and public settings, see [Example configuration](diagnostics-extension-schema-windows.md#publicconfig-element). --```JSON -{ - "PublicConfig": { - "WadCfg": { - "DiagnosticMonitorConfiguration": { - "overallQuotaInMB": 10000, - "DiagnosticInfrastructureLogs": { - "scheduledTransferLogLevelFilter": "Error" - }, - "PerformanceCounters": { - "scheduledTransferPeriod": "PT1M", - "PerformanceCounterConfiguration": [ - { - "counterSpecifier": "\\Processor(_Total)\\% Processor Time", - "sampleRate": "PT3M", - "unit": "percent" - } - ] - }, - "WindowsEventLog": { - "scheduledTransferPeriod": "PT1M", - "DataSource": [ - { - "name": "Application!*[System[(Level=1 or Level=2 or Level=3)]]" - } - ] - } - } - }, - "StorageAccount": "mystorageaccount", - "StorageType": "TableAndBlob" - }, - "PrivateConfig": { - "storageAccountName": "mystorageaccount", - "storageAccountKey": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx", - "storageAccountEndPoint": "https://core.windows.net" - } -} -``` --See also [Use PowerShell to enable Azure Diagnostics in a virtual machine running Windows](/azure/virtual-machines/extensions/diagnostics-windows). --## Data storage --The following table lists the different types of data collected from the diagnostics extension and whether they're stored as a table or a blob. The data stored in tables can also be stored in blobs depending on the [StorageType setting](diagnostics-extension-schema-windows.md#publicconfig-element) in your public configuration. --| Data | Storage type | Description | -|:|:|:| -| WADDiagnosticInfrastructureLogsTable | Table | Diagnostic monitor and configuration changes. | -| WADDirectoriesTable | Table | Directories that the diagnostic monitor is monitoring. This group includes IIS logs, IIS failed request logs, and custom directories. The location of the blob log file is specified in the Container field and the name of the blob is in the RelativePath field. The AbsolutePath field indicates the location and name of the file as it existed on the Azure virtual machine. | -| WadLogsTable | Table | Logs written in code by using the trace listener. | -| WADPerformanceCountersTable | Table | Performance counters. | -| WADWindowsEventLogsTable | Table | Windows Event logs. | -| wad-iis-failedreqlogfiles | Blob | Contains information from IIS Failed Request logs. | -| wad-iis-logfiles | Blob | Contains information about IIS logs. | -| "custom" | Blob | A custom container based on configuring directories that are monitored by the diagnostic monitor. The name of this blob container will be specified in WADDirectoriesTable. | --## Tools to view diagnostic data --Several tools are available to view the data after it's transferred to storage. For example: --* **Server Explorer in Visual Studio**: If you've installed the Azure Tools for Microsoft Visual Studio, you can use the Azure Storage node in Server Explorer to view read-only blob and table data from your Azure Storage accounts. You can display data from your local storage emulator account and from storage accounts you've created for Azure. For more information, see [Browsing and managing storage resources with Server Explorer](/visualstudio/azure/vs-azure-tools-storage-resources-server-explorer-browse-manage). -* [Microsoft Azure Storage Explorer](../../vs-azure-tools-storage-manage-with-storage-explorer.md): This standalone app enables you to easily work with Azure Storage data on Windows, OSX, and Linux. -* [Azure Management Studio](https://cerebrata.com/blog/introducing-azure-management-studio-and-azure-explorer): This tool includes Azure Diagnostics Manager. Use it to view, download, and manage the diagnostics data collected by the applications running on Azure. --## Next steps --For information on forwarding monitoring data to Azure Event Hubs, see [Send data from Azure Diagnostics extension to Event Hubs](diagnostics-extension-stream-event-hubs.md). |
| azure-monitor | Gateway | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/gateway.md | - Title: Connect computers by using the Log Analytics gateway | Microsoft Docs -description: Connect your devices and Operations Manager-monitored computers by using the Log Analytics gateway to send data to the Azure Automation and Log Analytics service when they do not have internet access. - Previously updated : 07/06/2023-----# Connect computers without internet access by using the Log Analytics gateway in Azure Monitor --This article describes how to configure communication with Azure Automation and Azure Monitor by using the Log Analytics gateway when computers that are directly connected or that are monitored by Operations Manager have no internet access. --The Log Analytics gateway is an HTTP forward proxy that supports HTTP tunneling using the HTTP CONNECT command. This gateway sends data to Azure Automation and a Log Analytics workspace in Azure Monitor on behalf of the computers that cannot directly connect to the internet. The gateway is only for log agent related connectivity and does not support Azure Automation features like runbook, DSC, and others. --> [!NOTE] -> The Log Analytic gateway has be updated to work with the Azure Monitor Agent (AMA) and will be supported beyond the deprication date of legacy agent (MMA/OMS) on August 31, 2024. -> --The Log Analytics gateway supports: --* Reporting up to the same Log Analytics workspaces configured on each agent behind it and that are configured with Azure Automation Hybrid Runbook Workers. -* Windows computers on which either the [Azure Monitor Agent](./azure-monitor-agent-overview.md) or the legacy Microsoft Monitoring Agent is directly connected to a Log Analytics workspace in Azure Monitor. Both the source and the gateway server must be running the same agent. You can't stream events from a server running Azure Monitor agent through a server running the gateway with the Log Analytics agent. -* Linux computers on which either the [Azure Monitor Agent](./azure-monitor-agent-overview.md) or the legacy Log Analytics agent for Linux is directly connected to a Log Analytics workspace in Azure Monitor. -* System Center Operations Manager 2012 SP1 with UR7, Operations Manager 2012 R2 with UR3, or a management group in Operations Manager 2016 or later that is integrated with Log Analytics. --Some IT security policies don't allow internet connection for network computers. These unconnected computers could be point of sale (POS) devices or servers supporting IT services, for example. To connect these devices to Azure Automation or a Log Analytics workspace so you can manage and monitor them, configure them to communicate directly with the Log Analytics gateway. The Log Analytics gateway can receive configuration information and forward data on their behalf. If the computers are configured with the Log Analytics agent to directly connect to a Log Analytics workspace, the computers instead communicate with the Log Analytics gateway. --The Log Analytics gateway transfers data from the agents to the service directly. It doesn't analyze any of the data in transit and the gateway does not cache data when it loses connectivity with the service. When the gateway is unable to communicate with service, the agent continues to run and queues the collected data on the disk of the monitored computer. When the connection is restored, the agent sends the cached data collected to Azure Monitor. --When an Operations Manager management group is integrated with Log Analytics, the management servers can be configured to connect to the Log Analytics gateway to receive configuration information and send collected data, depending on the solution you have enabled. Operations Manager agents send some data to the management server. For example, agents might send Operations Manager alerts, configuration assessment data, instance space data, and capacity data. Other high-volume data, such as Internet Information Services (IIS) logs, performance data, and security events, is sent directly to the Log Analytics gateway. --If one or more Operations Manager Gateway servers are deployed to monitor untrusted systems in a perimeter network or an isolated network, those servers can't communicate with a Log Analytics gateway. Operations Manager Gateway servers can report only to a management server. When an Operations Manager management group is configured to communicate with the Log Analytics gateway, the proxy configuration information is automatically distributed to every agent-managed computer that is configured to collect log data for Azure Monitor, even if the setting is empty. --To provide high availability for directly connected or Operations Management groups that communicate with a Log Analytics workspace through the gateway, use network load balancing (NLB) to redirect and distribute traffic across multiple gateway servers. That way, if one gateway server goes down, the traffic is redirected to another available node. --The computer that runs the Log Analytics gateway requires the agent to identify the service endpoints that the gateway needs to communicate with. The agent also needs to direct the gateway to report to the same workspaces that the agents or Operations Manager management group behind the gateway are configured with. This configuration allows the gateway and the agent to communicate with their assigned workspace. --A gateway can be multihomed to up to ten workspaces using the Azure Monitor Agent and [data collection rules](./azure-monitor-agent-data-collection.md). Using the legacy Microsoft Monitor Agent, you can only multihome up to four workspaces as that is the total number of workspaces the legacy Windows agent supports. --Each agent must have network connectivity to the gateway so that agents can automatically transfer data to and from the gateway. Avoid installing the gateway on a domain controller. Linux computers that are behind a gateway server cannot use the [wrapper script installation](../agents/agent-linux.md#install-the-agent) method to install the Log Analytics agent for Linux. The agent must be downloaded manually, copied to the computer, and installed manually because the gateway only supports communicating with the Azure services mentioned earlier. --The following diagram shows data flowing from direct agents, through the gateway, to Azure Automation and Log Analytics. The agent proxy configuration must match the port that the Log Analytics gateway is configured with. ---The following diagram shows data flow from an Operations Manager management group to Log Analytics. ---## Set up your system --Computers designated to run the Log Analytics gateway must have the following configuration: --* Windows 10, Windows 8.1, or Windows 7 -* Windows Server 2019, Windows Server 2016, Windows Server 2012 R2, Windows Server 2012, Windows Server 2008 R2, or Windows Server 2008 -* Microsoft .NET Framework 4.5 -* At least a 4-core processor and 8 GB of memory -* An [Azure Monitor agent](./azure-monitor-agent-overview.md) installed with [data collection rule(s)](./azure-monitor-agent-data-collection.md) configured, or the [Log Analytics agent for Windows](../agents/agent-windows.md) configured to report to the same workspace as the agents that communicate through the gateway --### Language availability --The Log Analytics gateway is available in these languages: --- Chinese (Simplified)-- Chinese (Traditional)-- Czech-- Dutch-- English-- French-- German-- Hungarian-- Italian-- Japanese-- Korean-- Polish-- Portuguese (Brazil)-- Portuguese (Portugal)-- Russian-- Spanish (International)--### Supported encryption protocols --The Log Analytics gateway supports only Transport Layer Security (TLS) 1.0, 1.1, 1.2 and 1.3. It doesn't support Secure Sockets Layer (SSL). To ensure the security of data in transit to Log Analytics, configure the gateway to use at least TLS 1.3. Although they currently allow for backward compatibility, avoid using older versions because they are vulnerable. --For additional information, review [Sending data securely using TLS](../logs/data-security.md#sending-data-securely-using-tls). --->[!NOTE] ->The gateway is a forwarding proxy that doesnΓÇÖt store any data. Once the agent establishes connection with Azure Monitor, it follows the same encryption flow with or without the gateway. The data is encrypted between the client and the endpoint. Since the gateway is just a tunnel, it doesnΓÇÖt have the ability the inspect what is being sent. --### Supported number of agent connections --The following table shows approximately how many agents can communicate with a gateway server. Support is based on agents that upload about 200 KB of data every 6 seconds. For each agent tested, data volume is about 2.7 GB per day. --|Gateway |Agents supported (approximate)| -|--|-| -|CPU: Intel Xeon Processor E5-2660 v3 \@ 2.6 GHz 2 Cores<br> Memory: 4 GB<br> Network bandwidth: 1 Gbps| 600| -|CPU: Intel Xeon Processor E5-2660 v3 \@ 2.6 GHz 4 Cores<br> Memory: 8 GB<br> Network bandwidth: 1 Gbps| 1000| --## Download the Log Analytics gateway --Get the latest version of the Log Analytics gateway Setup file from Microsoft Download Center ([Download Link](https://go.microsoft.com/fwlink/?linkid=837444)). --## Install Log Analytics gateway using setup wizard --To install a gateway using the setup wizard, follow these steps. --1. From the destination folder, double-click **Log Analytics gateway.msi**. -1. On the **Welcome** page, select **Next**. - <!-- convertborder later --> - :::image type="content" source="./media/gateway/gateway-wizard01.png" lightbox="./media/gateway/gateway-wizard01.png" alt-text="Screenshot of Welcome page in the Gateway Setup wizard" border="false"::: --1. On the **License Agreement** page, select **I accept the terms in the License Agreement** to agree to the Microsoft Software License Terms, and then select **Next**. -1. On the **Port and proxy address** page: -- a. Enter the TCP port number to be used for the gateway. Setup uses this port number to configure an inbound rule on Windows Firewall. The default value is 8080. - The valid range of the port number is 1 through 65535. If the input does not fall into this range, an error message appears. -- b. If the server where the gateway is installed needs to communicate through a proxy, enter the proxy address where the gateway needs to connect. For example, enter `http://myorgname.corp.contoso.com:80`. If you leave this field blank, the gateway will try to connect to the internet directly. If your proxy server requires authentication, enter a username and password. -- c. Select **Next**. - <!-- convertborder later --> - :::image type="content" source="./media/gateway/gateway-wizard02.png" lightbox="./media/gateway/gateway-wizard02.png" alt-text="Screenshot of configuration for the gateway proxy" border="false"::: --1. If you do not have Microsoft Update enabled, the Microsoft Update page appears, and you can choose to enable it. Make a selection and then select **Next**. Otherwise, continue to the next step. -1. On the **Destination Folder** page, either leave the default folder C:\Program Files\OMS Gateway or enter the location where you want to install the gateway. Then select **Next**. -1. On the **Ready to install** page, select **Install**. If User Account Control requests permission to install, select **Yes**. -1. After Setup finishes, select **Finish**. To verify that the service is running, open the services.msc snap-in and verify that **OMS Gateway** appears in the list of services and that its status is **Running**. - <!-- convertborder later --> - :::image type="content" source="./media/gateway/gateway-service.png" lightbox="./media/gateway/gateway-service.png" alt-text="Screenshot of local services, showing that OMS Gateway is running" border="false"::: --## Install the Log Analytics gateway using the command line --The downloaded file for the gateway is a Windows Installer package that supports silent installation from the command line or other automated method. If you are not familiar with the standard command-line options for Windows Installer, see [Command-line options](/windows/desktop/msi/command-line-options). - -The following table highlights the parameters supported by setup. --|Parameters| Notes| -|-|| -|PORTNUMBER | TCP port number for gateway to listen on | -|PROXY | IP address of proxy server | -|INSTALLDIR | Fully qualified path to specify install directory of gateway software files | -|USERNAME | User ID to authenticate with proxy server | -|PASSWORD | Password of the user ID to authenticate with proxy | -|LicenseAccepted | Specify a value of **1** to verify you accept license agreement | -|HASAUTH | Specify a value of **1** when USERNAME/PASSWORD parameters are specified | -|HASPROXY | Specify a value of **1** when specifying IP address for **PROXY** parameter | --To silently install the gateway and configure it with a specific proxy address, port number, type the following: --```dos -Msiexec.exe /I "oms gateway.msi" /qn PORTNUMBER=8080 PROXY="10.80.2.200" HASPROXY=1 LicenseAccepted=1 -``` --Using the /qn command-line option hides setup, /qb shows setup during silent install. --If you need to provide credentials to authenticate with the proxy, type the following: --```dos -Msiexec.exe /I "oms gateway.msi" /qn PORTNUMBER=8080 PROXY="10.80.2.200" HASPROXY=1 HASAUTH=1 USERNAME="<username>" PASSWORD="<password>" LicenseAccepted=1 -``` --After installation, you can confirm the settings are accepted (excluding the username and password) using the following PowerShell cmdlets: --- **Get-OMSGatewayConfig** ΓÇô Returns the TCP Port the gateway is configured to listen on.-- **Get-OMSGatewayRelayProxy** ΓÇô Returns the IP address of the proxy server you configured it to communicate with.--## Configure network load balancing --You can configure the gateway for high availability using network load balancing (NLB) using either Microsoft [Network Load Balancing (NLB)](/windows-server/networking/technologies/network-load-balancing), [Azure Load Balancer](../../load-balancer/load-balancer-overview.md), or hardware-based load balancers. The load balancer manages traffic by redirecting the requested connections from the Log Analytics agents or Operations Manager management servers across its nodes. If one Gateway server goes down, the traffic gets redirected to other nodes. --### Microsoft Network Load Balancing --To learn how to design and deploy a Windows Server 2016 network load balancing cluster, see [Network load balancing](/windows-server/networking/technologies/network-load-balancing). The following steps describe how to configure a Microsoft network load balancing cluster. --1. Sign onto the Windows server that is a member of the NLB cluster with an administrative account. -2. Open Network Load Balancing Manager in Server Manager, click **Tools**, and then click **Network Load Balancing Manager**. -3. To connect a Log Analytics gateway server with the Microsoft Monitoring Agent installed, right-click the cluster's IP address, and then click **Add Host to Cluster**. -- :::image type="content" source="./media/gateway/nlb02.png" lightbox="./media/gateway/nlb02.png" alt-text="Network Load Balancing Manager ΓÇô Add Host To Cluster"::: - -4. Enter the IP address of the gateway server that you want to connect. -- :::image type="content" source="./media/gateway/nlb03.png" lightbox="./media/gateway/nlb03.png" alt-text="Network Load Balancing Manager ΓÇô Add Host To Cluster: Connect"::: --### Azure Load Balancer --To learn how to design and deploy an Azure Load Balancer, see [What is Azure Load Balancer?](../../load-balancer/load-balancer-overview.md). To deploy a basic load balancer, follow the steps outlined in this [quickstart](../../load-balancer/quickstart-load-balancer-standard-public-portal.md) excluding the steps outlined in the section **Create back-end servers**. --> [!NOTE] -> Configuring the Azure Load Balancer using the **Basic SKU**, requires that Azure virtual machines belong to an Availability Set. To learn more about availability sets, see [Manage the availability of Windows virtual machines in Azure](/azure/virtual-machines/availability). To add existing virtual machines to an availability set, refer to [Set Azure Resource Manager VM Availability Set](/troubleshoot/azure/virtual-machines/allocation-failure#resize-a-vm-or-add-vms-to-an-existing-availability-set). -> --After the load balancer is created, a backend pool needs to be created, which distributes traffic to one or more gateway servers. Follow the steps described in the quickstart article section [Create resources for the load balancer](../../load-balancer/quickstart-load-balancer-standard-public-portal.md). -->[!NOTE] ->When configuring the health probe it should be configured to use the TCP port of the gateway server. The health probe dynamically adds or removes the gateway servers from the load balancer rotation based on their response to health checks. -> --## Configure the Azure Monitor agent to communicate using Log Analytics gateway --To configure the Azure Monitor agent (installed on the gateway server) to use the gateway to upload data for Windows or Linux: -1. Follow the instructions to [configure proxy settings on the agent](./azure-monitor-agent-network-configuration.md#proxy-configuration) and provide the IP address and port number corresponding to the gateway server. If you have deployed multiple gateway servers behind a load balancer, the agent proxy configuration is the virtual IP address of the load balancer instead. -2. Add the **configuration endpoint URL** to fetch data collection rules to the allowlist for the gateway - `Add-OMSGatewayAllowedHost -Host global.handler.control.monitor.azure.com` - `Add-OMSGatewayAllowedHost -Host <gateway-server-region-name>.handler.control.monitor.azure.com` - (If using private links on the agent, you must also add the [dce endpoints](../essentials/data-collection-endpoint-overview.md#components-of-a-dce)) -3. Add the **data ingestion endpoint URL** to the allowlist for the gateway - `Add-OMSGatewayAllowedHost -Host <log-analytics-workspace-id>.ods.opinsights.azure.com` -3. Restart the **OMS Gateway** service to apply the changes - `Stop-Service -Name <gateway-name>` - `Start-Service -Name <gateway-name>` - --## Configure the Log Analytics agent and Operations Manager management group --In this section, you'll see how to configure directly connected legacy Log Analytics agents, an Operations Manager management group, or Azure Automation Hybrid Runbook Workers with the Log Analytics gateway to communicate with Azure Automation or Log Analytics. --### Configure a standalone Log Analytics agent --When configuring the legacy Log Analytics agent, replace the proxy server value with the IP address of the Log Analytics gateway server and its port number. If you have deployed multiple gateway servers behind a load balancer, the Log Analytics agent proxy configuration is the virtual IP address of the load balancer. -->[!NOTE] ->To install the Log Analytics agent on the gateway and Windows computers that directly connect to Log Analytics, see [Connect Windows computers to the Log Analytics service in Azure](../agents/agent-windows.md). To connect Linux computers, see [Connect Linux computers to Azure Monitor](../agents/agent-linux.md). -> --After you install the agent on the gateway server, configure it to report to the workspace or workspace agents that communicate with the gateway. If the Log Analytics Windows agent is not installed on the gateway, event 300 is written to the OMS Gateway event log, indicating that the agent needs to be installed. If the agent is installed but not configured to report to the same workspace as the agents that communicate through it, event 105 is written to the same log, indicating that the agent on the gateway needs to be configured to report to the same workspace as the agents that communicate with the gateway. --After you complete configuration, restart the **OMS Gateway** service to apply the changes. Otherwise, the gateway will reject agents that attempt to communicate with Log Analytics and will report event 105 in the OMS Gateway event log. This will also happen when you add or remove a workspace from the agent configuration on the gateway server. --For information related to the Automation Hybrid Runbook Worker, see [Automate resources in your datacenter or cloud by using Hybrid Runbook Worker](../../automation/automation-hybrid-runbook-worker.md). --### Configure Operations Manager, where all agents use the same proxy server --The Operations Manager proxy configuration is automatically applied to all agents that report to Operations Manager, even if the setting is empty. --To use OMS Gateway to support Operations Manager, you must have: --* Microsoft Monitoring Agent (version 8.0.10900.0 or later) installed on the OMS Gateway server and configured with the same Log Analytics workspaces that your management group is configured to report to. -* Internet connectivity. Alternatively, OMS Gateway must be connected to a proxy server that is connected to the internet. --> [!NOTE] -> If you specify no value for the gateway, blank values are pushed to all agents. -> --If your Operations Manager management group is registering with a Log Analytics workspace for the first time, you won't see the option to specify the proxy configuration for the management group in the Operations console. This option is available only if the management group has been registered with the service. --To configure integration, update the system proxy configuration by using Netsh on the system where you're running the Operations console and on all management servers in the management group. Follow these steps: --1. Open an elevated command prompt: -- a. Select **Start** and enter **cmd**. -- b. Right-click **Command Prompt** and select **Run as administrator**. --1. Enter the following command: -- `netsh winhttp set proxy <proxy>:<port>` --After completing the integration with Log Analytics, remove the change by running `netsh winhttp reset proxy`. Then, in the Operations console, use the **Configure proxy server** option to specify the Log Analytics gateway server. --1. On the Operations Manager console, under **Operations Management Suite**, select **Connection**, and then select **Configure Proxy Server**. - <!-- convertborder later --> - :::image type="content" source="./media/gateway/scom01.png" lightbox="./media/gateway/scom01.png" alt-text="Screenshot of Operations Manager, showing the selection Configure Proxy Server" border="false"::: --1. Select **Use a proxy server to access the Operations Management Suite** and then enter the IP address of the Log Analytics gateway server or virtual IP address of the load balancer. Be careful to start with the prefix `http://`. - <!-- convertborder later --> - :::image type="content" source="./media/gateway/scom02.png" lightbox="./media/gateway/scom02.png" alt-text="Screenshot of Operations Manager, showing the proxy server address" border="false"::: --1. Select **Finish**. Your Operations Manager management group is now configured to communicate through the gateway server to the Log Analytics service. --### Configure Operations Manager, where specific agents use a proxy server --For large or complex environments, you might want only specific servers (or groups) to use the Log Analytics gateway server. For these servers, you can't update the Operations Manager agent directly because this value is overwritten by the global value for the management group. Instead, override the rule used to push these values. --> [!NOTE] -> Use this configuration technique if you want to allow for multiple Log Analytics gateway servers in your environment. For example, you can require specific Log Analytics gateway servers to be specified on a regional basis. -> --To configure specific servers or groups to use the Log Analytics gateway server: --1. Open the Operations Manager console and select the **Authoring** workspace. -1. In the Authoring workspace, select **Rules**. -1. On the Operations Manager toolbar, select the **Scope** button. If this button is not available, make sure you have selected an object, not a folder, in the **Monitoring** pane. The **Scope Management Pack Objects** dialog box displays a list of common targeted classes, groups, or objects. -1. In the **Look for** field, enter **Health Service** and select it from the list. Select **OK**. -1. Search for **Advisor Proxy Setting Rule**. -1. On the Operations Manager toolbar, select **Overrides** and then point to **Override the Rule\For a specific object of class: Health Service** and select an object from the list. Or create a custom group that contains the health service object of the servers you want to apply this override to. Then apply the override to your custom group. -1. In the **Override Properties** dialog box, add a check mark in the **Override** column next to the **WebProxyAddress** parameter. In the **Override Value** field, enter the URL of the Log Analytics gateway server. Be careful to start with the prefix `http://`. -- >[!NOTE] - > You don't need to enable the rule. It's already managed automatically with an override in the Microsoft System Center Advisor Secure Reference Override management pack that targets the Microsoft System Center Advisor Monitoring Server Group. - > --1. Select a management pack from the **Select destination management pack** list, or create a new unsealed management pack by selecting **New**. -1. When you finish, select **OK**. --### Configure for Automation Hybrid Runbook Workers --If you have Automation Hybrid Runbook Workers in your environment, follow these steps to configure the gateway to support the workers. --Refer to the [Configure your network](../../automation/automation-hybrid-runbook-worker.md#network-planning) section of the Automation documentation to find the URL for each region. --If your computer is registered as a Hybrid Runbook Worker automatically, for example if the Update Management solution is enabled for one or more VMs, follow these steps: --1. Add the Job Runtime Data service URLs to the Allowed Host list on the Log Analytics gateway. For example: - `Add-OMSGatewayAllowedHost we-jobruntimedata-prod-su1.azure-automation.net` -1. Restart the Log Analytics gateway service by using the following PowerShell cmdlet: - `Restart-Service OMSGatewayService` --If your computer is joined to Azure Automation by using the Hybrid Runbook Worker registration cmdlet, follow these steps: --1. Add the agent service registration URL to the Allowed Host list on the Log Analytics gateway. For example: - `Add-OMSGatewayAllowedHost ncus-agentservice-prod-1.azure-automation.net` -1. Add the Job Runtime Data service URLs to the Allowed Host list on the Log Analytics gateway. For example: - `Add-OMSGatewayAllowedHost we-jobruntimedata-prod-su1.azure-automation.net` -1. Restart the Log Analytics gateway service. - `Restart-Service OMSGatewayService` --## Useful PowerShell cmdlets --You can use cmdlets to complete the tasks to update the Log Analytics gateway's configuration settings. Before you use cmdlets, be sure to: --1. Install the Log Analytics gateway (Microsoft Windows Installer). -1. Open a PowerShell console window. -1. Import the module by typing this command: `Import-Module OMSGateway` -1. If no error occurred in the previous step, the module was successfully imported and the cmdlets can be used. Enter `Get-Module OMSGateway` -1. After you use the cmdlets to make changes, restart the OMS Gateway service. --An error in step 3 means that the module wasn't imported. The error might occur when PowerShell can't find the module. You can find the module in the OMS Gateway installation path: *C:\Program Files\Microsoft OMS Gateway\PowerShell\OmsGateway*. --| **Cmdlet** | **Parameters** | **Description** | **Example** | -| | | | | -| `Get-OMSGatewayConfig` |Key |Gets the configuration of the service |`Get-OMSGatewayConfig` | -| `Set-OMSGatewayConfig` |Key (required) <br> Value |Changes the configuration of the service |`Set-OMSGatewayConfig -Name ListenPort -Value 8080` | -| `Get-OMSGatewayRelayProxy` | |Gets the address of relay (upstream) proxy |`Get-OMSGatewayRelayProxy` | -| `Set-OMSGatewayRelayProxy` |Address<br> Username<br> Password (secure string) |Sets the address (and credential) of relay (upstream) proxy |1. Set a relay proxy and credential:<br> `Set-OMSGatewayRelayProxy`<br>`-Address http://www.myproxy.com:8080`<br>`-Username user1 -Password 123` <br><br> 2. Set a relay proxy that doesn't need authentication: `Set-OMSGatewayRelayProxy`<br> `-Address http://www.myproxy.com:8080` <br><br> 3. Clear the relay proxy setting:<br> `Set-OMSGatewayRelayProxy` <br> `-Address ""` | -| `Get-OMSGatewayAllowedHost` | |Gets the currently allowed host (only the locally configured allowed host, not automatically downloaded allowed hosts) |`Get-OMSGatewayAllowedHost` | -| `Add-OMSGatewayAllowedHost` |Host (required) |Adds the host to the allowed list |`Add-OMSGatewayAllowedHost -Host www.test.com` | -| `Remove-OMSGatewayAllowedHost` |Host (required) |Removes the host from the allowed list |`Remove-OMSGatewayAllowedHost`<br> `-Host www.test.com` | -| `Add-OMSGatewayAllowedClientCertificate` |Subject (required) |Adds the client certificate subject to the allowed list |`Add-OMSGatewayAllowed`<br>`ClientCertificate` <br> `-Subject mycert` | -| `Remove-OMSGatewayAllowedClientCertificate` |Subject (required) |Removes the client certificate subject from the allowed list |`Remove-OMSGatewayAllowed` <br> `ClientCertificate` <br> `-Subject mycert` | -| `Get-OMSGatewayAllowedClientCertificate` | |Gets the currently allowed client certificate subjects (only the locally configured allowed subjects, not automatically downloaded allowed subjects) |`Get-`<br>`OMSGatewayAllowed`<br>`ClientCertificate` | --## Troubleshooting --To collect events logged by the gateway, you should have the Log Analytics agent installed. -<!-- convertborder later --> --### Log Analytics gateway event IDs and descriptions --The following table shows the event IDs and descriptions for Log Analytics gateway log events. --| **ID** | **Description** | -| | | -| 400 |Any application error that has no specific ID. | -| 401 |Wrong configuration. For example, listenPort = "text" instead of an integer. | -| 402 |Exception in parsing TLS handshake messages. | -| 403 |Networking error. For example, cannot connect to target server. | -| 100 |General information. | -| 101 |Service has started. | -| 102 |Service has stopped. | -| 103 |An HTTP CONNECT command was received from client. | -| 104 |Not an HTTP CONNECT command. | -| 105 |Destination server is not in allowed list, or destination port is not secure (443). <br> <br> Ensure that the MMA agent on your OMS Gateway server and the agents that communicate with OMS Gateway are connected to the same Log Analytics workspace. | -| 105 |ERROR TcpConnection ΓÇô Invalid Client certificate: CN=Gateway. <br><br> Ensure that you're using OMS Gateway version 1.0.395.0 or greater. Also ensure that the MMA agent on your OMS Gateway server and the agents communicating with OMS Gateway are connected to the same Log Analytics workspace. | -| 106 |Unsupported TLS/SSL protocol version.<br><br> The Log Analytics gateway supports only TLS 1.0, TLS 1.1, and 1.2. It does not support SSL.| -| 107 |The TLS session has been verified. | --### Performance counters to collect --The following table shows the performance counters available for the Log Analytics gateway. Use Performance Monitor to add the counters. --| **Name** | **Description** | -| | | -| Log Analytics Gateway/Active Client Connection |Number of active client network (TCP) connections | -| Log Analytics Gateway/Error Count |Number of errors | -| Log Analytics Gateway/Connected Client |Number of connected clients | -| Log Analytics Gateway/Rejection Count |Number of rejections due to any TLS validation error | -<!-- convertborder later --> --## Assistance --When you're signed in to the Azure portal, you can get help with the Log Analytics gateway or any other Azure service or feature. -To get help, select the question mark icon in the upper-right corner of the portal and select **New support request**. Then complete the new support request form. ---## Next steps --[Add data sources](./../agents/agent-data-sources.md) to collect data from connected sources, and store the data in your Log Analytics workspace. |
| azure-monitor | Log Analytics Agent | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/log-analytics-agent.md | - Title: Log Analytics agent overview -description: This article helps you understand how to collect data and monitor computers hosted in Azure, on-premises, or other cloud environments with Log Analytics. --- Previously updated : 07/06/2023-----# Log Analytics agent overview --This article provides a detailed overview of the Log Analytics agent and the agent's system and network requirements and deployment methods. -->[!IMPORTANT] ->The Log Analytics agent is on a **deprecation path** and won't be supported after **August 31, 2024**. Any new data centers brought online after January 1 2024 will not support the Log Analytics agent. If you use the Log Analytics agent to ingest data to Azure Monitor, [migrate to the new Azure Monitor agent](./azure-monitor-agent-migration.md) prior to that date. --You might also see the Log Analytics agent referred to as Microsoft Monitoring Agent (MMA). --## Primary scenarios --Use the Log Analytics agent if you need to: --* Collect logs and performance data from Azure virtual machines or hybrid machines hosted outside of Azure. -* Send data to a Log Analytics workspace to take advantage of features supported by [Azure Monitor Logs](../logs/data-platform-logs.md), such as [log queries](../logs/log-query-overview.md). -* Use [VM insights](../vm/vminsights-overview.md), which allows you to monitor your machines at scale and monitor their processes and dependencies on other resources and external processes. -* Manage the security of your machines by using [Microsoft Defender for Cloud](../../security-center/security-center-introduction.md) or [Microsoft Sentinel](../../sentinel/overview.md). -* Use [Azure Automation Update Management](../../automation/update-management/overview.md), [Azure Automation State Configuration](../../automation/automation-dsc-overview.md), or [Azure Automation Change Tracking and Inventory](../../automation/change-tracking/overview.md) to deliver comprehensive management of your Azure and non-Azure machines. -* Use different [solutions](/previous-versions/azure/azure-monitor/insights/solutions) to monitor a particular service or application. --Limitations of the Log Analytics agent: --- Can't send data to Azure Monitor Metrics, Azure Storage, or Azure Event Hubs.-- Difficult to configure unique monitoring definitions for individual agents.-- Difficult to manage at scale because each virtual machine has a unique configuration.--## Comparison to other agents --For a comparison between the Log Analytics and other agents in Azure Monitor, see [Overview of Azure Monitor agents](agents-overview.md). --## Supported operating systems -- For a list of the Windows and Linux operating system versions that are supported by the Log Analytics agent, see [Supported operating systems](../agents/agents-overview.md#supported-operating-systems). --## Installation options --This section explains how to install the Log Analytics agent on different types of virtual machines and connect the machines to Azure Monitor. ---> [!NOTE] -> Cloning a machine with the Log Analytics Agent already configured is *not* supported. If the agent is already associated with a workspace, cloning won't work for "golden images." --### Azure virtual machine --- Use [VM insights](../vm/vminsights-enable-overview.md) to install the agent for a [single machine using the Azure portal](../vm/vminsights-enable-portal.md) or for [multiple machines at scale](../vm/vminsights-enable-policy.md). This installs the Log Analytics agent and [Dependency agent](../vm/vminsights-dependency-agent-maintenance.md). -- Log Analytics VM extension for [Windows](/azure/virtual-machines/extensions/oms-windows) or [Linux](/azure/virtual-machines/extensions/oms-linux) can be installed with the Azure portal, Azure CLI, Azure PowerShell, or an Azure Resource Manager template.-- [Microsoft Defender for Cloud can provision the Log Analytics agent](../../security-center/security-center-enable-data-collection.md) on all supported Azure VMs and any new ones that are created if you enable it to monitor for security vulnerabilities and threats.-- Install for individual Azure virtual machines [manually from the Azure portal](../vm/monitor-virtual-machine.md?toc=%2fazure%2fazure-monitor%2ftoc.json).-- Connect the machine to a workspace from the **Virtual machines (deprecated)** option in the **Log Analytics workspaces** menu in the Azure portal.--### Windows virtual machine on-premises or in another cloud --- Use [Azure Arc-enabled servers](../../azure-arc/servers/overview.md) to deploy and manage the Log Analytics VM extension. Review the [deployment options](../../azure-arc/servers/concept-log-analytics-extension-deployment.md) to understand the different deployment methods available for the extension on machines registered with Azure Arc-enabled servers.-- [Manually install](../agents/agent-windows.md) the agent from the command line.-- Automate the installation with [Azure Automation DSC](../agents/agent-windows.md#install-the-agent).-- Use a [Resource Manager template with Azure Stack](https://github.com/Azure/AzureStack-QuickStart-Templates/tree/master/MicrosoftMonitoringAgent-ext-win).--### Linux virtual machine on-premises or in another cloud --- Use [Azure Arc-enabled servers](../../azure-arc/servers/overview.md) to deploy and manage the Log Analytics VM extension. Review the [deployment options](../../azure-arc/servers/concept-log-analytics-extension-deployment.md) to understand the different deployment methods available for the extension on machines registered with Azure Arc-enabled servers.-- [Manually install](../agents/agent-linux.md#install-the-agent) the agent calling a wrapper-script hosted on GitHub.-- Integrate [System Center Operations Manager](./om-agents.md) with Azure Monitor to forward collected data from Windows computers reporting to a management group.--## Data collected --The following table lists the types of data you can configure a Log Analytics workspace to collect from all connected agents. --| Data Source | Description | -| | | -| [Windows Event logs](../agents/data-sources-windows-events.md) | Information sent to the Windows event logging system | -| [Syslog](../agents/data-sources-syslog.md) | Information sent to the Linux event logging system | -| [Performance](../agents/data-sources-performance-counters.md) | Numerical values measuring performance of different aspects of operating system and workloads | -| [IIS logs](../agents/data-sources-iis-logs.md) | Usage information for IIS websites running on the guest operating system | -| [Custom logs](../agents/data-sources-custom-logs.md) | Events from text files on both Windows and Linux computers | --## Other services --The agent for Linux and Windows isn't only for connecting to Azure Monitor. Other services such as Microsoft Defender for Cloud and Microsoft Sentinel rely on the agent and its connected Log Analytics workspace. The agent also supports Azure Automation to host the Hybrid Runbook Worker role and other services such as [Change Tracking](../../automation/change-tracking/overview.md), [Update Management](../../automation/update-management/overview.md), and [Microsoft Defender for Cloud](../../security-center/security-center-introduction.md). For more information about the Hybrid Runbook Worker role, see [Azure Automation Hybrid Runbook Worker](../../automation/automation-hybrid-runbook-worker.md). --## Workspace and management group limitations --For details on connecting an agent to an Operations Manager management group, see [Configure agent to report to an Operations Manager management group](../agents/agent-manage.md#configure-agent-to-report-to-an-operations-manager-management-group). --* Windows agents can connect to up to four workspaces, even if they're connected to a System Center Operations Manager management group. -* The Linux agent doesn't support multi-homing and can only connect to a single workspace or management group. --## Security limitations --The Windows and Linux agents support the [FIPS 140 standard](/windows/security/threat-protection/fips-140-validation), but [other types of hardening might not be supported](../agents/agent-linux.md#supported-linux-hardening). --## TLS protocol --To ensure the security of data in transit to Azure Monitor logs, we strongly encourage you to configure the agent to use at least Transport Layer Security (TLS) 1.2. Older versions of TLS/Secure Sockets Layer (SSL) have been found to be vulnerable. Although they still currently work to allow backward compatibility, they are *not recommended*. For more information, see [Sending data securely using TLS](../logs/data-security.md#sending-data-securely-using-tls). --## Network requirements --The agent for Linux and Windows communicates outbound to the Azure Monitor service over TCP port 443. If the machine connects through a firewall or proxy server to communicate over the internet, review the following requirements to understand the network configuration required. If your IT security policies do not allow computers on the network to connect to the internet, set up a [Log Analytics gateway](gateway.md) and configure the agent to connect through the gateway to Azure Monitor. The agent can then receive configuration information and send data collected. ---The following table lists the proxy and firewall configuration information required for the Linux and Windows agents to communicate with Azure Monitor logs. --### Firewall requirements --|Agent Resource|Ports |Direction |Bypass HTTPS inspection| -|||--|--| -|*.ods.opinsights.azure.com |Port 443 |Outbound|Yes | -|*.oms.opinsights.azure.com |Port 443 |Outbound|Yes | -|*.blob.core.windows.net |Port 443 |Outbound|Yes | -|*.azure-automation.net |Port 443 |Outbound|Yes | --For firewall information required for Azure Government, see [Azure Government management](../../azure-government/compare-azure-government-global-azure.md#azure-monitor). --> [!IMPORTANT] -> If your firewall is doing CNAME inspections, you need to configure it to allow all domains in the CNAME. --If you plan to use the Azure Automation Hybrid Runbook Worker to connect to and register with the Automation service to use runbooks or management features in your environment, it must have access to the port number and the URLs described in [Configure your network for the Hybrid Runbook Worker](../../automation/automation-hybrid-runbook-worker.md#network-planning). --### Proxy configuration --The Windows and Linux agent supports communicating either through a proxy server or Log Analytics gateway to Azure Monitor by using the HTTPS protocol. Both anonymous and basic authentication (username/password) are supported. --For the Windows agent connected directly to the service, the proxy configuration is specified during installation or [after deployment](../agents/agent-manage.md#update-proxy-settings) from Control Panel or with PowerShell. Log Analytics Agent (MMA) doesn't use the system proxy settings. As a result, the user has to pass the proxy setting while installing MMA. These settings will be stored under MMA configuration (registry) on the virtual machine. --For the Linux agent, the proxy server is specified during installation or [after installation](../agents/agent-manage.md#update-proxy-settings) by modifying the proxy.conf configuration file. The Linux agent proxy configuration value has the following syntax: --`[protocol://][user:password@]proxyhost[:port]` --|Property| Description | -|--|-| -|Protocol | https | -|user | Optional username for proxy authentication | -|password | Optional password for proxy authentication | -|proxyhost | Address or FQDN of the proxy server/Log Analytics gateway | -|port | Optional port number for the proxy server/Log Analytics gateway | --For example: -`https://user01:password@proxy01.contoso.com:30443` --> [!NOTE] -> If you use special characters such as "\@" in your password, you'll receive a proxy connection error because the value is parsed incorrectly. To work around this issue, encode the password in the URL by using a tool like [URLDecode](https://www.urldecoder.org/). --## Next steps --* Review [data sources](../agents/agent-data-sources.md) to understand the data sources available to collect data from your Windows or Linux system. -* Learn about [log queries](../logs/log-query-overview.md) to analyze the data collected from data sources and solutions. -* Learn about [monitoring solutions](/previous-versions/azure/azure-monitor/insights/solutions) that add functionality to Azure Monitor and also collect data into the Log Analytics workspace. |
| azure-monitor | Resource Manager Agent | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/resource-manager-agent.md | - Title: Resource Manager template samples for agents -description: Sample Azure Resource Manager templates to deploy and configure virtual machine agents in Azure Monitor. ---- Previously updated : 07/19/2023----# Resource Manager template samples for agents in Azure Monitor -This article includes sample [Azure Resource Manager templates](../../azure-resource-manager/templates/syntax.md) to deploy and configure the [Azure Monitor agent](./azure-monitor-agent-overview.md), the legacy [Log Analytics agent](./log-analytics-agent.md) and [diagnostic extension](./diagnostics-extension-overview.md) for virtual machines in Azure Monitor. Each sample includes a template file and a parameters file with sample values to provide to the template. ---## Azure Monitor agent --The samples in this section install the Azure Monitor agent on Windows and Linux virtual machines and Azure Arc-enabled servers. --### Prerequisites --To use the templates below, you'll need: -- To [create a user-assigned managed identity](../../active-directory/managed-identities-azure-resources/how-manage-user-assigned-managed-identities.md?pivots=identity-mi-methods-arm#create-a-user-assigned-managed-identity-3) and [assign the user-assigned managed identity](../../active-directory/managed-identities-azure-resources/qs-configure-template-windows-vm.md#user-assigned-managed-identity), or [enable a system-assigned managed identity](../../active-directory/managed-identities-azure-resources/qs-configure-template-windows-vm.md#system-assigned-managed-identity). A managed identity is required for Azure Monitor agent to collect and publish data. User-assigned managed identities are _strongly recommended_ over system-assigned managed identities due to their ease of management at scale.-- To configure data collection for Azure Monitor Agent, you must also deploy [Resource Manager template data collection rules and associations](./resource-manager-data-collection-rules.md).--### Permissions required --| Built-in Role | Scope(s) | Reason | -|:|:|:| -| <ul><li>[Virtual Machine Contributor](../../role-based-access-control/built-in-roles.md#virtual-machine-contributor)</li><li>[Azure Connected Machine Resource Administrator](../../role-based-access-control/built-in-roles.md#azure-connected-machine-resource-administrator)</li></ul> | <ul><li>Virtual machines, virtual machine scale sets</li><li>Arc-enabled servers</li></ul> | To deploy agent extension | -| Any role that includes the action *Microsoft.Resources/deployments/** | <ul><li>Subscription and/or</li><li>Resource group and/or </li><li>An existing data collection rule</li></ul> | To deploy ARM templates | --### Azure Windows virtual machine --The following sample installs the Azure Monitor agent on an Azure Windows virtual machine. Use the appropriate template below based on your chosen authentication method. --#### User-assigned managed identity (recommended) --# [Bicep](#tab/bicep) --```bicep -param vmName string -param location string -param userAssignedManagedIdentity string --resource windowsAgent 'Microsoft.Compute/virtualMachines/extensions@2021-11-01' = { - name: '${vmName}/AzureMonitorWindowsAgent' - location: location - properties: { - publisher: 'Microsoft.Azure.Monitor' - type: 'AzureMonitorWindowsAgent' - typeHandlerVersion: '1.0' - autoUpgradeMinorVersion: true - enableAutomaticUpgrade: true - settings: { - authentication: { - managedIdentity: { - 'identifier-name': 'mi_res_id' - 'identifier-value': userAssignedManagedIdentity - } - } - } - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "type": "string" - }, - "location": { - "type": "string" - }, - "userAssignedManagedIdentity": { - "type": "string" - } - }, - "resources": [ - { - "type": "Microsoft.Compute/virtualMachines/extensions", - "apiVersion": "2021-11-01", - "name": "[format('{0}/AzureMonitorWindowsAgent', parameters('vmName'))]", - "location": "[parameters('location')]", - "properties": { - "publisher": "Microsoft.Azure.Monitor", - "type": "AzureMonitorWindowsAgent", - "typeHandlerVersion": "1.0", - "settings": { - "authentication": { - "managedIdentity": { - "identifier-name": "mi_res_id", - "identifier-value": "[parameters('userAssignedManagedIdentity')]" - } - } - }, - "autoUpgradeMinorVersion": true, - "enableAutomaticUpgrade": true - } - } - ] -} -``` ----##### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "value": "my-windows-vm" - }, - "location": { - "value": "eastus" - }, - "userAssignedManagedIdentity": { - "value": "/subscriptions/<my-subscription-id>/resourceGroups/<my-resource-group>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<my-user-assigned-identity>" - } - } -} -``` --#### System-assigned managed identity --##### Template file --# [Bicep](#tab/bicep) --```bicep -param vmName string -param location string --resource windowsAgent 'Microsoft.Compute/virtualMachines/extensions@2021-11-01' = { - name: '${vmName}/AzureMonitorWindowsAgent' - location: location - properties: { - publisher: 'Microsoft.Azure.Monitor' - type: 'AzureMonitorWindowsAgent' - typeHandlerVersion: '1.0' - autoUpgradeMinorVersion: true - enableAutomaticUpgrade: true - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "type": "string" - }, - "location": { - "type": "string" - } - }, - "resources": [ - { - "type": "Microsoft.Compute/virtualMachines/extensions", - "apiVersion": "2021-11-01", - "name": "[format('{0}/AzureMonitorWindowsAgent', parameters('vmName'))]", - "location": "[parameters('location')]", - "properties": { - "publisher": "Microsoft.Azure.Monitor", - "type": "AzureMonitorWindowsAgent", - "typeHandlerVersion": "1.0", - "autoUpgradeMinorVersion": true, - "enableAutomaticUpgrade": true - } - } - ] -} -``` ----##### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "value": "my-windows-vm" - }, - "location": { - "value": "eastus" - } - } -} -``` --### Azure Linux virtual machine --The following sample installs the Azure Monitor agent on an Azure Linux virtual machine. Use the appropriate template below based on your chosen authentication method. --#### User-assigned managed identity (recommended) --##### Template file --# [Bicep](#tab/bicep) --```bicep -param vmName string -param location string -param userAssignedManagedIdentity string --resource linuxAgent 'Microsoft.Compute/virtualMachines/extensions@2021-11-01' = { - name: '${vmName}/AzureMonitorLinuxAgent' - location: location - properties: { - publisher: 'Microsoft.Azure.Monitor' - type: 'AzureMonitorLinuxAgent' - typeHandlerVersion: '1.21' - autoUpgradeMinorVersion: true - enableAutomaticUpgrade: true - settings: { - authentication: { - managedIdentity: { - 'identifier-name': 'mi_res_id' - 'identifier-value': userAssignedManagedIdentity - } - } - } - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "type": "string" - }, - "location": { - "type": "string" - }, - "userAssignedManagedIdentity": { - "type": "string" - } - }, - "resources": [ - { - "type": "Microsoft.Compute/virtualMachines/extensions", - "apiVersion": "2021-11-01", - "name": "[format('{0}/AzureMonitorLinuxAgent', parameters('vmName'))]", - "location": "[parameters('location')]", - "properties": { - "publisher": "Microsoft.Azure.Monitor", - "type": "AzureMonitorLinuxAgent", - "typeHandlerVersion": "1.21", - "settings": { - "authentication": { - "managedIdentity": { - "identifier-name": "mi_res_id", - "identifier-value": "[parameters('userAssignedManagedIdentity')]" - } - } - }, - "autoUpgradeMinorVersion": true, - "enableAutomaticUpgrade": true - } - } - ] -} -``` ----##### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "value": "my-linux-vm" - }, - "location": { - "value": "eastus" - }, - "userAssignedManagedIdentity": { - "value": "/subscriptions/<my-subscription-id>/resourceGroups/<my-resource-group>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<my-user-assigned-identity>" - } - } -} -``` --#### System-assigned managed identity --##### Template file --# [Bicep](#tab/bicep) --```bicep -param vmName string -param location string --resource linuxAgent 'Microsoft.Compute/virtualMachines/extensions@2021-11-01' = { - name: '${vmName}/AzureMonitorLinuxAgent' - location: location - properties: { - publisher: 'Microsoft.Azure.Monitor' - type: 'AzureMonitorLinuxAgent' - typeHandlerVersion: '1.21' - autoUpgradeMinorVersion: true - enableAutomaticUpgrade: true - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "type": "string" - }, - "location": { - "type": "string" - } - }, - "resources": [ - { - "type": "Microsoft.Compute/virtualMachines/extensions", - "apiVersion": "2021-11-01", - "name": "[format('{0}/AzureMonitorLinuxAgent', parameters('vmName'))]", - "location": "[parameters('location')]", - "properties": { - "publisher": "Microsoft.Azure.Monitor", - "type": "AzureMonitorLinuxAgent", - "typeHandlerVersion": "1.21", - "autoUpgradeMinorVersion": true, - "enableAutomaticUpgrade": true - } - } - ] -} -``` ----##### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "value": "my-linux-vm" - }, - "location": { - "value": "eastus" - } - } -} -``` --### Azure Arc-enabled Windows server --The following sample installs the Azure Monitor agent on an Azure Arc-enabled Windows server. --#### Template file --# [Bicep](#tab/bicep) --```bicep -param vmName string -param location string --resource windowsAgent 'Microsoft.HybridCompute/machines/extensions@2021-12-10-preview' = { - name: '${vmName}/AzureMonitorWindowsAgent' - location: location - properties: { - publisher: 'Microsoft.Azure.Monitor' - type: 'AzureMonitorWindowsAgent' - autoUpgradeMinorVersion: true - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "type": "string" - }, - "location": { - "type": "string" - } - }, - "resources": [ - { - "type": "Microsoft.HybridCompute/machines/extensions", - "apiVersion": "2021-12-10-preview", - "name": "[format('{0}/AzureMonitorWindowsAgent', parameters('vmName'))]", - "location": "[parameters('location')]", - "properties": { - "publisher": "Microsoft.Azure.Monitor", - "type": "AzureMonitorWindowsAgent", - "autoUpgradeMinorVersion": true - } - } - ] -} -``` ----#### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "value": "my-windows-vm" - }, - "location": { - "value": "eastus" - } - } -} -``` --### Azure Arc-enabled Linux server --The following sample installs the Azure Monitor agent on an Azure Arc-enabled Linux server. --#### Template file --# [Bicep](#tab/bicep) --```bicep -param vmName string -param location string --resource linuxAgent 'Microsoft.HybridCompute/machines/extensions@2021-12-10-preview'= { - name: '${vmName}/AzureMonitorLinuxAgent' - location: location - properties: { - publisher: 'Microsoft.Azure.Monitor' - type: 'AzureMonitorLinuxAgent' - autoUpgradeMinorVersion: true - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "type": "string" - }, - "location": { - "type": "string" - } - }, - "resources": [ - { - "type": "Microsoft.HybridCompute/machines/extensions", - "apiVersion": "2021-12-10-preview", - "name": "[format('{0}/AzureMonitorLinuxAgent', parameters('vmName'))]", - "location": "[parameters('location')]", - "properties": { - "publisher": "Microsoft.Azure.Monitor", - "type": "AzureMonitorLinuxAgent", - "autoUpgradeMinorVersion": true - } - } - ] -} -``` ----#### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "value": "my-linux-vm" - }, - "location": { - "value": "eastus" - } - } -} -``` --## Log Analytics agent --The samples in this section install the legacy Log Analytics agent on Windows and Linux virtual machines in Azure and connect it to a Log Analytics workspace. --### Windows --The following sample installs the Log Analytics agent on an Azure virtual machine. This is done by enabling the [Log Analytics virtual machine extension for Windows](/azure/virtual-machines/extensions/oms-windows). --#### Template file --# [Bicep](#tab/bicep) --```bicep -@description('Name of the virtual machine.') -param vmName string --@description('Location of the virtual machine') -param location string = resourceGroup().location --@description('Id of the workspace.') -param workspaceId string --@description('Primary or secondary workspace key.') -param workspaceKey string --resource vm 'Microsoft.Compute/virtualMachines@2021-11-01' = { - name: vmName - location: location - properties:{} -} --resource logAnalyticsAgent 'Microsoft.Compute/virtualMachines/extensions@2021-11-01' = { - parent: vm - name: 'Microsoft.Insights.LogAnalyticsAgent' - location: location - properties: { - publisher: 'Microsoft.EnterpriseCloud.Monitoring' - type: 'MicrosoftMonitoringAgent' - typeHandlerVersion: '1.0' - autoUpgradeMinorVersion: true - settings: { - workspaceId: workspaceId - } - protectedSettings: { - workspaceKey: workspaceKey - } - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "type": "string", - "metadata": { - "description": "Name of the virtual machine." - } - }, - "location": { - "type": "string", - "defaultValue": "[resourceGroup().location]", - "metadata": { - "description": "Location of the virtual machine" - } - }, - "workspaceId": { - "type": "string", - "metadata": { - "description": "Id of the workspace." - } - }, - "workspaceKey": { - "type": "string", - "metadata": { - "description": "Primary or secondary workspace key." - } - } - }, - "resources": [ - { - "type": "Microsoft.Compute/virtualMachines", - "apiVersion": "2021-11-01", - "name": "[parameters('vmName')]", - "location": "[parameters('location')]", - "properties": {} - }, - { - "type": "Microsoft.Compute/virtualMachines/extensions", - "apiVersion": "2021-11-01", - "name": "[format('{0}/{1}', parameters('vmName'), 'Microsoft.Insights.LogAnalyticsAgent')]", - "location": "[parameters('location')]", - "properties": { - "publisher": "Microsoft.EnterpriseCloud.Monitoring", - "type": "MicrosoftMonitoringAgent", - "typeHandlerVersion": "1.0", - "autoUpgradeMinorVersion": true, - "settings": { - "workspaceId": "[parameters('workspaceId')]" - }, - "protectedSettings": { - "workspaceKey": "[parameters('workspaceKey')]" - } - }, - "dependsOn": [ - "[resourceId('Microsoft.Compute/virtualMachines', parameters('vmName'))]" - ] - } - ] -} -``` ----#### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "value": "my-windows-vm" - }, - "location": { - "value": "westus" - }, - "workspaceId": { - "value": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" - }, - "workspaceKey": { - "value": "Tse-gj9CemT6A80urYa2hwtjvA5axv1xobXgKR17kbVdtacU6cEf+SNo2TdHGVKTsZHZd1W9QKRXfh+$fVY9dA==" - } - } -} -``` --### Linux --The following sample installs the Log Analytics agent on a Linux Azure virtual machine. This is done by enabling the [Log Analytics virtual machine extension for Linux](/azure/virtual-machines/extensions/oms-linux). --#### Template file --# [Bicep](#tab/bicep) --```bicep -@description('Name of the virtual machine.') -param vmName string --@description('Location of the virtual machine') -param location string = resourceGroup().location --@description('Id of the workspace.') -param workspaceId string --@description('Primary or secondary workspace key.') -param workspaceKey string --resource vm 'Microsoft.Compute/virtualMachines@2021-11-01' = { - name: vmName - location: location -} --resource logAnalyticsAgent 'Microsoft.Compute/virtualMachines/extensions@2021-11-01' = { - parent: vm - name: 'Microsoft.Insights.LogAnalyticsAgent' - location: location - properties: { - publisher: 'Microsoft.EnterpriseCloud.Monitoring' - type: 'OmsAgentForLinux' - typeHandlerVersion: '1.7' - autoUpgradeMinorVersion: true - settings: { - workspaceId: workspaceId - } - protectedSettings: { - workspaceKey: workspaceKey - } - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "type": "string", - "metadata": { - "description": "Name of the virtual machine." - } - }, - "location": { - "type": "string", - "defaultValue": "[resourceGroup().location]", - "metadata": { - "description": "Location of the virtual machine" - } - }, - "workspaceId": { - "type": "string", - "metadata": { - "description": "Id of the workspace." - } - }, - "workspaceKey": { - "type": "string", - "metadata": { - "description": "Primary or secondary workspace key." - } - } - }, - "resources": [ - { - "type": "Microsoft.Compute/virtualMachines", - "apiVersion": "2021-11-01", - "name": "[parameters('vmName')]", - "location": "[parameters('location')]" - }, - { - "type": "Microsoft.Compute/virtualMachines/extensions", - "apiVersion": "2021-11-01", - "name": "[format('{0}/{1}', parameters('vmName'), 'Microsoft.Insights.LogAnalyticsAgent')]", - "location": "[parameters('location')]", - "properties": { - "publisher": "Microsoft.EnterpriseCloud.Monitoring", - "type": "OmsAgentForLinux", - "typeHandlerVersion": "1.7", - "autoUpgradeMinorVersion": true, - "settings": { - "workspaceId": "[parameters('workspaceId')]" - }, - "protectedSettings": { - "workspaceKey": "[parameters('workspaceKey')]" - } - }, - "dependsOn": [ - "[resourceId('Microsoft.Compute/virtualMachines', parameters('vmName'))]" - ] - } - ] -} -``` ----#### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "value": "my-linux-vm" - }, - "location": { - "value": "westus" - }, - "workspaceId": { - "value": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" - }, - "workspaceKey": { - "value": "Tse-gj9CemT6A80urYa2hwtjvA5axv1xobXgKR17kbVdtacU6cEf+SNo2TdHGVKTsZHZd1W9QKRXfh+$fVY9dA==" - } - } -} -``` --## Diagnostic extension --The samples in this section install the diagnostic extension on Windows and Linux virtual machines in Azure and configure it for data collection. --### Windows --The following sample enables and configures the diagnostic extension on an Azure virtual machine. For details on the configuration, see [Windows diagnostics extension schema](./diagnostics-extension-schema-windows.md). --#### Template file --# [Bicep](#tab/bicep) --```bicep -@description('Name of the virtual machine.') -param vmName string --@description('Location for the virtual machine.') -param location string = resourceGroup().location --@description('Name of the storage account.') -param storageAccountName string --@description('Resource ID of the storage account.') -param storageAccountId string --@description('Resource ID of the workspace.') -param workspaceResourceId string --resource vm 'Microsoft.Compute/virtualMachines@2021-11-01' = { - name: vmName - location: location -} --resource vmDiagnosticsSettings 'Microsoft.Compute/virtualMachines/extensions@2021-11-01' = { - parent: vm - name: 'Microsoft.Insights.VMDiagnosticsSettings' - location: location - properties: { - publisher: 'Microsoft.Azure.Diagnostics' - type: 'IaaSDiagnostics' - typeHandlerVersion: '1.5' - autoUpgradeMinorVersion: true - settings: { - WadCfg: { - DiagnosticMonitorConfiguration: { - overallQuotaInMB: 10000 - DiagnosticInfrastructureLogs: { - scheduledTransferLogLevelFilter: 'Error' - } - PerformanceCounters: { - scheduledTransferPeriod: 'PT1M' - sinks: 'AzureMonitorSink' - PerformanceCounterConfiguration: [ - { - counterSpecifier: '\\Processor(_Total)\\% Processor Time' - sampleRate: 'PT1M' - unit: 'percent' - } - ] - } - WindowsEventLog: { - scheduledTransferPeriod: 'PT5M' - DataSource: [ - { - name: 'System!*[System[Provider[@Name=\'Microsoft Antimalware\']]]' - } - { - name: 'System!*[System[Provider[@Name=\'NTFS\'] and (EventID=55)]]' - } - { - name: 'System!*[System[Provider[@Name=\'disk\'] and (EventID=7 or EventID=52 or EventID=55)]]' - } - ] - } - } - SinksConfig: { - Sink: [ - { - name: 'AzureMonitorSink' - AzureMonitor: { - ResourceId: workspaceResourceId - } - } - ] - } - } - storageAccount: storageAccountName - } - protectedSettings: { - storageAccountName: storageAccountName - storageAccountKey: listkeys(storageAccountId, '2021-08-01').key1 - storageAccountEndPoint: 'https://${environment().suffixes.storage}' - } - } -} --resource managedIdentity 'Microsoft.Compute/virtualMachines/extensions@2021-11-01' = { - parent: vm - name: 'ManagedIdentityExtensionForWindows' - location: location - properties: { - publisher: 'Microsoft.ManagedIdentity' - type: 'ManagedIdentityExtensionForWindows' - typeHandlerVersion: '1.0' - autoUpgradeMinorVersion: true - settings: { - port: 50342 - } - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "type": "string", - "metadata": { - "description": "Name of the virtual machine." - } - }, - "location": { - "type": "string", - "defaultValue": "[resourceGroup().location]", - "metadata": { - "description": "Location for the virtual machine." - } - }, - "storageAccountName": { - "type": "string", - "metadata": { - "description": "Name of the storage account." - } - }, - "storageAccountId": { - "type": "string", - "metadata": { - "description": "Resource ID of the storage account." - } - }, - "workspaceResourceId": { - "type": "string", - "metadata": { - "description": "Resource ID of the workspace." - } - } - }, - "resources": [ - { - "type": "Microsoft.Compute/virtualMachines", - "apiVersion": "2021-11-01", - "name": "[parameters('vmName')]", - "location": "[parameters('location')]" - }, - { - "type": "Microsoft.Compute/virtualMachines/extensions", - "apiVersion": "2021-11-01", - "name": "[format('{0}/{1}', parameters('vmName'), 'Microsoft.Insights.VMDiagnosticsSettings')]", - "location": "[parameters('location')]", - "properties": { - "publisher": "Microsoft.Azure.Diagnostics", - "type": "IaaSDiagnostics", - "typeHandlerVersion": "1.5", - "autoUpgradeMinorVersion": true, - "settings": { - "WadCfg": { - "DiagnosticMonitorConfiguration": { - "overallQuotaInMB": 10000, - "DiagnosticInfrastructureLogs": { - "scheduledTransferLogLevelFilter": "Error" - }, - "PerformanceCounters": { - "scheduledTransferPeriod": "PT1M", - "sinks": "AzureMonitorSink", - "PerformanceCounterConfiguration": [ - { - "counterSpecifier": "\\Processor(_Total)\\% Processor Time", - "sampleRate": "PT1M", - "unit": "percent" - } - ] - }, - "WindowsEventLog": { - "scheduledTransferPeriod": "PT5M", - "DataSource": [ - { - "name": "System!*[System[Provider[@Name='Microsoft Antimalware']]]" - }, - { - "name": "System!*[System[Provider[@Name='NTFS'] and (EventID=55)]]" - }, - { - "name": "System!*[System[Provider[@Name='disk'] and (EventID=7 or EventID=52 or EventID=55)]]" - } - ] - } - }, - "SinksConfig": { - "Sink": [ - { - "name": "AzureMonitorSink", - "AzureMonitor": { - "ResourceId": "[parameters('workspaceResourceId')]" - } - } - ] - } - }, - "storageAccount": "[parameters('storageAccountName')]" - }, - "protectedSettings": { - "storageAccountName": "[parameters('storageAccountName')]", - "storageAccountKey": "[listkeys(parameters('storageAccountId'), '2021-08-01').key1]", - "storageAccountEndPoint": "[format('https://{0}', environment().suffixes.storage)]" - } - }, - "dependsOn": [ - "[resourceId('Microsoft.Compute/virtualMachines', parameters('vmName'))]" - ] - }, - { - "type": "Microsoft.Compute/virtualMachines/extensions", - "apiVersion": "2021-11-01", - "name": "[format('{0}/{1}', parameters('vmName'), 'ManagedIdentityExtensionForWindows')]", - "location": "[parameters('location')]", - "properties": { - "publisher": "Microsoft.ManagedIdentity", - "type": "ManagedIdentityExtensionForWindows", - "typeHandlerVersion": "1.0", - "autoUpgradeMinorVersion": true, - "settings": { - "port": 50342 - } - }, - "dependsOn": [ - "[resourceId('Microsoft.Compute/virtualMachines', parameters('vmName'))]" - ] - } - ] -} -``` ----#### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "value": "my-windows-vm" - }, - "location": { - "value": "westus" - }, - "storageAccountName": { - "value": "mystorageaccount" - }, - "storageAccountId": { - "value": "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/my-resource-group/providers/Microsoft.Storage/storageAccounts/my-windows-vm" - }, - "workspaceResourceId": { - "value": "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourcegroups/my-resource-group/providers/microsoft.operationalinsights/workspaces/my-workspace" - } - } -} -``` --### Linux --The following sample enables and configures the diagnostic extension on a Linux Azure virtual machine. For details on the configuration, see [Windows diagnostics extension schema](/azure/virtual-machines/extensions/diagnostics-linux). --#### Template file --# [Bicep](#tab/bicep) --```bicep -@description('Name of the virtual machine.') -param vmName string --@description('Resource ID of the virtual machine.') -param vmId string --@description('Location for the virtual machine.') -param location string = resourceGroup().location --@description('Name of the storage account.') -param storageAccountName string --@description('Resource ID of the storage account.') -param storageSasToken string --@description('URL of the event hub.') -param eventHubUrl string --resource vm 'Microsoft.Compute/virtualMachines@2021-11-01' = { - name: vmName - location: location -} --resource vmDiagnosticsSettings 'Microsoft.Compute/virtualMachines/extensions@2021-11-01' = { - parent: vm - name: 'Microsoft.Insights.VMDiagnosticsSettings' - location: location - properties: { - publisher: 'Microsoft.Azure.Diagnostics' - type: 'LinuxDiagnostic' - typeHandlerVersion: '3.0' - autoUpgradeMinorVersion: true - settings: { - StorageAccount: storageAccountName - ladCfg: { - sampleRateInSeconds: 15 - diagnosticMonitorConfiguration: { - performanceCounters: { - sinks: 'MyMetricEventHub,MyJsonMetricsBlob' - performanceCounterConfiguration: [ - { - unit: 'Percent' - type: 'builtin' - counter: 'PercentProcessorTime' - counterSpecifier: '/builtin/Processor/PercentProcessorTime' - annotation: [ - { - locale: 'en-us' - displayName: 'Aggregate CPU %utilization' - } - ] - condition: 'IsAggregate=TRUE' - class: 'Processor' - } - { - unit: 'Bytes' - type: 'builtin' - counter: 'UsedSpace' - counterSpecifier: '/builtin/FileSystem/UsedSpace' - annotation: [ - { - locale: 'en-us' - displayName: 'Used disk space on /' - } - ] - condition: 'Name="/"' - class: 'Filesystem' - } - ] - } - metrics: { - metricAggregation: [ - { - scheduledTransferPeriod: 'PT1H' - } - { - scheduledTransferPeriod: 'PT1M' - } - ] - resourceId: vmId - } - eventVolume: 'Large' - syslogEvents: { - sinks: 'MySyslogJsonBlob,MyLoggingEventHub' - syslogEventConfiguration: { - LOG_USER: 'LOG_INFO' - } - } - } - } - perfCfg: [ - { - query: 'SELECT PercentProcessorTime, PercentIdleTime FROM SCX_ProcessorStatisticalInformation WHERE Name=\'_TOTAL\'' - table: 'LinuxCpu' - frequency: 60 - sinks: 'MyLinuxCpuJsonBlob,MyLinuxCpuEventHub' - } - ] - fileLogs: [ - { - file: '/var/log/myladtestlog' - table: 'MyLadTestLog' - sinks: 'MyFilelogJsonBlob,MyLoggingEventHub' - } - ] - } - protectedSettings: { - storageAccountName: 'yourdiagstgacct' - storageAccountSasToken: storageSasToken - sinksConfig: { - sink: [ - { - name: 'MySyslogJsonBlob' - type: 'JsonBlob' - } - { - name: 'MyFilelogJsonBlob' - type: 'JsonBlob' - } - { - name: 'MyLinuxCpuJsonBlob' - type: 'JsonBlob' - } - { - name: 'MyJsonMetricsBlob' - type: 'JsonBlob' - } - { - name: 'MyLinuxCpuEventHub' - type: 'EventHub' - sasURL: eventHubUrl - } - { - name: 'MyMetricEventHub' - type: 'EventHub' - sasURL: eventHubUrl - } - { - name: 'MyLoggingEventHub' - type: 'EventHub' - sasURL: eventHubUrl - } - ] - } - } - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "type": "string", - "metadata": { - "description": "Name of the virtual machine." - } - }, - "vmId": { - "type": "string", - "metadata": { - "description": "Resource ID of the virtual machine." - } - }, - "location": { - "type": "string", - "defaultValue": "[resourceGroup().location]", - "metadata": { - "description": "Location for the virtual machine." - } - }, - "storageAccountName": { - "type": "string", - "metadata": { - "description": "Name of the storage account." - } - }, - "storageSasToken": { - "type": "string", - "metadata": { - "description": "Resource ID of the storage account." - } - }, - "eventHubUrl": { - "type": "string", - "metadata": { - "description": "URL of the event hub." - } - } - }, - "resources": [ - { - "type": "Microsoft.Compute/virtualMachines", - "apiVersion": "2021-11-01", - "name": "[parameters('vmName')]", - "location": "[parameters('location')]" - }, - { - "type": "Microsoft.Compute/virtualMachines/extensions", - "apiVersion": "2021-11-01", - "name": "[format('{0}/{1}', parameters('vmName'), 'Microsoft.Insights.VMDiagnosticsSettings')]", - "location": "[parameters('location')]", - "properties": { - "publisher": "Microsoft.Azure.Diagnostics", - "type": "LinuxDiagnostic", - "typeHandlerVersion": "3.0", - "autoUpgradeMinorVersion": true, - "settings": { - "StorageAccount": "[parameters('storageAccountName')]", - "ladCfg": { - "sampleRateInSeconds": 15, - "diagnosticMonitorConfiguration": { - "performanceCounters": { - "sinks": "MyMetricEventHub,MyJsonMetricsBlob", - "performanceCounterConfiguration": [ - { - "unit": "Percent", - "type": "builtin", - "counter": "PercentProcessorTime", - "counterSpecifier": "/builtin/Processor/PercentProcessorTime", - "annotation": [ - { - "locale": "en-us", - "displayName": "Aggregate CPU %utilization" - } - ], - "condition": "IsAggregate=TRUE", - "class": "Processor" - }, - { - "unit": "Bytes", - "type": "builtin", - "counter": "UsedSpace", - "counterSpecifier": "/builtin/FileSystem/UsedSpace", - "annotation": [ - { - "locale": "en-us", - "displayName": "Used disk space on /" - } - ], - "condition": "Name=\"/\"", - "class": "Filesystem" - } - ] - }, - "metrics": { - "metricAggregation": [ - { - "scheduledTransferPeriod": "PT1H" - }, - { - "scheduledTransferPeriod": "PT1M" - } - ], - "resourceId": "[parameters('vmId')]" - }, - "eventVolume": "Large", - "syslogEvents": { - "sinks": "MySyslogJsonBlob,MyLoggingEventHub", - "syslogEventConfiguration": { - "LOG_USER": "LOG_INFO" - } - } - } - }, - "perfCfg": [ - { - "query": "SELECT PercentProcessorTime, PercentIdleTime FROM SCX_ProcessorStatisticalInformation WHERE Name='_TOTAL'", - "table": "LinuxCpu", - "frequency": 60, - "sinks": "MyLinuxCpuJsonBlob,MyLinuxCpuEventHub" - } - ], - "fileLogs": [ - { - "file": "/var/log/myladtestlog", - "table": "MyLadTestLog", - "sinks": "MyFilelogJsonBlob,MyLoggingEventHub" - } - ] - }, - "protectedSettings": { - "storageAccountName": "yourdiagstgacct", - "storageAccountSasToken": "[parameters('storageSasToken')]", - "sinksConfig": { - "sink": [ - { - "name": "MySyslogJsonBlob", - "type": "JsonBlob" - }, - { - "name": "MyFilelogJsonBlob", - "type": "JsonBlob" - }, - { - "name": "MyLinuxCpuJsonBlob", - "type": "JsonBlob" - }, - { - "name": "MyJsonMetricsBlob", - "type": "JsonBlob" - }, - { - "name": "MyLinuxCpuEventHub", - "type": "EventHub", - "sasURL": "[parameters('eventHubUrl')]" - }, - { - "name": "MyMetricEventHub", - "type": "EventHub", - "sasURL": "[parameters('eventHubUrl')]" - }, - { - "name": "MyLoggingEventHub", - "type": "EventHub", - "sasURL": "[parameters('eventHubUrl')]" - } - ] - } - } - }, - "dependsOn": [ - "[resourceId('Microsoft.Compute/virtualMachines', parameters('vmName'))]" - ] - } - ] -} -``` ----#### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "value": "my-linux-vm" - }, - "vmId": { - "value": "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/my-resource-group/providers/Microsoft.Compute/virtualMachines/my-linux-vm" - }, - "location": { - "value": "westus" - }, - "storageAccountName": { - "value": "mystorageaccount" - }, - "storageSasToken": { - "value": "?sv=2019-10-10&ss=bfqt&srt=sco&sp=rwdlacupx&se=2020-04-26T23:06:44Z&st=2020-04-26T15:06:44Z&spr=https&sig=1QpoTvrrEW6VN2taweUq1BsaGkhDMnFGTfWakucZl4%3D" - }, - "eventHubUrl": { - "value": "https://my-eventhub-namespace.servicebus.windows.net/my-eventhub?sr=my-eventhub-namespace.servicebus.windows.net%2fmy-eventhub&sig=4VEGPTg8jxUAbTcyeF2kwOr8XZdfgTdMWEQWnVaMSqw=&skn=manage" - } - } -} -``` --## Next steps --* [Learn more about Azure Monitor agent](./azure-monitor-agent-overview.md) -* [Learn more about Data Collection rules and associations](./azure-monitor-agent-data-collection.md) -* [Get sample templates for Data Collection rules and associations](./resource-manager-data-collection-rules.md) -* [Get other sample templates for Azure Monitor](../resource-manager-samples.md). -* [Learn more about diagnostic extension](./diagnostics-extension-overview.md). |
| azure-monitor | Solution Agenthealth | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/solution-agenthealth.md | - Title: Agent Health solution in Azure Monitor | Microsoft Docs -description: Learn how to use this solution to monitor the health of your agents reporting directly to Log Analytics or System Center Operations Manager. - Previously updated : 08/09/2023-----# Agent Health solution in Azure Monitor -The Agent Health solution in Azure helps you understand which monitoring agents are unresponsive and submitting operational data. That includes all the agents that report directly to the Log Analytics workspace in Azure Monitor or to a System Center Operations Manager management group connected to Azure Monitor. --You can also use the Agent Health solution to: --* Keep track of how many agents are deployed and where they're distributed geographically. -* Perform other queries to maintain awareness of the distribution of agents deployed in Azure, in other cloud environments, or on-premises. --> [!IMPORTANT] -> The Agent Health solution only monitors the health of the [Log Analytics agent](log-analytics-agent.md) which is on a deprecation path. This solution doesn't monitor the health of the [Azure Monitor agent](agents-overview.md). --## Prerequisites -Before you deploy this solution, confirm that you have supported [Windows agents](../agents/agent-windows.md) reporting to the Log Analytics workspace or reporting to an [Operations Manager management group](agents-overview.md) integrated with your workspace. --## Management packs -If your Operations Manager management group is connected to a Log Analytics workspace, the following management packs are installed in Operations Manager. These management packs are also installed on directly connected Windows computers after you add this solution: --* Microsoft System Center Advisor HealthAssessment Direct Channel Intelligence Pack (Microsoft.IntelligencePacks.HealthAssessmentDirect) -* Microsoft System Center Advisor HealthAssessment Server Channel Intelligence Pack (Microsoft.IntelligencePacks.HealthAssessmentViaServer) --There's nothing to configure or manage with these management packs. For more information on how solution management packs are updated, see [Connect Operations Manager to Log Analytics](../agents/om-agents.md). --## Configuration -Add the Agent Health solution to your Log Analytics workspace by using the process described in [Add solutions](../insights/solutions.md). No further configuration is required. --## Supported agents -The following table describes the connected sources that this solution supports. --| Connected source | Supported | Description | -| | | | -| Windows agents | Yes | Heartbeat events are collected from direct Windows agents.| -| System Center Operations Manager management group | Yes | Heartbeat events are collected from agents that report to the management group every 60 seconds and are then forwarded to Azure Monitor. A direct connection from Operations Manager agents to Azure Monitor isn't required. Heartbeat event data is forwarded from the management group to the Log Analytics workspace.| --## Use the solution -When you add the solution to your Log Analytics workspace, the **Agent Health** tile is added to your dashboard. This tile shows the total number of agents and the number of unresponsive agents in the last 24 hours. ---Select the **Agent Health** tile to open the **Agent Health** dashboard. The dashboard includes the columns in the following table. Each column lists the top 10 events by count that match that column's criteria for the specified time range. You can run a log search that provides the entire list. Select **See all** beneath each column or select the column heading. --| Column | Description | -|--|-| -| Agent count over time | A trend of your agent count over a period of seven days for both Linux and Windows agents| -| Count of unresponsive agents | A list of agents that haven't sent a heartbeat in the past 24 hours| -| Distribution by OS type | A partition of how many Windows and Linux agents you have in your environment| -| Distribution by agent version | A partition of the agent versions installed in your environment and a count of each one| -| Distribution by agent category | A partition of the categories of agents that are sending up heartbeat events: direct agents, Operations Manager agents, or the Operations Manager management server| -| Distribution by management group | A partition of the Operations Manager management groups in your environment| -| Geo-location of agents | A partition of the countries/regions where you have agents, and a total count of the number of agents that have been installed in each country/region| -| Count of gateways installed | The number of servers that have the Log Analytics gateway installed, and a list of these servers| ---## Azure Monitor log records -The solution creates one type of record in the Log Analytics workspace: heartbeat. Heartbeat records have the properties listed in the following table. --| Property | Description | -| | | -| `Type` | `Heartbeat`| -| `Category` | `Direct Agent`, `SCOM Agent`, or `SCOM Management Server`| -| `Computer` | Computer name| -| `OSType` | Windows or Linux operating system| -| `OSMajorVersion` | Operating system major version| -| `OSMinorVersion` | Operating system minor version| -| `Version` | Log Analytics agent or Operations Manager agent version| -| `SCAgentChannel` | `Direct` and/or `SCManagementServer`| -| `IsGatewayInstalled` | `true` if the Log Analytics gateway is installed; otherwise `false`| -| `ComputerIP` | Public IP address for an Azure virtual machine, if one is available; Azure SNAT address (not the private IP address) for a virtual machine that uses a private IP | -| `ComputerPrivateIPs` | List of private IPs of the computer | -| `RemoteIPCountry` | Geographic location where the computer is deployed| -| `ManagementGroupName` | Name of the Operations Manager management group| -| `SourceComputerId` | Unique ID of the computer| -| `RemoteIPLongitude` | Longitude of the computer's geographic location| -| `RemoteIPLatitude` | Latitude of the computer's geographic location| --Each agent that reports to an Operations Manager management server will send two heartbeats. The `SCAgentChannel` property's value will include both `Direct` and `SCManagementServer`, depending on what data sources and monitoring solutions you've enabled in your subscription. --If you recall, data from solutions is sent either: --* Directly from an Operations Manager management server to Azure Monitor. -* Directly from the agent to Azure Monitor, because of the volume of data collected on the agent. --For heartbeat events that have the value `SCManagementServer`, the `ComputerIP` value is the IP address of the management server because it actually uploads the data. For heartbeats where `SCAgentChannel` is set to `Direct`, it's the public IP address of the agent. --## Sample log searches -The following table provides sample log searches for records that the solution collects. --| Query | Description | -|:|:| -| Heartbeat | distinct Computer |Total number of agents | -| Heartbeat | summarize LastCall = max(TimeGenerated) by Computer | where LastCall < ago(24h) |Count of unresponsive agents in the last 24 hours | -| Heartbeat | summarize LastCall = max(TimeGenerated) by Computer | where LastCall < ago(15m) |Count of unresponsive agents in the last 15 minutes | -| Heartbeat | where TimeGenerated > ago(24h) and Computer in ((Heartbeat | where TimeGenerated > ago(24h) | distinct Computer)) | summarize LastCall = max(TimeGenerated) by Computer |Computers online in the last 24 hours | -| Heartbeat | where TimeGenerated > ago(24h) and Computer !in ((Heartbeat | where TimeGenerated > ago(30m) | distinct Computer)) | summarize LastCall = max(TimeGenerated) by Computer |Total agents offline in the last 30 minutes (for the last 24 hours) | -| Heartbeat | summarize AggregatedValue = dcount(Computer) by OSType |Trend of the number of agents over time by OS type| -| Heartbeat | summarize AggregatedValue = dcount(Computer) by OSType |Distribution by OS type | -| Heartbeat | summarize AggregatedValue = dcount(Computer) by Version |Distribution by agent version | -| Heartbeat | summarize AggregatedValue = count() by Category |Distribution by agent category | -| Heartbeat | summarize AggregatedValue = dcount(Computer) by ManagementGroupName | Distribution by management group | -| Heartbeat | summarize AggregatedValue = dcount(Computer) by RemoteIPCountry |Geo-location of agents | -| Heartbeat | where iff(isnotnull(toint(IsGatewayInstalled)), IsGatewayInstalled == true, IsGatewayInstalled == "true") == true | distinct Computer |Number of Log Analytics gateways installed | --## Next steps --Learn about [generating alerts from log queries in Azure Monitor](../alerts/alerts-overview.md). |
| azure-monitor | Troubleshooter Ama Linux | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/troubleshooter-ama-linux.md | - Title: How to use the Linux Operating System (OS) Azure Monitor Agent Troubleshooter -description: Detailed instructions on using the Linux agent troubleshooter tool to diagnose potential issues. --- Previously updated : 12/14/2023---# Customer intent: When AMA is experiencing issues, I want to investigate the issues and determine if I can resolve the issue on my own. ---# How to use the Linux operating system (OS) Azure Monitor Agent Troubleshooter --> [!CAUTION] -> This article references CentOS, a Linux distribution that is End Of Life (EOL) status. Please consider your use and planning accordingly. For more information, see the [CentOS End Of Life guidance](/azure/virtual-machines/workloads/centos/centos-end-of-life). --The Azure Monitor Agent (AMA) Troubleshooter is designed to help identify issues with the agent and perform general health assessments. It can perform various checks to ensure that the agent is properly installed and connected, and can also gather AMA-related logs from the machine being diagnosed. --> [!Note] -> The AMA Troubleshooter is an executable that is shipped with the agent for all versions newer than **1.25.1** for Linux. --## Prerequisites --### Python requirement -The Linux AMA Troubleshooter requires **Python 2.6+** or any **Python 3** version installed on the machine. --To check if python is installed on your machine, copy the following command and run in Bash as root: -```Bash -sudo python -V -sudo python3 -V -``` ---Multiple versions of Python can be installed and aliased ΓÇô if multiple versions are installed, use: --```Bash -ls -ls /usr/bin/python* -``` ---If your virtual machine is using a distro that doesn't include Python 3 by default, then you must install it. The following sample commands install Python 3 on different distros: --# [Red Hat, CentOS, Oracle](#tab/redhat) -```Bash -sudo yum install -y python3 -``` -# [Ubuntu, Debian](#tab/ubuntu) -```Bash -sudo apt-get update -sudo apt-get install -y python3 -``` -# [Suse](#tab/suse) -```Bash -sudo zypper install -y python3 -``` ----In addition, the following Python packages are required to run (all should be present on a default install of Python 2 or Python 3): --|Python Package|Required for Python 2?|Required for Python 3?| -|:|:|:| -|copy|yes|yes| -|datetime|yes|yes| -|json|yes|yes| -|os|yes|yes| -|platform|yes|yes| -|re|yes|yes| -|requests|no|yes| -|shutil|yes|yes| -|subprocess|yes|yes| -|url lib|yes|no| -|xml.dom.minidom|yes|yes| --### Troubleshooter existence check -Check for the existence of the AMA Agent Troubleshooter directory on the machine to be diagnosed to confirm the installation of the agent troubleshooter: --***/var/lib/waagent/Microsoft.Azure.Monitor.AzureMonitorLinuxAgent-{version}*** --To verify the Azure Monitor Agent Troubleshooter is present, copy the following command and run in Bash as root: --```Bash -ls -ltr /var/lib/waagent | grep "Microsoft.Azure.Monitor.AzureMonitorLinuxAgent-*" -``` ---If directory doesn't exist or the installation is failed, follow [Basic troubleshooting steps](azure-monitor-agent-troubleshoot-linux-vm.md#basic-troubleshooting-steps). --If the directory exists, proceed to [Run the Troubleshooter](#run-the-troubleshooter). --## Run the Troubleshooter -On the machine to be diagnosed, run the Agent Troubleshooter. --**Log Mode** enables the collection of logs, which can then be compressed into .tgz format for export or review. **Interactive Mode** allows users to actively engage in troubleshooting scenarios and view the output directly within the shell. --# [Log Mode](#tab/GenerateLogs) --To start the Agent Troubleshooter in log mode, copy the following command and run in Bash as root: --> [!Note] -> You'll need to update the {version} to match your installed version number. In the following example, the version is 1.28.11. --```Bash -cd /var/lib/waagent/Microsoft.Azure.Monitor.AzureMonitorLinuxAgent-{version}/ama_tst/ -sudo sh ama_troubleshooter.sh -L -``` --Enter a path to output logs to. For instance, you might use **/tmp**. --It runs a series of activities and outputs a .tgz file to the Output Directory you specified. Be patient until this process completes. ---# [Interactive Mode](#tab/Interactive) --To start the Agent Troubleshooter in interactive mode, copy the following command and run in Bash as root: --> [!Note] -> You'll need to update the {version} to match your installed version number. In the following example, the version is 1.28.11. --```Bash -cd /var/lib/waagent/Microsoft.Azure.Monitor.AzureMonitorLinuxAgent-{version}/ama_tst/ -sudo sh ama_troubleshooter.sh -A -``` --It runs a series of scenarios and displays the results. --> [!Note] -> The interactive mode will **not** generate log files, but will **only** output results to the screen. Switch to log mode, if you need to generate log files. -----## Frequently Asked Questions --### Can I copy the Troubleshooter from a newer agent to an older agent and run it on the older agent to diagnose issues with the older agent? -It isn't possible to use the Troubleshooter to diagnose an older version of the agent by copying it. You must have an up-to-date version of the agent for the Troubleshooter to work properly. --## Next Steps -- [Troubleshooting guidance for the Azure Monitor agent](../agents/azure-monitor-agent-troubleshoot-linux-vm.md) on Linux virtual machines and scale sets-- [Syslog troubleshooting guide for Azure Monitor Agent](../agents/azure-monitor-agent-troubleshoot-linux-vm-rsyslog.md) for Linux |
| azure-monitor | Troubleshooter Ama Windows | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/troubleshooter-ama-windows.md | - Title: How to use the Windows operating system (OS) Azure Monitor Agent Troubleshooter -description: Detailed instructions on using the Windows agent troubleshooter tool to diagnose potential issues. --- Previously updated : 12/14/2023----# Customer intent: When AMA is experiencing issues, I want to investigate the issues and determine if I can resolve the issue on my own. ---# How to use the Windows operating system (OS) Azure Monitor Agent Troubleshooter -The Azure Monitor Agent (AMA) Troubleshooter is designed to help identify issues with the agent and perform general health assessments. It can perform various checks to ensure that the agent is properly installed and connected, and can also gather AMA-related logs from the machine being diagnosed. --> [!Note] -> The Windows AMA Troubleshooter is a command line executable that is shipped with the agent for all versions newer than **1.12.0.0**. --## Prerequisites -### Troubleshooter existence check -Check for the existence of the AMA Agent Troubleshooter directory on the machine to be diagnosed to confirm the installation of the agent troubleshooter: --# [AMA Extension - PowerShell](#tab/WindowsPowerShell) -To verify the Agent Troubleshooter is present, copy the following command and run in PowerShell as administrator: -```powershell -Test-Path -Path "C:/Packages/Plugins/Microsoft.Azure.Monitor.AzureMonitorWindowsAgent" -``` --If the directory exists, the Test-Path cmdlet returns `True`. ---# [AMA Extension - Command Prompt](#tab/WindowsCmd) -To verify the Agent Troubleshooter is present, copy the following command and run in Command Prompt as administrator: -```command -cd "C:/Packages/Plugins/Microsoft.Azure.Monitor.AzureMonitorWindowsAgent" -``` --If the directory exists, the cd command changes directories successfully. ---# [AMA Standalone - PowerShell](#tab/WindowsPowerShellStandalone) -To verify the Agent Troubleshooter is present, copy the following command and run in PowerShell as administrator: -```powershell -$installPath = (Get-ItemProperty -Path "Registry::HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\AzureMonitorAgent").AMAInstallPath -Test-Path -Path $installPath\Troubleshooter -``` --If the directory exists, the Test-Path cmdlet returns `True`. ---# [AMA Standalone - Command Prompt](#tab/WindowsCmdStandalone) -To verify the Agent Troubleshooter is present, copy the following command and run in Command Prompt as administrator: --> [!Note] -> If you have customized the AMAInstallPath, you'll need to adjust the below path to your custom path. --```command -cd "C:\Program Files\Azure Monitor Agent\Troubleshooter" -``` --If the directory exists, the cd command changes directories successfully. -----If directory doesn't exist or the installation is failed, follow [Basic troubleshooting steps](../agents/azure-monitor-agent-troubleshoot-windows-vm.md#basic-troubleshooting-steps-installation-agent-not-running-configuration-issues). --Yes, the directory exists. Proceed to [Run the Troubleshooter](#run-the-troubleshooter). --## Run the Troubleshooter -On the machine to be diagnosed, run the Agent Troubleshooter. --# [AMA Extension - PowerShell](#tab/WindowsPowerShell) -To start the Agent Troubleshooter, copy the following command and run in PowerShell as administrator: -```powershell -$currentVersion = ((Get-ChildItem -Path "Registry::HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows Azure\HandlerState\" ` - | where Name -like "*AzureMonitorWindowsAgent*" ` - | ForEach-Object {$_ | Get-ItemProperty} ` - | where InstallState -eq "Enabled").PSChildName -split('_'))[1] --$troubleshooterPath = "C:\Packages\Plugins\Microsoft.Azure.Monitor.AzureMonitorWindowsAgent\$currentVersion\Troubleshooter" -Set-Location -Path $troubleshooterPath -Start-Process -FilePath $troubleshooterPath\AgentTroubleshooter.exe -ArgumentList "--ama" -Invoke-Item $troubleshooterPath -``` --It runs a series of activities that could take up to 15 minutes to complete. Be patient until the process completes. ---# [AMA Extension - Command Prompt](#tab/WindowsCmd) -To start the Agent Troubleshooter, copy the following command and run in Command Prompt as administrator: --> [!Note] -> Note: You'll need to update the {version} to match your installed version number. In the following example, the version is 1.20.0.0. --```command -cd C:/Packages/Plugins/Microsoft.Azure.Monitor.AzureMonitorWindowsAgent/{version}/Troubleshooter/ -AgentTroubleshooter.exe --ama -``` --It runs a series of activities that could take up to 15 minutes to complete. Be patient until this process completes. ---# [AMA Standalone - PowerShell](#tab/WindowsPowerShellStandalone) -To start the Agent Troubleshooter, copy the following command and run in PowerShell as administrator: -```powershell -$installPath = (Get-ItemProperty -Path "Registry::HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\AzureMonitorAgent").AMAInstallPath -Set-Location -Path $installPath\Troubleshooter -Start-Process -FilePath $installPath\Troubleshooter\AgentTroubleshooter.exe -ArgumentList "--ama" -Invoke-Item $installPath\Troubleshooter -``` --It runs a series of activities that could take up to 15 minutes to complete. Be patient until the process completes. ---# [AMA Standalone - Command Prompt](#tab/WindowsCmdStandalone) -To start the Agent Troubleshooter, copy the following command and run in Command Prompt as administrator: --> [!Note] -> If you have customized the AMAInstallPath, you'll need to adjust the below path to your custom path. --```command -cd "C:\Program Files\Azure Monitor Agent\Troubleshooter" -AgentTroubleshooter.exe --ama -``` --It runs a series of activities that could take up to 15 minutes to complete. Be patient until this process completes. -----Log file is created in the directory where the AgentTroubleshooter.exe is located. --Example for extension-based install: --Example for standalone install: --## Frequently Asked Questions --### Can I copy the Troubleshooter from a newer agent to an older agent and run it on the older agent to diagnose issues with the older agent? -It isn't possible to use the Troubleshooter to diagnose an older version of the agent by copying it. You must have an up-to-date version of the agent for the Troubleshooter to work properly. --## Next Steps -- [Troubleshooting guidance for the Azure Monitor agent](../agents/azure-monitor-agent-troubleshoot-windows-vm.md) on Windows virtual machines and scale sets-- [Troubleshooting guidance for the Azure Monitor agent](../agents/azure-monitor-agent-troubleshoot-windows-arc.md) on Windows Arc-enabled server |
| azure-monitor | Vmext Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/agents/vmext-troubleshoot.md | - Title: Troubleshoot the Azure Log Analytics VM extension -description: Describe the symptoms, causes, and resolution for the most common issues with the Log Analytics VM extension for Windows and Linux Azure VMs. -- Previously updated : 10/19/2023---# Troubleshoot the Log Analytics VM extension in Azure Monitor -This article provides help troubleshooting errors you might experience with the Log Analytics VM extension for Windows and Linux virtual machines running on Azure. The article suggests possible solutions to resolve them. --To verify the status of the extension: --1. Sign in to the [Azure portal](https://portal.azure.com). -1. In the portal, select **All services**. In the list of resources, enter **virtual machines**. As you begin typing, the list filters based on your input. Select **Virtual machines**. -1. In your list of virtual machines, find and select it. -1. On the virtual machine, select **Extensions**. -1. From the list, check to see if the Log Analytics extension is enabled or not. For Linux, the agent is listed as **OMSAgentforLinux**. For Windows, the agent is listed as **MicrosoftMonitoringAgent**. - <!-- convertborder later --> - :::image type="content" source="./media/vmext-troubleshoot/log-analytics-vmview-extensions.png" lightbox="./media/vmext-troubleshoot/log-analytics-vmview-extensions.png" alt-text="Screenshot that shows the VM Extensions view." border="false"::: --1. Select the extension to view details. - <!-- convertborder later --> - :::image type="content" source="./media/vmext-troubleshoot/log-analytics-vmview-extensiondetails.png" lightbox="./media/vmext-troubleshoot/log-analytics-vmview-extensiondetails.png" alt-text="Screenshot that shows the VM extension details." border="false"::: --## Troubleshoot the Azure Windows VM extension --If the Microsoft Monitoring Agent VM extension isn't installing or reporting, perform the following steps to troubleshoot the issue: --1. Check if the Azure VM agent is installed and working correctly by using the steps in [KB 2965986](https://support.microsoft.com/kb/2965986#mt1): - * You can also review the VM agent log file `C:\WindowsAzure\logs\WaAppAgent.log`. - * If the log doesn't exist, the VM agent isn't installed. - * [Install the Azure VM Agent](/azure/virtual-machines/extensions/agent-windows#install-the-azure-windows-vm-agent). -1. Review the Microsoft Monitoring Agent VM extension log files in `C:\Packages\Plugins\Microsoft.EnterpriseCloud.Monitoring.MicrosoftMonitoringAgent`. -1. Ensure the virtual machine can run PowerShell scripts. -1. Ensure permissions on C:\Windows\temp haven't been changed. -1. View the status of the Microsoft Monitoring Agent by entering `(New-Object -ComObject 'AgentConfigManager.MgmtSvcCfg').GetCloudWorkspaces() | Format-List` in an elevated PowerShell window on the virtual machine. -1. Review the Microsoft Monitoring Agent setup log files in `C:\WindowsAzure\Logs\Plugins\Microsoft.EnterpriseCloud.Monitoring.MicrosoftMonitoringAgent\1.0.18053.0\`. This path changes based on the version number of the agent. --For more information, see [Troubleshooting Windows extensions](/azure/virtual-machines/extensions/oms-windows). --## Troubleshoot the Linux VM extension -If the Log Analytics agent for Linux VM extension isn't installing or reporting, perform the following steps to troubleshoot the issue: --1. If the extension status is **Unknown**, check if the Azure VM agent is installed and working correctly by reviewing the VM agent log file `/var/log/waagent.log`. - * If the log doesn't exist, the VM agent isn't installed. - * [Install the Azure VM Agent on Linux VMs](/azure/virtual-machines/extensions/agent-linux#installation). -1. For other unhealthy statuses, review the Log Analytics agent for Linux VM extension logs files in `/var/log/azure/Microsoft.EnterpriseCloud.Monitoring.OmsAgentForLinux/*/extension.log` and `/var/log/azure/Microsoft.EnterpriseCloud.Monitoring.OmsAgentForLinux/*/CommandExecution.log`. -1. If the extension status is healthy but data isn't being uploaded, review the Log Analytics agent for Linux log files in `/var/opt/microsoft/omsagent/log/omsagent.log`. --## Next steps --For more troubleshooting guidance related to the Log Analytics agent for Linux, see [Troubleshoot issues with the Log Analytics agent for Linux](../agents/agent-linux-troubleshoot.md). |
| azure-monitor | Action Groups | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/action-groups.md | - Title: Azure Monitor action groups -description: Find out how to create and manage action groups. Learn about notifications and actions that action groups enable, such as email, webhooks, and Azure functions. -- Previously updated : 04/01/2024----# Action groups --When Azure Monitor data indicates that there might be a problem with your infrastructure or application, an alert is triggered. You can use an action group to send a notification such as a voice call, SMS or email when the alert is triggered in addition to the alert itself. Action groups are a collection of notification preferences and actions. Azure Monitor, Azure Service Health, and Azure Advisor use action groups to notify users about the alert and take an action. -This article shows you how to create and manage action groups. --Each action is made up of: -- **Type**: The notification that's sent or action that's performed. Examples include sending a voice call, SMS, or email. You can also trigger various types of automated actions.-- **Name**: A unique identifier within the action group.-- **Details**: The corresponding details that vary by type.--In general, an action group is a global service. Efforts to make them more available regionally are in development. --Global requests from clients can be processed by action group services in any region. If one region of the action group service is down, the traffic is automatically routed and processed in other regions. As a global service, an action group helps provide a disaster recovery solution. Regional requests rely on availability zone redundancy to meet privacy requirements and offer a similar disaster recovery solution. -- You can add up to five action groups to an alert rule.-- Action groups are executed concurrently, in no specific order.-- Multiple alert rules can use the same action group.-- Action Groups are defined by the unique set of actions and the users to be notified. For example, if you want to notify User1, User2 and User3 by email for two different alert rules, you only need to create one action group which you can apply to both alert rules.--## Create an action group in the Azure portal -1. Go to the [Azure portal](https://portal.azure.com/). --1. Search for and select **Monitor**. The **Monitor** pane consolidates all your monitoring settings and data in one view. --1. Select **Alerts**, and then select **Action groups**. -- :::image type="content" source="./media/action-groups/manage-action-groups.png" alt-text="Screenshot of the Alerts page in the Azure portal with the action groups button highlighter."::: --1. Select **Create**. -- :::image type="content" source="./media/action-groups/create-action-group.png" alt-text="Screenshot that shows the Action groups page in the Azure portal. The Create button is called out."::: --1. Configure basic action group settings. In the **Project details** section: - - Select values for **Subscription** and **Resource group**. - - Select the region. - - > [!NOTE] - > Service Health Alerts are only supported in public clouds within the global region. For Action Groups to properly function in response to a Service Health Alert the region of the action group must be set as "Global". -- | Option | Behavior | - | | -- | - | Global | The action groups service decides where to store the action group. The action group is persisted in at least two regions to ensure regional resiliency. Processing of actions may be done in any [geographic region](https://azure.microsoft.com/explore/global-infrastructure/geographies/#overview).<br></br>Voice, SMS, and email actions performed as the result of [service health alerts](../../service-health/alerts-activity-log-service-notifications-portal.md) are resilient to Azure live-site incidents. | - | Regional | The action group is stored within the selected region. The action group is [zone-redundant](../../availability-zones/az-region.md#highly-available-services). Use this option if you want to ensure that the processing of your action group is performed within a specific [geographic boundary](https://azure.microsoft.com/explore/global-infrastructure/geographies/#overview). You can select one of these regions for regional processing of action groups: <br> - East US <br> - West US <br> - East US2 <br> - West US2 <br> - South Central US <br> - North Central US<br> - Sweden Central<br> - Germany West Central <br> - India Central <br> - India South <br> We're continually adding more regions for regional data processing of action groups.| -- The action group is saved in the subscription, region, and resource group that you select. --1. In the **Instance details** section, enter values for **Action group name** and **Display name**. The display name is used in place of a full action group name when the group is used to send notifications. -- :::image type="content" source="./media/action-groups/action-group-1-basics.png" alt-text="Screenshot that shows the Create action group dialog. Values are visible in the Subscription, Resource group, Action group name, and Display name boxes."::: --1. Configure notifications. Select **Next: Notifications**, or select the **Notifications** tab at the top of the page. -1. Define a list of notifications to send when an alert is triggered. -1. For each notification: -- 1. Select the **Notification type**, and then fill in the appropriate fields for that notification. The available options are: -- |Notification type|Description |Fields| - |||| - |Email Azure Resource Manager role|Send an email to the subscription members, based on their role.<br> See [Email](#email-azure-resource-manager).|Enter the primary email address configured for the Microsoft Entra user. See [Email](#email-azure-resource-manager).| - |Email| Ensure that your email filtering and any malware/spam prevention services are configured appropriately. Emails are sent from the following email addresses:<br> * azure-noreply@microsoft.com<br> * azureemail-noreply@microsoft.com<br> * alerts-noreply@mail.windowsazure.com|Enter the email where the notification should be sent.| - |SMS|SMS notifications support bi-directional communication. The SMS contains the following information:<br> * Shortname of the action group this alert was sent to<br> * The title of the alert.<br> A user can respond to an SMS to:<br> * Unsubscribe from all SMS alerts for all action groups or a single action group.<br> * Resubscribe to alerts<br> * Request help.<br> For more information about supported SMS replies, see [SMS replies](#sms-replies).|Enter the **Country code** and the **Phone number** for the SMS recipient. If you can't select your country/region code in the Azure portal, SMS isn't supported for your country/region. If your country/region code isn't available, you can vote to have your country/region added at [Share your ideas](https://feedback.azure.com/d365community/idea/e527eaa6-2025-ec11-b6e6-000d3a4f09d0). As a workaround until your country is supported, configure the action group to call a webhook to a third-party SMS provider that supports your country/region.| - |Azure app Push notifications|Send notifications to the Azure mobile app. To enable push notifications to the Azure mobile app, provide the For more information about the Azure mobile app, see [Azure mobile app](https://azure.microsoft.com/features/azure-portal/mobile-app/).|In the **Azure account email** field, enter the email address that you use as your account ID when you configure the Azure mobile app. | - |Voice | Voice notification.|Enter the **Country code** and the **Phone number** for the recipient of the notification. If you can't select your country/region code in the Azure portal, voice notifications aren't supported for your country/region. If your country/region code isn't available, you can vote to have your country/region added at [Share your ideas](https://feedback.azure.com/d365community/idea/e527eaa6-2025-ec11-b6e6-000d3a4f09d0). As a workaround until your country is supported, configure the action group to call a webhook to a third-party voice call provider that supports your country/region. | -- 1. Select if you want to enable the **Common alert schema**. The common alert schema is a single extensible and unified alert payload that can be used across all the alert services in Azure Monitor. For more information about the common schema, see [Common alert schema](./alerts-common-schema.md). -- :::image type="content" source="~/reusable-content/ce-skilling/azure/media/azure-monitor/action-group-2-notifications.png" alt-text="Screenshot that shows the Notifications tab of the Create action group dialog. Configuration information for an email notification is visible."::: -- 1. Select **OK**. --1. Configure actions. Select **Next: Actions**. or select the **Actions** tab at the top of the page. --1. Define a list of actions to trigger when an alert is triggered. Select an action type and enter a name for each action. -- |Action type|Details | - ||| - |Automation Runbook|Use Automation Runbook to automate tasks based on metrics. For example, shut down resources when a certain threshold in the associated budget is met. For information about limits on Automation runbook payloads, see [Automation limits](../../azure-resource-manager/management/azure-subscription-service-limits.md#automation-limits). | - |Event hubs |An Event Hubs action publishes notifications to Event Hubs. For more information about Event Hubs, see [Azure Event HubsΓÇöA big data streaming platform and event ingestion service](../../event-hubs/event-hubs-about.md). You can subscribe to the alert notification stream from your event receiver. | - |Functions |Calls an existing HTTP trigger endpoint in functions. For more information, see [Azure Functions](../../azure-functions/functions-get-started.md).<br>When you define the function action, the function's HTTP trigger endpoint and access key are saved in the action definition, for example, `https://azfunctionurl.azurewebsites.net/api/httptrigger?code=<access_key>`. If you change the access key for the function, you must remove and re-create the function action in the action group.<br>Your endpoint must support the HTTP POST method.<br>The function must have access to the storage account. If it doesn't have access, keys aren't available and the function URI isn't accessible.<br>[Learn about restoring access to the storage account](../../azure-functions/functions-recover-storage-account.md).| - |ITSM |An ITSM action requires an ITSM connection. To learn how to create an ITSM connection, see [ITSM integration](./itsmc-overview.md). | - |Logic apps |You can use [Azure Logic Apps](../../logic-apps/logic-apps-overview.md) to build and customize workflows for integration and to customize your alert notifications.| - |Secure webhook|When you use a secure webhook action, you must use Microsoft Entra ID to secure the connection between your action group and your endpoint, which is a protected web API. See [Configure authentication for Secure webhook](#configure-authentication-for-secure-webhook). Secure webhook doesn't support basic authentication. If you're using basic authentication, use the Webhook action.| - |Webhook| If you use the webhook action, your target webhook endpoint must be able to process the various JSON payloads that different alert sources emit.<br>You can't pass security certificates through a webhook action. To use basic authentication, you must pass your credentials through the URI.<br>If the webhook endpoint expects a specific schema, for example, the Microsoft Teams schema, use the **Logic Apps** action type to manipulate the alert schema to meet the target webhook's expectations.<br> For information about the rules used for retrying webhook actions, see [Webhook](#webhook).| -- :::image type="content" source="./media/action-groups/action-group-3-actions.png" alt-text="Screenshot that shows the Actions tab of the Create action group dialog. Several options are visible in the Action type list."::: --1. (Optional.) If you'd like to assign a key-value pair to the action group to categorize your Azure resources, select **Next: Tags** or the **Tags** tab. Otherwise, skip this step. -- :::image type="content" source="./media/action-groups/action-group-4-tags.png" alt-text="Screenshot that shows the Tags tab of the Create action group dialog. Values are visible in the Name and Value boxes."::: --1. Select **Review + create** to review your settings. This step quickly checks your inputs to make sure you've entered all required information. If there are issues, they're reported here. After you've reviewed the settings, select **Create** to create the action group. -- :::image type="content" source="./media/action-groups/action-group-5-review.png" alt-text="Screenshot that shows the Review + create tab of the Create action group dialog. All configured values are visible."::: -- > [!NOTE] - > - > When you configure an action to notify a person by email or SMS, they receive a confirmation that indicates they were added to the action group. --### Test an action group in the Azure portal --When you create or update an action group in the Azure portal, you can test the action group. -1. [Create an action group in the Azure portal](#create-an-action-group-in-the-azure-portal). -- > [!NOTE] - > The action group must be created and saved before testing. If you're editing an existing action group, save the changes to the action group before testing. --1. On the action group page, select **Test action group**. -- :::image type="content" source="./media/action-groups/test-action-group.png" alt-text="Screenshot that shows the test action group page with the Test option."::: --1. Select a sample type and the notification and action types that you want to test. Then select **Test**. -- :::image type="content" source="./media/action-groups/test-sample-action-group.png" alt-text="Screenshot that shows the Test sample action group page with an email notification type and a webhook action type."::: --1. If you close the window or select **Back to test setup** while the test is running, the test is stopped, and you don't get test results. -- :::image type="content" source="./media/action-groups/stop-running-test.png" alt-text="Screenshot that shows the Test Sample action group page. A dialog contains a Stop button and asks the user about stopping the test."::: --1. When the test is finished, a test status of either **Success** or **Failed** appears. If the test failed and you want to get more information, select **View details**. -- :::image type="content" source="./media/action-groups/test-sample-failed.png" alt-text="Screenshot that shows the Test sample action group page showing a test that failed."::: -- You can use the information in the **Error details** section to understand the issue. Then you can edit, save changes, and test the action group again. -- When you run a test and select a notification type, you get a message with "Test" in the subject. The tests provide a way to check that your action group works as expected before you enable it in a production environment. All the details and links in test email notifications are from a sample reference set. --### Role requirements for test action groups --The following table describes the role membership requirements that are needed for the *test actions* functionality: --| Role membership | Existing action group | Existing resource group and new action group | New resource group and new action group | -| - | - | -- | - | -| Subscription contributor | Supported | Supported | Supported | -| Resource group contributor | Supported | Supported | Not applicable | -| Action group resource contributor | Supported | Not applicable | Not applicable | -| Azure Monitor contributor | Supported | Supported | Not applicable | -| Custom role<sup>1</sup> | Supported | Supported | Not applicable | --<sup>1</sup> The custom role must have the **Microsoft.Insights/createNotifications/*** permission. -- > [!NOTE] - > - If a user is not a member of the above Role Memberships with the correct permissions to generate this notification, the minimum permission required to test an action group is "**Microsoft.Insights/createNotifications/***" - > - You can run a limited number of tests per time period. To check which limits apply to your situation, see [Azure Monitor service limits](../service-limits.md). - > - When you configure an action group in the portal, you can opt in or out of the common alert schema. - > - To find common schema samples for all sample types, see [Common alert schema definitions for Test Action Group](./alerts-common-schema-test-action-definitions.md). - > - To find non-common schema alert definitions, see [Non-common alert schema definitions for Test Action Group](./alerts-non-common-schema-definitions.md). -## Create an action group with a Resource Manager template -You can use an [Azure Resource Manager template](../../azure-resource-manager/templates/syntax.md) to configure action groups. Using templates, you can automatically set up action groups that can be reused in certain types of alerts. These action groups ensure that all the correct parties are notified when an alert is triggered. --The basic steps are: --1. Create a template as a JSON file that describes how to create the action group. -2. Deploy the template by using [any deployment method](../../azure-resource-manager/templates/deploy-powershell.md). --### Action group Resource Manager templates --To create an action group by using a Resource Manager template, you create a resource of the type `Microsoft.Insights/actionGroups`. Then you fill in all related properties. Here are two sample templates that create an action group. --The first template describes how to create a Resource Manager template for an action group where the action definitions are hard-coded in the template. The second template describes how to create a template that takes the webhook configuration information as input parameters when the template is deployed. --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "actionGroupName": { - "type": "string", - "metadata": { - "description": "Unique name (within the Resource Group) for the Action group." - } - }, - "actionGroupShortName": { - "type": "string", - "metadata": { - "description": "Short name (maximum 12 characters) for the Action group." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/actionGroups", - "apiVersion": "2021-09-01", - "name": "[parameters('actionGroupName')]", - "location": "Global", - "properties": { - "groupShortName": "[parameters('actionGroupShortName')]", - "enabled": true, - "smsReceivers": [ - { - "name": "contosoSMS", - "countryCode": "1", - "phoneNumber": "5555551212" - }, - { - "name": "contosoSMS2", - "countryCode": "1", - "phoneNumber": "5555552121" - } - ], - "emailReceivers": [ - { - "name": "contosoEmail", - "emailAddress": "devops@contoso.com", - "useCommonAlertSchema": true -- }, - { - "name": "contosoEmail2", - "emailAddress": "devops2@contoso.com", - "useCommonAlertSchema": true - } - ], - "webhookReceivers": [ - { - "name": "contosoHook", - "serviceUri": "http://requestb.in/1bq62iu1", - "useCommonAlertSchema": true - }, - { - "name": "contosoHook2", - "serviceUri": "http://requestb.in/1bq62iu2", - "useCommonAlertSchema": true - } - ], - "SecurewebhookReceivers": [ - { - "name": "contososecureHook", - "serviceUri": "http://requestb.in/1bq63iu1", - "useCommonAlertSchema": false - }, - { - "name": "contososecureHook2", - "serviceUri": "http://requestb.in/1bq63iu2", - "useCommonAlertSchema": false - } - ], - "eventHubReceivers": [ - { - "name": "contosoeventhub1", - "subscriptionId": "replace with subscription id GUID", - "eventHubNameSpace": "contosoeventHubNameSpace", - "eventHubName": "contosoeventHub", - "useCommonAlertSchema": true - } - ] - } - } - ], - "outputs":{ - "actionGroupId":{ - "type":"string", - "value":"[resourceId('Microsoft.Insights/actionGroups',parameters('actionGroupName'))]" - } - } -} -``` --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "actionGroupName": { - "type": "string", - "metadata": { - "description": "Unique name (within the Resource Group) for the Action group." - } - }, - "actionGroupShortName": { - "type": "string", - "metadata": { - "description": "Short name (maximum 12 characters) for the Action group." - } - }, - "webhookReceiverName": { - "type": "string", - "metadata": { - "description": "Webhook receiver service Name." - } - }, - "webhookServiceUri": { - "type": "string", - "metadata": { - "description": "Webhook receiver service URI." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/actionGroups", - "apiVersion": "2021-09-01", - "name": "[parameters('actionGroupName')]", - "location": "Global", - "properties": { - "groupShortName": "[parameters('actionGroupShortName')]", - "enabled": true, - "smsReceivers": [ - ], - "emailReceivers": [ - ], - "webhookReceivers": [ - { - "name": "[parameters('webhookReceiverName')]", - "serviceUri": "[parameters('webhookServiceUri')]", - "useCommonAlertSchema": true - } - ] - } - } - ], - "outputs":{ - "actionGroupResourceId":{ - "type":"string", - "value":"[resourceId('Microsoft.Insights/actionGroups',parameters('actionGroupName'))]" - } - } -} -``` -## Manage action groups --After you create an action group, you can view it in the portal: --1. Go to the [Azure portal](https://portal.azure.com). -1. From the **Monitor** page, select **Alerts**. -1. Select **Action groups**. -1. Select the action group that you want to manage. You can: -- - Add, edit, or remove actions. - - Delete the action group. --## Service limits for notifications --A phone number or email can be included in action groups in many subscriptions. Azure Monitor uses rate limiting to suspend notifications when too many notifications are sent to a particular phone number, email address or device. Rate limiting ensures that alerts are manageable and actionable. --Rate limiting applies to SMS, voice, and email notifications. All other notification actions aren't rate limited. Rate limiting applies across all subscriptions. Rate limiting is applied as soon as the threshold is reached, even if messages are sent from multiple subscriptions. When an email address is rate limited, a notification is sent to communicate that rate limiting was applied and when the rate limiting expires. --For information about rate limits, see [Azure Monitor service limits](../service-limits.md). - -## Email Azure Resource Manager --When you use Azure Resource Manager for email notifications, you can send email to the members of a subscription's role. Email is sent to Microsoft Entra ID **user** or **group** members of the role. This includes support for roles assigned through Azure Lighthouse. --> [!NOTE] -> Action Groups only supports emailing the following roles: Owner, Contributor, Reader, Monitoring Contributor, Monitoring Reader. --If your primary email doesn't receive notifications, configure the email address for the Email Azure Resource Manager role: --1. In the Azure portal, go to **Microsoft Entra ID**. -1. On the left, select **All users**. On the right, a list of users appears. -1. Select the user whose *primary email* you want to review. -- :::image type="content" source="media/action-groups/active-directory-user-profile.png" alt-text="Screenshot that shows the Azure portal All users page. Information about one user is visible but is indecipherable." border="true"::: --1. In the user profile, look under **Contact info** for an **Email** value. If it's blank: -- 1. At the top of the page, select **Edit**. - 1. Enter an email address. - 1. At the top of the page, select **Save**. -- :::image type="content" source="media/action-groups/active-directory-add-primary-email.png" alt-text="Screenshot that shows a user profile page in the Azure portal. The Edit button and the Email box are called out." border="true"::: --You may have a limited number of email actions per action group. To check which limits apply to your situation, see [Azure Monitor service limits](../service-limits.md). --When you set up the Resource Manager role: --1. Assign an entity of type **User** or **Group** to the role. -1. Make the assignment at the **subscription** level. -1. Make sure an email address is configured for the user in their **Microsoft Entra profile**. -> - If a user is not a member of the above Role Memberships with the correct permissions to generate this notification, the minimum permission required to test an action group is "**Microsoft.Insights/createNotifications/***" -> - You can run a limited number of tests per time period. To check which limits, apply to your situation, see [Azure Monitor service limits](../service-limits.md). -> - When you configure an action group in the portal, you can opt in or out of the common alert schema. -> - To find common schema samples for all sample types, see [Common alert schema definitions for Test Action Group](./alerts-common-schema-test-action-definitions.md). -> - To find non-common schema alert definitions, see [Non-common alert schema definitions for Test Action Group](./alerts-non-common-schema-definitions.md). -> [!NOTE] -> -> It can take up to 24 hours for a customer to start receiving notifications after they add a new Azure Resource Manager role to their subscription. -## SMS --You might have a limited number of SMS actions per action group. --- For information about rate limits, see [Azure Monitor service limits](../service-limits.md).-- For important information about using SMS notifications in action groups, see [SMS alert behavior in action groups](./alerts-sms-behavior.md).---> [!NOTE] -> -> If you can't select your country/region code in the Azure portal, SMS isn't supported for your country/region. If your country/region code isn't available, you can vote to have your country/region added at [Share your ideas](https://feedback.azure.com/d365community/idea/e527eaa6-2025-ec11-b6e6-000d3a4f09d0). In the meantime, as a workaround, configure your action group to call a webhook to a third-party SMS provider that offers support in your country/region. -### SMS replies --These replies are supported for SMS notifications. The recipient of the SMS can reply to the SMS with these values: --| REPLY | Description | -| -- | -- | -| DISABLE `<Action Group Short name>` | Disables further SMS from the Action Group | -| ENABLE `<Action Group Short name>` | Re-enables SMS from the Action Group | -| STOP | Disables further SMS from all Action Groups | -| START | Re-enables SMS from ALL Action Groups | -| HELP | A response is sent to the user with a link to this article. | -->[!NOTE] ->If a user has unsubscribed from SMS alerts, but is then added to a new action group; they WILL receive SMS alerts for that new action group, but remain unsubscribed from all previous action groups. -You might have a limited number of Azure app actions per action group. -### Countries/Regions with SMS notification support --| Country code | Country | -|:|:| -| 61 | Australia | -| 43 | Austria | -| 32 | Belgium | -| 55 | Brazil | -| 1 |Canada | -| 56 | Chile | -| 86 | China | -| 420 | Czech Republic | -| 45 | Denmark | -| 372 | Estonia | -| 358 | Finland | -| 33 | France | -| 49 | Germany | -| 852 | Hong Kong Special Administrative Region| -| 91 | India | -| 353 | Ireland | -| 972 | Israel | -| 39 | Italy | -| 81 | Japan | -| 352 | Luxembourg | -| 60 | Malaysia | -| 52 | Mexico | -| 31 | Netherlands | -| 64 | New Zealand | -| 47 | Norway | -| 351 | Portugal | -| 1 | Puerto Rico | -| 40 | Romania | -| 7 | Russia | -| 65 | Singapore | -| 27 | South Africa | -| 82 | South Korea | -| 34 | Spain | -| 41 | Switzerland | -| 886 | Taiwan | -| 971 | UAE | -| 44 | United Kingdom | -| 1 | United States | --## Voice -You might have a limited number of voice actions per action group. For important information about rate limits, see [Azure Monitor service limits](../service-limits.md). ----> [!NOTE] -> -> If you can't select your country/region code in the Azure portal, voice calls aren't supported for your country/region. If your country/region code isn't available, you can vote to have your country/region added at [Share your ideas](https://feedback.azure.com/d365community/idea/e527eaa6-2025-ec11-b6e6-000d3a4f09d0). In the meantime, as a workaround, configure your action group to call a webhook to a third-party voice call provider that offers support in your country/region. If a country is marked with an '*' calls will come from a USA based phone number. -### Countries/Regions with Voice notification support -| Country code | Country | -|:|:| -| 61 | Australia | -| 43 | Austria | -| 32 | Belgium | -| 55 | Brazil | -| 1 |Canada | -| 56 | Chile | -| 86 | China* | -| 420 | Czech Republic | -| 45 | Denmark | -| 372 | Estonia | -| 358 | Finland | -| 33 | France | -| 49 | Germany | -| 852 | Hong Kong* | -| 91 | India* | -| 353 | Ireland | -| 972 | Israel | -| 39 | Italy* | -| 81 | Japan* | -| 352 | Luxembourg | -| 60 | Malaysia | -| 52 | Mexico | -| 31 | Netherlands | -| 64 | New Zealand | -| 47 | Norway | -| 351 | Portugal | -| 40 | Romania* | -| 7 | Russia* | -| 65 | Singapore | -| 27 | South Africa | -| 82 | South Korea | -| 34 | Spain | -| 46 | Sweeden | -| 41 | Switzerland | -| 886 | Taiwan* | -| 971 | United Arab Emirates* | -| 44 | United Kingdom | -| 1 | United States | --For information about pricing for supported countries/regions, see [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/). -## Webhook --> [!NOTE] -> If you use the webhook action, your target webhook endpoint must be able to process the various JSON payloads that different alert sources emit. The webhook endpoint must also be publicly accessible. You can't pass security certificates through a webhook action. To use basic authentication, you must pass your credentials through the URI. If the webhook endpoint expects a specific schema, for example, the Microsoft Teams schema, use the Logic Apps action to transform the alert schema to meet the target webhook's expectations. -Webhook action groups generally follow these rules when called: -- When a webhook is invoked, if the first call fails, it is retried at least 1 more time, and up to 5 times (5 retries) at various delay intervals (5, 20, 40 seconds).- - The delay between 1st and 2nd attempt is 5 seconds - - The delay between 2nd and 3rd attempt is 20 seconds - - The delay between 3rd and 4th attempt is 5 seconds - - The delay between 4th and 5th attempt is 40 seconds - - The delay between 5th and 6th attempt is 5 seconds -- After retries attempted to call the webhook fail, no action group calls the endpoint for 15 minutes.-- The retry logic assumes that the call can be retried. The status codes: 408, 429, 503, 504, or HttpRequestException, WebException, `TaskCancellationException` allow for the call to be retriedΓÇ¥.--### Configure authentication for Secure webhook --The secure webhook action authenticates to the protected API by using a Service Principal instance in the Microsoft Entra tenant of the "AZNS Microsoft Entra Webhook" Microsoft Entra application. To make the action group work, this Microsoft Entra Webhook Service Principal must be added as a member of a role on the target Microsoft Entra application that grants access to the target endpoint. --For an overview of Microsoft Entra applications and service principals, see [Microsoft identity platform (v2.0) overview](../../active-directory/develop/v2-overview.md). Follow these steps to take advantage of the secure webhook functionality. --> [!NOTE] -> -> Basic authentication isn't supported for `SecureWebhook`. To use basic authentication, you must use `Webhook`. -If you use the webhook action, your target webhook endpoint must be able to process the various JSON payloads that different alert sources emit. If the webhook endpoint expects a specific schema, for example, the Microsoft Teams schema, use the Logic Apps action to transform the alert schema to meet the target webhook's expectations. ---1. Create a Microsoft Entra application for your protected web API. For more information, see [Protected web API: App registration](../../active-directory/develop/scenario-protected-web-api-app-registration.md). Configure your protected API to be called by a daemon app and expose application permissions, not delegated permissions. For more information about these permissions, see [If your web API is called by a service or daemon app](../../active-directory/develop/scenario-protected-web-api-app-registration.md#if-your-web-api-is-called-by-a-service-or-daemon-app). -- > [!NOTE] - > - > Configure your protected web API to accept V2.0 access tokens. For more information about this setting, see [Microsoft Entra app manifest](../../active-directory/develop/reference-app-manifest.md#accesstokenacceptedversion-attribute). -1. To enable the action group to use your Microsoft Entra application, use the PowerShell script that follows this procedure. -- > [!NOTE] - > - > You must be assigned the [Microsoft Entra Application Administrator role](../../active-directory/roles/permissions-reference.md#all-roles) to run this script. - 1. Modify the PowerShell script's `Connect-AzureAD` call to use your Microsoft Entra tenant ID. - 1. Modify the PowerShell script's `$myAzureADApplicationObjectId` variable to use the object ID of your Microsoft Entra application. - 1. Run the modified script. -- > [!NOTE] - > - > The service principal must be assigned an **owner role** of the Microsoft Entra application to be able to create or modify the secure webhook action in the action group. -1. Configure the secure webhook action. -- 1. Copy the `$myApp.ObjectId` value that's in the script. - 1. In the webhook action definition, in the **Object Id** box, enter the value that you copied. -- :::image type="content" source="./media/action-groups/action-groups-secure-webhook.png" alt-text="Screenshot that shows the Secured Webhook dialog in the Azure portal with the Object ID box." border="true"::: --### Secure webhook PowerShell script --> [!NOTE] -> ->Pre-requisites: [Install the Microsoft Graph PowerShell SDK](/powershell/microsoftgraph/installation?view=graph-powershell-1.0&preserve-view=true) --#### How to run? --1. Copy and paste the script below to your machine -2. Replace your tenantId, and the ObjectID in your App Registration -3. Save as *.ps1 -4. Open the PowerShell command from your machine, and run the *.ps1 script --```PowerShell -Write-Host "=================================================================================================" -$scopes = "Application.ReadWrite.All" -$myTenantId = "<<Customer's tenant id>>" -$myMicrosoftEntraAppRegistrationObjectId = "<<Customer's object id from the app registration>>" -$actionGroupRoleName = "ActionGroupsSecureWebhook" -$azureMonitorActionGroupsAppId = "461e8683-5575-4561-ac7f-899cc907d62a" # Required. Do not change. --Connect-MgGraph -Scopes $scopes -TenantId $myTenantId --Function CreateAppRole([string] $Name, [string] $Description) -{ - $appRole = @{ - AllowedMemberTypes = @("Application") - DisplayName = $Name - Id = New-Guid - IsEnabled = $true - Description = $Description - Value = $Name - } - return $appRole -} --$myApp = Get-MgApplication -ApplicationId $myMicrosoftEntraAppRegistrationObjectId -$myAppRoles = $myApp.AppRoles -$myActionGroupServicePrincipal = Get-MgServicePrincipal -Filter "appId eq '$azureMonitorActionGroupsAppId'" --Write-Host "App Roles before addition of new role.." -foreach ($role in $myAppRoles) { Write-Host $role.Value } --if ($myAppRoles.Value -contains $actionGroupRoleName) -{ - Write-Host "The Action Group role is already defined. No need to redefine.`n" - # Retrieve the application again to get the updated roles - $myApp = Get-MgApplication -ApplicationId $myMicrosoftEntraAppRegistrationObjectId - $myAppRoles = $myApp.AppRoles -} -else -{ - Write-Host "The Action Group role is not defined. Defining the role and adding it." - $newRole = CreateAppRole -Name $actionGroupRoleName -Description "This is a role for Action Group to join" - $myAppRoles += $newRole - Update-MgApplication -ApplicationId $myApp.Id -AppRole $myAppRoles -- # Retrieve the application again to get the updated roles - $myApp = Get-MgApplication -ApplicationId $myMicrosoftEntraAppRegistrationObjectId - $myAppRoles = $myApp.AppRoles -} --$myServicePrincipal = Get-MgServicePrincipal -Filter "appId eq '$($myApp.AppId)'" --if ($myActionGroupServicePrincipal.DisplayName -contains "AzNS AAD Webhook") -{ - Write-Host "The Service principal is already defined.`n" - Write-Host "The action group Service Principal is: " + $myActionGroupServicePrincipal.DisplayName + " and the id is: " + $myActionGroupServicePrincipal.Id -} -else -{ - Write-Host "The Service principal has NOT been defined/created in the tenant.`n" - $myActionGroupServicePrincipal = New-MgServicePrincipal -AppId $azureMonitorActionGroupsAppId - Write-Host "The Service Principal is been created successfully, and the id is: " + $myActionGroupServicePrincipal.Id -} --# Check if $myActionGroupServicePrincipal is not $null before trying to access its Id property -# Check if the role assignment already exists -$existingRoleAssignment = Get-MgServicePrincipalAppRoleAssignment -ServicePrincipalId $myActionGroupServicePrincipal.Id | Where-Object { $_.AppRoleId -eq $myApp.AppRoles[0].Id -and $_.PrincipalId -eq $myActionGroupServicePrincipal.Id -and $_.ResourceId -eq $myServicePrincipal.Id } --# If the role assignment does not exist, create it -if ($null -eq $existingRoleAssignment) { - Write-Host "Doing app role assignment to the new action group Service Principal`n" - New-MgServicePrincipalAppRoleAssignment -ServicePrincipalId $myActionGroupServicePrincipal.Id -AppRoleId $myApp.AppRoles[0].Id -PrincipalId $myActionGroupServicePrincipal.Id -ResourceId $myServicePrincipal.Id -} else { - Write-Host "Skip assigning because the role already existed." -} --Write-Host "myServicePrincipalId: " $myServicePrincipal.Id -Write-Host "My Azure AD Application (ObjectId): " $myApp.Id -Write-Host "My Azure AD Application's Roles" -foreach ($role in $myAppRoles) { Write-Host $role.Value } --Write-Host "=================================================================================================" -``` -### Migrate Runbook action from "Run as account" to "Run as Managed Identity" -> [!NOTE] -> -> Azure Automation "Run as account" has [retired](https://azure.microsoft.com/updates/azure-automation-runas-account-retiring-on-30-september-2023/) on 30 September 2023, which affects actions created with action type "Automation Runbook". Existing actions linking to "Run as account" runbooks won't be supported after retirement. However, those runbooks would continue to execute until the expiry of "Run as" certificate of the Automation account. -To ensure you can continue using the runbook actions, you need to: -1. Edit the action group by adding a new action with action type "Automation Runbook" and choose the same runbook from the dropdown. (All 5 runbooks in the dropdown have been reconfigured at the backend to authenticate using Managed Identity instead of Run as account. System-assigned Managed Identity in Automation account would be enabled with VM Contributor role at the subscription level would be assigned automatically.) -- :::image type="content" source="./media/action-groups/action-group-runbook-add.png" alt-text="Screenshot of adding a runbook action to an action group."::: -- :::image type="content" source="./media/action-groups/action-group-runbook-configure.png" alt-text="Screenshot of configuring the runbook action."::: --2. Delete old runbook action which links to a "Run as account" runbook. -3. Save the action group. --## Next steps --- Get an [overview of alerts](./alerts-overview.md) and learn how to receive alerts.-- Learn more about the [ITSM Connector](./itsmc-overview.md).-- Learn about the [activity log alert webhook schema](./activity-log-alerts-webhook.md). |
| azure-monitor | Activity Log Alerts Webhook | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/activity-log-alerts-webhook.md | - Title: Configure a webhook to get activity log alerts -description: Learn about the schema of the JSON that's posted to a webhook URL when an activity log alert activates. --- Previously updated : 04/01/2024---# Configure a webhook to get activity log alerts --As part of the definition of an action group, you can configure webhook endpoints to receive activity log alert notifications. With webhooks, you can route these notifications to other systems for post-processing or custom actions. This article shows what the payload for the HTTP POST to a webhook looks like. --For more information on activity log alerts, see how to [create Azure activity log alerts](./activity-log-alerts.md). --For information on action groups, see how to [create action groups](./action-groups.md). --> [!NOTE] -> You can also use the [common alert schema](./alerts-common-schema.md) for your webhook integrations. It provides the advantage of having a single extensible and unified alert payload across all the alert services in Azure Monitor. [Learn about the common alert schema](./alerts-common-schema.md)ΓÇï. --## Authenticate the webhook --The webhook can optionally use token-based authorization for authentication. The webhook URI is saved with a token ID, for example, `https://mysamplealert/webcallback?tokenid=sometokenid&someparameter=somevalue`. --## Payload schema --The JSON payload contained in the POST operation differs based on the payload's `data.context.activityLog.eventSource` field. --> [!NOTE] -> Currently, the description that's part of the activity log event is copied to the fired `Alert Description` property. -> -> To align the activity log payload with other alert types, as of April 1, 2021, the fired alert property `Description` contains the alert rule description instead. -> -> In preparation for that change, we created a new property, `Activity Log Event Description`, to the activity log fired alert. This new property is filled with the `Description` property that's already available for use. So, the new field `Activity Log Event Description` contains the description that's part of the activity log event. -> -> Review your alert rules, action rules, webhooks, logic app, or any other configurations where you might be using the `Description` property from the fired alert. Replace the `Description` property with the `Activity Log Event Description` property. -> -> If your condition in your action rules, webhooks, logic app, or any other configurations is currently based on the `Description` property for activity log alerts, you might need to modify it to be based on the `Activity Log Event Description` property instead. -> -> To fill the new `Description` property, you can add a description in the alert rule definition. --> :::image type="content" source="media/activity-log-alerts-webhook/activity-log-alert-fired.png" lightbox="media/activity-log-alerts-webhook/activity-log-alert-fired.png" alt-text="Screenshot that shows fired activity log alerts."::: --### Common --```json -{ - "schemaId": "Microsoft.Insights/activityLogs", - "data": { - "status": "Activated", - "context": { - "activityLog": { - "channels": "Operation", - "correlationId": "6ac88262-43be-4adf-a11c-bd2179852898", - "eventSource": "Administrative", - "eventTimestamp": "2017-03-29T15:43:08.0019532+00:00", - "eventDataId": "8195a56a-85de-4663-943e-1a2bf401ad94", - "level": "Informational", - "operationName": "Microsoft.Insights/actionGroups/write", - "operationId": "6ac88262-43be-4adf-a11c-bd2179852898", - "status": "Started", - "subStatus": "", - "subscriptionId": "52c65f65-0518-4d37-9719-7dbbfc68c57a", - "submissionTimestamp": "2017-03-29T15:43:20.3863637+00:00", - ... - } - }, - "properties": {} - } -} -``` --### Administrative --```json -{ - "schemaId": "Microsoft.Insights/activityLogs", - "data": { - "status": "Activated", - "context": { - "activityLog": { - "authorization": { - "action": "Microsoft.Insights/actionGroups/write", - "scope": "/subscriptions/52c65f65-0518-4d37-9719-7dbbfc68c57b/resourceGroups/CONTOSO-TEST/providers/Microsoft.Insights/actionGroups/IncidentActions" - }, - "claims": "{...}", - "caller": "me@contoso.com", - "description": "", - "httpRequest": "{...}", - "resourceId": "/subscriptions/52c65f65-0518-4d37-9719-7dbbfc68c57b/resourceGroups/CONTOSO-TEST/providers/Microsoft.Insights/actionGroups/IncidentActions", - "resourceGroupName": "CONTOSO-TEST", - "resourceProviderName": "Microsoft.Insights", - "resourceType": "Microsoft.Insights/actionGroups" - } - }, - "properties": {} - } -} -``` --### Security --```json -{ - "schemaId":"Microsoft.Insights/activityLogs", - "data":{"status":"Activated", - "context":{ - "activityLog":{ - "channels":"Operation", - "correlationId":"2518408115673929999", - "description":"Failed SSH brute force attack. Failed brute force attacks were detected from the following attackers: [\"IP Address: 01.02.03.04\"]. Attackers were trying to access the host with the following user names: [\"root\"].", - "eventSource":"Security", - "eventTimestamp":"2017-06-25T19:00:32.607+00:00", - "eventDataId":"Sec-07f2-4d74-aaf0-03d2f53d5a33", - "level":"Informational", - "operationName":"Microsoft.Security/locations/alerts/activate/action", - "operationId":"Sec-07f2-4d74-aaf0-03d2f53d5a33", - "properties":{ - "attackers":"[\"IP Address: 01.02.03.04\"]", - "numberOfFailedAuthenticationAttemptsToHost":"456", - "accountsUsedOnFailedSignInToHostAttempts":"[\"root\"]", - "wasSSHSessionInitiated":"No","endTimeUTC":"06/25/2017 19:59:39", - "actionTaken":"Detected", - "resourceType":"Virtual Machine", - "severity":"Medium", - "compromisedEntity":"LinuxVM1", - "remediationSteps":"[In case this is an Azure virtual machine, add the source IP to NSG block list for 24 hours (see https://azure.microsoft.com/documentation/articles/virtual-networks-nsg/)]", - "attackedResourceType":"Virtual Machine" - }, - "resourceId":"/subscriptions/12345-5645-123a-9867-123b45a6789/resourceGroups/contoso/providers/Microsoft.Security/locations/centralus/alerts/Sec-07f2-4d74-aaf0-03d2f53d5a33", - "resourceGroupName":"contoso", - "resourceProviderName":"Microsoft.Security", - "status":"Active", - "subscriptionId":"12345-5645-123a-9867-123b45a6789", - "submissionTimestamp":"2017-06-25T20:23:04.9743772+00:00", - "resourceType":"MICROSOFT.SECURITY/LOCATIONS/ALERTS" - } - }, - "properties":{} - } -} -``` --### Recommendation --```json -{ - "schemaId":"Microsoft.Insights/activityLogs", - "data":{ - "status":"Activated", - "context":{ - "activityLog":{ - "channels":"Operation", - "claims":"{\"http://schemas.xmlsoap.org/ws/2005/05/identity/claims/emailaddress\":\"Microsoft.Advisor\"}", - "caller":"Microsoft.Advisor", - "correlationId":"123b4c54-11bb-3d65-89f1-0678da7891bd", - "description":"A new recommendation is available.", - "eventSource":"Recommendation", - "eventTimestamp":"2017-06-29T13:52:33.2742943+00:00", - "httpRequest":"{\"clientIpAddress\":\"0.0.0.0\"}", - "eventDataId":"1bf234ef-e45f-4567-8bba-fb9b0ee1dbcb", - "level":"Informational", - "operationName":"Microsoft.Advisor/recommendations/available/action", - "properties":{ - "recommendationSchemaVersion":"1.0", - "recommendationCategory":"HighAvailability", - "recommendationImpact":"Medium", - "recommendationName":"Enable Soft Delete to protect your blob data", - "recommendationResourceLink":"https://portal.azure.com/#blade/Microsoft_Azure_Expert/RecommendationListBlade/recommendationTypeId/12dbf883-5e4b-4f56-7da8-123b45c4b6e6", - "recommendationType":"12dbf883-5e4b-4f56-7da8-123b45c4b6e6" - }, - "resourceId":"/subscriptions/12345-5645-123a-9867-123b45a6789/resourceGroups/contoso/providers/microsoft.storage/storageaccounts/contosoStore", - "resourceGroupName":"CONTOSO", - "resourceProviderName":"MICROSOFT.STORAGE", - "status":"Active", - "subStatus":"", - "subscriptionId":"12345-5645-123a-9867-123b45a6789", - "submissionTimestamp":"2017-06-29T13:52:33.2742943+00:00", - "resourceType":"MICROSOFT.STORAGE/STORAGEACCOUNTS" - } - }, - "properties":{} - } -} -``` --### ServiceHealth --```json -{ - "schemaId": "Microsoft.Insights/activityLogs", - "data": { - "status": "Activated", - "context": { - "activityLog": { - "channels": "Admin", - "correlationId": "bbac944f-ddc0-4b4c-aa85-cc7dc5d5c1a6", - "description": "Active: Virtual Machines - Australia East", - "eventSource": "ServiceHealth", - "eventTimestamp": "2017-10-18T23:49:25.3736084+00:00", - "eventDataId": "6fa98c0f-334a-b066-1934-1a4b3d929856", - "level": "Informational", - "operationName": "Microsoft.ServiceHealth/incident/action", - "operationId": "bbac944f-ddc0-4b4c-aa85-cc7dc5d5c1a6", - "properties": { - "title": "Virtual Machines - Australia East", - "service": "Virtual Machines", - "region": "Australia East", - "communication": "Starting at 02:48 UTC on 18 Oct 2017 you have been identified as a customer using Virtual Machines in Australia East who may receive errors starting Dv2 Promo and DSv2 Promo Virtual Machines which are in a stopped "deallocated" or suspended state. Customers can still provision Dv1 and Dv2 series Virtual Machines or try deploying Virtual Machines in other regions, as a possible workaround. Engineers have identified a possible fix for the underlying cause, and are exploring implementation options. The next update will be provided as events warrant.", - "incidentType": "Incident", - "trackingId": "0NIH-U2O", - "impactStartTime": "2017-10-18T02:48:00.0000000Z", - "impactedServices": "[{\"ImpactedRegions\":[{\"RegionName\":\"Australia East\"}],\"ServiceName\":\"Virtual Machines\"}]", - "defaultLanguageTitle": "Virtual Machines - Australia East", - "defaultLanguageContent": "Starting at 02:48 UTC on 18 Oct 2017 you have been identified as a customer using Virtual Machines in Australia East who may receive errors starting Dv2 Promo and DSv2 Promo Virtual Machines which are in a stopped "deallocated" or suspended state. Customers can still provision Dv1 and Dv2 series Virtual Machines or try deploying Virtual Machines in other regions, as a possible workaround. Engineers have identified a possible fix for the underlying cause, and are exploring implementation options. The next update will be provided as events warrant.", - "stage": "Active", - "communicationId": "636439673646212912", - "version": "0.1.1" - }, - "status": "Active", - "subscriptionId": "45529734-0ed9-4895-a0df-44b59a5a07f9", - "submissionTimestamp": "2017-10-18T23:49:28.7864349+00:00" - } - }, - "properties": {} - } -} -``` --For specific schema details on service health notification activity log alerts, see [Service health notifications](../../service-health/service-notifications.md). You can also learn how to [configure service health webhook notifications with your existing problem management solutions](../../service-health/service-health-alert-webhook-guide.md). --### ResourceHealth --```json -{ - "schemaId": "Microsoft.Insights/activityLogs", - "data": { - "status": "Activated", - "context": { - "activityLog": { - "channels": "Admin, Operation", - "correlationId": "a1be61fd-37ur-ba05-b827-cb874708babf", - "eventSource": "ResourceHealth", - "eventTimestamp": "2018-09-04T23:09:03.343+00:00", - "eventDataId": "2b37e2d0-7bda-4de7-ur8c6-1447d02265b2", - "level": "Informational", - "operationName": "Microsoft.Resourcehealth/healthevent/Activated/action", - "operationId": "2b37e2d0-7bda-489f-81c6-1447d02265b2", - "properties": { - "title": "Virtual Machine health status changed to unavailable", - "details": "Virtual machine has experienced an unexpected event", - "currentHealthStatus": "Unavailable", - "previousHealthStatus": "Available", - "type": "Downtime", - "cause": "PlatformInitiated" - }, - "resourceId": "/subscriptions/<subscription Id>/resourceGroups/<resource group>/providers/Microsoft.Compute/virtualMachines/<resource name>", - "resourceGroupName": "<resource group>", - "resourceProviderName": "Microsoft.Resourcehealth/healthevent/action", - "status": "Active", - "subscriptionId": "<subscription Id>", - "submissionTimestamp": "2018-09-04T23:11:06.1607287+00:00", - "resourceType": "Microsoft.Compute/virtualMachines" - } - } - } -} -``` --| Element name | Description | -| | | -| status |Used for metric alerts. Always set to `activated` for activity log alerts. | -| context |Context of the event. | -| resourceProviderName |The resource provider of the affected resource. | -| conditionType |Always `Event`. | -| name |Name of the alert rule. | -| ID |Resource ID of the alert. | -| description |Alert description set when the alert is created. | -| subscriptionId |Azure subscription ID. | -| timestamp |Time at which the event was generated by the Azure service that processed the request. | -| resourceId |Resource ID of the affected resource. | -| resourceGroupName |Name of the resource group for the affected resource. | -| properties |Set of `<Key, Value>` pairs (that is, `Dictionary<String, String>`) that includes details about the event. | -| event |Element that contains metadata about the event. | -| authorization |The Azure role-based access control properties of the event. These properties usually include the action, the role, and the scope. | -| category |Category of the event. Supported values include `Administrative`, `Alert`, `Security`, `ServiceHealth`, and `Recommendation`. | -| caller |Email address of the user who performed the operation, UPN claim, or SPN claim based on availability. Can be null for certain system calls. | -| correlationId |Usually a GUID in string format. Events with `correlationId` belong to the same larger action and usually share a `correlationId`. | -| eventDescription |Static text description of the event. | -| eventDataId |Unique identifier for the event. | -| eventSource |Name of the Azure service or infrastructure that generated the event. | -| httpRequest |The request usually includes the `clientRequestId`, `clientIpAddress`, and HTTP method (for example, PUT). | -| level |One of the following values: `Critical`, `Error`, `Warning`, and `Informational`. | -| operationId |Usually a GUID shared among the events corresponding to a single operation. | -| operationName |Name of the operation. | -| properties |Properties of the event. | -| status |String. Status of the operation. Common values include `Started`, `In Progress`, `Succeeded`, `Failed`, `Active`, and `Resolved`. | -| subStatus |Usually includes the HTTP status code of the corresponding REST call. It might also include other strings that describe a substatus. Common substatus values include `OK` (HTTP Status Code: 200), `Created` (HTTP Status Code: 201), `Accepted` (HTTP Status Code: 202), `No Content` (HTTP Status Code: 204), `Bad Request` (HTTP Status Code: 400), `Not Found` (HTTP Status Code: 404), `Conflict` (HTTP Status Code: 409), `Internal Server Error` (HTTP Status Code: 500), `Service Unavailable` (HTTP Status Code: 503), and `Gateway Timeout` (HTTP Status Code: 504). | --For specific schema details on all other activity log alerts, see [Overview of the Azure activity log](../essentials/platform-logs-overview.md). --## Next steps --* [Learn more about the activity log](../essentials/platform-logs-overview.md). -* [Execute Azure Automation scripts (Runbooks) on Azure alerts](https://go.microsoft.com/fwlink/?LinkId=627081). -* [Use a logic app to send an SMS via Twilio from an Azure alert](https://github.com/Azure/azure-quickstart-templates/tree/master/demos/alert-to-text-message-with-logic-app). This example is for metric alerts, but it can be modified to work with an activity log alert. -* [Use a logic app to send a Slack message from an Azure alert](https://github.com/Azure/azure-quickstart-templates/tree/master/demos/alert-to-slack-with-logic-app). This example is for metric alerts, but it can be modified to work with an activity log alert. -* [Use a logic app to send a message to an Azure queue from an Azure alert](https://github.com/Azure/azure-quickstart-templates/tree/master/demos/alert-to-queue-with-logic-app). This example is for metric alerts, but it can be modified to work with an activity log alert. |
| azure-monitor | Alert Options | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alert-options.md | - Title: Create alert rules for an Azure resource -description: Describes the different options for creating alert rules in Azure Monitor and where you can find more information about each option. --- Previously updated : 02/16/2024-----# Create alert rules for Azure resources -Alerts in Azure Monitor proactively notify you of critical conditions based on collected telemetry and potentially attempt to take corrective action. Alerts are generated from alert rules which define the criteria for the alert and what action to take when the alert triggers. There are no alert rules created by default in Azure Monitor. In addition to creating your own, there are multiple options for getting started quickly with alert rules based on pre-defined conditions, and different options are available for different Azure services. This article describes the different options for creating alert rules in Azure Monitor and where you can find more information about each option. ---## Recommended alerts -Recommended alerts is a feature in Azure Monitor for some services that allows you to quickly create a set of alert rules for a particular resource. Simply select **Set up recommendations** from the **Alerts** tab for the resource in the Azure portal, and select the rules you want to enable. This feature isn't available for all services, and you need to select the option for each resource you want to monitor. One strategy is to use the recommended alerts as guidance for the alert rules that should be created for a particular type of resource. You can use [Azure Policy](#azure-policy) to automatically create these same alert rules for all resources of a particular type. ---## Azure Monitor Baseline Alerts (AMBA) -AMBA is a central repository that combines product group and field experience driven alert definitions that allow customers and partners to improve their observability experience through the adoption of Azure Monitor. It's organized by resource type so you can quickly identify alert definitions that fit your requirements. AMBA leverages Azure Monitor alerts and helps you detect and address issues consistently and at scale indicating problems with monitored resource in your infrastructure. AMBA includes definitions for both metric and log alerts for resources including: --- Service Health-- Compute resources-- Networking resources-- Many more--AMBA also includes example snippets of alert definitions to be directly used in an ARM or BICEP deployments in addition to policy definitions. Read more about on Azure Landing Zone monitoring at [Monitor Azure platform landing zone components](/azure/cloud-adoption-framework/ready/landing-zone/design-area/management-monitor#azure-landing-zone-monitoring-guidance) . --AMBA has patterns that group alerts from different resource types to address specific scenarios. Azure landing zone (ALZ), which is also suitable for non-ALZ aligned customers, is a pattern of AMBA that collates platform alerts into a deployable at-scale solution. Other patterns are under development including SAP and Azure Virtual Desktop, which are intended to minimize friction in adopting observability into your environment. --See [Azure Monitor Baseline Alerts](https://aka.ms/amba) for details. --## Manual alert rules -You can manually create alert rules for any of your Azure resources using the appropriate metric values or log queries as a signal. You must create and maintain each alert rule for each resource individually, so you will probably want to use one of the other options when they're applicable and only manually create alert rules for special cases. Multiple services in Azure have documentation articles that describe recommended telemetry to collect and alert rules that are recommended for that service. These articles are typically found in the **Monitor** section of the service's documentation. For example, [Monitor Azure virtual machines](/azure/virtual-machines/monitor-vm) and [Monitor Azure Kubernetes Service (AKS)](/azure/aks/monitor-aks). --See [Choosing the right type of alert rule](./alerts-types.md) for more information about the different types of alert rules and articles such as [Create or edit a metric alert rule](./alerts-create-metric-alert-rule.yml) and [Create or edit a log alert rule](./alerts-create-log-alert-rule.md) for detailed guidance on manually creating alert rules. --## Azure Policy -Using [Azure Policy](../../governance/policy/overview.md), you can automatically create alert rules for all resources of a particular type instead of manually creating rules for each individual resource. You still must define the alerting condition, but the alert rules for each resource will automatically be created for you, for both existing resources and any new ones that you create. --See [Resource Manager template samples for metric alert rules in Azure Monitor](./resource-manager-alerts-metric.md) and [Resource Manager template samples for log alert rules in Azure Monitor](./resource-manager-alerts-log.md) for ARM templates that can be used in policy definitions. --## Next steps --- [Read more about alerts in Azure Monitor](./alerts-overview.md) |
| azure-monitor | Alerts Common Schema | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-common-schema.md | - Title: Common alert schema for Azure Monitor alerts -description: Understand the common alert schema, why you should use it, and how to enable it. - Previously updated : 12/24/2023------# Common alert schema --The common alert schema standardizes the consumption of Azure Monitor alert notifications. Historically, activity log, metric, and log search alerts each had their own email templates and webhook schemas. The common alert schema provides one standardized schema for all alert notifications. --Using a standardized schema helps minimize the number of integrations, which simplifies the process of managing and maintaining your integrations. The common schema enables a richer alert consumption experience in both the Azure portal and the Azure mobile app. --The common alert schema provides a consistent structure for: -- **Email templates**: Use the detailed email template to diagnose issues at a glance. Embedded links to the alert instance on the portal and to the affected resource ensure that you can quickly jump into the remediation process. -- **JSON structure**: Use the consistent JSON structure to build integrations for all alert types using:- - Azure Logic Apps - - Azure Functions - - Azure Automation runbook --> [!NOTE] -> - Alerts generated by [VM insights](../vm/vminsights-overview.md) do not support the common schema. ->- Smart detection alerts use the common schema by default. You don't have to enable the common schema for smart detection alerts. --## Structure of the common schema --The common schema includes information about the affected resource and the cause of the alert in these sections: -- **Essentials**: Standardized fields, used by all alert types that describe the resource affected by the alert and common alert metadata, such as severity or description.-- If you want to route alert instances to specific teams based on criteria such as a resource group, you can use the fields in the **Essentials** section to provide routing logic for all alert types. The teams that receive the alert notification can then use the context fields for their investigation. -- **Alert context**: Fields that vary depending on the type of the alert. The alert context fields describe the cause of the alert. For example, a metric alert would have fields like the metric name and metric value in the alert context. An activity log alert would have information about the event that generated the alert.-- **Custom properties**: Additional information that is not included in the alert payload by default can be included in the alert payload using custom properties. Custom properties are a **Key:Value** pair that can include any information configured in the alert rule. --## Sample alert payload --```json -{ - "schemaId": "azureMonitorCommonAlertSchema", - "data": { - "essentials": { - "alertId": "/subscriptions/<subscription ID>/providers/Microsoft.AlertsManagement/alerts/b9569717-bc32-442f-add5-83a997729330", - "alertRule": "WCUS-R2-Gen2", - "severity": "Sev3", - "signalType": "Metric", - "monitorCondition": "Resolved", - "monitoringService": "Platform", - "alertTargetIDs": [ - "/subscriptions/<subscription ID>/resourcegroups/pipelinealertrg/providers/microsoft.compute/virtualmachines/wcus-r2-gen2" - ], - "configurationItems": [ - "wcus-r2-gen2" - ], - "originAlertId": "3f2d4487-b0fc-4125-8bd5-7ad17384221e_PipeLineAlertRG_microsoft.insights_metricAlerts_WCUS-R2-Gen2_-117781227", - "firedDateTime": "2019-03-22T13:58:24.3713213Z", - "resolvedDateTime": "2019-03-22T14:03:16.2246313Z", - "description": "", - "essentialsVersion": "1.0", - "alertContextVersion": "1.0" - }, - "alertContext": { - "properties": null, - "conditionType": "SingleResourceMultipleMetricCriteria", - "condition": { - "windowSize": "PT5M", - "allOf": [ - { - "metricName": "Percentage CPU", - "metricNamespace": "Microsoft.Compute/virtualMachines", - "operator": "GreaterThan", - "threshold": "25", - "timeAggregation": "Average", - "dimensions": [ - { - "name": "ResourceId", - "value": "3efad9dc-3d50-4eac-9c87-8b3fd6f97e4e" - } - ], - "metricValue": 7.727 - } - ] - } - }, - "customProperties": { - "Key1": "Value1", - "Key2": "Value2" - } - } -} -``` --For sample alerts that use the common schema, see [Sample alert payloads](alerts-payload-samples.md). -## Essentials fields --| Field | Description| -|:|:| -| alertId | The unique resource ID that identifies the alert instance. | -| alertRule | The name of the alert rule that generated the alert instance. | -| Severity | The severity of the alert. Possible values are Sev0, Sev1, Sev2, Sev3, or Sev4. | -| signalType | Identifies the signal on which the alert rule was defined. Possible values are Metric, Log, or Activity Log. | -| monitorCondition | When an alert fires, the alert's monitor condition is set to **Fired**. When the underlying condition that caused the alert to fire clears, the monitor condition is set to **Resolved**. | -| monitoringService | The monitoring service or solution that generated the alert. The monitoring service determines which fields are in the alert context. | -| alertTargetIDs | The list of the Azure Resource Manager IDs that are affected targets of an alert. For a log search alert defined on a Log Analytics workspace or Application Insights instance, it's the respective workspace or application. | -| configurationItems |The list of affected resources of an alert.<br>In some cases, the configuration items can be different from the alert targets. For example, in metric-for-log or log search alerts defined on a Log Analytics workspace, the configuration items are the actual resources sending the data, and not the workspace.<br><ul><li>In the log search alerts API (Scheduled Query Rules) v2021-08-01, the `configurationItem` values are taken from explicitly defined dimensions in this priority: `_ResourceId`, `ResourceId`, `Resource`, `Computer`.</li><li>In earlier versions of the log search alerts API, the `configurationItem` values are taken implicitly from the results in this priority: `_ResourceId`, `ResourceId`, `Resource`, `Computer`.</li></ul>In ITSM systems, the `configurationItems` field is used to correlate alerts to resources in a configuration management database. | -| originAlertId | The ID of the alert instance, as generated by the monitoring service generating it. | -| firedDateTime | The date and time when the alert instance was fired in Coordinated Universal Time (UTC). | -| resolvedDateTime | The date and time when the monitor condition for the alert instance is set to **Resolved** in UTC. Currently only applicable for metric alerts.| -| description | The description, as defined in the alert rule. | -| alertRuleID | The ID of the alert rule that generated the alert instance.| -| resourceType | The resource type affected by the alert.| -| resourceGroupName | Name of the resource group for the impacted resource.| -|essentialsVersion| The version number for the essentials section.| -|alertContextVersion | The version number for the `alertContext` section.| -|investigationLink | Link to investigate the alert in Azure Monitor. Currently requires limited preview registration.| ---## Alert context fields for metric alerts --|Field |Description | -||| -|properties |(Optional.) A collection of customer-defined properties. | -|conditionType |The type of condition selected for the alert rule:<br> - static threshold<br> - dynamic threshold<br> - webtest | -|condition | | -|windowSize |The time period analyzed by the alert rule.| -|allOf |Indicates that all conditions defined in the alert rule must be met to trigger an alert.| -|alertSensitivity |In an alert rule with a dynamic threshold, indicates how sensitive the rule is, or how much the value can deviate from the upper or lower threshold.| -|failingPeriods |In an alert rule with a dynamic threshold, the number of evaluation periods that don't meet the alert threshold that trigger an alert. For example, you can indicate that an alert is triggered when 3 out of the last five evaluation periods aren't within the alert thresholds. | -|numberOfEvaluationPeriods|The total number of evaluations. | -|minFailingPeriodsToAlert|The minimum number of evaluations that do no meet the alert rule conditions.| -|ignoreDataBefore |(Optional.) In an alert rule with a dynamic threshold, the date from which the threshold is calculated. Use this value to indicate that the rule shouldn't calculate the dynamic threshold using data from before the specified date. | -|metricName |The name of the metric monitored by the alert rule. | -|metricNamespace |The namespace of the metric monitored by the alert rule. | -|operator |The logical operator of the alert rule. | -|threshold |The threshold defined in the alert rule. For an alert rule with a dynamic threshold, this value is the calculated threshold. | -|timeAggregation |The aggregation type of the alert rule. | -|dimensions |The metric dimension that triggered the alert. | -|name |The dimension name. | -|value |The dimension value. | -|metricValue |The metric value at the time that it violated the threshold. | -|webTestName |If the condition type is `webtest`, the name of the webtest. | -|windowStartTime |The start time of the evaluation window in which the alert fired. | -|windowEndTime |The end time of the evaluation window in which the alert fired. | -### Sample metric alert with a static threshold when the monitoringService = `Platform` --```json -{ - "alertContext": { - "properties": null, - "conditionType": "SingleResourceMultipleMetricCriteria", - "condition": { - "windowSize": "PT5M", - "allOf": [ - { - "metricName": "Percentage CPU", - "metricNamespace": "Microsoft.Compute/virtualMachines", - "operator": "GreaterThan", - "threshold": "25", - "timeAggregation": "Average", - "dimensions": [ - { - "name": "ResourceId", - "value": "3efad9dc-3d50-4eac-9c87-8b3fd6f97e4e" - } - ], - "metricValue": 31.1105 - } - ], - "windowStartTime": "2019-03-22T13:40:03.064Z", - "windowEndTime": "2019-03-22T13:45:03.064Z" - } - } -} -``` --### Sample metric alert with a dynamic threshold when the monitoringService = `Platform` --```json -{ - "alertContext": { - "properties": null, - "conditionType": "DynamicThresholdCriteria", - "condition": { - "windowSize": "PT5M", - "allOf": [ - { - "alertSensitivity": "High", - "failingPeriods": { - "numberOfEvaluationPeriods": 1, - "minFailingPeriodsToAlert": 1 - }, - "ignoreDataBefore": null, - "metricName": "Egress", - "metricNamespace": "microsoft.storage/storageaccounts", - "operator": "GreaterThan", - "threshold": "47658", - "timeAggregation": "Total", - "dimensions": [], - "metricValue": 50101 - } - ], - "windowStartTime": "2021-07-20T05:07:26.363Z", - "windowEndTime": "2021-07-20T05:12:26.363Z" - } - } -} -``` -### Sample metric alert for availability tests when the monitoringService = `Platform` --```json -{ - "alertContext": { - "properties": null, - "conditionType": "WebtestLocationAvailabilityCriteria", - "condition": { - "windowSize": "PT5M", - "allOf": [ - { - "metricName": "Failed Location", - "metricNamespace": null, - "operator": "GreaterThan", - "threshold": "2", - "timeAggregation": "Sum", - "dimensions": [], - "metricValue": 5, - "webTestName": "myAvailabilityTest-myApplication" - } - ], - "windowStartTime": "2019-03-22T13:40:03.064Z", - "windowEndTime": "2019-03-22T13:45:03.064Z" - } - } -} -``` --## Alert context fields for log search alerts --> [!NOTE] -> When you enable the common schema, the fields in the payload are reset to the common schema fields. Therefore, log search alerts have these limitations regarding the common schema: -> - The common schema is not supported for log search alerts using webhooks with a custom email subject and/or JSON payload, since the common schema overwrites the custom configurations. -> - Alerts using the common schema have an upper size limit of 256 KB per alert. If the log search alerts payload includes search results that cause the alert to exceed the maximum size, the search results aren't embedded in the log search alerts payload. You can check if the payload includes the search results with the `IncludedSearchResults` flag. Use `LinkToFilteredSearchResultsAPI` or `LinkToSearchResultsAPI` to access query results with the [Log Analytics API](/rest/api/loganalytics/dataaccess/query/get) if the search results are not included. --|Field |Description | -||| -|SearchQuery |The query defined in the alert rule. | -|SearchIntervalStartTimeUtc |The start time of the evaluation window in which the alert fired in UTC. | -|SearchIntervalEndTimeUtc |The end time of the evaluation window in which the alert fired in UTC. | -|ResultCount |The number of records returned by the query. For metric measurement rules, the number or records that match the specific dimension combination. | -|LinkToSearchResults |A link to the search results. | -|LinkToFilteredSearchResultsUI |For metric measurement rules, the link to the search results after they've been filtered by the dimension combinations. | -|LinkToSearchResultsAPI |A link to the query results using the Log Analytics API. | -|LinkToFilteredSearchResultsAPI |For metric measurement rules, the link to the search results using the Log Analytics API after they've been filtered by the dimension combinations. | -|SearchIntervalDurationMin |The total number of minutes in the search interval. | -|SearchIntervalInMin |The total number of minutes in the search interval. | -|Threshold |The threshold defined in the alert rule. | -|Operator |The operator defined in the alert rule. | -|ApplicationID |The Application Insights ID on which the alert was triggered. | -|Dimensions |For metric measurement rules, the metric dimensions on which the alert was triggered. | -|name |The dimension name. | -|value |The dimension value. | -|SearchResults |The complete search results. | -|table |The table of results in the search results. | -|name |The name of the table in the search results. | -|columns |The columns in the table. | -|name |The name of the column. | -|type |The type of the column. | -|rows |The rows in the table. | -|DataSources |The data sources on which the alert was triggered. | -|resourceID |The resource ID affected by the alert. | -|tables |The draft response tables included in the query. | -|IncludedSearchResults | Flag that indicates if the payload should contain the results. | -|AlertType |The alert type:<br> - Metric Measurement<br> - Number Of Results | ----### Sample log search alert when the monitoringService = Log Analytics --```json -{ - "alertContext": { - "SearchQuery": "Perf | where ObjectName == \"Processor\" and CounterName == \"% Processor Time\" | summarize AggregatedValue = avg(CounterValue) by bin(TimeGenerated, 5m), Computer", - "SearchIntervalStartTimeUtc": "3/22/2019 1:36:31 PM", - "SearchIntervalEndtimeUtc": "3/22/2019 1:51:31 PM", - "ResultCount": 2, - "LinkToSearchResults": "https://portal.azure.com/#Analyticsblade/search/index?_timeInterval.intervalEnd=2018-03-26T09%3a10%3a40.0000000Z&_timeInterval.intervalDuration=3600&q=Usage", - "LinkToFilteredSearchResultsUI": "https://portal.azure.com/#Analyticsblade/search/index?_timeInterval.intervalEnd=2018-03-26T09%3a10%3a40.0000000Z&_timeInterval.intervalDuration=3600&q=Usage", - "LinkToSearchResultsAPI": "https://api.loganalytics.io/v1/workspaces/workspaceID/query?query=Heartbeat×pan=2020-05-07T18%3a11%3a51.0000000Z%2f2020-05-07T18%3a16%3a51.0000000Z", - "LinkToFilteredSearchResultsAPI": "https://api.loganalytics.io/v1/workspaces/workspaceID/query?query=Heartbeat×pan=2020-05-07T18%3a11%3a51.0000000Z%2f2020-05-07T18%3a16%3a51.0000000Z", - "SeverityDescription": "Warning", - "WorkspaceId": "12345a-1234b-123c-123d-12345678e", - "SearchIntervalDurationMin": "15", - "AffectedConfigurationItems": [ - "INC-Gen2Alert" - ], - "SearchIntervalInMinutes": "15", - "Threshold": 10000, - "Operator": "Less Than", - "Dimensions": [ - { - "name": "Computer", - "value": "INC-Gen2Alert" - } - ], - "SearchResults": { - "tables": [ - { - "name": "PrimaryResult", - "columns": [ - { - "name": "$table", - "type": "string" - }, - { - "name": "Computer", - "type": "string" - }, - { - "name": "TimeGenerated", - "type": "datetime" - } - ], - "rows": [ - [ - "Fabrikam", - "33446677a", - "2018-02-02T15:03:12.18Z" - ], - [ - "Contoso", - "33445566b", - "2018-02-02T15:16:53.932Z" - ] - ] - } - ], - "dataSources": [ - { - "resourceId": "/subscriptions/a5ea55e2-7482-49ba-90b3-60e7496dd873/resourcegroups/test/providers/microsoft.operationalinsights/workspaces/test", - "tables": [ - "Heartbeat" - ] - } - ] - }, - "IncludedSearchResults": "True", - "AlertType": "Metric measurement" - } -} -``` -### Sample log search alert when the monitoringService = Application Insights --```json -{ - "alertContext": { - "SearchQuery": "requests | where resultCode == \"500\" | summarize AggregatedValue = Count by bin(Timestamp, 5m), IP", - "SearchIntervalStartTimeUtc": "3/22/2019 1:36:33 PM", - "SearchIntervalEndtimeUtc": "3/22/2019 1:51:33 PM", - "ResultCount": 2, - "LinkToSearchResults": "https://portal.azure.com/AnalyticsBlade/subscriptions/12345a-1234b-123c-123d-12345678e/?query=search+*+&timeInterval.intervalEnd=2018-03-26T09%3a10%3a40.0000000Z&_timeInterval.intervalDuration=3600&q=Usage", - "LinkToFilteredSearchResultsUI": "https://portal.azure.com/AnalyticsBlade/subscriptions/12345a-1234b-123c-123d-12345678e/?query=search+*+&timeInterval.intervalEnd=2018-03-26T09%3a10%3a40.0000000Z&_timeInterval.intervalDuration=3600&q=Usage", - "LinkToSearchResultsAPI": "https://api.applicationinsights.io/v1/apps/0MyAppId0/metrics/requests/count", - "LinkToFilteredSearchResultsAPI": "https://api.applicationinsights.io/v1/apps/0MyAppId0/metrics/requests/count", - "SearchIntervalDurationMin": "15", - "SearchIntervalInMinutes": "15", - "Threshold": 10000.0, - "Operator": "Less Than", - "ApplicationId": "8e20151d-75b2-4d66-b965-153fb69d65a6", - "Dimensions": [ - { - "name": "IP", - "value": "1.1.1.1" - } - ], - "SearchResults": { - "tables": [ - { - "name": "PrimaryResult", - "columns": [ - { - "name": "$table", - "type": "string" - }, - { - "name": "Id", - "type": "string" - }, - { - "name": "Timestamp", - "type": "datetime" - } - ], - "rows": [ - [ - "Fabrikam", - "33446677a", - "2018-02-02T15:03:12.18Z" - ], - [ - "Contoso", - "33445566b", - "2018-02-02T15:16:53.932Z" - ] - ] - } - ], - "dataSources": [ - { - "resourceId": "/subscriptions/a5ea27e2-7482-49ba-90b3-52e7496dd873/resourcegroups/test/providers/microsoft.operationalinsights/workspaces/test", - "tables": [ - "Heartbeat" - ] - } - ] - }, - "IncludedSearchResults": "True", - "AlertType": "Metric measurement" - } -} -``` -### Sample log search alert when the monitoringService = Log Alerts V2 --> [!NOTE] -> Log search alert rules from API version 2020-05-01 use this payload type, which only supports common schema. Search results aren't embedded in the log search alerts payload when you use this version. Use [dimensions](./alerts-types.md#monitor-the-same-condition-on-multiple-resources-using-splitting-by-dimensions-1) to provide context to fired alerts. You can also use `LinkToFilteredSearchResultsAPI` or `LinkToSearchResultsAPI` to access query results with the [Log Analytics API](/rest/api/loganalytics/dataaccess/query/get). If you must embed the results, use a logic app with the provided links to generate a custom payload. --```json -{ - "alertContext": { - "properties": { - "name1": "value1", - "name2": "value2" - }, - "conditionType": "LogQueryCriteria", - "condition": { - "windowSize": "PT10M", - "allOf": [ - { - "searchQuery": "Heartbeat", - "metricMeasureColumn": "CounterValue", - "targetResourceTypes": "['Microsoft.Compute/virtualMachines']", - "operator": "LowerThan", - "threshold": "1", - "timeAggregation": "Count", - "dimensions": [ - { - "name": "Computer", - "value": "TestComputer" - } - ], - "metricValue": 0.0, - "failingPeriods": { - "numberOfEvaluationPeriods": 1, - "minFailingPeriodsToAlert": 1 - }, - "linkToSearchResultsUI": "https://portal.azure.com#@12345a-1234b-123c-123d-12345678e/blade/Microsoft_Azure_Monitoring_Logs/LogsBlade/source/Alerts.EmailLinks/scope/%7B%22resources%22%3A%5B%7B%22resourceId%22%3A%22%2Fsubscriptions%212345a-1234b-123c-123d-12345678e%2FresourceGroups%2FContoso%2Fproviders%2FMicrosoft.Compute%2FvirtualMachines%2FContoso%22%7D%5D%7D/q/eJzzSE0sKklKTSypUSjPSC1KVQjJzE11T81LLUosSU1RSEotKU9NzdNIAfJKgDIaRgZGBroG5roGliGGxlYmJlbGJnoGEKCpp4dDmSmKMk0A/prettify/1/timespan/2020-07-07T13%3a54%3a34.0000000Z%2f2020-07-09T13%3a54%3a34.0000000Z", - "linkToFilteredSearchResultsUI": "https://portal.azure.com#@12345a-1234b-123c-123d-12345678e/blade/Microsoft_Azure_Monitoring_Logs/LogsBlade/source/Alerts.EmailLinks/scope/%7B%22resources%22%3A%5B%7B%22resourceId%22%3A%22%2Fsubscriptions%212345a-1234b-123c-123d-12345678e%2FresourceGroups%2FContoso%2Fproviders%2FMicrosoft.Compute%2FvirtualMachines%2FContoso%22%7D%5D%7D/q/eJzzSE0sKklKTSypUSjPSC1KVQjJzE11T81LLUosSU1RSEotKU9NzdNIAfJKgDIaRgZGBroG5roGliGGxlYmJlbGJnoGEKCpp4dDmSmKMk0A/prettify/1/timespan/2020-07-07T13%3a54%3a34.0000000Z%2f2020-07-09T13%3a54%3a34.0000000Z", - "linkToSearchResultsAPI": "https://api.loganalytics.io/v1/subscriptions/12345a-1234b-123c-123d-12345678e/resourceGroups/Contoso/providers/Microsoft.Compute/virtualMachines/Contoso/query?query=Heartbeat%7C%20where%20TimeGenerated%20between%28datetime%282020-07-09T13%3A44%3A34.0000000%29..datetime%282020-07-09T13%3A54%3A34.0000000%29%29×pan=2020-07-07T13%3a54%3a34.0000000Z%2f2020-07-09T13%3a54%3a34.0000000Z", - "linkToFilteredSearchResultsAPI": "https://api.loganalytics.io/v1/subscriptions/12345a-1234b-123c-123d-12345678e/resourceGroups/Contoso/providers/Microsoft.Compute/virtualMachines/Contoso/query?query=Heartbeat%7C%20where%20TimeGenerated%20between%28datetime%282020-07-09T13%3A44%3A34.0000000%29..datetime%282020-07-09T13%3A54%3A34.0000000%29%29×pan=2020-07-07T13%3a54%3a34.0000000Z%2f2020-07-09T13%3a54%3a34.0000000Z" - } - ], - "windowStartTime": "2020-07-07T13:54:34Z", - "windowEndTime": "2020-07-09T13:54:34Z" - } - } -} -``` -## Alert context fields for activity log alerts --See [Azure activity log event schema](../essentials/activity-log-schema.md) for detailed information about the fields in activity log alerts. --### Sample activity log alert when the monitoringService = Activity Log - Administrative --```json -{ - "alertContext": { - "authorization": { - "action": "Microsoft.Compute/virtualMachines/restart/action", - "scope": "/subscriptions/<subscription ID>/resourceGroups/PipeLineAlertRG/providers/Microsoft.Compute/virtualMachines/WCUS-R2-ActLog" - }, - "channels": "Operation", - "claims": "{\"aud\":\"https://management.core.windows.net/\",\"iss\":\"https://sts.windows.net/12345a-1234b-123c-123d-12345678e/\",\"iat\":\"1553260826\",\"nbf\":\"1553260826\",\"exp\":\"1553264726\",\"aio\":\"42JgYNjdt+rr+3j/dx68v018XhuFAwA=\",\"appid\":\"e9a02282-074f-45cf-93b0-50568e0e7e50\",\"appidacr\":\"2\",\"http://schemas.microsoft.com/identity/claims/identityprovider\":\"https://sts.windows.net/12345a-1234b-123c-123d-12345678e/\",\"http://schemas.microsoft.com/identity/claims/objectidentifier\":\"9778283b-b94c-4ac6-8a41-d5b493d03aa3\",\"http://schemas.xmlsoap.org/ws/2005/05/identity/claims/nameidentifier\":\"9778283b-b94c-4ac6-8a41-d5b493d03aa3\",\"http://schemas.microsoft.com/identity/claims/tenantid\":\"12345a-1234b-123c-123d-12345678e\",\"uti\":\"v5wYC9t9ekuA2rkZSVZbAA\",\"ver\":\"1.0\"}", - "caller": "9778283b-b94c-4ac6-8a41-d5b493d03aa3", - "correlationId": "8ee9c32a-92a1-4a8f-989c-b0ba09292a91", - "eventSource": "Administrative", - "eventTimestamp": "2019-03-22T13:56:31.2917159+00:00", - "eventDataId": "161fda7e-1cb4-4bc5-9c90-857c55a8f57b", - "level": "Informational", - "operationName": "Microsoft.Compute/virtualMachines/restart/action", - "operationId": "310db69b-690f-436b-b740-6103ab6b0cba", - "status": "Succeeded", - "subStatus": "", - "submissionTimestamp": "2019-03-22T13:56:54.067593+00:00" - } -} -``` -### Sample activity log alert when the monitoringService = Activity Log - Policy --```json -{ - "alertContext": { - "authorization": { - "action": "Microsoft.Resources/checkPolicyCompliance/read", - "scope": "/subscriptions/<GUID>" - }, - "channels": "Operation", - "claims": "{\"aud\":\"https://management.azure.com/\",\"iss\":\"https://sts.windows.net/<GUID>/\",\"iat\":\"1566711059\",\"nbf\":\"1566711059\",\"exp\":\"1566740159\",\"aio\":\"42FgYOhynHNw0scy3T/bL71+xLyqEwA=\",\"appid\":\"<GUID>\",\"appidacr\":\"2\",\"http://schemas.microsoft.com/identity/claims/identityprovider\":\"https://sts.windows.net/<GUID>/\",\"http://schemas.microsoft.com/identity/claims/objectidentifier\":\"<GUID>\",\"http://schemas.xmlsoap.org/ws/2005/05/identity/claims/nameidentifier\":\"<GUID>\",\"http://schemas.microsoft.com/identity/claims/tenantid\":\"<GUID>\",\"uti\":\"Miy1GzoAG0Scu_l3m1aIAA\",\"ver\":\"1.0\"}", - "caller": "<GUID>", - "correlationId": "<GUID>", - "eventSource": "Policy", - "eventTimestamp": "2019-08-25T11:11:34.2269098+00:00", - "eventDataId": "<GUID>", - "level": "Warning", - "operationName": "Microsoft.Authorization/policies/audit/action", - "operationId": "<GUID>", - "properties": { - "isComplianceCheck": "True", - "resourceLocation": "eastus2", - "ancestors": "<GUID>", - "policies": "[{\"policyDefinitionId\":\"/providers/Microsoft.Authorization/policyDefinitions/<GUID>/\",\"policySetDefinitionId\":\"/providers/Microsoft.Authorization/policySetDefinitions/<GUID>/\",\"policyDefinitionReferenceId\":\"vulnerabilityAssessmentMonitoring\",\"policySetDefinitionName\":\"<GUID>\",\"policyDefinitionName\":\"<GUID>\",\"policyDefinitionEffect\":\"AuditIfNotExists\",\"policyAssignmentId\":\"/subscriptions/<GUID>/providers/Microsoft.Authorization/policyAssignments/SecurityCenterBuiltIn/\",\"policyAssignmentName\":\"SecurityCenterBuiltIn\",\"policyAssignmentScope\":\"/subscriptions/<GUID>\",\"policyAssignmentSku\":{\"name\":\"A1\",\"tier\":\"Standard\"},\"policyAssignmentParameters\":{}}]" - }, - "status": "Succeeded", - "subStatus": "", - "submissionTimestamp": "2019-08-25T11:12:46.1557298+00:00" - } -} -``` -### Sample activity log alert when the monitoringService = Activity Log - Autoscale --```json -{ - "alertContext": { - "channels": "Admin, Operation", - "claims": "{\"http://schemas.xmlsoap.org/ws/2005/05/identity/claims/spn\":\"Microsoft.Insights/autoscaleSettings\"}", - "caller": "Microsoft.Insights/autoscaleSettings", - "correlationId": "<GUID>", - "eventSource": "Autoscale", - "eventTimestamp": "2019-08-21T16:17:47.1551167+00:00", - "eventDataId": "<GUID>", - "level": "Informational", - "operationName": "Microsoft.Insights/AutoscaleSettings/Scaleup/Action", - "operationId": "<GUID>", - "properties": { - "description": "The autoscale engine attempting to scale resource '/subscriptions/d<GUID>/resourceGroups/testRG/providers/Microsoft.Compute/virtualMachineScaleSets/testVMSS' from 9 instances count to 10 instances count.", - "resourceName": "/subscriptions/<GUID>/resourceGroups/voiceassistancedemo/providers/Microsoft.Compute/virtualMachineScaleSets/alexademo", - "oldInstancesCount": "9", - "newInstancesCount": "10", - "activeAutoscaleProfile": "{\r\n \"Name\": \"Auto created scale condition\",\r\n \"Capacity\": {\r\n \"Minimum\": \"1\",\r\n \"Maximum\": \"10\",\r\n \"Default\": \"1\"\r\n },\r\n \"Rules\": [\r\n {\r\n \"MetricTrigger\": {\r\n \"Name\": \"Percentage CPU\",\r\n \"Namespace\": \"microsoft.compute/virtualmachinescalesets\",\r\n \"Resource\": \"/subscriptions/<GUID>/resourceGroups/testRG/providers/Microsoft.Compute/virtualMachineScaleSets/testVMSS\",\r\n \"ResourceLocation\": \"eastus\",\r\n \"TimeGrain\": \"PT1M\",\r\n \"Statistic\": \"Average\",\r\n \"TimeWindow\": \"PT5M\",\r\n \"TimeAggregation\": \"Average\",\r\n \"Operator\": \"GreaterThan\",\r\n \"Threshold\": 0.0,\r\n \"Source\": \"/subscriptions/<GUID>/resourceGroups/testRG/providers/Microsoft.Compute/virtualMachineScaleSets/testVMSS\",\r\n \"MetricType\": \"MDM\",\r\n \"Dimensions\": [],\r\n \"DividePerInstance\": false\r\n },\r\n \"ScaleAction\": {\r\n \"Direction\": \"Increase\",\r\n \"Type\": \"ChangeCount\",\r\n \"Value\": \"1\",\r\n \"Cooldown\": \"PT1M\"\r\n }\r\n }\r\n ]\r\n}", - "lastScaleActionTime": "Wed, 21 Aug 2019 16:17:47 GMT" - }, - "status": "Succeeded", - "submissionTimestamp": "2019-08-21T16:17:47.2410185+00:00" - } -} -``` -### Sample activity log alert when the monitoringService = Activity Log - Security --```json -{ - "alertContext": { - "channels": "Operation", - "correlationId": "<GUID>", - "eventSource": "Security", - "eventTimestamp": "2019-08-26T08:34:14+00:00", - "eventDataId": "<GUID>", - "level": "Informational", - "operationName": "Microsoft.Security/locations/alerts/activate/action", - "operationId": "<GUID>", - "properties": { - "threatStatus": "Quarantined", - "category": "Virus", - "threatID": "2147519003", - "filePath": "C:\\AlertGeneration\\test.eicar", - "protectionType": "Windows Defender", - "actionTaken": "Blocked", - "resourceType": "Virtual Machine", - "severity": "Low", - "compromisedEntity": "testVM", - "remediationSteps": "[\"No user action is necessary\"]", - "attackedResourceType": "Virtual Machine" - }, - "status": "Active", - "submissionTimestamp": "2019-08-26T09:28:58.3019107+00:00" - } -} -``` -### Sample activity log alert when the monitoringService = ServiceHealth --```json -{ - "alertContext": { - "authorization": null, - "channels": 1, - "claims": null, - "caller": null, - "correlationId": "f3cf2430-1ee3-4158-8e35-7a1d615acfc7", - "eventSource": 2, - "eventTimestamp": "2019-06-24T11:31:19.0312699+00:00", - "httpRequest": null, - "eventDataId": "<GUID>", - "level": 3, - "operationName": "Microsoft.ServiceHealth/maintenance/action", - "operationId": "<GUID>", - "properties": { - "title": "Azure Synapse Analytics Scheduled Maintenance Pending", - "service": "Azure Synapse Analytics", - "region": "East US", - "communication": "<MESSAGE>", - "incidentType": "Maintenance", - "trackingId": "<GUID>", - "impactStartTime": "2019-06-26T04:00:00Z", - "impactMitigationTime": "2019-06-26T12:00:00Z", - "impactedServices": "[{\"ImpactedRegions\":[{\"RegionName\":\"East US\"}],\"ServiceName\":\"Azure Synapse Analytics\"}]", - "impactedServicesTableRows": "<tr>\r\n<td align='center' style='padding: 5px 10px; border-right:1px solid black; border-bottom:1px solid black'>Azure Synapse Analytics</td>\r\n<td align='center' style='padding: 5px 10px; border-bottom:1px solid black'>East US<br></td>\r\n</tr>\r\n", - "defaultLanguageTitle": "Azure Synapse Analytics Scheduled Maintenance Pending", - "defaultLanguageContent": "<MESSAGE>", - "stage": "Planned", - "communicationId": "<GUID>", - "maintenanceId": "<GUID>", - "isHIR": "false", - "version": "0.1.1" - }, - "status": "Active", - "subStatus": null, - "submissionTimestamp": "2019-06-24T11:31:31.7147357+00:00", - "ResourceType": null - } -} -``` -### Sample activity log alert when the monitoringService = ResourceHealth --```json -{ - "alertContext": { - "channels": "Admin, Operation", - "correlationId": "<GUID>", - "eventSource": "ResourceHealth", - "eventTimestamp": "2019-06-24T15:42:54.074+00:00", - "eventDataId": "<GUID>", - "level": "Informational", - "operationName": "Microsoft.Resourcehealth/healthevent/Activated/action", - "operationId": "<GUID>", - "properties": { - "title": "This virtual machine is stopping and deallocating as requested by an authorized user or process", - "details": null, - "currentHealthStatus": "Unavailable", - "previousHealthStatus": "Available", - "type": "Downtime", - "cause": "UserInitiated" - }, - "status": "Active", - "submissionTimestamp": "2019-06-24T15:45:20.4488186+00:00" - } -} -``` -## Alert context fields for Prometheus alerts --See [Azure Monitor managed service for Prometheus rule groups (preview)](../essentials/prometheus-rule-groups.md) for detailed information about the fields in Prometheus alerts. -### Sample Prometheus alert --```json -{ - "alertContext": { - "interval": "PT1M", - "expression": "sql_up > 0", - "expressionValue": "0", - "for": "PT2M", - "labels": { - "Environment": "Prod", - "cluster": "myCluster1" - }, - "annotations": { - "summary": "alert on SQL availability" - }, - "ruleGroup": "/subscriptions/<subscription ID>/resourceGroups/myResourceGroup/providers/Microsoft.AlertsManagement/prometheusRuleGroups/myRuleGroup" - } -} -``` -## Custom properties fields --If the alert rule that generated your alert contains action groups, custom properties can contain additional information about the alert. The custom properties section contains ΓÇ£key: valueΓÇ¥ objects that are added to webhook notifications. --If custom properties aren't set in the alert rule, the field is null. -## Enable the common alert schema --Use action groups in the Azure portal or use the REST API to enable the common alert schema. Schemas are defined at the action level. For example, you must separately enable the schema for an email action and a webhook action. --### Enable the common schema in the Azure portal -<!-- convertborder later --> --1. Open any existing action or a new action in an action group. -1. Select **Yes** to enable the common alert schema. -### Enable the common schema using the REST API --You can also use the [Action Groups API](/rest/api/monitor/actiongroups) to opt in to the common alert schema. In the [create or update](/rest/api/monitor/actiongroups/createorupdate) REST API call, -- Set the "useCommonAlertSchema" flag to `true` to enable the common schema-- Set the "useCommonAlertSchema" flag to `false` to use the non-common schema for email, webhook, Logic Apps, Azure Functions, or Automation runbook actions.-#### Sample REST API call for using the common schema --The following [create or update](/rest/api/monitor/actiongroups/createorupdate) REST API request: --- Enables the common alert schema for the email action "John Doe's email."-- Disables the common alert schema for the email action "Jane Smith's email."-- Enables the common alert schema for the webhook action "Sample webhook."--```json -{ - "properties": { - "groupShortName": "sample", - "enabled": true, - "emailReceivers": [ - { - "name": "John Doe's email", - "emailAddress": "johndoe@email.com", - "useCommonAlertSchema": true - }, - { - "name": "Jane Smith's email", - "emailAddress": "janesmith@email.com", - "useCommonAlertSchema": false - } - ], - "smsReceivers": [ - { - "name": "John Doe's mobile", - "countryCode": "1", - "phoneNumber": "1234567890" - }, - { - "name": "Jane Smith's mobile", - "countryCode": "1", - "phoneNumber": "0987654321" - } - ], - "webhookReceivers": [ - { - "name": "Sample webhook", - "serviceUri": "http://www.example.com/webhook", - "useCommonAlertSchema": true - } - ] - }, - "location": "Global", - "tags": {} -} -``` -## Next steps --- [Learn how to create a logic app that uses the common alert schema to handle all your alerts](./alerts-common-schema-integrations.md) |
| azure-monitor | Alerts Create Activity Log Alert Rule | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-create-activity-log-alert-rule.md | - Title: Create an activity log, service health, or resource health alert rule -description: This article shows you how to create or edit an activity log, service health, or resource health alert rule in Azure Monitor. --- Previously updated : 11/27/2023---# Customer intent: As an Azure cloud administrator, I want to create a new log search alert rule so that I can use a log search query to monitor the performance and availability of my resources. ---# Create or edit an activity log, service health, or resource health alert rule --This article shows you how to create or edit an activity log, service health, or resource health alert rule in Azure Monitor. To learn more about alerts, see the [alerts overview](alerts-overview.md). --You create an alert rule by combining the resources to be monitored, the monitoring data from the resource, and the conditions that you want to trigger the alert. You can then define [action groups](./action-groups.md) and [alert processing rules](alerts-action-rules.md) to determine what happens when an alert is triggered. --Alerts triggered by these alert rules contain a payload that uses the [common alert schema](alerts-common-schema.md). ---### Edit an existing alert rule --1. In the [Azure portal](https://portal.azure.com/), either from the home page or from a specific resource, select **Alerts** on the left pane. -1. Select **Alert rules**. -1. Select the alert rule you want to edit, and then select **Edit**. -- :::image type="content" source="media/alerts-create-activity-log-alert-rule/alerts-edit-activity-log-alert-rule.png" alt-text="Screenshot that shows the button for editing an existing activity log alert rule."::: -1. Select any of the tabs for the alert rule to edit the settings. ---## Configure alert rule conditions --1. On the **Condition** tab, select **Activity log**, **Resource health**, or **Service health**. Or select **See all signals** if you want to choose a different signal for the condition. -- :::image type="content" source="media/alerts-create-new-alert-rule/alerts-popular-signals.png" alt-text="Screenshot that shows popular signals for creating an alert rule."::: --1. (Optional) If you selected **See all signals** in the previous step, use the **Select a signal** pane to search for the signal name or filter the list of signals. Filter by: - - **Signal type**: The [type of alert rule](alerts-overview.md#types-of-alerts) that you're creating. - - **Signal source**: The service that sends the signal. -- This table describes the available services for activity log alert rules: -- | Signal source | Description | - |--|--| - | **Activity log ΓÇô Policy** | The service that provides the policy-related activity log events. | - | **Activity log ΓÇô Autoscale** | The service that provides the autoscale-related activity log events. | - | **Activity log ΓÇô Security** | The service that provides the security-related activity log events. | - | **Resource health** | The service that provides the resource-level health status. | - | **Service health** | The service that provides the subscription-level health status. | -- Select the signal name, and then select **Apply**. -- #### [Activity log alert](#tab/activity-log) -- 1. On the **Conditions** pane, select the **Chart period** value. -- The **Preview** chart shows the results of your selection. - 1. In the **Alert logic** section, select values for each of these fields: -- |Field |Description | - ||| - |**Event level**| Select the level of the events for this alert rule. Values are **Critical**, **Error**, **Warning**, **Informational**, **Verbose**, and **All**.| - |**Status**|Select the status levels for the alert.| - |**Event initiated by**|Select the user principal or service principal that initiated the event.| -- #### [Resource health alert](#tab/resource-health) -- - On the **Conditions** pane, select values for each of these fields: -- |Field |Description | - ||| - |**Event status**| Select the statuses of resource health events. Values are **Active**, **In Progress**, **Resolved**, and **Updated**.| - |**Current resource status**|Select the current resource status. Values are **Available**, **Degraded**, and **Unavailable**.| - |**Previous resource status**|Select the previous resource status. Values are **Available**, **Degraded**, **Unavailable**, and **Unknown**.| - |**Reason type**|Select the causes of the resource health events. Values are **Platform Initiated**, **Unknown**, and **User Initiated**.| - - #### [Service health alert](#tab/service-health) -- - On the **Conditions** pane, select values for each of these fields: -- |Field |Description | - ||| - |**Services**| Select the Azure services.| - |**Regions**|Select the Azure regions.| - |**Event types**|Select the types of service health events. Values are **Service issue**, **Planned maintenance**, **Health advisories**, and **Security advisories**.| -- ---## Configure alert rule details --1. On the **Details** tab, enter values for **Alert rule name** and **Alert rule description**. -1. Select **Enable alert rule upon creation** for the alert rule to start running as soon as you finish creating it. -1. (Optional) For **Region**, select a region in which your alert rule will be processed. If you need to make sure the rule is processed within the [EU Data Boundary](/privacy/eudb/eu-data-boundary-learn), select the North Europe or West Europe region. In all other cases, you can select the Global region (which is the default). -- > [!NOTE] - > Service Health alert rules can only be located in the Global region. -- :::image type="content" source="media/alerts-create-new-alert-rule/alerts-activity-log-rule-details-tab.png" alt-text="Screenshot that shows the Details tab for creating a new activity log alert rule."::: --1. [!INCLUDE [alerts-wizard-custom=properties](../includes/alerts-wizard-custom-properties.md)] ---## Related content --- [View and manage your alert instances](alerts-manage-alert-instances.md) |
| azure-monitor | Alerts Create Log Alert Rule | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-create-log-alert-rule.md | - Title: Create Azure Monitor log search alert rules -description: This article explains how to create a new Azure Monitor log search alert rule or edit an existing rule. --- Previously updated : 02/28/2024---#customer intent: As a customer, I want to create a new log search alert rule or edit an existing rule so that I can monitor my resources and receive alerts when certain conditions are met. ---# Create or edit a log search alert rule --This article shows you how to create a new alert rule or edit an existing alert rule for log search in Azure Monitor. To learn more about alerts, see the [alerts overview](alerts-overview.md). --You create an alert rule by combining the resources to be monitored, the monitoring data from the resource, and the conditions that you want to trigger the alert. You can then define [action groups](./action-groups.md) and [alert processing rules](alerts-action-rules.md) to determine what happens when an alert is triggered. --Alerts triggered by these alert rules contain a payload that uses the [common alert schema](alerts-common-schema.md). ---### Edit an existing alert rule --1. In the [Azure portal](https://portal.azure.com/), either from the home page or from a specific resource, select **Alerts** on the left pane. -1. Select **Alert rules**. -1. Select the alert rule that you want to edit, and then select **Edit**. -- :::image type="content" source="media/alerts-create-log-alert-rule/alerts-edit-log-search-alert-rule.png" alt-text="Screenshot that shows steps to edit an existing log search alert rule."::: -1. Select any of the tabs for the alert rule to edit the settings. ---## Configure alert rule conditions --1. On the **Condition** tab, when you select the **Signal name** field, select **Custom log search**. Or select **See all signals** if you want to choose a different signal for the condition. --1. (Optional) If you selected **See all signals** in the previous step, use the **Select a signal** pane to search for the signal name or filter the list of signals. Filter by: - - **Signal type**: Select **Log search**. - - **Signal source**: The service that sends the **Custom log search** and **Log (saved query)** signals. Select the signal name, and then select **Apply**. --1. On the **Logs** pane, write a query that returns the log events for which you want to create an alert. To use one of the predefined alert rule queries, expand the **Schema and filter** pane next to the **Logs** pane. Then select the **Queries** tab, and select one of the queries. -- Be aware of these limitations for log search alert rule queries: -- - Log search alert rule queries don't support `bag_unpack()`, `pivot()`, and `narrow()`. - - Log search alert rule queries support [ago()](/azure/data-explorer/kusto/query/ago-function) with [timespan literals](/azure/data-explorer/kusto/query/scalar-data-types/timespan#timespan-literals) only. - - `AggregatedValue` is a reserved word. You can't use it in the query on log search alert rules. - - The combined size of all data in the properties of the log search alert rules can't exceed 64 KB. - - When defining custom functions in the KQL query for log search alerts, it is important to be cautious with function code that includes relative time clauses (e.g., now()). Custom functions with relative time clauses that are not defined within the log search alert KQL query itself can introduce inconsistencies in query results, potentially impacting the accuracy and reliability of alert evaluations. Therefore: - - To ensure accurate and timely alerting, always define relative time clauses directly within the log search alert KQL query. - - If time ranges are needed inside the function, they should be passed as parameters and used in the function. -- :::image type="content" source="media/alerts-create-new-alert-rule/alerts-log-rule-query-pane.png" alt-text="Screenshot that shows the query pane during the creation of a new log search alert rule."::: --1. (Optional) If you're querying an Azure Data Explorer or Azure Resource Graph cluster, the Log Analytics workspace can't automatically identify the column with the event time stamp. We recommend that you add a time range filter to the query. For example: -- ```KQL - adx('https://help.kusto.windows.net/Samples').table - | where MyTS >= ago(5m) and MyTS <= now() - ``` -- ```KQL - arg("").Resources - | where type =~ 'Microsoft.Compute/virtualMachines' - | project _ResourceId=tolower(id), tags - ``` -- :::image type="content" source="media/alerts-create-new-alert-rule/alerts-logs-conditions-tab.png" alt-text="Screenshot that shows the Condition tab for creating a new log search alert rule."::: -- [Sample log search alert queries](./alerts-log-alert-query-samples.md) are available for Azure Data Explorer and Resource Graph. -- Cross-service queries aren't supported in government clouds. For more information about limitations, see [Cross-service query limitations](../logs/azure-monitor-data-explorer-proxy.md#limitations) and [Combine Azure Resource Graph tables with a Log Analytics workspace](../logs/azure-monitor-data-explorer-proxy.md#combine-azure-resource-graph-tables-with-a-log-analytics-workspace). --1. Select **Run** to run the alert. -1. The **Preview** section shows you the query results. When you finish editing your query, select **Continue Editing Alert**. -1. The **Condition** tab opens and is populated with your log query. By default, the rule counts the number of results in the last five minutes. If the system detects summarized query results, the rule is automatically updated with that information. --1. In the **Measurement** section, select values for these fields: -- |Field |Description | - ||| - |**Measure**|Log search alerts can measure two things that you can use for various monitoring scenarios:<br> **Table rows**: You can use the number of returned rows to work with events such as Windows event logs, Syslog, and application exceptions. <br>**Calculation of a numeric column**: You can use calculations based on any numeric column to include any number of resources. An example is CPU percentage. | - |**Aggregation type**| The calculation performed on multiple records to aggregate them to one numeric value by using the aggregation granularity. Examples are **Total**, **Average**, **Minimum**, and **Maximum**. | - |**Aggregation granularity**| The interval for aggregating multiple records to one numeric value.| -- :::image type="content" source="media/alerts-create-new-alert-rule/alerts-log-measurements.png" alt-text="Screenshot that shows the measurement options during the creation of a new log search alert rule."::: --1. <a name="dimensions"></a>(Optional) In the **Split by dimensions** section, you can use dimensions to help provide context for the triggered alert. -- Dimensions are columns from your query results that contain additional data. When you use dimensions, the alert rule groups the query results by the dimension values and evaluates the results of each group separately. If the condition is met, the rule fires an alert for that group. The alert payload includes the combination that triggered the alert. -- You can apply up to six dimensions per alert rule. Dimensions can be only string or numeric columns. If you want to use a column that isn't a number or string type as a dimension, you must convert it to a string or numeric value in your query. If you select more than one dimension value, each time series that results from the combination triggers its own alert and is charged separately. -- For example: -- - You could use dimensions to monitor CPU usage on multiple instances that run your website or app. Each instance is monitored individually, and notifications are sent for each instance where the CPU usage exceeds the configured value. - - You could decide not to split by dimensions when you want a condition applied to multiple resources in the scope. For example, you wouldn't use dimensions if you want to fire an alert if at least five machines in the resource group scope have CPU usage above the configured value. -- In general, if your alert rule scope is a workspace, the alerts are fired on the workspace. If you want a separate alert for each affected Azure resource, you can: -- - Use the Azure Resource Manager **Azure Resource ID** column as a dimension. When you use this option, the alert is fired on the workspace with the **Azure Resource ID** column as a dimension. - - Specify the alert as a dimension in the **Azure Resource ID** property. This option makes the resource that your query returns the target of the alert. Alerts are then fired on the resource that your query returns, such as a virtual machine or a storage account, as opposed to the workspace. -- When you use this option, if the workspace gets data from resources in more than one subscription, alerts can be triggered on resources from a subscription that's different from the alert rule subscription. -- Select values for these fields: -- |Field |Description | - ||| - |**Dimension name**|Dimensions can be either number or string columns. Dimensions are used to monitor specific time series and provide context to a fired alert.| - |**Operator**|The operator that's used on the dimension name and value. | - |**Dimension values**|The dimension values are based on data from the last 48 hours. Select **Add custom value** to add custom dimension values. | - |**Include all future values**| Select this field to include any future values added to the selected dimension. | -- :::image type="content" source="media/alerts-create-new-alert-rule/alerts-create-log-rule-dimensions.png" alt-text="Screenshot that shows the section for splitting by dimensions in a new log search alert rule."::: --1. In the **Alert logic** section, select values for these fields: -- |Field |Description | - ||| - |**Operator**| The query results are transformed into a number. In this field, select the operator to use for comparing the number against the threshold.| - |**Threshold value**| A number value for the threshold. | - |**Frequency of evaluation**|How often the query is run. You can set it anywhere from one minute to one day (24 hours).| -- :::image type="content" source="media/alerts-create-new-alert-rule/alerts-create-log-rule-logic.png" alt-text="Screenshot that shows the section for alert logic in a new log search alert rule."::: -- > [!NOTE] - > The frequency is not a specific time that the alert runs every day. It's how often the alert rule runs. - > - > There are some limitations to using an alert rule frequency of <a name="frequency">one minute</a>. When you set the alert rule frequency to one minute, an internal manipulation is performed to optimize the query. This manipulation can cause the query to fail if it contains unsupported operations. The most common reasons why a query isn't supported are: - > - > - The query contains the `search`, `union`, or `take` (limit) operation. - > - The query contains the `ingestion_time()` function. - > - The query uses the `adx` pattern. - > - The query calls a function that calls other tables. -- [Sample log search alert queries](./alerts-log-alert-query-samples.md) are available for Azure Data Explorer and Resource Graph. --1. (Optional) In the **Advanced options** section, you can specify the number of failures and the alert evaluation period that's required to trigger an alert. For example, if you set **Aggregation granularity** to 5 minutes, you can specify that you want to trigger an alert only if three failures (15 minutes) happened in the last hour. Your application's business policy determines this setting. -- Select values for these fields under **Number of violations to trigger the alert**: -- |Field |Description | - ||| - |**Number of violations**|The number of violations that trigger the alert.| - |**Evaluation period**|The time period within which the number of violations occur. | - |**Override query time range**| If you want the alert evaluation period to be different from the query time range, enter a time range here.<br> The alert time range is limited to a maximum of two days. Even if the query contains an `ago` command with a time range of longer than two days, the two-day maximum time range is applied. For example, even if the query text contains `ago(7d)`, the query only scans up to two days of data. If the query requires more data than the alert evaluation, you can change the time range manually. If the query contains an `ago` command, it changes automatically to two days (48 hours).| -- :::image type="content" source="media/alerts-create-new-alert-rule/alerts-rule-preview-advanced-options.png" alt-text="Screenshot that shows the section for advanced options in a new log search alert rule."::: -- > [!NOTE] - > If you or your administrator assigned the Azure policy **Azure Log Search Alerts over Log Analytics workspaces should use customer-managed keys**, you must select **Check workspace linked storage**. If you don't, the rule creation will fail because it won't meet the policy requirements. --1. The **Preview** chart shows the results of query evaluations over time. You can change the chart period or select different time series that resulted from a unique alert splitting by dimensions. -- :::image type="content" source="media/alerts-create-new-alert-rule/alerts-create-alert-rule-preview.png" alt-text="Screenshot that shows a preview of a new alert rule."::: --1. Select **Done**. From this point on, you can select the **Review + create** button at any time. ---## Configure alert rule details --1. On the **Details** tab, under **Project details**, select the **Subscription** and **Resource group** values. --1. Under **Alert rule details**: -- 1. Select the **Severity** value. - 1. Enter values for **Alert rule name** and **Alert rule description**. -- > [!NOTE] - > A rule that uses an identity can't have the semicolon (;) character in the **Alert rule name** value. - 1. Select the **Region** value. --1. <a name="managed-id"></a>In the **Identity** section, select which identity the log search alert rule uses for authentication when it sends the log query. -- Keep these points in mind when you're selecting an identity: -- - A managed identity is required if you're sending a query to Azure Data Explorer or Resource Graph. - - Use a managed identity if you want to be able to view or edit the permissions associated with the alert rule. - - If you don't use a managed identity, the alert rule permissions are based on the permissions of the last user to edit the rule, at the time that the rule was last edited. - - Use a managed identity to help you avoid a case where the rule doesn't work as expected because the user who last edited the rule didn't have permissions for all the resources added to the scope of the rule. -- The identity associated with the rule must have these roles: -- - If the query is accessing a Log Analytics workspace, the identity must be assigned a *reader* role for all workspaces that the query accesses. If you're creating resource-centric log search alerts, the alert rule might access multiple workspaces, and the identity must have a reader role on all of them. - - If you're querying an Azure Data Explorer or Resource Graph cluster, you must add the *reader* role for all data sources that the query accesses. For example, if the query is resource centric, it needs a reader role on that resource. - - If the query is [accessing a remote Azure Data Explorer cluster](../logs/azure-monitor-data-explorer-proxy.md), the identity must be assigned: - - A *reader* role for all data sources that the query accesses. For example, if the query is calling a remote Azure Data Explorer cluster by using the `adx()` function, it needs a reader role on that Azure Data Explorer cluster. - - A *database viewer* role for all databases that the query accesses. -- For detailed information on managed identities, see [Managed identities for Azure resources](../../active-directory/managed-identities-azure-resources/overview.md). -- Select one of the following options for the identity that the alert rule uses: -- |Identity option |Description | - ||| - |**None**|Alert rule permissions are based on the permissions of the last user who edited the rule, at the time that the rule was edited.| - |**Enable system assigned managed identity**| Azure creates a new, dedicated identity for this alert rule. This identity has no permissions and is automatically deleted when the rule is deleted. After you create the rule, you must assign permissions to this identity to access the necessary workspace and data sources for the query. For more information about assigning permissions, see [Assign Azure roles using the Azure portal](../../role-based-access-control/role-assignments-portal.yml). Log search alert rules that use linked storage are not supported. | - |**Enable user assigned managed identity**|Before you create the alert rule, you [create an identity](../../active-directory/managed-identities-azure-resources/how-manage-user-assigned-managed-identities.md#create-a-user-assigned-managed-identity) and assign it appropriate permissions for the log query. This is a regular Azure identity. You can use one identity in multiple alert rules. The identity isn't deleted when the rule is deleted. When you select this type of identity, a pane opens for you to select the associated identity for the rule. | -- :::image type="content" source="media/alerts-create-new-alert-rule/alerts-log-rule-details-tab.png" alt-text="Screenshot that shows the Details tab for creating a new log search alert rule."::: --1. (Optional) In the <a name="advanced"></a>**Advanced options** section, you can set several options: -- |Field |Description | - ||| - |**Enable upon creation**| Select this option to make the alert rule start running as soon as you finish creating it.| - |**Automatically resolve alerts** |Select this option to make the alert stateful. When an alert is stateful, the alert is resolved when the condition is no longer met for a specific time range. The time range differs based on the frequency of the alert:<br>**1 minute**: The alert condition isn't met for 10 minutes.<br>**5 to 15 minutes**: The alert condition isn't met for three frequency periods.<br>**15 minutes to 11 hours**: The alert condition isn't met for two frequency periods.<br>**11 to 12 hours**: The alert condition isn't met for one frequency period. <br><br>Note that stateful log search alerts have [these limitations](/azure/azure-monitor/service-limits#alerts).| - |**Mute actions** |Select this option to set a period of time to wait before alert actions are triggered again. In the **Mute actions for** field that appears, select the amount of time to wait after an alert is fired before triggering actions again.| - |**Check workspace linked storage**|Select this option if workspace linked storage for alerts is configured. If no linked storage is configured, the rule isn't created.| --1. [!INCLUDE [alerts-wizard-custom=properties](../includes/alerts-wizard-custom-properties.md)] ---## Related content --- [Get samples of log search alert queries](./alerts-log-alert-query-samples.md)-- [View and manage your alert instances](alerts-manage-alert-instances.md) |
| azure-monitor | Alerts Create Rule Cli Powershell Arm | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-create-rule-cli-powershell-arm.md | - Title: Create Azure Monitor alert rules using the CLI, PowerShell or an ARM template -description: This article shows you how to create a new alert rule using the CLI, PowerShell or an ARM template. ---- Previously updated : 01/03/2024----# Create a new alert rule using the CLI, PowerShell, or an ARM template --You can create a new alert rule using the [the CLI](#create-a-new-alert-rule-using-the-cli), [PowerShell](#create-a-new-alert-rule-using-powershell), or an [Azure Resource Manager template](#create-a-new-alert-rule-using-an-arm-template). --## Create a new alert rule using the CLI --You can create a new alert rule using the [Azure CLI](/cli/azure/get-started-with-azure-cli). The following code examples use [Azure Cloud Shell](../../cloud-shell/overview.md). You can see the full list of the [Azure CLI commands for Azure Monitor](/cli/azure/azure-cli-reference-for-monitor#azure-monitor-references). --1. In the [portal](https://portal.azure.com/), select **Cloud Shell**. At the prompt, use these. -- - To create a metric alert rule, use the [az monitor metrics alert create](/cli/azure/monitor/metrics/alert) command. - - To create a log search alert rule, use the [az monitor scheduled-query create](/cli/azure/monitor/scheduled-query) command. - - To create an activity log alert rule, use the [az monitor activity-log alert create](/cli/azure/monitor/activity-log/alert) command. -- For example, to create a metric alert rule that monitors if average Percentage CPU on a VM is greater than 90: - ```azurecli - az monitor metrics alert create -n {nameofthealert} -g {ResourceGroup} --scopes {VirtualMachineResourceID} --condition "avg Percentage CPU > 90" --description {descriptionofthealert} - ``` --## Create a new alert rule using PowerShell --- To create a metric alert rule using PowerShell, use the [Add-AzMetricAlertRuleV2](/powershell/module/az.monitor/add-azmetricalertrulev2) cmdlet.- > [!NOTE] - > When you create a metric alert on a single resource, the syntax uses the `TargetResourceId`. When you create a metric alert on multiple resources, the syntax contains the `TargetResourceScope`, `TargetResourceType`, and `TargetResourceRegion`. -- To create a log search alert rule using PowerShell, use the [New-AzScheduledQueryRule](/powershell/module/az.monitor/new-azscheduledqueryrule) cmdlet.-- To create an activity log alert rule using PowerShell, use the [New-AzActivityLogAlert](/powershell/module/az.monitor/new-azactivitylogalert) cmdlet.--## Create a new alert rule using an ARM template --You can use an [Azure Resource Manager template (ARM template)](../../azure-resource-manager/templates/syntax.md) to configure alert rules consistently in all of your environments. --1. Create a new resource, using the following resource types: - - For metric alerts: `Microsoft.Insights/metricAlerts` - > [!NOTE] - > - We recommend that you create the metric alert using the same resource group as your target resource. - > - Metric alerts for an Azure Log Analytics workspace resource type (`Microsoft.OperationalInsights/workspaces`) are configured differently than other metric alerts. For more information, see [Resource Template for Metric Alerts for Logs](alerts-metric-logs.md#resource-manager-templates). - > - If you are creating a metric alert for a single resource, the template uses the `ResourceId` of the target resource. If you are creating a metric alert for multiple resources, the template uses the `scope`, `TargetResourceType`, and `TargetResourceRegion` for the target resources. - - For log search alerts: `Microsoft.Insights/scheduledQueryRules` - - For activity log, service health, and resource health alerts: `microsoft.Insights/activityLogAlerts` --1. Copy one of the templates from these sample ARM templates. - - For metric alerts: [Resource Manager template samples for metric alert rules](resource-manager-alerts-metric.md) - - For log search alerts: [Resource Manager template samples for log search alert rules](resource-manager-alerts-log.md) - - For activity log alerts: [Resource Manager template samples for activity log alert rules](resource-manager-alerts-activity-log.md) - - For service health alerts: [Resource Manager template samples for service health alert rules](resource-manager-alerts-service-health.md) - - For resource health alerts: [Resource Manager template samples for resource health alert rules](resource-manager-alerts-resource-health.md) -1. Edit the template file to contain appropriate information for your alert, and save the file as \<your-alert-template-file\>.json. -1. Edit the corresponding parameters file to customize the alert, and save as \<your-alert-template-file\>.parameters.json. -1. Set the `metricName` parameter, using one of the values in [Azure Monitor supported metrics](../essentials/metrics-supported.md). -1. Deploy the template using [PowerShell](../../azure-resource-manager/templates/deploy-powershell.md#deploy-local-template) or the [CLI](../../azure-resource-manager/templates/deploy-cli.md#deploy-local-template). --## Next steps -- [Manage alert rules](alerts-manage-alert-rules.md)-- [Manage alert instances](alerts-manage-alert-instances.md)- |
| azure-monitor | Alerts Dynamic Thresholds | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-dynamic-thresholds.md | - Title: Create an Azure Monitor metric alert with dynamic thresholds -description: Get information about creating metric alerts with dynamic thresholds that are based on machine learning. ---- Previously updated : 06/19/2024---# Create a metric alert with dynamic thresholds --Dynamic thresholds apply advanced machine learning and use a set of algorithms and methods to: --- Learn the historical behavior of metrics.-- Analyze metrics over time and identify patterns such as hourly, daily, or weekly patterns.-- Recognize anomalies that indicate possible service issues.-- Calculate the most appropriate thresholds for metrics.--When you use dynamic thresholds, you don't have to know the right threshold for each metric. Dynamic thresholds calculate the most appropriate thresholds for you. --We recommend configuring alert rules with dynamic thresholds on these metrics: --- Virtual machine CPU percentage-- Application Insights HTTP request execution time--Dynamic thresholds help you: --- Create scalable alerts for hundreds of metric series with one alert rule. If you have fewer alert rules, you spend less time creating and managing them. Scalable alerts are especially useful for multiple dimensions or for multiple resources, such as all resources in a subscription.-- Create rules without having to know what threshold to configure.-- Configure metric alerts by using high-level concepts without needing extensive domain knowledge about the metric.-- Prevent noisy (low precision) or wide (low recall) thresholds that don't have an expected pattern.--You can use dynamic thresholds on: --- Most Azure Monitor platform and custom metrics.-- Common application and infrastructure metrics.-- Noisy metrics, such as machine CPU or memory.-- Metrics with low dispersion, such as availability and error rate.--You can configure dynamic thresholds by using: --- The [Azure portal](https://portal.azure.com/).-- The fully automated [Azure Resource Manager API](/rest/api/resources/).-- [Metric alert templates](./alerts-metric-create-templates.md).--## Alert threshold calculation and preview --When an alert rule is created, dynamic thresholds use 10 days of historical data to calculate hourly or daily seasonal patterns. The chart that you see in the alert preview reflects that data. --Dynamic thresholds continually use all available historical data to learn, and they make adjustments to be more accurate. After three weeks, dynamic thresholds have enough data to identify weekly patterns, and the model is adjusted to include weekly seasonality. --The system automatically recognizes prolonged outages and removes them from the threshold learning algorithm. If there's a prolonged outage, dynamic thresholds understand the data. They detect system issues with the same level of sensitivity as before the outage occurred. --## Considerations for using dynamic thresholds --- To help ensure accurate threshold calculation, alert rules that use dynamic thresholds don't trigger an alert before collecting three days and at least 30 samples of metric data. New resources or resources that are missing metric data don't trigger an alert until enough data is available.-- Dynamic thresholds need at least three weeks of historical data to detect weekly seasonality. Some detailed patterns, such as bihourly or semiweekly patterns, might not be detected.-- If the behavior of a metric changed recently, the changes aren't immediately reflected in the dynamic threshold's upper and lower bounds. The borders are calculated based on metric data from the last 10 days. When you view the dynamic threshold's borders for a particular metric, look at the metric trend in the last week and not only for recent hours or days.-- Dynamic thresholds are good for detecting significant deviations, as opposed to slowly evolving issues. Slow behavior changes probably won't trigger an alert.--## Known issues with dynamic threshold sensitivity --- If an alert rule that uses dynamic thresholds is too noisy or fires too much, you might need to reduce its sensitivity. Use one of the following options:-- - **Threshold sensitivity**: Set the sensitivity to **Low** to be more tolerant of deviations. - - **Number of violations** (under **Advanced settings**): Configure the alert rule to trigger only if several deviations occur within a certain period of time. This setting makes the rule less susceptible to transient deviations. --- You might find that an alert rule that uses dynamic thresholds doesn't fire or isn't sensitive enough, even though it's configured with high sensitivity. This scenario can happen when the metric's distribution is highly irregular. Consider one of the following solutions:-- - Move to monitoring a complementary metric that's suitable for your scenario, if applicable. For example, check for changes in success rate rather than failure rate. - - Try selecting a different value for **Aggregation granularity (Period)**. - - Check if a drastic change happened in the metric behavior in the last 10 days, such as an outage. An abrupt change can affect the upper and lower thresholds calculated for the metric and make them broader. Wait a few days until the outage is no longer included in the threshold calculation. You can also edit the alert rule to use the **Ignore data before** option in **Advanced settings**. - - If your data has weekly seasonality, but not enough history is available for the metric, the calculated thresholds can result in broad upper and lower bounds. For example, the calculation can treat weekdays and weekends in the same way and build wide borders that don't always fit the data. This issue should resolve itself after enough metric history is available. Then, the correct seasonality is detected and the calculated thresholds are updated accordingly. --- When a metric value exhibits large fluctuations, dynamic thresholds might build a wide model around the metric values, which can result in a lower or higher boundary than expected. This scenario can happen when:-- - The sensitivity is set to low. - - The metric exhibits an irregular behavior with high variance, which appears as spikes or dips in the data. -- Consider making the model less sensitive by choosing a higher sensitivity or selecting a larger **Lookback period** value. You can also use the **Ignore data before** option to exclude a recent irregularity from the historical data that's used to build the model. --## Configuration of dynamic thresholds --To configure dynamic thresholds, follow the [procedure for creating an alert rule](alerts-create-new-alert-rule.md#create-or-edit-an-alert-rule-in-the-azure-portal). Use these settings on the **Condition** tab: --- For **Threshold**, select **Dynamic**.-- For **Aggregation type**, we recommend that you don't select **Maximum**.-- For **Operator**, select **Greater than** unless the behavior represents the application usage.-- For **Threshold sensitivity**, select **Medium** or **Low** to reduce alert noise.-- For **Check every**, select how often the alert rule checks if the condition is met. To minimize the business impact of the alert, consider using a lower frequency. Make sure that this value is less than or equal to the **Lookback period** value.-- For **Lookback period**, set the time period to look back at each time that the data is checked. Make sure that this value is greater than or equal to the **Check every** value.-- For **Advanced options**, choose how many violations will trigger the alert within a specific time period. Optionally, set the date from which to start learning the metric historical data and calculate the dynamic thresholds.--> [!NOTE] -> Metric alert rules that you create through the portal are created in the same resource group as the target resource. --## Chart for dynamic thresholds --The following chart shows a metric, its dynamic threshold limits, and some alerts that fired when the value was outside the allowed thresholds. ---Use the following information to interpret the chart: --- **Blue line**: The metric measured over time.-- **Blue shaded area**: The allowed range for the metric. If the metric values stay within this range, no alert is triggered.-- **Blue dots**: Aggregated metric values. If you select part of the chart and then hover over the blue line, a blue dot appears under your cursor to indicate an individual aggregated metric value.-- **Pop-up box with blue dot**: The measured metric value (blue dot) and the upper and lower values of the allowed range. -- **Red dot with a black circle**: The first metric value outside the allowed range. This value fires a metric alert and puts it in an active state.-- **Red dots**: Other measured values outside the allowed range. They don't trigger more metric alerts, but the alert stays in the active state.-- **Red area**: The time when the metric value was outside the allowed range. The alert remains in the active state as long as subsequent measured values are outside the allowed range, but no new alerts are fired.-- **End of red area**: A return to allowed values. When the blue line is back inside the allowed values, the red area stops and the measured value line turns blue. The status of the metric alert fired at the time of the red dot with a black circle is set to resolved.--## Metrics not supported by dynamic thresholds --Dynamic thresholds support most metrics, but the following metrics can't use dynamic thresholds: --| Resource type | Metric name | -| | | -| Microsoft.ClassicStorage/storageAccounts | UsedCapacity | -| Microsoft.ClassicStorage/storageAccounts/blobServices | BlobCapacity | -| Microsoft.ClassicStorage/storageAccounts/blobServices | BlobCount | -| Microsoft.ClassicStorage/storageAccounts/blobServices | IndexCapacity | -| Microsoft.ClassicStorage/storageAccounts/fileServices | FileCapacity | -| Microsoft.ClassicStorage/storageAccounts/fileServices | FileCount | -| Microsoft.ClassicStorage/storageAccounts/fileServices | FileShareCount | -| Microsoft.ClassicStorage/storageAccounts/fileServices | FileShareSnapshotCount | -| Microsoft.ClassicStorage/storageAccounts/fileServices | FileShareSnapshotSize | -| Microsoft.ClassicStorage/storageAccounts/fileServices | FileShareQuota | -| Microsoft.Compute/disks | Composite Disk Read Bytes/sec | -| Microsoft.Compute/disks | Composite Disk Read Operations/sec | -| Microsoft.Compute/disks | Composite Disk Write Bytes/sec | -| Microsoft.Compute/disks | Composite Disk Write Operations/sec | -| Microsoft.ContainerService/managedClusters | NodesCount | -| Microsoft.ContainerService/managedClusters | PodCount | -| Microsoft.ContainerService/managedClusters | CompletedJobsCount | -| Microsoft.ContainerService/managedClusters | RestartingContainerCount | -| Microsoft.ContainerService/managedClusters | OomKilledContainerCount | -| Microsoft.Devices/IotHubs | TotalDeviceCount | -| Microsoft.Devices/IotHubs | ConnectedDeviceCount | -| Microsoft.Devices/IotHubs | TotalDeviceCount | -| Microsoft.Devices/IotHubs | ConnectedDeviceCount | -| Microsoft.DocumentDB/databaseAccounts | CassandraConnectionClosures | -| Microsoft.EventHub/clusters | Size | -| Microsoft.EventHub/namespaces | Size | -| Microsoft.IoTCentral/IoTApps | connectedDeviceCount | -| Microsoft.IoTCentral/IoTApps | provisionedDeviceCount | -| Microsoft.Kubernetes/connectedClusters | NodesCount | -| Microsoft.Kubernetes/connectedClusters | PodCount | -| Microsoft.Kubernetes/connectedClusters | CompletedJobsCount | -| Microsoft.Kubernetes/connectedClusters | RestartingContainerCount | -| Microsoft.Kubernetes/connectedClusters | OomKilledContainerCount | -| Microsoft.MachineLearningServices/workspaces/onlineEndpoints | RequestsPerMinute | -| Microsoft.MachineLearningServices/workspaces/onlineEndpoints/deployments | DeploymentCapacity | -| Microsoft.Maps/accounts | CreatorUsage | -| Microsoft.Media/mediaservices/streamingEndpoints | EgressBandwidth | -| Microsoft.Network/applicationGateways | Throughput | -| Microsoft.Network/azureFirewalls | Throughput | -| Microsoft.Network/expressRouteGateways | ExpressRouteGatewayPacketsPerSecond | -| Microsoft.Network/expressRouteGateways | ExpressRouteGatewayNumberOfVmInVnet | -| Microsoft.Network/expressRouteGateways | ExpressRouteGatewayFrequencyOfRoutesChanged | -| Microsoft.Network/virtualNetworkGateways | ExpressRouteGatewayBitsPerSecond | -| Microsoft.Network/virtualNetworkGateways | ExpressRouteGatewayPacketsPerSecond | -| Microsoft.Network/virtualNetworkGateways | ExpressRouteGatewayNumberOfVmInVnet | -| Microsoft.Network/virtualNetworkGateways | ExpressRouteGatewayFrequencyOfRoutesChanged | -| Microsoft.ServiceBus/namespaces | Size | -| Microsoft.ServiceBus/namespaces | Messages | -| Microsoft.ServiceBus/namespaces | ActiveMessages | -| Microsoft.ServiceBus/namespaces | DeadletteredMessages | -| Microsoft.ServiceBus/namespaces | ScheduledMessages | -| Microsoft.ServiceFabricMesh/applications | AllocatedCpu | -| Microsoft.ServiceFabricMesh/applications | AllocatedMemory | -| Microsoft.ServiceFabricMesh/applications | ActualCpu | -| Microsoft.ServiceFabricMesh/applications | ActualMemory | -| Microsoft.ServiceFabricMesh/applications | ApplicationStatus | -| Microsoft.ServiceFabricMesh/applications | ServiceStatus | -| Microsoft.ServiceFabricMesh/applications | ServiceReplicaStatus | -| Microsoft.ServiceFabricMesh/applications | ContainerStatus | -| Microsoft.ServiceFabricMesh/applications | RestartCount | -| Microsoft.Storage/storageAccounts | UsedCapacity | -| Microsoft.Storage/storageAccounts/blobServices | BlobCapacity | -| Microsoft.Storage/storageAccounts/blobServices | BlobCount | -| Microsoft.Storage/storageAccounts/blobServices | BlobProvisionedSize | -| Microsoft.Storage/storageAccounts/blobServices | IndexCapacity | -| Microsoft.Storage/storageAccounts/fileServices | FileCapacity | -| Microsoft.Storage/storageAccounts/fileServices | FileCount | -| Microsoft.Storage/storageAccounts/fileServices | FileShareCount | -| Microsoft.Storage/storageAccounts/fileServices | FileShareSnapshotCount | -| Microsoft.Storage/storageAccounts/fileServices | FileShareSnapshotSize | -| Microsoft.Storage/storageAccounts/fileServices | FileShareCapacityQuota | -| Microsoft.Storage/storageAccounts/fileServices | FileShareProvisionedIOPS | --## Related content --- [Manage your alert rules](alerts-manage-alert-rules.md)--If you have feedback about dynamic thresholds, [email us](mailto:azurealertsfeedback@microsoft.com). |
| azure-monitor | Alerts Log Alert Query Samples | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-log-alert-query-samples.md | - Title: Samples of Azure Monitor log search alert rule queries -description: See examples of Azure monitor log search alert rule queries. - Previously updated : 01/04/2024------# Sample log search alert queries that include ADX and ARG --A log search alert rule monitors a resource by using a Log Analytics query to evaluate logs at a set frequency. You can include data from Azure Data Explorer and Azure Resource Graph in your log search alert rule queries. --This article provides examples of log search alert rule queries that use Azure Data Explorer and Azure Resource Graph. For more information about creating a log search alert rule, see [Create a log search alert rule](./alerts-create-log-alert-rule.md). --## Queries that check virtual machine health --This query finds virtual machines marked as critical that haven't had a heartbeat in the last 2 minutes. --```kusto - arg("").Resources - | where type == "microsoft.compute/virtualmachines" - | summarize LastCall = max(case(isnull(TimeGenerated), make_datetime(1970, 1, 1), TimeGenerated)) by name, id - | extend SystemDown = case(LastCall < ago(2m), 1, 0) - | where SystemDown == 1 -``` ---This query finds virtual machines marked as critical that had a heartbeat more than 24 hours ago, but that haven't had a heartbeat in the last 2 minutes. --```kusto -{ - arg("").Resources - | where type == "microsoft.compute/virtualmachines" - | where tags.BusinessCriticality =~ 'critical' and subscriptionId == '123-456-123-456' - | join kind=leftouter ( - Heartbeat - | where TimeGenerated > ago(24h) - ) - on $left.name == $right.Resource - | summarize LastCall = max(case(isnull(TimeGenerated), make_datetime(1970, 1, 1), TimeGenerated)) by name, id - | extend SystemDown = case(LastCall < ago(2m), 1, 0) - | where SystemDown == 1 -} --``` --## Query that filters virtual machines that need to be monitored --```kusto - { - let RuleGroupTags = dynamic(['Linux']); - Perf | where ObjectName == 'Processor' and CounterName == '% Idle Time' and (InstanceName in ('_Total,'total')) - | extend CpuUtilisation = (100 - CounterValue)    - | join kind=inner hint.remote=left (arg("").Resources - | where type =~ 'Microsoft.Compute/virtualMachines' - | project _ResourceId=tolower(id), tags) on _ResourceId - | project-away _ResourceId1 - | where (tostring(tags.monitorRuleGroup) in (RuleGroupTags)) -} -``` --## Query that finds resources with certificates that are going to expire within 30 days --```kusto -{ - arg("").Resources - | where type == "microsoft.web/certificates" - | extend ExpirationDate = todatetime(properties.expirationDate) - | project ExpirationDate, name, resourceGroup, properties.expirationDate - | where ExpirationDate < now() + 30d - | order by ExpirationDate asc -} -``` --## Query that alerts when a new resource is created in the subscription --```kusto -{ - arg("").resourcechanges - | extend changeTime = todatetime(properties.changeAttributes.timestamp), - changeType = tostring(properties.changeType),targetResourceType = tostring(properties.targetResourceType), - changedBy = tostring(properties.changeAttributes.changedBy), - createdResource = tostring(properties.targetResourceId) - | where changeType == "Create" and changeTime <ago(1h) - | project changeTime,createdResource,changedBy --} -``` --## Next steps -- [Learn more about creating a log search alert rule](./alerts-create-log-alert-rule.md)-- [Learn how to optimize log search alert queries](./alerts-log-query.md) |
| azure-monitor | Alerts Log Api Switch | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-log-api-switch.md | - Title: Upgrade legacy rules management to the current Azure Monitor Scheduled Query Rules API -description: Learn how to switch log search alert management to ScheduledQueryRules API. --- Previously updated : 07/09/2023---# Upgrade to the Scheduled Query Rules API from the legacy Log Analytics Alert API --> [!IMPORTANT] -> As [announced](https://azure.microsoft.com/updates/switch-api-preference-log-alerts/), the Log Analytics Alert API will be retired on October 1, 2025. You must transition to using the Scheduled Query Rules API for log search alerts by that date. -> Log Analytics workspaces created after June 1, 2019 use the [scheduledQueryRules API](/rest/api/monitor/scheduledqueryrule-2021-08-01/scheduled-query-rules) to manage log search alert rules. [Switch to the current API](./alerts-log-api-switch.md) in older workspaces to take advantage of Azure Monitor scheduledQueryRules [benefits](./alerts-log-api-switch.md#benefits). -> Once you migrate rules to the [scheduledQueryRules API](/rest/api/monitor/scheduledqueryrule-2021-08-01/scheduled-query-rules), you cannot revert back to the older [legacy Log Analytics Alert API](/azure/azure-monitor/alerts/api-alerts). --In the past, users used the [legacy Log Analytics Alert API](/azure/azure-monitor/alerts/api-alerts) to manage log search alert rules. Currently workspaces use the [Scheduled Query Rules API](/rest/api/monitor/scheduledqueryrule-2021-08-01/scheduled-query-rules) for new rules. This article describes the benefits and the process of switching legacy log search alert rules management from the legacy API to the current API. --## Benefits --- Manage all log search alert rules in one API.-- Single template for creation of alert rules (previously needed three separate templates).-- Single API for all Azure resources log alerting.-- Support for stateful (preview) and 1-minute log search alerts.-- [PowerShell cmdlets](/azure/azure-monitor/alerts/alerts-manage-alerts-previous-version#manage-log-alerts-by-using-powershell) and [Azure CLI](/azure/azure-monitor/alerts/alerts-log#manage-log-alerts-using-cli) support for switched rules.-- Alignment of severities with all other alert types and newer rules.-- Ability to create a [cross workspace log alert](/azure/azure-monitor/logs/cross-workspace-query) that spans several external resources like Log Analytics workspaces or Application Insights resources for switched rules.-- Users can specify dimensions to split the alerts for switched rules.-- Log search alerts have an extended period of up to two days of data (previously limited to one day) for switched rules.--## Impact --- All switched rules must be created/edited with the current API. See [sample use via Azure Resource Template](/azure/azure-monitor/alerts/alerts-log-create-templates) and [sample use via PowerShell](/azure/azure-monitor/alerts/alerts-manage-alerts-previous-version#manage-log-alerts-by-using-powershell).-- As rules become Azure Resource Manager tracked resources in the current API and must be unique, the resource IDs for the rules change to this structure: `<WorkspaceName>|<savedSearchId>|<scheduleId>|<ActionId>`. Display names for the alert rules remain unchanged. --## Process --View workspaces to upgrade using this [Azure Resource Graph Explorer query](https://portal.azure.com/?feature.customportal=false#blade/HubsExtension/ArgQueryBlade/query/resources%0A%7C%20where%20type%20%3D~%20%22microsoft.insights%2Fscheduledqueryrules%22%0A%7C%20where%20properties.isLegacyLogAnalyticsRule%20%3D%3D%20true%0A%7C%20distinct%20tolower%28properties.scopes%5B0%5D%29). Open the [link](https://portal.azure.com/?feature.customportal=false#blade/HubsExtension/ArgQueryBlade/query/resources%0A%7C%20where%20type%20%3D~%20%22microsoft.insights%2Fscheduledqueryrules%22%0A%7C%20where%20properties.isLegacyLogAnalyticsRule%20%3D%3D%20true%0A%7C%20distinct%20tolower%28properties.scopes%5B0%5D%29), select all available subscriptions, and run the query. --The process of switching isn't interactive and doesn't require manual steps, in most cases. Your alert rules aren't stopped or stalled, during or after the switch. -Do this call to switch all alert rules associated with each of the Log Analytics workspaces: --``` -PUT /subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.OperationalInsights/workspaces/<workspaceName>/alertsversion?api-version=2017-04-26-preview -``` --With request body containing the below JSON: --```json -{ - "scheduledQueryRulesEnabled" : true -} -``` --Here is an example of using [ARMClient](https://github.com/projectkudu/ARMClient), an open-source command-line tool, that simplifies invoking the above API call: --```powershell -$switchJSON = '{"scheduledQueryRulesEnabled": true}' -armclient PUT /subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.OperationalInsights/workspaces/<workspaceName>/alertsversion?api-version=2017-04-26-preview $switchJSON -``` --You can also use the [Azure CLI](/cli/azure/reference-index#az-rest) tool: --```bash -az rest --method put --url /subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.OperationalInsights/workspaces/<workspaceName>/alertsversion?api-version=2017-04-26-preview --body "{\"scheduledQueryRulesEnabled\" : true}" -``` --If the switch is successful, the response is: --```json -{ - "version": 2, - "scheduledQueryRulesEnabled" : true -} -``` --## Check switching status of workspace --You can also use this API call to check the switch status: --``` -GET /subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.OperationalInsights/workspaces/<workspaceName>/alertsversion?api-version=2017-04-26-preview -``` --You can also use the [ARMClient](https://github.com/projectkudu/ARMClient) tool: --```powershell -armclient GET /subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.OperationalInsights/workspaces/<workspaceName>/alertsversion?api-version=2017-04-26-preview -``` --You can also use the [Azure CLI](/cli/azure/reference-index#az-rest) tool: --```bash -az rest --method get --url /subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.OperationalInsights/workspaces/<workspaceName>/alertsversion?api-version=2017-04-26-preview -``` --If the Log Analytics workspace was switched to [scheduledQueryRules API](/rest/api/monitor/scheduledqueryrule-2021-08-01/scheduled-query-rules), the response is: --```json -{ - "version": 2, - "scheduledQueryRulesEnabled" : true -} -``` -If the Log Analytics workspace wasn't switched, the response is: --```json -{ - "version": 2, - "scheduledQueryRulesEnabled" : false -} -``` --## Next steps --- Learn about the [Azure Monitor log search alerts](/azure/azure-monitor/alerts/alerts-types).-- Learn how to [manage your log search alerts using the API](/azure/azure-monitor/alerts/alerts-log-create-templates).-- Learn how to [manage your log search alerts using PowerShell](/azure/azure-monitor/alerts/alerts-manage-alerts-previous-version#manage-log-alerts-by-using-powershell).-- Learn more about the [Azure Alerts experience](/azure/azure-monitor/alerts/alerts-overview). |
| azure-monitor | Alerts Log Query | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-log-query.md | - Title: Optimize log search alert queries | Microsoft Docs -description: This article gives recommendations for writing efficient alert queries. -- Previously updated : 7/30/2024----# Optimize log search alert queries --This article describes how to write and convert [log search alerts](alerts-types.md#log-alerts) to achieve optimal performance. Optimized queries reduce latency and load of alerts, which run frequently. --## Start writing an alert log query --Alert queries start from [querying the log data in Log Analytics](alerts-log.md#create-a-new-log-alert-rule-in-the-azure-portal) that indicates the issue. To understand what you can discover, see [Using queries in Azure Monitor Log Analytics](../logs/queries.md). You can also [get started on writing your own query](../logs/log-analytics-tutorial.md). --### Queries that indicate the issue and not the alert --The alert flow was built to transform the results that indicate the issue to an alert. For example, in the case of a query like: --``` Kusto -SecurityEvent -| where EventID == 4624 -``` --If the intent of the user is to alert, when this event type happens, the alerting logic appends `count` to the query. The query that runs will be: --``` Kusto -SecurityEvent -| where EventID == 4624 -| count -``` --There's no need to add alerting logic to the query, and doing that might even cause issues. In the preceding example, if you include `count` in your query, it will always result in the value 1, because the alert service will do `count` of `count`. --### Avoid limit and take operators --Using `limit` and `take` in queries can increase latency and load of alerts because the results aren't consistent over time. Use them only if needed. --## Log query constraints --[Log queries in Azure Monitor](../logs/log-query-overview.md) start with either a table, [`search`](/azure/kusto/query/searchoperator), or [`union`](/azure/kusto/query/unionoperator) operator. --Queries for log search alert rules should always start with a table to define a clear scope, which improves query performance and the relevance of the results. Queries in alert rules run frequently. Using `search` and `union` can result in excessive overhead that adds latency to the alert because it requires scanning across multiple tables. These operators also reduce the ability of the alerting service to optimize the query. --We don't support creating or modifying log search alert rules that use `search` or `union` operators, except for cross-resource queries. --For example, the following alerting query is scoped to the _SecurityEvent_ table and searches for a specific event ID. It's the only table that the query must process. --``` Kusto -SecurityEvent -| where EventID == 4624 -``` --Log search alert rules using [cross-resource queries](../logs/cross-workspace-query.md) aren't affected by this change because cross-resource queries use a type of `union`, which limits the query scope to specific resources. The following example would be a valid log search alert query: --```Kusto -union -app('00000000-0000-0000-0000-000000000001').requests, -app('00000000-0000-0000-0000-000000000002').requests, -workspace('00000000-0000-0000-0000-000000000003').Perf -``` -->[!NOTE] -> [Cross-resource queries](../logs/cross-workspace-query.md) are supported in the new [scheduledQueryRules API](/rest/api/monitor/scheduledqueryrule-2021-08-01/scheduled-query-rules). If you still use the [legacy Log Analytics Alert API](./api-alerts.md) for creating log search alerts, see [Upgrade legacy rules management to the current Azure Monitor Scheduled Query Rules API](./alerts-log-api-switch.md) to learn about switching. --## Examples --The following examples include log queries that use `search` and `union`. They provide steps you can use to modify these queries for use in alert rules. --### Example 1 --You want to create a log search alert rule by using the following query that retrieves performance information using `search`: --``` Kusto -search * -| where Type == 'Perf' and CounterName == '% Free Space' -| where CounterValue < 30 -``` --1. To modify this query, start by using the following query to identify the table that the properties belong to: - - ``` Kusto - search * - | where CounterName == '% Free Space' - | summarize by $table - ``` -- The result of this query would show that the _CounterName_ property came from the _Perf_ table. --1. Use this result to create the following query that you would use for the alert rule: -- ``` Kusto - Perf - | where CounterName == '% Free Space' - | where CounterValue < 30 - ``` --### Example 2 --You want to create a log search alert rule by using the following query that retrieves performance information using `search`: --``` Kusto -search ObjectName =="Memory" and CounterName=="% Committed Bytes In Use" -| summarize Avg_Memory_Usage =avg(CounterValue) by Computer -| where Avg_Memory_Usage between(90 .. 95) -``` --1. To modify this query, start by using the following query to identify the table that the properties belong to: - - ``` Kusto - search ObjectName=="Memory" and CounterName=="% Committed Bytes In Use" - | summarize by $table - ``` - - The result of this query would show that the _ObjectName_ and _CounterName_ properties came from the _Perf_ table. --1. Use this result to create the following query that you would use for the alert rule: -- ``` Kusto - Perf - | where ObjectName =="Memory" and CounterName=="% Committed Bytes In Use" - | summarize Avg_Memory_Usage=avg(CounterValue) by Computer - | where Avg_Memory_Usage between(90 .. 95) - ``` --### Example 3 --You want to create a log search alert rule by using the following query that uses both `search` and `union` to retrieve performance information: --``` Kusto -search (ObjectName == "Processor" and CounterName == "% Idle Time" and InstanceName == "_Total") -| where Computer !in ( - union * - | where CounterName == "% Processor Utility" - | summarize by Computer) -| summarize Avg_Idle_Time = avg(CounterValue) by Computer -``` --1. To modify this query, start by using the following query to identify the table that the properties in the first part of the query belong to: -- ``` Kusto - search (ObjectName == "Processor" and CounterName == "% Idle Time" and InstanceName == "_Total") - | summarize by $table - ``` -- The result of this query would show that all these properties came from the _Perf_ table. --1. Use `union` with the `withsource` command to identify which source table has contributed each row: -- ``` Kusto - union withsource=table * - | where CounterName == "% Processor Utility" - | summarize by table - ``` -- The result of this query would show that these properties also came from the _Perf_ table. --1. Use these results to create the following query that you would use for the alert rule: -- ``` Kusto - Perf - | where ObjectName == "Processor" and CounterName == "% Idle Time" and InstanceName == "_Total" - | where Computer !in ( - (Perf - | where CounterName == "% Processor Utility" - | summarize by Computer)) - | summarize Avg_Idle_Time = avg(CounterValue) by Computer - ``` --### Example 4 --You want to create a log search alert rule by using the following query that joins the results of two `search` queries: --```Kusto -search Type == 'SecurityEvent' and EventID == '4625' -| summarize by Computer, Hour = bin(TimeGenerated, 1h) -| join kind = leftouter ( - search in (Heartbeat) OSType == 'Windows' - | summarize arg_max(TimeGenerated, Computer) by Computer , Hour = bin(TimeGenerated, 1h) - | project Hour , Computer -) on Hour -``` --1. To modify the query, start by using the following query to identify the table that contains the properties in the left side of the join: - - ``` Kusto - search Type == 'SecurityEvent' and EventID == '4625' - | summarize by $table - ``` -- The result indicates that the properties in the left side of the join belong to the _SecurityEvent_ table. --1. Use the following query to identify the table that contains the properties in the right side of the join: - - ``` Kusto - search in (Heartbeat) OSType == 'Windows' - | summarize by $table - ``` - - The result indicates that the properties in the right side of the join belong to the _Heartbeat_ table. --1. Use these results to create the following query that you would use for the alert rule: - - ``` Kusto - SecurityEvent - | where EventID == '4625' - | summarize by Computer, Hour = bin(TimeGenerated, 1h) - | join kind = leftouter ( - Heartbeat - | where OSType == 'Windows' - | summarize arg_max(TimeGenerated, Computer) by Computer , Hour = bin(TimeGenerated, 1h) - | project Hour , Computer - ) on Hour - ``` --## Next steps --- Learn about [log search alerts](alerts-log.md) in Azure Monitor.-- Learn about [log queries](../logs/log-query-overview.md). |
| azure-monitor | Alerts Log Webhook | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-log-webhook.md | - Title: Sample payloads for Azure Monitor log search alerts using webhook actions -description: This article describes how to configure log search alert rules with webhook actions and available customizations. --- Previously updated : 11/23/2023----# Sample payloads for log search alerts using webhook actions --You can use webhook actions in a log search alert rule to invoke a single HTTP POST request. In this article, we describe the properties that are available when you [configure action groups to use webhooks](./action-groups.md). The service that's called must support webhooks and know how to use the payload it receives. --We recommend that you use [common alert schema](../alerts/alerts-common-schema.md) for your webhook integrations. The common alert schema provides the advantage of having a single extensible and unified alert payload across all the alert services in Azure Monitor. --For log search alert rules that have a custom JSON payload defined, enabling the common alert schema reverts the payload schema to the one described in [Common alert schema](../alerts/alerts-common-schema.md#alert-context-fields-for-log-search-alerts). If you want to have a custom JSON payload defined, the webhook can't use the common alert schema. --Alerts with the common schema enabled have an upper size limit of 256 KB per alert. A bigger alert doesn't include search results. When the search results aren't included, use `LinkToFilteredSearchResultsAPI` or `LinkToSearchResultsAPI` to access query results via the Log Analytics API. --The sample payloads include examples when the payload is standard and when it's custom. --## Log search alert for all resources logs (from API version `2021-08-01`) --The following sample payload is for a standard webhook when it's used for log search alerts based on resources logs: --```json -{ - "schemaId": "azureMonitorCommonAlertSchema", - "data": { - "essentials": { - "alertId": "/subscriptions/12345a-1234b-123c-123d-12345678e/providers/Microsoft.AlertsManagement/alerts/12345a-1234b-123c-123d-12345678e", - "alertRule": "AcmeRule", - "severity": "Sev4", - "signalType": "Log", - "monitorCondition": "Fired", - "monitoringService": "Log Alerts V2", - "alertTargetIDs": [ - "/subscriptions/12345a-1234b-123c-123d-12345678e/resourcegroups/ai-engineering/providers/microsoft.compute/virtualmachines/testvm" - ], - "originAlertId": "123c123d-1a23-1bf3-ba1d-dd1234ff5a67", - "firedDateTime": "2020-07-09T14:04:49.99645Z", - "description": "log alert rule V2", - "essentialsVersion": "1.0", - "alertContextVersion": "1.0" - }, - "alertContext": { - "properties": { - "name1": "value1", - "name2": "value2" - }, - "conditionType": "LogQueryCriteria", - "condition": { - "windowSize": "PT10M", - "allOf": [ - { - "searchQuery": "Heartbeat", - "metricMeasureColumn": "CounterValue", - "targetResourceTypes": "['Microsoft.Compute/virtualMachines']", - "operator": "LowerThan", - "threshold": "1", - "timeAggregation": "Count", - "dimensions": [ - { - "name": "ResourceId", - "value": "/subscriptions/12345a-1234b-123c-123d-12345678e/resourceGroups/TEST/providers/Microsoft.Compute/virtualMachines/testvm" - } - ], - "metricValue": 0.0, - "failingPeriods": { - "numberOfEvaluationPeriods": 1, - "minFailingPeriodsToAlert": 1 - }, - "linkToSearchResultsUI": "https://portal.azure.com#@12f345bf-12f3-12af-12ab-1d2cd345db67/blade/Microsoft_Azure_Monitoring_Logs/LogsBlade/source/Alerts.EmailLinks/scope/%7B%22resources%22%3A%5B%7B%22resourceId%22%3A%22%2Fsubscriptions%2F12345a-1234b-123c-123d-12345678e%2FresourceGroups%2FTEST%2Fproviders%2FMicrosoft.Compute%2FvirtualMachines%2Ftestvm%22%7D%5D%7D/q/eJzzSE0sKklKTSypUSjPSC1KVQjJzE11T81LLUosSU1RSEotKU9NzdNIAfJKgDIaRgZGBroG5roGliGGxlYmJlbGJnoGEKCpp4dDmSmKMk0A/prettify/1/timespan/2020-07-07T13%3a54%3a34.0000000Z%2f2020-07-09T13%3a54%3a34.0000000Z", - "linkToFilteredSearchResultsUI": "https://portal.azure.com#@12f345bf-12f3-12af-12ab-1d2cd345db67/blade/Microsoft_Azure_Monitoring_Logs/LogsBlade/source/Alerts.EmailLinks/scope/%7B%22resources%22%3A%5B%7B%22resourceId%22%3A%22%2Fsubscriptions%2F12345a-1234b-123c-123d-12345678e%2FresourceGroups%2FTEST%2Fproviders%2FMicrosoft.Compute%2FvirtualMachines%2Ftestvm%22%7D%5D%7D/q/eJzzSE0sKklKTSypUSjPSC1KVQjJzE11T81LLUosSU1RSEotKU9NzdNIAfJKgDIaRgZGBroG5roGliGGxlYmJlbGJnoGEKCpp4dDmSmKMk0A/prettify/1/timespan/2020-07-07T13%3a54%3a34.0000000Z%2f2020-07-09T13%3a54%3a34.0000000Z", - "linkToSearchResultsAPI": "https://api.loganalytics.io/v1/subscriptions/12345a-1234b-123c-123d-12345678e/resourceGroups/TEST/providers/Microsoft.Compute/virtualMachines/testvm/query?query=Heartbeat%7C%20where%20TimeGenerated%20between%28datetime%282020-07-09T13%3A44%3A34.0000000%29..datetime%282020-07-09T13%3A54%3A34.0000000%29%29×pan=2020-07-07T13%3a54%3a34.0000000Z%2f2020-07-09T13%3a54%3a34.0000000Z", - "linkToFilteredSearchResultsAPI": "https://api.loganalytics.io/v1/subscriptions/12345a-1234b-123c-123d-12345678e/resourceGroups/TEST/providers/Microsoft.Compute/virtualMachines/testvm/query?query=Heartbeat%7C%20where%20TimeGenerated%20between%28datetime%282020-07-09T13%3A44%3A34.0000000%29..datetime%282020-07-09T13%3A54%3A34.0000000%29%29×pan=2020-07-07T13%3a54%3a34.0000000Z%2f2020-07-09T13%3a54%3a34.0000000Z" - } - ], - "windowStartTime": "2020-07-07T13:54:34Z", - "windowEndTime": "2020-07-09T13:54:34Z" - } - } - } -} -``` --## Log search alert for Log Analytics (up to API version `2018-04-16`) --The following sample payload is for a standard webhook action that's used for alerts based on Log Analytics: --> [!NOTE] -> The `"Severity"` field value changes if you've [switched to the current scheduledQueryRules API](./alerts-log-api-switch.md) from the [legacy Log Analytics Alert API](./api-alerts.md). --```json -{ - "SubscriptionId": "12345a-1234b-123c-123d-12345678e", - "AlertRuleName": "AcmeRule", - "SearchQuery": "Perf | where ObjectName == \"Processor\" and CounterName == \"% Processor Time\" | summarize AggregatedValue = avg(CounterValue) by bin(TimeGenerated, 5m), Computer", - "SearchIntervalStartTimeUtc": "2018-03-26T08:10:40Z", - "SearchIntervalEndtimeUtc": "2018-03-26T09:10:40Z", - "AlertThresholdOperator": "Greater Than", - "AlertThresholdValue": 0, - "ResultCount": 2, - "SearchIntervalInSeconds": 3600, - "LinkToSearchResults": "https://portal.azure.com/#Analyticsblade/search/index?_timeInterval.intervalEnd=2018-03-26T09%3a10%3a40.0000000Z&_timeInterval.intervalDuration=3600&q=Usage", - "LinkToFilteredSearchResultsUI": "https://portal.azure.com/#Analyticsblade/search/index?_timeInterval.intervalEnd=2018-03-26T09%3a10%3a40.0000000Z&_timeInterval.intervalDuration=3600&q=Usage", - "LinkToSearchResultsAPI": "https://api.loganalytics.io/v1/workspaces/workspaceID/query?query=Heartbeat×pan=2020-05-07T18%3a11%3a51.0000000Z%2f2020-05-07T18%3a16%3a51.0000000Z", - "LinkToFilteredSearchResultsAPI": "https://api.loganalytics.io/v1/workspaces/workspaceID/query?query=Heartbeat×pan=2020-05-07T18%3a11%3a51.0000000Z%2f2020-05-07T18%3a16%3a51.0000000Z", - "Description": "log alert rule", - "Severity": "Warning", - "AffectedConfigurationItems": [ - "INC-Gen2Alert" - ], - "Dimensions": [ - { - "name": "Computer", - "value": "INC-Gen2Alert" - } - ], - "SearchResult": { - "tables": [ - { - "name": "PrimaryResult", - "columns": [ - { - "name": "$table", - "type": "string" - }, - { - "name": "Computer", - "type": "string" - }, - { - "name": "TimeGenerated", - "type": "datetime" - } - ], - "rows": [ - [ - "Fabrikam", - "33446677a", - "2018-02-02T15:03:12.18Z" - ], - [ - "Contoso", - "33445566b", - "2018-02-02T15:16:53.932Z" - ] - ] - } - ] - }, - "WorkspaceId": "12345a-1234b-123c-123d-12345678e", - "AlertType": "Metric measurement" -} -``` --## Log search alert for Application Insights (up to API version `2018-04-16`) --The following sample payload is for a standard webhook when it's used for log search alerts based on Application Insights resources: - -```json -{ - "schemaId": "Microsoft.Insights/LogAlert", - "data": { - "SubscriptionId": "12345a-1234b-123c-123d-12345678e", - "AlertRuleName": "AcmeRule", - "SearchQuery": "requests | where resultCode == \"500\" | summarize AggregatedValue = Count by bin(Timestamp, 5m), IP", - "SearchIntervalStartTimeUtc": "2018-03-26T08:10:40Z", - "SearchIntervalEndtimeUtc": "2018-03-26T09:10:40Z", - "AlertThresholdOperator": "Greater Than", - "AlertThresholdValue": 0, - "ResultCount": 2, - "SearchIntervalInSeconds": 3600, - "LinkToSearchResults": "https://portal.azure.com/AnalyticsBlade/subscriptions/12345a-1234b-123c-123d-12345678e/?query=search+*+&timeInterval.intervalEnd=2018-03-26T09%3a10%3a40.0000000Z&_timeInterval.intervalDuration=3600&q=Usage", - "LinkToFilteredSearchResultsUI": "https://portal.azure.com/AnalyticsBlade/subscriptions/12345a-1234b-123c-123d-12345678e/?query=search+*+&timeInterval.intervalEnd=2018-03-26T09%3a10%3a40.0000000Z&_timeInterval.intervalDuration=3600&q=Usage", - "LinkToSearchResultsAPI": "https://api.applicationinsights.io/v1/apps/0MyAppId0/metrics/requests/count", - "LinkToFilteredSearchResultsAPI": "https://api.applicationinsights.io/v1/apps/0MyAppId0/metrics/requests/count", - "Description": null, - "Severity": "3", - "Dimensions": [ - { - "name": "IP", - "value": "1.1.1.1" - } - ], - "SearchResult": { - "tables": [ - { - "name": "PrimaryResult", - "columns": [ - { - "name": "$table", - "type": "string" - }, - { - "name": "Id", - "type": "string" - }, - { - "name": "Timestamp", - "type": "datetime" - } - ], - "rows": [ - [ - "Fabrikam", - "33446677a", - "2018-02-02T15:03:12.18Z" - ], - [ - "Contoso", - "33445566b", - "2018-02-02T15:16:53.932Z" - ] - ] - } - ] - }, - "ApplicationId": "123123f0-01d3-12ab-123f-abc1ab01c0a1", - "AlertType": "Metric measurement" - } -} -``` --## Log search alert with a custom JSON payload (up to API version `2018-04-16`) --> [!NOTE] -> A custom JSON-based webhook isn't supported from API version `2021-08-01`. --The following table lists default webhook action properties and their custom JSON parameter names. --| Parameter | Variable | Description | -|: |: |: | -| `AlertRuleName` |#alertrulename |Name of the alert rule. | -| `Severity` |#severity |Severity set for the fired log search alert. | -| `AlertThresholdOperator` |#thresholdoperator |Threshold operator for the alert rule. | -| `AlertThresholdValue` |#thresholdvalue |Threshold value for the alert rule. | -| `LinkToSearchResults` |#linktosearchresults |Link to the Analytics portal that returns the records from the query that created the alert. | -| `LinkToSearchResultsAPI` |#linktosearchresultsapi |Link to the Analytics API that returns the records from the query that created the alert. | -| `LinkToFilteredSearchResultsUI` |#linktofilteredsearchresultsui |Link to the Analytics portal that returns the records from the query filtered by dimensions value combinations that created the alert. | -| `LinkToFilteredSearchResultsAPI` |#linktofilteredsearchresultsapi |Link to the Analytics API that returns the records from the query filtered by dimensions value combinations that created the alert. | -| `ResultCount` |#searchresultcount |Number of records in the search results. | -| `Search Interval End time` |#searchintervalendtimeutc |End time for the query in UTC, with the format mm/dd/yyyy HH:mm:ss AM/PM. | -| `Search Interval` |#searchinterval |Time window for the alert rule, with the format HH:mm:ss. | -| `Search Interval StartTime` |#searchintervalstarttimeutc |Start time for the query in UTC, with the format mm/dd/yyyy HH:mm:ss AM/PM. | -| `SearchQuery` |#searchquery |Log search query used by the alert rule. | -| `SearchResults` |"IncludeSearchResults": true|Records returned by the query as a JSON table, limited to the first 1,000 records. "IncludeSearchResults": true is added in a custom JSON webhook definition as a top-level property. | -| `Dimensions` |"IncludeDimensions": true|Dimensions value combinations that triggered that alert as a JSON section. "IncludeDimensions": true is added in a custom JSON webhook definition as a top-level property. | -| `Alert Type`| #alerttype | The type of log search alert rule configured as [Metric measurement or Number of results](./alerts-types.md#log-alerts).| -| `WorkspaceID` |#workspaceid |ID of your Log Analytics workspace. | -| `Application ID` |#applicationid |ID of your Application Insights app. | -| `Subscription ID` |#subscriptionid |ID of your Azure subscription used. | --You can use **Include custom JSON payload for webhook** to get a custom JSON payload by using the parameters. You can also generate more properties. --For example, you might specify the following custom payload that includes a single parameter called `text`. The service that this webhook calls expects this parameter: --```json -- { - "text":"#alertrulename fired with #searchresultcount over threshold of #thresholdvalue." - } -``` --This example payload resolves to something like the following example when it's sent to the webhook: --```json - { - "text":"My Alert Rule fired with 18 records over threshold of 10 ." - } -``` --Variables in a custom webhook must be specified within a JSON enclosure. For example, referencing `#searchresultcount` in the webhook example generates output based on the alert results. --To include search results, add **IncludeSearchResults** as a top-level property in the custom JSON. Search results are included as a JSON structure, so results can't be referenced in custom-defined fields. --> [!NOTE] -> The **View Webhook** button next to the **Include custom JSON payload for webhook** option displays a preview of what was provided. It doesn't contain actual data but is representative of the JSON schema that will be used. --For example, to create a custom payload that includes only the alert name and the search results, use this configuration: --```json - { - "alertname":"#alertrulename", - "IncludeSearchResults":true - } -``` --The following sample payload is for a custom webhook action for any log search alert: - -```json - { - "alertname":"AcmeRule","IncludeSearchResults":true, - "SearchResults": - { - "tables":[ - {"name":"PrimaryResult","columns": - [ - {"name":"$table","type":"string"}, - {"name":"Id","type":"string"}, - {"name":"TimeGenerated","type":"datetime"} - ], - "rows": - [ - ["Fabrikam","33446677a","2018-02-02T15:03:12.18Z"], - ["Contoso","33445566b","2018-02-02T15:16:53.932Z"] - ] - } - ] - } - } -``` --## Next steps --- Learn about [Azure Monitor alerts](./alerts-overview.md).-- Create and manage [action groups in Azure](./action-groups.md).-- Learn more about [log queries](../logs/log-query-overview.md). |
| azure-monitor | Alerts Logic Apps | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-logic-apps.md | - Title: Customize alert notifications by using Logic Apps -description: Learn how to create a logic app to process Azure Monitor alerts. --- Previously updated : 03/10/2024---# Customer intent: As an administrator, I want to create a logic app that's triggered by an alert so that I can send emails or Teams messages when an alert is fired. ---# Customize alert notifications by using Logic Apps --This article shows you how to create a logic app and integrate it with an Azure Monitor alert. --You can use [Azure Logic Apps](../../logic-apps/logic-apps-overview.md) to build and customize workflows for integration. Use Logic Apps to customize your alert notifications. You can: --- Customize the alerts email by using your own email subject and body format.-- Customize the alert metadata by looking up tags for affected resources or fetching a log query search result. For information on how to access the search result rows that contain alerts data, see:- - [Azure Monitor Log Analytics API response format](../logs/api/response-format.md) - - [Query/management HTTP response](/azure/data-explorer/kusto/api/rest/response) -- Integrate with external services by using existing connectors like Outlook, Microsoft Teams, Slack, and PagerDuty. You can also configure the logic app for your own services.--This example creates a logic app that uses the [common alerts schema](./alerts-common-schema.md) to send details from the alert. --## Create a logic app --1. In the [Azure portal](https://portal.azure.com/), create a new logic app. In the **Search** bar at the top of the page, enter **Logic App**. -1. On the **Logic App** page, select **Add**. -1. Select the **Subscription** and **Resource group** for your logic app. -1. Set **Logic App name**. For **Plan type**, select **Consumption**. -1. Select **Review + create** > **Create**. -1. Select **Go to resource** after the deployment is finished. -- :::image type="content" source="./media/alerts-logic-apps/create-logic-app.png" alt-text="Screenshot that shows the Create Logic App page."::: -1. On the **Logic Apps Designer** page, select **When a HTTP request is received**. -- :::image type="content" source="./media/alerts-logic-apps/logic-apps-designer.png" alt-text="Screenshot that shows the Logic Apps Designer start page."::: --1. Paste the common alert schema into the **Request Body JSON Schema** field from the following JSON: - ```json - { - "type": "object", - "properties": { - "schemaId": { - "type": "string" - }, - "data": { - "type": "object", - "properties": { - "essentials": { - "type": "object", - "properties": { - "alertId": { - "type": "string" - }, - "alertRule": { - "type": "string" - }, - "severity": { - "type": "string" - }, - "signalType": { - "type": "string" - }, - "monitorCondition": { - "type": "string" - }, - "monitoringService": { - "type": "string" - }, - "alertTargetIDs": { - "type": "array", - "items": { - "type": "string" - } - }, - "originAlertId": { - "type": "string" - }, - "firedDateTime": { - "type": "string" - }, - "resolvedDateTime": { - "type": "string" - }, - "description": { - "type": "string" - }, - "essentialsVersion": { - "type": "string" - }, - "alertContextVersion": { - "type": "string" - } - } - }, - "alertContext": { - "type": "object", - "properties": {} - } - } - } - } - } - ``` -- :::image type="content" source="./media/alerts-logic-apps/configure-http-request-received.png" alt-text="Screenshot that shows the Parameters tab for the When an HTTP request is received pane."::: --1. (Optional). You can customize the alert notification by extracting information about the affected resource on which the alert fired, for example, the resource's tags. You can then include those resource tags in the alert payload and use the information in your logical expressions for sending the notifications. To do this step, we will: - - Create a variable for the affected resource IDs. - - Split the resource ID into an array so that we can use its various elements (for example, subscription and resource group). - - Use the Azure Resource Manager connector to read the resource's metadata. - - Fetch the resource's tags, which can then be used in subsequent steps of the logic app. -- 1. Select **+** > **Add an action** to insert a new step. - 1. In the **Search** field, search for and select **Initialize variable**. - 1. In the **Name** field, enter the name of the variable, such as **AffectedResource**. - 1. In the **Type** field, select **Array**. - 1. In the **Value** field, select **Add dynamic Content**. Select the **Expression** tab and enter the string `split(triggerBody()?['data']?['essentials']?['alertTargetIDs'][0], '/')`. -- :::image type="content" source="./media/alerts-logic-apps/initialize-variable.png" alt-text="Screenshot that shows the Parameters tab for the Initialize variable pane."::: -- 1. Select **+** > **Add an action** to insert another step. - 1. In the **Search** field, search for and select **Azure Resource Manager** > **Read a resource**. - 1. Populate the fields of the **Read a resource** action with the array values from the `AffectedResource` variable. In each of the fields, select the field and scroll down to **Enter a custom value**. Select **Add dynamic content**, and then select the **Expression** tab. Enter the strings from this table: -- |Field|String value| - ||| - |Subscription|`variables('AffectedResource')[2]`| - |Resource Group|`variables('AffectedResource')[4]`| - |Resource Provider|`variables('AffectedResource')[6]`| - |Short Resource ID|`concat(variables('AffectedResource')[7], '/', variables('AffectedResource')[8]`)| - |Client Api Version|Resource type's api version| - - To find your resource type's api version, select the **JSON view** link on the top right-hand side of the resource overview page. - The **Resource JSON** page is displayed with the **ResourceID** and **API version** at the top of the page. -- The dynamic content now includes tags from the affected resource. You can use those tags when you configure your notifications as described in the following steps. --1. Send an email or post a Teams message. -1. Select **+** > **Add an action** to insert a new step. -- :::image type="content" source="./media/alerts-logic-apps/configure-http-request-received.png" alt-text="Screenshot that shows the parameters for When an HTTP request is received."::: --## [Send an email](#tab/send-email) --1. In the search field, search for **Outlook**. -1. Select **Office 365 Outlook**. -- :::image type="content" source="./media/alerts-logic-apps/choose-operation-outlook.png" alt-text="Screenshot that shows the Add an action page of the Logic Apps Designer with Office 365 Outlook selected."::: -1. Select **Send an email (V2)** from the list of actions. -1. Sign in to Office 365 when you're prompted to create a connection. -1. Create the email **Body** by entering static text and including content taken from the alert payload by choosing fields from the **Dynamic content** list. -For example: - - **An alert has monitoring condition:** Select **monitorCondition** from the **Dynamic content** list. - - **Date fired:** Select **firedDateTime** from the **Dynamic content** list. - - **Affected resources:** Select **alertTargetIDs** from the **Dynamic content** list. --1. In the **Subject** field, create the subject text by entering static text and including content taken from the alert payload by choosing fields from the **Dynamic content** list. For example: - - **Alert:** Select **alertRule** from the **Dynamic content** list. - - **with severity:** Select **severity** from the **Dynamic content** list. - - **has condition:** Select **monitorCondition** from the **Dynamic content** list. --1. Enter the email address to send the alert to the **To** field. -1. Select **Save**. -- :::image type="content" source="./media/alerts-logic-apps/configure-email.png" alt-text="Screenshot that shows the Parameters tab on the Send an email pane."::: --You've created a logic app that sends an email to the specified address, with details from the alert that triggered it. --The next step is to create an action group to trigger your logic app. --## [Post a Teams message](#tab/send-teams-message) --1. In the search field, search for **Microsoft Teams**. -1. Select **Microsoft Teams**. -- :::image type="content" source="./media/alerts-logic-apps/choose-operation-teams.png" alt-text="Screenshot that shows the Add an action page of the Logic Apps Designer with Microsoft Teams selected."::: -1. Select **Post message in a chat or channel** from the list of actions. -1. Sign in to Teams when you're prompted to create a connection. -1. Select **User** from the **Post as** dropdown. -1. Select **Group chat** from the **Post in** dropdown. -1. Select your group from the **Group chat** dropdown. -1. Create the message text in the **Message** field by entering static text and including content taken from the alert payload by choosing fields from the **Dynamic content** list. For example: - 1. **Alert:** Select **alertRule** from the **Dynamic content** list. - 1. **with severity:** Select **severity** from the **Dynamic content** list. - 1. **was fired at:** Select **firedDateTime** from the **Dynamic content** list. - 1. Add more fields according to your requirements. -1. Select **Save**. -- :::image type="content" source="./media/alerts-logic-apps/configure-teams-message.png" alt-text="Screenshot that shows the Parameters tab on the Post message in a chat or channel pane."::: --You've created a logic app that sends a Teams message to the specified group, with details from the alert that triggered it. --The next step is to create an action group to trigger your logic app. ----## Create an action group --To trigger your logic app, create an action group. Then create an alert that uses that action group. --1. Go to the **Azure Monitor** page and select **Alerts** from the pane on the left. -1. Select **Action groups** > **Create**. -1. Select values for **Subscription**, **Resource group**, and **Region**. -1. Enter a name for **Action group name** and **Display name**. -1. Select the **Actions** tab. -- :::image type="content" source="./media/alerts-logic-apps/create-action-group.png" alt-text="Screenshot that shows the Actions tab on the Create an action group page."::: --1. On the **Actions** tab under **Action type**, select **Logic App**. -1. In the **Logic App** section, select your logic app from the dropdown. -1. Set **Enable common alert schema** to **Yes**. If you select **No**, the alert type determines which alert schema is used. For more information about alert schemas, see [Context-specific alert schemas](./alerts-non-common-schema-definitions.md). -1. Select **OK**. -1. Enter a name in the **Name** field. -1. Select **Review + create** > **Create**. -- :::image type="content" source="./media/alerts-logic-apps/create-action-group-actions.png" alt-text="Screenshot that shows the Actions tab on the Create an action group page and the Logic App pane."::: --## Test your action group --1. Select your action group. -1. In the **Logic App** section, select **Test action group (preview)**. -- :::image type="content" source="./media/alerts-logic-apps/test-action-group1.png" alt-text="Screenshot that shows an action group details page with the Test action group option."::: -1. Select a sample alert type from the **Select sample type** dropdown. -1. Select **Test**. -- :::image type="content" source="./media/alerts-logic-apps/test-action-group2.png" alt-text="Screenshot that shows an action group details Test page."::: -- The following email is sent to the specified account: -- :::image type="content" source="./media/alerts-logic-apps/sample-output-email.png" alt-text="Screenshot that shows a sample email sent by the Test page."::: --## Create a rule by using your action group --1. [Create a rule](./alerts-create-new-alert-rule.md) for one of your resources. -1. On the **Actions** tab of your rule, choose **Select action groups**. -1. Select your action group from the list. -1. Choose **Select**. -1. Finish the creation of your rule. -- :::image type="content" source="./media/alerts-logic-apps/select-action-groups.png" alt-text="Screenshot that shows the Actions tab on the Create an alert rule pane and the Select action groups pane."::: --## Next steps --* [Learn more about action groups](./action-groups.md) -* [Learn more about the common alert schema](./alerts-common-schema.md) |
| azure-monitor | Alerts Manage Alert Instances | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-manage-alert-instances.md | - Title: Manage your alert instances -description: The alerts page summarizes all alert instances in all your Azure resources generated in the last 30 days and allows you to manage your alert instances. -- Previously updated : 01/21/2024----# Manage your alert instances --The **Alerts** page summarizes all alert instances in all your Azure resources generated in the last 30 days. Alerts are stored for 30 days and are deleted after the 30-day retention period. -For stateful alerts, while the alert itself is deleted after 30 days, and isn't viewable on the alerts page, the alert condition is stored until the alert is resolved, to prevent firing another alert, and so that notifications can be sent when the alert is resolved. For more information, see [Alerts and state](alerts-overview.md#alerts-and-state). --## Access the Alerts page --You can get to the **Alerts** page in a few ways: --- From the home page in the [Azure portal](https://portal.azure.com/), select **Monitor** > **Alerts**. -- :::image type="content" source="media/alerts-managing-alert-instances/alerts-monitor-menu.png" alt-text="Screenshot that shows Alerts on the Azure Monitor menu. "::: - -- From a specific resource, go to the **Monitoring** section and select **Alerts**. The page that opens contains the alerts for the specific resource.-- :::image type="content" source="media/alerts-managing-alert-instances/alerts-resource-menu.png" alt-text="Screenshot that shows Alerts on the menu of a resource in the Azure portal."::: --## Alerts summary pane --The **Alerts** summary pane summarizes the alerts fired in the last 24 hours. You can filter the list of alert instances by **Time range**, **Subscription**, **Alert condition**, **Severity**, and more. If you selected a specific alert severity to open the **Alerts** page, the list is prefiltered for that severity. --To see more information about a specific alert instance, select the alert instance to open the **Alert details** page. -- :::image type="content" source="media/alerts-managing-alert-instances/alerts-page.png" lightbox="media/alerts-managing-alert-instances/alerts-page.png" alt-text="Screenshot that shows the Alerts summary page in the Azure portal."::: ---## View alerts as a timeline (preview) --You can see your alerts in a timeline view. In this view, you can see the number of alerts fired in a specific time range. The timeline shows you which resource the alerts were fired on to give you context of the alert in your Azure hierarchy. The alerts are grouped by the time they were fired. You can filter the alerts by severity, resource, and more. You can also select a specific time range to see the alerts fired in that time range. -- :::image type="content" source="media/alerts-managing-alert-instances/alerts-timeline.png" lightbox="media/alerts-managing-alert-instances/alerts-timeline.png" alt-text="Screenshot that shows the Alerts timeline page in the Azure portal."::: --To see the alerts in a timeline view, select **View as timeline** at the top of the Alerts summary page. You can choose to see the alerts timeline in with the severity of the alerts indicated by color, or a simplified view with critical or noncritical alerts. -- :::image type="content" source="media/alerts-managing-alert-instances/alerts-view-timeline.png" lightbox="media/alerts-managing-alert-instances/alerts-view-timeline.png" alt-text="Screenshot that shows the view timeline button in the Alerts summary page in the Azure portal."::: --You can drill down into a specific time range. Select one of the cards in the timeline to see the alerts fired in that time range. -- :::image type="content" source="media/alerts-managing-alert-instances/alerts-timeline-details.png" lightbox="media/alerts-managing-alert-instances/alerts-timeline-details.png" alt-text="Screenshot that shows the drilldown into a specific time range in the Alerts timeline page in the Azure portal."::: ---### Customize the timeline view --You can customize the timeline view to suit your needs by changing the grouping of your alerts. --1. From the timeline view of the alerts page, select the **Edit** icon in the groups box at the top of the page. -- :::image type="content" source="media/alerts-managing-alert-instances/alerts-timeline-edit-pencil.png" alt-text="Screenshot that shows the pencil icon to edit the timeline view of the alerts page in the Azure portal."::: --1. In the **Edit group** pane, drag and drop the fields to group by. You can change the order of the groupings, and add new dimensions, tags, labels, and more. Validation is run on the grouping to make sure that the grouping is valid. If you are at the alerts page for a specific resource, the options for grouping are filtered by that resource, and you can only group by items related to the resource. -- For AKS clusters, we provide suggested views based on popular groupings. -1. Select **Save**. -- :::image type="content" source="media/alerts-managing-alert-instances/alerts-edit-timeline-view.png" lightbox="media/alerts-managing-alert-instances/alerts-edit-timeline-view.png" alt-text="Screenshot that shows the edit group pane in the timeline view of the alerts page in the Azure portal."::: -1. The timeline displays the alerts grouped by the fields you selected. Alerts that don't logically belong in the grouping you selected are listed in a group called **Other**. -1. When you have the grouping you want, select **Save view** to save the view. --### Manage timeline views --You can save up to 10 views of the alerts timeline. The **default** view is the Azure default view. --1. From the main **Alerts** page, select **Manage views** to see the list of views you saved. -1. Select **Save view as** to save a new view. -1. Mark a view as **Favorite** to see that view every time you come to the **Alerts** page. -1. Select **Browse all views** to see all the views you saved, select a favorite view, or delete a view. You can only see all of the views from the main alerts page, not from the alerts of an individual resource. --## Alert details page --The **Alert details** page provides more information about the selected alert: ----## Manage your alerts programmatically --You can query your alerts instances to create custom views outside of the Azure portal or to analyze your alerts to identify patterns and trends. --We recommend that you use [Azure Resource Graph](https://portal.azure.com/?feature.customportal=false#blade/HubsExtension/ArgQueryBlade) with the `AlertsManagementResources` schema to manage alerts across multiple subscriptions. For a sample query, see [Azure Resource Graph sample queries for Azure Monitor](../resource-graph-samples.md). --You can use Resource Graph: --You can also use the [Alert Management REST API](/rest/api/monitor/alertsmanagement/alerts) for lower-scale querying or to update fired alerts. --## Next steps --- [Learn about Azure Monitor alerts](./alerts-overview.md)-- [Create a new alert rule](alerts-log.md) |
| azure-monitor | Alerts Manage Alert Rules | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-manage-alert-rules.md | - Title: Manage your alert rules -description: Manage your alert rules in the Azure portal, or using the CLI or PowerShell.Learn how to enable recommended alert rules. ---- Previously updated : 01/14/2024---# Customer intent: As a cloud administrator, I want to manage my alert rules so that I can ensure that my resources are monitored effectively. ---# Manage your alert rules --Manage your alert rules in the Azure portal, or using the CLI or PowerShell. --## Manage alert rules in the Azure portal --1. In the [portal](https://portal.azure.com/), select **Monitor**, then **Alerts**. -1. From the top command bar, select **Alert rules**. The page shows all your alert rules on all subscriptions. -- :::image type="content" source="media/alerts-managing-alert-instances/alerts-rules-page.png" alt-text="Screenshot that shows the alerts rules page."::: --1. You can filter the list of rules using the available filters: - - Subscription - - Alert condition - - Severity - - User response - - Monitor service - - Signal type - - Resource group - - Target resource type - - Resource name - - Suppression status -- > [!NOTE] - > If you filter on a `target resource type` scope, the alerts rules list doesnΓÇÖt include resource health alert rules. To see the resource health alert rules, remove the `Target resource type` filter, or filter the rules based on the `Resource group` or `Subscription`. --1. Select an alert rule or use the checkboxes on the left to select multiple alert rules. -1. If you select multiple alert rules, you can enable or disable the selected rules. Selecting multiple rules can be useful when you want to perform maintenance on specific resources. -1. If you select a single alert rule, you can edit, disable, duplicate, or delete the rule in the alert rule pane. -- :::image type="content" source="media/alerts-managing-alert-instances/alerts-rules-pane.png" alt-text="Screenshot that shows the alerts rules pane."::: --1. To edit an alert rule, select **Edit**, and then edit any of the fields in the following sections. You can't edit the **Alert Rule Name**, or the **Signal type** of an existing alert rule. - - **Scope**. You can edit the scope for all alert rules **other than**: - - Log search alert rules - - Metric alert rules that monitor a custom metric - - Smart detection alert rules - - **Condition**. Learn more about conditions for [metric alert rules](./alerts-create-new-alert-rule.md?tabs=metric#tabpanel_1_metric), [log search alert rules](./alerts-create-new-alert-rule.md?tabs=log#tabpanel_1_log), and [activity log alert rules](./alerts-create-new-alert-rule.md?tabs=activity-log#tabpanel_1_activity-log) - - **Actions** - - **Alert rule details** -1. Select **Save** on the top command bar. --> [!NOTE] -> This section describes how to manage alert rules created in the latest UI or using an API version later than `2018-04-16`. See [View and manage log search alert rules created in previous versions](alerts-manage-alerts-previous-version.md) for information about how to view and manage log search alert rules created in the previous UI. --## Enable recommended alert rules in the Azure portal --You can [create a new alert rule](alerts-log.md#create-a-new-log-alert-rule-in-the-azure-portal), or enable recommended out-of-the-box alert rules in the Azure portal. --The system compiles a list of recommended alert rules based on: -- The resource providerΓÇÖs knowledge of important signals and thresholds for monitoring the resource.-- Data that tells us what customers commonly alert on for this resource.--> [!NOTE] -> The alert rule recommendations feature is enabled for: -> - Virtual machines -> - AKS resources -> - Log Analytics workspaces ---To enable recommended alert rules: --1. In the left pane, select **Alerts**. -1. Select **View + set up**. The **Set up recommended alert rules** pane opens with a list of recommended alert rules based on your type of resource. -- :::image type="content" source="media/alerts-managing-alert-instances/set-up-recommended-alerts.png" alt-text="Screenshot of recommended alert rules pane."::: --1. In the **Select alert rules** section, all recommended alerts are populated with the default values for the rule condition, such as the percentage of CPU usage that you want to trigger an alert. You can change the default values if you would like, or turn off an alert. -1. Expand each of the alert rules to see its details. By default, the severity for each is **Informational**. You can change to another severity if you'd like. -- :::image type="content" source="media/alerts-managing-alert-instances/configure-alert-severity.png" alt-text="Screenshot of recommended alert rule severity configuration." lightbox="media/alerts-managing-alert-instances/configure-alert-severity.png"::: --1. In the **Notify me by** section, select the way you want to be notified if an alert is fired. -1. Select **Use an existing action group**, and enter the details of the existing action group if you want to use an action group that already exists. -1. Select **Save**. --## See the history of when an alert rule triggered --To see the history of an alert rule, you must have a role with read permissions on the subscription containing the resource on which the alert fired. --1. In the [portal](https://portal.azure.com/), select **Monitor**, then **Alerts**. -1. From the top command bar, select **Alert rules**. The page shows all your alert rules on all subscriptions. -- :::image type="content" source="media/alerts-managing-alert-instances/alerts-rules-page.png" alt-text="Screenshot that shows the alerts rules page."::: --1. Select an alert rule, and then select **History** on the left pane to see the history of when the alert rule triggered. -- :::image type="content" source="media/alerts-manage-alert-rules/alert-rule-history.png" alt-text="Screenshot that shows the history button from the alerts rule page." lightbox="media/alerts-manage-alert-rules/alert-rule-history.png"::: ---## Manage metric alert rules with the Azure CLI --This section describes how to manage metric alert rules using the cross-platform [Azure CLI](/cli/azure/get-started-with-azure-cli). The following examples use [Azure Cloud Shell](../../cloud-shell/overview.md). --1. In the [portal](https://portal.azure.com/), select **Cloud Shell**. -1. Use these options of the `az monitor metrics alert` CLI command in this table: -- - |What you want to do|CLI command | - ||| - |View all the metric alerts in a resource group|`az monitor metrics alert list -g {ResourceGroup}`| - |See the details of a metric alert rule|`az monitor metrics alert show -g {ResourceGroup} -n {AlertRuleName}`| - | |`az monitor metrics alert show --ids {RuleResourceId}`| - |Disable a metric alert rule|`az monitor metrics alert update -g {ResourceGroup} -n {AlertRuleName} --enabled false`| - |Delete a metric alert rule|`az monitor metrics alert delete -g {ResourceGroup} -n {AlertRuleName}`| - |Learn more about the command|`az monitor metrics alert --help`| --## Manage metric alert rules with PowerShell --Metric alert rules have these dedicated PowerShell cmdlets: --- [Add-AzMetricAlertRuleV2](/powershell/module/az.monitor/add-azmetricalertrulev2): Create a new metric alert rule or update an existing one.-- [Get-AzMetricAlertRuleV2](/powershell/module/az.monitor/get-azmetricalertrulev2): Get one or more metric alert rules.-- [Remove-AzMetricAlertRuleV2](/powershell/module/az.monitor/remove-azmetricalertrulev2): Delete a metric alert rule.--## Manage metric alert rules with REST API --- [Create Or Update](/rest/api/monitor/metricalerts/createorupdate): Create a new metric alert rule or update an existing one.-- [Get](/rest/api/monitor/metricalerts/get): Get a specific metric alert rule.-- [List By Resource Group](/rest/api/monitor/metricalerts/listbyresourcegroup): Get a list of metric alert rules in a specific resource group.-- [List By Subscription](/rest/api/monitor/metricalerts/listbysubscription): Get a list of metric alert rules in a specific subscription.-- [Update](/rest/api/monitor/metricalerts/update): Update a metric alert rule.-- [Delete](/rest/api/monitor/metricalerts/delete): Delete a metric alert rule.--## Delete metric alert rules defined on a deleted resource --When you delete an Azure resource, associated metric alert rules aren't deleted automatically. To delete alert rules associated with a resource that's been deleted: --1. Open the resource group in which the deleted resource was defined. -1. In the list that displays the resources, select the **Show hidden types** checkbox. -1. Filter the list by Type == **microsoft.insights/metricalerts**. -1. Select the relevant alert rules and select **Delete**. --## Check the number of metric alert rules in use --To check the current number of metric alert rules in use, follow the next steps. -### From the Azure portal -- 1. Open the **Alerts** screen and select **Manage alert rules**. - 1. Filter to the relevant subscription by using the **Subscription** dropdown box. - 1. Make sure *not* to filter to a specific resource group, resource type, or resource. - 1. In the **Signal type** dropdown box, select **Metrics**. - 1. Verify that the **Status** dropdown box is set to **Enabled**. - 1. The total number of metric alert rules are displayed above the alert rules list. - -### Using the API -- - **PowerShell**: [Get-AzMetricAlertRuleV2](/powershell/module/az.monitor/get-azmetricalertrulev2) - - **REST API**: [List by subscription](/rest/api/monitor/metricalerts/listbysubscription) - - **Azure CLI**: [az monitor metrics alert list](/cli/azure/monitor/metrics/alert#az-monitor-metrics-alert-list) --## Manage log search alert rules using the CLI --This section describes how to manage log search alerts using the cross-platform [Azure CLI](/cli/azure/get-started-with-azure-cli). The following examples use [Azure Cloud Shell](../../cloud-shell/overview.md). --> [!NOTE] -> Azure CLI support is only available for the scheduledQueryRules API version `2021-08-01` and later. Previous API versions can use the Azure Resource Manager CLI with templates as described below. If you use the legacy [Log Analytics Alert API](./api-alerts.md), you will need to switch to use CLI. [Learn more about switching](./alerts-log-api-switch.md). --1. In the [portal](https://portal.azure.com/), select **Cloud Shell**. -1. Use these options of the `az monitor scheduled-query alert` CLI command in this table: - - |What you want to do|CLI command | - ||| - |View all the log alert rules in a resource group|`az monitor scheduled-query list -g {ResourceGroup}`| - |See the details of a log alert rule|`az monitor scheduled-query show -g {ResourceGroup} -n {AlertRuleName}`| - | |`az monitor scheduled-query show --ids {RuleResourceId}`| - |Disable a log alert rule|`az monitor scheduled-query update -g {ResourceGroup} -n {AlertRuleName} --disabled true`| - |Delete a log alert rule|`az monitor scheduled-query delete -g {ResourceGroup} -n {AlertRuleName}`| - |Learn more about the command|`az monitor scheduled-query --help`| --### Manage log search alert rules using the Azure Resource Manager CLI with [templates](./alerts-log-create-templates.md) --```azurecli -az login -az deployment group create \ - --name AlertDeployment \ - --resource-group ResourceGroupofTargetResource \ - --template-file mylogalerttemplate.json \ - --parameters @mylogalerttemplate.parameters.json -``` --A 201 response is returned on successful creation. 200 is returned on successful updates. --## Manage log search alert rules with PowerShell --Log search alert rules have this dedicated PowerShell cmdlet: -- [New-AzScheduledQueryRule](/powershell/module/az.monitor/new-azscheduledqueryrule): Creates a new log search alert rule or updates an existing log search alert rule.--## Check the number of log alert rules in use --### In the Azure portal -1. On the Alerts screen in Azure Monitor, select **Alert rules**. -1. In the **Subscription** dropdown control, filter to the subscription you want. (Make sure you don't filter to a specific resource group, resource type, or resource.) -1. In the **Signal type** dropdown control, select **Log Search**. -1. Verify that the **Status** dropdown control is set to **Enabled**. --The total number of log search alert rules is displayed above the rules list. --### Using the API --- PowerShell - [Get-AzScheduledQueryRule](/powershell/module/az.monitor/get-azscheduledqueryrule)-- CLI: [az monitor scheduled-query list](/cli/azure/monitor/scheduled-query#az-monitor-scheduled-query-list)-- REST API - [List by subscription](/rest/api/monitor/scheduledqueryrule-2021-08-01/scheduled-query-rules/list-by-subscription)--## Manage activity log alert rules using PowerShell --Activity log alerts have these dedicated PowerShell cmdlets: --- [Set-AzActivityLogAlert](/powershell/module/az.monitor/set-azactivitylogalert): Creates a new activity log alert or updates an existing activity log alert.-- [Get-AzActivityLogAlert](/powershell/module/az.monitor/get-azactivitylogalert): Gets one or more activity log alert resources.-- [Enable-AzActivityLogAlert](/powershell/module/az.monitor/enable-azactivitylogalert): Enables an existing activity log alert and sets its tags.-- [Disable-AzActivityLogAlert](/powershell/module/az.monitor/disable-azactivitylogalert): Disables an existing activity log alert and sets its tags.-- [Remove-AzActivityLogAlert](/powershell/module/az.monitor/remove-azactivitylogalert): Removes an activity log alert.---## Next steps --- [Learn about Azure Monitor alerts](./alerts-overview.md)-- [Create a new alert rule](alerts-log.md) |
| azure-monitor | Alerts Manage Alerts Previous Version | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-manage-alerts-previous-version.md | - Title: View and manage log search alert rules created in previous versions| Microsoft Docs -description: Use the Azure Monitor portal to manage log search alert rules created in earlier versions. -- Previously updated : 07/30/2024-----# Manage alert rules created in previous versions --This article describes the process of managing alert rules created in the previous UI or by using API version `2018-04-16` or earlier. Alert rules created in the latest UI are viewed and managed in the new UI, as described in [Create, view, and manage log search alerts by using Azure Monitor](alerts-log.md). ---## Changes to the log search alert rule creation experience --The current alert rule wizard is different from the earlier experience: --- Previously, search results were included in the payload of the triggered alert and its associated notifications. The email included only 10 rows from the unfiltered results while the webhook payload contained 1,000 unfiltered results. To get detailed context information about the alert so that you can decide on the appropriate action:- - We recommend using [dimensions](alerts-types.md#narrow-the-target-using-dimensions). Dimensions provide the column value that fired the alert, which gives you context for why the alert fired and how to fix the issue. - - When you need to investigate in the logs, use the link in the alert to the search results in logs. - - If you need the raw search results or for any other advanced customizations, [use Azure Logic Apps](alerts-logic-apps.md). -- The new alert rule wizard doesn't support customization of the JSON payload.- - Use custom properties in the [new API](/rest/api/monitor/scheduledqueryrule-2021-08-01/scheduled-query-rules/create-or-update#actions) to add static parameters and associated values to the webhook actions triggered by the alert. - - For more advanced customizations, [use Azure Logic Apps](alerts-logic-apps.md). -- The new alert rule wizard doesn't support customization of the email subject.- - Customers often use the custom email subject to indicate the resource on which the alert fired, instead of using the Log Analytics workspace. Use the [new API](/rest/api/monitor/scheduledqueryrule-2021-08-01/scheduled-query-rules/create-or-update#actions) to trigger an alert of the desired resource by using the resource ID column. - - For more advanced customizations, [use Azure Logic Apps](alerts-logic-apps.md). ---## Manage alert rules created in previous versions in the Azure portal -1. In the [Azure portal](https://portal.azure.com/), select the resource you want. -1. Under **Monitoring**, select **Alerts**. -1. On the top bar, select **Alert rules**. -1. Select the alert rule that you want to edit. -1. In the **Condition** section, select the condition. -1. The **Configure signal logic** pane opens with historical data for the query that appears as a graph. You can change the **Time range** of the chart to display data from the last six hours to last week. - If your query results contain summarized data or specific columns without the time column, the chart shows a single value. - - :::image type="content" source="media/alerts-log/alerts-edit-alerts-rule.png" lightbox="media/alerts-log/alerts-edit-alerts-rule.png" alt-text="Screenshot that shows the Configure signal logic pane."::: --1. Edit the alert rule conditions by using these sections: - - **Search query**: In this section, you can modify your query. - - **Alert logic**: Log search alerts can be based on two types of [measures](./alerts-types.md#log-alerts): - 1. **Number of results**: Count of records returned by the query. - 1. **Metric measurement**: **Aggregate value** is calculated by using `summarize` grouped by the expressions chosen and the [bin()](/azure/data-explorer/kusto/query/binfunction) selection. For example: - ```Kusto - // Reported errors - union Event, Syslog // Event table stores Windows event records, Syslog stores Linux records - | where EventLevelName == "Error" // EventLevelName is used in the Event (Windows) records - or SeverityLevel== "err" // SeverityLevel is used in Syslog (Linux) records - | summarize AggregatedValue = count() by Computer, bin(TimeGenerated, 15m) - ``` - For metric measurements alert logic, you can specify how to [split the alerts by dimensions](./alerts-types.md#monitor-the-same-condition-on-multiple-resources-using-splitting-by-dimensions) by using the **Aggregate on** option. The row grouping expression must be unique and sorted. - - The [bin()](/azure/data-explorer/kusto/query/binfunction) function can result in uneven time intervals, so the alert service automatically converts the [bin()](/azure/data-explorer/kusto/query/binfunction) function to a [binat()](/azure/data-explorer/kusto/query/binatfunction) function with appropriate time at runtime to ensure results with a fixed point. - - > [!NOTE] - > The **Split by alert dimensions** option is only available for the current scheduledQueryRules API. If you use the legacy [Log Analytics Alert API](./api-alerts.md), you'll need to switch. [Learn more about switching](./alerts-log-api-switch.md). Resource-centric alerting at scale is only supported in the API version `2021-08-01` and later. - - :::image type="content" source="media/alerts-log/aggregate-on.png" lightbox="media/alerts-log/aggregate-on.png" alt-text="Screenshot that shows Aggregate on."::: -- - **Period**: Choose the time range over which to assess the specified condition by using the [Period](./alerts-types.md) option. --1. When you're finished editing the conditions, select **Done**. -1. Use the preview data to set the [Operator, Threshold value](./alerts-types.md), and [Frequency](./alerts-types.md). -1. Set the [number of violations to trigger an alert](./alerts-types.md) by using **Total** or **Consecutive breaches**. -1. Select **Done**. -1. You can edit the rule **Description** and **Severity**. These details are used in all alert actions. You can also choose to not activate the alert rule on creation by selecting **Enable rule upon creation**. -1. Use the [Suppress Alerts](./alerts-processing-rules.md) option if you want to suppress rule actions for a specified time after an alert is fired. The rule will still run and create alerts, but actions won't be triggered to prevent noise. The **Mute actions** value must be greater than the frequency of the alert to be effective. - <!-- convertborder later --> - :::image type="content" source="media/alerts-log/AlertsPreviewSuppress.png" lightbox="media/alerts-log/AlertsPreviewSuppress.png" alt-text="Screenshot that shows the Alert Details pane." border="false"::: -1. To make alerts stateful, select **Automatically resolve alerts (preview)**. -1. Specify if the alert rule should trigger one or more [action groups](./action-groups.md) when the alert condition is met. For limits on the actions that can be performed, see [Azure Monitor service limits](../../azure-monitor/service-limits.md). -1. (Optional) Customize actions in log search alert rules: - - **Custom email subject**: Overrides the *email subject* of email actions. You can't modify the body of the mail and this field *isn't for email addresses*. - - **Include custom Json payload for webhook**: Overrides the webhook JSON used by action groups, assuming that the action group contains a webhook action. Learn more about [webhook actions for log search alerts](./alerts-log-webhook.md). - <!-- convertborder later --> - :::image type="content" source="media/alerts-log/AlertsPreviewOverrideLog.png" lightbox="media/alerts-log/AlertsPreviewOverrideLog.png" alt-text="Screenshot that shows Action overrides for log search alerts." border="false"::: -1. After you've finished editing all the alert rule options, select **Save**. --## Manage log search alerts using PowerShell ---Use the following PowerShell cmdlets to manage rules with the [Scheduled Query Rules API](/rest/api/monitor/scheduledqueryrule-2018-04-16/scheduled-query-rules): --- [New-AzScheduledQueryRule](/powershell/module/az.monitor/new-azscheduledqueryrule): PowerShell cmdlet to create a new log search alert rule.-- [Set-AzScheduledQueryRule](/powershell/module/az.monitor/set-azscheduledqueryrule): PowerShell cmdlet to update an existing log search alert rule.-- [New-AzScheduledQueryRuleSource](/powershell/module/az.monitor/new-azscheduledqueryrulesource): PowerShell cmdlet to create or update the object that specifies source parameters for a log search alert. Used as input by the [New-AzScheduledQueryRule](/powershell/module/az.monitor/new-azscheduledqueryrule) and [Set-AzScheduledQueryRule](/powershell/module/az.monitor/set-azscheduledqueryrule) cmdlets.-- [New-AzScheduledQueryRuleSchedule](/powershell/module/az.monitor/new-azscheduledqueryruleschedule): PowerShell cmdlet to create or update the object that specifies schedule parameters for a log search alert. Used as input by the [New-AzScheduledQueryRule](/powershell/module/az.monitor/new-azscheduledqueryrule) and [Set-AzScheduledQueryRule](/powershell/module/az.monitor/set-azscheduledqueryrule) cmdlets.-- [New-AzScheduledQueryRuleAlertingAction](/powershell/module/az.monitor/new-azscheduledqueryrulealertingaction): PowerShell cmdlet to create or update the object that specifies action parameters for a log search alert. Used as input by the [New-AzScheduledQueryRule](/powershell/module/az.monitor/new-azscheduledqueryrule) and [Set-AzScheduledQueryRule](/powershell/module/az.monitor/set-azscheduledqueryrule) cmdlets.-- [New-AzScheduledQueryRuleAznsActionGroup](/powershell/module/az.monitor/new-azscheduledqueryruleaznsactiongroup): PowerShell cmdlet to create or update the object that specifies action group parameters for a log search alert. Used as input by the [New-AzScheduledQueryRuleAlertingAction](/powershell/module/az.monitor/new-azscheduledqueryrulealertingaction) cmdlet.-- [New-AzScheduledQueryRuleTriggerCondition](/powershell/module/az.monitor/new-azscheduledqueryruletriggercondition): PowerShell cmdlet to create or update the object that specifies trigger condition parameters for a log search alert. Used as input by the [New-AzScheduledQueryRuleAlertingAction](/powershell/module/az.monitor/new-azscheduledqueryrulealertingaction) cmdlet.-- [New-AzScheduledQueryRuleLogMetricTrigger](/powershell/module/az.monitor/new-azscheduledqueryrulelogmetrictrigger): PowerShell cmdlet to create or update the object that specifies metric trigger condition parameters for a metric measurement log search alert. Used as input by the [New-AzScheduledQueryRuleTriggerCondition](/powershell/module/az.monitor/new-azscheduledqueryruletriggercondition) cmdlet.-- [Get-AzScheduledQueryRule](/powershell/module/az.monitor/get-azscheduledqueryrule): PowerShell cmdlet to list existing log search alert rules or a specific log search alert rule.-- [Update-AzScheduledQueryRule](/powershell/module/az.monitor/update-azscheduledqueryrule): PowerShell cmdlet to enable or disable a log search alert rule.-- [Remove-AzScheduledQueryRule](/powershell/module/az.monitor/remove-azscheduledqueryrule): PowerShell cmdlet to delete an existing log search alert rule.--> [!NOTE] -> The `ScheduledQueryRules` PowerShell cmdlets can only manage rules created in [this version of the Scheduled Query Rules API](/rest/api/monitor/scheduledqueryrule-2018-04-16/scheduled-query-rules). Log search alert rules created by using the legacy [Log Analytics Alert API](./api-alerts.md) can only be managed by using PowerShell after you [switch to the Scheduled Query Rules API](./alerts-log-api-switch.md). --Example steps for creating a log search alert rule by using PowerShell: --```powershell -$source = New-AzScheduledQueryRuleSource -Query 'Heartbeat | summarize AggregatedValue = count() by bin(TimeGenerated, 5m), _ResourceId' -DataSourceId "/subscriptions/a123d7efg-123c-1234-5678-a12bc3defgh4/resourceGroups/contosoRG/providers/microsoft.OperationalInsights/workspaces/servicews" -$schedule = New-AzScheduledQueryRuleSchedule -FrequencyInMinutes 15 -TimeWindowInMinutes 30 -$metricTrigger = New-AzScheduledQueryRuleLogMetricTrigger -ThresholdOperator "GreaterThan" -Threshold 2 -MetricTriggerType "Consecutive" -MetricColumn "_ResourceId" -$triggerCondition = New-AzScheduledQueryRuleTriggerCondition -ThresholdOperator "LessThan" -Threshold 5 -MetricTrigger $metricTrigger -$aznsActionGroup = New-AzScheduledQueryRuleAznsActionGroup -ActionGroup "/subscriptions/a123d7efg-123c-1234-5678-a12bc3defgh4/resourceGroups/contosoRG/providers/microsoft.insights/actiongroups/sampleAG" -EmailSubject "Custom email subject" -CustomWebhookPayload "{ `"alert`":`"#alertrulename`", `"IncludeSearchResults`":true }" -$alertingAction = New-AzScheduledQueryRuleAlertingAction -AznsAction $aznsActionGroup -Severity "3" -Trigger $triggerCondition -New-AzScheduledQueryRule -ResourceGroupName "contosoRG" -Location "Region Name for your Application Insights App or Log Analytics Workspace" -Action $alertingAction -Enabled $true -Description "Alert description" -Schedule $schedule -Source $source -Name "Alert Name" -``` --Example steps for creating a log search alert rule by using PowerShell with cross-resource queries: --```powershell -$authorized = @ ("/subscriptions/a123d7efg-123c-1234-5678-a12bc3defgh4/resourceGroups/contosoRG/providers/microsoft.OperationalInsights/workspaces/servicewsCrossExample", "/subscriptions/a123d7efg-123c-1234-5678-a12bc3defgh4/resourceGroups/contosoRG/providers/microsoft.insights/components/serviceAppInsights") -$source = New-AzScheduledQueryRuleSource -Query 'Heartbeat | summarize AggregatedValue = count() by bin(TimeGenerated, 5m), _ResourceId' -DataSourceId "/subscriptions/a123d7efg-123c-1234-5678-a12bc3defgh4/resourceGroups/contosoRG/providers/microsoft.OperationalInsights/workspaces/servicews" -AuthorizedResource $authorized -$schedule = New-AzScheduledQueryRuleSchedule -FrequencyInMinutes 15 -TimeWindowInMinutes 30 -$metricTrigger = New-AzScheduledQueryRuleLogMetricTrigger -ThresholdOperator "GreaterThan" -Threshold 2 -MetricTriggerType "Consecutive" -MetricColumn "_ResourceId" -$triggerCondition = New-AzScheduledQueryRuleTriggerCondition -ThresholdOperator "LessThan" -Threshold 5 -MetricTrigger $metricTrigger -$aznsActionGroup = New-AzScheduledQueryRuleAznsActionGroup -ActionGroup "/subscriptions/a123d7efg-123c-1234-5678-a12bc3defgh4/resourceGroups/contosoRG/providers/microsoft.insights/actiongroups/sampleAG" -EmailSubject "Custom email subject" -CustomWebhookPayload "{ `"alert`":`"#alertrulename`", `"IncludeSearchResults`":true }" -$alertingAction = New-AzScheduledQueryRuleAlertingAction -AznsAction $aznsActionGroup -Severity "3" -Trigger $triggerCondition -New-AzScheduledQueryRule -ResourceGroupName "contosoRG" -Location "Region Name for your Application Insights App or Log Analytics Workspace" -Action $alertingAction -Enabled $true -Description "Alert description" -Schedule $schedule -Source $source -Name "Alert Name" -``` --You can also create the log search alert by using [a template and parameters](./alerts-log-create-templates.md) files using PowerShell: --```powershell -Connect-AzAccount -Select-AzSubscription -SubscriptionName <yourSubscriptionName> -New-AzResourceGroupDeployment -Name AlertDeployment -ResourceGroupName ResourceGroupofTargetResource ` - -TemplateFile mylogalerttemplate.json -TemplateParameterFile mylogalerttemplate.parameters.json -``` --## Next steps --* Learn about [log search alerts](./alerts-types.md#log-alerts). -* Create log search alerts by using [Azure Resource Manager templates](./alerts-log-create-templates.md). -* Understand [webhook actions for log search alerts](./alerts-log-webhook.md). -* Learn more about [log queries](../logs/log-query-overview.md). |
| azure-monitor | Alerts Metric Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-metric-logs.md | - Title: Create metric alerts in Azure Monitor Logs -description: Get information about creating near-real time metric alerts on popular Log Analytics data. -- Previously updated : 11/16/2023----# Create a metric alert in Azure Monitor Logs ---You can use metric alert capabilities on a predefined set of logs in Azure Monitor Logs. The monitored logs, which can be collected from Azure or on-premises computers, are converted to metrics and then monitored with metric alert rules, just like any other metric. --A Log Analytics workspace supports these log types: --- [Performance counters](./../agents/data-sources-performance-counters.md) for Windows and Linux machines (corresponding with the supported [Log Analytics workspace metrics](../essentials/metrics-supported.md#microsoftoperationalinsightsworkspaces))-- [Heartbeat records for Agent Health](../insights/solution-agenthealth.md)-- [Update management](../../automation/update-management/overview.md) records-- [Event data](./../agents/data-sources-windows-events.md) logs--Benefits of using metric alerts for logs over query-based [log search alerts](./alerts-log.md) in Azure include: --- Metric alerts offer a near real-time monitoring capability. They fork data from the log source to ensure this capability.-- Metric alerts are stateful. They notify you once when an alert is fired and once when the alert is resolved. Log search alerts are stateless and keep firing at every interval if the alert condition is met.-- Metric alerts provide multiple dimensions. They allow filtering to specific values like computers and OS types without the need for defining a complex query in Log Analytics.--> [!NOTE] -> A specific metric or dimension appears only if data for it exists in the chosen period. These metrics are available for customers who have Log Analytics workspaces. --## Supported metrics and dimensions for logs --With metric alerts, you can use dimensions to filter your metric to the right level. The full list of metrics supported for logs is equivalent to the [list of Log Analytics workspace metrics](../essentials/metrics-supported.md#supported-metrics-and-log-categories-by-resource-type). --> [!NOTE] -> To view a supported metric extracted from a Log Analytics workspace via [Azure Monitor metrics](../essentials/metrics-charts.md), you must create a metric alert for logs on that specific metric. The dimensions that you choose in the metric alert for logs will appear for exploration only via Azure Monitor metrics. --## Creating a metric alert for logs --Before metric data from popular logs is processed in Log Analytics, it's piped into Azure Monitor metrics. You can then take advantage of the capabilities of the metric platform in addition to metric alerts, including having alerts with a frequency as low as one minute. --The process for creating metric alerts for logs is two pronged: --1. Create a rule for extracting metrics from supported logs by using the [Scheduled Query Rules API](/rest/api/monitor/scheduledqueryrule-2018-04-16/scheduled-query-rules) (`scheduledQueryRules`). -2. Create a metric alert for the metric extracted from the log (in step 1) and the Log Analytics workspace as a target resource. --## Prerequisites --Before you create a metric alert for logs, make sure that the following items are set up and available: --- **Log Analytics workspace**: You must have a valid and active Log Analytics workspace. For more information, see [Create a Log Analytics workspace](../logs/quick-create-workspace.md).-- **Agent configured for the Log Analytics workspace**: You need to configure an agent for Azure virtual machines or on-premises machines to send data to the Log Analytics workspace. For more information, see [Azure Monitor Agent overview](./../agents/agents-overview.md).-- **Supported Log Analytics solution**: A Log Analytics solution should be configured and sending data to the Log Analytics workspace. Supported solutions are [performance counters for Windows and Linux](./../agents/data-sources-performance-counters.md), [heartbeat records for Agent Health](../insights/solution-agenthealth.md), [Azure Automation Update Management](../../automation/update-management/overview.md), and [event data](./../agents/data-sources-windows-events.md).-- **Logs configured for the Log Analytics solution**: The Log Analytics solution should have the required logs and data that correspond to [metrics supported for Log Analytics workspaces](../essentials/metrics-supported.md#microsoftoperationalinsightsworkspaces) enabled. For example, the *% Available Memory* counter must be configured in the [performance counters](./../agents/data-sources-performance-counters.md) solution first.--## Methods for creating a metric alert for logs --You can create and manage metric alerts by using the Azure portal, Azure Resource Manager templates, the REST API, Azure PowerShell, and the Azure CLI. --After you create metric alerts for logs for a specified Log Analytics workspace, they have all characteristics and functionalities of [metric alerts](./alerts-metric-near-real-time.md), including payload schema, applicable quota limits, and billed price. --For step-by-step details and samples, see [Create or edit a metric alert rule](./alerts-create-metric-alert-rule.yml). Follow the instructions for managing metric alerts and note the following considerations: --- The target for a metric alert must be a valid Log Analytics workspace.-- The signal chosen for a metric alert for a selected Log Analytics workspace must be of type **Metric**.-- You can filter for specific conditions or resources by using dimension filters, because metrics for logs are multidimensional.-- When you're configuring signal logic, you can create a single alert to span multiple values of dimension (like computer).-- When you're creating a metric alert for logs by using the Azure portal, a corresponding rule for converting log data into a metric via `scheduledQueryRules` is automatically created in the background, without the need for any user intervention or action.-- If you're *not* using the Azure portal to create a metric alert for a selected Log Analytics workspace, you must first manually create an explicit rule for converting log data into a metric by using `scheduledQueryRules`. --## Resource Manager templates --To create a metric alert for logs, you can use the following sample Resource Manager templates. --For metric alerts for logs created through means other than the Azure portal, you can use these sample templates to create a `scheduledQueryRules`-based log-to-metric conversion rule before you create a metric alert. If you don't, there will be no data for the metric alert in the logs. --### Metric alert for logs with a static threshold --In the following sample template, creation of a metric alert for a static threshold depends on successful creation of the rule for extracting metrics from logs via `scheduledQueryRules`. --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "convertRuleName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the rule to convert a log to a metric" - } - }, - "convertRuleDescription": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Description for the log converted to a metric." - } - }, - "convertRuleRegion": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the region used by the workspace." - } - }, - "convertRuleStatus": { - "type": "string", - "defaultValue": "true", - "metadata": { - "description": "Specifies whether the log conversion rule is enabled." - } - }, - "convertRuleMetric": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the metric after extraction is done from logs." - } - }, - "alertName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the alert." - } - }, - "alertDescription": { - "type": "string", - "defaultValue": "This is a metric alert", - "metadata": { - "description": "Description of the alert." - } - }, - "alertSeverity": { - "type": "int", - "defaultValue": 3, - "allowedValues": [ - 0, - 1, - 2, - 3, - 4 - ], - "metadata": { - "description": "Severity of the alert {0,1,2,3,4}." - } - }, - "isEnabled": { - "type": "bool", - "defaultValue": true, - "metadata": { - "description": "Specifies whether the alert is enabled." - } - }, - "resourceId": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Full resource ID of the resource emitting the metric that will be used for the comparison. For example: /subscriptions/00000000-0000-0000-0000-0000-00000000/resourceGroups/ResourceGroupName/providers/Microsoft.OperationalInsights/workspaces/workspaceName" - } - }, - "metricName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the metric used in the comparison to activate the alert." - } - }, - "operator": { - "type": "string", - "defaultValue": "GreaterThan", - "allowedValues": [ - "Equals", - "NotEquals", - "GreaterThan", - "GreaterThanOrEqual", - "LessThan", - "LessThanOrEqual" - ], - "metadata": { - "description": "Operator comparing the current value with the threshold value." - } - }, - "threshold": { - "type": "string", - "defaultValue": "0", - "metadata": { - "description": "The threshold value at which the alert is activated." - } - }, - "timeAggregation": { - "type": "string", - "defaultValue": "Average", - "allowedValues": [ - "Average", - "Minimum", - "Maximum", - "Total" - ], - "metadata": { - "description": "How the data that's collected should be combined over time." - } - }, - "windowSize": { - "type": "string", - "defaultValue": "PT5M", - "metadata": { - "description": "Period of time used to monitor alert activity based on the threshold. Must be between five minutes and one day. ISO 8601 duration format." - } - }, - "evaluationFrequency": { - "type": "string", - "defaultValue": "PT1M", - "metadata": { - "description": "How often the metric alert is evaluated, represented in ISO 8601 duration format." - } - }, - "actionGroupId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "The ID of the action group that's triggered when the alert is activated or deactivated." - } - } - }, - "variables": { - "convertRuleSourceWorkspace": { - "SourceId": "/subscriptions/1234-56789-1234-567a/resourceGroups/resourceGroupName/providers/Microsoft.OperationalInsights/workspaces/workspaceName" - } - }, - "resources": [ - { - "name": "[parameters('convertRuleName')]", - "type": "Microsoft.Insights/scheduledQueryRules", - "apiVersion": "2018-04-16", - "location": "[parameters('convertRuleRegion')]", - "properties": { - "description": "[parameters('convertRuleDescription')]", - "enabled": "[parameters('convertRuleStatus')]", - "source": { - "dataSourceId": "[variables('convertRuleSourceWorkspace').SourceId]" - }, - "action": { - "odata.type": "Microsoft.WindowsAzure.Management.Monitoring.Alerts.Models.Microsoft.AppInsights.Nexus.DataContracts.Resources.ScheduledQueryRules.LogToMetricAction", - "criteria": [{ - "metricName": "[parameters('convertRuleMetric')]", - "dimensions": [] - } - ] - } - } - }, - { - "name": "[parameters('alertName')]", - "type": "Microsoft.Insights/metricAlerts", - "location": "global", - "apiVersion": "2018-03-01", - "tags": {}, - "dependsOn":["[resourceId('Microsoft.Insights/scheduledQueryRules',parameters('convertRuleName'))]"], - "properties": { - "description": "[parameters('alertDescription')]", - "severity": "[parameters('alertSeverity')]", - "enabled": "[parameters('isEnabled')]", - "scopes": ["[parameters('resourceId')]"], - "evaluationFrequency":"[parameters('evaluationFrequency')]", - "windowSize": "[parameters('windowSize')]", - "criteria": { - "odata.type": "Microsoft.Azure.Monitor.SingleResourceMultipleMetricCriteria", - "allOf": [ - { - "name" : "1st criterion", - "metricName": "[parameters('metricName')]", - "dimensions":[], - "operator": "[parameters('operator')]", - "threshold" : "[parameters('threshold')]", - "timeAggregation": "[parameters('timeAggregation')]" - } - ] - }, - "actions": [ - { - "actionGroupId": "[parameters('actionGroupId')]" - } - ] - } - } - ] -} -``` --If you save the preceding JSON as *metricfromLogsAlertStatic.json*, you can couple it with a parameter JSON file for creation based on a Resource Manager template. Here's a sample parameter JSON file: --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "convertRuleName": { - "value": "TestLogtoMetricRule" - }, - "convertRuleDescription": { - "value": "Test rule to extract metrics from logs via template" - }, - "convertRuleRegion": { - "value": "West Central US" - }, - "convertRuleStatus": { - "value": "true" - }, - "convertRuleMetric": { - "value": "Average_% Idle Time" - }, - "alertName": { - "value": "TestMetricAlertonLog" - }, - "alertDescription": { - "value": "New multidimensional metric alert created via template" - }, - "alertSeverity": { - "value":3 - }, - "isEnabled": { - "value": true - }, - "resourceId": { - "value": "/subscriptions/1234-56789-1234-567a/resourceGroups/myRG/providers/Microsoft.OperationalInsights/workspaces/workspaceName" - }, - "metricName":{ - "value": "Average_% Idle Time" - }, - "operator": { - "value": "GreaterThan" - }, - "threshold":{ - "value": "1" - }, - "timeAggregation":{ - "value": "Average" - }, - "actionGroupId": { - "value": "/subscriptions/1234-56789-1234-567a/resourceGroups/myRG/providers/microsoft.insights/actionGroups/actionGroupName" - } - } -} -``` --Assuming that you saved the preceding parameter file as *metricfromLogsAlertStatic.parameters.json*, you can create metric alerts for logs by using the [Resource Manager template for creation in the Azure portal](../../azure-resource-manager/templates/deploy-portal.md). --Alternatively, you can use this Azure PowerShell command: --```powershell -New-AzResourceGroupDeployment -ResourceGroupName "myRG" -TemplateFile metricfromLogsAlertStatic.json TemplateParameterFile metricfromLogsAlertStatic.parameters.json -``` --Or, you can deploy the Resource Manager template by using the Azure CLI: --```azurecli -az deployment group create --resource-group myRG --template-file metricfromLogsAlertStatic.json --parameters @metricfromLogsAlertStatic.parameters.json -``` --### Metric alert for logs with dynamic thresholds --In the following sample template, creation of a metric alert for dynamic thresholds depends on successful creation of the rule for extracting metrics from logs via `scheduledQueryRules`. --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "convertRuleName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the rule to convert a log to a metric." - } - }, - "convertRuleDescription": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Description for the log converted to a metric." - } - }, - "convertRuleRegion": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the region used by the workspace." - } - }, - "convertRuleStatus": { - "type": "string", - "defaultValue": "true", - "metadata": { - "description": "Specifies whether the log conversion rule is enabled." - } - }, - "convertRuleMetric": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the metric after extraction is done from logs." - } - }, - "alertName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the alert." - } - }, - "alertDescription": { - "type": "string", - "defaultValue": "This is a metric alert", - "metadata": { - "description": "Description of the alert." - } - }, - "alertSeverity": { - "type": "int", - "defaultValue": 3, - "allowedValues": [ - 0, - 1, - 2, - 3, - 4 - ], - "metadata": { - "description": "Severity of the alert {0,1,2,3,4}." - } - }, - "isEnabled": { - "type": "bool", - "defaultValue": true, - "metadata": { - "description": "Specifies whether the alert is enabled." - } - }, - "resourceId": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Full resource ID of the resource emitting the metric that will be used for the comparison. For example: /subscriptions/00000000-0000-0000-0000-0000-00000000/resourceGroups/ResourceGroupName/providers/Microsoft.OperationalInsights/workspaces/workspaceName" - } - }, - "metricName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the metric used in the comparison to activate the alert." - } - }, - "operator": { - "type": "string", - "defaultValue": "GreaterOrLessThan", - "allowedValues": [ - "GreaterThan", - "LessThan", - "GreaterOrLessThan" - ], - "metadata": { - "description": "Operator comparing the current value with the threshold value." - } - }, - "alertSensitivity": { - "type": "string", - "defaultValue": "Medium", - "allowedValues": [ - "High", - "Medium", - "Low" - ], - "metadata": { - "description": "Tunes how 'noisy' the alerts for dynamic thresholds will be. 'High' will result in more alerts. 'Low' will result in fewer alerts." - } - }, - "numberOfEvaluationPeriods": { - "type": "string", - "defaultValue": "4", - "metadata": { - "description": "The number of periods to check in the alert evaluation." - } - }, - "minFailingPeriodsToAlert": { - "type": "string", - "defaultValue": "3", - "metadata": { - "description": "The number of unhealthy periods to alert on (must be lower or equal to numberOfEvaluationPeriods)." - } - }, - "timeAggregation": { - "type": "string", - "defaultValue": "Average", - "allowedValues": [ - "Average", - "Minimum", - "Maximum", - "Total" - ], - "metadata": { - "description": "How the data that's collected should be combined over time." - } - }, - "windowSize": { - "type": "string", - "defaultValue": "PT5M", - "metadata": { - "description": "Period of time used to monitor alert activity based on the threshold. Must be between five minutes and one day. ISO 8601 duration format." - } - }, - "evaluationFrequency": { - "type": "string", - "defaultValue": "PT1M", - "metadata": { - "description": "How often the metric alert is evaluated, represented in ISO 8601 duration format." - } - }, - "actionGroupId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "The ID of the action group that's triggered when the alert is activated or deactivated." - } - } - }, - "variables": { - "convertRuleSourceWorkspace": { - "SourceId": "/subscriptions/1234-56789-1234-567a/resourceGroups/resourceGroupName/providers/Microsoft.OperationalInsights/workspaces/workspaceName" - } - }, - "resources": [ - { - "name": "[parameters('convertRuleName')]", - "type": "Microsoft.Insights/scheduledQueryRules", - "apiVersion": "2018-04-16", - "location": "[parameters('convertRuleRegion')]", - "properties": { - "description": "[parameters('convertRuleDescription')]", - "enabled": "[parameters('convertRuleStatus')]", - "source": { - "dataSourceId": "[variables('convertRuleSourceWorkspace').SourceId]" - }, - "action": { - "odata.type": "Microsoft.WindowsAzure.Management.Monitoring.Alerts.Models.Microsoft.AppInsights.Nexus.DataContracts.Resources.ScheduledQueryRules.LogToMetricAction", - "criteria": [{ - "metricName": "[parameters('convertRuleMetric')]", - "dimensions": [] - } - ] - } - } - }, - { - "name": "[parameters('alertName')]", - "type": "Microsoft.Insights/metricAlerts", - "location": "global", - "apiVersion": "2018-03-01", - "tags": {}, - "dependsOn":["[resourceId('Microsoft.Insights/scheduledQueryRules',parameters('convertRuleName'))]"], - "properties": { - "description": "[parameters('alertDescription')]", - "severity": "[parameters('alertSeverity')]", - "enabled": "[parameters('isEnabled')]", - "scopes": ["[parameters('resourceId')]"], - "evaluationFrequency":"[parameters('evaluationFrequency')]", - "windowSize": "[parameters('windowSize')]", - "criteria": { - "odata.type": "Microsoft.Azure.Monitor.MultipleResourceMultipleMetricCriteria", - "allOf": [ - { - "criterionType": "DynamicThresholdCriterion", - "name" : "1st criterion", - "metricName": "[parameters('metricName')]", - "dimensions":[], - "operator": "[parameters('operator')]", - "alertSensitivity": "[parameters('alertSensitivity')]", - "failingPeriods": { - "numberOfEvaluationPeriods": "[parameters('numberOfEvaluationPeriods')]", - "minFailingPeriodsToAlert": "[parameters('minFailingPeriodsToAlert')]" - }, - "timeAggregation": "[parameters('timeAggregation')]" - } - ] - }, - "actions": [ - { - "actionGroupId": "[parameters('actionGroupId')]" - } - ] - } - } - ] -} -``` --If you save the preceding JSON as *metricfromLogsAlertDynamic.json*, you can couple it with a parameter JSON file for creation based on a Resource Manager template. Here's a sample parameter JSON file: --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "convertRuleName": { - "value": "TestLogtoMetricRule" - }, - "convertRuleDescription": { - "value": "Test rule to extract metrics from logs via template" - }, - "convertRuleRegion": { - "value": "West Central US" - }, - "convertRuleStatus": { - "value": "true" - }, - "convertRuleMetric": { - "value": "Average_% Idle Time" - }, - "alertName": { - "value": "TestMetricAlertonLog" - }, - "alertDescription": { - "value": "New multidimensional metric alert created via template" - }, - "alertSeverity": { - "value":3 - }, - "isEnabled": { - "value": true - }, - "resourceId": { - "value": "/subscriptions/1234-56789-1234-567a/resourceGroups/myRG/providers/Microsoft.OperationalInsights/workspaces/workspaceName" - }, - "metricName":{ - "value": "Average_% Idle Time" - }, - "operator": { - "value": "GreaterOrLessThan" - }, - "alertSensitivity": { - "value": "Medium" - }, - "numberOfEvaluationPeriods": { - "value": "4" - }, - "minFailingPeriodsToAlert": { - "value": "3" - }, - "timeAggregation":{ - "value": "Average" - }, - "actionGroupId": { - "value": "/subscriptions/1234-56789-1234-567a/resourceGroups/myRG/providers/microsoft.insights/actionGroups/actionGroupName" - } - } -} -``` --Assuming that you saved the preceding parameter file as *metricfromLogsAlertDynamic.parameters.json*, you can create metric alerts for logs by using the [Resource Manager template for creation in the Azure portal](../../azure-resource-manager/templates/deploy-portal.md). --Alternatively, you can use this Azure PowerShell command: --```powershell -New-AzResourceGroupDeployment -ResourceGroupName "myRG" -TemplateFile metricfromLogsAlertDynamic.json TemplateParameterFile metricfromLogsAlertDynamic.parameters.json -``` --Or, you can deploy the Resource Manager template by using the Azure CLI: --```azurecli -az deployment group create --resource-group myRG --template-file metricfromLogsAlertDynamic.json --parameters @metricfromLogsAlertDynamic.parameters.json -``` --## Related content --- Learn more about [metric alerts](../alerts/alerts-metric.md).-- Learn about [log search alerts in Azure](./alerts-types.md#log-alerts).-- Learn about [alerts in Azure](./alerts-overview.md). |
| azure-monitor | Alerts Metric Multiple Time Series Single Rule | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-metric-multiple-time-series-single-rule.md | - Title: Monitor multiple time series in a single metric alert rule -description: Alert at scale by using a single alert rule for multiple time series. -- Previously updated : 07/09/2023----# Monitor multiple time series in a single metric alert rule --A single metric alert rule can be used to monitor one or many metric time series. This capability makes it easier to monitor resources at scale. --## Metric time series --A metric time series is a series of measurements, or "metric values," captured over a period of time. --For example: --- The CPU utilization of a virtual machine-- The incoming bytes (ingress) to a storage account-- The number of failed requests of a web application--## Alert rule on a single time series --An alert rule monitors a single time series when it meets all the following conditions: --- It monitors a single target resource.-- It contains a single condition.-- It evaluates a metric without choosing dimensions (assuming the metric supports dimensions).--An example of such an alert rule, with only the relevant properties shown: --- **Target resource**: *VM-a*-- **Signal**: *Percentage CPU*-- **Operator**: *Greater Than*-- **Threshold**: *80*--For this alert rule, a single metric time series is monitored: --- Percentage CPU where *Resource*=ΓÇÖVM-aΓÇÖ > 80%---## Alert rule on multiple time series --An alert rule monitors multiple time series if it uses at least one of the following features: --- Multiple resources-- Multiple conditions-- Multiple dimensions--## Multiple resources (multi-resource) --A single metric alert rule can monitor multiple resources, provided the resources are of the same type and exist in the same Azure region. Using this type of rule reduces complexity and the total number of alert rules you have to maintain. --An example of such an alert rule: --- **Target resource**: *VM-a, myVM2*-- **Signal**: *Percentage CPU*-- **Operator**: *Greater Than*-- **Threshold**: *80*--For this alert rule, two metric time series are monitored separately: --- Percentage CPU where *Resource*=ΓÇÖVM-aΓÇÖ > 80%-- Percentage CPU where *Resource*=ΓÇÖmyVM2ΓÇÖ > 80%---In a multi-resource alert rule, the condition is evaluated separately for each of the resources (or more accurately, for each of the metric time series corresponded to each resource). As a result, alerts are also fired for each resource separately. --For example, assume we've set the preceding alert rule to monitor for CPU above 80%. In the evaluated time period, that is, the last 5 minutes: --- The *Percentage CPU* of *VM-a* is greater than 80%.-- The *Percentage CPU* of *myVM2* is at 50%.--The alert rule triggers on *VM-a* but not *VM-b*. These triggered alerts are independent. They can also resolve at different times depending on the individual behavior of each of the virtual machines. --For more information about multi-resource alert rules and the resource types supported for this capability, see [Monitoring at scale using metric alerts in Azure Monitor](alerts-types.md#monitor-multiple-resources-with-one-alert-rule). --> [!NOTE] -> In a metric alert rule that monitors multiple resources, only a single condition is allowed. --## Multiple conditions (multi-condition) --A single metric alert rule can also monitor up to five conditions per alert rule. --For example: --- **Target resource**: *VM-a*-- Condition1- - **Signal**: *Percentage CPU* - - **Operator**: *Greater Than* - - **Threshold**: *80* -- Condition2- - **Signal**: *Network In Total* - - **Operator**: *Greater Than* - - **Threshold**: *20 MB* --For this alert rule, two metric time series are being monitored: --- The *Percentage CPU* where *Resource*=ΓÇÖVM-aΓÇÖ > 80%.-- The *Network In Total* where *Resource*=ΓÇÖVM-aΓÇÖ > 20 MB.---An AND operator is used between the conditions. The alert rule fires an alert when *all* conditions are met. The fired alert resolves if at least one of the conditions is no longer met. --> [!NOTE] -> There are restrictions when you use dimensions in an alert rule with multiple conditions. For more information, see [Restrictions when using dimensions in a metric alert rule with multiple conditions](alerts-create-metric-alert-rule.yml#restrictions-when-you-use-dimensions-in-a-metric-alert-rule-with-multiple-conditions). --## Multiple dimensions (multi-dimension) --A single metric alert rule can also monitor multiple dimension values of a metric. The dimensions of a metric are name-value pairs that carry more data to describe the metric value. For example, the **Transactions** metric of a storage account has a dimension called **API name**. This dimension describes the name of the API called by each transaction, for example, GetBlob, DeleteBlob, and PutPage. The use of dimensions is optional, but it allows filtering the metric and only monitoring specific time series, instead of monitoring the metric as an aggregate of all the dimensional values put together. --For example, you can choose to have an alert fired when the number of transactions is high across all API names (which is the aggregated data). Or you can further break it down into only alerting when the number of transactions is high for specific API names. --An example of an alert rule monitoring multiple dimensions is: --- **Target resource**: *mystorage1*-- **Signal**: *Transactions*-- **Dimensions**:- * API name = *EntityGroupTransaction, GetBlob, PutPage* -- **Operator**: *Greater Than*-- **Threshold**: *80*--For this alert rule, three metric time series are being monitored: --- Transactions where *Resource*=ΓÇÖmystorage1ΓÇÖ and *API Name*=ΓÇÖEntityGroupTransactionΓÇÖ > 80-- Transactions where *Resource*=ΓÇÖmystorage1ΓÇÖ and *API Name*=ΓÇÖGetBlobΓÇÖ > 80-- Transactions where *Resource*=ΓÇÖmystorage1ΓÇÖ and *API Name*=ΓÇÖPutPageΓÇÖ > 80---A multi-dimension metric alert rule can also monitor multiple dimension values from *different* dimensions of a metric. In this case, the alert rule *separately* monitors all the dimension value combinations of the selected dimension values. --An example of this type of alert rule: --- **Target resource**: *myStorage1*-- **Signal**: *Transactions*-- **Dimensions**:- * API name = *GetBlob, DeleteBlob, PutPage* - * Authentication = *SAS, AccountKey* -- **Operator**: *Greater Than*-- **Threshold**: *80*--For this alert rule, six metric time series are being monitored separately: --- Transactions where *Resource*=ΓÇÖmyStorage1ΓÇÖ and *API Name*=ΓÇÖGetBlobΓÇÖ and *Authentication*=ΓÇÖSASΓÇÖ > 80-- Transactions where *Resource*=ΓÇÖmyStorage1ΓÇÖ and *API Name*=ΓÇÖGetBlobΓÇÖ and *Authentication*=ΓÇÖAccountKeyΓÇÖ > 80-- Transactions where *Resource*=ΓÇÖmyStorage1ΓÇÖ and *API Name*=ΓÇÖDeleteBlobΓÇÖ and *Authentication*=ΓÇÖSASΓÇÖ > 80-- Transactions where *Resource*=ΓÇÖmyStorage1ΓÇÖ and *API Name*=ΓÇÖDeleteBlobΓÇÖ and *Authentication*=ΓÇÖAccountKeyΓÇÖ > 80-- Transactions where *Resource*=ΓÇÖmyStorage1ΓÇÖ and *API Name*=ΓÇÖPutPageΓÇÖ and *Authentication*=ΓÇÖSASΓÇÖ > 80-- Transactions where *Resource*=ΓÇÖmyStorage1ΓÇÖ and *API Name*=ΓÇÖPutPageΓÇÖ and *Authentication*=ΓÇÖAccountKeyΓÇÖ > 80---### Advanced multi-dimension features --1. **Select all current and future dimensions**: You can choose to monitor all possible values of a dimension, including future values. Such an alert rule will scale automatically to monitor all values of the dimension without you needing to modify the alert rule every time a dimension value is added or removed. -1. **Exclude dimensions**: Selecting the **Γëá** (exclude) operator for a dimension value is equivalent to selecting all other values of that dimension, including future values. -1. **Add new and custom dimensions**: The dimension values displayed in the Azure portal are based on metric data collected in the last day. If the dimension value you're looking for isn't yet emitted, you can add a custom dimension value. -1. **Match dimensions with a prefix**: You can choose to monitor all dimension values that start with a specific pattern by selecting the **Starts with** operator and entering a custom prefix. ---## Metric alerts pricing --The pricing of metric alert rules is available on the [Azure Monitor pricing page](https://azure.microsoft.com/pricing/details/monitor/). --When you create a metric alert rule, the provided price estimation is based on the selected features and the number of monitored time series. This number is determined from the rule configuration and current metric values. The monthly charge is based on actual evaluations of the time series, so it can differ from the original estimation if some time series don't have data to evaluate, or if the alert rule uses features that can make it scale dynamically. --For example, an alert rule can show a high price estimation if it uses the multi-dimension feature, and a large number of dimension values combinations are selected, which results in the monitoring of many time series. But the actual charge for that alert rule can be lower if not all the time series resulting from the dimension values combinations actually have data to evaluate. --## Number of time series monitored by a single alert rule --To prevent excess costs, each alert rule can monitor up to 5,000 time series by default. To lift this limit from your subscription, open a support ticket. --## Next steps --Learn more about monitoring at scale by using metric alerts and [dynamic thresholds](../alerts/alerts-dynamic-thresholds.md). |
| azure-monitor | Alerts Metric Near Real Time | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-metric-near-real-time.md | - Title: Supported resources for metric alerts in Azure Monitor -description: Reference on support metrics and logs for metric alerts in Azure Monitor --- Previously updated : 11/22/2023----# Supported resources for Azure Monitor metric alerts --This article lists the subset of [Azure Monitor metrics](../essentials/metrics-supported.md) that are supported by metric alerts. --You can also use newer alerts on popular log data stored in a Log Analytics workspace extracted as metrics. For more information, see [Metric Alerts for Logs](./alerts-metric-logs.md). --You can create metric alerts in the Azure portal, the [REST API](/rest/api/monitor/metricalerts/), or [Azure Resource Manager templates](./alerts-metric-create-templates.md). --## Metrics and dimensions supported --Metric alerts support alerting for metrics that use dimensions. You can use dimensions to filter your metric to the proper level. All supported metrics along with applicable dimensions can be explored and visualized using the [Azure Monitor metrics explorer](../essentials/metrics-charts.md). --Here's the full list of Azure Monitor metric sources supported by metric alerts: --|Resource type |Dimensions supported |Multi-resource alerts| Metrics available| -|||--|-| -|Microsoft.ApiManagement/service | Yes | No | [Azure API Management](../essentials/metrics-supported.md#microsoftapimanagementservice) | -|Microsoft.App/containerApps | Yes | No | Azure Container Apps | -|Microsoft.AppConfiguration/configurationStores |Yes | No | [Azure App Configuration](../essentials/metrics-supported.md#microsoftappconfigurationconfigurationstores) | -|Microsoft.AppPlatform/spring | Yes | No | [Azure Spring Cloud](../essentials/metrics-supported.md#microsoftappplatformspring) | -|Microsoft.Automation/automationAccounts | Yes| No | [Azure Automation accounts](../essentials/metrics-supported.md#microsoftautomationautomationaccounts) | -|Microsoft.AVS/privateClouds | No | No | [Azure VMware Solution](../essentials/metrics-supported.md) | -|Microsoft.Batch/batchAccounts | Yes | No | [Azure Batch accounts](../essentials/metrics-supported.md#microsoftbatchbatchaccounts) | -|Microsoft.Bing/accounts | Yes | No | [Bing accounts](../essentials/metrics-supported.md#microsoftmapsaccounts) | -|Microsoft.BotService/botServices | Yes | No | [Azure Bot Service](../essentials/metrics-supported.md#microsoftbotservicebotservices) | -|Microsoft.Cache/redis | Yes | Yes | [Azure Cache for Redis](../essentials/metrics-supported.md#microsoftcacheredis) | -|Microsoft.Cache/redisEnterprise | Yes | No | [Azure Cache for Redis Enterprise](../essentials/metrics-supported.md#microsoftcacheredisenterprise) | -|microsoft.Cdn/profiles | Yes | No | [Azure Content Delivery Network profiles](../essentials/metrics-supported.md#microsoftcdnprofiles) | -|Microsoft.ClassicCompute/domainNames/slots/roles | No | No | [Azure Cloud Services (classic)](../essentials/metrics-supported.md#microsoftclassiccomputedomainnamesslotsroles) | -|Microsoft.ClassicCompute/virtualMachines | No | No | [Azure Virtual Machines (classic)](../essentials/metrics-supported.md#microsoftclassiccomputevirtualmachines) | -|Microsoft.ClassicStorage/storageAccounts | Yes | No | [Azure Storage accounts (classic)](../essentials/metrics-supported.md#microsoftclassicstoragestorageaccounts) | -|Microsoft.ClassicStorage/storageAccounts/blobServices | Yes | No | [Azure Blob Storage accounts (classic)](../essentials/metrics-supported.md#microsoftclassicstoragestorageaccountsblobservices) | -|Microsoft.ClassicStorage/storageAccounts/fileServices | Yes | No | [Azure Files storage accounts (classic)](../essentials/metrics-supported.md#microsoftclassicstoragestorageaccountsfileservices) | -|Microsoft.ClassicStorage/storageAccounts/queueServices | Yes | No | [Azure Queue Storage accounts (classic)](../essentials/metrics-supported.md#microsoftclassicstoragestorageaccountsqueueservices) | -|Microsoft.ClassicStorage/storageAccounts/tableServices | Yes | No | [Azure Table Storage accounts (classic)](../essentials/metrics-supported.md#microsoftclassicstoragestorageaccountstableservices) | -|Microsoft.CognitiveServices/accounts | Yes | No | [Azure AI services](../essentials/metrics-supported.md#microsoftcognitiveservicesaccounts) | -|Microsoft.Compute/cloudServices | Yes | No | [Azure Cloud Services](../essentials/metrics-supported.md#microsoftcomputecloudservices) | -|Microsoft.Compute/cloudServices/roles | Yes | No | [Azure Cloud Services roles](../essentials/metrics-supported.md#microsoftcomputecloudservicesroles) | -|Microsoft.Compute/virtualMachines | Yes | Yes<sup>1</sup> | [Azure Virtual Machines](../essentials/metrics-supported.md#microsoftcomputevirtualmachines) | -|Microsoft.Compute/virtualMachineScaleSets | Yes | No |[Azure Virtual Machine Scale Sets](../essentials/metrics-supported.md#microsoftcomputevirtualmachinescalesets) | -|Microsoft.Communication/CommunicationServices | Yes | No |[Communication Services](../essentials/metrics-supported.md#microsoftcommunicationcommunicationservices) | -|Microsoft.ConnectedVehicle/platformAccounts | Yes | No |[Connected Vehicle Platform Accounts](../essentials/metrics-supported.md) | -|Microsoft.ContainerInstance/containerGroups | Yes| No | [Container groups](../essentials/metrics-supported.md#microsoftcontainerinstancecontainergroups) | -|Microsoft.ContainerRegistry/registries | No | No | [Azure Container Registry](../essentials/metrics-supported.md#microsoftcontainerregistryregistries) | -|Microsoft.ContainerService/managedClusters | Yes | No | [Managed clusters](../essentials/metrics-supported.md#microsoftcontainerservicemanagedclusters) | -|Microsoft.DataBoxEdge/dataBoxEdgeDevices | Yes | Yes | [Azure Data Box](../essentials/metrics-supported.md#microsoftdataboxedgedataboxedgedevices) | -|Microsoft.DataFactory/datafactories| Yes| No | [Azure Data Factory V1](../essentials/metrics-supported.md#microsoftdatafactorydatafactories) | -|Microsoft.DataFactory/factories |Yes | No | [Azure Data Factory V2](../essentials/metrics-supported.md#microsoftdatafactoryfactories) | -|Microsoft.DataProtection/backupVaults | Yes | Yes | Azure Backup vaults | -|Microsoft.DataShare/accounts | Yes | No | [Azure Data Share](../essentials/metrics-supported.md#microsoftdatashareaccounts) | -|Microsoft.DBforMariaDB/servers | No | No | [Azure Database for MariaDB](../essentials/metrics-supported.md#microsoftdbformariadbservers) | -|Microsoft.DBforMySQL/servers | No | No |[Azure Database for MySQL](../essentials/metrics-supported.md#microsoftdbformysqlservers)| -|Microsoft.DBforPostgreSQL/flexibleServers | Yes | Yes | [Azure Database for PostgreSQL (flexible servers)](../essentials/metrics-supported.md#microsoftdbforpostgresqlflexibleservers)| -|Microsoft.DBforPostgreSQL/serverGroupsv2 | Yes | No | Azure Database for PostgreSQL (hyperscale) | -|Microsoft.DBforPostgreSQL/servers | No | No | [Azure Database for PostgreSQL](../essentials/metrics-supported.md#microsoftdbforpostgresqlservers)| -|Microsoft.DBforPostgreSQL/serversv2 | No | No | [Azure Database for PostgreSQL V2](../essentials/metrics-supported.md#microsoftdbforpostgresqlserversv2)| -|Microsoft.Devices/IotHubs | Yes | No |[Azure IoT Hub](../essentials/metrics-supported.md#microsoftdevicesiothubs) | -|Microsoft.Devices/provisioningServices| Yes | No | [Device Provisioning Service](../essentials/metrics-supported.md#microsoftdevicesprovisioningservices) | -|Microsoft.DigitalTwins/digitalTwinsInstances | Yes | No | [Azure Digital Twins](../essentials/metrics-supported.md#microsoftdigitaltwinsdigitaltwinsinstances) | -|Microsoft.DocumentDB/databaseAccounts | Yes | No | [Azure Cosmos DB](../essentials/metrics-supported.md#microsoftdocumentdbdatabaseaccounts) | -|Microsoft.EventGrid/domains | Yes | No | [Azure Event Grid domains](../essentials/metrics-supported.md#microsofteventgriddomains) | -|Microsoft.EventGrid/systemTopics | Yes | No | [Azure Event Grid system topics](../essentials/metrics-supported.md#microsofteventgridsystemtopics) | -|Microsoft.EventGrid/topics |Yes | No | [Azure Event Grid topics](../essentials/metrics-supported.md#microsofteventgridtopics) | -|Microsoft.EventHub/clusters |Yes| No | [Azure Event Hubs clusters](../essentials/metrics-supported.md#microsofteventhubclusters) | -|Microsoft.EventHub/namespaces |Yes| No | [Azure Event Hubs](../essentials/metrics-supported.md#microsofteventhubnamespaces) | -|Microsoft.HDInsight/clusters | Yes | No | [Azure HDInsight clusters](../essentials/metrics-supported.md#microsofthdinsightclusters) | -|Microsoft.Insights/Components | Yes | No | [Application Insights](../essentials/metrics-supported.md#microsoftinsightscomponents) | -|Microsoft.KeyVault/vaults | Yes |Yes |[Azure Key Vault](../essentials/metrics-supported.md#microsoftkeyvaultvaults)| -|Microsoft.Kusto/Clusters | Yes |No |[Data explorer clusters](../essentials/metrics-supported.md#microsoftkustoclusters)| -|Microsoft.Logic/integrationServiceEnvironments | Yes | No |[Azure Integration Services environments](../essentials/metrics-supported.md#microsoftlogicintegrationserviceenvironments) | -|Microsoft.Logic/workflows | No | No |[Azure Logic Apps](../essentials/metrics-supported.md#microsoftlogicworkflows) | -|Microsoft.MachineLearningServices/workspaces | Yes | No | [Azure Machine Learning](../essentials/metrics-supported.md#microsoftmachinelearningservicesworkspaces) | -|Microsoft.MachineLearningServices/workspaces/onlineEndpoints | Yes | No | Azure Machine Learning endpoints | -|Microsoft.MachineLearningServices/workspaces/onlineEndpoints/deployments | Yes | No | Azure Machine Learning endpoint deployments | -|Microsoft.ManagedNetworkFabric/networkDevices | Yes | No |[Managed Network Fabric Devices](../essentials/metrics-supported.md#microsoftmanagednetworkfabricnetworkdevices) | -|Microsoft.Maps/accounts | Yes | No | [Azure Maps accounts](../essentials/metrics-supported.md#microsoftmapsaccounts) | -|Microsoft.Medi#microsoftmediamediaservices) | -|Microsoft.Medi#microsoftmediamediaservicesliveevents) | -|Microsoft.Medi#microsoftmediamediaservicesstreamingendpoints) | -|Microsoft.Monitor/accounts | Yes | No | [Azure Monitor workspaces](../essentials/metrics-supported.md#microsoftmonitoraccounts) | -|Microsoft.NetApp/netAppAccounts/capacityPools | Yes | Yes | [Azure NetApp Files capacity pools](../essentials/metrics-supported.md#microsoftnetappnetappaccountscapacitypools) | -|Microsoft.NetApp/netAppAccounts/capacityPools/volumes | Yes | Yes | [Azure NetApp Files volumes](../essentials/metrics-supported.md#microsoftnetappnetappaccountscapacitypoolsvolumes) | -|Microsoft.Network/applicationGateways | Yes | No | [Azure Application Gateway](../essentials/metrics-supported.md#microsoftnetworkapplicationgateways) | -|Microsoft.Network/azureFirewalls | Yes | No | [Azure Firewall](../essentials/metrics-supported.md#microsoftnetworkazurefirewalls) | -|microsoft.Network/networkWatchers/connectionMonitors | Yes | No | [Connection Monitors](../essentials/metrics-supported.md#microsoftnetworknetworkwatchersconnectionmonitors) | -|Microsoft.Network/dnsZones | No | No | [Azure DNS zones](../essentials/metrics-supported.md#microsoftnetworkdnszones) | -|Microsoft.Network/expressRouteCircuits | Yes | No |[Azure ExpressRoute circuits](../essentials/metrics-supported.md#microsoftnetworkexpressroutecircuits) | -|Microsoft.Network/expressRouteGateways | Yes | No |[Azure ExpressRoute gateways](../essentials/metrics-supported.md#microsoftnetworkexpressroutegateways) | -|Microsoft.Network/expressRoutePorts | Yes | No |[Azure ExpressRoute direct](../essentials/metrics-supported.md#microsoftnetworkexpressrouteports) | -|Microsoft.Network/loadBalancers (only for Standard SKUs)| Yes| No | [Azure Load Balancer](../essentials/metrics-supported.md#microsoftnetworkloadbalancers) | -|Microsoft.Network/natGateways| No | No | [NAT Gateway](../essentials/metrics-supported.md#microsoftnetworknatgateways) | -|Microsoft.Network/privateEndpoints| No | No | [Private endpoints](../essentials/metrics-supported.md#microsoftnetworkprivateendpoints) | -|Microsoft.Network/privateLinkServices| No | No | [Azure Private Link services](../essentials/metrics-supported.md#microsoftnetworkprivatelinkservices) | -|Microsoft.Network/publicipaddresses | No | No | [Public IP addresses](../essentials/metrics-supported.md#microsoftnetworkpublicipaddresses)| -|Microsoft.Network/trafficManagerProfiles | Yes | No | [Azure Traffic Manager profiles](../essentials/metrics-supported.md#microsoftnetworktrafficmanagerprofiles) | -|Microsoft.OperationalInsights/workspaces| Yes | No | [Log Analytics workspaces](../essentials/metrics-supported.md#microsoftoperationalinsightsworkspaces)| -|Microsoft.Peering/peerings | Yes | No | [Azure Peering Service](../essentials/metrics-supported.md#microsoftpeeringpeerings) | -|Microsoft.Peering/peeringServices | Yes | No | [Azure Peering Service](../essentials/metrics-supported.md#microsoftpeeringpeeringservices) | -|Microsoft.PowerBIDedicated/capacities | No | No | [Power BI dedicated capacities](../essentials/metrics-supported.md#microsoftpowerbidedicatedcapacities) | -|Microsoft.Purview/accounts | Yes | No | [Azure Purview accounts](../essentials/metrics-supported.md#microsoftpurviewaccounts) | -|Microsoft.RecoveryServices/vaults | Yes | Yes | [Recovery Services vaults](../essentials/metrics-supported.md) | -|Microsoft.Relay/namespaces | Yes | No | [Relays](../essentials/metrics-supported.md#microsoftrelaynamespaces) | -|Microsoft.Search/searchServices | Yes | No | [Search services](../essentials/metrics-supported.md#microsoftsearchsearchservices) | -|Microsoft.ServiceBus/namespaces | Yes | No | [Azure Service Bus](../essentials/metrics-supported.md#microsoftservicebusnamespaces) | -|Microsoft.SignalRService/WebPubSub | Yes | No | [Azure Web PubSub service](../essentials/metrics-supported.md#microsoftsignalrservicewebpubsub) | -|Microsoft.Sql/managedInstances | No | No | [Azure SQL Managed Instance](../essentials/metrics-supported.md#microsoftsqlmanagedinstances) | -|Microsoft.Sql/servers/databases | No | Yes | [Azure SQL Database](../essentials/metrics-supported.md#microsoftsqlserversdatabases) | -|Microsoft.Sql/servers/elasticPools | No | Yes | [Azure SQL Database elastic pools](../essentials/metrics-supported.md#microsoftsqlserverselasticpools) | -|Microsoft.Storage/storageAccounts |Yes | No | [Azure Storage accounts](../essentials/metrics-supported.md#microsoftstoragestorageaccounts)| -|Microsoft.Storage/storageAccounts/blobServices | Yes| No | [Azure Blob Storage accounts](../essentials/metrics-supported.md#microsoftstoragestorageaccountsblobservices) | -|Microsoft.Storage/storageAccounts/fileServices | Yes| No | [Azure Files storage accounts](../essentials/metrics-supported.md#microsoftstoragestorageaccountsfileservices) | -|Microsoft.Storage/storageAccounts/queueServices | Yes| No | [Azure Queue Storage accounts](../essentials/metrics-supported.md#microsoftstoragestorageaccountsqueueservices) | -|Microsoft.Storage/storageAccounts/tableServices | Yes| No | [Azure Table Storage accounts](../essentials/metrics-supported.md#microsoftstoragestorageaccountstableservices) | -|Microsoft.StorageCache/caches | Yes | No | [Azure HPC Cache](../essentials/metrics-supported.md#microsoftstoragecachecaches) | -|Microsoft.StorageSync/storageSyncServices | Yes | No | [Storage sync services](../essentials/metrics-supported.md#microsoftstoragesyncstoragesyncservices) | -|Microsoft.StreamAnalytics/streamingjobs | Yes | No | [Azure Stream Analytics](../essentials/metrics-supported.md#microsoftstreamanalyticsstreamingjobs) | -|Microsoft.Synapse/workspaces | Yes | No | [Azure Synapse Analytics](../essentials/metrics-supported.md#microsoftsynapseworkspaces) | -|Microsoft.Synapse/workspaces/bigDataPools | Yes | No | [Azure Synapse Analytics Apache Spark pools](../essentials/metrics-supported.md#microsoftsynapseworkspacesbigdatapools) | -|Microsoft.Synapse/workspaces/sqlPools | Yes | No | [Azure Synapse Analytics SQL pools](../essentials/metrics-supported.md#microsoftsynapseworkspacessqlpools) | -|Microsoft.VMWareCloudSimple/virtualMachines | Yes | No | [CloudSimple virtual machines](../essentials/metrics-supported.md) | -|Microsoft.Web/hostingEnvironments/multiRolePools | Yes | No | [Azure App Service environment multi-role pools](../essentials/metrics-supported.md#microsoftwebhostingenvironmentsmultirolepools)| -|Microsoft.Web/hostingEnvironments/workerPools | Yes | No | [Azure App Service environment worker pools](../essentials/metrics-supported.md#microsoftwebhostingenvironmentsworkerpools)| -|Microsoft.Web/serverfarms | Yes | No | [Azure App Service plans](../essentials/metrics-supported.md#microsoftwebserverfarms)| -|Microsoft.Web/sites | Yes | No | [Azure App Service and Azure Functions](../essentials/metrics-supported.md#microsoftwebsites)| -|Microsoft.Web/sites/slots | Yes | No | [Azure App Service slots](../essentials/metrics-supported.md#microsoftwebsitesslots)| --<sup>1</sup> Not supported for virtual machine network metrics such as Network In Total, Network Out Total, Inbound Flows, Outbound Flows, Inbound Flows Maximum Creation Rate, and Outbound Flows Maximum Creation Rate. Also not supported for custom metrics. --## Payload schema --Use the [common alert schema](./alerts-common-schema.md), which uses a single extensible and unified alert payload across all the alert services in Azure Monitor, for your webhook integrations.ΓÇï ---## Next steps --* Learn more about [Azure Monitor alerts](./alerts-overview.md). -* See the [alerts payload](./alerts-common-schema.md). |
| azure-monitor | Alerts Non Common Schema Definitions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-non-common-schema-definitions.md | - Title: Noncommon alert schema definitions in Azure Monitor -description: Understanding the noncommon alert schema definitions for Azure Monitor. --- Previously updated : 07/30/2024----# Noncommon alert schema definitions --The noncommon alert schema were historically used to customize alert email templates and webhook schemas for metric, log search, and activity log alert rules. We recommend using the [common schema](./alerts-common-schema.md) for all alert types and integrations. --This article describes the noncommon alert schema definitions for Azure Monitor, including definitions for: -- Webhooks-- Azure Logic Apps-- Azure Functions-- Azure Automation runbooks--## Metric alerts --See sample values for metric alerts. --### Metric alerts: Static threshold --**Sample values** --```json -{ - "schemaId": "AzureMonitorMetricAlert", - "data": { - "version": "2.0", - "properties": { - "customKey1": "value1", - "customKey2": "value2" - }, - "status": "Activated", - "context": { - "timestamp": "2021-11-15T09:35:12.9703687Z", - "id": "/subscriptions/11111111-1111-1111-1111-111111111111/resourceGroups/test-RG/providers/microsoft.insights/metricAlerts/test-metricAlertRule", - "name": "test-metricAlertRule", - "description": "Alert rule description", - "conditionType": "SingleResourceMultipleMetricCriteria", - "severity": "3", - "condition": { - "windowSize": "PT5M", - "allOf": [ - { - "metricName": "Transactions", - "metricNamespace": "Microsoft.Storage/storageAccounts", - "operator": "GreaterThan", - "threshold": "0", - "timeAggregation": "Total", - "dimensions": [ - { - "name": "ApiName", - "value": "GetBlob" - } - ], - "metricValue": 100, - "webTestName": null - } - ] - }, - "subscriptionId": "11111111-1111-1111-1111-111111111111", - "resourceGroupName": "test-RG", - "resourceName": "test-storageAccount", - "resourceType": "Microsoft.Storage/storageAccounts", - "resourceId": "/subscriptions/11111111-1111-1111-1111-111111111111/resourceGroups/test-RG/providers/Microsoft.Storage/storageAccounts/test-storageAccount", - "portalLink": "https://portal.azure.com/#resource/subscriptions/11111111-1111-1111-1111-111111111111/resourceGroups/test-RG/providers/Microsoft.Storage/storageAccounts/test-storageAccount" - } - } -} -``` --### Metric alerts: Dynamic threshold --**Sample values** --```json -{ - "schemaId": "AzureMonitorMetricAlert", - "data": { - "version": "2.0", - "properties": { - "customKey1": "value1", - "customKey2": "value2" - }, - "status": "Activated", - "context": { - "timestamp": "2021-11-15T09:35:24.3468506Z", - "id": "/subscriptions/11111111-1111-1111-1111-111111111111/resourcegroups/test-RG/providers/microsoft.insights/metricalerts/test-metricAlertRule", - "name": "test-metricAlertRule", - "description": "Alert rule description", - "conditionType": "DynamicThresholdCriteria", - "severity": "3", - "condition": { - "windowSize": "PT15M", - "allOf": [ - { - "alertSensitivity": "Low", - "failingPeriods": { - "numberOfEvaluationPeriods": 3, - "minFailingPeriodsToAlert": 3 - }, - "ignoreDataBefore": null, - "metricName": "Transactions", - "metricNamespace": "Microsoft.Storage/storageAccounts", - "operator": "GreaterThan", - "threshold": "0.3", - "timeAggregation": "Average", - "dimensions": [], - "metricValue": 78.09, - "webTestName": null - } - ] - }, - "subscriptionId": "11111111-1111-1111-1111-111111111111", - "resourceGroupName": "test-RG", - "resourceName": "test-storageAccount", - "resourceType": "Microsoft.Storage/storageAccounts", - "resourceId": "/subscriptions/11111111-1111-1111-1111-111111111111/resourceGroups/test-RG/providers/Microsoft.Storage/storageAccounts/test-storageAccount", - "portalLink": "https://portal.azure.com/#resource/subscriptions/11111111-1111-1111-1111-111111111111/resourceGroups/test-RG/providers/Microsoft.Storage/storageAccounts/test-storageAccount" - } - } -} -``` --## Log search alerts --See sample values for log search alerts. --### monitoringService = Log Alerts V1 ΓÇô Metric --**Sample values** --```json -{ - "SubscriptionId": "11111111-1111-1111-1111-111111111111", - "AlertRuleName": "test-logAlertRule-v1-metricMeasurement", - "SearchQuery": "Heartbeat | summarize AggregatedValue=count() by bin(TimeGenerated, 5m)", - "SearchIntervalStartTimeUtc": "2021-11-15T15:16:49Z", - "SearchIntervalEndtimeUtc": "2021-11-16T15:16:49Z", - "AlertThresholdOperator": "Greater Than", - "AlertThresholdValue": 0, - "ResultCount": 2, - "SearchIntervalInSeconds": 86400, - "LinkToSearchResults": "https://portal.azure.com#@aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa/blade/Microsoft_Azure_Monitoring_Logs/LogsBlade/source/Alerts.EmailLinks/scope/%7B%22resources%22%3A%5B%7B%22resourceId%22%3A%22%2Fsubscriptions%2F11111111-1111-1111-1111-111111111111%2FresourceGroups%2Ftest-RG%2Fproviders%2FMicrosoft.OperationalInsights%2Fworkspaces%2Ftest-logAnalyticsWorkspace%22%7D%5D%7D/q/aBcDeFgHi%2BWqaBcDeFgHiMqsSlVwTE8vSk1PLElNCUvMKU2aBcDeFgHiaBcDeFgHiaBcDeFgHiaBcDeFgHiaBcDeFgHi/prettify/1/timespan/2021-11-15T15%3a16%3a49.0000000Z%2f2021-11-16T15%3a16%3a49.0000000Z", - "LinkToFilteredSearchResultsUI": "https://portal.azure.com#@aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa/blade/Microsoft_Azure_Monitoring_Logs/LogsBlade/source/Alerts.EmailLinks/scope/%7B%22resources%22%3A%5B%7B%22resourceId%22%3A%22%2Fsubscriptions%2F11111111-1111-1111-1111-111111111111%2FresourceGroups%2Ftest-RG%2Fproviders%2FMicrosoft.OperationalInsights%2Fworkspaces%2Ftest-logAnalyticsWorkspace%22%7D%5D%7D/q/aBcDeFgHiaBcDeFgHiaBcDeFgHiTP1DtWhcTfIApUfTx0dp%2BOPOhDKsHR%2FFeJXsaBcDeFgHiaBcDeFgHiaBcDeFgHiaBcDeFgHiaBcDeFgHiaBcDeFgHiRI9mhc%3D/prettify/1/timespan/2021-11-15T15%3a16%3a49.0000000Z%2f2021-11-16T15%3a16%3a49.0000000Z", - "LinkToSearchResultsAPI": "https://api.loganalytics.io/v1/workspaces/bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb/query?query=Heartbeat%20%0A%7C%20summarize%20AggregatedValue%3Dcount%28%29%20by%20bin%28TimeGenerated%2C%205m%29×pan=2021-11-15T15%3a16%3a49.0000000Z%2f2021-11-16T15%3a16%3a49.0000000Z", - "LinkToFilteredSearchResultsAPI": "https://api.loganalytics.io/v1/workspaces/bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb/query?query=Heartbeat%20%0A%7C%20summarize%20AggregatedValue%3Dcount%28%29%20by%20bin%28TimeGenerated%2C%205m%29%7C%20where%20todouble%28AggregatedValue%29%20%3E%200×pan=2021-11-15T15%3a16%3a49.0000000Z%2f2021-11-16T15%3a16%3a49.0000000Z", - "Description": "Alert rule description", - "Severity": "3", - "SearchResult": { - "tables": [ - { - "name": "PrimaryResult", - "columns": [ - { - "name": "TimeGenerated", - "type": "datetime" - }, - { - "name": "AggregatedValue", - "type": "long" - } - ], - "rows": [ - [ - "2021-11-16T10:56:49Z", - 11 - ], - [ - "2021-11-16T11:56:49Z", - 11 - ] - ] - } - ], - "dataSources": [ - { - "resourceId": "/subscriptions/11111111-1111-1111-1111-111111111111/resourcegroups/test-RG/providers/microsoft.operationalinsights/workspaces/test-logAnalyticsWorkspace", - "region": "eastus", - "tables": [ - "Heartbeat" - ] - } - ] - }, - "WorkspaceId": "bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb", - "ResourceId": "/subscriptions/11111111-1111-1111-1111-111111111111/resourceGroups/test-RG/providers/Microsoft.OperationalInsights/workspaces/test-logAnalyticsWorkspace", - "AlertType": "Metric measurement", - "Dimensions": [] -} -``` --### monitoringService = Log Alerts V1 - Numresults --**Sample values** --```json -{ - "SubscriptionId": "11111111-1111-1111-1111-111111111111", - "AlertRuleName": "test-logAlertRule-v1-numResults", - "SearchQuery": "Heartbeat", - "SearchIntervalStartTimeUtc": "2021-11-15T15:15:24Z", - "SearchIntervalEndtimeUtc": "2021-11-16T15:15:24Z", - "AlertThresholdOperator": "Greater Than", - "AlertThresholdValue": 0, - "ResultCount": 1, - "SearchIntervalInSeconds": 86400, - "LinkToSearchResults": "https://portal.azure.com#@aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa/blade/Microsoft_Azure_Monitoring_Logs/LogsBlade/source/Alerts.EmailLinks/scope/%7B%22resources%22%3A%5B%7B%22resourceId%22%3A%22%2Fsubscriptions%2F11111111-1111-1111-1111-111111111111%2FresourceGroups%2Ftest-RG%2Fproviders%2FMicrosoft.OperationalInsights%2Fworkspaces%2Ftest-logAnalyticsWorkspace%22%7D%5D%7D/q/aBcDeFgHi%2ABCDE%3D%3D/prettify/1/timespan/2021-11-15T15%3a15%3a24.0000000Z%2f2021-11-16T15%3a15%3a24.0000000Z", - "LinkToFilteredSearchResultsUI": "https://portal.azure.com#@aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa/blade/Microsoft_Azure_Monitoring_Logs/LogsBlade/source/Alerts.EmailLinks/scope/%7B%22resources%22%3A%5B%7B%22resourceId%22%3A%22%2Fsubscriptions%2F11111111-1111-1111-1111-111111111111%2FresourceGroups%2Ftest-RG%2Fproviders%2FMicrosoft.OperationalInsights%2Fworkspaces%2Ftest-logAnalyticsWorkspace%22%7D%5D%7D/q/aBcDeFgHi%2ABCDE%3D%3D/prettify/1/timespan/2021-11-15T15%3a15%3a24.0000000Z%2f2021-11-16T15%3a15%3a24.0000000Z", - "LinkToSearchResultsAPI": "https://api.loganalytics.io/v1/workspaces/bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb/query?query=Heartbeat%0A×pan=2021-11-15T15%3a15%3a24.0000000Z%2f2021-11-16T15%3a15%3a24.0000000Z", - "LinkToFilteredSearchResultsAPI": "https://api.loganalytics.io/v1/workspaces/bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb/query?query=Heartbeat%0A×pan=2021-11-15T15%3a15%3a24.0000000Z%2f2021-11-16T15%3a15%3a24.0000000Z", - "Description": "Alert rule description", - "Severity": "3", - "SearchResult": { - "tables": [ - { - "name": "PrimaryResult", - "columns": [ - { - "name": "TenantId", - "type": "string" - }, - { - "name": "Computer", - "type": "string" - }, - { - "name": "TimeGenerated", - "type": "datetime" - } - ], - "rows": [ - [ - "bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb", - "test-computer", - "2021-11-16T12:00:00Z" - ] - ] - } - ], - "dataSources": [ - { - "resourceId": "/subscriptions/11111111-1111-1111-1111-111111111111/resourcegroups/test-RG/providers/microsoft.operationalinsights/workspaces/test-logAnalyticsWorkspace", - "region": "eastus", - "tables": [ - "Heartbeat" - ] - } - ] - }, - "WorkspaceId": "bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb", - "ResourceId": "/subscriptions/11111111-1111-1111-1111-111111111111/resourceGroups/test-RG/providers/Microsoft.OperationalInsights/workspaces/test-logAnalyticsWorkspace", - "AlertType": "Number of results" -} -``` --## Activity log alerts --See sample values for four activity log alerts. --### monitoringService = Activity Log - Administrative --**Sample values** --```json -{ - "schemaId": "Microsoft.Insights/activityLogs", - "data": { - "status": "Activated", - "context": { - "activityLog": { - "authorization": { - "action": "Microsoft.Compute/virtualMachines/restart/action", - "scope": "/subscriptions/11111111-1111-1111-1111-111111111111/resourceGroups/test-RG/providers/Microsoft.Compute/virtualMachines/test-VM" - }, - "channels": "Operation", - "claims": "{}", - "caller": "user-email@domain.com", - "correlationId": "aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa", - "description": "", - "eventSource": "Administrative", - "eventTimestamp": "2021-11-16T08:27:36.1836909+00:00", - "eventDataId": "bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb", - "level": "Informational", - "operationName": "Microsoft.Compute/virtualMachines/restart/action", - "operationId": "cccccccc-cccc-cccc-cccc-cccccccccccc", - "properties": { - "eventCategory": "Administrative", - "entity": "/subscriptions/11111111-1111-1111-1111-111111111111/resourceGroups/test-RG/providers/Microsoft.Compute/virtualMachines/test-VM", - "message": "Microsoft.Compute/virtualMachines/restart/action", - "hierarchy": "22222222-2222-2222-2222-222222222222/CnAIOrchestrationServicePublicCorpprod/33333333-3333-3333-3333-3333333303333/44444444-4444-4444-4444-444444444444/55555555-5555-5555-5555-555555555555/11111111-1111-1111-1111-111111111111" - }, - "resourceId": "/subscriptions/11111111-1111-1111-1111-111111111111/resourceGroups/test-RG/providers/Microsoft.Compute/virtualMachines/test-VM", - "resourceGroupName": "test-RG", - "resourceProviderName": "Microsoft.Compute", - "status": "Succeeded", - "subStatus": "", - "subscriptionId": "11111111-1111-1111-1111-111111111111", - "submissionTimestamp": "2021-11-16T08:29:00.141807+00:00", - "resourceType": "Microsoft.Compute/virtualMachines" - } - }, - "properties": { - "customKey1": "value1", - "customKey2": "value2" - } - } -} -``` --### monitoringService = Service Health --**Sample values** --```json -{ - "schemaId": "Microsoft.Insights/activityLogs", - "data": { - "status": "Activated", - "context": { - "activityLog": { - "channels": "Admin", - "correlationId": "11223344-1234-5678-abcd-aabbccddeeff", - "description": "This alert rule will trigger when there are updates to a service issue impacting subscription <name>.", - "eventSource": "ServiceHealth", - "eventTimestamp": "2021-11-17T05:34:44.5778226+00:00", - "eventDataId": "12345678-1234-1234-1234-1234567890ab", - "level": "Warning", - "operationName": "Microsoft.ServiceHealth/incident/action", - "operationId": "12345678-abcd-efgh-ijkl-abcd12345678", - "properties": { - "title": "Test Action Group - Test Service Health Alert", - "service": "Azure Service Name", - "region": "Global", - "communication": "<p><strong>Summary of impact</strong>: This is the impact summary.</p>\n<p><br></p>\n<p><strong>Preliminary Root Cause</strong>: This is the preliminary root cause.</p>\n<p><br></p>\n<p><strong>Mitigation</strong>: Mitigation description.</p>\n<p><br></p>\n<p><strong>Next steps</strong>: These are the next steps. </p>\n<p><br></p>\n<p>Stay informed about Azure service issues by creating custom service health alerts: <a href=\"https://aka.ms/ash-videos\" rel=\"noopener noreferrer\" target=\"_blank\">https://aka.ms/ash-videos</a> for video tutorials and <a href=\"https://aka.ms/ash-alerts%20for%20how-to%20documentation\" rel=\"noopener noreferrer\" target=\"_blank\">https://aka.ms/ash-alerts for how-to documentation</a>.</p>\n<p><br></p>", - "incidentType": "Incident", - "trackingId": "ABC1-DEF", - "impactStartTime": "2021-11-16T20:00:00.0000000Z", - "impactMitigationTime": "2021-11-17T01:00:00.0000000Z", - "impactedServices": "[{\"ImpactedRegions\":[{\"RegionName\":\"Global\"}],\"ServiceName\":\"Azure Service Name\"}]", - "impactedServicesTableRows": "<tr>\r\n<td align='center' style='padding: 5px 10px; border-right:1px solid black; border-bottom:1px solid black'>Azure Service Name</td>\r\n<td align='center' style='padding: 5px 10px; border-bottom:1px solid black'>Global<br></td>\r\n</tr>\r\n", - "defaultLanguageTitle": "Test Action Group - Test Service Health Alert", - "defaultLanguageContent": "<p><strong>Summary of impact</strong>: This is the impact summary.</p>\n<p><br></p>\n<p><strong>Preliminary Root Cause</strong>: This is the preliminary root cause.</p>\n<p><br></p>\n<p><strong>Mitigation</strong>: Mitigation description.</p>\n<p><br></p>\n<p><strong>Next steps</strong>: These are the next steps. </p>\n<p><br></p>\n<p>Stay informed about Azure service issues by creating custom service health alerts: <a href=\"https://aka.ms/ash-videos\" rel=\"noopener noreferrer\" target=\"_blank\">https://aka.ms/ash-videos</a> for video tutorials and <a href=\"https://aka.ms/ash-alerts%20for%20how-to%20documentation\" rel=\"noopener noreferrer\" target=\"_blank\">https://aka.ms/ash-alerts for how-to documentation</a>.</p>\n<p><br></p>", - "stage": "Resolved", - "communicationId": "11223344556677", - "isHIR": "false", - "isSynthetic": "True", - "impactType": "SubscriptionList", - "version": "0.1.1" - }, - "status": "Resolved", - "subscriptionId": "11111111-1111-1111-1111-111111111111", - "submissionTimestamp": "2021-11-17T01:23:45.0623172+00:00" - } - }, - "properties": { - "customKey1": "value1", - "customKey2": "value2" - } - } -} -``` --### monitoringService = Resource Health --**Sample values** --```json -{ - "schemaId": "Microsoft.Insights/activityLogs", - "data": { - "status": "Activated", - "context": { - "activityLog": { - "channels": "Admin, Operation", - "correlationId": "aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa", - "eventSource": "ResourceHealth", - "eventTimestamp": "2021-11-16T09:50:20.406+00:00", - "eventDataId": "bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb", - "level": "Informational", - "operationName": "Microsoft.Resourcehealth/healthevent/Activated/action", - "operationId": "bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb", - "properties": { - "title": "Rebooted by user", - "details": null, - "currentHealthStatus": "Unavailable", - "previousHealthStatus": "Available", - "type": "Downtime", - "cause": "UserInitiated" - }, - "resourceId": "/subscriptions/11111111-1111-1111-1111-111111111111/resourceGroups/test-RG/providers/Microsoft.Compute/virtualMachines/test-VM", - "resourceGroupName": "test-RG", - "resourceProviderName": "Microsoft.Resourcehealth/healthevent/action", - "status": "Active", - "subscriptionId": "11111111-1111-1111-1111-111111111111", - "submissionTimestamp": "2021-11-16T09:54:08.5303319+00:00", - "resourceType": "MICROSOFT.COMPUTE/VIRTUALMACHINES" - } - }, - "properties": { - "customKey1": "value1", - "customKey2": "value2" - } - } -} -``` --### monitoringService = Actual Cost Budget or Forecasted Budget --**Sample values** --```json -{ - "schemaId": "AIP Budget Notification", - "data": { - "SubscriptionName": "test-subscription", - "SubscriptionId": "11111111-1111-1111-1111-111111111111", - "EnrollmentNumber": "", - "DepartmentName": "test-budgetDepartmentName", - "AccountName": "test-budgetAccountName", - "BillingAccountId": "", - "BillingProfileId": "", - "InvoiceSectionId": "", - "ResourceGroup": "test-RG", - "SpendingAmount": "1111.32", - "BudgetStartDate": "2023-01-20T23:49:40.216Z", - "Budget": "10000", - "Unit": "USD", - "BudgetCreator": "email@domain.com", - "BudgetName": "test-budgetName", - "BudgetType": "Cost", - "NotificationThresholdAmount": "8000.0" - } -} -``` |
| azure-monitor | Alerts Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-overview.md | - Title: Overview of Azure Monitor alerts -description: Learn about Azure Monitor alerts, alert rules, action processing rules, and action groups, and how they work together to monitor your system. --- Previously updated : 01/14/2024-----# What are Azure Monitor alerts? --Alerts help you detect and address issues before users notice them by proactively notifying you when Azure Monitor data indicates there might be a problem with your infrastructure or application. --You can alert on any metric or log data source in the Azure Monitor data platform. --This diagram shows you how alerts work. ---An **alert rule** monitors your data and captures a signal that indicates something is happening on the specified resource. The alert rule captures the signal and checks to see if the signal meets the criteria of the condition. --An alert rule combines: --An **alert** is triggered if the conditions of the alert rule are met. The alert initiates the associated action group and updates the state of the alert. If you're monitoring more than one resource, the alert rule condition is evaluated separately for each of the resources, and alerts are fired for each resource separately. --Alerts are stored for 30 days and are deleted after the 30-day retention period. You can see all alert instances for all of your Azure resources on the [Alerts page](alerts-manage-alert-instances.md) in the Azure portal. --Alerts consist of: - - Notification methods, such as email, SMS, and push notifications. - - Automation runbooks. - - Azure functions. - - ITSM incidents. - - Logic apps. - - Secure webhooks. - - Webhooks. - - Event hubs. -- **Alert conditions**: These conditions are set by the system. When an alert fires, the alert condition is set to **fired**. After the underlying condition that caused the alert to fire clears, the alert condition is set to **resolved**.-- **User response**: The response is set by the user and doesn't change until the user changes it. The User response can be **New**, **Acknowledged**, or **Closed**. -- **Alert processing rules**: You can use alert processing rules to make modifications to triggered alerts as they're being fired. You can use alert processing rules to add or suppress action groups, apply filters, or have the rule processed on a predefined schedule.-## Types of alerts --This table provides a brief description of each alert type. For more information about each alert type and how to choose which alert type best suits your needs, see [Types of Azure Monitor alerts](alerts-types.md). --|Alert type|Description| -|:|:| -|[Metric alerts](alerts-types.md#metric-alerts)|Metric alerts evaluate resource metrics at regular intervals. Metrics can be platform metrics, custom metrics, logs from Azure Monitor converted to metrics, or Application Insights metrics. Metric alerts can also apply multiple conditions and dynamic thresholds.| -|[Log search alerts](alerts-types.md#log-alerts)|Log search alerts allow users to use a Log Analytics query to evaluate resource logs at a predefined frequency.| -|[Activity log alerts](alerts-types.md#activity-log-alerts)|Activity log alerts are triggered when a new activity log event occurs that matches defined conditions. Resource Health alerts and Service Health alerts are activity log alerts that report on your service and resource health.| -|[Smart detection alerts](alerts-types.md#smart-detection-alerts)|Smart detection on an Application Insights resource automatically warns you of potential performance problems and failure anomalies in your web application. You can migrate smart detection on your Application Insights resource to create alert rules for the different smart detection modules.| -|[Prometheus alerts](alerts-types.md#prometheus-alerts)|Prometheus alerts are used for alerting on Prometheus metrics stored in [Azure Monitor managed services for Prometheus](../essentials/prometheus-metrics-overview.md). The alert rules are based on the PromQL open-source query language.| --## Alerts and state --Alerts can be stateful or stateless. -- Stateless alerts fire each time the condition is met, even if fired previously.-- Stateful alerts fire when the rule conditions are met, and will not fire again or trigger any more actions until the conditions are resolved. --Each alert rule is evaluated individually. There is no validation to check if there is another alert configured for the same conditions. If there is more than one alert rule configured for the same conditions, each of those alerts will fire when the conditions are met. --Alerts are stored for 30 days and are deleted after the 30-day retention period. --### Stateless alerts -Stateless alerts fire each time the condition is met. The alert condition for all stateless alerts is always `fired`. --- All activity log alerts are stateless.-- The frequency of notifications for stateless metric alerts differs based on the alert rule's configured frequency:- - **Alert frequency of less than 5 minutes**: While the condition continues to be met, a notification is sent sometime between one and six minutes. - - **Alert frequency of equal to or more than 5 minutes**: While the condition continues to be met, a notification is sent between the configured frequency and double the frequency. For example, for an alert rule with a frequency of 15 minutes, a notification is sent sometime between 15 to 30 minutes. --### Stateful alerts -Stateful alerts fire when the rule conditions are met, and will not fire again or trigger any more actions until the conditions are resolved. -The alert condition for stateful alerts is `fired`, until it is considered resolved. When an alert is considered resolved, the alert rule sends out a resolved notification by using webhooks or email, and the alert condition is set to `resolved`. --For stateful alerts, while the alert itself is deleted after 30 days, the alert condition is stored until the alert is resolved, to prevent firing another alert, and so that notifications can be sent when the alert is resolved. --See [service limits](/azure/azure-monitor/service-limits#alerts) for alerts limitations, including limitations for stateful log alerts. --This table describes when a stateful alert is considered resolved: --|Alert type |The alert is resolved when | -||| -|Metric alerts|The alert condition isn't met for three consecutive checks.| -|Log search alerts| The alert condition isn't met for a specific time range. The time range differs based on the frequency of the alert:<ul> <li>**1 minute**: The alert condition isn't met for 10 minutes.</li> <li>**5 to 15 minutes**: The alert condition isn't met for three frequency periods.</li> <li>**15 minutes to 11 hours**: The alert condition isn't met for two frequency periods.</li> <li>**11 to 12 hours**: The alert condition isn't met for one frequency period.</li></ul>| --## Recommended alert rules --You can [enable recommended out-of-the-box alert rules in the Azure portal](alerts-manage-alert-rules.md#enable-recommended-alert-rules-in-the-azure-portal). --The system compiles a list of recommended alert rules based on: --- The resource providerΓÇÖs knowledge of important signals and thresholds for monitoring the resource.-- Data that tells us what customers commonly alert on for this resource.--> [!NOTE] -> Recommended alert rules is enabled for: -> - Virtual machines -> - AKS resources -> - Log Analytics workspaces --## Alerting at-scale --You can use any of the following methods for creating alert rules at-scale. Each choice has advantages and disadvantages that could have an effect on cost and on maintenance of the alert rules. --### Metric alerts -You can use [one metric alert rule to monitor multiple resources](alerts-metric-multiple-time-series-single-rule.md) of the same type that exist in the same Azure region. Individual notifications are sent for each monitored resource. For a list of Azure services that are currently supported for this feature, see [Supported resources for metric alerts in Azure Monitor](alerts-metric-near-real-time.md). --For metric alert rules for Azure services that don't support multiple resources, use automation tools such as the Azure CLI, PowerShell, or Azure Resource Manager templates to create the same alert rule for multiple resources. For sample ARM templates, see [Resource Manager template samples for metric alert rules in Azure Monitor](resource-manager-alerts-metric.md). --Each metric alert rule is charged based on the number of time series that are monitored. --### Log search alerts --Use [log search alert rules](alerts-create-log-alert-rule.md) to monitor all resources that send data to the Log Analytics workspace. These resources can be from any subscription or region. Use data collection rules when setting up your Log Analytics workspace to collect the required data for your log search alert rule. --You can also create resource-centric alerts instead of workspace-centric alerts by using **Split by dimensions**. When you split on the resourceId column, you will get one alert per resource that meets the condition. --Log search alert rules that use splitting by dimensions are charged based on the number of time series created by the dimensions resulting from your query. If the data is already collected to a Log Analytics workspace, there is no additional cost. --If you use metric data at scale in the Log Analytics workspace, pricing will change based on the data ingestion. --### Using Azure policies for alerting at scale --You can use [Azure policies](/azure/governance/policy/overview) to set up alerts at-scale. This has the advantage of easily implementing alerts at-scale. You can see how this is implemented with [Azure Monitor baseline alerts](https://aka.ms/amba). --Keep in mind that if you use policies to create alert rules, you may have the increased overhead of maintaining a large alert rule set. --## Azure role-based access control for alerts --You can only access, create, or manage alerts for resources for which you have permissions. --To create an alert rule, you must have: --These built-in Azure roles, supported at all Azure Resource Manager scopes, have permissions to and can access alerts information and create alert rules: --If the target action group or rule location is in a different scope than the two built-in roles, create a user with the appropriate permissions. --## Pricing -For information about pricing, see [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/). --## Next steps --- [See your alert instances](./alerts-page.md)-- [Create a new alert rule](alerts-log.md)-- [Learn about action groups](../alerts/action-groups.md)-- [Learn about alert processing rules](alerts-action-rules.md)-- [Manage your alerts programmatically](alerts-manage-alert-instances.md#manage-your-alerts-programmatically)- |
| azure-monitor | Alerts Payload Samples | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-payload-samples.md | - Title: Samples of Azure Monitor alert payloads -description: See examples of payloads for Azure monitor alerts. - Previously updated : 01/23/2023------# Sample alert payloads --The common alert schema standardizes the consumption experience for alert notifications in Azure. Historically, activity log, metric, and log search alerts each had their own email templates and webhook schemas. The common alert schema provides one standardized schema for all alert notifications. --A standardized schema can help you minimize the number of integrations, which simplifies the process of managing and maintaining your integrations. --The common schema includes information about the affected resource and the cause of the alert in these sections: -- **Essentials**: Standardized fields, used by all alert types that describe the resource affected by the alert and common alert metadata, such as severity or description.-- If you want to route alert instances to specific teams based on criteria such as a resource group, you can use the fields in the **Essentials** section to provide routing logic for all alert types. The teams that receive the alert notification can then use the context fields for their investigation. -- **Alert context**: Fields that vary depending on the type of the alert. The alert context fields describe the cause of the alert. For example, a metric alert would have fields like the metric name and metric value in the alert context. An activity log alert would have information about the event that generated the alert.-- **Custom properties**: You can add more information to the alert payload by adding custom properties if you've configured action groups for a metric alert rule. -- > [!NOTE] - > Custom properties are currently only supported by metric alerts. For all other alert types, the **custom properties** field is null. --## Sample alert payload --```json -{ - "schemaId": "azureMonitorCommonAlertSchema", - "data": { - "essentials": { - "alertId": "/subscriptions/<subscription ID>/providers/Microsoft.AlertsManagement/alerts/b9569717-bc32-442f-add5-83a997729330", - "alertRule": "WCUS-R2-Gen2", - "severity": "Sev3", - "signalType": "Metric", - "monitorCondition": "Resolved", - "monitoringService": "Platform", - "alertTargetIDs": [ - "/subscriptions/<subscription ID>/resourcegroups/pipelinealertrg/providers/microsoft.compute/virtualmachines/wcus-r2-gen2" - ], - "configurationItems": [ - "wcus-r2-gen2" - ], - "originAlertId": "3f2d4487-b0fc-4125-8bd5-7ad17384221e_PipeLineAlertRG_microsoft.insights_metricAlerts_WCUS-R2-Gen2_-117781227", - "firedDateTime": "2019-03-22T13:58:24.3713213Z", - "resolvedDateTime": "2019-03-22T14:03:16.2246313Z", - "description": "", - "essentialsVersion": "1.0", - "alertContextVersion": "1.0" - }, - "alertContext": { - "properties": null, - "conditionType": "SingleResourceMultipleMetricCriteria", - "condition": { - "windowSize": "PT5M", - "allOf": [ - { - "metricName": "Percentage CPU", - "metricNamespace": "Microsoft.Compute/virtualMachines", - "operator": "GreaterThan", - "threshold": "25", - "timeAggregation": "Average", - "dimensions": [ - { - "name": "ResourceId", - "value": "3efad9dc-3d50-4eac-9c87-8b3fd6f97e4e" - } - ], - "metricValue": 7.727 - } - ] - } - } - } -} -``` ---## Sample metric alerts -The following are sample metric alert payloads. --### Metric alert with a static threshold and the monitoringService = `Platform` --```json -{ - "alertContext": { - "properties": null, - "conditionType": "SingleResourceMultipleMetricCriteria", - "condition": { - "windowSize": "PT5M", - "allOf": [ - { - "metricName": "Percentage CPU", - "metricNamespace": "Microsoft.Compute/virtualMachines", - "operator": "GreaterThan", - "threshold": "25", - "timeAggregation": "Average", - "dimensions": [ - { - "name": "ResourceId", - "value": "3efad9dc-3d50-4eac-9c87-8b3fd6f97e4e" - } - ], - "metricValue": 31.1105 - } - ], - "windowStartTime": "2019-03-22T13:40:03.064Z", - "windowEndTime": "2019-03-22T13:45:03.064Z" - } - } -} -``` --### Metric alert with a dynamic threshold and the monitoringService = Platform --```json -{ - "alertContext": { - "properties": null, - "conditionType": "DynamicThresholdCriteria", - "condition": { - "windowSize": "PT5M", - "allOf": [ - { - "alertSensitivity": "High", - "failingPeriods": { - "numberOfEvaluationPeriods": 1, - "minFailingPeriodsToAlert": 1 - }, - "ignoreDataBefore": null, - "metricName": "Egress", - "metricNamespace": "microsoft.storage/storageaccounts", - "operator": "GreaterThan", - "threshold": "47658", - "timeAggregation": "Total", - "dimensions": [], - "metricValue": 50101 - } - ], - "windowStartTime": "2021-07-20T05:07:26.363Z", - "windowEndTime": "2021-07-20T05:12:26.363Z" - } - } -} -``` -### Metric alert for availability tests and the monitoringService = Platform --```json -{ - "alertContext": { - "properties": null, - "conditionType": "WebtestLocationAvailabilityCriteria", - "condition": { - "windowSize": "PT5M", - "allOf": [ - { - "metricName": "Failed Location", - "metricNamespace": null, - "operator": "GreaterThan", - "threshold": "2", - "timeAggregation": "Sum", - "dimensions": [], - "metricValue": 5, - "webTestName": "myAvailabilityTest-myApplication" - } - ], - "windowStartTime": "2019-03-22T13:40:03.064Z", - "windowEndTime": "2019-03-22T13:45:03.064Z" - } - } -} -``` --## Sample log search alerts --> [!NOTE] -> When you enable the common schema, the fields in the payload are reset to the common schema fields. Therefore, log search alerts have these limitations regarding the common schema: -> - The common schema is not supported for log search alerts using webhooks with a custom email subject and/or JSON payload, since the common schema overwrites the custom configurations. -> - Alerts using the common schema have an upper size limit of 256 KB per alert. If the log search alerts payload includes search results that cause the alert to exceed the maximum size, the search results aren't embedded in the log search alerts payload. You can check if the payload includes the search results with the `IncludedSearchResults` flag. Use `LinkToFilteredSearchResultsAPI` or `LinkToSearchResultsAPI` to access query results with the [Log Analytics API](/rest/api/loganalytics/dataaccess/query/get) if the search results are not included. --### Log search alert with monitoringService = Platform --```json -{ - "alertContext": { - "SearchQuery": "Perf | where ObjectName == \"Processor\" and CounterName == \"% Processor Time\" | summarize AggregatedValue = avg(CounterValue) by bin(TimeGenerated, 5m), Computer", - "SearchIntervalStartTimeUtc": "3/22/2019 1:36:31 PM", - "SearchIntervalEndtimeUtc": "3/22/2019 1:51:31 PM", - "ResultCount": 2, - "LinkToSearchResults": "https://portal.azure.com/#Analyticsblade/search/index?_timeInterval.intervalEnd=2018-03-26T09%3a10%3a40.0000000Z&_timeInterval.intervalDuration=3600&q=Usage", - "LinkToFilteredSearchResultsUI": "https://portal.azure.com/#Analyticsblade/search/index?_timeInterval.intervalEnd=2018-03-26T09%3a10%3a40.0000000Z&_timeInterval.intervalDuration=3600&q=Usage", - "LinkToSearchResultsAPI": "https://api.loganalytics.io/v1/workspaces/workspaceID/query?query=Heartbeat×pan=2020-05-07T18%3a11%3a51.0000000Z%2f2020-05-07T18%3a16%3a51.0000000Z", - "LinkToFilteredSearchResultsAPI": "https://api.loganalytics.io/v1/workspaces/workspaceID/query?query=Heartbeat×pan=2020-05-07T18%3a11%3a51.0000000Z%2f2020-05-07T18%3a16%3a51.0000000Z", - "SeverityDescription": "Warning", - "WorkspaceId": "12345a-1234b-123c-123d-12345678e", - "SearchIntervalDurationMin": "15", - "AffectedConfigurationItems": [ - "INC-Gen2Alert" - ], - "SearchIntervalInMinutes": "15", - "Threshold": 10000, - "Operator": "Less Than", - "Dimensions": [ - { - "name": "Computer", - "value": "INC-Gen2Alert" - } - ], - "SearchResults": { - "tables": [ - { - "name": "PrimaryResult", - "columns": [ - { - "name": "$table", - "type": "string" - }, - { - "name": "Computer", - "type": "string" - }, - { - "name": "TimeGenerated", - "type": "datetime" - } - ], - "rows": [ - [ - "Fabrikam", - "33446677a", - "2018-02-02T15:03:12.18Z" - ], - [ - "Contoso", - "33445566b", - "2018-02-02T15:16:53.932Z" - ] - ] - } - ], - "dataSources": [ - { - "resourceId": "/subscriptions/a5ea55e2-7482-49ba-90b3-60e7496dd873/resourcegroups/test/providers/microsoft.operationalinsights/workspaces/test", - "tables": [ - "Heartbeat" - ] - } - ] - }, - "IncludedSearchResults": "True", - "AlertType": "Metric measurement" - } -} -``` -### Log search alert with monitoringService = Application Insights --```json -{ - "alertContext": { - "SearchQuery": "requests | where resultCode == \"500\" | summarize AggregatedValue = Count by bin(Timestamp, 5m), IP", - "SearchIntervalStartTimeUtc": "3/22/2019 1:36:33 PM", - "SearchIntervalEndtimeUtc": "3/22/2019 1:51:33 PM", - "ResultCount": 2, - "LinkToSearchResults": "https://portal.azure.com/AnalyticsBlade/subscriptions/12345a-1234b-123c-123d-12345678e/?query=search+*+&timeInterval.intervalEnd=2018-03-26T09%3a10%3a40.0000000Z&_timeInterval.intervalDuration=3600&q=Usage", - "LinkToFilteredSearchResultsUI": "https://portal.azure.com/AnalyticsBlade/subscriptions/12345a-1234b-123c-123d-12345678e/?query=search+*+&timeInterval.intervalEnd=2018-03-26T09%3a10%3a40.0000000Z&_timeInterval.intervalDuration=3600&q=Usage", - "LinkToSearchResultsAPI": "https://api.applicationinsights.io/v1/apps/0MyAppId0/metrics/requests/count", - "LinkToFilteredSearchResultsAPI": "https://api.applicationinsights.io/v1/apps/0MyAppId0/metrics/requests/count", - "SearchIntervalDurationMin": "15", - "SearchIntervalInMinutes": "15", - "Threshold": 10000.0, - "Operator": "Less Than", - "ApplicationId": "8e20151d-75b2-4d66-b965-153fb69d65a6", - "Dimensions": [ - { - "name": "IP", - "value": "1.1.1.1" - } - ], - "SearchResults": { - "tables": [ - { - "name": "PrimaryResult", - "columns": [ - { - "name": "$table", - "type": "string" - }, - { - "name": "Id", - "type": "string" - }, - { - "name": "Timestamp", - "type": "datetime" - } - ], - "rows": [ - [ - "Fabrikam", - "33446677a", - "2018-02-02T15:03:12.18Z" - ], - [ - "Contoso", - "33445566b", - "2018-02-02T15:16:53.932Z" - ] - ] - } - ], - "dataSources": [ - { - "resourceId": "/subscriptions/a5ea27e2-7482-49ba-90b3-52e7496dd873/resourcegroups/test/providers/microsoft.operationalinsights/workspaces/test", - "tables": [ - "Heartbeat" - ] - } - ] - }, - "IncludedSearchResults": "True", - "AlertType": "Metric measurement" - } -} -``` --### Log search alert with monitoringService = Log Alerts V2 --> [!NOTE] -> Log search alert rules from API version 2020-05-01 use this payload type, which only supports common schema. Search results aren't embedded in the log search alerts payload when you use this version. Use [dimensions](./alerts-types.md#monitor-the-same-condition-on-multiple-resources-using-splitting-by-dimensions-1) to provide context to fired alerts. You can also use `LinkToFilteredSearchResultsAPI` or `LinkToSearchResultsAPI` to access query results with the [Log Analytics API](/rest/api/loganalytics/dataaccess/query/get). If you must embed the results, use a logic app with the provided links to generate a custom payload. --```json -{ - "alertContext": { - "properties": { - "name1": "value1", - "name2": "value2" - }, - "conditionType": "LogQueryCriteria", - "condition": { - "windowSize": "PT10M", - "allOf": [ - { - "searchQuery": "Heartbeat", - "metricMeasureColumn": "CounterValue", - "targetResourceTypes": "['Microsoft.Compute/virtualMachines']", - "operator": "LowerThan", - "threshold": "1", - "timeAggregation": "Count", - "dimensions": [ - { - "name": "Computer", - "value": "TestComputer" - } - ], - "metricValue": 0.0, - "failingPeriods": { - "numberOfEvaluationPeriods": 1, - "minFailingPeriodsToAlert": 1 - }, - "linkToSearchResultsUI": "https://portal.azure.com#@12345a-1234b-123c-123d-12345678e/blade/Microsoft_Azure_Monitoring_Logs/LogsBlade/source/Alerts.EmailLinks/scope/%7B%22resources%22%3A%5B%7B%22resourceId%22%3A%22%2Fsubscriptions%212345a-1234b-123c-123d-12345678e%2FresourceGroups%2FContoso%2Fproviders%2FMicrosoft.Compute%2FvirtualMachines%2FContoso%22%7D%5D%7D/q/eJzzSE0sKklKTSypUSjPSC1KVQjJzE11T81LLUosSU1RSEotKU9NzdNIAfJKgDIaRgZGBroG5roGliGGxlYmJlbGJnoGEKCpp4dDmSmKMk0A/prettify/1/timespan/2020-07-07T13%3a54%3a34.0000000Z%2f2020-07-09T13%3a54%3a34.0000000Z", - "linkToFilteredSearchResultsUI": "https://portal.azure.com#@12345a-1234b-123c-123d-12345678e/blade/Microsoft_Azure_Monitoring_Logs/LogsBlade/source/Alerts.EmailLinks/scope/%7B%22resources%22%3A%5B%7B%22resourceId%22%3A%22%2Fsubscriptions%212345a-1234b-123c-123d-12345678e%2FresourceGroups%2FContoso%2Fproviders%2FMicrosoft.Compute%2FvirtualMachines%2FContoso%22%7D%5D%7D/q/eJzzSE0sKklKTSypUSjPSC1KVQjJzE11T81LLUosSU1RSEotKU9NzdNIAfJKgDIaRgZGBroG5roGliGGxlYmJlbGJnoGEKCpp4dDmSmKMk0A/prettify/1/timespan/2020-07-07T13%3a54%3a34.0000000Z%2f2020-07-09T13%3a54%3a34.0000000Z", - "linkToSearchResultsAPI": "https://api.loganalytics.io/v1/subscriptions/12345a-1234b-123c-123d-12345678e/resourceGroups/Contoso/providers/Microsoft.Compute/virtualMachines/Contoso/query?query=Heartbeat%7C%20where%20TimeGenerated%20between%28datetime%282020-07-09T13%3A44%3A34.0000000%29..datetime%282020-07-09T13%3A54%3A34.0000000%29%29×pan=2020-07-07T13%3a54%3a34.0000000Z%2f2020-07-09T13%3a54%3a34.0000000Z", - "linkToFilteredSearchResultsAPI": "https://api.loganalytics.io/v1/subscriptions/12345a-1234b-123c-123d-12345678e/resourceGroups/Contoso/providers/Microsoft.Compute/virtualMachines/Contoso/query?query=Heartbeat%7C%20where%20TimeGenerated%20between%28datetime%282020-07-09T13%3A44%3A34.0000000%29..datetime%282020-07-09T13%3A54%3A34.0000000%29%29×pan=2020-07-07T13%3a54%3a34.0000000Z%2f2020-07-09T13%3a54%3a34.0000000Z" - } - ], - "windowStartTime": "2020-07-07T13:54:34Z", - "windowEndTime": "2020-07-09T13:54:34Z" - } - } -} -``` --## Sample activity log alerts --### Activity log alert with monitoringService = `Activity Log - Administrative` --```json -{ - "alertContext": { - "authorization": { - "action": "Microsoft.Compute/virtualMachines/restart/action", - "scope": "/subscriptions/<subscription ID>/resourceGroups/PipeLineAlertRG/providers/Microsoft.Compute/virtualMachines/WCUS-R2-ActLog" - }, - "channels": "Operation", - "claims": "{\"aud\":\"https://management.core.windows.net/\",\"iss\":\"https://sts.windows.net/12345a-1234b-123c-123d-12345678e/\",\"iat\":\"1553260826\",\"nbf\":\"1553260826\",\"exp\":\"1553264726\",\"aio\":\"42JgYNjdt+rr+3j/dx68v018XhuFAwA=\",\"appid\":\"e9a02282-074f-45cf-93b0-50568e0e7e50\",\"appidacr\":\"2\",\"http://schemas.microsoft.com/identity/claims/identityprovider\":\"https://sts.windows.net/12345a-1234b-123c-123d-12345678e/\",\"http://schemas.microsoft.com/identity/claims/objectidentifier\":\"9778283b-b94c-4ac6-8a41-d5b493d03aa3\",\"http://schemas.xmlsoap.org/ws/2005/05/identity/claims/nameidentifier\":\"9778283b-b94c-4ac6-8a41-d5b493d03aa3\",\"http://schemas.microsoft.com/identity/claims/tenantid\":\"12345a-1234b-123c-123d-12345678e\",\"uti\":\"v5wYC9t9ekuA2rkZSVZbAA\",\"ver\":\"1.0\"}", - "caller": "9778283b-b94c-4ac6-8a41-d5b493d03aa3", - "correlationId": "8ee9c32a-92a1-4a8f-989c-b0ba09292a91", - "eventSource": "Administrative", - "eventTimestamp": "2019-03-22T13:56:31.2917159+00:00", - "eventDataId": "161fda7e-1cb4-4bc5-9c90-857c55a8f57b", - "level": "Informational", - "operationName": "Microsoft.Compute/virtualMachines/restart/action", - "operationId": "310db69b-690f-436b-b740-6103ab6b0cba", - "status": "Succeeded", - "subStatus": "", - "submissionTimestamp": "2019-03-22T13:56:54.067593+00:00" - } -} -``` --### Activity log alert with monitoringService = `Activity Log - Policy` --```json -{ - "alertContext": { - "authorization": { - "action": "Microsoft.Resources/checkPolicyCompliance/read", - "scope": "/subscriptions/<GUID>" - }, - "channels": "Operation", - "claims": "{\"aud\":\"https://management.azure.com/\",\"iss\":\"https://sts.windows.net/<GUID>/\",\"iat\":\"1566711059\",\"nbf\":\"1566711059\",\"exp\":\"1566740159\",\"aio\":\"42FgYOhynHNw0scy3T/bL71+xLyqEwA=\",\"appid\":\"<GUID>\",\"appidacr\":\"2\",\"http://schemas.microsoft.com/identity/claims/identityprovider\":\"https://sts.windows.net/<GUID>/\",\"http://schemas.microsoft.com/identity/claims/objectidentifier\":\"<GUID>\",\"http://schemas.xmlsoap.org/ws/2005/05/identity/claims/nameidentifier\":\"<GUID>\",\"http://schemas.microsoft.com/identity/claims/tenantid\":\"<GUID>\",\"uti\":\"Miy1GzoAG0Scu_l3m1aIAA\",\"ver\":\"1.0\"}", - "caller": "<GUID>", - "correlationId": "<GUID>", - "eventSource": "Policy", - "eventTimestamp": "2019-08-25T11:11:34.2269098+00:00", - "eventDataId": "<GUID>", - "level": "Warning", - "operationName": "Microsoft.Authorization/policies/audit/action", - "operationId": "<GUID>", - "properties": { - "isComplianceCheck": "True", - "resourceLocation": "eastus2", - "ancestors": "<GUID>", - "policies": "[{\"policyDefinitionId\":\"/providers/Microsoft.Authorization/policyDefinitions/<GUID>/\",\"policySetDefinitionId\":\"/providers/Microsoft.Authorization/policySetDefinitions/<GUID>/\",\"policyDefinitionReferenceId\":\"vulnerabilityAssessmentMonitoring\",\"policySetDefinitionName\":\"<GUID>\",\"policyDefinitionName\":\"<GUID>\",\"policyDefinitionEffect\":\"AuditIfNotExists\",\"policyAssignmentId\":\"/subscriptions/<GUID>/providers/Microsoft.Authorization/policyAssignments/SecurityCenterBuiltIn/\",\"policyAssignmentName\":\"SecurityCenterBuiltIn\",\"policyAssignmentScope\":\"/subscriptions/<GUID>\",\"policyAssignmentSku\":{\"name\":\"A1\",\"tier\":\"Standard\"},\"policyAssignmentParameters\":{}}]" - }, - "status": "Succeeded", - "subStatus": "", - "submissionTimestamp": "2019-08-25T11:12:46.1557298+00:00" - } -} -``` --### Activity log alert with monitoringService = `Activity Log - Autoscale` --```json -{ - "alertContext": { - "channels": "Admin, Operation", - "claims": "{\"http://schemas.xmlsoap.org/ws/2005/05/identity/claims/spn\":\"Microsoft.Insights/autoscaleSettings\"}", - "caller": "Microsoft.Insights/autoscaleSettings", - "correlationId": "<GUID>", - "eventSource": "Autoscale", - "eventTimestamp": "2019-08-21T16:17:47.1551167+00:00", - "eventDataId": "<GUID>", - "level": "Informational", - "operationName": "Microsoft.Insights/AutoscaleSettings/Scaleup/Action", - "operationId": "<GUID>", - "properties": { - "description": "The autoscale engine attempting to scale resource '/subscriptions/d<GUID>/resourceGroups/testRG/providers/Microsoft.Compute/virtualMachineScaleSets/testVMSS' from 9 instances count to 10 instances count.", - "resourceName": "/subscriptions/<GUID>/resourceGroups/voiceassistancedemo/providers/Microsoft.Compute/virtualMachineScaleSets/alexademo", - "oldInstancesCount": "9", - "newInstancesCount": "10", - "activeAutoscaleProfile": "{\r\n \"Name\": \"Auto created scale condition\",\r\n \"Capacity\": {\r\n \"Minimum\": \"1\",\r\n \"Maximum\": \"10\",\r\n \"Default\": \"1\"\r\n },\r\n \"Rules\": [\r\n {\r\n \"MetricTrigger\": {\r\n \"Name\": \"Percentage CPU\",\r\n \"Namespace\": \"microsoft.compute/virtualmachinescalesets\",\r\n \"Resource\": \"/subscriptions/<GUID>/resourceGroups/testRG/providers/Microsoft.Compute/virtualMachineScaleSets/testVMSS\",\r\n \"ResourceLocation\": \"eastus\",\r\n \"TimeGrain\": \"PT1M\",\r\n \"Statistic\": \"Average\",\r\n \"TimeWindow\": \"PT5M\",\r\n \"TimeAggregation\": \"Average\",\r\n \"Operator\": \"GreaterThan\",\r\n \"Threshold\": 0.0,\r\n \"Source\": \"/subscriptions/<GUID>/resourceGroups/testRG/providers/Microsoft.Compute/virtualMachineScaleSets/testVMSS\",\r\n \"MetricType\": \"MDM\",\r\n \"Dimensions\": [],\r\n \"DividePerInstance\": false\r\n },\r\n \"ScaleAction\": {\r\n \"Direction\": \"Increase\",\r\n \"Type\": \"ChangeCount\",\r\n \"Value\": \"1\",\r\n \"Cooldown\": \"PT1M\"\r\n }\r\n }\r\n ]\r\n}", - "lastScaleActionTime": "Wed, 21 Aug 2019 16:17:47 GMT" - }, - "status": "Succeeded", - "submissionTimestamp": "2019-08-21T16:17:47.2410185+00:00" - } -} -``` --### Activity log alert with monitoringService = `Activity Log - Security` --```json -{ - "alertContext": { - "channels": "Operation", - "correlationId": "<GUID>", - "eventSource": "Security", - "eventTimestamp": "2019-08-26T08:34:14+00:00", - "eventDataId": "<GUID>", - "level": "Informational", - "operationName": "Microsoft.Security/locations/alerts/activate/action", - "operationId": "<GUID>", - "properties": { - "threatStatus": "Quarantined", - "category": "Virus", - "threatID": "2147519003", - "filePath": "C:\\AlertGeneration\\test.eicar", - "protectionType": "Windows Defender", - "actionTaken": "Blocked", - "resourceType": "Virtual Machine", - "severity": "Low", - "compromisedEntity": "testVM", - "remediationSteps": "[\"No user action is necessary\"]", - "attackedResourceType": "Virtual Machine" - }, - "status": "Active", - "submissionTimestamp": "2019-08-26T09:28:58.3019107+00:00" - } -} -``` --### Activity log alert with `monitoringService = ServiceHealth` --```json -{ - "alertContext": { - "authorization": null, - "channels": 1, - "claims": null, - "caller": null, - "correlationId": "f3cf2430-1ee3-4158-8e35-7a1d615acfc7", - "eventSource": 2, - "eventTimestamp": "2019-06-24T11:31:19.0312699+00:00", - "httpRequest": null, - "eventDataId": "<GUID>", - "level": 3, - "operationName": "Microsoft.ServiceHealth/maintenance/action", - "operationId": "<GUID>", - "properties": { - "title": "Azure Synapse Analytics Scheduled Maintenance Pending", - "service": "Azure Synapse Analytics", - "region": "East US", - "communication": "<MESSAGE>", - "incidentType": "Maintenance", - "trackingId": "<GUID>", - "impactStartTime": "2019-06-26T04:00:00Z", - "impactMitigationTime": "2019-06-26T12:00:00Z", - "impactedServices": "[{\"ImpactedRegions\":[{\"RegionName\":\"East US\"}],\"ServiceName\":\"Azure Synapse Analytics\"}]", - "impactedServicesTableRows": "<tr>\r\n<td align='center' style='padding: 5px 10px; border-right:1px solid black; border-bottom:1px solid black'>Azure Synapse Analytics</td>\r\n<td align='center' style='padding: 5px 10px; border-bottom:1px solid black'>East US<br></td>\r\n</tr>\r\n", - "defaultLanguageTitle": "Azure Synapse Analytics Scheduled Maintenance Pending", - "defaultLanguageContent": "<MESSAGE>", - "stage": "Planned", - "communicationId": "<GUID>", - "maintenanceId": "<GUID>", - "isHIR": "false", - "version": "0.1.1" - }, - "status": "Active", - "subStatus": null, - "submissionTimestamp": "2019-06-24T11:31:31.7147357+00:00", - "ResourceType": null - } -} -``` --### Activity log alert with monitoringService = `ResourceHealth` --```json -{ - "alertContext": { - "channels": "Admin, Operation", - "correlationId": "<GUID>", - "eventSource": "ResourceHealth", - "eventTimestamp": "2019-06-24T15:42:54.074+00:00", - "eventDataId": "<GUID>", - "level": "Informational", - "operationName": "Microsoft.Resourcehealth/healthevent/Activated/action", - "operationId": "<GUID>", - "properties": { - "title": "This virtual machine is stopping and deallocating as requested by an authorized user or process", - "details": null, - "currentHealthStatus": "Unavailable", - "previousHealthStatus": "Available", - "type": "Downtime", - "cause": "UserInitiated" - }, - "status": "Active", - "submissionTimestamp": "2019-06-24T15:45:20.4488186+00:00" - } -} -``` --## Sample Prometheus alert --```json -{ - "alertContext": { - "interval": "PT1M", - "expression": "sql_up > 0", - "expressionValue": "0", - "for": "PT2M", - "labels": { - "Environment": "Prod", - "cluster": "myCluster1" - }, - "annotations": { - "summary": "alert on SQL availability" - }, - "ruleGroup": "/subscriptions/<subscription ID>/resourceGroups/myResourceGroup/providers/Microsoft.AlertsManagement/prometheusRuleGroups/myRuleGroup" - } -} -``` --## Sample payloads for test actions --### Sample test action alert -```json -{ - "schemaId": "azureMonitorCommonAlertSchema", - "data": { - "essentials": { - "alertId": "/subscriptions/<subscription ID>/providers/Microsoft.AlertsManagement/alerts/b9569717-bc32-442f-add5-83a997729330", - "alertRule": "WCUS-R2-Gen2", - "severity": "Sev3", - "signalType": "Metric", - "monitorCondition": "Resolved", - "monitoringService": "Platform", - "alertTargetIDs": [ - "/subscriptions/<subscription ID>/resourcegroups/pipelinealertrg/providers/microsoft.compute/virtualmachines/wcus-r2-gen2" - ], - "configurationItems": [ - "wcus-r2-gen2" - ], - "originAlertId": "3f2d4487-b0fc-4125-8bd5-7ad17384221e_PipeLineAlertRG_microsoft.insights_metricAlerts_WCUS-R2-Gen2_-117781227", - "firedDateTime": "2019-03-22T13:58:24.3713213Z", - "resolvedDateTime": "2019-03-22T14:03:16.2246313Z", - "description": "", - "essentialsVersion": "1.0", - "alertContextVersion": "1.0" - }, - "alertContext": { - "properties": null, - "conditionType": "SingleResourceMultipleMetricCriteria", - "condition": { - "windowSize": "PT5M", - "allOf": [ - { - "metricName": "Percentage CPU", - "metricNamespace": "Microsoft.Compute/virtualMachines", - "operator": "GreaterThan", - "threshold": "25", - "timeAggregation": "Average", - "dimensions": [ - { - "name": "ResourceId", - "value": "3efad9dc-3d50-4eac-9c87-8b3fd6f97e4e" - } - ], - "metricValue": 7.727 - } - ] - } - } - } -} -``` --### Sample test action metric alerts --#### Test action metric alert with a static threshold and the monitoringService = `Platform` --```json -{ - "schemaId":"azureMonitorCommonAlertSchema", - "data":{ - "essentials":{ - "alertId":"/subscriptions/11111111-1111-1111-1111-111111111111/providers/Microsoft.AlertsManagement/alerts/12345678-1234-1234-1234-1234567890ab", - "alertRule":"test-metricAlertRule", - "severity":"Sev3", - "signalType":"Metric", - "monitorCondition":"Fired", - "monitoringService":"Platform", - "alertTargetIDs":[ - "/subscriptions/11111111-1111-1111-1111-111111111111/resourcegroups/test-RG/providers/Microsoft.Storage/storageAccounts/test-storageAccount" - ], - "configurationItems":[ - "test-storageAccount" - ], - "originAlertId":"11111111-1111-1111-1111-111111111111_test-RG_microsoft.insights_metricAlerts_test-metricAlertRule_1234567890", - "firedDateTime":"2021-11-15T09:35:24.3468506Z", - "description":"Alert rule description", - "essentialsVersion":"1.0", - "alertContextVersion":"1.0" - }, - "alertContext":{ - "properties":{ - "customKey1":"value1", - "customKey2":"value2" - }, - "conditionType":"DynamicThresholdCriteria", - "condition":{ - "windowSize":"PT15M", - "allOf":[ - { - "alertSensitivity":"Low", - "failingPeriods":{ - "numberOfEvaluationPeriods":3, - "minFailingPeriodsToAlert":3 - }, - "ignoreDataBefore":null, - "metricName":"Transactions", - "metricNamespace":"Microsoft.Storage/storageAccounts", - "operator":"GreaterThan", - "threshold":"0.3", - "timeAggregation":"Average", - "dimensions":[ - - ], - "metricValue":78.09, - "webTestName":null - } - ], - "windowStartTime":"2021-12-15T01:04:11.719Z", - "windowEndTime":"2021-12-15T01:19:11.719Z" - } - }, - "customProperties":{ - "customKey1":"value1", - "customKey2":"value2" - } - } -} -``` --#### Test action metric alert with dynamic threshold and monitoringService = `Platform` ---```json -{ - "schemaId":"azureMonitorCommonAlertSchema", - "data":{ - "essentials":{ - "alertId":"/subscriptions/11111111-1111-1111-1111-111111111111/providers/Microsoft.AlertsManagement/alerts/12345678-1234-1234-1234-1234567890ab", - "alertRule":"test-metricAlertRule", - "severity":"Sev3", - "signalType":"Metric", - "monitorCondition":"Fired", - "monitoringService":"Platform", - "alertTargetIDs":[ - "/subscriptions/11111111-1111-1111-1111-111111111111/resourcegroups/test-RG/providers/Microsoft.Storage/storageAccounts/test-storageAccount" - ], - "configurationItems":[ - "test-storageAccount" - ], - "originAlertId":"11111111-1111-1111-1111-111111111111_test-RG_microsoft.insights_metricAlerts_test-metricAlertRule_1234567890", - "firedDateTime":"2021-11-15T09:35:24.3468506Z", - "description":"Alert rule description", - "essentialsVersion":"1.0", - "alertContextVersion":"1.0" - }, - "alertContext":{ - "properties":{ - "customKey1":"value1", - "customKey2":"value2" - }, - "conditionType":"DynamicThresholdCriteria", - "condition":{ - "windowSize":"PT15M", - "allOf":[ - { - "alertSensitivity":"Low", - "failingPeriods":{ - "numberOfEvaluationPeriods":3, - "minFailingPeriodsToAlert":3 - }, - "ignoreDataBefore":null, - "metricName":"Transactions", - "metricNamespace":"Microsoft.Storage/storageAccounts", - "operator":"GreaterThan", - "threshold":"0.3", - "timeAggregation":"Average", - "dimensions":[ - - ], - "metricValue":78.09, - "webTestName":null - } - ], - "windowStartTime":"2021-12-15T01:04:11.719Z", - "windowEndTime":"2021-12-15T01:19:11.719Z" - } - }, - "customProperties":{ - "customKey1":"value1", - "customKey2":"value2" - } - } -} -``` --### Sample test action log search alerts --#### Test action log search alert V1 ΓÇô Metric --```json -{ - "schemaId":"azureMonitorCommonAlertSchema", - "data":{ - "essentials":{ - "alertId":"/subscriptions/11111111-1111-1111-1111-111111111111/providers/Microsoft.AlertsManagement/alerts/12345678-1234-1234-1234-1234567890ab", - "alertRule":"test-logAlertRule-v1-metricMeasurement", - "severity":"Sev3", - "signalType":"Log", - "monitorCondition":"Fired", - "monitoringService":"Log Analytics", - "alertTargetIDs":[ - "/subscriptions/11111111-1111-1111-1111-111111111111/resourcegroups/test-RG/providers/microsoft.operationalinsights/workspaces/test-logAnalyticsWorkspace" - ], - "configurationItems":[ - - ], - "originAlertId":"12345678-4444-4444-4444-1234567890ab", - "firedDateTime":"2021-11-16T15:17:21.9232467Z", - "description":"Alert rule description", - "essentialsVersion":"1.0", - "alertContextVersion":"1.1" - }, - "alertContext":{ - "SearchQuery":"Heartbeat | summarize AggregatedValue=count() by bin(TimeGenerated, 5m)", - "SearchIntervalStartTimeUtc":"2021-11-15T15:16:49Z", - "SearchIntervalEndtimeUtc":"2021-11-16T15:16:49Z", - "ResultCount":2, - "LinkToSearchResults":"https://portal.azure.com#@aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa/blade/Microsoft_Azure_Monitoring_Logs/LogsBlade/source/Alerts.EmailLinks/scope/%7B%22resources%22%3A%5B%7B%22resourceId%22%3A%22%2Fsubscriptions%2F11111111-1111-1111-1111-111111111111%2FresourceGroups%2Ftest-RG%2Fproviders%2FMicrosoft.OperationalInsights%2Fworkspaces%2Ftest-logAnalyticsWorkspace%22%7D%5D%7D/q/aBcDeFgHi%2BWqUSguzc1NLMqsSlVwTE8vSk1PLElNCUvMKU21Tc4vzSvRaBcDeFgHiaBcDeFgHiaBcDeFgHiaBcDeFgHi/prettify/1/timespan/2021-11-15T15%3a16%3a49.0000000Z%2f2021-11-16T15%3a16%3a49.0000000Z", - "LinkToFilteredSearchResultsUI":"https://portal.azure.com#@aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa/blade/Microsoft_Azure_Monitoring_Logs/LogsBlade/source/Alerts.EmailLinks/scope/%7B%22resources%22%3A%5B%7B%22resourceId%22%3A%22%2Fsubscriptions%2F11111111-1111-1111-1111-111111111111%2FresourceGroups%2Ftest-RG%2Fproviders%2FMicrosoft.OperationalInsights%2Fworkspaces%2Ftest-logAnalyticsWorkspace%22%7D%5D%7D/q/aBcDeFgHiaBcDeFgHiaBcDeFgHiaBcDeFgHiaBcDeFgHidp%2BOPOhDKsHR%2FFeJXsTgzGJRmVui3KF3RpLyEJCX9A2iMl6jgxMn6jRevng3JmIHLdYtKP4DRI9mhc%3D/prettify/1/timespan/2021-11-15T15%3a16%3a49.0000000Z%2f2021-11-16T15%3a16%3a49.0000000Z", - "LinkToSearchResultsAPI":"https://api.loganalytics.io/v1/workspaces/bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb/query?query=Heartbeat%20%0A%7C%20summarize%20AggregatedValue%3Dcount%28%29%20by%20bin%28TimeGenerated%2C%205m%29×pan=2021-11-15T15%3a16%3a49.0000000Z%2f2021-11-16T15%3a16%3a49.0000000Z", - "LinkToFilteredSearchResultsAPI":"https://api.loganalytics.io/v1/workspaces/bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb/query?query=Heartbeat%20%0A%7C%20summarize%20AggregatedValue%3Dcount%28%29%20by%20bin%28TimeGenerated%2C%205m%29%7C%20where%20todouble%28AggregatedValue%29%20%3E%200×pan=2021-11-15T15%3a16%3a49.0000000Z%2f2021-11-16T15%3a16%3a49.0000000Z", - "SeverityDescription":"Informational", - "WorkspaceId":"bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb", - "SearchIntervalDurationMin":"1440", - "AffectedConfigurationItems":[ - - ], - "AlertType":"Metric measurement", - "IncludeSearchResults":true, - "Dimensions":[ - - ], - "SearchIntervalInMinutes":"1440", - "SearchResults":{ - "tables":[ - { - "name":"PrimaryResult", - "columns":[ - { - "name":"TimeGenerated", - "type":"datetime" - }, - { - "name":"AggregatedValue", - "type":"long" - } - ], - "rows":[ - [ - "2021-11-16T10:56:49Z", - 11 - ], - [ - "2021-11-16T11:56:49Z", - 11 - ] - ] - } - ], - "dataSources":[ - { - "resourceId":"/subscriptions/11111111-1111-1111-1111-111111111111/resourcegroups/test-RG/providers/microsoft.operationalinsights/workspaces/test-logAnalyticsWorkspace", - "region":"eastus", - "tables":[ - "Heartbeat" - ] - } - ] - }, - "Threshold":0, - "Operator":"Greater Than", - "IncludedSearchResults":"True" - } - } -} -``` --#### Test action log search alert V1 - Numresults --```json -{ - "schemaId":"azureMonitorCommonAlertSchema", - "data":{ - "essentials":{ - "alertId":"/subscriptions/11111111-1111-1111-1111-111111111111/providers/Microsoft.AlertsManagement/alerts/12345678-1234-1234-1234-1234567890ab", - "alertRule":"test-logAlertRule-v1-numResults", - "severity":"Sev3", - "signalType":"Log", - "monitorCondition":"Fired", - "monitoringService":"Log Analytics", - "alertTargetIDs":[ - "/subscriptions/11111111-1111-1111-1111-111111111111/resourcegroups/test-RG/providers/microsoft.operationalinsights/workspaces/test-logAnalyticsWorkspace" - ], - "configurationItems":[ - "test-computer" - ], - "originAlertId":"22222222-2222-2222-2222-222222222222", - "firedDateTime":"2021-11-16T15:15:58.3302205Z", - "description":"Alert rule description", - "essentialsVersion":"1.0", - "alertContextVersion":"1.1" - }, - "alertContext":{ - "SearchQuery":"Heartbeat", - "SearchIntervalStartTimeUtc":"2021-11-15T15:15:24Z", - "SearchIntervalEndtimeUtc":"2021-11-16T15:15:24Z", - "ResultCount":1, - "LinkToSearchResults":"https://portal.azure.com#@aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa/blade/Microsoft_Azure_Monitoring_Logs/LogsBlade/source/Alerts.EmailLinks/scope/%7B%22resources%22%3A%5B%7B%22resourceId%22%3A%22%2Fsubscriptions%2F11111111-1111-1111-1111-111111111111%2FresourceGroups%2Ftest-RG%2Fproviders%2FMicrosoft.OperationalInsights%2Fworkspaces%2Ftest-logAnalyticsWorkspace%22%7D%5D%7D/q/aBcDeFgHi%2ABCDE%3D%3D/prettify/1/timespan/2021-11-15T15%3a15%3a24.0000000Z%2f2021-11-16T15%3a15%3a24.0000000Z", - "LinkToFilteredSearchResultsUI":"https://portal.azure.com#@aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa/blade/Microsoft_Azure_Monitoring_Logs/LogsBlade/source/Alerts.EmailLinks/scope/%7B%22resources%22%3A%5B%7B%22resourceId%22%3A%22%2Fsubscriptions%2F11111111-1111-1111-1111-111111111111%2FresourceGroups%2Ftest-RG%2Fproviders%2FMicrosoft.OperationalInsights%2Fworkspaces%2Ftest-logAnalyticsWorkspace%22%7D%5D%7D/q/aBcDeFgHi%2ABCDE%3D%3D/prettify/1/timespan/2021-11-15T15%3a15%3a24.0000000Z%2f2021-11-16T15%3a15%3a24.0000000Z", - "LinkToSearchResultsAPI":"https://api.loganalytics.io/v1/workspaces/bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb/query?query=Heartbeat%0A×pan=2021-11-15T15%3a15%3a24.0000000Z%2f2021-11-16T15%3a15%3a24.0000000Z", - "LinkToFilteredSearchResultsAPI":"https://api.loganalytics.io/v1/workspaces/bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb/query?query=Heartbeat%0A×pan=2021-11-15T15%3a15%3a24.0000000Z%2f2021-11-16T15%3a15%3a24.0000000Z", - "SeverityDescription":"Informational", - "WorkspaceId":"bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb", - "SearchIntervalDurationMin":"1440", - "AffectedConfigurationItems":[ - "test-computer" - ], - "AlertType":"Number of results", - "IncludeSearchResults":true, - "SearchIntervalInMinutes":"1440", - "SearchResults":{ - "tables":[ - { - "name":"PrimaryResult", - "columns":[ - { - "name":"TenantId", - "type":"string" - }, - { - "name":"Computer", - "type":"string" - }, - { - "name":"TimeGenerated", - "type":"datetime" - } - ], - "rows":[ - [ - "bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb", - "test-computer", - "2021-11-16T12:00:00Z" - ] - ] - } - ], - "dataSources":[ - { - "resourceId":"/subscriptions/11111111-1111-1111-1111-111111111111/resourcegroups/test-RG/providers/microsoft.operationalinsights/workspaces/test-logAnalyticsWorkspace", - "region":"eastus", - "tables":[ - "Heartbeat" - ] - } - ] - }, - "Threshold":0, - "Operator":"Greater Than", - "IncludedSearchResults":"True" - } - } -} -``` --#### Test action log search alert V2 --> [!NOTE] -> Log search alerts rules from API version 2020-05-01 use this payload type, which only supports common schema. Search results aren't embedded in the log search alerts payload when you use this version. Use [dimensions](./alerts-types.md#monitor-the-same-condition-on-multiple-resources-using-splitting-by-dimensions-1) to provide context to fired alerts. --You can also use `LinkToFilteredSearchResultsAPI` or `LinkToSearchResultsAPI` to access query results with the [Log Analytics API](/rest/api/loganalytics/dataaccess/query/get). If you must embed the results, use a logic app with the provided links to generate a custom payload. --```json -{ - "schemaId":"azureMonitorCommonAlertSchema", - "data":{ - "essentials":{ - "alertId":"/subscriptions/11111111-1111-1111-1111-111111111111/providers/Microsoft.AlertsManagement/alerts/12345678-1234-1234-1234-1234567890ab", - "alertRule":"test-logAlertRule-v2", - "severity":"Sev3", - "signalType":"Log", - "monitorCondition":"Fired", - "monitoringService":"Log Alerts V2", - "alertTargetIDs":[ - "/subscriptions/11111111-1111-1111-1111-111111111111/resourcegroups/test-RG/providers/microsoft.operationalinsights/workspaces/test-logAnalyticsWorkspace" - ], - "configurationItems":[ - "test-computer" - ], - "originAlertId":"22222222-2222-2222-2222-222222222222", - "firedDateTime":"2021-11-16T11:47:41.4728231Z", - "description":"Alert rule description", - "essentialsVersion":"1.0", - "alertContextVersion":"1.0" - }, - "alertContext":{ - "properties":{ - "customKey1":"value1", - "customKey2":"value2" - }, - "conditionType":"LogQueryCriteria", - "condition":{ - "windowSize":"PT1H", - "allOf":[ - { - "searchQuery":"Heartbeat", - "metricMeasureColumn":null, - "targetResourceTypes":"['Microsoft.OperationalInsights/workspaces']", - "operator":"GreaterThan", - "threshold":"0", - "timeAggregation":"Count", - "dimensions":[ - { - "name":"Computer", - "value":"test-computer" - } - ], - "metricValue":3.0, - "failingPeriods":{ - "numberOfEvaluationPeriods":1, - "minFailingPeriodsToAlert":1 - }, - "linkToSearchResultsUI":"https://portal.azure.com#@aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa/blade/Microsoft_Azure_Monitoring_Logs/LogsBlade/source/Alerts.EmailLinks/scope/%7B%22resources%22%3A%5B%7B%22resourceId%22%3A%22%2Fsubscriptions%2F11111111-1111-1111-1111-111111111111%2FresourceGroups%2Ftest-RG%2Fproviders%2FMicrosoft.OperationalInsights%2Fworkspaces%2Ftest-logAnalyticsWorkspace%22%7D%5D%7D/q/aBcDeFgHiJkLmNaBcDeFgHiJkLmNaBcDeFgHiJkLmNaBcDeFgHiJkLmN1234567890ZAZBZiaGBlaG5lbKlnAAFRmnp6WNUZoqvTBAA%3D/prettify/1/timespan/2021-11-16T10%3a17%3a39.0000000Z%2f2021-11-16T11%3a17%3a39.0000000Z", - "linkToFilteredSearchResultsUI":"https://portal.azure.com#@aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa/blade/Microsoft_Azure_Monitoring_Logs/LogsBlade/source/Alerts.EmailLinks/scope/%7B%22resources%22%3A%5B%7B%22resourceId%22%3A%22%2Fsubscriptions%2F11111111-1111-1111-1111-111111111111%2FresourceGroups%2Ftest-RG%2Fproviders%2FMicrosoft.OperationalInsights%2Fworkspaces%2Ftest-logAnalyticsWorkspace%22%7D%5D%7D/q/aBcDeFgHiJkLmN%2Fl35oOTZoKioEOouaBcDeFgHiJkLmN%2BaBcDeFgHiJkLmN%2BaBcDeFgHiJkLmN7HHgOCZTR0Ak%2FaBcDeFgHiJkLmN1234567890Ltcw%2FOqZS%2FuX0L5d%2Bx3iMHNzQiu3Y%2BzsjpFSWlOzgA87vAxeHW2MoAtQxe6OUvVrZR3XYZPXrd%2FIE/prettify/1/timespan/2021-11-16T10%3a17%3a39.0000000Z%2f2021-11-16T11%3a17%3a39.0000000Z", - "linkToSearchResultsAPI":"https://api.loganalytics.io/v1/workspaces/bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb/query?query=Heartbeat%7C%20where%20TimeGenerated%20between%28datetime%282021-11-16T10%3A17%3A39.0000000Z%29..datetime%282021-11-16T11%3A17%3A39.0000000Z%29%29×pan=2021-11-16T10%3a17%3a39.0000000Z%2f2021-11-16T11%3a17%3a39.0000000Z", - "linkToFilteredSearchResultsAPI":"https://api.loganalytics.io/v1/workspaces/bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb/query?query=Heartbeat%7C%20where%20TimeGenerated%20between%28datetime%282021-11-16T10%3A17%3A39.0000000Z%29..datetime%282021-11-16T11%3A17%3A39.0000000Z%29%29%7C%20where%20tostring%28Computer%29%20%3D%3D%20%27test-computer%27×pan=2021-11-16T10%3a17%3a39.0000000Z%2f2021-11-16T11%3a17%3a39.0000000Z" - } - ], - "windowStartTime":"2021-11-16T10:17:39Z", - "windowEndTime":"2021-11-16T11:17:39Z" - } - } - } -} -``` --### Sample test action activity log alerts --#### Test action activity log alert with MonitoringService = `Administrative` --```json -{ - "schemaId":"azureMonitorCommonAlertSchema", - "data":{ - "essentials":{ - "alertId":"/subscriptions/11111111-1111-1111-1111-111111111111/providers/Microsoft.AlertsManagement/alerts/12345678-1234-1234-1234-1234567890ab", - "alertRule":"test-activityLogAlertRule", - "severity":"Sev4", - "signalType":"Activity Log", - "monitorCondition":"Fired", - "monitoringService":"Activity Log - Administrative", - "alertTargetIDs":[ - "/subscriptions/11111111-1111-1111-1111-111111111111/resourcegroups/test-RG/providers/microsoft.compute/virtualmachines/test-VM" - ], - "configurationItems":[ - "test-VM" - ], - "originAlertId":"bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb_123456789012345678901234567890ab", - "firedDateTime":"2021-11-16T08:29:01.2932462Z", - "description":"Alert rule description", - "essentialsVersion":"1.0", - "alertContextVersion":"1.0" - }, - "alertContext":{ - "authorization":{ - "action":"Microsoft.Compute/virtualMachines/restart/action", - "scope":"/subscriptions/11111111-1111-1111-1111-111111111111/resourceGroups/test-RG/providers/Microsoft.Compute/virtualMachines/test-VM" - }, - "channels":"Operation", - "claims":"{}", - "caller":"user-email@domain.com", - "correlationId":"aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa", - "eventSource":"Administrative", - "eventTimestamp":"2021-11-16T08:27:36.1836909+00:00", - "eventDataId":"bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb", - "level":"Informational", - "operationName":"Microsoft.Compute/virtualMachines/restart/action", - "operationId":"cccccccc-cccc-cccc-cccc-cccccccccccc", - "properties":{ - "eventCategory":"Administrative", - "entity":"/subscriptions/11111111-1111-1111-1111-111111111111/resourceGroups/test-RG/providers/Microsoft.Compute/virtualMachines/test-VM", - "message":"Microsoft.Compute/virtualMachines/restart/action", - "hierarchy":"22222222-2222-2222-2222-222222222222/CnAIOrchestrationServicePublicCorpprod/33333333-3333-3333-3333-3333333333333/44444444-4444-4444-4444-444444444444/55555555-5555-5555-5555-555555555555/11111111-1111-1111-1111-111111111111" - }, - "status":"Succeeded", - "subStatus":"", - "submissionTimestamp":"2021-11-16T08:29:00.141807+00:00", - "Activity Log Event Description":"" - } - } -} -``` --#### Test action activity log alert with MonitoringService = `ServiceHealth` --```json -{ - "schemaId":"azureMonitorCommonAlertSchema", - "data":{ - "essentials":{ - "alertId":"/subscriptions/11111111-1111-1111-1111-111111111111/providers/Microsoft.AlertsManagement/alerts/1234abcd5678efgh1234abcd5678efgh1234abcd5678efgh1234abcd5678efgh", - "alertRule":"test-ServiceHealthAlertRule", - "severity":"Sev4", - "signalType":"Activity Log", - "monitorCondition":"Fired", - "monitoringService":"ServiceHealth", - "alertTargetIDs":[ - "/subscriptions/11111111-1111-1111-1111-111111111111" - ], - "originAlertId":"12345678-1234-1234-1234-1234567890ab", - "firedDateTime":"2021-11-17T05:34:48.0623172Z", - "description":"Alert rule description", - "essentialsVersion":"1.0", - "alertContextVersion":"1.0" - }, - "alertContext":{ - "authorization":null, - "channels":1, - "claims":null, - "caller":null, - "correlationId":"12345678-abcd-efgh-ijkl-abcd12345678", - "eventSource":2, - "eventTimestamp":"2021-11-17T05:34:44.5778226+00:00", - "httpRequest":null, - "eventDataId":"12345678-1234-1234-1234-1234567890ab", - "level":3, - "operationName":"Microsoft.ServiceHealth/incident/action", - "operationId":"12345678-abcd-efgh-ijkl-abcd12345678", - "properties":{ - "title":"Test Action Group - Test Service Health Alert", - "service":"Azure Service Name", - "region":"Global", - "communication":"<p><strong>Summary of impact</strong>: This is the impact summary.</p>\n<p><br></p>\n<p><strong>Preliminary Root Cause</strong>: This is the preliminary root cause.</p>\n<p><br></p>\n<p><strong>Mitigation</strong>: Mitigation description.</p>\n<p><br></p>\n<p><strong>Next steps</strong>: These are the next steps. </p>\n<p><br></p>\n<p>Stay informed about Azure service issues by creating custom service health alerts: <a href=\"https://aka.ms/ash-videos\" rel=\"noopener noreferrer\" target=\"_blank\">https://aka.ms/ash-videos</a> for video tutorials and <a href=\"https://aka.ms/ash-alerts%20for%20how-to%20documentation\" rel=\"noopener noreferrer\" target=\"_blank\">https://aka.ms/ash-alerts for how-to documentation</a>.</p>\n<p><br></p>", - "incidentType":"Incident", - "trackingId":"ABC1-DEF", - "impactStartTime":"2021-11-16T20:00:00Z", - "impactMitigationTime":"2021-11-17T01:00:00Z", - "impactedServices":"[{\"ImpactedRegions\":[{\"RegionName\":\"Global\"}],\"ServiceName\":\"Azure Service Name\"}]", - "impactedServicesTableRows":"<tr>\r\n<td align='center' style='padding: 5px 10px; border-right:1px solid black; border-bottom:1px solid black'>Azure Service Name</td>\r\n<td align='center' style='padding: 5px 10px; border-bottom:1px solid black'>Global<br></td>\r\n</tr>\r\n", - "defaultLanguageTitle":"Test Action Group - Test Service Health Alert", - "defaultLanguageContent":"<p><strong>Summary of impact</strong>: This is the impact summary.</p>\n<p><br></p>\n<p><strong>Preliminary Root Cause</strong>: This is the preliminary root cause.</p>\n<p><br></p>\n<p><strong>Mitigation</strong>: Mitigation description.</p>\n<p><br></p>\n<p><strong>Next steps</strong>: These are the next steps. </p>\n<p><br></p>\n<p>Stay informed about Azure service issues by creating custom service health alerts: <a href=\"https://aka.ms/ash-videos\" rel=\"noopener noreferrer\" target=\"_blank\">https://aka.ms/ash-videos</a> for video tutorials and <a href=\"https://aka.ms/ash-alerts%20for%20how-to%20documentation\" rel=\"noopener noreferrer\" target=\"_blank\">https://aka.ms/ash-alerts for how-to documentation</a>.</p>\n<p><br></p>", - "stage":"Resolved", - "communicationId":"11223344556677", - "isHIR":"false", - "IsSynthetic":"True", - "impactType":"SubscriptionList", - "version":"0.1.1" - }, - "status":"Resolved", - "subStatus":null, - "submissionTimestamp":"2021-11-17T01:23:45.0623172+00:00", - "ResourceType":null - } - } -} -``` --#### Test action activity log alert with MonitoringService = `Resource Health` --```json -{ - "schemaId":"azureMonitorCommonAlertSchema", - "data":{ - "essentials":{ - "alertId":"/subscriptions/11111111-1111-1111-1111-111111111111/providers/Microsoft.AlertsManagement/alerts/12345678-1234-1234-1234-1234567890ab", - "alertRule":"test-ResourceHealthAlertRule", - "severity":"Sev4", - "signalType":"Activity Log", - "monitorCondition":"Fired", - "monitoringService":"Resource Health", - "alertTargetIDs":[ - "/subscriptions/11111111-1111-1111-1111-111111111111/resourcegroups/test-RG/providers/microsoft.compute/virtualmachines/test-VM" - ], - "configurationItems":[ - "test-VM" - ], - "originAlertId":"bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb_123456789012345678901234567890ab", - "firedDateTime":"2021-11-16T09:54:08.9938123Z", - "description":"Alert rule description", - "essentialsVersion":"1.0", - "alertContextVersion":"1.0" - }, - "alertContext":{ - "channels":"Admin, Operation", - "correlationId":"aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa", - "eventSource":"ResourceHealth", - "eventTimestamp":"2021-11-16T09:50:20.406+00:00", - "eventDataId":"bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb", - "level":"Informational", - "operationName":"Microsoft.Resourcehealth/healthevent/Activated/action", - "operationId":"bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb", - "properties":{ - "title":"Rebooted by user", - "details":null, - "currentHealthStatus":"Unavailable", - "previousHealthStatus":"Available", - "type":"Downtime", - "cause":"UserInitiated" - }, - "status":"Active", - "submissionTimestamp":"2021-11-16T09:54:08.5303319+00:00", - "Activity Log Event Description":null - } - } -} -``` --#### Test action activity log alert with MonitoringService = `Budget` --```json -{ - "schemaId":"AIP Budget Notification", - "data":{ - "SubscriptionName":"test-subscription", - "SubscriptionId":"11111111-1111-1111-1111-111111111111", - "EnrollmentNumber":"", - "DepartmentName":"test-budgetDepartmentName", - "AccountName":"test-budgetAccountName", - "BillingAccountId":"", - "BillingProfileId":"", - "InvoiceSectionId":"", - "ResourceGroup":"test-RG", - "SpendingAmount":"1111.32", - "BudgetStartDate":"11/17/2021 5:40:29 PM -08:00", - "Budget":"10000", - "Unit":"USD", - "BudgetCreator":"email@domain.com", - "BudgetName":"test-budgetName", - "BudgetType":"Cost", - "NotificationThresholdAmount":"8000.0" - } -} -``` --#### Test action activity log alert with MonitoringService = `Actual Cost Budget` --```json -{ - "schemaId": "azureMonitorCommonAlertSchema", - "data": { - "essentials": { - "monitoringService": "CostAlerts", - "firedDateTime": "2022-12-07T21:13:20.645Z", - "description": "Your spend for budget Test_actual_cost_budget is now $11,111.00 exceeding your specified threshold $25.00.", - "essentialsVersion": "1.0", - "alertContextVersion": "1.0", - "alertId": "/subscriptions/11111111-1111-1111-1111-111111111111/providers/Microsoft.CostManagement/alerts/Test_Alert", - "alertRule": null, - "severity": null, - "signalType": null, - "monitorCondition": null, - "alertTargetIDs": null, - "configurationItems": [ - "budgets" - ], - "originAlertId": null - }, - "alertContext": { - "AlertCategory": "budgets", - "AlertData": { - "Scope": "/subscriptions/11111111-1111-1111-1111-111111111111/", - "ThresholdType": "Actual", - "BudgetType": "Cost", - "BudgetThreshold": "$50.00", - "NotificationThresholdAmount": "$25.00", - "BudgetName": "Test_actual_cost_budget", - "BudgetId": "/subscriptions/11111111-1111-1111-1111-111111111111/providers/Microsoft.Consumption/budgets/Test_actual_cost_budget", - "BudgetStartDate": "2022-11-01", - "BudgetCreator": "test@sample.test", - "Unit": "USD", - "SpentAmount": "$11,111.00" - } - } - } -} -``` -#### Test action activity log alerts with MonitoringService = `Forecasted Budget` --```json -{ - "schemaId": "azureMonitorCommonAlertSchema", - "data": { - "essentials": { - "monitoringService": "CostAlerts", - "firedDateTime": "2022-12-07T21:13:29.576Z", - "description": "The total spend for your budget, Test_forcasted_budget, is forecasted to reach $1111.11 before the end of the period. This amount exceeds your specified budget threshold of $50.00.", - "essentialsVersion": "1.0", - "alertContextVersion": "1.0", - "alertId": "/subscriptions/11111111-1111-1111-1111-111111111111/providers/Microsoft.CostManagement/alerts/Test_Alert", - "alertRule": null, - "severity": null, - "signalType": null, - "monitorCondition": null, - "alertTargetIDs": null, - "configurationItems": [ - "budgets" - ], - "originAlertId": null - }, - "alertContext": { - "AlertCategory": "budgets", - "AlertData": { - "Scope": "/subscriptions/11111111-1111-1111-1111-111111111111/", - "ThresholdType": "Forecasted", - "BudgetType": "Cost", - "BudgetThreshold": "$50.00", - "NotificationThresholdAmount": "$50.00", - "BudgetName": "Test_forcasted_budget", - "BudgetId": "/subscriptions/11111111-1111-1111-1111-111111111111/providers/Microsoft.Consumption/budgets/Test_forcasted_budget", - "BudgetStartDate": "2022-11-01", - "BudgetCreator": "test@sample.test", - "Unit": "USD", - "SpentAmount": "$999.99", - "ForecastedTotalForPeriod": "$1111.11" - } - } - } -} -``` --#### Test action activity log alerts with MonitoringService = `Smart Alert` --```json -{ - "schemaId":"azureMonitorCommonAlertSchema", - "data":{ - "essentials":{ - "alertId":"/subscriptions/11111111-1111-1111-1111-111111111111/providers/Microsoft.AlertsManagement/alerts/12345678-1234-1234-1234-1234567890ab", - "alertRule":"Dependency Latency Degradation - test-applicationInsights", - "severity":"Sev3", - "signalType":"Log", - "monitorCondition":"Fired", - "monitoringService":"SmartDetector", - "alertTargetIDs":[ - "/subscriptions/11111111-1111-1111-1111-111111111111/resourcegroups/test-RG/providers/microsoft.insights/components/test-applicationInsights" - ], - "configurationItems":[ - "test-applicationInsights" - ], - "originAlertId":"1234abcd5678efgh1234abcd5678efgh1234abcd5678efgh1234abcd5678efgh", - "firedDateTime":"2021-10-28T19:09:09.1115084Z", - "description":"Dependency Latency Degradation notifies you of an unusual increase in response by a dependency your app is calling (e.g. REST API or database)", - "essentialsVersion":"1.0", - "alertContextVersion":"1.0" - }, - "alertContext":{ - "DetectionSummary":"A degradation in the dependency duration over the last 24 hours", - "FormattedOccurrenceTime":"2021-10-27T23:59:59Z", - "DetectedValue":"0.45 sec", - "NormalValue":"0.27 sec (over the last 7 days)", - "PresentationInsightEventRequest":"/subscriptions/11111111-1111-1111-1111-111111111111/resourceGroups/test-RG/providers/microsoft.insights/components/test-applicationInsights/query?query=systemEvents%0d%0a++++++++++++++++%7c+where+timestamp+%3e%3d+datetime(%272021-10-27T23%3a29%3a59.0000000Z%27)+%0d%0a++++++++++++++++%7c+where+itemType+%3d%3d+%27systemEvent%27+and+name+%3d%3d+%27ProactiveDetectionInsight%27+%0d%0a++++++++++++++++%7c+where+dimensions.InsightType+%3d%3d+3+%0d%0a++++++++++++++++%7c+where+dimensions.InsightVersion+%3d%3d+%27SmartAlert%27%0d%0a++++++++++++++++%7c+where+dimensions.InsightDocumentId+%3d%3d+%2712345678-abcd-1234-5678-abcd12345678%27+%0d%0a++++++++++++++++%7c+project+dimensions.InsightPropertiesTable%2cdimensions.InsightDegradationChart%2cdimensions.InsightCountChart%2cdimensions.InsightLinksTable%0d%0a++++++++++++++++&api-version=2018-04-20", - "SmartDetectorId":"DependencyPerformanceDegradationDetector", - "SmartDetectorName":"Dependency Performance Degradation Detector", - "AnalysisTimestamp":"2021-10-28T19:09:09.1115084Z" - } - } -} -``` --## Next steps --- [Learn how to create a logic app that uses the common alert schema to handle all your alerts](./alerts-common-schema-integrations.md) |
| azure-monitor | Alerts Plan | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-plan.md | - Title: Plan alerts and automated actions -description: Recommendations for deployment of Azure Monitor alerts and automated actions. --- Previously updated : 02/15/2024----# Plan alerts and automated actions --Alerts proactively notify you of important data or patterns identified in your monitoring data. You can create alerts that: --- Send a proactive notification.-- Initiate an automated action to attempt to remediate an issue.---Alert rules are defined by the type of data they use. Each has different capabilities and a different cost. The basic strategy is to use the alert rule type with the lowest cost that provides the logic you require. See [Choosing the right type of alert rule](alerts-types.md). --For more information about alerts, see [alerts overview](alerts-overview.md). --## Alerting strategy --Defining an alert strategy assists you in defining the configuration of alert rules including alert severity and action groups. --For factors to consider as you develop an alerting strategy, see [Successful alerting strategy](/azure/cloud-adoption-framework/manage/monitor/alerting#successful-alerting-strategy). --## Automated responses to alerts --Use [action groups](action-groups.md) to define automated responses to alerts. An action group is a collection of one or more notifications and actions triggered by the alert. A single action group can be used with multiple alert rules and contain one or more of the following items: --- **Notifications**: Messages that notify operators and administrators that an alert was created.-- **Actions**: Automated processes that attempt to correct the detected issue.---### Notifications --Notifications are messages sent to one or more users to notify them that an alert has been created. Because a single action group can be used with multiple alert rules, you should design a set of action groups for different sets of administrators and users who will receive the same sets of alerts. Use any of the following types of notifications depending on the preferences of your operators and your organizational standards: --- Email-- SMS-- Push to Azure app-- Voice-- Email Azure Resource Manager role--### Actions --Actions are automated responses to an alert. You can use the available actions for any scenario that they support, but the following sections describe how each action is typically used. --### Automated remediation --Use the following actions for automated remediation of the issue identified by the alert: --- **Automation runbook**: Start a built-in runbook or a custom runbook in Azure Automation. For example, built-in runbooks are available to perform such functions as restarting or scaling up a virtual machine.-- **Azure Functions**: Start an Azure function.--### ITSM and on-call management --- **IT service management (ITSM)**: Use the ITSM Connector to create work items in your ITSM tool based on alerts from Azure Monitor. You first configure the connector and then use the **ITSM** action in alert rules.-- **Webhooks**: Send the alert to an incident management system that supports webhooks such as PagerDuty and Splunk On-Call.-- **Secure webhook**: Integrate ITSM with Microsoft Entra authentication.--## Alerting at scale --As part of your alerting strategy, you'll want to alert on issues for all your critical Azure applications and resources. See [Alerting at-scale](alerts-overview.md#alerting-at-scale) for guidance. --## Minimize alert activity --You want to create alerts for any important information in your environment. But you don't want to create excessive alerts and notifications for issues that don't warrant them. To minimize your alert activity to ensure that critical issues are surfaced while you don't generate excess information and notifications for administrators, follow these guidelines: --- See [Successful alerting strategy](/azure/cloud-adoption-framework/manage/monitor/alerting#successful-alerting-strategy) to determine whether a symptom is an appropriate candidate for alerting.-- Use the **Automatically resolve alerts** option in [metric alert rules](alerts-create-metric-alert-rule.yml) to resolve alerts when the condition has been corrected.-- Use the **Suppress alerts** option in [log search query alert rules](alerts-create-log-alert-rule.md) to avoid creating multiple alerts for the same issue.-- Ensure that you use appropriate severity levels for alert rules so that high-priority issues are analyzed.-- Limit notifications for alerts with a severity of Warning or less because they don't require immediate attention.--## Next steps --[Optimize cost in Azure Monitor](../best-practices-cost.md). |
| azure-monitor | Alerts Processing Rules | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-processing-rules.md | - Title: Alert processing rules for Azure Monitor alerts -description: Understand Azure Monitor alert processing rules and how to configure and manage them. --- Previously updated : 7/30/2024----# Alert processing rules --<a name="configuring-an-action-rule"></a> -<a name="suppression-of-alerts"></a> --> [!NOTE] -> Alert processing rules were previously known as 'action rules'. For backward compatibility, the Azure resource type of these rules is still **Microsoft.AlertsManagement/actionRules** . --Alert processing rules allow you to apply processing on fired alerts. Alert processing rules are different from alert rules. Alert rules generate new alerts that notify you when something happens, while alert processing rules modify the fired alerts as they're being fired to change the usual alert behavior. --You can use alert processing rules to add [action groups](./action-groups.md) or remove (suppress) action groups from your fired alerts. You can apply alert processing rules to different resource scopes, from a single resource, or to an entire subscription, as long as they are within the same subscription as the alert processing rule. You can also use them to apply various filters or have the rule work on a predefined schedule. --Some common use cases for alert processing rules are described here. --## Suppress notifications during planned maintenance --Many customers set up a planned maintenance time for their resources, either on a one-time basis or on a regular schedule. The planned maintenance might cover a single resource, like a virtual machine, or multiple resources, like all virtual machines in a resource group. So, you might want to stop receiving alert notifications for those resources during the maintenance window. In other cases, you might prefer to not receive alert notifications outside of your business hours. Alert processing rules allow you to achieve that. --You could suppress alert notifications by disabling the alert rules themselves at the beginning of the maintenance window, and reenable them after the maintenance is over. In that case, the alerts won't fire in the first place. That approach has several limitations: -- * This approach is only practical if the scope of the alert rule is exactly the scope of the resources under maintenance. For example, a single alert rule might cover multiple resources, but only a few of those resources are going through maintenance. So, if you disable the alert rule, you won't be alerted when the remaining resources covered by that rule run into issues. - * You might have many alert rules that cover the resource. Updating all of them is time consuming and error prone. - * You might have some alerts that aren't created by an alert rule at all, like alerts from Azure Backup. --In all these cases, an alert processing rule provides an easy way to suppress notifications. --## Management at scale --Most customers tend to define a few action groups that are used repeatedly in their alert rules. For example, they might want to call a specific action group whenever any high-severity alert is fired. As their number of alert rules grows, manually making sure that each alert rule has the right set of action groups is becoming harder. --Alert processing rules allow you to specify that logic in a single rule, instead of having to set it consistently in all your alert rules. They also cover alert types that aren't generated by an alert rule. --## Add action groups to all alert types --Azure Monitor alert rules let you select which action groups will be triggered when their alerts are fired. However, not all Azure alert sources let you specify action groups. Some examples of such alerts include [Azure Backup alerts](../../backup/backup-azure-monitoring-built-in-monitor.md), [VM Insights guest health alerts](../vm/vminsights-health-alerts.md), [Azure Stack Edge](../../databox-online/azure-stack-edge-gpu-manage-device-event-alert-notifications.md), and Azure Stack Hub. --For those alert types, you can use alert processing rules to add action groups. --> [!NOTE] -> Alert processing rules don't affect [Azure Service Health](../../service-health/service-health-overview.md) alerts. --## Scope and filters for alert processing rules -<a name="filter-criteria"></a> --This section describes the scope and filters for alert processing rules. --Each alert processing rule has a scope. A scope is a list of one or more specific Azure resources, a specific resource group, or an entire subscription. The alert processing rule applies to alerts that fired on resources within that scope. You can't create an alert processing rule on a resource from a different subscription. --You can also define filters to narrow down which specific subset of alerts are affected within the scope. The available filters are described in the following table. --| Filter | Description| -|:|:| -Alert context (payload) | The rule applies only to alerts that contain any of the filter's strings within the [alert context](./alerts-common-schema.md) section of the alert. This section includes fields specific to each alert type. | -Alert rule ID | The rule applies only to alerts from a specific alert rule. The value should be the full resource ID, for example, `/subscriptions/SUB1/resourceGroups/RG1/providers/microsoft.insights/metricalerts/MY-API-LATENCY`. To locate the alert rule ID, open a specific alert rule in the portal, select **Properties**, and copy the **Resource ID** value. You can also locate it by listing your alert rules from PowerShell or the Azure CLI. | -Alert rule name | The rule applies only to alerts with this alert rule name. It can also be useful with a **Contains** operator. | -Description | The rule applies only to alerts that contain the specified string within the alert rule description field. | -Monitor condition | The rule applies only to alerts with the specified monitor condition, either **Fired** or **Resolved**. | -Monitor service | The rule applies only to alerts from any of the specified monitoring services that are sending the signal. Different services are available depending on the type of signal. For example: </br>**- Platform**: For metric signals, the monitor service is the metric namespace. ΓÇÿPlatformΓÇÖ means the metrics are provided by the resource provider, namely 'Azure'.</br>**- Azure.ApplicationInsights**: Customer-reported metrics, sent by the Application Insights SDK.</br>**- Azure.VM.Windows.GuestMetrics**: VM guest metrics, collected by an extension running on the VM. Can include built-in operating system perf counters, and custom perf counters.</br>**- _\<Custom namespace\>_**: A custom metric namespace, containing custom metrics sent with the Azure Monitor Metrics API.</br>**- Log Analytics**: The service that provides the ΓÇÿCustom log searchΓÇÖ and ΓÇÿLog (saved query)ΓÇÖ signals.</br>**- Activity Log ΓÇô Administrative**: The service that provides the ΓÇÿAdministrativeΓÇÖ activity log events.</br>**- Activity Log ΓÇô Policy**: The service that provides the 'Policy' activity log events.</br>**- Activity Log ΓÇô Autoscale** The service that provides the ΓÇÿAutoscaleΓÇÖ activity log events.</br>**- Activity Log ΓÇô Security**: The service that provides the ΓÇÿSecurityΓÇÖ activity log events.</br>**- Resource health**: The service that provides the resource-level health status.</br>**- Service health**: The service that provides the subscription-level health status.| -Resource | The rule applies only to alerts from the specified Azure resource. For example, you can use this filter with **Does not equal** to exclude one or more resources when the rule's scope is a subscription. | -Resource group | The rule applies only to alerts from the specified resource groups. For example, you can use this filter with **Does not equal** to exclude one or more resource groups when the rule's scope is a subscription. | -Resource type | The rule applies only to alerts on resources from the specified resource types, such as virtual machines. You can use **Equals** to match one or more specific resources. You can also use **Contains** to match a resource type and all its child resources. For example, use `resource type contains "MICROSOFT.SQL/SERVERS"` to match both SQL servers and all their child resources, like databases. -Severity | The rule applies only to alerts with the selected severities. | ---#### Alert processing rule filters --* If you define multiple filters in a rule, all the rules apply. There's a logical AND between all filters. - For example, if you set both `resource type = "Virtual Machines"` and `severity = "Sev0"`, then the rule applies only for `Sev0` alerts on virtual machines in the scope. -* Each filter can include up to five values. There's a logical OR between the values. - For example, if your set description contains "this, that" (in the field there's no need to write the apostrophes), then the rule applies only to alerts whose description contains either "this" or "that". -* Notice that you dont have any spaces (before, after or between) the string that is matched it effects the matching of the filter. --### What should this rule do? --Choose one of the following actions: --* **Suppression**: This action removes all the action groups from the affected fired alerts. So, the fired alerts won't invoke any of their action groups, not even at the end of the maintenance window. Those fired alerts will still be visible when you list your alerts in the portal, Azure Resource Graph, API, or PowerShell. The suppression action has a higher priority over the **Apply action groups** action. If a single fired alert is affected by different alert processing rules of both types, the action groups of that alert will be suppressed. -* **Apply action groups**: This action adds one or more action groups to the affected fired alerts. --### When should this rule apply? --You can control when the rule applies. The rule is always active, by default. You can select a one-time window for this rule to apply, or you can have a recurring window, such as a weekly recurrence. --## Configure an alert processing rule --### [Portal](#tab/portal) --You can access alert processing rules by going to the **Alerts** home page in Azure Monitor. Then you can select **Alert processing rules** to see and manage your existing rules. You can also select **Create** > **Alert processing rules** to open the new alert processing rule wizard. ---Let's review the new alert processing rule wizard. --1. On the **Scope** tab, you select which fired alerts are covered by this rule. Pick the **scope** of resources whose alerts will be covered. You can choose multiple resources and resource groups, or an entire subscription. You can also optionally add filters, as previously described. -- :::image type="content" source="media/alerts-processing-rules/alert-processing-rule-scope.png" alt-text="Screenshot that shows the Scope tab of the alert processing rules wizard."::: --1. On the **Rule settings** tab, you select which action to apply on the affected alerts. Choose between **Suppress notifications** or **Apply action group**. If you choose **Apply action group**, you can select existing action groups by selecting **Add action groups**. You can also create a new action group. -- :::image type="content" source="media/alerts-processing-rules/alert-processing-rule-settings.png" alt-text="Screenshot that shows the Rule settings tab of the alert processing rules wizard."::: --1. On the **Scheduling** tab, you select an optional schedule for the rule. By default, the rule works all the time, unless you disable it. You can set it to work **On a specific time**, or you can set up a **Recurring** schedule. - - Let's see an example of a schedule for a one-time, overnight, planned maintenance. It starts in the evening and continues until the next morning, in a specific time zone. -- :::image type="content" source="media/alerts-processing-rules/alert-processing-rule-scheduling-one-time.png" alt-text="Screenshot that shows the Scheduling tab of the alert processing rules wizard with a one-time rule."::: -- An example of a more complex schedule covers an "outside of business hours" case. It has a recurring schedule with two recurrences. One recurrence is daily from the afternoon until the morning. The other recurrence is weekly and covers full days for Saturday and Sunday. -- :::image type="content" source="media/alerts-processing-rules/alert-processing-rule-scheduling-recurring.png" alt-text="Screenshot that shows the Scheduling tab of the alert processing rules wizard with a recurring rule."::: --1. On the **Details** tab, you give this rule a name, pick where it is stored, and optionally add a description for your reference. --1. On the **Tags** tab, you can optionally add tags to the rule. --1. On the **Review + create** tab, you can review and create the alert processing rule. --### [Azure CLI](#tab/azure-cli) --You can use the Azure CLI to work with alert processing rules. For detailed documentation and examples, see the `az monitor alert-processing-rules` [page in the Azure CLI docs](/cli/azure/monitor/alert-processing-rule). --### Prepare your environment --1. Install the Azure CLI. -- Follow the [installation instructions for the Azure CLI](/cli/azure/install-azure-cli). -- Alternatively, you can use Azure Cloud Shell, which is an interactive shell environment that you use through your browser. To start: -- - Open [Azure Cloud Shell](https://shell.azure.com). - - Select the **Cloud Shell** button on the menu bar in the upper-right corner in the [Azure portal](https://portal.azure.com). --1. Sign in. -- If you're using a local installation of the CLI, sign in by using the `az login` [command](/cli/azure/reference-index#az-login). Follow the steps displayed in your terminal to complete the authentication process. -- ```azurecli - az login - ``` --1. Install the `alertsmanagement` extension. -- To use the `az monitor alert-processing-rule` commands, install the `alertsmanagement` preview extension. -- ```azurecli - az extension add --name alertsmanagement - ``` -- The following output is expected. -- ```output - The installed extension 'alertsmanagement' is in preview. - ``` - - To learn more about Azure CLI extensions, see [Use extensions with the Azure CLI](/cli/azure/azure-cli-extensions-overview?). --### Create an alert processing rule with the Azure CLI --Use the `az monitor alert-processing-rule create` command to create alert processing rules. -For example, to create a rule that adds an action group to all alerts in a subscription, run: --```azurecli -az monitor alert-processing-rule create \ - --name 'AddActionGroupToSubscription' \ - --rule-type AddActionGroups \ - --scopes "/subscriptions/SUB1" \ - --action-groups "/subscriptions/SUB1/resourcegroups/RG1/providers/microsoft.insights/actiongroups/AG1" \ - --resource-group RG1 \ - --description "Add action group AG1 to all alerts in the subscription" -``` --The [CLI documentation](/cli/azure/monitor/alert-processing-rule#az-monitor-alert-processing-rule-create) includes more examples and an explanation of each parameter. --### [PowerShell](#tab/powershell) --You can use PowerShell to work with alert processing rules. For detailed documentation and examples, see the `*-AzAlertProcessingRule` commands [in the PowerShell docs](/powershell/module/az.alertsmanagement). --### Create an alert processing rule using PowerShell --Use the `Set-AzAlertProcessingRule` command to create alert processing rules. For example, to create a rule that adds an action group to all alerts in a subscription, run: --```powershell -Set-AzAlertProcessingRule ` - -Name AddActionGroupToSubscription ` - -AlertProcessingRuleType AddActionGroups ` - -Scope /subscriptions/SUB1 ` - -ActionGroupId /subscriptions/SUB1/resourcegroups/RG1/providers/microsoft.insights/actiongroups/AG1 ` - -ResourceGroupName RG1 ` - -Description "Add action group AG1 to all alerts in the subscription" -``` --The [PowerShell documentation](/cli/azure/monitor/alert-processing-rule#az-monitor-alert-processing-rule-create) includes more examples and an explanation of each parameter. --* * * --## Manage alert processing rules --### [Portal](#tab/portal) --You can view and manage your alert processing rules from the list view: ---From here, you can enable, disable, or delete alert processing rules at scale by selecting the checkboxes next to them. Selecting an alert processing rule opens it for editing. You can enable or disable the rule on the **Details** tab. --### [Azure CLI](#tab/azure-cli) --You can view and manage your alert processing rules by using the [az monitor alert-processing-rules](/cli/azure/monitor/alert-processing-rule) commands from Azure CLI. --Before you manage alert processing rules with the Azure CLI, prepare your environment by using the instructions provided in [Configure an alert processing rule](#configure-an-alert-processing-rule). --```azurecli -# List all alert processing rules for a subscription -az monitor alert-processing-rules list --# Get details of an alert processing rule -az monitor alert-processing-rules show --resource-group RG1 --name MyRule --# Update an alert processing rule -az monitor alert-processing-rule update --resource-group RG1 --name MyRule --enabled true --# Delete an alert processing rule -az monitor alert-processing-rules delete --resource-group RG1 --name MyRule -``` --### [PowerShell](#tab/powershell) --You can view and manage your alert processing rules by using the [\*-AzAlertProcessingRule](/powershell/module/az.alertsmanagement) commands from the Azure CLI. --Before you manage alert processing rules with the Azure CLI, prepare your environment by following the instructions in [Configure an alert processing rule](#configure-an-alert-processing-rule). --```powershell -# List all alert processing rules for a subscription -Get-AzAlertProcessingRule --# Get details of an alert processing rule -Get-AzAlertProcessingRule -ResourceGroupName RG1 -Name MyRule | Format-List --# Update an alert processing rule -Update-AzAlertProcessingRule -ResourceGroupName RG1 -Name MyRule -Enabled False --# Delete an alert processing rule -Remove-AzAlertProcessingRule -ResourceGroupName RG1 -Name MyRule -``` --* * * --## Next steps --[Learn more about alerts in Azure](./alerts-overview.md) |
| azure-monitor | Alerts Resource Move | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-resource-move.md | - Title: How to update alert rules or alert processing rules when their target resource moves to a different Azure region -description: Background and instructions for how to update alert rules or alert processing rules when their target resource moves to a different Azure region. --- Previously updated : 06/19/2024----# Update alert rules or alert processing rules when their target resource moves to a different Azure region --This article describes why existing [alert rules](./alerts-overview.md) and [alert processing rules](./alerts-action-rules.md) may be impacted when you move other Azure resources between regions, and how to identify and resolve those issues. Check the main [resource move documentation](../../azure-resource-manager/management/move-resources-overview.md) for additional information on when is resource move between regions useful and a checklist of designing a move process. --## Why the problem exists --Alert rules and alert processing rules reference other Azure resources. Examples include [Azure VMs](../../site-recovery/azure-to-azure-tutorial-migrate.md), [Azure SQL](/azure/azure-sql/database/move-resources-across-regions), and [Azure Storage](../../storage/common/storage-account-move.md). When you move the resources those rules refer to, the rules are likely to stop working correctly because they can't find the resources they reference. --There are two main reasons why your rules might stop working after moving the target resources: --- The scope of your rule is explicitly referring to the old resource.-- Your alert rule is based on metrics.--## Rule scope explicitly refers to the old resource --When you move a resource, its resource ID changes in most cases. Behind the scenes, the system replicates the resource into the new region before deleting it from the old region. This process requires that two resources and thus two different resource IDs exist simultaneously for a small period of time. Since resource IDs must be unique, a new ID must be created during the process. --**How does moving the resource affect existing rules?** --Alert rules and alert processing rules have a scope of resources they apply to. The scope could be an entire subscription, a resource group, or one or more specific resources. -For example, here is a rule with a scope with two resources (two virtual machines): ---If the rule scope explicitly mentions a resource, and that resource has moved and changed its resource ID, then that rule will look for a wrong or non-existent resource and thus fail. --**How to fix the problem?** --Update or recreate the affected rule to point to the new resource. The process to update the scope is found later in this article. --The problem applies to these rule types: --- Activity log alert rules-- Alert processing rules-- Metric alerts ΓÇô For more information, see the next section [Alert rules based on metrics](#alert-rules-based-on-metrics).--> [!NOTE] -> Log search alert rules and smart detector alert rules are not affected because their scope is either a workspace or Application Insights. Neither of these scopes currently support region moves. --## Alert rules based on metrics --The metrics that Azure resources emit are regional. Whenever a resource moves to a new region, it starts emitting its metrics in that new region. As a result, any alert rules based on metrics need to be updated or recreated so they point to the current metric stream in the correct region. --This explanation applies to both [metric alert rules](alerts-metric-overview.md) and [availability test alert rules](/previous-versions/azure/azure-monitor/app/monitor-web-app-availability). --If **all** the resources in the scope have moved, you don't need to recreate the rule. You can just update any field of the alert rule, such as the alert rule description, and save it. -If **only some** of the resources in the scope have moved, you need to remove the moved resources from the existing rule and create a new rule that covers only the moved resources. --## Procedures to fix problems --### Identifying rules associated with a moved resource from the Azure portal --- **For alert rules** --Navigate to Alerts > Manage alert rules > filter by the containing subscription and the moved resource. -> [!NOTE] -> Activity Log alert rules do not support this process. It's not possible to update the scope of an activity log alert rule and have it point to a resource in another subscription. Instead you can create a new rule that will replace the old one. --- **For alert processing rules** - -Navigate to Alerts > Alert processing rules (preview) > filter by the containing subscription and the moved resource. --### Change scope of a rule from the Azure portal --1. Open the rule that you have identified in the previous step by clicking on it. -2. Under **Resource**, click **Edit** and adjust the scope, as needed. -3. Adjust other properties of the rule as needed. -4. Click **Save**. ---### Change the scope of a rule using Azure Resource Manager templates --1. Obtain the Azure Resource Manager template of the rule. To export the template of a rule from the Azure portal: - 1. Navigate to the Resource Groups section in the portal and open the resource group containing the rule. - 2. In the Overview section, check the **Show hidden type** checkbox, and filter by the relevant type of the rule. - 3. Select the relevant rule to view its details. - 4. Under **Settings**, select **Export template**. -2. Modify the template. If needed, split into two rules (relevant for some cases of metric alerts, as noted above). -3. Redeploy the template. --### Change scope of a rule using REST API --1. Get the existing rule ([metric alerts](/rest/api/monitor/metricalerts/get), [activity log alerts](/rest/api/monitor/activitylogalerts/get)) -2. Modify the scope ([activity log alerts](/rest/api/monitor/activitylogalerts/update)) -3. Redeploy the rule ([metric alerts](/rest/api/monitor/metricalerts/createorupdate), [activity log alerts](/rest/api/monitor/activitylogalerts/createorupdate)) --### Change scope of a rule using PowerShell --1. Get the existing rule ([metric alerts](/powershell/module/az.monitor/get-azmetricalertrulev2), [activity log alerts](/powershell/module/az.monitor/get-azactivitylogalert), alert [processing rules](/powershell/module/az.alertsmanagement/get-azalertprocessingrule)). -2. Modify the scope. If needed, split into two rules (relevant for some cases of metric alerts, as noted above). -3. Redeploy the rule ([metric alerts](/powershell/module/az.monitor/add-azmetricalertrulev2), [activity log alerts](/powershell/module/az.monitor/enable-azactivitylogalert), [alert processing rules](/powershell/module/az.alertsmanagement/set-azalertprocessingrule)). --### Change the scope of a rule using Azure CLI --1. Get the existing rule ([metric alerts](/cli/azure/monitor/metrics/alert#az-monitor-metrics-alert-show), [activity log alerts](/cli/azure/monitor/activity-log/alert#az-monitor-activity-log-alert-list)). -2. Update the rule scope directly ([metric alerts](/cli/azure/monitor/metrics/alert#az-monitor-metrics-alert-update), [activity log alerts](/cli/azure/monitor/activity-log/alert/scope)) -3. If needed, split into two rules (relevant for some cases of metric alerts, as noted above). --## Next steps --Learn about fixing other problems with [alert notifications](alerts-troubleshoot.md), [metric alerts](alerts-troubleshoot-metric.md), and [log search alerts](alerts-troubleshoot-log.md). |
| azure-monitor | Alerts Smart Detections Migration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-smart-detections-migration.md | - Title: Upgrade Azure Monitor Application Insights smart detection to alerts (preview) | Microsoft Docs -description: Learn about the steps required to upgrade your Azure Monitor Application Insights smart detection to alert rules. --- Previously updated : 04/01/2024---# Migrate Azure Monitor Application Insights smart detection to alerts (preview) --This article describes the process of migrating Application Insights smart detection to alerts. The migration creates alert rules for the different smart detection modules. You can manage and configure these rules like any other Azure Monitor alert rules. You can also configure action groups for these rules to get multiple methods of actions or notifications on new detections. --## Benefits of migration to alerts --With the migration, smart detection now allows you to take advantage of the full capabilities of Azure Monitor alerts, including: --- **Rich notification options for all detectors**: Use [action groups](../alerts/action-groups.md) to configure multiple types of notifications and actions that are triggered when an alert is fired. You can configure notification by email, SMS, voice call, or push notifications. You can configure actions like calling a secure webhook, logic app, and automation runbook. Action groups further management at scale by allowing you to configure actions once and use them across multiple alert rules.-- **At-scale management**: Smart detection alerts use the Azure Monitor alerts experience and API.-- **Rule-based suppression of notifications**: Use [action rules](../alerts/alerts-action-rules.md) to define or suppress actions at any Azure Resource Manager scope such as Azure subscription, resource group, or target resource. Filters help you narrow down the specific subset of alert instances that you want to act on.--## Migrated smart detection capabilities --A new set of alert rules is created when you migrate an Application Insights resource. One rule is created for each of the migrated smart detection capabilities. The following table maps the pre-migration smart detection capabilities to post-migration alert rules. --| Smart detection rule name <sup>(1)</sup> | Alert rule name <sup>(2)</sup> | -| - | | -| Degradation in server response time | Response latency degradation - *\<Application Insights resource name\>* | -| Degradation in dependency duration | Dependency latency degradation - *\<Application Insights resource name\>*| -| Degradation in trace severity ratio (preview) | Trace severity degradation - *\<Application Insights resource name\>*| -| Abnormal rise in exception volume (preview) | Exception anomalies - *\<Application Insights resource name\>*| -| Potential memory leak detected (preview) | Potential memory leak - *\<Application Insights resource name\>*| -| Slow page load time | No longer supported <sup>(3)</sup> | -| Slow server response time | No longer supported <sup>(3)</sup> | -| Long dependency duration | No longer supported <sup>(3)</sup> | -| Potential security issue detected (preview) | No longer supported <sup>(3)</sup> | -| Abnormal rise in daily data volume (preview) | No longer supported <sup>(3)</sup> | --<sup>(1)</sup> The name of the rule as it appears in the smart detection **Settings** pane.<br> -<sup>(2)</sup> The name of the new alert rule after migration.<br> -<sup>(3)</sup> These smart detection capabilities aren't converted to alerts because of low usage and reassessment of detection effectiveness. These detectors will no longer be supported for this resource after its migration is finished. -- > [!NOTE] - > The **Failure Anomalies** smart detector is already created as an alert rule and doesn't require migration. It isn't discussed in this article. --The migration doesn't change the algorithmic design and behavior of smart detection. The same detection performance is expected before and after the change. --You need to apply the migration to each Application Insights resource separately. For resources that aren't explicitly migrated, smart detection will continue to work as before. --### Action group configuration for the new smart detection alert rules --As part of migration, each new alert rule is automatically configured with an action group. The migration can assign a default action group for each rule. The default action group is configured according to the rule notification before the migration: --- If the smart detection rule had the default email or no notifications configured, the new alert rule is configured with an action group named Application Insights Smart Detection.- - If the migration tool finds an existing action group with that name, it links the new alert rule to that action group. - - Otherwise, it creates a new action group with that name. The new group is configured for Email Azure Resource Manager Role actions and sends notification to your Azure Resource Manager Monitoring Contributor and Monitoring Reader users. --- If the default email notification was changed before migration, an action group called Application Insights Smart Detection \<n\> is created, with an email action sending notifications to the previously configured email addresses.--Instead of using the default action group, you select an existing action group that will be configured for all the new alert rules. --## Execute the smart detection migration process --Use the Azure portal, the Azure CLI, or Azure Resource Manager templates (ARM templates) to perform the migration. --### Migrate your smart detection by using the Azure portal --To migrate smart detection in your resource: --1. Select **Smart detection** under the **Investigate** heading in your Application Insights resource. --1. Select the banner reading **Migrate smart detection to alerts (Preview)**. The migration dialog appears. - <!-- convertborder later --> - :::image type="content" source="media/alerts-smart-detections-migration/smart-detection-feed-banner.png" lightbox="media/alerts-smart-detections-migration/smart-detection-feed-banner.png" alt-text="Screenshot that shows the Smart Detection feed banner." border="false"::: --1. Select the **Migrate all Application Insights resources in this subscription** option. Or you can leave the option cleared if you want to migrate only the current resource you're in. - > [!NOTE] - > Selecting this option affects all existing Application Insights resources that weren't migrated yet. As long as the migration to alerts is in preview, new Application Insights resources will still be created with non-alerts smart detection. --1. Select an action group to be configured for the new alert rules. You can use the default action group as explained or use one of your existing action groups. --1. Select **Migrate** to start the migration process. - <!-- convertborder later --> - :::image type="content" source="media/alerts-smart-detections-migration/smart-detection-migration-dialog.png" lightbox="media/alerts-smart-detections-migration/smart-detection-migration-dialog.png" alt-text="Screenshot that shows the Smart Detection migration dialog." border="false"::: --After the migration, new alert rules are created for your Application Insight resource, as explained. --### Migrate your smart detection by using the Azure CLI --Start the smart detection migration by using the following Azure CLI command. The command triggers the preconfigured migration process as previously described. --```azurecli -az rest --method POST --uri /subscriptions/{subscriptionId}/providers/Microsoft.AlertsManagement/migrateFromSmartDetection?api-version=2021-01-01-preview --body @body.txt -``` --To migrate a single Application Insights resource, *body.txt* should include: --```json -{ - "scope": [ -"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/microsoft.insights/components/{resourceName}" - ], - "actionGroupCreationPolicy" : "{Auto/Custom}", - "customActionGroupName" : "{actionGroupName}" -} -``` --To migrate all the Application Insights resources in a subscription, *body.txt* should include: --```json -{ - "scope": [ - "/subscriptions/{subscriptionId} " - ], - "actionGroupCreationPolicy" : "{Auto/Custom}", - "customActionGroupName" : "{actionGroupName}" -} -``` --The `ActionGroupCreationPolicy` parameter selects the policy for migrating the email settings in the smart detection rules into action groups. Allowed values are: --- **Auto**: Uses the default action groups as described in this document.-- **Custom**: Creates all alert rules with the action group specified in `customActionGroupName`.-- **\<blank\>**: If `ActionGroupCreationPolicy` isn't specified, the `Auto` policy is used.--### Migrate your smart detection by using ARM templates --You can trigger the smart detection migration to alerts for a specific Application Insights resource by using ARM templates. To use this method, you need to: --- Create a smart detection alert rule for each of the supported detectors.-- Modify the Application Insight properties to indicate that the migration was completed.--With this method, you can control which alert rules to create, define your own alert rule name and description, and select any action group you desire for each rule. --Use the following templates for this purpose. Edit them as needed to provide your subscription ID and Application Insights resource name. --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "applicationInsightsResourceName": { - "type": "string" - }, - "actionGroupName": { - "type": "string", - "defaultValue": "Application Insights Smart Detection" - }, - "actionGroupResourceGroup": { - "type": "string", - "defaultValue": "[resourceGroup().Name]" - } - }, - "variables": { - "applicationInsightsResourceId": "[concat('/subscriptions/',subscription().subscriptionId,'/resourceGroups/',resourceGroup().Name,'/providers/microsoft.insights/components/',parameters('applicationInsightsResourceName'))]", - "actionGroupId": "[concat('/subscriptions/',subscription().subscriptionId,'/resourceGroups/',parameters('actionGroupResourceGroup'),'/providers/microsoft.insights/ActionGroups/',parameters('actionGroupName'))]", - "requestPerformanceDegradationDetectorRuleName": "[concat('Response Latency Degradation - ', parameters('applicationInsightsResourceName'))]", - "dependencyPerformanceDegradationDetectorRuleName": "[concat('Dependency Latency Degradation - ', parameters('applicationInsightsResourceName'))]", - "traceSeverityDetectorRuleName": "[concat('Trace Severity Degradation - ', parameters('applicationInsightsResourceName'))]", - "exceptionVolumeChangedDetectorRuleName": "[concat('Exception Anomalies - ', parameters('applicationInsightsResourceName'))]", - "memoryLeakRuleName": "[concat('Potential Memory Leak - ', parameters('applicationInsightsResourceName'))]" - }, - "resources": [ - { - "name": "[variables('requestPerformanceDegradationDetectorRuleName')]", - "type": "Microsoft.AlertsManagement/smartdetectoralertrules", - "location": "global", - "apiVersion": "2019-03-01", - "properties": { - "description": "Response Latency Degradation notifies you of an unusual increase in latency in your app response to requests.", - "state": "Enabled", - "severity": "Sev3", - "frequency": "PT24H", - "detector": { - "id": "RequestPerformanceDegradationDetector" - }, - "scope": [ - "[variables('applicationInsightsResourceId')]" - ], - "actionGroups": { - "groupIds": [ - "[variables('actionGroupId')]" - ] - } - } - }, - { - "name": "[variables('dependencyPerformanceDegradationDetectorRuleName')]", - "type": "Microsoft.AlertsManagement/smartdetectoralertrules", - "location": "global", - "apiVersion": "2019-03-01", - "properties": { - "description": "Dependency Latency Degradation notifies you of an unusual increase in response by a dependency your app is calling (e.g. REST API or database)", - "state": "Enabled", - "severity": "Sev3", - "frequency": "PT24H", - "detector": { - "id": "DependencyPerformanceDegradationDetector" - }, - "scope": [ - "[variables('applicationInsightsResourceId')]" - ], - "actionGroups": { - "groupIds": [ - "[variables('actionGroupId')]" - ] - } - } - }, - { - "name": "[variables('traceSeverityDetectorRuleName')]", - "type": "Microsoft.AlertsManagement/smartdetectoralertrules", - "location": "global", - "apiVersion": "2019-03-01", - "properties": { - "description": "Trace Severity Degradation notifies you of an unusual increase in the severity of the traces generated by your app.", - "state": "Enabled", - "severity": "Sev3", - "frequency": "PT24H", - "detector": { - "id": "TraceSeverityDetector" - }, - "scope": [ - "[variables('applicationInsightsResourceId')]" - ], - "actionGroups": { - "groupIds": [ - "[variables('actionGroupId')]" - ] - } - } - }, - { - "name": "[variables('exceptionVolumeChangedDetectorRuleName')]", - "type": "Microsoft.AlertsManagement/smartdetectoralertrules", - "location": "global", - "apiVersion": "2019-03-01", - "properties": { - "description": "Exception Anomalies notifies you of an unusual rise in the rate of exceptions thrown by your app.", - "state": "Enabled", - "severity": "Sev3", - "frequency": "PT24H", - "detector": { - "id": "ExceptionVolumeChangedDetector" - }, - "scope": [ - "[variables('applicationInsightsResourceId')]" - ], - "actionGroups": { - "groupIds": [ - "[variables('actionGroupId')]" - ] - } - } - }, - { - "name": "[variables('memoryLeakRuleName')]", - "type": "Microsoft.AlertsManagement/smartdetectoralertrules", - "location": "global", - "apiVersion": "2019-03-01", - "properties": { - "description": "Potential Memory Leak notifies you of increased memory consumption pattern by your app which may indicate a potential memory leak.", - "state": "Enabled", - "severity": "Sev3", - "frequency": "PT24H", - "detector": { - "id": "MemoryLeakDetector" - }, - "scope": [ - "[variables('applicationInsightsResourceId')]" - ], - "actionGroups": { - "groupIds": [ - "[variables('actionGroupId')]" - ] - } - } - }, - { - "name": "[concat(parameters('applicationInsightsResourceName'),'/migrationToAlertRulesCompleted')]", - "type": "Microsoft.Insights/components/ProactiveDetectionConfigs", - "location": "[resourceGroup().location]", - "apiVersion": "2018-05-01-preview", - "properties": { - "name": "migrationToAlertRulesCompleted", - "sendEmailsToSubscriptionOwners": false, - "customEmails": [], - "enabled": true - }, - "dependsOn": [ - "[resourceId('Microsoft.AlertsManagement/smartdetectoralertrules', variables('requestPerformanceDegradationDetectorRuleName'))]", - "[resourceId('Microsoft.AlertsManagement/smartdetectoralertrules', variables('dependencyPerformanceDegradationDetectorRuleName'))]", - "[resourceId('Microsoft.AlertsManagement/smartdetectoralertrules', variables('traceSeverityDetectorRuleName'))]", - "[resourceId('Microsoft.AlertsManagement/smartdetectoralertrules', variables('exceptionVolumeChangedDetectorRuleName'))]", - "[resourceId('Microsoft.AlertsManagement/smartdetectoralertrules', variables('memoryLeakRuleName'))]" - ] - } - ] -} -``` --## View your alerts after the migration --After migration, you can view your smart detection alerts by selecting the **Alerts** entry in your Application Insights resource. For **Signal type**, select **Smart Detector** to filter and present only smart detection alerts. You can select an alert to see its detection details. ---You can also still see the available detections in the **Smart Detection** feed of your Application Insights resource. -<!-- convertborder later --> --## Manage smart detection alert rules settings after migration --Use the Azure portal or ARM templates to manage smart detection alert rules settings after migration. --### Manage alert rules settings by using the Azure portal --After the migration is finished, you access the new smart detection alert rules in a similar way to other alert rules defined for the resource. --1. Select **Alerts** under the **Monitoring** heading in your Application Insights resource. - <!-- convertborder later --> - :::image type="content" source="media/alerts-smart-detections-migration/application-insights-alerts.png" lightbox="media/alerts-smart-detections-migration/application-insights-alerts.png" alt-text="Screenshot that shows the Alerts menu." border="false"::: --1. Select **Manage alert rules**. - <!-- convertborder later --> - :::image type="content" source="media/alerts-smart-detections-migration/manage-alert-rules.png" lightbox="media/alerts-smart-detections-migration/manage-alert-rules.png" alt-text="Screenshot that shows Manage alert rules." border="false"::: --1. For **Signal type**, select **Smart Detector** to filter and present the smart detection alert rules. -- :::image type="content" source="media/alerts-smart-detections-migration/smart-detector-rules.png" lightbox="media/alerts-smart-detections-migration/smart-detector-rules.png" alt-text="Screenshot that shows smart detection rules."::: --### Enable or disable smart detection alert rules --Smart detection alert rules can be enabled or disabled through the portal UI or programmatically, like any other alert rule. --If a specific smart detection rule was disabled before the migration, the new alert rule will also be disabled. --### Configure action groups for your alert rules --You can create and manage action groups for the new smart detection alert rules like for any other Azure Monitor alert rule. --### Manage alert rule settings by using ARM templates --After the migration is finished, you can use ARM templates to configure settings for smart detection alert rule settings. --> [!NOTE] -> After migration is finished, smart detection settings must be configured by using smart detection alert rule templates. They can no longer be configured by using the [Application Insights Resource Manager template](./proactive-arm-config.md#smart-detection-rule-configuration). --This ARM template example demonstrates how to configure a `Response Latency Degradation` alert rule in an `Enabled` state with a severity of `2`. -* Smart detection is a global service, so rule location is created in the `global` location. -* The `id` property should change according to the specific detector configured. The value must be one of: -- - `FailureAnomaliesDetector` - - `RequestPerformanceDegradationDetector` - - `DependencyPerformanceDegradationDetector` - - `ExceptionVolumeChangedDetector` - - `TraceSeverityDetector` - - `MemoryLeakDetector` - -```json -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "resources": [ - { - "type": "microsoft.alertsmanagement/smartdetectoralertrules", - "apiVersion": "2019-03-01", - "name": "Response Latency Degradation - my-app", - "location": "global", - "properties": { - "description": "Response Latency Degradation notifies you of an unusual increase in latency in your app response to requests.", - "state": "Enabled", - "severity": "2", - "frequency": "PT24H", - "detector": { - "id": "RequestPerformanceDegradationDetector" - }, - "scope": ["/subscriptions/00000000-1111-2222-3333-444444444444/resourceGroups/MyResourceGroup/providers/microsoft.insights/components/my-app"], - "actionGroups": { - "groupIds": ["/subscriptions/00000000-1111-2222-3333-444444444444/resourcegroups/MyResourceGroup/providers/microsoft.insights/actiongroups/MyActionGroup"] - } - } - } - ] -} -``` --## Next steps --- [Learn more about alerts in Azure](./alerts-overview.md)-- [Learn more about smart detection in Application Insights](./proactive-diagnostics.md) |
| azure-monitor | Alerts Troubleshoot Log | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-troubleshoot-log.md | - Title: Troubleshoot log alerts in Azure Monitor | Microsoft Docs -description: Common issues, errors, and resolutions for log alert rules in Azure. -- Previously updated : 02/28/2024----# Troubleshoot log search alerts in Azure Monitor --This article describes how to resolve common issues with log search alerts in Azure Monitor. It also provides solutions to common problems with the functionality and configuration of log alerts. --You can use log alerts to evaluate resources logs every set frequency by using a [Log Analytics](../logs/log-analytics-tutorial.md) query, and fire an alert that's based on the results. Rules can trigger one or more actions using [Action Groups](./action-groups.md). To learn more about functionality and terminology of log search alerts, see [Log alerts in Azure Monitor](alerts-types.md#log-alerts). --> [!NOTE] -> This article doesn't discuss cases where the alert rule was triggered, you can see it in the Azure portal, but the notification was not sent. See [troubleshooting alerts](alerts-troubleshoot.md) for cases like these. --## A log search alert didn't fire when it should have -If your log search alert didn't fire when it should have, check the following items: --1. **Is the alert rule is in a degraded or unavailable health state?** -- View the health status of your log search alert rule: - - 1. In the [portal](https://portal.azure.com/), select **Monitor**, then **Alerts**. - 1. From the top command bar, select **Alert rules**. The page shows all your alert rules on all subscriptions. - 1. Select the log search alert rule that you want to monitor. - 1. From the left pane, under **Help**, select **Resource health**. - - :::image type="content" source="media/log-search-alert-health/log-search-alert-resource-health.png" alt-text="Screenshot of the Resource health section in a log search alert rule."::: -- See [Monitor the health of log search alert rules](log-alert-rule-health.md#monitor-the-health-of-log-search-alert-rules) to learn more. --1. **Check the log ingestion latency.** -- Azure Monitor processes terabytes of customers' logs from across the world, which can cause [logs ingestion latency](../logs/data-ingestion-time.md). - - Logs are semi-structured data and are inherently more latent than metrics. If you're experiencing more than a 4-minute delay in fired alerts, you should consider using [metric alerts](alerts-metric-overview.md). You can send data to the metric store from logs using [metric alerts for logs](alerts-metric-logs.md). -- To mitigate latency, the system retries the alert evaluation multiple times. After the data arrives, the alert fires, which in most cases don't equal the log record time. --1. **Are the actions muted or was the alert rule configured to resolve automatically?** -- A common issue is that you think that the alert didn't fire, but the rule was configured so that the alert wouldn't fire. See the advanced options of the [log search alert rule](./alerts-create-log-alert-rule.md) to verify that both of the following aren't selected: - * The **Mute actions** checkbox: allows you to mute fired alert actions for a set amount of time. - * **Automatically resolve alerts**: configures the alert to only fire once per condition being met. - - :::image type="content" source="media/alerts-troubleshoot-log/LogAlertSuppress.png" lightbox="media/alerts-troubleshoot-log/LogAlertSuppress.png" alt-text="Suppress alerts"::: --1. **Was the alert rule resource moved or deleted?** -- If an alert rule resource moves, gets renamed, or is deleted, all log alert rules referring to that resource will break. To fix this issue, alert rules need to be recreated using a valid target resource for the scope. --1. **Does the alert rule use a system-assigned managed identity?** -- When you create a log alert rule with system-assigned managed identity, the identity is created without any permissions. After you create the rule, you need to assign the appropriate roles to the ruleΓÇÖs identity so that it can access the data you want to query. For example, you might need to give it a Reader role for the relevant Log Analytics workspaces, or a Reader role and a Database Viewer role for the relevant ADX cluster. See [managed identities](/azure/azure-monitor/alerts/alerts-create-log-alert-rule#configure-the-alert-rule-details) for more information about using managed identities in log alerts. --1. **Is the query used in the log search alert rule valid?** -- When a log alert rule is created, the query is validated for correct syntax. But sometimes the query provided in the log alert rule can start to fail. Some common reasons are: -- - Rules were created via the API, and the user skipped validation. - - The query [runs on multiple resources](../logs/cross-workspace-query.md), and one or more of the resources was deleted or moved. - - The [query fails](../logs/api/errors.md) because: - - The logging solution wasn't [deployed to the workspace](../insights/solutions.md#install-a-monitoring-solution), so tables aren't created. - - Data stopped flowing to a table in the query for more than 30 days. - - [Custom logs tables](../agents/data-sources-custom-logs.md) haven't been created because the data flow hasn't started. - - Changes in the [query language](/azure/kusto/query/) include a revised format for commands and functions, so the query provided earlier is no longer valid. - - Azure Service Health monitors the health of your cloud resources, including log search alert rules. When a log search alert rule is healthy, the rule runs and the query executes successfully. You can use [resource health for log search alert rules](https://learn.microsoft.com/azure/azure-monitor/alerts/log-alert-rule-health) to learn about the issues affecting your log search alert rules. --1. **Was the the log search alert rule disabled?** -- If a log search alert rule query fails to evaluate continuously for a week, Azure Monitor disables it automatically. -- The following sections list some reasons why Azure Monitor might disable a log search alert rule. Additionally, there's an example of the [Activity log](../../azure-monitor/essentials/activity-log.md) event that is submitted when a rule is disabled. --### Activity log example when rule is disabled --```json -{ - "caller": "Microsoft.Insights/ScheduledQueryRules", - "channels": "Operation", - "claims": { - "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/spn": "Microsoft.Insights/ScheduledQueryRules" - }, - "correlationId": "abcdefg-4d12-1234-4256-21233554aff", - "description": "Alert: test-bad-alerts is disabled by the System due to : Alert has been failing consistently with the same exception for the past week", - "eventDataId": "f123e07-bf45-1234-4565-123a123455b", - "eventName": { - "value": "", - "localizedValue": "" - }, - "category": { - "value": "Administrative", - "localizedValue": "Administrative" - }, - "eventTimestamp": "2019-03-22T04:18:22.8569543Z", - "id": "/SUBSCRIPTIONS/<subscriptionId>/RESOURCEGROUPS/<ResourceGroup>/PROVIDERS/MICROSOFT.INSIGHTS/SCHEDULEDQUERYRULES/TEST-BAD-ALERTS", - "level": "Informational", - "operationId": "", - "operationName": { - "value": "Microsoft.Insights/ScheduledQueryRules/disable/action", - "localizedValue": "Microsoft.Insights/ScheduledQueryRules/disable/action" - }, - "resourceGroupName": "<Resource Group>", - "resourceProviderName": { - "value": "MICROSOFT.INSIGHTS", - "localizedValue": "Microsoft Insights" - }, - "resourceType": { - "value": "MICROSOFT.INSIGHTS/scheduledqueryrules", - "localizedValue": "MICROSOFT.INSIGHTS/scheduledqueryrules" - }, - "resourceId": "/SUBSCRIPTIONS/<subscriptionId>/RESOURCEGROUPS/<ResourceGroup>/PROVIDERS/MICROSOFT.INSIGHTS/SCHEDULEDQUERYRULES/TEST-BAD-ALERTS", - "status": { - "value": "Succeeded", - "localizedValue": "Succeeded" - }, - "subStatus": { - "value": "", - "localizedValue": "" - }, - "submissionTimestamp": "2019-03-22T04:18:22.8569543Z", - "subscriptionId": "<SubscriptionId>", - "properties": { - "resourceId": "/SUBSCRIPTIONS/<subscriptionId>/RESOURCEGROUPS/<ResourceGroup>/PROVIDERS/MICROSOFT.INSIGHTS/SCHEDULEDQUERYRULES/TEST-BAD-ALERTS", - "subscriptionId": "<SubscriptionId>", - "resourceGroup": "<ResourceGroup>", - "eventDataId": "12e12345-12dd-1234-8e3e-12345b7a1234", - "eventTimeStamp": "03/22/2019 04:18:22", - "issueStartTime": "03/22/2019 04:18:22", - "operationName": "Microsoft.Insights/ScheduledQueryRules/disable/action", - "status": "Succeeded", - "reason": "Alert has been failing consistently with the same exception for the past week" - }, - "relatedEvents": [] -} -``` --## A log search alert fired when it shouldn't have --A configured [log alert rule in Azure Monitor](./alerts-log.md) might be triggered unexpectedly. The following sections describe some common reasons. --1. **Was the alert triggered due to latency issues?** -- Azure Monitor processes terabytes of customer logs globally, which can cause [logs ingestion latency](../logs/data-ingestion-time.md). There are built-in capabilities to prevent false alerts, but they can still occur on very latent data (over ~30 minutes) and data with latency spikes. - - Logs are semi-structured data and are inherently more latent than metrics. If you're experiencing many misfires in fired alerts, consider using [metric alerts](alerts-types.md#metric-alerts). You can send data to the metric store from logs using [metric alerts for logs](alerts-metric-logs.md). - - Log search alerts work best when you're trying to detect specific data in the logs. They're less effective when you're trying to detect lack of data in the logs, like alerting on virtual machine heartbeat. - --## Error messages when configuring log search alert rules -See the following sections for specific error messages and their resolutions. --### The query couldn't be validated since you need permission for the logs --If you receive this error message when creating or editing your alert rule query, make sure you have permissions to read the target resource logs. --- Permissions required to read logs in workspace-context access mode: `Microsoft.OperationalInsights/workspaces/query/read`. -- Permissions required to read logs in resource-context access mode (including workspace-based Application Insights resource): `Microsoft.Insights/logs/tableName/read`.--See [Manage access to Log Analytics workspaces](../logs/manage-access.md) to learn more about permissions. --### One-minute frequency isn't supported for this query --There are some limitations to using a one-minute alert rule frequency. When you set the alert rule frequency to one minute, an internal manipulation is performed to optimize the query. This manipulation can cause the query to fail if it contains unsupported operations. --For a list of unsupported scenarios, see [this note](https://aka.ms/lsa_1m_limits). --### Failed to resolve scalar expression named <> --This error message can be returned when creating or editing your alert rule query if: --- You're referencing a column that doesn't exist in the table schema.-- You're referencing a column that wasn't used in a prior project clause of the query.--To mitigate this, you can either add the column to the previous project clause or use the [columnifexists](/azure/data-explorer/kusto/query/column-ifexists-function) operator. --### ScheduledQueryRules API isn't supported for read only OMS Alerts --This error message is returned when trying to update or delete rules created with the legacy API version by using the Azure portal. --1. Edit or delete the rule programmatically using the Log Analytics [REST API](./api-alerts.md). -2. Recommended: [Upgrade your alert rules to use Scheduled Query Rules API](./alerts-log-api-switch.md) (legacy API is on a deprecation path). --## Alert rule service limit was reached --For details about the number of log search alert rules per subscription and maximum limits of resources, see [Azure Monitor service limits](../service-limits.md). -See [Check the total number of log alert rules in use](alerts-manage-alert-rules.md#check-the-number-of-log-alert-rules-in-use) to see how many metric alert rules are currently in use. -If you've reached the quota limit, the following steps might help resolve the issue. --1. Delete or disable log search alert rules that arenΓÇÖt used anymore. -1. Use [splitting by dimensions](alerts-types.md#monitor-multiple-instances-of-a-resource-using-dimensions) to reduce the number of rules. When you use splitting by dimensions, one rule can monitor many resources. -1. If you need the quota limit to be increased, continue to open a support request, and provide the following information: -- - The Subscription IDs and Resource IDs for which the quota limit needs to be increased - - The reason for quota increase - - The resource type for the quota increase, such as **Log Analytics** or **Application Insights** - - The requested quota limit ---## Next steps --- Learn about [log alerts in Azure](./alerts-unified-log.md).-- Learn more about [configuring log alerts](../logs/log-query-overview.md).-- Learn more about [log queries](../logs/log-query-overview.md). |
| azure-monitor | Alerts Troubleshoot Metric | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-troubleshoot-metric.md | - Title: Troubleshoot Azure Monitor metric alerts -description: Common issues with Azure Monitor metric alerts and possible solutions. -- Previously updated : 02/28/2024----# Troubleshoot Azure Monitor metric alerts --This article discusses common questions about Azure Monitor [metric alerts](alerts-types.md#metric-alerts) and how to troubleshoot them. --Azure Monitor alerts proactively notify you when important conditions are found in your monitoring data. They allow you to identify and address issues before the users of your system notice them. For more information on alerting, see [Overview of alerts in Microsoft Azure](./alerts-overview.md). --## Metric alert didn't fire when it should have --If you believe a metric alert should have fired but it didn't, and it isn't listed in the Azure portal, try the following steps: --1. **Review the metric alert rule configuration.** -- - Check that **Aggregation type** and **Aggregation granularity (Period)** are configured as expected. **Aggregation type** determines how metric values are aggregated. To learn more, see [Azure Monitor Metrics aggregation and display explained](../essentials/metrics-aggregation-explained.md#aggregation-types). **Aggregation granularity (Period)** controls how far back the evaluation aggregates the metric values each time the alert rule runs. - - Check that **Threshold value** or **Sensitivity** are configured as expected. - - For an alert rule that uses Dynamic Thresholds, check if advanced settings are configured. **Number of violations** might filter alerts, and **Ignore data before** can affect how the thresholds are calculated. - - > [!NOTE] - > Dynamic thresholds require at least 3 days and 30 metric samples before they become active. - -1. **Check if the alert fired but didn't send the notification.** -- Review the [fired alerts list](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/alertsV2) to see if you can locate the fired alert. If you can see the alert in the list but have an issue with some of its actions or notifications, see [Troubleshooting problems in Azure Monitor alerts](./alerts-troubleshoot.md). --1. **Check if the alert is already active.** -- Check if there's already a fired alert on the metric time series for which you expected to get an alert. Metric alerts are stateful, which means that once an alert is fired on a specific metric time series, more alerts on that time series won't be fired until the issue is no longer observed. This design choice reduces noise. The alert is resolved automatically when the alert condition isn't met for three consecutive evaluations. --1. **Check the dimensions used.** -- If you've selected some [dimension values for a metric](./alerts-metric-overview.md#using-dimensions), the alert rule monitors each individual metric time series (as defined by the combination of dimension values) for a threshold breach. To also monitor the aggregate metric time series, without any dimensions selected, configure another alert rule on the metric without selecting dimensions. --1. **Check the aggregation and time granularity.** -- If you're using [metrics charts](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/metrics), ensure that: - - The selected **Aggregation** in the metric chart is the same as **Aggregation type** in your alert rule. - - The selected **Time granularity** is the same as **Aggregation granularity (Period)** in your alert rule, and isn't set to **Automatic**. --1. **Check if the alert rule is missing the first evaluation period in a time series.** -- You can reduce the likelihood of missing the first evaluation of added time series by making sure that you choose an **Aggregation granularity (Period)** that's larger than the **Frequency of evaluation** in the following cases: -- - When a new dimension value combination is added to a metric alert rule that monitors multiple dimensions. - - When a new resource is added to the scope to a metric alert rule that monitors multiple resources. - - When the metric is emitted after a period longer than 24 hours in which it wasn't emitted for metric alert rule that monitors a metric that isn't emitted continuously (sparse metric). --## The metric alert is not triggered every time the condition is met --Metric alerts are stateful by default, so other alerts aren't fired if there's already a fired alert on a specific time series. To make a specific metric alert rule stateless and get alerted on every evaluation in which the alert condition is met, use one of these options: --- If you create the alert rule programmatically, for example, via [Azure Resource Manager](./alerts-metric-create-templates.md), [PowerShell](/powershell/module/az.monitor/), [REST](/rest/api/monitor/metricalerts/createorupdate), or the [Azure CLI](/cli/azure/monitor/metrics/alert), set the `autoMitigate` property to `False`.-- If you create the alert rule in the Azure portal, clear the **Automatically resolve alerts** option under the **Alert rule details** section.-The frequency of notifications for stateless metric alerts differs based on the alert rule's configured frequency: --- **Alert frequency of less than 5 minutes**: While the condition continues to be met, a notification is sent somewhere between one and six minutes.-- **Alert frequency of more than 5 minutes**: While the condition continues to be met, a notification is sent between the configured frequency and double the frequency. For example, for an alert rule with a frequency of 15 minutes, a notification is sent somewhere between 15 to 30 minutes.--> [!NOTE] -> Making a metric alert rule stateless prevents fired alerts from becoming resolved. So, even after the condition isn't met anymore, the fired alerts remain in a fired state until the 30-day retention period. --## A metric alert rule with dynamic threshold doesn't fire enough --You may encounter an alert rule that uses dynamic thresholds doesn't fire or isn't sensitive enough, even though it's configured with high sensitivity. This can happen when the metric's distribution is highly irregular. Consider one of the following solutions to fix the issue: --## A metric alert fired when it shouldn't have --If you believe your metric alert shouldn't have fired but it did, the following steps might help resolve the issue. --1. Review the [fired alerts list](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/alertsV2) to locate the fired alert. Select the alert to view its details. Review the information provided under **Why did this alert fire?** to see the metric chart, **Metric value**, and **Threshold value** at the time when the alert was triggered. -- > [!NOTE] - > If you're using dynamic thresholds, and think that the thresholds weren't correct, provide feedback by using the frown icon. This feedback affects the machine learning algorithmic research and will help improve future detections. --1. If you've selected multiple dimension values for a metric, the alert is triggered when *any* of the metric time series (as defined by the combination of dimension values) breaches the threshold. For more information about using dimensions in metric alerts, see [Narrow the target using dimensions](./alerts-types.md#narrow-the-target-using-dimensions). --1. Review the alert rule configuration to make sure it's properly configured: - - Check that **Aggregation type**, **Aggregation granularity (Period)**, and **Threshold value** or **Sensitivity** are configured as expected. - - For an alert rule that uses dynamic thresholds, check if advanced settings are configured, as **Number of violations** might filter alerts and **Ignore data before** can affect how the thresholds are calculated. -- > [!NOTE] - > Dynamic thresholds require at least 3 days and 30 metric samples before becoming active. --1. If you're using [metrics charts](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/metrics), ensure that: -- - The selected **Aggregation** in the metric chart is the same as the **Aggregation type** in your alert rule. - - The selected **Time granularity** is the same as the **Aggregation granularity (Period)** in your alert rule, and that it isn't set to **Automatic**. --1. If the alert fired while there are already fired alerts that monitor the same criteria that aren't resolved, check if the alert rule has been configured not to automatically resolve alerts. This means the alert rule is stateless, and doesn't auto-resolve fired alerts and doesn't require a fired alert to be resolved before firing again on the same time series. - To check if the alert rule is configured not to auto-resolve: - - Edit the alert rule in the Azure portal. See if the **Automatically resolve alerts** checkbox under the **Alert rule details** section is cleared. - - Review the script used to deploy the alert rule or retrieve the alert rule definition. Check if the `autoMitigate` property is set to `false`. --## A metric alert rule with dynamic thresholds fires too much or is too noisy --If an alert rule that uses dynamic thresholds is too noisy or fires too much, you may need to reduce the sensitivity of your dynamic thresholds alert rule. Use one of the following options: --## A metric alert rule with dynamic thresholds is showing values that aren't within the range of expected values --When a metric value exhibits large fluctuations, dynamic thresholds may build a wide model around the metric values, which can result in a lower or higher boundary than expected. This scenario can happen when: -- Consider making the model less sensitive by choosing a higher sensitivity or selecting a larger **Lookback period**. You can also use the **Ignore data before** option to exclude a recent irregularity from the historical data used to build the model. --## Issues configuring metric alert rules --### Can't find the metric to alert on --If you want to alert on a specific metric but you can't see it when you create an alert rule, check to determine: --- If you can't see any metrics for the resource, [check if the resource type is supported for metric alerts](./alerts-metric-near-real-time.md).-- If you can see some metrics for the resource but can't find a specific metric, [check if that metric is available](/azure/azure-monitor/reference/supported-metrics/metrics-index). If so, see the metric description to check if it's only available in specific versions or editions of the resource.-- If the metric isn't available for the resource, it might be available in the resource logs and can be monitored by using log alerts. For more information, see how to [collect and analyze resource logs from an Azure resource](../essentials/tutorial-resource-logs.md).--### Can't find the metric to alert on: Virtual machines guest metrics --To alert on guest operating system metrics of virtual machines, such as memory and disk space, ensure you've installed the required agent to collect this data to Azure Monitor Metrics for: --- [Windows VMs](../essentials/collect-custom-metrics-guestos-resource-manager-vm.md)-- [Linux VMs](../essentials/collect-custom-metrics-linux-telegraf.md)--For more information about collecting data from the guest operating system of a virtual machine, see [this website](../vm/monitor-vm-azure.md#guest-operating-system). --> [!NOTE] -> If you configured guest metrics to be sent to a Log Analytics workspace, the metrics appear under the Log Analytics workspace resource and start showing data *only* after you create an alert rule that monitors them. To do so, follow the steps to [configure a metric alert for logs](./alerts-metric-logs.md#methods-for-creating-a-metric-alert-for-logs). --Currently, monitoring a guest metric for multiple virtual machines with a single alert rule isn't supported by metric alerts. But you can use a [log alert rule](./alerts-unified-log.md). To do so, make sure the guest metrics are collected to a Log Analytics workspace and create a log alert rule on the workspace. --### Can't find the metric dimension to alert on --If you want to alert on [specific dimension values of a metric](./alerts-metric-overview.md#using-dimensions) but you can't find these values: --- It might take a few minutes for the dimension values to appear under the **Dimension values** list.-- The displayed dimension values are based on metric data collected in the last day.-- If the dimension value isn't yet emitted or isn't shown, you can use the **Add custom value** option to add a custom dimension value.-- If you want to alert on all possible values of a dimension and even include future values, choose the **Select all current and future values** option.-- Custom metrics dimensions of Application Insights resources are turned off by default. To turn on the collection of dimensions for these custom metrics, see [Log-based and preaggregated metrics in Application Insights](../app/pre-aggregated-metrics-log-metrics.md#custom-metrics-dimensions-and-preaggregation).--### You want to configure an alert rule on a custom metric that isn't emitted yet --When you create a metric alert rule, the metric name is validated against the [Metric Definitions API](/rest/api/monitor/metricdefinitions/list) to make sure it exists. In some cases, you want to create an alert rule on a custom metric even before it's emitted. An example is when you use a Resource Manager template to create an Application Insights resource that will emit a custom metric, along with an alert rule that monitors that metric. --To avoid a deployment failure when you try to validate the custom metric's definitions, use the `skipMetricValidation` parameter in the `criteria` section of the alert rule. This parameter causes the metric validation to be skipped. See the following example for how to use this parameter in a Resource Manager template. For more information, see the [complete Resource Manager template samples for creating metric alert rules](./alerts-metric-create-templates.md). --```json -"criteria": { - "odata.type": "Microsoft.Azure.Monitor.SingleResourceMultipleMetricCriteria", - "allOf": [ - { - "name" : "condition1", - "metricName": "myCustomMetric", - "metricNamespace": "myCustomMetricNamespace", - "dimensions":[], - "operator": "GreaterThan", - "threshold" : 10, - "timeAggregation": "Average", - "skipMetricValidation": true - } - ] - } -``` --> [!NOTE] -> Using the `skipMetricValidation` parameter might also be required when you define an alert rule on an existing custom metric that hasn't been emitted in several days. --### Warnings and errors when configuring metric alert rules --#### Dynamic thresholds is currently not available for this metric warning --Dynamic thresholds are supported for most metrics, but not all. -Refer to [Metrics not supported by dynamic thresholds](alerts-dynamic-thresholds.md#metrics-not-supported-by-dynamic-thresholds) for the list of metrics. --#### The metric isn't available for the selected scope. This might happen if the metric only applies to a specific version or SKU error --Review the metric description in [Supported metrics with Azure Monitor](/azure/azure-monitor/reference/supported-metrics/metrics-index) to check if it's only available in specific versions or editions of the resource or this specific type. --For example, in SQL Database resources or Storage file services, there are specific metrics only supported on specific versions of the resource. --#### There are no available signals to display. Try changing the scope of this alert rule error --This error indicates an issue with the alert rule scope. This can happen when editing an alert rule scoped to a resource type that supports multi-resource configuration (like Virtual machine or SQL database), and trying to add another resource of the same type, but from a different region. Alerting on multiple resources of the same type from different regions is not supported in Metric alerts. --## The service limits for metric alert rules is too small --The allowed number of metric alert rules per subscription is subject to [service limits](../service-limits.md). --See [Check the number of metric alert rules in use](alerts-manage-alert-rules.md#check-the-number-of-metric-alert-rules-in-use) to see how many metric alert rules are currently in use. --If you've reached the service limit, the following steps might help resolve the issue: -- 1. Try deleting or disabling metric alert rules that aren't used anymore. - 1. Switch to using metric alert rules that monitor multiple resources. With this capability, a single alert rule can monitor multiple resources by using only one alert rule counted against the quota. For more information about this capability and the supported resource types, see [metric-alerts](./alerts-types.md#monitor-the-same-condition-on-multiple-resources-using-splitting-by-dimensions). - 1. If you need the quota limit to be increased, open a support request and provide the: - - Subscription IDs for which the quota limit needs to be increased. - - Resource type for the quota increase. Select **Metric alerts**. - - Requested quota limit. ---## Next steps --For general troubleshooting information about alerts and notifications, see [Troubleshooting problems in Azure Monitor alerts](alerts-troubleshoot.md). -- |
| azure-monitor | Alerts Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-troubleshoot.md | - Title: Troubleshooting Azure Monitor alerts and notifications -description: Troubleshoot common problems with Azure Monitor alerts and possible solutions. -- Previously updated : 02/28/2024----# Troubleshooting problems in Azure Monitor alerts --This article discusses common problems in Azure Monitor alerts and notifications. [Azure Monitor alerts](./alerts-overview.md) proactively notify you when important conditions are found in your monitoring data. --For specific information about troubleshooting Azure metric or log search alerts, see: --- [Troubleshoot Azure Monitor metric alerts](alerts-troubleshoot-metric.md)-- [Troubleshoot Azure Monitor log search alerts](alerts-troubleshoot-log.md)--## Before troubleshooting --If the alert fires as intended, but the proper notifications don't perform as expected, [test your action group](./action-groups.md#test-an-action-group-in-the-azure-portal) first to ensure it's properly configured. --Otherwise, use the information in the rest of this article to troubleshoot your issue. --## I didn't receive the expected email --If you can see a fired alert in the Azure portal, but didn't receive the email that you configured, follow these steps: --1. **Was the email suppressed by an [alert processing rule](./alerts-processing-rules.md)**? -- Check by clicking on the fired alert in the portal, and look at the history tab for suppressed [action groups](./action-groups.md): - <!-- convertborder later --> - :::image type="content" source="media/alerts-troubleshoot/history-tab-alert-processing-rule-suppression.png" lightbox="media/alerts-troubleshoot/history-tab-alert-processing-rule-suppression.png" alt-text="Screenshot of alert history tab with suppression from alert processing rule." border="false"::: --1. **Is the type of action "Email Azure Resource Manager Role"?** -- This action only looks at Azure Resource Manager role assignments that are at the subscription scope, and of type *User* or *Group*. Make sure that you assigned the role at the subscription level, and not at the resource level or resource group level. - -1. **Are your email server and mailbox accepting external emails?** -- Verify that emails from these three addresses aren't blocked: - - azure-noreply@microsoft.com - - azureemail-noreply@microsoft.com - - alerts-noreply@mail.windowsazure.com -- It's common for internal mailing lists or distribution lists to block emails from external email addresses. Make sure that you allow mail from the above email addresses. - To test, add a regular work email address (not a mailing list) to the action group and see if alerts arrive to that email. --1. **Was the email processed by inbox rules or a spam filter?** -- Verify that there are no inbox rules that delete those emails or move them to a side folder. For example, inbox rules could catch specific senders or specific words in the subject. Also, check: -- - The spam settings of your email client (like Outlook, Gmail) - - The sender limits / spam settings / quarantine settings of your email server (like Exchange, Microsoft 365, G-suite) - - The settings of your email security appliance, if any (like Barracuda, Cisco). --1. **Have you accidentally unsubscribed from the action group?** - > [!NOTE] - > Keep in mind if you unsubscribe from an action group then all members from a distribution list will be unsubscribed as well. You can continue to use your distribution list email address. However, you will need to inform the users of your distribution list that if they unsubscribe, they are unsubscribing the whole distribution list rather than just themselves. A work around for this is to add the email address of all the users in the action group individually. One action group can contain up to 1000 email address. Then, if a specific user wants to unsubscribe, then they will be able to do so without affecting the other users. You will also be able to see which users have unsubscribed. -- The alert emails provide a link to unsubscribe from the action group. To check if you accidentally unsubscribed from this action group, either: -- 1. Open the action group in the portal and check the Status column: -- :::image type="content" source="media/alerts-troubleshoot/action-group-status.png" lightbox="media/alerts-troubleshoot/action-group-status.png" alt-text="Screenshot of action group status column."::: -- 2. Search your email for the unsubscribe confirmation: -- :::image type="content" source="media/alerts-troubleshoot/unsubscribe-action-group.png" lightbox="media/alerts-troubleshoot/unsubscribe-action-group.png" alt-text="Screenshot of email about being unsubscribed from alert action group."::: -- To subscribe again ΓÇô either use the link in the unsubscribe confirmation email you received, or remove the email address from the action group, and then add it back again. - -1. **Have you exceeded service limits by sending many emails going to a single email address?** -- Email is [rate limited](./action-groups.md#service-limits-for-notifications) to no more than 100 emails every hour to each email address. If you pass this threshold, no more email notifications are sent. Check if you received a message indicating that your email address is temporarily rate limited: -- :::image type="content" source="media/alerts-troubleshoot/email-paused.png" lightbox="media/alerts-troubleshoot/email-paused.png" alt-text="Screenshot of an email about being rate limited." border="false"::: -- If you want to receive a high volume of notifications without rate limiting, consider using a different action, such as: - - - Webhook - - Logic app - - Azure function - - Automation runbooks - - None of these actions are rate limited. --## I didn't receive the expected SMS, voice call, or push notification --If you can see a fired alert in the portal, but did not receive the SMS, voice call or push notification that you configured, follow these steps: --1. **Was the action suppressed by an [alert processing rule](./alerts-processing-rules.md)?** -- Check by clicking on the fired alert in the portal, and look at the history tab for suppressed [action groups](./action-groups.md): -- :::image type="content" source="media/alerts-troubleshoot/history-tab-alert-processing-rule-suppression.png" lightbox="media/alerts-troubleshoot/history-tab-alert-processing-rule-suppression.png" alt-text="Screenshot of alert history tab with suppression from alert processing rule." border="false"::: -- If that was unintentional, you can modify, disable, or delete the alert processing rule. - -1. **SMS/voice: Is your phone number correct?** -- Check the SMS action for typos in the country code or phone number. - -1. **SMS/voice: have you exceeded service limits?** -- SMS and voice calls are rate limited to no more than one notification every five minutes per phone number. If you pass this threshold, the notifications are dropped. -- - Voice call - check your call history and see if you had a different call from Azure in the preceding five minutes. - - SMS - check your SMS history for a message indicating that your phone number is rate limited. -- If you want to receive high-volume of notifications without rate limiting, consider using a different action, such as: - - - Webhook - - Logic app - - Azure function - - Automation runbooks - - None of these actions are rate limited. - -1. **SMS: Have you accidentally unsubscribed from the action group?** -- Open your SMS history and check if you opted out of SMS delivery from this specific action group (using the DISABLE action_group_short_name reply) or from all action groups (using the STOP reply). -- To subscribe again, either send the relevant SMS command (ENABLE action_group_short_name or START), or remove the SMS action from the action group, and then add it back again. For more information, see [SMS alert behavior in action groups](./action-groups.md#sms-replies). --1. **Have you accidentally blocked the notifications on your phone?** -- Most mobile phones allow you to block calls or SMS from specific phone numbers or short codes, or to block push notifications from specific apps (such as the Azure mobile app). To check if you accidentally blocked the notifications on your phone, search the documentation specific for your phone operating system and model, or test with a different phone and phone number. --## The expected action didn't trigger - -If you can see a fired alert in the portal, but its configured action didn't trigger, follow these steps: --1. **Was the action suppressed by an alert processing rule?** -- Check by clicking on the fired alert in the portal, and look at the history tab for suppressed [action groups](./action-groups.md): - <!-- convertborder later --> - :::image type="content" source="media/alerts-troubleshoot/history-tab-alert-processing-rule-suppression.png" lightbox="media/alerts-troubleshoot/history-tab-alert-processing-rule-suppression.png" alt-text="Screenshot of alert history tab with suppression from alert processing rule." border="false"::: - - If that was unintentional, you can modify, disable, or delete the alert processing rule. --1. **Did the webhook trigger?** -- 1. **Is the source IP address blocked?** - - Add the [IP addresses](../ip-addresses.md) that the webhook is called from to your allowlist. -- 1. **Does your webhook endpoint work correctly?** -- Verify the webhook endpoint you configured is correct and the endpoint is working correctly. Check your webhook logs or instrument its code so you could investigate (for example, log the incoming payload). -- 1. **Are you using the correct format for calling Slack or Microsoft Teams?** - Each of these endpoints expects a specific JSON format. Follow [these instructions](./alerts-logic-apps.md) to configure a logic app action instead. -- 1. **Did your webhook become unresponsive or return errors?** -- Webhook action groups generally follow these rules when called: - - When a webhook is invoked, if the first call fails, it's retried at least 1 more time, and up to five times (5 retries) at various delay intervals (5, 20, 40 seconds). - - The delay between 1st and 2nd attempt is 5 seconds - - The delay between 2nd and 3rd attempt is 20 seconds - - The delay between 3rd and 4th attempt is 5 seconds - - The delay between 4th and 5th attempt is 40 seconds - - The delay between 5th and 6th attempt is 5 seconds - - After retries attempted to call the webhook fail, no action group calls the endpoint for 15 minutes. - - The retry logic assumes that the call can be retried. The status codes: 408, 429, 503, 504, or `HttpRequestException`, `WebException`, or `TaskCancellationException` allow for the call to be retried. --## The action or notification happened more than once --If you received a notification for an alert (such as an email or an SMS) more than once, or the alert's action (such as webhook or Azure function) was triggered multiple times, follow these steps: --1. **Is it really the same alert?** -- In some cases, multiple similar alerts are fired at around the same time. So, it might just seem like the same alert triggered its actions multiple times. For example, an activity log alert rule might be configured to fire both when an event starts and finishes (succeeded or failed), by not filtering on the event status field. -- To check if these actions or notifications came from different alerts, examine the alert details, such as its timestamp and either the alert ID or its correlation ID. Alternatively, check the list of fired alerts in the portal. If that is the case, you would need to adapt the alert rule logic or otherwise configure the alert source. --1. **Does the action repeat in multiple action groups?** -- When an alert is fired, each of its action groups is processed independently. So, if an action (such as an email address) appears in multiple triggered action groups, it would be called once per action group. -- To check which action groups were triggered, check the alert history tab. You would see there both action groups defined in the alert rule, and action groups added to the alert by alert processing rules: - <!-- convertborder later --> - :::image type="content" source="media/alerts-troubleshoot/action-repeated-multi-action-groups.png" lightbox="media/alerts-troubleshoot/action-repeated-multi-action-groups.png" alt-text="Screenshot of multiple action groups in an alert." border="false"::: --## The action or notification has unexpected content --1. **Was there an outage that triggered the use of the fallback email provider?** -- Action Groups uses two different email providers to ensure email notification delivery. The primary email provider is resilient and quick but occasionally suffers outages. When there are outages, the secondary email provider handles email requests. The secondary provider is only a fallback solution. Due to provider differences, an email sent from our secondary provider might have a degraded email experience. The degradation results in slightly different email formatting and content. Since email templates differ in the two systems, maintaining parity across the two systems isn't feasible. -- Notifications generated by the fallback solution contain a note that says: -- "This is a degraded email experience. That means the formatting may be off or details could be missing. For more information on the degraded email experience, read here." - - If your notification doesn't contain this note and you received the alert, but believe some of its fields are missing or incorrect, check the payload format. --1. **What format did you use when configuring the alert rule?** -- Each action type (email, webhook, etc.) has two formats - the default, legacy format, and the [common schema format](./alerts-common-schema.md). When you create an action group, you specify the format of the action. Different actions in the action groups may have different formats. -- For example, for webhook actions: -- :::image type="content" source="media/alerts-troubleshoot/webhook.png" lightbox="media/alerts-troubleshoot/webhook.png" alt-text="Screenshot of webhook action schema option." border="false"::: -- Check if the format specified at the action level is what you expect. For example, you might have developed code that responds to alerts (webhook, function, logic app, etc.), expecting one format, but later in the action you or another person specified a different format. -- Also, check the payload format (JSON) for [activity log alerts](../alerts/activity-log-alerts-webhook.md), for [log search alerts](../alerts/alerts-log-webhook.md) (both Application Insights and log analytics), for [metric alerts](alerts-metric-near-real-time.md#payload-schema), for the [common alert schema](../alerts/alerts-common-schema.md), and for the deprecated [classic metric alerts](./alerts-webhooks.md). --### **The search results are not included in the log search alert notifications.** -- As of log search alerts API version 2021-08-01, search results were removed from alert notification payload. - Search results are only available for alert rules created with older API versions (2018-04-16). Creation of new alert rules through the Azure portal will, by default, create the rule with the newer version. - Follow [Changes to the log alert rule creation experience](./alerts-manage-alerts-previous-version.md#changes-to-the-log-search-alert-rule-creation-experience) to learn about the changes and recommended adjustments for using the updated version. --### **The `MetricValue` field contains "null" for resolved log search alert notifications.** -- This is by design. Stateful log search alerts use a [time-based resolution logic](./alerts-create-log-alert-rule.md#configure-alert-rule-details) rather than value-based. Azure Monitor is sending a null metric value since there's no value that caused the alert to resolve, but rather elapsed time. --### The dimensions list is empty or alert title doesn't contain a dimension name -- When you have a log search alert rule that returns no results, the alert can fire as expected, but the dimensions list is empty or alert title doesn't contain a dimension name. When a query does not return any rows, the resource ID field (which is the basis for populating dimension and title fields) is empty. - -### Information is missing in an activity log alert --[Activity log alerts](./alerts-types.md#activity-log-alerts) are alerts that are based on events written to the Azure activity log, such as events about creating, updating, or deleting Azure resources, service health and resource health events, or findings from Azure Advisor and Azure Policy. If you received an alert based on the activity log but some fields that you need are missing or incorrect, first check the events in the activity log itself. If the Azure resource did not write the fields you are looking for in its activity log event, those fields aren't included in the corresponding alert. --### The custom properties are missing from email, SMS, or push notifications. --Custom properties are only passed to the payload for actions, such as webhook, Azure function or logic apps. Custom properties aren't included in for notifications (email/SMS/push). --## The alert processing rule isn't working as expected --If you can see a fired alert in the portal, but a related alert processing rule didn't work as expected, follow these steps: --1. **Is the alert processing rule enabled?** -- Check the alert processing rule status field to verify that the related action role is enabled. By default, the portal only shows alert rules that are enabled, but you can change the filter to show all rules. -- :::image type="content" source="media/alerts-troubleshoot/alerts-troubleshoot-alert-processing-rules-status.png" lightbox="media/alerts-troubleshoot/alerts-troubleshoot-alert-processing-rules-status.png" alt-text="Screenshot of alert processing rule list highlighting the status field and status filter."::: - - If it isn't enabled, you can enable the alert processing rule by selecting it and clicking Enable. --1. **Is it a service health alert?** -- Service health alerts aren't affected by alert processing rules. So, if you have an alert processing rule configured for a scope that includes service health alerts, while the service health alerts are within the scope, the alert processing rule won't affect them. --1. **Did the alert processing rule process your alert?** -- Select the fired alert in the portal, and look at the **History** tab to see if the alert processing rule was processed. -- Here's an example of alert processing rule that suppresses all action groups: -- :::image type="content" source="media/alerts-troubleshoot/history-tab-alert-processing-rule-suppression.png" lightbox="media/alerts-troubleshoot/history-tab-alert-processing-rule-suppression.png" alt-text="Screenshot of alert history tab with suppression from alert processing rule." border="false"::: -- Here's an example of an alert processing rule that adds another action group: -- :::image type="content" source="media/alerts-troubleshoot/action-repeated-multi-action-groups.png" lightbox="media/alerts-troubleshoot/action-repeated-multi-action-groups.png" alt-text="Screenshot of action repeated in multiple action groups." border="false"::: --1. **Do the alert processing rule scope and filter match the fired alert?** -- If you think the alert processing rule should have fired but didn't, or that it shouldn't have fired but it did, carefully examine the alert processing rule scope and filter conditions and compare them to the properties of the fired alert. --## Problems creating, updating, or deleting alert processing rules in the Azure portal --If you received an error while trying to create, update or delete an [alert processing rule](./alerts-processing-rules.md), follow these steps: --1. **Check the permissions.** -- You should either have the [Monitoring Contributor built-in role](../../role-based-access-control/built-in-roles.md#monitoring-contributor), or the specific permissions related to alert processing rules and alerts. --1. **Check the alert processing rule parameters.** -- Check the [alert processing rule documentation](./alerts-processing-rules.md), or the [alert processing rule PowerShell Set-AzAlertProcessingRule](/powershell/module/az.alertsmanagement/set-azalertprocessingrule) command. --## Next steps --- [Troubleshoot Azure Monitor metric alerts](alerts-troubleshoot-metric.md)-- [Troubleshoot Azure Monitor log search alerts](alerts-troubleshoot-log.md) |
| azure-monitor | Alerts Types | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/alerts-types.md | - Title: Types of Azure Monitor alerts -description: This article explains the different types of Azure Monitor alerts and when to use each type. --- Previously updated : 03/10/2024-----# Choosing the right type of alert rule --This article describes the kinds of Azure Monitor alerts you can create. It helps you understand when to use each type of alert. -For more information about pricing, see the [pricing page](https://azure.microsoft.com/pricing/details/monitor/). --The types of alerts are: -- [Metric alerts](#metric-alerts)-- [Log search alerts](#log-alerts)-- [Activity log alerts](#activity-log-alerts)- - [Service Health alerts](#service-health-alerts) - - [Resource Health alerts](#resource-health-alerts) -- [Smart detection alerts](#smart-detection-alerts)-- [Prometheus alerts](#prometheus-alerts)--## Types of Azure Monitor alerts --|Alert type |When to use |Pricing information| -|||| -|Metric alert|Metric data is stored in the system already pre-computed. Metric alerts are useful when you want to be alerted about data that requires little or no manipulation. Use metric alerts if the data you want to monitor is available in metric data.|Each metric alert rule is charged based on the number of time series that are monitored. | -|Log search alert|You can use log search alerts to perform advanced logic operations on your data. If the data you want to monitor is available in logs, or requires advanced logic, you can use the robust features of Kusto Query Language (KQL) for data manipulation by using log search alerts.|Each log search alert rule is billed based on the interval at which the log query is evaluated. More frequent query evaluation results in a higher cost. For log search alerts configured for at-scale monitoring using splitting by dimensions, the cost also depends on the number of time series created by the dimensions resulting from your query. | -|Activity log alert|Activity logs provide auditing of all actions that occurred on resources. Use activity log alerts to be alerted when a specific event happens to a resource like a restart, a shutdown, or the creation or deletion of a resource. Service Health alerts and Resource Health alerts let you know when there's an issue with one of your services or resources.|For more information, see the [pricing page](https://azure.microsoft.com/pricing/details/monitor/).| -|Prometheus alerts|Prometheus alerts are used for alerting on Prometheus metrics stored in [Azure Monitor managed services for Prometheus](../essentials/prometheus-metrics-overview.md). The alert rules are based on the PromQL open-source query language. |Prometheus alert rules are only charged on the data queried by the rules. For more information, see the [pricing page](https://azure.microsoft.com/pricing/details/monitor/). | --## Metric alerts --A metric alert rule monitors a resource by evaluating conditions on the resource metrics at regular intervals. If the conditions are met, an alert is fired. A metric time-series is a series of metric values captured over a period of time. --You can create rules by using these metrics: -- [Platform metrics](alerts-metric-near-real-time.md#metrics-and-dimensions-supported)-- [Custom metrics](../essentials/metrics-custom-overview.md)-- [Application Insights custom metrics](../app/api-custom-events-metrics.md)-- [Selected logs from a Log Analytics workspace converted to metrics](alerts-metric-logs.md)--Metric alert rules include these features: -- You can use multiple conditions on an alert rule for a single resource.-- You can add granularity by [monitoring multiple metric dimensions](#narrow-the-target-using-dimensions). -- You can use [dynamic thresholds](#apply-advanced-machine-learning-with-dynamic-thresholds), which are driven by machine learning. -- You can configure if metric alerts are [stateful or stateless](alerts-overview.md#alerts-and-state). Metric alerts are stateful by default.--The target of the metric alert rule can be: -- A single resource, such as a virtual machine (VM). For supported resource types, see [Supported resources for metric alerts in Azure Monitor](alerts-metric-near-real-time.md).-- [Multiple resources](#monitor-multiple-resources-with-one-alert-rule) of the same type in the same Azure region, such as a resource group.--### Applying multiple conditions to a metric alert rule --When you create an alert rule for a single resource, you can apply multiple conditions. For example, you could create an alert rule to monitor an Azure virtual machine and alert when both "Percentage CPU is higher than 90%" and "Queue length is over 300 items". When an alert rule has multiple conditions, the alert fires when all the conditions in the alert rule are true and is resolved when at least one of the conditions is no longer true for three consecutive checks. --### Narrow the target using dimensions --For instructions on using dimensions in metric alert rules, see [Monitor multiple time series in a single metric alert rule](alerts-metric-multiple-time-series-single-rule.md). --### Monitor the same condition on multiple resources using splitting by dimensions --To monitor for the same condition on multiple Azure resources, you can use splitting by dimensions. When you use splitting by dimensions, you can create resource-centric alerts at scale for a subscription or resource group. Alerts are split into separate alerts by grouping combinations. Splitting on an Azure resource ID column makes the specified resource into the alert target. --You might also decide not to split when you want a condition applied to multiple resources in the scope. For example, you might want to fire an alert if at least five machines in the resource group scope have CPU usage over 80%. --### Monitor multiple resources with one alert rule --You can monitor at scale by applying the same metric alert rule to multiple resources of the same type for resources that exist in the same Azure region. Individual notifications are sent for each monitored resource. --The platform metrics for these services in the following Azure clouds are supported: --| Service | Resource Provider | Global Azure | Government | China | -|:|:|:-|:--|:--| -| Virtual machines |"Microsoft.Compute/virtualMachines"| Yes |Yes | Yes | -| SQL Server databases |"Microsoft.Sql/servers/databases"| Yes | Yes | Yes | -| SQL Server elastic pools |"Microsoft.Sql/servers/elasticpools"| Yes | Yes | Yes | -| NetApp files capacity pools |"Microsoft.NetApp/netAppAccounts/capacityPools"| Yes | Yes | Yes | -| NetApp files volumes |"Microsoft.NetApp/netAppAccounts/capacityPools/volumes"| Yes | Yes | Yes | -| Azure Key Vault |"Microsoft.KeyVault/vaults"| Yes | Yes | Yes | -| Azure Cache for Redis |"Microsoft.Cache/redis"| Yes | Yes | Yes | -| Azure Stack Edge devices |(There is no specific Resource provider for this resource. Because of how Stack edge devices work, **the metrics are retrieved from several resource providers**. You can check this documentation for more details regarding alerts for this resource: [Review alerts on Azure Stack Edge](../../databox-online/azure-stack-edge-alerts.md)) | Yes | Yes | Yes | -| Recovery Services vaults |"Microsoft.RecoveryServices/Vaults"| Yes | No | No | -| Azure Database for PostgreSQL - Flexible Server |"Microsoft.DBforPostgreSQL/flexibleServers"| Yes | Yes | Yes | -| Bare Metal Machines (Operator Nexus) |"Microsoft.NetworkCloud/bareMetalMachines"| Yes | Yes | Yes | -| Storage Appliances (Operator Nexus) |"Microsoft.NetworkCloud/storageAppliances"| Yes | Yes | Yes | -| Clusters (Operator Nexus) |"Microsoft.NetworkCloud/clusters"| Yes | Yes | Yes | -| Network Devices (Operator Nexus) |Microsoft.NetworkCloud/l2Networks, Microsoft.NetworkCloud/l3Networks| Yes | Yes | Yes | -| Data collection rules |"Microsoft.Insights/datacollectionrules"| Yes | Yes | Yes | -- > [!NOTE] - > Multi-resource metric alerts aren't supported for: - > - Alerting on VM guest metrics. - > - Alerting on VM network metrics (Network In Total, Network Out Total, Inbound Flows, Outbound Flows, Inbound Flows Maximum Creation Rate, and Outbound Flows Maximum Creation Rate). --You can specify the scope of monitoring with a single metric alert rule in one of three ways. For example, with VMs you can specify the scope as: --- A list of VMs in one Azure region within a subscription.-- All VMs in one Azure region in one or more resource groups in a subscription.-- All VMs in one Azure region in a subscription.--### Apply advanced machine learning with dynamic thresholds --Dynamic thresholds use advanced machine learning to: -- Learn the historical behavior of metrics.-- Identify patterns and adapt to metric changes over time, such as hourly, daily, or weekly patterns.-- Recognize anomalies that indicate possible service issues.-- Calculate the most appropriate threshold for the metric.--Machine learning continuously uses new data to learn more and make the threshold more accurate. Because the system adapts to the metrics' behavior over time, and alerts based on deviations from its pattern, you don't have to know the "right" threshold for each metric. --Dynamic thresholds help you: -- Create scalable alerts for hundreds of metric series with one alert rule. If you have fewer alert rules, you spend less time creating and managing alerts rules.-- Create rules without having to know what threshold to configure.-- Configure metric alerts by using high-level concepts without extensive domain knowledge about the metric.-- Prevent noisy (low precision) or wide (low recall) thresholds that donΓÇÖt have an expected pattern.-- Handle noisy metrics (such as machine CPU or memory) and metrics with low dispersion (such as availability and error rate).--See [dynamic thresholds](alerts-dynamic-thresholds.md) for detailed instructions on using dynamic thresholds in metric alert rules. --## <a name="log-alerts"></a>Log search alerts --A log search alert rule monitors a resource by using a Log Analytics query to evaluate resource logs at a set frequency. If the conditions are met, an alert is fired. Because you can use Log Analytics queries, you can perform advanced logic operations on your data and use the robust KQL features to manipulate log data. --The target of the log search alert rule can be: -- A single resource, such as a VM. -- A single container of resources, like a resource group or subscription.-- Multiple resources that use a [cross-resource query](../logs/cross-workspace-query.md).--Log search alerts can measure two different things, which can be used for different monitoring scenarios: -- **Table rows**: The number of rows returned can be used to work with events such as Windows event logs, Syslog, and application exceptions.-- **Calculation of a numeric column**: Calculations based on any numeric column can be used to include any number of resources. An example is CPU percentage.--You can configure if log search alerts are [stateful or stateless](alerts-overview.md#alerts-and-state). -Note that stateful log search alerts have these limitations: -- they can trigger up to 300 alerts per evaluation.-- you can have a maximum of 5000 alerts with the `fired` alert condition.--> [!NOTE] -> Log search alerts work best when you're trying to detect specific data in the logs, as opposed to when you're trying to detect a lack of data in the logs. Because logs are semi-structured data, they're inherently more latent than metric data on information like a VM heartbeat. To avoid misfires when you're trying to detect a lack of data in the logs, consider using [metric alerts](#metric-alerts). You can send data to the metric store from logs by using [metric alerts for logs](alerts-metric-logs.md). --### Monitor multiple instances of a resource using dimensions --You can use dimensions when you create log search alert rules to monitor the values of multiple instances of a resource with one rule. For example, you can monitor CPU usage on multiple instances running your website or app. Each instance is monitored individually. Notifications are sent for each instance. --### Monitor the same condition on multiple resources using splitting by dimensions --To monitor for the same condition on multiple Azure resources, you can use splitting by dimensions. When you use splitting by dimensions, you can create resource-centric alerts at scale for a subscription or resource group. Alerts are split into separate alerts by grouping combinations by using numerical or string columns. Splitting on the Azure resource ID column makes the specified resource into the alert target. --You might also decide not to split when you want a condition applied to multiple resources in the scope. For example, you might want to fire an alert if at least five machines in the resource group scope have CPU usage over 80%. --### Use the API for log search alert rules --Manage new rules in your workspaces by using the [ScheduledQueryRules](/rest/api/monitor/scheduledqueryrule-2021-08-01/scheduled-query-rules) API. --> [!NOTE] -> Log search alerts for Log Analytics used to be managed by using the legacy [Log Analytics Alert API](api-alerts.md). Learn more about [switching to the current ScheduledQueryRules API](alerts-log-api-switch.md). --### Log search alerts on your Azure bill --Log search alerts are listed under resource provider `microsoft.insights/scheduledqueryrules` with: -- Log search alerts on Application Insights shown with the exact resource name along with resource group and alert properties.-- Log search alerts on Log Analytics are shown with the exact resource name along with resource group and alert properties when they're created by using the scheduledQueryRules API.-- Log search alerts created from the [legacy Log Analytics API](./api-alerts.md) aren't tracked [Azure resources](../../azure-resource-manager/management/overview.md) and don't have enforced unique resource names. These alerts are still created on `microsoft.insights/scheduledqueryrules` as hidden resources, which have the resource naming structure `<WorkspaceName>|<savedSearchId>|<scheduleId>|<ActionId>`. Log search alerts on the legacy API are shown with the preceding hidden resource name along with resource group and alert properties.--> [!Note] -> Unsupported resource characters like <, >, %, &, \, ? and / are replaced with an underscore (_) in the hidden resource names. This character change is also reflected in the billing information. --## Activity log alerts --An activity log alert monitors a resource by checking the activity logs for a new activity log event that matches the defined conditions. --You might want to use activity log alerts for these types of scenarios: -- When a specific operation occurs on resources in a specific resource group or subscription. For example, you might want to be notified when:- - A VM in a production resource group is deleted. - - New roles are assigned to a user in your subscription. -- A Service Health event occurs. Service Health events include notifications of incidents and maintenance events that apply to resources in your subscription.--You can create an activity log alert on: -- Any of the activity log [event categories](../essentials/activity-log-schema.md), other than on alert events. -- Any activity log event in a top-level property in the JSON object.--Activity log alert rules are Azure resources, so they can be created by using an Azure Resource Manager template. They also can be created, updated, or deleted in the Azure portal. --An activity log alert only monitors events in the subscription in which the alert is created. --### Service Health alerts --Service Health alerts are a type of activity alert. [Service Health](../../service-health/overview.md) lets you know about outages, planned maintenance activities, and other health advisories because the authenticated Service Health experience knows which services and resources you currently use. --The best way to use Service Health is to set up Service Health alerts to notify you by using your preferred communication channels when service issues, planned maintenance, or other changes might affect the Azure services and regions you use. --### Resource Health alerts --Resource Health alerts are a type of activity alert. The [Resource Health overview](../../service-health/resource-health-overview.md) helps you diagnose and get support for service problems that affect your Azure resources. It reports on the current and past health of your resources. --Resource Health relies on signals from different Azure services to assess whether a resource is healthy. If a resource is unhealthy, Resource Health analyzes more information to determine the source of the problem. It also reports on actions that Microsoft is taking to fix the problem and identifies actions you can take to address it. --## Smart detection alerts --After you set up Application Insights for your project and your app generates a certain amount of data, smart detection takes 24 hours to learn the normal behavior of your app. Your app's performance has a typical pattern of behavior. Some requests or dependency calls will be more prone to failure than others, and the overall failure rate might go up as load increases. --Smart detection uses machine learning to find these anomalies. Smart detection monitors the data received from your app, and in particular the failure rates. Application Insights automatically alerts you in near real time if your web app experiences an abnormal rise in the rate of failed requests. --As data comes into Application Insights from your web app, smart detection compares the current behavior with the patterns seen over the past few days. If there's an abnormal rise in failure rate compared to previous performance, an analysis is triggered. --To help you triage and diagnose a problem, an analysis of the characteristics of the failures and related application data is provided in the alert details. There are also links to the Application Insights portal for further diagnosis. The feature doesn't need setup or configuration because it uses machine learning algorithms to predict the normal failure rate. --Although metric alerts tell you there might be a problem, smart detection starts the diagnostic work for you. It performs much of the analysis you would otherwise have to do yourself. You get the results neatly packaged, which helps you to quickly get to the root of the problem. --Smart detection works for web apps hosted in the cloud or on your own servers that generate application requests or dependency data. --## Prometheus alerts --Prometheus alerts are used to monitor metrics stored in [Azure Monitor managed services for Prometheus](../essentials/prometheus-metrics-overview.md). Prometheus alert rules are configured as part of [Prometheus rule groups](/azure/azure-monitor/essentials/prometheus-rule-groups). They fire when the result of a PromQL expression resolves to true. Fired Prometheus alerts are displayed and managed like other alert types. --## Next steps -- Get an [overview of alerts](alerts-overview.md).-- [Create an alert rule](alerts-log.md).-- Learn more about [smart detection](proactive-failure-diagnostics.md). |
| azure-monitor | Azure Cli Metrics Alert Sample | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/azure-cli-metrics-alert-sample.md | - Title: Create metric alert monitors in Azure CLI -description: Learn how to create metric alerts in Azure Monitor with Azure CLI commands. These samples create alerts for a virtual machine and an App Service Plan. --- Previously updated : 11/16/2023----# Create metric alert in Azure CLI --These samples create metric alert monitors in Azure Monitor by using Azure CLI commands. The first sample creates an alert for a virtual machine. The second command creates an alert that includes a dimension for an App Service Plan. ---## Create an alert --This alert monitors an existing virtual machine named `VM07` in the resource group named `ContosoVMRG`. --You can create a resource group by using the [az group create](/cli/azure/group#az-group-create) command. For information about creating virtual machines, see [Create a Windows virtual machine with the Azure CLI](/azure/virtual-machines/windows/quick-create-cli), [Create a Linux virtual machine with the Azure CLI](/azure/virtual-machines/linux/quick-create-cli), and the [az vm create](/cli/azure/vm#az-vm-create) command. --```azurecli -# resource group name: ContosoVMRG -# virtual machine name: VM07 --# Create scope -scope=$(az vm show --resource-group ContosoVMRG --name VM07 --output tsv --query id) --# Create action -action=$(az monitor action-group create --name ContosoWebhookAction \ - --resource-group ContosoVMRG --output tsv --query id \ - --action webhook https://alerts.contoso.com usecommonalertschema) --# Create condition -condition=$(az monitor metrics alert condition create --aggregation Average \ - --metric "Percentage CPU" --op GreaterThan --type static --threshold 90 --output tsv) --# Create metrics alert -az monitor metrics alert create --name alert-01 --resource-group ContosoVMRG \ - --scopes $scope --action $action --condition $condition --description "Test High CPU" -``` --This sample uses the `tsv` output type, which doesn't include unwanted symbols such as quotation marks. For more information, see [Use Azure CLI effectively](/cli/azure/use-cli-effectively). --## Create an alert with a dimension --This sample creates an App Service Plan and then creates a metrics alert for it. The example uses a dimension to specify that all instances of the App Service Plan will fall under this metric. The sample creates a resource group and application service plan. --```azurecli -# Create resource group -az group create --name ContosoRG --location eastus2 - -# Create application service plan -az appservice plan create --resource-group ContosoRG --name ContosoAppServicePlan \ - --is-linux --number-of-workers 4 --sku S1 - -# Create scope -scope=$(az appservice plan show --resource-group ContosoRG --name ContosoAppServicePlan \ - --output tsv --query id) - -# Create dimension -dim01=$(az monitor metrics alert dimension create --name Instance --value * --op Include --output tsv) - -# Create condition -condition=$(az monitor metrics alert condition create --aggregation Average \ - --metric CpuPercentage --op GreaterThan --type static --threshold 90 \ - --dimension $dim01 --output tsv) -``` --To see a list of the possible metrics, run the [az monitor metrics list-definitions](/cli/azure/monitor/metrics#az-monitor-metrics-list-definitions) command. The `--output` parameter displays the values in a readable format. ---```azurecli -az monitor metrics list-definitions --resource $scope --output table - -# Create metrics alert -az monitor metrics alert create --name alert-02 --resource-group ContosoRG \ - --scopes $scope --condition $condition --description "Service Plan High CPU" -``` --## Clean up deployment --If you created resource groups to test these commands, you can remove a resource group and all its contents by using the [az group delete](/cli/azure/group#az-group-delete) command: --```azurecli -az group delete --name ContosoVMRG --az group delete --name ContosoRG -``` --If you used existing resources that you want to keep, use the [az monitor metrics alert delete](/cli/azure/monitor/metrics/alert#az-monitor-metrics-alert-delete) command to delete your practice alerts: --```azurecli -az monitor metrics alert delete --name alert-01 --az monitor metrics alert delete --name alert-02 -``` --## Azure CLI commands used in this article --This article uses the following Azure CLI commands: --- [az appservice plan create](/cli/azure/appservice/plan#az-appservice-plan-create)-- [az appservice plan show](/cli/azure/appservice/plan#az-appservice-plan-show)-- [az group create](/cli/azure/group#az-group-create)-- [az group delete](/cli/azure/group#az-group-delete)-- [az monitor action-group create](/cli/azure/monitor/action-group#az-monitor-action-group-create)-- [az monitor metrics alert condition create](/cli/azure/monitor/metrics/alert#az-monitor-metrics-alert-condition-create)-- [az monitor metrics alert create](/cli/azure/monitor/metrics/alert#az-monitor-metrics-alert-create)-- [az monitor metrics alert delete](/cli/azure/monitor/metrics/alert#az-monitor-metrics-alert-delete)-- [az monitor metrics alert dimension create](/cli/azure/monitor/metrics/alert#az-monitor-metrics-alert-dimension-create)-- [az monitor metrics list-definitions](/cli/azure/monitor/metrics#az-monitor-metrics-list-definitions)-- [az vm show](/cli/azure/vm#az-vm-show)--## Next steps --- [Azure Monitor CLI samples](../cli-samples.md)-- [Understand how metric alerts work in Azure Monitor](alerts-metric-overview.md) |
| azure-monitor | It Service Management Connector Secure Webhook Connections | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/it-service-management-connector-secure-webhook-connections.md | - Title: 'IT Service Management Connector: Secure Webhook in Azure Monitor' -description: This article shows you how to connect your IT Service Management products and services with Secure Webhook in Azure Monitor to centrally monitor and manage ITSM work items. -- Previously updated : 07/30/2024----# Connect Azure to ITSM tools by using Secure Webhook --This article shows you how to configure the connection between your IT Service Management (ITSM) product or service by using Secure Webhook. --Secure Webhook is an updated version of [IT Service Management Connector (ITSMC)](./itsmc-overview.md). Both versions allow you to create work items in an ITSM tool when Azure Monitor sends alerts. The functionality includes metric, log search, and activity log alerts. --ITSMC uses username and password credentials. Secure Webhook has stronger authentication because it uses Microsoft Entra ID. Microsoft Entra ID is Microsoft's cloud-based identity and access management service. It helps users sign in and access internal or external resources. Using Microsoft Entra ID with ITSM helps to identify Azure alerts (through the Microsoft Entra application ID) that were sent to the external system. --## Secure Webhook architecture --The Secure Webhook architecture introduces the following new capabilities: --* **New action group**: Alerts are sent to the ITSM tool through the Secure Webhook action group, instead of the ITSM action group that ITSMC uses. -* **Microsoft Entra authentication**: Authentication occurs through Microsoft Entra ID instead of username and password credentials. --## Secure Webhook data flow --The steps of the Secure Webhook data flow are: --1. Azure Monitor sends an alert that's configured to use Secure Webhook. -1. The alert payload is sent by a Secure Webhook action to the ITSM tool. -1. The ITSM application checks with Microsoft Entra ID to determine if the alert is authorized to enter the ITSM tool. -1. If the alert is authorized, the application: -- 1. Creates a work item (for example, an incident) in the ITSM tool. - 1. Binds the ID of the configuration item to the customer management database. ---## Benefits of Secure Webhook --The main benefits of the integration are: --* **Better authentication**: Microsoft Entra ID provides more secure authentication without the timeouts that commonly occur in ITSMC. -* **Alerts resolved in the ITSM tool**: Metric alerts implement **fired** and **resolved** states. When the condition is met, the alert state is fired. When the condition isn't met anymore, the alert state is resolved. In ITSMC, alerts can't be resolved automatically. With Secure Webhook, the resolved state flows to the ITSM tool, so it's updated automatically. -* [Common alert schema](./alerts-common-schema.md): In ITSMC, the schema of the alert payload differs based on the alert type. In Secure Webhook, there's a common schema for all alert types. This common schema contains the configuration item for all alert types. All alert types will be able to bind their configuration item with the customer management database. --## Next steps --[Create ITSM work items from Azure alerts](./itsmc-overview.md) |
| azure-monitor | Itsm Connector Secure Webhook Connections Azure Configuration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/itsm-connector-secure-webhook-connections-azure-configuration.md | - Title: 'IT Service Management Connector: Secure Webhook in Azure Monitor - Azure configurations' -description: This article shows you how to configure Azure to connect your ITSM products or services with Secure Webhook in Azure Monitor to centrally monitor and manage ITSM work items. -- Previously updated : 07/30/2024----# Configure Azure to connect ITSM tools by using Secure Webhook --This article describes the required Azure configurations for using Secure Webhook. --<a name='register-with-azure-active-directory'></a> --## Register with Microsoft Entra ID --To register the application with Microsoft Entra ID: --1. Follow the steps in [Register an application with the Microsoft identity platform](../../active-directory/develop/quickstart-register-app.md). -1. In Microsoft Entra ID, select **Expose application**. -1. Select **Add** for **Application ID URI**. -- :::image type="content" source="media/itsm-connector-secure-webhook-connections-azure-configuration/azure-ad.png" lightbox="media/itsm-connector-secure-webhook-connections-azure-configuration/azure-ad.png" alt-text="Screenshot that shows the option for setting the U R I of the application I D."::: -1. Select **Save**. --## Define a service principal --The action group service is a first-party application. It has permission to acquire authentication tokens from your Microsoft Entra application to authenticate with ServiceNow. --As an optional step, you can define an application role in the created app's manifest. This way, you can further restrict access so that only certain applications with that specific role can send messages. This role has to be then assigned to the Action Group service principal. Tenant admin privileges are required. --You can do this step by using the same [PowerShell commands](../alerts/action-groups.md#secure-webhook-powershell-script). --## Create a Secure Webhook action group --After your application is registered with Microsoft Entra ID, you can create work items in your ITSM tool based on Azure alerts by using the Secure Webhook action in action groups. --Action groups provide a modular and reusable way of triggering actions for Azure alerts. You can use action groups with metric alerts, activity log alerts, and log search alerts in the Azure portal. --To learn more about action groups, see [Create and manage action groups in the Azure portal](../alerts/action-groups.md). --> [!NOTE] -> To map the configuration items to the ITSM payload when you define a Log Search alerts query, the query result must be included in the **Configuration items**, with one of these labels: -> - "Computer" -> - "Resource" -> - "_ResourceId" -> - "ResourceIdΓÇ¥ --To add a webhook to an action, follow these instructions for Secure Webhook: --1. In the [Azure portal](https://portal.azure.com/), search for and select **Monitor**. The **Monitor** pane consolidates all your monitoring settings and data in one view. -1. Select **Alerts** > **Manage actions**. -1. Select [Add action group](../alerts/action-groups.md#create-an-action-group-in-the-azure-portal) and fill in the fields. -1. Enter a name in the **Action group name** box and enter a name in the **Short name** box. The short name is used in place of a full action group name when notifications are sent by using this group. -1. Select **Secure Webhook**. -1. Select these details: - 1. Select the object ID of the Microsoft Entra instance that you registered. - 1. For the URI, paste in the webhook URL that you copied from the [ITSM tool environment](#configure-the-itsm-tool-environment). - 1. Set **Enable the common Alert Schema** to **Yes**. -- The following image shows the configuration of a sample Secure Webhook action: -- :::image type="content" source="media/itsm-connector-secure-webhook-connections-azure-configuration/secure-webhook.png" lightbox="media/itsm-connector-secure-webhook-connections-azure-configuration/secure-webhook.png" alt-text="Screenshot that shows a Secure Webhook action."::: --## Configure the ITSM tool environment -Secure Webhook supports connections with the following ITSM tools: - * [ServiceNow](./itsmc-secure-webhook-connections-servicenow.md) - * [BMC Helix](./itsmc-secure-webhook-connections-bmc.md) --To configure the ITSM tool environment: --1. Get the URI for the Secure Webhook definition. -1. Create definitions based on ITSM tool flow. --## Next steps --* [ServiceNow Secure Webhook configuration](./itsmc-secure-webhook-connections-servicenow.md) -* [BMC Secure Webhook configuration](./itsmc-secure-webhook-connections-bmc.md) |
| azure-monitor | Itsm Convert Servicenow To Webhook | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/itsm-convert-servicenow-to-webhook.md | - Title: Convert ITSM actions that send events to ServiceNow to secure webhook actions -description: Learn how to convert ITSM actions that send events to ServiceNow to secure webhook actions. - Previously updated : 01/30/2024------# Convert ITSM actions that send events to ServiceNow to secure webhook actions --> [!NOTE] -> As of September 2022, we are starting the 3-year process of deprecating support of using ITSM actions to send events to ServiceNow. --To migrate your ITSM connector to the new secure webhook integration, follow the [secure webhook configuration instructions](itsmc-secure-webhook-connections-servicenow.md). --If you're syncing work items between ServiceNow and an Azure Log Analytics workspace (bi-directional), follow the steps below to pull data from ServiceNow into your Log Analytics workspace. --## Pull data from your ServiceNow instance into a Log Analytics workspace --1. In the Azure portal, [create a Consumption logic app workflow](../../logic-apps/quickstart-create-example-consumption-workflow.md). -1. Create an HTTP GET request that uses the [ServiceNow **Table** API](https://developer.servicenow.com/dev.do#!/reference/api/sandiego/rest/c_TableAPI) to retrieve data from the ServiceNow instance. [See an example](https://docs.servicenow.com/bundle/sandiego-application-development/page/integrate/inbound-rest/concept/use-REST-API-Explorer.html#t_GetStartedRetrieveExisting) of how to use the Table call to retrieve incidents. -1. To see a list of tables in your ServiceNow instance, in ServiceNow, go to **System definitions**, then **Tables**. Example table names include: `change_request`, `em_alert`, `incident`, `em_event`. -- :::image type="content" source="media/itsmc-convert-servicenow-to-webhook/alerts-itsmc-service-now-tables.png" alt-text="Screenshot of the Service Now tables."::: --1. In Logic Apps, add a `Parse JSON` action on the results of the GET request you created in step 2. -1. Add a schema for the retrieved payload. You can use the **Use sample payload to generate schema** feature. See a sample schema for a `change_request` table. -- :::image type="content" source="media/itsmc-convert-servicenow-to-webhook/alerts-itsmc-service-now-parse-json.png" alt-text="Screenshot of a sample schema. "::: --1. Create a [Log Analytics workspace](../logs/quick-create-workspace.md#create-a-workspace). -1. Create a `for each` loop to insert each row of the data returned from the API into the data in the Log Analytics workspace. - - In the **Select an output from previous steps** section, enter the data set returned by the JSON parse action you created in step 4. - - Construct each row from the set that enters the loop. - - In the last step of the loop, use `Send data` to send the data to the Log Analytics workspace with these values. - - **Custom log name**: the name of the custom log you're using to save the data to the Log Analytics workspace. - - A connection to the LA workspace that you created in step 6. -- :::image type="content" source="media/itsmc-convert-servicenow-to-webhook/alerts-itsmc-service-now-for-loop.png" alt-text="Screenshot showing loop that imports data into a Log Analytics workspace."::: --The data is visible in the **Legacy custom logs** section of your Log Analytics workspace. --## Sample JSON schema for a change_request table --```json -{ - "properties": { - "content": { - "properties": { - "result": { - "items": { - "properties": { - "active": { - "type": "string" - }, - "activity_due": { - "type": "string" - }, - "additional_assignee_list": { - "type": "string" - }, - "approval": { - "type": "string" - }, - "approval_history": { - "type": "string" - }, - "approval_set": { - "type": "string" - }, - "assigned_to": { - "properties": { - "link": { - "type": "string" - }, - "value": { - "type": "string" - } - }, - "type": "object" - }, - "assignment_group": { - "type": "string" - }, - "backout_plan": { - "type": "string" - }, - "business_duration": { - "type": "string" - }, - "business_service": { - "type": "string" - }, - "cab_date": { - "type": "string" - }, - "cab_delegate": { - "type": "string" - }, - "cab_recommendation": { - "type": "string" - }, - "cab_required": { - "type": "string" - }, - "calendar_duration": { - "type": "string" - }, - "category": { - "type": "string" - }, - "change_plan": { - "type": "string" - }, - "chg_model": { - "type": "string" - }, - "close_code": { - "type": "string" - }, - "close_notes": { - "type": "string" - }, - "closed_at": { - "type": "string" - }, - "closed_by": { - "properties": { - "link": { - "type": "string" - }, - "value": { - "type": "string" - } - }, - "type": "object" - }, - "cmdb_ci": { - "properties": { - "link": { - "type": "string" - }, - "value": { - "type": "string" - } - }, - "type": "object" - }, - "comments": { - "type": "string" - }, - "comments_and_work_notes": { - "type": "string" - }, - "company": { - "type": "string" - }, - "conflict_last_run": { - "type": "string" - }, - "conflict_status": { - "type": "string" - }, - "contact_type": { - "type": "string" - }, - "correlation_display": { - "type": "string" - }, - "correlation_id": { - "type": "string" - }, - "delivery_plan": { - "type": "string" - }, - "delivery_task": { - "type": "string" - }, - "description": { - "type": "string" - }, - "due_date": { - "type": "string" - }, - "end_date": { - "type": "string" - }, - "escalation": { - "type": "string" - }, - "expected_start": { - "type": "string" - }, - "follow_up": { - "type": "string" - }, - "group_list": { - "type": "string" - }, - "impact": { - "type": "string" - }, - "implementation_plan": { - "type": "string" - }, - "justification": { - "type": "string" - }, - "knowledge": { - "type": "string" - }, - "location": { - "type": "string" - }, - "made_sla": { - "type": "string" - }, - "number": { - "type": "string" - }, - "on_hold": { - "type": "string" - }, - "on_hold_reason": { - "type": "string" - }, - "on_hold_task": { - "type": "string" - }, - "opened_at": { - "type": "string" - }, - "opened_by": { - "properties": { - "link": { - "type": "string" - }, - "value": { - "type": "string" - } - }, - "type": "object" - }, - "order": { - "type": "string" - }, - "outside_maintenance_schedule": { - "type": "string" - }, - "parent": { - "type": "string" - }, - "phase": { - "type": "string" - }, - "phase_state": { - "type": "string" - }, - "priority": { - "type": "string" - }, - "production_system": { - "type": "string" - }, - "reason": { - "type": "string" - }, - "reassignment_count": { - "type": "string" - }, - "requested_by": { - "properties": { - "link": { - "type": "string" - }, - "value": { - "type": "string" - } - }, - "type": "object" - }, - "requested_by_date": { - "type": "string" - }, - "review_comments": { - "type": "string" - }, - "review_date": { - "type": "string" - }, - "review_status": { - "type": "string" - }, - "risk": { - "type": "string" - }, - "risk_impact_analysis": { - "type": "string" - }, - "route_reason": { - "type": "string" - }, - "scope": { - "type": "string" - }, - "service_offering": { - "type": "string" - }, - "short_description": { - "type": "string" - }, - "sla_due": { - "type": "string" - }, - "start_date": { - "type": "string" - }, - "state": { - "type": "string" - }, - "std_change_producer_version": { - "type": "string" - }, - "sys_class_name": { - "type": "string" - }, - "sys_created_by": { - "type": "string" - }, - "sys_created_on": { - "type": "string" - }, - "sys_domain": { - "properties": { - "link": { - "type": "string" - }, - "value": { - "type": "string" - } - }, - "type": "object" - }, - "sys_domain_path": { - "type": "string" - }, - "sys_id": { - "type": "string" - }, - "sys_mod_count": { - "type": "string" - }, - "sys_tags": { - "type": "string" - }, - "sys_updated_by": { - "type": "string" - }, - "sys_updated_on": { - "type": "string" - }, - "task_effective_number": { - "type": "string" - }, - "test_plan": { - "type": "string" - }, - "time_worked": { - "type": "string" - }, - "type": { - "type": "string" - }, - "unauthorized": { - "type": "string" - }, - "universal_request": { - "type": "string" - }, - "upon_approval": { - "type": "string" - }, - "upon_reject": { - "type": "string" - }, - "urgency": { - "type": "string" - }, - "user_input": { - "type": "string" - }, - "watch_list": { - "type": "string" - }, - "work_end": { - "type": "string" - }, - "work_notes": { - "type": "string" - }, - "work_notes_list": { - "type": "string" - }, - "work_start": { - "type": "string" - } - }, - "required": [ - "parent", - "reason", - "watch_list", - "upon_reject", - "sys_updated_on", - "type", - "approval_history", - "number", - "test_plan", - "cab_delegate", - "requested_by_date", - "state", - "sys_created_by", - "knowledge", - "order", - "phase", - "cmdb_ci", - "delivery_plan", - "impact", - "active", - "work_notes_list", - "priority", - "sys_domain_path", - "cab_recommendation", - "production_system", - "review_date", - "business_duration", - "group_list", - "requested_by", - "change_plan", - "approval_set", - "implementation_plan", - "universal_request", - "end_date", - "short_description", - "correlation_display", - "delivery_task", - "work_start", - "additional_assignee_list", - "outside_maintenance_schedule", - "std_change_producer_version", - "service_offering", - "sys_class_name", - "closed_by", - "follow_up", - "reassignment_count", - "review_status", - "assigned_to", - "start_date", - "sla_due", - "comments_and_work_notes", - "escalation", - "upon_approval", - "correlation_id", - "made_sla", - "backout_plan", - "conflict_status", - "task_effective_number", - "sys_updated_by", - "opened_by", - "user_input", - "sys_created_on", - "on_hold_task", - "sys_domain", - "route_reason", - "closed_at", - "review_comments", - "business_service", - "time_worked", - "chg_model", - "expected_start", - "opened_at", - "work_end", - "phase_state", - "cab_date", - "work_notes", - "close_code", - "assignment_group", - "description", - "on_hold_reason", - "calendar_duration", - "close_notes", - "sys_id", - "contact_type", - "cab_required", - "urgency", - "scope", - "company", - "justification", - "activity_due", - "comments", - "approval", - "due_date", - "sys_mod_count", - "on_hold", - "sys_tags", - "conflict_last_run", - "unauthorized", - "location", - "risk", - "category", - "risk_impact_analysis" - ], - "type": "object" - }, - "type": "array" - } - }, - "type": "object" - }, - "schema": { - "properties": { - "properties": { - "properties": { - "result": { - "properties": { - "items": { - "properties": { - "properties": { - "properties": { - "active": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "activity_due": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "additional_assignee_list": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "approval": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "approval_history": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "approval_set": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "assigned_to": { - "properties": { - "properties": { - "properties": { - "link": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "value": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - } - }, - "type": "object" - }, - "type": { - "type": "string" - } - }, - "type": "object" - }, - "assignment_group": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "backout_plan": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "business_duration": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "business_service": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "cab_date": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "cab_delegate": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "cab_recommendation": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "cab_required": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "calendar_duration": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "category": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "change_plan": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "chg_model": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "close_code": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "close_notes": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "closed_at": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "closed_by": { - "properties": { - "properties": { - "properties": { - "link": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "value": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - } - }, - "type": "object" - }, - "type": { - "type": "string" - } - }, - "type": "object" - }, - "cmdb_ci": { - "properties": { - "properties": { - "properties": { - "link": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "value": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - } - }, - "type": "object" - }, - "type": { - "type": "string" - } - }, - "type": "object" - }, - "comments": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "comments_and_work_notes": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "company": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "conflict_last_run": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "conflict_status": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "contact_type": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "correlation_display": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "correlation_id": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "delivery_plan": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "delivery_task": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "description": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "due_date": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "end_date": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "escalation": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "expected_start": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "follow_up": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "group_list": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "impact": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "implementation_plan": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "justification": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "knowledge": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "location": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "made_sla": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "number": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "on_hold": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "on_hold_reason": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "on_hold_task": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "opened_at": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "opened_by": { - "properties": { - "properties": { - "properties": { - "link": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "value": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - } - }, - "type": "object" - }, - "type": { - "type": "string" - } - }, - "type": "object" - }, - "order": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "outside_maintenance_schedule": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "parent": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "phase": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "phase_state": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "priority": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "production_system": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "reason": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "reassignment_count": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "requested_by": { - "properties": { - "properties": { - "properties": { - "link": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "value": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - } - }, - "type": "object" - }, - "type": { - "type": "string" - } - }, - "type": "object" - }, - "requested_by_date": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "review_comments": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "review_date": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "review_status": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "risk": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "risk_impact_analysis": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "route_reason": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "scope": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "service_offering": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "short_description": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "sla_due": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "start_date": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "state": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "std_change_producer_version": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "sys_class_name": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "sys_created_by": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "sys_created_on": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "sys_domain": { - "properties": { - "properties": { - "properties": { - "link": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "value": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - } - }, - "type": "object" - }, - "type": { - "type": "string" - } - }, - "type": "object" - }, - "sys_domain_path": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "sys_id": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "sys_mod_count": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "sys_tags": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "sys_updated_by": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "sys_updated_on": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "task_effective_number": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "test_plan": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "time_worked": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "type": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "unauthorized": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "universal_request": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "upon_approval": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "upon_reject": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "urgency": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "user_input": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "watch_list": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "work_end": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "work_notes": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "work_notes_list": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - }, - "work_start": { - "properties": { - "type": { - "type": "string" - } - }, - "type": "object" - } - }, - "type": "object" - }, - "required": { - "items": { - "type": "string" - }, - "type": "array" - }, - "type": { - "type": "string" - } - }, - "type": "object" - }, - "type": { - "type": "string" - } - }, - "type": "object" - } - }, - "type": "object" - }, - "type": { - "type": "string" - } - }, - "type": "object" - } - }, - "type": "object" -} --``` --## Next steps --* [ITSM Connector overview](itsmc-overview.md) -* [Create ITSM work items from Azure alerts](./itsmc-definition.md#create-itsm-work-items-from-azure-alerts) -* [Troubleshooting problems in the ITSM Connector](./itsmc-resync-servicenow.md) |
| azure-monitor | Itsmc Connections Servicenow | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/itsmc-connections-servicenow.md | - Title: Connect ServiceNow with IT Service Management Connector -description: Learn how to connect ServiceNow with the IT Service Management Connector (ITSMC) in Azure Monitor to centrally monitor and manage ITSM work items. -- Previously updated : 7/30/2024----# Connect ServiceNow with IT Service Management Connector --This article shows you how to configure the connection between a ServiceNow instance and the IT Service Management Connector (ITSMC) in Log Analytics, so you can centrally manage your IT Service Management (ITSM) work items. --> [!NOTE] -> As of September 2022, we are starting the 3-year process of deprecating support for using ITSM actions to send alerts and events to ServiceNow. --## Prerequisites -Ensure that you meet the following prerequisites for the connection. --### ITSMC installation --For information about installing ITSMC, see [Add the IT Service Management Connector solution](./itsmc-definition.md#install-it-service-management-connector). --> [!NOTE] -> ITSMC supports only the official software as a service (SaaS) offering from ServiceNow. Private deployments of ServiceNow are not supported. --### OAuth setup --ServiceNow supported versions include Washington, Vancouver, Utah, Tokyo, San Diego, Rome, Quebec, Paris, Orlando, New York, Madrid, London, Kingston, Jakarta, Istanbul, Helsinki, and Geneva. --ServiceNow admins must generate a client ID and client secret for their ServiceNow instance. See the following information as required: --- [Set up OAuth for Vancouver](https://docs.servicenow.com/bundle/vancouver-platform-administration/page/administer/general/concept/intro-now-platform-landing.html)-- [Set up OAuth for Utah](https://docs.servicenow.com/bundle/utah-platform-administration/page/administer/security/task/t_SettingUpOAuth.html)-- [Set up OAuth for Tokyo](https://docs.servicenow.com/bundle/tokyo-platform-administration/page/administer/security/task/t_SettingUpOAuth.html)-- [Set up OAuth for San Diego](https://docs.servicenow.com/bundle/sandiego-platform-administration/page/administer/security/task/t_SettingUpOAuth.html)-- [Set up OAuth for Rome](https://docs.servicenow.com/bundle/rome-platform-administration/page/administer/security/task/t_SettingUpOAuth.html)-- [Set up OAuth for Quebec](https://docs.servicenow.com/bundle/quebec-platform-administration/page/administer/security/task/t_SettingUpOAuth.html)-- [Set up OAuth for Paris](https://docs.servicenow.com/bundle/paris-platform-administration/page/administer/security/task/t_SettingUpOAuth.html)--As a part of setting up OAuth, we recommend: --1. [Create an endpoint for clients to access the instance](https://docs.servicenow.com/bundle/rome-platform-administration/page/administer/security/task/t_CreateEndpointforExternalClients.html). --1. Update the lifespan of the refresh token: -- 1. On the **ServiceNow** pane, search for **System OAuth**, and then select **Application Registry**. - 1. Select the name of the OAuth that was defined, and change **Refresh Token Lifespan** to **7,776,000 seconds** (90 days). - 1. Select **Update**. --1. Establish an internal procedure to ensure that the connection remains alive. A couple of days before the expected expiration of the refresh token lifespan, perform the following operations: -- 1. [Complete a manual sync process for ITSM connector configuration](./itsmc-resync-servicenow.md). -- 1. Revoke to the old refresh token. We don't recommend keeping old keys for security reasons. - - 1. On the **ServiceNow** pane, search for **System OAuth**, and then select **Manage Tokens**. - - 1. Select the old token from the list according to the OAuth name and expiration date. -- :::image type="content" source="media/itsmc-connections-servicenow/snow-system-oauth.png" lightbox="media/itsmc-connections-servicenow/snow-system-oauth.png" alt-text="Screenshot that shows a list of tokens for OAuth."::: - 1. Select **Revoke Access** > **Revoke**. --## Install the user app and create the user role --Use the following procedure to install the ServiceNow user app and create the integration user role for it. You'll use these credentials to make the ServiceNow connection in Azure. --> [!NOTE] -> ITSMC supports only the official user app for Microsoft Log Analytics integration that's downloaded from the ServiceNow store. ITSMC does not support any code ingestion on the ServiceNow side or any application that's not part of the official ServiceNow solution. --1. Visit the [ServiceNow store](https://store.servicenow.com/sn_appstore_store.do#!/store/application/ab0265b2dbd53200d36cdc50cf961980/1.0.1) and install **User App for ServiceNow and Microsoft OMS Integration** in your ServiceNow instance. - - >[!NOTE] - >As part of the ongoing transition from Microsoft Operations Management Suite (OMS) to Azure Monitor, OMS is now called Log Analytics. -2. After installation, go to the left navigation bar of the ServiceNow instance, and then search for and select **Microsoft OMS integrator**. -3. Select **Installation Checklist**. -- The status is displayed as **Not complete** because the user role is not yet created. --4. In the text box next to **Create integration user**, enter the name for the user who can connect to ITSMC in Azure. -5. Enter the password for this user, and then select **OK**. --The newly created user is displayed with the default roles assigned: --- personalize_choices-- import_transformer-- x_mioms_microsoft.user-- itil-- template_editor-- view_changer--After you successfully create the user, the status of **Check Installation Checklist** moves to **Completed** and lists the details of the user role created for the app. --> [!NOTE] -> ITSMC can send incidents to ServiceNow without any other modules installed on your ServiceNow instance. If you're using the EventManagement module in your ServiceNow instance and want to create events or alerts in ServiceNow by using the connector, add the following roles to the integration user: -> -> - evt_mgmt_integration -> - evt_mgmt_operator --## Create a connection -Use the following procedure to create a ServiceNow connection. --> [!NOTE] -> The alerts that are sent from Azure Monitor can create one of the following elements in ServiceNow: events, incidents, or alerts. --1. In Azure portal, go to **All Resources** and look for **ServiceDesk(YourWorkspaceName)**. --2. Under **Workspace Data Sources**, select **ITSM Connections**. -- :::image type="content" source="media/itsmc-overview/add-new-itsm-connection.png" lightbox="media/itsmc-overview/add-new-itsm-connection.png" alt-text="Screenshot that shows selection of a data source."::: --3. At the top of the right pane, select **Add**. --4. Provide the information as described in the following table, and then select **OK**. -- | **Field** | **Description** | - | | | - | **Connection Name** | Enter a name for the ServiceNow instance that you want to connect with ITSMC. You use this name later in Log Analytics when you configure ITSM work items and view detailed analytics. | - | **Partner Type** | Select **ServiceNow**. | - | **Server Url** | Enter the URL of the ServiceNow instance that you want to connect to ITSMC. The URL should point to a supported SaaS version with the suffix *.servicenow.com* (for example `https://XXXXX.service-now.com/`).| - | **Username** | Enter the integration username that you created in the ServiceNow app to support the connection to ITSMC.| - | **Password** | Enter the password associated with this username. **Note**: The username and password are used for generating authentication tokens only. They're not stored anywhere within the ITSMC service. | - | **Client Id** | Enter the client ID that you want to use for OAuth2 authentication, which you generated earlier. For more information on generating a client ID and a secret, see [Set up OAuth](/azure/azure-monitor/alerts/itsmc-connections-servicenow#oauth-setup). | - | **Client Secret** | Enter the client secret generated for this ID. | - | **Data Sync Scope (in Days)** | Enter the number of past days that you want the data from. The limit is 120 days. | - | **Work Items To Sync** | Select the ServiceNow work items that you want to sync to Azure Log Analytics, through ITSMC. The selected values are imported into Log Analytics. Options are incidents and change requests.| - | **Create New Configuration Item in ITSM Product** | Select this option if you want to create the configuration items in the ITSM product. When it's selected, ITSMC creates configuration items (if none exist) in the supported ITSM system. It's disabled by default. | ---When you're successfully connected and synced: --- Selected work items from the ServiceNow instance are imported into Log Analytics. You can view the summary of these work items on the **IT Service Management Connector** tile.--- You can create incidents from log search alerts or log records, or from Azure alerts in this ServiceNow instance.--> [!NOTE] -> ServiceNow has a rate limit for requests per hour. To configure the limit, define **Inbound REST API rate limiting** in the ServiceNow instance. --## Payload structure --The payload that is sent to ServiceNow has a common structure. The structure has a section of `<Description>` that contains all the alert data. --The structure of the payload for all alert types except log search V1 alert is [common schema](./alerts-common-schema.md). --For Log search alerts (V1 only), the structure is: --- Alert (alert rule name) : \<value>-- Search Query : \<value>-- Search Start Time(UTC) : \<value>-- Search End Time(UTC) : \<value>-- AffectedConfigurationItems : [\<list of impacted configuration items>]--## Next steps --* [ITSM Connector overview](itsmc-overview.md) -* [Create ITSM work items from Azure alerts](./itsmc-definition.md#create-itsm-work-items-from-azure-alerts) -* [Troubleshooting problems in the ITSM Connector](./itsmc-resync-servicenow.md) |
| azure-monitor | Itsmc Connector Deletion | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/itsmc-connector-deletion.md | - Title: Delete unused ITSM connectors -description: This article provides an explanation of how to delete ITSM connectors and the action groups that are associated with it. -- Previously updated : 08/07/2023-----# Delete unused ITSM connectors --The process of deleting unused IT service management (ITSM) connectors has two phases. You delete all the actions that are associated with an ITSM connector, and then you delete the connector itself. You delete the actions first because actions without a connector might cause errors in your subscription. --## Delete associated actions --1. In the Azure portal, select Monitor, then **Alerts** and **Action groups**. -- :::image type="content" source="media/itsmc-connector-deletion/monitor-alerts-page.png" lightbox="media/itsmc-connector-deletion/monitor-alerts-page.png" alt-text="Screenshot of the Alerts page in the Azure portal. Monitor in the portal menu, Alerts on the left pane, and Action groups button are highlighted."::: --1. Select the action group associated with the ITSM Connector you want to delete. -- :::image type="content" source="media/itsmc-connector-deletion/select-action-group.png" lightbox="media/itsmc-connector-deletion/select-action-group.png" alt-text="Screenshot of the Action groups page in the Azure portal."::: --1. In the action group window, review the information and make sure this is the action group you want to delete. Then, select **Delete**. -- :::image type="content" source="media/itsmc-connector-deletion/delete-action-group.png" lightbox="media/itsmc-connector-deletion/delete-action-group.png" alt-text="Screenshot of the Action groups page in the Azure portal with an action group selected. The Delete button for deleting an action group is highlighted."::: --## Delete the connector --1. In the Azure portal, select **All resources**, then find and select your Service Desk. -- :::image type="content" source="media/itsmc-dashboard/select-service-desk.png" lightbox="media/itsmc-dashboard/select-service-desk.png" alt-text="Screenshot of the All resources page in the Azure portal. Only resources whose name includes the ServiceDes filter criteria are listed."::: --1. In the Service Desk window, select **ITSM Connections** from the **Workspace Data Sources** section on the left pane. -- :::image type="content" source="media/itsmc-resync-servicenow/select-itsm-connections.png" lightbox="media/itsmc-resync-servicenow/select-itsm-connections.png" alt-text="Screenshot of a Solution resource in the Azure portal. ITSM Connections on the left pane is highlighted."::: --1. Select the connector you want to delete. --1. In the **Edit ITSM** window, select **Delete**. -- :::image type="content" source="media/itsmc-connector-deletion/delete-itsm-connector.png" lightbox="media/itsmc-connector-deletion/delete-itsm-connector.png" alt-text="Screenshot of the Edit ITSM window in the Azure portal with the Delete button highlighted."::: --## Next steps --* [Troubleshooting problems in an ITSM connector](./itsmc-resync-servicenow.md) |
| azure-monitor | Itsmc Dashboard Errors | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/itsmc-dashboard-errors.md | - Title: Connector status errors in the ITSMC dashboard -description: Learn about common errors that exist in the IT Service Management Connector dashboard. -- Previously updated : 08/06/2024----# Connector status errors in the ITSMC dashboard --The IT Service Management Connector (ITSMC) dashboard presents errors that can help you to fix problems in your connector. --The following sections describe common errors that appear in the connector status section of the dashboard and how you can resolve them. --## Unexpected response --**Error**: "Unexpected response from ServiceNow along with success status code. Response: { "import_set": "{import_set_id}", "staging_table": "x_mioms_microsoft_oms_incident", "result": [ { "transform_map": "OMS Incident", "table": "incident", "status": "error", "error_message": "{Target record not found|Invalid table|Invalid staging table" }" --**Cause**: ServiceNow returns this error when: --* A custom script deployed in a ServiceNow instance causes incidents to be ignored. -* "OMS Integrator app" code was modified on the ServiceNow side (for example, through the `onBefore` script). --**Resolution**: Disable all custom scripts or code modifications. --## Exception update failure --**Error**: "{"error":{"message":"Operation Failed","detail":"ACL Exception Update Failed due to security constraints"}" --**Cause**: ServiceNow permissions are misconfigured. --**Resolution**: Check that all the roles are properly assigned as [specified](itsmc-connections-servicenow.md#install-the-user-app-and-create-the-user-role). --## Problem sending a request --**Error**: "An error occurred while sending the request." --**Cause**: A ServiceNow instance is unavailable. --**Resolution**: Check your instance in ServiceNow. It might be deleted or unavailable. --## ServiceNow rate problem --**Error**: "ServiceDeskHttpBadRequestException: StatusCode=429" --**Cause**: ServiceNow rate limits are too high or too low. --**Resolution**: Increase or cancel the rate limits in the ServiceNow instance, as explained in the ServiceNow documentation for each release: --* [Rate limit troubleshooting for ServiceNow Orlando](https://docs.servicenow.com/bundle/orlando-application-development/page/integrate/inbound-rest/task/investigate-rate-limit-violations.html) -* [Rate limit troubleshooting for ServiceNow Paris](https://docs.servicenow.com/bundle/paris-application-development/page/integrate/inbound-rest/task/investigate-rate-limit-violations.html) -* [Rate limit troubleshooting for ServiceNow Quebec](https://docs.servicenow.com/bundle/quebec-application-development/page/integrate/inbound-rest/task/investigate-rate-limit-violations.html) -* [Rate limit troubleshooting for ServiceNow Rome](https://docs.servicenow.com/bundle/rome-application-development/page/integrate/inbound-rest/task/investigate-rate-limit-violations.html) --## Invalid refresh token --**Error**: - * "AccessToken and RefreshToken invalid. User needs to authenticate again." - * "Could not sync templates configuration for Event,Alert,Incident. See Exception Message for more details." --**Cause**: A refresh token is expired. --**Resolution**: Sync ITSMC to generate a new refresh token, as explained in [How to manually fix sync problems](./itsmc-resync-servicenow.md). --## Missing connector --**Error**: "Could not create/update work item for alert {alertName}. ITSM Connector {connectionIdentifier} does not exist or was deleted." --**Cause**: ITSMC was deleted. --**Resolution**: ITSMC was deleted, but defined IT Service Management (ITSM) action groups are still associated with it. There are three options to solve this problem: --* Find and disable or delete such action groups. -* [Reconfigure the action groups](./itsmc-definition.md#create-itsm-work-items-from-azure-alerts) to use an existing ITSMC instance. -* [Create a new ITSMC instance](./itsmc-definition.md#create-an-itsm-connection) and [reconfigure the action groups to use it](itsmc-definition.md#create-itsm-work-items-from-azure-alerts). --## Lack of connection details --**Error**:"Something went wrong. Could not get connection details." This error appears when you define an ITSM action group. --**Cause**: Such an error appears in either of these situations: --* A newly created ITSM Connector instance has yet to finish the initial sync. -* The connector wasn't defined correctly. --**Resolution**: --* When a new ITSMC instance is created, it starts syncing information from the ITSM system, such as work item templates and work items. [Sync ITSMC to generate a new refresh token](./itsmc-resync-servicenow.md). -* [Review your connection details in ITSMC](./itsmc-connections-servicenow.md#create-a-connection) and check that ITSMC can successfully [sync](./itsmc-resync-servicenow.md). ---## IP restrictions -**Error**: -* "Failed to add ITSM Connection named "XXX" due to Bad Request. Error: Bad request. Invalid parameters provided for connection. Http Exception: Status Code Forbidden." -* "Failed to update ITSM Connection credentials" --**Cause**: The IP address of the ITSM application doesn't allow ITSM connections from partner ITSM tools. --**Resolution**: To allow ITSM connections make sure ActionGroup network tag is allowed on your network. --## Authentication -**Error**: "User Not Authenticated" --**Cause**: This error can occur in two cases: - - The token needs to be refreshed. - - User integration rights are missing. --**Resolution**: -- If the integration worked for you previously, the refresh token may have expired. [Sync with the ITSM Connector to generate a new refresh token](./itsmc-resync-servicenow.md). -- If the integration never worked, it may be missing integration user rights. See the instructions to [install the user app and create the user role](./itsmc-connections-servicenow.md#install-the-user-app-and-create-the-user-role).- |
| azure-monitor | Itsmc Dashboard | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/itsmc-dashboard.md | - Title: Investigate errors by using the ITSMC dashboard -description: Learn how to use the IT Service Management Connector dashboard to investigate errors. -- Previously updated : 07/09/2023----# Investigate errors by using the ITSMC dashboard --This article contains information about the IT Service Management Connector (ITSMC) dashboard. The dashboard helps you to investigate the status of your connector. --## View errors --To view errors in the dashboard: --1. In the Azure portal, select **All resources**, then find and select your Service Desk. -- :::image type="content" source="media/itsmc-dashboard/select-service-desk.png" lightbox="media/itsmc-dashboard/select-service-desk.png" alt-text="Screenshot of the All resources page in the Azure portal. Only resources whose name includes the ServiceDes filter criteria are listed."::: --1. In the Service Desk window, select **View Summary**. -- :::image type="content" source="media/itsmc-dashboard/view-summary.png" lightbox="media/itsmc-dashboard/view-summary.png" alt-text="Screenshot of a Solution resource in the Azure portal. The View Summary button is highlighted."::: --1. Select the graph that appears in the **IT Service Management Connector** section. --1. The IT Service Management Connector Dashboard opens with information about status and errors. -- :::image type="content" source="media/itsmc-resync-servicenow/connector-dashboard.png" lightbox="media/itsmc-resync-servicenow/connector-dashboard.png" alt-text="Screenshot that shows connector status on the dashboard."::: --## Understand dashboard elements --The dashboard contains information on the alerts that were sent to the ITSM tool through this connector. The dashboard is split into four parts. --### Created work items --In the **WORK ITEMS CREATED** area, the graph and the table below it contain the count of the work items per type. If you select the graph or the table, you can see more details about the work items. ---### Affected computers --In the **IMPACTED COMPUTERS** area, the table lists computers and their associated work items. By selecting rows in the tables, you can get more details about the computers. --The table contains a limited number of rows. If you want to see all the rows, select **See all**. ---### Connector status --In the **CONNECTOR STATUS** area, the graph and the table below it contain messages about the status of the connector. By selecting the graph or rows in the table, you can get more details about the messages. --The table contains a limited number of rows. If you want to see all the rows, select **See all**. --To learn more about the messages in the table, see [this article](itsmc-dashboard-errors.md). ---### Alert rules --In the **ALERT RULES** area, the table contains information on the number of alert rules that were detected. By selecting rows in the table, you can get more details about the detected rules. - -The table contains a limited number of rows. If you want to see all the rows, select **See all**. - |
| azure-monitor | Itsmc Definition | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/itsmc-definition.md | - Title: IT Service Management Connector in Log Analytics -description: This article provides an overview of IT Service Management Connector (ITSMC) and information about using it to monitor and manage ITSM work items in Log Analytics and resolve problems quickly. -- Previously updated : 03/07/2024-----# Connect Azure to ITSM tools by using IT Service Management ---This article provides information about how to configure IT Service Management Connector (ITSMC) in Log Analytics to centrally manage your IT Service Management (ITSM) work items. --## Install IT Service Management Connector --Before you create a connection, install ITSMC. --1. In the Azure portal, select **Create a resource**. -- :::image type="content" source="media/itsmc-overview/azure-add-new-resource.png" lightbox="media/itsmc-overview/azure-add-new-resource.png" alt-text="Screenshot that shows the menu item for creating a resource."::: --1. Search for **IT Service Management Connector** in Azure Marketplace. Then select **Create**. -- :::image type="content" source="media/itsmc-overview/add-itsmc-solution.png" lightbox="media/itsmc-overview/add-itsmc-solution.png" alt-text="Screenshot that shows the Create button in Azure Marketplace."::: --1. In the **Azure Log Analytics Workspace** section, select the Log Analytics workspace where you want to install ITSMC. - > [!NOTE] - > You can install ITSMC in Log Analytics workspaces only in the following regions: East US, West US 2, South Central US, West Central US, US Gov Arizona, US Gov Virginia, Canada Central, West Europe, South UK, Southeast Asia, Japan East, Central India, and Australia Southeast. --1. In the **Azure Log Analytics Workspace** section, select the resource group where you want to create the ITSMC resource. -- :::image type="content" source="media/itsmc-overview/itsmc-solution-workspace.png" lightbox="media/itsmc-overview/itsmc-solution-workspace.png" alt-text="Screenshot that shows the Azure Log Analytics Workspace section."::: -- > [!NOTE] - > As part of the ongoing transition from Microsoft Operations Management Suite to Azure Monitor, Operations Management workspaces are now called *Log Analytics workspaces*. --1. Select **OK**. --When the ITSMC resource is deployed, a notification appears in the upper-right corner of the screen. --## Create an ITSM connection --After you've installed ITSMC, and prepped your ITSM tool, create an ITSM connection. --1. [Configure ServiceNow](./itsmc-connections-servicenow.md) to allow the connection from ITSMC. -1. In **All resources**, look for **ServiceDesk(*your workspace name*)**. -- :::image type="content" source="media/itsmc-definition/create-new-connection-from-resource.png" lightbox="media/itsmc-definition/create-new-connection-from-resource.png" alt-text="Screenshot that shows recent resources in the Azure portal."::: --1. Under **Workspace Data Sources** on the left pane, select **ITSM Connections**. -- :::image type="content" source="media/itsmc-overview/add-new-itsm-connection.png" lightbox="media/itsmc-overview/add-new-itsm-connection.png" alt-text="Screenshot that shows the ITSM Connections menu item."::: --1. Select **Add Connection**. -1. Specify the ServiceNow connection settings. -1. By default, ITSMC refreshes the connection's configuration data once every 24 hours. To refresh your connection's data instantly to reflect any edits or template updates that you make, select the **Sync** button on your connection's pane. -- :::image type="content" source="media/itsmc-overview/itsmc-connections-refresh.png" lightbox="media/itsmc-overview/itsmc-connections-refresh.png" alt-text="Screenshot that shows the Sync button on the connection's pane."::: --## Create ITSM work items from Azure alerts --After you create your ITSM connection, use the ITSM action in action groups to create work items in your ITSM tool based on Azure alerts. Action groups provide a modular and reusable way to trigger actions for your Azure alerts. You can use action groups with metric alerts, activity log alerts, and log search alerts in the Azure portal. --> [!NOTE] -> Wait 30 minutes after you create the ITSM connection for the sync process to finish. -### Define a template --Certain work item types can use templates that you define in ServiceNow. When you use templates, you can define fields that will be automatically populated by using constant values defined in ServiceNow (not values from the payload). The templates are synced with Azure. You can define which template you want to use as a part of the definition of an action group. For information about how to create templates, see the [ServiceNow documentation](https://docs.servicenow.com/en-US/bundle/tokyo-platform-administration/page/administer/form-administration/task/t_CreateATemplateUsingTheTmplForm.html). --### Create ITSM work items --To create an action group: --1. In the Azure portal, select **Monitor** > **Alerts**. -1. On the menu at the top of the screen, select **Manage actions**. -- :::image type="content" source="media/itsmc-overview/action-groups-selection-big.png" lightbox="media/itsmc-overview/action-groups-selection-big.png" alt-text="Screenshot that shows selecting Action groups."::: --1. On the **Action groups** screen, select **+Create**. - The **Create action group** screen appears. -1. Select the **Subscription** and **Resource group** where you want to create your action group. Enter values in **Action group name** and **Display name** for your action group. Then select **Next: Notifications**. -- :::image type="content" source="media/itsmc-overview/action-groups-details.png" lightbox="media/itsmc-overview/action-groups-details.png" alt-text="Screenshot that shows the Create an action group screen."::: --1. On the **Notifications** tab, select **Next: Actions**. -1. On the **Actions** tab, select **ITSM** in the **Action type** list. For **Name**, provide a name for the action. Then select the pen button that represents **Edit details**. -- :::image type="content" source="media/itsmc-definition/action-group-pen.png" lightbox="media/itsmc-definition/action-group-pen.png" alt-text="Screenshot that shows selections for creating an action group."::: --1. In the **Subscription** list, select the subscription that contains your Log Analytics workspace. In the **Connection** list, select your ITSM Connector name. It will be followed by your workspace name. An example is *MyITSMConnector(MyWorkspace)*. -1. In the **Work Item** type field, select **Incident**. -- > [!NOTE] - > As of September 2022, we are starting the 3-year process of deprecating support for using ITSM actions to send alerts and events to ServiceNow. For information on the deprecated behavior, see [Use Azure alerts to create a ServiceNow alert or event work item](/previous-versions/azure/azure-monitor/alerts/alerts-create-itsm-work-items). - > As of October 2023, we are not supporting UI creation of connector for using ITSM actions to send alerts and events to ServiceNow. Until full deprecation the action creation should be by [API](/rest/api/monitor/action-groups/create-or-update?tabs=HTTP). --1. In the last section of the interface for creating an ITSM action group, if the alert is a log search alert, you can define how many work items will be created for each alert. For all other alert types, one work item is created per alert. - - :::image type="content" source="media/itsmc-definition/itsm-action-incident.png" lightbox="media/itsmc-definition/itsm-action-incident.png" alt-text="Screenshot that shows the ITSM Ticket area with an incident work item type."::: - -1. You can configure predefined fields to contain constant values as a part of the payload. Three options can be used as a part of the payload: - * **None**: Use a regular payload to ServiceNow without any extra predefined fields and values. - * **Use default fields**: Use a set of fields and values that will be sent automatically as a part of the payload to ServiceNow. Those fields aren't flexible, and the values are defined in ServiceNow lists. - * **Use saved templates from ServiceNow**: Use a predefined set of fields and values that were defined as a part of a template definition in ServiceNow. If you already defined the template in ServiceNow, you can use it from the **Template** list. Otherwise, you can define it in ServiceNow. For more information, see [define a template](#define-a-template). --1. Select **OK**. --When you create or edit an Azure alert rule, use an action group, which has an ITSM action. When the alert triggers, the work item is created or updated in the ITSM tool. --> [!NOTE] -> * For information about the pricing of the ITSM action, see the [pricing page](https://azure.microsoft.com/pricing/details/monitor/) for action groups. -> -> * The short description field in the alert rule definition is limited to 40 characters when you send it using the ITSM action. -> -> * If you have policies for inbound traffic for your ServiceNow instances, add ActionGroup service tag to allowList. -> -> * Notice that when you are defining a query in Log Search alerts you need to have in the query result the Configuration items names with one of the label names "Computer", "Resource", "_ResourceId" or "ResourceIdΓÇ¥. This mapping will enable to map the configuration items to the ITSM payload --## Next steps --[Troubleshoot problems in ITSMC](./itsmc-resync-servicenow.md) |
| azure-monitor | Itsmc Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/itsmc-overview.md | - Title: IT Service Management integration -description: This article provides an overview of the ways you can integrate with an IT Service Management product. --- Previously updated : 07/30/2024---# IT Service Management integration ---This article describes how you can integrate Azure Monitor with supported IT Service Management (ITSM) products. --Azure services like Log Analytics and Azure Monitor provide tools to detect, analyze, and troubleshoot problems with your Azure and non-Azure resources. But the work items related to an issue typically reside in an ITSM product or service. --Azure Monitor provides a bidirectional connection between Azure and ITSM tools to help you resolve issues faster. You can create work items in your ITSM tool based on your Azure metric alerts, activity log alerts, and log search alerts. --Azure Monitor supports connections with the following ITSM tools: --- ServiceNow ITSM or IT Operations Management (ITOM)-- BMC--## ITSM integration workflow -Depending on your integration, start connecting to your ITSM tool with these steps: --- For ServiceNow ITOM events or BMC Helix, use the secure webhook action:-- 1. [Register your app with Microsoft Entra ID](./itsm-connector-secure-webhook-connections-azure-configuration.md#register-with-azure-active-directory). - 1. [Define a service principal](./itsm-connector-secure-webhook-connections-azure-configuration.md#define-a-service-principal). - 1. [Create a secure webhook action group](./itsm-connector-secure-webhook-connections-azure-configuration.md#create-a-secure-webhook-action-group). - 1. Configure your partner environment. Secure Export supports connections with the following ITSM tools: - - [ServiceNow ITOM](./itsmc-secure-webhook-connections-servicenow.md) - - [BMC Helix](./itsmc-secure-webhook-connections-bmc.md) --- For ServiceNow ITSM, use the ITSM action:-- > [!NOTE] - > As of September 2022, we are starting the 3-year process of deprecating support for using ITSM actions to send alerts and events to ServiceNow. For information about legal terms and the privacy policy, see the [Microsoft privacy statement](https://go.microsoft.com/fwLink/?LinkID=522330&clcid=0x9). - > As of October 2023, we are not supporting UI creation of connector for using ITSM actions to send alerts and events to ServiceNow. Until full deprecation the action creation should be by [API](/rest/api/monitor/action-groups/create-or-update?tabs=HTTP). -- 1. Connect to your ITSM. For more information, see the [ServiceNow connection instructions](./itsmc-connections-servicenow.md). - 1. (Optional) Set up the IP ranges. To list the ITSM IP addresses to allow ITSM connections from partner ITSM tools, list the whole public IP range of an Azure region where the Log Analytics workspace belongs. For more information, see the [Microsoft Download Center](https://www.microsoft.com/en-us/download/details.aspx?id=56519). For regions EUS/WEU/WUS2/US South Central, the customer can list the ActionGroup network tag only. - 1. [Configure your Azure ITSM solution and create the ITSM connection](./itsmc-definition.md#install-it-service-management-connector). - 1. [Configure an action group to use the ITSM connector](./itsmc-definition.md#define-a-template). --## Next steps -[ServiceNow connection instructions](./itsmc-connections-servicenow.md) |
| azure-monitor | Itsmc Resync Servicenow | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/itsmc-resync-servicenow.md | - Title: How to manually fix ServiceNow sync problems -description: Reset the connection to ServiceNow so alerts in Microsoft Azure can again call ServiceNow -- Previously updated : 07/30/2024----# How to manually fix sync problems --Azure Monitor can connect to third-party IT Service Management (ITSM) providers. ServiceNow is one of those providers. --For security reasons, you may need to refresh the authentication token used for your connection with ServiceNow. -Use the following synchronization process to reactivate the connection and refresh the token: --1. In the Azure portal, select **All resources**, then find and select your Service Desk. -- :::image type="content" source="media/itsmc-dashboard/select-service-desk.png" lightbox="media/itsmc-dashboard/select-service-desk.png" alt-text="Screenshot of the All resources page in the Azure portal. Only resources whose name includes the ServiceDes filter criteria are listed."::: --1. In the Service Desk window, select **ITSM Connections** from the **Workspace Data Sources** section on the left pane. -- :::image type="content" source="media/itsmc-resync-servicenow/select-itsm-connections.png" lightbox="media/itsmc-resync-servicenow/select-itsm-connections.png" alt-text="Screenshot of a Solution resource in the Azure portal. ITSM Connections on the left pane is highlighted."::: --1. Select each connector in the list to edit the connector as necessary. --1. In the **Edit ITSM** window, -- 1. If this ITSM connector isnΓÇÖt being used, delete the connector. - 1. Make sure that all of the fields are configured correctly. See the instructions [here](./itsmc-overview.md) for the correct settings. - 1. Select **Sync**. - 1. Select **Save**. -- :::image type="content" source="media/itsmc-resync-servicenow/edit-itsm-connector.png" lightbox="media/itsmc-resync-servicenow/edit-itsm-connector.png" alt-text="Screenshot of the Edit ITSM window in the Azure portal."::: |
| azure-monitor | Itsmc Secure Webhook Connections Bmc | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/itsmc-secure-webhook-connections-bmc.md | - Title: 'IT Service Management Connector: Secure Webhook in Azure Monitor - Configuration with BMC' -description: This article shows you how to connect your ITSM products or services with BMC on Secure Webhook in Azure Monitor. - Previously updated : 06/19/2023------# Connect BMC Helix to Azure Monitor --The following sections provide details about how to connect your BMC Helix product and Secure Webhook in Azure. --## Prerequisites --Ensure that you've met the following prerequisites: --* Microsoft Entra ID is registered. -* You have the supported version of BMC Helix Multi-Cloud Service Management (version 19.08 or later). --## Configure the BMC Helix connection --1. Use the following procedure in the BMC Helix environment to get the URI for the Secure Webhook: -- 1. Sign in to Integration Studio. - 1. Search for the **Create Incident from Azure Alerts** flow. - 1. Copy the webhook URL. - - :::image type="content" source="media/itsmc-secure-webhook-connections-bmc/bmc-url.png" lightbox="media/itsmc-secure-webhook-connections-bmc/bmc-url.png" alt-text="Screenshot that shows the webhook U R L in Integration Studio."::: - -1. Follow the instructions according to the version: - * [Enabling prebuilt integration with Azure Monitor for version 20.02](https://docs.bmc.com/docs/multicloud/enabling-prebuilt-integration-with-azure-monitor-879728195.html) - * [Enabling prebuilt integration with Azure Monitor for version 19.11](https://docs.bmc.com/docs/multicloudprevious/enabling-prebuilt-integration-with-azure-monitor-904157623.html) --1. As a part of the configuration of the connection in BMC Helix, go into your integration BMC instance and follow these instructions: -- 1. Select **catalog**. - 1. Select **Azure alerts**. - 1. Select **connectors**. - 1. Select **configuration**. - 1. Select the **add new connection** configuration. - 1. Fill in the information for the configuration section: - - **Name**: Make up your own. - - **Authorization type**: **NONE** - - **Description**: Make up your own. - - **Site**: **Cloud** - - **Number of instances**: **2**, the default value. - - **Check**: Selected by default to enable usage. - - The Azure tenant ID and Azure application ID are taken from the application that you defined earlier. -- :::image type="content" source="media/itsmc-secure-webhook-connections-bmc/bmc-configuration.png" lightbox="media/itsmc-secure-webhook-connections-bmc/bmc-configuration.png" alt-text="Screenshot that shows BMC configuration."::: |
| azure-monitor | Itsmc Secure Webhook Connections Servicenow | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/itsmc-secure-webhook-connections-servicenow.md | - Title: 'ITSM Connector: Configure ServiceNow for Secure Webhook' -description: This article shows you how to connect your IT Service Management products and services with ServiceNow and Secure Webhook in Azure Monitor. -- Previously updated : 06/19/2023----# Connect ServiceNow to Azure Monitor --The following sections provide information about how to connect your ServiceNow product and Secure Webhook in Azure. --## Prerequisites --Ensure that you've met the following prerequisites: --* Microsoft Entra ID is registered. -* You have the supported version of ServiceNow Event Management - ITOM (version New York or later). -* The [application](https://store.servicenow.com/sn_appstore_store.do#!/store/application/ac4c9c57dbb1d090561b186c1396191a/2.2.0) is installed on the ServiceNow instance. --## Configure the ServiceNow connection --1. Use the link `https://(instance name).service-now.com/api/sn_em_connector/em/inbound_event?source=azuremonitor` to the URI for the Secure Webhook definition. --1. Follow the instructions according to the version: - * [Tokyo](https://docs.servicenow.com/bundle/tokyo-it-operations-management/page/product/event-management/concept/azure-integration.html) - * [Rome](https://docs.servicenow.com/bundle/rome-it-operations-management/page/product/event-management/concept/azure-integration.html) - * [Quebec](https://docs.servicenow.com/bundle/quebec-it-operations-management/page/product/event-management/concept/azure-integration.html) - * [Paris](https://docs.servicenow.com/bundle/paris-it-operations-management/page/product/event-management/concept/azure-integration.html) - * [Vancouver](https://docs.servicenow.com/bundle/vancouver-it-operations-management/page/product/event-management/concept/azure-integration.html) |
| azure-monitor | Itsmc Synced Data | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/itsmc-synced-data.md | - Title: Data synced from your ITSM product to LA Workspace -description: This article provides an overview of data synced from your ITSM product to LA Workspace. -- Previously updated : 08/07/2024-----# Data synced from your ITSM product --Incidents and change requests are synced from [ServiceNow](./itsmc-connections-servicenow.md) to your Log Analytics workspace based on the connection's configuration by using the **Sync Data** field. --## Synced data --This section shows some examples of data gathered by ITSM Connector. --The fields in **ServiceDesk_CL** vary depending on the work item type that you import into Log Analytics. Here are fields for two work item types: --**Work item:** **Incidents** -ServiceDeskWorkItemType_s="Incident" --**Fields** --- ServiceDeskConnectionName-- Service Desk ID-- State-- Urgency-- Impact-- Priority-- Escalation-- Created By-- Resolved By-- Closed By-- Source-- Assigned To-- Category-- Title-- Description-- Created Date-- Closed Date-- Resolved Date-- Last Modified Date-- Computer--**Work item:** **Change Requests** --ServiceDeskWorkItemType_s="ChangeRequest" --**Fields** -- ServiceDeskConnectionName-- Service Desk ID-- Created By-- Closed By-- Source-- Assigned To-- Title-- Type-- Category-- State-- Escalation-- Conflict Status-- Urgency-- Priority-- Risk-- Impact-- Assigned To-- Created Date-- Closed Date-- Last Modified Date-- Requested Date-- Planned Start Date-- Planned End Date-- Work Start Date-- Work End Date-- Description-- Computer--## ServiceNow example -### Output data for a ServiceNow incident --| Log Analytics field | ServiceNow field | -|: |: | -| ServiceDeskId_s| Number | -| IncidentState_s | State | -| Urgency_s |Urgency | -| Impact_s |Impact| -| Priority_s | Priority | -| CreatedBy_s | Opened by | -| ResolvedBy_s | Resolved by| -| ClosedBy_s | Closed by | -| Source_s| Contact type | -| AssignedTo_s | Assigned to | -| Category_s | Category | -| Title_s| Short description | -| Description_s| Notes | -| CreatedDate_t| Opened | -| ClosedDate_t| Closed| -| ResolvedDate_t|Resolved| -| Computer | Configuration item | --### Output data for a ServiceNow change request --| Log Analytics | ServiceNow field | -|: |: | -| ServiceDeskId_s| Number | -| CreatedBy_s | Requested by | -| ClosedBy_s | Closed by | -| AssignedTo_s | Assigned to | -| Title_s| Short description | -| Type_s| Type | -| Category_s| Category | -| CRState_s| State| -| Urgency_s| Urgency | -| Priority_s| Priority| -| Risk_s| Risk| -| Impact_s| Impact| -| RequestedDate_t | Requested by date | -| ClosedDate_t | Closed date | -| PlannedStartDate_t | Planned start date | -| PlannedEndDate_t | Planned end date | -| WorkStartDate_t | Actual start date | -| WorkEndDate_t | Actual end date| -| Description_s | Description | -| Computer | Configuration item | --## Next steps --[Troubleshooting problems in ITSM Connector](./itsmc-resync-servicenow.md) |
| azure-monitor | Itsmc Troubleshoot Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/itsmc-troubleshoot-overview.md | - Title: Troubleshoot problems in ITSMC -description: Learn how to resolve common problems in IT Service Management Connector. -- Previously updated : 07/30/2024----# Troubleshoot problems in IT Service Management Connector --This article discusses common problems in IT Service Management Connector (ITSMC) and how to troubleshoot them. --Azure Monitor proactively notifies you in alerts when it finds important conditions in your monitoring data. These alerts help you identify and address problems before the users of your system notice them. --You can select how you want to receive alerts. You can choose mail, SMS, or webhook, or even automate a solution. --An alternative is to be notified through ITSMC. ITSMC gives you the option to send alerts to an external ticketing system such as ServiceNow. --## Use the dashboard to analyze incident and change request data --Depending on your configuration when you set up a connection, ITSMC can sync up to 120 days of incident and change request data. To get the log record schema for this data, see the [Data synced from your ITSM product](./itsmc-synced-data.md) article. --You can visualize the incident and change request data by using the ITSMC dashboard: -<!-- convertborder later --> --The dashboard also provides information about connector status. You can use that information as a starting point to analyze problems with the connections. For more information, see [Error investigation using the dashboard](./itsmc-dashboard.md). --## Use Service Map to visualize incidents --You can also visualize the incidents synced against the affected computers in Service Map. --Service Map automatically discovers the application components on Windows and Linux systems and maps the communication between services. It allows you to view your servers as you think of them: as interconnected systems that deliver critical services. --Service Map shows connections between servers, processes, and ports across any TCP-connected architecture. Other than the installation of an agent, no configuration is required. For more information, see [Using Service Map](../vm/service-map.md). --If you're using Service Map, you can view the service desk items created in IT Service Management (ITSM) solutions, as shown in this example: -<!-- convertborder later --> --## Resolve problems --The following sections identify common symptoms, possible causes, and resolutions. --### A connection to the ITSM system fails and you get an "Error in saving connection" message --**Cause**: The cause can be one of these options: --* Credentials are incorrect. -* Privileges are insufficient. -* For Service Manager connections: The web app was incorrectly deployed. --**Resolution**: --* For ServiceNow, Cherwell, and Provance connections: - * Ensure that you correctly entered the username, password, client ID, and client secret for each of the connections. - * For ServiceNow, ensure that you have [sufficient privileges](itsmc-connections-servicenow.md#install-the-user-app-and-create-the-user-role) in the corresponding ITSM product. --* For Service Manager connections: - * Ensure that the web app is successfully deployed and that the hybrid connection is created. To verify that the connection is successfully established with the on-premises Service Manager computer, go to the web app URL. For more information, see the [documentation for making a hybrid connection](./itsmc-connections-scsm.md#configure-the-hybrid-connection). --### Duplicate work items are created --**Cause**: The cause can be one of these two options: --* More than one ITSM action is defined for the alert. -* The alert is resolved. --**Resolution**: There can be two solutions: --* Make sure that you have a single ITSM action group per alert. -* ITSMC doesn't support matching work items' status updates when an alert is resolved. Create a new resolved work item. --### Work items are not created --**Cause**: The cause can be one of several reasons: --* Code was modified on the ServiceNow side. -* Permissions are misconfigured. -* ServiceNow rate limits are too high or too low. -* A refresh token is expired. -* ITSMC was deleted. --**Resolution**: Check the [dashboard](itsmc-dashboard.md) and review the errors in the section for connector status. Then review the [common errors and their resolutions](itsmc-dashboard-errors.md). --### You can't create an ITSM action for an action group --**Cause**: A newly created ITSMC instance has yet to finish the initial sync. --**Resolution**: Review the [common errors and their resolutions](itsmc-dashboard-errors.md). --### Sync connection --**Cause**: The cause can be one of several reasons: --* Templates aren't shown as a part of the action definition dropdown and an error message is shown: "Can't retrieve the template configuration, see the connector logs for more information." -* Values aren't shown in the dropdowns of the default fields as a part of the action definition. In addition, an error message is shown: "No values found for the following fields: \<field names\>." -* Incidents/Events aren't created in ServiceNow. --**Resolution**: -* [Sync the connector](itsmc-resync-servicenow.md). -* Check the [dashboard](itsmc-dashboard.md) and review the errors in the section for connector status. Then review the [common errors and their resolutions](itsmc-dashboard-errors.md) --### In the incidents received from ServiceNow, the configuration item is blank -**Cause**: The cause can be one of several reasons: -* The alert isn't a log search alert. Configuration items are only supported by log search alerts. -* The search results don't include the **Computer** or **Resource** column. -* The values in the configuration item field don't match an entry in the CMDB. --**Resolution**: -* Check if the alert is a log search alert. If it isn't a log search alert, configuration items are not supported. -* If the search results don't have a Computer or Resource column, add them to the query. When you're defining a query in Log Search alerts you need to have in the query result the Configuration items names with one of the label names "Computer", "Resource", "_ResourceId" or "ResourceIdΓÇ¥. This mapping enables mapping the configuration items to the ITSM payload -* Check that the values in the Computer and Resource columns are identical to the values in the CMDB. If they aren't, add a new entry to the CMDB with the matching values. |
| azure-monitor | Log Alert Rule Health | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/log-alert-rule-health.md | - Title: Monitor the health of log search alert rules -description: This article how to monitor the health of a log search alert rule. ---- Previously updated : 02/08/2024--#Customer-intent: As a alerts administrator, I want to know when there are issues with an alert rule, so I can act to resolve the issue or know when to contact Microsoft for support. ---# Monitor the health of log search alert rules --[Azure Service Health](../../service-health/overview.md) monitors the health of your cloud resources, including log search alert rules. When a log search alert rule is healthy, the rule runs and the query executes successfully. This article explains how to view the health status of your log search alert rule, and tells you what to do if there are issues affecting your log search alert rules. --Azure Service Health monitors: -- [Resource health](../../service-health/resource-health-overview.md): information about the health of your individual cloud resources, such as a specific log search alert rule. See [here](../../service-health/resource-health-checks-resource-types.md) for the resource health checks performed on log search alert rules.-- [Service health](../../service-health/service-health-overview.md): information about the health of the Azure services and regions you're using, which might affect your log search alert rule, including communications about outages, planned maintenance activities, and other health advisories.-- > [!NOTE] -> Today, the report health status is supported only for rules with a frequency of 15 minutes or lower. For rules that run at a frequency greater than 15 minutes (such as 30 minutes, 1 hour, etc.), the status in the resource health blade will be ΓÇÿUnavailableΓÇÖ. --## Permissions required --- To view the health of a log search alert rule, you need `read` permissions to the log search alert rule. -- To set up health status alerts, you need `write` permissions to the log search alert rule, as provided by the [Monitoring Contributor built-in role](../roles-permissions-security.md#monitoring-contributor), for example.--## View health and set up health status alerts for log search alert rules --To view the health of your log search alert rule and set up health status alerts: --1. In the [portal](https://portal.azure.com/), select **Monitor**, then **Alerts**. -1. From the top command bar, select **Alert rules**. The page shows all your alert rules on all subscriptions. -1. Select the log search alert rule that you want to monitor. -1. From the left pane, under **Help**, select **Resource health**. - - :::image type="content" source="media/log-search-alert-health/log-search-alert-resource-health.png" alt-text="Screenshot of the Resource health section in a log search alert rule."::: --1. The **Resource health** screen shows: -- - **Health history**: Indicates whether Azure Service Health detected query execution issues in the specific log search alert rule. Select the health event to view details about the event. - - **Azure service issues**: Displayed when a known issue with an Azure service might affect execution of the log search alert query. Select the message to view details about the service issue in Azure Service Health. -- > [!NOTE] - > - Service health notifications do not indicate that your log search alert rule is necessarily affected by the known service issue. If your log search alert rule health status is **Available**, Azure Service Health did not detect issues in your alert rule. - - :::image type="content" source="media/log-search-alert-health/log-search-alert-resource-health-page.png" alt-text="Screenshot of the Resource health page for a log search alert rule."::: --This table describes the possible resource health status values for a log search alert rule: --|Resource health status|Description|Recommended steps| -|-|-|-| -|Available|There are no known issues affecting this log search alert rule.| | -|Unknown|This log search alert rule is currently disabled or in an unknown state.|Check if this log alert rule has been disabled. See [Log alert was disabled](alerts-troubleshoot-log.md) for more information. <br>| -|Unavailable|If your rule runs less frequently than every 15 minutes (for example, if it is set to run every 30 minutes or 1 hour), it wonΓÇÖt provide health status updates. An ΓÇÿunavailableΓÇÖ status is to be expected and is not indicative of an issue.|To get the health status of an alert rule, set the frequency of the alert rule to 15 min or less.| -|Unknown reason|This log search alert rule is currently unavailable due to an unknown reason.|Check if the alert rule was recently created. Health status is updated after the rule completes its first evaluation.| -|Degraded due to unknown reason|This log search alert rule is currently degraded due to an unknown reason.| | -|Setting up resource health|Setting up Resource health for this resource.|Check if the alert rule was recently created. Health status is updated after the rule completes its first evaluation.| -|Semantic error |The query is failing because of a semantic error. |Review the query and try again.| -|Syntax error |The query is failing because of a syntax error.| Review the query and try again.| -|The response size is too large|The query is failing because its response size is too large.|Review your query and the [log queries limits](../service-limits.md#log-queries-and-language).| -|Query consuming too many resources |The query is failing because it's consuming too many resources.|Review your query. View our [best practices for optimizing log queries](../logs/query-optimization.md).| -|Query validation error|The query is failing because of a validation error. |Check if the table referenced in your query is set to the [Basic or Auxiliary table plans](../logs/logs-table-plans.md), which don't support alerts. | -|Workspace not found |The target Log Analytics workspace for this alert rule couldn't be found. |The target specified in the scope of the alert rule was moved, renamed, or deleted. Recreate your alert rule with a valid Log Analytics workspace target.| -|Application Insights resource not found|The target Application Insights resource for this alert rule couldn't be found. |The target specified in the scope of the alert rule was moved, renamed, or deleted. Recreate your alert rule with a valid Log Analytics workspace target. | -|Query is throttled|The query is failing for the rule because of throttling (Error 429). |Review your query and the [log queries limits](../service-limits.md#user-query-throttling). | -|Unauthorized to run query |The query is failing because the query doesn't have the correct permissions. | Permissions are based on the permissions of the last user that edited the rule. If you suspect that the query doesn't have access, any user with the required permissions can edit or update the rule. Once the rule is saved, the new permissions take effect.</br>If you're using managed identities, check that the identity has permissions on the target resource. See [managed identities](alerts-create-log-alert-rule.md#managed-id).| -|NSP validation failed |The query is failing because of NSP validations issues.| Review your network security perimeter rules to ensure your alert rule is correctly configured.| -|Active alerts limit exceeded |Alert evaluation failed due to exceeding the limit of fired (non- resolved) alerts per day. |See [Azure Monitor service limits](../service-limits.md). | -|Dimension combinations limit exceeded | Alert evaluation failed due to exceeding the allowed limit of dimension combinations values meeting the threshold.|See [Azure Monitor service limits](../service-limits.md). | -|Unavailable for unknown reason | Today, the report health status is supported only for rules with a frequency of 15 minutes or lower.| For using Resource Health, the frequency should be 5 minutes or lower. | ---## Add a new resource health alert --1. Select **Add resource health alert**. - -1. The **Create alert rule** wizard opens, with the **Scope** and **Condition** panes prepopulated. If necessary, you can edit and modify the scope and condition of the alert rule at this stage. --1. Follow the rest of the steps in [Create or edit an activity log, service health, or resource health alert rule](../alerts/alerts-create-activity-log-alert-rule.md). --## Next steps --Learn more about: -- [Querying log data in Azure Monitor Logs](../logs/get-started-queries.md).-- [Create or edit a log alert rule](alerts-create-log-alert-rule.md)- |
| azure-monitor | Migrate From Alerts Summary Api | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/migrate-from-alerts-summary-api.md | - Title: Use ARG queries to get a summary of your alerts -description: Find out how to se ARG queries to migrate from the Azure Monitor alertsSummary API, which is being deprecated. - Previously updated : 03/13/2024-----# Use ARG queries to get a summary of your alerts --Azure Resource Graph queries allow you to query your Azure data and can be used to get information about your Azure monitor alerts. --The [alertsSummary API](/rest/api/monitor/alertsmanagement/alerts/get-summary) is being deprecated as of September 30,2026. Instead of the alertsSummary API, you can use Azure Resource Graph queries to get the same information. --Azure Resource Graph queries provide more functionality than the alertsSummary API, including: -* The ability to add new fields to the query that returns the alert summary. -* More flexibility in the query that returns the alert summary. --## Current implementation of the alertsSummary API --This is the format for the calling the alertsSummary API: -- `GET https://management.azure.com/subscriptions/{subId}/providers/Microsoft.AlertsManagement/alertsSummary?groupby=severity,alertState&api-version=2019-03-01` --Response: AlertSummary_Sev_Alertstate --This is an example of the output from the alertsSummary API: --```json -{ - "totalRecords": 2, - "count": 2, - "data": { - "columns": [ - {"name": "Severity", - "type": "string" - }, - {"name": "AlertState", - "type": "string" - }, - { - "name": "AlertsCount", - "type": "integer" - } - ], - "rows": [ - [ - "Sev2", - "New", - 2 - ], - [ - "Sev1", - "New", - 8 - ] - ] -}, -"facets": [], -"resultTruncated": false -} -``` --## Use the Azure Resource Graph queries for Azure Monitor alerts --Use these Azure Resource Graph queries instead of the alertsSummary API call to retrieve alert information, or use these queries as a basis for designing your own queries. --- [List Azure Monitor alerts ordered by severity](../../governance/resource-graph/samples/starter.md#list-azure-monitor-alerts-ordered-by-severity)-- [List Azure Monitor alerts ordered by severity and alert state](../../governance/resource-graph/samples/starter.md#list-azure-monitor-alerts-ordered-by-severity-and-alert-state)-- [List Azure Monitor alerts ordered by severity, monitor service, and target resource type](../../governance/resource-graph/samples/starter.md#list-azure-monitor-alerts-ordered-by-severity-monitor-service-and-target-resource-type)- - This is an example of the output from the Azure Resource Graph query: --```json -{ -"properties":{ - "groupedBy": "severity", - "smartGroupsCount": 100, - "total": 9692, - "values": [ - { - "name": "Sev0", - "count": 6517, - "groupedby": "alertState", - "values": [ - { - "name": "New", - "count": 6517 - }, - { - "name": "Acknowledged", - "count": 0 - }, - { - "name": "Closed", - "count": 0 - } - ] - }, - { - "name": "Sev1", - "count": 3175, - "groupedby": "alertState", - "values": [ - { - "name": "New", - "count": 3175 - }, - { - "name": "Acknowledged", - "count": 0 - }, - { - "name": "Closed", - "count": 0 - } - ] - }, - ] -} -}, -"id": "/subscriptions/1a2b3c4d-123a-1234-a12b-a1b2c34d5e6f/providers/Microsoft.AlertsManagement/alertsSummary/current", -"type": "Microsoft.AlertsManagement/alertsSummary", -"name": "current" --``` |
| azure-monitor | Proactive Application Security Detection Pack | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/proactive-application-security-detection-pack.md | - Title: Security detection Pack with Azure Application Insights -description: Monitor application with Azure Application Insights and smart detection for potential security issues. -- Previously updated : 04/01/2024----# Application security detection pack (preview) --Smart detection automatically analyzes the telemetry generated by your application, and detects potential security issues. It enables you to identify potential security problems. You can mitigate these problems by fixing the application, or by taking the necessary security measures. --This feature requires no special setup, other than [configuring your app to send telemetry](../app/usage.md). --## When would I get this type of smart detection notification? -There are three types of security issues that are detected: -1. Insecure URL access: a URL in the application is accessible via both HTTP and HTTPS. Typically, a URL that accepts HTTPS requests shouldn't accept HTTP requests. This detection may indicate a bug or security issue in your application. -2. Insecure form: a form (or other "POST" request) in the application uses HTTP instead of HTTPS. Using HTTP can compromise the user data that is sent by the form. -3. Suspicious user activity: the same user accesses the application from multiple countries or regions, around the same time. For example, the same user accessed the application from Spain and the United States within the same hour. This detection indicates a potentially malicious access attempt to your application. --## Does my app definitely have a security issue? -A notification doesn't mean that your app definitely has a security issue. A detection of any of the scenarios above can, in many cases, indicate a security issue. In other cases, the detection may have a natural business justification, and can be ignored. --## How do I fix the "Insecure URL access" detection? -1. **Triage.** The notification provides the number of users who accessed insecure URLs, and the URL that was most affected by insecure access. This information can help you assign a priority to the problem. -3. **Scope.** What percentage of the users accessed insecure URLs? How many URLs were affected? This information can be obtained from the notification. -4. **Diagnose.** The detection provides the list of insecure requests, and the lists of URLs and users that were affected, to help you further diagnose the issue. --## How do I fix the "Insecure form" detection? -1. **Triage.** The notification provides the number of insecure forms, and number of users whose data was potentially compromised. This information can help you assign a priority to the problem. -2. **Scope.** Which form was involved in the largest number of insecure transmissions, and what is the distribution of insecure transmissions over time? This information can be obtained from the notification. -3. **Diagnose.** The detection provides the list of insecure forms, and a breakdown of insecure transmissions for each form, to help you further diagnose the issue. --## How do I fix the "Suspicious user activity" detection? -1. **Triage.** The notification provides the number of different users that presented the suspicious behavior. This information can help you assign a priority to the problem. -2. **Scope.** From which countries or regions did the suspicious requests originate? Which user was the most suspicious? This information can be obtained from the notification. -3. **Diagnose.** The detection provides the list of suspicious users and the list of countries or regions for each user, to help you further diagnose the issue. |
| azure-monitor | Proactive Arm Config | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/proactive-arm-config.md | - Title: 'Smart detection rule settings: Application Insights' -description: Automate management and configuration of Application Insights smart detection rules with Azure Resource Manager templates. --- Previously updated : 04/01/2024----# Manage Application Insights smart detection rules by using Azure Resource Manager templates -->[!NOTE] ->You can migrate your Application Insight resources to alerts-based smart detection (preview). The migration creates alert rules for the different smart detection modules. After you create the rules, you can manage and configure them like any other Azure Monitor alert rules. You can also configure action groups for these rules to enable multiple methods of taking actions or triggering notification on new detections. -> -> For more information on the migration process and the behavior of smart detection after the migration, see [Smart detection alerts migration](./alerts-smart-detections-migration.md). -> -- You can manage and configure smart detection rules in Application Insights by using [Azure Resource Manager templates](../../azure-resource-manager/templates/syntax.md). --You can use this method when you deploy new Application Insights resources with Resource Manager automation or when you modify the settings of existing resources. --## Smart detection rule configuration --You can configure the following settings for a smart detection rule: -- If the rule is enabled. (The default is **true**.)-- If emails should be sent to users associated to the subscription's [Monitoring Reader](../../role-based-access-control/built-in-roles.md#monitoring-reader) and [Monitoring Contributor](../../role-based-access-control/built-in-roles.md#monitoring-contributor) roles when a detection is found. (The default is **true**.)-- Any other email recipients who should get a notification when a detection is found.- - Email configuration isn't available for smart detection rules marked as _preview_. --To allow configuring the rule settings via Resource Manager, the smart detection rule configuration is available as an inner resource within the Application Insights resource. It's named **ProactiveDetectionConfigs**. --For maximal flexibility, you can configure each smart detection rule with unique notification settings. --## Examples --The following examples show how to configure the settings of smart detection rules by using Resource Manager templates. --All samples refer to an Application Insights resource named _"myApplication"_. They also refer to the "long dependency duration smart detection rule." It's internally named _"longdependencyduration"_. --Make sure to replace the Application Insights resource name and to specify the relevant smart detection rule internal name. Check the following table for a list of the corresponding internal Resource Manager names for each smart detection rule. --### Disable a smart detection rule --```json -{ - "apiVersion": "2018-05-01-preview", - "name": "myApplication", - "type": "Microsoft.Insights/components", - "location": "[resourceGroup().location]", - "properties": { - "Application_Type": "web" - }, - "resources": [ - { - "apiVersion": "2018-05-01-preview", - "name": "longdependencyduration", - "type": "ProactiveDetectionConfigs", - "location": "[resourceGroup().location]", - "dependsOn": [ - "[resourceId('Microsoft.Insights/components', 'myApplication')]" - ], - "properties": { - "name": "longdependencyduration", - "sendEmailsToSubscriptionOwners": true, - "customEmails": [], - "enabled": false - } - } - ] - } -``` --### Disable sending email notifications for a smart detection rule --```json -{ - "apiVersion": "2018-05-01-preview", - "name": "myApplication", - "type": "Microsoft.Insights/components", - "location": "[resourceGroup().location]", - "properties": { - "Application_Type": "web" - }, - "resources": [ - { - "apiVersion": "2018-05-01-preview", - "name": "longdependencyduration", - "type": "ProactiveDetectionConfigs", - "location": "[resourceGroup().location]", - "dependsOn": [ - "[resourceId('Microsoft.Insights/components', 'myApplication')]" - ], - "properties": { - "name": "longdependencyduration", - "sendEmailsToSubscriptionOwners": false, - "customEmails": [], - "enabled": true - } - } - ] - } -``` --### Add more email recipients for a smart detection rule --```json -{ - "apiVersion": "2018-05-01-preview", - "name": "myApplication", - "type": "Microsoft.Insights/components", - "location": "[resourceGroup().location]", - "properties": { - "Application_Type": "web" - }, - "resources": [ - { - "apiVersion": "2018-05-01-preview", - "name": "longdependencyduration", - "type": "ProactiveDetectionConfigs", - "location": "[resourceGroup().location]", - "dependsOn": [ - "[resourceId('Microsoft.Insights/components', 'myApplication')]" - ], - "properties": { - "name": "longdependencyduration", - "sendEmailsToSubscriptionOwners": true, - "customEmails": ["alice@contoso.com", "bob@contoso.com"], - "enabled": true - } - } - ] - } --``` --## Smart detection rule names --The following table shows smart detection rule names as they appear in the portal. The table also shows their internal names to use in the Resource Manager template. --> [!NOTE] -> Smart detection rules marked as _preview_ don't support email notifications. You can only set the _enabled_ property for these rules. --| Azure portal rule name | Internal name -|:|:| -| Slow page load time | slowpageloadtime | -| Slow server response time | slowserverresponsetime | -| Long dependency duration | longdependencyduration | -| Degradation in server response time | degradationinserverresponsetime | -| Degradation in dependency duration | degradationindependencyduration | -| Degradation in trace severity ratio (preview) | extension_traceseveritydetector | -| Abnormal rise in exception volume (preview) | extension_exceptionchangeextension | -| Potential memory leak detected (preview) | extension_memoryleakextension | -| Potential security issue detected (preview) | extension_securityextensionspackage | -| Abnormal rise in daily data volume (preview) | extension_billingdatavolumedailyspikeextension | --### Failure Anomalies alert rule --This Resource Manager template demonstrates how to configure a Failure Anomalies alert rule with a severity of 2. --> [!NOTE] -> Failure Anomalies is a global service, so rule location is created on the global location. --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "resources": [ - { - "type": "microsoft.alertsmanagement/smartdetectoralertrules", - "apiVersion": "2019-03-01", - "name": "Failure Anomalies - my-app", - "location": "global", - "properties": { - "description": "Failure Anomalies notifies you of an unusual rise in the rate of failed HTTP requests or dependency calls.", - "state": "Enabled", - "severity": "2", - "frequency": "PT1M", - "detector": { - "id": "FailureAnomaliesDetector" - }, - "scope": ["/subscriptions/00000000-1111-2222-3333-444444444444/resourceGroups/MyResourceGroup/providers/microsoft.insights/components/my-app"], - "actionGroups": { - "groupIds": ["/subscriptions/00000000-1111-2222-3333-444444444444/resourcegroups/MyResourceGroup/providers/microsoft.insights/actiongroups/MyActionGroup"] - } - } - } - ] -} -``` --> [!NOTE] -> This Resource Manager template is unique to the Failure Anomalies alert rule and is different from the other classic smart detection rules described in this article. If you want to manage Failure Anomalies manually, use Azure Monitor alerts. All other smart detection rules are managed in the **Smart Detection** pane of the UI. --## Next steps --Learn more about automatically detecting: --- [Failure anomalies](./proactive-failure-diagnostics.md)-- [Memory leaks](./proactive-potential-memory-leak.md)-- [Performance anomalies](./smart-detection-performance.md) |
| azure-monitor | Proactive Diagnostics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/proactive-diagnostics.md | - Title: Smart detection in Application Insights | Microsoft Docs -description: Application Insights performs automatic deep analysis of your app telemetry and warns you about potential problems. -- Previously updated : 04/01/2024----# Smart detection in Application Insights -->[!NOTE] ->You can migrate smart detection on your Application Insights resource to be based on alerts. The migration creates alert rules for the different smart detection modules. After it's created, you can manage and configure these rules like any other Azure Monitor alert rules. You can also configure action groups for these rules to enable multiple methods of taking actions or triggering notification on new detections. -> -> For more information, see [Smart detection alerts migration](./alerts-smart-detections-migration.md). --Smart detection automatically warns you of potential performance problems and failure anomalies in your web application. It performs proactive analysis of the telemetry that your app sends to [Application Insights](../app/app-insights-overview.md). If there's a sudden rise in failure rates or abnormal patterns in client or server performance, you get an alert. This feature needs no configuration. It operates if your application sends enough telemetry. --You can access the detections issued by smart detection from the emails you receive and from the smart detection pane. --## Review your smart detections -You can discover detections in two ways: --* **You receive an email** from Application Insights. Here's a typical example: - <!-- convertborder later --> - :::image type="content" source="./media/proactive-diagnostics/03.png" lightbox="./media/proactive-diagnostics/03.png" alt-text="Screenshot that shows an email alert." border="false"::: - - Select **See the analysis of this issue** to see more information in the portal. -* **The smart detection pane** in Application Insights. Under the **Investigate** menu, select **Smart Detection** to see a list of recent detections. - <!-- convertborder later --> - :::image type="content" source="./media/proactive-diagnostics/04.png" lightbox="./media/proactive-diagnostics/04.png" alt-text="Screenshot that shows recent detections." border="false"::: --Select a detection to view its details. --## What problems are detected? --Smart detection detects and notifies you about various issues: --* [Smart detection - Failure Anomalies](./proactive-failure-diagnostics.md): Notifies if the failure rate goes outside the expected envelope. We use machine learning to set the expected rate of failed requests for your app, correlating with load and other factors. -* [Smart detection - Performance Anomalies](./smart-detection-performance.md): Notifies if response time of an operation or dependency duration is slowing down compared to the historical baseline. It also notifies if we identify an anomalous pattern in response time or page load time. -* **General degradations and issues**: [Trace degradation](./proactive-trace-severity.md), [Memory leak](./proactive-potential-memory-leak.md), [Abnormal rise in Exception volume](./proactive-exception-volume.md), and [Security anti-patterns](./proactive-application-security-detection-pack.md). --The help links in each notification take you to the relevant articles. --## Smart detection email notifications --All smart detection rules, except for rules marked as _preview_, are configured by default to send email notifications when detections are found. --You can configure email notifications for a specific smart detection rule. On the smart detection **Settings** pane, select the rule to open the **Edit rule** pane. --Alternatively, you can change the configuration by using Azure Resource Manager templates. For more information, see [Manage Application Insights smart detection rules by using Azure Resource Manager templates](./proactive-arm-config.md). --## Next steps -These diagnostic tools help you inspect the telemetry from your app: --* [Metric explorer](../essentials/metrics-charts.md) -* [Search explorer](../app/transaction-search-and-diagnostics.md?tabs=transaction-search) -* [Analytics: Powerful query language](../logs/log-analytics-tutorial.md) --Smart detection is automatic, but if you want to set up more alerts, see: --* [Manually configured metric alerts](./alerts-log.md) -* [Availability web tests](/previous-versions/azure/azure-monitor/app/monitor-web-app-availability) |
| azure-monitor | Proactive Email Notification | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/proactive-email-notification.md | - Title: Smart Detection notification change - Azure Application Insights -description: Change to the default notification recipients from Smart Detection. Smart Detection lets you monitor application traces with Azure Application Insights for unusual patterns in trace telemetry. -- Previously updated : 04/01/2024----# Smart Detection e-mail notification change -->[!NOTE] ->You can migrate your Application Insight resources to alerts-based smart detection (preview). The migration creates alert rules for the different smart detection modules. Once created, you can manage and configure these rules just like any other Azure Monitor alert rules. You can also configure action groups for these rules, thus enabling multiple methods of taking actions or triggering notification on new detections. -> -> See [Smart Detection Alerts migration](./alerts-smart-detections-migration.md) for more details on the migration process and the behavior of smart detection after the migration. --Based on customer feedback, on April 1, 2019, weΓÇÖre changing the default roles who receive email notifications from Smart Detection. --## What is changing? --Currently, Smart Detection email notifications are sent by default to the _Subscription Owner_, _Subscription Contributor_, and _Subscription Reader_ roles. These roles often include users who are not actively involved in monitoring, which causes many of these users to receive notifications unnecessarily. To improve this experience, we are making a change so that email notifications only go to the [Monitoring Reader](../../role-based-access-control/built-in-roles.md#monitoring-reader) and [Monitoring Contributor](../../role-based-access-control/built-in-roles.md#monitoring-contributor) roles by default. --## Scope of this change --This change will affect all Smart Detection rules, excluding the following ones: --* Smart Detection rules marked as preview. These Smart Detection rules donΓÇÖt support email notifications today. --* Failure Anomalies rule. --## How to prepare for this change? --To ensure that email notifications from Smart Detection are sent to relevant users, those users must be assigned to the [Monitoring Reader](../../role-based-access-control/built-in-roles.md#monitoring-reader) or [Monitoring Contributor](../../role-based-access-control/built-in-roles.md#monitoring-contributor) roles of the subscription. --To assign users to the Monitoring Reader or Monitoring Contributor roles via the Azure portal, follow the steps described in the [Assign Azure roles](../../role-based-access-control/role-assignments-portal.yml) article. Make sure to select the _Monitoring Reader_ or _Monitoring Contributor_ as the role to which users are assigned. --> [!NOTE] -> Specific recipients of Smart Detection notifications, configured using the _Additional email recipients_ option in the rule settings, will not be affected by this change. These recipients will continue receiving the email notifications. --If you have any questions or concerns about this change, donΓÇÖt hesitate to [contact us](mailto:smart-alert-feedback@microsoft.com). --## Next steps --Learn more about Smart Detection: --- [Failure anomalies](./proactive-failure-diagnostics.md)-- [Memory Leaks](./proactive-potential-memory-leak.md)-- [Performance anomalies](./smart-detection-performance.md)- |
| azure-monitor | Proactive Exception Volume | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/proactive-exception-volume.md | - Title: Abnormal rise in exception volume - Azure Application Insights -description: Monitor application exceptions with smart detection in Azure Application Insights for unusual patterns in exception volume. -- Previously updated : 04/01/2024----# Abnormal rise in exception volume (preview) -->[!NOTE] ->You can migrate your Application Insight resources to alerts-bases smart detection (preview). The migration creates alert rules for the different smart detection modules. Once created, you can manage and configure these rules just like any other Azure Monitor alert rules. You can also configure action groups for these rules, thus enabling multiple methods of taking actions or triggering notification on new detections. -> -> For more information, see [Smart Detection Alerts migration](./alerts-smart-detections-migration.md). --Smart detection automatically analyze the exceptions thrown in your application, and can warn you about unusual patterns in your exception telemetry. --This feature requires no special setup, other than [configuring exception reporting](../app/asp-net-exceptions.md#set-up-exception-reporting) for your app. It's active when your app generates enough exception telemetry. --## When would I get this type of smart detection notification? -You get this type of notification if your app is showing an abnormal rise in the number of exceptions of a specific type, during a day. This number is compared to a baseline calculated over the previous seven days. -Machine learning algorithms are used for detecting the rise in exception count, while taking into account a natural growth in your application usage. --## Does my app definitely have a problem? -No, a notification doesn't mean that your app definitely has a problem. Although an excessive number of exceptions usually indicates an application issue, these exceptions might be benign and handled correctly by your application. --## How do I fix it? -The notifications include diagnostic information to support in the diagnostics process: -1. **Triage.** The notification shows you how many users or how many requests are affected. This information can help you assign a priority to the problem. -2. **Scope.** Is the problem affecting all traffic, or just some operation? This information can be obtained from the notification. -3. **Diagnose.** The detection contains information about the method from which the exception was thrown, and the exception type. You can also use the related items and reports linking to supporting information, to help you further diagnose the issue. |
| azure-monitor | Proactive Failure Diagnostics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/proactive-failure-diagnostics.md | - Title: Smart Detection of Failure Anomalies in Application Insights | Microsoft Docs -description: Alerts you to unusual changes in the rate of failed requests to your web app, and provides diagnostic analysis. No configuration is needed. -- Previously updated : 04/01/2024----# Smart Detection - Failure Anomalies --[Application Insights](../app/app-insights-overview.md) automatically alerts you in near real time if your web app experiences an abnormal rise in the rate of failed requests. It detects an unusual rise in the rate of HTTP requests or dependency calls that are reported as failed. For requests, failed requests usually have response codes of 400 or higher. To help you triage and diagnose the problem, an analysis of the characteristics of the failures and related application data is provided in the alert details. There are also links to the Application Insights portal for further diagnosis. The feature needs no set-up nor configuration, as it uses machine learning algorithms to predict the normal failure rate. --This feature works for any web app, hosted in the cloud or on your own servers that generate application request or dependency data. For example, if you have a worker role that calls [TrackRequest()](../app/api-custom-events-metrics.md#trackrequest) or [TrackDependency()](../app/api-custom-events-metrics.md#trackdependency). --After setting up [Application Insights for your project](../app/app-insights-overview.md), and if your app generates a certain minimum amount of data, Smart Detection of Failure Anomalies takes 24 hours to learn the normal behavior of your app, before it's switched on and can send alerts. --Here's a sample alert: ---> [!NOTE] -> Smart Detector Failure Anomalies are calculated for the failure rates on the total requests in each App Insights. These notifications will not alert per API or application sending these requests. -The alert details tell you: --* The failure rate compared to normal app behavior. -* How many users are affected - so you know how much to worry. -* A characteristic pattern associated with the failures. In this example, there's a particular response code, request name (operation), and application version. That immediately tells you where to start looking in your code. Other possibilities could be a specific browser or client operating system. -* The exception, log traces, and dependency failure (databases or other external components) that appear to be associated with the characterized failures. -* Links directly to relevant searches on the data in Application Insights. --## Benefits of Smart Detection -Ordinary [metric alerts](./alerts-log.md) tell you there might be a problem. But Smart Detection starts the diagnostic work for you, performing much the analysis you would otherwise have to do yourself. You get the results neatly packaged, helping you to get quickly to the root of the problem. --## How it works -Smart Detection monitors the data received from your app, and in particular the failure rates. This rule counts the number of requests for which the `Successful request` property is false, and the number of dependency calls for which the `Successful call` property is false. For requests, by default, `Successful request == (resultCode < 400)` (unless you write custom code to [filter](../app/api-filtering-sampling.md#filtering) or generate your own [TrackRequest](../app/api-custom-events-metrics.md#trackrequest) calls). --Your app's performance has a typical pattern of behavior. Some requests or dependency calls are more prone to failure than others; and the overall failure rate may go up as load increases. Smart Detection uses machine learning to find these anomalies. --As data comes into Application Insights from your web app, Smart Detection compares the current behavior with the patterns seen over the past few days. If the detector discovers an abnormal rise in failure rate comparison with previous performance, the detector triggers a more in-depth analysis. --When an analysis is triggered, the service performs a cluster analysis on the failed request, to try to identify a pattern of values that characterize the failures. --In the example shown before, the analysis discovered that most failures are about a specific result code, request name, Server URL host, and role instance. --When you instrument your service with these calls, the analyzer looks for an exception and a dependency failure that are associated with requests in the identified cluster. It also looks for an example of any trace logs, associated with those requests. The alert you receive includes this additional information that can provide context to the detection and hint on the root cause for the detected problem. --### Alert logic details -Failure Anomalies detection relies on a proprietary machine learning algorithm, so the reasons for an alert firing or not firing aren't always deterministic. With that said, the primary factors that the algorithm uses are: --* Analysis of the failure percentage of requests/dependencies in a rolling time window of 20 minutes. -* A comparison of the failure percentage in the last 20 minutes, to the rate in the last 40 minutes and the past seven days. The algorithm is looking for significant deviations that exceed X-times of the standard deviation. -* The algorithm is using an adaptive limit for the minimum failure percentage, which varies based on the appΓÇÖs volume of requests/dependencies. -* The algorithm includes logic that can automatically resolve the fired alert, if the issue is no longer detected for 8-24 hours. - Note: in the current design. a notification or action isn't sent when a Smart Detection alert is resolved. You can check if a Smart Detection alert was resolved in the Azure portal. --## Managing Failure Anomalies alert rules --### Alert rule creation -A Failure Anomalies alert rule is created automatically when your Application Insights resource is created. The rule is automatically configured to analyze the telemetry on that resource. -You can create the rule again using Azure [REST API](/rest/api/monitor/smart-detector-alert-rules?view=rest-monitor-2019-06-01&preserve-view=true) or using a [Resource Manager template](proactive-arm-config.md#failure-anomalies-alert-rule). Creating the rule can be useful if the automatic creation of the rule failed for some reason, or if you deleted the rule. --### Alert rule configuration -To configure a Failure Anomalies alert rule in the portal, open the Alerts page and select Alert Rules. Failure Anomalies alert rules are included along with any alerts that you set manually. ---Click the alert rule to configure it. ---You can disable Smart Detection alert rule from the portal or using an [Azure Resource Manager template](proactive-arm-config.md#failure-anomalies-alert-rule). --This alert rule is created with an associated [Action Group](./action-groups.md) named "Application Insights Smart Detection." By default, this action group contains Email Azure Resource Manager Role actions and sends notification to users who have Monitoring Contributor or Monitoring Reader subscription Azure Resource Manager roles in your subscription. You can remove, change or add the action groups that the rule triggers, as for any other Azure alert rule. Notifications sent from this alert rule follow the [common alert schema](./alerts-common-schema.md). ---## Delete alerts --You can delete a Failure Anomalies alert rule. --You can do so manually on the Alert rules page or with the following Azure CLI command: --```azurecli -az resource delete --ids <Resource ID of Failure Anomalies alert rule> -``` -Notice that if you delete an Application Insights resource, the associated Failure Anomalies alert rule doesn't get deleted automatically. --## Example of Failure Anomalies alert webhook payload --```json -{ - "properties": { - "essentials": { - "severity": "Sev3", - "signalType": "Log", - "alertState": "New", - "monitorCondition": "Resolved", - "monitorService": "Smart Detector", - "targetResource": "/subscriptions/4f9b81be-fa32-4f96-aeb3-fc5c3f678df9/resourcegroups/test-group/providers/microsoft.insights/components/test-rule", - "targetResourceName": "test-rule", - "targetResourceGroup": "test-group", - "targetResourceType": "microsoft.insights/components", - "sourceCreatedId": "1a0a5b6436a9b2a13377f5c89a3477855276f8208982e0f167697a2b45fcbb3e", - "alertRule": "/subscriptions/4f9b81be-fa32-4f96-aeb3-fc5c3f678df9/resourcegroups/test-group/providers/microsoft.alertsmanagement/smartdetectoralertrules/failure anomalies - test-rule", - "startDateTime": "2019-10-30T17:52:32.5802978Z", - "lastModifiedDateTime": "2019-10-30T18:25:23.1072443Z", - "monitorConditionResolvedDateTime": "2019-10-30T18:25:26.4440603Z", - "lastModifiedUserName": "System", - "actionStatus": { - "isSuppressed": false - }, - "description": "Failure Anomalies notifies you of an unusual rise in the rate of failed HTTP requests or dependency calls." - }, - "context": { - "DetectionSummary": "An abnormal rise in failed request rate", - "FormattedOccurenceTime": "2019-10-30T17:50:00Z", - "DetectedFailureRate": "50.0% (200/400 requests)", - "NormalFailureRate": "0.0% (over the last 30 minutes)", - "FailureRateChart": [ - [ - "2019-10-30T05:20:00Z", - 0 - ], - [ - "2019-10-30T05:40:00Z", - 100 - ], - [ - "2019-10-30T06:00:00Z", - 0 - ], - [ - "2019-10-30T06:20:00Z", - 0 - ], - [ - "2019-10-30T06:40:00Z", - 100 - ], - [ - "2019-10-30T07:00:00Z", - 0 - ], - [ - "2019-10-30T07:20:00Z", - 0 - ], - [ - "2019-10-30T07:40:00Z", - 100 - ], - [ - "2019-10-30T08:00:00Z", - 0 - ], - [ - "2019-10-30T08:20:00Z", - 0 - ], - [ - "2019-10-30T08:40:00Z", - 100 - ], - [ - "2019-10-30T17:00:00Z", - 0 - ], - [ - "2019-10-30T17:20:00Z", - 0 - ], - [ - "2019-10-30T09:00:00Z", - 0 - ], - [ - "2019-10-30T09:20:00Z", - 0 - ], - [ - "2019-10-30T09:40:00Z", - 100 - ], - [ - "2019-10-30T10:00:00Z", - 0 - ], - [ - "2019-10-30T10:20:00Z", - 0 - ], - [ - "2019-10-30T10:40:00Z", - 100 - ], - [ - "2019-10-30T11:00:00Z", - 0 - ], - [ - "2019-10-30T11:20:00Z", - 0 - ], - [ - "2019-10-30T11:40:00Z", - 100 - ], - [ - "2019-10-30T12:00:00Z", - 0 - ], - [ - "2019-10-30T12:20:00Z", - 0 - ], - [ - "2019-10-30T12:40:00Z", - 100 - ], - [ - "2019-10-30T13:00:00Z", - 0 - ], - [ - "2019-10-30T13:20:00Z", - 0 - ], - [ - "2019-10-30T13:40:00Z", - 100 - ], - [ - "2019-10-30T14:00:00Z", - 0 - ], - [ - "2019-10-30T14:20:00Z", - 0 - ], - [ - "2019-10-30T14:40:00Z", - 100 - ], - [ - "2019-10-30T15:00:00Z", - 0 - ], - [ - "2019-10-30T15:20:00Z", - 0 - ], - [ - "2019-10-30T15:40:00Z", - 100 - ], - [ - "2019-10-30T16:00:00Z", - 0 - ], - [ - "2019-10-30T16:20:00Z", - 0 - ], - [ - "2019-10-30T16:40:00Z", - 100 - ], - [ - "2019-10-30T17:30:00Z", - 50 - ] - ], - "ArmSystemEventsRequest": "/subscriptions/4f9b81be-fa32-4f96-aeb3-fc5c3f678df9/resourceGroups/test-group/providers/microsoft.insights/components/test-rule/query?query=%0d%0a++++++++++++++++systemEvents%0d%0a++++++++++++++++%7c+where+timestamp+%3e%3d+datetime(%272019-10-30T17%3a20%3a00.0000000Z%27)+%0d%0a++++++++++++++++%7c+where+itemType+%3d%3d+%27systemEvent%27+and+name+%3d%3d+%27ProactiveDetectionInsight%27+%0d%0a++++++++++++++++%7c+where+dimensions.InsightType+in+(%275%27%2c+%277%27)+%0d%0a++++++++++++++++%7c+where+dimensions.InsightDocumentId+%3d%3d+%27718fb0c3-425b-4185-be33-4311dfb4deeb%27+%0d%0a++++++++++++++++%7c+project+dimensions.InsightOneClassTable%2c+%0d%0a++++++++++++++++++++++++++dimensions.InsightExceptionCorrelationTable%2c+%0d%0a++++++++++++++++++++++++++dimensions.InsightDependencyCorrelationTable%2c+%0d%0a++++++++++++++++++++++++++dimensions.InsightRequestCorrelationTable%2c+%0d%0a++++++++++++++++++++++++++dimensions.InsightTraceCorrelationTable%0d%0a++++++++++++&api-version=2018-04-20", - "LinksTable": [ - { - "Link": "<a href=\"https://portal.azure.com/#blade/AppInsightsExtension/ProactiveDetectionFeedBlade/ComponentId/{\"SubscriptionId\":\"4f9b81be-fa32-4f96-aeb3-fc5c3f678df9\",\"ResourceGroup\":\"test-group\",\"Name\":\"test-rule\"}/SelectedItemGroup/718fb0c3-425b-4185-be33-4311dfb4deeb/SelectedItemTime/2019-10-30T17:50:00Z/InsightType/5\" target=\"_blank\">View full details in Application Insights</a>" - } - ], - "SmartDetectorId": "FailureAnomaliesDetector", - "SmartDetectorName": "Failure Anomalies", - "AnalysisTimestamp": "2019-10-30T17:52:32.5802978Z" - }, - "egressConfig": { - "displayConfig": [ - { - "rootJsonNode": null, - "sectionName": null, - "displayControls": [ - { - "property": "DetectionSummary", - "displayName": "What was detected?", - "type": "Text", - "isOptional": false, - "isPropertySerialized": false - }, - { - "property": "FormattedOccurenceTime", - "displayName": "When did this occur?", - "type": "Text", - "isOptional": false, - "isPropertySerialized": false - }, - { - "property": "DetectedFailureRate", - "displayName": "Detected failure rate", - "type": "Text", - "isOptional": false, - "isPropertySerialized": false - }, - { - "property": "NormalFailureRate", - "displayName": "Normal failure rate", - "type": "Text", - "isOptional": false, - "isPropertySerialized": false - }, - { - "chartType": "Line", - "xAxisType": "Date", - "yAxisType": "Percentage", - "xAxisName": "", - "yAxisName": "", - "property": "FailureRateChart", - "displayName": "Failure rate over last 12 hours", - "type": "Chart", - "isOptional": false, - "isPropertySerialized": false - }, - { - "defaultLoad": true, - "displayConfig": [ - { - "rootJsonNode": null, - "sectionName": null, - "displayControls": [ - { - "showHeader": false, - "columns": [ - { - "property": "Name", - "displayName": "Name" - }, - { - "property": "Value", - "displayName": "Value" - } - ], - "property": "tables[0].rows[0][0]", - "displayName": "All of the failed requests had these characteristics:", - "type": "Table", - "isOptional": false, - "isPropertySerialized": true - } - ] - } - ], - "property": "ArmSystemEventsRequest", - "displayName": "", - "type": "ARMRequest", - "isOptional": false, - "isPropertySerialized": false - }, - { - "showHeader": false, - "columns": [ - { - "property": "Link", - "displayName": "Link" - } - ], - "property": "LinksTable", - "displayName": "Links", - "type": "Table", - "isOptional": false, - "isPropertySerialized": false - } - ] - } - ] - } - }, - "id": "/subscriptions/4f9b81be-fa32-4f96-aeb3-fc5c3f678df9/resourcegroups/test-group/providers/microsoft.insights/components/test-rule/providers/Microsoft.AlertsManagement/alerts/7daf8739-ca8a-4562-b69a-ff28db4ba0a5", - "type": "Microsoft.AlertsManagement/alerts", - "name": "Failure Anomalies - test-rule" -} -``` --## Triage and diagnose an alert --An alert indicates that an abnormal rise in the failed request rate was detected. It's likely that there's some problem with your app or its environment. --To investigate further, click on 'View full details in Application Insights.' The links in this page take you straight to a [search page](../app/diagnostic-search.md) filtered to the relevant requests, exception, dependency, or traces. -To investigate further, click on 'View full details in Application Insights' the links in this page take you straight to a [search page](../app/transaction-search-and-diagnostics.md?tabs=transaction-search) filtered to the relevant requests, exception, dependency, or traces. --You can also open the [Azure portal](https://portal.azure.com), navigate to the Application Insights resource for your app, and open the Failures page. --Clicking on 'Diagnose failures' can help you get more details and resolve the issue. ---From the percentage of requests and number of users affected, you can decide how urgent the issue is. In the example shown before, the failure rate of 78.5% compares with a normal rate of 2.2%, indicates that something bad is going on. On the other hand, only 46 users were affected. This information can help you to assess how serious the problem is. --In many cases, you can diagnose the problem quickly from the request name, exception, dependency failure, and trace data provided. --In this example, there was an exception from SQL Database due to request limit being reached. ---## Review recent alerts --Click **Alerts** in the Application Insights resource page to get to the most recent fired alerts: ---## If you receive a Smart Detection alert -*Why I received this alert?* --* We detected an abnormal rise in failed requests rate compared to the normal baseline of the preceding period. After analysis of the failures and associated application data, we think that there's a problem that you should look into. --*Does the notification mean I definitely have a problem?* --* We try to alert on app disruption or degradation, but only you can fully understand the semantics and the impact on the app or users. --*So, you're looking at my application data?* --* No. The service is entirely automatic. Only you get the notifications. Your data is [private](/previous-versions/azure/azure-monitor/app/data-retention-privacy). --*Do I have to subscribe to this alert?* --* No. Every application that sends request data has the Smart Detection alert rule. --*Can I unsubscribe or get the notifications sent to my colleagues instead?* --* Yes, In Alert rules, click the Smart Detection rule to configure it. You can disable the alert, or change recipients for the alert. --*I lost the email. Where can I find the notifications in the portal?* --* You can find Failure Anomalies alerts in the Azure portal, in your Application Insights alerts page. --*Some of the alerts are about known issues and I don't want to receive them.* --* You can use [alert action rules](./alerts-processing-rules.md) suppression feature. --## Next steps -These diagnostic tools help you inspect the data from your app: --* [Metric explorer](../essentials/metrics-charts.md) -* [Search explorer](../app/transaction-search-and-diagnostics.md?tabs=transaction-search) -* [Analytics - powerful query language](../logs/log-analytics-tutorial.md) --Smart detections are automatic. But maybe you'd like to set up some more alerts? --* [Manually configured metric alerts](./alerts-log.md) -* [Availability web tests](/previous-versions/azure/azure-monitor/app/monitor-web-app-availability) |
| azure-monitor | Proactive Potential Memory Leak | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/proactive-potential-memory-leak.md | - Title: 'Detect memory leak: Application Insights smart detection' -description: Monitor applications with Application Insights for potential memory leaks. -- Previously updated : 04/01/2024----# Memory leak detection (preview) -->[!NOTE] ->You can migrate your Application Insight resources to alerts-based smart detection (preview). The migration creates alert rules for the different smart detection modules. After you create the rules, you can manage and configure them like any other Azure Monitor alert rules. You can also configure action groups for these rules to enable multiple methods of taking actions or triggering notification on new detections. -> -> For more information, see [Smart detection alerts migration](./alerts-smart-detections-migration.md). --Smart detection automatically analyzes the memory consumption of each process in your application. It can warn you about potential memory leaks or increased memory consumption. --This feature requires no special setup other than [configuring performance counters](../app/performance-counters.md) for your app. It's active when your app generates enough memory performance counters telemetry (for example, Private Bytes). --## When would I get this type of smart detection notification? -A typical notification follows a consistent increase: --- In memory consumption over a long period of time.-- In one or more processes or machines that are part of your application.--Machine learning algorithms are used to detect increased memory consumption that matches the pattern of a memory leak. --## Does my app really have a problem? -A notification doesn't mean that your app definitely has a problem. Although memory leak patterns might indicate an application issue, these patterns might be typical to your specific process. Memory leak patterns might also have a natural business justification. In such cases, you can ignore the notification. --## How do I fix it? -The notifications include diagnostic information to support in the diagnostic analysis process: -1. **Triage:** The notification shows you the amount of memory increase (in GB) and the time range in which the memory has increased. This information can help you assign a priority to the problem. -1. **Scope:** How many machines exhibited the memory leak pattern? How many exceptions were triggered during the potential memory leak? You can obtain this information from the notification. -1. **Diagnose:** The detection contains the memory leak pattern and shows memory consumption of the process over time. You can also use the related items and reports linking to supporting information to help you further diagnose the issue. |
| azure-monitor | Proactive Trace Severity | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/proactive-trace-severity.md | - Title: Degradation in trace severity ratio - Azure Application Insights -description: Monitor application traces with Azure Application Insights for unusual patterns in trace telemetry with smart detection. -- Previously updated : 04/01/2024----# Degradation in trace severity ratio (preview) -->[!NOTE] ->You can migrate your Application Insight resources to alerts-bases smart detection (preview). The migration creates alert rules for the different smart detection modules. Once created, you can manage and configure these rules just like any other Azure Monitor alert rules. You can also configure action groups for these rules, thus enabling multiple methods of taking actions or triggering notification on new detections. -> -> For more information, see [Smart Detection Alerts migration](./alerts-smart-detections-migration.md). -> --Traces are widely used in applications, and they help tell the story of what happens behind the scenes. When things go wrong, traces provide crucial visibility into the sequence of events leading to the undesired state. While traces are mostly unstructured, their severity level can still provide valuable information. In an applicationΓÇÖs steady state, we would expect the ratio between ΓÇ£goodΓÇ¥ traces (*Info* and *Verbose*) and ΓÇ£badΓÇ¥ traces (*Warning*, *Error*, and *Critical*) to remain stable. --It's normal to expect some level of ΓÇ£BadΓÇ¥ traces because of any number of reasons, such as transient network issues. But when a real problem begins growing, it usually manifests as an increase in the relative proportion of ΓÇ£badΓÇ¥ traces vs ΓÇ£goodΓÇ¥ traces. Smart detection automatically analyzes the trace telemetry that your application logs, and can warn you about unusual patterns in their severity. --This feature requires no special setup, other than configuring trace logging for your app. See how to configure a trace log listener for [.NET](../app/asp-net-trace-logs.md) or [Java](../app/opentelemetry-enable.md?tabs=java). It's active when your app generates enough trace telemetry. --## When would I get this type of smart detection notification? -You get this type of notification if the ratio between ΓÇ£goodΓÇ¥ traces (traces logged with a level of *Info* or *Verbose*) and ΓÇ£badΓÇ¥ traces (traces logged with a level of *Warning*, *Error*, or *Fatal*) is degrading in a specific day, compared to a baseline calculated over the previous seven days. --## Does my app definitely have a problem? -A notification doesn't mean that your app definitely has a problem. Although a degradation in the ratio between ΓÇ£goodΓÇ¥ and ΓÇ£badΓÇ¥ traces might indicate an application issue, it can also be benign. For example, the increase can be because of a new flow in the application emitting more ΓÇ£badΓÇ¥ traces than existing flows). --## How do I fix it? -The notifications include diagnostic information to support in the diagnostics process: -1. **Triage.** The notification shows you how many operations are affected. This information can help you assign a priority to the problem. -2. **Scope.** Is the problem affecting all traffic, or just some operation? This information can be obtained from the notification. -3. **Diagnose.** You can use the related items and reports linking to supporting information, to help you further diagnose the issue. |
| azure-monitor | Prometheus Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/prometheus-alerts.md | - Title: Prometheus metric alerts in Azure Monitor -description: Overview of Prometheus alert rules in Azure Monitor generated by data in Azure Monitor managed services for Prometheus. ---- Previously updated : 04/01/2024---# Prometheus alerts in Azure Monitor --As part of [Azure Monitor managed services for Prometheus](../essentials/prometheus-metrics-overview.md), you can use Prometheus alert rules to define alert conditions by using queries written in Prometheus Query Language (PromQL). The rule queries are applied on Prometheus metrics stored in an [Azure Monitor workspace](../essentials/azure-monitor-workspace-overview.md). --Whenever the alert query results in one or more time series meeting the condition, the alert counts as pending for these metric and label sets. A pending alert becomes active after a user-defined period of time during which all the consecutive query evaluations for the respective time series meet the alert condition. After an alert becomes active, it's fired and triggers your actions or notifications of choice, as defined in the Azure action groups configured in your alert rule. --## Create Prometheus alert rules --You create and manage Prometheus alert rules as part of a Prometheus rule group. For details, see [Azure Monitor managed service for Prometheus rule groups](../essentials/prometheus-rule-groups.md). --## View Prometheus alerts --You can view fired and resolved Prometheus alerts in the Azure portal together with all other alert types. Use the following steps to filter on only Prometheus alerts: --1. On the **Monitor** menu in the Azure portal, select **Alerts**. -2. If **Monitor service** doesn't appear as a filter option, select **Add Filter** and add it. -3. Set the **Monitor service** filter to **Prometheus** to see Prometheus alerts. -- :::image type="content" source="media/prometheus-metric-alerts/view-alerts.png" lightbox="media/prometheus-metric-alerts/view-alerts.png" alt-text="Screenshot of a list of alerts in Azure Monitor with a filter for Prometheus alerts."::: -4. Select the alert name to view the details of a specific fired or resolved alert. -- :::image type="content" source="media/prometheus-metric-alerts/alert-details-grafana.png" lightbox="media/prometheus-metric-alerts/alert-details-grafana.png" alt-text="Screenshot of details for a Prometheus alert in Azure Monitor."::: --If your rule group is configured with [a specific cluster scope](../essentials/prometheus-rule-groups.md#limiting-rules-to-a-specific-cluster), you can also view alerts fired for this cluster. On the **Cluster** menu in the Azure portal, select **Alerts**. You can then filter for the Prometheus monitoring service. --## Explore Prometheus alerts in Grafana --1. On the pane that shows the details of fired alerts, select the **View query in Grafana** link. --2. A browser tab opens and takes you to the [Azure Managed Grafana](../../managed-grafan) instance that's connected to your Azure Monitor workspace. --3. Grafana opens in Explore mode and presents the chart for your alert rule expression query around the alert firing time. You can further explore the query in Grafana to identify the reason that the alert is firing. --> [!NOTE] -> - If no Azure Managed Grafana instance is connected to your Azure Monitor workspace, a link to Grafana isn't available. -> - To view the alert query in Explore mode, you must have either Grafana Admin or Grafana Editor role permissions. If you don't have the needed permissions, you get a Grafana error. --## Related content --- [Create a Prometheus rule group](../essentials/prometheus-rule-groups.md) |
| azure-monitor | Resource Manager Action Groups | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/resource-manager-action-groups.md | - Title: Resource Manager template samples for action groups -description: Sample Azure Resource Manager templates to deploy Azure Monitor action groups. --- Previously updated : 01/28/2024----# Resource Manager template samples for action groups in Azure Monitor --This article includes sample [Azure Resource Manager templates](../../azure-resource-manager/templates/syntax.md) to create [action groups](../alerts/action-groups.md) in Azure Monitor. Each sample includes a template file and a parameters file with sample values to provide to the template. ---## Create an action group --The following sample creates an action group. --### Template file --# [Bicep](#tab/bicep) --```bicep -@description('Unique name within the resource group for the Action group.') -param actionGroupName string --@description('Short name up to 12 characters for the Action group.') -param actionGroupShortName string --resource actionGroup 'Microsoft.Insights/actionGroups@2021-09-01' = { - name: actionGroupName - location: 'Global' - properties: { - groupShortName: actionGroupShortName - enabled: true - smsReceivers: [ - { - name: 'contosoSMS' - countryCode: '1' - phoneNumber: '5555551212' - } - { - name: 'contosoSMS2' - countryCode: '1' - phoneNumber: '5555552121' - } - ] - emailReceivers: [ - { - name: 'contosoEmail' - emailAddress: 'devops@contoso.com' - useCommonAlertSchema: true - } - { - name: 'contosoEmail2' - emailAddress: 'devops2@contoso.com' - useCommonAlertSchema: true - } - ] - webhookReceivers: [ - { - name: 'contosoHook' - serviceUri: 'http://requestb.in/1bq62iu1' - useCommonAlertSchema: true - } - { - name: 'contosoHook2' - serviceUri: 'http://requestb.in/1bq62iu2' - useCommonAlertSchema: true - } - ] - } -} --output actionGroupId string = actionGroup.id -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "actionGroupName": { - "type": "string", - "metadata": { - "description": "Unique name within the resource group for the Action group." - } - }, - "actionGroupShortName": { - "type": "string", - "metadata": { - "description": "Short name up to 12 characters for the Action group." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/actionGroups", - "apiVersion": "2021-09-01", - "name": "[parameters('actionGroupName')]", - "location": "Global", - "properties": { - "groupShortName": "[parameters('actionGroupShortName')]", - "enabled": true, - "smsReceivers": [ - { - "name": "contosoSMS", - "countryCode": "1", - "phoneNumber": "5555551212" - }, - { - "name": "contosoSMS2", - "countryCode": "1", - "phoneNumber": "5555552121" - } - ], - "emailReceivers": [ - { - "name": "contosoEmail", - "emailAddress": "devops@contoso.com", - "useCommonAlertSchema": true - }, - { - "name": "contosoEmail2", - "emailAddress": "devops2@contoso.com", - "useCommonAlertSchema": true - } - ], - "webhookReceivers": [ - { - "name": "contosoHook", - "serviceUri": "http://requestb.in/1bq62iu1", - "useCommonAlertSchema": true - }, - { - "name": "contosoHook2", - "serviceUri": "http://requestb.in/1bq62iu2", - "useCommonAlertSchema": true - } - ] - } - } - ], - "outputs": { - "actionGroupId": { - "type": "string", - "value": "[resourceId('Microsoft.Insights/actionGroups', parameters('actionGroupName'))]" - } - } -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "actionGroupName": { - "value": "My Action Group" - }, - "actionGroupShortName": { - "value": "mygroup" - } - } -} -``` --## Next steps --* [Get other sample templates for Azure Monitor](../resource-manager-samples.md). -* [Learn more about action groups](../alerts/action-groups.md). |
| azure-monitor | Resource Manager Alerts Activity Log | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/resource-manager-alerts-activity-log.md | - Title: Resource Manager template samples for activity log alerts -description: Sample Azure Resource Manager templates to deploy Azure Monitor activity log alerts. ----- Previously updated : 04/01/2024---# Resource Manager template samples for Azure Monitor activity log alert rules (Administrative category) --This article includes examples of [Azure Resource Manager templates](../../azure-resource-manager/templates/syntax.md) to create and configure activity log alerts for Administrative events in Azure Monitor. ---## Activity log alert rule condition for the **Administrative** event category: --This example sets the condition to the **Administrative** category: --```json -"condition": { - "allOf": [ - { - "field": "category", - "equals": "Administrative" - }, - { - "field": "resourceType", - "equals": "Microsoft.Resources/deployments" - } - ] - } -``` --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "activityLogAlertName": { - "type": "string", - "metadata": { - "description": "Unique name (within the Resource Group) for the Activity log alert." - } - }, - "activityLogAlertEnabled": { - "type": "bool", - "defaultValue": true, - "metadata": { - "description": "Indicates whether or not the alert is enabled." - } - }, - "actionGroupResourceId": { - "type": "string", - "metadata": { - "description": "Resource Id for the Action group." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/activityLogAlerts", - "apiVersion": "2017-04-01", - "name": "[parameters('activityLogAlertName')]", - "location": "Global", - "properties": { - "enabled": "[parameters('activityLogAlertEnabled')]", - "scopes": [ - "[subscription().id]" - ], - "condition": { - "allOf": [ - { - "field": "category", - "equals": "Administrative" - }, - { - "field": "operationName", - "equals": "Microsoft.Resources/deployments/write" - }, - { - "field": "resourceType", - "equals": "Microsoft.Resources/deployments" - } - ] - }, - "actions": { - "actionGroups": - [ - { - "actionGroupId": "[parameters('actionGroupResourceId')]" - } - ] - } - } - } - ] -} -``` --## Next steps --- [Get other sample templates for Azure Monitor](../resource-manager-samples.md).-- [Learn more about alert rules](./alerts-overview.md). |
| azure-monitor | Resource Manager Alerts Log | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/resource-manager-alerts-log.md | - Title: Resource Manager template samples for log search alerts -description: Sample Azure Resource Manager templates to deploy Azure Monitor log search alerts. ---- Previously updated : 11/07/2023---# Resource Manager template samples for log search alert rules in Azure Monitor --This article includes samples of [Azure Resource Manager templates](../../azure-resource-manager/templates/syntax.md) to create and configure log search alerts in Azure Monitor. Each sample includes a template file and a parameters file with sample values to provide to the template. ---> [!NOTE] -> The combined size of all data in the log alert rule properties cannot exceed 64KB. This can be caused by too many dimensions, the query being too large, too many action groups, or a long description. When creating a large alert rule, remember to optimize these areas. --## Template for all resource types (from version 2021-08-01) --The following sample creates a rule that can target any resource. --# [Bicep](#tab/bicep) --```bicep -@description('Name of the alert') -@minLength(1) -param alertName string --@description('Location of the alert') -@minLength(1) -param location string --@description('Description of alert') -param alertDescription string = 'This is a metric alert' --@description('Severity of alert {0,1,2,3,4}') -@allowed([ - 0 - 1 - 2 - 3 - 4 -]) -param alertSeverity int = 3 --@description('Specifies whether the alert is enabled') -param isEnabled bool = true --@description('Specifies whether the alert will automatically resolve') -param autoMitigate bool = true --@description('Specifies whether to check linked storage and fail creation if the storage was not found') -param checkWorkspaceAlertsStorageConfigured bool = false --@description('Full Resource ID of the resource emitting the metric that will be used for the comparison. For example /subscriptions/00000000-0000-0000-0000-0000-00000000/resourceGroups/ResourceGroupName/providers/Microsoft.compute/virtualMachines/VM_xyz') -@minLength(1) -param resourceId string --@description('Name of the metric used in the comparison to activate the alert.') -@minLength(1) -param query string --@description('Name of the measure column used in the alert evaluation.') -param metricMeasureColumn string --@description('Name of the resource ID column used in the alert targeting the alerts.') -param resourceIdColumn string --@description('Operator comparing the current value with the threshold value.') -@allowed([ - 'Equals' - 'GreaterThan' - 'GreaterThanOrEqual' - 'LessThan' - 'LessThanOrEqual' -]) -param operator string = 'GreaterThan' --@description('The threshold value at which the alert is activated.') -param threshold int = 0 --@description('The number of periods to check in the alert evaluation.') -param numberOfEvaluationPeriods int = 1 --@description('The number of unhealthy periods to alert on (must be lower or equal to numberOfEvaluationPeriods).') -param minFailingPeriodsToAlert int = 1 --@description('How the data that is collected should be combined over time.') -@allowed([ - 'Average' - 'Minimum' - 'Maximum' - 'Total' - 'Count' -]) -param timeAggregation string = 'Average' --@description('Period of time used to monitor alert activity based on the threshold. Must be between one minute and one day. ISO 8601 duration format.') -@allowed([ - 'PT1M' - 'PT5M' - 'PT10M' - 'PT15M' - 'PT30M' - 'PT45M' - 'PT1H' - 'PT2H' - 'PT3H' - 'PT4H' - 'PT5H' - 'PT6H' - 'PT24H' - 'PT48H' -]) -param windowSize string = 'PT5M' --@description('how often the metric alert is evaluated represented in ISO 8601 duration format') -@allowed([ - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' -]) -param evaluationFrequency string = 'PT5M' --@description('Mute actions for the chosen period of time (in ISO 8601 duration format) after the alert is fired.') -@allowed([ - 'PT1M' - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' - 'PT6H' - 'PT12H' - 'PT24H' -]) -param muteActionsDuration string --@description('The ID of the action group that is triggered when the alert is activated or deactivated') -param actionGroupId string = '' --resource alert 'Microsoft.Insights/scheduledQueryRules@2021-08-01' = { - name: alertName - location: location - tags: {} - properties: { - description: alertDescription - severity: alertSeverity - enabled: isEnabled - scopes: [ - resourceId - ] - evaluationFrequency: evaluationFrequency - windowSize: windowSize - criteria: { - allOf: [ - { - query: query - metricMeasureColumn: metricMeasureColumn - resourceIdColumn: resourceIdColumn - dimensions: [] - operator: operator - threshold: threshold - timeAggregation: timeAggregation - failingPeriods: { - numberOfEvaluationPeriods: numberOfEvaluationPeriods - minFailingPeriodsToAlert: minFailingPeriodsToAlert - } - } - ] - } - muteActionsDuration: muteActionsDuration - autoMitigate: autoMitigate - checkWorkspaceAlertsStorageConfigured: checkWorkspaceAlertsStorageConfigured - actions: { - actionGroups: [ - actionGroupId - ] - customProperties: { - key1: 'value1' - key2: 'value2' - } - } - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the alert" - } - }, - "location": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Location of the alert" - } - }, - "alertDescription": { - "type": "string", - "defaultValue": "This is a metric alert", - "metadata": { - "description": "Description of alert" - } - }, - "alertSeverity": { - "type": "int", - "defaultValue": 3, - "allowedValues": [ - 0, - 1, - 2, - 3, - 4 - ], - "metadata": { - "description": "Severity of alert {0,1,2,3,4}" - } - }, - "isEnabled": { - "type": "bool", - "defaultValue": true, - "metadata": { - "description": "Specifies whether the alert is enabled" - } - }, - "autoMitigate": { - "type": "bool", - "defaultValue": true, - "metadata": { - "description": "Specifies whether the alert will automatically resolve" - } - }, - "checkWorkspaceAlertsStorageConfigured": { - "type": "bool", - "defaultValue": false, - "metadata": { - "description": "Specifies whether to check linked storage and fail creation if the storage was not found" - } - }, - "resourceId": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Full Resource ID of the resource emitting the metric that will be used for the comparison. For example /subscriptions/00000000-0000-0000-0000-0000-00000000/resourceGroups/ResourceGroupName/providers/Microsoft.compute/virtualMachines/VM_xyz" - } - }, - "query": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the metric used in the comparison to activate the alert." - } - }, - "metricMeasureColumn": { - "type": "string", - "metadata": { - "description": "Name of the measure column used in the alert evaluation." - } - }, - "resourceIdColumn": { - "type": "string", - "metadata": { - "description": "Name of the resource ID column used in the alert targeting the alerts." - } - }, - "operator": { - "type": "string", - "defaultValue": "GreaterThan", - "allowedValues": [ - "Equals", - "GreaterThan", - "GreaterThanOrEqual", - "LessThan", - "LessThanOrEqual" - ], - "metadata": { - "description": "Operator comparing the current value with the threshold value." - } - }, - "threshold": { - "type": "int", - "defaultValue": 0, - "metadata": { - "description": "The threshold value at which the alert is activated." - } - }, - "numberOfEvaluationPeriods": { - "type": "int", - "defaultValue": 1, - "metadata": { - "description": "The number of periods to check in the alert evaluation." - } - }, - "minFailingPeriodsToAlert": { - "type": "int", - "defaultValue": 1, - "metadata": { - "description": "The number of unhealthy periods to alert on (must be lower or equal to numberOfEvaluationPeriods)." - } - }, - "timeAggregation": { - "type": "string", - "defaultValue": "Average", - "allowedValues": [ - "Average", - "Minimum", - "Maximum", - "Total", - "Count" - ], - "metadata": { - "description": "How the data that is collected should be combined over time." - } - }, - "windowSize": { - "type": "string", - "defaultValue": "PT5M", - "allowedValues": [ - "PT1M", - "PT5M", - "PT15M", - "PT30M", - "PT1H", - "PT6H", - "PT12H", - "PT24H" - ], - "metadata": { - "description": "Period of time used to monitor alert activity based on the threshold. Must be between one minute and one day. ISO 8601 duration format." - } - }, - "evaluationFrequency": { - "type": "string", - "defaultValue": "PT5M", - "allowedValues": [ - "PT5M", - "PT15M", - "PT30M", - "PT1H" - ], - "metadata": { - "description": "how often the metric alert is evaluated represented in ISO 8601 duration format" - } - }, - "muteActionsDuration": { - "type": "string", - "allowedValues": [ - "PT1M", - "PT5M", - "PT15M", - "PT30M", - "PT1H", - "PT6H", - "PT12H", - "PT24H" - ], - "metadata": { - "description": "Mute actions for the chosen period of time (in ISO 8601 duration format) after the alert is fired." - } - }, - "actionGroupId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "The ID of the action group that is triggered when the alert is activated or deactivated" - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/scheduledQueryRules", - "apiVersion": "2021-08-01", - "name": "[parameters('alertName')]", - "location": "[parameters('location')]", - "tags": {}, - "properties": { - "description": "[parameters('alertDescription')]", - "severity": "[parameters('alertSeverity')]", - "enabled": "[parameters('isEnabled')]", - "scopes": [ - "[parameters('resourceId')]" - ], - "evaluationFrequency": "[parameters('evaluationFrequency')]", - "windowSize": "[parameters('windowSize')]", - "criteria": { - "allOf": [ - { - "query": "[parameters('query')]", - "metricMeasureColumn": "[parameters('metricMeasureColumn')]", - "resourceIdColumn": "[parameters('resourceIdColumn')]", - "dimensions": [], - "operator": "[parameters('operator')]", - "threshold": "[parameters('threshold')]", - "timeAggregation": "[parameters('timeAggregation')]", - "failingPeriods": { - "numberOfEvaluationPeriods": "[parameters('numberOfEvaluationPeriods')]", - "minFailingPeriodsToAlert": "[parameters('minFailingPeriodsToAlert')]" - } - } - ] - }, - "muteActionsDuration": "[parameters('muteActionsDuration')]", - "autoMitigate": "[parameters('autoMitigate')]", - "checkWorkspaceAlertsStorageConfigured": "[parameters('checkWorkspaceAlertsStorageConfigured')]", - "actions": { - "actionGroups": [ - "[parameters('actionGroupId')]" - ], - "customProperties": { - "key1": "value1", - "key2": "value2" - } - } - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "value": "New Alert" - }, - "location": { - "value": "eastus" - }, - "alertDescription": { - "value": "New alert created via template" - }, - "alertSeverity": { - "value":3 - }, - "isEnabled": { - "value": true - }, - "resourceId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resourceGroup-name/providers/Microsoft.Compute/virtualMachines/replace-with-resource-name" - }, - "query": { - "value": "Perf | where ObjectName == \"Processor\" and CounterName == \"% Processor Time\"" - }, - "metricMeasureColumn": { - "value": "AggregatedValue" - }, - "operator": { - "value": "GreaterThan" - }, - "threshold": { - "value": 80 - }, - "timeAggregation": { - "value": "Average" - }, - "actionGroupId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/resource-group-name/providers/Microsoft.Insights/actionGroups/replace-with-action-group" - } - } -} -``` --## Number of results template (up to version 2018-04-16) --The following sample creates a [number of results alert rule](../alerts/alerts-types.md#log-alerts). --### Notes --- This sample includes a [webhook payload](../alerts/alerts-log-webhook.md). If the alert rule shouldn't trigger a webhook, then remove the **customWebhookPayload** element.--### Template file --# [Bicep](#tab/bicep) --```bicep -@description('Resource ID of the Log Analytics workspace.') -param sourceId string = '' --@description('Location for the alert. Must be the same location as the workspace.') -param location string = '' --@description('The ID of the action group that is triggered when the alert is activated.') -param actionGroupId string = '' --resource logQueryAlert 'Microsoft.Insights/scheduledQueryRules@2018-04-16' = { - name: 'Sample log query alert' - location: location - properties: { - description: 'Sample log query alert' - enabled: 'true' - source: { - query: 'Event | where EventLevelName == "Error" | summarize count() by Computer' - dataSourceId: sourceId - queryType: 'ResultCount' - } - schedule: { - frequencyInMinutes: 15 - timeWindowInMinutes: 60 - } - action: { - 'odata.type': 'Microsoft.WindowsAzure.Management.Monitoring.Alerts.Models.Microsoft.AppInsights.Nexus.DataContracts.Resources.ScheduledQueryRules.AlertingAction' - severity: '4' - aznsAction: { - actionGroup: array(actionGroupId) - emailSubject: 'Alert mail subject' - customWebhookPayload: '{ "alertname":"#alertrulename", "IncludeSearchResults":true }' - } - trigger: { - thresholdOperator: 'GreaterThan' - threshold: 1 - } - } - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "sourceId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "Resource ID of the Log Analytics workspace." - } - }, - "location": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "Location for the alert. Must be the same location as the workspace." - } - }, - "actionGroupId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "The ID of the action group that is triggered when the alert is activated." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/scheduledQueryRules", - "apiVersion": "2018-04-16", - "name": "Sample log query alert", - "location": "[parameters('location')]", - "properties": { - "description": "Sample log query alert", - "enabled": "true", - "source": { - "query": "Event | where EventLevelName == \"Error\" | summarize count() by Computer", - "dataSourceId": "[parameters('sourceId')]", - "queryType": "ResultCount" - }, - "schedule": { - "frequencyInMinutes": 15, - "timeWindowInMinutes": 60 - }, - "action": { - "odata.type": "Microsoft.WindowsAzure.Management.Monitoring.Alerts.Models.Microsoft.AppInsights.Nexus.DataContracts.Resources.ScheduledQueryRules.AlertingAction", - "severity": "4", - "aznsAction": { - "actionGroup": "[array(parameters('actionGroupId'))]", - "emailSubject": "Alert mail subject", - "customWebhookPayload": "{ \"alertname\":\"#alertrulename\", \"IncludeSearchResults\":true }" - }, - "trigger": { - "thresholdOperator": "GreaterThan", - "threshold": 1 - } - } - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "sourceId": { - "value": "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourcegroups/bw-samples-arm/providers/microsoft.operationalinsights/workspaces/bw-arm-01" - }, - "location": { - "value": "westus" - }, - "actionGroupId": { - "value": "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/bw-samples-arm/providers/microsoft.insights/actionGroups/ARM samples group 01" - } - } -} -``` --## Metric measurement template (up to version 2018-04-16) --The following sample creates a [metric measurement alert rule](../alerts/alerts-types.md#log-alerts). --### Template file --# [Bicep](#tab/bicep) --```bicep -@description('Resource ID of the Log Analytics workspace.') -param sourceId string = '' --@description('Location for the alert. Must be the same location as the workspace.') -param location string = '' --@description('The ID of the action group that is triggered when the alert is activated.') -param actionGroupId string = '' --resource metricMeasurementLogQueryAlert 'Microsoft.Insights/scheduledQueryRules@2018-04-16' = { - name: 'Sample metric measurement log query alert' - location: location - properties: { - description: 'Sample metric measurement query alert rule' - enabled: 'true' - source: { - query: 'Event | where EventLevelName == "Error" | summarize AggregatedValue = count() by bin(TimeGenerated,1h), Computer' - dataSourceId: sourceId - queryType: 'ResultCount' - } - schedule: { - frequencyInMinutes: 15 - timeWindowInMinutes: 60 - } - action: { - 'odata.type': 'Microsoft.WindowsAzure.Management.Monitoring.Alerts.Models.Microsoft.AppInsights.Nexus.DataContracts.Resources.ScheduledQueryRules.AlertingAction' - severity: '4' - aznsAction: { - actionGroup: array(actionGroupId) - emailSubject: 'Alert mail subject' - } - trigger: { - thresholdOperator: 'GreaterThan' - threshold: 10 - metricTrigger: { - thresholdOperator: 'Equal' - threshold: 1 - metricTriggerType: 'Consecutive' - metricColumn: 'Computer' - } - } - } - } -} --``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "sourceId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "Resource ID of the Log Analytics workspace." - } - }, - "location": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "Location for the alert. Must be the same location as the workspace." - } - }, - "actionGroupId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "The ID of the action group that is triggered when the alert is activated." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/scheduledQueryRules", - "apiVersion": "2018-04-16", - "name": "Sample metric measurement log query alert", - "location": "[parameters('location')]", - "properties": { - "description": "Sample metric measurement query alert rule", - "enabled": "true", - "source": { - "query": "Event | where EventLevelName == \"Error\" | summarize AggregatedValue = count() by bin(TimeGenerated,1h), Computer", - "dataSourceId": "[parameters('sourceId')]", - "queryType": "ResultCount" - }, - "schedule": { - "frequencyInMinutes": 15, - "timeWindowInMinutes": 60 - }, - "action": { - "odata.type": "Microsoft.WindowsAzure.Management.Monitoring.Alerts.Models.Microsoft.AppInsights.Nexus.DataContracts.Resources.ScheduledQueryRules.AlertingAction", - "severity": "4", - "aznsAction": { - "actionGroup": "[array(parameters('actionGroupId'))]", - "emailSubject": "Alert mail subject" - }, - "trigger": { - "thresholdOperator": "GreaterThan", - "threshold": 10, - "metricTrigger": { - "thresholdOperator": "Equal", - "threshold": 1, - "metricTriggerType": "Consecutive", - "metricColumn": "Computer" - } - } - } - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "sourceId": { - "value": "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourcegroups/bw-samples-arm/providers/microsoft.operationalinsights/workspaces/bw-arm-01" - }, - "location": { - "value": "westus" - }, - "actionGroupId": { - "value": "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/bw-samples-arm/providers/microsoft.insights/actionGroups/ARM samples group 01" - } - } -} -``` --## Next steps --- [Get other sample templates for Azure Monitor](../resource-manager-samples.md).-- [Learn more about alert rules](./alerts-overview.md). |
| azure-monitor | Resource Manager Alerts Metric | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/resource-manager-alerts-metric.md | - Title: Resource Manager template samples for metric alerts -description: This article provides sample Resource Manager templates used to create metric alerts in Azure Monitor. ---- Previously updated : 02/16/2024-----# Resource Manager template samples for metric alert rules in Azure Monitor --This article provides samples of using [Azure Resource Manager templates](../../azure-resource-manager/templates/syntax.md) to configure [metric alert rules](../alerts/alerts-metric-near-real-time.md) in Azure Monitor. Each sample includes a template file and a parameters file with sample values to provide to the template. ---See [Supported resources for metric alerts in Azure Monitor](../alerts/alerts-metric-near-real-time.md) for a list of resources that can be used with metric alert rules. An explanation of the schema and properties for an alert rule is available at [Metric Alerts - Create Or Update](/rest/api/monitor/metricalerts/createorupdate). --> [!NOTE] -> Resource template for creating metric alerts for resource type: Azure Log Analytics Workspace (i.e.) `Microsoft.OperationalInsights/workspaces`, requires additional steps. For details, see [Metric Alert for Logs - Resource Template](../alerts/alerts-metric-logs.md#resource-manager-templates). --## Template references --- [Microsoft.Insights metricAlerts](/azure/templates/microsoft.insights/2018-03-01/metricalerts)--## Single criteria, static threshold --The following sample creates a metric alert rule using a single criteria and a static threshold. --### Template file --# [Bicep](#tab/bicep) --```bicep -@description('Name of the alert') -@minLength(1) -param alertName string --@description('Description of alert') -param alertDescription string = 'This is a metric alert' --@description('Severity of alert {0,1,2,3,4}') -@allowed([ - 0 - 1 - 2 - 3 - 4 -]) -param alertSeverity int = 3 --@description('Specifies whether the alert is enabled') -param isEnabled bool = true --@description('Full Resource ID of the resource emitting the metric that will be used for the comparison. For example /subscriptions/00000000-0000-0000-0000-0000-00000000/resourceGroups/ResourceGroupName/providers/Microsoft.compute/virtualMachines/VM_xyz') -@minLength(1) -param resourceId string --@description('Name of the metric used in the comparison to activate the alert.') -@minLength(1) -param metricName string --@description('Operator comparing the current value with the threshold value.') -@allowed([ - 'Equals' - 'GreaterThan' - 'GreaterThanOrEqual' - 'LessThan' - 'LessThanOrEqual' -]) -param operator string = 'GreaterThan' --@description('The threshold value at which the alert is activated.') -param threshold int = 0 --@description('How the data that is collected should be combined over time.') -@allowed([ - 'Average' - 'Minimum' - 'Maximum' - 'Total' - 'Count' -]) -param timeAggregation string = 'Average' --@description('Period of time used to monitor alert activity based on the threshold. Must be between one minute and one day. ISO 8601 duration format.') -@allowed([ - 'PT1M' - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' - 'PT6H' - 'PT12H' - 'PT24H' -]) -param windowSize string = 'PT5M' --@description('how often the metric alert is evaluated represented in ISO 8601 duration format') -@allowed([ - 'PT1M' - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' -]) -param evaluationFrequency string = 'PT1M' --@description('The ID of the action group that is triggered when the alert is activated or deactivated') -param actionGroupId string = '' --resource metricAlert 'Microsoft.Insights/metricAlerts@2018-03-01' = { - name: alertName - location: 'global' - properties: { - description: alertDescription - severity: alertSeverity - enabled: isEnabled - scopes: [ - resourceId - ] - evaluationFrequency: evaluationFrequency - windowSize: windowSize - criteria: { - 'odata.type': 'Microsoft.Azure.Monitor.SingleResourceMultipleMetricCriteria' - allOf: [ - { - name: '1st criterion' - metricName: metricName - dimensions: [] - operator: operator - threshold: threshold - timeAggregation: timeAggregation - criterionType: 'StaticThresholdCriterion' - } - ] - } - actions: [ - { - actionGroupId: actionGroupId - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the alert" - } - }, - "alertDescription": { - "type": "string", - "defaultValue": "This is a metric alert", - "metadata": { - "description": "Description of alert" - } - }, - "alertSeverity": { - "type": "int", - "defaultValue": 3, - "allowedValues": [ - 0, - 1, - 2, - 3, - 4 - ], - "metadata": { - "description": "Severity of alert {0,1,2,3,4}" - } - }, - "isEnabled": { - "type": "bool", - "defaultValue": true, - "metadata": { - "description": "Specifies whether the alert is enabled" - } - }, - "resourceId": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Full Resource ID of the resource emitting the metric that will be used for the comparison. For example /subscriptions/00000000-0000-0000-0000-0000-00000000/resourceGroups/ResourceGroupName/providers/Microsoft.compute/virtualMachines/VM_xyz" - } - }, - "metricName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the metric used in the comparison to activate the alert." - } - }, - "operator": { - "type": "string", - "defaultValue": "GreaterThan", - "allowedValues": [ - "Equals", - "GreaterThan", - "GreaterThanOrEqual", - "LessThan", - "LessThanOrEqual" - ], - "metadata": { - "description": "Operator comparing the current value with the threshold value." - } - }, - "threshold": { - "type": "int", - "defaultValue": 0, - "metadata": { - "description": "The threshold value at which the alert is activated." - } - }, - "timeAggregation": { - "type": "string", - "defaultValue": "Average", - "allowedValues": [ - "Average", - "Minimum", - "Maximum", - "Total", - "Count" - ], - "metadata": { - "description": "How the data that is collected should be combined over time." - } - }, - "windowSize": { - "type": "string", - "defaultValue": "PT5M", - "allowedValues": [ - "PT1M", - "PT5M", - "PT15M", - "PT30M", - "PT1H", - "PT6H", - "PT12H", - "PT24H" - ], - "metadata": { - "description": "Period of time used to monitor alert activity based on the threshold. Must be between one minute and one day. ISO 8601 duration format." - } - }, - "evaluationFrequency": { - "type": "string", - "defaultValue": "PT1M", - "allowedValues": [ - "PT1M", - "PT5M", - "PT15M", - "PT30M", - "PT1H" - ], - "metadata": { - "description": "how often the metric alert is evaluated represented in ISO 8601 duration format" - } - }, - "actionGroupId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "The ID of the action group that is triggered when the alert is activated or deactivated" - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/metricAlerts", - "apiVersion": "2018-03-01", - "name": "[parameters('alertName')]", - "location": "global", - "properties": { - "description": "[parameters('alertDescription')]", - "severity": "[parameters('alertSeverity')]", - "enabled": "[parameters('isEnabled')]", - "scopes": [ - "[parameters('resourceId')]" - ], - "evaluationFrequency": "[parameters('evaluationFrequency')]", - "windowSize": "[parameters('windowSize')]", - "criteria": { - "odata.type": "Microsoft.Azure.Monitor.SingleResourceMultipleMetricCriteria", - "allOf": [ - { - "name": "1st criterion", - "metricName": "[parameters('metricName')]", - "dimensions": [], - "operator": "[parameters('operator')]", - "threshold": "[parameters('threshold')]", - "timeAggregation": "[parameters('timeAggregation')]", - "criterionType": "StaticThresholdCriterion" - } - ] - }, - "actions": [ - { - "actionGroupId": "[parameters('actionGroupId')]" - } - ] - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "value": "New Metric Alert" - }, - "alertDescription": { - "value": "New metric alert created via template" - }, - "alertSeverity": { - "value":3 - }, - "isEnabled": { - "value": true - }, - "resourceId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resourceGroup-name/providers/Microsoft.Compute/virtualMachines/replace-with-resource-name" - }, - "metricName": { - "value": "Percentage CPU" - }, - "operator": { - "value": "GreaterThan" - }, - "threshold": { - "value": 80 - }, - "timeAggregation": { - "value": "Average" - }, - "actionGroupId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/resource-group-name/providers/Microsoft.Insights/actionGroups/replace-with-action-group" - } - } -} -``` --## Single criteria, dynamic threshold --The following sample creates a metric alert rule using a single criteria and a dynamic threshold. --### Template file --# [Bicep](#tab/bicep) --```bicep -@description('Name of the alert') -@minLength(1) -param alertName string --@description('Description of alert') -param alertDescription string = 'This is a metric alert' --@description('Severity of alert {0,1,2,3,4}') -@allowed([ - 0 - 1 - 2 - 3 - 4 -]) -param alertSeverity int = 3 --@description('Specifies whether the alert is enabled') -param isEnabled bool = true --@description('Full Resource ID of the resource emitting the metric that will be used for the comparison. For example /subscriptions/00000000-0000-0000-0000-0000-00000000/resourceGroups/ResourceGroupName/providers/Microsoft.compute/virtualMachines/VM_xyz') -@minLength(1) -param resourceId string --@description('Name of the metric used in the comparison to activate the alert.') -@minLength(1) -param metricName string --@description('Operator comparing the current value with the threshold value.') -@allowed([ - 'GreaterThan' - 'LessThan' - 'GreaterOrLessThan' -]) -param operator string = 'GreaterOrLessThan' --@description('Tunes how \'noisy\' the Dynamic Thresholds alerts will be: \'High\' will result in more alerts while \'Low\' will result in fewer alerts.') -@allowed([ - 'High' - 'Medium' - 'Low' -]) -param alertSensitivity string = 'Medium' --@description('The number of periods to check in the alert evaluation.') -param numberOfEvaluationPeriods int = 4 --@description('The number of unhealthy periods to alert on (must be lower or equal to numberOfEvaluationPeriods).') -param minFailingPeriodsToAlert int = 3 --@description('Use this option to set the date from which to start learning the metric historical data and calculate the dynamic thresholds (in ISO8601 format, e.g. \'2019-12-31T22:00:00Z\').') -param ignoreDataBefore string = '' --@description('How the data that is collected should be combined over time.') -@allowed([ - 'Average' - 'Minimum' - 'Maximum' - 'Total' - 'Count' -]) -param timeAggregation string = 'Average' --@description('Period of time used to monitor alert activity based on the threshold. Must be between five minutes and one hour. ISO 8601 duration format.') -@allowed([ - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' -]) -param windowSize string = 'PT5M' --@description('how often the metric alert is evaluated represented in ISO 8601 duration format') -@allowed([ - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' -]) -param evaluationFrequency string = 'PT5M' --@description('The ID of the action group that is triggered when the alert is activated or deactivated') -param actionGroupId string = '' --resource metricAlert 'Microsoft.Insights/metricAlerts@2018-03-01' = { - name: alertName - location: 'global' - properties: { - description: alertDescription - severity: alertSeverity - enabled: isEnabled - scopes: [ - resourceId - ] - evaluationFrequency: evaluationFrequency - windowSize: windowSize - criteria: { - 'odata.type': 'Microsoft.Azure.Monitor.MultipleResourceMultipleMetricCriteria' - allOf: [ - { - criterionType: 'DynamicThresholdCriterion' - name: '1st criterion' - metricName: metricName - dimensions: [] - operator: operator - alertSensitivity: alertSensitivity - failingPeriods: { - numberOfEvaluationPeriods: numberOfEvaluationPeriods - minFailingPeriodsToAlert: minFailingPeriodsToAlert - } - ignoreDataBefore: ignoreDataBefore - timeAggregation: timeAggregation - } - ] - } - actions: [ - { - actionGroupId: actionGroupId - } - ] - } -} --``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the alert" - } - }, - "alertDescription": { - "type": "string", - "defaultValue": "This is a metric alert", - "metadata": { - "description": "Description of alert" - } - }, - "alertSeverity": { - "type": "int", - "defaultValue": 3, - "allowedValues": [ - 0, - 1, - 2, - 3, - 4 - ], - "metadata": { - "description": "Severity of alert {0,1,2,3,4}" - } - }, - "isEnabled": { - "type": "bool", - "defaultValue": true, - "metadata": { - "description": "Specifies whether the alert is enabled" - } - }, - "resourceId": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Full Resource ID of the resource emitting the metric that will be used for the comparison. For example /subscriptions/00000000-0000-0000-0000-0000-00000000/resourceGroups/ResourceGroupName/providers/Microsoft.compute/virtualMachines/VM_xyz" - } - }, - "metricName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the metric used in the comparison to activate the alert." - } - }, - "operator": { - "type": "string", - "defaultValue": "GreaterOrLessThan", - "allowedValues": [ - "GreaterThan", - "LessThan", - "GreaterOrLessThan" - ], - "metadata": { - "description": "Operator comparing the current value with the threshold value." - } - }, - "alertSensitivity": { - "type": "string", - "defaultValue": "Medium", - "allowedValues": [ - "High", - "Medium", - "Low" - ], - "metadata": { - "description": "Tunes how 'noisy' the Dynamic Thresholds alerts will be: 'High' will result in more alerts while 'Low' will result in fewer alerts." - } - }, - "numberOfEvaluationPeriods": { - "type": "int", - "defaultValue": 4, - "metadata": { - "description": "The number of periods to check in the alert evaluation." - } - }, - "minFailingPeriodsToAlert": { - "type": "int", - "defaultValue": 3, - "metadata": { - "description": "The number of unhealthy periods to alert on (must be lower or equal to numberOfEvaluationPeriods)." - } - }, - "ignoreDataBefore": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "Use this option to set the date from which to start learning the metric historical data and calculate the dynamic thresholds (in ISO8601 format, e.g. '2019-12-31T22:00:00Z')." - } - }, - "timeAggregation": { - "type": "string", - "defaultValue": "Average", - "allowedValues": [ - "Average", - "Minimum", - "Maximum", - "Total", - "Count" - ], - "metadata": { - "description": "How the data that is collected should be combined over time." - } - }, - "windowSize": { - "type": "string", - "defaultValue": "PT5M", - "allowedValues": [ - "PT5M", - "PT15M", - "PT30M", - "PT1H" - ], - "metadata": { - "description": "Period of time used to monitor alert activity based on the threshold. Must be between five minutes and one hour. ISO 8601 duration format." - } - }, - "evaluationFrequency": { - "type": "string", - "defaultValue": "PT5M", - "allowedValues": [ - "PT5M", - "PT15M", - "PT30M", - "PT1H" - ], - "metadata": { - "description": "how often the metric alert is evaluated represented in ISO 8601 duration format" - } - }, - "actionGroupId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "The ID of the action group that is triggered when the alert is activated or deactivated" - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/metricAlerts", - "apiVersion": "2018-03-01", - "name": "[parameters('alertName')]", - "location": "global", - "properties": { - "description": "[parameters('alertDescription')]", - "severity": "[parameters('alertSeverity')]", - "enabled": "[parameters('isEnabled')]", - "scopes": [ - "[parameters('resourceId')]" - ], - "evaluationFrequency": "[parameters('evaluationFrequency')]", - "windowSize": "[parameters('windowSize')]", - "criteria": { - "odata.type": "Microsoft.Azure.Monitor.MultipleResourceMultipleMetricCriteria", - "allOf": [ - { - "criterionType": "DynamicThresholdCriterion", - "name": "1st criterion", - "metricName": "[parameters('metricName')]", - "dimensions": [], - "operator": "[parameters('operator')]", - "alertSensitivity": "[parameters('alertSensitivity')]", - "failingPeriods": { - "numberOfEvaluationPeriods": "[parameters('numberOfEvaluationPeriods')]", - "minFailingPeriodsToAlert": "[parameters('minFailingPeriodsToAlert')]" - }, - "ignoreDataBefore": "[parameters('ignoreDataBefore')]", - "timeAggregation": "[parameters('timeAggregation')]" - } - ] - }, - "actions": [ - { - "actionGroupId": "[parameters('actionGroupId')]" - } - ] - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "value": "New Metric Alert with Dynamic Thresholds" - }, - "alertDescription": { - "value": "New metric alert with Dynamic Thresholds created via template" - }, - "alertSeverity": { - "value":3 - }, - "isEnabled": { - "value": true - }, - "resourceId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resourceGroup-name/providers/Microsoft.Compute/virtualMachines/replace-with-resource-name" - }, - "metricName": { - "value": "Percentage CPU" - }, - "operator": { - "value": "GreaterOrLessThan" - }, - "alertSensitivity": { - "value": "Medium" - }, - "numberOfEvaluationPeriods": { - "value": "4" - }, - "minFailingPeriodsToAlert": { - "value": "3" - }, - "ignoreDataBefore": { - "value": "" - }, - "timeAggregation": { - "value": "Average" - }, - "actionGroupId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/resource-group-name/providers/Microsoft.Insights/actionGroups/replace-with-action-group" - } - } -} -``` --## Multiple criteria, static threshold --Metric alerts support alerting on multi-dimensional metrics and up to 5 criteria per alert rule. The following sample creates a metric alert rule on dimensional metrics and specifies multiple criteria. --The following constraints apply when using dimensions in an alert rule that contains multiple criteria: --- You can only select one value per dimension within each criterion.-- You cannot use "\*" as a dimension value.-- When metrics that are configured in different criteria support the same dimension, then a configured dimension value must be explicitly set in the same way for all of those metrics in the relevant criteria.-- - In the example below, because both the **Transactions** and **SuccessE2ELatency** metrics have an **ApiName** dimension, and *criterion1* specifies the *"GetBlob"* value for the **ApiName** dimension, then *criterion2* must also set a *"GetBlob"* value for the **ApiName** dimension. --### Template file --# [Bicep](#tab/bicep) --```bicep -@description('Name of the alert') -param alertName string --@description('Description of alert') -param alertDescription string = 'This is a metric alert' --@description('Severity of alert {0,1,2,3,4}') -@allowed([ - 0 - 1 - 2 - 3 - 4 -]) -param alertSeverity int = 3 --@description('Specifies whether the alert is enabled') -param isEnabled bool = true --@description('Resource ID of the resource emitting the metric that will be used for the comparison.') -param resourceId string = '' --@description('Criterion includes metric name, dimension values, threshold and an operator. The alert rule fires when ALL criteria are met') -param criterion1 object --@description('Criterion includes metric name, dimension values, threshold and an operator. The alert rule fires when ALL criteria are met') -param criterion2 object --@description('Period of time used to monitor alert activity based on the threshold. Must be between one minute and one day. ISO 8601 duration format.') -@allowed([ - 'PT1M' - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' - 'PT6H' - 'PT12H' - 'PT24H' -]) -param windowSize string = 'PT5M' --@description('how often the metric alert is evaluated represented in ISO 8601 duration format') -@allowed([ - 'PT1M' - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' -]) -param evaluationFrequency string = 'PT1M' --@description('The ID of the action group that is triggered when the alert is activated or deactivated') -param actionGroupId string = '' --var criterion1_var = array(criterion1) -var criterion2_var = array(criterion2) -var criteria = concat(criterion1_var, criterion2_var) --resource metricAlert 'Microsoft.Insights/metricAlerts@2018-03-01' = { - name: alertName - location: 'global' - properties: { - description: alertDescription - severity: alertSeverity - enabled: isEnabled - scopes: [ - resourceId - ] - evaluationFrequency: evaluationFrequency - windowSize: windowSize - criteria: { - 'odata.type': 'Microsoft.Azure.Monitor.SingleResourceMultipleMetricCriteria' - allOf: criteria - } - actions: [ - { - actionGroupId: actionGroupId - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "type": "string", - "metadata": { - "description": "Name of the alert" - } - }, - "alertDescription": { - "type": "string", - "defaultValue": "This is a metric alert", - "metadata": { - "description": "Description of alert" - } - }, - "alertSeverity": { - "type": "int", - "defaultValue": 3, - "allowedValues": [ - 0, - 1, - 2, - 3, - 4 - ], - "metadata": { - "description": "Severity of alert {0,1,2,3,4}" - } - }, - "isEnabled": { - "type": "bool", - "defaultValue": true, - "metadata": { - "description": "Specifies whether the alert is enabled" - } - }, - "resourceId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "Resource ID of the resource emitting the metric that will be used for the comparison." - } - }, - "criterion1": { - "type": "object", - "metadata": { - "description": "Criterion includes metric name, dimension values, threshold and an operator. The alert rule fires when ALL criteria are met" - } - }, - "criterion2": { - "type": "object", - "metadata": { - "description": "Criterion includes metric name, dimension values, threshold and an operator. The alert rule fires when ALL criteria are met" - } - }, - "windowSize": { - "type": "string", - "defaultValue": "PT5M", - "allowedValues": [ - "PT1M", - "PT5M", - "PT15M", - "PT30M", - "PT1H", - "PT6H", - "PT12H", - "PT24H" - ], - "metadata": { - "description": "Period of time used to monitor alert activity based on the threshold. Must be between one minute and one day. ISO 8601 duration format." - } - }, - "evaluationFrequency": { - "type": "string", - "defaultValue": "PT1M", - "allowedValues": [ - "PT1M", - "PT5M", - "PT15M", - "PT30M", - "PT1H" - ], - "metadata": { - "description": "how often the metric alert is evaluated represented in ISO 8601 duration format" - } - }, - "actionGroupId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "The ID of the action group that is triggered when the alert is activated or deactivated" - } - } - }, - "variables": { - "criterion1_var": "[array(parameters('criterion1'))]", - "criterion2_var": "[array(parameters('criterion2'))]", - "criteria": "[concat(variables('criterion1_var'), variables('criterion2_var'))]" - }, - "resources": [ - { - "type": "Microsoft.Insights/metricAlerts", - "apiVersion": "2018-03-01", - "name": "[parameters('alertName')]", - "location": "global", - "properties": { - "description": "[parameters('alertDescription')]", - "severity": "[parameters('alertSeverity')]", - "enabled": "[parameters('isEnabled')]", - "scopes": [ - "[parameters('resourceId')]" - ], - "evaluationFrequency": "[parameters('evaluationFrequency')]", - "windowSize": "[parameters('windowSize')]", - "criteria": { - "odata.type": "Microsoft.Azure.Monitor.SingleResourceMultipleMetricCriteria", - "allOf": "[variables('criteria')]" - }, - "actions": [ - { - "actionGroupId": "[parameters('actionGroupId')]" - } - ] - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "value": "New Multi-dimensional Metric Alert (Replace with your alert name)" - }, - "alertDescription": { - "value": "New multi-dimensional metric alert created via template (Replace with your alert description)" - }, - "alertSeverity": { - "value": 3 - }, - "isEnabled": { - "value": true - }, - "resourceId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resourcegroup-name/providers/Microsoft.Storage/storageAccounts/replace-with-storage-account" - }, - "criterion1": { - "value": { - "name": "1st criterion", - "metricName": "Transactions", - "dimensions": [ - { - "name": "ResponseType", - "operator": "Include", - "values": [ "Success" ] - }, - { - "name": "ApiName", - "operator": "Include", - "values": [ "GetBlob" ] - } - ], - "operator": "GreaterThan", - "threshold": 5, - "timeAggregation": "Total" - } - }, - "criterion2": { - "value": { - "name": "2nd criterion", - "metricName": "SuccessE2ELatency", - "dimensions": [ - { - "name": "ApiName", - "operator": "Include", - "values": [ "GetBlob" ] - } - ], - "operator": "GreaterThan", - "threshold": 250, - "timeAggregation": "Average" - } - }, - "actionGroupId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resource-group-name/providers/Microsoft.Insights/actionGroups/replace-with-actiongroup-name" - } - } -} -``` --## Multiple dimensions, static threshold --A single alert rule can monitor multiple metric time series at a time, which results in fewer alert rules to manage. The following sample creates a static metric alert rule on dimensional metrics. --In this sample, the alert rule monitors the dimensions value combinations of the **ResponseType** and **ApiName** dimensions for the **Transactions** metric: --1. **ResponsType** - The use of the "\*" wildcard means that for each value of the **ResponseType** dimension, including future values, a different time series is monitored individually. -2. **ApiName** - A different time series is monitored only for the **GetBlob** and **PutBlob** dimension values. --For example, a few of the potential time series that are monitored by this alert rule are: --- Metric = *Transactions*, ResponseType = *Success*, ApiName = *GetBlob*-- Metric = *Transactions*, ResponseType = *Success*, ApiName = *PutBlob*-- Metric = *Transactions*, ResponseType = *Server Timeout*, ApiName = *GetBlob*-- Metric = *Transactions*, ResponseType = *Server Timeout*, ApiName = *PutBlob*--### Template file --# [Bicep](#tab/bicep) --```bicep -@description('Name of the alert') -param alertName string --@description('Description of alert') -param alertDescription string = 'This is a metric alert' --@description('Severity of alert {0,1,2,3,4}') -@allowed([ - 0 - 1 - 2 - 3 - 4 -]) -param alertSeverity int = 3 --@description('Specifies whether the alert is enabled') -param isEnabled bool = true --@description('Resource ID of the resource emitting the metric that will be used for the comparison.') -param resourceId string = '' --@description('Criterion includes metric name, dimension values, threshold and an operator. The alert rule fires when ALL criteria are met') -param criterion object --@description('Period of time used to monitor alert activity based on the threshold. Must be between one minute and one day. ISO 8601 duration format.') -@allowed([ - 'PT1M' - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' - 'PT6H' - 'PT12H' - 'PT24H' -]) -param windowSize string = 'PT5M' --@description('how often the metric alert is evaluated represented in ISO 8601 duration format') -@allowed([ - 'PT1M' - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' -]) -param evaluationFrequency string = 'PT1M' --@description('The ID of the action group that is triggered when the alert is activated or deactivated') -param actionGroupId string = '' --var criteria = array(criterion) --resource metricAlert 'Microsoft.Insights/metricAlerts@2018-03-01' = { - name: alertName - location: 'global' - properties: { - description: alertDescription - severity: alertSeverity - enabled: isEnabled - scopes: [ - resourceId - ] - evaluationFrequency: evaluationFrequency - windowSize: windowSize - criteria: { - 'odata.type': 'Microsoft.Azure.Monitor.SingleResourceMultipleMetricCriteria' - allOf: criteria - } - actions: [ - { - actionGroupId: actionGroupId - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "type": "string", - "metadata": { - "description": "Name of the alert" - } - }, - "alertDescription": { - "type": "string", - "defaultValue": "This is a metric alert", - "metadata": { - "description": "Description of alert" - } - }, - "alertSeverity": { - "type": "int", - "defaultValue": 3, - "allowedValues": [ - 0, - 1, - 2, - 3, - 4 - ], - "metadata": { - "description": "Severity of alert {0,1,2,3,4}" - } - }, - "isEnabled": { - "type": "bool", - "defaultValue": true, - "metadata": { - "description": "Specifies whether the alert is enabled" - } - }, - "resourceId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "Resource ID of the resource emitting the metric that will be used for the comparison." - } - }, - "criterion": { - "type": "object", - "metadata": { - "description": "Criterion includes metric name, dimension values, threshold and an operator. The alert rule fires when ALL criteria are met" - } - }, - "windowSize": { - "type": "string", - "defaultValue": "PT5M", - "allowedValues": [ - "PT1M", - "PT5M", - "PT15M", - "PT30M", - "PT1H", - "PT6H", - "PT12H", - "PT24H" - ], - "metadata": { - "description": "Period of time used to monitor alert activity based on the threshold. Must be between one minute and one day. ISO 8601 duration format." - } - }, - "evaluationFrequency": { - "type": "string", - "defaultValue": "PT1M", - "allowedValues": [ - "PT1M", - "PT5M", - "PT15M", - "PT30M", - "PT1H" - ], - "metadata": { - "description": "how often the metric alert is evaluated represented in ISO 8601 duration format" - } - }, - "actionGroupId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "The ID of the action group that is triggered when the alert is activated or deactivated" - } - } - }, - "variables": { - "criteria": "[array(parameters('criterion'))]" - }, - "resources": [ - { - "type": "Microsoft.Insights/metricAlerts", - "apiVersion": "2018-03-01", - "name": "[parameters('alertName')]", - "location": "global", - "properties": { - "description": "[parameters('alertDescription')]", - "severity": "[parameters('alertSeverity')]", - "enabled": "[parameters('isEnabled')]", - "scopes": [ - "[parameters('resourceId')]" - ], - "evaluationFrequency": "[parameters('evaluationFrequency')]", - "windowSize": "[parameters('windowSize')]", - "criteria": { - "odata.type": "Microsoft.Azure.Monitor.SingleResourceMultipleMetricCriteria", - "allOf": "[variables('criteria')]" - }, - "actions": [ - { - "actionGroupId": "[parameters('actionGroupId')]" - } - ] - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "value": "New multi-dimensional metric alert rule (replace with your alert name)" - }, - "alertDescription": { - "value": "New multi-dimensional metric alert rule created via template (replace with your alert description)" - }, - "alertSeverity": { - "value": 3 - }, - "isEnabled": { - "value": true - }, - "resourceId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resourcegroup-name/providers/Microsoft.Storage/storageAccounts/replace-with-storage-account" - }, - "criterion": { - "value": { - "name": "Criterion", - "metricName": "Transactions", - "dimensions": [ - { - "name": "ResponseType", - "operator": "Include", - "values": [ "*" ] - }, - { - "name": "ApiName", - "operator": "Include", - "values": [ "GetBlob", "PutBlob" ] - } - ], - "operator": "GreaterThan", - "threshold": 5, - "timeAggregation": "Total" - } - }, - "actionGroupId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resource-group-name/providers/Microsoft.Insights/actionGroups/replace-with-actiongroup-name" - } - } -} -``` --> [!NOTE] -> -> Using "All" as a dimension value is equivalent to selecting "\*" (all current and future values). ---## Multiple dimensions, dynamic thresholds --A single dynamic thresholds alert rule can create tailored thresholds for hundreds of metric time series (even different types) at a time, which results in fewer alert rules to manage. The following sample creates a dynamic thresholds metric alert rule on dimensional metrics. --In this sample, the alert rule monitors the dimensions value combinations of the **ResponseType** and **ApiName** dimensions for the **Transactions** metric: --1. **ResponsType** - For each value of the **ResponseType** dimension, including future values, a different time series is monitored individually. -2. **ApiName** - A different time series is monitored only for the **GetBlob** and **PutBlob** dimension values. --For example, a few of the potential time series that are monitored by this alert rule are: --- Metric = *Transactions*, ResponseType = *Success*, ApiName = *GetBlob*-- Metric = *Transactions*, ResponseType = *Success*, ApiName = *PutBlob*-- Metric = *Transactions*, ResponseType = *Server Timeout*, ApiName = *GetBlob*-- Metric = *Transactions*, ResponseType = *Server Timeout*, ApiName = *PutBlob*-->[!NOTE] -> Multiple criteria are not currently supported for metric alert rules that use dynamic thresholds. --### Template file --# [Bicep](#tab/bicep) --```bicep -@description('Name of the alert') -param alertName string --@description('Description of alert') -param alertDescription string = 'This is a metric alert' --@description('Severity of alert {0,1,2,3,4}') -@allowed([ - 0 - 1 - 2 - 3 - 4 -]) -param alertSeverity int = 3 --@description('Specifies whether the alert is enabled') -param isEnabled bool = true --@description('Resource ID of the resource emitting the metric that will be used for the comparison.') -param resourceId string = '' --@description('Criterion includes metric name, dimension values, threshold and an operator.') -param criterion object --@description('Period of time used to monitor alert activity based on the threshold. Must be between five minutes and one hour. ISO 8601 duration format.') -@allowed([ - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' -]) -param windowSize string = 'PT5M' --@description('how often the metric alert is evaluated represented in ISO 8601 duration format') -@allowed([ - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' -]) -param evaluationFrequency string = 'PT5M' --@description('The ID of the action group that is triggered when the alert is activated or deactivated') -param actionGroupId string = '' --var criteria = array(criterion) --resource metricAlert 'Microsoft.Insights/metricAlerts@2018-03-01' = { - name: alertName - location: 'global' - properties: { - description: alertDescription - severity: alertSeverity - enabled: isEnabled - scopes: [ - resourceId - ] - evaluationFrequency: evaluationFrequency - windowSize: windowSize - criteria: { - 'odata.type': 'Microsoft.Azure.Monitor.MultipleResourceMultipleMetricCriteria' - allOf: criteria - } - actions: [ - { - actionGroupId: actionGroupId - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "type": "string", - "metadata": { - "description": "Name of the alert" - } - }, - "alertDescription": { - "type": "string", - "defaultValue": "This is a metric alert", - "metadata": { - "description": "Description of alert" - } - }, - "alertSeverity": { - "type": "int", - "defaultValue": 3, - "allowedValues": [ - 0, - 1, - 2, - 3, - 4 - ], - "metadata": { - "description": "Severity of alert {0,1,2,3,4}" - } - }, - "isEnabled": { - "type": "bool", - "defaultValue": true, - "metadata": { - "description": "Specifies whether the alert is enabled" - } - }, - "resourceId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "Resource ID of the resource emitting the metric that will be used for the comparison." - } - }, - "criterion": { - "type": "object", - "metadata": { - "description": "Criterion includes metric name, dimension values, threshold and an operator." - } - }, - "windowSize": { - "type": "string", - "defaultValue": "PT5M", - "allowedValues": [ - "PT5M", - "PT15M", - "PT30M", - "PT1H" - ], - "metadata": { - "description": "Period of time used to monitor alert activity based on the threshold. Must be between five minutes and one hour. ISO 8601 duration format." - } - }, - "evaluationFrequency": { - "type": "string", - "defaultValue": "PT5M", - "allowedValues": [ - "PT5M", - "PT15M", - "PT30M", - "PT1H" - ], - "metadata": { - "description": "how often the metric alert is evaluated represented in ISO 8601 duration format" - } - }, - "actionGroupId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "The ID of the action group that is triggered when the alert is activated or deactivated" - } - } - }, - "variables": { - "criteria": "[array(parameters('criterion'))]" - }, - "resources": [ - { - "type": "Microsoft.Insights/metricAlerts", - "apiVersion": "2018-03-01", - "name": "[parameters('alertName')]", - "location": "global", - "properties": { - "description": "[parameters('alertDescription')]", - "severity": "[parameters('alertSeverity')]", - "enabled": "[parameters('isEnabled')]", - "scopes": [ - "[parameters('resourceId')]" - ], - "evaluationFrequency": "[parameters('evaluationFrequency')]", - "windowSize": "[parameters('windowSize')]", - "criteria": { - "odata.type": "Microsoft.Azure.Monitor.MultipleResourceMultipleMetricCriteria", - "allOf": "[variables('criteria')]" - }, - "actions": [ - { - "actionGroupId": "[parameters('actionGroupId')]" - } - ] - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "value": "New Multi-dimensional Metric Alert with Dynamic Thresholds (Replace with your alert name)" - }, - "alertDescription": { - "value": "New multi-dimensional metric alert with Dynamic Thresholds created via template (Replace with your alert description)" - }, - "alertSeverity": { - "value": 3 - }, - "isEnabled": { - "value": true - }, - "resourceId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resourcegroup-name/providers/Microsoft.Storage/storageAccounts/replace-with-storage-account" - }, - "criterion": { - "value": { - "criterionType": "DynamicThresholdCriterion", - "name": "1st criterion", - "metricName": "Transactions", - "dimensions": [ - { - "name": "ResponseType", - "operator": "Include", - "values": [ "*" ] - }, - { - "name": "ApiName", - "operator": "Include", - "values": [ "GetBlob", "PutBlob" ] - } - ], - "operator": "GreaterOrLessThan", - "alertSensitivity": "Medium", - "failingPeriods": { - "numberOfEvaluationPeriods": "4", - "minFailingPeriodsToAlert": "3" - }, - "timeAggregation": "Total" - } - }, - "actionGroupId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resource-group-name/providers/Microsoft.Insights/actionGroups/replace-with-actiongroup-name" - } - } -} -``` --## Custom metric, static threshold --You can use the following template to create a more advanced static threshold metric alert rule on a custom metric. --To learn more about custom metrics in Azure Monitor, see [Custom metrics in Azure Monitor](../essentials/metrics-custom-overview.md). --When creating an alert rule on a custom metric, you need to specify both the metric name and the metric namespace. You should also make sure that the custom metric is already being reported, as you cannot create an alert rule on a custom metric that doesn't yet exist. --### Template file --# [Bicep](#tab/bicep) --```bicep -@description('Name of the alert') -@minLength(1) -param alertName string --@description('Description of alert') -param alertDescription string = 'This is a metric alert' --@description('Severity of alert {0,1,2,3,4}') -@allowed([ - 0 - 1 - 2 - 3 - 4 -]) -param alertSeverity int = 3 --@description('Specifies whether the alert is enabled') -param isEnabled bool = true --@description('Full Resource ID of the resource emitting the metric that will be used for the comparison. For example /subscriptions/00000000-0000-0000-0000-0000-00000000/resourceGroups/ResourceGroupName/providers/Microsoft.compute/virtualMachines/VM_xyz') -@minLength(1) -param resourceId string --@description('Name of the metric used in the comparison to activate the alert.') -@minLength(1) -param metricName string --@description('Namespace of the metric used in the comparison to activate the alert.') -@minLength(1) -param metricNamespace string --@description('Operator comparing the current value with the threshold value.') -@allowed([ - 'Equals' - 'GreaterThan' - 'GreaterThanOrEqual' - 'LessThan' - 'LessThanOrEqual' -]) -param operator string = 'GreaterThan' --@description('The threshold value at which the alert is activated.') -param threshold int = 0 --@description('How the data that is collected should be combined over time.') -@allowed([ - 'Average' - 'Minimum' - 'Maximum' - 'Total' - 'Count' -]) -param timeAggregation string = 'Average' --@description('Period of time used to monitor alert activity based on the threshold. Must be between one minute and one day. ISO 8601 duration format.') -@allowed([ - 'PT1M' - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' - 'PT6H' - 'PT12H' - 'PT24H' -]) -param windowSize string = 'PT5M' --@description('How often the metric alert is evaluated represented in ISO 8601 duration format') -@allowed([ - 'PT1M' - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' -]) -param evaluationFrequency string = 'PT1M' --@description('The ID of the action group that is triggered when the alert is activated or deactivated') -param actionGroupId string = '' --resource metricAlert 'Microsoft.Insights/metricAlerts@2018-03-01' = { - name: alertName - location: 'global' - properties: { - description: alertDescription - severity: alertSeverity - enabled: isEnabled - scopes: [ - resourceId - ] - evaluationFrequency: evaluationFrequency - windowSize: windowSize - criteria: { - 'odata.type': 'Microsoft.Azure.Monitor.SingleResourceMultipleMetricCriteria' - allOf: [ - { - name: '1st criterion' - metricName: metricName - metricNamespace: metricNamespace - dimensions: [] - operator: operator - threshold: threshold - timeAggregation: timeAggregation - criterionType: 'StaticThresholdCriterion' - } - ] - } - actions: [ - { - actionGroupId: actionGroupId - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the alert" - } - }, - "alertDescription": { - "type": "string", - "defaultValue": "This is a metric alert", - "metadata": { - "description": "Description of alert" - } - }, - "alertSeverity": { - "type": "int", - "defaultValue": 3, - "allowedValues": [ - 0, - 1, - 2, - 3, - 4 - ], - "metadata": { - "description": "Severity of alert {0,1,2,3,4}" - } - }, - "isEnabled": { - "type": "bool", - "defaultValue": true, - "metadata": { - "description": "Specifies whether the alert is enabled" - } - }, - "resourceId": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Full Resource ID of the resource emitting the metric that will be used for the comparison. For example /subscriptions/00000000-0000-0000-0000-0000-00000000/resourceGroups/ResourceGroupName/providers/Microsoft.compute/virtualMachines/VM_xyz" - } - }, - "metricName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the metric used in the comparison to activate the alert." - } - }, - "metricNamespace": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Namespace of the metric used in the comparison to activate the alert." - } - }, - "operator": { - "type": "string", - "defaultValue": "GreaterThan", - "allowedValues": [ - "Equals", - "GreaterThan", - "GreaterThanOrEqual", - "LessThan", - "LessThanOrEqual" - ], - "metadata": { - "description": "Operator comparing the current value with the threshold value." - } - }, - "threshold": { - "type": "int", - "defaultValue": 0, - "metadata": { - "description": "The threshold value at which the alert is activated." - } - }, - "timeAggregation": { - "type": "string", - "defaultValue": "Average", - "allowedValues": [ - "Average", - "Minimum", - "Maximum", - "Total", - "Count" - ], - "metadata": { - "description": "How the data that is collected should be combined over time." - } - }, - "windowSize": { - "type": "string", - "defaultValue": "PT5M", - "allowedValues": [ - "PT1M", - "PT5M", - "PT15M", - "PT30M", - "PT1H", - "PT6H", - "PT12H", - "PT24H" - ], - "metadata": { - "description": "Period of time used to monitor alert activity based on the threshold. Must be between one minute and one day. ISO 8601 duration format." - } - }, - "evaluationFrequency": { - "type": "string", - "defaultValue": "PT1M", - "allowedValues": [ - "PT1M", - "PT5M", - "PT15M", - "PT30M", - "PT1H" - ], - "metadata": { - "description": "How often the metric alert is evaluated represented in ISO 8601 duration format" - } - }, - "actionGroupId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "The ID of the action group that is triggered when the alert is activated or deactivated" - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/metricAlerts", - "apiVersion": "2018-03-01", - "name": "[parameters('alertName')]", - "location": "global", - "properties": { - "description": "[parameters('alertDescription')]", - "severity": "[parameters('alertSeverity')]", - "enabled": "[parameters('isEnabled')]", - "scopes": [ - "[parameters('resourceId')]" - ], - "evaluationFrequency": "[parameters('evaluationFrequency')]", - "windowSize": "[parameters('windowSize')]", - "criteria": { - "odata.type": "Microsoft.Azure.Monitor.SingleResourceMultipleMetricCriteria", - "allOf": [ - { - "name": "1st criterion", - "metricName": "[parameters('metricName')]", - "metricNamespace": "[parameters('metricNamespace')]", - "dimensions": [], - "operator": "[parameters('operator')]", - "threshold": "[parameters('threshold')]", - "timeAggregation": "[parameters('timeAggregation')]", - "criterionType": "StaticThresholdCriterion" - } - ] - }, - "actions": [ - { - "actionGroupId": "[parameters('actionGroupId')]" - } - ] - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "value": "New alert rule on a custom metric" - }, - "alertDescription": { - "value": "New alert rule on a custom metric created via template" - }, - "alertSeverity": { - "value": 3 - }, - "isEnabled": { - "value": true - }, - "resourceId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resourceGroup-name/providers/microsoft.insights/components/replace-with-application-insights-resource-name" - }, - "metricName": { - "value": "The custom metric name" - }, - "metricNamespace": { - "value": "Azure.ApplicationInsights" - }, - "operator": { - "value": "GreaterThan" - }, - "threshold": { - "value": 80 - }, - "timeAggregation": { - "value": "Average" - }, - "actionGroupId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/resource-group-name/providers/Microsoft.Insights/actionGroups/replace-with-action-group" - } - } -} -``` --> [!NOTE] -> -> You can find the metric namespace of a specific custom metric by [browsing your custom metrics via the Azure portal](../essentials/metrics-custom-overview.md#browse-your-custom-metrics-via-the-azure-portal) --## Multiple resources --Azure Monitor supports monitoring multiple resources of the same type with a single metric alert rule, for resources that exist in the same Azure region. This feature is currently only supported in Azure public cloud and only for Virtual machines, SQL server databases, SQL server elastic pools and Azure Stack Edge devices. Also, this feature is only available for platform metrics, and isn't supported for custom metrics. --Dynamic Thresholds alerts rule can also help create tailored thresholds for hundreds of metric series (even different types) at a time, which results in fewer alert rules to manage. --This section will describe Azure Resource Manager templates for three scenarios to monitor multiple resources with a single rule. --- Monitoring all virtual machines (in one Azure region) in one or more resource groups.-- Monitoring all virtual machines (in one Azure region) in a subscription.-- Monitoring a list of virtual machines (in one Azure region) in a subscription.--> [!NOTE] -> -> - In a metric alert rule that monitors multiple resources, only one condition is allowed. -> - If you are creating a metric alert for a single resource, the template uses the `ResourceId` of the target resource. If you are creating a metric alert for multiple resources, the template uses the `scope`, `TargetResourceType`, and `TargetResourceRegion` for the target resources. --### Static threshold alert on all virtual machines in one or more resource groups --This template will create a static threshold metric alert rule that monitors Percentage CPU for all virtual machines (in one Azure region) in one or more resource groups. --Save the json below as all-vms-in-resource-group-static.json for the purpose of this walk-through. --### Template file --# [Bicep](#tab/bicep) --```bicep -@description('Name of the alert') -@minLength(1) -param alertName string --@description('Description of alert') -param alertDescription string = 'This is a metric alert' --@description('Severity of alert {0,1,2,3,4}') -@allowed([ - 0 - 1 - 2 - 3 - 4 -]) -param alertSeverity int = 3 --@description('Specifies whether the alert is enabled') -param isEnabled bool = true --@description('Full path of the resource group(s) where target resources to be monitored are in. For example - /subscriptions/00000000-0000-0000-0000-0000-00000000/resourceGroups/ResourceGroupName') -@minLength(1) -param targetResourceGroup array --@description('Azure region in which target resources to be monitored are in (without spaces). For example: EastUS') -@allowed([ - 'EastUS' - 'EastUS2' - 'CentralUS' - 'NorthCentralUS' - 'SouthCentralUS' - 'WestCentralUS' - 'WestUS' - 'WestUS2' - 'CanadaEast' - 'CanadaCentral' - 'BrazilSouth' - 'NorthEurope' - 'WestEurope' - 'FranceCentral' - 'FranceSouth' - 'UKWest' - 'UKSouth' - 'GermanyCentral' - 'GermanyNortheast' - 'GermanyNorth' - 'GermanyWestCentral' - 'SwitzerlandNorth' - 'SwitzerlandWest' - 'NorwayEast' - 'NorwayWest' - 'SoutheastAsia' - 'EastAsia' - 'AustraliaEast' - 'AustraliaSoutheast' - 'AustraliaCentral' - 'AustraliaCentral2' - 'ChinaEast' - 'ChinaNorth' - 'ChinaEast2' - 'ChinaNorth2' - 'CentralIndia' - 'WestIndia' - 'SouthIndia' - 'JapanEast' - 'JapanWest' - 'KoreaCentral' - 'KoreaSouth' - 'SouthAfricaWest' - 'SouthAfricaNorth' - 'UAECentral' - 'UAENorth' -]) -param targetResourceRegion string --@description('Resource type of target resources to be monitored.') -@minLength(1) -param targetResourceType string --@description('Name of the metric used in the comparison to activate the alert.') -@minLength(1) -param metricName string --@description('Operator comparing the current value with the threshold value.') -@allowed([ - 'Equals' - 'GreaterThan' - 'GreaterThanOrEqual' - 'LessThan' - 'LessThanOrEqual' -]) -param operator string = 'GreaterThan' --@description('The threshold value at which the alert is activated.') -param threshold string = '0' --@description('How the data that is collected should be combined over time.') -@allowed([ - 'Average' - 'Minimum' - 'Maximum' - 'Total' - 'Count' -]) -param timeAggregation string = 'Average' --@description('Period of time used to monitor alert activity based on the threshold. Must be between one minute and one day. ISO 8601 duration format.') -@allowed([ - 'PT1M' - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' - 'PT6H' - 'PT12H' - 'PT24H' -]) -param windowSize string = 'PT5M' --@description('how often the metric alert is evaluated represented in ISO 8601 duration format') -@allowed([ - 'PT1M' - 'PT5M' - 'PT15M' - 'PT30M' -]) -param evaluationFrequency string = 'PT1M' --@description('The ID of the action group that is triggered when the alert is activated or deactivated') -param actionGroupId string = '' --resource metricAlert 'Microsoft.Insights/metricAlerts@2018-03-01' = { - name: alertName - location: 'global' - properties: { - description: alertDescription - severity: alertSeverity - enabled: isEnabled - scopes: targetResourceGroup - targetResourceType: targetResourceType - targetResourceRegion: targetResourceRegion - evaluationFrequency: evaluationFrequency - windowSize: windowSize - criteria: { - 'odata.type': 'Microsoft.Azure.Monitor.MultipleResourceMultipleMetricCriteria' - allOf: [ - { - name: '1st criterion' - metricName: metricName - dimensions: [] - operator: operator - threshold: threshold - timeAggregation: timeAggregation - criterionType: 'StaticThresholdCriterion' - } - ] - } - actions: [ - { - actionGroupId: actionGroupId - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the alert" - } - }, - "alertDescription": { - "type": "string", - "defaultValue": "This is a metric alert", - "metadata": { - "description": "Description of alert" - } - }, - "alertSeverity": { - "type": "int", - "defaultValue": 3, - "allowedValues": [ - 0, - 1, - 2, - 3, - 4 - ], - "metadata": { - "description": "Severity of alert {0,1,2,3,4}" - } - }, - "isEnabled": { - "type": "bool", - "defaultValue": true, - "metadata": { - "description": "Specifies whether the alert is enabled" - } - }, - "targetResourceGroup": { - "type": "array", - "minLength": 1, - "metadata": { - "description": "Full path of the resource group(s) where target resources to be monitored are in. For example - /subscriptions/00000000-0000-0000-0000-0000-00000000/resourceGroups/ResourceGroupName" - } - }, - "targetResourceRegion": { - "type": "string", - "allowedValues": [ - "EastUS", - "EastUS2", - "CentralUS", - "NorthCentralUS", - "SouthCentralUS", - "WestCentralUS", - "WestUS", - "WestUS2", - "CanadaEast", - "CanadaCentral", - "BrazilSouth", - "NorthEurope", - "WestEurope", - "FranceCentral", - "FranceSouth", - "UKWest", - "UKSouth", - "GermanyCentral", - "GermanyNortheast", - "GermanyNorth", - "GermanyWestCentral", - "SwitzerlandNorth", - "SwitzerlandWest", - "NorwayEast", - "NorwayWest", - "SoutheastAsia", - "EastAsia", - "AustraliaEast", - "AustraliaSoutheast", - "AustraliaCentral", - "AustraliaCentral2", - "ChinaEast", - "ChinaNorth", - "ChinaEast2", - "ChinaNorth2", - "CentralIndia", - "WestIndia", - "SouthIndia", - "JapanEast", - "JapanWest", - "KoreaCentral", - "KoreaSouth", - "SouthAfricaWest", - "SouthAfricaNorth", - "UAECentral", - "UAENorth" - ], - "metadata": { - "description": "Azure region in which target resources to be monitored are in (without spaces). For example: EastUS" - } - }, - "targetResourceType": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Resource type of target resources to be monitored." - } - }, - "metricName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the metric used in the comparison to activate the alert." - } - }, - "operator": { - "type": "string", - "defaultValue": "GreaterThan", - "allowedValues": [ - "Equals", - "GreaterThan", - "GreaterThanOrEqual", - "LessThan", - "LessThanOrEqual" - ], - "metadata": { - "description": "Operator comparing the current value with the threshold value." - } - }, - "threshold": { - "type": "int", - "defaultValue": 0, - "metadata": { - "description": "The threshold value at which the alert is activated." - } - }, - "timeAggregation": { - "type": "string", - "defaultValue": "Average", - "allowedValues": [ - "Average", - "Minimum", - "Maximum", - "Total", - "Count" - ], - "metadata": { - "description": "How the data that is collected should be combined over time." - } - }, - "windowSize": { - "type": "string", - "defaultValue": "PT5M", - "allowedValues": [ - "PT1M", - "PT5M", - "PT15M", - "PT30M", - "PT1H", - "PT6H", - "PT12H", - "PT24H" - ], - "metadata": { - "description": "Period of time used to monitor alert activity based on the threshold. Must be between one minute and one day. ISO 8601 duration format." - } - }, - "evaluationFrequency": { - "type": "string", - "defaultValue": "PT1M", - "allowedValues": [ - "PT1M", - "PT5M", - "PT15M", - "PT30M" - ], - "metadata": { - "description": "how often the metric alert is evaluated represented in ISO 8601 duration format" - } - }, - "actionGroupId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "The ID of the action group that is triggered when the alert is activated or deactivated" - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/metricAlerts", - "apiVersion": "2018-03-01", - "name": "[parameters('alertName')]", - "location": "global", - "properties": { - "description": "[parameters('alertDescription')]", - "severity": "[parameters('alertSeverity')]", - "enabled": "[parameters('isEnabled')]", - "scopes": "[parameters('targetResourceGroup')]", - "targetResourceType": "[parameters('targetResourceType')]", - "targetResourceRegion": "[parameters('targetResourceRegion')]", - "evaluationFrequency": "[parameters('evaluationFrequency')]", - "windowSize": "[parameters('windowSize')]", - "criteria": { - "odata.type": "Microsoft.Azure.Monitor.MultipleResourceMultipleMetricCriteria", - "allOf": [ - { - "name": "1st criterion", - "metricName": "[parameters('metricName')]", - "dimensions": [], - "operator": "[parameters('operator')]", - "threshold": "[parameters('threshold')]", - "timeAggregation": "[parameters('timeAggregation')]", - "criterionType": "StaticThresholdCriterion" - } - ] - }, - "actions": [ - { - "actionGroupId": "[parameters('actionGroupId')]" - } - ] - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "value": "Multi-resource metric alert via Azure Resource Manager template" - }, - "alertDescription": { - "value": "New Multi-resource metric alert created via template" - }, - "alertSeverity": { - "value": 3 - }, - "isEnabled": { - "value": true - }, - "targetResourceGroup": { - "value": [ - "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resource-group-name1", - "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resource-group-name2" - ] - }, - "targetResourceRegion": { - "value": "SouthCentralUS" - }, - "targetResourceType": { - "value": "Microsoft.Compute/virtualMachines" - }, - "metricName": { - "value": "Percentage CPU" - }, - "operator": { - "value": "GreaterThan" - }, - "threshold": { - "value": 0 - }, - "timeAggregation": { - "value": "Average" - }, - "actionGroupId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resource-group-name/providers/Microsoft.Insights/actionGroups/replace-with-action-group-name" - } - } -} -``` --### Dynamic Thresholds alert on all virtual machines in one or more resource groups --This sample creates a dynamic thresholds metric alert rule that monitors Percentage CPU for all virtual machines in one Azure region in one or more resource groups. --### Template file --# [Bicep](#tab/bicep) --```bicep -@description('Name of the alert') -@minLength(1) -param alertName string --@description('Description of alert') -param alertDescription string = 'This is a metric alert' --@description('Severity of alert {0,1,2,3,4}') -@allowed([ - 0 - 1 - 2 - 3 - 4 -]) -param alertSeverity int = 3 --@description('Specifies whether the alert is enabled') -param isEnabled bool = true --@description('Full path of the resource group(s) where target resources to be monitored are in. For example - /subscriptions/00000000-0000-0000-0000-0000-00000000/resourceGroups/ResourceGroupName') -@minLength(1) -param targetResourceGroup array --@description('Azure region in which target resources to be monitored are in (without spaces). For example: EastUS') -@allowed([ - 'EastUS' - 'EastUS2' - 'CentralUS' - 'NorthCentralUS' - 'SouthCentralUS' - 'WestCentralUS' - 'WestUS' - 'WestUS2' - 'CanadaEast' - 'CanadaCentral' - 'BrazilSouth' - 'NorthEurope' - 'WestEurope' - 'FranceCentral' - 'FranceSouth' - 'UKWest' - 'UKSouth' - 'GermanyCentral' - 'GermanyNortheast' - 'GermanyNorth' - 'GermanyWestCentral' - 'SwitzerlandNorth' - 'SwitzerlandWest' - 'NorwayEast' - 'NorwayWest' - 'SoutheastAsia' - 'EastAsia' - 'AustraliaEast' - 'AustraliaSoutheast' - 'AustraliaCentral' - 'AustraliaCentral2' - 'ChinaEast' - 'ChinaNorth' - 'ChinaEast2' - 'ChinaNorth2' - 'CentralIndia' - 'WestIndia' - 'SouthIndia' - 'JapanEast' - 'JapanWest' - 'KoreaCentral' - 'KoreaSouth' - 'SouthAfricaWest' - 'SouthAfricaNorth' - 'UAECentral' - 'UAENorth' -]) -param targetResourceRegion string --@description('Resource type of target resources to be monitored.') -@minLength(1) -param targetResourceType string --@description('Name of the metric used in the comparison to activate the alert.') -@minLength(1) -param metricName string --@description('Operator comparing the current value with the threshold value.') -@allowed([ - 'GreaterThan' - 'LessThan' - 'GreaterOrLessThan' -]) -param operator string = 'GreaterOrLessThan' --@description('Tunes how \'noisy\' the Dynamic Thresholds alerts will be: \'High\' will result in more alerts while \'Low\' will result in fewer alerts.') -@allowed([ - 'High' - 'Medium' - 'Low' -]) -param alertSensitivity string = 'Medium' --@description('The number of periods to check in the alert evaluation.') -param numberOfEvaluationPeriods int = 4 --@description('The number of unhealthy periods to alert on (must be lower or equal to numberOfEvaluationPeriods).') -param minFailingPeriodsToAlert int = 3 --@description('How the data that is collected should be combined over time.') -@allowed([ - 'Average' - 'Minimum' - 'Maximum' - 'Total' - 'Count' -]) -param timeAggregation string = 'Average' --@description('Period of time used to monitor alert activity based on the threshold. Must be between five minutes and one hour. ISO 8601 duration format.') -@allowed([ - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' -]) -param windowSize string = 'PT5M' --@description('how often the metric alert is evaluated represented in ISO 8601 duration format') -@allowed([ - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' -]) -param evaluationFrequency string = 'PT5M' --@description('The ID of the action group that is triggered when the alert is activated or deactivated') -param actionGroupId string = '' --resource metricAlert 'Microsoft.Insights/metricAlerts@2018-03-01' = { - name: alertName - location: 'global' - properties: { - description: alertDescription - severity: alertSeverity - enabled: isEnabled - scopes: targetResourceGroup - targetResourceType: targetResourceType - targetResourceRegion: targetResourceRegion - evaluationFrequency: evaluationFrequency - windowSize: windowSize - criteria: { - 'odata.type': 'Microsoft.Azure.Monitor.MultipleResourceMultipleMetricCriteria' - allOf: [ - { - criterionType: 'DynamicThresholdCriterion' - name: '1st criterion' - metricName: metricName - dimensions: [] - operator: operator - alertSensitivity: alertSensitivity - failingPeriods: { - numberOfEvaluationPeriods: numberOfEvaluationPeriods - minFailingPeriodsToAlert: minFailingPeriodsToAlert - } - timeAggregation: timeAggregation - } - ] - } - actions: [ - { - actionGroupId: actionGroupId - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the alert" - } - }, - "alertDescription": { - "type": "string", - "defaultValue": "This is a metric alert", - "metadata": { - "description": "Description of alert" - } - }, - "alertSeverity": { - "type": "int", - "defaultValue": 3, - "allowedValues": [ - 0, - 1, - 2, - 3, - 4 - ], - "metadata": { - "description": "Severity of alert {0,1,2,3,4}" - } - }, - "isEnabled": { - "type": "bool", - "defaultValue": true, - "metadata": { - "description": "Specifies whether the alert is enabled" - } - }, - "targetResourceGroup": { - "type": "array", - "minLength": 1, - "metadata": { - "description": "Full path of the resource group(s) where target resources to be monitored are in. For example - /subscriptions/00000000-0000-0000-0000-0000-00000000/resourceGroups/ResourceGroupName" - } - }, - "targetResourceRegion": { - "type": "string", - "allowedValues": [ - "EastUS", - "EastUS2", - "CentralUS", - "NorthCentralUS", - "SouthCentralUS", - "WestCentralUS", - "WestUS", - "WestUS2", - "CanadaEast", - "CanadaCentral", - "BrazilSouth", - "NorthEurope", - "WestEurope", - "FranceCentral", - "FranceSouth", - "UKWest", - "UKSouth", - "GermanyCentral", - "GermanyNortheast", - "GermanyNorth", - "GermanyWestCentral", - "SwitzerlandNorth", - "SwitzerlandWest", - "NorwayEast", - "NorwayWest", - "SoutheastAsia", - "EastAsia", - "AustraliaEast", - "AustraliaSoutheast", - "AustraliaCentral", - "AustraliaCentral2", - "ChinaEast", - "ChinaNorth", - "ChinaEast2", - "ChinaNorth2", - "CentralIndia", - "WestIndia", - "SouthIndia", - "JapanEast", - "JapanWest", - "KoreaCentral", - "KoreaSouth", - "SouthAfricaWest", - "SouthAfricaNorth", - "UAECentral", - "UAENorth" - ], - "metadata": { - "description": "Azure region in which target resources to be monitored are in (without spaces). For example: EastUS" - } - }, - "targetResourceType": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Resource type of target resources to be monitored." - } - }, - "metricName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the metric used in the comparison to activate the alert." - } - }, - "operator": { - "type": "string", - "defaultValue": "GreaterOrLessThan", - "allowedValues": [ - "GreaterThan", - "LessThan", - "GreaterOrLessThan" - ], - "metadata": { - "description": "Operator comparing the current value with the threshold value." - } - }, - "alertSensitivity": { - "type": "string", - "defaultValue": "Medium", - "allowedValues": [ - "High", - "Medium", - "Low" - ], - "metadata": { - "description": "Tunes how 'noisy' the Dynamic Thresholds alerts will be: 'High' will result in more alerts while 'Low' will result in fewer alerts." - } - }, - "numberOfEvaluationPeriods": { - "type": "int", - "defaultValue": 4, - "metadata": { - "description": "The number of periods to check in the alert evaluation." - } - }, - "minFailingPeriodsToAlert": { - "type": "int", - "defaultValue": 3, - "metadata": { - "description": "The number of unhealthy periods to alert on (must be lower or equal to numberOfEvaluationPeriods)." - } - }, - "timeAggregation": { - "type": "string", - "defaultValue": "Average", - "allowedValues": [ - "Average", - "Minimum", - "Maximum", - "Total", - "Count" - ], - "metadata": { - "description": "How the data that is collected should be combined over time." - } - }, - "windowSize": { - "type": "string", - "defaultValue": "PT5M", - "allowedValues": [ - "PT5M", - "PT15M", - "PT30M", - "PT1H" - ], - "metadata": { - "description": "Period of time used to monitor alert activity based on the threshold. Must be between five minutes and one hour. ISO 8601 duration format." - } - }, - "evaluationFrequency": { - "type": "string", - "defaultValue": "PT5M", - "allowedValues": [ - "PT5M", - "PT15M", - "PT30M", - "PT1H" - ], - "metadata": { - "description": "how often the metric alert is evaluated represented in ISO 8601 duration format" - } - }, - "actionGroupId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "The ID of the action group that is triggered when the alert is activated or deactivated" - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/metricAlerts", - "apiVersion": "2018-03-01", - "name": "[parameters('alertName')]", - "location": "global", - "properties": { - "description": "[parameters('alertDescription')]", - "severity": "[parameters('alertSeverity')]", - "enabled": "[parameters('isEnabled')]", - "scopes": "[parameters('targetResourceGroup')]", - "targetResourceType": "[parameters('targetResourceType')]", - "targetResourceRegion": "[parameters('targetResourceRegion')]", - "evaluationFrequency": "[parameters('evaluationFrequency')]", - "windowSize": "[parameters('windowSize')]", - "criteria": { - "odata.type": "Microsoft.Azure.Monitor.MultipleResourceMultipleMetricCriteria", - "allOf": [ - { - "criterionType": "DynamicThresholdCriterion", - "name": "1st criterion", - "metricName": "[parameters('metricName')]", - "dimensions": [], - "operator": "[parameters('operator')]", - "alertSensitivity": "[parameters('alertSensitivity')]", - "failingPeriods": { - "numberOfEvaluationPeriods": "[parameters('numberOfEvaluationPeriods')]", - "minFailingPeriodsToAlert": "[parameters('minFailingPeriodsToAlert')]" - }, - "timeAggregation": "[parameters('timeAggregation')]" - } - ] - }, - "actions": [ - { - "actionGroupId": "[parameters('actionGroupId')]" - } - ] - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "value": "Multi-resource metric alert with Dynamic Thresholds via Azure Resource Manager template" - }, - "alertDescription": { - "value": "New Multi-resource metric alert with Dynamic Thresholds created via template" - }, - "alertSeverity": { - "value": 3 - }, - "isEnabled": { - "value": true - }, - "targetResourceGroup": { - "value": [ - "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resource-group-name1", - "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resource-group-name2" - ] - }, - "targetResourceRegion": { - "value": "SouthCentralUS" - }, - "targetResourceType": { - "value": "Microsoft.Compute/virtualMachines" - }, - "metricName": { - "value": "Percentage CPU" - }, - "operator": { - "value": "GreaterOrLessThan" - }, - "alertSensitivity": { - "value": "Medium" - }, - "numberOfEvaluationPeriods": { - "value": "4" - }, - "minFailingPeriodsToAlert": { - "value": "3" - }, - "timeAggregation": { - "value": "Average" - }, - "actionGroupId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resource-group-name/providers/Microsoft.Insights/actionGroups/replace-with-action-group-name" - } - } -} -``` --### Static threshold alert on all virtual machines in a subscription --This sample creates a static threshold metric alert rule that monitors Percentage CPU for all virtual machines in one Azure region in a subscription. --### Template file --# [Bicep](#tab/bicep) --```bicep -@description('Name of the alert') -@minLength(1) -param alertName string --@description('Description of alert') -param alertDescription string = 'This is a metric alert' --@description('Severity of alert {0,1,2,3,4}') -@allowed([ - 0 - 1 - 2 - 3 - 4 -]) -param alertSeverity int = 3 --@description('Specifies whether the alert is enabled') -param isEnabled bool = true --@description('Azure Resource Manager path up to subscription ID. For example - /subscriptions/00000000-0000-0000-0000-0000-00000000') -@minLength(1) -param targetSubscription string --@description('Azure region in which target resources to be monitored are in (without spaces). For example: EastUS') -@allowed([ - 'EastUS' - 'EastUS2' - 'CentralUS' - 'NorthCentralUS' - 'SouthCentralUS' - 'WestCentralUS' - 'WestUS' - 'WestUS2' - 'CanadaEast' - 'CanadaCentral' - 'BrazilSouth' - 'NorthEurope' - 'WestEurope' - 'FranceCentral' - 'FranceSouth' - 'UKWest' - 'UKSouth' - 'GermanyCentral' - 'GermanyNortheast' - 'GermanyNorth' - 'GermanyWestCentral' - 'SwitzerlandNorth' - 'SwitzerlandWest' - 'NorwayEast' - 'NorwayWest' - 'SoutheastAsia' - 'EastAsia' - 'AustraliaEast' - 'AustraliaSoutheast' - 'AustraliaCentral' - 'AustraliaCentral2' - 'ChinaEast' - 'ChinaNorth' - 'ChinaEast2' - 'ChinaNorth2' - 'CentralIndia' - 'WestIndia' - 'SouthIndia' - 'JapanEast' - 'JapanWest' - 'KoreaCentral' - 'KoreaSouth' - 'SouthAfricaWest' - 'SouthAfricaNorth' - 'UAECentral' - 'UAENorth' -]) -param targetResourceRegion string --@description('Resource type of target resources to be monitored.') -@minLength(1) -param targetResourceType string --@description('Name of the metric used in the comparison to activate the alert.') -@minLength(1) -param metricName string --@description('Operator comparing the current value with the threshold value.') -@allowed([ - 'Equals' - 'GreaterThan' - 'GreaterThanOrEqual' - 'LessThan' - 'LessThanOrEqual' -]) -param operator string = 'GreaterThan' --@description('The threshold value at which the alert is activated.') -param threshold string = '0' --@description('How the data that is collected should be combined over time.') -@allowed([ - 'Average' - 'Minimum' - 'Maximum' - 'Total' - 'Count' -]) -param timeAggregation string = 'Average' --@description('Period of time used to monitor alert activity based on the threshold. Must be between one minute and one day. ISO 8601 duration format.') -@allowed([ - 'PT1M' - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' - 'PT6H' - 'PT12H' - 'PT24H' -]) -param windowSize string = 'PT5M' --@description('how often the metric alert is evaluated represented in ISO 8601 duration format') -@allowed([ - 'PT1M' - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' -]) -param evaluationFrequency string = 'PT1M' --@description('The ID of the action group that is triggered when the alert is activated or deactivated') -param actionGroupId string = '' --resource metricAlert 'Microsoft.Insights/metricAlerts@2018-03-01' = { - name: alertName - location: 'global' - properties: { - description: alertDescription - severity: alertSeverity - enabled: isEnabled - scopes: [ - targetSubscription - ] - targetResourceType: targetResourceType - targetResourceRegion: targetResourceRegion - evaluationFrequency: evaluationFrequency - windowSize: windowSize - criteria: { - 'odata.type': 'Microsoft.Azure.Monitor.MultipleResourceMultipleMetricCriteria' - allOf: [ - { - name: '1st criterion' - metricName: metricName - dimensions: [] - operator: operator - threshold: threshold - timeAggregation: timeAggregation - criterionType: 'StaticThresholdCriterion' - } - ] - } - actions: [ - { - actionGroupId: actionGroupId - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the alert" - } - }, - "alertDescription": { - "type": "string", - "defaultValue": "This is a metric alert", - "metadata": { - "description": "Description of alert" - } - }, - "alertSeverity": { - "type": "int", - "defaultValue": 3, - "allowedValues": [ - 0, - 1, - 2, - 3, - 4 - ], - "metadata": { - "description": "Severity of alert {0,1,2,3,4}" - } - }, - "isEnabled": { - "type": "bool", - "defaultValue": true, - "metadata": { - "description": "Specifies whether the alert is enabled" - } - }, - "targetSubscription": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Azure Resource Manager path up to subscription ID. For example - /subscriptions/00000000-0000-0000-0000-0000-00000000" - } - }, - "targetResourceRegion": { - "type": "string", - "allowedValues": [ - "EastUS", - "EastUS2", - "CentralUS", - "NorthCentralUS", - "SouthCentralUS", - "WestCentralUS", - "WestUS", - "WestUS2", - "CanadaEast", - "CanadaCentral", - "BrazilSouth", - "NorthEurope", - "WestEurope", - "FranceCentral", - "FranceSouth", - "UKWest", - "UKSouth", - "GermanyCentral", - "GermanyNortheast", - "GermanyNorth", - "GermanyWestCentral", - "SwitzerlandNorth", - "SwitzerlandWest", - "NorwayEast", - "NorwayWest", - "SoutheastAsia", - "EastAsia", - "AustraliaEast", - "AustraliaSoutheast", - "AustraliaCentral", - "AustraliaCentral2", - "ChinaEast", - "ChinaNorth", - "ChinaEast2", - "ChinaNorth2", - "CentralIndia", - "WestIndia", - "SouthIndia", - "JapanEast", - "JapanWest", - "KoreaCentral", - "KoreaSouth", - "SouthAfricaWest", - "SouthAfricaNorth", - "UAECentral", - "UAENorth" - ], - "metadata": { - "description": "Azure region in which target resources to be monitored are in (without spaces). For example: EastUS" - } - }, - "targetResourceType": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Resource type of target resources to be monitored." - } - }, - "metricName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the metric used in the comparison to activate the alert." - } - }, - "operator": { - "type": "string", - "defaultValue": "GreaterThan", - "allowedValues": [ - "Equals", - "GreaterThan", - "GreaterThanOrEqual", - "LessThan", - "LessThanOrEqual" - ], - "metadata": { - "description": "Operator comparing the current value with the threshold value." - } - }, - "threshold": { - "type": "int", - "defaultValue": 0, - "metadata": { - "description": "The threshold value at which the alert is activated." - } - }, - "timeAggregation": { - "type": "string", - "defaultValue": "Average", - "allowedValues": [ - "Average", - "Minimum", - "Maximum", - "Total", - "Count" - ], - "metadata": { - "description": "How the data that is collected should be combined over time." - } - }, - "windowSize": { - "type": "string", - "defaultValue": "PT5M", - "allowedValues": [ - "PT1M", - "PT5M", - "PT15M", - "PT30M", - "PT1H", - "PT6H", - "PT12H", - "PT24H" - ], - "metadata": { - "description": "Period of time used to monitor alert activity based on the threshold. Must be between one minute and one day. ISO 8601 duration format." - } - }, - "evaluationFrequency": { - "type": "string", - "defaultValue": "PT1M", - "allowedValues": [ - "PT1M", - "PT5M", - "PT15M", - "PT30M", - "PT1H" - ], - "metadata": { - "description": "how often the metric alert is evaluated represented in ISO 8601 duration format" - } - }, - "actionGroupId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "The ID of the action group that is triggered when the alert is activated or deactivated" - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/metricAlerts", - "apiVersion": "2018-03-01", - "name": "[parameters('alertName')]", - "location": "global", - "properties": { - "description": "[parameters('alertDescription')]", - "severity": "[parameters('alertSeverity')]", - "enabled": "[parameters('isEnabled')]", - "scopes": [ - "[parameters('targetSubscription')]" - ], - "targetResourceType": "[parameters('targetResourceType')]", - "targetResourceRegion": "[parameters('targetResourceRegion')]", - "evaluationFrequency": "[parameters('evaluationFrequency')]", - "windowSize": "[parameters('windowSize')]", - "criteria": { - "odata.type": "Microsoft.Azure.Monitor.MultipleResourceMultipleMetricCriteria", - "allOf": [ - { - "name": "1st criterion", - "metricName": "[parameters('metricName')]", - "dimensions": [], - "operator": "[parameters('operator')]", - "threshold": "[parameters('threshold')]", - "timeAggregation": "[parameters('timeAggregation')]", - "criterionType": "StaticThresholdCriterion" - } - ] - }, - "actions": [ - { - "actionGroupId": "[parameters('actionGroupId')]" - } - ] - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "value": "Multi-resource sub level metric alert via Azure Resource Manager template" - }, - "alertDescription": { - "value": "New Multi-resource sub level metric alert created via template" - }, - "alertSeverity": { - "value": 3 - }, - "isEnabled": { - "value": true - }, - "targetSubscription": { - "value": "/subscriptions/replace-with-subscription-id" - }, - "targetResourceRegion": { - "value": "SouthCentralUS" - }, - "targetResourceType": { - "value": "Microsoft.Compute/virtualMachines" - }, - "metricName": { - "value": "Percentage CPU" - }, - "operator": { - "value": "GreaterThan" - }, - "threshold": { - "value": 0 - }, - "timeAggregation": { - "value": "Average" - }, - "actionGroupId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resource-group-name/providers/Microsoft.Insights/actionGroups/replace-with-action-group-name" - } - } -} -``` --### Dynamic Thresholds alert on all virtual machines in a subscription --This sample creates a Dynamic Thresholds metric alert rule that monitors Percentage CPU for all virtual machines (in one Azure region) in a subscription. --### Template file --# [Bicep](#tab/bicep) --```bicep -@description('Name of the alert') -@minLength(1) -param alertName string --@description('Description of alert') -param alertDescription string = 'This is a metric alert' --@description('Severity of alert {0,1,2,3,4}') -@allowed([ - 0 - 1 - 2 - 3 - 4 -]) -param alertSeverity int = 3 --@description('Specifies whether the alert is enabled') -param isEnabled bool = true --@description('Azure Resource Manager path up to subscription ID. For example - /subscriptions/00000000-0000-0000-0000-0000-00000000') -@minLength(1) -param targetSubscription string --@description('Azure region in which target resources to be monitored are in (without spaces). For example: EastUS') -@allowed([ - 'EastUS' - 'EastUS2' - 'CentralUS' - 'NorthCentralUS' - 'SouthCentralUS' - 'WestCentralUS' - 'WestUS' - 'WestUS2' - 'CanadaEast' - 'CanadaCentral' - 'BrazilSouth' - 'NorthEurope' - 'WestEurope' - 'FranceCentral' - 'FranceSouth' - 'UKWest' - 'UKSouth' - 'GermanyCentral' - 'GermanyNortheast' - 'GermanyNorth' - 'GermanyWestCentral' - 'SwitzerlandNorth' - 'SwitzerlandWest' - 'NorwayEast' - 'NorwayWest' - 'SoutheastAsia' - 'EastAsia' - 'AustraliaEast' - 'AustraliaSoutheast' - 'AustraliaCentral' - 'AustraliaCentral2' - 'ChinaEast' - 'ChinaNorth' - 'ChinaEast2' - 'ChinaNorth2' - 'CentralIndia' - 'WestIndia' - 'SouthIndia' - 'JapanEast' - 'JapanWest' - 'KoreaCentral' - 'KoreaSouth' - 'SouthAfricaWest' - 'SouthAfricaNorth' - 'UAECentral' - 'UAENorth' -]) -param targetResourceRegion string --@description('Resource type of target resources to be monitored.') -@minLength(1) -param targetResourceType string --@description('Name of the metric used in the comparison to activate the alert.') -@minLength(1) -param metricName string --@description('Operator comparing the current value with the threshold value.') -@allowed([ - 'GreaterThan' - 'LessThan' - 'GreaterOrLessThan' -]) -param operator string = 'GreaterOrLessThan' --@description('Tunes how \'noisy\' the Dynamic Thresholds alerts will be: \'High\' will result in more alerts while \'Low\' will result in fewer alerts.') -@allowed([ - 'High' - 'Medium' - 'Low' -]) -param alertSensitivity string = 'Medium' --@description('The number of periods to check in the alert evaluation.') -param numberOfEvaluationPeriods int = 4 --@description('The number of unhealthy periods to alert on (must be lower or equal to numberOfEvaluationPeriods).') -param minFailingPeriodsToAlert int = 3 --@description('How the data that is collected should be combined over time.') -@allowed([ - 'Average' - 'Minimum' - 'Maximum' - 'Total' - 'Count' -]) -param timeAggregation string = 'Average' --@description('Period of time used to monitor alert activity based on the threshold. Must be between five minutes and one hour. ISO 8601 duration format.') -@allowed([ - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' -]) -param windowSize string = 'PT5M' --@description('how often the metric alert is evaluated represented in ISO 8601 duration format') -@allowed([ - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' -]) -param evaluationFrequency string = 'PT5M' --@description('The ID of the action group that is triggered when the alert is activated or deactivated') -param actionGroupId string = '' --resource metricAlert 'Microsoft.Insights/metricAlerts@2018-03-01' = { - name: alertName - location: 'global' - properties: { - description: alertDescription - severity: alertSeverity - enabled: isEnabled - scopes: [ - targetSubscription - ] - targetResourceType: targetResourceType - targetResourceRegion: targetResourceRegion - evaluationFrequency: evaluationFrequency - windowSize: windowSize - criteria: { - 'odata.type': 'Microsoft.Azure.Monitor.MultipleResourceMultipleMetricCriteria' - allOf: [ - { - criterionType: 'DynamicThresholdCriterion' - name: '1st criterion' - metricName: metricName - dimensions: [] - operator: operator - alertSensitivity: alertSensitivity - failingPeriods: { - numberOfEvaluationPeriods: numberOfEvaluationPeriods - minFailingPeriodsToAlert: minFailingPeriodsToAlert - } - timeAggregation: timeAggregation - } - ] - } - actions: [ - { - actionGroupId: actionGroupId - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the alert" - } - }, - "alertDescription": { - "type": "string", - "defaultValue": "This is a metric alert", - "metadata": { - "description": "Description of alert" - } - }, - "alertSeverity": { - "type": "int", - "defaultValue": 3, - "allowedValues": [ - 0, - 1, - 2, - 3, - 4 - ], - "metadata": { - "description": "Severity of alert {0,1,2,3,4}" - } - }, - "isEnabled": { - "type": "bool", - "defaultValue": true, - "metadata": { - "description": "Specifies whether the alert is enabled" - } - }, - "targetSubscription": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Azure Resource Manager path up to subscription ID. For example - /subscriptions/00000000-0000-0000-0000-0000-00000000" - } - }, - "targetResourceRegion": { - "type": "string", - "allowedValues": [ - "EastUS", - "EastUS2", - "CentralUS", - "NorthCentralUS", - "SouthCentralUS", - "WestCentralUS", - "WestUS", - "WestUS2", - "CanadaEast", - "CanadaCentral", - "BrazilSouth", - "NorthEurope", - "WestEurope", - "FranceCentral", - "FranceSouth", - "UKWest", - "UKSouth", - "GermanyCentral", - "GermanyNortheast", - "GermanyNorth", - "GermanyWestCentral", - "SwitzerlandNorth", - "SwitzerlandWest", - "NorwayEast", - "NorwayWest", - "SoutheastAsia", - "EastAsia", - "AustraliaEast", - "AustraliaSoutheast", - "AustraliaCentral", - "AustraliaCentral2", - "ChinaEast", - "ChinaNorth", - "ChinaEast2", - "ChinaNorth2", - "CentralIndia", - "WestIndia", - "SouthIndia", - "JapanEast", - "JapanWest", - "KoreaCentral", - "KoreaSouth", - "SouthAfricaWest", - "SouthAfricaNorth", - "UAECentral", - "UAENorth" - ], - "metadata": { - "description": "Azure region in which target resources to be monitored are in (without spaces). For example: EastUS" - } - }, - "targetResourceType": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Resource type of target resources to be monitored." - } - }, - "metricName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the metric used in the comparison to activate the alert." - } - }, - "operator": { - "type": "string", - "defaultValue": "GreaterOrLessThan", - "allowedValues": [ - "GreaterThan", - "LessThan", - "GreaterOrLessThan" - ], - "metadata": { - "description": "Operator comparing the current value with the threshold value." - } - }, - "alertSensitivity": { - "type": "string", - "defaultValue": "Medium", - "allowedValues": [ - "High", - "Medium", - "Low" - ], - "metadata": { - "description": "Tunes how 'noisy' the Dynamic Thresholds alerts will be: 'High' will result in more alerts while 'Low' will result in fewer alerts." - } - }, - "numberOfEvaluationPeriods": { - "type": "int", - "defaultValue": 4, - "metadata": { - "description": "The number of periods to check in the alert evaluation." - } - }, - "minFailingPeriodsToAlert": { - "type": "int", - "defaultValue": 3, - "metadata": { - "description": "The number of unhealthy periods to alert on (must be lower or equal to numberOfEvaluationPeriods)." - } - }, - "timeAggregation": { - "type": "string", - "defaultValue": "Average", - "allowedValues": [ - "Average", - "Minimum", - "Maximum", - "Total", - "Count" - ], - "metadata": { - "description": "How the data that is collected should be combined over time." - } - }, - "windowSize": { - "type": "string", - "defaultValue": "PT5M", - "allowedValues": [ - "PT5M", - "PT15M", - "PT30M", - "PT1H" - ], - "metadata": { - "description": "Period of time used to monitor alert activity based on the threshold. Must be between five minutes and one hour. ISO 8601 duration format." - } - }, - "evaluationFrequency": { - "type": "string", - "defaultValue": "PT5M", - "allowedValues": [ - "PT5M", - "PT15M", - "PT30M", - "PT1H" - ], - "metadata": { - "description": "how often the metric alert is evaluated represented in ISO 8601 duration format" - } - }, - "actionGroupId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "The ID of the action group that is triggered when the alert is activated or deactivated" - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/metricAlerts", - "apiVersion": "2018-03-01", - "name": "[parameters('alertName')]", - "location": "global", - "properties": { - "description": "[parameters('alertDescription')]", - "severity": "[parameters('alertSeverity')]", - "enabled": "[parameters('isEnabled')]", - "scopes": [ - "[parameters('targetSubscription')]" - ], - "targetResourceType": "[parameters('targetResourceType')]", - "targetResourceRegion": "[parameters('targetResourceRegion')]", - "evaluationFrequency": "[parameters('evaluationFrequency')]", - "windowSize": "[parameters('windowSize')]", - "criteria": { - "odata.type": "Microsoft.Azure.Monitor.MultipleResourceMultipleMetricCriteria", - "allOf": [ - { - "criterionType": "DynamicThresholdCriterion", - "name": "1st criterion", - "metricName": "[parameters('metricName')]", - "dimensions": [], - "operator": "[parameters('operator')]", - "alertSensitivity": "[parameters('alertSensitivity')]", - "failingPeriods": { - "numberOfEvaluationPeriods": "[parameters('numberOfEvaluationPeriods')]", - "minFailingPeriodsToAlert": "[parameters('minFailingPeriodsToAlert')]" - }, - "timeAggregation": "[parameters('timeAggregation')]" - } - ] - }, - "actions": [ - { - "actionGroupId": "[parameters('actionGroupId')]" - } - ] - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "value": "Multi-resource sub level metric alert with Dynamic Thresholds via Azure Resource Manager template" - }, - "alertDescription": { - "value": "New Multi-resource sub level metric alert with Dynamic Thresholds created via template" - }, - "alertSeverity": { - "value": 3 - }, - "isEnabled": { - "value": true - }, - "targetSubscription": { - "value": "/subscriptions/replace-with-subscription-id" - }, - "targetResourceRegion": { - "value": "SouthCentralUS" - }, - "targetResourceType": { - "value": "Microsoft.Compute/virtualMachines" - }, - "metricName": { - "value": "Percentage CPU" - }, - "operator": { - "value": "GreaterOrLessThan" - }, - "alertSensitivity": { - "value": "Medium" - }, - "numberOfEvaluationPeriods": { - "value": "4" - }, - "minFailingPeriodsToAlert": { - "value": "3" - }, - "timeAggregation": { - "value": "Average" - }, - "actionGroupId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resource-group-name/providers/Microsoft.Insights/actionGroups/replace-with-action-group-name" - } - } -} -``` --### Static threshold alert on a list of virtual machines --This sample creates a static threshold metric alert rule that monitors Percentage CPU for a list of virtual machines in one Azure region in a subscription. --### Template file --# [Bicep](#tab/bicep) --```bicep -@description('Name of the alert') -@minLength(1) -param alertName string --@description('Description of alert') -param alertDescription string = 'This is a metric alert' --@description('Severity of alert {0,1,2,3,4}') -@allowed([ - 0 - 1 - 2 - 3 - 4 -]) -param alertSeverity int = 3 --@description('Specifies whether the alert is enabled') -param isEnabled bool = true --@description('array of Azure resource Ids. For example - /subscriptions/00000000-0000-0000-0000-0000-00000000/resourceGroup/resource-group-name/Microsoft.compute/virtualMachines/vm-name') -@minLength(1) -param targetResourceId array --@description('Azure region in which target resources to be monitored are in (without spaces). For example: EastUS') -@allowed([ - 'EastUS' - 'EastUS2' - 'CentralUS' - 'NorthCentralUS' - 'SouthCentralUS' - 'WestCentralUS' - 'WestUS' - 'WestUS2' - 'CanadaEast' - 'CanadaCentral' - 'BrazilSouth' - 'NorthEurope' - 'WestEurope' - 'FranceCentral' - 'FranceSouth' - 'UKWest' - 'UKSouth' - 'GermanyCentral' - 'GermanyNortheast' - 'GermanyNorth' - 'GermanyWestCentral' - 'SwitzerlandNorth' - 'SwitzerlandWest' - 'NorwayEast' - 'NorwayWest' - 'SoutheastAsia' - 'EastAsia' - 'AustraliaEast' - 'AustraliaSoutheast' - 'AustraliaCentral' - 'AustraliaCentral2' - 'ChinaEast' - 'ChinaNorth' - 'ChinaEast2' - 'ChinaNorth2' - 'CentralIndia' - 'WestIndia' - 'SouthIndia' - 'JapanEast' - 'JapanWest' - 'KoreaCentral' - 'KoreaSouth' - 'SouthAfricaWest' - 'SouthAfricaNorth' - 'UAECentral' - 'UAENorth' -]) -param targetResourceRegion string --@description('Resource type of target resources to be monitored.') -@minLength(1) -param targetResourceType string --@description('Name of the metric used in the comparison to activate the alert.') -@minLength(1) -param metricName string --@description('Operator comparing the current value with the threshold value.') -@allowed([ - 'Equals' - 'GreaterThan' - 'GreaterThanOrEqual' - 'LessThan' - 'LessThanOrEqual' -]) -param operator string = 'GreaterThan' --@description('The threshold value at which the alert is activated.') -param threshold string = '0' --@description('How the data that is collected should be combined over time.') -@allowed([ - 'Average' - 'Minimum' - 'Maximum' - 'Total' - 'Count' -]) -param timeAggregation string = 'Average' --@description('Period of time used to monitor alert activity based on the threshold. Must be between one minute and one day. ISO 8601 duration format.') -@allowed([ - 'PT1M' - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' - 'PT6H' - 'PT12H' - 'PT24H' -]) -param windowSize string = 'PT5M' --@description('how often the metric alert is evaluated represented in ISO 8601 duration format') -@allowed([ - 'PT1M' - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' -]) -param evaluationFrequency string = 'PT1M' --@description('The ID of the action group that is triggered when the alert is activated or deactivated') -param actionGroupId string = '' --resource metricAlert 'Microsoft.Insights/metricAlerts@2018-03-01' = { - name: alertName - location: 'global' - properties: { - description: alertDescription - severity: alertSeverity - enabled: isEnabled - scopes: targetResourceId - targetResourceType: targetResourceType - targetResourceRegion: targetResourceRegion - evaluationFrequency: evaluationFrequency - windowSize: windowSize - criteria: { - 'odata.type': 'Microsoft.Azure.Monitor.MultipleResourceMultipleMetricCriteria' - allOf: [ - { - name: '1st criterion' - metricName: metricName - dimensions: [] - operator: operator - threshold: threshold - timeAggregation: timeAggregation - criterionType: 'StaticThresholdCriterion' - } - ] - } - actions: [ - { - actionGroupId: actionGroupId - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the alert" - } - }, - "alertDescription": { - "type": "string", - "defaultValue": "This is a metric alert", - "metadata": { - "description": "Description of alert" - } - }, - "alertSeverity": { - "type": "int", - "defaultValue": 3, - "allowedValues": [ - 0, - 1, - 2, - 3, - 4 - ], - "metadata": { - "description": "Severity of alert {0,1,2,3,4}" - } - }, - "isEnabled": { - "type": "bool", - "defaultValue": true, - "metadata": { - "description": "Specifies whether the alert is enabled" - } - }, - "targetResourceId": { - "type": "array", - "minLength": 1, - "metadata": { - "description": "array of Azure resource Ids. For example - /subscriptions/00000000-0000-0000-0000-0000-00000000/resourceGroup/resource-group-name/Microsoft.compute/virtualMachines/vm-name" - } - }, - "targetResourceRegion": { - "type": "string", - "allowedValues": [ - "EastUS", - "EastUS2", - "CentralUS", - "NorthCentralUS", - "SouthCentralUS", - "WestCentralUS", - "WestUS", - "WestUS2", - "CanadaEast", - "CanadaCentral", - "BrazilSouth", - "NorthEurope", - "WestEurope", - "FranceCentral", - "FranceSouth", - "UKWest", - "UKSouth", - "GermanyCentral", - "GermanyNortheast", - "GermanyNorth", - "GermanyWestCentral", - "SwitzerlandNorth", - "SwitzerlandWest", - "NorwayEast", - "NorwayWest", - "SoutheastAsia", - "EastAsia", - "AustraliaEast", - "AustraliaSoutheast", - "AustraliaCentral", - "AustraliaCentral2", - "ChinaEast", - "ChinaNorth", - "ChinaEast2", - "ChinaNorth2", - "CentralIndia", - "WestIndia", - "SouthIndia", - "JapanEast", - "JapanWest", - "KoreaCentral", - "KoreaSouth", - "SouthAfricaWest", - "SouthAfricaNorth", - "UAECentral", - "UAENorth" - ], - "metadata": { - "description": "Azure region in which target resources to be monitored are in (without spaces). For example: EastUS" - } - }, - "targetResourceType": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Resource type of target resources to be monitored." - } - }, - "metricName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the metric used in the comparison to activate the alert." - } - }, - "operator": { - "type": "string", - "defaultValue": "GreaterThan", - "allowedValues": [ - "Equals", - "GreaterThan", - "GreaterThanOrEqual", - "LessThan", - "LessThanOrEqual" - ], - "metadata": { - "description": "Operator comparing the current value with the threshold value." - } - }, - "threshold": { - "type": "int", - "defaultValue": 0, - "metadata": { - "description": "The threshold value at which the alert is activated." - } - }, - "timeAggregation": { - "type": "string", - "defaultValue": "Average", - "allowedValues": [ - "Average", - "Minimum", - "Maximum", - "Total", - "Count" - ], - "metadata": { - "description": "How the data that is collected should be combined over time." - } - }, - "windowSize": { - "type": "string", - "defaultValue": "PT5M", - "allowedValues": [ - "PT1M", - "PT5M", - "PT15M", - "PT30M", - "PT1H", - "PT6H", - "PT12H", - "PT24H" - ], - "metadata": { - "description": "Period of time used to monitor alert activity based on the threshold. Must be between one minute and one day. ISO 8601 duration format." - } - }, - "evaluationFrequency": { - "type": "string", - "defaultValue": "PT1M", - "allowedValues": [ - "PT1M", - "PT5M", - "PT15M", - "PT30M", - "PT1H" - ], - "metadata": { - "description": "how often the metric alert is evaluated represented in ISO 8601 duration format" - } - }, - "actionGroupId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "The ID of the action group that is triggered when the alert is activated or deactivated" - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/metricAlerts", - "apiVersion": "2018-03-01", - "name": "[parameters('alertName')]", - "location": "global", - "properties": { - "description": "[parameters('alertDescription')]", - "severity": "[parameters('alertSeverity')]", - "enabled": "[parameters('isEnabled')]", - "scopes": "[parameters('targetResourceId')]", - "targetResourceType": "[parameters('targetResourceType')]", - "targetResourceRegion": "[parameters('targetResourceRegion')]", - "evaluationFrequency": "[parameters('evaluationFrequency')]", - "windowSize": "[parameters('windowSize')]", - "criteria": { - "odata.type": "Microsoft.Azure.Monitor.MultipleResourceMultipleMetricCriteria", - "allOf": [ - { - "name": "1st criterion", - "metricName": "[parameters('metricName')]", - "dimensions": [], - "operator": "[parameters('operator')]", - "threshold": "[parameters('threshold')]", - "timeAggregation": "[parameters('timeAggregation')]", - "criterionType": "StaticThresholdCriterion" - } - ] - }, - "actions": [ - { - "actionGroupId": "[parameters('actionGroupId')]" - } - ] - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "value": "Multi-resource metric alert by list via Azure Resource Manager template" - }, - "alertDescription": { - "value": "New Multi-resource metric alert by list created via template" - }, - "alertSeverity": { - "value": 3 - }, - "isEnabled": { - "value": true - }, - "targetResourceId": { - "value": [ - "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resource-group-name1/Microsoft.Compute/virtualMachines/replace-with-vm-name1", - "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resource-group-name2/Microsoft.Compute/virtualMachines/replace-with-vm-name2" - ] - }, - "targetResourceRegion": { - "value": "SouthCentralUS" - }, - "targetResourceType": { - "value": "Microsoft.Compute/virtualMachines" - }, - "metricName": { - "value": "Percentage CPU" - }, - "operator": { - "value": "GreaterThan" - }, - "threshold": { - "value": 0 - }, - "timeAggregation": { - "value": "Average" - }, - "actionGroupId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resource-group-name/providers/Microsoft.Insights/actionGroups/replace-with-action-group-name" - } - } -} -``` --### Dynamic Thresholds alert on a list of virtual machines --This sample creates a dynamic thresholds metric alert rule that monitors Percentage CPU for a list of virtual machines in one Azure region in a subscription. --### Template file --# [Bicep](#tab/bicep) --```bicep -@description('Name of the alert') -@minLength(1) -param alertName string --@description('Description of alert') -param alertDescription string = 'This is a metric alert' --@description('Severity of alert {0,1,2,3,4}') -@allowed([ - 0 - 1 - 2 - 3 - 4 -]) -param alertSeverity int = 3 --@description('Specifies whether the alert is enabled') -param isEnabled bool = true --@description('array of Azure resource Ids. For example - /subscriptions/00000000-0000-0000-0000-0000-00000000/resourceGroup/resource-group-name/Microsoft.compute/virtualMachines/vm-name') -@minLength(1) -param targetResourceId array --@description('Azure region in which target resources to be monitored are in (without spaces). For example: EastUS') -@allowed([ - 'EastUS' - 'EastUS2' - 'CentralUS' - 'NorthCentralUS' - 'SouthCentralUS' - 'WestCentralUS' - 'WestUS' - 'WestUS2' - 'CanadaEast' - 'CanadaCentral' - 'BrazilSouth' - 'NorthEurope' - 'WestEurope' - 'FranceCentral' - 'FranceSouth' - 'UKWest' - 'UKSouth' - 'GermanyCentral' - 'GermanyNortheast' - 'GermanyNorth' - 'GermanyWestCentral' - 'SwitzerlandNorth' - 'SwitzerlandWest' - 'NorwayEast' - 'NorwayWest' - 'SoutheastAsia' - 'EastAsia' - 'AustraliaEast' - 'AustraliaSoutheast' - 'AustraliaCentral' - 'AustraliaCentral2' - 'ChinaEast' - 'ChinaNorth' - 'ChinaEast2' - 'ChinaNorth2' - 'CentralIndia' - 'WestIndia' - 'SouthIndia' - 'JapanEast' - 'JapanWest' - 'KoreaCentral' - 'KoreaSouth' - 'SouthAfricaWest' - 'SouthAfricaNorth' - 'UAECentral' - 'UAENorth' -]) -param targetResourceRegion string --@description('Resource type of target resources to be monitored.') -@minLength(1) -param targetResourceType string --@description('Name of the metric used in the comparison to activate the alert.') -@minLength(1) -param metricName string --@description('Operator comparing the current value with the threshold value.') -@allowed([ - 'GreaterThan' - 'LessThan' - 'GreaterOrLessThan' -]) -param operator string = 'GreaterOrLessThan' --@description('Tunes how \'noisy\' the Dynamic Thresholds alerts will be: \'High\' will result in more alerts while \'Low\' will result in fewer alerts.') -@allowed([ - 'High' - 'Medium' - 'Low' -]) -param alertSensitivity string = 'Medium' --@description('The number of periods to check in the alert evaluation.') -param numberOfEvaluationPeriods int = 4 --@description('The number of unhealthy periods to alert on (must be lower or equal to numberOfEvaluationPeriods).') -param minFailingPeriodsToAlert int = 3 --@description('How the data that is collected should be combined over time.') -@allowed([ - 'Average' - 'Minimum' - 'Maximum' - 'Total' - 'Count' -]) -param timeAggregation string = 'Average' --@description('Period of time used to monitor alert activity based on the threshold. Must be between five minutes and one hour. ISO 8601 duration format.') -@allowed([ - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' -]) -param windowSize string = 'PT5M' --@description('how often the metric alert is evaluated represented in ISO 8601 duration format') -@allowed([ - 'PT5M' - 'PT15M' - 'PT30M' - 'PT1H' -]) -param evaluationFrequency string = 'PT5M' --@description('The ID of the action group that is triggered when the alert is activated or deactivated') -param actionGroupId string = '' --resource metricAlert 'Microsoft.Insights/metricAlerts@2018-03-01' = { - name: alertName - location: 'global' - properties: { - description: alertDescription - severity: alertSeverity - enabled: isEnabled - scopes: targetResourceId - targetResourceType: targetResourceType - targetResourceRegion: targetResourceRegion - evaluationFrequency: evaluationFrequency - windowSize: windowSize - criteria: { - 'odata.type': 'Microsoft.Azure.Monitor.MultipleResourceMultipleMetricCriteria' - allOf: [ - { - criterionType: 'DynamicThresholdCriterion' - name: '1st criterion' - metricName: metricName - dimensions: [] - operator: operator - alertSensitivity: alertSensitivity - failingPeriods: { - numberOfEvaluationPeriods: numberOfEvaluationPeriods - minFailingPeriodsToAlert: minFailingPeriodsToAlert - } - timeAggregation: timeAggregation - } - ] - } - actions: [ - { - actionGroupId: actionGroupId - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the alert" - } - }, - "alertDescription": { - "type": "string", - "defaultValue": "This is a metric alert", - "metadata": { - "description": "Description of alert" - } - }, - "alertSeverity": { - "type": "int", - "defaultValue": 3, - "allowedValues": [ - 0, - 1, - 2, - 3, - 4 - ], - "metadata": { - "description": "Severity of alert {0,1,2,3,4}" - } - }, - "isEnabled": { - "type": "bool", - "defaultValue": true, - "metadata": { - "description": "Specifies whether the alert is enabled" - } - }, - "targetResourceId": { - "type": "array", - "minLength": 1, - "metadata": { - "description": "array of Azure resource Ids. For example - /subscriptions/00000000-0000-0000-0000-0000-00000000/resourceGroup/resource-group-name/Microsoft.compute/virtualMachines/vm-name" - } - }, - "targetResourceRegion": { - "type": "string", - "allowedValues": [ - "EastUS", - "EastUS2", - "CentralUS", - "NorthCentralUS", - "SouthCentralUS", - "WestCentralUS", - "WestUS", - "WestUS2", - "CanadaEast", - "CanadaCentral", - "BrazilSouth", - "NorthEurope", - "WestEurope", - "FranceCentral", - "FranceSouth", - "UKWest", - "UKSouth", - "GermanyCentral", - "GermanyNortheast", - "GermanyNorth", - "GermanyWestCentral", - "SwitzerlandNorth", - "SwitzerlandWest", - "NorwayEast", - "NorwayWest", - "SoutheastAsia", - "EastAsia", - "AustraliaEast", - "AustraliaSoutheast", - "AustraliaCentral", - "AustraliaCentral2", - "ChinaEast", - "ChinaNorth", - "ChinaEast2", - "ChinaNorth2", - "CentralIndia", - "WestIndia", - "SouthIndia", - "JapanEast", - "JapanWest", - "KoreaCentral", - "KoreaSouth", - "SouthAfricaWest", - "SouthAfricaNorth", - "UAECentral", - "UAENorth" - ], - "metadata": { - "description": "Azure region in which target resources to be monitored are in (without spaces). For example: EastUS" - } - }, - "targetResourceType": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Resource type of target resources to be monitored." - } - }, - "metricName": { - "type": "string", - "minLength": 1, - "metadata": { - "description": "Name of the metric used in the comparison to activate the alert." - } - }, - "operator": { - "type": "string", - "defaultValue": "GreaterOrLessThan", - "allowedValues": [ - "GreaterThan", - "LessThan", - "GreaterOrLessThan" - ], - "metadata": { - "description": "Operator comparing the current value with the threshold value." - } - }, - "alertSensitivity": { - "type": "string", - "defaultValue": "Medium", - "allowedValues": [ - "High", - "Medium", - "Low" - ], - "metadata": { - "description": "Tunes how 'noisy' the Dynamic Thresholds alerts will be: 'High' will result in more alerts while 'Low' will result in fewer alerts." - } - }, - "numberOfEvaluationPeriods": { - "type": "int", - "defaultValue": 4, - "metadata": { - "description": "The number of periods to check in the alert evaluation." - } - }, - "minFailingPeriodsToAlert": { - "type": "int", - "defaultValue": 3, - "metadata": { - "description": "The number of unhealthy periods to alert on (must be lower or equal to numberOfEvaluationPeriods)." - } - }, - "timeAggregation": { - "type": "string", - "defaultValue": "Average", - "allowedValues": [ - "Average", - "Minimum", - "Maximum", - "Total", - "Count" - ], - "metadata": { - "description": "How the data that is collected should be combined over time." - } - }, - "windowSize": { - "type": "string", - "defaultValue": "PT5M", - "allowedValues": [ - "PT5M", - "PT15M", - "PT30M", - "PT1H" - ], - "metadata": { - "description": "Period of time used to monitor alert activity based on the threshold. Must be between five minutes and one hour. ISO 8601 duration format." - } - }, - "evaluationFrequency": { - "type": "string", - "defaultValue": "PT5M", - "allowedValues": [ - "PT5M", - "PT15M", - "PT30M", - "PT1H" - ], - "metadata": { - "description": "how often the metric alert is evaluated represented in ISO 8601 duration format" - } - }, - "actionGroupId": { - "type": "string", - "defaultValue": "", - "metadata": { - "description": "The ID of the action group that is triggered when the alert is activated or deactivated" - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/metricAlerts", - "apiVersion": "2018-03-01", - "name": "[parameters('alertName')]", - "location": "global", - "properties": { - "description": "[parameters('alertDescription')]", - "severity": "[parameters('alertSeverity')]", - "enabled": "[parameters('isEnabled')]", - "scopes": "[parameters('targetResourceId')]", - "targetResourceType": "[parameters('targetResourceType')]", - "targetResourceRegion": "[parameters('targetResourceRegion')]", - "evaluationFrequency": "[parameters('evaluationFrequency')]", - "windowSize": "[parameters('windowSize')]", - "criteria": { - "odata.type": "Microsoft.Azure.Monitor.MultipleResourceMultipleMetricCriteria", - "allOf": [ - { - "criterionType": "DynamicThresholdCriterion", - "name": "1st criterion", - "metricName": "[parameters('metricName')]", - "dimensions": [], - "operator": "[parameters('operator')]", - "alertSensitivity": "[parameters('alertSensitivity')]", - "failingPeriods": { - "numberOfEvaluationPeriods": "[parameters('numberOfEvaluationPeriods')]", - "minFailingPeriodsToAlert": "[parameters('minFailingPeriodsToAlert')]" - }, - "timeAggregation": "[parameters('timeAggregation')]" - } - ] - }, - "actions": [ - { - "actionGroupId": "[parameters('actionGroupId')]" - } - ] - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "alertName": { - "value": "Multi-resource metric alert with Dynamic Thresholds by list via Azure Resource Manager template" - }, - "alertDescription": { - "value": "New Multi-resource metric alert with Dynamic Thresholds by list created via template" - }, - "alertSeverity": { - "value": 3 - }, - "isEnabled": { - "value": true - }, - "targetResourceId": { - "value": [ - "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resource-group-name1/Microsoft.Compute/virtualMachines/replace-with-vm-name1", - "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resource-group-name2/Microsoft.Compute/virtualMachines/replace-with-vm-name2" - ] - }, - "targetResourceRegion": { - "value": "SouthCentralUS" - }, - "targetResourceType": { - "value": "Microsoft.Compute/virtualMachines" - }, - "metricName": { - "value": "Percentage CPU" - }, - "operator": { - "value": "GreaterOrLessThan" - }, - "alertSensitivity": { - "value": "Medium" - }, - "numberOfEvaluationPeriods": { - "value": "4" - }, - "minFailingPeriodsToAlert": { - "value": "3" - }, - "timeAggregation": { - "value": "Average" - }, - "actionGroupId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resource-group-name/providers/Microsoft.Insights/actionGroups/replace-with-action-group-name" - } - } -} -``` --## Availability test with metric alert --[Application Insights availability tests](/previous-versions/azure/azure-monitor/app/monitor-web-app-availability) help you monitor the availability of your web site/application from various locations around the globe. Availability test alerts notify you when availability tests fail from a certain number of locations. Availability test alerts of the same resource type as metric alerts (Microsoft.Insights/metricAlerts). The following sample creates a simple availability test and associated alert. --> [!NOTE] -> `&`; is the HTML entity reference for &. URL parameters are still separated by a single &, but if you mention the URL in HTML, you need to encode it. So, if you have any "&" in your pingURL parameter value, you have to escape it with "`&`;" --### Template file --# [Bicep](#tab/bicep) --```bicep -param appName string -param pingURL string -param pingText string = '' -param actionGroupId string -param location string --var pingTestName = 'PingTest-${toLower(appName)}' -var pingAlertRuleName = 'PingAlert-${toLower(appName)}-${subscription().subscriptionId}' --resource pingTest 'Microsoft.Insights/webtests@2020-10-05-preview' = { - name: pingTestName - location: location - tags: { - 'hidden-link:${resourceId('Microsoft.Insights/components', appName)}': 'Resource' - } - properties: { - Name: pingTestName - Description: 'Basic ping test' - Enabled: true - Frequency: 300 - Timeout: 120 - Kind: 'ping' - RetryEnabled: true - Locations: [ - { - Id: 'us-va-ash-azr' - } - { - Id: 'emea-nl-ams-azr' - } - { - Id: 'apac-jp-kaw-edge' - } - ] - Configuration: { - WebTest: '<WebTest Name="${pingTestName}" Enabled="True" CssProjectStructure="" CssIteration="" Timeout="120" WorkItemIds="" xmlns="http://microsoft.com/schemas/VisualStudio/TeamTest/2010" Description="" CredentialUserName="" CredentialPassword="" PreAuthenticate="True" Proxy="default" StopOnError="False" RecordedResultFile="" ResultsLocale=""> <Items> <Request Method="GET" Version="1.1" Url="${pingURL}" ThinkTime="0" Timeout="300" ParseDependentRequests="True" FollowRedirects="True" RecordResult="True" Cache="False" ResponseTimeGoal="0" Encoding="utf-8" ExpectedHttpStatusCode="200" ExpectedResponseUrl="" ReportingName="" IgnoreHttpStatusCode="False" /> </Items> <ValidationRules> <ValidationRule Classname="Microsoft.VisualStudio.TestTools.WebTesting.Rules.ValidationRuleFindText, Microsoft.VisualStudio.QualityTools.WebTestFramework, Version=10.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a" DisplayName="Find Text" Description="Verifies the existence of the specified text in the response." Level="High" ExecutionOrder="BeforeDependents"> <RuleParameters> <RuleParameter Name="FindText" Value="${pingText}" /> <RuleParameter Name="IgnoreCase" Value="False" /> <RuleParameter Name="UseRegularExpression" Value="False" /> <RuleParameter Name="PassIfTextFound" Value="True" /> </RuleParameters> </ValidationRule> </ValidationRules> </WebTest>' - } - SyntheticMonitorId: pingTestName - } -} --resource metricAlert 'Microsoft.Insights/metricAlerts@2018-03-01' = { - name: pingAlertRuleName - location: 'global' - tags: { - 'hidden-link:${resourceId('Microsoft.Insights/components', appName)}': 'Resource' - 'hidden-link:${pingTest.id}': 'Resource' - } - properties: { - description: 'Alert for web test' - severity: 1 - enabled: true - scopes: [ - pingTest.id - resourceId('Microsoft.Insights/components', appName) - ] - evaluationFrequency: 'PT1M' - windowSize: 'PT5M' - criteria: { - 'odata.type': 'Microsoft.Azure.Monitor.WebtestLocationAvailabilityCriteria' - webTestId: pingTest.id - componentId: resourceId('Microsoft.Insights/components', appName) - failedLocationCount: 2 - } - actions: [ - { - actionGroupId: actionGroupId - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "metadata": { - "parameters": { - "appName": { - "type": "string" - }, - "pingURL": { - "type": "string" - }, - "pingText": { - "type": "string", - "defaultValue": "" - }, - "actionGroupId": { - "type": "string" - }, - "location": { - "type": "string" - } - } - }, - "variables": { - "pingTestName": "[format('PingTest-{0}', toLower(parameters('appName')))]", - "pingAlertRuleName": "[format('PingAlert-{0}-{1}', toLower(parameters('appName')), subscription().subscriptionId)]" - }, - "resources": [ - { - "type": "Microsoft.Insights/webtests", - "apiVersion": "2020-10-05-preview", - "name": "[variables('pingTestName')]", - "location": "[parameters('location')]", - "tags": { - "[format('hidden-link:{0}', resourceId('Microsoft.Insights/components', parameters('appName')))]": "Resource" - }, - "properties": { - "Name": "[variables('pingTestName')]", - "Description": "Basic ping test", - "Enabled": true, - "Frequency": 300, - "Timeout": 120, - "Kind": "ping", - "RetryEnabled": true, - "Locations": [ - { - "Id": "us-va-ash-azr" - }, - { - "Id": "emea-nl-ams-azr" - }, - { - "Id": "apac-jp-kaw-edge" - } - ], - "Configuration": { - "WebTest": "[format('<WebTest Name=\"{0}\" Enabled=\"True\" CssProjectStructure=\"\" CssIteration=\"\" Timeout=\"120\" WorkItemIds=\"\" xmlns=\"http://microsoft.com/schemas/VisualStudio/TeamTest/2010\" Description=\"\" CredentialUserName=\"\" CredentialPassword=\"\" PreAuthenticate=\"True\" Proxy=\"default\" StopOnError=\"False\" RecordedResultFile=\"\" ResultsLocale=\"\"> <Items> <Request Method=\"GET\" Version=\"1.1\" Url=\"{1}\" ThinkTime=\"0\" Timeout=\"300\" ParseDependentRequests=\"True\" FollowRedirects=\"True\" RecordResult=\"True\" Cache=\"False\" ResponseTimeGoal=\"0\" Encoding=\"utf-8\" ExpectedHttpStatusCode=\"200\" ExpectedResponseUrl=\"\" ReportingName=\"\" IgnoreHttpStatusCode=\"False\" /> </Items> <ValidationRules> <ValidationRule Classname=\"Microsoft.VisualStudio.TestTools.WebTesting.Rules.ValidationRuleFindText, Microsoft.VisualStudio.QualityTools.WebTestFramework, Version=10.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a\" DisplayName=\"Find Text\" Description=\"Verifies the existence of the specified text in the response.\" Level=\"High\" ExecutionOrder=\"BeforeDependents\"> <RuleParameters> <RuleParameter Name=\"FindText\" Value=\"{2}\" /> <RuleParameter Name=\"IgnoreCase\" Value=\"False\" /> <RuleParameter Name=\"UseRegularExpression\" Value=\"False\" /> <RuleParameter Name=\"PassIfTextFound\" Value=\"True\" /> </RuleParameters> </ValidationRule> </ValidationRules> </WebTest>', variables('pingTestName'), parameters('pingURL'), parameters('pingText'))]" - }, - "SyntheticMonitorId": "[variables('pingTestName')]" - } - }, - { - "type": "Microsoft.Insights/metricAlerts", - "apiVersion": "2018-03-01", - "name": "[variables('pingAlertRuleName')]", - "location": "global", - "tags": { - "[format('hidden-link:{0}', resourceId('Microsoft.Insights/components', parameters('appName')))]": "Resource", - "[format('hidden-link:{0}', resourceId('Microsoft.Insights/webtests', variables('pingTestName')))]": "Resource" - }, - "properties": { - "description": "Alert for web test", - "severity": 1, - "enabled": true, - "scopes": [ - "[resourceId('Microsoft.Insights/webtests', variables('pingTestName'))]", - "[resourceId('Microsoft.Insights/components', parameters('appName'))]" - ], - "evaluationFrequency": "PT1M", - "windowSize": "PT5M", - "criteria": { - "odata.type": "Microsoft.Azure.Monitor.WebtestLocationAvailabilityCriteria", - "webTestId": "[resourceId('Microsoft.Insights/webtests', variables('pingTestName'))]", - "componentId": "[resourceId('Microsoft.Insights/components', parameters('appName'))]", - "failedLocationCount": 2 - }, - "actions": [ - { - "actionGroupId": "[parameters('actionGroupId')]" - } - ] - }, - "dependsOn": [ - "[resourceId('Microsoft.Insights/webtests', variables('pingTestName'))]" - ] - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "appName": { - "value": "Replace with your Application Insights resource name" - }, - "pingURL": { - "value": "https://www.yoursite.com" - }, - "actionGroupId": { - "value": "/subscriptions/replace-with-subscription-id/resourceGroups/replace-with-resourceGroup-name/providers/microsoft.insights/actiongroups/replace-with-action-group-name" - }, - "location": { - "value": "Replace with the location of your Application Insights resource" - }, - "pingText": { - "defaultValue": "Optional parameter that allows you to perform a content-match for the presence of a specific string within the content returned from a pingURL response", - "type": "String" - }, - } -} -``` --Additional configuration of the content-match `pingText` parameter is controlled in the `Configuration/Webtest` portion of the template file. Specifically the section below: --```xml -<RuleParameter Name=\"FindText\" Value=\"',parameters('pingText'), '\" /> -<RuleParameter Name=\"IgnoreCase\" Value=\"False\" /> -<RuleParameter Name=\"UseRegularExpression\" Value=\"False\" /> -<RuleParameter Name=\"PassIfTextFound\" Value=\"True\" /> -``` --### Test locations --|Id | Region | -|:-|:--| -| `emea-nl-ams-azr` | West Europe | -| `us-ca-sjc-azr` | West US | -| `emea-ru-msa-edge` | UK South | -| `emea-se-sto-edge` | UK West | -| `apac-sg-sin-azr` | Southeast Asia | -| `us-tx-sn1-azr` | South Central US | -| `us-il-ch1-azr` | North Central US | -| `emea-gb-db3-azr` | North Europe | -| `apac-jp-kaw-edge` | Japan East | -| `emea-fr-pra-edge` | France Central | -| `emea-ch-zrh-edge` | France South | -| `us-va-ash-azr` | East US | -| `apac-hk-hkn-azr` | East Asia | -| `us-fl-mia-edge` | Central US | -| `latam-br-gru-edge`| Brazil South | -| `emea-au-syd-edge` | Australia East | --### US Government test locations --|Id | Region | -|-|| -| `usgov-va-azr` | `USGov Virginia` | -| `usgov-phx-azr` | `USGov Arizona` | -| `usgov-tx-azr` | `USGov Texas` | -| `usgov-ddeast-azr` | `USDoD East` | -| `usgov-ddcentral-azr`| `USDoD Central` | --## Next steps --- [Get other sample templates for Azure Monitor](../resource-manager-samples.md).-- [Learn more about alerts](./alerts-overview.md).-- [Get a sample to create an action group with Resource Manager template](resource-manager-action-groups.md) |
| azure-monitor | Resource Manager Alerts Resource Health | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/resource-manager-alerts-resource-health.md | - Title: Resource Manager template samples for resource health alerts -description: Sample Azure Resource Manager templates to deploy Azure Monitor resource health alerts. ----- Previously updated : 04/01/2024---# Resource Manager template samples for resource health alert rules in Azure Monitor --This article includes samples of [Azure Resource Manager templates](../../azure-resource-manager/templates/syntax.md) to create and configure resource health alerts in Azure Monitor. ---See [Configure resource health alerts using Resource Manager templates](../../service-health/resource-health-alert-arm-template-guide.md) for information about configuring resource health alerts using ARM templates. --## Basic template for Resource Health alerts --You can use this base template as a starting point for creating Resource Health alerts. This template will work as written, and will sign you up to receive alerts for all newly activated resource health events across all resources in a subscription. --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "activityLogAlertName": { - "type": "string", - "metadata": { - "description": "Unique name (within the Resource Group) for the Activity log alert." - } - }, - "actionGroupResourceId": { - "type": "string", - "metadata": { - "description": "Resource Id for the Action group." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/activityLogAlerts", - "apiVersion": "2017-04-01", - "name": "[parameters('activityLogAlertName')]", - "location": "Global", - "properties": { - "enabled": true, - "scopes": [ - "[subscription().id]" - ], - "condition": { - "allOf": [ - { - "field": "category", - "equals": "ResourceHealth" - }, - { - "field": "status", - "equals": "Active" - } - ] - }, - "actions": { - "actionGroups": - [ - { - "actionGroupId": "[parameters('actionGroupResourceId')]" - } - ] - } - } - } - ] -} -``` ----## Template to maximize the signal to noise ratio --This sample template is configured to maximize the signal to noise ratio. Keep in mind that there can be instances cases where the currentHealthStatus, previousHealthStatus, and cause property values may be null in some events. --See [Configure resource health alerts using Resource Manager templates](../../service-health/resource-health-alert-arm-template-guide.md) for information about configuring resource health alerts using ARM templates. --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "activityLogAlertName": { - "type": "string", - "metadata": { - "description": "Unique name (within the Resource Group) for the Activity log alert." - } - }, - "actionGroupResourceId": { - "type": "string", - "metadata": { - "description": "Resource Id for the Action group." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/activityLogAlerts", - "apiVersion": "2017-04-01", - "name": "[parameters('activityLogAlertName')]", - "location": "Global", - "properties": { - "enabled": true, - "scopes": [ - "[subscription().id]" - ], - "condition": { - "allOf": [ - { - "field": "category", - "equals": "ResourceHealth", - "containsAny": null - }, - { - "anyOf": [ - { - "field": "properties.currentHealthStatus", - "equals": "Available", - "containsAny": null - }, - { - "field": "properties.currentHealthStatus", - "equals": "Unavailable", - "containsAny": null - }, - { - "field": "properties.currentHealthStatus", - "equals": "Degraded", - "containsAny": null - } - ] - }, - { - "anyOf": [ - { - "field": "properties.previousHealthStatus", - "equals": "Available", - "containsAny": null - }, - { - "field": "properties.previousHealthStatus", - "equals": "Unavailable", - "containsAny": null - }, - { - "field": "properties.previousHealthStatus", - "equals": "Degraded", - "containsAny": null - } - ] - }, - { - "anyOf": [ - { - "field": "properties.cause", - "equals": "PlatformInitiated", - "containsAny": null - } - ] - }, - { - "anyOf": [ - { - "field": "status", - "equals": "Active", - "containsAny": null - }, - { - "field": "status", - "equals": "Resolved", - "containsAny": null - }, - { - "field": "status", - "equals": "In Progress", - "containsAny": null - }, - { - "field": "status", - "equals": "Updated", - "containsAny": null - } - ] - } - ] - }, - "actions": { - "actionGroups": [ - { - "actionGroupId": "[parameters('actionGroupResourceId')]" - } - ] - } - } - } - ] -} -``` --## Next steps --Learn more about Resource Health: -- [Azure Resource Health overview](../../service-health/resource-health-overview.md)-- [Resource types and health checks available through Azure Resource Health](../../service-health/resource-health-checks-resource-types.md)-- [Configure Alerts for Service Health](../../service-health/alerts-activity-log-service-notifications-arm.md) |
| azure-monitor | Resource Manager Alerts Service Health | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/resource-manager-alerts-service-health.md | - Title: Resource Manager template samples for service health alerts -description: Sample Azure Resource Manager templates to deploy Azure Monitor service health alerts. ----- Previously updated : 12/25/2023---# Resource Manager template samples for Azure Monitor service health alert rules --This article includes samples of [Azure Resource Manager templates](../../azure-resource-manager/templates/syntax.md) to create and configure service health alerts in Azure Monitor. ----## Template for creating service health alert rules --The following template creates a service health alert rule that sends notifications of service health events for the target subscription. Save this template as `CreateServiceHealthAlert.json` and modify it as needed. --Points to note: --1. The 'scopes' of a service health alert rule can only contain a single subscription, which must be the same subscription in which the rule is created. Multiple subscriptions, a resource group, or other types of scope aren't supported. -1. You can create service health alert rules only in the "Global" location. -1. The "properties.incidentType", "properties.impactedServices[*].ServiceName" and "properties.impactedServices[*].ImpactedRegions[*].RegionName" clauses within the rule condition are optional. You can remove these clauses to be notified on events sent for all incident types, all services, and/or all regions, respectively. -1. The service names used in the "properties.impactedServices[*].ServiceName" must be a valid Azure service name. A list of valid names can be retrieved at the [Resource Health Metadata List API](/rest/api/resourcehealth/metadata/list) ---```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "actionGroups_name": { - "type": "string", - "defaultValue": "SubHealth" - }, - "activityLogAlerts_name": { - "type": "string", - "defaultValue": "ServiceHealthActivityLogAlert" - }, - "emailAddress": { - "type": "string" - } - }, - "variables": { - "alertScope": "[format('/subscriptions/{0}', subscription().subscriptionId)]" - }, - "resources": [ - { - "type": "microsoft.insights/actionGroups", - "apiVersion": "2020-10-01", - "name": "[parameters('actionGroups_name')]", - "location": "Global", - "properties": { - "groupShortName": "[parameters('actionGroups_name')]", - "enabled": true, - "emailReceivers": [ - { - "name": "[parameters('actionGroups_name')]", - "emailAddress": "[parameters('emailAddress')]" - } - ], - "smsReceivers": [], - "webhookReceivers": [] - } - }, - { - "type": "microsoft.insights/activityLogAlerts", - "apiVersion": "2017-04-01", - "name": "[parameters('activityLogAlerts_name')]", - "location": "Global", - "properties": { - "scopes": [ - "[variables('alertScope')]" - ], - "condition": { - "allOf": [ - { - "field": "category", - "equals": "ServiceHealth" - }, - { - "field": "properties.incidentType", - "equals": "Incident" - }, - { - "field": "properties.impactedServices[*].ServiceName", - "containsAny": [ - "SQL Database", - "SQL Managed Instance" - ] - }, - { - "field": "properties.impactedServices[*].ImpactedRegions[*].RegionName", - "containsAny": [ - "Australia Central" - ] - } - ] - }, - "actions": { - "actionGroups": [ - { - "actionGroupId": "[resourceId('microsoft.insights/actionGroups', parameters('actionGroups_name'))]", - "webhookProperties": {} - } - ] - }, - "enabled": true - }, - "dependsOn": [ - "[resourceId('microsoft.insights/actionGroups', parameters('actionGroups_name'))]" - ] - } - ] -} -``` --## Next steps --- [Get other sample templates for Azure Monitor](../resource-manager-samples.md).-- [Learn more about alert rules](./alerts-overview.md).- |
| azure-monitor | Smart Detection Performance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/smart-detection-performance.md | - Title: Smart detection - performance anomalies | Microsoft Docs -description: Smart detection analyzes your app telemetry and warns you of potential problems. This feature needs no setup. --- Previously updated : 04/01/2024---# Smart detection - Performance Anomalies -->[!NOTE] ->You can migrate your Application Insight resources to alerts-based smart detection (preview). The migration creates alert rules for the different smart detection modules. Once created, you can manage and configure these rules just like any other Azure Monitor alert rules. You can also configure action groups for these rules, thus enabling multiple methods of taking actions or triggering notification on new detections. -> -> For more information on the migration process, see [Smart Detection Alerts migration](./alerts-smart-detections-migration.md). --[Application Insights](../app/app-insights-overview.md) automatically analyzes the performance of your web application, and can warn you about potential problems. --This feature requires no special setup, other than configuring your app for Application Insights for your [supported language](../app/app-insights-overview.md#supported-languages). It's active when your app generates enough telemetry. --## When would I get a smart detection notification? --Application Insights has detected that the performance of your application has degraded in one of these ways: --* **Response time degradation** - Your app has started responding to requests more slowly than it used to. The change might have been rapid, for example because there was a regression in your latest deployment. Or it might have been gradual, maybe caused by a memory leak. -* **Dependency duration degradation** - Your app makes calls to a REST API, database, or other dependency. The dependency is responding more slowly than it used to. -* **Slow performance pattern** - Your app appears to have a performance issue that is affecting only some requests. For example, pages are loading more slowly on one type of browser than others; or requests are being served more slowly from one particular server. Currently, our algorithms look at page load times, request response times, and dependency response times. --To establish a baseline of normal performance, smart detection requires at least eight days of sufficient telemetry volume. After your application has been running for that period, significant anomalies will result in a notification. ---## Does my app definitely have a problem? --No, a notification doesn't mean that your app definitely has a problem. It's simply a suggestion about something you might want to look at more closely. --## How do I fix it? --The notifications include diagnostic information. Here's an example: ----1. **Triage**. The notification shows you how many users or how many operations are affected. This information can help you assign a priority to the problem. -2. **Scope**. Is the problem affecting all traffic, or just some pages? Is it restricted to particular browsers or locations? This information can be obtained from the notification. -3. **Diagnose**. Often, the diagnostic information in the notification will suggest the nature of the problem. For example, if response time slows down when request rate is high, it may indicate that your server or dependencies are beyond their capacity. -- Otherwise, open the Performance pane in Application Insights. You'll find there [Profiler](../profiler/profiler.md) data. If exceptions are thrown, you can also try the [snapshot debugger](../snapshot-debugger/snapshot-debugger.md). --## Configure Email Notifications --Smart detection notifications are enabled by default. They are sent to users that have [Monitoring Reader](../../role-based-access-control/built-in-roles.md#monitoring-reader) and [Monitoring Contributor](../../role-based-access-control/built-in-roles.md#monitoring-contributor) access to the subscription in which the Application Insights resource resides. To change the default notification, either click **Configure** in the email notification, or open **Smart detection settings** in Application Insights. - <!-- convertborder later --> - :::image type="content" source="media/smart-detection-performance/smart_detection_configuration.png" lightbox="media/smart-detection-performance/smart_detection_configuration.png" alt-text="Smart Detection Settings" border="false"::: - - * You can disable the default notification, and replace it with a specified list of emails. --Emails about smart detection performance anomalies are limited to one email per day per Application Insights resource. The email will be sent only if there is at least one new issue that was detected on that day. You won't get repeats of any message. --## Frequently asked questions --* *So, Microsoft staff look at my data?* - * No. The service is entirely automatic. Only you get the notifications. Your data is [private](/previous-versions/azure/azure-monitor/app/data-retention-privacy). -* *Do you analyze all the data collected by Application Insights?* - * Currently, we analyze request response time, dependency response time, and page load time. Analysis of other metrics is on our backlog looking forward. --* What types of application does this detection work for? - * These degradations are detected in any application that generates the appropriate telemetry. If you installed Application Insights in your web app, then requests and dependencies are automatically tracked. But in backend services or other apps, if you inserted calls to [TrackRequest()](../app/api-custom-events-metrics.md#trackrequest) or [TrackDependency](../app/api-custom-events-metrics.md#trackdependency), then smart detection will work in the same way. --* *Can I create my own anomaly detection rules or customize existing rules?* -- * Not yet, but you can: - * [Set up alerts](./alerts-log.md) that tell you when a metric crosses a threshold. - * [Export telemetry](/previous-versions/azure/azure-monitor/app/export-telemetry) to a [database](../../stream-analytics/app-insights-export-sql-stream-analytics.md) or [to Power BI](../logs/log-powerbi.md), where you can analyze it yourself. -* *How often is the analysis done?* -- * We run the analysis daily on the telemetry from the previous day (full day in UTC timezone). -* *Does this replace [metric alerts](./alerts-log.md)?* - * No. We don't commit to detecting every behavior that you might consider abnormal. ---* *If I don't do anything in response to a notification, will I get a reminder?* - * No, you get a message about each issue only once. If the issue persists, it will be updated in the smart detection feed pane. -* *I lost the email. Where can I find the notifications in the portal?* - * In the Application Insights overview of your app, click the **Smart detection** tile. There you'll find all notifications up to 90 days back. --## How can I improve performance? -Slow and failed responses are one of the biggest frustrations for web site users, as you know from your own experience. So, it's important to address the issues. --### Triage -First, does it matter? If a page is always slow to load, but only 1% of your site's users ever have to look at it, maybe you have more important things to think about. However, if only 1% of users open it, but it throws exceptions every time, that might be worth investigating. --Use the impact statement, such as affected users or % of traffic, as a general guide. Be aware that it may not be telling the whole story. Gather other evidence to confirm. --Consider the parameters of the issue. If it's geography-dependent, set up [availability tests](/previous-versions/azure/azure-monitor/app/monitor-web-app-availability) including that region: there might be network issues in that area. --### Diagnose slow page loads -Where is the problem? Is the server slow to respond, is the page too long, or does the browser need too much work to display it? --Open the Browsers metric pane. The segmented display of browser page load time shows where the time is going. --* If **Send Request Time** is high, either the server is responding slowly, or the request is a post with large amount of data. Look at the [performance metrics](../app/performance-counters.md) to investigate response times. -* Set up [dependency tracking](../app/asp-net-dependencies.md) to see whether the slowness is because of external services or your database. -* If **Receiving Response** is predominant, your page and its dependent parts - JavaScript, CSS, images, and so on (but not asynchronously loaded data) are long. Set up an [availability test](/previous-versions/azure/azure-monitor/app/monitor-web-app-availability), and be sure to set the option to load dependent parts. When you get some results, open the detail of a result and expand it to see the load times of different files. -* High **Client Processing time** suggests scripts are running slowly. If the reason isn't obvious, consider adding some timing code and send the times in trackMetric calls. --### Improve slow pages -There's a web full of advice on improving your server responses and page load times, so we won't try to repeat it all here. Here are a few tips that you probably already know about, just to get you thinking: --* Slow loading because of large files: Load the scripts and other parts asynchronously. Use script bundling. Break the main page into widgets that load their data separately. Don't send plain old HTML for long tables: use a script to request the data as JSON or other compact format, then fill the table in place. There are great frameworks to help with such tasks. (They also include large scripts, of course.) -* Slow server dependencies: Consider the geographical locations of your components. For example, if you're using Azure, make sure the web server and the database are in the same region. Do queries retrieve more information than they need? Would caching or batching help? -* Capacity issues: Look at the server metrics of response times and request counts. If response times peak disproportionately with peaks in request counts, it's likely that your servers are stretched. ---## Server Response Time Degradation --The response time degradation notification tells you: --* The response time compared to normal response time for this operation. -* How many users are affected. -* Average response time and 90th percentile response time for this operation on the day of the detection and seven days before. -* Count of this operation requests on the day of the detection and seven days before. -* Correlation between degradation in this operation and degradations in related dependencies. -* Links to help you diagnose the problem. - * Profiler traces can help you view where operation time is spent. The link is available if Profiler trace examples exist for this operation. - * Performance reports in Metric Explorer, where you can slice and dice time range/filters for this operation. - * Search for this call to view specific call properties. - * Failure reports - If count > 1, it means that there were failures in this operation that might have contributed to performance degradation. --## Dependency Duration Degradation --Modern applications often adopt a micro services design approach, which in many cases rely heavily on external services. For example, if your application relies on some data platform, or on a critical services provider such as Azure AI services. --Example of dependency degradation notification: ---Notice that it tells you: --* The duration compared to normal response time for this operation -* How many users are affected -* Average duration and 90th percentile duration for this dependency on the day of the detection and seven days before -* Number of dependency calls on the day of the detection and seven days before -* Links to help you diagnose the problem - * Performance reports in Metric Explorer for this dependency - * Search for this dependency calls to view calls properties - * Failure reports - If count > 1, it means that there were failed dependency calls during the detection period that might have contributed to duration degradation. - * Open Analytics with queries that calculate this dependency duration and count --## Smart detection of slow performing patterns --Application Insights finds performance issues that might only affect some portion of your users, or only affect users in some cases. For example, if a page loads slower on a specific browser type compared to others, or if a particular server handles requests more slowly than other servers. It can also discover problems that are associated with combinations of properties, such as slow page loads in one geographical area for clients using particular operating system. --Anomalies like these are hard to detect just by inspecting the data, but are more common than you might think. Often they only surface when your customers complain. By that time, it's too late: the affected users are already switching to your competitors! --Currently, our algorithms look at page load times, request response times at the server, and dependency response times. --You don't have to set any thresholds or configure rules. Machine learning and data mining algorithms are used to detect abnormal patterns. -<!-- convertborder later --> --* **When** shows the time the issue was detected. -* **What** describes the problem that was detected, and th characteristics of the set of events that we found, which displayed the problem behavior. -* The table compares the poorly performing set with the average behavior of all other events. --Click the links to open Metric Explorer to view reports, filtered by the time and properties of the slow performing set. --Modify the time range and filters to explore the telemetry. --## Next steps -These diagnostic tools help you inspect the telemetry from your app: --* [Profiler](../profiler/profiler.md) -* [snapshot debugger](../snapshot-debugger/snapshot-debugger.md) -* [Analytics](../logs/log-analytics-tutorial.md) -* [Analytics smart diagnostics](../logs/log-query-overview.md) --Smart detection is automatic. But maybe you'd like to set up some more alerts? --* [Manually configured metric alerts](./alerts-log.md) -* [Availability web tests](/previous-versions/azure/azure-monitor/app/monitor-web-app-availability) |
| azure-monitor | Test Action Group Errors | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/test-action-group-errors.md | - Title: Test Notification Troubleshooting Guide -description: Detailed description of error codes and actions to take when troubleshooting the test action group feature. -- Previously updated : 01/28/2024----# Test notification troubleshooting guide. --This article describes troubleshooting steps for error messages you may get when using the test action group feature. --> [!NOTE] -> Azure Action Groups doesn't support the use of private links today. It is reccomended that customers use public network access to avoid any issues. For other networking issues ensure you are properly using the [Action Group Service Tag](./../../virtual-network/service-tags-overview.md). --## Troubleshooting error codes for actions --The error messages in this section are related to these **actions**: ---> [!NOTE] -> Several errors could be due to a misunderstanding of your schema. Click here to learn more information about [Common alert schema](./alerts-common-schema.md) and [Non-common alert schema](./alerts-non-common-schema-definitions.md). --| Error Codes | Troubleshooting Steps | -| | | -|HTTP 400: The \<action\> returned a 'bad request' error. |Check the alert payload received on your endpoint, and make sure the endpoint can process the request successfully. -|HTTP 400: The \<action\> couldn't be triggered because this alert type doesn't support the common alert schema. |1. Check if the alert type supports common alert schema.</br>2. Change the ΓÇ£Enable the common alert schemaΓÇ¥ in the action group action to ΓÇ£NoΓÇ¥ and retry. -|HTTP 400: The \<action\> couldn't be triggered because the payload is empty or invalid. | Check if the payload is valid, and included as part of the request. -|HTTP 400: The \<action\> couldn't be triggered because Microsoft Entra auth is enabled but no auth context provided in the request. | 1. Check your Secure Webhook action settings.</br>2. Check your Microsoft Entra configuration. For more information, see [action groups](action-groups.md). | -|HTTP 400: ServiceNow returned error: No such host is known | Check your ServiceNow host url to make sure it's valid and retry. For more information, see [Connect ServiceNow with IT Service Management Connector](./itsmc-connections-servicenow.md) | -|</br>HTTP 401: The \<action\> returned an "Unauthorized" error.</br>HTTP 401: The request was rejected by the \<action\> endpoint. Make sure you have the required authorization. | 1. Check if the credential in the request is present and valid.</br>2. Check if your endpoint correctly validates the credentials from the request. | -|</br>HTTP 403: The \<action\> returned a "Forbidden" response.</br>HTTP 403: Couldn't trigger the \<action\>. Make sure you have the required authorization.</br>HTTP 403: The \<action\> returned a 'Forbidden' response. Make sure you have the proper permissions to access it.</br>HTTP 403: The \<action\> is "Forbidden".</br>HTTP 403: Couldn't access the ITSM system. Make sure you have the required authorization. | 1. Check if the credential in the request is present, and valid.</br>2. Check if your endpoint correctly validates the credentials.</br>3. If it's Secure Webhook, make sure the Microsoft Entra authentication is set up correctly. For more information, see [action groups](action-groups.md).| -| HTTP 403: The access token needs to be refreshed.| Refresh the access token and retry. For more information, see [Connect ServiceNow with IT Service Management Connector](./itsmc-connections-servicenow.md) | -|HTTP 404: The \<action\> wasn't found.</br>HTTP 404: The \<action\> target workflow wasn't found.</br>HTTP 404: The \<action\> target wasn't found.</br>HTTP 404: The \<action\> endpoint couldn't be found.</br>HTTP 404: The \<action\> was deleted. | 1. Check if the endpoints included in the requests are valid, up and running and accepting the requests.</br>2. For ITSM, check if the ITSM connector is still active.| -|HTTP 408: The call to the \<action\> timed out.</br>HTTP 408: The call to the Azure App service endpoint timed out. | 1.Check the client network connection, and retry.</br>2. Check if your endpoint is up and running and can process the request successfully.</br>3. Clear the browser cache, and retry. | -|HTTP 409: The \<action\> returned a 'conflict' error. |Check the alert payload received on your endpoint, and make sure the endpoint and its downstream service(s) can process the request successfully. | -|HTTP 429: The \<action\> couldn't be triggered because it is handling too many requests right now. |Check if your endpoint can handle the requests.</br>2. Wait a few minutes and retry. | -|HTTP 500: The \<action\> encountered an internal server error.</br>HTTP 500: Couldn't reach the Azure \<action\> server.</br>HTTP 500: The \<action\> returned an 'internal server' error.</br>HTTP 500: The ServiceNow endpoint returned an 'Unexpected' response.</li></ul> |Check the alert payload received on your endpoint, and make sure the endpoint and its downstream service(s) can process the request successfully. | -|HTTP 502: The \<action\> returned a bad gateway error. |Check if your endpoint, and its downstream service(s) are up and running and are accepting requests. | -|HTTP 503: The \<action\> host isn't running.</br>HTTP 503: The service providing the \<action\> endpoint is temporarily unavailable.</br>HTTP 503: The ServiceNow returned Service Unavailable|Check if your endpoint is up and running and is accepting requests. | -| The \<action\> couldn't be triggered because the \<action\> didn't succeeded after XXX retries. Calls to the \<action\> will be blocked for up to XXX minutes. Try again in XXX minutes. |Check the alert payload received on your endpoint, and make sure the endpoint and its downstream service(s) can process the request successfully.| --## Troubleshooting error codes for notifications --The error messages in this section are related to these **notifications**: ----| Error Codes | Troubleshooting Steps | -| | | -| The email couldn't be sent because the recipient address wasn't found.</br> The email couldn't be sent because the email domain is invalid, or the MX resource record doesn't exist on the Domain Name Server (DNS). |Verify the email address(es) is/are valid and try again. | -|</br>The email was sent but the delivery status couldn't be verified.</br> The email couldn't be sent because of a permanent error. |Wait a few minutes and retry. If the issue persists, file a support ticket. | -|</br>Invalid destination number.</br> Invalid source address.</br> Invalid phone number. | Verify that the phone number is valid and retry. -| The message couldn't be sent because it was blocked by the recipient's provider. | 1. Verify if you can receive SMS from other sources.</br>2. Check with your service provider. | -|</br>The message couldn't be sent because the delivery timed out.</br> The message couldn't be delivered to the recipient. |Wait a few minutes and retry. If the issue still persists, file a support ticket. | -|The message was sent successfully, but there was no confirmation of delivery from the recipient's device. | 1. Make sure your device is on, and service is available.</br>2. Wait for a few minutes and retry. | -|The call couldn't go through because the recipient's line was busy. | 1. Make sure your device is on, and service is available, and not busy.</br>2. Wait for a few minutes and retry. | -| The call went through, but the recipient did not select any response. The call might have been picked up by a voice mail service. |Make sure your device is on, the line isn't busy, your service isn't interrupted, and call doesn't go into voice mail. | -| HTTP 500: There was a problem connecting the call. Contact Azure support for assistance. | Wait a few minutes and retry. If the issue still persists, file a support ticket. | --> [!NOTE] -> If your issue persists after you try to troubleshoot, please fill out a support ticket here: [Help + support - Microsoft Azure](https://ms.portal.azure.com/#view/Microsoft_Azure_Support/HelpAndSupportBlade/~/overview). --## See Also -- [Action Groups](action-groups.md).-- [Common alert schema](./alerts-common-schema.md)-- [Non-common alert schema](./alerts-non-common-schema-definitions.md)-- [Connect ServiceNow with IT Service Management Connector](./itsmc-connections-servicenow.md) |
| azure-monitor | Tutorial Log Alert | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/tutorial-log-alert.md | - Title: Tutorial - Create a log search alert for an Azure resource -description: Tutorial to create a log search alert for an Azure resource. --- Previously updated : 11/07/2023---# Tutorial: Create a log search alert for an Azure resource --Azure Monitor alerts proactively notify you when important conditions are found in your monitoring data. Log search alert rules create an alert when a log query returns a particular result. For example, receive an alert when a particular event is created on a virtual machine, or send a warning when excessive anonymous requests are made to a storage account. --In this tutorial, you learn how to: --> [!div class="checklist"] -> * Access prebuilt log queries designed to support alert rules for different kinds of resources -> * Create a log search alert rule -> * Create an action group to define notification details --## Prerequisites --To complete this tutorial, you need the following: --- An Azure resource to monitor. You can use any resource in your Azure subscription that supports diagnostic settings. To determine whether a resource supports diagnostic settings, go to its menu in the Azure portal and verify that there's a **Diagnostic settings** option in the **Monitoring** section of the menu.--If you're using any Azure resource other than a virtual machine: --- A diagnostic setting to send the resource logs from your Azure resource to a Log Analytics workspace. See [Tutorial: Create Log Analytics workspace in Azure Monitor](../essentials/tutorial-resource-logs.md).--If you're using an Azure virtual machine: --- A data collection rule to send guest logs and metrics to a Log Analytics workspace. See [Tutorial: Collect guest logs and metrics from Azure virtual machine](../vm/tutorial-monitor-vm-guest.md).- -## Select a log query and verify results --Data is retrieved from a Log Analytics workspace using a log query written in Kusto Query Language (KQL). Insights and solutions in Azure Monitor provide log queries to retrieve data for a particular service, but you can work directly with log queries and their results in the Azure portal with Log Analytics. --Select **Logs** from your resource's menu. Log Analytics opens with the **Queries** window that includes prebuilt queries for your **Resource type**. Select **Alerts** to view queries designed for alert rules. --> [!NOTE] -> If the **Queries** window doesn't open, click **Queries** in the top right. ---Select a query and click **Run** to load it in the query editor and return results. You may want to modify the query and run it again. For example, the **Show anonymous requests** query for storage accounts is shown in the following screenshot. You may want to modify the **AuthenticationType** or filter on a different column. ---## Create alert rule --Once you verify your query, you can create the alert rule. Select **New alert rule** to create a new alert rule based on the current log query. The **Scope** is already set to the current resource. You don't need to change this value. ---## Configure condition --On the **Condition** tab, the **Log query** is already filled in. The **Measurement** section defines how the records from the log query are measured. If the query doesn't perform a summary, then the only option is to **Count** the number of **Table rows**. If the query includes one or more summarized columns, then you have the option to use the number of **Table rows** or a calculation based on any of the summarized columns. **Aggregation granularity** defines the time interval over which the collected values are aggregated. For example, if the aggregation granularity is set to 5 minutes, the alert rule evaluates the data aggregated over the last 5 minutes. If the aggregation granularity is set to 15 minutes, the alert rule evaluates the data aggregated over the last 15 minutes. It is important to choose the right aggregation granularity for your alert rule, as it can affect the accuracy of the alert. --> [!NOTE] -> The combined size of all data in the log alert rule properties cannot exceed 64KB. This can be caused by too many dimensions, the query being too large, too many action groups, or a long description. When creating a large alert rule, remember to optimize these areas. ---### Configure dimensions --**Split by dimensions** allows you to create separate alerts for different resources. This setting is useful when you're creating an alert rule that applies to multiple resources. With the scope set to a single resource, this setting typically isn't used. ---If you need certain dimensions included in the alert notification email, you can specify a dimension (for example, "Computer"), the alert notification email will include the computer name that triggered the alert. The alerting engine uses the alert query to determine the available dimensions. If you do not see the dimension you want in the drop-down list for the "Dimension name", it is because the alert query does not expose that column in the results. You can easily add the dimensions you want by adding a Project line to your query that includes the columns you want to use. You can also use the Summarize line to add more columns to the query results. ---## Configure alert logic --In the alert logic, configure the **Operator** and **Threshold value** to compare to the value returned from the measurement. An alert is created when this value is true. Select a value for **Frequency of evaluation** which defines how often the log query is run and evaluated. The cost for the alert rule increases with a lower frequency. When you select a frequency, the estimated monthly cost is displayed in addition to a preview of the query results over a time period. --For example, if the measurement is **Table rows**, the alert logic may be **Greater than 0** indicating that at least one record was returned. If the measurement is a columns value, then the logic may need to be greater than or less than a particular threshold value. In the following example, the log query is looking for anonymous requests to a storage account. If an anonymous request is made, then we should trigger an alert. In this case, a single row returned would trigger the alert, so the alert logic should be **Greater than 0**. ---## Configure actions --## Configure details ---Click **Create alert rule** to create the alert rule. --## View the alert --## Next steps --Now that you've learned how to create a log search alert for an Azure resource, have a look at workbooks for creating interactive visualizations of monitoring data. --> [!div class="nextstepaction"] -> [Azure Monitor Workbooks](../visualize/workbooks-overview.md) |
| azure-monitor | Tutorial Metric Alert | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/alerts/tutorial-metric-alert.md | - Title: Tutorial - Create a metric alert for an Azure resource -description: Learn how to create a metric chart with Azure metrics explorer. --- Previously updated : 11/28/2023---# Tutorial: Create a metric alert for an Azure resource --Azure Monitor alerts proactively notify you when important conditions are found in your monitoring data. Metric alert rules create an alert when a metric value from an Azure resource exceeds a threshold. --In this tutorial, you learn how to: --> [!div class="checklist"] -> * Create a metric alert rule from metrics explorer -> * Configure the alert threshold -> * Create an action group to define notification details --## Prerequisites -To complete this tutorial you need the following: --- An Azure resource to monitor. You can use any resource in your Azure subscription that supports metrics. To determine whether a resource supports metrics, go to its menu in the Azure portal and verify that there's a **Metrics** option in the **Monitoring** section of the menu.-- Chart in metrics explorer with one or more metrics that you want to alert on. Complete [Tutorial: Analyze metrics for an Azure resource](../essentials/tutorial-metrics.md).--## Create new alert rule -From metrics explorer, click **New alert rule**. The rule will be preconfigured with the target object and the metric that you selected in metrics explorer. ---## Configure alert logic -The resource will already be selected. You need to modify the signal logic to specify the threshold value and any other details for the alert rule. --To view these settings, select the **Condition** tab. ---The chart shows the value of the selected signal over time so that you can see when the alert would have been fired. This chart will update as you specify the signal logic. ---The **Alert logic** is defined by the condition and the evaluation time. The alert fires when this condition is true. Provide a **Threshold value** for your alert rule and modify the **Operator** and **Aggregation type** to define the logic you need. ---You can accept the default time granularity or modify it to your requirements. **Check every** defines how often the alert rule will check if the condition is met. **Lookback period** defines the time interval over which the collected values are aggregated. For example, every 5 minutes, youΓÇÖll be looking at the past 5 minutes. ---When you're done configuring the signal logic, click **Next: Actions >** or the **Actions** tab to configure actions. --## Configure actions --## Configure details ----Click **Review + create** and then **Create** to create the alert rule. ---## View the alert ---## Next steps -Now that you've learned how to create a metric alert for an Azure resource, use one of the following tutorials to collect log data. --> [!div class="nextstepaction"] -> [Collect resource logs from an Azure resource](../essentials/tutorial-resource-logs.md) -> [!div class="nextstepaction"] -> [Collect guest logs and metrics from Azure virtual machine](../vm/tutorial-monitor-vm-guest.md) |
| azure-monitor | Api Custom Events Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/api-custom-events-metrics.md | - Title: Application Insights API for custom events and metrics | Microsoft Docs -description: Insert a few lines of code in your device or desktop app, webpage, or service to track usage and diagnose issues. - Previously updated : 01/31/2024-# ms.devlang: csharp, java, javascript, vb -----# Application Insights API for custom events and metrics --Insert a few lines of code in your application to find out what users are doing with it, or to help diagnose issues. You can send telemetry from device and desktop apps, web clients, and web servers. Use the [Application Insights](./app-insights-overview.md) core telemetry API to send custom events and metrics and your own versions of standard telemetry. This API is the same API that the standard Application Insights data collectors use. ---## API summary --The core API is uniform across all platforms, apart from a few variations like `GetMetric` (.NET only). --| Method | Used for | -| | | -| [`TrackPageView`](#page-views) |Pages, screens, panes, or forms. | -| [`TrackEvent`](#trackevent) |User actions and other events. Used to track user behavior or to monitor performance. | -| [`GetMetric`](#getmetric) |Zero and multidimensional metrics, centrally configured aggregation, C# only. | -| [`TrackMetric`](#trackmetric) |Performance measurements such as queue lengths not related to specific events. | -| [`TrackException`](#trackexception) |Logging exceptions for diagnosis. Trace where they occur in relation to other events and examine stack traces. | -| [`TrackRequest`](#trackrequest) |Logging the frequency and duration of server requests for performance analysis. | -| [`TrackTrace`](#tracktrace) |Resource Diagnostic log messages. You can also capture third-party logs. | -| [`TrackDependency`](#trackdependency) |Logging the duration and frequency of calls to external components that your app depends on. | --You can [attach properties and metrics](#properties) to most of these telemetry calls. --## <a name="prep"></a>Before you start --If you don't have a reference on Application Insights SDK yet: --* Add the Application Insights SDK to your project: -- * [ASP.NET project](./asp-net.md) - * [ASP.NET Core project](./asp-net-core.md) - * [Java project](./opentelemetry-enable.md?tabs=java) - * [Node.js project](./nodejs.md) - * [JavaScript in each webpage](./javascript.md) -* In your device or web server code, include: -- *C#:* `using Microsoft.ApplicationInsights;` -- *Visual Basic:* `Imports Microsoft.ApplicationInsights` -- *Java:* `import com.microsoft.applicationinsights.TelemetryClient;` -- *Node.js:* `var applicationInsights = require("applicationinsights");` --## Get a TelemetryClient instance --Get an instance of `TelemetryClient` (except in JavaScript in webpages): --For [ASP.NET Core](asp-net-core.md) apps and [Non-HTTP/Worker for .NET/.NET Core](worker-service.md#how-can-i-track-telemetry-thats-not-automatically-collected) apps, get an instance of `TelemetryClient` from the dependency injection container as explained in their respective documentation. --If you use Azure Functions v2+ or Azure WebJobs v3+, see [Monitor Azure Functions](../../azure-functions/functions-monitoring.md). --*C#* --```csharp -private TelemetryClient telemetry = new TelemetryClient(); -``` --If you see a message that tells you this method is obsolete, see [microsoft/ApplicationInsights-dotnet#1152](https://github.com/microsoft/ApplicationInsights-dotnet/issues/1152) for more information. --*Visual Basic* --```vb -Private Dim telemetry As New TelemetryClient -``` --*Java* --```java -private TelemetryClient telemetry = new TelemetryClient(); -``` --*Node.js* --```javascript -var telemetry = applicationInsights.defaultClient; -``` --`TelemetryClient` is thread safe. --For ASP.NET and Java projects, incoming HTTP requests are automatically captured. You might want to create more instances of `TelemetryClient` for other modules of your app. For example, you might have one `TelemetryClient` instance in your middleware class to report business logic events. You can set properties such as `UserId` and `DeviceId` to identify the machine. This information is attached to all events that the instance sends. --*C#* --```csharp -TelemetryClient.Context.User.Id = "..."; -TelemetryClient.Context.Device.Id = "..."; -``` --*Java* --```java -telemetry.getContext().getUser().setId("..."); -telemetry.getContext().getDevice().setId("..."); -``` --In Node.js projects, you can use `new applicationInsights.TelemetryClient(instrumentationKey?)` to create a new instance. We recommend this approach only for scenarios that require isolated configuration from the singleton `defaultClient`. --## TrackEvent --In Application Insights, a *custom event* is a data point that you can display in [Metrics Explorer](../essentials/metrics-charts.md) as an aggregated count and in [Diagnostic Search](./transaction-search-and-diagnostics.md?tabs=transaction-search) as individual occurrences. (It isn't related to MVC or other framework "events.") --Insert `TrackEvent` calls in your code to count various events. For example, you might want to track how often users choose a particular feature. Or you might want to know how often they achieve certain goals or make specific types of mistakes. --For example, in a game app, send an event whenever a user wins the game: --*JavaScript* --```javascript -appInsights.trackEvent({name:"WinGame"}); -``` --*C#* --```csharp -telemetry.TrackEvent("WinGame"); -``` --*Visual Basic* --```vb -telemetry.TrackEvent("WinGame") -``` --*Java* --```java -telemetry.trackEvent("WinGame"); -``` --*Node.js* --```javascript -telemetry.trackEvent({name: "WinGame"}); -``` --### Custom events in Log Analytics --The telemetry is available in the `customEvents` table on the [Application Insights Logs tab](../logs/log-query-overview.md) or [usage experience](usage.md). Events might come from `trackEvent(..)` or the [Click Analytics Auto-collection plug-in](javascript-feature-extensions.md). --If [sampling](./sampling.md) is in operation, the `itemCount` property shows a value greater than `1`. For example, `itemCount==10` means that of 10 calls to `trackEvent()`, the sampling process transmitted only one of them. To get a correct count of custom events, use code such as `customEvents | summarize sum(itemCount)`. --> [!NOTE] -> itemCount has a minimum value of one; the record itself represents an entry. --## GetMetric --To learn how to effectively use the `GetMetric()` call to capture locally preaggregated metrics for .NET and .NET Core applications, see [Custom metric collection in .NET and .NET Core](./get-metric.md). --## TrackMetric --> [!NOTE] -> `Microsoft.ApplicationInsights.TelemetryClient.TrackMetric` isn't the preferred method for sending metrics. Metrics should always be preaggregated across a time period before being sent. Use one of the `GetMetric(..)` overloads to get a metric object for accessing SDK pre-aggregation capabilities. -> -> If you're implementing your own pre-aggregation logic, you can use the `TrackMetric()` method to send the resulting aggregates. If your application requires sending a separate telemetry item on every occasion without aggregation across time, you likely have a use case for event telemetry. See `TelemetryClient.TrackEvent -(Microsoft.ApplicationInsights.DataContracts.EventTelemetry)`. --Application Insights can chart metrics that aren't attached to particular events. For example, you could monitor a queue length at regular intervals. With metrics, the individual measurements are of less interest than the variations and trends, and so statistical charts are useful. --To send metrics to Application Insights, you can use the `TrackMetric(..)` API. There are two ways to send a metric: --* **Single value**. Every time you perform a measurement in your application, you send the corresponding value to Application Insights. -- For example, assume you have a metric that describes the number of items in a container. During a particular time period, you first put three items into the container and then you remove two items. Accordingly, you would call `TrackMetric` twice. First, you would pass the value `3` and then pass the value `-2`. Application Insights stores both values for you. --* **Aggregation**. When you work with metrics, every single measurement is rarely of interest. Instead, a summary of what happened during a particular time period is important. Such a summary is called _aggregation_. -- In the preceding example, the aggregate metric sum for that time period is `1` and the count of the metric values is `2`. When you use the aggregation approach, you invoke `TrackMetric` only once per time period and send the aggregate values. We recommend this approach because it can significantly reduce the cost and performance overhead by sending fewer data points to Application Insights, while still collecting all relevant information. --### Single value examples --To send a single metric value: --*JavaScript* --```javascript -appInsights.trackMetric({name: "queueLength", average: 42}); -``` --*C#* --```csharp -var sample = new MetricTelemetry(); -sample.Name = "queueLength"; -sample.Sum = 42.3; -telemetryClient.TrackMetric(sample); -``` --*Java* --```java -telemetry.trackMetric("queueLength", 42.0); -``` --*Node.js* --```javascript -telemetry.trackMetric({name: "queueLength", value: 42.0}); -``` --### Custom metrics in Log Analytics --The telemetry is available in the `customMetrics` table in [Application Insights Analytics](../logs/log-query-overview.md). Each row represents a call to `trackMetric(..)` in your app. --* `valueSum`: The sum of the measurements. To get the mean value, divide by `valueCount`. -* `valueCount`: The number of measurements that were aggregated into this `trackMetric(..)` call. --> [!NOTE] -> valueCount has a minimum value of one; the record itself represents an entry. --## Page views --In a device or webpage app, page view telemetry is sent by default when each screen or page is loaded. But you can change the default to track page views at more or different times. For example, in an app that displays tabs or panes, you might want to track a page whenever the user opens a new pane. --User and session data is sent as properties along with page views, so the user and session charts come alive when there's page view telemetry. --### Custom page views --*JavaScript* --```javascript -appInsights.trackPageView("tab1"); -``` --*C#* --```csharp -telemetry.TrackPageView("GameReviewPage"); -``` --*Visual Basic* --```vb -telemetry.TrackPageView("GameReviewPage") -``` --*Java* --```java -telemetry.trackPageView("GameReviewPage"); -``` --If you have several tabs within different HTML pages, you can specify the URL too: --```javascript -appInsights.trackPageView("tab1", "http://fabrikam.com/page1.htm"); -``` --### Timing page views --By default, the times reported as **Page view load time** are measured from when the browser sends the request until the browser's page load event is called. --Instead, you can either: --* Set an explicit duration in the [trackPageView](https://github.com/microsoft/ApplicationInsights-JS/blob/17ef50442f73fd02a758fbd74134933d92607ecf/legacy/API.md#trackpageview) call: `appInsights.trackPageView("tab1", null, null, null, durationInMilliseconds);`. -* Use the page view timing calls `startTrackPage` and `stopTrackPage`. --*JavaScript* --```javascript -// To start timing a page: -appInsights.startTrackPage("Page1"); --... --// To stop timing and log the page: -appInsights.stopTrackPage("Page1", url, properties, measurements); -``` --The name that you use as the first parameter associates the start and stop calls. It defaults to the current page name. --The resulting page load durations displayed in Metrics Explorer are derived from the interval between the start and stop calls. It's up to you what interval you actually time. --### Page telemetry in Log Analytics --In [Log Analytics](../logs/log-query-overview.md), two tables show data from browser operations: --* `pageViews`: Contains data about the URL and page title. -* `browserTimings`: Contains data about client performance like the time taken to process the incoming data. --To find how long the browser takes to process different pages: --```kusto -browserTimings -| summarize avg(networkDuration), avg(processingDuration), avg(totalDuration) by name -``` --To discover the popularity of different browsers: --```kusto -pageViews -| summarize count() by client_Browser -``` --To associate page views to AJAX calls, join with dependencies: --```kusto -pageViews -| join (dependencies) on operation_Id -``` --## TrackRequest --The server SDK uses `TrackRequest` to log HTTP requests. --You can also call it yourself if you want to simulate requests in a context where you don't have the web service module running. --The recommended way to send request telemetry is where the request acts as an <a href="#operation-context">operation context</a>. --## Operation context --You can correlate telemetry items together by associating them with operation context. The standard request-tracking module does this for exceptions and other events that are sent while an HTTP request is being processed. In [Search](./transaction-search-and-diagnostics.md?tabs=transaction-search) and [Analytics](../logs/log-query-overview.md), you can easily find any events associated with the request by using its operation ID. --For more information on correlation, see [Telemetry correlation in Application Insights](distributed-trace-data.md). --When you track telemetry manually, the easiest way to ensure telemetry correlation is by using this pattern: --*C#* --```csharp -// Establish an operation context and associated telemetry item: -using (var operation = telemetryClient.StartOperation<RequestTelemetry>("operationName")) -{ - // Telemetry sent in here will use the same operation ID. - ... - telemetryClient.TrackTrace(...); // or other Track* calls - ... -- // Set properties of containing telemetry item--for example: - operation.Telemetry.ResponseCode = "200"; -- // Optional: explicitly send telemetry item: - telemetryClient.StopOperation(operation); --} // When operation is disposed, telemetry item is sent. -``` --Along with setting an operation context, `StartOperation` creates a telemetry item of the type that you specify. It sends the telemetry item when you dispose of the operation or if you explicitly call `StopOperation`. If you use `RequestTelemetry` as the telemetry type, its duration is set to the timed interval between start and stop. --Telemetry items reported within a scope of operation become children of such an operation. Operation contexts could be nested. --In **Search**, the operation context is used to create the **Related Items** list. ---For more information on custom operations tracking, see [Track custom operations with Application Insights .NET SDK](./custom-operations-tracking.md). --### Requests in Log Analytics --In [Application Insights Analytics](../logs/log-query-overview.md), requests show up in the `requests` table. --If [sampling](./sampling.md) is in operation, the `itemCount` property shows a value greater than `1`. For example, `itemCount==10` means that of 10 calls to `trackRequest()`, the sampling process transmitted only one of them. To get a correct count of requests and average duration segmented by request names, use code such as: --```kusto -requests -| summarize count = sum(itemCount), avgduration = avg(duration) by name -``` --## TrackException --Send exceptions to Application Insights: --* To [count them](../essentials/metrics-charts.md), as an indication of the frequency of a problem. -* To [examine individual occurrences](./transaction-search-and-diagnostics.md?tabs=transaction-search). --The reports include the stack traces. --*C#* --```csharp -try -{ - ... -} -catch (Exception ex) -{ - telemetry.TrackException(ex); -} -``` --*Java* --```java -try { - ... -} catch (Exception ex) { - telemetry.trackException(ex); -} -``` --*JavaScript* --```javascript -try -{ - ... -} -catch (ex) -{ - appInsights.trackException({exception: ex}); -} -``` --*Node.js* --```javascript -try -{ - ... -} -catch (ex) -{ - telemetry.trackException({exception: ex}); -} -``` --The SDKs catch many exceptions automatically, so you don't always have to call `TrackException` explicitly: --* **ASP.NET**: [Write code to catch exceptions](./asp-net-exceptions.md). -* **Java EE**: [Exceptions are caught automatically](./opentelemetry-enable.md?tabs=java). -* **JavaScript**: Exceptions are caught automatically. If you want to disable automatic collection, add a line to the JavaScript (Web) SDK Loader Script that you insert in your webpages: --```javascript -({ - instrumentationKey: "your key", - disableExceptionTracking: true -}) -``` --### Exceptions in Log Analytics --In [Application Insights Analytics](../logs/log-query-overview.md), exceptions show up in the `exceptions` table. --If [sampling](./sampling.md) is in operation, the `itemCount` property shows a value greater than `1`. For example, `itemCount==10` means that of 10 calls to `trackException()`, the sampling process transmitted only one of them. To get a correct count of exceptions segmented by type of exception, use code such as: --```kusto -exceptions -| summarize sum(itemCount) by type -``` --Most of the important stack information is already extracted into separate variables, but you can pull apart the `details` structure to get more. Because this structure is dynamic, you should cast the result to the type you expect. For example: --```kusto -exceptions -| extend method2 = tostring(details[0].parsedStack[1].method) -``` --To associate exceptions with their related requests, use a join: --```kusto -exceptions -| join (requests) on operation_Id -``` --## TrackTrace --Use `TrackTrace` to help diagnose problems by sending a "breadcrumb trail" to Application Insights. You can send chunks of diagnostic data and inspect them in [Diagnostic Search](./transaction-search-and-diagnostics.md?tabs=transaction-search). --In .NET [Log adapters](./asp-net-trace-logs.md), use this API to send third-party logs to the portal. --In Java, the [Application Insights Java agent](opentelemetry-enable.md?tabs=java) autocollects and sends logs to the portal. --*C#* --```csharp -telemetry.TrackTrace(message, SeverityLevel.Warning, properties); -``` --*Java* --```java -telemetry.trackTrace(message, SeverityLevel.Warning, properties); -``` --*Node.js* --```javascript -telemetry.trackTrace({ - message: message, - severity: applicationInsights.Contracts.SeverityLevel.Warning, - properties: properties -}); -``` --*Client/Browser-side JavaScript* --```javascript -trackTrace({ - message: string, - properties?: {[string]:string}, - severityLevel?: SeverityLevel -}) -``` --Log a diagnostic event such as entering or leaving a method. -- Parameter | Description -| -`message` | Diagnostic data. Can be much longer than a name. -`properties` | Map of string to string. More data is used to [filter exceptions](#properties) in the portal. Defaults to empty. -`severityLevel` | Supported values: [SeverityLevel.ts](https://github.com/microsoft/ApplicationInsights-JS/blob/17ef50442f73fd02a758fbd74134933d92607ecf/shared/AppInsightsCommon/src/Interfaces/Contracts/Generated/SeverityLevel.ts). --You can search on message content, but unlike property values, you can't filter on it. --The size limit on `message` is much higher than the limit on properties. An advantage of `TrackTrace` is that you can put relatively long data in the message. For example, you can encode POST data there. --You can also add a severity level to your message. And, like other telemetry, you can add property values to help you filter or search for different sets of traces. For example: --*C#* --```csharp -var telemetry = new Microsoft.ApplicationInsights.TelemetryClient(); -telemetry.TrackTrace("Slow database response", - SeverityLevel.Warning, - new Dictionary<string,string> { {"database", db.ID} }); -``` --*Java* --```java -Map<String, Integer> properties = new HashMap<>(); -properties.put("Database", db.ID); -telemetry.trackTrace("Slow Database response", SeverityLevel.Warning, properties); -``` --In [Search](./transaction-search-and-diagnostics.md?tabs=transaction-search), you can then easily filter out all the messages of a particular severity level that relate to a particular database. --### Traces in Log Analytics --In [Application Insights Analytics](../logs/log-query-overview.md), calls to `TrackTrace` show up in the `traces` table. --If [sampling](./sampling.md) is in operation, the `itemCount` property shows a value greater than `1`. For example, `itemCount==10` means that of 10 calls to `trackTrace()`, the sampling process transmitted only one of them. To get a correct count of trace calls, use code such as `traces | summarize sum(itemCount)`. --## TrackDependency --Use the `TrackDependency` call to track the response times and success rates of calls to an external piece of code. The results appear in the dependency charts in the portal. The following code snippet must be added wherever a dependency call is made. --> [!NOTE] -> For .NET and .NET Core, you can alternatively use the `TelemetryClient.StartOperation` (extension) method that fills the `DependencyTelemetry` properties that are needed for correlation and some other properties like the start time and duration, so you don't need to create a custom timer as with the following examples. For more information, see the section on outgoing dependency tracking in [Track custom operations with Application Insights .NET SDK](./custom-operations-tracking.md#outgoing-dependencies-tracking). --*C#* --```csharp -var success = false; -var startTime = DateTime.UtcNow; -var timer = System.Diagnostics.Stopwatch.StartNew(); -try -{ - success = dependency.Call(); -} -catch(Exception ex) -{ - success = false; - telemetry.TrackException(ex); - throw new Exception("Operation went wrong", ex); -} -finally -{ - timer.Stop(); - telemetry.TrackDependency("DependencyType", "myDependency", "myCall", startTime, timer.Elapsed, success); -} -``` --*Java* --```java -boolean success = false; -Instant startTime = Instant.now(); -try { - success = dependency.call(); -} -finally { - Instant endTime = Instant.now(); - Duration delta = Duration.between(startTime, endTime); - RemoteDependencyTelemetry dependencyTelemetry = new RemoteDependencyTelemetry("My Dependency", "myCall", delta, success); - dependencyTelemetry.setTimeStamp(startTime); - telemetry.trackDependency(dependencyTelemetry); -} -``` --*Node.js* --```javascript -var success = false; -var startTime = new Date().getTime(); -try -{ - success = dependency.Call(); -} -finally -{ - var elapsed = new Date() - startTime; - telemetry.trackDependency({ - dependencyTypeName: "myDependency", - name: "myCall", - duration: elapsed, - success: success - }); -} -``` --Remember that the server SDKs include a [dependency module](./asp-net-dependencies.md) that discovers and tracks certain dependency calls automatically, for example, to databases and REST APIs. You have to install an agent on your server to make the module work. --In Java, many dependency calls can be automatically tracked by using the -[Application Insights Java agent](opentelemetry-enable.md?tabs=java). --You use this call if you want to track calls that the automated tracking doesn't catch. --To turn off the standard dependency-tracking module in C#, edit [ApplicationInsights.config](./configuration-with-applicationinsights-config.md) and delete the reference to `DependencyCollector.DependencyTrackingTelemetryModule`. For Java, see -[Suppressing specific autocollected telemetry](./java-standalone-config.md#suppress-specific-autocollected-telemetry). --### Dependencies in Log Analytics --In [Application Insights Analytics](../logs/log-query-overview.md), `trackDependency` calls show up in the `dependencies` table. --If [sampling](./sampling.md) is in operation, the `itemCount` property shows a value greater than 1. For example, `itemCount==10` means that of 10 calls to `trackDependency()`, the sampling process transmitted only one of them. To get a correct count of dependencies segmented by target component, use code such as: --```kusto -dependencies -| summarize sum(itemCount) by target -``` --To associate dependencies with their related requests, use a join: --```kusto -dependencies -| join (requests) on operation_Id -``` --## Flushing data --Normally, the SDK sends data at fixed intervals, typically 30 seconds, or whenever the buffer is full, which is typically 500 items. In some cases, you might want to flush the buffer. An example is if you're using the SDK in an application that shuts down. --*.NET* --When you use `Flush()`, we recommend this [pattern](./console.md#full-example): --```csharp -telemetry.Flush(); -// Allow some time for flushing before shutdown. -System.Threading.Thread.Sleep(5000); -``` --When you use `FlushAsync()`, we recommend this pattern: --```csharp -await telemetryClient.FlushAsync() -// No need to sleep -``` --We recommend always flushing as part of the application shutdown to guarantee that telemetry isn't lost. --*Java* --```java -telemetry.flush(); -//Allow some time for flushing before shutting down -Thread.sleep(5000); -``` --*Node.js* --```javascript -telemetry.flush(); -``` --The function is asynchronous for the [server telemetry channel](https://www.nuget.org/packages/Microsoft.ApplicationInsights.WindowsServer.TelemetryChannel/). --> [!NOTE] -> - The Java and JavaScript SDKs automatically flush on application shutdown. -> - **Review Autoflush configuration**: [Enabling autoflush](/dotnet/api/system.diagnostics.trace.autoflush) in your `web.config` file can lead to performance degradation in .NET applications instrumented with Application Insights. With autoflush enabled, every invocation of `System.Diagnostics.Trace.Trace*` methods results in individual telemetry items being sent as separate distinct web requests to the ingestion service. This can potentially cause network and storage exhaustion on your web servers. For enhanced performance, itΓÇÖs recommended to disable autoflush and also, utilize the [ServerTelemetryChannel](/azure/azure-monitor/app/telemetry-channels#built-in-telemetry-channels), designed for a more effective telemetry data transmission. --## Authenticated users --In a web app, users are [identified by cookies](./usage.md#users-sessions-and-eventsanalyze-telemetry-from-three-perspectives) by default. A user might be counted more than once if they access your app from a different machine or browser, or if they delete cookies. --If users sign in to your app, you can get a more accurate count by setting the authenticated user ID in the browser code: --*JavaScript* --```javascript -// Called when my app has identified the user. -function Authenticated(signInId) { - var validatedId = signInId.replace(/[,;=| ]+/g, "_"); - appInsights.setAuthenticatedUserContext(validatedId); - ... -} -``` --In an ASP.NET web MVC application, for example: --*Razor* --```cshtml -@if (Request.IsAuthenticated) -{ - <script> - appInsights.setAuthenticatedUserContext("@User.Identity.Name - .Replace("\\", "\\\\")" - .replace(/[,;=| ]+/g, "_")); - </script> -} -``` --It isn't necessary to use the user's actual sign-in name. It only has to be an ID that is unique to that user. It must not include spaces or any of the characters `,;=|`. --The user ID is also set in a session cookie and sent to the server. If the server SDK is installed, the authenticated user ID is sent as part of the context properties of both client and server telemetry. You can then filter and search on it. --If your app groups users into accounts, you can also pass an identifier for the account. The same character restrictions apply. --```javascript -appInsights.setAuthenticatedUserContext(validatedId, accountId); -``` --In [Metrics Explorer](../essentials/metrics-charts.md), you can create a chart that counts **Users, Authenticated**, and **User accounts**. --You can also [search](./transaction-search-and-diagnostics.md?tabs=transaction-search) for client data points with specific user names and accounts. --> [!NOTE] -> The [EnableAuthenticationTrackingJavaScript property in the ApplicationInsightsServiceOptions class](https://github.com/microsoft/ApplicationInsights-dotnet/blob/develop/NETCORE/src/Shared/Extensions/ApplicationInsightsServiceOptions.cs) in the .NET Core SDK simplifies the JavaScript configuration needed to inject the user name as the Auth ID for each trace sent by the Application Insights JavaScript SDK. -> ->When this property is set to `true`, the user name from the user in the ASP.NET Core is printed along with [client-side telemetry](asp-net-core.md#enable-client-side-telemetry-for-web-applications). For this reason, adding `appInsights.setAuthenticatedUserContext` manually wouldn't be needed anymore because it's already injected by the SDK for ASP.NET Core. The Auth ID will also be sent to the server where the SDK in .NET Core will identify it and use it for any server-side telemetry, as described in the [JavaScript API reference](https://github.com/microsoft/ApplicationInsights-JS/blob/master/API-reference.md#setauthenticatedusercontext). -> ->For JavaScript applications that don't work in the same way as ASP.NET Core MVC, such as SPA web apps, you would still need to add `appInsights.setAuthenticatedUserContext` manually. --## <a name="properties"></a>Filter, search, and segment your data by using properties --You can attach properties and measurements to your events, metrics, page views, exceptions, and other telemetry data. --*Properties* are string values that you can use to filter your telemetry in the usage reports. For example, if your app provides several games, you can attach the name of the game to each event so that you can see which games are more popular. --There's a limit of 8,192 on the string length. If you want to send large chunks of data, use the message parameter of `TrackTrace`. --*Metrics* are numeric values that can be presented graphically. For example, you might want to see if there's a gradual increase in the scores that your gamers achieve. The graphs can be segmented by the properties that are sent with the event so that you can get separate or stacked graphs for different games. --Metric values should be greater than or equal to 0 to display correctly. --There are some [limits on the number of properties, property values, and metrics](#limits) that you can use. --*JavaScript* --```javascript -appInsights.trackEvent({ - name: 'some event', - properties: { // accepts any type - prop1: 'string', - prop2: 123.45, - prop3: { nested: 'objects are okay too' } - } -}); --appInsights.trackPageView({ - name: 'some page', - properties: { // accepts any type - prop1: 'string', - prop2: 123.45, - prop3: { nested: 'objects are okay too' } - } -}); -``` --*C#* --```csharp -// Set up some properties and metrics: -var properties = new Dictionary <string, string> - {{"game", currentGame.Name}, {"difficulty", currentGame.Difficulty}}; -var metrics = new Dictionary <string, double> - {{"Score", currentGame.Score}, {"Opponents", currentGame.OpponentCount}}; --// Send the event: -telemetry.TrackEvent("WinGame", properties, metrics); -``` --*Node.js* --```javascript -// Set up some properties and metrics: -var properties = {"game": currentGame.Name, "difficulty": currentGame.Difficulty}; -var metrics = {"Score": currentGame.Score, "Opponents": currentGame.OpponentCount}; --// Send the event: -telemetry.trackEvent({name: "WinGame", properties: properties, measurements: metrics}); -``` --*Visual Basic* --```vb -' Set up some properties: -Dim properties = New Dictionary (Of String, String) -properties.Add("game", currentGame.Name) -properties.Add("difficulty", currentGame.Difficulty) --Dim metrics = New Dictionary (Of String, Double) -metrics.Add("Score", currentGame.Score) -metrics.Add("Opponents", currentGame.OpponentCount) --' Send the event: -telemetry.TrackEvent("WinGame", properties, metrics) -``` --*Java* --```java -Map<String, String> properties = new HashMap<String, String>(); -properties.put("game", currentGame.getName()); -properties.put("difficulty", currentGame.getDifficulty()); --Map<String, Double> metrics = new HashMap<String, Double>(); -metrics.put("Score", currentGame.getScore()); -metrics.put("Opponents", currentGame.getOpponentCount()); --telemetry.trackEvent("WinGame", properties, metrics); -``` --> [!NOTE] -> Make sure you don't log personally identifiable information in properties. --### Alternative way to set properties and metrics --If it's more convenient, you can collect the parameters of an event in a separate object: --```csharp -var event = new EventTelemetry(); --event.Name = "WinGame"; -event.Metrics["processingTime"] = stopwatch.Elapsed.TotalMilliseconds; -event.Properties["game"] = currentGame.Name; -event.Properties["difficulty"] = currentGame.Difficulty; -event.Metrics["Score"] = currentGame.Score; -event.Metrics["Opponents"] = currentGame.Opponents.Length; --telemetry.TrackEvent(event); -``` --> [!WARNING] -> Don't reuse the same telemetry item instance (`event` in this example) to call `Track*()` multiple times. This practice might cause telemetry to be sent with incorrect configuration. --### Custom measurements and properties in Log Analytics --In [Log Analytics](../logs/log-query-overview.md), custom metrics and properties show in the `customMeasurements` and `customDimensions` attributes of each telemetry record. --For example, if you add a property named "game" to your request telemetry, this query counts the occurrences of different values of "game" and shows the average of the custom metric "score": --```kusto -requests -| summarize sum(itemCount), avg(todouble(customMeasurements.score)) by tostring(customDimensions.game) -``` --Notice that: --* When you extract a value from the `customDimensions` or `customMeasurements` JSON, it has dynamic type, so you must cast it `tostring` or `todouble`. -* To take account of the possibility of [sampling](./sampling.md), use `sum(itemCount)` not `count()`. --## <a name="timed"></a> Timing events --Sometimes you want to chart how long it takes to perform an action. For example, you might want to know how long users take to consider choices in a game. To obtain this information, use the measurement parameter. --*C#* --```csharp -var stopwatch = System.Diagnostics.Stopwatch.StartNew(); --// ... perform the timed action ... --stopwatch.Stop(); --var metrics = new Dictionary <string, double> - {{"processingTime", stopwatch.Elapsed.TotalMilliseconds}}; --// Set up some properties: -var properties = new Dictionary <string, string> - {{"signalSource", currentSignalSource.Name}}; --// Send the event: -telemetry.TrackEvent("SignalProcessed", properties, metrics); -``` --*Java* --```java -long startTime = System.currentTimeMillis(); --// Perform timed action --long endTime = System.currentTimeMillis(); -Map<String, Double> metrics = new HashMap<>(); -metrics.put("ProcessingTime", (double)endTime-startTime); --// Setup some properties -Map<String, String> properties = new HashMap<>(); -properties.put("signalSource", currentSignalSource.getName()); --// Send the event -telemetry.trackEvent("SignalProcessed", properties, metrics); -``` --## <a name="defaults"></a>Default properties for custom telemetry --If you want to set default property values for some of the custom events that you write, set them in a `TelemetryClient` instance. They're attached to every telemetry item that's sent from that client. --*C#* --```csharp -using Microsoft.ApplicationInsights.DataContracts; --var gameTelemetry = new TelemetryClient(); -gameTelemetry.Context.GlobalProperties["Game"] = currentGame.Name; -// Now all telemetry will automatically be sent with the context property: -gameTelemetry.TrackEvent("WinGame"); -``` --*Visual Basic* --```vb -Dim gameTelemetry = New TelemetryClient() -gameTelemetry.Context.GlobalProperties("Game") = currentGame.Name -' Now all telemetry will automatically be sent with the context property: -gameTelemetry.TrackEvent("WinGame") -``` --*Java* --```java -import com.microsoft.applicationinsights.TelemetryClient; -import com.microsoft.applicationinsights.TelemetryContext; -... --TelemetryClient gameTelemetry = new TelemetryClient(); -TelemetryContext context = gameTelemetry.getContext(); -context.getProperties().put("Game", currentGame.Name); --gameTelemetry.TrackEvent("WinGame"); -``` --*Node.js* --```javascript -var gameTelemetry = new applicationInsights.TelemetryClient(); -gameTelemetry.commonProperties["Game"] = currentGame.Name; --gameTelemetry.TrackEvent({name: "WinGame"}); -``` --Individual telemetry calls can override the default values in their property dictionaries. --*For JavaScript web clients*, use JavaScript telemetry initializers. --*To add properties to all telemetry*, including the data from standard collection modules, [implement `ITelemetryInitializer`](./api-filtering-sampling.md#add-properties). --## Sample, filter, and process telemetry --See [Filter and preprocess telemetry in the Application Insights SDK](./api-filtering-sampling.md). --## Disable telemetry --To *dynamically stop and start* the collection and transmission of telemetry: --*C#* --```csharp -using Microsoft.ApplicationInsights.Extensibility; --TelemetryConfiguration.Active.DisableTelemetry = true; -``` --*Java* --```java -telemetry.getConfiguration().setTrackingDisabled(true); -``` --To *disable selected standard collectors*, for example, performance counters, HTTP requests, or dependencies, delete or comment out the relevant lines in [ApplicationInsights.config](./configuration-with-applicationinsights-config.md). An example is if you want to send your own `TrackRequest` data. --*Node.js* --```javascript -telemetry.config.disableAppInsights = true; -``` --To *disable selected standard collectors*, for example, performance counters, HTTP requests, or dependencies, at initialization time, chain configuration methods to your SDK initialization code. --```javascript -applicationInsights.setup() - .setAutoCollectRequests(false) - .setAutoCollectPerformance(false) - .setAutoCollectExceptions(false) - .setAutoCollectDependencies(false) - .setAutoCollectConsole(false) - .start(); -``` --To disable these collectors after initialization, use the Configuration object: `applicationInsights.Configuration.setAutoCollectRequests(false)`. --## <a name="debug"></a>Developer mode --During debugging, it's useful to have your telemetry expedited through the pipeline so that you can see results immediately. You also get other messages that help you trace any problems with the telemetry. Switch it off in production because it might slow down your app. --*C#* --```csharp -TelemetryConfiguration.Active.TelemetryChannel.DeveloperMode = true; -``` --*Visual Basic* --```vb -TelemetryConfiguration.Active.TelemetryChannel.DeveloperMode = True -``` --*Node.js* --For Node.js, you can enable developer mode by enabling internal logging via `setInternalLogging` and setting `maxBatchSize` to `0`, which causes your telemetry to be sent as soon as it's collected. --```js -applicationInsights.setup("ikey") - .setInternalLogging(true, true) - .start() -applicationInsights.defaultClient.config.maxBatchSize = 0; -``` --## <a name="ikey"></a> Set the instrumentation key for selected custom telemetry --*C#* --```csharp -var telemetry = new TelemetryClient(); -telemetry.InstrumentationKey = "my key"; -// ... -``` --## <a name="dynamic-ikey"></a> Dynamic instrumentation key --To avoid mixing up telemetry from development, test, and production environments, you can [create separate Application Insights resources](./create-workspace-resource.md) and change their keys, depending on the environment. --Instead of getting the instrumentation key from the configuration file, you can set it in your code. Set the key in an initialization method, such as `global.aspx.cs` in an ASP.NET service: --*C#* --```csharp -protected void Application_Start() -{ - Microsoft.ApplicationInsights.Extensibility. - TelemetryConfiguration.Active.InstrumentationKey = - // - for example - - WebConfigurationManager.Settings["ikey"]; - ... -} -``` --*JavaScript* --```javascript -appInsights.config.instrumentationKey = myKey; -``` --In webpages, you might want to set it from the web server's state instead of coding it literally into the script. For example, in a webpage generated in an ASP.NET app: --*JavaScript in Razor* --```cshtml -<script type="text/javascript"> -// Standard Application Insights webpage script: -var appInsights = window.appInsights || function(config){ ... -// Modify this part: -}({instrumentationKey: - // Generate from server property: - @Microsoft.ApplicationInsights.Extensibility. - TelemetryConfiguration.Active.InstrumentationKey; -}) // ... -``` --```java - String instrumentationKey = "00000000-0000-0000-0000-000000000000"; -- if (instrumentationKey != null) - { - TelemetryConfiguration.getActive().setInstrumentationKey(instrumentationKey); - } -``` --## TelemetryContext --`TelemetryClient` has a Context property, which contains values that are sent along with all telemetry data. They're normally set by the standard telemetry modules, but you can also set them yourself. For example: --```csharp -telemetry.Context.Operation.Name = "MyOperationName"; -``` --If you set any of these values yourself, consider removing the relevant line from [ApplicationInsights.config](./configuration-with-applicationinsights-config.md) so that your values and the standard values don't get confused. --* **Component**: The app and its version. -* **Device**: Data about the device where the app is running. In web apps, it's the server or client device that the telemetry is sent from. -* **InstrumentationKey**: The Application Insights resource in Azure where the telemetry appears. It's usually picked up from `ApplicationInsights.config`. -* **Location**: The geographic location of the device. -* **Operation**: In web apps, the current HTTP request. In other app types, you can set this value to group events together. - * **ID**: A generated value that correlates different events so that when you inspect any event in Diagnostic Search, you can find related items. - * **Name**: An identifier, usually the URL of the HTTP request. - * **SyntheticSource**: If not null or empty, a string that indicates that the source of the request has been identified as a robot or web test. By default, it's excluded from calculations in Metrics Explorer. -* **Session**: The user's session. The ID is set to a generated value, which is changed when the user hasn't been active for a while. -* **User**: User information. --## Limits ---To avoid hitting the data rate limit, use [sampling](./sampling.md). --To determine how long data is kept, see [Data retention and privacy](/previous-versions/azure/azure-monitor/app/data-retention-privacy). --## Reference docs --* [.NET reference](/dotnet/api/overview/azure/insights) -* [Java reference](/java/api/overview/azure/appinsights) -* [JavaScript reference](https://github.com/Microsoft/ApplicationInsights-JS/blob/master/API-reference.md) --## SDK code --* [.NET](https://github.com/Microsoft/ApplicationInsights-dotnet) -* [Windows Server packages](https://github.com/Microsoft/ApplicationInsights-dotnet) -* [Java SDK](https://github.com/Microsoft/ApplicationInsights-Java) -* [Node.js SDK](https://github.com/Microsoft/ApplicationInsights-Node.js) -* [JavaScript SDK](https://github.com/Microsoft/ApplicationInsights-JS) --## Frequently asked questions --This section provides answers to common questions. --### Why am I missing telemetry data? --Both [TelemetryChannels](telemetry-channels.md#what-are-telemetry-channels) will lose buffered telemetry if it isn't flushed before an application shuts down. --To avoid data loss, flush the TelemetryClient when an application is shutting down. --For more information, see [Flushing data](#flushing-data). --### What exceptions might `Track_()` calls throw? --None. You don't need to wrap them in try-catch clauses. If the SDK encounters problems, it will log messages in the debug console output and, if the messages get through, in Diagnostic Search. --### Is there a REST API to get data from the portal? --Yes, the [data access API](/rest/api/application-insights/). Other ways to extract data include [Power BI](..\logs\log-powerbi.md) if you've [migrated to a workspace-based resource](convert-classic-resource.md) or [continuous export](./export-telemetry.md) if you're still on a classic resource. --### Why are my calls to custom events and metrics APIs ignored? --The Application Insights SDK isn't compatible with autoinstrumentation. If autoinstrumentation is enabled, calls to <code class="notranslate">Track()</code> and other custom events and metrics APIs will be ignored. --Turn off autoinstrumentation in the Azure portal on the Application Insights tab of the App Service page or set <code class="notranslate">ApplicationInsightsAgent_EXTENSION_VERSION</code> to <code class="notranslate">disabled</code>. --### Why are the counts in Search and Metrics charts unequal? --[Sampling](./sampling.md) reduces the number of telemetry items (like requests and custom events) that are sent from your app to the portal. In Search, you see the number of items received. In metric charts that display a count of events, you see the number of original events that occurred. - -Each item that's transmitted carries an `itemCount` property that shows how many original events that item represents. To observe sampling in operation, you can run this query in Log Analytics: - -``` - requests | summarize original_events = sum(itemCount), transmitted_events = count() -``` --### How can I set an alert on an event? --Azure alerts are only on metrics. Create a custom metric that crosses a value threshold whenever your event occurs. Then set an alert on the metric. You get a notification whenever the metric crosses the threshold in either direction. You won't get a notification until the first crossing, no matter whether the initial value is high or low. There's always a latency of a few minutes. ---## <a name="next"></a>Next steps --* [Search events and logs](./transaction-search-and-diagnostics.md?tabs=transaction-search) |
| azure-monitor | Api Filtering Sampling | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/api-filtering-sampling.md | - Title: Filtering and preprocessing in the Application Insights SDK | Microsoft Docs -description: Write telemetry processors and telemetry initializers for the SDK to filter or add properties to the data before the telemetry is sent to the Application Insights portal. - Previously updated : 11/15/2023-# ms.devlang: csharp, javascript, python -----# Filter and preprocess telemetry in the Application Insights SDK --You can write code to filter, modify, or enrich your telemetry before it's sent from the SDK. The processing includes data that's sent from the standard telemetry modules, such as HTTP request collection and dependency collection. --* [Filtering](./api-filtering-sampling.md#filtering) can modify or discard telemetry before it's sent from the SDK by implementing `ITelemetryProcessor`. For example, you could reduce the volume of telemetry by excluding requests from robots. Unlike sampling, You have full control over what is sent or discarded, but it affects any metrics based on aggregated logs. Depending on how you discard items, you might also lose the ability to navigate between related items. --* [Add or Modify properties](./api-filtering-sampling.md#add-properties) to any telemetry sent from your app by implementing an `ITelemetryInitializer`. For example, you could add calculated values or version numbers by which to filter the data in the portal. --* [Sampling](sampling.md) reduces the volume of telemetry without affecting your statistics. It keeps together related data points so that you can navigate between them when you diagnose a problem. In the portal, the total counts are multiplied to compensate for the sampling. --> [!NOTE] -> [The SDK API](./api-custom-events-metrics.md) is used to send custom events and metrics. --## Prerequisites --Install the appropriate SDK for your application: [ASP.NET](asp-net.md), [ASP.NET Core](asp-net-core.md), [Non-HTTP/Worker for .NET/.NET Core](worker-service.md), or [JavaScript](javascript.md). --## Filtering --This technique gives you direct control over what's included or excluded from the telemetry stream. Filtering can be used to drop telemetry items from being sent to Application Insights. You can use filtering with sampling, or separately. --To filter telemetry, you write a telemetry processor and register it with `TelemetryConfiguration`. All telemetry goes through your processor. You can choose to drop it from the stream or give it to the next processor in the chain. Telemetry from the standard modules, such as the HTTP request collector and the dependency collector, and telemetry you tracked yourself is included. For example, you can filter out telemetry about requests from robots or successful dependency calls. --> [!WARNING] -> Filtering the telemetry sent from the SDK by using processors can skew the statistics that you see in the portal and make it difficult to follow related items. -> -> Instead, consider using [sampling](./sampling.md). --### .NET applications --1. Implement `ITelemetryProcessor`. -- Telemetry processors construct a chain of processing. When you instantiate a telemetry processor, you're given a reference to the next processor in the chain. When a telemetry data point is passed to the process method, it does its work and then calls (or doesn't call) the next telemetry processor in the chain. -- ```csharp - using Microsoft.ApplicationInsights.Channel; - using Microsoft.ApplicationInsights.Extensibility; - using Microsoft.ApplicationInsights.DataContracts; -- public class SuccessfulDependencyFilter : ITelemetryProcessor - { - private ITelemetryProcessor Next { get; set; } -- // next will point to the next TelemetryProcessor in the chain. - public SuccessfulDependencyFilter(ITelemetryProcessor next) - { - this.Next = next; - } -- public void Process(ITelemetry item) - { - // To filter out an item, return without calling the next processor. - if (!OKtoSend(item)) { return; } -- this.Next.Process(item); - } -- // Example: replace with your own criteria. - private bool OKtoSend (ITelemetry item) - { - var dependency = item as DependencyTelemetry; - if (dependency == null) return true; -- return dependency.Success != true; - } - } - ``` --2. Add your processor. -- #### [ASP.NET](#tab/dotnet) - - Insert this snippet in ApplicationInsights.config: - - ```xml - <TelemetryProcessors> - <Add Type="WebApplication9.SuccessfulDependencyFilter, WebApplication9"> - <!-- Set public property --> - <MyParamFromConfigFile>2-beta</MyParamFromConfigFile> - </Add> - </TelemetryProcessors> - ``` - - You can pass string values from the .config file by providing public named properties in your class. - - > [!WARNING] - > Take care to match the type name and any property names in the .config file to the class and property names in the code. If the .config file references a nonexistent type or property, the SDK may silently fail to send any telemetry. - > - - Alternatively, you can initialize the filter in code. In a suitable initialization class, for example, AppStart in `Global.asax.cs`, insert your processor into the chain: - - ```csharp - var builder = TelemetryConfiguration.Active.DefaultTelemetrySink.TelemetryProcessorChainBuilder; - builder.Use((next) => new SuccessfulDependencyFilter(next)); - - // If you have more processors: - builder.Use((next) => new AnotherProcessor(next)); - - builder.Build(); - ``` - - Telemetry clients created after this point use your processors. -- #### [ASP.NET Core/Worker service](#tab/dotnetcore) - - > [!NOTE] - > Adding a processor by using `ApplicationInsights.config` or `TelemetryConfiguration.Active` isn't valid for ASP.NET Core applications or if you're using the Microsoft.ApplicationInsights.WorkerService SDK. - - For apps written by using [ASP.NET Core](asp-net-core.md#add-telemetry-processors) or [WorkerService](worker-service.md#add-telemetry-processors), adding a new telemetry processor is done by using the `AddApplicationInsightsTelemetryProcessor` extension method on `IServiceCollection`, as shown. This method is called in the `ConfigureServices` method of your `Startup.cs` class. - - ```csharp - public void ConfigureServices(IServiceCollection services) - { - // ... - services.AddApplicationInsightsTelemetry(); - services.AddApplicationInsightsTelemetryProcessor<SuccessfulDependencyFilter>(); - - // If you have more processors: - services.AddApplicationInsightsTelemetryProcessor<AnotherProcessor>(); - } - ``` - - To register telemetry processors that need parameters in ASP.NET Core, create a custom class implementing **ITelemetryProcessorFactory**. Call the constructor with the desired parameters in the **Create** method and then use **AddSingleton<ITelemetryProcessorFactory, MyTelemetryProcessorFactory>()**. -- - -### Example filters --#### Synthetic requests --Filter out bots and web tests. Although Metrics Explorer gives you the option to filter out synthetic sources, this option reduces traffic and ingestion size by filtering them at the SDK itself. --```csharp -public void Process(ITelemetry item) -{ - if (!string.IsNullOrEmpty(item.Context.Operation.SyntheticSource)) {return;} - - // Send everything else: - this.Next.Process(item); -} -``` --#### Failed authentication --Filter out requests with a "401" response. --```csharp -public void Process(ITelemetry item) -{ - var request = item as RequestTelemetry; -- if (request != null && - request.ResponseCode.Equals("401", StringComparison.OrdinalIgnoreCase)) - { - // To filter out an item, return without calling the next processor. - return; - } -- // Send everything else - this.Next.Process(item); -} -``` --#### Filter out fast remote dependency calls --If you want to diagnose only calls that are slow, filter out the fast ones. --> [!NOTE] -> This filtering will skew the statistics you see on the portal. -> -> --```csharp -public void Process(ITelemetry item) -{ - var request = item as DependencyTelemetry; -- if (request != null && request.Duration.TotalMilliseconds < 100) - { - return; - } - this.Next.Process(item); -} -``` --#### Diagnose dependency issues --[This blog](https://azure.microsoft.com/blog/implement-an-application-insights-telemetry-processor/) describes a project to diagnose dependency issues by automatically sending regular pings to dependencies. --<a name="add-properties"></a> --### Java applications --To learn more about telemetry processors and their implementation in Java, reference the [Java telemetry processors documentation](./java-standalone-telemetry-processors.md). --### JavaScript web applications --You can filter telemetry from JavaScript web applications by using ITelemetryInitializer. --1. Create a telemetry initializer callback function. The callback function takes `ITelemetryItem` as a parameter, which is the event that's being processed. Returning `false` from this callback results in the telemetry item to be filtered out. -- ```js - var filteringFunction = (envelope) => { - if (envelope.data.someField === 'tobefilteredout') { - return false; - } - return true; - }; - ``` --2. Add your telemetry initializer callback: -- ```js - appInsights.addTelemetryInitializer(filteringFunction); - ``` --## Add/modify properties: ITelemetryInitializer --Use telemetry initializers to enrich telemetry with additional information or to override telemetry properties set by the standard telemetry modules. --For example, Application Insights for a web package collects telemetry about HTTP requests. By default, it flags any request with a response code >=400 as failed. If instead you want to treat 400 as a success, you can provide a telemetry initializer that sets the success property. --If you provide a telemetry initializer, it's called whenever any of the Track*() methods are called. This initializer includes `Track()` methods called by the standard telemetry modules. By convention, these modules don't set any property that was already set by an initializer. Telemetry initializers are called before calling telemetry processors, so any enrichments done by initializers are visible to processors. --### .NET applications --1. Define your initializer -- ```csharp - using System; - using Microsoft.ApplicationInsights.Channel; - using Microsoft.ApplicationInsights.DataContracts; - using Microsoft.ApplicationInsights.Extensibility; - - namespace MvcWebRole.Telemetry - { - /* - * Custom TelemetryInitializer that overrides the default SDK - * behavior of treating response codes >= 400 as failed requests - * - */ - public class MyTelemetryInitializer : ITelemetryInitializer - { - public void Initialize(ITelemetry telemetry) - { - var requestTelemetry = telemetry as RequestTelemetry; - // Is this a TrackRequest() ? - if (requestTelemetry == null) return; - int code; - bool parsed = Int32.TryParse(requestTelemetry.ResponseCode, out code); - if (!parsed) return; - if (code >= 400 && code < 500) - { - // If we set the Success property, the SDK won't change it: - requestTelemetry.Success = true; - - // Allow us to filter these requests in the portal: - requestTelemetry.Properties["Overridden400s"] = "true"; - } - // else leave the SDK to set the Success property - } - } - } - ``` --2. Load your initializer -- #### [ASP.NET](#tab/dotnet) - - In ApplicationInsights.config: - - ```xml - <ApplicationInsights> - <TelemetryInitializers> - <!-- Fully qualified type name, assembly name: --> - <Add Type="MvcWebRole.Telemetry.MyTelemetryInitializer, MvcWebRole"/> - ... - </TelemetryInitializers> - </ApplicationInsights> - ``` - - Alternatively, you can instantiate the initializer in code, for example, in Global.aspx.cs: - - ```csharp - protected void Application_Start() - { - // ... - TelemetryConfiguration.Active.TelemetryInitializers.Add(new MyTelemetryInitializer()); - } - ``` - - See more of [this sample](https://github.com/MohanGsk/ApplicationInsights-Home/tree/master/Samples/AzureEmailService/MvcWebRole). - - #### [ASP.NET Core/Worker service](#tab/dotnetcore) - - > [!NOTE] - > Adding an initializer by using `ApplicationInsights.config` or `TelemetryConfiguration.Active` isn't valid for ASP.NET Core applications or if you're using the Microsoft.ApplicationInsights.WorkerService SDK. - - For apps written using [ASP.NET Core](asp-net-core.md#add-telemetryinitializers) or [WorkerService](worker-service.md#add-telemetry-initializers), adding a new telemetry initializer is done by adding it to the Dependency Injection container, as shown. Accomplish this step in the `Startup.ConfigureServices` method. - - ```csharp - using Microsoft.ApplicationInsights.Extensibility; - using CustomInitializer.Telemetry; - public void ConfigureServices(IServiceCollection services) - { - services.AddSingleton<ITelemetryInitializer, MyTelemetryInitializer>(); - } - ``` - - --### JavaScript telemetry initializers --Insert a JavaScript telemetry initializer, if needed. For more information on the telemetry initializers for the Application Insights JavaScript SDK, see [Telemetry initializers](https://github.com/microsoft/ApplicationInsights-JS#telemetry-initializers). --#### [JavaScript (Web) SDK Loader Script](#tab/javascriptwebsdkloaderscript) --Insert a telemetry initializer by adding the onInit callback function in the [JavaScript (Web) SDK Loader Script configuration](./javascript-sdk.md?tabs=javascriptwebsdkloaderscript#javascript-web-sdk-loader-script-configuration): -<!-- IMPORTANT: If you're updating this code example, please remember to also update it in: 1) articles\azure-monitor\app\javascript-sdk.md and 2) articles\azure-monitor\app\javascript-feature-extensions.md --> -```html -<script type="text/javascript"> -!(function (cfg){function e(){cfg.onInit&&cfg.onInit(n)}var x,w,D,t,E,n,C=window,O=document,b=C.location,q="script",I="ingestionendpoint",L="disableExceptionTracking",j="ai.device.";"instrumentationKey"[x="toLowerCase"](),w="crossOrigin",D="POST",t="appInsightsSDK",E=cfg.name||"appInsights",(cfg.name||C[t])&&(C[t]=E),n=C[E]||function(g){var f=!1,m=!1,h={initialize:!0,queue:[],sv:"8",version:2,config:g};function v(e,t){var n={},i="Browser";function a(e){e=""+e;return 1===e.length?"0"+e:e}return n[j+"id"]=i[x](),n[j+"type"]=i,n["ai.operation.name"]=b&&b.pathname||"_unknown_",n["ai.internal.sdkVersion"]="javascript:snippet_"+(h.sv||h.version),{time:(i=new Date).getUTCFullYear()+"-"+a(1+i.getUTCMonth())+"-"+a(i.getUTCDate())+"T"+a(i.getUTCHours())+":"+a(i.getUTCMinutes())+":"+a(i.getUTCSeconds())+"."+(i.getUTCMilliseconds()/1e3).toFixed(3).slice(2,5)+"Z",iKey:e,name:"Microsoft.ApplicationInsights."+e.replace(/-/g,"")+"."+t,sampleRate:100,tags:n,data:{baseData:{ver:2}},ver:undefined,seq:"1",aiDataContract:undefined}}var n,i,t,a,y=-1,T=0,S=["js.monitor.azure.com","js.cdn.applicationinsights.io","js.cdn.monitor.azure.com","js0.cdn.applicationinsights.io","js0.cdn.monitor.azure.com","js2.cdn.applicationinsights.io","js2.cdn.monitor.azure.com","az416426.vo.msecnd.net"],o=g.url||cfg.src,r=function(){return s(o,null)};function s(d,t){if((n=navigator)&&(~(n=(n.userAgent||"").toLowerCase()).indexOf("msie")||~n.indexOf("trident/"))&&~d.indexOf("ai.3")&&(d=d.replace(/(\/)(ai\.3\.)([^\d]*)$/,function(e,t,n){return t+"ai.2"+n})),!1!==cfg.cr)for(var e=0;e<S.length;e++)if(0<d.indexOf(S[e])){y=e;break}var n,i=function(e){var a,t,n,i,o,r,s,c,u,l;h.queue=[],m||(0<=y&&T+1<S.length?(a=(y+T+1)%S.length,p(d.replace(/^(.*\/\/)([\w\.]*)(\/.*)$/,function(e,t,n,i){return t+S[a]+i})),T+=1):(f=m=!0,s=d,!0!==cfg.dle&&(c=(t=function(){var e,t={},n=g.connectionString;if(n)for(var i=n.split(";"),a=0;a<i.length;a++){var o=i[a].split("=");2===o.length&&(t[o[0][x]()]=o[1])}return t[I]||(e=(n=t.endpointsuffix)?t.location:null,t[I]="https://"+(e?e+".":"")+"dc."+(n||"services.visualstudio.com")),t}()).instrumentationkey||g.instrumentationKey||"",t=(t=(t=t[I])&&"/"===t.slice(-1)?t.slice(0,-1):t)?t+"/v2/track":g.endpointUrl,t=g.userOverrideEndpointUrl||t,(n=[]).push((i="SDK LOAD Failure: Failed to load Application Insights SDK script (See stack for details)",o=s,u=t,(l=(r=v(c,"Exception")).data).baseType="ExceptionData",l.baseData.exceptions=[{typeName:"SDKLoadFailed",message:i.replace(/\./g,"-"),hasFullStack:!1,stack:i+"\nSnippet failed to load ["+o+"] -- Telemetry is disabled\nHelp Link: https://go.microsoft.com/fwlink/?linkid=2128109\nHost: "+(b&&b.pathname||"_unknown_")+"\nEndpoint: "+u,parsedStack:[]}],r)),n.push((l=s,i=t,(u=(o=v(c,"Message")).data).baseType="MessageData",(r=u.baseData).message='AI (Internal): 99 message:"'+("SDK LOAD Failure: Failed to load Application Insights SDK script (See stack for details) ("+l+")").replace(/\"/g,"")+'"',r.properties={endpoint:i},o)),s=n,c=t,JSON&&((u=C.fetch)&&!cfg.useXhr?u(c,{method:D,body:JSON.stringify(s),mode:"cors"}):XMLHttpRequest&&((l=new XMLHttpRequest).open(D,c),l.setRequestHeader("Content-type","application/json"),l.send(JSON.stringify(s)))))))},a=function(e,t){m||setTimeout(function(){!t&&h.core||i()},500),f=!1},p=function(e){var n=O.createElement(q),e=(n.src=e,t&&(n.integrity=t),n.setAttribute("data-ai-name",E),cfg[w]);return!e&&""!==e||"undefined"==n[w]||(n[w]=e),n.onload=a,n.onerror=i,n.onreadystatechange=function(e,t){"loaded"!==n.readyState&&"complete"!==n.readyState||a(0,t)},cfg.ld&&cfg.ld<0?O.getElementsByTagName("head")[0].appendChild(n):setTimeout(function(){O.getElementsByTagName(q)[0].parentNode.appendChild(n)},cfg.ld||0),n};p(d)}cfg.sri&&(n=o.match(/^((http[s]?:\/\/.*\/)\w+(\.\d+){1,5})\.(([\w]+\.){0,2}js)$/))&&6===n.length?(d="".concat(n[1],".integrity.json"),i="@".concat(n[4]),l=window.fetch,t=function(e){if(!e.ext||!e.ext[i]||!e.ext[i].file)throw Error("Error Loading JSON response");var t=e.ext[i].integrity||null;s(o=n[2]+e.ext[i].file,t)},l&&!cfg.useXhr?l(d,{method:"GET",mode:"cors"}).then(function(e){return e.json()["catch"](function(){return{}})}).then(t)["catch"](r):XMLHttpRequest&&((a=new XMLHttpRequest).open("GET",d),a.onreadystatechange=function(){if(a.readyState===XMLHttpRequest.DONE)if(200===a.status)try{t(JSON.parse(a.responseText))}catch(e){r()}else r()},a.send())):o&&r();try{h.cookie=O.cookie}catch(k){}function e(e){for(;e.length;)!function(t){h[t]=function(){var e=arguments;f||h.queue.push(function(){h[t].apply(h,e)})}}(e.pop())}var c,u,l="track",d="TrackPage",p="TrackEvent",l=(e([l+"Event",l+"PageView",l+"Exception",l+"Trace",l+"DependencyData",l+"Metric",l+"PageViewPerformance","start"+d,"stop"+d,"start"+p,"stop"+p,"addTelemetryInitializer","setAuthenticatedUserContext","clearAuthenticatedUserContext","flush"]),h.SeverityLevel={Verbose:0,Information:1,Warning:2,Error:3,Critical:4},(g.extensionConfig||{}).ApplicationInsightsAnalytics||{});return!0!==g[L]&&!0!==l[L]&&(e(["_"+(c="onerror")]),u=C[c],C[c]=function(e,t,n,i,a){var o=u&&u(e,t,n,i,a);return!0!==o&&h["_"+c]({message:e,url:t,lineNumber:n,columnNumber:i,error:a,evt:C.event}),o},g.autoExceptionInstrumented=!0),h}(cfg.cfg),(C[E]=n).queue&&0===n.queue.length?(n.queue.push(e),n.trackPageView({})):e();})({ -src: "https://js.monitor.azure.com/scripts/b/ai.3.gbl.min.js", -crossOrigin: "anonymous", // When supplied this will add the provided value as the cross origin attribute on the script tag -onInit: function (sdk) { - sdk.addTelemetryInitializer(function (envelope) { - envelope.data = envelope.data || {}; - envelope.data.someField = 'This item passed through my telemetry initializer'; - }); -}, // Once the application insights instance has loaded and initialized this method will be called -// sri: false, // Custom optional value to specify whether fetching the snippet from integrity file and do integrity check -cfg: { // Application Insights Configuration - connectionString: "YOUR_CONNECTION_STRING" -}}); -</script> -``` --#### [npm package](#tab/npmpackage) --```js -import { ApplicationInsights } from '@microsoft/applicationinsights-web' --const appInsights = new ApplicationInsights({ config: { - connectionString: 'YOUR_CONNECTION_STRING' - /* ...Other Configuration Options... */ -} }); -appInsights.loadAppInsights(); -// To insert a telemetry initializer, uncomment the following code. -/** var telemetryInitializer = (envelope) => { envelope.data = envelope.data || {}; envelope.data.someField = 'This item passed through my telemetry initializer'; - }; -appInsights.addTelemetryInitializer(telemetryInitializer); **/ -appInsights.trackPageView(); -``` ----For a summary of the noncustom properties available on the telemetry item, see [Application Insights Export Data Model](./export-telemetry.md#application-insights-export-data-model). --You can add as many initializers as you like. They're called in the order that they're added. --### OpenCensus Python telemetry processors --Telemetry processors in OpenCensus Python are simply callback functions called to process telemetry before they're exported. The callback function must accept an [envelope](https://github.com/census-instrumentation/opencensus-python/blob/master/contrib/opencensus-ext-azure/opencensus/ext/azure/common/protocol.py#L86) data type as its parameter. To filter out telemetry from being exported, make sure the callback function returns `False`. You can see the schema for Azure Monitor data types in the envelopes [on GitHub](https://github.com/census-instrumentation/opencensus-python/blob/master/contrib/opencensus-ext-azure/opencensus/ext/azure/common/protocol.py). --> [!NOTE] -> You can modify `cloud_RoleName` by changing the `ai.cloud.role` attribute in the `tags` field. --```python -def callback_function(envelope): - envelope.tags['ai.cloud.role'] = 'new_role_name' -``` --```python -# Example for log exporter -import logging --from opencensus.ext.azure.log_exporter import AzureLogHandler --logger = logging.getLogger(__name__) --# Callback function to append '_hello' to each log message telemetry -def callback_function(envelope): - envelope.data.baseData.message += '_hello' - return True --handler = AzureLogHandler(connection_string='InstrumentationKey=<your-instrumentation_key-here>') -handler.add_telemetry_processor(callback_function) -logger.addHandler(handler) -logger.warning('Hello, World!') -``` -```python -# Example for trace exporter -import requests --from opencensus.ext.azure.trace_exporter import AzureExporter -from opencensus.trace import config_integration -from opencensus.trace.samplers import ProbabilitySampler -from opencensus.trace.tracer import Tracer --config_integration.trace_integrations(['requests']) --# Callback function to add os_type: linux to span properties -def callback_function(envelope): - envelope.data.baseData.properties['os_type'] = 'linux' - return True --exporter = AzureExporter( - connection_string='InstrumentationKey=<your-instrumentation-key-here>' -) -exporter.add_telemetry_processor(callback_function) -tracer = Tracer(exporter=exporter, sampler=ProbabilitySampler(1.0)) -with tracer.span(name='parent'): -response = requests.get(url='https://www.wikipedia.org/wiki/Rabbit') -``` --```python -# Example for metrics exporter -import time --from opencensus.ext.azure import metrics_exporter -from opencensus.stats import aggregation as aggregation_module -from opencensus.stats import measure as measure_module -from opencensus.stats import stats as stats_module -from opencensus.stats import view as view_module -from opencensus.tags import tag_map as tag_map_module --stats = stats_module.stats -view_manager = stats.view_manager -stats_recorder = stats.stats_recorder --CARROTS_MEASURE = measure_module.MeasureInt("carrots", - "number of carrots", - "carrots") -CARROTS_VIEW = view_module.View("carrots_view", - "number of carrots", - [], - CARROTS_MEASURE, - aggregation_module.CountAggregation()) --# Callback function to only export the metric if value is greater than 0 -def callback_function(envelope): - return envelope.data.baseData.metrics[0].value > 0 --def main(): - # Enable metrics - # Set the interval in seconds in which you want to send metrics - exporter = metrics_exporter.new_metrics_exporter(connection_string='InstrumentationKey=<your-instrumentation-key-here>') - exporter.add_telemetry_processor(callback_function) - view_manager.register_exporter(exporter) -- view_manager.register_view(CARROTS_VIEW) - mmap = stats_recorder.new_measurement_map() - tmap = tag_map_module.TagMap() -- mmap.measure_int_put(CARROTS_MEASURE, 1000) - mmap.record(tmap) - # Default export interval is every 15.0s - # Your application should run for at least this amount - # of time so the exporter will meet this interval - # Sleep can fulfill this - time.sleep(60) -- print("Done recording metrics") --if __name__ == "__main__": - main() -``` -You can add as many processors as you like. They're called in the order that they're added. If one processor throws an exception, it doesn't impact the following processors. --### Example TelemetryInitializers --#### Add a custom property --The following sample initializer adds a custom property to every tracked telemetry. --```csharp -public void Initialize(ITelemetry item) -{ - var itemProperties = item as ISupportProperties; - if(itemProperties != null && !itemProperties.Properties.ContainsKey("customProp")) - { - itemProperties.Properties["customProp"] = "customValue"; - } -} -``` --#### Add a cloud role name --The following sample initializer sets the cloud role name to every tracked telemetry. --```csharp -public void Initialize(ITelemetry telemetry) -{ - if (string.IsNullOrEmpty(telemetry.Context.Cloud.RoleName)) - { - telemetry.Context.Cloud.RoleName = "MyCloudRoleName"; - } -} -``` --#### Control the client IP address used for geolocation mappings --The following sample initializer sets the client IP, which is used for geolocation mapping, instead of the client socket IP address, during telemetry ingestion. --```csharp -public void Initialize(ITelemetry telemetry) -{ - var request = telemetry as RequestTelemetry; - if (request == null) return true; - request.Context.Location.Ip = "{client ip address}"; // Could utilize System.Web.HttpContext.Current.Request.UserHostAddress; - return true; -} -``` --## ITelemetryProcessor and ITelemetryInitializer --What's the difference between telemetry processors and telemetry initializers? --* There are some overlaps in what you can do with them. Both can be used to add or modify properties of telemetry, although we recommend that you use initializers for that purpose. -* Telemetry initializers always run before telemetry processors. -* Telemetry initializers may be called more than once. By convention, they don't set any property that was already set. -* Telemetry processors allow you to completely replace or discard a telemetry item. -* All registered telemetry initializers are called for every telemetry item. For telemetry processors, SDK guarantees calling the first telemetry processor. Whether the rest of the processors are called or not is decided by the preceding telemetry processors. -* Use telemetry initializers to enrich telemetry with more properties or override an existing one. Use a telemetry processor to filter out telemetry. --> [!NOTE] -> JavaScript only has telemetry initializers which can [filter out events by using ITelemetryInitializer](#javascript-web-applications) --## Troubleshoot ApplicationInsights.config --* Confirm that the fully qualified type name and assembly name are correct. -* Confirm that the applicationinsights.config file is in your output directory and contains any recent changes. --## Azure Monitor Telemetry Data Types Reference -- * [ASP.NET Core SDK](/dotnet/api/microsoft.applicationinsights.datacontracts) - * [ASP.NET SDK](/dotnet/api/microsoft.applicationinsights.datacontracts) - * [Node.js SDK](https://github.com/Microsoft/ApplicationInsights-node.js/tree/develop/Declarations/Contracts/TelemetryTypes) - * [Java SDK (via config)](/azure/azure-monitor/app/java-in-process-agent#modify-telemetry) - * [Python SDK](https://github.com/census-instrumentation/opencensus-python/blob/master/contrib/opencensus-ext-azure/opencensus/ext/azure/common/protocol.py) - * [JavaScript SDK](https://github.com/microsoft/ApplicationInsights-JS/tree/master/shared/AppInsightsCommon/src/Telemetry) --## Reference docs --* [API overview](./api-custom-events-metrics.md) -* [ASP.NET reference](/previous-versions/azure/dn817570(v=azure.100)) --## SDK code --* [ASP.NET Core SDK](https://github.com/Microsoft/ApplicationInsights-aspnetcore) -* [ASP.NET SDK](https://github.com/Microsoft/ApplicationInsights-dotnet) -* [JavaScript SDK](https://github.com/Microsoft/ApplicationInsights-JS) --## <a name="next"></a>Next steps -* [Search events and logs](./transaction-search-and-diagnostics.md?tabs=transaction-search) -* [sampling](./sampling.md) |
| azure-monitor | App Insights Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/app-insights-overview.md | - Title: Application Insights overview -description: Learn how Application Insights in Azure Monitor provides performance management and usage tracking of your live web application. - Previously updated : 08/12/2024---# Application Insights overview --Azure Monitor Application Insights, a feature of [Azure Monitor](..\overview.md), excels in Application Performance Management (APM) for live web applications. -----## Experiences --Application Insights provides many experiences to enhance the performance, reliability, and quality of your applications. --### Investigate --* [Application dashboard](overview-dashboard.md): An at-a-glance assessment of your application's health and performance. -* [Application map](app-map.md): A visual overview of application architecture and components' interactions. -* [Live metrics](live-stream.md): A real-time analytics dashboard for insight into application activity and performance. -* [Transaction search](transaction-search-and-diagnostics.md?tabs=transaction-search): Trace and diagnose transactions to identify issues and optimize performance. -* [Availability view](availability-overview.md): Proactively monitor and test the availability and responsiveness of application endpoints. -* [Failures view](failures-and-performance-views.md?tabs=failures-view): Identify and analyze failures in your application to minimize downtime. -* [Performance view](failures-and-performance-views.md?tabs=performance-view): Review application performance metrics and potential bottlenecks. --### Monitoring --* [Alerts](../alerts/alerts-overview.md): Monitor a wide range of aspects of your application and trigger various actions. -* [Metrics](../essentials/metrics-getting-started.md): Dive deep into metrics data to understand usage patterns and trends. -* [Diagnostic settings](../essentials/diagnostic-settings.md): Configure streaming export of platform logs and metrics to the destination of your choice. -* [Logs](../logs/log-analytics-overview.md): Retrieve, consolidate, and analyze all data collected into Azure Monitoring Logs. -* [Workbooks](../visualize/workbooks-overview.md): Create interactive reports and dashboards that visualize application monitoring data. --### Usage --* [Users, sessions, and events](usage.md#users-sessions-and-eventsanalyze-telemetry-from-three-perspectives): Determine when, where, and how users interact with your web app. -* [Funnels](usage.md#funnelsdiscover-how-customers-use-your-application): Analyze conversion rates to identify where users progress or drop off in the funnel. -* [Flows](usage.md#user-flowsanalyze-user-navigation-patterns): Visualize user paths on your site to identify high engagement areas and exit points. -* [Cohorts](usage.md#cohortsanalyze-a-specific-set-of-users-sessions-events-or-operations): Group users by shared characteristics to simplify trend identification, segmentation, and performance troubleshooting. --### Code analysis --* [Profiler](../profiler/profiler-overview.md): Capture, identify, and view performance traces for your application. -* [Code optimizations](../insights/code-optimizations.md): Harness AI to create better and more efficient applications. -* [Snapshot debugger](../snapshot-debugger/snapshot-debugger.md): Automatically collect debug snapshots when exceptions occur in .NET application ----## Logic model --The logic model diagram visualizes components of Application Insights and how they interact. ---> [!Note] -> Firewall settings must be adjusted for data to reach ingestion endpoints. For more information, see [IP addresses used by Azure Monitor](../ip-addresses.md). ----## Supported languages --This section outlines supported scenarios. --For detailed information about instrumenting applications to enable Application Insights, see [data collection basics](opentelemetry-overview.md). --### Automatic instrumentation (enable without code changes) -* [Autoinstrumentation supported environments and languages](codeless-overview.md#supported-environments-languages-and-resource-providers) --### Manual instrumentation --#### OpenTelemetry Distro --* [ASP.NET Core](opentelemetry-enable.md?tabs=aspnetcore) -* [.NET](opentelemetry-enable.md?tabs=net) -* [Java](opentelemetry-enable.md?tabs=java) -* [Node.js](opentelemetry-enable.md?tabs=nodejs) -* [Python](opentelemetry-enable.md?tabs=python) --#### Application Insights SDK (Classic API) --* [ASP.NET](./asp-net.md) -* [Java](./opentelemetry-enable.md?tabs=java) -* [Node.js](./nodejs.md) -* [Python](/previous-versions/azure/azure-monitor/app/opencensus-python) -* [ASP.NET Core](./asp-net-core.md) --#### Client-side JavaScript SDK --* [JavaScript](./javascript.md) - * [React](./javascript-framework-extensions.md) - * [React Native](./javascript-framework-extensions.md) - * [Angular](./javascript-framework-extensions.md) --### Supported platforms and frameworks --This section lists all supported platforms and frameworks. --#### Azure service integration (portal enablement, Azure Resource Manager deployments) -* [Azure Virtual Machines and Azure Virtual Machine Scale Sets](./azure-vm-vmss-apps.md) -* [Azure App Service](./azure-web-apps.md) -* [Azure Functions](../../azure-functions/functions-monitoring.md) -* [Azure Spring Apps](../../spring-apps/enterprise/how-to-application-insights.md) -* [Azure Cloud Services](./azure-web-apps-net-core.md), including both web and worker roles --#### Logging frameworks -* [`ILogger`](./ilogger.md) -* [Log4Net, NLog, or System.Diagnostics.Trace](./asp-net-trace-logs.md) -* [`Log4J`, Logback, or java.util.logging](./opentelemetry-add-modify.md?tabs=java#send-custom-telemetry-using-the-application-insights-classic-api) -* [LogStash plug-in](https://github.com/Azure/azure-diagnostics-tools/tree/master/Logstash/logstash-output-applicationinsights) -* [Azure Monitor](/archive/blogs/msoms/application-insights-connector-in-oms) --#### Export and data analysis -* [Integrate Log Analytics with Power BI](../logs/log-powerbi.md) --### Unsupported Software Development Kits (SDKs) --Many community-supported Application Insights SDKs exist, but Microsoft only provides support for instrumentation options listed in this article. ----## Frequently asked questions --This section provides answers to common questions. --### How do I instrument an application? --For detailed information about instrumenting applications to enable Application Insights, see [data collection basics](opentelemetry-overview.md). --### How do I use Application Insights? --After enabling Application Insights by [instrumenting an application](opentelemetry-overview.md), we suggest first checking out [Live metrics](live-stream.md) and the [Application map](app-map.md). --### What telemetry does Application Insights collect? --From server web apps: --* HTTP requests. -* [Dependencies](./asp-net-dependencies.md). Calls to SQL databases, HTTP calls to external services, Azure Cosmos DB, Azure Table Storage, Azure Blob Storage, and Azure Queue Storage. -* [Exceptions](./asp-net-exceptions.md) and stack traces. -* [Performance counters](./performance-counters.md): Performance counters are available when using: - * [Azure Monitor Application Insights agent](application-insights-asp-net-agent.md) - * [Azure monitoring for VMs or virtual machine scale sets](./azure-vm-vmss-apps.md) - * [Application Insights `collectd` writer](/previous-versions/azure/azure-monitor/app/deprecated-java-2x#collectd-linux-performance-metrics-in-application-insights-deprecated). -* [Custom events and metrics](./api-custom-events-metrics.md) that you code. -* [Trace logs](./asp-net-trace-logs.md) if you configure the appropriate collector. - -From [client webpages](./javascript-sdk.md): - -* Uncaught exceptions in your app, including information on - * Stack trace - * Exception details and message accompanying the error - * Line & column number of error - * URL where error was raised - * Network Dependency Requests made by your app XML Http Request (XHR) and Fetch (fetch collection is disabled by default) requests, include information on: - * Url of dependency source - * Command & Method used to request the dependency - * Duration of the request - * Result code and success status of the request - * ID (if any) of user making the request - * Correlation context (if any) where request is made -* User information (for example, Location, network, IP) -* Device information (for example, Browser, OS, version, language, model) -* Session information -- > [!Note] - > For some applications, such as single-page applications (SPAs), the duration may not be recorded and will default to 0. -- For more information, see [Data collection, retention, and storage in Application Insights](/previous-versions/azure/azure-monitor/app/data-retention-privacy). - -From other sources, if you configure them: - -* [Azure diagnostics](../agents/diagnostics-extension-to-application-insights.md) -* [Import to Log Analytics](../logs/data-collector-api.md) -* [Log Analytics](../logs/data-collector-api.md) -* [Logstash](../logs/data-collector-api.md) ---### How many Application Insights resources should I deploy? -To understand the number of Application Insights resources required to cover your application or components across environments, see the [Application Insights deployment planning guide](create-workspace-resource.md#how-many-application-insights-resources-should-i-deploy). --### How can I manage Application Insights resources with PowerShell? - -You can [write PowerShell scripts](./powershell.md) by using Azure Resource Monitor to: - -* Create and update Application Insights resources. -* Set the pricing plan. -* Get the instrumentation key. -* Add a metric alert. -* Add an availability test. - -You can't set up a metrics explorer report or set up continuous export. --### How can I query Application Insights telemetry? - -Use the [REST API](/rest/api/application-insights/) to run [Log Analytics](../logs/log-query-overview.md) queries. --### Can I send telemetry to the Application Insights portal? --We recommend the [Azure Monitor OpenTelemetry Distro](opentelemetry-enable.md). --The [ingestion schema](https://github.com/microsoft/ApplicationInsights-dotnet/tree/master/BASE/Schem) are available publicly. --### How long does it take for telemetry to be collected? --Most Application Insights data has a latency of under 5 minutes. Some data can take longer, which is typical for larger log files. See the [Application Insights service-level agreement](https://azure.microsoft.com/support/legal/sla/application-insights/v1_2/). - -### How does Application Insights handle data collection, retention, storage, and privacy? --#### Collection --Application Insights collects telemetry about your app, including web server telemetry, web page telemetry, and performance counters. This data can be used to monitor your app's performance, health, and usage. You can select the location when you [create a new Application Insights resource](./create-workspace-resource.md). --#### Retention and Storage --Data is sent to an Application Insights [Log Analytics workspace](../logs/log-analytics-workspace-overview.md). You can choose the retention period for raw data, from 30 to 730 days. Aggregated data is retained for 90 days, and debug snapshots are retained for 15 days. --#### Privacy --Application Insights doesn't handle sensitive data by default. We recommend you don't put sensitive data in URLs as plain text and ensure your custom code doesn't collect personal or other sensitive details. During development and testing, check the sent data in your IDE and browser's debugging output windows. --For archived information, see [Data collection, retention, and storage in Application Insights](/previous-versions/azure/azure-monitor/app/data-retention-privacy). --### What is the Application Insights pricing model? --Application Insights is billed through the Log Analytics workspace into which its log data ingested. The default Pay-as-you-go Log Analytics pricing tier includes 5 GB per month of free data allowance per billing account. Learn more about [Azure Monitor logs pricing options](https://azure.microsoft.com/pricing/details/monitor/). - -### Are there data transfer charges between an Azure web app and Application Insights? --* If your Azure web app is hosted in a datacenter where there's an Application Insights collection endpoint, there's no charge. -* If there's no collection endpoint in your host datacenter, your app's telemetry incurs [Azure outgoing charges](https://azure.microsoft.com/pricing/details/bandwidth/). - -This answer depends on the distribution of our endpoints, *not* on where your Application Insights resource is hosted. --### Do I incur network costs if my Application Insights resource is monitoring an Azure resource (that is, telemetry producer) in a different region? --Yes, you can incur more network costs, which vary depending on the region the telemetry is coming from and where it's going. -Refer to [Azure bandwidth pricing](https://azure.microsoft.com/pricing/details/bandwidth/) for details. --## Help and support --### Azure technical support --For Azure support issues, open an [Azure support ticket](https://azure.microsoft.com/support/create-ticket/). --### Microsoft Questions and Answers forum --Post general questions to the [Microsoft Questions and Answers forum](/answers/topics/24223/azure-monitor.html). --### Stack Overflow --Post coding questions to [Stack Overflow](https://stackoverflow.com/questions/tagged/azure-application-insights) by using an `azure-application-insights` tag. --### Feedback Community --Leave product feedback for the engineering team in the [Feedback Community](https://feedback.azure.com/d365community/forum/3887dc70-2025-ec11-b6e6-000d3a4f09d0). ----## Next steps --- [Data collection basics](opentelemetry-overview.md)-- [Workspace-based resources](create-workspace-resource.md)-- [Automatic instrumentation overview](codeless-overview.md)-- [Application dashboard](overview-dashboard.md)-- [Application Map](app-map.md)-- [Live metrics](live-stream.md)-- [Transaction search](transaction-search-and-diagnostics.md?tabs=transaction-search)-- [Availability overview](availability-overview.md)-- [Users, sessions, and events](usage.md) |
| azure-monitor | App Map | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/app-map.md | - Title: Application map in Azure Application Insights -description: Monitor complex application topologies with Application map and Intelligent view by using Application Insights in Azure Monitor. - Previously updated : 05/23/2024-# ms.devlang: csharp, java, javascript, python ----#customer intent: As a developer, I want use the Application map and Intelligent view features in Azure Monitor so that I can monitor complex application topologies. ---# Application map: Triage distributed applications --Developers use application maps to represent the logical structure of their distributed applications. A map is produced by identifying the individual application components with their `roleName` or `name` property in recorded telemetry. Circles (or _nodes_) on the map represent the components and directional lines (_connectors_ or _edges_) show the HTTP calls from _source_ nodes to _target_ nodes. --Azure Monitor provides the **Application map** feature to help you quickly implement a map and spot performance bottlenecks or failure hotspots across all components. Each map node is an application component or its dependencies, and provides health KPI and alerts status. You can select any node to see detailed diagnostics for the component, such as Application Insights events. If your app uses Azure services, you can also select Azure diagnostics, such as SQL Database Advisor recommendations. --**Application map** also features [Intelligent view](#explore-intelligent-view) to assist with fast service health investigations. --## Understand components --Components are independently deployable parts of your distributed or microservice application. Developers and operations teams have code-level visibility or access to telemetry generated by these application components. --Some considerations about components: --- Components are different from "observed" external dependencies, such as Azure SQL and Azure Event Hubs, which your team or organization might not have access to (code or telemetry).-- Components run on any number of server, role, or container instances.-- Components can be separate Application Insights resources, even if subscriptions are different. They can also be different roles that report to a single Application Insights resource. The preview map experience shows the components regardless of how they're set up.--## Explore Application map --**Application map** lets you see the full application topology across multiple levels of related application components. As described earlier, components can be different Application Insights resources, dependent components, or different roles in a single resource. **Application map** locates components by following HTTP dependency calls made between servers with the Application Insights SDK installed. --The mapping experience starts with the progressive discovery of the components within the application and their dependencies. When you first load **Application map**, a query set triggers to discover the components related to the main component. As components are discovered, a status bar shows the current number of discovered components: ---The following sections describe some of the actions available for working with **Application map** in the Azure portal. --### Update map components --The **Update map components** option triggers discovery of components and refreshes the map to show all current nodes. Depending on the complexity of your application, the update can take a minute to load: ---When all application components are roles within a single Application Insights resource, the discovery step isn't required. The initial load in this application scenario discovers all of the components. --### View component details --A key objective for the **Application map** experience is to help you visualize complex topologies that have hundreds of components. In this scenario, it's useful to enhance the map view with details for an individual node by using the **View details** option. The node details pane shows related insights, performance, and failure triage experience for the selected component: ---Each pane section includes an option to see more information in an expanded view, including failures, performance, and details about failed requests and dependencies. --### Investigate failures --In the node details pane, you can use the **Investigate failures** option to view all failures for the component: ---The **Failures** view lets you explore failure data for operations, dependencies, exceptions, and roles related to the selected component: ---### Investigate performance --In the node details pane, you can troubleshoot performance problems with the component by selecting the **Investigate performance** option: ---The **Performance** view lets you explore telemetry data for operations, dependencies, and roles connected with the selected component: ---### Go to details and stack trace --The **Go to details** option in the node details pane displays the end-to-end transaction experience for the component. This pane lets you view details at the call stack level: ---The page opens to show the **Timeline** view for the details: ---You can use the **View all** option to see the stack details with trace and event information for the component: ---### View in Logs (Analytics) --In the node details pane, you can query and investigate your applications data further with the **View in Logs (Analytics)** option: ---The **Logs (Analytics)** page provides options to explore your application telemetry table records with built-in or custom queries and functions. You can work with the data by adjusting the format, and saving and exporting your analysis: ---### View alerts and rules --The **View alerts** option in the node details pane lets you see active alerts: ---The **Alerts** page shows critical and fired alerts: ---The **Alert rules** option on the **Alerts** page shows the underlying rules that cause the alerts to trigger: ---<a name="understand-the-cloud-role-name-within-the-context-of-an-application-map"></a> --## Understand cloud role names and nodes --**Application map** uses the cloud role name property to identify the application components on a map. To explore how cloud role names are used with component nodes, look at an application map that has multiple cloud role names present. --The following example shows a map in **Hierarchical view** with five component nodes and connectors to nine dependent nodes. Each node has a cloud role name. ---**Application map** uses different colors, highlights, and sizes for nodes to depict the application component data and relationships: --- The cloud role names express the different aspects of the distributed application. In this example, some of the application roles include `Contoso Retail Check`, `Fabrikam-App`, `fabrikam-loadfunc`, `retailfabrikam-37ha6`, and `retailapp`.--- The dotted blue circle around a node indicates the last selected component. In this example, the last selected component is the `Web` node.--- When you select a node to see the details, a solid blue circle highlights the node. In the example, the currently selected node is `Contoso Retail Reports`.--- Distant or unrelated component nodes are shown smaller in comparison to the other nodes. These items are dimmed in the view to highlight performance for the currently selected component.--- In this example, each cloud role name also represents a different unique Application Insights resource with its own instrumentation keys. Because the owner of this application has access to each of those four disparate Application Insights resources, **Application map** can stitch together a map of the underlying relationships.--### Investigate cloud role instances --When a cloud role name reveals a problem somewhere in your web frontend, and you're running multiple load-balanced servers across your web frontend, using a _cloud role instance_ can be helpful. **Application map** lets you view deeper information about a component node by using Kusto queries. You can investigate a node to view details about specific cloud role instances. This approach helps you determine whether an issue affects all web front-end servers or only specific instances. --A scenario where you might want to override the value for a cloud role instance is when your app is running in a containerized environment. In this case, information about the individual server might not be sufficient to locate the specific issue. --For more information about how to override the cloud role name property with telemetry initializers, see [Add properties: ITelemetryInitializer](api-filtering-sampling.md#addmodify-properties-itelemetryinitializer). --<a name="set-or-override-cloud-role-name"></a> --## Set cloud role names --**Application map** uses the cloud role name property to identify the components on the map. This section provides examples to manually set or override cloud role names and change what appears on the application map. --> [!NOTE] -> The Application Insights SDK or Agent automatically adds the cloud role name property to the telemetry emitted by components in an Azure App Service environment. --The following snippet shows the schema definitions for the cloud role and cloud role instance: --```dotnetcli -[Description("Name of the role the application is a part of. Maps directly to the role name in Azure.")] -[MaxStringLength("256")] -705: string CloudRole = "ai.cloud.role"; --[Description("Name of the instance where the application is running. Computer name for on-premises, instance name for Azure.")] -[MaxStringLength("256")] -715: string CloudRoleInstance = "ai.cloud.roleInstance"; -``` --For the [official definitions](https://github.com/Microsoft/ApplicationInsights-dotnet/blob/39a5ef23d834777eefdd72149de705a016eb06b0/Schema/PublicSchema/ContextTagKeys.bond#L93): --# [.NET/.NetCore](#tab/net) --**Write custom TelemetryInitializer** --```csharp -using Microsoft.ApplicationInsights.Channel; -using Microsoft.ApplicationInsights.Extensibility; --namespace CustomInitializer.Telemetry -{ - public class MyTelemetryInitializer : ITelemetryInitializer - { - public void Initialize(ITelemetry telemetry) - { - if (string.IsNullOrEmpty(telemetry.Context.Cloud.RoleName)) - { - //set custom role name here - telemetry.Context.Cloud.RoleName = "Custom RoleName"; - telemetry.Context.Cloud.RoleInstance = "Custom RoleInstance"; - } - } - } -} -``` --**ASP.NET apps: Load initializer in the active TelemetryConfiguration** --In the _ApplicationInsights.config_ file: --```xml - <ApplicationInsights> - <TelemetryInitializers> - <!-- Fully qualified type name, assembly name: --> - <Add Type="CustomInitializer.Telemetry.MyTelemetryInitializer, CustomInitializer"/> - ... - </TelemetryInitializers> - </ApplicationInsights> -``` --An alternate method for ASP.NET Web apps is to instantiate the initializer in code. The following example shows code in the _Global.aspx.cs_ file: --```csharp - using Microsoft.ApplicationInsights.Extensibility; - using CustomInitializer.Telemetry; -- protected void Application_Start() - { - // ... - TelemetryConfiguration.Active.TelemetryInitializers.Add(new MyTelemetryInitializer()); - } -``` --> [!NOTE] -> Adding an initializer by using the `ApplicationInsights.config` or `TelemetryConfiguration.Active` property isn't valid for ASP.NET Core applications. --**ASP.NET Core apps: Load an initializer to TelemetryConfiguration** --For [ASP.NET Core](asp-net-core.md#add-telemetryinitializers) applications, to add a new `TelemetryInitializer` instance, you add it to the Dependency Injection container. The following example shows this approach. Add this code in the `ConfigureServices` method of your `Startup.cs` class. --```csharp - using Microsoft.ApplicationInsights.Extensibility; - using CustomInitializer.Telemetry; - public void ConfigureServices(IServiceCollection services) -{ - services.AddSingleton<ITelemetryInitializer, MyTelemetryInitializer>(); -} -``` --# [Java](#tab/java) --**Set cloud role name** --```json -{ - "role": { - "name": "my cloud role name" - } -} -``` --You can also set the cloud role name with an environment variable or system property. For more information, see [Configuring cloud role name](./java-standalone-config.md#cloud-role-name). --# [Node.js](#tab/nodejs) --**Set cloud role name** --```javascript -var appInsights = require("applicationinsights"); -appInsights.setup('INSTRUMENTATION_KEY').start(); -appInsights.defaultClient.context.tags["ai.cloud.role"] = "your role name"; -appInsights.defaultClient.context.tags["ai.cloud.roleInstance"] = "your role instance"; -``` --**Node.js: Set cloud role name** --```javascript -var appInsights = require("applicationinsights"); -appInsights.setup('INSTRUMENTATION_KEY').start(); --appInsights.defaultClient.addTelemetryProcessor(envelope => { - envelope.tags["ai.cloud.role"] = "your role name"; - envelope.tags["ai.cloud.roleInstance"] = "your role instance" -}); -``` --# [JavaScript](#tab/javascript) --**Set cloud role name** --```javascript -appInsights.queue.push(() => { -appInsights.addTelemetryInitializer((envelope) => { - envelope.tags["ai.cloud.role"] = "your role name"; - envelope.tags["ai.cloud.roleInstance"] = "your role instance"; -}); -}); -``` --# [Python](#tab/python) --**Set cloud role name** --For Python, you can use [OpenCensus Python telemetry processors](api-filtering-sampling.md#opencensus-python-telemetry-processors). --```python -def callback_function(envelope): - envelope.tags['ai.cloud.role'] = 'new_role_name' --# AzureLogHandler -handler.add_telemetry_processor(callback_function) --# AzureExporter -exporter.add_telemetry_processor(callback_function) -``` ---## Use Application map filters --**Application map** filters help you decrease the number of visible nodes and edges on your map. These filters can be used to reduce the scope of the map and show a smaller and more focused view. --A quick way to filter is to use the **Filter on this node** option on the context menu for any node on the map: ---You can also create a filter with the **Add filter** option: ---Select your filter type (node or connector) and desired settings, then review your choices and apply them to the current map. --### Create node filters --Node filters allow you to see only certain nodes in the application map and hide all other nodes. You configure parameters to search the properties of nodes in the map for values that match a condition. When a node filter removes a node, the filter also removes all connectors and edges for the node. --A node filter has three parameters to configure: --- **Nodes included**: The types of nodes to review in the application map for matching properties. There are four options:-- - **Nodes, sources and targets**: All nodes that match the search criteria are included in the results map. All source and target nodes for the matching nodes are also automatically included in the results map, even if the sources or targets don't satisfy the search criteria. The source and target nodes are collectively referred to as _connected_ nodes. -- - **Nodes and sources**: The same behavior as **Nodes, sources and targets**, but target nodes aren't automatically included in the results map. -- - **Nodes and targets**: The same behavior as **Nodes, sources and targets**, but source nodes aren't automatically included in the results map. -- - **Nodes only**: All nodes in the results map must have a property value that matches the search criteria. --- **Operator**: The type of conditional test to perform on each node's property values. There are four options:-- - `contains`: The node property value contains the value specified in the **Search value** parameter. - - `!contains` The node property value doesn't contain the value specified in the **Search value** parameter. - - `==`: The node property value is equal to the value specified in the **Search value** parameter. - - `!=`: The node property value isn't equal to the value specified in the **Search value** parameter. --- **Search value**: The text string to use for the property value conditional test. The dropdown list for the parameter shows values for existing nodes in the application map. You can select a value from the list, or create your own value. Enter your custom value in the parameter field and then select **Create option ...** in the list. For example, you might enter `test` and then select **Create option "test"** in the list.--The following image shows an example of a filter applied to an application map that shows 30 days of data. The filter instructs **Application map** to search for nodes and connected targets that have properties that contain the text "retailapp": ---Matching nodes and their connected target nodes are included in the results map: ---### Create connector (edge) filters --Connector filters allow you to see only certain nodes with specific connectors in the application map and hide all other nodes and connectors. You configure parameters to search the properties of connectors in the map for values that match a condition. When a node has no matching connectors, the filter removes the node from the map. --A connector filter has three parameters to configure: --- **Filter connectors by**: The types of connectors to review in the application map for matching properties. There are four choices. Your selection controls the available options for the other two parameters. --- **Operator**: The type of conditional test to perform on each connector's value. --- **Value**: The comparison value to use for the property value conditional test. The dropdown list for the parameter contains values relevant to the current application map. You can select a value from the list, or create your own value. For example, you might enter `16` and then select **Create option "16"** in the list.--The following table summarizes the configuration options based on your choice for the **Filter connectors by** parameter. --| Filter connectors by | Description | Operator parameter | Value parameter | Usage | -| | | | | | -| **Error connector (highlighted red)** | Search for connectors based on their color. The color red indicates the connector is in an error state. | `==`: Equal to <br> `!=`: Not equal to | Always set to **Errors** | Show only connectors with errors or only connectors without errors. | -| **Error rate (0% - 100%)** | Search for connectors based on their _average error rate_ (the number of failed calls divided by the number of all calls). The value is expressed as a percentage. | `>=` Greater than or Equal to <br> `<=` Less than or Equal to | The dropdown list shows average error rates relevant to current connectors in your application map. Choose a value from the list or enter a custom value by following the process described earlier. | Show connectors with failure rates greater than or lower than the selected value. | -| **Average call duration (ms)** | Search for connectors based on the average duration of all calls across the connector. The value is measured in milliseconds. | `>=` Greater than or Equal to <br> `<=` Less than or Equal to | The dropdown list shows average durations relevant to current connectors in your application map. For example, a value of `1000` refers to calls with an average duration of 1 second. Choose a value from the list or enter a custom value by following the process described earlier. | Show connectors with average call duration rates greater than or lower than the selected value. | -| **Calls count** | Search for connectors based on the total number of calls across the connector. | `>=` Greater than or Equal to <br> `<=` Less than or Equal to | The dropdown list shows total call counts relevant to current connectors in your application map. Choose a value from the list or enter a custom value by following the process described earlier. | Show connectors with call counts greater than or lower than your selected value. | --#### Percentile indicators for value --When you filter connectors by the **Error rate**, **Average call duration**, or **Calls count**, some options for the **Value** parameter include the `(Pxx)` designation. This indicator shows the percentile level. For an **Average call duration** filter, you might see the value `200 (P90)`. This option means 90% of all connectors (regardless of the number of calls they represent) have less than 200-ms call duration. --You can see the **Value** options that include the percentile level by entering `P` in the parameter field. --### Review your filters --After you make your selections, the **Review** section of the **Add filter** popup shows textual and visual descriptions about your filter. The summary display can help you understand how your filter applies to your application map. --The following example shows the **Review** summary for a node filter that searches for nodes and targets with properties that have the text "-west": ---This example shows the summary for a connector filter that searches for connectors (and they nodes they connect) with an average call duration equal to or greater than 42 ms: ---### Apply filters to map --After you configure and review your filter settings, select **Apply** to create the filter. You can apply multiple filters to the same application map. In **Application map**, the applied filters display as _pills_ above the map: ---The **Remove** action :::image type="icon" source="media/app-map/remove-filter.png"::: on a filter pill lets you delete a filter. When you delete an applied filter, the map view updates to subtract the filter logic. --**Application map** applies the filter logic to your map sequentially, starting from the left-most filter in the list. As filters are applied, nodes and connectors are removed from the map view. After a node or connector is removed from the view, a subsequent filter can't restore the item. --You can change the configuration for an applied filter by selecting the filter pill. As you change the filter settings, **Application map** shows a preview of the map view with the new filter logic. If you decide not to apply the changes, you can use the **Cancel** option to the current map view and filters. ---## Explore and save filters --When you discover an interesting filter, you can save the filter to reuse it later with the **Copy Link** or **Pin to dashboard** option: ---- The **Copy link** option encodes all current filter settings in the copied URL. You can save this link in your browser bookmarks or share it with others. This feature preserves the duration value in filter settings, but not the absolute time. When you use the link later, the produced application map might differ from the map present at the time the link was captured.--- The **Pin to dashboard** option adds the current application map to a dashboard, along with its current filters. A common diagnostic approach is to pin a map with an **Error connector** filter applied. You can monitor your application for nodes with errors in their HTTP calls.--The following sections describe some common filters that apply to most maps and can be useful to pin on a dashboard. --### Check for important errors --Produce a map view of only connectors with errors (highlighted red) over the last 24 hours. The filters include the **Error connector** parameter combined with **Intelligent view**: - --The [Intelligent view](#work-with-intelligent-view) feature is described later in this article. --### Hide low-traffic connectors --Hide low-traffic connectors without errors from the map view, so you can quickly focus on more significant issues. The filters include connectors over the last 24 hours with a **Calls count** greater than 2872 (P20): ---### Show high-traffic connectors --Reveal high-traffic connectors that also have a high average call duration time. This filter can help identify potential performance issues. The filters in this example include connectors over the last 24 hours with a **Calls count** greater than 10854 (P50) and **Average call duration** time greater than 578 (P80): ---### Locate components by name --Locate components (nodes and connectors) in your application by name according to your implementation of the component `roleName` property naming convention. You can use this approach to see the specific portion of a distributed application. The filter searches for **Nodes, sources and targets** over the last 24 hours that contain the specified value. In this example, the search value is "west": ---### Remove noisy components --Define filters to hide noisy components by removing them from the map. Sometimes application components can have active dependent nodes that produce data that's not essential for the map view. In this example, the filter searches for **Nodes, sources and targets** over the last 24 hours that don't contain the specified value "retail": ---### Look for error-prone connectors --Show only connectors that have higher error rates than a specific value. The filter in this example searches for connectors over the last 24 hours that have an **Error rate** greater than 3%: ---## Explore Intelligent view --The **Intelligent view** feature for **Application map** is designed to aid in service health investigations. It applies machine learning to quickly identify potential root causes of issues by filtering out noise. The machine learning model learns from **Application map** historical behavior to identify dominant patterns and anomalies that indicate potential causes of an incident. --In large distributed applications, there's always some degree of noise coming from "benign" failures, which might cause **Application map** to be noisy by showing many red edges. **Intelligent view** shows only the most probable causes of service failure and removes node-to-node red edges (service-to-service communication) in healthy services. **Intelligent view** highlights the edges in red that should be investigated. It also offers actionable insights for the highlighted edge. --There are many benefits to using **Intelligent view**: --- Reduces time to resolution by highlighting only failures that need to be investigated-- Provides actionable insights on why a certain red edge was highlighted-- Enables **Application map** to be used for large distributed applications seamlessly (by focusing only on edges marked in red)--**Intelligent view** has some limitations: --- Large distributed applications might take a minute to load.-- Time frames of up to seven days are supported.--### Work with Intelligent view --A toggle above the application map lets you enable **Intelligent view** and control the issue detection sensitivity: ---**Intelligent view** uses the patented AIOps machine learning model to highlight (red) the significant and important data in an application map. Various application data are used to determine which data to highlight on the map, including failure rates, request counts, durations, anomalies, and dependency type. For comparison, the standard map view utilizes only the _raw_ failure rate. --**Application map** highlights edges in red according to your sensitivity setting. You can adjust the sensitivity to achieve the desired confidence level in the highlighted edges. --| Sensitivity | Description | -| | | -| **High** | Fewer edges are highlighted. | -| **Medium** | (Default setting) A balanced number of edges are highlighted. | -| **Low** | More edges are highlighted. | --### Check actionable insights --After you enable **Intelligent view**, select a highlighted edge (red) on the map to see the "actionable insights" for the component. The insights display in a pane to the right and explain why the edge is highlighted. ---To start troubleshooting an issue, select **Investigate failures**. You can review the information about the component in the **Failures** pane to determine if the detected issue is the root cause. --When **Intelligent view** doesn't highlight any edges on the application map, the machine learning model didn't find potential incidents in the dependencies of your application. --## Troubleshooting tips --If you're having trouble getting **Application map** to work as expected, review the suggestions in the following sections. --Here are some general recommendations: --- Use an officially supported SDK. Unsupported or community SDKs might not support correlation. For a list of supported SDKs, see [Application Insights: Languages, platforms, and integrations](./app-insights-overview.md#supported-languages).--- Upgrade all components to the latest SDK version.--- Support Azure Functions with C# by upgrading to [Azure Functions V2](../../azure-functions/functions-versions.md).--- Ensure the [cloud role name](#set-cloud-role-names) is correctly configured.--- Confirm any missing dependencies are listed as [autocollected dependencies](asp-net-dependencies.md#dependency-auto-collection). If a dependency isn't listed, you can track it manually with a [track dependency call](./api-custom-events-metrics.md#trackdependency).--### Too many nodes on map --**Application map** adds a component node for each unique cloud role name in your request telemetry. The process also adds a dependency node for each unique combination of type, target, and cloud role name. --- If you have more than 10,000 nodes in your telemetry, **Application map** can't fetch all of the nodes and links. In this scenario, your map structure is incomplete. If this scenario occurs, a warning message appears when you view the map.--- **Application map** can render a maximum of 1,000 separate ungrouped nodes at once. **Application map** reduces visual complexity by grouping dependencies together when they have the same type and callers.--- If your telemetry has too many unique cloud role names or too many dependency types, the grouping is insufficient and the map isn't rendered.--To fix this issue, you need to change your instrumentation to properly set the cloud role name, dependency type, and dependency target fields. Confirm your application adheres to the following criteria: --- Each dependency target represents the logical name of a dependency. In many cases, this value is equivalent to the server or resource name of the dependency. For example, if there are HTTP dependencies, the value is the hostname. The value shouldn't contain unique IDs or parameters that change from one request to another.--- Each dependency type represents the logical type of a dependency. For example, HTTP, SQL, or Azure Blob are typical dependency types. This value shouldn't contain unique IDs.--- Each cloud role name purpose applies the description in the [Set or override cloud role name](#set-cloud-role-names) section.--### Intelligent view: Edge not highlighted --**Intelligent view** might not highlight an edge as expected, even with a low sensitivity setting. A dependency might appear to be in failure but the model doesn't indicate the issue as a potential incident. Here are some possible scenarios: --- If the dependency commonly fails, the model might consider the failure a standard state for the component and not highlight the edge. **Intelligent view** focuses on problem-solving in real time.--- If the dependency has a minimal effect on the overall performance of the application, **Intelligent view** might ignore the component during machine learning modeling.--If your scenario is unique, you can use the **Feedback** option to describe your experience and help improve future model versions. --### Intelligent view: Edge highlighted --When **intelligent view** highlights an edge, the actionable insights from the machine learning model should identify the significant issues that contribute to the high probability score. Keep in mind that the recommendation isn't based solely on failures, but on other indicators like unexpected latency in dominant flows. --### Intelligent view: Doesn't load --If **Intelligent view** doesn't load, set the configured time frame to six days or less. --### Intelligent view: Long load time --If **Intelligent view** takes longer to load than expected, avoid selecting the **Update map components** option. Enable **Intelligent view** only for a single Application Insights resource. --## Related content --- Learn how correlation works in Application Insights with [Telemetry correlation](distributed-trace-data.md).--- Explore the [end-to-end transaction diagnostic experience](./transaction-search-and-diagnostics.md?tabs=transaction-diagnostics) that correlates server-side telemetry from across all your Application Insights-monitored components into a single view.--- Support advanced correlation scenarios in ASP.NET Core and ASP.NET with [Track custom operations](custom-operations-tracking.md). |
| azure-monitor | Application Insights Asp Net Agent | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/application-insights-asp-net-agent.md | - Title: Deploy Application Insights Agent -description: Learn how to use Application Insights Agent to monitor website performance. It works with ASP.NET web apps hosted on-premises, in VMs, or on Azure. - Previously updated : 11/15/2023----# Deploy Azure Monitor Application Insights Agent for on-premises servers --Application Insights Agent (formerly named Status Monitor V2) is a PowerShell module published to the [PowerShell Gallery](https://www.powershellgallery.com/packages/Az.ApplicationMonitor). -It replaces Status Monitor. -Telemetry is sent to the Azure portal, where you can [monitor](./app-insights-overview.md) your app. --For a complete list of supported autoinstrumentation scenarios, see [Supported environments, languages, and resource providers](codeless-overview.md#supported-environments-languages-and-resource-providers). --> [!NOTE] -> The module currently supports codeless instrumentation of ASP.NET and ASP.NET Core web apps hosted with IIS. Use an SDK to instrument Java and Node.js applications. --## PowerShell Gallery --Application Insights Agent is located in the [PowerShell Gallery](https://www.powershellgallery.com/packages/Az.ApplicationMonitor). ---## Instructions -- To get started with concise code samples, see the **Getting started** tab.-- For a deep dive on how to get started, see the **Detailed instructions** tab.-- For PowerShell API reference, see the **API reference** tab.-- For release note updates, see the **Release notes** tab.--### [Getting started](#tab/getting-started) --This tab contains the quickstart commands that are expected to work for most environments. The instructions depend on PowerShell Gallery to distribute updates. These commands support the PowerShell `-Proxy` parameter. --For an explanation of these commands, customization instructions, and information about troubleshooting, see the [detailed instructions](?tabs=detailed-instructions#instructions). --If you don't have an Azure subscription, create a [free account](https://azure.microsoft.com/free/?WT.mc_id=A261C142F) before you begin. --### Download and install via PowerShell Gallery --Use PowerShell Gallery for download and installation. --#### Installation prerequisites --To enable monitoring, you must have a connection string. A connection string is displayed on the **Overview** pane of your Application Insights resource. For more information, see [Connection strings](./sdk-connection-string.md?tabs=net#find-your-connection-string). --> [!NOTE] -> As of April 2020, PowerShell Gallery has deprecated TLS 1.1 and 1.0. -> -> For more prerequisites that you might need, see [PowerShell Gallery TLS support](https://devblogs.microsoft.com/powershell/powershell-gallery-tls-support). -> --Run PowerShell as an admin. --```powershell -Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope Process -Force -Install-PackageProvider -Name NuGet -MinimumVersion 2.8.5.201 -Force -Set-PSRepository -Name "PSGallery" -InstallationPolicy Trusted -Install-Module -Name PowerShellGet -Force -``` --Close PowerShell. --#### Install Application Insights Agent -Run PowerShell as an admin. --```powershell -Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope Process -Force -Install-Module -Name Az.ApplicationMonitor -AllowPrerelease -AcceptLicense -``` --> [!NOTE] -> The `AllowPrerelease` switch in the `Install-Module` cmdlet allows installation of the beta release. -> -> For more information, see [Install-Module](/powershell/module/powershellget/install-module#parameters). -> --#### Enable monitoring --```powershell -Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope Process -Force -Enable-ApplicationInsightsMonitoring -ConnectionString 'InstrumentationKey=00000000-0000-0000-0000-000000000000;IngestionEndpoint=https://xxxx.applicationinsights.azure.com/' -``` --### Download and install manually (offline option) --You can also download and install manually. --#### Download the module -Manually download the latest version of the module from [PowerShell Gallery](https://www.powershellgallery.com/packages/Az.ApplicationMonitor). --#### Unzip and install Application Insights Agent --```powershell -$pathToNupkg = "C:\Users\t\Desktop\Az.ApplicationMonitor.0.3.0-alpha.nupkg" -$pathToZip = ([io.path]::ChangeExtension($pathToNupkg, "zip")) -$pathToNupkg | rename-item -newname $pathToZip -$pathInstalledModule = "$Env:ProgramFiles\WindowsPowerShell\Modules\Az.ApplicationMonitor" -Expand-Archive -LiteralPath $pathToZip -DestinationPath $pathInstalledModule -``` --#### Enable monitoring --```powershell -Enable-ApplicationInsightsMonitoring -ConnectionString 'InstrumentationKey=00000000-0000-0000-0000-000000000000;IngestionEndpoint=https://xxxx.applicationinsights.azure.com/' -``` --### [Detailed instructions](#tab/detailed-instructions) --This tab describes how to onboard to the PowerShell Gallery and download the ApplicationMonitor module. -Included are the most common parameters that you need to get started. -We've also provided manual download instructions in case you don't have internet access. --### Get a connection string --To get started, you need a connection string. For more information, see [Connection strings](sdk-connection-string.md). ---### Run PowerShell as Admin with an elevated execution policy --#### Run as Admin --PowerShell needs Administrator-level permissions to make changes to your computer. -#### Execution policy -- Description: By default, running PowerShell scripts is disabled. We recommend allowing RemoteSigned scripts for only the Current scope.-- Reference: [About Execution Policies](/powershell/module/microsoft.powershell.core/about/about_execution_policies) and [Set-ExecutionPolicy](/powershell/module/microsoft.powershell.security/set-executionpolicy).-- Command: `Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope Process`.-- Optional parameter:- - `-Force`. Bypasses the confirmation prompt. --**Example errors** --```output -Install-Module : The 'Install-Module' command was found in the module 'PowerShellGet', but the module could not be -loaded. For more information, run 'Import-Module PowerShellGet'. --Import-Module : File C:\Program Files\WindowsPowerShell\Modules\PackageManagement\1.3.1\PackageManagement.psm1 cannot -be loaded because running scripts is disabled on this system. For more information, see about_Execution_Policies at https://go.microsoft.com/fwlink/?LinkID=135170. -``` --### Prerequisites for PowerShell --Audit your instance of PowerShell by running the `$PSVersionTable` command. -This command produces the following output: --```output -Name Value -- ---PSVersion 5.1.17763.316 -PSEdition Desktop -PSCompatibleVersions {1.0, 2.0, 3.0, 4.0...} -BuildVersion 10.0.17763.316 -CLRVersion 4.0.30319.42000 -WSManStackVersion 3.0 -PSRemotingProtocolVersion 2.3 -SerializationVersion 1.1.0.1 -``` --These instructions were written and tested on a computer running Windows 10 and the following versions. --### Prerequisites for PowerShell Gallery --These steps prepare your server to download modules from PowerShell Gallery. --> [!NOTE] -> PowerShell Gallery is supported on Windows 10, Windows Server 2016, and PowerShell 6+. -> For information about earlier versions, see [Installing PowerShellGet](/powershell/gallery/powershellget/install-powershellget). ---1. Run PowerShell as Admin with an elevated execution policy. -2. Install the NuGet package provider. - - Description: You need this provider to interact with NuGet-based repositories like PowerShell Gallery. - - Reference: [Install-PackageProvider](/powershell/module/packagemanagement/install-packageprovider). - - Command: `Install-PackageProvider -Name NuGet -MinimumVersion 2.8.5.201`. - - Optional parameters: - - `-Proxy`. Specifies a proxy server for the request. - - `-Force`. Bypasses the confirmation prompt. -- You receive this prompt if NuGet isn't set up: -- ```output - NuGet provider is required to continue - PowerShellGet requires NuGet provider version '2.8.5.201' or newer to interact with NuGet-based repositories. - The NuGet provider must be available in 'C:\Program Files\PackageManagement\ProviderAssemblies' or - 'C:\Users\t\AppData\Local\PackageManagement\ProviderAssemblies'. You can also install the NuGet provider by running - 'Install-PackageProvider -Name NuGet -MinimumVersion 2.8.5.201 -Force'. Do you want PowerShellGet to install and import - the NuGet provider now? - [Y] Yes [N] No [S] Suspend [?] Help (default is "Y"): - ``` --3. Configure PowerShell Gallery as a trusted repository. - - Description: By default, PowerShell Gallery is an untrusted repository. - - Reference: [Set-PSRepository](/powershell/module/powershellget/set-psrepository). - - Command: `Set-PSRepository -Name "PSGallery" -InstallationPolicy Trusted`. - - Optional parameter: - - `-Proxy`. Specifies a proxy server for the request. -- You receive this prompt if PowerShell Gallery isn't trusted: -- ```output - Untrusted repository - You are installing the modules from an untrusted repository. - If you trust this repository, change its InstallationPolicy value - by running the Set-PSRepository cmdlet. Are you sure you want to - install the modules from 'PSGallery'? - [Y] Yes [A] Yes to All [N] No [L] No to All [S] Suspend [?] Help (default is "N"): - ``` -- You can confirm this change and audit all `PSRepositories` by running the `Get-PSRepository` command. --4. Install the newest version of PowerShellGet. - - Description: This module contains the tooling used to get other modules from PowerShell Gallery. Version 1.0.0.1 ships with Windows 10 and Windows Server. Version 1.6.0 or higher is required. To determine which version is installed, run the `Get-Command -Module PowerShellGet` command. - - Reference: [Installing PowerShellGet](/powershell/gallery/powershellget/install-powershellget). - - Command: `Install-Module -Name PowerShellGet`. - - Optional parameters: - - `-Proxy`. Specifies a proxy server for the request. - - `-Force`. Bypasses the "already installed" warning and installs the latest version. -- You receive this error if you're not using the newest version of PowerShellGet: -- ```output - Install-Module : A parameter cannot be found that matches parameter name 'AllowPrerelease'. - At line:1 char:20 - Install-Module abc -AllowPrerelease - ~~~~~~~~~~~~~~~~ - CategoryInfo : InvalidArgument: (:) [Install-Module], ParameterBindingException - FullyQualifiedErrorId : NamedParameterNotFound,Install-Module - ``` --5. Restart PowerShell. You can't load the new version in the current session. New PowerShell sessions load the latest version of PowerShellGet. --### Download and install the module via PowerShell Gallery --These steps download the Az.ApplicationMonitor module from PowerShell Gallery. --1. Ensure that all prerequisites for PowerShell Gallery are met. -2. Run PowerShell as Admin with an elevated execution policy. -3. Install the Az.ApplicationMonitor module. - - Reference: [Install-Module](/powershell/module/powershellget/install-module). - - Command: `Install-Module -Name Az.ApplicationMonitor`. - - Optional parameters: - - `-Proxy`. Specifies a proxy server for the request. - - `-AllowPrerelease`. Allows installation of alpha and beta releases. - - `-AcceptLicense`. Bypasses the "Accept License" prompt - - `-Force`. Bypasses the "Untrusted Repository" warning. --### Download and install the module manually (offline option) --If for any reason you can't connect to the PowerShell module, you can manually download and install the Az.ApplicationMonitor module. --#### Manually download the latest nupkg file --1. Go to https://www.powershellgallery.com/packages/Az.ApplicationMonitor. -2. Select the latest version of the file in the **Version History** table. -3. Under **Installation Options**, select **Manual Download**. --#### Option 1: Install into a PowerShell modules directory -Install the manually downloaded PowerShell module into a PowerShell directory so it's discoverable by PowerShell sessions. -For more information, see [Installing a PowerShell Module](/powershell/scripting/developer/module/installing-a-powershell-module). ---##### Unzip nupkg as a zip file by using Expand-Archive (v1.0.1.0) --- Description: The base version of Microsoft.PowerShell.Archive (v1.0.1.0) can't unzip nupkg files. Rename the file with the .zip extension.-- Reference: [Expand-Archive](/powershell/module/microsoft.powershell.archive/expand-archive).-- Command:-- ```console - $pathToNupkg = "C:\az.applicationmonitor.0.3.0-alpha.nupkg" - $pathToZip = ([io.path]::ChangeExtension($pathToNupkg, "zip")) - $pathToNupkg | rename-item -newname $pathToZip - $pathInstalledModule = "$Env:ProgramFiles\WindowsPowerShell\Modules\az.applicationmonitor" - Expand-Archive -LiteralPath $pathToZip -DestinationPath $pathInstalledModule - ``` --##### Unzip nupkg by using Expand-Archive (v1.1.0.0) --- Description: Use a current version of Expand-Archive to unzip nupkg files without changing the extension.-- Reference: [Expand-Archive](/powershell/module/microsoft.powershell.archive/expand-archive) and [Microsoft.PowerShell.Archive](https://www.powershellgallery.com/packages/Microsoft.PowerShell.Archive/1.1.0.0).-- Command:-- ```console - $pathToNupkg = "C:\az.applicationmonitor.0.2.1-alpha.nupkg" - $pathInstalledModule = "$Env:ProgramFiles\WindowsPowerShell\Modules\az.applicationmonitor" - Expand-Archive -LiteralPath $pathToNupkg -DestinationPath $pathInstalledModule - ``` --#### Option 2: Unzip and import nupkg manually -Install the manually downloaded PowerShell module into a PowerShell directory so it's discoverable by PowerShell sessions. -For more information, see [Installing a PowerShell Module](/powershell/scripting/developer/module/installing-a-powershell-module). --If you're installing the module into any other directory, manually import the module by using [Import-Module](/powershell/module/microsoft.powershell.core/import-module). --> [!IMPORTANT] -> DLLs will install via relative paths. -> Store the contents of the package in your intended runtime directory and confirm that access permissions allow read but not write. --1. Change the extension to ".zip" and extract the contents of the package into your intended installation directory. -2. Find the file path of Az.ApplicationMonitor.psd1. -3. Run PowerShell as Admin with an elevated execution policy. -4. Load the module by using the `Import-Module Az.ApplicationMonitor.psd1` command. ---### Route traffic through a proxy --When you monitor a computer on your private intranet, you need to route HTTP traffic through a proxy. --The PowerShell commands to download and install Az.ApplicationMonitor from the PowerShell Gallery support a `-Proxy` parameter. -Review the preceding instructions when you write your installation scripts. --The Application Insights SDK needs to send your app's telemetry to Microsoft. We recommend that you configure proxy settings for your app in your web.config file. For more information, see [How do I achieve proxy passthrough?](#how-do-i-achieve-proxy-passthrough). ---### Enable monitoring --Use the `Enable-ApplicationInsightsMonitoring` command to enable monitoring. --See the [API reference](?tabs=api-reference#enable-applicationinsightsmonitoring) for a detailed description of how to use this cmdlet. --### [API reference](#tab/api-reference) --This tab describes the following cmdlets, which are members of the [Az.ApplicationMonitor PowerShell module](https://www.powershellgallery.com/packages/Az.ApplicationMonitor/): --- [Enable-InstrumentationEngine](?tabs=api-reference#enable-instrumentationengine)-- [Enable-ApplicationInsightsMonitoring](?tabs=api-reference#enable-applicationinsightsmonitoring)-- [Disable-InstrumentationEngine](?tabs=api-reference#disable-instrumentationengine)-- [Disable-ApplicationInsightsMonitoring](?tabs=api-reference#disable-applicationinsightsmonitoring)-- [Get-ApplicationInsightsMonitoringConfig](?tabs=api-reference#get-applicationinsightsmonitoringconfig)-- [Get-ApplicationInsightsMonitoringStatus](?tabs=api-reference#get-applicationinsightsmonitoringstatus)-- [Set-ApplicationInsightsMonitoringConfig](?tabs=api-reference#set-applicationinsightsmonitoringconfig)-- [Start-ApplicationInsightsMonitoringTrace](?tabs=api-reference#start-applicationinsightsmonitoringtrace)--> [!NOTE] -> - To get started, you need a connection string. For more information, see [Create a resource](create-workspace-resource.md). -> - This cmdlet requires that you review and accept our license and privacy statement. ---> [!IMPORTANT] -> This cmdlet requires a PowerShell session with Admin permissions and an elevated execution policy. For more information, see [Run PowerShell as administrator with an elevated execution policy](?tabs=detailed-instructions#run-powershell-as-admin-with-an-elevated-execution-policy). -> - This cmdlet requires that you review and accept our license and privacy statement. -> - The instrumentation engine adds additional overhead and is off by default. --### Enable-InstrumentationEngine --Enables the instrumentation engine by setting some registry keys. -Restart IIS for the changes to take effect. --The instrumentation engine can supplement data collected by the .NET SDKs. -It collects events and messages that describe the execution of a managed process. These events and messages include dependency result codes, HTTP verbs, and [SQL command text](asp-net-dependencies.md#advanced-sql-tracking-to-get-full-sql-query). --Enable the instrumentation engine if: -- You've already enabled monitoring with the Enable cmdlet but didn't enable the instrumentation engine.-- You've manually instrumented your app with the .NET SDKs and want to collect extra telemetry.--#### Examples --```powershell -Enable-InstrumentationEngine -``` --#### Parameters --##### -AcceptLicense -**Optional.** Use this switch to accept the license and privacy statement in headless installations. --##### -Verbose -**Common parameter.** Use this switch to output detailed logs. --#### Output ---###### Example output from successfully enabling the instrumentation engine --``` -Configuring IIS Environment for instrumentation engine... -Configuring registry for instrumentation engine... -``` --### Enable-ApplicationInsightsMonitoring --Enables codeless attach monitoring of IIS apps on a target computer. --This cmdlet modifies the IIS applicationHost.config and sets some registry keys. -It creates an applicationinsights.ikey.config file, which defines the instrumentation key used by each app. -IIS loads the RedfieldModule on startup, which injects the Application Insights SDK into applications as the applications start. -Restart IIS for your changes to take effect. --After you enable monitoring, we recommend that you use [Live Metrics](live-stream.md) to quickly check if your app is sending us telemetry. --#### Examples --##### Example with a single connection string -In this example, all apps on the current computer are assigned a single connection string. --```powershell -Enable-ApplicationInsightsMonitoring -ConnectionString 'InstrumentationKey=xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx;IngestionEndpoint=https://xxxx.applicationinsights.azure.com/' -``` --##### Example with a single instrumentation key -In this example, all apps on the current computer are assigned a single instrumentation key. --```powershell -Enable-ApplicationInsightsMonitoring -InstrumentationKey xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx -``` --##### Example with an instrumentation key map -In this example: -- `MachineFilter` matches the current computer by using the `'.*'` wildcard.-- `AppFilter='WebAppExclude'` provides a `null` instrumentation key. The specified app isn't instrumented.-- `AppFilter='WebAppOne'` assigns the specified app a unique instrumentation key.-- `AppFilter='WebAppTwo'` assigns the specified app a unique instrumentation key.-- `AppFilter` uses the `'.*'` wildcard to match any web apps it doesn't already match and assigns a default instrumentation key.-- Spaces are added for readability.--```powershell -Enable-ApplicationInsightsMonitoring -InstrumentationKeyMap ` - ` @(@{MachineFilter='.*';AppFilter='WebAppExclude'}, - ` @{MachineFilter='.*';AppFilter='WebAppOne';InstrumentationSettings=@{InstrumentationKey='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx1'}}, - ` @{MachineFilter='.*';AppFilter='WebAppTwo';InstrumentationSettings=@{InstrumentationKey='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx2'}}, - ` @{MachineFilter='.*';AppFilter='.*';InstrumentationSettings=@{InstrumentationKey='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxdefault'}}) -``` --> [!NOTE] -> The naming of AppFilter in this context can be confusing, `AppFilter` sets the application name regex filter (HostingEnvironment.SiteName in the case of .NET on IIS). `VirtualPathFilter` sets the virtual path regex filter (HostingEnvironment.ApplicationVirtualPath in the case of .NET on IIS). To instrument a single app you would use the VirtualPathFilter as follows: `Enable-ApplicationInsightsMonitoring -InstrumentationKeyMap @(@{VirtualPathFilter="^/MyAppName$"; InstrumentationSettings=@{InstrumentationKey='<your ikey>'}})` --#### Parameters --##### -ConnectionString -**Required.** Use this parameter to supply a single connection string for use by all apps on the target computer. --##### -InstrumentationKey -**Required.** Use this parameter to supply a single instrumentation key for use by all apps on the target computer. --##### -InstrumentationKeyMap -**Required.** Use this parameter to supply multiple instrumentation keys and a mapping of the instrumentation keys used by each app. -You can create a single installation script for several computers by setting `MachineFilter`. --> [!IMPORTANT] -> Apps matches against rules in the order that the rules are provided. So you should specify the most specific rules first and the most generic rules last. --###### Schema -`@(@{MachineFilter='.*';AppFilter='.*';InstrumentationSettings=@{InstrumentationKey='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx'}})` --- **MachineFilter** is a required C# regex of the computer or VM name.- - '.*' matches all - - 'ComputerName' matches only computers with the exact name specified. -- **AppFilter** is a required C# regex of the IIS Site Name. You can get a list of sites on your server by running the command [get-iissite](/powershell/module/iisadministration/get-iissite).- - '.*' matches all - - 'SiteName' matches only the IIS Site with the exact name specified. -- **InstrumentationKey** is required to enable monitoring of apps that match the preceding two filters.- - Leave this value null if you want to define rules to exclude monitoring. ---##### -EnableInstrumentationEngine -**Optional.** Use this switch to enable the instrumentation engine to collect events and messages about what's happening during the execution of a managed process. These events and messages include dependency result codes, HTTP verbs, and SQL command text. --The instrumentation engine adds overhead and is off by default. --##### -AcceptLicense -**Optional.** Use this switch to accept the license and privacy statement in headless installations. --##### -IgnoreSharedConfig -When you have a cluster of web servers, you might be using a [shared configuration](/iis/web-hosting/configuring-servers-in-the-windows-web-platform/shared-configuration_211). -The HttpModule can't be injected into this shared configuration. -This script fails with the message that extra installation steps are required. -Use this switch to ignore this check and continue installing prerequisites. -For more information, see [known conflict-with-iis-shared-configuration](status-monitor-v2-troubleshoot.md#conflict-with-iis-shared-configuration) --##### -Verbose -**Common parameter.** Use this switch to display detailed logs. --##### -WhatIf -**Common parameter.** Use this switch to test and validate your input parameters without actually enabling monitoring. --#### Output --##### Example output from a successful enablement --```powershell -Initiating Disable Process -Applying transformation to 'C:\Windows\System32\inetsrv\config\applicationHost.config' -'C:\Windows\System32\inetsrv\config\applicationHost.config' backed up to 'C:\Windows\System32\inetsrv\config\applicationHost.config.backup-2019-03-26_08-59-52z' -in :1,237 -No element in the source document matches '/configuration/location[@path='']/system.webServer/modules/add[@name='ManagedHttpModuleHelper']' -Not executing RemoveAll (transform line 1, 546) -Transformation to 'C:\Windows\System32\inetsrv\config\applicationHost.config' was successfully applied. Operation: 'disable' -GAC Module will not be removed, since this operation might cause IIS instabilities -Configuring IIS Environment for codeless attach... -Registry: skipping non-existent 'HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\IISADMIN[Environment] -Registry: skipping non-existent 'HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W3SVC[Environment] -Registry: skipping non-existent 'HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\WAS[Environment] -Configuring IIS Environment for instrumentation engine... -Registry: skipping non-existent 'HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\IISADMIN[Environment] -Registry: skipping non-existent 'HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W3SVC[Environment] -Registry: skipping non-existent 'HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\WAS[Environment] -Configuring registry for instrumentation engine... -Successfully disabled Application Insights Agent -Installing GAC module 'C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\0.2.0\content\Runtime\Microsoft.AppInsights.IIS.ManagedHttpModuleHelper.dll' -Applying transformation to 'C:\Windows\System32\inetsrv\config\applicationHost.config' -Found GAC module Microsoft.AppInsights.IIS.ManagedHttpModuleHelper.ManagedHttpModuleHelper, Microsoft.AppInsights.IIS.ManagedHttpModuleHelper, Version=1.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35 -'C:\Windows\System32\inetsrv\config\applicationHost.config' backed up to 'C:\Windows\System32\inetsrv\config\applicationHost.config.backup-2019-03-26_08-59-52z_1' -Transformation to 'C:\Windows\System32\inetsrv\config\applicationHost.config' was successfully applied. Operation: 'enable' -Configuring IIS Environment for codeless attach... -Configuring IIS Environment for instrumentation engine... -Configuring registry for instrumentation engine... -Updating app pool permissions... -Successfully enabled Application Insights Agent -``` --### Disable-InstrumentationEngine --Disables the instrumentation engine by removing some registry keys. -Restart IIS for the changes to take effect. --#### Examples --```powershell -Disable-InstrumentationEngine -``` --#### Parameters --##### -Verbose -**Common parameter.** Use this switch to output detailed logs. --#### Output ---###### Example output from successfully disabling the instrumentation engine --```powershell -Configuring IIS Environment for instrumentation engine... -Registry: removing 'HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\IISADMIN[Environment]' -Registry: removing 'HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W3SVC[Environment]' -Registry: removing 'HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\WAS[Environment]' -Configuring registry for instrumentation engine... -``` --### Disable-ApplicationInsightsMonitoring --Disables monitoring on the target computer. -This cmdlet removes edits to the IIS applicationHost.config and remove registry keys. --#### Examples --```powershell -Disable-ApplicationInsightsMonitoring -``` --#### Parameters --##### -Verbose -**Common parameter.** Use this switch to display detailed logs. --#### Output ---###### Example output from successfully disabling monitoring --```powershell -Initiating Disable Process -Applying transformation to 'C:\Windows\System32\inetsrv\config\applicationHost.config' -'C:\Windows\System32\inetsrv\config\applicationHost.config' backed up to 'C:\Windows\System32\inetsrv\config\applicationHost.config.backup-2019-03-26_08-59-00z' -in :1,237 -No element in the source document matches '/configuration/location[@path='']/system.webServer/modules/add[@name='ManagedHttpModuleHelper']' -Not executing RemoveAll (transform line 1, 546) -Transformation to 'C:\Windows\System32\inetsrv\config\applicationHost.config' was successfully applied. Operation: 'disable' -GAC Module will not be removed, since this operation might cause IIS instabilities -Configuring IIS Environment for codeless attach... -Registry: skipping non-existent 'HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\IISADMIN[Environment] -Registry: skipping non-existent 'HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W3SVC[Environment] -Registry: skipping non-existent 'HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\WAS[Environment] -Configuring IIS Environment for instrumentation engine... -Registry: skipping non-existent 'HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\IISADMIN[Environment] -Registry: skipping non-existent 'HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W3SVC[Environment] -Registry: skipping non-existent 'HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\WAS[Environment] -Configuring registry for instrumentation engine... -Successfully disabled Application Insights Agent -``` ---### Get-ApplicationInsightsMonitoringConfig --Gets the config file and prints the values to the console. --#### Examples --```powershell -Get-ApplicationInsightsMonitoringConfig -``` --#### Parameters --No parameters required. --#### Output ---###### Example output from reading the config file --``` -RedfieldConfiguration: -Filters: -0)InstrumentationKey: AppFilter: WebAppExclude MachineFilter: .* -1)InstrumentationKey: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx2 AppFilter: WebAppTwo MachineFilter: .* -2)InstrumentationKey: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxdefault AppFilter: .* MachineFilter: .* -``` --### Get-ApplicationInsightsMonitoringStatus --This cmdlet provides troubleshooting information about Application Insights Agent. -Use this cmdlet to investigate the monitoring status, version of the PowerShell Module, and to inspect the running process. -This cmdlet reports version information and information about key files required for monitoring. --#### Examples --##### Example: Application status --Run the command `Get-ApplicationInsightsMonitoringStatus` to display the monitoring status of web sites. --```powershell -Get-ApplicationInsightsMonitoringStatus --IIS Websites: --SiteName : Default Web Site -ApplicationPoolName : DefaultAppPool -SiteId : 1 -SiteState : Stopped --SiteName : DemoWebApp111 -ApplicationPoolName : DemoWebApp111 -SiteId : 2 -SiteState : Started -ProcessId : not found --SiteName : DemoWebApp222 -ApplicationPoolName : DemoWebApp222 -SiteId : 3 -SiteState : Started -ProcessId : 2024 -Instrumented : true -InstrumentationKey : xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxx123 --SiteName : DemoWebApp333 -ApplicationPoolName : DemoWebApp333 -SiteId : 4 -SiteState : Started -ProcessId : 5184 -AppAlreadyInstrumented : true -``` --In this example; -- **Machine Identifier** is an anonymous ID used to uniquely identify your server. If you create a support request, we need this ID to find logs for your server.-- **Default Web Site** is Stopped in IIS-- **DemoWebApp111** has been started in IIS, but hasn't received any requests. This report shows that there's no running process (ProcessId: not found).-- **DemoWebApp222** is running and is being monitored (Instrumented: true). Based on the user configuration, Instrumentation Key xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxx123 was matched for this site.-- **DemoWebApp333** has been manually instrumented using the Application Insights SDK. Application Insights Agent detected the SDK and doesn't monitor this site.---- The presence of `AppAlreadyInstrumented : true` signifies that the Application Insights agent identified a [conflicting dll](/troubleshoot/azure/azure-monitor/app-insights/agent/status-monitor-v2-troubleshoot) loaded in the web application, assumed that the web app is manually instrumented, and the agent has backed-off and is not instrumenting this process.--- `Instrumented : true` indicates that the Application Insights agent successfully instrumented the web app running in the specified w3wp.exe process.--##### Example: PowerShell module information --Run the command `Get-ApplicationInsightsMonitoringStatus -PowerShellModule` to display information about the current module: --```powershell -Get-ApplicationInsightsMonitoringStatus -PowerShellModule --PowerShell Module version: -0.4.0-alpha --Application Insights SDK version: -2.9.0.3872 --Executing PowerShell Module Assembly: -Microsoft.ApplicationInsights.Redfield.Configurator.PowerShell, Version=2.8.14.11432, Culture=neutral, PublicKeyToken=31bf3856ad364e35 --PowerShell Module Directory: -C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\0.2.2\content\PowerShell --Runtime Paths: -ParentDirectory (Exists: True) -C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content --ConfigurationPath (Exists: True) -C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\applicationInsights.ikey.config --ManagedHttpModuleHelperPath (Exists: True) -C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Runtime\Microsoft.AppInsights.IIS.ManagedHttpModuleHelper.dll --RedfieldIISModulePath (Exists: True) -C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Runtime\Microsoft.ApplicationInsights.RedfieldIISModule.dll --InstrumentationEngine86Path (Exists: True) -C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Instrumentation32\MicrosoftInstrumentationEngine_x86.dll --InstrumentationEngine64Path (Exists: True) -C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Instrumentation64\MicrosoftInstrumentationEngine_x64.dll --InstrumentationEngineExtensionHost86Path (Exists: True) -C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Instrumentation32\Microsoft.ApplicationInsights.ExtensionsHost_x86.dll --InstrumentationEngineExtensionHost64Path (Exists: True) -C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Instrumentation64\Microsoft.ApplicationInsights.ExtensionsHost_x64.dll --InstrumentationEngineExtensionConfig86Path (Exists: True) -C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Instrumentation32\Microsoft.InstrumentationEngine.Extensions.config --InstrumentationEngineExtensionConfig64Path (Exists: True) -C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Instrumentation64\Microsoft.InstrumentationEngine.Extensions.config --ApplicationInsightsSdkPath (Exists: True) -C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Runtime\Microsoft.ApplicationInsights.dll -``` --##### Example: Runtime status --You can inspect the process on the instrumented computer to see if all DLLs are loaded. If monitoring is working, at least 12 DLLs should be loaded. --Run the command `Get-ApplicationInsightsMonitoringStatus -InspectProcess`: ---``` -Get-ApplicationInsightsMonitoringStatus -InspectProcess --iisreset.exe /status -Status for IIS Admin Service ( IISADMIN ) : Running -Status for Windows Process Activation Service ( WAS ) : Running -Status for Net.Msmq Listener Adapter ( NetMsmqActivator ) : Running -Status for Net.Pipe Listener Adapter ( NetPipeActivator ) : Running -Status for Net.Tcp Listener Adapter ( NetTcpActivator ) : Running -Status for World Wide Web Publishing Service ( W3SVC ) : Running --handle64.exe -accepteula -p w3wp -BF0: File (R-D) C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Runtime\Microsoft.AI.ServerTelemetryChannel.dll -C58: File (R-D) C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Runtime\Microsoft.AI.AzureAppServices.dll -C68: File (R-D) C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Runtime\Microsoft.AI.DependencyCollector.dll -C78: File (R-D) C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Runtime\Microsoft.AI.WindowsServer.dll -C98: File (R-D) C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Runtime\Microsoft.AI.Web.dll -CBC: File (R-D) C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Runtime\Microsoft.AI.PerfCounterCollector.dll -DB0: File (R-D) C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Runtime\Microsoft.AI.Agent.Intercept.dll -B98: File (R-D) C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Runtime\Microsoft.ApplicationInsights.RedfieldIISModule.dll -BB4: File (R-D) C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Runtime\Microsoft.ApplicationInsights.RedfieldIISModule.Contracts.dll -BCC: File (R-D) C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Runtime\Microsoft.ApplicationInsights.Redfield.Lightup.dll -BE0: File (R-D) C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Runtime\Microsoft.ApplicationInsights.dll --listdlls64.exe -accepteula w3wp -0x0000000019ac0000 0x127000 C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Instrumentation64\MicrosoftInstrumentationEngine_x64.dll -0x00000000198b0000 0x4f000 C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Instrumentation64\Microsoft.ApplicationInsights.ExtensionsHost_x64.dll -0x000000000c460000 0xb2000 C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Instrumentation64\Microsoft.ApplicationInsights.Extensions.Base_x64.dll -0x000000000ad60000 0x108000 C:\Windows\TEMP\2.4.0.0.Microsoft.ApplicationInsights.Extensions.Intercept_x64.dll -``` --#### Parameters --##### (No parameters) --By default, this cmdlet reports the monitoring status of web applications. -Use this option to review if your application was successfully instrumented. -You can also review which Instrumentation Key was matched to your site. ---##### -PowerShellModule -**Optional**. Use this switch to report the version numbers and paths of DLLs required for monitoring. -Use this option if you need to identify the version of any DLL, including the Application Insights SDK. --##### -InspectProcess --**Optional**. Use this switch to report whether IIS is running. -It downloads external tools to determine if the necessary DLLs are loaded into the IIS runtime. ---If this process fails for any reason, you can run these commands manually: -- iisreset.exe /status-- [handle64.exe](/sysinternals/downloads/handle) -p w3wp | findstr /I "InstrumentationEngine AI. ApplicationInsights"-- [listdlls64.exe](/sysinternals/downloads/listdlls) w3wp | findstr /I "InstrumentationEngine AI ApplicationInsights"---##### -Force --**Optional**. Used only with InspectProcess. Use this switch to skip the user prompt that appears before more tools are downloaded. ---### Set-ApplicationInsightsMonitoringConfig --Sets the config file without doing a full reinstallation. -Restart IIS for your changes to take effect. --> [!IMPORTANT] -> This cmdlet requires a PowerShell session with Admin permissions. ---#### Examples --##### Example with a single instrumentation key -In this example, all apps on the current computer are assigned a single instrumentation key. --```powershell -Enable-ApplicationInsightsMonitoring -InstrumentationKey xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx -``` --##### Example with an instrumentation key map -In this example: -- `MachineFilter` matches the current computer by using the `'.*'` wildcard.-- `AppFilter='WebAppExclude'` provides a `null` instrumentation key. The specified app isn't instrumented.-- `AppFilter='WebAppOne'` assigns the specified app a unique instrumentation key.-- `AppFilter='WebAppTwo'` assigns the specified app a unique instrumentation key.-- `AppFilter` uses the `'.*'` wildcard to match web apps it doesn't already match and assigns a default instrumentation key.-- Spaces are added for readability.--```powershell -Enable-ApplicationInsightsMonitoring -InstrumentationKeyMap ` - ` @(@{MachineFilter='.*';AppFilter='WebAppExclude'}, - ` @{MachineFilter='.*';AppFilter='WebAppOne';InstrumentationSettings=@{InstrumentationKey='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx1'}}, - ` @{MachineFilter='.*';AppFilter='WebAppTwo';InstrumentationSettings=@{InstrumentationKey='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx2'}}, - ` @{MachineFilter='.*';AppFilter='.*';InstrumentationSettings=@{InstrumentationKey='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxdefault'}}) -``` --#### Parameters --##### -InstrumentationKey -**Required.** Use this parameter to supply a single instrumentation key for use by all apps on the target computer. --##### -InstrumentationKeyMap -**Required.** Use this parameter to supply multiple instrumentation keys and a mapping of the instrumentation keys used by each app. -You can create a single installation script for several computers by setting `MachineFilter`. --> [!IMPORTANT] -> Apps matches against rules in the order that the rules are provided. So you should specify the most specific rules first and the most generic rules last. --###### Schema -`@(@{MachineFilter='.*';AppFilter='.*';InstrumentationKey='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx'})` --- **MachineFilter** is a required C# regex of the computer or VM name.- - '.*' matches all - - 'ComputerName' matches only computers with the specified name. -- **AppFilter** is a required C# regex of the computer or VM name.- - '.*' matches all - - 'ApplicationName' matches only IIS apps with the specified name. -- **InstrumentationKey** is required to enable monitoring of the apps that match the preceding two filters.- - Leave this value null if you want to define rules to exclude monitoring. ---##### -Verbose -**Common parameter.** Use this switch to display detailed logs. ---#### Output --By default, no output. --###### Example verbose output from setting the config file via -InstrumentationKey --``` -VERBOSE: Operation: InstallWithIkey -VERBOSE: InstrumentationKeyMap parsed: -Filters: -0)InstrumentationKey: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx AppFilter: .* MachineFilter: .* -VERBOSE: set config file -VERBOSE: Config File Path: -C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\applicationInsights.ikey.config -``` --###### Example verbose output from setting the config file via -InstrumentationKeyMap --``` -VERBOSE: Operation: InstallWithIkeyMap -VERBOSE: InstrumentationKeyMap parsed: -Filters: -0)InstrumentationKey: AppFilter: WebAppExclude MachineFilter: .* -1)InstrumentationKey: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx2 AppFilter: WebAppTwo MachineFilter: .* -2)InstrumentationKey: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxdefault AppFilter: .* MachineFilter: .* -VERBOSE: set config file -VERBOSE: Config File Path: -C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\applicationInsights.ikey.config -``` --### Start-ApplicationInsightsMonitoringTrace --Collects [ETW Events](/windows/desktop/etw/event-tracing-portal) from the codeless attach runtime. -This cmdlet is an alternative to running [PerfView](https://github.com/microsoft/perfview). --Events are collected, printed to the console in real-time, and saved to an ETL file. You can open the output ETL file with [PerfView](https://github.com/microsoft/perfview) for further investigation. --This cmdlet runs until it reaches the timeout duration (default 5 minutes) or is stopped manually (`Ctrl + C`). --#### Examples --##### How to collect events --Normally we would ask that you collect events to investigate why your application isn't being instrumented. --The codeless attach runtime emits ETW events when IIS starts up and when your application starts up. --To collect these events: -1. In a cmd console with admin privileges, execute `iisreset /stop` to stop IIS and all web apps. -2. Execute this cmdlet -3. In a cmd console with admin privileges, execute `iisreset /start` to start IIS. -4. Try to browse to your app. -5. After your app finishes loading, you can manually stop it (`Ctrl + C`) or wait for the timeout. --##### What events to collect --You have three options when collecting events: -1. Use the switch `-CollectSdkEvents` to collect events emitted from the Application Insights SDK. -2. Use the switch `-CollectRedfieldEvents` to collect events emitted by Application Insights Agent and the Redfield Runtime. These logs are helpful when diagnosing IIS and application startup. -3. Use both switches to collect both event types. -4. By default, if no switch is specified both event types are collected. ---#### Parameters --##### -MaxDurationInMinutes -**Optional.** Use this parameter to set how long this script should collect events. Default is 5 minutes. --##### -LogDirectory -**Optional.** Use this switch to set the output directory of the ETL file. -By default, this file is created in the PowerShell Modules directory. -The full path is displayed during script execution. ---##### -CollectSdkEvents -**Optional.** Use this switch to collect Application Insights SDK events. --##### -CollectRedfieldEvents -**Optional.** Use this switch to collect events from Application Insights Agent and the Redfield runtime. --##### -Verbose -**Common parameter.** Use this switch to output detailed logs. ----#### Output ---##### Example of application startup logs -```powershell -Start-ApplicationInsightsMonitoringTrace -CollectRedfieldEvents -Starting... -Log File: C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\logs\20190627_144217_ApplicationInsights_ETW_Trace.etl -Tracing enabled, waiting for events. -Tracing will timeout in 5 minutes. Press CTRL+C to cancel. --2:42:31 PM EVENT: Microsoft-ApplicationInsights-IIS-ManagedHttpModuleHelper Trace Resolved variables to: MicrosoftAppInsights_ManagedHttpModulePath='C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Runtime\Microsoft.ApplicationInsights.RedfieldIISModule.dll', MicrosoftAppInsights_ManagedHttpModuleType='Microsoft.ApplicationInsights.RedfieldIISModule.RedfieldIISModule' -2:42:31 PM EVENT: Microsoft-ApplicationInsights-IIS-ManagedHttpModuleHelper Trace Resolved variables to: MicrosoftDiagnosticServices_ManagedHttpModulePath2='', MicrosoftDiagnosticServices_ManagedHttpModuleType2='' -2:42:31 PM EVENT: Microsoft-ApplicationInsights-IIS-ManagedHttpModuleHelper Trace Environment variable 'MicrosoftDiagnosticServices_ManagedHttpModulePath2' or 'MicrosoftDiagnosticServices_ManagedHttpModuleType2' is null, skipping managed dll loading -2:42:31 PM EVENT: Microsoft-ApplicationInsights-IIS-ManagedHttpModuleHelper Trace MulticastHttpModule.constructor, success, 70 ms -2:42:31 PM EVENT: Microsoft-ApplicationInsights-RedfieldIISModule Trace Current assembly 'Microsoft.ApplicationInsights.RedfieldIISModule, Version=2.8.18.27202, Culture=neutral, PublicKeyToken=f23a46de0be5d6f3' location 'C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Runtime\Microsoft.ApplicationInsights.RedfieldIISModule.dll' -2:42:31 PM EVENT: Microsoft-ApplicationInsights-RedfieldIISModule Trace Matched filter '.*'~'STATUSMONITORTE', '.*'~'DemoWithSql' -2:42:31 PM EVENT: Microsoft-ApplicationInsights-RedfieldIISModule Trace Lightup assembly calculated path: 'C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Runtime\Microsoft.ApplicationInsights.Redfield.Lightup.dll' -2:42:31 PM EVENT: Microsoft-ApplicationInsights-FrameworkLightup Trace Loaded applicationInsights.config from assembly's resource Microsoft.ApplicationInsights.Redfield.Lightup, Version=2.8.18.27202, Culture=neutral, PublicKeyToken=f23a46de0be5d6f3/Microsoft.ApplicationInsights.Redfield.Lightup.ApplicationInsights-recommended.config -2:42:34 PM EVENT: Microsoft-ApplicationInsights-FrameworkLightup Trace Successfully attached ApplicationInsights SDK -2:42:34 PM EVENT: Microsoft-ApplicationInsights-RedfieldIISModule Trace RedfieldIISModule.LoadLightupAssemblyAndGetLightupHttpModuleClass, success, 2687 ms -2:42:34 PM EVENT: Microsoft-ApplicationInsights-RedfieldIISModule Trace RedfieldIISModule.CreateAndInitializeApplicationInsightsHttpModules(lightupHttpModuleClass), success -2:42:34 PM EVENT: Microsoft-ApplicationInsights-IIS-ManagedHttpModuleHelper Trace ManagedHttpModuleHelper, multicastHttpModule.Init() success, 3288 ms -2:42:35 PM EVENT: Microsoft-ApplicationInsights-IIS-ManagedHttpModuleHelper Trace Resolved variables to: MicrosoftAppInsights_ManagedHttpModulePath='C:\Program Files\WindowsPowerShell\Modules\Az.ApplicationMonitor\content\Runtime\Microsoft.ApplicationInsights.RedfieldIISModule.dll', MicrosoftAppInsights_ManagedHttpModuleType='Microsoft.ApplicationInsights.RedfieldIISModule.RedfieldIISModule' -2:42:35 PM EVENT: Microsoft-ApplicationInsights-IIS-ManagedHttpModuleHelper Trace Resolved variables to: MicrosoftDiagnosticServices_ManagedHttpModulePath2='', MicrosoftDiagnosticServices_ManagedHttpModuleType2='' -2:42:35 PM EVENT: Microsoft-ApplicationInsights-IIS-ManagedHttpModuleHelper Trace Environment variable 'MicrosoftDiagnosticServices_ManagedHttpModulePath2' or 'MicrosoftDiagnosticServices_ManagedHttpModuleType2' is null, skipping managed dll loading -2:42:35 PM EVENT: Microsoft-ApplicationInsights-IIS-ManagedHttpModuleHelper Trace MulticastHttpModule.constructor, success, 0 ms -2:42:35 PM EVENT: Microsoft-ApplicationInsights-RedfieldIISModule Trace RedfieldIISModule.CreateAndInitializeApplicationInsightsHttpModules(lightupHttpModuleClass), success -2:42:35 PM EVENT: Microsoft-ApplicationInsights-IIS-ManagedHttpModuleHelper Trace ManagedHttpModuleHelper, multicastHttpModule.Init() success, 0 ms -Timeout Reached. Stopping... -``` --### [Release notes](#tab/release-notes) --The release note updates are listed here. --### 2.0.0 --- Updated the Application Insights .NET/.NET Core SDK to `2.21.0-redfield`--### 2.0.0-beta3 --- Updated the Application Insights .NET/.NET Core SDK to `2.20.1-redfield`-- Enabled SQL query collection--### 2.0.0-beta2 --Updated the Application Insights .NET/.NET Core SDK to `2.18.1-redfield` --### 2.0.0-beta1 --Added the ASP.NET Core autoinstrumentation feature ----## Frequently asked questions --This section provides answers to common questions. --### Does Application Insights Agent support proxy installations? --Yes. There are multiple ways to download Application Insights Agent: --- If your computer has internet access, you can onboard to the PowerShell Gallery by using `-Proxy` parameters.-- You can also manually download the module and either install it on your computer or use it directly.--Each of these options is described in the [detailed instructions](?tabs=detailed-instructions#instructions). --### Does Application Insights Agent support ASP.NET Core applications? -- Yes. In [Application Insights Agent 2.0.0](https://www.powershellgallery.com/packages/Az.ApplicationMonitor/2.0.0) and later, ASP.NET Core applications hosted in IIS are supported. --### How do I verify that the enablement succeeded? --- You can use the [Get-ApplicationInsightsMonitoringStatus](?tabs=api-reference#get-applicationinsightsmonitoringstatus) cmdlet to verify that enablement succeeded.- - Use [Live Metrics](./live-stream.md) to quickly determine if your app is sending telemetry. - - You can also use [Log Analytics](../logs/log-analytics-tutorial.md) to list all the cloud roles currently sending telemetry: -- ```Kusto - union * | summarize count() by cloud_RoleName, cloud_RoleInstance - ``` --### How do I achieve proxy passthrough? --To achieve proxy passthrough, configure a machine-level proxy or an application-level proxy. -See [DefaultProxy](/dotnet/framework/configure-apps/file-schema/network/defaultproxy-element-network-settings). --Example Web.config: --```xml -<system.net> - <defaultProxy> - <proxy proxyaddress="http://xx.xx.xx.xx:yyyy" bypassonlocal="true"/> - </defaultProxy> -</system.net> -``` --## Troubleshooting --See the dedicated [troubleshooting article](/troubleshoot/azure/azure-monitor/app-insights/status-monitor-v2-troubleshoot). ---## Next steps --View your telemetry: -- [Explore metrics](../essentials/metrics-charts.md) to monitor performance and usage.-- [Search events and logs](./transaction-search-and-diagnostics.md?tabs=transaction-search) to diagnose problems.-- [Use Log Analytics](../logs/log-query-overview.md) for more advanced queries.-- [Create dashboards](./overview-dashboard.md).--Add more telemetry: -- [Availability overview](availability-overview.md)-- [Add web client telemetry](./javascript.md) to see exceptions from webpage code and to enable trace calls.-- [Add the Application Insights SDK to your code](./asp-net.md) so that you can insert trace and log calls.--Do more with Application Insights Agent: -- [Troubleshoot](status-monitor-v2-troubleshoot.md) Application Insights Agent. |
| azure-monitor | Asp Net Core | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/asp-net-core.md | - Title: Application Insights for ASP.NET Core applications | Microsoft Docs -description: Monitor ASP.NET Core web applications for availability, performance, and usage. -- Previously updated : 01/31/2024---# Application Insights for ASP.NET Core applications --This article describes how to enable and configure Application Insights for an [ASP.NET Core](/aspnet/core) application. ---Application Insights can collect the following telemetry from your ASP.NET Core application: --> [!div class="checklist"] -> * Requests -> * Dependencies -> * Exceptions -> * Performance counters -> * Heartbeats -> * Logs --We use an [MVC application](/aspnet/core/tutorials/first-mvc-app) example. If you're using the [Worker Service](/aspnet/core/fundamentals/host/hosted-services#worker-service-template), use the instructions in [Application Insights for Worker Service applications](./worker-service.md). --An [OpenTelemetry-based .NET offering](opentelemetry-enable.md?tabs=net) is available. For more information, see [OpenTelemetry overview](opentelemetry-overview.md). ---> [!NOTE] -> If you want to use standalone ILogger provider, use [Microsoft.Extensions.Logging.ApplicationInsight](./ilogger.md). --## Supported scenarios --The [Application Insights SDK for ASP.NET Core](https://nuget.org/packages/Microsoft.ApplicationInsights.AspNetCore) can monitor your applications no matter where or how they run. If your application is running and has network connectivity to Azure, telemetry can be collected. Application Insights monitoring is supported everywhere .NET Core is supported and covers the following scenarios: --* **Operating system**: Windows, Linux, or Mac -* **Hosting method**: In process or out of process -* **Deployment method**: Framework dependent or self-contained -* **Web server**: Internet Information Server (IIS) or Kestrel -* **Hosting platform**: The Web Apps feature of Azure App Service, Azure Virtual Machines, Docker, and Azure Kubernetes Service (AKS) -* **.NET version**: All officially [supported .NET versions](https://dotnet.microsoft.com/download/dotnet) that aren't in preview -* **IDE**: Visual Studio, Visual Studio Code, or command line --## Prerequisites --You need: --- A functioning ASP.NET Core application. If you need to create an ASP.NET Core application, follow this [ASP.NET Core tutorial](/aspnet/core/getting-started/).-- A reference to a supported version of the [Application Insights](https://www.nuget.org/packages/Microsoft.ApplicationInsights.AspNetCore) NuGet package.-- A valid Application Insights connection string. This string is required to send any telemetry to Application Insights. If you need to create a new Application Insights resource to get a connection string, see [Create an Application Insights resource](./create-workspace-resource.md).--## Enable Application Insights server-side telemetry (Visual Studio) --For Visual Studio for Mac, use the [manual guidance](#enable-application-insights-server-side-telemetry-no-visual-studio). Only the Windows version of Visual Studio supports this procedure. --1. Open your project in Visual Studio. --1. Go to **Project** > **Add Application Insights Telemetry**. --1. Select **Azure Application Insights** > **Next**. --1. Choose your subscription and Application Insights instance. Or you can create a new instance with **Create new**. Select **Next**. --1. Add or confirm your Application Insights connection string. It should be prepopulated based on your selection in the previous step. Select **Finish**. --1. After you add Application Insights to your project, check to confirm that you're using the latest stable release of the SDK. Go to **Project** > **Manage NuGet Packages** > **Microsoft.ApplicationInsights.AspNetCore**. If you need to, select **Update**. -- :::image type="content" source="./media/asp-net-core/update-nuget-package.png" alt-text="Screenshot that shows where to select the Application Insights package for update."::: --## Enable Application Insights server-side telemetry (no Visual Studio) --1. Install the [Application Insights SDK NuGet package for ASP.NET Core](https://nuget.org/packages/Microsoft.ApplicationInsights.AspNetCore). -- We recommend that you always use the latest stable version. Find full release notes for the SDK on the [open-source GitHub repo](https://github.com/Microsoft/ApplicationInsights-dotnet/releases). -- The following code sample shows the changes to add to your project's `.csproj` file: -- ```xml - <ItemGroup> - <PackageReference Include="Microsoft.ApplicationInsights.AspNetCore" Version="2.21.0" /> - </ItemGroup> - ``` --1. Add `AddApplicationInsightsTelemetry()` to your `startup.cs` or `program.cs` class. The choice depends on your .NET Core version. -- ### [ASP.NET Core 6 and later](#tab/netcorenew) -- Add `builder.Services.AddApplicationInsightsTelemetry();` after the `WebApplication.CreateBuilder()` method in your `Program` class, as in this example: - - ```csharp - // This method gets called by the runtime. Use this method to add services to the container. - var builder = WebApplication.CreateBuilder(args); - - // The following line enables Application Insights telemetry collection. - builder.Services.AddApplicationInsightsTelemetry(); - - // This code adds other services for your application. - builder.Services.AddMvc(); -- var app = builder.Build(); - ``` -- ### [ASP.NET Core 5 and earlier](#tab/netcoreold) -- Add `services.AddApplicationInsightsTelemetry();` to the `ConfigureServices()` method in your `Startup` class, as in this example: -- ```csharp - // This method gets called by the runtime. Use this method to add services to the container. - public void ConfigureServices(IServiceCollection services) - { - // The following line enables Application Insights telemetry collection. - services.AddApplicationInsightsTelemetry(); -- // This code adds other services for your application. - services.AddMvc(); - } - ``` -- > [!NOTE] - > This .NET version is no longer supported. -- - -1. Set up the connection string. -- Although you can provide a connection string as part of the `ApplicationInsightsServiceOptions` argument to `AddApplicationInsightsTelemetry`, we recommend that you specify the connection string in configuration. The following code sample shows how to specify a connection string in `appsettings.json`. Make sure `appsettings.json` is copied to the application root folder during publishing. -- ```json - { - "Logging": { - "LogLevel": { - "Default": "Information", - "Microsoft.AspNetCore": "Warning" - } - }, - "AllowedHosts": "*", - "ApplicationInsights": { - "ConnectionString": "Copy connection string from Application Insights Resource Overview" - } - } - ``` -- Alternatively, specify the connection string in the `APPLICATIONINSIGHTS_CONNECTION_STRING` environment variable or `ApplicationInsights:ConnectionString` in the JSON configuration file. - - For example: - - * `SET ApplicationInsights:ConnectionString = <Copy connection string from Application Insights Resource Overview>` - * `SET APPLICATIONINSIGHTS_CONNECTION_STRING = <Copy connection string from Application Insights Resource Overview>` - * Typically, `APPLICATIONINSIGHTS_CONNECTION_STRING` is used in [Web Apps](./azure-web-apps.md?tabs=net). It can also be used in all places where this SDK is supported. - - > [!NOTE] - > A connection string specified in code wins over the environment variable `APPLICATIONINSIGHTS_CONNECTION_STRING`, which wins over other options. --### User secrets and other configuration providers --If you want to store the connection string in ASP.NET Core user secrets or retrieve it from another configuration provider, you can use the overload with a `Microsoft.Extensions.Configuration.IConfiguration` parameter. An example parameter is `services.AddApplicationInsightsTelemetry(Configuration);`. --In `Microsoft.ApplicationInsights.AspNetCore` version [2.15.0](https://www.nuget.org/packages/Microsoft.ApplicationInsights.AspNetCore) and later, calling `services.AddApplicationInsightsTelemetry()` automatically reads the connection string from `Microsoft.Extensions.Configuration.IConfiguration` of the application. There's no need to explicitly provide `IConfiguration`. --If `IConfiguration` has loaded configuration from multiple providers, then `services.AddApplicationInsightsTelemetry` prioritizes configuration from `appsettings.json`, irrespective of the order in which providers are added. Use the `services.AddApplicationInsightsTelemetry(IConfiguration)` method to read configuration from `IConfiguration` without this preferential treatment for `appsettings.json`. --## Run your application --Run your application and make requests to it. Telemetry should now flow to Application Insights. The Application Insights SDK automatically collects incoming web requests to your application, along with the following telemetry. --### Live metrics --[Live metrics](./live-stream.md) can be used to quickly verify if application monitoring with Application Insights is configured correctly. Telemetry can take a few minutes to appear in the Azure portal, but the live metrics pane shows CPU usage of the running process in near real time. It can also show other telemetry like requests, dependencies, and traces. --#### Enable live metrics by using code for any .NET application --> [!NOTE] -> Live metrics are enabled by default when you onboard it by using the recommended instructions for .NET applications. --To manually configure live metrics: --1. Install the NuGet package [Microsoft.ApplicationInsights.PerfCounterCollector](https://www.nuget.org/packages/Microsoft.ApplicationInsights.PerfCounterCollector). -1. The following sample console app code shows setting up live metrics: --```csharp -using Microsoft.ApplicationInsights; -using Microsoft.ApplicationInsights.Extensibility; -using Microsoft.ApplicationInsights.Extensibility.PerfCounterCollector.QuickPulse; --// Create a TelemetryConfiguration instance. -TelemetryConfiguration config = TelemetryConfiguration.CreateDefault(); -config.InstrumentationKey = "INSTRUMENTATION-KEY-HERE"; -QuickPulseTelemetryProcessor quickPulseProcessor = null; -config.DefaultTelemetrySink.TelemetryProcessorChainBuilder - .Use((next) => - { - quickPulseProcessor = new QuickPulseTelemetryProcessor(next); - return quickPulseProcessor; - }) - .Build(); --var quickPulseModule = new QuickPulseTelemetryModule(); --// Secure the control channel. -// This is optional, but recommended. -quickPulseModule.AuthenticationApiKey = "YOUR-API-KEY-HERE"; -quickPulseModule.Initialize(config); -quickPulseModule.RegisterTelemetryProcessor(quickPulseProcessor); --// Create a TelemetryClient instance. It is important -// to use the same TelemetryConfiguration here as the one -// used to set up live metrics. -TelemetryClient client = new TelemetryClient(config); --// This sample runs indefinitely. Replace with actual application logic. -while (true) -{ - // Send dependency and request telemetry. - // These will be shown in live metrics. - // CPU/Memory Performance counter is also shown - // automatically without any additional steps. - client.TrackDependency("My dependency", "target", "http://sample", - DateTimeOffset.Now, TimeSpan.FromMilliseconds(300), true); - client.TrackRequest("My Request", DateTimeOffset.Now, - TimeSpan.FromMilliseconds(230), "200", true); - Task.Delay(1000).Wait(); -} -``` --The preceding sample is for a console app, but the same code can be used in any .NET applications. If any other telemetry modules are enabled to autocollect telemetry, it's important to ensure that the same configuration used for initializing those modules is used for the live metrics module. --### ILogger logs --The default configuration collects `ILogger` `Warning` logs and more severe logs. For more information, see [How do I customize ILogger logs collection?](#how-do-i-customize-ilogger-logs-collection). --### Dependencies --Dependency collection is enabled by default. [Dependency tracking in Application Insights](asp-net-dependencies.md#automatically-tracked-dependencies) explains the dependencies that are automatically collected and also contains steps to do manual tracking. --### Performance counters --Support for [performance counters](./performance-counters.md) in ASP.NET Core is limited: --* SDK versions 2.4.1 and later collect performance counters if the application is running in Web Apps (Windows). -* SDK versions 2.7.1 and later collect performance counters if the application is running in Windows and targets `netstandard2.0` or later. -* For applications that target the .NET Framework, all versions of the SDK support performance counters. -* SDK versions 2.8.0 and later support the CPU/memory counter in Linux. No other counter is supported in Linux. To get system counters in Linux and other non-Windows environments, use [EventCounters](#eventcounter). --### EventCounter --By default, `EventCounterCollectionModule` is enabled. To learn how to configure the list of counters to be collected, see [EventCounters introduction](eventcounters.md). --### Enrich data through HTTP --```csharp -HttpContext.Features.Get<RequestTelemetry>().Properties["myProp"] = someData -``` --## Enable client-side telemetry for web applications --The preceding steps are enough to help you start collecting server-side telemetry. If your application has client-side components, follow the next steps to start collecting [usage telemetry](./usage.md) using JavaScript (Web) SDK Loader Script injection by configuration. --1. In `_ViewImports.cshtml`, add injection: -- ```cshtml - @inject Microsoft.ApplicationInsights.AspNetCore.JavaScriptSnippet JavaScriptSnippet - ``` --1. In `_Layout.cshtml`, insert `HtmlHelper` at the end of the `<head>` section but before any other script. If you want to report any custom JavaScript telemetry from the page, inject it after this snippet: -- ```cshtml - @Html.Raw(JavaScriptSnippet.FullScript) - </head> - ``` --As an alternative to using `FullScript`, `ScriptBody` is available starting in Application Insights SDK for ASP.NET Core version 2.14. Use `ScriptBody` if you need to control the `<script>` tag to set a Content Security Policy: --```cshtml -<script> // apply custom changes to this script tag. - @Html.Raw(JavaScriptSnippet.ScriptBody) -</script> -``` --The `.cshtml` file names referenced earlier are from a default MVC application template. Ultimately, if you want to properly enable client-side monitoring for your application, the JavaScript JavaScript (Web) SDK Loader Script must appear in the `<head>` section of each page of your application that you want to monitor. Add the JavaScript JavaScript (Web) SDK Loader Script to `_Layout.cshtml` in an application template to enable client-side monitoring. --If your project doesn't include `_Layout.cshtml`, you can still add [client-side monitoring](./website-monitoring.md) by adding the JavaScript JavaScript (Web) SDK Loader Script to an equivalent file that controls the `<head>` of all pages within your app. Alternatively, you can add the JavaScript (Web) SDK Loader Script to multiple pages, but we don't recommend it. --> [!NOTE] -> JavaScript injection provides a default configuration experience. If you require [configuration](./javascript.md#configuration) beyond setting the connection string, you're required to remove auto-injection as described and manually add the [JavaScript SDK](./javascript.md#add-the-javascript-sdk). --## Configure the Application Insights SDK --You can customize the Application Insights SDK for ASP.NET Core to change the default configuration. Users of the Application Insights ASP.NET SDK might be familiar with changing configuration by using `ApplicationInsights.config` or by modifying `TelemetryConfiguration.Active`. For ASP.NET Core, make almost all configuration changes in the `ConfigureServices()` method of your `Startup.cs` class, unless you're directed otherwise. The following sections offer more information. --> [!NOTE] -> In ASP.NET Core applications, changing configuration by modifying `TelemetryConfiguration.Active` isn't supported. --### Use ApplicationInsightsServiceOptions --You can modify a few common settings by passing `ApplicationInsightsServiceOptions` to `AddApplicationInsightsTelemetry`, as in this example: --### [ASP.NET Core 6 and later](#tab/netcorenew) --```csharp -var builder = WebApplication.CreateBuilder(args); --var aiOptions = new Microsoft.ApplicationInsights.AspNetCore.Extensions.ApplicationInsightsServiceOptions(); --// Disables adaptive sampling. -aiOptions.EnableAdaptiveSampling = false; --// Disables live metrics (also known as QuickPulse). -aiOptions.EnableQuickPulseMetricStream = false; --builder.Services.AddApplicationInsightsTelemetry(aiOptions); -var app = builder.Build(); -``` --### [ASP.NET Core 5 and earlier](#tab/netcoreold) --```csharp -public void ConfigureServices(IServiceCollection services) -{ - Microsoft.ApplicationInsights.AspNetCore.Extensions.ApplicationInsightsServiceOptions aiOptions - = new Microsoft.ApplicationInsights.AspNetCore.Extensions.ApplicationInsightsServiceOptions(); - // Disables adaptive sampling. - aiOptions.EnableAdaptiveSampling = false; -- // Disables live metrics (also known as QuickPulse). - aiOptions.EnableQuickPulseMetricStream = false; - services.AddApplicationInsightsTelemetry(aiOptions); -} -``` --> [!NOTE] -> This .NET version is no longer supported. ----This table has the full list of `ApplicationInsightsServiceOptions` settings: --|Setting | Description | Default -||-|- -|EnablePerformanceCounterCollectionModule | Enable/Disable `PerformanceCounterCollectionModule`. | True -|EnableRequestTrackingTelemetryModule | Enable/Disable `RequestTrackingTelemetryModule`. | True -|EnableEventCounterCollectionModule | Enable/Disable `EventCounterCollectionModule`. | True -|EnableDependencyTrackingTelemetryModule | Enable/Disable `DependencyTrackingTelemetryModule`. | True -|EnableAppServicesHeartbeatTelemetryModule | Enable/Disable `AppServicesHeartbeatTelemetryModule`. | True -|EnableAzureInstanceMetadataTelemetryModule | Enable/Disable `AzureInstanceMetadataTelemetryModule`. | True -|EnableQuickPulseMetricStream | Enable/Disable LiveMetrics feature. | True -|EnableAdaptiveSampling | Enable/Disable Adaptive Sampling. | True -|EnableHeartbeat | Enable/Disable the heartbeats feature. It periodically (15-min default) sends a custom metric named `HeartbeatState` with information about the runtime like .NET version and Azure environment information, if applicable. | True -|AddAutoCollectedMetricExtractor | Enable/Disable the `AutoCollectedMetrics extractor`. This telemetry processor sends preaggregated metrics about requests/dependencies before sampling takes place. | True -|RequestCollectionOptions.TrackExceptions | Enable/Disable reporting of unhandled exception tracking by the request collection module. | False in `netstandard2.0` (because exceptions are tracked with `ApplicationInsightsLoggerProvider`). True otherwise. -|EnableDiagnosticsTelemetryModule | Enable/Disable `DiagnosticsTelemetryModule`. Disabling causes the following settings to be ignored: `EnableHeartbeat`, `EnableAzureInstanceMetadataTelemetryModule`, and `EnableAppServicesHeartbeatTelemetryModule`. | True --For the most current list, see the [configurable settings in `ApplicationInsightsServiceOptions`](https://github.com/microsoft/ApplicationInsights-dotnet/blob/develop/NETCORE/src/Shared/Extensions/ApplicationInsightsServiceOptions.cs). --### Configuration recommendation for Microsoft.ApplicationInsights.AspNetCore SDK 2.15.0 and later --In Microsoft.ApplicationInsights.AspNetCore SDK version [2.15.0](https://www.nuget.org/packages/Microsoft.ApplicationInsights.AspNetCore/2.15.0) and later, configure every setting available in `ApplicationInsightsServiceOptions`, including `ConnectionString`. Use the application's `IConfiguration` instance. The settings must be under the section `ApplicationInsights`, as shown in the following example. The following section from *appsettings.json* configures the connection string and disables adaptive sampling and performance counter collection. --```json -{ - "ApplicationInsights": { - "ConnectionString": "Copy connection string from Application Insights Resource Overview", - "EnableAdaptiveSampling": false, - "EnablePerformanceCounterCollectionModule": false - } -} -``` --If `builder.Services.AddApplicationInsightsTelemetry(aiOptions)` for ASP.NET Core 6.0 or `services.AddApplicationInsightsTelemetry(aiOptions)` for ASP.NET Core 3.1 and earlier is used, it overrides the settings from `Microsoft.Extensions.Configuration.IConfiguration`. --### Sampling --The Application Insights SDK for ASP.NET Core supports both fixed-rate and adaptive sampling. By default, adaptive sampling is enabled. --For more information, see [Configure adaptive sampling for ASP.NET Core applications](./sampling.md#configuring-adaptive-sampling-for-aspnet-core-applications). --### Add TelemetryInitializers --When you want to enrich telemetry with more information, use [telemetry initializers](./api-filtering-sampling.md#addmodify-properties-itelemetryinitializer). --Add any new `TelemetryInitializer` to the `DependencyInjection` container as shown in the following code. The SDK automatically picks up any `TelemetryInitializer` that's added to the `DependencyInjection` container. --### [ASP.NET Core 6 and later](#tab/netcorenew) --```csharp -var builder = WebApplication.CreateBuilder(args); --builder.Services.AddSingleton<ITelemetryInitializer, MyCustomTelemetryInitializer>(); --var app = builder.Build(); -``` --> [!NOTE] -> `builder.Services.AddSingleton<ITelemetryInitializer, MyCustomTelemetryInitializer>();` works for simple initializers. For others, `builder.Services.AddSingleton(new MyCustomTelemetryInitializer() { fieldName = "myfieldName" });` is required. --### [ASP.NET Core 5 and earlier](#tab/netcoreold) --```csharp -public void ConfigureServices(IServiceCollection services) -{ - services.AddSingleton<ITelemetryInitializer, MyCustomTelemetryInitializer>(); -} -``` --> [!NOTE] -> `services.AddSingleton<ITelemetryInitializer, MyCustomTelemetryInitializer>();` works for simple initializers. For others, `services.AddSingleton(new MyCustomTelemetryInitializer() { fieldName = "myfieldName" });` is required. -> This .NET version is no longer supported. ----### Remove TelemetryInitializers --By default, telemetry initializers are present. To remove all or specific telemetry initializers, use the following sample code *after* calling `AddApplicationInsightsTelemetry()`. --### [ASP.NET Core 6 and later](#tab/netcorenew) --```csharp -var builder = WebApplication.CreateBuilder(args); --builder.Services.AddApplicationInsightsTelemetry(); --// Remove a specific built-in telemetry initializer -var tiToRemove = builder.Services.FirstOrDefault<ServiceDescriptor> - (t => t.ImplementationType == typeof(AspNetCoreEnvironmentTelemetryInitializer)); -if (tiToRemove != null) -{ - builder.Services.Remove(tiToRemove); -} --// Remove all initializers -// This requires importing namespace by using Microsoft.Extensions.DependencyInjection.Extensions; -builder.Services.RemoveAll(typeof(ITelemetryInitializer)); --var app = builder.Build(); -``` --### [ASP.NET Core 5 and earlier](#tab/netcoreold) --```csharp -public void ConfigureServices(IServiceCollection services) -{ - services.AddApplicationInsightsTelemetry(); -- // Remove a specific built-in telemetry initializer - var tiToRemove = services.FirstOrDefault<ServiceDescriptor> - (t => t.ImplementationType == typeof(AspNetCoreEnvironmentTelemetryInitializer)); - if (tiToRemove != null) - { - services.Remove(tiToRemove); - } -- // Remove all initializers - // This requires importing namespace by using Microsoft.Extensions.DependencyInjection.Extensions; - services.RemoveAll(typeof(ITelemetryInitializer)); -} -``` --> [!NOTE] -> This .NET version is no longer supported. ----### Add telemetry processors --You can add custom telemetry processors to `TelemetryConfiguration` by using the extension method `AddApplicationInsightsTelemetryProcessor` on `IServiceCollection`. You use telemetry processors in [advanced filtering scenarios](./api-filtering-sampling.md#itelemetryprocessor-and-itelemetryinitializer). Use the following example: --### [ASP.NET Core 6 and later](#tab/netcorenew) --```csharp -var builder = WebApplication.CreateBuilder(args); --// ... -builder.Services.AddApplicationInsightsTelemetry(); -builder.Services.AddApplicationInsightsTelemetryProcessor<MyFirstCustomTelemetryProcessor>(); --// If you have more processors: -builder.Services.AddApplicationInsightsTelemetryProcessor<MySecondCustomTelemetryProcessor>(); --var app = builder.Build(); -``` --### [ASP.NET Core 5 and earlier](#tab/netcoreold) --```csharp -public void ConfigureServices(IServiceCollection services) -{ - // ... - services.AddApplicationInsightsTelemetry(); - services.AddApplicationInsightsTelemetryProcessor<MyFirstCustomTelemetryProcessor>(); -- // If you have more processors: - services.AddApplicationInsightsTelemetryProcessor<MySecondCustomTelemetryProcessor>(); -} -``` --> [!NOTE] -> This .NET version is no longer supported. ----### Configure or remove default TelemetryModules --Application Insights automatically collects telemetry about specific workloads without requiring manual tracking by user. --By default, the following automatic-collection modules are enabled. These modules are responsible for automatically collecting telemetry. You can disable or configure them to alter their default behavior. --* `RequestTrackingTelemetryModule`: Collects RequestTelemetry from incoming web requests. -* `DependencyTrackingTelemetryModule`: Collects [DependencyTelemetry](./asp-net-dependencies.md) from outgoing HTTP calls and SQL calls. -* `PerformanceCollectorModule`: Collects Windows PerformanceCounters. -* `QuickPulseTelemetryModule`: Collects telemetry to show in the live metrics pane. -* `AppServicesHeartbeatTelemetryModule`: Collects heartbeats (which are sent as custom metrics), about the App Service environment where the application is hosted. -* `AzureInstanceMetadataTelemetryModule`: Collects heartbeats (which are sent as custom metrics), about the Azure VM environment where the application is hosted. -* `EventCounterCollectionModule`: Collects [EventCounters](eventcounters.md). This module is a new feature and is available in SDK version 2.8.0 and later. --To configure any default `TelemetryModule`, use the extension method `ConfigureTelemetryModule<T>` on `IServiceCollection`, as shown in the following example: --### [ASP.NET Core 6 and later](#tab/netcorenew) --```csharp -using Microsoft.ApplicationInsights.DependencyCollector; -using Microsoft.ApplicationInsights.Extensibility.PerfCounterCollector; --var builder = WebApplication.CreateBuilder(args); --builder.Services.AddApplicationInsightsTelemetry(); --// The following configures DependencyTrackingTelemetryModule. -// Similarly, any other default modules can be configured. -builder.Services.ConfigureTelemetryModule<DependencyTrackingTelemetryModule>((module, o) => - { - module.EnableW3CHeadersInjection = true; - }); --// The following removes all default counters from EventCounterCollectionModule, and adds a single one. -builder.Services.ConfigureTelemetryModule<EventCounterCollectionModule>((module, o) => - { - module.Counters.Add(new EventCounterCollectionRequest("System.Runtime", "gen-0-size")); - }); --// The following removes PerformanceCollectorModule to disable perf-counter collection. -// Similarly, any other default modules can be removed. -var performanceCounterService = builder.Services.FirstOrDefault<ServiceDescriptor>(t => t.ImplementationType == typeof(PerformanceCollectorModule)); -if (performanceCounterService != null) -{ - builder.Services.Remove(performanceCounterService); -} --var app = builder.Build(); -``` --### [ASP.NET Core 5 and earlier](#tab/netcoreold) --```csharp -using Microsoft.ApplicationInsights.DependencyCollector; -using Microsoft.ApplicationInsights.Extensibility.PerfCounterCollector; --public void ConfigureServices(IServiceCollection services) -{ - services.AddApplicationInsightsTelemetry(); -- // The following configures DependencyTrackingTelemetryModule. - // Similarly, any other default modules can be configured. - services.ConfigureTelemetryModule<DependencyTrackingTelemetryModule>((module, o) => - { - module.EnableW3CHeadersInjection = true; - }); -- // The following removes all default counters from EventCounterCollectionModule, and adds a single one. - services.ConfigureTelemetryModule<EventCounterCollectionModule>( - (module, o) => - { - module.Counters.Add(new EventCounterCollectionRequest("System.Runtime", "gen-0-size")); - } - ); -- // The following removes PerformanceCollectorModule to disable perf-counter collection. - // Similarly, any other default modules can be removed. - var performanceCounterService = services.FirstOrDefault<ServiceDescriptor>(t => t.ImplementationType == typeof(PerformanceCollectorModule)); - if (performanceCounterService != null) - { - services.Remove(performanceCounterService); - } -} -``` --> [!NOTE] -> This .NET version is no longer supported. ----In versions 2.12.2 and later, [`ApplicationInsightsServiceOptions`](#use-applicationinsightsserviceoptions) includes an easy option to disable any of the default modules. --### Configure a telemetry channel --The default [telemetry channel](./telemetry-channels.md) is `ServerTelemetryChannel`. The following example shows how to override it. --### [ASP.NET Core 6 and later](#tab/netcorenew) --```csharp -using Microsoft.ApplicationInsights.Channel; --var builder = WebApplication.CreateBuilder(args); --// Use the following to replace the default channel with InMemoryChannel. -// This can also be applied to ServerTelemetryChannel. -builder.Services.AddSingleton(typeof(ITelemetryChannel), new InMemoryChannel() {MaxTelemetryBufferCapacity = 19898 }); --builder.Services.AddApplicationInsightsTelemetry(); --var app = builder.Build(); -``` --### [ASP.NET Core 5 and earlier](#tab/netcoreold) --```csharp -using Microsoft.ApplicationInsights.Channel; --public void ConfigureServices(IServiceCollection services) -{ - // Use the following to replace the default channel with InMemoryChannel. - // This can also be applied to ServerTelemetryChannel. - services.AddSingleton(typeof(ITelemetryChannel), new InMemoryChannel() {MaxTelemetryBufferCapacity = 19898 }); -- services.AddApplicationInsightsTelemetry(); -} -``` --> [!NOTE] -> This .NET version is no longer supported. ----> [!NOTE] -> If you want to flush the buffer, see [Flushing data](api-custom-events-metrics.md#flushing-data). For example, you might need to flush the buffer if you're using the SDK in an application that shuts down. --### Disable telemetry dynamically --If you want to disable telemetry conditionally and dynamically, you can resolve the `TelemetryConfiguration` instance with an ASP.NET Core dependency injection container anywhere in your code and set the `DisableTelemetry` flag on it. --### [ASP.NET Core 6 and later](#tab/netcorenew) --```csharp -var builder = WebApplication.CreateBuilder(args); --builder.Services.AddApplicationInsightsTelemetry(); --// any custom configuration can be done here: -builder.Services.Configure<TelemetryConfiguration>(x => x.DisableTelemetry = true); --var app = builder.Build(); -``` --### [ASP.NET Core 5 and earlier](#tab/netcoreold) --```csharp -public void ConfigureServices(IServiceCollection services) -{ - services.AddApplicationInsightsTelemetry(); -} --public void Configure(IApplicationBuilder app, IHostingEnvironment env, TelemetryConfiguration configuration) -{ - configuration.DisableTelemetry = true; - ... -} -``` --> [!NOTE] -> This .NET version is no longer supported. ----The preceding code sample prevents the sending of telemetry to Application Insights. It doesn't prevent any automatic collection modules from collecting telemetry. If you want to remove a particular autocollection module, see [Remove the telemetry module](#configure-or-remove-default-telemetrymodules). --## Frequently asked questions --This section provides answers to common questions. --### Does Application Insights support ASP.NET Core 3.1? --ASP.NET Core 3.1 is no longer supported by Microsoft. --[Application Insights SDK for ASP.NET Core](https://nuget.org/packages/Microsoft.ApplicationInsights.AspNetCore) version 2.8.0 and Visual Studio 2019 or later can be used with ASP.NET Core 3.1 applications. --### How can I track telemetry that's not automatically collected? --Get an instance of `TelemetryClient` by using constructor injection and call the required `TrackXXX()` method on it. We don't recommend creating new `TelemetryClient` or `TelemetryConfiguration` instances in an ASP.NET Core application. A singleton instance of `TelemetryClient` is already registered in the `DependencyInjection` container, which shares `TelemetryConfiguration` with the rest of the telemetry. Create a new `TelemetryClient` instance only if it needs a configuration that's separate from the rest of the telemetry. --The following example shows how to track more telemetry from a controller. --```csharp -using Microsoft.ApplicationInsights; --public class HomeController : Controller -{ - private TelemetryClient telemetry; -- // Use constructor injection to get a TelemetryClient instance. - public HomeController(TelemetryClient telemetry) - { - this.telemetry = telemetry; - } -- public IActionResult Index() - { - // Call the required TrackXXX method. - this.telemetry.TrackEvent("HomePageRequested"); - return View(); - } -``` --For more information about custom data reporting in Application Insights, see [Application Insights custom metrics API reference](./api-custom-events-metrics.md). A similar approach can be used for sending custom metrics to Application Insights by using the [GetMetric API](./get-metric.md). --### How do I capture Request and Response body in my telemetry? --ASP.NET Core has [built-in -support](/aspnet/core/fundamentals/http-logging) for -logging HTTP Request/Response information (including body) via -[`ILogger`](#ilogger-logs). It is recommended to leverage this. This may -potentially expose personally identifiable information (PII) in telemetry, and -can cause costs (performance costs and Application Insights billing) to -significantly increase, so evaluate the risks carefully before using this. --### How do I customize ILogger logs collection? --The default setting for Application Insights is to only capture **Warning** and more severe logs. --Capture **Information** and less severe logs by changing the logging configuration for the Application Insights provider as follows. --```json -{ - "Logging": { - "LogLevel": { - "Default": "Information" - }, - "ApplicationInsights": { - "LogLevel": { - "Default": "Information" - } - } - }, - "ApplicationInsights": { - "ConnectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000" - } -} -``` --It's important to note that the following example doesn't cause the Application Insights provider to capture `Information` logs. It doesn't capture it because the SDK adds a default logging filter that instructs `ApplicationInsights` to capture only `Warning` logs and more severe logs. Application Insights requires an explicit override. --```json -{ - "Logging": { - "LogLevel": { - "Default": "Information" - } - } -} -``` --For more information, see [ILogger configuration](/dotnet/core/extensions/logging#configure-logging). --### Some Visual Studio templates used the UseApplicationInsights() extension method on IWebHostBuilder to enable Application Insights. Is this usage still valid? --The extension method `UseApplicationInsights()` is still supported, but it's marked as obsolete in Application Insights SDK version 2.8.0 and later. It's removed in the next major version of the SDK. To enable Application Insights telemetry, use `AddApplicationInsightsTelemetry()` because it provides overloads to control some configuration. Also, in ASP.NET Core 3.X apps, `services.AddApplicationInsightsTelemetry()` is the only way to enable Application Insights. --### I'm deploying my ASP.NET Core application to Web Apps. Should I still enable the Application Insights extension from Web Apps? --If the SDK is installed at build time as shown in this article, you don't need to enable the [Application Insights extension](./azure-web-apps.md) from the App Service portal. If the extension is installed, it backs off when it detects the SDK is already added. If you enable Application Insights from the extension, you don't have to install and update the SDK. But if you enable Application Insights by following instructions in this article, you have more flexibility because: -- * Application Insights telemetry continues to work in: - * All operating systems, including Windows, Linux, and Mac. - * All publish modes, including self-contained or framework dependent. - * All target frameworks, including the full .NET Framework. - * All hosting options, including Web Apps, VMs, Linux, containers, AKS, and non-Azure hosting. - * All .NET Core versions, including preview versions. - * You can see telemetry locally when you're debugging from Visual Studio. - * You can track more custom telemetry by using the `TrackXXX()` API. - * You have full control over the configuration. --### Can I enable Application Insights monitoring by using tools like Azure Monitor Application Insights Agent (formerly Status Monitor v2)? -- Yes. In [Application Insights Agent 2.0.0-beta1](https://www.powershellgallery.com/packages/Az.ApplicationMonitor/2.0.0-beta1) and later, ASP.NET Core applications hosted in IIS are supported. --### Are all features supported if I run my application in Linux? --Yes. Feature support for the SDK is the same in all platforms, with the following exceptions: --* The SDK collects [event counters](./eventcounters.md) on Linux because [performance counters](./performance-counters.md) are only supported in Windows. Most metrics are the same. --### Is this SDK supported for Worker Services? --No. Please use [Application Insights for Worker Service applications (non-HTTP applications)](worker-service.md) for worker services. --### How can I uninstall the SDK? --To remove Application Insights, you need to remove the NuGet packages and references from the API in your application. You can uninstall NuGet packages by using the NuGet Package Manager in Visual Studio. --> [!NOTE] -> These instructions are for uninstalling the ASP.NET Core SDK. If you need to uninstall the ASP.NET SDK, see [How can I uninstall the ASP.NET SDK?](./asp-net.md#how-can-i-uninstall-the-sdk). --1. Uninstall the Microsoft.ApplicationInsights.AspNetCore package by using the [NuGet Package Manager](/nuget/consume-packages/install-use-packages-visual-studio#uninstall-a-package). -1. To fully remove Application Insights, check and manually delete the added code or files along with any API calls you added in your project. For more information, see [What is created when you add the Application Insights SDK?](#what-is-created-when-you-add-the-application-insights-sdk). --### What is created when you add the Application Insights SDK? --When you add Application Insights to your project, it creates files and adds code to some of your files. Solely uninstalling the NuGet Packages won't always discard the files and code. To fully remove Application Insights, you should check and manually delete the added code or files along with any API calls you added in your project. --When you add Application Insights Telemetry to a Visual Studio ASP.NET Core template project, it adds the following code: --- [Your project's name].csproj-- ```csharp - <PropertyGroup> - <TargetFramework>netcoreapp3.1</TargetFramework> - <ApplicationInsightsResourceId>/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/Default-ApplicationInsights-EastUS/providers/microsoft.insights/components/WebApplication4core</ApplicationInsightsResourceId> - </PropertyGroup> - - <ItemGroup> - <PackageReference Include="Microsoft.ApplicationInsights.AspNetCore" Version="2.12.0" /> - </ItemGroup> - - <ItemGroup> - <WCFMetadata Include="Connected Services" /> - </ItemGroup> - ``` --- Appsettings.json:-- ```json - "ApplicationInsights": { - "InstrumentationKey": "00000000-0000-0000-0000-000000000000" - ``` --- ConnectedService.json- - ```json - { - "ProviderId": "Microsoft.ApplicationInsights.ConnectedService.ConnectedServiceProvider", - "Version": "16.0.0.0", - "GettingStartedDocument": { - "Uri": "https://go.microsoft.com/fwlink/?LinkID=798432" - } - } - ``` -- Startup.cs-- ```csharp - public void ConfigureServices(IServiceCollection services) - { - services.AddRazorPages(); - services.AddApplicationInsightsTelemetry(); // This is added - } - ``` --### How can I disable telemetry correlation? --To disable telemetry correlation in code, see `<ExcludeComponentCorrelationHttpHeadersOnDomains>` in [Application Insights for console applications](/previous-versions/azure/azure-monitor/app/console). --## Troubleshooting --See the dedicated [troubleshooting article](/troubleshoot/azure/azure-monitor/app-insights/asp-net-troubleshoot-no-data). ---## Open-source SDK --[Read and contribute to the code](https://github.com/microsoft/ApplicationInsights-dotnet). --For the latest updates and bug fixes, see the [release notes](./release-notes.md). --## Release Notes --For version 2.12 and newer: [.NET SDKs (Including ASP.NET, ASP.NET Core, and Logging Adapters)](https://github.com/Microsoft/ApplicationInsights-dotnet/releases) --Our [Service Updates](https://azure.microsoft.com/updates/?service=application-insights) also summarize major Application Insights improvements. --## Next steps --* [Explore user flows](./usage.md#user-flowsanalyze-user-navigation-patterns) to understand how users move through your app. -* [Configure a snapshot collection](./snapshot-debugger.md) to see the state of source code and variables at the moment an exception is thrown. -* [Use the API](./api-custom-events-metrics.md) to send your own events and metrics for a detailed view of your app's performance and usage. -* Use [availability tests](./availability-overview.md) to check your app constantly from around the world. -* Learn about [dependency injection in ASP.NET Core](/aspnet/core/fundamentals/dependency-injection). |
| azure-monitor | Asp Net Dependencies | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/asp-net-dependencies.md | - Title: Dependency tracking in Application Insights | Microsoft Docs -description: Monitor dependency calls from your on-premises or Azure web application with Application Insights. - Previously updated : 08/11/2023-----# Dependency tracking in Application Insights ---A *dependency* is a component that's called by your application. It's typically a service called by using HTTP, a database, or a file system. [Application Insights](./app-insights-overview.md) measures the duration of dependency calls and whether it's failing or not, along with information like the name of the dependency. You can investigate specific dependency calls and correlate them to requests and exceptions. --## Automatically tracked dependencies --Application Insights SDKs for .NET and .NET Core ship with `DependencyTrackingTelemetryModule`, which is a telemetry module that automatically collects dependencies. This dependency collection is enabled automatically for [ASP.NET](./asp-net.md) and [ASP.NET Core](./asp-net-core.md) applications when it's configured according to the linked official docs. The module `DependencyTrackingTelemetryModule` is shipped as the [Microsoft.ApplicationInsights.DependencyCollector](https://www.nuget.org/packages/Microsoft.ApplicationInsights.DependencyCollector/) NuGet package. It's brought automatically when you use either the `Microsoft.ApplicationInsights.Web` NuGet package or the `Microsoft.ApplicationInsights.AspNetCore` NuGet package. -- Currently, `DependencyTrackingTelemetryModule` tracks the following dependencies automatically: --|Dependencies |Details| -||-| -|HTTP/HTTPS | Local or remote HTTP/HTTPS calls. | -|WCF calls| Only tracked automatically if HTTP-based bindings are used.| -|SQL | Calls made with `SqlClient`. See the section [Advanced SQL tracking to get full SQL query](#advanced-sql-tracking-to-get-full-sql-query) for capturing SQL queries. | -|[Azure Blob Storage, Table Storage, or Queue Storage](https://www.nuget.org/packages/WindowsAzure.Storage/) | Calls made with the Azure Storage client. | -|[Azure Event Hubs client SDK](https://nuget.org/packages/Azure.Messaging.EventHubs) | Use the latest package: https://nuget.org/packages/Azure.Messaging.EventHubs. | -|[Azure Service Bus client SDK](https://nuget.org/packages/Azure.Messaging.ServiceBus)| Use the latest package: https://nuget.org/packages/Azure.Messaging.ServiceBus. | -|[Azure Cosmos DB](https://www.nuget.org/packages/Microsoft.Azure.Cosmos) | Tracked automatically if HTTP/HTTPS is used. Tracing for operations in direct mode with TCP will also be captured automatically using preview package >= [3.33.0-preview](https://www.nuget.org/packages/Microsoft.Azure.Cosmos/3.33.0-preview). For more details visit the [documentation](/azure/cosmos-db/nosql/sdk-observability). | --If you're missing a dependency or using a different SDK, make sure it's in the list of [autocollected dependencies](#dependency-auto-collection). If the dependency isn't autocollected, you can track it manually with a [track dependency call](./api-custom-events-metrics.md#trackdependency). --## Set up automatic dependency tracking in console apps --To automatically track dependencies from .NET console apps, install the NuGet package `Microsoft.ApplicationInsights.DependencyCollector` and initialize `DependencyTrackingTelemetryModule`: --```csharp - DependencyTrackingTelemetryModule depModule = new DependencyTrackingTelemetryModule(); - depModule.Initialize(TelemetryConfiguration.Active); -``` --For .NET Core console apps, `TelemetryConfiguration.Active` is obsolete. See the guidance in the [Worker service documentation](./worker-service.md) and the [ASP.NET Core monitoring documentation](./asp-net-core.md). --### How does automatic dependency monitoring work? --Dependencies are automatically collected by using one of the following techniques: --* Using byte code instrumentation around select methods. Use `InstrumentationEngine` either from `StatusMonitor` or an Azure App Service Web Apps extension. -* `EventSource` callbacks. -* `DiagnosticSource` callbacks in the latest .NET or .NET Core SDKs. --## Manually tracking dependencies --The following examples of dependencies, which aren't automatically collected, require manual tracking: --* Azure Cosmos DB is tracked automatically only if [HTTP/HTTPS](/azure/cosmos-db/performance-tips#networking) is used. TCP mode won't be automatically captured by Application Insights for SDK versions older than [`2.22.0-Beta1`](https://github.com/microsoft/ApplicationInsights-dotnet/blob/main/CHANGELOG.md#version-2220-beta1). -* Redis --For those dependencies not automatically collected by SDK, you can track them manually by using the [TrackDependency API](api-custom-events-metrics.md#trackdependency) that's used by the standard autocollection modules. --**Example** --If you build your code with an assembly that you didn't write yourself, you could time all the calls to it. This scenario would allow you to find out what contribution it makes to your response times. --To have this data displayed in the dependency charts in Application Insights, send it by using `TrackDependency`: --```csharp -- var startTime = DateTime.UtcNow; - var timer = System.Diagnostics.Stopwatch.StartNew(); - try - { - // making dependency call - success = dependency.Call(); - } - finally - { - timer.Stop(); - telemetryClient.TrackDependency("myDependencyType", "myDependencyCall", "myDependencyData", startTime, timer.Elapsed, success); - } -``` --Alternatively, `TelemetryClient` provides the extension methods `StartOperation` and `StopOperation`, which can be used to manually track dependencies as shown in [Outgoing dependencies tracking](custom-operations-tracking.md#outgoing-dependencies-tracking). --If you want to switch off the standard dependency tracking module, remove the reference to `DependencyTrackingTelemetryModule` in [ApplicationInsights.config](../../azure-monitor/app/configuration-with-applicationinsights-config.md) for ASP.NET applications. For ASP.NET Core applications, follow the instructions in [Application Insights for ASP.NET Core applications](asp-net-core.md#configure-or-remove-default-telemetrymodules). --## Track AJAX calls from webpages --For webpages, the Application Insights JavaScript SDK automatically collects AJAX calls as dependencies. --## Advanced SQL tracking to get full SQL query --> [!NOTE] -> Azure Functions requires separate settings to enable SQL text collection. For more information, see [Enable SQL query collection](../../azure-functions/configure-monitoring.md#enable-sql-query-collection). --For SQL calls, the name of the server and database is always collected and stored as the name of the collected `DependencyTelemetry`. Another field, called data, can contain the full SQL query text. --For ASP.NET Core applications, It's now required to opt in to SQL Text collection by using: --```csharp -services.ConfigureTelemetryModule<DependencyTrackingTelemetryModule>((module, o) => { module. EnableSqlCommandTextInstrumentation = true; }); -``` --For ASP.NET applications, the full SQL query text is collected with the help of byte code instrumentation, which requires using the instrumentation engine or by using the [Microsoft.Data.SqlClient](https://www.nuget.org/packages/Microsoft.Data.SqlClient) NuGet package instead of the System.Data.SqlClient library. Platform-specific steps to enable full SQL Query collection are described in the following table. --| Platform | Steps needed to get full SQL query | -| | | -| Web Apps in Azure App Service|In your web app control panel, [open the Application Insights pane](../../azure-monitor/app/azure-web-apps.md) and enable SQL Commands under .NET. | -| IIS Server (Azure Virtual Machines, on-premises, and so on) | Either use the [Microsoft.Data.SqlClient](https://www.nuget.org/packages/Microsoft.Data.SqlClient) NuGet package or use the Application Insights Agent PowerShell Module to [install the instrumentation engine](../../azure-monitor/app/application-insights-asp-net-agent.md?tabs=api-reference#enable-instrumentationengine) and restart IIS. | -| Azure Cloud Services | Add a [startup task to install StatusMonitor](../../azure-monitor/app/azure-web-apps-net-core.md). <br> Your app should be onboarded to the ApplicationInsights SDK at build time by installing NuGet packages for [ASP.NET](./asp-net.md) or [ASP.NET Core applications](./asp-net-core.md). | -| IIS Express | Use the [Microsoft.Data.SqlClient](https://www.nuget.org/packages/Microsoft.Data.SqlClient) NuGet package. -| WebJobs in Azure App Service| Use the [Microsoft.Data.SqlClient](https://www.nuget.org/packages/Microsoft.Data.SqlClient) NuGet package. --In addition to the preceding platform-specific steps, you *must also explicitly opt in to enable SQL command collection* by modifying the `applicationInsights.config` file with the following code: --```xml -<TelemetryModules> - <Add Type="Microsoft.ApplicationInsights.DependencyCollector.DependencyTrackingTelemetryModule, Microsoft.AI.DependencyCollector"> - <EnableSqlCommandTextInstrumentation>true</EnableSqlCommandTextInstrumentation> - </Add> -``` --In the preceding cases, the proper way of validating that the instrumentation engine is correctly installed is by validating that the SDK version of collected `DependencyTelemetry` is `rddp`. Use of `rdddsd` or `rddf` indicates dependencies are collected via `DiagnosticSource` or `EventSource` callbacks, so the full SQL query won't be captured. --## Where to find dependency data --* [Application Map](app-map.md) visualizes dependencies between your app and neighboring components. -* [Transaction Diagnostics](./transaction-search-and-diagnostics.md?tabs=transaction-diagnostics) shows unified, correlated server data. -* [Browsers tab](javascript.md) shows AJAX calls from your users' browsers. -* Select from slow or failed requests to check their dependency calls. -* [Analytics](#logs-analytics) can be used to query dependency data. --## <a name="diagnosis"></a> Diagnose slow requests --Each request event is associated with the dependency calls, exceptions, and other events tracked while processing the request. So, if some requests are doing badly, you can find out whether it's because of slow responses from a dependency. --### Tracing from requests to dependencies --Select the **Performance** tab on the left and select the **Dependencies** tab at the top. --Select a **Dependency Name** under **Overall**. After you select a dependency, a graph of that dependency's distribution of durations appears on the right. ---Select the **Samples** button at the bottom right. Then select a sample to see the end-to-end transaction details. ---### Profile your live site --The [Application Insights profiler](../../azure-monitor/app/profiler.md) traces HTTP calls to your live site and shows you the functions in your code that took the longest time. --## Failed requests --Failed requests might also be associated with failed calls to dependencies. --Select the **Failures** tab on the left and then select the **Dependencies** tab at the top. ---Here you'll see the failed dependency count. To get more information about a failed occurrence, select a **Dependency Name** in the bottom table. Select the **Dependencies** button at the bottom right to see the end-to-end transaction details. --## Logs (Analytics) --You can track dependencies in the [Kusto query language](/azure/kusto/query/). Here are some examples. --* Find any failed dependency calls: - - ``` Kusto - - dependencies | where success != "True" | take 10 - ``` --* Find AJAX calls: -- ``` Kusto - - dependencies | where client_Type == "Browser" | take 10 - ``` --* Find dependency calls associated with requests: - - ``` Kusto - - dependencies - | where timestamp > ago(1d) and client_Type != "Browser" - | join (requests | where timestamp > ago(1d)) - on operation_Id - ``` --* Find AJAX calls associated with page views: - - ``` Kusto - - dependencies - | where timestamp > ago(1d) and client_Type == "Browser" - | join (browserTimings | where timestamp > ago(1d)) - on operation_Id - ``` --## Frequently asked questions --This section provides answers to common questions. --### How does the automatic dependency collector report failed calls to dependencies? --Failed dependency calls will have the `success` field set to False. The module `DependencyTrackingTelemetryModule` doesn't report `ExceptionTelemetry`. The full data model for dependency is described in [Application Insights telemetry data model](data-model-complete.md#dependency). --### How do I calculate ingestion latency for my dependency telemetry? --Use this code: --```kusto -dependencies -| extend E2EIngestionLatency = ingestion_time() - timestamp -| extend TimeIngested = ingestion_time() -``` --### How do I determine the time the dependency call was initiated? --In the Log Analytics query view, `timestamp` represents the moment the TrackDependency() call was initiated, which occurs immediately after the dependency call response is received. To calculate the time when the dependency call began, you would take `timestamp` and subtract the recorded `duration` of the dependency call. --### Does dependency tracking in Application Insights include logging response bodies? --Dependency tracking in Application Insights does not include logging response bodies as it would generate too much telemetry for most applications. --## Open-source SDK --Like every Application Insights SDK, the dependency collection module is also open source. Read and contribute to the code or report issues at [the official GitHub repo](https://github.com/Microsoft/ApplicationInsights-dotnet). --## Dependency auto-collection --Below is the currently supported list of dependency calls that are automatically detected as dependencies without requiring any additional modification to your application's code. These dependencies are visualized in the Application Insights [Application map](./app-map.md) and [Transaction diagnostics](./transaction-search-and-diagnostics.md?tabs=transaction-diagnostics) views. If your dependency isn't on the list below, you can still track it manually with a [track dependency call](./api-custom-events-metrics.md#trackdependency). --### .NET --| App frameworks| Versions | -| |-| -| ASP.NET Webforms | 4.5+ | -| ASP.NET MVC | 4+ | -| ASP.NET WebAPI | 4.5+ | -| ASP.NET Core | 1.1+ | -| <b> Communication libraries</b> | -| [HttpClient](https://dotnet.microsoft.com) | 4.5+, .NET Core 1.1+ | -| [SqlClient](https://www.nuget.org/packages/System.Data.SqlClient) | .NET Core 1.0+, NuGet 4.3.0 | -| [Microsoft.Data.SqlClient](https://www.nuget.org/packages/Microsoft.Data.SqlClient/1.1.2)| 1.1.0 - latest stable release. (See Note below.) -| [Event Hubs Client SDK](https://www.nuget.org/packages/Microsoft.Azure.EventHubs) | 1.1.0 | -| [ServiceBus Client SDK](https://www.nuget.org/packages/Azure.Messaging.ServiceBus) | 7.0.0 | -| <b>Storage clients</b>| | -| ADO.NET | 4.5+ | --> [!NOTE] -> There is a [known issue](https://github.com/microsoft/ApplicationInsights-dotnet/issues/1347) with older versions of Microsoft.Data.SqlClient. We recommend using 1.1.0 or later to mitigate this issue. Entity Framework Core does not necessarily ship with the latest stable release of Microsoft.Data.SqlClient so we advise confirming that you are on at least 1.1.0 to avoid this issue. ---### Java --See the list of Application Insights Java's -[autocollected dependencies](opentelemetry-add-modify.md?tabs=java#included-instrumentation-libraries). --### Node.js --A list of the latest [currently supported modules](https://github.com/microsoft/node-diagnostic-channel/tree/master/src/diagnostic-channel-publishers) is maintained [here](https://github.com/microsoft/node-diagnostic-channel/tree/master/src/diagnostic-channel-publishers). --### JavaScript --| Communication libraries | Versions | -| |-| -| [XMLHttpRequest](https://developer.mozilla.org/docs/Web/API/XMLHttpRequest) | All | --## Next steps --* [Exceptions](./asp-net-exceptions.md) -* [User and page data](./javascript.md) -* [Availability](./availability-overview.md) -* Set up custom dependency tracking for [Java](opentelemetry-add-modify.md?tabs=java#add-custom-spans). -* Set up custom dependency tracking for [OpenCensus Python](/previous-versions/azure/azure-monitor/app/opencensus-python-dependency). -* [Write custom dependency telemetry](./api-custom-events-metrics.md#trackdependency) -* See [data model](./data-model-complete.md) for Application Insights types and data model. -* Check out [platforms](./app-insights-overview.md#supported-languages) supported by Application Insights. |
| azure-monitor | Asp Net Exceptions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/asp-net-exceptions.md | - Title: Diagnose failures and exceptions with Azure Application Insights -description: Capture exceptions from ASP.NET apps along with request telemetry. -- Previously updated : 01/31/2024-----# Diagnose exceptions in web apps with Application Insights ---Exceptions in web applications can be reported with [Application Insights](./app-insights-overview.md). You can correlate failed requests with exceptions and other events on both the client and server so that you can quickly diagnose the causes. In this article, you'll learn how to set up exception reporting, report exceptions explicitly, diagnose failures, and more. --## Set up exception reporting --You can set up Application Insights to report exceptions that occur in either the server or the client. Depending on the platform your application is dependent on, you'll need the appropriate extension or SDK. --### Server side --To have exceptions reported from your server-side application, consider the following scenarios: -- * Add the [Application Insights Extension](./azure-web-apps.md) for Azure web apps. - * Add the [Application Monitoring Extension](./azure-vm-vmss-apps.md) for Azure Virtual Machines and Azure Virtual Machine Scale Sets IIS-hosted apps. - * Install [Application Insights SDK](./asp-net.md) in your app code, run [Application Insights Agent](./application-insights-asp-net-agent.md) for IIS web servers, or enable the [Java agent](./opentelemetry-enable.md?tabs=java) for Java web apps. --### Client side --The JavaScript SDK provides the ability for client-side reporting of exceptions that occur in web browsers. To set up exception reporting on the client, see [Application Insights for webpages](./javascript.md). --### Application frameworks --With some application frameworks, more configuration is required. Consider the following technologies: -- * [Web forms](#web-forms) - * [MVC](#mvc) - * [Web API 1.*](#web-api-1x) - * [Web API 2.*](#web-api-2x) - * [WCF](#wcf) --> [!IMPORTANT] -> This article is specifically focused on .NET Framework apps from a code example perspective. Some of the methods that work for .NET Framework are obsolete in the .NET Core SDK. For more information, see [.NET Core SDK documentation](./asp-net-core.md) when you build apps with .NET Core. --## Diagnose exceptions using Visual Studio --Open the app solution in Visual Studio. Run the app, either on your server or on your development machine by using <kbd>F5</kbd>. Re-create the exception. --Open the **Application Insights Search** telemetry window in Visual Studio. While debugging, select the **Application Insights** dropdown box. ---Select an exception report to show its stack trace. To open the relevant code file, select a line reference in the stack trace. --If CodeLens is enabled, you'll see data about the exceptions: ---## Diagnose failures using the Azure portal --Application Insights comes with a curated Application Performance Management experience to help you diagnose failures in your monitored applications. To start, in the Application Insights resource menu on the left, under **Investigate**, select the **Failures** option. --You'll see the failure rate trends for your requests, how many of them are failing, and how many users are affected. The **Overall** view shows some of the most useful distributions specific to the selected failing operation. You'll see the top three response codes, the top three exception types, and the top three failing dependency types. ---To review representative samples for each of these subsets of operations, select the corresponding link. As an example, to diagnose exceptions, you can select the count of a particular exception to be presented with the **End-to-end transaction details** tab. ---Alternatively, instead of looking at exceptions of a specific failing operation, you can start from the **Overall** view of exceptions by switching to the **Exceptions** tab at the top. Here you can see all the exceptions collected for your monitored app. --## Custom tracing and log data --To get diagnostic data specific to your app, you can insert code to send your own telemetry data. Your custom telemetry or log data is displayed in diagnostic search alongside the request, page view, and other automatically collected data. --Using the <xref:Microsoft.VisualStudio.ApplicationInsights.TelemetryClient?displayProperty=fullName>, you have several APIs available: --* <xref:Microsoft.VisualStudio.ApplicationInsights.TelemetryClient.TrackEvent%2A?displayProperty=nameWithType> is typically used for monitoring usage patterns, but the data it sends also appears under **Custom Events** in diagnostic search. Events are named and can carry string properties and numeric metrics on which you can [filter your diagnostic searches](./transaction-search-and-diagnostics.md?tabs=transaction-search). -* <xref:Microsoft.VisualStudio.ApplicationInsights.TelemetryClient.TrackTrace%2A?displayProperty=nameWithType> lets you send longer data such as POST information. -* <xref:Microsoft.VisualStudio.ApplicationInsights.TelemetryClient.TrackException%2A?displayProperty=nameWithType> sends exception details, such as stack traces to Application Insights. --To see these events, on the left menu, open [Search](./transaction-search-and-diagnostics.md?tabs=transaction-search). Select the dropdown menu **Event types**, and then choose **Custom Event**, **Trace**, or **Exception**. ---> [!NOTE] -> If your app generates a lot of telemetry, the adaptive sampling module will automatically reduce the volume that's sent to the portal by sending only a representative fraction of events. Events that are part of the same operation will be selected or deselected as a group so that you can navigate between related events. For more information, see [Sampling in Application Insights](./sampling.md). --### See request POST data --Request details don't include the data sent to your app in a POST call. To have this data reported: --* [Install the SDK](./asp-net.md) in your application project. -* Insert code in your application to call [Microsoft.ApplicationInsights.TrackTrace()](./api-custom-events-metrics.md#tracktrace). Send the POST data in the message parameter. There's a limit to the permitted size, so you should try to send only the essential data. -* When you investigate a failed request, find the associated traces. --## <a name="exceptions"></a> Capture exceptions and related diagnostic data --At first, you won't see in the portal all the exceptions that cause failures in your app. You'll see any browser exceptions, if you're using the [JavaScript SDK](./javascript.md) in your webpages. But most server exceptions are caught by IIS and you have to write a bit of code to see them. --You can: --* **Log exceptions explicitly** by inserting code in exception handlers to report the exceptions. -* **Capture exceptions automatically** by configuring your ASP.NET framework. The necessary additions are different for different types of framework. --## Report exceptions explicitly --The simplest way to report is to insert a call to `trackException()` in an exception handler. --```javascript -try -{ - // ... -} -catch (ex) -{ - appInsights.trackException(ex, "handler loc", - { - Game: currentGame.Name, - State: currentGame.State.ToString() - }); -} -``` --```csharp -var telemetry = new TelemetryClient(); --try -{ - // ... -} -catch (Exception ex) -{ - var properties = new Dictionary<string, string> - { - ["Game"] = currentGame.Name - }; -- var measurements = new Dictionary<string, double> - { - ["Users"] = currentGame.Users.Count - }; -- // Send the exception telemetry: - telemetry.TrackException(ex, properties, measurements); -} -``` --```VB -Dim telemetry = New TelemetryClient --Try - ' ... -Catch ex as Exception - ' Set up some properties: - Dim properties = New Dictionary (Of String, String) - properties.Add("Game", currentGame.Name) -- Dim measurements = New Dictionary (Of String, Double) - measurements.Add("Users", currentGame.Users.Count) -- ' Send the exception telemetry: - telemetry.TrackException(ex, properties, measurements) -End Try -``` --The properties and measurements parameters are optional, but they're useful for [filtering and adding](./transaction-search-and-diagnostics.md?tabs=transaction-search) extra information. For example, if you have an app that can run several games, you could find all the exception reports related to a particular game. You can add as many items as you want to each dictionary. --## Browser exceptions --Most browser exceptions are reported. --If your webpage includes script files from content delivery networks or other domains, ensure your script tag has the attribute `crossorigin="anonymous"` and that the server sends [CORS headers](https://enable-cors.org/). This behavior will allow you to get a stack trace and detail for unhandled JavaScript exceptions from these resources. --## Reuse your telemetry client --> [!NOTE] -> We recommend that you instantiate the `TelemetryClient` once and reuse it throughout the life of an application. --With [Dependency Injection (DI) in .NET](/dotnet/core/extensions/dependency-injection), the appropriate .NET SDK, and correctly configuring Application Insights for DI, you can require the <xref:Microsoft.VisualStudio.ApplicationInsights.TelemetryClient> as a constructor parameter. --```csharp -public class ExampleController : ApiController -{ - private readonly TelemetryClient _telemetryClient; -- public ExampleController(TelemetryClient telemetryClient) - { - _telemetryClient = telemetryClient; - } -} -``` --In the preceding example, the `TelemetryClient` is injected into the `ExampleController` class. --## Web forms --For web forms, the HTTP Module will be able to collect the exceptions when there are no redirects configured with `CustomErrors`. However, when you have active redirects, add the following lines to the `Application_Error` function in *Global.asax.cs*. --```csharp -void Application_Error(object sender, EventArgs e) -{ - if (HttpContext.Current.IsCustomErrorEnabled && - Server.GetLastError () != null) - { - _telemetryClient.TrackException(Server.GetLastError()); - } -} -``` --In the preceding example, the `_telemetryClient` is a class-scoped variable of type <xref:Microsoft.VisualStudio.ApplicationInsights.TelemetryClient>. --## MVC --Starting with Application Insights Web SDK version 2.6 (beta 3 and later), Application Insights collects unhandled exceptions thrown in the MVC 5+ controllers methods automatically. If you've previously added a custom handler to track such exceptions, you can remove it to prevent double tracking of exceptions. --There are several scenarios when an exception filter can't correctly handle errors when exceptions are thrown: --* From controller constructors -* From message handlers -* During routing -* During response content serialization -* During application start-up -* In background tasks --All exceptions *handled* by application still need to be tracked manually. Unhandled exceptions originating from controllers typically result in a 500 "Internal Server Error" response. If such response is manually constructed as a result of a handled exception, or no exception at all, it's tracked in corresponding request telemetry with `ResultCode` 500. However, the Application Insights SDK is unable to track a corresponding exception. --### Prior versions support --If you use MVC 4 (and prior) of Application Insights Web SDK 2.5 (and prior), refer to the following examples to track exceptions. --If the [CustomErrors](/previous-versions/dotnet/netframework-4.0/h0hfz6fc(v=vs.100)) configuration is `Off`, exceptions will be available for the [HTTP Module](/previous-versions/dotnet/netframework-3.0/ms178468(v=vs.85)) to collect. However, if it's `RemoteOnly` (default), or `On`, the exception will be cleared and not available for Application Insights to automatically collect. You can fix that behavior by overriding the [System.Web.Mvc.HandleErrorAttribute class](/dotnet/api/system.web.mvc.handleerrorattribute) and applying the overridden class as shown for the different MVC versions here (see the [GitHub source](https://github.com/AppInsightsSamples/Mvc2UnhandledExceptions/blob/master/MVC2App/Controllers/AiHandleErrorAttribute.cs)): --```csharp -using System; -using System.Web.Mvc; -using Microsoft.ApplicationInsights; --namespace MVC2App.Controllers -{ - [AttributeUsage(AttributeTargets.Class | AttributeTargets.Method, Inherited = true, AllowMultiple = true)] - public class AiHandleErrorAttribute : HandleErrorAttribute - { - public override void OnException(ExceptionContext filterContext) - { - if (filterContext != null && filterContext.HttpContext != null && filterContext.Exception != null) - { - //The attribute should track exceptions only when CustomErrors setting is On - //if CustomErrors is Off, exceptions will be caught by AI HTTP Module - if (filterContext.HttpContext.IsCustomErrorEnabled) - { //Or reuse instance (recommended!). See note above. - var ai = new TelemetryClient(); - ai.TrackException(filterContext.Exception); - } - } - base.OnException(filterContext); - } - } -} -``` --#### MVC 2 --Replace the HandleError attribute with your new attribute in your controllers: --```csharp - namespace MVC2App.Controllers - { - [AiHandleError] - public class HomeController : Controller - { - // Omitted for brevity - } - } -``` --[Sample](https://github.com/AppInsightsSamples/Mvc2UnhandledExceptions) --#### MVC 3 --Register `AiHandleErrorAttribute` as a global filter in *Global.asax.cs*: --```csharp -public class MyMvcApplication : System.Web.HttpApplication -{ - public static void RegisterGlobalFilters(GlobalFilterCollection filters) - { - filters.Add(new AiHandleErrorAttribute()); - } -} -``` --[Sample](https://github.com/AppInsightsSamples/Mvc3UnhandledExceptionTelemetry) --#### MVC 4, MVC 5 --Register `AiHandleErrorAttribute` as a global filter in *FilterConfig.cs*: --```csharp -public class FilterConfig -{ - public static void RegisterGlobalFilters(GlobalFilterCollection filters) - { - // Default replaced with the override to track unhandled exceptions - filters.Add(new AiHandleErrorAttribute()); - } -} -``` --[Sample](https://github.com/AppInsightsSamples/Mvc5UnhandledExceptionTelemetry) --## Web API --Starting with Application Insights Web SDK version 2.6 (beta 3 and later), Application Insights collects unhandled exceptions thrown in the controller methods automatically for Web API 2+. If you've previously added a custom handler to track such exceptions, as described in the following examples, you can remove it to prevent double tracking of exceptions. --There are several cases that the exception filters can't handle. For example: --* Exceptions thrown from controller constructors. -* Exceptions thrown from message handlers. -* Exceptions thrown during routing. -* Exceptions thrown during response content serialization. -* Exception thrown during application startup. -* Exception thrown in background tasks. --All exceptions *handled* by application still need to be tracked manually. Unhandled exceptions originating from controllers typically result in a 500 "Internal Server Error" response. If such a response is manually constructed as a result of a handled exception, or no exception at all, it's tracked in a corresponding request telemetry with `ResultCode` 500. However, the Application Insights SDK can't track a corresponding exception. --### Prior versions support --If you use Web API 1 (and earlier) of Application Insights Web SDK 2.5 (and earlier), refer to the following examples to track exceptions. --#### Web API 1.x --Override `System.Web.Http.Filters.ExceptionFilterAttribute`: --```csharp -using System.Web.Http.Filters; -using Microsoft.ApplicationInsights; --namespace WebAPI.App_Start -{ - public class AiExceptionFilterAttribute : ExceptionFilterAttribute - { - public override void OnException(HttpActionExecutedContext actionExecutedContext) - { - if (actionExecutedContext != null && actionExecutedContext.Exception != null) - { //Or reuse instance (recommended!). See note above. - var ai = new TelemetryClient(); - ai.TrackException(actionExecutedContext.Exception); - } - base.OnException(actionExecutedContext); - } - } -} -``` --You could add this overridden attribute to specific controllers, or add it to the global filter configuration in the `WebApiConfig` class: --```csharp -using System.Web.Http; -using WebApi1.x.App_Start; --namespace WebApi1.x -{ - public static class WebApiConfig - { - public static void Register(HttpConfiguration config) - { - config.Routes.MapHttpRoute( - name: "DefaultApi", - routeTemplate: "api/{controller}/{id}", - defaults: new { id = RouteParameter.Optional }); - - // ... - config.EnableSystemDiagnosticsTracing(); - - // Capture exceptions for Application Insights: - config.Filters.Add(new AiExceptionFilterAttribute()); - } - } -} -``` --[Sample](https://github.com/AppInsightsSamples/WebApi_1.x_UnhandledExceptions) --#### Web API 2.x --Add an implementation of `IExceptionLogger`: --```csharp -using System.Web.Http.ExceptionHandling; -using Microsoft.ApplicationInsights; --namespace ProductsAppPureWebAPI.App_Start -{ - public class AiExceptionLogger : ExceptionLogger - { - public override void Log(ExceptionLoggerContext context) - { - if (context != null && context.Exception != null) - { - //or reuse instance (recommended!). see note above - var ai = new TelemetryClient(); - ai.TrackException(context.Exception); - } - base.Log(context); - } - } -} -``` --Add this snippet to the services in `WebApiConfig`: --```csharp -using System.Web.Http; -using System.Web.Http.ExceptionHandling; -using ProductsAppPureWebAPI.App_Start; --namespace WebApi2WithMVC -{ - public static class WebApiConfig - { - public static void Register(HttpConfiguration config) - { - // Web API configuration and services - - // Web API routes - config.MapHttpAttributeRoutes(); - - config.Routes.MapHttpRoute( - name: "DefaultApi", - routeTemplate: "api/{controller}/{id}", - defaults: new { id = RouteParameter.Optional }); -- config.Services.Add(typeof(IExceptionLogger), new AiExceptionLogger()); - } - } -} -``` --[Sample](https://github.com/AppInsightsSamples/WebApi_2.x_UnhandledExceptions) --As alternatives, you could: --- Replace the only `ExceptionHandler` instance with a custom implementation of `IExceptionHandler`. This exception handler is only called when the framework is still able to choose which response message to send, not when the connection is aborted, for instance.-- Use exception filters, as described in the preceding section on Web API 1.x controllers, which aren't called in all cases.--## WCF --Add a class that extends `Attribute` and implements `IErrorHandler` and `IServiceBehavior`. --```csharp - using System; - using System.Collections.Generic; - using System.Linq; - using System.ServiceModel.Description; - using System.ServiceModel.Dispatcher; - using System.Web; - using Microsoft.ApplicationInsights; -- namespace WcfService4.ErrorHandling - { - public class AiLogExceptionAttribute : Attribute, IErrorHandler, IServiceBehavior - { - public void AddBindingParameters(ServiceDescription serviceDescription, - System.ServiceModel.ServiceHostBase serviceHostBase, - System.Collections.ObjectModel.Collection<ServiceEndpoint> endpoints, - System.ServiceModel.Channels.BindingParameterCollection bindingParameters) - { - } -- public void ApplyDispatchBehavior(ServiceDescription serviceDescription, - System.ServiceModel.ServiceHostBase serviceHostBase) - { - foreach (ChannelDispatcher disp in serviceHostBase.ChannelDispatchers) - { - disp.ErrorHandlers.Add(this); - } - } -- public void Validate(ServiceDescription serviceDescription, - System.ServiceModel.ServiceHostBase serviceHostBase) - { - } -- bool IErrorHandler.HandleError(Exception error) - {//or reuse instance (recommended!). see note above - var ai = new TelemetryClient(); -- ai.TrackException(error); - return false; - } -- void IErrorHandler.ProvideFault(Exception error, - System.ServiceModel.Channels.MessageVersion version, - ref System.ServiceModel.Channels.Message fault) - { - } - } - } -``` --Add the attribute to the service implementations: --```csharp -namespace WcfService4 -{ - [AiLogException] - public class Service1 : IService1 - { - // Omitted for brevity - } -} -``` --[Sample](https://github.com/AppInsightsSamples/WCFUnhandledExceptions) --## Exception performance counters --If you've [installed the Azure Monitor Application Insights Agent](./application-insights-asp-net-agent.md) on your server, you can get a chart of the exceptions rate, measured by .NET. Both handled and unhandled .NET exceptions are included. --Open a metrics explorer tab, add a new chart. Under **Performance Counters**, select **Exception rate**. --The .NET Framework calculates the rate by counting the number of exceptions in an interval and dividing by the length of the interval. --This count is different from the Exceptions count calculated by the Application Insights portal counting `TrackException` reports. The sampling intervals are different, and the SDK doesn't send `TrackException` reports for all handled and unhandled exceptions. --## Next steps --* [Monitor REST, SQL, and other calls to dependencies](./asp-net-dependencies.md) -* [Monitor page load times, browser exceptions, and AJAX calls](./javascript.md) -* [Monitor performance counters](./performance-counters.md) |
| azure-monitor | Asp Net Trace Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/asp-net-trace-logs.md | - Title: Explore .NET trace logs in Application Insights -description: Search logs generated by Trace, NLog, or Log4Net. -- Previously updated : 02/29/2024----# Explore .NET/.NET Core and Python trace logs in Application Insights --Send diagnostic tracing logs for your ASP.NET/ASP.NET Core application from ILogger, NLog, log4Net, or System.Diagnostics.Trace to Azure Application Insights. For Python applications, send diagnostic tracing logs by using AzureLogHandler in OpenCensus Python for Azure Monitor. You can then explore and search for them. Those logs are merged with the other log files from your application. You can use them to identify traces that are associated with each user request and correlate them with other events and exception reports. --> [!NOTE] -> Do you need the log-capture module? It's a useful adapter for third-party loggers. But if you aren't already using NLog, log4Net, or System.Diagnostics.Trace, consider calling [**Application Insights TrackTrace()**](./api-custom-events-metrics.md#tracktrace) directly. -> -> ---## Install logging on your app --Install your chosen logging framework in your project, which should result in an entry in *app.config* or *web.config*. --```xml - <configuration> - <system.diagnostics> - <trace> - <listeners> - <add name="myAppInsightsListener" type="Microsoft.ApplicationInsights.TraceListener.ApplicationInsightsTraceListener, Microsoft.ApplicationInsights.TraceListener" /> - </listeners> - </trace> - </system.diagnostics> -</configuration> -``` --## Configure Application Insights to collect logs --[Add Application Insights to your project](./asp-net.md) if you haven't done that yet and there is an option to include the log collector. --Or right-click your project in Solution Explorer to **Configure Application Insights**. Select the **Configure trace collection** option. --> [!NOTE] -> No Application Insights menu or log collector option? Try [Troubleshooting](#troubleshooting). --## Manual installation --Use this method if your project type isn't supported by the Application Insights installer. For example, if it's a Windows desktop project. --1. If you plan to use log4net or NLog, install it in your project. -1. In Solution Explorer, right-click your project, and select **Manage NuGet Packages**. -1. Search for **Application Insights**. -1. Select one of the following packages: -- - **ILogger**: [Microsoft.Extensions.Logging.ApplicationInsights](https://www.nuget.org/packages/Microsoft.Extensions.Logging.ApplicationInsights/) - - **NLog**: [Microsoft.ApplicationInsights.NLogTarget](https://www.nuget.org/packages/Microsoft.ApplicationInsights.NLogTarget/) - - **log4net**: [Microsoft.ApplicationInsights.Log4NetAppender](https://www.nuget.org/packages/Microsoft.ApplicationInsights.Log4NetAppender/) - - **System.Diagnostics**: [Microsoft.ApplicationInsights.TraceListener](https://www.nuget.org/packages/Microsoft.ApplicationInsights.TraceListener/) - - [Microsoft.ApplicationInsights.DiagnosticSourceListener](https://www.nuget.org/packages/Microsoft.ApplicationInsights.DiagnosticSourceListener/) - - [Microsoft.ApplicationInsights.EtwCollector](https://www.nuget.org/packages/Microsoft.ApplicationInsights.EtwCollector/) - - [Microsoft.ApplicationInsights.EventSourceListener](https://www.nuget.org/packages/Microsoft.ApplicationInsights.EventSourceListener/) --The NuGet package installs the necessary assemblies and modifies web.config or app.config if that's applicable. --## ILogger --For examples of using the Application Insights ILogger implementation with console applications and ASP.NET Core, see [ApplicationInsightsLoggerProvider for .NET Core ILogger logs](ilogger.md). --## Insert diagnostic log calls --If you use System.Diagnostics.Trace, a typical call would be: --```csharp -System.Diagnostics.Trace.TraceWarning("Slow response - database01"); -``` --If you prefer log4net or NLog, use: --```csharp - logger.Warn("Slow response - database01"); -``` --## Use EventSource events --You can configure [System.Diagnostics.Tracing.EventSource](/dotnet/api/system.diagnostics.tracing.eventsource) events to be sent to Application Insights as traces. First, install the `Microsoft.ApplicationInsights.EventSourceListener` NuGet package. Then edit the `TelemetryModules` section of the [ApplicationInsights.config](./configuration-with-applicationinsights-config.md) file. --```xml - <Add Type="Microsoft.ApplicationInsights.EventSourceListener.EventSourceTelemetryModule, Microsoft.ApplicationInsights.EventSourceListener"> - <Sources> - <Add Name="MyCompany" Level="Verbose" /> - </Sources> - </Add> -``` --For each source, you can set the following parameters: -- * **Name** specifies the name of the EventSource to collect. - * **Level** specifies the logging level to collect: *Critical*, *Error*, *Informational*, *LogAlways*, *Verbose*, or *Warning*. - * **Keywords** (optional) specify the integer value of keyword combinations to use. --## Use DiagnosticSource events --You can configure [System.Diagnostics.DiagnosticSource](https://github.com/dotnet/runtime/blob/main/src/libraries/System.Diagnostics.DiagnosticSource/src/DiagnosticSourceUsersGuide.md) events to be sent to Application Insights as traces. First, install the [`Microsoft.ApplicationInsights.DiagnosticSourceListener`](https://www.nuget.org/packages/Microsoft.ApplicationInsights.DiagnosticSourceListener) NuGet package. Then edit the "TelemetryModules" section of the [ApplicationInsights.config](./configuration-with-applicationinsights-config.md) file. --```xml - <Add Type="Microsoft.ApplicationInsights.DiagnosticSourceListener.DiagnosticSourceTelemetryModule, Microsoft.ApplicationInsights.DiagnosticSourceListener"> - <Sources> - <Add Name="MyDiagnosticSourceName" /> - </Sources> - </Add> -``` --For each diagnostic source you want to trace, add an entry with the `Name` attribute set to the name of your diagnostic source. --## Use ETW events --You can configure Event Tracing for Windows (ETW) events to be sent to Application Insights as traces. First, install the `Microsoft.ApplicationInsights.EtwCollector` NuGet package. Then edit the "TelemetryModules" section of the [ApplicationInsights.config](./configuration-with-applicationinsights-config.md) file. --> [!NOTE] -> ETW events can only be collected if the process that hosts the SDK runs under an identity that's a member of Performance Log Users or Administrators. --```xml - <Add Type="Microsoft.ApplicationInsights.EtwCollector.EtwCollectorTelemetryModule, Microsoft.ApplicationInsights.EtwCollector"> - <Sources> - <Add ProviderName="MyCompanyEventSourceName" Level="Verbose" /> - </Sources> - </Add> -``` --For each source, you can set the following parameters: -- * **ProviderName** is the name of the ETW provider to collect. - * **ProviderGuid** specifies the GUID of the ETW provider to collect. It can be used instead of `ProviderName`. - * **Level** sets the logging level to collect. It can be *Critical*, *Error*, *Informational*, *LogAlways*, *Verbose*, or *Warning*. - * **Keywords** (optional) set the integer value of keyword combinations to use. --## Use the Trace API directly --You can call the Application Insights trace API directly. The logging adapters use this API. --For example: --```csharp -TelemetryConfiguration configuration = TelemetryConfiguration.CreateDefault(); -var telemetryClient = new TelemetryClient(configuration); -telemetryClient.TrackTrace("Slow response - database01"); -``` --An advantage of `TrackTrace` is that you can put relatively long data in the message. For example, you can encode POST data there. --You can also add a severity level to your message. And, like other telemetry, you can add property values to help filter or search for different sets of traces. For example: -- ```csharp - TelemetryConfiguration configuration = TelemetryConfiguration.CreateDefault(); - var telemetryClient = new TelemetryClient(configuration); - telemetryClient.TrackTrace("Slow database response", - SeverityLevel.Warning, - new Dictionary<string, string> { { "database", "db.ID" } }); - ``` --Now you can easily filter out in **Transaction Search** all the messages of a particular severity level that relate to a particular database. --## AzureLogHandler for OpenCensus Python --The Azure Monitor Log Handler allows you to export Python logs to Azure Monitor. --Instrument your application with the [OpenCensus Python SDK](/previous-versions/azure/azure-monitor/app/opencensus-python) for Azure Monitor. --This example shows how to send a warning level log to Azure Monitor. --```python -import logging --from opencensus.ext.azure.log_exporter import AzureLogHandler --logger = logging.getLogger(__name__) -logger.addHandler(AzureLogHandler(connection_string='InstrumentationKey=<your-instrumentation_key-here>')) -logger.warning('Hello, World!') -``` --## Explore your logs --Run your app in debug mode or deploy it live. --In your app's overview pane in the Application Insights portal, select **Transaction Search**. --You can, for example: --* Filter on log traces or on items with specific properties. -* Inspect a specific item in detail. -* Find other system log data that relates to the same user request (has the same operation ID). -* Save the configuration of a page as a favorite. --> [!NOTE] -> If your application sends a lot of data and you're using the Application Insights SDK for ASP.NET version 2.0.0-beta3 or later, the *adaptive sampling* feature might operate and send only a portion of your telemetry. Learn more about [sampling](./sampling.md). -> --## Troubleshooting --Find answers to common questions. --### What causes delayed telemetry, an overloaded network, and inefficient transmission? --System.Diagnostics.Tracing has an [Autoflush feature](/dotnet/api/system.diagnostics.trace.autoflush). This feature causes SDK to flush with every telemetry item, which is undesirable, and can cause logging adapter issues like delayed telemetry, an overloaded network, and inefficient transmission. --### How do I do this for Java? --In Java codeless instrumentation, which is recommended, the logs are collected out of the box. Use [Java 3.0 agent](./opentelemetry-enable.md?tabs=java). --The Application Insights Java agent collects logs from Log4j, Logback, and java.util.logging out of the box. --### Why is there no Application Insights option on the project context menu? --* Make sure that Developer Analytics Tools is installed on the development machine. In Visual Studio, go to **Tools** > **Extensions and Updates**, and look for **Developer Analytics Tools**. If it isn't on the **Installed** tab, open the **Online** tab and install it. -* This project type might be one that Developer Analytics Tools doesn't support. Use [manual installation](#manual-installation). --### Why is there no log adapter option in the configuration tool? --* Install the logging framework first. -* If you're using System.Diagnostics.Trace, make sure that you've [configured it in *web.config*](/dotnet/api/system.diagnostics.eventlogtracelistener). -* Make sure that you have the latest version of Application Insights. In Visual Studio, go to **Tools** > **Extensions and Updates** and open the **Updates** tab. If **Developer Analytics Tools** is there, select it to update it. --### <a name="emptykey"></a>Why do I get the "Instrumentation key cannot be empty" error message? --You probably installed the logging adapter NuGet package without installing Application Insights. In Solution Explorer, right-click *ApplicationInsights.config*, and select **Update Application Insights**. You are prompted to sign in to Azure and create an Application Insights resource or reuse an existing one. It should fix the problem. --### Why can I see traces but not other events in diagnostic search? --It can take a while for all the events and requests to get through the pipeline. --### <a name="limits"></a>How much data is retained? --Several factors affect the amount of data that's retained. For more information, see the [Limits](./api-custom-events-metrics.md#limits) section of the customer event metrics page. --### Why don't I see some log entries that I expected? --Perhaps your application sends voluminous amounts of data and you're using the Application Insights SDK for ASP.NET version 2.0.0-beta3 or later. In this case, the adaptive sampling feature might operate and send only a portion of your telemetry. Learn more about [sampling](./sampling.md). --## <a name="add"></a>Next steps --* [Diagnose failures and exceptions in ASP.NET](asp-net-exceptions.md) -* [Learn more about Transaction Search](transaction-search-and-diagnostics.md?tabs=transaction-search) -* [Set up availability and responsiveness tests](availability-overview.md) --<!--Link references--> --[availability]: ./availability-overview.md -[diagnostic]: ./transaction-search-and-diagnostics.md?tabs=transaction-search -[exceptions]: asp-net-exceptions.md -[start]: ./app-insights-overview.md |
| azure-monitor | Asp Net | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/asp-net.md | - Title: Configure monitoring for ASP.NET with Azure Application Insights | Microsoft Docs -description: Configure performance, availability, and user behavior analytics tools for your ASP.NET website hosted on-premises or in Azure. - Previously updated : 01/31/2024---# Configure Application Insights for your ASP.NET website --This procedure configures your ASP.NET web app to send telemetry to the [Application Insights](./app-insights-overview.md) feature of the Azure Monitor service. It works for ASP.NET apps that are hosted either in your own Internet Information Servers (IIS) on-premises or in the cloud. ----## Prerequisites -To add Application Insights to your ASP.NET website, you need to: --- Install the latest version of [Visual Studio 2019 for Windows](https://www.visualstudio.com/downloads/) with the following workloads:- - ASP.NET and web development - - Azure development --- Create a [free Azure account](https://azure.microsoft.com/free/) if you don't already have an Azure subscription.--- Create an [Application Insights workspace-based resource](create-workspace-resource.md).--> [!IMPORTANT] -> We recommend [connection strings](./sdk-connection-string.md?tabs=net) over instrumentation keys. New Azure regions *require* the use of connection strings instead of instrumentation keys. -> -> A connection string identifies the resource that you want to associate with your telemetry data. It also allows you to modify the endpoints that your resource will use as a destination for your telemetry. You'll need to copy the connection string and add it to your application's code or to the ΓÇ£APPLICATIONINSIGHTS_CONNECTION_STRINGΓÇ¥ environment variable. --## Create a basic ASP.NET web app --1. Open Visual Studio 2019. -2. Select **File** > **New** > **Project**. -3. Select **ASP.NET Web Application(.NET Framework) C#**. -4. Enter a project name, and then select **Create**. -5. Select **MVC** > **Create**. --## Add Application Insights automatically --This section guides you through automatically adding Application Insights to a template-based ASP.NET web app. From within your ASP.NET web app project in Visual Studio: --1. Select **Project** > **Add Application Insights Telemetry** > **Application Insights Sdk (local)** > **Next** > **Finish** > **Close**. -2. Open the *ApplicationInsights.config* file. -3. Before the closing `</ApplicationInsights>` tag, add a line that contains the connection string for your Application Insights resource. Find your connection string on the overview pane of the newly created Application Insights resource. -- ```xml - <ConnectionString>Copy connection string from Application Insights Resource Overview</ConnectionString> - ``` --4. Select **Project** > **Manage NuGet Packages** > **Updates**. Then update each `Microsoft.ApplicationInsights` NuGet package to the latest stable release. -5. Run your application by selecting **IIS Express**. A basic ASP.NET app opens. As you browse through the pages on the site, telemetry is sent to Application Insights. --## Add Application Insights manually --This section guides you through manually adding Application Insights to a template-based ASP.NET web app. This section assumes that you're using a web app based on the standard Model, View, and Controller (MVC) web app template for the ASP.NET Framework. --1. Add the following NuGet packages and their dependencies to your project: -- - [`Microsoft.ApplicationInsights.WindowsServer`](https://www.nuget.org/packages/Microsoft.ApplicationInsights.WindowsServer) - - [`Microsoft.ApplicationInsights.Web`](https://www.nuget.org/packages/Microsoft.ApplicationInsights.Web) - - [`Microsoft.AspNet.TelemetryCorrelation`](https://www.nuget.org/packages/Microsoft.AspNet.TelemetryCorrelation) --2. In some cases, the *ApplicationInsights.config* file is created for you automatically. If the file is already present, skip to step 4. --Create it yourself if it's missing. In the root directory of an ASP.NET application, create a new file called *ApplicationInsights.config*. --3. Copy the following XML configuration into your newly created file: -- ```xml - <?xml version="1.0" encoding="utf-8"?> - <ApplicationInsights xmlns="http://schemas.microsoft.com/ApplicationInsights/2013/Settings"> - <TelemetryInitializers> - <Add Type="Microsoft.ApplicationInsights.DependencyCollector.HttpDependenciesParsingTelemetryInitializer, Microsoft.AI.DependencyCollector" /> - <Add Type="Microsoft.ApplicationInsights.WindowsServer.AzureRoleEnvironmentTelemetryInitializer, Microsoft.AI.WindowsServer" /> - <Add Type="Microsoft.ApplicationInsights.WindowsServer.BuildInfoConfigComponentVersionTelemetryInitializer, Microsoft.AI.WindowsServer" /> - <Add Type="Microsoft.ApplicationInsights.Web.WebTestTelemetryInitializer, Microsoft.AI.Web" /> - <Add Type="Microsoft.ApplicationInsights.Web.SyntheticUserAgentTelemetryInitializer, Microsoft.AI.Web"> - <!-- Extended list of bots: - search|spider|crawl|Bot|Monitor|BrowserMob|BingPreview|PagePeeker|WebThumb|URL2PNG|ZooShot|GomezA|Google SketchUp|Read Later|KTXN|KHTE|Keynote|Pingdom|AlwaysOn|zao|borg|oegp|silk|Xenu|zeal|NING|htdig|lycos|slurp|teoma|voila|yahoo|Sogou|CiBra|Nutch|Java|JNLP|Daumoa|Genieo|ichiro|larbin|pompos|Scrapy|snappy|speedy|vortex|favicon|indexer|Riddler|scooter|scraper|scrubby|WhatWeb|WinHTTP|voyager|archiver|Icarus6j|mogimogi|Netvibes|altavista|charlotte|findlinks|Retreiver|TLSProber|WordPress|wsr-agent|http client|Python-urllib|AppEngine-Google|semanticdiscovery|facebookexternalhit|web/snippet|Google-HTTP-Java-Client--> - <Filters>search|spider|crawl|Bot|Monitor|AlwaysOn</Filters> - </Add> - <Add Type="Microsoft.ApplicationInsights.Web.ClientIpHeaderTelemetryInitializer, Microsoft.AI.Web" /> - <Add Type="Microsoft.ApplicationInsights.Web.AzureAppServiceRoleNameFromHostNameHeaderInitializer, Microsoft.AI.Web" /> - <Add Type="Microsoft.ApplicationInsights.Web.OperationNameTelemetryInitializer, Microsoft.AI.Web" /> - <Add Type="Microsoft.ApplicationInsights.Web.OperationCorrelationTelemetryInitializer, Microsoft.AI.Web" /> - <Add Type="Microsoft.ApplicationInsights.Web.UserTelemetryInitializer, Microsoft.AI.Web" /> - <Add Type="Microsoft.ApplicationInsights.Web.AuthenticatedUserIdTelemetryInitializer, Microsoft.AI.Web" /> - <Add Type="Microsoft.ApplicationInsights.Web.AccountIdTelemetryInitializer, Microsoft.AI.Web" /> - <Add Type="Microsoft.ApplicationInsights.Web.SessionTelemetryInitializer, Microsoft.AI.Web" /> - </TelemetryInitializers> - <TelemetryModules> - <Add Type="Microsoft.ApplicationInsights.DependencyCollector.DependencyTrackingTelemetryModule, Microsoft.AI.DependencyCollector"> - <ExcludeComponentCorrelationHttpHeadersOnDomains> - <!-- - Requests to the following hostnames will not be modified by adding correlation headers. - Add entries here to exclude additional hostnames. - NOTE: this configuration will be lost upon NuGet upgrade. - --> - <Add>core.windows.net</Add> - <Add>core.chinacloudapi.cn</Add> - <Add>core.cloudapi.de</Add> - <Add>core.usgovcloudapi.net</Add> - </ExcludeComponentCorrelationHttpHeadersOnDomains> - <IncludeDiagnosticSourceActivities> - <Add>Microsoft.Azure.EventHubs</Add> - <Add>Azure.Messaging.ServiceBus</Add> - </IncludeDiagnosticSourceActivities> - </Add> - <Add Type="Microsoft.ApplicationInsights.Extensibility.PerfCounterCollector.PerformanceCollectorModule, Microsoft.AI.PerfCounterCollector"> - <!-- - Use the following syntax here to collect additional performance counters: - - <Counters> - <Add PerformanceCounter="\Process(??APP_WIN32_PROC??)\Handle Count" ReportAs="Process handle count" /> - ... - </Counters> - - PerformanceCounter must be either \CategoryName(InstanceName)\CounterName or \CategoryName\CounterName - - NOTE: performance counters configuration will be lost upon NuGet upgrade. - - The following placeholders are supported as InstanceName: - ??APP_WIN32_PROC?? - instance name of the application process for Win32 counters. - ??APP_W3SVC_PROC?? - instance name of the application IIS worker process for IIS/ASP.NET counters. - ??APP_CLR_PROC?? - instance name of the application CLR process for .NET counters. - --> - </Add> - <Add Type="Microsoft.ApplicationInsights.Extensibility.PerfCounterCollector.QuickPulse.QuickPulseTelemetryModule, Microsoft.AI.PerfCounterCollector" /> - <Add Type="Microsoft.ApplicationInsights.WindowsServer.AppServicesHeartbeatTelemetryModule, Microsoft.AI.WindowsServer" /> - <Add Type="Microsoft.ApplicationInsights.WindowsServer.AzureInstanceMetadataTelemetryModule, Microsoft.AI.WindowsServer"> - <!-- - Remove individual fields collected here by adding them to the ApplicationInsighs.HeartbeatProvider - with the following syntax: - - <Add Type="Microsoft.ApplicationInsights.Extensibility.Implementation.Tracing.DiagnosticsTelemetryModule, Microsoft.ApplicationInsights"> - <ExcludedHeartbeatProperties> - <Add>osType</Add> - <Add>location</Add> - <Add>name</Add> - <Add>offer</Add> - <Add>platformFaultDomain</Add> - <Add>platformUpdateDomain</Add> - <Add>publisher</Add> - <Add>sku</Add> - <Add>version</Add> - <Add>vmId</Add> - <Add>vmSize</Add> - <Add>subscriptionId</Add> - <Add>resourceGroupName</Add> - <Add>placementGroupId</Add> - <Add>tags</Add> - <Add>vmScaleSetName</Add> - </ExcludedHeartbeatProperties> - </Add> - - NOTE: exclusions will be lost upon upgrade. - --> - </Add> - <Add Type="Microsoft.ApplicationInsights.WindowsServer.DeveloperModeWithDebuggerAttachedTelemetryModule, Microsoft.AI.WindowsServer" /> - <Add Type="Microsoft.ApplicationInsights.WindowsServer.UnhandledExceptionTelemetryModule, Microsoft.AI.WindowsServer" /> - <Add Type="Microsoft.ApplicationInsights.WindowsServer.UnobservedExceptionTelemetryModule, Microsoft.AI.WindowsServer"> - <!--</Add> - <Add Type="Microsoft.ApplicationInsights.WindowsServer.FirstChanceExceptionStatisticsTelemetryModule, Microsoft.AI.WindowsServer">--> - </Add> - <Add Type="Microsoft.ApplicationInsights.Web.RequestTrackingTelemetryModule, Microsoft.AI.Web"> - <Handlers> - <!-- - Add entries here to filter out additional handlers: - - NOTE: handler configuration will be lost upon NuGet upgrade. - --> - <Add>Microsoft.VisualStudio.Web.PageInspector.Runtime.Tracing.RequestDataHttpHandler</Add> - <Add>System.Web.StaticFileHandler</Add> - <Add>System.Web.Handlers.AssemblyResourceLoader</Add> - <Add>System.Web.Optimization.BundleHandler</Add> - <Add>System.Web.Script.Services.ScriptHandlerFactory</Add> - <Add>System.Web.Handlers.TraceHandler</Add> - <Add>System.Web.Services.Discovery.DiscoveryRequestHandler</Add> - <Add>System.Web.HttpDebugHandler</Add> - </Handlers> - </Add> - <Add Type="Microsoft.ApplicationInsights.Web.ExceptionTrackingTelemetryModule, Microsoft.AI.Web" /> - <Add Type="Microsoft.ApplicationInsights.Web.AspNetDiagnosticTelemetryModule, Microsoft.AI.Web" /> - </TelemetryModules> - <ApplicationIdProvider Type="Microsoft.ApplicationInsights.Extensibility.Implementation.ApplicationId.ApplicationInsightsApplicationIdProvider, Microsoft.ApplicationInsights" /> - <TelemetrySinks> - <Add Name="default"> - <TelemetryProcessors> - <Add Type="Microsoft.ApplicationInsights.Extensibility.PerfCounterCollector.QuickPulse.QuickPulseTelemetryProcessor, Microsoft.AI.PerfCounterCollector" /> - <Add Type="Microsoft.ApplicationInsights.Extensibility.AutocollectedMetricsExtractor, Microsoft.ApplicationInsights" /> - <Add Type="Microsoft.ApplicationInsights.WindowsServer.TelemetryChannel.AdaptiveSamplingTelemetryProcessor, Microsoft.AI.ServerTelemetryChannel"> - <MaxTelemetryItemsPerSecond>5</MaxTelemetryItemsPerSecond> - <ExcludedTypes>Event</ExcludedTypes> - </Add> - <Add Type="Microsoft.ApplicationInsights.WindowsServer.TelemetryChannel.AdaptiveSamplingTelemetryProcessor, Microsoft.AI.ServerTelemetryChannel"> - <MaxTelemetryItemsPerSecond>5</MaxTelemetryItemsPerSecond> - <IncludedTypes>Event</IncludedTypes> - </Add> - <!-- - Adjust the include and exclude examples to specify the desired semicolon-delimited types. (Dependency, Event, Exception, PageView, Request, Trace) - --> - </TelemetryProcessors> - <TelemetryChannel Type="Microsoft.ApplicationInsights.WindowsServer.TelemetryChannel.ServerTelemetryChannel, Microsoft.AI.ServerTelemetryChannel" /> - </Add> - </TelemetrySinks> - <!-- - Learn more about Application Insights configuration with ApplicationInsights.config here: - http://go.microsoft.com/fwlink/?LinkID=513840 - --> - <ConnectionString>Copy connection string from Application Insights Resource Overview</ConnectionString> - </ApplicationInsights> - ``` --4. Before the closing `</ApplicationInsights>` tag, add the connection string for your Application Insights resource. You can find your connection string on the overview pane of the newly created Application Insights resource. -- ```xml - <ConnectionString>Copy connection string from Application Insights Resource Overview</ConnectionString> - ``` --5. At the same level of your project as the *ApplicationInsights.config* file, create a folder called *ErrorHandler* with a new C# file called *AiHandleErrorAttribute.cs*. The contents of the file look like this: -- ```csharp - using System; - using System.Web.Mvc; - using Microsoft.ApplicationInsights; - - namespace WebApplication10.ErrorHandler //namespace will vary based on your project name - { - [AttributeUsage(AttributeTargets.Class | AttributeTargets.Method, Inherited = true, AllowMultiple = true)] - public class AiHandleErrorAttribute : HandleErrorAttribute - { - public override void OnException(ExceptionContext filterContext) - { - if (filterContext != null && filterContext.HttpContext != null && filterContext.Exception != null) - { - //If customError is Off, then AI HTTPModule will report the exception - if (filterContext.HttpContext.IsCustomErrorEnabled) - { - var ai = new TelemetryClient(); - ai.TrackException(filterContext.Exception); - } - } - base.OnException(filterContext); - } - } - } - ``` --6. In the *App_Start* folder, open the *FilterConfig.cs* file and change it to match the sample: -- ```csharp - using System.Web; - using System.Web.Mvc; - - namespace WebApplication10 //Namespace will vary based on project name - { - public class FilterConfig - { - public static void RegisterGlobalFilters(GlobalFilterCollection filters) - { - filters.Add(new ErrorHandler.AiHandleErrorAttribute()); - } - } - } - ``` --7. If *Web.config* is already updated, skip this step. Otherwise, update the file as follows: - - ```xml - <?xml version="1.0" encoding="utf-8"?> - <!-- - For more information on how to configure your ASP.NET application, please visit - https://go.microsoft.com/fwlink/?LinkId=301880 - --> - <configuration> - <appSettings> - <add key="webpages:Version" value="3.0.0.0" /> - <add key="webpages:Enabled" value="false" /> - <add key="ClientValidationEnabled" value="true" /> - <add key="UnobtrusiveJavaScriptEnabled" value="true" /> - </appSettings> - <system.web> - <compilation debug="true" targetFramework="4.7.2" /> - <httpRuntime targetFramework="4.7.2" /> - <!-- Code added for Application Insights start --> - <httpModules> - <add name="TelemetryCorrelationHttpModule" type="Microsoft.AspNet.TelemetryCorrelation.TelemetryCorrelationHttpModule, Microsoft.AspNet.TelemetryCorrelation" /> - <add name="ApplicationInsightsWebTracking" type="Microsoft.ApplicationInsights.Web.ApplicationInsightsHttpModule, Microsoft.AI.Web" /> - </httpModules> - <!-- Code added for Application Insights end --> - </system.web> - <runtime> - <assemblyBinding xmlns="urn:schemas-microsoft-com:asm.v1"> - <dependentAssembly> - <assemblyIdentity name="Antlr3.Runtime" publicKeyToken="eb42632606e9261f" /> - <bindingRedirect oldVersion="0.0.0.0-3.5.0.2" newVersion="3.5.0.2" /> - </dependentAssembly> - <dependentAssembly> - <assemblyIdentity name="Newtonsoft.Json" publicKeyToken="30ad4fe6b2a6aeed" /> - <bindingRedirect oldVersion="0.0.0.0-12.0.0.0" newVersion="12.0.0.0" /> - </dependentAssembly> - <dependentAssembly> - <assemblyIdentity name="System.Web.Optimization" publicKeyToken="31bf3856ad364e35" /> - <bindingRedirect oldVersion="1.0.0.0-1.1.0.0" newVersion="1.1.0.0" /> - </dependentAssembly> - <dependentAssembly> - <assemblyIdentity name="WebGrease" publicKeyToken="31bf3856ad364e35" /> - <bindingRedirect oldVersion="0.0.0.0-1.6.5135.21930" newVersion="1.6.5135.21930" /> - </dependentAssembly> - <dependentAssembly> - <assemblyIdentity name="System.Web.Helpers" publicKeyToken="31bf3856ad364e35" /> - <bindingRedirect oldVersion="1.0.0.0-3.0.0.0" newVersion="3.0.0.0" /> - </dependentAssembly> - <dependentAssembly> - <assemblyIdentity name="System.Web.WebPages" publicKeyToken="31bf3856ad364e35" /> - <bindingRedirect oldVersion="1.0.0.0-3.0.0.0" newVersion="3.0.0.0" /> - </dependentAssembly> - <dependentAssembly> - <assemblyIdentity name="System.Web.Mvc" publicKeyToken="31bf3856ad364e35" /> - <bindingRedirect oldVersion="1.0.0.0-5.2.7.0" newVersion="5.2.7.0" /> - </dependentAssembly> - <!-- Code added for Application Insights start --> - <dependentAssembly> - <assemblyIdentity name="System.Memory" publicKeyToken="cc7b13ffcd2ddd51" culture="neutral" /> - <bindingRedirect oldVersion="0.0.0.0-4.0.1.1" newVersion="4.0.1.1" /> - </dependentAssembly> - <!-- Code added for Application Insights end --> - </assemblyBinding> - </runtime> - <system.codedom> - <compilers> - <compiler language="c#;cs;csharp" extension=".cs" type="Microsoft.CodeDom.Providers.DotNetCompilerPlatform.CSharpCodeProvider, Microsoft.CodeDom.Providers.DotNetCompilerPlatform, Version=2.0.1.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35" warningLevel="4" compilerOptions="/langversion:default /nowarn:1659;1699;1701" /> - <compiler language="vb;vbs;visualbasic;vbscript" extension=".vb" type="Microsoft.CodeDom.Providers.DotNetCompilerPlatform.VBCodeProvider, Microsoft.CodeDom.Providers.DotNetCompilerPlatform, Version=2.0.1.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35" warningLevel="4" compilerOptions="/langversion:default /nowarn:41008 /define:_MYTYPE=\"Web\" /optionInfer+" /> - </compilers> - </system.codedom> - <system.webServer> - <validation validateIntegratedModeConfiguration="false" /> - <!-- Code added for Application Insights start --> - <modules> - <remove name="TelemetryCorrelationHttpModule" /> - <add name="TelemetryCorrelationHttpModule" type="Microsoft.AspNet.TelemetryCorrelation.TelemetryCorrelationHttpModule, Microsoft.AspNet.TelemetryCorrelation" preCondition="managedHandler" /> - <remove name="ApplicationInsightsWebTracking" /> - <add name="ApplicationInsightsWebTracking" type="Microsoft.ApplicationInsights.Web.ApplicationInsightsHttpModule, Microsoft.AI.Web" preCondition="managedHandler" /> - </modules> - <!-- Code added for Application Insights end --> - </system.webServer> - </configuration> - - ``` --At this point, you successfully configured server-side application monitoring. If you run your web app, you see telemetry begin to appear in Application Insights. --## Add client-side monitoring --The previous sections provided guidance on methods to automatically and manually configure server-side monitoring. To add client-side monitoring, use the [client-side JavaScript SDK](javascript.md). You can monitor any web page's client-side transactions by adding a [JavaScript JavaScript (Web) SDK Loader Script](./javascript-sdk.md?tabs=javascriptwebsdkloaderscript#get-started) before the closing `</head>` tag of the page's HTML. --Although it's possible to manually add the JavaScript (Web) SDK Loader Script to the header of each HTML page, we recommend that you instead add the JavaScript (Web) SDK Loader Script to a primary page. That action injects the JavaScript (Web) SDK Loader Script into all pages of a site. --For the template-based ASP.NET MVC app from this article, the file that you need to edit is *_Layout.cshtml*. You can find it under **Views** > **Shared**. To add client-side monitoring, open *_Layout.cshtml* and follow the [JavaScript (Web) SDK Loader Script-based setup instructions](./javascript-sdk.md?tabs=javascriptwebsdkloaderscript#get-started) from the article about client-side JavaScript SDK configuration. --## Live metrics --[Live metrics](./live-stream.md) can be used to quickly verify if application monitoring with Application Insights is configured correctly. Telemetry can take a few minutes to appear in the Azure portal, but the live metrics pane shows CPU usage of the running process in near real time. It can also show other telemetry like requests, dependencies, and traces. --### Enable live metrics by using code for any .NET application --> [!NOTE] -> Live metrics are enabled by default when you onboard it by using the recommended instructions for .NET applications. --To manually configure live metrics: --1. Install the NuGet package [Microsoft.ApplicationInsights.PerfCounterCollector](https://www.nuget.org/packages/Microsoft.ApplicationInsights.PerfCounterCollector). -1. The following sample console app code shows setting up live metrics: --```csharp -using Microsoft.ApplicationInsights; -using Microsoft.ApplicationInsights.Extensibility; -using Microsoft.ApplicationInsights.Extensibility.PerfCounterCollector.QuickPulse; -using System; -using System.Threading.Tasks; --namespace LiveMetricsDemo -{ - class Program - { - static void Main(string[] args) - { - // Create a TelemetryConfiguration instance. - TelemetryConfiguration config = TelemetryConfiguration.CreateDefault(); - config.InstrumentationKey = "INSTRUMENTATION-KEY-HERE"; - QuickPulseTelemetryProcessor quickPulseProcessor = null; - config.DefaultTelemetrySink.TelemetryProcessorChainBuilder - .Use((next) => - { - quickPulseProcessor = new QuickPulseTelemetryProcessor(next); - return quickPulseProcessor; - }) - .Build(); -- var quickPulseModule = new QuickPulseTelemetryModule(); -- // Secure the control channel. - // This is optional, but recommended. - quickPulseModule.AuthenticationApiKey = "YOUR-API-KEY-HERE"; - quickPulseModule.Initialize(config); - quickPulseModule.RegisterTelemetryProcessor(quickPulseProcessor); -- // Create a TelemetryClient instance. It is important - // to use the same TelemetryConfiguration here as the one - // used to set up live metrics. - TelemetryClient client = new TelemetryClient(config); -- // This sample runs indefinitely. Replace with actual application logic. - while (true) - { - // Send dependency and request telemetry. - // These will be shown in live metrics. - // CPU/Memory Performance counter is also shown - // automatically without any additional steps. - client.TrackDependency("My dependency", "target", "http://sample", - DateTimeOffset.Now, TimeSpan.FromMilliseconds(300), true); - client.TrackRequest("My Request", DateTimeOffset.Now, - TimeSpan.FromMilliseconds(230), "200", true); - Task.Delay(1000).Wait(); - } - } - } -} -``` --The preceding sample is for a console app, but the same code can be used in any .NET applications. If any other telemetry modules are enabled to autocollect telemetry, it's important to ensure that the same configuration used for initializing those modules is used for the live metrics module. --## Frequently asked questions --This section provides answers to common questions. --### How can I uninstall the SDK? --To remove Application Insights, you need to remove the NuGet packages and references from the API in your application. You can uninstall NuGet packages by using the NuGet Package Manager in Visual Studio. --1. If trace collection is enabled, first uninstall the Microsoft.ApplicationInsights.TraceListener package by using the [NuGet Package Manager](/nuget/consume-packages/install-use-packages-visual-studio#uninstall-a-package) but don't remove any dependencies. -1. Uninstall the Microsoft.ApplicationInsights.Web package and remove its dependencies by using the [NuGet Package Manager](/nuget/consume-packages/install-use-packages-visual-studio#uninstall-a-package) and its [Uninstall options](/nuget/consume-packages/install-use-packages-visual-studio#uninstall-options) within the [NuGet Package Manager Options control](/nuget/consume-packages/install-use-packages-visual-studio#nuget-package-manager-options-control). -1. To fully remove Application Insights, check and manually delete the added code or files along with any API calls you added in your project. For more information, see [What is automatically created when you add the Application Insights SDK?](#what-is-automatically-created-when-you-add-the-application-insights-sdk). --### What is automatically created when you add the Application Insights SDK? --When you add Application Insights to your project, it automatically creates files and adds code to some of your files. Solely uninstalling the NuGet Packages doesn't always discard the files and code. To fully remove Application Insights, you should check and manually delete the added code or files along with any API calls you added in your project. --When you add Application Insights Telemetry to a Visual Studio ASP.NET project, it adds the following files: --- ApplicationInsights.config-- AiHandleErrorAttribute.cs--The following pieces of code are automatically added: ----- [Your project's name].csproj-- ```C# - <ApplicationInsightsResourceId>/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/Default-ApplicationInsights-EastUS/providers/microsoft.insights/components/WebApplication4</ApplicationInsightsResourceId> - ``` --- Packages.config-- ```xml - <packages> - ... - - <package id="Microsoft.ApplicationInsights" version="2.12.0" targetFramework="net472" /> - <package id="Microsoft.ApplicationInsights.Agent.Intercept" version="2.4.0" targetFramework="net472" /> - <package id="Microsoft.ApplicationInsights.DependencyCollector" version="2.12.0" targetFramework="net472" /> - <package id="Microsoft.ApplicationInsights.PerfCounterCollector" version="2.12.0" targetFramework="net472" /> - <package id="Microsoft.ApplicationInsights.Web" version="2.12.0" targetFramework="net472" /> - <package id="Microsoft.ApplicationInsights.WindowsServer" version="2.12.0" targetFramework="net472" /> - <package id="Microsoft.ApplicationInsights.WindowsServer.TelemetryChannel" version="2.12.0" targetFramework="net472" /> - - <package id="Microsoft.AspNet.TelemetryCorrelation" version="1.0.7" targetFramework="net472" /> - - <package id="System.Buffers" version="4.4.0" targetFramework="net472" /> - <package id="System.Diagnostics.DiagnosticSource" version="4.6.0" targetFramework="net472" /> - <package id="System.Memory" version="4.5.3" targetFramework="net472" /> - <package id="System.Numerics.Vectors" version="4.4.0" targetFramework="net472" /> - <package id="System.Runtime.CompilerServices.Unsafe" version="4.5.2" targetFramework="net472" /> - ... - </packages> - ``` --- Layout.cshtml-- If your project has a Layout.cshtml file, the following code is added. - - ```html - <head> - ... - <script type = 'text/javascript' > - var appInsights=window.appInsights||function(config) - { - function r(config){ t[config] = function(){ var i = arguments; t.queue.push(function(){ t[config].apply(t, i)})} } - var t = { config:config},u=document,e=window,o='script',s=u.createElement(o),i,f;for(s.src=config.url||'//az416426.vo.msecnd.net/scripts/a/ai.0.js',u.getElementsByTagName(o)[0].parentNode.appendChild(s),t.cookie=u.cookie,t.queue=[],i=['Event','Exception','Metric','PageView','Trace','Ajax'];i.length;)r('track'+i.pop());return r('setAuthenticatedUserContext'),r('clearAuthenticatedUserContext'),config.disableExceptionTracking||(i='onerror',r('_'+i),f=e[i],e[i]=function(config, r, u, e, o) { var s = f && f(config, r, u, e, o); return s !== !0 && t['_' + i](config, r, u, e, o),s}),t - }({ - instrumentationKey:'00000000-0000-0000-0000-000000000000' - }); - - window.appInsights=appInsights; - appInsights.trackPageView(); - </script> - ... - </head> - ``` --- ConnectedService.json-- ```json - { - "ProviderId": "Microsoft.ApplicationInsights.ConnectedService.ConnectedServiceProvider", - "Version": "16.0.0.0", - "GettingStartedDocument": { - "Uri": "https://go.microsoft.com/fwlink/?LinkID=613413" - } - } - ``` --- FilterConfig.cs-- ```csharp - public static void RegisterGlobalFilters(GlobalFilterCollection filters) - { - filters.Add(new ErrorHandler.AiHandleErrorAttribute());// This line was added - } - ``` --### How can I disable telemetry correlation? --To disable telemetry correlation in configuration, see `<ExcludeComponentCorrelationHttpHeadersOnDomains>` in [Application Insights for console applications](/previous-versions/azure/azure-monitor/app/console). --## Troubleshooting --See the dedicated [troubleshooting article](/troubleshoot/azure/azure-monitor/app-insights/asp-net-troubleshoot-no-data). --There's a known issue in the current version of Visual Studio 2019: storing the instrumentation key or connection string in a user secret is broken for .NET Framework-based apps. The key ultimately has to be hardcoded into the *applicationinsights.config* file to work around this bug. This article is designed to avoid this issue entirely, by not using user secrets. ---## Open-source SDK --[Read and contribute to the code](https://github.com/microsoft/ApplicationInsights-dotnet). --For the latest updates and bug fixes, [consult the release notes](./release-notes.md). --## Release Notes --For version 2.12 and newer: [.NET Software Development Kits (SDKs) including ASP.NET, ASP.NET Core, and Logging Adapters](https://github.com/Microsoft/ApplicationInsights-dotnet/releases) --Our [Service Updates](https://azure.microsoft.com/updates/?service=application-insights) also summarize major Application Insights improvements. --## Next steps --* Add synthetic transactions to test that your website is available from all over the world with [availability monitoring](availability-overview.md). -* [Configure sampling](sampling.md) to help reduce telemetry traffic and data storage costs. |
| azure-monitor | Availability | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/availability.md | - Title: Application Insights availability tests -description: Set up recurring web tests to monitor availability and responsiveness of your app or website. - Previously updated : 07/05/2024----# Application Insights availability tests --[Application Insights](./app-insights-overview.md) enables you to set up recurring web tests that monitor your website or application's availability and responsiveness from various points around the world. These availability tests send web requests to your application at regular intervals and alert you if your application isn't responding or if the response time is too slow. --Availability tests don't require any modifications to the website or application you're testing. They work for any HTTP or HTTPS endpoint accessible from the public internet, including REST APIs that your service depends on. This means you can monitor not only your own applications but also external services that are critical to your application's functionality. You can create up to 100 availability tests per Application Insights resource. --> [!NOTE] -> Availability tests are stored encrypted, according to [Azure data encryption at rest](../../security/fundamentals/encryption-atrest.md#encryption-at-rest-in-microsoft-cloud-services) policies. --## Types of availability tests --There are four types of availability tests: --* **Standard test:** A type of availability test that checks the availability of a website by sending a single request, similar to the deprecated URL ping test. In addition to validating whether an endpoint is responding and measuring the performance, Standard tests also include TLS/SSL certificate validity, proactive lifetime check, HTTP request verb (for example, `GET`,`HEAD`, and `POST`), custom headers, and custom data associated with your HTTP request. --* **Custom TrackAvailability test:** If you decide to create a custom application to run availability tests, you can use the [TrackAvailability()](/dotnet/api/microsoft.applicationinsights.telemetryclient.trackavailability) method to send the results to Application Insights. --* **[(Deprecated) Multi-step web test](availability-multistep.md):** You can play back this recording of a sequence of web requests to test more complex scenarios. Multi-step web tests are created in Visual Studio Enterprise and uploaded to the portal, where you can run them. --* **[(Deprecated) URL ping test](monitor-web-app-availability.md):** You can create this test through the Azure portal to validate whether an endpoint is responding and measure performance associated with that response. You can also set custom success criteria coupled with more advanced features, like parsing dependent requests and allowing for retries. --> [!IMPORTANT] -> There are two upcoming availability tests retirements: -> * **Multi-step web tests:** On August 31, 2024, multi-step web tests in Application Insights will be retired. We advise users of these tests to transition to alternative availability tests before the retirement date. Following this date, we will be taking down the underlying infrastructure which will break remaining multi-step tests. -> -> * **URL ping tests:** On September 30, 2026, URL ping tests in Application Insights will be retired. Existing URL ping tests will be removed from your resources. Review the [pricing](https://azure.microsoft.com/pricing/details/monitor/#pricing) for standard tests and [transition](https://aka.ms/availabilitytestmigration) to using them before September 30, 2026 to ensure you can continue to run single-step availability tests in your Application Insights resources. --## Create an availability test --## [Standard test](#tab/standard) --### Prerequisites --> [!div class="checklist"] -> * [Workspace-based Application Insights resource](create-workspace-resource.md) --### Get started --1. Go to your Application Insights resource and open the **Availability** experience. --1. Select **Add Standard test** from the top navigation bar. -- :::image type="content" source="media/availability/add-standard-test.png" alt-text="Screenshot showing the Availability experience with the Add Standard test tab open." lightbox="media/availability/add-standard-test.png"::: --1. Input your test name, URL, and other settings described in the following table, then select **Create**. -- | Section | Setting | Description | - |||-| - | **Basic Information** | | | - | | **URL** | The URL can be any webpage you want to test, but it must be visible from the public internet. The URL can include a query string. So, for example, you can exercise your database a little. If the URL resolves to a redirect, we follow it up to 10 redirects. | - | | **Parse dependent requests** | Test requests images, scripts, style files, and other files that are part of the webpage under test. The recorded response time includes the time taken to get these files. The test fails if any of these resources can't be successfully downloaded within the timeout for the whole test. If the option isn't selected, the test only requests the file at the URL you specified. Enabling this option results in a stricter check. The test could fail for cases, which might not be noticeable when you manually browse the site. We parse only up to 15 dependent requests. | - | | **Enable retries for availability test failures** | When the test fails, it retries after a short interval. A failure is reported only if three successive attempts fail. Subsequent tests are then performed at the usual test frequency. Retry is temporarily suspended until the next success. This rule is applied independently at each test location. *We recommend this option*. On average, about 80% of failures disappear on retry. | - | | **Enable SSL certificate validity** | You can verify the SSL certificate on your website to make sure it's correctly installed, valid, trusted, and doesn't give any errors to any of your users. | - | | **Proactive lifetime check** | This setting enables you to define a set time period before your SSL certificate expires. After it expires, your test will fail. | - | | **Test frequency** | Sets how often the test is run from each test location. With a default frequency of five minutes and five test locations, your site is tested on average every minute. | - | | **Test locations** | Our servers send web requests to your URL from these locations. *Our minimum number of recommended test locations is five* to ensure that you can distinguish problems in your website from network issues. You can select up to 16 locations. | - | **Standard test info** | | | - | | **HTTP request verb** | Indicate what action you want to take with your request. | - | | **Request body** | Custom data associated with your HTTP request. You can upload your own files, enter your content, or disable this feature. | - | | **Add custom headers** | Key value pairs that define the operating parameters. | - | **Success criteria** | | | - | | **Test Timeout** | Decrease this value to be alerted about slow responses. The test is counted as a failure if the responses from your site aren't received within this period. If you selected **Parse dependent requests**, all the images, style files, scripts, and other dependent resources must be received within this period. | - | | **HTTP response** | The returned status code counted as a success. The number 200 is the code that indicates that a normal webpage is returned. | - | | **Content match** | A string, like "Welcome!" We test that an exact case-sensitive match occurs in every response. It must be a plain string, without wildcards. Don't forget that if your page content changes, you might have to update it. *Only English characters are supported with content match.* | --## [TrackAvailability()](#tab/track) --> [!IMPORTANT] -> [TrackAvailability()](/dotnet/api/microsoft.applicationinsights.telemetryclient.trackavailability) requires making a developer investment in writing and maintanining potentially complex custom code. -> -> *Standard tests should always be used if possible*, as they require little investment, no maintenance, and have few prerequisites. --This example is designed only to show you the mechanics of how the `TrackAvailability()` API call works within an Azure Functions app. It doesn't show how to write the underlying HTTP test code or business logic required to turn this example into a fully functional availability test. --### Prerequisites --> [!div class="checklist"] -> * [Workspace-based Application Insights resource](create-workspace-resource.md) -> * Access to the source code of an [Azure Functions app](../../azure-functions/functions-how-to-use-azure-function-app-settings.md) -> * Developer expertise to author custom code for [TrackAvailability()](/dotnet/api/microsoft.applicationinsights.telemetryclient.trackavailability), tailored to your specific business needs --### Get started --> [!NOTE] -> To follow these instructions, you must use either the [App Service](../../azure-functions/dedicated-plan.md) plan or Functions Premium plan to allow editing code in App Service Editor. -> -> If you're testing behind a virtual network or testing nonpublic endpoints, you'll need to use the Functions Premium plan. --#### Create a timer trigger function --1. [Create an Azure Functions resource](../../azure-functions/functions-create-scheduled-function.md#create-a-function-app) with the following consideration: -- * **If you don't have an Application Insights resource yet for your timer-triggered function,** it's created *by default* when you create an Azure Functions app. -- * **If you already have an Application Insights resource,** go to the **Monitoring** tab while creating the Azure Functions app, and select or enter the name of your existing resource in the Application Insights dropdown: -- :::image type="content" source="media/availability/create-application-insights.png" alt-text="Screenshot showing selecting your existing Application Insights resource on the Monitoring tab."::: --1. Follow the instructions to [create a timer triggered function](../../azure-functions/functions-create-scheduled-function.md#create-a-timer-triggered-function). --#### Add and edit code in the App Service Editor --Go to your deployed Azure Functions app, and under **Development Tools**, select the **App Service Editor** tab. --To create a new file, right-click under your timer trigger function (for example, **TimerTrigger1**) and select **New File**. Then enter the name of the file and select **Enter**. --1. Create a new file called **function.proj** and paste the following code: -- ```xml - <Project Sdk="Microsoft.NET.Sdk"> - <PropertyGroup> - <TargetFramework>netstandard2.0</TargetFramework> - </PropertyGroup> - <ItemGroup> - <PackageReference Include="Microsoft.ApplicationInsights" Version="2.15.0" /> <!-- Ensure you’re using the latest version --> - </ItemGroup> - </Project> - ``` -- :::image type="content" source="media/availability/function-proj.png" alt-text=" Screenshot showing function.proj in the App Service Editor." lightbox="media/availability/function-proj.png"::: --1. Create a new file called **runAvailabilityTest.csx** and paste the following code: -- ```csharp - using System.Net.Http; -- public async static Task RunAvailabilityTestAsync(ILogger log) - { - using (var httpClient = new HttpClient()) - { - // TODO: Replace with your business logic - await httpClient.GetStringAsync("https://www.bing.com/"); - } - } - ``` --1. Replace the existing code in **run.csx** with the following: -- ```csharp - #load "runAvailabilityTest.csx" -- using System; -- using System.Diagnostics; -- using Microsoft.ApplicationInsights; -- using Microsoft.ApplicationInsights.Channel; -- using Microsoft.ApplicationInsights.DataContracts; -- using Microsoft.ApplicationInsights.Extensibility; -- private static TelemetryClient telemetryClient; -- // ============================================================= -- // ****************** DO NOT MODIFY THIS FILE ****************** -- // Business logic must be implemented in RunAvailabilityTestAsync function in runAvailabilityTest.csx -- // If this file does not exist, add it first -- // ============================================================= -- public async static Task Run(TimerInfo myTimer, ILogger log, ExecutionContext executionContext) -- { - if (telemetryClient == null) - { - // Initializing a telemetry configuration for Application Insights based on connection string -- var telemetryConfiguration = new TelemetryConfiguration(); - telemetryConfiguration.ConnectionString = Environment.GetEnvironmentVariable("APPLICATIONINSIGHTS_CONNECTION_STRING"); - telemetryConfiguration.TelemetryChannel = new InMemoryChannel(); - telemetryClient = new TelemetryClient(telemetryConfiguration); - } -- string testName = executionContext.FunctionName; - string location = Environment.GetEnvironmentVariable("REGION_NAME"); - var availability = new AvailabilityTelemetry - { - Name = testName, -- RunLocation = location, -- Success = false, - }; -- availability.Context.Operation.ParentId = Activity.Current.SpanId.ToString(); - availability.Context.Operation.Id = Activity.Current.RootId; - var stopwatch = new Stopwatch(); - stopwatch.Start(); -- try - { - using (var activity = new Activity("AvailabilityContext")) - { - activity.Start(); - availability.Id = Activity.Current.SpanId.ToString(); - // Run business logic - await RunAvailabilityTestAsync(log); - } - availability.Success = true; - } -- catch (Exception ex) - { - availability.Message = ex.Message; - throw; - } -- finally - { - stopwatch.Stop(); - availability.Duration = stopwatch.Elapsed; - availability.Timestamp = DateTimeOffset.UtcNow; - telemetryClient.TrackAvailability(availability); - telemetryClient.Flush(); - } - } -- ``` --> [!NOTE] -> Tests created with `TrackAvailability()` will appear with **CUSTOM** next to the test name. -> -> :::image type="content" source="media/availability/availability-test-list.png" alt-text="Screenshot showing the Availability experience with two different tests listed."::: ----## Availability alerts --Alerts are automatically enabled by default, but to fully configure an alert, you must initially create your availability test. --| Setting | Description | -||| -| **Near real time** | We recommend using near real time alerts. Configuring this type of alert is done after your availability test is created. | -| **Alert location threshold** | We recommend a minimum of 3/5 locations. The optimal relationship between alert location threshold and the number of test locations is **alert location threshold** = **number of test locations - 2, with a minimum of five test locations.** | --### Location population tags --You can use the following population tags for the geo-location attribute when you deploy a Standard test or URL ping test [by using Azure Resource Manager](../alerts/alerts-create-rule-cli-powershell-arm.md#create-a-new-alert-rule-using-an-arm-template). --| Provider | Display name | Population name | -||-|| -| **Azure** | | | -| | Australia East | emea-au-syd-edge | -| | Brazil South | latam-br-gru-edge | -| | Central US | us-fl-mia-edge | -| | East Asia | apac-hk-hkn-azr | -| | East US | us-va-ash-azr | -| | France South (Formerly France Central) | emea-ch-zrh-edge | -| | France Central | emea-fr-pra-edge | -| | Japan East | apac-jp-kaw-edge | -| | North Europe | emea-gb-db3-azr | -| | North Central US | us-il-ch1-azr | -| | South Central US | us-tx-sn1-azr | -| | Southeast Asia | apac-sg-sin-azr | -| | UK West | emea-se-sto-edge | -| | West Europe | emea-nl-ams-azr | -| | West US | us-ca-sjc-azr | -| | UK South | emea-ru-msa-edge | -| **Azure Government** | | | -| | USGov Virginia | usgov-va-azr | -| | USGov Arizona | usgov-phx-azr | -| | USGov Texas | usgov-tx-azr | -| | USDoD East | usgov-ddeast-azr | -| | USDoD Central | usgov-ddcentral-azr | -| **Microsoft Azure operated by 21Vianet** | | | -| | China East | mc-cne-azr | -| | China East 2 | mc-cne2-azr | -| | China North | mc-cnn-azr | -| | China North 2 | mc-cnn2-azr | --### Enable alerts --> [!NOTE] -> With the [new unified alerts](../alerts/alerts-overview.md), the alert rule severity and notification preferences with [action groups](../alerts/action-groups.md) *must be* configured in the alerts experience. Without the following steps, you'll only receive in-portal notifications. --1. After you save the availability test, open the context menu by the test you made, then select **Open Rules (Alerts) page**. -- :::image type="content" source="media/availability/open-rules-page.png" alt-text="Screenshot showing the Availability experience for an Application Insights resource in the Azure portal and the Open Rules (Alerts) page menu option." lightbox="media/availability/open-rules-page.png"::: --1. On the **Alert rules** page, open your alert, then select **Edit** in the top navigation bar. Here you can set the severity level, rule description, and action group that have the notification preferences you want to use for this alert rule. -- :::image type="content" source="media/availability/edit-alert.png" alt-text="Screenshot showing an alert rule page in the Azure portal with Edit highlighted." lightbox="media/availability/edit-alert.png"::: --### Alert criteria --Automatically enabled availability alerts trigger one email when the endpoint becomes unavailable, and another email when it's available again. Availability alerts that are created through this experience are *state based*. When the alert criteria are met, a single alert gets generated when the website is detected as unavailable. If the website is still down the next time the alert criteria is evaluated, it won't generate a new alert. --For example, suppose that your website is down for an hour and you set up an email alert with an evaluation frequency of 15 minutes. You only receive an email when the website goes down and another email when it's back online. You don't receive continuous alerts every 15 minutes to remind you that the website is still unavailable. --#### Change the alert criteria --You might not want to receive notifications when your website is down for only a short period of time, for example, during maintenance. You can change the evaluation frequency to a higher value than the expected downtime, up to 15 minutes. You can also increase the alert location threshold so that it only triggers an alert if the website is down for a specific number of regions. --> [!TIP] -> For longer scheduled downtimes, temporarily deactivate the alert rule or create a custom rule. It gives you more options to account for the downtime. --To make changes to the location threshold, aggregation period, and test frequency, go to the **Edit alert rule** page (see step 2 under [Enable alerts](#enable-alerts)), then select the condition to open the **Configure signal logic** window. ---### Create a custom alert rule --If you need advanced capabilities, you can create a custom alert rule on the **Alerts** tab. Select **Create** > **Alert rule**. Choose **Metrics** for **Signal type** to show all available signals and select **Availability**. --A custom alert rule offers higher values for the aggregation period (up to 24 hours instead of 6 hours) and the test frequency (up to 1 hour instead of 15 minutes). It also adds options to further define the logic by selecting different operators, aggregation types, and threshold values. --* **Alert on X out of Y locations reporting failures**: The X out of Y locations alert rule is enabled by default in the [new unified alerts experience](../alerts/alerts-overview.md) when you create a new availability test. You can opt out by selecting the "classic" option or by choosing to disable the alert rule. Configure the action groups to receive notifications when the alert triggers by following the preceding steps. Without this step, you only receive in-portal notifications when the rule triggers. --* **Alert on availability metrics**: By using the [new unified alerts](../alerts/alerts-overview.md), you can alert on segmented aggregate availability and test duration metrics too: -- 1. Select an Application Insights resource in the **Metrics** experience, and select an **Availability** metric. - - 1. The **Configure alerts** option from the menu takes you to the new experience where you can select specific tests or locations on which to set up alert rules. You can also configure the action groups for this alert rule here. --* **Alert on custom analytics queries**: By using the [new unified alerts](../alerts/alerts-overview.md), you can alert on [custom log queries](../alerts/alerts-types.md#log-alerts). With custom queries, you can alert on any arbitrary condition that helps you get the most reliable signal of availability issues. It's also applicable if you're sending custom availability results by using the TrackAvailability SDK. -- The metrics on availability data include any custom availability results you might be submitting by calling the TrackAvailability SDK. You can use the alerting on metrics support to alert on custom availability results. --### Automate alerts --To automate this process with Azure Resource Manager templates, see [Create a metric alert with an Azure Resource Manager template](../alerts/alerts-metric-create-templates.md#template-for-an-availability-test-along-with-a-metric-alert). --## See your availability test results --This section explains how to review availability test results in the Azure portal and query the data using [Log Analytics](../logs/log-analytics-overview.md#overview-of-log-analytics-in-azure-monitor). Availability test results can be visualized with both **Line** and **Scatter Plot** views. - -### Check availability --Start by reviewing the graph in the **Availability** experience in the Azure portal. ---By default, the Availability experience shows a line graph. Change the view to **Scatter Plot** (toggle above the graph) to see samples of the test results that have diagnostic test-step detail in them. The test engine stores diagnostic detail for tests that have failures. For successful tests, diagnostic details are stored for a subset of the executions. To see the test, test name, and location, hover over any of the green dots or red crosses. --Select a particular test or location. Or you can reduce the time period to see more results around the time period of interest. Use Search Explorer to see results from all executions. Or you can use Log Analytics queries to run custom reports on this data. --To see the end-to-end transaction details, under **Drill into**, select **Successful** or **Failed**. Then select a sample. You can also get to the end-to-end transaction details by selecting a data point on the graph. ---### Inspect and edit tests --To edit, temporarily disable, or delete a test, open the context menu (ellipsis) by the test, then select **Edit**. It might take up to 20 minutes for configuration changes to propagate to all test agents after a change is made. --> [!TIP] -> You might want to disable availability tests or the alert rules associated with them while you're performing maintenance on your service. --### If you see failures --Open the **End-to-end transaction details** view by selecting a red cross on the Scatter Plot. ---Here you can: --* Review the **Troubleshooting Report** to determine what potentially caused your test to fail. -* Inspect the response received from your server. -* Diagnose failure with correlated server-side telemetry collected while processing the failed availability test. -* Track the problem by logging an issue or work item in Git or Azure Boards. The bug contains a link to the event in the Azure portal. -* Open the web test result in Visual Studio. --To learn more about the end-to-end transaction diagnostics experience, see the [transaction diagnostics documentation](./transaction-search-and-diagnostics.md?tabs=transaction-diagnostics). --Select the exception row to see the details of the server-side exception that caused the synthetic availability test to fail. You can also get the [debug snapshot](./snapshot-debugger.md) for richer code-level diagnostics. --In addition to the raw results, you can also view two key availability metrics in [metrics explorer](../essentials/metrics-getting-started.md): --* **Availability**: Percentage of the tests that were successful across all test executions. -* **Test Duration**: Average test duration across all test executions. --### Query in Log Analytics --You can use Log Analytics to view your availability results (`availabilityResults`), dependencies (`dependencies`), and more. To learn more about Log Analytics, see [Log query overview](../logs/log-query-overview.md). ---## Migrate classic URL ping tests to standard tests --The following steps walk you through the process of creating [standard tests](availability-standard-tests.md) that replicate the functionality of your [URL ping tests](/previous-versions/azure/azure-monitor/app/monitor-web-app-availability). It allows you to more easily start using the advanced features of [standard tests](availability-standard-tests.md) using your previously created [URL ping tests](/previous-versions/azure/azure-monitor/app/monitor-web-app-availability). --> [!IMPORTANT] -> A cost is associated with running **[standard tests](/editor/availability-standard-tests.md)**. Once you create a **[standard test](/editor/availability-standard-tests.md)**, you will be charged for test executions. Refer to **[Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/#pricing)** before starting this process. --#### Prerequisites --> [!div class="checklist"] -> * Any [URL ping test](/previous-versions/azure/azure-monitor/app/monitor-web-app-availability) within Application Insights -> * [Azure PowerShell](/powershell/azure/get-started-azureps) access --#### Get started --1. Connect to your subscription with Azure PowerShell (`Connect-AzAccount` + `Set-AzContext`). --1. List all URL ping tests in the current subscription: -- ```azurepowershell - Get-AzApplicationInsightsWebTest | ` - Where-Object { $_.WebTestKind -eq "ping" } | ` - Format-Table -Property ResourceGroupName,Name,WebTestKind,Enabled; - ``` --1. Find the URL ping test you want to migrate and record its resource group and name. --1. Create a standard test with the same logic as the URL ping test using the following commands, which work for both HTTP and HTTPS endpoints. -- ```shell - $resourceGroup = "pingTestResourceGroup"; - $appInsightsComponent = "componentName"; - $pingTestName = "pingTestName"; - $newStandardTestName = "newStandardTestName"; - - $componentId = (Get-AzApplicationInsights -ResourceGroupName $resourceGroup -Name $appInsightsComponent).Id; - $pingTest = Get-AzApplicationInsightsWebTest -ResourceGroupName $resourceGroup -Name $pingTestName; - $pingTestRequest = ([xml]$pingTest.ConfigurationWebTest).WebTest.Items.Request; - $pingTestValidationRule = ([xml]$pingTest.ConfigurationWebTest).WebTest.ValidationRules.ValidationRule; - - $dynamicParameters = @{}; - - if ($pingTestRequest.IgnoreHttpStatusCode -eq [bool]::FalseString) { - $dynamicParameters["RuleExpectedHttpStatusCode"] = [convert]::ToInt32($pingTestRequest.ExpectedHttpStatusCode, 10); - } - - if ($pingTestValidationRule -and $pingTestValidationRule.DisplayName -eq "Find Text" ` - -and $pingTestValidationRule.RuleParameters.RuleParameter[0].Name -eq "FindText" ` - -and $pingTestValidationRule.RuleParameters.RuleParameter[0].Value) { - $dynamicParameters["ContentMatch"] = $pingTestValidationRule.RuleParameters.RuleParameter[0].Value; - $dynamicParameters["ContentPassIfTextFound"] = $true; - } - - New-AzApplicationInsightsWebTest @dynamicParameters -ResourceGroupName $resourceGroup -Name $newStandardTestName ` - -Location $pingTest.Location -Kind 'standard' -Tag @{ "hidden-link:$componentId" = "Resource" } -TestName $newStandardTestName ` - -RequestUrl $pingTestRequest.Url -RequestHttpVerb "GET" -GeoLocation $pingTest.PropertiesLocations -Frequency $pingTest.Frequency ` - -Timeout $pingTest.Timeout -RetryEnabled:$pingTest.RetryEnabled -Enabled:$pingTest.Enabled ` - -RequestParseDependent:($pingTestRequest.ParseDependentRequests -eq [bool]::TrueString); - ``` -- The new standard test doesn't have alert rules by default, so it doesn't create noisy alerts. No changes are made to your URL ping test so you can continue to rely on it for alerts. --1. Validate the functionality of the new standard test, then [update your alert rules](/azure/azure-monitor/alerts/alerts-manage-alert-rules) that reference the URL ping test to reference the standard test instead. --1. Disable or delete the URL ping test. To do so with Azure PowerShell, you can use this command: -- ```azurepowershell - Remove-AzApplicationInsightsWebTest -ResourceGroupName $resourceGroup -Name $pingTestName; - ``` --## Testing behind a firewall --To ensure endpoint availability behind firewalls, enable public availability tests or run availability tests in disconnected or no ingress scenarios. --### Public availability test enablement --Ensure your internal website has a public Domain Name System (DNS) record. Availability tests fail if DNS can't be resolved. For more information, see [Create a custom domain name for internal application](../../cloud-services/cloud-services-custom-domain-name-portal.md#add-an-a-record-for-your-custom-domain). --> [!WARNING] -> The IP addresses used by the availability tests service are shared and can expose your firewall-protected service endpoints to other tests. IP address filtering alone doesn't secure your service's traffic, so it's recommended to add extra custom headers to verify the origin of web request. For more information, see [Virtual network service tags](../../virtual-network/service-tags-overview.md#virtual-network-service-tags). --#### Authenticate traffic --Set custom headers in [standard availability tests](availability-standard-tests.md) to validate traffic. --1. Create an alphanumeric string without spaces to identify this availability test (for example, MyAppAvailabilityTest). From here on we refer to this string as the *availability test string identifier*. --1. Add the custom header *X-Customer-InstanceId* with the value `ApplicationInsightsAvailability:<your availability test string identifier>` under the **Standard test info** section when creating or updating your availability tests. -- :::image type="content" source="media/availability/custom-header.png" alt-text="Screenshot showing custom validation header."::: --1. Ensure your service checks if incoming traffic includes the header and value defined in the previous steps. --Alternatively, set the *availability test string identifier* as a query parameter. --**Example:** ```https://yourtestendpoint/?x-customer-instanceid=applicationinsightsavailability:<your availability test string identifier>``` --#### Configure your firewall to permit incoming requests from availability tests --> [!NOTE] -> This example is specific to network security group service tag usage. Many Azure services accept service tags, each requiring different configuration steps. --To simplify enabling Azure services without authorizing individual IPs or maintaining an up-to-date IP list, use [Service tags](../../virtual-network/service-tags-overview.md). Apply these tags across Azure Firewall and network security groups, allowing the availability test service access to your endpoints. The service tag `ApplicationInsightsAvailability` applies to all availability tests. --1. If you're using [Azure network security groups](../../virtual-network/network-security-groups-overview.md), go to your network security group resource and under **Settings**, open the **Inbound security rules** experience, then select **Add**. --1. Next, select *Service Tag* as the **Source** and *ApplicationInsightsAvailability* as the **Source service tag**. Use open ports 80 (http) and 443 (https) for incoming traffic from the service tag. --To manage access when your endpoints are outside Azure or when service tags aren't an option, allowlist the [IP addresses of our web test agents](ip-addresses.md). You can query IP ranges using PowerShell, Azure CLI, or a REST call with the [Service Tag API](../../virtual-network/service-tags-overview.md#use-the-service-tag-discovery-api). For a comprehensive list of current service tags and their IP details, download the [JSON file](../../virtual-network/service-tags-overview.md#discover-service-tags-by-using-downloadable-json-files). - -1. In your network security group resource, under **Settings**, open the **Inbound security rules** experience, then select **Add**. --1. Next, select *IP Addresses* as your **Source**. Then add your IP addresses in a comma-delimited list in **Source IP address/CIRD ranges**. --### Disconnected or no ingress scenarios --1. Connect your Application Insights resource to your internal service endpoint using [Azure Private Link](../logs/private-link-security.md). --1. Write custom code to periodically test your internal server or endpoints. Send the results to Application Insights using the [TrackAvailability()](availability-azure-functions.md) API in the core SDK package. --### Supported TLS configurations --To provide best-in-class encryption, all availability tests use Transport Layer Security (TLS) 1.2 and 1.3 as the encryption mechanisms of choice. In addition, the following Cipher suites and Elliptical curves are also supported within each version. --TLS 1.3 is currently only available in the availability test regions NorthCentralUS, CentralUS, EastUS, SouthCentralUS, and WestUS. --| Version | Cipher suites | Elliptical curves | -|||| -| TLS 1.2 | • TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384<br>• TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256<br>• TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384<br>• TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256<br>• TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA384<br>• TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256<br>• TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384<br>• TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256 | • NistP384<br>• NistP256 | -| TLS 1.3 | • TLS_AES_256_GCM_SHA384<br>• TLS_AES_128_GCM_SHA256 | • NistP384<br>• NistP256 | --### Deprecating TLS configuration --> [!IMPORTANT] -> On 31 October 2024, in alignment with the [Azure wide legacy TLS deprecation](https://azure.microsoft.com/updates/azure-support-tls-will-end-by-31-october-2024-2/), TLS 1.0/1.1 protocol versions and the listed TLS 1.2/1.3 legacy Cipher suites and Elliptical curves will be retired for Application Insights availability tests. --#### TLS 1.0 and TLS 1.1 --TLS 1.0 and TLS 1.1 are being retired. --#### TLS 1.2 and TLS 1.3 --| Version | Cipher suites | Elliptical curves | -|||| -| TLS 1.2 | • TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA<br>• TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA<br>• TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA<br>• TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA<br>• TLS_RSA_WITH_AES_256_GCM_SHA384<br>• TLS_RSA_WITH_AES_128_GCM_SHA256<br>• TLS_RSA_WITH_AES_256_CBC_SHA256<br>• TLS_RSA_WITH_AES_128_CBC_SHA256<br>• TLS_RSA_WITH_AES_256_CBC_SHA<br>• TLS_RSA_WITH_AES_128_CBC_SHA | • curve25519 | -| TLS 1.3 | | • curve25519 | --### Troubleshooting --> [!WARNING] -> We have recently enabled TLS 1.3 in availability tests. If you are seeing new error messages as a result, ensure that clients running on Windows Server 2022 with TLS 1.3 enabled can connect to your endpoint. If you are unable to do this, you may consider temporarily disabling TLS 1.3 on your endpoint so that availability tests will fall back to older TLS versions. -> -> For additional information, check the [troubleshooting article](/troubleshoot/azure/azure-monitor/app-insights/troubleshoot-availability). --## Downtime & Outages workbook --This section introduces a simple way to calculate and report service-level agreement (SLA) for web tests through a single pane of glass across your Application Insights resources and Azure subscriptions. The downtime and outage report provides powerful prebuilt queries and data visualizations to enhance your understanding of your customer's connectivity, typical application response time, and experienced downtime. --The SLA workbook template can be accessed from your Application Insights resource in two ways: --* Open the **Availability** experience, then select **SLA Report** from the top navigation bar. --* Open the **Workbooks** experience, then select **Downtime & Outages** template. --### Parameter flexibility --The parameters set in the workbook influence the rest of your report. ---* `Subscriptions`, `App Insights Resources`, and `Web Test`: These parameters determine your high-level resource options. They're based on Log Analytics queries and are used in every report query. -* `Failure Threshold` and `Outage Window`: You can use these parameters to determine your own criteria for a service outage. An example is the criteria for an Application Insights availability alert based on a failed location counter over a chosen period. The typical threshold is three locations over a five-minute window. -* `Maintenance Period`: You can use this parameter to select your typical maintenance frequency. `Maintenance Window` is a datetime selector for an example maintenance period. All data that occurs during the identified period is ignored in your results. -* `Availability Target %`: This parameter specifies your target objective and takes custom values. --### Overview page --The overview page contains high-level information about your: --* Total SLA (excluding maintenance periods, if defined) -* End-to-end outage instances -* Application downtime --Outage instances are determined from the moment a test begins to fail until it successfully passes again, according to your outage parameters. If a test starts failing at 8:00 AM and succeeds again at 10:00 AM, that entire period of data is considered the same outage. You can also investigate the longest outage that occurred over your reporting period. --Some tests are linkable back to their Application Insights resource for further investigation. But that's only possible in the [workspace-based Application Insights resource](create-workspace-resource.md). --### Downtime, outages, and failures --There are two more tabs next to the **Overview** page: --* The **Outages & Downtime** tab has information on total outage instances and total downtime broken down by test. --* The **Failures by Location** tab has a geo-map of failed testing locations to help identify potential problem connection areas. --### Other features --* **Customization:** You can edit the report like any other [Azure Monitor workbook](../visualize/workbooks-overview.md) and customize the queries or visualizations based on your team's needs. --* **Log Analytics:** The queries can all be run in [Log Analytics](../logs/log-analytics-overview.md) and used in other reports or dashboards. Remove the parameter restriction and reuse the core query. --* **Access and sharing:** The report can be shared with your teams and leadership or pinned to a dashboard for further use. The user needs read permissions and access to the Application Insights resource where the actual workbook is stored. --## Frequently asked questions --This section provides answers to common questions. --### General --#### Can I run availability tests on an intranet server? --Our [web tests](/previous-versions/azure/azure-monitor/app/monitor-web-app-availability) run on points of presence that are distributed around the globe. There are two solutions: - -* **Firewall door**: Allow requests to your server from [the long and changeable list of web test agents](../ip-addresses.md). -* **Custom code**: Write your own code to send periodic requests to your server from inside your intranet. You could run Visual Studio web tests for this purpose. The tester could send the results to Application Insights by using the `TrackAvailability()` API. --#### What is the user agent string for availability tests? --The user agent string is **Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; AppInsights)** --### TLS support --#### How does this deprecation impact my web test behavior? --Availability tests act as a distributed client in each of the supported web test locations. Every time a web test is executed the availability test service attempts to reach out to the remote endpoint defined in the web test configuration. A TLS Client Hello message is sent which contains all the currently supported TLS configuration. If the remote endpoint shares a common TLS configuration with the availability test client, then the TLS handshake succeeds. Otherwise, the web test fails with a TLS handshake failure. --#### How do I ensure my web test isn't impacted? --To avoid any impact, each remote endpoint (including dependent requests) your web test interacts with needs to support at least one combination of the same Protocol Version, Cipher Suite, and Elliptical Curve that availability test does. If the remote endpoint doesn't support the needed TLS configuration, it needs to be updated with support for some combination of the above-mentioned post-deprecation TLS configuration. These endpoints can be discovered through viewing the [Transaction Details](/azure/azure-monitor/app/availability-standard-tests#see-your-availability-test-results) of your web test (ideally for a successful web test execution). --#### How do I validate what TLS configuration a remote endpoint supports? --There are several tools available to test what TLS configuration an endpoint supports. One way would be to follow the example detailed on this [page](/security/engineering/solving-tls1-problem#appendix-a-handshake-simulation). If your remote endpoint isn't available via the Public internet, you need to ensure you validate the TLS configuration supported on the remote endpoint from a machine that has access to call your endpoint. --> [!NOTE] -> For steps to enable the needed TLS configuration on your web server, it is best to reach out to the team that owns the hosting platform your web server runs on if the process is not known. --#### After October 31, 2024, what will the web test behavior be for impacted tests? --There's no one exception type that all TLS handshake failures impacted by this deprecation would present themselves with. However, the most common exception your web test would start failing with would be `The request was aborted: Couldn't create SSL/TLS secure channel`. You should also be able to see any TLS related failures in the TLS Transport [Troubleshooting Step](/troubleshoot/azure/azure-monitor/app-insights/availability/diagnose-ping-test-failure) for the web test result that is potentially impacted. --#### Can I view what TLS configuration is currently in use by my web test? --The TLS configuration negotiated during a web test execution can't be viewed. As long as the remote endpoint supports common TLS configuration with availability tests, no impact should be seen post-deprecation. --#### Which components does the deprecation affect in the availability test service? --The TLS deprecation detailed in this document should only affect the availability test web test execution behavior after October 31, 2024. For more information about interacting with the availability test service for CRUD operations, see [Azure Resource Manager TLS Support](/azure/azure-resource-manager/management/tls-support). This resource provides more details on TLS support and deprecation timelines. --#### Where can I get TLS support? --For any general questions around the legacy TLS problem, see [Solving TLS problems](/security/engineering/solving-tls1-problem). --## Next steps --* [Troubleshooting](troubleshoot-availability.md) -* [Web tests Azure Resource Manager template](/azure/templates/microsoft.insights/webtests?tabs=json) -* [Web test REST API](/rest/api/application-insights/web-tests) |
| azure-monitor | Azure Ad Authentication | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/azure-ad-authentication.md | - Title: Microsoft Entra authentication for Application Insights -description: Learn how to enable Microsoft Entra authentication to ensure that only authenticated telemetry is ingested in your Application Insights resources. - Previously updated : 04/01/2024----# Microsoft Entra authentication for Application Insights --Application Insights now supports [Microsoft Entra authentication](../../active-directory/authentication/overview-authentication.md). By using Microsoft Entra ID, you can ensure that only authenticated telemetry is ingested in your Application Insights resources. --Using various authentication systems can be cumbersome and risky because it's difficult to manage credentials at scale. You can now choose to [opt out of local authentication](#disable-local-authentication) to ensure only telemetry exclusively authenticated by using [managed identities](../../active-directory/managed-identities-azure-resources/overview.md) and [Microsoft Entra ID](../../active-directory/fundamentals/active-directory-whatis.md) is ingested in your resource. This feature is a step to enhance the security and reliability of the telemetry used to make critical operational ([alerting](../alerts/alerts-overview.md#what-are-azure-monitor-alerts) and [autoscaling](../autoscale/autoscale-overview.md#overview-of-autoscale-in-azure)) and business decisions. --## Prerequisites --The following preliminary steps are required to enable Microsoft Entra authenticated ingestion. You need to: --* Be in the public cloud. -* Be familiar with: - * [Managed identity](../../active-directory/managed-identities-azure-resources/overview.md). - * [Service principal](../../active-directory/develop/howto-create-service-principal-portal.md). - * [Assigning Azure roles](../../role-based-access-control/role-assignments-portal.yml). -* Granting access using [Azure built-in roles](../../role-based-access-control/built-in-roles.md) requires having an Owner role to the resource group. -* Understand the [unsupported scenarios](#unsupported-scenarios). --## Unsupported scenarios --The following Software Development Kits (SDKs) and features are unsupported for use with Microsoft Entra authenticated ingestion: --* [Application Insights Java 2.x SDK](deprecated-java-2x.md#monitor-dependencies-caught-exceptions-and-method-execution-times-in-java-web-apps).<br /> - Microsoft Entra authentication is only available for Application Insights Java Agent greater than or equal to 3.2.0. -* [ApplicationInsights JavaScript web SDK](javascript.md). -* [Application Insights OpenCensus Python SDK](/previous-versions/azure/azure-monitor/app/opencensus-python) with Python version 3.4 and 3.5. -* [AutoInstrumentation for Python on Azure App Service](azure-web-apps-python.md) -* [Profiler](profiler-overview.md). --<a name='configure-and-enable-azure-ad-based-authentication'></a> --## Configure and enable Microsoft Entra ID-based authentication --1. If you don't already have an identity, create one by using either a managed identity or a service principal. -- * We recommend using a managed identity: -- [Set up a managed identity for your Azure service](../../active-directory/managed-identities-azure-resources/services-support-managed-identities.md) (Virtual Machines or App Service). -- * We don't recommend using a service principal: -- For more information on how to create a Microsoft Entra application and service principal that can access resources, see [Create a service principal](../../active-directory/develop/howto-create-service-principal-portal.md). --1. Assign the required Role-based access control (RBAC) role to the Azure identity, service principal, or Azure user account. -- Follow the steps in [Assign Azure roles](../../role-based-access-control/role-assignments-portal.yml) to add the Monitoring Metrics Publisher role to the expected identity, service principal, or Azure user account by setting the target Application Insights resource as the role scope. -- > [!NOTE] - > Although the Monitoring Metrics Publisher role says "metrics," it will publish all telemetry to the Application Insights resource. --1. Follow the configuration guidance in accordance with the language that follows. --### [.NET](#tab/net) --> [!NOTE] -> Support for Microsoft Entra ID in the Application Insights .NET SDK is included starting with [version 2.18-Beta3](https://www.nuget.org/packages/Microsoft.ApplicationInsights/2.18.0-beta3). --Application Insights .NET SDK supports the credential classes provided by [Azure Identity](https://github.com/Azure/azure-sdk-for-net/tree/master/sdk/identity/Azure.Identity#credential-classes). --* We recommend `DefaultAzureCredential` for local development. -* Authenticate on Visual Studio with the expected Azure user account. For more information, see [Authenticate via Visual Studio](https://github.com/Azure/azure-sdk-for-net/tree/main/sdk/identity/Azure.Identity#authenticate-via-visual-studio). -* We recommend `ManagedIdentityCredential` for system-assigned and user-assigned managed identities. - * For system-assigned, use the default constructor without parameters. - * For user-assigned, provide the client ID to the constructor. --The following example shows how to manually create and configure `TelemetryConfiguration` by using .NET: --```csharp -TelemetryConfiguration.Active.ConnectionString = "InstrumentationKey=00000000-0000-0000-0000-000000000000;IngestionEndpoint=https://xxxx.applicationinsights.azure.com/"; -var credential = new DefaultAzureCredential(); -TelemetryConfiguration.Active.SetAzureTokenCredential(credential); -``` --The following example shows how to configure `TelemetryConfiguration` by using .NET Core: --```csharp -services.Configure<TelemetryConfiguration>(config => -{ - var credential = new DefaultAzureCredential(); - config.SetAzureTokenCredential(credential); -}); -services.AddApplicationInsightsTelemetry(new ApplicationInsightsServiceOptions -{ - ConnectionString = "InstrumentationKey=00000000-0000-0000-0000-000000000000;IngestionEndpoint=https://xxxx.applicationinsights.azure.com/" -}); -``` -#### Environment variable configuration --Use the `APPLICATIONINSIGHTS_AUTHENTICATION_STRING` environment variable to let Application Insights authenticate to Microsoft Entra ID and send telemetry when using [Azure App Services autoinstrumentation](./azure-web-apps-net-core.md). --* For system-assigned identity: --| App setting | Value | -|-|| -| APPLICATIONINSIGHTS_AUTHENTICATION_STRING | `Authorization=AAD` | --* For user-assigned identity: --| App setting | Value | -|-|| -| APPLICATIONINSIGHTS_AUTHENTICATION_STRING | `Authorization=AAD;ClientId={Client id of the User-Assigned Identity}` | ---### [Node.js](#tab/nodejs) --Azure Monitor OpenTelemetry and Application Insights Node.JS supports the credential classes provided by [Azure Identity](https://github.com/Azure/azure-sdk-for-js/tree/master/sdk/identity/identity#credential-classes). --* We recommend `DefaultAzureCredential` for local development. -* We recommend `ManagedIdentityCredential` for system-assigned and user-assigned managed identities. - * For system-assigned, use the default constructor without parameters. - * For user-assigned, provide the client ID to the constructor. -* We recommend `ClientSecretCredential` for service principals. - * Provide the tenant ID, client ID, and client secret to the constructor. --If using @azure/monitor-opentelemetry -```typescript -const { useAzureMonitor, AzureMonitorOpenTelemetryOptions } = require("@azure/monitor-opentelemetry"); -const { ManagedIdentityCredential } = require("@azure/identity"); --const credential = new ManagedIdentityCredential(); -const options: AzureMonitorOpenTelemetryOptions = { - azureMonitorExporterOptions: { - connectionString: - process.env["APPLICATIONINSIGHTS_CONNECTION_STRING"] || "<your connection string>", - credential: credential - } -}; -useAzureMonitor(options); -``` --> [!NOTE] -> Support for Microsoft Entra ID in the Application Insights Node.JS is included starting with [version 2.1.0-beta.1](https://www.npmjs.com/package/applicationinsights/v/2.1.0-beta.1). --If using `applicationinsights` npm package. --```typescript -const appInsights = require("applicationinsights"); -const { DefaultAzureCredential } = require("@azure/identity"); - -const credential = new DefaultAzureCredential(); -appInsights.setup("InstrumentationKey=00000000-0000-0000-0000-000000000000;IngestionEndpoint=https://xxxx.applicationinsights.azure.com/").start(); -appInsights.defaultClient.config.aadTokenCredential = credential; --``` --#### Environment variable configuration --Use the `APPLICATIONINSIGHTS_AUTHENTICATION_STRING` environment variable to let Application Insights authenticate to Microsoft Entra ID and send telemetry when using [Azure App Services autoinstrumentation](./azure-web-apps-nodejs.md). --* For system-assigned identity: --| App setting | Value | -|-|| -| APPLICATIONINSIGHTS_AUTHENTICATION_STRING | `Authorization=AAD` | --* For user-assigned identity: --| App setting | Value | -|-|| -| APPLICATIONINSIGHTS_AUTHENTICATION_STRING | `Authorization=AAD;ClientId={Client id of the User-Assigned Identity}` | --### [Java](#tab/java) --> [!NOTE] -> Support for Microsoft Entra ID in the Application Insights Java agent is included starting with [Java 3.2.0-BETA](https://github.com/microsoft/ApplicationInsights-Java/releases/tag/3.2.0-BETA). --1. [Configure your application with the Java agent.](opentelemetry-enable.md?tabs=java#enable-opentelemetry-with-application-insights) -- > [!IMPORTANT] - > Use the full connection string, which includes `IngestionEndpoint`, when you configure your app with the Java agent. For example, use `InstrumentationKey=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX;IngestionEndpoint=https://XXXX.applicationinsights.azure.com/`. --1. Add the JSON configuration to the *ApplicationInsights.json* configuration file depending on the authentication you're using. We recommend using managed identities. --> [!NOTE] -> For more information about migrating from the `2.X` SDK to the `3.X` Java agent, see [Upgrading from Application Insights Java 2.x SDK](java-standalone-upgrade-from-2x.md). --#### System-assigned managed identity --The following example shows how to configure the Java agent to use system-assigned managed identity for authentication with Microsoft Entra ID. --```JSON -{ - "connectionString": "App Insights Connection String with IngestionEndpoint", - "authentication": { - "enabled": true, - "type": "SAMI" - } -} -``` --#### User-assigned managed identity --The following example shows how to configure the Java agent to use user-assigned managed identity for authentication with Microsoft Entra ID. --```JSON -{ - "connectionString": "App Insights Connection String with IngestionEndpoint", - "authentication": { - "enabled": true, - "type": "UAMI", - "clientId":"<USER-ASSIGNED MANAGED IDENTITY CLIENT ID>" - } -} -``` ---#### Environment variable configuration --The `APPLICATIONINSIGHTS_AUTHENTICATION_STRING` environment variable lets Application Insights authenticate to Microsoft Entra ID and send telemetry. --* For system-assigned identity: --| App setting | Value | -|-|| -| APPLICATIONINSIGHTS_AUTHENTICATION_STRING | `Authorization=AAD` | --* For user-assigned identity: --| App setting | Value | -|-|| -| APPLICATIONINSIGHTS_AUTHENTICATION_STRING | `Authorization=AAD;ClientId={Client id of the User-Assigned Identity}` | --Set the `APPLICATIONINSIGHTS_AUTHENTICATION_STRING` environment variable using this string. --**In Unix/Linux:** --```shell -export APPLICATIONINSIGHTS_AUTHENTICATION_STRING="Authorization=AAD" -``` --**In Windows:** --```shell -set APPLICATIONINSIGHTS_AUTHENTICATION_STRING="Authorization=AAD" -``` --After setting it, restart your application. It now sends telemetry to Application Insights using Microsoft Entra authentication. --### [Python](#tab/python) --To configure a secure connection to Azure using OpenTelemetry, see [Enable Microsoft Entra ID (formerly Azure AD) authentication](./opentelemetry-configuration.md?tabs=python#enable-microsoft-entra-id-formerly-azure-ad-authentication). --To configure using OpenCensus (deprecated), see [Configure and enable Microsoft Entra ID-based authentication](/previous-versions/azure/azure-monitor/app/opencensus-python#configure-and-enable-microsoft-entra-id-based-authentication). ----## Query Application Insights using Microsoft Entra authentication --You can submit a query request by using the Azure Monitor Application Insights endpoint `https://api.applicationinsights.io`. To access the endpoint, you must authenticate through Microsoft Entra ID. --### Set up authentication --To access the API, you register a client app with Microsoft Entra ID and request a token. --1. [Register an app in Microsoft Entra ID](../logs/api/register-app-for-token.md). --1. On the app's overview page, select **API permissions**. -1. Select **Add a permission**. -1. On the **APIs my organization uses** tab, search for **Application Insights** and select **Application Insights API** from the list. --1. Select **Delegated permissions**. -1. Select the **Data.Read** checkbox. -1. Select **Add permissions**. --Now that your app is registered and has permissions to use the API, grant your app access to your Application Insights resource. --1. From your **Application Insights resource** overview page, select **Access control (IAM)**. -1. Select **Add role assignment**. --1. Select the **Reader** role and then select **Members**. --1. On the **Members** tab, choose **Select members**. -1. Enter the name of your app in the **Select** box. -1. Select your app and choose **Select**. -1. Select **Review + assign**. --1. After you finish the Active Directory setup and permissions, request an authorization token. -->[!Note] -> For this example, we applied the Reader role. This role is one of many built-in roles and might include more permissions than you require. More granular roles and permissions can be created. --### Request an authorization token --Before you begin, make sure you have all the values required to make the request successfully. All requests require: --* Your Microsoft Entra tenant ID. -* Your App Insights App ID - If you're currently using API Keys, it's the same app ID. -* Your Microsoft Entra client ID for the app. -* A Microsoft Entra client secret for the app. --The Application Insights API supports Microsoft Entra authentication with three different [Microsoft Entra ID OAuth2](/azure/active-directory/develop/active-directory-protocols-oauth-code) flows: --* Client credentials -* Authorization code -* Implicit --#### Client credentials flow --In the client credentials flow, the token is used with the Application Insights endpoint. A single request is made to receive a token by using the credentials provided for your app in the previous step when you [register an app in Microsoft Entra ID](../logs/api/register-app-for-token.md). --Use the `https://api.applicationinsights.io` endpoint. --##### Client credentials token URL (POST request) --```http - POST /<your-tenant-id>/oauth2/token - Host: https://login.microsoftonline.com - Content-Type: application/x-www-form-urlencoded - - grant_type=client_credentials - &client_id=<app-client-id> - &resource=https://api.applicationinsights.io - &client_secret=<app-client-secret> -``` --A successful request receives an access token in the response: --```http - { - token_type": "Bearer", - "expires_in": "86399", - "ext_expires_in": "86399", - "access_token": ""eyJ0eXAiOiJKV1QiLCJ.....Ax" - } -``` --Use the token in requests to the Application Insights endpoint: --```http - POST /v1/apps/yous_app_id/query?timespan=P1D - Host: https://api.applicationinsights.io - Content-Type: application/json - Authorization: Bearer <your access token> -- Body: - { - "query": "requests | take 10" - } -``` --Example response: --```{ - "tables": [ - { - "name": "PrimaryResult", - "columns": [ - { - "name": "timestamp", - "type": "datetime" - }, - { - "name": "id", - "type": "string" - }, - { - "name": "source", - "type": "string" - }, - { - "name": "name", - "type": "string" - }, - { - "name": "url", - "type": "string" - }, - { - "name": "success", - "type": "string" - }, - { - "name": "resultCode", - "type": "string" - }, - { - "name": "duration", - "type": "real" - }, - { - "name": "performanceBucket", - "type": "string" - }, - { - "name": "customDimensions", - "type": "dynamic" - }, - { - "name": "customMeasurements", - "type": "dynamic" - }, - { - "name": "operation_Name", - "type": "string" - }, - { - "name": "operation_Id", - "type": "string" - }, - { - "name": "operation_ParentId", - "type": "string" - }, - { - "name": "operation_SyntheticSource", - "type": "string" - }, - { - "name": "session_Id", - "type": "string" - }, - { - "name": "user_Id", - "type": "string" - }, - { - "name": "user_AuthenticatedId", - "type": "string" - }, - { - "name": "user_AccountId", - "type": "string" - }, - { - "name": "application_Version", - "type": "string" - }, - { - "name": "client_Type", - "type": "string" - }, - { - "name": "client_Model", - "type": "string" - }, - { - "name": "client_OS", - "type": "string" - }, - { - "name": "client_IP", - "type": "string" - }, - { - "name": "client_City", - "type": "string" - }, - { - "name": "client_StateOrProvince", - "type": "string" - }, - { - "name": "client_CountryOrRegion", - "type": "string" - }, - { - "name": "client_Browser", - "type": "string" - }, - { - "name": "cloud_RoleName", - "type": "string" - }, - { - "name": "cloud_RoleInstance", - "type": "string" - }, - { - "name": "appId", - "type": "string" - }, - { - "name": "appName", - "type": "string" - }, - { - "name": "iKey", - "type": "string" - }, - { - "name": "sdkVersion", - "type": "string" - }, - { - "name": "itemId", - "type": "string" - }, - { - "name": "itemType", - "type": "string" - }, - { - "name": "itemCount", - "type": "int" - } - ], - "rows": [ - [ - "2018-02-01T17:33:09.788Z", - "|0qRud6jz3k0=.c32c2659_", - null, - "GET Reports/Index", - "http://fabrikamfiberapp.azurewebsites.net/Reports", - "True", - "200", - "3.3833", - "<250ms", - "{\"_MS.ProcessedByMetricExtractors\":\"(Name:'Requests', Ver:'1.0')\"}", - null, - "GET Reports/Index", - "0qRud6jz3k0=", - "0qRud6jz3k0=", - "Application Insights Availability Monitoring", - "9fc6738d-7e26-44f0-b88e-6fae8ccb6b26", - "us-va-ash-azr_9fc6738d-7e26-44f0-b88e-6fae8ccb6b26", - null, - null, - "AutoGen_49c3aea0-4641-4675-93b5-55f7a62d22d3", - "PC", - null, - null, - "52.168.8.0", - "Boydton", - "Virginia", - "United States", - null, - "fabrikamfiberapp", - "RD00155D5053D1", - "cf58dcfd-0683-487c-bc84-048789bca8e5", - "fabrikamprod", - "5a2e4e0c-e136-4a15-9824-90ba859b0a89", - "web:2.5.0-33031", - "051ad4ef-0776-11e8-ac6e-e30599af6943", - "request", - "1" - ], - [ - "2018-02-01T17:33:15.786Z", - "|x/Ysh+M1TfU=.c32c265a_", - null, - "GET Home/Index", - "http://fabrikamfiberapp.azurewebsites.net/", - "True", - "200", - "716.2912", - "500ms-1sec", - "{\"_MS.ProcessedByMetricExtractors\":\"(Name:'Requests', Ver:'1.0')\"}", - null, - "GET Home/Index", - "x/Ysh+M1TfU=", - "x/Ysh+M1TfU=", - "Application Insights Availability Monitoring", - "58b15be6-d1e6-4d89-9919-52f63b840913", - "emea-se-sto-edge_58b15be6-d1e6-4d89-9919-52f63b840913", - null, - null, - "AutoGen_49c3aea0-4641-4675-93b5-55f7a62d22d3", - "PC", - null, - null, - "51.141.32.0", - "Cardiff", - "Cardiff", - "United Kingdom", - null, - "fabrikamfiberapp", - "RD00155D5053D1", - "cf58dcfd-0683-487c-bc84-048789bca8e5", - "fabrikamprod", - "5a2e4e0c-e136-4a15-9824-90ba859b0a89", - "web:2.5.0-33031", - "051ad4f0-0776-11e8-ac6e-e30599af6943", - "request", - "1" - ] - ] - } - ] -} -``` --#### Authorization code flow --The main OAuth2 flow supported is through [authorization codes](/azure/active-directory/develop/active-directory-protocols-oauth-code). This method requires two HTTP requests to acquire a token with which to call the Azure Monitor Application Insights API. There are two URLs, with one endpoint per request. Their formats are described in the following sections. --##### Authorization code URL (GET request) --```http - GET https://login.microsoftonline.com/YOUR_Azure AD_TENANT/oauth2/authorize? - client_id=<app-client-id> - &response_type=code - &redirect_uri=<app-redirect-uri> - &resource=https://api.applicationinsights.io -``` --When a request is made to the authorized URL, the `client\_id` is the application ID from your Microsoft Entra app, copied from the app's properties menu. The `redirect\_uri` is the `homepage/login` URL from the same Microsoft Entra app. When a request is successful, this endpoint redirects you to the sign-in page you provided at sign-up with the authorization code appended to the URL. See the following example: --```http - http://<app-client-id>/?code=AUTHORIZATION_CODE&session_state=STATE_GUID -``` --At this point, you obtain an authorization code, which you now use to request an access token. --##### Authorization code token URL (POST request) --```http - POST /YOUR_Azure AD_TENANT/oauth2/token HTTP/1.1 - Host: https://login.microsoftonline.com - Content-Type: application/x-www-form-urlencoded - - grant_type=authorization_code - &client_id=<app client id> - &code=<auth code fom GET request> - &redirect_uri=<app-client-id> - &resource=https://api.applicationinsights.io - &client_secret=<app-client-secret> -``` --All values are the same as before, with some additions. The authorization code is the same code you received in the previous request after a successful redirect. The code is combined with the key obtained from the Microsoft Entra app. If you didn't save the key, you can delete it and create a new one from the keys tab of the Microsoft Entra app menu. The response is a JSON string that contains the token with the following schema. Types are indicated for the token values. --Response example: --```http - { - "access_token": "eyJ0eXAiOiJKV1QiLCJ.....Ax", - "expires_in": "3600", - "ext_expires_in": "1503641912", - "id_token": "not_needed_for_app_insights", - "not_before": "1503638012", - "refresh_token": "eyJ0esdfiJKV1ljhgYF.....Az", - "resource": "https://api.applicationinsights.io", - "scope": "Data.Read", - "token_type": "bearer" - } -``` --The access token portion of this response is what you present to the Application Insights API in the `Authorization: Bearer` header. You can also use the refresh token in the future to acquire a new access\_token and refresh\_token when yours go stale. For this request, the format and endpoint are: --```http - POST /YOUR_AAD_TENANT/oauth2/token HTTP/1.1 - Host: https://login.microsoftonline.com - Content-Type: application/x-www-form-urlencoded - - client_id=<app-client-id> - &refresh_token=<refresh-token> - &grant_type=refresh_token - &resource=https://api.applicationinsights.io - &client_secret=<app-client-secret> -``` --Response example: --```http - { - "token_type": "Bearer", - "expires_in": "3600", - "expires_on": "1460404526", - "resource": "https://api.applicationinsights.io", - "access_token": "eyJ0eXAiOiJKV1QiLCJ.....Ax", - "refresh_token": "eyJ0esdfiJKV1ljhgYF.....Az" - } -``` --#### Implicit code flow --The Application Insights API supports the OAuth2 [implicit flow](/azure/active-directory/develop/active-directory-dev-understanding-oauth2-implicit-grant). For this flow, only a single request is required, but no refresh token can be acquired. --##### Implicit code authorization URL --```http - GET https://login.microsoftonline.com/YOUR_AAD_TENANT/oauth2/authorize? - client_id=<app-client-id> - &response_type=token - &redirect_uri=<app-redirect-uri> - &resource=https://api.applicationinsights.io -``` --A successful request produces a redirect to your redirect URI with the token in the URL: --```http - http://YOUR_REDIRECT_URI/#access_token=YOUR_ACCESS_TOKEN&token_type=Bearer&expires_in=3600&session_state=STATE_GUID -``` --This access\_token serves as the `Authorization: Bearer` header value when it passes to the Application Insights API to authorize requests. --## Disable local authentication --After the Microsoft Entra authentication is enabled, you can choose to disable local authentication. This configuration allows you to ingest telemetry authenticated exclusively by Microsoft Entra ID and affects data access (for example, through API keys). --You can disable local authentication by using the Azure portal or Azure Policy or programmatically. --### Azure portal --1. From your Application Insights resource, select **Properties** under **Configure** in the menu on the left. Select **Enabled (click to change)** if the local authentication is enabled. -- :::image type="content" source="./media/azure-ad-authentication/enabled.png" alt-text="Screenshot that shows Properties under the Configure section and the Enabled (select to change) local authentication button."::: --1. Select **Disabled** and apply changes. -- :::image type="content" source="./media/azure-ad-authentication/disable.png" alt-text="Screenshot that shows local authentication with the Enabled/Disabled button."::: --1. After disabling local authentication on your resource, you'll see the corresponding information in the **Overview** pane. -- :::image type="content" source="./media/azure-ad-authentication/overview.png" alt-text="Screenshot that shows the Overview tab with the Disabled (select to change) local authentication button."::: --### Azure Policy --Azure Policy for `DisableLocalAuth` denies users the ability to create a new Application Insights resource without this property set to `true`. The policy name is `Application Insights components should block non-AAD auth ingestion`. --To apply this policy definition to your subscription, [create a new policy assignment and assign the policy](../../governance/policy/assign-policy-portal.md). --The following example shows the policy template definition: --```JSON -{ - "properties": { - "displayName": "Application Insights components should block non-AAD auth ingestion", - "policyType": "BuiltIn", - "mode": "Indexed", - "description": "Improve Application Insights security by disabling log ingestion that are not AAD-based.", - "metadata": { - "version": "1.0.0", - "category": "Monitoring" - }, - "parameters": { - "effect": { - "type": "String", - "metadata": { - "displayName": "Effect", - "description": "The effect determines what happens when the policy rule is evaluated to match" - }, - "allowedValues": [ - "audit", - "deny", - "disabled" - ], - "defaultValue": "audit" - } - }, - "policyRule": { - "if": { - "allOf": [ - { - "field": "type", - "equals": "Microsoft.Insights/components" - }, - { - "field": "Microsoft.Insights/components/DisableLocalAuth", - "notEquals": "true" - } - ] - }, - "then": { - "effect": "[parameters('effect')]" - } - } - } -} -``` --### Programmatic enablement --The property `DisableLocalAuth` is used to disable any local authentication on your Application Insights resource. When this property is set to `true`, it enforces that Microsoft Entra authentication must be used for all access. --The following example shows the Azure Resource Manager template you can use to create a workspace-based Application Insights resource with `LocalAuth` disabled. --```JSON -{ - "$schema": "http://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "name": { - "type": "string" - }, - "type": { - "type": "string" - }, - "regionId": { - "type": "string" - }, - "tagsArray": { - "type": "object" - }, - "requestSource": { - "type": "string" - }, - "workspaceResourceId": { - "type": "string" - }, - "disableLocalAuth": { - "type": "bool" - } - - }, - "resources": [ - { - "name": "[parameters('name')]", - "type": "microsoft.insights/components", - "location": "[parameters('regionId')]", - "tags": "[parameters('tagsArray')]", - "apiVersion": "2020-02-02-preview", - "dependsOn": [], - "properties": { - "Application_Type": "[parameters('type')]", - "Flow_Type": "Redfield", - "Request_Source": "[parameters('requestSource')]", - "WorkspaceResourceId": "[parameters('workspaceResourceId')]", - "DisableLocalAuth": "[parameters('disableLocalAuth')]" - } - } - ] -} --``` --### Token audience --When developing a custom client to obtain an access token from Microsoft Entra ID for submitting telemetry to Application Insights, refer to the following table to determine the appropriate audience string for your particular host environment. --| Azure cloud version | Token audience value | -|--|--| -| Azure public cloud | `https://monitor.azure.com` | -| Microsoft Azure operated by 21Vianet cloud | `https://monitor.azure.cn` | -| Azure US Government cloud | `https://monitor.azure.us` | --If you're using sovereign clouds, you can find the audience information in the connection string as well. The connection string follows this structure: --*InstrumentationKey={profile.InstrumentationKey};IngestionEndpoint={ingestionEndpoint};LiveEndpoint={liveDiagnosticsEndpoint};AADAudience={aadAudience}* --The audience parameter, AADAudience, can vary depending on your specific environment. --## Troubleshooting --This section provides distinct troubleshooting scenarios and steps that you can take to resolve an issue before you raise a support ticket. --### Ingestion HTTP errors --The ingestion service returns specific errors, regardless of the SDK language. Network traffic can be collected by using a tool such as Fiddler. You should filter traffic to the ingestion endpoint set in the connection string. --#### HTTP/1.1 400 Authentication not supported --This error shows the resource is set for Microsoft Entra-only. You need to correctly configure the SDK because it's sending to the wrong API. --> [!NOTE] -> "v2/track" doesn't support Microsoft Entra ID. When the SDK is correctly configured, telemetry will be sent to "v2.1/track". --Next, you should review the SDK configuration. --#### HTTP/1.1 401 Authorization required --This error indicates that the SDK is correctly configured but it's unable to acquire a valid token. This error might indicate an issue with Microsoft Entra ID. --Next, you should identify exceptions in the SDK logs or network errors from Azure Identity. --#### HTTP/1.1 403 Unauthorized --This error means the SDK uses credentials without permission for the Application Insights resource or subscription. --First, check the Application Insights resource's access control. You must configure the SDK with credentials that have the Monitoring Metrics Publisher role. --### Language-specific troubleshooting --### [.NET](#tab/net) --#### Event source --The Application Insights .NET SDK emits error logs by using the event source. To learn more about collecting event source logs, see [Troubleshooting no data - collect logs with PerfView](asp-net-troubleshoot-no-data.md#PerfView). --If the SDK fails to get a token, the exception message is logged as -`Failed to get AAD Token. Error message:`. --### [Node.js](#tab/nodejs) --Turn on internal logs by using the following setup. After you enable them, the console shows error logs, including any error related to Microsoft Entra integration. Examples include failing to generate the token with the wrong credentials or errors when the ingestion endpoint fails to authenticate using the provided credentials. --```javascript -let appInsights = require("applicationinsights"); -appInsights.setup("InstrumentationKey=00000000-0000-0000-0000-000000000000;IngestionEndpoint=https://xxxx.applicationinsights.azure.com/").setInternalLogging(true, true); -``` --### [Java](#tab/java) --#### HTTP traffic --You can inspect network traffic by using a tool like Fiddler. To enable the traffic to tunnel through Fiddler, either add the following proxy settings in the configuration file: --```JSON -"proxy": { -"host": "localhost", -"port": 8888 -} -``` --Or add the following Java Virtual Machine (JVM) args while running your application: `-Djava.net.useSystemProxies=true -Dhttps.proxyHost=localhost -Dhttps.proxyPort=8888` --If Microsoft Entra ID is enabled in the agent, outbound traffic includes the HTTP header `Authorization`. --#### 401 Unauthorized --If you see the message, `WARN c.m.a.TelemetryChannel - Failed to send telemetry with status code: 401, please check your credentials` in the log, it means the agent couldn't send telemetry. You likely didn't enable Microsoft Entra authentication on the agent, while your Application Insights resource has `DisableLocalAuth: true`. Ensure you pass a valid credential with access permission to your Application Insights resource. --If you're using Fiddler, you might see the response header `HTTP/1.1 401 Unauthorized - please provide the valid authorization token`. --#### CredentialUnavailableException --If you see the exception, `com.azure.identity.CredentialUnavailableException: ManagedIdentityCredential authentication unavailable. Connection to IMDS endpoint cannot be established` in the log file, it means the agent failed to acquire the access token. The likely cause is an invalid client ID in your User-Assigned Managed Identity configuration. --#### Failed to send telemetry --If you see the message, `WARN c.m.a.TelemetryChannel - Failed to send telemetry with status code: 403, please check your credentials` in the log, it means the agent couldn't send telemetry. The likely reason is that the credentials used don't allow telemetry ingestion. --Using Fiddler, you might notice the response `HTTP/1.1 403 Forbidden - provided credentials do not grant the access to ingest the telemetry into the component`. --The issue could be due to: --* Creating the resource with a system-assigned managed identity or associating a user-assigned identity without adding the Monitoring Metrics Publisher role to it. -* Using the correct credentials for access tokens but linking them to the wrong Application Insights resource. Ensure your resource (virtual machine or app service) or user-assigned identity has Monitoring Metrics Publisher roles in your Application Insights resource. --#### Invalid Client ID --If the exception, `com.microsoft.aad.msal4j.MsalServiceException: Application with identifier <CLIENT_ID> was not found in the directory` in the log, it means the agent failed to get the access token. This exception likely happens because the client ID in your client secret configuration is invalid or incorrect. --This issue occurs if the administrator doesn't install the application or no tenant user consents to it. It also happens if you send your authentication request to the wrong tenant. --### [Python](#tab/python) --#### Error starts with "credential error" (with no status code) --Something is incorrect about the credential you're using and the client isn't able to obtain a token for authorization. It's because the required data is lacking for the state. An example would be passing in a system `ManagedIdentityCredential` but the resource isn't configured to use system-managed identity. --#### Error starts with "authentication error" (with no status code) --The client failed to authenticate with the given credential. This error usually occurs when the credential used doesn't have the correct role assignments. --#### I'm getting a status code 400 in my error logs --You're probably missing a credential or your credential is set to `None`, but your Application Insights resource is configured with `DisableLocalAuth: true`. Make sure you're passing in a valid credential and that it has permission to access your Application Insights resource. --#### I'm getting a status code 403 in my error logs --This error usually occurs when the provided credentials don't grant access to ingest telemetry for the Application Insights resource. Make sure your Application Insights resource has the correct role assignments. ----## Next steps --* [Monitor your telemetry in the portal](overview-dashboard.md) -* [Diagnose with Live Metrics Stream](live-stream.md) -* [Query Application Insights using Microsoft Entra authentication](./app-insights-azure-ad-api.md) |
| azure-monitor | Azure Vm Vmss Apps | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/azure-vm-vmss-apps.md | - Title: Monitor performance on Azure VMs - Azure Application Insights -description: Application performance monitoring for Azure virtual machines and virtual machine scale sets. - Previously updated : 04/05/2024-# ms.devlang: csharp, java, javascript, python -----# Application Insights for Azure VMs and virtual machine scale sets --Enabling monitoring for your ASP.NET and ASP.NET Core IIS-hosted applications running on [Azure Virtual Machines](https://azure.microsoft.com/services/virtual-machines/) or [Azure Virtual Machine Scale Sets](/azure/virtual-machine-scale-sets/) is now easier than ever. Get all the benefits of using Application Insights without modifying your code. --This article walks you through enabling Application Insights monitoring by using the Application Insights Agent. It also provides preliminary guidance for automating the process for large-scale deployments. --## Enable Application Insights --Autoinstrumentation is easy to enable. Advanced configuration isn't required. --For a complete list of supported autoinstrumentation scenarios, see [Supported environments, languages, and resource providers](codeless-overview.md#supported-environments-languages-and-resource-providers). --> [!NOTE] -> Autoinstrumentation is available for ASP.NET, ASP.NET Core IIS-hosted applications, and Java. Use an SDK to instrument Node.js and Python applications hosted on Azure virtual machines and virtual machine scale sets. --### [.NET Framework](#tab/net) --The Application Insights Agent autocollects the same dependency signals out of the box as the SDK. To learn more, see [Dependency autocollection](./auto-collect-dependencies.md#net). --### [.NET Core / .NET](#tab/core) --The Application Insights Agent autocollects the same dependency signals out of the box as the SDK. To learn more, see [Dependency autocollection](./auto-collect-dependencies.md#net). --### [Java](#tab/Java) --We recommend the [Application Insights Java 3.0 agent](./opentelemetry-enable.md?tabs=java) for Java. The most popular libraries, frameworks, logs, and dependencies are [autocollected](./java-in-process-agent.md#autocollected-requests), along with many [other configurations](./java-standalone-config.md). --### [Node.js](#tab/nodejs) --To instrument your Node.js application, use the [OpenTelemetry Distro](./opentelemetry-enable.md). --### [Python](#tab/python) --To monitor Python apps, use the [OpenTelemetry Distro](./opentelemetry-enable.md). ----Before you install the Application Insights Agent extension, you'll need a connection string. [Create a new Application Insights resource](./create-workspace-resource.md) or copy the connection string from an existing Application Insights resource. --### Enable monitoring for virtual machines --You can use the Azure portal or PowerShell to enable monitoring for VMs. --#### Azure portal -1. In the Azure portal, go to your Application Insights resource. Copy your connection string to the clipboard. -- :::image type="content"source="./media/azure-vm-vmss-apps/connect-string.png" alt-text="Screenshot that shows the connection string." lightbox="./media/azure-vm-vmss-apps/connect-string.png"::: --1. Go to your virtual machine. Under the **Settings** section in the menu on the left side, select **Extensions + applications** > **Add**. -- :::image type="content"source="./media/azure-vm-vmss-apps/add-extension.png" alt-text="Screenshot that shows the Extensions + applications pane with the Add button." lightbox="media/azure-vm-vmss-apps/add-extension.png"::: --1. Select **Application Insights Agent** > **Next**. -- :::image type="content"source="./media/azure-vm-vmss-apps/select-extension.png" alt-text="Screenshot that shows the Install an Extension pane with the Next button." lightbox="media/azure-vm-vmss-apps/select-extension.png"::: --1. Paste the connection string you copied in step 1 and select **Review + create**. -- :::image type="content"source="./media/azure-vm-vmss-apps/install-extension.png" alt-text="Screenshot that shows the Create tab with the Review + create button." lightbox="media/azure-vm-vmss-apps/install-extension.png"::: --#### PowerShell --> [!NOTE] -> Are you new to PowerShell? Check out the [Get started guide](/powershell/azure/get-started-azureps). --Install or update the Application Insights Agent as an extension for Azure virtual machines: --```powershell -# define variables to match your environment before running -$ResourceGroup = "<myVmResourceGroup>" -$VMName = "<myVmName>" -$Location = "<myVmLocation>" -$ConnectionString = "<myAppInsightsResourceConnectionString>" --$publicCfgJsonString = @" -{ - "redfieldConfiguration": { - "instrumentationKeyMap": { - "filters": [ - { - "appFilter": ".*", - "machineFilter": ".*", - "virtualPathFilter": ".*", - "instrumentationSettings" : { - "connectionString": "$ConnectionString" - } - } - ] - } - } - } -"@ --$privateCfgJsonString = '{}' - -Set-AzVMExtension -ResourceGroupName $ResourceGroup -VMName $VMName -Location $Location -Name "ApplicationMonitoringWindows" -Publisher "Microsoft.Azure.Diagnostics" -Type "ApplicationMonitoringWindows" -Version "2.8" -SettingString $publicCfgJsonString -ProtectedSettingString $privateCfgJsonString --``` -> [!NOTE] -> For more complicated at-scale deployments, you can use a PowerShell loop to install or update the Application Insights Agent extension across multiple VMs. --Query the Application Insights Agent extension status for Azure virtual machines: --```powershell -Get-AzVMExtension -ResourceGroupName "<myVmResourceGroup>" -VMName "<myVmName>" -Name ApplicationMonitoringWindows -Status -``` --Get a list of installed extensions for Azure virtual machines: --```powershell -Get-AzResource -ResourceId "/subscriptions/<mySubscriptionId>/resourceGroups/<myVmResourceGroup>/providers/Microsoft.Compute/virtualMachines/<myVmName>/extensions" -``` --Uninstall the Application Insights Agent extension from Azure virtual machines: --```powershell -Remove-AzVMExtension -ResourceGroupName "<myVmResourceGroup>" -VMName "<myVmName>" -Name "ApplicationMonitoring" -``` --> [!NOTE] -> Verify installation by selecting **Live Metrics Stream** within the Application Insights resource associated with the connection string you used to deploy the Application Insights Agent extension. If you're sending data from multiple virtual machines, select the target Azure virtual machines under **Server Name**. It might take up to a minute for data to begin flowing. --## Enable monitoring for virtual machine scale sets --You can use the Azure portal or PowerShell to enable monitoring for virtual machine scale sets. --#### Azure portal -Follow the prior steps for VMs, but go to your virtual machine scale sets instead of your VM. --#### PowerShell -Install or update Application Insights Agent as an extension for virtual machine scale sets: --```powershell -# Set resource group, vmss name, and connection string to reflect your environment -$ResourceGroup = "<myVmResourceGroup>" -$VMSSName = "<myVmName>" -$ConnectionString = "<myAppInsightsResourceConnectionString>" -$publicCfgHashtable = -@{ - "redfieldConfiguration"= @{ - "instrumentationKeyMap"= @{ - "filters"= @( - @{ - "appFilter"= ".*"; - "machineFilter"= ".*"; - "virtualPathFilter"= ".*"; - "instrumentationSettings" = @{ - "connectionString"= "$ConnectionString" - } - } - ) - } - } -}; -$privateCfgHashtable = @{}; -$vmss = Get-AzVmss -ResourceGroupName $ResourceGroup -VMScaleSetName $VMSSName -Add-AzVmssExtension -VirtualMachineScaleSet $vmss -Name "ApplicationMonitoringWindows" -Publisher "Microsoft.Azure.Diagnostics" -Type "ApplicationMonitoringWindows" -TypeHandlerVersion "2.8" -Setting $publicCfgHashtable -ProtectedSetting $privateCfgHashtable -Update-AzVmss -ResourceGroupName $vmss.ResourceGroupName -Name $vmss -# Note: Depending on your update policy, you might need to run Update-AzVmssInstance for each instance -``` --Get a list of installed extensions for virtual machine scale sets: --```powershell -Get-AzResource -ResourceId "/subscriptions/<mySubscriptionId>/resourceGroups/<myResourceGroup>/providers/Microsoft.Compute/virtualMachineScaleSets/<myVmssName>/extensions" -``` --Uninstall the application monitoring extension from virtual machine scale sets: --```powershell -# set resource group and vmss name to reflect your environment -$vmss = Get-AzVmss -ResourceGroupName "<myResourceGroup>" -VMScaleSetName "<myVmssName>" -Remove-AzVmssExtension -VirtualMachineScaleSet $vmss -Name "ApplicationMonitoringWindows" -Update-AzVmss -ResourceGroupName $vmss.ResourceGroupName -Name $vmss.Name -VirtualMachineScaleSet $vmss -# Note: Depending on your update policy, you might need to run Update-AzVmssInstance for each instance -``` --## Troubleshooting --Find troubleshooting tips for the Application Insights Monitoring Agent extension for .NET applications running on Azure virtual machines and virtual machine scale sets. --If you're having trouble deploying the extension, review the execution output that's logged to files found in the following directories: --```Windows -C:\WindowsAzure\Logs\Plugins\Microsoft.Azure.Diagnostics.ApplicationMonitoringWindows\<version>\ -``` --If your extension deployed successfully but you're unable to see telemetry, it could be one of the following issues covered in [Agent troubleshooting](/troubleshoot/azure/azure-monitor/app-insights/status-monitor-v2-troubleshoot#known-issues): --- Conflicting DLLs in an app's bin directory-- Conflict with IIS shared configuration---## Release notes --### 2.8.44 --- Updated Application Insights .NET/.NET Core SDK to 2.20.1 - red field.-- Enabled SQL query collection.-- Enabled support for Microsoft Entra authentication.--### 2.8.42 --Updated Application Insights .NET/.NET Core SDK to 2.18.1 - red field. --### 2.8.41 --Added the ASP.NET Core autoinstrumentation feature. --## Next steps -* Learn how to [deploy an application to an Azure virtual machine scale set](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-deploy-app). -* [Availability overview](availability-overview.md) |
| azure-monitor | Azure Web Apps Java | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/azure-web-apps-java.md | - Title: Monitor Azure app services performance Java | Microsoft Docs -description: Application performance monitoring for Azure app services using Java. Chart load and response time, dependency information, and set alerts on performance. - Previously updated : 08/22/2024-----# Application Monitoring for Azure App Service and Java --Monitoring of your Java web applications running on [Azure App Services](../../app-service/index.yml) doesn't require any modifications to the code. This article walks you through enabling Azure Monitor Application Insights monitoring and provides preliminary guidance for automating the process for large-scale deployments. --> [!NOTE] -> With Spring Boot Native Image applications, use the [Azure Monitor OpenTelemetry Distro / Application Insights in Spring Boot native image Java application](https://aka.ms/AzMonSpringNative) project instead of the Application Insights Java agent solution described below. --## Enable Application Insights --The recommended way to enable application monitoring for Java applications running on Azure App Services is through Azure portal. -Turning on application monitoring in Azure portal will automatically instrument your application with Application Insights, and doesn't require any code changes. -You can apply extra configurations, and then based on your specific scenario you [add your own custom telemetry](./opentelemetry-add-modify.md?tabs=java#modify-telemetry) if needed. --### Autoinstrumentation through Azure portal --You can turn on monitoring for your Java apps running in Azure App Service just with one selection, no code change required. The integration adds [Application Insights Java 3.x](./opentelemetry-enable.md?tabs=java) and auto-collects telemetry. --For a complete list of supported autoinstrumentation scenarios, see [Supported environments, languages, and resource providers](codeless-overview.md#supported-environments-languages-and-resource-providers). --1. **Select Application Insights** in the Azure control panel for your app service, then select **Enable**. -- :::image type="content"source="./media/azure-web-apps/enable.png" alt-text="Screenshot of Application Insights tab with enable selected."::: --2. Choose to create a new resource, or select an existing Application Insights resource for this application. -- > [!NOTE] - > When you select **OK** to create the new resource you will be prompted to **Apply monitoring settings**. Selecting **Continue** will link your new Application Insights resource to your app service, doing so will also **trigger a restart of your app service**. -- :::image type="content"source="./media/azure-web-apps/change-resource.png" alt-text="Screenshot of Change your resource dropdown."::: --3. This last step is optional. After specifying which resource to use, you can configure the Java agent. If you don't configure the Java agent, default configurations apply. -- The full [set of configurations](./java-standalone-config.md) is available, you just need to paste a valid [json file](./java-standalone-config.md#an-example). **Exclude the connection string and any configurations that are in preview** - you're able to add the items that are currently in preview as they become generally available. -- Once you modify the configurations through Azure portal, APPLICATIONINSIGHTS_CONFIGURATION_FILE environment variable are automatically populated and appear in App Service settings panel. This variable contains the full json content that you've pasted in Azure portal configuration text box for your Java app. -- :::image type="content"source="./media/azure-web-apps-java/create-app-service-ai.png" alt-text="Screenshot of instrument your application."::: - --## Enable client-side monitoring --To enable client-side monitoring for your Java application, you need to [manually add the client-side JavaScript SDK to your application](./javascript.md). --## Automate monitoring --In order to enable telemetry collection with Application Insights, only the following Application settings need to be set: ---### Application settings definitions --| App setting name | Definition | Value | -|||:| -| ApplicationInsightsAgent_EXTENSION_VERSION | Main extension, which controls runtime monitoring. | `~2` in Windows or `~3` in Linux. | -| XDT_MicrosoftApplicationInsights_Java | Flag to control if Java agent is included. | 0 or 1 (only applicable in Windows). | --> [!NOTE] -> Profiler and snapshot debugger are not available for Java applications ---## Troubleshooting --Use our step-by-step guide to troubleshoot Java-based applications running on Azure App Services. --1. Check that `ApplicationInsightsAgent_EXTENSION_VERSION` app setting is set to a value of "~2" on Windows, "~3" on Linux -1. Examine the log file to see that the agent has started successfully: browse to `https://yoursitename.scm.azurewebsites.net/, under SSH change to the root directory, the log file is located under LogFiles/ApplicationInsights. - - :::image type="content"source="./media/azure-web-apps-java/app-insights-java-status.png" alt-text="Screenshot of the link above results page."::: --1. After enabling application monitoring for your Java app, you can validate that the agent is working by looking at the live metrics - even before you deploy and app to App Service you'll see some requests from the environment. Remember that the full set of telemetry is only available when you have your app deployed and running. -1. Set APPLICATIONINSIGHTS_SELF_DIAGNOSTICS_LEVEL environment variable to 'debug' if you don't see any errors and there's no telemetry ----## Manually deploy the latest Application Insights Java version --The Application Insights Java version is updated automatically as part of App Services updates. --If you encounter an issue that's fixed in the latest version of Application Insights Java, you can update it manually. --To manually update, follow these steps: --1. Upload the Java agent jar file to App Service -- > a. First, get the latest version of Azure CLI by following the instructions [here](/cli/azure/install-azure-cli-windows?tabs=azure-cli). -- > b. Next, get the latest version of the Application Insights Java agent by following the instructions [here](./opentelemetry-enable.md?tabs=java). -- > c. Then, deploy the Java agent jar file to App Service using the following command: `az webapp deploy --src-path applicationinsights-agent-{VERSION_NUMBER}.jar --target-path jav?tabs=javase&pivots=platform-linux#3configure-the-maven-plugin) to deploy the agent through the Maven plugin. --2. Disable Application Insights via the Application Insights tab in the Azure portal. --3. Once the agent jar file is uploaded, go to App Service configurations. If you - need to use **Startup Command** for Linux, please include jvm arguments: -- :::image type="content"source="./media/azure-web-apps/startup-command.png" alt-text="Screenshot of startup command."::: - - **Startup Command** doesn't honor `JAVA_OPTS` for JavaSE or `CATALINA_OPTS` for Tomcat. -- If you don't use **Startup Command**, create a new environment variable, `JAVA_OPTS` for JavaSE or `CATALINA_OPTS` for Tomcat, with the value - `-javaagent:{PATH_TO_THE_AGENT_JAR}/applicationinsights-agent-{VERSION_NUMBER}.jar`. --4. Restart the app to apply the changes. --> [!NOTE] -> If you set the `JAVA_OPTS` for JavaSE or `CATALINA_OPTS` for Tomcat environment variable, you will have to disable Application Insights in the portal. Alternatively, if you prefer to enable Application Insights from the portal, make sure that you don't set the `JAVA_OPTS` for JavaSE or `CATALINA_OPTS` for Tomcat variable in App Service configurations settings. --## Release notes --For the latest updates and bug fixes, [consult the release notes](web-app-extension-release-notes.md). --## Next steps --* [Monitor Azure Functions with Application Insights](monitor-functions.md). -* [Enable Azure diagnostics](../agents/diagnostics-extension-to-application-insights.md) to be sent to Application Insights. -* [Monitor service health metrics](../data-platform.md) to make sure your service is available and responsive. -* [Receive alert notifications](../alerts/alerts-overview.md) whenever operational events happen or metrics cross a threshold. -* Use [Application Insights for JavaScript apps and web pages](javascript.md) to get client telemetry from the browsers that visit a web page. -* [Availability overview](availability-overview.md) |
| azure-monitor | Azure Web Apps Net Core | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/azure-web-apps-net-core.md | - Title: Monitor Azure App Service performance in .NET Core | Microsoft Docs -description: Application performance monitoring for Azure App Service using ASP.NET Core. Chart load and response time, dependency information, and set alerts on performance. - Previously updated : 08/11/2023-----# Application monitoring for Azure App Service and ASP.NET Core --Enabling monitoring on your ASP.NET Core-based web applications running on [Azure App Service](../../app-service/index.yml) is now easier than ever. Previously, you needed to manually instrument your app. Now, the latest extension/agent is built into the App Service image by default. This article walks you through enabling Azure Monitor Application Insights monitoring. It also provides preliminary guidance for automating the process for large-scale deployments. ----## Enable autoinstrumentation monitoring --For a complete list of supported autoinstrumentation scenarios, see [Supported environments, languages, and resource providers](codeless-overview.md#supported-environments-languages-and-resource-providers). --# [Windows](#tab/Windows) --> [!IMPORTANT] -> Only .NET Core [Long Term Support](https://dotnet.microsoft.com/platform/support/policy/dotnet-core) is supported for autoinstrumentation on Windows. --[Trim self-contained deployments](/dotnet/core/deploying/trimming/trim-self-contained) is *not supported*. Use [manual instrumentation](./asp-net-core.md) via code instead. --> [!NOTE] -> Autoinstrumentation used to be known as "codeless attach" before October 2021. --See the following [Enable monitoring](#enable-monitoring) section to begin setting up Application Insights with your App Service resource. --# [Linux](#tab/Linux) --> [!IMPORTANT] -> Only .NET Core [Long Term Support](https://dotnet.microsoft.com/platform/support/policy/dotnet-core) is supported for autoinstrumentation on Linux. --[Trim self-contained deployments](/dotnet/core/deploying/trimming/trim-self-contained) is *not supported*. Use [manual instrumentation](./asp-net-core.md) via code instead. ---See the following [Enable monitoring](#enable-monitoring) section to begin setting up Application Insights with your App Service resource. ----### Enable monitoring --1. Select **Application Insights** in the left pane for your app service. Then select **Enable**. -- :::image type="content"source="./media/azure-web-apps/enable.png" alt-text=" Screenshot that shows the Application Insights tab with Enable selected."::: --1. Create a new resource or select an existing Application Insights resource for this application. -- > [!NOTE] - > When you select **OK** to create a new resource, you're prompted to **Apply monitoring settings**. Selecting **Continue** links your new Application Insights resource to your app service. Your app service then restarts. -- :::image type="content"source="./media/azure-web-apps/change-resource.png" alt-text="Screenshot that shows the Change your resource dropdown."::: --1. After you specify which resource to use, you can choose how you want Application Insights to collect data per platform for your application. ASP.NET Core collection options are **Recommended** or **Disabled**. -- :::image type="content"source="./media/azure-web-apps-net-core/instrument-net-core.png" alt-text=" Screenshot that shows instrumenting your application section."::: --## Enable client-side monitoring --Client-side monitoring is enabled by default for ASP.NET Core apps with **Recommended** collection, regardless of whether the app setting `APPINSIGHTS_JAVASCRIPT_ENABLED` is present. --If you want to disable client-side monitoring: --1. Select **Settings** > **Configuration**. -1. Under **Application settings**, create a **New application setting** with the following information: -- - **Name**: `APPINSIGHTS_JAVASCRIPT_ENABLED` - - **Value**: `false` --1. **Save** the settings. Restart your app. --## Automate monitoring --To enable telemetry collection with Application Insights, only the application settings must be set. ---### Application settings definitions --|App setting name | Definition | Value | -|--|:|-:| -|ApplicationInsightsAgent_EXTENSION_VERSION | Main extension, which controls runtime monitoring. | `~2` for Windows or `~3` for Linux | -|XDT_MicrosoftApplicationInsights_Mode | In default mode, only essential features are enabled to ensure optimal performance. | `disabled` or `recommended`. | -|XDT_MicrosoftApplicationInsights_PreemptSdk | For ASP.NET Core apps only. Enables Interop (interoperation) with the Application Insights SDK. Loads the extension side by side with the SDK and uses it to send telemetry. (Disables the Application Insights SDK.) |`1`| ---## Upgrade monitoring extension/agent - .NET --To upgrade the monitoring extension/agent, follow the steps in the next sections. --### Upgrade from versions 2.8.9 and up --Upgrading from version 2.8.9 happens automatically, without any extra actions. The new monitoring bits are delivered in the background to the target app service, and on application restart they'll be picked up. --To check which version of the extension you're running, go to `https://yoursitename.scm.azurewebsites.net/ApplicationInsights`. ---### Upgrade from versions 1.0.0 - 2.6.5 --Starting with version 2.8.9, the preinstalled site extension is used. If you're using an earlier version, you can update via one of two ways: --* [Upgrade by enabling via the portal](#enable-autoinstrumentation-monitoring): Even if you have the Application Insights extension for App Service installed, the UI shows only the **Enable** button. Behind the scenes, the old private site extension will be removed. -* [Upgrade through PowerShell](#enable-through-powershell): -- 1. Set the application settings to enable the preinstalled site extension `ApplicationInsightsAgent`. For more information, see [Enable through PowerShell](#enable-through-powershell). - 1. Manually remove the private site extension named **Application Insights extension for Azure App Service**. --If the upgrade is done from a version prior to 2.5.1, check that the `ApplicationInsights` DLLs are removed from the application bin folder. For more information, see [Troubleshooting steps](#troubleshooting). --## Troubleshooting --> [!NOTE] -> When you create a web app with the `ASP.NET Core` runtimes in App Service, it deploys a single static HTML page as a starter website. We *do not* recommend that you troubleshoot an issue with the default template. Deploy an application before you troubleshoot an issue. --What follows is our step-by-step troubleshooting guide for extension/agent-based monitoring for ASP.NET Core-based applications running on App Service. --# [Windows](#tab/windows) --1. Check that the `ApplicationInsightsAgent_EXTENSION_VERSION` app setting is set to a value of `~2`. -1. Browse to `https://yoursitename.scm.azurewebsites.net/ApplicationInsights`. -- :::image type="content"source="./media/azure-web-apps/app-insights-sdk-status.png" alt-text="Screenshot that shows the link above the results page."border ="false"::: - - - Confirm that **Application Insights Extension Status** is `Pre-Installed Site Extension, version 2.8.x.xxxx, is running.` - - If it isn't running, follow the instructions in the section [Enable Application Insights monitoring](#enable-autoinstrumentation-monitoring). -- - Confirm that the status source exists and looks like `Status source D:\home\LogFiles\ApplicationInsights\status\status_RD0003FF0317B6_4248_1.json`. -- If a similar value isn't present, it means the application isn't currently running or isn't supported. To ensure that the application is running, try manually visiting the application URL/application endpoints, which will allow the runtime information to become available. -- - Confirm that **IKeyExists** is `True`. If it's `False`, add `APPINSIGHTS_INSTRUMENTATIONKEY` and `APPLICATIONINSIGHTS_CONNECTION_STRING` with your ikey GUID to your application settings. -- - If your application refers to any Application Insights packages, enabling the App Service integration might not take effect and the data might not appear in Application Insights. An example would be if you've previously instrumented, or attempted to instrument, your app with the [ASP.NET Core SDK](./asp-net-core.md). To fix the issue, in the portal, turn on **Interop with Application Insights SDK**. You'll start seeing the data in Application Insights. - - > [!IMPORTANT] - > This functionality is in preview. -- :::image type="content"source="./media/azure-web-apps-net-core/interop.png" alt-text=" Screenshot that shows the interop setting enabled."::: - - The data will now be sent by using a codeless approach, even if the Application Insights SDK was originally used or attempted to be used. -- > [!IMPORTANT] - > If the application used the Application Insights SDK to send any telemetry, the telemetry will be disabled. In other words, custom telemetry (for example, any `Track*()` methods) and custom settings (such as sampling) will be disabled. --# [Linux](#tab/linux) --1. Check that the `ApplicationInsightsAgent_EXTENSION_VERSION` app setting is set to a value of `~3`. -1. Browse to `https://your site name.scm.azurewebsites.net/ApplicationInsights`. -1. Within this site, confirm: - * The status source exists and looks like `Status source /var/log/applicationinsights/status_abcde1234567_89_0.json`. - * The value `Auto-Instrumentation enabled successfully` is displayed. If a similar value isn't present, it means the application isn't running or isn't supported. To ensure that the application is running, try manually visiting the application URL/application endpoints, which will allow the runtime information to become available. - * **IKeyExists** is `True`. If it's `False`, add `APPINSIGHTS_INSTRUMENTATIONKEY` and `APPLICATIONINSIGHTS_CONNECTION_STRING` with your ikey GUID to your application settings. -- :::image type="content" source="media/azure-web-apps-net-core/auto-instrumentation-status.png" alt-text="Screenshot that shows the autoinstrumentation status webpage." lightbox="media/azure-web-apps-net-core/auto-instrumentation-status.png"::: -----### Default website deployed with web apps doesn't support automatic client-side monitoring --When you create a web app with the ASP.NET Core runtimes in App Service, it deploys a single static HTML page as a starter website. The static webpage also loads an ASP.NET-managed web part in IIS. This behavior allows for testing codeless server-side monitoring but doesn't support automatic client-side monitoring. --If you want to test out codeless server and client-side monitoring for ASP.NET Core in an App Service web app, we recommend that you follow the official guides for [creating an ASP.NET Core web app](../../app-service/quickstart-dotnetcore.md). Then use the instructions in the current article to enable monitoring. ----### PHP and WordPress aren't supported --PHP and WordPress sites aren't supported. There's currently no officially supported SDK/agent for server-side monitoring of these workloads. To manually instrument client-side transactions on a PHP or WordPress site by adding the client-side JavaScript to your webpages, use the [JavaScript SDK](./javascript.md). --The following table provides an explanation of what these values mean, their underlying causes, and recommended fixes. --|Problem value |Explanation |Fix | -|- |-|| -| `AppAlreadyInstrumented:true` | This value indicates that the extension detected that some aspect of the SDK is already present in the application and will back off. It can be because of a reference to `Microsoft.ApplicationInsights.AspNetCore` or `Microsoft.ApplicationInsights`. | Remove the references. Some of these references are added by default from certain Visual Studio templates. Older versions of Visual Studio reference `Microsoft.ApplicationInsights`. | -|`AppAlreadyInstrumented:true` | This value can also be caused by the presence of `Microsoft.ApplicationsInsights` DLL in the app folder from a previous deployment. | Clean the app folder to ensure that these DLLs are removed. Check both your local app's bin directory and the *wwwroot* directory on the App Service. (To check the wwwroot directory of your App Service web app, select **Advanced Tools (Kudu**) > **Debug console** > **CMD** > **home\site\wwwroot**). | -|`IKeyExists:false`|This value indicates that the instrumentation key isn't present in the app setting `APPINSIGHTS_INSTRUMENTATIONKEY`. Possible causes include accidentally removing the values or forgetting to set the values in automation script. | Make sure the setting is present in the App Service application settings. | --## Release notes --For the latest updates and bug fixes, see the [Release notes](web-app-extension-release-notes.md). --## Next steps --* [Run the Profiler on your live app](./profiler.md). -* [Monitor Azure Functions with Application Insights](monitor-functions.md). -* [Enable Azure diagnostics](../agents/diagnostics-extension-to-application-insights.md) to be sent to Application Insights. -* [Monitor service health metrics](../data-platform.md) to make sure your service is available and responsive. -* [Receive alert notifications](../alerts/alerts-overview.md) whenever operational events happen or metrics cross a threshold. -* Use [Application Insights for JavaScript apps and webpages](javascript.md) to get client telemetry from the browsers that visit a webpage. -* [Availability](availability-overview.md) - |
| azure-monitor | Azure Web Apps Net | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/azure-web-apps-net.md | - Title: Monitor Azure app services performance ASP.NET | Microsoft Docs -description: Learn about application performance monitoring for Azure app services by using ASP.NET. Chart load and response time and dependency information, and set alerts on performance. - Previously updated : 04/05/2024-----# Application monitoring for Azure App Service and ASP.NET --Enabling monitoring on your ASP.NET-based web applications running on [Azure App Service](../../app-service/index.yml) is now easier than ever. Previously, you needed to manually instrument your app. Now the latest extension/agent is built into the App Service image by default. This article will walk you through enabling Azure Monitor Application Insights monitoring and provide preliminary guidance for automating the process for large-scale deployments. --> [!NOTE] -> Manually adding an Application Insights site extension via **Development Tools** > **Extensions** is deprecated. This method of extension installation was dependent on manual updates for each new version. The latest stable release of the extension is now [preinstalled](https://github.com/projectkudu/kudu/wiki/Azure-Site-Extensions) as part of the App Service image. The files are located in *d:\Program Files (x86)\SiteExtensions\ApplicationInsightsAgent* and are automatically updated with each stable release. If you follow the autoinstrumentation instructions to enable monitoring, it will automatically remove the deprecated extension for you. --If both autoinstrumentation monitoring and manual SDK-based instrumentation are detected, only the manual instrumentation settings will be honored. This arrangement prevents duplicate data from being sent. To learn more, see the [Troubleshooting section](#troubleshooting). ---## Enable autoinstrumentation monitoring --For a complete list of supported autoinstrumentation scenarios, see [Supported environments, languages, and resource providers](codeless-overview.md#supported-environments-languages-and-resource-providers). --> [!NOTE] -> The combination of `APPINSIGHTS_JAVASCRIPT_ENABLED` and `urlCompression` isn't supported. For more information, see the explanation in the [Troubleshooting section](#appinsights_javascript_enabled-and-urlcompression-isnt-supported). --1. **Select Application Insights** in the Azure control panel for your app service. Then select **Enable**. -- :::image type="content"source="./media/azure-web-apps/enable.png" alt-text="Screenshot that shows the Application Insights tab with Enable selected."::: --1. Choose to create a new resource, or select an existing Application Insights resource for this application. -- > [!NOTE] - > When you select **OK** to create the new resource, you're prompted to select **Apply monitoring settings**. Selecting **Continue** links your new Application Insights resource to your app service. Doing so also triggers a restart of your app service. -- :::image type="content"source="./media/azure-web-apps/change-resource.png" alt-text="Screenshot that shows the Change your resource dropdown."::: --1. After you specify which resource to use, you can choose how you want Application Insights to collect data per platform for your application. ASP.NET app monitoring is on by default with two different levels of collection. -- :::image type="content"source="./media/azure-web-apps-net/instrument-net.png" alt-text="Screenshot that shows the Application Insights site extensions page with Create new resource selected."::: -- The following table summarizes the data that's collected for each route. - - | Data | ASP.NET basic collection | ASP.NET recommended collection | - | | | | - | Adds CPU, memory, and I/O usage trends |No |Yes | - | Collects usage trends, and enables correlation from availability results to transactions | Yes |Yes | - | Collects exceptions unhandled by the host process | Yes |Yes | - | Improves APM metrics accuracy under load, when sampling is used | Yes |Yes | - | Correlates micro-services across request/dependency boundaries | No (single-instance APM capabilities only) |Yes | --1. To configure sampling, which you could previously control via the *applicationinsights.config* file, you can now interact with it via application settings with the corresponding prefix `MicrosoftAppInsights_AdaptiveSamplingTelemetryProcessor`. -- - For example, to change the initial sampling percentage, you can create an application setting of `MicrosoftAppInsights_AdaptiveSamplingTelemetryProcessor_InitialSamplingPercentage` and a value of `100`. - - To disable sampling, set `MicrosoftAppInsights_AdaptiveSamplingTelemetryProcessor_MinSamplingPercentage` to a value of `100`. - - Supported settings include: - - `MicrosoftAppInsights_AdaptiveSamplingTelemetryProcessor_InitialSamplingPercentage` - - `MicrosoftAppInsights_AdaptiveSamplingTelemetryProcessor_MinSamplingPercentage` - - `MicrosoftAppInsights_AdaptiveSamplingTelemetryProcessor_EvaluationInterval` - - `MicrosoftAppInsights_AdaptiveSamplingTelemetryProcessor_MaxTelemetryItemsPerSecond` -- - For the list of supported adaptive sampling telemetry processor settings and definitions, see the [code](https://github.com/microsoft/ApplicationInsights-dotnet/blob/master/BASE/Test/ServerTelemetryChannel.Test/TelemetryChannel.Tests/AdaptiveSamplingTelemetryProcessorTest.cs) and [sampling documentation](./sampling.md#configuring-adaptive-sampling-for-aspnet-applications). --## Enable client-side monitoring --Client-side monitoring is an opt-in for ASP.NET. To enable client-side monitoring: --1. Select **Settings** > **Configuration**. -1. Under **Application settings**, create a new application setting: -- - **Name**: Enter **APPINSIGHTS_JAVASCRIPT_ENABLED**. - - **Value**: Enter **true**. --1. Save the settings and restart your app. --To disable client-side monitoring, either remove the associated key value pair from **Application settings** or set the value to **false**. --## Automate monitoring --To enable telemetry collection with Application Insights, only application settings need to be set. ---### Application settings definitions --|App setting name | Definition | Value | -|--|:|-:| -|ApplicationInsightsAgent_EXTENSION_VERSION | Main extension, which controls runtime monitoring. | `~2` | -|XDT_MicrosoftApplicationInsights_Mode | In default mode, only essential features are enabled to ensure optimal performance. | `default` or `recommended` | -|InstrumentationEngine_EXTENSION_VERSION | Controls if the binary-rewrite engine `InstrumentationEngine` will be turned on. This setting has performance implications and affects cold start/startup time. | `~1` | -|XDT_MicrosoftApplicationInsights_BaseExtensions | Controls if SQL and Azure table text will be captured along with the dependency calls. Performance warning: Application cold startup time will be affected. This setting requires the `InstrumentationEngine`. | `~1` | ---## Upgrade monitoring extension/agent: .NET --### Upgrade from versions 2.8.9 and up --Upgrading from version 2.8.9 happens automatically, without any extra actions. The new monitoring bits are delivered in the background to the target app service. They'll be picked when the application restarts. --To check which version of the extension you're running, go to `https://yoursitename.scm.azurewebsites.net/ApplicationInsights`. ---### Upgrade from versions 1.0.0 - 2.6.5 --Starting with version 2.8.9, the preinstalled site extension is used. If you're on an earlier version, you can update via one of two ways: --* [Upgrade by enabling via the portal](#enable-autoinstrumentation-monitoring): Even if you have the Application Insights extension for App Service installed. The UI shows only the **Enable** button. Behind the scenes, the old private site extension will be removed. -* [Upgrade through PowerShell](#enable-through-powershell): -- 1. Set the application settings to enable the preinstalled site extension `ApplicationInsightsAgent`. For more information, see [Enable through PowerShell](#enable-through-powershell). - 1. Manually remove the private site extension named Application Insights extension for App Service. --If the upgrade is done from a version prior to 2.5.1, check that the Application Insights DLLs are removed from the application bin folder. For more information, see the steps in the [Troubleshooting section](#troubleshooting). --## Troubleshooting --> [!NOTE] -> When you create a web app with the `ASP.NET` runtimes in App Service, it deploys a single static HTML page as a starter website. We do *not* recommend that you troubleshoot an issue with a default template. Deploy an application before you troubleshoot an issue. --Here's our step-by-step troubleshooting guide for extension/agent-based monitoring for ASP.NET-based applications running on App Service. --1. Check that the `ApplicationInsightsAgent_EXTENSION_VERSION` app setting is set to a value of `~2`. -1. Browse to `https://yoursitename.scm.azurewebsites.net/ApplicationInsights`. -- :::image type="content"source="./media/azure-web-apps/app-insights-sdk-status.png" alt-text="Screenshot that shows the preceding link's results page."border ="false"::: -- - Confirm that `Application Insights Extension Status` is `Pre-Installed Site Extension, version 2.8.x.xxxx` and is running. -- If it isn't running, follow the instructions to [enable Application Insights monitoring](#enable-autoinstrumentation-monitoring). -- - Confirm that the status source exists and looks like `Status source D:\home\LogFiles\ApplicationInsights\status\status_RD0003FF0317B6_4248_1.json`. -- If a similar value isn't present, it means the application isn't currently running or isn't supported. To ensure that the application is running, try manually visiting the application URL/application endpoints, which will allow the runtime information to become available. -- - Confirm that `IKeyExists` is `true`. - If not, add `APPINSIGHTS_INSTRUMENTATIONKEY` and `APPLICATIONINSIGHTS_CONNECTION_STRING` with your instrumentation key GUID to your application settings. -- - Confirm that there are no entries for `AppAlreadyInstrumented`, `AppContainsDiagnosticSourceAssembly`, and `AppContainsAspNetTelemetryCorrelationAssembly`. -- If any of these entries exist, remove the following packages from your application: `Microsoft.ApplicationInsights`, `System.Diagnostics.DiagnosticSource`, and `Microsoft.AspNet.TelemetryCorrelation`. --### Default website deployed with web apps doesn't support automatic client-side monitoring --When you create a web app with the `ASP.NET` runtimes in App Service, it deploys a single static HTML page as a starter website. The static webpage also loads an ASP.NET-managed web part in IIS. This page allows for testing codeless server-side monitoring but doesn't support automatic client-side monitoring. --If you want to test out codeless server and client-side monitoring for ASP.NET in an App Service web app, we recommend that you follow the official guides for [creating an ASP.NET Framework web app](../../app-service/quickstart-dotnetcore.md?tabs=netframework48). Then use the instructions in the current article to enable monitoring. --### APPINSIGHTS_JAVASCRIPT_ENABLED and urlCompression isn't supported --If you use `APPINSIGHTS_JAVASCRIPT_ENABLED=true` in cases where content is encoded, you might get errors like: --- 500 URL rewrite error.-- 500.53 URL rewrite module error with the message "Outbound rewrite rules can't be applied when the content of the HTTP response is encoded ('gzip')."--An error occurs because the `APPINSIGHTS_JAVASCRIPT_ENABLED` application setting is set to `true` and content encoding is present at the same time. This scenario isn't supported yet. The workaround is to remove `APPINSIGHTS_JAVASCRIPT_ENABLED` from your application settings. Unfortunately, if client/browser-side JavaScript instrumentation is still required, manual SDK references are needed for your webpages. Follow the [instructions](https://github.com/Microsoft/ApplicationInsights-JS#snippet-setup-ignore-if-using-npm-setup) for manual instrumentation with the JavaScript SDK. --For the latest information on the Application Insights agent/extension, see the [release notes](https://github.com/MohanGsk/ApplicationInsights-Home/blob/master/app-insights-web-app-extensions-releasenotes.md). ----### PHP and WordPress aren't supported --PHP and WordPress sites aren't supported. There's currently no officially supported SDK/agent for server-side monitoring of these workloads. You can manually instrument client-side transactions on a PHP or WordPress site by adding the client-side JavaScript to your webpages by using the [JavaScript SDK](./javascript.md). --The following table provides a more detailed explanation of what these values mean, their underlying causes, and recommended fixes. --|Problem value|Explanation|Fix -|- |-|| -| `AppAlreadyInstrumented:true` | This value indicates that the extension detected that some aspect of the SDK is already present in the application and will back off. It can be because of a reference to `System.Diagnostics.DiagnosticSource`, `Microsoft.AspNet.TelemetryCorrelation`, or `Microsoft.ApplicationInsights`. | Remove the references. Some of these references are added by default from certain Visual Studio templates. Older versions of Visual Studio might add references to `Microsoft.ApplicationInsights`. -|`AppAlreadyInstrumented:true` | This value can also be caused by the presence of the preceding DLLs in the app folder from a previous deployment. | Clean the app folder to ensure that these DLLs are removed. Check both your local app's bin directory and the wwwroot directory on the App Service resource. To check the wwwroot directory of your App Service web app, select **Advanced Tools (Kudu)** > **Debug console** > **CMD** > **home\site\wwwroot**. -|`AppContainsAspNetTelemetryCorrelationAssembly: true` | This value indicates that the extension detected references to `Microsoft.AspNet.TelemetryCorrelation` in the application and will back off. | Remove the reference. -|`AppContainsDiagnosticSourceAssembly**:true`|This value indicates that the extension detected references to `System.Diagnostics.DiagnosticSource` in the application and will back off.| For ASP.NET, remove the reference. -|`IKeyExists:false`|This value indicates that the instrumentation key isn't present in the app setting `APPINSIGHTS_INSTRUMENTATIONKEY`. Possible causes might be that the values were accidentally removed, or you forgot to set the values in the automation script. | Make sure the setting is present in the App Service application settings. --### System.IO.FileNotFoundException after 2.8.44 upgrade --The 2.8.44 version of autoinstrumentation upgrades Application Insights SDK to 2.20.0. The Application Insights SDK has an indirect reference to `System.Runtime.CompilerServices.Unsafe.dll` through `System.Diagnostics.DiagnosticSource.dll`. If the application has [binding redirect](/dotnet/framework/configure-apps/file-schema/runtime/bindingredirect-element) for `System.Runtime.CompilerServices.Unsafe.dll` and if this library isn't present in the application folder, it might throw `System.IO.FileNotFoundException`. --To resolve this issue, remove the binding redirect entry for `System.Runtime.CompilerServices.Unsafe.dll` from the web.config file. If the application wanted to use `System.Runtime.CompilerServices.Unsafe.dll`, set the binding redirect as shown here: --``` -<dependentAssembly> - <assemblyIdentity name="System.Runtime.CompilerServices.Unsafe" publicKeyToken="b03f5f7f11d50a3a" culture="neutral" /> - <bindingRedirect oldVersion="0.0.0.0-4.0.4.1" newVersion="4.0.4.1" /> -</dependentAssembly> -``` --As a temporary workaround, you could set the app setting `ApplicationInsightsAgent_EXTENSION_VERSION` to a value of `2.8.37`. This setting will trigger App Service to use the old Application Insights extension. Temporary mitigations should only be used as an interim. --## Release notes --For the latest updates and bug fixes, see the [release notes](web-app-extension-release-notes.md). --## Next steps --* [Run the profiler on your live app](./profiler.md). -* [Monitor Azure Functions with Application Insights](monitor-functions.md). -* [Enable Azure diagnostics](../agents/diagnostics-extension-to-application-insights.md) to be sent to Application Insights. -* [Monitor service health metrics](../data-platform.md) to make sure your service is available and responsive. -* [Receive alert notifications](../alerts/alerts-overview.md) whenever operational events happen or metrics cross a threshold. -* Use [Application Insights for JavaScript apps and webpages](javascript.md) to get client telemetry from the browsers that visit a webpage. -* [Availability overview](availability-overview.md) |
| azure-monitor | Azure Web Apps Nodejs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/azure-web-apps-nodejs.md | - Title: Monitor Azure app services performance Node.js | Microsoft Docs -description: Application performance monitoring for Azure app services using Node.js. Chart load and response time, dependency information, and set alerts on performance. - Previously updated : 12/15/2023-----# Application Monitoring for Azure App Service and Node.js --Monitoring of your Node.js web applications running on [Azure App Services](../../app-service/index.yml) doesn't require any modifications to the code. This article walks you through enabling Azure Monitor Application Insights monitoring and provides preliminary guidance for automating the process for large-scale deployments. --## Enable Application Insights --The easiest way to enable application monitoring for Node.js applications running on Azure App Services is through Azure portal. -Turning on application monitoring in Azure portal will automatically instrument your application with Application Insights, and doesn't require any code changes. -->[!NOTE] -> You can configure the automatically attached agent using the APPLICATIONINSIGHTS_CONFIGURATION_CONTENT environment variable in the App Service Environment variable blade. For details on the configuration options that can be passed via this environment variable, see [Node.js Configuration](https://github.com/microsoft/ApplicationInsights-node.js#Configuration). --> [!NOTE] -> If both automatic instrumentation and manual SDK-based instrumentation are detected, only the manual instrumentation settings are honored. This is to prevent duplicate data from being sent. For more information, see the [troubleshooting section](#troubleshooting) in this article. --### Autoinstrumentation through Azure portal --For a complete list of supported autoinstrumentation scenarios, see [Supported environments, languages, and resource providers](codeless-overview.md#supported-environments-languages-and-resource-providers). --You can turn on monitoring for your Node.js apps running in Azure App Service just with one click, no code change required. -Application Insights for Node.js is integrated with Azure App Service on Linux - both code-based and custom containers, and with App Service on Windows for code-based apps. -The integration is in public preview. The integration adds Node.js SDK, which is in GA. --1. **Select Application Insights** in the Azure control panel for your app service, then select **Enable**. -- :::image type="content"source="./media/azure-web-apps/enable.png" alt-text="Screenshot of Application Insights tab with enable selected."::: --2. Choose to create a new resource, or select an existing Application Insights resource for this application. -- > [!NOTE] - > When you select **OK** to create the new resource you will be prompted to **Apply monitoring settings**. Selecting **Continue** will link your new Application Insights resource to your app service, doing so will also **trigger a restart of your app service**. -- :::image type="content"source="./media/azure-web-apps/change-resource.png" alt-text="Screenshot of Change your resource dropdown."::: --3. Once you've specified which resource to use, you're all set to go. -- :::image type="content"source="./media/azure-web-apps-nodejs/app-service-node.png" alt-text="Screenshot of instrument your application."::: --## Configuration --The Node.js agent can be configured using JSON. Set the `APPLICATIONINSIGHTS_CONFIGURATION_CONTENT` environment variable to the JSON string or set the `APPLICATIONINSIGHTS_CONFIGURATION_FILE` environment variable to the file path containing the JSON. --```json -"samplingPercentage": 80, -"enableAutoCollectExternalLoggers": true, -"enableAutoCollectExceptions": true, -"enableAutoCollectHeartbeat": true, -"enableSendLiveMetrics": true, -... - -``` --The full [set of configurations](https://github.com/microsoft/ApplicationInsights-node.js#configuration) is available, you just need to use a valid json file. --## Enable client-side monitoring --To enable client-side monitoring for your Node.js application, you need to [manually add the client-side JavaScript SDK to your application](./javascript.md). --## Automate monitoring --In order to enable telemetry collection with Application Insights, only the following Application settings need to be set: ---### Application settings definitions --| App setting name | Definition | Value | -|||:| -| ApplicationInsightsAgent_EXTENSION_VERSION | Main extension, which controls runtime monitoring. | `~2` in Windows or `~3` in Linux. | -| XDT_MicrosoftApplicationInsights_NodeJS | Flag to control if Node.js agent is included. | 0 or 1 (only applicable in Windows). | --> [!NOTE] -> Profiler and snapshot debugger are not available for Node.js applications ---## Troubleshooting --Below is our step-by-step troubleshooting guide for extension/agent based monitoring for Node.js based applications running on Azure App Services. --# [Windows](#tab/windows) --1. Check that `ApplicationInsightsAgent_EXTENSION_VERSION` app setting is set to a value of "~2". -2. Browse to `https://yoursitename.scm.azurewebsites.net/ApplicationInsights`. -- :::image type="content"source="./media/azure-web-apps/app-insights-sdk-status.png" alt-text="Screenshot of the link above results page."border ="false"::: -- - Confirm that the `Application Insights Extension Status` is `Pre-Installed Site Extension, version 2.8.x.xxxx, is running.` -- If it isn't running, follow the [enable Application Insights monitoring instructions](#enable-application-insights). -- - Navigate to *D:\local\Temp\status.json* and open *status.json*. -- Confirm that `SDKPresent` is set to false, `AgentInitializedSuccessfully` to true and `IKey` to have a valid iKey. -- Below is an example of the JSON file: -- ```json - "AppType":"node.js", - - "MachineName":"c89d3a6d0357", - - "PID":"47", - - "AgentInitializedSuccessfully":true, - - "SDKPresent":false, - - "IKey":"00000000-0000-0000-0000-000000000000", - - "SdkVersion":"1.8.10" - - ``` -- If `SDKPresent` is true this indicates that the extension detected that some aspect of the SDK is already present in the Application, and will back-off. --# [Linux](#tab/linux) --1. Check that `ApplicationInsightsAgent_EXTENSION_VERSION` app setting is set to a value of "~3". -2. Navigate to */var/log/applicationinsights/* and open *status.json*. -- Confirm that `SDKPresent` is set to false, `AgentInitializedSuccessfully` to true and `IKey` to have a valid iKey. -- Below is an example of the JSON file: -- ```json - "AppType":"node.js", - - "MachineName":"c89d3a6d0357", - - "PID":"47", - - "AgentInitializedSuccessfully":true, - - "SDKPresent":false, - - "IKey":"00000000-0000-0000-0000-000000000000", - - "SdkVersion":"1.8.10" - - ``` -- If `SDKPresent` is true this indicates that the extension detected that some aspect of the SDK is already present in the Application, and will back-off. -------## Release notes --For the latest updates and bug fixes, [consult the release notes](web-app-extension-release-notes.md). --## Next steps --* [Monitor Azure Functions with Application Insights](monitor-functions.md). -* [Enable Azure diagnostics](../agents/diagnostics-extension-to-application-insights.md) to be sent to Application Insights. -* [Monitor service health metrics](../data-platform.md) to make sure your service is available and responsive. -* [Receive alert notifications](../alerts/alerts-overview.md) whenever operational events happen or metrics cross a threshold. -* Use [Application Insights for JavaScript apps and web pages](javascript.md) to get client telemetry from the browsers that visit a web page. -* [Availability overview](availability-overview.md) - |
| azure-monitor | Azure Web Apps Python | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/azure-web-apps-python.md | - Title: Monitor Azure app services performance Python (Preview) -description: Application performance monitoring for Azure app services using Python. Chart load and response time, dependency information, and set alerts on performance. - Previously updated : 04/01/2024-----# Application monitoring for Azure App Service and Python (Preview) --> [!IMPORTANT] -> See the [Supplemental Terms of Use for Microsoft Azure Previews](https://azure.microsoft.com/support/legal/preview-supplemental-terms/) for legal terms that apply to Azure features that are in beta, preview, or otherwise not yet released into general availability. --Monitor your Python web applications on Azure App Services without modifying the code. This guide shows you how to enable Azure Monitor Application Insights and offers tips for automating large-scale deployments. --The integration instruments popular Python libraries in your code, letting you automatically gather and correlate dependencies, logs, and metrics. After instrumenting, you collect calls and metrics from these Python libraries: --| Instrumentation | Supported library Name | Supported versions | -| | - | | -| [OpenTelemetry Django Instrumentation][ot_instrumentation_django] | [`django`][pypi_django] | [link][ot_instrumentation_django_version] -| [OpenTelemetry FastApi Instrumentation][ot_instrumentation_fastapi] | [`fastapi`][pypi_fastapi] | [link][ot_instrumentation_fastapi_version] -| [OpenTelemetry Flask Instrumentation][ot_instrumentation_flask] | [`flask`][pypi_flask] | [link][ot_instrumentation_flask_version] -| [OpenTelemetry Psycopg2 Instrumentation][ot_instrumentation_psycopg2] | [`psycopg2`][pypi_psycopg2] | [link][ot_instrumentation_psycopg2_version] -| [OpenTelemetry Requests Instrumentation][ot_instrumentation_requests] | [`requests`][pypi_requests] | [link][ot_instrumentation_requests_version] -| [OpenTelemetry UrlLib Instrumentation][ot_instrumentation_urllib] | [`urllib`][pypi_urllib] | All -| [OpenTelemetry UrlLib3 Instrumentation][ot_instrumentation_urllib3] | [`urllib3`][pypi_urllib3] | [link][ot_instrumentation_urllib3_version] --> [!NOTE] -> If using Django, see the additional [Django Instrumentation](#django-instrumentation) section in this article. --Logging telemetry is collected at the level of the root logger. To learn more about Python's native logging hierarchy, visit the [Python logging documentation][python_logging_docs]. --## Prerequisites --* Python version 3.11 or prior. -* App Service must be deployed as code. Custom containers aren't supported. --## Enable Application Insights --The easiest way to monitor Python applications on Azure App Services is through the Azure portal. --Activating monitoring in the Azure portal automatically instruments your application with Application Insights and requires no code changes. --> [!NOTE] -> You should only use autoinstrumentation on App Service if you aren't using manual instrumentation of OpenTelemetry in your code, such as the [Azure Monitor OpenTelemetry Distro](./opentelemetry-enable.md?tabs=python) or the [Azure Monitor OpenTelemetry Exporter][azure_monitor_opentelemetry_exporter]. This is to prevent duplicate data from being sent. To learn more about this, check out the [troubleshooting section](#troubleshooting) in this article. --### Autoinstrumentation through Azure portal --For a complete list of supported autoinstrumentation scenarios, see [Supported environments, languages, and resource providers](codeless-overview.md#supported-environments-languages-and-resource-providers). --Toggle on monitoring for your Python apps in Azure App Service with no code changes required. --Application Insights for Python integrates with code-based Linux Azure App Service. --The integration is in public preview. It adds the Python SDK, which is in GA. --1. **Select Application Insights** in the Azure control panel for your app service, then select **Enable**. -- :::image type="content"source="./media/azure-web-apps/enable.png" alt-text="Screenshot of Application Insights tab with enable selected." lightbox="./media/azure-web-apps/enable.png"::: --2. Choose to create a new resource, or select an existing Application Insights resource for this application. -- > [!NOTE] - > When you select **OK** to create the new resource you will be prompted to **Apply monitoring settings**. Selecting **Continue** will link your new Application Insights resource to your app service, doing so will also **trigger a restart of your app service**. -- :::image type="content"source="./media/azure-web-apps/change-resource.png" alt-text="Screenshot of Change your resource dropdown." lightbox="./media/azure-web-apps/change-resource.png"::: --3. You specify the resource, and it's ready to use. -- :::image type="content"source="./media/azure-web-apps-python/app-service-python.png" alt-text="Screenshot of instrument your application." lightbox="./media/azure-web-apps-python/app-service-python.png"::: --## Configuration --You can configure with [OpenTelemetry environment variables][ot_env_vars] such as: --| **Environment Variable** | **Description** | -|--|-| -| `OTEL_SERVICE_NAME`, `OTEL_RESOURCE_ATTRIBUTES` | Specifies the OpenTelemetry [Resource Attributes][opentelemetry_resource] associated with your application. You can set any Resource Attributes with [OTEL_RESOURCE_ATTRIBUTES][opentelemetry_spec_resource_attributes_env_var] or use [OTEL_SERVICE_NAME][opentelemetry_spec_service_name_env_var] to only set the `service.name`. | -| `OTEL_LOGS_EXPORTER` | If set to `None`, disables collection and export of logging telemetry. | -| `OTEL_METRICS_EXPORTER` | If set to `None`, disables collection and export of metric telemetry. | -| `OTEL_TRACES_EXPORTER` | If set to `None`, disables collection and export of distributed tracing telemetry. | -| `OTEL_BLRP_SCHEDULE_DELAY` | Specifies the logging export interval in milliseconds. Defaults to 5000. | -| `OTEL_BSP_SCHEDULE_DELAY` | Specifies the distributed tracing export interval in milliseconds. Defaults to 5000. | -| `OTEL_TRACES_SAMPLER_ARG` | Specifies the ratio of distributed tracing telemetry to be [sampled][application_insights_sampling]. Accepted values range from 0 to 1. The default is 1.0, meaning no telemetry is sampled out. | -| `OTEL_PYTHON_DISABLED_INSTRUMENTATIONS` | Specifies which OpenTelemetry instrumentations to disable. When disabled, instrumentations aren't executed as part of autoinstrumentation. Accepts a comma-separated list of lowercase [library names](#application-monitoring-for-azure-app-service-and-python-preview). For example, set it to `"psycopg2,fastapi"` to disable the Psycopg2 and FastAPI instrumentations. It defaults to an empty list, enabling all supported instrumentations. | --### Add a community instrumentation library --You can collect more data automatically when you include instrumentation libraries from the OpenTelemetry community. ---To add the community OpenTelemetry Instrumentation Library, install it via your app's `requirements.txt` file. OpenTelemetry autoinstrumentation automatically picks up and instruments all installed libraries. Find the list of community libraries [here](https://github.com/open-telemetry/opentelemetry-python-contrib/tree/main/instrumentation). --## Automate monitoring --In order to enable telemetry collection with Application Insights, only the following Application settings need to be set: ---### Application settings definitions --| App setting name | Definition | Value | -|||:| -| APPLICATIONINSIGHTS_CONNECTION_STRING | Connections string for your Application Insights resource | Example: abcd1234-ab12-cd34-abcd1234abcd | -| ApplicationInsightsAgent_EXTENSION_VERSION | Main extension, which controls runtime monitoring. | `~3` | --> [!NOTE] -> Profiler and snapshot debugger are not available for Python applications ---## Django Instrumentation --In order to use the OpenTelemetry Django Instrumentation, you need to set the `DJANGO_SETTINGS_MODULE` environment variable in the App Service settings to point from your app folder to your settings module. For more information, see the [Django documentation][django_settings_module_docs]. --## Frequently asked questions ---## Troubleshooting --Here we provide our troubleshooting guide for monitoring Python applications on Azure App Services using autoinstrumentation. --### Duplicate telemetry --You should only use autoinstrumentation on App Service if you aren't using manual instrumentation of OpenTelemetry in your code, such as the [Azure Monitor OpenTelemetry Distro](./opentelemetry-enable.md?tabs=python) or the [Azure Monitor OpenTelemetry Exporter][azure_monitor_opentelemetry_exporter]. Using autoinstrumentation on top of the manual instrumentation could cause duplicate telemetry and increase your cost. In order to use App Service OpenTelemetry autoinstrumentation, first remove manual instrumentation of OpenTelemetry from your code. --### Missing telemetry --If you're missing telemetry, follow these steps to confirm that autoinstrumentation is enabled correctly. --#### Step 1: Check the Application Insights blade on your App Service resource --Confirm that autoinstrumentation is enabled in the Application Insights blade on your App Service Resource: ---#### Step 2: Confirm that your App Settings are correct --Confirm that the `ApplicationInsightsAgent_EXTENSION_VERSION` app setting is set to a value of `~3` and that your `APPLICATIONINSIGHTS_CONNECTION_STRING` points to the appropriate Application Insights resource. ---#### Step 3: Check autoinstrumentation diagnostics and status logs -Navigate to */var/log/applicationinsights/* and open status_*.json. --Confirm that `AgentInitializedSuccessfully` is set to true and `IKey` to have a valid iKey. --Here's an example JSON file: --```json - "AgentInitializedSuccessfully":true, - - "AppType":"python", - - "MachineName":"c89d3a6d0357", - - "PID":"47", - - "IKey":"00000000-0000-0000-0000-000000000000", - - "SdkVersion":"1.0.0" --``` --The `applicationinsights-extension.log` file in the same folder may show other helpful diagnostics. --### Django apps --If your app uses Django and is either failing to start or using incorrect settings, make sure to set the `DJANGO_SETTINGS_MODULE` environment variable. See the [Django Instrumentation](#django-instrumentation) section for details. -----For the latest updates and bug fixes, [consult the release notes](web-app-extension-release-notes.md). --> --## Next steps --* [Enable Azure diagnostics](../agents/diagnostics-extension-to-application-insights.md) to be sent to Application Insights -* [Monitor service health metrics](../data-platform.md) to make sure your service is available and responsive -* [Receive alert notifications](../alerts/alerts-overview.md) whenever operational events happen or metrics cross a threshold -* [Availability overview](availability-overview.md) --[application_insights_sampling]: ./sampling.md -[azure_core_tracing_opentelemetry_plugin]: https://github.com/Azure/azure-sdk-for-python/tree/main/sdk/core/azure-core-tracing-opentelemetry -[azure_monitor_opentelemetry_exporter]: /python/api/overview/azure/monitor-opentelemetry-exporter-readme -[django_settings_module_docs]: https://docs.djangoproject.com/en/4.2/topics/settings/#envvar-DJANGO_SETTINGS_MODULE -[ot_env_vars]: https://opentelemetry.io/docs/reference/specification/sdk-environment-variables/ -[ot_instrumentation_django]: https://github.com/open-telemetry/opentelemetry-python-contrib/tree/main/instrumentation/opentelemetry-instrumentation-django -[ot_instrumentation_django_version]: https://github.com/open-telemetry/opentelemetry-python-contrib/blob/main/instrumentation/opentelemetry-instrumentation-django/src/opentelemetry/instrumentation/django/package.py#L16 -[ot_instrumentation_fastapi]: https://github.com/open-telemetry/opentelemetry-python-contrib/tree/main/instrumentation/opentelemetry-instrumentation-fastapi -[ot_instrumentation_fastapi_version]: https://github.com/open-telemetry/opentelemetry-python-contrib/blob/main/instrumentation/opentelemetry-instrumentation-fastapi/src/opentelemetry/instrumentation/fastapi/package.py#L16 -[ot_instrumentation_flask]: https://github.com/open-telemetry/opentelemetry-python-contrib/tree/main/instrumentation/opentelemetry-instrumentation-flask -[ot_instrumentation_flask_version]: https://github.com/open-telemetry/opentelemetry-python-contrib/blob/main/instrumentation/opentelemetry-instrumentation-flask/src/opentelemetry/instrumentation/flask/package.py#L16 -[ot_instrumentation_psycopg2]: https://github.com/open-telemetry/opentelemetry-python-contrib/tree/main/instrumentation/opentelemetry-instrumentation-psycopg2 -[ot_instrumentation_psycopg2_version]: https://github.com/open-telemetry/opentelemetry-python-contrib/blob/main/instrumentation/opentelemetry-instrumentation-psycopg2/src/opentelemetry/instrumentation/psycopg2/package.py#L16 -[ot_instrumentation_requests]: https://github.com/open-telemetry/opentelemetry-python-contrib/tree/main/instrumentation/opentelemetry-instrumentation-requests -[ot_instrumentation_requests_version]: https://github.com/open-telemetry/opentelemetry-python-contrib/blob/main/instrumentation/opentelemetry-instrumentation-requests/src/opentelemetry/instrumentation/requests/package.py#L16 -[ot_instrumentation_urllib]: https://github.com/open-telemetry/opentelemetry-python-contrib/tree/main/instrumentation/opentelemetry-instrumentation-urllib3 -[ot_instrumentation_urllib3]: https://github.com/open-telemetry/opentelemetry-python-contrib/tree/main/instrumentation/opentelemetry-instrumentation-urllib3 -[ot_instrumentation_urllib3_version]: https://github.com/open-telemetry/opentelemetry-python-contrib/blob/main/instrumentation/opentelemetry-instrumentation-urllib3/src/opentelemetry/instrumentation/urllib3/package.py#L16 -[opentelemetry_resource]: https://opentelemetry.io/docs/specs/otel/resource/sdk/ -[opentelemetry_spec_resource_attributes_env_var]: https://opentelemetry-python.readthedocs.io/en/latest/sdk/environment_variables.html?highlight=OTEL_RESOURCE_ATTRIBUTES%20#opentelemetry-sdk-environment-variables -[opentelemetry_spec_service_name_env_var]: https://opentelemetry-python.readthedocs.io/en/latest/sdk/environment_variables.html?highlight=OTEL_RESOURCE_ATTRIBUTES%20#opentelemetry.sdk.environment_variables.OTEL_SERVICE_NAME -[python_logging_docs]: https://docs.python.org/3/library/logging.html -[pypi_django]: https://pypi.org/project/Django/ -[pypi_fastapi]: https://pypi.org/project/fastapi/ -[pypi_flask]: https://pypi.org/project/Flask/ -[pypi_psycopg2]: https://pypi.org/project/psycopg2/ -[pypi_requests]: https://pypi.org/project/requests/ -[pypi_urllib]: https://docs.python.org/3/library/urllib.html -[pypi_urllib3]: https://pypi.org/project/urllib3/ |
| azure-monitor | Azure Web Apps | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/azure-web-apps.md | - Title: Monitor Azure App Service performance | Microsoft Docs -description: Application performance monitoring for Azure App Service. Chart load and response time, dependency information, and set alerts on performance. - Previously updated : 08/11/2023----# Application monitoring for Azure App Service overview --It's now easier than ever to enable monitoring on your web applications based on ASP.NET, ASP.NET Core, Java, and Node.js running on [Azure App Service](../../app-service/index.yml). Previously, you needed to manually instrument your app, but the latest extension/agent is now built into the App Service image by default. --## Enable Application Insights --There are two ways to enable monitoring for applications hosted on App Service: --- **Autoinstrumentation application monitoring** (ApplicationInsightsAgent).-- This method is the easiest to enable, and no code change or advanced configurations are required. It's often referred to as "runtime" monitoring. For App Service, we recommend that at a minimum you enable this level of monitoring. Based on your specific scenario, you can evaluate whether more advanced monitoring through manual instrumentation is needed. -- When you enable auto-instrumentation it enables Application Insights with a default setting (it includes sampling as well). Even if you set in Azure AppInsights: Sampling: **All Data 100%** this setting will be ignored. -- For a complete list of supported autoinstrumentation scenarios, see [Supported environments, languages, and resource providers](codeless-overview.md#supported-environments-languages-and-resource-providers). -- The following platforms are supported for autoinstrumentation monitoring: -- - [.NET Core](./azure-web-apps-net-core.md) - - [.NET](./azure-web-apps-net.md) - - [Java](./azure-web-apps-java.md) - - [Node.js](./azure-web-apps-nodejs.md) - - [Python](./azure-web-apps-python.md) --* **Manually instrumenting the application through code** by installing the Application Insights SDK. -- This approach is much more customizable, but it requires the following approaches: SDK for [.NET Core](./asp-net-core.md), [.NET](./asp-net.md), [Node.js](./nodejs.md), [Python](./opentelemetry-enable.md?tabs=python), and a standalone agent for [Java](./opentelemetry-enable.md?tabs=java). This method also means you must manage the updates to the latest version of the packages yourself. - - If you need to make custom API calls to track events/dependencies not captured by default with autoinstrumentation monitoring, you need to use this method. To learn more, see [Application Insights API for custom events and metrics](./api-custom-events-metrics.md). --If both autoinstrumentation monitoring and manual SDK-based instrumentation are detected, in .NET only the manual instrumentation settings are honored, while in Java only the autoinstrumentation are emitting the telemetry. This practice is to prevent duplicate data from being sent. --> [!NOTE] -> Snapshot Debugger and Profiler are only available in .NET and .NET Core. --## Release notes --This section contains the release notes for Azure Web Apps Extension for runtime instrumentation with Application Insights. --To find which version of the extension you're currently using, go to `https://<yoursitename>.scm.azurewebsites.net/ApplicationInsights`. --### Release notes --#### 2.8.44 --- .NET/.NET Core: Upgraded to [ApplicationInsights .NET SDK to 2.20.1](https://github.com/microsoft/ApplicationInsights-dotnet/tree/autoinstrumentation/2.20.1).--#### 2.8.43 --- Separate .NET/.NET Core, Java and Node.js package into different App Service Windows Site Extension. --#### 2.8.42 --- JAVA extension: Upgraded to [Java Agent 3.2.0](https://github.com/microsoft/ApplicationInsights-Java/releases/tag/3.2.0) from 2.5.1.-- Node.js extension: Updated AI SDK to [2.1.8](https://github.com/microsoft/ApplicationInsights-node.js/releases/tag/2.1.8) from 2.1.7. Added support for User and System assigned Microsoft Entra managed identities.-- .NET Core: Added self-contained deployments and .NET 6.0 support using [.NET Startup Hook](https://github.com/dotnet/runtime/blob/main/docs/design/features/host-startup-hook.md).--#### 2.8.41 --- Node.js extension: Updated AI SDK to [2.1.7](https://github.com/microsoft/ApplicationInsights-node.js/releases/tag/2.1.7) from 2.1.3.-- .NET Core: Removed out-of-support version (2.1). Supported versions are 3.1 and 5.0.--#### 2.8.40 --- JAVA extension: Upgraded to [Java Agent 3.1.1 (GA)](https://github.com/microsoft/ApplicationInsights-Java/releases/tag/3.1.1) from 3.0.2.-- Node.js extension: Updated AI SDK to [2.1.3](https://github.com/microsoft/ApplicationInsights-node.js/releases/tag/2.1.3) from 1.8.8.--#### 2.8.39 --- .NET Core: Added .NET Core 5.0 support.--#### 2.8.38 --- JAVA extension: upgraded to [Java Agent 3.0.2 (GA)](https://github.com/microsoft/ApplicationInsights-Java/releases/tag/3.0.2) from 2.5.1.-- Node.js extension: Updated AI SDK to [1.8.8](https://github.com/microsoft/ApplicationInsights-node.js/releases/tag/1.8.8) from 1.8.7.-- .NET Core: Removed out-of-support versions (2.0, 2.2, 3.0). Supported versions are 2.1 and 3.1.--#### 2.8.37 --- AppSvc Windows extension: Made .NET Core work with any version of System.Diagnostics.DiagnosticSource.dll.--#### 2.8.36 --- AppSvc Windows extension: Enabled Inter-op with AI SDK in .NET Core.--#### 2.8.35 --- AppSvc Windows extension: Added .NET Core 3.1 support.--#### 2.8.33 --- .NET, .NET core, Java, and Node.js agents and the Windows Extension: Support for sovereign clouds. Connections strings can be used to send data to sovereign clouds.--#### 2.8.31 --- The ASP.NET Core agent fixed an issue with the Application Insights SDK. If the runtime loaded the incorrect version of `System.Diagnostics.DiagnosticSource.dll`, the codeless extension doesn't crash the application and backs off. To fix the issue, customers should remove `System.Diagnostics.DiagnosticSource.dll` from the bin folder or use the older version of the extension by setting `ApplicationInsightsAgent_EXTENSIONVERSION=2.8.24`. If they don't, application monitoring isn't enabled.--#### 2.8.26 --- ASP.NET Core agent: Fixed issue related to updated Application Insights SDK. The agent doesn't try to load `AiHostingStartup` if the ApplicationInsights.dll is already present in the bin folder. It resolves issues related to reflection via Assembly\<AiHostingStartup\>.GetTypes().-- Known issues: Exception `System.IO.FileLoadException: Could not load file or assembly 'System.Diagnostics.DiagnosticSource, Version=4.0.4.0, Culture=neutral, PublicKeyToken=cc7b13ffcd2ddd51'` could be thrown if another version of `DiagnosticSource` dll is loaded. It could happen, for example, if `System.Diagnostics.DiagnosticSource.dll` is present in the publish folder. As mitigation, use the previous version of extension by setting app settings in app --#### 2.8.24 --- Repackaged version of 2.8.21.--#### 2.8.23 --- Added ASP.NET Core 3.0 codeless monitoring support.-- Updated ASP.NET Core SDK to [2.8.0](https://github.com/microsoft/ApplicationInsights-aspnetcore/releases/tag/2.8.0) for runtime versions 2.1, 2.2 and 3.0. Apps targeting .NET Core 2.0 continue to use 2.1.1 of the SDK.--#### 2.8.14 --- Updated ASP.NET Core SDK version from 2.3.0 to the latest (2.6.1) for apps targeting .NET Core 2.1, 2.2. Apps targeting .NET Core 2.0 continue to use 2.1.1 of the SDK.--#### 2.8.12 --- Support for ASP.NET Core 2.2 apps.-- Fixed a bug in ASP.NET Core extension causing injection of SDK even when the application is already instrumented with the SDK. For 2.1 and 2.2 apps, the presence of ApplicationInsights.dll in the application folder now causes the extension to back off. For 2.0 apps, the extension backs off only if ApplicationInsights is enabled with a `UseApplicationInsights()` call.--- Permanent fix for incomplete HTML response for ASP.NET Core apps. This fix is now extended to work for .NET Core 2.2 apps.--- Added support to turn off JavaScript injection for ASP.NET Core apps (`APPINSIGHTS_JAVASCRIPT_ENABLED=false appsetting`). For ASP.NET core, the JavaScript injection is in "Opt-Out" mode by default, unless explicitly turned off. (The default setting is done to retain current behavior.)--- Fixed ASP.NET Core extension bug that caused injection even if ikey wasn't present.-- Fixed a bug in the SDK version prefix logic that caused an incorrect SDK version in telemetry.--- Added SDK version prefix for ASP.NET Core apps to identify how telemetry was collected.-- Fixed SCM- ApplicationInsights page to correctly show the version of the pre-installed extension.--#### 2.8.10 --- Fix for incomplete HTML response for ASP.NET Core apps.--## Frequently asked questions --This section provides answers to common questions. --### What does Application Insights modify in my project? --The details depend on the type of project. For a web application: - -* Adds these files to your project: - * ApplicationInsights.config - * ai.js -* Installs these NuGet packages: - * Application Insights API: The core API - * Application Insights API for Web Applications: Used to send telemetry from the server - * Application Insights API for JavaScript Applications: Used to send telemetry from the client -* The packages include these assemblies: - * Microsoft.ApplicationInsights - * Microsoft.ApplicationInsights.Platform -* Inserts items into: - * Web.config - * packages.config -* (For new projects only, you [add Application Insights to an existing project manually](./app-insights-overview.md).) Inserts snippets into the client and server code to initialize them with the Application Insights resource ID. For example, in an MVC app, code is inserted into the main page *Views/Shared/\_Layout.cshtml*. - --## Next steps --Learn how to enable autoinstrumentation application monitoring for your [.NET Core](./azure-web-apps-net-core.md), [.NET](./azure-web-apps-net.md), [Java](./azure-web-apps-java.md), [Nodejs](./azure-web-apps-nodejs.md), or [Python](./azure-web-apps-python.md) application running on App Service. |
| azure-monitor | Codeless Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/codeless-overview.md | - Title: Autoinstrumentation for Azure Monitor Application Insights -description: Overview of autoinstrumentation for Azure Monitor Application Insights codeless application performance management. -- Previously updated : 08/12/2024----# What is autoinstrumentation for Azure Monitor Application Insights? --Autoinstrumentation enables [Application Insights](app-insights-overview.md) to make [telemetry](data-model-complete.md) like metrics, requests, and dependencies available in your [Application Insights resource](create-workspace-resource.md). It provides easy access to experiences such as the [application dashboard](overview-dashboard.md) and [application map](app-map.md). --The term "autoinstrumentation" is a portmanteau, a linguistic blend where parts of multiple words combine into a new word. "Autoinstrumentation" combines "auto" and "instrumentation." It sees widespread use in software observability and describes the process of adding instrumentation code to applications without manual coding by developers. --The autoinstrumentation process varies by language and platform, but often involves a toggle button in the Azure portal. The following example shows a toggle button for [Azure App Service](../../app-service/getting-started.md#getting-started-with-azure-app-service) autoinstrumentation. ---> [!TIP] -> *We do not provide autoinstrumentation specifics for all languages and platforms in this article.* For detailed information, select the corresponding link in the [Supported environments, languages, and resource providers table](#supported-environments-languages-and-resource-providers). In many cases, autoinstrumentation is enabled by default. --## What are the autoinstrumentation advantages? --> [!div class="checklist"] -> - Code changes aren't required. -> - Access to source code isn't required. -> - Configuration changes aren't required. -> - Instrumentation maintenance is eliminated. --## Supported environments, languages, and resource providers --The following table shows the current state of autoinstrumentation availability. --Links are provided to more information for each supported scenario. --> [!NOTE] -> If your hosting environment or resource provider is not listed in the following table, then autoinstrumentation is not supported. In this case, we recommend manually instrumenting using the [Azure Monitor OpenTelemetry Distro](opentelemetry-enable.md). For more information, see [Data Collection Basics of Azure Monitor Application Insights](opentelemetry-overview.md). --|Environment/Resource provider | .NET Framework | .NET Core / .NET | Java | Node.js | Python | -|-|-|-|--|-|--| -|Azure App Service on Windows - Publish as Code | [ :white_check_mark: :link: ](azure-web-apps-net.md) ┬╣ | [ :white_check_mark: :link: ](azure-web-apps-net-core.md) ┬╣ | [ :white_check_mark: :link: ](azure-web-apps-java.md) ┬╣ | [ :white_check_mark: :link: ](azure-web-apps-nodejs.md) ┬╣ | :x: | -|Azure App Service on Windows - Publish as Docker | [ :white_check_mark: :link: ](https://azure.github.io/AppService/2022/04/11/windows-containers-app-insights-preview.html) ┬▓ | [ :white_check_mark: :link: ](https://azure.github.io/AppService/2022/04/11/windows-containers-app-insights-preview.html) ┬▓ | [ :white_check_mark: :link: ](https://azure.github.io/AppService/2022/04/11/windows-containers-app-insights-preview.html) ┬▓ | [ :white_check_mark: :link: ](https://techcommunity.microsoft.com/t5/apps-on-azure-blog/public-preview-application-insights-auto-instrumentation-for/ba-p/3947971) ┬▓ | :x: | -|Azure App Service on Linux - Publish as Code | :x: | [ :white_check_mark: :link: ](azure-web-apps-net-core.md?tabs=linux) ┬╣ | [ :white_check_mark: :link: ](azure-web-apps-java.md) ┬╣ | [ :white_check_mark: :link: ](azure-web-apps-nodejs.md?tabs=linux)┬╣ | [ :white_check_mark: :link: ](azure-web-apps-python.md?tabs=linux) ┬▓ | -|Azure App Service on Linux - Publish as Docker | :x: | [ :white_check_mark: :link: ](azure-web-apps-net-core.md?tabs=linux) | [ :white_check_mark: :link: ](azure-web-apps-java.md) | [ :white_check_mark: :link: ](azure-web-apps-nodejs.md?tabs=linux) | :x: | -|Azure Functions - basic | [ :white_check_mark: :link: ](monitor-functions.md) ┬╣ | [ :white_check_mark: :link: ](monitor-functions.md) ┬╣ | [ :white_check_mark: :link: ](monitor-functions.md) ┬╣ | [ :white_check_mark: :link: ](monitor-functions.md) ┬╣ | [ :white_check_mark: :link: ](monitor-functions.md#distributed-tracing-for-python-function-apps) ┬╣ | -|Azure Functions - dependencies | :x: | :x: | [ :white_check_mark: :link: ](monitor-functions.md) | :x: | :x: | -|Azure Spring Apps | :x: | :x: | [ :white_check_mark: :link: ](../../spring-apps/enterprise/how-to-application-insights.md) | :x: | :x: | -|Azure Kubernetes Service (AKS) | :x: | :x: | [ :white_check_mark: :link: ](opentelemetry-enable.md?tabs=java) | :x: | :x: | -|Azure VMs Windows | [ :white_check_mark: :link: ](azure-vm-vmss-apps.md) ┬▓ ┬│ | [ :white_check_mark: :link: ](azure-vm-vmss-apps.md) ┬▓ ┬│ | [ :white_check_mark: :link: ](opentelemetry-enable.md?tabs=java) | :x: | :x: | -|On-premises VMs Windows | [ :white_check_mark: :link: ](application-insights-asp-net-agent.md) ┬│ | [ :white_check_mark: :link: ](application-insights-asp-net-agent.md) ┬▓ ┬│ | [ :white_check_mark: :link: ](opentelemetry-enable.md?tabs=java) | :x: | :x: | -|Standalone agent - any environment | :x: | :x: | [ :white_check_mark: :link: ](opentelemetry-enable.md?tabs=java) | :x: | :x: | --**Footnotes** -- ┬╣: Application Insights is on by default and enabled automatically.-- ┬▓: This feature is in public preview. See [Supplemental Terms of Use for Microsoft Azure Previews](https://azure.microsoft.com/support/legal/preview-supplemental-terms/).-- ┬│: An agent must be deployed and configured.--> [!NOTE] -> Autoinstrumentation was known as "codeless attach" before October 2021. --## Frequently asked questions --#### Should the term "autoinstrumentation" be hyphenated? --We follow the [Microsoft Style Guide](/style-guide/punctuation/dashes-hyphens/hyphens#prefixes) for product documentation published to the [Microsoft Learn](/) platform. --In general, we donΓÇÖt include a hyphen after the "auto" prefix. --## Next steps --* [Application Insights overview](app-insights-overview.md) -* [Application Insights overview dashboard](overview-dashboard.md) -* [Application map](app-map.md) |
| azure-monitor | Configuration With Applicationinsights Config | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/configuration-with-applicationinsights-config.md | - Title: ApplicationInsights.config reference - Azure | Microsoft Docs -description: Enable or disable data collection modules and add performance counters and other parameters. - Previously updated : 01/31/2024------# Configure the Application Insights SDK with ApplicationInsights.config or .xml --The Application Insights .NET SDK consists of many NuGet packages. The [core package](https://www.nuget.org/packages/Microsoft.ApplicationInsights) provides the API for sending telemetry to the Application Insights. [More packages](https://www.nuget.org/packages?q=Microsoft.ApplicationInsights) provide telemetry *modules* and *initializers* for automatically tracking telemetry from your application and its context. By adjusting the configuration file, you can enable or disable telemetry modules and initializers. You can also set parameters for some of them. ---The configuration file is named `ApplicationInsights.config` or `ApplicationInsights.xml`. The name depends on the type of your application. It's automatically added to your project when you [install most versions of the SDK][start]. By default, when you use the automated experience from the Visual Studio template projects that support **Add** > **Application Insights Telemetry**, the `ApplicationInsights.config` file is created in the project root folder. When it's compiled, it's copied to the bin folder. It's also added to a web app by [Application Insights Agent on an IIS server][redfield]. The configuration file is ignored if the [extension for Azure websites](azure-web-apps.md) or the [extension for Azure VMs and virtual machine scale sets](azure-vm-vmss-apps.md) is used. --There isn't an equivalent file to control the [SDK in a webpage][client]. --This article describes the sections you see in the configuration file, how they control the components of the SDK, and which NuGet packages load those components. --> [!NOTE] -> The `ApplicationInsights.config` and .xml instructions don't apply to the .NET Core SDK. To configure .NET Core applications, follow the instructions in [Application Insights for ASP.NET Core applications](./asp-net-core.md). --## Telemetry modules (ASP.NET) --Each telemetry module collects a specific type of data and uses the core API to send the data. The modules are installed by different NuGet packages, which also add the required lines to the .config file. --There's a node in the configuration file for each module. To disable a module, delete the node or comment it out. --### Dependency tracking --[Dependency tracking](./asp-net-dependencies.md) collects telemetry about calls your app makes to databases and external services and databases. To allow this module to work in an IIS server, you need to [install Application Insights Agent][redfield]. --You can also write your own dependency tracking code by using the [TrackDependency API](./api-custom-events-metrics.md#trackdependency). --* `Microsoft.ApplicationInsights.DependencyCollector.DependencyTrackingTelemetryModule` -* [Microsoft.ApplicationInsights.DependencyCollector](https://www.nuget.org/packages/Microsoft.ApplicationInsights.DependencyCollector) NuGet package --Dependencies can be autocollected without modifying your code by using agent-based (codeless) attach. To use it in Azure web apps, enable the [Application Insights extension](azure-web-apps.md). To use it in an Azure VM or an Azure virtual machine scale set, enable the [Application Monitoring extension for VMs and virtual machine scale sets](azure-vm-vmss-apps.md). --### Performance collector --The performance collector [collects system performance counters](./performance-counters.md), such as CPU, memory, and network load from IIS installations. You can specify which counters to collect, including performance counters you've set up yourself. --* `Microsoft.ApplicationInsights.Extensibility.PerfCounterCollector.PerformanceCollectorModule` -* [Microsoft.ApplicationInsights.PerfCounterCollector](https://www.nuget.org/packages/Microsoft.ApplicationInsights.PerfCounterCollector) NuGet package --### Application Insights diagnostics telemetry --The `DiagnosticsTelemetryModule` class reports errors in the Application Insights instrumentation code itself. Examples are if the code can't access performance counters or if `ITelemetryInitializer` throws an exception. Trace telemetry tracked by this module appears in the [Diagnostic Search][diagnostic]. --* `Microsoft.ApplicationInsights.Extensibility.Implementation.Tracing.DiagnosticsTelemetryModule` -* [Microsoft.ApplicationInsights](https://www.nuget.org/packages/Microsoft.ApplicationInsights) NuGet package. If you only install this package, the ApplicationInsights.config file is not automatically created. --### Developer mode --The `DeveloperModeWithDebuggerAttachedTelemetryModule` class forces the Application Insights `TelemetryChannel` to send data immediately, one telemetry item at a time, when a debugger is attached to the application process. This design reduces the amount of time between the moment when your application tracks telemetry and when it appears in the Application Insights portal. It causes significant overhead in CPU and network bandwidth. --* `Microsoft.ApplicationInsights.WindowsServer.DeveloperModeWithDebuggerAttachedTelemetryModule` -* [Application Insights Windows Server](https://www.nuget.org/packages/Microsoft.ApplicationInsights.WindowsServer/) NuGet package --### Web request tracking --Web request tracking reports the [response time and result code](../../azure-monitor/app/asp-net.md) of HTTP requests. --* `Microsoft.ApplicationInsights.Web.RequestTrackingTelemetryModule` -* [Microsoft.ApplicationInsights.Web](https://www.nuget.org/packages/Microsoft.ApplicationInsights.Web) NuGet package --### Exception tracking --The `ExceptionTrackingTelemetryModule` class tracks unhandled exceptions in your web app. For more information, see [Failures and exceptions][exceptions]. --* `Microsoft.ApplicationInsights.Web.ExceptionTrackingTelemetryModule`. -* [Microsoft.ApplicationInsights.Web](https://www.nuget.org/packages/Microsoft.ApplicationInsights.Web) NuGet package. -* `Microsoft.ApplicationInsights.WindowsServer.UnobservedExceptionTelemetryModule`: Tracks unobserved task. exceptions. -* `Microsoft.ApplicationInsights.WindowsServer.UnhandledExceptionTelemetryModule`: Tracks unhandled exceptions for worker roles, Windows services, and console applications. -* [Application Insights Windows Server](https://www.nuget.org/packages/Microsoft.ApplicationInsights.WindowsServer/) NuGet package. --### EventSource tracking --The `EventSourceTelemetryModule` class allows you to configure EventSource events to be sent to Application Insights as traces. For information on tracking EventSource events, see [Using EventSource events](./asp-net-trace-logs.md#use-eventsource-events). --* `Microsoft.ApplicationInsights.EventSourceListener.EventSourceTelemetryModule` -* [Microsoft.ApplicationInsights.EventSourceListener](https://www.nuget.org/packages/Microsoft.ApplicationInsights.EventSourceListener) --### ETW event tracking --The `EtwCollectorTelemetryModule` class allows you to configure events from ETW providers to be sent to Application Insights as traces. For information on tracking ETW events, see [Using ETW events](../../azure-monitor/app/asp-net-trace-logs.md#use-etw-events). --* `Microsoft.ApplicationInsights.EtwCollector.EtwCollectorTelemetryModule` -* [Microsoft.ApplicationInsights.EtwCollector](https://www.nuget.org/packages/Microsoft.ApplicationInsights.EtwCollector) --### Microsoft.ApplicationInsights --The `Microsoft.ApplicationInsights` package provides the [core API](/dotnet/api/microsoft.applicationinsights) of the SDK. The other telemetry modules use this API. You can also [use it to define your own telemetry](./api-custom-events-metrics.md). --* No entry in ApplicationInsights.config. -* [Microsoft.ApplicationInsights](https://www.nuget.org/packages/Microsoft.ApplicationInsights) NuGet package. If you just install this NuGet, no .config file is generated. --## Telemetry channel --The [telemetry channel](telemetry-channels.md) manages buffering and transmission of telemetry to the Application Insights service. --* `Microsoft.ApplicationInsights.WindowsServer.TelemetryChannel.ServerTelemetryChannel` is the default channel for web applications. It buffers data in memory and employs retry mechanisms and local disk storage for more reliable telemetry delivery. -* `Microsoft.ApplicationInsights.InMemoryChannel` is a lightweight telemetry channel. It's used if no other channel is configured. --## Telemetry initializers (ASP.NET) --Telemetry initializers set context properties that are sent along with every item of telemetry. --You can [write your own initializers](./api-filtering-sampling.md#add-properties) to set context properties. --The standard initializers are all set either by the web or WindowsServer NuGet packages: --* `AccountIdTelemetryInitializer` sets the `AccountId` property. -* `AuthenticatedUserIdTelemetryInitializer` sets the `AuthenticatedUserId` property as set by the JavaScript SDK. -* `AzureRoleEnvironmentTelemetryInitializer` updates the `RoleName` and `RoleInstance` properties of the `Device` context for all telemetry items with information extracted from the Azure runtime environment. -* `BuildInfoConfigComponentVersionTelemetryInitializer` updates the `Version` property of the `Component` context for all telemetry items with the value extracted from the `BuildInfo.config` file produced by MS Build. -* `ClientIpHeaderTelemetryInitializer` updates the `Ip` property of the `Location` context of all telemetry items based on the `X-Forwarded-For` HTTP header of the request. -* `DeviceTelemetryInitializer` updates the following properties of the `Device` context for all telemetry items. - * `Type` is set to `PC`. - * `Id` is set to the domain name of the computer where the web application is running. - * `OemName` is set to the value extracted from the `Win32_ComputerSystem.Manufacturer` field by using WMI. - * `Model` is set to the value extracted from the `Win32_ComputerSystem.Model` field by using WMI. - * `NetworkType` is set to the value extracted from the `NetworkInterface` property. - * `Language` is set to the name of the `CurrentCulture` property. -* `DomainNameRoleInstanceTelemetryInitializer` updates the `RoleInstance` property of the `Device` context for all telemetry items with the domain name of the computer where the web application is running. -* `OperationNameTelemetryInitializer` updates the `Name` property of `RequestTelemetry` and the `Name` property of the `Operation` context of all telemetry items based on the HTTP method, and the names of the ASP.NET MVC controller and action invoked to process the request. -* `OperationIdTelemetryInitializer` or `OperationCorrelationTelemetryInitializer` updates the `Operation.Id` context property of all telemetry items tracked while handling a request with the automatically generated `RequestTelemetry.Id`. -* `SessionTelemetryInitializer` updates the `Id` property of the `Session` context for all telemetry items with value extracted from the `ai_session` cookie generated by the `ApplicationInsights` JavaScript instrumentation code running in the user's browser. -* `SyntheticTelemetryInitializer` or `SyntheticUserAgentTelemetryInitializer` updates the `User`, `Session`, and `Operation` context properties of all telemetry items tracked when handling a request from a synthetic source, such as an availability test or search engine bot. By default, [metrics explorer](../essentials/metrics-charts.md) doesn't display synthetic telemetry. -- The `<Filters>` set identifying properties of the requests. -* `UserTelemetryInitializer` updates the `Id` and `AcquisitionDate` properties of the `User` context for all telemetry items with values extracted from the `ai_user` cookie generated by the Application Insights JavaScript instrumentation code running in the user's browser. -* `WebTestTelemetryInitializer` sets the user ID, session ID, and synthetic source properties for HTTP requests that come from [availability tests](availability-overview.md). The `<Filters>` set identifying properties of the requests. --For .NET applications running in Azure Service Fabric, you can include the `Microsoft.ApplicationInsights.ServiceFabric` NuGet package. This package includes a `FabricTelemetryInitializer` property, which adds Service Fabric properties to telemetry items. For more information, see the [GitHub page](https://github.com/Microsoft/ApplicationInsights-ServiceFabric/blob/master/README.md) about the properties added by this NuGet package. --## Telemetry processors (ASP.NET) --Telemetry processors can filter and modify each telemetry item before it's sent from the SDK to the portal. --You can [write your own telemetry processors](./api-filtering-sampling.md#filtering). --#### Adaptive sampling telemetry processor (from 2.0.0-beta3) --This functionality is enabled by default. If your app sends considerable telemetry, this processor removes some of it. --```xml -- <TelemetryProcessors> - <Add Type="Microsoft.ApplicationInsights.WindowsServer.TelemetryChannel.AdaptiveSamplingTelemetryProcessor, Microsoft.AI.ServerTelemetryChannel"> - <MaxTelemetryItemsPerSecond>5</MaxTelemetryItemsPerSecond> - </Add> - </TelemetryProcessors> --``` --The parameter provides the target that the algorithm tries to achieve. Each instance of the SDK works independently. So, if your server is a cluster of several machines, the actual volume of telemetry will be multiplied accordingly. --Learn more about [sampling](./sampling.md). --#### Fixed-rate sampling telemetry processor (from 2.0.0-beta1) --There's also a standard [sampling telemetry processor](./api-filtering-sampling.md) (from 2.0.1): --```xml -- <TelemetryProcessors> - <Add Type="Microsoft.ApplicationInsights.WindowsServer.TelemetryChannel.SamplingTelemetryProcessor, Microsoft.AI.ServerTelemetryChannel"> -- <!-- Set a percentage close to 100/N where N is an integer. --> - <!-- E.g. 50 (=100/2), 33.33 (=100/3), 25 (=100/4), 20, 1 (=100/100), 0.1 (=100/1000) --> - <SamplingPercentage>10</SamplingPercentage> - </Add> - </TelemetryProcessors> --``` --## ConnectionString --See connection string [code samples](sdk-connection-string.md#code-samples). --## InstrumentationKey ---This setting determines the Application Insights resource in which your data appears. Typically, you create a separate resource, with a separate key, for each of your applications. --If you want to set the key dynamically, for example, if you want to send results from your application to different resources, you can omit the key from the configuration file and set it in code instead. --To set the key for all instances of `TelemetryClient`, including standard telemetry modules, do this step in an initialization method, such as global.aspx.cs in an ASP.NET service: --```csharp -using Microsoft.ApplicationInsights.Extensibility; -using Microsoft.ApplicationInsights; -- protected void Application_Start() - { - TelemetryConfiguration configuration = TelemetryConfiguration.CreateDefault(); - configuration.InstrumentationKey = "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx"; - var telemetryClient = new TelemetryClient(configuration); --``` --If you want to send a specific set of events to a different resource, you can set the key for a specific telemetry client: --```csharp -- var tc = new TelemetryClient(); - tc.Context.InstrumentationKey = "-- my key -"; - tc.TrackEvent("myEvent"); - // ... --``` --To get a new key, [create a new resource in the Application Insights portal][new]. --## ApplicationId Provider --_The provider is available starting in v2.6.0_. --The purpose of this provider is to look up an application ID based on an instrumentation key. The application ID is included in `RequestTelemetry` and `DependencyTelemetry` and is used to determine correlation in the portal. --This functionality is available by setting `TelemetryConfiguration.ApplicationIdProvider` either in code or in the config file. --### Interface: IApplicationIdProvider --```csharp -public interface IApplicationIdProvider -{ - bool TryGetApplicationId(string instrumentationKey, out string applicationId); -} -``` --We provide two implementations in the [Microsoft.ApplicationInsights](https://www.nuget.org/packages/Microsoft.ApplicationInsights) SDK: `ApplicationInsightsApplicationIdProvider` and `DictionaryApplicationIdProvider`. --### ApplicationInsightsApplicationIdProvider --This wrapper is for our Profile API. It will throttle requests and cache results. --This provider is added to your config file when you install either [Microsoft.ApplicationInsights.DependencyCollector](https://www.nuget.org/packages/Microsoft.ApplicationInsights.DependencyCollector) or [Microsoft.ApplicationInsights.Web](https://www.nuget.org/packages/Microsoft.ApplicationInsights.Web/). --This class has an optional property `ProfileQueryEndpoint`. By default, it's set to `https://dc.services.visualstudio.com/api/profiles/{0}/appId`. If you need to configure a proxy for this configuration, we recommend that you proxy the base address and include `"/api/profiles/{0}/appId"`. A `{0}` is substituted at runtime per request with the instrumentation key. --#### Example configuration via ApplicationInsights.config --```xml -<ApplicationInsights> - ... - <ApplicationIdProvider Type="Microsoft.ApplicationInsights.Extensibility.Implementation.ApplicationId.ApplicationInsightsApplicationIdProvider, Microsoft.ApplicationInsights"> - <ProfileQueryEndpoint>https://dc.services.visualstudio.com/api/profiles/{0}/appId</ProfileQueryEndpoint> - </ApplicationIdProvider> - ... -</ApplicationInsights> -``` --#### Example configuration via code --```csharp -TelemetryConfiguration.Active.ApplicationIdProvider = new ApplicationInsightsApplicationIdProvider(); -``` --### DictionaryApplicationIdProvider --This static provider relies on your configured instrumentation key/application ID pairs. --This class has the `Defined` property, which is a `Dictionary<string,string>` of instrumentation key/application ID pairs. --This class has the optional property `Next`, which can be used to configure another provider to use when an instrumentation key is requested that doesn't exist in your configuration. --#### Example configuration via ApplicationInsights.config --```xml -<ApplicationInsights> - ... - <ApplicationIdProvider Type="Microsoft.ApplicationInsights.Extensibility.Implementation.ApplicationId.DictionaryApplicationIdProvider, Microsoft.ApplicationInsights"> - <Defined> - <Type key="InstrumentationKey_1" value="ApplicationId_1"/> - <Type key="InstrumentationKey_2" value="ApplicationId_2"/> - </Defined> - <Next Type="Microsoft.ApplicationInsights.Extensibility.Implementation.ApplicationId.ApplicationInsightsApplicationIdProvider, Microsoft.ApplicationInsights" /> - </ApplicationIdProvider> - ... -</ApplicationInsights> -``` --#### Example configuration via code --```csharp -TelemetryConfiguration.Active.ApplicationIdProvider = new DictionaryApplicationIdProvider{ - Defined = new Dictionary<string, string> - { - {"InstrumentationKey_1", "ApplicationId_1"}, - {"InstrumentationKey_2", "ApplicationId_2"} - } -}; -``` --## Configure snapshot collection for ASP.NET applications --Configure a [snapshot collection for ASP.NET applications](snapshot-debugger-vm.md#configure-snapshot-collection-for-aspnet-applications). --## Next steps --[Learn more about the API][api] --<!--Link references--> --[api]: ./api-custom-events-metrics.md -[client]: ./javascript.md -[diagnostic]: ./transaction-search-and-diagnostics.md?tabs=transaction-search -[exceptions]: ./asp-net-exceptions.md -[netlogs]: ./asp-net-trace-logs.md -[new]: ./create-workspace-resource.md -[redfield]: ./application-insights-asp-net-agent.md -[start]: ./app-insights-overview.md |
| azure-monitor | Convert Classic Resource | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/convert-classic-resource.md | - Title: Migrate an Application Insights classic resource to a workspace-based resource - Azure Monitor | Microsoft Docs -description: Learn how to upgrade your Application Insights classic resource to the new workspace-based model. - Previously updated : 06/28/2024----# Migrate to workspace-based Application Insights resources --This article walks you through migrating a classic Application Insights resource to a workspace-based resource. --Workspace-based resources: --> [!div class="checklist"] -> - Support full integration between Application Insights and [Log Analytics](../logs/log-analytics-overview.md). -> - Send Application Insights telemetry to a common [Log Analytics workspace](../logs/log-analytics-workspace-overview.md). -> - Allow you to access [the latest features of Azure Monitor](#new-capabilities) while keeping application, infrastructure, and platform logs in a consolidated location. -> - Enable common [Azure role-based access control](../../role-based-access-control/overview.md) across your resources. -> - Eliminate the need for cross-app/workspace queries. -> - Are available in all commercial regions and [Azure US Government](../../azure-government/index.yml). -> - Don't require changing instrumentation keys after migration from a classic resource. --## New capabilities --Workspace-based Application Insights resources allow you to take advantage of the latest capabilities of Azure Monitor and Log Analytics: --* [Customer-managed keys](../logs/customer-managed-keys.md) provide encryption at rest for your data with encryption keys that only you have access to. -* [Azure Private Link](../logs/private-link-security.md) allows you to securely link the Azure platform as a service (PaaS) to your virtual network by using private endpoints. -* [Profiler and Snapshot Debugger Bring your own storage (BYOS)](./profiler-bring-your-own-storage.md) gives you full control over: - - Encryption-at-rest policy. - - Lifetime management policy. - - Network access for all data associated with Application Insights Profiler and Snapshot Debugger. -* [Commitment tiers](../logs/cost-logs.md#commitment-tiers) enable you to save as much as 30% compared to the pay-as-you-go price. Otherwise, billing for pay-as-you-go data ingestion and data retention in Log Analytics is similar to the billing in Application Insights. -* Data is ingested faster via Log Analytics streaming ingestion. --> [!NOTE] -> After you migrate to a workspace-based Application Insights resource, telemetry from multiple Application Insights resources might be stored in a common Log Analytics workspace. You can still pull data from a specific Application Insights resource, as described in the section [Understand log queries](#understand-log-queries). --## Migration process --When you migrate to a workspace-based resource, no data is transferred from your classic resource's storage to the new workspace-based storage. Choosing to migrate changes the location where new data is written to a Log Analytics workspace while preserving access to your classic resource data. --Your classic resource data persists and is subject to the retention settings on your classic Application Insights resource. All new data ingested post migration is subject to the [retention settings](../logs/data-retention-configure.md) of the associated Log Analytics workspace, which also supports [different retention settings by data type](../logs/data-retention-configure.md#configure-table-level-retention). --*The migration process is permanent and can't be reversed.* After you migrate a resource to workspace-based Application Insights, it will always be a workspace-based resource. After you migrate, you can change the target workspace as often as needed. --If you don't need to migrate an existing resource, and instead want to create a new workspace-based Application Insights resource, see the [Workspace-based resource creation guide](create-workspace-resource.md). --> [!NOTE] -> The migration process shouldn't introduce any application downtime or restarts nor change your existing instrumentation key or connection string. --## Prerequisites --- A Log Analytics workspace with the access control mode set to the **"Use resource or workspace permissions"** setting:-- - Workspace-based Application Insights resources aren't compatible with workspaces set to the dedicated **workspace-based permissions** setting. To learn more about Log Analytics workspace access control, see the [Access control mode guidance](../logs/manage-access.md#access-control-mode). - - If you don't already have an existing Log Analytics workspace, see the [Log Analytics workspace creation documentation](../logs/quick-create-workspace.md). - -- **Continuous export** isn't compatible with workspace-based resources and must be disabled. After the migration is finished, you can use [diagnostic settings](../essentials/diagnostic-settings.md) to configure data archiving to a storage account or streaming to Azure Event Hubs.-- > [!CAUTION] - > * Diagnostic settings use a different export format/schema than continuous export. Migrating breaks any existing integrations with Azure Stream Analytics. - > * Diagnostic settings export might increase costs. For more information, see [Export telemetry from Application Insights](export-telemetry.md#diagnostic-settings-based-export). -- Check your current retention settings under **Settings** > **Usage and estimated costs** > **Data Retention** for your Log Analytics workspace. This setting affects how long any new ingested data is stored after you migrate your Application Insights resource.-- > [!NOTE] - > - If you currently store Application Insights data for longer than the default 90 days and want to retain this longer retention period after migration, adjust your [workspace retention settings](../logs/data-retention-configure.md?tabs=portal-1%2cportal-2#configure-table-level-retention). - > - If you've selected data retention longer than 90 days on data ingested into the classic Application Insights resource prior to migration, data retention continues to be billed through that Application Insights resource until the data exceeds the retention period. - > - If the retention setting for your Application Insights instance under **Configure** > **Usage and estimated costs** > **Data Retention** is enabled, use that setting to control the retention days for the telemetry data still saved in your classic resource's storage. -- Understand [workspace-based Application Insights](../logs/cost-logs.md#application-insights-billing) usage and costs.--## Find your Classic Application Insights resources --You can use on of the following methods to find Classic Application Insights resources within your subscription: --#### Application Insights resource in Azure portal --Within the Overview of an Application Insights resource, Classic Application Insights resources don't have a linked Workspace and the Classic Application Insights retirement warning banner appears. Workspace-based resources have a linked workspace within the overview section --Classic resource: --Workspace-based resource: --#### Azure Resource Graph --You can use the Azure Resource Graph (ARG) Explorer and run a query on the 'resources' table to pull this information: --```kusto -resources -| where subscriptionId == 'Replace with your own subscription ID' -| where type contains 'microsoft.insights/components' -| distinct resourceGroup, name, tostring(properties['IngestionMode']), tostring(properties['WorkspaceResourceId']) -``` -> [!NOTE] -> Classic resources are identified by ΓÇÿApplicationInsightsΓÇÖ, 'N/A', or *Empty* values. -#### Azure CLI: --Run the following script from Cloud Shell in the portal where authentication is built in or anywhere else after authenticating using `az login`: --```azurecli -$resources = az resource list --resource-type 'microsoft.insights/components' | ConvertFrom-Json --$resources | Sort-Object -Property Name | Format-Table -Property @{Label="App Insights Resource"; Expression={$_.name}; width = 35}, @{Label="Ingestion Mode"; Expression={$mode = az resource show --name $_.name --resource-group $_.resourceGroup --resource-type microsoft.insights/components --query "properties.IngestionMode" -o tsv; $mode}; width = 45} -``` -> [!NOTE] -> Classic resources are identified by ΓÇÿApplicationInsightsΓÇÖ, 'N/A', or *Empty* values. -The following PowerShell script can be run from the Azure CLI: --```azurepowershell -$subscription = "SUBSCRIPTION ID GOES HERE" -$token = (Get-AZAccessToken).Token -$header = @{Authorization = "Bearer $token"} -$uri = "https://management.azure.com/subscriptions/$subscription/providers/Microsoft.Insights/components?api-version=2015-05-01" -$RestResult="" -$RestResult = Invoke-RestMethod -Method GET -Uri $uri -Headers $header -ContentType "application/json" -ErrorAction Stop -Verbose - $list=@() -$ClassicList=@() -foreach ($app in $RestResult.value) - { - #"processing: " + $app.properties.WorkspaceResourceId ## Classic Application Insights do not have a workspace. - if ($app.properties.WorkspaceResourceId) - { - $Obj = New-Object -TypeName PSObject - #$app.properties.WorkspaceResourceId - $Obj | Add-Member -Type NoteProperty -Name Name -Value $app.name - $Obj | Add-Member -Type NoteProperty -Name WorkspaceResourceId -Value $app.properties.WorkspaceResourceId - $list += $Obj - } - else - { - $Obj = New-Object -TypeName PSObject - $app.properties.WorkspaceResourceId - $Obj | Add-Member -Type NoteProperty -Name Name -Value $app.name - $ClassicList += $Obj - } - } -$list |Format-Table -Property Name, WorkspaceResourceId -Wrap - "";"Classic:" -$ClassicList | FT -``` --## Migrate your resource --To migrate a classic Application Insights resource to a workspace-based resource: --1. From your Application Insights resource, select **"Properties"** under the **"Configure"** heading in the menu on the left. -- :::image type="content" source="./media/convert-classic-resource/properties.png" lightbox="./media/convert-classic-resource/properties.png" alt-text="Screenshot that shows Properties under the Configured heading."::: --1. Select **Migrate to Workspace-based**. -- :::image type="content" source="./media/convert-classic-resource/migrate.png" lightbox="./media/convert-classic-resource/migrate.png" alt-text="Screenshot that shows the Migrate to Workspace-based button."::: --1. Select the Log Analytics workspace where you want all future ingested Application Insights telemetry to be stored. It can either be a Log Analytics workspace in the same subscription or a different subscription that shares the same Microsoft Entra tenant. The Log Analytics workspace doesn't have to be in the same resource group as the Application Insights resource. -- > [!NOTE] - > Migrating to a workspace-based resource can take up to 24 hours, but the process is usually faster. Rely on accessing data through your Application Insights resource while you wait for the migration process to finish. After it's finished, you'll see new data stored in the Log Analytics workspace tables. -- :::image type="content" source="./media/convert-classic-resource/migration.png" lightbox="./media/convert-classic-resource/migration.png" alt-text="Screenshot that shows the Migration wizard UI with the option to select target workspace."::: -- After your resource is migrated, you'll see the corresponding workspace information in the **Overview** pane. -- :::image type="content" source="./media/create-workspace-resource/workspace-name.png" lightbox="./media/create-workspace-resource/workspace-name.png" alt-text="Screenshot that shows the Workspace name."::: -- Selecting the blue link text takes you to the associated Log Analytics workspace where you can take advantage of the new unified workspace query environment. --> [!TIP] -> After you migrate to a workspace-based Application Insights resource, use the [workspace's daily cap](../logs/daily-cap.md) to limit ingestion and costs instead of the cap in Application Insights. --## Understand log queries --We provide full backward compatibility for your Application Insights classic resource queries, workbooks, and log-based alerts within the Application Insights experience. --To write queries against the [new workspace-based table structure/schema](#workspace-based-resource-changes), you must first go to your Log Analytics workspace. --To ensure the queries run successfully, validate that the query's fields align with the [new schema fields](#appmetrics). --You might have multiple Application Insights resources that store telemetry in one Log Analytics workspace, but you want to query data from one specific Application Insights resource. You have two options: --- Go to your Application Insights resource and select the **Logs** tab. All queries from this tab automatically pull data from the selected Application Insights resource.-- Go to the Log Analytics workspace that you configured as the destination for your Application Insights telemetry and select the **Logs** tab. To query data from a specific Application Insights resource, filter for the built-in `_ResourceId` property that's available in all application-specific tables.--When you query directly from the Log Analytics workspace, you only see data that's ingested post migration. To see both your classic Application Insights data and the new data ingested after migration in a unified query experience, use the **Logs** tab from within your migrated Application Insights resource. --> [!NOTE] -> If you rename your Application Insights resource after you migrate to the workspace-based model, the Application Insights **Logs** tab no longer shows the telemetry collected before renaming. You can see all old and new data on the **Logs** tab of the associated Log Analytics resource. --## Identifying the Application Insights resources by ingestion type --Use the following script to identify your Application Insights resources by ingestion type. --#### Example --```powershell -Get-AzApplicationInsights -SubscriptionId 'Your Subscription ID' | Format-Table -Property Name, IngestionMode, Id, @{label='Type';expression={ - if ([string]::IsNullOrEmpty($_.IngestionMode)) { - 'Unknown' - } elseif ($_.IngestionMode -eq 'LogAnalytics') { - 'Workspace-based' - } elseif ($_.IngestionMode -eq 'ApplicationInsights' -or $_.IngestionMode -eq 'ApplicationInsightsWithDiagnosticSettings') { - 'Classic' - } else { - 'Unknown' - } -}} -``` --## Programmatic resource migration --This section helps you migrate your resources. --### Azure CLI --To access the preview Application Insights Azure CLI commands, you first need to run: --```azurecli - az extension add -n application-insights -``` --If you don't run the `az extension add` command, you see an error message that states `az : ERROR: az monitor: 'app-insights' is not in the 'az monitor' command group. See 'az monitor --help'.` --Now you can run the following code to create your Application Insights resource: --```azurecli -az monitor app-insights component update --app - --resource-group - [--ingestion-access {Disabled, Enabled}] - [--kind] - [--query-access {Disabled, Enabled}] - [--retention-time] - [--workspace] -``` --#### Example --```azurecli -az monitor app-insights component update --app your-app-insights-resource-name -g your_resource_group --workspace "/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/test1234/providers/microsoft.operationalinsights/workspaces/test1234555" -``` --For the full Azure CLI documentation for this command, see the [Azure CLI documentation](/cli/azure/monitor/app-insights/component#az-monitor-app-insights-component-update). --### Azure PowerShell --Starting with version 8.0 or higher of [Azure PowerShell](/powershell/azure/what-is-azure-powershell), you can use the `Update-AzApplicationInsights` PowerShell command to migrate a classic Application Insights resource to workspace based. --To use this cmdlet, you need to specify the name and resource group of the Application Insights resource that you want to update. Use the `IngestionMode` and `WorkspaceResoruceId` parameters to migrate your classic instance to workspace-based. For more information on the parameters and syntax of this cmdlet, see [Update-AzApplicationInsights](/powershell/module/az.applicationinsights/update-azapplicationinsights). --#### Example --```powershell -# Get the resource ID of the Log Analytics workspace -$workspaceResourceId = (Get-AzOperationalInsightsWorkspace -ResourceGroupName "rgName" -Name "laName").ResourceId --# Update the Application Insights resource with the workspace parameter -Update-AzApplicationInsights -Name "aiName" -ResourceGroupName "rgName" -IngestionMode LogAnalytics -WorkspaceResourceId $workspaceResourceId -``` --### Azure Resource Manager templates --This section provides templates. -- > [!CAUTION] - > Ensure that you have removed all Continous Export settings from your resource before running the migration templates. See [Prerequisites](#prerequisites) --#### Template file --```json -{ - "$schema": "http://schema.management.azure.com/schemas/2014-04-01-preview/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "name": { - "type": "string" - }, - "type": { - "type": "string" - }, - "regionId": { - "type": "string" - }, - "tagsArray": { - "type": "object" - }, - "requestSource": { - "type": "string" - }, - "workspaceResourceId": { - "type": "string" - } - }, - "resources": [ - { - "name": "[parameters('name')]", - "type": "microsoft.insights/components", - "location": "[parameters('regionId')]", - "tags": "[parameters('tagsArray')]", - "apiVersion": "2020-02-02-preview", - "properties": { - "ApplicationId": "[parameters('name')]", - "Application_Type": "[parameters('type')]", - "Flow_Type": "Redfield", - "Request_Source": "[parameters('requestSource')]", - "WorkspaceResourceId": "[parameters('workspaceResourceId')]" - } - } - ] -} -``` --#### Parameters file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "type": { - "value": "web" - }, - "name": { - "value": "customresourcename" - }, - "regionId": { - "value": "eastus" - }, - "tagsArray": { - "value": {} - }, - "requestSource": { - "value": "Custom" - }, - "workspaceResourceId": { - "value": "/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/my_resource_group/providers/microsoft.operationalinsights/workspaces/myworkspacename" - } - } -} --``` --## Modify the associated workspace --After you create a workspace-based Application Insights resource, you can modify the associated Log Analytics workspace. --From within the Application Insights resource pane, select **Properties** > **Change Workspace** > **Log Analytics Workspaces**. --## Frequently asked questions --This section provides answers to common questions. --### What happens if I don't migrate my Application Insights classic resource to a workspace-based resource? --Microsoft began a phased approach to migrating classic resources to workspace-based resources in May 2024 and this migration is ongoing for several months. We can't provide approximate dates that specific resources, subscriptions, or regions are migrated. --We strongly encourage manual migration to workspace-based resources. This process is initiated by selecting the retirement notice banner. You can find it in the classic Application Insights resource Overview pane of the Azure portal. This process typically involves a single step of choosing which Log Analytics workspace is used to store your application data. If you use continuous export, you need to additionally migrate to diagnostic settings or disable the feature first. --If you don't wish to have your classic resource automatically migrated to a workspace-based resource, you can delete or manually migrate the resource. --### Is there any implication on the cost from migration? --There's usually no difference, with two exceptions. --- Application Insights resources that were receiving 1 GB per month free via legacy Application Insights pricing model doesn't receive the free data.-- Application Insights resources that were in the basic pricing tier before April 2018 continue to be billed at the same nonregional price point as before April 2018. Application Insights resources created after that time, or those resources converted to be workspace-based, will receive the current regional pricing. For current prices in your currency and region, see [Application Insights pricing](https://azure.microsoft.com/pricing/details/monitor/).--The migration to workspace-based Application Insights offers many options to further [optimize cost](../logs/cost-logs.md), including [Log Analytics commitment tiers](../logs/cost-logs.md#commitment-tiers), [dedicated clusters](../logs/cost-logs.md#dedicated-clusters), and [Basic and Auxiliary logs](../logs/cost-logs.md#basic-and-auxiliary-table-plans). --### How will telemetry capping work? --You can set a [daily cap on the Log Analytics workspace](../logs/daily-cap.md#application-insights). --There's no strict billing capping available. --### How will ingestion-based sampling work? --There are no changes to ingestion-based sampling. --### Are there gaps in data collected during migration? --No. We merge data during query time. --### Do old log queries continue to work? --Yes, they continue to work. --### Will my dashboards with pinned metric and log charts continue to work after migration? --Yes, they continue to work. --### Does migration affect AppInsights API accessing data? --No. Migration doesn't affect existing API access to data. After migration, you can access data directly from a workspace by using a [slightly different schema](#workspace-based-resource-changes). --### Is there any impact on Live Metrics or other monitoring experiences? --No. There's no impact to [Live Metrics](live-stream.md#live-metrics-monitor-and-diagnose-with-1-second-latency) or other monitoring experiences. --### What happens with continuous export after migration? --To continue with automated exports, you need to migrate to [diagnostic settings](/previous-versions/azure/azure-monitor/app/continuous-export-diagnostic-setting) before migrating to workspace-based resource. The diagnostic setting carries over in the migration to workspace-based Application Insights. --### How do I ensure a successful migration of my App Insights resource using Terraform? --If you're using Terraform to manage your Azure resources, it's important to use the latest version of the Terraform azurerm provider before attempting to upgrade your App Insights resource. Use of an older version of the provider, such as version 3.12, can result in the deletion of the classic component before creating the replacement workspace-based Application Insights resource. It can cause the loss of previous data and require updating the configurations in your monitored apps with new connection string and instrumentation key values. --To avoid this issue, make sure to use the latest version of the Terraform [azurerm provider](https://registry.terraform.io/providers/hashicorp/azurerm/latest), version 3.89 or higher. It performs the proper migration steps by issuing the appropriate Azure Resource Manager (ARM) call to upgrade the App Insights classic resource to a workspace-based resource while preserving all the old data and connection string/instrumentation key values. --### Can I still use the old API to create Application Insights resources programmatically? --For backwards compatibility, calls to the old API for creating Application Insights resources continue to work. Each of these calls creates both a workspace-based Application Insights resource and a Log Analytics workspace to store the data. --We strongly encourage updating to the [new API](create-workspace-resource.md) for better control over resource creation. --### Should I migrate diagnostic settings on classic Application Insights before moving to a workspace-based AI? -Yes, we recommend migrating diagnostic settings on classic Application Insights resources before transitioning to a workspace-based Application Insights. It ensures continuity and compatibility of your diagnostic settings. --## Troubleshooting --This section provides troubleshooting tips. --### Access mode --**Error message:** "The selected workspace is configured with workspace-based access mode. Some Application Performance Monitoring (APM) features can be impacted. Select another workspace or allow resource-based access in the workspace settings. You can override this error by using CLI." --For your workspace-based Application Insights resource to operate properly, you need to change the access control mode of your target Log Analytics workspace to the **Resource or workspace permissions** setting. This setting is located in the Log Analytics workspace UI under **Properties** > **Access control mode**. For instructions, see the [Log Analytics configure access control mode guidance](../logs/manage-access.md#access-control-mode). If your access control mode is set to the exclusive **Require workspace permissions** setting, migration via the portal migration experience remains blocked. --If you can't change the access control mode for security reasons for your current target workspace, create a new Log Analytics workspace to use for the migration. --### Continuous export --**Error message:** "Continuous Export needs to be disabled before continuing. After migration, use Diagnostic Settings for export." --The legacy **Continuous export** functionality isn't supported for workspace-based resources. Before migrating, you need to enable diagnostic settings and disable continuous export. --1. [Enable Diagnostic Settings](/previous-versions/azure/azure-monitor/app/continuous-export-diagnostic-setting) on your classic Application Insights resource. -1. From your Application Insights resource view, under the **"Configure"** heading, select **"Continuous export"**. -- :::image type="content" source="./media/convert-classic-resource/continuous-export.png" lightbox="./media/convert-classic-resource/continuous-export.png" alt-text="Screenshot that shows the Continuous export menu item."::: --1. Select **Disable**. -- :::image type="content" source="./media/convert-classic-resource/disable.png" lightbox="./media/convert-classic-resource/disable.png" alt-text="Screenshot that shows the Continuous export Disable button."::: -- - After you select **Disable**, you can go back to the migration UI. If the **Edit continuous export** page prompts you that your settings aren't saved, select **OK**. This prompt doesn't pertain to disabling or enabling continuous export. -- - After migrating your Application Insights resource, you can use diagnostic settings to replace the functionality that continuous export used to provide. Select **Diagnostics settings** > **Add diagnostic setting** in your Application Insights resource. You can select all tables, or a subset of tables, to archive to a storage account or stream to Azure Event Hubs. For more information on diagnostic settings, see the [Azure Monitor diagnostic settings guidance](../essentials/diagnostic-settings.md). --### Retention settings --**Warning message:** "Your customized Application Insights retention settings doesn't apply to data sent to the workspace. You need to reconfigure them separately." --You don't have to make any changes before migrating. This message alerts you that your current Application Insights retention settings aren't set to the default 90-day retention period. This warning message means you might want to modify the retention settings for your Log Analytics workspace before migrating and starting to ingest new data. --You can check your current retention settings for Log Analytics under **Settings** > **Usage and estimated costs** > **Data Retention** in the Log Analytics UI. This setting affects how long any new ingested data is stored after you migrate your Application Insights resource. --## Workspace-based resource changes --Before the introduction of [workspace-based Application Insights resources](create-workspace-resource.md), Application Insights data was stored separately from other log data in Azure Monitor. Both are based on Azure Data Explorer and use the same Kusto Query Language (KQL). Workspace-based Application Insights resources data is stored in a Log Analytics workspace, together with other monitoring data and application data. This arrangement simplifies your configuration. You can analyze data across multiple solutions more easily and use the capabilities of workspaces. --### Classic data structure --The structure of a Log Analytics workspace is described in [Log Analytics workspace overview](../logs/log-analytics-workspace-overview.md). For a classic application, the data isn't stored in a Log Analytics workspace. It uses the same query language. You create and run queries by using the same Log Analytics tool in the Azure portal. Data items for classic applications are stored separately from each other. The general structure is the same as for workspace-based applications, although the table and column names are different. --> [!NOTE] -> The classic Application Insights experience includes backward compatibility for your resource queries, workbooks, and log-based alerts. To query or view against the [new workspace-based table structure or schema](#table-structure), first go to your Log Analytics workspace. During the preview, selecting **Logs** in the Application Insights pane gives you access to the classic Application Insights query experience. For more information, see [Query scope](../logs/scope.md). ---### Table structure --| Legacy table name | New table name | Description | -|:|:|:| -| availabilityResults | AppAvailabilityResults | Summary data from availability tests.| -| browserTimings | AppBrowserTimings | Data about client performance, such as the time taken to process the incoming data.| -| dependencies | AppDependencies | Calls from the application to other components (including external components) recorded via `TrackDependency()`. Examples are calls to the REST API or database or a file system. | -| customEvents | AppEvents | Custom events created by your application. | -| customMetrics | AppMetrics | Custom metrics created by your application. | -| pageViews | AppPageViews| Data about each website view with browser information. | -| performanceCounters | AppPerformanceCounters | Performance measurements from the compute resources that support the application. An example is Windows performance counters. | -| requests | AppRequests | Requests received by your application. For example, a separate request record is logged for each HTTP request that your web app receives. | -| exceptions | AppExceptions | Exceptions thrown by the application runtime. Captures both server side and client-side (browsers) exceptions. | -| traces | AppTraces | Detailed logs (traces) emitted through application code/logging frameworks recorded via `TrackTrace()`. | --> [!CAUTION] -> Wait for new telemetry in Log Analytics before relying on it. After starting the migration, telemetry first goes to Classic Application Insights. Telemetry ingestion is switched to Log Analytics within 24 hours. Once done, Log Analytics solely captures new telemetry. --### Table schemas --The following sections show the mapping between the classic property names and the new workspace-based Application Insights property names. Use this information to convert any queries by using legacy tables. --Most of the columns have the same name with different capitalization. KQL is case sensitive, so you need to change each column name along with the table names in existing queries. Columns with changes in addition to capitalization are highlighted. You can still use your classic Application Insights queries within the **Logs** pane of your Application Insights resource, even if it's a workspace-based resource. The new property names are required when you query from within the context of the Log Analytics workspace experience. --#### AppAvailabilityResults --Legacy table: availabilityResults --|ApplicationInsights|Type|LogAnalytics|Type| -|:|:|:|:| -|appId|string|ResourceGUID|string| -|application_Version|string|AppVersion|string| -|appName|string|\(removed)|| -|client_Browser|string|ClientBrowser|string| -|client_City|string|ClientCity|string| -|client_CountryOrRegion|string|ClientCountryOrRegion|string| -|client_IP|string|ClientIP|string| -|client_Model|string|ClientModel|string| -|client_OS|string|ClientOS|string| -|client_StateOrProvince|string|ClientStateOrProvince|string| -|client_Type|string|ClientType|string| -|cloud_RoleInstance|string|AppRoleInstance|string| -|cloud_RoleName|string|AppRoleName|string| -|customDimensions|dynamic|Properties|Dynamic| -|customMeasurements|dynamic|Measurements|Dynamic| -|duration|real|DurationMs|real| -|`id`|string|`Id`|string| -|`iKey`|string|`IKey`|string| -|itemCount|int|ItemCount|int| -|itemId|string|\(removed)|| -|itemType|string|Type|String| -|location|string|Location|string| -|message|string|Message|string| -|name|string|Name|string| -|operation_Id|string|OperationId|string| -|operation_Name|string|OperationName|string| -|operation_ParentId|string|ParentId|string| -|operation_SyntheticSource|string|SyntheticSource|string| -|performanceBucket|string|PerformanceBucket|string| -|sdkVersion|string|SDKVersion|string| -|session_Id|string|SessionId|string| -|size|real|Size|real| -|success|string|Success|Bool| -|timestamp|datetime|TimeGenerated|datetime| -|user_AccountId|string|UserAccountId|string| -|user_AuthenticatedId|string|UserAuthenticatedId|string| -|user_Id|string|UserId|string| --#### AppBrowserTimings --Legacy table: browserTimings --|ApplicationInsights|Type|LogAnalytics|Type| -|:|:|:|:| -|appId|string|ResourceGUID|string| -|application_Version|string|AppVersion|string| -|appName|string|\(removed)|| -|client_Browser|string|ClientBrowser|string| -|client_City|string|ClientCity|string| -|client_CountryOrRegion|string|ClientCountryOrRegion|string| -|client_IP|string|ClientIP|string| -|client_Model|string|ClientModel|string| -|client_OS|string|ClientOS|string| -|client_StateOrProvince|string|ClientStateOrProvince|string| -|client_Type|string|ClientType|string| -|cloud_RoleInstance|string|AppRoleInstance|string| -|cloud_RoleName|string|AppRoleName|string| -|customDimensions|dynamic|Properties|Dynamic| -|customMeasurements|dynamic|Measurements|Dynamic| -|`iKey`|string|`IKey`|string| -|itemCount|int|ItemCount|int| -|itemId|string|\(removed)|| -|itemType|string|Type|string| -|name|string|Name|datetime| -|networkDuration|real|NetworkDurationMs|real| -|operation_Id|string|OperationId|string| -|operation_Name|string|OperationName|string| -|operation_ParentId|string|ParentId|string| -|operation_SyntheticSource|string|SyntheticSource|string| -|performanceBucket|string|PerformanceBucket|string| -|processingDuration|real|ProcessingDurationMs|real| -|receiveDuration|real|ReceiveDurationMs|real| -|sdkVersion|string|SDKVersion|string| -|sendDuration|real|SendDurationMs|real| -|session_Id|string|SessionId|string| -|timestamp|datetime|TimeGenerated|datetime| -|totalDuration|real|TotalDurationMs|real| -|url|string|Url|string| -|user_AccountId|string|UserAccountId|string| -|user_AuthenticatedId|string|UserAuthenticatedId|string| -|user_Id|string|UserId|string| --#### AppDependencies --Legacy table: dependencies --|ApplicationInsights|Type|LogAnalytics|Type| -|:|:|:|:| -|appId|string|ResourceGUID|string| -|application_Version|string|AppVersion|string| -|appName|string|\(removed)|| -|client_Browser|string|ClientBrowser|string| -|client_City|string|ClientCity|string| -|client_CountryOrRegion|string|ClientCountryOrRegion|string| -|client_IP|string|ClientIP|string| -|client_Model|string|ClientModel|string| -|client_OS|string|ClientOS|string| -|client_StateOrProvince|string|ClientStateOrProvince|string| -|client_Type|string|ClientType|string| -|cloud_RoleInstance|string|AppRoleInstance|string| -|cloud_RoleName|string|AppRoleName|string| -|customDimensions|dynamic|Properties|Dynamic| -|customMeasurements|dynamic|Measurements|Dynamic| -|data|string|Data|string| -|duration|real|DurationMs|real| -|`id`|string|`Id`|string| -|`iKey`|string|`IKey`|string| -|itemCount|int|ItemCount|int| -|itemId|string|\(removed)|| -|itemType|string|Type|String| -|name|string|Name|string| -|operation_Id|string|OperationId|string| -|operation_Name|string|OperationName|string| -|operation_ParentId|string|ParentId|string| -|operation_SyntheticSource|string|SyntheticSource|string| -|performanceBucket|string|PerformanceBucket|string| -|resultCode|string|ResultCode|string| -|sdkVersion|string|SDKVersion|string| -|session_Id|string|SessionId|string| -|success|string|Success|Bool| -|target|string|Target|string| -|timestamp|datetime|TimeGenerated|datetime| -|type|string|DependencyType|string| -|user_AccountId|string|UserAccountId|string| -|user_AuthenticatedId|string|UserAuthenticatedId|string| -|user_Id|string|UserId|string| --#### AppEvents --Legacy table: customEvents --|ApplicationInsights|Type|LogAnalytics|Type| -|:|:|:|:| -|appId|string|ResourceGUID|string| -|application_Version|string|AppVersion|string| -|appName|string|\(removed)|| -|client_Browser|string|ClientBrowser|string| -|client_City|string|ClientCity|string| -|client_CountryOrRegion|string|ClientCountryOrRegion|string| -|client_IP|string|ClientIP|string| -|client_Model|string|ClientModel|string| -|client_OS|string|ClientOS|string| -|client_StateOrProvince|string|ClientStateOrProvince|string| -|client_Type|string|ClientType|string| -|cloud_RoleInstance|string|AppRoleInstance|string| -|cloud_RoleName|string|AppRoleName|string| -|customDimensions|dynamic|Properties|Dynamic| -|customMeasurements|dynamic|Measurements|Dynamic| -|`iKey`|string|`IKey`|string| -|itemCount|int|ItemCount|int| -|itemId|string|\(removed)|| -|itemType|string|Type|string| -|name|string|Name|string| -|operation_Id|string|OperationId|string| -|operation_Name|string|OperationName|string| -|operation_ParentId|string|ParentId|string| -|operation_SyntheticSource|string|SyntheticSource|string| -|sdkVersion|string|SDKVersion|string| -|session_Id|string|SessionId|string| -|timestamp|datetime|TimeGenerated|datetime| -|user_AccountId|string|UserAccountId|string| -|user_AuthenticatedId|string|UserAuthenticatedId|string| -|user_Id|string|UserId|string| --#### AppMetrics --Legacy table: customMetrics --|ApplicationInsights|Type|LogAnalytics|Type| -|:|:|:|:| -|appId|string|ResourceGUID|string| -|application_Version|string|AppVersion|string| -|appName|string|\(removed)|| -|client_Browser|string|ClientBrowser|string| -|client_City|string|ClientCity|string| -|client_CountryOrRegion|string|ClientCountryOrRegion|string| -|client_IP|string|ClientIP|string| -|client_Model|string|ClientModel|string| -|client_OS|string|ClientOS|string| -|client_StateOrProvince|string|ClientStateOrProvince|string| -|client_Type|string|ClientType|string| -|cloud_RoleInstance|string|AppRoleInstance|string| -|cloud_RoleName|string|AppRoleName|string| -|customDimensions|dynamic|Properties|Dynamic| -|`iKey`|string|`IKey`|string| -|itemId|string|\(removed)|| -|itemType|string|Type|string| -|name|string|Name|string| -|operation_Id|string|OperationId|string| -|operation_Name|string|OperationName|string| -|operation_ParentId|string|ParentId|string| -|operation_SyntheticSource|string|SyntheticSource|string| -|sdkVersion|string|SDKVersion|string| -|session_Id|string|SessionId|string| -|timestamp|datetime|TimeGenerated|datetime| -|user_AccountId|string|UserAccountId|string| -|user_AuthenticatedId|string|UserAuthenticatedId|string| -|user_Id|string|UserId|string| -|value|real|(removed)|| -|valueCount|int|ItemCount|int| -|valueMax|real|Max|real| -|valueMin|real|Min|real| -|valueSum|real|Sum|real| -|valueStdDev|real|(removed)|| --> [!NOTE] -> Older versions of Application Insights SDKs are used to report standard deviation (`valueStdDev`) in the metrics pre-aggregation. Because adoption in metrics analysis was light, the field was removed and is no longer aggregated by the SDKs. If the value is received by the Application Insights data collection endpoint, it's dropped during ingestion and isn't sent to the Log Analytics workspace. If you want to use standard deviation in your analysis, use queries against Application Insights raw events. --#### AppPageViews --Legacy table: pageViews --|ApplicationInsights|Type|LogAnalytics|Type| -|:|:|:|:| -|appId|string|ResourceGUID|string| -|application_Version|string|AppVersion|string| -|appName|string|\(removed)|| -|client_Browser|string|ClientBrowser|string| -|client_City|string|ClientCity|string| -|client_CountryOrRegion|string|ClientCountryOrRegion|string| -|client_IP|string|ClientIP|string| -|client_Model|string|ClientModel|string| -|client_OS|string|ClientOS|string| -|client_StateOrProvince|string|ClientStateOrProvince|string| -|client_Type|string|ClientType|string| -|cloud_RoleInstance|string|AppRoleInstance|string| -|cloud_RoleName|string|AppRoleName|string| -|customDimensions|dynamic|Properties|Dynamic| -|customMeasurements|dynamic|Measurements|Dynamic| -|duration|real|DurationMs|real| -|`id`|string|`Id`|string| -|`iKey`|string|`IKey`|string| -|itemCount|int|ItemCount|int| -|itemId|string|\(removed)|| -|itemType|string|Type|String| -|name|string|Name|string| -|operation_Id|string|OperationId|string| -|operation_Name|string|OperationName|string| -|operation_ParentId|string|ParentId|string| -|operation_SyntheticSource|string|SyntheticSource|string| -|performanceBucket|string|PerformanceBucket|string| -|sdkVersion|string|SDKVersion|string| -|session_Id|string|SessionId|string| -|timestamp|datetime|TimeGenerated|datetime| -|url|string|Url|string| -|user_AccountId|string|UserAccountId|string| -|user_AuthenticatedId|string|UserAuthenticatedId|string| -|user_Id|string|UserId|string| --#### AppPerformanceCounters --Legacy table: performanceCounters --|ApplicationInsights|Type|LogAnalytics|Type| -|:|:|:|:| -|appId|string|ResourceGUID|string| -|application_Version|string|AppVersion|string| -|appName|string|\(removed)|| -|category|string|Category|string| -|client_Browser|string|ClientBrowser|string| -|client_City|string|ClientCity|string| -|client_CountryOrRegion|string|ClientCountryOrRegion|string| -|client_IP|string|ClientIP|string| -|client_Model|string|ClientModel|string| -|client_OS|string|ClientOS|string| -|client_StateOrProvince|string|ClientStateOrProvince|string| -|client_Type|string|ClientType|string| -|cloud_RoleInstance|string|AppRoleInstance|string| -|cloud_RoleName|string|AppRoleName|string| -|counter|string|(removed)|| -|customDimensions|dynamic|Properties|Dynamic| -|`iKey`|string|`IKey`|string| -|instance|string|Instance|string| -|itemId|string|\(removed)|| -|itemType|string|Type|string| -|name|string|Name|string| -|operation_Id|string|OperationId|string| -|operation_Name|string|OperationName|string| -|operation_ParentId|string|ParentId|string| -|operation_SyntheticSource|string|SyntheticSource|string| -|sdkVersion|string|SDKVersion|string| -|session_Id|string|SessionId|string| -|timestamp|datetime|TimeGenerated|datetime| -|user_AccountId|string|UserAccountId|string| -|user_AuthenticatedId|string|UserAuthenticatedId|string| -|user_Id|string|UserId|string| -|value|real|Value|real| --#### AppRequests --Legacy table: requests --|ApplicationInsights|Type|LogAnalytics|Type| -|:|:|:|:| -|appId|string|ResourceGUID|string| -|application_Version|string|AppVersion|string| -|appName|string|\(removed)|| -|client_Browser|string|ClientBrowser|string| -|client_City|string|ClientCity|string| -|client_CountryOrRegion|string|ClientCountryOrRegion|string| -|client_IP|string|ClientIP|string| -|client_Model|string|ClientModel|string| -|client_OS|string|ClientOS|string| -|client_StateOrProvince|string|ClientStateOrProvince|string| -|client_Type|string|ClientType|string| -|cloud_RoleInstance|string|AppRoleInstance|string| -|cloud_RoleName|string|AppRoleName|string| -|customDimensions|dynamic|Properties|Dynamic| -|customMeasurements|dynamic|Measurements|Dynamic| -|duration|real|DurationMs|Real| -|`id`|string|`Id`|String| -|`iKey`|string|`IKey`|string| -|itemCount|int|ItemCount|int| -|itemId|string|\(removed)|| -|itemType|string|Type|String| -|name|string|Name|String| -|operation_Id|string|OperationId|string| -|operation_Name|string|OperationName|string| -|operation_ParentId|string|ParentId|string| -|operation_SyntheticSource|string|SyntheticSource|string| -|performanceBucket|string|PerformanceBucket|String| -|resultCode|string|ResultCode|String| -|sdkVersion|string|SDKVersion|string| -|session_Id|string|SessionId|string| -|source|string|Source|String| -|success|string|Success|Bool| -|timestamp|datetime|TimeGenerated|datetime| -|url|string|Url|String| -|user_AccountId|string|UserAccountId|string| -|user_AuthenticatedId|string|UserAuthenticatedId|string| -|user_Id|string|UserId|string| --#### AppExceptions --Legacy table: exceptions --|ApplicationInsights|Type|LogAnalytics|Type| -|:|:|:|:| -|appId|string|ResourceGUID|string| -|application_Version|string|AppVersion|string| -|appName|string|\(removed)|| -|assembly|string|Assembly|string| -|client_Browser|string|ClientBrowser|string| -|client_City|string|ClientCity|string| -|client_CountryOrRegion|string|ClientCountryOrRegion|string| -|client_IP|string|ClientIP|string| -|client_Model|string|ClientModel|string| -|client_OS|string|ClientOS|string| -|client_StateOrProvince|string|ClientStateOrProvince|string| -|client_Type|string|ClientType|string| -|cloud_RoleInstance|string|AppRoleInstance|string| -|cloud_RoleName|string|AppRoleName|string| -|customDimensions|dynamic|Properties|dynamic| -|customMeasurements|dynamic|Measurements|dynamic| -|details|dynamic|Details|dynamic| -|handledAt|string|HandledAt|string| -|`iKey`|string|`IKey`|string| -|innermostAssembly|string|InnermostAssembly|string| -|innermostMessage|string|InnermostMessage|string| -|innermostMethod|string|InnermostMethod|string| -|innermostType|string|InnermostType|string| -|itemCount|int|ItemCount|int| -|itemId|string|\(removed)|| -|itemType|string|Type|string| -|message|string|Message|string| -|method|string|Method|string| -|operation_Id|string|OperationId|string| -|operation_Name|string|OperationName|string| -|operation_ParentId|string|ParentId|string| -|operation_SyntheticSource|string|SyntheticSource|string| -|outerAssembly|string|OuterAssembly|string| -|outerMessage|string|OuterMessage|string| -|outerMethod|string|OuterMethod|string| -|outerType|string|OuterType|string| -|problemId|string|ProblemId|string| -|sdkVersion|string|SDKVersion|string| -|session_Id|string|SessionId|string| -|severityLevel|int|SeverityLevel|int| -|timestamp|datetime|TimeGenerated|datetime| -|type|string|ExceptionType|string| -|user_AccountId|string|UserAccountId|string| -|user_AuthenticatedId|string|UserAuthenticatedId|string| -|user_Id|string|UserId|string| --#### AppTraces --Legacy table: traces --|ApplicationInsights|Type|LogAnalytics|Type| -|:|:|:|:| -|appId|string|ResourceGUID|string| -|application_Version|string|AppVersion|string| -|appName|string|\(removed)|| -|client_Browser|string|ClientBrowser|string| -|client_City|string|ClientCity|string| -|client_CountryOrRegion|string|ClientCountryOrRegion|string| -|client_IP|string|ClientIP|string| -|client_Model|string|ClientModel|string| -|client_OS|string|ClientOS|string| -|client_StateOrProvince|string|ClientStateOrProvince|string| -|client_Type|string|ClientType|string| -|cloud_RoleInstance|string|AppRoleInstance|string| -|cloud_RoleName|string|AppRoleName|string| -|customDimensions|dynamic|Properties|dynamic| -|customMeasurements|dynamic|Measurements|dynamic| -|`iKey`|string|`IKey`|string| -|itemCount|int|ItemCount|int| -|itemId|string|\(removed)|| -|itemType|string|Type|string| -|message|string|Message|string| -|operation_Id|string|OperationId|string| -|operation_Name|string|OperationName|string| -|operation_ParentId|string|ParentId|string| -|operation_SyntheticSource|string|SyntheticSource|string| -|sdkVersion|string|SDKVersion|string| -|session_Id|string|SessionId|string| -|severityLevel|int|SeverityLevel|int| -|timestamp|datetime|TimeGenerated|datetime| -|user_AccountId|string|UserAccountId|string| -|user_AuthenticatedId|string|UserAuthenticatedId|string| -|user_Id|string|UserId|string| --## Next steps --* [Explore metrics](../essentials/metrics-charts.md) -* [Write Log Analytics queries](../logs/log-query-overview.md) |
| azure-monitor | Create Workspace Resource | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/create-workspace-resource.md | - Title: Create a new Azure Monitor Application Insights workspace-based resource -description: Learn about the steps required to enable the new Azure Monitor Application Insights workspace-based resources. - Previously updated : 12/15/2023-----# Workspace-based Application Insights resources --[Azure Monitor](../overview.md) [Application Insights](app-insights-overview.md#application-insights-overview) workspace-based resources integrate [Application Insights](app-insights-overview.md#application-insights-overview) and [Log Analytics](../logs/log-analytics-overview.md#overview-of-log-analytics-in-azure-monitor). --With workspace-based resources, [Application Insights](app-insights-overview.md#application-insights-overview) sends telemetry to a common [Log Analytics](../logs/log-analytics-overview.md#overview-of-log-analytics-in-azure-monitor) workspace, providing full access to all the features of [Log Analytics](../logs/log-analytics-overview.md#overview-of-log-analytics-in-azure-monitor) while keeping your application, infrastructure, and platform logs in a single consolidated location. This integration allows for common [Azure role-based access control](../roles-permissions-security.md) across your resources and eliminates the need for cross-app/workspace queries. --> [!NOTE] -> Data ingestion and retention for workspace-based Application Insights resources are billed through the Log Analytics workspace where the data is located. To learn more about billing for workspace-based Application Insights resources, see [Azure Monitor Logs pricing details](../logs/cost-logs.md). --## New capabilities --Workspace-based Application Insights integrates with Azure Monitor and Log Analytics to enhance capabilities: --- [Customer-managed key](../logs/customer-managed-keys.md) encrypts your data at rest with keys only you access.-- [Azure Private Link](../logs/private-link-security.md) securely connects Azure PaaS services to your virtual network using private endpoints.-- [Bring your own storage (BYOS) for Profiler and Snapshot Debugger](./profiler-bring-your-own-storage.md) lets you manage data from Application Insights [Profiler](../profiler/profiler-overview.md) and [Snapshot Debugger](../snapshot-debugger/snapshot-debugger.md) with policies on encryption, lifetime, and network access.-- [Commitment tiers](../logs/cost-logs.md#commitment-tiers) offer up to a 30% saving over pay-as-you-go pricing.-- Log Analytics streaming processes data more quickly.--## Create a workspace-based resource --Sign in to the [Azure portal](https://portal.azure.com), and create an Application Insights resource. --> [!div class="mx-imgBorder"] -> :::image type="content" source="./media/create-workspace-resource/create-workspace-based.png" lightbox="./media/create-workspace-resource/create-workspace-based.png" alt-text="Screenshot that shows a workspace-based Application Insights resource."::: --If you don't have an existing Log Analytics workspace, see the [Log Analytics workspace creation documentation](../logs/quick-create-workspace.md). --*Workspace-based resources are currently available in all commercial regions and Azure Government. Having Application Insights and Log Analytics in two different regions can impact latency and reduce overall reliability of the monitoring solution.* --After you create your resource, you'll see corresponding workspace information in the **Overview** pane. ---Select the blue link text to go to the associated Log Analytics workspace where you can take advantage of the new unified workspace query environment. --> [!NOTE] -> We still provide full backward compatibility for your Application Insights classic resource queries, workbooks, and log-based alerts. To query or view the [new workspace-based table structure or schema](convert-classic-resource.md#workspace-based-resource-changes), you must first go to your Log Analytics workspace. Select **Logs (Analytics)** in the **Application Insights** panes for access to the classic Application Insights query experience. --## Copy the connection string --The [connection string](./sdk-connection-string.md?tabs=net) identifies the resource that you want to associate your telemetry data with. You can also use it to modify the endpoints your resource uses as a destination for your telemetry. You must copy the connection string and add it to your application's code or to an environment variable. --## Configure monitoring --After creating a workspace-based Application Insights resource, you configure monitoring. --### Code-based application monitoring --For code-based application monitoring, you install the appropriate Application Insights SDK and point the connection string to your newly created resource. --For information on how to set up an Application Insights SDK for code-based monitoring, see the following documentation specific to the language or framework: --- [ASP.NET](./asp-net.md)-- [ASP.NET Core](./asp-net-core.md)-- [Background tasks and modern console applications (.NET/.NET Core)](./worker-service.md)-- [Classic console applications (.NET)](./console.md)-- [Java](./opentelemetry-enable.md?tabs=java)-- [JavaScript](./javascript.md)-- [Node.js](./nodejs.md)-- [Python](/previous-versions/azure/azure-monitor/app/opencensus-python)--### Codeless monitoring --For codeless monitoring of services like Azure Functions and Azure App Services, you can first create your workspace-based Application Insights resource. Then you point to that resource when you configure monitoring. Alternatively, you can create an new Application Insights resource as part of Application Insights enablement. --## Create a resource automatically --### Azure CLI --To access the preview Application Insights Azure CLI commands, you first need to run: --```azurecli - az extension add -n application-insights -``` --If you don't run the `az extension add` command, you see an error message that states `az : ERROR: az monitor: 'app-insights' is not in the 'az monitor' command group. See 'az monitor --help'`. --Now you can run the following code to create your Application Insights resource: --```azurecli -az monitor app-insights component create --app - --location - --resource-group - [--application-type] - [--ingestion-access {Disabled, Enabled}] - [--kind] - [--only-show-errors] - [--query-access {Disabled, Enabled}] - [--tags] - [--workspace] -``` --#### Example --```azurecli -az monitor app-insights component create --app demoApp --location eastus --kind web -g my_resource_group --workspace "/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/test1234/providers/microsoft.operationalinsights/workspaces/test1234555" -``` --For the full Azure CLI documentation for this command, see the [Azure CLI documentation](/cli/azure/monitor/app-insights/component#az-monitor-app-insights-component-create). --### Azure PowerShell --Create a new workspace-based Application Insights resource. --```powershell -New-AzApplicationInsights -Name <String> -ResourceGroupName <String> -Location <String> -WorkspaceResourceId <String> - [-SubscriptionId <String>] - [-ApplicationType <ApplicationType>] - [-DisableIPMasking] - [-DisableLocalAuth] - [-Etag <String>] - [-FlowType <FlowType>] - [-ForceCustomerStorageForProfiler] - [-HockeyAppId <String>] - [-ImmediatePurgeDataOn30Day] - [-IngestionMode <IngestionMode>] - [-Kind <String>] - [-PublicNetworkAccessForIngestion <PublicNetworkAccessType>] - [-PublicNetworkAccessForQuery <PublicNetworkAccessType>] - [-RequestSource <RequestSource>] - [-RetentionInDays <Int32>] - [-SamplingPercentage <Double>] - [-Tag <Hashtable>] - [-DefaultProfile <PSObject>] - [-Confirm] - [-WhatIf] - [<CommonParameters>] -``` --#### Example --```powershell -New-AzApplicationInsights -Kind java -ResourceGroupName testgroup -Name test1027 -location eastus -WorkspaceResourceId "/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/test1234/providers/microsoft.operationalinsights/workspaces/test1234555" -``` --For the full PowerShell documentation for this cmdlet, and to learn how to retrieve the connection string, see the [Azure PowerShell documentation](/powershell/module/az.applicationinsights/new-azapplicationinsights). --### Azure Resource Manager templates --# [Bicep](#tab/bicep) --```bicep -@description('Name of Application Insights resource.') -param name string --@description('Type of app you are deploying. This field is for legacy reasons and will not impact the type of App Insights resource you deploy.') -param type string --@description('Which Azure Region to deploy the resource to. This must be a valid Azure regionId.') -param regionId string --@description('See documentation on tags: https://learn.microsoft.com/azure/azure-resource-manager/management/tag-resources.') -param tagsArray object --@description('Source of Azure Resource Manager deployment') -param requestSource string --@description('Log Analytics workspace ID to associate with your Application Insights resource.') -param workspaceResourceId string --resource component 'Microsoft.Insights/components@2020-02-02' = { - name: name - location: regionId - tags: tagsArray - kind: 'other' - properties: { - Application_Type: type - Flow_Type: 'Bluefield' - Request_Source: requestSource - WorkspaceResourceId: workspaceResourceId - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "name": { - "type": "string", - "metadata": { - "description": "Name of Application Insights resource." - } - }, - "type": { - "type": "string", - "metadata": { - "description": "Type of app you are deploying. This field is for legacy reasons and will not impact the type of App Insights resource you deploy." - } - }, - "regionId": { - "type": "string", - "metadata": { - "description": "Which Azure Region to deploy the resource to. This must be a valid Azure regionId." - } - }, - "tagsArray": { - "type": "object", - "metadata": { - "description": "See documentation on tags: https://learn.microsoft.com/azure/azure-resource-manager/management/tag-resources." - } - }, - "requestSource": { - "type": "string", - "metadata": { - "description": "Source of Azure Resource Manager deployment" - } - }, - "workspaceResourceId": { - "type": "string", - "metadata": { - "description": "Log Analytics workspace ID to associate with your Application Insights resource." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/components", - "apiVersion": "2020-02-02", - "name": "[parameters('name')]", - "location": "[parameters('regionId')]", - "tags": "[parameters('tagsArray')]", - "kind": "other", - "properties": { - "Application_Type": "[parameters('type')]", - "Flow_Type": "Bluefield", - "Request_Source": "[parameters('requestSource')]", - "WorkspaceResourceId": "[parameters('workspaceResourceId')]" - } - } - ] -} -``` --> [!NOTE] -> For more information on resource properties, see [Property values](/azure/templates/microsoft.insights/components?tabs=bicep#property-values). -> `Flow_Type` and `Request_Source` aren't used but are included in this sample for completeness. ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "name": { - "value": "my_workspace_based_resource" - }, - "type": { - "value": "web" - }, - "regionId": { - "value": "westus2" - }, - "tagsArray": { - "value": {} - }, - "requestSource": { - "value": "CustomDeployment" - }, - "workspaceResourceId": { - "value": "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourcegroups/testxxxx/providers/microsoft.operationalinsights/workspaces/testworkspace" - } - } -} -``` --## Modify the associated workspace --After creating a workspace-based Application Insights resource, you can modify the associated Log Analytics workspace. --In the Application Insights resource pane, select **Properties** > **Change Workspace** > **Log Analytics Workspaces**. --## Export telemetry --The legacy continuous export functionality isn't supported for workspace-based resources. Instead, select **Diagnostic settings** > **Add diagnostic setting** in your Application Insights resource. You can select all tables, or a subset of tables, to archive to a storage account. You can also stream to an Azure event hub. --> [!NOTE] -> Diagnostic settings export might increase costs. For more information, see [Export telemetry from Application Insights](export-telemetry.md#diagnostic-settings-based-export). -> For pricing information for this feature, see the [Azure Monitor pricing page](https://azure.microsoft.com/pricing/details/monitor/). Prior to the start of billing, notifications will be sent. If you continue to use telemetry export after the notice period, you'll be billed at the applicable rate. --## How many Application Insights resources should I deploy? --When you're developing the next version of a web application, you don't want to mix up the [Application Insights](../../azure-monitor/app/app-insights-overview.md) telemetry from the new version and the already released version. --To avoid confusion, send the telemetry from different development stages to separate Application Insights resources with separate connection strings. --If your system is an instance of Azure Cloud Services, there's [another method of setting separate connection strings](../../azure-monitor/app/azure-web-apps-net-core.md). --### About resources and connection strings --When you set up Application Insights monitoring for your web app, you create an Application Insights resource in Azure. You open the resource in the Azure portal to see and analyze the telemetry collected from your app. A connection string identifies the resource. When you install the Application Insights package to monitor your app, you configure it with the connection string so that it knows where to send the telemetry. --Each Application Insights resource comes with metrics that are available out of the box. If separate components report to the same Application Insights resource, it might not make sense to alert on these metrics. --#### When to use a single Application Insights resource --Use a single Application Insights resource for: --- Streamlining DevOps/ITOps management for applications deployed together, typically developed and managed by the same team.-- Centralizing key performance indicators, such as response times and failure rates, in a dashboard by default. Segment by role name in the metrics explorer if necessary.-- When there's no need for different Azure role-based access control management between application components.-- When identical metrics alert criteria, continuous exports, and billing/quotas management across components suffice.-- When it's acceptable for an API key to access data from all components equally, and 10 API keys meet the needs across all components.-- When the same smart detection and work item integration settings are suitable across all roles.--> [!NOTE] -> If you want to consolidate multiple Application Insights resources, you can point your existing application components to a new, consolidated Application Insights resource. The telemetry stored in your old resource won't be transferred to the new resource. Only delete the old resource when you have enough telemetry in the new resource for business continuity. --#### Other considerations --To activate portal experiences, add custom code to assign meaningful values to the [Cloud_RoleName](./app-map.md?tabs=net#set-or-override-cloud-role-name) attribute. Without these values, portal features don't function. --For Azure Service Fabric applications and classic cloud services, the SDK automatically configures services by reading from the Azure Role Environment. For other app types, you typically need to set it explicitly. --Live Metrics can't split data by role name. --### Create more Application Insights resources --To create an Applications Insights resource, see [Create an Application Insights resource](#workspace-based-application-insights-resources). --> [!WARNING] -> You might incur additional network costs if your Application Insights resource is monitoring an Azure resource (i.e., telemetry producer) in a different region. Costs will vary depending on the region the telemetry is coming from and where it is going. Refer to [Azure bandwidth pricing](https://azure.microsoft.com/pricing/details/bandwidth/) for details. --#### Get the connection string -The connection string identifies the resource that you created. --You need the connection strings of all the resources to which your app sends data. --### Filter on the build number -When you publish a new version of your app, you want to be able to separate the telemetry from different builds. --You can set the **Application Version** property so that you can filter [search](../../azure-monitor/app/transaction-search-and-diagnostics.md?tabs=transaction-search) and [metric explorer](../../azure-monitor/essentials/metrics-charts.md) results. --There are several different methods of setting the **Application Version** property. --* Set directly: -- `telemetryClient.Context.Component.Version = typeof(MyProject.MyClass).Assembly.GetName().Version;` -* Wrap that line in a [telemetry initializer](../../azure-monitor/app/api-custom-events-metrics.md#defaults) to ensure that all `TelemetryClient` instances are set consistently. -* ASP.NET: Set the version in `BuildInfo.config`. The web module picks up the version from the `BuildLabel` node. Include this file in your project and remember to set the **Copy Always** property in Solution Explorer. -- ```xml - <?xml version="1.0" encoding="utf-8"?> - <DeploymentEvent xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="https://www.w3.org/2001/XMLSchema" xmlns="http://schemas.microsoft.com/VisualStudio/DeploymentEvent/2013/06"> - <ProjectName>AppVersionExpt</ProjectName> - <Build type="MSBuild"> - <MSBuild> - <BuildLabel kind="label">1.0.0.2</BuildLabel> - </MSBuild> - </Build> - </DeploymentEvent> -- ``` --* ASP.NET: Generate `BuildInfo.config` automatically in the Microsoft Build Engine. Add a few lines to your `.csproj` file: -- ```xml - <PropertyGroup> - <GenerateBuildInfoConfigFile>true</GenerateBuildInfoConfigFile> <IncludeServerNameInBuildInfo>true</IncludeServerNameInBuildInfo> - </PropertyGroup> - ``` -- This step generates a file called *yourProjectName*`.BuildInfo.config`. The Publish process renames it to `BuildInfo.config`. -- The build label contains a placeholder `(*AutoGen_...*)` when you build with Visual Studio. But when built with the Microsoft Build Engine, it's populated with the correct version number. -- To allow the Microsoft Build Engine to generate version numbers, set the version like `1.0.*` in `AssemblyReference.cs`. --### Version and release tracking -To track the application version, make sure your Microsoft Build Engine process generates `buildinfo.config`. In your `.csproj` file, add: --```xml -<PropertyGroup> - <GenerateBuildInfoConfigFile>true</GenerateBuildInfoConfigFile> - <IncludeServerNameInBuildInfo>true</IncludeServerNameInBuildInfo> -</PropertyGroup> -``` --When the Application Insights web module has the build information, it automatically adds **Application Version** as a property to every item of telemetry. For this reason, you can filter by version when you perform [diagnostic searches](../../azure-monitor/app/transaction-search-and-diagnostics.md?tabs=transaction-search) or when you [explore metrics](../../azure-monitor/essentials/metrics-charts.md). --The Microsoft Build Engine exclusively generates the build version number, not the developer build from Visual Studio. --#### Release annotations --If you use Azure DevOps, you can [get an annotation marker](./release-and-work-item-insights.md?tabs=release-annotations) added to your charts whenever you release a new version. --## Frequently asked questions --This section provides answers to common questions. --### How do I move an Application Insights resource to a new region? --Transferring existing Application Insights resources between regions isn't supported, and you can't migrate historical data to a new region. The workaround involves: --- Creating a new workspace-based Application Insights resource in the desired region.-- Re-creating any unique customizations from the original resource in the new one.-- Updating your application with the new region resource's [connection string](./sdk-connection-string.md).-- Testing to ensure everything works as expected with the new Application Insights resource.-- Decide to either keep or delete the original Application Insights resource. Deleting a classic resource means losing all historical data. If the resource is workspace-based, the data remains in Log Analytics, enabling access to historical data until the retention period expires.-- -Unique customizations that commonly need to be manually re-created or updated for the resource in the new region include but aren't limited to: - -- Re-create custom dashboards and workbooks.-- Re-create or update the scope of any custom log/metric alerts.-- Re-create availability alerts.-- Re-create any custom Azure role-based access control settings that are required for your users to access the new resource.-- Replicate settings involving ingestion sampling, data retention, daily cap, and custom metrics enablement. These settings are controlled via the **Usage and estimated costs** pane.-- Any integration that relies on API keys, such as [release annotations](./release-and-work-item-insights.md?tabs=release-annotations) and [live metrics secure control channel](./live-stream.md#secure-the-control-channel). You need to generate new API keys and update the associated integration.-- Continuous export in classic resources must be configured again.-- Diagnostic settings in workspace-based resources must be configured again.- -> [!NOTE] -> If the resource you're creating in a new region is replacing a classic resource, we recommend that you explore the benefits of [creating a new workspace-based resource](#workspace-based-application-insights-resources). Alternatively, [migrate your existing resource to workspace based](./convert-classic-resource.md). --### Can I use providers('Microsoft.Insights', 'components').apiVersions[0] in my Azure Resource Manager deployments? --We don't recommend using this method of populating the API version. The newest version can represent preview releases, which might contain breaking changes. Even with newer nonpreview releases, the API versions aren't always backward compatible with existing templates. In some cases, the API version might not be available to all subscriptions. --## Next steps --* [Explore metrics](../essentials/metrics-charts.md) -* [Write Log Analytics queries](../logs/log-query-overview.md) -* [Shared resources for multiple roles](./app-map.md) -* [Create a Telemetry Initializer to distinguish A|B variants](./api-filtering-sampling.md#add-properties) |
| azure-monitor | Custom Operations Tracking | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/custom-operations-tracking.md | - Title: Track custom operations with Application Insights .NET SDK -description: Learn how to track custom operations with the Application Insights .NET SDK. -- Previously updated : 10/10/2023----# Track custom operations with Application Insights .NET SDK --Application Insights SDKs automatically track incoming HTTP requests and calls to dependent services, such as HTTP requests and SQL queries. Tracking and correlation of requests and dependencies give you visibility into the whole application's responsiveness and reliability across all microservices that combine this application. --There's a class of application patterns that can't be supported generically. Proper monitoring of such patterns requires manual code instrumentation. This article covers a few patterns that might require manual instrumentation, such as custom queue processing and running long-running background tasks. --This article provides guidance on how to track custom operations with the Application Insights SDK. This documentation is relevant for: --- Application Insights for .NET (also known as Base SDK) version 2.4+.-- Application Insights for web applications (running ASP.NET) version 2.4+.-- Application Insights for ASP.NET Core version 2.1+.---## Overview --An operation is a logical piece of work run by an application. It has a name, start time, duration, result, and a context of execution like user name, properties, and result. If operation A was initiated by operation B, then operation B is set as a parent for A. An operation can have only one parent, but it can have many child operations. For more information on operations and telemetry correlation, see [Application Insights telemetry correlation](distributed-trace-data.md). --In the Application Insights .NET SDK, the operation is described by the abstract class [OperationTelemetry](https://github.com/microsoft/ApplicationInsights-dotnet/blob/7633ae849edc826a8547745b6bf9f3174715d4bd/BASE/src/Microsoft.ApplicationInsights/Extensibility/Implementation/OperationTelemetry.cs) and its descendants [RequestTelemetry](https://github.com/microsoft/ApplicationInsights-dotnet/blob/7633ae849edc826a8547745b6bf9f3174715d4bd/BASE/src/Microsoft.ApplicationInsights/DataContracts/RequestTelemetry.cs) and [DependencyTelemetry](https://github.com/microsoft/ApplicationInsights-dotnet/blob/7633ae849edc826a8547745b6bf9f3174715d4bd/BASE/src/Microsoft.ApplicationInsights/DataContracts/DependencyTelemetry.cs). --## Incoming operations tracking --The Application Insights web SDK automatically collects HTTP requests for ASP.NET applications that run in an IIS pipeline and all ASP.NET Core applications. There are community-supported solutions for other platforms and frameworks. If the application isn't supported by any of the standard or community-supported solutions, you can instrument it manually. --Another example that requires custom tracking is the worker that receives items from the queue. For some queues, the call to add a message to this queue is tracked as a dependency. The high-level operation that describes message processing isn't automatically collected. --Let's see how such operations could be tracked. --On a high level, the task is to create `RequestTelemetry` and set known properties. After the operation is finished, you track the telemetry. The following example demonstrates this task. --### HTTP request in Owin self-hosted app --In this example, trace context is propagated according to the [HTTP Protocol for Correlation](https://github.com/dotnet/runtime/blob/master/src/libraries/System.Diagnostics.DiagnosticSource/src/HttpCorrelationProtocol.md). You should expect to receive headers that are described there. --```csharp -public class ApplicationInsightsMiddleware : OwinMiddleware -{ - // You may create a new TelemetryConfiguration instance, reuse one you already have, - // or fetch the instance created by Application Insights SDK. - private readonly TelemetryConfiguration telemetryConfiguration = TelemetryConfiguration.CreateDefault(); - private readonly TelemetryClient telemetryClient = new TelemetryClient(telemetryConfiguration); - - public ApplicationInsightsMiddleware(OwinMiddleware next) : base(next) {} -- public override async Task Invoke(IOwinContext context) - { - // Let's create and start RequestTelemetry. - var requestTelemetry = new RequestTelemetry - { - Name = $"{context.Request.Method} {context.Request.Uri.GetLeftPart(UriPartial.Path)}" - }; -- // If there is a Request-Id received from the upstream service, set the telemetry context accordingly. - if (context.Request.Headers.ContainsKey("Request-Id")) - { - var requestId = context.Request.Headers.Get("Request-Id"); - // Get the operation ID from the Request-Id (if you follow the HTTP Protocol for Correlation). - requestTelemetry.Context.Operation.Id = GetOperationId(requestId); - requestTelemetry.Context.Operation.ParentId = requestId; - } -- // StartOperation is a helper method that allows correlation of - // current operations with nested operations/telemetry - // and initializes start time and duration on telemetry items. - var operation = telemetryClient.StartOperation(requestTelemetry); -- // Process the request. - try - { - await Next.Invoke(context); - } - catch (Exception e) - { - requestTelemetry.Success = false; - requestTelemetry.ResponseCode; - telemetryClient.TrackException(e); - throw; - } - finally - { - // Update status code and success as appropriate. - if (context.Response != null) - { - requestTelemetry.ResponseCode = context.Response.StatusCode.ToString(); - requestTelemetry.Success = context.Response.StatusCode >= 200 && context.Response.StatusCode <= 299; - } - else - { - requestTelemetry.Success = false; - } -- // Now it's time to stop the operation (and track telemetry). - telemetryClient.StopOperation(operation); - } - } - - public static string GetOperationId(string id) - { - // Returns the root ID from the '|' to the first '.' if any. - int rootEnd = id.IndexOf('.'); - if (rootEnd < 0) - rootEnd = id.Length; -- int rootStart = id[0] == '|' ? 1 : 0; - return id.Substring(rootStart, rootEnd - rootStart); - } -} -``` --The HTTP Protocol for Correlation also declares the `Correlation-Context` header. It's omitted here for simplicity. --## Queue instrumentation --The [W3C Trace Context](https://www.w3.org/TR/trace-context/) and [HTTP Protocol for Correlation](https://github.com/dotnet/runtime/blob/master/src/libraries/System.Diagnostics.DiagnosticSource/src/HttpCorrelationProtocol.md) pass correlation details with HTTP requests, but every queue protocol has to define how the same details are passed along the queue message. Some queue protocols, such as AMQP, allow passing more metadata. Other protocols, such as Azure Storage Queue, require the context to be encoded into the message payload. --> [!NOTE] -> Cross-component tracing isn't supported for queues yet. -> -> With HTTP, if your producer and consumer send telemetry to different Application Insights resources, transaction diagnostics experience and Application Map show transactions and map end-to-end. In the case of queues, this capability isn't supported yet. --### Service Bus queue --For tracing information, see [Distributed tracing and correlation through Azure Service Bus messaging](../../service-bus-messaging/service-bus-end-to-end-tracing.md#distributed-tracing-and-correlation-through-service-bus-messaging). --### Azure Storage queue --The following example shows how to track the [Azure Storage queue](/azure/storage/queues/storage-quickstart-queues-dotnet?tabs=passwordless%2Croles-azure-portal%2Cenvironment-variable-windows%2Csign-in-azure-cli) operations and correlate telemetry between the producer, the consumer, and Azure Storage. --The Storage queue has an HTTP API. All calls to the queue are tracked by the Application Insights Dependency Collector for HTTP requests. It's configured by default on ASP.NET and ASP.NET Core applications. With other kinds of applications, see the [Console applications documentation](./console.md). --You also might want to correlate the Application Insights operation ID with the Storage request ID. For information on how to set and get a Storage request client and a server request ID, see [Monitor, diagnose, and troubleshoot Azure Storage](../../storage/common/storage-monitoring-diagnosing-troubleshooting.md#end-to-end-tracing). --#### Enqueue --Because Storage queues support the HTTP API, all operations with the queue are automatically tracked by Application Insights. In many cases, this instrumentation should be enough. To correlate traces on the consumer side with producer traces, you must pass some correlation context similarly to how we do it in the HTTP Protocol for Correlation. --This example shows how to track the `Enqueue` operation. You can: ---The `Enqueue` operation is the child of a parent operation. An example is an incoming HTTP request. The HTTP dependency call is the child of the `Enqueue` operation and the grandchild of the incoming request. --```csharp -public async Task Enqueue(CloudQueue queue, string message) -{ - var operation = telemetryClient.StartOperation<DependencyTelemetry>("enqueue " + queue.Name); - operation.Telemetry.Type = "Azure queue"; - operation.Telemetry.Data = "Enqueue " + queue.Name; -- // MessagePayload represents your custom message and also serializes correlation identifiers into payload. - // For example, if you choose to pass payload serialized to JSON, it might look like - // {'RootId' : 'some-id', 'ParentId' : '|some-id.1.2.3.', 'message' : 'your message to process'} - var jsonPayload = JsonConvert.SerializeObject(new MessagePayload - { - RootId = operation.Telemetry.Context.Operation.Id, - ParentId = operation.Telemetry.Id, - Payload = message - }); - - CloudQueueMessage queueMessage = new CloudQueueMessage(jsonPayload); -- // Add operation.Telemetry.Id to the OperationContext to correlate Storage logs and Application Insights telemetry. - OperationContext context = new OperationContext { ClientRequestID = operation.Telemetry.Id}; -- try - { - await queue.AddMessageAsync(queueMessage, null, null, new QueueRequestOptions(), context); - } - catch (StorageException e) - { - operation.Telemetry.Properties.Add("AzureServiceRequestID", e.RequestInformation.ServiceRequestID); - operation.Telemetry.Success = false; - operation.Telemetry.ResultCode = e.RequestInformation.HttpStatusCode.ToString(); - telemetryClient.TrackException(e); - } - finally - { - // Update status code and success as appropriate. - telemetryClient.StopOperation(operation); - } -} -``` --To reduce the amount of telemetry your application reports or if you don't want to track the `Enqueue` operation for other reasons, use the `Activity` API directly: --- Create (and start) a new `Activity` instead of starting the Application Insights operation. You do *not* need to assign any properties on it except the operation name.-- Serialize `yourActivity.Id` into the message payload instead of `operation.Telemetry.Id`. You can also use `Activity.Current.Id`.--#### Dequeue --Similarly to `Enqueue`, an actual HTTP request to the Storage queue is automatically tracked by Application Insights. The `Enqueue` operation presumably happens in the parent context, such as an incoming request context. Application Insights SDKs automatically correlate such an operation, and its HTTP part, with the parent request and other telemetry reported in the same scope. --The `Dequeue` operation is tricky. The Application Insights SDK automatically tracks HTTP requests. But it doesn't know the correlation context until the message is parsed. It's not possible to correlate the HTTP request to get the message with the rest of the telemetry, especially when more than one message is received. --```csharp -public async Task<MessagePayload> Dequeue(CloudQueue queue) -{ - var operation = telemetryClient.StartOperation<DependencyTelemetry>("dequeue " + queue.Name); - operation.Telemetry.Type = "Azure queue"; - operation.Telemetry.Data = "Dequeue " + queue.Name; - - try - { - var message = await queue.GetMessageAsync(); - } - catch (StorageException e) - { - operation.telemetry.Properties.Add("AzureServiceRequestID", e.RequestInformation.ServiceRequestID); - operation.telemetry.Success = false; - operation.telemetry.ResultCode = e.RequestInformation.HttpStatusCode.ToString(); - telemetryClient.TrackException(e); - } - finally - { - // Update status code and success as appropriate. - telemetryClient.StopOperation(operation); - } -- return null; -} -``` --#### Process --In the following example, an incoming message is tracked in a manner similar to an incoming HTTP request: --```csharp -public async Task Process(MessagePayload message) -{ - // After the message is dequeued from the queue, create RequestTelemetry to track its processing. - RequestTelemetry requestTelemetry = new RequestTelemetry { Name = "process " + queueName }; - - // It might also make sense to get the name from the message. - requestTelemetry.Context.Operation.Id = message.RootId; - requestTelemetry.Context.Operation.ParentId = message.ParentId; -- var operation = telemetryClient.StartOperation(requestTelemetry); -- try - { - await ProcessMessage(); - } - catch (Exception e) - { - telemetryClient.TrackException(e); - throw; - } - finally - { - // Update status code and success as appropriate. - telemetryClient.StopOperation(operation); - } -} -``` --Similarly, other queue operations can be instrumented. A peek operation should be instrumented in a similar way as a dequeue operation. Instrumenting queue management operations isn't necessary. Application Insights tracks operations such as HTTP, and in most cases, it's enough. --When you instrument message deletion, make sure you set the operation (correlation) identifiers. Alternatively, you can use the `Activity` API. Then you don't need to set operation identifiers on the telemetry items because Application Insights SDK does it for you: --- Create a new `Activity` after you've got an item from the queue.-- Use `Activity.SetParentId(message.ParentId)` to correlate consumer and producer logs.-- Start the `Activity`.-- Track dequeue, process, and delete operations by using `Start/StopOperation` helpers. Do it from the same asynchronous control flow (execution context). In this way, they're correlated properly.-- Stop the `Activity`.-- Use `Start/StopOperation` or call `Track` telemetry manually.--### Dependency types --Application Insights uses dependency type to customize UI experiences. For queues, it recognizes the following types of `DependencyTelemetry` that improve [Transaction diagnostics experience](./transaction-search-and-diagnostics.md?tabs=transaction-diagnostics): --- `Azure queue` for Azure Storage queues-- `Azure Event Hubs` for Azure Event Hubs-- `Azure Service Bus` for Azure Service Bus--### Batch processing --With some queues, you can dequeue multiple messages with one request. Processing such messages is presumably independent and belongs to the different logical operations. It's not possible to correlate the `Dequeue` operation to a particular message being processed. --Each message should be processed in its own asynchronous control flow. For more information, see the [Outgoing dependencies tracking](#outgoing-dependencies-tracking) section. --## Long-running background tasks --Some applications start long-running operations that might be caused by user requests. From the tracing/instrumentation perspective, it's not different from request or dependency instrumentation: --```csharp -async Task BackgroundTask() -{ - var operation = telemetryClient.StartOperation<DependencyTelemetry>(taskName); - operation.Telemetry.Type = "Background"; - try - { - int progress = 0; - while (progress < 100) - { - // Process the task. - telemetryClient.TrackTrace($"done {progress++}%"); - } - // Update status code and success as appropriate. - } - catch (Exception e) - { - telemetryClient.TrackException(e); - // Update status code and success as appropriate. - throw; - } - finally - { - telemetryClient.StopOperation(operation); - } -} -``` --In this example, `telemetryClient.StartOperation` creates `DependencyTelemetry` and fills the correlation context. Let's say you have a parent operation that was created by incoming requests that scheduled the operation. As long as `BackgroundTask` starts in the same asynchronous control flow as an incoming request, it's correlated with that parent operation. `BackgroundTask` and all nested telemetry items are automatically correlated with the request that caused it, even after the request ends. --When the task starts from the background thread that doesn't have any operation (`Activity`) associated with it, `BackgroundTask` doesn't have any parent. However, it can have nested operations. All telemetry items reported from the task are correlated to the `DependencyTelemetry` created in `BackgroundTask`. --## Outgoing dependencies tracking --You can track your own dependency kind or an operation that's not supported by Application Insights. --The `Enqueue` method in the Service Bus queue or the Storage queue can serve as examples for such custom tracking. --The general approach for custom dependency tracking is to: --- Call the `TelemetryClient.StartOperation` (extension) method that fills the `DependencyTelemetry` properties that are needed for correlation and some other properties, like start, time stamp, and duration.-- Set other custom properties on the `DependencyTelemetry`, such as the name and any other context you need.-- Make a dependency call and wait for it.-- Stop the operation with `StopOperation` when it's finished.-- Handle exceptions.--```csharp -public async Task RunMyTaskAsync() -{ - using (var operation = telemetryClient.StartOperation<DependencyTelemetry>("task 1")) - { - try - { - var myTask = await StartMyTaskAsync(); - // Update status code and success as appropriate. - } - catch(...) - { - // Update status code and success as appropriate. - } - } -} -``` --Disposing an operation causes the operation to stop, so you might do it instead of calling `StopOperation`. --> [!WARNING] -> In some cases, an unhanded exception might [prevent](/dotnet/csharp/language-reference/keywords/try-finally) `finally` from being called, so operations might not be tracked. --### Parallel operations processing and tracking --Calling `StopOperation` only stops the operation that was started. If the current running operation doesn't match the one you want to stop, `StopOperation` does nothing. This situation might happen if you start multiple operations in parallel in the same execution context. --```csharp -var firstOperation = telemetryClient.StartOperation<DependencyTelemetry>("task 1"); -var firstTask = RunMyTaskAsync(); --var secondOperation = telemetryClient.StartOperation<DependencyTelemetry>("task 2"); -var secondTask = RunMyTaskAsync(); --await firstTask; --// FAILURE!!! This will do nothing and will not report telemetry for the first operation -// as currently secondOperation is active. -telemetryClient.StopOperation(firstOperation); --await secondTask; -``` --Make sure you always call `StartOperation` and process the operation in the same **async** method to isolate operations running in parallel. If the operation is synchronous (or not async), wrap the process and track with `Task.Run`. --```csharp -public void RunMyTask(string name) -{ - using (var operation = telemetryClient.StartOperation<DependencyTelemetry>(name)) - { - Process(); - // Update status code and success as appropriate. - } -} --public async Task RunAllTasks() -{ - var task1 = Task.Run(() => RunMyTask("task 1")); - var task2 = Task.Run(() => RunMyTask("task 2")); - - await Task.WhenAll(task1, task2); -} -``` --## ApplicationInsights operations vs. System.Diagnostics.Activity --`System.Diagnostics.Activity` represents the distributed tracing context and is used by frameworks and libraries to create and propagate context inside and outside of the process and correlate telemetry items. `Activity` works together with `System.Diagnostics.DiagnosticSource` as the notification mechanism between the framework/library to notify about interesting events like incoming or outgoing requests and exceptions. --Activities are first-class citizens in Application Insights. Automatic dependency and request collection rely heavily on them along with `DiagnosticSource` events. If you created `Activity` in your application, it wouldn't result in Application Insights telemetry being created. Application Insights needs to receive `DiagnosticSource` events and know the events names and payloads to translate `Activity` into telemetry. --Each Application Insights operation (request or dependency) involves `Activity`. When `StartOperation` is called, it creates `Activity` underneath. `StartOperation` is the recommended way to track request or dependency telemetries manually and ensure everything is correlated. --## Next steps --- Learn the basics of [telemetry correlation](distributed-trace-data.md) in Application Insights.-- Check out how correlated data powers [transaction diagnostics experience](./transaction-search-and-diagnostics.md?tabs=transaction-diagnostics) and [Application Map](./app-map.md).-- See the [data model](./data-model-complete.md) for Application Insights types and data model.-- Report custom [events and metrics](./api-custom-events-metrics.md) to Application Insights.-- Check out standard [configuration](configuration-with-applicationinsights-config.md#telemetry-initializers-aspnet) for context properties collection.-- Check the [System.Diagnostics.Activity User Guide](https://github.com/dotnet/runtime/blob/master/src/libraries/System.Diagnostics.DiagnosticSource/src/ActivityUserGuide.md) to see how we correlate telemetry. |
| azure-monitor | Data Model Complete | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/data-model-complete.md | - Title: Application Insights telemetry data model -description: This article describes the Application Insights telemetry data model including request, dependency, exception, trace, event, metric, PageView, and context. -- Previously updated : 01/31/2024---# Application Insights telemetry data model --[Application Insights](./app-insights-overview.md) sends telemetry from your web application to the Azure portal so that you can analyze the performance and usage of your application. The telemetry model is standardized, so it's possible to create platform- and language-independent monitoring. --Data collected by Application Insights models this typical application execution pattern. ---The following types of telemetry are used to monitor the execution of your app. The Application Insights SDK from the web application framework automatically collects these three types: --* [Request](#request): Generated to log a request received by your app. For example, the Application Insights web SDK automatically generates a Request telemetry item for each HTTP request that your web app receives. -- An *operation* is made up of the threads of execution that process a request. You can also [write code](./api-custom-events-metrics.md#trackrequest) to monitor other types of operation, such as a "wake up" in a web job or function that periodically processes data. Each operation has an ID. The ID can be used to [group](distributed-trace-data.md) all telemetry generated while your app is processing the request. Each operation either succeeds or fails and has a duration of time. -* [Exception](#exception): Typically represents an exception that causes an operation to fail. -* [Dependency](#dependency): Represents a call from your app to an external service or storage, such as a REST API or SQL. In ASP.NET, dependency calls to SQL are defined by `System.Data`. Calls to HTTP endpoints are defined by `System.Net`. --Application Insights provides three data types for custom telemetry: --* [Trace](#trace): Used either directly or through an adapter to implement diagnostics logging by using an instrumentation framework that's familiar to you, such as `Log4Net` or `System.Diagnostics`. -* [Event](#event): Typically used to capture user interaction with your service to analyze usage patterns. -* [Metric](#metric): Used to report periodic scalar measurements. --Every telemetry item can define the [context information](#context) like application version or user session ID. Context is a set of strongly typed fields that unblocks certain scenarios. When application version is properly initialized, Application Insights can detect new patterns in application behavior correlated with redeployment. --You can use session ID to calculate an outage or an issue impact on users. Calculating the distinct count of session ID values for a specific failed dependency, error trace, or critical exception gives you a good understanding of an impact. --The Application Insights telemetry model defines a way to [correlate](distributed-trace-data.md) telemetry to the operation of which it's a part. For example, a request can make a SQL Database call and record diagnostics information. You can set the correlation context for those telemetry items that tie it back to the request telemetry. --## Schema improvements --The Application Insights data model is a basic yet powerful way to model your application telemetry. We strive to keep the model simple and slim to support essential scenarios and allow the schema to be extended for advanced use. --To report data model or schema problems and suggestions, use our [GitHub repository](https://github.com/microsoft/ApplicationInsights-dotnet/issues/new/choose). --## Request --A request telemetry item in [Application Insights](./app-insights-overview.md) represents the logical sequence of execution triggered by an external request to your application. Every request execution is identified by a unique `id` and `url` that contain all the execution parameters. --You can group requests by logical `name` and define the `source` of this request. Code execution can result in `success` or `fail` and has a certain `duration`. You can further group success and failure executions by using `resultCode`. Start time for the request telemetry is defined on the envelope level. --Request telemetry supports the standard extensibility model by using custom `properties` and `measurements`. ---### Name --This field is the name of the request and it represents the code path taken to process the request. A low cardinality value allows for better grouping of requests. For HTTP requests, it represents the HTTP method and URL path template like `GET /values/{id}` without the actual `id` value. --The Application Insights web SDK sends a request name "as is" about letter case. Grouping on the UI is case sensitive, so `GET /Home/Index` is counted separately from `GET /home/INDEX` even though often they result in the same controller and action execution. The reason for that is that URLs in general are [case sensitive](https://www.w3.org/TR/WD-html40-970708/htmlweb.html). You might want to see if all `404` errors happened for URLs typed in uppercase. You can read more about request name collection by the ASP.NET web SDK in the [blog post](https://apmtips.com/posts/2015-02-23-request-name-and-url/). --**Maximum length:** 1,024 characters --### ID --ID is the identifier of a request call instance. It's used for correlation between the request and other telemetry items. The ID should be globally unique. For more information, see [Telemetry correlation in Application Insights](distributed-trace-data.md). --**Maximum length:** 128 characters --### URL --URL is the request URL with all query string parameters. --**Maximum length:** 2,048 characters --### Source --Source is the source of the request. Examples are the instrumentation key of the caller or the IP address of the caller. For more information, see [Telemetry correlation in Application Insights](distributed-trace-data.md). --**Maximum length:** 1,024 characters --### Duration --The request duration is formatted as `DD.HH:MM:SS.MMMMMM`. It must be positive and less than `1000` days. This field is required because request telemetry represents the operation with the beginning and the end. --### Response code --The response code is the result of a request execution. It's the HTTP status code for HTTP requests. It might be an `HRESULT` value or an exception type for other request types. --**Maximum length:** 1,024 characters --### Success --Success indicates whether a call was successful or unsuccessful. This field is required. When a request isn't set explicitly to `false`, it's considered to be successful. If an exception or returned error result code interrupted the operation, set this value to `false`. --For web applications, Application Insights defines a request as successful when the response code is less than `400` or equal to `401`. However, there are cases when this default mapping doesn't match the semantics of the application. --Response code `404` might indicate "no records," which can be part of regular flow. It also might indicate a broken link. For broken links, you can implement more advanced logic. You can mark broken links as failures only when those links are located on the same site by analyzing the URL referrer. Or you can mark them as failures when they're accessed from the company's mobile application. Similarly, `301` and `302` indicate failure when they're accessed from the client that doesn't support redirect. --Partially accepted content `206` might indicate a failure of an overall request. For instance, an Application Insights endpoint might receive a batch of telemetry items as a single request. It returns `206` when some items in the batch weren't processed successfully. An increasing rate of `206` indicates a problem that needs to be investigated. Similar logic applies to `207` Multi-Status, where the success might be the worst of separate response codes. --### Custom properties ---### Custom measurements ---## Dependency --Dependency telemetry (in [Application Insights](./app-insights-overview.md)) represents an interaction of the monitored component with a remote component such as SQL or an HTTP endpoint. --### Name --This field is the name of the command initiated with this dependency call. It has a low cardinality value. Examples are stored procedure name and URL path template. --### ID --ID is the identifier of a dependency call instance. It's used for correlation with the request telemetry item that corresponds to this dependency call. For more information, see [Telemetry correlation in Application Insights](distributed-trace-data.md). --### Data --This field is the command initiated by this dependency call. Examples are SQL statement and HTTP URL with all query parameters. --### Type --This field is the dependency type name. It has a low cardinality value for logical grouping of dependencies and interpretation of other fields like `commandName` and `resultCode`. Examples are SQL, Azure table, and HTTP. --### Target --This field is the target site of a dependency call. Examples are server name and host address. For more information, see [Telemetry correlation in Application Insights](distributed-trace-data.md). --### Duration --The request duration is in the format `DD.HH:MM:SS.MMMMMM`. It must be less than `1000` days. --### Result code --This field is the result code of a dependency call. Examples are SQL error code and HTTP status code. --### Success --This field is the indication of a successful or unsuccessful call. --### Custom properties ---### Custom measurements ---## Exception --In [Application Insights](./app-insights-overview.md), an instance of exception represents a handled or unhandled exception that occurred during execution of the monitored application. --### Problem ID --The problem ID identifies where the exception was thrown in code. It's used for exceptions grouping. Typically, it's a combination of an exception type and a function from the call stack. --**Maximum length:** 1,024 characters --### Severity level --This field is the trace severity level. The value can be `Verbose`, `Information`, `Warning`, `Error`, or `Critical`. --### Exception details --(To be extended) --### Custom properties ---### Custom measurements ---## Trace --Trace telemetry in [Application Insights](./app-insights-overview.md) represents `printf`-style trace statements that are text searched. `Log4Net`, `NLog`, and other text-based log file entries are translated into instances of this type. The trace doesn't have measurements as an extensibility. --### Message --Trace message. --**Maximum length:** 32,768 characters --### Severity level --Trace severity level. --**Values:** `Verbose`, `Information`, `Warning`, `Error`, and `Critical` --### Custom properties ---## Event --You can create event telemetry items (in [Application Insights](./app-insights-overview.md)) to represent an event that occurred in your application. Typically, it's a user interaction such as a button click or an order checkout. It can also be an application lifecycle event like initialization or a configuration update. --Semantically, events might or might not be correlated to requests. If used properly, event telemetry is more important than requests or traces. Events represent business telemetry and should be subject to separate, less aggressive [sampling](./api-filtering-sampling.md). --### Name --**Event name:** To allow proper grouping and useful metrics, restrict your application so that it generates a few separate event names. For example, don't use a separate name for each generated instance of an event. --**Maximum length:** 512 characters --### Custom properties ---### Custom measurements ---## Metric --[Application Insights](./app-insights-overview.md) supports two types of metric telemetry: single measurement and preaggregated metric. Single measurement is just a name and value. Preaggregated metric specifies the minimum and maximum value of the metric in the aggregation interval and the standard deviation of it. --Preaggregated metric telemetry assumes that the aggregation period was one minute. --Application Insights supports several well-known metric names. These metrics are placed into the `performanceCounters` table. --The following table shows the metrics that represent system and process counters. --| .NET name | Platform-agnostic name | Description -| - | -- | - -| `\Processor(_Total)\% Processor Time` | Work in progress... | Total machine CPU. -| `\Memory\Available Bytes` | Work in progress... | Shows the amount of physical memory, in bytes, available to processes running on the computer. It's calculated by summing the amount of space on the zeroed, free, and standby memory lists. Free memory is ready for use. Zeroed memory consists of pages of memory filled with zeros to prevent later processes from seeing data used by a previous process. Standby memory is memory that's been removed from a process's working set (its physical memory) en route to disk but is still available to be recalled. See [Memory Object](/previous-versions/ms804008(v=msdn.10)). -| `\Process(??APP_WIN32_PROC??)\% Processor Time` | Work in progress... | CPU of the process hosting the application. -| `\Process(??APP_WIN32_PROC??)\Private Bytes` | Work in progress... | Memory used by the process hosting the application. -| `\Process(??APP_WIN32_PROC??)\IO Data Bytes/sec` | Work in progress... | Rate of I/O operations run by the process hosting the application. -| `\ASP.NET Applications(??APP_W3SVC_PROC??)\Requests/Sec` | Work in progress... | Rate of requests processed by an application. -| `\.NET CLR Exceptions(??APP_CLR_PROC??)\# of Exceps Thrown / sec` | Work in progress... | Rate of exceptions thrown by an application. -| `\ASP.NET Applications(??APP_W3SVC_PROC??)\Request Execution Time` | Work in progress... | Average request execution time. -| `\ASP.NET Applications(??APP_W3SVC_PROC??)\Requests In Application Queue` | Work in progress... | Number of requests waiting for the processing in a queue. --For more information on the Metrics REST API, see [Metrics - Get](/rest/api/application-insights/metrics/get). --### Name --This field is the name of the metric you want to see in the Application Insights portal and UI. --### Value --This field is the single value for measurement. It's the sum of individual measurements for the aggregation. --### Count --This field is the metric weight of the aggregated metric. It shouldn't be set for a measurement. --### Min --This field is the minimum value of the aggregated metric. It shouldn't be set for a measurement. --### Max --This field is the maximum value of the aggregated metric. It shouldn't be set for a measurement. --### Standard deviation --This field is the standard deviation of the aggregated metric. It shouldn't be set for a measurement. --### Custom properties --The metric with the custom property `CustomPerfCounter` set to `true` indicates that the metric represents the Windows performance counter. These metrics are placed in the `performanceCounters` table, not in `customMetrics`. Also, the name of this metric is parsed to extract category, counter, and instance names. ---## PageView --PageView telemetry (in [Application Insights](./app-insights-overview.md)) is logged when an application user opens a new page of a monitored application. The `Page` in this context is a logical unit that's defined by the developer to be an application tab or a screen and isn't necessarily correlated to a browser webpage load or a refresh action. This distinction can be further understood in the context of single-page applications (SPAs), where the switch between pages isn't tied to browser page actions. The [`pageViews.duration`](/azure/azure-monitor/reference/tables/pageviews) is the time it takes for the application to present the page to the user. --> [!NOTE] -> * By default, Application Insights SDKs log single `PageView` events on each browser webpage load action, with [`pageViews.duration`](/azure/azure-monitor/reference/tables/pageviews) populated by [browser timing](#measure-browsertiming-in-application-insights). Developers can extend additional tracking of `PageView` events by using the [trackPageView API call](./api-custom-events-metrics.md#page-views). -> * The default logs retention is 30 days. If you want to view `PageView` statistics over a longer period of time, you must adjust the setting. --### Measure browserTiming in Application Insights --Modern browsers expose measurements for page load actions with the [Performance API](https://developer.mozilla.org/en-US/docs/Web/API/Performance_API). Application Insights simplifies these measurements by consolidating related timings into [standard browser metrics](../essentials/metrics-supported.md#microsoftinsightscomponents) as defined by these processing time definitions: --* **Client <--> DNS**: Client reaches out to DNS to resolve website hostname, and DNS responds with the IP address. -* **Client <--> Web Server**: Client creates TCP and then TLS handshakes with the web server. -* **Client <--> Web Server**: Client sends request payload, waits for the server to execute the request, and receives the first response packet. -* **Client <--Web Server**: Client receives the rest of the response payload bytes from the web server. -* **Client**: Client now has full response payload and has to render contents into the browser and load the DOM. --* `browserTimings/networkDuration` = #1 + #2 -* `browserTimings/sendDuration` = #3 -* `browserTimings/receiveDuration` = #4 -* `browserTimings/processingDuration` = #5 -* `browsertimings/totalDuration` = #1 + #2 + #3 + #4 + #5 -* `pageViews/duration` - * The `PageView` duration is from the browser's performance timing interface, [`PerformanceNavigationTiming.duration`](https://developer.mozilla.org/en-US/docs/Web/API/PerformanceEntry/duration). - * If `PerformanceNavigationTiming` is available, that duration is used. - - If it's not, the *deprecated* [`PerformanceTiming`](https://developer.mozilla.org/en-US/docs/Web/API/PerformanceTiming) interface is used and the delta between [`NavigationStart`](https://developer.mozilla.org/en-US/docs/Web/API/PerformanceTiming/navigationStart) and [`LoadEventEnd`](https://developer.mozilla.org/en-US/docs/Web/API/PerformanceTiming/loadEventEnd) is calculated. - * The developer specifies a duration value when logging custom `PageView` events by using the [trackPageView API call](./api-custom-events-metrics.md#page-views). ---## Context --Every telemetry item might have a strongly typed context field. Every field enables a specific monitoring scenario. Use the custom properties collection to store custom or application-specific contextual information. --### Application version --Information in the application context fields is always about the application that's sending the telemetry. The application version is used to analyze trend changes in the application behavior and its correlation to the deployments. --**Maximum length:** 1,024 --### Client IP address --This field is the IP address of the client device. IPv4 and IPv6 are supported. When telemetry is sent from a service, the location context is about the user who initiated the operation in the service. Application Insights extract the geo-location information from the client IP and then truncate it. The client IP by itself can't be used as user identifiable information. --**Maximum length:** 46 --### Device type --Originally, this field was used to indicate the type of the device the user of the application is using. Today it's used primarily to distinguish JavaScript telemetry with the device type `Browser` from server-side telemetry with the device type `PC`. --**Maximum length:** 64 --### Operation ID --This field is the unique identifier of the root operation. This identifier allows grouping telemetry across multiple components. For more information, see [Telemetry correlation](distributed-trace-data.md). Either a request or a page view creates the operation ID. All other telemetry sets this field to the value for the containing request or page view. --**Maximum length:** 128 --### Parent operation ID --This field is the unique identifier of the telemetry item's immediate parent. For more information, see [Telemetry correlation](distributed-trace-data.md). --**Maximum length:** 128 --### Operation name --This field is the name (group) of the operation. Either a request or a page view creates the operation name. All other telemetry items set this field to the value for the containing request or page view. The operation name is used for finding all the telemetry items for a group of operations (for example, `GET Home/Index`). This context property is used to answer questions like What are the typical exceptions thrown on this page? --**Maximum length:** 1,024 --### Synthetic source of the operation --This field is the name of the synthetic source. Some telemetry from the application might represent synthetic traffic. It might be the web crawler indexing the website, site availability tests, or traces from diagnostic libraries like the Application Insights SDK itself. --**Maximum length:** 1,024 --### Session ID --Session ID is the instance of the user's interaction with the app. Information in the session context fields is always about the user. When telemetry is sent from a service, the session context is about the user who initiated the operation in the service. --**Maximum length:** 64 --### Anonymous user ID --The anonymous user ID (User.Id) represents the user of the application. When telemetry is sent from a service, the user context is about the user who initiated the operation in the service. --[Sampling](./sampling.md) is one of the techniques to minimize the amount of collected telemetry. A sampling algorithm attempts to either sample in or out all the correlated telemetry. An anonymous user ID is used for sampling score generation, so an anonymous user ID should be a random-enough value. --> [!NOTE] -> The count of anonymous user IDs isn't the same as the number of unique application users. The count of anonymous user IDs is typically higher because each time the user opens your app on a different device or browser, or cleans up browser cookies, a new unique anonymous user ID is allocated. This calculation might result in counting the same physical users multiple times. --User IDs can be cross-referenced with session IDs to provide unique telemetry dimensions and establish user activity over a session duration. --Using an anonymous user ID to store a username is a misuse of the field. Use an authenticated user ID. --**Maximum length:** 128 --### Authenticated user ID --An authenticated user ID is the opposite of an anonymous user ID. This field represents the user with a friendly name. This ID is only collected by default with the ASP.NET Framework SDK's [`AuthenticatedUserIdTelemetryInitializer`](https://github.com/microsoft/ApplicationInsights-dotnet/blob/develop/WEB/Src/Web/Web/AuthenticatedUserIdTelemetryInitializer.cs). --Use the Application Insights SDK to initialize the authenticated user ID with a value that identifies the user persistently across browsers and devices. In this way, all telemetry items are attributed to that unique ID. This ID enables querying for all telemetry collected for a specific user (subject to [sampling configurations](./sampling.md) and [telemetry filtering](./api-filtering-sampling.md)). --User IDs can be cross-referenced with session IDs to provide unique telemetry dimensions and establish user activity over a session duration. --**Maximum length:** 1,024 --### Account ID --The account ID, in multitenant applications, is the tenant account ID or name that the user is acting with. It's used for more user segmentation when a user ID and an authenticated user ID aren't sufficient. Examples might be a subscription ID for the Azure portal or the blog name for a blogging platform. --**Maximum length:** 1,024 --### Cloud role --This field is the name of the role of which the application is a part. It maps directly to the role name in Azure. It can also be used to distinguish micro services, which are part of a single application. --**Maximum length:** 256 --### Cloud role instance --This field is the name of the instance where the application is running. For example, it's the computer name for on-premises or the instance name for Azure. --**Maximum length:** 256 --### Internal: SDK version --For more information, see [SDK version](https://github.com/MohanGsk/ApplicationInsights-Home/blob/master/EndpointSpecs/SDK-VERSIONS.md). --**Maximum length:** 64 --### Internal: Node name --This field represents the node name used for billing purposes. Use it to override the standard detection of nodes. --**Maximum length:** 256 --## Frequently asked questions --This section provides answers to common questions. --### How would I measure the impact of a monitoring campaign? --PageView Telemetry includes URL and you could parse the UTM parameter using a regex function in Kusto. - -Occasionally, this data might be missing or inaccurate if the user or enterprise disables sending User Agent in browser settings. The [UA Parser regexes](https://github.com/ua-parser/uap-core/blob/master/regexes.yaml) might not include all device information. Or Application Insights might not have adopted the latest updates. --### Why would a custom measurement succeed without error but the log doesn't show up? --This can occur if you're using string values. Only numeric values work with custom measurements. --## Next steps --Learn how to use the [Application Insights API for custom events and metrics](./api-custom-events-metrics.md), including: -* [Custom request telemetry](./api-custom-events-metrics.md#trackrequest) -* [Custom dependency telemetry](./api-custom-events-metrics.md#trackdependency) -* [Custom trace telemetry](./api-custom-events-metrics.md#tracktrace) -* [Custom event telemetry](./api-custom-events-metrics.md#trackevent) -* [Custom metric telemetry](./api-custom-events-metrics.md#trackmetric) --Set up dependency tracking for: -* [.NET](./asp-net-dependencies.md) -* [Java](./opentelemetry-enable.md?tabs=java) --To learn more: --* Check out [platforms](./app-insights-overview.md#supported-languages) supported by Application Insights. -* Check out standard context properties collection [configuration](./configuration-with-applicationinsights-config.md#telemetry-initializers-aspnet). -* Explore [.NET trace logs in Application Insights](./asp-net-trace-logs.md). -* Explore [Java trace logs in Application Insights](./opentelemetry-add-modify.md?tabs=java#send-custom-telemetry-using-the-application-insights-classic-api). -* Learn about the [Azure Functions built-in integration with Application Insights](../../azure-functions/functions-monitoring.md?toc=/azure/azure-monitor/toc.json) to monitor functions executions. -* Learn how to [configure an ASP.NET Core](./asp-net.md) application with Application Insights. -* Learn how to [diagnose exceptions in your web apps with Application Insights](./asp-net-exceptions.md). -* Learn how to [extend and filter telemetry](./api-filtering-sampling.md). -* Use [sampling](./sampling.md) to minimize the amount of telemetry based on data model. |
| azure-monitor | Distributed Trace Data | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/distributed-trace-data.md | - Title: Distributed tracing and telemetry correlation in Azure Application Insights -description: This article provides information about distributed tracing and telemetry correlation - Previously updated : 10/14/2023--# ms.devlang: csharp, java, javascript, python ----# What is distributed tracing and telemetry correlation? ---Modern cloud and [microservices](https://azure.com/microservices) architectures have enabled simple, independently deployable services that reduce costs while increasing availability and throughput. However, it has made overall systems more difficult to reason about and debug. Distributed tracing solves this problem by providing a performance profiler that works like call stacks for cloud and microservices architectures. --Azure Monitor provides two experiences for consuming distributed trace data: the [transaction diagnostics](./transaction-search-and-diagnostics.md?tabs=transaction-diagnostics) view for a single transaction/request and the [application map](./app-map.md) view to show how systems interact. --[Application Insights](app-insights-overview.md#application-insights-overview) can monitor each component separately and detect which component is responsible for failures or performance degradation by using distributed telemetry correlation. This article explains the data model, context-propagation techniques, protocols, and implementation of correlation tactics on different languages and platforms used by Application Insights. --## Enable distributed tracing --To enable distributed tracing for an application, add the right agent, SDK, or library to each service based on its programming language. --### Enable via Application Insights through autoinstrumentation or SDKs --The Application Insights agents and SDKs for .NET, .NET Core, Java, Node.js, and JavaScript all support distributed tracing natively. Instructions for installing and configuring each Application Insights SDK are available for: --* [.NET](asp-net.md) -* [.NET Core](asp-net-core.md) -* [Java](./opentelemetry-enable.md?tabs=java) -* [Node.js](../app/nodejs.md) -* [JavaScript](./javascript.md#enable-distributed-tracing) -* [Python](/previous-versions/azure/azure-monitor/app/opencensus-python) --With the proper Application Insights SDK installed and configured, tracing information is automatically collected for popular frameworks, libraries, and technologies by SDK dependency autocollectors. The full list of supported technologies is available in the [Dependency autocollection documentation](asp-net-dependencies.md#dependency-auto-collection). -- Any technology also can be tracked manually with a call to [TrackDependency](./api-custom-events-metrics.md) on the [TelemetryClient](./api-custom-events-metrics.md). --### Enable via OpenTelemetry --Application Insights now supports distributed tracing through [OpenTelemetry](https://opentelemetry.io/). OpenTelemetry provides a vendor-neutral instrumentation to send traces, metrics, and logs to Application Insights. Initially, the OpenTelemetry community took on distributed tracing. Metrics and logs are still in progress. --A complete observability story includes all three pillars. Check the status of our [Azure Monitor OpenTelemetry-based offerings](opentelemetry-enable.md) to see the latest status on what's included, which offerings are generally available, and support options. --The following pages consist of language-by-language guidance to enable and configure Microsoft's OpenTelemetry-based offerings. Importantly, we share the available functionality and limitations of each offering so you can determine whether OpenTelemetry is right for your project. --* [.NET](opentelemetry-enable.md?tabs=net) -* [Java](opentelemetry-enable.md?tabs=java) -* [Node.js](opentelemetry-enable.md?tabs=nodejs) -* [Python](opentelemetry-enable.md?tabs=python) --### Enable via OpenCensus --In addition to the Application Insights SDKs, Application Insights also supports distributed tracing through [OpenCensus](https://opencensus.io/). OpenCensus is an open-source, vendor-agnostic, single distribution of libraries to provide metrics collection and distributed tracing for services. It also enables the open-source community to enable distributed tracing with popular technologies like Redis, Memcached, or MongoDB. [Microsoft collaborates on OpenCensus with several other monitoring and cloud partners](https://open.microsoft.com/2018/06/13/microsoft-joins-the-opencensus-project/). --For more information on OpenCensus for Python, see [Set up Azure Monitor for your Python application](/previous-versions/azure/azure-monitor/app/opencensus-python). --The OpenCensus website maintains API reference documentation for [Python](https://opencensus.io/api/python/trace/usage.html), [Go](https://godoc.org/go.opencensus.io), and various guides for using OpenCensus. --## Data model for telemetry correlation --Application Insights defines a [data model](../../azure-monitor/app/data-model-complete.md) for distributed telemetry correlation. To associate telemetry with a logical operation, every telemetry item has a context field called `operation_Id`. Every telemetry item in the distributed trace shares this identifier. So even if you lose telemetry from a single layer, you can still associate telemetry reported by other components. --A distributed logical operation typically consists of a set of smaller operations that are requests processed by one of the components. [Request telemetry](../../azure-monitor/app/data-model-complete.md#request) defines these operations. Every request telemetry item has its own `id` that identifies it uniquely and globally. And all telemetry items (such as traces and exceptions) that are associated with the request should set the `operation_parentId` to the value of the request `id`. --[Dependency telemetry](../../azure-monitor/app/data-model-complete.md#dependency) represents every outgoing operation, such as an HTTP call to another component. It also defines its own `id` that's globally unique. Request telemetry, initiated by this dependency call, uses this `id` as its `operation_parentId`. --You can build a view of the distributed logical operation by using `operation_Id`, `operation_parentId`, and `request.id` with `dependency.id`. These fields also define the causality order of telemetry calls. --In a microservices environment, traces from components can go to different storage items. Every component can have its own connection string in Application Insights. To get telemetry for the logical operation, Application Insights queries data from every storage item. --When the number of storage items is large, you need a hint about where to look next. The Application Insights data model defines two fields to solve this problem: `request.source` and `dependency.target`. The first field identifies the component that initiated the dependency request. The second field identifies which component returned the response of the dependency call. --For information on querying from multiple disparate instances by using the `app` query expression, see [app() expression in Azure Monitor query](../logs/app-expression.md#app-expression-in-azure-monitor-query). --## Example --Let's look at an example. An application called Stock Prices shows the current market price of a stock by using an external API called Stock. The Stock Prices application has a page called Stock page that the client web browser opens by using `GET /Home/Stock`. The application queries the Stock API by using the HTTP call `GET /api/stock/value`. --You can analyze the resulting telemetry by running a query: --```kusto -(requests | union dependencies | union pageViews) -| where operation_Id == "STYz" -| project timestamp, itemType, name, id, operation_ParentId, operation_Id -``` --In the results, all telemetry items share the root `operation_Id`. When an Ajax call is made from the page, a new unique ID (`qJSXU`) is assigned to the dependency telemetry, and the ID of the pageView is used as `operation_ParentId`. The server request then uses the Ajax ID as `operation_ParentId`. --| itemType | name | ID | operation_ParentId | operation_Id | -|||-|-|-| -| pageView | Stock page | `STYz` | | `STYz` | -| dependency | GET /Home/Stock | `qJSXU` | `STYz` | `STYz` | -| request | GET Home/Stock | `KqKwlrSt9PA=` | `qJSXU` | `STYz` | -| dependency | GET /api/stock/value | `bBrf2L7mm2g=` | `KqKwlrSt9PA=` | `STYz` | --When the call `GET /api/stock/value` is made to an external service, you need to know the identity of that server so you can set the `dependency.target` field appropriately. When the external service doesn't support monitoring, `target` is set to the host name of the service. An example is `stock-prices-api.com`. But if the service identifies itself by returning a predefined HTTP header, `target` contains the service identity that allows Application Insights to build a distributed trace by querying telemetry from that service. --## Correlation headers using W3C TraceContext --Application Insights is transitioning to [W3C Trace-Context](https://w3c.github.io/trace-context/), which defines: --- `traceparent`: Carries the globally unique operation ID and unique identifier of the call.-- `tracestate`: Carries system-specific tracing context.--The latest version of the Application Insights SDK supports the Trace-Context protocol, but you might need to opt in to it. (Backward compatibility with the previous correlation protocol supported by the Application Insights SDK is maintained.) --The [correlation HTTP protocol, also called Request-Id](https://github.com/dotnet/runtime/blob/master/src/libraries/System.Diagnostics.DiagnosticSource/src/HttpCorrelationProtocol.md), is being deprecated. This protocol defines two headers: --- `Request-Id`: Carries the globally unique ID of the call.-- `Correlation-Context`: Carries the name-value pairs collection of the distributed trace properties.--Application Insights also defines the [extension](https://github.com/lmolkov) for the correlation HTTP protocol. It uses `Request-Context` name-value pairs to propagate the collection of properties used by the immediate caller or callee. The Application Insights SDK uses this header to set the `dependency.target` and `request.source` fields. --The [W3C Trace-Context](https://w3c.github.io/trace-context/) and Application Insights data models map in the following way: --| Application Insights | W3C TraceContext | -| |-| -| `Id` of `Request` and `Dependency` | [parent-id](https://w3c.github.io/trace-context/#parent-id) | -| `Operation_Id` | [trace-id](https://w3c.github.io/trace-context/#trace-id) | -| `Operation_ParentId` | [parent-id](https://w3c.github.io/trace-context/#parent-id) of this span's parent span. This field must be empty if it's a root span.| --For more information, see [Application Insights telemetry data model](../../azure-monitor/app/data-model-complete.md). --### Enable W3C distributed tracing support for .NET apps --W3C TraceContext-based distributed tracing is enabled by default in all recent -.NET Framework/.NET Core SDKs, along with backward compatibility with legacy Request-Id protocol. --### Enable W3C distributed tracing support for Java apps --#### Java 3.0 agent -- Java 3.0 agent supports W3C out of the box, and no more configuration is needed. --#### Java SDK --- **Incoming configuration**-- For Java EE apps, add the following code to the `<TelemetryModules>` tag in *ApplicationInsights.xml*: -- ```xml - <Add type="com.microsoft.applicationinsights.web.extensibility.modules.WebRequestTrackingTelemetryModule> - <Param name = "W3CEnabled" value ="true"/> - <Param name ="enableW3CBackCompat" value = "true" /> - </Add> - ``` -- For Spring Boot apps, add these properties: -- - `azure.application-insights.web.enable-W3C=true` - - `azure.application-insights.web.enable-W3C-backcompat-mode=true` --- **Outgoing configuration**-- Add the following code to *AI-Agent.xml*: -- ```xml - <Instrumentation> - <BuiltIn enabled="true"> - <HTTP enabled="true" W3C="true" enableW3CBackCompat="true"/> - </BuiltIn> - </Instrumentation> - ``` -- > [!NOTE] - > Backward compatibility mode is enabled by default, and the `enableW3CBackCompat` parameter is optional. Use it only when you want to turn backward compatibility off. - > - > Ideally, you'll' turn off this mode when all your services are updated to newer versions of SDKs that support the W3C protocol. We highly recommend that you move to these newer SDKs as soon as possible. --It's important to make sure the incoming and outgoing configurations are exactly the same. --### Enable W3C distributed tracing support for web apps --This feature is enabled by default for JavaScript and the headers are automatically included when the hosting page domain is the same as the domain the requests are sent to (for example, the hosting page is `example.com` and the Ajax requests are sent to `example.com`). To change the distributed tracing mode, use the [`distributedTracingMode` configuration field](./javascript-sdk-configuration.md#sdk-configuration). AI_AND_W3C is provided by default for backward compatibility with any legacy services instrumented by Application Insights. --- **[npm-based setup](./javascript-sdk.md?tabs=npmpackage#get-started)**-- Add the following configuration: - ```JavaScript - distributedTracingMode: DistributedTracingModes.W3C - ``` --- **[JavaScript (Web) SDK Loader Script-based setup](./javascript-sdk.md?tabs=javascriptwebsdkloaderscript#get-started)**-- Add the following configuration: - ``` - distributedTracingMode: 2 // DistributedTracingModes.W3C - ``` --If the XMLHttpRequest or Fetch Ajax requests are sent to a different domain host, including subdomains, the correlation headers aren't included by default. To enable this feature, set the [`enableCorsCorrelation` configuration field](./javascript-sdk-configuration.md#sdk-configuration) to `true`. If you set `enableCorsCorrelation` to `true`, all XMLHttpRequest and Fetch Ajax requests include the correlation headers. As a result, if the application on the server that is being called doesn't support the `traceparent` header, the request might fail, depending on whether the browser / version can validate the request based on which headers the server accepts. You can use the [`correlationHeaderExcludedDomains` configuration field](./javascript-sdk-configuration.md#sdk-configuration) to exclude the server's domain from cross-component correlation header injection. For example, you can use `correlationHeaderExcludedDomains: ['*.auth0.com']` to exclude correlation headers from requests sent to the Auth0 identity provider. --> [!IMPORTANT] -> To see all configurations required to enable correlation, see the [JavaScript correlation documentation](./javascript.md#enable-distributed-tracing). --## Telemetry correlation in OpenCensus Python --OpenCensus Python supports [W3C Trace-Context](https://w3c.github.io/trace-context/) without requiring extra configuration. --For a reference, you can find the OpenCensus data model on [this GitHub page](https://github.com/census-instrumentation/opencensus-specs/tree/master/trace). --### Incoming request correlation --OpenCensus Python correlates W3C Trace-Context headers from incoming requests to the spans that are generated from the requests themselves. OpenCensus correlates automatically with integrations for these popular web application frameworks: Flask, Django, and Pyramid. You just need to populate the W3C Trace-Context headers with the [correct format](https://www.w3.org/TR/trace-context/#trace-context-http-headers-format) and send them with the request. --Explore this sample Flask application. Install Flask, OpenCensus, and the extensions for Flask and Azure. --```shell --pip install flask opencensus opencensus-ext-flask opencensus-ext-azure --``` --You need to add your Application Insights connection string to the environment variable. --```shell -APPLICATIONINSIGHTS_CONNECTION_STRING=<appinsights-connection-string> -``` --**Sample Flask Application** --```python -from flask import Flask -from opencensus.ext.azure.trace_exporter import AzureExporter -from opencensus.ext.flask.flask_middleware import FlaskMiddleware -from opencensus.trace.samplers import ProbabilitySampler --app = Flask(__name__) -middleware = FlaskMiddleware( - app, - exporter=AzureExporter( - connection_string='<appinsights-connection-string>', # or set environment variable APPLICATION_INSIGHTS_CONNECTION_STRING - ), - sampler=ProbabilitySampler(rate=1.0), -) --@app.route('/') -def hello(): - return 'Hello World!' --if __name__ == '__main__': - app.run(host='localhost', port=8080, threaded=True) -``` --This code runs a sample Flask application on your local machine, listening to port `8080`. To correlate trace context, you send a request to the endpoint. In this example, you can use a `curl` command: --``` -curl --header "traceparent: 00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01" localhost:8080 -``` --By looking at the [Trace-Context header format](https://www.w3.org/TR/trace-context/#trace-context-http-headers-format), you can derive the following information: --`version`: `00` --`trace-id`: `4bf92f3577b34da6a3ce929d0e0e4736` --`parent-id/span-id`: `00f067aa0ba902b7` --`trace-flags`: `01` --If you look at the request entry that was sent to Azure Monitor, you can see fields populated with the trace header information. You can find the data under **Logs (Analytics)** in the Azure Monitor Application Insights resource. ---The `id` field is in the format `<trace-id>.<span-id>`, where `trace-id` is taken from the trace header that was passed in the request and `span-id` is a generated 8-byte array for this span. --The `operation_ParentId` field is in the format `<trace-id>.<parent-id>`, where both `trace-id` and `parent-id` are taken from the trace header that was passed in the request. --### Log correlation --OpenCensus Python enables you to correlate logs by adding a trace ID, a span ID, and a sampling flag to log records. You add these attributes by installing OpenCensus [logging integration](https://pypi.org/project/opencensus-ext-logging/). The following attributes are added to Python `LogRecord` objects: `traceId`, `spanId`, and `traceSampled` (applicable only for loggers that are created after the integration). --Install the OpenCensus logging integration: --```console -python -m pip install opencensus-ext-logging -``` --**Sample application** --```python -import logging --from opencensus.trace import config_integration -from opencensus.trace.samplers import AlwaysOnSampler -from opencensus.trace.tracer import Tracer --config_integration.trace_integrations(['logging']) -logging.basicConfig(format='%(asctime)s traceId=%(traceId)s spanId=%(spanId)s %(message)s') -tracer = Tracer(sampler=AlwaysOnSampler()) --logger = logging.getLogger(__name__) -logger.warning('Before the span') -with tracer.span(name='hello'): - logger.warning('In the span') -logger.warning('After the span') -``` -When this code runs, the following prints in the console: -``` -2019-10-17 11:25:59,382 traceId=c54cb1d4bbbec5864bf0917c64aeacdc spanId=0000000000000000 Before the span -2019-10-17 11:25:59,384 traceId=c54cb1d4bbbec5864bf0917c64aeacdc spanId=70da28f5a4831014 In the span -2019-10-17 11:25:59,385 traceId=c54cb1d4bbbec5864bf0917c64aeacdc spanId=0000000000000000 After the span -``` --Notice that there's a `spanId` present for the log message that's within the span. The `spanId` is the same as that which belongs to the span named `hello`. --You can export the log data by using `AzureLogHandler`. For more information, see [Set up Azure Monitor for your Python application](/previous-versions/azure/azure-monitor/app/opencensus-python#logs). --We can also pass trace information from one component to another for proper correlation. For example, consider a scenario where there are two components, `module1` and `module2`. Module 1 calls functions in Module 2. To get logs from both `module1` and `module2` in a single trace, we can use the following approach: ---```python -# module1.py -import logging --from opencensus.trace import config_integration -from opencensus.trace.samplers import AlwaysOnSampler -from opencensus.trace.tracer import Tracer -from module_2 import function_1 --config_integration.trace_integrations(["logging"]) -logging.basicConfig( - format="%(asctime)s traceId=%(traceId)s spanId=%(spanId)s %(message)s" -) -tracer = Tracer(sampler=AlwaysOnSampler()) --logger = logging.getLogger(__name__) -logger.warning("Before the span") --with tracer.span(name="hello"): - logger.warning("In the span") - function_1(logger, tracer) -logger.warning("After the span") -``` --```python -# module_2.py -import logging --from opencensus.trace import config_integration -from opencensus.trace.samplers import AlwaysOnSampler -from opencensus.trace.tracer import Tracer --config_integration.trace_integrations(["logging"]) -logging.basicConfig( - format="%(asctime)s traceId=%(traceId)s spanId=%(spanId)s %(message)s" -) -logger = logging.getLogger(__name__) -tracer = Tracer(sampler=AlwaysOnSampler()) ---def function_1(logger=logger, parent_tracer=None): - if parent_tracer is not None: - tracer = Tracer( - span_context=parent_tracer.span_context, - sampler=AlwaysOnSampler(), - ) - else: - tracer = Tracer(sampler=AlwaysOnSampler()) -- with tracer.span("function_1"): - logger.info("In function_1") --``` --## Telemetry correlation in .NET --Correlation is handled by default when onboarding an app. No special actions are required. --* [Application Insights for ASP.NET Core applications](asp-net-core.md#application-insights-for-aspnet-core-applications) -* [Configure Application Insights for your ASP.NET website](asp-net.md#configure-application-insights-for-your-aspnet-website) -* [Application Insights for Worker Service applications (non-HTTP applications)](worker-service.md#application-insights-for-worker-service-applications-non-http-applications) --.NET runtime supports distributed with the help of [Activity](https://github.com/dotnet/runtime/blob/master/src/libraries/System.Diagnostics.DiagnosticSource/src/ActivityUserGuide.md) and [DiagnosticSource](https://github.com/dotnet/runtime/blob/master/src/libraries/System.Diagnostics.DiagnosticSource/src/DiagnosticSourceUsersGuide.md) --The Application Insights .NET SDK uses `DiagnosticSource` and `Activity` to collect and correlate telemetry. --<a name="java-correlation"></a> -## Telemetry correlation in Java --[Java agent](./opentelemetry-enable.md?tabs=java) supports automatic correlation of telemetry. It automatically populates `operation_id` for all telemetry (like traces, exceptions, and custom events) issued within the scope of a request. It also propagates the correlation headers that were described earlier for service-to-service calls via HTTP, if the [Java SDK agent](deprecated-java-2x.md#monitor-dependencies-caught-exceptions-and-method-execution-times-in-java-web-apps) is configured. --> [!NOTE] -> Application Insights Java agent autocollects requests and dependencies for JMS, Kafka, Netty/Webflux, and more. For Java SDK, only calls made via Apache HttpClient are supported for the correlation feature. Automatic context propagation across messaging technologies like Kafka, RabbitMQ, and Azure Service Bus isn't supported in the SDK. --To collect custom telemetry, you need to instrument the application with Java 2.6 SDK. --### Role names --You might want to customize the way component names are displayed in [Application Map](../../azure-monitor/app/app-map.md). To do so, you can manually set `cloud_RoleName` by taking one of the following actions: --- For Application Insights Java, set the cloud role name as follows:-- ```json - { - "role": { - "name": "my cloud role name" - } - } - ``` -- You can also set the cloud role name by using the environment variable `APPLICATIONINSIGHTS_ROLE_NAME`. --- With Application Insights Java SDK 2.5.0 and later, you can specify `cloud_RoleName`- by adding `<RoleName>` to your *ApplicationInsights.xml* file: -- :::image type="content" source="media/migrate-from-instrumentation-keys-to-connection-strings/migrate-from-instrumentation-keys-to-connection-strings.png" alt-text="Screenshot that shows Application Insights overview and connection string." lightbox="media/migrate-from-instrumentation-keys-to-connection-strings/migrate-from-instrumentation-keys-to-connection-strings.png"::: -- ```xml - <?xml version="1.0" encoding="utf-8"?> - <ApplicationInsights xmlns="http://schemas.microsoft.com/ApplicationInsights/2013/Settings" schemaVersion="2014-05-30"> - <ConnectionString>InstrumentationKey=00000000-0000-0000-0000-000000000000</ConnectionString> - <RoleName>** Your role name **</RoleName> - ... - </ApplicationInsights> - ``` --- If you use Spring Boot with the Application Insights Spring Boot Starter, set your custom name for the application in the *application.properties* file:-- `spring.application.name=<name-of-app>` --You can also set the cloud role name via environment variable or system property. See [Configuring cloud role name](./java-standalone-config.md#cloud-role-name) for details. --## Next steps --- [Application map](./app-map.md)-- Write [custom telemetry](../../azure-monitor/app/api-custom-events-metrics.md).-- For advanced correlation scenarios in ASP.NET Core and ASP.NET, see [Track custom operations](custom-operations-tracking.md).-- Learn more about [setting cloud_RoleName](./app-map.md#set-or-override-cloud-role-name) for other SDKs.-- Onboard all components of your microservice on Application Insights. Check out the [supported platforms](./app-insights-overview.md#supported-languages).-- See the [data model](./data-model-complete.md) for Application Insights types.-- Learn how to [extend and filter telemetry](./api-filtering-sampling.md).-- Review the [Application Insights config reference](configuration-with-applicationinsights-config.md). |
| azure-monitor | Eventcounters | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/eventcounters.md | - Title: Event counters in Application Insights | Microsoft Docs -description: Monitor system and custom .NET/.NET Core EventCounters in Application Insights. - Previously updated : 01/31/2024-----# EventCounters introduction --[`EventCounter`](/dotnet/core/diagnostics/event-counters) is .NET/.NET Core mechanism to publish and consume counters or statistics. EventCounters are supported in all OS platforms - Windows, Linux, and macOS. It can be thought of as a cross-platform equivalent for the [PerformanceCounters](/dotnet/api/system.diagnostics.performancecounter) that is only supported in Windows systems. --While users can publish any custom `EventCounters` to meet their needs, [.NET](/dotnet/fundamentals/) publishes a set of these counters by default. This document walks through the steps required to collect and view `EventCounters` (system defined or user defined) in Azure Application Insights. ---## Using Application Insights to collect EventCounters --Application Insights supports collecting `EventCounters` with its `EventCounterCollectionModule`, which is part of the newly released NuGet package [Microsoft.ApplicationInsights.EventCounterCollector](https://www.nuget.org/packages/Microsoft.ApplicationInsights.EventCounterCollector). `EventCounterCollectionModule` is automatically enabled when using either [AspNetCore](asp-net-core.md) or [WorkerService](worker-service.md). `EventCounterCollectionModule` collects counters with a nonconfigurable collection frequency of 60 seconds. There are no special permissions required to collect EventCounters. For ASP.NET Core applications, you also want to add the [Microsoft.ApplicationInsights.AspNetCore](https://www.nuget.org/packages/Microsoft.ApplicationInsights.AspNetCore) package. --```dotnetcli -dotnet add package Microsoft.ApplicationInsights.EventCounterCollector -dotnet add package Microsoft.ApplicationInsights.AspNetCore -``` --## Default counters collected --Starting with 2.15.0 version of either [AspNetCore SDK](asp-net-core.md) or [WorkerService SDK](worker-service.md), no counters are collected by default. The module itself is enabled, so users can add the desired counters to -collect them. --To get a list of well known counters published by the .NET Runtime, see [Available Counters](/dotnet/core/diagnostics/event-counters#available-counters) document. --## Customizing counters to be collected --The following example shows how to add/remove counters. This customization would be done as part of your application service configuration after Application Insights telemetry collection is enabled using either `AddApplicationInsightsTelemetry()` or `AddApplicationInsightsWorkerService()`. Following is an example code from an ASP.NET Core application. For other type of applications, refer to [this](worker-service.md#configure-or-remove-default-telemetry-modules) document. ---# [ASP.NET Core 6.0+](#tab/dotnet6) --```csharp -using Microsoft.ApplicationInsights.Extensibility.EventCounterCollector; -using Microsoft.Extensions.DependencyInjection; --builder.Services.ConfigureTelemetryModule<EventCounterCollectionModule>( - (module, o) => - { - // Removes all default counters, if any. - module.Counters.Clear(); -- // Adds a user defined counter "MyCounter" from EventSource named "MyEventSource" - module.Counters.Add( - new EventCounterCollectionRequest("MyEventSource", "MyCounter")); -- // Adds the system counter "gen-0-size" from "System.Runtime" - module.Counters.Add( - new EventCounterCollectionRequest("System.Runtime", "gen-0-size")); - } - ); -``` --# [ASP.NET Core 3.1](#tab/dotnet31) --```csharp -using Microsoft.ApplicationInsights.Extensibility.EventCounterCollector; -using Microsoft.Extensions.DependencyInjection; --public void ConfigureServices(IServiceCollection services) -{ - //... other code... -- // The following code shows how to configure the module to collect - // additional counters. - services.ConfigureTelemetryModule<EventCounterCollectionModule>( - (module, o) => - { - // Removes all default counters, if any. - module.Counters.Clear(); -- // Adds a user defined counter "MyCounter" from EventSource named "MyEventSource" - module.Counters.Add( - new EventCounterCollectionRequest("MyEventSource", "MyCounter")); -- // Adds the system counter "gen-0-size" from "System.Runtime" - module.Counters.Add( - new EventCounterCollectionRequest("System.Runtime", "gen-0-size")); - } - ); -} -``` ----## Disabling EventCounter collection module --`EventCounterCollectionModule` can be disabled by using `ApplicationInsightsServiceOptions`. --The following example uses the ASP.NET Core SDK. --# [ASP.NET Core 6.0+](#tab/dotnet6) --```csharp -using Microsoft.ApplicationInsights.AspNetCore.Extensions; -using Microsoft.Extensions.DependencyInjection; --var applicationInsightsServiceOptions = new ApplicationInsightsServiceOptions(); -applicationInsightsServiceOptions.EnableEventCounterCollectionModule = false; -builder.Services.AddApplicationInsightsTelemetry(applicationInsightsServiceOptions); -``` --# [ASP.NET Core 3.1](#tab/dotnet31) --```csharp -using Microsoft.ApplicationInsights.AspNetCore.Extensions; -using Microsoft.Extensions.DependencyInjection; --public void ConfigureServices(IServiceCollection services) -{ - //... other code... -- var applicationInsightsServiceOptions = new ApplicationInsightsServiceOptions(); - applicationInsightsServiceOptions.EnableEventCounterCollectionModule = false; - services.AddApplicationInsightsTelemetry(applicationInsightsServiceOptions); -} -``` ----A similar approach can be used for the WorkerService SDK as well, but the namespace must be changed as shown in the following example. --# [ASP.NET Core 6.0+](#tab/dotnet6) --```csharp -using Microsoft.ApplicationInsights.AspNetCore.Extensions; -using Microsoft.Extensions.DependencyInjection; --var applicationInsightsServiceOptions = new ApplicationInsightsServiceOptions(); -applicationInsightsServiceOptions.EnableEventCounterCollectionModule = false; -builder.Services.AddApplicationInsightsTelemetry(applicationInsightsServiceOptions); -``` --# [ASP.NET Core 3.1](#tab/dotnet31) --```csharp -using Microsoft.ApplicationInsights.WorkerService; -using Microsoft.Extensions.DependencyInjection; --public void ConfigureServices(IServiceCollection services) -{ - //... other code... -- var applicationInsightsServiceOptions = new ApplicationInsightsServiceOptions(); - applicationInsightsServiceOptions.EnableEventCounterCollectionModule = false; - services.AddApplicationInsightsTelemetryWorkerService(applicationInsightsServiceOptions); -} -``` ----## Event counters in Metric Explorer --To view EventCounter metrics in [Metric Explorer](../essentials/metrics-charts.md), select Application Insights resource, and chose Log-based metrics as metric namespace. Then EventCounter metrics get displayed under Custom category. --> [!div class="mx-imgBorder"] -> :::image type="content" source="./media/event-counters/metrics-explorer-counter-list.png" lightbox="./media/event-counters/metrics-explorer-counter-list.png" alt-text="Event counters reported in Application Insights Metric Explorer"::: --## Event counters in Analytics --You can also search and display event counter reports in [Analytics](../logs/log-query-overview.md), in the **customMetrics** table. --For example, run the following query to see what counters are collected and available to query: --```Kusto -customMetrics | summarize avg(value) by name -``` --> [!div class="mx-imgBorder"] -> :::image type="content" source="./media/event-counters/analytics-event-counters.png" lightbox="./media/event-counters/analytics-event-counters.png" alt-text="Event counters reported in Application Insights Analytics"::: --To get a chart of a specific counter (for example: `ThreadPool Completed Work Item Count`) over the recent period, run the following query. --```Kusto -customMetrics -| where name contains "System.Runtime|ThreadPool Completed Work Item Count" -| where timestamp >= ago(1h) -| summarize avg(value) by cloud_RoleInstance, bin(timestamp, 1m) -| render timechart -``` -> [!div class="mx-imgBorder"] -> :::image type="content" source="./media/event-counters/analytics-completeditems-counters.png" lightbox="./media/event-counters/analytics-completeditems-counters.png" alt-text="Chat of a single counter in Application Insights"::: --Like other telemetry, **customMetrics** also has a column `cloud_RoleInstance` that indicates the identity of the host server instance on which your app is running. The above query shows the counter value per instance, and can be used to compare performance of different server instances. --## Alerts -Like other metrics, you can [set an alert](../alerts/alerts-log.md) to warn you if an event counter goes outside a limit you specify. Open the Alerts pane and select Add Alert. --## Frequently asked questions --### Can I see EventCounters in Live Metrics? --Live Metrics don't show EventCounters as of today. Use Metric Explorer or Analytics to see the telemetry. --### I have enabled Application Insights from Azure Web App Portal. Why can't I see EventCounters? -- [Application Insights extension](./azure-web-apps.md) for ASP.NET Core doesn't yet support this feature. --## <a name="next"></a>Next steps --* [Dependency tracking](./asp-net-dependencies.md) |
| azure-monitor | Failures And Performance Views | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/failures-and-performance-views.md | - Title: Failures and Performance views in Application Insights | Microsoft Docs -description: Monitor application performance and failures with Application Insights. --- Previously updated : 02/15/2024----# Failures and Performance views --[Application Insights](./app-insights-overview.md) features two key tools: the Failures view and the Performance view. The Failures view tracks errors, exceptions, and faults, offering clear insights for fast problem-solving and enhanced stability. The Performance view quickly identifies and helps resolve application bottlenecks by displaying response times and operation counts. Together, they ensure the ongoing health and efficiency of web applications. --## [Failures view](#tab/failures-view) --Application Insights comes with a curated Application Performance Management (APM) experience to help you diagnose failures in your monitored applications. Select the **Failures** option in the Application Insights resource menu on the left, under **Investigate**, to get a list of all failures collected for your application and drill into each one. ---To continue your investigation into the root cause of the error or exception, you can drill into the problematic transaction for a detailed end-to-end transaction view that includes dependencies and exception details. ---You can also diagnose failures in your application or its components from the application map, by selecting **Investigate failures** from the triage pane of [Application Map](app-map.md). --## [Performance view](#tab/performance-view) --You can further investigate slow transactions to identify slow requests and server-side dependencies. Select the **Performance** option in the Application Insights resource menu on the left, under **Investigate**, to get a list of operations collected for your application and drill into each one. ---You can also analyze performance in your application or its components from the application map, by selecting **Investigate performance** from the triage pane of [Application Map](app-map.md). --On the **Performance** page, you can isolate slow transactions by selecting the time range, operation name, and durations of interest. You're also prompted with automatically identified anomalies and commonalities across transactions. From this page, you can drill into an individual transaction for an end-to-end view of transaction details with a Gantt chart of dependencies. --If you instrument your web pages with Application Insights, you can also gain visibility into page views, browser operations, and dependencies. Collecting this browser data requires adding a script to your web pages. After you add the script, you can access page views and their associated performance metrics by selecting the **Browser** toggle. ----## Next steps --* Learn more about using [Application Map](app-map.md) to spot performance bottlenecks and failure hotspots across all components of your application. -* Learn more about using the [Availability view](availability-overview.md) to set up recurring tests to monitor availability and responsiveness for your application. |
| azure-monitor | Get Metric | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/get-metric.md | - Title: Get-Metric in Azure Monitor Application Insights -description: Learn how to effectively use the GetMetric() call to capture locally preaggregated metrics for .NET and .NET Core applications with Azure Monitor Application Insights. -- Previously updated : 01/31/2024-----# Custom metric collection in .NET and .NET Core --The Azure Monitor Application Insights .NET and .NET Core SDKs have two different methods of collecting custom metrics: `TrackMetric()` and `GetMetric()`. The key difference between these two methods is local aggregation. The `TrackMetric()` method lacks preaggregation. The `GetMetric()` method has preaggregation. We recommend that you use aggregation, so `TrackMetric()` is no longer the preferred method of collecting custom metrics. This article walks you through using the `GetMetric()` method and some of the rationale behind how it works. ---## Preaggregating vs. non-preaggregating API --The `TrackMetric()` method sends raw telemetry denoting a metric. It's inefficient to send a single telemetry item for each value. The `TrackMetric()` method is also inefficient in terms of performance because every `TrackMetric(item)` goes through the full SDK pipeline of telemetry initializers and processors. --Unlike `TrackMetric()`, `GetMetric()` handles local preaggregation for you and then only submits an aggregated summary metric at a fixed interval of one minute. If you need to closely monitor some custom metric at the second or even millisecond level, you can do so while only incurring the storage and network traffic cost of only monitoring every minute. This behavior also greatly reduces the risk of throttling occurring because the total number of telemetry items that need to be sent for an aggregated metric are greatly reduced. --In Application Insights, custom metrics collected via `TrackMetric()` and `GetMetric()` aren't subject to [sampling](./sampling.md). Sampling important metrics can lead to scenarios where alerting you might have built around those metrics could become unreliable. By never sampling your custom metrics, you can generally be confident that when your alert thresholds are breached, an alert fires. Because custom metrics aren't sampled, there are some potential concerns. --Trend tracking in a metric every second, or at an even more granular interval, can result in: --- **Increased data storage costs.** There's a cost associated with how much data you send to Azure Monitor. The more data you send, the greater the overall cost of monitoring.-- **Increased network traffic or performance overhead.** In some scenarios, this overhead could have both a monetary and application performance cost.-- **Risk of ingestion throttling.** Azure Monitor drops ("throttles") data points when your app sends a high rate of telemetry in a short time interval.--Throttling is a concern because it can lead to missed alerts. The condition to trigger an alert could occur locally and then be dropped at the ingestion endpoint because of too much data being sent. We don't recommend using `TrackMetric()` for .NET and .NET Core unless you've implemented your own local aggregation logic. If you're trying to track every instance an event occurs over a given time period, you might find that [`TrackEvent()`](./api-custom-events-metrics.md#trackevent) is a better fit. Keep in mind that unlike custom metrics, custom events are subject to sampling. You can still use `TrackMetric()` even without writing your own local preaggregation. But if you do so, be aware of the pitfalls. --In summary, we recommend `GetMetric()` because it does preaggregation, it accumulates values from all the `Track()` calls, and sends a summary/aggregate once every minute. The `GetMetric()` method can significantly reduce the cost and performance overhead by sending fewer data points while still collecting all relevant information. --> [!NOTE] -> Only the .NET and .NET Core SDKs have a `GetMetric()` method. If you're using Java, see [Sending custom metrics using micrometer](./java-standalone-config.md#autocollected-micrometer-metrics-including-spring-boot-actuator-metrics). For JavaScript and Node.js, you would still use `TrackMetric()`, but keep in mind the caveats that were outlined in the previous section. For Python, you can use [OpenCensus.stats](/previous-versions/azure/azure-monitor/app/opencensus-python#metrics) to send custom metrics, but the metrics implementation is different. --## Get started with GetMetric --For our examples, we're going to use a basic .NET Core 3.1 worker service application. If you want to replicate the test environment used with these examples, follow steps 1-6 in the [Monitoring worker service article](worker-service.md#net-core-worker-service-application). These steps add Application Insights to a basic worker service project template. The concepts apply to any general application where the SDK can be used, including web apps and console apps. --### Send metrics --Replace the contents of your `worker.cs` file with the following code: --```csharp -using System; -using System.Threading; -using System.Threading.Tasks; -using Microsoft.Extensions.Hosting; -using Microsoft.Extensions.Logging; -using Microsoft.ApplicationInsights; --namespace WorkerService3 -{ - public class Worker : BackgroundService - { - private readonly ILogger<Worker> _logger; - private TelemetryClient _telemetryClient; -- public Worker(ILogger<Worker> logger, TelemetryClient tc) - { - _logger = logger; - _telemetryClient = tc; - } -- protected override async Task ExecuteAsync(CancellationToken stoppingToken) - { // The following line demonstrates usages of GetMetric API. - // Here "computersSold", a custom metric name, is being tracked with a value of 42 every second. - while (!stoppingToken.IsCancellationRequested) - { - _telemetryClient.GetMetric("ComputersSold").TrackValue(42); -- _logger.LogInformation("Worker running at: {time}", DateTimeOffset.Now); - await Task.Delay(1000, stoppingToken); - } - } - } -} -``` --When you run the sample code, you see the `while` loop repeatedly executing with no telemetry being sent in the Visual Studio output window. A single telemetry item is sent by around the 60-second mark, which in our test looks like: --```json -Application Insights Telemetry: {"name":"Microsoft.ApplicationInsights.Dev.00000000-0000-0000-0000-000000000000.Metric", "time":"2019-12-28T00:54:19.0000000Z", -"ikey":"00000000-0000-0000-0000-000000000000", -"tags":{"ai.application.ver":"1.0.0.0", -"ai.cloud.roleInstance":"Test-Computer-Name", -"ai.internal.sdkVersion":"m-agg2c:2.12.0-21496", -"ai.internal.nodeName":"Test-Computer-Name"}, -"data":{"baseType":"MetricData", -"baseData":{"ver":2,"metrics":[{"name":"ComputersSold", -"kind":"Aggregation", -"value":1722, -"count":41, -"min":42, -"max":42, -"stdDev":0}], -"properties":{"_MS.AggregationIntervalMs":"42000", -"DeveloperMode":"true"}}}} -``` --This single telemetry item represents an aggregate of 41 distinct metric measurements. Because we were sending the same value over and over again, we have a standard deviation (`stDev`) of `0` with identical maximum (`max`) and minimum (`min`) values. The `value` property represents a sum of all the individual values that were aggregated. --> [!NOTE] -> The `GetMetric` method doesn't support tracking the last value (for example, `gauge`) or tracking histograms or distributions. --If we examine our Application Insights resource in the **Logs (Analytics)** experience, the individual telemetry item would look like the following screenshot. ---> [!NOTE] -> While the raw telemetry item didn't contain an explicit sum property/field once ingested, we create one for you. In this case, both the `value` and `valueSum` property represent the same thing. --You can also access your custom metric telemetry in the [_Metrics_](../essentials/metrics-charts.md) section of the portal as both a [log-based and custom metric](pre-aggregated-metrics-log-metrics.md). The following screenshot is an example of a log-based metric. ---### Cache metric reference for high-throughput usage --Metric values might be observed frequently in some cases. For example, a high-throughput service that processes 500 requests per second might want to emit 20 telemetry metrics for each request. The result means tracking 10,000 values per second. In such high-throughput scenarios, users might need to help the SDK by avoiding some lookups. --For example, the preceding example performed a lookup for a handle for the metric `ComputersSold` and then tracked an observed value of `42`. Instead, the handle might be cached for multiple track invocations: --```csharp -//... -- protected override async Task ExecuteAsync(CancellationToken stoppingToken) - { - // This is where the cache is stored to handle faster lookup - Metric computersSold = _telemetryClient.GetMetric("ComputersSold"); - while (!stoppingToken.IsCancellationRequested) - { -- computersSold.TrackValue(42); -- computersSold.TrackValue(142); -- _logger.LogInformation("Worker running at: {time}", DateTimeOffset.Now); - await Task.Delay(50, stoppingToken); - } - } --``` --In addition to caching the metric handle, the preceding example also reduced `Task.Delay` to 50 milliseconds so that the loop would execute more frequently. The result is 772 `TrackValue()` invocations. --## Multidimensional metrics --The examples in the previous section show zero-dimensional metrics. Metrics can also be multidimensional. We currently support up to 10 dimensions. -- Here's an example of how to create a one-dimensional metric: --```csharp -//... -- protected override async Task ExecuteAsync(CancellationToken stoppingToken) - { - // This is an example of a metric with a single dimension. - // FormFactor is the name of the dimension. - Metric computersSold= _telemetryClient.GetMetric("ComputersSold", "FormFactor"); -- while (!stoppingToken.IsCancellationRequested) - { - // The number of arguments (dimension values) - // must match the number of dimensions specified while GetMetric. - // Laptop, Tablet, etc are values for the dimension "FormFactor" - computersSold.TrackValue(42, "Laptop"); - computersSold.TrackValue(20, "Tablet"); - computersSold.TrackValue(126, "Desktop"); --- _logger.LogInformation("Worker running at: {time}", DateTimeOffset.Now); - await Task.Delay(50, stoppingToken); - } - } --``` --Running the sample code for at least 60 seconds results in three distinct telemetry items being sent to Azure. Each item represents the aggregation of one of the three form factors. As before, you can further examine in the **Logs (Analytics)** view. ---In the metrics explorer: ---Notice that you can't split the metric by your new custom dimension or view your custom dimension with the metrics view. ---By default, multidimensional metrics within the metric explorer aren't turned on in Application Insights resources. --### Enable multidimensional metrics --To enable multidimensional metrics for an Application Insights resource, select **Usage and estimated costs** > **Custom Metrics** > **Enable alerting on custom metric dimensions** > **OK**. For more information, see [Custom metrics dimensions and preaggregation](pre-aggregated-metrics-log-metrics.md#custom-metrics-dimensions-and-preaggregation). --After you've made that change and sent new multidimensional telemetry, you can select **Apply splitting**. --> [!NOTE] -> Only newly sent metrics after the feature was turned on in the portal will have dimensions stored. ---View your metric aggregations for each `FormFactor` dimension. ---### Use MetricIdentifier when there are more than three dimensions --Currently, 10 dimensions are supported. More than three dimensions requires the use of `MetricIdentifier`: --```csharp -// Add "using Microsoft.ApplicationInsights.Metrics;" to use MetricIdentifier -// MetricIdentifier id = new MetricIdentifier("[metricNamespace]","[metricId],"[dim1]","[dim2]","[dim3]","[dim4]","[dim5]"); -MetricIdentifier id = new MetricIdentifier("CustomMetricNamespace","ComputerSold", "FormFactor", "GraphicsCard", "MemorySpeed", "BatteryCapacity", "StorageCapacity"); -Metric computersSold = _telemetryClient.GetMetric(id); -computersSold.TrackValue(110,"Laptop", "Nvidia", "DDR4", "39Wh", "1TB"); -``` --## Custom metric configuration --If you want to alter the metric configuration, you must make alterations in the place where the metric is initialized. --### Special dimension names --Metrics don't use the telemetry context of the `TelemetryClient` used to access them. Using special dimension names available as constants in the `MetricDimensionNames` class is the best workaround for this limitation. --Metric aggregates sent by the following `Special Operation Request Size` metric *won't* have `Context.Operation.Name` set to `Special Operation`. The `TrackMetric()` method or any other `TrackXXX()` method will have `OperationName` set correctly to `Special Operation`. --``` csharp - //... - TelemetryClient specialClient; - private static int GetCurrentRequestSize() - { - // Do stuff - return 1100; - } - int requestSize = GetCurrentRequestSize() -- protected override async Task ExecuteAsync(CancellationToken stoppingToken) - { - while (!stoppingToken.IsCancellationRequested) - { - //... - specialClient.Context.Operation.Name = "Special Operation"; - specialClient.GetMetric("Special Operation Request Size").TrackValue(requestSize); - //... - } - - } -``` --In this circumstance, use the special dimension names listed in the `MetricDimensionNames` class to specify the `TelemetryContext` values. --For example, when the metric aggregate resulting from the next statement is sent to the Application Insights cloud endpoint, its `Context.Operation.Name` data field will be set to `Special Operation`: --```csharp -_telemetryClient.GetMetric("Request Size", MetricDimensionNames.TelemetryContext.Operation.Name).TrackValue(requestSize, "Special Operation"); -``` --The values of this special dimension will be copied into `TelemetryContext` and won't be used as a *normal* dimension. If you want to also keep an operation dimension for normal metric exploration, you need to create a separate dimension for that purpose: --```csharp -_telemetryClient.GetMetric("Request Size", "Operation Name", MetricDimensionNames.TelemetryContext.Operation.Name).TrackValue(requestSize, "Special Operation", "Special Operation"); -``` --### Dimension and time-series capping -- To prevent the telemetry subsystem from accidentally using up your resources, you can control the maximum number of data series per metric. The default limits are no more than 1,000 total data series per metric, and no more than 100 different values per dimension. --> [!IMPORTANT] -> Use low cardinal values for dimensions to avoid throttling. -- In the context of dimension and time series capping, we use `Metric.TrackValue(..)` to make sure that the limits are observed. If the limits are already reached, `Metric.TrackValue(..)` returns `False` and the value won't be tracked. Otherwise, it returns `True`. This behavior is useful if the data for a metric originates from user input. --The `MetricConfiguration` constructor takes some options on how to manage different series within the respective metric and an object of a class implementing `IMetricSeriesConfiguration` that specifies aggregation behavior for each individual series of the metric: --``` csharp -var metConfig = new MetricConfiguration(seriesCountLimit: 100, valuesPerDimensionLimit:2, - new MetricSeriesConfigurationForMeasurement(restrictToUInt32Values: false)); --Metric computersSold = _telemetryClient.GetMetric("ComputersSold", "Dimension1", "Dimension2", metConfig); --// Start tracking. -computersSold.TrackValue(100, "Dim1Value1", "Dim2Value1"); -computersSold.TrackValue(100, "Dim1Value1", "Dim2Value2"); --// The following call gives 3rd unique value for dimension2, which is above the limit of 2. -computersSold.TrackValue(100, "Dim1Value1", "Dim2Value3"); -// The above call does not track the metric, and returns false. -``` --* `seriesCountLimit` is the maximum number of data time series a metric can contain. When this limit is reached, calls to `TrackValue()` that would normally result in a new series return `false`. -* `valuesPerDimensionLimit` limits the number of distinct values per dimension in a similar manner. -* `restrictToUInt32Values` determines whether or not only non-negative integer values should be tracked. --Here's an example of how to send a message to know if cap limits are exceeded: --```csharp -if (! computersSold.TrackValue(100, "Dim1Value1", "Dim2Value3")) -{ -// Add "using Microsoft.ApplicationInsights.DataContract;" to use SeverityLevel.Error -_telemetryClient.TrackTrace("Metric value not tracked as value of one of the dimension exceeded the cap. Revisit the dimensions to ensure they are within the limits", -SeverityLevel.Error); -} -``` --## Next steps --* [Metrics - Get - REST API](/rest/api/application-insights/metrics/get) -* [Application Insights API for custom events and metrics](api-custom-events-metrics.md) -* [Learn more](./worker-service.md) about monitoring worker service applications. -* Use [log-based and preaggregated metrics](./pre-aggregated-metrics-log-metrics.md). -* Analyze metrics with [metrics explorer](../essentials/analyze-metrics.md). -* Learn how to enable Application Insights for [ASP.NET Core applications](asp-net-core.md). -* Learn how to enable Application Insights for [ASP.NET applications](asp-net.md). |
| azure-monitor | Ilogger | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/ilogger.md | - Title: Application Insights logging with .NET -description: Learn how to use Application Insights with the ILogger interface in .NET. - Previously updated : 01/31/2024-----# Application Insights logging with .NET --In this article, you learn how to capture logs with Application Insights in .NET apps by using the [`Microsoft.Extensions.Logging.ApplicationInsights`][nuget-ai] provider package. If you use this provider, you can query and analyze your logs by using the Application Insights tools. ---[nuget-ai]: https://www.nuget.org/packages/Microsoft.Extensions.Logging.ApplicationInsights -[nuget-ai-ws]: https://www.nuget.org/packages/Microsoft.ApplicationInsights.WorkerService --> [!NOTE] -> If you want to implement the full range of Application Insights telemetry along with logging, see [Configure Application Insights for your ASP.NET websites](./asp-net.md) or [Application Insights for ASP.NET Core applications](./asp-net-core.md). --> [!TIP] -> The [`Microsoft.ApplicationInsights.WorkerService`][nuget-ai-ws] NuGet package, used to enable Application Insights for background services, is out of scope. For more information, see [Application Insights for Worker Service apps](./worker-service.md). --## ASP.NET Core applications --To add Application Insights logging to ASP.NET Core applications: --1. Install the [`Microsoft.Extensions.Logging.ApplicationInsights`][nuget-ai]. --1. Add `ApplicationInsightsLoggerProvider`: --# [.NET 6.0+](#tab/dotnet6) --```csharp -using Microsoft.Extensions.Logging.ApplicationInsights; --var builder = WebApplication.CreateBuilder(args); --// Add services to the container. --builder.Services.AddControllers(); -// Learn more about configuring Swagger/OpenAPI at https://aka.ms/aspnetcore/swashbuckle -builder.Services.AddEndpointsApiExplorer(); -builder.Services.AddSwaggerGen(); --builder.Logging.AddApplicationInsights( - configureTelemetryConfiguration: (config) => - config.ConnectionString = builder.Configuration.GetConnectionString("APPLICATIONINSIGHTS_CONNECTION_STRING"), - configureApplicationInsightsLoggerOptions: (options) => { } - ); --builder.Logging.AddFilter<ApplicationInsightsLoggerProvider>("your-category", LogLevel.Trace); --var app = builder.Build(); --// Configure the HTTP request pipeline. -if (app.Environment.IsDevelopment()) -{ - app.UseSwagger(); - app.UseSwaggerUI(); -} --app.UseHttpsRedirection(); --app.UseAuthorization(); --app.MapControllers(); --app.Run(); -``` --# [.NET 5.0](#tab/dotnet5) --```csharp -using Microsoft.AspNetCore.Hosting; -using Microsoft.Extensions.DependencyInjection; -using Microsoft.Extensions.Hosting; -using Microsoft.Extensions.Logging; -using Microsoft.Extensions.Logging.ApplicationInsights; --namespace WebApplication -{ - public class Program - { - public static void Main(string[] args) - { - var host = CreateHostBuilder(args).Build(); -- var logger = host.Services.GetRequiredService<ILogger<Program>>(); - logger.LogInformation("From Program, running the host now."); -- host.Run(); - } -- public static IHostBuilder CreateHostBuilder(string[] args) => - Host.CreateDefaultBuilder(args) - .ConfigureWebHostDefaults(webBuilder => - { - webBuilder.UseStartup<Startup>(); - }) - .ConfigureLogging((context, builder) => - { - builder.AddApplicationInsights( - configureTelemetryConfiguration: (config) => config.ConnectionString = context.Configuration["APPLICATIONINSIGHTS_CONNECTION_STRING"], - configureApplicationInsightsLoggerOptions: (options) => { } - ); -- // Capture all log-level entries from Startup - builder.AddFilter<ApplicationInsightsLoggerProvider>( - typeof(Startup).FullName, LogLevel.Trace); - }); - } -} -``` ----With the NuGet package installed, and the provider being registered with dependency injection, the app is ready to log. With constructor injection, either <xref:Microsoft.Extensions.Logging.ILogger> or the generic-type alternative <xref:Microsoft.Extensions.Logging.ILogger%601> is required. When these implementations are resolved, `ApplicationInsightsLoggerProvider` provides them. Logged messages or exceptions are sent to Application Insights. --Consider the following example controller: --```csharp -public class ValuesController : ControllerBase -{ - private readonly ILogger _logger; -- public ValuesController(ILogger<ValuesController> logger) - { - _logger = logger; - } -- [HttpGet] - public ActionResult<IEnumerable<string>> Get() - { - _logger.LogWarning("An example of a Warning trace.."); - _logger.LogError("An example of an Error level message"); -- return new string[] { "value1", "value2" }; - } -} -``` --For more information, see [Logging in ASP.NET Core](/aspnet/core/fundamentals/logging) and [What Application Insights telemetry type is produced from ILogger logs? Where can I see ILogger logs in Application Insights?](#what-application-insights-telemetry-type-is-produced-from-ilogger-logs-where-can-i-see-ilogger-logs-in-application-insights). --## Console application --To add Application Insights logging to console applications, first install the following NuGet packages: --* [`Microsoft.Extensions.Logging.ApplicationInsights`][nuget-ai] -* [`Microsoft.Extensions.DependencyInjection`][nuget-ai] --The following example uses the Microsoft.Extensions.Logging.ApplicationInsights package and demonstrates the default behavior for a console application. The Microsoft.Extensions.Logging.ApplicationInsights package should be used in a console application or whenever you want a bare minimum implementation of Application Insights without the full feature set such as metrics, distributed tracing, sampling, and telemetry initializers. --# [.NET 6.0+](#tab/dotnet6) --```csharp -using Microsoft.ApplicationInsights.Channel; -using Microsoft.ApplicationInsights.Extensibility; -using Microsoft.Extensions.DependencyInjection; -using Microsoft.Extensions.Logging; --using var channel = new InMemoryChannel(); --try -{ - IServiceCollection services = new ServiceCollection(); - services.Configure<TelemetryConfiguration>(config => config.TelemetryChannel = channel); - services.AddLogging(builder => - { - // Only Application Insights is registered as a logger provider - builder.AddApplicationInsights( - configureTelemetryConfiguration: (config) => config.ConnectionString = "<YourConnectionString>", - configureApplicationInsightsLoggerOptions: (options) => { } - ); - }); -- IServiceProvider serviceProvider = services.BuildServiceProvider(); - ILogger<Program> logger = serviceProvider.GetRequiredService<ILogger<Program>>(); -- logger.LogInformation("Logger is working..."); -} -finally -{ - // Explicitly call Flush() followed by Delay, as required in console apps. - // This ensures that even if the application terminates, telemetry is sent to the back end. - channel.Flush(); -- await Task.Delay(TimeSpan.FromMilliseconds(1000)); -} -``` --# [.NET 5.0](#tab/dotnet5) --```csharp -using Microsoft.ApplicationInsights.Channel; -using Microsoft.ApplicationInsights.Extensibility; -using Microsoft.Extensions.DependencyInjection; -using Microsoft.Extensions.Logging; -using Microsoft.Extensions.Logging.ApplicationInsights; -using System; -using System.Threading.Tasks; --namespace ConsoleApp -{ - class Program - { - static async Task Main(string[] args) - { - using var channel = new InMemoryChannel(); -- try - { - IServiceCollection services = new ServiceCollection(); - services.Configure<TelemetryConfiguration>(config => config.TelemetryChannel = channel); - services.AddLogging(builder => - { - // Only Application Insights is registered as a logger provider - builder.AddApplicationInsights( - configureTelemetryConfiguration: (config) => config.ConnectionString = "<YourConnectionString>", - configureApplicationInsightsLoggerOptions: (options) => { } - ); - }); -- IServiceProvider serviceProvider = services.BuildServiceProvider(); - ILogger<Program> logger = serviceProvider.GetRequiredService<ILogger<Program>>(); -- logger.LogInformation("Logger is working..."); - } - finally - { - // Explicitly call Flush() followed by Delay, as required in console apps. - // This ensures that even if the application terminates, telemetry is sent to the back end. - channel.Flush(); -- await Task.Delay(TimeSpan.FromMilliseconds(1000)); - } - } - } -} --``` ----For more information, see [What Application Insights telemetry type is produced from ILogger logs? Where can I see ILogger logs in Application Insights?](#what-application-insights-telemetry-type-is-produced-from-ilogger-logs-where-can-i-see-ilogger-logs-in-application-insights). --## Logging scopes --`ApplicationInsightsLoggingProvider` supports [log scopes](/dotnet/core/extensions/logging#log-scopes). Scopes are enabled by default. --If the scope is of type `IReadOnlyCollection<KeyValuePair<string,object>>`, then each key/value pair in the collection is added to the Application Insights telemetry as custom properties. In the following example, logs are captured as `TraceTelemetry` and has `("MyKey", "MyValue")` in properties. --```csharp -using (_logger.BeginScope(new Dictionary<string, object> { ["MyKey"] = "MyValue" })) -{ - _logger.LogError("An example of an Error level message"); -} -``` --If any other type is used as a scope, it's stored under the property `Scope` in Application Insights telemetry. In the following example, `TraceTelemetry` has a property called `Scope` that contains the scope. --```csharp - using (_logger.BeginScope("hello scope")) - { - _logger.LogError("An example of an Error level message"); - } -``` --## Frequently asked questions --### What Application Insights telemetry type is produced from ILogger logs? Where can I see ILogger logs in Application Insights? --`ApplicationInsightsLoggerProvider` captures `ILogger` logs and creates `TraceTelemetry` from them. If an `Exception` object is passed to the `Log` method on `ILogger`, `ExceptionTelemetry` is created instead of `TraceTelemetry`. --**Viewing ILogger Telemetry** --In the Azure Portal: -1. Go to the Azure Portal and access your Application Insights resource. -2. Click on the "Logs" section inside Application Insights. -3. Use Kusto Query Language (KQL) to query ILogger messages, usually stored in the `traces` table. - - Example Query: `traces | where message contains "YourSearchTerm"`. -4. Refine your queries to filter ILogger data by severity, time range, or specific message content. --In Visual Studio (Local Debugger): -1. Start your application in debug mode within Visual Studio. -2. Open the "Diagnostic Tools" window while the application runs. -3. In the "Events" tab, ILogger logs appear along with other telemetry data. -4. Utilize the search and filter features in the "Diagnostic Tools" window to locate specific ILogger messages. --If you prefer to always send `TraceTelemetry`, use this snippet: --```csharp -builder.AddApplicationInsights( - options => options.TrackExceptionsAsExceptionTelemetry = false); -``` -### Why do some ILogger logs not have the same properties as others? --Application Insights captures and sends `ILogger` logs by using the same `TelemetryConfiguration` information that's used for every other telemetry. But there's an exception. By default, `TelemetryConfiguration` isn't fully set up when you log from *Program.cs* or *Startup.cs*. Logs from these places don't have the default configuration, so they aren't running all `TelemetryInitializer` instances and `TelemetryProcessor` instances. --### I'm using the standalone package Microsoft.Extensions.Logging.ApplicationInsights, and I want to log more custom telemetry manually. How should I do that? --When you use the standalone package, `TelemetryClient` isn't injected to the dependency injection (DI) container. You need to create a new instance of `TelemetryClient` and use the same configuration that the logger provider uses, as the following code shows. This requirement ensures that the same configuration is used for all custom telemetry and telemetry from `ILogger`. --```csharp -public class MyController : ApiController -{ - // This TelemetryClient instance can be used to track additional telemetry through the TrackXXX() API. - private readonly TelemetryClient _telemetryClient; - private readonly ILogger _logger; -- public MyController(IOptions<TelemetryConfiguration> options, ILogger<MyController> logger) - { - _telemetryClient = new TelemetryClient(options.Value); - _logger = logger; - } -} -``` --> [!NOTE] -> If you use the `Microsoft.ApplicationInsights.AspNetCore` package to enable Application Insights, modify this code to get `TelemetryClient` directly in the constructor. --### I don't have the SDK installed, and I use the Azure Web Apps extension to enable Application Insights for my ASP.NET Core applications. How do I use the new provider? --The Application Insights extension in Azure Web Apps uses the new provider. You can modify the filtering rules in the *appsettings.json* file for your application. --## Next steps --* [Logging in .NET](/dotnet/core/extensions/logging) -* [Logging in ASP.NET Core](/aspnet/core/fundamentals/logging) -* [.NET trace logs in Application Insights](./asp-net-trace-logs.md) |
| azure-monitor | Ip Collection | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/ip-collection.md | - Title: Application Insights IP address collection | Microsoft Docs -description: Understand how Application Insights handles IP addresses and geolocation. - Previously updated : 07/24/2024----# Geolocation and IP address handling --This article explains how geolocation lookup and IP address handling work in [Application Insights](app-insights-overview.md#application-insights-overview). --## Default behavior --By default, IP addresses are temporarily collected but not stored. --When telemetry is sent to Azure, the IP address is used in a geolocation lookup. The result is used to populate the fields `client_City`, `client_StateOrProvince`, and `client_CountryOrRegion`. The address is then discarded, and `0.0.0.0` is written to the `client_IP` field. --The telemetry types are: --* **Browser telemetry**: Application Insights collects the sender's IP address. The ingestion endpoint calculates the IP address. -* **Server telemetry**: The Application Insights telemetry module temporarily collects the client IP address when the `X-Forwarded-For` header isn't set. When the incoming IP address list has more than one item, the last IP address is used to populate geolocation fields. --This behavior is by design to help avoid unnecessary collection of personal data and IP address location information. --When IP addresses aren't collected, city and other geolocation attributes also aren't collected. --## Storage of IP address data --> [!WARNING] -> The default and our recommendation is to not collect IP addresses. If you override this behavior, verify the collection doesn't break any compliance requirements or local regulations. -> -> To learn more about handling personal data, see [Guidance for personal data](../logs/personal-data-mgmt.md). --To enable IP collection and storage, the `DisableIpMasking` property of the Application Insights component must be set to `true`. --Options to set this property include: --- [ARM template](#arm-template)-- [Portal](#portal)-- [REST API](#rest-api)-- [PowerShell](#powershell)--### ARM template --```json -{ - "id": "/subscriptions/<subscription-id>/resourceGroups/<resource-group-name>/providers/microsoft.insights/components/<resource-name>", - "name": "<resource-name>", - "type": "microsoft.insights/components", - "location": "westcentralus", - "tags": { - - }, - "kind": "web", - "properties": { - "Application_Type": "web", - "Flow_Type": "Redfield", - "Request_Source": "IbizaAIExtension", - // ... - "DisableIpMasking": true - } -} -``` --### Portal --If you need to modify the behavior for only a single Application Insights resource, use the Azure portal. --1. Go to your Application Insights resource, and then select **Automation** > **Export template**. --1. Select **Deploy**. -- :::image type="content" source="media/ip-collection/deploy.png" lightbox="media/ip-collection/deploy.png" alt-text="Screenshot that shows the Deploy button."::: --1. Select **Edit template**. -- :::image type="content" source="media/ip-collection/edit-template.png" lightbox="media/ip-collection/edit-template.png" alt-text="Screenshot that shows the Edit button, along with a warning about the resource group."::: -- > [!NOTE] - > If you experience the error shown in the preceding screenshot, you can resolve it. It states: "The resource group is in a location that is not supported by one or more resources in the template. Please choose a different resource group." Temporarily select a different resource group from the dropdown list and then re-select your original resource group. --1. In the JSON template, locate `properties` inside `resources`. Add a comma to the last JSON field, and then add the following new line: `"DisableIpMasking": true`. Then select **Save**. -- :::image type="content" source="media/ip-collection/save.png" lightbox="media/ip-collection/save.png" alt-text="Screenshot that shows the addition of a comma and a new line after the property for request source."::: --1. Select **Review + create** > **Create**. -- > [!NOTE] - > If you see "Your deployment failed," look through your deployment details for the one with the type `microsoft.insights/components` and check the status. If that one succeeds, the changes made to `DisableIpMasking` were deployed. --1. After the deployment is complete, new telemetry data will be recorded. -- If you select and edit the template again, only the default template without the newly added property. If you aren't seeing IP address data and want to confirm that `"DisableIpMasking": true` is set, run the following PowerShell commands: - - ```powershell - # Replace `Fabrikam-dev` with the appropriate resource and resource group name. - # If you aren't using Azure Cloud Shell, you need to connect to your Azure account - # Connect-AzAccount - $AppInsights = Get-AzResource -Name 'Fabrikam-dev' -ResourceType 'microsoft.insights/components' -ResourceGroupName 'Fabrikam-dev' - $AppInsights.Properties - ``` - - A list of properties is returned as a result. One of the properties should read `DisableIpMasking: true`. If you run the PowerShell commands before you deploy the new property with Azure Resource Manager, the property doesn't exist. --### REST API --The following [REST API](/rest/api/azure/) payload makes the same modifications: --```json -PATCH https://management.azure.com/subscriptions/<sub-id>/resourceGroups/<rg-name>/providers/microsoft.insights/components/<resource-name>?api-version=2018-05-01-preview HTTP/1.1 -Host: management.azure.com -Authorization: AUTH_TOKEN -Content-Type: application/json -Content-Length: 54 --{ - "location": "<resource location>", - "kind": "web", - "properties": { - "Application_Type": "web", - "DisableIpMasking": true - } -} -``` --### PowerShell --The PowerShell `Update-AzApplicationInsights` cmdlet can disable IP masking with the `DisableIPMasking` parameter. --```powershell -Update-AzApplicationInsights -Name "aiName" -ResourceGroupName "rgName" -DisableIPMasking:$true -``` --For more information on the `Update-AzApplicationInsights` cmdlet, see [Update-AzApplicationInsights](/powershell/module/az.applicationinsights/update-azapplicationinsights) --## Next steps --* Learn more about [personal data collection](../logs/personal-data-mgmt.md) in Azure Monitor. -* Learn how to [set the user IP](opentelemetry-add-modify.md#set-the-user-ip) using OpenTelemetry. |
| azure-monitor | Java Get Started Supplemental | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/java-get-started-supplemental.md | - Title: Application Insights with containers -description: This article shows you how to set up Application Insights. - Previously updated : 07/29/2024-----# Get Started (Supplemental) --In the following sections, learn how to get Java autoinstrumentation for specific technical environments. --## Azure App Service --For more information, see [Application monitoring for Azure App Service and Java](./azure-web-apps-java.md). --## Azure Functions --For more information, see [Monitoring Azure Functions with Azure Monitor Application Insights](./monitor-functions.md#distributed-tracing-for-java-applications). --## Azure Spring Apps --For more information, see [Use Application Insights Java In-Process Agent in Azure Spring Apps](../../spring-apps/enterprise/how-to-application-insights.md). --## Containers --> [!NOTE] -> With Spring Boot Native Image applications, use the [Azure Monitor OpenTelemetry Distro / Application Insights in Spring Boot native image Java application](https://aka.ms/AzMonSpringNative) project instead of the Application Insights Java agent. --### Docker entry point --If you're using the *exec* form, add the parameter `-javaagent:"path/to/applicationinsights-agent-3.5.4.jar"` to the parameter list somewhere before the `"-jar"` parameter, for example: --```dockerfile -ENTRYPOINT ["java", "-javaagent:path/to/applicationinsights-agent-3.5.4.jar", "-jar", "<myapp.jar>"] -``` --If you're using the *shell* form, add the Java Virtual Machine (JVM) arg `-javaagent:"path/to/applicationinsights-agent-3.5.4.jar"` somewhere before `-jar`, for example: --```dockerfile -ENTRYPOINT java -javaagent:"path/to/applicationinsights-agent-3.5.4.jar" -jar <myapp.jar> -``` ---### Docker file --A Dockerfile example: --```dockerfile -FROM ... --COPY target/*.jar app.jar --COPY agent/applicationinsights-agent-3.5.4.jar applicationinsights-agent-3.5.4.jar --COPY agent/applicationinsights.json applicationinsights.json --ENV APPLICATIONINSIGHTS_CONNECTION_STRING="CONNECTION-STRING" - -ENTRYPOINT["java", "-javaagent:applicationinsights-agent-3.5.4.jar", "-jar", "app.jar"] -``` --In this example, you copy the `applicationinsights-agent-3.5.4.jar` and `applicationinsights.json` files from an `agent` folder (you can choose any folder of your machine). These two files have to be in the same folder in the Docker container. --### Partner container images --If you're using a partner container image that you can't modify, mount the Application Insights Java agent jar into the container from outside. Set the environment variable for the container -`JAVA_TOOL_OPTIONS=-javaagent:/path/to/applicationinsights-agent.jar`. --## Spring Boot --For more information, see [Using Azure Monitor Application Insights with Spring Boot](./java-spring-boot.md). --## Java Application servers --For information on setting up the Application Insights Java agent, see [Enabling Azure Monitor OpenTelemetry for Java](./opentelemetry-enable.md?tabs=java). The following sections provide details that might be helpful when configuring the `-javaagent:...` JVM arg on different application servers. --### Tomcat 8 (Linux) --#### Tomcat installed via apt-get or yum --If you installed Tomcat via `apt-get` or `yum`, you should have a file `/etc/tomcat8/tomcat8.conf`. Add this line to the end of that file: --```console -JAVA_OPTS="$JAVA_OPTS -javaagent:path/to/applicationinsights-agent-3.5.4.jar" -``` --#### Tomcat installed via download and unzip --If you installed Tomcat via download and unzip from [https://tomcat.apache.org](https://tomcat.apache.org), you should have a file `<tomcat>/bin/catalina.sh`. Create a new file in the same directory named `<tomcat>/bin/setenv.sh` with the following content: --```console -CATALINA_OPTS="$CATALINA_OPTS -javaagent:path/to/applicationinsights-agent-3.5.4.jar" -``` --If the file `<tomcat>/bin/setenv.sh` already exists, modify that file and add `-javaagent:path/to/applicationinsights-agent-3.5.4.jar` to `CATALINA_OPTS`. --### Tomcat 8 (Windows) --#### Run Tomcat from the command line --Locate the file `<tomcat>/bin/catalina.bat`. Create a new file in the same directory named `<tomcat>/bin/setenv.bat` with the following content: --```console -set CATALINA_OPTS=%CATALINA_OPTS% -javaagent:path/to/applicationinsights-agent-3.5.4.jar -``` --Quotes aren't necessary, but if you want to include them, the proper placement is: --```console -set "CATALINA_OPTS=%CATALINA_OPTS% -javaagent:path/to/applicationinsights-agent-3.5.4.jar" -``` --If the file `<tomcat>/bin/setenv.bat` already exists, modify that file and add `-javaagent:path/to/applicationinsights-agent-3.5.4.jar` to `CATALINA_OPTS`. --#### Run Tomcat as a Windows service --Locate the file `<tomcat>/bin/tomcat8w.exe`. Run that executable and add `-javaagent:path/to/applicationinsights-agent-3.5.4.jar` to the `Java Options` under the `Java` tab. --### JBoss Enterprise Application Platform 7 --In Red Hat JBoss Enterprise Application Platform (EAP) 7, you can set up a standalone server or a domain server. --#### Standalone server --Add `-javaagent:path/to/applicationinsights-agent-3.5.4.jar` to the existing `JAVA_OPTS` environment variable in the file `JBOSS_HOME/bin/standalone.conf` (Linux) or `JBOSS_HOME/bin/standalone.conf.bat` (Windows): --```java ... - JAVA_OPTS="-javaagent:path/to/applicationinsights-agent-3.5.4.jar -Xms1303m -Xmx1303m ..." - ... -``` --#### Domain server --Add `-javaagent:path/to/applicationinsights-agent-3.5.4.jar` to the existing `jvm-options` in `JBOSS_HOME/domain/configuration/host.xml`: --```xml -... -<jvms> - <jvm name="default"> - <heap size="64m" max-size="256m"/> - <jvm-options> - <option value="-server"/> - <!--Add Java agent jar file here--> - <option value="-javaagent:path/to/applicationinsights-agent-3.5.4.jar"/> - <option value="-XX:MetaspaceSize=96m"/> - <option value="-XX:MaxMetaspaceSize=256m"/> - </jvm-options> - </jvm> -</jvms> -... -``` --If you're running multiple managed servers on a single host, you need to add `applicationinsights.agent.id` to the `system-properties` for each `server`: --```xml -... -<servers> - <server name="server-one" group="main-server-group"> - <!--Edit system properties for server-one--> - <system-properties> - <property name="applicationinsights.agent.id" value="..."/> - </system-properties> - </server> - <server name="server-two" group="main-server-group"> - <socket-bindings port-offset="150"/> - <!--Edit system properties for server-two--> - <system-properties> - <property name="applicationinsights.agent.id" value="..."/> - </system-properties> - </server> -</servers> -... -``` --The specified `applicationinsights.agent.id` value must be unique. You use the value to create a subdirectory under the Application Insights directory. Each JVM process needs its own local Application Insights config and local Application Insights log file. Also, if reporting to the central collector, multiple managed servers share the `applicationinsights.properties` file, so the specified `applicationinsights.agent.id` is needed to override the `agent.id` setting in that shared file. The `applicationinsights.agent.rollup.id` can be similarly specified in the server's `system-properties` if you need to override the `agent.rollup.id` setting per managed server. --### Jetty 9 --Add these lines to `start.ini`: --```console exec--javaagent:path/to/applicationinsights-agent-3.5.4.jar-``` --### Payara 5 --Add `-javaagent:path/to/applicationinsights-agent-3.5.4.jar` to the existing `jvm-options` in `glassfish/domains/domain1/config/domain.xml`: --```xml -... -<java-config ...> - <!--Edit the JVM options here--> - <jvm-options> - -javaagent:path/to/applicationinsights-agent-3.5.4.jar> - </jvm-options> - ... -</java-config> -... -``` --### WebSphere 8 --1. Open Management Console. -1. Go to **Servers** > **WebSphere application servers** > **Application servers**. Choose the appropriate application servers and select **Java and Process Management** > **Process definition** > **Java Virtual Machine**. --1. In `Generic JVM arguments`, add the following JVM argument. -- ```console - -javaagent:path/to/applicationinsights-agent-3.5.4.jar - ``` --1. Save and restart the application server. --### OpenLiberty 18 --Create a new file `jvm.options` in the server directory (for example, `<openliberty>/usr/servers/defaultServer`), and add this line: --```console --javaagent:path/to/applicationinsights-agent-3.5.4.jar-``` --### Others --See your application server documentation on how to add JVM args. |
| azure-monitor | Java Jmx Metrics Configuration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/java-jmx-metrics-configuration.md | - Title: How to configure JMX metrics - Azure Monitor application insights for Java -description: Configure extra Java Management Extensions (JMX) metrics collection for Azure Monitor Application Insights Java agent. - Previously updated : 12/15/2023-----# Configuring JMX metrics --Application Insights Java 3.x collects some of the Java Management Extensions (JMX) metrics by default, but in many cases it isn't enough. This document describes the JMX configuration option in details. --## How do I collect extra JMX metrics? --JMX metrics collection can be configured by adding a ```"jmxMetrics"``` section to the applicationinsights.json file. Enter a name for the metric as you want it to appear in Azure portal in application insights resource. Object name and attribute are required for each of the metrics you want collected. You may use `*` in object names for glob-style wildcard ([details](/azure/azure-monitor/app/java-standalone-config#java-management-extensions-metrics)). --## How do I know what metrics are available to configure? --You nailed it - you must know the object names and the attributes, those properties are different for various libraries, frameworks, and application servers, and are often not well documented. Luckily, it's easy to find exactly what JMX metrics are supported for your particular environment. --To view the available metrics, set the self-diagnostics level to `DEBUG` in your `applicationinsights.json` configuration file, for example: --```json -{ - "selfDiagnostics": { - "level": "DEBUG" - } -} -``` --Available JMX metrics, with object names and attribute names, appear in your Application Insights log file. --Log file output looks similar to these examples. In some cases, it can be extensive. --> :::image type="content" source="media/java-ipa/jmx/available-mbeans.png" lightbox="media/java-ipa/jmx/available-mbeans.png" alt-text="Screenshot of available JMX metrics in the log file."::: --You can also use a [command line tool](https://github.com/microsoft/ApplicationInsights-Java/wiki/Troubleshoot-JMX-metrics) to check the available JMX metrics. --## Configuration example --Knowing what metrics are available, you can configure the agent to collect them. The first one is an example of a nested metric - `LastGcInfo` that has several properties, and we want to capture the `GcThreadCount`. --```json -"jmxMetrics": [ - { - "name": "Demo - GC Thread Count", - "objectName": "java.lang:type=GarbageCollector,name=PS MarkSweep", - "attribute": "LastGcInfo.GcThreadCount" - }, - { - "name": "Demo - GC Collection Count", - "objectName": "java.lang:type=GarbageCollector,name=PS MarkSweep", - "attribute": "CollectionCount" - }, - { - "name": "Demo - Thread Count", - "objectName": "java.lang:type=Threading", - "attribute": "ThreadCount" - } -], -``` --## Where do I find the JMX Metrics in application insights? --You can view the JMX metrics collected while your application is running by navigating to your application insights resource in the Azure portal. Under Metrics tab, select the dropdown as shown to view the metrics. --> :::image type="content" source="media/java-ipa/jmx/jmx-portal.png" lightbox="media/java-ipa/jmx/jmx-portal.png" alt-text="Screenshot of metrics in portal"::: |
| azure-monitor | Java Spring Boot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/java-spring-boot.md | - Title: Configure Azure Monitor Application Insights for Spring Boot -description: How to configure Azure Monitor Application Insights for Spring Boot applications - Previously updated : 07/29/2024----# Using Azure Monitor Application Insights with Spring Boot --> [!NOTE] -> With _Spring Boot native image applications_, you can use [this project](https://aka.ms/AzMonSpringNative). --There are two options for enabling Application Insights Java with Spring Boot: Java Virtual Machine (JVM) argument and programmatically. --## Enabling with JVM argument --Add the JVM arg `-javaagent:"path/to/applicationinsights-agent-3.5.4.jar"` somewhere before `-jar`, for example: --```console -java -javaagent:"path/to/applicationinsights-agent-3.5.4.jar" -jar <myapp.jar> -``` --### Spring Boot via Docker entry point --See the [documentation related to containers](./java-get-started-supplemental.md). --### Configuration --See [configuration options](./java-standalone-config.md). --## Enabling programmatically --To enable Application Insights Java programmatically, you must add the following dependency: --```xml -<dependency> - <groupId>com.microsoft.azure</groupId> - <artifactId>applicationinsights-runtime-attach</artifactId> - <version>3.5.4</version> -</dependency> -``` --And invoke the `attach()` method of the `com.microsoft.applicationinsights.attach.ApplicationInsights` class that's in the beginning line of your `main()` method. --> [!WARNING] -> -> The invocation must be at the beginning of the `main` method. --> [!WARNING] -> -> JRE is not supported. --> [!WARNING] -> -> The temporary directory of the operating system should be writable. --Example: --```java -@SpringBootApplication -public class SpringBootApp { -- public static void main(String[] args) { - ApplicationInsights.attach(); - SpringApplication.run(SpringBootApp.class, args); - } -} -``` --### Configuration --Programmatic enablement supports all the same [configuration options](./java-standalone-config.md) as the JVM argument enablement, with the differences that are described in the next sections. --#### Configuration file location --By default, when enabling Application Insights Java programmatically, the configuration file `applicationinsights.json` -is read from the classpath (`src/main/resources`, `src/test/resources`). --From 3.4.3, you can configure the name of a JSON file in the classpath with the `applicationinsights.runtime-attach.configuration.classpath.file` system property. -For example, with `-Dapplicationinsights.runtime-attach.configuration.classpath.file=applicationinsights-dev.json`, Application Insights uses the `applicationinsights-dev.json` file for configuration. To programmatically configure another file in the classpath: --```java -public static void main(String[] args) { - System.setProperty("applicationinsights.runtime-attach.configuration.classpath.file", "applicationinsights-dev.json"); - ApplicationInsights.attach(); - SpringApplication.run(PetClinicApplication.class, args); -} -``` --> [!NOTE] -> Spring's `application.properties` or `application.yaml` files are not supported as -> as sources for Application Insights Java configuration. --See [configuration file path configuration options](./java-standalone-config.md#configuration-file-path) -to change the location for a file outside the classpath. --To programmatically configure a file outside the classpath: -```java -public static void main(String[] args) { - System.setProperty("applicationinsights.configuration.file", "{path}/applicationinsights-dev.json"); - ApplicationInsights.attach(); - SpringApplication.run(PetClinicApplication.class, args); -} -``` --#### Programmatically configure the connection string --First, add the `applicationinsights-core` dependency: --```xml -<dependency> - <groupId>com.microsoft.azure</groupId> - <artifactId>applicationinsights-core</artifactId> - <version>3.5.4</version> -</dependency> -``` --Then, call the `ConnectionString.configure` method after `ApplicationInsights.attach()`: --```java -public static void main(String[] args) { - System.setProperty("applicationinsights.configuration.file", "{path}/applicationinsights-dev.json"); - ApplicationInsights.attach(); - SpringApplication.run(PetClinicApplication.class, args); -} -``` -Alternatively, call the `ConnectionString.configure` method from a Spring component. --Enable connection string configured at runtime: --```json -{ - "connectionStringConfiguredAtRuntime": true -} -``` --#### Self-diagnostic log file location --By default, when enabling Application Insights Java programmatically, the `applicationinsights.log` file containing the agent logs are located in the directory from where the JVM is launched (user directory). --To learn how to change this location, see your [self-diagnostic configuration options](./java-standalone-config.md#self-diagnostics). |
| azure-monitor | Java Standalone Config | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/java-standalone-config.md | - Title: Configuration options - Azure Monitor Application Insights for Java -description: This article shows you how to configure Azure Monitor Application Insights for Java. - Previously updated : 07/29/2024-----# Configuration options: Azure Monitor Application Insights for Java --This article shows you how to configure Azure Monitor Application Insights for Java. --## Connection string and role name --Connection string and role name are the most common settings you need to get started: --```json -{ - "connectionString": "...", - "role": { - "name": "my cloud role name" - } -} -``` -Connection string is required. Role name is important anytime you're sending data from different applications to the same Application Insights resource. --More information and configuration options are provided in the following sections. --## Configuration file path --By default, Application Insights Java 3.x expects the configuration file to be named `applicationinsights.json`, and to be located in the same directory as `applicationinsights-agent-3.5.4.jar`. --You can specify your own configuration file path by using one of these two options: --* `APPLICATIONINSIGHTS_CONFIGURATION_FILE` environment variable -* `applicationinsights.configuration.file` Java system property --If you specify a relative path, it resolves relative to the directory where `applicationinsights-agent-3.5.4.jar` is located. --Alternatively, instead of using a configuration file, you can specify the entire _content_ of the JSON configuration via the environment variable `APPLICATIONINSIGHTS_CONFIGURATION_CONTENT`. --## Connection string --Connection string is required. You can find your connection string in your Application Insights resource. ----```json -{ - "connectionString": "..." -} -``` --You can also set the connection string by using the environment variable `APPLICATIONINSIGHTS_CONNECTION_STRING`. It then takes precedence over the connection string specified in the JSON configuration. --Or you can set the connection string by using the Java system property `applicationinsights.connection.string`. It also takes precedence over the connection string specified in the JSON configuration. --You can also set the connection string by specifying a file to load the connection string from. --If you specify a relative path, it resolves relative to the directory where `applicationinsights-agent-3.5.4.jar` is located. --```json -{ - "connectionString": "${file:connection-string-file.txt}" -} -``` --The file should contain only the connection string and nothing else. --Not setting the connection string disables the Java agent. --If you have multiple applications deployed in the same Java Virtual Machine (JVM) and want them to send telemetry to different connection strings, see [Connection string overrides (preview)](#connection-string-overrides-preview). --## Cloud role name --The cloud role name is used to label the component on the application map. --If you want to set the cloud role name: --```json -{ - "role": { - "name": "my cloud role name" - } -} -``` --If the cloud role name isn't set, the Application Insights resource's name is used to label the component on the application map. --You can also set the cloud role name by using the environment variable `APPLICATIONINSIGHTS_ROLE_NAME`. It then takes precedence over the cloud role name specified in the JSON configuration. --Or you can set the cloud role name by using the Java system property `applicationinsights.role.name`. It also takes precedence over the cloud role name specified in the JSON configuration. --If you have multiple applications deployed in the same JVM and want them to send telemetry to different cloud role names, see [Cloud role name overrides (preview)](#cloud-role-name-overrides-preview). --## Cloud role instance --The cloud role instance defaults to the machine name. --If you want to set the cloud role instance to something different rather than the machine name: --```json -{ - "role": { - "name": "my cloud role name", - "instance": "my cloud role instance" - } -} -``` --You can also set the cloud role instance by using the environment variable `APPLICATIONINSIGHTS_ROLE_INSTANCE`. It then takes precedence over the cloud role instance specified in the JSON configuration. --Or you can set the cloud role instance by using the Java system property `applicationinsights.role.instance`. -It also takes precedence over the cloud role instance specified in the JSON configuration. --## Sampling --> [!NOTE] -> Sampling can be a great way to reduce the cost of Application Insights. Make sure to set up your sampling -> configuration appropriately for your use case. --Sampling is based on request, which means that if a request is captured (sampled), so are its dependencies, logs, and exceptions. --Sampling is also based on trace ID to help ensure consistent sampling decisions across different services. --Sampling only applies to logs inside of a request. Logs that aren't inside of a request (for example, startup logs) are always collected by default. -If you want to sample those logs, you can use [Sampling overrides](./java-standalone-sampling-overrides.md). --### Rate-limited sampling --Starting from 3.4.0, rate-limited sampling is available and is now the default. --If no sampling is configured, the default is now rate-limited sampling configured to capture at most -(approximately) five requests per second, along with all the dependencies and logs on those requests. --This configuration replaces the prior default, which was to capture all requests. If you still want to capture all requests, use [fixed-percentage sampling](#fixed-percentage-sampling) and set the sampling percentage to 100. --> [!NOTE] -> The rate-limited sampling is approximate because internally it must adapt a "fixed" sampling percentage over time to emit accurate item counts on each telemetry record. Internally, the rate-limited sampling is -tuned to adapt quickly (0.1 seconds) to new application loads. For this reason, you shouldn't see it exceed the configured rate by much, or for very long. --This example shows how to set the sampling to capture at most (approximately) one request per second: --```json -{ - "sampling": { - "requestsPerSecond": 1.0 - } -} -``` --The `requestsPerSecond` can be a decimal, so you can configure it to capture less than one request per second if you want. For example, a value of `0.5` means capture at most one request every 2 seconds. --You can also set the sampling percentage by using the environment variable `APPLICATIONINSIGHTS_SAMPLING_REQUESTS_PER_SECOND`. It then takes precedence over the rate limit specified in the JSON configuration. --### Fixed-percentage sampling --This example shows how to set the sampling to capture approximately a third of all requests: --```json -{ - "sampling": { - "percentage": 33.333 - } -} -``` --You can also set the sampling percentage by using the environment variable `APPLICATIONINSIGHTS_SAMPLING_PERCENTAGE`. It then takes precedence over the sampling percentage specified in the JSON configuration. --> [!NOTE] -> For the sampling percentage, choose a percentage that's close to 100/N, where N is an integer. Currently, sampling doesn't support other values. --## Sampling overrides --Sampling overrides allow you to override the [default sampling percentage](#sampling). For example, you can: --* Set the sampling percentage to 0, or some small value, for noisy health checks. -* Set the sampling percentage to 0, or some small value, for noisy dependency calls. -* Set the sampling percentage to 100 for an important request type. For example, you can use `/login` even though you have the default sampling configured to something lower. --For more information, see the [Sampling overrides](./java-standalone-sampling-overrides.md) documentation. --## Java Management Extensions metrics --If you want to collect some other Java Management Extensions (JMX) metrics: --```json -{ - "jmxMetrics": [ - { - "name": "JVM uptime (millis)", - "objectName": "java.lang:type=Runtime", - "attribute": "Uptime" - }, - { - "name": "MetaSpace Used", - "objectName": "java.lang:type=MemoryPool,name=Metaspace", - "attribute": "Usage.used" - } - ] -} -``` --In the preceding configuration example: --* `name` is the metric name that is assigned to this JMX metric (can be anything). -* `objectName` is the [Object Name](https://docs.oracle.com/javase/8/docs/api/javax/management/ObjectName.html) of the `JMX MBean` that you want to collect. Wildcard character asterisk (*) is supported. -* `attribute` is the attribute name inside of the `JMX MBean` that you want to collect. --Numeric and Boolean JMX metric values are supported. Boolean JMX metrics are mapped to `0` for false and `1` for true. --For more information, see the [JMX metrics](./java-jmx-metrics-configuration.md) documentation. --## Custom dimensions --If you want to add custom dimensions to all your telemetry: --```json -{ - "customDimensions": { - "mytag": "my value", - "anothertag": "${ANOTHER_VALUE}" - } -} -``` --You can use `${...}` to read the value from the specified environment variable at startup. --> [!NOTE] -> Starting from version 3.0.2, if you add a custom dimension named `service.version`, the value is stored in the `application_Version` column in the Application Insights Logs table instead of as a custom dimension. --## Inherited attribute (preview) --Starting with version 3.2.0, you can set a custom dimension programmatically on your request telemetry. It ensures inheritance by dependency and log telemetry. All are captured in the context of that request. --```json -{ - "preview": { - "inheritedAttributes": [ - { - "key": "mycustomer", - "type": "string" - } - ] - } -} -``` --And then at the beginning of each request, call: --```java -Span.current().setAttribute("mycustomer", "xyz"); -``` --Also see: [Add a custom property to a Span](./opentelemetry-add-modify.md?tabs=java#add-a-custom-property-to-a-span). --## Connection string overrides (preview) --This feature is in preview, starting from 3.4.0. --Connection string overrides allow you to override the [default connection string](#connection-string). For example, you can: --* Set one connection string for one HTTP path prefix `/myapp1`. -* Set another connection string for another HTTP path prefix `/myapp2/`. --```json -{ - "preview": { - "connectionStringOverrides": [ - { - "httpPathPrefix": "/myapp1", - "connectionString": "..." - }, - { - "httpPathPrefix": "/myapp2", - "connectionString": "..." - } - ] - } -} -``` --## Cloud role name overrides (preview) --This feature is in preview, starting from 3.3.0. --Cloud role name overrides allow you to override the [default cloud role name](#cloud-role-name). For example, you can: --* Set one cloud role name for one HTTP path prefix `/myapp1`. -* Set another cloud role name for another HTTP path prefix `/myapp2/`. --```json -{ - "preview": { - "roleNameOverrides": [ - { - "httpPathPrefix": "/myapp1", - "roleName": "Role A" - }, - { - "httpPathPrefix": "/myapp2", - "roleName": "Role B" - } - ] - } -} -``` --## Connection string configured at runtime --Starting from version 3.4.8, if you need the ability to configure the connection string at runtime, -add this property to your json configuration: --```json -{ - "connectionStringConfiguredAtRuntime": true -} -``` --Add `applicationinsights-core` to your application: --```xml -<dependency> - <groupId>com.microsoft.azure</groupId> - <artifactId>applicationinsights-core</artifactId> - <version>3.5.4</version> -</dependency> -``` --Use the static `configure(String)` method in the class -`com.microsoft.applicationinsights.connectionstring.ConnectionString`. --> [!NOTE] -> Any telemetry that is captured prior to configuring the connection string will be dropped, -> so it is best to configure it as early as possible in your application startup. --## Autocollect InProc dependencies (preview) --Starting from version 3.2.0, if you want to capture controller "InProc" dependencies, use the following configuration: --```json -{ - "preview": { - "captureControllerSpans": true - } -} -``` --## Browser SDK Loader (preview) --This feature automatically injects the [Browser SDK Loader](javascript-sdk.md#add-the-javascript-code) into your application's HTML pages, including configuring the appropriate Connection String. --For example, when your java application returns a response like: --```html -<!DOCTYPE html> -<html lang="en"> - <head> - <title>Title</title> - </head> - <body> - </body> -</html> -``` --It automatically modifies to return: --```html -<!DOCTYPE html> -<html lang="en"> - <head> - <script type="text/javascript"> - !function(v,y,T){var S=v.location,k="script" - <!-- Removed for brevity --> - connectionString: "YOUR_CONNECTION_STRING" - <!-- Removed for brevity --> }}); - </script> - <title>Title</title> - </head> - <body> - </body> -</html> -``` --The script is aiming at helping customers to track the web user data, and sent the collecting server-side telemetry back to users' Azure portal. Details can be found at [ApplicationInsights-JS](https://github.com/microsoft/ApplicationInsights-JS). --If you want to enable this feature, add the below configuration option: --```json -{ - "preview": { - "browserSdkLoader": { - "enabled": true - } - } -} -``` --## Telemetry processors (preview) --You can use telemetry processors to configure rules that are applied to request, dependency, and trace telemetry. For example, you can: -- * Mask sensitive data. - * Conditionally add custom dimensions. - * Update the span name, which is used to aggregate similar telemetry in the Azure portal. - * Drop specific span attributes to control ingestion costs. --For more information, see the [Telemetry processor](./java-standalone-telemetry-processors.md) documentation. --> [!NOTE] -> If you want to drop specific (whole) spans for controlling ingestion cost, see [Sampling overrides](./java-standalone-sampling-overrides.md). --## Custom instrumentation (preview) --Starting from verion 3.3.1, you can capture spans for a method in your application: --```json -{ - "preview": { - "customInstrumentation": [ - { - "className": "my.package.MyClass", - "methodName": "myMethod" - } - ] - } -} -``` --## Locally disabling ingestion sampling (preview) --By default, when the effective sampling percentage in the Java agent is 100% -and [ingestion sampling](./sampling-classic-api.md#ingestion-sampling) has been configured on your Application Insights resource, -then the ingestion sampling percentage will be applied. --Note that this behavior applies to both fixed-rate sampling of 100% and also applies to rate-limited sampling when the -request rate doesn't exceed the rate limit (effectively capturing 100% during the continuously sliding time window). --Starting from 3.5.3, you can disable this behavior -(and keep 100% of telemetry in these cases even when ingestion sampling has been configured -on your Application Insights resource): --```json -{ - "preview": { - "sampling": { - "ingestionSamplingEnabled": false - } - } -} -``` --## Autocollected logging --Log4j, Logback, JBoss Logging, and java.util.logging are autoinstrumented. Logging performed via these logging frameworks is autocollected. --Logging is only captured if it: --* Meets the configured level for the logging framework. -* Also meets the configured level for Application Insights. --For example, if your logging framework is configured to log `WARN` (and you configured it as described earlier) from the package `com.example`, -and Application Insights is configured to capture `INFO` (and you configured as described), Application Insights only captures `WARN` (and more severe) from the package `com.example`. --The default level configured for Application Insights is `INFO`. If you want to change this level: --```json -{ - "instrumentation": { - "logging": { - "level": "WARN" - } - } -} -``` --You can also set the level by using the environment variable `APPLICATIONINSIGHTS_INSTRUMENTATION_LOGGING_LEVEL`. It then takes precedence over the level specified in the JSON configuration. --You can use these valid `level` values to specify in the `applicationinsights.json` file. The table shows how they correspond to logging levels in different logging frameworks. --| Level | Log4j | Logback | JBoss | JUL | -|-|--||--|| -| OFF | OFF | OFF | OFF | OFF | -| FATAL | FATAL | ERROR | FATAL | SEVERE | -| ERROR (or SEVERE) | ERROR | ERROR | ERROR | SEVERE | -| WARN (or WARNING) | WARN | WARN | WARN | WARNING | -| INFO | INFO | INFO | INFO | INFO | -| CONFIG | DEBUG | DEBUG | DEBUG | CONFIG | -| DEBUG (or FINE) | DEBUG | DEBUG | DEBUG | FINE | -| FINER | DEBUG | DEBUG | DEBUG | FINER | -| TRACE (or FINEST) | TRACE | TRACE | TRACE | FINEST | -| ALL | ALL | ALL | ALL | ALL | --> [!NOTE] -> If an exception object is passed to the logger, the log message (and exception object details) will show up in the Azure portal under the `exceptions` table instead of the `traces` table. If you want to see the log messages across both the `traces` and `exceptions` tables, you can write a Logs (Kusto) query to union across them. For example: -> -> ``` -> union traces, (exceptions | extend message = outerMessage) -> | project timestamp, message, itemType -> ``` --### Log markers (preview) --Starting from 3.4.2, you can capture the log markers for Logback and Log4j 2: --```json -{ - "preview": { - "captureLogbackMarker": true, - "captureLog4jMarker": true - } -} -``` --### Other log attributes for Logback (preview) --Starting from 3.4.3, you can capture `FileName`, `ClassName`, `MethodName`, and `LineNumber`, for Logback: --```json -{ - "preview": { - "captureLogbackCodeAttributes": true - } -} -``` --> [!WARNING] -> -> Capturing code attributes might add a performance overhead. --### Logging level as a custom dimension --Starting from version 3.3.0, `LoggingLevel` isn't captured by default as part of the Traces custom dimension because that data is already captured in the `SeverityLevel` field. --If needed, you can temporarily re-enable the previous behavior: --```json -{ - "preview": { - "captureLoggingLevelAsCustomDimension": true - } -} -``` --## Autocollected Micrometer metrics (including Spring Boot Actuator metrics) --If your application uses [Micrometer](https://micrometer.io), metrics that are sent to the Micrometer global registry are autocollected. --Also, if your application uses [Spring Boot Actuator](https://docs.spring.io/spring-boot/docs/current/reference/html/production-ready-features.html), metrics configured by Spring Boot Actuator are also autocollected. --To send custom metrics using micrometer: --1. Add Micrometer to your application as shown in the following example. - - ```xml - <dependency> - <groupId>io.micrometer</groupId> - <artifactId>micrometer-core</artifactId> - <version>1.6.1</version> - </dependency> - ``` --1. Use the Micrometer [global registry](https://micrometer.io/?/docs/concepts#_global_registry) to create a meter as shown in the following example. -- ```java - static final Counter counter = Metrics.counter("test.counter"); - ``` --1. Use the counter to record metrics by using the following command. -- ```java - counter.increment(); - ``` --1. The metrics are ingested into the - [customMetrics](/azure/azure-monitor/reference/tables/custommetrics) table, with tags captured in the - `customDimensions` column. You can also view the metrics in the - [metrics explorer](../essentials/metrics-getting-started.md) under the `Log-based metrics` metric namespace. -- > [!NOTE] - > Application Insights Java replaces all non-alphanumeric characters (except dashes) in the Micrometer metric name with underscores. As a result, the preceding `test.counter` metric will show up as `test_counter`. --To disable autocollection of Micrometer metrics and Spring Boot Actuator metrics: --> [!NOTE] -> Custom metrics are billed separately and might generate extra costs. Make sure to check the [Pricing information](https://azure.microsoft.com/pricing/details/monitor/). To disable the Micrometer and Spring Boot Actuator metrics, add the following configuration to your config file. --```json -{ - "instrumentation": { - "micrometer": { - "enabled": false - } - } -} -``` --## Java Database Connectivity query masking --Literal values in Java Database Connectivity (JDBC) queries are masked by default to avoid accidentally capturing sensitive data. --Starting from 3.4.0, this behavior can be disabled. For example: --```json -{ - "instrumentation": { - "jdbc": { - "masking": { - "enabled": false - } - } - } -} -``` --## Mongo query masking --Literal values in Mongo queries are masked by default to avoid accidentally capturing sensitive data. --Starting from 3.4.0, this behavior can be disabled. For example: --```json -{ - "instrumentation": { - "mongo": { - "masking": { - "enabled": false - } - } - } -} -``` --## HTTP headers --Starting from version 3.3.0, you can capture request and response headers on your server (request) telemetry: --```json -{ - "preview": { - "captureHttpServerHeaders": { - "requestHeaders": [ - "My-Header-A" - ], - "responseHeaders": [ - "My-Header-B" - ] - } - } -} -``` --The header names are case insensitive. --The preceding examples are captured under the property names `http.request.header.my_header_a` and -`http.response.header.my_header_b`. --Similarly, you can capture request and response headers on your client (dependency) telemetry: --```json -{ - "preview": { - "captureHttpClientHeaders": { - "requestHeaders": [ - "My-Header-C" - ], - "responseHeaders": [ - "My-Header-D" - ] - } - } -} -``` --Again, the header names are case insensitive. The preceding examples are captured under the property names -`http.request.header.my_header_c` and `http.response.header.my_header_d`. --## HTTP server 4xx response codes --By default, HTTP server requests that result in 4xx response codes are captured as errors. --Starting from version 3.3.0, you can change this behavior to capture them as success: --```json -{ - "preview": { - "captureHttpServer4xxAsError": false - } -} -``` --## Suppress specific autocollected telemetry --Starting from version 3.0.3, specific autocollected telemetry can be suppressed by using these configuration options: --```json -{ - "instrumentation": { - "azureSdk": { - "enabled": false - }, - "cassandra": { - "enabled": false - }, - "jdbc": { - "enabled": false - }, - "jms": { - "enabled": false - }, - "kafka": { - "enabled": false - }, - "logging": { - "enabled": false - }, - "micrometer": { - "enabled": false - }, - "mongo": { - "enabled": false - }, - "quartz": { - "enabled": false - }, - "rabbitmq": { - "enabled": false - }, - "redis": { - "enabled": false - }, - "springScheduling": { - "enabled": false - } - } -} -``` --You can also suppress these instrumentations by setting these environment variables to `false`: --* `APPLICATIONINSIGHTS_INSTRUMENTATION_AZURE_SDK_ENABLED` -* `APPLICATIONINSIGHTS_INSTRUMENTATION_CASSANDRA_ENABLED` -* `APPLICATIONINSIGHTS_INSTRUMENTATION_JDBC_ENABLED` -* `APPLICATIONINSIGHTS_INSTRUMENTATION_JMS_ENABLED` -* `APPLICATIONINSIGHTS_INSTRUMENTATION_KAFKA_ENABLED` -* `APPLICATIONINSIGHTS_INSTRUMENTATION_LOGGING_ENABLED` -* `APPLICATIONINSIGHTS_INSTRUMENTATION_MICROMETER_ENABLED` -* `APPLICATIONINSIGHTS_INSTRUMENTATION_MONGO_ENABLED` -* `APPLICATIONINSIGHTS_INSTRUMENTATION_RABBITMQ_ENABLED` -* `APPLICATIONINSIGHTS_INSTRUMENTATION_REDIS_ENABLED` -* `APPLICATIONINSIGHTS_INSTRUMENTATION_SPRING_SCHEDULING_ENABLED` --These variables then take precedence over the enabled variables specified in the JSON configuration. --> [!NOTE] -> If you're looking for more fine-grained control, for example, to suppress some redis calls but not all redis calls, see [Sampling overrides](./java-standalone-sampling-overrides.md). --## Preview instrumentations --Starting from version 3.2.0, you can enable the following preview instrumentations: --``` -{ - "preview": { - "instrumentation": { - "akka": { - "enabled": true - }, - "apacheCamel": { - "enabled": true - }, - "grizzly": { - "enabled": true - }, - "ktor": { - "enabled": true - }, - "play": { - "enabled": true - }, - "r2dbc": { - "enabled": true - }, - "springIntegration": { - "enabled": true - }, - "vertx": { - "enabled": true - } - } - } -} -``` --> [!NOTE] -> Akka instrumentation is available starting from version 3.2.2. Vertx HTTP Library instrumentation is available starting from version 3.3.0. --## Metric interval --By default, metrics are captured every 60 seconds. --Starting from version 3.0.3, you can change this interval: --```json -{ - "metricIntervalSeconds": 300 -} -``` --Starting from 3.4.9 GA, you can also set the `metricIntervalSeconds` by using the environment variable `APPLICATIONINSIGHTS_METRIC_INTERVAL_SECONDS`. It then takes precedence over the `metricIntervalSeconds` specified in the JSON configuration. --The setting applies to the following metrics: --* **Default performance counters**: For example, CPU and memory -* **Default custom metrics**: For example, garbage collection timing -* **Configured JMX metrics**: [See the JMX metric section](#java-management-extensions-metrics) -* **Micrometer metrics**: [See the Autocollected Micrometer metrics section](#autocollected-micrometer-metrics-including-spring-boot-actuator-metrics) --## Heartbeat --By default, Application Insights Java 3.x sends a heartbeat metric once every 15 minutes. If you're using the heartbeat metric to trigger alerts, you can increase the frequency of this heartbeat: --```json -{ - "heartbeat": { - "intervalSeconds": 60 - } -} -``` --> [!NOTE] -> You can't increase the interval to longer than 15 minutes because the heartbeat data is also used to track Application Insights usage. --## Authentication --> [!NOTE] -> The authentication feature is GA since version 3.4.17. --You can use authentication to configure the agent to generate [token credentials](/java/api/overview/azure/identity-readme#credentials) that are required for Microsoft Entra authentication. -For more information, see the [Authentication](./azure-ad-authentication.md) documentation. --## HTTP proxy --If your application is behind a firewall and can't connect directly to Application Insights, refer to [IP addresses used by Application Insights](../ip-addresses.md). --To work around this issue, you can configure Application Insights Java 3.x to use an HTTP proxy. --```json -{ - "proxy": { - "host": "myproxy", - "port": 8080 - } -} -``` --You can also set the http proxy using the environment variable `APPLICATIONINSIGHTS_PROXY`, which takes the format `https://<host>:<port>`. It then takes precedence over the proxy specified in the JSON configuration. --You can provide a user and a password for your proxy with the `APPLICATIONINSIGHTS_PROXY` environment variable: `https://<user>:<password>@<host>:<port>`. --Application Insights Java 3.x also respects the global `https.proxyHost` and `https.proxyPort` system properties if they're set, and `http.nonProxyHosts`, if needed. --## Recovery from ingestion failures --When sending telemetry to the Application Insights service fails, Application Insights Java 3.x stores the telemetry to disk and continues retrying from disk. --The default limit for disk persistence is 50 Mb. If you have high telemetry volume or need to be able to recover from longer network or ingestion service outages, you can increase this limit starting from version 3.3.0: --```json -{ - "preview": { - "diskPersistenceMaxSizeMb": 50 - } -} -``` --## Self-diagnostics --"Self-diagnostics" refers to internal logging from Application Insights Java 3.x. This functionality can be helpful for spotting and diagnosing issues with Application Insights itself. --By default, Application Insights Java 3.x logs at level `INFO` to both the file `applicationinsights.log` -and the console, corresponding to this configuration: --```json -{ - "selfDiagnostics": { - "destination": "file+console", - "level": "INFO", - "file": { - "path": "applicationinsights.log", - "maxSizeMb": 5, - "maxHistory": 1 - } - } -} -``` --In the preceding configuration example: --* `level` can be one of `OFF`, `ERROR`, `WARN`, `INFO`, `DEBUG`, or `TRACE`. -* `path` can be an absolute or relative path. Relative paths are resolved against the directory where -`applicationinsights-agent-3.5.4.jar` is located. --Starting from version 3.0.2, you can also set the self-diagnostics `level` by using the environment variable -`APPLICATIONINSIGHTS_SELF_DIAGNOSTICS_LEVEL`. It then takes precedence over the self-diagnostics level specified in the JSON configuration. --Starting from version 3.0.3, you can also set the self-diagnostics file location by using the environment variable `APPLICATIONINSIGHTS_SELF_DIAGNOSTICS_FILE_PATH`. It then takes precedence over the self-diagnostics file path specified in the JSON configuration. --## Telemetry correlation --Telemetry correlation is enabled by default, but you may disable it in configuration. --```json -{ - "preview": { - "disablePropagation": true - } -} -``` --## An example --This example shows what a configuration file looks like with multiple components. Configure specific options based on your needs. --```json -{ - "connectionString": "...", - "role": { - "name": "my cloud role name" - }, - "sampling": { - "percentage": 100 - }, - "jmxMetrics": [ - ], - "customDimensions": { - }, - "instrumentation": { - "logging": { - "level": "INFO" - }, - "micrometer": { - "enabled": true - } - }, - "proxy": { - }, - "preview": { - "processors": [ - ] - }, - "selfDiagnostics": { - "destination": "file+console", - "level": "INFO", - "file": { - "path": "applicationinsights.log", - "maxSizeMb": 5, - "maxHistory": 1 - } - } -} -``` |
| azure-monitor | Java Standalone Profiler | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/java-standalone-profiler.md | - Title: Java Profiler for Azure Monitor Application Insights -description: How to configure the Azure Monitor Application Insights for Java Profiler - Previously updated : 11/15/2023----# Java Profiler for Azure Monitor Application Insights --> [!NOTE] -> The Java Profiler feature is in preview, starting from 3.4.0. --The Application Insights Java Profiler provides a system for: --> [!div class="checklist"] -> - Generating JDK Flight Recorder (JFR) profiles on demand from the Java Virtual Machine (JVM). -> - Generating JFR profiles automatically when certain trigger conditions are met from JVM, such as CPU or memory breaching a configured threshold. --## Overview --The Application Insights Java profiler uses the JFR profiler provided by the JVM to record profiling data, allowing users to download the JFR recordings at a later time and analyze them to identify the cause of performance issues. --This data is gathered on demand when trigger conditions are met. The available triggers are thresholds over CPU usage, Memory consumption, and Request (service-level agreement triggers). Request triggers monitor Spans generated by OpenTelemetry and allow the user to configure service-level agreement (SLA) requirements over the duration of those Spans. --When a threshold is reached, a profile of the configured type and duration is gathered and uploaded. This profile is then visible within the performance pane of the associated Application Insights Portal UI. --> [!WARNING] -> The JFR profiler by default executes the "profile-without-env-data" profile. A JFR file is a series of events emitted by the JVM. The "profile-without-env-data" configuration, is similar to the "profile" configuration that ships with the JVM, however has had some events disabled that have the potential to contain sensitive deployment information such as environment variables, arguments provided to the JVM and processes running on the system. --The flags that are no longer available are: --- jdk.JVMInformation-- jdk.InitialSystemProperty-- jdk.OSInformation-- jdk.InitialEnvironmentVariable-- jdk.SystemProcess--However, you should review all enabled flags to ensure that profiles don't contain sensitive data. --See [Configuring Profile Contents](#configuring-profile-contents) on setting a custom profiler configuration. --## Prerequisites --- JVM with Java Flight Recorder (JFR) capability- - Java 8 update 262+ - - Java 11+ --> [!WARNING] -> OpenJ9 JVM is not supported --## Usage --### Triggers --For more detailed description of the various triggers available, see [profiler overview](../profiler/profiler-overview.md). --The ApplicationInsights Java Agent monitors CPU, memory, and request duration such as a business transaction. If it breaches a configured threshold, a profile is triggered. --#### Profile now --A **Profile now** button is located in the profiler user interface (see [profiler settings](../profiler/profiler-settings.md)). Selecting this button immediately requests a profile in all agents that are attached to the Application Insights instance. The default profiling duration is two minutes. You can change it by overriding `periodicRecordingDurationSeconds` (see [Configuration file](#configuration-file)). --> [!WARNING] -> Invoking Profile now will enable the profiler feature, and Application Insights will apply default CPU and memory SLA triggers. When your application breaches those SLAs, Application Insights will gather Java profiles. If you wish to disable profiling later on, you can do so within the trigger menu shown in [Installation](#installation). --#### CPU --CPU threshold is a percentage of the usage of all available cores on the system. --As an example, if one core of an eight core machine were saturated the CPU percentage would be considered 12.5%. --#### Memory --Memory percentage is the current Tenured memory region (OldGen) occupancy against the maximum possible size of the region. --Occupancy is evaluated after a tenured collection is performed. The maximum size of the tenured region is the size it would be if the Java Virtual Machine (JVM) heap grew to its maximum size. --For instance, take the following scenario: --- The Java heap could grow to a maximum of 1,024 mb.-- The Tenured Generation could grow to 90% of the heap.-- The maximum possible size of tenured would be 922 mb.-- Your threshold was set via the user interface to 75%, therefore your threshold would be 75% of 922 mb, 691 mb.--In this scenario, a profile occurs in the following circumstances: --- Full garbage collection is executed-- The Tenured regions occupancy is above 691 mb after collection--### Request --SLA triggers are based on OpenTelemetry, and they initiate a profile if certain criteria are fulfilled. --Each individual trigger configuration is formed as follows: --- `Name` - A unique identifier for the trigger.-- `Filter` - Filters the requests of interest for the trigger.-- `Aggregation` - Calculates the ratio of requests that breached a given threshold.- - `Threshold` - A minimum value (in milliseconds) at which a request breach is determined to occur. - - `Minimum samples` - The minimum number of samples that must be collected for the aggregation to produce data, this setting is to prevent triggering off of small sample sizes. - - `Window` - Rolling time window (in milliseconds). -- `Threshold` - The threshold value (percentage) applied to the aggregation output. If this value is exceeded, a profile is initiated.--For instance, the following scenario would trigger a profile if: more than 75% of requests to a specific endpoint (/users/.*) take longer than 30 ms within a 60-second window, when at least 100 samples were gathered. ---### Installation --The following steps guide you through enabling the profiling component on the agent and configuring resource limits that trigger a profile if breached. --1. Configure the resource thresholds that cause a profile to be collected: - - 1. Browse to the Performance -> Profiler section of the Application Insights instance. - :::image type="content" source="./media/java-standalone-profiler/performance-blade.png" alt-text="Screenshot of the link to open performance pane." lightbox="media/java-standalone-profiler/performance-blade.png"::: - :::image type="content" source="./media/java-standalone-profiler/profiler-button.png" alt-text="Screenshot of the Profiler button from the Performance pane." lightbox="media/java-standalone-profiler/profiler-button.png"::: - - 2. Select "Triggers" - - 3. Configure the required CPU, Memory, or Request triggers (if enabled) and select Apply. - :::image type="content" source="./media/java-standalone-profiler/trigger-settings.png" alt-text="Screenshot of trigger settings"::: --> [!WARNING] -> The Java profiler does not support the "Sampling" trigger. Configuring this will have no effect. --After these steps are completed, the agent will monitor the resource usage of your process and trigger a profile when the threshold is exceeded. When a profile is triggered and completed, it's viewable from the -Application Insights instance within the Performance -> Profiler section. From that screen the profile can be downloaded, once download the JFR recording file can be opened and analyzed within a tool of your choosing, for example Oracle JDK Mission Control (JMC). ---### Configuration --Configuration of the profiler triggering settings, such as thresholds and profiling periods, are set within the ApplicationInsights UI under the Performance, Profiler, Triggers UI as described in [Installation](#installation). --Additionally, many parameters can be configured using environment variables and the `applicationinsights.json` configuration file. --#### Configuring Profile Contents --If you wish to provide a custom profile configuration, alter the `memoryTriggeredSettings`, and `cpuTriggeredSettings` to provide the path to a `.jfc` file with your required configuration. --Profiles can be generated/edited in the JDK Mission Control (JMC) user interface under the `Window->Flight Recording Template Manager` menu and control over individual flags is found inside `Edit->Advanced` of this user interface. --### Environment variables --- `APPLICATIONINSIGHTS_PREVIEW_PROFILER_ENABLED`: boolean (default: `true`)- Enables/disables the profiling feature. By default the feature is enabled within the agent (since agent 3.4.9). However, even though this feature is enabled within the agent, profiles aren't gathered unless enabled within the Portal as described in [Installation](#installation). --### Configuration file --Example configuration: --```json -{ - "preview": { - "profiler": { - "enabled": true, - "cpuTriggeredSettings": "profile-without-env-data", - "memoryTriggeredSettings": "profile-without-env-data", - "manualTriggeredSettings": "profile-without-env-data", - "enableRequestTriggering": true, - "periodicRecordingDurationSeconds": 60 - } - } -} --``` --`memoryTriggeredSettings` This configuration is used if a memory profile is requested. This value can be one of: --- `profile-without-env-data` (default value). A profile with certain sensitive events disabled, see Warning section for details.-- `profile`. Uses the `profile.jfc` configuration that ships with JFR.-- A path to a custom jfc configuration file on the file system, for example, `/tmp/myconfig.jfc`.--`cpuTriggeredSettings` This configuration is used if a cpu profile is requested. -This value can be one of: --- `profile-without-env-data` (default value). A profile with certain sensitive events disabled, see Warning section for details.-- `profile`. Uses the `profile.jfc` jfc configuration that ships with JFR.-- A path to a custom jfc configuration file on the file system, for example, `/tmp/myconfig.jfc`.--`manualTriggeredSettings` This configuration is used if a manual profile is requested. -This value can be one of: --- `profile-without-env-data` (default value). A profile with certain sensitive events disabled, see- Warning section for details. -- `profile`. Uses the `profile.jfc` jfc configuration that ships with JFR.-- A path to a custom jfc configuration file on the file system, for example, `/tmp/myconfig.jfc`.--`enableRequestTriggering` Whether JFR profiling should be triggered based on request configuration. -This value can be one of: --- `true` Profiling is triggered if a request trigger threshold is breached.-- `false` (default value). Request configuration doesn't trigger profiling.--`periodicRecordingDurationSeconds` Profiling recording duration in seconds when a profiling session is started by using the **Profile now** button. The default value is `120`. --## Frequently asked questions --### What is Azure Monitor Application Insights Java Profiling? -Azure Monitor Application Insights Java profiler uses Java Flight Recorder (JFR) to profile your application using a customized configuration. --### What is Java Flight Recorder? -Java Flight Recorder (JFR) is a tool for collecting profiling data of a running Java application. JFR is integrated into the Java Virtual Machine (JVM) and is used for troubleshooting performance issues. Learn more about [Java SE JFR Runtime](https://docs.oracle.com/javacomponents/jmc-5-4/jfr-runtime-guide/about.htm#JFRUH170). --### What is the price and/or licensing fee implications for enabling App Insights Java Profiling? -Java Profiling is a free feature with Application Insights. [Azure Monitor Application Insights pricing](https://azure.microsoft.com/pricing/details/monitor/) is based on ingestion cost. --### Which Java profiling information is collected? -Profiling data collected by the JFR includes: method and execution profiling data, garbage collection data, and lock profiles. --### How can I use App Insights Java Profiling and visualize the data? -JFR recording can be viewed and analyzed with your preferred tool, for example [Java Mission Control (JMC)](https://jdk.java.net/jmc/8/). --### Are performance diagnosis and fix recommendations provided with App Insights Java Profiling? -'Performance diagnostics and recommendations' is a new feature that is available soon as Application Insights Java Diagnostics. You can [sign up](https://aka.ms/JavaO11y) to preview this feature. JFR recording can be viewed with Java Mission Control (JMC). --### What's the difference between on-demand and automatic Java Profiling in App Insights? --On-demand is user triggered profiling in real-time whereas automatic profiling is with preconfigured triggers. --Use [Profile Now](../profiler/profiler-settings.md) for the on-demand profiling option. [Profile Now](../profiler/profiler-settings.md) immediately profiles all agents that are attached to the Application Insights instance. --Automated profiling is triggered a breach in a resource threshold. --### Which Java profiling triggers can I configure? -Application Insights Java Agent currently supports monitoring of CPU and memory consumption. CPU threshold is configured as a percentage of all available cores on the machine. Memory is the current Tenured memory region (OldGen) occupancy against the maximum possible size of the region. --### What are the required prerequisites to enable Java Profiling? --Review the [Prerequisites](#prerequisites) at the top of this article. --### Can I use Java Profiling for microservices application? --Yes, you can profile a JVM running microservices using the JFR. |
| azure-monitor | Java Standalone Sampling Overrides | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/java-standalone-sampling-overrides.md | - Title: Sampling overrides - Azure Monitor Application Insights for Java -description: Learn to configure sampling overrides in Azure Monitor Application Insights for Java. - Previously updated : 11/15/2023-----# Sampling overrides - Azure Monitor Application Insights for Java --> [!NOTE] -> The sampling overrides feature is in GA, starting from 3.5.0. --Sampling overrides allow you to override the [default sampling percentage](./java-standalone-config.md#sampling), -for example: -* Set the sampling percentage to 0 (or some small value) for noisy health checks. - * Set the sampling percentage to 0 (or some small value) for noisy dependency calls. - * Set the sampling percentage to 100 for an important request type (for example, `/login`) - even though you have the default sampling configured to something lower. --## Terminology --Before you learn about sampling overrides, you should understand the term *span*. A span is a general term for: --* An incoming request. -* An outgoing dependency (for example, a remote call to another service). -* An in-process dependency (for example, work being done by subcomponents of the service). --For sampling overrides, these span components are important: --* Attributes --The span attributes represent both standard and custom properties of a given request or dependency. --## Getting started --To begin, create a configuration file named *applicationinsights.json*. Save it in the same directory as *applicationinsights-agent-\*.jar*. Use the following template. --```json -{ - "connectionString": "...", - "sampling": { - "percentage": 10, - "overrides": [ - { - "telemetryType": "request", - "attributes": [ - ... - ], - "percentage": 0 - }, - { - "telemetryType": "request", - "attributes": [ - ... - ], - "percentage": 100 - } - ] - } -} -``` --## How it works --`telemetryType` (`telemetryKind` in Application Insights 3.4.0) must be one of `request`, `dependency`, `trace` (log), or `exception`. --When a span is started, the type of span and the attributes present on it at that time are used to check if any of the sampling -overrides match. --Matches can be either `strict` or `regexp`. Regular expression matches are performed against the entire attribute value, -so if you want to match a value that contains `abc` anywhere in it, then you need to use `.*abc.*`. -A sampling override can specify multiple attribute criteria, in which case all of them must match for the sampling -override to match. --If one of the sampling overrides matches, then its sampling percentage is used to decide whether to sample the span or -not. --Only the first sampling override that matches is used. --If no sampling overrides match: --* If it's the first span in the trace, then the - [top-level sampling configuration](./java-standalone-config.md#sampling) is used. -* If it isn't the first span in the trace, then the parent sampling decision is used. --## Example: Suppress collecting telemetry for health checks --This example suppresses collecting telemetry for all requests to `/health-checks`. --This example also suppresses collecting any downstream spans (dependencies) that would normally be collected under -`/health-checks`. --```json -{ - "connectionString": "...", - "sampling": { - "overrides": [ - { - "telemetryType": "request", - "attributes": [ - { - "key": "url.path", - "value": "/health-check", - "matchType": "strict" - } - ], - "percentage": 0 - } - ] - } -} -``` --## Example: Suppress collecting telemetry for a noisy dependency call --This example suppresses collecting telemetry for all `GET my-noisy-key` redis calls. --```json -{ - "connectionString": "...", - "sampling": { - "overrides": [ - { - "telemetryType": "dependency", - "attributes": [ - { - "key": "db.system", - "value": "redis", - "matchType": "strict" - }, - { - "key": "db.statement", - "value": "GET my-noisy-key", - "matchType": "strict" - } - ], - "percentage": 0 - } - ] - } -} -``` --## Example: Collect 100% of telemetry for an important request type --This example collects 100% of telemetry for `/login`. --Since downstream spans (dependencies) respect the parent's sampling decision -(absent any sampling override for that downstream span), -they're also collected for all '/login' requests. --```json -{ - "connectionString": "...", - "sampling": { - "percentage": 10 - }, - "sampling": { - "overrides": [ - { - "telemetryType": "request", - "attributes": [ - { - "key": "url.path", - "value": "/login", - "matchType": "strict" - } - ], - "percentage": 100 - } - ] - } -} -``` --## Span attributes available for sampling --Span attribute names are based on the OpenTelemetry semantic conventions. (HTTP, Messaging, Database, RPC) --https://github.com/open-telemetry/semantic-conventions/blob/main/docs/README.md -->[!Note] -> To see the exact set of attributes captured by Application Insights Java for your application, set the -[self-diagnostics level to debug](./java-standalone-config.md#self-diagnostics), and look for debug messages starting -with the text "exporting span". -->[!Note] -> Only attributes set at the start of the span are available for sampling, -so attributes such as `http.response.status_code` or request duration which are captured later on can be filtered through [OpenTelemetry Java extensions](https://opentelemetry.io/docs/languages/java/automatic/extensions/). Here is a [sample extension that filters spans based on request duration](https://github.com/Azure-Samples/ApplicationInsights-Java-Samples/tree/main/opentelemetry-api/java-agent/TelemetryFilteredBaseOnRequestDuration). ---## Troubleshooting --If you use `regexp` and the sampling override doesn't work, try with the `.*` regex. If the sampling now works, it means -you have an issue with the first regex and read [this regex documentation](https://docs.oracle.com/javase/8/docs/api/java/util/regex/Pattern.html). --If it doesn't work with `.*`, you might have a syntax issue in your `application-insights.json file`. Look at the Application Insights logs and see if you notice -warning messages. - |
| azure-monitor | Java Standalone Telemetry Processors Examples | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/java-standalone-telemetry-processors-examples.md | - Title: Telemetry processor examples - Azure Monitor Application Insights for Java -description: Explore examples that show telemetry processors in Azure Monitor Application Insights for Java. - Previously updated : 12/15/2023-----# Telemetry processor examples - Azure Monitor Application Insights for Java --This article provides examples of telemetry processors in Application Insights for Java, including samples for include and exclude configurations. It also includes samples for attribute processors and span processors. --## Include and exclude Span samples --In this section, learn how to include and exclude spans. You also learn how to exclude multiple spans and apply selective processing. --### Include spans --This section shows how to include spans for an attribute processor. The processor doesn't process spans that don't match the properties. --A match requires the span name to be equal to `spanA` or `spanB`. --These spans match the `include` properties, and the processor actions are applied: -* `Span1` Name: 'spanA' Attributes: {env: dev, test_request: 123, credit_card: 1234} -* `Span2` Name: 'spanB' Attributes: {env: dev, test_request: false} -* `Span3` Name: 'spanA' Attributes: {env: 1, test_request: dev, credit_card: 1234} --This span doesn't match the `include` properties, and the processor actions aren't applied: -* `Span4` Name: 'spanC' Attributes: {env: dev, test_request: false} --```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000", - "preview": { - "processors": [ - { - "type": "attribute", - "include": { - "matchType": "strict", - "spanNames": [ - "spanA", - "spanB" - ] - }, - "actions": [ - { - "key": "credit_card", - "action": "delete" - } - ] - } - ] - } -} -``` --### Exclude spans --This section demonstrates how to exclude spans for an attribute processor. This processor doesn't process spans that match the properties. --A match requires the span name to be equal to `spanA` or `spanB`. --The following spans match the `exclude` properties, and the processor actions aren't applied: -* `Span1` Name: 'spanA' Attributes: {env: dev, test_request: 123, credit_card: 1234} -* `Span2` Name: 'spanB' Attributes: {env: dev, test_request: false} -* `Span3` Name: 'spanA' Attributes: {env: 1, test_request: dev, credit_card: 1234} --This span doesn't match the `exclude` properties, and the processor actions are applied: -* `Span4` Name: 'spanC' Attributes: {env: dev, test_request: false} --```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000", - "preview": { - "processors": [ - { - "type": "attribute", - "exclude": { - "matchType": "strict", - "spanNames": [ - "spanA", - "spanB" - ] - }, - "actions": [ - { - "key": "credit_card", - "action": "delete" - } - ] - } - ] - } -} -``` --### Exclude spans by using multiple criteria --This section demonstrates how to exclude spans for an attribute processor. This processor doesn't process spans that match the properties. --A match requires the following conditions to be met: -* An attribute (for example, `env` with value `dev`) must exist in the span. -* The span must have an attribute that has key `test_request`. --The following spans match the `exclude` properties, and the processor actions aren't applied. -* `Span1` Name: 'spanB' Attributes: {env: dev, test_request: 123, credit_card: 1234} -* `Span2` Name: 'spanA' Attributes: {env: dev, test_request: false} --The following span doesn't match the `exclude` properties, and the processor actions are applied: -* `Span3` Name: 'spanB' Attributes: {env: 1, test_request: dev, credit_card: 1234} -* `Span4` Name: 'spanC' Attributes: {env: dev, dev_request: false} ---```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000", - "preview": { - "processors": [ - { - "type": "attribute", - "exclude": { - "matchType": "strict", - "spanNames": [ - "spanA", - "spanB" - ], - "attributes": [ - { - "key": "env", - "value": "dev" - }, - { - "key": "test_request" - } - ] - }, - "actions": [ - { - "key": "credit_card", - "action": "delete" - } - ] - } - ] - } -} -``` --### Selective processing --This section shows how to specify the set of span properties that -indicate which spans this processor should be applied to. The `include` properties indicate which spans should be processed. The `exclude` properties filter out spans that shouldn't be processed. --In the following configuration, these spans match the properties, and processor actions are applied: --* `Span1` Name: 'spanB' Attributes: {env: production, test_request: 123, credit_card: 1234, redact_trace: "false"} -* `Span2` Name: 'spanA' Attributes: {env: staging, test_request: false, redact_trace: true} --These spans don't match the `include` properties, and processor actions aren't applied: -* `Span3` Name: 'spanB' Attributes: {env: production, test_request: true, credit_card: 1234, redact_trace: false} -* `Span4` Name: 'spanC' Attributes: {env: dev, test_request: false} --```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000", - "preview": { - "processors": [ - { - "type": "attribute", - "include": { - "matchType": "strict", - "spanNames": [ - "spanA", - "spanB" - ] - }, - "exclude": { - "matchType": "strict", - "attributes": [ - { - "key": "redact_trace", - "value": "false" - } - ] - }, - "actions": [ - { - "key": "credit_card", - "action": "delete" - }, - { - "key": "duplicate_key", - "action": "delete" - } - ] - } - ] - } -} -``` --## Attribute processor samples --### Insert --The following sample inserts the new attribute `{"attribute1": "attributeValue1"}` into spans and logs where the key `attribute1` doesn't exist. --```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000", - "preview": { - "processors": [ - { - "type": "attribute", - "actions": [ - { - "key": "attribute1", - "value": "attributeValue1", - "action": "insert" - } - ] - } - ] - } -} -``` --### Insert from another key --The following sample uses the value from attribute `anotherkey` to insert the new attribute `{"newKey": "<value from attribute anotherkey>"}` into spans and logs where the key `newKey` doesn't exist. If the attribute `anotherkey` doesn't exist, no new attribute is inserted into spans and logs. --```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000", - "preview": { - "processors": [ - { - "type": "attribute", - "actions": [ - { - "key": "newKey", - "fromAttribute": "anotherKey", - "action": "insert" - } - ] - } - ] - } -} -``` --### Update --The following sample updates the attribute to `{"db.secret": "redacted"}`. It updates the attribute `boo` by using the value from attribute `foo`. Spans and logs that don't have the attribute `boo` don't change. --```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000", - "preview": { - "processors": [ - { - "type": "attribute", - "actions": [ - { - "key": "db.secret", - "value": "redacted", - "action": "update" - }, - { - "key": "boo", - "fromAttribute": "foo", - "action": "update" - } - ] - } - ] - } -} -``` --### Delete --The following sample shows how to delete an attribute that has the key `credit_card`. --```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000", - "preview": { - "processors": [ - { - "type": "attribute", - "actions": [ - { - "key": "credit_card", - "action": "delete" - } - ] - } - ] - } -} -``` --### Hash --The following sample shows how to hash existing attribute values. --```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000", - "preview": { - "processors": [ - { - "type": "attribute", - "actions": [ - { - "key": "user.email", - "action": "hash" - } - ] - } - ] - } -} -``` --### Extract --The following sample shows how to use a regular expression (regex) to create new attributes based on the value of another attribute. -For example, given `url.path = /path?queryParam1=value1,queryParam2=value2`, the following attributes are inserted: -* httpProtocol: `http` -* httpDomain: `example.com` -* httpPath: `path` -* httpQueryParams: `queryParam1=value1,queryParam2=value2` -* url.path: *no* change --```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000", - "preview": { - "processors": [ - { - "type": "attribute", - "actions": [ - { - "key": "url.path", - "pattern": "^(?<httpProtocol>.*):\\/\\/(?<httpDomain>.*)\\/(?<httpPath>.*)(\\?|\\&)(?<httpQueryParams>.*)", - "action": "extract" - } - ] - } - ] - } -} -``` --### Mask --For example, given `url.path = https://example.com/user/12345622` is updated to `url.path = https://example.com/user/****` using either of the below configurations. ---First configuration example: --```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000", - "preview": { - "processors": [ - { - "type": "attribute", - "actions": [ - { - "key": "url.path", - "pattern": "user\\/\\d+", - "replace": "user\\/****", - "action": "mask" - } - ] - } - ] - } -} -``` ---Second configuration example with regular expression group name: --```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000", - "preview": { - "processors": [ - { - "type": "attribute", - "actions": [ - { - "key": "url.path", - "pattern": "^(?<userGroupName>[a-zA-Z.:\/]+)\d+", - "replace": "${userGroupName}**", - "action": "mask" - } - ] - } - ] - } -} -``` -### Nonstring typed attributes samples --Starting 3.4.19 GA, telemetry processors support nonstring typed attributes: -`boolean`, `double`, `long`, `boolean-array`, `double-array`, `long-array`, and `string-array`. --When `attributes.type` isn't provided in the json, it's default to `string`. --The following sample inserts the new attribute `{"newAttributeKeyStrict": "newAttributeValueStrict"}` into spans and logs where the attributes match the following examples: -`{"longAttributeKey": 1234}` -`{"booleanAttributeKey": true}` -`{"doubleArrayAttributeKey": [1.0, 2.0, 3.0, 4.0]}` --```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000", - "preview": { - "processors": [ - { - "type": "attribute", - "include": { - "matchType": "strict", - "attributes": [ - { - "key": "longAttributeKey", - "value": 1234, - "type": "long" - }, - { - "key": "booleanAttributeKey", - "value": true, - "type": "boolean" - }, - { - "key": "doubleArrayAttributeKey", - "value": [1.0, 2.0, 3.0, 4.0], - "type": "double-array" - } - ] - }, - "actions": [ - { - "key": "newAttributeKeyStrict", - "value": "newAttributeValueStrict", - "action": "insert" - } - ], - "id": "attributes/insertNewAttributeKeyStrict" - } - ] - } -} --``` --Additionally, nonstring typed attributes support `regexp`. --The following sample inserts the new attribute `{"newAttributeKeyRegexp": "newAttributeValueRegexp"}` into spans and logs where the attribute `longRegexpAttributeKey` matches the value from `400` to `499`. --```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000", - "preview": { - "processors": [ - { - "type": "attribute", - "include": { - "matchType": "regexp", - "attributes": [ - { - "key": "longRegexpAttributeKey", - "value": "4[0-9][0-9]", - "type": "long" - } - ] - }, - "actions": [ - { - "key": "newAttributeKeyRegexp", - "value": "newAttributeValueRegexp", - "action": "insert" - } - ], - "id": "attributes/insertNewAttributeKeyRegexp" - } - ] - } -} --``` --## Span processor samples --### Name a span --The following sample specifies the values of attributes `db.svc`, `operation`, and `id`. It forms the new name of the span by using those attributes, in that order, separated by the value `::`. -```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000", - "preview": { - "processors": [ - { - "type": "span", - "name": { - "fromAttributes": [ - "db.svc", - "operation", - "id" - ], - "separator": "::" - } - } - ] - } -} -``` --### Extract attributes from a span name --Let's assume the input span name is `/api/v1/document/12345678/update`. The following sample results in the output span name `/api/v1/document/{documentId}/update`. It adds the new attribute `documentId=12345678` to the span. -```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000", - "preview": { - "processors": [ - { - "type": "span", - "name": { - "toAttributes": { - "rules": [ - "^/api/v1/document/(?<documentId>.*)/update$" - ] - } - } - } - ] - } -} -``` --### Extract attributes from a span name by using include and exclude --The following sample shows how to change the span name to `{operation_website}`. It adds an attribute with key `operation_website` and value `{oldSpanName}` when the span has the following properties: -- The span name contains `/` anywhere in the string.-- The span name isn't `donot/change`.-```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000", - "preview": { - "processors": [ - { - "type": "span", - "include": { - "matchType": "regexp", - "spanNames": [ - "^(.*?)/(.*?)$" - ] - }, - "exclude": { - "matchType": "strict", - "spanNames": [ - "donot/change" - ] - }, - "name": { - "toAttributes": { - "rules": [ - "(?<operation_website>.*?)$" - ] - } - } - } - ] - } -} -``` ---## Log processor samples --### Extract attributes from a log message body --Let's assume the input log message body is `Starting PetClinicApplication on WorkLaptop with PID 27984 (C:\randompath\target\classes started by userx in C:\randompath)`. The following sample results in the output message body `Starting PetClinicApplication on WorkLaptop with PID {PIDVALUE} (C:\randompath\target\classes started by userx in C:\randompath)`. It adds the new attribute `PIDVALUE=27984` to the log. --```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000", - "preview": { - "processors": [ - { - "type": "log", - "body": { - "toAttributes": { - "rules": [ - "^Starting PetClinicApplication on WorkLaptop with PID (?<PIDVALUE>\\d+) .*" - ] - } - } - } - ] - } -} -``` --### Masking sensitive data in log message --The following sample shows how to mask sensitive data in a log message body using both log processor and attribute processor. -Let's assume the input log message body is `User account with userId 123456xx failed to login`. The log processor updates output message body to `User account with userId {redactedUserId} failed to login` and the attribute processor deletes the new attribute `redactedUserId`, which was adding in the previous step. -```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000", - "preview": { - "processors": [ - { - "type": "log", - "body": { - "toAttributes": { - "rules": [ - "userId (?<redactedUserId>[0-9a-zA-Z]+)" - ] - } - } - }, - { - "type": "attribute", - "actions": [ - { - "key": "redactedUserId", - "action": "delete" - } - ] - } - ] - } -} -``` --## Frequently asked questions --### Why doesn't the log processor process log files using TelemetryClient.trackTrace()? --TelemetryClient.trackTrace() is part of the Application Insights Classic SDK bridge, and the log processors only work with the new [OpenTelemetry-based instrumentation](opentelemetry-enable.md). |
| azure-monitor | Java Standalone Telemetry Processors | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/java-standalone-telemetry-processors.md | - Title: Telemetry processors (preview) - Azure Monitor Application Insights for Java -description: Learn to configure telemetry processors in Azure Monitor Application Insights for Java. - Previously updated : 11/15/2023-----# Telemetry processors (preview) - Azure Monitor Application Insights for Java --> [!NOTE] -> The telemetry processors feature is designated as preview because we cannot guarantee backwards compatibility from release to release due to the experimental state of the attribute [semantic conventions](https://opentelemetry.io/docs/reference/specification/trace/semantic_conventions). However, the feature has been tested and is supported in production. --Application Insights Java 3.x can process telemetry data before the data is exported. --Some use cases: - * Mask sensitive data. - * Conditionally add custom dimensions. - * Update the span name, which is used to aggregate similar telemetry in the Azure portal. - * Drop specific span attributes to control ingestion costs. - * Filter out some metrics to control ingestion costs. --> [!NOTE] -> If you are looking to drop specific (whole) spans for controlling ingestion cost, -> see [sampling overrides](./java-standalone-sampling-overrides.md). --## Terminology --Before you learn about telemetry processors, you should understand the terms *span* and *log*. --A span is a type of telemetry that represents one of: --* An incoming request. -* An outgoing dependency (for example, a remote call to another service). -* An in-process dependency (for example, work being done by subcomponents of the service). --A log is a type of telemetry that represents: --* log data captured from Log4j, Logback, and java.util.logging --For telemetry processors, these span/log components are important: --* Name -* Body -* Attributes --The span name is the primary display for requests and dependencies in the Azure portal. Span attributes represent both standard and custom properties of a given request or dependency. --The trace message or body is the primary display for logs in the Azure portal. Log attributes represent both standard and custom properties of a given log. --## Telemetry processor types --Currently, the four types of telemetry processors are -* Attribute processors -* Span processors -* Log processors -* Metric filters --An attribute processor can insert, update, delete, or hash attributes of a telemetry item (`span` or `log`). -It can also use a regular expression to extract one or more new attributes from an existing attribute. --A span processor can update the telemetry name of requests and dependencies. -It can also use a regular expression to extract one or more new attributes from the span name. --A log processor can update the telemetry name of logs. -It can also use a regular expression to extract one or more new attributes from the log name. --A metric filter can filter out metrics to help control ingestion cost. --> [!NOTE] -> Currently, telemetry processors process only attributes of type string. They don't process attributes of type Boolean or number. --## Getting started --To begin, create a configuration file named *applicationinsights.json*. Save it in the same directory as *applicationinsights-agent-\*.jar*. Use the following template. --```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000", - "preview": { - "processors": [ - { - "type": "attribute", - ... - }, - { - "type": "attribute", - ... - }, - { - "type": "span", - ... - }, - { - "type": "log", - ... - }, - { - "type": "metric-filter", - ... - } - ] - } -} -``` --## Attribute processor --The attribute processor modifies attributes of a `span` or a `log`. It can support the ability to include or exclude `span` or `log`. It takes a list of actions that are performed in the order that the configuration file specifies. The processor supports these actions: --- `insert`-- `update`-- `delete`-- `hash`-- `extract`-- `mask`--### `insert` --The `insert` action inserts a new attribute in telemetry item where the `key` doesn't already exist. --```json -"processors": [ - { - "type": "attribute", - "actions": [ - { - "key": "attribute1", - "value": "value1", - "action": "insert" - } - ] - } -] -``` -The `insert` action requires the following settings: -* `key` -* Either `value` or `fromAttribute` -* `action`: `insert` --### `update` --The `update` action updates an attribute in telemetry item where the `key` already exists. --```json -"processors": [ - { - "type": "attribute", - "actions": [ - { - "key": "attribute1", - "value": "newValue", - "action": "update" - } - ] - } -] -``` -The `update` action requires the following settings: -* `key` -* Either `value` or `fromAttribute` -* `action`: `update` ---### `delete` --The `delete` action deletes an attribute from a telemetry item. --```json -"processors": [ - { - "type": "attribute", - "actions": [ - { - "key": "attribute1", - "action": "delete" - } - ] - } -] -``` -The `delete` action requires the following settings: -* `key` -* `action`: `delete` --### `hash` --The `hash` action hashes (SHA1) an existing attribute value. --```json -"processors": [ - { - "type": "attribute", - "actions": [ - { - "key": "attribute1", - "action": "hash" - } - ] - } -] -``` -The `hash` action requires the following settings: -* `key` -* `action`: `hash` --### `extract` --> [!NOTE] -> The `extract` feature is available only in version 3.0.2 and later. --The `extract` action extracts values by using a regular expression rule from the input key to target keys that the rule specifies. If a target key already exists, the `extract` action overrides the target key. This action behaves like the [span processor](#extract-attributes-from-the-span-name) `toAttributes` setting, where the existing attribute is the source. --```json -"processors": [ - { - "type": "attribute", - "actions": [ - { - "key": "attribute1", - "pattern": "<regular pattern with named matchers>", - "action": "extract" - } - ] - } -] -``` -The `extract` action requires the following settings: -* `key` -* `pattern` -* `action`: `extract` --### `mask` --> [!NOTE] -> The `mask` feature is available only in version 3.2.5 and later. --The `mask` action masks attribute values by using a regular expression rule specified in the `pattern` and `replace`. --```json -"processors": [ - { - "type": "attribute", - "actions": [ - { - "key": "attributeName", - "pattern": "<regular expression pattern>", - "replace": "<replacement value>", - "action": "mask" - } - ] - } -] -``` -The `mask` action requires the following settings: -* `key` -* `pattern` -* `replace` -* `action`: `mask` --`pattern` can contain a named group placed between `?<` and `>:`. Example: `(?<userGroupName>[a-zA-Z.:\/]+)\d+`? The group is `(?<userGroupName>[a-zA-Z.:\/]+)` and `userGroupName` is the name of the group. `pattern` can then contain the same named group placed between `${` and `}` followed by the mask. Example where the mask is **: `${userGroupName}**`. --See [Telemetry processor examples](./java-standalone-telemetry-processors-examples.md) for masking examples. --### Include criteria and exclude criteria --Attribute processors support optional `include` and `exclude` criteria. -An attribute processor is applied only to telemetry that matches its `include` criteria (if it's available) -_and_ don't match its `exclude` criteria (if it's available). --To configure this option, under `include` or `exclude` (or both), specify at least one `matchType` and either `spanNames` or `attributes`. -The `include` or `exclude` configuration allows more than one specified condition. -All specified conditions must evaluate to true to result in a match. --* **Required fields**: -- * `matchType` controls how items in `spanNames` arrays and `attributes` arrays are interpreted. Possible values are `regexp` and `strict`. Regular expression matches are performed against the entire attribute value, so if you want to match a value that contains `abc` anywhere in it, then you need to use `.*abc.*`. --* **Optional fields**: -- * `spanNames` must match at least one of the items. - * `attributes` specifies the list of attributes to match. All of these attributes must match exactly to result in a match. - -> [!NOTE] -> If both `include` and `exclude` are specified, the `include` properties are checked before the `exclude` properties are checked. --> [!NOTE] -> If the `include` or `exclude` configuration do not have `spanNames` specified, then the matching criteria is applied on both `spans` and `logs`. --### Sample usage --```json -"processors": [ - { - "type": "attribute", - "include": { - "matchType": "strict", - "spanNames": [ - "spanA", - "spanB" - ] - }, - "exclude": { - "matchType": "strict", - "attributes": [ - { - "key": "redact_trace", - "value": "false" - } - ] - }, - "actions": [ - { - "key": "credit_card", - "action": "delete" - }, - { - "key": "duplicate_key", - "action": "delete" - } - ] - } -] -``` -For more information, see [Telemetry processor examples](./java-standalone-telemetry-processors-examples.md). --## Span processor --The span processor modifies either the span name or attributes of a span based on the span name. It can support the ability to include or exclude spans. --### Name a span --The `name` section requires the `fromAttributes` setting. The values from these attributes are used to create a new name, concatenated in the order that the configuration specifies. The processor changes the span name only if all of these attributes are present on the span. --The `separator` setting is optional. This setting is a string, and you can use split values. -> [!NOTE] -> If renaming relies on the attributes processor to modify attributes, ensure the span processor is specified after the attributes processor in the pipeline specification. --```json -"processors": [ - { - "type": "span", - "name": { - "fromAttributes": [ - "attributeKey1", - "attributeKey2", - ], - "separator": "::" - } - } -] -``` --### Extract attributes from the span name --The `toAttributes` section lists the regular expressions to match the span name against. It extracts attributes based on subexpressions. --The `rules` setting is required. This setting lists the rules that are used to extract attribute values from the span name. --Extracted attribute names replace the values in the span name. Each rule in the list is a regular expression (regex) pattern string. --Here's how extracted attribute names replace values: --1. The span name is checked against the regex. -2. All named subexpressions of the regex are extracted as attributes if the regex matches. -3. The extracted attributes are added to the span. -4. Each subexpression name becomes an attribute name. -5. The subexpression matched portion becomes the attribute value. -6. The extracted attribute name replaces the matched portion in the span name. If the attributes already exist in the span, they're overwritten. - -This process is repeated for all rules in the order they're specified. Each subsequent rule works on the span name that's the output of the previous rule. --```json -"processors": [ - { - "type": "span", - "name": { - "toAttributes": { - "rules": [ - "rule1", - "rule2", - "rule3" - ] - } - } - } -] --``` --## Common span attributes --This section lists some common span attributes that telemetry processors can use. --### HTTP spans --| Attribute | Type | Description | -|||| -| `http.request.method` (used to be `http.method`) | string | HTTP request method.| -| `url.full` (client span) or `url.path` (server span) (used to be `http.url`) | string | Full HTTP request URL in the form `scheme://host[:port]/path?query[#fragment]`. The fragment typically isn't transmitted over HTTP. But if the fragment is known, it should be included.| -| `http.response.status_code` (used to be `http.status_code`) | number | [HTTP response status code](https://tools.ietf.org/html/rfc7231#section-6).| -| `network.protocol.version` (used to be `http.flavor`) | string | Type of HTTP protocol. | -| `user_agent.original` (used to be `http.user_agent`) | string | Value of the [HTTP User-Agent](https://tools.ietf.org/html/rfc7231#section-5.5.3) header sent by the client. | --### Java Database Connectivity spans --The following table describes attributes that you can use in Java Database Connectivity (JDBC) spans: --| Attribute | Type | Description | -|||| -| `db.system` | string | Identifier for the database management system (DBMS) product being used. See [Semantic Conventions for database operations](https://github.com/open-telemetry/semantic-conventions/blob/main/docs/README.md). | -| `db.connection_string` | string | Connection string used to connect to the database. We recommend that you remove embedded credentials.| -| `db.user` | string | Username for accessing the database. | -| `db.name` | string | String used to report the name of the database being accessed. For commands that switch the database, this string should be set to the target database, even if the command fails.| -| `db.statement` | string | Database statement that's being run.| --### Include criteria and exclude criteria --Span processors support optional `include` and `exclude` criteria. -A span processor is applied only to telemetry that matches its `include` criteria (if it's available) -_and_ don't match its `exclude` criteria (if it's available). --To configure this option, under `include` or `exclude` (or both), specify at least one `matchType` and either `spanNames` or span `attributes`. -The `include` or `exclude` configuration allows more than one specified condition. -All specified conditions must evaluate to true to result in a match. --* **Required fields**: - * `matchType` controls how items in `spanNames` arrays and `attributes` arrays are interpreted. Possible values are `regexp` and `strict`. Regular expression matches are performed against the entire attribute value, so if you want to match a value that contains `abc` anywhere in it, then you need to use `.*abc.*`. --* **Optional fields**: - * `spanNames` must match at least one of the items. - * `attributes` specifies the list of attributes to match. All of these attributes must match exactly to result in a match. - -> [!NOTE] -> If both `include` and `exclude` are specified, the `include` properties are checked before the `exclude` properties are checked. --### Sample usage --```json -"processors": [ - { - "type": "span", - "include": { - "matchType": "strict", - "spanNames": [ - "spanA", - "spanB" - ] - }, - "exclude": { - "matchType": "strict", - "attributes": [ - { - "key": "attribute1", - "value": "attributeValue1" - } - ] - }, - "name": { - "toAttributes": { - "rules": [ - "rule1", - "rule2", - "rule3" - ] - } - } - } -] -``` -For more information, see [Telemetry processor examples](./java-standalone-telemetry-processors-examples.md). --## Log processor --> [!NOTE] -> Log processors are available starting from version 3.1.1. --The log processor modifies either the log message body or attributes of a log based on the log message body. It can support the ability to include or exclude logs. --### Update Log message body --The `body` section requires the `fromAttributes` setting. The values from these attributes are used to create a new body, concatenated in the order that the configuration specifies. The processor changes the log body only if all of these attributes are present on the log. --The `separator` setting is optional. This setting is a string. You can specify it to split values. -> [!NOTE] -> If renaming relies on the attributes processor to modify attributes, ensure the log processor is specified after the attributes processor in the pipeline specification. --```json -"processors": [ - { - "type": "log", - "body": { - "fromAttributes": [ - "attributeKey1", - "attributeKey2", - ], - "separator": "::" - } - } -] -``` --### Extract attributes from the log message body --The `toAttributes` section lists the regular expressions to match the log message body. It extracts attributes based on subexpressions. --The `rules` setting is required. This setting lists the rules that are used to extract attribute values from the body. --Extracted attribute names replace the values in the log message body. Each rule in the list is a regular expression (regex) pattern string. --Here's how extracted attribute names replace values: --1. The log message body is checked against the regex. -2. All named subexpressions of the regex are extracted as attributes if the regex matches. -3. The extracted attributes are added to the log. -4. Each subexpression name becomes an attribute name. -5. The subexpression matched portion becomes the attribute value. -6. The extracted attribute name replaces the matched portion in the log name. If the attributes already exist in the log, they're overwritten. - -This process is repeated for all rules in the order they're specified. Each subsequent rule works on the log name that's the output of the previous rule. --```json -"processors": [ - { - "type": "log", - "body": { - "toAttributes": { - "rules": [ - "rule1", - "rule2", - "rule3" - ] - } - } - } -] --``` --### Include criteria and exclude criteria --Log processors support optional `include` and `exclude` criteria. -A log processor is applied only to telemetry that matches its `include` criteria (if it's available) -_and_ don't match its `exclude` criteria (if it's available). --To configure this option, under `include` or `exclude` (or both), specify the `matchType` and `attributes`. -The `include` or `exclude` configuration allows more than one specified condition. -All specified conditions must evaluate to true to result in a match. --* **Required field**: - * `matchType` controls how items in `attributes` arrays are interpreted. Possible values are `regexp` and `strict`. - Regular expression matches are performed against the entire attribute value, - so if you want to match a value that contains `abc` anywhere in it, then you need to use `.*abc.*`. - * `attributes` specifies the list of attributes to match. All of these attributes must match exactly to result in a match. - -> [!NOTE] -> If both `include` and `exclude` are specified, the `include` properties are checked before the `exclude` properties are checked. --> [!NOTE] -> Log processors do not support `spanNames`. --### Sample usage --```json -"processors": [ - { - "type": "log", - "include": { - "matchType": "strict", - "attributes": [ - { - "key": "attribute1", - "value": "value1" - } - ] - }, - "exclude": { - "matchType": "strict", - "attributes": [ - { - "key": "attribute2", - "value": "value2" - } - ] - }, - "body": { - "toAttributes": { - "rules": [ - "rule1", - "rule2", - "rule3" - ] - } - } - } -] -``` -For more information, see [Telemetry processor examples](./java-standalone-telemetry-processors-examples.md). --## Metric filter --> [!NOTE] -> Metric filters are available starting from version 3.1.1. --Metric filters are used to exclude some metrics in order to help control ingestion cost. --Metric filters only support `exclude` criteria. Metrics that match its `exclude` criteria aren't exported. --To configure this option, under `exclude`, specify the `matchType` one or more `metricNames`. --* **Required field**: - * `matchType` controls how items in `metricNames` are matched. Possible values are `regexp` and `strict`. - Regular expression matches are performed against the entire attribute value, - so if you want to match a value that contains `abc` anywhere in it, then you need to use `.*abc.*`. - * `metricNames` must match at least one of the items. --### Sample usage --The following sample shows how to exclude metrics with names "metricA" and "metricB": --```json -"processors": [ - { - "type": "metric-filter", - "exclude": { - "matchType": "strict", - "metricNames": [ - "metricA", - "metricB" - ] - } - } -] -``` --The following sample shows how to turn off all metrics including the default autocollected performance metrics like cpu and memory. --```json -"processors": [ - { - "type": "metric-filter", - "exclude": { - "matchType": "regexp", - "metricNames": [ - ".*" - ] - } - } -] -``` --### Default metrics captured by Java agent --| Metric name | Metric type | Description | Filterable | -||||| -| `Current Thread Count` | custom metrics | See [ThreadMXBean.getThreadCount()](https://docs.oracle.com/javase/8/docs/api/java/lang/management/ThreadMXBean.html#getThreadCount--). | yes | -| `Loaded Class Count` | custom metrics | See [ClassLoadingMXBean.getLoadedClassCount()](https://docs.oracle.com/javase/8/docs/api/java/lang/management/ClassLoadingMXBean.html#getLoadedClassCount--). | yes | -| `GC Total Count` | custom metrics | Sum of counts across all GarbageCollectorMXBean instances (diff since last reported). See [GarbageCollectorMXBean.getCollectionCount()](https://docs.oracle.com/javase/7/docs/api/java/lang/management/GarbageCollectorMXBean.html). | yes | -| `GC Total Time` | custom metrics | Sum of time across all GarbageCollectorMXBean instances (diff since last reported). See [GarbageCollectorMXBean.getCollectionTime()](https://docs.oracle.com/javase/7/docs/api/java/lang/management/GarbageCollectorMXBean.html).| yes | -| `Heap Memory Used (MB)` | custom metrics | See [MemoryMXBean.getHeapMemoryUsage().getUsed()](https://docs.oracle.com/javase/8/docs/api/java/lang/management/MemoryMXBean.html#getHeapMemoryUsage--). | yes | -| `% Of Max Heap Memory Used` | custom metrics | java.lang:type=Memory / maximum amount of memory in bytes. See [MemoryUsage](https://docs.oracle.com/javase/7/docs/api/java/lang/management/MemoryUsage.html)| yes | -| `\Processor(_Total)\% Processor Time` | default metrics | Difference in [system wide CPU load tick counters](https://www.oshi.ooo/oshi-core/apidocs/oshi/hardware/CentralProcessor.html#getProcessorCpuLoadTicks()) (Only User and System) divided by the number of [logical processors count](https://www.oshi.ooo/oshi-core/apidocs/oshi/hardware/CentralProcessor.html#getLogicalProcessors()) in a given interval of time | no | -| `\Process(??APP_WIN32_PROC??)\% Processor Time` | default metrics | See [OperatingSystemMXBean.getProcessCpuTime()](https://docs.oracle.com/javase/8/docs/jre/api/management/extension/com/sun/management/OperatingSystemMXBean.html#getProcessCpuTime--) (diff since last reported, normalized by time and number of CPUs). | no | -| `\Process(??APP_WIN32_PROC??)\Private Bytes` | default metrics | Sum of [MemoryMXBean.getHeapMemoryUsage()](https://docs.oracle.com/javase/8/docs/api/java/lang/management/MemoryMXBean.html#getHeapMemoryUsage--) and [MemoryMXBean.getNonHeapMemoryUsage()](https://docs.oracle.com/javase/8/docs/api/java/lang/management/MemoryMXBean.html#getNonHeapMemoryUsage--). | no | -| `\Process(??APP_WIN32_PROC??)\IO Data Bytes/sec` | default metrics | `/proc/[pid]/io` Sum of bytes read and written by the process (diff since last reported). See [proc(5)](https://man7.org/linux/man-pages/man5/proc.5.html). | no | -| `\Memory\Available Bytes` | default metrics | See [OperatingSystemMXBean.getFreePhysicalMemorySize()](https://docs.oracle.com/javase/7/docs/jre/api/management/extension/com/sun/management/OperatingSystemMXBean.html#getFreePhysicalMemorySize()). | no | --## Frequently asked questions --### Why doesn't the log processor process log files using TelemetryClient.trackTrace()? --TelemetryClient.trackTrace() is part of the Application Insights Classic SDK bridge, and the log processors only work with the new [OpenTelemetry-based instrumentation](opentelemetry-enable.md). |
| azure-monitor | Java Standalone Upgrade From 2X | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/java-standalone-upgrade-from-2x.md | - Title: Upgrading from 2.x - Azure Monitor Application Insights Java -description: Upgrading from Azure Monitor Application Insights Java 2.x - Previously updated : 07/29/2024-----# Upgrading from Application Insights Java 2.x SDK --There are typically no code changes when upgrading to 3.x. The 3.x SDK dependencies are no-op API versions of the 2.x SDK dependencies. However, when used with the 3.x Java agent, the 3.x Java agent provides the implementation for them. As a result, your custom instrumentation is correlated with all the new autoinstrumentation provided by the 3.x Java agent. --## Step 1: Update dependencies --| 2.x dependency | Action | Remarks | -|-|--|| -| `applicationinsights-core` | Update the version to `3.4.3` or later | | -| `applicationinsights-web` | Update the version to `3.4.3` or later, and remove the Application Insights web filter your `web.xml` file. | | -| `applicationinsights-web-auto` | Replace with `3.4.3` or later of `applicationinsights-web` | | -| `applicationinsights-logging-log4j1_2` | Remove the dependency and remove the Application Insights appender from your Log4j configuration. | No longer needed since Log4j 1.2 is autoinstrumented in the 3.x Java agent. | -| `applicationinsights-logging-log4j2` | Remove the dependency and remove the Application Insights appender from your Log4j configuration. | No longer needed since Log4j 2 is autoinstrumented in the 3.x Java agent. | -| `applicationinsights-logging-logback` | Remove the dependency and remove the Application Insights appender from your Logback configuration. | No longer needed since Logback is autoinstrumented in the 3.x Java agent. | -| `applicationinsights-spring-boot-starter` | Replace with `3.4.3` or later of `applicationinsights-web` | The cloud role name no longer defaults to `spring.application.name`. To learn how to configure the cloud role name, see the [3.x configuration docs](./java-standalone-config.md#cloud-role-name). | --## Step 2: Add the 3.x Java agent --Add the 3.x Java agent to your Java Virtual Machine (JVM) command-line args, for example: --``` --javaagent:path/to/applicationinsights-agent-3.5.4.jar-``` --If you're using the Application Insights 2.x Java agent, just replace your existing `-javaagent:...` with the previous example. --> [!Note] -> If you were using the spring-boot-starter and if you prefer, there is an alternative to using the Java agent. See [3.x Spring Boot](./java-spring-boot.md). --## Step 3: Configure your Application Insights connection string --See [configuring the connection string](./java-standalone-config.md#connection-string). --## Other notes --The rest of this document describes limitations and changes that you might encounter -when upgrading from 2.x to 3.x, and some workarounds that you might find helpful. --## TelemetryInitializers --2.x SDK TelemetryInitializers don't run when using the 3.x agent. -Many of the use cases that previously required writing a `TelemetryInitializer` can be solved in Application Insights Java 3.x -by configuring [custom dimensions](./java-standalone-config.md#custom-dimensions). -Or using [inherited attributes](./java-standalone-config.md#inherited-attribute-preview). --## TelemetryProcessors --2.x SDK TelemetryProcessors don't run when using the 3.x agent. -Many of the use cases that previously required writing a `TelemetryProcessor` can be solved in Application Insights Java 3.x -by configuring [sampling overrides](./java-standalone-config.md#sampling-overrides). --## Multiple applications in a single JVM --This use case is supported in Application Insights Java 3.x using -[Cloud role name overrides (preview)](./java-standalone-config.md#cloud-role-name-overrides-preview) and/or -[Connection string overrides (preview)](./java-standalone-config.md#connection-string-overrides-preview). --## Operation names --In the Application Insights Java 2.x SDK, in some cases, the operation names contained the full path, for example: ---Operation names in Application Insights Java 3.x changed to generally provide a better aggregated view -in the Application Insights Portal U/X, for example: ---However, for some applications, you might still prefer the aggregated view in the U/X that was provided by the previous operation names. In this case, you can use the [telemetry processors](./java-standalone-telemetry-processors.md) (preview) feature in 3.x to replicate the previous behavior. --The following snippet configures three telemetry processors that combine to replicate the previous behavior. -The telemetry processors perform the following actions (in order): --1. The first telemetry processor is an attribute processor (has type `attribute`), - which means it applies to all telemetry that has attributes - (currently `requests` and `dependencies`, but soon also `traces`). -- It matches any telemetry that has attributes named `http.request.method` and `url.path`. -- Then it extracts `url.path` attribute into a new attribute named `tempName`. --2. The second telemetry processor is a span processor (has type `span`), - which means it applies to `requests` and `dependencies`. -- It matches any span that has an attribute named `tempPath`. -- Then it updates the span name from the attribute `tempPath`. --3. The last telemetry processor is an attribute processor, same type as the first telemetry processor. -- It matches any telemetry that has an attribute named `tempPath`. -- Then it deletes the attribute named `tempPath`, and the attribute appears as a custom dimension. --```json -{ - "preview": { - "processors": [ - { - "type": "attribute", - "include": { - "matchType": "strict", - "attributes": [ - { "key": "http.request.method" }, - { "key": "url.path" } - ] - }, - "actions": [ - { - "key": "url.path", - "pattern": "https?://[^/]+(?<tempPath>/[^?]*)", - "action": "extract" - } - ] - }, - { - "type": "span", - "include": { - "matchType": "strict", - "attributes": [ - { "key": "tempPath" } - ] - }, - "name": { - "fromAttributes": [ "http.request.method", "tempPath" ], - "separator": " " - } - }, - { - "type": "attribute", - "include": { - "matchType": "strict", - "attributes": [ - { "key": "tempPath" } - ] - }, - "actions": [ - { "key": "tempPath", "action": "delete" } - ] - } - ] - } -} -``` --## Project example --This [Java 2.x SDK project](https://github.com/Azure-Samples/ApplicationInsights-Java-Samples/tree/main/advanced/migration-2x) is migrated to [a new project using the 3.x Java agent](https://github.com/Azure-Samples/ApplicationInsights-Java-Samples/tree/main/advanced/migration-3x). |
| azure-monitor | Javascript Feature Extensions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/javascript-feature-extensions.md | - Title: Feature extensions for Application Insights JavaScript SDK (Click Analytics) -description: Learn how to install and use JavaScript feature extensions (Click Analytics) for the Application Insights JavaScript SDK. -- Previously updated : 11/15/2023-----# Enable Click Analytics Auto-Collection plug-in --Application Insights JavaScript SDK feature extensions are extra features that can be added to the Application Insights JavaScript SDK to enhance its functionality. --In this article, we cover the Click Analytics plug-in, which automatically tracks click events on webpages and uses `data-*` attributes or customized tags on HTML elements to populate event telemetry. --## Prerequisites --[Install the JavaScript SDK](./javascript-sdk.md) before you enable the Click Analytics plug-in. --## What data does the plug-in collect? --The following key properties are captured by default when the plug-in is enabled. --### Custom event properties --| Name | Description | Sample | -| | |--| -| Name | The name of the custom event. For more information on how a name gets populated, see [Name column](#name).| About | -| itemType | Type of event. | customEvent | -|sdkVersion | Version of Application Insights SDK along with click plug-in.|JavaScript:2_ClickPlugin2| --### Custom dimensions --| Name | Description | Sample | -| | |--| -| actionType | Action type that caused the click event. It can be a left or right click. | CL | -| baseTypeSource | Base Type source of the custom event. | ClickEvent | -| clickCoordinates | Coordinates where the click event is triggered. | 659X47 | -| content | Placeholder to store extra `data-*` attributes and values. | [{sample1:value1, sample2:value2}] | -| pageName | Title of the page where the click event is triggered. | Sample Title | -| parentId | ID or name of the parent element. For more information on how a parentId is populated, see [parentId key](#parentid-key). | navbarContainer | --### Custom measurements --| Name | Description | Sample | -| | |--| -| timeToAction | Time taken in milliseconds for the user to click the element since the initial page load. | 87407 | ---## Add the Click Analytics plug-in --Users can set up the Click Analytics Auto-Collection plug-in via JavaScript (Web) SDK Loader Script or npm and then optionally add a framework extension. ---### Add the code --#### [JavaScript (Web) SDK Loader Script](#tab/javascriptwebsdkloaderscript) --Paste the JavaScript (Web) SDK Loader Script at the top of each page for which you want to enable Application Insights. -<!-- IMPORTANT: If you're updating this code example, please remember to also update it in: 1) articles\azure-monitor\app\javascript-sdk.md and 2) articles\azure-monitor\app\api-filtering-sampling.md --> --```html -<script type="text/javascript" src="https://js.monitor.azure.com/scripts/b/ext/ai.clck.2.min.js"></script> -<script type="text/javascript"> -var clickPluginInstance = new Microsoft.ApplicationInsights.ClickAnalyticsPlugin(); - // Click Analytics configuration -var clickPluginConfig = { - autoCapture : true, - dataTags: { - useDefaultContentNameOrId: true - } -} -// Application Insights configuration -var configObj = { - connectionString: "YOUR_CONNECTION_STRING", - // Alternatively, you can pass in the instrumentation key, - // but support for instrumentation key ingestion will end on March 31, 2025. - // instrumentationKey: "YOUR INSTRUMENTATION KEY", - extensions: [ - clickPluginInstance - ], - extensionConfig: { - [clickPluginInstance.identifier] : clickPluginConfig - }, -}; -// Application Insights JavaScript (Web) SDK Loader Script code -!(function (cfg){function e(){cfg.onInit&&cfg.onInit(n)}var x,w,D,t,E,n,C=window,O=document,b=C.location,q="script",I="ingestionendpoint",L="disableExceptionTracking",j="ai.device.";"instrumentationKey"[x="toLowerCase"](),w="crossOrigin",D="POST",t="appInsightsSDK",E=cfg.name||"appInsights",(cfg.name||C[t])&&(C[t]=E),n=C[E]||function(g){var f=!1,m=!1,h={initialize:!0,queue:[],sv:"8",version:2,config:g};function v(e,t){var n={},i="Browser";function a(e){e=""+e;return 1===e.length?"0"+e:e}return n[j+"id"]=i[x](),n[j+"type"]=i,n["ai.operation.name"]=b&&b.pathname||"_unknown_",n["ai.internal.sdkVersion"]="javascript:snippet_"+(h.sv||h.version),{time:(i=new Date).getUTCFullYear()+"-"+a(1+i.getUTCMonth())+"-"+a(i.getUTCDate())+"T"+a(i.getUTCHours())+":"+a(i.getUTCMinutes())+":"+a(i.getUTCSeconds())+"."+(i.getUTCMilliseconds()/1e3).toFixed(3).slice(2,5)+"Z",iKey:e,name:"Microsoft.ApplicationInsights."+e.replace(/-/g,"")+"."+t,sampleRate:100,tags:n,data:{baseData:{ver:2}},ver:undefined,seq:"1",aiDataContract:undefined}}var n,i,t,a,y=-1,T=0,S=["js.monitor.azure.com","js.cdn.applicationinsights.io","js.cdn.monitor.azure.com","js0.cdn.applicationinsights.io","js0.cdn.monitor.azure.com","js2.cdn.applicationinsights.io","js2.cdn.monitor.azure.com","az416426.vo.msecnd.net"],o=g.url||cfg.src,r=function(){return s(o,null)};function s(d,t){if((n=navigator)&&(~(n=(n.userAgent||"").toLowerCase()).indexOf("msie")||~n.indexOf("trident/"))&&~d.indexOf("ai.3")&&(d=d.replace(/(\/)(ai\.3\.)([^\d]*)$/,function(e,t,n){return t+"ai.2"+n})),!1!==cfg.cr)for(var e=0;e<S.length;e++)if(0<d.indexOf(S[e])){y=e;break}var n,i=function(e){var a,t,n,i,o,r,s,c,u,l;h.queue=[],m||(0<=y&&T+1<S.length?(a=(y+T+1)%S.length,p(d.replace(/^(.*\/\/)([\w\.]*)(\/.*)$/,function(e,t,n,i){return t+S[a]+i})),T+=1):(f=m=!0,s=d,!0!==cfg.dle&&(c=(t=function(){var e,t={},n=g.connectionString;if(n)for(var i=n.split(";"),a=0;a<i.length;a++){var o=i[a].split("=");2===o.length&&(t[o[0][x]()]=o[1])}return t[I]||(e=(n=t.endpointsuffix)?t.location:null,t[I]="https://"+(e?e+".":"")+"dc."+(n||"services.visualstudio.com")),t}()).instrumentationkey||g.instrumentationKey||"",t=(t=(t=t[I])&&"/"===t.slice(-1)?t.slice(0,-1):t)?t+"/v2/track":g.endpointUrl,t=g.userOverrideEndpointUrl||t,(n=[]).push((i="SDK LOAD Failure: Failed to load Application Insights SDK script (See stack for details)",o=s,u=t,(l=(r=v(c,"Exception")).data).baseType="ExceptionData",l.baseData.exceptions=[{typeName:"SDKLoadFailed",message:i.replace(/\./g,"-"),hasFullStack:!1,stack:i+"\nSnippet failed to load ["+o+"] -- Telemetry is disabled\nHelp Link: https://go.microsoft.com/fwlink/?linkid=2128109\nHost: "+(b&&b.pathname||"_unknown_")+"\nEndpoint: "+u,parsedStack:[]}],r)),n.push((l=s,i=t,(u=(o=v(c,"Message")).data).baseType="MessageData",(r=u.baseData).message='AI (Internal): 99 message:"'+("SDK LOAD Failure: Failed to load Application Insights SDK script (See stack for details) ("+l+")").replace(/\"/g,"")+'"',r.properties={endpoint:i},o)),s=n,c=t,JSON&&((u=C.fetch)&&!cfg.useXhr?u(c,{method:D,body:JSON.stringify(s),mode:"cors"}):XMLHttpRequest&&((l=new XMLHttpRequest).open(D,c),l.setRequestHeader("Content-type","application/json"),l.send(JSON.stringify(s)))))))},a=function(e,t){m||setTimeout(function(){!t&&h.core||i()},500),f=!1},p=function(e){var n=O.createElement(q),e=(n.src=e,t&&(n.integrity=t),n.setAttribute("data-ai-name",E),cfg[w]);return!e&&""!==e||"undefined"==n[w]||(n[w]=e),n.onload=a,n.onerror=i,n.onreadystatechange=function(e,t){"loaded"!==n.readyState&&"complete"!==n.readyState||a(0,t)},cfg.ld&&cfg.ld<0?O.getElementsByTagName("head")[0].appendChild(n):setTimeout(function(){O.getElementsByTagName(q)[0].parentNode.appendChild(n)},cfg.ld||0),n};p(d)}cfg.sri&&(n=o.match(/^((http[s]?:\/\/.*\/)\w+(\.\d+){1,5})\.(([\w]+\.){0,2}js)$/))&&6===n.length?(d="".concat(n[1],".integrity.json"),i="@".concat(n[4]),l=window.fetch,t=function(e){if(!e.ext||!e.ext[i]||!e.ext[i].file)throw Error("Error Loading JSON response");var t=e.ext[i].integrity||null;s(o=n[2]+e.ext[i].file,t)},l&&!cfg.useXhr?l(d,{method:"GET",mode:"cors"}).then(function(e){return e.json()["catch"](function(){return{}})}).then(t)["catch"](r):XMLHttpRequest&&((a=new XMLHttpRequest).open("GET",d),a.onreadystatechange=function(){if(a.readyState===XMLHttpRequest.DONE)if(200===a.status)try{t(JSON.parse(a.responseText))}catch(e){r()}else r()},a.send())):o&&r();try{h.cookie=O.cookie}catch(k){}function e(e){for(;e.length;)!function(t){h[t]=function(){var e=arguments;f||h.queue.push(function(){h[t].apply(h,e)})}}(e.pop())}var c,u,l="track",d="TrackPage",p="TrackEvent",l=(e([l+"Event",l+"PageView",l+"Exception",l+"Trace",l+"DependencyData",l+"Metric",l+"PageViewPerformance","start"+d,"stop"+d,"start"+p,"stop"+p,"addTelemetryInitializer","setAuthenticatedUserContext","clearAuthenticatedUserContext","flush"]),h.SeverityLevel={Verbose:0,Information:1,Warning:2,Error:3,Critical:4},(g.extensionConfig||{}).ApplicationInsightsAnalytics||{});return!0!==g[L]&&!0!==l[L]&&(e(["_"+(c="onerror")]),u=C[c],C[c]=function(e,t,n,i,a){var o=u&&u(e,t,n,i,a);return!0!==o&&h["_"+c]({message:e,url:t,lineNumber:n,columnNumber:i,error:a,evt:C.event}),o},g.autoExceptionInstrumented=!0),h}(cfg.cfg),(C[E]=n).queue&&0===n.queue.length?(n.queue.push(e),n.trackPageView({})):e();})({ - src: "https://js.monitor.azure.com/scripts/b/ai.3.gbl.min.js", - crossOrigin: "anonymous", - // sri: false, // Custom optional value to specify whether fetching the snippet from integrity file and do integrity check - cfg: configObj // configObj is defined above. -}); -</script> -``` --To add or update JavaScript (Web) SDK Loader Script configuration, see [JavaScript (Web) SDK Loader Script configuration](./javascript-sdk.md?tabs=javascriptwebsdkloaderscript#javascript-web-sdk-loader-script-configuration). --#### [npm package](#tab/npmpackage) --Install the npm package: --```bash -npm install --save @microsoft/applicationinsights-clickanalytics-js @microsoft/applicationinsights-web -``` --```js --import { ApplicationInsights } from '@microsoft/applicationinsights-web'; -import { ClickAnalyticsPlugin } from '@microsoft/applicationinsights-clickanalytics-js'; --const clickPluginInstance = new ClickAnalyticsPlugin(); -// Click Analytics configuration -const clickPluginConfig = { - autoCapture: true -}; -// Application Insights Configuration -const configObj = { - connectionString: "YOUR_CONNECTION_STRING", - // Alternatively, you can pass in the instrumentation key, - // but support for instrumentation key ingestion will end on March 31, 2025. - // instrumentationKey: "YOUR INSTRUMENTATION KEY", - extensions: [clickPluginInstance], - extensionConfig: { - [clickPluginInstance.identifier]: clickPluginConfig - }, -}; --const appInsights = new ApplicationInsights({ config: configObj }); -appInsights.loadAppInsights(); -``` ----> [!TIP] -> If you want to add a framework extension or you've already added one, see the [React, React Native, and Angular code samples for how to add the Click Analytics plug-in](./javascript-framework-extensions.md#add-the-extension-to-your-code). --### (Optional) Set the authenticated user context --If you want to set this optional setting, see [Set the authenticated user context](https://github.com/microsoft/ApplicationInsights-JS/blob/master/API-reference.md#setauthenticatedusercontext). --If you're using a HEART workbook with the Click Analytics plug-in, you don't need to set the authenticated user context to see telemetry data. For more information, see the [HEART workbook documentation](./usage.md#confirm-that-data-is-flowing). --## Use the plug-in --The following sections describe how to use the plug-in. --### Telemetry data storage --Telemetry data generated from the click events are stored as `customEvents` in the Azure portal > Application Insights > Logs section. --### `name` --The `name` column of the `customEvent` is populated based on the following rules: - 1. If [`customDataPrefix`](#customdataprefix) isn't declared in the advanced configuration, the `id` provided in the `data-id` is used as the `customEvent` name. - 1. If [`customDataPrefix`](#customdataprefix) is declared, the `id` provided in the `data-*-id`, which means it must start with `data` and end with `id`, is used as the `customEvent` name. For example, if the clicked HTML element has the attribute `"data-sample-id"="button1"`, then `"button1"` is the `customEvent` name. - 1. If the `data-id` or `data-*-id` attribute doesn't exist and if [`useDefaultContentNameOrId`](#icustomdatatags) is set to `true`, the clicked element's HTML attribute `id` or content name of the element is used as the `customEvent` name. If both `id` and the content name are present, precedence is given to `id`. - 1. If `useDefaultContentNameOrId` is `false`, the `customEvent` name is `"not_specified"`. We recommend setting `useDefaultContentNameOrId` to `true` for generating meaningful data. --### `contentName` --If you have the [`contentName` callback function](#ivaluecallback) in advanced configuration defined, the `contentName` column of the `customEvent` is populated based on the following rules: --- For a clicked HTML `<a>` element, the plugin attempts to collect the value of its innerText (text) attribute. If the plugin can't find this attribute, it attempts to collect the value of its innerHtml attribute.-- For a clicked HTML `<img>` or `<area>` element, the plugin collects the value of its `alt` attribute.-- For all other clicked HTML elements, `contentName` is populated based on the following rules, which are listed in order of precedence:-- 1. The value of the `value` attribute for the element - 1. The value of the `name` attribute for the element - 1. The value of the `alt` attribute for the element - 1. The value of the innerText attribute for the element - 1. The value of the `id` attribute for the element --### `parentId` key --To populate the `parentId` key within `customDimensions` of the `customEvent` table in the logs, declare the tag `parentDataTag` or define the `data-parentid` attribute. - -The value for `parentId` is fetched based on the following rules: --- When you declare the `parentDataTag`, the plug-in fetches the value of `id` or `data-*-id` defined within the element that is closest to the clicked element as `parentId`. -- If both `data-*-id` and `id` are defined, precedence is given to `data-*-id`. -- If `parentDataTag` is defined but the plug-in can't find this tag under the DOM tree, the plug-in uses the `id` or `data-*-id` defined within the element that is closest to the clicked element as `parentId`. However, we recommend defining the `data-{parentDataTag}` or `customDataPrefix-{parentDataTag}` attribute to reduce the number of loops needed to find `parentId`. Declaring `parentDataTag` is useful when you need to use the plug-in with customized options.-- If no `parentDataTag` is defined and no `parentId` information is included in current element, no `parentId` value is collected. -- If `parentDataTag` is defined, `useDefaultContentNameOrId` is set to `false`, and only an `id` attribute is defined within the element closest to the clicked element, the `parentId` populates as `"not_specified"`. To fetch the value of `id`, set `useDefaultContentNameOrId` to `true`.--When you define the `data-parentid` or `data-*-parentid` attribute, the plug-in fetches the instance of this attribute that is closest to the clicked element, including within the clicked element if applicable. --If you declare `parentDataTag` and define the `data-parentid` or `data-*-parentid` attribute, precedence is given to `data-parentid` or `data-*-parentid`. --If the "Click Event rows with no parentId value" telemetry warning appears, see [Fix the "Click Event rows with no parentId value" warning](/troubleshoot/azure/azure-monitor/app-insights/javascript-sdk-troubleshooting#fix-the-click-event-rows-with-no-parentid-value-warning). --For examples showing which value is fetched as the `parentId` for different configurations, see [Examples of `parentid` key](#examples-of-parentid-key). --> [!CAUTION] -> - Once `parentDataTag` is included in *any* HTML element across your application *the SDK begins looking for parents tags across your entire application* and not just the HTML element where you used it. -> - If you're using the HEART workbook with the Click Analytics plug-in, for HEART events to be logged or detected, the tag `parentDataTag` must be declared in all other parts of an end user's application. --### `customDataPrefix` --The [`customDataPrefix` option in advanced configuration](#icustomdatatags) provides the user the ability to configure a data attribute prefix to help identify where heart is located within the individual's codebase. The prefix must always be lowercase and start with `data-`. For example: --- `data-heart-` -- `data-team-name-`-- `data-example-`- -In HTML, the `data-*` global attributes are called custom data attributes that allow proprietary information to be exchanged between the HTML and its DOM representation by scripts. Older browsers like Internet Explorer and Safari drop attributes they don't understand, unless they start with `data-`. --You can replace the asterisk (`*`) in `data-*` with any name following the [production rule of XML names](https://www.w3.org/TR/REC-xml/#NT-Name) with the following restrictions. -- The name must not start with "xml," whatever case is used for the letters.-- The name must not contain a semicolon (U+003A).-- The name must not contain capital letters.--## Add advanced configuration --| Name | Type | Default | Description | -| | --| --| - | -| autoCapture | Boolean | True | Automatic capture configuration. | -| callback | [IValueCallback](#ivaluecallback) | Null | Callbacks configuration. | -| pageTags | Object | Null | Page tags. | -| dataTags | [ICustomDataTags](#icustomdatatags)| Null | Custom Data Tags provided to override default tags used to capture click data. | -| urlCollectHash | Boolean | False | Enables the logging of values after a "#" character of the URL. | -| urlCollectQuery | Boolean | False | Enables the logging of the query string of the URL. | -| behaviorValidator | Function | Null | Callback function to use for the `data-*-bhvr` value validation. For more information, see the [behaviorValidator section](#behaviorvalidator).| -| defaultRightClickBhvr | String (or) number | '' | Default behavior value when a right-click event has occurred. This value is overridden if the element has the `data-*-bhvr` attribute. | -| dropInvalidEvents | Boolean | False | Flag to drop events that don't have useful click data. | --### IValueCallback --| Name | Type | Default | Description | -| | -- | - | | -| pageName | Function | Null | Function to override the default `pageName` capturing behavior. | -| pageActionPageTags | Function | Null | A callback function to augment the default `pageTags` collected during a `pageAction` event. | -| contentName | Function | Null | A callback function to populate customized `contentName`. | --### ICustomDataTags --| Name | Type | Default | Default tag to use in HTML | Description | -|||--|-|-| -| useDefaultContentNameOrId | Boolean | False | N/A | If `true`, collects standard HTML attribute `id` for `contentName` when a particular element isn't tagged with default data prefix or `customDataPrefix`. Otherwise, the standard HTML attribute `id` for `contentName` isn't collected. | -| customDataPrefix | String | `data-` | `data-*`| Automatic capture content name and value of elements that are tagged with provided prefix. For example, `data-*-id`, `data-<yourcustomattribute>` can be used in the HTML tags. | -| aiBlobAttributeTag | String | `ai-blob` | `data-ai-blob`| Plug-in supports a JSON blob attribute instead of individual `data-*` attributes. | -| metaDataPrefix | String | Null | N/A | Automatic capture HTML Head's meta element name and content with provided prefix when captured. For example, `custom-` can be used in the HTML meta tag. | -| captureAllMetaDataContent | Boolean | False | N/A | Automatic capture all HTML Head's meta element names and content. Default is false. If enabled, it overrides provided `metaDataPrefix`. | -| parentDataTag | String | Null | N/A | Fetches the `parentId` in the logs when `data-parentid` or `data-*-parentid` isn't encountered. For efficiency, stops traversing up the DOM to capture content name and value of elements when `data-{parentDataTag}` or `customDataPrefix-{parentDataTag}` attribute is encountered. For more information, see [parentId key](#parentid-key). | -| dntDataTag | String | `ai-dnt` | `data-ai-dnt`| The plug-in for capturing telemetry data ignores HTML elements with this attribute.| --### behaviorValidator --The `behaviorValidator` functions automatically check that tagged behaviors in code conform to a predefined list. The functions ensure that tagged behaviors are consistent with your enterprise's established taxonomy. It isn't required or expected that most Azure Monitor customers use these functions, but they're available for advanced scenarios. The behaviorValidator functions can help with more accessible practices. --Behaviors show up in the customDimensions field within the CustomEvents table. --#### Callback functions --Three different `behaviorValidator` callback functions are exposed as part of this extension. You can also use your own callback functions if the exposed functions don't solve your requirement. The intent is to bring your own behavior's data structure. The plug-in uses this validator function while extracting the behaviors from the data tags. --| Name | Description | -| - | --| -| BehaviorValueValidator | Use this callback function if your behavior's data structure is an array of strings.| -| BehaviorMapValidator | Use this callback function if your behavior's data structure is a dictionary. | -| BehaviorEnumValidator | Use this callback function if your behavior's data structure is an Enum. | --#### Passing in string vs. numerical values --To reduce the bytes you pass, pass in the number value instead of the full text string. If cost isnΓÇÖt an issue, you can pass in the full text string (for example, NAVIGATIONBACK). --#### Sample usage with behaviorValidator --Here's a sample of what a behavior map validator might look like. Yours could look different, depending on your organization's taxonomy and the events you collect. --```js -var clickPlugin = Microsoft.ApplicationInsights.ClickAnalyticsPlugin; -var clickPluginInstance = new clickPlugin(); --// Behavior enum values -var behaviorMap = { - UNDEFINED: 0, // default, Undefined -- /////////////////////////////////////////////////////////////////////////////////////////////////// - // Page Experience [1-19] - /////////////////////////////////////////////////////////////////////////////////////////////////// - NAVIGATIONBACK: 1, // Advancing to the previous index position within a webpage - NAVIGATION: 2, // Advancing to a specific index position within a webpage - NAVIGATIONFORWARD: 3, // Advancing to the next index position within a webpage - APPLY: 4, // Applying filter(s) or making selections - REMOVE: 5, // Applying filter(s) or removing selections - SORT: 6, // Sorting content - EXPAND: 7, // Expanding content or content container - REDUCE: 8, // Sorting content - CONTEXTMENU: 9, // Context menu - TAB: 10, // Tab control - COPY: 11, // Copy the contents of a page - EXPERIMENTATION: 12, // Used to identify a third-party experimentation event - PRINT: 13, // User printed page - SHOW: 14, // Displaying an overlay - HIDE: 15, // Hiding an overlay - MAXIMIZE: 16, // Maximizing an overlay - MINIMIZE: 17, // Minimizing an overlay - BACKBUTTON: 18, // Clicking the back button -- /////////////////////////////////////////////////////////////////////////////////////////////////// - // Scenario Process [20-39] - /////////////////////////////////////////////////////////////////////////////////////////////////// - STARTPROCESS: 20, // Initiate a web process unique to adopter - PROCESSCHECKPOINT: 21, // Represents a checkpoint in a web process unique to adopter - COMPLETEPROCESS: 22, // Page Actions that complete a web process unique to adopter - SCENARIOCANCEL: 23, // Actions resulting from cancelling a process/scenario -- /////////////////////////////////////////////////////////////////////////////////////////////////// - // Download [40-59] - /////////////////////////////////////////////////////////////////////////////////////////////////// - DOWNLOADCOMMIT: 40, // Initiating an unmeasurable off-network download - DOWNLOAD: 41, // Initiating a download -- /////////////////////////////////////////////////////////////////////////////////////////////////// - // Search [60-79] - /////////////////////////////////////////////////////////////////////////////////////////////////// - SEARCHAUTOCOMPLETE: 60, // Auto-completing a search query during user input - SEARCH: 61, // Submitting a search query - SEARCHINITIATE: 62, // Initiating a search query - TEXTBOXINPUT: 63, // Typing or entering text in the text box -- /////////////////////////////////////////////////////////////////////////////////////////////////// - // Commerce [80-99] - /////////////////////////////////////////////////////////////////////////////////////////////////// - VIEWCART: 82, // Viewing the cart - ADDWISHLIST: 83, // Adding a physical or digital good or services to a wishlist - FINDSTORE: 84, // Finding a physical store - CHECKOUT: 85, // Before you fill in credit card info - REMOVEFROMCART: 86, // Remove an item from the cart - PURCHASECOMPLETE: 87, // Used to track the pageView event that happens when the CongratsPage or Thank You page loads after a successful purchase - VIEWCHECKOUTPAGE: 88, // View the checkout page - VIEWCARTPAGE: 89, // View the cart page - VIEWPDP: 90, // View a PDP - UPDATEITEMQUANTITY: 91, // Update an item's quantity - INTENTTOBUY: 92, // User has the intent to buy an item - PUSHTOINSTALL: 93, // User has selected the push to install option -- /////////////////////////////////////////////////////////////////////////////////////////////////// - // Authentication [100-119] - /////////////////////////////////////////////////////////////////////////////////////////////////// - SIGNIN: 100, // User sign-in - SIGNOUT: 101, // User sign-out -- /////////////////////////////////////////////////////////////////////////////////////////////////// - // Social [120-139] - /////////////////////////////////////////////////////////////////////////////////////////////////// - SOCIALSHARE: 120, // "Sharing" content for a specific social channel - SOCIALLIKE: 121, // "Liking" content for a specific social channel - SOCIALREPLY: 122, // "Replying" content for a specific social channel - CALL: 123, // Click on a "call" link - EMAIL: 124, // Click on an "email" link - COMMUNITY: 125, // Click on a "community" link -- /////////////////////////////////////////////////////////////////////////////////////////////////// - // Feedback [140-159] - /////////////////////////////////////////////////////////////////////////////////////////////////// - VOTE: 140, // Rating content or voting for content - SURVEYCHECKPOINT: 145, // Reaching the survey page/form -- /////////////////////////////////////////////////////////////////////////////////////////////////// - // Registration, Contact [160-179] - /////////////////////////////////////////////////////////////////////////////////////////////////// - REGISTRATIONINITIATE: 161, // Initiating a registration process - REGISTRATIONCOMPLETE: 162, // Completing a registration process - CANCELSUBSCRIPTION: 163, // Canceling a subscription - RENEWSUBSCRIPTION: 164, // Renewing a subscription - CHANGESUBSCRIPTION: 165, // Changing a subscription - REGISTRATIONCHECKPOINT: 166, // Reaching the registration page/form -- /////////////////////////////////////////////////////////////////////////////////////////////////// - // Chat [180-199] - /////////////////////////////////////////////////////////////////////////////////////////////////// - CHATINITIATE: 180, // Initiating a chat experience - CHATEND: 181, // Ending a chat experience -- /////////////////////////////////////////////////////////////////////////////////////////////////// - // Trial [200-209] - /////////////////////////////////////////////////////////////////////////////////////////////////// - TRIALSIGNUP: 200, // Signing up for a trial - TRIALINITIATE: 201, // Initiating a trial -- /////////////////////////////////////////////////////////////////////////////////////////////////// - // Signup [210-219] - /////////////////////////////////////////////////////////////////////////////////////////////////// - SIGNUP: 210, // Signing up for a notification or service - FREESIGNUP: 211, // Signing up for a free service -- /////////////////////////////////////////////////////////////////////////////////////////////////// - // Referrals [220-229] - /////////////////////////////////////////////////////////////////////////////////////////////////// - PARTNERREFERRAL: 220, // Navigating to a partner's web property -- /////////////////////////////////////////////////////////////////////////////////////////////////// - // Intents [230-239] - /////////////////////////////////////////////////////////////////////////////////////////////////// - LEARNLOWFUNNEL: 230, // Engaging in learning behavior on a commerce page (for example, "Learn more click") - LEARNHIGHFUNNEL: 231, // Engaging in learning behavior on a non-commerce page (for example, "Learn more click") - SHOPPINGINTENT: 232, // Shopping behavior prior to landing on a commerce page -- /////////////////////////////////////////////////////////////////////////////////////////////////// - // Video [240-259] - /////////////////////////////////////////////////////////////////////////////////////////////////// - VIDEOSTART: 240, // Initiating a video - VIDEOPAUSE: 241, // Pausing a video - VIDEOCONTINUE: 242, // Pausing or resuming a video - VIDEOCHECKPOINT: 243, // Capturing predetermined video percentage complete - VIDEOJUMP: 244, // Jumping to a new video location - VIDEOCOMPLETE: 245, // Completing a video (or % proxy) - VIDEOBUFFERING: 246, // Capturing a video buffer event - VIDEOERROR: 247, // Capturing a video error - VIDEOMUTE: 248, // Muting a video - VIDEOUNMUTE: 249, // Unmuting a video - VIDEOFULLSCREEN: 250, // Making a video full screen - VIDEOUNFULLSCREEN: 251, // Making a video return from full screen to original size - VIDEOREPLAY: 252, // Making a video replay - VIDEOPLAYERLOAD: 253, // Loading the video player - VIDEOPLAYERCLICK: 254, // Click on a button within the interactive player - VIDEOVOLUMECONTROL: 255, // Click on video volume control - VIDEOAUDIOTRACKCONTROL: 256, // Click on audio control within a video - VIDEOCLOSEDCAPTIONCONTROL: 257, // Click on the closed-caption control - VIDEOCLOSEDCAPTIONSTYLE: 258, // Click to change closed-caption style - VIDEORESOLUTIONCONTROL: 259, // Click to change resolution -- /////////////////////////////////////////////////////////////////////////////////////////////////// - // Advertisement Engagement [280-299] - /////////////////////////////////////////////////////////////////////////////////////////////////// - ADBUFFERING: 283, // Ad is buffering - ADERROR: 284, // Ad error - ADSTART: 285, // Ad start - ADCOMPLETE: 286, // Ad complete - ADSKIP: 287, // Ad skipped - ADTIMEOUT: 288, // Ad timed out - OTHER: 300 // Other -}; --// Application Insights Configuration -var configObj = { - connectionString: "YOUR_CONNECTION_STRING", - // Alternatively, you can pass in the instrumentation key, - // but support for instrumentation key ingestion will end on March 31, 2025. - // instrumentationKey: "YOUR INSTRUMENTATION KEY", - extensions: [clickPluginInstance], - extensionConfig: { - [clickPluginInstance.identifier]: { - behaviorValidator: Microsoft.ApplicationInsights.BehaviorMapValidator(behaviorMap), - defaultRightClickBhvr: 9 - }, - }, -}; -var appInsights = new Microsoft.ApplicationInsights.ApplicationInsights({ - config: configObj -}); -appInsights.loadAppInsights(); -``` --## Sample app --See a [simple web app with the Click Analytics Autocollection Plug-in enabled](https://go.microsoft.com/fwlink/?linkid=2152871) for how to implement custom event properties such as `Name` and `parentid` and custom behavior and content. See the [sample app readme](https://github.com/Azure-Samples/Application-Insights-Click-Plugin-Demo/blob/main/README.md) for information about where to find click data. --## Examples of `parentId` key --The following examples show which value is fetched as the `parentId` for different configurations. --The examples show how if `parentDataTag` is defined but the plug-in can't find this tag under the DOM tree, the plug-in uses the `id` of its closest parent element. --### Example 1 --In example 1, the `parentDataTag` isn't declared and `data-parentid` or `data-*-parentid` isn't defined in any element. This example shows a configuration where a value for `parentId` isn't collected. --```javascript -export const clickPluginConfigWithUseDefaultContentNameOrId = { - dataTags : { - customDataPrefix: "", - parentDataTag: "", - dntDataTag: "ai-dnt", - captureAllMetaDataContent:false, - useDefaultContentNameOrId: true, - autoCapture: true - }, -}; --<div className="test1" data-id="test1parent"> - <div>Test1</div> - <div>with id, data-id, parent data-id defined</div> - <Button id="id1" data-id="test1id" variant="info" onClick={trackEvent}>Test1</Button> -</div> -``` --For clicked element `<Button>` the value of `parentId` is `ΓÇ£not_specifiedΓÇ¥`, because no `parentDataTag` details are defined and no parent element ID is provided within the current element. --### Example 2 --In example 2, `parentDataTag` is declared and `data-parentid` is defined. This example shows how parent ID details are collected. --```javascript -export const clickPluginConfigWithParentDataTag = { - dataTags : { - customDataPrefix: "", - parentDataTag: "group", - ntDataTag: "ai-dnt", - captureAllMetaDataContent:false, - useDefaultContentNameOrId: false, - autoCapture: true - }, -}; --<div className="test2" data-group="buttongroup1" data-id="test2parent"> - <div>Test2</div> - <div>with data-id, parentid, parent data-id defined</div> - <Button data-id="test2id" data-parentid = "parentid2" variant="info" onClick={trackEvent}>Test2</Button> -</div> -``` --For clicked element `<Button>`, the value of `parentId` is `parentid2`. Even though `parentDataTag` is declared, the `data-parentid` is directly defined within the element. Therefore, this value takes precedence over all other parent IDs or ID details defined in its parent elements. - -### Example 3 --In example 3, `parentDataTag` is declared and the `data-parentid` or `data-*-parentid` attribute isnΓÇÖt defined. This example shows how declaring `parentDataTag` can be helpful to collect a value for `parentId` for cases when dynamic elements don't have an `id` or `data-*-id`. --```javascript -export const clickPluginConfigWithParentDataTag = { - dataTags : { - customDataPrefix: "", - parentDataTag: "group", - dntDataTag: "ai-dnt", - captureAllMetaDataContent:false, - useDefaultContentNameOrId: false, - autoCapture: true - }, -}; --<div className="test6" data-group="buttongroup1" data-id="test6grandparent"> - <div>Test6</div> - <div>with data-id, grandparent data-group defined, parent data-id defined</div> - <div data-id="test6parent"> - <Button data-id="test6id" variant="info" onClick={trackEvent}>Test6</Button> - </div> -</div> -``` --For clicked element `<Button>`, the value of `parentId` is `test6parent`, because `parentDataTag` is declared. This declaration allows the plugin to traverse the current element tree and therefore the ID of its closest parent will be used when parent ID details aren't directly provided within the current element. With the `data-group="buttongroup1"` defined, the plug-in finds the `parentId` more efficiently. --If you remove the `data-group="buttongroup1"` attribute, the value of `parentId` is still `test6parent`, because `parentDataTag` is still declared. --## Troubleshooting --See the dedicated [troubleshooting article](/troubleshoot/azure/azure-monitor/app-insights/javascript-sdk-troubleshooting). --## Next steps --* [Confirm data is flowing](./javascript-sdk.md#confirm-data-is-flowing). -* See the [documentation on utilizing HEART workbook](usage.md#heartfive-dimensions-of-customer-experience) for expanded product analytics. -* See the [GitHub repository](https://github.com/microsoft/ApplicationInsights-JS/tree/master/extensions/applicationinsights-clickanalytics-js) and [npm Package](https://www.npmjs.com/package/@microsoft/applicationinsights-clickanalytics-js) for the Click Analytics Autocollection Plug-in. -* Use [Events Analysis in the Usage experience](usage.md#users-sessions-and-eventsanalyze-telemetry-from-three-perspectives) to analyze top clicks and slice by available dimensions. -* See [Log Analytics](../logs/log-analytics-tutorial.md#write-a-query) if you arenΓÇÖt familiar with the process of writing a query. -* Build a [workbook](../visualize/workbooks-overview.md) or [export to Power BI](../logs/log-powerbi.md) to create custom visualizations of click data. |
| azure-monitor | Javascript Framework Extensions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/javascript-framework-extensions.md | - Title: Enable a framework extension for Application Insights JavaScript SDK -description: Learn how to install and use JavaScript framework extensions for the Application Insights JavaScript SDK. -- Previously updated : 11/15/2023-----# Enable a framework extension for Application Insights JavaScript SDK --In addition to the core SDK, there are also plugins available for specific frameworks, such as the [React plugin](javascript-framework-extensions.md?tabs=react), the [React Native plugin](javascript-framework-extensions.md?tabs=reactnative), and the [Angular plugin](javascript-framework-extensions.md?tabs=angular). --These plugins provide extra functionality and integration with the specific framework. --## Prerequisites --- Install the [JavaScript SDK](./javascript-sdk.md).--### [React](#tab/react) --- Make sure the version of the React plugin that you want to install is compatible with your version of Application Insights. For more information, see [Compatibility Matrix for the React plugin](https://github.com/microsoft/applicationinsights-react-js#compatibility-matrix). --### [React Native](#tab/reactnative) --- You must be using a version >= 2.0.0 of `@microsoft/applicationinsights-web`. This plugin only works in react-native apps. It doesn't work with [apps using the Expo framework](https://docs.expo.io/) or Create React Native App, which is based on the Expo framework.--### [Angular](#tab/angular) --- The Angular plugin is NOT ECMAScript 3 (ES3) compatible.-- When we add support for a new Angular version, our npm package becomes incompatible with down-level Angular versions. Continue to use older npm packages until you're ready to upgrade your Angular version.----## What does the plug-in enable? --### [React](#tab/react) --The React plug-in for the Application Insights JavaScript SDK enables: --- Track router history-- Track exceptions-- Track components usage-- Use Application Insights with React Context--### [React Native](#tab/reactnative) --The React Native plugin for Application Insights JavaScript SDK enables: --- Track exceptions -- Collect device information-- By default, this plugin automatically collects: -- - **Unique Device ID** (Also known as Installation ID.) - - **Device Model Name** (Such as iPhone XS, Samsung Galaxy Fold, Huawei P30 Pro etc.) - - **Device Type** (For example, handset, tablet, etc.) --- Disable automatic device info collection-- Use your own device info collection class-- Override the device information--### [Angular](#tab/angular) --The Angular plugin for the Application Insights JavaScript SDK enables: --- Track router history-- Track exceptions-- Chain more custom exception handlers----## Add a plug-in --To add a plug-in, follow the steps in this section. --### Install the package --#### [React](#tab/react) --```bash --npm install @microsoft/applicationinsights-react-js --``` --#### [React Native](#tab/reactnative) --- **React Native Plugin**-- By default, the React Native Plugin relies on the [`react-native-device-info` package](https://www.npmjs.com/package/react-native-device-info). You must install and link to this package. Keep the `react-native-device-info` package up to date to collect the latest device names using your app. -- Since v3, support for accessing the DeviceInfo has been abstracted into an interface `IDeviceInfoModule` to enable you to use / set your own device info module. This interface uses the same function names and result `react-native-device-info`. -- ```zsh -- npm install --save @microsoft/applicationinsights-react-native @microsoft/applicationinsights-web - npm install --save react-native-device-info - react-native link react-native-device-info -- ``` --- **React Native Manual Device Plugin**-- If you're using React Native Expo, add the React Native Manual Device Plugin instead of the React Native Plugin. The React Native Plugin uses the `react-native-device-info package` package, which React Native Expo doesn't support. -- ```bash -- npm install --save @microsoft/applicationinsights-react-native @microsoft/applicationinsights-web -- ``` ----#### [Angular](#tab/angular) --```bash -npm install @microsoft/applicationinsights-angularplugin-js -``` ----### Add the extension to your code ---#### [React](#tab/react) --Initialize a connection to Application Insights: --```javascript -import React from 'react'; -import { ApplicationInsights } from '@microsoft/applicationinsights-web'; -import { ReactPlugin } from '@microsoft/applicationinsights-react-js'; -import { createBrowserHistory } from "history"; -const browserHistory = createBrowserHistory({ basename: '' }); -var reactPlugin = new ReactPlugin(); -// *** Add the Click Analytics plug-in. *** -/* var clickPluginInstance = new ClickAnalyticsPlugin(); - var clickPluginConfig = { - autoCapture: true -}; */ -var appInsights = new ApplicationInsights({ - config: { - connectionString: 'YOUR_CONNECTION_STRING_GOES_HERE', - // *** If you're adding the Click Analytics plug-in, delete the next line. *** - extensions: [reactPlugin], - // *** Add the Click Analytics plug-in. *** - // extensions: [reactPlugin, clickPluginInstance], - extensionConfig: { - [reactPlugin.identifier]: { history: browserHistory } - // *** Add the Click Analytics plug-in. *** - // [clickPluginInstance.identifier]: clickPluginConfig - } - } -}); -appInsights.loadAppInsights(); -``` --#### [React Native](#tab/reactnative) --- **React Native Plug-in**-- To use this plugin, you need to construct the plugin and add it as an `extension` to your existing Application Insights instance. -- ```typescript - import { ApplicationInsights } from '@microsoft/applicationinsights-web'; - import { ReactNativePlugin } from '@microsoft/applicationinsights-react-native'; - // *** Add the Click Analytics plug-in. *** - // import { ClickAnalyticsPlugin } from '@microsoft/applicationinsights-clickanalytics-js'; - var RNPlugin = new ReactNativePlugin(); - // *** Add the Click Analytics plug-in. *** - /* var clickPluginInstance = new ClickAnalyticsPlugin(); - var clickPluginConfig = { - autoCapture: true - }; */ - var appInsights = new ApplicationInsights({ - config: { - connectionString: 'YOUR_CONNECTION_STRING_GOES_HERE', - // *** If you're adding the Click Analytics plug-in, delete the next line. *** - extensions: [RNPlugin] - // *** Add the Click Analytics plug-in. *** - /* extensions: [RNPlugin, clickPluginInstance], - extensionConfig: { - [clickPluginInstance.identifier]: clickPluginConfig - } */ - } - }); - appInsights.loadAppInsights(); -- ``` --- **React Native Manual Device Plugin**-- To use this plugin, you must either disable automatic device info collection or use your own device info collection class after you add the extension to your code. -- 1. Construct the plugin and add it as an `extension` to your existing Application Insights instance. -- ```typescript - import { ApplicationInsights } from '@microsoft/applicationinsights-web'; - import { ReactNativePlugin } from '@microsoft/applicationinsights-react-native'; -- var RNMPlugin = new ReactNativePlugin(); - var appInsights = new ApplicationInsights({ - config: { - instrumentationKey: 'YOUR_INSTRUMENTATION_KEY_GOES_HERE', - extensions: [RNMPlugin] - } - }); - appInsights.loadAppInsights(); - ``` -- 1. Do one of the following: -- - Disable automatic device info collection. -- ```typescript - import { ApplicationInsights } from '@microsoft/applicationinsights-web'; -- var RNMPlugin = new ReactNativeManualDevicePlugin(); - var appInsights = new ApplicationInsights({ - config: { - instrumentationKey: 'YOUR_INSTRUMENTATION_KEY_GOES_HERE', - disableDeviceCollection: true, - extensions: [RNMPlugin] - } - }); - appInsights.loadAppInsights(); - ``` -- - Use your own device info collection class. -- ```typescript - import { ApplicationInsights } from '@microsoft/applicationinsights-web'; -- // Simple inline constant implementation - const myDeviceInfoModule = { - getModel: () => "deviceModel", - getDeviceType: () => "deviceType", - // v5 returns a string while latest returns a promise - getUniqueId: () => "deviceId", // This "may" also return a Promise<string> - }; -- var RNMPlugin = new ReactNativeManualDevicePlugin(); - RNMPlugin.setDeviceInfoModule(myDeviceInfoModule); -- var appInsights = new ApplicationInsights({ - config: { - instrumentationKey: 'YOUR_INSTRUMENTATION_KEY_GOES_HERE', - extensions: [RNMPlugin] - } - }); -- appInsights.loadAppInsights(); - ``` --#### [Angular](#tab/angular) --Set up an instance of Application Insights in the entry component in your app: --> [!IMPORTANT] -> When using the ErrorService, there is an implicit dependency on the `@microsoft/applicationinsights-analytics-js` extension. you MUST include either the `'@microsoft/applicationinsights-web'` or include the `@microsoft/applicationinsights-analytics-js` extension. Otherwise, unhandled exceptions caught by the error service will not be sent. --```js -import { Component } from '@angular/core'; -import { ApplicationInsights } from '@microsoft/applicationinsights-web'; -import { AngularPlugin } from '@microsoft/applicationinsights-angularplugin-js'; -// *** Add the Click Analytics plug-in. *** -// import { ClickAnalyticsPlugin } from '@microsoft/applicationinsights-clickanalytics-js'; -import { Router } from '@angular/router'; --@Component({ - selector: 'app-root', - templateUrl: './app.component.html', - styleUrls: ['./app.component.css'] -}) -export class AppComponent { - constructor( - private router: Router - ){ - var angularPlugin = new AngularPlugin(); - // *** Add the Click Analytics plug-in. *** - /* var clickPluginInstance = new ClickAnalyticsPlugin(); - var clickPluginConfig = { - autoCapture: true - }; */ - const appInsights = new ApplicationInsights({ - config: { - connectionString: 'YOUR_CONNECTION_STRING_GOES_HERE', - // *** If you're adding the Click Analytics plug-in, delete the next line. *** - extensions: [angularPlugin], - // *** Add the Click Analytics plug-in. *** - // extensions: [angularPlugin, clickPluginInstance], - extensionConfig: { - [angularPlugin.identifier]: { router: this.router } - // *** Add the Click Analytics plug-in. *** - // [clickPluginInstance.identifier]: clickPluginConfig - } - } - }); - appInsights.loadAppInsights(); - } -} -``` ----### (Optional) Add the Click Analytics plug-in - -If you want to add the [Click Analytics plug-in](./javascript-feature-extensions.md): - -1. Uncomment the lines for Click Analytics. -1. Do one of the following, depending on which plug-in you're adding: -- - For React, delete `extensions: [reactPlugin],`. - - For React Native, delete `extensions: [RNPlugin]`. - - For Angular, delete `extensions: [angularPlugin],`. --1. See [Use the Click Analytics plug-in](./javascript-feature-extensions.md#use-the-plug-in) to continue with the setup process. --## Configuration --This section covers configuration settings for the framework extensions for Application Insights JavaScript SDK. --### Track router history --#### [React](#tab/react) --| Name | Type | Required? | Default | Description | -||--|--||| -| history | object | Optional | null | Track router history. For more information, see the [React router package documentation](https://reactrouter.com/en/main).<br><br>To track router history, most users can use the `enableAutoRouteTracking` field in the [JavaScript SDK configuration](./javascript-sdk-configuration.md#sdk-configuration). This field collects the same data for page views as the `history` object.<br><br>Use the `history` object when you're using a router implementation that doesn't update the browser URL, which is what the configuration listens to. You shouldn't enable both the `enableAutoRouteTracking` field and `history` object, because you'll get multiple page view events. | --The following code example shows how to enable the `enableAutoRouteTracking` field. --```javascript -var reactPlugin = new ReactPlugin(); -var appInsights = new ApplicationInsights({ - config: { - connectionString: 'YOUR_CONNECTION_STRING_GOES_HERE', - enableAutoRouteTracking: true, - extensions: [reactPlugin] - } -}); -appInsights.loadAppInsights(); -``` --#### [React Native](#tab/reactnative) --React Native doesn't track router changes but does track [page views](./api-custom-events-metrics.md#page-views). --#### [Angular](#tab/angular) --| Name | Type | Required? | Default | Description | -||--|--||| -| router | object | Optional | null | Angular router for enabling Application Insights PageView tracking. | --The following code example shows how to enable tracking of router history. --```javascript -import { Component } from '@angular/core'; -import { ApplicationInsights } from '@microsoft/applicationinsights-web'; -import { AngularPlugin } from '@microsoft/applicationinsights-angularplugin-js'; -import { Router } from '@angular/router'; ----@Component({ - selector: 'app-root', - templateUrl: './app.component.html', - styleUrls: ['./app.component.css'] -}) -export class AppComponent { - constructor( - private router: Router - ){ - var angularPlugin = new AngularPlugin(); - const appInsights = new ApplicationInsights({ config: { - connectionString: 'YOUR_CONNECTION_STRING', - extensions: [angularPlugin], - extensionConfig: { - [angularPlugin.identifier]: { router: this.router } - } - } }); - appInsights.loadAppInsights(); - } -} -``` ----### Track exceptions --#### [React](#tab/react) --[React error boundaries](https://react.dev/reference/react/Component#catching-rendering-errors-with-an-error-boundary) provide a way to gracefully handle an uncaught exception when it occurs within a React application. When such an exception occurs, it's likely that the exception needs to be logged. The React plug-in for Application Insights provides an error boundary component that automatically logs the exception when it occurs. --```javascript -import React from "react"; -import { reactPlugin } from "./AppInsights"; -import { AppInsightsErrorBoundary } from "@microsoft/applicationinsights-react-js"; --const App = () => { - return ( - <AppInsightsErrorBoundary onError={() => <h1>I believe something went wrong</h1>} appInsights={reactPlugin}> - /* app here */ - </AppInsightsErrorBoundary> - ); -}; -``` --The `AppInsightsErrorBoundary` requires two props to be passed to it. They're the `ReactPlugin` instance created for the application and a component to be rendered when an exception occurs. When an unhandled exception occurs, `trackException` is called with the information provided to the error boundary, and the `onError` component appears. --#### [React Native](#tab/reactnative) --The tracking of uncaught exceptions is enabled by default. If you want to disable the tracking of uncaught exceptions, set `disableExceptionCollection` to `true`. --```javascript -import { ApplicationInsights } from '@microsoft/applicationinsights-web'; --var RNPlugin = new ReactNativePlugin(); -var appInsights = new ApplicationInsights({ - config: { - connectionString: 'YOUR_CONNECTION_STRING_GOES_HERE', - disableExceptionCollection: true, - extensions: [RNPlugin] - } -}); -appInsights.loadAppInsights(); -``` --#### [Angular](#tab/angular) --To track uncaught exceptions, set up ApplicationinsightsAngularpluginErrorService in `app.module.ts`: --> [!IMPORTANT] -> When using the ErrorService, there is an implicit dependency on the `@microsoft/applicationinsights-analytics-js` extension. you MUST include either the `'@microsoft/applicationinsights-web'` or include the `@microsoft/applicationinsights-analytics-js` extension. Otherwise, unhandled exceptions caught by the error service will not be sent. --```js -import { ApplicationinsightsAngularpluginErrorService } from '@microsoft/applicationinsights-angularplugin-js'; --@NgModule({ - ... - providers: [ - { - provide: ErrorHandler, - useClass: ApplicationinsightsAngularpluginErrorService - } - ] - ... -}) -export class AppModule { } -``` --#### Chain more custom exception handlers --Chain more custom exception handlers when you want to want the application to gracefully handle what would previously have been an unhandled exception, but you still want to report this exception as an application failure. --To chain more custom exception handlers: --1. Create custom exception handlers that implement IErrorService. -- ```javascript - import { IErrorService } from '@microsoft/applicationinsights-angularplugin-js'; -- export class CustomErrorHandler implements IErrorService { - handleError(error: any) { - ... - } - } - ``` --1. Pass errorServices array through extensionConfig. -- ```javascript - extensionConfig: { - [angularPlugin.identifier]: { - router: this.router, - error - } - } - ``` ----### Collect device information --#### [React](#tab/react) --The device information, which includes Browser, OS, version, and language, is already being collected by the Application Insights web package. --#### [React Native](#tab/reactnative) --- **React Native Plugin**: In addition to user agent info from the browser, which is collected by Application Insights web package, React Native also collects device information. Device information is automatically collected when you add the plug-in.-- **React Native Manual Device Plugin**: Depending on how you configured the plugin when you added the extension to your code, this plugin either:- - Doesn't collect device information - - Uses your own device info collection class --#### [Angular](#tab/angular) --The device information, which includes Browser, OS, version, and language, is already being collected by the Application Insights web package. ----### Configuration (other) --#### [React](#tab/react) --#### Track components usage --A feature that's unique to the React plug-in is that you're able to instrument specific components and track them individually. --To instrument React components with usage tracking, apply the `withAITracking` higher-order component function. To enable Application Insights for a component, wrap `withAITracking` around the component: --```javascript -import React from 'react'; -import { withAITracking } from '@microsoft/applicationinsights-react-js'; -import { reactPlugin, appInsights } from './AppInsights'; --// To instrument various React components usage tracking, apply the `withAITracking` higher-order -// component function. --class MyComponent extends React.Component { - ... -} --// withAITracking takes 4 parameters (reactPlugin, Component, ComponentName, className). -// The first two are required and the other two are optional. --export default withAITracking(reactPlugin, MyComponent); -``` --It measures time from the [`ComponentDidMount`](https://react.dev/reference/react/Component#componentdidmount) event through the [`ComponentWillUnmount`](https://react.dev/reference/react/Component#componentwillunmount) event. To make the result more accurate, it subtracts the time in which the user was idle by using `React Component Engaged Time = ComponentWillUnmount timestamp - ComponentDidMount timestamp - idle time`. --##### Explore your data --Use [Azure Monitor metrics explorer](../essentials/analyze-metrics.md) to plot a chart for the custom metric name `React Component Engaged Time (seconds)` and [split](../essentials/analyze-metrics.md#use-dimension-filters-and-splitting) this custom metric by `Component Name`. ---You can also run [custom queries](../logs/log-analytics-tutorial.md) to divide Application Insights data to generate reports and visualizations as per your requirements. HereΓÇÖs an example of a custom query. Go ahead and paste it directly into the query editor to test it out. --```Kusto -customMetrics -| where name contains "React Component Engaged Time (seconds)" -| summarize avg(value), count() by tostring(customDimensions["Component Name"]) -``` --It can take up to 10 minutes for new custom metrics to appear in the Azure portal. --#### Use Application Insights with React Context --We provide general hooks to allow you to customize the change tracking for individual components. Alternatively, you can use [useTrackMetric](#usetrackmetric) or [useTrackEvent](#usetrackevent), which are pre-defined contacts we provide for tracking the changes to components. --The React Hooks for Application Insights are designed to use [React Context](https://react.dev/learn/passing-data-deeply-with-context) as a containing aspect for it. To use Context, initialize Application Insights, and then import the Context object: --```javascript -import React from "react"; -import { AppInsightsContext } from "@microsoft/applicationinsights-react-js"; -import { reactPlugin } from "./AppInsights"; --const App = () => { - return ( - <AppInsightsContext.Provider value={reactPlugin}> - /* your application here */ - </AppInsightsContext.Provider> - ); -}; -``` --This Context Provider makes Application Insights available as a `useContext` Hook within all children components of it: --```javascript -import React from "react"; -import { useAppInsightsContext } from "@microsoft/applicationinsights-react-js"; --const MyComponent = () => { - const appInsights = useAppInsightsContext(); - const metricData = { - average: engagementTime, - name: "React Component Engaged Time (seconds)", - sampleCount: 1 - }; - const additionalProperties = { "Component Name": 'MyComponent' }; - appInsights.trackMetric(metricData, additionalProperties); - - return ( - <h1>My Component</h1> - ); -} -export default MyComponent; -``` --##### useTrackMetric --The `useTrackMetric` Hook replicates the functionality of the `withAITracking` higher-order component, without adding another component to the component structure. The Hook takes two arguments: --- The Application Insights instance, which can be obtained from the `useAppInsightsContext` Hook.-- An identifier for the component for tracking, such as its name.--```javascript -import React from "react"; -import { useAppInsightsContext, useTrackMetric } from "@microsoft/applicationinsights-react-js"; --const MyComponent = () => { - const appInsights = useAppInsightsContext(); - const trackComponent = useTrackMetric(appInsights, "MyComponent"); - - return ( - <h1 onHover={trackComponent} onClick={trackComponent}>My Component</h1> - ); -} -export default MyComponent; -``` --It operates like the higher-order component, but it responds to Hooks lifecycle events rather than a component lifecycle. If there's a need to run on particular interactions, the Hook needs to be explicitly provided to user events. --##### useTrackEvent --Use the `useTrackEvent` Hook to track any custom event that an application might need to track, such as a button click or other API call. It takes four arguments: --- Application Insights instance, which can be obtained from the `useAppInsightsContext` Hook.-- Name for the event.-- Event data object that encapsulates the changes that have to be tracked.-- skipFirstRun (optional) flag to skip calling the `trackEvent` call on initialization. The default value is set to `true` to mimic more closely the way the non-Hook version works. With `useEffect` Hooks, the effect is triggered on each value update _including_ the initial setting of the value. As a result, tracking starts too early, which causes potentially unwanted events to be tracked.--```javascript -import React, { useState, useEffect } from "react"; -import { useAppInsightsContext, useTrackEvent } from "@microsoft/applicationinsights-react-js"; --const MyComponent = () => { - const appInsights = useAppInsightsContext(); - const [cart, setCart] = useState([]); - const trackCheckout = useTrackEvent(appInsights, "Checkout", cart); - const trackCartUpdate = useTrackEvent(appInsights, "Cart Updated", cart); - useEffect(() => { - trackCartUpdate({ cartCount: cart.length }); - }, [cart]); - - const performCheckout = () => { - trackCheckout(); - // submit data - }; - - return ( - <div> - <ul> - <li>Product 1 <button onClick={() => setCart([...cart, "Product 1"])}>Add to Cart</button></li> - <li>Product 2 <button onClick={() => setCart([...cart, "Product 2"])}>Add to Cart</button></li> - <li>Product 3 <button onClick={() => setCart([...cart, "Product 3"])}>Add to Cart</button></li> - <li>Product 4 <button onClick={() => setCart([...cart, "Product 4"])}>Add to Cart</button></li> - </ul> - <button onClick={performCheckout}>Checkout</button> - </div> - ); -} --export default MyComponent; -``` --When the Hook is used, a data payload can be provided to it to add more data to the event when it's stored in Application Insights. --#### [React Native](#tab/reactnative) --#### Disable automatic device info collection --If you donΓÇÖt want to collect the device information, you can set `disableDeviceCollection` to `true`. --```typescript -import { ApplicationInsights } from '@microsoft/applicationinsights-web'; --var RNPlugin = new ReactNativePlugin(); -var appInsights = new ApplicationInsights({ - config: { - connectionString: 'YOUR_CONNECTION_STRING_GOES_HERE', - disableDeviceCollection: true, - extensions: [RNPlugin] - } -}); -appInsights.loadAppInsights(); -``` --#### Use your own device info collection class --If you want to override your own deviceΓÇÖs information, you can use `myDeviceInfoModule` to collect your own device information. --```typescript -import { ApplicationInsights } from '@microsoft/applicationinsights-web'; --// Simple inline constant implementation -const myDeviceInfoModule = { - getModel: () => "deviceModel", - getDeviceType: () => "deviceType", - // v5 returns a string while latest returns a promise - getUniqueId: () => "deviceId", // This "may" also return a Promise<string> -}; --var RNPlugin = new ReactNativePlugin(); -RNPlugin.setDeviceInfoModule(myDeviceInfoModule); --var appInsights = new ApplicationInsights({ - config: { - connectionString: 'YOUR_CONNECTION_STRING_GOES_HERE', - extensions: [RNPlugin] - } -}); --appInsights.loadAppInsights(); -``` --#### Override the device information --Use the `IDeviceInfoModule` interface to abstract how the plug-in can access the Device Info. This interface is a stripped down version of the `react-native-device-info` interface and is mostly supplied for testing. --```typescript -export interface IDeviceInfoModule { - /** - * Returns the Device Model - */ - getModel: () => string; -- /** - * Returns the device type - */ - getDeviceType: () => string; -- /** - * Returns the unique Id for the device. To support both the current version and previous - * versions react-native-device-info, this may return either a `string` or `Promise<string>`. - * When a promise is returned, the plugin will "wait" for the promise to `resolve` or `reject` - * before processing any events. This WILL cause telemetry to be BLOCKED until either of these - * states, so when returning a Promise, it MUST `resolve` or `reject`. Tt can't just never resolve. - * There is a default timeout configured via `uniqueIdPromiseTimeout` to automatically unblock - * event processing when this issue occurs. - */ - getUniqueId: () => Promise<string> | string; -} -``` --If events are getting "blocked" because the `Promise` returned via `getUniqueId` is never resolved / rejected, you can call `setDeviceId()` on the plugin to "unblock" this waiting state. There is also an automatic timeout configured via `uniqueIdPromiseTimeout` (defaults to 5 seconds), which will internally call `setDeviceId()` with any previously configured value. --#### [Angular](#tab/angular) --N/A ----## Sample app --### [React](#tab/react) --Check out the [Application Insights React demo](https://github.com/microsoft/applicationinsights-react-js/tree/main/sample/applicationinsights-react-sample). --### [React Native](#tab/reactnative) --Currently unavailable. --### [Angular](#tab/angular) --Check out the [Application Insights Angular demo](https://github.com/microsoft/applicationinsights-angularplugin-js/tree/main/sample/applicationinsights-angularplugin-sample). ----## Frequently asked questions --This section provides answers to common questions. --### How does Application Insights generate device information like browser, OS, language, and model? --The browser passes the User Agent string in the HTTP header of the request. The Application Insights ingestion service uses [UA Parser](https://github.com/ua-parser/uap-core) to generate the fields you see in the data tables and experiences. As a result, Application Insights users are unable to change these fields. - -Occasionally, this data might be missing or inaccurate if the user or enterprise disables sending User Agent in browser settings. The [UA Parser regexes](https://github.com/ua-parser/uap-core/blob/master/regexes.yaml) might not include all device information. Or Application Insights might not have adopted the latest updates. --## Next steps --- [Confirm data is flowing](javascript-sdk.md#confirm-data-is-flowing). |
| azure-monitor | Javascript Sdk Configuration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/javascript-sdk-configuration.md | - Title: Microsoft Azure Monitor Application Insights JavaScript SDK configuration -description: Microsoft Azure Monitor Application Insights JavaScript SDK configuration. - Previously updated : 11/15/2023-----# Microsoft Azure Monitor Application Insights JavaScript SDK configuration --The Azure Application Insights JavaScript SDK provides configuration for tracking, monitoring, and debugging your web applications. --> [!div class="checklist"] -> - [SDK configuration](#sdk-configuration) -> - [Cookie management and configuration](#cookie-management) -> - [Source map un-minify support](#source-map) -> - [Tree shaking optimized code](#tree-shaking) --## SDK configuration --These configuration fields are optional and default to false unless otherwise stated. --For instructions on how to add SDK configuration, see [Add SDK configuration](./javascript-sdk.md#optional-add-sdk-configuration). --| Name | Type | Default | -|||| -| accountId<br><br>An optional account ID, if your app groups users into accounts. No spaces, commas, semicolons, equals, or vertical bars | string | null | -| addRequestContext<br><br>Provide a way to enrich dependencies logs with context at the beginning of api call. Default is undefined. You need to check if `xhr` exists if you configure `xhr` related context. You need to check if `fetch request` and `fetch response` exist if you configure `fetch` related context. Otherwise you may not get the data you need. | (requestContext: IRequestionContext) => {[key: string]: any} | undefined | -| ajaxPerfLookupDelay<br><br>Defaults to 25 ms. The amount of time to wait before reattempting to find the windows.performance timings for an Ajax request, time is in milliseconds and is passed directly to setTimeout(). | numeric | 25 | -| appId<br><br>AppId is used for the correlation between AJAX dependencies happening on the client-side with the server-side requests. When Beacon API is enabled, it can't be used automatically, but can be set manually in the configuration. Default is null | string | null | -| autoTrackPageVisitTime<br><br>If true, on a pageview, the _previous_ instrumented page's view time is tracked and sent as telemetry and a new timer is started for the current pageview. It's sent as a custom metric named `PageVisitTime` in `milliseconds` and is calculated via the Date [now()](https://developer.mozilla.org/docs/Web/JavaScript/Reference/Global_Objects/Date/now) function (if available) and falls back to (new Date()).[getTime()](https://developer.mozilla.org/docs/Web/JavaScript/Reference/Global_Objects/Date/getTime) if now() is unavailable (IE8 or less). Default is false. | boolean | false | -| convertUndefined<br><br>Provide user an option to convert undefined field to user defined value. | `any` | undefined | -| cookieCfg<br><br>Defaults to cookie usage enabled see [ICookieCfgConfig](#cookie-management) settings for full defaults. | [ICookieCfgConfig](#cookie-management)<br>[Optional]<br>(Since 2.6.0) | undefined | -| cookieDomain<br><br>Custom cookie domain. It's helpful if you want to share Application Insights cookies across subdomains.<br>(Since v2.6.0) If `cookieCfg.domain` is defined it takes precedence over this value. | alias for [`cookieCfg.domain`](#cookie-management)<br>[Optional] | null | -| cookiePath<br><br>Custom cookie path. It's helpful if you want to share Application Insights cookies behind an application gateway.<br>If `cookieCfg.path` is defined, it takes precedence. | alias for [`cookieCfg.path`](#cookie-management)<br>[Optional]<br>(Since 2.6.0) | null | -| correlationHeaderDomains<br><br>Enable correlation headers for specific domains | string[] | undefined | -| correlationHeaderExcludedDomains<br><br>Disable correlation headers for specific domains | string[] | undefined | -| correlationHeaderExcludePatterns<br><br>Disable correlation headers using regular expressions | regex[] | undefined | -| createPerfMgr<br><br>Callback function that will be called to create a IPerfManager instance when required and ```enablePerfMgr``` is enabled, it enables you to override the default creation of a PerfManager() without needing to ```setPerfMgr()``` after initialization. | (core: IAppInsightsCore, notification -| customHeaders<br><br>The ability for the user to provide extra headers when using a custom endpoint. customHeaders aren't added on browser shutdown moment when beacon sender is used. And adding custom headers isn't supported on IE9 or earlier. | `[{header: string, value: string}]` | undefined | -| diagnosticLogInterval<br><br>(internal) Polling interval (in ms) for internal logging queue | numeric | 10000 | -| disableAjaxTracking<br><br>If true, Ajax calls aren't autocollected. Default is false. | boolean | false | -| disableCookiesUsage<br><br>Default false. A boolean that indicates whether to disable the use of cookies by the SDK. If true, the SDK doesn't store or read any data from cookies.<br>(Since v2.6.0) If `cookieCfg.enabled` is defined it takes precedence. Cookie usage can be re-enabled after initialization via the core.getCookieMgr().setEnabled(true). | alias for [`cookieCfg.enabled`](#cookie-management)<br>[Optional] | false | -| disableCorrelationHeaders<br><br>If false, the SDK adds two headers ('Request-Id' and 'Request-Context') to all dependency requests to correlate them with corresponding requests on the server side. Default is false. | boolean | false | -| disableDataLossAnalysis<br><br>If false, internal telemetry sender buffers are checked at startup for items not yet sent. | boolean | true | -| disableExceptionTracking<br><br>If true, exceptions aren't autocollected. Default is false. | boolean | false | -| disableFetchTracking<br><br>The default setting for `disableFetchTracking` is `false`, meaning it's enabled. However, in versions prior to 2.8.10, it was disabled by default. When set to `true`, Fetch requests aren't automatically collected. The default setting changed from `true` to `false` in version 2.8.0. | boolean | false | -| disableFlushOnBeforeUnload<br><br>Default false. If true, flush method isn't called when onBeforeUnload event triggers | boolean | false | -| disableIkeyDeprecationMessage<br><br>Disable instrumentation Key deprecation error message. If true, error messages are NOT sent. | boolean | true | -| disableInstrumentationKeyValidation<br><br>If true, instrumentation key validation check is bypassed. Default value is false. | boolean | false | -| disableTelemetry<br><br>If true, telemetry isn't collected or sent. Default is false. | boolean | false | -| disableXhr<br><br>Don't use XMLHttpRequest or XDomainRequest (for Internet Explorer < version 9) by default instead attempt to use fetch() or sendBeacon. If no other transport is available, it uses XMLHttpRequest | boolean | false | -| distributedTracingMode<br><br>Sets the distributed tracing mode. If AI_AND_W3C mode or W3C mode is set, W3C trace context headers (traceparent/tracestate) are generated and included in all outgoing requests. AI_AND_W3C is provided for back-compatibility with any legacy Application Insights instrumented services. | numeric or `DistributedTracingModes` | `DistributedTracing Modes.AI_AND_W3C` | -| enableAjaxErrorStatusText<br><br>Default false. If true, include response error data text boolean in dependency event on failed AJAX requests. | boolean | false | -| enableAjaxPerfTracking<br><br>Default false. Flag to enable looking up and including extra browser window.performance timings in the reported Ajax (XHR and fetch) reported metrics. | boolean | false | -| enableAutoRouteTracking<br><br>Automatically track route changes in Single Page Applications (SPA). If true, each route change sends a new Pageview to Application Insights. Hash route changes (`example.com/foo#bar`) are also recorded as new page views.<br>***Note***: If you enable this field, don't enable the `history` object for [React router configuration](./javascript-framework-extensions.md?tabs=react#track-router-history) because you'll get multiple page view events. | boolean | false | -| enableCorsCorrelation<br><br>If true, the SDK adds two headers ('Request-Id' and 'Request-Context') to all CORS requests to correlate outgoing AJAX dependencies with corresponding requests on the server side. Default is false | boolean | false | -| enableDebug<br><br>If true, **internal** debugging data is thrown as an exception **instead** of being logged, regardless of SDK logging settings. Default is false. <br>***Note:*** Enabling this setting results in dropped telemetry whenever an internal error occurs. It can be useful for quickly identifying issues with your configuration or usage of the SDK. If you don't want to lose telemetry while debugging, consider using `loggingLevelConsole` or `loggingLevelTelemetry` instead of `enableDebug`. | boolean | false | -| enablePerfMgr<br><br>When enabled (true) it creates local perfEvents for code that has been instrumented to emit perfEvents (via the doPerf() helper). It can be used to identify performance issues within the SDK based on your usage or optionally within your own instrumented code. | boolean | false | -| enableRequestHeaderTracking<br><br>If true, AJAX & Fetch request headers is tracked, default is false. If ignoreHeaders isn't configured, Authorization and X-API-Key headers aren't logged. | boolean | false | -| enableResponseHeaderTracking<br><br>If true, AJAX & Fetch request's response headers is tracked, default is false. If ignoreHeaders isn't configured, WWW-Authenticate header isn't logged. | boolean | false | -| enableSessionStorageBuffer<br><br>Default true. If true, the buffer with all unsent telemetry is stored in session storage. The buffer is restored on page load | boolean | true | -| enableUnhandledPromiseRejectionTracking<br><br>If true, unhandled promise rejections are autocollected as a JavaScript error. When disableExceptionTracking is true (don't track exceptions), the config value is ignored and unhandled promise rejections aren't reported. | boolean | false | -| eventsLimitInMem<br><br>The number of events that can be kept in memory before the SDK starts to drop events when not using Session Storage (the default). | number | 10000 | -| excludeRequestFromAutoTrackingPatterns<br><br>Provide a way to exclude specific route from automatic tracking for XMLHttpRequest or Fetch request. If defined, for an Ajax / fetch request that the request url matches with the regex patterns, auto tracking is turned off. Default is undefined. | string[] \| RegExp[] | undefined | -| featureOptIn<br><br>Set Feature opt in details.<br><br>This configuration field is only available in version 3.0.3 and later. | IFeatureOptIn | undefined | -| idLength<br><br>Identifies the default length used to generate new random session and user IDs. Defaults to 22, previous default value was 5 (v2.5.8 or less), if you need to keep the previous maximum length you should set the value to 5. | numeric | 22 | -| ignoreHeaders<br><br>AJAX & Fetch request and response headers to be ignored in log data. To override or discard the default, add an array with all headers to be excluded or an empty array to the configuration. | string[] | ["Authorization", "X-API-Key", "WWW-Authenticate"] | -| isBeaconApiDisabled<br><br>If false, the SDK sends all telemetry using the [Beacon API](https://www.w3.org/TR/beacon) | boolean | true | -| isBrowserLinkTrackingEnabled<br><br>Default is false. If true, the SDK tracks all [Browser Link](/aspnet/core/client-side/using-browserlink) requests. | boolean | false | -| isRetryDisabled<br><br>Default false. If false, retry on 206 (partial success), 408 (timeout), 429 (too many requests), 500 (internal server error), 503 (service unavailable), and 0 (offline, only if detected) | boolean | false | -| isStorageUseDisabled<br><br>If true, the SDK doesn't store or read any data from local and session storage. Default is false. | boolean | false | -| loggingLevelConsole<br><br>Logs **internal** Application Insights errors to console. <br>0: off, <br>1: Critical errors only, <br>2: Everything (errors & warnings) | numeric | 0 | -| loggingLevelTelemetry<br><br>Sends **internal** Application Insights errors as telemetry. <br>0: off, <br>1: Critical errors only, <br>2: Everything (errors & warnings) | numeric | 1 | -| maxAjaxCallsPerView<br><br>Default 500 - controls how many Ajax calls are monitored per page view. Set to -1 to monitor all (unlimited) Ajax calls on the page. | numeric | 500 | -| maxAjaxPerfLookupAttempts<br><br>Defaults to 3. The maximum number of times to look for the window.performance timings (if available) is required. Not all browsers populate the window.performance before reporting the end of the XHR request. For fetch requests, it's added after it's complete. | numeric | 3 | -| maxBatchInterval<br><br>How long to batch telemetry for before sending (milliseconds) | numeric | 15000 | -| maxBatchSizeInBytes<br><br>Max size of telemetry batch. If a batch exceeds this limit, it's immediately sent and a new batch is started | numeric | 10000 | -| namePrefix<br><br>An optional value that is used as name postfix for localStorage and session cookie name. | string | undefined | -| onunloadDisableBeacon<br><br>Default false. when tab is closed, the SDK sends all remaining telemetry using the [Beacon API](https://www.w3.org/TR/beacon) | boolean | false | -| onunloadDisableFetch<br><br>If fetch keepalive is supported don't use it for sending events during unload, it may still fall back to fetch() without keepalive | boolean | false | -| overridePageViewDuration<br><br>If true, default behavior of trackPageView is changed to record end of page view duration interval when trackPageView is called. If false and no custom duration is provided to trackPageView, the page view performance is calculated using the navigation timing API. Default is false. | boolean | false | -| perfEvtsSendAll<br><br>When _enablePerfMgr_ is enabled and the [IPerfManager](https://github.com/microsoft/ApplicationInsights-JS/blob/master/shared/AppInsightsCore/src/JavaScriptSDK.Interfaces/IPerfManager.ts) fires a [INotificationManager](https://github.com/microsoft/ApplicationInsights-JS/blob/master/shared/AppInsightsCore/src/JavaScriptSDK.Interfaces/INotificationManager.ts).perfEvent() this flag determines whether an event is fired (and sent to all listeners) for all events (true) or only for 'parent' events (false <default>).<br />A parent [IPerfEvent](https://github.com/microsoft/ApplicationInsights-JS/blob/master/shared/AppInsightsCore/src/JavaScriptSDK.Interfaces/IPerfEvent.ts) is an event where no other IPerfEvent is still running at the point of the event being created and its _parent_ property isn't null or undefined. Since v2.5.7 | boolean | false | -| samplingPercentage<br><br>Percentage of events that is sent. Default is 100, meaning all events are sent. Set it if you wish to preserve your data cap for large-scale applications. | numeric | 100 | -| sdkExtension<br><br>Sets the SDK extension name. Only alphabetic characters are allowed. The extension name is added as a prefix to the 'ai.internal.sdkVersion' tag (for example, 'ext_javascript:2.0.0'). Default is null. | string | null | -| sessionCookiePostfix<br><br>An optional value that is used as name postfix for session cookie name. If undefined, namePrefix is used as name postfix for session cookie name. | string | undefined | -| sessionExpirationMs<br><br>A session is logged if it has continued for this amount of time in milliseconds. Default is 24 hours | numeric | 86400000 | -| sessionRenewalMs<br><br>A session is logged if the user is inactive for this amount of time in milliseconds. Default is 30 minutes | numeric | 1800000 | -| throttleMgrCfg<br><br>Set throttle mgr configuration by key.<br><br>This configuration field is only available in version 3.0.3 and later. | `{[key: number]: IThrottleMgrConfig}` | undefined | -| userCookiePostfix<br><br>An optional value that is used as name postfix for user cookie name. If undefined, no postfix is added on user cookie name. | string | undefined | --## Cookie management --Starting from version 2.6.0, the Azure Application Insights JavaScript SDK provides instance-based cookie management that can be disabled and re-enabled after initialization. --If you disabled cookies during initialization using the `disableCookiesUsage` or `cookieCfg.enabled` configurations, you can re-enable them using the `setEnabled` function of the [ICookieMgr object](https://microsoft.github.io/ApplicationInsights-JS/webSdk/applicationinsights-core-js/interfaces/ICookieMgr.html). --The instance-based cookie management replaces the previous CoreUtils global functions of `disableCookies()`, `setCookie()`, `getCookie()`, and `deleteCookie()`. --To take advantage of the tree-shaking enhancements introduced in version 2.6.0, it's recommended to no longer use the global functions. --### Cookie configuration --ICookieMgrConfig is a cookie configuration for instance-based cookie management added in 2.6.0. The options provided allow you to enable or disable the use of cookies by the SDK. You can also set custom cookie domains and paths and customize the functions for fetching, setting, and deleting cookies. --The ICookieMgrConfig options are defined in the following table. --| Name | Type | Default | Description | -||||-| -| enabled | boolean | true | The current instance of the SDK uses this boolean to indicate whether the use of cookies is enabled. If false, the instance of the SDK initialized by this configuration doesn't store or read any data from cookies. | -| domain | string | null | Custom cookie domain. It's helpful if you want to share Application Insights cookies across subdomains. If not provided uses the value from root `cookieDomain` value. | -| path | string | / | Specifies the path to use for the cookie, if not provided it uses any value from the root `cookiePath` value. | -| ignoreCookies | string[] | undefined | Specify the cookie name(s) to be ignored, it causes any matching cookie name to never be read or written. They may still be explicitly purged or deleted. You don't need to repeat the name in the `blockedCookies` configuration. (since v2.8.8) -| blockedCookies | string[] | undefined | Specify the cookie name(s) to never write. It prevents creating or updating any cookie name, but they can still be read unless also included in the ignoreCookies. They may still be purged or deleted explicitly. If not provided, it defaults to the same list in ignoreCookies. (Since v2.8.8) -| getCookie | `(name: string) => string` | null | Function to fetch the named cookie value, if not provided it uses the internal cookie parsing / caching. | -| setCookie | `(name: string, value: string) => void` | null | Function to set the named cookie with the specified value, only called when adding or updating a cookie. | -| delCookie | `(name: string, value: string) => void` | null | Function to delete the named cookie with the specified value, separated from setCookie to avoid the need to parse the value to determine whether the cookie is being added or removed. If not provided it uses the internal cookie parsing / caching. | --## Source map --Source map support helps you debug minified JavaScript code with the ability to unminify the minified callstack of your exception telemetry. --> [!div class="checklist"] -> - Compatible with all current integrations on the **Exception Details** panel -> - Supports all current and future JavaScript SDKs, including Node.JS, without the need for an SDK upgrade --### Link to Blob Storage account --Application Insights supports the uploading of source maps to your Azure Storage account blob container. You can use source maps to unminify call stacks found on the **End-to-end transaction details** page. You can also use source maps to unminify any exception sent by the [JavaScript SDK][ApplicationInsights-JS] or the [Node.js SDK][ApplicationInsights-Node.js]. ---#### Create a new storage account and blob container --If you already have an existing storage account or blob container, you can skip this step. --1. [Create a new storage account][create storage account]. -1. [Create a blob container][create blob container] inside your storage account. Set **Public access level** to **Private** to ensure that your source maps aren't publicly accessible. -- :::image type="content" source="./media/javascript-sdk-configuration/container-access-level.png" lightbox="./media/javascript-sdk-configuration/container-access-level.png" alt-text="Screenshot that shows setting the container access level to Private."::: --#### Push your source maps to your blob container --Integrate your continuous deployment pipeline with your storage account by configuring it to automatically upload your source maps to the configured blob container. --You can upload source maps to your Azure Blob Storage container with the same folder structure they were compiled and deployed with. A common use case is to prefix a deployment folder with its version, for example, `1.2.3/static/js/main.js`. When you unminify via an Azure blob container called `sourcemaps`, the pipeline tries to fetch a source map located at `sourcemaps/1.2.3/static/js/main.js.map`. --##### Upload source maps via Azure Pipelines (recommended) --If you're using Azure Pipelines to continuously build and deploy your application, add an [Azure file copy][azure file copy] task to your pipeline to automatically upload your source maps. ---#### Configure your Application Insights resource with a source map storage account --You have two options for configuring your Application Insights resource with a source map storage account. --##### End-to-end transaction details tab --From the **End-to-end transaction details** tab, select **Unminify**. Configure your resource if it's unconfigured. --1. In the Azure portal, view the details of an exception that's minified. -1. Select **Unminify**. -1. If your resource isn't configured, configure it. --##### Properties tab --To configure or change the storage account or blob container that's linked to your Application Insights resource: --1. Go to the **Properties** tab of your Application Insights resource. -1. Select **Change source map Blob Container**. -1. Select a different blob container as your source map container. -1. Select **Apply**. -- :::image type="content" source="./media/javascript-sdk-configuration/reconfigure.png" lightbox="./media/javascript-sdk-configuration/reconfigure.png" alt-text="Screenshot that shows reconfiguring your selected Azure blob container on the Properties pane."::: --### View the unminified callstack - -To view the unminified callstack, select an Exception Telemetry item in the Azure portal, find the source maps that match the call stack, and drag and drop the source maps onto the call stack in the Azure portal. The source map must have the same name as the source file of a stack frame, but with a `map` extension. --If you experience issues that involve source map support for JavaScript applications, see [Troubleshoot source map support for JavaScript applications](/troubleshoot/azure/azure-monitor/app-insights/javascript-sdk-troubleshooting#troubleshoot-source-map-support-for-javascript-applications). ---## Tree shaking --Tree shaking eliminates unused code from the final JavaScript bundle. --To take advantage of tree shaking, import only the necessary components of the SDK into your code. By doing so, unused code isn't included in the final bundle, reducing its size and improving performance. --### Tree shaking enhancements and recommendations --In version 2.6.0, we deprecated and removed the internal usage of these static helper classes to improve support for tree-shaking algorithms. It lets npm packages safely drop unused code. --- `CoreUtils`-- `EventHelper`-- `Util`-- `UrlHelper`-- `DateTimeUtils`-- `ConnectionStringParser`-- The functions are now exported as top-level roots from the modules, making it easier to refactor your code for better tree-shaking. --The static classes were changed to const objects that reference the new exported functions, and future changes are planned to further refactor the references. --### Tree shaking deprecated functions and replacements --This section only applies to you if you're using the deprecated functions and you want to optimize package size. We recommend using the replacement functions to reduce size and support all the versions of Internet Explorer. --| Existing | Replacement | -|-|-| -| **CoreUtils** | **@microsoft/applicationinsights-core-js** | -| CoreUtils._canUseCookies | None. Don't use as it causes all of CoreUtils reference to be included in your final code.<br> Refactor your cookie handling to use the `appInsights.getCookieMgr().setEnabled(true/false)` to set the value and `appInsights.getCookieMgr().isEnabled()` to check the value. | -| CoreUtils.isTypeof | isTypeof | -| CoreUtils.isUndefined | isUndefined | -| CoreUtils.isNullOrUndefined | isNullOrUndefined | -| CoreUtils.hasOwnProperty | hasOwnProperty | -| CoreUtils.isFunction | isFunction | -| CoreUtils.isObject | isObject | -| CoreUtils.isDate | isDate | -| CoreUtils.isArray | isArray | -| CoreUtils.isError | isError | -| CoreUtils.isString | isString | -| CoreUtils.isNumber | isNumber | -| CoreUtils.isBoolean | isBoolean | -| CoreUtils.toISOString | toISOString or getISOString | -| CoreUtils.arrForEach | arrForEach | -| CoreUtils.arrIndexOf | arrIndexOf | -| CoreUtils.arrMap | arrMap | -| CoreUtils.arrReduce | arrReduce | -| CoreUtils.strTrim | strTrim | -| CoreUtils.objCreate | objCreateFn | -| CoreUtils.objKeys | objKeys | -| CoreUtils.objDefineAccessors | objDefineAccessors | -| CoreUtils.addEventHandler | addEventHandler | -| CoreUtils.dateNow | dateNow | -| CoreUtils.isIE | isIE | -| CoreUtils.disableCookies | disableCookies<br>Referencing either causes CoreUtils to be referenced for backward compatibility.<br> Refactor your cookie handling to use the `appInsights.getCookieMgr().setEnabled(false)` | -| CoreUtils.newGuid | newGuid | -| CoreUtils.perfNow | perfNow | -| CoreUtils.newId | newId | -| CoreUtils.randomValue | randomValue | -| CoreUtils.random32 | random32 | -| CoreUtils.mwcRandomSeed | mwcRandomSeed | -| CoreUtils.mwcRandom32 | mwcRandom32 | -| CoreUtils.generateW3CId | generateW3CId | -| **EventHelper** | **@microsoft/applicationinsights-core-js** | -| EventHelper.Attach | attachEvent | -| EventHelper.AttachEvent | attachEvent | -| EventHelper.Detach | detachEvent | -| EventHelper.DetachEvent | detachEvent | -| **Util** | **@microsoft/applicationinsights-common-js** | -| Util.NotSpecified | strNotSpecified | -| Util.createDomEvent | createDomEvent | -| Util.disableStorage | utlDisableStorage | -| Util.isInternalApplicationInsightsEndpoint | isInternalApplicationInsightsEndpoint | -| Util.canUseLocalStorage | utlCanUseLocalStorage | -| Util.getStorage | utlGetLocalStorage | -| Util.setStorage | utlSetLocalStorage | -| Util.removeStorage | utlRemoveStorage | -| Util.canUseSessionStorage | utlCanUseSessionStorage | -| Util.getSessionStorageKeys | utlGetSessionStorageKeys | -| Util.getSessionStorage | utlGetSessionStorage | -| Util.setSessionStorage | utlSetSessionStorage | -| Util.removeSessionStorage | utlRemoveSessionStorage | -| Util.disableCookies | disableCookies<br>Referencing either causes CoreUtils to be referenced for backward compatibility.<br> Refactor your cookie handling to use the `appInsights.getCookieMgr().setEnabled(false)` | -| Util.canUseCookies | canUseCookies<br>Referencing either causes CoreUtils to be referenced for backward compatibility.<br>Refactor your cookie handling to use the `appInsights.getCookieMgr().isEnabled()` | -| Util.disallowsSameSiteNone | uaDisallowsSameSiteNone | -| Util.setCookie | coreSetCookie<br>Referencing causes CoreUtils to be referenced for backward compatibility.<br>Refactor your cookie handling to use the `appInsights.getCookieMgr().set(name: string, value: string)` | -| Util.stringToBoolOrDefault | stringToBoolOrDefault | -| Util.getCookie | coreGetCookie<br>Referencing causes CoreUtils to be referenced for backward compatibility.<br>Refactor your cookie handling to use the `appInsights.getCookieMgr().get(name: string)` | -| Util.deleteCookie | coreDeleteCookie<br>Referencing causes CoreUtils to be referenced for backward compatibility.<br>Refactor your cookie handling to use the `appInsights.getCookieMgr().del(name: string, path?: string)` | -| Util.trim | strTrim | -| Util.newId | newId | -| Util.random32 | <br>No replacement, refactor your code to use the core random32(true) | -| Util.generateW3CId | generateW3CId | -| Util.isArray | isArray | -| Util.isError | isError | -| Util.isDate | isDate | -| Util.toISOStringForIE8 | toISOString | -| Util.getIEVersion | getIEVersion | -| Util.msToTimeSpan | msToTimeSpan | -| Util.isCrossOriginError | isCrossOriginError | -| Util.dump | dumpObj | -| Util.getExceptionName | getExceptionName | -| Util.addEventHandler | attachEvent | -| Util.IsBeaconApiSupported | isBeaconApiSupported | -| Util.getExtension | getExtensionByName -| **UrlHelper** | **@microsoft/applicationinsights-common-js** | -| UrlHelper.parseUrl | urlParseUrl | -| UrlHelper.getAbsoluteUrl | urlGetAbsoluteUrl | -| UrlHelper.getPathName | urlGetPathName | -| UrlHelper.getCompeteUrl | urlGetCompleteUrl | -| UrlHelper.parseHost | urlParseHost | -| UrlHelper.parseFullHost | urlParseFullHost -| **DateTimeUtils** | **@microsoft/applicationinsights-common-js** | -| DateTimeUtils.Now | dateTimeUtilsNow | -| DateTimeUtils.GetDuration | dateTimeUtilsDuration | -| **ConnectionStringParser** | **@microsoft/applicationinsights-common-js** | -| ConnectionStringParser.parse | parseConnectionString | --## Service notifications --Service notifications is a feature built into the SDK to provide actionable recommendations to help ensure your telemetry flows uninterrupted to Application Insights. You will see the notifications as an exception message within Application Insights. We ensure notifications are relevant to you based on your SDK settings, and we adjust the verbosity based on the urgency of the recommendation. We recommend leaving service notifications on, but you are able to opt out via the `featureOptIn` configuration. See below for a list of active notifications. --Currently, no active notifications are being sent. --## Troubleshooting --See the dedicated [troubleshooting article](/troubleshoot/azure/azure-monitor/app-insights/javascript-sdk-troubleshooting). --## Frequently asked questions --This section provides answers to common questions. --### How can I update my third-party server configuration for the JavaScript SDK? --The server side needs to be able to accept connections with those headers present. Depending on the `Access-Control-Allow-Headers` configuration on the server side, it's often necessary to extend the server-side list by manually adding `Request-Id`, `Request-Context`, and `traceparent` (W3C distributed header). --Access-Control-Allow-Headers: `Request-Id`, `traceparent`, `Request-Context`, `<your header>` --### How can I disable distributed tracing for the JavaScript SDK? --Distributed tracing can be disabled in configuration. --### Are the HTTP 502 and 503 responses always captured by Application Insights? --No. The "502 bad gateway" and "503 service unavailable" errors aren't always captured by Application Insights. If only client-side JavaScript is being used for monitoring, this behavior would be expected because the error response is returned prior to the page containing the HTML header with the monitoring JavaScript snippet being rendered. - -If the 502 or 503 response was sent from a server with server-side monitoring enabled, the errors are collected by the Application Insights SDK. - -Even when server-side monitoring is enabled on an application's web server, sometimes a 502 or 503 error isn't captured by Application Insights. Many modern web servers don't allow a client to communicate directly. Instead, they employ solutions like reverse proxies to pass information back and forth between the client and the front-end web servers. - -In this scenario, a 502 or 503 response might be returned to a client because of an issue at the reverse proxy layer, so it isn't captured out-of-box by Application Insights. To help detect issues at this layer, you might need to forward logs from your reverse proxy to Log Analytics and create a custom rule to check for 502 or 503 responses. To learn more about common causes of 502 and 503 errors, see [Troubleshoot HTTP errors of "502 bad gateway" and "503 service unavailable" in Azure App Service](../../app-service/troubleshoot-http-502-http-503.md). --## Next steps --* [Track usage](usage.md) -* [Custom events and metrics](api-custom-events-metrics.md) -* [Azure file copy task](/azure/devops/pipelines/tasks/deploy/azure-file-copy) --<!-- Remote URLs --> -[create storage account]: ../../storage/common/storage-account-create.md?toc=%2Fazure%2Fstorage%2Fblobs%2Ftoc.json&tabs=azure-portal -[create blob container]: ../../storage/blobs/storage-quickstart-blobs-portal.md -[storage blob data reader]: ../../role-based-access-control/built-in-roles.md#storage-blob-data-reader -[ApplicationInsights-JS]: https://github.com/microsoft/applicationinsights-js -[ApplicationInsights-Node.js]: https://github.com/microsoft/applicationinsights-node.js -[azure file copy]: https://aka.ms/azurefilecopyreadme |
| azure-monitor | Javascript Sdk Upgrade | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/javascript-sdk-upgrade.md | - Title: Azure Application Insights JavaScript SDK upgrade information -description: Azure Application Insights JavaScript SDK upgrade information - Previously updated : 10/11/2023-----# Upgrade from old versions of the Application Insights JavaScript SDK --Upgrading to the new version of the Application Insights JavaScript SDK can provide several advantages such as: --> [!div class="checklist"] -> - Improved performance and bug fixes -> - New features and functionalities -> - Better compatibility with other technologies -> - Enhanced security and data privacy --## Breaking changes in the SDK V2 version: --- To allow for better API signatures, some of the API calls, such as trackPageView and trackException, have been updated. Running in Internet Explorer 8 and earlier versions of the browser isn't supported.-- The telemetry envelope has field name and structure changes due to data schema updates.-- Moved `context.operation` to `context.telemetryTrace`. Some fields were also changed (`operation.id` --> `telemetryTrace.traceID`).- - To manually refresh the current pageview ID, for example, in single-page applications, use `appInsights.properties.context.telemetryTrace.traceID = Microsoft.ApplicationInsights.Telemetry.Util.generateW3CId()`. -- > [!NOTE] - > To keep the trace ID unique, now use `Util.generateW3CId()` where you previously used `Util.newId()`. Both ultimately end up being the operation ID. --If you're using the current application insights PRODUCTION SDK (1.0.20) and want to see if the new SDK works in runtime, update the URL depending on your current SDK loading scenario. --- Download via CDN scenario: Update the JavaScript (Web) SDK Loader Script that you currently use to point to the following URL:- ``` - "https://js.monitor.azure.com/scripts/b/ai.3.gbl.min.js" - ``` --- npm scenario: Call `downloadAndSetup` to download the full ApplicationInsights script from CDN and initialize it with a connection string:-- ```ts - appInsights.downloadAndSetup({ - connectionString: "Copy connection string from Application Insights Resource Overview", - url: "https://js.monitor.azure.com/scripts/b/ai.3.gbl.min.js" - }); - ``` --Test in an internal environment to verify the monitoring telemetry is working as expected. If all works, update your API signatures appropriately to SDK v2 and deploy in your production environments. --## Next steps -- To learn more about the JavaScript SDK, see the [Application Insights JavaScript SDK documentation](javascript.md).-- To learn about the Kusto Query Language and querying data in Log Analytics, see the [Log query overview](../../azure-monitor/logs/log-query-overview.md). |
| azure-monitor | Javascript Sdk | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/javascript-sdk.md | - Title: Microsoft Azure Monitor Application Insights JavaScript SDK -description: Microsoft Azure Monitor Application Insights JavaScript SDK is a powerful tool for monitoring and analyzing web application performance. - Previously updated : 10/11/2023-----# Enable Azure Monitor Application Insights Real User Monitoring --The Microsoft Azure Monitor Application Insights JavaScript SDK collects usage data, which allows you to monitor and analyze the performance of JavaScript web applications. This is commonly referred to as Real User Monitoring or RUM. --The Application Insights JavaScript SDK has a base SDK and several plugins for more capabilities. ---We collect page views by default. But if you want to also collect clicks by default, consider adding the [Click Analytics Auto-Collection plug-in](./javascript-feature-extensions.md): --- If you're adding a [framework extension](./javascript-framework-extensions.md), which you can [add](#optional-add-advanced-sdk-configuration) after you follow the steps to [get started](#get-started), you can optionally add Click Analytics when you add the framework extension. -- If you're not adding a framework extension, [add the Click Analytics plug-in](./javascript-feature-extensions.md) after you follow the steps to get started.--We provide the [Debug plugin](https://github.com/microsoft/ApplicationInsights-JS/blob/main/extensions/applicationinsights-debugplugin-js/README.md) and [Performance plugin](https://github.com/microsoft/ApplicationInsights-JS/blob/main/extensions/applicationinsights-perfmarkmeasure-js/README.md) for debugging/testing. In rare cases, it's possible to build your own extension by adding a [custom plugin](https://github.com/microsoft/ApplicationInsights-JS/blob/e4be62c0aa9318b540157118b729bb0c4d8b6c6e/API-reference.md#custom-extension). --## Prerequisites --- Azure subscription: [Create an Azure subscription for free](https://azure.microsoft.com/free/)-- Application Insights resource: [Create an Application Insights resource](create-workspace-resource.md#create-a-workspace-based-resource)-- An application that uses [JavaScript](/visualstudio/javascript)--## Get started --Follow the steps in this section to instrument your application with the Application Insights JavaScript SDK. --> [!TIP] -> Good news! We're making it even easier to enable JavaScript with JavaScript (Web) SDK Loader Script injection by configuration. -> -> - [ASP.NET Core](./asp-net-core.md?tabs=netcorenew%2Cnetcore6#enable-client-side-telemetry-for-web-applications) -> - [Node.js](./nodejs.md#browser-sdk-loader) -> - [Java](./java-standalone-config.md#browser-sdk-loader-preview) --### Add the JavaScript code --Two methods are available to add the code to enable Application Insights via the Application Insights JavaScript SDK: --| Method | When would I use this method? | -|:-|:| -| JavaScript (Web) SDK Loader Script | For most customers, we recommend the JavaScript (Web) SDK Loader Script because you never have to update the SDK and you get the latest updates automatically. Also, you have control over which pages you add the Application Insights JavaScript SDK to. | -| npm package | You want to bring the SDK into your code and enable IntelliSense. This option is only needed for developers who require more custom events and configuration. This method is required if you plan to use the React, React Native, or Angular Framework Extension. | --#### [JavaScript (Web) SDK Loader Script](#tab/javascriptwebsdkloaderscript) --1. Paste the JavaScript (Web) SDK Loader Script at the top of each page for which you want to enable Application Insights. -- Preferably, you should add it as the first script in your `<head>` section so that it can monitor any potential issues with all of your dependencies. - - If Internet Explorer 8 is detected, JavaScript SDK v2.x is automatically loaded. - <!-- IMPORTANT: If you're updating this code example, please remember to also update it in: 1) articles\azure-monitor\app\javascript-feature-extensions.md and 2) articles\azure-monitor\app\api-filtering-sampling.md --> - ```html - <script type="text/javascript"> - !(function (cfg){function e(){cfg.onInit&&cfg.onInit(n)}var x,w,D,t,E,n,C=window,O=document,b=C.location,q="script",I="ingestionendpoint",L="disableExceptionTracking",j="ai.device.";"instrumentationKey"[x="toLowerCase"](),w="crossOrigin",D="POST",t="appInsightsSDK",E=cfg.name||"appInsights",(cfg.name||C[t])&&(C[t]=E),n=C[E]||function(g){var f=!1,m=!1,h={initialize:!0,queue:[],sv:"8",version:2,config:g};function v(e,t){var n={},i="Browser";function a(e){e=""+e;return 1===e.length?"0"+e:e}return n[j+"id"]=i[x](),n[j+"type"]=i,n["ai.operation.name"]=b&&b.pathname||"_unknown_",n["ai.internal.sdkVersion"]="javascript:snippet_"+(h.sv||h.version),{time:(i=new Date).getUTCFullYear()+"-"+a(1+i.getUTCMonth())+"-"+a(i.getUTCDate())+"T"+a(i.getUTCHours())+":"+a(i.getUTCMinutes())+":"+a(i.getUTCSeconds())+"."+(i.getUTCMilliseconds()/1e3).toFixed(3).slice(2,5)+"Z",iKey:e,name:"Microsoft.ApplicationInsights."+e.replace(/-/g,"")+"."+t,sampleRate:100,tags:n,data:{baseData:{ver:2}},ver:undefined,seq:"1",aiDataContract:undefined}}var n,i,t,a,y=-1,T=0,S=["js.monitor.azure.com","js.cdn.applicationinsights.io","js.cdn.monitor.azure.com","js0.cdn.applicationinsights.io","js0.cdn.monitor.azure.com","js2.cdn.applicationinsights.io","js2.cdn.monitor.azure.com","az416426.vo.msecnd.net"],o=g.url||cfg.src,r=function(){return s(o,null)};function s(d,t){if((n=navigator)&&(~(n=(n.userAgent||"").toLowerCase()).indexOf("msie")||~n.indexOf("trident/"))&&~d.indexOf("ai.3")&&(d=d.replace(/(\/)(ai\.3\.)([^\d]*)$/,function(e,t,n){return t+"ai.2"+n})),!1!==cfg.cr)for(var e=0;e<S.length;e++)if(0<d.indexOf(S[e])){y=e;break}var n,i=function(e){var a,t,n,i,o,r,s,c,u,l;h.queue=[],m||(0<=y&&T+1<S.length?(a=(y+T+1)%S.length,p(d.replace(/^(.*\/\/)([\w\.]*)(\/.*)$/,function(e,t,n,i){return t+S[a]+i})),T+=1):(f=m=!0,s=d,!0!==cfg.dle&&(c=(t=function(){var e,t={},n=g.connectionString;if(n)for(var i=n.split(";"),a=0;a<i.length;a++){var o=i[a].split("=");2===o.length&&(t[o[0][x]()]=o[1])}return t[I]||(e=(n=t.endpointsuffix)?t.location:null,t[I]="https://"+(e?e+".":"")+"dc."+(n||"services.visualstudio.com")),t}()).instrumentationkey||g.instrumentationKey||"",t=(t=(t=t[I])&&"/"===t.slice(-1)?t.slice(0,-1):t)?t+"/v2/track":g.endpointUrl,t=g.userOverrideEndpointUrl||t,(n=[]).push((i="SDK LOAD Failure: Failed to load Application Insights SDK script (See stack for details)",o=s,u=t,(l=(r=v(c,"Exception")).data).baseType="ExceptionData",l.baseData.exceptions=[{typeName:"SDKLoadFailed",message:i.replace(/\./g,"-"),hasFullStack:!1,stack:i+"\nSnippet failed to load ["+o+"] -- Telemetry is disabled\nHelp Link: https://go.microsoft.com/fwlink/?linkid=2128109\nHost: "+(b&&b.pathname||"_unknown_")+"\nEndpoint: "+u,parsedStack:[]}],r)),n.push((l=s,i=t,(u=(o=v(c,"Message")).data).baseType="MessageData",(r=u.baseData).message='AI (Internal): 99 message:"'+("SDK LOAD Failure: Failed to load Application Insights SDK script (See stack for details) ("+l+")").replace(/\"/g,"")+'"',r.properties={endpoint:i},o)),s=n,c=t,JSON&&((u=C.fetch)&&!cfg.useXhr?u(c,{method:D,body:JSON.stringify(s),mode:"cors"}):XMLHttpRequest&&((l=new XMLHttpRequest).open(D,c),l.setRequestHeader("Content-type","application/json"),l.send(JSON.stringify(s)))))))},a=function(e,t){m||setTimeout(function(){!t&&h.core||i()},500),f=!1},p=function(e){var n=O.createElement(q),e=(n.src=e,t&&(n.integrity=t),n.setAttribute("data-ai-name",E),cfg[w]);return!e&&""!==e||"undefined"==n[w]||(n[w]=e),n.onload=a,n.onerror=i,n.onreadystatechange=function(e,t){"loaded"!==n.readyState&&"complete"!==n.readyState||a(0,t)},cfg.ld&&cfg.ld<0?O.getElementsByTagName("head")[0].appendChild(n):setTimeout(function(){O.getElementsByTagName(q)[0].parentNode.appendChild(n)},cfg.ld||0),n};p(d)}cfg.sri&&(n=o.match(/^((http[s]?:\/\/.*\/)\w+(\.\d+){1,5})\.(([\w]+\.){0,2}js)$/))&&6===n.length?(d="".concat(n[1],".integrity.json"),i="@".concat(n[4]),l=window.fetch,t=function(e){if(!e.ext||!e.ext[i]||!e.ext[i].file)throw Error("Error Loading JSON response");var t=e.ext[i].integrity||null;s(o=n[2]+e.ext[i].file,t)},l&&!cfg.useXhr?l(d,{method:"GET",mode:"cors"}).then(function(e){return e.json()["catch"](function(){return{}})}).then(t)["catch"](r):XMLHttpRequest&&((a=new XMLHttpRequest).open("GET",d),a.onreadystatechange=function(){if(a.readyState===XMLHttpRequest.DONE)if(200===a.status)try{t(JSON.parse(a.responseText))}catch(e){r()}else r()},a.send())):o&&r();try{h.cookie=O.cookie}catch(k){}function e(e){for(;e.length;)!function(t){h[t]=function(){var e=arguments;f||h.queue.push(function(){h[t].apply(h,e)})}}(e.pop())}var c,u,l="track",d="TrackPage",p="TrackEvent",l=(e([l+"Event",l+"PageView",l+"Exception",l+"Trace",l+"DependencyData",l+"Metric",l+"PageViewPerformance","start"+d,"stop"+d,"start"+p,"stop"+p,"addTelemetryInitializer","setAuthenticatedUserContext","clearAuthenticatedUserContext","flush"]),h.SeverityLevel={Verbose:0,Information:1,Warning:2,Error:3,Critical:4},(g.extensionConfig||{}).ApplicationInsightsAnalytics||{});return!0!==g[L]&&!0!==l[L]&&(e(["_"+(c="onerror")]),u=C[c],C[c]=function(e,t,n,i,a){var o=u&&u(e,t,n,i,a);return!0!==o&&h["_"+c]({message:e,url:t,lineNumber:n,columnNumber:i,error:a,evt:C.event}),o},g.autoExceptionInstrumented=!0),h}(cfg.cfg),(C[E]=n).queue&&0===n.queue.length?(n.queue.push(e),n.trackPageView({})):e();})({ - src: "https://js.monitor.azure.com/scripts/b/ai.3.gbl.min.js", - // name: "appInsights", // Global SDK Instance name defaults to "appInsights" when not supplied - // ld: 0, // Defines the load delay (in ms) before attempting to load the sdk. -1 = block page load and add to head. (default) = 0ms load after timeout, - // useXhr: 1, // Use XHR instead of fetch to report failures (if available), - // dle: true, // Prevent the SDK from reporting load failure log - crossOrigin: "anonymous", // When supplied this will add the provided value as the cross origin attribute on the script tag - // onInit: null, // Once the application insights instance has loaded and initialized this callback function will be called with 1 argument -- the sdk instance (DON'T ADD anything to the sdk.queue -- As they won't get called) - // sri: false, // Custom optional value to specify whether fetching the snippet from integrity file and do integrity check - cfg: { // Application Insights Configuration - connectionString: "YOUR_CONNECTION_STRING" - }}); - </script> - ``` --1. (Optional) Add or update optional [JavaScript (Web) SDK Loader Script configuration](#javascript-web-sdk-loader-script-configuration), if you need to optimize the loading of your web page or resolve loading errors. -- :::image type="content" source="media/javascript-sdk/sdk-loader-script-configuration.png" alt-text="Screenshot of the JavaScript (Web) SDK Loader Script. The parameters for configuring the JavaScript (Web) SDK Loader Script are highlighted." lightbox="media/javascript-sdk/sdk-loader-script-configuration.png"::: --#### JavaScript (Web) SDK Loader Script configuration --| Name | Type | Required? | Description -|||--| -| src | string | Required | The full URL for where to load the SDK from. This value is used for the "src" attribute of a dynamically added <script /> tag. You can use the public CDN location or your own privately hosted one. -| name | string | Optional | The global name for the initialized SDK. Use this setting if you need to initialize two different SDKs at the same time.<br><br>The default value is appInsights, so ```window.appInsights``` is a reference to the initialized instance.<br><br> Note: If you assign a name value or if a previous instance is assigned to the global name appInsightsSDK, the SDK initialization code requires it to be in the global namespace as `window.appInsightsSDK=<name value>` to ensure the correct JavaScript (Web) SDK Loader Script skeleton, and proxy methods are initialized and updated. -| ld | number in ms | Optional | Defines the load delay to wait before attempting to load the SDK. Use this setting when the HTML page is failing to load because the JavaScript (Web) SDK Loader Script is loading at the wrong time.<br><br>The default value is 0ms after timeout. If you use a negative value, the script tag is immediately added to the `<head>` region of the page and blocks the page load event until the script is loaded or fails. -| useXhr | boolean | Optional | This setting is used only for reporting SDK load failures. For example, this setting is useful when the JavaScript (Web) SDK Loader Script is preventing the HTML page from loading, causing fetch() to be unavailable.<br><br>Reporting first attempts to use fetch() if available and then fallback to XHR. Set this setting to `true` to bypass the fetch check. This setting is necessary only in environments where fetch cannot transmit failure events, for example, when the JavaScript (Web) SDK Loader Script fails to load successfully. -| crossOrigin | string | Optional | By including this setting, the script tag added to download the SDK includes the crossOrigin attribute with this string value. Use this setting when you need to provide support for CORS. When not defined (the default), no crossOrigin attribute is added. Recommended values aren't defined (the default), "", or "anonymous". For all valid values, see the [cross origin HTML attribute](https://developer.mozilla.org/docs/Web/HTML/Attributes/crossorigin) documentation. -| onInit | function(aiSdk) { ... } | Optional | This callback function is called after the main SDK script is successfully loaded and initialized from the CDN (based on the src value). This callback function is useful when you need to insert a telemetry initializer. It's passed one argument, which is a reference to the SDK instance that's being called for and is also called before the first initial page view. If the SDK has already been loaded and initialized, this callback is still called. NOTE: During the processing of the sdk.queue array, this callback is called. You CANNOT add any more items to the queue because they're ignored and dropped. (Added as part of JavaScript (Web) SDK Loader Script version 5--the sv:"5" value within the script). | -| cr | boolean | Optional | If the SDK fails to load and the endpoint value defined for `src` is the public CDN location, this configuration option attempts to immediately load the SDK from one of the following backup CDN endpoints:<ul><li>js.monitor.azure.com</li><li>js.cdn.applicationinsights.io</li><li>js.cdn.monitor.azure.com</li><li>js0.cdn.applicationinsights.io</li><li>js0.cdn.monitor.azure.com</li><li>js2.cdn.applicationinsights.io</li><li>js2.cdn.monitor.azure.com</li><li>az416426.vo.msecnd.net</li></ul>NOTE: az416426.vo.msecnd.net is partially supported, so it's not recommended.<br><br>If the SDK successfully loads from a backup CDN endpoint, it loads from the first available one, which is determined when the server performs a successful load check. If the SDK fails to load from any of the backup CDN endpoints, the SDK Failure error message appears.<br><br>When not defined, the default value is `true`. If you donΓÇÖt want to load the SDK from the backup CDN endpoints, set this configuration option to `false`.<br><br>If youΓÇÖre loading the SDK from your own privately hosted CDN endpoint, this configuration option isn't applicable. --#### [npm package](#tab/npmpackage) --1. Use the following command to install the Microsoft Application Insights JavaScript SDK - Web package. -- ```sh - npm i --save @microsoft/applicationinsights-web - ``` -- *Typings are included with this package*, so you *don't* need to install a separate typings package. --1. Add the following JavaScript to your application's code. -- Where and also how you add this JavaScript code depends on your application code. For example, you might be able to add it exactly as it appears below or you may need to create wrappers around it. - - ```js - import { ApplicationInsights } from '@microsoft/applicationinsights-web' - - const appInsights = new ApplicationInsights({ config: { - connectionString: 'YOUR_CONNECTION_STRING' - /* ...Other Configuration Options... */ - } }); - appInsights.loadAppInsights(); - appInsights.trackPageView(); - ``` ----### Paste the connection string in your environment --To paste the connection string in your environment, follow these steps: --1. Navigate to the **Overview** pane of your Application Insights resource. -1. Locate the **Connection String**. -1. Select the **Copy to clipboard** icon to copy the connection string to the clipboard. -- :::image type="content" source="media/migrate-from-instrumentation-keys-to-connection-strings/migrate-from-instrumentation-keys-to-connection-strings.png" alt-text="Screenshot that shows Application Insights overview and connection string." lightbox="media/migrate-from-instrumentation-keys-to-connection-strings/migrate-from-instrumentation-keys-to-connection-strings.png"::: --1. Replace the placeholder `"YOUR_CONNECTION_STRING"` in the JavaScript code with your [connection string](./sdk-connection-string.md) copied to the clipboard. -- The `connectionString` format must follow "InstrumentationKey=xxxx;....". If the string provided doesn't meet this format, the SDK load process fails. - - The connection string isn't considered a security token or key. For more information, see [Do new Azure regions require the use of connection strings?](./sdk-connection-string.md#do-new-azure-regions-require-the-use-of-connection-strings). --### (Optional) Add SDK configuration --The optional [SDK configuration](./javascript-sdk-configuration.md#sdk-configuration) is passed to the Application Insights JavaScript SDK during initialization. --To add SDK configuration, add each configuration option directly under `connectionString`. For example: ---### (Optional) Add advanced SDK configuration --If you want to use the extra features provided by plugins for specific frameworks and optionally enable the Click Analytics plug-in, see: --- [React plugin](javascript-framework-extensions.md?tabs=react)-- [React native plugin](javascript-framework-extensions.md?tabs=reactnative)-- [Angular plugin](javascript-framework-extensions.md?tabs=angular)--### Confirm data is flowing --1. Go to your Application Insights resource that you've enabled the SDK for. -1. In the Application Insights resource menu on the left, under **Investigate**, select the **Transaction search** pane. -1. Open the **Event types** dropdown menu and select **Select all** to clear the checkboxes in the menu. -1. From the **Event types** dropdown menu, select: -- - **Page View** for Azure Monitor Application Insights Real User Monitoring - - **Custom Event** for the Click Analytics Auto-Collection plug-in. - - It might take a few minutes for data to show up in the portal. If the only data you see showing up is a load failure exception, see [Troubleshoot SDK load failure for JavaScript web apps](/troubleshoot/azure/azure-monitor/app-insights/javascript-sdk-troubleshooting#troubleshoot-sdk-load-failure-for-javascript-web-apps). - - In some cases, if multiple instances of different versions of Application Insights are running on the same page, errors can occur during initialization. For these cases and the error message that appears, see [Running multiple versions of the Application Insights JavaScript SDK in one session](https://github.com/microsoft/ApplicationInsights-JS/blob/main/versionConflict.md). If you've encountered one of these errors, try changing the namespace by using the `name` setting. For more information, see [JavaScript (Web) SDK Loader Script configuration](#javascript-web-sdk-loader-script-configuration). - - :::image type="content" source="media/javascript-sdk/confirm-data-flowing.png" alt-text="Screenshot of the Application Insights Transaction search pane in the Azure portal with the Page View option selected. The page views are highlighted." lightbox="media/javascript-sdk/confirm-data-flowing.png"::: --1. If you want to query data to confirm data is flowing: -- 1. Select **Logs** in the left pane. - - When you select Logs, the [Queries dialog](../logs/queries.md#queries-dialog) opens, which contains sample queries relevant to your data. - - 1. Select **Run** for the sample query you want to run. - - 1. If needed, you can update the sample query or write a new query by using [Kusto Query Language (KQL)](/azure/data-explorer/kusto/query/). - - For essential KQL operators, see [Learn common KQL operators](/azure/data-explorer/kusto/query/tutorials/learn-common-operators). --## Frequently asked questions --This section provides answers to common questions. --### What are the user and session counts? --* The JavaScript SDK sets a user cookie on the web client, to identify returning users, and a session cookie to group activities. -* If there's no client-side script, you can [set cookies at the server](https://apmtips.com/posts/2016-07-09-tracking-users-in-api-apps/). -* If one real user uses your site in different browsers, or by using in-private/incognito browsing, or different machines, they're counted more than once. -* To identify a signed-in user across machines and browsers, add a call to [setAuthenticatedUserContext()](./api-custom-events-metrics.md#authenticated-users). --### What is the JavaScript SDK performance/overhead? --The Application Insights JavaScript SDK has a minimal overhead on your website. At just 36 KB gzipped, and taking only ~15 ms to initialize, the SDK adds a negligible amount of load time to your website. The minimal components of the library are quickly loaded when you use the SDK, and the full script is downloaded in the background. --Additionally, while the script is downloading from the CDN, all tracking of your page is queued, so you don't lose any telemetry during the entire life cycle of your page. This setup process provides your page with a seamless analytics system that's invisible to your users. --### What browsers are supported by the JavaScript SDK? -- | | | | | -Chrome Latest Γ£ö | Firefox Latest Γ£ö | v3.x: IE 9+ & Microsoft Edge Γ£ö<br>v2.x: IE 8+ Compatible & Microsoft Edge Γ£ö | Opera Latest Γ£ö | Safari Latest Γ£ö | --### Where can I find code examples for the JavaScript SDK? --For runnable examples, see [Application Insights JavaScript SDK samples](https://github.com/microsoft/ApplicationInsights-JS/tree/master/examples). --### What is the ES3/Internet Explorer 8 compatibility with the JavaScript SDK? --We need to take necessary measures to ensure that this SDK continues to "work" and doesn't break the JavaScript execution when loaded by an older browser. It would be ideal to not support older browsers, but numerous large customers can't control which browser their users choose to use. --This statement doesn't mean that we only support the lowest common set of features. We need to maintain ES3 code compatibility. New features need to be added in a manner that wouldn't break ES3 JavaScript parsing and added as an optional feature. --See GitHub for full details on [Internet Explorer 8 support](https://github.com/Microsoft/ApplicationInsights-JS#es3ie8-compatibility). - -### Is the JavaScript SDK open-source? --Yes, the Application Insights JavaScript SDK is open source. To view the source code or to contribute to the project, see the [official GitHub repository](https://github.com/Microsoft/ApplicationInsights-JS). - --## Support --- If you can't run the application or you aren't getting data as expected, see the dedicated [troubleshooting article](/troubleshoot/azure/azure-monitor/app-insights/javascript-sdk-troubleshooting).-- For common question about the JavaScript SDK, see the [FAQ](#frequently-asked-questions).-- For Azure support issues, open an [Azure support ticket](https://azure.microsoft.com/support/create-ticket/).-- For a list of open issues related to the Application Insights JavaScript SDK, see the [GitHub Issues Page](https://github.com/microsoft/ApplicationInsights-JS/issues).-- Use the [Telemetry Viewer extension](https://github.com/microsoft/ApplicationInsights-JS/tree/master/tools/chrome-debug-extension) to list out the individual events in the network payload and monitor the internal calls within Application Insights.--## Next steps --* [Explore Application Insights usage experiences](usage.md) -* [Track page views](api-custom-events-metrics.md#page-views) -* [Track custom events and metrics](api-custom-events-metrics.md) -* [Insert a JavaScript telemetry initializer](api-filtering-sampling.md#javascript-telemetry-initializers) -* [Add JavaScript SDK configuration](javascript-sdk-configuration.md) -* See the detailed [release notes](https://github.com/microsoft/ApplicationInsights-JS/releases) on GitHub for updates and bug fixes. -* [Query data in Log Analytics](../../azure-monitor/logs/log-query-overview.md). |
| azure-monitor | Kubernetes Codeless | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/kubernetes-codeless.md | - Title: Monitor applications on AKS with Application Insights - Azure Monitor | Microsoft Docs -description: Azure Monitor integrates seamlessly with your application running on Azure Kubernetes Service and allows you to spot the problems with your apps quickly. -- Previously updated : 02/29/2024----# Zero instrumentation application monitoring for Kubernetes - Azure Monitor Application Insights --> [!IMPORTANT] -> Currently, you can enable monitoring for your Java apps running on Azure Kubernetes Service (AKS) without instrumenting your code by using the [Java standalone agent](./opentelemetry-enable.md?tabs=java). -> While the solution to seamlessly enable application monitoring is in process for other languages, use the SDKs to monitor your apps running on AKS. Use [ASP.NET Core](./asp-net-core.md), [ASP.NET](./asp-net.md), [Node.js](./nodejs.md), [JavaScript](./javascript.md), and [Python](/previous-versions/azure/azure-monitor/app/opencensus-python). --## Application monitoring without instrumenting the code -Currently, only Java lets you enable application monitoring without instrumenting the code. To monitor applications in other languages, use the SDKs. --For a list of supported autoinstrumentation scenarios, see [Supported environments, languages, and resource providers](codeless-overview.md#supported-environments-languages-and-resource-providers). --## Java -After the Java agent is enabled, it automatically collects a multitude of requests, dependencies, logs, and metrics from the most widely used libraries and frameworks. --Follow [the detailed instructions](./opentelemetry-enable.md?tabs=java) to monitor your Java apps running in Kubernetes apps and other environments. --## Other languages --For the applications in other languages, we currently recommend using the SDKs: -* [ASP.NET Core](./asp-net-core.md) -* [ASP.NET](./asp-net.md) -* [Node.js](./nodejs.md) -* [JavaScript](./javascript.md) -* [Python](/previous-versions/azure/azure-monitor/app/opencensus-python) --## Troubleshooting --Troubleshoot the following issue. ---## Next steps --* Learn more about [Azure Monitor](../overview.md) and [Application Insights](./app-insights-overview.md). -* Get an overview of [distributed tracing](distributed-trace-data.md) and see what [Application Map](./app-map.md?tabs=net) can do for your business. |
| azure-monitor | Live Stream | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/live-stream.md | - Title: Diagnose with live metrics - Application Insights - Azure Monitor -description: Monitor your web app in real time with custom metrics, and diagnose issues with a live feed of failures, traces, and events. - Previously updated : 08/11/2023----# Live metrics: Monitor and diagnose with 1-second latency --Monitor your live, in-production web application by using live metrics (also known as QuickPulse) from [Application Insights](./app-insights-overview.md). You can select and filter metrics and performance counters to watch in real time, without any disturbance to your service. You can also inspect stack traces from sample failed requests and exceptions. Together with [Profiler](./profiler.md) and [Snapshot Debugger](./snapshot-debugger.md), live metrics provide a powerful and noninvasive diagnostic tool for your live website. --> [!NOTE] -> Live metrics only support TLS 1.2. For more information, see [Troubleshooting](#troubleshooting). --With live metrics, you can: --* Validate a fix while it's released by watching performance and failure counts. -* Watch the effect of test loads and diagnose issues live. -* Focus on particular test sessions or filter out known issues by selecting and filtering the metrics you want to watch. -* Get exception traces as they happen. -* Experiment with filters to find the most relevant KPIs. -* Monitor any Windows performance counter live. -* Easily identify a server that's having issues and filter all the KPI/live feed to just that server. ---Live metrics are currently supported for ASP.NET, ASP.NET Core, Azure Functions, Java, and Node.js apps. --> [!NOTE] -> The number of monitored server instances displayed by live metrics might be lower than the actual number of instances allocated for the application. This mismatch is because many modern web servers will unload applications that don't receive requests over a period of time to conserve resources. Because live metrics only count servers that are currently running the application, servers that have already unloaded the process won't be included in that total. --## Get started --> [!IMPORTANT] -> To enable Application Insights, ensure that it's activated in the Azure portal and your app is using a recent version of the [Azure Monitor OpenTelemetry Distro](opentelemetry-enable.md) or Classic [Application Insights](https://www.nuget.org/packages/Microsoft.ApplicationInsights.AspNetCore) NuGet package. Without the NuGet package, some telemetry is sent to Application Insights, but that telemetry won't show in the live metrics pane. --1. Follow language-specific guidelines to enable live metrics: -- # [OpenTelemetry (Recommended)](#tab/otel) -- * [ASP.NET](opentelemetry-enable.md?tabs=net): *Not supported*. - * [ASP.NET Core](opentelemetry-enable.md?tabs=aspnetcore): Enabled by default. - * [Java](./opentelemetry-enable.md?tabs=java): Enabled by default. - * [Node.js](opentelemetry-enable.md?tabs=nodejs): Enabled by default. - * [Python](opentelemetry-enable.md?tabs=python): Pass `enable_live_metrics=True` into `configure_azure_monitor`. See the [Azure Monitor OpenTelemetry Distro](https://github.com/Azure/azure-sdk-for-python/tree/main/sdk/monitor/azure-monitor-opentelemetry#usage) documentation for more information. - - # [Classic API](#tab/classic) - - * [ASP.NET](./asp-net.md): Enabled by default but can also be [enabled manually using code](asp-net.md#enable-live-metrics-by-using-code-for-any-net-application). - * [ASP.NET Core](./asp-net-core.md): Enabled by default but can also be [enabled manually using code](asp-net-core.md#enable-live-metrics-by-using-code-for-any-net-application). - * [.NET/.NET Core Console/Worker](./worker-service.md): Enabled by default. - * [Node.js](./nodejs.md#live-metrics): *Not enabled by default*. ----2. Open the Application Insights resource for your application in the [Azure portal](https://portal.azure.com). Select **Live metrics**, which is listed under **Investigate** in the left hand menu. --3. [Secure the control channel](#secure-the-control-channel) if you might use sensitive data like customer names in your filters. ---## How do live metrics differ from metrics explorer and Log Analytics? --| Capabilities |Live Stream | Metrics explorer and Log Analytics | -|||| -|Latency|Data displayed within one second.|Aggregated over minutes.| -|No retention|Data persists while it's on the chart and is then discarded.|[Data retained for 90 days.](/previous-versions/azure/azure-monitor/app/data-retention-privacy#how-long-is-the-data-kept)| -|On demand|Data is only streamed while the live metrics pane is open. |Data is sent whenever the SDK is installed and enabled.| -|Free|There's no charge for Live Stream data.|Subject to [pricing](../logs/cost-logs.md#application-insights-billing). -|Sampling|All selected metrics and counters are transmitted. Failures and stack traces are sampled. |Events can be [sampled](./api-filtering-sampling.md).| -|Control channel|Filter control signals are sent to the SDK. We recommend you secure this channel.|Communication is one way, to the portal.| --## Select and filter your metrics --These capabilities are available with ASP.NET, ASP.NET Core, and Azure Functions (v2). --You can monitor custom KPI live by applying arbitrary filters on any Application Insights telemetry from the portal. Select the filter control that shows when you mouse-over any of the charts. The following chart plots a custom **Request** count KPI with filters on **URL** and **Duration** attributes. Validate your filters with the stream preview section that shows a live feed of telemetry that matches the criteria you've specified at any point in time. ---You can monitor a value different from **Count**. The options depend on the type of stream, which could be any Application Insights telemetry like requests, dependencies, exceptions, traces, events, or metrics. It can also be your own [custom measurement](./api-custom-events-metrics.md#properties). ---Along with Application Insights telemetry, you can also monitor any Windows performance counter. Select it from the stream options and provide the name of the performance counter. --Live metrics are aggregated at two points: locally on each server and then across all servers. You can change the default at either one by selecting other options in the respective dropdown lists. --## Sample telemetry: Custom live diagnostic events -By default, the live feed of events shows samples of failed requests and dependency calls, exceptions, events, and traces. Select the filter icon to see the applied criteria at any point in time. ---As with metrics, you can specify any arbitrary criteria to any of the Application Insights telemetry types. In this example, we're selecting specific request failures and events. ---> [!NOTE] -> Currently, for exception message-based criteria, use the outermost exception message. In the preceding example, to filter out the benign exception with an inner exception message (follows the "<--" delimiter) "The client disconnected," use a message not-contains "Error reading request content" criteria. --To see the details of an item in the live feed, select it. You can pause the feed either by selecting **Pause** or by scrolling down and selecting an item. Live feed resumes after you scroll back to the top, or when you select the counter of items collected while it was paused. ---## Filter by server instance --If you want to monitor a particular server role instance, you can filter by server. To filter, select the server name under **Servers**. ---## Secure the control channel --Live metrics custom filters allow you to control which of your application's telemetry is streamed to the live metrics pane in the Azure portal. The filters criteria are sent to the apps that are instrumented with the Application Insights SDK. The filter value could potentially contain sensitive information, such as the customer ID. To keep this value secured and prevent potential disclosure to unauthorized applications, secure the live metrics channel by using [Microsoft Entra authentication](./azure-ad-authentication.md#configure-and-enable-azure-ad-based-authentication). --> [!NOTE] -> On September 30, 2025, API keys used to stream live metrics telemetry into Application Insights will be retired. After that date, applications that use API keys won't be able to send live metrics data to your Application Insights resource. Authenticated telemetry ingestion for live metrics streaming to Application Insights will need to be done with [Microsoft Entra authentication for Application Insights](./azure-ad-authentication.md). --It's possible to try custom filters without having to set up an authenticated channel. Select any of the filter icons and authorize the connected servers. If you choose this option, you have to authorize the connected servers once every new session or whenever a new server comes online. --> [!WARNING] -> We strongly discourage the use of unsecured channels and will disable this option six months after you start using it. The **Authorize connected servers** dialog displays the date after which this option will be disabled. ---## Supported features table --| Language | Basic metrics | Performance metrics | Custom filtering | Sample telemetry | CPU split by process | -|-|:--|:--|:--|:--|:| -| .NET Framework | Supported ([LTS](https://dotnet.microsoft.com/platform/support/policy/dotnet-core)) | Supported ([LTS](https://dotnet.microsoft.com/platform/support/policy/dotnet-core)) | Supported ([LTS](https://dotnet.microsoft.com/platform/support/policy/dotnet-core)) | Supported ([LTS](https://dotnet.microsoft.com/platform/support/policy/dotnet-core)) | Supported ([LTS](https://dotnet.microsoft.com/platform/support/policy/dotnet-core)) | -| .NET Core (target=.NET Framework)| Supported ([LTS](https://dotnet.microsoft.com/platform/support/policy/dotnet-core)) | Supported ([LTS](https://dotnet.microsoft.com/platform/support/policy/dotnet-core)) | Supported ([LTS](https://dotnet.microsoft.com/platform/support/policy/dotnet-core)) | Supported ([LTS](https://dotnet.microsoft.com/platform/support/policy/dotnet-core)) | Supported ([LTS](https://dotnet.microsoft.com/platform/support/policy/dotnet-core)) | -| .NET Core (target=.NET Core) | Supported ([LTS](https://dotnet.microsoft.com/platform/support/policy/dotnet-core)) | Supported* | Supported ([LTS](https://dotnet.microsoft.com/platform/support/policy/dotnet-core)) | Supported ([LTS](https://dotnet.microsoft.com/platform/support/policy/dotnet-core)) | **Not supported** | -| Azure Functions v2 | Supported | Supported | Supported | Supported | **Not supported** | -| Java | Supported (V2.0.0+) | Supported (V2.0.0+) | **Not supported** | Supported (V3.2.0+) | **Not supported** | -| Node.js | Supported (V1.3.0+) | Supported (V1.3.0+) | **Not supported** | Supported (V1.3.0+) | **Not supported** | -| Python | Supported (Distro Version 1.6.0+) | **Not supported** | **Not supported** | **Not supported** | **Not supported** | --Basic metrics include request, dependency, and exception rate. Performance metrics (performance counters) include memory and CPU. Sample telemetry shows a stream of detailed information for failed requests and dependencies, exceptions, events, and traces. -- PerfCounters support varies slightly across versions of .NET Core that don't target the .NET Framework: --- PerfCounters metrics are supported when running in Azure App Service for Windows (ASP.NET Core SDK version 2.4.1 or higher).-- PerfCounters are supported when the app is running on *any* Windows machine for apps that target .NET Core [LTS](https://dotnet.microsoft.com/platform/support/policy/dotnet-core) or higher.-- PerfCounters are supported when the app is running *anywhere* (such as Linux, Windows, app service for Linux, or containers) in the latest versions, but only for apps that target .NET Core [LTS](https://dotnet.microsoft.com/platform/support/policy/dotnet-core) or higher.--## Troubleshooting --Live metrics use different IP addresses than other Application Insights telemetry. Make sure [those IP addresses](../ip-addresses.md) are open in your firewall. Also check that [outgoing ports for live metrics](../ip-addresses.md#outgoing-ports) are open in the firewall of your servers. --As described in the [Azure TLS 1.2 migration announcement](https://azure.microsoft.com/updates/azuretls12/), live metrics now only support TLS 1.2. If you're using an older version of TLS, the live metrics pane doesn't display any data. For applications based on .NET Framework 4.5.1, see [Enable Transport Layer Security (TLS) 1.2 on clients - Configuration Manager](/mem/configmgr/core/plan-design/security/enable-tls-1-2-client#bkmk_net) to support the newer TLS version. --### Missing configuration for .NET --1. Verify that you're using the latest version of the NuGet package [Microsoft.ApplicationInsights.PerfCounterCollector](https://www.nuget.org/packages/Microsoft.ApplicationInsights.PerfCounterCollector). -1. Edit the `ApplicationInsights.config` file: - * Verify that the connection string points to the Application Insights resource you're using. - * Locate the `QuickPulseTelemetryModule` configuration option. If it isn't there, add it. - * Locate the `QuickPulseTelemetryProcessor` configuration option. If it isn't there, add it. - - ```xml - <TelemetryModules> - <Add Type="Microsoft.ApplicationInsights.Extensibility.PerfCounterCollector. - QuickPulse.QuickPulseTelemetryModule, Microsoft.AI.PerfCounterCollector"/> - </TelemetryModules> - - <TelemetryProcessors> - <Add Type="Microsoft.ApplicationInsights.Extensibility.PerfCounterCollector. - QuickPulse.QuickPulseTelemetryProcessor, Microsoft.AI.PerfCounterCollector"/> - </TelemetryProcessors> - ```` -1. Restart the application. --### "Data is temporarily inaccessible" status message --When navigating to live metrics, you may see a banner with the status message: "Data is temporarily inaccessible. The updates on our status are posted here https://aka.ms/aistatus " --Follow the link to the *Azure status* page and check if there's an activate outage affecting Application Insights. Verify that firewalls and browser extensions aren't blocking access to live metrics if an outage isn't occurring. For example, some popular ad-blocker extensions block connections to `*.monitor.azure.com`. In order to use the full capabilities of live metrics, either disable the ad-blocker extension or add an exclusion rule for the domain `*.livediagnostics.monitor.azure.com` to your ad-blocker, firewall, etc. --### Unexpected large number of requests to livediagnostics.monitor.azure.com --Application Insights SDKs use a REST API to communicate with QuickPulse endpoints, which provide live metrics for your web application. By default, the SDKs poll the endpoints once every five seconds to check if you are viewing the live metrics pane in the Azure portal. --If you open live metrics, the SDKs switch to a higher frequency mode and send new metrics to QuickPulse every second. This allows you to monitor and diagnose your live application with 1-second latency, but also generates more network traffic. To restore normal flow of traffic, naviage away from the live metrics pane. --> [!NOTE] -> The REST API calls made by the SDKs to QuickPulse endpoints are not tracked by Application Insights and do not affect your dependency calls or other metrics. However, you may see them in other network monitoring tools. --## Next steps --* [Monitor usage with Application Insights](./usage.md) -* [Use Diagnostic Search](./transaction-search-and-diagnostics.md?tabs=transaction-search) -* [Profiler](./profiler.md) -* [Snapshot Debugger](./snapshot-debugger.md) |
| azure-monitor | Migrate From Instrumentation Keys To Connection Strings | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/migrate-from-instrumentation-keys-to-connection-strings.md | - Title: Migrate from Application Insights instrumentation keys to connection strings -description: Learn the steps required to upgrade from Azure Monitor Application Insights instrumentation keys to connection strings. - Previously updated : 12/15/2023----# Migrate from Application Insights instrumentation keys to connection strings --This article walks through migrating from instrumentation keys to [connection strings](sdk-connection-string.md#overview). --## Prerequisites --- A [supported SDK version](#supported-sdk-versions)-- An existing [Application Insights resource](create-workspace-resource.md)--## Migration ---1. Go to the **Overview** pane of your Application Insights resource. --1. Find your **Connection String** displayed on the right. --1. Hover over the connection string and select the **Copy to clipboard** icon. --1. Configure the Application Insights SDK by following [How to set connection strings](sdk-connection-string.md#set-a-connection-string). --> [!IMPORTANT] -> Don't use both a connection string and an instrumentation key. The latter one set supersedes the other, and could result in telemetry not appearing on the portal. See [missing data](#missing-data). --## Migration at scale --Use environment variables to pass a connection string to the Application Insights SDK or agent. --To set a connection string via an environment variable, place the value of the connection string into an environment variable named `APPLICATIONINSIGHTS_CONNECTION_STRING`. --This process can be [automated in your Azure deployments](../../azure-resource-manager/templates/deploy-portal.md#deploy-resources-with-arm-templates-and-azure-portal). For example, the following Azure Resource Manager template shows how you can automatically include the correct connection string with an Azure App Service deployment. Be sure to include any other app settings your app requires: --```JSON -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "appServiceName": { - "type": "string", - "metadata": { - "description": "Name of the App Services resource" - } - }, - "appServiceLocation": { - "type": "string", - "metadata": { - "description": "Location to deploy the App Services resource" - } - }, - "appInsightsName": { - "type": "string", - "metadata": { - "description": "Name of the existing Application Insights resource to use with this App Service. Expected to be in the same Resource Group." - } - } - }, - "resources": [ - { - "apiVersion": "2016-03-01", - "name": "[parameters('appServiceName')]", - "type": "microsoft.web/sites", - "location": "[parameters('appServiceLocation')]", - "properties": { - "siteConfig": { - "appSettings": [ - { - "name": "APPLICATIONINSIGHTS_CONNECTION_STRING", - "value": "[reference(concat('microsoft.insights/components/', parameters('appInsightsName')), '2015-05-01').ConnectionString]" - } - ] - }, - "name": "[parameters('appServiceName')]" - } - } - ] -} --``` --## New capabilities --Connection strings provide a single configuration setting and eliminate the need for multiple proxy settings. --- **Reliability**: Connection strings make telemetry ingestion more reliable by removing dependencies on global ingestion endpoints.-- **Security**: Connection strings allow authenticated telemetry ingestion by using [Microsoft Entra authentication for Application Insights](azure-ad-authentication.md).-- **Customized endpoints (sovereign or hybrid cloud environments)**: Endpoint settings allow sending data to a specific Azure Government region. ([See examples](sdk-connection-string.md#set-a-connection-string).)-- **Privacy (regional endpoints)**: Connection strings ease privacy concerns by sending data to regional endpoints, ensuring data doesn't leave a geographic region.--## Supported SDK versions --- .NET and .NET Core v2.12.0+-- Java v2.5.1 and Java 3.0+-- JavaScript v2.3.0+-- NodeJS v1.5.0+-- Python v1.0.0+--## Troubleshooting --This section provides troubleshooting solutions. --### Alert: "Transition to using connection strings for data ingestion" --Follow the [migration steps](#migration) in this article to resolve this alert. --### Missing data --- Confirm you're using a [supported SDK version](#supported-sdk-versions). If you use Application Insights integration in another Azure product offering, check its documentation on how to properly configure a connection string.-- Confirm you aren't setting both an instrumentation key and connection string at the same time. Instrumentation key settings should be removed from your configuration.-- Confirm your connection string is exactly as provided in the Azure portal.--### Environment variables aren't working -- If you hardcode an instrumentation key in your application code, that programming might take precedence before environment variables. --## Frequently asked questions --This section provides answers to common questions. --### Where else can I find my connection string? --The connection string is also included in the Resource Manager resource properties for your Application Insights resource, under the field name `ConnectionString`. --### How does this affect autoinstrumentation? --Autoinstrumentation scenarios aren't affected. --<a name='can-i-use-azure-ad-authentication-with-autoinstrumentation'></a> --### Can I use Microsoft Entra authentication with autoinstrumentation? --You can't enable [Microsoft Entra authentication](azure-ad-authentication.md) for [autoinstrumentation](codeless-overview.md) scenarios. We have plans to address this limitation in the future. --### What's the difference between global and regional ingestion? --Global ingestion sends all telemetry data to a single endpoint, no matter where this data will be stored. Regional ingestion allows you to define specific endpoints per region for data ingestion. This capability ensures data stays within a specific region during processing and storage. --### How do connection strings affect the billing? --Billing isn't affected. --### Microsoft Q&A --Post questions to the [answers forum](/answers/topics/24223/azure-monitor.html). |
| azure-monitor | Monitor Functions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/monitor-functions.md | - Title: Monitor applications running on Azure Functions with Application Insights - Azure Monitor | Microsoft Docs -description: Azure Monitor integrates with your Azure Functions application, allowing performance monitoring and quickly identifying problems. -- Previously updated : 08/24/2024----# Monitor Azure Functions with Azure Monitor Application Insights --[Azure Functions](../../azure-functions/functions-overview.md) offers built-in integration with Application Insights to monitor functions. For languages other than .NET and .NET Core, other language-specific workers/extensions are needed to get the full benefits of distributed tracing. --Application Insights collects log, performance, and error data and automatically detects performance anomalies. Application Insights includes powerful analytics tools to help you diagnose issues and understand how your functions are used. When you have visibility into your application data, you can continually improve performance and usability. You can even use Application Insights during local function app project development. --The required Application Insights instrumentation is built into Azure Functions. All you need is a valid connection string to connect your function app to an Application Insights resource. The connection string should be added to your application settings when your function app resource is created in Azure. If your function app doesn't already have a connection string, you can set it manually. For more information, see [Monitor executions in Azure Functions](../../azure-functions/functions-monitoring.md?tabs=cmd) and [Connection strings](sdk-connection-string.md). ---For a list of supported autoinstrumentation scenarios, see [Supported environments, languages, and resource providers](codeless-overview.md#supported-environments-languages-and-resource-providers). --## Distributed tracing for Java applications --> [!Note] -> This feature used to have an 8- to 9-second cold startup implication, which has been reduced to less than 1 second. If you were an early adopter of this feature (for example, prior to February 2023), review the "Troubleshooting" section to update to the current version and benefit from the new faster startup. --To view more data from your Java-based Azure Functions applications than is [collected by default](../../azure-functions/functions-monitoring.md?tabs=cmd), enable the [Application Insights Java 3.x agent](./java-in-process-agent.md). This agent allows Application Insights to automatically collect and correlate dependencies, logs, and metrics from popular libraries and Azure Software Development Kits (SDKs). This telemetry is in addition to the request telemetry already captured by Functions. --By using the application map and having a more complete view of end-to-end transactions, you can better diagnose issues. You have a topological view of how systems interact along with data on average performance and error rates. You also have more data for end-to-end diagnostics. You can use the application map to easily find the root cause of reliability issues and performance bottlenecks on a per-request basis. --For more advanced use cases, you can modify telemetry by adding spans, updating span status, and adding span attributes. You can also send custom telemetry by using standard APIs. --### Enable distributed tracing for Java function apps --On the function app **Overview** pane, go to **Application Insights**. Under **Collection Level**, select **Recommended**. --> [!div class="mx-imgBorder"] --### Configuration --To configure this feature for an Azure Function App not on a consumption plan, add environment variables in App settings. To review available configurations, see [Configuration options: Azure Monitor Application Insights for Java](../app/java-standalone-config.md). --For Azure Functions on a consumption plan, the available configuration options are limited to APPLICATIONINSIGHTS_INSTRUMENTATION_LOGGING_LEVEL and APPLICATIONINSIGHTS_SELF_DIAGNOSTICS_LEVEL. To make additional configurations on a consumption plan Function, deploy your own agent, see [Custom Distributed Tracing Agent for Java Functions](https://github.com/Azure/azure-functions-java-worker/wiki/Distributed-Tracing-for-Java-Azure-Functions#customize-distribute-agent). --Deploying your own agent will result in a longer cold start implication for consumption plan Functions. --### Troubleshooting --Your Java functions might have slow startup times if you adopted this feature before February 2023. From the function app **Overview** pane, go to **Configuration** in the left-hand side navigation menu. Then select **Application settings** and use the following steps to fix the issue. --#### Windows --1. Check to see if the following settings exist and remove them: -- ``` - XDT_MicrosoftApplicationInsights_Java -> 1 - ApplicationInsightsAgent_EXTENSION_VERSION -> ~2 - ``` --2. Enable the latest version by adding this setting: - - ``` - APPLICATIONINSIGHTS_ENABLE_AGENT: true - ``` --#### Linux Dedicated/Premium --1. Check to see if the following settings exist and remove them: -- ``` - ApplicationInsightsAgent_EXTENSION_VERSION -> ~3 - ``` --2. Enable the latest version by adding this setting: - - ``` - APPLICATIONINSIGHTS_ENABLE_AGENT: true - ``` --> [!NOTE] -> If the latest version of the Application Insights Java agent isn't available in Azure Functions, upload it manually by following [these instructions](https://github.com/Azure/azure-functions-java-worker/wiki/Distributed-Tracing-for-Java-Azure-Functions#customize-distribute-agent). ---#### Duplicate logs --If you're using `log4j` or `logback` for console logging, distributed tracing for Java Functions creates duplicate logs. These duplicate logs are then sent to Application Insights. To avoid this behavior, use the following workarounds. --##### Log4j --Add the following filter to your log4j.xml: --```xml -<Filters> - <ThresholdFilter level="ALL" onMatch="DENY" onMismatch="NEUTRAL"/> -</Filters> -``` --Example: --```xml -<?xml version="1.0" encoding="UTF-8"?> -<Configuration status="WARN"> - <Appenders> - <Console name="Console" target="SYSTEM_OUT"> - <PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/> - <Filters> - <ThresholdFilter level="ALL" onMatch="DENY" onMismatch="NEUTRAL"/> - </Filters> - </Console> - </Appenders> - <Loggers> - <Root level="error"> - <AppenderRef ref="Console"/> - </Root> - </Loggers> -</Configuration> -``` --##### Logback --Add the following filter to your logback.xml: --```xml -<filter class="ch.qos.logback.classic.filter.ThresholdFilter"> - <level>OFF</level> -</filter> -``` --Example: --```xml -<configuration debug="true"> - <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> - <!-- encoders are by default assigned the type - ch.qos.logback.classic.encoder.PatternLayoutEncoder --> - <encoder> - <pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} -%kvp- %msg%n</pattern> - <filter class="ch.qos.logback.classic.filter.ThresholdFilter"> - <level>OFF</level> - </filter> - </encoder> - </appender> - <root level="debug"> - <appender-ref ref="STDOUT" /> - </root> -</configuration> -``` --## Distributed tracing for Node.js function apps --To view more data from your Node Azure Functions applications than is [collected by default](../../azure-functions/functions-monitoring.md#collecting-telemetry-data), instrument your Function using the [Azure Monitor OpenTelemetry Distro](./opentelemetry-enable.md?tabs=nodejs). --## Distributed tracing for Python function apps --To collect telemetry from services such as Requests, urllib3, `httpx`, PsycoPG2, and more, use the [Azure Monitor OpenTelemetry Distro](./opentelemetry-enable.md?tabs=python). Tracked incoming requests coming into your Python application hosted in Azure Functions aren't automatically correlated with telemetry being tracked within it. You can manually achieve trace correlation by extracting the TraceContext directly as follows: --<!-- TODO: Remove after Azure Functions implements this automatically --> --```python -import azure.functions as func --from azure.monitor.opentelemetry import configure_azure_monitor -from opentelemetry import trace -from opentelemetry.propagate import extract --# Configure Azure monitor collection telemetry pipeline -configure_azure_monitor() --def main(req: func.HttpRequest, context) -> func.HttpResponse: - ... - # Store current TraceContext in dictionary format - carrier = { - "traceparent": context.trace_context.Traceparent, - "tracestate": context.trace_context.Tracestate, - } - tracer = trace.get_tracer(__name__) - # Start a span using the current context - with tracer.start_as_current_span( - "http_trigger_span", - context=extract(carrier), - ): - ... -``` --## Next steps --* Read more instructions and information about [monitoring Azure Functions](../../azure-functions/functions-monitoring.md). -* Get an overview of [distributed tracing](distributed-trace-data.md). -* See what [Application Map](./app-map.md?tabs=net) can do for your business. -* Read about [requests and dependencies for Java apps](./java-in-process-agent.md). -* Learn more about [Azure Monitor](../overview.md) and [Application Insights](./app-insights-overview.md). |
| azure-monitor | Nodejs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/nodejs.md | - Title: Monitor Node.js services with Application Insights | Microsoft Docs -description: Monitor performance and diagnose problems in Node.js services with Application Insights. - Previously updated : 01/31/2024-----# Monitor your Node.js services and apps with Application Insights --[Application Insights](./app-insights-overview.md) monitors your components after deployment to discover performance and other issues. You can use Application Insights for Node.js services that are hosted in your datacenter, Azure VMs and web apps, and even in other public clouds. --To receive, store, and explore your monitoring data, include the SDK in your code. Then set up a corresponding Application Insights resource in Azure. The SDK sends data to that resource for further analysis and exploration. --The Node.js client library can automatically monitor incoming and outgoing HTTP requests, exceptions, and some system metrics. Beginning in version 0.20, the client library also can monitor some common [third-party packages](https://github.com/microsoft/node-diagnostic-channel/tree/master/src/diagnostic-channel-publishers#currently-supported-modules), like MongoDB, MySQL, and Redis. --All events related to an incoming HTTP request are correlated for faster troubleshooting. --You can use the TelemetryClient API to manually instrument and monitor more aspects of your app and system. We describe the TelemetryClient API in more detail later in this article. ---## Get started --Complete the following tasks to set up monitoring for an app or service. --### Prerequisites --Before you begin, make sure that you have an Azure subscription, or [get a new one for free][azure-free-offer]. If your organization already has an Azure subscription, an administrator can follow [these instructions][add-aad-user] to add you to it. --[azure-free-offer]: https://azure.microsoft.com/free/ -[add-aad-user]: ../../active-directory/fundamentals/add-users-azure-active-directory.md --### <a name="resource"></a> Set up an Application Insights resource --1. Sign in to the [Azure portal](https://portal.azure.com). -1. Create an [Application Insights resource](create-workspace-resource.md). ---### <a name="sdk"></a> Set up the Node.js client library --Include the SDK in your app so that it can gather data. --1. Copy your resource's connection string from your new resource. Application Insights uses the connection string to map data to your Azure resource. Before the SDK can use your connection string, you must specify the connection string in an environment variable or in your code. -- :::image type="content" source="media/migrate-from-instrumentation-keys-to-connection-strings/migrate-from-instrumentation-keys-to-connection-strings.png" alt-text="Screenshot that shows the Application Insights overview and connection string." lightbox="media/migrate-from-instrumentation-keys-to-connection-strings/migrate-from-instrumentation-keys-to-connection-strings.png"::: --1. Add the Node.js client library to your app's dependencies via `package.json`. From the root folder of your app, run: -- ```bash - npm install applicationinsights --save - ``` -- > [!NOTE] - > If you're using TypeScript, don't install separate "typings" packages. This NPM package contains built-in typings. --1. Explicitly load the library in your code. Because the SDK injects instrumentation into many other libraries, load the library as early as possible, even before other `require` statements. -- ```javascript - let appInsights = require('applicationinsights'); - ``` -1. You also can provide a connection string via the environment variable `APPLICATIONINSIGHTS_CONNECTION_STRING`, instead of passing it manually to `setup()` or `new appInsights.TelemetryClient()`. This practice lets you keep connection strings out of committed source code, and you can specify different connection strings for different environments. To manually configure, call `appInsights.setup('[your connection string]');`. -- For more configuration options, see the following sections. -- You can try the SDK without sending telemetry by setting `appInsights.defaultClient.config.disableAppInsights = true`. --1. Start automatically collecting and sending data by calling `appInsights.start();`. --> [!NOTE] -> As part of using Application Insights instrumentation, we collect and send diagnostic data to Microsoft. This data helps us run and improve Application Insights. You have the option to disable non-essential data collection. [Learn more](./statsbeat.md). --### <a name="monitor"></a> Monitor your app --The SDK automatically gathers telemetry about the Node.js runtime and some common third-party modules. Use your application to generate some of this data. --Then, in the [Azure portal](https://portal.azure.com) go to the Application Insights resource that you created earlier. In the **Overview timeline**, look for your first few data points. To see more detailed data, select different components in the charts. --To view the topology that's discovered for your app, you can use [Application Map](app-map.md). --#### No data --Because the SDK batches data for submission, there might be a delay before items appear in the portal. If you don't see data in your resource, try some of the following fixes: --* Continue to use the application. Take more actions to generate more telemetry. -* Select **Refresh** in the portal resource view. Charts periodically refresh on their own, but manually refreshing forces them to refresh immediately. -* Verify that [required outgoing ports](../ip-addresses.md) are open. -* Use [Search](./transaction-search-and-diagnostics.md?tabs=transaction-search) to look for specific events. -* Check the [FAQ][FAQ]. --## Basic usage --For out-of-the-box collection of HTTP requests, popular third-party library events, unhandled exceptions, and system metrics: --```javascript --let appInsights = require("applicationinsights"); -appInsights.setup("[your connection string]").start(); --``` --> [!NOTE] -> If the connection string is set in the environment variable `APPLICATIONINSIGHTS_CONNECTION_STRING`, `.setup()` can be called with no arguments. This makes it easy to use different connection strings for different environments. --Load the Application Insights library `require("applicationinsights")` as early as possible in your scripts before you load other packages. This step is needed so that the Application Insights library can prepare later packages for tracking. If you encounter conflicts with other libraries doing similar preparation, try loading the Application Insights library afterwards. --Because of the way JavaScript handles callbacks, more work is necessary to track a request across external dependencies and later callbacks. By default, this extra tracking is enabled. Disable it by calling `setAutoDependencyCorrelation(false)` as described in the [SDK configuration](#sdk-configuration) section. --## Migrate from versions prior to 0.22 --There are breaking changes between releases prior to version 0.22 and after. These changes are designed to bring consistency with other Application Insights SDKs and allow future extensibility. --In general, you can migrate with the following actions: --- Replace references to `appInsights.client` with `appInsights.defaultClient`.-- Replace references to `appInsights.getClient()` with `new appInsights.TelemetryClient()`.-- Replace all arguments to client.track* methods with a single object containing named properties as arguments. See your IDE's built-in type hinting or [TelemetryTypes](https://github.com/Microsoft/ApplicationInsights-node.js/tree/develop/Declarations/Contracts/TelemetryTypes) for the excepted object for each type of telemetry.--If you access SDK configuration functions without chaining them to `appInsights.setup()`, you can now find these functions at `appInsights.Configurations`. An example is `appInsights.Configuration.setAutoCollectDependencies(true)`. Review the changes to the default configuration in the next section. --## SDK configuration --The `appInsights` object provides many configuration methods. They're listed in the following snippet with their default values. --```javascript -let appInsights = require("applicationinsights"); -appInsights.setup("<connection_string>") - .setAutoDependencyCorrelation(true) - .setAutoCollectRequests(true) - .setAutoCollectPerformance(true, true) - .setAutoCollectExceptions(true) - .setAutoCollectDependencies(true) - .setAutoCollectConsole(true) - .setUseDiskRetryCaching(true) - .setSendLiveMetrics(false) - .setDistributedTracingMode(appInsights.DistributedTracingModes.AI) - .start(); -``` --To fully correlate events in a service, be sure to set `.setAutoDependencyCorrelation(true)`. With this option set, the SDK can track context across asynchronous callbacks in Node.js. --Review their descriptions in your IDE's built-in type hinting or [applicationinsights.ts](https://github.com/microsoft/ApplicationInsights-node.js/blob/develop/applicationinsights.ts) for detailed information and optional secondary arguments. --> [!NOTE] -> By default, `setAutoCollectConsole` is configured to *exclude* calls to `console.log` and other console methods. Only calls to supported third-party loggers (for example, winston and bunyan) will be collected. You can change this behavior to include calls to `console` methods by using `setAutoCollectConsole(true, true)`. --### Sampling --By default, the SDK sends all collected data to the Application Insights service. If you want to enable sampling to reduce the amount of data, set the `samplingPercentage` field on the `config` object of a client. Setting `samplingPercentage` to 100 (the default) means all data will be sent, and 0 means nothing will be sent. --If you're using automatic correlation, all data associated with a single request is included or excluded as a unit. --Add code such as the following to enable sampling: --```javascript -const appInsights = require("applicationinsights"); -appInsights.setup("<connection_string>"); -appInsights.defaultClient.config.samplingPercentage = 33; // 33% of all telemetry will be sent to Application Insights -appInsights.start(); -``` --### Multiple roles for multi-component applications --In some scenarios, your application might consist of multiple components that you want to instrument all with the same connection string. You want to still see these components as separate units in the portal, as if they were using separate connection strings. An example is separate nodes on Application Map. You need to manually configure the `RoleName` field to distinguish one component's telemetry from other components that send data to your Application Insights resource. --Use the following code to set the `RoleName` field: --```javascript -const appInsights = require("applicationinsights"); -appInsights.setup("<connection_string>"); -appInsights.defaultClient.context.tags[appInsights.defaultClient.context.keys.cloudRole] = "MyRoleName"; -appInsights.start(); -``` --### Browser SDK Loader --> [!NOTE] -> Available as a public preview. [Supplemental Terms of Use for Microsoft Azure Previews](https://azure.microsoft.com/support/legal/preview-supplemental-terms/) -- Automatic web Instrumentation can be enabled for node server via JavaScript (Web) SDK Loader Script injection by configuration. --<!-- This feature enables web instrumentation for node server. It automatically injects the [Browser SDK Loader Script](javascript-sdk.md?tabs=javascriptwebsdkloaderscript#add-the-javascript-code) into your application's HTML pages, including configuring the appropriate Connection String. --> --```javascript -let appInsights = require("applicationinsights"); -appInsights.setup("<connection_string>") - .enableWebInstrumentation(true) - .start(); -``` --or by setting environment variable `APPLICATIONINSIGHTS_WEB_INSTRUMENTATION_ENABLED = true`. --Web Instrumentation is enabled on node server responses when all of the following requirements are met: --- Response has status code `200`.-- Response method is `GET`.-- Server response has `Content-Type` html.-- Server response contains both `<head>` and `</head>` Tags.-- If response is compressed, it must have only one `Content-Encoding` type, and encoding type must be one of `gzip`, `br` or `deflate`.-- Response does not contain current /backup web Instrumentation CDN endpoints. (current and backup Web Instrumentation CDN endpoints [here](https://github.com/microsoft/ApplicationInsights-JS#active-public-cdn-endpoints))--web Instrumentation CDN endpoint can be changed by setting environment variable `APPLICATIONINSIGHTS_WEB_INSTRUMENTATION_SOURCE = "web Instrumentation CDN endpoints"`. -web Instrumentation connection string can be changed by setting environment variable `APPLICATIONINSIGHTS_WEB_INSTRUMENTATION_CONNECTION_STRING = "web Instrumentation connection string"` --> [!Note] -> Web Instrumentation may slow down server response time, especially when response size is large or response is compressed. For the case in which some middle layers are applied, it may result in web Instrumentation not working and original response will be returned. --### Automatic third-party instrumentation --To track context across asynchronous calls, some changes are required in third-party libraries, such as MongoDB and Redis. By default, Application Insights uses [`diagnostic-channel-publishers`](https://github.com/Microsoft/node-diagnostic-channel/tree/master/src/diagnostic-channel-publishers) to monkey-patch some of these libraries. This feature can be disabled by setting the `APPLICATION_INSIGHTS_NO_DIAGNOSTIC_CHANNEL` environment variable. --> [!NOTE] -> By setting that environment variable, events might not be correctly associated with the right operation. -- Individual monkey patches can be disabled by setting the `APPLICATION_INSIGHTS_NO_PATCH_MODULES` environment variable to a comma-separated list of packages to disable. For example, use `APPLICATION_INSIGHTS_NO_PATCH_MODULES=console,redis` to avoid patching the `console` and `redis` packages. --Currently, nine packages are instrumented: `bunyan`,`console`,`mongodb`,`mongodb-core`,`mysql`,`redis`,`winston`,`pg`, and `pg-pool`. For information about exactly which version of these packages are patched, see the [diagnostic-channel-publishers' README](https://github.com/Microsoft/node-diagnostic-channel/blob/master/src/diagnostic-channel-publishers/README.md). --The `bunyan`, `winston`, and `console` patches generate Application Insights trace events based on whether `setAutoCollectConsole` is enabled. The rest generates Application Insights dependency events based on whether `setAutoCollectDependencies` is enabled. --### Live metrics --To enable sending live metrics from your app to Azure, use `setSendLiveMetrics(true)`. Currently, filtering of live metrics in the portal isn't supported. --### Extended metrics --> [!NOTE] -> The ability to send extended native metrics was added in version 1.4.0. --To enable sending extended native metrics from your app to Azure, install the separate native metrics package. The SDK automatically loads when it's installed and start collecting Node.js native metrics. --```bash -npm install applicationinsights-native-metrics -``` --Currently, the native metrics package performs autocollection of garbage collection CPU time, event loop ticks, and heap usage: --- **Garbage collection**: The amount of CPU time spent on each type of garbage collection, and how many occurrences of each type.-- **Event loop**: How many ticks occurred and how much CPU time was spent in total.-- **Heap vs. non-heap**: How much of your app's memory usage is in the heap or non-heap.--### Distributed tracing modes --By default, the SDK sends headers understood by other applications or services instrumented with an Application Insights SDK. You can enable sending and receiving of [W3C Trace Context](https://github.com/w3c/trace-context) headers in addition to the existing AI headers. In this way, you won't break correlation with any of your existing legacy services. Enabling W3C headers allows your app to correlate with other services not instrumented with Application Insights but that do adopt this W3C standard. --```Javascript -const appInsights = require("applicationinsights"); -appInsights - .setup("<your connection string>") - .setDistributedTracingMode(appInsights.DistributedTracingModes.AI_AND_W3C) - .start() -``` --## TelemetryClient API --For a full description of the TelemetryClient API, see [Application Insights API for custom events and metrics](./api-custom-events-metrics.md). --You can track any request, event, metric, or exception by using the Application Insights client library for Node.js. The following code example demonstrates some of the APIs that you can use: --```javascript -let appInsights = require("applicationinsights"); -appInsights.setup().start(); // assuming connection string in env var. start() can be omitted to disable any non-custom data -let client = appInsights.defaultClient; -client.trackEvent({name: "my custom event", properties: {customProperty: "custom property value"}}); -client.trackException({exception: new Error("handled exceptions can be logged with this method")}); -client.trackMetric({name: "custom metric", value: 3}); -client.trackTrace({message: "trace message"}); -client.trackDependency({target:"http://dbname", name:"select customers proc", data:"SELECT * FROM Customers", duration:231, resultCode:0, success: true, dependencyTypeName: "ZSQL"}); -client.trackRequest({name:"GET /customers", url:"http://myserver/customers", duration:309, resultCode:200, success:true}); --let http = require("http"); -http.createServer( (req, res) => { - client.trackNodeHttpRequest({request: req, response: res}); // Place at the beginning of your request handler -}); -``` --### Track your dependencies --Use the following code to track your dependencies: --```javascript -let appInsights = require("applicationinsights"); -let client = new appInsights.TelemetryClient(); --var success = false; -let startTime = Date.now(); -// execute dependency call here.... -let duration = Date.now() - startTime; -success = true; --client.trackDependency({target:"http://dbname", name:"select customers proc", data:"SELECT * FROM Customers", duration:duration, resultCode:0, success: true, dependencyTypeName: "ZSQL"});; -``` --An example utility using `trackMetric` to measure how long event loop scheduling takes: --```javascript -function startMeasuringEventLoop() { - var startTime = process.hrtime(); - var sampleSum = 0; - var sampleCount = 0; -- // Measure event loop scheduling delay - setInterval(() => { - var elapsed = process.hrtime(startTime); - startTime = process.hrtime(); - sampleSum += elapsed[0] * 1e9 + elapsed[1]; - sampleCount++; - }, 0); -- // Report custom metric every second - setInterval(() => { - var samples = sampleSum; - var count = sampleCount; - sampleSum = 0; - sampleCount = 0; -- if (count > 0) { - var avgNs = samples / count; - var avgMs = Math.round(avgNs / 1e6); - client.trackMetric({name: "Event Loop Delay", value: avgMs}); - } - }, 1000); -} -``` --### Add a custom property to all events --Use the following code to add a custom property to all events: --```javascript -appInsights.defaultClient.commonProperties = { - environment: process.env.SOME_ENV_VARIABLE -}; -``` --### Track HTTP GET requests --Use the following code to manually track HTTP GET requests: --> [!NOTE] -> - All requests are tracked by default. To disable automatic collection, call `.setAutoCollectRequests(false)` before calling `start()`. -> - Native fetch API requests arenΓÇÖt automatically tracked by classic Application Insights; manual dependency tracking is required. --```javascript -appInsights.defaultClient.trackRequest({name:"GET /customers", url:"http://myserver/customers", duration:309, resultCode:200, success:true}); -``` --Alternatively, you can track requests by using the `trackNodeHttpRequest` method: --```javascript -var server = http.createServer((req, res) => { - if ( req.method === "GET" ) { - appInsights.defaultClient.trackNodeHttpRequest({request:req, response:res}); - } - // other work here.... - res.end(); -}); -``` --### Track server startup time --Use the following code to track server startup time: --```javascript -let start = Date.now(); -server.on("listening", () => { - let duration = Date.now() - start; - appInsights.defaultClient.trackMetric({name: "server startup time", value: duration}); -}); -``` --### Flush --By default, telemetry is buffered for 15 seconds before it's sent to the ingestion server. If your application has a short lifespan, such as a CLI tool, it might be necessary to manually flush your buffered telemetry when the application terminates by using `appInsights.defaultClient.flush()`. --If the SDK detects that your application is crashing, it calls flush for you by using `appInsights.defaultClient.flush({ isAppCrashing: true })`. With the flush option `isAppCrashing`, your application is assumed to be in an abnormal state and isn't suitable to send telemetry. Instead, the SDK saves all buffered telemetry to [persistent storage](/previous-versions/azure/azure-monitor/app/data-retention-privacy#nodejs) and lets your application terminate. When your application starts again, it tries to send any telemetry that was saved to persistent storage. --### Preprocess data with telemetry processors --You can process and filter collected data before it's sent for retention by using *telemetry processors*. Telemetry processors are called one by one in the order they were added before the telemetry item is sent to the cloud. --```javascript -public addTelemetryProcessor(telemetryProcessor: (envelope: Contracts.Envelope, context: { http.RequestOptions, http.ClientRequest, http.ClientResponse, correlationContext }) => boolean) -``` --If a telemetry processor returns `false`, that telemetry item isn't sent. --All telemetry processors receive the telemetry data and its envelope to inspect and modify. They also receive a context object. The contents of this object are defined by the `contextObjects` parameter when calling a track method for manually tracked telemetry. For automatically collected telemetry, this object is filled with available request information and the persistent request content as provided by `appInsights.getCorrelationContext()` (if automatic dependency correlation is enabled). --The TypeScript type for a telemetry processor is: --```javascript -telemetryProcessor: (envelope: ContractsModule.Contracts.Envelope, context: { http.RequestOptions, http.ClientRequest, http.ClientResponse, correlationContext }) => boolean; -``` --For example, a processor that removes stacks trace data from exceptions might be written and added as follows: --```javascript -function removeStackTraces ( envelope, context ) { - if (envelope.data.baseType === "Microsoft.ApplicationInsights.ExceptionData") { - var data = envelope.data.baseData; - if (data.exceptions && data.exceptions.length > 0) { - for (var i = 0; i < data.exceptions.length; i++) { - var exception = data.exceptions[i]; - exception.parsedStack = null; - exception.hasFullStack = false; - } - } - } - return true; -} --appInsights.defaultClient.addTelemetryProcessor(removeStackTraces); -``` --## Use multiple connection strings --You can create multiple Application Insights resources and send different data to each by using their respective connection strings. -- For example: --```javascript -let appInsights = require("applicationinsights"); --// configure auto-collection under one connection string -appInsights.setup("Connection String A").start(); --// track some events manually under another connection string -let otherClient = new appInsights.TelemetryClient("Connection String B"); -otherClient.trackEvent({name: "my custom event"}); -``` --## Advanced configuration options --The client object contains a `config` property with many optional settings for advanced scenarios. To set them, use: --```javascript -client.config.PROPERTYNAME = VALUE; -``` --These properties are client specific, so you can configure `appInsights.defaultClient` separately from clients created with `new appInsights.TelemetryClient()`. --| Property | Description | -| - || -| connectionString | An identifier for your Application Insights resource. | -| endpointUrl | The ingestion endpoint to send telemetry payloads to. | -| quickPulseHost | The Live Metrics Stream host to send live metrics telemetry to. | -| proxyHttpUrl | A proxy server for SDK HTTP traffic. (Optional. Default is pulled from `http_proxy` environment variable.) | -| proxyHttpsUrl | A proxy server for SDK HTTPS traffic. (Optional. Default is pulled from `https_proxy` environment variable.) | -| httpAgent | An http.Agent to use for SDK HTTP traffic. (Optional. Default is undefined.) | -| httpsAgent | An https.Agent to use for SDK HTTPS traffic. (Optional. Default is undefined.) | -| maxBatchSize | The maximum number of telemetry items to include in a payload to the ingestion endpoint. (Default is `250`.) | -| maxBatchIntervalMs | The maximum amount of time to wait for a payload to reach maxBatchSize. (Default is `15000`.) | -| disableAppInsights | A flag indicating if telemetry transmission is disabled. (Default is `false`.) | -| samplingPercentage | The percentage of telemetry items tracked that should be transmitted. (Default is `100`.) | -| correlationIdRetryIntervalMs | The time to wait before retrying to retrieve the ID for cross-component correlation. (Default is `30000`.) | -| correlationHeaderExcludedDomains| A list of domains to exclude from cross-component correlation header injection. (Default. See [Config.ts](https://github.com/Microsoft/ApplicationInsights-node.js/blob/develop/Library/Config.ts).)| --## Frequently asked questions --#### How can I disable telemetry correlation? --To disable telemetry correlation, use the `correlationHeaderExcludedDomains` property in configuration. For more information, see [ApplicationInsights-node.js](https://github.com/microsoft/ApplicationInsights-node.js#configuration). --## Troubleshooting --For troubleshooting information, including "no data" scenarios and customizing logs, see [Troubleshoot Application Insights monitoring of Node.js apps and services](/troubleshoot/azure/azure-monitor/app-insights/troubleshoot-app-insights-nodejs). --## Next steps --* [Monitor your telemetry in the portal](./overview-dashboard.md) -* [Write Analytics queries over your telemetry](../logs/log-analytics-tutorial.md) --<!--references--> --[FAQ]: ./app-insights-overview.md#frequently-asked-questions |
| azure-monitor | Opentelemetry Add Modify | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/opentelemetry-add-modify.md | - Title: Add, modify, and filter Azure Monitor OpenTelemetry for .NET, Java, Node.js, and Python applications -description: This article provides guidance on how to add, modify, and filter OpenTelemetry for applications using Azure Monitor. - Previously updated : 12/15/2023-# ms.devlang: csharp, javascript, typescript, python -----# Add, modify, and filter OpenTelemetry --This article provides guidance on how to add, modify, and filter OpenTelemetry for applications using [Azure Monitor Application Insights](app-insights-overview.md#application-insights-overview). --To learn more about OpenTelemetry concepts, see the [OpenTelemetry overview](opentelemetry-overview.md) or [OpenTelemetry FAQ](#frequently-asked-questions). --<!NOTE TO CONTRIBUTORS: PLEASE DO NOT SEPARATE OUT JAVASCRIPT AND TYPESCRIPT INTO DIFFERENT TABS.> --## Automatic data collection --The distros automatically collect data by bundling OpenTelemetry instrumentation libraries. --### Included instrumentation libraries --#### [ASP.NET Core](#tab/aspnetcore) --**Requests** --* [ASP.NET - Core](https://github.com/open-telemetry/opentelemetry-dotnet/blob/1.0.0-rc9.14/src/OpenTelemetry.Instrumentation.AspNetCore/README.md) ¹² --**Dependencies** --* [HttpClient](https://github.com/open-telemetry/opentelemetry-dotnet/blob/1.0.0-rc9.14/src/OpenTelemetry.Instrumentation.Http/README.md) ¹² -* [SqlClient](https://github.com/open-telemetry/opentelemetry-dotnet/blob/1.0.0-rc9.14/src/OpenTelemetry.Instrumentation.SqlClient/README.md) ¹ --**Logging** --* `ILogger` --For more information about `ILogger`, see [Logging in C# and .NET](/dotnet/core/extensions/logging) and [code examples](https://github.com/open-telemetry/opentelemetry-dotnet/tree/main/docs/logs). --#### [.NET](#tab/net) --The Azure Monitor Exporter doesn't include any instrumentation libraries. --#### [Java](#tab/java) --**Requests** --* JMS consumers -* Kafka consumers -* Netty -* Quartz -* RabbitMQ -* Servlets -* Spring scheduling --> [!NOTE] -> Servlet and Netty autoinstrumentation covers the majority of Java HTTP services, including Java EE, Jakarta EE, Spring Boot, Quarkus, and Micronaut. --**Dependencies (plus downstream distributed trace propagation)** --* Apache HttpClient -* Apache HttpAsyncClient -* AsyncHttpClient -* Google HttpClient -* gRPC -* java.net.HttpURLConnection -* Java 11 HttpClient -* JAX-RS client -* Jetty HttpClient -* JMS -* Kafka -* Netty client -* OkHttp -* RabbitMQ --**Dependencies (without downstream distributed trace propagation)** --* Cassandra -* JDBC -* MongoDB (async and sync) -* Redis (Lettuce and Jedis) --**Metrics** --* Micrometer Metrics, including Spring Boot Actuator metrics -* JMX Metrics --**Logs** --* Logback (including MDC properties) ¹ ³ -* Log4j (including MDC/Thread Context properties) ¹ ³ -* JBoss Logging (including MDC properties) ¹ ³ -* java.util.logging ¹ ³ --**Default collection** --Telemetry emitted by the following Azure SDKs is automatically collected by default: --* [Azure App Configuration](/java/api/overview/azure/data-appconfiguration-readme) 1.1.10+ -* [Azure AI Search](/java/api/overview/azure/search-documents-readme) 11.3.0+ -* [Azure Communication Chat](/java/api/overview/azure/communication-chat-readme) 1.0.0+ -* [Azure Communication Common](/java/api/overview/azure/communication-common-readme) 1.0.0+ -* [Azure Communication Identity](/java/api/overview/azure/communication-identity-readme) 1.0.0+ -* [Azure Communication Phone Numbers](/java/api/overview/azure/communication-phonenumbers-readme) 1.0.0+ -* [Azure Communication SMS](/java/api/overview/azure/communication-sms-readme) 1.0.0+ -* [Azure Cosmos DB](/java/api/overview/azure/cosmos-readme) 4.22.0+ -* [Azure Digital Twins - Core](/java/api/overview/azure/digitaltwins-core-readme) 1.1.0+ -* [Azure Event Grid](/java/api/overview/azure/messaging-eventgrid-readme) 4.0.0+ -* [Azure Event Hubs](/java/api/overview/azure/messaging-eventhubs-readme) 5.6.0+ -* [Azure Event Hubs - Azure Blob Storage Checkpoint Store](/java/api/overview/azure/messaging-eventhubs-checkpointstore-blob-readme) 1.5.1+ -* [Azure AI Document Intelligence](/java/api/overview/azure/ai-formrecognizer-readme) 3.0.6+ -* [Azure Identity](/java/api/overview/azure/identity-readme) 1.2.4+ -* [Azure Key Vault - Certificates](/java/api/overview/azure/security-keyvault-certificates-readme) 4.1.6+ -* [Azure Key Vault - Keys](/java/api/overview/azure/security-keyvault-keys-readme) 4.2.6+ -* [Azure Key Vault - Secrets](/java/api/overview/azure/security-keyvault-secrets-readme) 4.2.6+ -* [Azure Service Bus](/java/api/overview/azure/messaging-servicebus-readme) 7.1.0+ -* [Azure Storage - Blobs](/java/api/overview/azure/storage-blob-readme) 12.11.0+ -* [Azure Storage - Blobs Batch](/java/api/overview/azure/storage-blob-batch-readme) 12.9.0+ -* [Azure Storage - Blobs Cryptography](/java/api/overview/azure/storage-blob-cryptography-readme) 12.11.0+ -* [Azure Storage - Common](/java/api/overview/azure/storage-common-readme) 12.11.0+ -* [Azure Storage - Files Data Lake](/java/api/overview/azure/storage-file-datalake-readme) 12.5.0+ -* [Azure Storage - Files Shares](/java/api/overview/azure/storage-file-share-readme) 12.9.0+ -* [Azure Storage - Queues](/java/api/overview/azure/storage-queue-readme) 12.9.0+ -* [Azure Text Analytics](/java/api/overview/azure/ai-textanalytics-readme) 5.0.4+ --[//]: # "Azure Cosmos DB 4.22.0+ due to https://github.com/Azure/azure-sdk-for-java/pull/25571" --[//]: # "the remaining above names and links scraped from https://azure.github.io/azure-sdk/releases/latest/java.html" -[//]: # "and version synched manually against the oldest version in maven central built on azure-core 1.14.0" -[//]: # "" -[//]: # "var table = document.querySelector('#tg-sb-content > div > table')" -[//]: # "var str = ''" -[//]: # "for (var i = 1, row; row = table.rows[i]; i++) {" -[//]: # " var name = row.cells[0].getElementsByTagName('div')[0].textContent.trim()" -[//]: # " var stableRow = row.cells[1]" -[//]: # " var versionBadge = stableRow.querySelector('.badge')" -[//]: # " if (!versionBadge) {" -[//]: # " continue" -[//]: # " }" -[//]: # " var version = versionBadge.textContent.trim()" -[//]: # " var link = stableRow.querySelectorAll('a')[2].href" -[//]: # " str += '* [' + name + '](' + link + ') ' + version + '\n'" -[//]: # "}" -[//]: # "console.log(str)" --#### [Java native](#tab/java-native) --**Requests for Spring Boot native applications** --* Spring Web -* Spring Web MVC -* Spring WebFlux --**Dependencies for Spring Boot native applications** --* JDBC -* R2DBC -* MongoDB -* Kafka --**Metrics** --* Micrometer Metrics --**Logs for Spring Boot native applications** --* Logback --For Quartz native applications, look at the [Quarkus documentation](https://quarkus.io/guides/opentelemetry). --#### [Node.js](#tab/nodejs) --The following OpenTelemetry Instrumentation libraries are included as part of the Azure Monitor Application Insights Distro. For more information, see [Azure SDK for JavaScript](https://github.com/Azure/azure-sdk-for-js/blob/main/sdk/monitor/monitor-opentelemetry/README.md#instrumentation-libraries). --**Requests** --* [HTTP/HTTPS](https://github.com/open-telemetry/opentelemetry-js/tree/main/experimental/packages/opentelemetry-instrumentation-http)² --**Dependencies** --* [MongoDB](https://github.com/open-telemetry/opentelemetry-js-contrib/tree/main/plugins/node/opentelemetry-instrumentation-mongodb) -* [MySQL](https://github.com/open-telemetry/opentelemetry-js-contrib/tree/main/plugins/node/opentelemetry-instrumentation-mysql) -* [Postgres](https://github.com/open-telemetry/opentelemetry-js-contrib/tree/main/plugins/node/opentelemetry-instrumentation-pg) -* [Redis](https://github.com/open-telemetry/opentelemetry-js-contrib/tree/main/plugins/node/opentelemetry-instrumentation-redis) -* [Redis-4](https://github.com/open-telemetry/opentelemetry-js-contrib/tree/main/plugins/node/opentelemetry-instrumentation-redis-4) -* [Azure SDK](https://github.com/Azure/azure-sdk-for-js/tree/main/sdk/instrumentation/opentelemetry-instrumentation-azure-sdk) --**Logs** --* [Bunyan](https://github.com/open-telemetry/opentelemetry-js-contrib/tree/main/plugins/node/opentelemetry-instrumentation-bunyan) -<!-- -* [Winston](https://github.com/open-telemetry/opentelemetry-js-contrib/tree/main/plugins/node/opentelemetry-instrumentation-winston) >--Instrumentations can be configured using `AzureMonitorOpenTelemetryOptions`: --```typescript -// Import Azure Monitor OpenTelemetry -const { useAzureMonitor, AzureMonitorOpenTelemetryOptions } = require("@azure/monitor-opentelemetry"); -// Import OpenTelemetry HTTP Instrumentation to get config type -const { HttpInstrumentationConfig } = require("@azure/monitor-opentelemetry"); - // Import HTTP to get type -const { IncomingMessage } = require("http"); --// Specific Instrumentation configs could be added -const httpInstrumentationConfig: HttpInstrumentationConfig = { - ignoreIncomingRequestHook: (request: IncomingMessage) => { - return false; //Return true if you want to ignore a specific request - }, - enabled: true -}; -// Instrumentations configuration -const options: AzureMonitorOpenTelemetryOptions = { -instrumentationOptions: { - http: httpInstrumentationConfig, - azureSdk: { enabled: true }, - mongoDb: { enabled: true }, - mySql: { enabled: true }, - postgreSql: { enabled: true }, - redis: { enabled: true }, - redis4: { enabled: true }, -} -}; --// Enable Azure Monitor integration -useAzureMonitor(options); --``` --#### [Python](#tab/python) --**Requests** --* [Django](https://github.com/open-telemetry/opentelemetry-python-contrib/tree/main/instrumentation/opentelemetry-instrumentation-django) ¹ -* [FastApi](https://github.com/open-telemetry/opentelemetry-python-contrib/tree/main/instrumentation/opentelemetry-instrumentation-fastapi) ¹ -* [Flask](https://github.com/open-telemetry/opentelemetry-python-contrib/tree/main/instrumentation/opentelemetry-instrumentation-flask) ¹ --**Dependencies** --* [Psycopg2](https://github.com/open-telemetry/opentelemetry-python-contrib/tree/main/instrumentation/opentelemetry-instrumentation-psycopg2) -* [Requests](https://github.com/open-telemetry/opentelemetry-python-contrib/tree/main/instrumentation/opentelemetry-instrumentation-requests) ¹ -* [`Urllib`](https://github.com/open-telemetry/opentelemetry-python-contrib/tree/main/instrumentation/opentelemetry-instrumentation-urllib) ¹ -* [`Urllib3`](https://github.com/open-telemetry/opentelemetry-python-contrib/tree/main/instrumentation/opentelemetry-instrumentation-urllib3) ¹ --**Logs** --* [Python logging library](https://docs.python.org/3/howto/logging.html) ⁴ --Examples of using the Python logging library can be found on [GitHub](https://github.com/Azure/azure-sdk-for-python/tree/main/sdk/monitor/azure-monitor-opentelemetry/samples/logging). --Telemetry emitted by Azure SDKS is automatically [collected](https://github.com/Azure/azure-sdk-for-python/blob/main/sdk/monitor/azure-monitor-opentelemetry/README.md#officially-supported-instrumentations) by default. ----**Footnotes** --* ¹: Supports automatic reporting of *unhandled/uncaught* exceptions -* ²: Supports OpenTelemetry Metrics -* ³: By default, logging is only collected at INFO level or higher. To change this setting, see the [configuration options](./java-standalone-config.md#autocollected-logging). -* ⁴: By default, logging is only collected when that logging is performed at the WARNING level or higher. --> [!NOTE] -> The Azure Monitor OpenTelemetry Distros include custom mapping and logic to automatically emit [Application Insights standard metrics](standard-metrics.md). --> [!TIP] -> All OpenTelemetry metrics whether automatically collected from instrumentation libraries or manually collected from custom coding are currently considered Application Insights "custom metrics" for billing purposes. [Learn more](pre-aggregated-metrics-log-metrics.md#custom-metrics-dimensions-and-preaggregation). --### Add a community instrumentation library --You can collect more data automatically when you include instrumentation libraries from the OpenTelemetry community. ---#### [ASP.NET Core](#tab/aspnetcore) --To add a community library, use the `ConfigureOpenTelemetryMeterProvider` or `ConfigureOpenTelemetryTracerProvider` methods, -after adding the NuGet package for the library. --The following example demonstrates how the [Runtime Instrumentation](https://www.nuget.org/packages/OpenTelemetry.Instrumentation.Runtime) can be added to collect extra metrics: --```dotnetcli -dotnet add package OpenTelemetry.Instrumentation.Runtime -``` --```csharp -// Create a new ASP.NET Core web application builder. -var builder = WebApplication.CreateBuilder(args); --// Configure the OpenTelemetry meter provider to add runtime instrumentation. -builder.Services.ConfigureOpenTelemetryMeterProvider((sp, builder) => builder.AddRuntimeInstrumentation()); --// Add the Azure Monitor telemetry service to the application. -// This service will collect and send telemetry data to Azure Monitor. -builder.Services.AddOpenTelemetry().UseAzureMonitor(); --// Build the ASP.NET Core web application. -var app = builder.Build(); --// Start the ASP.NET Core web application. -app.Run(); -``` --#### [.NET](#tab/net) --The following example demonstrates how the [Runtime Instrumentation](https://www.nuget.org/packages/OpenTelemetry.Instrumentation.Runtime) can be added to collect extra metrics: --```csharp -// Create a new OpenTelemetry meter provider and add runtime instrumentation and the Azure Monitor metric exporter. -// It is important to keep the MetricsProvider instance active throughout the process lifetime. -var metricsProvider = Sdk.CreateMeterProviderBuilder() - .AddRuntimeInstrumentation() - .AddAzureMonitorMetricExporter(); -``` --#### [Java](#tab/java) --You can't extend the Java Distro with community instrumentation libraries. To request that we include another instrumentation library, open an issue on our GitHub page. You can find a link to our GitHub page in [Next Steps](#next-steps). --#### [Java native](#tab/java-native) --You can't use community instrumentation libraries with GraalVM Java native applications. --#### [Node.js](#tab/nodejs) --Other OpenTelemetry Instrumentations are available [here](https://github.com/open-telemetry/opentelemetry-js-contrib/tree/main/plugins/node) and could be added using TraceHandler in ApplicationInsightsClient: -- ```javascript - // Import the Azure Monitor OpenTelemetry plugin and OpenTelemetry API - const { useAzureMonitor } = require("@azure/monitor-opentelemetry"); - const { metrics, trace, ProxyTracerProvider } = require("@opentelemetry/api"); -- // Import the OpenTelemetry instrumentation registration function and Express instrumentation - const { registerInstrumentations } = require( "@opentelemetry/instrumentation"); - const { ExpressInstrumentation } = require('@opentelemetry/instrumentation-express'); -- // Get the OpenTelemetry tracer provider and meter provider - const tracerProvider = (trace.getTracerProvider() as ProxyTracerProvider).getDelegate(); - const meterProvider = metrics.getMeterProvider(); -- // Enable Azure Monitor integration - useAzureMonitor(); - - // Register the Express instrumentation - registerInstrumentations({ - // List of instrumentations to register - instrumentations: [ - new ExpressInstrumentation(), // Express instrumentation - ], - // OpenTelemetry tracer provider - tracerProvider: tracerProvider, - // OpenTelemetry meter provider - meterProvider: meterProvider - }); - ``` --#### [Python](#tab/python) --To add a community instrumentation library (not officially supported/included in Azure Monitor distro), you can instrument directly with the instrumentations. The list of community instrumentation libraries can be found [here](https://github.com/open-telemetry/opentelemetry-python-contrib/tree/main/instrumentation). --> [!NOTE] -> Instrumenting a [supported instrumentation library](.\opentelemetry-add-modify.md?tabs=python#included-instrumentation-libraries) manually with `instrument()` in conjunction with the distro `configure_azure_monitor()` is not recommended. This is not a supported scenario and you may get undesired behavior for your telemetry. --```python -# Import the `configure_azure_monitor()`, `SQLAlchemyInstrumentor`, `create_engine`, and `text` functions from the appropriate packages. -from azure.monitor.opentelemetry import configure_azure_monitor -from opentelemetry.instrumentation.sqlalchemy import SQLAlchemyInstrumentor -from sqlalchemy import create_engine, text --# Configure OpenTelemetry to use Azure Monitor. -configure_azure_monitor() --# Create a SQLAlchemy engine. -engine = create_engine("sqlite:///:memory:") --# SQLAlchemy instrumentation is not officially supported by this package, however, you can use the OpenTelemetry `instrument()` method manually in conjunction with `configure_azure_monitor()`. -SQLAlchemyInstrumentor().instrument( - engine=engine, -) --# Database calls using the SQLAlchemy library will be automatically captured. -with engine.connect() as conn: - result = conn.execute(text("select 'hello world'")) - print(result.all()) --``` ----## Collect custom telemetry --This section explains how to collect custom telemetry from your application. - -Depending on your language and signal type, there are different ways to collect custom telemetry, including: - -* OpenTelemetry API -* Language-specific logging/metrics libraries -* Application Insights [Classic API](api-custom-events-metrics.md) - -The following table represents the currently supported custom telemetry types: --| Language | Custom Events | Custom Metrics | Dependencies | Exceptions | Page Views | Requests | Traces | -|-||-|--|||-|--| -| **ASP.NET Core** | | | | | | | | -| OpenTelemetry API | | Yes | Yes | Yes | | Yes | | -| `ILogger` API | | | | | | | Yes | -| AI Classic API | | | | | | | | -| | | | | | | | | -| **Java** | | | | | | | | -| OpenTelemetry API | | Yes | Yes | Yes | | Yes | | -| Logback, `Log4j`, JUL | | | | Yes | | | Yes | -| Micrometer Metrics | | Yes | | | | | | -| AI Classic API | Yes | Yes | Yes | Yes | Yes | Yes | Yes | -| | | | | | | | | -| **Node.js** | | | | | | | | -| OpenTelemetry API | | Yes | Yes | Yes | | Yes | | -| | | | | | | | | -| **Python** | | | | | | | | -| OpenTelemetry API | | Yes | Yes | Yes | | Yes | | -| Python Logging Module | | | | | | | Yes | -| Events Extension | Yes | | | | | | Yes | --> [!NOTE] -> Application Insights Java 3.x listens for telemetry that's sent to the Application Insights [Classic API](api-custom-events-metrics.md). Similarly, Application Insights Node.js 3.x collects events created with the Application Insights [Classic API](api-custom-events-metrics.md). This makes upgrading easier and fills a gap in our custom telemetry support until all custom telemetry types are supported via the OpenTelemetry API. --### Add custom metrics --In this context, custom metrics refers to manually instrumenting your code to collect additional metrics beyond what the OpenTelemetry Instrumentation Libraries automatically collect. --The OpenTelemetry API offers six metric "instruments" to cover various metric scenarios and you need to pick the correct "Aggregation Type" when visualizing metrics in Metrics Explorer. This requirement is true when using the OpenTelemetry Metric API to send metrics and when using an instrumentation library. --The following table shows the recommended [aggregation types](../essentials/metrics-aggregation-explained.md#aggregation-types) for each of the OpenTelemetry Metric Instruments. --| OpenTelemetry Instrument | Azure Monitor Aggregation Type | -||| -| Counter | Sum | -| Asynchronous Counter | Sum | -| Histogram | Min, Max, Average, Sum, and Count | -| Asynchronous Gauge | Average | -| UpDownCounter | Sum | -| Asynchronous UpDownCounter | Sum | --> [!CAUTION] -> Aggregation types beyond what's shown in the table typically aren't meaningful. --The [OpenTelemetry Specification](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/metrics/api.md#instrument) -describes the instruments and provides examples of when you might use each one. --> [!TIP] -> The histogram is the most versatile and most closely equivalent to the Application Insights GetMetric [Classic API](api-custom-events-metrics.md). Azure Monitor currently flattens the histogram instrument into our five supported aggregation types, and support for percentiles is underway. Although less versatile, other OpenTelemetry instruments have a lesser impact on your application's performance. --#### Histogram example --##### [ASP.NET Core](#tab/aspnetcore) --Application startup must subscribe to a Meter by name: --```csharp -// Create a new ASP.NET Core web application builder. -var builder = WebApplication.CreateBuilder(args); --// Configure the OpenTelemetry meter provider to add a meter named "OTel.AzureMonitor.Demo". -builder.Services.ConfigureOpenTelemetryMeterProvider((sp, builder) => builder.AddMeter("OTel.AzureMonitor.Demo")); --// Add the Azure Monitor telemetry service to the application. -// This service will collect and send telemetry data to Azure Monitor. -builder.Services.AddOpenTelemetry().UseAzureMonitor(); --// Build the ASP.NET Core web application. -var app = builder.Build(); --// Start the ASP.NET Core web application. -app.Run(); -``` --The `Meter` must be initialized using that same name: --```csharp -// Create a new meter named "OTel.AzureMonitor.Demo". -var meter = new Meter("OTel.AzureMonitor.Demo"); --// Create a new histogram metric named "FruitSalePrice". -Histogram<long> myFruitSalePrice = meter.CreateHistogram<long>("FruitSalePrice"); --// Create a new Random object. -var rand = new Random(); --// Record a few random sale prices for apples and lemons, with different colors. -myFruitSalePrice.Record(rand.Next(1, 1000), new("name", "apple"), new("color", "red")); -myFruitSalePrice.Record(rand.Next(1, 1000), new("name", "lemon"), new("color", "yellow")); -myFruitSalePrice.Record(rand.Next(1, 1000), new("name", "lemon"), new("color", "yellow")); -myFruitSalePrice.Record(rand.Next(1, 1000), new("name", "apple"), new("color", "green")); -myFruitSalePrice.Record(rand.Next(1, 1000), new("name", "apple"), new("color", "red")); -myFruitSalePrice.Record(rand.Next(1, 1000), new("name", "lemon"), new("color", "yellow")); -``` --##### [.NET](#tab/net) --```csharp -public class Program -{ - // Create a static readonly Meter object named "OTel.AzureMonitor.Demo". - // This meter will be used to track metrics about the application. - private static readonly Meter meter = new("OTel.AzureMonitor.Demo"); -- public static void Main() - { - // Create a new MeterProvider object using the OpenTelemetry SDK. - // The MeterProvider object is responsible for managing meters and sending - // metric data to exporters. - // It is important to keep the MetricsProvider instance active - // throughout the process lifetime. - // - // The MeterProviderBuilder is configured to add a meter named - // "OTel.AzureMonitor.Demo" and an Azure Monitor metric exporter. - using var meterProvider = Sdk.CreateMeterProviderBuilder() - .AddMeter("OTel.AzureMonitor.Demo") - .AddAzureMonitorMetricExporter() - .Build(); -- // Create a new Histogram metric named "FruitSalePrice". - // This metric will track the distribution of fruit sale prices. - Histogram<long> myFruitSalePrice = meter.CreateHistogram<long>("FruitSalePrice"); -- // Create a new Random object. This object will be used to generate random sale prices. - var rand = new Random(); - - // Record a few random sale prices for apples and lemons, with different colors. - // Each record includes a timestamp, a value, and a set of attributes. - // The attributes can be used to filter and analyze the metric data. - myFruitSalePrice.Record(rand.Next(1, 1000), new("name", "apple"), new("color", "red")); - myFruitSalePrice.Record(rand.Next(1, 1000), new("name", "lemon"), new("color", "yellow")); - myFruitSalePrice.Record(rand.Next(1, 1000), new("name", "lemon"), new("color", "yellow")); - myFruitSalePrice.Record(rand.Next(1, 1000), new("name", "apple"), new("color", "green")); - myFruitSalePrice.Record(rand.Next(1, 1000), new("name", "apple"), new("color", "red")); - myFruitSalePrice.Record(rand.Next(1, 1000), new("name", "lemon"), new("color", "yellow")); -- // Display a message to the user and wait for them to press Enter. - // This allows the user to see the message and the console before the - // application exits. - System.Console.WriteLine("Press Enter key to exit."); - System.Console.ReadLine(); - } -} -``` --##### [Java](#tab/java) --```java -import io.opentelemetry.api.GlobalOpenTelemetry; -import io.opentelemetry.api.metrics.DoubleHistogram; -import io.opentelemetry.api.metrics.Meter; --public class Program { -- public static void main(String[] args) { - Meter meter = GlobalOpenTelemetry.getMeter("OTEL.AzureMonitor.Demo"); - DoubleHistogram histogram = meter.histogramBuilder("histogram").build(); - histogram.record(1.0); - histogram.record(100.0); - histogram.record(30.0); - } -} -``` --##### [Java native](#tab/java-native) --1. Inject `OpenTelemetry`: -- * **Spring** - ```java - import io.opentelemetry.api.OpenTelemetry; - - @Autowired - OpenTelemetry openTelemetry; - ``` -- * **Quarkus** - ```java - import io.opentelemetry.api.OpenTelemetry; - - @Inject - OpenTelemetry openTelemetry; - ``` ---1. Create a histogram: -- ```java - import io.opentelemetry.api.metrics.DoubleHistogram; - import io.opentelemetry.api.metrics.Meter; - - Meter meter = openTelemetry.getMeter("OTEL.AzureMonitor.Demo"); - DoubleHistogram histogram = meter.histogramBuilder("histogram").build(); - histogram.record(1.0); - histogram.record(100.0); - histogram.record(30.0); - ``` --##### [Node.js](#tab/nodejs) --```javascript -// Import the Azure Monitor OpenTelemetry plugin and OpenTelemetry API -const { useAzureMonitor } = require("@azure/monitor-opentelemetry"); -const { metrics } = require("@opentelemetry/api"); --// Enable Azure Monitor integration -useAzureMonitor(); --// Get the meter for the "testMeter" namespace -const meter = metrics.getMeter("testMeter"); --// Create a histogram metric -let histogram = meter.createHistogram("histogram"); --// Record values to the histogram metric with different tags -histogram.record(1, { "testKey": "testValue" }); -histogram.record(30, { "testKey": "testValue2" }); -histogram.record(100, { "testKey2": "testValue" }); -``` --##### [Python](#tab/python) --```python -# Import the `configure_azure_monitor()` and `metrics` functions from the appropriate packages. -from azure.monitor.opentelemetry import configure_azure_monitor -from opentelemetry import metrics --# Configure OpenTelemetry to use Azure Monitor with the specified connection string. -# Replace `<your-connection-string>` with the connection string to your Azure Monitor Application Insights resource. -configure_azure_monitor( - connection_string="<your-connection-string>", -) --# Get a meter provider and a meter with the name "otel_azure_monitor_histogram_demo". -meter = metrics.get_meter_provider().get_meter("otel_azure_monitor_histogram_demo") --# Record three values to the histogram. -histogram = meter.create_histogram("histogram") -histogram.record(1.0, {"test_key": "test_value"}) -histogram.record(100.0, {"test_key2": "test_value"}) -histogram.record(30.0, {"test_key": "test_value2"}) --# Wait for background execution. -input() -``` ----#### Counter example --##### [ASP.NET Core](#tab/aspnetcore) --Application startup must subscribe to a Meter by name: --```csharp -// Create a new ASP.NET Core web application builder. -var builder = WebApplication.CreateBuilder(args); --// Configure the OpenTelemetry meter provider to add a meter named "OTel.AzureMonitor.Demo". -builder.Services.ConfigureOpenTelemetryMeterProvider((sp, builder) => builder.AddMeter("OTel.AzureMonitor.Demo")); --// Add the Azure Monitor telemetry service to the application. -// This service will collect and send telemetry data to Azure Monitor. -builder.Services.AddOpenTelemetry().UseAzureMonitor(); --// Build the ASP.NET Core web application. -var app = builder.Build(); --// Start the ASP.NET Core web application. -app.Run(); -``` --The `Meter` must be initialized using that same name: --```csharp -// Create a new meter named "OTel.AzureMonitor.Demo". -var meter = new Meter("OTel.AzureMonitor.Demo"); --// Create a new counter metric named "MyFruitCounter". -Counter<long> myFruitCounter = meter.CreateCounter<long>("MyFruitCounter"); --// Record the number of fruits sold, grouped by name and color. -myFruitCounter.Add(1, new("name", "apple"), new("color", "red")); -myFruitCounter.Add(2, new("name", "lemon"), new("color", "yellow")); -myFruitCounter.Add(1, new("name", "lemon"), new("color", "yellow")); -myFruitCounter.Add(2, new("name", "apple"), new("color", "green")); -myFruitCounter.Add(5, new("name", "apple"), new("color", "red")); -myFruitCounter.Add(4, new("name", "lemon"), new("color", "yellow")); -``` --##### [.NET](#tab/net) --```csharp -public class Program -{ - // Create a static readonly Meter object named "OTel.AzureMonitor.Demo". - // This meter will be used to track metrics about the application. - private static readonly Meter meter = new("OTel.AzureMonitor.Demo"); -- public static void Main() - { - // Create a new MeterProvider object using the OpenTelemetry SDK. - // The MeterProvider object is responsible for managing meters and sending - // metric data to exporters. - // It is important to keep the MetricsProvider instance active - // throughout the process lifetime. - // - // The MeterProviderBuilder is configured to add a meter named - // "OTel.AzureMonitor.Demo" and an Azure Monitor metric exporter. - using var meterProvider = Sdk.CreateMeterProviderBuilder() - .AddMeter("OTel.AzureMonitor.Demo") - .AddAzureMonitorMetricExporter() - .Build(); -- // Create a new counter metric named "MyFruitCounter". - // This metric will track the number of fruits sold. - Counter<long> myFruitCounter = meter.CreateCounter<long>("MyFruitCounter"); -- // Record the number of fruits sold, grouped by name and color. - myFruitCounter.Add(1, new("name", "apple"), new("color", "red")); - myFruitCounter.Add(2, new("name", "lemon"), new("color", "yellow")); - myFruitCounter.Add(1, new("name", "lemon"), new("color", "yellow")); - myFruitCounter.Add(2, new("name", "apple"), new("color", "green")); - myFruitCounter.Add(5, new("name", "apple"), new("color", "red")); - myFruitCounter.Add(4, new("name", "lemon"), new("color", "yellow")); -- // Display a message to the user and wait for them to press Enter. - // This allows the user to see the message and the console before the - // application exits. - System.Console.WriteLine("Press Enter key to exit."); - System.Console.ReadLine(); - } -} -``` --##### [Java](#tab/java) --```Java -import io.opentelemetry.api.GlobalOpenTelemetry; -import io.opentelemetry.api.common.AttributeKey; -import io.opentelemetry.api.common.Attributes; -import io.opentelemetry.api.metrics.LongCounter; -import io.opentelemetry.api.metrics.Meter; --public class Program { -- public static void main(String[] args) { - Meter meter = GlobalOpenTelemetry.getMeter("OTEL.AzureMonitor.Demo"); -- LongCounter myFruitCounter = meter - .counterBuilder("MyFruitCounter") - .build(); -- myFruitCounter.add(1, Attributes.of(AttributeKey.stringKey("name"), "apple", AttributeKey.stringKey("color"), "red")); - myFruitCounter.add(2, Attributes.of(AttributeKey.stringKey("name"), "lemon", AttributeKey.stringKey("color"), "yellow")); - myFruitCounter.add(1, Attributes.of(AttributeKey.stringKey("name"), "lemon", AttributeKey.stringKey("color"), "yellow")); - myFruitCounter.add(2, Attributes.of(AttributeKey.stringKey("name"), "apple", AttributeKey.stringKey("color"), "green")); - myFruitCounter.add(5, Attributes.of(AttributeKey.stringKey("name"), "apple", AttributeKey.stringKey("color"), "red")); - myFruitCounter.add(4, Attributes.of(AttributeKey.stringKey("name"), "lemon", AttributeKey.stringKey("color"), "yellow")); - } -} -``` -##### [Java native](#tab/java-native) --1. Inject `OpenTelemetry`: -- * **Spring** - ```java - import io.opentelemetry.api.OpenTelemetry; - - @Autowired - OpenTelemetry openTelemetry; - ``` -- * **Quarkus** - ```java - import io.opentelemetry.api.OpenTelemetry; - - @Inject - OpenTelemetry openTelemetry; - ``` --1. Create the counter: -- ```Java - import io.opentelemetry.api.common.AttributeKey; - import io.opentelemetry.api.common.Attributes; - import io.opentelemetry.api.metrics.LongCounter; - import io.opentelemetry.api.metrics.Meter; - - - Meter meter = openTelemetry.getMeter("OTEL.AzureMonitor.Demo"); - - LongCounter myFruitCounter = meter.counterBuilder("MyFruitCounter") - .build(); - - myFruitCounter.add(1, Attributes.of(AttributeKey.stringKey("name"), "apple", AttributeKey.stringKey("color"), "red")); - myFruitCounter.add(2, Attributes.of(AttributeKey.stringKey("name"), "lemon", AttributeKey.stringKey("color"), "yellow")); - myFruitCounter.add(1, Attributes.of(AttributeKey.stringKey("name"), "lemon", AttributeKey.stringKey("color"), "yellow")); - myFruitCounter.add(2, Attributes.of(AttributeKey.stringKey("name"), "apple", AttributeKey.stringKey("color"), "green")); - myFruitCounter.add(5, Attributes.of(AttributeKey.stringKey("name"), "apple", AttributeKey.stringKey("color"), "red")); - myFruitCounter.add(4, Attributes.of(AttributeKey.stringKey("name"), "lemon", AttributeKey.stringKey("color"), "yellow")); - ``` --##### [Node.js](#tab/nodejs) --```javascript -// Import the Azure Monitor OpenTelemetry plugin and OpenTelemetry API -const { useAzureMonitor } = require("@azure/monitor-opentelemetry"); -const { metrics } = require("@opentelemetry/api"); --// Enable Azure Monitor integration -useAzureMonitor(); --// Get the meter for the "testMeter" namespace -const meter = metrics.getMeter("testMeter"); --// Create a counter metric -let counter = meter.createCounter("counter"); --// Add values to the counter metric with different tags -counter.add(1, { "testKey": "testValue" }); -counter.add(5, { "testKey2": "testValue" }); -counter.add(3, { "testKey": "testValue2" }); -``` --##### [Python](#tab/python) --```python -# Import the `configure_azure_monitor()` and `metrics` functions from the appropriate packages. -from azure.monitor.opentelemetry import configure_azure_monitor -from opentelemetry import metrics --# Configure OpenTelemetry to use Azure Monitor with the specified connection string. -# Replace `<your-connection-string>` with the connection string to your Azure Monitor Application Insights resource. -configure_azure_monitor( - connection_string="<your-connection-string>", -) -# Get a meter provider and a meter with the name "otel_azure_monitor_counter_demo". -meter = metrics.get_meter_provider().get_meter("otel_azure_monitor_counter_demo") --# Create a counter metric with the name "counter". -counter = meter.create_counter("counter") --# Add three values to the counter. -# The first argument to the `add()` method is the value to add. -# The second argument is a dictionary of dimensions. -# Dimensions are used to group related metrics together. -counter.add(1.0, {"test_key": "test_value"}) -counter.add(5.0, {"test_key2": "test_value"}) -counter.add(3.0, {"test_key": "test_value2"}) --# Wait for background execution. -input() -``` ----#### Gauge example --##### [ASP.NET Core](#tab/aspnetcore) --Application startup must subscribe to a Meter by name: --```csharp -// Create a new ASP.NET Core web application builder. -var builder = WebApplication.CreateBuilder(args); --// Configure the OpenTelemetry meter provider to add a meter named "OTel.AzureMonitor.Demo". -builder.Services.ConfigureOpenTelemetryMeterProvider((sp, builder) => builder.AddMeter("OTel.AzureMonitor.Demo")); --// Add the Azure Monitor telemetry service to the application. -// This service will collect and send telemetry data to Azure Monitor. -builder.Services.AddOpenTelemetry().UseAzureMonitor(); --// Build the ASP.NET Core web application. -var app = builder.Build(); --// Start the ASP.NET Core web application. -app.Run(); -``` --The `Meter` must be initialized using that same name: --```csharp -// Get the current process. -var process = Process.GetCurrentProcess(); --// Create a new meter named "OTel.AzureMonitor.Demo". -var meter = new Meter("OTel.AzureMonitor.Demo"); --// Create a new observable gauge metric named "Thread.State". -// This metric will track the state of each thread in the current process. -ObservableGauge<int> myObservableGauge = meter.CreateObservableGauge("Thread.State", () => GetThreadState(process)); --private static IEnumerable<Measurement<int>> GetThreadState(Process process) -{ - // Iterate over all threads in the current process. - foreach (ProcessThread thread in process.Threads) - { - // Create a measurement for each thread, including the thread state, process ID, and thread ID. - yield return new((int)thread.ThreadState, new("ProcessId", process.Id), new("ThreadId", thread.Id)); - } -} -``` --##### [.NET](#tab/net) --```csharp -public class Program -{ - // Create a static readonly Meter object named "OTel.AzureMonitor.Demo". - // This meter will be used to track metrics about the application. - private static readonly Meter meter = new("OTel.AzureMonitor.Demo"); -- public static void Main() - { - // Create a new MeterProvider object using the OpenTelemetry SDK. - // The MeterProvider object is responsible for managing meters and sending - // metric data to exporters. - // It is important to keep the MetricsProvider instance active - // throughout the process lifetime. - // - // The MeterProviderBuilder is configured to add a meter named - // "OTel.AzureMonitor.Demo" and an Azure Monitor metric exporter. - using var meterProvider = Sdk.CreateMeterProviderBuilder() - .AddMeter("OTel.AzureMonitor.Demo") - .AddAzureMonitorMetricExporter() - .Build(); -- // Get the current process. - var process = Process.GetCurrentProcess(); - - // Create a new observable gauge metric named "Thread.State". - // This metric will track the state of each thread in the current process. - ObservableGauge<int> myObservableGauge = meter.CreateObservableGauge("Thread.State", () => GetThreadState(process)); -- // Display a message to the user and wait for them to press Enter. - // This allows the user to see the message and the console before the - // application exits. - System.Console.WriteLine("Press Enter key to exit."); - System.Console.ReadLine(); - } - - private static IEnumerable<Measurement<int>> GetThreadState(Process process) - { - // Iterate over all threads in the current process. - foreach (ProcessThread thread in process.Threads) - { - // Create a measurement for each thread, including the thread state, process ID, and thread ID. - yield return new((int)thread.ThreadState, new("ProcessId", process.Id), new("ThreadId", thread.Id)); - } - } -} -``` --##### [Java](#tab/java) --```Java -import io.opentelemetry.api.GlobalOpenTelemetry; -import io.opentelemetry.api.common.AttributeKey; -import io.opentelemetry.api.common.Attributes; -import io.opentelemetry.api.metrics.Meter; --public class Program { -- public static void main(String[] args) { - Meter meter = GlobalOpenTelemetry.getMeter("OTEL.AzureMonitor.Demo"); -- meter.gaugeBuilder("gauge") - .buildWithCallback( - observableMeasurement -> { - double randomNumber = Math.floor(Math.random() * 100); - observableMeasurement.record(randomNumber, Attributes.of(AttributeKey.stringKey("testKey"), "testValue")); - }); - } -} -``` -##### [Java native](#tab/java-native) --1. Inject `OpenTelemetry`: -- * **Spring** - ```java - import io.opentelemetry.api.OpenTelemetry; - - @Autowired - OpenTelemetry openTelemetry; - ``` -- * **Quarkus** - ```java - import io.opentelemetry.api.OpenTelemetry; - - @Inject - OpenTelemetry openTelemetry; - ``` --1. Create a gauge: -- ```Java - import io.opentelemetry.api.common.AttributeKey; - import io.opentelemetry.api.common.Attributes; - import io.opentelemetry.api.metrics.Meter; - - Meter meter = openTelemetry.getMeter("OTEL.AzureMonitor.Demo"); - - meter.gaugeBuilder("gauge") - .buildWithCallback( - observableMeasurement -> { - double randomNumber = Math.floor(Math.random() * 100); - observableMeasurement.record(randomNumber, Attributes.of(AttributeKey.stringKey("testKey"), "testValue")); - }); - ``` --##### [Node.js](#tab/nodejs) --```typescript -// Import the useAzureMonitor function and the metrics module from the @azure/monitor-opentelemetry and @opentelemetry/api packages, respectively. -const { useAzureMonitor } = require("@azure/monitor-opentelemetry"); -const { metrics } = require("@opentelemetry/api"); --// Enable Azure Monitor integration. -useAzureMonitor(); --// Get the meter for the "testMeter" meter name. -const meter = metrics.getMeter("testMeter"); --// Create an observable gauge metric with the name "gauge". -let gauge = meter.createObservableGauge("gauge"); --// Add a callback to the gauge metric. The callback will be invoked periodically to generate a new value for the gauge metric. -gauge.addCallback((observableResult: ObservableResult) => { - // Generate a random number between 0 and 99. - let randomNumber = Math.floor(Math.random() * 100); -- // Set the value of the gauge metric to the random number. - observableResult.observe(randomNumber, {"testKey": "testValue"}); -}); -``` --##### [Python](#tab/python) --```python -# Import the necessary packages. -from typing import Iterable --from azure.monitor.opentelemetry import configure_azure_monitor -from opentelemetry import metrics -from opentelemetry.metrics import CallbackOptions, Observation --# Configure OpenTelemetry to use Azure Monitor with the specified connection string. -# Replace `<your-connection-string>` with the connection string to your Azure Monitor Application Insights resource. -configure_azure_monitor( - connection_string="<your-connection-string>", -) --# Get a meter provider and a meter with the name "otel_azure_monitor_gauge_demo". -meter = metrics.get_meter_provider().get_meter("otel_azure_monitor_gauge_demo") --# Define two observable gauge generators. -# The first generator yields a single observation with the value 9. -# The second generator yields a sequence of 10 observations with the value 9 and a different dimension value for each observation. -def observable_gauge_generator(options: CallbackOptions) -> Iterable[Observation]: - yield Observation(9, {"test_key": "test_value"}) --def observable_gauge_sequence(options: CallbackOptions) -> Iterable[Observation]: - observations = [] - for i in range(10): - observations.append( - Observation(9, {"test_key": i}) - ) - return observations --# Create two observable gauges using the defined generators. -gauge = meter.create_observable_gauge("gauge", [observable_gauge_generator]) -gauge2 = meter.create_observable_gauge("gauge2", [observable_gauge_sequence]) --# Wait for background execution. -input() -``` ----### Add custom exceptions --Select instrumentation libraries automatically report exceptions to Application Insights. -However, you might want to manually report exceptions beyond what instrumentation libraries report. -For instance, exceptions caught by your code aren't ordinarily reported. You might wish to report them -to draw attention in relevant experiences including the failures section and end-to-end transaction views. --#### [ASP.NET Core](#tab/aspnetcore) --* To log an Exception using an Activity: -- ```csharp - // Start a new activity named "ExceptionExample". - using (var activity = activitySource.StartActivity("ExceptionExample")) - { - // Try to execute some code. - try - { - throw new Exception("Test exception"); - } - // If an exception is thrown, catch it and set the activity status to "Error". - catch (Exception ex) - { - activity?.SetStatus(ActivityStatusCode.Error); - activity?.RecordException(ex); - } - } - ``` --* To log an Exception using `ILogger`: -- ```csharp - // Create a logger using the logger factory. The logger category name is used to filter and route log messages. - var logger = loggerFactory.CreateLogger(logCategoryName); - - // Try to execute some code. - try - { - throw new Exception("Test Exception"); - } - catch (Exception ex) - { - // Log an error message with the exception. The log level is set to "Error" and the event ID is set to 0. - // The log message includes a template and a parameter. The template will be replaced with the value of the parameter when the log message is written. - logger.Log( - logLevel: LogLevel.Error, - eventId: 0, - exception: ex, - message: "Hello {name}.", - args: new object[] { "World" }); - } - ``` --#### [.NET](#tab/net) --* To log an Exception using an Activity: -- ```csharp - // Start a new activity named "ExceptionExample". - using (var activity = activitySource.StartActivity("ExceptionExample")) - { - // Try to execute some code. - try - { - throw new Exception("Test exception"); - } - // If an exception is thrown, catch it and set the activity status to "Error". - catch (Exception ex) - { - activity?.SetStatus(ActivityStatusCode.Error); - activity?.RecordException(ex); - } - } - ``` --* To log an Exception using `ILogger`: -- ```csharp - // Create a logger using the logger factory. The logger category name is used to filter and route log messages. - var logger = loggerFactory.CreateLogger("ExceptionExample"); - - try - { - // Try to execute some code. - throw new Exception("Test Exception"); - } - catch (Exception ex) - { - // Log an error message with the exception. The log level is set to "Error" and the event ID is set to 0. - // The log message includes a template and a parameter. The template will be replaced with the value of the parameter when the log message is written. - logger.Log( - logLevel: LogLevel.Error, - eventId: 0, - exception: ex, - message: "Hello {name}.", - args: new object[] { "World" }); - } - ``` --#### [Java](#tab/java) --You can use `opentelemetry-api` to update the status of a span and record exceptions. --1. Add `opentelemetry-api-1.0.0.jar` (or later) to your application: -- ```xml - <dependency> - <groupId>io.opentelemetry</groupId> - <artifactId>opentelemetry-api</artifactId> - <version>1.0.0</version> - </dependency> - ``` --1. Set status to `error` and record an exception in your code: -- ```java - import io.opentelemetry.api.trace.Span; - import io.opentelemetry.api.trace.StatusCode; -- Span span = Span.current(); - span.setStatus(StatusCode.ERROR, "errorMessage"); - span.recordException(e); - ``` --#### [Java native](#tab/java-native) --Set status to `error` and record an exception in your code: --```java -import io.opentelemetry.api.trace.Span; -import io.opentelemetry.api.trace.StatusCode; --Span span = Span.current(); -span.setStatus(StatusCode.ERROR, "errorMessage"); -span.recordException(e); -``` --#### [Node.js](#tab/nodejs) --```javascript -// Import the Azure Monitor OpenTelemetry plugin and OpenTelemetry API -const { useAzureMonitor } = require("@azure/monitor-opentelemetry"); -const { trace } = require("@opentelemetry/api"); --// Enable Azure Monitor integration -useAzureMonitor(); --// Get the tracer for the "testTracer" namespace -const tracer = trace.getTracer("testTracer"); --// Start a span with the name "hello" -let span = tracer.startSpan("hello"); --// Try to throw an error -try{ - throw new Error("Test Error"); -} --// Catch the error and record it to the span -catch(error){ - span.recordException(error); -} -``` --#### [Python](#tab/python) --The OpenTelemetry Python SDK is implemented in such a way that exceptions thrown are automatically captured and recorded. See the following code sample for an example of this behavior: --```python -# Import the necessary packages. -from azure.monitor.opentelemetry import configure_azure_monitor -from opentelemetry import trace --# Configure OpenTelemetry to use Azure Monitor with the specified connection string. -# Replace `<your-connection-string>` with the connection string to your Azure Monitor Application Insights resource. -configure_azure_monitor( - connection_string="<your-connection-string>", -) --# Get a tracer for the current module. -tracer = trace.get_tracer("otel_azure_monitor_exception_demo") --# Exception events -try: - # Start a new span with the name "hello". - with tracer.start_as_current_span("hello") as span: - # This exception will be automatically recorded - raise Exception("Custom exception message.") -except Exception: - print("Exception raised") --``` --If you would like to record exceptions manually, you can disable that option -within the context manager and use `record_exception()` directly as shown in the following example: --```python -... -# Start a new span with the name "hello" and disable exception recording. -with tracer.start_as_current_span("hello", record_exception=False) as span: - try: - # Raise an exception. - raise Exception("Custom exception message.") - except Exception as ex: - # Manually record exception - span.record_exception(ex) -... --``` ----### Add custom spans --You might want to add a custom span in two scenarios. First, when there's a dependency request not already collected by an instrumentation library. Second, when you wish to model an application process as a span on the end-to-end transaction view. - -#### [ASP.NET Core](#tab/aspnetcore) --> [!NOTE] -> The `Activity` and `ActivitySource` classes from the `System.Diagnostics` namespace represent the OpenTelemetry concepts of `Span` and `Tracer`, respectively. You create `ActivitySource` directly by using its constructor instead of by using `TracerProvider`. Each [`ActivitySource`](https://github.com/open-telemetry/opentelemetry-dotnet/tree/main/docs/trace/customizing-the-sdk#activity-source) class must be explicitly connected to `TracerProvider` by using `AddSource()`. That's because parts of the OpenTelemetry tracing API are incorporated directly into the .NET runtime. To learn more, see [Introduction to OpenTelemetry .NET Tracing API](https://github.com/open-telemetry/opentelemetry-dotnet/blob/main/src/OpenTelemetry.Api/README.md#introduction-to-opentelemetry-net-tracing-api). ---```csharp -// Define an activity source named "ActivitySourceName". This activity source will be used to create activities for all requests to the application. -internal static readonly ActivitySource activitySource = new("ActivitySourceName"); --// Create an ASP.NET Core application builder. -var builder = WebApplication.CreateBuilder(args); --// Configure the OpenTelemetry tracer provider to add a source named "ActivitySourceName". This will ensure that all activities created by the activity source are traced. -builder.Services.ConfigureOpenTelemetryTracerProvider((sp, builder) => builder.AddSource("ActivitySourceName")); --// Add the Azure Monitor telemetry service to the application. This service will collect and send telemetry data to Azure Monitor. -builder.Services.AddOpenTelemetry().UseAzureMonitor(); --// Build the ASP.NET Core application. -var app = builder.Build(); --// Map a GET request to the root path ("/") to the specified action. -app.MapGet("/", () => -{ - // Start a new activity named "CustomActivity". This activity will be traced and the trace data will be sent to Azure Monitor. - using (var activity = activitySource.StartActivity("CustomActivity")) - { - // your code here - } -- // Return a response message. - return $"Hello World!"; -}); --// Start the ASP.NET Core application. -app.Run(); -``` --`StartActivity` defaults to `ActivityKind.Internal`, but you can provide any other `ActivityKind`. -`ActivityKind.Client`, `ActivityKind.Producer`, and `ActivityKind.Internal` are mapped to Application Insights `dependencies`. -`ActivityKind.Server` and `ActivityKind.Consumer` are mapped to Application Insights `requests`. --#### [.NET](#tab/net) --> [!NOTE] -> The `Activity` and `ActivitySource` classes from the `System.Diagnostics` namespace represent the OpenTelemetry concepts of `Span` and `Tracer`, respectively. You create `ActivitySource` directly by using its constructor instead of by using `TracerProvider`. Each [`ActivitySource`](https://github.com/open-telemetry/opentelemetry-dotnet/tree/main/docs/trace/customizing-the-sdk#activity-source) class must be explicitly connected to `TracerProvider` by using `AddSource()`. That's because parts of the OpenTelemetry tracing API are incorporated directly into the .NET runtime. To learn more, see [Introduction to OpenTelemetry .NET Tracing API](https://github.com/open-telemetry/opentelemetry-dotnet/blob/main/src/OpenTelemetry.Api/README.md#introduction-to-opentelemetry-net-tracing-api). --```csharp -// Create an OpenTelemetry tracer provider builder. -// It is important to keep the TracerProvider instance active throughout the process lifetime. -using var tracerProvider = Sdk.CreateTracerProviderBuilder() - .AddSource("ActivitySourceName") - .AddAzureMonitorTraceExporter() - .Build(); --// Create an activity source named "ActivitySourceName". -var activitySource = new ActivitySource("ActivitySourceName"); --// Start a new activity named "CustomActivity". This activity will be traced and the trace data will be sent to Azure Monitor. -using (var activity = activitySource.StartActivity("CustomActivity")) -{ - // your code here -} -``` --`StartActivity` defaults to `ActivityKind.Internal`, but you can provide any other `ActivityKind`. -`ActivityKind.Client`, `ActivityKind.Producer`, and `ActivityKind.Internal` are mapped to Application Insights `dependencies`. -`ActivityKind.Server` and `ActivityKind.Consumer` are mapped to Application Insights `requests`. --#### [Java](#tab/java) - -* **Use the OpenTelemetry annotation** -- The simplest way to add your own spans is by using OpenTelemetry's `@WithSpan` annotation. - - Spans populate the `requests` and `dependencies` tables in Application Insights. - - 1. Add `opentelemetry-instrumentation-annotations-1.32.0.jar` (or later) to your application: - - ```xml - <dependency> - <groupId>io.opentelemetry.instrumentation</groupId> - <artifactId>opentelemetry-instrumentation-annotations</artifactId> - <version>1.32.0</version> - </dependency> - ``` - - 1. Use the `@WithSpan` annotation to emit a span each time your method is executed: - - ```java - import io.opentelemetry.instrumentation.annotations.WithSpan; - - @WithSpan(value = "your span name") - public void yourMethod() { - } - ``` - - By default, the span ends up in the `dependencies` table with dependency type `InProc`. - - For methods representing a background job not captured by autoinstrumentation, we recommend applying the attribute `kind = SpanKind.SERVER` to the `@WithSpan` annotation to ensure they appear in the Application Insights `requests` table. --* **Use the OpenTelemetry API** -- If the preceding OpenTelemetry `@WithSpan` annotation doesn't meet your needs, - you can add your spans by using the OpenTelemetry API. - - 1. Add `opentelemetry-api-1.0.0.jar` (or later) to your application: - - ```xml - <dependency> - <groupId>io.opentelemetry</groupId> - <artifactId>opentelemetry-api</artifactId> - <version>1.0.0</version> - </dependency> - ``` - - 1. Use the `GlobalOpenTelemetry` class to create a `Tracer`: - - ```java - import io.opentelemetry.api.GlobalOpenTelemetry; - import io.opentelemetry.api.trace.Tracer; - - static final Tracer tracer = GlobalOpenTelemetry.getTracer("com.example"); - ``` - - 1. Create a span, make it current, and then end it: - - ```java - Span span = tracer.spanBuilder("my first span").startSpan(); - try (Scope ignored = span.makeCurrent()) { - // do stuff within the context of this - } catch (Throwable t) { - span.recordException(t); - } finally { - span.end(); - } - ``` --#### [Java native](#tab/java-native) --1. Inject `OpenTelemetry`: -- * **Spring** - ```java - import io.opentelemetry.api.OpenTelemetry; - - @Autowired - OpenTelemetry openTelemetry; - ``` - - * **Quarkus** - ```java - import io.opentelemetry.api.OpenTelemetry; -- @Inject - OpenTelemetry openTelemetry; - ``` --1. Create a `Tracer`: -- ```java - import io.opentelemetry.api.trace.Tracer; -- static final Tracer tracer = openTelemetry.getTracer("com.example"); - ``` --1. Create a span, make it current, and then end it: -- ```java - Span span = tracer.spanBuilder("my first span").startSpan(); - try (Scope ignored = span.makeCurrent()) { - // do stuff within the context of this - } catch (Throwable t) { - span.recordException(t); - } finally { - span.end(); - } - ``` --#### [Node.js](#tab/nodejs) --```javascript -// Import the Azure Monitor OpenTelemetry plugin and OpenTelemetry API -const { useAzureMonitor } = require("@azure/monitor-opentelemetry"); -const { trace } = require("@opentelemetry/api"); --// Enable Azure Monitor integration -useAzureMonitor(); --// Get the tracer for the "testTracer" namespace -const tracer = trace.getTracer("testTracer"); --// Start a span with the name "hello" -let span = tracer.startSpan("hello"); --// End the span -span.end(); -``` --#### [Python](#tab/python) --The OpenTelemetry API can be used to add your own spans, which appear in the `requests` and `dependencies` tables in Application Insights. --The code example shows how to use the `tracer.start_as_current_span()` method to start, make the span current, and end the span within its context. --```python -... -# Import the necessary packages. -from opentelemetry import trace --# Get a tracer for the current module. -tracer = trace.get_tracer(__name__) --# Start a new span with the name "my first span" and make it the current span. -# The "with" context manager starts, makes the span current, and ends the span within it's context -with tracer.start_as_current_span("my first span") as span: - try: - # Do stuff within the context of this span. - # All telemetry generated within this scope will be attributed to this span. - except Exception as ex: - # Record the exception on the span. - span.record_exception(ex) -... --``` --By default, the span is in the `dependencies` table with a dependency type of `InProc`. --If your method represents a background job not already captured by autoinstrumentation, we recommend setting the attribute `kind = SpanKind.SERVER` to ensure it appears in the Application Insights `requests` table. --```python -... -# Import the necessary packages. -from opentelemetry import trace -from opentelemetry.trace import SpanKind --# Get a tracer for the current module. -tracer = trace.get_tracer(__name__) --# Start a new span with the name "my request span" and the kind set to SpanKind.SERVER. -with tracer.start_as_current_span("my request span", kind=SpanKind.SERVER) as span: - # Do stuff within the context of this span. -... -``` ----<!-- --### Add Custom Events --#### Span Events --The OpenTelemetry Logs/Events API is still under development. In the meantime, you can use the OpenTelemetry Span API to create "Span Events", which populate the traces table in Application Insights. The string passed in to addEvent() is saved to the message field within the trace. --> [!CAUTION] -> Span Events are only recommended for when you need additional diagnostic metadata associated with your span. For other scenarios, such as describing business events, we recommend you wait for the release of the OpenTelemetry Events API. --#### [ASP.NET Core](#tab/aspnetcore) - -Currently unavailable. - -#### [.NET](#tab/net) --Currently unavailable. --#### [Java](#tab/java) --You can use `opentelemetry-api` to create span events, which populate the `traces` table in Application Insights. The string passed in to `addEvent()` is saved to the `message` field within the trace. --1. Add `opentelemetry-api-1.0.0.jar` (or later) to your application: -- ```xml - <dependency> - <groupId>io.opentelemetry</groupId> - <artifactId>opentelemetry-api</artifactId> - <version>1.0.0</version> - </dependency> - ``` --1. Add span events in your code: -- ```java - import io.opentelemetry.api.trace.Span; -- Span.current().addEvent("eventName"); - ``` --#### [Java native](#tab/java-native) --You can use OpenTelemetry API to create span events, which populate the `traces` table in Application Insights. The string passed in to `addEvent()` is saved to the `message` field within the trace. --Add span events in your code: -- ```java - import io.opentelemetry.api.trace.Span; -- Span.current().addEvent("eventName"); - ``` --#### [Node.js](#tab/nodejs) --Currently unavailable. - -#### [Python](#tab/python) --Currently unavailable. --->- -### Send custom telemetry using the Application Insights Classic API --We recommend you use the OpenTelemetry APIs whenever possible, but there might be some scenarios when you have to use the Application Insights [Classic API](api-custom-events-metrics.md). - -#### [ASP.NET Core](#tab/aspnetcore) - -**Events** --1. Add `Microsoft.ApplicationInsights` to your application. --1. Create a `TelemetryClient` instance: -- > [!NOTE] - > It's important to only create once instance of the TelemetryClient per application. - - ```csharp - var telemetryConfiguration = new TelemetryConfiguration { ConnectionString = "" }; - var telemetryClient = new TelemetryClient(telemetryConfiguration); - ``` --1. Use the client to send custom telemetry: -- ```csharp - telemetryClient.TrackEvent("testEvent"); - ``` --#### [.NET](#tab/net) --**Events** --1. Add `Microsoft.ApplicationInsights` to your application. --1. Create a `TelemetryClient` instance: -- > [!NOTE] - > It's important to only create once instance of the TelemetryClient per application. - - ```csharp - var telemetryConfiguration = new TelemetryConfiguration { ConnectionString = "" }; - var telemetryClient = new TelemetryClient(telemetryConfiguration); - ``` --1. Use the client to send custom telemetry: -- ```csharp - telemetryClient.TrackEvent("testEvent"); - ``` --#### [Java](#tab/java) --1. Add `applicationinsights-core` to your application: -- ```xml - <dependency> - <groupId>com.microsoft.azure</groupId> - <artifactId>applicationinsights-core</artifactId> - <version>3.4.18</version> - </dependency> - ``` --1. Create a `TelemetryClient` instance: - - ```java - static final TelemetryClient telemetryClient = new TelemetryClient(); - ``` --1. Use the client to send custom telemetry: -- **Events** - - ```java - telemetryClient.trackEvent("WinGame"); - ``` -- **Logs** - - ```java - telemetryClient.trackTrace(message, SeverityLevel.Warning, properties); - ``` -- **Metrics** - - ```java - telemetryClient.trackMetric("queueLength", 42.0); - ``` -- **Dependencies** - - ```java - boolean success = false; - long startTime = System.currentTimeMillis(); - try { - success = dependency.call(); - } finally { - long endTime = System.currentTimeMillis(); - RemoteDependencyTelemetry telemetry = new RemoteDependencyTelemetry(); - telemetry.setSuccess(success); - telemetry.setTimestamp(new Date(startTime)); - telemetry.setDuration(new Duration(endTime - startTime)); - telemetryClient.trackDependency(telemetry); - } - ``` -- **Exceptions** - - ```java - try { - ... - } catch (Exception e) { - telemetryClient.trackException(e); - } ---#### [Java native](#tab/java-native) --It's not possible to send custom telemetry using the Application Insights Classic API in Java native. --#### [Node.js](#tab/nodejs) --If you want to add custom events or access the Application Insights API, replace the @azure/monitor-opentelemetry package with the `applicationinsights` [v3 Beta package](https://www.npmjs.com/package/applicationinsights/v/beta). It offers the same methods and interfaces, and all sample code for @azure/monitor-opentelemetry applies to the v3 Beta package. --You need to use the `applicationinsights` v3 Beta package to send custom telemetry using the Application Insights classic API. (https://www.npmjs.com/package/applicationinsights/v/beta) --```javascript -// Import the TelemetryClient class from the Application Insights SDK for JavaScript. -const { TelemetryClient } = require("applicationinsights"); --// Create a new TelemetryClient instance. -const telemetryClient = new TelemetryClient(); -``` --Then use the `TelemetryClient` to send custom telemetry: --**Events** --```javascript -// Create an event telemetry object. -let eventTelemetry = { - name: "testEvent" -}; --// Send the event telemetry object to Azure Monitor Application Insights. -telemetryClient.trackEvent(eventTelemetry); -``` --**Logs** --```javascript -// Create a trace telemetry object. -let traceTelemetry = { - message: "testMessage", - severity: "Information" -}; --// Send the trace telemetry object to Azure Monitor Application Insights. -telemetryClient.trackTrace(traceTelemetry); -``` --**Exceptions** --```javascript -// Try to execute a block of code. -try { - ... -} --// If an error occurs, catch it and send it to Azure Monitor Application Insights as an exception telemetry item. -catch (error) { - let exceptionTelemetry = { - exception: error, - severity: "Critical" - }; - telemetryClient.trackException(exceptionTelemetry); -} -``` --#### [Python](#tab/python) - -Unlike other languages, Python doesn't have an Application Insights SDK. You can meet all your monitoring needs with the Azure Monitor OpenTelemetry Distro, except for sending `customEvents`. Until the OpenTelemetry Events API stabilizes, use the [Azure Monitor Events Extension](https://pypi.org/project/azure-monitor-events-extension/0.1.0/) with the Azure Monitor OpenTelemetry Distro to send `customEvents` to Application Insights. --Install the distro and the extension: --```console -pip install azure-monitor-opentelemetry -pip install azure-monitor-events-extension -``` --Use the `track_event` API offered in the extension to send customEvents: --```python -... -from azure.monitor.events.extension import track_event -from azure.monitor.opentelemetry import configure_azure_monitor --configure_azure_monitor() --# Use the track_event() api to send custom event telemetry -# Takes event name and custom dimensions -track_event("Test event", {"key1": "value1", "key2": "value2"}) --input() -... -``` ----## Modify telemetry --This section explains how to modify telemetry. --### Add span attributes --These attributes might include adding a custom property to your telemetry. You might also use attributes to set optional fields in the Application Insights schema, like Client IP. --#### Add a custom property to a Span --Any [attributes](#add-span-attributes) you add to spans are exported as custom properties. They populate the *customDimensions* field in the requests, dependencies, traces, or exceptions table. --##### [ASP.NET Core](#tab/aspnetcore) --To add span attributes, use either of the following two ways: --* Use options provided by [instrumentation libraries](opentelemetry-enable.md#install-the-client-library). -* Add a custom span processor. --> [!TIP] -> The advantage of using options provided by instrumentation libraries, when they're available, is that the entire context is available. As a result, users can select to add or filter more attributes. For example, the enrich option in the HttpClient instrumentation library gives users access to the [HttpRequestMessage](/dotnet/api/system.net.http.httprequestmessage) and the [HttpResponseMessage](/dotnet/api/system.net.http.httpresponsemessage) itself. They can select anything from it and store it as an attribute. --1. Many instrumentation libraries provide an enrich option. For guidance, see the readme files of individual instrumentation libraries: -- * [ASP.NET Core](https://github.com/open-telemetry/opentelemetry-dotnet/blob/1.0.0-rc9.14/src/OpenTelemetry.Instrumentation.AspNetCore/README.md#enrich) - * [HttpClient](https://github.com/open-telemetry/opentelemetry-dotnet/blob/1.0.0-rc9.14/src/OpenTelemetry.Instrumentation.Http/README.md#enrich) --1. Use a custom processor: -- > [!TIP] - > Add the processor shown here *before* adding Azure Monitor. - - ```csharp - // Create an ASP.NET Core application builder. - var builder = WebApplication.CreateBuilder(args); - - // Configure the OpenTelemetry tracer provider to add a new processor named ActivityEnrichingProcessor. - builder.Services.ConfigureOpenTelemetryTracerProvider((sp, builder) => builder.AddProcessor(new ActivityEnrichingProcessor())); - - // Add the Azure Monitor telemetry service to the application. This service will collect and send telemetry data to Azure Monitor. - builder.Services.AddOpenTelemetry().UseAzureMonitor(); - - // Build the ASP.NET Core application. - var app = builder.Build(); - - // Start the ASP.NET Core application. - app.Run(); - ``` - - Add `ActivityEnrichingProcessor.cs` to your project with the following code: - - ```csharp - public class ActivityEnrichingProcessor : BaseProcessor<Activity> - { - public override void OnEnd(Activity activity) - { - // The updated activity will be available to all processors which are called after this processor. - activity.DisplayName = "Updated-" + activity.DisplayName; - activity.SetTag("CustomDimension1", "Value1"); - activity.SetTag("CustomDimension2", "Value2"); - } - } - ``` --##### [.NET](#tab/net) --To add span attributes, use either of the following two ways: --* Use options provided by instrumentation libraries. -* Add a custom span processor. --> [!TIP] -> The advantage of using options provided by instrumentation libraries, when they're available, is that the entire context is available. As a result, users can select to add or filter more attributes. For example, the enrich option in the HttpClient instrumentation library gives users access to the httpRequestMessage itself. They can select anything from it and store it as an attribute. --1. Many instrumentation libraries provide an enrich option. For guidance, see the readme files of individual instrumentation libraries: -- * [ASP.NET](https://github.com/open-telemetry/opentelemetry-dotnet-contrib/blob/Instrumentation.AspNet-1.0.0-rc9.8/src/OpenTelemetry.Instrumentation.AspNet/README.md#enrich) - * [ASP.NET Core](https://github.com/open-telemetry/opentelemetry-dotnet/blob/1.0.0-rc9.14/src/OpenTelemetry.Instrumentation.AspNetCore/README.md#enrich) - * [HttpClient](https://github.com/open-telemetry/opentelemetry-dotnet/blob/1.0.0-rc9.14/src/OpenTelemetry.Instrumentation.Http/README.md#enrich) --1. Use a custom processor: -- > [!TIP] - > Add the processor shown here *before* the Azure Monitor Exporter. - - ```csharp - // Create an OpenTelemetry tracer provider builder. - // It is important to keep the TracerProvider instance active throughout the process lifetime. - using var tracerProvider = Sdk.CreateTracerProviderBuilder() - // Add a source named "OTel.AzureMonitor.Demo". - .AddSource("OTel.AzureMonitor.Demo") // Add a new processor named ActivityEnrichingProcessor. - .AddProcessor(new ActivityEnrichingProcessor()) // Add the Azure Monitor trace exporter. - .AddAzureMonitorTraceExporter() // Add the Azure Monitor trace exporter. - .Build(); - ``` - - Add `ActivityEnrichingProcessor.cs` to your project with the following code: - - ```csharp - public class ActivityEnrichingProcessor : BaseProcessor<Activity> - { - // The OnEnd method is called when an activity is finished. This is the ideal place to enrich the activity with additional data. - public override void OnEnd(Activity activity) - { - // Update the activity's display name. - // The updated activity will be available to all processors which are called after this processor. - activity.DisplayName = "Updated-" + activity.DisplayName; - // Set custom tags on the activity. - activity.SetTag("CustomDimension1", "Value1"); - activity.SetTag("CustomDimension2", "Value2"); - } - } - ``` --##### [Java](#tab/java) --You can use `opentelemetry-api` to add attributes to spans. --Adding one or more span attributes populates the `customDimensions` field in the `requests`, `dependencies`, `traces`, or `exceptions` table. --1. Add `opentelemetry-api-1.0.0.jar` (or later) to your application: -- ```xml - <dependency> - <groupId>io.opentelemetry</groupId> - <artifactId>opentelemetry-api</artifactId> - <version>1.0.0</version> - </dependency> - ``` --1. Add custom dimensions in your code: -- ```java - import io.opentelemetry.api.trace.Span; - import io.opentelemetry.api.common.AttributeKey; - - AttributeKey attributeKey = AttributeKey.stringKey("mycustomdimension"); - Span.current().setAttribute(attributeKey, "myvalue1"); - ``` --##### [Java native](#tab/java-native) --Add custom dimensions in your code: --```java -import io.opentelemetry.api.trace.Span; -import io.opentelemetry.api.common.AttributeKey; --AttributeKey attributeKey = AttributeKey.stringKey("mycustomdimension"); -Span.current().setAttribute(attributeKey, "myvalue1"); -``` --##### [Node.js](#tab/nodejs) --```typescript -// Import the necessary packages. -const { useAzureMonitor } = require("@azure/monitor-opentelemetry"); -const { ReadableSpan, Span, SpanProcessor } = require("@opentelemetry/sdk-trace-base"); -const { SemanticAttributes } = require("@opentelemetry/semantic-conventions"); --// Create a new SpanEnrichingProcessor class. -class SpanEnrichingProcessor implements SpanProcessor { - forceFlush(): Promise<void> { - return Promise.resolve(); - } -- shutdown(): Promise<void> { - return Promise.resolve(); - } -- onStart(_span: Span): void {} -- onEnd(span: ReadableSpan) { - // Add custom dimensions to the span. - span.attributes["CustomDimension1"] = "value1"; - span.attributes["CustomDimension2"] = "value2"; - } -} --// Enable Azure Monitor integration. -const options: AzureMonitorOpenTelemetryOptions = { - // Add the SpanEnrichingProcessor - spanProcessors: [new SpanEnrichingProcessor()] -} -useAzureMonitor(options); --``` --##### [Python](#tab/python) --Use a custom processor: --```python -... -# Import the necessary packages. -from azure.monitor.opentelemetry import configure_azure_monitor -from opentelemetry import trace --# Create a SpanEnrichingProcessor instance. -span_enrich_processor = SpanEnrichingProcessor() --# Configure OpenTelemetry to use Azure Monitor with the specified connection string. -# Replace `<your-connection-string>` with the connection string to your Azure Monitor Application Insights resource. -configure_azure_monitor( - connection_string="<your-connection-string>", - # Configure the custom span processors to include span enrich processor. - span_processors=[span_enrich_processor], -) --... -``` --Add `SpanEnrichingProcessor` to your project with the following code: --```python -# Import the SpanProcessor class from the opentelemetry.sdk.trace module. -from opentelemetry.sdk.trace import SpanProcessor --class SpanEnrichingProcessor(SpanProcessor): -- def on_end(self, span): - # Prefix the span name with the string "Updated-". - span._name = "Updated-" + span.name - # Add the custom dimension "CustomDimension1" with the value "Value1". - span._attributes["CustomDimension1"] = "Value1" - # Add the custom dimension "CustomDimension2" with the value "Value2". - span._attributes["CustomDimension2"] = "Value2" -``` ----#### Set the user IP --You can populate the _client_IP_ field for requests by setting an attribute on the span. Application Insights uses the IP address to generate user location attributes and then [discards it by default](ip-collection.md#default-behavior). --##### [ASP.NET Core](#tab/aspnetcore) --Use the add [custom property example](#add-a-custom-property-to-a-span), but replace the following lines of code in `ActivityEnrichingProcessor.cs`: --```C# -// Add the client IP address to the activity as a tag. -// only applicable in case of activity.Kind == Server -activity.SetTag("client.address", "<IP Address>"); -``` --##### [.NET](#tab/net) --Use the add [custom property example](#add-a-custom-property-to-a-span), but replace the following lines of code in `ActivityEnrichingProcessor.cs`: --```C# -// Add the client IP address to the activity as a tag. -// only applicable in case of activity.Kind == Server -activity.SetTag("client.address", "<IP Address>"); -``` --##### [Java](#tab/java) --Java automatically populates this field. --##### [Java native](#tab/java-native) --This field is automatically populated. --##### [Node.js](#tab/nodejs) --Use the add [custom property example](#add-a-custom-property-to-a-span), but replace the following lines of code: --```typescript -... -// Import the SemanticAttributes class from the @opentelemetry/semantic-conventions package. -const { SemanticAttributes } = require("@opentelemetry/semantic-conventions"); --// Create a new SpanEnrichingProcessor class. -class SpanEnrichingProcessor implements SpanProcessor { -- onEnd(span) { - // Set the HTTP_CLIENT_IP attribute on the span to the IP address of the client. - span.attributes[SemanticAttributes.HTTP_CLIENT_IP] = "<IP Address>"; - } -} -``` --##### [Python](#tab/python) --Use the add [custom property example](#add-a-custom-property-to-a-span), but replace the following lines of code in `SpanEnrichingProcessor.py`: --```python -# Set the `http.client_ip` attribute of the span to the specified IP address. -span._attributes["http.client_ip"] = "<IP Address>" -``` ----#### Set the user ID or authenticated user ID --You can populate the _user_Id_ or _user_AuthenticatedId_ field for requests by using the following guidance. User ID is an anonymous user identifier. Authenticated User ID is a known user identifier. --> [!IMPORTANT] -> Consult applicable privacy laws before you set the Authenticated User ID. --##### [ASP.NET Core](#tab/aspnetcore) --Use the add [custom property example](#add-a-custom-property-to-a-span): --```csharp -// Add the user ID to the activity as a tag, but only if the activity is not null. -activity?.SetTag("enduser.id", "<User Id>"); -``` --##### [.NET](#tab/net) --Use the add [custom property example](#add-a-custom-property-to-a-span): --```csharp -// Add the user ID to the activity as a tag, but only if the activity is not null. -activity?.SetTag("enduser.id", "<User Id>"); -``` --##### [Java](#tab/java) --Populate the `user ID` field in the `requests`, `dependencies`, or `exceptions` table. --1. Add `opentelemetry-api-1.0.0.jar` (or later) to your application: -- ```xml - <dependency> - <groupId>io.opentelemetry</groupId> - <artifactId>opentelemetry-api</artifactId> - <version>1.0.0</version> - </dependency> - ``` --1. Set `user_Id` in your code: -- ```java - import io.opentelemetry.api.trace.Span; - - Span.current().setAttribute("enduser.id", "myuser"); - ``` --##### [Java native](#tab/java-native) --Populate the `user ID` field in the `requests`, `dependencies`, or `exceptions` table. --Set `user_Id` in your code: --```java -import io.opentelemetry.api.trace.Span; --Span.current().setAttribute("enduser.id", "myuser"); -``` --##### [Node.js](#tab/nodejs) --Use the add [custom property example](#add-a-custom-property-to-a-span), but replace the following lines of code: --```typescript -... -// Import the SemanticAttributes class from the @opentelemetry/semantic-conventions package. -import { SemanticAttributes } from "@opentelemetry/semantic-conventions"; --// Create a new SpanEnrichingProcessor class. -class SpanEnrichingProcessor implements SpanProcessor { -- onEnd(span: ReadableSpan) { - // Set the ENDUSER_ID attribute on the span to the ID of the user. - span.attributes[SemanticAttributes.ENDUSER_ID] = "<User ID>"; - } -} -``` --##### [Python](#tab/python) --Use the add [custom property example](#add-a-custom-property-to-a-span), but replace the following lines of code: --```python -# Set the `enduser.id` attribute of the span to the specified user ID. -span._attributes["enduser.id"] = "<User ID>" -``` ----### Add log attributes - -#### [ASP.NET Core](#tab/aspnetcore) --OpenTelemetry uses .NET's `ILogger`. -Attaching custom dimensions to logs can be accomplished using a [message template](/dotnet/core/extensions/logging?tabs=command-line#log-message-template). --#### [.NET](#tab/net) --OpenTelemetry uses .NET's `ILogger`. -Attaching custom dimensions to logs can be accomplished using a [message template](/dotnet/core/extensions/logging?tabs=command-line#log-message-template). --#### [Java](#tab/java) --Logback, Log4j, and java.util.logging are [autoinstrumented](#send-custom-telemetry-using-the-application-insights-classic-api). Attaching custom dimensions to your logs can be accomplished in these ways: --* [Log4j 2.0 MapMessage](https://logging.apache.org/log4j/2.0/javadoc/log4j-api/org/apache/logging/log4j/message/MapMessage.html) (a `MapMessage` key of `"message"` is captured as the log message) -* [Log4j 2.0 Thread Context](https://logging.apache.org/log4j/2.x/manual/thread-context.html) -* [Log4j 1.2 MDC](https://logging.apache.org/log4j/1.2/apidocs/org/apache/log4j/MDC.html) --#### [Java native](#tab/java-native) --For Spring Boot native applications, Logback is instrumented out of the box. --#### [Node.js](#tab/nodejs) --```typescript -const { useAzureMonitor } = require("@azure/monitor-opentelemetry"); -const bunyan = require('bunyan'); --// Instrumentations configuration -const options: AzureMonitorOpenTelemetryOptions = { - instrumentationOptions: { - // Instrumentations generating logs - bunyan: { enabled: true }, - } -}; --// Enable Azure Monitor integration -useAzureMonitor(options); --var log = bunyan.createLogger({ name: 'testApp' }); -log.info({ - "testAttribute1": "testValue1", - "testAttribute2": "testValue2", - "testAttribute3": "testValue3" -}, 'testEvent'); -``` --#### [Python](#tab/python) - -The Python [logging](https://docs.python.org/3/howto/logging.html) library is [autoinstrumented](.\opentelemetry-add-modify.md?tabs=python#included-instrumentation-libraries). You can attach custom dimensions to your logs by passing a dictionary into the `extra` argument of your logs: --```python -... -# Create a warning log message with the properties "key1" and "value1". -logger.warning("WARNING: Warning log with properties", extra={"key1": "value1"}) -... --``` ----## Filter telemetry --You might use the following ways to filter out telemetry before it leaves your application. --### [ASP.NET Core](#tab/aspnetcore) --1. Many instrumentation libraries provide a filter option. For guidance, see the readme files of individual instrumentation libraries: -- * [ASP.NET Core](https://github.com/open-telemetry/opentelemetry-dotnet/blob/1.0.0-rc9.14/src/OpenTelemetry.Instrumentation.AspNetCore/README.md#filter) - * [HttpClient](https://github.com/open-telemetry/opentelemetry-dotnet/blob/1.0.0-rc9.14/src/OpenTelemetry.Instrumentation.Http/README.md#filter) --1. Use a custom processor: - - > [!TIP] - > Add the processor shown here *before* adding Azure Monitor. -- ```csharp - // Create an ASP.NET Core application builder. - var builder = WebApplication.CreateBuilder(args); -- // Configure the OpenTelemetry tracer provider to add a new processor named ActivityFilteringProcessor. - builder.Services.ConfigureOpenTelemetryTracerProvider((sp, builder) => builder.AddProcessor(new ActivityFilteringProcessor())); - // Configure the OpenTelemetry tracer provider to add a new source named "ActivitySourceName". - builder.Services.ConfigureOpenTelemetryTracerProvider((sp, builder) => builder.AddSource("ActivitySourceName")); - // Add the Azure Monitor telemetry service to the application. This service will collect and send telemetry data to Azure Monitor. - builder.Services.AddOpenTelemetry().UseAzureMonitor(); -- // Build the ASP.NET Core application. - var app = builder.Build(); -- // Start the ASP.NET Core application. - app.Run(); - ``` - - Add `ActivityFilteringProcessor.cs` to your project with the following code: - - ```csharp - public class ActivityFilteringProcessor : BaseProcessor<Activity> - { - // The OnStart method is called when an activity is started. This is the ideal place to filter activities. - public override void OnStart(Activity activity) - { - // prevents all exporters from exporting internal activities - if (activity.Kind == ActivityKind.Internal) - { - activity.IsAllDataRequested = false; - } - } - } - ``` --1. If a particular source isn't explicitly added by using `AddSource("ActivitySourceName")`, then none of the activities created by using that source are exported. --### [.NET](#tab/net) --1. Many instrumentation libraries provide a filter option. For guidance, see the readme files of individual instrumentation libraries: -- * [ASP.NET](https://github.com/open-telemetry/opentelemetry-dotnet-contrib/blob/Instrumentation.AspNet-1.0.0-rc9.8/src/OpenTelemetry.Instrumentation.AspNet/README.md#filter) - * [ASP.NET Core](https://github.com/open-telemetry/opentelemetry-dotnet/blob/1.0.0-rc9.14/src/OpenTelemetry.Instrumentation.AspNetCore/README.md#filter) - * [HttpClient](https://github.com/open-telemetry/opentelemetry-dotnet/blob/1.0.0-rc9.14/src/OpenTelemetry.Instrumentation.Http/README.md#filter) --1. Use a custom processor: - - ```csharp - // Create an OpenTelemetry tracer provider builder. - // It is important to keep the TracerProvider instance active throughout the process lifetime. - using var tracerProvider = Sdk.CreateTracerProviderBuilder() - .AddSource("OTel.AzureMonitor.Demo") // Add a source named "OTel.AzureMonitor.Demo". - .AddProcessor(new ActivityFilteringProcessor()) // Add a new processor named ActivityFilteringProcessor. - .AddAzureMonitorTraceExporter() // Add the Azure Monitor trace exporter. - .Build(); - ``` - - Add `ActivityFilteringProcessor.cs` to your project with the following code: - - ```csharp - public class ActivityFilteringProcessor : BaseProcessor<Activity> - { - // The OnStart method is called when an activity is started. This is the ideal place to filter activities. - public override void OnStart(Activity activity) - { - // prevents all exporters from exporting internal activities - if (activity.Kind == ActivityKind.Internal) - { - activity.IsAllDataRequested = false; - } - } - } - ``` --1. If a particular source isn't explicitly added by using `AddSource("ActivitySourceName")`, then none of the activities created by using that source are exported. --### [Java](#tab/java) --See [sampling overrides](java-standalone-config.md#sampling-overrides) and [telemetry processors](java-standalone-telemetry-processors.md). --### [Java native](#tab/java-native) --It's not possible to filter telemetry in Java native. --### [Node.js](#tab/nodejs) --1. Exclude the URL option provided by many HTTP instrumentation libraries. -- The following example shows how to exclude a certain URL from being tracked by using the [HTTP/HTTPS instrumentation library](https://github.com/open-telemetry/opentelemetry-js/tree/main/experimental/packages/opentelemetry-instrumentation-http): - - ```typescript - // Import the useAzureMonitor function and the ApplicationInsightsOptions class from the @azure/monitor-opentelemetry package. - const { useAzureMonitor, ApplicationInsightsOptions } = require("@azure/monitor-opentelemetry"); -- // Import the HttpInstrumentationConfig class from the @opentelemetry/instrumentation-http package. - const { HttpInstrumentationConfig }= require("@opentelemetry/instrumentation-http"); -- // Import the IncomingMessage and RequestOptions classes from the http and https packages, respectively. - const { IncomingMessage } = require("http"); - const { RequestOptions } = require("https"); -- // Create a new HttpInstrumentationConfig object. - const httpInstrumentationConfig: HttpInstrumentationConfig = { - enabled: true, - ignoreIncomingRequestHook: (request: IncomingMessage) => { - // Ignore OPTIONS incoming requests. - if (request.method === 'OPTIONS') { - return true; - } - return false; - }, - ignoreOutgoingRequestHook: (options: RequestOptions) => { - // Ignore outgoing requests with the /test path. - if (options.path === '/test') { - return true; - } - return false; - } - }; -- // Create a new ApplicationInsightsOptions object. - const config: ApplicationInsightsOptions = { - instrumentationOptions: { - http: { - httpInstrumentationConfig - } - } - }; -- // Enable Azure Monitor integration using the useAzureMonitor function and the ApplicationInsightsOptions object. - useAzureMonitor(config); - ``` --1. Use a custom processor. You can use a custom span processor to exclude certain spans from being exported. To mark spans to not be exported, set `TraceFlag` to `DEFAULT`. -- Use the add [custom property example](#add-a-custom-property-to-a-span), but replace the following lines of code: -- ```typescript - // Import the necessary packages. - const { SpanKind, TraceFlags } = require("@opentelemetry/api"); - const { ReadableSpan, Span, SpanProcessor } = require("@opentelemetry/sdk-trace-base"); -- // Create a new SpanEnrichingProcessor class. - class SpanEnrichingProcessor implements SpanProcessor { - forceFlush(): Promise<void> { - return Promise.resolve(); - } -- shutdown(): Promise<void> { - return Promise.resolve(); - } -- onStart(_span: Span): void {} -- onEnd(span) { - // If the span is an internal span, set the trace flags to NONE. - if(span.kind == SpanKind.INTERNAL){ - span.spanContext().traceFlags = TraceFlags.NONE; - } - } - } - ``` --### [Python](#tab/python) --1. Exclude the URL with the `OTEL_PYTHON_EXCLUDED_URLS` environment variable: -- ``` - export OTEL_PYTHON_EXCLUDED_URLS="http://localhost:8080/ignore" - ``` - Doing so excludes the endpoint shown in the following Flask example: - - ```python - ... - # Import the Flask and Azure Monitor OpenTelemetry SDK libraries. - import flask - from azure.monitor.opentelemetry import configure_azure_monitor - - # Configure OpenTelemetry to use Azure Monitor with the specified connection string. - # Replace `<your-connection-string>` with the connection string to your Azure Monitor Application Insights resource. - configure_azure_monitor( - connection_string="<your-connection-string>", - ) - - # Create a Flask application. - app = flask.Flask(__name__) -- # Define a route. Requests sent to this endpoint will not be tracked due to - # flask_config configuration. - @app.route("/ignore") - def ignore(): - return "Request received but not tracked." - ... - ``` --1. Use a custom processor. You can use a custom span processor to exclude certain spans from being exported. To mark spans to not be exported, set `TraceFlag` to `DEFAULT`: - - ```python - ... - # Import the necessary libraries. - from azure.monitor.opentelemetry import configure_azure_monitor - from opentelemetry import trace -- # Configure OpenTelemetry to use Azure Monitor with the specified connection string. - # Replace `<your-connection-string>` with the connection string to your Azure Monitor Application Insights resource. - configure_azure_monitor( - connection_string="<your-connection-string>", - # Configure the custom span processors to include span filter processor. - span_processors=[span_filter_processor], - ) -- ... - ``` - - Add `SpanFilteringProcessor` to your project with the following code: - - ```python - # Import the necessary libraries. - from opentelemetry.trace import SpanContext, SpanKind, TraceFlags - from opentelemetry.sdk.trace import SpanProcessor - - # Define a custom span processor called `SpanFilteringProcessor`. - class SpanFilteringProcessor(SpanProcessor): - - # Prevents exporting spans from internal activities. - def on_start(self, span, parent_context): - # Check if the span is an internal activity. - if span._kind is SpanKind.INTERNAL: - # Create a new span context with the following properties: - # * The trace ID is the same as the trace ID of the original span. - # * The span ID is the same as the span ID of the original span. - # * The is_remote property is set to `False`. - # * The trace flags are set to `DEFAULT`. - # * The trace state is the same as the trace state of the original span. - span._context = SpanContext( - span.context.trace_id, - span.context.span_id, - span.context.is_remote, - TraceFlags(TraceFlags.DEFAULT), - span.context.trace_state, - ) - - ``` --- -<!-- For more information, see [GitHub Repo](link). --> --## Get the trace ID or span ID - -You can obtain the `Trace ID` and `Span ID` of the currently active Span using following steps. --### [ASP.NET Core](#tab/aspnetcore) --> [!NOTE] -> The `Activity` and `ActivitySource` classes from the `System.Diagnostics` namespace represent the OpenTelemetry concepts of `Span` and `Tracer`, respectively. That's because parts of the OpenTelemetry tracing API are incorporated directly into the .NET runtime. To learn more, see [Introduction to OpenTelemetry .NET Tracing API](https://github.com/open-telemetry/opentelemetry-dotnet/blob/main/src/OpenTelemetry.Api/README.md#introduction-to-opentelemetry-net-tracing-api). --```csharp -// Get the current activity. -Activity activity = Activity.Current; -// Get the trace ID of the activity. -string traceId = activity?.TraceId.ToHexString(); -// Get the span ID of the activity. -string spanId = activity?.SpanId.ToHexString(); -``` --### [.NET](#tab/net) --> [!NOTE] -> The `Activity` and `ActivitySource` classes from the `System.Diagnostics` namespace represent the OpenTelemetry concepts of `Span` and `Tracer`, respectively. That's because parts of the OpenTelemetry tracing API are incorporated directly into the .NET runtime. To learn more, see [Introduction to OpenTelemetry .NET Tracing API](https://github.com/open-telemetry/opentelemetry-dotnet/blob/main/src/OpenTelemetry.Api/README.md#introduction-to-opentelemetry-net-tracing-api). --```csharp -// Get the current activity. -Activity activity = Activity.Current; -// Get the trace ID of the activity. -string traceId = activity?.TraceId.ToHexString(); -// Get the span ID of the activity. -string spanId = activity?.SpanId.ToHexString(); -``` --### [Java](#tab/java) --You can use `opentelemetry-api` to get the trace ID or span ID. --1. Add `opentelemetry-api-1.0.0.jar` (or later) to your application: -- ```xml - <dependency> - <groupId>io.opentelemetry</groupId> - <artifactId>opentelemetry-api</artifactId> - <version>1.0.0</version> - </dependency> - ``` --1. Get the request trace ID and the span ID in your code: -- ```java - import io.opentelemetry.api.trace.Span; - - Span span = Span.current(); - String traceId = span.getSpanContext().getTraceId(); - String spanId = span.getSpanContext().getSpanId(); - ``` --### [Java native](#tab/java-native) --Get the request trace ID and the span ID in your code: --```java -import io.opentelemetry.api.trace.Span; --Span span = Span.current(); -String traceId = span.getSpanContext().getTraceId(); -String spanId = span.getSpanContext().getSpanId(); -``` --### [Node.js](#tab/nodejs) --Get the request trace ID and the span ID in your code: --```javascript -// Import the trace module from the OpenTelemetry API. -const { trace } = require("@opentelemetry/api"); --// Get the span ID and trace ID of the active span. -let spanId = trace.getActiveSpan().spanContext().spanId; -let traceId = trace.getActiveSpan().spanContext().traceId; -``` --### [Python](#tab/python) --Get the request trace ID and the span ID in your code: --```python -# Import the necessary libraries. -from opentelemetry import trace --# Get the trace ID and span ID of the current span. -trace_id = trace.get_current_span().get_span_context().trace_id -span_id = trace.get_current_span().get_span_context().span_id -``` ----## Next steps --### [ASP.NET Core](#tab/aspnetcore) --* To further configure the OpenTelemetry distro, see [Azure Monitor OpenTelemetry configuration](opentelemetry-configuration.md). -* To review the source code, see the [Azure Monitor AspNetCore GitHub repository](https://github.com/Azure/azure-sdk-for-net/tree/main/sdk/monitor/Azure.Monitor.OpenTelemetry.AspNetCore). -* To install the NuGet package, check for updates, or view release notes, see the [Azure Monitor AspNetCore NuGet Package](https://www.nuget.org/packages/Azure.Monitor.OpenTelemetry.AspNetCore) page. -* To become more familiar with Azure Monitor and OpenTelemetry, see the [Azure Monitor Example Application](https://github.com/Azure/azure-sdk-for-net/tree/main/sdk/monitor/Azure.Monitor.OpenTelemetry.AspNetCore/tests/Azure.Monitor.OpenTelemetry.AspNetCore.Demo). -* To learn more about OpenTelemetry and its community, see the [OpenTelemetry .NET GitHub repository](https://github.com/open-telemetry/opentelemetry-dotnet). -* To enable usage experiences, [enable web or browser user monitoring](javascript.md). --#### [.NET](#tab/net) --* To further configure the OpenTelemetry distro, see [Azure Monitor OpenTelemetry configuration](opentelemetry-configuration.md) -* To review the source code, see the [Azure Monitor Exporter GitHub repository](https://github.com/Azure/azure-sdk-for-net/tree/main/sdk/monitor/Azure.Monitor.OpenTelemetry.Exporter). -* To install the NuGet package, check for updates, or view release notes, see the [Azure Monitor Exporter NuGet Package](https://www.nuget.org/packages/Azure.Monitor.OpenTelemetry.Exporter) page. -* To become more familiar with Azure Monitor and OpenTelemetry, see the [Azure Monitor Example Application](https://github.com/Azure/azure-sdk-for-net/tree/main/sdk/monitor/Azure.Monitor.OpenTelemetry.Exporter/tests/Azure.Monitor.OpenTelemetry.Exporter.Demo). -* To learn more about OpenTelemetry and its community, see the [OpenTelemetry .NET GitHub repository](https://github.com/open-telemetry/opentelemetry-dotnet). -* To enable usage experiences, [enable web or browser user monitoring](javascript.md). --### [Java](#tab/java) --* Review [Java autoinstrumentation configuration options](java-standalone-config.md). -* To review the source code, see the [Azure Monitor Java autoinstrumentation GitHub repository](https://github.com/Microsoft/ApplicationInsights-Java). -* To learn more about OpenTelemetry and its community, see the [OpenTelemetry Java GitHub repository](https://github.com/open-telemetry/opentelemetry-java-instrumentation). -* To enable usage experiences, see [Enable web or browser user monitoring](javascript.md). -* See the [release notes](https://github.com/microsoft/ApplicationInsights-Java/releases) on GitHub. --### [Java native](#tab/java-native) --* For details on adding and modifying Azure Monitor OpenTelemetry, see [Add and modify Azure Monitor OpenTelemetry](opentelemetry-add-modify.md). -* To review the source code, see [Azure Monitor OpenTelemetry Distro in Spring Boot native image Java application](https://github.com/Azure/azure-sdk-for-java/tree/main/sdk/spring/spring-cloud-azure-starter-monitor) and [Quarkus OpenTelemetry Exporter for Azure](https://github.com/quarkiverse/quarkus-opentelemetry-exporter/tree/main/quarkus-opentelemetry-exporter-azure). -* To learn more about OpenTelemetry and its community, see the [OpenTelemetry Java GitHub repository](https://github.com/open-telemetry/opentelemetry-java-instrumentation). -* See the [release notes](https://github.com/Azure/azure-sdk-for-jav) on GitHub. --### [Node.js](#tab/nodejs) --* To review the source code, see the [Azure Monitor OpenTelemetry GitHub repository](https://github.com/Azure/azure-sdk-for-js/tree/main/sdk/monitor/monitor-opentelemetry). -* To install the npm package and check for updates, see the [`@azure/monitor-opentelemetry` npm Package](https://www.npmjs.com/package/@azure/monitor-opentelemetry) page. -* To become more familiar with Azure Monitor Application Insights and OpenTelemetry, see the [Azure Monitor Example Application](https://github.com/Azure-Samples/azure-monitor-opentelemetry-node.js). -* To learn more about OpenTelemetry and its community, see the [OpenTelemetry JavaScript GitHub repository](https://github.com/open-telemetry/opentelemetry-js). -* To enable usage experiences, [enable web or browser user monitoring](javascript.md). --### [Python](#tab/python) --* To review the source code and extra documentation, see the [Azure Monitor Distro GitHub repository](https://github.com/Azure/azure-sdk-for-python/blob/main/sdk/monitor/azure-monitor-opentelemetry/README.md). -* To see extra samples and use cases, see [Azure Monitor Distro samples](https://github.com/Azure/azure-sdk-for-python/tree/main/sdk/monitor/azure-monitor-opentelemetry/samples). -* See the [release notes](https://github.com/Azure/azure-sdk-for-python/blob/main/sdk/monitor/azure-monitor-opentelemetry/CHANGELOG.md) on GitHub. -* To install the PyPI package, check for updates, or view release notes, see the [Azure Monitor Distro PyPI Package](https://pypi.org/project/azure-monitor-opentelemetry/) page. -* To become more familiar with Azure Monitor Application Insights and OpenTelemetry, see the [Azure Monitor Example Application](https://github.com/Azure-Samples/azure-monitor-opentelemetry-python). -* To learn more about OpenTelemetry and its community, see the [OpenTelemetry Python GitHub repository](https://github.com/open-telemetry/opentelemetry-python). -* To see available OpenTelemetry instrumentations and components, see the [OpenTelemetry Contributor Python GitHub repository](https://github.com/open-telemetry/opentelemetry-python-contrib). -* To enable usage experiences, [enable web or browser user monitoring](javascript.md). ---- |
| azure-monitor | Opentelemetry Configuration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/opentelemetry-configuration.md | - Title: Configure Azure Monitor OpenTelemetry for .NET, Java, Node.js, and Python applications -description: This article provides configuration guidance for .NET, Java, Node.js, and Python applications. - Previously updated : 12/27/2023-# ms.devlang: csharp, javascript, typescript, python -----# Configure Azure Monitor OpenTelemetry --This article covers configuration settings for the Azure Monitor OpenTelemetry distro. --## Connection string --A connection string in Application Insights defines the target location for sending telemetry data. -### [ASP.NET Core](#tab/aspnetcore) --Use one of the following three ways to configure the connection string: --- Add `UseAzureMonitor()` to your `program.cs` file:-- ```csharp - var builder = WebApplication.CreateBuilder(args); -- // Add the OpenTelemetry telemetry service to the application. - // This service will collect and send telemetry data to Azure Monitor. - builder.Services.AddOpenTelemetry().UseAzureMonitor(options => { - options.ConnectionString = "<Your Connection String>"; - }); -- var app = builder.Build(); -- app.Run(); - ``` --- Set an environment variable.-- ```console - APPLICATIONINSIGHTS_CONNECTION_STRING=<Your Connection String> - ``` --- Add the following section to your `appsettings.json` config file.-- ```json - { - "AzureMonitor": { - "ConnectionString": "<Your Connection String>" - } - } - ``` - -> [!NOTE] -> If you set the connection string in more than one place, we adhere to the following precedence: -> 1. Code -> 2. Environment Variable -> 3. Configuration File --### [.NET](#tab/net) --Use one of the following two ways to configure the connection string: --- Add the Azure Monitor Exporter to each OpenTelemetry signal in application startup.-- ```csharp - // Create a new OpenTelemetry tracer provider. - // It is important to keep the TracerProvider instance active throughout the process lifetime. - var tracerProvider = Sdk.CreateTracerProviderBuilder() - .AddAzureMonitorTraceExporter(options => - { - options.ConnectionString = "<Your Connection String>"; - }); -- // Create a new OpenTelemetry meter provider. - // It is important to keep the MetricsProvider instance active throughout the process lifetime. - var metricsProvider = Sdk.CreateMeterProviderBuilder() - .AddAzureMonitorMetricExporter(options => - { - options.ConnectionString = "<Your Connection String>"; - }); -- // Create a new logger factory. - // It is important to keep the LoggerFactory instance active throughout the process lifetime. - var loggerFactory = LoggerFactory.Create(builder => - { - builder.AddOpenTelemetry(options => - { - options.AddAzureMonitorLogExporter(options => - { - options.ConnectionString = "<Your Connection String>"; - }); - }); - }); - ``` --- Set an environment variable.- ```console - APPLICATIONINSIGHTS_CONNECTION_STRING=<Your Connection String> - ``` --> [!NOTE] -> If you set the connection string in more than one place, we adhere to the following precedence: -> 1. Code -> 2. Environment Variable --### [Java](#tab/java) --To set the connection string, see [Connection string](java-standalone-config.md#connection-string). --### [Java native](#tab/java-native) --Use one of the following two ways to configure the connection string: --- Set an environment variable.-- ```console - APPLICATIONINSIGHTS_CONNECTION_STRING=<Your Connection String> - ``` --- Set a property.- ```properties - applicationinsights.connection.string=<Your Connection String> - ``` --### [Node.js](#tab/nodejs) --Use one of the following two ways to configure the connection string: --- Set an environment variable.-- ```console - APPLICATIONINSIGHTS_CONNECTION_STRING=<Your Connection String> - ``` --- Use a configuration object.-- ```typescript - // Import the useAzureMonitor function and the AzureMonitorOpenTelemetryOptions class from the @azure/monitor-opentelemetry package. - const { useAzureMonitor, AzureMonitorOpenTelemetryOptions } = require("@azure/monitor-opentelemetry"); -- // Create a new AzureMonitorOpenTelemetryOptions object. - const options: AzureMonitorOpenTelemetryOptions = { - azureMonitorExporterOptions: { - connectionString: "<your connection string>" - } - }; -- // Enable Azure Monitor integration using the useAzureMonitor function and the AzureMonitorOpenTelemetryOptions object. - useAzureMonitor(options); - ``` --### [Python](#tab/python) --Use one of the following two ways to configure the connection string: --- Set an environment variable.-- ```console - APPLICATIONINSIGHTS_CONNECTION_STRING=<Your Connection String> - ``` --- Use the `configure_azure_monitor`function.--```python -# Import the `configure_azure_monitor()` function from the `azure.monitor.opentelemetry` package. -from azure.monitor.opentelemetry import configure_azure_monitor --# Configure OpenTelemetry to use Azure Monitor with the specified connection string. -# Replace `<your-connection-string>` with the connection string of your Azure Monitor Application Insights resource. -configure_azure_monitor( - connection_string="<your-connection-string>", -) -``` ----## Set the Cloud Role Name and the Cloud Role Instance --For [supported languages](opentelemetry-enable.md#whats-the-current-release-state-of-features-within-the-azure-monitor-opentelemetry-distro), the Azure Monitor OpenTelemetry Distro automatically detects the resource context and provides default values for the [Cloud Role Name](app-map.md#understand-the-cloud-role-name-within-the-context-of-an-application-map) and the Cloud Role Instance properties of your component. However, you might want to override the default values to something that makes sense to your team. The cloud role name value appears on the Application Map as the name underneath a node. --### [ASP.NET Core](#tab/aspnetcore) --Set the Cloud Role Name and the Cloud Role Instance via [Resource](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/resource/sdk.md#resource-sdk) attributes. Cloud Role Name uses `service.namespace` and `service.name` attributes, although it falls back to `service.name` if `service.namespace` isn't set. Cloud Role Instance uses the `service.instance.id` attribute value. For information on standard attributes for resources, see [OpenTelemetry Semantic Conventions](https://github.com/open-telemetry/semantic-conventions/blob/main/docs/README.md). --```csharp -// Setting role name and role instance --// Create a dictionary of resource attributes. -var resourceAttributes = new Dictionary<string, object> { - { "service.name", "my-service" }, - { "service.namespace", "my-namespace" }, - { "service.instance.id", "my-instance" }}; --// Create a new ASP.NET Core web application builder. -var builder = WebApplication.CreateBuilder(args); --// Add the OpenTelemetry telemetry service to the application. -// This service will collect and send telemetry data to Azure Monitor. -builder.Services.AddOpenTelemetry() - .UseAzureMonitor() - // Configure the ResourceBuilder to add the custom resource attributes to all signals. - // Custom resource attributes should be added AFTER AzureMonitor to override the default ResourceDetectors. - .ConfigureResource(resourceBuilder => resourceBuilder.AddAttributes(_testResourceAttributes)); --// Build the ASP.NET Core web application. -var app = builder.Build(); --// Start the ASP.NET Core web application. -app.Run(); -``` --### [.NET](#tab/net) --Set the Cloud Role Name and the Cloud Role Instance via [Resource](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/resource/sdk.md#resource-sdk) attributes. Cloud Role Name uses `service.namespace` and `service.name` attributes, although it falls back to `service.name` if `service.namespace` isn't set. Cloud Role Instance uses the `service.instance.id` attribute value. For information on standard attributes for resources, see [OpenTelemetry Semantic Conventions](https://github.com/open-telemetry/semantic-conventions/blob/main/docs/README.md). --```csharp -// Setting role name and role instance --// Create a dictionary of resource attributes. -var resourceAttributes = new Dictionary<string, object> { - { "service.name", "my-service" }, - { "service.namespace", "my-namespace" }, - { "service.instance.id", "my-instance" }}; --// Create a resource builder. -var resourceBuilder = ResourceBuilder.CreateDefault().AddAttributes(resourceAttributes); --// Create a new OpenTelemetry tracer provider and set the resource builder. -// It is important to keep the TracerProvider instance active throughout the process lifetime. -var tracerProvider = Sdk.CreateTracerProviderBuilder() - // Set ResourceBuilder on the TracerProvider. - .SetResourceBuilder(resourceBuilder) - .AddAzureMonitorTraceExporter(); --// Create a new OpenTelemetry meter provider and set the resource builder. -// It is important to keep the MetricsProvider instance active throughout the process lifetime. -var metricsProvider = Sdk.CreateMeterProviderBuilder() - // Set ResourceBuilder on the MeterProvider. - .SetResourceBuilder(resourceBuilder) - .AddAzureMonitorMetricExporter(); --// Create a new logger factory and add the OpenTelemetry logger provider with the resource builder. -// It is important to keep the LoggerFactory instance active throughout the process lifetime. -var loggerFactory = LoggerFactory.Create(builder => -{ - builder.AddOpenTelemetry(options => - { - // Set ResourceBuilder on the Logging config. - options.SetResourceBuilder(resourceBuilder); - options.AddAzureMonitorLogExporter(); - }); -}); -``` --### [Java](#tab/java) --To set the cloud role name, see [cloud role name](java-standalone-config.md#cloud-role-name). --To set the cloud role instance, see [cloud role instance](java-standalone-config.md#cloud-role-instance). --### [Java native](#tab/java-native) --To set the cloud role name: -* Use the `spring.application.name` for Spring Boot native image applications -* Use the `quarkus.application.name` for Quarkus native image applications --### [Node.js](#tab/nodejs) --Set the Cloud Role Name and the Cloud Role Instance via [Resource](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/resource/sdk.md#resource-sdk) attributes. Cloud Role Name uses `service.namespace` and `service.name` attributes, although it falls back to `service.name` if `service.namespace` isn't set. Cloud Role Instance uses the `service.instance.id` attribute value. For information on standard attributes for resources, see [OpenTelemetry Semantic Conventions](https://github.com/open-telemetry/semantic-conventions/blob/main/docs/README.md). --```typescript -// Import the useAzureMonitor function, the AzureMonitorOpenTelemetryOptions class, the Resource class, and the SemanticResourceAttributes class from the @azure/monitor-opentelemetry, @opentelemetry/resources, and @opentelemetry/semantic-conventions packages, respectively. -const { useAzureMonitor, AzureMonitorOpenTelemetryOptions } = require("@azure/monitor-opentelemetry"); -const { Resource } = require("@opentelemetry/resources"); -const { SemanticResourceAttributes } = require("@opentelemetry/semantic-conventions"); --// Create a new Resource object with the following custom resource attributes: -// -// * service_name: my-service -// * service_namespace: my-namespace -// * service_instance_id: my-instance -const customResource = new Resource({ - [SemanticResourceAttributes.SERVICE_NAME]: "my-service", - [SemanticResourceAttributes.SERVICE_NAMESPACE]: "my-namespace", - [SemanticResourceAttributes.SERVICE_INSTANCE_ID]: "my-instance", -}); --// Create a new AzureMonitorOpenTelemetryOptions object and set the resource property to the customResource object. -const options: AzureMonitorOpenTelemetryOptions = { - resource: customResource -}; --// Enable Azure Monitor integration using the useAzureMonitor function and the AzureMonitorOpenTelemetryOptions object. -useAzureMonitor(options); -``` --### [Python](#tab/python) --Set the Cloud Role Name and the Cloud Role Instance via [Resource](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/resource/sdk.md#resource-sdk) attributes. Cloud Role Name uses `service.namespace` and `service.name` attributes, although it falls back to `service.name` if `service.namespace` isn't set. Cloud Role Instance uses the `service.instance.id` attribute value. For information on standard attributes for resources, see [OpenTelemetry Semantic Conventions](https://github.com/open-telemetry/semantic-conventions/blob/main/docs/README.md). --Set Resource attributes using the `OTEL_RESOURCE_ATTRIBUTES` and/or `OTEL_SERVICE_NAME` environment variables. `OTEL_RESOURCE_ATTRIBUTES` takes series of comma-separated key-value pairs. For example, to set the Cloud Role Name to `my-namespace.my-helloworld-service` and set Cloud Role Instance to `my-instance`, you can set `OTEL_RESOURCE_ATTRIBUTES` and `OTEL_SERVICE_NAME` as such: --``` -export OTEL_RESOURCE_ATTRIBUTES="service.namespace=my-namespace,service.instance.id=my-instance" -export OTEL_SERVICE_NAME="my-helloworld-service" -``` --If you don't set the `service.namespace` Resource attribute, you can alternatively set the Cloud Role Name with only the OTEL_SERVICE_NAME environment variable or the `service.name` Resource attribute. For example, to set the Cloud Role Name to `my-helloworld-service` and set Cloud Role Instance to `my-instance`, you can set `OTEL_RESOURCE_ATTRIBUTES` and `OTEL_SERVICE_NAME` as such: --``` -export OTEL_RESOURCE_ATTRIBUTES="service.instance.id=my-instance" -export OTEL_SERVICE_NAME="my-helloworld-service" -``` ----## Enable Sampling --You might want to enable sampling to reduce your data ingestion volume, which reduces your cost. Azure Monitor provides a custom *fixed-rate* sampler that populates events with a sampling ratio, which Application Insights converts to `ItemCount`. The *fixed-rate* sampler ensures accurate experiences and event counts. The sampler is designed to preserve your traces across services, and it's interoperable with older Application Insights Software Development Kits (SDKs). For more information, see [Learn More about sampling](sampling.md#brief-summary). --> [!NOTE] -> Metrics and Logs are unaffected by sampling. --### [ASP.NET Core](#tab/aspnetcore) --The sampler expects a sample rate of between 0 and 1 inclusive. A rate of 0.1 means approximately 10% of your traces are sent. --```csharp -// Create a new ASP.NET Core web application builder. -var builder = WebApplication.CreateBuilder(args); --// Add the OpenTelemetry telemetry service to the application. -// This service will collect and send telemetry data to Azure Monitor. -builder.Services.AddOpenTelemetry().UseAzureMonitor(o => -{ - // Set the sampling ratio to 10%. This means that 10% of all traces will be sampled and sent to Azure Monitor. - o.SamplingRatio = 0.1F; -}); --// Build the ASP.NET Core web application. -var app = builder.Build(); --// Start the ASP.NET Core web application. -app.Run(); -``` --### [.NET](#tab/net) --The sampler expects a sample rate of between 0 and 1 inclusive. A rate of 0.1 means approximately 10% of your traces are sent. --```csharp -// Create a new OpenTelemetry tracer provider. -// It is important to keep the TracerProvider instance active throughout the process lifetime. -var tracerProvider = Sdk.CreateTracerProviderBuilder() - .AddAzureMonitorTraceExporter(options => - { - // Set the sampling ratio to 10%. This means that 10% of all traces will be sampled and sent to Azure Monitor. - options.SamplingRatio = 0.1F; - }); -``` --### [Java](#tab/java) --Starting from 3.4.0, rate-limited sampling is available and is now the default. For more information about sampling, see [Java sampling]( java-standalone-config.md#sampling). --### [Java native](#tab/java-native) --For Spring Boot native applications, the [sampling configurations of the OpenTelemetry Java SDK are applicable](https://opentelemetry.io/docs/languages/java/configuration/#sampler). --For Quarkus native applications, please look at the [Quarkus OpenTelemetry documentation](https://quarkus.io/guides/opentelemetry#sampler). --### [Node.js](#tab/nodejs) --The sampler expects a sample rate of between 0 and 1 inclusive. A rate of 0.1 means approximately 10% of your traces are sent. --```typescript -// Import the useAzureMonitor function and the AzureMonitorOpenTelemetryOptions class from the @azure/monitor-opentelemetry package. -const { useAzureMonitor, AzureMonitorOpenTelemetryOptions } = require("@azure/monitor-opentelemetry"); --// Create a new AzureMonitorOpenTelemetryOptions object and set the samplingRatio property to 0.1. -const options: AzureMonitorOpenTelemetryOptions = { - samplingRatio: 0.1 -}; --// Enable Azure Monitor integration using the useAzureMonitor function and the AzureMonitorOpenTelemetryOptions object. -useAzureMonitor(options); -``` --### [Python](#tab/python) --The `configure_azure_monitor()` function automatically utilizes -ApplicationInsightsSampler for compatibility with Application Insights SDKs and -to sample your telemetry. The `OTEL_TRACES_SAMPLER_ARG` environment variable can be used to specify -the sampling rate, with a valid range of 0 to 1, where 0 is 0% and 1 is 100%. -For example, a value of 0.1 means 10% of your traces are sent. --``` -export OTEL_TRACES_SAMPLER_ARG=0.1 -``` ----> [!TIP] -> When using fixed-rate/percentage sampling and you aren't sure what to set the sampling rate as, start at 5% (i.e., 0.05 sampling ratio) and adjust the rate based on the accuracy of the operations shown in the failures and performance panes. A higher rate generally results in higher accuracy. However, ANY sampling will affect accuracy so we recommend alerting on [OpenTelemetry metrics](opentelemetry-add-modify.md#add-custom-metrics), which are unaffected by sampling. --<a name='enable-entra-id-formerly-azure-ad-authentication'></a> --## Live metrics --[Live metrics](live-stream.md) provides a real-time analytics dashboard for insight into application activity and performance. --### [ASP.NET Core](#tab/aspnetcore) --> [!IMPORTANT] -> See the [Supplemental Terms of Use for Microsoft Azure Previews](https://azure.microsoft.com/support/legal/preview-supplemental-terms/) for legal terms that apply to Azure features that are in beta, preview, or otherwise not yet released into general availability. --This feature is enabled by default. --Users can disable Live Metrics when configuring the Distro. --```csharp -builder.Services.AddOpenTelemetry().UseAzureMonitor(options => { - // Disable the Live Metrics feature. - options.EnableLiveMetrics = false; -}); -``` --### [.NET](#tab/net) --This feature isn't available in the Azure Monitor .NET Exporter. --### [Java](#tab/java) --The Live Metrics experience is enabled by default. --For more information on Java configuration, see [Configuration options: Azure Monitor Application Insights for Java](java-standalone-config.md#configuration-options-azure-monitor-application-insights-for-java). --### [Java native](#tab/java-native) --The Live Metrics are not available today for GraalVM native applications. --### [Node.js](#tab/nodejs) --> [!IMPORTANT] -> See the [Supplemental Terms of Use for Microsoft Azure Previews](https://azure.microsoft.com/support/legal/preview-supplemental-terms/) for legal terms that apply to Azure features that are in beta, preview, or otherwise not yet released into general availability. --Users can enable/disable Live Metrics when configuring the Distro using the `enableLiveMetrics` property. --```typescript -const options: AzureMonitorOpenTelemetryOptions = { - azureMonitorExporterOptions: { - connectionString: - process.env["APPLICATIONINSIGHTS_CONNECTION_STRING"] || "<your connection string>", - }, - enableLiveMetrics: false -}; --useAzureMonitor(options); -``` --<!-- --TODO: --This feature is/isn't enabled by default. --Functionality and customization are covered in the following configuration sample. --``` -Configuration sample -``` ->--### [Python](#tab/python) --> [!IMPORTANT] -> See the [Supplemental Terms of Use for Microsoft Azure Previews](https://azure.microsoft.com/support/legal/preview-supplemental-terms/) for legal terms that apply to Azure features that are in beta, preview, or otherwise not yet released into general availability. --You can enable live metrics using the Azure monitor OpenTelemetry Distro for Python as follows: --```python -... -configure_azure_monitor( - enable_live_metrics=True -) -... -``` ----## Enable Microsoft Entra ID (formerly Azure AD) authentication --You might want to enable Microsoft Entra authentication for a more secure connection to Azure, which prevents unauthorized telemetry from being ingested into your subscription. --### [ASP.NET Core](#tab/aspnetcore) --We support the credential classes provided by [Azure Identity](https://github.com/Azure/azure-sdk-for-net/tree/main/sdk/identity/Azure.Identity#credential-classes). --- We recommend `DefaultAzureCredential` for local development.-- We recommend `ManagedIdentityCredential` for system-assigned and user-assigned managed identities.- - For system-assigned, use the default constructor without parameters. - - For user-assigned, provide the client ID to the constructor. -- We recommend `ClientSecretCredential` for service principals.- - Provide the tenant ID, client ID, and client secret to the constructor. --1. Install the latest [Azure.Identity](https://www.nuget.org/packages/Azure.Identity) package: -- ```dotnetcli - dotnet add package Azure.Identity - ``` --1. Provide the desired credential class: -- ```csharp - // Create a new ASP.NET Core web application builder. - var builder = WebApplication.CreateBuilder(args); -- // Add the OpenTelemetry telemetry service to the application. - // This service will collect and send telemetry data to Azure Monitor. - builder.Services.AddOpenTelemetry().UseAzureMonitor(options => { - // Set the Azure Monitor credential to the DefaultAzureCredential. - // This credential will use the Azure identity of the current user or - // the service principal that the application is running as to authenticate - // to Azure Monitor. - options.Credential = new DefaultAzureCredential(); - }); -- // Build the ASP.NET Core web application. - var app = builder.Build(); -- // Start the ASP.NET Core web application. - app.Run(); - ``` --### [.NET](#tab/net) --We support the credential classes provided by [Azure Identity](https://github.com/Azure/azure-sdk-for-net/tree/main/sdk/identity/Azure.Identity#credential-classes). --- We recommend `DefaultAzureCredential` for local development.-- We recommend `ManagedIdentityCredential` for system-assigned and user-assigned managed identities.- - For system-assigned, use the default constructor without parameters. - - For user-assigned, provide the client ID to the constructor. -- We recommend `ClientSecretCredential` for service principals.- - Provide the tenant ID, client ID, and client secret to the constructor. --1. Install the latest [Azure.Identity](https://www.nuget.org/packages/Azure.Identity) package: -- ```dotnetcli - dotnet add package Azure.Identity - ``` --1. Provide the desired credential class: -- ```csharp - // Create a DefaultAzureCredential. - var credential = new DefaultAzureCredential(); -- // Create a new OpenTelemetry tracer provider and set the credential. - // It is important to keep the TracerProvider instance active throughout the process lifetime. - var tracerProvider = Sdk.CreateTracerProviderBuilder() - .AddAzureMonitorTraceExporter(options => - { - options.Credential = credential; - }); -- // Create a new OpenTelemetry meter provider and set the credential. - // It is important to keep the MetricsProvider instance active throughout the process lifetime. - var metricsProvider = Sdk.CreateMeterProviderBuilder() - .AddAzureMonitorMetricExporter(options => - { - options.Credential = credential; - }); -- // Create a new logger factory and add the OpenTelemetry logger provider with the credential. - // It is important to keep the LoggerFactory instance active throughout the process lifetime. - var loggerFactory = LoggerFactory.Create(builder => - { - builder.AddOpenTelemetry(options => - { - options.AddAzureMonitorLogExporter(options => - { - options.Credential = credential; - }); - }); - }); - ``` --### [Java](#tab/java) --For more information about Java, see the [Java supplemental documentation](java-standalone-config.md). --### [Java native](#tab/java-native) --Microsoft Entra ID authentication is not available for GraalVM Native applications. --### [Node.js](#tab/nodejs) --We support the credential classes provided by [Azure Identity](https://github.com/Azure/azure-sdk-for-js/tree/main/sdk/identity/identity#credential-classes). --```typescript -// Import the useAzureMonitor function, the AzureMonitorOpenTelemetryOptions class, and the ManagedIdentityCredential class from the @azure/monitor-opentelemetry and @azure/identity packages, respectively. -const { useAzureMonitor, AzureMonitorOpenTelemetryOptions } = require("@azure/monitor-opentelemetry"); -const { ManagedIdentityCredential } = require("@azure/identity"); --// Create a new ManagedIdentityCredential object. -const credential = new ManagedIdentityCredential(); --// Create a new AzureMonitorOpenTelemetryOptions object and set the credential property to the credential object. -const options: AzureMonitorOpenTelemetryOptions = { - azureMonitorExporterOptions: { - connectionString: - process.env["APPLICATIONINSIGHTS_CONNECTION_STRING"] || "<your connection string>", - credential: credential - } -}; --// Enable Azure Monitor integration using the useAzureMonitor function and the AzureMonitorOpenTelemetryOptions object. -useAzureMonitor(options); -``` --### [Python](#tab/python) --Azure Monitor OpenTelemetry Distro for Python support the credential classes provided by [Azure Identity](https://github.com/Azure/azure-sdk-for-js/tree/master/sdk/identity/identity#credential-classes). --- We recommend `DefaultAzureCredential` for local development.-- We recommend `ManagedIdentityCredential` for system-assigned and user-assigned managed identities.- - For system-assigned, use the default constructor without parameters. - - For user-assigned, provide the `client_id` to the constructor. -- We recommend `ClientSecretCredential` for service principals.- - Provide the tenant ID, client ID, and client secret to the constructor. --If using `ManagedIdentityCredential` -```python -# Import the `ManagedIdentityCredential` class from the `azure.identity` package. -from azure.identity import ManagedIdentityCredential -# Import the `configure_azure_monitor()` function from the `azure.monitor.opentelemetry` package. -from azure.monitor.opentelemetry import configure_azure_monitor -from opentelemetry import trace --# Configure the Distro to authenticate with Azure Monitor using a managed identity credential. -credential = ManagedIdentityCredential(client_id="<client_id>") -configure_azure_monitor( - connection_string="your-connection-string", - credential=credential, -) --tracer = trace.get_tracer(__name__) --with tracer.start_as_current_span("hello with aad managed identity"): - print("Hello, World!") --``` --If using `ClientSecretCredential` -```python -# Import the `ClientSecretCredential` class from the `azure.identity` package. -from azure.identity import ClientSecretCredential -# Import the `configure_azure_monitor()` function from the `azure.monitor.opentelemetry` package. -from azure.monitor.opentelemetry import configure_azure_monitor -from opentelemetry import trace --# Configure the Distro to authenticate with Azure Monitor using a client secret credential. -credential = ClientSecretCredential( - tenant_id="<tenant_id", - client_id="<client_id>", - client_secret="<client_secret>", -) -configure_azure_monitor( - connection_string="your-connection-string", - credential=credential, -) --with tracer.start_as_current_span("hello with aad client secret identity"): - print("Hello, World!") --``` ---## Offline Storage and Automatic Retries --To improve reliability and resiliency, Azure Monitor OpenTelemetry-based offerings write to offline/local storage by default when an application loses its connection with Application Insights. It saves the application telemetry to disk and periodically tries to send it again for up to 48 hours. In high-load applications, telemetry is occasionally dropped for two reasons. First, when the allowable time is exceeded, and second, when the maximum file size is exceeded or the SDK doesn't have an opportunity to clear out the file. If we need to choose, the product saves more recent events over old ones. [Learn More](/previous-versions/azure/azure-monitor/app/data-retention-privacy#does-the-sdk-create-temporary-local-storage) --### [ASP.NET Core](#tab/aspnetcore) --The Distro package includes the AzureMonitorExporter, which by default uses one of the following locations for offline storage (listed in order of precedence): --- Windows- - %LOCALAPPDATA%\Microsoft\AzureMonitor - - %TEMP%\Microsoft\AzureMonitor -- Non-Windows- - %TMPDIR%/Microsoft/AzureMonitor - - /var/tmp/Microsoft/AzureMonitor - - /tmp/Microsoft/AzureMonitor --To override the default directory, you should set `AzureMonitorOptions.StorageDirectory`. --```csharp -// Create a new ASP.NET Core web application builder. -var builder = WebApplication.CreateBuilder(args); --// Add the OpenTelemetry telemetry service to the application. -// This service will collect and send telemetry data to Azure Monitor. -builder.Services.AddOpenTelemetry().UseAzureMonitor(options => -{ - // Set the Azure Monitor storage directory to "C:\\SomeDirectory". - // This is the directory where the OpenTelemetry SDK will store any telemetry data that cannot be sent to Azure Monitor immediately. - options.StorageDirectory = "C:\\SomeDirectory"; -}); --// Build the ASP.NET Core web application. -var app = builder.Build(); --// Start the ASP.NET Core web application. -app.Run(); -``` --To disable this feature, you should set `AzureMonitorOptions.DisableOfflineStorage = true`. --### [.NET](#tab/net) --By default, the AzureMonitorExporter uses one of the following locations for offline storage (listed in order of precedence): --- Windows- - %LOCALAPPDATA%\Microsoft\AzureMonitor - - %TEMP%\Microsoft\AzureMonitor -- Non-Windows- - %TMPDIR%/Microsoft/AzureMonitor - - /var/tmp/Microsoft/AzureMonitor - - /tmp/Microsoft/AzureMonitor --To override the default directory, you should set `AzureMonitorExporterOptions.StorageDirectory`. --```csharp -// Create a new OpenTelemetry tracer provider and set the storage directory. -// It is important to keep the TracerProvider instance active throughout the process lifetime. -var tracerProvider = Sdk.CreateTracerProviderBuilder() - .AddAzureMonitorTraceExporter(options => - { - // Set the Azure Monitor storage directory to "C:\\SomeDirectory". - // This is the directory where the OpenTelemetry SDK will store any trace data that cannot be sent to Azure Monitor immediately. - options.StorageDirectory = "C:\\SomeDirectory"; - }); --// Create a new OpenTelemetry meter provider and set the storage directory. -// It is important to keep the MetricsProvider instance active throughout the process lifetime. -var metricsProvider = Sdk.CreateMeterProviderBuilder() - .AddAzureMonitorMetricExporter(options => - { - // Set the Azure Monitor storage directory to "C:\\SomeDirectory". - // This is the directory where the OpenTelemetry SDK will store any metric data that cannot be sent to Azure Monitor immediately. - options.StorageDirectory = "C:\\SomeDirectory"; - }); --// Create a new logger factory and add the OpenTelemetry logger provider with the storage directory. -// It is important to keep the LoggerFactory instance active throughout the process lifetime. -var loggerFactory = LoggerFactory.Create(builder => -{ - builder.AddOpenTelemetry(options => - { - options.AddAzureMonitorLogExporter(options => - { - // Set the Azure Monitor storage directory to "C:\\SomeDirectory". - // This is the directory where the OpenTelemetry SDK will store any log data that cannot be sent to Azure Monitor immediately. - options.StorageDirectory = "C:\\SomeDirectory"; - }); - }); -}); -``` --To disable this feature, you should set `AzureMonitorExporterOptions.DisableOfflineStorage = true`. --### [Java](#tab/java) --Configuring Offline Storage and Automatic Retries isn't available in Java. --For a full list of available configurations, see [Configuration options](./java-standalone-config.md). --### [Java native](#tab/java-native) --Configuring Offline Storage and Automatic Retries isn't available in Java native image applications. --### [Node.js](#tab/nodejs) --By default, the AzureMonitorExporter uses one of the following locations for offline storage. --- Windows- - %TEMP%\Microsoft\AzureMonitor -- Non-Windows- - %TMPDIR%/Microsoft/AzureMonitor - - /var/tmp/Microsoft/AzureMonitor --To override the default directory, you should set `storageDirectory`. --For example: ---```typescript -// Import the useAzureMonitor function and the AzureMonitorOpenTelemetryOptions class from the @azure/monitor-opentelemetry package. -const { useAzureMonitor, AzureMonitorOpenTelemetryOptions } = require("@azure/monitor-opentelemetry"); --// Create a new AzureMonitorOpenTelemetryOptions object and set the azureMonitorExporterOptions property to an object with the following properties: -// -// * connectionString: The connection string for your Azure Monitor Application Insights resource. -// * storageDirectory: The directory where the Azure Monitor OpenTelemetry exporter will store telemetry data when it is offline. -// * disableOfflineStorage: A boolean value that specifies whether to disable offline storage. -const options: AzureMonitorOpenTelemetryOptions = { - azureMonitorExporterOptions: { - connectionString: "<Your Connection String>", - storageDirectory: "C:\\SomeDirectory", - disableOfflineStorage: false - } -}; --// Enable Azure Monitor integration using the useAzureMonitor function and the AzureMonitorOpenTelemetryOptions object. -useAzureMonitor(options); -``` --To disable this feature, you should set `disableOfflineStorage = true`. --### [Python](#tab/python) --By default, Azure Monitor exporters use the following path: --`<tempfile.gettempdir()>/Microsoft/AzureMonitor/opentelemetry-python-<your-instrumentation-key>` --To override the default directory, you should set `storage_directory` to the directory you want. --For example: -```python -... -# Configure OpenTelemetry to use Azure Monitor with the specified connection string and storage directory. -# Replace `your-connection-string` with the connection string to your Azure Monitor Application Insights resource. -# Replace `C:\\SomeDirectory` with the directory where you want to store the telemetry data before it is sent to Azure Monitor. -configure_azure_monitor( - connection_string="your-connection-string", - storage_directory="C:\\SomeDirectory", -) -... --``` --To disable this feature, you should set `disable_offline_storage` to `True`. Defaults to `False`. --For example: -```python -... -# Configure OpenTelemetry to use Azure Monitor with the specified connection string and disable offline storage. -# Replace `your-connection-string` with the connection string to your Azure Monitor Application Insights resource. -configure_azure_monitor( - connection_string="your-connection-string", - disable_offline_storage=True, -) -... --``` ----## Enable the OTLP Exporter --You might want to enable the OpenTelemetry Protocol (OTLP) Exporter alongside the Azure Monitor Exporter to send your telemetry to two locations. --> [!NOTE] -> The OTLP Exporter is shown for convenience only. We don't officially support the OTLP Exporter or any components or third-party experiences downstream of it. --### [ASP.NET Core](#tab/aspnetcore) --1. Install the [OpenTelemetry.Exporter.OpenTelemetryProtocol](https://www.nuget.org/packages/OpenTelemetry.Exporter.OpenTelemetryProtocol/) package in your project. -- ```dotnetcli - dotnet add package OpenTelemetry.Exporter.OpenTelemetryProtocol - ``` --1. Add the following code snippet. This example assumes you have an OpenTelemetry Collector with an OTLP receiver running. For details, see the [example on GitHub](https://github.com/open-telemetry/opentelemetry-dotnet/blob/main/examples/Console/TestOtlpExporter.cs). -- ```csharp - // Create a new ASP.NET Core web application builder. - var builder = WebApplication.CreateBuilder(args); -- // Add the OpenTelemetry telemetry service to the application. - // This service will collect and send telemetry data to Azure Monitor. - builder.Services.AddOpenTelemetry().UseAzureMonitor(); - - // Add the OpenTelemetry OTLP exporter to the application. - // This exporter will send telemetry data to an OTLP receiver, such as Prometheus - builder.Services.AddOpenTelemetry().WithTracing(builder => builder.AddOtlpExporter()); - builder.Services.AddOpenTelemetry().WithMetrics(builder => builder.AddOtlpExporter()); -- // Build the ASP.NET Core web application. - var app = builder.Build(); -- // Start the ASP.NET Core web application. - app.Run(); - ``` --### [.NET](#tab/net) --1. Install the [OpenTelemetry.Exporter.OpenTelemetryProtocol](https://www.nuget.org/packages/OpenTelemetry.Exporter.OpenTelemetryProtocol/) package in your project. -- ```dotnetcli - dotnet add package OpenTelemetry.Exporter.OpenTelemetryProtocol - ``` --1. Add the following code snippet. This example assumes you have an OpenTelemetry Collector with an OTLP receiver running. For details, see the [example on GitHub](https://github.com/open-telemetry/opentelemetry-dotnet/blob/main/examples/Console/TestOtlpExporter.cs). -- ```csharp - // Create a new OpenTelemetry tracer provider and add the Azure Monitor trace exporter and the OTLP trace exporter. - // It is important to keep the TracerProvider instance active throughout the process lifetime. - var tracerProvider = Sdk.CreateTracerProviderBuilder() - .AddAzureMonitorTraceExporter() - .AddOtlpExporter(); -- // Create a new OpenTelemetry meter provider and add the Azure Monitor metric exporter and the OTLP metric exporter. - // It is important to keep the MetricsProvider instance active throughout the process lifetime. - var metricsProvider = Sdk.CreateMeterProviderBuilder() - .AddAzureMonitorMetricExporter() - .AddOtlpExporter(); - ``` --### [Java](#tab/java) --For more information about Java, see the [Java supplemental documentation](java-standalone-config.md). --### [Java native](#tab/java-native) --You can't enable the OpenTelemetry Protocol (OTLP) Exporter alongside the Azure Monitor Exporter to send your telemetry to two locations. --### [Node.js](#tab/nodejs) --1. Install the [OpenTelemetry Collector Trace Exporter](https://www.npmjs.com/package/@opentelemetry/exporter-trace-otlp-http) and other OpenTelemetry packages in your project. -- ```sh - npm install @opentelemetry/api - npm install @opentelemetry/exporter-trace-otlp-http - npm install @opentelemetry/sdk-trace-base - npm install @opentelemetry/sdk-trace-node - ``` --1. Add the following code snippet. This example assumes you have an OpenTelemetry Collector with an OTLP receiver running. For details, see the [example on GitHub](https://github.com/open-telemetry/opentelemetry-js/tree/main/examples/otlp-exporter-node). -- ```typescript - // Import the useAzureMonitor function, the AzureMonitorOpenTelemetryOptions class, the trace module, the ProxyTracerProvider class, the BatchSpanProcessor class, the NodeTracerProvider class, and the OTLPTraceExporter class from the @azure/monitor-opentelemetry, @opentelemetry/api, @opentelemetry/sdk-trace-base, @opentelemetry/sdk-trace-node, and @opentelemetry/exporter-trace-otlp-http packages, respectively. - const { useAzureMonitor, AzureMonitorOpenTelemetryOptions } = require("@azure/monitor-opentelemetry"); - const { BatchSpanProcessor } = require('@opentelemetry/sdk-trace-base'); - const { OTLPTraceExporter } = require('@opentelemetry/exporter-trace-otlp-http'); -- // Create a new OTLPTraceExporter object. - const otlpExporter = new OTLPTraceExporter(); -- // Enable Azure Monitor integration. - const options: AzureMonitorOpenTelemetryOptions = { - // Add the SpanEnrichingProcessor - spanProcessors: [new BatchSpanProcessor(otlpExporter)] - } - useAzureMonitor(options); - ``` --### [Python](#tab/python) --1. Install the [opentelemetry-exporter-otlp](https://pypi.org/project/opentelemetry-exporter-otlp/) package. --1. Add the following code snippet. This example assumes you have an OpenTelemetry Collector with an OTLP receiver running. For details, see this [README](https://github.com/Azure/azure-sdk-for-python/tree/main/sdk/monitor/azure-monitor-opentelemetry-exporter/samples/traces#collector). -- ```python - # Import the `configure_azure_monitor()`, `trace`, `OTLPSpanExporter`, and `BatchSpanProcessor` classes from the appropriate packages. - from azure.monitor.opentelemetry import configure_azure_monitor - from opentelemetry import trace - from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter - from opentelemetry.sdk.trace.export import BatchSpanProcessor -- # Configure OpenTelemetry to use Azure Monitor with the specified connection string. - # Replace `<your-connection-string>` with the connection string to your Azure Monitor Application Insights resource. - configure_azure_monitor( - connection_string="<your-connection-string>", - ) - - # Get the tracer for the current module. - tracer = trace.get_tracer(__name__) - - # Create an OTLP span exporter that sends spans to the specified endpoint. - # Replace `http://localhost:4317` with the endpoint of your OTLP collector. - otlp_exporter = OTLPSpanExporter(endpoint="http://localhost:4317") - - # Create a batch span processor that uses the OTLP span exporter. - span_processor = BatchSpanProcessor(otlp_exporter) - - # Add the batch span processor to the tracer provider. - trace.get_tracer_provider().add_span_processor(span_processor) - - # Start a new span with the name "test". - with tracer.start_as_current_span("test"): - print("Hello world!") - ``` ----## OpenTelemetry configurations --The following OpenTelemetry configurations can be accessed through environment variables while using the Azure Monitor OpenTelemetry Distros. --### [ASP.NET Core](#tab/aspnetcore) --| Environment variable | Description | -| -- | -- | -| `APPLICATIONINSIGHTS_CONNECTION_STRING` | Set it to the connection string for your Application Insights resource. | -| `APPLICATIONINSIGHTS_STATSBEAT_DISABLED` | Set it to `true` to opt out of internal metrics collection. | -| `OTEL_RESOURCE_ATTRIBUTES` | Key-value pairs to be used as resource attributes. For more information about resource attributes, see the [Resource SDK specification](https://github.com/open-telemetry/opentelemetry-specification/blob/v1.5.0/specification/resource/sdk.md#specifying-resource-information-via-an-environment-variable). | -| `OTEL_SERVICE_NAME` | Sets the value of the `service.name` resource attribute. If `service.name` is also provided in `OTEL_RESOURCE_ATTRIBUTES`, then `OTEL_SERVICE_NAME` takes precedence. | --### [.NET](#tab/net) --| Environment variable | Description | -| -- | -- | -| `APPLICATIONINSIGHTS_CONNECTION_STRING` | Set it to the connection string for your Application Insights resource. | -| `APPLICATIONINSIGHTS_STATSBEAT_DISABLED` | Set it to `true` to opt out of internal metrics collection. | -| `OTEL_RESOURCE_ATTRIBUTES` | Key-value pairs to be used as resource attributes. For more information about resource attributes, see the [Resource SDK specification](https://github.com/open-telemetry/opentelemetry-specification/blob/v1.5.0/specification/resource/sdk.md#specifying-resource-information-via-an-environment-variable). | -| `OTEL_SERVICE_NAME` | Sets the value of the `service.name` resource attribute. If `service.name` is also provided in `OTEL_RESOURCE_ATTRIBUTES`, then `OTEL_SERVICE_NAME` takes precedence. | --### [Java](#tab/java) --For more information about Java, see the [Java supplemental documentation](java-standalone-config.md). --### [Java native](#tab/java-native) --| Environment variable | Description | -| -- | -- | -| `APPLICATIONINSIGHTS_CONNECTION_STRING` | Set it to the connection string for your Application Insights resource. | --For Spring Boot native applications, the [OpenTelemetry Java SDK configurations](https://opentelemetry.io/docs/languages/java/configuration/) are available. --For Quarkus native applications, please look at the [Quarkus OpenTelemetry documentation](https://quarkus.io/guides/opentelemetry#configuration). --### [Node.js](#tab/nodejs) --For more information about OpenTelemetry SDK configuration, see the [OpenTelemetry documentation](https://opentelemetry.io/docs/concepts/sdk-configuration). --### [Python](#tab/python) --For more information about OpenTelemetry SDK configuration, see the [OpenTelemetry documentation](https://opentelemetry.io/docs/concepts/sdk-configuration) and [Azure monitor Distro Usage](https://github.com/Azure/azure-sdk-for-python/blob/main/sdk/monitor/azure-monitor-opentelemetry/README.md#usage). ---- |
| azure-monitor | Opentelemetry Dotnet Migrate | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/opentelemetry-dotnet-migrate.md | - Title: Migrate from Application Insights .NET SDKs to Azure Monitor OpenTelemetry -description: This article provides guidance on how to migrate .NET applications from the Application Insights Classic API SDKs to Azure Monitor OpenTelemetry. - Previously updated : 06/07/2024-----# Migrate from .NET Application Insights SDKs to Azure Monitor OpenTelemetry --This guide provides step-by-step instructions to migrate various .NET applications from using Application Insights software development kits (SDKs) to Azure Monitor OpenTelemetry. --Expect a similar experience with Azure Monitor OpenTelemetry instrumentation as with the Application Insights SDKs. For more information and a feature-by-feature comparison, see [release state of features](opentelemetry-enable.md#whats-the-current-release-state-of-features-within-the-azure-monitor-opentelemetry-distro). --> [!div class="checklist"] -> - ASP.NET Core migration to the [Azure Monitor OpenTelemetry Distro](https://www.nuget.org/packages/Azure.Monitor.OpenTelemetry.AspNetCore). (`Azure.Monitor.OpenTelemetry.AspNetCore` NuGet package) -> - ASP.NET, console, and WorkerService migration to the [Azure Monitor OpenTelemetry Exporter](https://www.nuget.org/packages/Azure.Monitor.OpenTelemetry.Exporter). (`Azure.Monitor.OpenTelemetry.Exporter` NuGet package) --If you're getting started with Application Insights and don't need to migrate from the Classic API, see [Enable Azure Monitor OpenTelemetry](opentelemetry-enable.md). --## Prerequisites --### [ASP.NET Core](#tab/aspnetcore) --* An ASP.NET Core web application already instrumented with Application Insights without any customizations -* An actively supported version of [.NET](https://dotnet.microsoft.com/platform/support/policy/dotnet-core) --### [ASP.NET](#tab/net) --* An ASP.NET web application already instrumented with Application Insights -* An actively supported version of [.NET Framework](/lifecycle/products/microsoft-net-framework) --### [Console](#tab/console) --* A Console application already instrumented with Application Insights -* An actively supported version of [.NET Framework](/lifecycle/products/microsoft-net-framework) or [.NET](https://dotnet.microsoft.com/platform/support/policy/dotnet-core) --### [WorkerService](#tab/workerservice) --* A WorkerService application already instrumented with Application Insights without any customizations -* An actively supported version of [.NET](https://dotnet.microsoft.com/platform/support/policy/dotnet-core) ----> [!Tip] -> Our product group is actively seeking feedback on this documentation. Provide feedback to otel@microsoft.com or see the [Support](#support) section. --## Remove the Application Insights SDK --> [!Note] -> Before continuing with these steps, you should confirm that you have a current backup of your application. --### [ASP.NET Core](#tab/aspnetcore) --1. Remove NuGet packages -- Remove the `Microsoft.ApplicationInsights.AspNetCore` package from your `csproj`. -- ```terminal - dotnet remove package Microsoft.ApplicationInsights.AspNetCore - ``` --2. Remove Initialization Code and customizations -- Remove any references to Application Insights types in your codebase. -- > [!Tip] - > After removing the Application Insights package, you can re-build your application to get a list of references that need to be removed. -- - Remove Application Insights from your `ServiceCollection` by deleting the following line: -- ```csharp - builder.Services.AddApplicationInsightsTelemetry(); - ``` -- - Remove the `ApplicationInsights` section from your `appsettings.json`. -- ```json - { - "ApplicationInsights": { - "ConnectionString": "<Your Connection String>" - } - } - ``` --3. Clean and Build -- Inspect your bin directory to validate that all references to `Microsoft.ApplicationInsights.*` were removed. --4. Test your application -- Verify that your application has no unexpected consequences. --### [ASP.NET](#tab/net) --1. Remove NuGet packages -- Remove the `Microsoft.AspNet.TelemetryCorrelation` package and any `Microsoft.ApplicationInsights.*` packages from your `csproj` and `packages.config`. --2. Delete the `ApplicationInsights.config` file --3. Delete section from your application's `Web.config` file -- - Two [HttpModules](/troubleshoot/developer/webapps/aspnet/development/http-modules-handlers) were automatically added to your web.config when you first added ApplicationInsights to your project. - Any references to the `TelemetryCorrelationHttpModule` and the `ApplicationInsightsWebTracking` should be removed. - If you added Application Insights to your [Internet Information Server (IIS) Modules](/iis/get-started/introduction-to-iis/iis-modules-overview), it should also be removed. -- ```xml - <configuration> - <system.web> - <httpModules> - <add name="TelemetryCorrelationHttpModule" type="Microsoft.AspNet.TelemetryCorrelation.TelemetryCorrelationHttpModule, Microsoft.AspNet.TelemetryCorrelation" /> - <add name="ApplicationInsightsWebTracking" type="Microsoft.ApplicationInsights.Web.ApplicationInsightsHttpModule, Microsoft.AI.Web" /> - </httpModules> - </system.web> - <system.webServer> - <modules> - <remove name="TelemetryCorrelationHttpModule" /> - <add name="TelemetryCorrelationHttpModule" type="Microsoft.AspNet.TelemetryCorrelation.TelemetryCorrelationHttpModule, Microsoft.AspNet.TelemetryCorrelation" preCondition="managedHandler" /> - <remove name="ApplicationInsightsWebTracking" /> - <add name="ApplicationInsightsWebTracking" type="Microsoft.ApplicationInsights.Web.ApplicationInsightsHttpModule, Microsoft.AI.Web" preCondition="managedHandler" /> - </modules> - </system.webServer> - </configuration> - ``` -- - Also review any [assembly version redirections](/dotnet/framework/configure-apps/redirect-assembly-versions) added to your web.config. --4. Remove Initialization Code and customizations -- Remove any references to Application Insights types in your codebase. -- > [!Tip] - > After removing the Application Insights package, you can re-build your application to get a list of references that need to be removed. -- - Remove references to `TelemetryConfiguration` or `TelemetryClient`. It's a part of your application startup to initialize the Application Insights SDK. -- The following scenarios are optional and apply to advanced users. -- - If you have any more references to the `TelemetryClient`, which are used to [manually record telemetry](./api-custom-events-metrics.md), they should be removed. - - If you added any [custom filtering or enrichment](./api-filtering-sampling.md) in the form of a custom `TelemetryProcessor` or `TelemetryInitializer`, they should be removed. You can find them referenced in your configuration. - - If your project has a `FilterConfig.cs` in the `App_Start` directory, check for any custom exception handlers that reference Application Insights and remove. --5. Remove JavaScript Snippet -- If you added the JavaScript SDK to collect client-side telemetry, it can also be removed although it continues to work without the .NET SDK. - For full code samples of what to remove, review the [onboarding guide for the JavaScript SDK](./javascript-sdk.md). --6. Remove any Visual Studio Artifacts -- If you used Visual Studio to onboard to Application Insights, you could have more files left over in your project. -- - `ConnectedService.json` might have a reference to your Application Insights resource. - - `[Your project's name].csproj` might have a reference to your Application Insights resource: -- ```xml - <ApplicationInsightsResourceId>/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/Default-ApplicationInsights-EastUS/providers/microsoft.insights/components/WebApplication4</ApplicationInsightsResourceId> - ``` --7. Clean and Build -- Inspect your bin directory to validate that all references to `Microsoft.ApplicationInsights.` were removed. --8. Test your application -- Verify that your application has no unexpected consequences. --### [Console](#tab/console) --1. Remove NuGet packages -- Remove any `Microsoft.ApplicationInsights.*` packages from your `csproj` and `packages.config`. -- ```terminal - dotnet remove package Microsoft.ApplicationInsights - ``` -- > [!Tip] - > If you've used [Microsoft.ApplicationInsights.WorkerService](https://www.nuget.org/packages/Microsoft.ApplicationInsights.WorkerService), refer to the WorkerService tabs. --2. Remove Initialization Code and customizations -- Remove any references to Application Insights types in your codebase. -- > [!Tip] - > After removing the Application Insights package, you can re-build your application to get a list of references that need to be removed. -- - Remove references to `TelemetryConfiguration` or `TelemetryClient`. It should be part of your application startup to initialize the Application Insights SDK. -- ```csharp - var config = TelemetryConfiguration.CreateDefault(); - var client = new TelemetryClient(config); - ``` -- > [!Tip] - > If you've used `AddApplicationInsightsTelemetryWorkerService()` to add Application Insights to your `ServiceCollection`, refer to the WorkerService tabs. --3. Clean and Build -- Inspect your bin directory to validate that all references to `Microsoft.ApplicationInsights.` were removed. --4. Test your application -- Verify that your application has no unexpected consequences. --### [WorkerService](#tab/workerservice) --1. Remove NuGet packages -- Remove the `Microsoft.ApplicationInsights.WorkerService` package from your `csproj`. -- ```terminal - dotnet remove package Microsoft.ApplicationInsights.AspNetCore - ``` --2. Remove Initialization Code and customizations -- Remove any references to Application Insights types in your codebase. -- > [!Tip] - > After removing the Application Insights package, you can re-build your application to get a list of references that need to be removed. -- - Remove Application Insights from your `ServiceCollection` by deleting the following line: -- ```csharp - builder.Services.AddApplicationInsightsTelemetryWorkerService(); - ``` -- - Remove the `ApplicationInsights` section from your `appsettings.json`. -- ```json - { - "ApplicationInsights": { - "ConnectionString": "<Your Connection String>" - } - } - ``` --3. Clean and Build -- Inspect your bin directory to validate that all references to `Microsoft.ApplicationInsights.*` were removed. --4. Test your application -- Verify that your application has no unexpected consequences. ----> [!Tip] -> Our product group is actively seeking feedback on this documentation. Provide feedback to otel@microsoft.com or see the [Support](#support) section. --## Enable OpenTelemetry --We recommended creating a development [resource](./create-workspace-resource.md) and using its [connection string](./sdk-connection-string.md) when following these instructions. ---Plan to update the connection string to send telemetry to the original resource after confirming migration is successful. --### [ASP.NET Core](#tab/aspnetcore) --1. Install the Azure Monitor Distro -- Our Azure Monitor Distro enables automatic telemetry by including OpenTelemetry instrumentation libraries for collecting traces, metrics, logs, and exceptions, and allows collecting custom telemetry. -- Installing the Azure Monitor Distro brings the [OpenTelemetry SDK](https://www.nuget.org/packages/OpenTelemetry) as a dependency. -- ```terminal - dotnet add package Azure.Monitor.OpenTelemetry.AspNetCore - ``` --2. Add and configure both OpenTelemetry and Azure Monitor -- The OpenTelemery SDK must be configured at application startup as part of your `ServiceCollection`, typically in the `Program.cs`. -- OpenTelemetry has a concept of three signals; Traces, Metrics, and Logs. - The Azure Monitor Distro configures each of these signals. --##### Program.cs --The following code sample demonstrates the basics. --```csharp -using Azure.Monitor.OpenTelemetry.AspNetCore; -using Microsoft.AspNetCore.Builder; -using Microsoft.Extensions.DependencyInjection; --public class Program -{ - public static void Main(string[] args) - { - var builder = WebApplication.CreateBuilder(args); -- // Call AddOpenTelemetry() to add OpenTelemetry to your ServiceCollection. - // Call UseAzureMonitor() to fully configure OpenTelemetry. - builder.Services.AddOpenTelemetry().UseAzureMonitor(); -- var app = builder.Build(); - app.MapGet("/", () => "Hello World!"); - app.Run(); - } -} -``` --We recommend setting your Connection String in an environment variable: --`APPLICATIONINSIGHTS_CONNECTION_STRING=<Your Connection String>` --More options to configure the Connection String are detailed here: [Configure the Application Insights Connection String](./opentelemetry-configuration.md?tabs=aspnetcore#connection-string). --### [ASP.NET](#tab/net) --1. Install the OpenTelemetry SDK via Azure Monitor -- Installing the Azure Monitor Exporter brings the [OpenTelemetry SDK](https://www.nuget.org/packages/OpenTelemetry) as a dependency. -- ```terminal - dotnet add package Azure.Monitor.OpenTelemetry.Exporter - ``` --2. Configure OpenTelemetry as part of your application startup -- The OpenTelemery SDK must be configured at application startup, typically in the `Global.asax.cs`. - OpenTelemetry has a concept of three signals; Traces, Metrics, and Logs. - Each of these signals needs to be configured as part of your application startup. - `TracerProvider`, `MeterProvider`, and `ILoggerFactory` should be created once for your application and disposed when your application shuts down. --##### Global.asax.cs --The following code sample shows a simple example meant only to show the basics. -No telemetry is collected at this point. --```csharp -using Microsoft.Extensions.Logging; -using OpenTelemetry; -using OpenTelemetry.Metrics; -using OpenTelemetry.Trace; --public class Global : System.Web.HttpApplication -{ - private TracerProvider? tracerProvider; - private MeterProvider? meterProvider; - // The LoggerFactory needs to be accessible from the rest of your application. - internal static ILoggerFactory loggerFactory; -- protected void Application_Start() - { - this.tracerProvider = Sdk.CreateTracerProviderBuilder() - .Build(); -- this.meterProvider = Sdk.CreateMeterProviderBuilder() - .Build(); -- loggerFactory = LoggerFactory.Create(builder => - { - builder.AddOpenTelemetry(); - }); - } -- protected void Application_End() - { - this.tracerProvider?.Dispose(); - this.meterProvider?.Dispose(); - loggerFactory?.Dispose(); - } -} -``` --### [Console](#tab/console) --1. Install the OpenTelemetry SDK via Azure Monitor -- Installing the [Azure Monitor Exporter](https://www.nuget.org/packages/Azure.Monitor.OpenTelemetry.Exporter) brings the [OpenTelemetry SDK](https://www.nuget.org/packages/OpenTelemetry) as a dependency. -- ```terminal - dotnet add package Azure.Monitor.OpenTelemetry.Exporter - ``` --2. Configure OpenTelemetry as part of your application startup -- The OpenTelemery SDK must be configured at application startup, typically in the `Program.cs`. - OpenTelemetry has a concept of three signals; Traces, Metrics, and Logs. - Each of these signals needs to be configured as part of your application startup. - `TracerProvider`, `MeterProvider`, and `ILoggerFactory` should be created once for your application and disposed when your application shuts down. --The following code sample shows a simple example meant only to show the basics. -No telemetry is collected at this point. --##### Program.cs --```csharp -using Microsoft.Extensions.Logging; -using OpenTelemetry; -using OpenTelemetry.Metrics; -using OpenTelemetry.Trace; --internal class Program -{ - static void Main(string[] args) - { - TracerProvider tracerProvider = Sdk.CreateTracerProviderBuilder() - .Build(); -- MeterProvider meterProvider = Sdk.CreateMeterProviderBuilder() - .Build(); -- ILoggerFactory loggerFactory = LoggerFactory.Create(builder => - { - builder.AddOpenTelemetry(); - }); -- Console.WriteLine("Hello, World!"); -- // Dispose tracer provider before the application ends. - // It will flush the remaining spans and shutdown the tracing pipeline. - tracerProvider.Dispose(); -- // Dispose meter provider before the application ends. - // It will flush the remaining metrics and shutdown the metrics pipeline. - meterProvider.Dispose(); -- // Dispose logger factory before the application ends. - // It will flush the remaining logs and shutdown the logging pipeline. - loggerFactory.Dispose(); - } -} -``` --### [WorkerService](#tab/workerservice) --1. Install the OpenTelemetry SDK via Azure Monitor -- Installing the [Azure Monitor Exporter](https://www.nuget.org/packages/Azure.Monitor.OpenTelemetry.Exporter) brings the [OpenTelemetry SDK](https://www.nuget.org/packages/OpenTelemetry) as a dependency. -- ```terminal - dotnet add package Azure.Monitor.OpenTelemetry.Exporter - ``` -- You must also install the [OpenTelemetry Extensions Hosting](https://www.nuget.org/packages/OpenTelemetry.Extensions.Hosting) package. -- ```terminal - dotnet add package OpenTelemetry.Extensions.Hosting - ``` --2. Configure OpenTelemetry as part of your application startup -- The OpenTelemery SDK must be configured at application startup, typically in the `Program.cs`. - OpenTelemetry has a concept of three signals; Traces, Metrics, and Logs. - Each of these signals needs to be configured as part of your application startup. - `TracerProvider`, `MeterProvider`, and `ILoggerFactory` should be created once for your application and disposed when your application shuts down. --The following code sample shows a simple example meant only to show the basics. -No telemetry is collected at this point. --##### Program.cs --```csharp -using Microsoft.Extensions.DependencyInjection; -using Microsoft.Extensions.Hosting; -using Microsoft.Extensions.Logging; --public class Program -{ - public static void Main(string[] args) - { - var builder = Host.CreateApplicationBuilder(args); - builder.Services.AddHostedService<Worker>(); -- builder.Services.AddOpenTelemetry() - .WithTracing() - .WithMetrics(); -- builder.Logging.AddOpenTelemetry(); -- var host = builder.Build(); - host.Run(); - } -} -``` ----> [!Tip] -> Our product group is actively seeking feedback on this documentation. Provide feedback to otel@microsoft.com or see the [Support](#support) section. --## Install and configure instrumentation libraries --### [ASP.NET Core](#tab/aspnetcore) --[Instrumentation libraries](https://opentelemetry.io/docs/specs/otel/overview/#instrumentation-libraries) can be added to your project to auto collect telemetry about specific components or dependencies. --The following libraries are included in the Distro. --- [HTTP](https://www.nuget.org/packages/OpenTelemetry.Instrumentation.Http)-- [ASP.NET Core](https://www.nuget.org/packages/OpenTelemetry.Instrumentation.AspNetCore)-- [SQL](https://www.nuget.org/packages/OpenTelemetry.Instrumentation.sqlclient)--#### Customizing instrumentation libraries --The Azure Monitor Distro includes .NET OpenTelemetry instrumentation for [ASP.NET Core](https://www.nuget.org/packages/OpenTelemetry.Instrumentation.AspNetCore/), [HttpClient](https://www.nuget.org/packages/OpenTelemetry.Instrumentation.Http/), and [SQLClient](https://www.nuget.org/packages/OpenTelemetry.Instrumentation.SqlClient). -You can customize these included instrumentations or manually add extra instrumentation on your own using the OpenTelemetry API. --Here are some examples of how to customize the instrumentation: --##### Customizing AspNetCoreTraceInstrumentationOptions --```C# -builder.Services.AddOpenTelemetry().UseAzureMonitor(); -builder.Services.Configure<AspNetCoreTraceInstrumentationOptions>(options => -{ - options.RecordException = true; - options.Filter = (httpContext) => - { - // only collect telemetry about HTTP GET requests - return HttpMethods.IsGet(httpContext.Request.Method); - }; -}); -``` --##### Customizing HttpClientTraceInstrumentationOptions --```C# -builder.Services.AddOpenTelemetry().UseAzureMonitor(); -builder.Services.Configure<HttpClientTraceInstrumentationOptions>(options => -{ - options.RecordException = true; - options.FilterHttpRequestMessage = (httpRequestMessage) => - { - // only collect telemetry about HTTP GET requests - return HttpMethods.IsGet(httpRequestMessage.Method.Method); - }; -}); -``` --##### Customizing SqlClientInstrumentationOptions --We vendor the [SQLClient](https://www.nuget.org/packages/OpenTelemetry.Instrumentation.SqlClient) instrumentation within our package while it's still in beta. When it reaches a stable release, we include it as a standard package reference. Until then, to customize the SQLClient instrumentation, add the `OpenTelemetry.Instrumentation.SqlClient` package reference to your project and use its public API. --``` -dotnet add package --prerelease OpenTelemetry.Instrumentation.SqlClient -``` --```C# -builder.Services.AddOpenTelemetry().UseAzureMonitor().WithTracing(builder => -{ - builder.AddSqlClientInstrumentation(options => - { - options.SetDbStatementForStoredProcedure = false; - }); -}); -``` --### [ASP.NET](#tab/net) --[Instrumentation libraries](https://opentelemetry.io/docs/specs/otel/overview/#instrumentation-libraries) can be added to your project to auto collect telemetry about specific components or dependencies. We recommend the following libraries: --1. [OpenTelemetry.Instrumentation.AspNet](https://www.nuget.org/packages/OpenTelemetry.Instrumentation.AspNet) can be used to collect telemetry for incoming requests. Azure Monitor maps it to [Request Telemetry](./data-model-complete.md#request). -- ```terminal - dotnet add package OpenTelemetry.Instrumentation.AspNet - ``` -- It requires adding an extra HttpModule to your `Web.config`: -- ```xml - <system.webServer> - <modules> - <add - name="TelemetryHttpModule" - type="OpenTelemetry.Instrumentation.AspNet.TelemetryHttpModule, - OpenTelemetry.Instrumentation.AspNet.TelemetryHttpModule" - preCondition="integratedMode,managedHandler" /> - </modules> - </system.webServer> - ``` -- A complete getting started guide is available here: [OpenTelemetry.Instrumentation.AspNet Readme](https://github.com/open-telemetry/opentelemetry-dotnet-contrib/tree/main/src/OpenTelemetry.Instrumentation.AspNet) --2. [OpenTelemetry.Instrumentation.Http](https://www.nuget.org/packages/OpenTelemetry.Instrumentation.Http) can be used to collect telemetry for outbound http dependencies. Azure Monitor maps it to [Dependency Telemetry](./data-model-complete.md#dependency). -- ```terminal - dotnet add package OpenTelemetry.Instrumentation.Http - ``` -- A complete getting started guide is available here: [OpenTelemetry.Instrumentation.Http Readme](https://github.com/open-telemetry/opentelemetry-dotnet-contrib/tree/main/src/OpenTelemetry.Instrumentation.Http) --3. [OpenTelemetry.Instrumentation.SqlClient](https://www.nuget.org/packages/OpenTelemetry.Instrumentation.SqlClient) can be used to collect telemetry for MS SQL dependencies. Azure Monitor maps it to [Dependency Telemetry](./data-model-complete.md#dependency). -- ```terminal - dotnet add package --prerelease OpenTelemetry.Instrumentation.SqlClient - ``` -- A complete getting started guide is available here: [OpenTelemetry.Instrumentation.SqlClient Readme](https://github.com/open-telemetry/opentelemetry-dotnet-contrib/tree/main/src/OpenTelemetry.Instrumentation.SqlClient) --##### Global.asax.cs --The following code sample expands on the previous example. -It now collects telemetry, but doesn't yet send to Application Insights. --```csharp -using Microsoft.Extensions.Logging; -using OpenTelemetry; -using OpenTelemetry.Metrics; -using OpenTelemetry.Trace; --public class Global : System.Web.HttpApplication -{ - private TracerProvider? tracerProvider; - private MeterProvider? meterProvider; - internal static ILoggerFactory loggerFactory; -- protected void Application_Start() - { - this.tracerProvider = Sdk.CreateTracerProviderBuilder() - .AddAspNetInstrumentation() - .AddHttpClientInstrumentation() - .AddSqlClientInstrumentation() - .Build(); -- this.meterProvider = Sdk.CreateMeterProviderBuilder() - .AddAspNetInstrumentation() - .AddHttpClientInstrumentation() - .Build(); -- loggerFactory = LoggerFactory.Create(builder => - { - builder.AddOpenTelemetry(); - }); - } -- protected void Application_End() - { - this.tracerProvider?.Dispose(); - this.meterProvider?.Dispose(); - loggerFactory?.Dispose(); - } -} -``` --### [Console](#tab/console) --[Instrumentation libraries](https://opentelemetry.io/docs/specs/otel/overview/#instrumentation-libraries) can be added to your project to auto collect telemetry about specific components or dependencies. We recommend the following libraries: --1. [OpenTelemetry.Instrumentation.Http](https://www.nuget.org/packages/OpenTelemetry.Instrumentation.Http) can be used to collect telemetry for outbound http dependencies. Azure Monitor maps it to [Dependency Telemetry](./data-model-complete.md#dependency). -- ```terminal - dotnet add package OpenTelemetry.Instrumentation.Http - ``` -- A complete getting started guide is available here: [OpenTelemetry.Instrumentation.Http Readme](https://github.com/open-telemetry/opentelemetry-dotnet-contrib/tree/main/src/OpenTelemetry.Instrumentation.Http) --2. [OpenTelemetry.Instrumentation.SqlClient](https://www.nuget.org/packages/OpenTelemetry.Instrumentation.SqlClient) can be used to collect telemetry for MS SQL dependencies. Azure Monitor maps it to [Dependency Telemetry](./data-model-complete.md#dependency). -- ```terminal - dotnet add package --prerelease OpenTelemetry.Instrumentation.SqlClient - ``` -- A complete getting started guide is available here: [OpenTelemetry.Instrumentation.SqlClient Readme](https://github.com/open-telemetry/opentelemetry-dotnet-contrib/tree/main/src/OpenTelemetry.Instrumentation.SqlClient) --The following code sample expands on the previous example. -It now collects telemetry, but doesn't yet send to Application Insights. --##### Program.cs --```csharp -using Microsoft.Extensions.Logging; -using OpenTelemetry; -using OpenTelemetry.Metrics; -using OpenTelemetry.Trace; --internal class Program -{ - static void Main(string[] args) - { - TracerProvider tracerProvider = Sdk.CreateTracerProviderBuilder() - .AddHttpClientInstrumentation() - .AddSqlClientInstrumentation() - .Build(); -- MeterProvider meterProvider = Sdk.CreateMeterProviderBuilder() - .AddHttpClientInstrumentation() - .Build(); -- ILoggerFactory loggerFactory = LoggerFactory.Create(builder => - { - builder.AddOpenTelemetry(); - }); -- Console.WriteLine("Hello, World!"); -- tracerProvider.Dispose(); - meterProvider.Dispose(); - loggerFactory.Dispose(); - } -} -``` --### [WorkerService](#tab/workerservice) --[Instrumentation libraries](https://opentelemetry.io/docs/specs/otel/overview/#instrumentation-libraries) can be added to your project to auto collect telemetry about specific components or dependencies. We recommend the following libraries: --1. [OpenTelemetry.Instrumentation.Http](https://www.nuget.org/packages/OpenTelemetry.Instrumentation.Http) can be used to collect telemetry for outbound http dependencies. Azure Monitor maps it to [Dependency Telemetry](./data-model-complete.md#dependency). -- ```terminal - dotnet add package OpenTelemetry.Instrumentation.Http - ``` -- A complete getting started guide is available here: [OpenTelemetry.Instrumentation.Http Readme](https://github.com/open-telemetry/opentelemetry-dotnet-contrib/tree/main/src/OpenTelemetry.Instrumentation.Http) --2. [OpenTelemetry.Instrumentation.SqlClient](https://www.nuget.org/packages/OpenTelemetry.Instrumentation.SqlClient) can be used to collect telemetry for MS SQL dependencies. Azure Monitor maps it to [Dependency Telemetry](./data-model-complete.md#dependency). -- ```terminal - dotnet add package --prerelease OpenTelemetry.Instrumentation.SqlClient - ``` -- A complete getting started guide is available here: [OpenTelemetry.Instrumentation.SqlClient Readme](https://github.com/open-telemetry/opentelemetry-dotnet-contrib/tree/main/src/OpenTelemetry.Instrumentation.SqlClient) --The following code sample expands on the previous example. -It now collects telemetry, but doesn't yet send to Application Insights. --##### Program.cs --```csharp -using Microsoft.Extensions.DependencyInjection; -using Microsoft.Extensions.Hosting; -using Microsoft.Extensions.Logging; --public class Program -{ - public static void Main(string[] args) - { - var builder = Host.CreateApplicationBuilder(args); - builder.Services.AddHostedService<Worker>(); -- builder.Services.AddOpenTelemetry() - .WithTracing(builder => - { - builder.AddHttpClientInstrumentation(); - builder.AddSqlClientInstrumentation(); - }) - .WithMetrics(builder => - { - builder.AddHttpClientInstrumentation(); - }); -- builder.Logging.AddOpenTelemetry(); -- var host = builder.Build(); - host.Run(); - } -} -``` ----## Configure Azure Monitor --### [ASP.NET Core](#tab/aspnetcore) --Application Insights offered many more configuration options via `ApplicationInsightsServiceOptions`. --| Application Insights Setting | OpenTelemetry Alternative | -|--|-| -| AddAutoCollectedMetricExtractor | N/A | -| ApplicationVersion | Set "service.version" on Resource | -| ConnectionString | See [instructions](./opentelemetry-configuration.md?tabs=aspnetcore#connection-string) on configuring the Connection String. | -| DependencyCollectionOptions | N/A. To customize dependencies, review the available configuration options for applicable Instrumentation libraries. | -| DeveloperMode | N/A | -| EnableActiveTelemetryConfigurationSetup | N/A | -| EnableAdaptiveSampling | N/A. Only fixed-rate sampling is supported. | -| EnableAppServicesHeartbeatTelemetryModule | N/A | -| EnableAuthenticationTrackingJavaScript | N/A | -| EnableAzureInstanceMetadataTelemetryModule | N/A | -| EnableDependencyTrackingTelemetryModule | See instructions on filtering Traces. | -| EnableDiagnosticsTelemetryModule | N/A | -| EnableEventCounterCollectionModule | N/A | -| EnableHeartbeat | N/A | -| EnablePerformanceCounterCollectionModule | N/A | -| EnableQuickPulseMetricStream | AzureMonitorOptions.EnableLiveMetrics | -| EnableRequestTrackingTelemetryModule | See instructions on filtering Traces. | -| EndpointAddress | Use ConnectionString. | -| InstrumentationKey | Use ConnectionString. | -| RequestCollectionOptions | N/A. See OpenTelemetry.Instrumentation.AspNetCore options. | --### Remove custom configurations --The following scenarios are optional and only apply to advanced users. --* If you have any more references to the `TelemetryClient`, which could be used to [manually record telemetry](./api-custom-events-metrics.md), they should be removed. -* If you added any [custom filtering or enrichment](./api-filtering-sampling.md) in the form of a custom `TelemetryProcessor` or `TelemetryInitializer`, they should be removed. They can be found in your `ServiceCollection`. -- ```csharp - builder.Services.AddSingleton<ITelemetryInitializer, MyCustomTelemetryInitializer>(); - ``` -- ```csharp - builder.Services.AddApplicationInsightsTelemetryProcessor<MyCustomTelemetryProcessor>(); - ``` --* Remove JavaScript Snippet -- If you used the Snippet provided by the Application Insights .NET SDK, it must also be removed. - For full code samples of what to remove, review the guide [enable client-side telemetry for web applications](./asp-net-core.md?tabs=netcorenew#enable-client-side-telemetry-for-web-applications). -- If you added the JavaScript SDK to collect client-side telemetry, it can also be removed although it continues to work without the .NET SDK. - For full code samples of what to remove, review the [onboarding guide for the JavaScript SDK](./javascript-sdk.md). --* Remove any Visual Studio Artifacts -- If you used Visual Studio to onboard to Application Insights, you could have more files left over in your project. -- - `Properties/ServiceDependencies` directory might have a reference to your Application Insights resource. --### [ASP.NET](#tab/net) --To send your telemetry to Application Insights, the Azure Monitor Exporter must be added to the configuration of all three signals. --##### Global.asax.cs --The following code sample expands on the previous example. -It now collects telemetry and sends to Application Insights. --```csharp -public class Global : System.Web.HttpApplication -{ - private TracerProvider? tracerProvider; - private MeterProvider? meterProvider; - internal static ILoggerFactory loggerFactory; -- protected void Application_Start() - { - this.tracerProvider = Sdk.CreateTracerProviderBuilder() - .AddAspNetInstrumentation() - .AddHttpClientInstrumentation() - .AddSqlClientInstrumentation() - .AddAzureMonitorTraceExporter() - .Build(); -- this.meterProvider = Sdk.CreateMeterProviderBuilder() - .AddAspNetInstrumentation() - .AddHttpClientInstrumentation() - .AddAzureMonitorMetricExporter() - .Build(); -- loggerFactory = LoggerFactory.Create(builder => - { - builder.AddOpenTelemetry(o => o.AddAzureMonitorLogExporter()); - }); - } -- protected void Application_End() - { - this.tracerProvider?.Dispose(); - this.meterProvider?.Dispose(); - loggerFactory?.Dispose(); - } -} -``` --We recommend setting your Connection String in an environment variable: --`APPLICATIONINSIGHTS_CONNECTION_STRING=<Your Connection String>` --More options to configure the Connection String are detailed here: [Configure the Application Insights Connection String](./opentelemetry-configuration.md?tabs=net#connection-string). --### [Console](#tab/console) --To send your telemetry to Application Insights, the Azure Monitor Exporter must be added to the configuration of all three signals. --##### Program.cs --The following code sample expands on the previous example. -It now collects telemetry and sends to Application Insights. --```csharp -using Microsoft.Extensions.Logging; -using OpenTelemetry; -using OpenTelemetry.Metrics; -using OpenTelemetry.Trace; --internal class Program -{ - static void Main(string[] args) - { - TracerProvider tracerProvider = Sdk.CreateTracerProviderBuilder() - .AddHttpClientInstrumentation() - .AddSqlClientInstrumentation() - .AddAzureMonitorTraceExporter() - .Build(); -- MeterProvider meterProvider = Sdk.CreateMeterProviderBuilder() - .AddHttpClientInstrumentation() - .AddAzureMonitorMetricExporter() - .Build(); -- ILoggerFactory loggerFactory = LoggerFactory.Create(builder => - { - builder.AddOpenTelemetry(o => o.AddAzureMonitorLogExporter()); - }); -- Console.WriteLine("Hello, World!"); -- tracerProvider.Dispose(); - meterProvider.Dispose(); - loggerFactory.Dispose(); - } -} -``` --We recommend setting your Connection String in an environment variable: --`APPLICATIONINSIGHTS_CONNECTION_STRING=<Your Connection String>` --More options to configure the Connection String are detailed here: [Configure the Application Insights Connection String](./opentelemetry-configuration.md?tabs=net#connection-string). --### Remove custom configurations --The following scenarios are optional and apply to advanced users. --* If you have any more references to the `TelemetryClient`, which is used to [manually record telemetry](./api-custom-events-metrics.md), they should be removed. --* Remove any [custom filtering or enrichment](./api-filtering-sampling.md) added as a custom `TelemetryProcessor` or `TelemetryInitializer`. The configuration references them. --* Remove any Visual Studio Artifacts -- If you used Visual Studio to onboard to Application Insights, you could have more files left over in your project. -- - `ConnectedService.json` might have a reference to your Application Insights resource. - - `[Your project's name].csproj` might have a reference to your Application Insights resource: -- ```xml - <ApplicationInsightsResourceId>/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/Default-ApplicationInsights-EastUS/providers/microsoft.insights/components/WebApplication4</ApplicationInsightsResourceId> - ``` --### [WorkerService](#tab/workerservice) --To send your telemetry to Application Insights, the Azure Monitor Exporter must be added to the configuration of all three signals. --##### Program.cs --The following code sample expands on the previous example. -It now collects telemetry and sends to Application Insights. --```csharp -using Microsoft.Extensions.DependencyInjection; -using Microsoft.Extensions.Hosting; -using Microsoft.Extensions.Logging; --public class Program -{ - public static void Main(string[] args) - { - var builder = Host.CreateApplicationBuilder(args); - builder.Services.AddHostedService<Worker>(); -- builder.Services.AddOpenTelemetry() - .WithTracing(builder => - { - builder.AddHttpClientInstrumentation(); - builder.AddSqlClientInstrumentation(); - builder.AddAzureMonitorTraceExporter(); - }) - .WithMetrics(builder => - { - builder.AddHttpClientInstrumentation(); - builder.AddAzureMonitorMetricExporter(); - }); -- builder.Logging.AddOpenTelemetry(builder => builder.AddAzureMonitorLogExporter()); -- var host = builder.Build(); - host.Run(); - } -} -``` --We recommend setting your Connection String in an environment variable: --`APPLICATIONINSIGHTS_CONNECTION_STRING=<Your Connection String>` --More options to configure the Connection String are detailed here: [Configure the Application Insights Connection String](./opentelemetry-configuration.md?tabs=net#connection-string). --#### More configurations --Application Insights offered many more configuration options via `ApplicationInsightsServiceOptions`. --| Application Insights Setting | OpenTelemetry Alternative | -|--|-| -| AddAutoCollectedMetricExtractor | N/A | -| ApplicationVersion | Set "service.version" on Resource | -| ConnectionString | See [instructions](./opentelemetry-configuration.md?tabs=aspnetcore#connection-string) on configuring the Connection String. | -| DependencyCollectionOptions | N/A. To customize dependencies, review the available configuration options for applicable Instrumentation libraries. | -| DeveloperMode | N/A | -| EnableAdaptiveSampling | N/A. Only fixed-rate sampling is supported. | -| EnableAppServicesHeartbeatTelemetryModule | N/A | -| EnableAzureInstanceMetadataTelemetryModule | N/A | -| EnableDependencyTrackingTelemetryModule | See instructions on filtering Traces. | -| EnableDiagnosticsTelemetryModule | N/A | -| EnableEventCounterCollectionModule | N/A | -| EnableHeartbeat | N/A | -| EnablePerformanceCounterCollectionModule | N/A | -| EnableQuickPulseMetricStream | AzureMonitorOptions.EnableLiveMetrics | -| EndpointAddress | Use ConnectionString. | -| InstrumentationKey | Use ConnectionString. | --### Remove Custom Configurations --The following scenarios are optional and apply to advanced users. --* If you have any more references to the `TelemetryClient`, which are used to [manually record telemetry](./api-custom-events-metrics.md), they should be removed. --* If you added any [custom filtering or enrichment](./api-filtering-sampling.md) in the form of a custom `TelemetryProcessor` or `TelemetryInitializer`, it should be removed. You can find references in your `ServiceCollection`. -- ```csharp - builder.Services.AddSingleton<ITelemetryInitializer, MyCustomTelemetryInitializer>(); - ``` -- ```csharp - builder.Services.AddApplicationInsightsTelemetryProcessor<MyCustomTelemetryProcessor>(); - ``` --* Remove any Visual Studio Artifacts -- If you used Visual Studio to onboard to Application Insights, you could have more files left over in your project. -- - `Properties/ServiceDependencies` directory might have a reference to your Application Insights resource. ----> [!Tip] -> Our product group is actively seeking feedback on this documentation. Provide feedback to otel@microsoft.com or see the [Support](#support) section. --## Frequently asked questions --This section is for customers who use telemetry initializers or processors, or write custom code against the classic Application Insights API to create custom telemetry. --### How do the SDK API's map to OpenTelemetry concepts? --[OpenTelemetry](https://opentelemetry.io/) is a vendor neutral observability framework. There are no Application Insights APIs in the OpenTelemetry SDK or libraries. Before migrating, it's important to understand some of OpenTelemetry's concepts. --* In Application Insights, all telemetry was managed through a single `TelemetryClient` and `TelemetryConfiguration`. In OpenTelemetry, each of the three telemetry signals (Traces, Metrics, and Logs) has its own configuration. You can manually create telemetry via the .NET runtime without external libraries. For more information, see the .NET guides on [distributed tracing](/dotnet/core/diagnostics/distributed-tracing-instrumentation-walkthroughs), [metrics](/dotnet/core/diagnostics/metrics), and [logging](/dotnet/core/extensions/logging). --* Application Insights used `TelemetryModules` to automatically collect telemetry for your application. -Instead, OpenTelemetry uses [Instrumentation libraries](https://opentelemetry.io/docs/specs/otel/overview/#instrumentation-libraries) to collect telemetry from specific components (such as [AspNetCore](https://www.nuget.org/packages/OpenTelemetry.Instrumentation.AspNetCore) for Requests and [HttpClient](https://www.nuget.org/packages/OpenTelemetry.Instrumentation.Http) for Dependencies). --* Application Insights used `TelemetryInitializers` to enrich telemetry with additional information or to override properties. -With OpenTelemetry, you can write a [Processor](https://opentelemetry.io/docs/collector/configuration/#processors) to customize a specific signal. Additionally, many OpenTelemetry Instrumentation libraries offer an `Enrich` method to customize the telemetry generated by that specific component. --* Application Insights used `TelemetryProcessors` to filter telemetry. An OpenTelemetry [Processor](https://opentelemetry.io/docs/collector/configuration/#processors) can also be used to apply filtering rules on a specific signal. --### How do Application Insights telemetry types map to OpenTelemetry? --This table maps Application Insights data types to OpenTelemetry concepts and their .NET implementations. --| Azure Monitor Table | Application Insights DataType | OpenTelemetry DataType | .NET Implementation | -||-||--| -| customEvents | EventTelemetry | N/A | N/A | -| customMetrics | MetricTelemetry | Metrics | System.Diagnostics.Metrics.Meter | -| dependencies | DependencyTelemetry | Spans (Client, Internal, Consumer) | System.Diagnostics.Activity | -| exceptions | ExceptionTelemetry | Exceptions | System.Exception | -| requests | RequestTelemetry | Spans (Server, Producer) | System.Diagnostics.Activity | -| traces | TraceTelemetry | Logs | Microsoft.Extensions.Logging.ILogger | --The following documents provide more information. --- [Data Collection Basics of Azure Monitor Application Insights](./opentelemetry-overview.md)-- [Application Insights telemetry data model](./data-model-complete.md)-- [OpenTelemetry Concepts](https://opentelemetry.io/docs/concepts/)--### How do Application Insights sampling concepts map to OpenTelemetry? --While Application Insights offered multiple options to configure sampling, Azure Monitor Exporter or Azure Monitor Distro only offers fixed rate sampling. Only *Requests* and *Dependencies* (*OpenTelemetry Traces*) can be sampled. --For code samples detailing how to configure sampling, see our guide [Enable Sampling](./opentelemetry-configuration.md#enable-sampling) --### How do Telemetry Processors and Initializers map to OpenTelemetry? --In the Application Insights .NET SDK, use telemetry processors to filter and modify or discard telemetry. Use telemetry initializers to add or modify custom properties. For more information, see the [Azure Monitor documentation](./api-filtering-sampling.md). OpenTelemetry replaces these concepts with activity or log processors, which enrich and filter telemetry. --#### Filtering Traces --To filter telemetry data in OpenTelemetry, you can implement an activity processor. This example is equivalent to the Application Insights example for filtering telemetry data as described in [Azure Monitor documentation](./api-filtering-sampling.md). The example illustrates where unsuccessful dependency calls are filtered. --```csharp -using System.Diagnostics; -using OpenTelemetry; --internal sealed class SuccessfulDependencyFilterProcessor : BaseProcessor<Activity> -{ - public override void OnEnd(Activity activity) - { - if (!OKtoSend(activity)) - { - activity.ActivityTraceFlags &= ~ActivityTraceFlags.Recorded; - } - } -- private bool OKtoSend(Activity activity) - { - return activity.Kind == ActivityKind.Client && activity.Status == ActivityStatusCode.Ok; - } -} -``` --To use this processor, you need to create a `TracerProvider` and add the processor before `AddAzureMonitorTraceExporter`. --```csharp -using OpenTelemetry.Trace; --public static void Main() -{ - var tracerProvider = Sdk.CreateTracerProviderBuilder() - .AddProcessor(new SuccessfulDependencyFilterProcessor()) - .AddAzureMonitorTraceExporter() - .Build(); -} -``` --#### Filtering Logs --[`ILogger`](/dotnet/core/extensions/logging) -implementations have a built-in mechanism to apply [log -filtering](/dotnet/core/extensions/logging?tabs=command-line#how-filtering-rules-are-applied). -This filtering lets you control the logs that are sent to each registered -provider, including the `OpenTelemetryLoggerProvider`. "OpenTelemetry" is the -[alias](/dotnet/api/microsoft.extensions.logging.provideraliasattribute) -for `OpenTelemetryLoggerProvider`, used in configuring filtering rules. --The following example defines "Error" as the default `LogLevel` -and also defines "Warning" as the minimum `LogLevel` for a user defined category. -These rules as defined only apply to the `OpenTelemetryLoggerProvider`. --```csharp -builder.AddFilter<OpenTelemetryLoggerProvider>("*", LogLevel.Error); -builder.AddFilter<OpenTelemetryLoggerProvider>("MyProduct.MyLibrary.MyClass", LogLevel.Warning); -``` --For more information, please read the [OpenTelemetry .NET documentation on logs](https://github.com/open-telemetry/opentelemetry-dotnet/blob/main/docs/logs/README.md). --#### Adding Custom Properties to Traces --In OpenTelemetry, you can use activity processors to enrich telemetry data with more properties. It's similar to using telemetry initializers in Application Insights, where you can modify telemetry properties. --By default, Azure Monitor Exporter flags any HTTP request with a response code of 400 or greater as failed. However, if you want to treat 400 as a success, you can add an enriching activity processor that sets the success on the activity and adds a tag to include more telemetry properties. It's similar to adding or modifying properties using an initializer in Application Insights as described in [Azure Monitor documentation](./api-filtering-sampling.md?tabs=javascriptwebsdkloaderscript#addmodify-properties-itelemetryinitializer). --Here's an example of how to add custom properties and override the default behavior for certain response codes: --```csharp -using System.Diagnostics; -using OpenTelemetry; --/// <summary> -/// Custom Processor that overrides the default behavior of treating response codes >= 400 as failed requests. -/// </summary> -internal class MyEnrichingProcessor : BaseProcessor<Activity> -{ - public override void OnEnd(Activity activity) - { - if (activity.Kind == ActivityKind.Server) - { - int responseCode = GetResponseCode(activity); -- if (responseCode >= 400 && responseCode < 500) - { - // If we set the Success property, the SDK won't change it - activity.SetStatus(ActivityStatusCode.Ok); -- // Allow to filter these requests in the portal - activity.SetTag("Overridden400s", "true"); - } -- // else leave the SDK to set the Success property - } - } -- private int GetResponseCode(Activity activity) - { - foreach (ref readonly var tag in activity.EnumerateTagObjects()) - { - if (tag.Key == "http.response.status_code" && tag.Value is int value) - { - return value; - } - } -- return 0; - } -} -``` --To use this processor, you need to create a `TracerProvider` and add the processor before `AddAzureMonitorTraceExporter`. --```csharp -using OpenTelemetry.Trace; --public static void Main() -{ - var tracerProvider = Sdk.CreateTracerProviderBuilder() - .AddSource("Company.Product.Name") - .AddProcessor(new MyEnrichingProcessor()) - .AddAzureMonitorTraceExporter() - .Build(); -} -``` --### How do I manually track telemetry using OpenTelemetry? --#### Sending Traces - Manual --Traces in Application Insights are stored as `RequestTelemetry` and `DependencyTelemetry`. In OpenTelemetry, traces are modeled as `Span` using the `Activity` class. --OpenTelemetry .NET utilizes the `ActivitySource` and `Activity` classes for tracing, which are part of the .NET runtime. This approach is distinctive because the .NET implementation integrates the tracing API directly into the runtime itself. The `System.Diagnostics.DiagnosticSource` package allows developers to use `ActivitySource` to create and manage `Activity` instances. This method provides a seamless way to add tracing to .NET applications without relying on external libraries, applying the built-in capabilities of the .NET ecosystem. For more detailed information, refer to the [distributed tracing instrumentation walkthroughs](/dotnet/core/diagnostics/distributed-tracing-instrumentation-walkthroughs). --Here's how to migrate manual tracing: -- > [!Note] - > In Application Insights, the role name and role instance could be set at a per-telemetry level. However, with the Azure Monitor Exporter, we cannot customize at a per-telemetry level. The role name and role instance are extracted from the OpenTelemetry resource and applied across all telemetry. Please read this document for more information: [Set the cloud role name and the cloud role instance](./opentelemetry-configuration.md?tabs=aspnetcore#set-the-cloud-role-name-and-the-cloud-role-instance). --#### DependencyTelemetry --Application Insights `DependencyTelemetry` is used to model outgoing requests. Here's how to convert it to OpenTelemetry: --**Application Insights Example:** --```csharp -DependencyTelemetry dep = new DependencyTelemetry -{ - Name = "DependencyName", - Data = "https://www.example.com/", - Type = "Http", - Target = "www.example.com", - Duration = TimeSpan.FromSeconds(10), - ResultCode = "500", - Success = false -}; --dep.Context.Cloud.RoleName = "MyRole"; -dep.Context.Cloud.RoleInstance = "MyRoleInstance"; -dep.Properties["customprop1"] = "custom value1"; -client.TrackDependency(dep); -``` --**OpenTelemetry Example:** --```csharp -var activitySource = new ActivitySource("Company.Product.Name"); -var resourceAttributes = new Dictionary<string, object> -{ - { "service.name", "MyRole" }, - { "service.instance.id", "MyRoleInstance" } -}; --var resourceBuilder = ResourceBuilder.CreateDefault().AddAttributes(resourceAttributes); --using var tracerProvider = Sdk.CreateTracerProviderBuilder() - .SetResourceBuilder(resourceBuilder) - .AddSource(activitySource.Name) - .AddAzureMonitorTraceExporter() - .Build(); --// Emit traces -using (var activity = activitySource.StartActivity("DependencyName", ActivityKind.Client)) -{ - activity?.SetTag("url.full", "https://www.example.com/"); - activity?.SetTag("server.address", "www.example.com"); - activity?.SetTag("http.request.method", "GET"); - activity?.SetTag("http.response.status_code", "500"); - activity?.SetTag("customprop1", "custom value1"); - activity?.SetStatus(ActivityStatusCode.Error); - activity?.SetEndTime(activity.StartTimeUtc.AddSeconds(10)); -} -``` --#### RequestTelemetry --Application Insights `RequestTelemetry` models incoming requests. Here's how to migrate it to OpenTelemetry: --**Application Insights Example:** --```csharp -RequestTelemetry req = new RequestTelemetry -{ - Name = "RequestName", - Url = new Uri("http://example.com"), - Duration = TimeSpan.FromSeconds(10), - ResponseCode = "200", - Success = true, - Properties = { ["customprop1"] = "custom value1" } -}; --req.Context.Cloud.RoleName = "MyRole"; -req.Context.Cloud.RoleInstance = "MyRoleInstance"; -client.TrackRequest(req); -``` --**OpenTelemetry Example:** --```csharp -var activitySource = new ActivitySource("Company.Product.Name"); -var resourceAttributes = new Dictionary<string, object> -{ - { "service.name", "MyRole" }, - { "service.instance.id", "MyRoleInstance" } -}; --var resourceBuilder = ResourceBuilder.CreateDefault().AddAttributes(resourceAttributes); --using var tracerProvider = Sdk.CreateTracerProviderBuilder() - .SetResourceBuilder(resourceBuilder) - .AddSource(activitySource.Name) - .AddAzureMonitorTraceExporter() - .Build(); --// Emit traces -using (var activity = activitySource.StartActivity("RequestName", ActivityKind.Server)) -{ - activity?.SetTag("url.scheme", "https"); - activity?.SetTag("server.address", "www.example.com"); - activity?.SetTag("url.path", "/"); - activity?.SetTag("http.response.status_code", "200"); - activity?.SetTag("customprop1", "custom value1"); - activity?.SetStatus(ActivityStatusCode.Ok); -} -``` --#### Custom Operations Tracking --In Application Insights, track custom operations using `StartOperation` and `StopOperation` methods. Achieve it using `ActivitySource` and `Activity` in OpenTelemetry .NET. For operations with `ActivityKind.Server` and `ActivityKind.Consumer`, Azure Monitor Exporter generates `RequestTelemetry`. For `ActivityKind.Client`, `ActivityKind.Producer`, and `ActivityKind.Internal`, it generates `DependencyTelemetry`. For more information on custom operations tracking, see the [Azure Monitor documentation](./custom-operations-tracking.md). For more on using `ActivitySource` and `Activity` in .NET, see the [.NET distributed tracing instrumentation walkthroughs](/dotnet/core/diagnostics/distributed-tracing-instrumentation-walkthroughs#activity). --Here's an example of how to start and stop an activity for custom operations: --```csharp -using System.Diagnostics; -using OpenTelemetry; --var activitySource = new ActivitySource("Company.Product.Name"); --using var tracerProvider = Sdk.CreateTracerProviderBuilder() - .AddSource(activitySource.Name) - .AddAzureMonitorTraceExporter() - .Build(); --// Start a new activity -using (var activity = activitySource.StartActivity("CustomOperation", ActivityKind.Server)) -{ - activity?.SetTag("customTag", "customValue"); -- // Perform your custom operation logic here -- // No need to explicitly call Activity.Stop() because the using block automatically disposes the Activity object, which stops it. -} -``` --#### Sending Logs --Logs in Application Insights are stored as `TraceTelemetry` and `ExceptionTelemetry`. --##### TraceTelemetry --In OpenTelemetry, logging is integrated via the `ILogger` interface. Here's how to migrate `TraceTelemetry`: --**Application Insights Example:** --```csharp -TraceTelemetry traceTelemetry = new TraceTelemetry -{ - Message = "hello from tomato 2.99", - SeverityLevel = SeverityLevel.Warning, -}; --traceTelemetry.Context.Cloud.RoleName = "MyRole"; -traceTelemetry.Context.Cloud.RoleInstance = "MyRoleInstance"; -client.TrackTrace(traceTelemetry); -``` --**OpenTelemetry Example:** --```csharp -var resourceAttributes = new Dictionary<string, object> -{ - { "service.name", "MyRole" }, - { "service.instance.id", "MyRoleInstance" } -}; --var resourceBuilder = ResourceBuilder.CreateDefault().AddAttributes(resourceAttributes); --using var loggerFactory = LoggerFactory.Create(builder => builder - .AddOpenTelemetry(loggerOptions => - { - loggerOptions.SetResourceBuilder(resourceBuilder); - loggerOptions.AddAzureMonitorLogExporter(); - })); --// Create a new instance `ILogger` from the above LoggerFactory -var logger = loggerFactory.CreateLogger<Program>(); --// Use the logger instance to write a new log -logger.FoodPrice("tomato", 2.99); --internal static partial class LoggerExtensions -{ - [LoggerMessage(LogLevel.Warning, "Hello from `{name}` `{price}`.")] - public static partial void FoodPrice(this ILogger logger, string name, double price); -} -``` --##### ExceptionTelemetry --Application Insights uses `ExceptionTelemetry` to log exceptions. Here's how to migrate to OpenTelemetry: --**Application Insights Example:** --```csharp -ExceptionTelemetry exceptionTelemetry = new ExceptionTelemetry(new Exception("Test exception")) -{ - SeverityLevel = SeverityLevel.Error -}; --exceptionTelemetry.Context.Cloud.RoleName = "MyRole"; -exceptionTelemetry.Context.Cloud.RoleInstance = "MyRoleInstance"; -exceptionTelemetry.Properties["customprop1"] = "custom value1"; -client.TrackException(exceptionTelemetry); -``` --**OpenTelemetry Example:** --```csharp -var resourceAttributes = new Dictionary<string, object> -{ - { "service.name", "MyRole" }, - { "service.instance.id", "MyRoleInstance" } -}; --var resourceBuilder = ResourceBuilder.CreateDefault().AddAttributes(resourceAttributes); --using var loggerFactory = LoggerFactory.Create(builder => builder - .AddOpenTelemetry(loggerOptions => - { - loggerOptions.SetResourceBuilder(resourceBuilder); - loggerOptions.AddAzureMonitorLogExporter(); - })); --// Create a new instance `ILogger` from the above LoggerFactory. -var logger = loggerFactory.CreateLogger<Program>(); --try -{ - // Simulate exception - throw new Exception("Test exception"); -} -catch (Exception ex) -{ - logger?.LogError(ex, "An error occurred"); -} -``` --#### Sending Metrics --Metrics in Application Insights are stored as `MetricTelemetry`. In OpenTelemetry, metrics are modeled as `Meter` from the `System.Diagnostics.DiagnosticSource` package. --Application Insights has both non-pre-aggregating (`TrackMetric()`) and preaggregating (`GetMetric().TrackValue()`) Metric APIs. Unlike OpenTelemetry, Application Insights has no notion of [Instruments](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/metrics/supplementary-guidelines.md#instrument-selection). Application Insights has the same API for all the metric scenarios. --OpenTelemetry, on the other hand, requires users to first [pick the right metric instrument](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/metrics/supplementary-guidelines.md#instrument-selection) based on the actual semantics of the metric. For example, if the intention is to count something (like the number of total server requests received, etc.), [OpenTelemetry Counter](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/metrics/api.md#counter) should be used. If the intention is to calculate various percentiles (like the P99 value of server latency), then [OpenTelemetry Histogram](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/metrics/api.md#histogram) instrument should be used. Due to this fundamental difference between Application Insights and OpenTelemetry, no direct comparison is made between them. --Unlike Application Insights, OpenTelemetry doesn't provide built-in mechanisms to enrich or filter metrics. In Application Insights, telemetry processors and initializers could be used to modify or discard metrics, but this capability isn't available in OpenTelemetry. --Additionally, OpenTelemetry doesn't support sending raw metrics directly, as there's no equivalent to the `TrackMetric()` functionality found in Application Insights. --Migrating from Application Insights to OpenTelemetry involves replacing all Application Insights Metric API usages with the OpenTelemetry API. It requires understanding the various OpenTelemetry Instruments and their semantics. --> [!Tip] -> The histogram is the most versatile and the closest equivalent to the Application Insights `GetMetric().TrackValue()` API. You can replace Application Insights Metric APIs with Histogram to achieve the same purpose. --#### Other Telemetry Types --##### CustomEvents --Not supported in OpenTelemetry. --**Application Insights Example:** --```csharp -TelemetryClient.TrackEvent() -``` --##### AvailabilityTelemetry --Not supported in OpenTelemetry. --**Application Insights Example:** --```csharp -TelemetryClient.TrackAvailability() -``` --##### PageViewTelemetry --Not supported in OpenTelemetry. --**Application Insights Example:** --```csharp -TelemetryClient.TrackPageView() -``` --## Next steps --### [ASP.NET Core](#tab/aspnetcore) --* [Azure Monitor Distro Demo project](https://github.com/Azure/azure-sdk-for-net/tree/main/sdk/monitor/Azure.Monitor.OpenTelemetry.AspNetCore/tests/Azure.Monitor.OpenTelemetry.AspNetCore.Demo) -* [OpenTelemetry SDK's getting started guide](https://github.com/open-telemetry/opentelemetry-dotnet/tree/main/src/OpenTelemetry) -* [OpenTelemetry's example ASP.NET Core project](https://github.com/open-telemetry/opentelemetry-dotnet/tree/main/examples/AspNetCore) -* [C# and .NET Logging](/dotnet/core/extensions/logging) -* [Azure Monitor OpenTelemetry getting started with ASP.NET Core](./opentelemetry-enable.md?tabs=aspnetcore) --### [ASP.NET](#tab/net) --* [OpenTelemetry SDK's getting started guide](https://github.com/open-telemetry/opentelemetry-dotnet/tree/main/src/OpenTelemetry) -* [OpenTelemetry's example ASP.NET project](https://github.com/open-telemetry/opentelemetry-dotnet-contrib/blob/main/examples/AspNet/Global.asax.cs) -* [C# and .NET Logging](/dotnet/core/extensions/logging) -* [Azure Monitor OpenTelemetry getting started with .NET](./opentelemetry-enable.md?tabs=net) --### [Console](#tab/console) --* [OpenTelemetry SDK's getting started guide](https://github.com/open-telemetry/opentelemetry-dotnet/tree/main/src/OpenTelemetry) -* OpenTelemetry's example projects: - * [Getting Started with Traces](https://github.com/open-telemetry/opentelemetry-dotnet/tree/main/docs/trace/getting-started-console) - * [Getting Started with Metrics](https://github.com/open-telemetry/opentelemetry-dotnet/tree/main/docs/metrics/getting-started-console) - * [Getting Started with Logs](https://github.com/open-telemetry/opentelemetry-dotnet/tree/main/docs/logs/getting-started-console) -* [C# and .NET Logging](/dotnet/core/extensions/logging) -* [Azure Monitor OpenTelemetry getting started with .NET](./opentelemetry-enable.md?tabs=net) --### [WorkerService](#tab/workerservice) --* [OpenTelemetry SDK's getting started guide](https://github.com/open-telemetry/opentelemetry-dotnet/tree/main/src/OpenTelemetry) -* [Logging in C# and .NET](/dotnet/core/extensions/logging) -* [Azure Monitor OpenTelemetry getting started with .NET](./opentelemetry-enable.md?tabs=net) ----> [!Tip] -> Our product group is actively seeking feedback on this documentation. Provide feedback to otel@microsoft.com or see the [Support](#support) section. --## Support --### [ASP.NET Core](#tab/aspnetcore) --- For Azure support issues, open an [Azure support ticket](https://azure.microsoft.com/support/create-ticket/).-- For OpenTelemetry issues, contact the [OpenTelemetry .NET community](https://github.com/open-telemetry/opentelemetry-dotnet) directly.-- For a list of open issues related to Azure Monitor Exporter, see the [GitHub Issues Page](https://github.com/Azure/azure-sdk-for-net/issues?q=is%3Aopen+is%3Aissue+label%3A%22Monitor+-+Exporter%22).--#### [.NET](#tab/net) --- For Azure support issues, open an [Azure support ticket](https://azure.microsoft.com/support/create-ticket/).-- For OpenTelemetry issues, contact the [OpenTelemetry .NET community](https://github.com/open-telemetry/opentelemetry-dotnet) directly.-- For a list of open issues related to Azure Monitor Exporter, see the [GitHub Issues Page](https://github.com/Azure/azure-sdk-for-net/issues?q=is%3Aopen+is%3Aissue+label%3A%22Monitor+-+Exporter%22).--### [Console](#tab/console) --- For Azure support issues, open an [Azure support ticket](https://azure.microsoft.com/support/create-ticket/).-- For OpenTelemetry issues, contact the [OpenTelemetry .NET community](https://github.com/open-telemetry/opentelemetry-dotnet) directly.-- For a list of open issues related to Azure Monitor Exporter, see the [GitHub Issues Page](https://github.com/Azure/azure-sdk-for-net/issues?q=is%3Aopen+is%3Aissue+label%3A%22Monitor+-+Exporter%22).--### [WorkerService](#tab/workerservice) --- For Azure support issues, open an [Azure support ticket](https://azure.microsoft.com/support/create-ticket/).-- For OpenTelemetry issues, contact the [OpenTelemetry .NET community](https://github.com/open-telemetry/opentelemetry-dotnet) directly.-- For a list of open issues related to Azure Monitor Exporter, see the [GitHub Issues Page](https://github.com/Azure/azure-sdk-for-net/issues?q=is%3Aopen+is%3Aissue+label%3A%22Monitor+-+Exporter%22).-- |
| azure-monitor | Opentelemetry Enable | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/opentelemetry-enable.md | - Title: Enable Azure Monitor OpenTelemetry for .NET, Java, Node.js, and Python applications -description: This article provides guidance on how to enable Azure Monitor on applications by using OpenTelemetry. - Previously updated : 08/27/2024-# ms.devlang: csharp, java, javascript, typescript, python -----# Enable Azure Monitor OpenTelemetry for .NET, Node.js, Python, and Java applications --This article describes how to enable and configure OpenTelemetry-based data collection within [Application Insights](app-insights-overview.md#application-insights-overview). The Azure Monitor OpenTelemetry Distro: --* Provides an [OpenTelemetry distribution](https://opentelemetry.io/docs/concepts/distributions/#what-is-a-distribution) which includes support for features specific to Azure Monitor. -* Enables [automatic](opentelemetry-add-modify.md#automatic-data-collection) telemetry by including OpenTelemetry instrumentation libraries for collecting traces, metrics, logs, and exceptions. -* Allows collecting [custom](opentelemetry-add-modify.md#collect-custom-telemetry) telemetry. -* Supports [Live Metrics](live-stream.md) to monitor and collect more telemetry from live, in-production web applications. --For more information about the advantages of using the Azure Monitor OpenTelemetry Distro, see [Why should I use the Azure Monitor OpenTelemetry Distro](#why-should-i-use-the-azure-monitor-opentelemetry-distro). --To learn more about collecting data using OpenTelemetry, check out [Data Collection Basics](opentelemetry-overview.md) or the [OpenTelemetry FAQ](#frequently-asked-questions). --### OpenTelemetry release status --OpenTelemetry offerings are available for .NET, Node.js, Python, and Java applications. For a feature-by-feature release status, see the [FAQ](#whats-the-current-release-state-of-features-within-the-azure-monitor-opentelemetry-distro). --## Enable OpenTelemetry with Application Insights --Follow the steps in this section to instrument your application with OpenTelemetry. Select a tab for langauge-specific instructions. --> [!NOTE] -> .NET covers multiple scenarios, including classic ASP.NET, console apps, Windows Forms (WinForms), and more. --### Prerequisites --> [!div class="checklist"] -> * Azure subscription: [Create an Azure subscription for free](https://azure.microsoft.com/free/) -> * Application Insights resource: [Create an Application Insights resource](create-workspace-resource.md#create-a-workspace-based-resource) --<!NOTE TO CONTRIBUTORS: PLEASE DO NOT SEPARATE OUT JAVASCRIPT AND TYPESCRIPT INTO DIFFERENT TABS.> --#### [ASP.NET Core](#tab/aspnetcore) --> [!div class="checklist"] -> * [ASP.NET Core Application](/aspnet/core/introduction-to-aspnet-core) using an officially supported version of [.NET](https://dotnet.microsoft.com/download/dotnet) --> [!Tip] -> If you're migrating from the Application Insights Classic API, see our [migration documentation](./opentelemetry-dotnet-migrate.md). --#### [.NET](#tab/net) --> [!div class="checklist"] -> * Application using a [supported version](https://dotnet.microsoft.com/platform/support/policy) of [.NET](https://dotnet.microsoft.com/download/dotnet) or [.NET Framework](https://dotnet.microsoft.com/download/dotnet-framework) 4.6.2 and later. --> [!Tip] -> If you're migrating from the Application Insights Classic API, see our [migration documentation](./opentelemetry-dotnet-migrate.md). --#### [Java](#tab/java) --> [!div class="checklist"] -> * A Java application using Java 8+ --#### [Java native](#tab/java-native) --> [!div class="checklist"] -> * A Java application using GraalVM 17+ --#### [Node.js](#tab/nodejs) --> [!div class="checklist"] -> * Application using an officially [supported version](https://github.com/Azure/azure-sdk-for-js/tree/main/sdk/monitor/monitor-opentelemetry-exporter#currently-supported-environments) of Node.js runtime:<br>ΓÇó [OpenTelemetry supported runtimes](https://github.com/open-telemetry/opentelemetry-js#supported-runtimes)<br>ΓÇó [Azure Monitor OpenTelemetry Exporter supported runtimes](https://github.com/Azure/azure-sdk-for-js/tree/main/sdk/monitor/monitor-opentelemetry-exporter#currently-supported-environments) --> [!NOTE] -> If you don't rely on any properties listed in the [not-supported table](https://github.com/microsoft/ApplicationInsights-node.js/blob/bet#ApplicationInsights-Shim-Unsupported-Properties), the *ApplicationInsights shim* will be your easiest path forward once out of beta. -> -> If you rely on any those properties, proceed with the Azure Monitor OpenTelemetry Distro. We'll provide a migration guide soon. --> [!Tip] -> If you're migrating from the Application Insights Classic API, see our [migration documentation](./opentelemetry-nodejs-migrate.md). --#### [Python](#tab/python) --> [!div class="checklist"] -> * Python Application using Python 3.8+ --> [!Tip] -> If you're migrating from OpenCensus, see our [migration documentation](./opentelemetry-python-opencensus-migrate.md). ----### Install the client library --#### [ASP.NET Core](#tab/aspnetcore) --Install the latest `Azure.Monitor.OpenTelemetry.AspNetCore` [NuGet package](https://www.nuget.org/packages/Azure.Monitor.OpenTelemetry.AspNetCore): --```dotnetcli -dotnet add package Azure.Monitor.OpenTelemetry.AspNetCore -``` --#### [.NET](#tab/net) --Install the latest `Azure.Monitor.OpenTelemetry.Exporter` [NuGet package](https://www.nuget.org/packages/Azure.Monitor.OpenTelemetry.Exporter): --```dotnetcli -dotnet add package Azure.Monitor.OpenTelemetry.Exporter -``` --#### [Java](#tab/java) --Download the [applicationinsights-agent-3.5.4.jar](https://github.com/microsoft/ApplicationInsights-Java/releases/download/3.5.4/applicationinsights-agent-3.5.4.jar) file. --> [!WARNING] -> -> If you are upgrading from an earlier 3.x version, you may be impacted by changing defaults or slight differences in the data we collect. For more information, see the migration section in the release notes. -> [3.5.0](https://github.com/microsoft/ApplicationInsights-Java/releases/tag/3.5.0), -> [3.4.0](https://github.com/microsoft/ApplicationInsights-Java/releases/tag/3.4.0), -> [3.3.0](https://github.com/microsoft/ApplicationInsights-Java/releases/tag/3.3.0), -> [3.2.0](https://github.com/microsoft/ApplicationInsights-Java/releases/tag/3.2.0), and -> [3.1.0](https://github.com/microsoft/ApplicationInsights-Java/releases/tag/3.1.0) --#### [Java native](#tab/java-native) --For *Spring Boot* native applications: --* [Import the OpenTelemetry Bills of Materials (BOM)](https://opentelemetry.io/docs/zero-code/java/spring-boot-starter/getting-started/). -* Add the [Spring Cloud Azure Starter Monitor](https://central.sonatype.com/artifact/com.azure.spring/spring-cloud-azure-starter-monitor) dependency. -* Follow [these instructions](/azure//developer/java/spring-framework/developer-guide-overview#configuring-spring-boot-3) for the Azure SDK JAR (Java Archive) files. --For *Quarkus* native applications: --* Add the [Quarkus OpenTelemetry Exporter for Azure](https://mvnrepository.com/artifact/io.quarkiverse.opentelemetry.exporter/quarkus-opentelemetry-exporter-azure) dependency. --#### [Node.js](#tab/nodejs) --Install the latest [@azure/monitor-opentelemetry](https://www.npmjs.com/package/@azure/monitor-opentelemetry) package: --```sh -npm install @azure/monitor-opentelemetry -``` --The following packages are also used for some specific scenarios described later in this article: --* [@opentelemetry/api](https://www.npmjs.com/package/@opentelemetry/api) -* [@opentelemetry/sdk-metrics](https://www.npmjs.com/package/@opentelemetry/sdk-metrics) -* [@opentelemetry/resources](https://www.npmjs.com/package/@opentelemetry/resources) -* [@opentelemetry/semantic-conventions](https://www.npmjs.com/package/@opentelemetry/semantic-conventions) -* [@opentelemetry/sdk-trace-base](https://www.npmjs.com/package/@opentelemetry/sdk-trace-base) --```sh -npm install @opentelemetry/api -npm install @opentelemetry/sdk-metrics -npm install @opentelemetry/resources -npm install @opentelemetry/semantic-conventions -npm install @opentelemetry/sdk-trace-base -``` --#### [Python](#tab/python) --Install the latest [azure-monitor-opentelemetry](https://pypi.org/project/azure-monitor-opentelemetry/) PyPI package: --```sh -pip install azure-monitor-opentelemetry -``` ----### Modify your application --#### [ASP.NET Core](#tab/aspnetcore) --Import the `Azure.Monitor.OpenTelemetry.AspNetCore` namespace, add OpenTelemetry, and configure it to use Azure Monitor in your `program.cs` class: --```csharp -// Import the Azure.Monitor.OpenTelemetry.AspNetCore namespace. -using Azure.Monitor.OpenTelemetry.AspNetCore; --var builder = WebApplication.CreateBuilder(args); --// Add OpenTelemetry and configure it to use Azure Monitor. -builder.Services.AddOpenTelemetry().UseAzureMonitor(); --var app = builder.Build(); --app.Run(); -``` --#### [.NET](#tab/net) --Add the Azure Monitor Exporter to each OpenTelemetry signal in the `program.cs` class: --```csharp -// Create a new tracer provider builder and add an Azure Monitor trace exporter to the tracer provider builder. -// It is important to keep the TracerProvider instance active throughout the process lifetime. -// See https://github.com/open-telemetry/opentelemetry-dotnet/tree/main/docs/trace#tracerprovider-management -var tracerProvider = Sdk.CreateTracerProviderBuilder() - .AddAzureMonitorTraceExporter(); --// Add an Azure Monitor metric exporter to the metrics provider builder. -// It is important to keep the MetricsProvider instance active throughout the process lifetime. -// See https://github.com/open-telemetry/opentelemetry-dotnet/tree/main/docs/metrics#meterprovider-management -var metricsProvider = Sdk.CreateMeterProviderBuilder() - .AddAzureMonitorMetricExporter(); --// Create a new logger factory. -// It is important to keep the LoggerFactory instance active throughout the process lifetime. -// See https://github.com/open-telemetry/opentelemetry-dotnet/tree/main/docs/logs#logger-management -var loggerFactory = LoggerFactory.Create(builder => -{ - builder.AddOpenTelemetry(options => - { - options.AddAzureMonitorLogExporter(); - }); -}); -``` --> [!NOTE] -> For more information, see the [getting-started tutorial for OpenTelemetry .NET](https://github.com/open-telemetry/opentelemetry-dotnet/tree/main#getting-started) --#### [Java](#tab/java) --Autoinstrumentation is enabled through configuration changes. *No code changes are required.* --Point the Java virtual machine (JVM) to the jar file by adding `-javaagent:"path/to/applicationinsights-agent-3.5.4.jar"` to your application's JVM args. --> [!NOTE] -> Sampling is enabled by default at a rate of 5 requests per second, aiding in cost management. Telemetry data may be missing in scenarios exceeding this rate. For more information on modifying sampling configuration, see [sampling overrides](./java-standalone-sampling-overrides.md). --> [!TIP] -> For scenario-specific guidance, see [Get Started (Supplemental)](./java-get-started-supplemental.md). --> [!TIP] -> If you develop a Spring Boot application, you can optionally replace the JVM argument by a programmatic configuration. For more information, see [Using Azure Monitor Application Insights with Spring Boot](./java-spring-boot.md). --#### [Java native](#tab/java-native) --Autoinstrumentation is enabled through configuration changes. *No code changes are required.* --#### [Node.js](#tab/nodejs) --```typescript -// Import the `useAzureMonitor()` function from the `@azure/monitor-opentelemetry` package. -const { useAzureMonitor } = require("@azure/monitor-opentelemetry"); --// Call the `useAzureMonitor()` function to configure OpenTelemetry to use Azure Monitor. -useAzureMonitor(); -``` --#### [Python](#tab/python) --```python -# Import the `configure_azure_monitor()` function from the -# `azure.monitor.opentelemetry` package. -from azure.monitor.opentelemetry import configure_azure_monitor --# Import the tracing api from the `opentelemetry` package. -from opentelemetry import trace --# Configure OpenTelemetry to use Azure Monitor with the -# APPLICATIONINSIGHTS_CONNECTION_STRING environment variable. -configure_azure_monitor() --``` ----### Copy the connection string from your Application Insights resource --The connection string is unique and specifies where the Azure Monitor OpenTelemetry Distro sends the telemetry it collects. --> [!TIP] -> If you don't already have an Application Insights resource, create one following [this guide](create-workspace-resource.md#create-a-workspace-based-resource). We recommend you create a new resource rather than [using an existing one](create-workspace-resource.md#when-to-use-a-single-application-insights-resource). --To copy the connection string: --1. Go to the **Overview** pane of your Application Insights resource. -2. Find your **connection string**. -3. Hover over the connection string and select the **Copy to clipboard** icon. ---### Paste the connection string in your environment --To paste your connection string, select from the following options: --> [!IMPORTANT] -> We recommend setting the connection string through code only in local development and test environments. -> -> For production, use an environment variable or configuration file (Java only). --* **Set via environment variable** - *recommended* -- Replace `<Your connection string>` in the following command with your connection string. - - ```console - APPLICATIONINSIGHTS_CONNECTION_STRING=<Your connection string> - ``` --* **Set via configuration file** - *Java only* - - Create a configuration file named `applicationinsights.json`, and place it in the same directory as `applicationinsights-agent-3.5.4.jar` with the following content: - - ```json - { - "connectionString": "<Your connection string>" - } - ``` - - Replace `<Your connection string>` in the preceding JSON with *your* unique connection string. --* **Set via code** - *ASP.NET Core, Node.js, and Python only* - - See [connection string configuration](opentelemetry-configuration.md#connection-string) for an example of setting connection string via code. --> [!NOTE] -> If you set the connection string in multiple places, the environment variable will be prioritized in the following order: -> 1. Code -> 2. Environment variable -> 3. Configuration file --### Confirm data is flowing --Run your application, then open Application Insights in the Azure portal. It might take a few minutes for data to show up. ---Application Insights is now enabled for your application. The following steps are optional and allow for further customization. --> [!IMPORTANT] -> If you have two or more services that emit telemetry to the same Application Insights resource, you're required to [set Cloud Role Names](opentelemetry-configuration.md#set-the-cloud-role-name-and-the-cloud-role-instance) to represent them properly on the Application Map. --As part of using Application Insights instrumentation, we collect and send diagnostic data to Microsoft. This data helps us run and improve Application Insights. To learn more, see [Statsbeat in Azure Application Insights](./statsbeat.md). --## Sample applications --Azure Monitor OpenTelemetry sample applications are available for all supported languages: --* [ASP.NET Core sample app](https://github.com/Azure/azure-sdk-for-net/tree/main/sdk/monitor/Azure.Monitor.OpenTelemetry.AspNetCore/tests/Azure.Monitor.OpenTelemetry.AspNetCore.Demo) -* [NET sample app](https://github.com/Azure/azure-sdk-for-net/tree/main/sdk/monitor/Azure.Monitor.OpenTelemetry.Exporter/tests/Azure.Monitor.OpenTelemetry.Exporter.Demo) -* [Java sample apps](https://github.com/Azure-Samples/ApplicationInsights-Java-Samples) -* [Java GraalVM native sample apps](https://github.com/Azure-Samples/java-native-telemetry) -* [Node.js sample app](https://github.com/Azure-Samples/azure-monitor-opentelemetry-node.js) -* [Python sample apps](https://github.com/Azure/azure-sdk-for-python/tree/main/sdk/monitor/azure-monitor-opentelemetry/samples) --## Next steps --### [ASP.NET Core](#tab/aspnetcore) --* For details on adding and modifying Azure Monitor OpenTelemetry, see [Add and modify Azure Monitor OpenTelemetry](opentelemetry-add-modify.md). -* To further configure the OpenTelemetry distro, see [Azure Monitor OpenTelemetry configuration](opentelemetry-configuration.md). -* To review the source code, see the [Azure Monitor AspNetCore GitHub repository](https://github.com/Azure/azure-sdk-for-net/tree/main/sdk/monitor/Azure.Monitor.OpenTelemetry.AspNetCore). -* To install the NuGet package, check for updates, or view release notes, see the [Azure Monitor AspNetCore NuGet Package](https://www.nuget.org/packages/Azure.Monitor.OpenTelemetry.AspNetCore) page. -* To become more familiar with Azure Monitor and OpenTelemetry, see the [Azure Monitor Example Application](https://github.com/Azure/azure-sdk-for-net/tree/main/sdk/monitor/Azure.Monitor.OpenTelemetry.AspNetCore/tests/Azure.Monitor.OpenTelemetry.AspNetCore.Demo). -* To learn more about OpenTelemetry and its community, see the [OpenTelemetry .NET GitHub repository](https://github.com/open-telemetry/opentelemetry-dotnet). -* To enable usage experiences, [enable web or browser user monitoring](javascript.md). --### [.NET](#tab/net) --* For details on adding and modifying Azure Monitor OpenTelemetry, see [Add and modify Azure Monitor OpenTelemetry](opentelemetry-add-modify.md). -* To further configure the OpenTelemetry distro, see [Azure Monitor OpenTelemetry configuration](opentelemetry-configuration.md). -* To review the source code, see the [Azure Monitor Exporter GitHub repository](https://github.com/Azure/azure-sdk-for-net/tree/main/sdk/monitor/Azure.Monitor.OpenTelemetry.Exporter). -* To install the NuGet package, check for updates, or view release notes, see the [Azure Monitor Exporter NuGet Package](https://www.nuget.org/packages/Azure.Monitor.OpenTelemetry.Exporter) page. -* To become more familiar with Azure Monitor and OpenTelemetry, see the [Azure Monitor Example Application](https://github.com/Azure/azure-sdk-for-net/tree/main/sdk/monitor/Azure.Monitor.OpenTelemetry.Exporter/tests/Azure.Monitor.OpenTelemetry.Exporter.Demo). -* To learn more about OpenTelemetry and its community, see the [OpenTelemetry .NET GitHub repository](https://github.com/open-telemetry/opentelemetry-dotnet). -* To enable usage experiences, [enable web or browser user monitoring](javascript.md). --### [Java](#tab/java) --* See [Add and modify Azure Monitor OpenTelemetry](opentelemetry-add-modify.md) for details on adding and modifying Azure Monitor OpenTelemetry. -* Review [Java autoinstrumentation configuration options](java-standalone-config.md). -* Review the source code in the [Azure Monitor Java autoinstrumentation GitHub repository](https://github.com/Microsoft/ApplicationInsights-Java). -* Learn more about OpenTelemetry and its community in the [OpenTelemetry Java GitHub repository](https://github.com/open-telemetry/opentelemetry-java-instrumentation). -* Enable usage experiences by seeing [Enable web or browser user monitoring](javascript.md). -* Review the [release notes](https://github.com/microsoft/ApplicationInsights-Java/releases) on GitHub. --### [Java native](#tab/java-native) -* See [Add and modify Azure Monitor OpenTelemetry](opentelemetry-add-modify.md) for details on adding and modifying Azure Monitor OpenTelemetry. -* Review the source code in the [Azure Monitor OpenTelemetry Distro in Spring Boot native image Java application](https://github.com/Azure/azure-sdk-for-java/tree/main/sdk/spring/spring-cloud-azure-starter-monitor) and [Quarkus OpenTelemetry Exporter for Azure](https://github.com/quarkiverse/quarkus-opentelemetry-exporter/tree/main/quarkus-opentelemetry-exporter-azure). -* Learn more about OpenTelemetry and its community in the [OpenTelemetry Java GitHub repository](https://github.com/open-telemetry/opentelemetry-java-instrumentation). -* Learn more features for Spring Boot native image applications in [OpenTelemetry SpringBoot starter](https://opentelemetry.io/docs/zero-code/java/spring-boot-starter/.) -* Learn more features for Quarkus native applications in [Quarkus OpenTelemetry Exporter for Azure](https://quarkus.io/guides/opentelemetry). -* Review the [release notes](https://github.com/Azure/azure-sdk-for-jav) on GitHub. --### [Node.js](#tab/nodejs) --* For details on adding and modifying Azure Monitor OpenTelemetry, see [Add and modify Azure Monitor OpenTelemetry](opentelemetry-add-modify.md). -* To review the source code, see the [Azure Monitor OpenTelemetry GitHub repository](https://github.com/Azure/azure-sdk-for-js/tree/main/sdk/monitor/monitor-opentelemetry). -* To install the npm package and check for updates, see the [`@azure/monitor-opentelemetry` npm Package](https://www.npmjs.com/package/@azure/monitor-opentelemetry) page. -* To become more familiar with Azure Monitor Application Insights and OpenTelemetry, see the [Azure Monitor Example Application](https://github.com/Azure-Samples/azure-monitor-opentelemetry-node.js). -* To learn more about OpenTelemetry and its community, see the [OpenTelemetry JavaScript GitHub repository](https://github.com/open-telemetry/opentelemetry-js). -* To enable usage experiences, [enable web or browser user monitoring](javascript.md). --### [Python](#tab/python) --* See [Add and modify Azure Monitor OpenTelemetry](opentelemetry-add-modify.md) for details on adding and modifying Azure Monitor OpenTelemetry. -* Review the source code and extra documentation in the [Azure Monitor Distro GitHub repository](https://github.com/Azure/azure-sdk-for-python/blob/main/sdk/monitor/azure-monitor-opentelemetry/README.md). -* See extra samples and use cases in [Azure Monitor Distro samples](https://github.com/Azure/azure-sdk-for-python/tree/main/sdk/monitor/azure-monitor-opentelemetry/samples). -* Review the [changelog](https://github.com/Azure/azure-sdk-for-python/blob/main/sdk/monitor/azure-monitor-opentelemetry/CHANGELOG.md) on GitHub. -* Install the PyPI package, check for updates, or view release notes on the [Azure Monitor Distro PyPI Package](https://pypi.org/project/azure-monitor-opentelemetry/) page. -* Become more familiar with Azure Monitor Application Insights and OpenTelemetry in the [Azure Monitor Example Application](https://github.com/Azure-Samples/azure-monitor-opentelemetry-python). -* Learn more about OpenTelemetry and its community in the [OpenTelemetry Python GitHub repository](https://github.com/open-telemetry/opentelemetry-python). -* See available OpenTelemetry instrumentations and components in the [OpenTelemetry Contributor Python GitHub repository](https://github.com/open-telemetry/opentelemetry-python-contrib). -* Enable usage experiences by [enabling web or browser user monitoring](javascript.md). ---- |
| azure-monitor | Opentelemetry Nodejs Migrate | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/opentelemetry-nodejs-migrate.md | - Title: Migrating Azure Monitor Application Insights Node.js from Application Insights SDK 2.X to OpenTelemetry -description: This article provides guidance on how to migrate from the Azure Monitor Application Insights Node.js SDK 2.X to OpenTelemetry. - Previously updated : 04/16/2024-----# Migrate from the Node.js Application Insights SDK 2.X to Azure Monitor OpenTelemetry --This guide provides two options to upgrade from the Azure Monitor Application Insights Node.js SDK 2.X to OpenTelemetry. --* **Clean install** the [Node.js Azure Monitor OpenTelemetry Distro](https://github.com/microsoft/opentelemetry-azure-monitor-js). - * Remove dependencies on the Application Insights classic API. - * Familiarize yourself with OpenTelemetry APIs and terms. - * Position yourself to use all that OpenTelemetry offers now and in the future. -* **Upgrade** to Node.js SDK 3.X. - * Postpone code changes while preserving compatibility with existing custom events and metrics. - * Access richer OpenTelemetry instrumentation libraries. - * Maintain eligibility for the latest bug and security fixes. --## [Clean install](#tab/cleaninstall) --1. Gain prerequisite knowledge of the OpenTelemetry JavaScript Application Programming Interface (API) and Software Development Kit (SDK). -- * Read [OpenTelemetry JavaScript documentation](https://opentelemetry.io/docs/languages/js/). - * Review [Configure Azure Monitor OpenTelemetry](opentelemetry-configuration.md?tabs=nodejs). - * Evaluate [Add, modify, and filter OpenTelemetry](opentelemetry-add-modify.md?tabs=nodejs). --2. Uninstall the `applicationinsights` dependency from your project. -- ```shell - npm uninstall applicationinsights - ``` --3. Remove SDK 2.X implementation from your code. -- Remove all Application Insights instrumentation from your code. Delete any sections where the Application Insights client is initialized, modified, or called. --4. Enable Application Insights with the Azure Monitor OpenTelemetry Distro. - > [!IMPORTANT] - > *Before* you import anything else, `useAzureMonitor` must be called. There might be telemetry loss if other libraries are imported first. - Follow [getting started](opentelemetry-enable.md?tabs=nodejs) to onboard to the Azure Monitor OpenTelemetry Distro. --#### Azure Monitor OpenTelemetry Distro changes and limitations -- * The APIs from the Application Insights SDK 2.X aren't available in the Azure Monitor OpenTelemetry Distro. You can access these APIs through a nonbreaking upgrade path in the Application Insights SDK 3.X. - * Filtering dependencies, logs, and exceptions by operation name is not yet supported. --## [Upgrade](#tab/upgrade) --1. Upgrade the `applicationinsights` package dependency. -- ```shell - npm update applicationinsights - ``` --2. Rebuild your application. --3. Test your application. -- To avoid using unsupported configuration options in the Application Insights SDK 3.X, see [Unsupported Properties](https://github.com/microsoft/ApplicationInsights-node.js/tree/beta?tab=readme-ov-file#applicationinsights-shim-unsupported-properties). -- If the SDK logs warnings about unsupported API usage after a major version bump, and you need the related functionality, continue using the Application Insights SDK 2.X. ----## Changes and limitations --The following changes and limitations apply to both upgrade paths. --##### Node.js version support --For a version of Node.js to be supported by the ApplicationInsights 3.X SDK, it must have overlapping support from both the Azure SDK and OpenTelemetry. Check the [OpenTelemetry supported runtimes](https://github.com/open-telemetry/opentelemetry-js#supported-runtimes) for the latest updates. Users on older versions like Node 8, previously supported by the ApplicationInsights SDK, can still use OpenTelemetry solutions but can experience unexpected or breaking behavior. The ApplicationInsights SDK also depends on the Azure SDK for JS which does not guarantee support for any Node.js versions that have reached end-of-life. See [the Azure SDK for JS support policy](https://github.com/Azure/azure-sdk-for-js/blob/main/SUPPORT.md). For a version of Node.js to be supported by the ApplicationInsights 3.X SDK, it must have overlapping support from both the Azure SDK and OpenTelemetry. --##### Configuration options --The Application Insights SDK version 2.X offers configuration options that aren't available in the Azure Monitor OpenTelemetry Distro or in the major version upgrade to Application Insights SDK 3.X. To find these changes, along with the options we still support, see [SDK configuration documentation](https://github.com/microsoft/ApplicationInsights-node.js/tree/beta?tab=readme-ov-file#applicationinsights-shim-unsupported-properties). --##### Extended metrics --Extended metrics are supported in the Application Insights SDK 2.X; however, support for these metrics ends in both version 3.X of the ApplicationInsights SDK and the Azure Monitor OpenTelemetry Distro. --##### Telemetry Processors --While the Azure Monitor OpenTelemetry Distro and Application Insights SDK 3.X don't support TelemetryProcessors, they do allow you to pass span and log record processors. For more information on how, see [Azure Monitor OpenTelemetry Distro project](https://github.com/Azure/azure-sdk-for-js/tree/main/sdk/monitor/monitor-opentelemetry#modify-telemetry). --This example shows the equivalent of creating and applying a telemetry processor that attaches a custom property in the Application Insights SDK 2.X. --```typescript -const applicationInsights = require("applicationinsights"); -applicationInsights.setup("YOUR_CONNECTION_STRING"); -applicationInsights.defaultClient.addTelemetryProcessor(addCustomProperty); -applicationInsights.start(); --function addCustomProperty(envelope: EnvelopeTelemetry) { - const data = envelope.data.baseData; - if (data?.properties) { - data.properties.customProperty = "Custom Property Value"; - } - return true; -} -``` --This example shows how to modify an Azure Monitor OpenTelemetry Distro implementation to pass a SpanProcessor to the configuration of the distro. --```typescript -import { Context, Span} from "@opentelemetry/api"; -import { ReadableSpan, SpanProcessor } from "@opentelemetry/sdk-trace-base"; -const { useAzureMonitor } = require("@azure/monitor-opentelemetry"); --class SpanEnrichingProcessor implements SpanProcessor { - forceFlush(): Promise<void> { - return Promise.resolve(); - } - onStart(span: Span, parentContext: Context): void { - return; - } - onEnd(span: ReadableSpan): void { - span.attributes["custom-attribute"] = "custom-value"; - } - shutdown(): Promise<void> { - return Promise.resolve(); - } -} --const options = { - azureMonitorExporterOptions: { - connectionString: "YOUR_CONNECTION_STRING" - }, - spanProcessors: [new SpanEnrichingProcessor()], -}; -useAzureMonitor(options); -``` |
| azure-monitor | Opentelemetry Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/opentelemetry-overview.md | - Title: Data Collection Basics of Azure Monitor Application Insights -description: This article provides an overview of how to collect telemetry to send to Azure Monitor Application Insights. - Previously updated : 12/15/2023----# Data Collection Basics of Azure Monitor Application Insights --Before you can monitor your application, it needs to be instrumented. --In the following sections, we cover some data collection basics of Azure Monitor Application Insights. --## Instrumentation Options --At a basic level, "instrumenting" is simply enabling an application to capture telemetry. --There are two methods to instrument your application: --- Automatic instrumentation (autoinstrumentation)-- Manual instrumentation--**Autoinstrumentation** enables telemetry collection through configuration without touching the application's code. Although it's more convenient, it tends to be less configurable. It's also not available in all languages. See [Autoinstrumentation supported environments and languages](codeless-overview.md). When autoinstrumentation is available, it's the easiest way to enable Azure Monitor Application Insights. --**Manual instrumentation** is coding against the Application Insights or OpenTelemetry API. In the context of a user, it typically refers to installing a language-specific SDK in an application. This means that you have to manage the updates to the latest package version by yourself. You can use this option if you need to make custom dependency calls or API calls that are not captured by default with autoinstrumentation. There are two options for manual instrumentation: --- [Application Insights SDKs](asp-net-core.md)-- [Azure Monitor OpenTelemetry Distros](opentelemetry-enable.md).--While we see OpenTelemetry as our future direction, we have no plans to stop collecting data from older SDKs. We still have a way to go before our Azure OpenTelemetry Distros [reach feature parity with our Application Insights SDKs](./opentelemetry-enable.md#whats-the-current-release-state-of-features-within-the-azure-monitor-opentelemetry-distro). In many cases, customers continue to choose to use Application Insights SDKs for quite some time. --> [!IMPORTANT] -> "Manual" doesn't mean you'll be required to write complex code to define spans for distributed traces, although it remains an option. Instrumentation Libraries packaged into our Distros enable you to effortlessly capture telemetry signals across common frameworks and libraries. We're actively working to [instrument the most popular Azure Service SDKs using OpenTelemetry](https://devblogs.microsoft.com/azure-sdk/introducing-experimental-opentelemetry-support-in-the-azure-sdk-for-net/) so these signals are available to customers who use the Azure Monitor OpenTelemetry Distro. --## Telemetry Types --Telemetry, the data collected to observe your application, can be broken into three types or "pillars": --- Distributed Tracing-- Metrics-- Logs--A complete observability story includes all three pillars, and Application Insights further breaks down these pillars into tables based on our [data model](data-model-complete.md). Our Application Insights SDKs or Azure Monitor OpenTelemetry Distros include everything you need to power Application Performance Monitoring on Azure. The package itself is free to install, and you only pay for the data you ingest in Azure Monitor. --The following sources explain the three pillars: --- [OpenTelemetry community website](https://opentelemetry.io/docs/concepts/data-collection/)-- [OpenTelemetry specifications](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/overview.md)-- [Distributed Systems Observability](https://www.oreilly.com/library/view/distributed-systems-observability/9781492033431/ch04.html) by Cindy Sridharan--## Telemetry Routing --There are two ways to send your data to Azure Monitor (or any vendor): --- Via a direct exporter-- Via an agent--A direct exporter sends telemetry in-process (from the application's code) directly to the Azure Monitor ingestion endpoint. The main advantage of this approach is onboarding simplicity. --*The currently available Application Insights SDKs and Azure Monitor OpenTelemetry Distros rely on a direct exporter*. --> [!NOTE] -> For Azure Monitor's position on the OpenTelemetry-Collector, see the [OpenTelemetry FAQ](./opentelemetry-enable.md#can-i-use-the-opentelemetry-collector). --> [!TIP] -> If you are planning to use OpenTelemetry-Collector for sampling or additional data processing, you may be able to get these same capabilities built-in to Azure Monitor. Customers who have migrated to [Workspace-based Application Insights](convert-classic-resource.md) can benefit from [Ingestion-time Transformations](../essentials/data-collection-transformations.md). To enable, follow the details in the [tutorial](../logs/tutorial-workspace-transformations-portal.md), skipping the step that shows how to set up a diagnostic setting since with Workspace-centric Application Insights this is already configured. If youΓÇÖre filtering less than 50% of the overall volume, itΓÇÖs no additional cost. After 50%, there is a cost but much less than the standard per GB charge. --## OpenTelemetry --Microsoft is excited to embrace [OpenTelemetry](https://opentelemetry.io/) as the future of telemetry instrumentation. You, our customers, asked for vendor-neutral instrumentation, and we're pleased to partner with the OpenTelemetry community to create consistent APIs and SDKs across languages. --Microsoft worked with project stakeholders from two previously popular open-source telemetry projects, [OpenCensus](https://opencensus.io/) and [OpenTracing](https://opentracing.io/). Together, we helped to create a single project, OpenTelemetry. OpenTelemetry includes contributions from all major cloud and Application Performance Management (APM) vendors and lives within the [Cloud Native Computing Foundation (CNCF)](https://www.cncf.io/). Microsoft is a Platinum Member of the CNCF. --For terminology, see the [glossary](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/glossary.md) in the OpenTelemetry specifications. --Some legacy terms in Application Insights are confusing because of the industry convergence on OpenTelemetry. The following table highlights these differences. OpenTelemetry terms are replacing Application Insights terms. --Application Insights | OpenTelemetry - | -Autocollectors | Instrumentation libraries -Channel | Exporter -Codeless / Agent-based | Autoinstrumentation -Traces | Logs -Requests | Server Spans -Dependencies | Other Span Types (Client, Internal, etc.) -Operation ID | Trace ID -ID or Operation Parent ID | Span ID ---## Frequently asked questions --#### Where can I find a list of Application Insights SDK versions and their names? --A list of SDK versions and names is hosted on GitHub. For more information, see [SDK Version](https://github.com/microsoft/ApplicationInsights-dotnet/blob/develop/docs/versions_and_names.md). --## Next steps --Select your enablement approach: --- [Autoinstrumentation](codeless-overview.md)-- Application Insights SDKs- - [ASP.NET](./asp-net.md) - - [ASP.NET Core](./asp-net-core.md) - - [Node.js](./nodejs.md) - - [Python](/previous-versions/azure/azure-monitor/app/opencensus-python) - - [JavaScript: Web](./javascript.md) -- [Azure Monitor OpenTelemetry Distro](opentelemetry-enable.md)--Check out the [Azure Monitor Application Insights FAQ](./app-insights-overview.md#frequently-asked-questions) and [OpenTelemetry FAQ](./opentelemetry-enable.md#frequently-asked-questions) for more information. |
| azure-monitor | Opentelemetry Python Opencensus Migrate | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/opentelemetry-python-opencensus-migrate.md | - Title: Migrating Azure Monitor Application Insights Python from OpenCensus to OpenTelemetry -description: This article provides guidance on how to migrate from the Azure Monitor Application Insights Python SDK and OpenCensus exporter to OpenTelemetry. - Previously updated : 10/10/2023-----# Migrating from OpenCensus Python SDK and Azure Monitor OpenCensus exporter for Python to Azure Monitor OpenTelemetry Python Distro --> [!NOTE] -> [OpenCensus Python SDK is deprecated](https://opentelemetry.io/blog/2023/sunsetting-opencensus/), but Microsoft supports it until retirement on September 30, 2024. We now recommend the [OpenTelemetry-based Python offering](./opentelemetry-enable.md?tabs=python) and provide [migration guidance](./opentelemetry-python-opencensus-migrate.md?tabs=aspnetcore). --Follow these steps to migrate Python applications to the [Azure Monitor](../overview.md) [Application Insights](./app-insights-overview.md) [OpenTelemetry Distro](./opentelemetry-enable.md?tabs=python). --> [!WARNING] -> * The [OpenCensus "How to Migrate to OpenTelemetry" blog](https://opentelemetry.io/blog/2023/sunsetting-opencensus/#how-to-migrate-to-opentelemetry) is not applicable to Azure Monitor users. -> * The [OpenTelemetry OpenCensus shim](https://pypi.org/project/opentelemetry-opencensus-shim/) is not recommended or supported by Microsoft. -> * The following outlines the only migration plan for Azure Monitor customers. --## Step 1: Uninstall OpenCensus libraries --Uninstall all libraries related to OpenCensus, including all Pypi packages that start with `opencensus-*`. --``` -pip freeze | grep opencensus | xargs pip uninstall -y -``` --## Step 2: Remove OpenCensus from your code --Remove all instances of the OpenCensus SDK and the Azure Monitor OpenCensus exporter from your code. --Check for import statements starting with `opencensus` to find all integrations, exporters, and instances of OpenCensus API/SDK that must be removed. --The following are examples of import statements that must be removed. --``` -from opencensus.ext.azure import metrics_exporter -from opencensus.stats import aggregation as aggregation_module -from opencensus.stats import measure as measure_module --from opencensus.ext.azure.trace_exporter import AzureExporter -from opencensus.trace.samplers import ProbabilitySampler -from opencensus.trace.tracer import Tracer --from opencensus.ext.azure.log_exporter import AzureLogHandler -``` --## Step 3: Familiarize yourself with OpenTelemetry Python APIs/SDKs --The following documentation provides prerequisite knowledge of the OpenTelemetry Python APIs/SDKs. --* OpenTelemetry Python [documentation](https://opentelemetry-python.readthedocs.io/en/stable/) -* Azure Monitor Distro documentation on [configuration](./opentelemetry-configuration.md?tabs=python) and [telemetry](./opentelemetry-add-modify.md?tabs=python) --> [!NOTE] -> OpenTelemetry Python and OpenCensus Python have different API surfaces, autocollection capabilities, and onboarding instructions. --## Step 4: Set up the Azure Monitor OpenTelemetry Distro --Follow the [getting started](./opentelemetry-enable.md?tabs=python#enable-opentelemetry-with-application-insights) -page to onboard onto the Azure Monitor OpenTelemetry Distro. --## Changes and limitations --The following changes and limitations may be encountered when migrating from OpenCensus to OpenTelemetry. --### Python < 3.7 support --OpenTelemetry's Python-based monitoring solutions only support Python 3.7 and greater, excluding the previously supported Python versions 2.7, 3.4, 3.5, and 3.6 from OpenCensus. We suggest upgrading for users who are on the older versions of Python since, as of writing this document, those versions have already reached [end of life](https://devguide.python.org/versions/). Users who are adamant about not upgrading may still use the OpenTelemetry solutions, but may find unexpected or breaking behavior that is unsupported. In any case, the last supported version of [opencensus-ext-azure](https://pypi.org/project/opencensus-ext-azure/) always exists, and stills work for those versions, but no new releases are made for that project. --### Configurations --OpenCensus Python provided some [configuration](https://github.com/census-instrumentation/opencensus-python#customization) options related to the collection and exporting of telemetry. You achieve the same configurations, and more, by using the [OpenTelemetry Python](https://opentelemetry-python.readthedocs.io/en/stable/) APIs and SDK. The OpenTelemetry Azure monitor Python Distro is more of a one-stop-shop for the most common monitoring needs for your Python applications. Since the Distro encapsulates the OpenTelemetry APIs/SDk, some configuration for more uncommon use cases may not currently be supported for the Distro. Instead, you can opt to onboard onto the [Azure monitor OpenTelemetry exporter](https://github.com/Azure/azure-sdk-for-python/tree/main/sdk/monitor/azure-monitor-opentelemetry-exporter), which, with the OpenTelemetry APIs/SDKs, should be able to fit your monitoring needs. Some of these configurations include: --* Custom propagators -* Custom samplers -* Adding extra span/log processors/metrics readers --### Cohesion with Azure Functions --In order to provide distributed tracing capabilities for Python applications that call other Python applications within an Azure function, the package [opencensus-extension-azure-functions](https://pypi.org/project/opencensus-extension-azure-functions/) was provided to allow for a connected distributed graph. --Currently, the OpenTelemetry solutions for Azure Monitor don't support this scenario. As a workaround, you can manually propagate the trace context in your Azure functions application as shown in the following example. --```python -from opentelemetry.context import attach, detach -from opentelemetry.trace.propagation.tracecontext import \ - TraceContextTextMapPropagator --# Context parameter is provided for the body of the function -def main(req, context): - functions_current_context = { - "traceparent": context.trace_context.Traceparent, - "tracestate": context.trace_context.Tracestate - } - parent_context = TraceContextTextMapPropagator().extract( - carrier=functions_current_context - ) - token = attach(parent_context) -- ... - # Function logic - ... - detach(token) -``` --### Extensions and exporters --The OpenCensus SDK offered ways to collect and export telemetry through OpenCensus integrations and exporters respectively. In OpenTelemetry, integrations are now referred to as instrumentations, whereas exporters have stayed with the same terminology. The OpenTelemetry Python instrumentations and exporters are a superset of what was provided in OpenCensus, so in terms of library coverage and functionality, OpenTelemetry libraries are a direct upgrade. As for the Azure Monitor OpenTelemetry Distro, it comes with some of the popular OpenTelemetry Python [instrumentations](.\opentelemetry-add-modify.md?tabs=python#included-instrumentation-libraries) out of the box so no extra code is necessary. Microsoft fully supports these instrumentations. --As for the other OpenTelemetry Python [instrumentations](https://github.com/open-telemetry/opentelemetry-python-contrib/tree/main/instrumentation) that aren't included in this list, users may still manually instrument with them. However, it's important to note that stability and behavior aren't guaranteed or supported in those cases. Therefore, use them at your own discretion. --If you would like to suggest a community instrumentation library us to include in our distro, post or up-vote an idea in our [feedback community](https://feedback.azure.com/d365community/forum/3887dc70-2025-ec11-b6e6-000d3a4f09d0). For exporters, the Azure Monitor OpenTelemetry distro comes bundled with the [Azure Monitor OpenTelemetry exporter](https://pypi.org/project/azure-monitor-opentelemetry-exporter/). If you would like to use other exporters as well, you can use them with the distro, like in this [example](./opentelemetry-configuration.md?tabs=python#enable-the-otlp-exporter). --### TelemetryProcessors --OpenCensus Python telemetry [processors](./api-filtering-sampling.md#opencensus-python-telemetry-processors) are a powerful mechanism in which allowed users to modify their telemetry before they're sent to the exporter. There's no concept of TelemetryProcessors in the OpenTelemetry world, but there are APIs and classes that you can use to replicate the same behavior. --#### Setting Cloud Role Name and Cloud Role Instance --Follow the instructions [here](./opentelemetry-configuration.md?tabs=python#set-the-cloud-role-name-and-the-cloud-role-instance) for how to set cloud role name and cloud role instance for your telemetry. The OpenTelemetry Azure Monitor Distro automatically fetches the values from the environment variables and fills the respective fields. --#### Modifying spans with SpanProcessors --Coming soon. --#### Modifying metrics with Views --Coming soon. --### Performance Counters --The OpenCensus Python Azure Monitor exporter automatically collected system and performance related metrics called [performance counters](https://github.com/census-instrumentation/opencensus-python/tree/master/contrib/opencensus-ext-azure#performance-counters). These metrics appear in `performanceCounters` in your Application Insights instance. In OpenTelemetry, we no longer send these metrics explicitly to `performanceCounters`. Metrics related to incoming/outgoing requests can be found under [standard metrics](./standard-metrics.md). If you would like OpenTelemetry to autocollect system related metrics, you can use the experimental system metrics [instrumentation](https://github.com/open-telemetry/opentelemetry-python-contrib/tree/main/instrumentation/opentelemetry-instrumentation-system-metrics), contributed by the OpenTelemetry Python community. This package is experimental and not officially supported by Microsoft. - |
| azure-monitor | Opentelemetry | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/opentelemetry.md | - Title: OpenTelemetry on Azure -description: This article provides an overview of OpenTelemetry on Azure. - Previously updated : 06/21/2024----# OpenTelemetry on Azure --Azure's integration with OpenTelemetry provides a suite of products for: --> [!div class="checklist"] -> - Collection of telemetry data in a standardized way -> - Consumption of data using curated experiences on Azure Monitor and local tools --This article guides you through our OpenTelemetry offerings to help you understand MicrosoftΓÇÖs strategic investments. --For more information about OpenTelemetry on Azure, see [our OpenTelemetry Roadmap](https://techcommunity.microsoft.com/t5/azure-observability-blog/making-azure-the-best-place-to-observe-your-apps-with/ba-p/3995896). --## Data collection --The **Azure Monitor OpenTelemetry Distro** is MicrosoftΓÇÖs customized, supported, and open-sourced version of the OpenTelemetry software development kits (SDKs). It supports .NET, Java, JavaScript (Node.js), and Python. We recommend the Azure Monitor OpenTelemetry Distro for most customers, and we continue to invest in adding new capabilities to it. --It focuses on ease-of-enablement by bundling together: --> [!div class="checklist"] -> - The OpenTelemetry SDK and API -> - Instrumentation Libraries across logs, metrics, and traces --In addition, Azure Monitor OpenTelemetry Distro-based automatic instrumentation solutions are integrated into App Service for Java and Python apps and into Java Functions. --- [Enable Azure Monitor OpenTelemetry for .NET, Java, Node.js, and Python applications](./opentelemetry-enable.md)-- [Diagnose with Live Metrics](./live-stream.md)-- [Migrating Azure Monitor Application Insights Python from OpenCensus to OpenTelemetry](./opentelemetry-python-opencensus-migrate.md)-- [Monitor Azure app services performance Python (Preview)](./azure-web-apps-python.md)-- [Monitor Azure app services performance Java](./azure-web-apps-java.md)-- [Monitor applications running on Azure Functions with Application Insights](./monitor-functions.md)--**Azure SDKs** are instrumented with OpenTelemetry APIs to power end-to-end observability. All supported languages are instrumented to emit OpenTelemetry HTTP and/or Messaging Tracing Semantics; .NET and Java are being instrumented to emit OpenTelemetry HTTP Metrics Semantics. --- [Azure SDK semantic conventions](https://github.com/Azure/azure-sdk/blob/main/docs/tracing/distributed-tracing-conventions.md)-- [Tracing in the Azure SDK for Java](/azure/developer/java/sdk/tracing)-- [Azure Cosmos DB SDK observability](/azure/cosmos-db/nosql/sdk-observability)--The **.NET** OpenTelemetry implementation uses logging, metrics, and activity APIs in the framework for instrumentation. The OpenTelemetry SDK collects telemetry from those APIs and other sources (via instrumentation libraries) and then exports the data to an application performance monitoring (APM) system for storage and analysis. --- [.NET Observability with OpenTelemetry](/dotnet/core/diagnostics/observability-with-otel)--**Azure Monitor pipeline at edge** is a powerful solution designed to facilitate high-scale data ingestion and routing from edge environments to seamlessly enable observability across cloud, edge, and multicloud. It uses the OpenTelemetry Collector. Currently, in public preview, it can be deployed on a single Arc-enabled Kubernetes cluster, and it can collect OpenTelemetry Protocol (OTLP) logs. --- [Accelerate your observability journey with Azure Monitor pipeline (preview)](https://techcommunity.microsoft.com/t5/azure-observability-blog/accelerate-your-observability-journey-with-azure-monitor/ba-p/4124852)-- [Configure Azure Monitor pipeline for edge and multicloud](../essentials/edge-pipeline-configure.md)--**OpenTelemetry Collector Azure Data Explorer Exporter** is a data exporter component that can be plugged into the OpenTelemetry Collector. It supports ingestion of data from many receivers into to Azure Data Explorer, Azure Synapse Data Explorer, and Real-Time Analytics in Fabric. --- [Data ingestion from OpenTelemetry to Azure Data Explorer](/azure/data-explorer/open-telemetry-connector)-- [GitHub repository of Azure Data Explorer Exporter](https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/exporter/azuredataexplorerexporter)-- [Azure Synapse Data Explorer](/azure/synapse-analytics/data-explorer/data-explorer-overview)-- [Real-Time Intelligence](/fabric/real-time-intelligence/overview)--**Azure Functions** allows exporting log and trace data in OTLP format. It supports telemetry from both the host process and the worker process. When enabled, the data can be sent to any OpenTelemetry-compliant endpoints. --- [Use OpenTelemetry with Azure Functions](/azure/azure-functions/opentelemetry-howto)-- [Monitor Azure Functions](/azure/azure-functions/monitor-functions)--## Data platform and consumption --**.NET Aspire** is an opinionated cloud-native stack that includes observability by default with OpenTelemetry. Part of it's a "Developer Dashboard" to observe OpenTelemetry signals in real-time during debugging. It collects logs, metrics, and traces using OTLP from applications of any OpenTelemetry-supported languages besides .NET. --- [.NET Aspire: Simplifying Cloud-Native Development with .NET 8](https://devblogs.microsoft.com/dotnet/introducing-dotnet-aspire-simplifying-cloud-native-development-with-dotnet-8/)-- [.NET Aspire dashboard overview](/dotnet/aspire/fundamentals/dashboard/overview)--**Azure Monitor Application Insights** is AzureΓÇÖs APM that supports cloud-scale application monitoring and excels at observability for both cloud-native applications and VM-based applications. Application Insights provides experiences powered by OpenTelemetry to enhance the performance, reliability, and quality of your applications. For example, Application map is a visual overview of application architecture and components' interactions; Transaction search helps identify issues and optimize performance. --- [Application Insights overview](./app-insights-overview.md)-- [Application map in Azure Application Insights](./app-map.md)-- [Transaction Search and Diagnostics](./transaction-search-and-diagnostics.md)-- [Live Metrics](./live-stream.md) |
| azure-monitor | Overview Dashboard | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/overview-dashboard.md | - Title: Application Insights Overview dashboard | Microsoft Docs -description: Monitor applications with Application Insights and Overview dashboard functionality. - Previously updated : 10/11/2023---# Application Insights Overview dashboard --Application Insights provides a summary in the overview pane to allow at-a-glance assessment of your application's health and performance. ---A time range selection is available at the top of the interface. ---Each tile can be selected to navigate to the corresponding experience. As an example, selecting the **Failed requests** tile opens the **Failures** experience. ---## Application dashboard --The application dashboard uses the existing dashboard technology within Azure to provide a fully customizable single pane view of your application health and performance. --To access the default dashboard, select **Application Dashboard**. ---If it's your first time accessing the dashboard, it opens a default view. ---You can keep the default view if you like it. Or you can also add and delete from the dashboard to best fit the needs of your team. --> [!NOTE] -> All users with access to the Application Insights resource share the same **Application Dashboard** experience. Changes made by one user will modify the view for all users. --## Frequently asked questions --### Can I display more than 30 days of data? --No, there's a limit of 30 days of data displayed in a dashboard. --### I'm seeing a "resource not found" error on the dashboard --A "resource not found" error can occur if you move or rename your Application Insights instance. --To work around this behavior, delete the default dashboard and select **Application Dashboard** again to re-create a new one. --## Create custom KPI dashboards using Application Insights --You can create multiple dashboards in the Azure portal that include tiles visualizing data from multiple Azure resources across different resource groups and subscriptions. You can pin different charts and views from Application Insights to create custom dashboards that provide you with a complete picture of the health and performance of your application. This tutorial walks you through the creation of a custom dashboard that includes multiple types of data and visualizations from Application Insights. -- You learn how to: --> [!div class="checklist"] -> * Create a custom dashboard in Azure. -> * Add a tile from the **Tile Gallery**. -> * Add standard metrics in Application Insights to the dashboard. -> * Add a custom metric chart based on Application Insights to the dashboard. -> * Add the results of a Log Analytics query to the dashboard. --### Prerequisites --To complete this tutorial: --- Deploy a .NET application to Azure.-- Enable the [Application Insights SDK](../app/asp-net.md).--> [!NOTE] -> Required permissions for working with dashboards are discussed in the article on [understanding access control for dashboards](../../azure-portal/azure-portal-dashboard-share-access.md). --### Sign in to Azure --Sign in to the [Azure portal](https://portal.azure.com). --### Create a new dashboard --> [!WARNING] -> If you move your Application Insights resource over to a different resource group or subscription, you'll need to manually update the dashboard by removing the old tiles and pinning new tiles from the same Application Insights resource at the new location. --A single dashboard can contain resources from multiple applications, resource groups, and subscriptions. Start the tutorial by creating a new dashboard for your application. --1. In the menu dropdown on the left in the Azure portal, select **Dashboard**. -- :::image type="content" source="media/overview-dashboard/dashboard-from-menu.png" lightbox="media/overview-dashboard/dashboard-from-menu.png" alt-text="Screenshot that shows the Azure portal menu dropdown."::: --1. On the **Dashboard** pane, select **New dashboard** > **Blank dashboard**. -- :::image type="content" source="media/overview-dashboard/new-dashboard.png" lightbox="media/overview-dashboard/new-dashboard.png" alt-text="Screenshot that shows the Dashboard pane."::: --1. Enter a name for the dashboard. -1. Look at the **Tile Gallery** for various tiles that you can add to your dashboard. You can also pin charts and other views directly from Application Insights to the dashboard. -1. Locate the **Markdown** tile and drag it on to your dashboard. With this tile, you can add text formatted in Markdown, which is ideal for adding descriptive text to your dashboard. To learn more, see [Use a Markdown tile on Azure dashboards to show custom content](../../azure-portal/azure-portal-markdown-tile.md). -1. Add text to the tile's properties and resize it on the dashboard canvas. -- :::image type="content" source="media/overview-dashboard/markdown.png" lightbox="media/overview-dashboard/markdown.png" alt-text="Screenshot that shows the Edit Markdown tile."::: --1. Select **Done customizing** at the top of the screen to exit tile customization mode. --### Add health overview --A dashboard with static text isn't very interesting, so add a tile from Application Insights to show information about your application. You can add Application Insights tiles from the **Tile Gallery**. You can also pin them directly from Application Insights screens. In this way, you can configure charts and views that you're already familiar with before you pin them to your dashboard. --Start by adding the standard health overview for your application. This tile requires no configuration and allows minimal customization in the dashboard. --1. Select your **Application Insights** resource on the home screen. -1. On the **Overview** pane, select the pin icon :::image type="content" source="media/overview-dashboard/pushpin.png" lightbox="media/overview-dashboard/pushpin.png" alt-text="pin icon"::: to add the tile to a dashboard. -1. On the **Pin to dashboard** tab, select which dashboard to add the tile to or create a new one. -1. At the top right, a notification appears that your tile was pinned to your dashboard. Select **Pinned to dashboard** in the notification to return to your dashboard or use the **Dashboard** pane. -1. Select **Edit** to change the positioning of the tile you added to your dashboard. Select and drag it into position and then select **Done customizing**. Your dashboard now has a tile with some useful information. -- :::image type="content" source="media/overview-dashboard/dashboard-edit-mode.png" lightbox="media/overview-dashboard/dashboard-edit-mode.png" alt-text="Screenshot that shows the dashboard in edit mode."::: --### Add custom metric chart --You can use the **Metrics** panel to graph a metric collected by Application Insights over time with optional filters and grouping. Like everything else in Application Insights, you can add this chart to the dashboard. This step does require you to do a little customization first. --1. Select your **Application Insights** resource on the home screen. -1. Select **Metrics**. -1. An empty chart appears, and you're prompted to add a metric. Add a metric to the chart and optionally add a filter and a grouping. The following example shows the number of server requests grouped by success. This chart gives a running view of successful and unsuccessful requests. -- :::image type="content" source="media/overview-dashboard/metrics.png" lightbox="media/overview-dashboard/metrics.png" alt-text="Screenshot that shows adding a metric."::: --1. Select **Pin to dashboard** on the right. --1. In the top right, a notification appears that your tile was pinned to your dashboard. Select **Pinned to dashboard** in the notification to return to your dashboard or use the dashboard tab. --1. That tile is now added to your dashboard. Select **Edit** to change the positioning of the tile. Select and drag the tile into position and then select **Done customizing**. --### Add a logs query --Application Insights Logs provides a rich query language that you can use to analyze all the data collected by Application Insights. Like with charts and other views, you can add the output of a logs query to your dashboard. --1. Select your **Application Insights** resource in the home screen. -1. On the left under **Monitoring**, select **Logs** to open the **Logs** tab. -1. Enter the following query, which returns the top 10 most requested pages and their request count: -- ``` Kusto - requests - | summarize count() by name - | sort by count_ desc - | take 10 - ``` --1. Select **Run** to validate the results of the query. -1. Select the pin icon :::image type="content" source="media/overview-dashboard/pushpin.png" lightbox="media/overview-dashboard/pushpin.png" alt-text="Pin icon"::: and then select the name of your dashboard. --1. Before you go back to the dashboard, add another query, but render it as a chart. Now you'll see the different ways to visualize a logs query in a dashboard. Start with the following query that summarizes the top 10 operations with the most exceptions: -- ``` Kusto - exceptions - | summarize count() by operation_Name - | sort by count_ desc - | take 10 - ``` --1. Select **Chart** and then select **Doughnut** to visualize the output. -- :::image type="content" source="media/overview-dashboard/logs-doughnut.png" lightbox="media/overview-dashboard/logs-doughnut.png" alt-text="Screenshot that shows the doughnut chart with the preceding query."::: --1. Select the pin icon :::image type="content" source="media/overview-dashboard/pushpin.png" lightbox="media/overview-dashboard/pushpin.png" alt-text="Pin icon"::: at the top right to pin the chart to your dashboard. Then return to your dashboard. -1. The results of the queries are added to your dashboard in the format that you selected. Select and drag each result into position. Then select **Done customizing**. -1. Select the pencil icon :::image type="content" source="media/overview-dashboard/pencil.png" lightbox="media/overview-dashboard/pencil.png" alt-text="Pencil icon"::: on each title and use it to make the titles descriptive. --### Share dashboard --1. At the top of the dashboard, select **Share** to publish your changes. -1. You can optionally define specific users who should have access to the dashboard. For more information, see [Share Azure dashboards by using Azure role-based access control](../../azure-portal/azure-portal-dashboard-share-access.md). -1. Select **Publish**. --## Next steps --* [Funnels](./usage.md#funnelsdiscover-how-customers-use-your-application) -* [Retention](./usage.md#user-retention-analysis) -* [User flows](./usage.md#user-flowsanalyze-user-navigation-patterns) -* In the tutorial, you learned how to create custom dashboards. Now look at the rest of the Application Insights documentation, which also includes a case study. - > [!div class="nextstepaction"] - > [Deep diagnostics](../app/devops.md) - |
| azure-monitor | Performance Counters | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/performance-counters.md | - Title: Performance counters in Application Insights | Microsoft Docs -description: Monitor system and custom .NET performance counters in Application Insights. - Previously updated : 01/31/2024-----# System performance counters in Application Insights --Windows provides a variety of [performance counters](/windows/desktop/perfctrs/about-performance-counters), such as those used to gather processor, memory, and disk usage statistics. You can also define your own performance counters. --Performance counters collection is supported if your application is running under IIS on an on-premises host or is a virtual machine to which you have administrative access. Although applications running as Azure Web Apps don't have direct access to performance counters, a subset of available counters is collected by Application Insights. ---## Prerequisites --Grant the app pool service account permission to monitor performance counters by adding it to the [Performance Monitor Users](/windows/security/identity-protection/access-control/active-directory-security-groups#bkmk-perfmonitorusers) group. --```shell -net localgroup "Performance Monitor Users" /add "IIS APPPOOL\NameOfYourPool" -``` --## View counters --The **Metrics** pane shows the default set of performance counters. ---Current default counters for ASP.NET web applications: --- % Process\\Processor Time-- % Process\\Processor Time Normalized-- Memory\\Available Bytes-- ASP.NET Requests/Sec-- .NET CLR Exceptions Thrown / sec-- ASP.NET ApplicationsRequest Execution Time-- Process\\Private Bytes-- Process\\IO Data Bytes/sec-- ASP.NET Applications\\Requests In Application Queue-- Processor(_Total)\\% Processor Time--Current default counters collected for ASP.NET Core web applications: --- % Process\\Processor Time-- % Process\\Processor Time Normalized-- Memory\\Available Bytes-- Process\\Private Bytes-- Process\\IO Data Bytes/sec-- Processor(_Total)\\% Processor Time--## Add counters --If the performance counter you want isn't included in the list of metrics, you can add it. --1. Find out what counters are available in your server by using this PowerShell command on the local server: -- ```shell - Get-Counter -ListSet * - ``` -- For more information, see [`Get-Counter`](/powershell/module/microsoft.powershell.diagnostics/get-counter). --1. Open `ApplicationInsights.config`. -- If you added Application Insights to your app during development: - 1. Edit `ApplicationInsights.config` in your project. - 1. Redeploy it to your servers. --1. Edit the performance collector directive: -- ```xml -- <Add Type="Microsoft.ApplicationInsights.Extensibility.PerfCounterCollector.PerformanceCollectorModule, Microsoft.AI.PerfCounterCollector"> - <Counters> - <Add PerformanceCounter="\Objects\Processes"/> - <Add PerformanceCounter="\Sales(photo)\# Items Sold" ReportAs="Photo sales"/> - </Counters> - </Add> - ``` --> [!NOTE] -> ASP.NET Core applications don't have `ApplicationInsights.config`, so the preceding method isn't valid for ASP.NET Core applications. --You can capture both standard counters and counters you've implemented yourself. `\Objects\Processes` is an example of a standard counter that's available on all Windows systems. `\Sales(photo)\# Items Sold` is an example of a custom counter that might be implemented in a web service. --The format is `\Category(instance)\Counter`, or for categories that don't have instances, just `\Category\Counter`. --The `ReportAs` parameter is required for counter names that don't match `[a-zA-Z()/-_ \.]+`. That is, they contain characters that aren't in the following sets: letters, round brackets, forward slash, hyphen, underscore, space, and dot. --If you specify an instance, it will be collected as a dimension `CounterInstanceName` of the reported metric. --### Collect performance counters in code for ASP.NET web applications or .NET/.NET Core console applications -To collect system performance counters and send them to Application Insights, you can adapt the following snippet: --```csharp - var perfCollectorModule = new PerformanceCollectorModule(); - perfCollectorModule.Counters.Add(new PerformanceCounterCollectionRequest( - @"\Process([replace-with-application-process-name])\Page Faults/sec", "PageFaultsPerfSec")); - perfCollectorModule.Initialize(TelemetryConfiguration.Active); -``` --Or you can do the same thing with custom metrics that you created: --```csharp - var perfCollectorModule = new PerformanceCollectorModule(); - perfCollectorModule.Counters.Add(new PerformanceCounterCollectionRequest( - @"\Sales(photo)\# Items Sold", "Photo sales")); - perfCollectorModule.Initialize(TelemetryConfiguration.Active); -``` --### Collect performance counters in code for ASP.NET Core web applications --### [ASP.NET Core 6 and later](#tab/net-core-new) --Configure `PerformanceCollectorModule` after the `WebApplication.CreateBuilder()` method in `Program.cs`: --```csharp -using Microsoft.ApplicationInsights.Extensibility.PerfCounterCollector; --var builder = WebApplication.CreateBuilder(args); --builder.Services.AddApplicationInsightsTelemetry(); --// The following configures PerformanceCollectorModule. --builder.Services.ConfigureTelemetryModule<PerformanceCollectorModule>((module, o) => - { - // The application process name could be "dotnet" for ASP.NET Core self-hosted applications. - module.Counters.Add(new PerformanceCounterCollectionRequest(@"\Process([replace-with-application-process-name])\Page Faults/sec", "DotnetPageFaultsPerfSec")); - }); --var app = builder.Build(); -``` --### [ASP.NET Core 5 and earlier](#tab/net-core-old) --Configure `PerformanceCollectorModule` in the `ConfigureServices()` method in `Startup.cs`: --```csharp -using Microsoft.ApplicationInsights.Extensibility.PerfCounterCollector; --public void ConfigureServices(IServiceCollection services) -{ - services.AddApplicationInsightsTelemetry(); -- // The following configures PerformanceCollectorModule: - services.ConfigureTelemetryModule<PerformanceCollectorModule>((module, o) => - { - // The application process name could be "dotnet" for ASP.NET Core self-hosted applications. - module.Counters.Add(new PerformanceCounterCollectionRequest(@"\Process([replace-with-application-process-name])\PageFaults/sec", "DotnetPageFaultsPerfSec")); - }); -} -``` ----## Performance counters in Log Analytics -You can search and display performance counter reports in [Log Analytics](../logs/log-query-overview.md). --The **performanceCounters** schema exposes the `category`, `counter` name, and `instance` name of each performance counter. In the telemetry for each application, you'll see only the counters for that application. For example, to see what counters are available: ---Here, `Instance` refers to the performance counter instance, not the role or server machine instance. The performance counter instance name typically segments counters, such as processor time, by the name of the process or application. --To get a chart of available memory over the recent period: ---Like other telemetry, **performanceCounters** also has a column `cloud_RoleInstance` that indicates the identity of the host server instance on which your app is running. For example, to compare the performance of your app on the different machines: ---## ASP.NET and Application Insights counts --The next sections discuss ASP.NET and Application Insights counts. --### What's the difference between the Exception rate and Exceptions metrics? --* `Exception rate`: The Exception rate is a system performance counter. The CLR counts all the handled and unhandled exceptions that are thrown and divides the total in a sampling interval by the length of the interval. The Application Insights SDK collects this result and sends it to the portal. -* `Exceptions`: The Exceptions metric is a count of the `TrackException` reports received by the portal in the sampling interval of the chart. It includes only the handled exceptions where you've written `TrackException` calls in your code. It doesn't include all [unhandled exceptions](./asp-net-exceptions.md). --## Performance counters for applications running in Azure Web Apps and Windows containers on Azure App Service --Both ASP.NET and ASP.NET Core applications deployed to Azure Web Apps run in a special sandbox environment. Applications deployed to Azure App Service can utilize a [Windows container](../../app-service/quickstart-custom-container.md?pivots=container-windows&tabs=dotnet) or be hosted in a sandbox environment. If the application is deployed in a Windows container, all standard performance counters are available in the container image. --The sandbox environment doesn't allow direct access to system performance counters. However, a limited subset of counters is exposed as environment variables as described in [Perf Counters exposed as environment variables](https://github.com/projectkudu/kudu/wiki/Perf-Counters-exposed-as-environment-variables). Only a subset of counters is available in this environment. For the full list, see [Perf Counters exposed as environment variables](https://github.com/microsoft/ApplicationInsights-dotnet/blob/main/WEB/Src/PerformanceCollector/PerformanceCollector/Implementation/WebAppPerformanceCollector/CounterFactory.cs). --The Application Insights SDK for [ASP.NET](https://nuget.org/packages/Microsoft.ApplicationInsights.Web) and [ASP.NET Core](https://nuget.org/packages/Microsoft.ApplicationInsights.AspNetCore) detects if code is deployed to a web app or a non-Windows container. The detection determines whether it collects performance counters in a sandbox environment or utilizes the standard collection mechanism when hosted on a Windows container or virtual machine. --## Performance counters in ASP.NET Core applications --Support for performance counters in ASP.NET Core is limited: --* [SDK](https://nuget.org/packages/Microsoft.ApplicationInsights.AspNetCore) versions 2.4.1 and later collect performance counters if the application is running in Azure Web Apps (Windows). -* SDK versions 2.7.1 and later collect performance counters if the application is running in Windows and targets `NETSTANDARD2.0` or later. -* For applications that target the .NET Framework, all versions of the SDK support performance counters. -* SDK versions 2.8.0 and later support the CPU/Memory counter in Linux. No other counter is supported in Linux. To get system counters in Linux (and other non-Windows environments), use [EventCounters](eventcounters.md). --## Alerts -Like other metrics, you can [set an alert](../alerts/alerts-log.md) to warn you if a performance counter goes outside a limit you specify. To set an alert, open the **Alerts** pane and select **Add Alert**. --## <a name="next"></a>Next steps --* [Dependency tracking](./asp-net-dependencies.md) -* [Exception tracking](./asp-net-exceptions.md) |
| azure-monitor | Powershell | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/powershell.md | - Title: Automate Application Insights with PowerShell | Microsoft Docs -description: Automate creating and managing resources, alerts, and availability tests in PowerShell by using an Azure Resource Manager template. - Previously updated : 09/12/2023-----# Manage Application Insights resources by using PowerShell ---This article shows you how to automate the creation and update of [Application Insights](./app-insights-overview.md) resources automatically by using Azure Resource Manager. You might, for example, do so as part of a build process. Along with the basic Application Insights resource, you can create [availability web tests](./availability-overview.md), set up [alerts](../alerts/alerts-log.md), set the [pricing scheme](../logs/cost-logs.md#application-insights-billing), and create other Azure resources. --The key to creating these resources is JSON templates for [Resource Manager](../../azure-resource-manager/management/manage-resources-powershell.md). The basic procedure is: --- Download the JSON definitions of existing resources.-- Parameterize certain values, such as names.-- Run the template whenever you want to create a new resource.--You can package several resources together to create them all in one go. For example, you can create an app monitor with availability tests, alerts, and storage for continuous export. There are some subtleties to some of the parameterizations, which we'll explain here. --## One-time setup -If you haven't used PowerShell with your Azure subscription before, install the Azure PowerShell module on the machine where you want to run the scripts: --1. Install [Microsoft Web Platform Installer (v5 or higher)](https://www.microsoft.com/web/downloads/platform.aspx). -1. Use it to install Azure PowerShell. --In addition to using Azure Resource Manager templates (ARM templates), there's a rich set of [Application Insights PowerShell cmdlets](/powershell/module/az.applicationinsights). These cmdlets make it easy to configure Application Insights resources programatically. You can use the capabilities enabled by the cmdlets to: --* Create and delete Application Insights resources. -* Get lists of Application Insights resources and their properties. -* Create and manage continuous export. -* Create and manage application keys. -* Set the daily cap. -* Set the pricing plan. --## Create Application Insights resources by using a PowerShell cmdlet --Here's how to create a new Application Insights resource in the Azure East US datacenter by using the [New-AzApplicationInsights](/powershell/module/az.applicationinsights/new-azapplicationinsights) cmdlet: --```PS -New-AzApplicationInsights -ResourceGroupName <resource group> -Name <resource name> -location eastus -``` --## Create Application Insights resources by using an ARM template --Here's how to create a new Application Insights resource by using an ARM template. --### Create the ARM template --Create a new .json file. Let's call it `template1.json` in this example. Copy this content into it: --```JSON - { - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "appName": { - "type": "string", - "metadata": { - "description": "Enter the name of your Application Insights resource." - } - }, - "appType": { - "type": "string", - "defaultValue": "web", - "allowedValues": [ - "web", - "java", - "other" - ], - "metadata": { - "description": "Enter the type of the monitored application." - } - }, - "appLocation": { - "type": "string", - "defaultValue": "eastus", - "metadata": { - "description": "Enter the location of your Application Insights resource." - } - }, - "retentionInDays": { - "type": "int", - "defaultValue": 90, - "allowedValues": [ - 30, - 60, - 90, - 120, - 180, - 270, - 365, - 550, - 730 - ], - "metadata": { - "description": "Data retention in days" - } - }, - "ImmediatePurgeDataOn30Days": { - "type": "bool", - "defaultValue": false, - "metadata": { - "description": "If set to true when changing retention to 30 days, older data will be immediately deleted. Use this with extreme caution. This only applies when retention is being set to 30 days." - } - }, - "priceCode": { - "type": "int", - "defaultValue": 1, - "allowedValues": [ - 1, - 2 - ], - "metadata": { - "description": "Pricing plan: 1 = Per GB (or legacy Basic plan), 2 = Per Node (legacy Enterprise plan)" - } - }, - "dailyQuota": { - "type": "int", - "defaultValue": 100, - "minValue": 1, - "metadata": { - "description": "Enter daily quota in GB." - } - }, - "dailyQuotaResetTime": { - "type": "int", - "defaultValue": 0, - "metadata": { - "description": "Enter daily quota reset hour in UTC (0 to 23). Values outside the range will get a random reset hour." - } - }, - "warningThreshold": { - "type": "int", - "defaultValue": 90, - "minValue": 1, - "maxValue": 100, - "metadata": { - "description": "Enter the % value of daily quota after which warning mail to be sent. " - } - } - }, - "variables": { - "priceArray": [ - "Basic", - "Application Insights Enterprise" - ], - "pricePlan": "[take(variables('priceArray'),parameters('priceCode'))]", - "billingplan": "[concat(parameters('appName'),'/', variables('pricePlan')[0])]" - }, - "resources": [ - { - "type": "microsoft.insights/components", - "kind": "[parameters('appType')]", - "name": "[parameters('appName')]", - "apiVersion": "2014-04-01", - "location": "[parameters('appLocation')]", - "tags": {}, - "properties": { - "ApplicationId": "[parameters('appName')]", - "retentionInDays": "[parameters('retentionInDays')]", - "ImmediatePurgeDataOn30Days": "[parameters('ImmediatePurgeDataOn30Days')]" - }, - "dependsOn": [] - }, - { - "name": "[variables('billingplan')]", - "type": "microsoft.insights/components/CurrentBillingFeatures", - "location": "[parameters('appLocation')]", - "apiVersion": "2015-05-01", - "dependsOn": [ - "[resourceId('microsoft.insights/components', parameters('appName'))]" - ], - "properties": { - "CurrentBillingFeatures": "[variables('pricePlan')]", - "DataVolumeCap": { - "Cap": "[parameters('dailyQuota')]", - "WarningThreshold": "[parameters('warningThreshold')]", - "ResetTime": "[parameters('dailyQuotaResetTime')]" - } - } - } - ] - } -``` --### Use the ARM template to create a new Application Insights resource --1. In PowerShell, sign in to Azure by using `$Connect-AzAccount`. -1. Set your context to a subscription with `Set-AzContext "<subscription ID>"`. -1. Run a new deployment to create a new Application Insights resource: -- ```PS - New-AzResourceGroupDeployment -ResourceGroupName Fabrikam ` - -TemplateFile .\template1.json ` - -appName myNewApp -- ``` -- * `-ResourceGroupName` is the group where you want to create the new resources. - * `-TemplateFile` must occur before the custom parameters. - * `-appName` is the name of the resource to create. --You can add other parameters. You'll find their descriptions in the parameters section of the template. --## Get the instrumentation key --After you create an application resource, you'll want the instrumentation key: --1. Sign in to Azure by using `$Connect-AzAccount`. -1. Set your context to a subscription with `Set-AzContext "<subscription ID>"`. -1. Then use: - 1. `$resource = Get-AzResource -Name "<resource name>" -ResourceType "Microsoft.Insights/components"` - 1. `$details = Get-AzResource -ResourceId $resource.ResourceId` - 1. `$details.Properties.InstrumentationKey` --To see a list of many other properties of your Application Insights resource, use: --```PS -Get-AzApplicationInsights -ResourceGroupName Fabrikam -Name FabrikamProd | Format-List -``` --More properties are available via the cmdlets: --* `Set-AzApplicationInsightsDailyCap` -* `Set-AzApplicationInsightsPricingPlan` -* `Get-AzApplicationInsightsApiKey` -* `Get-AzApplicationInsightsContinuousExport` --See the [detailed documentation](/powershell/module/az.applicationinsights) for the parameters for these cmdlets. ---## Set the data retention --You can use the following three methods to programmatically set the data retention on an Application Insights resource. --### Set data retention by using PowerShell commands --Here's a simple set of PowerShell commands to set the data retention for your Application Insights resource: --```PS -$Resource = Get-AzResource -ResourceType Microsoft.Insights/components -ResourceGroupName MyResourceGroupName -ResourceName MyResourceName -$Resource.Properties.RetentionInDays = 365 -$Resource | Set-AzResource -Force -``` --### Set data retention by using REST --To get the current data retention for your Application Insights resource, you can use the OSS tool [ARMClient](https://github.com/projectkudu/ARMClient). Learn more about ARMClient from articles by [David Ebbo](http://blog.davidebbo.com/2015/01/azure-resource-manager-client.html) and Daniel Bowbyes. Here's an example that uses `ARMClient` to get the current retention: --```PS -armclient GET /subscriptions/00000000-0000-0000-0000-00000000000/resourceGroups/MyResourceGroupName/providers/microsoft.insights/components/MyResourceName?api-version=2018-05-01-preview -``` --To set the retention, the command is a similar PUT: --```PS -armclient PUT /subscriptions/00000000-0000-0000-0000-00000000000/resourceGroups/MyResourceGroupName/providers/microsoft.insights/components/MyResourceName?api-version=2018-05-01-preview "{location: 'eastus', properties: {'retentionInDays': 365}}" -``` --To set the data retention to 365 days by using the preceding template, run: --```PS -New-AzResourceGroupDeployment -ResourceGroupName "<resource group>" ` - -TemplateFile .\template1.json ` - -retentionInDays 365 ` - -appName myApp -``` --### Set data retention by using a PowerShell script --The following script can also be used to change retention. Copy this script to save it as `Set-ApplicationInsightsRetention.ps1`. --```PS -Param( - [Parameter(Mandatory = $True)] - [string]$SubscriptionId, -- [Parameter(Mandatory = $True)] - [string]$ResourceGroupName, -- [Parameter(Mandatory = $True)] - [string]$Name, -- [Parameter(Mandatory = $True)] - [string]$RetentionInDays -) -$ErrorActionPreference = 'Stop' -if (-not (Get-Module Az.Accounts)) { - Import-Module Az.Accounts -} -$azProfile = [Microsoft.Azure.Commands.Common.Authentication.Abstractions.AzureRmProfileProvider]::Instance.Profile -if (-not $azProfile.Accounts.Count) { - Write-Error "Ensure you have logged in before calling this function." -} -$currentAzureContext = Get-AzContext -$profileClient = New-Object Microsoft.Azure.Commands.ResourceManager.Common.RMProfileClient($azProfile) -$token = $profileClient.AcquireAccessToken($currentAzureContext.Tenant.TenantId) -$UserToken = $token.AccessToken -$RequestUri = "https://management.azure.com/subscriptions/$($SubscriptionId)/resourceGroups/$($ResourceGroupName)/providers/Microsoft.Insights/components/$($Name)?api-version=2015-05-01" -$Headers = @{ - "Authorization" = "Bearer $UserToken" - "x-ms-client-tenant-id" = $currentAzureContext.Tenant.TenantId -} -## Get Component object via ARM -$GetResponse = Invoke-RestMethod -Method "GET" -Uri $RequestUri -Headers $Headers --## Update RetentionInDays property -if($($GetResponse.properties | Get-Member "RetentionInDays")) -{ - $GetResponse.properties.RetentionInDays = $RetentionInDays -} -else -{ - $GetResponse.properties | Add-Member -Type NoteProperty -Name "RetentionInDays" -Value $RetentionInDays -} -## Upsert Component object via ARM -$PutResponse = Invoke-RestMethod -Method "PUT" -Uri "$($RequestUri)" -Headers $Headers -Body $($GetResponse | ConvertTo-Json) -ContentType "application/json" -$PutResponse -``` --This script can then be used as: --```PS -Set-ApplicationInsightsRetention ` - [-SubscriptionId] <String> ` - [-ResourceGroupName] <String> ` - [-Name] <String> ` - [-RetentionInDays <Int>] -``` --## Set the daily cap --To get the daily cap properties, use the [Set-AzApplicationInsightsPricingPlan](/powershell/module/az.applicationinsights/set-azapplicationinsightspricingplan) cmdlet: --```PS -Set-AzApplicationInsightsDailyCap -ResourceGroupName <resource group> -Name <resource name> | Format-List -``` --To set the daily cap properties, use the same cmdlet. For instance, to set the cap to 300 GB per day: --```PS -Set-AzApplicationInsightsDailyCap -ResourceGroupName <resource group> -Name <resource name> -DailyCapGB 300 -``` --You can also use [ARMClient](https://github.com/projectkudu/ARMClient) to get and set daily cap parameters. To get the current values, use: --```PS -armclient GET /subscriptions/00000000-0000-0000-0000-00000000000/resourceGroups/MyResourceGroupName/providers/microsoft.insights/components/MyResourceName/CurrentBillingFeatures?api-version=2018-05-01-preview -``` --## Set the daily cap reset time --To set the daily cap reset time, you can use [ARMClient](https://github.com/projectkudu/ARMClient). Here's an example using `ARMClient` to set the reset time to a new hour. This example shows 12:00 UTC: --```PS -armclient PUT /subscriptions/00000000-0000-0000-0000-00000000000/resourceGroups/MyResourceGroupName/providers/microsoft.insights/components/MyResourceName/CurrentBillingFeatures?api-version=2018-05-01-preview "{'CurrentBillingFeatures':['Basic'],'DataVolumeCap':{'Cap':100,'WarningThreshold':80,'ResetTime':12}}" -``` --<a id="price"></a> --## Set the pricing plan --To get the current pricing plan, use the [Set-AzApplicationInsightsPricingPlan](/powershell/module/az.applicationinsights/set-azapplicationinsightspricingplan) cmdlet: --```PS -Set-AzApplicationInsightsPricingPlan -ResourceGroupName <resource group> -Name <resource name> | Format-List -``` --To set the pricing plan, use the same cmdlet with the `-PricingPlan` specified: --```PS -Set-AzApplicationInsightsPricingPlan -ResourceGroupName <resource group> -Name <resource name> -PricingPlan Basic -``` --You can also set the pricing plan on an existing Application Insights resource by using the preceding ARM template, omitting the "microsoft.insights/components" resource and the `dependsOn` node from the billing resource. For instance, to set it to the Per GB plan (formerly called the Basic plan), run: --```PS - New-AzResourceGroupDeployment -ResourceGroupName "<resource group>" ` - -TemplateFile .\template1.json ` - -priceCode 1 ` - -appName myApp -``` --The `priceCode` is defined as: --|priceCode|Plan| -||| -|1|Per GB (formerly named the Basic plan)| -|2|Per Node (formerly name the Enterprise plan)| --Finally, you can use [ARMClient](https://github.com/projectkudu/ARMClient) to get and set pricing plans and daily cap parameters. To get the current values, use: --```PS -armclient GET /subscriptions/00000000-0000-0000-0000-00000000000/resourceGroups/MyResourceGroupName/providers/microsoft.insights/components/MyResourceName/CurrentBillingFeatures?api-version=2018-05-01-preview -``` --You can set all of these parameters by using: --```PS -armclient PUT /subscriptions/00000000-0000-0000-0000-00000000000/resourceGroups/MyResourceGroupName/providers/microsoft.insights/components/MyResourceName/CurrentBillingFeatures?api-version=2018-05-01-preview -"{'CurrentBillingFeatures':['Basic'],'DataVolumeCap':{'Cap':200,'ResetTime':12,'StopSendNotificationWhenHitCap':true,'WarningThreshold':90,'StopSendNotificationWhenHitThreshold':true}}" -``` --This code will set the daily cap to 200 GB per day, configure the daily cap reset time to 12:00 UTC, send emails both when the cap is hit and the warning level is met, and set the warning threshold to 90% of the cap. --## Add a metric alert --To automate the creation of metric alerts, see the [Metric alerts template](../alerts/alerts-metric-create-templates.md#template-for-a-simple-static-threshold-metric-alert) article. --## Add an availability test --To automate availability tests, see the [Metric alerts template](../alerts/alerts-metric-create-templates.md#template-for-an-availability-test-along-with-a-metric-alert) article. --## Add more resources --To automate the creation of any other resource of any kind, create an example manually and then copy and parameterize its code from [Azure Resource Manager](https://resources.azure.com/). --1. Open [Azure Resource Manager](https://resources.azure.com/). Navigate down through `subscriptions/resourceGroups/<your resource group>/providers/Microsoft.Insights/components` to your application resource. -- :::image type="content" source="./media/powershell/01.png" lightbox="./media/powershell/01.png" alt-text="Screenshot that shows navigation in Azure Resource Explorer."::: -- *Components* are the basic Application Insights resources for displaying applications. There are separate resources for the associated alert rules and availability web tests. -1. Copy the JSON of the component into the appropriate place in `template1.json`. -1. Delete these properties: -- * `id` - * `InstrumentationKey` - * `CreationDate` - * `TenantId` -1. Open the `webtests` and `alertrules` sections and copy the JSON for individual items into your template. Don't copy from the `webtests` or `alertrules` nodes. Go into the items under them. -- Each web test has an associated alert rule, so you have to copy both of them. --1. Insert this line in each resource: -- `"apiVersion": "2015-05-01",` --### Parameterize the template -Now you have to replace the specific names with parameters. To [parameterize a template](../../azure-resource-manager/templates/syntax.md), you write expressions using a [set of helper functions](../../azure-resource-manager/templates/template-functions.md). --You can't parameterize only part of a string, so use `concat()` to build strings. --Here are examples of the substitutions you'll want to make. There are several occurrences of each substitution. You might need others in your template. These examples use the parameters and variables we defined at the top of the template. --| Find | Replace with | -| | | -| `"hidden-link:/subscriptions/.../../components/MyAppName"` |`"[concat('hidden-link:',`<br/>`resourceId('microsoft.insights/components',` <br/> `parameters('appName')))]"` | -| `"/subscriptions/.../../alertrules/myAlertName-myAppName-subsId",` |`"[resourceId('Microsoft.Insights/alertrules', variables('alertRuleName'))]",` | -| `"/subscriptions/.../../webtests/myTestName-myAppName",` |`"[resourceId('Microsoft.Insights/webtests', parameters('webTestName'))]",` | -| `"myWebTest-myAppName"` |`"[variables(testName)]"'` | -| `"myTestName-myAppName-subsId"` |`"[variables('alertRuleName')]"` | -| `"myAppName"` |`"[parameters('appName')]"` | -| `"myappname"` (lower case) |`"[toLower(parameters('appName'))]"` | -| `"<WebTest Name=\"myWebTest\" ...`<br/>`Url=\"http://fabrikam.com/home\" ...>"` |`[concat('<WebTest Name=\"',` <br/> `parameters('webTestName'),` <br/> `'\" ... Url=\"', parameters('Url'),` <br/> `'\"...>')]"`| --### Set dependencies between the resources -Azure should set up the resources in strict order. To make sure one setup completes before the next begins, add dependency lines: --* In the availability test resource: - - `"dependsOn": ["[resourceId('Microsoft.Insights/components', parameters('appName'))]"],` -* In the alert resource for an availability test: - - `"dependsOn": ["[resourceId('Microsoft.Insights/webtests', variables('testName'))]"],` --## Next steps --See these other automation articles: --* [Create an Application Insights resource](./create-workspace-resource.md) -* [Create web tests](../alerts/resource-manager-alerts-metric.md#availability-test-with-metric-alert). -* [Send Azure Diagnostics to Application Insights](../agents/diagnostics-extension-to-application-insights.md). -* [Create release annotations](release-and-work-item-insights.md?tabs=release-annotations). |
| azure-monitor | Pre Aggregated Metrics Log Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/pre-aggregated-metrics-log-metrics.md | - Title: Log-based and preaggregated metrics in Application Insights | Microsoft Docs -description: This article explains when to use log-based versus preaggregated metrics in Application Insights. - Previously updated : 01/31/2024----# Log-based and preaggregated metrics in Application Insights ---This article explains the difference between "traditional" Application Insights metrics that are based on logs and preaggregated metrics. Both types of metrics are available to users of Application Insights. Each one brings a unique value in monitoring application health, diagnostics, and analytics. The developers who are instrumenting applications can decide which type of metric is best suited to a particular scenario. Decisions are based on the size of the application, expected volume of telemetry, and business requirements for metrics precision and alerting. --## Log-based metrics --In the past, the application monitoring telemetry data model in Application Insights was solely based on a few predefined types of events, such as requests, exceptions, dependency calls, and page views. Developers can use the SDK to emit these events manually by writing code that explicitly invokes the SDK. Or they can rely on the automatic collection of events from autoinstrumentation. In either case, the Application Insights back end stores all collected events as logs. The Application Insights panes in the Azure portal act as an analytical and diagnostic tool for visualizing event-based data from logs. --Using logs to retain a complete set of events can bring great analytical and diagnostic value. For example, you can get an exact count of requests to a particular URL with the number of distinct users who made these calls. Or you can get detailed diagnostic traces, including exceptions and dependency calls for any user session. Having this type of information can improve visibility into the application health and usage. It can also cut down the time necessary to diagnose issues with an app. --At the same time, collecting a complete set of events might be impractical or even impossible for applications that generate a large volume of telemetry. For situations when the volume of events is too high, Application Insights implements several telemetry volume reduction techniques that reduce the number of collected and stored events. These techniques include [sampling](./sampling.md) and [filtering](./api-filtering-sampling.md). Unfortunately, lowering the number of stored events also lowers the accuracy of the metrics that, behind the scenes, must perform query-time aggregations of the events stored in logs. --> [!NOTE] -> In Application Insights, the metrics that are based on the query-time aggregation of events and measurements stored in logs are called log-based metrics. These metrics typically have many dimensions from the event properties, which makes them superior for analytics. The accuracy of these metrics is negatively affected by sampling and filtering. --## Preaggregated metrics --In addition to log-based metrics, in late 2018, the Application Insights team shipped a public preview of metrics that are stored in a specialized repository that's optimized for time series. The new metrics are no longer kept as individual events with lots of properties. Instead, they're stored as preaggregated time series, and only with key dimensions. This change makes the new metrics superior at query time. Retrieving data happens faster and requires less compute power. As a result, new scenarios are enabled, such as [near real time alerting on dimensions of metrics](../alerts/alerts-metric-near-real-time.md) and more responsive [dashboards](./overview-dashboard.md). --> [!IMPORTANT] -> Both log-based and preaggregated metrics coexist in Application Insights. To differentiate the two, in the Application Insights user experience the preaggregated metrics are now called standard metrics. The traditional metrics from the events were renamed to log-based metrics. --The newer SDKs ([Application Insights 2.7](https://www.nuget.org/packages/Microsoft.ApplicationInsights/2.7.2) SDK or later for .NET) preaggregate metrics during collection. This process applies to [standard metrics sent by default](../essentials/metrics-supported.md#microsoftinsightscomponents), so the accuracy isn't affected by sampling or filtering. It also applies to custom metrics sent by using [GetMetric](./api-custom-events-metrics.md#getmetric), which results in less data ingestion and lower cost. --For the SDKs that don't implement preaggregation (that is, older versions of Application Insights SDKs or for browser instrumentation), the Application Insights back end still populates the new metrics by aggregating the events received by the Application Insights event collection endpoint. Although you don't benefit from the reduced volume of data transmitted over the wire, you can still use the preaggregated metrics and experience better performance and support of the near real time dimensional alerting with SDKs that don't preaggregate metrics during collection. --The collection endpoint preaggregates events before ingestion sampling. For this reason, [ingestion sampling](./sampling.md) never affects the accuracy of preaggregated metrics, regardless of the SDK version you use with your application. --### SDK supported preaggregated metrics table --| Current production SDKs | Standard metrics (SDK preaggregation) | Custom metrics (without SDK preaggregation) | Custom metrics (with SDK preaggregation)| -||--|-|| -| .NET Core and .NET Framework | Supported (V2.13.1+)| Supported via [TrackMetric](api-custom-events-metrics.md#trackmetric)| Supported (V2.7.2+) via [GetMetric](get-metric.md) | -| Java | Not supported | Supported via [TrackMetric](api-custom-events-metrics.md#trackmetric)| Not supported | -| Node.js | Supported (V2.0.0+) | Supported via [TrackMetric](api-custom-events-metrics.md#trackmetric)| Not supported | -| Python | Not supported | Supported | Partially supported via [OpenCensus.stats](/previous-versions/azure/azure-monitor/app/opencensus-python#metrics) | --> [!NOTE] -> The metrics implementation for Python by using OpenCensus.stats is different from GetMetric. For more information, see the [Python documentation on metrics](/previous-versions/azure/azure-monitor/app/opencensus-python#metrics). --### Codeless supported preaggregated metrics table --| Current production SDKs | Standard metrics (SDK preaggregation) | Custom metrics (without SDK preaggregation) | Custom metrics (with SDK preaggregation)| -|-|--|-|--| -| ASP.NET | Supported <sup>1<sup> | Not supported | Not supported | -| ASP.NET Core | Supported <sup>2<sup> | Not supported | Not supported | -| Java | Not supported | Not supported | [Supported](opentelemetry-add-modify.md?tabs=java#send-custom-telemetry-using-the-application-insights-classic-api) | -| Node.js | Not supported | Not supported | Not supported | --1. [ASP.NET autoinstrumentation on virtual machines/virtual machine scale sets](./azure-vm-vmss-apps.md) and [on-premises](./application-insights-asp-net-agent.md) emits standard metrics without dimensions. The same is true for Azure App Service, but the collection level must be set to recommended. The SDK is required for all dimensions. -2. [ASP.NET Core autoinstrumentation on App Service](./azure-web-apps-net-core.md) emits standard metrics without dimensions. SDK is required for all dimensions. --## Use preaggregation with Application Insights custom metrics --You can use preaggregation with custom metrics. The two main benefits are: --- Configure and alert on a dimension of a custom metric-- Reduce the volume of data sent from the SDK to the Application Insights collection endpoint--There are several [ways of sending custom metrics from the Application Insights SDK](./api-custom-events-metrics.md). If your version of the SDK offers [GetMetric and TrackValue](./api-custom-events-metrics.md#getmetric), these methods are the preferred way of sending custom metrics. In this case, preaggregation happens inside the SDK. This approach reduces the volume of data stored in Azure and also the volume of data transmitted from the SDK to Application Insights. Otherwise, use the [trackMetric](./api-custom-events-metrics.md#trackmetric) method, which preaggregates metric events during data ingestion. --## Custom metrics dimensions and preaggregation --All metrics that you send using [OpenTelemetry](opentelemetry-add-modify.md), [trackMetric](./api-custom-events-metrics.md#trackmetric), or [GetMetric and TrackValue](./api-custom-events-metrics.md#getmetric) API calls are automatically stored in both logs and metrics stores. These metrics can be found in the customMetrics table in Application Insights and in Metrics Explorer under the Custom Metric Namespace called "azure.applicationinsights". Although the log-based version of your custom metric always retains all dimensions, the preaggregated version of the metric is stored by default with no dimensions. Retaining dimensions of custom metrics is a Preview feature that can be turned on from the [Usage and estimated cost](../cost-usage.md#usage-and-estimated-costs) tab by selecting **With dimensions** under **Send custom metrics to Azure Metric Store**. ---## Quotas --Preaggregated metrics are stored as time series in Azure Monitor. [Azure Monitor quotas on custom metrics](../essentials/metrics-custom-overview.md#quotas-and-limits) apply. --> [!NOTE] -> Going over the quota might have unintended consequences. Azure Monitor might become unreliable in your subscription or region. To learn how to avoid exceeding the quota, see [Design limitations and considerations](../essentials/metrics-custom-overview.md#design-limitations-and-considerations). --## Why is collection of custom metrics dimensions turned off by default? --The collection of custom metrics dimensions is turned off by default because in the future storing custom metrics with dimensions will be billed separately from Application Insights. Storing the nondimensional custom metrics remain free (up to a quota). You can learn about the upcoming pricing model changes on our official [pricing page](https://azure.microsoft.com/pricing/details/monitor/). --## Create charts and explore log-based and standard preaggregated metrics --Use [Azure Monitor metrics explorer](../essentials/metrics-getting-started.md) to plot charts from preaggregated and log-based metrics and to author dashboards with charts. After you select the Application Insights resource you want, use the namespace picker to switch between standard and log-based metrics. You can also select a custom metric namespace. ---## Pricing models for Application Insights metrics --Ingesting metrics into Application Insights, whether log-based or preaggregated, generates costs based on the size of the ingested data. For more information, see [Azure Monitor Logs pricing details](../logs/cost-logs.md#application-insights-billing). Your custom metrics, including all its dimensions, are always stored in the Application Insights log store. Also, a preaggregated version of your custom metrics with no dimensions is forwarded to the metrics store by default. --Selecting the [Enable alerting on custom metric dimensions](#custom-metrics-dimensions-and-preaggregation) option to store all dimensions of the preaggregated metrics in the metric store can generate *extra costs* based on [custom metrics pricing](https://azure.microsoft.com/pricing/details/monitor/). --## Next steps --* [Metrics - Get - REST API](/rest/api/application-insights/metrics/get) -* [Application Insights API for custom events and metrics](api-custom-events-metrics.md) -* [Near real time alerting](../alerts/alerts-metric-near-real-time.md) -* [GetMetric and TrackValue](./api-custom-events-metrics.md#getmetric) |
| azure-monitor | Release And Work Item Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/release-and-work-item-insights.md | - Title: Release and work item insights for Application Insights -description: Learn how to set up continuous monitoring of your release pipeline, create work items in GitHub or Azure DevOps, and track deployment or other significant events. -- Previously updated : 11/15/2023----# Release and work item insights --Release and work item insights are crucial for optimizing the software development lifecycle. As applications evolve, it's vital to monitor each release and its work items closely. These insights highlight performance bottlenecks and let teams address issues proactively, ensuring smooth deployment and user experience. They equip developers and stakeholders to make decisions, adjust processes, and deliver high-quality software. --## [Continuous monitoring](#tab/continuous-monitoring) --Azure Pipelines integrates with Application Insights to allow continuous monitoring of your Azure DevOps release pipeline throughout the software development lifecycle. --With continuous monitoring, release pipelines can incorporate monitoring data from Application Insights and other Azure resources. When the release pipeline detects an Application Insights alert, the pipeline can gate or roll back the deployment until the alert is resolved. If all checks pass, deployments can proceed automatically from test all the way to production, without the need for manual intervention. --## Configure continuous monitoring --1. In [Azure DevOps](https://dev.azure.com), select an organization and project. --1. On the left menu of the project page, select **Pipelines** > **Releases**. --1. Select the dropdown arrow next to **New** and select **New release pipeline**. Or, if you don't have a pipeline yet, select **New pipeline** on the page that appears. --1. On the **Select a template** pane, search for and select **Azure App Service deployment with continuous monitoring**, and then select **Apply**. -- :::image type="content" source="media/release-and-work-item-insights/001.png" lightbox="media/release-and-work-item-insights/001.png" alt-text="Screenshot that shows a new Azure Pipelines release pipeline."::: --1. In the **Stage 1** box, select the hyperlink to **View stage tasks.** -- :::image type="content" source="media/release-and-work-item-insights/002.png" lightbox="media/release-and-work-item-insights/002.png" alt-text="Screenshot that shows View stage tasks."::: --1. In the **Stage 1** configuration pane, fill in the following fields: -- | Parameter | Value | - | - |:--| - | **Stage name** | Provide a stage name or leave it at **Stage 1**. | - | **Azure subscription** | Select the dropdown arrow and select the linked Azure subscription you want to use.| - | **App type** | Select the dropdown arrow and select your app type. | - | **App Service name** | Enter the name of your Azure App Service. | - | **Resource Group name for Application Insights** | Select the dropdown arrow and select the resource group you want to use. | - | **Application Insights resource name** | Select the dropdown arrow and select the Application Insights resource for the resource group you selected. --1. To save the pipeline with default alert rule settings, select **Save** in the upper-right corner of the Azure DevOps window. Enter a descriptive comment and select **OK**. --## Modify alert rules --Out of the box, the **Azure App Service deployment with continuous monitoring** template has four alert rules: **Availability**, **Failed requests**, **Server response time**, and **Server exceptions**. You can add more rules or change the rule settings to meet your service level needs. --To modify alert rule settings: --In the left pane of the release pipeline page, select **Configure Application Insights Alerts**. --The four default alert rules are created via an Inline script: --```azurecli -$subscription = az account show --query "id";$subscription.Trim("`"");$resource="/subscriptions/$subscription/resourcegroups/"+"$(Parameters.AppInsightsResourceGroupName)"+"/providers/microsoft.insights/components/" + "$(Parameters.ApplicationInsightsResourceName)"; -az monitor metrics alert create -n 'Availability_$(Release.DefinitionName)' -g $(Parameters.AppInsightsResourceGroupName) --scopes $resource --condition 'avg availabilityResults/availabilityPercentage < 99' --description "created from Azure DevOps"; -az monitor metrics alert create -n 'FailedRequests_$(Release.DefinitionName)' -g $(Parameters.AppInsightsResourceGroupName) --scopes $resource --condition 'count requests/failed > 5' --description "created from Azure DevOps"; -az monitor metrics alert create -n 'ServerResponseTime_$(Release.DefinitionName)' -g $(Parameters.AppInsightsResourceGroupName) --scopes $resource --condition 'avg requests/duration > 5' --description "created from Azure DevOps"; -az monitor metrics alert create -n 'ServerExceptions_$(Release.DefinitionName)' -g $(Parameters.AppInsightsResourceGroupName) --scopes $resource --condition 'count exceptions/server > 5' --description "created from Azure DevOps"; -``` --You can modify the script and add more alert rules. You can also modify the alert conditions. And you can remove alert rules that don't make sense for your deployment purposes. --## Add deployment conditions --When you add deployment gates to your release pipeline, an alert that exceeds the thresholds you set prevents unwanted release promotion. After you resolve the alert, the deployment can proceed automatically. --To add deployment gates: --1. On the main pipeline page, under **Stages**, select the **Pre-deployment conditions** or **Post-deployment conditions** symbol, depending on which stage needs a continuous monitoring gate. -- :::image type="content" source="media/release-and-work-item-insights/004.png" lightbox="media/release-and-work-item-insights/004.png" alt-text="Screenshot that shows Pre-deployment conditions."::: --1. In the **Pre-deployment conditions** configuration pane, set **Gates** to **Enabled**. --1. Next to **Deployment gates**, select **Add**. --1. Select **Query Azure Monitor alerts** from the dropdown menu. This option lets you access both Azure Monitor and Application Insights alerts. -- :::image type="content" source="media/release-and-work-item-insights/005.png" lightbox="media/release-and-work-item-insights/005.png" alt-text="Screenshot that shows Query Azure Monitor alerts."::: --1. Under **Evaluation options**, enter the values you want for settings like **The time between re-evaluation of gates** and **The timeout after which gates fail**. --## View release logs --You can see deployment gate behavior and other release steps in the release logs. To open the logs: --1. Select **Releases** from the left menu of the pipeline page. --1. Select any release. --1. Under **Stages**, select any stage to view a release summary. --1. To view logs, select **View logs** in the release summary, select the **Succeeded** or **Failed** hyperlink in any stage, or hover over any stage and select **Logs**. -- :::image type="content" source="media/release-and-work-item-insights/006.png" lightbox="media/release-and-work-item-insights/006.png" alt-text="Screenshot that shows viewing release logs."::: --## [Release annotations](#tab/release-annotations) --Annotations show where you deployed a new build or other significant events. Annotations make it easy to see whether your changes had any effect on your application's performance. They can be automatically created by the [Azure Pipelines](/azure/devops/pipelines/tasks/) build system. You can also create annotations to flag any event you want by creating them from PowerShell. --## Release annotations with Azure Pipelines build --Release annotations are a feature of the cloud-based Azure Pipelines service of Azure DevOps. --If all the following criteria are met, the deployment task creates the release annotation automatically: --- The resource to which you're deploying is linked to Application Insights via the `APPINSIGHTS_INSTRUMENTATIONKEY` app setting.-- The Application Insights resource is in the same subscription as the resource to which you're deploying.-- You're using one of the following Azure DevOps pipeline tasks:-- | Task code | Task name | Versions | - ||-|--| - | AzureAppServiceSettings | Azure App Service Settings | Any | - | AzureRmWebAppDeployment | Azure App Service deploy | V3 and above | - | AzureFunctionApp | Azure Functions | Any | - | AzureFunctionAppContainer | Azure Functions for container | Any | - | AzureWebAppContainer | Azure Web App for Containers | Any | - | AzureWebApp | Azure Web App | Any | --> [!NOTE] -> If you're still using the Application Insights annotation deployment task, you should delete it. --### Configure release annotations --If you can't use one of the deployment tasks in the previous section, you need to add an inline script task in your deployment pipeline. --1. Go to a new or existing pipeline and select a task. -- :::image type="content" source="./media/release-and-work-item-insights/task.png" alt-text="Screenshot that shows a task selected under Stages." lightbox="./media/release-and-work-item-insights/task.png"::: -1. Add a new task and select **Azure CLI**. -- :::image type="content" source="./media/release-and-work-item-insights/add-azure-cli.png" alt-text="Screenshot that shows adding a new task and selecting Azure CLI." lightbox="./media/release-and-work-item-insights/add-azure-cli.png"::: -1. Specify the relevant Azure subscription. Change **Script Type** to **PowerShell** and **Script Location** to **Inline**. -1. Add the [PowerShell script from step 2 in the next section](#create-release-annotations-with-the-azure-cli) to **Inline Script**. -1. Add the following arguments. Replace the angle-bracketed placeholders with your values to **Script Arguments**. The `-releaseProperties` are optional. -- ```powershell - -aiResourceId "<aiResourceId>" ` - -releaseName "<releaseName>" ` - -releaseProperties @{"ReleaseDescription"="<a description>"; - "TriggerBy"="<Your name>" } - ``` -- :::image type="content" source="./media/release-and-work-item-insights/inline-script.png" alt-text="Screenshot of Azure CLI task settings with Script Type, Script Location, Inline Script, and Script Arguments highlighted." lightbox="./media/release-and-work-item-insights/inline-script.png"::: -- The following example shows metadata you can set in the optional `releaseProperties` argument by using [build](/azure/devops/pipelines/build/variables#build-variables-devops-services) and [release](/azure/devops/pipelines/release/variables#default-variablesrelease) variables. -- ```powershell - -releaseProperties @{ - "BuildNumber"="$(Build.BuildNumber)"; - "BuildRepositoryName"="$(Build.Repository.Name)"; - "BuildRepositoryProvider"="$(Build.Repository.Provider)"; - "ReleaseDefinitionName"="$(Build.DefinitionName)"; - "ReleaseDescription"="Triggered by $(Build.DefinitionName) $(Build.BuildNumber)"; - "ReleaseEnvironmentName"="$(Release.EnvironmentName)"; - "ReleaseId"="$(Release.ReleaseId)"; - "ReleaseName"="$(Release.ReleaseName)"; - "ReleaseRequestedFor"="$(Release.RequestedFor)"; - "ReleaseWebUrl"="$(Release.ReleaseWebUrl)"; - "SourceBranch"="$(Build.SourceBranch)"; - "TeamFoundationCollectionUri"="$(System.TeamFoundationCollectionUri)" } - ``` --1. Select **Save**. --## Create release annotations with the Azure CLI --You can use the `CreateReleaseAnnotation` PowerShell script to create annotations from any process you want without using Azure DevOps. --1. Sign in to the [Azure CLI](/cli/azure/authenticate-azure-cli). --1. Make a local copy of the following script and call it `CreateReleaseAnnotation.ps1`. -- ```powershell - param( - [parameter(Mandatory = $true)][string]$aiResourceId, - [parameter(Mandatory = $true)][string]$releaseName, - [parameter(Mandatory = $false)]$releaseProperties = @() - ) -- # Function to ensure all Unicode characters in a JSON string are properly escaped - function Convert-UnicodeToEscapeHex { - param ( - [parameter(Mandatory = $true)][string]$JsonString - ) - $JsonObject = ConvertFrom-Json -InputObject $JsonString - foreach ($property in $JsonObject.PSObject.Properties) { - $name = $property.Name - $value = $property.Value - if ($value -is [string]) { - $value = [regex]::Unescape($value) - $OutputString = "" - foreach ($char in $value.ToCharArray()) { - $dec = [int]$char - if ($dec -gt 127) { - $hex = [convert]::ToString($dec, 16) - $hex = $hex.PadLeft(4, '0') - $OutputString += "\u$hex" - } - else { - $OutputString += $char - } - } - $JsonObject.$name = $OutputString - } - } - return ConvertTo-Json -InputObject $JsonObject -Compress - } - - $annotation = @{ - Id = [GUID]::NewGuid(); - AnnotationName = $releaseName; - EventTime = (Get-Date).ToUniversalTime().GetDateTimeFormats("s")[0]; - Category = "Deployment"; #Application Insights only displays annotations from the "Deployment" Category - Properties = ConvertTo-Json $releaseProperties -Compress - } - - $annotation = ConvertTo-Json $annotation -Compress - $annotation = Convert-UnicodeToEscapeHex -JsonString $annotation - - $accessToken = (az account get-access-token | ConvertFrom-Json).accessToken - $headers = @{ - "Authorization" = "Bearer $accessToken" - "Accept" = "application/json" - "Content-Type" = "application/json" - } - $params = @{ - Headers = $headers - Method = "Put" - Uri = "https://management.azure.com$($aiResourceId)/Annotations?api-version=2015-05-01" - Body = $annotation - } - Invoke-RestMethod @params - ``` -- > [!NOTE] - > - Your annotations must have **Category** set to **Deployment** to appear in the Azure portal. - > - If you receive an error, "The request contains an entity body but no Content-Type header", try removing the replace parameters in the following line. - > - > `$body = (ConvertTo-Json $annotation -Compress)` --1. Call the PowerShell script with the following code. Replace the angle-bracketed placeholders with your values. The `-releaseProperties` are optional. -- ```powershell - .\CreateReleaseAnnotation.ps1 ` - -aiResourceId "<aiResourceId>" ` - -releaseName "<releaseName>" ` - -releaseProperties @{"ReleaseDescription"="<a description>"; - "TriggerBy"="<Your name>" } - ``` -- |Argument | Definition | Note| - |--|--|--| - |`aiResourceId` | The resource ID to the target Application Insights resource. | Example:<br> /subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/MyRGName/providers/microsoft.insights/components/MyResourceName| - |`releaseName` | The name to give the created release annotation. | | - |`releaseProperties` | Used to attach custom metadata to the annotation. | Optional| - -## View annotations --> [!NOTE] -> Release annotations aren't currently available in the **Metrics** pane of Application Insights. --Whenever you use the release template to deploy a new release, an annotation is sent to Application Insights. You can view annotations in the following locations: --- **Performance:**-- :::image type="content" source="./media/release-and-work-item-insights/performance.png" alt-text="Screenshot that shows the Performance tab with a release annotation selected to show the Release Properties tab." lightbox="./media/release-and-work-item-insights/performance.png"::: --- **Failures:**-- :::image type="content" source="./media/release-and-work-item-insights/failures.png" alt-text="Screenshot that shows the Failures tab with a release annotation selected to show the Release Properties tab." lightbox="./media/release-and-work-item-insights/failures.png"::: -- **Usage:**-- :::image type="content" source="./media/release-and-work-item-insights/usage-pane.png" alt-text="Screenshot that shows the Users tab bar with release annotations selected. Release annotations appear as blue arrows above the chart indicating the moment in time that a release occurred." lightbox="./media/release-and-work-item-insights/usage-pane.png"::: --- **Workbooks:**-- In any log-based workbook query where the visualization displays time along the x-axis: - - :::image type="content" source="./media/release-and-work-item-insights/workbooks-annotations.png" alt-text="Screenshot that shows the Workbooks pane with a time series log-based query with annotations displayed." lightbox="./media/release-and-work-item-insights/workbooks-annotations.png"::: - -To enable annotations in your workbook, go to **Advanced Settings** and select **Show annotations**. - --Select any annotation marker to open details about the release, including requestor, source control branch, release pipeline, and environment. --## Release annotations by using API keys --Release annotations are a feature of the cloud-based Azure Pipelines service of Azure DevOps. --> [!IMPORTANT] -> Annotations using API keys is deprecated. We recommend using the [Azure CLI](#create-release-annotations-with-the-azure-cli) instead. --### Install the annotations extension (one time) --To create release annotations, install one of the many Azure DevOps extensions available in Visual Studio Marketplace. --1. Sign in to your [Azure DevOps](https://azure.microsoft.com/services/devops/) project. --1. On the **Visual Studio Marketplace** [Release Annotations extension](https://marketplace.visualstudio.com/items/ms-appinsights.appinsightsreleaseannotations) page, select your Azure DevOps organization. Select **Install** to add the extension to your Azure DevOps organization. -- :::image type="content" source="./media/release-and-work-item-insights/1-install.png" lightbox="./media/release-and-work-item-insights/1-install.png" alt-text="Screenshot that shows selecting an Azure DevOps organization and selecting Install."::: --You only need to install the extension once for your Azure DevOps organization. You can now configure release annotations for any project in your organization. --### Configure release annotations by using API keys --Create a separate API key for each of your Azure Pipelines release templates. --1. Sign in to the [Azure portal](https://portal.azure.com) and open the Application Insights resource that monitors your application. Or if you don't have one, [create a new Application Insights resource](create-workspace-resource.md). --1. Open the **API Access** tab and copy the **Application Insights ID**. -- :::image type="content" source="./media/release-and-work-item-insights/2-app-id.png" lightbox="./media/release-and-work-item-insights/2-app-id.png" alt-text="Screenshot that shows under API Access, copying the Application ID."::: --1. In a separate browser window, open or create the release template that manages your Azure Pipelines deployments. --1. Select **Add task** and then select the **Application Insights Release Annotation** task from the menu. - - :::image type="content" source="./media/release-and-work-item-insights/3-add-task.png" lightbox="./media/release-and-work-item-insights/3-add-task.png" alt-text="Screenshot that shows selecting Add Task and Application Insights Release Annotation."::: -- > [!NOTE] - > The Release Annotation task currently supports only Windows-based agents. It won't run on Linux, macOS, or other types of agents. --1. Under **Application ID**, paste the Application Insights ID you copied from the **API Access** tab. -- :::image type="content" source="./media/release-and-work-item-insights/4-paste-app-id.png" lightbox="./media/release-and-work-item-insights/4-paste-app-id.png" alt-text="Screenshot that shows pasting the Application Insights ID."::: --1. Back in the Application Insights **API Access** window, select **Create API Key**. -- :::image type="content" source="./media/release-and-work-item-insights/5-create-api-key.png" lightbox="./media/release-and-work-item-insights/5-create-api-key.png" alt-text="Screenshot that shows selecting the Create API Key on the API Access tab."::: --1. In the **Create API key** window, enter a description, select **Write annotations**, and then select **Generate key**. Copy the new key. -- :::image type="content" source="./media/release-and-work-item-insights/6-create-api-key.png" lightbox="./media/release-and-work-item-insights/6-create-api-key.png" alt-text="Screenshot that shows in the Create API key window, entering a description, selecting Write annotations, and then selecting the Generate key."::: --1. In the release template window, on the **Variables** tab, select **Add** to create a variable definition for the new API key. --1. Under **Name**, enter **ApiKey**. Under **Value**, paste the API key you copied from the **API Access** tab. -- :::image type="content" source="./media/release-and-work-item-insights/7-paste-api-key.png" lightbox="./media/release-and-work-item-insights/7-paste-api-key.png" alt-text="Screenshot that shows in the Azure DevOps Variables tab, selecting Add, naming the variable ApiKey, and pasting the API key under Value."::: --1. Select **Save** in the main release template window to save the template. -- > [!NOTE] - > Limits for API keys are described in the [REST API rate limits documentation](/rest/api/yammer/rest-api-rate-limits). --### Transition to the new release annotation --To use the new release annotations: -1. [Remove the Release Annotations extension](/azure/devops/marketplace/uninstall-disable-extensions). -1. Remove the Application Insights Release Annotation task in your Azure Pipelines deployment. -1. Create new release annotations with [Azure Pipelines](#release-annotations-with-azure-pipelines-build) or the [Azure CLI](#create-release-annotations-with-the-azure-cli). --## [Work item integration](#tab/work-item-integration) --Work item integration functionality allows you to easily create work items in GitHub or Azure DevOps that have relevant Application Insights data embedded in them. ---The new work item integration offers the following features over [classic](#classic-work-item-integration): -- Advanced fields like assignee, projects, or milestones.-- Repo icons so you can differentiate between GitHub & Azure DevOps workbooks.-- Multiple configurations for any number of repositories or work items.-- Deployment through Azure Resource Manager templates.-- Pre-built & customizable Keyword Query Language (KQL) queries to add Application Insights data to your work items.-- Customizable workbook templates.---## Create and configure a work item template --1. To create a work item template, go to your Application Insights resource and on the left under *Configure* select **Work Items** then at the top select **Create a new template** -- :::image type="content" source="./media/release-and-work-item-insights/create-work-item-template.png" alt-text=" Screenshot of the Work Items tab with create a new template selected." lightbox="./media/release-and-work-item-insights/create-work-item-template.png"::: -- You can also create a work item template from the end-to-end transaction details tab, if no template currently exists. Select an event and on the right select **Create a work item**, then **Start with a workbook template**. -- :::image type="content" source="./media/release-and-work-item-insights/create-template-from-transaction-details.png" alt-text=" Screenshot of end-to-end transaction details tab with create a work item, start with a workbook template selected." lightbox="./media/release-and-work-item-insights/create-template-from-transaction-details.png"::: --2. After you select **create a new template**, you can choose your tracking systems, name your workbook, link to your selected tracking system, and choose a region to storage the template (the default is the region your Application Insights resource is located in). The URL parameters are the default URL for your repository, for example, `https://github.com/myusername/reponame` or `https://dev.azure.com/{org}/{project}`. -- :::image type="content" source="./media/release-and-work-item-insights/create-workbook.png" alt-text=" Screenshot of create a new work item workbook template."::: -- You can set specific work item properties directly from the template itself. This includes the assignee, iteration path, projects, & more depending on your version control provider. -- > [!NOTE] - > For on-premises Azure DevOps environments, a sample URL such as https://dev.azure.com/test/test can be used as a placeholder for the Azure DevOps Project URL. Once the work item template is created, you can modify the URL and its validation rule within the generated [Azure workbook](/azure/azure-monitor/visualize/workbooks-create-workbook). --## Create a work item -- You can access your new template from any End-to-end transaction details that you can access from Performance, Failures, Availability, or other tabs. --1. To create a work item go to End-to-end transaction details, select an event then select **Create work item** and choose your work item template. -- :::image type="content" source="./media/release-and-work-item-insights/create-work-item.png" alt-text=" Screenshot of end to end transaction details tab with create work item selected." lightbox="./media/release-and-work-item-insights/create-work-item.png"::: --1. A new tab in your browser will open up to your select tracking system. In Azure DevOps you can create a bug or task, and in GitHub you can create a new issue in your repository. A new work item is automatically create with contextual information provided by Application Insights. -- :::image type="content" source="./media/release-and-work-item-insights/github-work-item.png" alt-text=" Screenshot of automatically created GitHub issue." lightbox="./media/release-and-work-item-insights/github-work-item.png"::: -- :::image type="content" source="./media/release-and-work-item-insights/azure-devops-work-item.png" alt-text=" Screenshot of automatically create bug in Azure DevOps." lightbox="./media/release-and-work-item-insights/azure-devops-work-item.png"::: --## Edit a template --To edit your template, go to the **Work Items** tab under *Configure* and select the pencil icon next to the workbook you would like to update. ---Select edit :::image type="icon" source="./media/release-and-work-item-insights/edit-icon.png"::: in the top toolbar. ---You can create more than one work item configuration and have a custom workbook to meet each scenario. The workbooks can also be deployed by Azure Resource Manager ensuring standard implementations across your environments. --## Classic work item integration --1. In your Application Insights resource under *Configure* select **Work Items**. -1. Select **Switch to Classic**, fill out the fields with your information, and authorize. -- :::image type="content" source="./media/release-and-work-item-insights/classic.png" alt-text=" Screenshot of how to configure classic work items." lightbox="./media/release-and-work-item-insights/classic.png"::: --1. Create a work item by going to the end-to-end transaction details, select an event then select **Create work item (Classic)**. --### Migrate to new work item integration --To migrate, delete your classic work item configuration then [create and configure a work item template](#create-and-configure-a-work-item-template) to recreate your integration. --To delete, go to in your Application Insights resource under *Configure* select **Work Items** then select **Switch to Classic** and **Delete* at the top. ----## See also --* [Azure Pipelines documentation](/azure/devops/pipelines) -* [Create work items](./transaction-search-and-diagnostics.md?tabs=transaction-search#create-work-item) -* [Automation with PowerShell](./powershell.md) -* [Availability test](availability-overview.md) |
| azure-monitor | Sampling Classic Api | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/sampling-classic-api.md | - Title: Telemetry sampling in Azure Application Insights | Microsoft Docs -description: How to keep the volume of telemetry under control. - Previously updated : 10/11/2023-----# Sampling in Application Insights --Sampling is a feature in [Application Insights](./app-insights-overview.md). It's the recommended way to reduce telemetry traffic, data costs, and storage costs, while preserving a statistically correct analysis of application data. Sampling also helps you avoid Application Insights throttling your telemetry. The sampling filter selects items that are related, so that you can navigate between items when you're doing diagnostic investigations. --When metric counts are presented in the portal, they're renormalized to take into account sampling. Doing so minimizes any effect on the statistics. --> [!NOTE] -> - If you've adopted our OpenTelemetry Distro and are looking for configuration options, see [Enable Sampling](opentelemetry-configuration.md#enable-sampling). ----## Brief summary --* There are three different types of sampling: adaptive sampling, fixed-rate sampling, and ingestion sampling. -* Adaptive sampling is enabled by default in all the latest versions of the Application Insights ASP.NET and ASP.NET Core Software Development Kits (SDKs), and [Azure Functions](../../azure-functions/functions-overview.md). -* Fixed-rate sampling is available in recent versions of the Application Insights SDKs for ASP.NET, ASP.NET Core, Java (both the agent and the SDK), JavaScript, and Python. -* In Java, sampling overrides are available, and are useful when you need to apply different sampling rates to selected dependencies, requests, and health checks. Use [sampling overrides](./java-standalone-sampling-overrides.md) to tune out some noisy dependencies while, for example, all important errors are kept at 100%. This behavior is a form of fixed sampling that gives you a fine-grained level of control over your telemetry. -* Ingestion sampling works on the Application Insights service endpoint. It only applies when no other sampling is in effect. If the SDK samples your telemetry, ingestion sampling is disabled. -* For web applications, if you log custom events and need to ensure that a set of events is retained or discarded together, the events must have the same `OperationId` value. -* If you write Analytics queries, you should [take account of sampling](/azure/data-explorer/kusto/query/samples?&pivots=azuremonitor#aggregations). In particular, instead of simply counting records, you should use `summarize sum(itemCount)`. -* Some telemetry types, including performance metrics and custom metrics, are always kept regardless of whether sampling is enabled or not. --The following table summarizes the sampling types available for each SDK and type of application: --| Application Insights SDK | Adaptive sampling supported | Fixed-rate sampling supported | Ingestion sampling supported | -|--||--|-| -| ASP.NET | [Yes (on by default)](#configuring-adaptive-sampling-for-aspnet-applications) | [Yes](#configuring-fixed-rate-sampling-for-aspnet-applications) | Only if no other sampling is in effect | -| ASP.NET Core | [Yes (on by default)](#configuring-adaptive-sampling-for-aspnet-core-applications) | [Yes](#configuring-fixed-rate-sampling-for-aspnet-core-applications) | Only if no other sampling is in effect | -| Azure Functions | [Yes (on by default)](#configuring-adaptive-sampling-for-azure-functions) | No | Only if no other sampling is in effect | -| Java | No | [Yes](#configuring-sampling-overrides-and-fixed-rate-sampling-for-java-applications) | Only if no other sampling is in effect | -| JavaScript | No | [Yes](#configuring-fixed-rate-sampling-for-web-pages-with-javascript) | Only if no other sampling is in effect | -| Node.JS | No | [Yes](./nodejs.md#sampling) | Only if no other sampling is in effect | -| Python | No | [Yes](#configuring-fixed-rate-sampling-for-opencensus-python-applications) | Only if no other sampling is in effect | -| All others | No | No | [Yes](#ingestion-sampling) | --> [!NOTE] -> - The Java Application Agent 3.4.0 and later uses rate-limited sampling as the default when sending telemetry to Application Insights. For more information, see [Rate-limited sampling](java-standalone-config.md#rate-limited-sampling). -> - The information on most of this page applies to the current versions of the Application Insights SDKs. For information on older versions of the SDKs, see [older SDK versions](#older-sdk-versions). --## When to use sampling --In general, for most small and medium size applications you don't need sampling. The most useful diagnostic information and most accurate statistics are obtained by collecting data on all your user activities. --The main advantages of sampling are: --* Application Insights service drops ("throttles") data points when your app sends a high rate of telemetry in a short time interval. Sampling reduces the likelihood that your application sees throttling occur. -* To keep within the [quota](../logs/daily-cap.md) of data points for your pricing tier. -* To reduce network traffic from the collection of telemetry. --## How sampling works --The sampling algorithm decides which telemetry items it keeps or drops, whether the SDK or Application Insights service does the sampling. It follows rules to keep all interrelated data points intact, ensuring Application Insights provides an actionable and reliable diagnostic experience, even with less data. For instance, if a sample includes a failed request, it retains all related telemetry items like exceptions and traces. This way, when you view request details in Application Insights, you always see the request and its associated telemetry. --The sampling decision is based on the operation ID of the request, which means that all telemetry items belonging to a particular operation is either preserved or dropped. For the telemetry items that don't have an operation ID set (such as telemetry items reported from asynchronous threads with no HTTP context) sampling simply captures a percentage of telemetry items of each type. --When presenting telemetry back to you, the Application Insights service adjusts the metrics by the same sampling percentage that was used at the time of collection, to compensate for the missing data points. Hence, when looking at the telemetry in Application Insights, the users are seeing statistically correct approximations that are close to the real numbers. --The accuracy of the approximation largely depends on the configured sampling percentage. Also, the accuracy increases for applications that handle a large volume of similar requests from lots of users. On the other hand, for applications that don't work with a significant load, sampling isn't needed as these applications can usually send all their telemetry while staying within the quota, without causing data loss from throttling. --## Types of sampling --There are three different sampling methods: --* **Adaptive sampling** automatically adjusts the volume of telemetry sent from the SDK in your ASP.NET/ASP.NET Core app, and from Azure Functions. It's the default sampling when you use the ASP.NET or ASP.NET Core SDK. Adaptive sampling is currently only available for ASP.NET/ASP.NET Core server-side telemetry, and for Azure Functions. --* **Fixed-rate sampling** reduces the volume of telemetry sent from both your ASP.NET or ASP.NET Core or Java server and from your users' browsers. You set the rate. The client and server synchronize their sampling so that, in Search, you can navigate between related page views and requests. --* **Ingestion sampling** happens at the Application Insights service endpoint. It discards some of the telemetry that arrives from your app, at a sampling rate that you set. It doesn't reduce telemetry traffic sent from your app, but helps you keep within your monthly quota. The main advantage of ingestion sampling is that you can set the sampling rate without redeploying your app. Ingestion sampling works uniformly for all servers and clients, but it doesn't apply when any other types of sampling are in operation. --> [!IMPORTANT] -> If adaptive or fixed rate sampling methods are enabled for a telemetry type, ingestion sampling is disabled for that telemetry. However, telemetry types that are excluded from sampling at the SDK level will still be subject to ingestion sampling at the rate set in the portal. --## Adaptive sampling --Adaptive sampling affects the volume of telemetry sent from your web server app to the Application Insights service endpoint. --> [!TIP] -> Adaptive sampling is enabled by default when you use the ASP.NET SDK or the ASP.NET Core SDK, and is also enabled by default for Azure Functions. --The volume automatically adjusts to stay within the `MaxTelemetryItemsPerSecond` rate limit. If the application generates low telemetry, like during debugging or low usage, it doesn't drop items as long as the volume stays under `MaxTelemetryItemsPerSecond`. As telemetry volume rises, it adjusts the sampling rate to hit the target volume. This adjustment, recalculated at regular intervals, is based on the moving average of the outgoing transmission rate. --To achieve the target volume, some of the generated telemetry is discarded. But like other types of sampling, the algorithm retains related telemetry items. For example, when you're inspecting the telemetry in Search, you're able to find the request related to a particular exception. --Metric counts such as request rate and exception rate are adjusted to compensate for the sampling rate, so that they show approximate values in Metric Explorer. --### Configuring adaptive sampling for ASP.NET applications --> [!NOTE] -> This section applies to ASP.NET applications, not to ASP.NET Core applications. [Learn about configuring adaptive sampling for ASP.NET Core applications later in this document.](#configuring-adaptive-sampling-for-aspnet-core-applications) --In [`ApplicationInsights.config`](./configuration-with-applicationinsights-config.md), you can adjust several parameters in the `AdaptiveSamplingTelemetryProcessor` node. The figures shown are the default values: --* `<MaxTelemetryItemsPerSecond>5</MaxTelemetryItemsPerSecond>` - - The target rate of [logical operations](distributed-trace-data.md#data-model-for-telemetry-correlation) that the adaptive algorithm aims to collect **on each server host**. If your web app runs on many hosts, reduce this value so as to remain within your target rate of traffic at the Application Insights portal. --* `<EvaluationInterval>00:00:15</EvaluationInterval>` - - The interval at which the current rate of telemetry is reevaluated. Evaluation is performed as a moving average. You might want to shorten this interval if your telemetry is liable to sudden bursts. --* `<SamplingPercentageDecreaseTimeout>00:02:00</SamplingPercentageDecreaseTimeout>` - - When the sampling percentage value changes, it determines how quickly we can reduce the sampling percentage again to capture less data. --* `<SamplingPercentageIncreaseTimeout>00:15:00</SamplingPercentageIncreaseTimeout>` - - When the sampling percentage value changes, it dictates how soon we can increase the sampling percentage again to capture more data. --* `<MinSamplingPercentage>0.1</MinSamplingPercentage>` - - As sampling percentage varies, what is the minimum value we're allowed to set? --* `<MaxSamplingPercentage>100.0</MaxSamplingPercentage>` - - As sampling percentage varies, what is the maximum value we're allowed to set? --* `<MovingAverageRatio>0.25</MovingAverageRatio>` - - In the calculation of the moving average, this value specifies the weight that should be assigned to the most recent value. Use a value equal to or less than 1. Smaller values make the algorithm less reactive to sudden changes. --* `<InitialSamplingPercentage>100</InitialSamplingPercentage>` - - The amount of telemetry to sample when the app starts. Don't reduce this value while you're debugging. --* `<ExcludedTypes>type;type</ExcludedTypes>` - - A semi-colon delimited list of types that you don't want to be subject to sampling. Recognized types are: [`Dependency`](data-model-complete.md#dependency), [`Event`](data-model-complete.md#event), [`Exception`](data-model-complete.md#exception), [`PageView`](data-model-complete.md#pageview), [`Request`](data-model-complete.md#request), [`Trace`](data-model-complete.md#trace). All telemetry of the specified types is transmitted; the types that aren't specified are sampled. --* `<IncludedTypes>type;type</IncludedTypes>` - - A semi-colon delimited list of types that you do want to subject to sampling. Recognized types are: [`Dependency`](data-model-complete.md#dependency), [`Event`](data-model-complete.md#event), [`Exception`](data-model-complete.md#exception), [`PageView`](data-model-complete.md#pageview), [`Request`](data-model-complete.md#request), [`Trace`](data-model-complete.md#trace). The specified types are sampled; all telemetry of the other types is always transmitted. --**To switch off** adaptive sampling, remove the `AdaptiveSamplingTelemetryProcessor` node(s) from `ApplicationInsights.config`. --#### Alternative: Configure adaptive sampling in code --Instead of setting the sampling parameter in the `.config` file, you can programmatically set these values. --1. Remove all the `AdaptiveSamplingTelemetryProcessor` node(s) from the `.config` file. -1. Use the following snippet to configure adaptive sampling: -- ```csharp - using Microsoft.ApplicationInsights; - using Microsoft.ApplicationInsights.Extensibility; - using Microsoft.ApplicationInsights.WindowsServer.Channel.Implementation; - using Microsoft.ApplicationInsights.WindowsServer.TelemetryChannel; - - // ... -- var builder = TelemetryConfiguration.Active.DefaultTelemetrySink.TelemetryProcessorChainBuilder; - // For older versions of the Application Insights SDK, use the following line instead: - // var builder = TelemetryConfiguration.Active.TelemetryProcessorChainBuilder; -- // Enable AdaptiveSampling so as to keep overall telemetry volume to 5 items per second. - builder.UseAdaptiveSampling(maxTelemetryItemsPerSecond:5); -- // If you have other telemetry processors: - builder.Use((next) => new AnotherProcessor(next)); -- builder.Build(); - ``` -- ([Learn about telemetry processors](./api-filtering-sampling.md#filtering).) --You can also adjust the sampling rate for each telemetry type individually, or can even exclude certain types from being sampled at all: --```csharp -// The following configures adaptive sampling with 5 items per second, and also excludes Dependency telemetry from being subjected to sampling. -builder.UseAdaptiveSampling(maxTelemetryItemsPerSecond:5, excludedTypes: "Dependency"); -``` --### Configuring adaptive sampling for ASP.NET Core applications --ASP.NET Core applications can be configured in code or through the `appsettings.json` file. For more information, see [Configuration in ASP.NET Core](/aspnet/core/fundamentals/configuration). --Adaptive sampling is enabled by default for all ASP.NET Core applications. You can disable or customize the sampling behavior. --#### Turning off adaptive sampling --The default sampling feature can be disabled while adding the Application Insights service. --Add `ApplicationInsightsServiceOptions` after the `WebApplication.CreateBuilder()` method in the `Program.cs` file: --```csharp -var builder = WebApplication.CreateBuilder(args); --var aiOptions = new Microsoft.ApplicationInsights.AspNetCore.Extensions.ApplicationInsightsServiceOptions(); -aiOptions.EnableAdaptiveSampling = false; -builder.Services.AddApplicationInsightsTelemetry(aiOptions); --var app = builder.Build(); -``` --The above code disables adaptive sampling. Follow the following steps to add sampling with more customization options. --#### Configure sampling settings --Use the following extension methods of `TelemetryProcessorChainBuilder` to customize sampling behavior. --> [!IMPORTANT] -> If you use this method to configure sampling, please make sure to set the `aiOptions.EnableAdaptiveSampling` property to `false` when calling `AddApplicationInsightsTelemetry()`. After making this change, you then need to follow the instructions in the following code block **exactly** in order to re-enable adaptive sampling with your customizations in place. Failure to do so can result in excess data ingestion. Always test post changing sampling settings, and set an appropriate [daily data cap](../logs/daily-cap.md) to help control your costs. --```csharp -using Microsoft.ApplicationInsights.AspNetCore.Extensions; -using Microsoft.ApplicationInsights.Extensibility; --var builder = WebApplication.CreateBuilder(args); --builder.Services.Configure<TelemetryConfiguration>(telemetryConfiguration => -{ - var telemetryProcessorChainBuilder = telemetryConfiguration.DefaultTelemetrySink.TelemetryProcessorChainBuilder; -- // Using adaptive sampling - telemetryProcessorChainBuilder.UseAdaptiveSampling(maxTelemetryItemsPerSecond: 5); -- // Alternately, the following configures adaptive sampling with 5 items per second, and also excludes DependencyTelemetry from being subject to sampling: - // telemetryProcessorChainBuilder.UseAdaptiveSampling(maxTelemetryItemsPerSecond:5, excludedTypes: "Dependency"); -- telemetryProcessorChainBuilder.Build(); -}); --builder.Services.AddApplicationInsightsTelemetry(new ApplicationInsightsServiceOptions -{ - EnableAdaptiveSampling = false, -}); --var app = builder.Build(); -``` --You can customize other sampling settings using the [SamplingPercentageEstimatorSettings](https://github.com/microsoft/ApplicationInsights-dotnet/blob/main/BASE/src/ServerTelemetryChannel/Implementation/SamplingPercentageEstimatorSettings.cs) class: --```csharp -using Microsoft.ApplicationInsights.WindowsServer.Channel.Implementation; --telemetryProcessorChainBuilder.UseAdaptiveSampling(new SamplingPercentageEstimatorSettings -{ - MinSamplingPercentage = 0.01, - MaxSamplingPercentage = 100, - MaxTelemetryItemsPerSecond = 5 - }, null, excludedTypes: "Dependency"); -``` --### Configuring adaptive sampling for Azure Functions --Follow instructions from [this page](../../azure-functions/configure-monitoring.md#configure-sampling) to configure adaptive sampling for apps running in Azure Functions. --## Fixed-rate sampling --Fixed-rate sampling reduces the traffic sent from your web server and web browsers. Unlike adaptive sampling, it reduces telemetry at a fixed rate decided by you. Fixed-rate sampling is available for ASP.NET, ASP.NET Core, Java and Python applications. --Like other techniques, it also retains related items. It also synchronizes the client and server sampling so that related items are retained. As an example, when you look at a page view in Search you can find its related server requests. --In Metrics Explorer, rates such as request and exception counts are multiplied by a factor to compensate for the sampling rate, so that they're as accurate as possible. --### Configuring fixed-rate sampling for ASP.NET applications --1. **Disable adaptive sampling**: In [`ApplicationInsights.config`](./configuration-with-applicationinsights-config.md), remove or comment out the `AdaptiveSamplingTelemetryProcessor` node. -- ```xml - <TelemetryProcessors> - <!-- Disabled adaptive sampling: - <Add Type="Microsoft.ApplicationInsights.WindowsServer.TelemetryChannel.AdaptiveSamplingTelemetryProcessor, Microsoft.AI.ServerTelemetryChannel"> - <MaxTelemetryItemsPerSecond>5</MaxTelemetryItemsPerSecond> - </Add> - --> - ``` --1. **Enable the fixed-rate sampling module.** Add this snippet to [`ApplicationInsights.config`](./configuration-with-applicationinsights-config.md): -- In this example, SamplingPercentage is 20, so **20%** of all items are sampled. Values in Metrics Explorer are multiplied by (100/20) = **5** to compensate. - - ```xml - <TelemetryProcessors> - <Add Type="Microsoft.ApplicationInsights.WindowsServer.TelemetryChannel.SamplingTelemetryProcessor, Microsoft.AI.ServerTelemetryChannel"> - <!-- Set a percentage close to 100/N where N is an integer. --> - <!-- E.g. 50 (=100/2), 33.33 (=100/3), 25 (=100/4), 20, 1 (=100/100), 0.1 (=100/1000) --> - <SamplingPercentage>20</SamplingPercentage> - </Add> - </TelemetryProcessors> - ``` -- Alternatively, instead of setting the sampling parameter in the `ApplicationInsights.config` file, you can programmatically set these values: - - ```csharp - using Microsoft.ApplicationInsights.Extensibility; - using Microsoft.ApplicationInsights.WindowsServer.TelemetryChannel; -- // ... -- var builder = TelemetryConfiguration.Active.DefaultTelemetrySink.TelemetryProcessorChainBuilder; - // For older versions of the Application Insights SDK, use the following line instead: - // var builder = TelemetryConfiguration.Active.TelemetryProcessorChainBuilder; -- builder.UseSampling(10.0); // percentage -- // If you have other telemetry processors: - builder.Use((next) => new AnotherProcessor(next)); -- builder.Build(); - ``` -- ([Learn about telemetry processors](./api-filtering-sampling.md#filtering).) --### Configuring fixed-rate sampling for ASP.NET Core applications --1. **Disable adaptive sampling** - - Changes can be made after the `WebApplication.CreateBuilder()` method, using `ApplicationInsightsServiceOptions`: - - ```csharp - var builder = WebApplication.CreateBuilder(args); -- var aiOptions = new Microsoft.ApplicationInsights.AspNetCore.Extensions.ApplicationInsightsServiceOptions(); - aiOptions.EnableAdaptiveSampling = false; - builder.Services.AddApplicationInsightsTelemetry(aiOptions); - - var app = builder.Build(); - ``` --1. **Enable the fixed-rate sampling module** - - Changes can be made after the `WebApplication.CreateBuilder()` method: - - ```csharp - var builder = WebApplication.CreateBuilder(args); -- builder.Services.Configure<TelemetryConfiguration>(telemetryConfiguration => - { - var builder = telemetryConfiguration.DefaultTelemetrySink.TelemetryProcessorChainBuilder; - - // Using fixed rate sampling - double fixedSamplingPercentage = 10; - builder.UseSampling(fixedSamplingPercentage); - builder.Build(); - }); - - builder.Services.AddApplicationInsightsTelemetry(new ApplicationInsightsServiceOptions - { - EnableAdaptiveSampling = false, - }); -- var app = builder.Build(); - ``` --### Configuring sampling overrides and fixed-rate sampling for Java applications --By default no sampling is enabled in the Java autoinstrumentation and SDK. Currently the Java autoinstrumentation, [sampling overrides](./java-standalone-sampling-overrides.md) and fixed rate sampling are supported. Adaptive sampling isn't supported in Java. --#### Configuring Java autoinstrumentation --* To configure sampling overrides that override the default sampling rate and apply different sampling rates to selected requests and dependencies, use the [sampling override guide](./java-standalone-sampling-overrides.md#getting-started). -* To configure fixed-rate sampling that applies to all of your telemetry, use the [fixed rate sampling guide](./java-standalone-config.md#sampling). --> [!NOTE] -> For the sampling percentage, choose a percentage that is close to 100/N where N is an integer. Currently sampling doesn't support other values. --### Configuring fixed-rate sampling for OpenCensus Python applications --Instrument your application with the latest [OpenCensus Azure Monitor exporters](/previous-versions/azure/azure-monitor/app/opencensus-python). --> [!NOTE] -> Fixed-rate sampling is not available for the metrics exporter. This means custom metrics are the only types of telemetry where sampling can NOT be configured. The metrics exporter will send all telemetry that it tracks. --#### Fixed-rate sampling for tracing #### -You can specify a `sampler` as part of your `Tracer` configuration. If no explicit sampler is provided, the `ProbabilitySampler` is used by default. The `ProbabilitySampler` would use a rate of 1/10000 by default, meaning one out of every 10,000 requests are sent to Application Insights. If you want to specify a sampling rate, see the following details. --To specify the sampling rate, make sure your `Tracer` specifies a sampler with a sampling rate between 0.0 and 1.0 inclusive. A sampling rate of 1.0 represents 100%, meaning all of your requests are sent as telemetry to Application Insights. --```python -tracer = Tracer( - exporter=AzureExporter( - instrumentation_key='00000000-0000-0000-0000-000000000000', - ), - sampler=ProbabilitySampler(1.0), -) -``` --#### Fixed-rate sampling for logs #### -You can configure fixed-rate sampling for `AzureLogHandler` by modifying the `logging_sampling_rate` optional argument. If no argument is supplied, a sampling rate of 1.0 is used. A sampling rate of 1.0 represents 100%, meaning all of your requests is sent as telemetry to Application Insights. --```python -handler = AzureLogHandler( - instrumentation_key='00000000-0000-0000-0000-000000000000', - logging_sampling_rate=0.5, -) -``` --### Configuring fixed-rate sampling for web pages with JavaScript --JavaScript-based web pages can be configured to use Application Insights. Telemetry is sent from the client application running within the user's browser, and the pages can be hosted from any server. --When you [configure your JavaScript-based web pages for Application Insights](javascript.md), modify the JavaScript snippet that you get from the Application Insights portal. --> [!TIP] -> In ASP.NET apps with JavaScript included, the snippet typically goes in `_Layout.cshtml`. --Insert a line like `samplingPercentage: 10,` before the instrumentation key: --```xml -<script> - var appInsights = // ... - ({ - // Value must be 100/N where N is an integer. - // Valid examples: 50, 25, 20, 10, 5, 1, 0.1, ... - samplingPercentage: 10, -- instrumentationKey: ... - }); -- window.appInsights = appInsights; - appInsights.trackPageView(); -</script> -``` --For the sampling percentage, choose a percentage that is close to 100/N where N is an integer. Currently sampling doesn't support other values. --#### Coordinating server-side and client-side sampling --The client-side JavaScript SDK participates in fixed-rate sampling with the server-side SDK. The instrumented pages only send client-side telemetry from the same user for which the server-side SDK made its decision to include in the sampling. This logic is designed to maintain the integrity of user sessions across client- and server-side applications. As a result, from any particular telemetry item in Application Insights you can find all other telemetry items for this user or session and in Search, you can navigate between related page views and requests. --If your client and server-side telemetry don't show coordinated samples: --* Verify that you enabled sampling both on the server and client. -* Check that you set the same sampling percentage in both the client and server. -* Make sure that the SDK version is 2.0 or higher. --## Ingestion sampling --Ingestion sampling operates at the point where the telemetry from your web server, browsers, and devices reaches the Application Insights service endpoint. Although it doesn't reduce the telemetry traffic sent from your app, it does reduce the amount processed and retained (and charged for) by Application Insights. --Use this type of sampling if your app often goes over its monthly quota and you don't have the option of using either of the SDK-based types of sampling. --Set the sampling rate in the Usage and estimated costs page: ---Like other types of sampling, the algorithm retains related telemetry items. For example, when you're inspecting the telemetry in Search, you're able to find the request related to a particular exception. Metric counts such as request rate and exception rate are correctly retained. --Sampling discards certain data points, making them unavailable in any Application Insights feature such as [Continuous Export](./export-telemetry.md). --Ingestion sampling doesn't work alongside adaptive or fixed-rate sampling. Adaptive sampling automatically activates with the ASP.NET SDK, the ASP.NET Core SDK, in [Azure App Service](azure-web-apps.md), or with the Application Insights Agent. When the Application Insights service endpoint receives telemetry and detects a sampling rate below 100% (indicating active sampling), it ignores any set ingestion sampling rate. --> [!WARNING] -> The value shown on the portal tile indicates the value that you set for ingestion sampling. It doesn't represent the actual sampling rate if any sort of SDK sampling (adaptive or fixed-rate sampling) is in operation. --### Which type of sampling should I use? --**Use ingestion sampling if:** --* You often use your monthly quota of telemetry. -* You're getting too much telemetry from your users' web browsers. -* You're using a version of the SDK that doesn't support sampling - for example ASP.NET versions earlier than 2.0. --**Use fixed-rate sampling if:** --* You need synchronized sampling between client and server to navigate between related events. For example, page views and HTTP requests in [Search](./transaction-search-and-diagnostics.md?tabs=transaction-search) while investigating events. -* You're confident of the appropriate sampling percentage for your app. It should be high enough to get accurate metrics, but below the rate that exceeds your pricing quota and the throttling limits. --**Use adaptive sampling:** --If the conditions to use the other forms of sampling don't apply, we recommend adaptive sampling. This setting is enabled by default in the ASP.NET/ASP.NET Core SDK. It doesn't reduce traffic until a certain minimum rate is reached, therefore low-use sites are probably not sampled at all. --## Knowing whether sampling is in operation --Use an [Analytics query](../logs/log-query-overview.md) to find the sampling rate. --```kusto -union requests,dependencies,pageViews,browserTimings,exceptions,traces -| where timestamp > ago(1d) -| summarize RetainedPercentage = 100/avg(itemCount) by bin(timestamp, 1h), itemType -``` --If you see that `RetainedPercentage` for any type is less than 100, then that type of telemetry is being sampled. --> [!IMPORTANT] -> Application Insights does not sample session, metrics (including custom metrics), or performance counter telemetry types in any of the sampling techniques. These types are always excluded from sampling as a reduction in precision can be highly undesirable for these telemetry types. --## Log query accuracy and high sample rates --As the application is scaled up, it can be processing dozens, hundreds, or thousands of work items per second. Logging an event for each of them isn't resource nor cost effective. Application Insights uses sampling to adapt to growing telemetry volume in a flexible manner and to control resource usage and cost. -> [!WARNING] -> A distributed operation's end-to-end view integrity may be impacted if any application in the distributed operation has turned on sampling. Different sampling decisions are made by each application in a distributed operation, so telemetry for one Operation ID may be saved by one application while other applications may decide to not sample the telemetry for that same Operation ID. --As sampling rates increase, log based queries accuracy decrease and are inflated. It only impacts the accuracy of log-based queries when sampling is enabled and the sample rates are in a higher range (~ 60%). The impact varies based on telemetry types, telemetry counts per operation and other factors. --SDKs use preaggregated metrics to solve problems caused by sampling. For more information on these metrics, see [Azure Application Insights - Azure Monitor | Microsoft Docs](./pre-aggregated-metrics-log-metrics.md#sdk-supported-preaggregated-metrics-table). The SDKs identify relevant properties of logged data and extract statistics before sampling. To minimize resource use and costs, metrics are aggregated. This process results in a few metric telemetry items per minute, rather than thousands of event telemetry items. For example, these metrics might report ΓÇ£this web app processed 25 requestsΓÇ¥ to the MDM account, with an `itemCount` of 100 in the sent request telemetry record. These preaggregated metrics provide accurate numbers and are reliable even when sampling impacts log-based query results. You can view them in the Metrics pane of the Application Insights portal. --## Frequently asked questions --*Does sampling affect alerting accuracy?* -* Yes. Alerts can only trigger upon sampled data. Aggressive filtering can result in alerts not firing as expected. --> [!NOTE] -> Sampling is not applied to Metrics, but Metrics can be derived from sampled data. In this way sampling may indirectly affect alerting accuracy. --*What is the default sampling behavior in the ASP.NET and ASP.NET Core SDKs?* --* If you're using one of the latest versions of the above SDK, Adaptive Sampling is enabled by default with five telemetry items per second. - By default, the system adds two `AdaptiveSamplingTelemetryProcessor` nodes: one includes the `Event` type in sampling, while the other excludes it. This configuration limits telemetry to five `Event` type items and five items of all other types combined, ensuring `Events` are sampled separately from other telemetry types. --Use the [examples in the earlier section of this page](#configuring-adaptive-sampling-for-aspnet-core-applications) to change this default behavior. --*Can telemetry be sampled more than once?* --* No. SamplingTelemetryProcessors ignore items from sampling considerations if the item is already sampled. The same is true for ingestion sampling as well, which doesn't apply sampling to those items already sampled in the SDK itself. --*Why isn't sampling a simple "collect X percent of each telemetry type"?* --* While this sampling approach would provide with a high level of precision in metric approximations, it would break the ability to correlate diagnostic data per user, session, and request, which is critical for diagnostics. Therefore, sampling works better with policies like "collect all telemetry items for X percent of app users," or "collect all telemetry for X percent of app requests." For the telemetry items not associated with the requests (such as background asynchronous processing), the fallback is to "collect X percent of all items for each telemetry type." --*Can the sampling percentage change over time?* --* Yes, adaptive sampling gradually changes the sampling percentage, based on the currently observed volume of the telemetry. --*If I use fixed-rate sampling, how do I know which sampling percentage works the best for my app?* --* One way is to start with adaptive sampling, find out what rate it settles on (see the above question), and then switch to fixed-rate sampling using that rate. - - Otherwise, you have to guess. Analyze your current telemetry usage in Application Insights, observe any throttling that is occurring, and estimate the volume of the collected telemetry. These three inputs, together with your selected pricing tier, suggest how much you might want to reduce the volume of the collected telemetry. However, an increase in the number of your users or some other shift in the volume of telemetry might invalidate your estimate. --*What happens if I configure the sampling percentage to be too low?* --* Excessively low sampling percentages cause over-aggressive sampling, and reduce the accuracy of the approximations when Application Insights attempts to compensate the visualization of the data for the data volume reduction. Also your diagnostic experience might be negatively impacted, as some of the infrequently failing or slow requests can be sampled out. --*What happens if I configure the sampling percentage to be too high?* --* Configuring too high a sampling percentage (not aggressive enough) results in an insufficient reduction in the volume of the collected telemetry. You can still experience telemetry data loss related to throttling, and the cost of using Application Insights might be higher than you planned due to overage charges. --*What happens if I configure both IncludedTypes and ExcludedTypes settings?* --* It's best not to set both `ExcludedTypes` and `IncludedTypes` in your configuration to prevent any conflicts and ensure clear telemetry collection settings. -* Telemetry types that are listed in `ExcludedTypes` are excluded even if they are also set in `IncludedTypes` settings. ExcludedTypes will take precedence over IncludedTypes. --*On what platforms can I use sampling?* --* Ingestion sampling can occur automatically for any telemetry above a certain volume, if the SDK isn't performing sampling. This configuration would work, for example, if you're using an older version of the ASP.NET SDK or Java SDK. -* If you're using the current ASP.NET or ASP.NET Core SDKs (hosted either in Azure or on your own server), you get adaptive sampling by default, but you can switch to fixed-rate as previously described. With fixed-rate sampling, the browser SDK automatically synchronizes to sample related events. -* If you're using the current Java agent, you can configure `applicationinsights.json` (for Java SDK, configure `ApplicationInsights.xml`) to turn on fixed-rate sampling. Sampling is turned off by default. With fixed-rate sampling, the browser SDK and the server automatically synchronize to sample related events. --*There are certain rare events I always want to see. How can I get them past the sampling module?* --* The best way to always see certain events is to write a custom [TelemetryInitializer](./api-filtering-sampling.md#addmodify-properties-itelemetryinitializer), which sets the `SamplingPercentage` to 100 on the telemetry item you want retained, as shown in the following example. Initializers are guaranteed to run before telemetry processors (including sampling), so it ensures that all sampling techniques ignore this item from any sampling considerations. Custom telemetry initializers are available in the ASP.NET SDK, the ASP.NET Core SDK, the JavaScript SDK, and the Java SDK. For example, you can configure a telemetry initializer using the ASP.NET SDK: -- ```csharp - public class MyTelemetryInitializer : ITelemetryInitializer - { - public void Initialize(ITelemetry telemetry) - { - if(somecondition) - { - ((ISupportSampling)telemetry).SamplingPercentage = 100; - } - } - } - ``` --## Older SDK versions --Adaptive sampling is available for the Application Insights SDK for ASP.NET v2.0.0-beta3 and later, Microsoft.ApplicationInsights.AspNetCore SDK v2.2.0-beta1 and later, and is enabled by default. --Fixed-rate sampling is a feature of the SDK in ASP.NET versions from 2.0.0 and Java SDK version 2.0.1 and onwards. --Before v2.5.0-beta2 of the ASP.NET SDK and v2.2.0-beta3 of the ASP.NET Core SDK, sampling decisions for applications defining "user" (like most web applications) relied on the user ID's hash. For applications not defining users (such as web services), it based the decision on the request's operation ID. Recent versions of both the ASP.NET and ASP.NET Core SDKs now use the operation ID for sampling decisions. --## Next steps --* [Filtering](./api-filtering-sampling.md) can provide more strict control of what your SDK sends. -* Read the Developer Network article [Optimize Telemetry with Application Insights](/archive/msdn-magazine/2017/may/devops-optimize-telemetry-with-application-insights). |
| azure-monitor | Sdk Connection String | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/sdk-connection-string.md | - Title: Connection strings in Application Insights | Microsoft Docs -description: This article shows how to use connection strings. - Previously updated : 02/29/2024-----# Connection strings --This article shows how to use connection strings. --## Overview ---Connection strings define where to send telemetry data. --Key-value pairs provide an easy way for users to define a prefix suffix combination for each Application Insights service or product. ---## Scenario overview --Scenarios most affected by this change: --- Firewall exceptions or proxy redirects:-- In cases where monitoring for intranet web server is required, our earlier solution asked you to add individual service endpoints to your configuration. For more information, see the [Can I monitor an intranet web server?](../ip-addresses.md#can-i-monitor-an-intranet-web-server). Connection strings offer a better alternative by reducing this effort to a single setting. A simple prefix, suffix amendment, allows automatic population and redirection of all endpoints to the right services. --- Sovereign or hybrid cloud environments:-- Users can send data to a defined [Azure Government region](../../azure-government/compare-azure-government-global-azure.md#application-insights). By using connection strings, you can define endpoint settings for your intranet servers or hybrid cloud settings. --## Get started --Review the following sections to get started. --### Find your connection string --Your connection string appears in the **Overview** section of your Application Insights resource. ---### Schema --Schema elements are explained in the following sections. --#### Max length --The connection has a maximum supported length of 4,096 characters. --#### Key-value pairs --A connection string consists of a list of settings represented as key-value pairs separated by a semicolon: -`key1=value1;key2=value2;key3=value3` --#### Syntax --- `InstrumentationKey` (for example, 00000000-0000-0000-0000-000000000000).- `InstrumentationKey` is a *required* field. -- `Authorization` (for example, ikey). This setting is optional because today we only support ikey authorization.-- `EndpointSuffix` (for example, applicationinsights.azure.cn).- Setting the endpoint suffix tells the SDK which Azure cloud to connect to. The SDK assembles the rest of the endpoint for individual services. -- Explicit endpoints.- Any service can be explicitly overridden in the connection string: - - `IngestionEndpoint` (for example, `https://dc.applicationinsights.azure.com`) - - `LiveEndpoint` (for example, `https://live.applicationinsights.azure.com`) - - `ProfilerEndpoint` (for example, `https://profiler.monitor.azure.com`) - - `SnapshotEndpoint` (for example, `https://snapshot.monitor.azure.com`) --#### Endpoint schema --`<prefix>.<suffix>` -- Prefix: Defines a service.-- Suffix: Defines the common domain name.--##### Valid suffixes --- applicationinsights.azure.cn-- applicationinsights.us--For more information, see [Regions that require endpoint modification](./create-new-resource.md#regions-that-require-endpoint-modification). --##### Valid prefixes --- [Telemetry Ingestion](./app-insights-overview.md): `dc`-- [Live Metrics](./live-stream.md): `live`-- [Profiler](./profiler-overview.md): `profiler`-- [Snapshot](./snapshot-debugger.md): `snapshot`--#### Is the connection string a secret? --The connection string contains an ikey, which is a unique identifier used by the ingestion service to associate telemetry to a specific Application Insights resource. These ikey unique identifiers aren't security tokens or security keys. If you want to protect your AI resource from misuse, the ingestion endpoint provides authenticated telemetry ingestion options based on [Microsoft Entra ID](azure-ad-authentication.md#microsoft-entra-authentication-for-application-insights). --> [!NOTE] -> The Application Insights JavaScript SDK requires the connection string to be passed in during initialization and configuration. It's viewable in plain text in client browsers. There's no easy way to use the [Microsoft Entra ID-based authentication](azure-ad-authentication.md#microsoft-entra-authentication-for-application-insights) for browser telemetry. We recommend that you consider creating a separate Application Insights resource for browser telemetry if you need to secure the service telemetry. --## Connection string examples --Here are some examples of connection strings. --### Connection string with an endpoint suffix --`InstrumentationKey=00000000-0000-0000-0000-000000000000;EndpointSuffix=ai.contoso.com;` --In this example, the connection string specifies the endpoint suffix and the SDK constructs service endpoints: --- Authorization scheme defaults to "ikey"-- Instrumentation key: 00000000-0000-0000-0000-000000000000-- The regional service URIs are based on the provided endpoint suffix:- - Ingestion: `https://dc.ai.contoso.com` - - Live metrics: `https://live.ai.contoso.com` - - Profiler: `https://profiler.ai.contoso.com` - - Debugger: `https://snapshot.ai.contoso.com` --### Connection string with explicit endpoint overrides --`InstrumentationKey=00000000-0000-0000-0000-000000000000;IngestionEndpoint=https://custom.com:111/;LiveEndpoint=https://custom.com:222/;ProfilerEndpoint=https://custom.com:333/;SnapshotEndpoint=https://custom.com:444/;` --In this example, the connection string specifies explicit overrides for every service. The SDK uses the exact endpoints provided without modification: --- Authorization scheme defaults to "ikey"-- Instrumentation key: 00000000-0000-0000-0000-000000000000-- The regional service URIs are based on the explicit override values:- - Ingestion: `https://custom.com:111/` - - Live metrics: `https://custom.com:222/` - - Profiler: `https://custom.com:333/` - - Debugger: `https://custom.com:444/` --### Connection string with an explicit region --`InstrumentationKey=00000000-0000-0000-0000-000000000000;IngestionEndpoint=https://southcentralus.in.applicationinsights.azure.com/` --In this example, the connection string specifies the South Central US region: --- Authorization scheme defaults to "ikey"-- Instrumentation key: 00000000-0000-0000-0000-000000000000-- The regional service URIs are based on the explicit override values:- - Ingestion: `https://southcentralus.in.applicationinsights.azure.com/` --Run the following command in the [Azure CLI](/cli/azure/account?view=azure-cli-latest#az-account-list-locations&preserve-view=true) to list available regions: --`az account list-locations -o table` --## Set a connection string --Connection strings are supported in the following SDK versions: -- .NET v2.12.0-- Java v2.5.1 and Java 3.0-- JavaScript v2.3.0-- NodeJS v1.5.0-- Python v1.0.0--You can set a connection string in code or by using an environment variable or a configuration file. --### Environment variable --Connection string: `APPLICATIONINSIGHTS_CONNECTION_STRING` --### Code samples --# [.NET 5.0+](#tab/dotnet5) --1. Set the connection string in the `appsettings.json` file: -- ```json - { - "ApplicationInsights": { - "ConnectionString" : "InstrumentationKey=00000000-0000-0000-0000-000000000000;IngestionEndpoint=https://{region}.in.applicationinsights.azure.com/;LiveEndpoint=https://{region}.livediagnostics.monitor.azure.com/" - } - } - ``` --2. Retrieve the connection string in `Program.cs` when registering the `ApplicationInsightsTelemetry` service: -- ```csharp - var options = new ApplicationInsightsServiceOptions { ConnectionString = app.Configuration["ApplicationInsights:ConnectionString"] }; - builder.Services.AddApplicationInsightsTelemetry(options: options); - ``` --# [.NET Framework](#tab/dotnet-framework) --Set the property [TelemetryConfiguration.ConnectionString](https://github.com/microsoft/ApplicationInsights-dotnet/blob/add45ceed35a817dc7202ec07d3df1672d1f610d/BASE/src/Microsoft.ApplicationInsights/Extensibility/TelemetryConfiguration.cs#L271-L274) or [ApplicationInsightsServiceOptions.ConnectionString](https://github.com/microsoft/ApplicationInsights-dotnet/blob/81288f26921df1e8e713d31e7e9c2187ac9e6590/NETCORE/src/Shared/Extensions/ApplicationInsightsServiceOptions.cs#L66-L69). --Explicitly set the connection string in code: --```csharp -var configuration = new TelemetryConfiguration -{ - ConnectionString = "InstrumentationKey=00000000-0000-0000-0000-000000000000;IngestionEndpoint=https://{region}.in.applicationinsights.azure.com/;LiveEndpoint=https://{region}.livediagnostics.monitor.azure.com/" -}; -``` --Set the connection string using a configuration file: --```xml -<?xml version="1.0" encoding="utf-8"?> -<ApplicationInsights xmlns="http://schemas.microsoft.com/ApplicationInsights/2013/Settings"> - <ConnectionString>InstrumentationKey=00000000-0000-0000-0000-000000000000;IngestionEndpoint=https://{region}.in.applicationinsights.azure.com/;LiveEndpoint=https://{region}.livediagnostics.monitor.azure.com/</ConnectionString> -</ApplicationInsights> -``` --# [Java](#tab/java) --You can set the connection string in the `applicationinsights.json` configuration file: --```json -{ - "connectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000;IngestionEndpoint=https://{region}.in.applicationinsights.azure.com/;LiveEndpoint=https://{region}.livediagnostics.monitor.azure.com/" -} -``` --For more information, see [Connection string configuration](./java-standalone-config.md#connection-string). --# [JavaScript](#tab/js) --JavaScript doesn't support the use of environment variables. You have two options: --- To use the JavaScript (Web) SDK Loader Script, see [JavaScript (Web) SDK Loader Script](./javascript-sdk.md?tabs=javascriptwebsdkloaderscript#get-started).-- Manual setup:- ```javascript - import { ApplicationInsights } from '@microsoft/applicationinsights-web' -- const appInsights = new ApplicationInsights({ config: { - connectionString: 'InstrumentationKey=00000000-0000-0000-0000-000000000000;' - /* ...Other Configuration Options... */ - } }); - appInsights.loadAppInsights(); - appInsights.trackPageView(); - ``` --# [Node.js](#tab/nodejs) --```javascript -const appInsights = require("applicationinsights"); -appInsights.setup("InstrumentationKey=00000000-0000-0000-0000-000000000000;IngestionEndpoint=https://{region}.in.applicationinsights.azure.com/;LiveEndpoint=https://{region}.livediagnostics.monitor.azure.com/"); -appInsights.start(); -``` --# [Python](#tab/python) --We recommend that users set the environment variable. --To explicitly set the connection string: --```python -from opencensus.ext.azure.trace_exporter import AzureExporter -from opencensus.trace.samplers import ProbabilitySampler -from opencensus.trace.tracer import Tracer --tracer = Tracer(exporter=AzureExporter(connection_string='InstrumentationKey=00000000-0000-0000-0000-000000000000;IngestionEndpoint=https://{region}.in.applicationinsights.azure.com/;LiveEndpoint=https://{region}.livediagnostics.monitor.azure.com/'), sampler=ProbabilitySampler(1.0)) -``` ----## Frequently asked questions --This section provides answers to common questions. --### Do new Azure regions require the use of connection strings? --New Azure regions *require* the use of connection strings instead of instrumentation keys. Connection string identifies the resource that you want to associate with your telemetry data. It also allows you to modify the endpoints your resource uses as a destination for your telemetry. Copy the connection string and add it to your application's code or to an environment variable. --### Should I use connection strings or instrumentation keys? --We recommend that you use connection strings instead of instrumentation keys. --## Next steps --Get started at runtime with: --* [Azure VM and Azure Virtual Machine Scale Sets IIS-hosted apps](./azure-vm-vmss-apps.md) -* [IIS server](./application-insights-asp-net-agent.md) -* [Web Apps feature of Azure App Service](./azure-web-apps.md) --Get started at development time with: --* [ASP.NET](./asp-net.md) -* [ASP.NET Core](./asp-net-core.md) -* [Java](./opentelemetry-enable.md?tabs=java) -* [Node.js](./nodejs.md) -* [Python](/previous-versions/azure/azure-monitor/app/opencensus-python) |
| azure-monitor | Sdk Support Guidance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/sdk-support-guidance.md | - Title: Application Insights SDK support guidance -description: Support guidance for Application Insights legacy and preview SDKs -- Previously updated : 06/08/2024----# Application Insights SDK support guidance --Microsoft announces feature deprecations or breaking changes at least one year in advance and strives to provide a seamless process for migration to the replacement experience. --For more information, review the [Azure SDK Lifecycle and Support Policy](https://azure.github.io/azure-sdk/policies_support.html). --> [!NOTE] -> Diagnostic tools often provide better insight into the root cause of a problem when the latest stable SDK version is used. --## SDK update guidance --Support engineers are expected to provide SDK update guidance according to the following table, referencing the current SDK version in use and any alternatives. --|Current SDK version in use |Alternative version available |Update policy for support | -|||| -|Latest GA SDK | Newer preview version available | **NO UPDATE NECESSARY** | -|GA SDK | Newer GA released < one year ago | **UPDATE RECOMMENDED** | -|GA SDK | Newer GA released > one year ago | **UPDATE REQUIRED** | -|Unsupported ([support policy](/lifecycle/faq/azure)) | Any supported version | **UPDATE REQUIRED** | -|Latest Preview | No newer version available | **NO UPDATE NECESSARY** | -|Latest Preview | Newer GA SDK | **UPDATE REQUIRED** | -|Preview | Newer preview version | **UPDATE REQUIRED** | --> [!NOTE] -> * General Availability (GA) refers to non-beta versions. -> * Preview refers to beta versions. --> [!TIP] -> Switching to [autoinstrumentation](codeless-overview.md) eliminates the need for manual SDK updates. --> [!WARNING] -> Only commercially reasonable support is provided for Preview versions of the SDK. If a support incident requires escalation to development for further guidance, customers will be asked to use a fully supported SDK version to continue support. Commercially reasonable support does not include an option to engage Microsoft product development resources; technical workarounds may be limited or not possible. --## Release notes --Reference the release notes to see the current version of Application Insights SDKs and previous versions release dates. --- [.NET SDKs (Including ASP.NET, ASP.NET Core, and Logging Adapters)](https://github.com/Microsoft/ApplicationInsights-dotnet/releases)-- [Python](https://github.com/census-instrumentation/opencensus-python/blob/master/contrib/opencensus-ext-azure/CHANGELOG.md)-- [Node.js](https://github.com/Microsoft/ApplicationInsights-node.js/releases)-- [JavaScript](https://github.com/microsoft/ApplicationInsights-JS/releases)--Our [Service Updates](https://azure.microsoft.com/updates/?service=application-insights) also summarize major Application Insights improvements. |
| azure-monitor | Standard Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/standard-metrics.md | - Title: Azure Application Insights standard metrics | Microsoft Docs -description: This article lists Azure Application Insights metrics with supported aggregations and dimensions. -- Previously updated : 01/31/2024----# Application Insights standard metrics --Standard metrics are preaggregated during collection, which gives them better performance at query time. This makes them the best choice for dashboards and real-time alerting. ---## Availability metrics --Metrics in the Availability category enable you to see the health of your web application as observed from points around the world. [Configure the availability tests](../app/availability-overview.md) to start using any metrics from this category. --### Availability (availabilityResults/availabilityPercentage) -The *Availability* metric shows the percentage of the web test runs that didn't detect any issues. The lowest possible value is 0, which indicates that all of the web test runs have failed. The value of 100 means that all of the web test runs passed the validation criteria. --|Unit of measure|Supported aggregations|Supported dimensions| -||||||| -|Percentage|Average|`Run location`, `Test name`| ---### Availability test duration (availabilityResults/duration) --The *Availability test duration* metric shows how much time it took for the web test to run. For the [multi-step web tests](/previous-versions/azure/azure-monitor/app/availability-multistep), the metric reflects the total execution time of all steps. --|Unit of measure|Supported aggregations|Supported dimensions| -||||||| -|Milliseconds|Average, Min, Max|`Run location`, `Test name`, `Test result` --### Availability tests (availabilityResults/count) --The *Availability tests* metric reflects the count of the web tests runs by Azure Monitor. --|Unit of measure|Supported aggregations|Supported dimensions| -||||||| -|Count|Count|`Run location`, `Test name`, `Test result`| ---## Browser metrics --Browser metrics are collected by the Application Insights JavaScript SDK from real end-user browsers. They provide great insights into your users' experience with your web app. Browser metrics are typically not sampled, which means that they provide higher precision of the usage numbers compared to server-side metrics which might be skewed by sampling. --> [!NOTE] -> To collect browser metrics, your application must be instrumented with the [Application Insights JavaScript SDK](../app/javascript.md). --### Browser page load time (browserTimings/totalDuration) --|Unit of measure|Supported aggregations| Supported dimensions| -|||| -|Milliseconds|Average, Min, Max|None| --### Client processing time (browserTiming/processingDuration) --|Unit of measure|Supported aggregations|Supported dimensions| -|||| -|Milliseconds|Average, Min, Max|None| --### Page load network connect time (browserTimings/networkDuration) --|Unit of measure|Supported aggregations| Supported dimensions| -|||| -|Milliseconds|Average, Min, Max|None| --### Receiving response time (browserTimings/receiveDuration) --|Unit of measure|Supported aggregations| Supported dimensions| -|||| -|Milliseconds|Average, Min, Max|None| --### Send request time (browserTimings/sendDuration) --|Unit of measure|Supported aggregations| Supported dimensions| -|||| -|Milliseconds|Average, Min, Max|None| --## Failure metrics --The metrics in **Failures** show problems with processing requests, dependency calls, and thrown exceptions. --### Browser exceptions (exceptions/browser) --This metric reflects the number of thrown exceptions from your application code running in browser. Only exceptions that are tracked with a ```trackException()``` Application Insights API call are included in the metric. --|Unit of measure|Supported aggregations | Supported dimensions| -||||| -| Count | Count | `Cloud role name` | --### Dependency call failures (dependencies/failed) --The number of failed dependency calls. --|Unit of measure|Supported aggregations | Supported dimensions | -||||| -|Count|Count| `Cloud role instance`, `Cloud role name`, `Dependency performance`, `Dependency type`, `Is traffic synthetic`, `Result code`, `Target of dependency call`. ---### Exceptions (exceptions/count) --Each time when you log an exception to Application Insights, there is a call to the [trackException() method](../app/api-custom-events-metrics.md#trackexception) of the SDK. The Exceptions metric shows the number of logged exceptions. --|Unit of measure|Supported aggregations | Supported dimensions | -||||| -|Count|Count|`Cloud role instance`, `Cloud role name`, `Device type`| --### Failed requests (requests/failed) --The count of tracked server requests that were marked as *failed*. By default, the Application Insights SDK automatically marks each server request that returned HTTP response code 5xx or 4xx as a failed request. You can customize this logic by modifying *success* property of request telemetry item in a [custom telemetry initializer](../app/api-filtering-sampling.md#addmodify-properties-itelemetryinitializer). ---|Unit of measure|Supported aggregations | Supported dimensions | -||||| -|Count|Count|`Cloud role instance`, `Cloud role name`, `Is synthetic traffic`, `Request performance`, `Result code`| ---### Server exceptions (exceptions/server) --This metric shows the number of server exceptions. --|Unit of measure|Supported aggregations | Supported dimensions | -||||| -|Count|Count|`Cloud role instance`, `Cloud role name`| --## Performance counters --Use metrics in the **Performance counters** category to access [system performance counters collected by Application Insights](../app/performance-counters.md). --### Available memory (performanceCounters/availableMemory) --|Unit of measure|Supported aggregations | Supported dimensions | -||||| -|Data dependent: Megabytes, Gigabytes|Average, Max, Min|`Cloud role instance`| ---### Exception rate (performanceCounters/exceptionRate) --|Unit of measure|Supported aggregations | Supported dimensions | -||||| -| Count | Average, Max, Min | `Cloud role instance` | ---### HTTP request execution time (performanceCounters/requestExecutionTime) --|Unit of measure|Supported aggregations | Supported dimensions | -||||| -| Milliseconds | Average, Max, Min | `Cloud role instance` | --### HTTP request rate (performanceCounters/requestsPerSecond) --|Unit of measure|Supported aggregations | Supported dimensions | -||||| -| Requests per second | Average, Max, Min | `Cloud role instance` | --### HTTP requests in application queue (performanceCounters/requestsInQueue) --|Unit of measure|Supported aggregations | Supported dimensions | -||||| -| Count | Average, Max, Min | `Cloud role instance` | ---### Process CPU (performanceCounters/processCpuPercentage) --The metric shows how much of the total processor capacity is consumed by the process that is hosting your monitored app. --|Unit of measure|Supported aggregations|Supported dimensions| -|||| -|Percentage|Average, Max, Min| `Cloud role instance` | --> [!NOTE] -> The range of the metric is between 0 and 100 * n, where n is the number of available CPU cores. For example, the metric value of 200% could represent full utilization of two CPU core or half utilization of 4 CPU cores and so on. The *Process CPU Normalized* is an alternative metric collected by many SDKs which represents the same value but divides it by the number of available CPU cores. Thus, the range of *Process CPU Normalized* metric is 0 through 100. --### Process IO rate (performanceCounters/processIOBytesPerSecond) --|Unit of measure|Supported aggregations|Supported dimensions| -|||| -|Bytes per second|Average, Min, Max|`Cloud role instance` | ----### Process private bytes (performanceCounters/processPrivateBytes) --Amount of non-shared memory that the monitored process allocated for its data. --|Unit of measure|Supported aggregations|Supported dimensions| -|||| -|Bytes|Average, Min, Max|`Cloud role instance` | --### Processor time (performanceCounters/processorCpuPercentage) --CPU consumption by *all* processes running on the monitored server instance. --|Unit of measure|Supported aggregations|Supported dimensions| -|||| -|Percentage|Average, Min, Max|`Cloud role instance` | -->[!NOTE] -> The processor time metric is not available for the applications hosted in Azure App Services. Use the [Process CPU](#process-cpu-performancecountersprocesscpupercentage) metric to track CPU utilization of the web applications hosted in App Services. --## Server metrics --### Dependency calls (dependencies/count) --This metric is in relation to the number of dependency calls. --|Unit of measure|Supported aggregations|Supported dimensions| -|||| -| Count | Count | `Cloud role instance`, `Cloud role name`, `Dependency performance`, `Dependency type`, `Is traffic synthetic`, `Result code`, `Successful call`, `Target of a dependency call` | --### Dependency duration (dependencies/duration) --This metric refers to duration of dependency calls. --|Unit of measure|Supported aggregations|Supported dimensions| -|||| -| Milliseconds | Average, Min, Max | `Cloud role instance`, `Cloud role name`, `Dependency performance`, `Dependency type`, `Is traffic synthetic`, `Result code`, `Successful call`, `Target of a dependency call` | ---### Server request rate (requests/rate) --This metric reflects the number of incoming server requests that were received by your web application. --|Unit of measure|Supported aggregations|Supported dimensions| -|||| -| Count Per Second | Average | `Cloud role instance`, `Cloud role name`, `Is traffic synthetic`, `Result performance` `Result code`, `Successful request` | --### Server requests (requests/count) --|Unit of measure|Supported aggregations|Supported dimensions| -|||| -| Count | Count | `Cloud role instance`, `Cloud role name`, `Is traffic synthetic`, `Result performance` `Result code`, `Successful request` | --### Server response time (requests/duration) --This metric reflects the time it took for the servers to process incoming requests. --|Unit of measure|Supported aggregations|Supported dimensions| -|||| -| MilliSeconds | Average, Min, Max | `Cloud role instance`, `Cloud role name`, `Is traffic synthetic`, `Result performance` `Result code`, `Successful request` | --## Usage metrics --### Page view load time (pageViews/duration) --This metric refers to the amount of time it took for PageView events to load. --|Unit of measure|Supported aggregations|Supported dimensions| -|||| -| MilliSeconds | Average, Min, Max | `Cloud role name`, `Is traffic synthetic` | --### Page views (pageViews/count) --The count of PageView events logged with the TrackPageView() Application Insights API. --|Unit of measure|Supported aggregations|Supported dimensions| -|||| -| Count | Count | `Cloud role name`, `Is traffic synthetic` | --### Traces (traces/count) --The count of trace statements logged with the TrackTrace() Application Insights API call. --|Unit of measure|Supported aggregations|Supported dimensions| -|||| -| Count | Count | `Cloud role instance`, `Cloud role name`, `Is traffic synthetic`, `Severity level` | ---## Next steps --* [Metrics - Get - REST API](/rest/api/application-insights/metrics/get) -* [Application Insights API for custom events and metrics](api-custom-events-metrics.md) -* Learn about [Log-based and preaggregated metrics](./pre-aggregated-metrics-log-metrics.md). -* [Log-based metrics queries and definitions](../essentials/app-insights-metrics.md). |
| azure-monitor | Statsbeat | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/statsbeat.md | - Title: Statsbeat in Application Insights | Microsoft Docs -description: Statistics about Application Insights SDKs and autoinstrumentation - Previously updated : 08/24/2022--ms.reviwer: heya ---# Statsbeat in Application Insights --Statsbeat collects essential and nonessential [custom metrics](../essentials/metrics-custom-overview.md) about Application Insights SDKs and autoinstrumentation. Statsbeat serves three benefits for Application Insights customers: --* Service health and reliability (outside-in monitoring of connectivity to ingestion endpoint) -* Support diagnostics (self-help insights and CSS insights) -* Product improvement (insights for design optimizations) --Statsbeat data is stored in a Microsoft data store. It doesn't affect customers' overall monitoring volume and cost. --> [!NOTE] -> Statsbeat doesn't support [Azure Private Link](../../automation/how-to/private-link-security.md). --## Supported languages --| C# | Java | JavaScript | Node.js | Python | -|-|--|-|--|--| -| Currently not supported | Supported | Currently not supported | Supported | Supported | --## Supported EU regions --Statsbeat supports EU Data Boundary for Application Insights resources in the following regions: --| Geo name | Region name | -|-|-| -| Europe | North Europe | -| Europe | West Europe | -| France | France Central | -| France | France South | -| Germany | Germany West Central | -| Norway | Norway East | -| Norway | Norway West | -| Sweden | Sweden Central | -| Switzerland | Switzerland North | -| Switzerland | Switzerland West | -| United Kingdom | United Kingdom South | -| United Kingdom | United Kingdom West | --## Supported metrics --Statsbeat collects [essential](#essential-statsbeat) and [nonessential](#nonessential-statsbeat) metrics: --| Language | Essential metrics | Non-essential metrics | -|-|-|--| -| Java | ✅ | ✅ | -| Node.js | ✅ | ❌ | -| Python | ✅ | ❌ | --### Essential Statsbeat --#### Network Statsbeat --| Metric name | Unit | Supported dimensions | -||-|| -| Request Success Count | Count | `Resource Provider`, `Attach Type`, `Instrumentation Key`, `Runtime Version`, `Operating System`, `Language`, `Version`, `Endpoint`, `Host` | -| Requests Failure Count | Count | `Resource Provider`, `Attach Type`, `Instrumentation Key`, `Runtime Version`, `Operating System`, `Language`, `Version`, `Endpoint`, `Host`, `Status Code` | -| Request Duration | Count | `Resource Provider`, `Attach Type`, `Instrumentation Key`, `Runtime Version`, `Operating System`, `Language`, `Version`, `Endpoint`, `Host` | -| Retry Count | Count | `Resource Provider`, `Attach Type`, `Instrumentation Key`, `Runtime Version`, `Operating System`, `Language`, `Version`, `Endpoint`, `Host`, `Status Code` | -| Throttle Count | Count | `Resource Provider`, `Attach Type`, `Instrumentation Key`, `Runtime Version`, `Operating System`, `Language`, `Version`, `Endpoint`, `Host`, `Status Code` | -| Exception Count | Count | `Resource Provider`, `Attach Type`, `Instrumentation Key`, `Runtime Version`, `Operating System`, `Language`, `Version`, `Endpoint`, `Host`, `Exception Type` | ---#### Attach Statsbeat --| Metric name | Unit | Supported dimensions | -|-|-|| -| Attach | Count | `Resource Provider`, `Resource Provider Identifier`, `Attach Type`, `Instrumentation Key`, `Runtime Version`, `Operating System`, `Language`, `Version` | --#### Feature Statsbeat --| Metric name | Unit | Supported dimensions | -|-|-|--| -| Feature | Count | `Resource Provider`, `Attach Type`, `Instrumentation Key`, `Runtime Version`, `Feature`, `Type`, `Operating System`, `Language`, `Version` | --### Nonessential Statsbeat --Track the Disk I/O failure when you use disk persistence for reliable telemetry. --| Metric name | Unit | Supported dimensions | -||-|-| -| Read Failure Count | Count | `Resource Provider`, `Attach Type`, `Instrumentation Key`, `Runtime Version`, `Operating System`, `Language`, `Version` | -| Write Failure Count | Count | `Resource Provider`, `Attach Type`, `Instrumentation Key`, `Runtime Version`, `Operating System`, `Language`, `Version` | --## Firewall configuration --Metrics are sent to the following locations, to which outgoing connections must be opened in firewalls: --| Location | URL | -|-|-| -| Europe | `westeurope-5.in.applicationinsights.azure.com` | -| Outside of Europe | `westus-0.in.applicationinsights.azure.com` | --## Disable Statsbeat --### [Java](#tab/java) --> [!NOTE] -> Only nonessential Statsbeat can be disabled in Java. --To disable nonessential Statsbeat, add the following configuration to your config file: --```json -{ - "preview": { - "statsbeat": { - "disabled": "true" - } - } -} -``` --You can also disable this feature by setting the environment variable `APPLICATIONINSIGHTS_STATSBEAT_DISABLED` to `true`. This setting then takes precedence over `disabled`, which is specified in the JSON configuration. --### [Node](#tab/node) --Statsbeat is enabled by default. It can be disabled by setting the environment variable `APPLICATION_INSIGHTS_NO_STATSBEAT` to `true`. --### [Python](#tab/python) --Statsbeat is enabled by default. It can be disabled by setting the environment variable `APPLICATIONINSIGHTS_STATSBEAT_DISABLED_ALL` to `true`. -- |
| azure-monitor | Telemetry Channels | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/telemetry-channels.md | - Title: Telemetry channels in Application Insights | Microsoft Docs -description: How to customize telemetry channels in Application Insights SDKs for .NET and .NET Core. - Previously updated : 01/31/2024-----# Telemetry channels in Application Insights --Telemetry channels are an integral part of the [Application Insights SDKs](./app-insights-overview.md). They manage buffering and transmission of telemetry to the Application Insights service. The .NET and .NET Core versions of the SDKs have two built-in telemetry channels: `InMemoryChannel` and `ServerTelemetryChannel`. This article describes each channel and shows how to customize channel behavior. ---## What are telemetry channels? --Telemetry channels are responsible for buffering telemetry items and sending them to the Application Insights service, where they're stored for querying and analysis. A telemetry channel is any class that implements the [`Microsoft.ApplicationInsights.ITelemetryChannel`](/dotnet/api/microsoft.applicationinsights.channel.itelemetrychannel) interface. --The `Send(ITelemetry item)` method of a telemetry channel is called after all telemetry initializers and telemetry processors are called. So, any items dropped by a telemetry processor won't reach the channel. The `Send()` method doesn't ordinarily send the items to the back end instantly. Typically, it buffers them in memory and sends them in batches for efficient transmission. --[Live Metrics Stream](live-stream.md) also has a custom channel that powers the live streaming of telemetry. This channel is independent of the regular telemetry channel, and this document doesn't apply to it. --## Built-in telemetry channels --The Application Insights .NET and .NET Core SDKs ship with two built-in channels: --* `InMemoryChannel`: A lightweight channel that buffers items in memory until they're sent. Items are buffered in memory and flushed once every 30 seconds, or whenever 500 items are buffered. This channel offers minimal reliability guarantees because it doesn't retry sending telemetry after a failure. This channel also doesn't keep items on disk. So any unsent items are lost permanently upon application shutdown, whether it's graceful or not. This channel implements a `Flush()` method that can be used to force-flush any in-memory telemetry items synchronously. This channel is well suited for short-running applications where a synchronous flush is ideal. -- This channel is part of the larger Microsoft.ApplicationInsights NuGet package and is the default channel that the SDK uses when nothing else is configured. --* `ServerTelemetryChannel`: A more advanced channel that has retry policies and the capability to store data on a local disk. This channel retries sending telemetry if transient errors occur. This channel also uses local disk storage to keep items on disk during network outages or high telemetry volumes. Because of these retry mechanisms and local disk storage, this channel is considered more reliable. We recommend it for all production scenarios. This channel is the default for [ASP.NET](./asp-net.md) and [ASP.NET Core](./asp-net-core.md) applications that are configured according to the official documentation. This channel is optimized for server scenarios with long-running processes. The [`Flush()`](#which-channel-should-i-use) method that's implemented by this channel isn't synchronous. -- This channel is shipped as the Microsoft.ApplicationInsights.WindowsServer.TelemetryChannel NuGet package and is acquired automatically when you use either the Microsoft.ApplicationInsights.Web or Microsoft.ApplicationInsights.AspNetCore NuGet package. --## Configure a telemetry channel --You configure a telemetry channel by setting it to the active telemetry configuration. For ASP.NET applications, configuration involves setting the telemetry channel instance to `TelemetryConfiguration.Active` or by modifying `ApplicationInsights.config`. For ASP.NET Core applications, configuration involves adding the channel to the dependency injection container. --The following sections show examples of configuring the `StorageFolder` setting for the channel in various application types. `StorageFolder` is just one of the configurable settings. For the full list of configuration settings, see the [Configurable settings in channels](#configurable-settings-in-channels) section later in this article. --### Configuration by using ApplicationInsights.config for ASP.NET applications --The following section from [ApplicationInsights.config](configuration-with-applicationinsights-config.md) shows the `ServerTelemetryChannel` channel configured with `StorageFolder` set to a custom location: --```xml - <TelemetrySinks> - <Add Name="default"> - <TelemetryProcessors> - <!-- Telemetry processors omitted for brevity --> - </TelemetryProcessors> - <TelemetryChannel Type="Microsoft.ApplicationInsights.WindowsServer.TelemetryChannel.ServerTelemetryChannel, Microsoft.AI.ServerTelemetryChannel"> - <StorageFolder>d:\temp\applicationinsights</StorageFolder> - </TelemetryChannel> - </Add> - </TelemetrySinks> -``` --### Configuration in code for ASP.NET applications --The following code sets up a `ServerTelemetryChannel` instance with `StorageFolder` set to a custom location. Add this code at the beginning of the application, typically in the `Application_Start()` method in Global.aspx.cs. --```csharp -using Microsoft.ApplicationInsights.Extensibility; -using Microsoft.ApplicationInsights.WindowsServer.TelemetryChannel; -protected void Application_Start() -{ - var serverTelemetryChannel = new ServerTelemetryChannel(); - serverTelemetryChannel.StorageFolder = @"d:\temp\applicationinsights"; - serverTelemetryChannel.Initialize(TelemetryConfiguration.Active); - TelemetryConfiguration.Active.TelemetryChannel = serverTelemetryChannel; -} -``` --### Configuration in code for ASP.NET Core applications --Modify the `ConfigureServices` method of the `Startup.cs` class as shown here: --```csharp -using Microsoft.ApplicationInsights.Channel; -using Microsoft.ApplicationInsights.WindowsServer.TelemetryChannel; --public void ConfigureServices(IServiceCollection services) -{ - // This sets up ServerTelemetryChannel with StorageFolder set to a custom location. - services.AddSingleton(typeof(ITelemetryChannel), new ServerTelemetryChannel() {StorageFolder = @"d:\temp\applicationinsights" }); -- services.AddApplicationInsightsTelemetry(); -} --``` --> [!IMPORTANT] -> Configuring the channel by using `TelemetryConfiguration.Active` isn't supported for ASP.NET Core applications. --### Configuration in code for .NET/.NET Core console applications --For console apps, the code is the same for both .NET and .NET Core: --```csharp -var serverTelemetryChannel = new ServerTelemetryChannel(); -serverTelemetryChannel.StorageFolder = @"d:\temp\applicationinsights"; -serverTelemetryChannel.Initialize(TelemetryConfiguration.Active); -TelemetryConfiguration.Active.TelemetryChannel = serverTelemetryChannel; -``` --## Operational details of ServerTelemetryChannel --`ServerTelemetryChannel` stores arriving items in an in-memory buffer. The items are serialized, compressed, and stored into a `Transmission` instance once every 30 seconds, or when 500 items have been buffered. A single `Transmission` instance contains up to 500 items and represents a batch of telemetry that's sent over a single HTTPS call to the Application Insights service. --By default, a maximum of 10 `Transmission` instances can be sent in parallel. If telemetry is arriving at faster rates, or if the network or the Application Insights back end is slow, `Transmission` instances are stored in memory. The default capacity of this in-memory `Transmission` buffer is 5 MB. When the in-memory capacity has been exceeded, `Transmission` instances are stored on local disk up to a limit of 50 MB. --`Transmission` instances are stored on local disk also when there are network problems. Only those items that are stored on a local disk survive an application crash. They're sent whenever the application starts again. If network issues persist, `ServerTelemetryChannel` will use an exponential backoff logic ranging from 10 seconds to 1 hour before retrying to send telemetry. --## Configurable settings in channels --For the full list of configurable settings for each channel, see: --* [InMemoryChannel](https://github.com/microsoft/ApplicationInsights-dotnet/blob/develop/BASE/src/Microsoft.ApplicationInsights/Channel/InMemoryChannel.cs) -* [ServerTelemetryChannel](https://github.com/microsoft/ApplicationInsights-dotnet/blob/develop/BASE/src/ServerTelemetryChannel/ServerTelemetryChannel.cs) --Here are the most commonly used settings for `ServerTelemetryChannel`: --- `MaxTransmissionBufferCapacity`: The maximum amount of memory, in bytes, used by the channel to buffer transmissions in memory. When this capacity is reached, new items are stored directly to local disk. The default value is 5 MB. Setting a higher value leads to less disk usage, but remember that items in memory will be lost if the application crashes.-- `MaxTransmissionSenderCapacity`: The maximum number of `Transmission` instances that will be sent to Application Insights at the same time. The default value is 10. This setting can be configured to a higher number, which we recommend when a huge volume of telemetry is generated. High volume typically occurs during load testing or when sampling is turned off.-- `StorageFolder`: The folder that's used by the channel to store items to disk as needed. In Windows, either %LOCALAPPDATA% or %TEMP% is used if no other path is specified explicitly. In environments other than Windows, you must specify a valid location or telemetry won't be stored to local disk.--## Which channel should I use? --We recommend `ServerTelemetryChannel` for most production scenarios that involve long-running applications. The `Flush()` method implemented by `ServerTelemetryChannel` isn't synchronous. It also doesn't guarantee sending all pending items from memory or disk. --If you use this channel in scenarios where the application is about to shut down, introduce some delay after you call `Flush()`. The exact amount of delay that you might require isn't predictable. It depends on factors like how many items or `Transmission` instances are in memory, how many are on disk, how many are being transmitted to the back end, and whether the channel is in the middle of exponential back-off scenarios. --If you need to do a synchronous flush, use `InMemoryChannel`. --## Frequently asked questions --This section provides answers to common questions. --### Does the Application Insights channel guarantee telemetry delivery? If not, what are the scenarios in which telemetry can be lost? --The short answer is that none of the built-in channels offer a transaction-type guarantee of telemetry delivery to the back end. `ServerTelemetryChannel` is more advanced compared with `InMemoryChannel` for reliable delivery, but it also makes only a best-effort attempt to send telemetry. Telemetry can still be lost in several situations, including these common scenarios: --- Items in memory are lost when the application crashes.-- Telemetry is lost during extended periods of network problems. Telemetry is stored to local disk during network outages or when problems occur with the Application Insights back end. However, items older than 48 hours are discarded.-- The default disk locations for storing telemetry in Windows are %LOCALAPPDATA% or %TEMP%. These locations are typically local to the machine. If the application migrates physically from one location to another, any telemetry stored in the original location is lost.-- In Azure Web Apps on Windows, the default disk-storage location is D:\local\LocalAppData. This location isn't persisted. It's wiped out in app restarts, scale-outs, and other such operations, which leads to loss of any telemetry stored there. You can override the default and specify storage to a persisted location like D:\home. However, such persisted locations are served by remote storage and so can be slow.--Although less likely, it's also possible that the channel can cause duplicate telemetry items. This behavior occurs when `ServerTelemetryChannel` retries because of network failure or timeout, when the telemetry was delivered to the back end, but the response was lost because of network issues or there was a timeout. --### Does ServerTelemetryChannel work on systems other than Windows? --Although the name of its package and namespace includes "WindowsServer," this channel is supported on systems other than Windows, with the following exception. On systems other than Windows, the channel doesn't create a local storage folder by default. You must create a local storage folder and configure the channel to use it. After local storage has been configured, the channel works the same way on all systems. --> [!NOTE] -> With the release 2.15.0-beta3 and greater, local storage is now automatically created for Linux, Mac, and Windows. For non-Windows systems, the SDK will automatically create a local storage folder based on the following logic: -> -> - `${TMPDIR}`: If the `${TMPDIR}` environment variable is set, this location is used. -> - `/var/tmp`: If the previous location doesn't exist, we try `/var/tmp`. -> - `/tmp`: If both the previous locations don't exist, we try `tmp`. -> - If none of those locations exist, local storage isn't created and manual configuration is still required. For full implementation details, see [this GitHub repo](https://github.com/microsoft/ApplicationInsights-dotnet/pull/1860). --### Does the SDK create temporary local storage? Is the data encrypted at storage? --The SDK stores telemetry items in local storage during network problems or during throttling. This data isn't encrypted locally. --For Windows systems, the SDK automatically creates a temporary local folder in the %TEMP% or %LOCALAPPDATA% directory and restricts access to administrators and the current user only. --For systems other than Windows, no local storage is created automatically by the SDK, so no data is stored locally by default. --> [!NOTE] -> With the release 2.15.0-beta3 and greater, local storage is now automatically created for Linux, Mac, and Windows. -- You can create a storage directory yourself and configure the channel to use it. In this case, you're responsible for ensuring that the directory is secured. Read more about [data protection and privacy](/previous-versions/azure/azure-monitor/app/data-retention-privacy#does-the-sdk-create-temporary-local-storage). --## Open-source SDK -Like every SDK for Application Insights, channels are open source. Read and contribute to the code or report problems at [the official GitHub repo](https://github.com/Microsoft/ApplicationInsights-dotnet). --## Next steps --* [Sampling](./sampling.md) -* [SDK troubleshooting](./asp-net-troubleshoot-no-data.md) |
| azure-monitor | Transaction Search And Diagnostics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/transaction-search-and-diagnostics.md | - Title: Transaction Search and Diagnostics -description: This article explains Application Insights end-to-end transaction diagnostics and how to search and filter raw telemetry sent by your web app. - Previously updated : 11/16/2023----# Transaction Search and Diagnostics --Azure Monitor Application Insights offers Transaction Search for pinpointing specific telemetry items and Transaction Diagnostics for comprehensive end-to-end transaction analysis. --**Transaction Search**: This experience enables users to locate and examine individual telemetry items such as page views, exceptions, and web requests. Additionally, it offers the capability to view log traces and events coded into the application. It identifies performance issues and errors within the application. --**Transaction Diagnostics**: Quickly identify issues in components through comprehensive insight into end-to-end transaction details, including dependencies and exceptions. Access this feature via the Search interface by choosing an item from the search results. --## [Transaction Search](#tab/transaction-search) --Transaction search is a feature of [Application Insights](./app-insights-overview.md) that you use to find and explore individual telemetry items, such as page views, exceptions, or web requests. You can also view log traces and events that you code. --For more complex queries over your data, use [Log Analytics](../logs/log-analytics-tutorial.md). --## Where do you see Search? --You can find **Search** in the Azure portal or Visual Studio. --### In the Azure portal --You can open transaction search from the Application Insights **Overview** tab of your application. You can also select **Search** under **Investigate** on the left menu. ---Go to the **Event types** dropdown menu to see a list of telemetry items such as server requests, page views, and custom events you coded. The top of the **Results** list has a summary chart showing counts of events over time. --Back out of the dropdown menu or select **Refresh** to get new events. --### In Visual Studio --In Visual Studio, there's also an **Application Insights Search** window. It's most useful for displaying telemetry events generated by the application that you're debugging. But it can also show the events collected from your published app at the Azure portal. --Open the **Application Insights Search** window in Visual Studio: ---The **Application Insights Search** window has features similar to the web portal: ---The **Track Operation** tab is available when you open a request or a page view. An "operation" is a sequence of events associated with a single request or page view. For example, dependency calls, exceptions, trace logs, and custom events might be part of a single operation. The **Track Operation** tab shows graphically the timing and duration of these events in relation to the request or page view. --## Inspect individual items --Select any telemetry item to see key fields and related items. ---The end-to-end transaction details view opens. --## Filter event types --Open the **Event types** dropdown menu and choose the event types you want to see. If you want to restore the filters later, select **Reset**. --The event types are: --* **Trace**: [Diagnostic logs](./asp-net-trace-logs.md) including TrackTrace, log4Net, NLog, and System.Diagnostic.Trace calls. -* **Request**: HTTP requests received by your server application including pages, scripts, images, style files, and data. These events are used to create the request and response overview charts. -* **Page View**: [Telemetry sent by the web client](./javascript.md) used to create page view reports. -* **Custom Event**: If you inserted calls to `TrackEvent()` to [monitor usage](./api-custom-events-metrics.md), you can search them here. -* **Exception**: Uncaught [exceptions in the server](./asp-net-exceptions.md), and the exceptions that you log by using `TrackException()`. -* **Dependency**: [Calls from your server application](./asp-net-dependencies.md) to other services such as REST APIs or databases, and AJAX calls from your [client code](./javascript.md). -* **Availability**: Results of [availability tests](availability-overview.md) --## Filter on property values --You can filter events on the values of their properties. The available properties depend on the event types you selected. Select **Filter** :::image type="content" source="./media/search-and-transaction-diagnostics/filter-icon.png" lightbox="./media/search-and-transaction-diagnostics/filter-icon.png" alt-text="Filter icon"::: to start. --Choosing no values of a particular property has the same effect as choosing all values. It switches off filtering on that property. --Notice that the counts to the right of the filter values show how many occurrences there are in the current filtered set. --## Find events with the same property --To find all the items with the same property value, either enter it in the **Search** box or select the checkbox when you look through properties on the **Filter** tab. ---## Search the data --> [!NOTE] -> To write more complex queries, open [Logs (Analytics)](../logs/log-analytics-tutorial.md) at the top of the **Search** pane. -> --You can search for terms in any of the property values. This capability is useful if you write [custom events](./api-custom-events-metrics.md) with property values. --You might want to set a time range because searches over a shorter range are faster. ---Search for complete words, not substrings. Use quotation marks to enclose special characters. --| String | *Not* found | Found | -| | | | -| HomeController.About |`home`<br/>`controller`<br/>`out` | `homecontroller`<br/>`about`<br/>`"homecontroller.about"`| -|United States|`Uni`<br/>`ted`|`united`<br/>`states`<br/>`united AND states`<br/>`"united states"` --You can use the following search expressions: --| Sample query | Effect | -| | | -| `apple` |Find all events in the time range whose fields include the word `apple`. | -| `apple AND banana` <br/>`apple banana` |Find events that contain both words. Use capital `AND`, not `and`. <br/>Short form. | -| `apple OR banana` |Find events that contain either word. Use `OR`, not `or`. | -| `apple NOT banana` |Find events that contain one word but not the other. | --## Sampling --If your app generates significant telemetry and uses ASP.NET SDK version 2.0.0-beta3 or later, it automatically reduces the volume sent to the portal through adaptive sampling. This module sends only a representative fraction of events. It selects or deselects events related to the same request as a group, allowing you to navigate between related events. --Learn about [sampling](./sampling.md). --## Create work item --You can create a bug in GitHub or Azure DevOps with the details from any telemetry item. --Go to the end-to-end transaction detail view by selecting any telemetry item. Then select **Create work item**. ---The first time you do this step, you're asked to configure a link to your Azure DevOps organization and project. You can also configure the link on the **Work Items** tab. --## Send more telemetry to Application Insights --In addition to the out-of-the-box telemetry sent by Application Insights SDK, you can: --* Capture log traces from your favorite logging framework in [.NET](./asp-net-trace-logs.md) or [Java](./opentelemetry-add-modify.md?tabs=java#send-custom-telemetry-using-the-application-insights-classic-api). This means you can search through your log traces and correlate them with page views, exceptions, and other events. --* [Write code](./api-custom-events-metrics.md) to send custom events, page views, and exceptions. --Learn how to [send logs and custom telemetry to Application Insights](./asp-net-trace-logs.md). --## <a name="questions"></a>Frequently asked questions --Find answers to common questions. --### <a name="limits"></a>How much data is retained? --See the [Limits summary](../service-limits.md#application-insights). --### How can I see POST data in my server requests? --We don't log the POST data automatically, but you can use [TrackTrace or log calls](./asp-net-trace-logs.md). Put the POST data in the message parameter. You can't filter on the message in the same way you can filter on properties, but the size limit is longer. --### Why does my Azure Function search return no results? --Azure Functions doesn't log URL query strings. --## [Transaction Diagnostics](#tab/transaction-diagnostics) --The unified diagnostics experience automatically correlates server-side telemetry from across all your Application Insights monitored components into a single view. It doesn't matter if you have multiple resources. Application Insights detects the underlying relationship and allows you to easily diagnose the application component, dependency, or exception that caused a transaction slowdown or failure. --## What is a component? --Components are independently deployable parts of your distributed or microservice application. Developers and operations teams have code-level visibility or access to telemetry generated by these application components. --* Components are different from "observed" external dependencies, such as SQL and event hubs, which your team or organization might not have access to (code or telemetry). -* Components run on any number of server, role, or container instances. -* Components can be separate Application Insights instrumentation keys, even if subscriptions are different. Components also can be different roles that report to a single Application Insights instrumentation key. The new experience shows details across all components, regardless of how they were set up. --> [!NOTE] -> Are you missing the related item links? All the related telemetry is on the left side in the [top](#cross-component-transaction-chart) and [bottom](#all-telemetry-with-this-operation-id) sections. --## Transaction diagnostics experience --This view has four key parts: --- a results list-- a cross-component transaction chart-- a time-sequence list of all telemetry related to this operation-- the details pane for any selected telemetry item---## Cross-component transaction chart --This chart provides a timeline with horizontal bars during requests and dependencies across components. Any exceptions that are collected are also marked on the timeline. --- The top row on this chart represents the entry point. It's the incoming request to the first component called in this transaction. The duration is the total time taken for the transaction to complete.-- Any calls to external dependencies are simple noncollapsible rows, with icons that represent the dependency type.-- Calls to other components are collapsible rows. Each row corresponds to a specific operation invoked at the component.-- By default, the request, dependency, or exception that you selected appears to the side. Select any row to see its [details](#details-of-the-selected-telemetry).--> [!NOTE] -> Calls to other components have two rows. One row represents the outbound call (dependency) from the caller component. The other row corresponds to the inbound request at the called component. The leading icon and distinct styling of the duration bars help differentiate between them. --## All telemetry with this Operation ID --This section shows a flat list view in a time sequence of all the telemetry related to this transaction. It also shows the custom events and traces that aren't displayed in the transaction chart. You can filter this list to telemetry generated by a specific component or call. You can select any telemetry item in this list to see corresponding [details on the side](#details-of-the-selected-telemetry). ---## Details of the selected telemetry --This collapsible pane shows the detail of any selected item from the transaction chart or the list. **Show all** lists all the standard attributes that are collected. Any custom attributes are listed separately under the standard set. Select the ellipsis button (...) under the **Call Stack** trace window to get an option to copy the trace. **Open profiler traces** and **Open debug snapshot** show code-level diagnostics in corresponding detail panes. ---## Search results --This collapsible pane shows the other results that meet the filter criteria. Select any result to update the respective details of the preceding three sections. We try to find samples that are most likely to have the details available from all components, even if sampling is in effect in any of them. These samples are shown as suggestions. ---## Profiler and Snapshot Debugger --[Application Insights Profiler](./profiler.md) or [Snapshot Debugger](snapshot-debugger.md) help with code-level diagnostics of performance and failure issues. With this experience, you can see Profiler traces or snapshots from any component with a single selection. --If you can't get Profiler working, contact serviceprofilerhelp\@microsoft.com. --If you can't get Snapshot Debugger working, contact snapshothelp\@microsoft.com. ---## Frequently asked questions --This section provides answers to common questions. --### Why do I see a single component on the chart and the other components only show as external dependencies without any details? --Potential reasons: --* Are the other components instrumented with Application Insights? -* Are they using the latest stable Application Insights SDK? -* If these components are separate Application Insights resources, validate you have [access](../roles-permissions-security.md). -If you do have access and the components are instrumented with the latest Application Insights SDKs, let us know via the feedback channel in the upper-right corner. --### I see duplicate rows for the dependencies. Is this behavior expected? --Currently, we're showing the outbound dependency call separate from the inbound request. Typically, the two calls look identical with only the duration value being different because of the network round trip. The leading icon and distinct styling of the duration bars help differentiate between them. Is this presentation of the data confusing? Give us your feedback! --### What about clock skews across different component instances? --Timelines are adjusted for clock skews in the transaction chart. You can see the exact timestamps in the details pane or by using Log Analytics. --### Why is the new experience missing most of the related items queries? --This behavior is by design. All the related items, across all components, are already available on the left side in the top and bottom sections. The new experience has two related items that the left side doesn't cover: all telemetry from five minutes before and after this event and the user timeline. --### Is there a way to see fewer events per transaction when I use the Application Insights JavaScript SDK? --The transaction diagnostics experience shows all telemetry in a [single operation](distributed-trace-data.md#data-model-for-telemetry-correlation) that shares an [Operation ID](data-model-complete.md#operation-id). By default, the Application Insights SDK for JavaScript creates a new operation for each unique page view. In a single-page application (SPA), only one page view event is generated and a single Operation ID is used for all telemetry generated. As a result, many events might be correlated to the same operation. --In these scenarios, you can use Automatic Route Tracking to automatically create new operations for navigation in your SPA. You must turn on [enableAutoRouteTracking](javascript.md#single-page-applications) so that a page view is generated every time the URL route is updated (logical page view occurs). If you want to manually refresh the Operation ID, call `appInsights.properties.context.telemetryTrace.traceID = Microsoft.ApplicationInsights.Telemetry.Util.generateW3CId()`. Manually triggering a PageView event also resets the Operation ID. --### Why do transaction detail durations not add up to the top-request duration? --Time not explained in the Gantt chart is time that isn't covered by a tracked dependency. This issue can occur because external calls weren't instrumented, either automatically or manually. It can also occur because the time taken was in process rather than because of an external call. --If all calls were instrumented, in process is the likely root cause for the time spent. A useful tool for diagnosing the process is the [Application Insights profiler](./profiler.md). --### What if I see the message ***Error retrieving data*** while navigating Application Insights in the Azure portal? --This error indicates that the browser was unable to call into a required API or the API returned a failure response. To troubleshoot the behavior, open a browser [InPrivate window](https://support.microsoft.com/microsoft-edge/browse-inprivate-in-microsoft-edge-cd2c9a48-0bc4-b98e-5e46-ac40c84e27e2) and [disable any browser extensions](https://support.microsoft.com/microsoft-edge/add-turn-off-or-remove-extensions-in-microsoft-edge-9c0ec68c-2fbc-2f2c-9ff0-bdc76f46b026) that are running, then identify if you can still reproduce the portal behavior. If the portal error still occurs, try testing with other browsers, or other machines, investigate DNS or other network related issues from the client machine where the API calls are failing. If the portal error continues and needs more investigation, [collect a browser network trace](../../azure-portal/capture-browser-trace.md#capture-a-browser-trace-for-troubleshooting) while reproducing the unexpected portal behavior, then open a support case from the Azure portal. ----## See also --* [Write complex queries in Analytics](../logs/log-analytics-tutorial.md) -* [Send logs and custom telemetry to Application Insights](./asp-net-trace-logs.md) -* [Availability overview](availability-overview.md) |
| azure-monitor | Usage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/usage.md | - Title: Usage analysis with Application Insights | Azure Monitor -description: Understand your users and what they do with your application. - Previously updated : 07/16/2024----# Usage analysis with Application Insights --Which features of your web or mobile app are most popular? Do your users achieve their goals with your app? Do they drop out at particular points, and do they return later? --[Application Insights](./app-insights-overview.md) is a powerful tool for monitoring the performance and usage of your applications. It provides insights into how users interact with your app, identifies areas for improvement, and helps you understand the impact of changes. With this knowledge, you can make data-driven decisions about your next development cycles. --This article covers the following areas: --* [Users, Sessions & Events](#users-sessions-and-eventsanalyze-telemetry-from-three-perspectives) - Track and analyze user interaction with your application, session trends, and specific events to gain insights into user behavior and app performance. -* [Funnels](#funnelsdiscover-how-customers-use-your-application) - Understand how users progress through a series of steps in your application and where they might be dropping off. -* [User Flows](#user-flowsanalyze-user-navigation-patterns) - Visualize user paths to identify the most common routes and pinpointing areas where users are most engaged users or may encounter issues. -* [Cohorts](#cohortsanalyze-a-specific-set-of-users-sessions-events-or-operations) - Group users or events by common characteristics to analyze behavior patterns, feature usage, and the impact of changes over time. -* [Impact Analysis](#impact-analysisdiscover-how-different-properties-influence-conversion-rates) - Analyze how application performance metrics, like load times, influence user experience and behavior, to help you to prioritize improvements. -* [HEART](#heartfive-dimensions-of-customer-experience) - Utilize the HEART framework to measure and understand user Happiness, Engagement, Adoption, Retention, and Task success. --## Send telemetry from your application --To optimize your experience, consider integrating Application Insights into both your app server code and your webpages. This dual implementation enables telemetry collection from both the client and server components of your application. --1. **Server code:** Install the appropriate module for your [ASP.NET](./asp-net.md), [Azure](./app-insights-overview.md), [Java](./opentelemetry-enable.md?tabs=java), [Node.js](./nodejs.md), or [other](./app-insights-overview.md#supported-languages) app. -- If you don't want to install server code, [create an Application Insights resource](./create-workspace-resource.md). --1. **Webpage code:** Use the JavaScript SDK to collect data from webpages, see [Get started with the JavaScript SDK](./javascript-sdk.md). -- [!INCLUDE [azure-monitor-log-analytics-rebrand](~/reusable-content/ce-skilling/azure/includes/azure-monitor-instrumentation-key-deprecation.md)] -- To learn more advanced configurations for monitoring websites, check out the [JavaScript SDK reference article](./javascript.md). --1. **Mobile app code:** Use the App Center SDK to collect events from your app. Then send copies of these events to Application Insights for analysis by [following this guide](https://github.com/Microsoft/appcenter). --1. **Get telemetry:** Run your project in debug mode for a few minutes. Then look for results in the **Overview** pane in Application Insights. -- Publish your app to monitor your app's performance and find out what your users are doing with your app. --## Users, Sessions, and Events - Analyze telemetry from three perspectives --Three of the **Usage** panes use the same tool to slice and dice telemetry from your web app from three perspectives. By filtering and splitting the data, you can uncover insights about the relative use of different pages and features. --* **Users tool**: How many people used your app and its features? Users are counted by using anonymous IDs stored in browser cookies. A single person using different browsers or machines will be counted as more than one user. --* **Sessions tool**: How many sessions of user activity have included certain pages and features of your app? A session is reset after half an hour of user inactivity, or after 24 hours of continuous use. --* **Events tool**: How often are certain pages and features of your app used? A page view is counted when a browser loads a page from your app, provided you've [instrumented it](./javascript.md). -- A custom event represents one occurrence of something happening in your app. It's often a user interaction like a button selection or the completion of a task. You insert code in your app to [generate custom events](./api-custom-events-metrics.md#trackevent) or use the [Click Analytics](javascript-feature-extensions.md) extension. --> [!NOTE] -> For information on an alternatives to using [anonymous IDs](./data-model-complete.md#anonymous-user-id) and ensuring an accurate count, see the documentation for [authenticated IDs](./data-model-complete.md#authenticated-user-id). --Clicking **View More Insights** displays the following information: --* **Application Performance:** Sessions, Events, and a Performance evaluation related to users' perception of responsiveness. -* **Properties:** Charts containing up to six user properties such as browser version, country or region, and operating system. -* **Meet Your Users:** View timelines of user activity. --### Explore usage demographics and statistics --Find out when people use your web app, what pages they're most interested in, where your users are located, and what browsers and operating systems they use. Analyze business and usage telemetry by using Application Insights. ---* The **Users** report counts the numbers of unique users that access your pages within your chosen time periods. For web apps, users are counted by using cookies. If someone accesses your site with different browsers or client machines, or clears their cookies, they're counted more than once. --* The **Sessions** report tabulates the number of user sessions that access your site. A session represents a period of activity initiated by a user and concludes with a period of inactivity exceeding half an hour. --#### Query for certain users --Explore different groups of users by adjusting the query options at the top of the Users pane: --| Option | Description | -|--|-| -| During | Choose a time range. | -| Show | Choose a cohort of users to analyze. | -| Who used | Choose custom events, requests, and page views. | -| Events | Choose multiple events, requests, and page views that will show users who did at least one, not necessarily all, of the selected options. | -| By value x-axis | Choose how to categorize the data, either by time range or by another property, such as browser or city. | -| Split By | Choose a property to use to split or segment the data. | -| Add Filters | Limit the query to certain users, sessions, or events based on their properties, such as browser or city. | --#### Meet your users --The **Meet your users** section shows information about five sample users matched by the current query. Exploring the behaviors of individuals and in aggregate can provide insights about how people use your app. --### User retention analysis --The Application Insights retention feature provides valuable insights into user engagement by tracking the frequency and patterns of users returning to your app and their interactions with specific features. It enables you to compare user behaviors, such as the difference in return rates between users who win or lose a game, offering actionable data to enhance user experience and inform business strategies. --By analyzing cohorts of users based on their actions within a given timeframe, you can identify which features drive repeat usage. This knowledge can help you: --* Understand what specific features cause users to come back more than others. -* Determine whether retention is a problem in your product. -* Form hypotheses based on real user data to help you improve the user experience and your business strategy. ---You can use the retention controls on top to define specific events and time ranges to calculate retention. The graph in the middle gives a visual representation of the overall retention percentage by the time range specified. The graph on the bottom represents individual retention in a specific time period. This level of detail allows you to understand what your users are doing and what might affect returning users on a more detailed granularity. --For more information about the Retention workbook, see the section below. --#### The retention workbook --To use the retention workbook in Application Insights, navigate to the **Workbooks** pane, select **Public Templates** at the top, and locate the **User Retention Analysis** workbook listed under the **Usage** category. ---**Workbook capabilities:** --* By default, retention shows all users who did anything and then came back and did anything else over a defined period. You can select different combinations of events to narrow the focus on specific user activities. --* To add one or more filters on properties, select **Add Filters**. For example, you can focus on users in a particular country or region. --* The **Overall Retention** chart shows a summary of user retention across the selected time period. --* The grid shows the number of users retained. Each row represents a cohort of users who performed any event in the time period shown. Each cell in the row shows how many of that cohort returned at least once in a later period. Some users might return in more than one period. --* The insights cards show the top five initiating events and the top five returned events. This information gives users a better understanding of their retention report. -- :::image type="content" source="./media/usage-retention/retention-2.png" alt-text="Screenshot that shows the Retention workbook showing the User returned after number of weeks chart." lightbox="./media/usage-retention/retention-2.png"::: --#### Use business events to track retention --You should measure events that represent significant business activities to get the most useful retention analysis. --For more information and example code, see the section below. --### Track user interactions with custom events --To understand user interactions in your app, insert code lines to log custom events. These events track various user actions, like button selections, or important business events, such as purchases or game victories. --You can also use the [Click Analytics Autocollection plug-in](javascript-feature-extensions.md) to collect custom events. --> [!TIP] -> When you design each feature of your app, consider how you're going to measure its success with your users. Decide what business events you need to record, and code the tracking calls for those events into your app from the start. --In some cases, page views can represent useful events, but it isn't true in general. A user can open a product page without buying the product. --With specific business events, you can chart your users' progress through your site. You can find out their preferences for different options and where they drop out or have difficulties. With this knowledge, you can make informed decisions about the priorities in your development backlog. --Events can be logged from the client side of the app: --```javascript -appInsights.trackEvent({name: "incrementCount"}); -``` --Or events can be logged from the server side: --```csharp -var tc = new Microsoft.ApplicationInsights.TelemetryClient(); -tc.TrackEvent("CreatedAccount", new Dictionary<string,string> {"AccountType":account.Type}, null); -... -tc.TrackEvent("AddedItemToCart", new Dictionary<string,string> {"Item":item.Name}, null); -... -tc.TrackEvent("CompletedPurchase"); -``` --You can attach property values to these events so that you can filter or split the events when you inspect them in the portal. A standard set of properties is also attached to each event, such as anonymous user ID, which allows you to trace the sequence of activities of an individual user. --Learn more about [custom events](./api-custom-events-metrics.md#trackevent) and [properties](./api-custom-events-metrics.md#properties). --#### Slice and dice events --In the Users, Sessions, and Events tools, you can slice and dice custom events by user, event name, and properties. ---Whenever youΓÇÖre in any usage experience, select the **Open the last run query** icon to take you back to the underlying query. ---You can then modify the underlying query to get the kind of information youΓÇÖre looking for. --HereΓÇÖs an example of an underlying query about page views. Go ahead and paste it directly into the query editor to test it out. --```kusto -// average pageView duration by name -let timeGrain=5m; -let dataset=pageViews -// additional filters can be applied here -| where timestamp > ago(1d) -| where client_Type == "Browser" ; -// calculate average pageView duration for all pageViews -dataset -| summarize avg(duration) by bin(timestamp, timeGrain) -| extend pageView='Overall' -// render result in a chart -| render timechart -``` --### Determine feature success with A/B testing --If you're unsure which feature variant is more successful, release both and let different users access each variant. Measure the success of each variant, and then transition to a unified version. --In this technique, you attach unique property values to all the telemetry sent by each version of your app. You can do it by defining properties in the active TelemetryContext. These default properties get included in every telemetry message sent by the application. It includes both custom messages and standard telemetry. --In the Application Insights portal, filter and split your data on the property values so that you can compare the different versions. --To do this step, [set up a telemetry initializer](./api-filtering-sampling.md#addmodify-properties-itelemetryinitializer): --```csharp -// Telemetry initializer class -public class MyTelemetryInitializer : ITelemetryInitializer -{ - // In this example, to differentiate versions, we use the value specified in the AssemblyInfo.cs - // for ASP.NET apps, or in your project file (.csproj) for the ASP.NET Core apps. Make sure that - // you set a different assembly version when you deploy your application for A/B testing. - static readonly string _version = - System.Reflection.Assembly.GetExecutingAssembly().GetName().Version.ToString(); - - public void Initialize(ITelemetry item) - { - item.Context.Component.Version = _version; - } -} -``` --#### [.NET Core](#tab/aspnetcore) --For [ASP.NET Core](asp-net-core.md#add-telemetryinitializers) applications, add a new telemetry initializer to the Dependency Injection service collection in the `Program.cs` class: --```csharp -using Microsoft.ApplicationInsights.Extensibility; --builder.Services.AddSingleton<ITelemetryInitializer, MyTelemetryInitializer>(); -``` --#### [.NET Framework 4.8](#tab/aspnet-framework) --In the web app initializer, such as `Global.asax.cs`: --```csharp -protected void Application_Start() -{ - // ... - TelemetryConfiguration.Active.TelemetryInitializers - .Add(new MyTelemetryInitializer()); -} -``` ----## Funnels - Discover how customers use your application --Understanding the customer experience is of great importance to your business. If your application involves multiple stages, you need to know if customers are progressing through the entire process or ending the process at some point. The progression through a series of steps in a web application is known as a *funnel*. You can use Application Insights funnels to gain insights into your users and monitor step-by-step conversion rates. --**Funnel features:** --* If your app is sampled, you'll see a banner. Selecting it opens a context pane that explains how to turn off sampling. -* Select a step to see more details on the right. -* The historical conversion graph shows the conversion rates over the last 90 days. -* Understand your users better by accessing the users tool. You can use filters in each step. --### Create a funnel --#### Prerequisites --Before you create a funnel, decide on the question you want to answer. For example, you might want to know how many users view the home page, view a customer profile, and create a ticket. --#### Get started --To create a funnel: --1. On the **Funnels** tab, select **Edit**. --1. Choose your **Top Step**. -- :::image type="content" source="./media/usage-funnels/funnel.png" alt-text="Screenshot that shows the Funnel tab and selecting steps on the Edit tab." lightbox="./media/usage-funnels/funnel.png"::: --1. To apply filters to the step, select **Add filters**. This option appears after you choose an item for the top step. --1. Then choose your **Second Step** and so on. -- > [!NOTE] - > Funnels are limited to a maximum of six steps. --1. Select the **View** tab to see your funnel results. -- :::image type="content" source="./media/usage-funnels/funnel-2.png" alt-text="Screenshot that shows the Funnels View tab that shows results from the top and second steps." lightbox="./media/usage-funnels/funnel-2.png"::: --1. To save your funnel to view at another time, select **Save** at the top. Use **Open** to open your saved funnels. --## User Flows - Analyze user navigation patterns ---The User Flows tool visualizes how users move between the pages and features of your site. It's great for answering questions like: --* How do users move away from a page on your site? -* What do users select on a page on your site? -* Where are the places that users churn most from your site? -* Are there places where users repeat the same action over and over? --The User Flows tool starts from an initial custom event, exception, dependency, page view or request that you specify. From this initial event, User Flows shows the events that happened before and after user sessions. Lines of varying thickness show how many times users followed each path. Special **Session Started** nodes show where the subsequent nodes began a session. **Session Ended** nodes show how many users sent no page views or custom events after the preceding node, highlighting where users probably left your site. --> [!NOTE] -> Your Application Insights resource must contain page views or custom events to use the User Flows tool. [Learn how to set up your app to collect page views automatically with the Application Insights JavaScript SDK](./javascript.md). --### Choose an initial event ---To begin answering questions with the User Flows tool, choose an initial custom event, exception, dependency, page view or request to serve as the starting point for the visualization: --1. Select the link in the **What do users do after?** title or select **Edit**. -1. Select a custom event, exception, dependency, page view or request from the **Initial event** dropdown list. -1. Select **Create graph**. --The **Step 1** column of the visualization shows what users did most frequently after the initial event. The items are ordered from top to bottom and from most to least frequent. The **Step 2** and subsequent columns show what users did next. The information creates a picture of all the ways that users moved through your site. --By default, the User Flows tool randomly samples only the last 24 hours of page views and custom events from your site. You can increase the time range and change the balance of performance and accuracy for random sampling on the **Edit** menu. --If some of the page views, custom events, and exceptions aren't relevant to you, select **X** on the nodes you want to hide. After you've selected the nodes you want to hide, select **Create graph**. To see all the nodes you've hidden, select **Edit** and look at the **Excluded events** section. --If page views or custom events you expect to see in the visualization are missing that: --* Check the **Excluded events** section on the **Edit** menu. -* Use the plus buttons on **Others** nodes to include less-frequent events in the visualization. -* If the page view or custom event you expect is sent infrequently by users, increase the time range of the visualization on the **Edit** menu. -* Make sure the custom event, exception, dependency, page view or request you expect is set up to be collected by the Application Insights SDK in the source code of your site. --If you want to see more steps in the visualization, use the **Previous steps** and **Next steps** dropdown lists above the visualization. --### After users visit a page or feature, where do they go and what do they select? ---If your initial event is a page view, the first column (**Step 1**) of the visualization is a quick way to understand what users did immediately after they visited the page. --Open your site in a window next to the User Flows visualization. Compare your expectations of how users interact with the page to the list of events in the **Step 1** column. Often, a UI element on the page that seems insignificant to your team can be among the most used on the page. It can be a great starting point for design improvements to your site. --If your initial event is a custom event, the first column shows what users did after they performed that action. As with page views, consider if the observed behavior of your users matches your team's goals and expectations. --If your selected initial event is **Added Item to Shopping Cart**, for example, look to see if **Go to Checkout** and **Completed Purchase** appear in the visualization shortly thereafter. If user behavior is different from your expectations, use the visualization to understand how users are getting "trapped" by your site's current design. --### Where are the places that users churn most from your site? --Watch for **Session Ended** nodes that appear high up in a column in the visualization, especially early in a flow. This positioning means many users probably churned from your site after they followed the preceding path of pages and UI interactions. --Sometimes churn is expected. For example, it's expected after a user makes a purchase on an e-commerce site. But usually churn is a sign of design problems, poor performance, or other issues with your site that can be improved. --Keep in mind that **Session Ended** nodes are based only on telemetry collected by this Application Insights resource. If Application Insights doesn't receive telemetry for certain user interactions, users might have interacted with your site in those ways after the User Flows tool says the session ended. --### Are there places where users repeat the same action over and over? --Look for a page view or custom event that's repeated by many users across subsequent steps in the visualization. This activity usually means that users are performing repetitive actions on your site. If you find repetition, think about changing the design of your site or adding new functionality to reduce repetition. For example, you might add bulk edit functionality if you find users performing repetitive actions on each row of a table element. --## Cohorts - Analyze a specific set of users, sessions, events, or operations --A cohort is a set of users, sessions, events, or operations that have something in common. In Application Insights, cohorts are defined by an analytics query. In cases where you have to analyze a specific set of users or events repeatedly, cohorts can give you more flexibility to express exactly the set you're interested in. --### Cohorts vs basic filters --You can use cohorts in ways similar to filters. But cohorts' definitions are built from custom analytics queries, so they're much more adaptable and complex. Unlike filters, you can save cohorts so that other members of your team can reuse them. --You might define a cohort of users who have all tried a new feature in your app. You can save this cohort in your Application Insights resource. It's easy to analyze this saved group of specific users in the future. --> [!NOTE] -> After cohorts are created, they're available from the Users, Sessions, Events, and User Flows tools. --### Example: Engaged users --Your team defines an engaged user as anyone who uses your app five or more times in a given month. In this section, you define a cohort of these engaged users. --1. Select **Create a Cohort**. --1. Select the **Template Gallery** tab to see a collection of templates for various cohorts. --1. Select **Engaged Users -- by Days Used**. -- There are three parameters for this cohort: - * **Activities**: Where you choose which events and page views count as usage. - * **Period**: The definition of a month. - * **UsedAtLeastCustom**: The number of times users need to use something within a period to count as engaged. --1. Change **UsedAtLeastCustom** to **5+ days**. Leave **Period** set as the default of 28 days. -- Now this cohort represents all user IDs sent with any custom event or page view on 5 separate days in the past 28 days. --1. Select **Save**. -- > [!TIP] - > Give your cohort a name, like *Engaged Users (5+ Days)*. Save it to *My reports* or *Shared reports*, depending on whether you want other people who have access to this Application Insights resource to see this cohort. --1. Select **Back to Gallery**. --#### What can you do by using this cohort? --Open the Users tool. In the **Show** dropdown box, choose the cohort you created under **Users who belong to**. ---Important points to notice: --* You can't create this set through normal filters. The date logic is more advanced. -* You can further filter this cohort by using the normal filters in the Users tool. Although the cohort is defined on 28-day windows, you can still adjust the time range in the Users tool to be 30, 60, or 90 days. --These filters support more sophisticated questions that are impossible to express through the query builder. An example is *people who were engaged in the past 28 days. How did those same people behave over the past 60 days?* --### Example: Events cohort --You can also make cohorts of events. In this section, you define a cohort of events and page views. Then you see how to use them from the other tools. This cohort might define a set of events that your team considers *active usage* or a set related to a certain new feature. --1. Select **Create a Cohort**. -1. Select the **Template Gallery** tab to see a collection of templates for various cohorts. -1. Select **Events Picker**. -1. In the **Activities** dropdown box, select the events you want to be in the cohort. -1. Save the cohort and give it a name. --### Example: Active users where you modify a query --The previous two cohorts were defined by using dropdown boxes. You can also define cohorts by using analytics queries for total flexibility. To see how, create a cohort of users from the United Kingdom. --1. Open the Cohorts tool, select the **Template Gallery** tab, and select **Blank Users cohort**. -- :::image type="content" source="./media/usage-cohorts/cohort.png" alt-text="Screenshot that shows the template gallery for cohorts." lightbox="./media/usage-cohorts/cohort.png"::: -- There are three sections: -- * **Markdown text**: Where you describe the cohort in more detail for other members on your team. - * **Parameters**: Where you make your own parameters, like **Activities**, and other dropdown boxes from the previous two examples. - * **Query**: Where you define the cohort by using an analytics query. -- In the query section, you [write an analytics query](/azure/kusto/query). The query selects the certain set of rows that describe the cohort you want to define. The Cohorts tool then implicitly adds a `| summarize by user_Id` clause to the query. This data appears as a preview underneath the query in a table, so you can make sure your query is returning results. -- > [!NOTE] - > If you don't see the query, resize the section to make it taller and reveal the query. --1. Copy and paste the following text into the query editor: -- ```KQL - union customEvents, pageViews - | where client_CountryOrRegion == "United Kingdom" - ``` --1. Select **Run Query**. If you don't see user IDs appear in the table, change to a country/region where your application has users. --1. Save and name the cohort. --## Impact Analysis - Discover how different properties influence conversion rates --Impact Analysis discovers how any dimension of a page view, custom event, or request affects the usage of a different page view or custom event. --One way to think of Impact is as the ultimate tool for settling arguments with someone on your team about how slowness in some aspect of your site is affecting whether users stick around. Users might tolerate some slowness, but Impact gives you insight into how best to balance optimization and performance to maximize user conversion. --Analyzing performance is only a subset of Impact's capabilities. Impact supports custom events and dimensions, so you can easily answer questions like, How does user browser choice correlate with different rates of conversion? --> [!NOTE] -> Your Application Insights resource must contain page views or custom events to use the Impact analysis workbook. Learn how to [set up your app to collect page views automatically with the Application Insights JavaScript SDK](./javascript.md). Also, because you're analyzing correlation, sample size matters. --### Impact analysis workbook --To use the Impact analysis workbook, in your Application Insights resources go to **Usage** > **More** and select **User Impact Analysis Workbook**. Or on the **Workbooks** tab, select **Public Templates**. Then under **Usage**, select **User Impact Analysis**. ---#### Use the workbook ---1. From the **Selected event** dropdown list, select an event. -1. From the **analyze how its** dropdown list, select a metric. -1. From the **Impacting event** dropdown list, select an event. -1. To add a filter, use the **Add selected event filters** tab or the **Add impacting event filters** tab. --### Is page load time affecting how many people convert on my page? --To begin answering questions with the Impact workbook, choose an initial page view, custom event, or request. --1. From the **Selected event** dropdown list, select an event. --1. Leave the **analyze how its** dropdown list on the default selection of **Duration**. (In this context, **Duration** is an alias for **Page Load Time**.) --1. From the **Impacting event** dropdown list, select a custom event. This event should correspond to a UI element on the page view you selected in step 1. -- :::image type="content" source="./media/usage-impact/impact.png" alt-text="Screenshot that shows an example with the selected event as Home Page analyzed by duration." lightbox="./media/usage-impact/impact.png"::: --### What if I'm tracking page views or load times in custom ways? --Impact supports both standard and custom properties and measurements. Use whatever you want. Instead of duration, use filters on the primary and secondary events to get more specific. --### Do users from different countries or regions convert at different rates? --1. From the **Selected event** dropdown list, select an event. --1. From the **analyze how its** dropdown list, select **Country or region**. --1. From the **Impacting event** dropdown list, select a custom event that corresponds to a UI element on the page view you chose in step 1. -- :::image type="content" source="./media/usage-impact/regions.png" alt-text="Screenshot that shows an example with the selected event as GET analyzed by country and region." lightbox="./media/usage-impact/regions.png"::: --### How does the Impact analysis workbook calculate these conversion rates? --Under the hood, the Impact analysis workbook relies on the [Pearson correlation coefficient](https://en.wikipedia.org/wiki/Pearson_correlation_coefficient). Results are computed between -1 and 1. The coefficient -1 represents a negative linear correlation and 1 represents a positive linear correlation. --The basic breakdown of how Impact analysis works is listed here: --* Let *A* = the main page view, custom event, or request you select in the **Selected event** dropdown list. -* Let *B* = the secondary page view or custom event you select in the **impacts the usage of** dropdown list. --Impact looks at a sample of all the sessions from users in the selected time range. For each session, it looks for each occurrence of *A*. --Sessions are then broken into two different kinds of *subsessions* based on one of two conditions: --* A converted subsession consists of a session ending with a *B* event and encompasses all *A* events that occur prior to *B*. -* An unconverted subsession occurs when all *A*s occur without a terminal *B*. --How Impact is ultimately calculated varies based on whether we're analyzing by metric or by dimension. For metrics, all *A*s in a subsession are averaged. For dimensions, the value of each *A* contributes *1/N* to the value assigned to *B*, where *N* is the number of *A*s in the subsession. --## HEART - Five dimensions of customer experience --This article describes how to enable and use the Heart Workbook on Azure Monitor. The HEART workbook is based on the HEART measurement framework, which was originally introduced by Google. Several Microsoft internal teams use HEART to deliver better software. --### Overview --HEART is an acronym that stands for happiness, engagement, adoption, retention, and task success. It helps product teams deliver better software by focusing on five dimensions of customer experience: --* **Happiness**: Measure of user attitude -* **Engagement**: Level of active user involvement -* **Adoption**: Target audience penetration -* **Retention**: Rate at which users return -* **Task success**: Productivity empowerment --These dimensions are measured independently, but they interact with each other. ---* Adoption, engagement, and retention form a user activity funnel. Only a portion of users who adopt the tool come back to use it. --* Task success is the driver that progresses users down the funnel and moves them from adoption to retention. --* Happiness is an outcome of the other dimensions and not a stand-alone measurement. Users who have progressed down the funnel and are showing a higher level of activity are ideally happier. --### Get started --#### Prerequisites --* **Azure subscription**: [Create an Azure subscription for free](https://azure.microsoft.com/free/) --* **Application Insights resource**: [Create an Application Insights resource](create-workspace-resource.md#create-a-workspace-based-resource) --* **Click Analytics**: Set up the [Click Analytics Autocollection plug-in](javascript-feature-extensions.md). --* **Specific attributes**: Instrument the following attributes to calculate HEART metrics. -- | Source | Attribute | Description | - |-|-|--| - | customEvents | session_Id | Unique session identifier | - | customEvents | appName | Unique Application Insights app identifier | - | customEvents | itemType | Category of customEvents record | - | customEvents | timestamp | Datetime of event | - | customEvents | operation_Id | Correlate telemetry events | - | customEvents | user_Id | Unique user identifier | - | customEvents ┬╣ | parentId | Name of feature | - | customEvents ┬╣ | pageName | Name of page | - | customEvents ┬╣ | actionType | Category of Click Analytics record | - | pageViews | user_AuthenticatedId | Unique authenticated user identifier | - | pageViews | session_Id | Unique session identifier | - | pageViews | appName | Unique Application Insights app identifier | - | pageViews | timestamp | Datetime of event | - | pageViews | operation_Id | Correlate telemetry events | - | pageViews | user_Id | Unique user identifier | --* If you're setting up the authenticated user context, instrument the below attributes: --| Source | Attribute | Description | -|--|-|--| -| customEvents | user_AuthenticatedId | Unique authenticated user identifier | --**Footnotes** --┬╣: To emit these attributes, use the [Click Analytics Autocollection plug-in](javascript-feature-extensions.md) via npm. -->[!TIP] -> To understand how to effectively use the Click Analytics plug-in, see [Feature extensions for the Application Insights JavaScript SDK (Click Analytics)](javascript-feature-extensions.md#use-the-plug-in). --#### Open the workbook --You can find the workbook in the gallery under **Public Templates**. The workbook appears in the section **Product Analytics using the Click Analytics Plugin**. ---There are seven workbooks. ---You only have to interact with the main workbook, **HEART Analytics - All Sections**. This workbook contains the other six workbooks as tabs. You can also access the individual workbooks related to each tab through the gallery. --#### Confirm that data is flowing --To validate that data is flowing as expected to light up the metrics accurately, select the **Development Requirements** tab. --> [!IMPORTANT] -> Unless you [set the authenticated user context](./javascript-feature-extensions.md#optional-set-the-authenticated-user-context), you must select **Anonymous Users** from the **ConversionScope** dropdown to see telemetry data. ---If data isn't flowing as expected, this tab shows the specific attributes with issues. ---### Workbook structure --The workbook shows metric trends for the HEART dimensions split over seven tabs. Each tab contains descriptions of the dimensions, the metrics contained within each dimension, and how to use them. --The tabs are: --* **Summary**: Summarizes usage funnel metrics for a high-level view of visits, interactions, and repeat usage. -* **Adoption**: Helps you understand the penetration among the target audience, acquisition velocity, and total user base. -* **Engagement**: Shows frequency, depth, and breadth of usage. -* **Retention**: Shows repeat usage. -* **Task success**: Enables understanding of user flows and their time distributions. -* **Happiness**: We recommend using a survey tool to measure customer satisfaction score (CSAT) over a five-point scale. On this tab, we've provided the likelihood of happiness via usage and performance metrics. -* **Feature metrics**: Enables understanding of HEART metrics at feature granularity. --> [!WARNING] -> The HEART workbook is currently built on logs and effectively are [log-based metrics](pre-aggregated-metrics-log-metrics.md). The accuracy of these metrics are negatively affected by sampling and filtering. --### How HEART dimensions are defined and measured --#### Happiness --Happiness is a user-reported dimension that measures how users feel about the product offered to them. --A common approach to measure happiness is to ask users a CSAT question like How satisfied are you with this product? Users' responses on a three- or a five-point scale (for example, *no, maybe,* and *yes*) are aggregated to create a product-level score that ranges from 1 to 5. Because user-initiated feedback tends to be negatively biased, HEART tracks happiness from surveys displayed to users at predefined intervals. --Common happiness metrics include values such as **Average Star Rating** and **Customer Satisfaction Score**. Send these values to Azure Monitor by using one of the custom ingestion methods described in [Custom sources](../data-sources.md#custom-sources). --#### Engagement --Engagement is a measure of user activity. Specifically, user actions are intentional, such as clicks. Active usage can be broken down into three subdimensions: --* **Activity frequency**: Measures how often a user interacts with the product. For example, users typically interact daily, weekly, or monthly. --* **Activity breadth**: Measures the number of features users interact with over a specific time period. For example, users interacted with a total of five features in June 2021. --* **Activity depth**: Measures the number of features users interact with each time they launch the product. For example, users interacted with two features on every launch. --Measuring engagement can vary based on the type of product being used. For example, a product like Microsoft Teams is expected to have a high daily usage, which makes it an important metric to track. But for a product like a paycheck portal, measurement might make more sense at a monthly or weekly level. -->[!IMPORTANT] ->A user who performs an intentional action, such as clicking a button or typing an input, is counted as an active user. For this reason, engagement metrics require the [Click Analytics plug-in for Application Insights](javascript-feature-extensions.md) to be implemented in the application. --#### Adoption --Adoption enables understanding of penetration among the relevant users, who you're gaining as your user base, and how you're gaining them. Adoption metrics are useful for measuring: --* Newly released products. -* Newly updated products. -* Marketing campaigns. --#### Retention --A retained user is a user who was active in a specified reporting period and its previous reporting period. Retention is typically measured with the following metrics. --| Metric | Definition | Question answered | -|-|-|-| -| Retained users | Count of active users who were also active the previous period | How many users are staying engaged with the product? | -| Retention | Proportion of active users from the previous period who are also active this period | What percent of users are staying engaged with the product? | -->[!IMPORTANT] ->Because active users must have at least one telemetry event with an action type, retention metrics require the [Click Analytics plug-in for Application Insights](javascript-feature-extensions.md) to be implemented in the application. --#### Task success --Task success tracks whether users can do a task efficiently and effectively by using the product's features. Many products include structures that are designed to funnel users through completing a task. Some examples include: --* Adding items to a cart and then completing a purchase. -* Searching a keyword and then selecting a result. -* Starting a new account and then completing account registration. --A successful task meets three requirements: --* **Expected task flow**: The intended task flow of the feature was completed by the user and aligns with the expected task flow. -* **High performance**: The intended functionality of the feature was accomplished in a reasonable amount of time. -* **High reliability**: The intended functionality of the feature was accomplished without failure. --A task is considered unsuccessful if any of the preceding requirements isn't met. -->[!IMPORTANT] ->Task success metrics require the [Click Analytics plug-in for Application Insights](javascript-feature-extensions.md) to be implemented in the application. --Set up a custom task by using the following parameters. --| Parameter | Description | -||| -| First step | The feature that starts the task. In the cart/purchase example, **Adding items to a cart** is the first step. | -| Expected task duration | The time window to consider a completed task a success. Any tasks completed outside of this constraint are considered a failure. Not all tasks necessarily have a time constraint. For such tasks, select **No Time Expectation**. | -| Last step | The feature that completes the task. In the cart/purchase example, **Purchasing items from the cart** is the last step. | --## Frequently asked questions --### Does the initial event represent the first time the event appears in a session or any time it appears in a session? --The initial event on the visualization only represents the first time a user sent that page view or custom event during a session. If users can send the initial event multiple times in a session, then the **Step 1** column only shows how users behave after the *first* instance of an initial event, not all instances. --### Some of the nodes in my visualization have a level that's too high. How can I get more detailed nodes? --Use the **Split by** options on the **Edit** menu: --1. Select the event you want to break down on the **Event** menu. --1. Select a dimension on the **Dimension** menu. For example, if you have an event called **Button Clicked**, try a custom property called **Button Name**. --### I defined a cohort of users from a certain country/region. When I compare this cohort in the Users tool to setting a filter on that country/region, why do I see different results? --Cohorts and filters are different. Suppose you have a cohort of users from the United Kingdom (defined like the previous example), and you compare its results to setting the filter `Country or region = United Kingdom`: --* The cohort version shows all events from users who sent one or more events from the United Kingdom in the current time range. If you split by country or region, you likely see many countries and regions. --* The filters version only shows events from the United Kingdom. If you split by country or region, you see only the United Kingdom. --### How do I view the data at different grains (daily, monthly, or weekly)? --You can select the **Date Grain** filter to change the grain. The filter is available across all the dimension tabs. ---### How do I access insights from my application that aren't available on the HEART workbooks? --You can dig into the data that feeds the HEART workbook if the visuals don't answer all your questions. To do this task, under the **Monitoring** section, select **Logs** and query the `customEvents` table. Some of the Click Analytics attributes are contained within the `customDimensions` field. A sample query is shown here. ---To learn more about Logs in Azure Monitor, see [Azure Monitor Logs overview](../logs/data-platform-logs.md). --### Can I edit visuals in the workbook? --Yes. When you select the public template of the workbook: --1. Select **Edit** and make your changes. -- :::image type="content" source="media/usage-overview/workbook-edit-faq.png" alt-text="Screenshot that shows the Edit button in the upper-left corner of the workbook template."::: --1. After you make your changes, select **Done Editing**, and then select the **Save** icon. -- :::image type="content" source="media/usage-overview/workbook-save-faq.png" alt-text="Screenshot that shows the Save icon at the top of the workbook template that becomes available after you make edits."::: --1. To view your saved workbook, under **Monitoring**, go to the **Workbooks** section and then select the **Workbooks** tab. A copy of your customized workbook appears there. You can make any further changes you want in this copy. -- :::image type="content" source="media/usage-overview/workbook-view-faq.png" alt-text="Screenshot that shows the Workbooks tab next to the Public Templates tab, where the edited copy of the workbook is located."::: --For more on editing workbook templates, see [Azure Workbooks templates](../visualize/workbooks-templates.md). --## Next steps --* Check out the [GitHub repository](https://github.com/microsoft/ApplicationInsights-JS/tree/master/extensions/applicationinsights-clickanalytics-js) and [npm Package](https://www.npmjs.com/package/@microsoft/applicationinsights-clickanalytics-js) for the Click Analytics Autocollection plug-in. -* Learn more about the [Google HEART framework](https://storage.googleapis.com/pub-tools-public-publication-data/pdf/36299.pdf). -* To learn more about workbooks, see the [Workbooks overview](../visualize/workbooks-overview.md). |
| azure-monitor | Worker Service | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/app/worker-service.md | - Title: Application Insights for Worker Service apps (non-HTTP apps) -description: Monitoring .NET Core/.NET Framework non-HTTP apps with Azure Monitor Application Insights. -- Previously updated : 01/31/2024----# Application Insights for Worker Service applications (non-HTTP applications) --[Application Insights SDK for Worker Service](https://www.nuget.org/packages/Microsoft.ApplicationInsights.WorkerService) is a new SDK, which is best suited for non-HTTP workloads like messaging, background tasks, and console applications. These types of applications don't have the notion of an incoming HTTP request like a traditional ASP.NET/ASP.NET Core web application. For this reason, using Application Insights packages for [ASP.NET](asp-net.md) or [ASP.NET Core](asp-net-core.md) applications isn't supported. ---The new SDK doesn't do any telemetry collection by itself. Instead, it brings in other well-known Application Insights auto collectors like [DependencyCollector](https://www.nuget.org/packages/Microsoft.ApplicationInsights.DependencyCollector/), [PerfCounterCollector](https://www.nuget.org/packages/Microsoft.ApplicationInsights.PerfCounterCollector/), and [ApplicationInsightsLoggingProvider](https://www.nuget.org/packages/Microsoft.Extensions.Logging.ApplicationInsights). This SDK exposes extension methods on `IServiceCollection` to enable and configure telemetry collection. --## Supported scenarios --The [Application Insights SDK for Worker Service](https://www.nuget.org/packages/Microsoft.ApplicationInsights.WorkerService) is best suited for non-HTTP applications no matter where or how they run. If your application is running and has network connectivity to Azure, telemetry can be collected. Application Insights monitoring is supported everywhere .NET Core is supported. This package can be used in the newly introduced [.NET Core Worker Service](https://devblogs.microsoft.com/aspnet/dotnet-core-workers-in-azure-container-instances), [background tasks in ASP.NET Core](/aspnet/core/fundamentals/host/hosted-services), and console apps like .NET Core and .NET Framework. --## Prerequisites --You must have a valid Application Insights connection string. This string is required to send any telemetry to Application Insights. If you need to create a new Application Insights resource to get a connection string, see [Connection Strings](./sdk-connection-string.md). ---## Use Application Insights SDK for Worker Service --1. Install the [Microsoft.ApplicationInsights.WorkerService](https://www.nuget.org/packages/Microsoft.ApplicationInsights.WorkerService) package to the application. - The following snippet shows the changes that must be added to your project's `.csproj` file: - - ```xml - <ItemGroup> - <PackageReference Include="Microsoft.ApplicationInsights.WorkerService" Version="2.22.0" /> - </ItemGroup> - ``` --1. Configure the connection string in the `APPLICATIONINSIGHTS_CONNECTION_STRING` environment variable or in configuration (`appsettings.json`). -- :::image type="content" source="media/migrate-from-instrumentation-keys-to-connection-strings/migrate-from-instrumentation-keys-to-connection-strings.png" alt-text="Screenshot displaying Application Insights overview and connection string." lightbox="media/migrate-from-instrumentation-keys-to-connection-strings/migrate-from-instrumentation-keys-to-connection-strings.png"::: --1. Retrieve an `ILogger` instance or `TelemetryClient` instance from the Dependency Injection (DI) container by calling `serviceProvider.GetRequiredService<TelemetryClient>();` or by using Constructor Injection. This step will trigger setting up of `TelemetryConfiguration` and auto-collection modules. --Specific instructions for each type of application are described in the following sections. --## .NET Core Worker Service application --The full example is shared at the [NuGet website](https://github.com/microsoft/ApplicationInsights-dotnet/tree/develop/examples/WorkerService). --1. [Download and install the .NET SDK](https://dotnet.microsoft.com/download). -1. Create a new Worker Service project either by using a Visual Studio new project template or the command line `dotnet new worker`. -1. Add the [Microsoft.ApplicationInsights.WorkerService](https://www.nuget.org/packages/Microsoft.ApplicationInsights.WorkerService) package to the application. --1. Add `services.AddApplicationInsightsTelemetryWorkerService();` to the `CreateHostBuilder()` method in your `Program.cs` class, as in this example: -- ```csharp - public static IHostBuilder CreateHostBuilder(string[] args) => - Host.CreateDefaultBuilder(args) - .ConfigureServices((hostContext, services) => - { - services.AddHostedService<Worker>(); - services.AddApplicationInsightsTelemetryWorkerService(); - }); - ``` --1. Modify your `Worker.cs` as per the following example: -- ```csharp - using Microsoft.ApplicationInsights; - using Microsoft.ApplicationInsights.DataContracts; - - public class Worker : BackgroundService - { - private readonly ILogger<Worker> _logger; - private TelemetryClient _telemetryClient; - private static HttpClient _httpClient = new HttpClient(); - - public Worker(ILogger<Worker> logger, TelemetryClient tc) - { - _logger = logger; - _telemetryClient = tc; - } - - protected override async Task ExecuteAsync(CancellationToken stoppingToken) - { - while (!stoppingToken.IsCancellationRequested) - { - _logger.LogInformation("Worker running at: {time}", DateTimeOffset.Now); - - using (_telemetryClient.StartOperation<RequestTelemetry>("operation")) - { - _logger.LogWarning("A sample warning message. By default, logs with severity Warning or higher is captured by Application Insights"); - _logger.LogInformation("Calling bing.com"); - var res = await _httpClient.GetAsync("https://bing.com"); - _logger.LogInformation("Calling bing completed with status:" + res.StatusCode); - _telemetryClient.TrackEvent("Bing call event completed"); - } - - await Task.Delay(1000, stoppingToken); - } - } - } - ``` --1. Set up the connection string. -- :::image type="content" source="media/migrate-from-instrumentation-keys-to-connection-strings/migrate-from-instrumentation-keys-to-connection-strings.png" alt-text="Screenshot that shows Application Insights overview and connection string." lightbox="media/migrate-from-instrumentation-keys-to-connection-strings/migrate-from-instrumentation-keys-to-connection-strings.png"::: -- > [!NOTE] - > We recommend that you specify the connection string in configuration. The following code sample shows how to specify a connection string in `appsettings.json`. Make sure `appsettings.json` is copied to the application root folder during publishing. -- ```json - { - "ApplicationInsights": - { - "ConnectionString" : "InstrumentationKey=00000000-0000-0000-0000-000000000000;" - }, - "Logging": - { - "LogLevel": - { - "Default": "Warning" - } - } - } - ``` --Alternatively, specify the connection string in the `APPLICATIONINSIGHTS_CONNECTION_STRING` environment variable. --Typically, `APPLICATIONINSIGHTS_CONNECTION_STRING` specifies the connection string for applications deployed to web apps as web jobs. --> [!NOTE] -> A connection string specified in code takes precedence over the environment variable `APPLICATIONINSIGHTS_CONNECTION_STRING`, which takes precedence over other options. --## ASP.NET Core background tasks with hosted services --[This document](/aspnet/core/fundamentals/host/hosted-services?tabs=visual-studio) describes how to create background tasks in an ASP.NET Core application. --The full example is shared at this [GitHub page](https://github.com/microsoft/ApplicationInsights-dotnet/tree/develop/examples/BackgroundTasksWithHostedService). --1. Install the [Microsoft.ApplicationInsights.WorkerService](https://www.nuget.org/packages/Microsoft.ApplicationInsights.WorkerService) package to the application. -1. Add `services.AddApplicationInsightsTelemetryWorkerService();` to the `ConfigureServices()` method, as in this example: -- ```csharp - public static async Task Main(string[] args) - { - var host = new HostBuilder() - .ConfigureAppConfiguration((hostContext, config) => - { - config.AddJsonFile("appsettings.json", optional: true); - }) - .ConfigureServices((hostContext, services) => - { - services.AddLogging(); - services.AddHostedService<TimedHostedService>(); - - // connection string is read automatically from appsettings.json - services.AddApplicationInsightsTelemetryWorkerService(); - }) - .UseConsoleLifetime() - .Build(); - - using (host) - { - // Start the host - await host.StartAsync(); - - // Wait for the host to shutdown - await host.WaitForShutdownAsync(); - } - } - ``` -- The following code is for `TimedHostedService`, where the background task logic resides: -- ```csharp - using Microsoft.ApplicationInsights; - using Microsoft.ApplicationInsights.DataContracts; - - public class TimedHostedService : IHostedService, IDisposable - { - private readonly ILogger _logger; - private Timer _timer; - private TelemetryClient _telemetryClient; - private static HttpClient httpClient = new HttpClient(); - - public TimedHostedService(ILogger<TimedHostedService> logger, TelemetryClient tc) - { - _logger = logger; - this._telemetryClient = tc; - } - - public Task StartAsync(CancellationToken cancellationToken) - { - _logger.LogInformation("Timed Background Service is starting."); - - _timer = new Timer(DoWork, null, TimeSpan.Zero, - TimeSpan.FromSeconds(1)); - - return Task.CompletedTask; - } - - private void DoWork(object state) - { - _logger.LogInformation("Worker running at: {time}", DateTimeOffset.Now); - - using (_telemetryClient.StartOperation<RequestTelemetry>("operation")) - { - _logger.LogWarning("A sample warning message. By default, logs with severity Warning or higher is captured by Application Insights"); - _logger.LogInformation("Calling bing.com"); - var res = httpClient.GetAsync("https://bing.com").GetAwaiter().GetResult(); - _logger.LogInformation("Calling bing completed with status:" + res.StatusCode); - _telemetryClient.TrackEvent("Bing call event completed"); - } - } - } - ``` --1. Set up the connection string. - Use the same `appsettings.json` from the preceding [.NET](/dotnet/fundamentals/) Worker Service example. --## .NET Core/.NET Framework console application --As mentioned in the beginning of this article, the new package can be used to enable Application Insights telemetry from even a regular console application. This package targets [`netstandard2.0`](/dotnet/standard/net-standard), so it can be used for console apps in [.NET Core](/dotnet/fundamentals/) or higher, and [.NET Framework](/dotnet/framework/) or higher. --The full example is shared at this [GitHub page](https://github.com/microsoft/ApplicationInsights-dotnet/tree/main/examples/ConsoleApp). --1. Install the [Microsoft.ApplicationInsights.WorkerService](https://www.nuget.org/packages/Microsoft.ApplicationInsights.WorkerService) package to the application. --1. Modify *Program.cs* as shown in the following example: -- ```csharp - using Microsoft.ApplicationInsights; - using Microsoft.ApplicationInsights.DataContracts; - using Microsoft.ApplicationInsights.WorkerService; - using Microsoft.Extensions.DependencyInjection; - using Microsoft.Extensions.Logging; - using System; - using System.Net.Http; - using System.Threading.Tasks; - - namespace WorkerSDKOnConsole - { - class Program - { - static async Task Main(string[] args) - { - // Create the DI container. - IServiceCollection services = new ServiceCollection(); - - // Being a regular console app, there is no appsettings.json or configuration providers enabled by default. - // Hence instrumentation key/ connection string and any changes to default logging level must be specified here. - services.AddLogging(loggingBuilder => loggingBuilder.AddFilter<Microsoft.Extensions.Logging.ApplicationInsights.ApplicationInsightsLoggerProvider>("Category", LogLevel.Information)); - services.AddApplicationInsightsTelemetryWorkerService((ApplicationInsightsServiceOptions options) => options.ConnectionString = "InstrumentationKey=<instrumentation key here>"); - - // To pass a connection string - // - aiserviceoptions must be created - // - set connectionstring on it - // - pass it to AddApplicationInsightsTelemetryWorkerService() - - // Build ServiceProvider. - IServiceProvider serviceProvider = services.BuildServiceProvider(); - - // Obtain logger instance from DI. - ILogger<Program> logger = serviceProvider.GetRequiredService<ILogger<Program>>(); - - // Obtain TelemetryClient instance from DI, for additional manual tracking or to flush. - var telemetryClient = serviceProvider.GetRequiredService<TelemetryClient>(); - - var httpClient = new HttpClient(); - - while (true) // This app runs indefinitely. Replace with actual application termination logic. - { - logger.LogInformation("Worker running at: {time}", DateTimeOffset.Now); - - // Replace with a name which makes sense for this operation. - using (telemetryClient.StartOperation<RequestTelemetry>("operation")) - { - logger.LogWarning("A sample warning message. By default, logs with severity Warning or higher is captured by Application Insights"); - logger.LogInformation("Calling bing.com"); - var res = await httpClient.GetAsync("https://bing.com"); - logger.LogInformation("Calling bing completed with status:" + res.StatusCode); - telemetryClient.TrackEvent("Bing call event completed"); - } - - await Task.Delay(1000); - } - - // Explicitly call Flush() followed by sleep is required in console apps. - // This is to ensure that even if application terminates, telemetry is sent to the back-end. - telemetryClient.Flush(); - Task.Delay(5000).Wait(); - } - } - } - ``` --This console application also uses the same default `TelemetryConfiguration`. It can be customized in the same way as the examples in earlier sections. --## Run your application --Run your application. The workers from all the preceding examples make an HTTP call every second to bing.com and also emit few logs by using `ILogger`. These lines are wrapped inside the `StartOperation` call of `TelemetryClient`, which is used to create an operation. In this example, `RequestTelemetry` is named "operation." --Application Insights collects these ILogger logs, with a severity of Warning or above by default, and dependencies. They're correlated to `RequestTelemetry` with a parent-child relationship. Correlation also works across process/network boundaries. For example, if the call was made to another monitored component, it's correlated to this parent as well. --This custom operation of `RequestTelemetry` can be thought of as the equivalent of an incoming web request in a typical web application. It isn't necessary to use an operation, but it fits best with the [Application Insights correlation data model](distributed-trace-data.md). `RequestTelemetry` acts as the parent operation and every telemetry generated inside the worker iteration is treated as logically belonging to the same operation. --This approach also ensures all the telemetry generated, both automatic and manual, will have the same `operation_id`. Because sampling is based on `operation_id`, the sampling algorithm either keeps or drops all the telemetry from a single iteration. --The following sections list the full telemetry automatically collected by Application Insights. --### Live metrics --[Live metrics](./live-stream.md) can be used to quickly verify if application monitoring with Application Insights is configured correctly. Telemetry can take a few minutes to appear in the Azure portal, but the live metrics pane shows CPU usage of the running process in near real time. It can also show other telemetry like requests, dependencies, and traces. --### ILogger logs --Logs emitted via `ILogger` with the severity Warning or greater are automatically captured. To change this behavior, explicitly override the logging configuration for the provider `ApplicationInsights`, as shown in the following code. The following configuration allows Application Insights to capture all `Information` logs and more severe logs. --```json -{ - "Logging": { - "LogLevel": { - "Default": "Warning" - }, - "ApplicationInsights": { - "LogLevel": { - "Default": "Information" - } - } - } -} -``` --It's important to note that the following example doesn't cause the Application Insights provider to capture `Information` logs. It doesn't capture it because the SDK adds a default logging filter that instructs `ApplicationInsights` to capture only `Warning` logs and more severe logs. Application Insights requires an explicit override. --```json -{ - "Logging": { - "LogLevel": { - "Default": "Information" - } - } -} -``` --For more information, follow [ILogger docs](/dotnet/core/extensions/logging#configure-logging) to customize which log levels are captured by Application Insights. --### Dependencies --Dependency collection is enabled by default. The article [Dependency tracking in Application Insights](asp-net-dependencies.md#automatically-tracked-dependencies) explains the dependencies that are automatically collected and also contains steps to do manual tracking. --### EventCounter --`EventCounterCollectionModule` is enabled by default, and it will collect a default set of counters from [.NET](/dotnet/fundamentals/) apps. The [EventCounter](eventcounters.md) tutorial lists the default set of counters collected. It also has instructions on how to customize the list. --### Manually track other telemetry --Although the SDK automatically collects telemetry as explained, in most cases, you'll need to send other telemetry to Application Insights. The recommended way to track other telemetry is by obtaining an instance of `TelemetryClient` from Dependency Injection and then calling one of the supported `TrackXXX()` [API](api-custom-events-metrics.md) methods on it. Another typical use case is [custom tracking of operations](custom-operations-tracking.md). This approach is demonstrated in the preceding worker examples. --## Configure the Application Insights SDK --The default `TelemetryConfiguration` used by the Worker Service SDK is similar to the automatic configuration used in an ASP.NET or ASP.NET Core application, minus the telemetry initializers used to enrich telemetry from `HttpContext`. --You can customize the Application Insights SDK for Worker Service to change the default configuration. Users of the Application Insights ASP.NET Core SDK might be familiar with changing configuration by using ASP.NET Core built-in [dependency injection](/aspnet/core/fundamentals/dependency-injection). The Worker Service SDK is also based on similar principles. Make almost all configuration changes in the `ConfigureServices()` section by calling appropriate methods on `IServiceCollection`, as detailed in the next section. --> [!NOTE] -> When you use this SDK, changing configuration by modifying `TelemetryConfiguration.Active` isn't supported and changes won't be reflected. --### Use ApplicationInsightsServiceOptions --You can modify a few common settings by passing `ApplicationInsightsServiceOptions` to `AddApplicationInsightsTelemetryWorkerService`, as in this example: --```csharp -using Microsoft.ApplicationInsights.WorkerService; --public void ConfigureServices(IServiceCollection services) -{ - var aiOptions = new ApplicationInsightsServiceOptions(); - // Disables adaptive sampling. - aiOptions.EnableAdaptiveSampling = false; -- // Disables live metrics (also known as QuickPulse). - aiOptions.EnableQuickPulseMetricStream = false; - services.AddApplicationInsightsTelemetryWorkerService(aiOptions); -} -``` --The `ApplicationInsightsServiceOptions` in this SDK is in the namespace `Microsoft.ApplicationInsights.WorkerService` as opposed to `Microsoft.ApplicationInsights.AspNetCore.Extensions` in the ASP.NET Core SDK. --The following table lists commonly used settings in `ApplicationInsightsServiceOptions`. --|Setting | Description | Default -||-|- -|EnableQuickPulseMetricStream | Enable/Disable the live metrics feature. | True -|EnableAdaptiveSampling | Enable/Disable Adaptive Sampling. | True -|EnableHeartbeat | Enable/Disable the Heartbeats feature, which periodically (15-min default) sends a custom metric named "HeartBeatState" with information about the runtime like .NET version and Azure environment, if applicable. | True -|AddAutoCollectedMetricExtractor | Enable/Disable the AutoCollectedMetrics extractor, which is a telemetry processor that sends preaggregated metrics about Requests/Dependencies before sampling takes place. | True -|EnableDiagnosticsTelemetryModule | Enable/Disable `DiagnosticsTelemetryModule`. Disabling this setting will cause the following settings to be ignored: `EnableHeartbeat`, `EnableAzureInstanceMetadataTelemetryModule`, and `EnableAppServicesHeartbeatTelemetryModule`. | True --For the most up-to-date list, see the [configurable settings in `ApplicationInsightsServiceOptions`](https://github.com/microsoft/ApplicationInsights-dotnet/blob/develop/NETCORE/src/Shared/Extensions/ApplicationInsightsServiceOptions.cs). --### Sampling --The Application Insights SDK for Worker Service supports both [fixed-rate sampling](sampling.md#fixed-rate-sampling) and [adaptive sampling](sampling.md#adaptive-sampling). Adaptive sampling is enabled by default. Sampling can be disabled by using the `EnableAdaptiveSampling` option in [ApplicationInsightsServiceOptions](#use-applicationinsightsserviceoptions). --To configure other sampling settings, you can use the following example: --```csharp -using Microsoft.ApplicationInsights.AspNetCore.Extensions; -using Microsoft.ApplicationInsights.Extensibility; --var builder = WebApplication.CreateBuilder(args); --builder.Services.Configure<TelemetryConfiguration>(telemetryConfiguration => -{ - var telemetryProcessorChainBuilder = telemetryConfiguration.DefaultTelemetrySink.TelemetryProcessorChainBuilder; -- // Using adaptive sampling - telemetryProcessorChainBuilder.UseAdaptiveSampling(maxTelemetryItemsPerSecond: 5); -- // Alternately, the following configures adaptive sampling with 5 items per second, and also excludes DependencyTelemetry from being subject to sampling: - // telemetryProcessorChainBuilder.UseAdaptiveSampling(maxTelemetryItemsPerSecond:5, excludedTypes: "Dependency"); -}); --builder.Services.AddApplicationInsightsTelemetry(new ApplicationInsightsServiceOptions -{ - EnableAdaptiveSampling = false, -}); --var app = builder.Build(); -``` --For more information, see the [Sampling](#sampling) document. --### Add telemetry initializers --Use [telemetry initializers](./api-filtering-sampling.md#addmodify-properties-itelemetryinitializer) when you want to define properties that are sent with all telemetry. --Add any new telemetry initializer to the `DependencyInjection` container and the SDK automatically adds them to `TelemetryConfiguration`. --```csharp - using Microsoft.ApplicationInsights.Extensibility; -- public void ConfigureServices(IServiceCollection services) - { - services.AddSingleton<ITelemetryInitializer, MyCustomTelemetryInitializer>(); - services.AddApplicationInsightsTelemetryWorkerService(); - } -``` --### Remove telemetry initializers --Telemetry initializers are present by default. To remove all or specific telemetry initializers, use the following sample code *after* calling `AddApplicationInsightsTelemetryWorkerService()`. --```csharp - public void ConfigureServices(IServiceCollection services) - { - services.AddApplicationInsightsTelemetryWorkerService(); - // Remove a specific built-in telemetry initializer. - var tiToRemove = services.FirstOrDefault<ServiceDescriptor> - (t => t.ImplementationType == typeof(AspNetCoreEnvironmentTelemetryInitializer)); - if (tiToRemove != null) - { - services.Remove(tiToRemove); - } -- // Remove all initializers. - // This requires importing namespace by using Microsoft.Extensions.DependencyInjection.Extensions; - services.RemoveAll(typeof(ITelemetryInitializer)); - } -``` --### Add telemetry processors --You can add custom telemetry processors to `TelemetryConfiguration` by using the extension method `AddApplicationInsightsTelemetryProcessor` on `IServiceCollection`. You use telemetry processors in [advanced filtering scenarios](./api-filtering-sampling.md#itelemetryprocessor-and-itelemetryinitializer) to allow for more direct control over what's included or excluded from the telemetry you send to Application Insights. Use the following example: --```csharp - public void ConfigureServices(IServiceCollection services) - { - services.AddApplicationInsightsTelemetryWorkerService(); - services.AddApplicationInsightsTelemetryProcessor<MyFirstCustomTelemetryProcessor>(); - // If you have more processors: - services.AddApplicationInsightsTelemetryProcessor<MySecondCustomTelemetryProcessor>(); - } -``` --### Configure or remove default telemetry modules --Application Insights uses telemetry modules to automatically collect telemetry about specific workloads without requiring manual tracking. --The following auto-collection modules are enabled by default. These modules are responsible for automatically collecting telemetry. You can disable or configure them to alter their default behavior. --* `DependencyTrackingTelemetryModule` -* `PerformanceCollectorModule` -* `QuickPulseTelemetryModule` -* `AppServicesHeartbeatTelemetryModule` (There's currently an issue involving this telemetry module. For a temporary workaround, see [GitHub Issue 1689](https://github.com/microsoft/ApplicationInsights-dotnet/issues/1689).) -* `AzureInstanceMetadataTelemetryModule` --To configure any default telemetry module, use the extension method `ConfigureTelemetryModule<T>` on `IServiceCollection`, as shown in the following example: --```csharp - using Microsoft.ApplicationInsights.Extensibility.PerfCounterCollector.QuickPulse; - using Microsoft.ApplicationInsights.Extensibility.PerfCounterCollector; -- public void ConfigureServices(IServiceCollection services) - { - services.AddApplicationInsightsTelemetryWorkerService(); -- // The following configures QuickPulseTelemetryModule. - // Similarly, any other default modules can be configured. - services.ConfigureTelemetryModule<QuickPulseTelemetryModule>((module, o) => - { - module.AuthenticationApiKey = "keyhere"; - }); -- // The following removes PerformanceCollectorModule to disable perf-counter collection. - // Similarly, any other default modules can be removed. - var performanceCounterService = services.FirstOrDefault<ServiceDescriptor> - (t => t.ImplementationType == typeof(PerformanceCollectorModule)); - if (performanceCounterService != null) - { - services.Remove(performanceCounterService); - } - } -``` --### Configure the telemetry channel --The default channel is `ServerTelemetryChannel`. You can override it as the following example shows: --```csharp -using Microsoft.ApplicationInsights.Channel; -- public void ConfigureServices(IServiceCollection services) - { - // Use the following to replace the default channel with InMemoryChannel. - // This can also be applied to ServerTelemetryChannel. - services.AddSingleton(typeof(ITelemetryChannel), new InMemoryChannel() {MaxTelemetryBufferCapacity = 19898 }); -- services.AddApplicationInsightsTelemetryWorkerService(); - } -``` --### Disable telemetry dynamically --If you want to disable telemetry conditionally and dynamically, you can resolve the `TelemetryConfiguration` instance with an ASP.NET Core dependency injection container anywhere in your code and set the `DisableTelemetry` flag on it. --```csharp - public void ConfigureServices(IServiceCollection services) - { - services.AddApplicationInsightsTelemetryWorkerService(); - } -- public void Configure(IApplicationBuilder app, IHostingEnvironment env, TelemetryConfiguration configuration) - { - configuration.DisableTelemetry = true; - ... - } -``` --## Frequently asked questions --This section provides answers to common questions. --### Which package should I use? --| .NET Core app scenario | Package | -||| -| Without HostedServices | WorkerService | -| With HostedServices | AspNetCore (not WorkerService) | -| With HostedServices, monitoring only HostedServices | WorkerService (rare scenario) | --### Can HostedServices inside a .NET Core app using the AspNetCore package have TelemetryClient injected to it? --Yes. The configuration will be shared with the rest of the web application. --### How can I track telemetry that's not automatically collected? --Get an instance of `TelemetryClient` by using constructor injection and call the required `TrackXXX()` method on it. We don't recommend creating new `TelemetryClient` instances. A singleton instance of `TelemetryClient` is already registered in the `DependencyInjection` container, which shares `TelemetryConfiguration` with the rest of the telemetry. Creating a new `TelemetryClient` instance is recommended only if it needs a configuration that's separate from the rest of the telemetry. --### Can I use Visual Studio IDE to onboard Application Insights to a Worker Service project? --Visual Studio IDE onboarding is currently supported only for ASP.NET/ASP.NET Core applications. This document will be updated when Visual Studio ships support for onboarding Worker Service applications. --### Can I enable Application Insights monitoring by using tools like Azure Monitor Application Insights Agent (formerly Status Monitor v2)? --No. [Azure Monitor Application Insights Agent](./application-insights-asp-net-agent.md) currently supports [.NET](/dotnet/fundamentals/) only. --### Are all features supported if I run my application in Linux? --Yes. Feature support for this SDK is the same in all platforms, with the following exceptions: --* Performance counters are supported only in Windows except for Process CPU/Memory shown in live metrics. -* Even though `ServerTelemetryChannel` is enabled by default, if the application is running in Linux or macOS, the channel doesn't automatically create a local storage folder to keep telemetry temporarily if there are network issues. Because of this limitation, telemetry is lost when there are temporary network or server issues. To work around this issue, configure a local folder for the channel: -- ```csharp - using Microsoft.ApplicationInsights.Channel; - using Microsoft.ApplicationInsights.WindowsServer.TelemetryChannel; -- public void ConfigureServices(IServiceCollection services) - { - // The following will configure the channel to use the given folder to temporarily - // store telemetry items during network or Application Insights server issues. - // User should ensure that the given folder already exists - // and that the application has read/write permissions. - services.AddSingleton(typeof(ITelemetryChannel), - new ServerTelemetryChannel () {StorageFolder = "/tmp/myfolder"}); - services.AddApplicationInsightsTelemetryWorkerService(); - } - ``` --## Sample applications --[.NET Core console application](https://github.com/microsoft/ApplicationInsights-dotnet/tree/develop/examples/ConsoleApp): -Use this sample if you're using a console application written in either .NET Core (2.0 or higher) or .NET Framework (4.7.2 or higher). --[ASP.NET Core background tasks with HostedServices](https://github.com/microsoft/ApplicationInsights-dotnet/tree/develop/examples/BackgroundTasksWithHostedService): -Use this sample if you're in ASP.NET Core and creating background tasks in accordance with [official guidance](/aspnet/core/fundamentals/host/hosted-services). --[.NET Core Worker Service](https://github.com/microsoft/ApplicationInsights-dotnet/tree/develop/examples/WorkerService): -Use this sample if you have a [.NET](/dotnet/fundamentals/) Worker Service application in accordance with [official guidance](/aspnet/core/fundamentals/host/hosted-services?tabs=visual-studio#worker-service-template). --## Open-source SDK --[Read and contribute to the code](https://github.com/microsoft/ApplicationInsights-dotnet). --For the latest updates and bug fixes, [see the Release Notes](./release-notes.md). --## Next steps --* [Use the API](./api-custom-events-metrics.md) to send your own events and metrics for a detailed view of your app's performance and usage. -* [Track more dependencies not automatically tracked](asp-net-dependencies.md#dependency-auto-collection). -* [Enrich or filter auto-collected telemetry](./api-filtering-sampling.md). -* [Dependency Injection in ASP.NET Core](/aspnet/core/fundamentals/dependency-injection). |
| azure-monitor | Autoscale Best Practices | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/autoscale/autoscale-best-practices.md | - Title: Best practices for autoscale -description: Autoscale patterns in the Web Apps feature of Azure App Service, Azure Virtual Machine Scale Sets, and Azure Cloud Services. --- Previously updated : 01/07/2024----# Best practices for autoscale -Azure Monitor autoscale applies only to [Azure Virtual Machine Scale Sets](https://azure.microsoft.com/services/virtual-machine-scale-sets/), [Azure Cloud Services](https://azure.microsoft.com/services/cloud-services/), the [Web Apps feature of Azure App Service](https://azure.microsoft.com/services/app-service/web/), and [Azure API Management](../../api-management/api-management-key-concepts.md). --## Autoscale concepts -* A resource can have only *one* autoscale setting. -* An autoscale setting can have one or more profiles, and each profile can have one or more autoscale rules. -* An autoscale setting scales instances horizontally, which is *out* by increasing the instances and *in* by decreasing the number of instances. -* An autoscale setting has a maximum, minimum, and default value of instances. -* An autoscale job always reads the associated metric to scale by, checking if it has crossed the configured threshold for scale-out or scale-in. You can view a list of metrics that autoscale can scale by at [Azure Monitor autoscaling common metrics](autoscale-common-metrics.md). -* All thresholds are calculated at an instance level. An example is "scale out by one instance when average CPU > 80% when instance count is 2." It means scale-out when the average CPU across all instances is greater than 80%. -* All autoscale failures are logged to the activity log. You can then configure an [activity log alert](../alerts/activity-log-alerts.md) so that you can be notified via email, SMS, or webhooks whenever there's an autoscale failure. -* Similarly, all successful scale actions are posted to the activity log. You can then configure an activity log alert so that you can be notified via email, SMS, or webhooks whenever there's a successful autoscale action. You can also configure email or webhook notifications to get notified for successful scale actions via the notifications tab on the autoscale setting. --## Autoscale best practices -Use the following best practices as you use autoscale. --### Ensure the maximum and minimum values are different and have an adequate margin between them -If you have a setting that has minimum=2, maximum=2, and the current instance count is 2, no scale action can occur. Keep an adequate margin between the maximum and minimum instance counts, which are inclusive. Autoscale always scales between these limits. --### Manual scaling is reset by autoscale minimum and maximum -If you manually update the instance count to a value above or below the maximum, the autoscale engine automatically scales back to the minimum (if below) or the maximum (if above). For example, you set the range between 3 and 6. If you have one running instance, the autoscale engine scales to three instances on its next run. Likewise, if you manually set the scale to eight instances, on the next run autoscale will scale it back to six instances on its next run. Manual scaling is temporary unless you also reset the autoscale rules. --### Always use a scale-out and scale-in rule combination that performs an increase and decrease -If you use only one part of the combination, autoscale only takes action in a single direction (scale out or in) until it reaches the maximum, or minimum instance counts, as defined in the profile. This situation isn't optimal. Ideally, you want your resource to scale out at times of high usage to ensure availability. Similarly, at times of low usage, you want your resource to scale in so that you can realize cost savings. --When you use a scale-in and scale-out rule, ideally use the same metric to control both. Otherwise, it's possible that the scale-in and scale-out conditions could be met at the same time and result in some level of flapping. For example, we don't recommend the following rule combination because there's no scale-in rule for memory usage: --* If CPU > 90%, scale out by 1 -* If Memory > 90%, scale out by 1 -* If CPU < 45%, scale in by 1 --In this example, you can have a situation in which the memory usage is over 90% but the CPU usage is under 45%. This scenario can lead to flapping for as long as both conditions are met. --### Choose the appropriate statistic for your diagnostics metric -For diagnostics metrics, you can choose among **Average**, **Minimum**, **Maximum**, and **Total** as a metric to scale by. The most common statistic is **Average**. --### Considerations for scaling threshold values for special metrics -For special metrics such as an Azure Storage or Azure Service Bus queue length metric, the threshold is the average number of messages available per current number of instances. Carefully choose the threshold value for this metric. --Let's illustrate it with an example to ensure you understand the behavior better: --* Increase instances by 1 count when Storage queue message count >= 50 -* Decrease instances by 1 count when Storage queue message count <= 10 --Consider the following sequence: --1. There are two Storage queue instances. -1. Messages keep coming and when you review the Storage queue, the total count reads 50. You might assume that autoscale should start a scale-out action. However, notice that it's still 50/2 = 25 messages per instance. So, scale-out doesn't occur. For the first scale-out action to happen, the total message count in the Storage queue should be 100. -1. Next, assume that the total message count reaches 100. -1. A third Storage queue instance is added because of a scale-out action. The next scale-out action won't happen until the total message count in the queue reaches 150 because 150/3 = 50. -1. Now the number of messages in the queue gets smaller. With three instances, the first scale-in action happens when the total messages in all queues add up to 30 because 30/3 = 10 messages per instance, which is the scale-in threshold. --### Considerations for scaling when multiple rules are configured in a profile --There are cases where you might have to set multiple rules in a profile. The following autoscale rules are used by the autoscale engine when multiple rules are set: --- On *scale-out*, autoscale runs if any rule is met.-- On *scale-in*, autoscale requires all rules to be met.--To illustrate, assume that you have four autoscale rules: --* If CPU < 30%, scale in by 1 -* If Memory < 50%, scale in by 1 -* If CPU > 75%, scale out by 1 -* If Memory > 75%, scale out by 1 --Then the following action occurs: --* If CPU is 76% and Memory is 50%, we scale out. -* If CPU is 50% and Memory is 76%, we scale out. --On the other hand, if CPU is 25% and Memory is 51%, autoscale *doesn't* scale in. To scale in, CPU must be 29% and Memory 49%. --### Always select a safe default instance count --The default instance count is important because autoscale scales your service to that count when metrics aren't available. As a result, select a default instance count that's safe for your workloads. --### Configure autoscale notifications --Autoscale posts to the activity log if any of the following conditions occur: --* Autoscale issues a scale operation. -* Autoscale service successfully completes a scale action. -* Autoscale service fails to take a scale action. -* Metrics aren't available for autoscale service to make a scale decision. -* Metrics are available (recovery) again to make a scale decision. -* Autoscale detects flapping and aborts the scale attempt. You see a log type of `Flapping` in this situation. If you see this log type, consider whether your thresholds are too narrow. -* Autoscale detects flapping but is still able to successfully scale. You see a log type of `FlappingOccurred` in this situation. If you see this log type, the autoscale engine has attempted to scale (for example, from four instances to two) but has determined that this change would cause flapping. Instead, the autoscale engine has scaled to a different number of instances (for example, using three instances instead of two), which no longer causes flapping, so it has scaled to this number of instances. --You can also use an activity log alert to monitor the health of the autoscale engine. One example shows how to [create an activity log alert to monitor all autoscale engine operations on your subscription](https://github.com/Azure/azure-quickstart-templates/tree/master/demos/monitor-autoscale-alert). Another example shows how to [create an activity log alert to monitor all failed autoscale scale-in/scale-out operations on your subscription](https://github.com/Azure/azure-quickstart-templates/tree/master/demos/monitor-autoscale-failed-alert). --In addition to using activity log alerts, you can also configure email or webhook notifications to get notified for scale actions via the notifications tab on the autoscale setting. --## Send data securely by using TLS 1.2 --To ensure the security of data in transit to Azure Monitor, we strongly encourage you to configure the agent to use at least Transport Layer Security (TLS) 1.2. Older versions of TLS/Secure Sockets Layer (SSL) have been found to be vulnerable. Although they still currently work to allow backwards compatibility, we *don't* recommend them. The industry is quickly moving to abandon support for these older protocols. --The [PCI Security Standards Council](https://www.pcisecuritystandards.org/) has set a deadline of [June 30, 2018](https://www.pcisecuritystandards.org/pdfs/PCI_SSC_Migrating_from_SSL_and_Early_TLS_Resource_Guide.pdf), to disable older versions of TLS/SSL and upgrade to more secure protocols. After Azure drops legacy support, if your agents can't communicate over at least TLS 1.2, you won't be able to send data to Azure Monitor Logs. --We recommend that you *don't* explicitly set your agent to only use TLS 1.2 unless necessary. Allowing the agent to automatically detect, negotiate, and take advantage of future security standards is preferable. Otherwise, you might miss the added security of the newer standards and possibly experience problems if TLS 1.2 is ever deprecated in favor of those newer standards. --## Next steps -- [Autoscale flapping](./autoscale-flapping.md)-- [Create an activity log alert to monitor all autoscale engine operations on your subscription](https://github.com/Azure/azure-quickstart-templates/tree/master/demos/monitor-autoscale-alert)-- [Create an activity log alert to monitor all failed autoscale scale-in/scale-out operations on your subscription](https://github.com/Azure/azure-quickstart-templates/tree/master/demos/monitor-autoscale-failed-alert) |
| azure-monitor | Autoscale Common Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/autoscale/autoscale-common-metrics.md | - Title: Autoscale common metrics -description: Learn which metrics are commonly used for autoscaling your cloud services, virtual machines, and web apps. --- Previously updated : 04/15/2024----# customer intent: As an Azure administrator, I want to learn which metrics are best to scale my resources using Azure Monitor autoscale ---# Azure Monitor autoscaling common metrics --Azure Monitor autoscaling allows you to scale the number of running instances in or out, based on telemetry data or metrics. Scaling can be based on any metric, even metrics from a different resource. For example, scale a Virtual Machine Scale Set based on the amount of traffic on a firewall. --This article describes metrics that are commonly used to trigger scale events. --Azure autoscale supports many resource types. For more information about supported resources, see [autoscale supported resources](./autoscale-overview.md#supported-services-for-autoscale). --For all resources, you can get a list of the available metrics using the PowerShell or Azure CLI --```azurepowershell -Get-AzMetricDefinition -ResourceId <resource_id> -``` --```azurecli -az monitor metrics list-definitions --resource <resource_id> -``` --## Compute metrics for Resource Manager-based VMs --By default, Azure Resource Manager-based virtual machines and Virtual Machine Scale Sets emit basic (host-level) metrics. In addition, when you configure diagnostics data collection for an Azure VM and Virtual Machine Scale Sets, the Azure Diagnostics extension also emits guest-OS performance counters. These counters are commonly known as "guest-OS metrics." You use all these metrics in autoscale rules. --If you're using Virtual Machine Scale Sets and you don't see a particular metric listed, it's likely *disabled* in your Diagnostics extension. --If a particular metric isn't being sampled or transferred at the frequency you want, you can update the diagnostics configuration. --If either preceding case is true, see [Use PowerShell to enable Azure Diagnostics in a virtual machine running Windows](/azure/virtual-machines/extensions/diagnostics-windows) to configure and update your Azure VM Diagnostics extension to enable the metric. The article also includes a sample diagnostics configuration file. --### Host metrics for Resource Manager-based Windows and Linux VMs --The following host-level metrics are emitted by default for Azure VM and Virtual Machine Scale Sets in both Windows and Linux instances. These metrics describe your Azure VM but are collected from the Azure VM host rather than via agent installed on the guest VM. You can use these metrics in autoscaling rules. --- [Host metrics for Resource Manager-based Windows and Linux VMs](../essentials/metrics-supported.md#microsoftcomputevirtualmachines)-- [Host metrics for Resource Manager-based Windows and Linux Virtual Machine Scale Sets](../essentials/metrics-supported.md#microsoftcomputevirtualmachinescalesets)--### Guest OS metrics for Resource Manager-based Windows VMs --When you create a VM in Azure, diagnostics is enabled by using the Diagnostics extension. The Diagnostics extension emits a set of metrics taken from inside of the VM. This means you can autoscale using metrics that aren't emitted by default. --You can create an alert for the following metrics: --| Metric name | Unit | -| | | -| \Processor(_Total)\% Processor Time |Percent | -| \Processor(_Total)\% Privileged Time |Percent | -| \Processor(_Total)\% User Time |Percent | -| \Processor Information(_Total)\Processor Frequency |Count | -| \System\Processes |Count | -| \Process(_Total)\Thread Count |Count | -| \Process(_Total)\Handle Count |Count | -| \Memory\% Committed Bytes In Use |Percent | -| \Memory\Available Bytes |Bytes | -| \Memory\Committed Bytes |Bytes | -| \Memory\Commit Limit |Bytes | -| \Memory\Pool Paged Bytes |Bytes | -| \Memory\Pool Nonpaged Bytes |Bytes | -| \PhysicalDisk(_Total)\% Disk Time |Percent | -| \PhysicalDisk(_Total)\% Disk Read Time |Percent | -| \PhysicalDisk(_Total)\% Disk Write Time |Percent | -| \PhysicalDisk(_Total)\Disk Transfers/sec |CountPerSecond | -| \PhysicalDisk(_Total)\Disk Reads/sec |CountPerSecond | -| \PhysicalDisk(_Total)\Disk Writes/sec |CountPerSecond | -| \PhysicalDisk(_Total)\Disk Bytes/sec |BytesPerSecond | -| \PhysicalDisk(_Total)\Disk Read Bytes/sec |BytesPerSecond | -| \PhysicalDisk(_Total)\Disk Write Bytes/sec |BytesPerSecond | -| \PhysicalDisk(_Total)\Avg. Disk Queue Length |Count | -| \PhysicalDisk(_Total)\Avg. Disk Read Queue Length |Count | -| \PhysicalDisk(_Total)\Avg. Disk Write Queue Length |Count | -| \LogicalDisk(_Total)\% Free Space |Percent | -| \LogicalDisk(_Total)\Free Megabytes |Count | --### Guest OS metrics Linux VMs --When you create a VM in Azure, diagnostics is enabled by default by using the Diagnostics extension. -- You can create an alert for the following metrics: --| Metric name | Unit | -| | | -| \Memory\AvailableMemory |Bytes | -| \Memory\PercentAvailableMemory |Percent | -| \Memory\UsedMemory |Bytes | -| \Memory\PercentUsedMemory |Percent | -| \Memory\PercentUsedByCache |Percent | -| \Memory\PagesPerSec |CountPerSecond | -| \Memory\PagesReadPerSec |CountPerSecond | -| \Memory\PagesWrittenPerSec |CountPerSecond | -| \Memory\AvailableSwap |Bytes | -| \Memory\PercentAvailableSwap |Percent | -| \Memory\UsedSwap |Bytes | -| \Memory\PercentUsedSwap |Percent | -| \Processor\PercentIdleTime |Percent | -| \Processor\PercentUserTime |Percent | -| \Processor\PercentNiceTime |Percent | -| \Processor\PercentPrivilegedTime |Percent | -| \Processor\PercentInterruptTime |Percent | -| \Processor\PercentDPCTime |Percent | -| \Processor\PercentProcessorTime |Percent | -| \Processor\PercentIOWaitTime |Percent | -| \PhysicalDisk\BytesPerSecond |BytesPerSecond | -| \PhysicalDisk\ReadBytesPerSecond |BytesPerSecond | -| \PhysicalDisk\WriteBytesPerSecond |BytesPerSecond | -| \PhysicalDisk\TransfersPerSecond |CountPerSecond | -| \PhysicalDisk\ReadsPerSecond |CountPerSecond | -| \PhysicalDisk\WritesPerSecond |CountPerSecond | -| \PhysicalDisk\AverageReadTime |Seconds | -| \PhysicalDisk\AverageWriteTime |Seconds | -| \PhysicalDisk\AverageTransferTime |Seconds | -| \PhysicalDisk\AverageDiskQueueLength |Count | -| \NetworkInterface\BytesTransmitted |Bytes | -| \NetworkInterface\BytesReceived |Bytes | -| \NetworkInterface\PacketsTransmitted |Count | -| \NetworkInterface\PacketsReceived |Count | -| \NetworkInterface\BytesTotal |Bytes | -| \NetworkInterface\TotalRxErrors |Count | -| \NetworkInterface\TotalTxErrors |Count | -| \NetworkInterface\TotalCollisions |Count | --## Commonly used App Service (server farm) metrics --You can also perform autoscale based on common web server metrics such as the HTTP queue length. Its metric name is **HttpQueueLength**. The following section lists available server farm (App Service) metrics. --### Web Apps metrics --For Web Apps, you can alert on or scale by these metrics. --| Metric name | Unit | -| | | -| CpuPercentage |Percent | -| MemoryPercentage |Percent | -| DiskQueueLength |Count | -| HttpQueueLength |Count | -| BytesReceived |Bytes | -| BytesSent |Bytes | --## Commonly used Storage metrics --You can scale by Azure Storage queue length, which is the number of messages in the Storage queue. Storage queue length is a special metric, and the threshold is the number of messages per instance. For example, if there are two instances and if the threshold is set to 100, scaling occurs when the total number of messages in the queue is 200. That amount can be 100 messages per instance, 120 plus 80, or any other combination that adds up to 200 or more. --Configure this setting in the Azure portal in the **Settings** pane. For Virtual Machine Scale Sets, you can update the autoscale setting in the Resource Manager template to use `metricName` as `ApproximateMessageCount` and pass the ID of the storage queue as `metricResourceUri`. --For example, with a Classic Storage account, the autoscale setting `metricTrigger` would include: --``` -"metricName": "ApproximateMessageCount", -"metricNamespace": "", -"metricResourceUri": "/subscriptions/SUBSCRIPTION_ID/resourceGroups/RES_GROUP_NAME/providers/Microsoft.ClassicStorage/storageAccounts/STORAGE_ACCOUNT_NAME/services/queue/queues/QUEUE_NAME" -``` --For a (non-classic) Storage account, the `metricTrigger` setting would include: --``` -"metricName": "ApproximateMessageCount", -"metricNamespace": "", -"metricResourceUri": "/subscriptions/SUBSCRIPTION_ID/resourceGroups/RES_GROUP_NAME/providers/Microsoft.Storage/storageAccounts/STORAGE_ACCOUNT_NAME/services/queue/queues/QUEUE_NAME" -``` --## Commonly used Service Bus metrics --You can scale by Azure Service Bus queue length, which is the number of messages in the Service Bus queue. Service Bus queue length is a special metric, and the threshold is the number of messages per instance. For example, if there are two instances, and if the threshold is set to 100, scaling occurs when the total number of messages in the queue is 200. That amount can be 100 messages per instance, 120 plus 80, or any other combination that adds up to 200 or more. --For Virtual Machine Scale Sets, you can update the autoscale setting in the Resource Manager template to use `metricName` as `ActiveMessageCount` and pass the ID of the Service Bus Queue as `metricResourceUri`. --``` -"metricName": "ActiveMessageCount", -"metricNamespace": "", -"metricResourceUri": "/subscriptions/SUBSCRIPTION_ID/resourceGroups/RES_GROUP_NAME/providers/Microsoft.ServiceBus/namespaces/SB_NAMESPACE/queues/QUEUE_NAME" -``` --> [!NOTE] -> For Service Bus, the resource group concept doesn't exist. Azure Resource Manager creates a default resource group per region. The resource group is usually in the Default-ServiceBus-[region] format. Examples are Default-ServiceBus-EastUS, Default-ServiceBus-WestUS, and Default-ServiceBus-AustraliaEast. |
| azure-monitor | Autoscale Common Scale Patterns | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/autoscale/autoscale-common-scale-patterns.md | - Title: Overview of common autoscale patterns -description: Learn some of the common patterns to use with autoscale for your resource in Azure. -- Previously updated : 05/31/2024-----# Overview of common autoscale patterns --Autoscale settings help ensure that you have the right amount of resources running to handle the fluctuating load of your application. You can configure autoscale settings to be triggered based on metrics that indicate load or performance, or triggered at a scheduled date and time. --Azure autoscale supports many resource types. For more information about supported resources, see [Autoscale supported resources](./autoscale-overview.md#supported-services-for-autoscale). --This article describes some of the common patterns you can use to scale your resources in Azure. --## Prerequisites --This article assumes that you're familiar with autoscale. For more information, see [Get started here to scale your resource](./autoscale-get-started.md). --## Scale based on metrics --Scale your resource based on metrics produced by the resource itself or any other resource. -For example: --* Scale your virtual machine scale set based on the CPU usage of the virtual machine. -* Ensure a minimum number of instances. -* Set a maximum limit on the number of instances. --The following image shows a default scale condition for a virtual machine scale set: -- * The **Scale rule** tab shows that the metric source is the scale set itself and the metric used is **Percentage CPU**. - * The minimum number of instances running is set to **2**. - * The maximum number of instances is set to **10**. - * When the scale set starts, the default number of instances is **3**. ---## Scale based on another resource's metric --Scale a resource based on the metrics from a different resource. The following image shows a scale rule that's scaling a virtual machine scale set based on the number of allocated ports on a load balancer. ---## Scale differently on weekends --You can scale your resources differently on different days of the week. For example, you might have a virtual machine scale set and want to: --- Set a minimum of **3** instances on weekdays, scaling based on inbound flows.-- Scale in to a fixed **1** instance on weekends when there's less traffic.--In this example: --- The weekend profile starts at 00:01 Saturday morning and ends at 04:00 on Monday morning.-- The end times are left blank. The weekday profile ends when the weekend profile starts and vice-versa.-- The default profile is irrelevant because there's no time that isn't covered by the other profiles.-->[!Note] -> Creating a recurring profile with no end time is only supported via the Azure portal and Azure Resource Manager templates (ARM templates). For more information on how to create recurring profiles with ARM templates, see [Add a recurring profile by using ARM templates](./autoscale-multiprofile.md?tabs=templates#add-a-recurring-profile-using-arm-templates). -> -> If the end time isn't included in the CLI command, a default end time of 23:59 will be implemented by creating a copy of the default profile with the naming convention `"name": {\"name\": \"Auto created default scale condition\", \"for\": \"<non-default profile name>\"}`. ---## Scale differently during specific events --You can set your scale rules and instance limits differently for specific events. For example: --- Set a minimum of **3** instances by default.-- For the week of Black Friday, set the minimum number of instances to **10** to handle the anticipated traffic.-- :::image type="content" source="./media/autoscale-common-scale-patterns/scale-for-event.png" alt-text="Screenshot that shows two autoscale profiles, one default and one for a specific date range." lightbox="./media/autoscale-common-scale-patterns/scale-for-event.png"::: --## Scale based on custom metrics -Scale by custom metrics generated by your application. For example, you might have a web front end and an API tier that communicates with the back end and you want to scale the API tier based on custom events in the front end. ---## Next steps --Learn more about autoscale in the following articles: --* [Azure Monitor autoscale common metrics](./autoscale-common-metrics.md) -* [Azure Monitor autoscale custom metrics](./autoscale-custom-metric.md) -* [Autoscale with multiple profiles](./autoscale-multiprofile.md) -* [Flapping in autoscale](./autoscale-custom-metric.md) -* [Use autoscale actions to send email and webhook alert notifications](./autoscale-webhook-email.md) -* [Autoscale REST API](/rest/api/monitor/autoscalesettings) |
| azure-monitor | Autoscale Custom Metric | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/autoscale/autoscale-custom-metric.md | - Title: Autoscale in Azure using a custom metric -description: Learn how to scale your web app by using custom metrics in the Azure portal. ----- Previously updated : 08/07/2024---# Customer intent: As a user or dev ops administrator, I want to use the portal to set up autoscale so I can scale my resources. ---# Autoscale a web app by using custom metrics --This article takes you through how to set up autoscale for a web app by using a custom metric in the Azure portal. --Autoscale allows you to add and remove resources to handle increases and decreases in load. In this article, we'll show you how to set up autoscale for a web app by using one of the Application Insights metrics to scale the web app in and out. --> [!NOTE] -> Autoscaling on custom metrics in Application Insights is supported only for metrics published to **Standard** and **Azure.ApplicationInsights** namespaces. If any other namespaces are used for custom metrics in Application Insights, it returns an **Unsupported Metric** error. --Azure Monitor autoscale applies to: --+ [Azure Virtual Machine Scale Sets](https://azure.microsoft.com/services/virtual-machine-scale-sets/) -+ [Azure Cloud Services](https://azure.microsoft.com/services/cloud-services/) -+ [Azure App Service - Web Apps](https://azure.microsoft.com/services/app-service/web/) -+ [Azure Data Explorer cluster](https://azure.microsoft.com/services/data-explorer/) -+ [Azure API Management](../../api-management/api-management-key-concepts.md) --## Prerequisite --You must have an Azure account with an active subscription. You can [create an account for free](https://azure.microsoft.com/free). --## Overview --To create an autoscaled web app: --1. If you don't already have one, [create an App Service plan](#create-an-app-service-plan). You can't set up autoscale for free or basic tiers. -1. If you don't already have one, [create a web app](#create-a-web-app) by using your service plan. -1. [Configure autoscaling](#configure-autoscale) for your service plan. --## Create an App Service plan --An App Service plan defines a set of compute resources for a web app to run on. --1. Open the [Azure portal](https://portal.azure.com). -1. Search for and select **App Service plans**. -- :::image type="content" source="media\autoscale-custom-metric\search-app-service-plan.png" lightbox="media\autoscale-custom-metric\search-app-service-plan.png" alt-text="Screenshot that shows searching for App Service plans."::: --1. On the **App Service plan** page, select **Create**. -1. Select a **Resource group** or create a new one. -1. Enter a **Name** for your plan. -1. Select an **Operating system** and **Region**. -1. Select an **SKU** and **size**. -- > [!NOTE] - > You can't use autoscale with free or basic tiers. --1. Select **Review + create** > **Create**. -- :::image type="content" source="media\autoscale-custom-metric\create-app-service-plan.png" lightbox="media\autoscale-custom-metric\create-app-service-plan.png" alt-text="Screenshot that shows the Basics tab of the Create App Service Plan screen on which you configure the App Service plan."::: --## Create a web app --1. Search for and select **App services**. -- :::image type="content" source="media\autoscale-custom-metric\search-app-services.png" lightbox="media\autoscale-custom-metric\search-app-services.png" alt-text="Screenshot that shows searching for App Services."::: --1. On the **App Services** page, select **Create**. -1. On the **Basics** tab, enter a **Name** and select a **Runtime stack**. -1. Select the **Operating System** and **Region** that you chose when you defined your App Service plan. -1. Select the **App Service plan** that you created earlier. -1. Select the **Monitoring** tab. -- :::image type="content" source="media\autoscale-custom-metric\create-web-app.png" lightbox="media\autoscale-custom-metric\create-web-app.png" alt-text="Screenshot that shows the Basics tab of the Create Web App page where you set up a web app."::: --1. On the **Monitoring** tab, select **Yes** to enable Application Insights. -1. Select **Review + create** > **Create**. -- :::image type="content" source="media\autoscale-custom-metric\enable-application-insights.png" lightbox="media\autoscale-custom-metric\enable-application-insights.png" alt-text="Screenshot that shows the Monitoring tab of the Create Web App page where you enable Application Insights."::: --## Configure autoscale --Configure the autoscale settings for your App Service plan. --1. Search and select **autoscale** in the search bar or select **Autoscale** under **Monitor** in the menu bar on the left. -1. Select your App Service plan. You can only configure production plans. -- :::image type="content" source="media\autoscale-custom-metric\autoscale-overview-page.png" lightbox="media\autoscale-custom-metric\autoscale-overview-page.png" alt-text="Screenshot that shows the Autoscale page where you select the resource to set up autoscale."::: --### Set up a scale-out rule --Set up a scale-out rule so that Azure spins up another instance of the web app when your web app is handling more than 70 sessions per instance. --1. Select **Custom autoscale**. -1. In the **Rules** section of the default scale condition, select **Add a rule**. -- :::image type="content" source="media/autoscale-custom-metric/autoscale-settings.png" lightbox="media/autoscale-custom-metric/autoscale-settings.png" alt-text="Screenshot that shows the Autoscale setting page where you set up the basic autoscale settings."::: --1. From the **Metric source** dropdown, select **Other resource**. -1. From **Resource type**, select **Application Insights**. -1. From the **Resource** dropdown, select your web app. -1. Select a **Metric name** to base your scaling on. For example, use **Sessions**. -1. Select the **Enable metric divide by instance count** checkbox so that the number of sessions per instance is measured. -1. From the **Operator** dropdown, select **Greater than**. -1. Enter the **Metric threshold to trigger the scale action**. For example, use **70**. -1. Under **Action**, set **Operation** to **Increase count by**. Set **Instance count** to **1**. -1. Select **Add**. -- :::image type="content" source="media/autoscale-custom-metric/scale-out-rule.png" lightbox="media/autoscale-custom-metric/scale-out-rule.png" alt-text="Screenshot that shows the Scale rule page where you configure the scale-out rule."::: --### Set up a scale-in rule --Set up a scale-in rule so that Azure spins down one of the instances when the number of sessions your web app is handling is less than 60 per instance. Azure reduces the number of instances each time this rule is run until the minimum number of instances is reached. --1. In the **Rules** section of the default scale condition, select **Add a rule**. -1. From the **Metric source** dropdown, select **Other resource**. -1. From **Resource type**, select **Application Insights**. -1. From the **Resource** dropdown, select your web app. -1. Select a **Metric name** to base your scaling on. For example, use **Sessions**. -1. Select the **Enable metric divide by instance count** checkbox so that the number of sessions per instance is measured. -1. From the **Operator** dropdown, select **Less than**. -1. Enter the **Metric threshold to trigger the scale action**. For example, use **60**. -1. Under **Action**, set **Operation** to **Decrease count by** and set **Instance count** to **1**. -1. Select **Add**. -- :::image type="content" source="media/autoscale-custom-metric/scale-in-rule.png" lightbox="media/autoscale-custom-metric/scale-in-rule.png" alt-text="Screenshot that shows the Scale rule page where you configure the scale-in rule."::: --### Limit the number of instances --1. Set the maximum number of instances that can be spun up in the **Maximum** field of the **Instance limits** section. For example, use **4**. -1. Select **Save**. -- :::image type="content" source="media/autoscale-custom-metric/autoscale-instance-limits.png" lightbox="media/autoscale-custom-metric/autoscale-instance-limits.png" alt-text="Screenshot that shows the Autoscale setting page where you set up instance limits."::: --## Clean up resources --If you're not going to continue to use this application, delete resources. --1. On the App Service overview page, select **Delete**. -- :::image type="content" source="media/autoscale-custom-metric/delete-web-app.png" lightbox="media/autoscale-custom-metric/delete-web-app.png" alt-text="Screenshot that shows the App Service page where you can delete the web app."::: --1. On the **Autoscale setting** page, in the **JSON** tab, select the trash bin icon next to the **Autoscale setting name**. Note that the autoscale settings aren't deleted along with the App Service plan unless you delete the resource group. If you don't delete the Autoscale settings and you recreate an app service plan with the same name, it inherits the original autoscale settings. --1. On the **App Service plans** page, select **Delete**. -- :::image type="content" source="media/autoscale-custom-metric/delete-service-plan.png" lightbox="media/autoscale-custom-metric/delete-service-plan.png" alt-text="Screenshot that shows the App Service plans page where you can delete the App Service plan."::: --## Next steps --To learn more about autoscale, see the following articles: --+ [Use autoscale actions to send email and webhook alert notifications](./autoscale-webhook-email.md) -+ [Overview of autoscale](./autoscale-overview.md) -+ [Azure Monitor autoscale common metrics](./autoscale-common-metrics.md) -+ [Best practices for Azure Monitor autoscale](./autoscale-best-practices.md) -+ [Autoscale REST API](/rest/api/monitor/autoscalesettings) |
| azure-monitor | Autoscale Diagnostics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/autoscale/autoscale-diagnostics.md | - Title: Autoscale diagnostics -description: This article shows you how to configure diagnostics in autoscale. ----- Previously updated : 04/15/2024---# Customer intent: As a DevOps admin, I want to collect and analyze autoscale metrics and logs. --# Diagnostic settings in autoscale --Autoscale has two log categories and a set of metrics that can be enabled via the **Diagnostics settings** tab on the **Autoscale setting** page. ---The two categories are: --* [Autoscale Evaluations](/azure/azure-monitor/reference/tables/autoscaleevaluationslog) contain log data relating to rule evaluation. -* [Autoscale Scale Actions](/azure/azure-monitor/reference/tables/autoscalescaleactionslog) log data relating to each scale event. --For more information about autoscale metrics, see the [Supported metrics](../essentials/metrics-supported.md#microsoftinsightsautoscalesettings) document. --You can send logs and metrics to various destinations: --* Log Analytics workspaces -* Storage accounts -* Event hubs -* Partner solutions --For more information on diagnostics, see [Diagnostic settings in Azure Monitor](../essentials/diagnostic-settings.md?tabs=portal). --## Run history --View the history of your autoscale activity on the **Run history** tab. The **Run history** tab includes a chart of resource instance counts over time and the resource activity log entries for autoscale. ---## Resource log schemas --The following examples are the general formats for autoscale resource logs with example data included. Not all the examples are properly formed JSON because they might include a valid list for a given field. --Use these logs to troubleshoot issues in autoscale. For more information, see [Troubleshooting autoscale problems](autoscale-troubleshoot.md). --> [!NOTE] -> Although the logs may refer to "scale up" and "scale down" actions, the actual action taken is scale in or scale out. --## Autoscale evaluations log -The following schemas appear in the autoscale evaluations log. --### Profile evaluation --Logged when autoscale first looks at an autoscale profile: --```JSON -{ - "time": "2018-09-10 18:12:00.6132593", - "resourceId": "/SUBSCRIPTIONS/BA13C41D-C957-4774-8A37-092D62ACFC85/RESOURCEGROUPS/AUTOSCALETRACKING12042017/PROVIDERS/MICROSOFT.INSIGHTS/AUTOSCALESETTINGS/DEFAULTSETTING", - "operationName": ["FixedDateProfileEvaluation", "RecurrentProfileEvaluation", "DefaultProfileEvaluation"], - "category": "AutoscaleEvaluations", - "correlationId": "e8f67045-f381-445d-bc2d-eeff81ec0d77", - "property": { - "targetResourceId": "/subscriptions/d45c994a-809b-4cb3-a952-e75f8c488d23/resourceGroups/RingAhoy/providers/Microsoft.Web/serverfarms/ringahoy", - "profile": "defaultProfile", - "profileSelected": [true, false] - } -} -``` --### Profile cool-down evaluation --Logged when autoscale evaluates if it shouldn't scale because of a cool-down period: --```JSON -{ - "time": "2018-09-10 18:12:00.6132593", - "resourceId": "/SUBSCRIPTIONS/BA13C41D-C957-4774-8A37-092D62ACFC85/RESOURCEGROUPS/AUTOSCALETRACKING12042017/PROVIDERS/MICROSOFT.INSIGHTS/AUTOSCALESETTINGS/DEFAULTSETTING", - "operationName": "ScaleRuleCooldownEvaluation", - "category": "AutoscaleEvaluations", - "correlationId": "e8f67045-f381-445d-bc2d-eeff81ec0d77", - "property": { - "targetResourceId": "/subscriptions/d45c994a-809b-4cb3-a952-e75f8c488d23/resourceGroups/RingAhoy/providers/Microsoft.Web/serverfarms/ringahoy", - "selectedProfile": "defaultProfile", - "scaleDirection": ["Increase", "Decrease"] - "lastScaleActionTime": "2018-09-10 18:08:00.6132593", - "cooldown": "00:30:00", - "evaluationTime": "2018-09-10 18:11:00.6132593", - "skipRuleEvaluationForCooldown": true - } -} -``` --### Rule evaluation --Logged when autoscale first starts evaluating a particular scale rule: --```JSON -{ - "time": "2018-09-10 18:12:00.6132593", - "resourceId": "/SUBSCRIPTIONS/BA13C41D-C957-4774-8A37-092D62ACFC85/RESOURCEGROUPS/AUTOSCALETRACKING12042017/PROVIDERS/MICROSOFT.INSIGHTS/AUTOSCALESETTINGS/DEFAULTSETTING", - "operationName": "ScaleRuleEvaluation", - "category": "AutoscaleEvaluations", - "correlationId": "e8f67045-f381-445d-bc2d-eeff81ec0d77", - "property": { - "targetResourceId": "/subscriptions/d45c994a-809b-4cb3-a952-e75f8c488d23/resourceGroups/RingAhoy/providers/Microsoft.Web/serverfarms/ringahoy", - "metricName": "Percentage CPU", - "metricNamespace": "", - "timeGrain": "00:01:00", - "timeGrainStatistic": "Average", - "timeWindow": "00:10:00", - "timeAggregationType": "Average", - "operator": "GreaterThan", - "threshold": 70, - "observedValue": 25, - "estimateScaleResult": ["Triggered", "NotTriggered", "Unknown"] - } -} -``` --### Metric evaluation --Logged when autoscale evaluates the metric being used to trigger a scale action: --```JSON -{ - "time": "2018-09-10 18:12:00.6132593", - "resourceId": "/SUBSCRIPTIONS/BA13C41D-C957-4774-8A37-092D62ACFC85/RESOURCEGROUPS/AUTOSCALETRACKING12042017/PROVIDERS/MICROSOFT.INSIGHTS/AUTOSCALESETTINGS/DEFAULTSETTING", - "operationName": "MetricEvaluation", - "category": "AutoscaleEvaluations", - "correlationId": "e8f67045-f381-445d-bc2d-eeff81ec0d77", - "property": { - "targetResourceId": "/subscriptions/d45c994a-809b-4cb3-a952-e75f8c488d23/resourceGroups/RingAhoy/providers/Microsoft.Web/serverfarms/ringahoy", - "metricName": "Percentage CPU", - "metricNamespace": "", - "timeGrain": "00:01:00", - "timeGrainStatistic": "Average", - "startTime": "2018-09-10 18:00:00.43833793", - "endTime": "2018-09-10 18:10:00.43833793", - "data": [0.33333333333333331,0.16666666666666666,1.0,0.33333333333333331,2.0,0.16666666666666666,9.5] - } -} -``` --### Instance count evaluation --Logged when autoscale evaluates the number of instances already running in preparation for deciding if it should start more, shut down some, or do nothing: --```JSON -{ - "time": "2018-09-10 18:12:00.6132593", - "resourceId": "/SUBSCRIPTIONS/BA13C41D-C957-4774-8A37-092D62ACFC85/RESOURCEGROUPS/AUTOSCALETRACKING12042017/PROVIDERS/MICROSOFT.INSIGHTS/AUTOSCALESETTINGS/DEFAULTSETTING", - "operationName": "InstanceCountEvaluation", - "category": "AutoscaleEvaluations", - "correlationId": "e8f67045-f381-445d-bc2d-eeff81ec0d77", - "property": { - "targetResourceId": "/subscriptions/d45c994a-809b-4cb3-a952-e75f8c488d23/resourceGroups/RingAhoy/providers/Microsoft.Web/serverfarms/ringahoy", - "currentInstanceCount": 20, - "minimumInstanceCount": 15, - "maximumInstanceCount": 30, - "defaultInstanceCount": 20 - } -} -``` --### Scale action evaluation --Logged when autoscale starts evaluation if a scale action should take place: --```JSON -{ - "time": "2018-09-10 18:12:00.6132593", - "resourceId": "/SUBSCRIPTIONS/BA13C41D-C957-4774-8A37-092D62ACFC85/RESOURCEGROUPS/AUTOSCALETRACKING12042017/PROVIDERS/MICROSOFT.INSIGHTS/AUTOSCALESETTINGS/DEFAULTSETTING", - "operationName": "ScaleActionOperationEvaluation", - "category": "AutoscaleEvaluations", - "correlationId": "e8f67045-f381-445d-bc2d-eeff81ec0d77", - "property": { - "targetResourceId": "/subscriptions/d45c994a-809b-4cb3-a952-e75f8c488d23/resourceGroups/RingAhoy/providers/Microsoft.Web/serverfarms/ringahoy", - "lastScaleActionOperationId": "378ejr-7yye-892d-17dd-92ndijfe1738", - "lastScaleActionOperationStatus": ["InProgress", "Timeout"] - "skipCurrentAutoscaleEvaluation": [true, false] - } -} -``` --### Instance update evaluation --Logged when autoscale updates the number of compute instances running, either up or down: --```JSON -{ - "time": "2018-09-10 18:12:00.6132593", - "resourceId": "/SUBSCRIPTIONS/BA13C41D-C957-4774-8A37-092D62ACFC85/RESOURCEGROUPS/AUTOSCALETRACKING12042017/PROVIDERS/MICROSOFT.INSIGHTS/AUTOSCALESETTINGS/DEFAULTSETTING", - "operationName": "InstanceUpdateEvaluation", - "category": "AutoscaleEvaluations", - "correlationId": "e8f67045-f381-445d-bc2d-eeff81ec0d77", - "property": { - "targetResourceId": "/subscriptions/d45c994a-809b-4cb3-a952-e75f8c488d23/resourceGroups/RingAhoy/providers/Microsoft.Web/serverfarms/ringahoy", - "currentInstanceCount": 20, - "newInstanceCount": 21, - "shouldUpdateInstance": [true, false], - "reason": ["Scale down action triggered", "Scale up to default instance count", ...] - } -} -``` --## Autoscale scale actions log --The following schemas appear in the autoscale evaluations log. --### Scale action --Logged when autoscale initiates a scale action, either up or down: --```JSON -{ - "time": "2018-09-10 18:12:00.6132593", - "resourceId": "/SUBSCRIPTIONS/BA13C41D-C957-4774-8A37-092D62ACFC85/RESOURCEGROUPS/AUTOSCALETRACKING12042017/PROVIDERS/MICROSOFT.INSIGHTS/AUTOSCALESETTINGS/DEFAULTSETTING", - "operationName": "InstanceScaleAction", - "category": "AutoscaleScaleActions", - "resultType": ["Succeeded", "InProgress", "Failed"], - "resultDescription": ["Create async operation job failed", ...] - "correlationId": "e8f67045-f381-445d-bc2d-eeff81ec0d77", - "property": { - "targetResourceId": "/subscriptions/d45c994a-809b-4cb3-a952-e75f8c488d23/resourceGroups/RingAhoy/providers/Microsoft.Web/serverfarms/ringahoy", - "currentInstanceCount": 20, - "newInstanceCount": 21, - "scaleDirection": ["Increase", "Decrease"], - ["createdAsyncScaleActionJob": [true, false],] - ["createdAsyncScaleActionJobId": "378ejr-7yye-892d-17dd-92ndijfe1738",] - } -} -``` --### Scale action tracking --Logged at different intervals of an instance scale action: --```JSON -{ - "time": "2018-09-10 18:12:00.6132593", - "resourceId": "/SUBSCRIPTIONS/BA13C41D-C957-4774-8A37-092D62ACFC85/RESOURCEGROUPS/AUTOSCALETRACKING12042017/PROVIDERS/MICROSOFT.INSIGHTS/AUTOSCALESETTINGS/DEFAULTSETTING", - "operationName": "InstanceScaleAction", - "category": "AutoscaleScaleActions", - "correlationId": "e8f67045-f381-445d-bc2d-eeff81ec0d77", - "property": { - "targetResourceId": "/subscriptions/d45c994a-809b-4cb3-a952-e75f8c488d23/resourceGroups/RingAhoy/providers/Microsoft.Web/serverfarms/ringahoy", - "scaleActionOperationId": "378ejr-7yye-892d-17dd-92ndijfe1738", - "scaleActionOperationStatus": ["InProgress", "Timeout", "Canceled", ...], - "scaleActionMessage": ["Scale action is inprogress", ...] - } -} -``` --## Activity logs -The following events are logged to the activity log with a `CategoryValue` of `Autoscale`: --* Autoscale scale-up initiated -* Autoscale scale-up completed -* Autoscale scale-down initiated -* Autoscale scale-down completed -* Predictive autoscale scale-up initiated -* Predictive autoscale scale-up completed -* Metric failure -* Metric recovery -* Predictive metric failure -* Flapping --An extract of each log event name, showing the relevant parts of the `Properties` element, are shown next. --### Autoscale action --Logged when autoscale attempts to scale in or out: --```JSON -{ - "eventCategory": "Autoscale", - "eventName": "AutoscaleAction", - ... - "eventProperties": "{ - "Description": "The autoscale engine attempting to scale resource '/subscriptions/d1234567-9876-a1b2-a2b1-123a567b9f8767/resourcegroups/ed-rg-001/providers/Microsoft.Web/serverFarms/ScaleableAppServicePlan' from 2 instances count to 1 instancescount.", - "ResourceName": "/subscriptions/d1234567-9876-a1b2-a2b1-123a567b9f8767/resourcegroups/ed-rg-001/providers/Microsoft.Web/serverFarms/ScaleableAppServicePlan", - "OldInstancesCount": 2, - "NewInstancesCount": 1, - "ActiveAutoscaleProfile": { - "Name": "Default scale condition", - "Capacity": { - "Minimum": "1", - "Maximum": "5", - "Default": "1" - }, - "Rules": [ - { - "MetricTrigger": { - "Name": "CpuPercentage", - "Namespace": "microsoft.web/serverfarms", - "Resource": "/subscriptions/d1234567-9876-a1b2-a2b1-123a567b9f8767/resourceGroups/ed-rg-001/providers/Microsoft.Web/serverFarms/ScaleableAppServicePlan", - "ResourceLocation": "West Central US", - "TimeGrain": "PT1M", - "Statistic": "Average", - "TimeWindow": "PT2M", - "TimeAggregation": "Average", - "Operator": "GreaterThan", - "Threshold": 40.0, - "Source": "/subscriptions/d1234567-9876-a1b2-a2b1-123a567b9f8767/resourceGroups/ed-rg-001/providers/Microsoft.Web/serverFarms/ScaleableAppServicePlan", - "MetricType": "MDM", - "Dimensions": [], - "DividePerInstance": false - }, - "ScaleAction": { - "Direction": "Increase", - "Type": "ChangeCount", - "Value": "1", - "Cooldown": "PT3M" - } - }, - { - "MetricTrigger": { - "Name": "CpuPercentage", - "Namespace": "microsoft.web/serverfarms", - "Resource": "/subscriptions/d1234567-9876-a1b2-a2b1-123a567b9f8767/resourceGroups/ed-rg-001/providers/Microsoft.Web/serverFarms/ScaleableAppServicePlan", - "ResourceLocation": "West Central US", - "TimeGrain": "PT1M", - "Statistic": "Average", - "TimeWindow": "PT5M", - "TimeAggregation": "Average", - "Operator": "LessThanOrEqual", - "Threshold": 30.0, - "Source": "/subscriptions/d1234567-9876-a1b2-a2b1-123a567b9f8767/resourceGroups/ed-rg-001/providers/Microsoft.Web/serverFarms/ScaleableAppServicePlan", - "MetricType": "MDM", - "Dimensions": [], - "DividePerInstance": false - }, - "ScaleAction": { - "Direction": "Decrease", - "Type": "ExactCount", - "Value": "1", - "Cooldown": "PT5M" - } - } - ] - }, - "LastScaleActionTime": "Thu, 26 Jan 2023 12:57:14 GMT" - }", - ... - "activityStatusValue": "Succeeded" -} --``` --### Get operation status result --Logged following a scale event: --```JSON --"Properties":{ - "eventCategory": "Autoscale", - "eventName": "GetOperationStatusResult", - ... - "eventProperties": "{"OldInstancesCount":3,"NewInstancesCount":2}", - ... - "activityStatusValue": "Succeeded" -} --``` --### Metric failure --Logged when autoscale can't determine the value of the metric used in the scale rule: --```JSON -"Properties":{ - "eventCategory": "Autoscale", - "eventName": "MetricFailure", - ... - "eventProperties": "{ - "Notes":"To ensure service availability, Autoscale will scale out the resource to the default capacity if it is greater than the current capacity}", - ... - "activityStatusValue": "Failed" -} -``` --### Metric recovery --Logged when autoscale can once again determine the value of the metric used in the scale rule after a `MetricFailure` event: --```JSON -"Properties":{ - "eventCategory": "Autoscale", - "eventName": "MetricRecovery", - ... - "eventProperties": "{}", - ... - "activityStatusValue": "Succeeded" -} -``` --### Predictive metric failure --Logged when autoscale can't calculate predicted scale events because the metric is unavailable: --```JSON -"Properties": { - "eventCategory": "Autoscale", - "eventName": "PredictiveMetricFailure", - ... - "eventProperties": "{ - "Notes": "To ensure service availability, Autoscale will scale out the resource to the default capacity if it is greater than the current capacity" - }", - ... - "activityStatusValue": "Failed" -} -``` --### Flapping occurred --Logged when autoscale detects flapping could occur and scales differently to avoid it: --```JSON -"Properties":{ - "eventCategory": "Autoscale", - "eventName": "FlappingOccurred", - ... - "eventProperties": - "{"Description":"Scale down will occur with updated instance count to avoid flapping. - Resource: '/subscriptions/d1234567-9876-a1b2-a2b1-123a567b9f8767/resourcegroups/rg-001/providers/Microsoft.Web/serverFarms/ScaleableAppServicePlan'. - Current instance count: '6', - Intended new instance count: '1'. - Actual new instance count: '4'", - "ResourceName":"/subscriptions/d1234567-9876-a1b2-a2b1-123a567b9f8767/resourcegroups/rg-001/providers/Microsoft.Web/serverFarms/ScaleableAppServicePlan", - "OldInstancesCount":6, - "NewInstancesCount":4, - "ActiveAutoscaleProfile":{"Name":"Auto created scale condition", - "Capacity":{"Minimum":"1","Maximum":"30","Default":"1"}, - "Rules":[{"MetricTrigger":{"Name":"Requests","Namespace":"microsoft.web/sites","Resource":"/subscriptions/ d1234567-9876-a1b2-a2b1-123a567b9f8767/resourceGroups/rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1", "ResourceLocation":"West Central US","TimeGrain":"PT1M","Statistic":"Average","TimeWindow":"PT1M","TimeAggregation":"Maximum", "Operator":"GreaterThanOrEqual","Threshold":3.0,"Source":"/subscriptions/d1234567-9876-a1b2-a2b1-123a567b9f8767/resourceGroups/ rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","MetricType":"MDM","Dimensions":[],"DividePerInstance":true}, "ScaleAction":{"Direction":"Increase","Type":"ChangeCount","Value":"10","Cooldown":"PT1M"}},{"MetricTrigger":{"Name":"Requests", "Namespace":"microsoft.web/sites","Resource":"/subscriptions/d1234567-9876-a1b2-a2b1-123a567b9f8767/resourceGroups/rg-001/ providers/Microsoft.Web/sites/ScaleableWebApp1","ResourceLocation":"West Central US","TimeGrain":"PT1M","Statistic":"Max", "TimeWindow":"PT1M","TimeAggregation":"Maximum","Operator":"LessThan","Threshold":3.0,"Source":"/subscriptions/ d1234567-9876-a1b2-a2b1-123a567b9f8767/resourceGroups/rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","MetricType":"MDM", "Dimensions":[],"DividePerInstance":true},"ScaleAction":{"Direction":"Decrease","Type":"ChangeCount","Value":"5", "Cooldown":"PT1M"}}]}}", - ... - "activityStatusValue": "Succeeded" -} -``` --### Flapping --Logged when autoscale detects flapping could occur and defers scaling in to avoid it: --```JSON -"Properties": { - "eventCategory": "Autoscale", - "eventName": "Flapping", - "Description": "{"Cannot scale down due to flapping observed. Resource: '/subscriptions/d1234567-9876-a1b2-a2b1-123a567b9f8767/resourcegroups/rg-001/providers/Microsoft.Compute/virtualMachineScaleSets/mac2'. Current instance count: '2', Intended new instance count '1'", - "ResourceName": "/subscriptions/d1234567-9876-a1b2-a2b1-123a567b9f8767/resourcegroups/rg-001/providers/Microsoft.Compute/virtualMachineScaleSets/mac2", - "OldInstancesCount": "2", - "NewInstancesCount": "2", - "ActiveAutoscaleProfile": "ActiveAutoscaleProfile": { - "Name": "Auto created default scale condition", - "Capacity": { - "Minimum": "1", - "Maximum": "2", - "Default": "1" - }, - "Rules": [ - { - "MetricTrigger": { - "Name": "StorageSuccesses", - "Namespace": "monitoringbackgroundjob", - "Resource": "/subscriptions/d1234567-9876-a1b2-a2b1-123a567b9f8767/resourceGroups/rg-001/providers/microsoft.monitor/accounts/MACAzureInsightsPROD", - "ResourceLocation": "EastUS2", - "TimeGrain": "PT1M", - "Statistic": "Average", - "TimeWindow": "PT10M", - "TimeAggregation": "Average", - "Operator": "LessThan", - "Threshold": 600.0, - "Source": "/subscriptions/d1234567-9876-a1b2-a2b1-123a567b9f8767/resourceGroups/rg-001/providers/microsoft.monitor/accounts/MACAzureInsightsPROD", - "MetricType": "MDM", - "Dimensions": [], - "DividePerInstance": false - }, - "ScaleAction": { - "Direction": "Decrease", - "Type": "ChangeCount", - "Value": "1", - "Cooldown": "PT5M" - } - }, - { - "MetricTrigger": { - "Name": "TimeToStartupInMs", - "Namespace": "armrpclient", - "Resource": "/subscriptions/d1234567-9876-a1b2-a2b1-123a567b9f8767/resourceGroups/rg-123/providers/microsoft.monitor/accounts/MACMetricsRP", - "ResourceLocation": "eastus2", - "TimeGrain": "PT1M", - "Statistic": "Percentile99th", - "TimeWindow": "PT10M", - "TimeAggregation": "Average", - "Operator": "GreaterThan", - "Threshold": 70.0, - "Source": "/subscriptions/d1234567-9876-a1b2-a2b1-123a567b9f8767/resourceGroups/rg-123/providers/microsoft.monitor/accounts/MACMetricsRP", - "MetricType": "MDM", - "Dimensions": [], - "DividePerInstance": false - }, - "ScaleAction": { - "Direction": "Increase", - "Type": "ChangeCount", - "Value": "1", - "Cooldown": "PT5M" - } - } - ] - }" -}... -``` --## Next steps --* [Troubleshooting autoscale](./autoscale-troubleshoot.md) -* [Autoscale flapping](./autoscale-flapping.md) -* [Autoscale settings](./autoscale-understanding-settings.md) |
| azure-monitor | Autoscale Flapping | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/autoscale/autoscale-flapping.md | - Title: Autoscale flapping -description: "Flapping in Autoscale" ----- Previously updated : 08/07/2024---#Customer intent: As a cloud administrator, I want understand flapping so that I can configure autoscale correctly. ---# Flapping in Autoscale --This article describes flapping in autoscale and how to avoid it. --Flapping refers to a loop condition that causes a series of opposing scale events. Flapping happens when a scale event triggers the opposite scale event. --Autoscale evaluates a pending scale-in action to see if it would cause flapping. In cases where flapping could occur, autoscale may skip the scale action and reevaluate at the next run, or autoscale may scale by less than the specified number of resource instances. The autoscale evaluation process occurs each time the autoscale engine runs, which is every 30 to 60 seconds, depending on the resource type. --To ensure adequate resources, checking for potential flapping doesn't occur for scale-out events. Autoscale will only defer a scale-in event to avoid flapping. --For example, let's assume the following rules: --* Scale out increasing by 1 instance when average CPU usage is above 50%. -* Scale in decreasing the instance count by 1 instance when average CPU usage is lower than 30%. -- In the table below at T0, when usage is at 56%, a scale-out action is triggered and results in 56% CPU usage across 2 instances. That gives an average of 28% for the scale set. As 28% is less than the scale-in threshold, autoscale should scale back in. Scaling in would return the scale set to 56% CPU usage, which triggers a scale-out action. --|Time| Instance count| CPU% |CPU% per instance| Scale event| Resulting instance count -||||||| -T0|1|56%|56%|Scale out|2| -T1|2|56%|28%|Scale in|1| -T2|1|56%|56%|Scale out|2| -T3|2|56%|28%|Scale in|1| --If left uncontrolled, there would be an ongoing series of scale events. However, in this situation, the autoscale engine will defer the scale-in event at *T1* and reevaluate during the next autoscale run. The scale-in will only happen once the average CPU usage is below 30%. --Flapping is often caused by: --* Small or no margins between thresholds -* Scaling by more than one instance -* Scaling in and out using different metrics --## Small or no margins between thresholds --To avoid flapping, keep adequate margins between scaling thresholds. --For example, the following rules where there's no margin between thresholds, cause flapping. --* Scale out when thread count >=600 -* Scale in when thread count < 600 ---The table below shows a potential outcome of these autoscale rules: --|Time| Instance count| Thread count|Thread count per instance| Scale event| Resulting instance count -||||||| -T0|2|1250|625|Scale out|3| -T1|3|1250|417|Scale in|2| --* At time T0, there are two instances handling 1250 threads, or 625 treads per instance. Autoscale scales out to three instances. -* Following the scale-out, at T1, we have the same 1250 threads, but with three instances, only 417 threads per instance. A scale-in event is triggered. -* Before scaling-in, autoscale evaluates what would happen if the scale-in event occurs. In this example, 1250 / 2 = 625, that is, 625 threads per instance. Autoscale would have to immediately scale out again after it scaled in. If it scaled out again, the process would repeat, leading to flapping loop. -* To avoid this situation, autoscale doesn't scale in. Autoscale skips the current scale event and reevaluates the rule in the next execution cycle. --In this case, it looks like autoscale isn't working since no scale event takes place. Check the *Run history* tab on the autoscale setting page to see if there's any flapping. ---Setting an adequate margin between thresholds avoids the above scenario. For example, --* Scale out when thread count >=600 -* Scale in when thread count < 400 ---If the scale-in thread count is 400, the total thread count would have to drop to below 1200 before a scale event would take place. See the table below. --|Time| Instance count| Thread count|Thread count per instance| Scale event| Resulting instance count -||||||| -T0|2|1250|625|Scale out|3| -T1|3|1250|417|no scale event|3| -T2|3|1180|394|scale in|2| -T3|3|1180|590|no scale event|2| --## Scaling by more than one instance --To avoid flapping when scaling in or out by more than one instance, autoscale may scale by less than the number of instances specified in the rule. --For example, the following rules can cause flapping: --* Scale out by 20 when the request count >=200 per instance. -* OR when CPU > 70% per instance. -* Scale in by 10 when the request count <=50 per instance. ---The table below shows a potential outcome of these autoscale rules: --|Time|Number of instances|CPU |Request count| Scale event| Resulting instances|Comments| -|||||||| -|T0|30|65%|3000, or 100 per instance.|No scale event|30| -|T1|30|65|1500| Scale in by 3 instances |27|Scaling-in by 10 would cause an estimated CPU rise above 70%, leading to a scale-out event. --At time T0, the app is running with 30 instances, a total request count of 3000, and a CPU usage of 65% per instance. --At T1, when the request count drops to 1500 requests, or 50 requests per instance, autoscale will try to scale in by 10 instances to 20. However, autoscale estimates that the CPU load for 20 instances will be above 70%, causing a scale-out event. --To avoid flapping, the autoscale engine estimates the CPU usage for instance counts above 20 until it finds an instance count where all metrics are with in the defined thresholds: --* Keep the CPU below 70%. -* Keep the number of requests per instance is above 50. -* Reduce the number of instances below 30. --In this situation, autoscale may scale in by 3, from 30 to 27 instances in order to satisfy the rules, even though the rule specifies a decrease of 10. A log message is written to the activity log with a description that includes *Scale down will occur with updated instance count to avoid flapping* --If autoscale can't find a suitable number of instances, it will skip the scale in event and reevaluate during the next cycle. --> [!NOTE] -> If the autoscale engine detects that flapping could occur as a result of scaling to the target number of instances, it will also try to scale to a lower number of instances between the current count and the target count. If flapping does not occur within this range, autoscale will continue the scale operation with the new target. --## Log files --Find flapping in the activity log with the following query: --````KQL -// Activity log, CategoryValue: Autoscale -// Lists latest Autoscale operations from the activity log, with OperationNameValue =="Microsoft.Insights/AutoscaleSettings/Flapping/Action -AzureActivity -|where CategoryValue =="Autoscale" and OperationNameValue =="Microsoft.Insights/AutoscaleSettings/Flapping/Action" -|sort by TimeGenerated desc -```` --Below is an example of an activity log record for flapping: ---````JSON -{ -"eventCategory": "Autoscale", -"eventName": "FlappingOccurred", -"operationId": "1111bbbb-22cc-dddd-ee33-ffffff444444", -"eventProperties": - "{"Description":"Scale down will occur with updated instance count to avoid flapping. - Resource: '/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/ed-rg-001/providers/Microsoft.Web/serverFarms/ScaleableAppServicePlan'. - Current instance count: '6', - Intended new instance count: '1'. - Actual new instance count: '4'", - "ResourceName":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/rg-001/providers/Microsoft.Web/serverFarms/ScaleableAppServicePlan", - "OldInstancesCount":6, - "NewInstancesCount":4, - "ActiveAutoscaleProfile":{"Name":"Auto created scale condition", - "Capacity":{"Minimum":"1","Maximum":"30","Default":"1"}, - "Rules":[{"MetricTrigger":{"Name":"Requests","Namespace":"microsoft.web/sites","Resource":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","ResourceLocation":"West Central US","TimeGrain":"PT1M","Statistic":"Average","TimeWindow":"PT1M","TimeAggregation":"Maximum","Operator":"GreaterThanOrEqual","Threshold":3.0,"Source":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/ed-rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","MetricType":"MDM","Dimensions":[],"DividePerInstance":true},"ScaleAction":{"Direction":"Increase","Type":"ChangeCount","Value":"10","Cooldown":"PT1M"}},{"MetricTrigger":{"Name":"Requests","Namespace":"microsoft.web/sites","Resource":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","ResourceLocation":"West Central US","TimeGrain":"PT1M","Statistic":"Max","TimeWindow":"PT1M","TimeAggregation":"Maximum","Operator":"LessThan","Threshold":3.0,"Source":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/ed-rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","MetricType":"MDM","Dimensions":[],"DividePerInstance":true},"ScaleAction":{"Direction":"Decrease","Type":"ChangeCount","Value":"5","Cooldown":"PT1M"}}]}}", -"eventDataId": "dddd3333-ee44-5555-66ff-777777aaaaaa", -"eventSubmissionTimestamp": "2022-09-13T07:20:41.1589076Z", -"resource": "scaleableappserviceplan", -"resourceGroup": "RG-001", -"resourceProviderValue": "MICROSOFT.WEB", -"subscriptionId": "aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e", -"activityStatusValue": "Succeeded" -} -```` --## Next steps --To learn more about autoscale, see the following resources: --* [Overview of common autoscale patterns](./autoscale-common-scale-patterns.md) -* [Automatically scale a virtual machine scale](/azure/virtual-machine-scale-sets/tutorial-autoscale-powershell) -* [Use autoscale actions to send email and webhook alert notifications](./autoscale-webhook-email.md) |
| azure-monitor | Autoscale Get Started | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/autoscale/autoscale-get-started.md | - Title: Get started with autoscale in Azure -description: "Learn how to scale your resource web app, cloud service, virtual machine, or Virtual Machine Scale Set in Azure." -- Previously updated : 08/26/2024--# Get started with autoscale in Azure --Autoscale allows you to automatically scale your applications or resources based on demand. Use Autoscale to provision enough resources to support the demand on your application without over provisioning and incurring unnecessary costs. --This article describes how to configure the autoscale settings for your resources in the Azure portal. --Azure autoscale supports many resource types. For more information about supported resources, see [autoscale supported resources](./autoscale-overview.md#supported-services-for-autoscale). --## Discover the autoscale settings in your subscription - -> [!VIDEO https://www.microsoft.com/en-us/videoplayer/embed/RE4u7ts] --To discover the resources that you can autoscale, follow these steps. --1. Open the [Azure portal.](https://portal.azure.com) --1. Search for and select *Azure Monitor* using the search bar at the top of the page. --1. Select **Autoscale** to view all the resources for which autoscale is applicable, along with their current autoscale status. --1. Use the filter pane at the top to select resources a specific resource group, resource types, or a specific resource. -- :::image type="content" source="./media/autoscale-get-started/view-resources.png" lightbox="./media/autoscale-get-started/view-resources.png" alt-text="A screenshot showing resources that can use autoscale and their statuses."::: -- The page shows the instance count and the autoscale status for each resource. Autoscale statuses are: - - **Not configured**: Autoscale isn't set up yet for this resource. - - **Enabled**: Autoscale is enabled for this resource. - - **Disabled**: Autoscale is disabled for this resource. -- You can also reach the scaling page by selecting **Scaling** from the **Settings** menu for each resource. -- :::image type="content" source="./media/autoscale-get-started/scaling-page.png" lightbox="./media/autoscale-get-started/scaling-page.png" alt-text="A screenshot showing a resource overview page with the scaling menu item."::: --## Create your first autoscale setting --> [!NOTE] -> In addition to the Autoscale instructions in this article, there's new, automatic scaling in Azure App Service. You'll find more on this capability in the [automatic scaling](../../app-service/manage-automatic-scaling.md) article. -> --Follow the steps below to create your first autoscale setting. --1. Open the **Autoscale** pane in Azure Monitor and select a resource that you want to scale. The following steps use an App Service plan associated with a web app. You can [create your first ASP.NET web app in Azure in 5 minutes.](../../app-service/quickstart-dotnetcore.md) -1. The current instance count is 1. Select **Custom autoscale**. --1. Enter a **Name** and **Resource group** or use the default. --1. Select **Scale based on a metric**. -1. Select **Add a rule**. to open a context pane on the right side. -- :::image type="content" source="./media/autoscale-get-started/custom-scale.png" lightbox="./media/autoscale-get-started/custom-scale.png" alt-text="A screenshot showing the Configure tab of the Autoscale Settings page."::: --1. The default rule scales your resource by one instance if the `Percentage CPU` metric is greater than 70 percent. -- Keep the default values and select **Add**. --1. You've created your first scale-out rule. Best practice is to have at least one scale-in rule. To add another rule, select **Add a rule**. --1. Set **Operator** to *Less than*. -1. Set **Metric threshold to trigger scale action** to *20*. -1. Set **Operation** to *Decrease count by*. -1. Select **Add**. -- :::image type="content" source="./media/autoscale-get-started/scale-rule.png" lightbox="./media/autoscale-get-started/scale-rule.png" alt-text="A screenshot showing a scale rule."::: -- You have configured a scale setting that scales out and scales in based on CPU usage, but you're still limited to a maximum of one instance. Change the instance limits to allow for more instances. --1. Under **Instance limits** set **Maximum** to *3* --1. Select **Save**. -- :::image type="content" source="./media/autoscale-get-started/instance-limits.png" lightbox="./media/autoscale-get-started/instance-limits.png" alt-text="A screenshot showing the configure tab of the autoscale setting page with configured rules."::: --You have successfully created your first scale setting to autoscale your web app based on CPU usage. When CPU usage is greater than 70%, an additional instance is added, up to a maximum of 3 instances. When CPU usage is below 20%, an instance is removed up to a minimum of 1 instance. By default there will be 1 instance. --## Scheduled scale conditions --The default scale condition defines the scale rules that are active when no other scale condition is in effect. You can add scale conditions that are active on a given date and time, or that recur on a weekly basis. --### Scale based on a repeating schedule --Set your resource to scale to a single instance on a Sunday. --1. Select **Add a scale condition**. --1. Enter a description for the scale condition. --1. Select **Scale to a specific instance count**. You can also scale based on metrics and thresholds that are specific to this scale condition. -1. Enter *1* in the **Instance count** field. -1. Select **Repeat specific days**. -1. Select **Sunday** -1. Set the **Start time** and **End time** for when the scale condition should be applied. Outside of this time range, the default scale condition applies. -1. Select **Save** ---You have now defined a scale condition that reduces the number of instances of your resource to 1 every Sunday. --### Scale differently on specific dates --Set Autoscale to scale differently for specific dates, when you know that there will be an unusual level of demand for the service. --1. Select **Add a scale condition**. --1. Select **Scale based on a metric**. -1. Select **Add a rule** to define your scale-out and scale-in rules. Set the rules to be same as the default condition. -1. Set the **Maximum** instance limit to *10* -1. Set the **Default** instance limit to *3* -1. Select **Specify start/end dates** -1. Enter the **Start date** and **End date** for when the scale condition should be applied. -1. Select **Save** ---You have now defined a scale condition for a specific day. When CPU usage is greater than 70%, an additional instance is added, up to a maximum of 10 instances to handle anticipated load. When CPU usage is below 20%, an instance is removed up to a minimum of 1 instance. By default, autoscale scales to 3 instances when this scale condition becomes active. --## Additional settings --### View the history of your resource's scale events --Whenever your resource has any scaling event, it's logged in the activity log. You can view the history of the scale events in the **Run history** tab. ---### View the scale settings for your resource --Autoscale is an Azure Resource Manager resource. Like other resources, you can see the resource definition in JSON format. To view the autoscale settings in JSON, select the **JSON** tab. ---You can make changes in JSON directly, if necessary. These changes will be reflected after you save them. --### Predictive autoscale --Predictive autoscale uses machine learning to help manage and scale Azure Virtual Machine Scale Sets with cyclical workload patterns. It forecasts the overall CPU load to your virtual machine scale set, based on your historical CPU usage patterns. It predicts the overall CPU load by observing and learning from historical usage. This process ensures that scale-out occurs in time to meet the demand. For more information, see [Predictive autoscale](autoscale-predictive.md). ---### Scale-in policy --When scaling a Virtual machine Scale Set, the scale-in policy determines which virtual machines are selected for removal when a scale-in event occurs. The scale-in policy can be set to either **Default**, **NewestVM**, or **OldestVM**. For more information, see [Use custom scale-in policies with Azure Virtual Machine Scale Sets](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-scale-in-policy?WT.mc_id=Portal-Microsoft_Azure_Monitoring). ----### Notify --You can configure notifications to be sent when a scale event occurs. Notifications can be sent to an email address or to a webhook. For more information, see [Autoscale notifications](autoscale-webhook-email.md). ---### Cool-down period effects --Autoscale uses a cool-down period. This period is the amount of time to wait after a scale operation before scaling again. The cool-down period allows the metrics to stabilize and avoids scaling more than once for the same condition. Cool-down applies to both scale-in and scale-out events. For example, if the cooldown is set to 10 minutes and Autoscale has just scaled-in, Autoscale won't attempt to scale again for another 10 minutes in either direction. For more information, see [Autoscale evaluation steps](autoscale-understanding-settings.md#autoscale-evaluation). --### Flapping --Flapping refers to a loop condition that causes a series of opposing scale events. Flapping happens when one scale event triggers an opposite scale event. For example, scaling in reduces the number of instances causing the CPU to rise in the remaining instances. This in turn triggers a scale-out event, which causes CPU usage to drop, repeating the process. For more information, see [Flapping in Autoscale](autoscale-flapping.md) and [Troubleshooting autoscale](autoscale-troubleshoot.md) --## Move autoscale to a different region --This section describes how to move Azure autoscale to another region under the same subscription and resource group. You can use REST API to move autoscale settings. --### Prerequisites --- Ensure that the subscription and resource group are available and the details in both the source and destination regions are identical.-- Ensure that Azure autoscale is available in the [Azure region you want to move to](https://azure.microsoft.com/global-infrastructure/services/?products=monitor®ions=all).--### Move --Use [REST API](/rest/api/monitor/autoscalesettings/createorupdate) to create an autoscale setting in the new environment. The autoscale setting created in the destination region is a copy of the autoscale setting in the source region. --[Diagnostic settings](../essentials/diagnostic-settings.md) that were created in association with the autoscale setting in the source region can't be moved. You'll need to re-create diagnostic settings in the destination region, after the creation of autoscale settings is completed. --### Learn more about moving resources across Azure regions --To learn more about moving resources between regions and disaster recovery in Azure, see [Move resources to a new resource group or subscription](../../azure-resource-manager/management/move-resource-group-and-subscription.md). --## Next steps --- [Create an activity log alert to monitor all autoscale engine operations on your subscription](https://github.com/Azure/azure-quickstart-templates/tree/master/demos/monitor-autoscale-alert)-- [Create an activity log alert to monitor all failed autoscale scale-in/scale-out operations on your subscription](https://github.com/Azure/azure-quickstart-templates/tree/master/demos/monitor-autoscale-failed-alert)-- [Use autoscale actions to send email and webhook alert notifications in Azure Monitor ](autoscale-webhook-email.md) |
| azure-monitor | Autoscale Multiprofile | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/autoscale/autoscale-multiprofile.md | - Title: Autoscale with multiple profiles -description: "Using multiple and recurring profiles in autoscale" ------ Previously updated : 08/25/2024---# Customer intent: As a user or dev ops administrator, I want to understand how set up autoscale with more than one profile so I can scale my resources with more flexibility. ---# Autoscale with multiple profiles --Scaling your resources for a particular day of the week, or a specific date and time can reduce your costs while still providing the capacity you need when you need it. --You can use multiple profiles in autoscale to scale in different ways at different times. If for example, your business isn't active on the weekend, create a recurring profile to scale in your resources on Saturdays and Sundays. If black Friday is a busy day, create a profile to automatically scale out your resources on black Friday. --This article explains the different profiles in autoscale and how to use them. --You can have one or more profiles in your autoscale setting. --There are three types of profile: --* The default profile. The default profile is created automatically and isn't dependent on a schedule. The default profile can't be deleted. The default profile is used when there are no other profiles that match the current date and time. -* Recurring profiles. A recurring profile is valid for a specific time range and repeats for selected days of the week. -* Fixed date and time profiles. A profile that is valid for a time range on a specific date. --Each time the autoscale service runs, the profiles are evaluated in the following order: --1. Fixed date profiles -1. Recurring profiles -1. Default profile --If a profile's date and time settings match the current time, autoscale applies that profile's rules and capacity limits. Only the first applicable profile is used. --The following example shows an autoscale setting with a default profile and recurring profile. ---In the example above, on Monday after 3 AM, the recurring profile will cease to be used. If the instance count is less than 3, autoscale scales to the new minimum of three. Autoscale continues to use this profile and scales based on CPU% until Monday at 8 PM. At all other times scaling is done according to the default profile, based on the number of requests. After 8 PM on Monday, autoscale switches to the default profile. If for example, the number of instances at the time is 12, autoscale scales in to 10, which the maximum allowed for the default profile. --## Multiple contiguous profiles -Autoscale transitions between profiles based on their start times. The end time for a given profile is determined by the start time of the following profile. --In the portal, the end time field becomes the next start time for the default profile. You can't specify the same time for the end of one profile and the start of the next. The portal forces the end time to be one minute before the start time of the following profile. During this minute, the default profile becomes active. If you don't want the default profile to become active between recurring profiles, leave the end time field empty. --> [!TIP] -> To set up multiple contiguous profiles using the portal, leave the end time empty. The current profile will stop being used when the next profile becomes active. Only specify an end time when you want to revert to the default profile. -> Creating a recurring profile with no end time is only supported via the portal and ARM templates. --## Multiple profiles using templates, CLI, and PowerShell --When creating multiple profiles using templates, the CLI, and PowerShell, follow the guidelines below. --## [ARM templates](#tab/templates) --See the autoscale section of the [ARM template resource definition](/azure/templates/microsoft.insights/autoscalesettings) for a full template reference. --There's no specification in the template for end time. A profile will remain active until the next profile's start time. ---## Add a recurring profile using ARM templates --The following example shows how to create two recurring profiles. One profile for weekends from 00:01 on Saturday morning and a second Weekday profile starting on Mondays at 04:00. That means that the weekend profile starts on Saturday morning at one minute passed midnight and end on Monday morning at 04:00. The Weekday profile will start at 4am on Monday and end just after midnight on Saturday morning. --Use the following command to deploy the template: -`az deployment group create --name VMSS1-Autoscale-607 --resource-group rg-vmss1 --template-file VMSS1-autoscale.json` -where *VMSS1-autoscale.json* is the file containing the following JSON object. --``` JSON -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "resources": [ - { - "type": "Microsoft.Insights/autoscaleSettings", - "apiVersion": "2015-04-01", - "name": "VMSS1-Autoscale-607", - "location": "eastus", - "properties": { -- "name": "VMSS1-Autoscale-607", - "enabled": true, - "targetResourceUri": "/subscriptions/0000aaaa-11BB-cccc-dd22-eeeeee333333/resourceGroups/rg-vmss1/providers/Microsoft.Compute/virtualMachineScaleSets/VMSS1", - "profiles": [ - { - "name": "Weekday profile", - "capacity": { - "minimum": "3", - "maximum": "20", - "default": "3" - }, - "rules": [ - { - "scaleAction": { - "direction": "Increase", - "type": "ChangeCount", - "value": "1", - "cooldown": "PT5M" - }, - "metricTrigger": { - "metricName": "Inbound Flows", - "metricNamespace": "microsoft.compute/virtualmachinescalesets", - "metricResourceUri": "/subscriptions/0000aaaa-11BB-cccc-dd22-eeeeee333333/resourceGroups/rg-vmss1/providers/Microsoft.Compute/virtualMachineScaleSets/VMSS1", - "operator": "GreaterThan", - "statistic": "Average", - "threshold": 100, - "timeAggregation": "Average", - "timeGrain": "PT1M", - "timeWindow": "PT10M", - "Dimensions": [], - "dividePerInstance": true - } - }, - { - "scaleAction": { - "direction": "Decrease", - "type": "ChangeCount", - "value": "1", - "cooldown": "PT5M" - }, - "metricTrigger": { - "metricName": "Inbound Flows", - "metricNamespace": "microsoft.compute/virtualmachinescalesets", - "metricResourceUri": "/subscriptions/0000aaaa-11BB-cccc-dd22-eeeeee333333/resourceGroups/rg-vmss1/providers/Microsoft.Compute/virtualMachineScaleSets/VMSS1", - "operator": "LessThan", - "statistic": "Average", - "threshold": 60, - "timeAggregation": "Average", - "timeGrain": "PT1M", - "timeWindow": "PT10M", - "Dimensions": [], - "dividePerInstance": true - } - } - ], - "recurrence": { - "frequency": "Week", - "schedule": { - "timeZone": "E. Europe Standard Time", - "days": [ - "Monday" - ], - "hours": [ - 4 - ], - "minutes": [ - 0 - ] - } - } - }, - { - "name": "Weekend profile", - "capacity": { - "minimum": "1", - "maximum": "3", - "default": "1" - }, - "rules": [], - "recurrence": { - "frequency": "Week", - "schedule": { - "timeZone": "E. Europe Standard Time", - "days": [ - "Saturday" - ], - "hours": [ - 0 - ], - "minutes": [ - 1 - ] - } - } - } - ], - "notifications": [], - "targetResourceLocation": "eastus" - } -- } - ] -} -``` --## [CLI](#tab/cli) --The CLI can be used to create multiple profiles in your autoscale settings. --See the [Autoscale CLI reference](/cli/azure/monitor/autoscale) for the full set of autoscale CLI commands. --The following steps show how to create a recurring autoscale profile using the CLI. --1. Create the recurring profile using `az monitor autoscale profile create`. Specify the `--start` and `--end` time and the `--recurrence` -1. Create a scale out rule using `az monitor autoscale rule create` using `--scale out` -1. Create a scale in rule using `az monitor autoscale rule create` using `--scale in` --## Add a recurring profile using CLI --The following example shows how to add a recurring autoscale profile, recurring on Thursdays between 06:00 and 22:50. --``` azurecli --az account set --subscription 0000aaaa-11bb-cccc-dd22-eeeeee333333 -export autoscaleName=vmss-autoscalesetting-002 -export resourceGroupName=rg-vmss-001 ---az monitor autoscale profile create \ autoscale-name $autoscaleName \count 2 \name Thursdays \resource-group $resourceGroupName \max-count 10 \min-count 1 \recurrence week thu \start 06:00 \end 22:50 \timezone "Pacific Standard Time" ---az monitor autoscale rule create \ autoscale-name $autoscaleName \--g $resourceGroupName \scale in 1 \condition "Percentage CPU < 25 avg 5m" \profile-name Thursdays--az monitor autoscale rule create \ autoscale-name $autoscaleName \--g $resourceGroupName \scale out 2 \condition "Percentage CPU > 50 avg 5m" \profile-name Thursdays---az monitor autoscale profile list \ autoscale-name $autoscaleName \resource-group $resourceGroupName- -``` --> [!NOTE] -> * The JSON for your autoscale default profile is modified by adding a recurring profile. -> The `name` element of the default profile is changed to an object in the format: `"name": "{\"name\":\"Auto created default scale condition\",\"for\":\"recurring profile name\"}"` where *recurring profile* is the profile name of your recurring profile. -> The default profile also has a recurrence clause added to it that starts at the end time specified for the new recurring profile. -> * A new default profile is created for each recurring profile. -> * If the end time is not specified in the CLI command, the end time will be defaulted to 23:59. --## Updating the default profile when you have recurring profiles --After you add recurring profiles, your default profile is renamed. If you have multiple recurring profiles and want to update your default profile, the update must be made to each default profile corresponding to a recurring profile. --For example, if you have two recurring profiles called *Wednesdays* and *Thursdays*, you need two commands to add a rule to the default profile. --```azurecli -az monitor autoscale rule create -g rg-vmss1--autoscale-name VMSS1-Autoscale-607 --scale out 8 --condition "Percentage CPU > 52 avg 5m" --profile-name "{\"name\": \"Auto created default scale condition\", \"for\": \"Wednesdays\"}" - -az monitor autoscale rule create -g rg-vmss1--autoscale-name VMSS1-Autoscale-607 --scale out 8 --condition "Percentage CPU > 52 avg 5m" --profile-name "{\"name\": \"Auto created default scale condition\", \"for\": \"Thursdays\"}" -``` --## [PowerShell](#tab/powershell) --PowerShell can be used to create multiple profiles in your autoscale settings. --See the [PowerShell Az PowerShell module.Monitor Reference](/powershell/module/az.monitor/#monitor) for the full set of autoscale PowerShell commands. --The following steps show how to create an autoscale profile using PowerShell. --1. Create rules using `New-AzAutoscaleRule`. -1. Create profiles using `New-AzAutoscaleProfile` using the rules from the previous step. -1. Use `Add-AzAutoscaleSetting` to apply the profiles to your autoscale setting. --## Add a recurring profile using PowerShell --The following example shows how to create default profile and a recurring autoscale profile, recurring on Wednesdays and Fridays between 09:00 and 23:00. -The default profile uses the `CpuIn` and `CpuOut` Rules. The recurring profile uses the `BandwidthIn` and `BandwidthOut` rules. --```azurepowershell --Set-AzureSubscription -SubscriptionId "0000aaaa-11BB-cccc-dd22-eeeeee333333" -$ResourceGroupName="rg-vmss-001" -$TargetResourceId="/subscriptions/0000aaaa-11BB-cccc-dd22-eeeeee333333/resourceGroups/rg-vmss-001/providers/Microsoft.Compute/virtualMachineScaleSets/vmss-001" -$ScaleSettingName="vmss-autoscalesetting=001" --$CpuOut=New-AzAutoscaleScaleRuleObject ` - -MetricTriggerMetricName "Percentage CPU" ` - -MetricTriggerMetricResourceUri "$TargetResourceId" ` - -MetricTriggerTimeGrain ([System.TimeSpan]::New(0,1,0)) ` - -MetricTriggerStatistic "Average" ` - -MetricTriggerTimeWindow ([System.TimeSpan]::New(0,5,0)) ` - -MetricTriggerTimeAggregation "Average" ` - -MetricTriggerOperator "GreaterThan" ` - -MetricTriggerThreshold 50 ` - -MetricTriggerDividePerInstance $false ` - -ScaleActionDirection "Increase" ` - -ScaleActionType "ChangeCount" ` - -ScaleActionValue 1 ` - -ScaleActionCooldown ([System.TimeSpan]::New(0,5,0)) ---$CpuIn=New-AzAutoscaleScaleRuleObject ` - -MetricTriggerMetricName "Percentage CPU" ` - -MetricTriggerMetricResourceUri "$TargetResourceId" ` - -MetricTriggerTimeGrain ([System.TimeSpan]::New(0,1,0)) ` - -MetricTriggerStatistic "Average" ` - -MetricTriggerTimeWindow ([System.TimeSpan]::New(0,5,0)) ` - -MetricTriggerTimeAggregation "Average" ` - -MetricTriggerOperator "LessThan" ` - -MetricTriggerThreshold 30 ` - -MetricTriggerDividePerInstance $false ` - -ScaleActionDirection "Decrease" ` - -ScaleActionType "ChangeCount" ` - -ScaleActionValue 1 ` - -ScaleActionCooldown ([System.TimeSpan]::New(0,5,0)) ---$defaultProfile=New-AzAutoscaleProfileObject ` - -Name "Default" ` - -CapacityDefault 1 ` - -CapacityMaximum 5 ` - -CapacityMinimum 1 ` - -Rule $CpuOut, $CpuIn ---$BandwidthIn=New-AzAutoscaleScaleRuleObject ` - -MetricTriggerMetricName "VM Cached Bandwidth Consumed Percentage" ` - -MetricTriggerMetricResourceUri "$TargetResourceId" ` - -MetricTriggerTimeGrain ([System.TimeSpan]::New(0,1,0)) ` - -MetricTriggerStatistic "Average" ` - -MetricTriggerTimeWindow ([System.TimeSpan]::New(0,5,0)) ` - -MetricTriggerTimeAggregation "Average" ` - -MetricTriggerOperator "LessThan" ` - -MetricTriggerThreshold 30 ` - -MetricTriggerDividePerInstance $false ` - -ScaleActionDirection "Decrease" ` - -ScaleActionType "ChangeCount" ` - -ScaleActionValue 1 ` - -ScaleActionCooldown ([System.TimeSpan]::New(0,5,0)) ---$BandwidthOut=New-AzAutoscaleScaleRuleObject ` - -MetricTriggerMetricName "VM Cached Bandwidth Consumed Percentage" ` - -MetricTriggerMetricResourceUri "$TargetResourceId" ` - -MetricTriggerTimeGrain ([System.TimeSpan]::New(0,1,0)) ` - -MetricTriggerStatistic "Average" ` - -MetricTriggerTimeWindow ([System.TimeSpan]::New(0,5,0)) ` - -MetricTriggerTimeAggregation "Average" ` - -MetricTriggerOperator "GreaterThan" ` - -MetricTriggerThreshold 60 ` - -MetricTriggerDividePerInstance $false ` - -ScaleActionDirection "Increase" ` - -ScaleActionType "ChangeCount" ` - -ScaleActionValue 1 ` - -ScaleActionCooldown ([System.TimeSpan]::New(0,5,0)) --$RecurringProfile=New-AzAutoscaleProfileObject ` - -Name "Wednesdays and Fridays" ` - -CapacityDefault 1 ` - -CapacityMaximum 10 ` - -CapacityMinimum 1 ` - -RecurrenceFrequency week ` - -ScheduleDay "Wednesday","Friday" ` - -ScheduleHour 09 ` - -ScheduleMinute 00 ` - -ScheduleTimeZone "Pacific Standard Time" ` - -Rule $BandwidthIn, $BandwidthOut ----$DefaultProfile2=New-AzAutoscaleProfileObject ` - -Name "Back to default after Wednesday and Friday" ` - -CapacityDefault 1 ` - -CapacityMaximum 5 ` - -CapacityMinimum 1 ` - -RecurrenceFrequency week ` - -ScheduleDay "Wednesday","Friday" ` - -ScheduleHour 23 ` - -ScheduleMinute 00 ` - -ScheduleTimeZone "Pacific Standard Time" ` - -Rule $CpuOut, $CpuIn ---Update-AzAutoscaleSetting ` --name $ScaleSettingName `--ResourceGroup $ResourceGroupName `--Enabled $true `--TargetResourceUri $TargetResourceId `--Profile $DefaultProfile, $RecurringProfile, $DefaultProfile2--``` --> [!NOTE] -> You can't specify an end date for recurring profiles in PowerShell. To end a recurring profile, create a copy of default profile with the same recurrence parameters as the recurring profile. Set the start time to be the time you want the recurring profile to end. Each recurring profile requires its own copy of the default profile to specify an end time. --## Updating the default profile when you have recurring profiles --If you have multiple recurring profiles and want to change your default profile, the change must be made to each default profile corresponding to a recurring profile. --For example, if you have two recurring profiles called *SundayProfile* and *ThursdayProfile*, you need two `New-AzAutoscaleProfile` commands to change to the default profile. --```azurepowershell ---$DefaultProfileSundayProfile = New-AzAutoscaleProfile -DefaultCapacity "1" -MaximumCapacity "10" -MinimumCapacity "1" -Rule $CpuOut,$CpuIn -Name "Defalut for Sunday" -RecurrenceFrequency week -ScheduleDay "Sunday" -ScheduleHour 19 -ScheduleMinute 00 -ScheduleTimeZone "Pacific Standard Time"` ---$DefaultProfileThursdayProfile = New-AzAutoscaleProfile -DefaultCapacity "1" -MaximumCapacity "10" -MinimumCapacity "1" -Rule $CpuOut,$CpuIn -Name "Default for Thursday" -RecurrenceFrequency week -ScheduleDay "Thursday" -ScheduleHour 19 -ScheduleMinute 00 -ScheduleTimeZone "Pacific Standard Time"` -``` ----## Next steps --* [Autoscale CLI reference](/cli/azure/monitor/autoscale) -* [ARM template resource definition](/azure/templates/microsoft.insights/autoscalesettings) -* [PowerShell Az PowerShell module.Monitor Reference](/powershell/module/az.monitor/#monitor) -* [REST API reference. Autoscale Settings](/rest/api/monitor/autoscale-settings). -* [Tutorial: Automatically scale a Virtual Machine Scale Set with an Azure template](/azure/virtual-machine-scale-sets/tutorial-autoscale-template) -* [Tutorial: Automatically scale a Virtual Machine Scale Set with the Azure CLI](/azure/virtual-machine-scale-sets/tutorial-autoscale-cli) -* [Tutorial: Automatically scale a Virtual Machine Scale Set with an Azure template](/azure/virtual-machine-scale-sets/tutorial-autoscale-powershell) |
| azure-monitor | Autoscale Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/autoscale/autoscale-overview.md | - Title: Autoscale in Azure Monitor -description: This article describes the autoscale feature in Azure Monitor and its benefits. ----- Previously updated : 04/15/2024--# customer intent: 'I want to learn about autoscale in Azure Monitor.' ---# Overview of autoscale in Azure --This article describes the autoscale feature in Azure Monitor and its benefits. --Autoscale supports many resource types. For more information about supported resources, see [Autoscale supported resources](#supported-services-for-autoscale). --> [!NOTE] -> [Availability sets](/archive/blogs/kaevans/autoscaling-azurevirtual-machines) are an older scaling feature for virtual machines with limited support. We recommend migrating to [Azure Virtual Machine Scale Sets](/azure/virtual-machine-scale-sets/overview) for faster and more reliable autoscale support. --## What is autoscale --Autoscale is a service that you can use to automatically add and remove resources according to the load on your application. --When your application experiences higher load, autoscale adds resources to handle the increased load. When load is low, autoscale reduces the number of resources, which lowers your costs. You can scale your application based on metrics like CPU usage, queue length, and available memory. You can also scale based on a schedule. Metrics and schedules are set up in rules. The rules include a minimum level of resources that you need to run your application and a maximum level of resources that won't be exceeded. --For example, scale out your application by adding VMs when the average CPU usage per VM is above 70%. Scale it back by removing VMs when CPU usage drops to 40%. ---When the conditions in the rules are met, one or more autoscale actions are triggered, adding or removing VMs. You can also perform other actions like sending email, notifications, or webhooks to trigger processes in other systems. --## Horizontal vs. vertical scaling --Autoscale scales in and out, or horizontally. Scaling horizontally is an increase or decrease of the number of resource instances. For example, for a virtual machine scale set, scaling out means adding more virtual machines. Scaling in means removing virtual machines. Horizontal scaling is flexible in a cloud situation because you can use it to run a large number of VMs to handle load. --Autoscale does not support vertical scaling. In contrast, scaling up and down, or vertical scaling, keeps the same number of resource instances constant but gives them more capacity in terms of memory, CPU speed, disk space, and network. Vertical scaling is limited by the availability of larger hardware, which eventually reaches an upper limit. Hardware size availability varies in Azure by region. Vertical scaling might also require a restart of the VM during the scaling process. ---When the conditions in the rules are met, one or more autoscale actions are triggered, adding or removing VMs. You can also perform other actions like sending email, notifications, or webhooks to trigger processes in other systems. --### Predictive autoscale --[Predictive autoscale](./autoscale-predictive.md) uses machine learning to help manage and scale virtual machine scale sets with cyclical workload patterns. It forecasts the overall CPU load on your virtual machine scale set, based on historical CPU usage patterns. The scale set can then be scaled out in time to meet the predicted demand. --## Autoscale setup --You can set up autoscale via: --* [Azure portal](autoscale-get-started.md) -* [PowerShell](../powershell-samples.md#create-and-manage-autoscale-settings) -* [Cross-platform command-line interface (CLI)](../cli-samples.md#autoscale) -* [Azure Monitor REST API](/rest/api/monitor/autoscalesettings) ---## Resource metrics --Resources generate metrics that are used in autoscale rules to trigger scale events. Virtual machine scale sets use telemetry data from Azure diagnostics agents to generate metrics. Telemetry for the Web Apps feature of Azure App Service and Azure Cloud Services comes directly from the Azure infrastructure. Some commonly used metrics include CPU usage, memory usage, thread counts, queue length, and disk usage. For a list of available metrics, see [Autoscale Common Metrics](autoscale-common-metrics.md). --## Custom metrics --Use your own custom metrics that your application generates. Configure your application to send metrics to [Application Insights](../app/app-insights-overview.md) so that you can use those metrics to decide when to scale. --## Time --Set up schedule-based rules to trigger scale events. Use schedule-based rules when you see time patterns in your load and want to scale before an anticipated change in load occurs. --## Rules --Rules define the conditions needed to trigger a scale event, the direction of the scaling, and the amount to scale by. Combine multiple rules by using different metrics like CPU usage and queue length. Define up to 10 rules per profile. --Rules can be: --* **Metric-based**: Trigger based on a metric value, for example, when CPU usage is above 50%. -* **Time-based**: Trigger based on a schedule, for example, every Saturday at 8 AM. --Autoscale scales out if *any* of the rules are met. Autoscale scales in only if *all* the rules are met. -In terms of logic operators, the OR operator is used for scaling out with multiple rules. The AND operator is used for scaling in with multiple rules. --## Actions and automation --Rules can trigger one or more actions. Actions include: --* **Scale**: Scale resources in or out. -* **Email**: Send an email to the subscription admins, co-admins, and/or any other email address. -* **Webhooks**: Call webhooks to trigger multiple complex actions inside or outside Azure. In Azure, you can: - * Start an [Azure Automation runbook](../../automation/overview.md). - * Call an [Azure function](../../azure-functions/functions-overview.md). - * Trigger an [Azure logic app](../../logic-apps/logic-apps-overview.md). --## Autoscale settings --Autoscale settings includes scale conditions that define rules, limits, and schedules and notifications. Define one or more scale conditions in the settings and one notification setup. --Autoscale uses the following terminology and structure. --| UI | JSON/CLI | Description | -||--|-| -| Scale conditions | profiles | A collection of rules, instance limits, and schedules based on a metric or time. You can define one or more scale conditions or profiles. Define up to 20 profiles per autoscale setting. | -| Rules | rules | A set of conditions based on time or metrics that triggers a scale action. You can define one or more rules for both scale-in and scale-out actions. Define up to a total of 10 rules per profile. | -| Instance limits | capacity | Each scale condition or profile defines the default, maximum, and minimum number of instances that can run under that profile. | -| Schedule | recurrence | Indicates when autoscale puts this scale condition or profile into effect. You can have multiple scale conditions, which allow you to handle different and overlapping requirements. For example, you can have different scale conditions for different times of day or days of the week. | -| Notify | notification | Defines the notifications to send when an autoscale event occurs. Autoscale can notify one or more email addresses or make a call by using one or more webhooks. You can configure multiple webhooks in the JSON but only one in the UI. | ---The full list of configurable fields and descriptions is available in the [Autoscale REST API](/rest/api/monitor/autoscalesettings). --For code examples, see: --* [Tutorial: Automatically scale a virtual machine scale set with the Azure CLI](/azure/virtual-machine-scale-sets/tutorial-autoscale-cli) -* [Tutorial: Automatically scale a virtual machine scale set with an Azure template](/azure/virtual-machine-scale-sets/tutorial-autoscale-powershell) --## Supported services for autoscale --Autoscale supports the following services. --| Service | Schema and documentation | -||--| -| Azure Virtual Machines Scale Sets | [Overview of autoscale with Azure Virtual Machine Scale Sets](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-autoscale-overview) | -| Web Apps feature of Azure App Service | [Scaling Web Apps](autoscale-get-started.md) | -| Azure API Management service | [Automatically scale an Azure API Management instance](../../api-management/api-management-howto-autoscale.md) | -| Azure Data Explorer clusters | [Manage Azure Data Explorer clusters scaling to accommodate changing demand](/azure/data-explorer/manage-cluster-horizontal-scaling) | -| Azure Stream Analytics | [Autoscale streaming units (preview)](../../stream-analytics/stream-analytics-autoscale.md) | -| Azure SignalR Service (Premium tier) | [Automatically scale units of an Azure SignalR service](../../azure-signalr/signalr-howto-scale-autoscale.md) | -| Azure Machine Learning workspace | [Autoscale an online endpoint](/azure/machine-learning/how-to-autoscale-endpoints) | -| Azure Spring Apps | [Set up autoscale for applications](../../spring-apps/enterprise/how-to-setup-autoscale.md) | -| Azure Media Services | [Autoscaling in Media Services](/azure/media-services/latest/release-notes#autoscaling) | -| Azure Service Bus | [Automatically update messaging units of an Azure Service Bus namespace](../../service-bus-messaging/automate-update-messaging-units.md) | --## Next steps --To learn more about autoscale, see the following resources: --* [Azure Monitor autoscale common metrics](autoscale-common-metrics.md) -* [Use autoscale actions to send email and webhook alert notifications](autoscale-webhook-email.md) -* [Tutorial: Automatically scale a virtual machine scale set with the Azure CLI](/azure/virtual-machine-scale-sets/tutorial-autoscale-cli) -* [Tutorial: Automatically scale a virtual machine scale set with Azure PowerShell](/azure/virtual-machine-scale-sets/tutorial-autoscale-powershell) -* [Autoscale CLI reference](/cli/azure/monitor/autoscale) -* [ARM template resource definition](/azure/templates/microsoft.insights/autoscalesettings) -* [PowerShell Az.Monitor reference](/powershell/module/az.monitor/#monitor) -* [REST API reference: Autoscale settings](/rest/api/monitor/autoscale-settings) |
| azure-monitor | Autoscale Predictive | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/autoscale/autoscale-predictive.md | - Title: Use predictive autoscale to scale out before load demands in virtual machine scale sets -description: This article provides information on the new predictive autoscale feature in Azure Monitor. ---- Previously updated : 04/15/2024----# customer intent: As an azure andministarttor I want to learn how to use predictive autoscale to scale out before load demands in virtual machine scale sets. ---# Use predictive autoscale to scale out before load demands in virtual machine scale sets --Predictive autoscale uses machine learning to help manage and scale Azure Virtual Machine Scale Sets with cyclical workload patterns. It forecasts the overall CPU load to your virtual machine scale set, based on your historical CPU usage patterns. It predicts the overall CPU load by observing and learning from historical usage. This process ensures that scale-out occurs in time to meet the demand. --Predictive autoscale needs a minimum of seven days of history to provide predictions. The most accurate results come from 15 days of historical data. --Predictive autoscale adheres to the scaling boundaries you've set for your virtual machine scale set. When the system predicts that the percentage CPU load of your virtual machine scale set will cross your scale-out boundary, new instances are added according to your specifications. You can also configure how far in advance you want new instances to be provisioned, up to 1 hour before the predicted workload spike occurs. --*Forecast only* allows you to view your predicted CPU forecast without triggering the scaling action based on the prediction. You can then compare the forecast with your actual workload patterns to build confidence in the prediction models before you enable the predictive autoscale feature. --## Predictive autoscale offerings --- Predictive autoscale is for workloads exhibiting cyclical CPU usage patterns.-- Support is only available for virtual machine scale sets.-- The *Percentage CPU* metric with the aggregation type *Average* is the only metric currently supported.-- Predictive autoscale supports scale-out only. Configure standard autoscale to manage to scale in actions.-- Predictive autoscale is only available for the Azure Commercial cloud. Azure Government clouds aren't currently supported.---## Enable predictive autoscale or forecast only with the Azure portal --1. Go to the **Virtual machine scale set** screen and select **Scaling**. -- :::image type="content" source="media/autoscale-predictive/main-scaling-screen-1.png" lightbox="media/autoscale-predictive/main-scaling-screen-1.png" alt-text="Screenshot that shows selecting Scaling on the left menu in the Azure portal."::: --1. Under the **Custom autoscale** section, **Predictive autoscale** appears. - - :::image type="content"source="media/autoscale-predictive/custom-autoscale-2.png" lightbox="media/autoscale-predictive/custom-autoscale-2.png" alt-text="Screenshot that shows selecting Custom autoscale and the Predictive autoscale option in the Azure portal."::: -- By using the dropdown selection, you can: - - Disable predictive autoscale. Disable is the default selection when you first land on the page for predictive autoscale. - - Enable forecast-only mode. - - Enable predictive autoscale. -- > [!NOTE] - > Before you can enable predictive autoscale or forecast-only mode, you must set up the standard reactive autoscale conditions. --1. To enable forecast-only mode, select it from the dropdown. Define a scale-out trigger based on *Percentage CPU*. Then select **Save**. The same process applies to enable predictive autoscale. To disable predictive autoscale or forecast-only mode, select **Disable** from the dropdown. -- :::image type="content" source="media/autoscale-predictive/enable-forecast-only-mode-3.png" alt-text="Screenshot that shows enabling forecast-only mode."::: --1. If desired, specify a prelaunch time so the instances are fully running before they're needed. You can prelaunch instances between 5 and 60 minutes before the needed prediction time. -- :::image type="content" source="media/autoscale-predictive/pre-launch-4.png" alt-text="Screenshot that shows predictive autoscale prelaunch setup."::: - -1. After you've enabled predictive autoscale or forecast-only mode and saved it, select **Predictive charts**. - - :::image type="content" source="media/autoscale-predictive/predictve-charts-option-5.png" alt-text="Screenshot that shows selecting the Predictive charts menu option."::: --1. You see three charts: -- :::image type="content" source="media/autoscale-predictive/predictive-charts-6.png" alt-text="Screenshot that shows three charts for predictive autoscale." lightbox="media/autoscale-predictive/predictive-charts-6.png"::: -- - The top chart shows an overlaid comparison of actual versus predicted total CPU percentage. The time span of the graph shown is from the last seven days to the next 24 hours. - - The middle chart shows the maximum number of instances running over the last seven days. - - The bottom chart shows the current Average CPU utilization over the last seven days. --## Enable using an Azure Resource Manager template --1. Retrieve the virtual machine scale set resource ID and resource group of your virtual machine scale set. For example: /subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/patest2/providers/Microsoft.Compute/virtualMachineScaleSets/patest2 --1. Update the *autoscale_only_parameters* file with the virtual machine scale set resource ID and any autoscale setting parameters. --1. Use a PowerShell command to deploy the template that contains the autoscale settings. For example: --```cmd -PS G:\works\kusto_onboard\test_arm_template> new-azurermresourcegroupdeployment -name binzAutoScaleDeploy -resourcegroupname cpatest2 -templatefile autoscale_only.json -templateparameterfile autoscale_only_parameters.json -``` ---```powershell -PS C:\works\autoscale\predictive_autoscale\arm_template> new-azurermresourcegroupdeployment -name binzAutoScaleDeploy - resourcegroupname patest2 -templatefile autoscale_only_binz.json -templateparameterfile autoscale_only_parameters_binz.json -- DeploymentName : binzAutoScaleDeploy - ResourceGroupName : patest2 - ProvisioningState : Succeeded - Timestamp : 3/30/2021 10:11:02 PM - Mode : Incremental - TemplateLink - Parameters : -- Name Type Value - ================ ============================= ==================== - targetVmssResourceld String /subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/patest2/providers/Microsoft.Compute/virtualMachineScaleSets/patest2 - location String East US - minimumCapacity Int 1 - maximumCapacity Int 4 - defaultCapacity Int 4 - metricThresholdToScaleOut Int 50 - metricTimeWindowForScaleOut String PT5M - metricThresholdToScaleln Int 30 - metricTimeWindowForScaleln String PT5M - changeCountScaleOut Int 1 - changeCountScaleln Int 1 - predictiveAutoscaleMode String Enabled - -Outputs : - Name Type Value - ================ ============================== ==================== - - targetVmssResourceld String /subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/patest2/providers/Microsoft.Compute/virtualMachineScaleSets/patest2 - settingLocation String East US - predictiveAutoscaleMode String Enabled --DeloymentDebugLoglevel : --PS C:\works\autoscale\predictive_autoscale\arm_template> --``` -----**autoscale_only.json** -```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "targetVmssResourceId": { - "type": "string" - }, - "location": { - "type": "string" - }, - "minimumCapacity": { - "type": "Int", - "defaultValue": 2, - "metadata": { - "description": "The minimum capacity. Autoscale engine will ensure the instance count is at least this value." - } - }, - "maximumCapacity": { - "type": "Int", - "defaultValue": 5, - "metadata": { - "description": "The maximum capacity. Autoscale engine will ensure the instance count is not greater than this value." - } - }, - "defaultCapacity": { - "type": "Int", - "defaultValue": 3, - "metadata": { - "description": "The default capacity. Autoscale engine will preventively set the instance count to be this value if it can not find any metric data." - } - }, - "metricThresholdToScaleOut": { - "type": "Int", - "defaultValue": 30, - "metadata": { - "description": "The metric upper threshold. If the metric value is above this threshold then autoscale engine will initiate scale out action." - } - }, - "metricTimeWindowForScaleOut": { - "type": "string", - "defaultValue": "PT5M", - "metadata": { - "description": "The metric look up time window." - } - }, - "metricThresholdToScaleIn": { - "type": "Int", - "defaultValue": 20, - "metadata": { - "description": "The metric lower threshold. If the metric value is below this threshold then autoscale engine will initiate scale in action." - } - }, - "metricTimeWindowForScaleIn": { - "type": "string", - "defaultValue": "PT5M", - "metadata": { - "description": "The metric look up time window." - } - }, - "changeCountScaleOut": { - "type": "Int", - "defaultValue": 1, - "metadata": { - "description": "The instance count to increase when autoscale engine is initiating scale out action." - } - }, - "changeCountScaleIn": { - "type": "Int", - "defaultValue": 1, - "metadata": { - "description": "The instance count to decrease the instance count when autoscale engine is initiating scale in action." - } - }, - "predictiveAutoscaleMode": { - "type": "String", - "defaultValue": "ForecastOnly", - "metadata": { - "description": "The predictive Autoscale mode." - } - } - }, - "variables": { - }, - "resources": [{ - "type": "Microsoft.Insights/autoscalesettings", - "name": "cpuPredictiveAutoscale", - "apiVersion": "2022-10-01", - "location": "[parameters('location')]", - "properties": { - "profiles": [{ - "name": "DefaultAutoscaleProfile", - "capacity": { - "minimum": "[parameters('minimumCapacity')]", - "maximum": "[parameters('maximumCapacity')]", - "default": "[parameters('defaultCapacity')]" - }, - "rules": [{ - "metricTrigger": { - "metricName": "Percentage CPU", - "metricNamespace": "", - "metricResourceUri": "[parameters('targetVmssResourceId')]", - "timeGrain": "PT1M", - "statistic": "Average", - "timeWindow": "[parameters('metricTimeWindowForScaleOut')]", - "timeAggregation": "Average", - "operator": "GreaterThan", - "threshold": "[parameters('metricThresholdToScaleOut')]" - }, - "scaleAction": { - "direction": "Increase", - "type": "ChangeCount", - "value": "[parameters('changeCountScaleOut')]", - "cooldown": "PT5M" - } - }, { - "metricTrigger": { - "metricName": "Percentage CPU", - "metricNamespace": "", - "metricResourceUri": "[parameters('targetVmssResourceId')]", - "timeGrain": "PT1M", - "statistic": "Average", - "timeWindow": "[parameters('metricTimeWindowForScaleIn')]", - "timeAggregation": "Average", - "operator": "LessThan", - "threshold": "[parameters('metricThresholdToScaleIn')]" - }, - "scaleAction": { - "direction": "Decrease", - "type": "ChangeCount", - "value": "[parameters('changeCountScaleOut')]", - "cooldown": "PT5M" - } - } - ] - } - ], - "enabled": true, - "targetResourceUri": "[parameters('targetVmssResourceId')]", - "predictiveAutoscalePolicy": { - "scaleMode": "[parameters('predictiveAutoscaleMode')]" - } - } - } - ], - "outputs": { - "targetVmssResourceId" : { - "type" : "string", - "value" : "[parameters('targetVmssResourceId')]" - }, - "settingLocation" : { - "type" : "string", - "value" : "[parameters('location')]" - }, - "predictiveAutoscaleMode" : { - "type" : "string", - "value" : "[parameters('predictiveAutoscaleMode')]" - } - } -} -``` --**autoscale_only_parameters.json** -```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "targetVmssResourceId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/patest2/providers/Microsoft.Compute/virtualMachineScaleSets/patest2" - }, - "location": { - "value": "East US" - }, - "minimumCapacity": { - "value": 1 - }, - "maximumCapacity": { - "value": 4 - }, - "defaultCapacity": { - "value": 4 - }, - "metricThresholdToScaleOut": { - "value": 50 - }, - "metricTimeWindowForScaleOut": { - "value": "PT5M" - }, - "metricThresholdToScaleIn": { - "value": 30 - }, - "metricTimeWindowForScaleIn": { - "value": "PT5M" - }, - "changeCountScaleOut": { - "value": 1 - }, - "changeCountScaleIn": { - "value": 1 - }, - "predictiveAutoscaleMode": { - "value": "Enabled" - } - } -} -``` --For more information on Azure Resource Manager templates, see [Resource Manager template overview](../../azure-resource-manager/templates/overview.md). --## Frequently asked questions --This section answers frequently asked questions. --### Why is CPU percentage over 100 percent on predictive charts? -The predictive chart shows the cumulative load for all machines in the scale set. If you have 5 VMs in a scale set, the maximum cumulative load for all VMs will be 500%, that is, five times the 100% maximum CPU load of each VM. --### What happens over time when you turn on predictive autoscale for a virtual machine scale set? --Prediction autoscale uses the history of a running virtual machine scale set. If your scale set has been running less than seven days, you'll receive a message that the model is being trained. For more information, see the [no predictive data message](#errors-and-warnings). Predictions improve as time goes by and achieve maximum accuracy 15 days after the virtual machine scale set is created. --If changes to the workload pattern occur but remain periodic, the model recognizes the change and begins to adjust the forecast. The forecast improves as time goes by. Maximum accuracy is reached 15 days after the change in the traffic pattern happens. Remember that your standard autoscale rules still apply. If a new unpredicted increase in traffic occurs, your virtual machine scale set will still scale out to meet the demand. --### What if the model isn't working well for me? --The modeling works best with workloads that exhibit periodicity. We recommend that you first evaluate the predictions by enabling "forecast only," which will overlay the scale set's predicted CPU usage with the actual, observed usage. After you compare and evaluate the results, you can then choose to enable scaling based on the predicted metrics if the model predictions are close enough for your scenario. --### Why do I need to enable standard autoscale before I enable predictive autoscale? --Standard autoscaling is a necessary fallback if the predictive model doesn't work well for your scenario. Standard autoscale will cover unexpected load spikes, which aren't part of your typical CPU load pattern. It also provides a fallback if an error occurs in retrieving the predictive data. --### Which rule takes effect if both predictive and standard autoscale rules are set? -Standard autoscale rules are used if there's an unexpected spike in the CPU load, or an error occurs when retrieving predictive data --We use the threshold set in the standard autoscale rules to understand when youΓÇÖd like to scale out and by how many instances. If you want your Virtual Machine Scale Set to scale out when the CPU usage exceeds 70% and actual or predicted data shows that CPU usage is or will be over 70%, then a scale out will occur. --## Errors and warnings --This section addresses common errors and warnings. --### Didn't enable standard autoscale --You receive the following error message: -- *To enable predictive autoscale, create a scale out rule based on 'Percentage CPU' metric. Click here to go to the 'Configure' tab to set an autoscale rule.* ---This message means you attempted to enable predictive autoscale before you enabled standard autoscale and set it up to use the *Percentage CPU* metric with the *Average* aggregation type. --### No predictive data --You won't see data on the predictive charts under certain conditions. This behavior isn't an error, it's the intended behavior. --When predictive autoscale is disabled, you instead receive a message that begins with "No data to show..." You then see instructions on what to enable so that you can see a predictive chart. - - :::image type="content" source="media/autoscale-predictive/error-no-data-to-show.png" alt-text="Screenshot that shows the message No data to show."::: --When you first create a virtual machine scale set and enable forecast-only mode, you receive the message "Predictive data is being trained..." and a time to return to see the chart. - - :::image type="content" source="media/autoscale-predictive/message-being-trained-12.png" alt-text="Screenshot that shows the message Predictive data is being trained."::: --## Next steps --Learn more about autoscale in the following articles: --- [Overview of autoscale](./autoscale-overview.md)-- [Azure Monitor autoscale common metrics](./autoscale-common-metrics.md)-- [Best practices for Azure Monitor autoscale](./autoscale-best-practices.md)-- [Use autoscale actions to send email and webhook alert notifications](./autoscale-webhook-email.md)-- [Autoscale REST API](/rest/api/monitor/autoscalesettings) |
| azure-monitor | Autoscale Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/autoscale/autoscale-troubleshoot.md | - Title: Troubleshoot Azure Monitor autoscale -description: Tracking down problems with Azure Monitor autoscaling used in Azure Service Fabric, Azure Virtual Machines, the Web Apps feature of Azure App Service, and Azure Cloud Services. --- Previously updated : 02/21/2024-----# Troubleshoot Azure Monitor autoscale --Azure Monitor autoscale helps you to have the right amount of resources running to handle the load on your application. It enables you to add resources to handle increases in load and also save money by removing resources that are sitting idle. You can scale based on a schedule, a fixed date-time, or a resource metric you choose. For more information, see [Autoscale overview](autoscale-overview.md). --The autoscale service provides metrics and logs to help you understand what scale actions occurred and the evaluation of the conditions that led to those actions. You can find answers to questions like: --- Why did my service scale-out or scale-in?-- Why did my service not scale?-- Why did an autoscale action fail?-- Why is an autoscale action taking time to scale?--## Flex Virtual Machine Scale Sets --Autoscale scaling actions are delayed up to several hours after a manual scaling action is applied to a [Flex Microsoft.Compute/virtualMachineScaleSets (VMSS)](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-orchestration-modes#scale-sets-with-flexible-orchestration) resource for a specific set of Virtual Machine operations. -For example, [Azure VM CLI Delete](/cli/azure/vm?view=azure-cli-latest#az-vm-delete), or [Azure VM Rest API Delete](/rest/api/compute/virtual-machines/delete?view=rest-compute-2023-10-02&tabs=HTTP) where the operation is performed on an individual VM. - -In these cases, the autoscale service isn't aware of the individual VM operations. - -To avoid this scenario, use the same operation, but at Virtual Machine Scale Set level. For example, [Azure VMSS CLI Delete instance](/cli/azure/vmss?view=azure-cli-latest#az-vmss-delete-instances), or [Azure VMSS Rest API Delete Instance](/en-us/rest/api/compute/virtual-machine-scale-sets/delete-instances?view=rest-compute-2023-10-02&tabs=HTTP). Autoscale detects the instance count change in the Virtual Machine Scale Set and performs the appropriate scaling actions. - -## Autoscale metrics --Autoscale provides you with [four metrics](../essentials/metrics-supported.md#microsoftinsightsautoscalesettings) to understand its operation: --- **Observed Metric Value**: The value of the metric you chose to take the scale action on, as seen or computed by the autoscale engine. Because a single autoscale setting can have multiple rules and therefore multiple metric sources, you can filter by using "metric source" as a dimension.-- **Metric Threshold**: The threshold you set to take the scale action. Because a single autoscale setting can have multiple rules and therefore multiple metric sources, you can filter by using "metric rule" as a dimension.-- **Observed Capacity**: The active number of instances of the target resource as seen by the autoscale engine.-- **Scale Actions Initiated**: The number of scale out and scale-in actions initiated by the autoscale engine. You can filter by scale-out versus scale-in actions.--You can use the [metrics explorer](../essentials/metrics-getting-started.md) to chart the preceding metrics all in one place. The chart should show the: -- - Actual metric. - - Metric as seen/computed by autoscale engine. - - Threshold for a scale action. - - Change in capacity. --## Example 1: Analyze an autoscale rule --An autoscale setting for a virtual machine scale set: --- Scales out when the average CPU percentage of a set is greater than 70% for 10 minutes.-- Scales in when the CPU percentage of the set is less than 5% for more than 10 minutes.--Let's review the metrics from the autoscale service. --The following chart shows a **Percentage CPU** metric for a virtual machine scale set. -<!-- convertborder later --> --The next chart shows the **Observed Metric Value** metric for an autoscale setting. -<!-- convertborder later --> --The final chart shows the **Metric Threshold** and **Observed Capacity** metrics. The **Metric Threshold** metric at the top for the scale-out rule is 70. The **Observed Capacity** metric at the bottom shows the number of active instances, which is currently 3. -<!-- convertborder later --> --> [!NOTE] -> You can filter **Metric Threshold** by the metric trigger rule dimension scale-out (increase) rule to see the scale-out threshold and by the scale-in rule (decrease). --## Example 2: Advanced autoscaling for a virtual machine scale set --An autoscale setting allows a virtual machine scale set resource to scale out based on its own **Outbound Flows** metric. The **Divide metric by instance count** option for the metric threshold is selected. --The scale action rule is if the value of **Outbound Flow per instance** is greater than 10, the autoscale service should scale out by 1 instance. --In this case, the autoscale engine's observed metric value is calculated as the actual metric value divided by the number of instances. If the observed metric value is less than the threshold, no scale-out action is initiated. --The following screenshots show two metric charts. --The **Avg Outbound Flows** chart shows the value of the **Outbound Flows** metric. The actual value is 6. -<!-- convertborder later --> --The following chart shows a few values: -- <!-- convertborder later --> - :::image type="content" source="media/autoscale-troubleshoot/autoscale-vmss-metric-chart-ex-2.png" lightbox="media/autoscale-troubleshoot/autoscale-vmss-metric-chart-ex-2.png" alt-text="Screenshot that shows a virtual machine scale set autoscale metrics charts example." border="false"::: --If there are multiple scale action rules, you can use splitting or the **add filter** option in the metrics explorer chart to look at a metric by a specific source or rule. For more information on splitting a metric chart, see [Advanced features of metric charts - splitting](../essentials/metrics-charts.md#apply-splitting). --## Example 3: Understand autoscale events --In the autoscale setting screen, go to the **Run history** tab to see the most recent scale actions. The tab also shows the change in **Observed Capacity** over time. To find more information about all autoscale actions, including operations such as update/delete autoscale settings, view the activity log and filter by autoscale operations. -<!-- convertborder later --> --## Autoscale resource logs --The autoscale service provides [resource logs](../essentials/platform-logs-overview.md). There are two categories of logs: --- **Autoscale Evaluations**: The autoscale engine records log entries for every single condition evaluation every time it does a check. The entry includes details on the observed values of the metrics, the rules evaluated, and if the evaluation resulted in a scale action or not.-- **Autoscale Scale Actions**: The engine records scale action events initiated by the autoscale service and the results of those scale actions (success, failure, and how much scaling occurred as seen by the autoscale service).--As with any Azure Monitor supported service, you can use [diagnostic settings](../essentials/diagnostic-settings.md) to route these logs to: --- Your Log Analytics workspace for detailed analytics.-- Azure Event Hubs and then to non-Azure tools.-- Your Azure Storage account for archive.-<!-- convertborder later --> --The preceding screenshot shows the Azure portal autoscale **Diagnostics settings** pane. There you can select the **Diagnostic/Resource Logs** tab and enable log collection and routing. You can also perform the same action by using the REST API, the Azure CLI, PowerShell, and Azure Resource Manager templates for diagnostic settings by choosing the resource type as **Microsoft.Insights/AutoscaleSettings**. --## Troubleshoot by using autoscale logs --For the best troubleshooting experience, we recommend routing your logs to Azure Monitor Logs (Log Analytics) through a workspace when you create the autoscale setting. This process is shown in the screenshot in the previous section. You can validate the evaluations and scale actions better by using Log Analytics. --After you've configured your autoscale logs to be sent to the Log Analytics workspace, you can execute the following queries to check the logs. --To get started, try this query to view the most recent autoscale evaluation logs: --```Kusto -AutoscaleEvaluationsLog -| limit 50 -``` --Or try the following query to view the most recent scale action logs: --```Kusto -AutoscaleScaleActionsLog -| limit 50 -``` --Use the following sections to answer these questions. --## A scale action occurred that you didn't expect --First, execute the query for a scale action to find the scale action you're interested in. If it's the latest scale action, use the following query: --```Kusto -AutoscaleScaleActionsLog -| take 1 -``` --Select the `CorrelationId` field from the scale actions log. Use `CorrelationId` to find the right evaluation log. Executing the following query displays all the rules and conditions that were evaluated and led to that scale action. --```Kusto -AutoscaleEvaluationsLog -| where CorrelationId = "<correliationId>" -``` --## What profile caused a scale action? --A scaled action occurred, but you have overlapping rules and profiles and need to track down which one caused the action. --Find the `CorrelationId` of the scale action, as explained in example 1. Then execute the query on evaluation logs to learn more about the profile. --```Kusto -AutoscaleEvaluationsLog -| where CorrelationId = "<correliationId_Guid>" -| where ProfileSelected == true -| project ProfileEvaluationTime, Profile, ProfileSelected, EvaluationResult -``` --The whole profile evaluation can also be understood better by using the following query: --```Kusto -AutoscaleEvaluationsLog -| where TimeGenerated > ago(2h) -| where OperationName contains == "profileEvaluation" -| project OperationName, Profile, ProfileEvaluationTime, ProfileSelected, EvaluationResult -``` --## A scale action didn't occur --You expected a scale action and it didn't occur. There might be no scale action events or logs. --Review the autoscale metrics if you're using a metric-based scale rule. It's possible that the **Observed Metric** value or **Observed Capacity** value aren't what you expected them to be, so the scale rule didn't fire. You would still see evaluations, but not a scale-out rule. It's also possible that the cool-down time kept a scale action from occurring. -- Review the autoscale evaluation logs during the time period when you expected the scale action to occur. Review all the evaluations it did and why it decided to not trigger a scale action. --```Kusto -AutoscaleEvaluationsLog -| where TimeGenerated > ago(2h) -| where OperationName == "MetricEvaluation" or OperationName == "ScaleRuleEvaluation" -| project OperationName, MetricData, ObservedValue, Threshold, EstimateScaleResult -``` --## Scale action failed --There might be a case where the autoscale service took the scale action but the system decided not to scale or failed to complete the scale action. Use this query to find the failed scale actions: --```Kusto -AutoscaleScaleActionsLog -| where ResultType == "Failed" -| project ResultDescription -``` --Create alert rules to get notified of autoscale actions or failures. You can also create alert rules to get notified on autoscale events. --## Schema of autoscale resource logs --For more information, see [Autoscale resource logs](autoscale-resource-log-schema.md). --## Next steps --Read information on [autoscale best practices](autoscale-best-practices.md). |
| azure-monitor | Autoscale Understanding Settings | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/autoscale/autoscale-understanding-settings.md | - Title: Understand autoscale settings in Azure Monitor -description: This article explains autoscale settings, how they work, and how they apply to Azure Virtual Machines, Azure Cloud Services, and the Web Apps feature of Azure App Service. --- Previously updated : 11/29/2023-----# Understand autoscale settings --Autoscale settings help ensure that you have the right amount of resources running to handle the fluctuating load of your application. You can configure autoscale settings to be triggered based on metrics that indicate load or performance, or triggered at a scheduled date and time. --This article explains the autoscale settings. --## Autoscale setting schema --The following example shows an autoscale setting with these attributes: --- A single default profile.-- Two metric rules in this profile: one for scale-out, and one for scale-in.- - The scale-out rule is triggered when the virtual machine scale set's average percentage CPU metric is greater than 85% for the past 10 minutes. - - The scale-in rule is triggered when the virtual machine scale set's average is less than 60% for the past minute. --> [!NOTE] -> A setting can have multiple profiles. To learn more, see the [profiles](#autoscale-profiles) section. A profile can also have multiple scale-out rules and scale-in rules defined. To see how they're evaluated, see the [evaluation](#autoscale-evaluation) section. --```JSON -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "resources": [ - { - "type": "Microsoft.Insights/autoscaleSettings", - "apiVersion": "2015-04-01", - "name": "VMSS1-Autoscale-607", - "location": "eastus", - "properties": { -- "name": "VMSS1-Autoscale-607", - "enabled": true, - "targetResourceUri": "/subscriptions/abc123456-987-f6e5-d43c-9a8d8e7f6541/resourceGroups/rg-vmss1/providers/Microsoft.Compute/virtualMachineScaleSets/VMSS1", - "profiles": [ - { - "name": "Auto created default scale condition", - "capacity": { - "minimum": "1", - "maximum": "4", - "default": "1" - }, - "rules": [ - { - "metricTrigger": { - "metricName": "Percentage CPU", - "metricResourceUri": "/subscriptions/abc123456-987-f6e5-d43c-9a8d8e7f6541/resourceGroups/rg-vmss1/providers/Microsoft.Compute/virtualMachineScaleSets/VMSS1", - "timeGrain": "PT1M", - "statistic": "Average", - "timeWindow": "PT10M", - "timeAggregation": "Average", - "operator": "GreaterThan", - "threshold": 85 - }, - "scaleAction": { - "direction": "Increase", - "type": "ChangeCount", - "value": "1", - "cooldown": "PT5M" - } - }, - { - "metricTrigger": { - "metricName": "Percentage CPU", - "metricResourceUri": "/subscriptions/abc123456-987-f6e5-d43c-9a8d8e7f6541/resourceGroups/rg-vmss1/providers/Microsoft.Compute/virtualMachineScaleSets/VMSS1", - "timeGrain": "PT1M", - "statistic": "Average", - "timeWindow": "PT10M", - "timeAggregation": "Average", - "operator": "LessThan", - "threshold": 60 - }, - "scaleAction": { - "direction": "Decrease", - "type": "ChangeCount", - "value": "1", - "cooldown": "PT5M" - } - } - ] - } - ] - } -} -``` --The following table describes the elements in the preceding autoscale setting's JSON. --| Section | Element name |Portal name| Description | -| | | | | -| Setting | ID | |The autoscale setting's resource ID. Autoscale settings are an Azure Resource Manager resource. | -| Setting | name | |The autoscale setting name. | -| Setting | location | |The location of the autoscale setting. This location can be different from the location of the resource being scaled. | -| properties | targetResourceUri | |The resource ID of the resource being scaled. You can only have one autoscale setting per resource. | -| properties | profiles | Scale condition |An autoscale setting is composed of one or more profiles. Each time the autoscale engine runs, it executes one profile. Configure up to 20 profiles per autoscale setting. | -| profiles | name | |The name of the profile. You can choose any name that helps you identify the profile. | -| profiles | capacity.maximum | Instance limits - Maximum |The maximum capacity allowed. It ensures that autoscale doesn't scale your resource above this number when it executes the profile. | -| profiles | capacity.minimum | Instance limits - Minimum |The minimum capacity allowed. It ensures that autoscale doesn't scale your resource below this number when it executes the profile | -| profiles | capacity.default | Instance limits - Default |If there's a problem reading the resource metric, and the current capacity is below the default, autoscale scales out to the default. This action ensures the availability of the resource. If the current capacity is already higher than the default capacity, autoscale doesn't scale in. | -| profiles | rules | Rules |Autoscale automatically scales between the maximum and minimum capacities by using the rules in the profile. Define up to 10 individual rules in a profile. Typically rules are defined in pairs, one to determine when to scale out, and the other to determine when to scale in. | -| rule | metricTrigger | Scale rule |Defines the metric condition of the rule. | -| metricTrigger | metricName | Metric name |The name of the metric. | -| metricTrigger | metricResourceUri | |The resource ID of the resource that emits the metric. In most cases, it's the same as the resource being scaled. In some cases, it can be different. For example, you can scale a virtual machine scale set based on the number of messages in a storage queue. | -| metricTrigger | timeGrain | Time grain (minutes) |The metric sampling duration. For example, **timeGrain = "PT1M"** means that the metrics should be aggregated every 1 minute, by using the aggregation method specified in the statistic element. | -| metricTrigger | statistic | Time grain statistic |The aggregation method within the timeGrain period. For example, **statistic = "Average"** and **timeGrain = "PT1M"** means that the metrics should be aggregated every 1 minute, by taking the average. This property dictates how the metric is sampled. | -| metricTrigger | timeWindow | Duration |The amount of time to look back for metrics. For example, **timeWindow = "PT10M"** means that every time autoscale runs, it queries metrics for the past 10 minutes. The time window allows your metrics to be normalized and avoids reacting to transient spikes. | -| metricTrigger | timeAggregation |Time aggregation |The aggregation method used to aggregate the sampled metrics. For example, **timeAggregation = "Average"** should aggregate the sampled metrics by taking the average. In the preceding case, take the ten 1-minute samples, and average them. | -| rule | scaleAction | Action |The action to take when the metricTrigger of the rule is triggered. | -| scaleAction | direction | Operation |"Increase" to scale out, or "Decrease" to scale in.| -| scaleAction | value |Instance count |How much to increase or decrease the capacity of the resource. | -| scaleAction | cooldown | Cool down (minutes)|The amount of time to wait after a scale operation before scaling again. The cooldown period comes into effect after a scale-in or a scale-out event. For example, if **cooldown = "PT10M"**, autoscale doesn't attempt to scale again for another 10 minutes. The cooldown is to allow the metrics to stabilize after the addition or removal of instances. | --## Autoscale profiles --Define up to 20 different profiles per autoscale setting. -There are three types of autoscale profiles: --- **Default profile**: Use the default profile if you don't need to scale your resource based on a particular date and time or day of the week. The default profile runs when there are no other applicable profiles for the current date and time. You can only have one default profile.-- **Fixed-date profile**: The fixed-date profile is relevant for a single date and time. Use the fixed-date profile to set scaling rules for a specific event. The profile runs only once, on the event's date and time. For all other times, autoscale uses the default profile.-- ```json - ... - "profiles": [ - { - "name": " regularProfile", - "capacity": { - ... - }, - "rules": [ - ... - ] - }, - { - "name": "eventProfile", - "capacity": { - ... - }, - "rules": [ - ... - ], - "fixedDate": { - "timeZone": "Pacific Standard Time", - "start": "2017-12-26T00:00:00", - "end": "2017-12-26T23:59:00" - } - } - ] - ``` --- **Recurrence profile**: A recurrence profile is used for a day or set of days of the week. The schema for a recurring profile doesn't include an end date. The end of date and time for a recurring profile is set by the start time of the following profile. When the portal is used to configure recurring profiles, the default profile is automatically updated to start at the end time that you specify for the recurring profile. For more information on configuring multiple profiles, see [Autoscale with multiple profiles](./autoscale-multiprofile.md)-- The partial schema example here shows a recurring profile. It starts at 06:00 and ends at 19:00 on Saturdays and Sundays. The default profile has been modified to start at 19:00 on Saturdays and Sundays. - - ``` JSON - { - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "resources": [ - { - "type": "Microsoft.Insights/ autoscaleSettings", - "apiVersion": "2015-04-01", - "name": "VMSS1-Autoscale-607", - "location": "eastus", - "properties": { - - "name": "VMSS1-Autoscale-607", - "enabled": true, - "targetResourceUri": "/subscriptions/ abc123456-987-f6e5-d43c-9a8d8e7f6541/ resourceGroups/rg-vmss1/providers/ Microsoft.Compute/ virtualMachineScaleSets/VMSS1", - "profiles": [ - { - "name": "Weekend profile", - "capacity": { - ... - }, - "rules": [ - ... - ], - "recurrence": { - "frequency": "Week", - "schedule": { - "timeZone": "E. Europe Standard Time", - "days": [ - "Saturday", - "Sunday" - ], - "hours": [ - 6 - ], - "minutes": [ - 0 - ] - } - } - }, - { - "name": "{\"name\":\"Auto created default scale condition\",\"for\":\"Weekend profile\"}", - "capacity": { - ... - }, - "recurrence": { - "frequency": "Week", - "schedule": { - "timeZone": "E. Europe Standard Time", - "days": [ - "Saturday", - "Sunday" - ], - "hours": [ - 19 - ], - "minutes": [ - 0 - ] - } - }, - "rules": [ - ... - ] - } - ], - "notifications": [], - "targetResourceLocation": "eastus" - } - - } - ] - } - - ``` --## Autoscale evaluation --Autoscale settings can have multiple profiles. Each profile can have multiple rules. Each time the autoscale job runs, it begins by choosing the applicable profile for that time. Autoscale then evaluates the minimum and maximum values, any metric rules in the profile, and decides if a scale action is necessary. The autoscale job runs every 30 to 60 seconds, depending on the resource type. After a scale action occurs, the autoscale job waits for the cooldown period before it scales again. The cooldown period applies to both scale-out and scale-in actions. --### Which profile will autoscale use? --Each time the autoscale service runs, the profiles are evaluated in the following order: --1. Fixed-date profiles -1. Recurring profiles -1. Default profile --The first suitable profile that's found is used. --### How does autoscale evaluate multiple rules? --After autoscale determines which profile to run, it evaluates the scale-out rules in the profile, that is, where **direction = "Increase"**. If one or more scale-out rules are triggered, autoscale calculates the new capacity determined by the **scaleAction** specified for each of the rules. If more than one scale-out rule is triggered, autoscale scales to the highest specified capacity to ensure service availability. --For example, assume that there are two rules: Rule 1 specifies a scale-out by three instances, and rule 2 specifies a scale-out by five. If both rules are triggered, autoscale scales out by five instances. Similarly, if one rule specifies scale-out by three instances and another rule specifies scale-out by 15%, the higher of the two instance counts is used. --If no scale-out rules are triggered, autoscale evaluates the scale-in rules, that is, rules with **direction = "Decrease"**. Autoscale only scales in if all the scale-in rules are triggered. --Autoscale calculates the new capacity determined by the **scaleAction** of each of those rules. To ensure service availability, autoscale scales in by as little as possible to achieve the maximum capacity specified. For example, assume two scale-in rules, one that decreases capacity by 50% and one that decreases capacity by three instances. If the first rule results in five instances and the second rule results in seven, autoscale scales in to seven instances. --Each time autoscale calculates the result of a scale-in action, it evaluates whether that action would trigger a scale-out action. The scenario where a scale action triggers the opposite scale action is known as flapping. Autoscale might defer a scale-in action to avoid flapping or might scale by a number less than what was specified in the rule. For more information on flapping, see [Flapping in autoscale](./autoscale-custom-metric.md). --## Next steps --Learn more about autoscale: --* [Overview of autoscale](./autoscale-overview.md) -* [Azure Monitor autoscale common metrics](./autoscale-common-metrics.md) -* [Autoscale with multiple profiles](./autoscale-multiprofile.md) -* [Flapping in autoscale](./autoscale-custom-metric.md) -* [Use autoscale actions to send email and webhook alert notifications](./autoscale-webhook-email.md) -* [Autoscale REST API](/rest/api/monitor/autoscalesettings) |
| azure-monitor | Autoscale Using Powershell | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/autoscale/autoscale-using-powershell.md | - Title: Configure autoscale using PowerShell -description: Configure autoscale for a Virtual Machine Scale Set using PowerShell --- Previously updated : 04/15/2024-----# Customer intent: As a user or dev ops administrator, I want to use powershell to set up autoscale so I can scale my Virtual Machine Scale Set. ---# Configure autoscale with PowerShell --Autoscale ensures that you have the right amount of resources running to handle the fluctuating load of your application. You can configure autoscale using the Azure portal, Azure CLI, PowerShell or ARM or Bicep templates. --This article shows you how to configure autoscale for a Virtual Machine Scale Set with PowerShell. The configurations use the following steps: --+ Create a scale set that you can autoscale -+ Create rules to scale in and scale out -+ Create a profile that uses your rules -+ Apply the autoscale settings -+ Update your autoscale settings with notifications --## Prerequisites --To configure autoscale using PowerShell, you need an Azure account with an active subscription. You can [create an account for free](https://azure.microsoft.com/free). --## Set up your environment --```azurepowershell -#Set the subscription Id, VMSS name, and resource group name -$subscriptionId = (Get-AzContext).Subscription.Id -$resourceGroupName="rg-powershell-autoscale" -$vmssName="vmss-001" -``` --## Create a Virtual Machine Scale Set --Create a scale set using the following cmdlets. Set the `$resourceGroupName` and `$vmssName` variables to suite your environment. --```azurepowershell -# create a new resource group -New-AzResourceGroup -ResourceGroupName $resourceGroupName -Location "EastUS" --# Create login credentials for the VMSS -$Cred = Get-Credential -$vmCred = New-Object System.Management.Automation.PSCredential($Cred.UserName, $Cred.Password) ---New-AzVmss ` - -ResourceGroupName $resourceGroupName ` - -Location "EastUS" ` - -VMScaleSetName $vmssName ` - -Credential $vmCred ` - -VirtualNetworkName "myVnet" ` - -SubnetName "mySubnet" ` - -PublicIpAddressName "myPublicIPAddress" ` - -LoadBalancerName "myLoadBalancer" ` - -OrchestrationMode "Flexible" --``` --## Create autoscale settings --To create autoscale setting using PowerShell, follow the sequence below: --1. Create rules using `New-AzAutoscaleScaleRuleObject` -1. Create a profile using `New-AzAutoscaleProfileObject` -1. Create the autoscale settings using `New-AzAutoscaleSetting` -1. Update the settings using `Update-AzAutoscaleSetting` --### Create rules --Create scale in and scale out rules then associated them with a profile. -Rules are created using the [`New-AzAutoscaleScaleRuleObject`](/powershell/module/az.monitor/new-azautoscalescaleruleobject). --The following PowerShell script creates two rules. --+ Scale out when Percentage CPU exceeds 70% -+ Scale in when Percentage CPU is less than 30% --```azurepowershell --$rule1=New-AzAutoscaleScaleRuleObject ` - -MetricTriggerMetricName "Percentage CPU" ` - -MetricTriggerMetricResourceUri "/subscriptions/$subscriptionId/resourceGroups/$resourceGroupName/providers/Microsoft.Compute/virtualMachineScaleSets/$vmssName" ` - -MetricTriggerTimeGrain ([System.TimeSpan]::New(0,1,0)) ` - -MetricTriggerStatistic "Average" ` - -MetricTriggerTimeWindow ([System.TimeSpan]::New(0,5,0)) ` - -MetricTriggerTimeAggregation "Average" ` - -MetricTriggerOperator "GreaterThan" ` - -MetricTriggerThreshold 70 ` - -MetricTriggerDividePerInstance $false ` - -ScaleActionDirection "Increase" ` - -ScaleActionType "ChangeCount" ` - -ScaleActionValue 1 ` - -ScaleActionCooldown ([System.TimeSpan]::New(0,5,0)) ---$rule2=New-AzAutoscaleScaleRuleObject ` - -MetricTriggerMetricName "Percentage CPU" ` - -MetricTriggerMetricResourceUri "/subscriptions/$subscriptionId/resourceGroups/$resourceGroupName/providers/Microsoft.Compute/virtualMachineScaleSets/$vmssName" ` - -MetricTriggerTimeGrain ([System.TimeSpan]::New(0,1,0)) ` - -MetricTriggerStatistic "Average" ` - -MetricTriggerTimeWindow ([System.TimeSpan]::New(0,5,0)) ` - -MetricTriggerTimeAggregation "Average" ` - -MetricTriggerOperator "LessThan" ` - -MetricTriggerThreshold 30 ` - -MetricTriggerDividePerInstance $false ` - -ScaleActionDirection "Decrease" ` - -ScaleActionType "ChangeCount" ` - -ScaleActionValue 1 ` - -ScaleActionCooldown ([System.TimeSpan]::New(0,5,0)) -``` -The table below describes the parameters used in the `New-AzAutoscaleScaleRuleObject` cmdlet. --|Parameter| Description| -||| -|`MetricTriggerMetricName` |Sets the autoscale trigger metric -|`MetricTriggerMetricResourceUri`| Specifies the resource that the `MetricTriggerMetricName` metric belongs to. `MetricTriggerMetricResourceUri` can be any resource and not just the resource that's being scaled. For example, you can scale your Virtual Machine Scale Sets based on metrics created by a load balancer, database, or the scale set itself. The `MetricTriggerMetricName` must exist for the specified `MetricTriggerMetricResourceUri`. -|`MetricTriggerTimeGrain`|The sampling frequency of the metric that the rule monitors. `MetricTriggerTimeGrain` must be one of the predefined values for the specified metric and must be between 12 hours and 1 minute. For example, `MetricTriggerTimeGrain` = *PT1M*"* means that the metrics are sampled every 1 minute and aggregated using the aggregation method specified in `MetricTriggerStatistic`. -|`MetricTriggerTimeAggregation` | The aggregation method within the timeGrain period. For example, statistic = "Average" and timeGrain = "PT1M" means that the metrics are aggregated every 1 minute by taking the average. -|`MetricTriggerStatistic` |The aggregation method used to aggregate the sampled metrics. For example, TimeAggregation = "Average" aggregates the sampled metrics by taking the average. -|`MetricTriggerTimeWindow` | The amount of time that the autoscale engine looks back to aggregate the metric. This value must be greater than the delay in metric collection, which varies by resource. It must be between 5 minutes and 12 hours. For example, 10 minutes means that every time autoscale runs, it queries metrics for the past 10 minutes. This feature allows your metrics to stabilize and avoids reacting to transient spikes. -|`MetricTriggerThreshold`|Defines the value of the metric that triggers a scale event. -|`MetricTriggerOperator` |Specifies the logical comparative operating to use when evaluating the metric value. -|`MetricTriggerDividePerInstance`| When set to `true` divides the trigger metric by the total number of instances. For example, If message count is 300 and there are 5 instances running, the calculated metric value is 60 messages per instance. This property isn't applicable for all metrics. -| `ScaleActionDirection`| Specify scaling in or out. Valid values are `Increase` and `Decrease`. -|`ScaleActionType` |Scale by a specific number of instances, scale to a specific instance count, or scale by percentage of the current instance count. Valid values include `ChangeCount`, `ExactCount`, and `PercentChangeCount`. -|`ScaleActionCooldown`| The minimum amount of time to wait between scale operations. This is to allow the metrics to stabilize and avoids [flapping](./autoscale-flapping.md). For example, if `ScaleActionCooldown` is 10 minutes and a scale operation just occurred, Autoscale won't attempt to scale again for 10 minutes. ---### Create a default autoscale profile and associate the rules --After defining the scale rules, create a profile. The profile specifies the default, upper, and lower instance count limits, and the times that the associated rules can be applied. Use the [`New-AzAutoscaleProfileObject`](/powershell/module/az.monitor/new-azautoscaleprofileobject) cmdlet to create a new autoscale profile. As this is a default profile, it doesn't have any schedule parameters. The default profile is active at times that no other profiles are active --```azurepowershell -$defaultProfile=New-AzAutoscaleProfileObject ` - -Name "default" ` - -CapacityDefault 1 ` - -CapacityMaximum 10 ` - -CapacityMinimum 1 ` - -Rule $rule1, $rule2 -``` --The table below describes the parameters used in the `New-AzAutoscaleProfileObject` cmdlet. --|Parameter|Description| -||| -|`CapacityDefault`| The number of instances that are if metrics aren't available for evaluation. The default is only used if the current instance count is lower than the default. -| `CapacityMaximum` |The maximum number of instances for the resource. The maximum number of instances is further limited by the number of cores that are available in the subscription. -| `CapacityMinimum` |The minimum number of instances for the resource. -|`FixedDateEnd`| The end time for the profile in ISO 8601 format for. -|`FixedDateStart` |The start time for the profile in ISO 8601 format. -| `Rule` |A collection of rules that provide the triggers and parameters for the scaling action when this profile is active. A maximum of 10, comma separated rules can be specified. -|`RecurrenceFrequency` | How often the scheduled profile takes effect. This value must be `week`. -|`ScheduleDay`| A collection of days that the profile takes effect on when specifying a recurring schedule. Possible values are Sunday through Saturday. For more information on recurring schedules, see [Add a recurring profile using CLI](./autoscale-multiprofile.md?tabs=powershell#add-a-recurring-profile-using-powershell) -|`ScheduleHour`| A collection of hours that the profile takes effect on. Values supported are 0 to 23. -|`ScheduleMinute`| A collection of minutes at which the profile takes effect. -|`ScheduleTimeZone` |The timezone for the hours of the profile. --### Apply the autoscale settings --After fining the rules and profile, apply the autoscale settings using [`New-AzAutoscaleSetting`](/powershell/module/az.monitor/new-azautoscalesetting). To update existing autoscale setting use [`Update-AzAutoscaleSetting`](/powershell/module/az.monitor/add-azautoscalesetting) --```azurepowershell -New-AzAutoscaleSetting ` - -Name vmss-autoscalesetting1 ` - -ResourceGroupName $resourceGroupName ` - -Location eastus ` - -Profile $defaultProfile ` - -Enabled ` - -PropertiesName "vmss-autoscalesetting1" ` - -TargetResourceUri "/subscriptions/$subscriptionId/resourceGroups/$resourceGroupName/providers/Microsoft.Compute/virtualMachineScaleSets/$vmssName" -``` --### Add notifications to your autoscale settings --Add notifications to your sale setting to trigger a webhook or send email notifications when a scale event occurs. -For more information on webhook notifications, see [`New-AzAutoscaleWebhookNotificationObject`](/powershell/module/az.monitor/new-azautoscalewebhooknotificationobject) --Set a webhook using the following cmdlet; -```azurepowershell -- $webhook1=New-AzAutoscaleWebhookNotificationObject -Property @{} -ServiceUri "http://contoso.com/webhook1" -``` --Configure the notification using the webhook and set up email notification using the [`New-AzAutoscaleNotificationObject`](/powershell/module/az.monitor/new-azautoscalenotificationobject) cmdlet: --```azurepowershell -- $notification1=New-AzAutoscaleNotificationObject ` - -EmailCustomEmail "jason@contoso.com" ` - -EmailSendToSubscriptionAdministrator $true ` - -EmailSendToSubscriptionCoAdministrator $true ` - -Webhook $webhook1 -``` --Update your autoscale settings to apply the notification --```azurepowershell --Update-AzAutoscaleSetting ` - -Name vmss-autoscalesetting1 ` - -ResourceGroupName $resourceGroupName ` - -Profile $defaultProfile ` - -Notification $notification1 ` - -TargetResourceUri "/subscriptions/$subscriptionId/resourceGroups/$resourceGroupName/providers/Microsoft.Compute/virtualMachineScaleSets/$vmssName" --``` --## Review your autoscale settings --To review your autoscale settings, load the settings into a variable using `Get-AzAutoscaleSetting` then output the variable as follows: --```azurepowershell - $autoscaleSetting=Get-AzAutoscaleSetting -ResourceGroupName $resourceGroupName -Name vmss-autoscalesetting1 - $autoscaleSetting | Select-Object -Property * -``` --Get your autoscale history using `AzAutoscaleHistory` -```azurepowershell -Get-AzAutoscaleHistory -ResourceId /subscriptions/<subscriptionId/resourceGroups/$resourceGroupName/providers/Microsoft.Compute/virtualMachineScaleSets/$vmssName -``` --## Scheduled and recurring profiles --### Add a scheduled profile for a special event --Set up autoscale profiles to scale differently for specific events. For example, for a day when demand will be higher than usual, create a profile with increased maximum and minimum instance limits. --The following example uses the same rules as the default profile defined above, but sets new instance limits for a specific date. You can also configure different rules to be used with the new profile. --```azurepowershell -$highDemandDay=New-AzAutoscaleProfileObject ` - -Name "High-demand-day" ` - -CapacityDefault 7 ` - -CapacityMaximum 30 ` - -CapacityMinimum 5 ` - -FixedDateEnd ([System.DateTime]::Parse("2023-12-31T14:00:00Z")) ` - -FixedDateStart ([System.DateTime]::Parse("2023-12-31T13:00:00Z")) ` - -FixedDateTimeZone "UTC" ` - -Rule $rule1, $rule2 --Update-AzAutoscaleSetting ` - -Name vmss-autoscalesetting1 ` - -ResourceGroupName $resourceGroupName ` - -Profile $defaultProfile, $highDemandDay ` - -Notification $notification1 ` - -TargetResourceUri "/subscriptions/$subscriptionId/resourceGroups/$resourceGroupName/providers/Microsoft.Compute/virtualMachineScaleSets/$vmssName" --``` --### Add a recurring scheduled profile --Recurring profiles let you schedule a scaling profile that repeats each week. For example, scale to a single instance on the weekend from Friday night to Monday morning. --While scheduled profiles have a start and end date, recurring profiles don't have an end time. A profile remains active until the next profile's start time. Therefore, when you create a recurring profile you must create a recurring default profile that starts when you want the previous recurring profile to finish. --For example, to configure a weekend profile that starts on Friday nights and ends on Monday mornings, create a profile that starts on Friday night, then create recurring profile with your default settings that starts on Monday morning. --The following script creates a weekend profile and an addition default profile to end the weekend profile. -```azurepowershell -$fridayProfile=New-AzAutoscaleProfileObject ` - -Name "Weekend" ` - -CapacityDefault 1 ` - -CapacityMaximum 1 ` - -CapacityMinimum 1 ` - -RecurrenceFrequency week ` - -ScheduleDay "Friday" ` - -ScheduleHour 22 ` - -ScheduleMinute 00 ` - -ScheduleTimeZone "Pacific Standard Time" ` - -Rule $rule1, $rule2 ---$defaultRecurringProfile=New-AzAutoscaleProfileObject ` - -Name "default recurring profile" ` - -CapacityDefault 2 ` - -CapacityMaximum 10 ` - -CapacityMinimum 2 ` - -RecurrenceFrequency week ` - -ScheduleDay "Monday" ` - -ScheduleHour 00 ` - -ScheduleMinute 00 ` - -ScheduleTimeZone "Pacific Standard Time" ` - -Rule $rule1, $rule2 --New-AzAutoscaleSetting ` - -Location eastus ` - -Name vmss-autoscalesetting1 ` - -ResourceGroupName $resourceGroupName ` - -Profile $defaultRecurringProfile, $fridayProfile ` - -Notification $notification1 ` - -TargetResourceUri "/subscriptions/$subscriptionId/resourceGroups/$resourceGroupName/providers/Microsoft.Compute/virtualMachineScaleSets/$vmssName" --``` --For more information on scheduled profiles, see [Autoscale with multiple profiles](./autoscale-multiprofile.md) --## Other autoscale commands --For a complete list of PowerShell cmdlets for autoscale, see the [PowerShell Module Browser](/powershell/module/?term=azautoscale) --## Clean up resources --To clean up the resources you created in this tutorial, delete the resource group that you created. -The following cmdlet deletes the resource group and all of its resources. -```azurecli --Remove-AzResourceGroup -Name $resourceGroupName --``` |
| azure-monitor | Autoscale Webhook Email | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/autoscale/autoscale-webhook-email.md | - Title: Use autoscale to send email and webhook alert notifications -description: Learn how to use autoscale actions to call web URLs or send email notifications in Azure Monitor. --- Previously updated : 08/25/2024----# Use autoscale actions to send email and webhook alert notifications in Azure Monitor -This article shows you how to set up notifications so that you can call specific web URLs or send emails based on autoscale actions in Azure. --## Webhooks -Webhooks allow you to send HTTP requests to a specific URL endpoint (callback URL) when a certain event or trigger occurs. Using webhooks, you can automate and streamline processes by enabling the automatic exchange of information between different systems or applications. Use webhooks to trigger custom code, notifications, or other actions to run when an autoscale event occurs. --## Email -You can send email to any valid email address when an autoscale event occurs. --> [!NOTE] -> Starting April 3, 2024, you won't be able to add any new Co-Administrators for Azure Autoscale Notifications. Azure Classic administrators will be retired on August 31, 2024, and you would not be able to send Azure Autoscale Notifications using Administrators and Co-Administrators after August 31, 2024. For moe information, see [Prepare for Co-administrators retirement](/azure/role-based-access-control/classic-administrators?WT.mc_id=Portal-Microsoft_Azure_Monitoring&tabs=azure-portal#prepare-for-co-administrators-retirement) ---## Configure Notifications --Use the Azure portal, CLI, PowerShell, or Resource Manager templates to configure notifications. --### [Portal](#tab/portal) --### Set up notifications using the Azure portal. --Select the **Notify** tab on the autoscale settings page to configure notifications. --Enter a list of email addresses to send notifications to. - -Enter a webhook URI to send a notification to a web service. You can also add custom headers to the webhook request. For example, you can add an authentication token in the header, query parameters, or add a custom header to identify the source of the request. ----### [CLI](#tab/cli) --### Use CLI to configure notifications. --Use the `az monitor autoscale update` or the `az monitor autoscale create` command to configure notifications using Azure CLI. --The following parameters are used to configure notifications: --+ `--add-action` - The action to take when the autoscale rule is triggered. The value must be `email` or `webhook`, and followed by the email address or webhook URI. -+ `--remove-action` - Remove an action previously added by `--add-action`. The value must be `email` or `webhook`. The parameter is only relevant for the `az monitor autoscale update` command. ---For example, the following command adds an email notification and a webhook notification to and existing autoscale setting. --```azurecli - az monitor autoscale update \ resource-group <resource group name> \name <autoscale setting name> \add-action email pdavis@contoso.com \add-action webhook http://myservice.com/webhook-listerner-123-``` --> [!NOTE] -> You can add mote than one email or webhook notification by using the `--add-action` parameter multiple times. While multiple webhook notifications are supported and can be seen in the JSON, the portal only shows the first webhook. ---For more information, see [az monitor autoscale](/cli/azure/monitor/autoscale). ----### [PowerShell](#tab/powershell) --### Use PowerShell to configure notifications. --The following example shows how to configure a webhook and email notification. --1. Create the webhook object. --1. Create the notification object. -1. Add the notification object to the autoscale setting using `New-AzAutoscaleSetting` or `Update-AzAutoscaleSetting` cmdlets. --```powershell -# Assumining you have already created a profile object and have a vmssName, resourceGroup, and subscriptionId -- $webhook=New-AzAutoscaleWebhookNotificationObject ` --Property @{"method"='GET'; "headers"= '"Authorization", "tokenvalue-12345678abcdef"'} `--ServiceUri "http://myservice.com/webhook-listerner-123"--$notification=New-AzAutoscaleNotificationObject ` --EmailCustomEmail "pdavis@contoso.com" `--Webhook $webhook---New-AzAutoscaleSetting -Name autoscalesetting2 ` --ResourceGroupName $resourceGroup `--Location eastus `--Profile $profile `--Enabled -Notification $notification `--PropertiesName "autoscalesetting" `--TargetResourceUri "/subscriptions/$subscriptionId/resourceGroups/$resourceGroup/providers/Microsoft.Compute/virtualMachineScaleSets/$vmssName"-``` ---### [Resource Manager](#tab/resourcemanager) --### Use Resource Manager templates to configure notifications. --When you use the Resource Manager templates or REST API, include the `notifications` element in your [autoscale settings](/azure/templates/microsoft.insights/autoscalesettings?pivots=deployment-language-arm-template#resource-format-1), for example: --```JSON -"notifications": [ - { - "operation": "Scale", - "email": { - "sendToSubscriptionAdministrator": false, - "sendToSubscriptionCoAdministrators": false, - "customEmails": [ - "user1@mycompany.com", - "user2@mycompany.com" - ] - }, - "webhooks": [ - { - "serviceUri": "https://my.webhook.example.com?token=abcd1234", - "properties": { - "optional_key1": "optional_value1", - "optional_key2": "optional_value2" - } - } - ] - } - ] -``` --| Field | Mandatory | Description | -| | | | -| `operation` |Yes |Value must be `Scale`. | -| `sendToSubscriptionAdministrator` |Yes |No longer supported. Value must be `false`. | -| `sendToSubscriptionCoAdministrators` |Yes |No longer supported. Value must be `false`.| -| `customEmails` |Yes |Value can be null [] or a string array of emails. | -| `webhooks` |Yes |Value can be null or valid URI. | -| `serviceUri` |Yes |Valid HTTPS URI. | -| `properties` |Yes |Value must be empty {} or can contain key-value pairs. | ----## Authentication in webhooks -The webhook can authenticate by using token-based authentication, where you save the webhook URI with a token ID as a query parameter. For example, `https://mysamplealert/webcallback?tokenid=123-abc456-7890&myparameter2=value123`. --## Autoscale notification webhook payload schema -When the autoscale notification is generated, the following metadata is included in the webhook payload: --```JSON -{ - "version": "1.0", - "status": "Activated", - "operation": "Scale Out", - "context": { - "timestamp": "2023-06-22T07:01:47.8926726Z", - "id": "/subscriptions/0000aaaa-11BB-cccc-dd22-eeeeee333333/resourceGroups/rg-001/providers/microsoft.insights/autoscalesettings/AutoscaleSettings-002", - "name": "AutoscaleSettings-002", - "details": "Autoscale successfully started scale operation for resource 'ScaleableAppServicePlan' from capacity '1' to capacity '2'", - "subscriptionId": "0000aaaa-11BB-cccc-dd22-eeeeee333333", - "resourceGroupName": "rg-001", - "resourceName": "ScaleableAppServicePlan", - "resourceType": "microsoft.web/serverfarms", - "resourceId": "/subscriptions/0000aaaa-11BB-cccc-dd22-eeeeee333333/resourceGroups/rg-001/providers/Microsoft.Web/serverfarms/ScaleableAppServicePlan", - "portalLink": "https://portal.azure.com/#resource/subscriptions/0000aaaa-11BB-cccc-dd22-eeeeee333333/resourceGroups/rg-001/providers/Microsoft.Web/serverfarms/ScaleableAppServicePlan", - "resourceRegion": "West Central US", - "oldCapacity": "1", - "newCapacity": "2" - }, - "properties": { - "key1": "value1", - "key2": "value2" - } -} -``` --| Field | Mandatory | Description | -| | | | -| status |Yes |Status that indicates that an autoscale action was generated. | -| operation |Yes |For an increase of instances, it's' "Scale Out." For a decrease in instances, it's' "Scale In." | -| context |Yes |Autoscale action context. | -| timestamp |Yes |Time stamp when the autoscale action was triggered. | -| id |Yes |Resource Manager ID of the autoscale setting. | -| name |Yes |Name of the autoscale setting. | -| details |Yes |Explanation of the action that the autoscale service took and the change in the instance count. | -| subscriptionId |Yes |Subscription ID of the target resource that's being scaled. | -| resourceGroupName |Yes |Resource group name of the target resource that's being scaled. | -| resourceName |Yes |Name of the target resource that's being scaled. | -| resourceType |Yes |Three supported values: "microsoft.classiccompute/domainnames/slots/roles" - Azure Cloud Services roles, "microsoft.compute/virtualmachinescalesets" - Azure Virtual Machine Scale Sets, and "Microsoft.Web/serverfarms" - Web App feature of Azure Monitor. | -| resourceId |Yes |Resource Manager ID of the target resource that's being scaled. | -| portalLink |Yes |Azure portal link to the summary page of the target resource. | -| oldCapacity |Yes |Current (old) instance count when autoscale took a scale action. | -| newCapacity |Yes |New instance count to which autoscale scaled the resource. | -| properties |No |Optional. Set of <Key, Value> pairs (for example, Dictionary <String, String>). The properties field is optional. In a custom user interface or logic app-based workflow, you can enter keys and values that can be passed by using the payload. An alternate way to pass custom properties back to the outgoing webhook call is to use the webhook URI itself (as query parameters). | |
| azure-monitor | Azure Monitor Operations Manager | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/azure-monitor-operations-manager.md | - Title: Migrate from System Center Operations Manager (SCOM) to Azure Monitor -description: Guidance for existing users of System Center Operations Manager (SCOM) to transition monitoring of workloads to Azure Monitor as part of a transition to the cloud. --- Previously updated : 07/26/2024-----# Migrate from System Center Operations Manager (SCOM) to Azure Monitor -This article provides guidance for customers who currently use [System Center Operations Manager (SCOM)](/system-center/scom/welcome) and are planning a transition to cloud based monitoring with [Azure Monitor](overview.md) as they migrate business applications and other resources into Azure. --There's no standard process for migrating from SCOM, and you may rely on SCOM management packs for an extended time as opposed to performing a quick migration. This article describes the different options available and decision criteria you can use to determine the best strategy for your particular environment. ----## Hybrid cloud monitoring -Most customers use a [hybrid cloud monitoring](/azure/cloud-adoption-framework/manage/monitor/cloud-models-monitor-overview#hybrid-cloud-monitoring) strategy that allows you to make a gradual transition to the cloud. This approach allows you to maintain your existing business processes as you become more familiar with the new platform. Only move away from SCOM functionality as you can replace it with Azure Monitor. Multiple monitoring tools add complexity, but it allows you to take advantage of Azure Monitor's ability to monitor next generation cloud workloads while retaining SCOM's ability to monitor server software and workloads. --Your environment before moving any components into Azure is based on virtual and physical machines located on-premises or with a managed service provider. It relies on SCOM to monitor business applications, server software, and other infrastructure components in your environment such as physical servers and networks. You use standard management packs for server software such as IIS, SQL Server, and various vendor software, and you tune those management packs for your specific requirements. You create custom management packs for your business applications and components that can't be monitored with existing management packs, and you also configure SCOM to support your business processes. --As you move services into the cloud, Azure Monitor starts collecting [platform metrics](essentials/data-platform-metrics.md) and the [activity log](essentials/activity-log.md) for each of your resources. You create [diagnostic settings](essentials/diagnostic-settings.md) to collect [resource logs](essentials/resource-logs.md) so you can interactively analyze all available telemetry using [log queries](logs/log-query-overview.md) and [insights](insights/insights-overview.md). --During this period of transition, you have two independent monitoring tools. You use insights and workbooks to analyze your cloud telemetry in the Azure portal while still using the Operations console to analyze your data collected by SCOM. Since each system has its own alerting, you need to create action groups in Azure Monitor equivalent to your notification groups in SCOM. --The following table describes the different features and strategies that are available for a hybrid monitoring environment using SCOM and Azure Monitor. --| Method | Description | -|:|:| -| Dual-homed agents | SCOM uses the Microsoft Management Agent (MMA), which is the same as [Log Analytics agent](agents/log-analytics-agent.md) used by Azure Monitor. You can configure this agent to have a single machine connect to both SCOM and Azure Monitor simultaneously. This configuration does require that your Azure VMs have a connection to your on-premises management servers.<br><br>The [Log Analytics agent](agents/log-analytics-agent.md) has been replaced with the [Azure Monitor agent](agents/agents-overview.md), which provides significant advantages including simpler management and better control over data collection. The two agents can coexist on the same machine allowing you to connect to both Azure Monitor and SCOM. This configuration is a better option than dual-homing the legacy agent because of the significant [advantages of the Azure Monitor agent](agents/agents-overview.md#benefits). | -| Connected management group | [Connect your SCOM management group to Azure Monitor](agents/om-agents.md) to forward data collected from your SCOM agents to Azure Monitor. This is similar to using dual-homed agents, but doesn't require each agent to be configured to connect to Azure Monitor. This strategy requires the legacy agent, so you can't specify monitoring with data collection rules. You also can't use VM insights unless you connect each VM directly to Azure Monitor. | -| SCOM Managed instance | [SCOM managed instance](vm/scom-managed-instance-overview.md) is a full implementation of SCOM in Azure allowing you to continue running the same management packs that you run in your on-premises SCOM environment. You can continue to use the same Operations console for analyzing your health and alerts and can also view alerts in Azure Monitor and analyze SCOM data in Grafana.<br><br>SCOM MI is similar to maintaining your existing SCOM environment and dual-homing agents, although you can consolidate your monitoring configuration in Azure and retire your on-premises components such as database and management servers. Agents from Azure VMs can connect to the SCOM managed instance in Azure rather than connecting to management servers in your own data center. | -| Azure management pack | The [Azure management pack](https://www.microsoft.com/download/details.aspx?id=50013) allows Operations Manager to discover Azure resources and monitor their health based on a particular set of monitoring scenarios. This management pack does require you to perform extra configuration for each resource in Azure. It may be helpful though to provide some visibility of your Azure resources in the Operations Console until you evolve your business processes to focus on Azure Monitor. | --## Monitor business applications -You typically require custom management packs to monitor your business applications with SCOM, using agents installed on each virtual machine. Application Insights in Azure Monitor monitors web-based applications whether they're in Azure, other clouds, or on-premises. It can be used for all of your applications whether or not you migrated them to Azure. --If your monitoring of a business application is limited to functionality provided by the [.NET app performance template](/system-center/scom/net-application-performance-monitoring-template) in SCOM, then you can most likely migrate to Application Insights with no loss of functionality. In fact, Application Insights includes a significant number of other features including the following: --- Automatically discover and monitor application components.-- Collect detailed application usage and performance data such as response time, failure rates, and request rates.-- Collect browser data such as page views and load performance.-- Detect exceptions and drill into stack trace and related requests.-- Perform advanced analysis using features such as [distributed tracing](app/distributed-trace-data.md) and [smart detection](alerts/proactive-diagnostics.md).-- Use [metrics explorer](essentials/metrics-getting-started.md) to interactively analyze performance data.-- Use [log queries](logs/log-query-overview.md) to interactively analyze collected telemetry together with data collected for Azure services and VM insights.--There are certain scenarios though where you may need to continue using SCOM in addition to Application Insights until you're able to achieve required functionality. Examples where you may need to continue with SCOM include the following: --- [Availability tests](/previous-versions/azure/azure-monitor/app/monitor-web-app-availability), which allow you to monitor and alert on the availability and responsiveness of your applications require incoming requests from the IP addresses of web test agents. If your policy doesn't allow such access, you may need to keep using [Web Application Availability Monitors](/system-center/scom/web-application-availability-monitoring-template) in SCOM.-- In SCOM you can set any polling interval for availability tests, with many customers checking every 60-120 seconds. Application Insights has a minimum polling interval of five minutes, which may be too long for some customers.-- A significant amount of monitoring in SCOM is performed by collecting events generated by applications and by running scripts on the local agent. These aren't standard options in Application Insights, so you could require custom work to achieve your business requirements. This might include custom alert rules using event data stored in a Log Analytics workspace and scripts launched in a virtual machines guest using [hybrid runbook worker](../automation/automation-hybrid-runbook-worker.md).-- Depending on the language that your application is written in, you may be limited in the [instrumentation you can use with Application Insights](app/app-insights-overview.md#supported-languages).--Following the basic strategy in the other sections of this guide, continue to use SCOM for your business applications, but take advantage of other features provided by Application Insights. As you're able to replace critical functionality with Azure Monitor, you can start to retire your custom management packs. ----## Monitor virtual machines --Monitoring the software on your virtual machines in a hybrid environment often use a combination of Azure Monitor and SCOM, depending on the requirements of the workloads running on your VMs. As soon as a virtual machine is created in Azure, [platform metrics](essentials/data-platform-metrics.md) and [activity logs](essentials/activity-log.md) for the VM host automatically start being collected. [Enable recommended alerts](vm/tutorial-monitor-vm-alert-recommended.md) to notify you of common errors for the VM host such as server down and high CPU utilization. --Enable [VM insights](vm/vminsights-overview.md) to install the Azure Monitor agent and begin collecting common performance data from the client operating system. This may overlap with some data that you're already collecting in SCOM, but it allows you to start viewing trends over time and monitor your Azure VMs with other cloud resources. You may also choose to enable the [map feature](vm/vminsights-maps.md), which gives you insight into the processes running on your virtual machines and their dependencies on other services. --Continue to use management packs for functionality that isn't provided by other features in Azure Monitor. This includes management packs for critical server software like IIS, SQL Server, or Exchange. You may also have custom management packs developed for on-premises infrastructure that can't be reached with Azure Monitor. Also continue to use SCOM if you tightly integrated into your operational processes until you can transition to modernizing your service operations where Azure Monitor and other Azure services can augment or replace. --> [!NOTE] -> If you enable VM Insights with the Log Analytics agent instead of the Azure Monitor agent, then no additional agent needs to be installed on the VM. Azure Monitor agent is recommended though because of its significant improvements in monitoring the VM in the cloud. The complexity from maintaining multiple agents is offset by the ability to define monitoring in data collection rules, which allow you to configure different data collection for different sets of VMs, similar to your strategy for designing management packs. --## Migrate management pack logic for VM workloads -There are no migration tools to convert SCOM management packs to Azure Monitor because their logic is fundamentally different than Azure Monitor data collection. Migrating management pack logic typically focuses on analyzing the data collected by SCOM and identifying those monitoring scenarios that can be replicated by Azure Monitor. As you customize Azure Monitor to meet your requirements for different applications and components, then you can start to retire different management packs and legacy agents in SCOM. --Management packs in SCOM contain rules and monitors that combine collection of data and the resulting alert into a single end-to-end workflow. Data already collected by SCOM is rarely used for alerting. Azure Monitor separates data collection and alerts into separate processes. Alert rules access data from Azure Monitor Logs and Azure Monitor Metrics collected from agents. Also, rules and monitors are typically focused on specific data such as a particular event or performance counter. Data collection rules in Azure Monitor are typically more broad collecting multiple sets of events and performance counters in a single DCR. --See the following content for guidance on creating data collection and alerting for common monitoring scenarios: --- Data that you need to collect to support alerting, analysis, and visualization. See [Monitor virtual machines with Azure Monitor: Data collection](vm/monitor-virtual-machine-data-collection.md)-- Alerts rules that analyze the collected data to proactively notify of you of issues. See [Monitor virtual machines with Azure Monitor: Alerts](vm/monitor-virtual-machine-alerts.md)--Instead of attempting to replicate the entire functionality of a management pack, analyze the critical monitoring that each provides. Decide whether you can replicate those monitoring requirements by using alternate methods. In many cases, you can configure data collection and alert rules in Azure Monitor that replicate enough functionality that you can retire a particular management pack. Management packs can often include hundreds and even thousands of rules and monitors. --One strategy is to focus on those monitors and rules that triggered alerts in your environment. Refer to [existing reports available in Operations Manager](/system-center/scom/manage-reports-installed-during-setup), such as **Alerts** and **Most Common Alerts**, which can help you identify alerts over time. You can also run the following query on the Operations Database to evaluate the most common recent alerts. --```sql -select AlertName, COUNT(AlertName) as 'Total Alerts' from -Alert.vAlertResolutionState ars -inner join Alert.vAlertDetail adt on ars.AlertGuid = adt.AlertGuid -inner join Alert.vAlert alt on ars.AlertGuid = alt.AlertGuid -group by AlertName -order by 'Total Alerts' DESC -``` --Evaluate the output to identify specific alerts for migration. Ignore any alerts that were tuned out or are known to be problematic. Review your management packs to identify any critical alerts of interest that never fired. --### Synthetic transactions -Management packs often make use of synthetic transactions that connect to an application or service running on a machine to simulate a user connection or actual user traffic. If the application is available, you can assume that the machine is running properly. [Application Insights availability tests](app/availability-overview.md) in Azure Monitor provides this functionality. It only works for applications that are accessible from the internet. For internal applications, you must open a firewall to allow access from specific Microsoft URLs performing the test. Or you can continue to use your existing management pack. --## Next steps --- See the [Cloud Monitoring Guide](/azure/cloud-adoption-framework/manage/monitor/) for a detailed comparison of Azure Monitor and System Center Operations Manager and more details on designing and implementing a hybrid monitoring environment.-- Read more about [monitoring Azure virtual machines in Azure Monitor](vm/monitor-vm-azure.md).-- Read more about [VM insights](vm/vminsights-overview.md).-- Read more about [Application Insights](app/app-insights-overview.md).- |
| azure-monitor | Azure Monitor Rest Api Index | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/azure-monitor-rest-api-index.md | - Title: Azure Monitor REST API index -description: Lists the operation groups for the Azure Monitor REST API, which includes Application Insights, Log Analytics, and Monitor. Previously updated : 05/07/2024------# Azure Monitor REST API index --Organized by subject area. --| Operation groups | Description | -|-|-| -| [Operations](/rest/api/monitor/alertsmanagement/operations) | Lists the available REST API operations for Azure Monitor. | -| ***Activity Log*** | | -| [Activity log(s)](/rest/api/monitor/activity-logs) | Get a list of event entries in the [activity log](./essentials/platform-logs-overview.md). | -| [(Activity log) event categories](/rest/api/monitor/event-categories) | Lists the types of Activity Log Entries. | -| [Activity log profiles](/rest/api/monitor/log-profiles) | Operations to manage [activity log profiles](./essentials/platform-logs-overview.md) so you can route activity log events to other locations. | -| [Activity log tenant events](/rest/api/monitor/tenant-activity-logs) | Gets the [Activity Log](./essentials/platform-logs-overview.md) event entries for a specific tenant. | -| ***Alerts Management and Action Groups*** | | -| [Action groups](/rest/api/monitor/action-groups) | Manages and lists [action groups](./alerts/action-groups.md). | -| [Activity log alerts](/rest/api/monitor/activity-log-alerts) | Manages and lists [activity log alert rules](./alerts/alerts-types.md#activity-log-alerts). | -| [Alert management](/rest/api/monitor/alertsmanagement/alerts) | Lists and updates [fired alerts](./alerts/alerts-overview.md). | -| [Alert processing rules](/rest/api/monitor/alertsmanagement/alert-processing-rules) | Manages and lists [alert processing rules](./alerts/alerts-processing-rules.md). | -| [Metric alert baseline](/rest/api/monitor/baselines) | List the metric baselines used in alert rules with [dynamic thresholds](./alerts/alerts-dynamic-thresholds.md). | -| [Metric alerts](/rest/api/monitor/metric-alerts) | Manages and lists [metric alert rules](./alerts/alerts-overview.md). | -| [Metric alerts status](/rest/api/monitor/metric-alerts-status) | Lists the status of [metric alert rules](./alerts/alerts-overview.md). | -| [Prometheus rule groups](/rest/api/monitor/prometheus-rule-groups) | Manages and lists [Prometheus rule groups](./essentials/prometheus-rule-groups.md) (alert rules and recording rules). | -| [Scheduled query rules - 2023-03-15 (preview)](/rest/api/monitor/scheduled-query-rules?view=rest-monitor-2023-03-15-preview&preserve-view=true) | Manages and lists [log search alert rules](./alerts/alerts-types.md#log-alerts). | -| [Scheduled query rules - 2018-04-16](/rest/api/monitor/scheduled-query-rules?view=rest-monitor-2018-04-16&preserve-view=true) | Manages and lists [log search alert rules](./alerts/alerts-types.md#log-alerts). | -| [Scheduled query rules - 2021-08-01](/rest/api/monitor/scheduled-query-rules?view=rest-monitor-2021-08-01&preserve-view=true) | Manages and lists [log search alert rules](./alerts/alerts-types.md#log-alerts). | -| [Smart Detector alert rules](/rest/api/monitor/smart-detector-alert-rules) | Manages and lists [smart detection alert rules](./alerts/alerts-types.md#smart-detection-alerts). | -| ***Application Insights*** | | -| [Components](/rest/api/application-insights/components) | Enables you to manage components that contain Application Insights data. | -| [Data Access](./logs/api/overview.md) | Query Application Insights data. | -| [Events](/rest/api/application-insights/events) | Retrieve the data for a single event or multiple events by event type and retrieve the Odata EDMX metadata for an application. | -| [Metadata](/rest/api/application-insights/metadata) | Retrieve and export the metadata information for an application. | -| [Metrics](/rest/api/application-insights/metrics) | Retrieve or export the metric data for an application and retrieve the metadata describing the available metrics for an application. | -| [Query](/rest/api/application-insights/query) | The Query operation group, which includes Execute and Get operations, enables running analytics queries on resources and retrieving the results, even for large data sets that require extended processing time. | -| [Web Tests](/rest/api/application-insights/web-tests) | Set up web tests to monitor a web endpointΓÇÖs availability and responsiveness. | -| [Workbooks](/rest/api/application-insights/workbooks) | Manage Azure workbooks for an Application Insights component resource and retrieve workbooks within resource group or subscription by category. | -| ***Autoscale Settings*** | | -| [Autoscale settings](/rest/api/monitor/autoscale-settings) | Operations to manage autoscale settings. | -| [Predictive metric](/rest/api/monitor/predictive-metric) | Retrieves predicted autoscale metric data. | -| ***Data Collection Endpoints*** | | -| [Data collection endpoints](/rest/api/monitor/data-collection-endpoints) | Create and manage a data collection endpoint and retrieve the data collection endpoints within a resource group or subscription. | -| ***Data Collection Rules*** | | -| [Data collection rule associations](/rest/api/monitor/data-collection-rule-associations) | Create and manage a data collection rule association and retrieve the data collection rule associations for a data collection endpoint, resource, or data collection rule. | -| [Data collection rules](/rest/api/monitor/data-collection-rules) | Create and manage a data collection rule and retrieve the data collection rules within a resource group or subscription. | -| ***Diagnostic Settings*** | | -| [Diagnostic settings](/rest/api/monitor/diagnostic-settings) | Operations to create, update, and retrieve the [diagnostic settings](./essentials/platform-logs-overview.md) for a resource. Controls the routing of metric data and diagnostic logs. | -| [Diagnostic settings category](/rest/api/monitor/diagnostic-settings-category) | Relates to the [possible categories](./essentials/resource-logs-schema.md) for a given resource. | -| [Management group diagnostic settings](/rest/api/monitor/management-group-diagnostic-settings) | Manage the management group diagnostic settings for a resource and retrieve the management group diagnostic settings list for a management group. | -| [Subscription diagnostic settings](/rest/api/monitor/subscription-diagnostic-settings) | Manage the subscription diagnostic settings for a resource and retrieve the subscription diagnostic settings list for a subscriptionId. | -| ***Manage Log Analytics workspaces and related resources*** | | -| [Available service tiers](/rest/api/loganalytics/available-service-tiers) | Retrieve the available service tiers for a Log Analytics workspace. | -| [Clusters](/rest/api/loganalytics/clusters) | Manage Log Analytics clusters. | -| Data Collector Logs (Preview) | Delete or retrieve a data collector log tables for a Log Analytics workspace and retrieve all data collector log tables for a Log Analytics workspace. | -| [Data exports](/rest/api/loganalytics/data-exports) | Manage a data export for a Log Analytics workspace or retrieve the data export instances within a Log Analytics workspace. | -| [Data Sources](/rest/api/loganalytics/data-sources) | Create or update data sources. | -| [Deleted workspaces](/rest/api/loganalytics/deleted-workspaces) | Retrieve the recently deleted workspaces within a subscription or resource group. | -| [Gateways](/rest/api/loganalytics/gateways) | Delete a Log Analytics gateway. | -| [Intelligence Packs](/rest/api/loganalytics/intelligence-packs) | Enable or disable an intelligence pack for a Log Analytics workspace or retrieve all intelligence packs for a Log Analytics workspace. | -| [Linked Services](/rest/api/loganalytics/linked-services) | Create or update linked services. | -| [Linked Storage Accounts](/rest/api/loganalytics/linked-storage-accounts) | Manage a link relation between a workspace and storage accounts and retrieve all linked storage accounts associated with a workspace. | -| [Management Groups](/rest/api/loganalytics/management-groups) | Retrieve all management groups connected to a Log Analytics workspace. | -| [Metadata](/rest/api/loganalytics/metadata) | Retrieve the metadata information for a Log Analytics workspace. | -| [Operation Statuses](/rest/api/loganalytics/operation-statuses) | Retrieve the status of a long running azure asynchronous operation. | -| [Operations](/rest/api/loganalytics/operations) | Retrieve all of the available OperationalInsights Rest API operations. | -| [Query](/rest/api/loganalytics/query) | Execute a batch of Analytics queries for data. | -| [Query pack queries](/rest/api/monitor/query-pack-queries) | Manage a query defined within a Log Analytics QueryPack and retrieve or search the list of queries defined within a Log Analytics QueryPack. | -| [Query packs](/rest/api/monitor/query-packs) | Manage a Log Analytics QueryPack including updating its tags and retrieve a list of all Log Analytics QueryPacks within a subscription or resource group. | -| [Saved Searches](/rest/api/loganalytics/saved-searches) | Create or update saved searches. | -| [Storage Insights](/rest/api/loganalytics/storage-insights) | Create or update storage insights. | -| [Tables](/rest/api/loganalytics/tables) | Manage Log Analytics workspace tables. | -| [Workspace purge](/rest/api/loganalytics/workspace-purge) | Retrieve the status of an ongoing purge operation or purge the data in a Log Analytics workspace. | -| Workspace schema | Retrieves the schema for a Log Analytics workspace. | -| Workspace shared keys | Retrieve or regenerate the shared keys for a Log Analytics workspace. | -| Workspace usages | Retrieve the usage metrics for a Log Analytics workspace. | -| [Workspaces](/rest/api/loganalytics/workspaces) | Manage Log Analytics workspaces. | -| ***Metrics*** | | -| [Azure Monitor Workspaces](/rest/api/monitor/azure-monitor-workspaces) | Manage an Azure Monitor workspace and retrieve the Azure Monitor workspaces within a resource group or subscription. | -| [Metric definitions](/rest/api/monitor/metric-definitions) | Lists the metric definitions available for the resource. That is, what [specific metrics](/azure/azure-monitor/reference/supported-metrics/metrics-index) can you collect. | -| [Metric namespaces](/rest/api/monitor/metric-namespaces) | Lists the metric namespaces. Most relevant when using [custom metrics](./essentials/metrics-custom-overview.md). | -| [Metrics Batch](/rest/api/monitor/metrics-batch) | List the metric values for multiple resources. | -| [Metrics](/rest/api/monitor/metrics) | Lists the metric values for a resource you identify. | -| [Metrics ΓÇô Custom](/rest/api/monitor/metrics-custom) | Post the metric values for a resource. | -| ***Private Link Networking*** | | -| [Private endpoint connections (preview)](/rest/api/monitor/private-endpoint-connections) | Approve, reject, delete, and retrieve a private endpoint connection and retrieve all project endpoint connections on a private link scope. | -| [Private link resources (preview)](/rest/api/monitor/private-link-resources) | Retrieve a single private link resource that needs to be created for an Azure Monitor PrivateLinkScope or all private link resources within an Azure Monitor PrivateLinkScope resource that need to be created for an Azure Monitor PrivateLinkScope. | -| [Private link scope operation status (preview)](/rest/api/monitor/private-link-scope-operation-status) | Retrieves the status of an Azure asynchronous operation associated with a private link scope operation. | -| [Private link scoped resources (preview)](/rest/api/monitor/private-link-scoped-resources) | Approve, reject, delete, and retrieve a scoped resource object and retrieve all scoped resource objects within an Azure Monitor PrivateLinkScope resource. | -| [Private link scopes (preview)](/rest/api/monitor/private-link-scopes) | Manage an Azure Monitor PrivateLinkScope including its tags and retrieve a list of all Azure Monitor PrivateLinkScopes within a subscription or resource group. | -| ***Query log data*** | | -| [Data Access](./logs/api/overview.md) | Query Log Analytics data. | -| ***Send Custom Log Data to Log Analytics*** | | -| [Logs Ingestion](./logs/logs-ingestion-api-overview.md) | Lets you send data to a Log Analytics workspace using either a [REST API call](./logs/logs-ingestion-api-overview.md#rest-api-call) or [client libraries](./logs/logs-ingestion-api-overview.md#client-libraries). | -| ***Retired or being retired*** | | -| [Alerts (classic) rule incidents](/rest/api/monitor/alert-rule-incidents) | [Being retired in 2019](/previous-versions/azure/azure-monitor/alerts/monitoring-classic-retirement) in the public cloud. Older classic alerts functions. Gets an incident associated to a [classic metric alert rule](./alerts/alerts-classic.overview.md). When an alert rule fires because the threshold is crossed in the up or down direction, an incident is created and an entry added to the [Activity Log](./essentials/platform-logs-overview.md). | -| [Alert (classic) rules](/rest/api/monitor/alert-rules) | [Being retired in 2019](/previous-versions/azure/azure-monitor/alerts/monitoring-classic-retirement) in the public cloud. Provides operations for managing [classic alert](./alerts/alerts-classic.overview.md) rules. | -| [Data Collector](/rest/api/loganalytics/create-request) | Data Collector API Reference. | |
| azure-monitor | Best Practices Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/best-practices-alerts.md | - Title: Best practices for Azure Monitor alerts -description: Provides a template for a Well-Architected Framework (WAF) article specific to Azure Monitor alerts. --- Previously updated : 06/19/2024----# Best practices for Azure Monitor alerts -This article provides architectural best practices for Azure Monitor alerts, alert processing rules, and action groups. The guidance is based on the five pillars of architecture excellence described in [Azure Well-Architected Framework](/azure/architecture/framework/). ---For more information about alerts and notifications, see [Azure Monitor alerts overview](./alerts/alerts-overview.md). -For more information about alerting at-scale solutions, see [Alerting at-scale](alerts/alerts-overview.md#alerting-at-scale). --## Reliability -In the cloud, we acknowledge that failures happen. Instead of trying to prevent failures altogether, the goal is to minimize the effects of a single failing component. Use the following information to minimize failure of your Azure Monitor alert rule components. ---## Security -Security is one of the most important aspects of any architecture. Azure Monitor provides features to employ both the principle of least privilege and defense-in-depth. Use the following information to maximize the security of Azure Monitor alerts. ---## Cost optimization -Cost optimization refers to ways to reduce unnecessary expenses and improve operational efficiencies. You can significantly reduce your cost for Azure Monitor by understanding your different configuration options and opportunities to reduce the amount of data that it collects. See [Azure Monitor cost and usage](cost-usage.md) to understand the different ways that Azure Monitor charges and how to view your monthly bill. --> [!NOTE] -> See [Optimize costs in Azure Monitor](best-practices-cost.md) for cost optimization recommendations across all features of Azure Monitor. ---## Operational excellence -Operational excellence refers to operations processes required keep a service running reliably in production. Use the following information to minimize the operational requirements for supporting Azure Monitor alerts. ---## Performance efficiency -Performance efficiency is the ability of your workload to scale to meet the demands placed on it by users in an efficient manner. -Alerts offer a high degree of performance efficiency without any design decisions. --## Next step --- [Get best practices for a complete deployment of Azure Monitor](best-practices.md). |
| azure-monitor | Best Practices Analysis | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/best-practices-analysis.md | - Title: Azure Monitor best practices - Analysis and visualizations -description: Guidance and recommendations for customizing visualizations beyond standard analysis features in Azure Monitor. --- Previously updated : 06/07/2023----# Analyze and visualize monitoring data --This article describes built-in features for visualizing and analyzing collected data in Azure Monitor. Visualizations like charts and graphs can help you analyze your monitoring data to drill down on issues and identify patterns. You can create custom visualizations to meet the requirements of different users in your organization. --## Built-in analysis features --This table describes Azure Monitor features that provide analysis of collected data without any configuration. --| Component | Description | Required training and/or configuration | -|||--| -| Overview page |Most Azure services have an **Overview** page in the Azure portal that includes a **Monitor** section with charts that show recent critical metrics. This information is intended for owners of individual services to quickly assess the performance of the resource. | This page is based on platform metrics that are collected automatically. No configuration is required. | -| [Metrics Explorer](essentials/metrics-getting-started.md)| You can use Metrics Explorer to interactively work with metric data and create metric alerts. You need minimal training to use Metrics Explorer, but you must be familiar with the metrics you want to analyze. | ΓÇó Once data collection is configured, no other configuration is required.<br>ΓÇó Platform metrics for Azure resources are automatically available.<br>ΓÇó Guest metrics for virtual machines are available after an Azure Monitor agent is deployed to the virtual machine.<br>ΓÇó Application metrics are available after Application Insights is configured. | -| [Log Analytics](logs/log-analytics-overview.md) | With Log Analytics, you can create log queries to interactively work with log data and create log search alerts.| Some training is required for you to become familiar with the query language, although you can use prebuilt queries for common requirements. You can also add [query packs](logs/query-packs.md) with queries that are unique to your organization. Then if you're familiar with the query language, you can build queries for others in your organization. | --## Built-in visualization tools --### Azure workbooks --[Azure workbooks](./visualize/workbooks-overview.md) provide a flexible canvas for data analysis and the creation of rich visual reports. You can use workbooks to tap into the most complete set of data sources from across Azure and combine them into unified interactive experiences. They're especially useful to prepare end-to-end monitoring views across multiple Azure resources. Insights use prebuilt workbooks to present you with critical health and performance information for a particular service. You can access a gallery of workbooks on the **Workbooks** tab in Azure Monitor, create custom workbooks, or leverage Azure GitHub community templates to meet the requirements of your different users. ---### Azure dashboards --[Azure dashboards](../azure-portal/azure-portal-dashboards.md) are useful in providing a "single pane of glass" of your Azure infrastructure and services. While a workbook provides richer functionality, a dashboard can combine Azure Monitor data with data from other Azure services. ---Here's a video about how to create dashboards: --> [!VIDEO https://www.microsoft.com/en-us/videoplayer/embed/RE4AslH] --### Grafana --[Grafana](https://grafana.com/) is an open platform that excels in operational dashboards. It's useful for: --* Detecting, isolating, and triaging operational incidents. -* Combining visualizations of Azure and non-Azure data sources. These sources include on-premises, third-party tools, and data stores in other clouds. --Grafana has popular plug-ins and dashboard templates for application performance monitoring (APM) tools such as Dynatrace, New Relic, and AppDynamics. You can use these resources to visualize Azure platform data alongside other metrics from higher in the stack collected by other tools. It also has AWS CloudWatch and GCP BigQuery plug-ins for multicloud monitoring in a single pane of glass. --Grafana allows you to leverage the extensive flexibility included for combining data queries, query results, and performing open-ended client-side data processing, as well as using open-source community dashboards. --All versions of Grafana include the [Azure Monitor datasource plug-in](visualize/grafana-plugin.md) to visualize your Azure Monitor metrics and logs. --[Azure Managed Grafana](../managed-grafan) to get started. --The [out-of-the-box Grafana Azure alerts dashboard](https://grafana.com/grafana/dashboards/15128-azure-alert-consumption/) allows you to view and consume Azure monitor alerts for Azure Monitor, your Azure datasources, and Azure Monitor managed service for Prometheus. --* For more information on define Azure Monitor alerts, see [Create a new alert rule](alerts/alerts-create-new-alert-rule.md). -* For Azure Monitor managed service for Prometheus, define your alerts using [Prometheus alert rules](alerts/prometheus-alerts.md) that are created as part of a [Prometheus rule group](essentials/prometheus-rule-groups.md), applied on the Azure Monitor workspace. ---### Power BI --[Power BI](https://powerbi.microsoft.com/documentation/powerbi-service-get-started/) is useful for creating business-centric dashboards and reports, along with reports that analyze long-term KPI (Key Performance Indicator) trends. You can [import the results of a log query](./logs/log-powerbi.md) into a Power BI dataset, which allows you to take advantage of features such as combining data from different sources and sharing reports on the web and mobile devices. ---## Choose the right visualization tool --We recommend using Azure Managed Grafana for data visualizations and dashboards in cloud-native scenarios, such as Kubernetes and Azure Kubernetes Service (AKS), as well as multicloud, open source software, and third-party integrations. For other Azure scenarios, including Azure hybrid environments with Azure Arc, we recommend Azure workbooks. --#### When to use Azure Managed Grafana --* Cloud native environments monitored with Prometheus and CNCF tools -* Multi-cloud and multi-platform environments -* Multi-tenancy and portability support -* Interoperability with open-source and third-party tools -* Sharing dashboards outside of the Azure portal --#### When to use Azure workbooks --* Azure managed hybrid and edge environments -* Integrations with Azure actions and automation -* Creating custom reports based on Azure Monitor insights --### Benefits and use cases --| Visualization tool | Benefits | Recommended uses | -|--|-|| -| [**Azure workbooks**](./visualize/workbooks-overview.md) | | | -| | Native Azure dashboarding platform | Use as a tool for engineering and technical teams to visualize and investigate scenarios. | -| | Autorefresh | Use as a reporting tool for App developers, Cloud engineers, and other technical personnel | -| | Out-of-the-box and public GitHub templates and reports | | -| | Parameters allow dynamic real time updates | | -| | Can provide high-level summaries that allow you to select any item for more in-depth data using the selected value in the query | | -| | Can query more sources than other visualizations | | -| | Fully customizable | | -| | Designed for collaborating and troubleshooting | | -| [**Azure dashboards**](../azure-portal/azure-portal-dashboards.md) | | | -| | Native Azure dashboarding platform | For Azure/Arc exclusive environments | -| | No added cost | | -| | Supports at scale deployments | | -| | Can combine a metrics graph and the results of a log query with operational data for related services | | -| | Share a dashboard with service owners through integration with [Azure role-based access control](../role-based-access-control/overview.md) | | -| [**Azure Managed Grafana**](../managed-grafan) | | | -| | Multi-platform, multicloud single pane of glass visualizations | For users without Azure access | -| | Seamless integration with Azure | Use for external visualization experiences, especially for RAG type dashboards in SOC and NOC environments | -| | Can combine time-series and event data in a single visualization panel | Cloud Native CNCF monitoring | -| | Can create dynamic dashboards based on user selection of dynamic variables | Multicloud environments | -| | Prometheus support|Overall Statuses, Up/Down, and high level trend reports for management or executive level users | -| | Integrates with third party monitoring tools|Use to show status of environments, apps, security, and network for continuous display in Network Operations Center (NOC) dashboards | -| | Out-of-the-box plugins from most monitoring tools and platforms | | -| | Dashboard templates with focus on operations | | -| | Can create a dashboard from a community-created and community-supported template | | -| | Can create a vendor-agnostic business continuity and disaster scenario that runs on any cloud provider or on-premises | | -| [**Power BI**](https://powerbi.microsoft.com/documentation/powerbi-service-get-started/) | | | -| | Rich visualizations | Use for external visualizations aimed at management and executive levels | -| | Supports BI analytics with extensive slicing and dicing | Use to help design business centric KPI dashboards for long term trends | -| | Integrate data from multiple data sources | | -| | Results cached in a cube for better performance | | -| | Extensive interactivity, including zoom-in and cross-filtering | | -| | Share easily throughout your organization | | --## Other options --Some Azure Monitor partners provide visualization functionality. An Azure Monitor partner might provide out-of-the-box visualizations to save you time, although these solutions might have an extra cost. --You can also build your own custom websites and applications using metric and log data in Azure Monitor using the REST API. The REST API gives you flexibility in UI, visualization, interactivity, and features. --## Next steps --* [Deploy Azure Monitor: Alerts and automated actions](best-practices-alerts.md) -* [Optimize costs in Azure Monitor](best-practices-cost.md) |
| azure-monitor | Best Practices Containers | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/best-practices-containers.md | - Title: Best practices for monitoring Kubernetes with Azure Monitor -description: Provides a template for a Well-Architected Framework (WAF) article specific to monitoring Kubernetes with Azure Monitor. --- Previously updated : 03/29/2023----# Best practices for monitoring Kubernetes with Azure Monitor -This article provides best practices for monitoring the health and performance of your [Azure Kubernetes Service (AKS)](/azure/aks/intro-kubernetes) and [Azure Arc-enabled Kubernetes](../azure-arc/kubernetes/overview.md) clusters. The guidance is based on the five pillars of architecture excellence described in [Azure Well-Architected Framework](/azure/architecture/framework/). ----## Reliability -In the cloud, we acknowledge that failures happen. Instead of trying to prevent failures altogether, the goal is to minimize the effects of a single failing component. Use the following information to best leverage Azure Monitor to ensure the reliability of your Kubernetes clusters and monitoring environment. ----## Security -Security is one of the most important aspects of any architecture. Azure Monitor provides features to employ both the principle of least privilege and defense-in-depth. Use the following information to monitor your Kubernetes clusters and ensure that only authorized users access collected data. ----## Cost optimization -Cost optimization refers to ways to reduce unnecessary expenses and improve operational efficiencies. You can significantly reduce your cost for Azure Monitor by understanding your different configuration options and opportunities to reduce the amount of data that it collects. See [Azure Monitor cost and usage](cost-usage.md) to understand the different ways that Azure Monitor charges and how to view your monthly bill. --> [!NOTE] -> See [Optimize costs in Azure Monitor](best-practices-cost.md) for cost optimization recommendations across all features of Azure Monitor. ----## Operational excellence -Operational excellence refers to operations processes required keep a service running reliably in production. Use the following information to minimize the operational requirements for monitoring your Kubernetes clusters. ----## Performance efficiency -Performance efficiency is the ability of your workload to scale to meet the demands placed on it by users in an efficient manner. Use the following information to monitor the performance of your Kubernetes clusters and ensure they're configured for maximum performance. ---## Next step --- [Get best practices for a complete deployment of Azure Monitor](best-practices.md). |
| azure-monitor | Best Practices Cost | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/best-practices-cost.md | - Title: Cost optimization in Azure Monitor -description: Recommendations for reducing costs in Azure Monitor. --- Previously updated : 03/12/2024----# Cost optimization in Azure Monitor --Cost optimization refers to ways to reduce unnecessary expenses and improve operational efficiencies. You can significantly reduce your cost for Azure Monitor by understanding your different configuration options and opportunities to reduce the amount of data that it collects. Before you use this article, you should see [Azure Monitor cost and usage](cost-usage.md) to understand the different ways that Azure Monitor charges and how to view your monthly bill. --This article describes [Cost optimization](/azure/architecture/framework/cost/) for Azure Monitor as part of the [Azure Well-Architected Framework](/azure/architecture/framework/). The Azure Well-Architected Framework is a set of guiding tenets that can be used to improve the quality of a workload. The framework consists of five pillars of architectural excellence: --- Reliability--## Azure Monitor Logs ---## Azure resources --### Design checklist --> [!div class="checklist"] -> - Collect only critical resource log data from Azure resources. --### Configuration recommendations --| Recommendation | Benefit | -|:|:| -| Collect only critical resource log data from Azure resources. | When you create [diagnostic settings](essentials/diagnostic-settings.md) to send [resource logs](essentials/resource-logs.md) for your Azure resources to a Log Analytics database, only specify those categories that you require. Since diagnostic settings don't allow granular filtering of resource logs, you can use a [workspace transformation](essentials/data-collection-transformations-workspace.md) to filter unneeded data for those resources that use a [supported table](logs/tables-feature-support.md). See [Diagnostic settings in Azure Monitor](essentials/diagnostic-settings.md#controlling-costs) for details on how to configure diagnostic settings and using transformations to filter their data. | --## Alerts ---## Virtual machines ---## Containers ---## Application Insights ---## Next step --- [Get best practices for a complete deployment of Azure Monitor](best-practices.md).- |
| azure-monitor | Best Practices Data Collection | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/best-practices-data-collection.md | - Title: 'Azure Monitor best practices: Configure data collection' -description: Guidance and recommendations for configuring data collection in Azure Monitor. --- Previously updated : 07/26/2024-----# Azure Monitor best practices: Configure data collection --This article is part of the scenario [Recommendations for configuring Azure Monitor](best-practices.md). It describes recommended steps to configure data collection required to enable Azure Monitor features for your Azure and hybrid applications and resources. --> [!IMPORTANT] -> The features of Azure Monitor and their configuration will vary depending on your business requirements balanced with the cost of the enabled features. Each of the following steps identifies whether there's potential cost, and you should assess these costs before proceeding. See [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/) for complete pricing details. --## Design Log Analytics workspace architecture --You require at least one Log Analytics workspace to enable [Azure Monitor Logs](logs/data-platform-logs.md), which is required for: --- Collecting data such as logs from Azure resources.-- Collecting data from the guest operating system of Azure Virtual Machines.-- Enabling most Azure Monitor insights.--Other services such as Microsoft Sentinel and Microsoft Defender for Cloud also use a Log Analytics workspace and can share the same one that you use for Azure Monitor. --There's no cost for creating a Log Analytics workspace, but there's a potential charge after you configure data to be collected into it. See [Azure Monitor Logs pricing details](logs/cost-logs.md) for information on how log data is charged. --See [Create a Log Analytics workspace in the Azure portal](logs/quick-create-workspace.md) to create an initial Log Analytics workspace, and see [Manage access to Log Analytics workspaces](logs/manage-access.md) to configure access. You can use scalable methods such as Resource Manager templates to configure workspaces, although this step is often not required because most environments will require a minimal number. --Start with a single workspace to support initial monitoring. See [Design a Log Analytics workspace configuration](logs/workspace-design.md) for guidance on when to use multiple workspaces and how to locate and configure them. --## Collect data from Azure resources --Some monitoring of Azure resources is available automatically with no configuration required. To collect more monitoring data, you must perform configuration steps. --The following table shows the configuration steps required to collect all available data from your Azure resources. It also shows at which step data is sent to Azure Monitor Metrics and Azure Monitor Logs. The following sections describe each step in further detail. -<!-- convertborder later --> --### Collect tenant and subscription logs --The [Microsoft Entra logs](../active-directory/reports-monitoring/overview-reports.md) for your tenant and the [activity log](essentials/platform-logs-overview.md) for your subscription are collected automatically. When you send them to a Log Analytics workspace, you can analyze these events with other log data by using log queries in Log Analytics. You can also create log search alerts, which are the only way to alert on Microsoft Entra logs and provide more complex logic than activity log alerts. --There's no cost for sending the activity log to a workspace, but there's a data ingestion and retention charge for Microsoft Entra logs. --See [Integrate Microsoft Entra logs with Azure Monitor logs](../active-directory/reports-monitoring/howto-integrate-activity-logs-with-log-analytics.md) and [Create diagnostic settings to send platform logs and metrics to different destinations](essentials/diagnostic-settings.md) to create a diagnostic setting for your tenant and subscription to send log entries to your Log Analytics workspace. --### Collect resource logs and platform metrics --Resources in Azure automatically generate [resource logs](essentials/platform-logs-overview.md) that provide details of operations performed within the resource. Unlike platform metrics, you need to configure resource logs to be collected. Create a diagnostic setting to send them to a Log Analytics workspace and combine them with the other data used with Azure Monitor Logs. The same diagnostic setting also can be used to send the platform metrics for most resources to the same workspace. This way, you can analyze metric data by using log queries with other collected data. --There's a cost for collecting resource logs in your Log Analytics workspace, so only select those log categories with valuable data. Collecting all categories will incur cost for collecting data with little value. See the monitoring documentation for each Azure service for a description of categories and recommendations for which to collect. Also see [Azure Monitor best practices - cost management](logs/cost-logs.md) for recommendations on optimizing the cost of your log collection. --See [Create diagnostic settings to collect resource logs and metrics in Azure](essentials/create-diagnostic-settings.md) to create a diagnostic setting for an Azure resource. --Because a diagnostic setting needs to be created for each Azure resource, use Azure Policy to automatically create a diagnostic setting as each resource is created. Each Azure resource type has a unique set of categories that need to be listed in the diagnostic setting. Because of this, each resource type requires a separate policy definition. Some resource types have built-in policy definitions that you can assign without modification. For other resource types, you need to create a custom definition. --See [Create diagnostic settings at scale using Azure Policy](essentials/diagnostic-settings-policy.md) for a process for creating policy definitions for a particular Azure service and details for creating diagnostic settings at scale. --### Enable insights --Insights provide a specialized monitoring experience for a particular service. They use the same data already being collected such as platform metrics and resource logs, but they provide custom workbooks that assist you in identifying and analyzing the most critical data. Most insights will be available in the Azure portal with no configuration required, other than collecting resource logs for that service. See the monitoring documentation for each Azure service to determine whether it has an insight and if it requires configuration. --There's no cost for insights, but you might be charged for any data they collect. --See [Azure Monitor Insights overview](insights/insights-overview.md) for a list of available insights and solutions in Azure Monitor. See the documentation for each for any unique configuration or pricing information. --> [!IMPORTANT] -> The following insights are much more complex than others and have more guidance for their configuration: -> -> - [VM insights](#monitor-virtual-machines) -> - [Container insights](#monitor-containers) -> - [Monitor applications](#monitor-applications) --## Monitor virtual machines --Virtual machines generate similar data as other Azure resources, but they require an agent to collect data from the guest operating system. Virtual machines also have unique monitoring requirements because of the different workloads running on them. See [Monitoring Azure virtual machines with Azure Monitor](vm/monitor-vm-azure.md) for a dedicated scenario on monitoring virtual machines with Azure Monitor. --## Monitor containers --Containers generate similar data as other Azure resources, but they require a containerized version of the Log Analytics agent to collect required data. Container insights help you prepare your containerized environment for monitoring. It works in conjunction with third-party tools to provide comprehensive monitoring of Azure Kubernetes Service (AKS) and the workflows it supports. See [Monitoring Azure Kubernetes Service with Azure Monitor](/azure/aks/monitor-aks?toc=/azure/azure-monitor/toc.json) for a dedicated scenario on monitoring AKS with Azure Monitor. --## Monitor applications --Azure Monitor monitors your custom applications by using [Application Insights](app/app-insights-overview.md), which you must configure for each application you want to monitor. The configuration process varies depending on the type of application being monitored and the type of monitoring that you want to perform. Data collected by Application Insights is stored in Azure Monitor Metrics, Azure Monitor Logs, and Azure Blob Storage, depending on the feature. Performance data is stored in both Azure Monitor Metrics and Azure Monitor Logs with no more configuration required. --### Create an application resource --Application Insights is the feature of Azure Monitor for monitoring your cloud native and hybrid applications. --You can create a resource in Application Insights for each application that you're going to monitor or a single application resource for multiple applications. Whether to use separate or a single application resource for multiple applications is a fundamental decision of your monitoring strategy. Separate resources can save costs and prevent mixing data from different applications, but a single resource can simplify your monitoring by keeping all relevant telemetry together. See [How many Application Insights resources should I deploy](app/create-workspace-resource.md#how-many-application-insights-resources-should-i-deploy) for criteria to help you make this design decision. --When you create the application resource, you must select whether to use classic or workspace based. See [Create an Application Insights resource](/previous-versions/azure/azure-monitor/app/create-new-resource) to create a classic application. -See [Workspace-based Application Insights resources](app/create-workspace-resource.md) to create a workspace-based application. Log data collected by Application Insights is stored in Azure Monitor Logs for a workspace-based application. Log data for classic applications is stored separately from your Log Analytics workspace. --### Configure codeless or code-based monitoring --To enable monitoring for an application, you must decide whether you'll use codeless or code-based monitoring. The configuration process varies depending on this decision and the type of application you're going to monitor. --**Codeless monitoring** is easiest to implement and can be configured after your code development. It doesn't require any updates to your code. For information on how to enable monitoring based on your application, see: --- [Applications hosted on Azure Web Apps](app/azure-web-apps.md)-- [Java applications](app/opentelemetry-enable.md?tabs=java)-- [ASP.NET applications hosted in IIS on Azure Virtual Machines or Azure Virtual Machine Scale Sets](app/azure-vm-vmss-apps.md)-- [ASP.NET applications hosted in IIS on-premises](app/application-insights-asp-net-agent.md)--**Code-based monitoring** is more customizable and collects more telemetry, but it requires adding a dependency to your code on the Application Insights SDK NuGet packages. For information on how to enable monitoring based on your application, see: --- [ASP.NET applications](app/asp-net.md)-- [ASP.NET Core applications](app/asp-net-core.md)-- [.NET console applications](app/console.md)-- [Java](app/opentelemetry-enable.md?tabs=java)-- [Node.js](app/nodejs.md)-- [Python](/previous-versions/azure/azure-monitor/app/opencensus-python)-- [Other platforms](app/app-insights-overview.md#supported-languages)--### Configure availability testing --Availability tests in Application Insights are recurring tests that monitor the availability and responsiveness of your application at regular intervals from points around the world. You can create a simple ping test for free. You can also create a sequence of web requests to simulate user transactions, which have associated costs. --See [Monitor the availability of any website](/previous-versions/azure/azure-monitor/app/monitor-web-app-availability) for a summary of the different kinds of tests and information on creating them. --### Configure Profiler --Profiler in Application Insights provides performance traces for .NET applications. It helps you identify the "hot" code path that takes the longest time when it's handling a particular web request. The process for configuring the profiler varies depending on the type of application. --See [Profile production applications in Azure with Application Insights](app/profiler-overview.md) for information on configuring Profiler. --### Configure Snapshot Debugger --Snapshot Debugger in Application Insights monitors exception telemetry from your .NET application. It collects snapshots on your top-throwing exceptions so that you have the information you need to diagnose issues in production. The process for configuring Snapshot Debugger varies depending on the type of application. --See [Debug snapshots on exceptions in .NET apps](app/snapshot-debugger.md) for information on configuring Snapshot Debugger. --## Next steps --With data collection configured for all your Azure resources, see [Analyze and visualize data](best-practices-analysis.md) to see options for analyzing this data. |
| azure-monitor | Best Practices Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/best-practices-logs.md | - Title: Best practices for Azure Monitor Logs -description: Provides a template for a Well-Architected Framework (WAF) article specific to Log Analytics workspaces in Azure Monitor. --- Previously updated : 08/16/2023----# Best practices for Azure Monitor Logs -This article provides architectural best practices for Azure Monitor Logs. The guidance is based on the five pillars of architecture excellence described in [Azure Well-Architected Framework](/azure/architecture/framework/). ----## Reliability -[Reliability](/azure/well-architected/resiliency/overview) refers to the ability of a system to recover from failures and continue to function. The goal is to minimize the effects of a single failing component. Use the following information to minimize failure of your Log Analytics workspaces and to protect the data they collect. ----## Security -[Security](/azure/well-architected/security/overview) is one of the most important aspects of any architecture. Azure Monitor provides features to employ both the principle of least privilege and defense-in-depth. Use the following information to maximize the security of your Log Analytics workspaces and ensure that only authorized users access collected data. ----## Cost optimization -[Cost optimization](/azure/well-architected/cost/overview) refers to ways to reduce unnecessary expenses and improve operational efficiencies. You can significantly reduce your cost for Azure Monitor by understanding your different configuration options and opportunities to reduce the amount of data that it collects. See [Azure Monitor cost and usage](usage-estimated-costs.md) to understand the different ways that Azure Monitor charges and how to view your monthly bill. --> [!NOTE] -> See [Optimize costs in Azure Monitor](best-practices-cost.md) for cost optimization recommendations across all features of Azure Monitor. ----## Operational excellence -[Operational excellence](/azure/well-architected/devops/overview) refers to operations processes required keep a service running reliably in production. Use the following information to minimize the operational requirements for supporting Log Analytics workspaces. ----## Performance efficiency -[Performance efficiency](/azure/well-architected/scalability/overview) is the ability of your workload to scale to meet the demands placed on it by users in an efficient manner. Use the following information to ensure that your Log Analytics workspaces and log queries are configured for maximum performance. ---## Next step --- [Get best practices for a complete deployment of Azure Monitor](best-practices.md). |
| azure-monitor | Best Practices Multicloud | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/best-practices-multicloud.md | - Title: Multicloud monitoring with Azure Monitor -description: Guidance and recommendations for using Azure Monitor to monitor resources and applications in other clouds. - Previously updated : 02/16/2024-----# Multicloud monitoring with Azure Monitor -In addition to monitoring services and application in Azure, Azure Monitor can provide complete monitoring for your resources and applications running in other clouds including Amazon Web Services (AWS) and Google Cloud Platform (GCP). This article describes features of Azure Monitor that allow you to provide complete monitoring across your AWS and GCP environments. --## Virtual machines - [Azure Arc-enabled servers](../azure-arc/servers/overview.md) provide a consistent experience between both Azure virtual machines and your AWS EC2 or GCP VM instances. This includes using standard Azure constructs such as Azure Policy and applying tags. The [Azure Monitor agent](agents/agents-overview.md) collects telemetry from the client operating system of virtual machines regardless of their location, and you can use the same [data collection rules](essentials/data-collection-rule-overview.md) that define your data collection across all of the virtual machines across your different cloud environments. If you use [VM insights](vm/vminsights-overview.md) in Azure Monitor, you can view your hybrid machines right alongside your Azure machines and onboard them using identical methods. --- [Plan and deploy Azure Arc-enabled servers](../azure-arc/servers/plan-at-scale-deployment.md)-- [Manage Azure Monitor Agent](agents/azure-monitor-agent-manage.md)-- [Enable VM insights overview](vm/vminsights-enable-overview.md)--If you use Defender for Cloud for security management and threat detection, then you can use auto provisioning to automate the deployment of the Azure Arc agent to your AWS EC2 and GCP VM instances. --- [Connect your AWS accounts to Microsoft Defender for Cloud](/azure/defender-for-cloud/quickstart-onboard-aws)-- [Connect your GCP projects to Microsoft Defender for Cloud](/azure/defender-for-cloud/quickstart-onboard-gcp)--## Kubernetes -[Managed Prometheus](essentials/prometheus-metrics-overview.md) and [Container insights](containers/container-insights-overview.md) in Azure Monitor use [Azure Arc-enabled Kubernetes](../azure-arc/servers/overview.md) to provide a consistent experience between both [Azure Kubernetes Service (AKS)](/azure/aks/intro-kubernetes) and Kubernetes clusters in your AWS EKS or GCP GKE instances. You can view your hybrid clusters right alongside your Azure machines and onboard them using the same methods. This includes using standard Azure constructs such as Azure Policy and applying tags. --Use Prometheus [remote write](./essentials/prometheus-remote-write.md) from your on-premises, AWS, or GCP clusters to send data to Azure managed service for Prometheus. --The [Azure Monitor agent](agents/agents-overview.md) installed by Container insights collects telemetry from the client operating system of clusters regardless of their location. Use the same analysis tools, [Managed Grafana](../managed-grafan) and Container insights, to monitor clusters across your different cloud environments. --- [Connect an existing Kubernetes cluster to Azure Arc](../azure-arc/kubernetes/quickstart-connect-cluster.md)-- [Azure Monitor Container Insights for Azure Arc-enabled Kubernetes clusters](containers/container-insights-enable-arc-enabled-clusters.md)-- [Monitoring Azure Kubernetes Service (AKS) with Azure Monitor](/azure/aks/monitor-aks)--## Applications -Applications hosted outside of Azure must be hard coded to send telemetry to [Azure Monitor Application Insights](app/app-insights-overview.md) using SDKs for [supported languages](app/app-insights-overview.md#supported-languages). Annual code maintenance should be planned to upgrade the SDKs per [Application Insights SDK support guidance](app/sdk-support-guidance.md). --- If you use [Grafana](https://grafana.com/grafana/) for visualization of monitoring data across your different clouds. use the [Azure Monitor data source](https://grafana.com/docs/grafana/latest/datasources/azure-monitor/) to include application log and metric data in your dashboards.-- If you use [Data Dog](https://www.datadoghq.com/), use [Azure integrations](https://www.datadoghq.com/blog/azure-monitoring-enhancements/) to include application log and metric data in your Data Dog UI.---## Audit -In addition to monitoring the health of your cloud resources, you can consolidate auditing data from your AWS and GCP clouds into your Log Analytics workspace so that you can consolidate your analysis and reporting. This is best performed by Azure Sentinel which uses the same workspace as Azure Monitor and provides additional features for collecting and analyzing security and auditing data. --Use the following methods to ingest AWS service log data into Microsoft Sentinel. --- [Microsoft Sentinel connector](../sentinel/connect-aws.md)-- [Azure function](https://github.com/andedevsecops/AWS-CloudTrail-AzFunc)-- [AWS Lambda function](https://github.com/andedevsecops/aws-data-connector-az-sentinel)---Use the following methods to use a plugin to collect events, including pub/sub events, stored in GCP Cloud Storage, and then ingest into Log Analytics. --- [Google Cloud Storage Input Plugin](https://www.elastic.co/guide/en/logstash/current/plugins-inputs-google_cloud_storage.html)-- [GCP Cloud Functions](https://github.com/andedevsecops/azure-sentinel-gcp-data-connector)-- [Google_pubsub input plugin](https://www.elastic.co/guide/en/logstash/current/plugins-inputs-google_pubsub.html#plugins-inputs-google_pubsub)-- [Azure Log Analytics output plugin for Logstash](https://github.com/Azure/Azure-Sentinel/tree/master/DataConnectors/microsoft-logstash-output-azure-loganalytics)---## Custom data sources -Use the following methods to collect data from your cloud resources that doesn't fit into standard collection methods. --- Send custom log data from any REST API client with the [Logs Ingestion API in Azure Monitor](logs/logs-ingestion-api-overview.md)-- Use Logstash to collect data and the [Azure Log Analytics output plugin for Logstash](https://github.com/Azure/Azure-Sentinel/tree/master/DataConnectors/microsoft-logstash-output-azure-loganalytics) to ingest it into a Log Analytics workspace.--## Automation -[Azure Automation](../automation/overview.md) delivers cloud-based automation, operating system updates, and configuration services that support consistent management across your Azure and non-Azure environments. It includes process automation, configuration management, update management, shared capabilities, and heterogeneous features. [Hybrid Runbook Worker](../automation/automation-hybrid-runbook-worker.md) enables automation runbooks to run directly on the non-Azure virtual machines against resources in the environment to manage those local resources. --Through [Arc-enabled servers](../azure-arc/servers/overview.md), Azure Automation provides a consistent deployment and management experience for your non-Azure machines. It enables integration with the Automation service using the VM extension framework to deploy the Hybrid Runbook Worker role, and simplify onboarding to Update Management and Change Tracking and Inventory. - |
| azure-monitor | Best Practices Plan | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/best-practices-plan.md | - Title: Plan your Azure Monitor implementation -description: Guidance and recommendations for planning and design before deploying Azure Monitor. --- Previously updated : 02/11/2024----# Plan your Azure Monitor implementation -This article describes the things that you should consider before starting your implementation. Proper planning helps you choose the configuration options to meet your business requirements. --To start learning about high-level monitoring concepts and guidance about defining requirements for your monitoring environment, see the [Cloud monitoring guide](/azure/cloud-adoption-framework/manage/monitor), which is part of the [Microsoft Cloud Adoption Framework for Azure](/azure/cloud-adoption-framework/). ---## Define a strategy -First, [formulate a monitoring strategy](/azure/cloud-adoption-framework/strategy/monitoring-strategy) to clarify the goals and requirements of your plan. The strategy defines your particular requirements, the configuration that best meets those requirements, and processes to use the monitoring environment to maximize your applications' performance and reliability. --See [Monitoring strategy for cloud deployment models](/azure/cloud-adoption-framework/manage/monitor/cloud-models-monitor-overview), which assist in comparing completely cloud based monitoring with a hybrid model. --## Gather required information -Before you determine the details of your implementation, gather this information: -- ### What needs to be monitored? -Focus on your critical applications and the components they depend on to reduce monitoring and the complexity of your monitoring environment. See [Cloud monitoring guide: Collect the right data](/azure/cloud-adoption-framework/manage/monitor/data-collection) for guidance on defining the data that you require. --### Who needs to have access and who needs be notified? -Determine which users need access to monitoring data and which users need to be notified when an issue is detected. These may be application and resource owners, or you may have a centralized monitoring team. This information determines how you configure permissions for data access and notifications for alerts. You may also decide to configure custom workbooks to present particular sets of information to different users. --### Consider service level agreement (SLA) requirements -Your organization may have SLAs that define your commitments for performance and uptime of your applications. Take these SLAs into consideration when configuring time sensitive features of Azure Monitor such as alerts. Learn about [data latency in Azure Monitor](logs/data-ingestion-time.md) which affects the responsiveness of monitoring scenarios and your ability to meet SLAs. --## Identify supporting monitoring services and products -Azure Monitor is designed to address health and status monitoring. A complete monitoring solution usually involves multiple Azure services and may include other products to achieve other [monitoring objectives](/azure/cloud-adoption-framework/strategy/monitoring-strategy#formulate-monitoring-requirements). --Consider using these other products and services along with Azure Monitor: --### Security monitoring solutions -While the operational data stored in Azure Monitor might be useful for investigating security incidents, other services in Azure were designed to monitor security. Security monitoring in Azure is performed by Microsoft Defender for Cloud and Microsoft Sentinel. --|Security monitoring solution |Description | -||| -|[Microsoft Defender for Cloud](../security-center/security-center-introduction.md) |Collects information about Azure resources and hybrid servers. Although it can collect security events, Defender for Cloud focuses on collecting inventory data, assessment scan results, and policy audits to highlight vulnerabilities and recommend corrective actions. Noteworthy features include an interactive network map, just-in-time VM access, adaptive network hardening, and adaptive application controls to block suspicious executables. | -|[Microsoft Defender for servers](../security-center/azure-defender.md) |The server assessment solution provided by Defender for Cloud. Defender for servers can send Windows Security Events to Log Analytics. Defender for Cloud doesn't rely on Windows Security Events for alerting or analysis. Using this feature allows centralized archival of events for investigation or other purposes. | -|[Microsoft Sentinel](../sentinel/overview.md) |A security information event management (SIEM) and security orchestration automated response (SOAR) solution. Sentinel collects security data from a wide range of Microsoft and third-party sources to provide alerting, visualization, and automation. This solution focuses on consolidating as many security logs as possible, including Windows Security Events. Microsoft Sentinel can also collect Windows Security Event Logs and commonly shares a Log Analytics workspace with Defender for Cloud. Security events can only be collected from Microsoft Sentinel or Defender for Cloud when they share the same workspace. Unlike Defender for Cloud, security events are a key component of alerting and analysis in Microsoft Sentinel. | -|[Defender for Endpoint](/microsoft-365/security/defender-endpoint/microsoft-defender-endpoint) |An enterprise endpoint security platform designed to help enterprise networks prevent, detect, investigate, and respond to advanced threats. It was designed with a primary focus on protecting Windows user devices. Defender for Endpoint monitors workstations, servers, tablets, and cellphones with various operating systems for security issues and vulnerabilities. Defender for Endpoint is closely aligned with Microsoft Intune to collect data and provide security assessments. Data collection is primarily based on ETW trace logs and is stored in an isolated workspace. | --### System Center Operations Manager -If you have an existing investment in System Center Operations Manager for monitoring on-premises resources and workloads running on your virtual machines, you may choose to [migrate this monitoring to Azure Monitor](azure-monitor-operations-manager.md) or continue to use both products together in a hybrid configuration. --See [Cloud monitoring guide: Monitoring platforms overview](/azure/cloud-adoption-framework/manage/monitor/platform-overview) for a comparison of products. See [Monitoring strategy for cloud deployment models](/azure/cloud-adoption-framework/manage/monitor/cloud-models-monitor-overview) for how to use the two products in a hybrid configuration and determine the most appropriate model for your environment. ---## Next steps --- See [Configure data collection](best-practices-data-collection.md) for steps and recommendations to configure data collection in Azure Monitor. |
| azure-monitor | Best Practices Vm | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/best-practices-vm.md | - Title: Best practices for monitoring virtual machines in Azure Monitor -description: Best practices organized by the pillars of the Well-Architected Framework (WAF) for monitoring virtual machines in Azure Monitor. --- Previously updated : 07/26/2024----# Best practices for monitoring virtual machines in Azure Monitor -This article provides architectural best practices for monitoring virtual machines and their client workloads using Azure Monitor. The guidance is based on the five pillars of architecture excellence described in [Azure Well-Architected Framework](/azure/architecture/framework/). ----## Reliability -In the cloud, we acknowledge that failures happen. Instead of trying to prevent failures altogether, the goal is to minimize the effects of a single failing component. Use the following information to monitor your virtual machines and their client workloads for failure. ----## Security -Security is one of the most important aspects of any architecture. Azure Monitor provides features to employ both the principle of least privilege and defense-in-depth. Use the following information to monitor the security of your virtual machines. ----## Cost optimization -Cost optimization refers to ways to reduce unnecessary expenses and improve operational efficiencies. You can significantly reduce your cost for Azure Monitor by understanding your different configuration options and opportunities to reduce the amount of data that it collects. See [Azure Monitor cost and usage](cost-usage.md) to understand the different ways that Azure Monitor charges and how to view your monthly bill. --> [!NOTE] -> See [Optimize costs in Azure Monitor](best-practices-cost.md) for cost optimization recommendations across all features of Azure Monitor. ----## Operational excellence -Operational excellence refers to operations processes required keep a service running reliably in production. Use the following information to minimize the operational requirements for monitoring of your virtual machines. ----## Performance efficiency -Performance efficiency is the ability of your workload to scale to meet the demands placed on it by users in an efficient manner. Use the following information to monitor the performance of your virtual machines. ---## Next step --- [Get complete guidance on configuring monitoring for virtual machines](vm/monitor-virtual-machine.md). |
| azure-monitor | Change Analysis Enable | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/change/change-analysis-enable.md | - Title: Enable Change Analysis | Microsoft Docs -description: Use Change Analysis in Azure Monitor to track and troubleshoot issues on your live site. --- Previously updated : 11/17/2023----# Enable Change Analysis ---The Change Analysis service: -- Computes and aggregates change data from the data sources mentioned earlier. -- Provides a set of analytics for users to:- - Easily navigate through all resource changes. - - Identify relevant changes in the troubleshooting or monitoring context. --Register the `Microsoft.ChangeAnalysis` resource provider with an Azure Resource Manager subscription to make the resource properties and configuration change data available. The `Microsoft.ChangeAnalysis` resource provider is automatically registered as you either: -- Enter any UI entry point, like the Web App **Diagnose and Solve Problems** tool, or -- Bring up the Change Analysis standalone tab.--In this guide, you learn the two ways to enable Change Analysis for Azure Functions and web app in-guest changes: -- For one or a few Azure Functions or web apps, [enable Change Analysis via the UI](#enable-azure-functions-and-web-app-in-guest-change-collection-via-the-change-analysis-portal).-- For a large number of web apps (for example, 50+ web apps), [enable Change Analysis using the provided PowerShell script](#enable-change-analysis-at-scale-using-powershell).--> [!NOTE] -> Slot-level enablement for Azure Functions or web app is not supported at the moment. --## Enable Azure Functions and web app in-guest change collection via the Change Analysis portal --For web app in-guest changes, separate enablement is required for scanning code files within a web app. For more information, see [Change Analysis in the Diagnose and solve problems tool](change-analysis-visualizations.md#view-changes-using-the-diagnose-and-solve-problems-tool) section. --> [!NOTE] -> You may not immediately see web app in-guest file changes and configuration changes. Prepare for downtime and restart your web app to view changes within 30 minutes. If you still can't see changes, refer to [the troubleshooting guide](./change-analysis-troubleshoot.md#cannot-see-in-guest-changes-for-newly-enabled-web-app). --1. Navigate to Azure Monitor's Change Analysis UI in the portal. --1. Enable web app in-guest change tracking by either: -- - Selecting **Enable Now** in the banner, or -- :::image type="content" source="./media/change-analysis/enable-changeanalysis.png" alt-text="Screenshot of the Application Changes options from the banner."::: -- - Selecting **Configure** from the top menu. - - :::image type="content" source="./media/change-analysis/configure-button.png" alt-text="Screenshot of the Application Changes options from the top menu."::: --1. Toggle on **Change Analysis** status and select **Save**. -- :::image type="content" source="./media/change-analysis/change-analysis-on.png" alt-text="Screenshot of the Enable Change Analysis user interface."::: - - - The tool displays all web apps under an App Service plan, which you can toggle on and off individually. -- :::image type="content" source="./media/change-analysis/change-analysis-on-2.png" alt-text="Screenshot of the Enable Change Analysis user interface expanded."::: --## Enable Change Analysis at scale using PowerShell --If your subscription includes several web apps, run the following script to enable *all web apps* in your subscription. --### Prerequisites --PowerShell Az Module. Follow instructions at [Install the Azure PowerShell module](/powershell/azure/install-azure-powershell) --### Run the following script: --```PowerShell -# Log in to your Azure subscription -Connect-AzAccount --# Get subscription Id -$SubscriptionId = Read-Host -Prompt 'Input your subscription Id' --# Make Feature Flag visible to the subscription -Set-AzContext -SubscriptionId $SubscriptionId --# Register resource provider -Register-AzResourceProvider -ProviderNamespace "Microsoft.ChangeAnalysis" --# Enable each web app -$webapp_list = Get-AzWebApp | Where-Object {$_.kind -eq 'app'} -foreach ($webapp in $webapp_list) -{ - $tags = $webapp.Tags - $tags["hidden-related:diagnostics/changeAnalysisScanEnabled"]=$true - Set-AzResource -ResourceId $webapp.Id -Tag $tags -Force -} -``` --## Frequently asked questions --This section provides answers to common questions. --### How can I enable Change Analysis for a web application? --Enable Change Analysis for web application in guest changes by using the [Diagnose and solve problems tool](./change-analysis-visualizations.md#view-changes-using-the-diagnose-and-solve-problems-tool). --## Next steps --- Learn about [visualizations in Change Analysis](change-analysis-visualizations.md)-- Learn how to [troubleshoot problems in Change Analysis](change-analysis-troubleshoot.md)-- Enable Application Insights for [Azure web apps](../../azure-monitor/app/azure-web-apps.md).-- Enable Application Insights for [Azure VM and Azure virtual machine scale set IIS-hosted apps](../../azure-monitor/app/azure-vm-vmss-apps.md). |
| azure-monitor | Change Analysis Track Outages | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/change/change-analysis-track-outages.md | - Title: "Tutorial: Track a web app outage using Change Analysis" -description: Describes how to identify the root cause of a web app outage using Azure Monitor Change Analysis. --- Previously updated : 11/17/2023----# Tutorial: Track a web app outage using Change Analysis ---When your application runs into an issue, you need configurations and resources to triage breaking changes and discover root-cause issues. Change Analysis provides a centralized view of the changes in your subscriptions for up to 14 days prior to provide the history of changes for troubleshooting issues. --To track an outage, we will: --> [!div class="checklist"] -> - Clone, create, and deploy a [sample web application](https://github.com/Azure-Samples/changeanalysis-webapp-storage-sample) with a storage account. -> - Enable Change Analysis to track changes for Azure resources and for Azure Web App configurations -> - Troubleshoot a Web App issue using Change Analysis --## Prerequisites --- Install [.NET 7.0 or above](https://dotnet.microsoft.com/download). -- Install [the Azure CLI](/cli/azure/install-azure-cli). --## Set up the test application --### Clone --1. In your preferred terminal, log in to your Azure subscription. -- ```bash - az login - az account set -s {azure-subscription-id} - ``` --1. Clone the [sample web application with storage to test Change Analysis](https://github.com/Azure-Samples/changeanalysis-webapp-storage-sample). -- ```bash - git clone https://github.com/Azure-Samples/changeanalysis-webapp-storage-sample.git - ``` --1. Change the working directory to the project folder. -- ```bash - cd changeanalysis-webapp-storage-sample - ``` --### Run the PowerShell script --1. In the project folder, open `Publish-WebApp.ps1`. --1. Edit the `SUBSCRIPTION_ID` and `LOCATION` environment variables. -- | Environment variable | Description | - | -- | -- | - | `SUBSCRIPTION_ID` | Your Azure subscription ID. | - | `LOCATION` | The location of the resource group where you'd like to deploy the sample application. | --1. Save your changes. --1. Run the script from the `./changeanalysis-webapp-storage-sample` directory. --```bash -./Publish-WebApp.ps1 -``` --## Enable Change Analysis --In the Azure portal, [navigate to the Change Analysis standalone UI](./change-analysis-visualizations.md#access-change-analysis-screens). Page loading may take a few minutes as the `Microsoft.ChangeAnalysis` resource provider is registered. ---Once the Change Analysis page loads, you can see resource changes in your subscriptions. To view detailed web app in-guest change data: --- Select **Enable now** from the banner, or -- Select **Configure** from the top menu.--In the web app in-guest enablement pane, select the web app you'd like to enable: ---Now Change Analysis is fully enabled to track both resources and web app in-guest changes. --## Simulate a web app outage --In a typical team environment, multiple developers can work on the same application without notifying the other developers. Simulate this scenario and make a change to the web app setting: --```azurecli -az webapp config appsettings set -g {resourcegroup_name} -n {webapp_name} --settings AzureStorageConnection=WRONG_CONNECTION_STRING -``` --Visit the web app URL to view the following error: ---## Troubleshoot the outage using Change Analysis --In the Azure portal, navigate to the Change Analysis overview page. Since you triggered a web app outage, you can see an entry of change for `AzureStorageConnection`: --Since the connection string is a secret value, we hide it on the overview page for security purposes. With sufficient permission to read the web app, you can select the change to view details around the old and new values: ---The change details pane also shows important information, including who made the change. --Now that you discovered the web app in-guest change and understand next steps, you can proceed with troubleshooting the issue. --## Virtual network changes --Knowing what changed in your application's networking resources is critical due to their effect on connectivity, availability, and performance. Change Analysis supports all network resource changes and captures those changes immediately. Networking changes include: --- Firewalls created or edited-- Network critical changes (for example, blocking port 22 for TCP connections)-- Load balancer changes-- Virtual network changes--The sample application includes a virtual network to make sure the application remains secure. Via the Azure portal, you can view and assess the network changes captured by Change Analysis. --## Next steps --Learn more about [Change Analysis](./change-analysis.md). |
| azure-monitor | Change Analysis Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/change/change-analysis-troubleshoot.md | - Title: Troubleshoot Azure Monitor's Change Analysis -description: Learn how to troubleshoot problems in Azure Monitor's Change Analysis. --- Previously updated : 11/17/2023 ----# Troubleshoot Azure Monitor's Change Analysis ---## Trouble registering Microsoft.ChangeAnalysis resource provider from Change history tab. --If you're viewing Change history after its first integration with Azure Monitor's Change Analysis, you'll see it automatically registering the **Microsoft.ChangeAnalysis** resource provider. The resource may fail and incur the following error messages: --### You don't have enough permissions to register Microsoft.ChangeAnalysis resource provider. -You're receiving this error message because your role in the current subscription isn't associated with the **Microsoft.Support/register/action** scope. For example, you aren't the owner of your subscription and instead received shared access permissions through a coworker (like view access to a resource group). --To resolve the issue, contact the owner of your subscription to register the **Microsoft.ChangeAnalysis** resource provider. -1. In the Azure portal, search for **Subscriptions**. -1. Select your subscription. -1. Navigate to **Resource providers** under **Settings** in the side menu. -1. Search for **Microsoft.ChangeAnalysis** and register via the UI, Azure PowerShell, or Azure CLI. -- Example for registering the resource provider through PowerShell: - ```PowerShell - # Register resource provider - Register-AzResourceProvider -ProviderNamespace "Microsoft.ChangeAnalysis" - ``` --### Failed to register Microsoft.ChangeAnalysis resource provider. -This error message is likely a temporary internet connectivity issue, since: -* The UI sent the resource provider registration request. -* You've resolved your [permissions issue](#you-dont-have-enough-permissions-to-register-microsoftchangeanalysis-resource-provider). --Try refreshing the page and checking your internet connection. If the error persists, [submit an Azure support ticket](https://azure.microsoft.com/support/). --### This is taking longer than expected. -You'll receive this error message when the registration takes longer than 2 minutes. While unusual, it doesn't mean something went wrong. --1. Prepare for downtime. -1. Restart your web app to see your registration changes. --Changes should show up within a few hours of app restart. If your changes still don't show after 6 hours, [submit an Azure support ticket](https://azure.microsoft.com/support/). --## Azure Lighthouse subscription is not supported. --### Failed to query Microsoft.ChangeAnalysis resource provider. -Often, this message includes: `Azure Lighthouse subscription is not supported, the changes are only available in the subscription's home tenant`. --Azure Lighthouse allows for cross-tenant resource administration. However, cross-tenant support needs to be built for each resource provider. Currently, Change Analysis has not built this support. If you're signed into one tenant, you can't query for resource or subscription changes whose home is in another tenant. --If this is a blocking issue for you, [submit an Azure support ticket](https://azure.microsoft.com/support/) to describe how you're trying to use Change Analysis. --## An error occurred while getting changes. Please refresh this page or come back later to view changes. --When changes can't be loaded, Azure Monitor's Change Analysis service presents this general error message. A few known causes are: --- Internet connectivity error from the client device.-- Change Analysis service being temporarily unavailable.--Refreshing the page after a few minutes usually fixes this issue. If the error persists, [submit an Azure support ticket](https://azure.microsoft.com/support/). --## Only partial data loaded. --This error message may occur in the Azure portal when loading change data via the Change Analysis home page. Typically, the Change Analysis service calculates and returns all change data. However, in a network failure or a temporary outage of service, you may receive an error message indicating only partial data was loaded. --To load all change data, try waiting a few minutes and refreshing the page. If you are still only receiving partial data, [submit an Azure support ticket](https://azure.microsoft.com/support/). ---## You don't have enough permissions to view some changes. Contact your Azure subscription administrator. --This general unauthorized error message occurs when the current user doesn't have sufficient permissions to view the change. At minimum, -* To view infrastructure changes returned by Azure Resource Graph and Azure Resource Manager, reader access is required. -* For web app in-guest file changes and configuration changes, contributor role is required. --## Cannot see in-guest changes for newly enabled Web App. --You may not immediately see web app in-guest file changes and configuration changes. --1. Prepare for brief downtime. -1. Restart your web app. --You should be able to view changes within 30 minutes. If not, [submit an Azure support ticket](https://azure.microsoft.com/support/). --## Diagnose and solve problems tool for virtual machines --To troubleshoot virtual machine issues using the troubleshooting tool in the Azure portal: -1. Navigate to your virtual machine. -1. Select **Diagnose and solve problems** from the side menu. -1. Browse and select the troubleshooting tool that fits your issue. --<!-- convertborder later --> --## Can't filter to your resource to view changes --When filtering down to a particular resource in the Change Analysis standalone page, you may encounter a known limitation that only returns 1,000 resource results. To filter through and pinpoint changes for one of your 1,000+ resources: --1. In the Azure portal, select **All resources**. -1. Select the actual resource you want to view. -1. In that resource's left side menu, select **Diagnose and solve problems**. -1. In the Change Analysis card, select **View change details**. -- :::image type="content" source="./media/change-analysis/change-details-card.png" lightbox="./media/change-analysis/change-details-card.png" alt-text="Screenshot of viewing change details from the Change Analysis card in Diagnose and solve problems tool."::: --From here, you'll be able to view all of the changes for that one resource. --## Next steps --Learn more about [Azure Resource Graph](../../governance/resource-graph/overview.md), which helps power Change Analysis. |
| azure-monitor | Change Analysis Visualizations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/change/change-analysis-visualizations.md | - Title: View and use Change Analysis in Azure Monitor -description: Learn the various scenarios in which you can use Azure Monitor's Change Analysis. --- Previously updated : 11/17/2023----# View and use Change Analysis in Azure Monitor ---Change Analysis provides data for various management and troubleshooting scenarios to help you understand what changes to your application caused breaking issues. --## View Change Analysis data --### Access Change Analysis screens --You can access the Change Analysis overview portal under Azure Monitor, where you can view all changes and application dependency/resource insights. You can access Change Analysis through two entry points: --#### Via the Azure Monitor home page --From the Azure portal home page, select **Monitor** from the menu. ---In the Monitor overview page, select the **Change Analysis** card. ---#### Via search --In the Azure portal, search for Change Analysis to launch the experience. -- -Select one or more subscriptions to view: -- All of its resources' changes from the past 24 hours. -- Old and new values to provide insights at one glance.- - -Click into a change to view full Resource Manager snippet and other properties. - - -Send feedback from the Change Analysis pane: ---### Multiple subscription support --The UI supports selecting multiple subscriptions to view resource changes. Use the subscription filter: ---### View the Activity Log change history --Use the [View change history](../essentials/activity-log-insights.md#view-change-history) feature to call the Azure Monitor Change Analysis service backend to view changes associated with an operation. Changes returned include: --- Resource level changes from [Azure Resource Graph](../../governance/resource-graph/overview.md).-- Resource properties from [Azure Resource Manager](../../azure-resource-manager/management/overview.md).-- In-guest changes from PaaS services, such as a web app.--1. From within your resource, select **Activity Log** from the side menu. -1. Select a change from the list. -1. Select the **Change history** tab. -1. For the Azure Monitor Change Analysis service to scan for changes in users' subscriptions, a resource provider needs to be registered. When you select the **Change history** tab, the tool automatically registers **Microsoft.ChangeAnalysis** resource provider. -1. Once registered, you can view changes from **Azure Resource Graph** immediately from the past 14 days. - - Changes from other sources will be available after ~4 hours after subscription is onboard. -- :::image type="content" source="./media/change-analysis/activity-log-change-history.png" alt-text="Screenshot showing Activity Log change history integration."::: --### View changes using the Diagnose and Solve Problems tool --From your resource's overview page in Azure portal, you can view change data by selecting **Diagnose and solve problems** the left menu. As you enter the Diagnose and Solve Problems tool, the **Microsoft.ChangeAnalysis** resource provider is automatically registered. --Learn how to use the Diagnose and Solve Problems tool for: -- [Web App](#diagnose-and-solve-problems-tool-for-web-app)-- [Virtual Machines](#diagnose-and-solve-problems-tool-for-virtual-machines)-- [Azure SQL Database and other resources](#diagnose-and-solve-problems-tool-for-azure-sql-database-and-other-resources)--#### Diagnose and solve problems tool for Web App --Azure Monitor's Change Analysis is: -- A standalone detector in the Web App **Diagnose and solve problems** tool. -- Aggregated in **Application Crashes** and **Web App Down detectors**. --You can view change data via the **Web App Down** and **Application Crashes** detectors. The graph summarizes: -- The change types over time.-- Details on those changes. --By default, the graph displays changes from within the past 24 hours help with immediate problems. --#### Diagnose and solve problems tool for Virtual Machines --Change Analysis displays as an insight card in your virtual machine's **Diagnose and solve problems** tool. The insight card displays the number of changes or issues a resource experiences within the past 72 hours. --1. Within your virtual machine, select **Diagnose and solve problems** from the left menu. -1. Go to **Troubleshooting tools**. -1. Scroll to the end of the troubleshooting options and select **Analyze recent changes** to view changes on the virtual machine. -- :::image type="content" source="./media/change-analysis/vm-dnsp-troubleshootingtools.png" alt-text="Screenshot of the VM Diagnose and Solve Problems"::: -- :::image type="content" source="./media/change-analysis/analyze-recent-changes.png" alt-text="Change analyzer in troubleshooting tools"::: --#### Diagnose and solve problems tool for Azure SQL Database and other resources --You can view Change Analysis data for [multiple Azure resources](./change-analysis.md#supported-resource-types), but we highlight Azure SQL Database in these steps. --1. Within your resource, select **Diagnose and solve problems** from the left menu. -1. Under **Common problems**, select **View change details** to view the filtered view from Change Analysis standalone UI. -- :::image type="content" source="./media/change-analysis/change-insight-diagnose-and-solve.png" alt-text="Screenshot of viewing common problems in Diagnose and Solve Problems tool."::: --## Activities using Change Analysis --### Integrate with VM Insights --If you enabled [VM Insights](../vm/vminsights-overview.md), you can view changes in your virtual machines that caused any spikes in a metric chart, such as CPU or Memory. --1. Within your virtual machine, select **Insights** from under **Monitoring** in the left menu. -1. Select the **Performance** tab. -1. Expand the property panel. -- :::image type="content" source="./media/change-analysis/vm-insights.png" alt-text="Virtual machine insights performance and property panel."::: --1. Select the **Changes** tab. -1. Select the **Investigate Changes** button to view change details in the Azure Monitor Change Analysis standalone UI. -- :::image type="content" source="./media/change-analysis/vm-insights-2.png" alt-text="View of the property panel, selecting Investigate Changes button."::: --### Drill to Change Analysis logs --You can also drill to Change Analysis logs via a chart you've created or pinned to your resource's **Monitoring** dashboard. --1. Navigate to the resource for which you'd like to view Change Analysis logs. -1. On the resource's overview page, select the **Monitoring** tab. -1. Select a chart from the **Key Metrics** dashboard. -- :::image type="content" source="./media/change-analysis/view-change-analysis-1.png" alt-text="Chart from the Monitoring tab of the resource."::: --1. From the chart, select **Drill into logs** and choose **Change Analysis** to view it. -- :::image type="content" source="./media/change-analysis/view-change-analysis-2.png" alt-text="Drill into logs and select to view Change Analysis."::: --### Browse using custom filters and search bar --Browsing through a long list of changes in the entire subscription is time consuming. With Change Analysis custom filters and search capability, you can efficiently navigate to changes relevant to issues for troubleshooting. ---#### Filters --| Filter | Description | -| | -- | -| Subscription | This filter is in-sync with the Azure portal subscription selector. It supports multiple-subscription selection. | -| Time range | Specifies how far back the UI display changes, up to 14 days. By default, itΓÇÖs set to the past 24 hours. | -| Resource group | Select the resource group to scope the changes. By default, all resource groups are selected. | -| Change level | Controls which levels of changes to display. Levels include: important, normal, and noisy. </br> **Important:** related to availability and security </br> **Noisy:** Read-only properties that are unlikely to cause any issues </br> By default, important and normal levels are checked. | -| Resource | Select **Add filter** to use this filter. </br> Filter the changes to specific resources. Helpful if you already know which resources to look at for changes. [If the filter is only returning 1,000 resources, see the corresponding solution in troubleshooting guide](./change-analysis-troubleshoot.md#cant-filter-to-your-resource-to-view-changes). | -| Resource type | Select **Add filter** to use this filter. </br> Filter the changes to specific resource types. | --#### Search bar --The search bar filters the changes according to the input keywords. Search bar results apply only to the changes loaded by the page already and don't pull in results from the server side. --### Pin and share a Change Analysis query to the Azure dashboard --Let's say you want to curate a change view on specific resources, like all Virtual Machine changes in your subscription, and include it in a report sent periodically. You can pin the view to an Azure dashboard for monitoring or sharing scenarios. If you'd like to share a specific change with your team members, you can use the share feature in the Change Details page. --### Pin to the Azure dashboard --Once you applied filters to the Change Analysis homepage: --1. Select **Pin current filters** from the top menu. -1. Enter a name for the pin. -1. Click **OK** to proceed. -- :::image type="content" source="./media/change-analysis/click-pin-menu.png" alt-text="Screenshot of selecting Pin current filters button in Change Analysis."::: --A side pane opens to configure the dashboard where you place your pin. You can select one of two dashboard types: --| Dashboard type | Description | -| -- | -- | -| Private | Only you can access a private dashboard. Choose this option if you're creating the pin for your own easy access to the changes. | -| Shared | A shared dashboard supports role-based access control for view/read access. Shared dashboards are created as a resource in your subscription with a region and resource group to host it. Choose this option if you're creating the pin to share with your team. | --#### Select an existing dashboard --If you already have a dashboard to place the pin: --1. Select the **Existing** tab. -1. Select either **Private** or **Shared**. -1. Select the dashboard you'd like to use. -1. If you selected **Shared**, select the subscription in which you'd like to place the dashboard. -1. Select **Pin**. - - :::image type="content" source="./media/change-analysis/existing-dashboard-small.png" alt-text="Screenshot of selecting an existing dashboard to pin your changes to. "::: --#### Create a new dashboard --You can create a new dashboard for this pin. - -1. Select the **Create new** tab. -1. Select either **Private** or **Shared**. -1. Enter the name of the new dashboard. -1. If you're creating a shared dashboard, enter the resource group and region information. -1. Click **Create and pin**. -- :::image type="content" source="./media/change-analysis/create-pin-dashboard-small.png" alt-text="Screenshot of creating a new dashboard to pin your changes to."::: --Once the dashboard and pin are created, navigate to the Azure dashboard to view them. --1. From the Azure portal home menu, select **Dashboard**. -1. Use the **Manage Sharing** button in the top menu to handle access or "unshare". -1. Click on the pin to navigate to the curated view of changes. -- :::image type="content" source="./media/change-analysis/azure-dashboard.png" alt-text="Screenshot of selecting the Dashboard in the Azure portal home menu."::: -- :::image type="content" source="./media/change-analysis/view-share-dashboard.png" alt-text="Screenshot of the pin in the dashboard."::: --### Share a single change with your team --In the Change Analysis homepage, select a line of change to view details on the change. --1. On the Changed properties page, select **Share** from the top menu. -1. On the Share Change Details pane, copy the deep link of the page and share with your team in messages, emails, reports, or whichever communication channel your team prefers. -- :::image type="content" source="./media/change-analysis/share-single-change.png" alt-text="Screenshot of selecting the share button on the dashboard and copying link."::: --## Next steps --- Learn how to [troubleshoot problems in Change Analysis](change-analysis-troubleshoot.md) |
| azure-monitor | Change Analysis | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/change/change-analysis.md | - Title: Use Change Analysis in Azure Monitor to find web-app issues | Microsoft Docs -description: Use Change Analysis in Azure Monitor to troubleshoot issues on live sites. --- Previously updated : 11/17/2023----# Use Change Analysis in Azure Monitor ---While standard monitoring solutions might alert you to a live site issue, outage, or component failure, they often don't explain the cause. Let's say your site worked five minutes ago, and now it's broken. What changed in the last five minutes? --Change Analysis is designed to answer that question in Azure Monitor. --Building on the power of [Azure Resource Graph](../../governance/resource-graph/overview.md), Change Analysis: -- Provides insights into your Azure application changes.-- Increases observability.-- Reduces mean time to repair (MTTR).--> [!NOTE] -> Change Analysis is currently only available in Public Azure Cloud. --## Change Analysis architecture --Change Analysis detects various types of changes, from the infrastructure layer through application deployment. Change Analysis is a subscription-level Azure resource provider that: -- Checks resource changes in the subscription. -- Provides data for various diagnostic tools to help users understand what changes caused issues.--The following diagram illustrates the architecture of Change Analysis: ---## Supported resource types --Azure Monitor Change Analysis service supports resource property level changes in all Azure resource types, including common resources like: -- Virtual Machine-- Virtual machine scale set-- App Service-- Azure Kubernetes Service (AKS)-- Azure Function-- Networking resources: - - Network Security Group - - Virtual Network - - Application Gateway, etc. -- Data - - Storage - - SQL - - Redis Cache - - Azure Cosmos DB, etc. --## Data sources --Azure Monitor's Change Analysis queries for: -- [Azure Resource Manager resource properties.](#azure-resource-manager-resource-properties-changes)-- [Resource configuration changes.](#resource-configuration-changes)-- [App Service Function and Web App in-guest changes.](#changes-in-azure-function-and-web-apps-in-guest-changes) --Change Analysis also tracks [resource dependency changes](#dependency-changes) to diagnose and monitor an application end-to-end. --### Azure Resource Manager resource properties changes --Using [Azure Resource Graph](../../governance/resource-graph/overview.md), Change Analysis provides a historical record of how the Azure resources that host your application changed over time. The following basic configuration settings are set using Azure Resource Manager and tracked by Azure Resource Graph: -- Managed identities-- Platform OS upgrade-- Hostnames--### Resource configuration changes --In addition to the settings set via Azure Resource Manager, you can set configuration settings using the CLI, Bicep, etc., such as: -- IP Configuration rules-- TLS settings-- Extension versions--Azure Resource Graph doesn't capture these setting changes. Change Analysis fills this gap by capturing snapshots of changes in those main configuration properties, like changes to the connection string, etc. Snapshots are taken of configuration changes and change details every up to 6 hours. --[See known limitations regarding resource configuration change analysis.](#limitations) --### Changes in Azure Function and Web Apps (in-guest changes) --Every 30 minutes, Change Analysis captures the configuration state of a web application. For example, it can detect changes in the application environment variables, configuration files, and WebJobs. The tool computes the differences and presents the changes. ---Refer to [our troubleshooting guide](./change-analysis-troubleshoot.md#cannot-see-in-guest-changes-for-newly-enabled-web-app) if you don't see: -- File changes within 30 minutes-- Configuration changes within 6 hours --[See known limitations regarding in-guest change analysis.](#limitations) --Currently, all text-based files under site root **wwwroot** with the following extensions are supported: --- *.json-- *.xml-- *.ini-- *.yml-- *.config-- *.properties-- *.html-- *.cshtml-- *.js-- requirements.txt-- Gemfile-- Gemfile.lock-- config.gemspec--### Dependency changes --Changes to resource dependencies can also cause issues in a resource. For example, if a web app calls into a Redis cache, the Redis cache SKU could affect the web app performance. --As another example, if port 22 was closed in a virtual machine's Network Security Group, it causes connectivity errors. --#### Web App diagnose and solve problems navigator (preview) --Change Analysis checks the web app's DNS record, to detect changes in dependencies and app components that could cause issues. --Currently, the following dependencies are supported in **Web App Diagnose and solve problems | Navigator**: --- Web Apps-- Azure Storage-- Azure SQL--## Limitations --- **OS environment**: For Azure Function and Web App in-guest changes, Change Analysis currently only works with Windows environments, not Linux.-- **Web app deployment changes**: Code deployment change information might not be available immediately in the Change Analysis tool. To view the latest changes in Change Analysis, select **Refresh**.-- **Function and Web App file changes**: File changes take up to 30 minutes to display.-- **Function and Web App configuration changes**: Due to the snapshot approach to configuration changes, timestamps of configuration changes could take up to 6 hours to display from when the change actually happened.-- **Web app deployment and configuration changes**: A site extension collects these changes and stores them on disk space owned by your application. Thus, data collection and storage is subject to your application's behavior. Check to see if a misbehaving application is affecting the results.-- **Snapshot retention for all changes**: Azure Resource Graphs (ARG) tracks the Change Analysis data for resources. ARG only keeps snapshot history of tracked resources for _14 days_.--## Frequently asked questions --This section provides answers to common questions. --### Does using Change Analysis incur cost? --You can use Change Analysis at no extra cost. Enable the `Microsoft.ChangeAnalysis` resource provider, and anything supported by Change Analysis is open to you. --## Next steps --- Learn about [enabling Change Analysis](change-analysis-enable.md)-- Learn about [visualizations in Change Analysis](change-analysis-visualizations.md)-- Learn how to [troubleshoot problems in Change Analysis](change-analysis-troubleshoot.md)-- Enable Application Insights for [Azure web apps](../../azure-monitor/app/azure-web-apps.md).-- Enable Application Insights for [Azure VM and Azure virtual machine scale set IIS-hosted apps](../../azure-monitor/app/azure-vm-vmss-apps.md). |
| azure-monitor | Container Insights Analyze | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-analyze.md | - Title: Monitor your Kubernetes cluster performance with Container insights -description: This article describes how you can view and analyze the performance of a Kubernetes cluster with Container insights. - Previously updated : 08/19/2024----# Monitor your Kubernetes cluster performance with Container insights --Use the workbooks, performance charts, and health status in Container insights to monitor the workload of Kubernetes clusters hosted on Azure Kubernetes Service (AKS), Azure Stack, or another environment. This article helps you understand how to use Azure Monitor to help you quickly assess, investigate, and resolve detected issues. ----## Workbooks --Workbooks combine text, log queries, metrics, and parameters into rich interactive reports that you can use to analyze cluster performance. For a description of the workbooks available for Container insights and how to access them, see [Workbooks in Container insights](container-insights-reports.md). ---## Multi-cluster view from Azure Monitor -Azure Monitor provides a multi-cluster view that shows the health status of all monitored Kubernetes clusters deployed across resource groups in your subscriptions. It also shows clusters discovered across all environments that aren't monitored by the solution. With this view, you can immediately understand cluster health and then drill down to the node and controller performance page or navigate to see performance charts for the cluster. For AKS clusters that were discovered and identified as unmonitored, you can enable monitoring from the view. --To access the multi-cluster view, select **Monitor** from the left pane in the Azure portal. Under the **Insights** section, select **Containers**. ---You can scope the results presented in the grid to show clusters that are: --* **Azure**: AKS and AKS Engine clusters hosted in Azure Kubernetes Service. -* **Azure Stack (Preview)**: AKS Engine clusters hosted on Azure Stack. -* **Non-Azure (Preview)**: Kubernetes clusters hosted on-premises. -* **All**: View all the Kubernetes clusters hosted in Azure, Azure Stack, and on-premises environments that are onboarded to Container insights. --To view clusters from a specific environment, select it from **Environment** in the upper-left corner. ---On the **Monitored clusters** tab, you learn the following: --- How many clusters are in a critical or unhealthy state versus how many are healthy or not reporting (referred to as an Unknown state).-- Whether all of the [Azure Kubernetes Engine (AKS Engine)](https://github.com/Azure/aks-engine) deployments are healthy.-- How many nodes and user and system pods are deployed per cluster.--The health statuses included are: --* **Healthy**: No issues are detected for the VM, and it's functioning as required. -* **Critical**: One or more critical issues are detected that must be addressed to restore normal operational state as expected. -* **Warning**: One or more issues are detected that must be addressed or the health condition could become critical. -* **Unknown**: If the service wasn't able to make a connection with the node or pod, the status changes to an Unknown state. -* **Not found**: Either the workspace, the resource group, or subscription that contains the workspace for this solution was deleted. -* **Unauthorized**: User doesn't have required permissions to read the data in the workspace. -* **Error**: An error occurred while attempting to read data from the workspace. -* **Misconfigured**: Container insights wasn't configured correctly in the specified workspace. -* **No data**: Data hasn't reported to the workspace for the last 30 minutes. --Health state calculates the overall cluster status as the *worst of* the three states with one exception. If any of the three states is Unknown, the overall cluster state shows **Unknown**. --The following table provides a breakdown of the calculation that controls the health states for a monitored cluster on the multi-cluster view. --| Monitored cluster |Status |Availability | -|-|-|--| -|**User pod**| Healthy<br>Warning<br>Critical<br>Unknown |100%<br>90 - 99%<br><90%<br>Not reported in last 30 minutes | -|**System pod**| Healthy<br>Warning<br>Critical<br>Unknown |100%<br>N/A<br>100%<br>Not reported in last 30 minutes | -|**Node** | Healthy<br>Warning<br>Critical<br>Unknown | >85%<br>60 - 84%<br><60%<br>Not reported in last 30 minutes | --From the list of clusters, you can drill down to the **Cluster** page by selecting the name of the cluster. Then go to the **Nodes** performance page by selecting the rollup of nodes in the **Nodes** column for that specific cluster. Or, you can drill down to the **Controllers** performance page by selecting the rollup of the **User pods** or **System pods** column. --## View performance directly from a cluster --Access to Container insights is available directly from an AKS cluster by selecting **Insights** > **Cluster** from the left pane, or when you selected a cluster from the multi-cluster view. Information about your cluster is organized into four perspectives: --- Cluster-- Nodes-- Controllers-- Containers-->[!NOTE] ->The experiences described in the remainder of this article are also applicable for viewing performance and health status of your Kubernetes clusters hosted on Azure Stack or another environment when selected from the multi-cluster view. --The default page opens and displays four line performance charts that show key performance metrics of your cluster. ---The performance charts display four performance metrics: --- **Node CPU utilization %**: An aggregated perspective of CPU utilization for the entire cluster. To filter the results for the time range, select **Avg**, **Min**, **50th**, **90th**, **95th**, or **Max** in the percentiles selector above the chart. The filters can be used either individually or combined.-- **Node memory utilization %**: An aggregated perspective of memory utilization for the entire cluster. To filter the results for the time range, select **Avg**, **Min**, **50th**, **90th**, **95th**, or **Max** in the percentiles selector above the chart. The filters can be used either individually or combined.-- **Node count**: A node count and status from Kubernetes. Statuses of the cluster nodes represented are **Total**, **Ready**, and **Not Ready**. They can be filtered individually or combined in the selector above the chart.-- **Active pod count**: A pod count and status from Kubernetes. Statuses of the pods represented are **Total**, **Pending**, **Running**, **Unknown**, **Succeeded**, or **Failed**. They can be filtered individually or combined in the selector above the chart.--Use the Left and Right arrow keys to cycle through each data point on the chart. Use the Up and Down arrow keys to cycle through the percentile lines. Select the pin icon in the upper-right corner of any one of the charts to pin the selected chart to the last Azure dashboard you viewed. From the dashboard, you can resize and reposition the chart. Selecting the chart from the dashboard redirects you to Container insights and loads the correct scope and view. --Container insights also supports Azure Monitor [Metrics Explorer](../essentials/metrics-getting-started.md), where you can create your own plot charts, correlate and investigate trends, and pin to dashboards. From Metrics Explorer, you also can use the criteria that you set to visualize your metrics as the basis of a [metric-based alert rule](../alerts/alerts-metric.md). --## View container metrics in Metrics Explorer --In Metrics Explorer, you can view aggregated node and pod utilization metrics from Container insights. The following table summarizes the details to help you understand how to use the metric charts to visualize container metrics. --|Namespace | Metric | Description | -|-|--|-| -| insights.container/nodes | | -| | cpuUsageMillicores | Aggregated measurement of CPU utilization across the cluster. It's a CPU core split into 1,000 units (milli = 1000). Used to determine the usage of cores in a container where many applications might be using one core.| -| | cpuUsagePercentage | Aggregated average CPU utilization measured in percentage across the cluster.| -| | memoryRssBytes | Container RSS memory used in bytes.| -| | memoryRssPercentage | Container RSS memory used in percent.| -| | memoryWorkingSetBytes | Container working set memory used.| -| | memoryWorkingSetPercentage | Container working set memory used in percent. | -| | nodesCount | A node count from Kubernetes.| -| insights.container/pods | | -| | PodCount | A pod count from Kubernetes.| --You can [split](../essentials/metrics-charts.md#apply-splitting) a metric to view it by dimension and visualize how different segments of it compare to each other. For a node, you can segment the chart by the *host* dimension. From a pod, you can segment it by the following dimensions: --* Controller -* Kubernetes namespace -* Node -* Phase --## Analyze nodes, controllers, and container health --When you switch to the **Nodes**, **Controllers**, and **Containers** tabs, a property pane automatically displays on the right side of the page. It shows the properties of the item selected, which includes the labels you defined to organize Kubernetes objects. When a Linux node is selected, the **Local Disk Capacity** section also shows the available disk space and the percentage used for each disk presented to the node. Select the **>>** link in the pane to view or hide the pane. --As you expand the objects in the hierarchy, the properties pane updates based on the object selected. From the pane, you also can view Kubernetes container logs (stdout/stderror), events, and pod metrics by selecting the **Live Events** tab at the top of the pane. For more information about the configuration required to grant and control access to view this data, see [Set up the Live Data](container-insights-livedata-setup.md). --While you review cluster resources, you can see this data from the container in real time. For more information about this feature, see [How to view Kubernetes logs, events, and pod metrics in real time](container-insights-livedata-overview.md). --To view Kubernetes log data stored in your workspace based on predefined log searches, select **View container logs** from the **View in analytics** dropdown list. For more information, see [How to query logs from Container insights](container-insights-log-query.md). --Use the **+ Add Filter** option at the top of the page to filter the results for the view by **Service**, **Node**, **Namespace**, or **Node Pool**. After you select the filter scope, select one of the values shown in the **Select value(s)** field. After the filter is configured, it's applied globally while viewing any perspective of the AKS cluster. The formula only supports the equal sign. You can add more filters on top of the first one to further narrow your results. For example, if you specify a filter by **Node**, you can only select **Service** or **Namespace** for the second filter. --Specifying a filter in one tab continues to be applied when you select another. It's deleted after you select the **x** symbol next to the specified filter. --Switch to the **Nodes** tab and the row hierarchy follows the Kubernetes object model, which starts with a node in your cluster. Expand the node to view one or more pods running on the node. If more than one container is grouped to a pod, they're displayed as the last row in the hierarchy. You also can view how many non-pod-related workloads are running on the host if the host has processor or memory pressure. ---Windows Server containers that run the Windows Server 2019 OS are shown after all the Linux-based nodes in the list. When you expand a Windows Server node, you can view one or more pods and containers that run on the node. After a node is selected, the properties pane shows version information. ---Azure Container Instances virtual nodes that run the Linux OS are shown after the last AKS cluster node in the list. When you expand a Container Instances virtual node, you can view one or more Container Instances pods and containers that run on the node. Metrics aren't collected and reported for nodes, only for pods. ---From an expanded node, you can drill down from the pod or container that runs on the node to the controller to view performance data filtered for that controller. Select the value under the **Controller** column for the specific node. ---Select controllers or containers at the top of the page to review the status and resource utilization for those objects. To review memory utilization, in the **Metric** dropdown list, select **Memory RSS** or **Memory working set**. **Memory RSS** is supported only for Kubernetes version 1.8 and later. Otherwise, you view values for **Min %** as *NaN %*, which is a numeric data type value that represents an undefined or unrepresentable value. ---**Memory working set** shows both the resident memory and virtual memory (cache) included and is a total of what the application is using. **Memory RSS** shows only main memory, which is nothing but the resident memory. This metric shows the actual capacity of available memory. What's the difference between resident memory and virtual memory? --- **Resident memory**, or main memory, is the actual amount of machine memory available to the nodes of the cluster.-- **Virtual memory** is reserved hard disk space (cache) used by the operating system to swap data from memory to disk when under memory pressure, and then fetch it back to memory when needed.--By default, performance data is based on the last six hours, but you can change the window by using the **TimeRange** option at the upper left. You also can filter the results within the time range by selecting **Min**, **Avg**, **50th**, **90th**, **95th**, and **Max** in the percentile selector. ---When you hover over the bar graph under the **Trend** column, each bar shows either CPU or memory usage, depending on which metric is selected, within a sample period of 15 minutes. After you select the trend chart through a keyboard, use the Alt+Page up key or Alt+Page down key to cycle through each bar individually. You get the same details that you would if you hovered over the bar. ---In the next example, for the first node in the list, *aks-nodepool1-*, the value for **Containers** is 25. This value is a rollup of the total number of containers deployed. ---This information can help you quickly identify whether you have a proper balance of containers between nodes in your cluster. --The information that's presented when you view the **Nodes** tab is described in the following table. --| Column | Description | -|--|-| -| Name | The name of the host. | -| Status | Kubernetes view of the node status. | -| Min %, Avg %, 50th %, 90th %, 95th %, Max % | Average node percentage based on percentile during the selected duration. | -| Min, Avg, 50th, 90th, 95th, Max | Average nodes' actual value based on percentile during the time duration selected. The average value is measured from the CPU/Memory limit set for a node. For pods and containers, it's the average value reported by the host. | -| Containers | Number of containers. | -| Uptime | Represents the time since a node started or was rebooted. | -| Controller | Only for containers and pods. It shows which controller it resides in. Not all pods are in a controller, so some might display **N/A**. | -| Trend Min %, Avg %, 50th %, 90th %, 95th %, Max % | Bar graph trend represents the average percentile metric percentage of the controller. | --You might notice a workload after expanding a node named **Other process**. It represents non-containerized processes that run on your node, and includes: --* Self-managed or managed Kubernetes non-containerized processes. -* Container run-time processes. -* Kubelet. -* System processes running on your node. -* Other non-Kubernetes workloads running on node hardware or a VM. --It's calculated by *Total usage from CAdvisor* - *Usage from containerized process*. --In the selector, select **Controllers**. ---Here you can view the performance health of your controllers and Container Instances virtual node controllers or virtual node pods not connected to a controller. ---The row hierarchy starts with a controller. When you expand a controller, you view one or more pods. Expand a pod, and the last row displays the container grouped to the pod. From an expanded controller, you can drill down to the node it's running on to view performance data filtered for that node. Container Instances pods not connected to a controller are listed last in the list. ---Select the value under the **Node** column for the specific controller. ---The information that's displayed when you view controllers is described in the following table. --| Column | Description | -|--|-| -| Name | The name of the controller.| -| Status | The rollup status of the containers after it's finished running with status such as **OK**, **Terminated**, **Failed**, **Stopped**, or **Paused**. If the container is running but the status either wasn't properly displayed or wasn't picked up by the agent and hasn't responded for more than 30 minutes, the status is **Unknown**. More details of the status icon are provided in the following table.| -| Min %, Avg %, 50th %, 90th %, 95th %, Max %| Rollup average of the average percentage of each entity for the selected metric and percentile. | -| Min, Avg, 50th, 90th, 95th, Max | Rollup of the average CPU millicore or memory performance of the container for the selected percentile. The average value is measured from the CPU/Memory limit set for a pod. | -| Containers | Total number of containers for the controller or pod. | -| Restarts | Rollup of the restart count from containers. | -| Uptime | Represents the time since a container started. | -| Node | Only for containers and pods. It shows which controller it resides in. | -| Trend Min %, Avg %, 50th %, 90th %, 95th %, Max % | Bar graph trend represents the average percentile metric of the controller. | --The icons in the status field indicate the online status of the containers. --| Icon | Status | -|--|-| -| :::image type="content" source="./media/container-insights-analyze/containers-ready-icon.png" alt-text="Ready running status icon.":::| Running | -| :::image type="content" source="./media/container-insights-analyze/containers-waiting-icon.png" alt-text="Waiting or Paused status icon."::: | Waiting or Paused| -| :::image type="content" source="./media/container-insights-analyze/containers-grey-icon.png" alt-text="Last reported running status icon."::: | Last reported running but hasn't responded for more than 30 minutes| -| :::image type="content" source="./media/container-insights-analyze/containers-green-icon.png" alt-text="Successful status icon."::: | Successfully stopped or failed to stop| --The status icon displays a count based on what the pod provides. It shows the worst two states. When you hover over the status, it displays a rollup status from all pods in the container. If there isn't a ready state, the status value displays **(0)**. --In the selector, select **Containers**. ---Here you can view the performance health of your AKS and Container Instances containers. ---From a container, you can drill down to a pod or node to view performance data filtered for that object. Select the value under the **Pod** or **Node** column for the specific container. ---The information that's displayed when you view containers is described in the following table. --| Column | Description | -|--|-| -| Name | The name of the controller.| -| Status | Status of the containers, if any. More details of the status icon are provided in the next table.| -| Min %, Avg %, 50th %, 90th %, 95th %, Max % | The rollup of the average percentage of each entity for the selected metric and percentile. | -| Min, Avg, 50th, 90th, 95th, Max | The rollup of the average CPU millicore or memory performance of the container for the selected percentile. The average value is measured from the CPU/Memory limit set for a pod. | -| Pod | Container where the pod resides.| -| Node |  Node where the container resides. | -| Restarts | Represents the time since a container started. | -| Uptime | Represents the time since a container was started or rebooted. | -| Trend Min %, Avg %, 50th %, 90th %, 95th %, Max % | Bar graph trend represents the average percentile metric percentage of the container. | --### Other processes -The *Other processes* entry in the **Node** view is intended to help you clearly understand the root cause of the high resource usage on your node. This information helps you to distinguish usage between containerized processes versus noncontainerized processes. These are noncontainerized processes that run on your node and include the following: - -- Self-managed or managed Kubernetes noncontainerized processes.-- Container run-time processes.-- Kubelet.-- System processes running on your node.-- Other non-Kubernetes workloads running on node hardware or a VM.--The value of *other processes* is `Total usage from CAdvisor - Usage from containerized process`. --### Status --The icons in the status field indicate the online statuses of pods, as described in the following table. --| Icon | Status | -|--|-| -| :::image type="content" source="./media/container-insights-analyze/containers-ready-icon.png" alt-text="Ready running status icon.":::| -| :::image type="content" source="./media/container-insights-analyze/containers-waiting-icon.png" alt-text="Waiting or Paused status icon."::: | Waiting or Paused| -| :::image type="content" source="./media/container-insights-analyze/containers-grey-icon.png" alt-text="Last reported running status icon."::: | Last reported running but hasn't responded in more than 30 minutes| -| :::image type="content" source="./media/container-insights-analyze/containers-terminated-icon.png" alt-text="Terminated status icon."::: | Successfully stopped or failed to stop| -| :::image type="content" source="./media/container-insights-analyze/containers-failed-icon.png" alt-text="Failed status icon."::: | Failed state | --## Monitor and visualize network configurations --Azure Network Policy Manager includes informative Prometheus metrics that you can use to monitor and better understand your network configurations. It provides built-in visualizations in either the Azure portal or Grafana Labs. For more information, see [Monitor and visualize network configurations with Azure npm](../../virtual-network/kubernetes-network-policies.md#monitor-and-visualize-network-configurations-with-azure-npm). ---## Next steps --- See [Create performance alerts with Container insights](./container-insights-log-alerts.md) to learn how to create alerts for high CPU and memory utilization to support your DevOps or operational processes and procedures.-- See [Log query examples](container-insights-log-query.md) to see predefined queries and examples to evaluate or customize to alert, visualize, or analyze your clusters.-- See [Monitor cluster health](./container-insights-overview.md) to learn about viewing the health status of your Kubernetes cluster. |
| azure-monitor | Container Insights Authentication | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-authentication.md | - Title: Configure agent authentication for the Container Insights agent -description: This article describes how to configure authentication for the containerized agent used by Container insights. -- Previously updated : 10/18/2023----# Legacy authentication for Container Insights --Container Insights defaults to managed identity authentication, which has a monitoring agent that uses the [cluster's managed identity](/azure/aks/use-managed-identity) to send data to Azure Monitor. It replaced the legacy certificate-based local authentication and removed the requirement of adding a Monitoring Metrics Publisher role to the cluster. --This article describes how to migrate to managed identity authentication if you enabled Container insights using legacy authentication method and also how to enable legacy authentication if you have that requirement. --> [!IMPORTANT] -> If you have a cluster with legacy authentication and Log Analytics workspace keys are rotated, then monitoring data will stop flowing to the Log Analytics workspace. You must disable and then reenable the Container insights addon to get monitoring data to start flowing again with the new rotated workspace keys.  You should migrate to Container insights managed identity authentication which doesn't use Log Analytics workspace keys. --## Migrate to managed identity authentication --If you enabled Container insights before managed identity authentication was available, you can use the following methods to migrate your clusters. --## [Azure portal](#tab/portal-azure-monitor) --You can migrate to Managed Identity authentication from the *Monitor settings* panel for your AKS cluster. From the **Monitoring** section, click on the **Insights** tab. In the Insights tab, click on the *Monitor Settings* option and check the box for *Use managed identity* ---If you don't see the *Use managed identity* option, you are using an SPN cluster. In that case, you must use command line tools to migrate. See other tabs for migration instructions and templates. --## [Azure CLI](#tab/cli) --### AKS -AKS clusters must first disable monitoring and then upgrade to managed identity. Only Azure public cloud, Microsoft Azure operated by 21Vianet cloud, and Azure Government cloud are currently supported for this migration. For clusters with user-assigned identity, only Azure public cloud is supported. --> [!NOTE] -> Minimum Azure CLI version 2.49.0 or higher. --1. Get the configured Log Analytics workspace resource ID: -- ```cli - az aks show -g <resource-group-name> -n <cluster-name> | grep -i "logAnalyticsWorkspaceResourceID" - ``` --2. Disable monitoring with the following command: -- ```cli - az aks disable-addons -a monitoring -g <resource-group-name> -n <cluster-name> - ``` --3. If the cluster is using a service principal, upgrade it to system managed identity with the following command: -- ```cli - az aks update -g <resource-group-name> -n <cluster-name> --enable-managed-identity - ``` --4. Enable the monitoring add-on with the managed identity authentication option by using the Log Analytics workspace resource ID obtained in step 1: -- ```cli - az aks enable-addons -a monitoring -g <resource-group-name> -n <cluster-name> --workspace-resource-id <workspace-resource-id> - ``` ---### Arc-enabled Kubernetes -->[!NOTE] -> Managed identity authentication is not supported for Arc-enabled Kubernetes clusters with **ARO**. --1. Retrieve the Log Analytics workspace configured for Container insights extension. -- ```cli - az k8s-extension show --name azuremonitor-containers --cluster-name \<cluster-name\> --resource-group \<resource-group\> --cluster-type connectedClusters -n azuremonitor-containers - ``` --2. Enable Container insights extension with managed identity authentication option using the workspace returned in the first step. -- ```cli - az k8s-extension create --name azuremonitor-containers --cluster-name \<cluster-name\> --resource-group \<resource-group\> --cluster-type connectedClusters --extension-type Microsoft.AzureMonitor.Containers --configuration-settings amalogs.useAADAuth=true logAnalyticsWorkspaceResourceID=\<workspace-resource-id\> - ``` -----## Timeline -Any new clusters being created or being onboarded now default to Managed Identity authentication. However, existing clusters with legacy solution-based authentication are still supported. --## Next steps -If you experience issues when you upgrade the agent, review the [troubleshooting guide](container-insights-troubleshoot.md) for support. |
| azure-monitor | Container Insights Cost | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-cost.md | - Title: Monitoring cost for Container insights -description: This article describes the monitoring cost for metrics and inventory data collected by Container insights to help customers manage their usage and associated costs. - Previously updated : 03/02/2023----# Optimize monitoring costs for Container insights --Kubernetes clusters generate a large amount of data that's collected by Container insights. Since you're charged for the ingestion and retention of this data, you want to configure your environment to optimize your costs. You can significantly reduce your monitoring costs by filtering out data that you don't need and also by optimizing the configuration of the Log Analytics workspace where you're storing your data. --Once you've analyzed your collected data and determined if there's any data that you're collecting that you don't require, there are several options to filter any data that you don't want to collect. This ranges from selecting from a set of predefined cost configurations to leveraging different features to filter data based on specific criteria. This article provides a walkthrough of guidance on how to analyze and optimize your data collection for Container insights. ----## Analyze your data ingestion --To identify your best opportunities for cost savings, analyze the amount of data being collected in different tables. This information will help you identify which tables are consuming the most data and help you make informed decisions about how to reduce costs. --You can visualize how much data is ingested in each workspace by using the **Container Insights Usage** runbook, which is available from the **Workspace** page of a monitored cluster. ---The report will let you view the data usage by different categories such as table, namespace, and log source. Use these different views to determine any data that you're not using and can be filtered out to reduce costs. ---Select the option to open the query in Log Analytics where you can perform more detailed analysis including viewing the individual records being collected. See [Query logs from Container insights -](./container-insights-log-query.md) for additional queries you can use to analyze your collected data. --For example, the following screenshot shows a modification to the log query used for **By Table** that shows the data by namespace and table. ---## Filter collected data -Once you've identified data that you can filter, use different configuration options in Container insights to filter out data that you don't require. Options are available to select predefined configurations, set individual parameters, and use custom log queries for detailed filtering. --### Cost presets -The simplest way to filter data is using the cost presets in the Azure portal. Each preset includes different sets of tables to collect based on different operation and cost profiles. The cost presets are designed to help you quickly configure your data collection based on common scenarios. ---> [!TIP] -> If you've configured your cluster to use the Prometheus experience for Container insights, then you can disable **Performance** collection since performance data is being collected by Prometheus. --For details on selecting a cost preset, see [Configure DCR with Azure portal](./container-insights-data-collection-configure.md#configure-dcr-with-azure-portal) --### Filtering options -After you've chosen an appropriate cost preset, you can filter additional data using the different methods in the following table. Each option will allow you to filter data based on different criteria. When you're done with your configuration, you should only be collecting data that you require for analysis and alerting. --| Filter by | Description | -|:|:--| -| Tables | Manually modify the DCR if you want to select individual tables to populate other than the cost preset groups. For example, you may want to collect **ContainerLogV2** but not collect **KubeEvents** which is included in the same cost preset. <br><br>See [Stream values in DCR](./container-insights-data-collection-configure.md#stream-values-in-dcr) for a list of the streams to use in the DCR and use the guidance in . | -| Container logs | `ContainerLogV2` stores the stdout/stderr records generated by the containers in the cluster. While you can disable collection of the entire table using the DCR, you can configure the collection of stderr and stdout logs separately using the ConfigMap for the cluster. Since `stdout` and `stderr` settings can be configured separately, you can choose to enable one and not the other.<br><br>See [Filter container logs](./container-insights-data-collection-filter.md#filter-container-logs) for details on filtering container logs. | -| Namespace | Namespaces in Kubernetes are used to group resources within a cluster. You can filter out data from resources in specific namespaces that you don't require. Using the DCR, you can only filter performance data by namespace, if you've enabled collection for the `Perf` table. Use ConfigMap to filter data for particular namespaces in `stdout` and `stderr` logs.<br><br>See [Filter container logs](./container-insights-data-collection-filter.md#filter-container-logs) for details on filtering logs by namespace and [Platform log filtering (System Kubernetes Namespaces)](./container-insights-data-collection-filter.md#platform-log-filtering-system-kubernetes-namespaces) for details on the system namespace. | -| Pods and containers | Annotation filtering allows you to filter out container logs based on annotations that you make to the pod. Using the ConfigMap you can specify whether stdout and stderr logs should be collected for individual pods and containers.<br><br>See [Annotation based filtering for workloads](./container-insights-data-collection-filter.md#annotation-based-filtering-for-workloads) for details on updating your ConfigMap and on setting annotations in your pods. | ---## Transformations -[Ingestion time transformations](../essentials/data-collection-transformations.md) allow you to apply a KQL query to filter and transform data in the [Azure Monitor pipeline](../essentials/pipeline-overview.md) before it's stored in the Log Analytics workspace. This allows you to filter data based on criteria that you can't perform with the other options. --For example, you may choose to filter container logs based on the log level in ContainerLogV2. You could add a transformation to your Container insights DCR that would perform the functionality in the following diagram. In this example, only `error` and `critical` level events are collected, while any other events are ignored. --An alternate strategy would be to save the less important events to a separate table configured for basic logs. The events would still be available for troubleshooting, but with a significant cost savings for data ingestion. --See [Data transformations in Container insights](./container-insights-transformations.md) for details on adding a transformation to your Container insights DCR including sample DCRs using transformations. --## Configure pricing tiers --[Basic Logs in Azure Monitor](../logs/logs-table-plans.md) offer a significant cost discount for ingestion of data in your Log Analytics workspace for data that you occasionally use for debugging and troubleshooting. Tables configured for basic logs offer a significant cost discount for data ingestion in exchange for a cost for log queries meaning that they're ideal for data that you require but that you access infrequently. --[ContainerLogV2](container-insights-logs-schema.md) can be configured for basic logs which can give you significant cost savings if you query the data infrequently. Using [transformations](#transformations), you can specify data that should be sent to alternate tables configured for basic logs. See [Data transformations in Container insights](./container-insights-transformations.md) for an example of this strategy. ----## Next steps --To help you understand what the costs are likely to be based on recent usage patterns from data collected with Container insights, see [Analyze usage in a Log Analytics workspace](../logs/analyze-usage.md). |
| azure-monitor | Container Insights Data Collection Configure | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-data-collection-configure.md | - Title: Configure Container insights data collection -description: Details on configuring data collection in Azure Monitor Container insights after you enable it on your Kubernetes cluster. - Previously updated : 05/14/2024----# Configure log collection in Container insights --This article provides details on how to configure data collection in [Container insights](./container-insights-overview.md) for your Kubernetes cluster once it's been onboarded. For guidance on enabling Container insights on your cluster, see [Enable monitoring for Kubernetes clusters](./kubernetes-monitoring-enable.md). --## Configuration methods -There are two methods use to configure and filter data being collected in Container insights. Depending on the setting, you may be able to choose between the two methods or you may be required to use one or the other. The two methods are described in the table below with detailed information in the following sections. --| Method | Description | -|:|:| -| [Data collection rule (DCR)](#configure-data-collection-using-dcr) | [Data collection rules](../essentials/data-collection-rule-overview.md) are sets of instructions supporting data collection using the [Azure Monitor pipeline](../essentials/pipeline-overview.md). A DCR is created when you enable Container insights, and you can modify the settings in this DCR either using the Azure portal or other methods. | -| [ConfigMap](#configure-data-collection-using-configmap) | [ConfigMaps](https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/) are a Kubernetes mechanism that allows you to store non-confidential data such as a configuration file or environment variables. Container insights looks for a ConfigMap on each cluster with particular settings that define data that it should collect.| --## Configure data collection using DCR -The DCR created by Container insights is named *MSCI-\<cluster-region\>-\<cluster-name\>*. You can [view this DCR](../essentials/data-collection-rule-view.md) along with others in your subscription, and you can edit it using methods described in [Create and edit data collection rules (DCRs) in Azure Monitor](../essentials/data-collection-rule-create-edit.md). While you can directly modify the DCR for particular customizations, you can perform most required configuration using the methods described below. See [Data transformations in Container insights](./container-insights-transformations.md) for details on editing the DCR directly for more advanced configurations. --> [!IMPORTANT] -> AKS clusters must use either a system-assigned or user-assigned managed identity. If cluster is using a service principal, you must update the cluster to use a [system-assigned managed identity](/azure/aks/use-managed-identity#update-an-existing-aks-cluster-to-use-a-system-assigned-managed-identity) or a [user-assigned managed identity](/azure/aks/use-managed-identity#update-an-existing-cluster-to-use-a-user-assigned-managed-identity). ----### [Azure portal](#tab/portal) --### Configure DCR with Azure portal -Using the Azure portal, you can select from multiple preset configurations for data collection in Container insights. These configurations include different sets of tables and collection frequencies depending on your particular priorities. You can also customize the settings to collect only the data you require. You can use the Azure portal to customize configuration on your existing cluster after Container insights has been enabled, or you can perform this configuration when you enable Container insights on your cluster. --1. Select the cluster in the Azure portal. -2. Select the **Insights** option in the **Monitoring** section of the menu. -3. If Container insights has already been enabled on the cluster, select the **Monitoring Settings** button. If not, select **Configure Azure Monitor** and see [Enable monitoring on your Kubernetes cluster with Azure Monitor](container-insights-onboard.md) for details on enabling monitoring. -- :::image type="content" source="media/container-insights-cost-config/monitor-settings-button.png" alt-text="Screenshot of AKS cluster with monitor settings button." lightbox="media/container-insights-cost-config/monitor-settings-button.png" ::: ---4. For AKS and Arc-enabled Kubernetes, select **Use managed identity** if you haven't yet migrated the cluster to [managed identity authentication](../containers/container-insights-onboard.md#authentication). -5. Select one of the cost presets. -- :::image type="content" source="media/container-insights-cost-config/cost-settings-onboarding.png" alt-text="Screenshot that shows the onboarding options." lightbox="media/container-insights-cost-config/cost-settings-onboarding.png" ::: -- | Cost preset | Collection frequency | Namespace filters | Syslog collection | Collected data | - | | | | | | - | Standard | 1 m | None | Not enabled | All standard container insights tables | - | Cost-optimized | 5 m | Excludes kube-system, gatekeeper-system, azure-arc | Not enabled | All standard container insights tables | - | Syslog | 1 m | None | Enabled by default | All standard container insights tables | - | Logs and Events | 1 m | None | Not enabled | ContainerLog/ContainerLogV2<br> KubeEvents<br>KubePodInventory | --6. If you want to customize the settings, click **Edit collection settings**. -- :::image type="content" source="media/container-insights-cost-config/advanced-collection-settings.png" alt-text="Screenshot that shows the collection settings options." lightbox="media/container-insights-cost-config/advanced-collection-settings.png" ::: -- | Name | Description | - |:|:| - | Collection frequency | Determines how often the agent collects data. Valid values are 1m - 30m in 1m intervals The default value is 1m.| - | Namespace filtering | *Off*: Collects data on all namespaces.<br>*Include*: Collects only data from the values in the *namespaces* field.<br>*Exclude*: Collects data from all namespaces except for the values in the *namespaces* field.<br><br>Array of comma separated Kubernetes namespaces to collect inventory and perf data based on the _namespaceFilteringMode_. For example, *namespaces = ["kube-system", "default"]* with an _Include_ setting collects only these two namespaces. With an _Exclude_ setting, the agent collects data from all other namespaces except for _kube-system_ and _default_. | - | Collected Data | Defines which Container insights tables to collect. See below for a description of each grouping. | - | Enable ContainerLogV2 | Boolean flag to enable [ContainerLogV2 schema](./container-insights-logs-schema.md). If set to true, the stdout/stderr Logs are ingested to [ContainerLogV2](container-insights-logs-schema.md) table. If not, the container logs are ingested to **ContainerLog** table, unless otherwise specified in the ConfigMap. When specifying the individual streams, you must include the corresponding table for ContainerLog or ContainerLogV2. | - | Enable Syslog collection | Enables Syslog collection from the cluster. | - -- The **Collected data** option allows you to select the tables that are populated for the cluster. The tables are grouped by the most common scenarios. To specify individual tables, you must modify the DCR using another method. - - :::image type="content" source="media/container-insights-cost-config/collected-data-options.png" alt-text="Screenshot that shows the collected data options." lightbox="media/container-insights-cost-config/collected-data-options.png" ::: - - | Grouping | Tables | Notes | - | | | | - | All (Default) | All standard container insights tables | Required for enabling the default Container insights visualizations | - | Performance | Perf, InsightsMetrics | | - | Logs and events | ContainerLog or ContainerLogV2, KubeEvents, KubePodInventory | Recommended if you have enabled managed Prometheus metrics | - | Workloads, Deployments, and HPAs | InsightsMetrics, KubePodInventory, KubeEvents, ContainerInventory, ContainerNodeInventory, KubeNodeInventory, KubeServices | | - | Persistent Volumes | InsightsMetrics, KubePVInventory | | - -1. Click **Configure** to save the settings. --### [CLI](#tab/cli) --### Configure DCR with Azure portal --#### Prerequisites --- Azure CLI minimum version 2.51.0.-- For AKS clusters, [aks-preview](/azure/aks/cluster-configuration) version 0.5.147 or higher-- For Arc enabled Kubernetes and AKS hybrid, [k8s-extension](../../azure-arc/kubernetes/extensions.md#prerequisites) version 1.4.3 or higher--#### Configuration file --When you use CLI to configure monitoring for your AKS cluster, you provide the configuration as a JSON file using the following format. See the section below for how to use CLI to apply these settings to different cluster configurations. --```json -{ - "interval": "1m", - "namespaceFilteringMode": "Include", - "namespaces": ["kube-system"], - "enableContainerLogV2": true, - "streams": ["Microsoft-Perf", "Microsoft-ContainerLogV2"] -} -``` --Each of the settings in the configuration is described in the following table. --| Name | Description | -|:|:| -| `interval` | Determines how often the agent collects data. Valid values are 1m - 30m in 1m intervals The default value is 1m. If the value is outside the allowed range, then it defaults to *1 m*. | -| `namespaceFilteringMode` | *Include*: Collects only data from the values in the *namespaces* field.<br>*Exclude*: Collects data from all namespaces except for the values in the *namespaces* field.<br>*Off*: Ignores any *namespace* selections and collect data on all namespaces. -| `namespaces` | Array of comma separated Kubernetes namespaces to collect inventory and perf data based on the _namespaceFilteringMode_.<br>For example, *namespaces = ["kube-system", "default"]* with an _Include_ setting collects only these two namespaces. With an _Exclude_ setting, the agent collects data from all other namespaces except for _kube-system_ and _default_. With an _Off_ setting, the agent collects data from all namespaces including _kube-system_ and _default_. Invalid and unrecognized namespaces are ignored. | -| `enableContainerLogV2` | Boolean flag to enable ContainerLogV2 schema. If set to true, the stdout/stderr Logs are ingested to [ContainerLogV2](container-insights-logs-schema.md) table. If not, the container logs are ingested to **ContainerLog** table, unless otherwise specified in the ConfigMap. When specifying the individual streams, you must include the corresponding table for ContainerLog or ContainerLogV2. | -| `streams` | An array of container insights table streams. See [Stream values in DCR](#stream-values-in-dcr) for a list of the valid streams and their corresponding tables. | ----### AKS cluster -->[!IMPORTANT] -> In the commands in this section, when deploying on a Windows machine, the dataCollectionSettings field must be escaped. For example, dataCollectionSettings={\"interval\":\"1m\",\"namespaceFilteringMode\": \"Include\", \"namespaces\": [ \"kube-system\"]} instead of dataCollectionSettings='{"interval":"1m","namespaceFilteringMode": "Include", "namespaces": [ "kube-system"]}' ---#### New AKS cluster --Use the following command to create a new AKS cluster with monitoring enabled. This assumes a configuration file named **dataCollectionSettings.json**. --```azcli -az aks create -g <clusterResourceGroup> -n <clusterName> --enable-managed-identity --node-count 1 --enable-addons monitoring --data-collection-settings dataCollectionSettings.json --generate-ssh-keys -``` --#### Existing AKS cluster --**Cluster without the monitoring addon** -Use the following command to add monitoring to an existing cluster without Container insights enabled. This assumes a configuration file named **dataCollectionSettings.json**. --```azcli -az aks enable-addons -a monitoring -g <clusterResourceGroup> -n <clusterName> --data-collection-settings dataCollectionSettings.json -``` --**Cluster with an existing monitoring addon** -Use the following command to add a new configuration to an existing cluster with Container insights enabled. This assumes a configuration file named **dataCollectionSettings.json**. --```azcli -# get the configured log analytics workspace resource id -az aks show -g <clusterResourceGroup> -n <clusterName> | grep -i "logAnalyticsWorkspaceResourceID" --# disable monitoring -az aks disable-addons -a monitoring -g <clusterResourceGroup> -n <clusterName> --# enable monitoring with data collection settings -az aks enable-addons -a monitoring -g <clusterResourceGroup> -n <clusterName> --workspace-resource-id <logAnalyticsWorkspaceResourceId> --data-collection-settings dataCollectionSettings.json -``` --### Arc-enabled Kubernetes cluster -Use the following command to add monitoring to an existing Arc-enabled Kubernetes cluster. -```azcli -az k8s-extension create --name azuremonitor-containers --cluster-name <cluster-name> --resource-group <resource-group> --cluster-type connectedClusters --extension-type Microsoft.AzureMonitor.Containers --configuration-settings amalogs.useAADAuth=true dataCollectionSettings='{"interval":"1m","namespaceFilteringMode": "Include", "namespaces": [ "kube-system"],"enableContainerLogV2": true,"streams": ["<streams to be collected>"]}' -``` --### AKS hybrid cluster -Use the following command to add monitoring to an existing AKS hybrid cluster. --```azcli -az k8s-extension create --name azuremonitor-containers --cluster-name <cluster-name> --resource-group <resource-group> --cluster-type provisionedclusters --cluster-resource-provider "microsoft.hybridcontainerservice" --extension-type Microsoft.AzureMonitor.Containers --configuration-settings amalogs.useAADAuth=true dataCollectionSettings='{"interval":"1m","namespaceFilteringMode":"Include", "namespaces": ["kube-system"],"enableContainerLogV2": true,"streams": ["<streams to be collected>"]}' -``` ---### [ARM](#tab/arm) --### Configure DCR with ARM templates --The following template and parameter files are available for different cluster configurations. --**AKS cluster** -- Template: https://aka.ms/aks-enable-monitoring-costopt-onboarding-template-file-- Parameter: https://aka.ms/aks-enable-monitoring-costopt-onboarding-template-parameter-file --**Arc-enabled Kubernetes** -- Template: https://aka.ms/arc-k8s-enable-monitoring-costopt-onboarding-template-file-- Parameter: https://aka.ms/arc-k8s-enable-monitoring-costopt-onboarding-template-parameter-file--**AKS hybrid cluster** -- Template: https://aka.ms/existingClusterOnboarding.json-- Parameter: https://aka.ms/existingClusterParam.json--The following table describes the parameters you need to provide values for in each of the parameter files. --| Name | Description | -|:|:| -| `aksResourceId` | Resource ID for the cluster.| -| `aksResourceLocation` | Location of the cluster.| -| `workspaceRegion` | Location of the Log Analytics workspace. | -| `enableContainerLogV2` | Boolean flag to enable ContainerLogV2 schema. If set to true, the stdout/stderr Logs are ingested to [ContainerLogV2](container-insights-logs-schema.md) table. If not, the container logs are ingested to **ContainerLog** table, unless otherwise specified in the ConfigMap. When specifying the individual streams, you must include the corresponding table for ContainerLog or ContainerLogV2. | -| `enableSyslog` | Specifies whether Syslog collection should be enabled. | -| `syslogLevels` | If Syslog collection is enabled, specifies the log levels to collect. | -| `dataCollectionInterval` | Determines how often the agent collects data. Valid values are 1m - 30m in 1m intervals The default value is 1m. If the value is outside the allowed range, then it defaults to *1 m*. | -| `namespaceFilteringModeForDataCollection` | *Include*: Collects only data from the values in the *namespaces* field.<br>*Exclude*: Collects data from all namespaces except for the values in the *namespaces* field.<br>*Off*: Ignores any *namespace* selections and collect data on all namespaces. -| `namespacesForDataCollection` | Array of comma separated Kubernetes namespaces to collect inventory and perf data based on the _namespaceFilteringMode_.<br>For example, *namespaces = ["kube-system", "default"]* with an _Include_ setting collects only these two namespaces. With an _Exclude_ setting, the agent collects data from all other namespaces except for _kube-system_ and _default_. With an _Off_ setting, the agent collects data from all namespaces including _kube-system_ and _default_. Invalid and unrecognized namespaces are ignored. | -| `streams` | An array of container insights table streams. See [Stream values in DCR](#stream-values-in-dcr) for a list of the valid streams and their corresponding tables.<br><br>To enable [high scale mode](./container-insights-high-scale.md) for container logs, use `Microsoft-ContainerLogV2-HighScale`. | -| `useAzureMonitorPrivateLinkScope` | Specifies whether to use private link for the cluster connection to Azure Monitor. | -| `azureMonitorPrivateLinkScopeResourceId` | If private link is used, resource ID of the private link scope. | ----### Applicable tables and metrics for DCR -The settings for **collection frequency** and **namespace filtering** in the DCR don't apply to all Container insights data. The following tables list the tables in the Log Analytics workspace used by Container insights and the metrics it collects along with the settings that apply to each. --| Table name | Interval? | Namespaces? | Remarks | -|:|::|::|:| -| ContainerInventory | Yes | Yes | | -| ContainerNodeInventory | Yes | No | Data collection setting for namespaces isn't applicable since Kubernetes Node isn't a namespace scoped resource | -| KubeNodeInventory | Yes | No | Data collection setting for namespaces isn't applicable Kubernetes Node isn't a namespace scoped resource | -| KubePodInventory | Yes | Yes || -| KubePVInventory | Yes | Yes | | -| KubeServices | Yes | Yes | | -| KubeEvents | No | Yes | Data collection setting for interval isn't applicable for the Kubernetes Events | -| Perf | Yes | Yes | Data collection setting for namespaces isn't applicable for the Kubernetes Node related metrics since the Kubernetes Node isn't a namespace scoped object. | -| InsightsMetrics| Yes | Yes | Data collection settings are only applicable for the metrics collecting the following namespaces: container.azm.ms/kubestate, container.azm.ms/pv and container.azm.ms/gpu | ---| Metric namespace | Interval? | Namespaces? | Remarks | -|:|::|::|:| -| Insights.container/nodes| Yes | No | Node isn't a namespace scoped resource | -|Insights.container/pods | Yes | Yes| | -| Insights.container/containers | Yes | Yes | | -| Insights.container/persistentvolumes | Yes | Yes | | ----### Stream values in DCR -When you specify the tables to collect using CLI or ARM, you specify a stream name that corresponds to a particular table in the Log Analytics workspace. The following table lists the stream name for each table. --> [!NOTE] -> If you're familiar with the [structure of a data collection rule](../essentials/data-collection-rule-structure.md), the stream names in this table are specified in the [dataFlows](../essentials/data-collection-rule-structure.md#dataflows) section of the DCR. --| Stream | Container insights table | -| | | -| Microsoft-ContainerInventory | ContainerInventory | -| Microsoft-ContainerLog | ContainerLog | -| Microsoft-ContainerLogV2 | ContainerLogV2 | -| Microsoft-ContainerLogV2-HighScale | ContainerLogV2 (High scale mode)<sup>1</sup> | -| Microsoft-ContainerNodeInventory | ContainerNodeInventory | -| Microsoft-InsightsMetrics | InsightsMetrics | -| Microsoft-KubeEvents | KubeEvents | -| Microsoft-KubeMonAgentEvents | KubeMonAgentEvents | -| Microsoft-KubeNodeInventory | KubeNodeInventory | -| Microsoft-KubePodInventory | KubePodInventory | -| Microsoft-KubePVInventory | KubePVInventory | -| Microsoft-KubeServices | KubeServices | -| Microsoft-Perf | Perf | --<sup>1</sup> You shouldn't use both Microsoft-ContainerLogV2 and Microsoft-ContainerLogV2-HighScale in the same DCR. This will result in duplicate data. ---## Share DCR with multiple clusters -When you enable Container insights on a Kubernetes cluster, a new DCR is created for that cluster, and the DCR for each cluster can be modified independently. If you have multiple clusters with custom monitoring configurations, you may want to share a single DCR with multiple clusters. You can then make changes to a single DCR that are automatically implemented for any clusters associated with it. --A DCR is associated with a cluster with a [data collection rule associates (DCRA)](../essentials/data-collection-rule-overview.md#data-collection-rule-associations-dcra). Use the [preview DCR experience](../essentials/data-collection-rule-view.md#preview-dcr-experience) to view and remove existing DCR associations for each cluster. You can then use this feature to add an association to a single DCR for multiple clusters. --## Configure data collection using ConfigMap --[ConfigMaps](https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/) are a Kubernetes mechanism that allow you to store non-confidential data such as a configuration file or environment variables. Container insights looks for a ConfigMap on each cluster with particular settings that define data that it should collect. --> [!IMPORTANT] -> ConfigMap is a global list and there can be only one ConfigMap applied to the agent for Container insights. Applying another ConfigMap will overrule the previous ConfigMap collection settings. --### Prerequisites -- The minimum agent version supported to collect stdout, stderr, and environmental variables from container workloads is **ciprod06142019** or later. --### Configure and deploy ConfigMap --Use the following procedure to configure and deploy your ConfigMap configuration file to your cluster: --1. If you don't already have a ConfigMap for Container insights, download the [template ConfigMap YAML file](https://aka.ms/container-azm-ms-agentconfig) and open it in an editor. --1. Edit the ConfigMap YAML file with your customizations. The template includes all valid settings with descriptions. To enable a setting, remove the comment character (#) and set its value. --1. Create a ConfigMap by running the following kubectl command: -- ```azurecli - kubectl config set-context <cluster-name> - kubectl apply -f <configmap_yaml_file.yaml> - - # Example: - kubectl config set-context my-cluster - kubectl apply -f container-azm-ms-agentconfig.yaml - ``` --- The configuration change can take a few minutes to finish before taking effect. Then all Azure Monitor Agent pods in the cluster will restart. The restart is a rolling restart for all Azure Monitor Agent pods, so not all of them restart at the same time. When the restarts are finished, you'll receive a message similar to the following result: - - ```output - configmap "container-azm-ms-agentconfig" created`. - ``` --### Verify configuration --To verify the configuration was successfully applied to a cluster, use the following command to review the logs from an agent pod. --```azurecli -kubectl logs ama-logs-fdf58 -n kube-system -c ama-logs -``` --If there are configuration errors from the Azure Monitor Agent pods, the output will show errors similar to the following: --```output -***************Start Config Processing******************** -config::unsupported/missing config schema version - 'v21' , using defaults -``` --Use the following options to perform more troubleshooting of configuration changes: --- Use the same `kubectl logs` command from an agent pod.-- Review live logs for errors similar to the following:-- ``` - config::error::Exception while parsing config map for log collection/env variable settings: \nparse error on value \"$\" ($end), using defaults, please check config map for errors - ``` --- Data is sent to the `KubeMonAgentEvents` table in your Log Analytics workspace every hour with error severity for configuration errors. If there are no errors, the entry in the table will have data with severity info, which reports no errors. The `Tags` column contains more information about the pod and container ID on which the error occurred and also the first occurrence, last occurrence, and count in the last hour.--### Verify schema version --Supported config schema versions are available as pod annotation (schema-versions) on the Azure Monitor Agent pod. You can see them with the following kubectl command. --```bash -kubectl describe pod ama-logs-fdf58 -n=kube-system. -``` ---## ConfigMap settings --The following table describes the settings you can configure to control data collection with ConfigMap. ---| Setting | Data type | Value | Description | -|:|:|:|:| -| `schema-version` | String (case sensitive) | v1 | Used by the agent when parsing this ConfigMap. Currently supported schema-version is v1. Modifying this value isn't supported and will be rejected when the ConfigMap is evaluated. | -| `config-version` | String | | Allows you to keep track of this config file's version in your source control system/repository. Maximum allowed characters are 10, and all other characters are truncated. | -| **[log_collection_settings]** | | | | -| `[stdout]`<br>`enabled` | Boolean | true<br>false | Controls whether stdout container log collection is enabled. When set to `true` and no namespaces are excluded for stdout log collection, stdout logs will be collected from all containers across all pods and nodes in the cluster. If not specified in the ConfigMap, the default value is `true`. | -| `[stdout]`<br>`exclude_namespaces` | String | Comma-separated array | Array of Kubernetes namespaces for which stdout logs won't be collected. This setting is effective only if `enabled` is set to `true`. If not specified in the ConfigMap, the default value is<br> `["kube-system","gatekeeper-system"]`. | -| `[stderr]`<br>`enabled` | Boolean | true<br>false | Controls whether stderr container log collection is enabled. When set to `true` and no namespaces are excluded for stderr log collection, stderr logs will be collected from all containers across all pods and nodes in the cluster. If not specified in the ConfigMap, the default value is `true`. | -| `[stderr]`<br>`exclude_namespaces` | String | Comma-separated array | Array of Kubernetes namespaces for which stderr logs won't be collected. This setting is effective only if `enabled` is set to `true`. If not specified in the ConfigMap, the default value is<br> `["kube-system","gatekeeper-system"]`. | -| `[env_var]`<br>`enabled` | Boolean | true<br>false | Controls environment variable collection across all pods and nodes in the cluster. If not specified in the ConfigMap, the default value is `true`. | -| `[enrich_container_logs]`<br>`enabled` | Boolean | true<br>false | Controls container log enrichment to populate the `Name` and `Image` property values for every log record written to the **ContainerLog** table for all container logs in the cluster. If not specified in the ConfigMap, the default value is `false`. | -| `[collect_all_kube_events]`<br>`enabled` | Boolean | true<br>false| Controls whether Kube events of all types are collected. By default, the Kube events with type **Normal** aren't collected. When this setting is `true`, the **Normal** events are no longer filtered, and all events are collected. If not specified in the ConfigMap, the default value is `false`. | -| `[schema]`<br>`containerlog_schema_version` | String (case sensitive) | v2<br>v1 | Sets the log ingestion format. If `v2`, the **ContainerLogV2** table is used. If `v1`, the **ContainerLog** table is used (this table has been deprecated). For clusters enabling container insights using Azure CLI version 2.54.0 or greater, the default setting is `v2`. See [Container insights log schema](./container-insights-logs-schema.md) for details. | -| `[enable_multiline_logs]`<br>`enabled` | Boolean | true<br>false | Controls whether multiline container logs are enabled. See [Multi-line logging in Container Insights](./container-insights-logs-schema.md#multi-line-logging) for details. If not specified in the ConfigMap, the default value is `false`. This requires the `schema` setting to be `v2`. | -| `[metadata_collection]`<br>`enabled` | Boolean | true<br>false | Controls whether metadata is collected in the `KubernetesMetadata` column of the `ContainerLogV2` table. | -| `[metadata_collection]`<br>`include_fields` | String | Comma-separated array | List of metadata fields to include. If the setting isn't used then all fields are collected. Valid values are `["podLabels","podAnnotations","podUid","image","imageID","imageRepo","imageTag"]` | -| **[metric_collection_settings]** | | | | -| `[collect_kube_system_pv_metrics]`<br>`enabled` | Boolean | true<br>false | Allows persistent volume (PV) usage metrics to be collected in the kube-system namespace. By default, usage metrics for persistent volumes with persistent volume claims in the kube-system namespace aren't collected. When this setting is set to `true`, PV usage metrics for all namespaces are collected. If not specified in the ConfigMap, the default value is `false`. | -| **[agent_settings]** | | | | -| `[proxy_config]`<br>`ignore_proxy_settings` | Boolean | true<br>false | When `true`, proxy settings are ignored. For both AKS and Arc-enabled Kubernetes environments, if your cluster is configured with forward proxy, then proxy settings are automatically applied and used for the agent. For certain configurations, such as with AMPLS + Proxy, you might want the proxy configuration to be ignored. If not specified in the ConfigMap, the default value is `false`. | ----## Next steps --- See [Filter log collection in Container insights](./container-insights-data-collection-filter.md) for details on saving costs by configuring Container insights to filter data that you don't require.- |
| azure-monitor | Container Insights Data Collection Filter | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-data-collection-filter.md | - Title: Filter log collection in Container insights -description: Options for filtering Container insights data that you don't require. - Previously updated : 05/14/2024----# Filter log collection in Container insights --This article describes the different filtering options available in [Container insights](./container-insights-overview.md). Kubernetes clusters generate a large amount of data that's collected by Container insights. Since you're charged for the ingestion and retention of this data, you can significantly reduce your monitoring costs by filtering out data that you don't need. --> [!IMPORTANT] -> This article describes different filtering options that require you to modify the DCR or ConfigMap for a monitored cluster. See [Configure log collection in Container insights](container-insights-data-collection-configure.md) for details on performing this configuration. --## Filter container logs --Container logs are stderr and stdout logs generated by containers in your Kubernetes cluster. These logs are stored in the [ContainerLogV2 table](./container-insights-logs-schema.md) in your Log Analytics workspace. By default all container logs are collected, but you can filter out logs from specific namespaces or disable collection of container logs entirely. --Using the [Data collection rule (DCR)](./container-insights-data-collection-configure.md#configure-data-collection-using-dcr), you can enable or disable stdout and stderr logs and filter specific namespaces from each. Settings for Container logs and namespace filtering are included in the cost presets configured in the Azure portal, and you can set these values individually using the other DCR configuration methods. ---Using [ConfigMap](./container-insights-data-collection-configure.md#configure-data-collection-using-configmap), you can configure the collection of `stderr` and `stdout` logs separately for the clustery, so you can choose to enable one and not the other. --The following example shows the ConfigMap settings to collect stdout and stderr excluding the `kube-system` and `gatekeeper-system` namespaces. --```yml -[log_collection_settings] - [log_collection_settings.stdout] - enabled = true - exclude_namespaces = ["kube-system","gatekeeper-system"] -- [log_collection_settings.stderr] - enabled = true - exclude_namespaces = ["kube-system","gatekeeper-system"] -- [log_collection_settings.enrich_container_logs] - enabled = true -``` ---## Platform log filtering (System Kubernetes namespaces) -By default, container logs from the system namespace are excluded from collection to minimize the Log Analytics cost. Container logs of system containers can be critical though in specific troubleshooting scenarios. This feature is restricted to the following system namespaces: `kube-system`, `gatekeeper-system`, `calico-system`, `azure-arc`, `kube-public`, and `kube-node-lease`. --Enable platform logs using [ConfigMap](./container-insights-data-collection-configure.md#configure-data-collection-using-configmap) with the `collect_system_pod_logs` setting. You must also ensure that the system namespace is not in the `exclude_namespaces` setting. --The following example shows the ConfigMap settings to collect stdout and stderr logs of `coredns` container in the `kube-system` namespace. --```yaml -[log_collection_settings] - [log_collection_settings.stdout] - enabled = true - exclude_namespaces = ["gatekeeper-system"] - collect_system_pod_logs = ["kube-system:coredns"] -- [log_collection_settings.stderr] - enabled = true - exclude_namespaces = ["kube-system","gatekeeper-system"] - collect_system_pod_logs = ["kube-system:coredns"] -``` --## Annotation based filtering for workloads -Annotation-based filtering enables you to exclude log collection for certain pods and containers by annotating the pod. This can reduce your logs ingestion cost significantly and allow you to focus on relevant information without sifting through noise. --Enable annotation based filtering using [ConfigMap](./container-insights-data-collection-configure.md#configure-data-collection-using-configmap) with the following settings. --```yml -[log_collection_settings.filter_using_annotations] - enabled = true -``` --You must also add the required annotations on your workload pod spec. The following table highlights different possible pod annotations. --| Annotation | Description | -| | - | -| `fluentbit.io/exclude: "true"` | Excludes both stdout & stderr streams on all the containers in the Pod | -| `fluentbit.io/exclude_stdout: "true"` | Excludes only stdout stream on all the containers in the Pod | -| `fluentbit.io/exclude_stderr: "true"` | Excludes only stderr stream on all the containers in the Pod | -| `fluentbit.io/exclude_container1: "true"` | Exclude both stdout & stderr streams only for the container1 in the pod | -| `fluentbit.io/exclude_stdout_container1: "true"` | Exclude only stdout only for the container1 in the pod | -->[!NOTE] ->These annotations are fluent bit based. If you use your own fluent-bit based log collection solution with the Kubernetes plugin filter and annotation based exclusion, it will stop collecting logs from both Container Insights and your solution. --Following is an example of `fluentbit.io/exclude: "true"` annotation in a Pod spec: --``` -apiVersion: v1 -kind: Pod -metadata: - name: apache-logs - labels: - app: apache-logs - annotations: - fluentbit.io/exclude: "true" -spec: - containers: - image: edsiper/apache_logs -``` --## Filter environment variables -Enable collection of environment variables across all pods and nodes in the cluster using [ConfigMap](./container-insights-data-collection-configure.md#configure-data-collection-using-configmap) with the following settings. --```yaml -[log_collection_settings.env_var] - enabled = true -``` --If collection of environment variables is globally enabled, you can disable it for a specific container by setting the environment variable `AZMON_COLLECT_ENV` to `False` either with a Dockerfile setting or in the [configuration file for the Pod](https://kubernetes.io/docs/tasks/inject-data-application/define-environment-variable-container/) under the `env:` section. If collection of environment variables is globally disabled, you can't enable collection for a specific container. The only override that can be applied at the container level is to disable collection when it's already enabled globally. ----## Impact on visualizations and alerts --If you have any custom alerts or workbooks using Container insights data, then modifying your data collection settings might degrade those experiences. If you're excluding namespaces or reducing data collection frequency, review your existing alerts, dashboards, and workbooks using this data. --To scan for alerts that reference these tables, run the following Azure Resource Graph query: --```Kusto -resources -| where type in~ ('microsoft.insights/scheduledqueryrules') and ['kind'] !in~ ('LogToMetric') -| extend severity = strcat("Sev", properties["severity"]) -| extend enabled = tobool(properties["enabled"]) -| where enabled in~ ('true') -| where tolower(properties["targetResourceTypes"]) matches regex 'microsoft.operationalinsights/workspaces($|/.*)?' or tolower(properties["targetResourceType"]) matches regex 'microsoft.operationalinsights/workspaces($|/.*)?' or tolower(properties["scopes"]) matches regex 'providers/microsoft.operationalinsights/workspaces($|/.*)?' -| where properties contains "Perf" or properties contains "InsightsMetrics" or properties contains "ContainerInventory" or properties contains "ContainerNodeInventory" or properties contains "KubeNodeInventory" or properties contains"KubePodInventory" or properties contains "KubePVInventory" or properties contains "KubeServices" or properties contains "KubeEvents" -| project id,name,type,properties,enabled,severity,subscriptionId -| order by tolower(name) asc -``` ---## Next steps --- See [Data transformations in Container insights](./container-insights-transformations.md) to add transformations to the DCR that will further filter data based on detailed criteria.- |
| azure-monitor | Container Insights Deployment Hpa Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-deployment-hpa-metrics.md | - Title: Deployment and HPA metrics with Container insights | Microsoft Docs -description: This article describes what deployment and HPA metrics are collected with Container insights. - Previously updated : 2/28/2024----# Deployment and HPA metrics with Container insights --The Container insights integrated agent automatically collects metrics for deployments and horizontal pod autoscalers (HPAs). --## Deployment metrics --Container insights automatically starts monitoring deployments by collecting the following metrics at 60-second intervals and storing them in the **InsightMetrics** table. --|Metric name |Metric dimension (tags) |Description | -|||| -|kube_deployment_status_replicas_ready |container.azm.ms/clusterId, container.azm.ms/clusterName, creationTime, deployment, deploymentStrategy, k8sNamespace, spec_replicas, status_replicas_available, status_replicas_updated (status.updatedReplicas) | Total number of ready pods targeted by this deployment (status.readyReplicas). The dimensions of this metric are: <ul> <li> deployment - name of the deployment </li> <li> k8sNamespace - Kubernetes namespace for the deployment </li> <li> deploymentStrategy - Deployment strategy to use to replace pods with new ones (spec.strategy.type)</li><li> creationTime - deployment creation timestamp </li> <li> spec_replicas - Number of desired pods (spec.replicas) </li> <li>status_replicas_available - Total number of available pods (ready for at least minReadySeconds) targeted by this deployment (status.availableReplicas)</li><li>status_replicas_updated - Total number of non-terminated pods targeted by this deployment that have the desired template spec (status.updatedReplicas) </li></ul>| --## HPA metrics --Container insights automatically starts monitoring HPAs by collecting the following metrics at 60-second intervals and storing them in the **InsightMetrics** table. --|Metric name |Metric dimension (tags) |Description | -|||| -|kube_hpa_status_current_replicas |container.azm.ms/clusterId, container.azm.ms/clusterName, creationTime, hpa, k8sNamespace, lastScaleTime, spec_max_replicas, spec_min_replicas, status_desired_replicas, targetKind, targetName | Current number of replicas of pods managed by this autoscaler (status.currentReplicas). The dimensions of this metric are: <ul> <li> hpa - name of the HPA </li> <li> k8sNamespace - Kubernetes namespace for the HPA </li> <li> lastScaleTime - Last time the HPA scaled the number of pods (status.lastScaleTime)</li><li> creationTime - HPA creation timestamp </li> <li> spec_max_replicas - Upper limit for the number of pods that can be set by the autoscaler (spec.maxReplicas) </li> <li> spec_min_replicas - Lower limit for the number of replicas to which the autoscaler can scale down (spec.minReplicas) </li><li>status_desired_replicas - Desired number of replicas of pods managed by this autoscaler (status.desiredReplicas)</li><li>targetKind - Kind of the HPA's target (spec.scaleTargetRef.kind) </li><li>targetName - Name of the HPA's target (spec.scaleTargetRef.name) </li></ul>| --## Deployment and HPA charts --Container insights includes preconfigured charts for the metrics listed earlier in the table as a workbook for every cluster. You can find the deployments and HPA workbook **Deployments & HPA** directly from an Azure Kubernetes Service cluster. On the left pane, select **Workbooks** and select **View Workbooks** from the dropdown list in the insight. --## Next steps --Review [Kube-state metrics in Kubernetes](https://github.com/kubernetes/kube-state-metrics/tree/master/docs) to learn more about Kube-state metrics. |
| azure-monitor | Container Insights Experience V2 | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-experience-v2.md | - Title: Switch to use Container Insights with managed Prometheus | Microsoft Docs -description: This article describes how you can replace your Container Insights visualizations to use Prometheus metrics. - Previously updated : 05/15/2024----# Switch to using managed Prometheus visualizations for Container Insights (preview) --Container Insights currently uses data from Log Analytics to power the visualizations in the Azure portal. However, with the release of managed Prometheus, this new format of metrics collection is cheaper and more efficient. Container Insights now offers the ability to visualize using only managed Prometheus data. This article helps you with the setup to start using managed Prometheus as your primary Container Insights visualization tool. --> [!Note] -> This feature is currently in public preview. For additional information, please read the [Supplemental Terms of Use for Microsoft Azure Previews](https://azure.microsoft.com/support/legal/preview-supplemental-terms). --## Prerequisites --To view your Container Insights data using Prometheus, ensure the following steps are complete. --* Azure Kubernetes Service (AKS) [configured with managed Prometheus](./kubernetes-monitoring-enable.md#existing-cluster-prometheus-only) -* User has `Reader` permission or higher on the associated [Azure Monitor workspace](../essentials/azure-monitor-workspace-overview.md) -* Ad block is disabled or set to allow `monitor.azure.com` traffic -* For Windows clusters, [enable Windows metric collection](./kubernetes-monitoring-enable.md#enable-windows-metrics-collection-preview) --## Accessing Prometheus based Container Insights --Because Azure Monitor supports various levels of customization, your cluster may currently have logs based Container Insights, managed Prometheus, or some other combination. --> [!Note] -> Managed Prometheus visualizations for Container Insights use recording rules to improve chart performance, learn more about [what rules are configured](./prometheus-metrics-scrape-default.md#prometheus-visualization-recording-rules). --### [No Prometheus or logs based Container Insights enabled](#tab/unmonitored) --1. Open the Azure portal and navigate to your desired AKS cluster. --2. Choose the `Insights` menu item from the menu, displaying a splash screen indicating no monitoring enabled. -- --3. Select the `Configure monitoring` button to open up the monitoring configuration blade. --4. Underneath the advanced settings blade, choose `Logs and events` from the Cost presets dropdown. --5. To finish the setup, click the `Configure` button. --6. Once the onboarding deployment completes, you should be able to see the Insights experience using Prometheus as the data source, indicated by the toolbar dropdown showing `Managed Prometheus visualizations (Preview)`. -- --### [Logs based Container Insights enabled](#tab/LA) --1. Open the Azure portal and navigate to your desired AKS cluster. --2. Choose the `Insights` menu item from the menu, which displays a banner at the top to configure managed Prometheus. --3. Using the banner, select the `Configure` button to complete onboarding to managed Prometheus or deploy the requisite recording rules. -- --If the banner was previously dismissed, you can instead use the dropdown in the toolbar that says `Log Analytics visualizations (Classic)`, and select the `Managed Prometheus visualizations (Preview)` option, which opens up a pop-up to complete onboarding. -- --4. Once the monitoring deployment is complete, the Insights blade should switch to using Prometheus as the data source, indicated by the toolbar dropdown showing `Managed Prometheus visualizations (Preview)`. -- ---### [Prometheus enabled and logs based Container Insights not enabled or with custom settings applied](#tab/Prom) --1. Open the Azure portal and navigate to your desired AKS cluster. --2. Choose the `Insights` menu item from the menu, which displays a banner for enabling Prometheus recording rules. -- --3. Click `Enable` to deploy the recording rules. --4. Once the monitoring deployment is complete, the Insights blade should switch to using Prometheus as the data source, indicated by the toolbar dropdown showing `Managed Prometheus visualizations (Preview)`. --> [!Note] -> Some charts will only have partial data for the default time range until sufficient time has elapsed for the recording rules to collect data. -- ----## Optional steps --While the above steps are sufficient, for the full visualization experience, a few optional steps can be completed. --### Node and Pod labels collection --By default the labels for nodes and pods aren't available, but can be collected through re-enabling the addon. Node labels are required for filtering data by node pools. --1. If the managed Prometheus addon is currently deployed, we must first disable it --```azurecli -az aks update --disable-azure-monitor-metrics -n <clusterName> -g <resourceGroup> -``` --2. Then, re-enable the addon with the flag `--ksm-metric-labels-allow-list` - -```azurecli -az aks update -n <clusterName> -g <resourceGroup> --enable-azure-monitor-metrics --ksm-metric-labels-allow-list "nodes=[*], pods=[*]" --azure-monitor-workspace-resource-id <amw-id -``` --### Disable Log Analytics data collection --If you're currently using the logs based Container Insights experience, then you can choose to stop ingesting metrics to Log Analytics to save on billing. Once you confirm the Prometheus backed Container Insights experience is sufficient for your purposes, complete the steps to stop metrics ingestion to Log Analytics. --1. Navigate to the monitoring settings for your clusters by following the instructions on how to configure your [Container Insights data collection rule](./container-insights-data-collection-dcr.md#configure-data-collection) --2. From the Cost presets dropdown, select "Logs and Events" and save to configure. --> [!Note] -> Disabling the Log Analytics metrics also disables the visualization dropdown in the toolbar. Revert to using one of the standard cost presets in the `Monitoring Settings` blade to re-enable the Log Analytics visualizations. --## Known limitations and issues --As this feature is currently in preview, there are several, known limitations, the following features aren't supported --* Environment variable details -* Filtering data by individual services -* Live data viewing on the Cluster tab -* Workbooks reports data -* Node memory working set and RSS metrics -* Partial or no data available in the multi-cluster view based on Container Insights DCR settings --## Troubleshooting --When using the Prometheus based Container Insights experience, you may encounter the following errors. --### The charts are stuck in a loading state --This issue occurs if the network traffic for the Azure Monitor workspace is blocked. The root cause of this is typically related to network policies, such as ad blocking software. To resolve this issue, disable the ad block or allowlist `monitor.azure.com` traffic and reload the page. --### Unable to access Data Collection Rule --This error occurs when the user doesn't have permissions to view the associated Prometheus data collection rule for the cluster or the data collection rule may have been deleted. To resolve this error, grant access to the Prometheus data collection rule or reconfigure managed Prometheus using the `Monitoring Settings` button in the toolbar. --### Unable to access Azure Monitor workspace --This error occurs when the user doesn't have permissions to view the associated Azure Monitor workspace for the cluster or the Azure Monitor workspace may have been deleted. To resolve this error, grant access to the Azure Monitor workspace or reconfigure managed Prometheus by deleting and [redeploying the addon](./kubernetes-monitoring-enable.md#enable-prometheus-and-grafana). --### The data could not be retrieved --This error typically occurs when querying large volumes of data and may be resolved by reducing the time range to a shorter window or filtering for fewer objects. --### Data configuration error --This error occurs when the recording rules may have been modified or deleted. Use the `Reconfigure` button to patch the recording rules and try again. --### Access denied --This occurs when the user's portal token expires or doesn't have permissions to view the associated Azure Monitor workspace for the cluster. This can typically be resolved by refreshing the browser session or logging in again. --### An unknown error occurred --If this error message persists, then contact support to open up a ticket. |
| azure-monitor | Container Insights Gpu Monitoring | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-gpu-monitoring.md | - Title: Configure GPU monitoring with Container insights -description: This article describes how you can configure monitoring Kubernetes clusters with NVIDIA and AMD GPU enabled nodes with Container insights. - Previously updated : 08/19/2024----# Configure GPU monitoring with Container insights --Container insights supports monitoring GPU clusters from the following GPU vendors: --- [NVIDIA](https://developer.nvidia.com/kubernetes-gpu)-- [AMD](https://github.com/RadeonOpenCompute/k8s-device-plugin)--Container insights automatically starts monitoring GPU usage on nodes and GPU requesting pods and workloads by collecting the following metrics at 60-second intervals and storing them in the **InsightMetrics** table. -->[!NOTE] ->After you provision clusters with GPU nodes, ensure that the [GPU driver](/azure/aks/gpu-cluster) is installed as required by Azure Kubernetes Service (AKS) to run GPU workloads. Container insights collect GPU metrics through GPU driver pods running in the node. --|Metric name |Metric dimension (tags) |Description | -|||| -|containerGpuDutyCycle* |container.azm.ms/clusterId, container.azm.ms/clusterName, containerName, gpuId, gpuModel, gpuVendor|Percentage of time over the past sample period (60 seconds) during which the GPU was busy/actively processing for a container. Duty cycle is a number between 1 and 100. | -|containerGpuLimits |container.azm.ms/clusterId, container.azm.ms/clusterName, containerName |Each container can specify limits as one or more GPUs. It isn't possible to request or limit a fraction of a GPU. | -|containerGpuRequests |container.azm.ms/clusterId, container.azm.ms/clusterName, containerName |Each container can request one or more GPUs. It isn't possible to request or limit a fraction of a GPU.| -|containerGpumemoryTotalBytes* |container.azm.ms/clusterId, container.azm.ms/clusterName, containerName, gpuId, gpuModel, gpuVendor |Amount of GPU memory in bytes available to use for a specific container. | -|containerGpumemoryUsedBytes* |container.azm.ms/clusterId, container.azm.ms/clusterName, containerName, gpuId, gpuModel, gpuVendor |Amount of GPU memory in bytes used by a specific container. | -|nodeGpuAllocatable |container.azm.ms/clusterId, container.azm.ms/clusterName, gpuVendor |Number of GPUs in a node that can be used by Kubernetes. | -|nodeGpuCapacity |container.azm.ms/clusterId, container.azm.ms/clusterName, gpuVendor |Total number of GPUs in a node. | --\* Based on Kubernetes upstream changes, these metrics are no longer collected out of the box. As a temporary hotfix, for AKS, upgrade your GPU node pool to the latest version or \*-2022.06.08 or higher. For Azure Arc-enabled Kubernetes, enable the feature gate `DisableAcceleratorUsageMetrics=false` in kubelet configuration of the node and restart the kubelet. After the upstream changes reach general availability, this fix will no longer work. -## GPU performance charts --Container insights includes preconfigured charts for the metrics listed earlier in the table as a GPU workbook for every cluster. For a description of the workbooks available for Container insights, see [Workbooks in Container insights](container-insights-reports.md). --## Next steps --- See [Use GPUs for compute-intensive workloads on Azure Kubernetes Service](/azure/aks/gpu-cluster) to learn how to deploy an AKS cluster that includes GPU-enabled nodes.-- Learn more about [GPU optimized VM SKUs in Azure](/azure/virtual-machines/sizes-gpu).-- Review [GPU support in Kubernetes](https://kubernetes.io/docs/tasks/manage-gpus/scheduling-gpus/) to learn more about Kubernetes experimental support for managing GPUs across one or more nodes in a cluster. |
| azure-monitor | Container Insights High Scale | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-high-scale.md | - Title: High scale logs collection in Container Insights (Preview) -description: Enable high scale logs collection in Container Insights (Preview). - Previously updated : 08/06/2024---# High scale logs collection in Container Insights (Preview) -High scale mode is a feature in Container Insights that enables you to collect container console (stdout & stderr) logs with high throughput from your Azure Kubernetes Service (AKS) cluster nodes. This feature enables you to collect up to 50,000 logs/sec per node. --> [!NOTE] -> This feature is currently in public preview. For additional information, please read the [Supplemental Terms of Use for Microsoft Azure Previews](https://azure.microsoft.com/support/legal/preview-supplemental-terms). --## Overview -When high scale mode is enabled, Container Insights performs multiple configuration changes resulting in a higher overall throughput. This includes using an upgraded agent and Azure Monitor data pipeline with scale improvements. These changes are all made in the background by Azure Monitor and don't require input or configuration after the feature is enabled. --High scale mode impacts only the data collection layer. The rest of the Container insights experience remains the same, with logs being ingested into same `ContainerLogV2` table. Existing queries and alerts continue to work since the same data is being collected. --To achieve the maximum supported logs throughput, you should use high-end VM SKUs with 16 CPU cores or more for your AKS cluster nodes. Using low end VM SKUs will impact your logs throughput. --## Does my cluster qualify? -High scale logs collection is suited for environments sending more than 2,000 logs/sec (or 2 MB/sec) per node in their Kubernetes clusters and has been designed and tested for sending up to 50,000 logs/sec per node. Use the following [log queries](../logs/log-query-overview.md) to determine whether your cluster is suitable for high scale logs collection. ---**Logs per second and per node** --```kusto -ContainerLogV2 -| where _ResourceId = "<cluster-resource-id>" -| summarize count() by bin(TimeGenerated, 1s), Computer -| render timechart -``` --**Log size (in MB) per second per node** --```kusto - ContainerLogV2 -| where _ResourceId = "<cluster-resource-id>" -| summarize BillableDataMB = sum(_BilledSize)/1024/1024 by bin(TimeGenerated, 1s), Computer -| render timechart -``` --## Prerequisites --- Azure CLI version 2.63.0 or higher.-- AKS-preview CLI extension version must be 7.0.0b4 or higher if an aks-preview CLI extension is installed.-- Cluster schema must be [configured for ContainerLogV2](./container-insights-logs-schema.md#enable-the-containerlogv2-schema).-- If the default resource limits (CPU and memory) on ama-logs daemon set container doesn't meet your log scale requirements, please contact the Microsoft support channel to increase the resource limits of your ama-logs container.--## Network firewall requirements -In addition to the [network firewall requirements](./kubernetes-monitoring-firewall.md) for monitoring a Kubernetes cluster, additional configurations in the following table are needed for enabling high scale mode depending on your cloud. --| Cloud | Endpoint | Port | -|:|:--|:--| -| Azure Public Cloud | `<dce-name>-<suffix>.<cluster-region-name>-<suffix>.ingest.monitor.azure.com` | 443 | -| Microsoft Azure operated by 21Vianet cloud | `<dce-name>-<suffix>.<cluster-region-name>-<suffix>.ingest.monitor.azure.cn` | 443 | -| Azure Government cloud | `<dce-name>-<suffix>.<cluster-region-name>-<suffix>.ingest.monitor.azure.us` | 443 | --The endpoint is the **Logs Ingestion** endpoint from the data collection endpoint (DCE) for the data collection rule (DCR) used by the cluster. This DCE is created when you enable high scale mode for the cluster and will start with the prefix `MSCI-ingest`. ----## Limitations --The following scenarios aren't supported during the preview release. These will be addressed when the feature becomes generally available. --- AKS Clusters with Arm64 nodes -- Azure Arc-enabled Kubernetes-- HTTP proxy with trusted certificate-- Onboarding through Azure portal, Azure Policy, Terraform and Bicep -- Configuring through **Monitor Settings** in the AKS Insights portal experience -- Automatic migration from existing Container Insights --## Enable high scale logs collection -Follow the two steps in the following sections to enable high scale mode for your cluster. --> [!NOTE] -> High log scale mode requires a [data collection endpoint (DCE)](../essentials/data-collection-endpoint-overview.md) for ingestion. An ingestion DCE is created with the prefix `MSCI-ingest` for each cluster when you onboard them. If Azure Monitor private link scope is configured, then there will also be configuration DCE created with the prefix `MSCI-config`. --### Update configmap -The first step is to update configmap for the cluster to instruct the container insights ama-logs deamonset pods to run in high scale mode. --Follow the guidance in [Configure and deploy ConfigMap](./container-insights-data-collection-configmap.md#configure-and-deploy-configmap) to download and update ConfigMap for the cluster. The only change you need to make for high scale logs is to enable `agent_settings.high_log_scale` under `agent-settings` as in the following: --```yml -[agent_settings.high_log_scale] - enabled = true -``` --After applying this configmap, `ama-logs-*` pods will get restarted automatically and configure the ama-logs daemonset pods to run in high scale mode. --### Enable high scale mode for Monitoring add-on -Enable the Monitoring Add-on with high scale mode using the following Azure CLI commands to enable high scale logs mode for the Monitoring add-on depending on your AKS configuration. --> [!NOTE] -> Instead of CLI, you can use an ARM template to enable high scale mode for the Monitoring add-on. See [Enable Container insights](./kubernetes-monitoring-enable.md?tabs=arm#enable-container-insights) for guidance on enabling Container Insights using an ARM template. To enable high scale mode, use `Microsoft-ContainerLogV2-HighScale` instead of `Microsoft-ContainerLogV2` in the `streams` parameter as described in [Configure DCR with ARM templates](./container-insights-data-collection-configure.md?tabs=arm#configure-dcr-with-arm-templates). ---**Existing AKS cluster** --```azurecli -az aks enable-addons -a monitoring -g <resource-group-name> -n <cluster-name> --enable-high-log-scale-mode -``` --**Existing AKS Private cluster** --```azurecli -az aks enable-addons -a monitoring -g <resource-group-name> -n <cluster-name> --enable-high-scale-mode --ampls-resource-id /subscriptions/<subscription-id>/resourceGroups/<resource-group-name>/providers/microsoft.insights/privatelinkscopes/<resourceName> -``` --**New AKS cluster** --```azurecli -az aks create -g <cluster-name> -n <cluster-name> enable-addons -a monitoring --enable-high-log-scale-mode -``` --**New AKS Private cluster** --See [Create a private Azure Kubernetes Service (AKS) cluster](/azure/aks/private-clusters?tabs=azure-portal) for details on creating an AKS Private cluster. Use the additional parameters `--enable-high-scale-mode` and `--ampls-resource-id` to configure high log scale mode with Azure Monitor Private Link Scope Resource ID. --## Migration -If Container insights is already enabled for your cluster, then you need to disable it and then re-enable it with high scale mode. --- Since high scale mode uses a different data pipeline, you must ensure that pipeline endpoints are not blocked by a firewall or other network connections.-- High scale mode requires a data collection endpoint (DCE) for ingestion in addition to the standard DCR for data collection. If you've created any DCRs that use `Microsoft.ContainerLogV2`, you must replace this with `Microsoft.ContainerLogV2-HighScale` or data will be duplicated. You should also create a DCE for ingestion and link it to the DCR if the DCR isn't already using one. Refer to Container Insights onboarding through Azure Resource Manager for reference for the dependencies. ---## Next steps -- Share any feedback or issues with High Scale mode at [https://aka.ms/cihsfeedback](https://aka.ms/cihsfeedback).- |
| azure-monitor | Container Insights Hybrid Setup | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-hybrid-setup.md | - Title: Configure hybrid Kubernetes clusters with Container insights | Microsoft Docs -description: This article describes how you can configure Container insights to monitor Kubernetes clusters hosted on Azure Stack or other environments. - Previously updated : 08/21/2023----# Configure hybrid Kubernetes clusters with Container insights --Container insights provides a rich monitoring experience for the Azure Kubernetes Service (AKS). This article describes how to enable monitoring of Kubernetes clusters hosted outside of Azure and achieve a similar monitoring experience. --## Supported configurations --The following configurations are officially supported with Container insights. If you have a different version of Kubernetes and operating system versions, please open a support ticket.. --- Environments:- - Kubernetes on-premises. - - [OpenShift](https://docs.openshift.com/container-platform/4.3/welcome/https://docsupdatetracker.net/index.html) version 4 and higher, on-premises or in other cloud environments. -- Versions of Kubernetes and support policy are the same as versions of [AKS supported](/azure/aks/supported-kubernetes-versions).-- The following container runtimes are supported: Moby and CRI compatible runtimes such CRI-O and ContainerD.-- The Linux OS release for main and worker nodes supported are Ubuntu (18.04 LTS and 16.04 LTS) and Red Hat Enterprise Linux CoreOS 43.81.-- Azure Access Control service supported: Kubernetes role-based access control (RBAC) and non-RBAC.--## Prerequisites --Before you start, make sure that you meet the following prerequisites: --- You have a [Log Analytics workspace](../logs/design-logs-deployment.md). Container insights supports a Log Analytics workspace in the regions listed in Azure [Products by region](https://azure.microsoft.com/global-infrastructure/services/?regions=all&products=monitor). You can create your own workspace through [Azure Resource Manager](../logs/resource-manager-workspace.md), [PowerShell](../logs/powershell-workspace-configuration.md?toc=%2fpowershell%2fmodule%2ftoc.json), or the [Azure portal](../logs/quick-create-workspace.md).-- >[!NOTE] - >Enabling the monitoring of multiple clusters with the same cluster name to the same Log Analytics workspace isn't supported. Cluster names must be unique. - > --- You're a member of the Log Analytics contributor role to enable container monitoring. For more information about how to control access to a Log Analytics workspace, see [Manage access to workspace and log data](../logs/manage-access.md).-- To view the monitoring data, you must have the [Log Analytics reader](../logs/manage-access.md#azure-rbac) role in the Log Analytics workspace, configured with Container insights.-- You have a [Helm client](https://helm.sh/docs/using_helm/) to onboard the Container insights chart for the specified Kubernetes cluster.-- The following proxy and firewall configuration information is required for the containerized version of the Log Analytics agent for Linux to communicate with Azure Monitor:-- |Agent resource|Ports | - ||| - |`*.ods.opinsights.azure.com` |Port 443 | - |`*.oms.opinsights.azure.com` |Port 443 | - |`*.dc.services.visualstudio.com` |Port 443 | --- The containerized agent requires the Kubelet `cAdvisor secure port: 10250` or `unsecure port :10255` to be opened on all nodes in the cluster to collect performance metrics. We recommend that you configure `secure port: 10250` on the Kubelet cAdvisor if it isn't configured already.-- The containerized agent requires the following environmental variables to be specified on the container to communicate with the Kubernetes API service within the cluster to collect inventory data: `KUBERNETES_SERVICE_HOST` and `KUBERNETES_PORT_443_TCP_PORT`.-->[!IMPORTANT] ->The minimum agent version supported for monitoring hybrid Kubernetes clusters is *ciprod10182019* or later. --## Enable monitoring --To enable Container insights for the hybrid Kubernetes cluster: --1. Configure your Log Analytics workspace with the Container insights solution. --1. Enable the Container insights Helm chart with a Log Analytics workspace. --For more information on monitoring solutions in Azure Monitor, see [Monitoring solutions in Azure Monitor](/previous-versions/azure/azure-monitor/insights/solutions). --### Add the Azure Monitor Containers solution --You can deploy the solution with the provided Azure Resource Manager template by using the Azure PowerShell cmdlet `New-AzResourceGroupDeployment` or with the Azure CLI. --If you're unfamiliar with the concept of deploying resources by using a template, see: --- [Deploy resources with Resource Manager templates and Azure PowerShell](../../azure-resource-manager/templates/deploy-powershell.md)-- [Deploy resources with Resource Manager templates and the Azure CLI](../../azure-resource-manager/templates/deploy-cli.md)--If you choose to use the Azure CLI, you first need to install and use the CLI locally. You must be running the Azure CLI version 2.0.59 or later. To identify your version, run `az --version`. If you need to install or upgrade the Azure CLI, see [Install the Azure CLI](/cli/azure/install-azure-cli). --This method includes two JSON templates. One template specifies the configuration to enable monitoring. The other template contains parameter values that you configure to specify: --- `workspaceResourceId`: The full resource ID of your Log Analytics workspace.-- `workspaceRegion`: The region the workspace is created in, which is also referred to as **Location** in the workspace properties when you view them from the Azure portal.--To first identify the full resource ID of your Log Analytics workspace that's required for the `workspaceResourceId` parameter value in the *containerSolutionParams.json* file, perform the following steps. Then run the PowerShell cmdlet or Azure CLI command to add the solution. --1. List all the subscriptions to which you have access by using the following command: -- ```azurecli - az account list --all -o table - ``` -- The output will resemble the following example: -- ```azurecli - Name CloudName SubscriptionId State IsDefault - -- - -- - Microsoft Azure AzureCloud 0fb60ef2-03cc-4290-b595-e71108e8f4ce Enabled True - ``` -- Copy the value for **SubscriptionId**. --1. Switch to the subscription hosting the Log Analytics workspace by using the following command: -- ```azurecli - az account set -s <subscriptionId of the workspace> - ``` --1. The following example displays the list of workspaces in your subscriptions in the default JSON format: -- ```azurecli - az resource list --resource-type Microsoft.OperationalInsights/workspaces -o json - ``` -- In the output, find the workspace name. Then copy the full resource ID of that Log Analytics workspace under the field **ID**. --1. Copy and paste the following JSON syntax into your file: -- ```json - { - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceResourceId": { - "type": "string", - "metadata": { - "description": "Azure Monitor Log Analytics Workspace Resource ID" - } - }, - "workspaceRegion": { - "type": "string", - "metadata": { - "description": "Azure Monitor Log Analytics Workspace region" - } - } - }, - "resources": [ - { - "type": "Microsoft.Resources/deployments", - "name": "[Concat('ContainerInsights', '-', uniqueString(parameters('workspaceResourceId')))]", - "apiVersion": "2017-05-10", - "subscriptionId": "[split(parameters('workspaceResourceId'),'/')[2]]", - "resourceGroup": "[split(parameters('workspaceResourceId'),'/')[4]]", - "properties": { - "mode": "Incremental", - "template": { - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": {}, - "variables": {}, - "resources": [ - { - "apiVersion": "2015-11-01-preview", - "type": "Microsoft.OperationsManagement/solutions", - "location": "[parameters('workspaceRegion')]", - "name": "[Concat('ContainerInsights', '(', split(parameters('workspaceResourceId'),'/')[8], ')')]", - "properties": { - "workspaceResourceId": "[parameters('workspaceResourceId')]" - }, - "plan": { - "name": "[Concat('ContainerInsights', '(', split(parameters('workspaceResourceId'),'/')[8], ')')]", - "product": "[Concat('OMSGallery/', 'ContainerInsights')]", - "promotionCode": "", - "publisher": "Microsoft" - } - } - ] - }, - "parameters": {} - } - } - ] - } - ``` --1. Save this file as **containerSolution.json** to a local folder. --1. Paste the following JSON syntax into your file: -- ```json - { - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceResourceId": { - "value": "<workspaceResourceId>" - }, - "workspaceRegion": { - "value": "<workspaceRegion>" - } - } - } - ``` --1. Edit the values for **workspaceResourceId** by using the value you copied in step 3. For **workspaceRegion**, copy the **Region** value after running the Azure CLI command [az monitor log-analytics workspace show](/cli/azure/monitor/log-analytics/workspace#az-monitor-log-analytics-workspace-list&preserve-view=true). --1. Save this file as **containerSolutionParams.json** to a local folder. --1. You're ready to deploy this template. -- - To deploy with Azure PowerShell, use the following commands in the folder that contains the template: -- ```powershell - # configure and login to the cloud of Log Analytics workspace.Specify the corresponding cloud environment of your workspace to below command. - Connect-AzureRmAccount -Environment <AzureCloud | AzureChinaCloud | AzureUSGovernment> - ``` -- ```powershell - # set the context of the subscription of Log Analytics workspace - Set-AzureRmContext -SubscriptionId <subscription Id of Log Analytics workspace> - ``` -- ```powershell - # execute deployment command to add Container Insights solution to the specified Log Analytics workspace - New-AzureRmResourceGroupDeployment -Name OnboardCluster -ResourceGroupName <resource group of Log Analytics workspace> -TemplateFile .\containerSolution.json -TemplateParameterFile .\containerSolutionParams.json - ``` -- The configuration change can take a few minutes to finish. When it's finished, a message similar to the following example includes this result: -- ```powershell - provisioningState : Succeeded - ``` -- - To deploy with the Azure CLI, run the following commands: -- ```azurecli - az login - az account set --name <AzureCloud | AzureChinaCloud | AzureUSGovernment> - az login - az account set --subscription "Subscription Name" - # execute deployment command to add container insights solution to the specified Log Analytics workspace - az deployment group create --resource-group <resource group of log analytics workspace> --name <deployment name> --template-file ./containerSolution.json --parameters @./containerSolutionParams.json - ``` -- The configuration change can take a few minutes to finish. When it's finished, a message similar to the following example includes this result: -- ```azurecli - provisioningState : Succeeded - ``` -- After you've enabled monitoring, it might take about 15 minutes before you can view health metrics for the cluster. --## Install the Helm chart --In this section, you install the containerized agent for Container insights. Before you proceed, identify the workspace ID required for the `amalogsagent.secret.wsid` parameter and the primary key required for the `amalogsagent.secret.key` parameter. To identify this information, follow these steps and then run the commands to install the agent by using the Helm chart. --1. Run the following command to identify the workspace ID: -- `az monitor log-analytics workspace list --resource-group <resourceGroupName>` -- In the output, find the workspace name under the field **name**. Then copy the workspace ID of that Log Analytics workspace under the field **customerID**. --1. Run the following command to identify the primary key for the workspace: -- `az monitor log-analytics workspace get-shared-keys --resource-group <resourceGroupName> --workspace-name <logAnalyticsWorkspaceName>` -- In the output, find the primary key under the field **primarySharedKey** and then copy the value. -- >[!NOTE] - >The following commands are applicable only for Helm version 2. Use of the `--name` parameter isn't applicable with Helm version 3. - - If your Kubernetes cluster communicates through a proxy server, configure the parameter `amalogsagent.proxy` with the URL of the proxy server. If the cluster doesn't communicate through a proxy server, you don't need to specify this parameter. For more information, see the section [Configure the proxy endpoint](#configure-the-proxy-endpoint) later in this article. --1. Add the Azure charts repository to your local list by running the following command: -- ``` - helm repo add microsoft https://microsoft.github.io/charts/repo - ```` --1. Install the chart by running the following command: -- ``` - $ helm install --name myrelease-1 \ - --set amalogsagent.secret.wsid=<logAnalyticsWorkspaceId>,amalogsagent.secret.key=<logAnalyticsWorkspaceKey>,amalogsagent.env.clusterName=<my_prod_cluster> microsoft/azuremonitor-containers - ``` -- If the Log Analytics workspace is in Azure China 21Vianet, run the following command: -- ``` - $ helm install --name myrelease-1 \ - --set amalogsagent.domain=opinsights.azure.cn,amalogsagent.secret.wsid=<logAnalyticsWorkspaceId>,amalogsagent.secret.key=<logAnalyticsWorkspaceKey>,amalogsagent.env.clusterName=<your_cluster_name> incubator/azuremonitor-containers - ``` -- If the Log Analytics workspace is in Azure US Government, run the following command: -- ``` - $ helm install --name myrelease-1 \ - --set amalogsagent.domain=opinsights.azure.us,amalogsagent.secret.wsid=<logAnalyticsWorkspaceId>,amalogsagent.secret.key=<logAnalyticsWorkspaceKey>,amalogsagent.env.clusterName=<your_cluster_name> incubator/azuremonitor-containers - ``` --### Enable the Helm chart by using the API model --You can specify an add-on in the AKS Engine cluster specification JSON file, which is also referred to as the API model. In this add-on, provide the base64-encoded version of `WorkspaceGUID` and `WorkspaceKey` of the Log Analytics workspace where the collected monitoring data is stored. You can find `WorkspaceGUID` and `WorkspaceKey` by using steps 1 and 2 in the previous section. --Supported API definitions for the Azure Stack Hub cluster can be found in the example [kubernetes-container-monitoring_existing_workspace_id_and_key.json](https://github.com/Azure/aks-engine/blob/master/examples/addons/container-monitoring/kubernetes-container-monitoring_existing_workspace_id_and_key.json). Specifically, find the **addons** property in **kubernetesConfig**: --```json -"orchestratorType": "Kubernetes", - "kubernetesConfig": { - "addons": [ - { - "name": "container-monitoring", - "enabled": true, - "config": { - "workspaceGuid": "<Azure Log Analytics Workspace Id in Base-64 encoded>", - "workspaceKey": "<Azure Log Analytics Workspace Key in Base-64 encoded>" - } - } - ] - } -``` --## Configure agent data collection --Starting with chart version 1.0.0, the agent data collection settings are controlled from the ConfigMap. For more information on agent data collection settings, see [Configure agent data collection for Container insights](container-insights-data-collection-configmap.md). --After you've successfully deployed the chart, you can review the data for your hybrid Kubernetes cluster in Container insights from the Azure portal. -->[!NOTE] ->Ingestion latency is around 5 to 10 minutes from the agent to commit in the Log Analytics workspace. Status of the cluster shows the value **No data** or **Unknown** until all the required monitoring data is available in Azure Monitor. --## Configure the proxy endpoint --Starting with chart version 2.7.1, the chart will support specifying the proxy endpoint with the `amalogsagent.proxy` chart parameter. In this way, it can communicate through your proxy server. Communication between the Container insights agent and Azure Monitor can be an HTTP or HTTPS proxy server. Both anonymous and basic authentication with a username and password are supported. --The proxy configuration value has the syntax `[protocol://][user:password@]proxyhost[:port]`. --> [!NOTE] ->If your proxy server doesn't require authentication, you still need to specify a pseudo username and password. It can be any username or password. --|Property| Description | -|--|-| -|protocol | HTTP or HTTPS | -|user | Optional username for proxy authentication | -|password | Optional password for proxy authentication | -|proxyhost | Address or FQDN of the proxy server | -|port | Optional port number for the proxy server | --An example is `amalogsagent.proxy=http://user01:password@proxy01.contoso.com:8080`. --If you specify the protocol as **http**, the HTTP requests are created by using an SSL/TLS secure connection. Your proxy server must support SSL/TLS protocols. --## Troubleshooting --If you encounter an error while you attempt to enable monitoring for your hybrid Kubernetes cluster, use the PowerShell script [TroubleshootError_nonAzureK8s.ps1](https://aka.ms/troubleshoot-non-azure-k8s) to help you detect and fix the issues you encounter. It's designed to detect and attempt correction of the following issues: --- The specified Log Analytics workspace is valid.-- The Log Analytics workspace is configured with the Container insights solution. If not, configure the workspace.-- The Azure Monitor Agent replicaset pods are running.-- The Azure Monitor Agent daemonset pods are running.-- The Azure Monitor Agent Health service is running.-- The Log Analytics workspace ID and key configured on the containerized agent match with the workspace that the insight is configured with.-- Validate that all the Linux worker nodes have the `kubernetes.io/role=agent` label to the schedulers pod. If it doesn't exist, add it.-- Identify conditions that may indicate `cAdvisor secure port:10250` or `unsecure port: 10255` is not opened on all nodes in the cluster.--To execute with Azure PowerShell, use the following commands in the folder that contains the script: --```powershell -.\TroubleshootError_nonAzureK8s.ps1 - azureLogAnalyticsWorkspaceResourceId </subscriptions/<subscriptionId>/resourceGroups/<resourcegroupName>/providers/Microsoft.OperationalInsights/workspaces/<workspaceName> -kubeConfig <kubeConfigFile> -clusterContextInKubeconfig <clusterContext> -``` --## Next steps --Now that monitoring is enabled to collect health and resource utilization of your hybrid Kubernetes clusters and workloads are running on them, learn [how to use](container-insights-analyze.md) Container insights. |
| azure-monitor | Container Insights Livedata Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-livedata-metrics.md | - Title: View metrics in real time with Container insights -description: This article describes the real-time view of metrics without using kubectl with Container insights. - Previously updated : 05/24/2022-----# View metrics in real time --With Container insights Live Data, you can visualize metrics about node and pod state in a cluster in real time. The feature emulates direct access to the `kubectl top nodes`, `kubectl get pods --all-namespaces`, and `kubectl get nodes` commands to call, parse, and visualize the data in performance charts that are included with this insight. --This article provides a detailed overview and helps you understand how to use this feature. -->[!NOTE] ->Azure Kubernetes Service (AKS) clusters enabled as [private clusters](https://azure.microsoft.com/updates/aks-private-cluster/) aren't supported with this feature. This feature relies on directly accessing the Kubernetes API through a proxy server from your browser. Enabling networking security to block the Kubernetes API from this proxy will block this traffic. --For help with setting up or troubleshooting the Live Data feature, review the [setup guide](container-insights-livedata-setup.md). --## How it works --The Live Data feature directly accesses the Kubernetes API. For more information about the authentication model, see [The Kubernetes API](https://kubernetes.io/docs/concepts/overview/kubernetes-api/). --This feature performs a polling operation against the metrics endpoints including `/api/v1/nodes`, `/apis/metrics.k8s.io/v1beta1/nodes`, and `/api/v1/pods`. The interval is every five seconds by default. This data is cached in your browser and charted in four performance charts included in Container insights. Each subsequent poll is charted into a rolling five-minute visualization window. To see the charts, slide the **Live** option to **On**. ---The polling interval is configured from the **Set interval** dropdown list. Use this dropdown list to set polling for new data every 1, 5, 15, and 30 seconds. --->[!IMPORTANT] ->We recommend that you set the polling interval to one second while you troubleshoot an issue for a short period of time. These requests might affect the availability and throttling of the Kubernetes API on your cluster. Afterward, reconfigure to a longer polling interval. --These charts can't be pinned to the last Azure dashboard you viewed in live mode. -->[!IMPORTANT] ->No data is stored permanently during operation of this feature. All information captured during this session is immediately deleted when you close your browser or navigate away from the feature. Data only remains present for visualization inside the five-minute window. Any metrics older than five minutes are also permanently deleted. --## Metrics captured --The following metrics are captured and displayed in four performance charts. --### Node CPU utilization % and Node memory utilization % --These two performance charts map to an equivalent of invoking `kubectl top nodes` and capturing the results of the **CPU%** and **MEMORY%** columns to the respective chart. -<!-- convertborder later --> -<!-- convertborder later --> -<!-- convertborder later --> --The percentile calculations will function in larger clusters to help identify outlier nodes in your cluster. For example, you can understand if nodes are underutilized for scale-down purposes. By using the **Min** aggregation, you can see which nodes have low utilization in the cluster. To further investigate, select the **Nodes** tab and sort the grid by CPU or memory utilization. --This information also helps you understand which nodes are being pushed to their limits and if scale-out might be required. By using both the **Max** and **P95** aggregations, you can see if there are nodes in the cluster with high resource utilization. For further investigation, you would again switch to the **Nodes** tab. --### Node count --This performance chart maps to an equivalent of invoking `kubectl get nodes` and mapping the **STATUS** column to a chart grouped by status types. -<!-- convertborder later --> -<!-- convertborder later --> --Nodes are reported either in a **Ready** or **Not Ready** state and they're counted to create a total count. The results of these two aggregations are charted so that, for example, you can understand if your nodes are falling into failed states. By using the **Not Ready** aggregation, you can quickly see the number of nodes in your cluster currently in the **Not Ready** state. --### Active pod count --This performance chart maps to an equivalent of invoking `kubectl get pods --all-namespaces` and maps the **STATUS** column the chart grouped by status types. --<!-- convertborder later --> -->[!NOTE] ->Names of status as interpreted by `kubectl` might not exactly match in the chart. --## Next steps --View [log query examples](container-insights-log-query.md) to see predefined queries and examples to create alerts and visualizations or perform further analysis of your clusters. |
| azure-monitor | Container Insights Livedata Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-livedata-overview.md | - Title: View live data with Container insights -description: This article describes the real-time view of Kubernetes logs, events, and pod metrics without using kubectl in Container insights. - Previously updated : 2/28/2024-----# View Kubernetes logs, events, and pod metrics in real time --The Live Data feature in Container insights gives you direct access to your Azure Kubernetes Service (AKS) container logs (stdout/stderror), events, and pod metrics. It exposes direct access to `kubectl logs -c`, `kubectl get` events, and `kubectl top pods`. A console pane shows the logs, events, and metrics generated by the container engine to help with troubleshooting issues in real time. --> [!NOTE] -> AKS uses [Kubernetes cluster-level logging architectures](https://kubernetes.io/docs/concepts/cluster-administration/logging/#cluster-level-logging-architectures). The container logs are located inside `/var/log/containers` on the node. To access a node, see [Connect to Azure Kubernetes Service (AKS) cluster nodes](/azure/aks/node-access). --This article provides an overview of this feature and helps you understand how to use it. --For help with setting up or troubleshooting the Live Data feature, see the [Setup guide](container-insights-livedata-setup.md). This feature directly accesses the Kubernetes API. For more information about the authentication model, see [The Kubernetes API](https://kubernetes.io/docs/concepts/overview/kubernetes-api/). --## View AKS resource live logs --> [!NOTE] -> You must be on a machine on the same private network to access live logs from a private cluster. --To view the live logs for pods, deployments, replica sets, stateful sets, daemon sets, and jobs with or without Container insights from the AKS resource view: --1. In the Azure portal, browse to the AKS cluster resource group and select your AKS resource. --1. Select **Workloads** in the **Kubernetes resources** section of the menu. --1. Select a pod, deployment, replica set, stateful set, daemon set, or job from the respective tab. --1. Select **Live Logs** from the resource's menu. --1. Select a pod to start collecting the live data. -- :::image type="content" source="./media/container-insights-livedata-overview/live-data-deployment.png" alt-text="Screenshot that shows the deployment of live logs." lightbox="./media/container-insights-livedata-overview/live-data-deployment.png"::: --## View logs --You can view real-time log data as it's generated by the container engine on the **Nodes**, **Controllers**, or **Containers** view. To view log data: --1. In the Azure portal, browse to the AKS cluster resource group and select your AKS resource. --1. On the AKS cluster dashboard, under **Monitoring** on the left side, select **Insights**. --1. Select the **Nodes**, **Controllers**, or **Containers** tab. --1. Select an object from the performance grid. In the **Properties** pane on the right side, select the **Live Logs** tab. If the AKS cluster is configured with single sign-on by using Microsoft Entra ID, you're prompted to authenticate on first use during that browser session. Select your account and finish authentication with Azure. -- >[!NOTE] - >To view the data from your Log Analytics workspace, select **View in Log analytics** in the **Properties** pane. The log search results potentially show **Nodes**, **Daemon Sets**, **Replica Sets**, **Stateful Sets**, **Jobs**, **Cron Jobs**, **Pods**, and **Containers**. These logs might no longer exist. The log search results for **Stateful Sets** shows the data for the pods in a stateful set. Attempting to search logs for a container that isn't available in `kubectl` will also fail here. To learn more about viewing historical logs, events, and metrics, see [How to query logs from Container insights](container-insights-log-query.md). --After successful authentication, if data can be retrieved, it begins streaming to the Live Logs tab. You can view log data here in a continuous stream. ---## View events --You can view real-time event data as it's generated by the container engine on the **Nodes**, **Controllers**, **Containers**, or **Deployments** view when a container, pod, node, ReplicaSet, StatefulSet, DaemonSet, job, CronJob, or Deployment is selected. To view events: --1. In the Azure portal, browse to the AKS cluster resource group and select your AKS resource. --1. On the AKS cluster dashboard, under **Monitoring** on the left side, select **Insights**. --1. Select the **Nodes**, **Controllers**, **Containers**, or **Deployments** tab. --1. Select an object from the performance grid. In the **Properties** pane on the right side, select the **Live Events** tab. If the AKS cluster is configured with single sign-on by using Microsoft Entra ID, you're prompted to authenticate on first use during that browser session. Select your account and finish authentication with Azure. -- >[!NOTE] - >To view the data from your Log Analytics workspace, select **View in Log Analytics** in the **Properties** pane. The log search results potentially show **Nodes**, **Daemon Sets**, **Replica Sets**, **Stateful Sets**, **Jobs**, **Cron Jobs**, **Pods**, and **Containers**. These logs might no longer exist. The log search results for **Stateful Sets** shows the data for the pods in a stateful set. Attempting to search logs for a container that isn't available in `kubectl` will also fail here. To learn more about viewing historical logs, events, and metrics, see [How to query logs from Container insights](container-insights-log-query.md). --After successful authentication, if data can be retrieved, it begins streaming to the Live Events tab. ---### Filter events --While you view events, you can also limit the results by using the **Filter** pill found below the search bar. Depending on the resource you select, the pill lists a node, pod, namespace, or cluster to choose from. --## View metrics --You can view real-time metric data as it's generated by the container engine from the **Nodes** or **Controllers** view only when a **Pod** is selected. To view metrics: --1. In the Azure portal, browse to the AKS cluster resource group and select your AKS resource. --1. On the AKS cluster dashboard, under **Monitoring** on the left side, select **Insights**. --1. Select either the **Nodes** or **Controllers** tab. --1. Select a **Pod** object from the performance grid. In the **Properties** pane on the right side, select the **Live Metrics** tab. If the AKS cluster is configured with single sign-on by using Microsoft Entra ID, you're prompted to authenticate on first use during that browser session. Select your account and finish authentication with Azure. -- >[!NOTE] - >To view the data from your Log Analytics workspace, select the **View in Log Analytics** option in the **Properties** pane. The log search results potentially show **Nodes**, **Daemon Sets**, **Replica Sets**, **Stateful Sets**, **Jobs**, **Cron Jobs**, **Pods**, and **Containers**. These logs might no longer exist. The log search results for **Stateful Sets** shows the data for the pods in a stateful set. Attempting to search logs for a container that isn't available in `kubectl` will also fail here. To learn more about viewing historical logs, events, and metrics, see [How to query logs from Container insights](container-insights-log-query.md). --After successful authentication, metric data is retrieved and begins streaming to the Live Metrics tab for presentation in the two charts. ---## Use live data views --The following sections describe functionality that you can use in the different live data views. --### Search --The Live Data feature includes search functionality. In the **Search** box, you can filter results by entering a keyword or term. Any matching results are highlighted to allow quick review. While you view the events, you can also limit the results by using the **Filter** feature below the search bar. Depending on what resource you've selected, you can choose from a node, pod, namespace, or cluster. ----### Scroll lock and pause --To suspend autoscroll and control the behavior of the tab so that you can manually scroll through the new data read, select the **Scroll** option. To re-enable autoscroll, select **Scroll** again. You can also pause retrieval of log or event data by selecting the **Pause** option. When you're ready to resume, select **Play**. ----Suspend or pause autoscroll for only a short period of time while you're troubleshooting an issue. These requests might affect the availability and throttling of the Kubernetes API on your cluster. -->[!IMPORTANT] ->No data is stored permanently during the operation of this feature. All information captured during the session is deleted when you close your browser or navigate away from it. Data only remains present for visualization inside the five-minute window of the metrics feature. Any metrics older than five minutes are also deleted. The Live Data buffer queries within reasonable memory usage limits. --## Frequently asked questions --This section provides answers to common questions. ---## Next steps --- To continue learning how to use Azure Monitor and monitor other aspects of your AKS cluster, see [View Azure Kubernetes Service health](container-insights-analyze.md).-- To see predefined queries and examples to create alerts and visualizations or perform further analysis of your clusters, see [How to query logs from Container insights](container-insights-log-query.md). |
| azure-monitor | Container Insights Livedata Setup | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-livedata-setup.md | - Title: Configure Live Data in Container insights -description: This article describes how to set up the real-time view of container logs (stdout/stderr) and events without using kubectl with Container insights. - Previously updated : 2/28/2024-----# Configure Live Data in Container insights --To view live data with Container insights from Azure Kubernetes Service (AKS) clusters, configure authentication to grant permission to access your Kubernetes data. This security configuration allows real-time access to your data through the Kubernetes API directly in the Azure portal. --This feature supports the following methods to control access to logs, events, and metrics: --- AKS without Kubernetes role-based access control (RBAC) authorization enabled-- AKS enabled with Kubernetes RBAC authorization- - AKS configured with the cluster role binding [clusterMonitoringUser](/rest/api/aks/managedclusters/listclustermonitoringusercredentials) -- AKS enabled with Microsoft Entra SAML-based single sign-on--These instructions require administrative access to your Kubernetes cluster. If you're configuring to use Microsoft Entra ID for user authentication, you also need administrative access to Microsoft Entra ID. --This article explains how to configure authentication to control access to the Live Data feature from the cluster: --- Kubernetes RBAC-enabled AKS cluster-- Microsoft Entra integrated AKS cluster--## Authentication model --The Live Data feature uses the Kubernetes API, which is identical to the `kubectl` command-line tool. The Kubernetes API endpoints use a self-signed certificate, which your browser will be unable to validate. This feature uses an internal proxy to validate the certificate with the AKS service, ensuring the traffic is trusted. --The Azure portal prompts you to validate your sign-in credentials for a Microsoft Entra ID cluster. It redirects you to the client registration setup during cluster creation (and reconfigured in this article). This behavior is similar to the authentication process required by `kubectl`. -->[!NOTE] ->Authorization to your cluster is managed by Kubernetes and the security model it's configured with. Users who access this feature require permission to download the Kubernetes configuration (*kubeconfig*), which is similar to running `az aks get-credentials -n {your cluster name} -g {your resource group}`. -> ->This configuration file contains the authorization and authentication token for the *Azure Kubernetes Service Cluster User Role*, in the case of Azure RBAC enabled and AKS clusters without Kubernetes RBAC authorization enabled. It contains information about Microsoft Entra ID and client registration details when AKS is enabled with Microsoft Entra SAML-based single sign-on. --Users of this feature require the [Azure Kubernetes Cluster User Role](../../role-based-access-control/built-in-roles.md) to access the cluster to download the `kubeconfig` and use this feature. Users do *not* require contributor access to the cluster to use this feature. --## Use clusterMonitoringUser with Kubernetes RBAC-enabled clusters --To eliminate the need to apply more configuration changes to allow the Kubernetes user role binding **clusterUser** access to the Live Data feature after [enabling Kubernetes RBAC](#configure-kubernetes-rbac-authorization) authorization, AKS has added a new Kubernetes cluster role binding called **clusterMonitoringUser**. This cluster role binding has all the necessary permissions out of the box to access the Kubernetes API and the endpoints for using the Live Data feature. --To use the Live Data feature with this new user, you must be a member of the [Azure Kubernetes Service Cluster User](../../role-based-access-control/built-in-roles.md#azure-kubernetes-service-cluster-user-role) or [Contributor](../../role-based-access-control/built-in-roles.md#contributor) role on the AKS cluster resource. Container insights, when enabled, is configured to authenticate by using `clusterMonitoringUser` by default. If the `clusterMonitoringUser` role binding doesn't exist on a cluster, **clusterUser** is used for authentication instead. Contributor gives you access to `clusterMonitoringUser` (if it exists), and Azure Kubernetes Service Cluster User gives you access to **clusterUser**. Any of these two roles give sufficient access to use this feature. --AKS released this new role binding in January 2020, so clusters created before January 2020 don't have it. If you have a cluster that was created before January 2020, the new **clusterMonitoringUser** can be added to an existing cluster by performing a PUT operation on the cluster. Or you can perform any other operation on the cluster that performs a PUT operation on the cluster, such as updating the cluster version. --## Kubernetes cluster without Kubernetes RBAC enabled --If you have a Kubernetes cluster that isn't configured with Kubernetes RBAC authorization or integrated with Microsoft Entra single sign-on, you don't need to follow these steps. You already have administrative permissions by default in a non-RBAC configuration. --## Configure Kubernetes RBAC authorization --When you enable Kubernetes RBAC authorization, **clusterUser** and **clusterAdmin** are used to access the Kubernetes API. This configuration is similar to running `az aks get-credentials -n {cluster_name} -g {rg_name}` without the administrative option. For this reason, **clusterUser** needs to be granted access to the endpoints in the Kubernetes API. --The following example steps demonstrate how to configure cluster role binding from this YAML configuration template. --1. Copy and paste the YAML file and save it as **LogReaderRBAC.yaml**. -- ``` - apiVersion: rbac.authorization.k8s.io/v1 - kind: ClusterRole - metadata: - name: containerHealth-log-reader - rules: - - apiGroups: ["", "metrics.k8s.io", "extensions", "apps"] - resources: - - "pods/log" - - "events" - - "nodes" - - "pods" - - "deployments" - - "replicasets" - verbs: ["get", "list"] - - apiVersion: rbac.authorization.k8s.io/v1 - kind: ClusterRoleBinding - metadata: - name: containerHealth-read-logs-global - roleRef: - kind: ClusterRole - name: containerHealth-log-reader - apiGroup: rbac.authorization.k8s.io - subjects: - - kind: User - name: clusterUser - apiGroup: rbac.authorization.k8s.io - ``` --1. To update your configuration, run the command `kubectl apply -f LogReaderRBAC.yaml`. -->[!NOTE] -> If you've applied a previous version of the **LogReaderRBAC.yaml** file to your cluster, update it by copying and pasting the new code shown in step 1. Then run the command shown in step 2 to apply it to your cluster. --<a name='configure-azure-ad-integrated-authentication'></a> --## Configure Microsoft Entra integrated authentication --An AKS cluster configured to use Microsoft Entra ID for user authentication uses the sign-in credentials of the person accessing this feature. In this configuration, you can sign in to an AKS cluster by using your Microsoft Entra authentication token. --Microsoft Entra client registration must be reconfigured to allow the Azure portal to redirect authorization pages as a trusted redirect URL. Users from Microsoft Entra ID are then granted access directly to the same Kubernetes API endpoints through **ClusterRoles** and **ClusterRoleBindings**. --For more information on advanced security setup in Kubernetes, review the [Kubernetes documentation](https://kubernetes.io/docs/reference/access-authn-authz/rbac/). -->[!NOTE] ->If you're creating a new Kubernetes RBAC-enabled cluster, see [Integrate Microsoft Entra ID with Azure Kubernetes Service](/azure/aks/azure-ad-integration-cli) and follow the steps to configure Microsoft Entra authentication. During the steps to create the client application, a note in that section highlights the two redirect URLs you need to create for Container insights matching those specified in step 3. --### Client registration reconfiguration --1. Locate the client registration for your Kubernetes cluster in Microsoft Entra ID under **Microsoft Entra ID** > **App registrations** in the Azure portal. --1. On the left pane, select **Authentication**. --1. Add two redirect URLs to this list as **Web** application types. The first base URL value should be `https://afd.hosting.portal.azure.net/monitoring/Content/iframe/infrainsights.app/web/base-libs/auth/auth.html`. The second base URL value should be `https://monitoring.hosting.portal.azure.net/monitoring/Content/iframe/infrainsights.app/web/base-libs/auth/auth.html`. -- >[!NOTE] - >If you're using this feature in Microsoft Azure operated by 21Vianet, the first base URL value should be `https://afd.hosting.azureportal.chinaloudapi.cn/monitoring/Content/iframe/infrainsights.app/web/base-libs/auth/auth.html`. The second base URL value should be `https://monitoring.hosting.azureportal.chinaloudapi.cn/monitoring/Content/iframe/infrainsights.app/web/base-libs/auth/auth.html`. --1. After you register the redirect URLs, under **Implicit grant**, select the options **Access tokens** and **ID tokens**. Then save your changes. --You can configure authentication with Microsoft Entra ID for single sign-on only during initial deployment of a new AKS cluster. You can't configure single sign-on for an AKS cluster that's already deployed. -->[!IMPORTANT] ->If you reconfigured Microsoft Entra ID for user authentication by using the updated URI, clear your browser's cache to ensure the updated authentication token is downloaded and applied. --## Grant permission --Each Microsoft Entra account must be granted permission to the appropriate APIs in Kubernetes to access the Live Data feature. The steps to grant the Microsoft Entra account are similar to the steps described in the [Kubernetes RBAC authentication](#configure-kubernetes-rbac-authorization) section. Before you apply the YAML configuration template to your cluster, replace **clusterUser** under **ClusterRoleBinding** with the desired user. -->[!IMPORTANT] ->If the user you grant the Kubernetes RBAC binding for is in the same Microsoft Entra tenant, assign permissions based on `userPrincipalName`. If the user is in a different Microsoft Entra tenant, query for and use the `objectId` property. --For more help in configuring your AKS cluster **ClusterRoleBinding**, see [Create Kubernetes RBAC binding](/azure/aks/azure-ad-integration-cli#create-kubernetes-rbac-binding). --## Next steps --Now that you've set up authentication, you can view [metrics](container-insights-livedata-metrics.md) and [events and logs](container-insights-livedata-overview.md) in real time from your cluster. |
| azure-monitor | Container Insights Log Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-log-alerts.md | - Title: Log search alerts from Container insights | Microsoft Docs -description: This article describes how to create custom log search alerts for memory and CPU utilization from Container insights. - Previously updated : 2/28/2024-----# Create log search alerts from Container insights --Container insights monitors the performance of container workloads that are deployed to managed or self-managed Kubernetes clusters. To alert on what matters, this article describes how to create log-based alerts for the following situations with Azure Kubernetes Service (AKS) clusters: --- When CPU or memory utilization on cluster nodes exceeds a threshold-- When CPU or memory utilization on any container within a controller exceeds a threshold as compared to a limit that's set on the corresponding resource-- `NotReady` status node counts-- `Failed`, `Pending`, `Unknown`, `Running`, or `Succeeded` pod-phase counts-- When free disk space on cluster nodes exceeds a threshold--To alert for high CPU or memory utilization, or low free disk space on cluster nodes, use the queries that are provided to create a metric alert or a metric measurement alert. Metric alerts have lower latency than log search alerts, but log search alerts provide advanced querying and greater sophistication. Log search alert queries compare a datetime to the present by using the `now` operator and going back one hour. (Container insights stores all dates in Coordinated Universal Time [UTC] format.) --> [!IMPORTANT] -> The queries in this article depend on data collected by Container insights and stored in a Log Analytics workspace. If you've modified the default data collection settings, the queries might not return the expected results. Most notably, if you've disabled collection of performance data since you've enabled Prometheus metrics for the cluster, any queries using the `Perf` table won't return results. -> -> See [Configure data collection in Container insights using data collection rule](./container-insights-data-collection-dcr.md) for preset configurations including disabling performance data collection. See [Configure data collection in Container insights using ConfigMap](./container-insights-data-collection-configmap.md) for further data collection options. -- -If you aren't familiar with Azure Monitor alerts, see [Overview of alerts in Microsoft Azure](../alerts/alerts-overview.md) before you start. To learn more about alerts that use log queries, see [Log search alerts in Azure Monitor](../alerts/alerts-types.md#log-alerts). For more about metric alerts, see [Metric alerts in Azure Monitor](../alerts/alerts-metric-overview.md). --## Log query measurements -[Log search alerts](../alerts/alerts-types.md#log-alerts) can measure two different things, which can be used to monitor virtual machines in different scenarios: --- [Result count](../alerts/alerts-types.md#log-alerts): Counts the number of rows returned by the query and can be used to work with events such as Windows event logs, Syslog, and application exceptions.-- [Calculation of a value](../alerts/alerts-types.md#log-alerts): Makes a calculation based on a numeric column and can be used to include any number of resources. An example is CPU percentage.--### Target resources and dimensions --You can use one rule to monitor the values of multiple instances by using dimensions. For example, you would use dimensions if you wanted to monitor the CPU usage on multiple instances running your website or app, and create an alert for CPU usage of over 80%. --To create resource-centric alerts at scale for a subscription or resource group, you can *split by dimensions*. When you want to monitor the same condition on multiple Azure resources, splitting by dimensions splits the alerts into separate alerts by grouping unique combinations by using numerical or string columns. Splitting an Azure resource ID column makes the specified resource into the alert target. --You might also decide not to split when you want a condition on multiple resources in the scope. For example, you might want to create an alert if at least five machines in the resource group scope have CPU usage over 80%. ---You might want to see a list of the alerts by affected computer. You can use a custom workbook that uses a custom [resource graph](../../governance/resource-graph/overview.md) to provide this view. Use the following query to display alerts, and use the data source **Azure Resource Graph** in the workbook. --## Create a log search alert rule -To create a log search alert rule by using the portal, see [this example of a log search alert](../alerts/tutorial-log-alert.md), which provides a complete walkthrough. You can use these same processes to create alert rules for AKS clusters by using queries similar to the ones in this article. --To create a query alert rule by using an Azure Resource Manager (ARM) template, see [Resource Manager template samples for log search alert rules in Azure Monitor](../alerts/resource-manager-alerts-log.md). You can use these same processes to create ARM templates for the log queries in this article. --## Resource utilization --Average CPU utilization as an average of member nodes' CPU utilization every minute (metric measurement): --```kusto -let endDateTime = now(); -let startDateTime = ago(1h); -let trendBinSize = 1m; -let capacityCounterName = 'cpuCapacityNanoCores'; -let usageCounterName = 'cpuUsageNanoCores'; -KubeNodeInventory -| where TimeGenerated < endDateTime -| where TimeGenerated >= startDateTime -// cluster filter would go here if multiple clusters are reporting to the same Log Analytics workspace -| distinct ClusterName, Computer -| join hint.strategy=shuffle ( - Perf - | where TimeGenerated < endDateTime - | where TimeGenerated >= startDateTime - | where ObjectName == 'K8SNode' - | where CounterName == capacityCounterName - | summarize LimitValue = max(CounterValue) by Computer, CounterName, bin(TimeGenerated, trendBinSize) - | project Computer, CapacityStartTime = TimeGenerated, CapacityEndTime = TimeGenerated + trendBinSize, LimitValue -) on Computer -| join kind=inner hint.strategy=shuffle ( - Perf - | where TimeGenerated < endDateTime + trendBinSize - | where TimeGenerated >= startDateTime - trendBinSize - | where ObjectName == 'K8SNode' - | where CounterName == usageCounterName - | project Computer, UsageValue = CounterValue, TimeGenerated -) on Computer -| where TimeGenerated >= CapacityStartTime and TimeGenerated < CapacityEndTime -| project ClusterName, Computer, TimeGenerated, UsagePercent = UsageValue * 100.0 / LimitValue -| summarize AggValue = avg(UsagePercent) by bin(TimeGenerated, trendBinSize), ClusterName -``` --Average memory utilization as an average of member nodes' memory utilization every minute (metric measurement): --```kusto -let endDateTime = now(); -let startDateTime = ago(1h); -let trendBinSize = 1m; -let capacityCounterName = 'memoryCapacityBytes'; -let usageCounterName = 'memoryRssBytes'; -KubeNodeInventory -| where TimeGenerated < endDateTime -| where TimeGenerated >= startDateTime -// cluster filter would go here if multiple clusters are reporting to the same Log Analytics workspace -| distinct ClusterName, Computer -| join hint.strategy=shuffle ( - Perf - | where TimeGenerated < endDateTime - | where TimeGenerated >= startDateTime - | where ObjectName == 'K8SNode' - | where CounterName == capacityCounterName - | summarize LimitValue = max(CounterValue) by Computer, CounterName, bin(TimeGenerated, trendBinSize) - | project Computer, CapacityStartTime = TimeGenerated, CapacityEndTime = TimeGenerated + trendBinSize, LimitValue -) on Computer -| join kind=inner hint.strategy=shuffle ( - Perf - | where TimeGenerated < endDateTime + trendBinSize - | where TimeGenerated >= startDateTime - trendBinSize - | where ObjectName == 'K8SNode' - | where CounterName == usageCounterName - | project Computer, UsageValue = CounterValue, TimeGenerated -) on Computer -| where TimeGenerated >= CapacityStartTime and TimeGenerated < CapacityEndTime -| project ClusterName, Computer, TimeGenerated, UsagePercent = UsageValue * 100.0 / LimitValue -| summarize AggValue = avg(UsagePercent) by bin(TimeGenerated, trendBinSize), ClusterName -``` -->[!IMPORTANT] ->The following queries use the placeholder values \<your-cluster-name> and \<your-controller-name> to represent your cluster and controller. Replace them with values specific to your environment when you set up alerts. --Average CPU utilization of all containers in a controller as an average of CPU utilization of every container instance in a controller every minute (metric measurement): --```kusto -let endDateTime = now(); -let startDateTime = ago(1h); -let trendBinSize = 1m; -let capacityCounterName = 'cpuLimitNanoCores'; -let usageCounterName = 'cpuUsageNanoCores'; -let clusterName = '<your-cluster-name>'; -let controllerName = '<your-controller-name>'; -KubePodInventory -| where TimeGenerated < endDateTime -| where TimeGenerated >= startDateTime -| where ClusterName == clusterName -| where ControllerName == controllerName -| extend InstanceName = strcat(ClusterId, '/', ContainerName), - ContainerName = strcat(controllerName, '/', tostring(split(ContainerName, '/')[1])) -| distinct Computer, InstanceName, ContainerName -| join hint.strategy=shuffle ( - Perf - | where TimeGenerated < endDateTime - | where TimeGenerated >= startDateTime - | where ObjectName == 'K8SContainer' - | where CounterName == capacityCounterName - | summarize LimitValue = max(CounterValue) by Computer, InstanceName, bin(TimeGenerated, trendBinSize) - | project Computer, InstanceName, LimitStartTime = TimeGenerated, LimitEndTime = TimeGenerated + trendBinSize, LimitValue -) on Computer, InstanceName -| join kind=inner hint.strategy=shuffle ( - Perf - | where TimeGenerated < endDateTime + trendBinSize - | where TimeGenerated >= startDateTime - trendBinSize - | where ObjectName == 'K8SContainer' - | where CounterName == usageCounterName - | project Computer, InstanceName, UsageValue = CounterValue, TimeGenerated -) on Computer, InstanceName -| where TimeGenerated >= LimitStartTime and TimeGenerated < LimitEndTime -| project Computer, ContainerName, TimeGenerated, UsagePercent = UsageValue * 100.0 / LimitValue -| summarize AggValue = avg(UsagePercent) by bin(TimeGenerated, trendBinSize) , ContainerName -``` --Average memory utilization of all containers in a controller as an average of memory utilization of every container instance in a controller every minute (metric measurement): --```kusto -let endDateTime = now(); -let startDateTime = ago(1h); -let trendBinSize = 1m; -let capacityCounterName = 'memoryLimitBytes'; -let usageCounterName = 'memoryRssBytes'; -let clusterName = '<your-cluster-name>'; -let controllerName = '<your-controller-name>'; -KubePodInventory -| where TimeGenerated < endDateTime -| where TimeGenerated >= startDateTime -| where ClusterName == clusterName -| where ControllerName == controllerName -| extend InstanceName = strcat(ClusterId, '/', ContainerName), - ContainerName = strcat(controllerName, '/', tostring(split(ContainerName, '/')[1])) -| distinct Computer, InstanceName, ContainerName -| join hint.strategy=shuffle ( - Perf - | where TimeGenerated < endDateTime - | where TimeGenerated >= startDateTime - | where ObjectName == 'K8SContainer' - | where CounterName == capacityCounterName - | summarize LimitValue = max(CounterValue) by Computer, InstanceName, bin(TimeGenerated, trendBinSize) - | project Computer, InstanceName, LimitStartTime = TimeGenerated, LimitEndTime = TimeGenerated + trendBinSize, LimitValue -) on Computer, InstanceName -| join kind=inner hint.strategy=shuffle ( - Perf - | where TimeGenerated < endDateTime + trendBinSize - | where TimeGenerated >= startDateTime - trendBinSize - | where ObjectName == 'K8SContainer' - | where CounterName == usageCounterName - | project Computer, InstanceName, UsageValue = CounterValue, TimeGenerated -) on Computer, InstanceName -| where TimeGenerated >= LimitStartTime and TimeGenerated < LimitEndTime -| project Computer, ContainerName, TimeGenerated, UsagePercent = UsageValue * 100.0 / LimitValue -| summarize AggValue = avg(UsagePercent) by bin(TimeGenerated, trendBinSize) , ContainerName -``` --## Resource availability --Nodes and counts that have a status of Ready and NotReady (metric measurement): --```kusto -let endDateTime = now(); -let startDateTime = ago(1h); -let trendBinSize = 1m; -let clusterName = '<your-cluster-name>'; -KubeNodeInventory -| where TimeGenerated < endDateTime -| where TimeGenerated >= startDateTime -| distinct ClusterName, Computer, TimeGenerated -| summarize ClusterSnapshotCount = count() by bin(TimeGenerated, trendBinSize), ClusterName, Computer -| join hint.strategy=broadcast kind=inner ( - KubeNodeInventory - | where TimeGenerated < endDateTime - | where TimeGenerated >= startDateTime - | summarize TotalCount = count(), ReadyCount = sumif(1, Status contains ('Ready')) - by ClusterName, Computer, bin(TimeGenerated, trendBinSize) - | extend NotReadyCount = TotalCount - ReadyCount -) on ClusterName, Computer, TimeGenerated -| project TimeGenerated, - ClusterName, - Computer, - ReadyCount = todouble(ReadyCount) / ClusterSnapshotCount, - NotReadyCount = todouble(NotReadyCount) / ClusterSnapshotCount -| order by ClusterName asc, Computer asc, TimeGenerated desc -``` --The following query returns pod phase counts based on all phases: `Failed`, `Pending`, `Unknown`, `Running`, or `Succeeded`. --```kusto -let endDateTime = now(); -let startDateTime = ago(1h); -let trendBinSize = 1m; -let clusterName = '<your-cluster-name>'; -KubePodInventory - | where TimeGenerated < endDateTime - | where TimeGenerated >= startDateTime - | where ClusterName == clusterName - | distinct ClusterName, TimeGenerated - | summarize ClusterSnapshotCount = count() by bin(TimeGenerated, trendBinSize), ClusterName - | join hint.strategy=broadcast ( - KubePodInventory - | where TimeGenerated < endDateTime - | where TimeGenerated >= startDateTime - | summarize PodStatus=any(PodStatus) by TimeGenerated, PodUid, ClusterName - | summarize TotalCount = count(), - PendingCount = sumif(1, PodStatus =~ 'Pending'), - RunningCount = sumif(1, PodStatus =~ 'Running'), - SucceededCount = sumif(1, PodStatus =~ 'Succeeded'), - FailedCount = sumif(1, PodStatus =~ 'Failed') - by ClusterName, bin(TimeGenerated, trendBinSize) - ) on ClusterName, TimeGenerated - | extend UnknownCount = TotalCount - PendingCount - RunningCount - SucceededCount - FailedCount - | project TimeGenerated, - TotalCount = todouble(TotalCount) / ClusterSnapshotCount, - PendingCount = todouble(PendingCount) / ClusterSnapshotCount, - RunningCount = todouble(RunningCount) / ClusterSnapshotCount, - SucceededCount = todouble(SucceededCount) / ClusterSnapshotCount, - FailedCount = todouble(FailedCount) / ClusterSnapshotCount, - UnknownCount = todouble(UnknownCount) / ClusterSnapshotCount -| summarize AggValue = avg(PendingCount) by bin(TimeGenerated, trendBinSize) -``` -->[!NOTE] ->To alert on certain pod phases, such as `Pending`, `Failed`, or `Unknown`, modify the last line of the query. For example, to alert on `FailedCount`, use `| summarize AggValue = avg(FailedCount) by bin(TimeGenerated, trendBinSize)`. --The following query returns cluster nodes disks that exceed 90% free space used. To get the cluster ID, first run the following query and copy the value from the `ClusterId` property: --```kusto -InsightsMetrics -| extend Tags = todynamic(Tags) -| project ClusterId = Tags['container.azm.ms/clusterId'] -| distinct tostring(ClusterId) -``` --```kusto -let clusterId = '<cluster-id>'; -let endDateTime = now(); -let startDateTime = ago(1h); -let trendBinSize = 1m; -InsightsMetrics -| where TimeGenerated < endDateTime -| where TimeGenerated >= startDateTime -| where Origin == 'container.azm.ms/telegraf' -| where Namespace == 'container.azm.ms/disk' -| extend Tags = todynamic(Tags) -| project TimeGenerated, ClusterId = Tags['container.azm.ms/clusterId'], Computer = tostring(Tags.hostName), Device = tostring(Tags.device), Path = tostring(Tags.path), DiskMetricName = Name, DiskMetricValue = Val -| where ClusterId =~ clusterId -| where DiskMetricName == 'used_percent' -| summarize AggValue = max(DiskMetricValue) by bin(TimeGenerated, trendBinSize) -| where AggValue >= 90 -``` --Individual container restarts (number of results) alert when the individual system container restart count exceeds a threshold for the last 10 minutes: --```kusto -let _threshold = 10m; -let _alertThreshold = 2; -let Timenow = (datetime(now) - _threshold); -let starttime = ago(5m); -KubePodInventory -| where TimeGenerated >= starttime -| where Namespace in ('default', 'kube-system') // the namespace filter goes here -| where ContainerRestartCount > _alertThreshold -| extend Tags = todynamic(ContainerLastStatus) -| extend startedAt = todynamic(Tags.startedAt) -| where startedAt >= Timenow -| summarize arg_max(TimeGenerated, *) by Name -``` --## Next steps --- View [log query examples](container-insights-log-query.md) to see predefined queries and examples to evaluate or customize for alerting, visualizing, or analyzing your clusters.-- To learn more about Azure Monitor and how to monitor other aspects of your Kubernetes cluster, see [View Kubernetes cluster performance](container-insights-analyze.md) and [View Kubernetes cluster health](./container-insights-overview.md). |
| azure-monitor | Container Insights Log Query | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-log-query.md | - Title: Query logs from Container insights -description: Container insights collects metrics and log data, and this article describes the records and includes sample queries. - Previously updated : 2/28/2024----# Query logs from Container insights --Container insights collects performance metrics, inventory data, and health state information from container hosts and containers. The data is collected every three minutes and forwarded to the Log Analytics workspace in Azure Monitor where it's available for [log queries](../logs/log-query-overview.md) using [Log Analytics](../logs/log-analytics-overview.md) in Azure Monitor. --You can apply this data to scenarios that include migration planning, capacity analysis, discovery, and on-demand performance troubleshooting. Azure Monitor Logs can help you look for trends, diagnose bottlenecks, forecast, or correlate data that can help you determine whether the current cluster configuration is performing optimally. --For information on using these queries, see [Using queries in Azure Monitor Log Analytics](../logs/queries.md). For a complete tutorial on using Log Analytics to run queries and work with their results, see [Log Analytics tutorial](../logs/log-analytics-tutorial.md). --> [!IMPORTANT] -> The queries in this article depend on data collected by Container insights and stored in a Log Analytics workspace. If you've modified the default data collection settings, the queries might not return the expected results. Most notably, if you've disabled collection of performance data since you've enabled Prometheus metrics for the cluster, any queries using the `Perf` table won't return results. -> -> See [Configure data collection in Container insights using data collection rule](./container-insights-data-collection-dcr.md) for preset configurations including disabling performance data collection. See [Configure data collection in Container insights using ConfigMap](./container-insights-data-collection-configmap.md) for further data collection options. --## Open Log Analytics --There are multiple options for starting Log Analytics. Each option starts with a different [scope](../logs/scope.md). For access to all data in the workspace, on the **Monitoring** menu, select **Logs**. To limit the data to a single Kubernetes cluster, select **Logs** from that cluster's menu. ---## Existing log queries --You don't necessarily need to understand how to write a log query to use Log Analytics. You can select from multiple prebuilt queries. You can either run the queries without modification or use them as a start to a custom query. Select **Queries** at the top of the Log Analytics screen, and view queries with a **Resource type** of **Kubernetes Services**. ---## Container tables --For a list of tables and their detailed descriptions used by Container insights, see the [Azure Monitor table reference](/azure/azure-monitor/reference/tables/tables-resourcetype#kubernetes-services). All these tables are available for log queries. --## Example log queries --It's often useful to build queries that start with an example or two and then modify them to fit your requirements. To help build more advanced queries, you can experiment with the following sample queries. --### List all of a container's lifecycle information --```kusto -ContainerInventory -| project Computer, Name, Image, ImageTag, ContainerState, CreatedTime, StartedTime, FinishedTime -| render table -``` --### Kubernetes events --> [!NOTE] -> By default, Normal event types aren't collected, so you won't see them when you query the KubeEvents table unless the *collect_all_kube_events* ConfigMap setting is enabled. If you need to collect Normal events, enable *collect_all_kube_events setting* in the *container-azm-ms-agentconfig* ConfigMap. See [Configure agent data collection for Container insights](./container-insights-data-collection-configmap.md) for information on how to configure the ConfigMap. ---``` kusto -KubeEvents -| where not(isempty(Namespace)) -| sort by TimeGenerated desc -| render table -``` --### Container CPU --``` kusto -Perf -| where ObjectName == "K8SContainer" and CounterName == "cpuUsageNanoCores" -| summarize AvgCPUUsageNanoCores = avg(CounterValue) by bin(TimeGenerated, 30m), InstanceName -``` --### Container memory -This query uses `memoryRssBytes` which is only available for Linux nodes. --```kusto -Perf -| where ObjectName == "K8SContainer" and CounterName == "memoryRssBytes" -| summarize AvgUsedRssMemoryBytes = avg(CounterValue) by bin(TimeGenerated, 30m), InstanceName -``` --### Requests per minute with custom metrics --```kusto -InsightsMetrics -| where Name == "requests_count" -| summarize Val=any(Val) by TimeGenerated=bin(TimeGenerated, 1m) -| sort by TimeGenerated asc -| project RequestsPerMinute = Val - prev(Val), TimeGenerated -| render barchart -``` --### Pods by name and namespace --```kusto -let startTimestamp = ago(1h); -KubePodInventory -| where TimeGenerated > startTimestamp -| project ContainerID, PodName=Name, Namespace -| where PodName contains "name" and Namespace startswith "namespace" -| distinct ContainerID, PodName -| join -( - ContainerLog - | where TimeGenerated > startTimestamp -) -on ContainerID -// at this point before the next pipe, columns from both tables are available to be "projected". Due to both -// tables having a "Name" column, we assign an alias as PodName to one column which we actually want -| project TimeGenerated, PodName, LogEntry, LogEntrySource -| summarize by TimeGenerated, LogEntry -| order by TimeGenerated desc -``` --### Pod scale-out (HPA) --This query returns the number of scaled-out replicas in each deployment. It calculates the scale-out percentage with the maximum number of replicas configured in HPA. --```kusto -let _minthreshold = 70; // minimum threshold goes here if you want to setup as an alert -let _maxthreshold = 90; // maximum threshold goes here if you want to setup as an alert -let startDateTime = ago(60m); -KubePodInventory -| where TimeGenerated >= startDateTime -| where Namespace !in('default', 'kube-system') // List of non system namespace filter goes here. -| extend labels = todynamic(PodLabel) -| extend deployment_hpa = reverse(substring(reverse(ControllerName), indexof(reverse(ControllerName), "-") + 1)) -| distinct tostring(deployment_hpa) -| join kind=inner (InsightsMetrics - | where TimeGenerated > startDateTime - | where Name == 'kube_hpa_status_current_replicas' - | extend pTags = todynamic(Tags) //parse the tags for values - | extend ns = todynamic(pTags.k8sNamespace) //parse namespace value from tags - | extend deployment_hpa = todynamic(pTags.targetName) //parse HPA target name from tags - | extend max_reps = todynamic(pTags.spec_max_replicas) // Parse maximum replica settings from HPA deployment - | extend desired_reps = todynamic(pTags.status_desired_replicas) // Parse desired replica settings from HPA deployment - | summarize arg_max(TimeGenerated, *) by tostring(ns), tostring(deployment_hpa), Cluster=toupper(tostring(split(_ResourceId, '/')[8])), toint(desired_reps), toint(max_reps), scale_out_percentage=(desired_reps * 100 / max_reps) - //| where scale_out_percentage > _minthreshold and scale_out_percentage <= _maxthreshold - ) - on deployment_hpa -``` --### Nodepool scale-outs --This query returns the number of active nodes in each node pool. It calculates the number of available active nodes and the max node configuration in the autoscaler settings to determine the scale-out percentage. See commented lines in the query to use it for a **number of results** alert rule. --```kusto -let nodepoolMaxnodeCount = 10; // the maximum number of nodes in your auto scale setting goes here. -let _minthreshold = 20; -let _maxthreshold = 90; -let startDateTime = 60m; -KubeNodeInventory -| where TimeGenerated >= ago(startDateTime) -| extend nodepoolType = todynamic(Labels) //Parse the labels to get the list of node pool types -| extend nodepoolName = todynamic(nodepoolType[0].agentpool) // parse the label to get the nodepool name or set the specific nodepool name (like nodepoolName = 'agentpool)' -| summarize nodeCount = count(Computer) by ClusterName, tostring(nodepoolName), TimeGenerated -//(Uncomment the below two lines to set this as a log search alert) -//| extend scaledpercent = iff(((nodeCount * 100 / nodepoolMaxnodeCount) >= _minthreshold and (nodeCount * 100 / nodepoolMaxnodeCount) < _maxthreshold), "warn", "normal") -//| where scaledpercent == 'warn' -| summarize arg_max(TimeGenerated, *) by nodeCount, ClusterName, tostring(nodepoolName) -| project ClusterName, - TotalNodeCount= strcat("Total Node Count: ", nodeCount), - ScaledOutPercentage = (nodeCount * 100 / nodepoolMaxnodeCount), - TimeGenerated, - nodepoolName -``` --### System containers (replicaset) availability --This query returns the system containers (replicasets) and reports the unavailable percentage. See commented lines in the query to use it for a **number of results** alert rule. --```kusto -let startDateTime = 5m; // the minimum time interval goes here -let _minalertThreshold = 50; //Threshold for minimum and maximum unavailable or not running containers -let _maxalertThreshold = 70; -KubePodInventory -| where TimeGenerated >= ago(startDateTime) -| distinct ClusterName, TimeGenerated -| summarize Clustersnapshot = count() by ClusterName -| join kind=inner ( - KubePodInventory - | where TimeGenerated >= ago(startDateTime) - | where Namespace in('default', 'kube-system') and ControllerKind == 'ReplicaSet' // the system namespace filter goes here - | distinct ClusterName, Computer, PodUid, TimeGenerated, PodStatus, ServiceName, PodLabel, Namespace, ContainerStatus - | summarize arg_max(TimeGenerated, *), TotalPODCount = count(), podCount = sumif(1, PodStatus == 'Running' or PodStatus != 'Running'), containerNotrunning = sumif(1, ContainerStatus != 'running') - by ClusterName, TimeGenerated, ServiceName, PodLabel, Namespace - ) - on ClusterName -| project ClusterName, ServiceName, podCount, containerNotrunning, containerNotrunningPercent = (containerNotrunning * 100 / podCount), TimeGenerated, PodStatus, PodLabel, Namespace, Environment = tostring(split(ClusterName, '-')[3]), Location = tostring(split(ClusterName, '-')[4]), ContainerStatus -//Uncomment the below line to set for automated alert -//| where PodStatus == "Running" and containerNotrunningPercent > _minalertThreshold and containerNotrunningPercent < _maxalertThreshold -| summarize arg_max(TimeGenerated, *), c_entry=count() by PodLabel, ServiceName, ClusterName -//Below lines are to parse the labels to identify the impacted service/component name -| extend parseLabel = replace(@'k8s-app', @'k8sapp', PodLabel) -| extend parseLabel = replace(@'app.kubernetes.io\\/component', @'appkubernetesiocomponent', parseLabel) -| extend parseLabel = replace(@'app.kubernetes.io\\/instance', @'appkubernetesioinstance', parseLabel) -| extend tags = todynamic(parseLabel) -| extend tag01 = todynamic(tags[0].app) -| extend tag02 = todynamic(tags[0].k8sapp) -| extend tag03 = todynamic(tags[0].appkubernetesiocomponent) -| extend tag04 = todynamic(tags[0].aadpodidbinding) -| extend tag05 = todynamic(tags[0].appkubernetesioinstance) -| extend tag06 = todynamic(tags[0].component) -| project ClusterName, TimeGenerated, - ServiceName = strcat( ServiceName, tag01, tag02, tag03, tag04, tag05, tag06), - ContainerUnavailable = strcat("Unavailable Percentage: ", containerNotrunningPercent), - PodStatus = strcat("PodStatus: ", PodStatus), - ContainerStatus = strcat("Container Status: ", ContainerStatus) -``` --### System containers (daemonsets) availability --This query returns the system containers (daemonsets) and reports the unavailable percentage. See commented lines in the query to use it for a **number of results** alert rule. --```kusto -let startDateTime = 5m; // the minimum time interval goes here -let _minalertThreshold = 50; //Threshold for minimum and maximum unavailable or not running containers -let _maxalertThreshold = 70; -KubePodInventory -| where TimeGenerated >= ago(startDateTime) -| distinct ClusterName, TimeGenerated -| summarize Clustersnapshot = count() by ClusterName -| join kind=inner ( - KubePodInventory - | where TimeGenerated >= ago(startDateTime) - | where Namespace in('default', 'kube-system') and ControllerKind == 'DaemonSet' // the system namespace filter goes here - | distinct ClusterName, Computer, PodUid, TimeGenerated, PodStatus, ServiceName, PodLabel, Namespace, ContainerStatus - | summarize arg_max(TimeGenerated, *), TotalPODCount = count(), podCount = sumif(1, PodStatus == 'Running' or PodStatus != 'Running'), containerNotrunning = sumif(1, ContainerStatus != 'running') - by ClusterName, TimeGenerated, ServiceName, PodLabel, Namespace - ) - on ClusterName -| project ClusterName, ServiceName, podCount, containerNotrunning, containerNotrunningPercent = (containerNotrunning * 100 / podCount), TimeGenerated, PodStatus, PodLabel, Namespace, Environment = tostring(split(ClusterName, '-')[3]), Location = tostring(split(ClusterName, '-')[4]), ContainerStatus -//Uncomment the below line to set for automated alert -//| where PodStatus == "Running" and containerNotrunningPercent > _minalertThreshold and containerNotrunningPercent < _maxalertThreshold -| summarize arg_max(TimeGenerated, *), c_entry=count() by PodLabel, ServiceName, ClusterName -//Below lines are to parse the labels to identify the impacted service/component name -| extend parseLabel = replace(@'k8s-app', @'k8sapp', PodLabel) -| extend parseLabel = replace(@'app.kubernetes.io\\/component', @'appkubernetesiocomponent', parseLabel) -| extend parseLabel = replace(@'app.kubernetes.io\\/instance', @'appkubernetesioinstance', parseLabel) -| extend tags = todynamic(parseLabel) -| extend tag01 = todynamic(tags[0].app) -| extend tag02 = todynamic(tags[0].k8sapp) -| extend tag03 = todynamic(tags[0].appkubernetesiocomponent) -| extend tag04 = todynamic(tags[0].aadpodidbinding) -| extend tag05 = todynamic(tags[0].appkubernetesioinstance) -| extend tag06 = todynamic(tags[0].component) -| project ClusterName, TimeGenerated, - ServiceName = strcat( ServiceName, tag01, tag02, tag03, tag04, tag05, tag06), - ContainerUnavailable = strcat("Unavailable Percentage: ", containerNotrunningPercent), - PodStatus = strcat("PodStatus: ", PodStatus), - ContainerStatus = strcat("Container Status: ", ContainerStatus) -``` --## Container logs --Container logs for AKS are stored in [the ContainerLogV2 table](./container-insights-logs-schema.md). You can run the following sample queries to look for the stderr/stdout log output from target pods, deployments, or namespaces. --### Container logs for a specific pod, namespace, and container --```kusto -ContainerLogV2 -| where _ResourceId =~ "clusterResourceID" //update with resource ID -| where PodNamespace == "podNameSpace" //update with target namespace -| where PodName == "podName" //update with target pod -| where ContainerName == "containerName" //update with target container -| project TimeGenerated, Computer, ContainerId, LogMessage, LogSource -``` --### Container logs for a specific deployment --``` kusto -let KubePodInv = KubePodInventory -| where _ResourceId =~ "clusterResourceID" //update with resource ID -| where Namespace == "deploymentNamespace" //update with target namespace -| where ControllerKind == "ReplicaSet" -| extend deployment = reverse(substring(reverse(ControllerName), indexof(reverse(ControllerName), "-") + 1)) -| where deployment == "deploymentName" //update with target deployment -| extend ContainerId = ContainerID -| summarize arg_max(TimeGenerated, *) by deployment, ContainerId, PodStatus, ContainerStatus -| project deployment, ContainerId, PodStatus, ContainerStatus; --KubePodInv -| join -( - ContainerLogV2 - | where TimeGenerated >= startTime and TimeGenerated < endTime - | where PodNamespace == "deploymentNamespace" //update with target namespace - | where PodName startswith "deploymentName" //update with target deployment -) on ContainerId -| project TimeGenerated, deployment, PodName, PodStatus, ContainerName, ContainerId, ContainerStatus, LogMessage, LogSource --``` --### Container logs for any failed pod in a specific namespace --``` kusto - let KubePodInv = KubePodInventory - | where TimeGenerated >= startTime and TimeGenerated < endTime - | where _ResourceId =~ "clustereResourceID" //update with resource ID - | where Namespace == "podNamespace" //update with target namespace - | where PodStatus == "Failed" - | extend ContainerId = ContainerID - | summarize arg_max(TimeGenerated, *) by ContainerId, PodStatus, ContainerStatus - | project ContainerId, PodStatus, ContainerStatus; -- KubePodInv - | join - ( - ContainerLogV2 - | where TimeGenerated >= startTime and TimeGenerated < endTime - | where PodNamespace == "podNamespace" //update with target namespace - ) on ContainerId - | project TimeGenerated, PodName, PodStatus, ContainerName, ContainerId, ContainerStatus, LogMessage, LogSource --``` --## Container insights default visualization queries --These queries are generated from the [out of the box visualizations](./container-insights-analyze.md) from container insights. You can choose to use these if you have enabled custom [cost optimization settings](./container-insights-cost-config.md), in lieu of the default charts. --### Node count by status --The required tables for this chart include KubeNodeInventory. --```kusto - let trendBinSize = 5m; - let maxListSize = 1000; - let clusterId = 'clusterResourceID'; //update with resource ID - - let rawData = KubeNodeInventory -| where ClusterId =~ clusterId -| distinct ClusterId, TimeGenerated -| summarize ClusterSnapshotCount = count() by Timestamp = bin(TimeGenerated, trendBinSize), ClusterId -| join hint.strategy=broadcast ( KubeNodeInventory -| where ClusterId =~ clusterId -| summarize TotalCount = count(), ReadyCount = sumif(1, Status contains ('Ready')) by ClusterId, Timestamp = bin(TimeGenerated, trendBinSize) -| extend NotReadyCount = TotalCount - ReadyCount ) on ClusterId, Timestamp -| project ClusterId, Timestamp, TotalCount = todouble(TotalCount) / ClusterSnapshotCount, ReadyCount = todouble(ReadyCount) / ClusterSnapshotCount, NotReadyCount = todouble(NotReadyCount) / ClusterSnapshotCount; -- rawData -| order by Timestamp asc -| summarize makelist(Timestamp, maxListSize), makelist(TotalCount, maxListSize), makelist(ReadyCount, maxListSize), makelist(NotReadyCount, maxListSize) by ClusterId -| join ( rawData -| summarize Avg_TotalCount = avg(TotalCount), Avg_ReadyCount = avg(ReadyCount), Avg_NotReadyCount = avg(NotReadyCount) by ClusterId ) on ClusterId -| project ClusterId, Avg_TotalCount, Avg_ReadyCount, Avg_NotReadyCount, list_Timestamp, list_TotalCount, list_ReadyCount, list_NotReadyCount -``` --### Pod count by status --The required tables for this chart include KubePodInventory. --```kusto - let trendBinSize = 5m; - let maxListSize = 1000; - let clusterId = 'clusterResourceID'; //update with resource ID - - let rawData = KubePodInventory -| where ClusterId =~ clusterId -| distinct ClusterId, TimeGenerated -| summarize ClusterSnapshotCount = count() by bin(TimeGenerated, trendBinSize), ClusterId -| join hint.strategy=broadcast ( KubePodInventory -| where ClusterId =~ clusterId -| summarize PodStatus=any(PodStatus) by TimeGenerated, PodUid, ClusterId -| summarize TotalCount = count(), PendingCount = sumif(1, PodStatus =~ 'Pending'), RunningCount = sumif(1, PodStatus =~ 'Running'), SucceededCount = sumif(1, PodStatus =~ 'Succeeded'), FailedCount = sumif(1, PodStatus =~ 'Failed'), TerminatingCount = sumif(1, PodStatus =~ 'Terminating') by ClusterId, bin(TimeGenerated, trendBinSize) ) on ClusterId, TimeGenerated -| extend UnknownCount = TotalCount - PendingCount - RunningCount - SucceededCount - FailedCount - TerminatingCount -| project ClusterId, Timestamp = TimeGenerated, TotalCount = todouble(TotalCount) / ClusterSnapshotCount, PendingCount = todouble(PendingCount) / ClusterSnapshotCount, RunningCount = todouble(RunningCount) / ClusterSnapshotCount, SucceededCount = todouble(SucceededCount) / ClusterSnapshotCount, FailedCount = todouble(FailedCount) / ClusterSnapshotCount, TerminatingCount = todouble(TerminatingCount) / ClusterSnapshotCount, UnknownCount = todouble(UnknownCount) / ClusterSnapshotCount; -- let rawDataCached = rawData; - - rawDataCached -| order by Timestamp asc -| summarize makelist(Timestamp, maxListSize), makelist(TotalCount, maxListSize), makelist(PendingCount, maxListSize), makelist(RunningCount, maxListSize), makelist(SucceededCount, maxListSize), makelist(FailedCount, maxListSize), makelist(TerminatingCount, maxListSize), makelist(UnknownCount, maxListSize) by ClusterId -| join ( rawDataCached -| summarize Avg_TotalCount = avg(TotalCount), Avg_PendingCount = avg(PendingCount), Avg_RunningCount = avg(RunningCount), Avg_SucceededCount = avg(SucceededCount), Avg_FailedCount = avg(FailedCount), Avg_TerminatingCount = avg(TerminatingCount), Avg_UnknownCount = avg(UnknownCount) by ClusterId ) on ClusterId -| project ClusterId, Avg_TotalCount, Avg_PendingCount, Avg_RunningCount, Avg_SucceededCount, Avg_FailedCount, Avg_TerminatingCount, Avg_UnknownCount, list_Timestamp, list_TotalCount, list_PendingCount, list_RunningCount, list_SucceededCount, list_FailedCount, list_TerminatingCount, list_UnknownCount -``` -### List of containers by status --The required tables for this chart include KubePodInventory and Perf. --```kusto - let startDateTime = datetime('start time'); - let endDateTime = datetime('end time'); - let trendBinSize = 15m; - let maxResultCount = 10000; - let metricUsageCounterName = 'cpuUsageNanoCores'; - let metricLimitCounterName = 'cpuLimitNanoCores'; - - let KubePodInventoryTable = KubePodInventory -| where TimeGenerated >= startDateTime -| where TimeGenerated < endDateTime -| where isnotempty(ClusterName) -| where isnotempty(Namespace) -| where isnotempty(Computer) -| project TimeGenerated, ClusterId, ClusterName, Namespace, ServiceName, ControllerName, Node = Computer, Pod = Name, ContainerInstance = ContainerName, ContainerID, ReadySinceNow = format_timespan(endDateTime - ContainerCreationTimeStamp , 'ddd.hh:mm:ss.fff'), Restarts = ContainerRestartCount, Status = ContainerStatus, ContainerStatusReason = columnifexists('ContainerStatusReason', ''), ControllerKind = ControllerKind, PodStatus; -- let startRestart = KubePodInventoryTable -| summarize arg_min(TimeGenerated, *) by Node, ContainerInstance -| where ClusterId =~ 'clusterResourceID' //update with resource ID -| project Node, ContainerInstance, InstanceName = strcat(ClusterId, '/', ContainerInstance), StartRestart = Restarts; -- let IdentityTable = KubePodInventoryTable -| summarize arg_max(TimeGenerated, *) by Node, ContainerInstance -| where ClusterId =~ 'clusterResourceID' //update with resource ID -| project ClusterName, Namespace, ServiceName, ControllerName, Node, Pod, ContainerInstance, InstanceName = strcat(ClusterId, '/', ContainerInstance), ContainerID, ReadySinceNow, Restarts, Status = iff(Status =~ 'running', 0, iff(Status=~'waiting', 1, iff(Status =~'terminated', 2, 3))), ContainerStatusReason, ControllerKind, Containers = 1, ContainerName = tostring(split(ContainerInstance, '/')[1]), PodStatus, LastPodInventoryTimeGenerated = TimeGenerated, ClusterId; -- let CachedIdentityTable = IdentityTable; - - let FilteredPerfTable = Perf -| where TimeGenerated >= startDateTime -| where TimeGenerated < endDateTime -| where ObjectName == 'K8SContainer' -| where InstanceName startswith 'clusterResourceID' -| project Node = Computer, TimeGenerated, CounterName, CounterValue, InstanceName ; -- let CachedFilteredPerfTable = FilteredPerfTable; - - let LimitsTable = CachedFilteredPerfTable -| where CounterName =~ metricLimitCounterName -| summarize arg_max(TimeGenerated, *) by Node, InstanceName -| project Node, InstanceName, LimitsValue = iff(CounterName =~ 'cpuLimitNanoCores', CounterValue/1000000, CounterValue), TimeGenerated; - let MetaDataTable = CachedIdentityTable -| join kind=leftouter ( LimitsTable ) on Node, InstanceName -| join kind= leftouter ( startRestart ) on Node, InstanceName -| project ClusterName, Namespace, ServiceName, ControllerName, Node, Pod, InstanceName, ContainerID, ReadySinceNow, Restarts, LimitsValue, Status, ContainerStatusReason = columnifexists('ContainerStatusReason', ''), ControllerKind, Containers, ContainerName, ContainerInstance, StartRestart, PodStatus, LastPodInventoryTimeGenerated, ClusterId; -- let UsagePerfTable = CachedFilteredPerfTable -| where CounterName =~ metricUsageCounterName -| project TimeGenerated, Node, InstanceName, CounterValue = iff(CounterName =~ 'cpuUsageNanoCores', CounterValue/1000000, CounterValue); -- let LastRestartPerfTable = CachedFilteredPerfTable -| where CounterName =~ 'restartTimeEpoch' -| summarize arg_max(TimeGenerated, *) by Node, InstanceName -| project Node, InstanceName, UpTime = CounterValue, LastReported = TimeGenerated; -- let AggregationTable = UsagePerfTable -| summarize Aggregation = max(CounterValue) by Node, InstanceName -| project Node, InstanceName, Aggregation; -- let TrendTable = UsagePerfTable -| summarize TrendAggregation = max(CounterValue) by bin(TimeGenerated, trendBinSize), Node, InstanceName -| project TrendTimeGenerated = TimeGenerated, Node, InstanceName , TrendAggregation -| summarize TrendList = makelist(pack("timestamp", TrendTimeGenerated, "value", TrendAggregation)) by Node, InstanceName; -- let containerFinalTable = MetaDataTable -| join kind= leftouter( AggregationTable ) on Node, InstanceName -| join kind = leftouter (LastRestartPerfTable) on Node, InstanceName -| order by Aggregation desc, ContainerName -| join kind = leftouter ( TrendTable) on Node, InstanceName -| extend ContainerIdentity = strcat(ContainerName, ' ', Pod) -| project ContainerIdentity, Status, ContainerStatusReason = columnifexists('ContainerStatusReason', ''), Aggregation, Node, Restarts, ReadySinceNow, TrendList = iif(isempty(TrendList), parse_json('[]'), TrendList), LimitsValue, ControllerName, ControllerKind, ContainerID, Containers, UpTimeNow = datetime_diff('Millisecond', endDateTime, datetime_add('second', toint(UpTime), make_datetime(1970,1,1))), ContainerInstance, StartRestart, LastReportedDelta = datetime_diff('Millisecond', endDateTime, LastReported), PodStatus, InstanceName, Namespace, LastPodInventoryTimeGenerated, ClusterId; -containerFinalTable -| limit 200 -``` --### List of Controllers by status --The required tables for this chart include KubePodInventory and Perf. --```kusto - let endDateTime = datetime('start time'); - let startDateTime = datetime('end time'); - let trendBinSize = 15m; - let metricLimitCounterName = 'cpuLimitNanoCores'; - let metricUsageCounterName = 'cpuUsageNanoCores'; - - let primaryInventory = KubePodInventory -| where TimeGenerated >= startDateTime -| where TimeGenerated < endDateTime -| where isnotempty(ClusterName) -| where isnotempty(Namespace) -| extend Node = Computer -| where ClusterId =~ 'clusterResourceID' //update with resource ID -| project TimeGenerated, ClusterId, ClusterName, Namespace, ServiceName, Node = Computer, ControllerName, Pod = Name, ContainerInstance = ContainerName, ContainerID, InstanceName, PerfJoinKey = strcat(ClusterId, '/', ContainerName), ReadySinceNow = format_timespan(endDateTime - ContainerCreationTimeStamp, 'ddd.hh:mm:ss.fff'), Restarts = ContainerRestartCount, Status = ContainerStatus, ContainerStatusReason = columnifexists('ContainerStatusReason', ''), ControllerKind = ControllerKind, PodStatus, ControllerId = strcat(ClusterId, '/', Namespace, '/', ControllerName); --let podStatusRollup = primaryInventory -| summarize arg_max(TimeGenerated, *) by Pod -| project ControllerId, PodStatus, TimeGenerated -| summarize count() by ControllerId, PodStatus = iif(TimeGenerated < ago(30m), 'Unknown', PodStatus) -| summarize PodStatusList = makelist(pack('Status', PodStatus, 'Count', count_)) by ControllerId; --let latestContainersByController = primaryInventory -| where isnotempty(Node) -| summarize arg_max(TimeGenerated, *) by PerfJoinKey -| project ControllerId, PerfJoinKey; --let filteredPerformance = Perf -| where TimeGenerated >= startDateTime -| where TimeGenerated < endDateTime -| where ObjectName == 'K8SContainer' -| where InstanceName startswith 'clusterResourceID' //update with resource ID -| project TimeGenerated, CounterName, CounterValue, InstanceName, Node = Computer ; --let metricByController = filteredPerformance -| where CounterName =~ metricUsageCounterName -| extend PerfJoinKey = InstanceName -| summarize Value = percentile(CounterValue, 95) by PerfJoinKey, CounterName -| join (latestContainersByController) on PerfJoinKey -| summarize Value = sum(Value) by ControllerId, CounterName -| project ControllerId, CounterName, AggregationValue = iff(CounterName =~ 'cpuUsageNanoCores', Value/1000000, Value); --let containerCountByController = latestContainersByController -| summarize ContainerCount = count() by ControllerId; --let restartCountsByController = primaryInventory -| summarize Restarts = max(Restarts) by ControllerId; --let oldestRestart = primaryInventory -| summarize ReadySinceNow = min(ReadySinceNow) by ControllerId; --let trendLineByController = filteredPerformance -| where CounterName =~ metricUsageCounterName -| extend PerfJoinKey = InstanceName -| summarize Value = percentile(CounterValue, 95) by bin(TimeGenerated, trendBinSize), PerfJoinKey, CounterName -| order by TimeGenerated asc -| join kind=leftouter (latestContainersByController) on PerfJoinKey -| summarize Value=sum(Value) by ControllerId, TimeGenerated, CounterName -| project TimeGenerated, Value = iff(CounterName =~ 'cpuUsageNanoCores', Value/1000000, Value), ControllerId -| summarize TrendList = makelist(pack("timestamp", TimeGenerated, "value", Value)) by ControllerId; --let latestLimit = filteredPerformance -| where CounterName =~ metricLimitCounterName -| extend PerfJoinKey = InstanceName -| summarize arg_max(TimeGenerated, *) by PerfJoinKey -| join kind=leftouter (latestContainersByController) on PerfJoinKey -| summarize Value = sum(CounterValue) by ControllerId, CounterName -| project ControllerId, LimitValue = iff(CounterName =~ 'cpuLimitNanoCores', Value/1000000, Value); --let latestTimeGeneratedByController = primaryInventory -| summarize arg_max(TimeGenerated, *) by ControllerId -| project ControllerId, LastTimeGenerated = TimeGenerated; --primaryInventory -| distinct ControllerId, ControllerName, ControllerKind, Namespace -| join kind=leftouter (podStatusRollup) on ControllerId -| join kind=leftouter (metricByController) on ControllerId -| join kind=leftouter (containerCountByController) on ControllerId -| join kind=leftouter (restartCountsByController) on ControllerId -| join kind=leftouter (oldestRestart) on ControllerId -| join kind=leftouter (trendLineByController) on ControllerId -| join kind=leftouter (latestLimit) on ControllerId -| join kind=leftouter (latestTimeGeneratedByController) on ControllerId -| project ControllerId, ControllerName, ControllerKind, PodStatusList, AggregationValue, ContainerCount = iif(isempty(ContainerCount), 0, ContainerCount), Restarts, ReadySinceNow, Node = '-', TrendList, LimitValue, LastTimeGenerated, Namespace -| limit 250; -``` --### List of Nodes by status --The required tables for this chart include KubeNodeInventory, KubePodInventory, and Perf. --```kusto - let endDateTime = datetime('start time'); - let startDateTime = datetime('end time'); - let binSize = 15m; - let limitMetricName = 'cpuCapacityNanoCores'; - let usedMetricName = 'cpuUsageNanoCores'; - - let materializedNodeInventory = KubeNodeInventory -| where TimeGenerated < endDateTime -| where TimeGenerated >= startDateTime -| project ClusterName, ClusterId, Node = Computer, TimeGenerated, Status, NodeName = Computer, NodeId = strcat(ClusterId, '/', Computer), Labels -| where ClusterId =~ 'clusterResourceID'; //update with resource ID -- let materializedPerf = Perf -| where TimeGenerated < endDateTime -| where TimeGenerated >= startDateTime -| where ObjectName == 'K8SNode' -| extend NodeId = InstanceName; -- let materializedPodInventory = KubePodInventory -| where TimeGenerated < endDateTime -| where TimeGenerated >= startDateTime -| where isnotempty(ClusterName) -| where isnotempty(Namespace) -| where ClusterId =~ 'clusterResourceID'; //update with resource ID -- let inventoryOfCluster = materializedNodeInventory -| summarize arg_max(TimeGenerated, Status) by ClusterName, ClusterId, NodeName, NodeId; -- let labelsByNode = materializedNodeInventory -| summarize arg_max(TimeGenerated, Labels) by ClusterName, ClusterId, NodeName, NodeId; -- let countainerCountByNode = materializedPodInventory -| project ContainerName, NodeId = strcat(ClusterId, '/', Computer) -| distinct NodeId, ContainerName -| summarize ContainerCount = count() by NodeId; -- let latestUptime = materializedPerf -| where CounterName == 'restartTimeEpoch' -| summarize arg_max(TimeGenerated, CounterValue) by NodeId -| extend UpTimeMs = datetime_diff('Millisecond', endDateTime, datetime_add('second', toint(CounterValue), make_datetime(1970,1,1))) -| project NodeId, UpTimeMs; -- let latestLimitOfNodes = materializedPerf -| where CounterName == limitMetricName -| summarize CounterValue = max(CounterValue) by NodeId -| project NodeId, LimitValue = CounterValue; -- let actualUsageAggregated = materializedPerf -| where CounterName == usedMetricName -| summarize Aggregation = percentile(CounterValue, 95) by NodeId //This line updates to the desired aggregation -| project NodeId, Aggregation; -- let aggregateTrendsOverTime = materializedPerf -| where CounterName == usedMetricName -| summarize TrendAggregation = percentile(CounterValue, 95) by NodeId, bin(TimeGenerated, binSize) //This line updates to the desired aggregation -| project NodeId, TrendAggregation, TrendDateTime = TimeGenerated; -- let unscheduledPods = materializedPodInventory -| where isempty(Computer) -| extend Node = Computer -| where isempty(ContainerStatus) -| where PodStatus == 'Pending' -| order by TimeGenerated desc -| take 1 -| project ClusterName, NodeName = 'unscheduled', LastReceivedDateTime = TimeGenerated, Status = 'unscheduled', ContainerCount = 0, UpTimeMs = '0', Aggregation = '0', LimitValue = '0', ClusterId; -- let scheduledPods = inventoryOfCluster -| join kind=leftouter (aggregateTrendsOverTime) on NodeId -| extend TrendPoint = pack("TrendTime", TrendDateTime, "TrendAggregation", TrendAggregation) -| summarize make_list(TrendPoint) by NodeId, NodeName, Status -| join kind=leftouter (labelsByNode) on NodeId -| join kind=leftouter (countainerCountByNode) on NodeId -| join kind=leftouter (latestUptime) on NodeId -| join kind=leftouter (latestLimitOfNodes) on NodeId -| join kind=leftouter (actualUsageAggregated) on NodeId -| project ClusterName, NodeName, ClusterId, list_TrendPoint, LastReceivedDateTime = TimeGenerated, Status, ContainerCount, UpTimeMs, Aggregation, LimitValue, Labels -| limit 250; -- union (scheduledPods), (unscheduledPods) -| project ClusterName, NodeName, LastReceivedDateTime, Status, ContainerCount, UpTimeMs = UpTimeMs_long, Aggregation = Aggregation_real, LimitValue = LimitValue_real, list_TrendPoint, Labels, ClusterId -``` --## Prometheus metrics --The following examples require the configuration described in [Send Prometheus metrics to Log Analytics workspace with Container insights](container-insights-prometheus-logs.md). --To view Prometheus metrics scraped by Azure Monitor and filtered by namespace, specify *"prometheus"*. Here's a sample query to view Prometheus metrics from the `default` Kubernetes namespace. --``` -InsightsMetrics -| where Namespace contains "prometheus" -| extend tags=parse_json(Tags) -| summarize count() by Name -``` --Prometheus data can also be directly queried by name. --``` -InsightsMetrics -| where Namespace contains "prometheus" -| where Name contains "some_prometheus_metric" -``` --To identify the ingestion volume of each metrics size in GB per day to understand if it's high, the following query is provided. --``` -InsightsMetrics -| where Namespace contains "prometheus" -| where TimeGenerated > ago(24h) -| summarize VolumeInGB = (sum(_BilledSize) / (1024 * 1024 * 1024)) by Name -| order by VolumeInGB desc -| render barchart -``` --The output will show results similar to the following example. -<!-- convertborder later --> --To estimate what each metrics size in GB is for a month to understand if the volume of data ingested received in the workspace is high, the following query is provided. --``` -InsightsMetrics -| where Namespace contains "prometheus" -| where TimeGenerated > ago(24h) -| summarize EstimatedGBPer30dayMonth = (sum(_BilledSize) / (1024 * 1024 * 1024)) * 30 by Name -| order by EstimatedGBPer30dayMonth desc -| render barchart -``` --The output will show results similar to the following example. -<!-- convertborder later --> ----## Configuration or scraping errors -To investigate any configuration or scraping errors, the following example query returns informational events from the `KubeMonAgentEvents` table. --``` -KubeMonAgentEvents | where Level != "Info" -``` --The output shows results similar to the following example: ---## Frequently asked questions -This section provides answers to common questions. --### Can I view metrics collected in Grafana? -Container insights support viewing metrics stored in your Log Analytics workspace in Grafana dashboards. We've provided a template that you can download from the Grafana [dashboard repository](https://grafana.com/grafana/dashboards?dataSource=grafana-azure-monitor-datasource&category=docker). Use it to get started and as a reference to help you learn how to query data from your monitored clusters to visualize in custom Grafana dashboards. --### Why are log lines larger than 16 KB split into multiple records in Log Analytics? -The agent uses the [Docker JSON file logging driver](https://docs.docker.com/config/containers/logging/json-file/) to capture the stdout and stderr of containers. This logging driver splits log lines [larger than 16 KB](https://github.com/moby/moby/pull/22982) into multiple lines when they're copied from stdout or stderr to a file. Use [Multi-line logging](./container-insights-logs-schema.md#multi-line-logging) to get log record size up to 64KB. -- --## Next steps --Container insights doesn't include a predefined set of alerts. To learn how to create recommended alerts for high CPU and memory utilization to support your DevOps or operational processes and procedures, see [Create performance alerts with Container insights](./container-insights-log-alerts.md). |
| azure-monitor | Container Insights Logs Schema | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-logs-schema.md | - Title: Configure the ContainerLogV2 schema for Container Insights -description: Switch your ContainerLog table to the ContainerLogV2 schema. ---- Previously updated : 08/28/2023----# Container insights log schema -Container insights stores log data it collects in a table called *ContainerLogV2* in a Log Analytics workspace. This article describes the schema of this table and configuration options for it. It also compares this table to the legacy *ContainerLog* table and provides detail for migrating from it. ---## Table comparison --*ContainerLogV2* is the default schema for CLI version 2.54.0 and greater. This is the default table for customers who onboard Container insights with managed identity authentication. ContainerLogV2 can be explicitly enabled through CLI version 2.51.0 or higher using data collection settings. -->[!IMPORTANT] -> Support for the *ContainerLog* table will be retired on 30th September 2026. --The following table highlights the key differences between using ContainerLogV2 and ContainerLog schema. --| Feature differences | ContainerLog | ContainerLogV2 | -| - | -- | - | -| Schema | Details at [ContainerLog](/azure/azure-monitor/reference/tables/containerlog). | Details at [ContainerLogV2](/azure/azure-monitor/reference/tables/containerlogv2).<br>Additional columns are:<br>- `ContainerName`<br>- `PodName`<br>- `PodNamespace`<br>- `LogLevel`<sup>1</sup><br>- `KubernetesMetadata`<sup>2</sup> | -| Onboarding | Only configurable through ConfigMap. | Configurable through both ConfigMap and DCR. <sup>3</sup>| -| Pricing | Only compatible with full-priced analytics logs. | Supports the low cost [basic logs](../logs/logs-table-plans.md) tier in addition to analytics logs. | -| Querying | Requires multiple join operations with inventory tables for standard queries. | Includes additional pod and container metadata to reduce query complexity and join operations. | -| Multiline | Not supported, multiline entries are split into multiple rows. | Support for multiline logging to allow consolidated, single entries for multiline output. | --<sup>1</sup> If `LogMessage` is valid JSON and has a key named `level`, its value will be used. Otherwise, regex based keyword matching is used to infer `LogLevel` from `LogMessage`. This inference may result in some misclassifications. `LogLevel` is a string field with a health value such as `CRITICAL`, `ERROR`, `WARNING`, `INFO`, `DEBUG`, `TRACE`, or `UNKNOWN`. --<sup>2</sup> `KubernetesMetadata` is an optional column that is enabled with [Kubernetes metadata](). The value of this field is JSON with the fields `podLabels`, `podAnnotations`, `podUid`, `Image`, `ImageTag`, and `Image repo`. --<sup>3</sup> DCR configuration requires [managed identity authentication](./container-insights-authentication.md). -->[!NOTE] -> [Export](../logs/logs-data-export.md) to Event Hub and Storage Account is not supported if the incoming `LogMessage` is not valid JSON. For best performance, emit container logs in JSON format. ---## Enable the ContainerLogV2 schema -Enable the **ContainerLogV2** schema for a cluster either using the cluster's [Data Collection Rule (DCR)](./container-insights-data-collection-configure.md#configure-data-collection-using-dcr) or [ConfigMap](./container-insights-data-collection-configure.md#configure-data-collection-using-configmap). If both settings are enabled, the ConfigMap takes precedence. The `ContainerLog` table is used only when both the DCR and ConfigMap are explicitly set to off. --Before you enable the **ContainerLogsV2** schema, you should assess whether you have any alert rules that rely on the **ContainerLog** table. Any such alerts need to be updated to use the new table. Run the following Azure Resource Graph query to scan for alert rules that reference the `ContainerLog` table. --```Kusto -resources -| where type in~ ('microsoft.insights/scheduledqueryrules') and ['kind'] !in~ ('LogToMetric') -| extend severity = strcat("Sev", properties["severity"]) -| extend enabled = tobool(properties["enabled"]) -| where enabled in~ ('true') -| where tolower(properties["targetResourceTypes"]) matches regex 'microsoft.operationalinsights/workspaces($|/.*)?' or tolower(properties["targetResourceType"]) matches regex 'microsoft.operationalinsights/workspaces($|/.*)?' or tolower(properties["scopes"]) matches regex 'providers/microsoft.operationalinsights/workspaces($|/.*)?' -| where properties contains "ContainerLog" -| project id,name,type,properties,enabled,severity,subscriptionId -| order by tolower(name) asc -``` --## Kubernetes metadata and logs filtering -Kubernetes metadata and logs filtering extends the ContainerLogsV2 schema with additional Kubernetes metadata. The logs filtering feature provides filtering capabilities for both workload and platform containers. These features give you richer context and improved visibility into your workloads. --### Features --- **Enhanced ContainerLogV2 schema**- When Kubernetes Logs Metadata is enabled, it adds a column to `ContainerLogV2` called `KubernetesMetadata` that enhances troubleshooting with simple log queries and removes the need for joining with other tables. The fields in this column include: `PodLabels`, `PodAnnotations`, `PodUid`, `Image`, `ImageID`, `ImageRepo`, `ImageTag`. These fields enhance the troubleshooting experience using log queries without having to join with other tables. See below for details on enabling the Kubernetes metadata feature. -- **Log level**- This feature adds a `LogLevel` column to ContainerLogV2 with the possible values **critical**, **error**, **warning**, **info**, **debug**, **trace**, or **unknown**. This helps you assess application health based on severity level. Adding the Grafana dashboard, you can visualize the log level trends over time and quickly pinpoint affected resources. -- **Grafana dashboard for visualization**- The Grafana dashboard provides a color-coded visualization of the **log level** and also provides insights into Log Volume, Log Rate, Log Records, Logs. You can get time-sensitive analysis, dynamic insights into log level trends over time, and crucial real-time monitoring. The dashboard also provides a detailed breakdown by computer, pod, and container, which empowers in-depth analysis and pinpointed troubleshooting. See below for details on installing the Grafana dashboard. -- **Annotation based log filtering for workloads**- Efficient log filtering through pod annotations. This allows you to focus on relevant information without sifting through noise. Annotation-based filtering enables you to exclude log collection for certain pods and containers by annotating the pod, which would help reduce the log analytics cost significantly. See [Annotation-based log filtering](./container-insights-data-collection-filter.md#annotation-based-filtering-for-workloads) for details on configuring annotation based filtering. -- **ConfigMap based log filtering for platform logs (System Kubernetes Namespaces)**- Platform logs are emitted by containers in the system (or similar restricted) namespaces. By default, all the container logs from the system namespace are excluded to minimize the cost of data in your Log Analytics workspace. In specific troubleshooting scenarios though, container logs of system container play a crucial role. One example is the `coredns` container in the `kube-system` namespace. -- > [!VIDEO https://learn-video.azurefd.net/vod/player?id=15c1c297-9e96-47bf-a31e-76056d026bd1] ---### Enable Kubernetes metadata --> [!IMPORTANT] -> Collection of Kubernetes metadata requires [managed identity authentication](./container-insights-authentication.md#migrate-to-managed-identity-authentication) and [ContainerLogsV2](./container-insights-logs-schema.md) ---Enable Kubernetes metadata using [ConfigMap](./container-insights-data-collection-configure.md#configure-data-collection-using-configmap) with the following settings. All metadata fields are collected by default when the `metadata_collection` is enabled. Uncomment `include_fields` to specify individual fields to be collected. --```yaml -[log_collection_settings.metadata_collection] - enabled = true - include_fields = ["podLabels","podAnnotations","podUid","image","imageID","imageRepo","imageTag"] -``` --After a few minutes, the `KubernetesMetadata` column should be included with any log queries for `ContainerLogV2` table as shown below. ----### Install Grafana dashboard --> [!IMPORTANT] -> If you enabled Grafana using the guidance at [Enable monitoring for Kubernetes clusters](./kubernetes-monitoring-enable.md#enable-prometheus-and-grafana) then your Grafana instance should already have access to your Azure Monitor workspace for Prometheus metrics. The Kubernetes Logs Metadata dashboard also requires access to your Log Analytics workspace which contains log data. See [How to modify access permissions to Azure Monitor](../../managed-grafan) for guidance on granting your Grafana instance the Monitoring Reader role for your Log Analytics workspace. --Import the dashboard from the Grafana gallery at [ContainerLogV2 Dashboard](https://grafana.com/grafana/dashboards/20995-azure-monitor-container-insights-containerlogv2/). You can then open the dashboard and select values for DataSource, Subscription, ResourceGroup, Cluster, Namespace, and Labels. --->[!NOTE] -> When you initially load the Grafana Dashboard, you may see errors due to variables not yet being selected. To prevent this from recurring, save the dashboard after selecting a set of variables so that it becomes default on the first open. --## Multi-line logging -With multiline logging enabled, previously split container logs are stitched together and sent as single entries to the ContainerLogV2 table. If the stitched log line is larger than 64 KB, it will be truncated due to Log Analytics workspace limits. This feature also has support for .NET, Go, Python and Java stack traces, which appear as single entries in the ContainerLogV2 table. Enable multiline logging with ConfigMap as described in [Configure data collection in Container insights using ConfigMap](container-insights-data-collection-configmap.md). -->[!NOTE] -> The configmap now features a language specification option, wherein the customers can select only the languages that they are interested in. This feature can be enabled by editing the languages in the stacktrace_languages option in the [configmap](https://github.com/microsoft/Docker-Provider/blob/ci_prod/kubernetes/container-azm-ms-agentconfig.yaml). --The following screenshots show multi-line logging for Go exception stack trace: --**Multi-line logging disabled** --<!-- convertborder later --> --**Multi-line logging enabled** --<!-- convertborder later --> --**Java stack trace** ---**Python stack trace** -----## Next steps -* Configure [Basic Logs](../logs/logs-table-plans.md) for ContainerLogv2. -* Learn how [query data](./container-insights-log-query.md#container-logs) from ContainerLogV2 |
| azure-monitor | Container Insights Manage Agent | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-manage-agent.md | - Title: Manage the Container insights agent -description: Describes how to manage the most common maintenance tasks with the containerized Log Analytics agent used by Container insights. - Previously updated : 12/19/2023----# Manage the Container insights agent --Container Insights uses a containerized version of the Log Analytics agent for Linux. After initial deployment, you might need to perform routine or optional tasks during its lifecycle. This article explains how to manually upgrade the agent and disable collection of environmental variables from a particular container. --> [!NOTE] -> If you've already deployed an AKS cluster and enabled monitoring by using either the Azure CLI or a Resource Manager template, you can't use `kubectl` to upgrade, delete, redeploy, or deploy the agent. The template needs to be deployed in the same resource group as the cluster. ---## Upgrade the Container insights agent --Container Insights uses a containerized version of the Log Analytics agent for Linux. When a new version of the agent is released, the agent is automatically upgraded on your managed Kubernetes clusters hosted on Azure Kubernetes Service (AKS) and Azure Arc-enabled Kubernetes. --If the agent upgrade fails for a cluster hosted on AKS, this article also describes the process to manually upgrade the agent. To follow the versions released, see [Agent release announcements](https://aka.ms/ci-logs-agent-release-notes). --### Upgrade the agent on an AKS cluster --The process to upgrade the agent on an AKS cluster consists of two steps. The first step is to disable monitoring with Container insights by using the Azure CLI. Follow the steps described in [Disable Container insights on your Kubernetes cluster](kubernetes-monitoring-disable.md) article. By using the Azure CLI, you can remove the agent from the nodes in the cluster without affecting the solution and the corresponding data that's stored in the workspace. -->[!NOTE] ->While you're performing this maintenance activity, the nodes in the cluster aren't forwarding collected data. Performance views won't show data between the time you removed the agent and installed the new version. -> --The second step is to install the new version of the agent. Follow the steps described in [Enable monitoring by using the Azure CLI](container-insights-enable-new-cluster.md#enable-using-azure-cli) to finish this process. --After you've reenabled monitoring, it might take about 15 minutes before you can view updated health metrics for the cluster. You have two methods to verify the agent upgraded successfully: --* Run the command `kubectl get pod <ama-logs-agent-pod-name> -n kube-system -o=jsonpath='{.spec.containers[0].image}'`. In the status returned, note the value under **Image** for Azure Monitor Agent in the **Containers** section of the output. -* On the **Nodes** tab, select the cluster node. On the **Properties** pane to the right, note the value under **Agent Image Tag**. --The version of the agent shown should match the latest version listed on the [Release history](https://github.com/microsoft/docker-provider/tree/ci_feature_prod) page. --### Upgrade the agent on a hybrid Kubernetes cluster --Perform the following steps to upgrade the agent on a Kubernetes cluster that runs on: --* Self-managed Kubernetes clusters hosted on Azure by using the AKS engine. -* Self-managed Kubernetes clusters hosted on Azure Stack or on-premises by using the AKS engine. --If the Log Analytics workspace is in commercial Azure, run the following command: --```console -$ helm upgrade --set omsagent.secret.wsid=<your_workspace_id>,omsagent.secret.key=<your_workspace_key>,omsagent.env.clusterName=<my_prod_cluster> incubator/azuremonitor-containers -``` --If the Log Analytics workspace is in Microsoft Azure operated by 21Vianet, run the following command: --```console -$ helm upgrade --set omsagent.domain=opinsights.azure.cn,omsagent.secret.wsid=<your_workspace_id>,omsagent.secret.key=<your_workspace_key>,omsagent.env.clusterName=<your_cluster_name> incubator/azuremonitor-containers -``` --If the Log Analytics workspace is in Azure US Government, run the following command: --```console -$ helm upgrade --set omsagent.domain=opinsights.azure.us,omsagent.secret.wsid=<your_workspace_id>,omsagent.secret.key=<your_workspace_key>,omsagent.env.clusterName=<your_cluster_name> incubator/azuremonitor-containers -``` --## Disable environment variable collection on a container --Container Insights collects environmental variables from the containers running in a pod and presents them in the property pane of the selected container in the **Containers** view. You can control this behavior by disabling collection for a specific container either during deployment of the Kubernetes cluster or after by setting the environment variable `AZMON_COLLECT_ENV`. This feature is available from the agent version ciprod11292018 and higher. --To disable collection of environmental variables on a new or existing container, set the variable `AZMON_COLLECT_ENV` with a value of `False` in your Kubernetes deployment YAML configuration file. --```yaml -- name: AZMON_COLLECT_ENV - value: "False" -``` --Run the following command to apply the change to Kubernetes clusters other than Azure Red Hat OpenShift: `kubectl apply -f <path to yaml file>`. To edit ConfigMap and apply this change for Azure Red Hat OpenShift clusters, run the following command: --```bash -oc edit configmaps container-azm-ms-agentconfig -n openshift-azure-logging -``` --This command opens your default text editor. After you set the variable, save the file in the editor. --To verify the configuration change took effect, select a container in the **Containers** view in Container insights. In the property pane, expand **Environment Variables**. The section should show only the variable created earlier, which is `AZMON_COLLECT_ENV=FALSE`. For all other containers, the **Environment Variables** section should list all the environment variables discovered. --To reenable discovery of the environmental variables, apply the same process you used earlier and change the value from `False` to `True`. Then rerun the `kubectl` command to update the container. -```yaml -- name: AZMON_COLLECT_ENV - value: "True" -``` -## Semantic version update of container insights agent version --Container Insights has shifted the image version and naming convention to [semver format] (https://semver.org/). SemVer helps developers keep track of every change made to software during its development phase and ensures that the software versioning is consistent and meaningful. The old version was in format of ciprod\<timestamp\>-\<commitId\> and win-ciprod\<timestamp\>-\<commitId\>, our first image versions using the Semver format are 3.1.4 for Linux and win-3.1.4 for Windows. --Semver is a universal software versioning schema that's defined in the format MAJOR.MINOR.PATCH, which follows the following constraints: --1. Increment the MAJOR version when you make incompatible API changes. -2. Increment the MINOR version when you add functionality in a backwards compatible manner. -3. Increment the PATCH version when you make backwards compatible bug fixes. - -With the rise of Kubernetes and the OSS ecosystem, Container Insights migrate to use semver image following the K8s recommended standard wherein with each minor version introduced, all breaking changes were required to be publicly documented with each new Kubernetes release. --## Repair duplicate agents --If you manually enabled Container Insights using custom methods prior to October 2022, you can end up with multiple versions of the agent running together. Follow the steps below to clear this duplication. ---1. Gather details of any custom settings, such as memory and CPU limits on your omsagent containers. --2. Review default resource limits for ama-logs and determine if they meet your needs. If not, you may need to create a support topic to help investigate and toggle memory/cpu limits. This can help address the scale limitations issues that some customers encountered previously that resulted in OOMKilled exceptions. -- | OS | Controller Name | Default Limits | - |||| - | Linux | ds-cpu-limit-linux | 500m | - | Linux | ds-memory-limit-linux | 750Mi | - | Linux | rs-cpu-limit | 1 | - | Linux | rs-memory-limit | 1.5Gi | - | Windows | ds-cpu-limit-windows | 500m | - | Windows | ds-memory-limit-windows | 1Gi | ---4. Clean resources from previous onboarding: -- **If you previously onboarded using helm chart** : - - List all releases across namespaces with the following command: - - ```console - helm list --all-namespaces - ``` - - Clean the chart installed for Container insights with the following command: - - ```console - helm uninstall <releaseName> --namespace <Namespace> - ``` -- **If you previously onboarded using yaml deployment** : - - Download previous custom deployment yaml file with the following command: - - ```console - curl -LO raw.githubusercontent.com/microsoft/Docker-Provider/ci_dev/kubernetes/omsagent.yaml - ``` - - Clean the old omsagent chart with the following command: - - ```console - kubectl delete -f omsagent.yaml - ``` --5. Disable Container insights to clean all related resources using the guidance at [Disable Container insights on your Kubernetes cluster](../containers/kubernetes-monitoring-disable.md) ---6. Re-onboard to Container insights using the guidance at [Enable Container insights on your Kubernetes cluster](kubernetes-monitoring-enable.md) ----## Next steps --If you experience issues when you upgrade the agent, review the [troubleshooting guide](container-insights-troubleshoot.md) for support. - |
| azure-monitor | Container Insights Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-overview.md | - Title: Azure Monitor features for Kubernetes monitoring -description: Describes Container insights and Managed Prometheus in Azure Monitor, which work together to monitor your Kubernetes clusters. -- Previously updated : 12/20/2023----# Azure Monitor features for Kubernetes monitoring --[Azure Monitor managed service for Prometheus](../essentials/prometheus-metrics-overview.md) and Container insights work together for complete monitoring of your Kubernetes environment. This article describes both features and the data they collect. --- [Azure Monitor managed service for Prometheus](../essentials/prometheus-metrics-overview.md) is a fully managed service based on the [Prometheus](https://aka.ms/azureprometheus-promio) project from the Cloud Native Computing Foundation. It allows you to collect and analyze metrics from your Kubernetes cluster at scale and analyze them using prebuilt dashboards in [Grafana](../../managed-grafan).-- Container insights is a feature of Azure Monitor that collects and analyzes container logs from [Azure Kubernetes clusters](/azure/aks/intro-kubernetes) or [Azure Arc-enabled Kubernetes](../../azure-arc/kubernetes/overview.md) clusters and their components. You can analyze the collected data for the different components in your cluster with a collection of [views](container-insights-analyze.md) and prebuilt [workbooks](container-insights-reports.md).--> [!IMPORTANT] -> Container insights collects metric data from your cluster in addition to logs. This functionality has been replaced by [Azure Monitor managed service for Prometheus](../essentials/prometheus-metrics-overview.md). You can analyze that data using built-in dashboards in [Managed Grafana](../../managed-grafan). -> -> You can continue to have Container insights collect metric data so you can use the Container insights monitoring experience. Or you can save cost by disabling this collection and using Grafana for metric analysis. See [Configure data collection in Container insights using data collection rule](container-insights-data-collection-dcr.md) for configuration options. -> -## Data collected -Container insights sends data to a [Log Analytics workspace](../logs/data-platform-logs.md) where you can analyze it using different features of Azure Monitor. Managed Prometheus sends data to an [Azure Monitor workspace](../essentials/azure-monitor-workspace-overview.md) where it can be accessed by Managed Grafana. See [Monitoring data](/azure/aks/monitor-aks#monitoring-data) for further details on this data. ---## Supported configurations -Container insights supports the following environments: --- [Azure Kubernetes Service (AKS)](/azure/aks/)-- Following [Azure Arc-enabled Kubernetes cluster distributions](../../azure-arc/kubernetes/validation-program.md):- - AKS on Azure Stack HCI - - AKS Edge Essentials - - Canonical - - Cluster API Provider on Azure - - K8s on Azure Stack Edge - - Red Hat OpenShift version 4.x - - SUSE Rancher (Rancher Kubernetes engine) - - SUSE Rancher K3s - - VMware (TKG) --> [!NOTE] -> Container insights supports ARM64 nodes on AKS. See [Cluster requirements](../../azure-arc/kubernetes/system-requirements.md#cluster-requirements) for the details of Azure Arc-enabled clusters that support ARM64 nodes. -> -> Container insights support for Windows Server 2022 operating system is in public preview. --## Security --- Container Insights supports FIPS enabled Linux and Windows node pools starting with Agent version 3.1.17 (Linux) & Win-3.1.17 (Windows).-- Starting with Agent version 3.1.17 (Linux) and Win-3.1.17 (Windows), Container Insights agents images (both Linux and Windows) are signed and for Windows agent, binaries inside the container are signed as well--## Access Container insights --Access Container insights in the Azure portal from **Containers** in the **Monitor** menu or directly from the selected AKS cluster by selecting **Insights**. The Azure Monitor menu gives you the global perspective of all the containers that are deployed and monitored. This information allows you to search and filter across your subscriptions and resource groups. You can then drill into Container insights from the selected container. Access Container insights for a particular cluster from its page in the Azure portal. ----## Agent --Container insights and Managed Prometheus rely on a containerized [Azure Monitor agent](../agents/agents-overview.md) for Linux. This specialized agent collects performance and event data from all nodes in the cluster. The agent is deployed and registered with the specified workspaces during deployment. When you enable Container insights on a cluster, a [Data collection rule (DCR)](../essentials/data-collection-rule-overview.md) is created with the name `MSCI-<cluster-region>-<cluster-name>` that contains the definition of data that should be collected by Azure Monitor agent. --Since March 1, 2023 Container insights uses a semver compliant agent version. The agent version is *mcr.microsoft.com/azuremonitor/containerinsights/ciprod:3.1.4* or later. When a new version of the agent is released, it will be automatically upgraded on your managed Kubernetes clusters that are hosted on AKS. To track which versions are released, see [Agent release announcements](https://github.com/microsoft/Docker-Provider/blob/ci_prod/ReleaseNotes.md). ---### Log Analytics agent --When Container insights doesn't use managed identity authentication, it relies on a containerized [Log Analytics agent for Linux](../agents/log-analytics-agent.md). The agent version is *microsoft/oms:ciprod04202018* or later. When a new version of the agent is released, it's automatically upgraded on your managed Kubernetes clusters that are hosted on AKS. To track which versions are released, see [Agent release announcements](https://github.com/microsoft/docker-provider/tree/ci_feature_prod). --With the general availability of Windows Server support for AKS, an AKS cluster with Windows Server nodes has a preview agent installed as a daemon set pod on each individual Windows Server node to collect logs and forward them to Log Analytics. For performance metrics, a Linux node is automatically deployed in the cluster as part of the standard deployment collects and forwards the data to Azure Monitor for all Windows nodes in the cluster. ---## Frequently asked questions --This section provides answers to common questions. --**Is there support for collecting Kubernetes audit logs for ARO clusters?** -No. Container insights don't support collection of Kubernetes audit logs. --**Does Container Insights support pod sandboxing?** -Yes, Container Insights supports pod sandboxing through support for Kata Containers. See [Pod Sandboxing (preview) with Azure Kubernetes Service (AKS)](/azure/aks/use-pod-sandboxing). --**Is it possible for a single AKS cluster to use multiple Log Analytics workspaces in Container Insights?** -No. Container insights only accepts one Log Analytics Workspace in Container Insights for each AKS cluster. --## Next steps --- See [Enable monitoring for Kubernetes clusters](kubernetes-monitoring-enable.md) to enable Managed Prometheus and Container insights on your cluster.--<!-- LINKS - external --> -[aks-release-notes]: https://github.com/Azure/AKS/releases |
| azure-monitor | Container Insights Persistent Volumes | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-persistent-volumes.md | - Title: Configure PV monitoring with Container insights | Microsoft Docs -description: This article describes how you can configure monitoring Kubernetes clusters with persistent volumes with Container insights. - Previously updated : 5/15/2024----# Configure PV monitoring with Container insights --Container insights automatically starts monitoring PV usage by collecting the following metrics at 60-second intervals and storing them in the **InsightsMetrics** table. --| Metric name | Metric dimension (tags) | Metric description | -|--|--|-| -| `pvUsedBytes`| `podUID`, `podName`, `pvcName`, `pvcNamespace`, `capacityBytes`, `clusterId`, `clusterName`| Used space in bytes for a specific persistent volume with a claim used by a specific pod. The `capacityBytes` tag is folded in as a dimension in the Tags field to reduce data ingestion cost and to simplify queries.| --To learn more about how to configure collected PV metrics, see [Configure agent data collection for Container insights](./container-insights-data-collection-configmap.md). --## PV inventory --Container insights automatically starts monitoring PVs by collecting the following information at 60-second intervals and storing them in the **KubePVInventory** table. --|Data |Data source| Data type| Fields| -|--|--|-|-| -|Inventory of persistent volumes in a Kubernetes cluster |Kube API |`KubePVInventory` | `PVName`, `PVCapacityBytes`, `PVCName`, `PVCNamespace`, `PVStatus`, `PVAccessModes`, `PVType`, `PVTypeInfo`, `PVStorageClassName`, `PVCreationTimestamp`, `TimeGenerated`, `ClusterId`, `ClusterName`, `_ResourceId` | --## Monitor persistent volumes --Container insights includes preconfigured charts for this usage metric and inventory information in workbook templates for every cluster. You can also enable a recommended alert for PV usage and query these metrics in Log Analytics. --### Workload Details workbook --You can find usage charts for specific workloads on the **Persistent Volumes** tab of the **Workload Details** workbook directly from an Azure Kubernetes Service (AKS) cluster. Select **Workbooks** on the left pane, from the **View Workbooks** dropdown list in the Insights pane, or from the **Reports (preview) tab** in the Insights pane. ---### Persistent Volume Details workbook --You can find an overview of persistent volume inventory in the **Persistent Volume Details** workbook directly from an AKS cluster by selecting **Workbooks** from the left pane. You can also open this workbook from the **View Workbooks** dropdown list in the Insights pane or from the **Reports** tab in the Insights pane. ---### Persistent Volume Usage recommended alert -You can enable a recommended alert to alert you when average PV usage for a pod is above 80%. To learn more about alerting, see [Metric alert rules in Container insights (preview)](./container-insights-metric-alerts.md). To learn how to override the default threshold, see the [Configure alertable metrics in ConfigMaps](./container-insights-metric-alerts.md#configure-alertable-metrics-in-configmaps) section. --## Limitations -Persistent volumes where storage class is "azureblob-*" won't collect PV metrics due to a limitation in CAdvisor. The following command will show persistent volumes and their properties (including storage class). - -```kubectl get pvc``` --## Next steps --To learn more about collected PV metrics, see [Configure agent data collection for Container insights](./container-insights-data-collection-configmap.md). |
| azure-monitor | Container Insights Prometheus Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-prometheus-logs.md | - Title: Collect Prometheus metrics with Container insights -description: Describes different methods for configuring the Container insights agent to scrape Prometheus metrics from your Kubernetes cluster. - Previously updated : 07/26/2024----# Send Prometheus metrics to Log Analytics workspace with Container insights -This article describes how to send Prometheus metrics from your Kubernetes cluster monitored by Container insights to a Log Analytics workspace. Before you perform this configuration, you should first ensure that you're [scraping Prometheus metrics from your cluster using Azure Monitor managed service for Prometheus](/azure/azure-monitor/containers/prometheus-metrics-scrape-configuration), which is the recommended method for monitoring your clusters. Use the configuration described in this article only if you also want to send this same data to a Log Analytics workspace where you can analyze it using [log queries](../logs/log-query-overview.md) and [log search alerts](../alerts/alerts-log-query.md). --This configuration requires configuring the *monitoring addon* for the Azure Monitor agent, which is the same one used by Container insights to send data to a Log Analytics workspace. It requires exposing the Prometheus metrics endpoint through your exporters or pods and then configuring the monitoring addon for the Azure Monitor agent used by Container insights as shown the following diagram. -----## Prometheus scraping settings (for metrics stored as logs) --Active scraping of metrics from Prometheus is performed from one of two perspectives below and metrics are sent to configured log analytics workspace : --- **Cluster-wide**: Defined in the ConfigMap section *[Prometheus data_collection_settings.cluster]*.-- **Node-wide**: Defined in the ConfigMap section *[Prometheus_data_collection_settings.node]*.--| Endpoint | Scope | Example | -|-|-|| -| Pod annotation | Cluster-wide | `prometheus.io/scrape: "true"` <br>`prometheus.io/path: "/mymetrics"` <br>`prometheus.io/port: "8000"` <br>`prometheus.io/scheme: "http"` | -| Kubernetes service | Cluster-wide | `http://my-service-dns.my-namespace:9100/metrics` <br>`http://metrics-server.kube-system.svc.cluster.local/metrics`ΓÇï | -| URL/endpoint | Per-node and/or cluster-wide | `http://myurl:9101/metrics` | --When a URL is specified, Container insights only scrapes the endpoint. When Kubernetes service is specified, the service name is resolved with the cluster DNS server to get the IP address. Then the resolved service is scraped. --|Scope | Key | Data type | Value | Description | -||--|--|-|-| -| Cluster-wide | | | | Specify any one of the following three methods to scrape endpoints for metrics. | -| | `urls` | String | Comma-separated array | HTTP endpoint (either IP address or valid URL path specified). For example: `urls=[$NODE_IP/metrics]`. ($NODE_IP is a specific Container insights parameter and can be used instead of a node IP address. Must be all uppercase.) | -| | `kubernetes_services` | String | Comma-separated array | An array of Kubernetes services to scrape metrics from kube-state-metrics. Fully qualified domain names must be used here. For example,`kubernetes_services = ["http://metrics-server.kube-system.svc.cluster.local/metrics",http://my-service-dns.my-namespace.svc.cluster.local:9100/metrics]`| -| | `monitor_kubernetes_pods` | Boolean | true or false | When set to `true` in the cluster-wide settings, the Container insights agent scrapes Kubernetes pods across the entire cluster for the following Prometheus annotations:<br> `prometheus.io/scrape:`<br> `prometheus.io/scheme:`<br> `prometheus.io/path:`<br> `prometheus.io/port:` | -| | `prometheus.io/scrape` | Boolean | true or false | Enables scraping of the pod, and `monitor_kubernetes_pods` must be set to `true`. | -| | `prometheus.io/scheme` | String | http | Defaults to scraping over HTTP. | -| | `prometheus.io/path` | String | Comma-separated array | The HTTP resource path from which to fetch metrics. If the metrics path isn't `/metrics`, define it with this annotation. | -| | `prometheus.io/port` | String | 9102 | Specify a port to scrape from. If the port isn't set, it defaults to 9102. | -| | `monitor_kubernetes_pods_namespaces` | String | Comma-separated array | An allowlist of namespaces to scrape metrics from Kubernetes pods.<br> For example, `monitor_kubernetes_pods_namespaces = ["default1", "default2", "default3"]` | -| Node-wide | `urls` | String | Comma-separated array | HTTP endpoint (either IP address or valid URL path specified). For example: `urls=[$NODE_IP/metrics]`. ($NODE_IP is a specific Container insights parameter and can be used instead of a node IP address. Must be all uppercase.) | -| Node-wide or cluster-wide | `interval` | String | 60s | The collection interval default is one minute (60 seconds). You can modify the collection for either the *[prometheus_data_collection_settings.node]* and/or *[prometheus_data_collection_settings.cluster]* to time units such as s, m, and h. | -| Node-wide or cluster-wide | `fieldpass`<br> `fielddrop`| String | Comma-separated array | You can specify certain metrics to be collected or not from the endpoint by setting the allow (`fieldpass`) and disallow (`fielddrop`) listing. You must set the allowlist first. | --## Configure ConfigMaps to specify Prometheus scrape configuration (for metrics stored as logs) -Perform the following steps to configure your ConfigMap configuration file for your cluster. ConfigMaps is a global list and there can be only one ConfigMap applied to the agent. You can't have another ConfigMaps overruling the collections. ----1. [Download](https://aka.ms/container-azm-ms-agentconfig) the template ConfigMap YAML file and save it as c*ontainer-azm-ms-agentconfig.yaml*. If you've already deployed a ConfigMap to your cluster and you want to update it with a newer configuration, you can edit the ConfigMap file you've previously used. -1. Edit the ConfigMap YAML file with your customizations to scrape Prometheus metrics. --- ### [Cluster-wide](#tab/cluster-wide) -- To collect Kubernetes services cluster-wide, configure the ConfigMap file by using the following example: -- ``` - prometheus-data-collection-settings: |- ΓÇï - # Custom Prometheus metrics data collection settings - [prometheus_data_collection_settings.cluster] ΓÇï - interval = "1m" ## Valid time units are s, m, h. - fieldpass = ["metric_to_pass1", "metric_to_pass12"] ## specify metrics to pass through ΓÇï - fielddrop = ["metric_to_drop"] ## specify metrics to drop from collecting - kubernetes_services = ["http://my-service-dns.my-namespace:9102/metrics"] - ``` -- ### [Specific URL](#tab/url) -- To configure scraping of Prometheus metrics from a specific URL across the cluster, configure the ConfigMap file by using the following example: -- ``` - prometheus-data-collection-settings: |- ΓÇï - # Custom Prometheus metrics data collection settings - [prometheus_data_collection_settings.cluster] ΓÇï - interval = "1m" ## Valid time units are s, m, h. - fieldpass = ["metric_to_pass1", "metric_to_pass12"] ## specify metrics to pass through ΓÇï - fielddrop = ["metric_to_drop"] ## specify metrics to drop from collecting - urls = ["http://myurl:9101/metrics"] ## An array of urls to scrape metrics from - ``` -- ### [DaemonSet](#tab/deamonset) -- To configure scraping of Prometheus metrics from an agent's DaemonSet for every individual node in the cluster, configure the following example in the ConfigMap: -- ``` - prometheus-data-collection-settings: |- ΓÇï - # Custom Prometheus metrics data collection settings ΓÇï - [prometheus_data_collection_settings.node] ΓÇï - interval = "1m" ## Valid time units are s, m, h. - urls = ["http://$NODE_IP:9103/metrics"] ΓÇï - fieldpass = ["metric_to_pass1", "metric_to_pass2"] ΓÇï - fielddrop = ["metric_to_drop"] ΓÇï - ``` -- `$NODE_IP` is a specific Container insights parameter and can be used instead of a node IP address. It must be all uppercase. -- ### [Pod annotation](#tab/pod) -- To configure scraping of Prometheus metrics by specifying a pod annotation: -- 1. In the ConfigMap, specify the following configuration: -- ``` - prometheus-data-collection-settings: |- ΓÇï - # Custom Prometheus metrics data collection settings - [prometheus_data_collection_settings.cluster] ΓÇï - interval = "1m" ## Valid time units are s, m, h - monitor_kubernetes_pods = true - ``` -- 2. Specify the following configuration for pod annotations: -- ``` - - prometheus.io/scrape:"true" #Enable scraping for this pod ΓÇï - - prometheus.io/scheme:"http" #If the metrics endpoint is secured then you will need to set this to `https`, if not default ΓÇÿhttpΓÇÖΓÇï - - prometheus.io/path:"/mymetrics" #If the metrics path is not /metrics, define it with this annotation. ΓÇï - - prometheus.io/port:"8000" #If port is not 9102 use this annotationΓÇï - ``` - - If you want to restrict monitoring to specific namespaces for pods that have annotations, for example, only include pods dedicated for production workloads, set the `monitor_kubernetes_pod` to `true` in ConfigMap. Then add the namespace filter `monitor_kubernetes_pods_namespaces` to specify the namespaces to scrape from. An example is `monitor_kubernetes_pods_namespaces = ["default1", "default2", "default3"]`. --2. Run the following kubectl command: `kubectl apply -f <configmap_yaml_file.yaml>`. - - Example: `kubectl apply -f container-azm-ms-agentconfig.yaml`. --The configuration change can take a few minutes to finish before taking effect. All ama-logs pods in the cluster will restart. When the restarts are finished, a message appears that's similar to the following and includes the result `configmap "container-azm-ms-agentconfig" created`. ---## Verify configuration --To verify the configuration was successfully applied to a cluster, use the following command to review the logs from an agent pod: `kubectl logs ama-logs-fdf58 -n=kube-system`. ---If there are configuration errors from the Azure Monitor Agent pods, the output shows errors similar to the following example: --``` -***************Start Config Processing******************** -config::unsupported/missing config schema version - 'v21' , using defaults -``` --Errors related to applying configuration changes are also available for review. The following options are available to perform additional troubleshooting of configuration changes and scraping of Prometheus metrics: --- From an agent pod logs using the same `kubectl logs` command.--- From Live Data. Live Data logs show errors similar to the following example:-- ``` - 2019-07-08T18:55:00Z E! [inputs.prometheus]: Error in plugin: error making HTTP request to http://invalidurl:1010/metrics: Get http://invalidurl:1010/metrics: dial tcp: lookup invalidurl on 10.0.0.10:53: no such host - ``` --- From the **KubeMonAgentEvents** table in your Log Analytics workspace. Data is sent every hour with *Warning* severity for scrape errors and *Error* severity for configuration errors. If there are no errors, the entry in the table has data with severity *Info*, which reports no errors. The **Tags** property contains more information about the pod and container ID on which the error occurred and also the first occurrence, last occurrence, and count in the last hour.-- For Azure Red Hat OpenShift v3.x and v4.x, check the Azure Monitor Agent logs by searching the **ContainerLog** table to verify if log collection of openshift-azure-logging is enabled.--Errors prevent Azure Monitor Agent from parsing the file, causing it to restart and use the default configuration. After you correct the errors in ConfigMap on clusters other than Azure Red Hat OpenShift v3.x, save the YAML file and apply the updated ConfigMaps by running the command `kubectl apply -f <configmap_yaml_file.yaml`. --For Azure Red Hat OpenShift v3.x, edit and save the updated ConfigMaps by running the command `oc edit configmaps container-azm-ms-agentconfig -n openshift-azure-logging`. --## Query Prometheus metrics data --To view Prometheus metrics scraped by Azure Monitor and any configuration/scraping errors reported by the agent, review [Query Prometheus metrics data](container-insights-log-query.md#prometheus-metrics). --## View Prometheus metrics in Grafana --Container insights supports viewing metrics stored in your Log Analytics workspace in Grafana dashboards. We've provided a template that you can download from Grafana's [dashboard repository](https://grafana.com/grafana/dashboards?dataSource=grafana-azure-monitor-datasource&category=docker). Use the template to get started and reference it to help you learn how to query other data from your monitored clusters to visualize in custom Grafana dashboards. ---## Next steps --- [See the default configuration for Prometheus metrics](../essentials/prometheus-metrics-scrape-default.md).-- [Customize Prometheus metric scraping for the cluster](../essentials/prometheus-metrics-scrape-configuration.md). |
| azure-monitor | Container Insights Region Mapping | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-region-mapping.md | - Title: Container insights region mappings -description: Describes the region mappings supported between Container insights, Log Analytics Workspace, and custom metrics. - Previously updated : 2/28/2024-----# Regions supported by Container insights --## Kubernetes cluster region -The following table specifies the regions that are supported for Container insights on different platforms. --| Platform | Regions | -|:|:| -| AKS | All regions supported by AKS as specified in [Azure Products by Region](https://azure.microsoft.com/explore/global-infrastructure/products-by-region/?products=kubernetes-service). | -| Arc-enabled Kubernetes | All public regions supported by Arc-enabled Kubernetes as specified in [Azure Products by Region](https://azure.microsoft.com/explore/global-infrastructure/products-by-region/?products=azure-arc). | --## Log Analytics workspace region -The Log Analytics workspace supporting Container insights must be in the same region except for the regions listed in the following table. ---|**Cluster region** | **Log Analytics Workspace region** | -|--|| -|**Africa** | | -|SouthAfricaNorth |WestEurope | -|SouthAfricaWest |WestEurope | -|**Australia** | | -|AustraliaCentral2 |AustraliaCentral | -|**Brazil** | | -|BrazilSouth | SouthCentralUS | -|**Canada** || -|CanadaEast |CanadaCentral | -|**Europe** | | -|FranceSouth |FranceCentral | -|UKWest |UKSouth | -|**India** | | -|SouthIndia |CentralIndia | -|WestIndia |CentralIndia | -|**Japan** | | -|JapanWest |JapanEast | -|**Korea** | | -|KoreaSouth |KoreaCentral | -|**US** | | -|WestCentralUS|EastUS | ---## Next steps --To begin monitoring your cluster, see [Enable monitoring for Kubernetes clusters](kubernetes-monitoring-enable.md) to understand the requirements and available methods to enable monitoring. |
| azure-monitor | Container Insights Reports | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-reports.md | - Title: Reports in Container insights -description: This article describes reports that are available to analyze data collected by Container insights. - Previously updated : 07/26/2024----# Reports in Container insights -Reports in Container insights are recommended out-of-the-box for [Azure workbooks](../visualize/workbooks-overview.md). This article describes the different workbooks that are available and how to access them. --> [!NOTE] -> The **Reports** tab will not be available if you enable the [Prometheus experience for Container insights](./container-insights-experience-v2.md). You can still access the workbooks from the **Workbooks** page for the cluster. -> -> :::image type="content" source="media/container-insights-reports/workbooks-page.png" alt-text="Screenshot of workbook option for a cluster." lightbox="media/container-insights-reports/workbooks-page.png"::: --## View workbooks -On the **Azure Monitor** menu in the Azure portal, select **Containers**. In the **Monitoring** section, select **Insights**, choose a particular cluster, and then select the **Reports** tab. You can also view them from the [workbook gallery](../visualize/workbooks-overview.md#the-gallery) in Azure Monitor. -<!-- convertborder later --> ---## Cluster Optimization Workbook -The Cluster Optimization Workbook provides multiple analyzers that give you a quick view of the health and performance of your Kubernetes cluster. It has multiple analyzers that each provide different information related to your cluster. The workbook requires no configuration once Container insights has been enabled on the cluster. ----### Liveness Probe Failures -The liveness probe failures analyzer shows which liveness probes have failed recently and how often. Select one to see a time-series of occurrences. This analyzer has the following columns: --- Total: counts liveness probe failures over the entire time range-- Controller Total: counts liveness probe failures from all containers managed by a controller---### Event Anomaly -The **event anomaly** analyzer groups similar events together for easier analysis. It also shows which event groups have recently increased in volume. Events in the list are grouped based on common phrases. For example, two events with messages *"pod-abc-123 failed, can not pull image"* and *"pod-def-456 failed, can not pull image"* would be grouped together. The **Spikiness** column rates which events have occurred more recently. For example, if Events A and B occurred on average 10 times a day in the last month, but event A occurred 1,000 times yesterday while event B occurred 2 times yesterday, then event A would have a much higher spikiness rating than B. ---### Container optimizer -The **container optimizer** analyzer shows containers with excessive cpu and memory limits and requests. Each tile can represent multiple containers with the same spec. For example, if a deployment creates 100 identical pods each with a container C1 and C2, then there will be a single tile for all C1 containers and a single tile for all C2 containers. Containers with set limits and requests are color-coded in a gradient from green to red. --> [!IMPORTANT] -> This view doesn't include containers in the **kube-system** namespace and doesn't support Windows Server nodes. -> --The number on each tile represents how far the container limits/requests are from the optimal/suggested value. The closer the number is to 0 the better it is. Each tile has a color to indicate the following: --- green: well set limits and requests-- red: excessive limits or requests-- gray: unset limits or requests-----## Node Monitoring workbooks --- **Disk Capacity**: Interactive disk usage charts for each disk presented to the node within a container by the following perspectives:-- - Disk percent usage for all disks. - - Free disk space for all disks. - - A grid that shows each node's disk, its percentage of used space, trend of percentage of used space, free disk space (GiB), and trend of free disk space (GiB). When a row is selected in the table, the percentage of used space and free disk space (GiB) is shown underneath the row. --- **Disk IO**: Interactive disk utilization charts for each disk presented to the node within a container by the following perspectives:-- - Disk I/O is summarized across all disks by read bytes/sec, writes bytes/sec, and read and write bytes/sec trends. - - Eight performance charts show key performance indicators to help measure and identify disk I/O bottlenecks. --- **GPU**: Interactive GPU usage charts for each GPU-aware Kubernetes cluster node.-->[!NOTE] -> In accordance with the Kubernetes [upstream announcement](https://kubernetes.io/blog/2020/12/16/third-party-device-metrics-reaches-g). --- **Subnet IP Usage**: Interactive IP usage charts for each node within a cluster by the following perspectives:- - - IPs allocated from subnet. - - IPs assigned to a pod. -->[!NOTE] -> By default 16 IP's are allocated from subnet to each node. This cannot be modified to be less than 16. For instructions on how to enable subnet IP usage metrics, see [Monitor IP Subnet Usage](/azure/aks/configure-azure-cni-dynamic-ip-allocation#monitor-ip-subnet-usage). --## Resource Monitoring workbooks --- **Deployments**: Status of your deployments and horizontal pod autoscaler (HPA) including custom HPAs.-- **Workload Details**: Interactive charts that show performance statistics of workloads for a namespace. Includes the following multiple tabs:-- - **Overview** of CPU and memory usage by pod. - - **POD/Container Status** showing pod restart trend, container restart trend, and container status for pods. - - **Kubernetes Events** showing a summary of events for the controller. --- **Kubelet**: Includes two grids that show key node operating statistics:-- - Overview by node grid summarizes total operation, total errors, and successful operations by percent and trend for each node. - - Overview by operation type summarizes for each operation the total operation, total errors, and successful operations by percent and trend. --## Billing workbook --- **Data Usage**: Helps you to visualize the source of your data without having to build your own library of queries from what we share in our documentation. In this workbook, you can view charts that present billable data such as:-- - Total billable data ingested in GB by solution. - - Billable data ingested by Container logs (application logs). - - Billable container logs data ingested per by Kubernetes namespace. - - Billable container logs data ingested segregated by Cluster name. - - Billable container log data ingested by log source entry. - - Billable diagnostic data ingested by diagnostic main node logs. --## Networking workbooks --- **NPM Configuration**: Monitoring of your network configurations, which are configured through the network policy manager (npm) for the:-- - Summary information about overall configuration complexity. - - Policy, rule, and set counts over time, allowing insight into the relationship between the three and adding a dimension of time to debugging a configuration. - - Number of entries in all IPSets and each IPSet. - - Worst and average case performance per node for adding components to your Network Configuration. --- **Network**: Interactive network utilization charts for each node's network adapter. A grid presents the key performance indicators to help measure the performance of your network adapters.--## Create a custom workbook -To create a custom workbook based on any of these workbooks, select the **View Workbooks** dropdown list and then select **Go to AKS Gallery** at the bottom of the list. For more information about workbooks and using workbook templates, see [Azure Monitor workbooks](../visualize/workbooks-overview.md). -<!-- convertborder later --> --## Next steps --For more information about workbooks in Azure Monitor, see [Azure Monitor workbooks](../visualize/workbooks-overview.md). |
| azure-monitor | Container Insights Syslog | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-syslog.md | - Title: Access Syslog data in Container Insights -description: Describes how to access Syslog data collected from AKS nodes using Container insights. - Previously updated : 08/19/2024----# Access Syslog data in Container Insights --Container Insights offers the ability to collect Syslog events from Linux nodes in your [Azure Kubernetes Service (AKS)](/azure/aks/intro-kubernetes) clusters. This includes the ability to collect logs from control plane components like kubelet. Customers can also use Syslog for monitoring security and health events, typically by ingesting syslog into a SIEM system like [Microsoft Sentinel](https://azure.microsoft.com/products/microsoft-sentinel/#overview). --## Prerequisites --- Syslog collection needs to be enabled for your cluster using the guidance in [Configure and filter log collection in Container insights](./container-insights-data-collection-configure.md#configure-data-collection-using-dcr).-- Port 28330 should be available on the host node.---## Built-in workbooks --To get a quick snapshot of your syslog data, use the built-in Syslog workbook using one of the following methods: --> [!NOTE] -> The **Reports** tab won't be available if you enable the [Container insights Prometheus experience](./container-insights-experience-v2.md) for your cluster. --- **Reports** tab in Container Insights. -Navigate to your cluster in the Azure portal and open the **Insights**. Open the **Reports** tab and locate the **Syslog** workbook. -- :::image type="content" source="media/container-insights-syslog/syslog-workbook-cluster.gif" lightbox="media/container-insights-syslog/syslog-workbook-cluster.gif" alt-text="Video of Syslog workbook being accessed from Container Insights Reports tab." border="true"::: --- **Workbooks** tab in AKS-Navigate to your cluster in the Azure portal. Open the **Workbooks** tab and locate the **Syslog** workbook. -- :::image type="content" source="media/container-insights-syslog/syslog-workbook-container-insights-reports-tab.gif" lightbox="media/container-insights-syslog/syslog-workbook-container-insights-reports-tab.gif" alt-text="Video of Syslog workbook being accessed from cluster workbooks tab." border="true"::: --## Grafana dashboard --If you use Grafana, you can use the Syslog dashboard for Grafana to get an overview of your Syslog data. This dashboard is available by default if you create a new Azure-managed Grafana instance. Otherwise, you can [import the Syslog dashboard from the Grafana marketplace](https://grafana.com/grafana/dashboards/19866-azure-monitor-container-insights-syslog/). --> [!NOTE] -> You need the **Monitoring Reader** role on the Subscription containing the Azure Managed Grafana instance to access syslog from Container Insights. ---## Log queries --Syslog data is stored in the [Syslog](/azure/azure-monitor/reference/tables/syslog) table in your Log Analytics workspace. You can create your own [log queries](../logs/log-query-overview.md) in [Log Analytics](../logs/log-analytics-overview.md) to analyze this data or use any of the [prebuilt queries](../logs/log-query-overview.md). ---You can open Log Analytics from the **Logs** menu in the **Monitor** menu to access Syslog data for all clusters or from the AKS cluster's menu to access Syslog data for a single cluster. - - -### Sample queries - -The following table provides different examples of log queries that retrieve Syslog records. --| Query | Description | -|: |: | -| `Syslog` |All Syslogs | -| `Syslog | where SeverityLevel == "error"` | All Syslog records with severity of error | -| `Syslog | summarize AggregatedValue = count() by Computer` | Count of Syslog records by computer | -| `Syslog | summarize AggregatedValue = count() by Facility` | Count of Syslog records by facility | -| `Syslog | where ProcessName == "kubelet"` | All Syslog records from the kubelet process | -| `Syslog | where ProcessName == "kubelet" and SeverityLevel == "error"` | Syslog records from kubelet process with errors | ----## Next steps --Once setup customers can start sending Syslog data to the tools of their choice -- [Send Syslog to Microsoft Sentinel](/azure/sentinel/connect-syslog)-- [Export data from Log Analytics](/azure/azure-monitor/logs/logs-data-export?tabs=portal)-- [Syslog record properties](/azure/azure-monitor/reference/tables/syslog)--Share your feedback for this feature here: https://forms.office.com/r/BBvCjjDLTS |
| azure-monitor | Container Insights Transformations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-transformations.md | - Title: Data transformations in Container insights -description: Describes how to transform data using a DCR transformation in Container insights. - Previously updated : 07/17/2024----# Data transformations in Container insights --This article describes how to implement data transformations in Container insights. [Transformations](../essentials/data-collection-transformations.md) in Azure Monitor allow you to modify or filter data before it's ingested in your Log Analytics workspace. They allow you to perform such actions as filtering out data collected from your cluster to save costs or processing incoming data to assist in your data queries. --> [!IMPORTANT] -> The articles [Configure log collection in Container insights](./container-insights-data-collection-configure.md) and [Filtering log collection in Container insights](./container-insights-data-collection-filter.md) describe standard configuration settings to configure and filter data collection for Container insights. You should perform any required configuration using these features before using transformations. Use a transformation to perform filtering or other data configuration that you can't perform with the standard configuration settings. --## Data collection rule -Transformations are implemented in [data collection rules (DCRs)](../essentials/data-collection-rule-overview.md) which are used to configure data collection in Azure Monitor. [Configure data collection using DCR](./container-insights-data-collection-configure.md) describes the DCR that's automatically created when you enable Container insights on a cluster. To create a transformation, you must perform one of the following actions: --- **New cluster**. Use an existing [ARM template ](https://github.com/microsoft/Docker-Provider/tree/ci_prod/scripts/onboarding/aks/onboarding-using-msi-auth) to onboard an AKS cluster to Container insights. Modify the DCR in that template with your required configuration, including a transformation similar to one of the samples below.-- **Existing DCR**. After a cluster has been onboarded to Container insights and data collection configured, edit its DCR to include a transformation using any of the methods in [Editing Data Collection Rules](../essentials/data-collection-rule-edit.md). --> [!NOTE] -> There is currently minimal UI for editing DCRs, which is required to add transformations. In most cases, you need to manually edit the the DCR. This article describes the DCR structure to implement. See [Create and edit data collection rules (DCRs) in Azure Monitor](../essentials/data-collection-rule-edit.md) for guidance on how to implement that structure. ---## Data sources -The [dataSources section of the DCR](../essentials/data-collection-rule-structure.md#datasources) defines the different types of incoming data that the DCR will process. For Container insights, this is the Container insights extension, which includes one or more predefined `streams` starting with the prefix *Microsoft-*. --The list of Container insights streams in the DCR depends on the [Cost preset](container-insights-cost-config.md#cost-presets) that you selected for the cluster. If you collect all tables, the DCR will use the `Microsoft-ContainerInsights-Group-Default` stream, which is a group stream that includes all of the streams listed in [Stream values](container-insights-cost-config.md#stream-values). You must change this to individual streams if you're going to use a transformation. Any other cost preset settings will already use individual streams. --The sample below shows the `Microsoft-ContainerInsights-Group-Default` stream. See the [Sample DCRs](#sample-dcrs) for samples using individual streams. --```json -"dataSources": { - "extensions": [ - { - "streams": [ - "Microsoft-ContainerInsights-Group-Default" - ], - "name": "ContainerInsightsExtension", - "extensionName": "ContainerInsights", - "extensionSettings": { - "dataCollectionSettings": { - "interval": "1m", - "namespaceFilteringMode": "Off", - "namespaces": null, - "enableContainerLogV2": true - } - } - } - ] -} -``` ----## Data flows -The [dataFlows section of the DCR](../essentials/data-collection-rule-structure.md#dataflows) matches streams with destinations that are defined in the `destinations` section of the DCR. Table names don't have to be specified for known streams if the data is being sent to the default table. The streams that don't require a transformation can be grouped together in a single entry that includes only the workspace destination. Each will be sent to its default table. --Create a separate entry for streams that require a transformation. This should include the workspace destination and the `transformKql` property. If you're sending data to an alternate table, then you need to include the `outputStream` property which specifies the name of the destination table. --The sample below shows the `dataFlows` section for a single stream with a transformation. See the [Sample DCRs](#sample-dcrs) for multiple data flows in a single DCR. --```json -"dataFlows": [ - { - "streams": [ - "Microsoft-ContainerLogV2" - ], - "destinations": [ - "ciworkspace" - ], - "transformKql": "source | where PodNamespace == 'kube-system'" - } -] -``` --## Sample DCRs ---### Filter data --The first example filters out data from the `ContainerLogV2` based on the `LogLevel` column. Only records with a `LogLevel` of `error` or `critical` will be collected since these are the entries that you might use for alerting and identifying issues in the cluster. Collecting and storing other levels such as `info` and `debug` generate cost without significant value. --You can retrieve these records using the following log query. --```kusto -ContainerLogV2 | where LogLevel in ('error', 'critical') -``` --This logic is shown in the following diagram. ----In a transformation, the table name `source` is used to represent the incoming data. Following is the modified query to use in the transformation. --```kusto -source | where LogLevel in ('error', 'critical') -``` --The following sample shows this transformation added to the Container insights DCR. Note that a separate data flow is used for `Microsoft-ContainerLogV2` since this is the only incoming stream that the transformation should be applied to. A separate data flow is used for the other streams. --```json -{ - "properties": { - "location": "eastus2", - "kind": "Linux", - "dataSources": { - "syslog": [], - "extensions": [ - { - "streams": [ - "Microsoft-ContainerLogV2", - "Microsoft-KubeEvents", - "Microsoft-KubePodInventory" - ], - "extensionName": "ContainerInsights", - "extensionSettings": { - "dataCollectionSettings": { - "interval": "1m", - "namespaceFilteringMode": "Off", - "enableContainerLogV2": true - } - }, - "name": "ContainerInsightsExtension" - } - ] - }, - "destinations": { - "logAnalytics": [ - { - "workspaceResourceId": "/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/my-resource-group/providers/microsoft.operationalinsights/workspaces/my-workspace", - "workspaceId": "00000000-0000-0000-0000-000000000000", - "name": "ciworkspace" - } - ] - }, - "dataFlows": [ - { - "streams": [ - "Microsoft-KubeEvents", - "Microsoft-KubePodInventory" - ], - "destinations": [ - "ciworkspace" - ], - }, - { - "streams": [ - "Microsoft-ContainerLogV2" - ], - "destinations": [ - "ciworkspace" - ], - "transformKql": "source | where LogLevel in ('error', 'critical')" - } - ], - }, -} -``` --### Send data to different tables --In the example above, only records with a `LogLevel` of `error` or `critical` are collected. An alternate strategy instead of not collecting these records at all is to save them to an alternate table configured for basic logs. --For this strategy, two transformations are needed. The first transformation sends the records with `LogLevel` of `error` or `critical` to the default table. The second transformation sends the other records to a custom table named `ContainerLogV2_CL`. The queries for each are shown below using `source` for the incoming data as described in the previous example. --```kusto -# Return error and critical logs -source | where LogLevel in ('error', 'critical') --# Return logs that aren't error or critical -source | where LogLevel !in ('error', 'critical') -``` --This logic is shown in the following diagram. ---> [!IMPORTANT] -> Before you install the DCR in this sample, you must [create a new table](../logs/create-custom-table.md) with the same schema as `ContainerLogV2`. Name it `ContainerLogV2_CL` and [configure it for basic logs](../logs/basic-logs-configure.md). --The following sample shows this transformation added to the Container insights DCR. There are two data flows for `Microsoft-ContainerLogV2` in this DCR, one for each transformation. The first sends to the default table you don't need to specify a table name. The second requires the `outputStream` property to specify the destination table. --```json -{ - "properties": { - "location": "eastus2", - "kind": "Linux", - "dataSources": { - "syslog": [], - "extensions": [ - { - "streams": [ - "Microsoft-ContainerLogV2", - "Microsoft-KubeEvents", - "Microsoft-KubePodInventory" - ], - "extensionName": "ContainerInsights", - "extensionSettings": { - "dataCollectionSettings": { - "interval": "1m", - "namespaceFilteringMode": "Off", - "enableContainerLogV2": true - } - }, - "name": "ContainerInsightsExtension" - } - ] - }, - "destinations": { - "logAnalytics": [ - { - "workspaceResourceId": "/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/my-resource-group/providers/microsoft.operationalinsights/workspaces/my-workspace", - "workspaceId": "00000000-0000-0000-0000-000000000000", - "name": "ciworkspace" - } - ] - }, - "dataFlows": [ - { - "streams": [ - "Microsoft-KubeEvents", - "Microsoft-KubePodInventory" - ], - "destinations": [ - "ciworkspace" - ], - }, - { - "streams": [ - "Microsoft-ContainerLogV2" - ], - "destinations": [ - "ciworkspace" - ], - "transformKql": "source | where LogLevel in ('error', 'critical')" - }, - { - "streams": [ - "Microsoft-ContainerLogV2" - ], - "destinations": [ - "ciworkspace" - ], - "transformKql": "source | where LogLevel !in ('error','critical')", - "outputStream": "Custom-ContainerLogV2_CL" - } - ], - }, -} -``` ----## Next steps --- Read more about [transformations](../essentials/data-collection-transformations.md) and [data collection rules](../essentials/data-collection-rule-overview.md) in Azure Monitor. |
| azure-monitor | Container Insights Transition Solution | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-transition-solution.md | - Title: Transition from the Container Monitoring Solution to using Container Insights Previously updated : 2/28/2024- -description: "Learn how to migrate from using the legacy OMS solution to monitoring your containers using Container Insights" ----# Transition from the Container Monitoring Solution to using Container Insights --With both the underlying platform and agent deprecations, on August 31, 2024 the [Container Monitoring Solution](./containers.md) will be retired. If you use the Container Monitoring Solution to ingest data to your Log Analytics workspace, make sure to transition to using [Container Insights](./container-insights-overview.md) prior to that date. --## Steps to complete the transition --To transition to Container Insights, we recommend the following approach. --1. Learn about the feature differences between the Container Monitoring Solution and Container Insights to determine which option suits your needs. --2. To use Container Insights, you will need to migrate your workload to Kubernetes. You can find more information on the compatible Kubernetes platforms from [Azure Kubernetes Services (AKS)](/azure/aks/intro-kubernetes) or [Azure Arc enabled Kubernetes](../../azure-arc/kubernetes/overview.md). If using AKS, you can choose to [deploy Container Insights](./container-insights-enable-new-cluster.md) as a part of the process. --3. Disable the existing monitoring of the Container Monitoring Solution using one of the following options: [Azure portal](/previous-versions/azure/azure-monitor/insights/solutions?tabs=portal#remove-a-monitoring-solution), [PowerShell](/powershell/module/az.monitoringsolutions/remove-azmonitorloganalyticssolution), or [Azure CLI](/cli/azure/monitor/log-analytics/solution#az-monitor-log-analytics-solution-delete) -4. If you elected to not onboard to Container Insights earlier, you can then deploy Container Insights using Azure CLI, ARM, or Portal following the instructions for [AKS](./container-insights-enable-existing-clusters.md) or [Arc enabled Kubernetes](./container-insights-enable-arc-enabled-clusters.md) -5. Validate that the installation was successful for either your [AKS](./container-insights-enable-existing-clusters.md#verify-agent-and-solution-deployment) or [Arc](./container-insights-enable-arc-enabled-clusters.md#verify-extension-installation-status) cluster. ---## Container Monitoring Solution vs Container Insights --The following table highlights the key differences between monitoring using the Container Monitoring Solution versus Container Insights. Container Insights to that of the Container Monitoring Solution. --| Feature Differences | Container Monitoring Solution | Container Insights | -| - | -- | - | -| Onboarding | Multi-step installation using Azure Marketplace & configuring Log Analytics Agent | Single step onboarding via Azure portal, CLI, or ARM | -| Agent | Log Analytics Agent (deprecated in 2024) | [Azure Monitor Agent](../agents/azure-monitor-agent-overview.md) -| Alerting | Log based alerts tied to Log Analytics Workspace | Log based alerting and [recommended metric-based](./container-insights-metric-alerts.md) alerts | -| Metrics | Does not support Azure Monitor metrics | Supports Azure Monitor metrics | -| Consumption | Viewable only from Log Analytics Workspace | Accessible from both Azure Monitor and AKS/Arc resource pane | -| Agent | Manual agent upgrades | Automatic updates for monitoring agent with version control through Azure Arc cluster extensions | --## Next steps --- [Disable Container Monitoring Solution](./containers.md#removing-solution-from-your-workspace)-- [Deploy an Azure Kubernetes Service](./container-insights-enable-new-cluster.md)-- [Connect your cluster](../../azure-arc/kubernetes/quickstart-connect-cluster.md) to the Azure Arc enabled Kubernetes platform-- Configure Container Insights for [Azure Kubernetes Service](./container-insights-enable-existing-clusters.md) or [Arc enabled Kubernetes](./container-insights-enable-arc-enabled-clusters.md) |
| azure-monitor | Container Insights Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/container-insights-troubleshoot.md | - Title: Troubleshoot Container insights | Microsoft Docs -description: This article describes how you can troubleshoot and resolve issues with Container insights. - Previously updated : 02/15/2024-----# Troubleshoot Container insights --When you configure monitoring of your Azure Kubernetes Service (AKS) cluster with Container insights, you might encounter an issue that prevents data collection or reporting status. This article discusses some common issues and troubleshooting steps. --## Known error messages --The following table summarizes known errors you might encounter when you use Container insights. --| Error messages | Action | -| - | | -| Error message "No data for selected filters" | It might take some time to establish monitoring data flow for newly created clusters. Allow at least 10 to 15 minutes for data to appear for your cluster.<br><br>If data still doesn't show up, check if the Log Analytics workspace is configured for `disableLocalAuth = true`. If yes, update back to `disableLocalAuth = false`.<br><br>`az resource show --ids "/subscriptions/[Your subscription ID]/resourcegroups/[Your resource group]/providers/microsoft.operationalinsights/workspaces/[Your workspace name]"`<br><br>`az resource update --ids "/subscriptions/[Your subscription ID]/resourcegroups/[Your resource group]/providers/microsoft.operationalinsights/workspaces/[Your workspace name]" --api-version "2021-06-01" --set properties.features.disableLocalAuth=False` | -| Error message "Error retrieving data" | While an AKS cluster is setting up for health and performance monitoring, a connection is established between the cluster and a Log Analytics workspace. A Log Analytics workspace is used to store all monitoring data for your cluster. This error might occur when your Log Analytics workspace has been deleted. Check if the workspace was deleted. If it was, reenable monitoring of your cluster with Container insights. Then specify an existing workspace or create a new one. To reenable, [disable](kubernetes-monitoring-disable.md) monitoring for the cluster and [enable](kubernetes-monitoring-enable.md) Container insights again. | -| "Error retrieving data" after adding Container insights through `az aks cli` | When you enable monitoring by using `az aks cli`, Container insights might not be properly deployed. Check whether the solution is deployed. To verify, go to your Log Analytics workspace and see if the solution is available by selecting **Legacy solutions** from the pane on the left side. To resolve this issue, redeploy the solution. Follow the instructions in [Enable Container insights](container-insights-onboard.md). | -| Error message "Missing Subscription registration" | If you receive the error "Missing Subscription registration for Microsoft.OperationsManagement," you can resolve it by registering the resource provider **Microsoft.OperationsManagement** in the subscription where the workspace is defined. For the steps, see [Resolve errors for resource provider registration](../../azure-resource-manager/templates/error-register-resource-provider.md). | -| Error message "The reply url specified in the request doesn't match the reply urls configured for the application: '<application ID\>'." | You might see this error message when you enable live logs. For the solution, see [View container data in real time with Container insights](./container-insights-livedata-setup.md#configure-azure-ad-integrated-authentication). | --To help diagnose the problem, we've provided a [troubleshooting script](https://github.com/microsoft/Docker-Provider/tree/ci_prod/scripts/troubleshoot). ---## Authorization error during onboarding or update operation --When you enable Container insights or update a cluster to support collecting metrics, you might receive an error like "The client `<user's Identity>` with object id `<user's objectId>` does not have authorization to perform action `Microsoft.Authorization/roleAssignments/write` over scope." --During the onboarding or update process, granting the **Monitoring Metrics Publisher** role assignment is attempted on the cluster resource. The user initiating the process to enable Container insights or the update to support the collection of metrics must have access to the **Microsoft.Authorization/roleAssignments/write** permission on the AKS cluster resource scope. Only members of the Owner and User Access Administrator built-in roles are granted access to this permission. If your security policies require you to assign granular-level permissions, see [Azure custom roles](../../role-based-access-control/custom-roles.md) and assign permission to the users who require it. --You can also manually grant this role from the Azure portal: Assign the **Publisher** role to the **Monitoring Metrics** scope. For detailed steps, see [Assign Azure roles by using the Azure portal](../../role-based-access-control/role-assignments-portal.yml). --## Container insights is enabled but not reporting any information -To diagnose the problem if you can't view status information or no results are returned from a log query: --1. Check the status of the agent by running the following command: -- `kubectl get ds ama-logs --namespace=kube-system` -- The number of pods should be equal to the number of Linux nodes on the cluster. The output should resemble the following example, which indicates that it was deployed properly: -- ``` - User@aksuser:~$ kubectl get ds ama-logs --namespace=kube-system - NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE - ama-logs 2 2 2 2 2 <none> 1d - ``` --1. If you have Windows Server nodes, check the status of the agent by running the following command: -- `kubectl get ds ama-logs-windows --namespace=kube-system` -- The number of pods should be equal to the number of Windows nodes on the cluster. The output should resemble the following example, which indicates that it was deployed properly: -- ``` - User@aksuser:~$ kubectl get ds ama-logs-windows --namespace=kube-system - NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE - ama-logs-windows 2 2 2 2 2 <none> 1d - ``` --1. Check the deployment status by using the following command: -- `kubectl get deployment ama-logs-rs --namespace=kube-system` -- The output should resemble the following example, which indicates that it was deployed properly: -- ``` - User@aksuser:~$ kubectl get deployment ama-logs-rs --namespace=kube-system - NAME READY UP-TO-DATE AVAILABLE AGE - ama-logs-rs 1/1 1 1 24d - ``` --1. Check the status of the pod to verify that it's running by using the command `kubectl get pods --namespace=kube-system`. -- The output should resemble the following example with a status of `Running` for ama-logs: -- ``` - User@aksuser:~$ kubectl get pods --namespace=kube-system - NAME READY STATUS RESTARTS AGE - aks-ssh-139866255-5n7k5 1/1 Running 0 8d - azure-vote-back-4149398501-7skz0 1/1 Running 0 22d - azure-vote-front-3826909965-30n62 1/1 Running 0 22d - ama-logs-484hw 1/1 Running 0 1d - ama-logs-fkq7g 1/1 Running 0 1d - ama-logs-windows-6drwq 1/1 Running 0 1d - ``` --1. If the pods are in a running state, but there is no data in Log Analytics or data appears to only send during a certain part of the day, it might be an indication that the daily cap has been met. When this limit is met each day, data stops ingesting into the Log Analytics Workspace and resets at the reset time. For more information, see [Log Analytics Daily Cap](../../azure-monitor/logs/daily-cap.md#determine-your-daily-cap). --1. If Containter insights is enabled using Terraform and `msi_auth_for_monitoring_enabled` is set to `true`, ensure that DCR and DCRA resources are also deployed to enable log collection. For detailed steps, see [enable Container insights](./kubernetes-monitoring-enable.md?tabs=terraform#enable-container-insights). --## Container insights agent ReplicaSet Pods aren't scheduled on a non-AKS cluster --Container insights agent ReplicaSet Pods have a dependency on the following node selectors on the worker (or agent) nodes for the scheduling: --``` -nodeSelector: - beta.kubernetes.io/os: Linux - kubernetes.io/role: agent -``` --If your worker nodes don’t have node labels attached, agent ReplicaSet Pods won't get scheduled. For instructions on how to attach the label, see [Kubernetes assign label selectors](https://kubernetes.io/docs/concepts/configuration/assign-pod-node/). --## Performance charts don't show CPU or memory of nodes and containers on a non-Azure cluster --Container insights agent pods use the cAdvisor endpoint on the node agent to gather performance metrics. Verify the containerized agent on the node is configured to allow `cAdvisor secure port: 10250` or `cAdvisor unsecure port: 10255` to be opened on all nodes in the cluster to collect performance metrics. See the [prerequisites for hybrid Kubernetes clusters](./container-insights-hybrid-setup.md#prerequisites) for more information. --## Non-AKS clusters aren't showing in Container insights --To view the non-AKS cluster in Container insights, read access is required on the Log Analytics workspace that supports this insight and on the Container insights solution resource **ContainerInsights (*workspace*)**. --## Metrics aren't being collected --1. Verify that the **Monitoring Metrics Publisher** role assignment exists by using the following CLI command: -- ``` azurecli - az role assignment list --assignee "SP/UserassignedMSI for Azure Monitor Agent" --scope "/subscriptions/<subid>/resourcegroups/<RG>/providers/Microsoft.ContainerService/managedClusters/<clustername>" --role "Monitoring Metrics Publisher" - ``` - For clusters with MSI, the user-assigned client ID for Azure Monitor Agent changes every time monitoring is enabled and disabled, so the role assignment should exist on the current MSI client ID. --1. For clusters with Microsoft Entra pod identity enabled and using MSI: -- - Verify that the required label **kubernetes.azure.com/managedby: aks** is present on the Azure Monitor Agent pods by using the following command: -- `kubectl get pods --show-labels -n kube-system | grep ama-logs` -- - Verify that exceptions are enabled when pod identity is enabled by using one of the supported methods at https://github.com/Azure/aad-pod-identity#1-deploy-aad-pod-identity. -- Run the following command to verify: -- `kubectl get AzurePodIdentityException -A -o yaml` -- You should receive output similar to the following example: -- ``` - apiVersion: "aadpodidentity.k8s.io/v1" - kind: AzurePodIdentityException - metadata: - name: mic-exception - namespace: default - spec: - podLabels: - app: mic - component: mic - - apiVersion: "aadpodidentity.k8s.io/v1" - kind: AzurePodIdentityException - metadata: - name: aks-addon-exception - namespace: kube-system - spec: - podLabels: - kubernetes.azure.com/managedby: aks - ``` --## Installation of Azure Monitor Containers Extension fails on an Azure Arc-enabled Kubernetes cluster -The error "manifests contain a resource that already exists" indicates that resources of the Container insights agent already exist on the Azure Arc-enabled Kubernetes cluster. This error indicates that the Container insights agent is already installed. It's installed either through an azuremonitor-containers Helm chart or the Monitoring Add-on if it's an AKS cluster that's connected via Azure Arc. --The solution to this issue is to clean up the existing resources of the Container insights agent if it exists. Then enable the Azure Monitor Containers Extension. --### For non-AKS clusters -1. Against the K8s cluster that's connected to Azure Arc, run the following command to verify whether the `azmon-containers-release-1` Helm chart release exists or not: -- `helm list -A` --1. If the output of the preceding command indicates that the `azmon-containers-release-1` exists, delete the Helm chart release: -- `helm del azmon-containers-release-1` --### For AKS clusters -1. Run the following commands and look for the Azure Monitor Agent add-on profile to verify whether the AKS Monitoring Add-on is enabled: -- ``` - az account set -s <clusterSubscriptionId> - az aks show -g <clusterResourceGroup> -n <clusterName> - ``` --1. If the output includes an Azure Monitor Agent add-on profile config with a Log Analytics workspace resource ID, this information indicates that the AKS Monitoring Add-on is enabled and must be disabled: -- `az aks disable-addons -a monitoring -g <clusterResourceGroup> -n <clusterName>` --If the preceding steps didn't resolve the installation of Azure Monitor Containers Extension issues, create a support ticket to send to Microsoft for further investigation. --## Duplicate alerts being received -You might have enabled Prometheus alert rules without disabling Container insights recommended alerts. See [Migrate from Container insights recommended alerts to Prometheus recommended alert rules (preview)](container-insights-metric-alerts.md#migrate-from-metric-rules-to-prometheus-rules-preview). -- ## I see info banner "You do not have the right cluster permissions which will restrict your access to Container Insights features. Please reach out to your cluster admin to get the right permission" --Container Insights has historically allowed users to access the Azure portal experience based on the access permission of the Log Analytics workspace. It now checks cluster-level permission to provide access to the Azure portal experience. You might need your cluster admin to assign this permission. --For basic read-only cluster level access, assign the **Monitoring Reader** role for the following types of clusters. --- AKS without Kubernetes role-based access control (RBAC) authorization enabled-- AKS enabled with Microsoft Entra SAML-based single sign-on-- AKS enabled with Kubernetes RBAC authorization-- AKS configured with the cluster role binding clusterMonitoringUser-- [Azure Arc-enabled Kubernetes clusters](../../azure-arc/kubernetes/overview.md)--See [Assign role permissions to a user or group](/azure/aks/control-kubeconfig-access#assign-role-permissions-to-a-user-or-group) for details on how to assign these roles for AKS and [Access and identity options for Azure Kubernetes Service (AKS)](/azure/aks/concepts-identity) to learn more about role assignments. --## I don't see Image and Name property values populated when I query the ContainerLog table --For agent version ciprod12042019 and later, by default these two properties aren't populated for every log line to minimize cost incurred on log data collected. There are two options to query the table that include these properties with their values: --### Option 1 --Join other tables to include these property values in the results. --Modify your queries to include `Image` and `ImageTag` properties from the `ContainerInventory` table by joining on `ContainerID` property. You can include the `Name` property (as it previously appeared in the `ContainerLog` table) from the `KubepodInventory` table's `ContainerName` field by joining on the `ContainerID` property. We recommend this option. - -The following example is a sample detailed query that explains how to get these field values with joins. --``` -//Let's say we're querying an hour's worth of logs -let startTime = ago(1h); -let endTime = now(); -//Below gets the latest Image & ImageTag for every containerID, during the time window -let ContainerInv = ContainerInventory | where TimeGenerated >= startTime and TimeGenerated < endTime | summarize arg_max(TimeGenerated, *) by ContainerID, Image, ImageTag | project-away TimeGenerated | project ContainerID1=ContainerID, Image1=Image ,ImageTag1=ImageTag; -//Below gets the latest Name for every containerID, during the time window -let KubePodInv = KubePodInventory | where ContainerID != "" | where TimeGenerated >= startTime | where TimeGenerated < endTime | summarize arg_max(TimeGenerated, *) by ContainerID2 = ContainerID, Name1=ContainerName | project ContainerID2 , Name1; -//Now join the above 2 to get a 'jointed table' that has name, image & imagetag. Outer left is safer in case there are no kubepod records or if they're latent -let ContainerData = ContainerInv | join kind=leftouter (KubePodInv) on $left.ContainerID1 == $right.ContainerID2; -//Now join ContainerLog table with the 'jointed table' above and project-away redundant fields/columns and rename columns that were rewritten -//Outer left is safer so you don't lose logs even if we can't find container metadata for loglines (due to latency, time skew between data types, etc.) -ContainerLog -| where TimeGenerated >= startTime and TimeGenerated < endTime -| join kind= leftouter ( - ContainerData -) on $left.ContainerID == $right.ContainerID2 | project-away ContainerID1, ContainerID2, Name, Image, ImageTag | project-rename Name = Name1, Image=Image1, ImageTag=ImageTag1 -``` --### Option 2 --Reenable collection for these properties for every container log line. --If the first option isn't convenient because of query changes involved, you can reenable collecting these fields. Enable the setting `log_collection_settings.enrich_container_logs` in the agent config map as described in the [data collection configuration settings](./container-insights-data-collection-configmap.md). --> [!NOTE] -> We don't recommend the second option for large clusters that have more than 50 nodes. It generates API server calls from every node in the cluster to perform this enrichment. This option also increases data size for every log line collected. --## I can't upgrade a cluster after onboarding --Here's the scenario: You enabled Container insights for an Azure Kubernetes Service cluster. Then you deleted the Log Analytics workspace where the cluster was sending its data. Now when you attempt to upgrade the cluster, it fails. To work around this issue, you must disable monitoring and then reenable it by referencing a different valid workspace in your subscription. When you try to perform the cluster upgrade again, it should process and complete successfully. ---## Not collecting logs on Azure Stack HCI cluster -If you registered your cluster and/or configured HCI Insights before November 2023, features that use the Azure Monitor agent on HCI, such as Arc for Servers Insights, VM Insights, Container Insights, Defender for Cloud, or Microsoft Sentinel might not be collecting logs and event data properly. See [Repair AMA agent for HCI](/azure-stack/hci/manage/monitor-hci-single?tabs=22h2-and-later#repair-ama-for-azure-stack-hci) for steps to reconfigure the agent and HCI Insights. ---## Next steps --When monitoring is enabled to capture health metrics for the AKS cluster nodes and pods, these health metrics are available in the Azure portal. To learn how to use Container insights, see [View Azure Kubernetes Service health](container-insights-analyze.md). |
| azure-monitor | Integrate Keda | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/integrate-keda.md | - Title: Integrate KEDA with your Azure Kubernetes Service cluster -description: How to integrate KEDA with your Azure Kubernetes Service cluster. ----- Previously updated : 07/26/2024- ---# Integrate KEDA with your Azure Kubernetes Service cluster --KEDA is a Kubernetes-based Event Driven Autoscaler. KEDA lets you drive the scaling of any container in Kubernetes based on the load to be processed, by querying metrics from systems such as Prometheus. Integrate KEDA with your Azure Kubernetes Service (AKS) cluster to scale your workloads based on Prometheus metrics from your Azure Monitor workspace. --To integrate KEDA into your Azure Kubernetes Service, you have to deploy and configure a workload identity or pod identity on your cluster. The identity allows KEDA to authenticate with Azure and retrieve metrics for scaling from your Monitor workspace. --This article walks you through the steps to integrate KEDA into your AKS cluster using a workload identity. --> [!NOTE] -> We recommend using Microsoft Entra Workload ID. This authentication method replaces pod-managed identity (preview), which integrates with the Kubernetes native capabilities to federate with any external identity providers on behalf of the application. -> -> The open source Microsoft Entra pod-managed identity (preview) in Azure Kubernetes Service has been deprecated as of 10/24/2022, and the project will be archived in Sept. 2023. For more information, see the deprecation notice. The AKS Managed add-on begins deprecation in Sept. 2023. -> -> Azure Managed Prometheus support starts from KEDA v2.10. If you have an older version of KEDA installed, you must upgrade in order to work with Azure Managed Prometheus. --## Prerequisites --+ Azure Kubernetes Service (AKS) cluster -+ Prometheus sending metrics to an Azure Monitor workspace. For more information, see [Azure Monitor managed service for Prometheus](../essentials/prometheus-metrics-overview.md). --## Set up a workload identity --1. Start by setting up some environment variables. Change the values to suit your AKS cluster. - - ```bash - export RESOURCE_GROUP="rg-keda-integration" - export LOCATION="eastus" - export SUBSCRIPTION="$(az account show --query id --output tsv)" - export USER_ASSIGNED_IDENTITY_NAME="keda-int-identity" - export FEDERATED_IDENTITY_CREDENTIAL_NAME="kedaFedIdentity" - export SERVICE_ACCOUNT_NAMESPACE="keda" - export SERVICE_ACCOUNT_NAME="keda-operator" - export AKS_CLUSTER_NAME="aks-cluster-name" - ``` -- + `SERVICE_ACCOUNT_NAME` - KEDA must use the service account that was used to create federated credentials. This can be any user defined name. - + `AKS_CLUSTER_NAME`- The name of the AKS cluster where you want to deploy KEDA. - + `SERVICE_ACCOUNT_NAMESPACE` Both KEDA and service account must be in same namespace. - + `USER_ASSIGNED_IDENTITY_NAME` is the name of the Microsoft Entra identity that's created for KEDA. - + `FEDERATED_IDENTITY_CREDENTIAL_NAME` is the name of the credential that's created for KEDA to use to authenticate with Azure. --1. If your AKS cluster hasn't been created with workload-identity or oidc-issuer enabled, you'll need to enable it. If you aren't sure, you can run the following command to check if it's enabled. -- ```azurecli - az aks show --resource-group $RESOURCE_GROUP --name $AKS_CLUSTER_NAME --query oidcIssuerProfile - az aks show --resource-group $RESOURCE_GROUP --name $AKS_CLUSTER_NAME --query securityProfile.workloadIdentity - ``` - - To enable workload identity and oidc-issuer, run the following command. - - ```azurecli - az aks update -g $RESOURCE_GROUP -n $AKS_CLUSTER_NAME --enable-workload-identity --enable-oidc-issuer - ``` - -1. Store the OIDC issuer url in an environment variable to be used later. - - ```bash - export AKS_OIDC_ISSUER="$(az aks show -n $AKS_CLUSTER_NAME -g $RESOURCE_GROUP --query "oidcIssuerProfile.issuerUrl" -otsv)" - ``` - -1. Create a user assigned identity for KEDA. This identity is used by KEDA to authenticate with Azure Monitor. - - ```azurecli - az identity create --name $USER_ASSIGNED_IDENTITY_NAME --resource-group $RESOURCE_GROUP --location $LOCATION --subscription $SUBSCRIPTION - ``` - - The output will be similar to the following: - - ```json - { - "clientId": "abcd1234-abcd-abcd-abcd-9876543210ab", - "id": "/subscriptions/abcdef01-2345-6789-0abc-def012345678/resourcegroups/rg-keda-integration/providers/Microsoft. ManagedIdentity/userAssignedIdentities/keda-int-identity", - "location": "eastus", - "name": "keda-int-identity", - "principalId": "12345678-abcd-abcd-abcd-1234567890ab", - "resourceGroup": "rg-keda-integration", - "systemData": null, - "tags": {}, - "tenantId": "1234abcd-9876-9876-9876-abcdef012345", - "type": "Microsoft.ManagedIdentity/userAssignedIdentities" - } - ``` --1. Store the `clientId` and `tenantId` in environment variables to use later. - ```bash - export USER_ASSIGNED_CLIENT_ID="$(az identity show --resource-group $RESOURCE_GROUP --name $USER_ASSIGNED_IDENTITY_NAME --query 'clientId' -otsv)" - export TENANT_ID="$(az identity show --resource-group $RESOURCE_GROUP --name $USER_ASSIGNED_IDENTITY_NAME --query 'tenantId' -otsv)" - ``` - -1. Assign the *Monitoring Data Reader* role to the identity for your Azure Monitor workspace. This role allows the identity to read metrics from your workspace. Replace the *Azure Monitor Workspace resource group* and *Azure Monitor Workspace name* with the resource group and name of the Azure Monitor workspace which is configured to collect metrics from the AKS cluster. - - ```azurecli - az role assignment create \ - --assignee $USER_ASSIGNED_CLIENT_ID \ - --role "Monitoring Data Reader" \ - --scope /subscriptions/$SUBSCRIPTION/resourceGroups/<Azure Monitor Workspace resource group>/providers/microsoft.monitor/accounts/<Azure monitor workspace name> - ``` - - -1. Create the KEDA namespace, then create Kubernetes service account. This service account is used by KEDA to authenticate with Azure. - - ```azurecli - - az aks get-credentials -n $AKS_CLUSTER_NAME -g $RESOURCE_GROUP - - kubectl create namespace keda - - cat <<EOF | kubectl apply -f - - apiVersion: v1 - kind: ServiceAccount - metadata: - annotations: - azure.workload.identity/client-id: $USER_ASSIGNED_CLIENT_ID - name: $SERVICE_ACCOUNT_NAME - namespace: $SERVICE_ACCOUNT_NAMESPACE - EOF - ``` --1. Check your service account by running - ```bash - kubectl describe serviceaccount $SERVICE_ACCOUNT_NAME -n keda - ``` --1. Establish a federated credential between the service account and the user assigned identity. The federated credential allows the service account to use the user assigned identity to authenticate with Azure. -- ```azurecli - az identity federated-credential create --name $FEDERATED_IDENTITY_CREDENTIAL_NAME --identity-name $USER_ASSIGNED_IDENTITY_NAME --resource-group $RESOURCE_GROUP --issuer $AKS_OIDC_ISSUER --subject system:serviceaccount:$SERVICE_ACCOUNT_NAMESPACE:$SERVICE_ACCOUNT_NAME --audience api://AzureADTokenExchange - ``` -- > [!Note] - > It takes a few seconds for the federated identity credential to be propagated after being initially added. If a token request is made immediately after adding the federated identity credential, it might lead to failure for a couple of minutes as the cache is populated in the directory with old data. To avoid this issue, you can add a slight delay after adding the federated identity credential. --## Deploy KEDA --KEDA can be deployed using YAML manifests, Helm charts, or Operator Hub. This article uses Helm charts. For more information on deploying KEDA, see [Deploying KEDA](https://keda.sh/docs/2.10/deploy/) --Add helm repository: --```bash -helm repo add kedacore https://kedacore.github.io/charts -helm repo update -``` --Deploy KEDA using the following command: --```bash -helm install keda kedacore/keda --namespace keda \ set serviceAccount.create=false \set serviceAccount.name=keda-operator \set podIdentity.azureWorkload.enabled=true \set podIdentity.azureWorkload.clientId=$USER_ASSIGNED_CLIENT_ID \set podIdentity.azureWorkload.tenantId=$TENANT_ID-``` - -Check your deployment by running the following command. -```bash -kubectl get pods -n keda -``` -The output will be similar to the following: --```bash -NAME READY STATUS RESTARTS AGE -keda-admission-webhooks-ffcb8f688-kqlxp 1/1 Running 0 4m -keda-operator-5d9f7d975-mgv7r 1/1 Running 1 (4m ago) 4m -keda-operator-metrics-apiserver-7dc6f59678-745nz 1/1 Running 0 4m -``` --## Scalers --Scalers define how and when KEDA should scale a deployment. KEDA supports a variety of scalers. For more information on scalers, see [Scalers](https://keda.sh/docs/2.10/scalers/prometheus/). Azure Managed Prometheus utilizes already existing Prometheus scaler to retrieve Prometheus metrics from Azure Monitor Workspace. The following yaml file is an example to use Azure Managed Prometheus. ---+ `serverAddress` is the Query endpoint of your Azure Monitor workspace. For more information, see [Query Prometheus metrics using the API and PromQL](../essentials/prometheus-api-promql.md#query-endpoint) -+ `metricName` is the name of the metric you want to scale on. -+ `query` is the query used to retrieve the metric. -+ `threshold` is the value at which the deployment scales. -+ Set the `podIdentity.provider` according to the type of identity you're using. --## Troubleshooting --The following section provides troubleshooting tips for common issues. --### Federated credentials --Federated credentials can take up to 10 minutes to propagate. If you're having issues with KEDA authenticating with Azure, try the following steps. --The following log excerpt shows an error with the federated credentials. --``` -kubectl logs -n keda keda-operator-5d9f7d975-mgv7r --{ - \"error\": \"unauthorized_client\",\n \"error_description\": \"AADSTS70021: No matching federated identity record found for presented assertion. -Assertion Issuer: 'https://eastus.oic.prod-aks.azure.com/abcdef01-2345-6789-0abc-def012345678/12345678-abcd-abcd-abcd-1234567890ab/'. -Assertion Subject: 'system:serviceaccount:keda:keda-operator'. -Assertion Audience: 'api://AzureADTokenExchange'. https://docs.microsoft.com/azure/active-directory/develop/workload-identity-federation -Trace ID: 12dd9ea0-3a65-408f-a41f-5d0403a25100\\r\\nCorrelation ID: 8a2dce68-17f1-4f11-bed2-4bcf9577f2af\\r\\nTimestamp: 2023-05-30 11:11:53Z\", -\"error_codes\": [\n 70021\n ],\n \"timestamp\": \"2023-05-30 11:11:53Z\", -\"trace_id\": \"12345678-3a65-408f-a41f-5d0403a25100\", -\"correlation_id\": \"12345678-17f1-4f11-bed2-4bcf9577f2af\", -\"error_uri\": \"https://login.microsoftonline.com/error?code=70021\"\n} -\n--\n"} -``` --Check the values used to create the ServiceAccount and the credentials created with `az identity federated-credential create` and ensure the `subject` value matches the `system:serviceaccount` value. --### Azure Monitor workspace permissions --If you're having issues with KEDA authenticating with Azure, check the permissions for the Azure Monitor workspace. -The following log excerpt shows that the identity doesn't have read permissions for the Azure Monitor workspace. --``` -kubectl logs -n keda keda-operator-5d9f7d975-mgv7r --2023-05-30T11:15:45Z ERROR scale_handler error getting metric for scaler -{"scaledObject.Namespace": "default", "scaledObject.Name": "azure-managed-prometheus-scaler", "scaler": "prometheusScaler", -"error": "prometheus query api returned error. status: 403 response: {\"status\":\"error\", -\"errorType\":\"Forbidden\",\"error\":\"User \\u0027abc123ab-1234-1234-abcd-abcdef123456 -\\u0027 does not have access to perform any of the following actions -\\u0027microsoft.monitor/accounts/data/metrics/read, microsoft.monitor/accounts/data/metrics/read -\\u0027 on resource \\u0027/subscriptions/abcdef01-2345-6789-0abc-def012345678/resourcegroups/rg-azmon-ws-01/providers/microsoft.monitor/accounts/azmon-ws-01\\u0027. RequestId: 123456c427f348258f3e5aeeefef834a\"}"} -``` --Ensure the identity has the `Monitoring Data Reader` role on the Azure Monitor workspace. |
| azure-monitor | Kubernetes Metric Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/kubernetes-metric-alerts.md | - Title: Recommended alert rules for Kubernetes clusters -description: Describes how to enable recommended metric alerts rules for a Kubernetes cluster in Azure Monitor. - Previously updated : 08/19/2024----# Recommended alert rules for Kubernetes clusters -[Alerts](../alerts/alerts-overview.md) in Azure Monitor proactively identify issues related to the health and performance of your Azure resources. This article describes how to enable and edit a set of recommended metric alert rules that are predefined for your Kubernetes clusters. --## Enable recommended alert rules -Use one of the following methods to enable the recommended alert rules for your cluster. You can enable both Prometheus and platform metric alert rules for the same cluster. -->[!NOTE] -> ARM templates are the only supported method to enable recommended alerts on Arc-enabled Kubernetes clusters. -> --### [Azure portal](#tab/portal) -Using the Azure portal, the Prometheus rule group will be created in the same region as the cluster. --1. From the **Alerts** menu for your cluster, select **Set up recommendations**. -- :::image type="content" source="media/kubernetes-metric-alerts/setup-recommendations.png" lightbox="media/kubernetes-metric-alerts/setup-recommendations.png" alt-text="Screenshot of AKS cluster showing Set up recommendations button."::: --2. The available Prometheus and platform alert rules are displayed with the Prometheus rules organized by pod, cluster, and node level. Toggle a group of Prometheus rules to enable that set of rules. Expand the group to see the individual rules. You can leave the defaults or disable individual rules and edit their name and severity. -- :::image type="content" source="media/kubernetes-metric-alerts/recommended-alert-rules-enable-prometheus.png" lightbox="media/kubernetes-metric-alerts/recommended-alert-rules-enable-prometheus.png" alt-text="Screenshot of enabling Prometheus alert rule."::: --3. Toggle a platform metric rule to enable that rule. You can expand the rule to modify its details such as the name, severity, and threshold. -- :::image type="content" source="media/kubernetes-metric-alerts/recommended-alert-rules-enable-platform.png" lightbox="media/kubernetes-metric-alerts/recommended-alert-rules-enable-platform.png" alt-text="Screenshot of enabling platform metric alert rule."::: --4. Either select one or more notification methods to create a new action group, or select an existing action group with the notification details for this set of alert rules. -5. Click **Save** to save the rule group. ---### [Azure Resource Manager](#tab/arm) -Using an ARM template, you can specify the region for the Prometheus rule group, but you should create it in the same region as the cluster. --Download the required files for the template you're working with and deploy using the parameters in the tables below. For examples of different methods, see [Deploy the sample templates](../resource-manager-samples.md#deploy-the-sample-templates). --### ARM --- Template file: [https://aka.ms/azureprometheus-recommendedmetricalerts](https://aka.ms/azureprometheus-recommendedmetricalerts)--- Parameters:-- | Parameter | Description | - |:|:| - | clusterResourceId | Resource ID of the cluster. | - | actionGroupResourceId | Resource ID of action group that defines responses to alerts. | - | azureMonitorWorkspaceResourceId | Resource ID of the Azure Monitor workspace receiving the cluster's Prometheus metrics. | - | location | Region to store the alert rule group. | --### Bicep -See the [README](https://github.com/Azure/prometheus-collector/blob/main/AddonBicepTemplate/README.md) for further details. --- Template file: [https://aka.ms/azureprometheus-recommendedmetricalertsbicep](https://aka.ms/azureprometheus-recommendedmetricalertsbicep)-- Parameters:-- | Parameter | Description | - |:|:| - | aksResourceId | Resource ID of the cluster. | - | actionGroupResourceId | Resource ID of action group that defines responses to alerts. | - | monitorWorkspaceName | Name of the Azure Monitor workspace receiving the cluster's Prometheus metrics. | - | location | Region to store the alert rule group. | - ------## Edit recommended alert rules --Once the rule group has been created, you can't use the same page in the portal to edit the rules. For Prometheus metrics, you must edit the rule group to modify any rules in it, including enabling any rules that weren't already enabled. For platform metrics, you can edit each alert rule. --### [Azure portal](#tab/portal) --1. From the **Alerts** menu for your cluster, select **Set up recommendations**. Any rules or rule groups that have already been created will be labeled as **Already created**. -2. Expand the rule or rule group. Click on **View rule group** for Prometheus and **View alert rule** for platform metrics. -- :::image type="content" source="media/kubernetes-metric-alerts/recommended-alert-rules-already-enabled.png" lightbox="media/kubernetes-metric-alerts/recommended-alert-rules-already-enabled.png" alt-text="Screenshot of view rule group option."::: --3. For Prometheus rule groups: - 1. select **Rules** to view the alert rules in the group. - 2. Click the **Edit** icon next a rule that you want to modify. Use the guidance in [Create an alert rule](../essentials/prometheus-rule-groups.md#configure-the-rules-in-the-group) to modify the rule. -- :::image type="content" source="media/kubernetes-metric-alerts/edit-prometheus-rule.png" lightbox="media/kubernetes-metric-alerts/edit-prometheus-rule.png" alt-text="Screenshot of option to edit Prometheus alert rules."::: -- 3. When you're done editing rules in the group, click **Save** to save the rule group. --4. For platform metrics: -- 1. click **Edit** to open the details for the alert rule. Use the guidance in [Create an alert rule](../alerts/alerts-create-metric-alert-rule.yml) to modify the rule. -- :::image type="content" source="media/kubernetes-metric-alerts/edit-platform-metric-rule.png" lightbox="media/kubernetes-metric-alerts/edit-platform-metric-rule.png" alt-text="Screenshot of option to edit platform metric rule."::: --### [Azure Resource Manager](#tab/arm) --Edit the query and threshold or configure an action group for your alert rules in the ARM template described in [Enable recommended alert rules](#enable-recommended-alert-rules) and redeploy it by using any deployment method. -----## Disable alert rule group -Disable the rule group to stop receiving alerts from the rules in it. --### [Azure portal](#tab/portal) --1. View the Prometheus alert rule group or platform metric alert rule as described in [Edit recommended alert rules](#edit-recommended-alert-rules). --2. From the **Overview** menu, select **Disable**. -- :::image type="content" source="media/kubernetes-metric-alerts/disable-prometheus-rule-group.png" lightbox="media/kubernetes-metric-alerts/disable-prometheus-rule-group.png" alt-text="Screenshot of option to disable a rule group."::: --### [ARM template](#tab/arm) --Set the **enabled** flag to false for the rule group in the ARM template described in [Enable recommended alert rules](#enable-recommended-alert-rules) and redeploy it by using any deployment method. ----## Recommended alert rule details --The following tables list the details of each recommended alert rule. Source code for each is available in [GitHub](https://aka.ms/azureprometheus-recommendedmetricalerts) along with [troubleshooting guides](https://aka.ms/aks-alerts/community-runbooks) from the Prometheus community. --### Prometheus community alert rules --#### Cluster level alerts --| Alert name | Description | Default threshold | Timeframe (minutes) | -|:|:|::|::| -| KubeCPUQuotaOvercommit | The CPU resource quota allocated to namespaces exceeds the available CPU resources on the cluster's nodes by more than 50% for the last 5 minutes. | >1.5 | 5 | -| KubeMemoryQuotaOvercommit | The memory resource quota allocated to namespaces exceeds the available memory resources on the cluster's nodes by more than 50% for the last 5 minutes. | >1.5 | 5 | -| KubeContainerOOMKilledCount | One or more containers within pods have been killed due to out-of-memory (OOM) events for the last 5 minutes. | >0 | 5 | -| KubeClientErrors | The rate of client errors (HTTP status codes starting with 5xx) in Kubernetes API requests exceeds 1% of the total API request rate for the last 15 minutes. | >0.01 | 15 | -| KubePersistentVolumeFillingUp | The persistent volume is filling up and is expected to run out of available space evaluated on the available space ratio, used space, and predicted linear trend of available space over the last 6 hours. These conditions are evaluated over the last 60 minutes. | N/A | 60 | -| KubePersistentVolumeInodesFillingUp | Less than 3% of the inodes within a persistent volume are available for the last 15 minutes. | <0.03 | 15 | -| KubePersistentVolumeErrors | One or more persistent volumes are in a failed or pending phase for the last 5 minutes. | >0 | 5 | -| KubeContainerWaiting | One or more containers within Kubernetes pods are in a waiting state for the last 60 minutes. | >0 | 60 | -| KubeDaemonSetNotScheduled | One or more pods are not scheduled on any node for the last 15 minutes. | >0 | 15 | -| KubeDaemonSetMisScheduled | One or more pods are misscheduled within the cluster for the last 15 minutes. | >0 | 15 | -| KubeQuotaAlmostFull | The utilization of Kubernetes resource quotas is between 90% and 100% of the hard limits for the last 15 minutes. | >0.9 <1 | 15 | ---#### Node level alerts --| Alert name | Description | Default threshold | Timeframe (minutes) | -|:|:|::|::| -| KubeNodeUnreachable | A node has been unreachable for the last 15 minutes. | 1 | 15 | -| KubeNodeReadinessFlapping | The readiness status of a node has changed more than 2 times for the last 15 minutes. | 2 | 15 | --#### Pod level alerts --| Alert name | Description | Default threshold | Timeframe (minutes) | -|:|:|::|::| -| KubePVUsageHigh | The average usage of Persistent Volumes (PVs) on pod exceeds 80% for the last 15 minutes. | >0.8 | 15 | -| KubeDeploymentReplicasMismatch | There is a mismatch between the desired number of replicas and the number of available replicas for the last 10 minutes. | N/A | 10 | -| KubeStatefulSetReplicasMismatch | The number of ready replicas in the StatefulSet does not match the total number of replicas in the StatefulSet for the last 15 minutes. | N/A | 15 | -| KubeHpaReplicasMismatch | The Horizontal Pod Autoscaler in the cluster has not matched the desired number of replicas for the last 15 minutes. | N/A | 15 | -| KubeHpaMaxedOut | The Horizontal Pod Autoscaler (HPA) in the cluster has been running at the maximum replicas for the last 15 minutes. | N/A | 15 | -| KubePodCrashLooping | One or more pods is in a CrashLoopBackOff condition, where the pod continuously crashes after startup and fails to recover successfully for the last 15 minutes. | >=1 | 15 | -| KubeJobStale | At least one Job instance did not complete successfully for the last 6 hours. | >0 | 360 | -| KubePodContainerRestart | One or more containers within pods in the Kubernetes cluster have been restarted at least once within the last hour. | >0 | 15 | -| KubePodReadyStateLow | The percentage of pods in a ready state falls below 80% for any deployment or daemonset in the Kubernetes cluster for the last 5 minutes. | <0.8 | 5 | -| KubePodFailedState | One or more pods is in a failed state for the last 5 minutes. | >0 | 5 | -| KubePodNotReadyByController | One or more pods are not in a ready state (i.e., in the "Pending" or "Unknown" phase) for the last 15 minutes. | >0 | 15 | -| KubeStatefulSetGenerationMismatch | The observed generation of a Kubernetes StatefulSet does not match its metadata generation for the last 15 minutes. | N/A | 15 | -| KubeJobFailed | One or more Kubernetes jobs have failed within the last 15 minutes. | >0 | 15 | -| KubeContainerAverageCPUHigh | The average CPU usage per container exceeds 95% for the last 5 minutes. | >0.95 | 5 | -| KubeContainerAverageMemoryHigh | The average memory usage per container exceeds 95% for the last 5 minutes. | >0.95 | 10 | -| KubeletPodStartUpLatencyHigh | The 99th percentile of the pod startup latency exceeds 60 seconds for the last 10 minutes. | >60 | 10 | --### Platform metric alert rules --| Alert name | Description | Default threshold | Timeframe (minutes) | -|:|:|::|::| -| Node cpu percentage is greater than 95% | The node CPU percentage is greater than 95% for the last 5 minutes. | 95 | 5 | -| Node memory working set percentage is greater than 100% | The node memory working set percentage is greater than 100% for the last 5 minutes. | 100 | 5 | ---## Legacy Container insights metric alerts (preview) --Metric rules in Container insights were retired on May 31, 2024. These rules were in public preview but were retired without reaching general availability since the new recommended metric alerts described in this article are now available. --If you already enabled these legacy alert rules, you should disable them and enable the new experience. --### Disable metric alert rules --1. From the **Insights** menu for your cluster, select **Recommended alerts (preview)**. -2. Change the status for each alert rule to **Disabled**. ----### Legacy alert mapping -The following table maps each of the legacy Container insights metric alerts to its equivalent recommended Prometheus metric alerts. --| Custom metric recommended alert | Equivalent Prometheus/Platform metric recommended alert | Condition | -|:|:|:| -| Completed job count | KubeJobStale (Pod level alerts) | At least one Job instance did not complete successfully for the last 6 hours. | -| Container CPU % | KubeContainerAverageCPUHigh (Pod level alerts) | The average CPU usage per container exceeds 95% for the last 5 minutes. | -| Container working set memory % | KubeContainerAverageMemoryHigh (Pod level alerts) | The average memory usage per container exceeds 95% for the last 5 minutes. | -| Failed Pod counts | KubePodFailedState (Pod level alerts) | One or more pods is in a failed state for the last 5 minutes. | -| Node CPU % | Node cpu percentage is greater than 95% (Platform metric) | The node CPU percentage is greater than 95% for the last 5 minutes. | -| Node Disk Usage % | N/A | Average disk usage for a node is greater than 80%. | -| Node NotReady status | KubeNodeUnreachable (Node level alerts) | A node has been unreachable for the last 15 minutes. | -| Node working set memory % | Node memory working set percentage is greater than 100% | The node memory working set percentage is greater than 100% for the last 5 minutes. | -| OOM Killed Containers | KubeContainerOOMKilledCount (Cluster level alerts) | One or more containers within pods have been killed due to out-of-memory (OOM) events for the last 5 minutes. | -| Persistent Volume Usage % | KubePVUsageHigh (Pod level alerts) | The average usage of Persistent Volumes (PVs) on pod exceeds 80% for the last 15 minutes. | -| Pods ready % | KubePodReadyStateLow (Pod level alerts) | The percentage of pods in a ready state falls below 80% for any deployment or daemonset in the Kubernetes cluster for the last 5 minutes. | -| Restarting container count | KubePodContainerRestart (Pod level alerts) | One or more containers within pods in the Kubernetes cluster have been restarted at least once within the last hour. | --## Next steps --- Read about the [different alert rule types in Azure Monitor](../alerts/alerts-types.md).-- Read about [alerting rule groups in Azure Monitor managed service for Prometheus](../essentials/prometheus-rule-groups.md).- |
| azure-monitor | Kubernetes Monitoring Disable | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/kubernetes-monitoring-disable.md | - Title: Disable monitoring of your Kubernetes cluster -description: Describes how to remove Container insights and scraping of Prometheus metrics from your Kubernetes cluster. - Previously updated : 01/23/2024-----# Disable monitoring of your Kubernetes cluster --Use the following methods to remove [Container insights](#disable-container-insights) or [Prometheus](#disable-prometheus) from your Kubernetes cluster. --## Required permissions --- You require at least [Contributor](../../role-based-access-control/built-in-roles.md#contributor) access to the cluster.--## Disable Container insights --### AKS cluster --Use the [az aks disable-addons](/cli/azure/aks#az-aks-disable-addons) CLI command to disable Container insights on a cluster. The command removes the agent from the cluster nodes. It doesn't remove the data already collected and stored in the Log Analytics workspace for your cluster. --```azurecli -az aks disable-addons -a monitoring -n MyExistingManagedCluster -g MyExistingManagedClusterRG -``` --Alternatively, you can use the following ARM template below to remove Container insights. -- ```json -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "aksResourceId": { - "type": "string", - "metadata": { - "description": "AKS Cluster Resource ID" - } - }, - "aksResourceLocation": { - "type": "string", - "metadata": { - "description": "Location of the AKS resource e.g. \"East US\"" - } - }, - "aksResourceTagValues": { - "type": "object", - "metadata": { - "description": "Existing all tags on AKS Cluster Resource" - } - } - }, - "resources": [ - { - "name": "[split(parameters('aksResourceId'),'/')[8]]", - "type": "Microsoft.ContainerService/managedClusters", - "location": "[parameters('aksResourceLocation')]", - "tags": "[parameters('aksResourceTagValues')]", - "apiVersion": "2018-03-31", - "properties": { - "mode": "Incremental", - "id": "[parameters('aksResourceId')]", - "addonProfiles": { - "omsagent": { - "enabled": false, - "config": null - } - } - } - } - ] - } - ``` --### Arc-enabled Kubernetes cluster -Use the following CLI command to delete the `azuremonitor-containers` extension and all the Kubernetes resources related to the extension. --```azurecli -az k8s-extension delete --name azuremonitor-containers --cluster-name <cluster-name> --resource-group <cluster-resource-group> --cluster-type connectedClusters -``` --### Remove Container insights with Helm --The following steps apply to the following environments: --- AKS Engine on Azure and Azure Stack-- OpenShift version 4 and higher--1. Run the following helm command to identify the Container insights helm chart release installed on your cluster -- ``` - helm list - ``` -- The output resembles the following: -- ``` - NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION - azmon-containers-release-1 default 3 2020-04-21 15:27:24.1201959 -0700 PDT deployed azuremonitor-containers-2.7.0 7.0.0-1 - ``` -- *azmon-containers-release-1* represents the helm chart release for Container insights. --2. To delete the chart release, run the following helm command. -- `helm delete <releaseName>` -- Example: -- `helm delete azmon-containers-release-1` -- This removes the release from the cluster. You can verify by running the `helm list` command: -- ``` - NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION - ``` --The configuration change can take a few minutes to complete. Because Helm tracks your releases even after youΓÇÖve deleted them, you can audit a clusterΓÇÖs history, and even undelete a release with `helm rollback`. -----## Disable Prometheus --Use the following `az aks update` Azure CLI command with the `--disable-azure-monitor-metrics` parameter to remove the metrics add-on from your AKS cluster or `az k8s-extension delete` Azure CLI command with the `--name azuremonitor-metrics` parameter to remove the metrics add-on from Arc-enabled cluster, and stop sending Prometheus metrics to Azure Monitor managed service for Prometheus. It doesn't remove the data already collected and stored in the Azure Monitor workspace for your cluster. --### AKS Cluster: --```azurecli -az aks update --disable-azure-monitor-metrics -n <cluster-name> -g <cluster-resource-group> -``` --### Azure Arc-enabled Cluster: -``` -az k8s-extension delete --name azuremonitor-metrics --cluster-name <cluster-name> --resource-group <cluster-resource-group> --cluster-type connectedClusters -``` --This command performs the following actions: --+ Removes the ama-metrics agent from the cluster nodes. -+ Deletes the recording rules created for that cluster. -+ Deletes the data collection endpoint (DCE). -+ Deletes the data collection rule (DCR). -+ Deletes the data collection rule association (DCRA) and recording rules groups created as part of onboarding. -----## Next steps --If the workspace was created only to support monitoring the cluster and it's no longer needed, you must delete it manually. If you aren't familiar with how to delete a workspace, see [Delete an Azure Log Analytics workspace with the Azure portal](../logs/delete-workspace.md). Don't forget about the **Workspace Resource ID** copied earlier in step 4. You'll need that information. |
| azure-monitor | Kubernetes Monitoring Enable | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/kubernetes-monitoring-enable.md | - Title: Enable monitoring for Azure Kubernetes Service (AKS) cluster -description: Learn how to enable Container insights and Managed Prometheus on an Azure Kubernetes Service (AKS) cluster. - Previously updated : 03/11/2024-----# Enable monitoring for Kubernetes clusters --This article describes how to enable complete monitoring of your Kubernetes clusters using the following Azure Monitor features: --- [Managed Prometheus](../essentials/prometheus-metrics-overview.md) for metric collection-- [Container insights](./container-insights-overview.md) for log collection-- [Managed Grafana](../../managed-grafan) for visualization.--[Using the Azure portal](#enable-full-monitoring-with-azure-portal), you can enable all of the features at the same time. You can also enable them individually by using the Azure CLI, Azure Resource Manager template, Terraform, or Azure Policy. Each of these methods is described in this article. --> [!IMPORTANT] -> Kubernetes clusters generate a lot of log data, which can result in significant costs if you aren't selective about the logs that you collect. Before you enable monitoring for your cluster, see the following articles to ensure that your environment is optimized for cost and that you limit your log collection to only the data that you require: -> ->- [Configure data collection and cost optimization in Container insights using data collection rule](./container-insights-data-collection-dcr.md)<br>Details on customizing log collection once you've enabled monitoring, including using preset cost optimization configurations. ->- [Best practices for monitoring Kubernetes with Azure Monitor](../best-practices-containers.md)<br>Best practices for monitoring Kubernetes clusters organized by the five pillars of the [Azure Well-Architected Framework](/azure/architecture/framework/), including cost optimization. ->- [Cost optimization in Azure Monitor](../best-practices-cost.md)<br>Best practices for configuring all features of Azure Monitor to optimize your costs and limit the amount of data that you collect. --## Supported clusters --This article provides onboarding guidance for the following types of clusters. Any differences in the process for each type are noted in the relevant sections. --- [Azure Kubernetes clusters (AKS)](/azure/aks/intro-kubernetes)-- [Arc-enabled Kubernetes clusters](../../azure-arc/kubernetes/overview.md)--## Prerequisites --**Permissions** --- You require at least [Contributor](../../role-based-access-control/built-in-roles.md#contributor) access to the cluster for onboarding.-- You require [Monitoring Reader](../roles-permissions-security.md#monitoring-reader) or [Monitoring Contributor](../roles-permissions-security.md#monitoring-contributor) to view data after monitoring is enabled.--**Managed Prometheus prerequisites** -- - The cluster must use [managed identity authentication](/azure/aks/use-managed-identity). - - The following resource providers must be registered in the subscription of the AKS cluster and the Azure Monitor workspace: - - Microsoft.ContainerService - - Microsoft.Insights - - Microsoft.AlertsManagement - - Microsoft.Monitor - - The following resource providers must be registered in the subscription of the Grafana workspace subscription: - - Microsoft.Dashboard --**Arc-Enabled Kubernetes clusters prerequisites** --- Prerequisites for [Azure Arc-enabled Kubernetes cluster extensions](../../azure-arc/kubernetes/extensions.md#prerequisites).- - Verify the [firewall requirements](kubernetes-monitoring-firewall.md) in addition to the [Azure Arc-enabled Kubernetes network requirements](../../azure-arc/kubernetes/network-requirements.md). - - If you previously installed monitoring for AKS, ensure that you have [disabled monitoring](kubernetes-monitoring-disable.md) before proceeding to avoid issues during the extension install. - - If you previously installed monitoring on a cluster using a script without cluster extensions, follow the instructions at [Disable monitoring of your Kubernetes cluster](kubernetes-monitoring-disable.md) to delete this Helm chart. --> [!NOTE] -> The Managed Prometheus Arc-Enabled Kubernetes extension does not support the following configurations: -> * Red Hat Openshift distributions, including Azure Red Hat OpenShift (ARO) -> * Windows nodes ---## Workspaces --The following table describes the workspaces that are required to support Managed Prometheus and Container insights. You can create each workspace as part of the onboarding process or use an existing workspace. See [Design a Log Analytics workspace architecture](../logs/workspace-design.md) for guidance on how many workspaces to create and where they should be placed. --| Feature | Workspace | Notes | -|:|:|:| -| Managed Prometheus | [Azure Monitor workspace](../essentials/azure-monitor-workspace-overview.md) | `Contributor` permission is enough for enabling the addon to send data to the Azure Monitor workspace. You will need `Owner` level permission to link your Azure Monitor Workspace to view metrics in Azure Managed Grafana. This is required because the user executing the onboarding step, needs to be able to give the Azure Managed Grafana System Identity `Monitoring Reader` role on the Azure Monitor Workspace to query the metrics. | -| Container insights | [Log Analytics workspace](../logs/log-analytics-workspace-overview.md) | You can attach an AKS cluster to a Log Analytics workspace in a different Azure subscription in the same Microsoft Entra tenant, but you must use the Azure CLI or an Azure Resource Manager template. You can't currently perform this configuration with the Azure portal.<br><br>If you're connecting an existing AKS cluster to a Log Analytics workspace in another subscription, the *Microsoft.ContainerService* resource provider must be registered in the subscription with the Log Analytics workspace. For more information, see [Register resource provider](../../azure-resource-manager/management/resource-providers-and-types.md#register-resource-provider).<br><br>For a list of the supported mapping pairs to use for the default workspace, see [Region mappings supported by Container insights](container-insights-region-mapping.md). | -| Managed Grafana | [Azure Managed Grafana workspace](../../managed-grafan) to make the Prometheus metrics collected from your cluster available to Grafana dashboards. | ---## Enable Prometheus and Grafana -Use one of the following methods to enable scraping of Prometheus metrics from your cluster and enable Managed Grafana to visualize the metrics. See [Link a Grafana workspace](../../managed-grafan) for options to connect your Azure Monitor workspace and Azure Managed Grafana workspace. --> [!NOTE] -> If you have a single Azure Monitor Resource that is private-linked, then Prometheus enablement won't work if the AKS cluster and Azure Monitor Workspace are in different regions. -> The configuration needed for the Prometheus add-on isn't available cross region because of the private link constraint. -> To resolve this, create a new DCE in the AKS cluster location and a new DCRA (association) in the same AKS cluster region. Associate the new DCE with the AKS cluster and name the new association (DCRA) as configurationAccessEndpoint. -> For full instructions on how to configure the DCEs associated with your Azure Monitor workspace to use a Private Link for data ingestion, see [Enable private link for Kubernetes monitoring in Azure Monitor](./kubernetes-monitoring-private-link.md). --### [CLI](#tab/cli) --If you don't specify an existing Azure Monitor workspace in the following commands, the default workspace for the resource group will be used. If a default workspace doesn't already exist in the cluster's region, one with a name in the format `DefaultAzureMonitorWorkspace-<mapped_region>` will be created in a resource group with the name `DefaultRG-<cluster_region>`. --#### Prerequisites --- Az CLI version of 2.49.0 or higher is required. -- The aks-preview extension must be [uninstalled from AKS clusters](/cli/azure/azure-cli-extensions-overview) by using the command `az extension remove --name aks-preview`. -- The k8s-extension extension must be installed using the command `az extension add --name k8s-extension`.-- The k8s-extension version 1.4.1 or higher is required. --#### AKS cluster -Use the `-enable-azure-monitor-metrics` option `az aks create` or `az aks update` (depending whether you're creating a new cluster or updating an existing cluster) to install the metrics add-on that scrapes Prometheus metrics. ---**Sample commands** --```azurecli -### Use default Azure Monitor workspace -az aks create/update --enable-azure-monitor-metrics --name <cluster-name> --resource-group <cluster-resource-group> --### Use existing Azure Monitor workspace -az aks create/update --enable-azure-monitor-metrics --name <cluster-name> --resource-group <cluster-resource-group> --azure-monitor-workspace-resource-id <workspace-name-resource-id> --### Use an existing Azure Monitor workspace and link with an existing Grafana workspace -az aks create/update --enable-azure-monitor-metrics --name <cluster-name> --resource-group <cluster-resource-group> --azure-monitor-workspace-resource-id <azure-monitor-workspace-name-resource-id> --grafana-resource-id <grafana-workspace-name-resource-id> --### Use optional parameters -az aks create/update --enable-azure-monitor-metrics --name <cluster-name> --resource-group <cluster-resource-group> --ksm-metric-labels-allow-list "namespaces=[k8s-label-1,k8s-label-n]" --ksm-metric-annotations-allow-list "pods=[k8s-annotation-1,k8s-annotation-n]" -``` --#### Arc-enabled cluster ---```azurecli -### Use default Azure Monitor workspace -az k8s-extension create --name azuremonitor-metrics --cluster-name <cluster-name> --resource-group <resource-group> --cluster-type connectedClusters --extension-type Microsoft.AzureMonitor.Containers.Metrics --## Use existing Azure Monitor workspace -az k8s-extension create --name azuremonitor-metrics --cluster-name <cluster-name> --resource-group <resource-group> --cluster-type connectedClusters --extension-type Microsoft.AzureMonitor.Containers.Metrics --configuration-settings azure-monitor-workspace-resource-id=<workspace-name-resource-id> --### Use an existing Azure Monitor workspace and link with an existing Grafana workspace -az k8s-extension create --name azuremonitor-metrics --cluster-name <cluster-name> --resource-group <resource-group> --cluster-type connectedClusters --extension-type Microsoft.AzureMonitor.Containers.Metrics --configuration-settings azure-monitor-workspace-resource-id=<workspace-name-resource-id> grafana-resource-id=<grafana-workspace-name-resource-id> --### Use optional parameters -az k8s-extension create --name azuremonitor-metrics --cluster-name <cluster-name> --resource-group <resource-group> --cluster-type connectedClusters --extension-type Microsoft.AzureMonitor.Containers.Metrics --configuration-settings azure-monitor-workspace-resource-id=<workspace-name-resource-id> grafana-resource-id=<grafana-workspace-name-resource-id> AzureMonitorMetrics.KubeStateMetrics.MetricAnnotationsAllowList="pods=[k8s-annotation-1,k8s-annotation-n]" AzureMonitorMetrics.KubeStateMetrics.MetricLabelsAllowlist "namespaces=[k8s-label-1,k8s-label-n]" -``` --Any of the commands can use the following optional parameters: --- AKS: `--ksm-metric-annotations-allow-list`<br>Arc: `--AzureMonitorMetrics.KubeStateMetrics.MetricAnnotationsAllowList`<br>Comma-separated list of Kubernetes annotations keys used in the resource's kube_resource_annotations metric. For example, kube_pod_annotations is the annotations metric for the pods resource. By default, this metric contains only name and namespace labels. To include more annotations, provide a list of resource names in their plural form and Kubernetes annotation keys that you want to allow for them. A single `*` can be provided for each resource to allow any annotations, but this has severe performance implications. For example, `pods=[kubernetes.io/team,...],namespaces=[kubernetes.io/team],...`.<br>-- AKS: `--ksm-metric-labels-allow-list`<br>Arc: `--AzureMonitorMetrics.KubeStateMetrics.MetricLabelsAllowlist`<br>Comma-separated list of more Kubernetes label keys that is used in the resource's kube_resource_labels metric kube_resource_labels metric. For example, kube_pod_labels is the labels metric for the pods resource. By default this metric contains only name and namespace labels. To include more labels, provide a list of resource names in their plural form and Kubernetes label keys that you want to allow for them A single `*` can be provided for each resource to allow any labels, but i this has severe performance implications. For example, `pods=[app],namespaces=[k8s-label-1,k8s-label-n,...],...`.<br>-- AKS: `--enable-windows-recording-rules` Lets you enable the recording rule groups required for proper functioning of the Windows dashboards.----### [Azure Resource Manager](#tab/arm) --Both ARM and Bicep templates are provided in this section. --#### Prerequisites --- The Azure Monitor workspace and Azure Managed Grafana instance must already be created.-- The template must be deployed in the same resource group as the Azure Managed Grafana instance.-- If the Azure Managed Grafana instance is in a subscription other than the Azure Monitor workspace subscription, register the Azure Monitor workspace subscription with the `Microsoft.Dashboard` resource provider using the guidance at [Register resource provider](../../azure-resource-manager/management/resource-providers-and-types.md#register-resource-provider).-- Users with the `User Access Administrator` role in the subscription of the AKS cluster can enable the `Monitoring Reader` role directly by deploying the template.--> [!NOTE] -> Currently in Bicep, there's no way to explicitly scope the `Monitoring Reader` role assignment on a string parameter "resource ID" for an Azure Monitor workspace like in an ARM template. Bicep expects a value of type `resource | tenant`. There is also no REST API [spec](https://github.com/Azure/azure-rest-api-specs) for an Azure Monitor workspace. -> -> Therefore, the default scoping for the `Monitoring Reader` role is on the resource group. The role is applied on the same Azure Monitor workspace by inheritance, which is the expected behavior. After you deploy this Bicep template, the Grafana instance is given `Monitoring Reader` permissions for all the Azure Monitor workspaces in that resource group. ---#### Retrieve required values for Grafana resource -If the Azure Managed Grafana instance is already linked to an Azure Monitor workspace, then you must include this list in the template. On the **Overview** page for the Azure Managed Grafana instance in the Azure portal, select **JSON view**, and copy the value of `azureMonitorWorkspaceIntegrations` which will look similar to the sample below. If it doesn't exist, then the instance hasn't been linked with any Azure Monitor workspace. --```json -"properties": { - "grafanaIntegrations": { - "azureMonitorWorkspaceIntegrations": [ - { - "azureMonitorWorkspaceResourceId": "full_resource_id_1" - }, - { - "azureMonitorWorkspaceResourceId": "full_resource_id_2" - } - ] - } -} -``` --#### Download and edit template and parameter file --1. Download the required files for the type of Kubernetes cluster you're working with. -- **AKS cluster ARM** -- - Template file: [https://aka.ms/azureprometheus-enable-arm-template](https://aka.ms/azureprometheus-enable-arm-template) - - Parameter file: [https://aka.ms/azureprometheus-enable-arm-template-parameters](https://aka.ms/azureprometheus-enable-arm-template-parameters) -- **AKS cluster Bicep** -- - Template file: [https://aka.ms/azureprometheus-enable-bicep-template](https://aka.ms/azureprometheus-enable-bicep-template) - - Parameter file: [https://aka.ms/azureprometheus-enable-bicep-template-parameters](https://aka.ms/azureprometheus-enable-arm-template-parameters) - - DCRA module: [https://aka.ms/nested_azuremonitormetrics_dcra_clusterResourceId](https://aka.ms/nested_azuremonitormetrics_dcra_clusterResourceId) - - Profile module: [https://aka.ms/nested_azuremonitormetrics_profile_clusterResourceId](https://aka.ms/nested_azuremonitormetrics_profile_clusterResourceId) - - Azure Managed Grafana Role Assignment module: [https://aka.ms/nested_grafana_amw_role_assignment](https://aka.ms/nested_grafana_amw_role_assignment) -- **Arc-Enabled cluster ARM** -- - Template file: [https://aka.ms/azureprometheus-arc-arm-template](https://aka.ms/azureprometheus-arc-arm-template) - - Parameter file: [https://aka.ms/azureprometheus-arc-arm-template-parameters](https://aka.ms/azureprometheus-arc-arm-template-parameters) ----2. Edit the following values in the parameter file. The same set of values are used for both the ARM and Bicep templates. Retrieve the resource ID of the resources from the **JSON View** of their **Overview** page. --- | Parameter | Value | - |:|:| - | `azureMonitorWorkspaceResourceId` | Resource ID for the Azure Monitor workspace. Retrieve from the **JSON view** on the **Overview** page for the Azure Monitor workspace. | - | `azureMonitorWorkspaceLocation` | Location of the Azure Monitor workspace. Retrieve from the **JSON view** on the **Overview** page for the Azure Monitor workspace. | - | `clusterResourceId` | Resource ID for the AKS cluster. Retrieve from the **JSON view** on the **Overview** page for the cluster. | - | `clusterLocation` | Location of the AKS cluster. Retrieve from the **JSON view** on the **Overview** page for the cluster. | - | `metricLabelsAllowlist` | Comma-separated list of Kubernetes labels keys to be used in the resource's labels metric. | - | `metricAnnotationsAllowList` | Comma-separated list of more Kubernetes label keys to be used in the resource's annotations metric. | - | `grafanaResourceId` | Resource ID for the managed Grafana instance. Retrieve from the **JSON view** on the **Overview** page for the Grafana instance. | - | `grafanaLocation` | Location for the managed Grafana instance. Retrieve from the **JSON view** on the **Overview** page for the Grafana instance. | - | `grafanaSku` | SKU for the managed Grafana instance. Retrieve from the **JSON view** on the **Overview** page for the Grafana instance. Use the **sku.name**. | ----3. Open the template file and update the `grafanaIntegrations` property at the end of the file with the values that you retrieved from the Grafana instance. This will look similar to the following samples. In these samples, `full_resource_id_1` and `full_resource_id_2` were already in the Azure Managed Grafana resource JSON. The final `azureMonitorWorkspaceResourceId` entry is already in the template and is used to link to the Azure Monitor workspace resource ID provided in the parameters file. -- **ARM** -- ```json - { - "type": "Microsoft.Dashboard/grafana", - "apiVersion": "2022-08-01", - "name": "[split(parameters('grafanaResourceId'),'/')[8]]", - "sku": { - "name": "[parameters('grafanaSku')]" - }, - "location": "[parameters('grafanaLocation')]", - "properties": { - "grafanaIntegrations": { - "azureMonitorWorkspaceIntegrations": [ - { - "azureMonitorWorkspaceResourceId": "full_resource_id_1" - }, - { - "azureMonitorWorkspaceResourceId": "full_resource_id_2" - }, - { - "azureMonitorWorkspaceResourceId": "[parameters('azureMonitorWorkspaceResourceId')]" - } - ] - } - } - } - ``` --- **Bicep** -- -- ```bicep - resource grafanaResourceId_8 'Microsoft.Dashboard/grafana@2022-08-01' = { - name: split(grafanaResourceId, '/')[8] - sku: { - name: grafanaSku - } - identity: { - type: 'SystemAssigned' - } - location: grafanaLocation - properties: { - grafanaIntegrations: { - azureMonitorWorkspaceIntegrations: [ - { - azureMonitorWorkspaceResourceId: 'full_resource_id_1' - } - { - azureMonitorWorkspaceResourceId: 'full_resource_id_2' - } - { - azureMonitorWorkspaceResourceId: azureMonitorWorkspaceResourceId - } - ] - } - } - } - ``` --4. Deploy the template with the parameter file by using any valid method for deploying Resource Manager templates. For examples of different methods, see [Deploy the sample templates](../resource-manager-samples.md#deploy-the-sample-templates). ---### [Terraform](#tab/terraform) --#### Prerequisites --- The Azure Monitor workspace and Azure Managed Grafana workspace must already be created.-- The template needs to be deployed in the same resource group as the Azure Managed Grafana workspace.-- Users with the User Access Administrator role in the subscription of the AKS cluster can enable the Monitoring Reader role directly by deploying the template.-- If the Azure Managed Grafana instance is in a subscription other than the Azure Monitor Workspaces subscription, register the Azure Monitor Workspace subscription with the `Microsoft.Dashboard` resource provider by following [this documentation](../../azure-resource-manager/management/resource-providers-and-types.md#register-resource-provider).--#### Retrieve required values for a Grafana resource --On the **Overview** page for the Azure Managed Grafana instance in the Azure portal, select **JSON view**. --If you're using an existing Azure Managed Grafana instance that's already linked to an Azure Monitor workspace, you need the list of Grafana integrations. Copy the value of the `azureMonitorWorkspaceIntegrations` field. If it doesn't exist, the instance hasn't been linked with any Azure Monitor workspace. Update the `azure_monitor_workspace_integrations` block in `main.tf` with the list of grafana integrations. --```.tf - azure_monitor_workspace_integrations { - resource_id = var.monitor_workspace_id[var.monitor_workspace_id1, var.monitor_workspace_id2] - } -``` --#### Download and edit the templates --If you're deploying a new AKS cluster using Terraform with managed Prometheus addon enabled, follow these steps: --1. Download all files under [AddonTerraformTemplate](https://aka.ms/AAkm357). -2. Edit the variables in variables.tf file with the correct parameter values. -3. Run `terraform init -upgrade` to initialize the Terraform deployment. -4. Run `terraform plan -out main.tfplan` to initialize the Terraform deployment. -5. Run `terraform apply main.tfplan` to apply the execution plan to your cloud infrastructure. ---Note: Pass the variables for `annotations_allowed` and `labels_allowed` keys in main.tf only when those values exist. These are optional blocks. --> [!NOTE] -> Edit the main.tf file appropriately before running the terraform template. Add in any existing azure_monitor_workspace_integrations values to the grafana resource before running the template. Else, older values gets deleted and replaced with what is there in the template during deployment. Users with 'User Access Administrator' role in the subscription of the AKS cluster can enable 'Monitoring Reader' role directly by deploying the template. Edit the grafanaSku parameter if you're using a nonstandard SKU and finally run this template in the Grafana Resource's resource group. --### [Azure Policy](#tab/policy) --1. Download Azure Policy template and parameter files. -- - Template file: [https://aka.ms/AddonPolicyMetricsProfile](https://aka.ms/AddonPolicyMetricsProfile) - - Parameter file: [https://aka.ms/AddonPolicyMetricsProfile.parameters](https://aka.ms/AddonPolicyMetricsProfile.parameters) --1. Create the policy definition using the following CLI command: -- `az policy definition create --name "Prometheus Metrics addon" --display-name "Prometheus Metrics addon" --mode Indexed --metadata version=1.0.0 category=Kubernetes --rules AddonPolicyMetricsProfile.rules.json --params AddonPolicyMetricsProfile.parameters.json` --1. After you create the policy definition, in the Azure portal, select **Policy** and then **Definitions**. Select the policy definition you created. -1. Select **Assign** and fill in the details on the **Parameters** tab. Select **Review + Create**. -1. If you want to apply the policy to an existing cluster, create a **Remediation task** for that cluster resource from **Policy Assignment**. --After the policy is assigned to the subscription, whenever you create a new cluster without Prometheus enabled, the policy will run and deploy to enable Prometheus monitoring. ------## Enable Container insights -Use one of the following methods to enable Container insights on your cluster. Once this is complete, see [Configure agent data collection for Container insights](container-insights-data-collection-configmap.md) to customize your configuration to ensure that you aren't collecting more data than you require. ---### [CLI](#tab/cli) --Use one of the following commands to enable monitoring of your AKS and Arc-enabled clusters. If you don't specify an existing Log Analytics workspace, the default workspace for the resource group will be used. If a default workspace doesn't already exist in the cluster's region, one will be created with a name in the format `DefaultWorkspace-<GUID>-<Region>`. --#### Prerequisites --- Azure CLI version 2.43.0 or higher-- Managed identity authentication is default in CLI version 2.49.0 or higher.-- Azure k8s-extension version 1.3.7 or higher-- Managed identity authentication is the default in k8s-extension version 1.43.0 or higher.-- Managed identity authentication is not supported for Arc-enabled Kubernetes clusters with ARO (Azure Red Hat Openshift) or Windows nodes. Use legacy authentication.-- For CLI version 2.54.0 or higher, the logging schema will be configured to [ContainerLogV2](container-insights-logs-schema.md) using [ConfigMap](container-insights-data-collection-configmap.md).-> [!NOTE] -> You can enable the **ContainerLogV2** schema for a cluster either using the cluster's Data Collection Rule (DCR) or ConfigMap. If both settings are enabled, the ConfigMap will take precedence. Stdout and stderr logs will only be ingested to the ContainerLog table when both the DCR and ConfigMap are explicitly set to off. -#### AKS cluster --```azurecli -### Use default Log Analytics workspace -az aks enable-addons --addon monitoring --name <cluster-name> --resource-group <cluster-resource-group-name> --### Use existing Log Analytics workspace -az aks enable-addons --addon monitoring --name <cluster-name> --resource-group <cluster-resource-group-name> --workspace-resource-id <workspace-resource-id> -``` --**Example** --```azurecli -az aks enable-addons --addon monitoring --name "my-cluster" --resource-group "my-resource-group" --workspace-resource-id "/subscriptions/my-subscription/resourceGroups/my-resource-group/providers/Microsoft.OperationalInsights/workspaces/my-workspace" -``` ---#### Arc-enabled cluster --```azurecli -### Use default Log Analytics workspace -az k8s-extension create --name azuremonitor-containers --cluster-name <cluster-name> --resource-group <resource-group> --cluster-type connectedClusters --extension-type Microsoft.AzureMonitor.Containers --### Use existing Log Analytics workspace -az k8s-extension create --name azuremonitor-containers --cluster-name <cluster-name> --resource-group <resource-group> --cluster-type connectedClusters --extension-type Microsoft.AzureMonitor.Containers --configuration-settings logAnalyticsWorkspaceResourceID=<workspace-resource-id> --### Use managed identity authentication (default as k8s-extension version 1.43.0) -az k8s-extension create --name azuremonitor-containers --cluster-name <cluster-name> --resource-group <resource-group> --cluster-type connectedClusters --extension-type Microsoft.AzureMonitor.Containers --configuration-settings amalogs.useAADAuth=true --### Use advanced configuration settings -az k8s-extension create --name azuremonitor-containers --cluster-name <cluster-name> --resource-group <resource-group> --cluster-type connectedClusters --extension-type Microsoft.AzureMonitor.Containers --configuration-settings amalogs.resources.daemonset.limits.cpu=150m amalogs.resources.daemonset.limits.memory=600Mi amalogs.resources.deployment.limits.cpu=1 amalogs.resources.deployment.limits.memory=750Mi --### With custom mount path for container stdout & stderr logs -### Custom mount path not required for Azure Stack Edge version > 2318. Custom mount path must be /home/data/docker for Azure Stack Edge cluster with version <= 2318 -az k8s-extension create --name azuremonitor-containers --cluster-name <cluster-name> --resource-group <resource-group> --cluster-type connectedClusters --extension-type Microsoft.AzureMonitor.Containers --configuration-settings amalogs.logsettings.custommountpath=<customMountPath> --``` --See the [resource requests and limits section of Helm chart](https://github.com/microsoft/Docker-Provider/blob/ci_prod/charts/azuremonitor-containers/values.yaml) for the available configuration settings. ---**Example** --```azurecli -az k8s-extension create --name azuremonitor-containers --cluster-name "my-cluster" --resource-group "my-resource-group" --cluster-type connectedClusters --extension-type Microsoft.AzureMonitor.Containers --configuration-settings logAnalyticsWorkspaceResourceID="/subscriptions/my-subscription/resourceGroups/my-resource-group/providers/Microsoft.OperationalInsights/workspaces/my-workspace" -``` --**Arc-enabled cluster with forward proxy** --If the cluster is configured with a forward proxy, then proxy settings are automatically applied to the extension. In the case of a cluster with AMPLS + proxy, proxy config should be ignored. Onboard the extension with the configuration setting `amalogs.ignoreExtensionProxySettings=true`. --```azurecli -az k8s-extension create --name azuremonitor-containers --cluster-name <cluster-name> --resource-group <resource-group> --cluster-type connectedClusters --extension-type Microsoft.AzureMonitor.Containers --configuration-settings amalogs.ignoreExtensionProxySettings=true -``` --**Arc-enabled cluster with ARO or OpenShift or Windows nodes** --Managed identity authentication is not supported for Arc-enabled Kubernetes clusters with ARO (Azure Red Hat OpenShift) or OpenShift or Windows nodes. Use legacy authentication by specifying `amalogs.useAADAuth=false` as in the following example. --```azurecli -az k8s-extension create --name azuremonitor-containers --cluster-name <cluster-name> --resource-group <resource-group> --cluster-type connectedClusters --extension-type Microsoft.AzureMonitor.Containers --configuration-settings amalogs.useAADAuth=false -``` --**Delete extension instance** --The following command only deletes the extension instance, but doesn't delete the Log Analytics workspace. The data in the Log Analytics resource is left intact. --```azurecli -az k8s-extension delete --name azuremonitor-containers --cluster-type connectedClusters --cluster-name <cluster-name> --resource-group <resource-group> -``` --### [Azure Resource Manager](#tab/arm) --Both ARM and Bicep templates are provided in this section. --#### Prerequisites - -- The template must be deployed in the same resource group as the cluster.--#### Download and install template --1. Download and edit template and parameter file -- **AKS cluster ARM** - - Template file: [https://aka.ms/aks-enable-monitoring-msi-onboarding-template-file](https://aka.ms/aks-enable-monitoring-msi-onboarding-template-file) - - Parameter file: [https://aka.ms/aks-enable-monitoring-msi-onboarding-template-parameter-file](https://aka.ms/aks-enable-monitoring-msi-onboarding-template-parameter-file) -- **AKS cluster Bicep** - - Template file (Syslog): [https://aka.ms/enable-monitoring-msi-syslog-bicep-template](https://aka.ms/enable-monitoring-msi-syslog-bicep-template) - - Parameter file (No Syslog): [https://aka.ms/enable-monitoring-msi-syslog-bicep-parameters](https://aka.ms/enable-monitoring-msi-syslog-bicep-parameters) - - Template file (No Syslog): [https://aka.ms/enable-monitoring-msi-bicep-template](https://aka.ms/enable-monitoring-msi-bicep-template) - - Parameter file (No Syslog): [https://aka.ms/enable-monitoring-msi-bicep-parameters](https://aka.ms/enable-monitoring-msi-bicep-parameters) -- **Arc-enabled cluster ARM** - - Template file: [https://aka.ms/arc-k8s-azmon-extension-msi-arm-template](https://aka.ms/arc-k8s-azmon-extension-msi-arm-template) - - Parameter file: [https://aka.ms/arc-k8s-azmon-extension-msi-arm-template-params](https://aka.ms/arc-k8s-azmon-extension-msi-arm-template-params) - - Template file (legacy authentication): [https://aka.ms/arc-k8s-azmon-extension-arm-template](https://aka.ms/arc-k8s-azmon-extension-arm-template) - - Parameter file (legacy authentication): [https://aka.ms/arc-k8s-azmon-extension-arm-template-params](https://aka.ms/arc-k8s-azmon-extension-arm-template-params) --2. Edit the following values in the parameter file. The same set of values are used for both the ARM and Bicep templates. Retrieve the resource ID of the resources from the **JSON View** of their **Overview** page. -- | Parameter | Description | - |:|:| - | AKS: `aksResourceId`<br>Arc: `clusterResourceId` | Resource ID of the cluster. | - | AKS: `aksResourceLocation`<br>Arc: `clusterRegion` | Location of the cluster. | - | AKS: `workspaceResourceId`<br>Arc: `workspaceResourceId` | Resource ID of the Log Analytics workspace. | - | Arc: `workspaceRegion` | Region of the Log Analytics workspace. | - | Arc: `workspaceDomain` | Domain of the Log Analytics workspace.<br>`opinsights.azure.com` for Azure public cloud<br>`opinsights.azure.us` for AzureUSGovernment. | - | AKS: `resourceTagValues` | Tag values specified for the existing Container insights extension data collection rule (DCR) of the cluster and the name of the DCR. The name will be `MSCI-<clusterName>-<clusterRegion>` and this resource created in an AKS clusters resource group. For first time onboarding, you can set arbitrary tag values. | ---3. Deploy the template with the parameter file by using any valid method for deploying Resource Manager templates. For examples of different methods, see [Deploy the sample templates](../resource-manager-samples.md#deploy-the-sample-templates). ----### [Terraform](#tab/terraform) --#### New AKS cluster --1. Download Terraform template file depending on whether you want to enable Syslog collection. -- **Syslog** - - [https://aka.ms/enable-monitoring-msi-syslog-terraform](https://aka.ms/enable-monitoring-msi-syslog-terraform) -- **No Syslog** - - [https://aka.ms/enable-monitoring-msi-terraform](https://aka.ms/enable-monitoring-msi-terraform) --2. Adjust the `azurerm_kubernetes_cluster` resource in *main.tf* based on your cluster settings. -3. Update parameters in *variables.tf* to replace values in "<>" -- | Parameter | Description | - |:|:| - | `aks_resource_group_name` | Use the values on the AKS Overview page for the resource group. | - | `resource_group_location` | Use the values on the AKS Overview page for the resource group. | - | `cluster_name` | Define the cluster name that you would like to create. | - | `workspace_resource_id` | Use the resource ID of your Log Analytics workspace. | - | `workspace_region` | Use the location of your Log Analytics workspace. | - | `resource_tag_values` | Match the existing tag values specified for the existing Container insights extension data collection rule (DCR) of the cluster and the name of the DCR. The name will match `MSCI-<clusterName>-<clusterRegion>` and this resource is created in the same resource group as the AKS clusters. For first time onboarding, you can set the arbitrary tag values. | - | `enabledContainerLogV2` | Set this parameter value to be true to use the default recommended ContainerLogV2. | - | Cost optimization parameters | Refer to [Data collection parameters](container-insights-cost-config.md#data-collection-parameters) | ---4. Run `terraform init -upgrade` to initialize the Terraform deployment. -5. Run `terraform plan -out main.tfplan` to initialize the Terraform deployment. -6. Run `terraform apply main.tfplan` to apply the execution plan to your cloud infrastructure. ---#### Existing AKS cluster -1. Import the existing cluster resource first with the command: ` terraform import azurerm_kubernetes_cluster.k8s <aksResourceId>` -2. Add the oms_agent add-on profile to the existing azurerm_kubernetes_cluster resource. - ``` - oms_agent { - log_analytics_workspace_id = var.workspace_resource_id - msi_auth_for_monitoring_enabled = true - } - ``` -3. Copy the DCR and DCRA resources from the Terraform templates -4. Run `terraform plan -out main.tfplan` and make sure the change is adding the oms_agent property. Note: If the `azurerm_kubernetes_cluster` resource defined is different during terraform plan, the existing cluster will get destroyed and recreated. -5. Run `terraform apply main.tfplan` to apply the execution plan to your cloud infrastructure. --> [!TIP] -> - Edit the `main.tf` file appropriately before running the terraform template -> - Data will start flowing after 10 minutes since the cluster needs to be ready first -> - WorkspaceID needs to match the format `/subscriptions/12345678-1234-9876-4563-123456789012/resourceGroups/example-resource-group/providers/Microsoft.OperationalInsights/workspaces/workspaceValue` -> - If resource group already exists, run `terraform import azurerm_resource_group.rg /subscriptions/<Subscription_ID>/resourceGroups/<Resource_Group_Name>` before terraform plan --### [Azure Policy](#tab/policy) --#### Azure portal --1. From the **Definitions** tab of the **Policy** menu in the Azure portal, create a policy definition with the following details. -- - **Definition location**: Azure subscription where the policy definition should be stored. - - **Name**: AKS-Monitoring-Addon - - **Description**: Azure custom policy to enable the Monitoring Add-on onto Azure Kubernetes clusters. - - **Category**: Select **Use existing** and then *Kubernetes* from the dropdown list. - - **Policy rule**: Replace the existing sample JSON with the contents of [https://aka.ms/aks-enable-monitoring-custom-policy](https://aka.ms/aks-enable-monitoring-custom-policy). --1. Select the new policy definition **AKS Monitoring Addon**. -1. Select **Assign** and specify a **Scope** of where the policy should be assigned. -1. Select **Next** and provide the resource ID of the Log Analytics workspace. -1. Create a remediation task if you want to apply the policy to existing AKS clusters in the selected scope. -1. Select **Review + create** to create the policy assignment. --#### Azure CLI --1. Download Azure Policy template and parameter files. -- - Template file: [https://aka.ms/enable-monitoring-msi-azure-policy-template](https://aka.ms/enable-monitoring-msi-azure-policy-template) - - Parameter file: [https://aka.ms/enable-monitoring-msi-azure-policy-parameters](https://aka.ms/enable-monitoring-msi-azure-policy-parameters) ---2. Create the policy definition using the following CLI command: -- ``` - az policy definition create --name "AKS-Monitoring-Addon-MSI" --display-name "AKS-Monitoring-Addon-MSI" --mode Indexed --metadata version=1.0.0 category=Kubernetes --rules azure-policy.rules.json --params azure-policy.parameters.json - ``` --2. Create the policy definition using the following CLI command: - - ``` - az policy assignment create --name aks-monitoring-addon --policy "AKS-Monitoring-Addon-MSI" --assign-identity --identity-scope /subscriptions/<subscriptionId> --role Contributor --scope /subscriptions/<subscriptionId> --location <location> --role Contributor --scope /subscriptions/<subscriptionId> -p "{ \"workspaceResourceId\": { \"value\": \"/subscriptions/<subscriptionId>/resourcegroups/<resourceGroupName>/providers/microsoft.operationalinsights/workspaces/<workspaceName>\" } }" - ``` --After the policy is assigned to the subscription, whenever you create a new cluster without Prometheus enabled, the policy will run and deploy to enable Prometheus monitoring. ----## Enable full monitoring with Azure portal --### New AKS cluster (Prometheus, Container insights, and Grafana) --When you create a new AKS cluster in the Azure portal, you can enable Prometheus, Container insights, and Grafana from the **Monitoring** tab. Make sure that you check the **Enable Container Logs**, **Enable Prometheus metrics**, and **Enable Grafana** checkboxes. ---### Existing cluster (Prometheus, Container insights, and Grafana) --1. Navigate to your AKS cluster in the Azure portal. -2. In the service menu, under **Monitoring**, select **Insights** > **Configure monitoring**. -3. Container insights is already enabled. Select the **Enable Prometheus metrics** and **Enable Grafana** checkboxes. If you have existing Azure Monitor workspace and Grafana workspace, then they're selected for you. -4. Select **Advanced settings** if you want to select alternate workspaces or create new ones. The **Cost presets** setting allows you to modify the default collection details to reduce your monitoring costs. See [Enable cost optimization settings in Container insights](./container-insights-cost-config.md) for details. -5. Select **Configure**. --### Existing cluster (Prometheus only) --1. Navigate to your AKS cluster in the Azure portal. -2. In the service menu, under **Monitoring**, select **Insights** > **Configure monitoring**. -3. Select the **Enable Prometheus metrics** checkbox. -4. Select **Advanced settings** if you want to select alternate workspaces or create new ones. The **Cost presets** setting allows you to modify the default collection details to reduce your monitoring costs. -5. Select **Configure**. --## Enable Windows metrics collection (preview) --> [!NOTE] -> There is no CPU/Memory limit in windows-exporter-daemonset.yaml so it may over-provision the Windows nodes -> For more details see [Resource reservation](https://kubernetes.io/docs/concepts/configuration/windows-resource-management/#resource-reservation) -> -> As you deploy workloads, set resource memory and CPU limits on containers. This also subtracts from NodeAllocatable and helps the cluster-wide scheduler in determining which pods to place on which nodes. -> Scheduling pods without limits may over-provision the Windows nodes and in extreme cases can cause the nodes to become unhealthy. ---As of version 6.4.0-main-02-22-2023-3ee44b9e of the Managed Prometheus addon container (prometheus_collector), Windows metric collection has been enabled for the AKS clusters. Onboarding to the Azure Monitor Metrics add-on enables the Windows DaemonSet pods to start running on your node pools. Both Windows Server 2019 and Windows Server 2022 are supported. Follow these steps to enable the pods to collect metrics from your Windows node pools. --1. Manually install windows-exporter on AKS nodes to access Windows metrics by deploying the [windows-exporter-daemonset YAML](https://github.com/prometheus-community/windows_exporter/blob/master/kubernetes/windows-exporter-daemonset.yaml) file. Enable the following collectors: -- * `[defaults]` - * `container` - * `memory` - * `process` - * `cpu_info` - - For more collectors, please see [Prometheus exporter for Windows metrics](https://github.com/prometheus-community/windows_exporter#windows_exporter). -- Deploy the [windows-exporter-daemonset YAML](https://github.com/prometheus-community/windows_exporter/blob/master/kubernetes/windows-exporter-daemonset.yaml) file. Note that if there are any taints applied in the node, you will need to apply the appropriate tolerations. -- ``` - kubectl apply -f windows-exporter-daemonset.yaml - ``` --1. Apply the [ama-metrics-settings-configmap](https://github.com/Azure/prometheus-collector/blob/main/otelcollector/configmaps/ama-metrics-settings-configmap.yaml) to your cluster. Set the `windowsexporter` and `windowskubeproxy` Booleans to `true`. For more information, see [Metrics add-on settings configmap](./prometheus-metrics-scrape-configuration.md#metrics-add-on-settings-configmap). -1. Enable the recording rules that are required for the out-of-the-box dashboards: -- * If onboarding using the CLI, include the option `--enable-windows-recording-rules`. - * If onboarding using an ARM template, Bicep, or Azure Policy, set `enableWindowsRecordingRules` to `true` in the parameters file. - * If the cluster is already onboarded, use [this ARM template](https://github.com/Azure/prometheus-collector/blob/main/AddonArmTemplate/WindowsRecordingRuleGroupTemplate/WindowsRecordingRules.json) and [this parameter file](https://github.com/Azure/prometheus-collector/blob/main/AddonArmTemplate/WindowsRecordingRuleGroupTemplate/WindowsRecordingRulesParameters.json) to create the rule groups. This will add the required recording rules and is not an ARM operation on the cluster and does not impact current monitoring state of the cluster. -----## Verify deployment -Use the [kubectl command line tool](/azure/aks/learn/quick-kubernetes-deploy-cli#connect-to-the-cluster) to verify that the agent is deployed properly. --### Managed Prometheus --**Verify that the DaemonSet was deployed properly on the Linux node pools** --```AzureCLI -kubectl get ds ama-metrics-node --namespace=kube-system -``` --The number of pods should be equal to the number of Linux nodes on the cluster. The output should resemble the following example: --```output -User@aksuser:~$ kubectl get ds ama-metrics-node --namespace=kube-system -NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE -ama-metrics-node 1 1 1 1 1 <none> 10h -``` --**Verify that Windows nodes were deployed properly** --```AzureCLI -kubectl get ds ama-metrics-win-node --namespace=kube-system -``` --The number of pods should be equal to the number of Windows nodes on the cluster. The output should resemble the following example: --```output -User@aksuser:~$ kubectl get ds ama-metrics-node --namespace=kube-system -NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE -ama-metrics-win-node 3 3 3 3 3 <none> 10h -``` --**Verify that the two ReplicaSets were deployed for Prometheus** --```AzureCLI -kubectl get rs --namespace=kube-system -``` --The output should resemble the following example: --```output -User@aksuser:~$kubectl get rs --namespace=kube-system -NAME DESIRED CURRENT READY AGE -ama-metrics-5c974985b8 1 1 1 11h -ama-metrics-ksm-5fcf8dffcd 1 1 1 11h -``` ---### Container insights --**Verify that the DaemonSets were deployed properly on the Linux node pools** --```AzureCLI -kubectl get ds ama-logs --namespace=kube-system -``` --The number of pods should be equal to the number of Linux nodes on the cluster. The output should resemble the following example: --```output -User@aksuser:~$ kubectl get ds ama-logs --namespace=kube-system -NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE -ama-logs 2 2 2 2 2 <none> 1d -``` --**Verify that Windows nodes were deployed properly** --``` -kubectl get ds ama-logs-windows --namespace=kube-system -``` --The number of pods should be equal to the number of Windows nodes on the cluster. The output should resemble the following example: --```output -User@aksuser:~$ kubectl get ds ama-logs-windows --namespace=kube-system -NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE -ama-logs-windows 2 2 2 2 2 <none> 1d -``` ---**Verify deployment of the Container insights solution** --``` -kubectl get deployment ama-logs-rs --namespace=kube-system -``` --The output should resemble the following example: --```output -User@aksuser:~$ kubectl get deployment ama-logs-rs --namespace=kube-system -NAME READY UP-TO-DATE AVAILABLE AGE -ama-logs-rs 1/1 1 1 24d -``` --**View configuration with CLI** --Use the `aks show` command to find out whether the solution is enabled, the Log Analytics workspace resource ID, and summary information about the cluster. --```azurecli -az aks show --resource-group <resourceGroupofAKSCluster> --name <nameofAksCluster> -``` --The command will return JSON-formatted information about the solution. The `addonProfiles` section should include information on the `omsagent` as in the following example: --```output -"addonProfiles": { - "omsagent": { - "config": { - "logAnalyticsWorkspaceResourceID": "/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/my-resource-group/providers/microsoft.operationalinsights/workspaces/my-workspace", - "useAADAuth": "true" - }, - "enabled": true, - "identity": null - }, -} -``` ---## Resources provisioned --When you enable monitoring, the following resources are created in your subscription: --| Resource Name | Resource Type | Resource Group | Region/Location | Description | -|:|:|:|:|:| -| `MSCI-<aksclusterregion>-<clustername>` | **Data Collection Rule** | Same as cluster | Same as Log Analytics workspace | This data collection rule is for log collection by Azure Monitor agent, which uses the Log Analytics workspace as destination, and is associated to the AKS cluster resource. | -| `MSPROM-<aksclusterregion>-<clustername>` | **Data Collection Rule** | Same as cluster | Same as Azure Monitor workspace | This data collection rule is for prometheus metrics collection by metrics addon, which has the chosen Azure monitor workspace as destination, and also it is associated to the AKS cluster resource | -| `MSPROM-<aksclusterregion>-<clustername>` | **Data Collection endpoint** | Same as cluster | Same as Azure Monitor workspace | This data collection endpoint is used by the above data collection rule for ingesting Prometheus metrics from the metrics addon| - -When you create a new Azure Monitor workspace, the following additional resources are created as part of it --| Resource Name | Resource Type | Resource Group | Region/Location | Description | -|:|:|:|:|:| -| `<azuremonitor-workspace-name>` | **Data Collection Rule** | MA_\<azuremonitor-workspace-name>_\<azuremonitor-workspace-region>_managed | Same as Azure Monitor Workspace | DCR created when you use OSS Prometheus server to Remote Write to Azure Monitor Workspace. | -| `<azuremonitor-workspace-name>` | **Data Collection Endpoint** | MA_\<azuremonitor-workspace-name>_\<azuremonitor-workspace-region>_managed | Same as Azure Monitor Workspace | DCE created when you use OSS Prometheus server to Remote Write to Azure Monitor Workspace.| - --## Differences between Windows and Linux clusters --The main differences in monitoring a Windows Server cluster compared to a Linux cluster include: --- Windows doesn't have a Memory RSS metric. As a result, it isn't available for Windows nodes and containers. The [Working Set](/windows/win32/memory/working-set) metric is available.-- Disk storage capacity information isn't available for Windows nodes.-- Only pod environments are monitored, not Docker environments.-- With the preview release, a maximum of 30 Windows Server containers are supported. This limitation doesn't apply to Linux containers.-->[!NOTE] -> Container insights support for the Windows Server 2022 operating system is in preview. ---The containerized Linux agent (replicaset pod) makes API calls to all the Windows nodes on Kubelet secure port (10250) within the cluster to collect node and container performance-related metrics. Kubelet secure port (:10250) should be opened in the cluster's virtual network for both inbound and outbound for Windows node and container performance-related metrics collection to work. --If you have a Kubernetes cluster with Windows nodes, review and configure the network security group and network policies to make sure the Kubelet secure port (:10250) is open for both inbound and outbound in the cluster's virtual network. ----## Next steps --* If you experience issues while you attempt to onboard the solution, review the [Troubleshooting guide](container-insights-troubleshoot.md). -* With monitoring enabled to collect health and resource utilization of your AKS cluster and workloads running on them, learn [how to use](container-insights-analyze.md) Container insights. |
| azure-monitor | Kubernetes Monitoring Firewall | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/kubernetes-monitoring-firewall.md | - Title: Network firewall requirements for monitoring Kubernetes cluster -description: Proxy and firewall configuration information required for the containerized agent to communicate with Managed Prometheus and Container insights. - Previously updated : 11/14/2023----# Network firewall requirements for monitoring Kubernetes cluster --The following table lists the proxy and firewall configuration information required for the containerized agent to communicate with Managed Prometheus and Container insights. All network traffic from the agent is outbound to Azure Monitor. --## Azure public cloud --| Endpoint| Purpose | Port | -|:|:|:| -| `*.ods.opinsights.azure.com` | | 443 | -| `*.oms.opinsights.azure.com` | | 443 | -| `dc.services.visualstudio.com` | | 443 | -| `*.monitoring.azure.com` | | 443 | -| `login.microsoftonline.com` | | 443 | -| `global.handler.control.monitor.azure.com` | Access control service | 443 | -| `<cluster-region-name>.ingest.monitor.azure.com` | Azure monitor managed service for Prometheus - metrics ingestion endpoint (DCE) | 443 | -| `<cluster-region-name>.handler.control.monitor.azure.com` | Fetch data collection rules for specific cluster | 443 | --## Microsoft Azure operated by 21Vianet cloud --| Endpoint| Purpose | Port | -|:|:|:| -| `*.ods.opinsights.azure.cn` | Data ingestion | 443 | -| `*.oms.opinsights.azure.cn` | Azure Monitor agent (AMA) onboarding | 443 | -| `dc.services.visualstudio.com` | For agent telemetry that uses Azure Public Cloud Application Insights | 443 | -| `global.handler.control.monitor.azure.cn` | Access control service | 443 | -| `<cluster-region-name>.handler.control.monitor.azure.cn` | Fetch data collection rules for specific cluster | 443 | --## Azure Government cloud --| Endpoint| Purpose | Port | -|:|:|:| -| `*.ods.opinsights.azure.us` | Data ingestion | 443 | -| `*.oms.opinsights.azure.us` | Azure Monitor agent (AMA) onboarding | 443 | -| `dc.services.visualstudio.com` | For agent telemetry that uses Azure Public Cloud Application Insights | 443 | -| `global.handler.control.monitor.azure.us` | Access control service | 443 | -| `<cluster-region-name>.handler.control.monitor.azure.us` | Fetch data collection rules for specific cluster | 443 | ---## Next steps --* If you experience issues while you attempt to onboard the solution, review the [Troubleshooting guide](container-insights-troubleshoot.md). -* With monitoring enabled to collect health and resource utilization of your AKS cluster and workloads running on them, learn [how to use](container-insights-analyze.md) Container insights. |
| azure-monitor | Kubernetes Monitoring Private Link | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/kubernetes-monitoring-private-link.md | - Title: Enable private link with Container insights -description: Learn how to enable private link on an Azure Kubernetes Service (AKS) cluster. - Previously updated : 06/05/2024-----# Enable private link for Kubernetes monitoring in Azure Monitor -[Azure Private Link](../../private-link/private-link-overview.md) enables you to access Azure platform as a service (PaaS) resources to your virtual network by using private endpoints. An [Azure Monitor Private Link Scope (AMPLS)](../logs/private-link-security.md) connects a private endpoint to a set of Azure Monitor resources to define the boundaries of your monitoring network. This article describes how to configure Container insights and Managed Prometheus to use private link for data ingestion from your Azure Kubernetes Service (AKS) cluster. ---> [!NOTE] -> - See [Connect to a data source privately](../../../articles/managed-grafan) for details on how to configure private link to query data from your Azure Monitor workspace using Grafana. -> - See [Use private endpoints for Managed Prometheus and Azure Monitor workspace](../essentials/azure-monitor-workspace-private-endpoint.md) for details on how to configure private link to query data from your Azure Monitor workspace using workbooks. ---## Prerequisites -- This article describes how to connect your cluster to an existing Azure Monitor Private Link Scope (AMPLS). Create an AMPLS following the guidance in [Configure your private link](../logs/private-link-configure.md).--## Managed Prometheus (Azure Monitor workspace) -Data for Managed Prometheus is stored in an [Azure Monitor workspace](../essentials/azure-monitor-workspace-overview.md), so you must make this workspace accessible over a private link. --### Configure DCEs -Private links for data ingestion for Managed Prometheus are configured on the Data Collection Endpoints (DCE) of the Azure Monitor workspace that stores the data. To identify the DCEs associated with your Azure Monitor workspace, select **Data Collection Endpoints** from your Azure Monitor workspace in the Azure portal. ---If your AKS cluster isn't in the same region as your Azure Monitor workspace, then you need to [create another DCE](../essentials/data-collection-endpoint-overview.md#create-a-data-collection-endpoint) in the same region as the AKS cluster. In this case, open the data collection rule (DCR) created when you enabled Managed Prometheus. This DCR will be named **MSProm-\<clusterName\>-\<clusterRegion\>**. The cluster will be listed on the **Resources** page. On the **Data collection endpoint** dropdown, select the DCE in the same region as the AKS cluster. ----### Ingestion from a private AKS cluster -By default, a private AKS cluster can send data to Managed Prometheus and your Azure Monitor workspace over the public network using a public Data Collection Endpoint. --If you choose to use an Azure Firewall to limit the egress from your cluster, you can implement one of the following: --- Open a path to the public ingestion endpoint. Update the routing table with the following two endpoints:- - `*.handler.control.monitor.azure.com` - - `*.ingest.monitor.azure.com` -- Enable the Azure Firewall to access the Azure Monitor Private Link scope and DCE that's used for data ingestion.--### Private link ingestion for remote write -Use the following steps to set up remote write for a Kubernetes cluster over a private link virtual network and an Azure Monitor Private Link scope. --1. Create your Azure virtual network. -1. Configure the on-premises cluster to connect to an Azure VNET using a VPN gateway or ExpressRoutes with private-peering. -1. Create an Azure Monitor Private Link scope. -1. Connect the Azure Monitor Private Link scope to a private endpoint in the virtual network used by the on-premises cluster. This private endpoint is used to access your DCEs. -1. From your Azure Monitor workspace in the portal, select **Data Collection Endpoints** from the Azure Monitor workspace menu. -1. You'll have at least one DCE which will have the same name as your workspace. Click on the DCE to open its details. -1. Select the **Network Isolation** page for the DCE. -2. Click **Add** and select your Azure Monitor Private Link scope. It takes a few minutes for the settings to propagate. Once completed, data from your private AKS cluster is ingested into your Azure Monitor workspace over the private link. ---## Container insights (Log Analytics workspace) -Data for Container insights, is stored in a [Log Analytics workspace](../logs/log-analytics-workspace-overview.md), so you must make this workspace accessible over a private link. --> [!NOTE] -> This section describes how to enable private link for Container insights using CLI. For details on using an ARM template, see [Enable Container insights](./kubernetes-monitoring-enable.md?tabs=arm#enable-container-insights) and note the parameters `useAzureMonitorPrivateLinkScope` and `azureMonitorPrivateLinkScopeResourceId`. --### Cluster using managed identity authentication --**Existing AKS cluster with default Log Analytics workspace** --```azurecli -az aks enable-addons --addon monitoring --name <cluster-name> --resource-group <cluster-resource-group-name> --ampls-resource-id "<azure-monitor-private-link-scope-resource-id>" -``` --Example: --```azurecli -az aks enable-addons --addon monitoring --name "my-cluster" --resource-group "my-resource-group" --workspace-resource-id "/subscriptions/my-subscription/resourceGroups/my-resource-group/providers/Microsoft.OperationalInsights/workspaces/my-workspace" --ampls-resource-id "/subscriptions/my-subscription /resourceGroups/my-resource-group/providers/microsoft.insights/privatelinkscopes/my-ampls-resource" -``` --**Existing AKS cluster with existing Log Analytics workspace** --```azurecli -az aks enable-addons --addon monitoring --name <cluster-name> --resource-group <cluster-resource-group-name> --workspace-resource-id <workspace-resource-id> --ampls-resource-id "<azure-monitor-private-link-scope-resource-id>" -``` --Example: --```azurecli -az aks enable-addons --addon monitoring --name "my-cluster" --resource-group "my-resource-group" --workspace-resource-id "/subscriptions/my-subscription/resourceGroups/my-resource-group/providers/Microsoft.OperationalInsights/workspaces/my-workspace" --ampls-resource-id "/subscriptions/my-subscription /resourceGroups/ my-resource-group/providers/microsoft.insights/privatelinkscopes/my-ampls-resource" -``` --**New AKS cluster** --```azurecli -az aks create --resource-group rgName --name clusterName --enable-addons monitoring --workspace-resource-id "workspaceResourceId" --ampls-resource-id "azure-monitor-private-link-scope-resource-id" -``` --Example: --```azurecli -az aks create --resource-group "my-resource-group" --name "my-cluster" --enable-addons monitoring --workspace-resource-id "/subscriptions/my-subscription/resourceGroups/my-resource-group/providers/Microsoft.OperationalInsights/workspaces/my-workspace" --ampls-resource-id "/subscriptions/my-subscription /resourceGroups/ my-resource-group/providers/microsoft.insights/privatelinkscopes/my-ampls-resource" -``` ---### Cluster using legacy authentication -Use the following procedures to enable network isolation by connecting your cluster to the Log Analytics workspace using [Azure Private Link](../logs/private-link-security.md) if your cluster is not using managed identity authentication. This requires a [private AKS cluster](/azure/aks/private-clusters). --1. Create a private AKS cluster following the guidance in [Create a private Azure Kubernetes Service cluster](/azure/aks/private-clusters). --2. Disable public Ingestion on your Log Analytics workspace. -- Use the following command to disable public ingestion on an existing workspace. -- ```cli - az monitor log-analytics workspace update --resource-group <azureLogAnalyticsWorkspaceResourceGroup> --workspace-name <azureLogAnalyticsWorkspaceName> --ingestion-access Disabled - ``` -- Use the following command to create a new workspace with public ingestion disabled. -- ```cli - az monitor log-analytics workspace create --resource-group <azureLogAnalyticsWorkspaceResourceGroup> --workspace-name <azureLogAnalyticsWorkspaceName> --ingestion-access Disabled - ``` --3. Configure private link by following the instructions at [Configure your private link](../logs/private-link-configure.md). Set ingestion access to public and then set to private after the private endpoint is created but before monitoring is enabled. The private link resource region must be same as AKS cluster region. --4. Enable monitoring for the AKS cluster. -- ```cli - az aks enable-addons -a monitoring --resource-group <AKSClusterResourceGorup> --name <AKSClusterName> --workspace-resource-id <workspace-resource-id> --enable-msi-auth-for-monitoring false - ``` ----## Next steps --* If you experience issues while you attempt to onboard the solution, review the [Troubleshooting guide](container-insights-troubleshoot.md). -* With monitoring enabled to collect health and resource utilization of your AKS cluster and workloads running on them, learn [how to use](container-insights-analyze.md) Container insights. |
| azure-monitor | Monitor Kubernetes | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/monitor-kubernetes.md | - Title: Monitor Kubernetes clusters using Azure services and cloud native tools -description: Describes how to monitor the health and performance of the different layers of your Kubernetes environment using Azure Monitor and cloud native services in Azure. ---- Previously updated : 07/30/2024---# Monitor Kubernetes clusters using Azure services and cloud native tools --This article describes how to monitor the health and performance of your Kubernetes clusters and the workloads running on them using Azure Monitor and related Azure and cloud native services. This includes clusters running in Azure Kubernetes Service (AKS) or other clouds such as [AWS](https://aws.amazon.com/kubernetes/) and [GCP](https://cloud.google.com/kubernetes-engine). Different sets of guidance are provided for the different roles that typically manage unique components that make up a Kubernetes environment. ---> [!IMPORTANT] -> This article provides complete guidance on monitoring the different layers of your Kubernetes environment based on Azure Kubernetes Service (AKS) or Kubernetes clusters in other clouds. If you're just getting started with AKS or Azure Monitor, see [Monitoring AKS](/azure/aks/monitor-aks) for basic information for getting started monitoring an AKS cluster. --## Layers and roles of Kubernetes environment --Following is an illustration of a common model of a typical Kubernetes environment, starting from the infrastructure layer up through applications. Each layer has distinct monitoring requirements that are addressed by different services and typically managed by different roles in the organization. ---Responsibility for the different layers of a Kubernetes environment and the applications that depend on it are typically addressed by multiple roles. Depending on the size of your organization, these roles may be performed by different people or even different teams. The following table describes the different roles while the sections below provide the monitoring scenarios that each will typically encounter. --| Roles | Description | -|:|:| -| [Developer](#developer) | Develop and maintaining the application running on the cluster. Responsible for application specific traffic including application performance and failures. Maintains reliability of the application according to SLAs. | -| [Platform engineer](#platform-engineer) | Responsible for the Kubernetes cluster. Provisions and maintains the platform used by developer. | -| [Network engineer](#network-engineer) | Responsible for traffic between workloads and any ingress/egress with the cluster. Analyzes network traffic and performs threat analysis. | --## Selection of monitoring tools --Azure provides a complete set of services based on [Azure Monitor](../overview.md) for monitoring the health and performance of different layers of your Kubernetes infrastructure and the applications that depend on it. These services work in conjunction with each other to provide a complete monitoring solution and are recommended both for [AKS](/azure/aks/intro-kubernetes) and your Kubernetes clusters running in other clouds. You may have an existing investment in cloud native technologies endorsed by the [Cloud Native Computing Foundation](https://www.cncf.io/), in which case you may choose to integrate Azure tools into your existing environment. --Your choice of which tools to deploy and their configuration will depend on the requirements of your particular environment. For example, you may use the managed offerings in Azure for Prometheus and Grafana, or you may choose to use your existing installation of these tools with your Kubernetes clusters in Azure. Your organization may also use alternative tools to Container insights to collect and analyze Kubernetes logs, such as Splunk or Datadog. --> [!IMPORTANT] -> Monitoring a complex environment such as Kubernetes involves collecting a significant amount of telemetry, much of which incurs a cost. You should collect just enough data to meet your requirements. This includes the amount of data collected, the frequency of collection, and the retention period. If you're very cost conscious, you may choose to implement a subset of the full functionality in order to reduce your monitoring spend. --## Network engineer -The *Network Engineer* is responsible for traffic between workloads and any ingress/egress with the cluster. They analyze network traffic and perform threat analysis. ---### Azure services for network administrator --The following table lists the services that are commonly used by the network engineer to monitor the health and performance of the network supporting the Kubernetes cluster. ---| Service | Description | -|:|:| -| [Network Watcher](../../network-watcher/network-watcher-monitoring-overview.md) | Suite of tools in Azure to monitor the virtual networks used by your Kubernetes clusters and diagnose detected issues. | -| [Traffic analytics](../../network-watcher/traffic-analytics.md) | Feature of Network Watcher that analyzes flow logs to provide insights into traffic flow. | -| [Network insights](../../network-watcher/network-insights-overview.md) | Feature of Azure Monitor that includes a visual representation of the performance and health of different network components and provides access to the network monitoring tools that are part of Network Watcher. | --[Network insights](../../network-watcher/network-insights-overview.md) is enabled by default and requires no configuration. Network Watcher is also typically [enabled by default in each Azure region](../../network-watcher/network-watcher-create.md). --### Monitor level 1 - Network --Following are common scenarios for monitoring the network. --- Create [flow logs](../../network-watcher/network-watcher-nsg-flow-logging-overview.md) to log information about the IP traffic flowing through network security groups used by your cluster and then use [traffic analytics](../../network-watcher/traffic-analytics.md) to analyze and provide insights on this data. You'll most likely use the same Log Analytics workspace for traffic analytics that you use for Container insights and your control plane logs.-- Using [traffic analytics](../../network-watcher/traffic-analytics.md), you can determine if any traffic is flowing either to or from any unexpected ports used by the cluster and also if any traffic is flowing over public IPs that shouldn't be exposed. Use this information to determine whether your network rules need modification.-- For AKS clusters, use the [Network Observability add-on for AKS (preview)](https://aka.ms/NetObsAddonDoc) to monitor and observe access between services in the cluster (east-west traffic).---## Platform engineer --The *platform engineer*, also known as the cluster administrator, is responsible for the Kubernetes cluster itself. They provision and maintain the platform used by developers. They need to understand the health of the cluster and its components, and be able to troubleshoot any detected issues. They also need to understand the cost to operate the cluster and potentially to be able to allocate costs to different teams. ----Large organizations may also have a *fleet architect*, which is similar to the platform engineer but is responsible for multiple clusters. They need visibility across the entire environment and must perform administrative tasks at scale. At scale recommendations are included in the guidance below. See [What is Azure Kubernetes Fleet Manager?](../../kubernetes-fleet/overview.md) for details on creating a Fleet resource for multi-cluster and at-scale scenarios. ---### Azure services for platform engineer --The following table lists the Azure services for the platform engineer to monitor the health and performance of the Kubernetes cluster and its components. --| Service | Description | -|:|:| -| [Container Insights](container-insights-overview.md) | Azure service for AKS and Azure Arc-enabled Kubernetes clusters that use a containerized version of the [Azure Monitor agent](../agents/agents-overview.md) to collect stdout/stderr logs, performance metrics, and Kubernetes events from each node in your cluster. You can view the data in the Azure portal or query it using [Log Analytics](../logs/log-analytics-overview.md). Configure the [Prometheus experience](./container-insights-experience-v2.md) to use Container insights views with Prometheus data. | -| [Azure Monitor managed service for Prometheus](../essentials/prometheus-metrics-overview.md) | [Prometheus](https://prometheus.io) is a cloud-native metrics solution from the Cloud Native Compute Foundation and the most common tool used for collecting and analyzing metric data from Kubernetes clusters. Azure Monitor managed service for Prometheus is a fully managed solution that's compatible with the Prometheus query language (PromQL) and Prometheus alerts and integrates with Azure Managed Grafana for visualization. This service supports your investment in open source tools without the complexity of managing your own Prometheus environment. | -| [Azure Arc-enabled Kubernetes](container-insights-enable-arc-enabled-clusters.md) | Allows you to attach to Kubernetes clusters running in other clouds so that you can manage and configure them in Azure. With the Arc agent installed, you can monitor AKS and hybrid clusters together using the same methods and tools, including Container insights and Prometheus. | -| [Azure Managed Grafana](../../managed-grafan) | Fully managed implementation of [Grafana](https://grafana.com/), which is an open-source data visualization platform commonly used to present Prometheus and other data. Multiple predefined Grafana dashboards are available for monitoring Kubernetes and full-stack troubleshooting.| --### Configure monitoring for platform engineer --The sections below identify the steps for complete monitoring of your Kubernetes environment using the Azure services in the above table. Functionality and integration options are provided for each to help you determine where you may need to modify this configuration to meet your particular requirements. --Onboarding Container insights and Managed Prometheus can be part of the same experience as described in [Enable monitoring for Kubernetes clusters](../containers/kubernetes-monitoring-enable.md). The following sections described each separately so you can consider your all of your onboarding and configuration options for each. --#### Enable scraping of Prometheus metrics --> [!IMPORTANT] -> To use Azure Monitor managed service for Prometheus, you need to have an [Azure Monitor workspace](../essentials/azure-monitor-workspace-overview.md). For information on design considerations for a workspace configuration, see [Azure Monitor workspace architecture](../essentials/azure-monitor-workspace-overview.md#azure-monitor-workspace-architecture). --Enable scraping of Prometheus metrics by Azure Monitor managed service for Prometheus from your cluster using one of the following methods: --- Select the option **Enable Prometheus metrics** when you [create an AKS cluster](/azure/aks/learn/quick-kubernetes-deploy-portal).-- Select the option **Enable Prometheus metrics** when you enable Container insights on an existing [AKS cluster](container-insights-enable-aks.md) or [Azure Arc-enabled Kubernetes cluster](container-insights-enable-arc-enabled-clusters.md).-- Enable for an existing [AKS cluster](../containers/kubernetes-monitoring-enable.md#enable-prometheus-and-grafana) or [Arc-enabled Kubernetes cluster](../containers/kubernetes-monitoring-enable.md#enable-prometheus-and-grafana).---If you already have a Prometheus environment that you want to use for your AKS clusters, then enable Azure Monitor managed service for Prometheus and then use remote-write to send data to your existing Prometheus environment. You can also [use remote-write to send data from your existing self-managed Prometheus environment to Azure Monitor managed service for Prometheus](../essentials/prometheus-remote-write.md). --See [Default Prometheus metrics configuration in Azure Monitor](../essentials/prometheus-metrics-scrape-default.md) for details on the metrics that are collected by default and their frequency of collection. If you want to customize the configuration, see [Customize scraping of Prometheus metrics in Azure Monitor managed service for Prometheus](../essentials/prometheus-metrics-scrape-configuration.md). ---#### Enable Grafana for analysis of Prometheus data --> [!NOTE] -> Use Grafana for your monitoring your Kubernetes environment if you have an existing investment in Grafana or if you prefer to use Grafana dashboards instead of Container insights to analyze your Prometheus data. If you don't want to use Grafana, then enable the [Prometheus experience in Container insights](./container-insights-experience-v2.md) so that you can use Container insights views with your Prometheus data. --[Create an instance of Managed Grafana](../../managed-grafan#use-out-of-the-box-dashboards) are available for monitoring Kubernetes clusters including several that present similar information as Container insights views. --If you have an existing Grafana environment, then you can continue to use it and add Azure Monitor managed service for [Prometheus as a data source](https://grafana.com/docs/grafana/latest/datasources/prometheus/). You can also [add the Azure Monitor data source to Grafana](https://grafana.com/docs/grafana/latest/datasources/azure-monitor/) to use data collected by Container insights in custom Grafana dashboards. Perform this configuration if you want to focus on Grafana dashboards rather than using the Container insights views and reports. ----#### Enable Container Insights for collection of logs --When you enable Container Insights for your Kubernetes cluster, it deploys a containerized version of the [Azure Monitor agent](../agents/log-analytics-agent.md) that sends data to a Log Analytics workspace in Azure Monitor. Container insights collects container stdout/stderr, infrastructure logs, and performance data. All log data is stored in a Log Analytics workspace where they can be analyzed using [Kusto Query Language (KQL)](../logs/log-query-overview.md). --See [Enable Container insights](../containers/container-insights-onboard.md) for prerequisites and configuration options for onboarding your Kubernetes clusters. [Onboard using Azure Policy](/azure/azure-monitor/containers/kubernetes-monitoring-enable?tabs=policy#enable-container-insights) to ensure that all clusters retain a consistent configuration. --Once Container insights is enabled for a cluster, perform the following actions to optimize your installation. --- Enable the [Prometheus experience in Container insights](./container-insights-experience-v2.md) so that you can use Container insights views with your Prometheus data.-- To improve your query experience with data collected by Container insights and to reduce collection costs, [enable the ContainerLogV2 schema](container-insights-logs-schema.md) for each cluster. If you only use logs for occasional troubleshooting, then consider configuring this table as [basic logs](../logs/logs-table-plans.md).-- Use cost presets described in [Enable cost optimization settings in Container insights](../containers/container-insights-cost-config.md#enable-cost-settings) to reduce your cost for Container insights data ingestion by reducing the amount of data that's collected. Disable collection of metrics by configuring Container insights to only collect **Logs and events** since many of the same metric values as [Prometheus](#enable-scraping-of-prometheus-metrics).--If you have an existing solution for collection of logs, then follow the guidance for that tool or enable Container insights and use the [data export feature of Log Analytics workspace](../logs/logs-data-export.md) to send data to [Azure Event Hubs](../../event-hubs/event-hubs-about.md) to forward to alternate system. ---#### Collect control plane logs for AKS clusters --The logs for AKS control plane components are implemented in Azure as [resource logs](../essentials/resource-logs.md). Container Insights doesn't use these logs, so you need to create your own log queries to view and analyze them. For details on log structure and queries, see [How to query logs from Container Insights](/azure/aks/monitor-aks#aks-control-planeresource-logs). --[Create a diagnostic setting](/azure/aks/monitor-aks#aks-control-planeresource-logs) for each AKS cluster to send resource logs to a Log Analytics workspace. Use [Azure Policy](../essentials/diagnostic-settings-policy.md) to ensure consistent configuration across multiple clusters. --There's a cost for sending resource logs to a workspace, so you should only collect those log categories that you intend to use. For a description of the categories that are available for AKS, see [Resource logs](/azure/aks/monitor-aks-reference#resource-logs). Start by collecting a minimal number of categories and then modify the diagnostic setting to collect additional categories as your needs increase and as you understand your associated costs. You can send logs to an Azure storage account to reduce costs if you need to retain the information for compliance reasons. For details on the cost of ingesting and retaining log data, see [Azure Monitor Logs pricing details](../logs/cost-logs.md). --If you're unsure which resource logs to initially enable, use the following recommendations, which are based on the most common customer requirements. You can enable other categories later if you need to. ---| Category | Enable? | Destination | -|:|:|:| -| kube-apiserver | Enable | Log Analytics workspace | -| kube-audit | Enable | Azure storage. This keeps costs to a minimum yet retains the audit logs if they're required by an auditor. | -| kube-audit-admin | Enable | Log Analytics workspace | -| kube-controller-manager | Enable | Log Analytics workspace | -| kube-scheduler | Disable | | -| cluster-autoscaler | Enable if autoscale is enabled | Log Analytics workspace | -| guard | Enable if Microsoft Entra ID is enabled | Log Analytics workspace | -| AllMetrics | Disable since metrics are collected in Managed Prometheus | Log Analytics workspace | ---If you have an existing solution for collection of logs, either follow the guidance for that tool or enable Container insights and use the [data export feature of Log Analytics workspace](../logs/logs-data-export.md) to send data to Azure event hub to forward to alternate system. --#### Collect Activity log for AKS clusters -Configuration changes to your AKS clusters are stored in the [Activity log](../essentials/activity-log.md). [Create a diagnostic setting to send this data to your Log Analytics workspace](../essentials/activity-log.md#send-to-log-analytics-workspace) to analyze it with other monitoring data. There's no cost for this data collection, and you can analyze or alert on the data using Log Analytics. ---### Monitor level 2 - Cluster level components --The cluster level includes the following components: --| Component | Monitoring requirements | -|:|:| -| Node | Understand the readiness status and performance of CPU, memory, disk and IP usage for each node and proactively monitor their usage trends before deploying any workloads. | --Following are common scenarios for monitoring the cluster level components. --**Container insights**<br> -- Use the **Cluster** view to see the performance of the nodes in your cluster, including CPU and memory utilization.-- Use the **Nodes** view to see the health of each node and the health and performance of the pods running on them. For more information on analyzing node health and performance, see [Monitor your Kubernetes cluster performance with Container Insights](container-insights-analyze.md).-- Under **Reports**, use the **Node Monitoring** workbooks to analyze disk capacity, disk IO, and GPU usage. For more information about these workbooks, see [Node Monitoring workbooks](container-insights-reports.md#node-monitoring-workbooks).-- Under **Monitoring**, select **Workbooks**, then **Subnet IP Usage** to see the IP allocation and assignment on each node for a selected time-range.--**Grafana dashboards**<br> -- Use the [prebuilt dashboard](../visualize/grafana-plugin.md#use-out-of-the-box-dashboards) in Managed Grafana for **Kubelet** to see the health and performance of each.-- Use Grafana dashboards with [Prometheus metric values](../essentials/prometheus-metrics-scrape-default.md) related to disk such as `node_disk_io_time_seconds_total` and `windows_logical_disk_free_bytes` to monitor attached storage.-- Multiple [Kubernetes dashboards](https://grafana.com/grafana/dashboards/?search=kubernetes) are available that visualize the performance and health of your nodes based on data stored in Prometheus.--**Log Analytics** -- Select the [Containers category](../logs/queries.md?tabs=groupby#find-and-filter-queries) in the [queries dialog](../logs/queries.md#queries-dialog) for your Log Analytics workspace to access prebuilt log queries for your cluster, including the **Image inventory** log query that retrieves data from the [ContainerImageInventory](/azure/azure-monitor/reference/tables/containerimageinventory) table populated by Container insights.--**Troubleshooting**<br> -- For troubleshooting scenarios, you may need to access nodes directly for maintenance or immediate log collection. For security purposes, AKS nodes aren't exposed to the internet but you can use the `kubectl debug` command to SSH to the AKS nodes. For more information on this process, see [Connect with SSH to Azure Kubernetes Service (AKS) cluster nodes for maintenance or troubleshooting](/azure/aks/ssh).--**Cost analysis**<br> -- Configure [OpenCost](https://www.opencost.io), which is an open-source, vendor-neutral CNCF sandbox project for understanding your Kubernetes costs, to support your analysis of your cluster costs. It exports detailed costing data to Azure storage.-- Use data from OpenCost to breakdown relative usage of the cluster by different teams in your organization so that you can allocate the cost between each.-- Use data from OpenCost to ensure that the cluster is using the full capacity of its nodes by densely packing workloads, using fewer large nodes as opposed to many smaller nodes. ---### Monitor level 3 - Managed Kubernetes components --The managed Kubernetes level includes the following components: --| Component | Monitoring | -|:|:| -| API Server | Monitor the status of API server and identify any increase in request load and bottlenecks if the service is down. | -| Kubelet | Monitor Kubelet to help troubleshoot pod management issues, pods not starting, nodes not ready, or pods getting killed. | --Following are common scenarios for monitoring your managed Kubernetes components. --**Container insights**<br> -- Under **Monitoring**, select **Metrics** to view the **Inflight Requests** counter.-- Under **Reports**, use the **Kubelet** workbook to see the health and performance of each kubelet. For more information about these workbooks, see [Resource Monitoring workbooks](container-insights-reports.md#resource-monitoring-workbooks). --**Grafana**<br> -- Use the [prebuilt dashboard](../visualize/grafana-plugin.md#use-out-of-the-box-dashboards) in Managed Grafana for **Kubelet** to see the health and performance of each kubelet.-- Use a dashboard such as [Kubernetes apiserver](https://grafana.com/grafana/dashboards/12006) for a complete view of the API server performance. This includes such values as request latency and workqueue processing time.--**Log Analytics**<br> -- Use [log queries with resource logs](/azure/aks/monitor-aks#sample-log-queries) to analyze [control plane logs](#collect-control-plane-logs-for-aks-clusters) generated by AKS components.-- Any configuration activities for AKS are logged in the Activity log. When you [send the Activity log to a Log Analytics workspace](#collect-activity-log-for-aks-clusters) you can analyze it with Log Analytics. For example, the following sample query can be used to return records identifying a successful upgrade across all your AKS clusters. -- ``` kql - AzureActivity - | where CategoryValue == "Administrative" - | where OperationNameValue == "MICROSOFT.CONTAINERSERVICE/MANAGEDCLUSTERS/WRITE" - | extend properties=parse_json(Properties_d) - | where properties.message == "Upgrade Succeeded" - | order by TimeGenerated desc - ``` ---**Troubleshooting**<br> -- For troubleshooting scenarios, you can access kubelet logs using the process described at [Get kubelet logs from Azure Kubernetes Service (AKS) cluster nodes](/azure/aks/kubelet-logs).--### Monitor level 4 - Kubernetes objects and workloads --The Kubernetes objects and workloads level includes the following components: --| Component | Monitoring requirements | -|:|:| -| Deployments | Monitor actual vs desired state of the deployment and the status and resource utilization of the pods running on them. | -| Pods | Monitor status and resource utilization, including CPU and memory, of the pods running on your AKS cluster. | -| Containers | Monitor resource utilization, including CPU and memory, of the containers running on your AKS cluster. | --Following are common scenarios for monitoring your Kubernetes objects and workloads. ----**Container insights**<br> -- Use the **Nodes** and **Controllers** views to see the health and performance of the pods running on them and drill down to the health and performance of their containers.-- Use the **Containers** view to see the health and performance for the containers. For more information on analyzing container health and performance, see [Monitor your Kubernetes cluster performance with Container Insights](container-insights-analyze.md#analyze-nodes-controllers-and-container-health).-- Under **Reports**, use the **Deployments** workbook to see deployment metrics. For more information, see [Deployment & HPA metrics with Container Insights](container-insights-deployment-hpa-metrics.md).--**Grafana dashboards**<br> -- Use the [prebuilt dashboards](../visualize/grafana-plugin.md#use-out-of-the-box-dashboards) in Managed Grafana for **Nodes** and **Pods** to view their health and performance.-- Multiple [Kubernetes dashboards](https://grafana.com/grafana/dashboards/?search=kubernetes) are available that visualize the performance and health of your nodes based on data stored in Prometheus.---**Live data** -- In troubleshooting scenarios, Container Insights provides access to live AKS container logs (stdout/stderror), events and pod metrics. For more information about this feature, see [How to view Kubernetes logs, events, and pod metrics in real-time](container-insights-livedata-overview.md).--### Alerts for the platform engineer --[Alerts in Azure Monitor](..//alerts/alerts-overview.md) proactively notify you of interesting data and patterns in your monitoring data. They allow you to identify and address issues in your system before your customers notice them. If you have an existing [ITSM solution](../alerts/itsmc-overview.md) for alerting, you can [integrate it with Azure Monitor](../alerts/itsmc-overview.md). You can also [export workspace data](../logs/logs-data-export.md) to send data from your Log Analytics workspace to another location that supports your current alerting solution. --#### Alert types -The following table describes the different types of custom alert rules that you can create based on the data collected by the services described above. --| Alert type | Description | -|:|:| -| Prometheus alerts | [Prometheus alerts](../alerts/prometheus-alerts.md) are written in Prometheus Query Language (Prom QL) and applied on Prometheus metrics stored in [Azure Monitor managed services for Prometheus](../essentials/prometheus-metrics-overview.md). Recommended alerts already include the most common Prometheus alerts, and you can [create addition alert rules](../essentials/prometheus-rule-groups.md) as required. | -| Metric alert rules | Metric alert rules use the same metric values as the Metrics explorer. In fact, you can create an alert rule directly from the metrics explorer with the data you're currently analyzing. Metric alert rules can be useful to alert on AKS performance using any of the values in [AKS data reference metrics](/azure/aks/monitor-aks-reference#metrics). | -| Log search alert rules | Use log search alert rules to generate an alert from the results of a log query. For more information, see [How to create log search alerts from Container Insights](container-insights-log-alerts.md) and [How to query logs from Container Insights](container-insights-log-query.md). | --#### Recommended alerts -Start with a set of recommended Prometheus alerts from [Metric alert rules in Container insights (preview)](container-insights-metric-alerts.md#prometheus-alert-rules) which include the most common alerting conditions for a Kubernetes cluster. You can add more alert rules later as you identify additional alerting conditions. --## Developer --In addition to developing the application, the *developer* maintains the application running on the cluster. They're responsible for application specific traffic including application performance and failures and maintain reliability of the application according to company-defined SLAs. ---### Azure services for developer --The following table lists the services that are commonly used by the developer to monitor the health and performance of the application running on the cluster. ------| Service | Description | -|:|:| -| [Application insights](../app/app-insights-overview.md) | Feature of Azure Monitor that provides application performance monitoring (APM) to monitor applications running on your Kubernetes cluster from development, through test, and into production. Quickly identify and mitigate latency and reliability issues using distributed traces. Supports [OpenTelemetry](../app/opentelemetry-overview.md#opentelemetry) for vendor-neutral instrumentation. | ------See [Data Collection Basics of Azure Monitor Application Insights](../app/opentelemetry-overview.md) for options on configuring data collection from the application running on your cluster and decision criteria on the best method for your particular requirements. --### Monitor level 5 - Application --Following are common scenarios for monitoring your application. ------**Application performance**<br> -- Use the **Performance** view in Application insights to view the performance of different operations in your application.-- Use [Profiler](../profiler/profiler-overview.md) to capture and view performance traces for your application.-- Use [Application Map](../app/app-map.md) to view the dependencies between your application components and identify any bottlenecks.-- Enable [distributed tracing](../app/distributed-trace-data.md), which provides a performance profiler that works like call stacks for cloud and microservices architectures, to gain better observability into the interaction between services.--**Application failures**<br> -- Use the **Failures** tab of Application insights to view the number of failed requests and the most common exceptions.-- Ensure that alerts for [failure anomalies](../alerts/proactive-failure-diagnostics.md) identified with [smart detection](../alerts/proactive-diagnostics.md) are configured properly.--**Health monitoring**<br> -- Create an [Availability test](../app/availability-overview.md) in Application insights to create a recurring test to monitor the availability and responsiveness of your application.-- Use the [SLA report](../app/sla-report.md) to calculate and report SLA for web tests.-- Use [annotations](../app/release-and-work-item-insights.md?tabs=release-annotations) to identify when a new build is deployed so that you can visually inspect any change in performance after the update.--**Application logs**<br> -- Container insights sends stdout/stderr logs to a Log Analytics workspace. See [Resource logs](/azure/aks/monitor-aks-reference#resource-logs) for a description of the different logs and [Kubernetes Services](/azure/azure-monitor/reference/tables/tables-resourcetype#kubernetes-services) for a list of the tables each is sent to.--**Service mesh** --- For AKS clusters, deploy the [Istio-based service mesh add-on](/azure/aks/istio-about) which provides observability to your microservices architecture. [Istio](https://istio.io/) is an open-source service mesh that layers transparently onto existing distributed applications. The add-on assists in the deployment and management of Istio for AKS.--## See also --- See [Monitoring AKS](/azure/aks/monitor-aks) for guidance on monitoring specific to Azure Kubernetes Service (AKS). |
| azure-monitor | Prometheus Argo Cd Integration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/prometheus-argo-cd-integration.md | - Title: Configure Argo CD integration for Prometheus metrics in Azure Monitor -description: Describes how to configure Argo CD monitoring using Prometheus metrics in Azure Monitor to Kubernetes cluster. - Previously updated : 3/25/2024-----# Argo CD -Argo CD is a declarative, GitOps continuous delivery tool for Kubernetes. Argo CD follows the GitOps pattern of using Git repositories as the source of truth for defining the desired application state. It automates the deployment of the desired application states in the specified target environments. Application deployments can track updates to branches, tags, or pinned to a specific version of manifests at a Git commit. -This article describes how to configure Azure Managed Prometheus with Azure Kubernetes Service(AKS) to monitor Argo CD by scraping prometheus metrics. --## Prerequisites --+ Argo CD running on AKS -+ Azure Managed Prometheus enabled on the AKS cluster - [Enable Azure Managed Prometheus on AKS](kubernetes-monitoring-enable.md#enable-prometheus-and-grafana) --### Deploy Service Monitors -Deploy the following service monitors to configure Azure managed prometheus addon to scrape prometheus metrics from the argocd workload. --> [!NOTE] -> Please specify the right labels in the matchLabels for the service monitors if they do not match the configured ones in the sample. --```yaml -apiVersion: azmonitoring.coreos.com/v1 -kind: ServiceMonitor -metadata: - name: azmon-argocd-metrics -spec: - labelLimit: 63 - labelNameLengthLimit: 511 - labelValueLengthLimit: 1023 - selector: - matchLabels: - app.kubernetes.io/name: argocd-metrics - namespaceSelector: - any: true - endpoints: - - port: metrics --apiVersion: azmonitoring.coreos.com/v1 -kind: ServiceMonitor -metadata: - name: azmon-argocd-repo-server-metrics -spec: - labelLimit: 63 - labelNameLengthLimit: 511 - labelValueLengthLimit: 1023 - selector: - matchLabels: - app.kubernetes.io/name: argocd-repo-server - namespaceSelector: - any: true - endpoints: - - port: metrics --apiVersion: azmonitoring.coreos.com/v1 -kind: ServiceMonitor -metadata: - name: azmon-argocd-server-metrics -spec: - labelLimit: 63 - labelNameLengthLimit: 511 - labelValueLengthLimit: 1023 - selector: - matchLabels: - app.kubernetes.io/name: argocd-server-metrics - namespaceSelector: - any: true - endpoints: - - port: metrics - ``` --> [!NOTE] -> If you want to configure any other service or pod monitors, please follow the instructions [here](prometheus-metrics-scrape-crd.md#create-a-pod-or-service-monitor). --### Deploy Rules -1. Download the template and parameter files -- **Alerting Rules** - - [Template file](https://github.com/Azure/prometheus-collector/blob/main/Azure-ARM-templates/Workload-Rules/Argo/argocd-alerting-rules.json) - - [Parameter file](https://github.com/Azure/prometheus-collector/blob/main/Azure-ARM-templates/Workload-Rules/Alert-Rules-Parameters.json) ---2. Edit the following values in the parameter files. Retrieve the resource ID of the resources from the **JSON View** of their **Overview** page. -- | Parameter | Value | - |:|:| - | `azureMonitorWorkspace` | Resource ID for the Azure Monitor workspace. Retrieve from the **JSON view** on the **Overview** page for the Azure Monitor workspace. | - | `location` | Location of the Azure Monitor workspace. Retrieve from the **JSON view** on the **Overview** page for the Azure Monitor workspace. | - | `clusterName` | Name of the AKS cluster. Retrieve from the **JSON view** on the **Overview** page for the cluster. | - | `actionGroupId` | Resource ID for the alert action group. Retrieve from the **JSON view** on the **Overview** page for the action group. Learn more about [action groups](../alerts/action-groups.md) | --3. Deploy the template by using any standard methods for installing ARM templates. For guidance, see [ARM template samples for Azure Monitor](../resource-manager-samples.md). --4. Once deployed, you can view the rules in the Azure portal as described in - [Prometheus Alerts](../essentials/prometheus-rule-groups.md#view-prometheus-rule-groups) --> [!Note] -> Review the alert thresholds to make sure it suits your cluster/workloads and update it accordingly. -> -> Please note that the above rules are not scoped to a cluster. If you would like to scope the rules to a specific cluster, see [Limiting rules to a specific cluster](../essentials/prometheus-rule-groups.md#limiting-rules-to-a-specific-cluster) for more details. -> -> Learn more about [Prometheus Alerts](../essentials/prometheus-rule-groups.md). -> -> If you want to use any other OSS prometheus alerting/recording rules please use the converter here to create the azure equivalent prometheus rules [az-prom-rules-converter](https://aka.ms/az-prom-rules-converter) ---### Import the Grafana Dashboard --To import the grafana dashboards using the ID or JSON, follow the instructions to [Import a dashboard from Grafana Labs](../../managed-grafan#import-a-grafana-dashboard). </br> --[ArgoCD](https://grafana.com/grafana/dashboards/14584-argocd/)(ID-14191) ---### Troubleshooting -When the service monitors is successfully applied, if you want to make sure that the service monitor targets get picked up by the addon, follow the instructions [here](prometheus-metrics-troubleshoot.md#prometheus-interface). -- |
| azure-monitor | Prometheus Elasticsearch Integration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/prometheus-elasticsearch-integration.md | - Title: Configure Elasticsearch integration for Prometheus metrics in Azure Monitor -description: Describes how to configure Elasticsearch monitoring using Prometheus metrics in Azure Monitor to Kubernetes cluster. - Previously updated : 3/19/2024-----# Elasticsearch -Elasticsearch is the distributed search and analytics engine at the heart of the Elastic Stack. It is where the indexing, search, and analysis magic happen. -This article describes how to configure Azure Managed Prometheus with Azure Kubernetes Service(AKS) to monitor elastic search clusters by scraping prometheus metrics. --## Prerequisites --+ Elasticsearch cluster running on AKS -+ Azure Managed prometheus enabled on the AKS cluster - [Enable Azure Managed Prometheus on AKS](kubernetes-monitoring-enable.md#enable-prometheus-and-grafana) ---### Install Elasticsearch Exporter -Install the [Elasticsearch exporter](https://github.com/prometheus-community/helm-charts/tree/main/charts/prometheus-elasticsearch-exporter) using the helm chart. --```bash -helm install azmon-elasticsearch-exporter --version 5.7.0 prometheus-community/prometheus-elasticsearch-exporter --set es.uri="https://username:password@elasticsearch-service.namespace:9200" --set podMonitor.enabled=true --set podMonitor.apiVersion=azmonitoring.coreos.com/v1 -``` --> [!NOTE] -> Managed prometheus pod/service monitor configuration with helm chart installation is only supported with the helm chart version >=5.7.0. -> -> The [prometheus-elasticsearch-exporter](https://github.com/prometheus-community/helm-charts/tree/main/charts/prometheus-elasticsearch-exporter) helm chart can be configured with [values](https://github.com/prometheus-community/helm-charts/blob/main/charts/prometheus-elasticsearch-exporter/values.yaml) yaml. -Please specify the right server address where the Elasticsearch server can be reached. Based on your configuration set the username,password or certs used to authenticate with the Elasticsearch server. Set the address where Elasticsearch is reachable using the argument "es.uri" ex - . -> -> You could also use service monitor, instead of pod monitor by using the **--set serviceMonitor.enabled=true** helm chart paramaters. Make sure to use the api version supported by Azure Managed Prometheus using the parameter **serviceMonitor.apiVersion=azmonitoring.coreos.com/v1**. -> -> If you want to configure any other service or pod monitors, please follow the instructions [here](prometheus-metrics-scrape-crd.md#create-a-pod-or-service-monitor). ---### Deploy Rules -1. Download the template and parameter files -- **Recording Rules** - - [Template file](https://github.com/Azure/prometheus-collector/blob/main/Azure-ARM-templates/Workload-Rules/ElasticSearch/elasticsearch-recording-rules.json) - - [Parameter file](https://github.com/Azure/prometheus-collector/blob/main/Azure-ARM-templates/Workload-Rules/Recording-Rules-Parameters.json) -- **Alerting Rules** - - [Template file](https://github.com/Azure/prometheus-collector/blob/main/Azure-ARM-templates/Workload-Rules/ElasticSearch/elasticsearch-alerting-rules.json) - - [Parameter file](https://github.com/Azure/prometheus-collector/blob/main/Azure-ARM-templates/Workload-Rules/Alert-Rules-Parameters.json) ---2. Edit the following values in the parameter files. Retrieve the resource ID of the resources from the **JSON View** of their **Overview** page. -- | Parameter | Value | - |:|:| - | `azureMonitorWorkspace` | Resource ID for the Azure Monitor workspace. Retrieve from the **JSON view** on the **Overview** page for the Azure Monitor workspace. | - | `location` | Location of the Azure Monitor workspace. Retrieve from the **JSON view** on the **Overview** page for the Azure Monitor workspace. | - | `clusterName` | Name of the AKS cluster. Retrieve from the **JSON view** on the **Overview** page for the cluster. | - | `actionGroupId` | Resource ID for the alert action group. Retrieve from the **JSON view** on the **Overview** page for the action group. Learn more about [action groups](../alerts/action-groups.md) | --3. Deploy the template by using any standard methods for installing ARM templates. For guidance, see [ARM template samples for Azure Monitor](../resource-manager-samples.md). --4. Once deployed, you can view the rules in the Azure portal as described in - [Prometheus Alerts](../essentials/prometheus-rule-groups.md#view-prometheus-rule-groups) --> [!Note] -> Review the alert thresholds to make sure it suits your cluster/worklaods and update it accordingly. -> -> Please note that the above rules are not scoped to a cluster. If you would like to scope the rules to a specific cluster, see [Limiting rules to a specific cluster](../essentials/prometheus-rule-groups.md#limiting-rules-to-a-specific-cluster) for more details. -> -> Learn more about [Prometheus Alerts](../essentials/prometheus-rule-groups.md). -> -> If you want to use any other OSS prometheus alerting/recording rules please use the converter here to create the azure equivalent prometheus rules [az-prom-rules-converter](https://aka.ms/az-prom-rules-converter) --### Import the Grafana Dashboard --Follow the instructions on [Import a dashboard from Grafana Labs](../../managed-grafan#import-a-grafana-dashboard) to import the grafana dashboards using the ID or JSON.</br> --[Elastic Search Overview](https://github.com/grafana/jsonnet-libs/blob/master/elasticsearch-mixin/dashboards/elasticsearch-overview.json)(ID-2322)</br> -[Elasticsearch Exporter Quickstart and Dashboard](https://grafana.com/grafana/dashboards/14191-elasticsearch-overview/)(ID-14191) ---### Troubleshooting -When the service monitors is successfully applied, if you want to make sure that the service monitor targets get picked up by the addon, follow the instructions [here](prometheus-metrics-troubleshoot.md#prometheus-interface). - |
| azure-monitor | Prometheus Exporters | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/prometheus-exporters.md | - Title: Integrate common workloads with Azure Managed Prometheus -description: Describes how to integrate Azure Kubernetes Service workloads with Azure Managed Prometheus and list of available workloads that are ready to be integrated. - Previously updated : 6/20/2024------# Use Prometheus exporters for common workloads with Azure Managed Prometheus --You can use Prometheus exporters to collect metrics from third-party workloads or other applications and send them to Azure Monitor Workspace along with other metrics collected by Azure Managed Prometheus running on AKS. --The enablement of Managed Prometheus automatically deploys the custom resource definitions (CRD) for [pod monitors](https://github.com/Azure/prometheus-collector/blob/main/otelcollector/deploy/addon-chart/azure-monitor-metrics-addon/templates/ama-metrics-podmonitor-crd.yaml) and [service monitors](https://github.com/Azure/prometheus-collector/blob/main/otelcollector/deploy/addon-chart/azure-monitor-metrics-addon/templates/ama-metrics-servicemonitor-crd.yaml). --You can configure any Prometheus exporter to work with Azure Managed Prometheus. For more information, see [Configure collection using Service and Pod Monitor custom resources](./prometheus-metrics-scrape-crd.md). --This document lists a set of commonly used workloads which have curated configurations and instructions to help you set up metrics collection from the workload. You can use this only with the managed add-on for Azure Managed Prometheus. For self-managed Prometheus, refer to the relevant exporter documentation for setting up metrics collection. --## Common workloads --- [Apache Kafka](./prometheus-kafka-integration.md)-- [Argo CD](./prometheus-argo-cd-integration.md)-- [Elastic Search](./prometheus-elasticsearch-integration.md)--## Next steps --[Customize collection using CRDs (Service and Pod Monitors)](./prometheus-metrics-scrape-crd.md) -[Customize metrics scraping with Azure Managed Prometheus](./prometheus-metrics-scrape-configuration.md) |
| azure-monitor | Prometheus Kafka Integration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/prometheus-kafka-integration.md | - Title: Configure Kafka integration for Prometheus metrics in Azure Monitor -description: Describes how to configure Kafka monitoring using Prometheus metrics in Azure Monitor to Kubernetes cluster. - Previously updated : 3/19/2024-----# Apache Kafka -Apache Kafka is an open-source distributed event streaming platform used by high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. -This article describes how to configure Azure Managed Prometheus with Azure Kubernetes Service(AKS) to monitor kafka clusters by scraping prometheus metrics. --## Prerequisites --+ Kafka cluster running on AKS -+ Azure Managed prometheus enabled on the AKS cluster - [Enable Azure Managed Prometheus on AKS](kubernetes-monitoring-enable.md#enable-prometheus-and-grafana) ---### Install Kafka Exporter -Install the [Kafka Exporter](https://github.com/prometheus-community/helm-charts/tree/main/charts/prometheus-kafka-exporter) using the helm chart. --```bash -helm install azmon-kafka-exporter --namespace=azmon-kafka-exporter --create-namespace --version 2.10.0 prometheus-community/prometheus-kafka-exporter --set kafkaServer="{kafka-server.namespace.svc:9092,.....}" --set prometheus.serviceMonitor.enabled=true --set prometheus.serviceMonitor.apiVersion=azmonitoring.coreos.com/v1 -``` --> [!NOTE] -> Managed prometheus pod/service monitor configuration with helm chart installation is only supported with the helm chart version >=2.10.0. -> -> The [prometheus kafka exporter](https://github.com/prometheus-community/helm-charts/tree/main/charts/prometheus-kafka-exporter) helm chart can be configured with [values](https://github.com/prometheus-community/helm-charts/blob/main/charts/prometheus-kafka-exporter/values.yaml) yaml. -Please specify the right server addresses where the kafka servers can be reached. Set the server address(es) using the argument "kafkaServer". -> -> If you want to configure any other service or pod monitors, please follow the instructions [here](prometheus-metrics-scrape-crd.md#create-a-pod-or-service-monitor). ---### Import the Grafana Dashboard --To import the Grafana Dashboards using the ID or JSON, follow the instructions to [Import a dashboard from Grafana Labs](../../managed-grafan#import-a-grafana-dashboard). </br> --[Kafka Exporter Grafana Dashboard](https://grafana.com/grafana/dashboards/7589-kafka-exporter-overview/)(ID-7589) --### Deploy Rules -1. Download the template and parameter files -- **Alerting Rules** - - [Template file](https://github.com/Azure/prometheus-collector/blob/main/Azure-ARM-templates/Workload-Rules/Kafka/kafka-alerting-rules.json) - - [Parameter file](https://github.com/Azure/prometheus-collector/blob/main/Azure-ARM-templates/Workload-Rules/Alert-Rules-Parameters.json) ---2. Edit the following values in the parameter files. Retrieve the resource ID of the resources from the **JSON View** of their **Overview** page. -- | Parameter | Value | - |:|:| - | `azureMonitorWorkspace` | Resource ID for the Azure Monitor workspace. Retrieve from the **JSON view** on the **Overview** page for the Azure Monitor workspace. | - | `location` | Location of the Azure Monitor workspace. Retrieve from the **JSON view** on the **Overview** page for the Azure Monitor workspace. | - | `clusterName` | Name of the AKS cluster. Retrieve from the **JSON view** on the **Overview** page for the cluster. | - | `actionGroupId` | Resource ID for the alert action group. Retrieve from the **JSON view** on the **Overview** page for the action group. Learn more about [action groups](../alerts/action-groups.md) | --3. Deploy the template by using any standard methods for installing ARM templates. For guidance, see [ARM template samples for Azure Monitor](../resource-manager-samples.md). --4. Once deployed, you can view the rules in the Azure portal as described in - [Prometheus Alerts](../essentials/prometheus-rule-groups.md#view-prometheus-rule-groups) --> [!Note] -> Review the alert thresholds to make sure it suits your cluster/workloads and update it accordingly. -> -> Please note that the above rules are not scoped to a cluster. If you would like to scope the rules to a specific cluster, see [Limiting rules to a specific cluster](../essentials/prometheus-rule-groups.md#limiting-rules-to-a-specific-cluster) for more details. -> -> Learn more about [Prometheus Alerts](../essentials/prometheus-rule-groups.md). -> -> If you want to use any other OSS prometheus alerting/recording rules please use the converter here to create the azure equivalent prometheus rules [az-prom-rules-converter](https://aka.ms/az-prom-rules-converter) ---### More jmx_exporter metrics using strimzi -If you are using the [strimzi operator](https://github.com/strimzi/strimzi-kafka-operator.git) for deploying the kafka clusters, deploy the pod monitors to get more jmx_exporter metrics. -> [!Note] -> Metrics need to be exposed by the kafka cluster deployments like the examples [here](https://github.com/strimzi/strimzi-kafka-operator/tree/main/examples/metrics). Refer to the kafka-.*-metrics.yaml files to configure metrics to be exposed. -> ->The pod monitors here also assume that the namespace where the kafka workload is deployed in 'kafka'. Update it accordingly if the workloads are deployed in another namespace. --```yaml -apiVersion: azmonitoring.coreos.com/v1 -kind: PodMonitor -metadata: - name: azmon-cluster-operator-metrics - labels: - app: strimzi -spec: - selector: - matchLabels: - strimzi.io/kind: cluster-operator - namespaceSelector: - matchNames: - - kafka - podMetricsEndpoints: - - path: /metrics - port: http --apiVersion: azmonitoring.coreos.com/v1 -kind: PodMonitor -metadata: - name: azmon-entity-operator-metrics - labels: - app: strimzi -spec: - selector: - matchLabels: - app.kubernetes.io/name: entity-operator - namespaceSelector: - matchNames: - - kafka - podMetricsEndpoints: - - path: /metrics - port: healthcheck --apiVersion: azmonitoring.coreos.com/v1 -kind: PodMonitor -metadata: - name: azmon-bridge-metrics - labels: - app: strimzi -spec: - selector: - matchLabels: - strimzi.io/kind: KafkaBridge - namespaceSelector: - matchNames: - - kafka - podMetricsEndpoints: - - path: /metrics - port: rest-api --apiVersion: azmonitoring.coreos.com/v1 -kind: PodMonitor -metadata: - name: azmon-kafka-resources-metrics - labels: - app: strimzi -spec: - selector: - matchExpressions: - - key: "strimzi.io/kind" - operator: In - values: ["Kafka", "KafkaConnect", "KafkaMirrorMaker", "KafkaMirrorMaker2"] - namespaceSelector: - matchNames: - - kafka - podMetricsEndpoints: - - path: /metrics - port: tcp-prometheus - relabelings: - - separator: ; - regex: __meta_kubernetes_pod_label_(strimzi_io_.+) - replacement: $1 - action: labelmap - - sourceLabels: [__meta_kubernetes_namespace] - separator: ; - regex: (.*) - targetLabel: namespace - replacement: $1 - action: replace - - sourceLabels: [__meta_kubernetes_pod_name] - separator: ; - regex: (.*) - targetLabel: kubernetes_pod_name - replacement: $1 - action: replace - - sourceLabels: [__meta_kubernetes_pod_node_name] - separator: ; - regex: (.*) - targetLabel: node_name - replacement: $1 - action: replace - - sourceLabels: [__meta_kubernetes_pod_host_ip] - separator: ; - regex: (.*) - targetLabel: node_ip - replacement: $1 - action: replace -``` --#### Alerts with strimzi -Rich set of alerts based off of strimzi metrics can also be configured by refering to the [examples](https://github.com/strimzi/strimzi-kafka-operator/blob/main/examples/metrics/prometheus-install/prometheus-rules.yaml). --> [!NOTE] -> If using any other way of exposing the jmx_exporter on your kafka cluster, please follow the instructions [here](prometheus-metrics-scrape-crd.md) on how to configure the pod or service monitors accordingly. --### Grafana Dashboards for more jmx metrics with strimzi -Please also see the [grafana-dashboards-for-strimzi](https://github.com/strimzi/strimzi-kafka-operator/tree/main/examples/metrics/grafana-dashboards) to view dashboards for metrics exposed by strimzi operator. ---### Troubleshooting -When the service monitors or pod monitors are successfully applied, if you want to make sure that the service monitor targets get picked up by the addon, follow the instructions [here](prometheus-metrics-troubleshoot.md#prometheus-interface). - |
| azure-monitor | Prometheus Metrics Multiple Workspaces | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/prometheus-metrics-multiple-workspaces.md | - Title: Send Prometheus metrics to multiple Azure Monitor workspaces -description: Describes data collection rules required to send Prometheus metrics from a cluster in Azure Monitor to multiple Azure Monitor workspaces. - Previously updated : 2/28/2024----# Send Prometheus metrics to multiple Azure Monitor workspaces -- Routing different metrics to more Azure Monitor workspaces can be done through the creation of additional data collection rules. -- You can create Data Collection Rules with corresponding Data Collection Endpoints for different metrics to be sent to additional Azure Monitor workspaces from the same Kubernetes cluster. - Currently, this is only available through onboarding through Resource Manager templates. You can follow the [regular onboarding process](kubernetes-monitoring-enable.md#enable-prometheus-and-grafana) and then edit the same Resource Manager templates to add additional DCRs and DCEs for your additional Azure Monitor workspaces. You'll need to edit the template to add an additional parameters for every additional Azure Monitor workspace, add another DCR for every additional Azure Monitor workspace, add another DCE, add the Monitor Reader Role for the new Azure Monitor workspace and add an additional Azure Monitor workspace integration for Grafana. --- Add the following parameters:- ```json - "parameters": { - "azureMonitorWorkspaceResourceId2": { - "type": "string" - }, - "azureMonitorWorkspaceLocation2": { - "type": "string", - "defaultValue": "", - "allowedValues": [ - "eastus2euap", - "centraluseuap", - "centralus", - "eastus", - "eastus2", - "northeurope", - "southcentralus", - "southeastasia", - "uksouth", - "westeurope", - "westus", - "westus2" - ] - }, - ... - } - ``` --- Add an additional Data Collection Endpoint. You *must* replace `<dceName>`:- ```json - { - "type": "Microsoft.Insights/dataCollectionEndpoints", - "apiVersion": "2021-09-01-preview", - "name": "[variables('dceName')]", - "location": "[parameters('azureMonitorWorkspaceLocation2')]", - "kind": "Linux", - "properties": {} - } - ``` -- Add an additional DCR with the new Data Collection Endpoint. You *must* replace `<dcrName>`:- ```json - { - "type": "Microsoft.Insights/dataCollectionRules", - "apiVersion": "2021-09-01-preview", - "name": "<dcrName>", - "location": "[parameters('azureMonitorWorkspaceLocation2')]", - "kind": "Linux", - "properties": { - "dataCollectionEndpointId": "[resourceId('Microsoft.Insights/dataCollectionEndpoints/', variables('dceName'))]", - "dataFlows": [ - { - "destinations": ["MonitoringAccount2"], - "streams": ["Microsoft-PrometheusMetrics"] - } - ], - "dataSources": { - "prometheusForwarder": [ - { - "name": "PrometheusDataSource", - "streams": ["Microsoft-PrometheusMetrics"], - "labelIncludeFilter": - "microsoft_metrics_include_label": "MonitoringAccountLabel2" - } - ] - }, - "description": "DCR for Azure Monitor Metrics Profile (Managed Prometheus)", - "destinations": { - "monitoringAccounts": [ - { - "accountResourceId": "[parameters('azureMonitorWorkspaceResourceId2')]", - "name": "MonitoringAccount2" - } - ] - } - }, - "dependsOn": [ - "[resourceId('Microsoft.Insights/dataCollectionEndpoints/', variables('dceName'))]" - ] - } - ``` --- Add an additional Data Collection Rule Association (DCRA) with the relevant Data Collection Rule (DCR). This associates the DCR with the cluster. You must replace `<dcraName>`:- ```json - { - "type": "Microsoft.Resources/deployments", - "name": "<dcraName>", - "apiVersion": "2017-05-10", - "subscriptionId": "[variables('clusterSubscriptionId')]", - "resourceGroup": "[variables('clusterResourceGroup')]", - "dependsOn": [ - "[resourceId('Microsoft.Insights/dataCollectionEndpoints/', variables('dceName'))]", - "[resourceId('Microsoft.Insights/dataCollectionRules', variables('dcrName'))]" - ], - "properties": { - "mode": "Incremental", - "template": { - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": {}, - "variables": {}, - "resources": [ - { - "type": "Microsoft.ContainerService/managedClusters/providers/dataCollectionRuleAssociations", - "name": "[concat(variables('clusterName'),'/microsoft.insights/', variables('dcraName'))]", - "apiVersion": "2021-09-01-preview", - "location": "[parameters('clusterLocation')]", - "properties": { - "description": "Association of data collection rule. Deleting this association will break the data collection for this AKS Cluster.", - "dataCollectionRuleId": "[resourceId('Microsoft.Insights/dataCollectionRules', variables('dcrName'))]" - } - } - ] - }, - "parameters": {} - } - } - ``` -- Add an additional Grafana integration:- ```json - { - "type": "Microsoft.Dashboard/grafana", - "apiVersion": "2022-08-01", - "name": "[split(parameters('grafanaResourceId'),'/')[8]]", - "sku": { - "name": "[parameters('grafanaSku')]" - }, - "location": "[parameters('grafanaLocation')]", - "properties": { - "grafanaIntegrations": { - "azureMonitorWorkspaceIntegrations": [ - // Existing azureMonitorWorkspaceIntegrations values (if any) - // { - // "azureMonitorWorkspaceResourceId": "<value>" - // }, - // { - // "azureMonitorWorkspaceResourceId": "<value>" - // }, - { - "azureMonitorWorkspaceResourceId": "[parameters('azureMonitorWorkspaceResourceId')]" - }, - { - "azureMonitorWorkspaceResourceId": "[parameters('azureMonitorWorkspaceResourceId2')]" - } - ] - } - } - } - ``` - - Assign `Monitoring Data Reader` role to read data from the new Azure Monitor Workspace: -- ```json - { - "type": "Microsoft.Authorization/roleAssignments", - "apiVersion": "2022-04-01", - "name": "[parameters('roleNameGuid')]", - "scope": "[parameters('azureMonitorWorkspaceResourceId2')]", - "properties": { - "roleDefinitionId": "[concat('/subscriptions/', variables('clusterSubscriptionId'), '/providers/Microsoft.Authorization/roleDefinitions/', 'b0d8363b-8ddd-447d-831f-62ca05bff136')]", - "principalId": "[reference(resourceId('Microsoft.Dashboard/grafana', split(parameters('grafanaResourceId'),'/')[8]), '2022-08-01', 'Full').identity.principalId]" - } - } ---Then configure which metrics are routed to which workspace, by adding an extra pre-defined label, `microsoft_metrics_account` to the metrics. The value should be the same as the corresponding `microsoft_metrics_include_label` in the DCR for that workspace. To add the label to the metrics, you can utilize `relabel_configs` in your scrape config. To send all metrics from one job to a certain workspace, add the following relabel config: --```yaml -relabel_configs: -- source_labels: [__address__]- target_label: microsoft_metrics_account - action: replace - replacement: "MonitoringAccountLabel2" -``` --The source label is `__address__` because this label will always exist so this relabel config will always be applied. The target label will always be `microsoft_metrics_account` and its value should be replaced with the corresponding label value for the workspace. ----### Example --If you want to configure three different jobs to send the metrics to three different workspaces, then include the following in each data collection rule: --```json -"labelIncludeFilter": { - "microsoft_metrics_include_label": "MonitoringAccountLabel1" -} -``` --```json -"labelIncludeFilter": { - "microsoft_metrics_include_label": "MonitoringAccountLabel2" -} -``` --```json -"labelIncludeFilter": { - "microsoft_metrics_include_label": "MonitoringAccountLabel3" -} -``` --Then in your scrape config, include the same label value for each: -```yaml -scrape_configs: -- job_name: prometheus_ref_app_1- kubernetes_sd_configs: - - role: pod - relabel_configs: - - source_labels: [__meta_kubernetes_pod_label_app] - action: keep - regex: "prometheus-reference-app-1" - - source_labels: [__address__] - target_label: microsoft_metrics_account - action: replace - replacement: "MonitoringAccountLabel1" -- job_name: prometheus_ref_app_2- kubernetes_sd_configs: - - role: pod - relabel_configs: - - source_labels: [__meta_kubernetes_pod_label_app] - action: keep - regex: "prometheus-reference-app-2" - - source_labels: [__address__] - target_label: microsoft_metrics_account - action: replace - replacement: "MonitoringAccountLabel2" -- job_name: prometheus_ref_app_3- kubernetes_sd_configs: - - role: pod - relabel_configs: - - source_labels: [__meta_kubernetes_pod_label_app] - action: keep - regex: "prometheus-reference-app-3" - - source_labels: [__address__] - target_label: microsoft_metrics_account - action: replace - replacement: "MonitoringAccountLabel3" -``` ---## Next steps --- [Learn more about Azure Monitor managed service for Prometheus](../essentials/prometheus-metrics-overview.md).-- [Collect Prometheus metrics from AKS cluster](kubernetes-monitoring-enable.md#enable-prometheus-and-grafana). |
| azure-monitor | Prometheus Metrics Scrape Configuration Minimal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/prometheus-metrics-scrape-configuration-minimal.md | - Title: Minimal Prometheus ingestion profile in Azure Monitor -description: Describes minimal ingestion profile in Azure Monitor managed service for Prometheus and how you can configure it to collect more data. - Previously updated : 2/28/2024------# Minimal ingestion profile for Prometheus metrics in Azure Monitor -Azure monitor metrics addon collects number of Prometheus metrics by default. `Minimal ingestion profile` is a setting that helps reduce ingestion volume of metrics, as only metrics used by default dashboards, default recording rules & default alerts are collected. This article describes how this setting is configured. This article also lists metrics collected by default when `minimal ingestion profile` is enabled. You can modify collection to enable collecting more metrics, as specified below. --> [!NOTE] -> For addon based collection, `Minimal ingestion profile` setting is enabled by default. --Following targets are **enabled/ON** by default - meaning you don't have to provide any scrape job configuration for scraping these targets, as metrics addon will scrape these targets automatically by default --- `cadvisor` (`job=cadvisor`)-- `nodeexporter` (`job=node`)-- `kubelet` (`job=kubelet`)-- `kube-state-metrics` (`job=kube-state-metrics`)-- `controlplane-apiserver` (`job=controlplane-apiserver`)-- `controlplane-etcd` (`job=controlplane-etcd`)--Following targets are available to scrape, but scraping isn't enabled (**disabled/OFF**) by default - meaning you don't have to provide any scrape job configuration for scraping these targets but they're disabled/OFF by default and you need to turn ON/enable scraping for these targets using [ama-metrics-settings-configmap](https://aka.ms/azureprometheus-addon-settings-configmap) under `default-scrape-settings-enabled` section --- `core-dns` (`job=kube-dns`)-- `kube-proxy` (`job=kube-proxy`)-- `api-server` (`job=kube-apiserver`)-- `controlplane-cluster-autoscaler` (`job=controlplane-cluster-autoscaler`)-- `controlplane-kube-scheduler` (`job=controlplane-kube-scheduler`)-- `controlplane-kube-controller-manager` (`job=controlplane-kube-controller-manager`)--> [!NOTE] -> The default scrape frequency for all default targets and scrapes is `30 seconds`. You can override it per target using the [ama-metrics-settings-configmap](https://aka.ms/azureprometheus-addon-settings-configmap) under `default-targets-scrape-interval-settings` section. -> The control plane targets have a fixed scrape interval of `30 seconds` and cannot be overwritten. -> You can read more about four different configmaps used by metrics addon [here](prometheus-metrics-scrape-configuration.md) --## Configuration setting -The setting `default-targets-metrics-keep-list.minimalIngestionProfile="true"` is enabled by default on the metrics addon. You can specify this setting in [ama-metrics-settings-configmap](https://aka.ms/azureprometheus-addon-settings-configmap) under `default-targets-metrics-keep-list` section. --## Scenarios --There are four scenarios where you may want to customize this behavior: --**Ingest only minimal metrics per default target.**<br> -This is the default behavior with the setting `default-targets-metrics-keep-list.minimalIngestionProfile="true"`. Only metrics listed below are ingested for each of the default targets. --**Ingest a few other metrics for one or more default targets in addition to minimal metrics.**<br> -Keep ` minimalIngestionProfile="true"` and specify the appropriate `keeplistRegexes.*` specific to the target, for example `keeplistRegexes.coreDns="X``Y"`. X,Y is merged with default metric list for the target and then ingested. `` ---**Ingest only a specific set of metrics for a target, and nothing else.**<br> -Set `minimalIngestionProfile="false"` and specify the appropriate `default-targets-metrics-keep-list.="X``Y"` specific to the target in the `ama-metrics-settings-configmap`. ---**Ingest all metrics scraped for the default target.**<br> -Set `minimalIngestionProfile="false"` and don't specify any `default-targets-metrics-keep-list.<targetname>` for that target. Changing to `false` can increase metric ingestion volume by a factor per target. ---> [!NOTE] -> `up` metric is not part of the allow/keep list because it is ingested per scrape, per target, regardless of `keepLists` specified. This metric is not actually scraped but produced as result of scrape operation by the metrics addon. For histograms and summaries, each series has to be included explicitly in the list (`*bucket`, `*sum`, `*count` series). --### Minimal ingestion for default ON targets -The following metrics are allow-listed with `minimalingestionprofile=true` for default ON targets. The below metrics are collected by default as these targets are scraped by default. --**kubelet**<br> -- `kubelet_volume_stats_used_bytes`-- `kubelet_node_name`-- `kubelet_running_pods`-- `kubelet_running_pod_count`-- `kubelet_running_containers`-- `kubelet_running_container_count`-- `volume_manager_total_volumes`-- `kubelet_node_config_error`-- `kubelet_runtime_operations_total`-- `kubelet_runtime_operations_errors_total`-- `kubelet_runtime_operations_duration_seconds` `kubelet_runtime_operations_duration_seconds_bucket` `kubelet_runtime_operations_duration_seconds_sum` `kubelet_runtime_operations_duration_seconds_count`-- `kubelet_pod_start_duration_seconds` `kubelet_pod_start_duration_seconds_bucket` `kubelet_pod_start_duration_seconds_sum` `kubelet_pod_start_duration_seconds_count`-- `kubelet_pod_worker_duration_seconds` `kubelet_pod_worker_duration_seconds_bucket` `kubelet_pod_worker_duration_seconds_sum` `kubelet_pod_worker_duration_seconds_count`-- `storage_operation_duration_seconds` `storage_operation_duration_seconds_bucket` `storage_operation_duration_seconds_sum` `storage_operation_duration_seconds_count`-- `storage_operation_errors_total`-- `kubelet_cgroup_manager_duration_seconds` `kubelet_cgroup_manager_duration_seconds_bucket` `kubelet_cgroup_manager_duration_seconds_sum` `kubelet_cgroup_manager_duration_seconds_count`-- `kubelet_pleg_relist_duration_seconds` `kubelet_pleg_relist_duration_seconds_bucket` `kubelet_pleg_relist_duration_sum` `kubelet_pleg_relist_duration_seconds_count`-- `kubelet_pleg_relist_interval_seconds` `kubelet_pleg_relist_interval_seconds_bucket` `kubelet_pleg_relist_interval_seconds_sum` `kubelet_pleg_relist_interval_seconds_count`-- `rest_client_requests_total`-- `rest_client_request_duration_seconds` `rest_client_request_duration_seconds_bucket` `rest_client_request_duration_seconds_sum` `rest_client_request_duration_seconds_count`-- `process_resident_memory_bytes`-- `process_cpu_seconds_total`-- `go_goroutines`-- `kubelet_volume_stats_capacity_bytes`-- `kubelet_volume_stats_available_bytes`-- `kubelet_volume_stats_inodes_used`-- `kubelet_volume_stats_inodes`-- `kubernetes_build_info"`--**cadvisor**<br> -- `container_spec_cpu_period`-- `container_spec_cpu_quota`-- `container_cpu_usage_seconds_total`-- `container_memory_rss`-- `container_network_receive_bytes_total`-- `container_network_transmit_bytes_total`-- `container_network_receive_packets_total`-- `container_network_transmit_packets_total`-- `container_network_receive_packets_dropped_total`-- `container_network_transmit_packets_dropped_total`-- `container_fs_reads_total`-- `container_fs_writes_total`-- `container_fs_reads_bytes_total`-- `container_fs_writes_bytes_total`-- `container_memory_working_set_bytes`-- `container_memory_cache`-- `container_memory_swap`-- `container_cpu_cfs_throttled_periods_total`-- `container_cpu_cfs_periods_total`-- `container_memory_usage_bytes`-- `kubernetes_build_info"`--**kube-state-metrics**<br> -- `kube_node_status_capacity`-- `kube_job_status_succeeded`-- `kube_job_spec_completions`-- `kube_daemonset_status_desired_number_scheduled`-- `kube_daemonset_status_number_ready`-- `kube_deployment_spec_replicas`-- `kube_deployment_status_replicas_ready`-- `kube_pod_container_status_last_terminated_reason`-- `kube_node_status_condition`-- `kube_pod_container_status_restarts_total`-- `kube_pod_container_resource_requests`-- `kube_pod_status_phase`-- `kube_pod_container_resource_limits`-- `kube_node_status_allocatable`-- `kube_pod_info`-- `kube_pod_owner`-- `kube_resourcequota`-- `kube_statefulset_replicas`-- `kube_statefulset_status_replicas`-- `kube_statefulset_status_replicas_ready`-- `kube_statefulset_status_replicas_current`-- `kube_statefulset_status_replicas_updated`-- `kube_namespace_status_phase`-- `kube_node_info`-- `kube_statefulset_metadata_generation`-- `kube_pod_labels`-- `kube_pod_annotations`-- `kube_horizontalpodautoscaler_status_current_replicas`-- `kube_horizontalpodautoscaler_status_desired_replicas`-- `kube_horizontalpodautoscaler_spec_min_replicas`-- `kube_horizontalpodautoscaler_spec_max_replicas`-- `kube_node_status_condition`-- `kube_node_spec_taint`-- `kube_pod_container_status_waiting_reason`-- `kube_job_failed`-- `kube_job_status_start_time`-- `kube_deployment_spec_replicas`-- `kube_deployment_status_replicas_available`-- `kube_deployment_status_replicas_updated`-- `kube_job_status_active`-- `kubernetes_build_info`-- `kube_pod_container_info`-- `kube_replicaset_owner`-- `kube_resource_labels` (ex - kube_pod_labels, kube_deployment_labels)-- `kube_resource_annotations` (ex - kube_pod_annotations, kube_deployment_annotations)--**node-exporter (linux)**<br> -- `node_cpu_seconds_total`-- `node_memory_MemAvailable_bytes`-- `node_memory_Buffers_bytes`-- `node_memory_Cached_bytes`-- `node_memory_MemFree_bytes`-- `node_memory_Slab_bytes`-- `node_memory_MemTotal_bytes`-- `node_netstat_Tcp_RetransSegs`-- `node_netstat_Tcp_OutSegs`-- `node_netstat_TcpExt_TCPSynRetrans`-- `node_load1``node_load5`-- `node_load15`-- `node_disk_read_bytes_total`-- `node_disk_written_bytes_total`-- `node_disk_io_time_seconds_total`-- `node_filesystem_size_bytes`-- `node_filesystem_avail_bytes`-- `node_filesystem_readonly`-- `node_network_receive_bytes_total`-- `node_network_transmit_bytes_total`-- `node_vmstat_pgmajfault`-- `node_network_receive_drop_total`-- `node_network_transmit_drop_total`-- `node_disk_io_time_weighted_seconds_total`-- `node_exporter_build_info`-- `node_time_seconds`-- `node_uname_info"`--**controlplane-apiserver**<br> -- `apiserver_request_total`-- `apiserver_cache_list_fetched_objects_total`-- `apiserver_cache_list_returned_objects_total`-- `apiserver_flowcontrol_demand_seats_average`-- `apiserver_flowcontrol_current_limit_seats`-- `apiserver_request_sli_duration_seconds_bucket`-- `apiserver_request_sli_duration_seconds_count`-- `apiserver_request_sli_duration_seconds_sum`-- `process_start_time_seconds`-- `apiserver_request_duration_seconds_bucket`-- `apiserver_request_duration_seconds_count`-- `apiserver_request_duration_seconds_sum`-- `apiserver_storage_list_fetched_objects_total`-- `apiserver_storage_list_returned_objects_total`-- `apiserver_current_inflight_requests`--**controlplane-etcd**<br> -- `etcd_server_has_leader`-- `rest_client_requests_total`-- `etcd_mvcc_db_total_size_in_bytes`-- `etcd_mvcc_db_total_size_in_use_in_bytes`-- `etcd_server_slow_read_indexes_total`-- `etcd_server_slow_apply_total`-- `etcd_network_client_grpc_sent_bytes_total`-- `etcd_server_heartbeat_send_failures_total`--### Minimal ingestion for default OFF targets -The following are metrics that are allow-listed with `minimalingestionprofile=true` for default OFF targets. These metrics are not collected by default as these targets are not scraped by default (due to being OFF by default). You can turn ON scraping for these targets using `default-scrape-settings-enabled.<target-name>=true`' using [ama-metrics-settings-configmap](https://aka.ms/azureprometheus-addon-settings-configmap) under `default-scrape-settings-enabled` section. --**core-dns** -- `coredns_build_info`-- `coredns_panics_total`-- `coredns_dns_responses_total`-- `coredns_forward_responses_total`-- `coredns_dns_request_duration_seconds` `coredns_dns_request_duration_seconds_bucket` `coredns_dns_request_duration_seconds_sum` `coredns_dns_request_duration_seconds_count`-- `coredns_forward_request_duration_seconds` `coredns_forward_request_duration_seconds_bucket` `coredns_forward_request_duration_seconds_sum` `coredns_forward_request_duration_seconds_count`-- `coredns_dns_requests_total`-- `coredns_forward_requests_total`-- `coredns_cache_hits_total`-- `coredns_cache_misses_total`-- `coredns_cache_entries`-- `coredns_plugin_enabled`-- `coredns_dns_request_size_bytes` `coredns_dns_request_size_bytes_bucket` `coredns_dns_request_size_bytes_sum` `coredns_dns_request_size_bytes_count` -- `coredns_dns_response_size_bytes` `coredns_dns_response_size_bytes_bucket` `coredns_dns_response_size_bytes_sum` `coredns_dns_response_size_bytes_count`-- `coredns_dns_response_size_bytes` `coredns_dns_response_size_bytes_bucket` `coredns_dns_response_size_bytes_sum` `coredns_dns_response_size_bytes_count` -- `process_resident_memory_bytes`-- `process_cpu_seconds_total`-- `go_goroutines`-- `kubernetes_build_info"`--**kube-proxy** -- `kubeproxy_sync_proxy_rules_duration_seconds` `kubeproxy_sync_proxy_rules_duration_seconds_bucket` `kubeproxy_sync_proxy_rules_duration_seconds_sum` `kubeproxy_sync_proxy_rules_duration_seconds_count` `kubeproxy_network_programming_duration_seconds`-- `kubeproxy_network_programming_duration_seconds` `kubeproxy_network_programming_duration_seconds_bucket` `kubeproxy_network_programming_duration_seconds_sum` `kubeproxy_network_programming_duration_seconds_count` `rest_client_requests_total`-- `rest_client_request_duration_seconds` `rest_client_request_duration_seconds_bucket` `rest_client_request_duration_seconds_sum` `rest_client_request_duration_seconds_count`-- `process_resident_memory_bytes`-- `process_cpu_seconds_total`-- `go_goroutines`-- `kubernetes_build_info"`--**api-server** -- `apiserver_request_duration_seconds` `apiserver_request_duration_seconds_bucket` `apiserver_request_duration_seconds_sum` `apiserver_request_duration_seconds_count` -- `apiserver_request_total` -- `workqueue_adds_total``workqueue_depth`-- `workqueue_queue_duration_seconds` `workqueue_queue_duration_seconds_bucket` `workqueue_queue_duration_seconds_sum` `workqueue_queue_duration_seconds_count` -- `process_resident_memory_bytes`-- `process_cpu_seconds_total`-- `go_goroutines`-- `kubernetes_build_info"`--**windows-exporter (job=windows-exporter)**<br> -- `windows_system_system_up_time`-- `windows_cpu_time_total`-- `windows_memory_available_bytes`-- `windows_os_visible_memory_bytes`-- `windows_memory_cache_bytes`-- `windows_memory_modified_page_list_bytes`-- `windows_memory_standby_cache_core_bytes`-- `windows_memory_standby_cache_normal_priority_bytes`-- `windows_memory_standby_cache_reserve_bytes`-- `windows_memory_swap_page_operations_total`-- `windows_logical_disk_read_seconds_total`-- `windows_logical_disk_write_seconds_total`-- `windows_logical_disk_size_bytes`-- `windows_logical_disk_free_bytes`-- `windows_net_bytes_total`-- `windows_net_packets_received_discarded_total`-- `windows_net_packets_outbound_discarded_total`-- `windows_container_available`-- `windows_container_cpu_usage_seconds_total`-- `windows_container_memory_usage_commit_bytes`-- `windows_container_memory_usage_private_working_set_bytes`-- `windows_container_network_receive_bytes_total`-- `windows_container_network_transmit_bytes_total`--**kube-proxy-windows (job=kube-proxy-windows)**<br> -- `kubeproxy_sync_proxy_rules_duration_seconds`-- `kubeproxy_sync_proxy_rules_duration_seconds_bucket`-- `kubeproxy_sync_proxy_rules_duration_seconds_sum`-- `kubeproxy_sync_proxy_rules_duration_seconds_count`-- `rest_client_requests_total`-- `rest_client_request_duration_seconds`-- `rest_client_request_duration_seconds_bucket`-- `rest_client_request_duration_seconds_sum`-- `rest_client_request_duration_seconds_count`-- `process_resident_memory_bytes`-- `process_cpu_seconds_total`-- `go_goroutines`--**controlplane-cluster-autoscaler**<br> -- `rest_client_requests_total`-- `cluster_autoscaler_last_activity`-- `cluster_autoscaler_cluster_safe_to_autoscale`-- `cluster_autoscaler_scale_down_in_cooldown`-- `cluster_autoscaler_scaled_up_nodes_total`-- `cluster_autoscaler_unneeded_nodes_count`-- `cluster_autoscaler_unschedulable_pods_count`-- `cluster_autoscaler_nodes_count`-- `cloudprovider_azure_api_request_errors`-- `cloudprovider_azure_api_request_duration_seconds_bucket`-- `cloudprovider_azure_api_request_duration_seconds_count`--**controlplane-kube-scheduler**<br> -- `scheduler_pending_pods`-- `scheduler_unschedulable_pods`-- `scheduler_pod_scheduling_attempts`-- `scheduler_queue_incoming_pods_total`-- `scheduler_preemption_attempts_total`-- `scheduler_preemption_victims`-- `scheduler_scheduling_attempt_duration_seconds`-- `scheduler_schedule_attempts_total`-- `scheduler_pod_scheduling_duration_seconds`--**controlplane-kube-controller-manager**<br> -- `rest_client_request_duration_seconds`-- `rest_client_requests_total`-- `workqueue_depth`--## Next steps --- [Learn more about customizing Prometheus metric scraping in Container insights](prometheus-metrics-scrape-configuration.md). |
| azure-monitor | Prometheus Metrics Scrape Configuration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/prometheus-metrics-scrape-configuration.md | - Title: Customize scraping of Prometheus metrics in Azure Monitor -description: Customize metrics scraping for a Kubernetes cluster with the metrics add-on in Azure Monitor. - Previously updated : 2/28/2024----# Customize scraping of Prometheus metrics in Azure Monitor managed service for Prometheus --This article provides instructions on customizing metrics scraping for a Kubernetes cluster with the [metrics addon](kubernetes-monitoring-enable.md#enable-prometheus-and-grafana) in Azure Monitor. --## Configmaps --Four different configmaps can be configured to provide scrape configuration and other settings for the metrics add-on. All config-maps should be applied to `kube-system` namespace for any cluster. --> [!NOTE] -> None of the four configmaps exist by default in the cluster when Managed Prometheus is enabled. Depending on what needs to be customized, you need to deploy any or all of these four configmaps with the same name specified, in `kube-system` namespace. AMA-Metrics pods will pick up these configmaps after you deploy them to `kube-system` namespace, and will restart in 2-3 minutes to apply the configuration settings specified in the configmap(s). ---1. [`ama-metrics-settings-configmap`](https://aka.ms/azureprometheus-addon-settings-configmap) - This config map has below simple settings that can be configured. You can take the configmap from the above git hub repo, change the settings are required and apply/deploy the configmap to `kube-system` namespace for your cluster - * cluster alias (to change the value of `cluster` label in every time-series/metric that's ingested from a cluster) - * enable/disable default scrape targets - Turn ON/OFF default scraping based on targets. Scrape configuration for these default targets are already pre-defined/built-in - * enable pod annotation based scraping per namespace - * metric keep-lists - this setting is used to control which metrics are listed to be allowed from each default target and to change the default behavior - * scrape intervals for default/pre-definetargets. `30 secs` is the default scrape frequency and it can be changed per default target using this configmap - * debug-mode - turning this ON helps to debug missing metric/ingestion issues - see more on [troubleshooting](prometheus-metrics-troubleshoot.md#debug-mode) -2. [`ama-metrics-prometheus-config`](https://aka.ms/azureprometheus-addon-rs-configmap) - This config map can be used to provide Prometheus scrape config for addon replica. Addon runs a singleton replica, and any cluster level services can be discovered and scraped by providing scrape jobs in this configmap. You can take the sample configmap from the above git hub repo, add scrape jobs that you would need and apply/deploy the config map to `kube-system` namespace for your cluster. - **Although this is supported, please note that the recommended way of scraping custom targets is using [custom resources](prometheus-metrics-scrape-configuration.md#custom-resource-definitions)** -3. [`ama-metrics-prometheus-config-node`](https://aka.ms/azureprometheus-addon-ds-configmap) (**Advanced**) - This config map can be used to provide Prometheus scrape config for addon DaemonSet that runs on every **Linux** node in the cluster, and any node level targets on each node can be scraped by providing scrape jobs in this configmap. When you use this configmap, you can use `$NODE_IP` variable in your scrape config, which gets substituted by corresponding node's ip address in DaemonSet pod running on each node. This way you get access to scrape anything that runs on that node from the metrics addon DaemonSet. **Please be careful when you use discoveries in scrape config in this node level config map, as every node in the cluster will setup & discover the target(s) and will collect redundant metrics**. - You can take the sample configmap from the above git hub repo, add scrape jobs that you would need and apply/deploy the config map to `kube-system` namespace for your cluster -4. [`ama-metrics-prometheus-config-node-windows`](https://aka.ms/azureprometheus-addon-ds-configmap-windows) (**Advanced**) - This config map can be used to provide Prometheus scrape config for addon DaemonSet that runs on every **Windows** node in the cluster, and node level targets on each node can be scraped by providing scrape jobs in this configmap. When you use this configmap, you can use `$NODE_IP` variable in your scrape config, which will be substituted by corresponding node's ip address in DaemonSet pod running on each node. This way you get access to scrape anything that runs on that node from the metrics addon DaemonSet. **Please be careful when you use discoveries in scrape config in this node level config map, as every node in the cluster will setup & discover the target(s) and will collect redundant metrics**. - You can take the sample configmap from the above git hub repo, add scrape jobs that you would need and apply/deploy the config map to `kube-system` namespace for your cluster --## Custom Resource Definitions -The Azure Monitor metrics add-on supports scraping Prometheus metrics using Prometheus - Pod Monitors and Service Monitors, similar to the OSS Prometheus operator. Enabling the add-on will deploy the Pod and Service Monitor custom resource definitions to allow you to create your own custom resources. -Follow the instructions to [create and apply custom resources](prometheus-metrics-scrape-crd.md) on your cluster. --## Metrics add-on settings configmap --The [ama-metrics-settings-configmap](https://aka.ms/azureprometheus-addon-settings-configmap) can be downloaded, edited, and applied to the cluster to customize the out-of-the-box features of the metrics add-on. --### Enable and disable default targets -The following table has a list of all the default targets that the Azure Monitor metrics add-on can scrape by default and whether it's initially enabled. Default targets are scraped every 30 seconds. A replica is deployed to scrape cluster-wide targets such as kube-state-metrics. A DaemonSet is also deployed to scrape node-wide targets such as kubelet. --| Key | Type | Enabled | Pod | Description | -|--||-|-|-| -| kubelet | bool | `true` | Linux DaemonSet | Scrape kubelet in every node in the K8s cluster without any extra scrape config. | -| cadvisor | bool | `true` | Linux DaemonSet | Scrape cadvisor in every node in the K8s cluster without any extra scrape config.<br>Linux only. | -| kubestate | bool | `true` | Linux replica | Scrape kube-state-metrics in the K8s cluster (installed as a part of the add-on) without any extra scrape config. | -| nodeexporter | bool | `true` | Linux DaemonSet | Scrape node metrics without any extra scrape config.<br>Linux only. | -| coredns | bool | `false` | Linux replica | Scrape coredns service in the K8s cluster without any extra scrape config. | -| kubeproxy | bool | `false` | Linux DaemonSet | Scrape kube-proxy in every Linux node discovered in the K8s cluster without any extra scrape config.<br>Linux only. | -| apiserver | bool | `false` | Linux replica | Scrape the Kubernetes API server in the K8s cluster without any extra scrape config. | -| windowsexporter | bool | `false` | Windows DaemonSet | Scrape windows-exporter in every node in the K8s cluster without any extra scrape config.<br>Windows only. | -| windowskubeproxy | bool | `false` | Windows DaemonSet | Scrape windows-kube-proxy in every node in the K8s cluster without any extra scrape config.<br>Windows only. | -| prometheuscollectorhealth | bool | `false` | Linux replica | Scrape information about the prometheus-collector container, such as the amount and size of time series scraped. | --If you want to turn on the scraping of the default targets that aren't enabled by default, edit the [configmap](https://aka.ms/azureprometheus-addon-settings-configmap) `ama-metrics-settings-configmap` to update the targets listed under `default-scrape-settings-enabled` to `true`. Apply the configmap to your cluster. --### Enable pod annotation-based scraping -To scrape application pods without needing to create a custom Prometheus config, annotations can be added to the pods. The annotation `prometheus.io/scrape: "true"` is required for the pod to be scraped. The annotations `prometheus.io/path` and `prometheus.io/port` indicate the path and port that the metrics are hosted at on the pod. The annotations for a pod that is hosting metrics at `<pod IP>:8080/metrics` would be: --```yaml -metadata: - annotations: - prometheus.io/scrape: 'true' - prometheus.io/path: '/metrics' - prometheus.io/port: '8080' -``` --Scraping these pods with specific annotations is disabled by default. To enable, in the `ama-metrics-settings-configmap`, add the regex for the namespace(s) of the pods with annotations you wish to scrape as the value of the field `podannotationnamespaceregex`. --For example, the following setting scrapes pods with annotations only in the namespaces `kube-system` and `my-namespace`: --```yaml -pod-annotation-based-scraping: |- - podannotationnamespaceregex = "kube-system|my-namespace" -``` --To enable scraping for pods with annotations in all namespaces, use: --```yaml -pod-annotation-based-scraping: |- - podannotationnamespaceregex = ".*" -``` --> [!WARNING] -> Scraping the pod annotations from many namespaces can generate a very large volume of metrics depending on the number of pods that have annotations. --### Customize metrics collected by default targets -By default, for all the default targets, only minimal metrics used in the default recording rules, alerts, and Grafana dashboards are ingested as described in [minimal-ingestion-profile](prometheus-metrics-scrape-configuration-minimal.md). To collect all metrics from default targets, update the keep-lists in the settings configmap under `default-targets-metrics-keep-list`, and set `minimalingestionprofile` to `false`. --To allowlist more metrics in addition to default metrics that are listed to be allowed, for any default targets, edit the settings under `default-targets-metrics-keep-list` for the corresponding job you want to change. --For example, `kubelet` is the metric filtering setting for the default target kubelet. Use the following script to filter *in* metrics collected for the default targets by using regex-based filtering. --``` -kubelet = "metricX|metricY" -apiserver = "mymetric.*" -``` --> [!NOTE] -> If you use quotation marks or backslashes in the regex, you need to escape them by using a backslash like the examples `"test\'smetric\"s\""` and `testbackslash\\*`. --To further customize the default jobs to change properties like collection frequency or labels, disable the corresponding default target by setting the configmap value for the target to `false`. Then apply the job by using a custom configmap. For details on custom configuration, see [Customize scraping of Prometheus metrics in Azure Monitor](prometheus-metrics-scrape-configuration.md#configure-custom-prometheus-scrape-jobs). --### Cluster alias -The cluster label appended to every time series scraped uses the last part of the full AKS cluster's Azure Resource Manager resource ID. For example, if the resource ID is `/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/rg-name/providers/Microsoft.ContainerService/managedClusters/myclustername`, the cluster label is `myclustername`. --To override the cluster label in the time series scraped, update the setting `cluster_alias` to any string under `prometheus-collector-settings` in the [configmap](https://aka.ms/azureprometheus-addon-settings-configmap) `ama-metrics-settings-configmap`. You can create this configmap if it doesn't exist in the cluster or you can edit the existing one if it already exists in your cluster. --The new label also shows up in the cluster parameter dropdown in the Grafana dashboards instead of the default one. --> [!NOTE] -> Only alphanumeric characters are allowed. Any other characters are replaced with `_`. This change is to ensure that different components that consume this label adhere to the basic alphanumeric convention. -> If you are enabling recording and alerting rules, please make sure to use the cluster alias name in the cluster name parameter of the rule onboarding template for the rules to work. --### Debug mode --> [!WARNING] -> This mode can affect performance and should only be enabled for a short time for debugging purposes. --To view every metric that's being scraped for debugging purposes, the metrics add-on agent can be configured to run in debug mode by updating the setting `enabled` to `true` under the `debug-mode` setting in the [configmap](https://aka.ms/azureprometheus-addon-settings-configmap) `ama-metrics-settings-configmap`. You can either create this configmap or edit an existing one. For more information, see the [Debug mode section in Troubleshoot collection of Prometheus metrics](prometheus-metrics-troubleshoot.md#debug-mode). --### Scrape interval settings -To update the scrape interval settings for any target, you can update the duration in the setting `default-targets-scrape-interval-settings` for that target in the [configmap](https://aka.ms/azureprometheus-addon-settings-configmap) `ama-metrics-settings-configmap`. You have to set the scrape intervals in the correct format specified in [this website](https://prometheus.io/docs/prometheus/latest/configuration/configuration/#configuration-file). Otherwise, the default value of 30 seconds is applied to the corresponding targets. For example - If you want to update the scrape interval for the `kubelet` job to `60s` then you can update the following section in the YAML: --``` -default-targets-scrape-interval-settings: |- - kubelet = "60s" - coredns = "30s" - cadvisor = "30s" - kubeproxy = "30s" - apiserver = "30s" - kubestate = "30s" - nodeexporter = "30s" - windowsexporter = "30s" - windowskubeproxy = "30s" - kappiebasic = "30s" - prometheuscollectorhealth = "30s" - podannotations = "30s" -``` -and apply the YAML using the following command: `kubectl apply -f .\ama-metrics-settings-configmap.yaml` --## Configure custom Prometheus scrape jobs --You can scrape Prometheus metrics using Prometheus - Pod Monitors and Service Monitors(**Recommended**), similar to the OSS Prometheus operator. -Follow the instructions to [create and apply custom resources](prometheus-metrics-scrape-crd.md) on your cluster. --Additionally, you can follow the instructions to [create, validate, and apply the configmap](prometheus-metrics-scrape-validate.md) for your cluster. -The configuration format is similar to [Prometheus configuration file](https://prometheus.io/docs/prometheus/latest/configuration/configuration/#configuration-file). --## Prometheus configuration tips and examples --Learn some tips from examples in this section. --### [Configuration using CRD for custom scrape config](#tab/CRDConfig) -Use the [Pod and Service Monitor templates](https://github.com/Azure/prometheus-collector/tree/main/otelcollector/customresources) and follow the API specification to create your custom resources([PodMonitor](https://github.com/prometheus-operator/prometheus-operator/blob/main/Documentation/api.md#podmonitor) and [Service Monitor](https://github.com/prometheus-operator/prometheus-operator/blob/main/Documentation/api.md#monitoring.coreos.com/v1.ServiceMonitor)). **Note** that the only change required to the existing OSS CRs for being picked up by the Managed Prometheus is the API group - **azmonitoring.coreos.com/v1**. See [here](prometheus-metrics-scrape-crd.md) to learn more ---### [Configuration file for custom scrape config](#tab/ConfigFile) --The configuration format is the same as the [Prometheus configuration file](https://aka.ms/azureprometheus-promioconfig). Currently, the following sections are supported: --```yaml -global: - scrape_interval: <duration> - scrape_timeout: <duration> - external_labels: - <labelname1>: <labelvalue> - <labelname2>: <labelvalue> -scrape_configs: - - <job-x> - - <job-y> -``` --Any other unsupported sections must be removed from the config before they're applied as a configmap. Otherwise, the custom configuration fails validation and isn't applied. --See the [Apply config file](prometheus-metrics-scrape-validate.md#deploy-config-file-as-configmap) section to create a configmap from the Prometheus config. ----> [!NOTE] -> When custom scrape configuration fails to apply because of validation errors, default scrape configuration continues to be used. --> If you want to use global settings that apply to all the scrape jobs, and only have [Custom Resources](prometheus-metrics-scrape-crd.md) you would still need to create a configmap with just the global settings(Settings for each of these in the custom resources will override the ones in the global section) ---## Scrape configs -### [Scrape Configs using CRD](#tab/CRDScrapeConfig) -Currently, the supported methods of target discovery for custom resources are pod and service monitor --#### Pod and Service Monitors -Targets discovered using pod and service monitors have different `__meta_*` labels depending on what monitor is used. You can use the labels in the `relabelings` section to filter targets or replace labels for the targets. --See the [Pod and Service Monitor examples](https://github.com/Azure/prometheus-collector/tree/main/otelcollector/deploy/example-custom-resources) of pod and service monitors. --### Relabelings -The `relabelings` section is applied at the time of target discovery and applies to each target for the job. The following examples show ways to use `relabelings`. --#### Add a label -Add a new label called `example_label` with the value `example_value` to every metric of the job. Use `__address__` as the source label only because that label always exists and adds the label for every target of the job. --```yaml -relabelings: -- sourceLabels: [__address__]- targetLabel: example_label - replacement: 'example_value' -``` --#### Use Pod or Service Monitor labels --Targets discovered using pod and service monitors have different `__meta_*` labels depending on what monitor is used. The `__*` labels are dropped after discovering the targets. To filter by using them at the metrics level, first keep them using `relabelings` by assigning a label name. Then use `metricRelabelings` to filter. --```yaml -# Use the kubernetes namespace as a label called 'kubernetes_namespace' -relabelings: -- sourceLabels: [__meta_kubernetes_namespace]- action: replace - targetLabel: kubernetes_namespace --# Keep only metrics with the kubernetes namespace 'default' -metricRelabelings: -- sourceLabels: [kubernetes_namespace]- action: keep - regex: 'default' -``` --#### Job and instance relabeling --You can change the `job` and `instance` label values based on the source label, just like any other label. --```yaml -# Replace the job name with the pod label 'k8s app' -relabelings: -- sourceLabels: [__meta_kubernetes_pod_label_k8s_app]- targetLabel: job --# Replace the instance name with the node name. This is helpful to replace a node IP -# and port with a value that is more readable -relabelings: -- sourceLabels: [__meta_kubernetes_node_name]]- targetLabel: instance -``` --> [!NOTE] -> If you have relabeling configs, ensure that the relabeling does not filter out the targets, and the labels configured correctly match the targets. --### Metric Relabelings --Metric relabelings are applied after scraping and before ingestion. Use the `metricRelabelings` section to filter metrics after scraping. The following examples show how to do so. --#### Drop metrics by name --```yaml -# Drop the metric named 'example_metric_name' -metricRelabelings: -- sourceLabels: [__name__]- action: drop - regex: 'example_metric_name' -``` --#### Keep only certain metrics by name --```yaml -# Keep only the metric named 'example_metric_name' -metricRelabelings: -- sourceLabels: [__name__]- action: keep - regex: 'example_metric_name' -``` --```yaml -# Keep only metrics that start with 'example_' -metricRelabelings: -- sourceLabels: [__name__]- action: keep - regex: '(example_.*)' -``` --#### Rename metrics -Metric renaming isn't supported. --#### Filter metrics by labels --```yaml -# Keep metrics only where example_label = 'example' -metricRelabelings: -- sourceLabels: [example_label]- action: keep - regex: 'example' -``` --```yaml -# Keep metrics only if `example_label` equals `value_1` or `value_2` -metricRelabelings: -- sourceLabels: [example_label]- action: keep - regex: '(value_1|value_2)' -``` --```yaml -# Keep metrics only if `example_label_1 = value_1` and `example_label_2 = value_2` -metricRelabelings: -- sourceLabels: [example_label_1, example_label_2]- separator: ';' - action: keep - regex: 'value_1;value_2' -``` --```yaml -# Keep metrics only if `example_label` exists as a label -metricRelabelings: -- sourceLabels: [example_label_1]- action: keep - regex: '.+' -``` ---### [Scrape Configs using Config file](#tab/ConfigFileScrapeConfig) -Currently, the supported methods of target discovery for a [scrape config](https://aka.ms/azureprometheus-promioconfig-scrape) are either [`static_configs`](https://aka.ms/azureprometheus-promioconfig-static) or [`kubernetes_sd_configs`](https://aka.ms/azureprometheus-promioconfig-sdk8s) for specifying or discovering targets. --#### Static config --A static config has a list of static targets and any extra labels to add to them. --```yaml -scrape_configs: - - job_name: example - - targets: [ '10.10.10.1:9090', '10.10.10.2:9090', '10.10.10.3:9090' ... ] - - labels: [ label1: value1, label1: value2, ... ] -``` --#### Kubernetes Service Discovery config --Targets discovered using [`kubernetes_sd_configs`](https://aka.ms/azureprometheus-promioconfig-sdk8s) each have different `__meta_*` labels depending on what role is specified. You can use the labels in the `relabel_configs` section to filter targets or replace labels for the targets. --See the [Prometheus examples](https://aka.ms/azureprometheus-promsampleossconfig) of scrape configs for a Kubernetes cluster. --### Relabel configs -The `relabel_configs` section is applied at the time of target discovery and applies to each target for the job. The following examples show ways to use `relabel_configs`. --#### Add a label -Add a new label called `example_label` with the value `example_value` to every metric of the job. Use `__address__` as the source label only because that label always exists and adds the label for every target of the job. --```yaml -relabel_configs: -- source_labels: [__address__]- target_label: example_label - replacement: 'example_value' -``` --#### Use Kubernetes Service Discovery labels --If a job is using [`kubernetes_sd_configs`](https://aka.ms/azureprometheus-promioconfig-sdk8s) to discover targets, each role has associated `__meta_*` labels for metrics. The `__*` labels are dropped after discovering the targets. To filter by using them at the metrics level, first keep them using `relabel_configs` by assigning a label name. Then use `metric_relabel_configs` to filter. --```yaml -# Use the kubernetes namespace as a label called 'kubernetes_namespace' -relabel_configs: -- source_labels: [__meta_kubernetes_namespace]- action: replace - target_label: kubernetes_namespace --# Keep only metrics with the kubernetes namespace 'default' -metric_relabel_configs: -- source_labels: [kubernetes_namespace]- action: keep - regex: 'default' -``` --#### Job and instance relabeling --You can change the `job` and `instance` label values based on the source label, just like any other label. --```yaml -# Replace the job name with the pod label 'k8s app' -relabel_configs: -- source_labels: [__meta_kubernetes_pod_label_k8s_app]- target_label: job --# Replace the instance name with the node name. This is helpful to replace a node IP -# and port with a value that is more readable -relabel_configs: -- source_labels: [__meta_kubernetes_node_name]]- target_label: instance -``` --### Metric relabel configs --Metric relabel configs are applied after scraping and before ingestion. Use the `metric_relabel_configs` section to filter metrics after scraping. The following examples show how to do so. --#### Drop metrics by name --```yaml -# Drop the metric named 'example_metric_name' -metric_relabel_configs: -- source_labels: [__name__]- action: drop - regex: 'example_metric_name' -``` --#### Keep only certain metrics by name --```yaml -# Keep only the metric named 'example_metric_name' -metric_relabel_configs: -- source_labels: [__name__]- action: keep - regex: 'example_metric_name' -``` --```yaml -# Keep only metrics that start with 'example_' -metric_relabel_configs: -- source_labels: [__name__]- action: keep - regex: '(example_.*)' -``` --#### Rename metrics -Metric renaming isn't supported. --#### Filter metrics by labels --```yaml -# Keep metrics only where example_label = 'example' -metric_relabel_configs: -- source_labels: [example_label]- action: keep - regex: 'example' -``` --```yaml -# Keep metrics only if `example_label` equals `value_1` or `value_2` -metric_relabel_configs: -- source_labels: [example_label]- action: keep - regex: '(value_1|value_2)' -``` --```yaml -# Keep metrics only if `example_label_1 = value_1` and `example_label_2 = value_2` -metric_relabel_configs: -- source_labels: [example_label_1, example_label_2]- separator: ';' - action: keep - regex: 'value_1;value_2' -``` --```yaml -# Keep metrics only if `example_label` exists as a label -metric_relabel_configs: -- source_labels: [example_label_1]- action: keep - regex: '.+' -``` --> [!NOTE] -> -> If you wish to add labels to all the jobs in your custom configuration, explicitly add labels using metrics_relabel_configs for each job. Global external labels are not supported via configmap based prometheus configuration. -> ```yaml -> relabel_configs: -> - source_labels: [__address__] -> target_label: example_label -> replacement: 'example_value' -> ``` -> ------### Basic Authentication -### [Scrape Configs using Config file](#tab/ConfigFileScrapeConfigBasicAuth) --If you are using `basic_auth` setting in your prometheus configuration, please follow the steps - --1. Create a secret in the **kube-system** namespace named **ama-metrics-mtls-secret** --The value for password1 is **base64encoded**. --The key *password1* can be anything, but just needs to match your scrapeconfig *password_file* filepath. --```yaml -apiVersion: v1 -kind: Secret -metadata: - name: ama-metrics-mtls-secret - namespace: kube-system -type: Opaque -data: - password1: <base64-encoded-string> -``` -The **ama-metrics-mtls-secret** secret is mounted on to the ama-metrics containers at path - **/etc/prometheus/certs/** and is made available to the process that is scraping prometheus metrics. The key( ex - password1) in the above example will be the file name and the value is base64 decoded and added to the contents of the file within the container and the prometheus scraper uses the contents of this file to get the value that is used as the password used to scrape the endpoint. --2. In the configmap for the custom scrape configuration use the following setting. The username field should contain the actual username string. The password_file field should contain the path to a file that contains the password. --```yaml -basic_auth: - username: <username string> - password_file: /etc/prometheus/certs/password1 --``` -By providing the path to the password_file above, the prometheus scraper uses the contents of the file named password1 in the path /etc/prometheus/certs as the value of password for basic auth based scraping. --### [Scrape Configs using CRD(Pod/Service Monitor)](#tab/CRDScrapeConfigBasicAuth) -Scraping targets using basic auth is currently not supported using pod/service monitors. Support for this will be added in the upcoming releases. ----If you are using both basic auth and tls auth, please refer to the [section](#basic-auth-and-tls) below. -For more details, refer to the [note section](#note) below. ---### TLS based scraping --If you have a Prometheus instance served with TLS and you want to scrape metrics from it, you need to set scheme to `https` and set the TLS settings in your configmap or respective CRD. -Please follow the below steps. --1. Create a secret in the kube-system namespace named ama-metrics-mtls-secret. Each key-value pair specified in the data section of the secret object will be mounted as a separate file in this /etc/prometheus/certs location with filename(s) same as key(s) specified in the data section. The secret values should be base64 encoded before putting them under the data section, like below. -- Below is an example of creating secret through YAML. -- ```yaml - apiVersion: v1 - kind: Secret - metadata: - name: ama-metrics-mtls-secret - namespace: kube-system - type: Opaque - data: - <certfile>: base64_cert_content - <keyfile>: base64_key_content - ``` - - The **ama-metrics-mtls-secret** secret is mounted on to the ama-metrics containers at path - **/etc/prometheus/certs/** and is made available to the process that is scraping prometheus metrics. The key( ex - certfile) in the above example will be the file name and the value is base64 decoded and added to the contents of the file within the container and the prometheus scraper uses the contents of this file to get the value that is used as the password used to scrape the endpoint. ---2. Below are the details about how to provide the TLS config settings through a configmap or CRD. - -### [Scrape Config using Config File](#tab/ConfigFileScrapeConfigTLSAuth) -- - To provide the TLS config setting in a configmap, please follow the below example. - - ```yaml - tls_config: - ca_file: /etc/prometheus/certs/<certfile> # since it is self-signed - cert_file: /etc/prometheus/certs/<certfile> - key_file: /etc/prometheus/certs/<keyfile> - insecure_skip_verify: false - ``` --### [Scrape Config using CRD(Pod/Service Monitor)](#tab/CRDScrapeConfigTLSAuth) -- - To provide the TLS config setting in a CRD(Pod/Service Monitor), please follow the below example. - - ```yaml - tlsConfig: - ca: - secret: - key: "<certfile>" # since it is self-signed - name: "ama-metrics-mtls-secret" - cert: - secret: - key: "<certfile>" - name: "ama-metrics-mtls-secret" - keySecret: - key: "<keyfile>" - name: "ama-metrics-mtls-secret" - insecureSkipVerify: false - ``` ---- -### Basic Auth and TLS -- If you want to use both basic and Tls authentication settings in your configmap/CRD, just make sure that the secret **ama-metrics-mtls-secret** includes all the files(keys) under the data section with their corresponding base 64 encoded values, as shown below. - - ```yaml - apiVersion: v1 - kind: Secret - metadata: - name: ama-metrics-mtls-secret - namespace: kube-system - type: Opaque - data: - certfile: base64_cert_content # used for Tls - keyfile: base64_key_content # used for Tls - password1: base64-encoded-string # used for basic auth - password2: base64-encoded-string # used for basic auth - ``` --### Note -> [!NOTE] -> -> The **/etc/prometheus/certs/** path is mandatory, but *password1* can be any string and needs to match the key for the data in the secret created above. This is because the secret **ama-metrics-mtls-secret** is mounted in the path **/etc/prometheus/certs/** within the container. -> -> The base64 encoded value is automatically decoded by the agent pods when the secret is mounted as file. -> -> Make sure the secret name is **ama-metrics-mtls-secret** and it is in **kube-system** namespace. -> -> The secret should be created and then the configmap/CRD should be created in kube-system namespace. The order of secret creation matters. When there's no secret but a valid CRD/config map, you will find errors in collector log -> `no file found for cert....` -> -> To read more on TLS configuration settings, please follow this [Configurations](https://aka.ms/tlsconfigsetting). --## Next steps --[Setup Alerts on Prometheus metrics](./container-insights-metric-alerts.md)<br> -[Query Prometheus metrics](../essentials/prometheus-grafana.md)<br> -[Learn more about collecting Prometheus metrics](../essentials/prometheus-metrics-overview.md) |
| azure-monitor | Prometheus Metrics Scrape Crd | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/prometheus-metrics-scrape-crd.md | - Title: Create and apply Pod and Service Monitors for Prometheus metrics in Azure Monitor -description: Describes how to create and apply pod and service monitors to scrape Prometheus metrics in Azure Monitor to Kubernetes cluster. - Previously updated : 3/13/2024---# Customize collection using CRDs (Service and Pod Monitors) ---The enablement of Managed Prometheus automatically deploys the custom resource definitions (CRD) for [pod monitors](https://github.com/Azure/prometheus-collector/blob/main/otelcollector/deploy/addon-chart/azure-monitor-metrics-addon/templates/ama-metrics-podmonitor-crd.yaml) and [service monitors](https://github.com/Azure/prometheus-collector/blob/main/otelcollector/deploy/addon-chart/azure-monitor-metrics-addon/templates/ama-metrics-servicemonitor-crd.yaml). These custom resource definitions are the same custom resource definitions (CRD) as [OSS Pod monitors](https://github.com/prometheus-operator/prometheus-operator/blob/main/Documentation/api.md#monitoring.coreos.com/v1.PodMonitor) and [OSS service monitors](https://github.com/prometheus-operator/prometheus-operator/blob/main/Documentation/api.md#monitoring.coreos.com/v1.ServiceMonitor) for Prometheus, except for a change in the group name. If you have existing Prometheus CRDs and custom resources on your cluster, these CRDs won't conflict with the CRDs created by the add-on. At the same time, the managed Prometheus addon does not pick up the CRDs created for the OSS Prometheus. This separation is intentional for the purposes of isolation of scrape jobs. --## Create a Pod or Service Monitor --Use the [Pod and Service Monitor templates](https://github.com/Azure/prometheus-collector/tree/main/otelcollector/customresources) and follow the API specification to create your custom resources([PodMonitor](https://github.com/prometheus-operator/prometheus-operator/blob/main/Documentation/api.md#podmonitor) and [Service Monitor](https://github.com/prometheus-operator/prometheus-operator/blob/main/Documentation/api.md#monitoring.coreos.com/v1.ServiceMonitor)). **Note** that the only change required to the existing OSS CRs(Custom Resources) for being picked up by the Managed Prometheus is the API group - **azmonitoring.coreos.com/v1**. ->Note - Please make sure to use the **labelLimit, labelNameLengthLimit and labelValueLengthLimit** specified in the templates so that they are not dropped during processing. --Your pod and service monitors should look like the following examples: --### Example Pod Monitor --```yaml -# Note the API version is azmonitoring.coreos.com/v1 instead of monitoring.coreos.com/v1 -apiVersion: azmonitoring.coreos.com/v1 -kind: PodMonitor --# Can be deployed in any namespace -metadata: - name: reference-app - namespace: app-namespace -spec: - labelLimit: 63 - labelNameLengthLimit: 511 - labelValueLengthLimit: 1023 -- # The selector specifies which pods to filter for - selector: -- # Filter by pod labels - matchLabels: - environment: test - matchExpressions: - - key: app - operator: In - values: [app-frontend, app-backend] -- # [Optional] Filter by pod namespace - namespaceSelector: - matchNames: [app-frontend, app-backend] -- # [Optional] Labels on the pod with these keys will be added as labels to each metric scraped - podTargetLabels: [app, region, environment] -- # Multiple pod endpoints can be specified. Port requires a named port. - podMetricsEndpoints: - - port: metrics -``` --### Example Service Monitor --```yaml -# Note the API version is azmonitoring.coreos.com/v1 instead of monitoring.coreos.com/v1 -apiVersion: azmonitoring.coreos.com/v1 -kind: ServiceMonitor --# Can be deployed in any namespace -metadata: - name: reference-app - namespace: app-namespace -spec: - labelLimit: 63 - labelNameLengthLimit: 511 - labelValueLengthLimit: 1023 -- # The selector filters endpoints by service labels. - selector: - matchLabels: - app: reference-app -- # Multiple endpoints can be specified. Port requires a named port. - endpoints: - - port: metrics -``` --### Deploy a Pod or Service Monitor --You can then deploy the pod or service monitor using kubectl apply. --When applied, any errors in the custom resources should show up and the pod or service monitors should fail to apply. -A successful pod monitor creation looks like the following - --```bash -podmonitor.azmonitoring.coreos.com/my-pod-monitor created -``` --### Examples --#### Create a sample application --Deploy a sample application exposing prometheus metrics to be configured by pod/service monitor. --```bash -kubectl apply -f https://github.com/Azure/prometheus-collector/blob/main/internal/referenceapp/prometheus-reference-app.yaml -``` --#### Create a pod monitor and/or service monitor to scrape metrics --Deploy a pod monitor that is configured to scrape metrics from the example application from the previous step. --##### Pod Monitor --```bash -kubectl apply -f https://github.com/Azure/prometheus-collector/blob/main/otelcollector/deploy/example-custom-resources/pod-monitor/pod-monitor-reference-app.yaml -``` --##### Service Monitor --```bash -kubectl apply -f https://github.com/Azure/prometheus-collector/blob/main/otelcollector/deploy/example-custom-resources/service-monitor/service-monitor-reference-app.yaml -``` --### Troubleshooting --When the pod or service monitors are successfully applied, the addon should automatically start collecting metrics from the targets. To confirm this, follow the instructions [here](prometheus-metrics-troubleshoot.md#prometheus-interface) for general troubleshooting of custom resources and also to ensure the targets show up in 127.0.0.1/targets. -- :::image type="content" source="media/prometheus-metrics-troubleshoot/image-pod-service-monitor.png" alt-text="Screenshot showing targets for pod/service monitor" lightbox="media/prometheus-metrics-troubleshoot/image-pod-service-monitor.png"::: --## Next steps --- [Learn more about collecting Prometheus metrics](../essentials/prometheus-metrics-overview.md). |
| azure-monitor | Prometheus Metrics Scrape Default | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/prometheus-metrics-scrape-default.md | - Title: Default Prometheus metrics configuration in Azure Monitor -description: This article lists the default targets, dashboards, and recording rules for Prometheus metrics in Azure Monitor. - Previously updated : 05/15/2024----# Default Prometheus metrics configuration in Azure Monitor --This article lists the default targets, dashboards, and recording rules when you [configure Prometheus metrics to be scraped from an Azure Kubernetes Service (AKS) cluster](kubernetes-monitoring-enable.md#enable-prometheus-and-grafana) for any AKS cluster. --## Minimal ingestion profile -`Minimal ingestion profile` is a setting that helps reduce ingestion volume of metrics, as only metrics used by default dashboards, default recording rules & default alerts are collected. For addon based collection, `Minimal ingestion profile` setting is enabled by default. You can modify collection to enable collecting more metrics, as specified below. --## Scrape frequency -- The default scrape frequency for all default targets and scrapes is 30 seconds. --## Targets scraped by default -Following targets are **enabled/ON** by default - meaning you don't have to provide any scrape job configuration for scraping these targets, as metrics addon will scrape these targets automatically by default. --- `cadvisor` (`job=cadvisor`)-- `nodeexporter` (`job=node`)-- `kubelet` (`job=kubelet`)-- `kube-state-metrics` (`job=kube-state-metrics`)-- `controlplane-apiserver` (`job=controlplane-apiserver`)-- `controlplane-etcd` (`job=controlplane-etcd`)--## Metrics collected from default targets --The following metrics are collected by default from each default target. All other metrics are dropped through relabeling rules. -- **cadvisor (job=cadvisor)**<br> - - `container_spec_cpu_period` - - `container_spec_cpu_quota` - - `container_cpu_usage_seconds_total` - - `container_memory_rss` - - `container_network_receive_bytes_total` - - `container_network_transmit_bytes_total` - - `container_network_receive_packets_total` - - `container_network_transmit_packets_total` - - `container_network_receive_packets_dropped_total` - - `container_network_transmit_packets_dropped_total` - - `container_fs_reads_total` - - `container_fs_writes_total` - - `container_fs_reads_bytes_total` - - `container_fs_writes_bytes_total` - - `container_memory_working_set_bytes` - - `container_memory_cache` - - `container_memory_swap` - - `container_cpu_cfs_throttled_periods_total` - - `container_cpu_cfs_periods_total` - - `container_memory_usage_bytes` - - `kubernetes_build_info"` -- **kubelet (job=kubelet)**<br> - - `kubelet_volume_stats_used_bytes` - - `kubelet_node_name` - - `kubelet_running_pods` - - `kubelet_running_pod_count` - - `kubelet_running_containers` - - `kubelet_running_container_count` - - `volume_manager_total_volumes` - - `kubelet_node_config_error` - - `kubelet_runtime_operations_total` - - `kubelet_runtime_operations_errors_total` - - `kubelet_runtime_operations_duration_seconds` `kubelet_runtime_operations_duration_seconds_bucket` `kubelet_runtime_operations_duration_seconds_sum` `kubelet_runtime_operations_duration_seconds_count` - - `kubelet_pod_start_duration_seconds` `kubelet_pod_start_duration_seconds_bucket` `kubelet_pod_start_duration_seconds_sum` `kubelet_pod_start_duration_seconds_count` - - `kubelet_pod_worker_duration_seconds` `kubelet_pod_worker_duration_seconds_bucket` `kubelet_pod_worker_duration_seconds_sum` `kubelet_pod_worker_duration_seconds_count` - - `storage_operation_duration_seconds` `storage_operation_duration_seconds_bucket` `storage_operation_duration_seconds_sum` `storage_operation_duration_seconds_count` - - `storage_operation_errors_total` - - `kubelet_cgroup_manager_duration_seconds` `kubelet_cgroup_manager_duration_seconds_bucket` `kubelet_cgroup_manager_duration_seconds_sum` `kubelet_cgroup_manager_duration_seconds_count` - - `kubelet_pleg_relist_duration_seconds` `kubelet_pleg_relist_duration_seconds_bucket` `kubelet_pleg_relist_duration_sum` `kubelet_pleg_relist_duration_seconds_count` - - `kubelet_pleg_relist_interval_seconds` `kubelet_pleg_relist_interval_seconds_bucket` `kubelet_pleg_relist_interval_seconds_sum` `kubelet_pleg_relist_interval_seconds_count` - - `rest_client_requests_total` - - `rest_client_request_duration_seconds` `rest_client_request_duration_seconds_bucket` `rest_client_request_duration_seconds_sum` `rest_client_request_duration_seconds_count` - - `process_resident_memory_bytes` - - `process_cpu_seconds_total` - - `go_goroutines` - - `kubelet_volume_stats_capacity_bytes` - - `kubelet_volume_stats_available_bytes` - - `kubelet_volume_stats_inodes_used` - - `kubelet_volume_stats_inodes` - - `kubernetes_build_info"` -- **nodexporter (job=node)**<br> - - `node_cpu_seconds_total` - - `node_memory_MemAvailable_bytes` - - `node_memory_Buffers_bytes` - - `node_memory_Cached_bytes` - - `node_memory_MemFree_bytes` - - `node_memory_Slab_bytes` - - `node_memory_MemTotal_bytes` - - `node_netstat_Tcp_RetransSegs` - - `node_netstat_Tcp_OutSegs` - - `node_netstat_TcpExt_TCPSynRetrans` - - `node_load1``node_load5` - - `node_load15` - - `node_disk_read_bytes_total` - - `node_disk_written_bytes_total` - - `node_disk_io_time_seconds_total` - - `node_filesystem_size_bytes` - - `node_filesystem_avail_bytes` - - `node_filesystem_readonly` - - `node_network_receive_bytes_total` - - `node_network_transmit_bytes_total` - - `node_vmstat_pgmajfault` - - `node_network_receive_drop_total` - - `node_network_transmit_drop_total` - - `node_disk_io_time_weighted_seconds_total` - - `node_exporter_build_info` - - `node_time_seconds` - - `node_uname_info"` -- **kube-state-metrics (job=kube-state-metrics)**<br> - - `kube_job_status_succeeded` - - `kube_job_spec_completions` - - `kube_daemonset_status_desired_number_scheduled` - - `kube_daemonset_status_number_ready` - - `kube_deployment_status_replicas_ready` - - `kube_pod_container_status_last_terminated_reason` - - `kube_pod_container_status_waiting_reason` - - `kube_pod_container_status_restarts_total` - - `kube_node_status_allocatable` - - `kube_pod_owner` - - `kube_pod_container_resource_requests` - - `kube_pod_status_phase` - - `kube_pod_container_resource_limits` - - `kube_replicaset_owner` - - `kube_resourcequota` - - `kube_namespace_status_phase` - - `kube_node_status_capacity` - - `kube_node_info` - - `kube_pod_info` - - `kube_deployment_spec_replicas` - - `kube_deployment_status_replicas_available` - - `kube_deployment_status_replicas_updated` - - `kube_statefulset_status_replicas_ready` - - `kube_statefulset_status_replicas` - - `kube_statefulset_status_replicas_updated` - - `kube_job_status_start_time` - - `kube_job_status_active` - - `kube_job_failed` - - `kube_horizontalpodautoscaler_status_desired_replicas` - - `kube_horizontalpodautoscaler_status_current_replicas` - - `kube_horizontalpodautoscaler_spec_min_replicas` - - `kube_horizontalpodautoscaler_spec_max_replicas` - - `kubernetes_build_info` - - `kube_node_status_condition` - - `kube_node_spec_taint` - - `kube_pod_container_info` - - `kube_resource_labels` (ex - kube_pod_labels, kube_deployment_labels) - - `kube_resource_annotations` (ex - kube_pod_annotations, kube_deployment_annotations) -- **controlplane-apiserver (job=controlplane-apiserver)**<br> - - `apiserver_request_total` - - `apiserver_cache_list_fetched_objects_total` - - `apiserver_cache_list_returned_objects_total` - - `apiserver_flowcontrol_demand_seats_average` - - `apiserver_flowcontrol_current_limit_seats` - - `apiserver_request_sli_duration_seconds_bucket` - - `apiserver_request_sli_duration_seconds_count` - - `apiserver_request_sli_duration_seconds_sum` - - `process_start_time_seconds` - - `apiserver_request_duration_seconds_bucket` - - `apiserver_request_duration_seconds_count` - - `apiserver_request_duration_seconds_sum` - - `apiserver_storage_list_fetched_objects_total` - - `apiserver_storage_list_returned_objects_total` - - `apiserver_current_inflight_requests` -- **controlplane-etcd (job=controlplane-etcd)**<br> - - `etcd_server_has_leader` - - `rest_client_requests_total` - - `etcd_mvcc_db_total_size_in_bytes` - - `etcd_mvcc_db_total_size_in_use_in_bytes` - - `etcd_server_slow_read_indexes_total` - - `etcd_server_slow_apply_total` - - `etcd_network_client_grpc_sent_bytes_total` - - `etcd_server_heartbeat_send_failures_total` --## Default targets scraped for Windows -Following Windows targets are configured to scrape, but scraping isn't enabled (**disabled/OFF**) by default - meaning you don't have to provide any scrape job configuration for scraping these targets but they are disabled/OFF by default and you need to turn ON/enable scraping for these targets using [ama-metrics-settings-configmap](https://aka.ms/azureprometheus-addon-settings-configmap) under `default-scrape-settings-enabled` section. --Two default jobs can be run for Windows that scrape metrics required for the dashboards specific to Windows. -- `windows-exporter` (`job=windows-exporter`)-- `kube-proxy-windows` (`job=kube-proxy-windows`)--> [!NOTE] -> This requires applying or updating the `ama-metrics-settings-configmap` configmap and installing `windows-exporter` on all Windows nodes. For more information, see the [enablement document](kubernetes-monitoring-enable.md#enable-windows-metrics-collection-preview). --## Metrics scraped for Windows --The following metrics are collected when windows-exporter and kube-proxy-windows are enabled. --**windows-exporter (job=windows-exporter)**<br> - - `windows_system_system_up_time` - - `windows_cpu_time_total` - - `windows_memory_available_bytes` - - `windows_os_visible_memory_bytes` - - `windows_memory_cache_bytes` - - `windows_memory_modified_page_list_bytes` - - `windows_memory_standby_cache_core_bytes` - - `windows_memory_standby_cache_normal_priority_bytes` - - `windows_memory_standby_cache_reserve_bytes` - - `windows_memory_swap_page_operations_total` - - `windows_logical_disk_read_seconds_total` - - `windows_logical_disk_write_seconds_total` - - `windows_logical_disk_size_bytes` - - `windows_logical_disk_free_bytes` - - `windows_net_bytes_total` - - `windows_net_packets_received_discarded_total` - - `windows_net_packets_outbound_discarded_total` - - `windows_container_available` - - `windows_container_cpu_usage_seconds_total` - - `windows_container_memory_usage_commit_bytes` - - `windows_container_memory_usage_private_working_set_bytes` - - `windows_container_network_receive_bytes_total` - - `windows_container_network_transmit_bytes_total` --**kube-proxy-windows (job=kube-proxy-windows)**<br> - - `kubeproxy_sync_proxy_rules_duration_seconds` - - `kubeproxy_sync_proxy_rules_duration_seconds_bucket` - - `kubeproxy_sync_proxy_rules_duration_seconds_sum` - - `kubeproxy_sync_proxy_rules_duration_seconds_count` - - `rest_client_requests_total` - - `rest_client_request_duration_seconds` - - `rest_client_request_duration_seconds_bucket` - - `rest_client_request_duration_seconds_sum` - - `rest_client_request_duration_seconds_count` - - `process_resident_memory_bytes` - - `process_cpu_seconds_total` - - `go_goroutines` --## Dashboards --The following default dashboards are automatically provisioned and configured by Azure Monitor managed service for Prometheus when you [link your Azure Monitor workspace to an Azure Managed Grafana instance](../essentials/azure-monitor-workspace-manage.md#link-a-grafana-workspace). Source code for these dashboards can be found in [this GitHub repository](https://aka.ms/azureprometheus-mixins). The below dashboards will be provisioned in the specified Azure Grafana instance under `Managed Prometheus` folder in Grafana. These are the standard open source community dashboards for monitoring Kubernetes clusters with Prometheus and Grafana. --- `Kubernetes / Compute Resources / Cluster`-- `Kubernetes / Compute Resources / Namespace (Pods)`-- `Kubernetes / Compute Resources / Node (Pods)`-- `Kubernetes / Compute Resources / Pod`-- `Kubernetes / Compute Resources / Namespace (Workloads)`-- `Kubernetes / Compute Resources / Workload`-- `Kubernetes / Kubelet`-- `Node Exporter / USE Method / Node`-- `Node Exporter / Nodes`-- `Kubernetes / Compute Resources / Cluster (Windows)`-- `Kubernetes / Compute Resources / Namespace (Windows)`-- `Kubernetes / Compute Resources / Pod (Windows)`-- `Kubernetes / USE Method / Cluster (Windows)`-- `Kubernetes / USE Method / Node (Windows)`--## Recording rules --The following default recording rules are automatically configured by Azure Monitor managed service for Prometheus when you [configure Prometheus metrics to be scraped from an Azure Kubernetes Service (AKS) cluster](kubernetes-monitoring-enable.md#enable-prometheus-and-grafana). Source code for these recording rules can be found in [this GitHub repository](https://aka.ms/azureprometheus-mixins). These are the standard open source recording rules used in the dashboards above. --- `cluster:node_cpu:ratio_rate5m`-- `namespace_cpu:kube_pod_container_resource_requests:sum`-- `namespace_cpu:kube_pod_container_resource_limits:sum`-- `:node_memory_MemAvailable_bytes:sum`-- `namespace_memory:kube_pod_container_resource_requests:sum`-- `namespace_memory:kube_pod_container_resource_limits:sum`-- `namespace_workload_pod:kube_pod_owner:relabel`-- `node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate`-- `cluster:namespace:pod_cpu:active:kube_pod_container_resource_requests`-- `cluster:namespace:pod_cpu:active:kube_pod_container_resource_limits`-- `cluster:namespace:pod_memory:active:kube_pod_container_resource_requests`-- `cluster:namespace:pod_memory:active:kube_pod_container_resource_limits`-- `node_namespace_pod_container:container_memory_working_set_bytes`-- `node_namespace_pod_container:container_memory_rss`-- `node_namespace_pod_container:container_memory_cache`-- `node_namespace_pod_container:container_memory_swap`-- `instance:node_cpu_utilisation:rate5m`-- `instance:node_load1_per_cpu:ratio`-- `instance:node_memory_utilisation:ratio`-- `instance:node_vmstat_pgmajfault:rate5m`-- `instance:node_network_receive_bytes_excluding_lo:rate5m`-- `instance:node_network_transmit_bytes_excluding_lo:rate5m`-- `instance:node_network_receive_drop_excluding_lo:rate5m`-- `instance:node_network_transmit_drop_excluding_lo:rate5m`-- `instance_device:node_disk_io_time_seconds:rate5m`-- `instance_device:node_disk_io_time_weighted_seconds:rate5m`-- `instance:node_num_cpu:sum`-- `node:windows_node:sum`-- `node:windows_node_num_cpu:sum`-- `:windows_node_cpu_utilisation:avg5m`-- `node:windows_node_cpu_utilisation:avg5m`-- `:windows_node_memory_utilisation:`-- `:windows_node_memory_MemFreeCached_bytes:sum`-- `node:windows_node_memory_totalCached_bytes:sum`-- `:windows_node_memory_MemTotal_bytes:sum`-- `node:windows_node_memory_bytes_available:sum`-- `node:windows_node_memory_bytes_total:sum`-- `node:windows_node_memory_utilisation:ratio`-- `node:windows_node_memory_utilisation:`-- `node:windows_node_memory_swap_io_pages:irate`-- `:windows_node_disk_utilisation:avg_irate`-- `node:windows_node_disk_utilisation:avg_irate`-- `node:windows_node_filesystem_usage:`-- `node:windows_node_filesystem_avail:`-- `:windows_node_net_utilisation:sum_irate`-- `node:windows_node_net_utilisation:sum_irate`-- `:windows_node_net_saturation:sum_irate`-- `node:windows_node_net_saturation:sum_irate`-- `windows_pod_container_available`-- `windows_container_total_runtime`-- `windows_container_memory_usage`-- `windows_container_private_working_set_usage`-- `windows_container_network_received_bytes_total`-- `windows_container_network_transmitted_bytes_total`-- `kube_pod_windows_container_resource_memory_request`-- `kube_pod_windows_container_resource_memory_limit`-- `kube_pod_windows_container_resource_cpu_cores_request`-- `kube_pod_windows_container_resource_cpu_cores_limit`-- `namespace_pod_container:windows_container_cpu_usage_seconds_total:sum_rate`--## Prometheus visualization recording rules --When you use [Prometheus based Container Insights](./container-insights-experience-v2.md), more recording rules will be deployed to support the Prometheus visualizations. --- `ux:cluster_pod_phase_count:sum`-- `ux:node_cpu_usage:sum_irate`-- `ux:node_memory_usage:sum`-- `ux:controller_pod_phase_count:sum`-- `ux:controller_container_count:sum`-- `ux:controller_workingset_memory:sum`-- `ux:controller_cpu_usage:sum_irate`-- `ux:controller_rss_memory:sum`-- `ux:controller_resource_limit:sum`-- `ux:controller_container_restarts:max`-- `ux:pod_container_count:sum`-- `ux:pod_cpu_usage:sum_irate`-- `ux:pod_workingset_memory:sum`-- `ux:pod_rss_memory:sum`-- `ux:pod_resource_limit:sum`-- `ux:pod_container_restarts:max`-- `ux:node_network_receive_drop_total:sum_irate`-- `ux:node_network_transmit_drop_total:sum_irate`--The following recording rules are required for Windows support. These rules are deployed along with the above rules, however, they aren't enabled by default. Follow the instructions for [enabling and disabling rule groups](../essentials/prometheus-rule-groups.md#disable-and-enable-rule-groups) in your Azure Monitor workspace. --- `ux:node_cpu_usage_windows:sum_irate`-- `ux:node_memory_usage_windows:sum`-- `ux:controller_cpu_usage_windows:sum_irate`-- `ux:controller_workingset_memory_windows:sum`-- `ux:pod_cpu_usage_windows:sum_irate`-- `ux:pod_workingset_memory_windows:sum`--## Next steps --[Customize scraping of Prometheus metrics.](prometheus-metrics-scrape-configuration.md) |
| azure-monitor | Prometheus Metrics Scrape Scale | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/prometheus-metrics-scrape-scale.md | - Title: Scrape Prometheus metrics at scale in Azure Monitor -description: Guidance on performance that can be expected when collection metrics at high scale for Azure Monitor managed service for Prometheus. - Previously updated : 2/28/2024----# Scrape Prometheus metrics at scale in Azure Monitor -This article provides guidance on performance that can be expected when collection metrics at high scale for [Azure Monitor managed service for Prometheus](../essentials/prometheus-metrics-overview.md). ---## CPU and memory -The CPU and memory usage is correlated with the number of bytes of each sample and the number of samples scraped. These benchmarks are based on the [default targets scraped](prometheus-metrics-scrape-default.md), volume of custom metrics scraped, and number of nodes, pods, and containers. These numbers are meant as a reference since usage can still vary significantly depending on the number of time series and bytes per metric. --The upper volume limit per pod is currently about 3-3.5 million samples per minute, depending on the number of bytes per sample. This limitation is addressed when sharding is added in future. --The agent consists of a deployment with one replica and DaemonSet for scraping metrics. The DaemonSet scrapes any node-level targets such as cAdvisor, kubelet, and node exporter. You can also configure it to scrape any custom targets at the node level with static configs. The replicaset scrapes everything else such as kube-state-metrics or custom scrape jobs that utilize service discovery. --## Comparison between small and large cluster for replica --| Scrape Targets | Samples Sent / Minute | Node Count | Pod Count | Prometheus-Collector CPU Usage (cores) |Prometheus-Collector Memory Usage (bytes) | -|:|:|:|:|:|:| -| default targets | 11,344 | 3 | 40 | 12.9 mc | 148 Mi | -| default targets | 260,000 | 340 | 13000 | 1.10 c | 1.70 GB | -| default targets<br>+ custom targets | 3.56 million | 340 | 13000 | 5.13 c | 9.52 GB | --## Comparison between small and large cluster for DaemonSets --| Scrape Targets | Samples Sent / Minute Total | Samples Sent / Minute / Pod | Node Count | Pod Count | Prometheus-Collector CPU Usage Total (cores) |Prometheus-Collector Memory Usage Total (bytes) | Prometheus-Collector CPU Usage / Pod (cores) |Prometheus-Collector Memory Usage / Pod (bytes) | -|:|:|:|:|:|:|:|:|:| -| default targets | 9,858 | 3,327 | 3 | 40 | 41.9 mc | 581 Mi | 14.7 mc | 189 Mi | -| default targets | 2.3 million | 14,400 | 340 | 13000 | 805 mc | 305.34 GB | 2.36 mc | 898 Mi | --For more custom metrics, the single pod behaves the same as the replica pod depending on the volume of custom metrics. ---## Schedule ama-metrics replica pod on a node pool with more resources --A large volume of metrics per pod requires a large enough node to be able to handle the CPU and memory usage required. If the *ama-metrics* replica pod doesn't get scheduled on a node or nodepool that has enough resources, it might keep getting OOMKilled and go to CrashLoopBackoff. In order to overcome this issue, if you have a node or nodepool on your cluster that has higher resources (in [system node pool](/azure/aks/use-system-pools#system-and-user-node-pools)) and want to get the replica scheduled on that node, you can add the label `azuremonitor/metrics.replica.preferred=true` on the node and the replica pod will get scheduled on this node. Also you can create additional system pool(s), if needed, with larger nodes and can add the same label to their node(s) or nodepool. It's also better to add labels to [nodepool](/azure/aks/use-labels#updating-labels-on-existing-node-pools) rather than nodes so newer nodes in the same pool can also be used for scheduling when this label is applicable to all nodes in the pool. -- ``` - kubectl label nodes <node-name> azuremonitor/metrics.replica.preferred="true" - ``` -## Next steps --- [Troubleshoot issues with Prometheus data collection](prometheus-metrics-troubleshoot.md). |
| azure-monitor | Prometheus Metrics Scrape Validate | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/prometheus-metrics-scrape-validate.md | - Title: Create, validate and troubleshoot custom configuration file for Prometheus metrics in Azure Monitor -description: Describes how to create custom configuration file Prometheus metrics in Azure Monitor and use validation tool before applying to Kubernetes cluster. - Previously updated : 2/28/2024----# Create and validate custom configuration file for Prometheus metrics in Azure Monitor --In addition to the default scrape targets that Azure Monitor Prometheus agent scrapes by default, use the following steps to provide more scrape config to the agent using a configmap. The Azure Monitor Prometheus agent doesn't understand or process operator [CRDs](https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/) for scrape configuration, but instead uses the native Prometheus configuration as defined in [Prometheus configuration](https://aka.ms/azureprometheus-promioconfig-scrape). --The three configmaps that can be used for custom target scraping are - -- ama-metrics-prometheus-config (**Recommended**) - When a configmap with this name is created, scrape jobs defined in it are run from the Azure monitor metrics replica pod running in the cluster.-- ama-metrics-prometheus-config-node (**Advanced**) - When a configmap with this name is created, scrape jobs defined in it are run from each **Linux** DaemonSet pod running in the cluster. For more information, see [Advanced Setup](#advanced-setup-configure-custom-prometheus-scrape-jobs-for-the-daemonset).-- ama-metrics-prometheus-config-node-windows (**Advanced**) - When a configmap with this name is created, scrape jobs defined in it are run from each **windows** DaemonSet. For more information, see [Advanced Setup](#advanced-setup-configure-custom-prometheus-scrape-jobs-for-the-daemonset).--## Create Prometheus configuration file --One easier way to author Prometheus scrape configuration jobs: -- Step:1 Use a config file (yaml) to author/define scrape jobs -- Step:2 Validate the scrape config file using a custom tool (as specified in this article) and then convert that configfile to configmap -- Step:3 Deploy the scrape config file as configmap to your clusters. - -Doing this way is easier to author yaml config (which is extremely space sensitive), and not add unintended spaces by directly authoring scrape config inside config map. --Create a Prometheus scrape configuration file named `prometheus-config`. For more information, see [configuration tips and examples](prometheus-metrics-scrape-configuration.md#prometheus-configuration-tips-and-examples) which gives more details on authoring scrape config for Prometheus. You can also refer to [Prometheus.io](https://aka.ms/azureprometheus-promio) scrape configuration [reference](https://aka.ms/azureprometheus-promioconfig-scrape). Your config file lists the scrape configs under the section `scrape_configs` section and can optionally use the global section for setting the global `scrape_interval`, `scrape_timeout`, and `external_labels`. ---> [!TIP] -> Changes to global section will impact the default configs and the custom config. --Here is a sample Prometheus scrape config file: --```yaml -global: - scrape_interval: 30s -scrape_configs: -- job_name: my_static_config- scrape_interval: 60s - static_configs: - - targets: ['my-static-service.svc.cluster.local:1234'] --- job_name: prometheus_example_app- scheme: http - kubernetes_sd_configs: - - role: service - relabel_configs: - - source_labels: [__meta_kubernetes_service_name] - action: keep - regex: "prometheus-example-service" -``` --## Validate the scrape config file --The agent uses a custom `promconfigvalidator` tool to validate the Prometheus config given to it through the configmap. If the config isn't valid, then the custom configuration given gets rejected by the addon agent. Once you have your Prometheus config file, you can *optionally* use the `promconfigvalidator` tool to validate your config before creating a configmap that the agent consumes. --The `promconfigvalidator` tool is shipped inside the Azure Monitor metrics addon pod(s). You can use any of the `ama-metrics-node-*` pods in `kube-system` namespace in your cluster to download the tool for validation. Use `kubectl cp` to download the tool and its configuration: --```bash -for podname in $(kubectl get pods -l rsName=ama-metrics -n=kube-system -o json | jq -r '.items[].metadata.name'); do kubectl cp -n=kube-system "${podname}":/opt/promconfigvalidator ./promconfigvalidator; kubectl cp -n=kube-system "${podname}":/opt/microsoft/otelcollector/collector-config-template.yml ./collector-config-template.yml; chmod 500 promconfigvalidator; done -``` --After copying the executable and the yaml, locate the path of your Prometheus configuration file that you authored. Then replace `<config path>` in the command and run the validator with the command: --```bash -./promconfigvalidator/promconfigvalidator --config "<config path>" --otelTemplate "./promconfigvalidator/collector-config-template.yml" -``` --Running the validator generates the merged configuration file `merged-otel-config.yaml` if no path is provided with the optional `output` parameter. Don't use this autogenerated merged file as config to the metrics collector agent, as it's only used for tool validation and debugging purposes. --### Deploy config file as configmap -Your custom Prometheus configuration file is consumed as a field named `prometheus-config` inside metrics addon configmap(s) `ama-metrics-prometheus-config` (or) `ama-metrics-prometheus-config-node` (or) `ama-metrics-prometheus-config-node-windows` in the `kube-system` namespace. You can create a configmap from the scrape config file you created above, by renaming your Prometheus configuration file to `prometheus-config` (with no file extension) and running one or more of the following commands, depending on which configmap you want to create for your custom scrape job(s) config. --Ex;- to create configmap to be used by replicsset -```bash -kubectl create configmap ama-metrics-prometheus-config --from-file=prometheus-config -n kube-system -``` -This creates a configmap named `ama-metrics-prometheus-config` in `kube-system` namespace. The Azure Monitor metrics replica pod restarts in 30-60 secs to apply the new config. To see if there any issues with the config validation, processing, or merging, you can look at the `ama-metrics` replica pods --Ex;- to create configmap to be used by linux DaemonSet -```bash -kubectl create configmap ama-metrics-prometheus-config-node --from-file=prometheus-config -n kube-system -``` -This creates a configmap named `ama-metrics-prometheus-config-node` in `kube-system` namespace. Every Azure Monitor metrics Linux DaemonSet pod restarts in 30-60 secs to apply the new config. To see if there any issues with the config validation, processing, or merging, you can look at the `ama-metrics-node` linux deamonset pods ---Ex;- to create configmap to be used by windows DaemonSet -```bash -kubectl create configmap ama-metrics-prometheus-config-node-windows --from-file=prometheus-config -n kube-system -``` --This creates a configmap named `ama-metrics-prometheus-config-node-windows` in `kube-system` namespace. Every Azure Monitor metrics Windows DaemonSet pod restarts in 30-60 secs to apply the new config. To see if there any issues with the config validation, processing, or merging, you can look at the `ama-metrics-win-node` windows deamonset pods ---*Ensure that the Prometheus config file is named `prometheus-config` before running the following command since the file name is used as the configmap setting name.* --This creates a configmap named `ama-metrics-prometheus-config` in `kube-system` namespace. The Azure Monitor metrics pod restarts to apply the new config. To see if there any issues with the config validation, processing, or merging, you can look at the `ama-metrics` pods. --A sample of the `ama-metrics-prometheus-config` configmap is [here](https://github.com/Azure/prometheus-collector/blob/main/otelcollector/configmaps/ama-metrics-prometheus-config-configmap.yaml). --### Troubleshooting -If you successfully created the configmap (ama-metrics-prometheus-config or ama-metrics-prometheus-config-node) in the **kube-system** namespace and still don't see the custom targets being scraped, check for errors in the **replica pod** logs for **ama-metrics-prometheus-config** configmap or **DaemonSet pod** logs for **ama-metrics-prometheus-config-node** configmap) using *kubectl logs* and make sure there are no errors in the *Start Merging Default and Custom Prometheus Config* section with prefix *prometheus-config-merger* --> [!NOTE] -> ### Advanced setup: Configure custom Prometheus scrape jobs for the DaemonSet -> -> The `ama-metrics` Replica pod consumes the custom Prometheus config and scrapes the specified targets. For a cluster with a large number of nodes and pods and a large volume of metrics to scrape, some of the applicable custom scrape targets can be off-loaded from the single `ama-metrics` Replica pod to the `ama-metrics` DaemonSet pod. -> -> The [ama-metrics-prometheus-config-node configmap](https://aka.ms/azureprometheus-addon-ds-configmap), is similar to the replica-set configmap, and can be created to have static scrape configs on each node. The scrape config should only target a single node and shouldn't use service discovery/pod annotations. Otherwise, each node tries to scrape all targets and makes many calls to the Kubernetes API server. -> -> Custom scrape targets can follow the same format by using `static_configs` with targets and using the `$NODE_IP` environment variable and specifying the port to scrape. Each pod of the DaemonSet takes the config, scrapes the metrics, and sends them for that node. -> -> Example:- The following `node-exporter` config is one of the default targets for the DaemonSet pods. It uses the `$NODE_IP` environment variable, which is already set for every `ama-metrics` add-on container to target a specific port on the node. -> -> ```yaml -> - job_name: nodesample -> scrape_interval: 30s -> scheme: http -> metrics_path: /metrics -> relabel_configs: -> - source_labels: [__metrics_path__] -> regex: (.*) -> target_label: metrics_path -> - source_labels: [__address__] -> replacement: '$NODE_NAME' -> target_label: instance -> static_configs: -> - targets: ['$NODE_IP:9100'] -> ``` --## Next steps --- [Learn more about collecting Prometheus metrics](../essentials/prometheus-metrics-overview.md). |
| azure-monitor | Prometheus Metrics Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/prometheus-metrics-troubleshoot.md | - Title: Troubleshoot collection of Prometheus metrics in Azure Monitor -description: Steps that you can take if you aren't collecting Prometheus metrics as expected. - Previously updated : 02/28/2024----# Troubleshoot collection of Prometheus metrics in Azure Monitor --Follow the steps in this article to determine the cause of Prometheus metrics not being collected as expected in Azure Monitor. --Replica pod scrapes metrics from `kube-state-metrics`, custom scrape targets in the `ama-metrics-prometheus-config` configmap and custom scrape targets defined in the [Custom Resources](prometheus-metrics-scrape-crd.md). DaemonSet pods scrape metrics from the following targets on their respective node: `kubelet`, `cAdvisor`, `node-exporter`, and custom scrape targets in the `ama-metrics-prometheus-config-node` configmap. The pod that you want to view the logs and the Prometheus UI for it depends on which scrape target you're investigating. --## Troubleshoot using PowerShell script --If you encounter an error while you attempt to enable monitoring for your AKS cluster, follow [these instructions](https://github.com/Azure/prometheus-collector/tree/main/internal/scripts/troubleshoot) to run the troubleshooting script. This script is designed to do a basic diagnosis for any configuration issues on your cluster and you can attach the generated files while creating a support request for faster resolution for your support case. --## Metrics Throttling --In the Azure portal, navigate to your Azure Monitor Workspace. Go to `Metrics`, click on the `Add Metric` dropdown and then click on the `Add with builder` option to verify that the metrics `Active Time Series % Utilization` and `Events Per Minute Ingested % Utilization` are below 100%. ---If either of them are more than 100%, ingestion into this workspace is being throttled. In the same workspace, navigate to `New Support Request` to create a request to increase the limits. Select the issue type as `Service and subscription limits (quotas)` and the quota type as `Managed Prometheus`. --You can also monitor and set up an alert on the ingestion limits. See [Monitor ingestion limits](../essentials/prometheus-metrics-overview.md#how-can-i-monitor-the-service-limits-and-quota) to avoid metrics ingestion throttling. --## Intermittent gaps in metric data collection --During node updates, you may see a 1 to 2 minute gap in metric data for metrics collected from our cluster level collector. This gap is because the node it runs on is being updated as part of a normal update process. It affects cluster-wide targets such as kube-state-metrics and custom application targets that are specified. It occurs when your cluster is updated manually or via autoupdate. This behavior is expected and occurs due to the node it runs on being updated. None of our recommended alert rules are affected by this behavior. --## Pod status --Check the pod status with the following command: --``` -kubectl get pods -n kube-system | grep ama-metrics -``` --- There should be one `ama-metrics-xxxxxxxxxx-xxxxx` replica pod, one `ama-metrics-operator-targets-*`, one `ama-metrics-ksm-*` pod, and an `ama-metrics-node-*` pod for each node on the cluster.-- Each pod state should be `Running` and have an equal number of restarts to the number of configmap changes that have been applied. The ama-metrics-operator-targets-* pod might have an extra restart at the beginning and this is expected:---If each pod state is `Running` but one or more pods have restarts, run the following command: --``` -kubectl describe pod <ama-metrics pod name> -n kube-system -``` --- This command provides the reason for the restarts. Pod restarts are expected if configmap changes have been made. If the reason for the restart is `OOMKilled`, the pod can't keep up with the volume of metrics. See the scale recommendations for the volume of metrics.--If the pods are running as expected, the next place to check is the container logs. --## Check for relabeling configs --If metrics are missing, you can also check if you have relabeling configs. With relabeling configs, ensure that the relabeling does not filter out the targets, and the labels configured correctly match the targets. Refer to [Prometheus relabel config documentation](https://prometheus.io/docs/prometheus/latest/configuration/configuration/#relabel_config) for more details. --## Container logs -View the container logs with the following command: --``` -kubectl logs <ama-metrics pod name> -n kube-system -c prometheus-collector -``` -- At startup, any initial errors are printed in red, while warnings are printed in yellow. (Viewing the colored logs requires at least PowerShell version 7 or a linux distribution.) --- Verify if there's an issue with getting the authentication token:- - The message *No configuration present for the AKS resource* gets logged every 5 minutes. - - The pod restarts every 15 minutes to try again with the error: *No configuration present for the AKS resource*. - - If so, check that the Data Collection Rule and Data Collection Endpoint exist in your resource group. - - Also verify that the Azure Monitor Workspace exists. - - Verify that you don't have a private AKS cluster and that it's not linked to an Azure Monitor Private Link Scope for any other service. This scenario is currently not supported. --### Config Processing -View the container logs with the following command: --``` -kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c config-reader -``` --- Verify there are no errors with parsing the Prometheus config, merging with any default scrape targets enabled, and validating the full config.-- If you did include a custom Prometheus config, verify that it's recognized in the logs. If not:- - Verify that your configmap has the correct name: `ama-metrics-prometheus-config` in the `kube-system` namespace. - - Verify that in the configmap your Prometheus config is under a section called `prometheus-config` under `data` like shown here: - ``` - kind: ConfigMap - apiVersion: v1 - metadata: - name: ama-metrics-prometheus-config - namespace: kube-system - data: - prometheus-config: |- - scrape_configs: - - job_name: <your scrape job here> - ``` -- If you did create [Custom Resources](prometheus-metrics-scrape-crd.md), you should have seen any validation errors during the creation of pod/service monitors. If you still don't see the metrics from the targets make sure that the logs show no errors.-``` -kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c targetallocator -``` -- Verify there are no errors from `MetricsExtension` regarding authenticating with the Azure Monitor workspace.-- Verify there are no errors from the `OpenTelemetry collector` about scraping the targets.--Run the following command: --``` -kubectl logs <ama-metrics pod name> -n kube-system -c addon-token-adapter -``` --- This command shows an error if there's an issue with authenticating with the Azure Monitor workspace. The example below shows logs with no issues:- :::image type="content" source="media/prometheus-metrics-troubleshoot/addon-token-adapter.png" alt-text="Screenshot showing addon token log." lightbox="media/prometheus-metrics-troubleshoot/addon-token-adapter.png" ::: --If there are no errors in the logs, the Prometheus interface can be used for debugging to verify the expected configuration and targets being scraped. --## Prometheus interface --Every `ama-metrics-*` pod has the Prometheus Agent mode User Interface available on port 9090. -Custom config and [Custom Resources](prometheus-metrics-scrape-crd.md) targets are scraped by the `ama-metrics-*` pod and the node targets by the `ama-metrics-node-*` pod. -Port-forward into either the replica pod or one of the daemon set pods to check the config, service discovery and targets endpoints as described here to verify the custom configs are correct, the intended targets have been discovered for each job, and there are no errors with scraping specific targets. --Run the command `kubectl port-forward <ama-metrics pod> -n kube-system 9090`. --- Open a browser to the address `127.0.0.1:9090/config`. This user interface has the full scrape configuration. Verify all jobs are included in the config.--- Go to `127.0.0.1:9090/service-discovery` to view the targets discovered by the service discovery object specified and what the relabel_configs have filtered the targets to be. For example, when missing metrics from a certain pod, you can find if that pod was discovered and what its URI is. You can then use this URI when looking at the targets to see if there are any scrape errors. ---- Go to `127.0.0.1:9090/targets` to view all jobs, the last time the endpoint for that job was scraped, and any errors --### Custom Resources -- If you did include [Custom Resources](prometheus-metrics-scrape-crd.md), make sure they show up under configuration, service discovery and targets.--#### Configuration --#### Service Discovery --#### Targets ---If there are no issues and the intended targets are being scraped, you can view the exact metrics being scraped by enabling debug mode. --## Debug mode --> [!WARNING] -> This mode can affect performance and should only be enabled for a short time for debugging purposes. --The metrics addon can be configured to run in debug mode by changing the configmap setting `enabled` under `debug-mode` to `true` by following the instructions [here](prometheus-metrics-scrape-configuration.md#debug-mode). --When enabled, all Prometheus metrics that are scraped are hosted at port 9091. Run the following command: --``` -kubectl port-forward <ama-metrics pod name> -n kube-system 9091 -``` --Go to `127.0.0.1:9091/metrics` in a browser to see if the metrics were scraped by the OpenTelemetry Collector. This user interface can be accessed for every `ama-metrics-*` pod. If metrics aren't there, there could be an issue with the metric or label name lengths or the number of labels. Also check for exceeding the ingestion quota for Prometheus metrics as specified in this article. --## Metric names, label names & label values --Metrics scraping currently has the limitations in the following table: --| Property | Limit | -|:|:| -| Label name length | Less than or equal to 511 characters. When this limit is exceeded for any time-series in a job, the entire scrape job fails, and metrics get dropped from that job before ingestion. You can see up=0 for that job and also target Ux shows the reason for up=0. | -| Label value length | Less than or equal to 1023 characters. When this limit is exceeded for any time-series in a job, the entire scrape fails, and metrics get dropped from that job before ingestion. You can see up=0 for that job and also target Ux shows the reason for up=0. | -| Number of labels per time series | Less than or equal to 63. When this limit is exceeded for any time-series in a job, the entire scrape job fails, and metrics get dropped from that job before ingestion. You can see up=0 for that job and also target Ux shows the reason for up=0. | -| Metric name length | Less than or equal to 511 characters. When this limit is exceeded for any time-series in a job, only that particular series get dropped. MetricextensionConsoleDebugLog has traces for the dropped metric. | -| Label names with different casing | Two labels within the same metric sample, with different casing is treated as having duplicate labels and are dropped when ingested. For example, the time series `my_metric{ExampleLabel="label_value_0", examplelabel="label_value_1}` is dropped due to duplicate labels since `ExampleLabel` and `examplelabel` are seen as the same label name. | --## Check ingestion quota on Azure Monitor workspace --If you see metrics missed, you can first check if the ingestion limits are being exceeded for your Azure Monitor workspace. In the Azure portal, you can check the current usage for any Azure monitor Workspace. You can see current usage metrics under `Metrics` menu for the Azure Monitor workspace. Following utilization metrics are available as standard metrics for each Azure Monitor workspace. --- Active Time Series - The number of unique time series recently ingested into the workspace over the previous 12 hours-- Active Time Series Limit - The limit on the number of unique time series that can be actively ingested into the workspace-- Active Time Series % Utilization - The percentage of current active time series being utilized-- Events Per Minute Ingested - The number of events (samples) per minute recently received-- Events Per Minute Ingested Limit - The maximum number of events per minute that can be ingested before getting throttled-- Events Per Minute Ingested % Utilization - The percentage of current metric ingestion rate limit being util--To avoid metrics ingestion throttling, you can **monitor and set up an alert on the ingestion limits**. See [Monitor ingestion limits](../essentials/prometheus-metrics-overview.md#how-can-i-monitor-the-service-limits-and-quota). --Refer to [service quotas and limits](../service-limits.md#prometheus-metrics) for default quotas and also to understand what can be increased based on your usage. You can request quota increase for Azure Monitor workspaces using the `Support Request` menu for the Azure Monitor workspace. Ensure you include the ID, internal ID and Location/Region for the Azure Monitor workspace in the support request, which you can find in the `Properties' menu for the Azure Monitor workspace in the Azure portal. --## Creation of Azure Monitor Workspace failed due to Azure Policy evaluation --If creation of Azure Monitor Workspace fails with an error saying "*Resource 'resource-name-xyz' was disallowed by policy*", there might be an Azure policy that is preventing the resource to be created. If there is a policy that enforces a naming convention for your Azure resources or resource groups, you will need to create an exemption for the naming convention for creation of an Azure Monitor Workspace. --When you create an Azure Monitor workspace, by default a data collection rule and a data collection endpoint in the form "*azure-monitor-workspace-name*" will automatically be created in a resource group in the form "*MA_azure-monitor-workspace-name_location_managed*". Currently there is no way to change the names of these resources, and you will need to set an exemption on the Azure Policy to exempt the above resources from policy evaluation. See [Azure Policy exemption structure](../../governance/policy/concepts/exemption-structure.md). --## Next steps --- [Check considerations for collecting metrics at high scale](prometheus-metrics-scrape-scale.md). |
| azure-monitor | Prometheus Remote Write Active Directory | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/prometheus-remote-write-active-directory.md | - Title: Set up Prometheus remote write by using Microsoft Entra authentication -description: Learn how to set up remote write in Azure Monitor managed service for Prometheus. Use Microsoft Entra authentication to send data from a self-managed Prometheus server running in your Azure Kubernetes Server (AKS) cluster or Azure Arc-enabled Kubernetes cluster on-premises or in a different cloud. --- Previously updated : 4/18/2024---# Send Prometheus data to Azure Monitor by using Microsoft Entra authentication --This article describes how to set up [remote write](prometheus-remote-write.md) to send data from a self-managed Prometheus server running in your Azure Kubernetes Service (AKS) cluster or Azure Arc-enabled Kubernetes cluster by using Microsoft Entra authentication and a side car container that Azure Monitor provides. Note that you can also directly configure remote-write in the Prometheus configuration for the same. --> [!NOTE] -> We recommend that you directly configure Prometheus running on your Kubernetes cluster to remote-write into Azure Monitor Workspace. See [Send Prometheus data to Azure Monitor using Microsoft Entra Id authentication](../essentials/prometheus-remote-write-virtual-machines.md#set-up-authentication-for-remote-write) to learn more. The steps below use the Azure Monitor side car container. --## Cluster configurations --This article applies to the following cluster configurations: --- Azure Kubernetes Service cluster-- Azure Arc-enabled Kubernetes cluster-- Kubernetes cluster running in a different cloud or on-premises--> [!NOTE] -> For an AKS cluster or an Azure Arc-enabled Kubernetes cluster, we recommend that you use managed identity authentication. For more information, see [Azure Monitor managed service for Prometheus remote write for managed identity](prometheus-remote-write-managed-identity.md). --## Prerequisites --### Supported versions --- Prometheus versions greater than v2.48 are required for Microsoft Entra ID application authentication. --### Azure Monitor workspace --This article covers sending Prometheus metrics to an Azure Monitor workspace. To create an Azure monitor workspace, see [Manage an Azure Monitor workspace](/azure/azure-monitor/essentials/azure-monitor-workspace-manage#create-an-azure-monitor-workspace). --## Permissions -Administrator permissions for the cluster or resource are required to complete the steps in this article. --## Set up an application for Microsoft Entra ID --The process to set up Prometheus remote write for an application by using Microsoft Entra authentication involves completing the following tasks: --1. Register an application with Microsoft Entra ID. -1. Get the client ID of the Microsoft Entra application. -1. Assign the Monitoring Metrics Publisher role on the workspace data collection rule to the application. -1. Create an Azure key vault and generate a certificate. -1. Add a certificate to the Microsoft Entra application. -1. Add a CSI driver and storage for the cluster. -1. Deploy a sidecar container to set up remote write. --The tasks are described in the following sections. --<a name='create-azure-active-directory-application'></a> --### Register an application with Microsoft Entra ID --Complete the steps to [register an application with Microsoft Entra ID](../../active-directory/develop/howto-create-service-principal-portal.md#register-an-application-with-azure-ad-and-create-a-service-principal) and create a service principal. --<a name='get-the-client-id-of-the-azure-active-directory-application'></a> --### Get the client ID of the Microsoft Entra application --1. In the Azure portal, go to the **Microsoft Entra ID** menu and select **App registrations**. -1. In the list of applications, copy the value for **Application (client) ID** for the registered application. ---### Assign the Monitoring Metrics Publisher role on the workspace data collection rule to the application --The application must be assigned the Monitoring Metrics Publisher role on the data collection rule that is associated with your Azure Monitor workspace. --1. On the resource menu for your Azure Monitor workspace, select **Overview**. For **Data collection rule**, select the link. -- :::image type="content" source="media/prometheus-remote-write-managed-identity/azure-monitor-account-data-collection-rule.png" alt-text="Screenshot that shows the data collection rule that's used by Azure Monitor workspace." lightbox="media/prometheus-remote-write-managed-identity/azure-monitor-account-data-collection-rule.png"::: --1. On the resource menu for the data collection rule, select **Access control (IAM)**. --1. Select **Add**, and then select **Add role assignment**. -- :::image type="content" source="media/prometheus-remote-write-managed-identity/data-collection-rule-add-role-assignment.png" alt-text="Screenshot that shows adding a role assignment on Access control pages." lightbox="media/prometheus-remote-write-managed-identity/data-collection-rule-add-role-assignment.png"::: --1. Select the **Monitoring Metrics Publisher** role, and then select **Next**. -- :::image type="content" source="media/prometheus-remote-write-managed-identity/add-role-assignment.png" alt-text="Screenshot that shows a list of role assignments." lightbox="media/prometheus-remote-write-managed-identity/add-role-assignment.png"::: --1. Select **User, group, or service principal**, and then choose **Select members**. Select the application that you created, and then choose **Select**. -- :::image type="content" source="media/prometheus-remote-write-active-directory/select-application.png" alt-text="Screenshot that shows selecting the application." lightbox="media/prometheus-remote-write-active-directory/select-application.png"::: --1. To complete the role assignment, select **Review + assign**. --### Create an Azure key vault and generate a certificate --1. If you don't already have an Azure key vault, [create a vault](/azure/key-vault/general/quick-create-portal#create-a-vault). -1. Create a certificate by using the guidance in [Add a certificate to Key Vault](/azure/key-vault/certificates/quick-create-portal#add-a-certificate-to-key-vault). -1. Download the certificate in CER format by using the guidance in [Export a certificate from Key Vault](/azure/key-vault/certificates/quick-create-portal#export-certificate-from-key-vault). --<a name='add-certificate-to-the-azure-active-directory-application'></a> --### Add a certificate to the Microsoft Entra application --1. On the resource menu for your Microsoft Entra application, select **Certificates & secrets**. -1. On the **Certificates** tab, select **Upload certificate** and select the certificate that you downloaded. -- :::image type="content" source="media/prometheus-remote-write-active-directory/upload-certificate.png" alt-text="Screenshot that shows uploading a certificate for a Microsoft Entra application." lightbox="media/prometheus-remote-write-active-directory/upload-certificate.png"::: --> [!WARNING] -> Certificates have an expiration date. It's the responsibility of the user to keep certificates valid. --### Add a CSI driver and storage for the cluster --> [!NOTE] -> Azure Key Vault CSI driver configuration is only one of the ways to get a certificate mounted on a pod. The remote write container needs a local path to a certificate in the pod only for the `<AZURE_CLIENT_CERTIFICATE_PATH>` value in the step [Deploy a sidecar container to set up remote write](#deploy-a-sidecar-container-to-set-up-remote-write). --This step is required only if you didn't turn on Azure Key Vault Provider for Secrets Store CSI Driver when you created your cluster. --1. To turn on Azure Key Vault Provider for Secrets Store CSI Driver for your cluster, run the following Azure CLI command: -- ```azurecli - az aks enable-addons --addons azure-keyvault-secrets-provider --name <aks-cluster-name> --resource-group <resource-group-name> - ``` --1. To give the identity access to the key vault, run these commands: -- ```azurecli - # show client id of the managed identity of the cluster - az aks show -g <resource-group> -n <cluster-name> --query addonProfiles.azureKeyvaultSecretsProvider.identity.clientId -o tsv -- # set policy to access keys in your key vault - az keyvault set-policy -n <keyvault-name> --key-permissions get --spn <identity-client-id> -- # set policy to access secrets in your key vault - az keyvault set-policy -n <keyvault-name> --secret-permissions get --spn <identity-client-id> - - # set policy to access certs in your key vault - az keyvault set-policy -n <keyvault-name> --certificate-permissions get --spn <identity-client-id> - ``` --1. Create `SecretProviderClass` by saving the following YAML to a file named *secretproviderclass.yml*. Replace the values for `userAssignedIdentityID`, `keyvaultName`, `tenantId`, and the objects to retrieve from your key vault. For information about what values to use, see [Provide an identity to access the Azure Key Vault Provider for Secrets Store CSI Driver](/azure/aks/csi-secrets-store-identity-access). -- [!INCLUDE [secret-provider-class-yaml](../includes/secret-procider-class-yaml.md)] --1. Apply `SecretProviderClass` by running the following command on your cluster: -- ```bash - kubectl apply -f secretproviderclass.yml - ``` --### Deploy a sidecar container to set up remote write --1. Copy the following YAML and save it to a file. The YAML uses port 8081 as the listening port. If you use a different port, modify that value in the YAML. -- [!INCLUDE [prometheus-sidecar-remote-write-entra-yaml](../includes/prometheus-sidecar-remote-write-entra-yaml.md)] --1. Replace the following values in the YAML file: -- | Value | Description | - |:|:| - | `<CLUSTER-NAME>` | The name of your AKS cluster. | - | `<CONTAINER-IMAGE-VERSION>` | [!INCLUDE [version](../includes/prometheus-remotewrite-image-version.md)]<br>The remote write container image version. | - | `<INGESTION-URL>` | The value for **Metrics ingestion endpoint** from the **Overview** page for the Azure Monitor workspace. | - | `<APP-REGISTRATION -CLIENT-ID>` | The client ID of your application. | - | `<TENANT-ID>` | The tenant ID of the Microsoft Entra application. | - | `<CERT-NAME>` | The name of the certificate. | - | `<CLUSTER-NAME>` | The name of the cluster that Prometheus is running on. | --1. Open Azure Cloud Shell and upload the YAML file. -1. Use Helm to apply the YAML file and update your Prometheus configuration: -- ```azurecli - # set the context to your cluster - az aks get-credentials -g <aks-rg-name> -n <aks-cluster-name> - - # use Helm to update your remote write config - helm upgrade -f <YAML-FILENAME>.yml prometheus prometheus-community/kube-prometheus-stack -namespace <namespace where Prometheus pod resides> - ``` --## Verification and troubleshooting --For verification and troubleshooting information, see [Troubleshooting remote write](/azure/azure-monitor/containers/prometheus-remote-write-troubleshooting) and [Azure Monitor managed service for Prometheus remote write](prometheus-remote-write.md#verify-remote-write-is-working-correctly). --## Next steps --- [Collect Prometheus metrics from an AKS cluster](../containers/kubernetes-monitoring-enable.md#enable-prometheus-and-grafana)-- [Learn more about Azure Monitor managed service for Prometheus](../essentials/prometheus-metrics-overview.md)-- [Remote write in Azure Monitor managed service for Prometheus](prometheus-remote-write.md)-- [Send Prometheus data to Azure Monitor by using managed identity authentication](./prometheus-remote-write-managed-identity.md)-- [Send Prometheus data to Azure Monitor by using Microsoft Entra Workload ID (preview) authentication](./prometheus-remote-write-azure-workload-identity.md)-- [Send Prometheus data to Azure Monitor by using Microsoft Entra pod-managed identity (preview) authentication](./prometheus-remote-write-azure-ad-pod-identity.md) |
| azure-monitor | Prometheus Remote Write Azure Ad Pod Identity | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/prometheus-remote-write-azure-ad-pod-identity.md | - Title: Set up Prometheus remote write by using Microsoft Entra pod-managed identity authentication -description: Learn how to set up remote write for Azure Monitor managed service for Prometheus by using Microsoft Entra pod-managed identity (preview) authentication. --- Previously updated : 4/18/2024----# Send Prometheus data to Azure Monitor by using Microsoft Entra pod-managed identity (preview) authentication --This article describes how to set up remote write for Azure Monitor managed service for Prometheus by using Microsoft Entra pod-managed identity (preview) authentication. --> [!NOTE] -> The remote write sidecar container that's described in this article should be set up only by using the following steps, and only if the Azure Kubernetes Service (AKS) cluster already has a Microsoft Entra pod enabled. Microsoft Entra pod-managed identities have been deprecated to be replaced by [Microsoft Entra Workload ID](/azure/active-directory/workload-identities/workload-identities-overview). We recommend that you use Microsoft Entra Workload ID authentication. --## Prerequisites --### Supported versions --Prometheus versions greater than v2.45 are required for managed identity authentication. --### Azure Monitor workspace --This article covers sending Prometheus metrics to an Azure Monitor workspace. To create an Azure monitor workspace, see [Manage an Azure Monitor workspace](/azure/azure-monitor/essentials/azure-monitor-workspace-manage#create-an-azure-monitor-workspace). --## Permissions --Administrator permissions for the cluster or resource are required to complete the steps in this article. --## Set up an application for Microsoft Entra pod-managed identity --The process to set up Prometheus remote write for an application by using Microsoft Entra pod-managed identity authentication involves completing the following tasks: --1. Register a user-assigned managed identity with Microsoft Entra ID. -1. Assign the Managed Identity Operator and Virtual Machine Contributor roles to the managed identity. -1. Assign the Monitoring Metrics Publisher role to the user-assigned managed identity. -1. Create an Azure identity binding. -1. Add the aadpodidbinding label to the Prometheus pod. -1. Deploy a sidecar container to set up remote write. --The tasks are described in the following sections. --### Register a managed identity with Microsoft Entra ID --Create a user-assigned managed identity or register an existing user-assigned managed identity. --For information about creating a managed identity, see [Set up remote write for Azure Monitor managed service for Prometheus by using managed identity authentication](./prometheus-remote-write-managed-identity.md#get-the-client-id-of-the-user-assigned-managed-identity). --### Assign the Managed Identity Operator and Virtual Machine Contributor roles to the managed identity --```azurecli -az role assignment create --role "Managed Identity Operator" --assignee <managed identity clientID> --scope <NodeResourceGroupResourceId> - -az role assignment create --role "Virtual Machine Contributor" --assignee <managed identity clientID> --scope <Node ResourceGroup Id> -``` --The node resource group of the AKS cluster contains resources that you use in other steps in this process. This resource group has the name `MC_<AKS-RESOURCE-GROUP>_<AKS-CLUSTER-NAME>_<REGION>`. You can find the resource group name by using the **Resource groups** menu in the Azure portal. --### Assign the Monitoring Metrics Publisher role to the managed identity --```azurecli -az role assignment create --role "Monitoring Metrics Publisher" --assignee <managed identity clientID> --scope <NodeResourceGroupResourceId> -``` --### Create an Azure identity binding --The user-assigned managed identity requires an identity binding for the identity to be used as a pod-managed identity. --Copy the following YAML to the *aadpodidentitybinding.yaml* file: --```yaml --apiVersion: "aadpodidentity.k8s.io/v1" --kind: AzureIdentityBinding -metadata: -name: demo1-azure-identity-binding -spec: -AzureIdentity: ΓÇ£<AzureIdentityName>ΓÇ¥ -Selector: ΓÇ£<AzureIdentityBindingSelector>ΓÇ¥ -``` --Run the following command: --```azurecli -kubectl create -f aadpodidentitybinding.yaml -``` --### Add the aadpodidbinding label to the Prometheus pod --The `aadpodidbinding` label must be added to the Prometheus pod for the pod-managed identity to take effect. You can add the label by updating the *deployment.yaml* file or by injecting labels when you deploy the sidecar container as described in the next section. --### Deploy a sidecar container to set up remote write --1. Copy the following YAML and save it to a file. The YAML uses port 8081 as the listening port. If you use a different port, modify that value in the YAML. -- [!INCLUDE[pod-identity-yaml](../includes/prometheus-sidecar-remote-write-pod-identity-yaml.md)] --1. Replace the following values in the YAML: -- | Value | Description | - |:|:| - | `<AKS-CLUSTER-NAME>` | The name of your AKS cluster. | - | `<CONTAINER-IMAGE-VERSION>` | [!INCLUDE [version](../includes/prometheus-remotewrite-image-version.md)]<br> The remote write container image version. | - | `<INGESTION-URL>` | The value for **Metrics ingestion endpoint** from the **Overview** page for the Azure Monitor workspace. | - | `<MANAGED-IDENTITY-CLIENT-ID>` | The value for **Client ID** from the **Overview** page for the managed identity. | - | `<CLUSTER-NAME>` | Name of the cluster that Prometheus is running on. | -- > [!IMPORTANT] - > For Azure Government cloud, add the following environment variables in the `env` section of the YAML file: - > - > `- name: INGESTION_AAD_AUDIENCE value: https://monitor.azure.us/` --1. Use Helm to apply the YAML file and update your Prometheus configuration: -- ```azurecli - # set the context to your cluster - az aks get-credentials -g <aks-rg-name> -n <aks-cluster-name> -- # use Helm to update your remote write config - helm upgrade -f <YAML-FILENAME>.yml prometheus prometheus-community/kube-prometheus-stack --namespace <namespace where Prometheus pod resides> - ``` --## Verification and troubleshooting --For verification and troubleshooting information, see [Troubleshooting remote write](/azure/azure-monitor/containers/prometheus-remote-write-troubleshooting) and [Azure Monitor managed service for Prometheus remote write](prometheus-remote-write.md#verify-remote-write-is-working-correctly). --## Next steps --- [Collect Prometheus metrics from an AKS cluster](../containers/kubernetes-monitoring-enable.md#enable-prometheus-and-grafana)-- [Learn more about Azure Monitor managed service for Prometheus](../essentials/prometheus-metrics-overview.md)-- [Remote write in Azure Monitor managed service for Prometheus](prometheus-remote-write.md)-- [Send Prometheus data to Azure Monitor by using Microsoft Entra authentication](./prometheus-remote-write-active-directory.md)-- [Send Prometheus data to Azure Monitor by using managed identity authentication](./prometheus-remote-write-managed-identity.md)-- [Send Prometheus data to Azure Monitor by using Microsoft Entra Workload ID (preview) authentication](./prometheus-remote-write-azure-workload-identity.md) |
| azure-monitor | Prometheus Remote Write Azure Workload Identity | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/prometheus-remote-write-azure-workload-identity.md | - Title: Set up Prometheus remote write by using Microsoft Entra Workload ID authentication -description: Learn how to set up remote write in Azure Monitor managed service for Prometheus. Use Microsoft Entra Workload ID (preview) authentication to send data from a self-managed Prometheus server to your Azure Monitor workspace. ----- Previously updated : 4/18/2024----# Send Prometheus data to Azure Monitor by using Microsoft Entra Workload ID (preview) authentication --This article describes how to set up [remote write](prometheus-remote-write.md) to send data from your Azure Monitor managed Prometheus cluster by using Microsoft Entra Workload ID authentication. --## Prerequisites --- Prometheus versions greater than v2.48 are required for Microsoft Entra ID application authentication. --- A cluster that has feature flags that are specific to OpenID Connect (OIDC) and an OIDC issuer URL:- - For managed clusters (Azure Kubernetes Service, Amazon Elastic Kubernetes Service, and Google Kubernetes Engine), see [Managed Clusters - Microsoft Entra Workload ID](https://azure.github.io/azure-workload-identity/docs/installation/managed-clusters.html). - - For self-managed clusters, see [Self-Managed Clusters - Microsoft Entra Workload ID](https://azure.github.io/azure-workload-identity/docs/installation/self-managed-clusters.html). -- An installed mutating admission webhook. For more information, see [Mutating Admission Webhook - Microsoft Entra Workload ID](https://azure.github.io/azure-workload-identity/docs/installation/mutating-admission-webhook.html).-- Prometheus running in the cluster. This article assumes that the Prometheus cluster is set up by using the [kube-prometheus stack](https://azure.github.io/azure-workload-identity/docs/installation/managed-clusters.html), but you can set up Prometheus by using other methods.--## Set up a workload for Microsoft Entra Workload ID --The process to set up Prometheus remote write for a workload by using Microsoft Entra Workload ID authentication involves completing the following tasks: --1. Set up the workload identity. -1. Create a Microsoft Entra application or user-assigned managed identity and grant permissions. -1. Assign the Monitoring Metrics Publisher role on the workspace data collection rule to the application. -1. Create or update your Kubernetes service account Prometheus pod. -1. Establish federated identity credentials between the identity and the service account issuer and subject. -1. Deploy a sidecar container to set up remote write. --The tasks are described in the following sections. --### Set up the workload identity --To set up the workload identity, export the following environment variables: --```bash -# [OPTIONAL] Set this if you're using a Microsoft Entra application -export APPLICATION_NAME="<your application name>" - -# [OPTIONAL] Set this only if you're using a user-assigned managed identity -export USER_ASSIGNED_IDENTITY_NAME="<your user-assigned managed identity name>" - -# Environment variables for the Kubernetes service account and federated identity credential -export SERVICE_ACCOUNT_NAMESPACE="<namespace of Prometheus pod>" -export SERVICE_ACCOUNT_NAME="<name of service account associated with Prometheus pod>" -export SERVICE_ACCOUNT_ISSUER="<your service account issuer URL>" -``` --For `SERVICE_ACCOUNT_NAME`, check to see whether a service account (separate from the *default* service account) is already associated with the Prometheus pod. Look for the value of `serviceaccountName` or `serviceAccount` (deprecated) in the `spec` of your Prometheus pod. Use this value if it exists. If `serviceaccountName` and `serviceAccount` don't exist, enter the name of the service account you want to associate with your Prometheus pod. --### Create a Microsoft Entra application or user-assigned managed identity and grant permissions --Create a Microsoft Entra application or a user-assigned managed identity and grant permission to publish metrics to Azure Monitor workspace: --```azurecli -# create a Microsoft Entra application -az ad sp create-for-rbac --name "${APPLICATION_NAME}" --# create a user-assigned managed identity if you use a user-assigned managed identity for this article -az identity create --name "${USER_ASSIGNED_IDENTITY_NAME}" --resource-group "${RESOURCE_GROUP}" -``` --### Assign the Monitoring Metrics Publisher role on the workspace data collection rule to the application or managed identity --For information about assigning the role, see [Assign the Monitoring Metrics Publisher role on the workspace data collection rule to the managed identity](prometheus-remote-write-managed-identity.md#assign-the-monitoring-metrics-publisher-role-on-the-workspace-data-collection-rule-to-the-managed-identity). --### Create or update your Kubernetes service account Prometheus pod --Often, a Kubernetes service account is created and associated with the pod running the Prometheus container. If you're using the kube-prometheus stack, the code automatically creates the prometheus-kube-prometheus-prometheus service account. --If no Kubernetes service account except the default service account is associated with Prometheus, create a new service account specifically for the pod running Prometheus. --To create the service account, run the following kubectl command: --```bash -cat <<EOF | kubectl apply -f - -apiVersion: v1 -kind: service account -metadata: - annotations: - azure.workload.identity/client-id: ${APPLICATION_CLIENT_ID:-$USER_ASSIGNED_IDENTITY_CLIENT_ID} - name: ${SERVICE_ACCOUNT_NAME} - namespace: ${SERVICE_ACCOUNT_NAMESPACE} -EOF -``` --If a Kubernetes service account other than default service account is associated with your pod, add the following annotation to your service account: --```bash -kubectl annotate sa ${SERVICE_ACCOUNT_NAME} -n ${SERVICE_ACCOUNT_NAMESPACE} azure.workload.identity/client-id="${APPLICATION_OR_USER_ASSIGNED_IDENTITY_CLIENT_ID}" ΓÇôoverwrite -``` --If your Microsoft Entra application or user-assigned managed identity isn't in the same tenant as your cluster, add the following annotation to your service account: --```bash -kubectl annotate sa ${SERVICE_ACCOUNT_NAME} -n ${SERVICE_ACCOUNT_NAMESPACE} azure.workload.identity/tenant-id="${APPLICATION_OR_USER_ASSIGNED_IDENTITY_TENANT_ID}" ΓÇôoverwrite -``` --### Establish federated identity credentials between the identity and the service account issuer and subject --Create federated credentials by using the Azure CLI. --#### User-assigned managed identity --```cli -az identity federated-credential create \ - --name "kubernetes-federated-credential" \ - --identity-name "${USER_ASSIGNED_IDENTITY_NAME}" \ - --resource-group "${RESOURCE_GROUP}" \ - --issuer "${SERVICE_ACCOUNT_ISSUER}" \ - --subject "system:serviceaccount:${SERVICE_ACCOUNT_NAMESPACE}:${SERVICE_ACCOUNT_NAME}" -``` --#### Microsoft Entra application --```cli -# Get the ObjectID of the Microsoft Entra app. --export APPLICATION_OBJECT_ID="$(az ad app show --id ${APPLICATION_CLIENT_ID} --query id -otsv)" --# Add a federated identity credential. --cat <<EOF > params.json -{ - "name": "kubernetes-federated-credential", - "issuer": "${SERVICE_ACCOUNT_ISSUER}", - "subject": "system:serviceaccount:${SERVICE_ACCOUNT_NAMESPACE}:${SERVICE_ACCOUNT_NAME}", - "description": "Kubernetes service account federated credential", - "audiences": [ - "api://AzureADTokenExchange" - ] -} -EOF --az ad app federated-credential create --id ${APPLICATION_OBJECT_ID} --parameters @params.json -``` --### Deploy a sidecar container to set up remote write --> [!IMPORTANT] -> ->The Prometheus pod must have the following label: `azure.workload.identity/use: "true"` -> -> The remote write sidecar container requires the following environment values: -> -> - `INGESTION_URL`: The metrics ingestion endpoint that's shown on the **Overview** page for the Azure Monitor workspace -> - `LISTENING_PORT`: `8081` (any port is supported) -> - `IDENTITY_TYPE`: `workloadIdentity` --1. Copy the following YAML and save it to a file. The YAML uses port 8081 as the listening port. If you use a different port, modify that value in the YAML. -- [!INCLUDE [prometheus-sidecar-remote-write-workload-identity-yaml](../includes/prometheus-sidecar-remote-write-workload-identity-yaml.md)] --1. Replace the following values in the YAML: - - | Value | Description | - |:|:| - | `<CLUSTER-NAME>` | The name of your AKS cluster. | - | `<CONTAINER-IMAGE-VERSION>` | [!INCLUDE [version](../includes/prometheus-remotewrite-image-version.md)]<br>The remote write container image version.| - | `<INGESTION-URL>` | The value for **Metrics ingestion endpoint** from the **Overview** page for the Azure Monitor workspace. | - --1. Use Helm to apply the YAML file and update your Prometheus configuration: -- ```azurecli - # set a context to your cluster - az aks get-credentials -g <aks-rg-name> -n <aks-cluster-name> - - # use Helm to update your remote write config - helm upgrade -f <YAML-FILENAME>.yml prometheus prometheus-community/kube-prometheus-stack -namespace <namespace where Prometheus pod resides> - ``` --## Verification and troubleshooting --For verification and troubleshooting information, see [Troubleshooting remote write](/azure/azure-monitor/containers/prometheus-remote-write-troubleshooting) and [Azure Monitor managed service for Prometheus remote write](prometheus-remote-write.md#verify-remote-write-is-working-correctly). --## Next steps --- [Collect Prometheus metrics from an AKS cluster](../containers/kubernetes-monitoring-enable.md#enable-prometheus-and-grafana)-- [Learn more about Azure Monitor managed service for Prometheus](../essentials/prometheus-metrics-overview.md)-- [Remote write in Azure Monitor managed service for Prometheus](prometheus-remote-write.md)-- [Send Prometheus data to Azure Monitor by using Microsoft Entra authentication](./prometheus-remote-write-active-directory.md)-- [Send Prometheus data to Azure Monitor by using managed identity authentication](./prometheus-remote-write-managed-identity.md)-- [Send Prometheus data to Azure Monitor by using Microsoft Entra pod-managed identity (preview) authentication](./prometheus-remote-write-azure-ad-pod-identity.md) |
| azure-monitor | Prometheus Remote Write Managed Identity | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/prometheus-remote-write-managed-identity.md | - Title: Set up Prometheus remote write by using managed identity authentication -description: Learn how to set up remote write in Azure Monitor managed service for Prometheus. Use managed identity authentication to send data from a self-managed Prometheus server running in your Azure Kubernetes Server (AKS) cluster or Azure Arc-enabled Kubernetes cluster. -- Previously updated : 4/18/2024---# Send Prometheus data to Azure Monitor by using managed identity authentication --This article describes how to set up [remote write](prometheus-remote-write.md) to send data from a self-managed Prometheus server running in your Azure Kubernetes Service (AKS) cluster or Azure Arc-enabled Kubernetes cluster by using managed identity authentication and a side car container provided by Azure Monitor. You can either use an existing identity that's created by AKS or [create your own](../../active-directory/managed-identities-azure-resources/how-manage-user-assigned-managed-identities.md). Both options are described here. --> [!NOTE] -> If you are using the user-assigned managed identity, we recommend that you directly configure Prometheus running on your Kubernetes cluster to remote-write into Azure Monitor Workspace. See [Send Prometheus data to Azure Monitor using user-assigned managed identity](../essentials/prometheus-remote-write-virtual-machines.md#set-up-authentication-for-remote-write) to learn more. The steps below use the Azure Monitor side car container. --## Cluster configurations --This article applies to the following cluster configurations: --- Azure Kubernetes Service cluster-- Azure Arc-enabled Kubernetes cluster--> [!NOTE] -> For information about setting up remote write for a Kubernetes cluster running in a different cloud or on-premises, see [Send Prometheus data to Azure Monitor by using Microsoft Entra authentication](prometheus-remote-write-active-directory.md). --## Prerequisites --### Supported versions --Prometheus versions greater than v2.45 are required for managed identity authentication. --### Azure Monitor workspace --This article covers sending Prometheus metrics to an Azure Monitor workspace. To create an Azure monitor workspace, see [Manage an Azure Monitor workspace](/azure/azure-monitor/essentials/azure-monitor-workspace-manage#create-an-azure-monitor-workspace). --## Permissions --Administrator permissions for the cluster or resource are required to complete the steps in this article. --## Set up an application for managed identity --The process to set up Prometheus remote write for an application by using managed identity authentication involves completing the following tasks: --1. Get the name of the AKS node resource group. -1. Get the client ID of the user-assigned managed identity. -1. Assign the Monitoring Metrics Publisher role on the workspace data collection rule to the managed identity. -1. Give the AKS cluster access to the managed identity. -1. Deploy a sidecar container to set up remote write. --The tasks are described in the following sections. --### Get the name of the AKS node resource group --The node resource group of the AKS cluster contains resources that you use in other steps in this process. This resource group has the name `MC_<AKS-RESOURCE-GROUP>_<AKS-CLUSTER-NAME>_<REGION>`. You can find the resource group name by using the **Resource groups** menu in the Azure portal. ---### Get the client ID of the user-assigned managed identity --You must get the client ID of the identity that you're going to use. Copy the client ID to use later in the process. --Instead of creating your own client ID, you can use one of the identities that are created by AKS. To learn more about the identities, see [Use a managed identity in Azure Kubernetes Service](/azure/aks/use-managed-identity). --This article uses the kubelet identity. The name of this identity is `<AKS-CLUSTER-NAME>-agentpool`, and it's in the node resource group of the AKS cluster. ---Select the `<AKS-CLUSTER-NAME>-agentpool` managed identity. On the **Overview** page, copy the value for **Client ID**. For more information, see [Manage user-assigned managed identities](../../active-directory/managed-identities-azure-resources/how-manage-user-assigned-managed-identities.md). ---### Assign the Monitoring Metrics Publisher role on the workspace data collection rule to the managed identity --The managed identity must be assigned the Monitoring Metrics Publisher role on the data collection rule that is associated with your Azure Monitor workspace. --1. On the resource menu for your Azure Monitor workspace, select **Overview**. For **Data collection rule**, select the link. -- :::image type="content" source="media/prometheus-remote-write-managed-identity/azure-monitor-account-data-collection-rule.png" alt-text="Screenshot that shows the data collection rule that's associated with an Azure Monitor workspace." lightbox="media/prometheus-remote-write-managed-identity/azure-monitor-account-data-collection-rule.png"::: --1. On the resource menu for the data collection rule, select **Access control (IAM)**. --1. Select **Add**, and then select **Add role assignment**. -- :::image type="content" source="media/prometheus-remote-write-managed-identity/data-collection-rule-add-role-assignment.png" alt-text="Screenshot that shows adding a role assignment on Access control pages." lightbox="media/prometheus-remote-write-managed-identity/data-collection-rule-add-role-assignment.png"::: --1. Select the **Monitoring Metrics Publisher** role, and then select **Next**. -- :::image type="content" source="media/prometheus-remote-write-managed-identity/add-role-assignment.png" alt-text="Screenshot that shows a list of role assignments." lightbox="media/prometheus-remote-write-managed-identity/add-role-assignment.png"::: --1. Select **Managed Identity**, and then choose **Select members**. Select the subscription that contains the user-assigned identity, and then select **User-assigned managed identity**. Select the user-assigned identity that you want to use, and then choose **Select**. -- :::image type="content" source="media/prometheus-remote-write-managed-identity/select-managed-identity.png" alt-text="Screenshot that shows selecting a user-assigned managed identity." lightbox="media/prometheus-remote-write-managed-identity/select-managed-identity.png"::: --1. To complete the role assignment, select **Review + assign**. --### Give the AKS cluster access to the managed identity --This step isn't required if you're using an AKS identity. An AKS identity already has access to the cluster. --> [!IMPORTANT] -> To complete the steps in this section, you must have owner or user access administrator permissions for the cluster. --1. Identify the virtual machine scale sets in the [node resource group](#get-the-name-of-the-aks-node-resource-group) for your AKS cluster. -- :::image type="content" source="media/prometheus-remote-write-managed-identity/resource-group-details-virtual-machine-scale-sets.png" alt-text="Screenshot that shows virtual machine scale sets in the node resource group." lightbox="media/prometheus-remote-write-managed-identity/resource-group-details-virtual-machine-scale-sets.png"::: --2. For each virtual machine scale set, run the following command in the Azure CLI: -- ```azurecli - az vmss identity assign -g <AKS-NODE-RESOURCE-GROUP> -n <AKS-VMSS-NAME> --identities <USER-ASSIGNED-IDENTITY-RESOURCE-ID> - ``` --### Deploy a sidecar container to set up remote write --1. Copy the following YAML and save it to a file. The YAML uses port 8081 as the listening port. If you use a different port, modify the port in the YAML. -- [!INCLUDE[managed-identity-yaml](../includes/prometheus-sidecar-remote-write-managed-identity-yaml.md)] --1. Replace the following values in the YAML: -- | Value | Description | - |:|:| - | `<AKS-CLUSTER-NAME>` | The name of your AKS cluster. | - | `<CONTAINER-IMAGE-VERSION>` | [!INCLUDE [version](../includes/prometheus-remotewrite-image-version.md)]<br> The remote write container image version. | - | `<INGESTION-URL>` | The value for **Metrics ingestion endpoint** from the **Overview** page for the Azure Monitor workspace. | - | `<MANAGED-IDENTITY-CLIENT-ID>` | The value for **Client ID** from the **Overview** page for the managed identity. | - | `<CLUSTER-NAME>` | Name of the cluster that Prometheus is running on. | -- > [!IMPORTANT] - > For Azure Government cloud, add the following environment variables in the `env` section of the YAML file: - > - > `- name: INGESTION_AAD_AUDIENCE value: https://monitor.azure.us/` --1. Open Azure Cloud Shell and upload the YAML file. -1. Use Helm to apply the YAML file and update your Prometheus configuration: -- ```azurecli - # set context to your cluster - az aks get-credentials -g <aks-rg-name> -n <aks-cluster-name> - - # use Helm to update your remote write config - helm upgrade -f <YAML-FILENAME>.yml prometheus prometheus-community/kube-prometheus-stack --namespace <namespace where Prometheus pod resides> - ``` --## Verification and troubleshooting --For verification and troubleshooting information, see [Troubleshooting remote write](/azure/azure-monitor/containers/prometheus-remote-write-troubleshooting) and [Azure Monitor managed service for Prometheus remote write](prometheus-remote-write.md#verify-remote-write-is-working-correctly). --## Next steps --- [Collect Prometheus metrics from an AKS cluster](../containers/kubernetes-monitoring-enable.md#enable-prometheus-and-grafana)-- [Learn more about Azure Monitor managed service for Prometheus](../essentials/prometheus-metrics-overview.md)-- [Remote write in Azure Monitor managed service for Prometheus](prometheus-remote-write.md)-- [Send Prometheus data to Azure Monitor by using Microsoft Entra authentication](./prometheus-remote-write-active-directory.md)-- [Send Prometheus data to Azure Monitor by using Microsoft Entra Workload ID (preview) authentication](./prometheus-remote-write-azure-workload-identity.md)-- [Send Prometheus data to Azure Monitor by using Microsoft Entra pod-managed identity (preview) authentication](./prometheus-remote-write-azure-ad-pod-identity.md) |
| azure-monitor | Prometheus Remote Write Troubleshooting | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/prometheus-remote-write-troubleshooting.md | - Title: Troubleshooting Remote-write in Azure Monitor Managed Service for Prometheus -description: Describes how to troubleshoot remote-write in Azure Monitor Managed Service for Prometheus ----- Previously updated : 4/18/2024--# customer intent: As a user of Azure Monitor Managed Service for Prometheus, I want to troubleshoot remote-write issues so that I can ensure that my data is flowing correctly. ---# Troubleshoot remote write --This article describes how to troubleshoot remote write in Azure Monitor Managed Service for Prometheus. For more information about remote write, see [Remote write in Azure Monitor Managed Service for Prometheus](./prometheus-remote-write.md). --## Supported versions --- Prometheus versions greater than v2.45 are required for managed identity authentication.-- Prometheus versions greater than v2.48 are required for Microsoft Entra ID application authentication. ---## HTTP 403 error in the Prometheus log --It takes about 30 minutes for the assignment of the role to take effect. During this time, you may see an HTTP 403 error in the Prometheus log. Check that you have configured the managed identity or Microsoft Entra ID application correctly with the `Monitoring Metrics Publisher` role on the workspace's data collection rule. If the configuration is correct, wait 30 minutes for the role assignment to take effect. ---## No Kubernetes data is flowing --If remote data isn't flowing, run the following command to find errors in the remote write container. --```azurecli -kubectl --namespace <Namespace> describe pod <Prometheus-Pod-Name> -``` ---## Container restarts repeatedly --A container regularly restarting is likely due to misconfiguration of the container. Run the following command to view the configuration values set for the container. Verify the configuration values especially `AZURE_CLIENT_ID` and `IDENTITY_TYPE`. --```azureccli -kubectl get pod <Prometheus-Pod-Name> -o json | jq -c '.spec.containers[] | select( .name | contains("<Azure-Monitor-Side-Car-Container-Name>"))' -``` --The output from this command has the following format: --``` -{"env":[{"name":"INGESTION_URL","value":"https://my-azure-monitor-workspace.eastus2-1.metrics.ingest.monitor.azure.com/dataCollectionRules/dcr-00000000000000000/streams/Microsoft-PrometheusMetrics/api/v1/write?api-version=2021-11-01-preview"},{"name":"LISTENING_PORT","value":"8081"},{"name":"IDENTITY_TYPE","value":"userAssigned"},{"name":"AZURE_CLIENT_ID","value":"00000000-0000-0000-0000-00000000000"}],"image":"mcr.microsoft.com/azuremonitor/prometheus/promdev/prom-remotewrite:prom-remotewrite-20221012.2","imagePullPolicy":"Always","name":"prom-remotewrite","ports":[{"containerPort":8081,"name":"rw-port","protocol":"TCP"}],"resources":{},"terminationMessagePath":"/dev/termination-log","terminationMessagePolicy":"File","volumeMounts":[{"mountPath":"/var/run/secrets/kubernetes.io/serviceaccount","name":"kube-api-access-vbr9d","readOnly":true}]} -``` ---## Ingestion quotas and limits --When configuring Prometheus remote write to send data to an Azure Monitor workspace, you typically begin by using the remote write endpoint displayed on the Azure Monitor workspace overview page. This endpoint involves a system-generated Data Collection Rule (DCR) and Data Collection Endpoint (DCE). These resources have ingestion limits. For more information on ingestion limits, see [Azure Monitor service limits](../service-limits.md#prometheus-metrics). When setting up remote write for multiple clusters sending data to the same endpoint, you might reach these limits. Consider creating additional DCRs and DCEs to distribute the ingestion load across multiple endpoints. This approach helps optimize performance and ensures efficient data handling. For more information about creating DCRs and DCEs, see [how to create custom Data collection endpoint(DCE) and custom Data collection rule(DCR) for an existing Azure monitor workspace(AMW) to ingest Prometheus metrics](https://aka.ms/prometheus/remotewrite/dcrartifacts). |
| azure-monitor | Prometheus Remote Write | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/containers/prometheus-remote-write.md | - Title: Remote-write in Azure Monitor Managed Service for Prometheus -description: Describes how to configure remote-write to send data from self-managed Prometheus running in your AKS cluster or Azure Arc-enabled Kubernetes cluster -- Previously updated : 4/18/2024---# Azure Monitor managed service for Prometheus remote write -Azure Monitor managed service for Prometheus is intended to be a replacement for self managed Prometheus so you don't need to manage a Prometheus server in your Kubernetes clusters. You may also choose to use the managed service to centralize data from self-managed Prometheus clusters for long term data retention and to create a centralized view across your clusters. In this case, you can use [remote_write](https://prometheus.io/docs/prometheus/latest/configuration/configuration/#remote_write) to send data from your self-managed Prometheus into the Azure managed service. --## Architecture --You can configure Prometheus running on your Kubernetes cluster to remote-write into Azure Monitor Workspace. Currently user-assigned managed identity or Microsoft Entra ID application are the supported authentication types using Prometheus remote-write configuration to ingest metrics to Azure Monitor Workspace. --Azure Monitor also provides a reverse proxy container (Azure Monitor [side car container](/azure/architecture/patterns/sidecar)) that provides an abstraction for ingesting Prometheus remote write metrics and helps in authenticating packets. --We recommend configuring remote-write directly in your self-managed Prometheus config running in your environment. The Azure Monitor side car container can be used in case your preferred authentication is not supported through directly configuration. ---## Supported versions --- Prometheus versions greater than v2.45 are required for managed identity authentication.-- Prometheus versions greater than v2.48 are required for Microsoft Entra ID application authentication. ---## Configure remote write --Configuring remote write depends on your cluster configuration and the type of authentication that you use. --- Managed identity is recommended for Azure Kubernetes service (AKS) and Azure Arc-enabled Kubernetes cluster. -- Microsoft Entra ID can be used for Azure Kubernetes service (AKS) and Azure Arc-enabled Kubernetes cluster and is required for Kubernetes cluster running in another cloud or on-premises.--See the following articles for more information on how to configure remote write for Kubernetes clusters: --- (**Recommended**) [Send Prometheus data to Azure Monitor by directly configuring Prometheus remote-write](../essentials/prometheus-remote-write-virtual-machines.md#set-up-authentication-for-remote-write). This option can be used for self-managed Prometheus running in any environment. The supported authentication options are user-assigned managed identity and Microsoft Entra ID application.-- [Send Prometheus data from AKS to Azure Monitor using side car container with managed identity authentication](/azure/azure-monitor/containers/prometheus-remote-write-managed-identity)-- [Send Prometheus data from AKS to Azure Monitor using side car container with Microsoft Entra ID authentication](/azure/azure-monitor/containers/prometheus-remote-write-active-directory)-- [Send Prometheus data to Azure Monitor using side car container with Microsoft Entra ID pod-managed identity (preview) authentication](/azure/azure-monitor/containers/prometheus-remote-write-azure-ad-pod-identity)-- [Send Prometheus data to Azure Monitor using side car container with Microsoft Entra ID Workload ID (preview) authentication](/azure/azure-monitor/containers/prometheus-remote-write-azure-workload-identity)--## Remote write from Virtual Machines and Virtual Machine Scale sets --You can send Prometheus data from Virtual Machines and Virtual Machines Scale Sets to Azure Monitor workspaces using remote write. The servers can be Azure-managed or in any other environment. For more information, see [Send Prometheus metrics from Virtual Machines to an Azure Monitor workspace](/azure/azure-monitor/essentials/prometheus-remote-write-virtual-machines). ---## Verify remote write is working correctly --Use the following methods to verify that Prometheus data is being sent into your Azure Monitor workspace. --### Kubectl commands --Use the following command to view logs from the side car container. Remote write data is flowing if the output has nonzero value for `avgBytesPerRequest` and `avgRequestDuration`. --```azurecli -kubectl logs <Prometheus-Pod-Name> <Azure-Monitor-Side-Car-Container-Name> --namespace <namespace-where-Prometheus-is-running> -# example: kubectl logs prometheus-prometheus-kube-prometheus-prometheus-0 prom-remotewrite --namespace monitoring -``` --The output from this command has the following format: --``` -time="2022-11-02T21:32:59Z" level=info msg="Metric packets published in last 1 minute" avgBytesPerRequest=19713 avgRequestDurationInSec=0.023 failedPublishing=0 successfullyPublished=122 -``` ---### Azure Monitor metrics explorer with PromQL --To check if the metrics are flowing to the Azure Monitor workspace, from your Azure Monitor workspace in the Azure portal, select **Metrics**. Use the metrics explorer to query the metrics that you're expecting from the self-managed Prometheus environment. For more information, see [Metrics explorer](/azure/azure-monitor/essentials/metrics-explorer). ---### Prometheus explorer in Azure Monitor Workspace --Prometheus Explorer provides a convenient way to interact with Prometheus metrics within your Azure environment, making monitoring and troubleshooting more efficient. To use the Prometheus explorer, from to your Azure Monitor workspace in the Azure portal and select **Prometheus Explorer** to query the metrics that you're expecting from the self-managed Prometheus environment. -For more information, see [Prometheus explorer](/azure/azure-monitor/essentials/prometheus-workbooks). --### Grafana --Use PromQL queries in Grafana and verify that the results return expected data. For more information on configuring Grafana for Azure managed service for Prometheus, see [Use Azure Monitor managed service for Prometheus as data source for Grafana using managed system identity](../essentials/prometheus-grafana.md) ---## Troubleshoot remote write --If remote data isn't appearing in your Azure Monitor workspace, see [Troubleshoot remote write](../containers/prometheus-remote-write-troubleshooting.md) for common issues and solutions. ---## Next steps --- [Learn more about Azure Monitor managed service for Prometheus](../essentials/prometheus-metrics-overview.md).-- [Collect Prometheus metrics from an AKS cluster](../containers/kubernetes-monitoring-enable.md#enable-prometheus-and-grafana) |
| azure-monitor | Cost Estimate | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/cost-estimate.md | - Title: Estimate Azure Monitor costs -description: Guidance on using the Azure Monitor pricing calculator to estimate Azure Monitor billable usage. --- Previously updated : 10/27/2023--# Estimate Azure Monitor costs --Your Azure Monitor cost varies significantly based on your expected utilization and configuration. Use the [Azure Monitor Pricing calculator](https://azure.microsoft.com/pricing/calculator/?service=monitor) to get cost estimates for different features of Azure Monitor based on your particular environment. --Since Azure Monitor has [multiple types of charges](cost-usage.md#pricing-model), its calculator has multiple categories. See the sections below for an explanation of these categories and guidance for providing estimates. See [Azure Monitor Pricing](https://azure.microsoft.com/pricing/details/monitor/) for current pricing details. --Some of the values required by the calculator might be difficult to provide if you're just getting started with Azure Monitor. For example, you might have no idea of the volume of Analytics logs generated from the different Azure resources that you intend to monitor. A common strategy is to enable monitoring for a small group of resources and use the observed data volumes with the calculator to determine your costs for a full environment. See [Analyze usage in Log Analytics workspace](logs/analyze-usage.md) for queries and other methods to measure the billable data in your Log Analytics workspace. ----## Log data ingestion -This section includes the ingestion and retention of data in your Log Analytics workspaces. This includes such features as Container insights and Application insights in addition to resource logs collected from your Azure resources and agents installed on your virtual machines. This is where the bulk of monitoring costs are typically incurred in most environments. --| Category | Description | -|:|:| -| Estimate Data Volume For Monitoring VMs | Data collected from your virtual machines either using VM insights or by creating a DCR to events and performance data. The data collected from each virtual machine varies significantly depending on your collection settings and the workloads running on your virtual machines, so you should validate these estimates in your own environment. | -| Estimate Data Volume Using Container Insights | Data collected from your Kubernetes clusters. The estimate is based on the number of clusters and their configuration. This estimate applies only for metrics and inventory data collected. Container logs (stdout, stderr, and environmental variables) vary significantly based on the log sizes generated by the workload, and they're excluded from this estimate. You should include their volume in the *Analytics Logs* category. | -| Estimate Data Volume Based On Application Activity | Data collected from your workspace-based applications using Application Insights. The data collected from each application varies significantly depending on your particular collection settings and applications, so you should validate these estimates in your own environment. -| Analytics Logs | Resource logs collected from Azure resources and any other data aside from those listed above sent to Logs tables configured for the [Analytics table plan](../azure-monitor/logs/data-platform-logs.md#table-plans). This can be difficult to estimate so you should enable monitoring for a small group of resources and use the observed data volumes to extrapolate for a full environment. | -| Basic Logs | Resource logs collected from Azure resources and any other data aside from those listed above sent to Logs tables configured for [Basic table plan](../azure-monitor/logs/data-platform-logs.md#table-plans). This can be difficult to estimate so you should enable monitoring for a small group of resources and use the observed data volumes to extrapolate for a full environment. | -| Auxiliary Logs | Resource logs collected from non-Azure resources sent to Logs tables configured for [Auxiliary table plan](logs/logs-table-plans.md). This can be difficult to estimate so you should enable monitoring for a small group of resources and use the observed data volumes to extrapolate for a full environment. | -| Interactive Data Retention | [Interactive retention](logs/data-retention-configure.md) setting for your Log Analytics workspace. | -| Data Archive | [Total retention](logs/data-retention-configure.md) setting for your Log Analytics workspace. | -| Basic and Auxiliary Logs Search Queries | Estimated number and scanned data of the queries that you expect to run using tables configured for the [Basic and Auxiliary table plans](../azure-monitor/logs/data-platform-logs.md#table-plans). | -| Search Jobs | Estimated number and scanned data of the [search jobs](logs/search-jobs.md) that you expect to run against [data in long-term retention](logs/data-retention-configure.md). | -| Platform logs| Resource logs collected from Azure resources to an Event Hub, Storage account, or a partner. This doesn't include logs sent to your Log Analytics workspace, which are included in the **Analytics Logs**, **Basic Logs**, and **Auxiliary Logs** categories. This can be difficult to estimate so you should enable monitoring for a small group of resources and use the observed data volumes to extrapolate for a full environment. | --## Managed Prometheus -This section includes charges for the ingestion and query of Prometheus metrics by your Kubernetes clusters. --| Category | Description | -|:|:| -| Metric Sample Ingestion | Number and frequency of the Prometheus metrics collected by your AKS nodes. See [Default Prometheus metrics configuration in Azure Monitor](containers/prometheus-metrics-scrape-default.md). | -| Query Samples Processed | Number of query samples can be estimated from the dashboards and alerting rules that use them. | --## Alert rules -This section includes charges for alert rules. --| Category | Description | -|:|:| -| Metric Signals Monitored | Number of [metrics alert rules](alerts/alerts-types.md#metric-alerts) and their time series. | -| Log Signals Monitored | Number of [log search alert rules](alerts/alerts-types.md#log-alerts) and their frequency. | --## ITSM connector - ticket creation/update -This section includes charges for ITSM events, which are sent in response to alerts being triggered. --| Category | Description | -|:|:| -| Estimate the number of ITSM events that will be sent beyond the number included for free. | ---## Notifications -This section includes charges for notifications, which are sent in response to alerts being triggered. --| Category | Description | -|:|:| -| Emails, web hooks and push notifications | Estimate the number of different types of notifications that will be sent beyond the number included for free. | ----## Next steps --- See [Azure Monitor Logs pricing details](logs/cost-logs.md) for details on how charges are calculated for data in a Log Analytics workspace and different configuration options to reduce your charges.-- See [Analyze usage in Log Analytics workspace](logs/analyze-usage.md) for details on analyzing the data in your workspace to determine to source of any higher than expected usage and opportunities to reduce your amount of data collected.-- See [Azure Monitor best practices - Cost management](best-practices-cost.md) for best practices on configuring and managing Azure Monitor to minimize your charges. |
| azure-monitor | Cost Meters | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/cost-meters.md | - Title: Azure Monitor billing meter names -description: Reference of Azure Monitor billing meter names. --- Previously updated : 09/20/2023--# Azure Monitor billing meter names --This article contains a reference of the billing meter names used by Azure Monitor in [Azure Cost Management + Billing](cost-usage.md#azure-cost-management--billing). Use this information to interpret your monthly charges for Azure Monitor. --## Log data ingestion -The following table lists the meters used to bill for data ingestion in your Log Analytics workspaces, and whether the meter is regional. There's a different billing meter, `MeterId` in the export usage report for each region. Note that Basic Logs ingestion can be used when the workspace's pricing tier is Pay-as-you-go or any commitment tier. ---| Pricing tier |ServiceName | MeterName | Regional Meter? | -| -- | -- | -- | -- | -| (any) | Azure Monitor | Auxiliary Logs Data Ingestion | yes | -| (any) | Azure Monitor | Basic Logs Data Ingestion | yes | -| Pay-as-you-go | Log Analytics | Pay-as-you-go Data Ingestion | yes | -| 100 GB/day Commitment Tier | Azure Monitor | 100 GB Commitment Tier Capacity Reservation | yes | -| 200 GB/day Commitment Tier | Azure Monitor | 200 GB Commitment Tier Capacity Reservation | yes | -| 300 GB/day Commitment Tier | Azure Monitor | 300 GB Commitment Tier Capacity Reservation | yes | -| 400 GB/day Commitment Tier | Azure Monitor | 400 GB Commitment Tier Capacity Reservation | yes | -| 500 GB/day Commitment Tier | Azure Monitor | 500 GB Commitment Tier Capacity Reservation | yes | -| 1000 GB/day Commitment Tier | Azure Monitor | 1000 GB Commitment Tier Capacity Reservation | yes | -| 2000 GB/day Commitment Tier | Azure Monitor | 2000 GB Commitment Tier Capacity Reservation | yes | -| 5000 GB/day Commitment Ties | Azure Monitor | 5000 GB Commitment Tier Capacity Reservation | yes | -| Per Node (legacy tier) | Insight and Analytics | Standard Node | no | -| Per Node (legacy tier) | Insight and Analytics | Standard Data Overage per Node | no | -| Per Node (legacy tier) | Insight and Analytics | Standard Data Included per Node | no | -| Standalone (legacy tier) | Log Analytics | Pay-as-you-go Data Analyzed | no | -| Standard (legacy tier) | Log Analytics | Standard Data Analyzed | no | -| Premium (legacy tier) | Log Analytics | Premium Data Analyzed | no | -| (any) | Azure Monitor | Free Benefit - Microsoft 365 Defender Data Ingestion | yes | ---The **Standard Data Included per Node** meter is used both for the Log Analytics [Per Node tier](logs/cost-logs.md#per-node-pricing-tier) data allowance, and also the [Defender for Servers data allowance](logs/cost-logs.md#workspaces-with-microsoft-defender-for-cloud), for workspaces in any pricing tier. --The **Free Benefit - M365 Defender Data Ingestion** meter is used to record the benefit from the [Microsoft Sentinel benefit for Microsoft 365 E5, A5, F5, and G5 customers](https://azure.microsoft.com/offers/sentinel-microsoft-365-offer/). --## Other Azure Monitor logs meters --| ServiceName | MeterName | Regional Meter? | -| -- | | | -| Log Analytics | Pay-as-you-go Data Retention | yes | -| Insight and Analytics | Standard Data Retention | no | -| Azure Monitor | Data Archive | yes | -| Azure Monitor | Search Queries Scanned | yes | -| Azure Monitor | Search Jobs Scanned | yes | -| Azure Monitor | Data Restore | yes | -| Azure Monitor | Log Analytics data export Data Exported | yes | -| Azure Monitor | Platform Logs Data Processed | yes | --*Pay-as-you-go Data Retention* is used for workspaces in all modern pricing tiers (Pay-as-you-go and Commitment Tiers). "Standard Data Retention" is used for workspaces in the legacy Per Node and Standalone pricing tiers. --## Azure Monitor metrics meters: --| ServiceName | MeterName | Regional Meter? | -| -- | | | -| Azure Monitor | Metrics ingestion Metric samples | yes | -| Azure Monitor | Prometheus Metrics Queries Metric samples | yes | -| Azure Monitor | Native Metric Queries API Calls | yes | --## Azure Monitor alerts meters --| ServiceName | MeterName | Regional Meter? | -| -- | | | -| Azure Monitor | Alerts Metric Monitored | no | -| Azure Monitor | Alerts Dynamic Threshold | no | -| Azure Monitor | Alerts System Log Monitored at 1 Minute Frequency | no | -| Azure Monitor | Alerts System Log Monitored at 10 Minute Frequency | no | -| Azure Monitor | Alerts System Log Monitored at 15 Minute Frequency | no | -| Azure Monitor | Alerts System Log Monitored at 5 Minute Frequency | no | -| Azure Monitor | Alerts Resource Monitored at 1 Minute Frequency | no | -| Azure Monitor | Alerts Resource Monitored at 10 Minute Frequency | no | -| Azure Monitor | Alerts Resource Monitored at 15 Minute Frequency | no | -| Azure Monitor | Alerts Resource Monitored at 5 Minute Frequency | no | --## Azure Monitor web test meters --| ServiceName | MeterName | Regional Meter? | -| -- | | | -| Azure Monitor | Standard Web Test Execution | yes | -| Application Insights | Multi-step Web Test | no | --## Legacy classic Application Insights meters --| ServiceName | MeterName | Regional Meter? | -| -- | | | -| Application Insights | Enterprise Node | no | -| Application Insights | Enterprise Overage Data | no | ---### Legacy Application Insights meters --Most Application Insights usage for both classic and workspace-based resources is reported on meters with **Log Analytics** for **Meter Category** because there's a single log back-end for all Azure Monitor components. Only Application Insights resources on legacy pricing tiers and multiple-step web tests are reported with **Application Insights** for **Meter Category**. The usage is shown in the **Consumed Quantity** column. The unit for each entry is shown in the **Unit of Measure** column. For more information, see [Understand your Microsoft Azure bill](../cost-management-billing/understand/review-individual-bill.md). --To separate costs from your Log Analytics and classic Application Insights usage, [create a filter](../cost-management-billing/costs/group-filter.md) on **Resource type**. To see all Application Insights costs, filter **Resource type** to **microsoft.insights/components**. For Log Analytics costs, filter **Resource type** to **microsoft.operationalinsights/workspaces**. (Workspace-based Application Insights is all billed to the Log Analytics workspace resourced.) |
| azure-monitor | Cost Usage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/cost-usage.md | - Title: Azure Monitor cost and usage -description: Overview of how Azure Monitor is billed and how to analyze billable usage. --- Previously updated : 01/24/2024---# Azure Monitor cost and usage -This article describes the different ways that Azure Monitor charges for usage and how to evaluate charges on your Azure bill. ---## Pricing model --Azure Monitor uses a consumption-based pricing (pay-as-you-go) billing model where you only pay for what you use. Features of Azure Monitor that are enabled by default don't incur any charge. This includes collection and alerting on the [Activity log](essentials/activity-log.md) and collection and analysis of [platform metrics](essentials/metrics-supported.md). --Several other features don't have a direct cost, but you instead pay for the ingestion and retention of data that they collect. The following table describes the different types of usage that are charged in Azure Monitor. Detailed current pricing for each is provided in [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/). ---| Type | Description | -|:|:| -| Logs |Ingestion, retention, and export of data in [Log Analytics workspaces](logs/log-analytics-workspace-overview.md) and [legacy Application insights resources](app/convert-classic-resource.md). Log data ingestion is the largest component of Azure Monitor charges for most customers. There's no charge for querying this data except in the case of [Basic and Auxiliary logs](../azure-monitor/logs/data-platform-logs.md#table-plans) or [data in long-term retention](logs/data-retention-configure.md).<br><br>Charges for Logs can vary significantly on the configuration that you choose. See [Azure Monitor Logs pricing details](logs/cost-logs.md) for details on how charges for Logs data are calculated and the different pricing tiers available. | -| Platform Logs | Processing of [diagnostic and auditing information](essentials/resource-logs.md) is charged for [certain services](essentials/resource-logs-categories.md#costs) when sent to destinations other than a Log Analytics workspace. There's no direct charge when this data is sent to a Log Analytics workspace, but there's a charge for the workspace data ingestion and collection. | -| Metrics | There's no charge for [standard metrics](essentials/metrics-supported.md) collected from Azure resources. There's a cost for collecting [custom metrics](essentials/metrics-custom-overview.md) and for retrieving metrics from the [REST API](essentials/rest-api-walkthrough.md#retrieve-metric-values). | -| Prometheus Metrics | Pricing for [Azure Monitor managed service for Prometheus](essentials/prometheus-metrics-overview.md) is based on [data samples ingested](containers/kubernetes-monitoring-enable.md#enable-prometheus-and-grafana) and [query samples processed](essentials/azure-monitor-workspace-manage.md#link-a-grafana-workspace). Data is retained for 18 months at no extra charge. | -| Alerts | Alerts are charged based on the type and number of [signals](alerts/alerts-overview.md) used by the alert rule, its frequency, and the type of [notification](alerts/action-groups.md) used in response. For [log search alerts](alerts/alerts-types.md#log-alerts) configured for [at scale monitoring](alerts/alerts-types.md#monitor-the-same-condition-on-multiple-resources-using-splitting-by-dimensions-1), the cost also depends on the number of time series created by the dimensions resulting from your query. | -| Web tests | There's a cost for [standard web tests](app/availability-standard-tests.md) and [multi-step web tests](app/availability-multistep.md) in Application Insights. Multi-step web tests are deprecated.| --A list of Azure Monitor billing meter names is available [here](cost-meters.md). --### Data transfer charges -Sending data to Azure Monitor can incur data bandwidth charges. As described in the [Azure Bandwidth pricing page](https://azure.microsoft.com/pricing/details/bandwidth/), data transfer between Azure services located in two regions charged as outbound data transfer at the normal rate. Inbound data transfer is free. Data transfer charges for Azure Monitor though are typically very small compared to the costs for data ingestion and retention. You should focus more on your ingested data volume to control your costs. --> [!NOTE] -> Data sent to a different region using [Diagnostic Settings](essentials/diagnostic-settings.md) does not incur data transfer charges --## View Azure Monitor usage and charges -There are two primary tools to view, analyze, and optimize your Azure Monitor costs. Each is described in detail in the following sections. --| Tool | Description | -|:|:| -| [Azure Cost Management + Billing](#azure-cost-management--billing) | Gives you powerful capabilities use to understand your billed costs. There are multiple options to analyze your charges for different Azure Monitor features and their projected cost over time. | -| [Usage and Estimated Costs](#usage-and-estimated-costs) | Provides estimates of log data ingestion costs based on your daily usage patterns to help you optimize to use the most cost-effective logs pricing tier. | ---## Azure Cost Management + Billing -To get started analyzing your Azure Monitor charges, open [Cost Management + Billing](../cost-management-billing/costs/quick-acm-cost-analysis.md?toc=/azure/billing/TOC.json) in the Azure portal. This tool includes several built-in dashboards for deep cost analysis like cost by resource and invoice details. Access policies are described [here](/azure/cost-management-billing/manage/manage-billing-access#give-others-access-to-view-billing-information). Select **Cost Management** and then **Cost analysis**. Select your subscription or another [scope](../cost-management-billing/costs/understand-work-scopes.md). --Next, create a **Daily Costs** view, and change the **Group by** to show costs by **Meter** so that you can see each the costs from each feature. The meter names for each Azure Monitor feature are listed [here](cost-meters.md). -->[!NOTE] ->You might need additional access to use Cost Management data. See [Assign access to Cost Management data](../cost-management-billing/costs/assign-access-acm-data.md). ----To limit the view to Azure Monitor charges, [create a filter](../cost-management-billing/costs/group-filter.md) for the following **Service names**. -- Azure Monitor-- Log Analytics-- Insight and Analytics-- Application Insights--See [Azure Monitor billing meter names](cost-meters.md) for a list of all Azure Monitor billing meters that are included in each of these services. --Other services such as Microsoft Defender for Cloud and Microsoft Sentinel also bill their usage against Log Analytics workspace resources. See [Common cost analysis uses](../cost-management-billing/costs/cost-analysis-common-uses.md) for details on using this view. ---> [!NOTE] -> Alternatively, you can go to the **Overview** page of a Log Analytics workspace or Application Insights resource and click **View Cost** in the upper right corner of the **Essentials** section. This will launch the **Cost Analysis** from Azure Cost Management + Billing already scoped to the workspace or application. (You might need to use the [preview version](https://preview.portal.azure.com/) of the Azure portal to see this option.) -> :::image type="content" source="logs/media/view-bill/view-cost-option.png" lightbox="logs/media/view-bill/view-cost-option.png" alt-text="Screenshot of option to view cost for Log Analytics workspace."::: -### Automated mails and alerts -Rather than manually analyzing your costs in the Azure portal, you can automate delivery of information using the following methods. --- **Daily cost analysis emails.** After you configure your Cost Analysis view, select **Subscribe** at the top of the screen to receive regular email updates from Cost Analysis.-- **Budget alerts.** To be notified if there are significant increases in your spending, create a [budget alerts](../cost-management-billing/costs/cost-mgt-alerts-monitor-usage-spending.md) for a single workspace or group of workspaces. --### Export usage details --To gain deeper understanding of your usage and costs, create exports using **Cost Analysis**. See [Tutorial: Create and manage exported data](../cost-management-billing/costs/tutorial-export-acm-data.md) to learn how to automatically create a daily export you can use for regular analysis. --These exports are in CSV format and contain a list of daily usage (billed quantity and cost) by resource, [billing meter](cost-meters.md), and several other fields such as [AdditionalInfo](../cost-management-billing/automate/understand-usage-details-fields.md#list-of-fields-and-descriptions). You can use Microsoft Excel to do rich analyses of your usage not possible in the **Cost Analytics** experiences in the portal. --For example, usage from Log Analytics can be found by first filtering on the **Meter Category** column to show: --1. **Log Analytics** (for Pay-as-you-go data ingestion and interactive Data Retention), -2. **Insight and Analytics** (used by some of the legacy pricing tiers), and -3. **Azure Monitor** (used by most other Log Analytics features such as Commitment Tiers, Basic Logs ingesting, Long-Term Retention, Search Queries, Search Jobs, and so on) --Add a filter on the **Instance ID** column for **contains workspace** or **contains cluster**. The usage is shown in the **Consumed Quantity** column. The unit for each entry is shown in the **Unit of Measure** column. --> [!NOTE] -> See [Azure Monitor billing meter names](cost-meters.md) for a reference of the billing meter names used by Azure Monitor in Azure Cost Management + Billing. --## View data allocation benefits --There are several approaches to view the benefits a workspace receives from offers that are part of other products. These offers are: --1. [Defender for Servers data allowance](logs/cost-logs.md#workspaces-with-microsoft-defender-for-cloud) and --1. [Microsoft Sentinel benefit for Microsoft 365 E5, A5, F5, and G5 customers](https://azure.microsoft.com/offers/sentinel-microsoft-365-offer/). --> [!NOTE] -> To receive the Defender for Servers data allowance on your Log Analytics workspace, the **Security** solution must have been [created on the workspace](/cli/azure/monitor/log-analytics/solution). --### View benefits in a usage export --Since a usage export has both the number of units of usage and their cost, you can use this export to see the benefits you're receiving. In the usage export, to see the benefits, filter the *Instance ID* column to your workspace. (To select all of your workspaces in the spreadsheet, filter the *Instance ID* column to "contains /workspaces/".) Then filter on the Meter to either of the following 2 meters: --- **Standard Data Included per Node**: this meter is under the service "Insight and Analytics" and tracks the benefits received when a workspace in either in Log Analytics [Per Node tier](logs/cost-logs.md#per-node-pricing-tier) data allowance and/or has [Defender for Servers](logs/cost-logs.md#workspaces-with-microsoft-defender-for-cloud) enabled. Each of these allowances provides a 500 MB/server/day data allowance. --- **Free Benefit - M365 Defender Data Ingestion**: this meter, under the service "Azure Monitor", tracks the benefit from the [Microsoft Sentinel benefit for Microsoft 365 E5, A5, F5, and G5 customers](https://azure.microsoft.com/offers/sentinel-microsoft-365-offer/).--### View benefits in Usage and estimated costs --You can also see these data benefits in the Log Analytics Usage and estimated costs page. If the workspace is receiving these benefits, there's a sentence below the cost estimate table that gives the data volume of the benefits used over the last 31 days. ----### Query benefits from the Operation table --The [Operation](/azure/azure-monitor/reference/tables/operation) table contains daily events which given the amount of benefit used from the [Defender for Servers data allowance](logs/cost-logs.md#workspaces-with-microsoft-defender-for-cloud) and the [Microsoft Sentinel benefit for Microsoft 365 E5, A5, F5, and G5 customers](https://azure.microsoft.com/offers/sentinel-microsoft-365-offer/). The `Detail` column for these events is in the format `Benefit amount used 1.234 GB`, and the type of benefit is in the `OperationKey` column. Here's a query that charts the benefits used in the last 31-days: --```kusto -Operation -| where TimeGenerated >= ago(31d) -| where Detail startswith "Benefit amount used" -| parse Detail with "Benefit amount used: " BenefitUsedGB " GB" -| extend BenefitUsedGB = toreal(BenefitUsedGB) -| parse OperationKey with "Benefit type used: " BenefitType -| project BillingDay=TimeGenerated, BenefitType, BenefitUsedGB -| sort by BillingDay asc, BenefitType asc -| render columnchart -``` --(This functionality of reporting the benefits used in the `Operation` table started January 27, 2024.) --> [!TIP] -> If you [increase the data retention](logs/data-retention-configure.md) of the [Operation](/azure/azure-monitor/reference/tables/operation) table, you will be able to view these benefit trends over longer periods. -> --## Usage and estimated costs -You can get more usage details about Log Analytics workspaces and Application Insights resources from the **Usage and Estimated Costs** option for each. --### Log Analytics workspace -To learn about your usage trends and optimize your costs using the most cost-effective [commitment tier](logs/cost-logs.md#commitment-tiers) for your Log Analytics workspace, select **Usage and Estimated Costs** from the **Log Analytics workspace** menu in the Azure portal. ---This view includes the following sections: --A. Estimated monthly charges based on usage from the past 31 days using the current pricing tier.<br> -B. Estimated monthly charges using different commitment tiers.<br> -C. Billable data ingestion by solution from the past 31 days. --To explore the data in more detail, select the icon in the upper-right corner of either chart to work with the query in Log Analytics. ---### Application insights --#### Workspace-based resources --To learn about usage on your workspace-based resources, see [Data volume trends for workspace-based resources](logs/analyze-usage.md#data-volume-trends-for-workspace-based-resources). --#### Classic resources --To learn about usage on retired classic Application Insights resources, select **Usage and Estimated Costs** from the **Applications** menu in the Azure portal. ---This view includes the following: --A. Estimated monthly charges based on usage from the past month.<br> -B. Billable data ingestion by table from the past month. --To investigate your Application Insights usage more deeply, open the **Metrics** page, add the metric named *Data point volume*, and then select the *Apply splitting* option to split the data by "Telemetry item type". --## Operations Management Suite subscription entitlements --Customers who purchased Microsoft Operations Management Suite E1 and E2 are eligible for per-node data ingestion entitlements for Log Analytics and Application Insights. Each Application Insights node includes up to 200 MB of data ingested per day (separate from Log Analytics data ingestion), with 90-day data retention at no extra cost. --To receive these entitlements for Log Analytics workspaces or Application Insights resources in a subscription, they must use the Per-Node (OMS) pricing tier. This entitlement isn't visible in the estimated costs shown in the Usage and estimated cost pane. --Depending on the number of nodes of the suite that your organization purchased, moving some subscriptions into a Per GB (pay-as-you-go) pricing tier might be advantageous, but this change in pricing tier requires careful consideration. --> [!TIP] -> If your organization has Microsoft Operations Management Suite E1 or E2, it's usually best to keep your Log Analytics workspaces in the Per-Node (OMS) pricing tier and your Application Insights resources in the Enterprise pricing tier. -> --## Azure Migrate data benefits --Workspaces linked to [classic Azure Migrate](/azure/migrate/migrate-services-overview#azure-migrate-versions) receive free data benefits for the data tables related to Azure Migrate (`ServiceMapProcess_CL`, `ServiceMapComputer_CL`, `VMBoundPort`, `VMConnection`, `VMComputer`, `VMProcess`, `InsightsMetrics`). This version of Azure Migrate was retired in February 2024. --Starting from 1 July 2024, the data benefit for Azure Migrate in Log Analytics will no longer be available. We suggest moving to the [Azure Migrate agentless dependency analysis](/azure/migrate/how-to-create-group-machine-dependencies-agentless). If you continue with agent-based dependency analysis, standard [Azure Monitor charges](https://azure.microsoft.com/pricing/details/monitor/) apply for the data ingestion that enables dependency visualization. --## Next steps --- See [Azure Monitor Logs pricing details](logs/cost-logs.md) for details on how charges are calculated for data in a Log Analytics workspace and different configuration options to reduce your charges.-- See [Analyze usage in Log Analytics workspace](logs/analyze-usage.md) for details on analyzing the data in your workspace to determine to source of any higher than expected usage and opportunities to reduce your amount of data collected.-- See [Set daily cap on Log Analytics workspace](logs/daily-cap.md) to control your costs by setting a daily limit on the amount of data that might be ingested in a workspace.-- See [Azure Monitor best practices - Cost management](best-practices-cost.md) for best practices on configuring and managing Azure Monitor to minimize your charges. |
| azure-monitor | Data Platform | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/data-platform.md | - Title: Azure Monitor data platform -description: Overview of the Azure Monitor data platform and collection of observability data. -- Previously updated : 08/09/2023----# Azure Monitor data platform --Today's complex computing environments run distributed applications that rely on both cloud and on-premises services. To enable observability, operational data must be collected from every layer and component of the distributed system. You need to be able to perform deep insights on this data and consolidate it with different perspectives so that it supports the range of stakeholders in your organization. --[Azure Monitor](overview.md) collects and aggregates data from various sources into a common data platform where it can be used for analysis, visualization, and alerting. It provides a consistent experience on top of data from multiple sources. You can gain deep insights across all your monitored resources and even with data from other services that store their data in Azure Monitor. ---## Observability data in Azure Monitor --Metrics, logs, and distributed traces are commonly referred to as the three pillars of observability. A monitoring tool must collect and analyze these three different kinds of data to provide sufficient observability of a monitored system. Observability can be achieved by correlating data from multiple pillars and aggregating data across the entire set of resources being monitored. Because Azure Monitor stores data from multiple sources together, the data can be correlated and analyzed by using a common set of tools. It also correlates data across multiple Azure subscriptions and tenants, in addition to hosting data for other services. --Azure resources generate a significant amount of monitoring data. Azure Monitor consolidates this data along with monitoring data from other sources into either a Metrics or Logs platform. Each is optimized for particular monitoring scenarios, and each supports different features in Azure Monitor. Features such as data analysis, visualizations, or alerting require you to understand the differences so that you can implement your required scenario in the most efficient and cost effective manner. Insights in Azure Monitor such as [Application Insights](app/app-insights-overview.md) or [Container insights](containers/container-insights-overview.md) have analysis tools that allow you to focus on the particular monitoring scenario without having to understand the differences between the two types of data. --### Metrics --[Metrics](essentials/data-platform-metrics.md) are numerical values that describe some aspect of a system at a particular point in time. They're collected at regular intervals and are identified with a timestamp, a name, a value, and one or more defining labels. Metrics can be aggregated by using various algorithms. They can be compared to other metrics and analyzed for trends over time. --Metrics in Azure Monitor are stored in a time-series database that's optimized for analyzing time-stamped data. Time-stamping makes metrics well suited for alerting and fast detection of issues. Metrics can tell you how your system is performing but typically must be combined with logs to identify the root cause of issues. --Azure Monitor Metrics includes two types of metrics - native metrics and Prometheus metrics. See a comparison of the two and further details about Azure Monitor metrics, including their sources of data, at [Metrics in Azure Monitor](essentials/data-platform-metrics.md). --### Logs --[Logs](logs/data-platform-logs.md) are events that occurred within the system. They can contain different kinds of data and might be structured or freeform text with a timestamp. They might be created sporadically as events in the environment generate log entries. A system under heavy load typically generates more log volume. --Logs in Azure Monitor are stored in a Log Analytics workspace that's based on [Azure Data Explorer](/azure/data-explorer/), which provides a powerful analysis engine and [rich query language](/azure/kusto/query/). Logs typically provide enough information to provide complete context of the issue being identified and are valuable for identifying the root cause of issues. --> [!NOTE] -> It's important to distinguish between Azure Monitor Logs and sources of log data in Azure. For example, subscription-level events in Azure are written to an [Activity log](essentials/platform-logs-overview.md) that you can view from the Azure Monitor menu. Most resources will write operational information to a [resource log](essentials/platform-logs-overview.md) that you can forward to different locations. -> ->Azure Monitor Logs is a log data platform that collects Activity logs and resource logs along with other monitoring data to provide deep analysis across your entire set of resources. -- You can work with [log queries](logs/log-query-overview.md) interactively with [Log Analytics](logs/log-query-overview.md) in the Azure portal. You can also add the results to an [Azure dashboard](app/overview-dashboard.md#create-custom-kpi-dashboards-using-application-insights) for visualization in combination with other data. You can create [log search alerts](alerts/alerts-log.md), which will trigger an alert based on the results of a schedule query. --Read more about Azure Monitor logs including their sources of data in [Logs in Azure Monitor](logs/data-platform-logs.md). --### Distributed traces --Traces are series of related events that follow a user request through a distributed system. They can be used to determine the behavior of application code and the performance of different transactions. While logs will often be created by individual components of a distributed system, a trace measures the operation and performance of your application across the entire set of components. --Distributed tracing in Azure Monitor is enabled with the [Application Insights SDK](app/distributed-trace-data.md). Trace data is stored with other application log data collected by Application Insights. This way it's available to the same analysis tools as other log data including log queries, dashboards, and alerts. --Read more about distributed tracing at [What is distributed tracing?](app/distributed-trace-data.md). --### Changes --[Changes](./change/change-analysis-visualizations.md) are a series of events that occur in your Azure application, from the infrastructure layer through application deployment. Changes are traced on a subscription-level using [the Change Analysis tool](./change/change-analysis.md). The Change Analysis tool increases observability by building on the power of [Azure Resource Graph](../governance/resource-graph/overview.md) to provide detailed insights into your application changes. --Once [Change Analysis is enabled](./change/change-analysis-enable.md), the `Microsoft.ChangeAnalysis` resource provider is registered with an Azure Resource Manager subscription to make the resource properties and configuration change data available. Change Analysis provides data for various management and troubleshooting scenarios to help users understand what changes might have caused the issues: -- Troubleshoot your application via the [Diagnose & solve problems tool](./change/change-analysis-enable.md).-- Perform general management and monitoring via the [Change Analysis overview portal](./change/change-analysis-visualizations.md#view-change-analysis-data) and [the activity log](./change/change-analysis-visualizations.md#view-the-activity-log-change-history).-- [Learn more about how to view data results for other scenarios](./change/change-analysis-visualizations.md).--Read more about Change Analysis, including data sources in [Use Change Analysis in Azure Monitor](./change/change-analysis.md). --## Collect monitoring data -Different [sources of data for Azure Monitor](data-sources.md) will write to either a Log Analytics workspace (Logs) or the Azure Monitor metrics database (Metrics) or both. Some sources will write directly to these data stores, while others might write to another location such as Azure storage and require some configuration to populate logs or metrics. --For a listing of different data sources that populate each type, see [Metrics in Azure Monitor](essentials/data-platform-metrics.md) and [Logs in Azure Monitor](logs/data-platform-logs.md). --## Stream data to external systems --In addition to using the tools in Azure to analyze monitoring data, you might have a requirement to forward it to an external tool like a security information and event management product. This forwarding is typically done directly from monitored resources through [Azure Event Hubs](../event-hubs/index.yml). --Some sources can be configured to send data directly to an event hub while you can use another process, such as a logic app, to retrieve the required data. For more information, see [Stream Azure monitoring data to an event hub for consumption by an external tool](essentials/stream-monitoring-data-event-hubs.md). ------## Next steps -- Read more about [Metrics in Azure Monitor](essentials/data-platform-metrics.md).-- Read more about [Logs in Azure Monitor](logs/data-platform-logs.md).-- Learn about the [monitoring data available](data-sources.md) for different resources in Azure. |
| azure-monitor | Data Sources | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/data-sources.md | - Title: Azure Monitor data sources and data collection methods -description: Describes the different types of data that can be collected in Azure Monitor and the method of data collection for each. --- Previously updated : 04/08/2024---# Customer intent: As an Azure Monitor user, I want to understand the different types of data that can be collected in Azure Monitor and the method of data collection for each so that I can configure my environment to collect the data that I need. ---# Azure Monitor data sources and data collection methods --Azure Monitor is based on a [common monitoring data platform](data-platform.md) that allows different types of data from multiple types of resources to be analyzed together using a common set of tools. Currently, different sources of data for Azure Monitor use different methods to deliver their data, and each typically require different types of configuration. This article describes common sources of monitoring data collected by Azure Monitor and their data collection methods. Use this article as a starting point to understand the option for collecting different types of data being generated in your environment. --> [!IMPORTANT] -> There is a cost for collecting and retaining most types of data in Azure Monitor. To minimize your cost, ensure that you don't collect any more data than you require and that your environment is configured to optimize your costs. See [Cost optimization in Azure Monitor](best-practices-cost.md) for a summary of recommendations. --## Azure resources -Most resources in Azure generate the monitoring data described in the following table. Some services will also have other data that can be collected by enabling other features of Azure Monitor (described in other sections in this article). Regardless of the services that you're monitoring though, you should start by understanding and configuring collection of this data. --Create diagnostic settings for each of the following data types can be sent to a Log Analytics workspace, archived to a storage account, or streamed to an event hub to send it to services outside of Azure. See [Create diagnostic settings in Azure Monitor](essentials/create-diagnostic-settings.md). --| Data type | Description | Data collection method | -|:|:|:| -|Activity log | The Activity log provides insight into subscription-level events for Azure services including service health records and configuration changes. | Collected automatically. View in the Azure portal or create a diagnostic setting to send it to other destinations. Can be collected in Log Analytics workspace at no charge. See [Azure Monitor activity log](essentials/activity-log.md). | -| Platform metrics | Platform metrics are numerical values that are automatically collected at regular intervals for different aspects of a resource. The specific metrics vary for each type of resource. | Collected automatically and stored in [Azure Monitor Metrics](./essentials/data-platform-metrics.md). View in metrics explorer or create a diagnostic setting to send it to other destinations. See [Azure Monitor Metrics overview](essentials/data-platform-metrics.md) and [Supported metrics with Azure Monitor](/azure/azure-monitor/reference/supported-metrics/metrics-index) for a list of metrics for different services. | -| Resource logs | Provide insight into operations that were performed within an Azure resource. The content of resource logs varies by the Azure service and resource type. | You must create a diagnostic setting to collect resources logs. See [Azure resource logs](essentials/resource-logs.md) and [Supported services, schemas, and categories for Azure resource logs](essentials/resource-logs-schema.md) for details on each service. | ---## Log data from Microsoft Entra ID -Audit logs and sign in logs in Microsoft Entra ID are similar to the activity logs in Azure Monitor. Use diagnostic settings to send the activity log to a Log Analytics workspace, to archive it to a storage account, or to stream to an event hub to send it to services outside of Azure. See [Configure Microsoft Entra diagnostic settings for activity logs](/entra/identity/monitoring-health/howto-configure-diagnostic-settings). --| Data type | Description | Data collection method | -|:|:|:| -| Audit logs</br>Signin logs | Enable you to assess many aspects of your Microsoft Entra ID environment, including history of sign-in activity, audit trail of changes made within a particular tenant, and activities performed by the provisioning service. | Collected automatically. View in the Azure portal or create a diagnostic setting to send it to other destinations. | --## Apps and workloads --### Application data -Application monitoring in Azure Monitor is done with [Application Insights](/azure/azure-monitor/app/app-insights-overview/), which collects data from applications running on various platforms in Azure, another cloud, or on-premises. When you enable Application Insights for an application, it collects metrics and logs related to the performance and operation of the application and stores it in the same Azure Monitor data platform used by other data sources. --See [Application Insights overview](./app/app-insights-overview.md) for further details about the data that Application insights collected and links to articles on onboarding your application. --| Data type | Description | Data collection method | -|:|:|:| -| Logs | Operational data about your application including page views, application requests, exceptions, and traces. Also includes dependency information between application components to support Application Map and data correlation. | Application logs are stored in a Log Analytics workspace that you select as part of the onboarding process. | -| Metrics | Numeric data measuring the performance of your application and user requests measured over intervals of time. | Metric data is stored in both Azure Monitor Metrics and the Log Analytics workspace. | -| Traces | Traces are a series of related events tracking end-to-end requests through the components of your application. | Traces are stored in the Log Analytics workspace for the app. | --## Infrastructure --### Virtual machine data -Azure virtual machines create the same activity logs and platform metrics as other Azure resources. In addition to this host data though, you need to monitor the guest operating system and the workloads running on it, which requires the [Azure Monitor agent](./agents/agents-overview.md) or [SCOM Managed Instance](./vm/scom-managed-instance-overview.md). The following table includes the most common data to collect from VMs. See [Monitor virtual machines with Azure Monitor: Collect data](./vm/monitor-virtual-machine-data-collection.md) for a more complete description of the different kinds of data you can collect from virtual machines. --| Data type | Description | Data collection method | -|:|:|:| -| Windows Events | Logs for the client operating system and different applications on Windows VMs. | Deploy the Azure Monitor agent (AMA) and create a data collection rule (DCR) to send data to Log Analytics workspace. See [Collect data with Azure Monitor Agent](./agents/azure-monitor-agent-data-collection.md). | -| Syslog | Logs for the client operating system and different applications on Linux VMs. | Deploy the Azure Monitor agent (AMA) and create a data collection rule (DCR) to send data to Log Analytics workspace. See [Collect Syslog events with Azure Monitor Agent](./agents/data-collection-syslog.md). To use the VM as a Syslog forwarder, see [Tutorial: Forward Syslog data to a Log Analytics workspace with Microsoft Sentinel by using Azure Monitor Agent](../sentinel/forward-syslog-monitor-agent.md) | -| Client Performance data | Performance counter values for the operating system and applications running on the virtual machine. | Deploy the Azure Monitor agent (AMA) and create a data collection rule (DCR) to send data to Azure Monitor Metrics and/or Log Analytics workspace. See [Collect data with Azure Monitor Agent](./agents/azure-monitor-agent-data-collection.md).<br><br>Enable VM insights to send predefined aggregated performance data to Log Analytics workspace. See [Enable VM Insights overview](./vm/vminsights-enable-overview.md) for installation options. | -| Processes and dependencies | Details about processes running on the machine and their dependencies on other machines and external services. Enables the [map feature in VM insights](vm/vminsights-maps.md). | Enable VM insights on the machine with the *processes and dependencies* option. See [Enable VM Insights overview](./vm/vminsights-enable-overview.md) for installation options. | -| Text logs | Application logs written to a text file. | Deploy the Azure Monitor agent (AMA) and create a data collection rule (DCR) to send data to Log Analytics workspace. See [Collect logs from a text or JSON file with Azure Monitor Agent](./agents/data-collection-text-log.md). | -| IIS logs | Logs created by Internet Information Service (IIS). | Deploy the Azure Monitor agent (AMA) and create a data collection rule (DCR) to send data to Log Analytics workspace. See [Collect IIS logs with Azure Monitor Agent](./agents/data-collection-iis.md). | -| SNMP traps | Widely deployed management protocol for monitoring and configuring Linux devices and appliances. | See [Collect SNMP trap data with Azure Monitor Agent](./agents/data-collection-snmp-data.md). | -| Management pack data | If you have an existing investment in SCOM, you can migrate to the cloud while retaining your investment in existing management packs using [SCOM MI](./vm/scom-managed-instance-overview.md). | SCOM MI stores data collected by management packs in an instance of SQL MI. See [Configure Log Analytics for Azure Monitor SCOM Managed Instance](/system-center/scom/configure-log-analytics-for-scom-managed-instance) to send this data to a Log Analytics workspace. | --### Kubernetes cluster data -Azure Kubernetes Service (AKS) clusters create the same activity logs and platform metrics as other Azure resources. In addition to this host data though, they generate a common set of cluster logs and metrics that you can collect from your AKS clusters and Arc-enabled Kubernetes clusters. --| Data type | Description | Data collection method | -|:|:|:| -| Cluster Metrics | Usage and performance data for the cluster, nodes, deployments, and workloads. | Enable managed Prometheus for the cluster to send cluster metrics to an [Azure Monitor workspace](./essentials/azure-monitor-workspace-overview.md). See [Enable Prometheus and Grafana](./containers/kubernetes-monitoring-enable.md#enable-prometheus-and-grafana) for onboarding and [Default Prometheus metrics configuration in Azure Monitor](containers/prometheus-metrics-scrape-default.md) for a list of metrics that are collected by default. | -| Logs | Standard Kubernetes logs including events for the cluster, nodes, deployments, and workloads. | Enable Container insights for the cluster to send container logs to a Log Analytics workspace. See [Enable Container insights](./containers/kubernetes-monitoring-enable.md#enable-container-insights) for onboarding and [Configure data collection in Container insights using data collection rule](./containers/container-insights-data-collection-dcr.md) to configure which logs are collected. | ---## Custom sources -For any monitoring data that you can't collect with the other methods described in this article, you can use the APIs in the following table to send data to Azure Monitor. --| Data type | Description | Data collection method | -|:|:|:| -| Logs | Collect log data from any REST client and store in Log Analytics workspace. | Create a data collection rule to define destination workspace and any data transformations. See [Logs ingestion API in Azure Monitor](logs/logs-ingestion-api-overview.md). | -| Metrics | Collect custom metrics for Azure resources from any REST client. | See [Send custom metrics for an Azure resource to the Azure Monitor metric store by using a REST API](essentials/metrics-store-custom-rest-api.md). | --## Next steps --- Learn more about the [types of monitoring data collected by Azure Monitor](data-platform.md) and how to view and analyze this data. |
| azure-monitor | Activity Log Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/activity-log-insights.md | - Title: Azure activity log and activity log insights -description: Learn how to monitor changes to resources and resource groups in an Azure subscription with Azure Monitor activity log insights. --- Previously updated : 12/11/2023----# Customer intent: As an IT manager, I want to understand how I can use the activity log and activity log insights to monitor changes to resources and resource groups in an Azure subscription. ---# Use the Azure Monitor activity log and activity log insights --The Azure Monitor activity log is a platform log that provides insight into subscription-level events. The activity log includes information like when a resource is modified or a virtual machine is started. This article provides information on how to view the activity log and send it to different destinations. --## View the activity log --You can access the activity log from most menus in the Azure portal. The menu that you open it from determines its initial filter. If you open it from the **Monitor** menu, the only filter is on the subscription. If you open it from a resource's menu, the filter is set to that resource. You can always change the filter to view all other entries. Select **Add Filter** to add more properties to the filter. -<!-- convertborder later --> --For a description of activity log categories, see [Azure activity log event schema](activity-log-schema.md#categories). --## Download the activity log --Select **Download as CSV** to download the events in the current view. -<!-- convertborder later --> --### View change history --For some events, you can view the change history, which shows what changes happened during that event time. Select an event from the activity log you want to look at more deeply. Select the **Change history** tab to view any changes on the resource up to 30 minutes before and after the time of the operation. ---If any changes are associated with the event, you'll see a list of changes that you can select. Selecting a change opens the **Change history** page. This page displays the changes to the resource. In the following example, you can see that the VM changed sizes. The page displays the VM size before the change and after the change. To learn more about change history, see [Get resource changes](../../governance/resource-graph/how-to/get-resource-changes.md). ---## Retention period --Activity log events are retained in Azure for *90 days* and then deleted. There's no charge for entries during this time regardless of volume. For more functionality, such as longer retention, create a diagnostic setting and route the entries to another location based on your needs. See the criteria in the preceding section. --## Activity log insights --Activity log insights provide you with a set of dashboards that monitor the changes to resources and resource groups in a subscription. The dashboards also present data about which users or services performed activities in the subscription and the activities' status. This article explains how to onboard and view activity log insights in the Azure portal. --Activity log insights are a curated [Log Analytics workbook](../visualize/workbooks-overview.md) with dashboards that visualize the data in the `AzureActivity` table. For example, data might include which administrators deleted, updated, or created resources and whether the activities failed or succeeded. --Azure Monitor stores all activity logs you send to a [Log Analytics workspace](../logs/log-analytics-workspace-overview.md) in a table called `AzureActivity`. Before you use activity log insights, you must [enable sending logs to your Log Analytics workspace](./diagnostic-settings.md). ---## View resource group or subscription-level activity log insights --To view activity log insights at the resource group or subscription level: --1. In the Azure portal, select **Monitor** > **Workbooks**. -1. In the **Insights** section, select **Activity Logs Insights**. -- :::image type="content" source="media/activity-log/open-activity-log-insights-workbook.png" lightbox= "media/activity-log/open-activity-log-insights-workbook.png" alt-text="Screenshot that shows how to locate and open the Activity Logs Insights workbook on a scale level."::: --1. At the top of the **Activity Logs Insights** page, select: -- - One or more subscriptions from the **Subscriptions** dropdown. - - Resources and resource groups from the **CurrentResource** dropdown. - - A time range for which to view data from the **TimeRange** dropdown. --## View resource-level activity log insights -->[!Note] -> Activity log insights does not currently support Application Insights resources. --To view activity log insights at the resource level: --1. In the Azure portal, go to your resource and select **Workbooks**. -1. In the **Activity Logs Insights** section, select **Activity Logs Insights**. -- :::image type="content" source="media/activity-log/activity-log-resource-level.png" lightbox= "media/activity-log/activity-log-resource-level.png" alt-text="Screenshot that shows how to locate and open the Activity Logs Insights workbook on a resource level."::: --1. At the top of the **Activity Logs Insights** page, select a time range for which to view data from the **TimeRange** dropdown: - - * **Azure Activity Log Entries** shows the count of activity log records in each activity log category. - - :::image type="content" source="media/activity-log/activity-logs-insights-category-value.png" lightbox= "media/activity-log/activity-logs-insights-category-value.png" alt-text="Screenshot that shows Azure activity logs by category value."::: - - * **Activity Logs by Status** shows the count of activity log records in each status. - - :::image type="content" source="media/activity-log/activity-logs-insights-status.png" lightbox= "media/activity-log/activity-logs-insights-status.png" alt-text="Screenshot that shows Azure activity logs by status."::: - - * At the subscription and resource group level, **Activity Logs by Resource** and **Activity Logs by Resource Provider** show the count of activity log records for each resource and resource provider. - - :::image type="content" source="media/activity-log/activity-logs-insights-resource.png" lightbox= "media/activity-log/activity-logs-insights-resource.png" alt-text="Screenshot that shows Azure activity logs by resource."::: --## Next steps --Learn more about: --* [Activity logs](./activity-log.md) -* [The activity log event schema](activity-log-schema.md) - |
| azure-monitor | Activity Log Schema | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/activity-log-schema.md | - Title: Azure Activity Log event schema -description: Describes the event schema for each category in the Azure Activity log. ---- Previously updated : 09/30/2020---# Azure Activity Log event schema -The [Azure Activity log](./platform-logs-overview.md) provides insight into any subscription-level events that occurred in Azure. This article describes Activity log categories and the schema for each. --The schema varies depending on how you access the log: - -- The schemas described in this article are when you access the Activity log from the [REST API](/rest/api/monitor/activitylogs). The schema is also used when you select the **JSON** option when viewing an event in the Azure portal.-- See the final section [Schema from storage account and event hubs](#schema-from-storage-account-and-event-hubs) for the schema when you use a [diagnostic setting](./diagnostic-settings.md) to send the Activity log to Azure Storage or Azure Event Hubs.-- See [Azure Monitor data reference](/azure/azure-monitor/reference/) for the schema when you use a [diagnostic setting](./diagnostic-settings.md) to send the Activity log to a Log Analytics workspace.--## Severity Level -Each entry in the activity log has a severity level. Severity level can have one of the following values: --|Severity |Description | -||| -|Critical |Events that demand the immediate attention of a system administrator. Might indicate that an application or system failed or stopped responding. | -|Error |Events that indicate a problem, but don't require immediate attention. | -|Warning | Events that provide forewarning of potential problems, although not an actual error. Indicate that a resource isn't in an ideal state and may degrade later into showing errors or critical events. | -|Informational | Events that pass noncritical information to the administrator. Similar to a note that says: "For your information". | --The developers of each resource provider choose the severity levels of their resource entries. As a result, the actual severity to you can vary depending on how your application is built. For example, items that are "critical" to a particular resource taken in isolation might not be as important as "errors" in a resource type that is central to your Azure application. Be sure to consider this fact when deciding what events to alert on. --## Categories -Each event in the Activity Log has a particular category that is described in the following table. See the sections below for more detail on each category and its schema when you access the Activity log from the portal, PowerShell, CLI, and REST API. The schema is different when you [stream the Activity log to storage or Event Hubs](./resource-logs.md#send-to-azure-event-hubs). A mapping of the properties to the [resource logs schema](./resource-logs-schema.md) is provided in the last section of the article. --| Category | Description | -|:|:| -| [Administrative](#administrative-category) | Contains the record of all create, update, delete, and action operations performed through Resource Manager. Examples of Administrative events include _create virtual machine_ and _delete network security group_.<br><br>Every action taken by a user or application using Resource Manager is modeled as an operation on a particular resource type. If the operation type is _Write_, _Delete_, or _Action_, the records of both the start and success or fail of that operation are recorded in the Administrative category. Administrative events also include any changes to Azure role-based access control in a subscription. | -| [Service Health](#service-health-category) | Contains the record of any service health incidents that occurred in Azure. An example of a Service Health event _SQL Azure in East US is experiencing downtime_. <br><br>Service Health events come in Six varieties: _Action Required_, _Assisted Recovery_, _Incident_, _Maintenance_, _Information_, or _Security_. These events are only created if you have a resource in the subscription impacted by the event. -| [Resource Health](#resource-health-category) | Contains the record of any resource health events that occurred to your Azure resources. An example of a Resource Health event is _Virtual Machine health status changed to unavailable_.<br><br>Resource Health events can represent one of four health statuses: _Available_, _Unavailable_, _Degraded_, and _Unknown_. Additionally, Resource Health events can be categorized as being _Platform Initiated_ or _User Initiated_. | -| [Alert](#alert-category) | Contains the record of activations for Azure alerts. An example of an Alert event is _CPU % on myVM above 80 for the past 5 minutes_.| -| [Autoscale](#autoscale-category) | Contains the record of any events related to the operation of the autoscale engine based on any autoscale settings you defined in your subscription. An example of an Autoscale event is _Autoscale scale up action failed_. | -| [Recommendation](#recommendation-category) | Contains recommendation events from Azure Advisor. | -| [Security](#security-category) | Contains the record of any alerts generated by Microsoft Defender for Cloud. An example of a Security event is _Suspicious double extension file executed_. | -| [Policy](#policy-category) | Contains records of all effect action operations performed by Azure Policy. Examples of Policy events include _Audit_ and _Deny_. Every action taken by Policy is modeled as an operation on a resource. | --## Administrative category -This category contains the record of all create, update, delete, and action operations performed through Resource Manager. Examples of the types of events you would see in this category include "create virtual machine" and "delete network security group". Every action taken by a user or application using Resource Manager is modeled as an operation on a particular resource type. If the operation type is Write, Delete, or Action, the records of both the start and success or fail of that operation are recorded in the Administrative category. The Administrative category also includes any changes to Azure role-based access control in a subscription. --### Sample event -```json -{ - "authorization": { - "action": "Microsoft.Network/networkSecurityGroups/write", - "scope": "/subscriptions/<subscription ID>/resourcegroups/myResourceGroup/providers/Microsoft.Network/networkSecurityGroups/myNSG" - }, - "caller": "rob@contoso.com", - "channels": "Operation", - "claims": { - "aud": "https://management.core.windows.net/", - "iss": "https://sts.windows.net/1114444b-7467-4144-a616-e3a5d63e147b/", - "iat": "1234567890", - "nbf": "1234567890", - "exp": "1234567890", - "_claim_names": "{\"groups\":\"src1\"}", - "_claim_sources": "{\"src1\":{\"endpoint\":\"https://graph.microsoft.com/1114444b-7467-4144-a616-e3a5d63e147b/users/f409edeb-4d29-44b5-9763-ee9348ad91bb/getMemberObjects\"}}", - "http://schemas.microsoft.com/claims/authnclassreference": "1", - "aio": "A3GgTJdwK4vy7Fa7l6DgJC2mI0GX44tML385OpU1Q+z+jaPnFMwB", - "http://schemas.microsoft.com/claims/authnmethodsreferences": "rsa,mfa", - "appid": "355249ed-15d9-460d-8481-84026b065942", - "appidacr": "2", - "http://schemas.microsoft.com/2012/01/devicecontext/claims/identifier": "10845a4d-ffa4-4b61-a3b4-e57b9b31cdb5", - "e_exp": "262800", - "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/surname": "Robertson", - "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/givenname": "Rob", - "ipaddr": "111.111.1.111", - "name": "Rob Robertson", - "http://schemas.microsoft.com/identity/claims/objectidentifier": "f409edeb-4d29-44b5-9763-ee9348ad91bb", - "onprem_sid": "S-1-5-21-4837261184-168309720-1886587427-18514304", - "puid": "18247BBD84827C6D", - "http://schemas.microsoft.com/identity/claims/scope": "user_impersonation", - "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/nameidentifier": "b-24Jf94A3FH2sHWVIFqO3-RSJEiv24Jnif3gj7s", - "http://schemas.microsoft.com/identity/claims/tenantid": "1114444b-7467-4144-a616-e3a5d63e147b", - "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/name": "rob@contoso.com", - "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/upn": "rob@contoso.com", - "uti": "IdP3SUJGtkGlt7dDQVRPAA", - "ver": "1.0" - }, - "correlationId": "b5768deb-836b-41cc-803e-3f4de2f9e40b", - "eventDataId": "d0d36f97-b29c-4cd9-9d3d-ea2b92af3e9d", - "eventName": { - "value": "EndRequest", - "localizedValue": "End request" - }, - "category": { - "value": "Administrative", - "localizedValue": "Administrative" - }, - "eventTimestamp": "2018-01-29T20:42:31.3810679Z", - "id": "/subscriptions/<subscription ID>/resourcegroups/myResourceGroup/providers/Microsoft.Network/networkSecurityGroups/myNSG/events/d0d36f97-b29c-4cd9-9d3d-ea2b92af3e9d/ticks/636528553513810679", - "level": "Informational", - "operationId": "04e575f8-48d0-4c43-a8b3-78c4eb01d287", - "operationName": { - "value": "Microsoft.Network/networkSecurityGroups/write", - "localizedValue": "Microsoft.Network/networkSecurityGroups/write" - }, - "resourceGroupName": "myResourceGroup", - "resourceProviderName": { - "value": "Microsoft.Network", - "localizedValue": "Microsoft.Network" - }, - "resourceType": { - "value": "Microsoft.Network/networkSecurityGroups", - "localizedValue": "Microsoft.Network/networkSecurityGroups" - }, - "resourceId": "/subscriptions/<subscription ID>/resourcegroups/myResourceGroup/providers/Microsoft.Network/networkSecurityGroups/myNSG", - "status": { - "value": "Succeeded", - "localizedValue": "Succeeded" - }, - "subStatus": { - "value": "", - "localizedValue": "" - }, - "submissionTimestamp": "2018-01-29T20:42:50.0724829Z", - "subscriptionId": "<subscription ID>", - "properties": { - "statusCode": "Created", - "serviceRequestId": "a4c11dbd-697e-47c5-9663-12362307157d", - "responseBody": "", - "requestbody": "" - }, - "relatedEvents": [] -} --``` --### Property descriptions -| Element Name | Description | -| | | -| authorization |Blob of Azure RBAC properties of the event. Usually includes the ΓÇ£actionΓÇ¥, ΓÇ£roleΓÇ¥ and ΓÇ£scopeΓÇ¥ properties. | -| caller |Email address of the user who has performed the operation, UPN claim, or SPN claim based on availability. | -| channels |One of the following values: ΓÇ£AdminΓÇ¥, ΓÇ£OperationΓÇ¥ | -| claims |The JWT token used by Active Directory to authenticate the user or application to perform this operation in Resource Manager. | -| correlationId |Usually a GUID in the string format. Events that share a correlationId belong to the same uber action. | -| description |Static text description of an event. | -| eventDataId |Unique identifier of an event. | -| eventName | Friendly name of the Administrative event. | -| category | Always "Administrative" | -| httpRequest |Blob describing the Http Request. Usually includes the ΓÇ£clientRequestIdΓÇ¥, ΓÇ£clientIpAddressΓÇ¥ and ΓÇ£methodΓÇ¥ (HTTP method. For example, PUT). | -| level |[Severity level](#severity-level) of the event. | -| resourceGroupName |Name of the resource group for the impacted resource. | -| resourceProviderName |Name of the resource provider for the impacted resource | -| resourceType | The type of resource affected by an Administrative event. | -| resourceId |Resource ID of the impacted resource. | -| operationId |A GUID shared among the events that correspond to a single operation. | -| operationName |Name of the operation. | -| properties |Set of `<Key, Value>` pairs (that is, a Dictionary) describing the details of the event. | -| status |String describing the status of the operation. Some common values are: Started, In Progress, Succeeded, Failed, Active, Resolved. | -| subStatus |Usually the HTTP status code of the corresponding REST call, but can also include other strings describing a subStatus, such as these common values: OK (HTTP Status Code: 200), Created (HTTP Status Code: 201), Accepted (HTTP Status Code: 202), No Content (HTTP Status Code: 204), Bad Request (HTTP Status Code: 400), Not Found (HTTP Status Code: 404), Conflict (HTTP Status Code: 409), Internal Server Error (HTTP Status Code: 500), Service Unavailable (HTTP Status Code: 503), Gateway Timeout (HTTP Status Code: 504). | -| eventTimestamp |Timestamp when the event was generated by the Azure service processing the request corresponding the event. | -| submissionTimestamp |Timestamp when the event became available for querying. | -| subscriptionId |Azure Subscription ID. | --## Service health category -This category contains the record of any service health incidents that occurred in Azure. An example of the type of event you would see in this category is "SQL Azure in East US is experiencing downtime." Service health events come in five varieties: Action Required, Incident, Maintenance, Information, or Security, and only appear if you have a resource in the subscription that would be impacted by the event. --### Sample event -```json -{ - "channels": "Admin", - "correlationId": "c550176b-8f52-4380-bdc5-36c1b59d3a44", - "description": "Active: Network Infrastructure - UK South", - "eventDataId": "c5bc4514-6642-2be3-453e-c6a67841b073", - "eventName": { - "value": null - }, - "category": { - "value": "ServiceHealth", - "localizedValue": "Service Health" - }, - "eventTimestamp": "2017-07-20T23:30:14.8022297Z", - "id": "/subscriptions/<subscription ID>/events/c5bc4514-6642-2be3-453e-c6a67841b073/ticks/636361902148022297", - "level": "Warning", - "operationName": { - "value": "Microsoft.ServiceHealth/incident/action", - "localizedValue": "Microsoft.ServiceHealth/incident/action" - }, - "resourceProviderName": { - "value": null - }, - "resourceType": { - "value": null, - "localizedValue": "" - }, - "resourceId": "/subscriptions/<subscription ID>", - "status": { - "value": "Active", - "localizedValue": "Active" - }, - "subStatus": { - "value": null - }, - "submissionTimestamp": "2017-07-20T23:30:34.7431946Z", - "subscriptionId": "<subscription ID>", - "properties": { - "title": "Network Infrastructure - UK South", - "service": "Service Fabric", - "region": "UK South", - "communication": "Starting at approximately 21:41 UTC on 20 Jul 2017, a subset of customers in UK South may experience degraded performance, connectivity drops or timeouts when accessing their Azure resources hosted in this region. Engineers are investigating underlying Network Infrastructure issues in this region. Impacted services may include, but are not limited to App Services, Automation, Service Bus, Log Analytics, Key Vault, SQL Database, Service Fabric, Event Hubs, Stream Analytics, Azure Data Movement, API Management, and Azure Cognitive Search. Multiple engineering teams are engaged in multiple workflows to mitigate the impact. The next update will be provided in 60 minutes, or as events warrant.", - "incidentType": "Incident", - "trackingId": "NA0F-BJG", - "impactStartTime": "2017-07-20T21:41:00.0000000Z", - "impactedServices": "[{\"ImpactedRegions\":[{\"RegionName\":\"UK South\"}],\"ServiceName\":\"Service Fabric\"}]", - "defaultLanguageTitle": "Network Infrastructure - UK South", - "defaultLanguageContent": "Starting at approximately 21:41 UTC on 20 Jul 2017, a subset of customers in UK South may experience degraded performance, connectivity drops or timeouts when accessing their Azure resources hosted in this region. Engineers are investigating underlying Network Infrastructure issues in this region. Impacted services may include, but are not limited to App Services, Automation, Service Bus, Log Analytics, Key Vault, SQL Database, Service Fabric, Event Hubs, Stream Analytics, Azure Data Movement, API Management, and Azure Cognitive Search. Multiple engineering teams are engaged in multiple workflows to mitigate the impact. The next update will be provided in 60 minutes, or as events warrant.", - "stage": "Active", - "communicationId": "636361902146035247", - "version": "0.1.1" - } -} -``` -Refer to the [service health notifications](../../service-health/service-notifications.md) article for documentation about the values in the properties. --## Resource health category -This category contains the record of resource health events that have occurred to your Azure resources. An example of the type of event you would see in this category is "Virtual Machine health status changed to unavailable." Resource health events can represent one of four health statuses: Available, Unavailable, Degraded, and Unknown. Additionally, resource health events can be categorized as being Platform Initiated or User Initiated. --A resource health event is recorded in the activity log when: -- An annotation, for example "ResourceDegraded" or "AccountClientThrottling", is submitted for a resource.-- A resource transitioned to or from Unhealthy.-- A resource was Unhealthy for more than 15 minutes.--The following resource health transitions aren't recorded in the activity log: -- A transition to Unknown state.-- A transition from Unknown state if:- - This is the first transition. - - If the state prior to Unknown is the same as the new state after. (For example, if the resource transitioned from Healthy to Unknown and back to Healthy). - - For compute resources: VMs that transition from Healthy to Unhealthy, and back to Healthy, when the Unhealthy time is less than 35 seconds. --### Sample event --```json -{ - "channels": "Admin, Operation", - "correlationId": "28f1bfae-56d3-7urb-bff4-194d261248e9", - "description": "", - "eventDataId": "a80024e1-883d-37ur-8b01-7591a1befccb", - "eventName": { - "value": "", - "localizedValue": "" - }, - "category": { - "value": "ResourceHealth", - "localizedValue": "Resource Health" - }, - "eventTimestamp": "2018-09-04T15:33:43.65Z", - "id": "/subscriptions/<subscription ID>/resourceGroups/<resource group>/providers/Microsoft.Compute/virtualMachines/<resource name>/events/a80024e1-883d-42a5-8b01-7591a1befccb/ticks/636716720236500000", - "level": "Critical", - "operationId": "", - "operationName": { - "value": "Microsoft.Resourcehealth/healthevent/Activated/action", - "localizedValue": "Health Event Activated" - }, - "resourceGroupName": "<resource group>", - "resourceProviderName": { - "value": "Microsoft.Resourcehealth/healthevent/action", - "localizedValue": "Microsoft.Resourcehealth/healthevent/action" - }, - "resourceType": { - "value": "Microsoft.Compute/virtualMachines", - "localizedValue": "Microsoft.Compute/virtualMachines" - }, - "resourceId": "/subscriptions/<subscription ID>/resourceGroups/<resource group>/providers/Microsoft.Compute/virtualMachines/<resource name>", - "status": { - "value": "Active", - "localizedValue": "Active" - }, - "subStatus": { - "value": "", - "localizedValue": "" - }, - "submissionTimestamp": "2018-09-04T15:36:24.2240867Z", - "subscriptionId": "<subscription ID>", - "properties": { - "stage": "Active", - "title": "Virtual Machine health status changed to unavailable", - "details": "Virtual machine has experienced an unexpected event", - "healthStatus": "Unavailable", - "healthEventType": "Downtime", - "healthEventCause": "PlatformInitiated", - "healthEventCategory": "Unplanned" - }, - "relatedEvents": [] -} -``` --### Property descriptions -| Element Name | Description | -| | | -| channels | Always ΓÇ£Admin, OperationΓÇ¥ | -| correlationId | A GUID in the string format. | -| description |Static text description of the alert event. | -| eventDataId |Unique identifier of the alert event. | -| category | Always "ResourceHealth" | -| eventTimestamp |Timestamp when the event was generated by the Azure service processing the request corresponding the event. | -| level |[Severity level](#severity-level) of the event. | -| operationId |A GUID shared among the events that correspond to a single operation. | -| operationName |Name of the operation. | -| resourceGroupName |Name of the resource group that contains the resource. | -| resourceProviderName |Always "Microsoft.Resourcehealth/healthevent/action". | -| resourceType | The type of resource affected by a Resource Health event. | -| resourceId | Name of the resource ID for the impacted resource. | -| status |String describing the status of the health event. Values can be: Active, Resolved, InProgress, Updated. | -| subStatus | Usually null for alerts. | -| submissionTimestamp |Timestamp when the event became available for querying. | -| subscriptionId |Azure Subscription ID. | -| properties |Set of `<Key, Value>` pairs (that is, a Dictionary) describing the details of the event.| -| properties.title | A user-friendly string that describes the health status of the resource. | -| properties.details | A user-friendly string that describes further details about the event. | -| properties.currentHealthStatus | The current health status of the resource. One of the following values: "Available", "Unavailable", "Degraded", and "Unknown". | -| properties.previousHealthStatus | The previous health status of the resource. One of the following values: "Available", "Unavailable", "Degraded", and "Unknown". | -| properties.type | A description of the type of resource health event. | -| properties.cause | A description of the cause of the resource health event. Either "UserInitiated" and "PlatformInitiated". | ---## Alert category -This category contains the record of all activations of classic Azure alerts. An example of the type of event you would see in this category is "CPU % on myVM is over 80 for the past 5 minutes." Various Azure systems have an alerting concept: you can define a rule of some sort and receive a notification when conditions match that rule. Each time a supported Azure alert type 'activates,' or the conditions are met to generate a notification, a record of the activation is also pushed to this category of the Activity Log. --### Sample event --```json -{ - "caller": "Microsoft.Insights/alertRules", - "channels": "Admin, Operation", - "claims": { - "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/spn": "Microsoft.Insights/alertRules" - }, - "correlationId": "/subscriptions/<subscription ID>/resourceGroups/myResourceGroup/providers/microsoft.insights/alertrules/myalert/incidents/L3N1YnNjcmlwdGlvbnMvZGY2MDJjOWMtN2FhMC00MDdkLWE2ZmItZWIyMGM4YmQxMTkyL3Jlc291cmNlR3JvdXBzL0NzbUV2ZW50RE9HRk9PRC1XZXN0VVMvcHJvdmlkZXJzL21pY3Jvc29mdC5pbnNpZ2h0cy9hbGVydHJ1bGVzL215YWxlcnQwNjM2MzYyMjU4NTM1MjIxOTIw", - "description": "'Disk read LessThan 100000 ([Count]) in the last 5 minutes' has been resolved for CloudService: myResourceGroup/Production/Event.BackgroundJobsWorker.razzle (myResourceGroup)", - "eventDataId": "149d4baf-53dc-4cf4-9e29-17de37405cd9", - "eventName": { - "value": "Alert", - "localizedValue": "Alert" - }, - "category": { - "value": "Alert", - "localizedValue": "Alert" - }, - "id": "/subscriptions/<subscription ID>/resourceGroups/myResourceGroup/providers/Microsoft.ClassicCompute/domainNames/myResourceGroup/slots/Production/roles/Event.BackgroundJobsWorker.razzle/events/149d4baf-53dc-4cf4-9e29-17de37405cd9/ticks/636362258535221920", - "level": "Informational", - "resourceGroupName": "myResourceGroup", - "resourceProviderName": { - "value": "Microsoft.ClassicCompute", - "localizedValue": "Microsoft.ClassicCompute" - }, - "resourceId": "/subscriptions/<subscription ID>/resourceGroups/myResourceGroup/providers/Microsoft.ClassicCompute/domainNames/myResourceGroup/slots/Production/roles/Event.BackgroundJobsWorker.razzle", - "resourceType": { - "value": "Microsoft.ClassicCompute/domainNames/slots/roles", - "localizedValue": "Microsoft.ClassicCompute/domainNames/slots/roles" - }, - "operationId": "/subscriptions/<subscription ID>/resourceGroups/myResourceGroup/providers/microsoft.insights/alertrules/myalert/incidents/L3N1YnNjcmlwdGlvbnMvZGY2MDJjOWMtN2FhMC00MDdkLWE2ZmItZWIyMGM4YmQxMTkyL3Jlc291cmNlR3JvdXBzL0NzbUV2ZW50RE9HRk9PRC1XZXN0VVMvcHJvdmlkZXJzL21pY3Jvc29mdC5pbnNpZ2h0cy9hbGVydHJ1bGVzL215YWxlcnQwNjM2MzYyMjU4NTM1MjIxOTIw", - "operationName": { - "value": "Microsoft.Insights/AlertRules/Resolved/Action", - "localizedValue": "Microsoft.Insights/AlertRules/Resolved/Action" - }, - "properties": { - "RuleUri": "/subscriptions/<subscription ID>/resourceGroups/myResourceGroup/providers/microsoft.insights/alertrules/myalert", - "RuleName": "myalert", - "RuleDescription": "", - "Threshold": "100000", - "WindowSizeInMinutes": "5", - "Aggregation": "Average", - "Operator": "LessThan", - "MetricName": "Disk read", - "MetricUnit": "Count" - }, - "status": { - "value": "Resolved", - "localizedValue": "Resolved" - }, - "subStatus": { - "value": null - }, - "eventTimestamp": "2017-07-21T09:24:13.522192Z", - "submissionTimestamp": "2017-07-21T09:24:15.6578651Z", - "subscriptionId": "<subscription ID>" -} -``` --### Property descriptions -| Element Name | Description | -| | | -| caller | Always Microsoft.Insights/alertRules | -| channels | Always ΓÇ£Admin, OperationΓÇ¥ | -| claims | JSON blob with the SPN (service principal name), or resource type, of the alert engine. | -| correlationId | A GUID in the string format. | -| description |Static text description of the alert event. | -| eventDataId |Unique identifier of the alert event. | -| category | Always "Alert" | -| level |[Severity level](#severity-level) of the event. | -| resourceGroupName |Name of the resource group for the impacted resource if it's a metric alert. For other alert types, it's the name of the resource group that contains the alert itself. | -| resourceProviderName |Name of the resource provider for the impacted resource if it's a metric alert. For other alert types, it's the name of the resource provider for the alert itself. | -| resourceId | Name of the resource ID for the impacted resource if it's a metric alert. For other alert types, it's the resource ID of the alert resource itself. | -| operationId |A GUID shared among the events that correspond to a single operation. | -| operationName |Name of the operation. | -| properties |Set of `<Key, Value>` pairs (that is, a Dictionary) describing the details of the event. | -| status |String describing the status of the operation. Some common values are: Started, In Progress, Succeeded, Failed, Active, Resolved. | -| subStatus | Usually null for alerts. | -| eventTimestamp |Timestamp when the event was generated by the Azure service processing the request corresponding the event. | -| submissionTimestamp |Timestamp when the event became available for querying. | -| subscriptionId |Azure Subscription ID. | --### Properties field per alert type -The properties field will contain different values depending on the source of the alert event. Two common alert event providers are Activity Log alerts and metric alerts. --#### Properties for Activity Log alerts -| Element Name | Description | -| | | -| properties.subscriptionId | The subscription ID from the activity log event that caused this activity log alert rule to be activated. | -| properties.eventDataId | The event data ID from the activity log event that caused this activity log alert rule to be activated. | -| properties.resourceGroup | The resource group from the activity log event that caused this activity log alert rule to be activated. | -| properties.resourceId | The resource ID from the activity log event that caused this activity log alert rule to be activated. | -| properties.eventTimestamp | The event timestamp of the activity log event that caused this activity log alert rule to be activated. | -| properties.operationName | The operation name from the activity log event that caused this activity log alert rule to be activated. | -| properties.status | The status from the activity log event that caused this activity log alert rule to be activated.| --#### Properties for metric alerts -| Element Name | Description | -| | | -| properties.RuleUri | Resource ID of the metric alert rule itself. | -| properties.RuleName | The name of the metric alert rule. | -| properties.RuleDescription | The description of the metric alert rule (as defined in the alert rule). | -| properties.Threshold | The threshold value used in the evaluation of the metric alert rule. | -| properties.WindowSizeInMinutes | The window size used in the evaluation of the metric alert rule. | -| properties.Aggregation | The aggregation type defined in the metric alert rule. | -| properties.Operator | The conditional operator used in the evaluation of the metric alert rule. | -| properties.MetricName | The metric name of the metric used in the evaluation of the metric alert rule. | -| properties.MetricUnit | The metric unit for the metric used in the evaluation of the metric alert rule. | --## Autoscale category -This category contains the record of any events related to the operation of the autoscale engine based on any autoscale settings you have defined in your subscription. An example of the type of event you would see in this category is "Autoscale scale up action failed." Using autoscale, you can automatically scale out or scale in the number of instances in a supported resource type based on time of day and/or load (metric) data using an autoscale setting. When the conditions are met to scale up or down, the start and succeeded or failed events are recorded in this category. --### Sample event -```json -{ - "caller": "Microsoft.Insights/autoscaleSettings", - "channels": "Admin, Operation", - "claims": { - "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/spn": "Microsoft.Insights/autoscaleSettings" - }, - "correlationId": "fc6a7ff5-ff68-4bb7-81b4-3629212d03d0", - "description": "The autoscale engine attempting to scale resource '/subscriptions/<subscription ID>/resourceGroups/myResourceGroup/providers/Microsoft.ClassicCompute/domainNames/myResourceGroup/slots/Production/roles/myResource' from 3 instances count to 2 instances count.", - "eventDataId": "a5b92075-1de9-42f1-b52e-6f3e4945a7c7", - "eventName": { - "value": "AutoscaleAction", - "localizedValue": "AutoscaleAction" - }, - "category": { - "value": "Autoscale", - "localizedValue": "Autoscale" - }, - "id": "/subscriptions/<subscription ID>/resourceGroups/myResourceGroup/providers/microsoft.insights/autoscalesettings/myResourceGroup-Production-myResource-myResourceGroup/events/a5b92075-1de9-42f1-b52e-6f3e4945a7c7/ticks/636361956518681572", - "level": "Informational", - "resourceGroupName": "myResourceGroup", - "resourceProviderName": { - "value": "microsoft.insights", - "localizedValue": "microsoft.insights" - }, - "resourceId": "/subscriptions/<subscription ID>/resourceGroups/myResourceGroup/providers/microsoft.insights/autoscalesettings/myResourceGroup-Production-myResource-myResourceGroup", - "resourceType": { - "value": "microsoft.insights/autoscalesettings", - "localizedValue": "microsoft.insights/autoscalesettings" - }, - "operationId": "fc6a7ff5-ff68-4bb7-81b4-3629212d03d0", - "operationName": { - "value": "Microsoft.Insights/AutoscaleSettings/Scaledown/Action", - "localizedValue": "Microsoft.Insights/AutoscaleSettings/Scaledown/Action" - }, - "properties": { - "Description": "The autoscale engine attempting to scale resource '/subscriptions/<subscription ID>/resourceGroups/myResourceGroup/providers/Microsoft.ClassicCompute/domainNames/myResourceGroup/slots/Production/roles/myResource' from 3 instances count to 2 instances count.", - "ResourceName": "/subscriptions/<subscription ID>/resourceGroups/myResourceGroup/providers/Microsoft.ClassicCompute/domainNames/myResourceGroup/slots/Production/roles/myResource", - "OldInstancesCount": "3", - "NewInstancesCount": "2", - "LastScaleActionTime": "Fri, 21 Jul 2017 01:00:51 GMT" - }, - "status": { - "value": "Succeeded", - "localizedValue": "Succeeded" - }, - "subStatus": { - "value": null - }, - "eventTimestamp": "2017-07-21T01:00:51.8681572Z", - "submissionTimestamp": "2017-07-21T01:00:52.3008754Z", - "subscriptionId": "<subscription ID>" -} --``` --### Property descriptions -| Element Name | Description | -| | | -| caller | Always Microsoft.Insights/autoscaleSettings | -| channels | Always ΓÇ£Admin, OperationΓÇ¥ | -| claims | JSON blob with the SPN (service principal name), or resource type, of the autoscale engine. | -| correlationId | A GUID in the string format. | -| description |Static text description of the autoscale event. | -| eventDataId |Unique identifier of the autoscale event. | -| level |[Severity level](#severity-level) of the event. | -| resourceGroupName |Name of the resource group for the autoscale setting. | -| resourceProviderName |Name of the resource provider for the autoscale setting. | -| resourceId |Resource ID of the autoscale setting. | -| operationId |A GUID shared among the events that correspond to a single operation. | -| operationName |Name of the operation. | -| properties |Set of `<Key, Value>` pairs (that is, a Dictionary) describing the details of the event. | -| properties.Description | Detailed description of what the autoscale engine was doing. | -| properties.ResourceName | Resource ID of the impacted resource (the resource on which the scale action was being performed) | -| properties.OldInstancesCount | The number of instances before the autoscale action took effect. | -| properties.NewInstancesCount | The number of instances after the autoscale action took effect. | -| properties.LastScaleActionTime | The timestamp of when the autoscale action occurred. | -| status |String describing the status of the operation. Some common values are: Started, In Progress, Succeeded, Failed, Active, Resolved. | -| subStatus | Usually null for autoscale. | -| eventTimestamp |Timestamp when the event was generated by the Azure service processing the request corresponding the event. | -| submissionTimestamp |Timestamp when the event became available for querying. | -| subscriptionId |Azure Subscription ID. | --## Security category -This category contains the record any alerts generated by Microsoft Defender for Cloud. An example of the type of event you would see in this category is "Suspicious double extension file executed." --### Sample event -```json -{ - "channels": "Operation", - "correlationId": "965d6c6a-a790-4a7e-8e9a-41771b3fbc38", - "description": "Suspicious double extension file executed. Machine logs indicate an execution of a process with a suspicious double extension.\r\nThis extension may trick users into thinking files are safe to be opened and might indicate the presence of malware on the system.", - "eventDataId": "965d6c6a-a790-4a7e-8e9a-41771b3fbc38", - "eventName": { - "value": "Suspicious double extension file executed", - "localizedValue": "Suspicious double extension file executed" - }, - "category": { - "value": "Security", - "localizedValue": "Security" - }, - "eventTimestamp": "2017-10-18T06:02:18.6179339Z", - "id": "/subscriptions/<subscription ID>/providers/Microsoft.Security/locations/centralus/alerts/965d6c6a-a790-4a7e-8e9a-41771b3fbc38/events/965d6c6a-a790-4a7e-8e9a-41771b3fbc38/ticks/636439033386179339", - "level": "Informational", - "operationId": "965d6c6a-a790-4a7e-8e9a-41771b3fbc38", - "operationName": { - "value": "Microsoft.Security/locations/alerts/activate/action", - "localizedValue": "Microsoft.Security/locations/alerts/activate/action" - }, - "resourceGroupName": "myResourceGroup", - "resourceProviderName": { - "value": "Microsoft.Security", - "localizedValue": "Microsoft.Security" - }, - "resourceType": { - "value": "Microsoft.Security/locations/alerts", - "localizedValue": "Microsoft.Security/locations/alerts" - }, - "resourceId": "/subscriptions/<subscription ID>/providers/Microsoft.Security/locations/centralus/alerts/2518939942613820660_a48f8653-3fc6-4166-9f19-914f030a13d3", - "status": { - "value": "Active", - "localizedValue": "Active" - }, - "subStatus": { - "value": null - }, - "submissionTimestamp": "2017-10-18T06:02:52.2176969Z", - "subscriptionId": "<subscription ID>", - "properties": { - "accountLogonId": "0x2r4", - "commandLine": "c:\\mydirectory\\doubleetension.pdf.exe", - "domainName": "hpc", - "parentProcess": "unknown", - "parentProcess id": "0", - "processId": "6988", - "processName": "c:\\mydirectory\\doubleetension.pdf.exe", - "userName": "myUser", - "UserSID": "S-3-2-12", - "ActionTaken": "Detected", - "Severity": "High" - }, - "relatedEvents": [] -} --``` --### Property descriptions -| Element Name | Description | -| | | -| channels | Always ΓÇ£OperationΓÇ¥ | -| correlationId | A GUID in the string format. | -| description |Static text description of the security event. | -| eventDataId |Unique identifier of the security event. | -| eventName |Friendly name of the security event. | -| category | Always "Security" | -| ID |Unique resource identifier of the security event. | -| level |[Severity level](#severity-level) of the event.| -| resourceGroupName |Name of the resource group for the resource. | -| resourceProviderName |Name of the resource provider for Microsoft Defender for Cloud. Always "Microsoft.Security". | -| resourceType |The type of resource that generated the security event, such as "Microsoft.Security/locations/alerts" | -| resourceId |Resource ID of the security alert. | -| operationId |A GUID shared among the events that correspond to a single operation. | -| operationName |Name of the operation. | -| properties |Set of `<Key, Value>` pairs (that is, a Dictionary) describing the details of the event. These properties vary depending on the type of security alert. See [this page](../../security-center/security-center-alerts-overview.md) for a description of the types of alerts that come from Defender for Cloud. | -| properties.Severity |The severity level. Possible values are "High," "Medium," or "Low." | -| status |String describing the status of the operation. Some common values are: Started, In Progress, Succeeded, Failed, Active, Resolved. | -| subStatus | Usually null for security events. | -| eventTimestamp |Timestamp when the event was generated by the Azure service processing the request corresponding the event. | -| submissionTimestamp |Timestamp when the event became available for querying. | -| subscriptionId |Azure Subscription ID. | --## Recommendation category -This category contains the record of any new recommendations that are generated for your services. An example of a recommendation would be "Use availability sets for improved fault tolerance." There are four types of Recommendation events that can be generated: High Availability, Performance, Security, and Cost Optimization. --### Sample event -```json -{ - "channels": "Operation", - "correlationId": "92481dfd-c5bf-4752-b0d6-0ecddaa64776", - "description": "The action was successful.", - "eventDataId": "06cb0e44-111b-47c7-a4f2-aa3ee320c9c5", - "eventName": { - "value": "", - "localizedValue": "" - }, - "category": { - "value": "Recommendation", - "localizedValue": "Recommendation" - }, - "eventTimestamp": "2018-06-07T21:30:42.976919Z", - "id": "/SUBSCRIPTIONS/<Subscription ID>/RESOURCEGROUPS/MYRESOURCEGROUP/PROVIDERS/MICROSOFT.COMPUTE/VIRTUALMACHINES/MYVM/events/06cb0e44-111b-47c7-a4f2-aa3ee320c9c5/ticks/636640038429769190", - "level": "Informational", - "operationId": "", - "operationName": { - "value": "Microsoft.Advisor/generateRecommendations/action", - "localizedValue": "Microsoft.Advisor/generateRecommendations/action" - }, - "resourceGroupName": "MYRESOURCEGROUP", - "resourceProviderName": { - "value": "MICROSOFT.COMPUTE", - "localizedValue": "MICROSOFT.COMPUTE" - }, - "resourceType": { - "value": "MICROSOFT.COMPUTE/virtualmachines", - "localizedValue": "MICROSOFT.COMPUTE/virtualmachines" - }, - "resourceId": "/SUBSCRIPTIONS/<Subscription ID>/RESOURCEGROUPS/MYRESOURCEGROUP/PROVIDERS/MICROSOFT.COMPUTE/VIRTUALMACHINES/MYVM", - "status": { - "value": "Active", - "localizedValue": "Active" - }, - "subStatus": { - "value": "", - "localizedValue": "" - }, - "submissionTimestamp": "2018-06-07T21:30:42.976919Z", - "subscriptionId": "<Subscription ID>", - "properties": { - "recommendationSchemaVersion": "1.0", - "recommendationCategory": "Security", - "recommendationImpact": "High", - "recommendationRisk": "None" - }, - "relatedEvents": [] -} --``` -### Property descriptions -| Element Name | Description | -| | | -| channels | Always ΓÇ£OperationΓÇ¥ | -| correlationId | A GUID in the string format. | -| description |Static text description of the recommendation event | -| eventDataId | Unique identifier of the recommendation event. | -| category | Always "Recommendation" | -| ID |Unique resource identifier of the recommendation event. | -| level |[Severity level](#severity-level) of the event.| -| operationName |Name of the operation. Always "Microsoft.Advisor/generateRecommendations/action"| -| resourceGroupName |Name of the resource group for the resource. | -| resourceProviderName |Name of the resource provider for the resource that this recommendation applies to, such as "MICROSOFT.COMPUTE" | -| resourceType |Name of the resource type for the resource that this recommendation applies to, such as "MICROSOFT.COMPUTE/virtualmachines" | -| resourceId |Resource ID of the resource that the recommendation applies to | -| status | Always "Active" | -| submissionTimestamp |Timestamp when the event became available for querying. | -| subscriptionId |Azure Subscription ID. | -| properties |Set of `<Key, Value>` pairs (that is, a Dictionary) describing the details of the recommendation.| -| properties.recommendationSchemaVersion| Schema version of the recommendation properties published in the Activity Log entry | -| properties.recommendationCategory | Category of the recommendation. Possible values are "High Availability", "Performance", "Security", and "Cost" | -| properties.recommendationImpact| Impact of the recommendation. Possible values are "High", "Medium", "Low" | -| properties.recommendationRisk| Risk of the recommendation. Possible values are "Error", "Warning", "None" | --## Policy category --This category contains records of all effect action operations performed by [Azure Policy](../../governance/policy/overview.md). Examples of the types of events you would see in this category include _Audit_ and _Deny_. Every action taken by Policy is modeled as an operation on a resource. --### Sample Policy event --```json -{ - "authorization": { - "action": "Microsoft.Resources/checkPolicyCompliance/read", - "scope": "/subscriptions/<subscriptionID>" - }, - "caller": "33a68b9d-63ce-484c-a97e-94aef4c89648", - "channels": "Operation", - "claims": { - "aud": "https://management.azure.com/", - "iss": "https://sts.windows.net/1114444b-7467-4144-a616-e3a5d63e147b/", - "iat": "1234567890", - "nbf": "1234567890", - "exp": "1234567890", - "aio": "A3GgTJdwK4vy7Fa7l6DgJC2mI0GX44tML385OpU1Q+z+jaPnFMwB", - "appid": "1d78a85d-813d-46f0-b496-dd72f50a3ec0", - "appidacr": "2", - "http://schemas.microsoft.com/identity/claims/identityprovider": "https://sts.windows.net/1114444b-7467-4144-a616-e3a5d63e147b/", - "http://schemas.microsoft.com/identity/claims/objectidentifier": "f409edeb-4d29-44b5-9763-ee9348ad91bb", - "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/nameidentifier": "b-24Jf94A3FH2sHWVIFqO3-RSJEiv24Jnif3gj7s", - "http://schemas.microsoft.com/identity/claims/tenantid": "1114444b-7467-4144-a616-e3a5d63e147b", - "uti": "IdP3SUJGtkGlt7dDQVRPAA", - "ver": "1.0" - }, - "correlationId": "b5768deb-836b-41cc-803e-3f4de2f9e40b", - "description": "", - "eventDataId": "d0d36f97-b29c-4cd9-9d3d-ea2b92af3e9d", - "eventName": { - "value": "EndRequest", - "localizedValue": "End request" - }, - "category": { - "value": "Policy", - "localizedValue": "Policy" - }, - "eventTimestamp": "2019-01-15T13:19:56.1227642Z", - "id": "/subscriptions/<subscriptionID>/resourceGroups/myResourceGroup/providers/Microsoft.Sql/servers/contososqlpolicy/events/13bbf75f-36d5-4e66-b693-725267ff21ce/ticks/636831551961227642", - "level": "Warning", - "operationId": "04e575f8-48d0-4c43-a8b3-78c4eb01d287", - "operationName": { - "value": "Microsoft.Authorization/policies/audit/action", - "localizedValue": "Microsoft.Authorization/policies/audit/action" - }, - "resourceGroupName": "myResourceGroup", - "resourceProviderName": { - "value": "Microsoft.Sql", - "localizedValue": "Microsoft SQL" - }, - "resourceType": { - "value": "Microsoft.Resources/checkPolicyCompliance", - "localizedValue": "Microsoft.Resources/checkPolicyCompliance" - }, - "resourceId": "/subscriptions/<subscriptionID>/resourceGroups/myResourceGroup/providers/Microsoft.Sql/servers/contososqlpolicy", - "status": { - "value": "Succeeded", - "localizedValue": "Succeeded" - }, - "subStatus": { - "value": "", - "localizedValue": "" - }, - "submissionTimestamp": "2019-01-15T13:20:17.1077672Z", - "subscriptionId": "<subscriptionID>", - "properties": { - "isComplianceCheck": "True", - "resourceLocation": "westus2", - "ancestors": "72f988bf-86f1-41af-91ab-2d7cd011db47", - "policies": "[{\"policyDefinitionId\":\"/subscriptions/<subscriptionID>/providers/Microsoft. - Authorization/policyDefinitions/5775cdd5-d3d3-47bf-bc55-bb8b61746506/\",\"policyDefiniti - onName\":\"5775cdd5-d3d3-47bf-bc55-bb8b61746506\",\"policyDefinitionEffect\":\"Deny\",\" - policyAssignmentId\":\"/subscriptions/<subscriptionID>/providers/Microsoft.Authorization - /policyAssignments/991a69402a6c484cb0f9b673/\",\"policyAssignmentName\":\"991a69402a6c48 - 4cb0f9b673\",\"policyAssignmentScope\":\"/subscriptions/<subscriptionID>\",\"policyAssig - nmentParameters\":{}}]" - }, - "relatedEvents": [] -} -``` --### Policy event property descriptions --| Element Name | Description | -| | | -| authorization | Array of Azure RBAC properties of the event. For new resources, this is the action and scope of the request that triggered evaluation. For existing resources, the action is "Microsoft.Resources/checkPolicyCompliance/read". | -| caller | For new resources, the identity that initiated a deployment. For existing resources, the GUID of the Microsoft Azure Policy Insights RP. | -| channels | Policy events use only the "Operation" channel. | -| claims | The JWT token used by Active Directory to authenticate the user or application to perform this operation in Resource Manager. | -| correlationId | Usually a GUID in the string format. Events that share a correlationId belong to the same uber action. | -| description | This field is blank for Policy events. | -| eventDataId | Unique identifier of an event. | -| eventName | Either "BeginRequest" or "EndRequest". "BeginRequest" is used for delayed auditIfNotExists and deployIfNotExists evaluations and when a deployIfNotExists effect starts a template deployment. All other operations return "EndRequest". | -| category | Declares the activity log event as belonging to "Policy". | -| eventTimestamp | Timestamp when the event was generated by the Azure service processing the request corresponding the event. | -| ID | Unique identifier of the event on the specific resource. | -| level | [Severity level](#severity-level) of the event. Audit uses "Warning" and Deny uses "Error". An auditIfNotExists or deployIfNotExists error can generate "Warning" or "Error" depending on severity. All other Policy events use "Informational". | -| operationId | A GUID shared among the events that correspond to a single operation. | -| operationName | Name of the operation and directly correlates to the Policy effect. | -| resourceGroupName | Name of the resource group for the evaluated resource. | -| resourceProviderName | Name of the resource provider for the evaluated resource. | -| resourceType | For new resources, it's the type being evaluated. For existing resources, returns "Microsoft.Resources/checkPolicyCompliance". | -| resourceId | Resource ID of the evaluated resource. | -| status | String describing the status of the Policy evaluation result. Most Policy evaluations return "Succeeded", but a Deny effect returns "Failed". Errors in auditIfNotExists or deployIfNotExists also return "Failed". | -| subStatus | Field is blank for Policy events. | -| submissionTimestamp | Timestamp when the event became available for querying. | -| subscriptionId | Azure Subscription ID. | -| properties.isComplianceCheck | Returns "False" when a new resource is deployed or an existing resource's Resource Manager properties are updated. All other [evaluation triggers](../../governance/policy/how-to/get-compliance-data.md#evaluation-triggers) result in "True". | -| properties.resourceLocation | The Azure region of the resource being evaluated. | -| properties.ancestors | A comma-separated list of parent management groups ordered from direct parent to farthest grandparent. | -| properties.policies | Includes details about the policy definition, assignment, effect, and parameters that this Policy evaluation is a result of. | -| relatedEvents | This field is blank for Policy events. | ---## Schema from storage account and event hubs -When streaming the Azure Activity log to a storage account or event hub, the data follows the [resource log schema](./resource-logs-schema.md). The table below provides a mapping of properties from the above schemas to the resource logs schema. --> [!IMPORTANT] -> The format of Activity log data written to a storage account changed to JSON Lines on Nov. 1st, 2018. See [Prepare for format change to Azure Monitor resource logs archived to a storage account](./resource-logs-blob-format.md) for details on this format change. ---| Resource logs schema property | Activity Log REST API schema property | Notes | -| | | | -| time | eventTimestamp | | -| resourceId | resourceId | subscriptionId, resourceType, resourceGroupName are all inferred from the resourceId. | -| operationName | operationName.value | | -| category | Part of operation name | Breakout of the operation type. "Write", "Delete", or "Action". | -| resultType | status.value | | -| resultSignature | substatus.value | | -| resultDescription | description | | -| durationMs | N/A | Always 0 | -| callerIpAddress | httpRequest.clientIpAddress | | -| correlationId | correlationId | | -| identity | claims and authorization properties | | -| Level | Level | | -| location | N/A | Location of where the event was processed. *This isn't the location of the resource, but rather where the event was processed. This property will be removed in a future update.* | -| Properties | properties.eventProperties | | -| properties.eventCategory | category | If properties.eventCategory isn't present, category is "Administrative" | -| properties.eventName | eventName | | -| properties.operationId | operationId | | -| properties.eventProperties | properties | | --Following is an example of an event using this schema: --```json -{ - "records": [ - { - "time": "2019-01-21T22:14:26.9792776Z", - "resourceId": "/subscriptions/s1/resourceGroups/MSSupportGroup/providers/microsoft.support/supporttickets/123456112305841", - "operationName": "microsoft.support/supporttickets/write", - "category": "Write", - "resultType": "Success", - "resultSignature": "Succeeded.Created", - "durationMs": 2826, - "callerIpAddress": "111.111.111.11", - "correlationId": "c776f9f4-36e5-4e0e-809b-c9b3c3fb62a8", - "identity": { - "authorization": { - "scope": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/rg-001/providers/Microsoft.Storage/storageAccounts/ msftstorageaccount", - "action": "Microsoft.Storage/storageAccounts/listAccountSas/action", - "evidence": { - "role": "Azure Eventhubs Service Role", - "roleAssignmentScope": "/subscriptions/00000000-0000-0000-0000-000000000000", - "roleAssignmentId": "123abc2a6c314b0ab03a891259123abc", - "roleDefinitionId": "123456789de042a6a64b29b123456789", - "principalId": "abcdef038c6444c18f1c31311fabcdef", - "principalType": "ServicePrincipal" - } - }, - "claims": { - "aud": "https://management.core.windows.net/", - "iss": "https://sts.windows.net/abcde123-86f1-41af-91ab-abcde1234567/", - "iat": "1421876371", - "nbf": "1421876371", - "exp": "1421880271", - "ver": "1.0", - "http://schemas.microsoft.com/identity/claims/tenantid": "00000000-0000-0000-0000-000000000000", - "http://schemas.microsoft.com/claims/authnmethodsreferences": "pwd", - "http://schemas.microsoft.com/identity/claims/objectidentifier": "123abc45-8211-44e3-95xq-85137af64708", - "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/upn": "admin@contoso.com", - "puid": "20030000801A118C", - "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/nameidentifier": "9876543210DKk1YzIY8k0t1_EAPaXoeHyPRn6f413zM", - "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/givenname": "John", - "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/surname": "Smith", - "name": "John Smith", - "groups": "12345678-cacfe77c-e058-4712-83qw-f9b08849fd60,12345678-4c41-4b23-99d2-d32ce7aa621c,12345678-0578-4ea0-9gdc-e66cc564d18c", - "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/name": " admin@contoso.com", - "appid": "12345678-3bq0-49c1-b47d-974e53cbdf3c", - "appidacr": "2", - "http://schemas.microsoft.com/identity/claims/scope": "user_impersonation", - "http://schemas.microsoft.com/claims/authnclassreference": "1" - } - }, - "level": "Information", - "location": "global", - "properties": { - "statusCode": "Created", - "serviceRequestId": "12345678-8ca0-47ad-9b80-6cde2207f97c" - } - } - ] -} -``` ----## Next steps -* [Learn more about the Activity Log](./platform-logs-overview.md) -* [Create a diagnostic setting to send Activity Log to Log Analytics workspace, Azure storage, or event hubs](./diagnostic-settings.md) |
| azure-monitor | Activity Log | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/activity-log.md | - Title: Send Azure activity log data -description: Send Azure Monitor activity log data to Azure Monitor Logs, Azure Event Hubs, and Azure Storage. --- Previously updated : 12/11/2023-----# Send Azure Monitor Activity log data --The Azure Monitor Activity Log is a platform log that provides insight into subscription-level events. The Activity Log includes information like when a resource is modified or a virtual machine is started. You can view the Activity Log in the Azure portal or retrieve entries with PowerShell and the Azure CLI. This article provides information on how to view the Activity Log and send it to different destinations. --Create a diagnostic setting to send the Activity Log to one or more of these locations: ---For details on how to create a diagnostic setting, see [Create diagnostic settings to send platform logs and metrics to different destinations](./diagnostic-settings.md). -> [!TIP] -> Send Activity Logs to a Log Analytics workspace for the following benefits: -> * Sending logs to a Log Analytics workspace is free of charge for the default retention period. -> * Send logs to a Log Analytics workspace for [longer retention of up to 12 years](../logs/data-retention-configure.md). -> * Logs exported to a Log Analytics workspace can be [shown in Power BI](/power-bi/transform-model/log-analytics/desktop-log-analytics-overview) -> * [Insights](./activity-log-insights.md) are provided for Activity Logs exported to Log Analytics. --> [!NOTE] -> * Entries in the Activity Log are system generated and can't be changed or deleted. -> * Entries in the Activity Log are representing control plane changes like a virtual machine restart, any non related entries should be written into [Azure Resource Logs](resource-logs.md) -> * Entries in the Activity Log are typically a result of changes (create, update or delete operations) or an action having been initiated. Operations focused on reading details of a resource are not typically captured. --## Send to Log Analytics workspace -- Send the activity log to a Log Analytics workspace to enable the [Azure Monitor Logs](../logs/data-platform-logs.md) feature, where you: --- Correlate activity log data with other monitoring data collected by Azure Monitor.-- Consolidate log entries from multiple Azure subscriptions and tenants into one location for analysis together.-- Use log queries to perform complex analysis and gain deep insights on activity log entries.-- Use log search alerts with Activity entries for more complex alerting logic.-- Store activity log entries for longer than the activity log retention period.-- Incur no data ingestion or retention charges for activity log data stored in a Log Analytics workspace.-- The default retention period in Log Analytics is 90 days-- Select **Export Activity Logs** to send the activity log to a Log Analytics workspace. -- :::image type="content" source="media/activity-log/diagnostic-settings-export.png" lightbox="media/activity-log/diagnostic-settings-export.png" alt-text="Screenshot that shows exporting activity logs."::: --You can send the activity log from any single subscription to up to five workspaces. --Activity log data in a Log Analytics workspace is stored in a table called `AzureActivity` that you can retrieve with a [log query](../logs/log-query-overview.md) in [Log Analytics](../logs/log-analytics-tutorial.md). The structure of this table varies depending on the [category of the log entry](activity-log-schema.md). For a description of the table properties, see the [Azure Monitor data reference](/azure/azure-monitor/reference/tables/azureactivity). --For example, to view a count of activity log records for each category, use the following query: --```kusto -AzureActivity -| summarize count() by CategoryValue -``` --To retrieve all records in the administrative category, use the following query: --```kusto -AzureActivity -| where CategoryValue == "Administrative" -``` --> [!Important] -> In some scenarios, it's possible that values in fields of AzureActivity might have different casings from otherwise equivalent values. Take care when querying data in AzureActivity to use case-insensitive operators for string comparisons, or use a scalar function to force a field to a uniform casing before any comparisons. For example, use the [tolower()](/azure/kusto/query/tolowerfunction) function on a field to force it to always be lowercase or the [=~ operator](/azure/kusto/query/datatypes-string-operators) when performing a string comparison. --## Send to Azure Event Hubs --Send the activity log to Azure Event Hubs to send entries outside of Azure, for example, to a third-party SIEM or other log analytics solutions. Activity log events from event hubs are consumed in JSON format with a `records` element that contains the records in each payload. The schema depends on the category and is described in [Azure activity log event schema](activity-log-schema.md). --The following sample output data is from event hubs for an activity log: --```json -{ - "records": [ - { - "time": "2019-01-21T22:14:26.9792776Z", - "resourceId": "/subscriptions/s1/resourceGroups/MSSupportGroup/providers/microsoft.support/supporttickets/115012112305841", - "operationName": "microsoft.support/supporttickets/write", - "category": "Write", - "resultType": "Success", - "resultSignature": "Succeeded.Created", - "durationMs": 2826, - "callerIpAddress": "111.111.111.11", - "correlationId": "c776f9f4-36e5-4e0e-809b-c9b3c3fb62a8", - "identity": { - "authorization": { - "scope": "/subscriptions/s1/resourceGroups/MSSupportGroup/providers/microsoft.support/supporttickets/115012112305841", - "action": "microsoft.support/supporttickets/write", - "evidence": { - "role": "Subscription Admin" - } - }, - "claims": { - "aud": "https://management.core.windows.net/", - "iss": "https://sts.windows.net/72f988bf-86f1-41af-91ab-2d7cd011db47/", - "iat": "1421876371", - "nbf": "1421876371", - "exp": "1421880271", - "ver": "1.0", - "http://schemas.microsoft.com/identity/claims/tenantid": "00000000-0000-0000-0000-000000000000", - "http://schemas.microsoft.com/claims/authnmethodsreferences": "pwd", - "http://schemas.microsoft.com/identity/claims/objectidentifier": "2468adf0-8211-44e3-95xq-85137af64708", - "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/upn": "admin@contoso.com", - "puid": "20030000801A118C", - "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/nameidentifier": "9vckmEGF7zDKk1YzIY8k0t1_EAPaXoeHyPRn6f413zM", - "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/givenname": "John", - "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/surname": "Smith", - "name": "John Smith", - "groups": "cacfe77c-e058-4712-83qw-f9b08849fd60,7f71d11d-4c41-4b23-99d2-d32ce7aa621c,31522864-0578-4ea0-9gdc-e66cc564d18c", - "http://schemas.xmlsoap.org/ws/2005/05/identity/claims/name": " admin@contoso.com", - "appid": "c44b4083-3bq0-49c1-b47d-974e53cbdf3c", - "appidacr": "2", - "http://schemas.microsoft.com/identity/claims/scope": "user_impersonation", - "http://schemas.microsoft.com/claims/authnclassreference": "1" - } - }, - "level": "Information", - "location": "global", - "properties": { - "statusCode": "Created", - "serviceRequestId": "50d5cddb-8ca0-47ad-9b80-6cde2207f97c" - } - } - ] -} -``` --## Send to Azure Storage --Send the activity log to an Azure Storage account if you want to retain your log data longer than 90 days for audit, static analysis, or back up. If you're required to retain your events for 90 days or less, you don't need to set up archival to a storage account. Activity log events are retained in the Azure platform for 90 days. --When you send the activity log to Azure, a storage container is created in the storage account as soon as an event occurs. The blobs in the container use the following naming convention: --``` -insights-activity-logs/resourceId=/SUBSCRIPTIONS/{subscription ID}/y={four-digit numeric year}/m={two-digit numeric month}/d={two-digit numeric day}/h={two-digit 24-hour clock hour}/m=00/PT1H.json -``` --For example, a particular blob might have a name similar to: --``` -insights-activity-logs/resourceId=/SUBSCRIPTIONS/00000000-0000-0000-0000-000000000000/y=2020/m=06/d=08/h=18/m=00/PT1H.json -``` --Each PT1H.json blob contains a JSON object with events from log files that were received during the hour specified in the blob URL. During the present hour, events are appended to the PT1H.json file as they're received, regardless of when they were generated. The minute value in the URL, `m=00` is always `00` as blobs are created on a per hour basis. --Each event is stored in the PT1H.json file with the following format. This format uses a common top-level schema but is otherwise unique for each category, as described in [Activity log schema](activity-log-schema.md). --```json -{ "time": "2020-06-12T13:07:46.766Z", "resourceId": "/SUBSCRIPTIONS/00000000-0000-0000-0000-000000000000/RESOURCEGROUPS/MY-RESOURCE-GROUP/PROVIDERS/MICROSOFT.COMPUTE/VIRTUALMACHINES/MV-VM-01", "correlationId": "0f0cb6b4-804b-4129-b893-70aeeb63997e", "operationName": "Microsoft.Resourcehealth/healthevent/Updated/action", "level": "Information", "resultType": "Updated", "category": "ResourceHealth", "properties": {"eventCategory":"ResourceHealth","eventProperties":{"title":"This virtual machine is starting as requested by an authorized user or process. It will be online shortly.","details":"VirtualMachineStartInitiatedByControlPlane","currentHealthStatus":"Unknown","previousHealthStatus":"Unknown","type":"Downtime","cause":"UserInitiated"}}} -``` -### Other methods to retrieve activity log events --You can also access activity log events by using the following methods: --- Use the [Get-AzLog](/powershell/module/az.monitor/get-azlog) cmdlet to retrieve the activity log from PowerShell. See [Azure Monitor PowerShell samples](../powershell-samples.md#retrieve-activity-log).-- Use [az monitor activity-log](/cli/azure/monitor/activity-log) to retrieve the activity log from the CLI. See [Azure Monitor CLI samples](../cli-samples.md#view-activity-log).-- Use the [Azure Monitor REST API](/rest/api/monitor/) to retrieve the activity log from a REST client.-## Legacy collection methods --> [!NOTE] -> * Azure Activity logs solution was used to forward Activity Logs to Azure Log Analytics. This solution is being retired on the 15th of Sept 2026 and will be automatically converted to Diagnostic settings. --If you're collecting activity logs using the legacy collection method, we recommend you [export activity logs to your Log Analytics workspace](#send-to-log-analytics-workspace) and disable the legacy collection using the [Data Sources - Delete API](/rest/api/loganalytics/data-sources/delete?tabs=HTTP) as follows: --1. List all data sources connected to the workspace using the [Data Sources - List By Workspace API](/rest/api/loganalytics/data-sources/list-by-workspace?tabs=HTTP#code-try-0) and filter for activity logs by setting `kind eq 'AzureActivityLog'`. -- :::image type="content" source="media/activity-log/data-sources-list-by-workspace-api.png" alt-text="Screenshot showing the configuration of the Data Sources - List By Workspace API." lightbox="media/activity-log/data-sources-list-by-workspace-api.png"::: --1. Copy the name of the connection you want to disable from the API response. -- :::image type="content" source="media/activity-log/data-sources-list-by-workspace-api-connection.png" alt-text="Screenshot showing the connection information you need to copy from the output of the Data Sources - List By Workspace API." lightbox="media/activity-log/data-sources-list-by-workspace-api-connection.png"::: - -1. Use the [Data Sources - Delete API](/rest/api/loganalytics/data-sources/delete?tabs=HTTP) to stop collecting activity logs for the specific resource. -- :::image type="content" source="media/activity-log/data-sources-delete-api.png" alt-text="Screenshot of the configuration of the Data Sources - Delete API." lightbox="media/activity-log/data-sources-delete-api.png"::: -### Managing legacy Log Profiles - retiring -> [!NOTE] -> * Logs Profiles was used to forward Activity Logs to storage accounts and Event Hubs. This method is being retired on the 15th of Sept 2026. -> * If you are using this method, transition to Diagnostic Settings before 15th of Sept 2025, when we will stop allowing new creates of Log Profiles. --Log profiles are the legacy method for sending the activity log to storage or event hubs. If you're using this method, transition to Diagnostic Settings, which provide better functionality and consistency with resource logs. --#### [PowerShell](#tab/powershell) --If a log profile already exists, you first must remove the existing log profile, and then create a new one. --1. Use `Get-AzLogProfile` to identify if a log profile exists. If a log profile exists, note the `Name` property. --1. Use `Remove-AzLogProfile` to remove the log profile by using the value from the `Name` property. -- ```powershell - # For example, if the log profile name is 'default' - Remove-AzLogProfile -Name "default" - ``` --1. Use `Add-AzLogProfile` to create a new log profile: -- ```powershell - Add-AzLogProfile -Name my_log_profile -StorageAccountId /subscriptions/s1/resourceGroups/myrg1/providers/Microsoft.Storage/storageAccounts/my_storage -serviceBusRuleId /subscriptions/s1/resourceGroups/Default-ServiceBus-EastUS/providers/Microsoft.ServiceBus/namespaces/mytestSB/authorizationrules/RootManageSharedAccessKey -Location global,westus,eastus -RetentionInDays 90 -Category Write,Delete,Action - ``` -- | Property | Required | Description | - | | | | - | Name |Yes |Name of your log profile. | - | StorageAccountId |No |Resource ID of the storage account where the activity log should be saved. | - | serviceBusRuleId |No |Service Bus Rule ID for the Service Bus namespace where you want to have event hubs created. This string has the format `{service bus resource ID}/authorizationrules/{key name}`. | - | Location |Yes |Comma-separated list of regions for which you want to collect activity log events. | - | RetentionInDays |Yes |Number of days for which events should be retained in the storage account, from 1 through 365. A value of zero stores the logs indefinitely. | - | Category |No |Comma-separated list of event categories to be collected. Possible values are Write, Delete, and Action. | --**Example script** --This sample PowerShell script creates a log profile that writes the activity log to both a storage account and an event hub. -- ```powershell - # Settings needed for the new log profile - $logProfileName = "default" - $locations = (Get-AzLocation).Location - $locations += "global" - $subscriptionId = "<your Azure subscription Id>" - $resourceGroupName = "<resource group name your Event Hub belongs to>" - $eventHubNamespace = "<Event Hub namespace>" -- # Build the service bus rule Id from the settings above - $serviceBusRuleId = "/subscriptions/$subscriptionId/resourceGroups/$resourceGroupName/providers/Microsoft.EventHub/namespaces/$eventHubNamespace/authorizationrules/RootManageSharedAccessKey" -- # Build the Storage Account Id from the settings above - $storageAccountId = "/subscriptions/$subscriptionId/resourceGroups/$resourceGroupName/providers/Microsoft.Storage/storageAccounts/$storageAccountName" -- Add-AzLogProfile -Name $logProfileName -Location $locations -StorageAccountId $storageAccountId -ServiceBusRuleId $serviceBusRuleId - ``` --#### [CLI](#tab/cli) --If a log profile already exists, you first must remove the existing log profile, and then create a log profile. --1. Use `az monitor log-profiles list` to identify if a log profile exists. -1. Use `az monitor log-profiles delete --name "<log profile name>` to remove the log profile by using the value from the `name` property. -1. Use `az monitor log-profiles create` to create a log profile: -- ```azurecli-interactive - az monitor log-profiles create --name "default" --location null --locations "global" "eastus" "westus" --categories "Delete" "Write" "Action" --enabled false --days 0 --service-bus-rule-id "/subscriptions/<YOUR SUBSCRIPTION ID>/resourceGroups/<RESOURCE GROUP NAME>/providers/Microsoft.EventHub/namespaces/<Event Hub NAME SPACE>/authorizationrules/RootManageSharedAccessKey" - ``` - | Property | Required | Description | - | | | | - | `name` |Yes |Name of your log profile. | - | `storage-account-id` |Yes |Resource ID of the storage account to which activity logs should be saved. | - | `locations` |Yes |Space-separated list of regions for which you want to collect activity log events. View a list of all regions for your subscription by using `az account list-locations --query [].name`. | - | `days` |Yes |Number of days for which events should be retained, from 1 through 365. A value of zero stores the logs indefinitely (forever). If zero, then the enabled parameter should be set to False. | - |`enabled` | Yes |True or False. Used to enable or disable the retention policy. If True, then the `days` parameter must be a value greater than zero. - | `categories` |Yes |Space-separated list of event categories that should be collected. Possible values are Write, Delete, and Action. | -----### Data structure changes --The Export activity logs experience sends the same data as the legacy method used to send the activity log with some changes to the structure of the `AzureActivity` table. --The columns in the following table are deprecated in the updated schema. They still exist in `AzureActivity`, but they have no data. The replacements for these columns aren't new, but they contain the same data as the deprecated column. They're in a different format, so you might need to modify log queries that use them. --|Activity log JSON | Log Analytics column name<br/>*(older deprecated)* | New Log Analytics column name | Notes | -|:|:|:|:| -|category | Category | CategoryValue || -|status<br/><br/>Values are success, start, accept, failure |ActivityStatus <br/><br/>Values same as JSON |ActivityStatusValue<br/><br/>Values change to succeeded, started, accepted, failed |The valid values change as shown.| -|subStatus |ActivitySubstatus |ActivitySubstatusValue|| -|operationName | OperationName | OperationNameValue |REST API localizes the operation name value. Log Analytics UI always shows English. | -|resourceProviderName | ResourceProvider | ResourceProviderValue || --> [!Important] -> In some cases, the values in these columns might be all uppercase. If you have a query that includes these columns, use the [=~ operator](/azure/kusto/query/datatypes-string-operators) to do a case-insensitive comparison. --The following columns have been added to `AzureActivity` in the updated schema: --- Authorization_d-- Claims_d-- Properties_d--## Next steps --Learn more about: --* [Platform logs](./platform-logs-overview.md) -* [Activity log event schema](activity-log-schema.md) -* [Activity log insights](activity-log-insights.md) |
| azure-monitor | Analyze Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/analyze-metrics.md | - Title: Analyze metrics with Azure Monitor metrics explorer -description: Learn how to analyze metrics with Azure Monitor metrics explorer by creating metrics charts, setting chart dimensions, time ranges, aggregation, filters, splitting, and sharing. ---- Previously updated : 10/23/2023----# Analyze metrics with Azure Monitor metrics explorer --In Azure Monitor, [metrics](data-platform-metrics.md) are a series of measured values and counts that are collected and stored over time. Metrics can be standard (also called *platform*) or custom. The Azure platform provides standard metrics. These metrics reflect the health and usage statistics of your Azure resources. --In addition to standard metrics, your application emits extra _custom_ performance indicators or business-related metrics. Custom metrics can be emitted by any application or Azure resource and collected by using [Azure Monitor Insights](../insights/insights-overview.md), agents running on virtual machines, or [OpenTelemetry](../app/opentelemetry-enable.md). --Azure Monitor metrics explorer is a component of the Azure portal that helps you plot charts, visually correlate trends, and investigate spikes and dips in metrics values. You can use metrics explorer to investigate the health and utilization of your resources. --Watch the following video for an overview of creating and working with metrics charts in Azure Monitor metrics explorer. --> [!VIDEO https://www.microsoft.com/videoplayer/embed/RE4qO59] --## Create a metric chart using PromQL --You can now create charts using Prometheus query language (PromQL) for metrics stored in an Azure Monitor workspace. For more information, see [Metrics explorer with PromQL (Preview)](./metrics-explorer.md). --## Create a metric chart --You can open metrics explorer from the **Azure Monitor overview** page, or from the **Monitoring** section of any resource. In the Azure portal, select **Metrics**. ---If you open metrics explorer from Azure Monitor, the **Select a scope** page opens. Set the **Subscription**, **Resource**, and region **Location** fields to the resource to explore. If you open metrics explorer for a specific resource, the scope is prepopulated with information about that resource. --Here's a summary of configuration tasks for creating a chart to analyze metrics: --- [Select your resource and metric](#set-the-resource-scope) to see the chart. You can choose to work with one or multiple resources and view a single or multiple metrics.--- [Configure the time settings](#configure-the-time-range) that are relevant for your investigation. You can set the time granularity to allow for pan and zoom on your chart, and configure aggregations to show values like the maximum and minimum.--- [Use dimension filters and splitting](#use-dimension-filters-and-splitting) to analyze which segments of the metric contribute to the overall metric value and identify possible outliers in the data.--- Work with advanced settings to customize your chart. [Lock the y-axis range](#lock-the-y-axis-range) to identify small data variations that might have significant consequences. [Correlate metrics to logs](#correlate-metrics-to-logs) to diagnose the cause of anomalies in your chart.--- [Configure alerts](../alerts/alerts-metric-overview.md) and [receive notifications](#set-up-alert-rules) when the metric value exceeds or drops below a threshold.--- [Share your chart](#share-your-charts) or pin it to dashboards.--## Set the resource scope --The resource **scope picker** lets you scope your chart to view metrics for a single resource or for multiple resources. To view metrics across multiple resources, the resources must be within the same subscription and region location. --> [!NOTE] -> You must have _Monitoring Reader_ permission at the subscription level to visualize metrics across multiple resources, resource groups, or a subscription. For more information, see [Assign Azure roles in the Azure portal](../../role-based-access-control/role-assignments-portal.yml). --### Select a single resource --1. Choose **Select a scope**. -- :::image source="./media/analyze-metrics/scope-picker.png" alt-text="Screenshot that shows how to open the resource scope picker for metrics explorer."::: --1. Use the scope picker to select the resources whose metrics you want to see. If you open metrics explorer for a specific resource, the scope should be populated. -- For some resources, you can view only one resource's metrics at a time. On the **Resource types** menu, these resources are shown in the **All resource types** section. -- :::image source="./media/analyze-metrics/single-resource-scope.png" alt-text="Screenshot that shows available resources in the scope picker." lightbox="./media/analyze-metrics/single-resource-scope.png"::: --1. Select a resource. The picker updates to show all subscriptions and resource groups that contain the selected resource. -- :::image source="./media/analyze-metrics/available-single-resource.png" alt-text="Screenshot that shows a single resource." lightbox="./media/analyze-metrics/available-single-resource.png"::: -- > [!TIP] - > If you want the capability to view the metrics for multiple resources at the same time, or to view metrics across a subscription or resource group, select **Upvote**. --1. When you're satisfied with your selection, select **Apply**. --### Select multiple resources --You can see which metrics can be queried across multiple resources at the top of the **Resource types** menu in the scope picker. ---1. To visualize metrics over multiple resources, start by selecting multiple resources within the resource scope picker. -- :::image source="./media/analyze-metrics/select-multiple-resources.png" alt-text="Screenshot that shows how to select multiple resources in the resource scope picker."::: -- The resources you select must be within the same resource type, location, and subscription. Resources that don't meet these criteria aren't selectable. --1. Select **Apply**. --### Select a resource group or subscription --For types that are compatible with multiple resources, you can query for metrics across a subscription or multiple resource groups. --1. Start by selecting a subscription or one or more resource groups. -- :::image source="./media/analyze-metrics/query-across-multiple-resource-groups.png" alt-text="Screenshot that shows how to query across multiple resource groups."::: --1. Select a resource type and location. -- :::image source="./media/analyze-metrics/select-resource-group.png" alt-text="Screenshot that shows how to select resource groups in the resource scope picker."::: --1. Expand the selected scopes to verify the resources your selections apply to. -- :::image source="./media/analyze-metrics/verify-selected-resources.png" alt-text="Screenshot that shows the selected resources within the groups."::: --1. Select **Apply**. --## Configure the time range --The **time picker** lets you configure the time range for your metric chart to view data that's relevant to your monitoring scenario. By default, the chart shows the most recent 24 hours of metrics data. --> [!NOTE] -> [Most metrics in Azure are stored for 93 days](../essentials/data-platform-metrics.md#retention-of-metrics). You can query no more than 30 days of data on any single chart. You can [pan](#pan-across-metrics-data) the chart to view the full retention. The 30-day limitation doesn't apply to [log-based metrics](../app/pre-aggregated-metrics-log-metrics.md#log-based-metrics). --Use the time picker to change the **Time range** for your data, such as the last 12 hours or the last 30 days. ---In addition to changing the time range with the time picker, you can pan and zoom by using the controls in the chart area. --## Interactive chart features --### Pan across metrics data --To pan, select the left and right arrows at the edge of the chart. The arrow control moves the selected time range back and forward by one half of the chart's time span. If you're viewing the past 24 hours, selecting the left arrow causes the time range to shift to span a day and a half to 12 hours ago. ---### Zoom into metrics data --You can configure the _time granularity_ of the chart data to support zoom in and zoom out for the time range. Use the **time brush** to investigate an interesting area of the chart like a spike or a dip in the data. Select an area on the chart and the chart zooms in to show more detail for the selected area based on your granularity settings. If the time grain is set to **Automatic**, zooming selects a smaller time grain. The new time range applies to all charts in metrics explorer. ---## View multiple metric lines and charts --You can create charts that plot multiple metric lines or show multiple metric charts at the same time. This functionality allows you to: --- Correlate related metrics on the same graph to see how one value relates to another.-- Display metrics that use different units of measure in close proximity.-- Visually aggregate and compare metrics from multiple resources.--Suppose you have five storage accounts and you want to know how much space they consume together. You can create a stacked area chart that shows the individual values and the sum of all the values at points in time. --After you create a chart, select **Add metric** to add another metric to the same chart. ---### Add multiple charts --Typically, your charts shouldn't mix metrics that use different units of measure. For example, avoid mixing one metric that uses milliseconds with another that uses kilobytes. Also avoid mixing metrics whose scales differ significantly. In these cases, consider using multiple charts instead. --- To create another chart that uses a different metric, select **New chart**.--- To reorder or delete multiple charts, select **More options** (...), and then select the **Move up**, **Move down**, or **Delete** action.-- :::image source="./media/analyze-metrics/multiple-charts.png" alt-text="Screenshot that shows multiple charts." lightbox="./media/analyze-metrics/multiple-charts.png"::: --### Use different line colors --Chart lines are automatically assigned a color from a default palette. To change the color of a chart line, select the colored bar in the legend that corresponds to the line on the chart. Use the **color picker** to select the line color. ---Customized colors are preserved when you pin the chart to a dashboard. The following section shows how to pin a chart. --## Configure aggregation --When you add a metric to a chart, metrics explorer applies a default aggregation. The default makes sense in basic scenarios, but you can use a different aggregation to gain more insights about the metric. --Before you use different aggregations on a chart, you should understand how metrics explorer handles them. Metrics are a series of measurements (or "metric values") that are captured over a time period. When you plot a chart, the values of the selected metric are separately aggregated over the _time granularity_. --You select the size of the time grain by using the time picker in metrics explorer. If you don't explicitly select the time grain, metrics explorer uses the currently selected time range by default. After metrics explorer determines the time grain, the metric values that it captures during each time grain are aggregated on the chart, one data point per time grain. --Suppose a chart shows the *Server response time* metric. It uses the average aggregation over the time span of the last 24 hours. ---In this scenario, if you set the time granularity to 30 minutes, metrics explorer draws the chart from 48 aggregated data points. That is, it uses two data points per hour for 24 hours. The line chart connects 48 dots in the chart plot area. Each data point represents the average of all captured response times for server requests that occurred during each of the relevant 30-minute time periods. If you switch the time granularity to 15 minutes, you get 96 aggregated data points. That is, you get four data points per hour for 24 hours. --Metrics explorer has five aggregation types: --- **Sum**: The sum of all values captured during the aggregation interval. The sum aggregation is sometimes called the *total* aggregation.-- **Count**: The number of measurements captured during the aggregation interval.-- When the metric is always captured with the value of 1, the count aggregation is equal to the sum aggregation. This scenario is common when the metric tracks the count of distinct events and each measurement represents one event. The code emits a metric record every time a new request arrives. --- **Average**: The average of the metric values captured during the aggregation interval.-- **Min**: The smallest value captured during the aggregation interval.-- **Max**: The largest value captured during the aggregation interval.---Metrics explorer hides the aggregations that are irrelevant and can't be used. --For more information about how metric aggregation works, see [Azure Monitor metrics aggregation and display explained](metrics-aggregation-explained.md). --## Use dimension filters and splitting --Filtering and splitting are powerful diagnostic tools for metrics that have dimensions. You can implement these options to analyze which segments of the metric contribute to the overall metric value and identify possible outliers in the metric data. These features show how various metric segments or dimensions affect the overall value of the metric. --**Filtering** lets you choose which dimension values are included in the chart. You might want to show successful requests when you chart the *server response time* metric. You apply the filter on the *success of request* dimension. --**Splitting** controls whether the chart displays separate lines for each value of a dimension or aggregates the values into a single line. Splitting allows you to visualize how different segments of the metric compare with each other. You can see one line for an average CPU usage across all server instances, or you can see separate lines for each server. --> [!TIP] -> To hide segments that are irrelevant for your scenario and to make your charts easier to read, use both filtering and splitting on the same dimension. --### Add filters --You can apply filters to charts whose metrics have dimensions. Consider a *Transaction count* metric that has a *Response type* dimension. This dimension indicates whether the response from transactions succeeded or failed. If you filter on this dimension, metrics explorer displays a chart line for only successful or only failed transactions. --1. Above the chart, select **Add filter** to open the **filter picker**. --1. Select a dimension from the **Property** dropdown list. -- :::image type="content" source="./media/analyze-metrics/filter-property.png" alt-text="Screenshot that shows the dropdown list for filter properties in metrics explorer." lightbox="./media/analyze-metrics/filter-property.png"::: --1. Select the operator that you want to apply against the dimension (or _property_). The default operator is equals (`=`). - - :::image type="content" source="./media/analyze-metrics/filter-operator.png" alt-text="Screenshot that shows the operator that you can use with the filter."::: --1. Select which dimension values you want to apply to the filter when you're plotting the chart. This example shows filtering out the successful storage transactions. -- :::image type="content" source="./media/analyze-metrics/filter-values.png" alt-text="Screenshot that shows the dropdown list for filter values in metrics explorer."::: --1. After you select the filter values, click outside the **filter picker** to complete the action. The chart shows how many storage transactions have failed. -- :::image type="content" source="./media/analyze-metrics/filtered-chart.png" alt-text="Screenshot that shows the successful filtered storage transactions in the updated chart in metrics explorer." lightbox="./media/analyze-metrics/filtered-chart.png"::: --1. Repeat these steps to apply multiple filters to the same charts. --### Apply metric splitting --You can split a metric by dimension to visualize how different segments of the metric compare. Splitting can also help you identify the outlying segments of a dimension. --1. Above the chart, select **Apply splitting** to open the **segment picker**. --1. Choose the dimensions to use to segment your chart. -- :::image type="content" source="./media/analyze-metrics/apply-splitting.png" alt-text="Screenshot that shows the selected dimension on which to segment the chart for splitting."::: -- The chart shows multiple lines with one line for each dimension segment. -- :::image type="content" source="./media/analyze-metrics/segment-dimension.png" alt-text="Screenshot that shows multiple lines, one for each segment of dimension." lightbox="./media/analyze-metrics/segment-dimension.png"::: --1. Choose a limit on the number of values to display after you split by the selected dimension. The default limit is 10, as shown in the preceding chart. The range of the limit is 1 to 50. -- :::image type="content" source="./media/analyze-metrics/segment-dimension-limit.png" alt-text="Screenshot that shows the split limit, which restricts the number of values after splitting." lightbox="./media/analyze-metrics/segment-dimension-limit.png"::: --1. Choose the sort order on segments: **Descending** (default) or **Ascending**. -- :::image type="content" source="./media/analyze-metrics/segment-dimension-sort.png" alt-text="Screenshot that shows the sort order on split values." lightbox="./media/analyze-metrics/segment-dimension-sort.png"::: --1. Segment by multiple segments by selecting multiple dimensions from the **Values** dropdown list. The legend shows a comma-separated list of dimension values for each segment. -- :::image type="content" source="./media/analyze-metrics/segment-dimension-multiple.png" alt-text="Screenshot that shows multiple segments selected, and the corresponding chart." lightbox="./media/analyze-metrics/segment-dimension-multiple.png"::: --1. Click outside the segment picker to complete the action and update the chart. --### Split metrics for multiple resources --When you plot a metric for multiple resources, you can choose **Apply splitting** to split by resource ID or resource group. The split allows you to compare a single metric across multiple resources or resource groups. The following chart shows the percentage CPU across nine virtual machines. When you split by resource ID, you see how percentage CPU differs by virtual machine. ---For more examples that use filtering and splitting, see [Metric chart examples](../essentials/metric-chart-samples.md). --## Lock the y-axis range --Locking the range of the value (y) axis becomes important in charts that show small fluctuations of large values. Consider how a drop in the volume of successful requests from 99.99 percent to 99.5 percent might represent a significant reduction in the quality of service. Noticing a small fluctuation in a numeric value would be difficult or even impossible if you're using the default chart settings. In this case, you could lock the lowest boundary of the chart to 99 percent to make a small drop more apparent. --Another example is a fluctuation in the available memory. In this scenario, the value technically never reaches 0. Fixing the range to a higher value might make drops in available memory easier to spot. --1. To control the y-axis range, browse to the advanced chart settings by selecting **More options** (...) > **Chart settings**. -- :::image source="./media/analyze-metrics/select-chart-settings.png" alt-text="Screenshot that shows the menu option for chart settings." lightbox="./media/analyze-metrics/select-chart-settings.png"::: --1. Modify the values in the **Y-axis range** section, or select **Auto** to revert to the default values. -- :::image type="content" source="./media/analyze-metrics/chart-settings.png" alt-text="Screenshot that shows the Y-axis range section." lightbox="./media/analyze-metrics/chart-settings.png"::: --If you lock the boundaries of the y-axis for a chart that tracks count, sum, minimum, or maximum aggregations over a period of time, specify a fixed time granularity. Don't rely on the automatic defaults. --You choose a fixed time granularity because chart values change when the time granularity is automatically modified after a user resizes a browser window or changes screen resolution. The resulting change in time granularity affects the appearance of the chart, invalidating the selection of the y-axis range. --## Set up alert rules --You can use your visualization criteria to create a metric-based alert rule. The new alert rule includes your chart's target resource, metric, splitting, and filter dimensions. You can modify these settings by using the **Create an alert rule** pane. --1. To create an alert rule, select **New alert rule** in the upper-right corner of the chart. -- :::image source="./media/analyze-metrics/new-alert.png" alt-text="Screenshot that shows the button for creating a new alert rule." lightbox="./media/analyze-metrics/new-alert.png"::: --1. Select the **Condition** tab. The **Signal name** entry defaults to the metric from your chart. You can choose a different metric. --1. Enter a number for **Threshold value**. The threshold value is the value that triggers the alert. The **Preview** chart shows the threshold value as a horizontal line over the metric values. When you're ready, select the **Details** tab. -- :::image source="./media/analyze-metrics/alert-rule-condition.png" alt-text="Screenshot that shows the Condition tab on the pane for creating an alert rule." lightbox="./media/analyze-metrics/alert-rule-condition.png"::: --1. Enter **Name** and **Description** values for the alert rule. --1. Select a **Severity** level for the alert rule. Severities include **Critical**, **Error Warning**, **Informational**, and **Verbose**. --1. Select **Review + create** to review the alert rule. -- :::image source="./media/analyze-metrics/alert-rule-details.png" alt-text="Screenshot that shows the Details tab on the pane for creating an alert rule." lightbox="./media/analyze-metrics/alert-rule-details.png"::: --1. Select **Create** to create the alert rule. --For more information, see [Create, view, and manage metric alerts](../alerts/alerts-metric.md). --## Correlate metrics to logs --In metrics explorer, the **Drill into Logs** feature helps you diagnose the root cause of anomalies in your metric chart. Drilling into logs allows you to correlate spikes in your metric chart to the following types of logs and queries: --- **Activity log**: Provides insight into the operations on each Azure resource in the subscription from the outside (the management plane) and updates on Azure Service Health events. Use the activity log to determine the what, who, and when for any write operations (`PUT`, `POST`, or `DELETE`) taken on the resources in your subscription. There's a single activity log for each Azure subscription.-- **Diagnostic log**: Provides insight into operations that you performed within an Azure resource (the data plane). Examples include getting a secret from a key vault or making a request to a database. The content of resource logs varies by the Azure service and resource type. You must enable logs for the resource.-- **Recommended log** Provides scenario-based queries that you can use to investigate anomalies in metrics explorer.--Currently, **Drill into Logs** is available for select resource providers. Resource providers that offer the complete **Drill into Logs** experience include Azure Application Insights, Autoscale, Azure App Service, and Azure Storage. --1. To diagnose a spike in failed requests, select **Drill into Logs**. -- :::image source="./media/analyze-metrics/drill-into-log-ai.png" alt-text="Screenshot that shows a spike in failures on an Application Insights metrics pane." lightbox="./media/analyze-metrics/drill-into-log-ai.png"::: --1. In the dropdown list, select **Failures**. -- :::image source="./media/analyze-metrics/drill-into-logs-dropdown.png" alt-text="Screenshot that shows the dropdown menu for drilling into logs." lightbox="./media/analyze-metrics/drill-into-logs-dropdown.png"::: --1. On the custom failure pane, check for failed operations, top exception types, and failed dependencies. -- :::image source="./media/analyze-metrics/ai-failure-blade.png" alt-text="Screenshot of the Application Insights failure pane." lightbox="./media/analyze-metrics/ai-failure-blade.png"::: --## Share your charts --After you configure a chart, you can add it to a dashboard or workbook. By adding a chart to a dashboard or workbook, you can make it accessible to your team. You can also gain insights by viewing it in the context of other monitoring information. --- To pin a configured chart to a dashboard, in the upper-right corner of the chart, select **Save to dashboard** > **Pin to dashboard**.--- To save a configured chart to a workbook, in the upper-right corner of the chart, select **Save to dashboard** > **Save to workbook**.---The Azure Monitor metrics explorer **Share** menu includes several options for sharing your metric chart. --- Use the **Download to Excel** option to immediately download your chart.--- Choose the **Copy link** option to add a link to your chart to the clipboard. You receive a notification when the link is copied successfully.--- In the **Send to Workbook** window, send your chart to a new or existing workbook.--- In the **Pin to Grafana** window, pin your chart to a new or existing Grafana dashboard.---## Frequently asked questions --This section provides answers to common questions. --### Why are metrics from the guest OS of my Azure virtual machine not showing up in metrics explorer? --[Platform metrics](./monitor-azure-resource.md#monitoring-data) are collected automatically for Azure resources. You must perform some configuration, though, to collect metrics from the guest OS of a virtual machine. For a Windows VM, install the diagnostic extension and configure the Azure Monitor sink as described in [Install and configure Azure Diagnostics extension for Windows (WAD)](../agents/diagnostics-extension-windows-install.md). For Linux, install the Telegraf agent as described in [Collect custom metrics for a Linux VM with the InfluxData Telegraf agent](./collect-custom-metrics-linux-telegraf.md). ---## Next steps --- [Troubleshoot metrics explorer](metrics-troubleshoot.md)-- [Review available metrics for Azure services](./metrics-supported.md)-- [Explore examples of configured charts](../essentials/metric-chart-samples.md)-- [Create custom KPI dashboards](../app/tutorial-app-dashboards.md) |
| azure-monitor | App Insights Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/app-insights-metrics.md | - Title: Azure Application Insights log-based metrics | Microsoft Docs -description: This article lists Azure Application Insights metrics with supported aggregations and dimensions. The details about log-based metrics include the underlying Kusto query statements. --- Previously updated : 07/03/2019 ----# Application Insights log-based metrics --Application Insights log-based metrics let you analyze the health of your monitored apps, create powerful dashboards, and configure alerts. There are two kinds of metrics: --* [Log-based metrics](../app/pre-aggregated-metrics-log-metrics.md#log-based-metrics) behind the scene are translated into [Kusto queries](/azure/kusto/query/) from stored events. -* [Standard metrics](../app/pre-aggregated-metrics-log-metrics.md#preaggregated-metrics) are stored as preaggregated time series. --Since *standard metrics* are preaggregated during collection, they have better performance at query time. This makes them a better choice for dashboarding and in real-time alerting. The *log-based metrics* have more dimensions, which makes them the superior option for data analysis and ad-hoc diagnostics. Use the [namespace selector](./metrics-store-custom-rest-api.md#namespace) to switch between log-based and standard metrics in [metrics explorer](./analyze-metrics.md). --## Interpret and use queries from this article --This article lists metrics with supported aggregations and dimensions. The details about log-based metrics include the underlying Kusto query statements. For convenience, each query uses defaults for time granularity, chart type, and sometimes splitting dimension which simplifies using the query in Log Analytics without any need for modification. --When you plot the same metric in [metrics explorer](./analyze-metrics.md), there are no defaults - the query is dynamically adjusted based on your chart settings: --- The selected **Time range** is translated into an additional *where timestamp...* clause to only pick the events from selected time range. For example, a chart showing data for the most recent 24 hours, the query includes *| where timestamp > ago(24 h)*.--- The selected **Time granularity** is put into the final *summarize ... by bin(timestamp, [time grain])* clause.--- Any selected **Filter** dimensions are translated into additional *where* clauses.--- The selected **Split chart** dimension is translated into an extra summarize property. For example, if you split your chart by *location*, and plot using a 5-minute time granularity, the *summarize* clause is summarized *... by bin(timestamp, 5 m), location*.--> [!NOTE] -> If you're new to the Kusto query language, you start by copying and pasting Kusto statements into the Log Analytics query pane without making any modifications. Click **Run** to see basic chart. As you begin to understand the syntax of query language, you can start making small modifications and see the impact of your change. Exploring your own data is a great way to start realizing the full power of [Log Analytics](../logs/log-analytics-tutorial.md) and [Azure Monitor](../overview.md). --## Availability metrics --Metrics in the Availability category enable you to see the health of your web application as observed from points around the world. [Configure the availability tests](/previous-versions/azure/azure-monitor/app/monitor-web-app-availability) to start using any metrics from this category. --### Availability (availabilityResults/availabilityPercentage) -The *Availability* metric shows the percentage of the web test runs that didn't detect any issues. The lowest possible value is 0, which indicates that all of the web test runs have failed. The value of 100 means that all of the web test runs passed the validation criteria. --|Unit of measure|Supported aggregations|Supported dimensions| -||||||| -|Percentage|Average|Run location, Test name| --```Kusto -availabilityResults -| summarize sum(todouble(success == 1) * 100) / count() by bin(timestamp, 5m), location -| render timechart -``` --### Availability test duration (availabilityResults/duration) --The *Availability test duration* metric shows how much time it took for the web test to run. For the [multi-step web tests](/previous-versions/azure/azure-monitor/app/availability-multistep), the metric reflects the total execution time of all steps. --|Unit of measure|Supported aggregations|Supported dimensions| -||||||| -|Milliseconds|Average, Min, Max|Run location, Test name, Test result --```Kusto -availabilityResults -| where notempty(duration) -| extend availabilityResult_duration = iif(itemType == 'availabilityResult', duration, todouble('')) -| summarize sum(availabilityResult_duration)/sum(itemCount) by bin(timestamp, 5m), location -| render timechart -``` --### Availability tests (availabilityResults/count) --The *Availability tests* metric reflects the count of the web tests runs by Azure Monitor. --|Unit of measure|Supported aggregations|Supported dimensions| -||||||| -|Count|Count|Run location, Test name, Test result| --```Kusto -availabilityResults -| summarize sum(itemCount) by bin(timestamp, 5m) -| render timechart -``` --## Browser metrics --Browser metrics are collected by the Application Insights JavaScript SDK from real end-user browsers. They provide great insights into your users' experience with your web app. Browser metrics are typically not sampled, which means that they provide higher precision of the usage numbers compared to server-side metrics which might be skewed by sampling. --> [!NOTE] -> To collect browser metrics, your application must be instrumented with the [Application Insights JavaScript SDK](../app/javascript.md). --### Browser page load time (browserTimings/totalDuration) --Time from user request until DOM, stylesheets, scripts and images are loaded. --|Unit of measure|Supported aggregations|Preaggregated dimensions| -|||| -|Milliseconds|Average, Min, Max|None| --```Kusto -browserTimings -| where notempty(totalDuration) -| extend _sum = totalDuration -| extend _count = itemCount -| extend _sum = _sum * _count -| summarize sum(_sum) / sum(_count) by bin(timestamp, 5m) -| render timechart -``` --### Client processing time (browserTiming/processingDuration) --Time between receiving the last byte of a document until the DOM is loaded. Async requests may still be processing. --|Unit of measure|Supported aggregations|Preaggregated dimensions| -|||| -|Milliseconds|Average, Min, Max|None| --```Kusto -browserTimings -| where notempty(processingDuration) -| extend _sum = processingDuration -| extend _count = itemCount -| extend _sum = _sum * _count -| summarize sum(_sum)/sum(_count) by bin(timestamp, 5m) -| render timechart -``` --### Page load network connect time (browserTimings/networkDuration) --Time between user request and network connection. Includes DNS lookup and transport connection. --|Unit of measure|Supported aggregations|Preaggregated dimensions| -|||| -|Milliseconds|Average, Min, Max|None| --```Kusto -browserTimings -| where notempty(networkDuration) -| extend _sum = networkDuration -| extend _count = itemCount -| extend _sum = _sum * _count -| summarize sum(_sum) / sum(_count) by bin(timestamp, 5m) -| render timechart -``` --### Receiving response time (browserTimings/receiveDuration) --Time between the first and last bytes, or until disconnection. --|Unit of measure|Supported aggregations|Preaggregated dimensions| -|||| -|Milliseconds|Average, Min, Max|None| --```Kusto -browserTimings -| where notempty(receiveDuration) -| extend _sum = receiveDuration -| extend _count = itemCount -| extend _sum = _sum * _count -| summarize sum(_sum) / sum(_count) by bin(timestamp, 5m) -| render timechart -``` --### Send request time (browserTimings/sendDuration) --Time between network connection and receiving the first byte. --|Unit of measure|Supported aggregations|Preaggregated dimensions| -|||| -|Milliseconds|Average, Min, Max|None| --```Kusto -browserTimings -| where notempty(sendDuration) -| extend _sum = sendDuration -| extend _count = itemCount -| extend _sum = _sum * _count -| summarize sum(_sum) / sum(_count) by bin(timestamp, 5m) -| render timechart -``` --## Failure metrics --The metrics in **Failures** show problems with processing requests, dependency calls, and thrown exceptions. --### Browser exceptions (exceptions/browser) --This metric reflects the number of thrown exceptions from your application code running in browser. Only exceptions that are tracked with a ```trackException()``` Application Insights API call are included in the metric. --|Unit of measure|Supported aggregations|Preaggregated dimensions|Notes| -||||| -|Count|Count|None|Log-based version uses **Sum** aggregation| --```Kusto -exceptions -| where notempty(client_Browser) -| summarize sum(itemCount) by bin(timestamp, 5m) -| render barchart -``` --### Dependency call failures (dependencies/failed) --The number of failed dependency calls. --|Unit of measure|Supported aggregations|Preaggregated dimensions|Notes| -||||| -|Count|Count|None|Log-based version uses **Sum** aggregation| --```Kusto -dependencies -| where success == 'False' -| summarize sum(itemCount) by bin(timestamp, 5m) -| render barchart -``` --### Exceptions (exceptions/count) --Each time when you log an exception to Application Insights, there is a call to the [trackException() method](../app/api-custom-events-metrics.md#trackexception) of the SDK. The Exceptions metric shows the number of logged exceptions. --|Unit of measure|Supported aggregations|Preaggregated dimensions|Notes| -||||| -|Count|Count|Cloud role name, Cloud role instance, Device type|Log-based version uses **Sum** aggregation| --```Kusto -exceptions -| summarize sum(itemCount) by bin(timestamp, 5m) -| render barchart -``` --### Failed requests (requests/failed) --The count of tracked server requests that were marked as *failed*. By default, the Application Insights SDK automatically marks each server request that returned HTTP response code 5xx or 4xx as a failed request. You can customize this logic by modifying *success* property of request telemetry item in a [custom telemetry initializer](../app/api-filtering-sampling.md#addmodify-properties-itelemetryinitializer). --|Unit of measure|Supported aggregations|Preaggregated dimensions|Notes| -||||| -|Count|Count|Cloud role instance, Cloud role name, Real or synthetic traffic, Request performance, Response code|Log-based version uses **Sum** aggregation| --```Kusto -requests -| where success == 'False' -| summarize sum(itemCount) by bin(timestamp, 5m) -| render barchart -``` --### Server exceptions (exceptions/server) --This metric shows the number of server exceptions. --|Unit of measure|Supported aggregations|Preaggregated dimensions|Notes| -||||| -|Count|Count|Cloud role name, Cloud role instance|Log-based version uses **Sum** aggregation| --```Kusto -exceptions -| where isempty(client_Browser) -| summarize sum(itemCount) by bin(timestamp, 5m) -| render barchart -``` --## Performance counters --Use metrics in the **Performance counters** category to access [system performance counters collected by Application Insights](../app/performance-counters.md). --### Available memory (performanceCounters/availableMemory) --```Kusto -performanceCounters -| where ((category == "Memory" and counter == "Available Bytes") or name == "availableMemory") -| extend performanceCounter_value = iif(itemType == "performanceCounter", value, todouble('')) -| summarize sum(performanceCounter_value) / count() by bin(timestamp, 1m) -| render timechart -``` --### Exception rate (performanceCounters/exceptionRate) --```Kusto -performanceCounters -| where ((category == ".NET CLR Exceptions" and counter == "# of Exceps Thrown / sec") or name == "exceptionRate") -| extend performanceCounter_value = iif(itemType == 'performanceCounter',value,todouble('')) -| summarize sum(performanceCounter_value) / count() by bin(timestamp, 1m) -| render timechart -``` --### HTTP request execution time (performanceCounters/requestExecutionTime) --```Kusto -performanceCounters -| where ((category == "ASP.NET Applications" and counter == "Request Execution Time") or name == "requestExecutionTime") -| extend performanceCounter_value = iif(itemType == "performanceCounter", value, todouble('')) -| summarize sum(performanceCounter_value) / count() by bin(timestamp, 1m) -| render timechart -``` --### HTTP request rate (performanceCounters/requestsPerSecond) --```Kusto -performanceCounters -| where ((category == "ASP.NET Applications" and counter == "Requests/Sec") or name == "requestsPerSecond") -| extend performanceCounter_value = iif(itemType == "performanceCounter", value, todouble('')) -| summarize sum(performanceCounter_value) / count() by bin(timestamp, 1m) -| render timechart -``` --### HTTP requests in application queue (performanceCounters/requestsInQueue) --```Kusto -performanceCounters -| where ((category == "ASP.NET Applications" and counter == "Requests In Application Queue") or name == "requestsInQueue") -| extend performanceCounter_value = iif(itemType == "performanceCounter", value, todouble('')) -| summarize sum(performanceCounter_value) / count() by bin(timestamp, 1m) -| render timechart -``` --### Process CPU (performanceCounters/processCpuPercentage) --The metric shows how much of the total processor capacity is consumed by the process that is hosting your monitored app. --|Unit of measure|Supported aggregations|Supported dimensions| -|||| -|Percentage|Average, Min, Max|Cloud role instance| --```Kusto -performanceCounters -| where ((category == "Process" and counter == "% Processor Time Normalized") or name == "processCpuPercentage") -| extend performanceCounter_value = iif(itemType == "performanceCounter", value, todouble('')) -| summarize sum(performanceCounter_value) / count() by bin(timestamp, 1m) -| render timechart -``` --> [!NOTE] -> The range of the metric is between 0 and 100 * n, where n is the number of available CPU cores. For example, the metric value of 200% could represent full utilization of two CPU core or half utilization of 4 CPU cores and so on. The *Process CPU Normalized* is an alternative metric collected by many SDKs which represents the same value but divides it by the number of available CPU cores. Thus, the range of *Process CPU Normalized* metric is 0 through 100. --### Process IO rate (performanceCounters/processIOBytesPerSecond) --|Unit of measure|Supported aggregations|Supported dimensions| -|||| -|Bytes per second|Average, Min, Max|Cloud role instance| --```Kusto -performanceCounters -| where ((category == "Process" and counter == "IO Data Bytes/sec") or name == "processIOBytesPerSecond") -| extend performanceCounter_value = iif(itemType == "performanceCounter", value, todouble('')) -| summarize sum(performanceCounter_value) / count() by bin(timestamp, 1m) -| render timechart -``` --### Process private bytes (performanceCounters/processPrivateBytes) --Amount of non-shared memory that the monitored process allocated for its data. --|Unit of measure|Supported aggregations|Supported dimensions| -|||| -|Bytes|Average, Min, Max|Cloud role instance| --```Kusto -performanceCounters -| where ((category == "Process" and counter == "Private Bytes") or name == "processPrivateBytes") -| extend performanceCounter_value = iif(itemType == "performanceCounter", value, todouble('')) -| summarize sum(performanceCounter_value) / count() by bin(timestamp, 1m) -| render timechart -``` --### Processor time (performanceCounters/processorCpuPercentage) --CPU consumption by *all* processes running on the monitored server instance. --|Unit of measure|Supported aggregations|Supported dimensions| -|||| -|Percentage|Average, Min, Max|Cloud role instance| -->[!NOTE] -> The processor time metric is not available for the applications hosted in Azure App Services. Use the [Process CPU](#process-cpu-performancecountersprocesscpupercentage) metric to track CPU utilization of the web applications hosted in App Services. --```Kusto -performanceCounters -| where ((category == "Processor" and counter == "% Processor Time") or name == "processorCpuPercentage") -| extend performanceCounter_value = iif(itemType == "performanceCounter", value, todouble('')) -| summarize sum(performanceCounter_value) / count() by bin(timestamp, 1m) -| render timechart -``` --## Server metrics --### Dependency calls (dependencies/count) --This metric is in relation to the number of dependency calls. --```Kusto -dependencies -| summarize sum(itemCount) by bin(timestamp, 5m) -| render barchart -``` --### Dependency duration (dependencies/duration) --This metric refers to duration of dependency calls. --```Kusto -dependencies -| where notempty(duration) -| extend dependency_duration = iif(itemType == 'dependency',duration,todouble('')) -| extend _sum = dependency_duration -| extend _count = itemCount -| extend _sum = _sum*_count -| summarize sum(_sum)/sum(_count) by bin(timestamp, 1m) -| render timechart -``` --### Server requests (requests/count) --This metric reflects the number of incoming server requests that were received by your web application. --```Kusto -requests -| summarize sum(itemCount) by bin(timestamp, 5m) -| render barchart -``` --### Server response time (requests/duration) --This metric reflects the time it took for the servers to process incoming requests. --```Kusto -requests -| where notempty(duration) -| extend request_duration = iif(itemType == 'request', duration, todouble('')) -| extend _sum = request_duration -| extend _count = itemCount -| extend _sum = _sum*_count -| summarize sum(_sum) / sum(_count) by bin(timestamp, 1m) -| render timechart -``` --## Usage metrics --### Page view load time (pageViews/duration) --This metric refers to the amount of time it took for PageView events to load. --```Kusto -pageViews -| where notempty(duration) -| extend pageView_duration = iif(itemType == 'pageView', duration, todouble('')) -| extend _sum = pageView_duration -| extend _count = itemCount -| extend _sum = _sum * _count -| summarize sum(_sum) / sum(_count) by bin(timestamp, 5m) -| render barchart -``` --### Page views (pageViews/count) --The count of PageView events logged with the TrackPageView() Application Insights API. --```Kusto -pageViews -| summarize sum(itemCount) by bin(timestamp, 1h) -| render barchart -``` --### Sessions (sessions/count) --This metric refers to the count of distinct session IDs. --```Kusto -union traces, requests, pageViews, dependencies, customEvents, availabilityResults, exceptions, customMetrics, browserTimings -| where notempty(session_Id) -| summarize dcount(session_Id) by bin(timestamp, 1h) -| render barchart -``` --### Traces (traces/count) --The count of trace statements logged with the TrackTrace() Application Insights API call. --```Kusto -traces -| summarize sum(itemCount) by bin(timestamp, 1h) -| render barchart -``` --### Users (users/count) --The number of distinct users who accessed your application. The accuracy of this metric may be significantly impacted by using telemetry sampling and filtering. --```Kusto -union traces, requests, pageViews, dependencies, customEvents, availabilityResults, exceptions, customMetrics, browserTimings -| where notempty(user_Id) -| summarize dcount(user_Id) by bin(timestamp, 1h) -| render barchart -``` --### Users, Authenticated (users/authenticated) --The number of distinct users who authenticated into your application. --```Kusto -union traces, requests, pageViews, dependencies, customEvents, availabilityResults, exceptions, customMetrics, browserTimings -| where notempty(user_AuthenticatedId) -| summarize dcount(user_AuthenticatedId) by bin(timestamp, 1h) -| render barchart -``` --## Access all your data directly with the Application Insights REST API --The Application Insights REST API enables programmatic retrieval of log-based metrics. It also features an optional parameter ΓÇ£ai.include-query-payloadΓÇ¥ that when added to a query string, prompts the API to return not only the timeseries data, but also the Kusto Query Language (KQL) statement used to fetch it. This parameter can be particularly beneficial for users aiming to comprehend the connection between raw events in Log Analytics and the resulting log-based metric. --To access your data directly, pass the parameter ΓÇ£ai.include-query-payloadΓÇ¥ to the Application Insights API in a query using KQL. --```Kusto -api.applicationinsights.io/v1/apps/DEMO_APP/metrics/users/authenticated?api_key=DEMO_KEY&prefer=ai.include-query-payload -``` --The following is an example of a return KQL statement for the metric "Authenticated Users.ΓÇ¥ (In this example, "users/authenticated" is the metric id.) --```Kusto -output -{ - "value": { - "start": "2024-06-21T09:14:25.450Z", - "end": "2024-06-21T21:14:25.450Z", - "users/authenticated": { - "unique": 0 - } - }, - "@ai.query": "union (traces | where timestamp >= datetime(2024-06-21T09:14:25.450Z) and timestamp < datetime(2024-06-21T21:14:25.450Z)), (requests | where timestamp >= datetime(2024-06-21T09:14:25.450Z) and timestamp < datetime(2024-06-21T21:14:25.450Z)), (pageViews | where timestamp >= datetime(2024-06-21T09:14:25.450Z) and timestamp < datetime(2024-06-21T21:14:25.450Z)), (dependencies | where timestamp >= datetime(2024-06-21T09:14:25.450Z) and timestamp < datetime(2024-06-21T21:14:25.450Z)), (customEvents | where timestamp >= datetime(2024-06-21T09:14:25.450Z) and timestamp < datetime(2024-06-21T21:14:25.450Z)), (availabilityResults | where timestamp >= datetime(2024-06-21T09:14:25.450Z) and timestamp < datetime(2024-06-21T21:14:25.450Z)), (exceptions | where timestamp >= datetime(2024-06-21T09:14:25.450Z) and timestamp < datetime(2024-06-21T21:14:25.450Z)), (customMetrics | where timestamp >= datetime(2024-06-21T09:14:25.450Z) and timestamp < datetime(2024-06-21T21:14:25.450Z)), (browserTimings | where timestamp >= datetime(2024-06-21T09:14:25.450Z) and timestamp < datetime(2024-06-21T21:14:25.450Z)) | where notempty(user_AuthenticatedId) | summarize ['users/authenticated_unique'] = dcount(user_AuthenticatedId)" -} -``` |
| azure-monitor | Azure Monitor Workspace Manage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/azure-monitor-workspace-manage.md | - Title: Manage an Azure Monitor workspace -description: How to create and delete Azure Monitor workspaces. ----- Previously updated : 05/31/2024---# Manage an Azure Monitor workspace --This article shows you how to create and delete an Azure Monitor workspace. When you configure Azure Monitor managed service for Prometheus, you can select an existing Azure Monitor workspace or create a new one. --> [!NOTE] -> When you create an Azure Monitor workspace, by default a data collection rule and a data collection endpoint in the form `<azure-monitor-workspace-name>` will automatically be created in a resource group in the form `MA_<azure-monitor-workspace-name>_<location>_managed`. In case there are any Azure policies with restrictions on resource or resource group names, [create an exemption](../../governance/policy/concepts/exemption-structure.md) to exempt these resources from evaluation. --## Create an Azure Monitor workspace -### [Azure portal](#tab/azure-portal) --1. Open the **Azure Monitor workspaces** menu in the Azure portal. -2. Select **Create**. -- :::image type="content" source="media/azure-monitor-workspace-overview/view-azure-monitor-workspaces.png" lightbox="media/azure-monitor-workspace-overview/view-azure-monitor-workspaces.png" alt-text="Screenshot of Azure Monitor workspaces menu and page."::: --3. On the **Create an Azure Monitor Workspace** page, select a **Subscription** and **Resource group** where the workspace should be created. -4. Provide a **Name** and a **Region** for the workspace. -5. Select **Review + create** to create the workspace. --### [CLI](#tab/cli) -Use the following command to create an Azure Monitor workspace using Azure CLI. --```azurecli -az monitor account create --name <azure-monitor-workspace-name> --resource-group <resource-group-name> --location <location> -``` --For more details, visit [Azure CLI for Azure Monitor Workspace](/cli/azure/monitor/account) --### [Resource Manager](#tab/resource-manager) -Use one of the following Resource Manager templates with any of the [standard deployment options](../resource-manager-samples.md#deploy-the-sample-templates) to create an Azure Monitor workspace. --```json -{ - "$schema": "http://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "name": { - "type": "string" - }, - "location": { - "type": "string", - "defaultValue": "" - } - }, - "resources": [ - { - "type": "microsoft.monitor/accounts", - "apiVersion": "2021-06-03-preview", - "name": "[parameters('name')]", - "location": "[if(empty(parameters('location')), resourceGroup().location, parameters('location'))]" - } - ] -} -``` --```bicep -@description('Specify the name of the workspace.') -param workspaceName string --@description('Specify the location for the workspace.') -param location string = resourceGroup().location --resource workspace 'microsoft.monitor/accounts@2021-06-03-preview' = { - name: workspaceName - location: location -} --``` ---When you create an Azure Monitor workspace, a new resource group is created. The resource group name has the following format: `MA_<azure-monitor-workspace-name>_<location>_managed`, where the tokenized elements are lowercased. The resource group contains both a data collection endpoint and a data collection rule with the same name as the workspace. The resource group and its resources are automatically deleted when you delete the workspace. - -To connect your Azure Monitor managed service for Prometheus to your Azure Monitor workspace, see [Collect Prometheus metrics from AKS cluster](../containers/kubernetes-monitoring-enable.md#enable-prometheus-and-grafana) ---## Delete an Azure Monitor workspace -When you delete an Azure Monitor workspace, unlike with a [Log Analytics workspace](../logs/delete-workspace.md), there is no soft delete operation. The data in the workspace is immediately deleted, and there's no recovery option. ---### [Azure portal](#tab/azure-portal) --1. Open the **Azure Monitor workspaces** menu in the Azure portal. -2. Select your workspace. -4. Select **Delete**. -- :::image type="content" source="media/azure-monitor-workspace-overview/delete-azure-monitor-workspace.png" lightbox="media/azure-monitor-workspace-overview/delete-azure-monitor-workspace.png" alt-text="Screenshot of Azure Monitor workspaces delete button."::: --### [CLI](#tab/cli) -To delete an AzureMonitor workspace use `az resource delete` --For example: -```azurecli - az monitor account delete --name <azure-monitor-workspace-name> --resource-group <resource-group-name> -``` --For more details, visit [Azure CLI for Azure Monitor Workspace](/cli/azure/monitor/account) --### [Resource Manager](#tab/resource-manager) -For information on deleting resources and Azure Resource Manager, see [Azure Resource Manager resource group and resource deletion](../../azure-resource-manager/management/delete-resource-group.md) ------## Link a Grafana workspace -Connect an Azure Monitor workspace to an [Azure Managed Grafana](../../managed-grafan) workspace to allow Grafana to use the Azure Monitor workspace data in a Grafana dashboard. An Azure Monitor workspace can be connected to multiple Grafana workspaces, and a Grafana workspace can be connected to multiple Azure Monitor workspaces. --> [!NOTE] -> When you add the Azure Monitor workspace as a data source to Grafana, it will be listed in form `Managed_Prometheus_<azure-monitor-workspace-name>`. -### [Azure portal](#tab/azure-portal) --1. Open the **Azure Monitor workspace** menu in the Azure portal. -2. Select your workspace. -3. Select **Linked Grafana workspaces**. -4. Select a Grafana workspace. --### [CLI](#tab/cli) --Create a link between the Azure Monitor workspace and the Grafana workspace by updating the Azure Kubernetes Service cluster that you're monitoring. --If your cluster is already configured to send data to an Azure Monitor managed service for Prometheus, you must disable it first using the following command: --```azurecli -az aks update --disable-azure-monitor-metrics -g <cluster-resource-group> -n <cluster-name> -``` --Then, either enable or re-enable using the following command: -```azurecli -az aks update --enable-azure-monitor-metrics -n <cluster-name> -g <cluster-resource-group> --azure-monitor-workspace-resource-id -<azure-monitor-workspace-name-resource-id> --grafana-resource-id <grafana-workspace-name-resource-id> -``` --Output -```JSON -"azureMonitorProfile": { - "metrics": { - "enabled": true, - "kubeStateMetrics": { - "metricAnnotationsAllowList": "", - "metricLabelsAllowlist": "" - } - } -} -``` --### [Resource Manager](#tab/resource-manager) - --To set up an Azure monitor workspace as a data source for Grafana using a Resource Manager template, see [Collect Prometheus metrics from AKS cluster](../containers/kubernetes-monitoring-enable.md?tabs=arm#enable-prometheus-and-grafana) ----If your Grafana instance is self managed, see [Use Azure Monitor managed service for Prometheus as data source for self-managed Grafana using managed system identity](./prometheus-self-managed-grafana-azure-active-directory.md) ---## Frequently asked questions --This section provides answers to common questions. --### Can I use Azure Managed Grafana in a different region than my Azure Monitor workspace and managed service for Prometheus? - -Yes. When you use managed service for Prometheus, you can create your Azure Monitor workspace in any of the supported regions. Your Azure Kubernetes Service clusters can be in any region and send data into an Azure Monitor workspace in a different region. Azure Managed Grafana can also be in a different region than where you created your Azure Monitor workspace. ------## Next steps -- Learn more about the [Azure Monitor data platform](../data-platform.md).-- [Azure Monitor workspace Overview](./azure-monitor-workspace-overview.md) |
| azure-monitor | Azure Monitor Workspace Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/azure-monitor-workspace-overview.md | - Title: Azure Monitor workspace overview -description: Overview of Azure Monitor workspace, which is a unique environment for data collected by Azure Monitor. ---- Previously updated : 07/24/2024---# Azure Monitor workspace -An Azure Monitor workspace is a unique environment for data collected by Azure Monitor. Each workspace has its own data repository, configuration, and permissions. --> [!Note] -> Log Analytics workspaces contain logs and metrics data from multiple Azure resources, whereas Azure Monitor workspaces currently contain only metrics related to Prometheus. - -## Contents of Azure Monitor workspace -Azure Monitor workspaces will eventually contain all metric data collected by Azure Monitor. Currently, only Prometheus metrics are data hosted in an Azure Monitor workspace. --## Azure Monitor workspace architecture --While a single Azure Monitor workspace can be sufficient for many use cases using Azure Monitor, many organizations create multiple workspaces to better meet their needs. This article presents a set of criteria for deciding whether to use a single Azure Monitor workspace, multiple Azure Monitor workspaces, and the configuration and placement of those workspaces. --### Design criteria --As you identify the right criteria to create additional Azure Monitor workspaces, your design should use the lowest number of workspaces that will match your requirements, while optimizing for minimal administrative management overhead. --The following table presents criteria to consider when designing an Azure Monitor workspace architecture. --|Criteria|Description| -||| -|Segregate by logical boundaries |Create separate Azure Monitor workspaces for operational data based on logical boundaries, such as by a role, application type, type of metric etc.| -|Azure tenants | For multiple Azure tenants, create an Azure Monitor workspace in each tenant. Data sources can only send monitoring data to an Azure Monitor workspace in the same Azure tenant. | -|Azure regions |Each Azure Monitor workspace resides in a particular Azure region. Regulatory or compliance requirements might dictate the storage of data in particular locations. | -|Data ownership |Create separate Azure Monitor workspaces to define data ownership, such as by subsidiaries or affiliated companies.| --### Considerations when creating an Azure Monitor workspace --* Azure Monitor workspaces are regional. When you create a new Azure Monitor workspace, you provide a region which sets the location in which the data is stored. --* Start with a single workspace to reduce the complexity of managing and querying data from multiple Azure resources. --* The default Azure Monitor workspace limit is 1 million active times series and 1 million events per minute ingested. --* There's no reduction in performance due to the amount of data in your Azure Monitor workspace. Multiple services can send data to the same account simultaneously. There is, however, a limit on how much an Azure Monitor workspace can scale, as explained below. --### Growing account capacity --Azure Monitor workspaces have default quotas and limitations for metrics. As your product grows and you need more metrics, you can request an increase to 50 million events or active time series. If your capacity needs to be exceptionally large and your data ingestion needs can no longer be met by a single Azure Monitor workspace, consider creating multiple Azure Monitor workspaces. --### Multiple Azure Monitor workspaces --When an Azure Monitor workspace reaches 80% of its maximum capacity or is forecasted to reach that volume of metrics, it's recommended to split the Azure Monitor workspace into multiple workspaces. You should split the workspace based on how the data in the workspace is used by your applications and business processes and by how you want to access that data in the future. - -In certain circumstances, splitting an Azure Monitor workspace into multiple workspaces can be necessary. For example: -* Monitoring data in sovereign clouds: Create an Azure Monitor workspace in each sovereign cloud. -* Compliance or regulatory requirements that mandate storage of data in specific regions: Create an Azure Monitor workspace per region as per requirements. There might be a need to manage the scale of metrics for large services or financial institutions with regional accounts. -* Separating metrics in test, pre-production, and production environments: Create an Azure Monitor workspace per environment. -->[!Note] -> A single query cannot access multiple Azure Monitor workspaces. Keep data that you want to retrieve in a single query in same workspace. For visualization purposes, setting up Grafana with each workspace as a dedicated data source will allow for querying multiple workspaces in a single Grafana panel. --## Limitations -See [Azure Monitor service limits](../service-limits.md#prometheus-metrics) for performance related service limits for Azure Monitor managed service for Prometheus. --## Data considerations --Data stored in the Azure Monitor Workspace is handled in accordance with all standards described in the [Azure Trust Center](https://www.microsoft.com/en-us/trust-center?rtc=1). Several considerations exist specific to data stored in the Azure Monitor Workspace: -- Data is physically stored in the same region that the Azure Monitor Workspace is provisioned in-- Data is encrypted at rest using a Microsoft-managed key-- Data is retained for 18 months-- For details about the Azure Monitor managed service for Prometheus' support of PII/EUII data, please see details [here](./prometheus-metrics-overview.md)--## Regional availability --When you create a new Azure Monitor workspace, you provide a region which sets the location in which the data is stored. Currently Azure Monitor Workspace is available in the below regions. --|Geo|Regions| -||| -|Africa|South Africa North| -|Asia Pacific|East Asia, Southeast Asia| -|Australia|Australia Central, Australia East, Australia Southeast| -|Brazil|Brazil South, Brazil Southeast| -|Canada|Canada Central, Canada East| -|China|China North 3 (Preview), China East 3 (Preview)| -|Europe|North Europe, West Europe| -|France|France Central, France South| -|Germany|Germany West Central| -|India|Central India, South India| -|Israel|Israel Central| -|Italy|Italy North| -|Japan|Japan East, Japan West| -|Korea|Korea Central, Korea South| -|Norway|Norway East, Norway West| -|Spain|Spain Central| -|Sweden|Sweden South, Sweden Central| -|Switzerland|Switzerland North, Switzerland West| -|UAE|UAE North| -|UK|UK South, UK West| -|US|Central US, East US, East US 2, South Central US, West Central US, West US, West US 2, West US 3| -|US Government|USGov Virginia, USGov Texas| ---If you have clusters in regions where Azure Monitor Workspace is not yet available, you can select another region in the same geography. --## Frequently asked questions --This section provides answers to common questions. --### What's the difference between an Azure Monitor workspace and a Log Analytics workspace? --An Azure Monitor workspace is a unique environment for data collected by Azure Monitor. Each workspace has its own data repository, configuration, and permissions. Azure Monitor workspaces will eventually contain all metrics collected by Azure Monitor, including native metrics. Currently, the only data hosted by an Azure Monitor workspace is Prometheus metrics. --You cannot use quota limits, similar to the Log Anlytics Workspace (Daily Cap or Data retention) in the Azure Monitor workspace. --### Can I delete Prometheus metrics from an Azure Monitor workspace? - -Data is removed from the Azure Monitor workspace according to its data retention period, which is 18 months. ---## Next steps --- Learn more about the [Azure Monitor data platform](../data-platform.md).-- [Manage an Azure Monitor workspace](./azure-monitor-workspace-manage.md) |
| azure-monitor | Azure Monitor Workspace Private Endpoint | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/azure-monitor-workspace-private-endpoint.md | - Title: Use private endpoints for Managed Prometheus and Azure Monitor workspaces -description: Overview of private endpoints for secure query access to Azure Monitor workspace from virtual networks. ---- Previously updated : 06/25/2024---# Use private endpoints for Managed Prometheus and Azure Monitor workspace --Use [private endpoints](../../private-link/private-endpoint-overview.md) for Managed Prometheus and your Azure Monitor workspace to allow clients on a virtual network (VNet) to securely query data over a [Private Link](../../private-link/private-link-overview.md). The private endpoint uses a separate IP address within the VNet address space of your Azure Monitor workspace resource. Network traffic between the clients on the VNet and the workspace resource traverses the VNet and a private link on the Microsoft backbone network, eliminating exposure from the public internet. --> [!NOTE] -> If you are using Azure Managed Grafana to query your data, configure a [Managed Private Endpoint](https://aka.ms/ags/mpe) to ensure the queries from Managed Grafana into your Azure Monitor workspace use the Microsoft backbone network without going through the internet. ---Using private endpoints for your workspace enables you to: --- Secure your workspace by configuring the public access network setting to block all connections on the public query endpoint for the workspace.-- Increase security for the VNet, by enabling you to block exfiltration of data from the VNet.-- Securely connect to workspaces from on-premises networks that connect to the VNet using [VPN](../../vpn-gateway/vpn-gateway-about-vpngateways.md) or [ExpressRoutes](../../expressroute/expressroute-locations.md) with private-peering.--## Conceptual overview ---A private endpoint is a special network interface for an Azure service in your [Virtual Network](../../virtual-network/virtual-networks-overview.md) (VNet). When you create a private endpoint for your workspace, it provides secure connectivity between clients on your VNet and your workspace. The private endpoint is assigned an IP address from the IP address range of your VNet. The connection between the private endpoint and the workspace uses a secure private link. --Applications in the VNet can connect to the workspace over the private endpoint seamlessly, **using the same connection strings and authorization mechanisms that they would use otherwise**. --Private endpoints can be created in subnets that use [Service Endpoints](../../virtual-network/virtual-network-service-endpoints-overview.md). Clients in the subnet can then connect to a workspace using a private endpoint, while using service endpoints to access other services. --When you create a private endpoint for a workspace in your VNet, a consent request is sent for approval to the workspace account owner. If the user requesting the creation of the private endpoint is also an owner of the workspace, this consent request is automatically approved. --Azure Monitor workspace owners can manage consent requests and the private endpoints through the '*Private Access*' tab on the Networking page for the workspace in the [Azure portal](https://portal.azure.com). ---> [!TIP] -> If you want to restrict access to your workspace through the private endpoint only, select 'Disable public access and use private access' on the '*Public Access*' tab on the Networking page for the workspace in the [Azure portal](https://portal.azure.com). --## Create a private endpoint --To create a private endpoint by using the Azure portal, PowerShell, or the Azure CLI, see the following articles. The articles feature an Azure web app as the target service, but the steps to create a private link are the same for an Azure Monitor workspace. --When you create a private endpoint, make the following selections from the dropdown lists on the basic tab: -- **Resource type** - Select `Microsoft.Monitor/accounts`. Specify the Azure Monitor workspace to which it connects. -- **Target sub-resource** - Select `prometheusMetrics` .--Create a private endpoint using the following articles: -- [Create a private endpoint using Azure portal](../../private-link/create-private-endpoint-portal.md#create-a-private-endpoint)--- [Create a private endpoint using Azure CLI](../../private-link/create-private-endpoint-cli.md#create-a-private-endpoint)--- [Create a private endpoint using Azure PowerShell](../../private-link/create-private-endpoint-powershell.md#create-a-private-endpoint)---## Connect to a private endpoint --Clients on a VNet using the private endpoint should use the same query endpoint for the Azure monitor workspace as clients connecting to the public endpoint. We rely upon DNS resolution to automatically route the connections from the VNet to the workspace over a private link. --By default, We create a [private DNS zone](../../dns/private-dns-overview.md) attached to the VNet with the necessary updates for the private endpoints. However, if you're using your own DNS server, you may need to make additional changes to your DNS configuration. The section on [DNS changes](#dns-changes-for-private-endpoints) below describes the updates required for private endpoints. --## DNS changes for private endpoints --> [!NOTE] -> For details on how to configure your DNS settings for private endpoints, see [Azure Private Endpoint DNS configuration](../../private-link/private-endpoint-dns.md). --When you create a private endpoint, the DNS CNAME resource record for the workspace is updated to an alias in a subdomain with the prefix `privatelink`. By default, we also create a [private DNS zone](../../dns/private-dns-overview.md), corresponding to the `privatelink` subdomain, with the DNS A resource records for the private endpoints. --When you resolve the query endpoint URL from outside the VNet with the private endpoint, it resolves to the public endpoint of the workspace. When resolved from the VNet hosting the private endpoint, the query endpoint URL resolves to the private endpoint's IP address. --For the example below we're using `k8s02-workspace` located in the East US region. The resource name isn't guaranteed to be unique, which requires us to add a few characters after the name to make the URL path unique; for example, `k8s02-workspace-<key>`. This unique query endpoint is shown on the Azure Monitor workspace Overview page. ---The DNS resource records for the Azure Monitor workspace when resolved from outside the VNet hosting the private endpoint, are: --| Name | Type | Value | -| :- | :: | :- | -| `k8s02-workspace-<key>.<region>.prometheus.monitor.azure.com` | CNAME | `k8s02-workspace-<key>.privatelink.<region>.prometheus.monitor.azure.com` | -| `k8s02-workspace-<key>.privatelink.<region>.prometheus.monitor.azure.com` | CNAME | \<AMW regional service public endpoint\> | -| <AMW regional service public endpoint\> | A | \<AMW regional service public IP address\> | --As previously mentioned, you can deny or control access for clients outside the VNet through the public endpoint using the '*Public Access*' tab on the Networking page of your workspace. --The DNS resource records for 'k8s02-workspace' when resolved by a client in the VNet hosting the private endpoint, are: --| Name | Type | Value | -| : | :: | : | -| `k8s02-workspace-<key>.<region>.prometheus.monitor.azure.com` | CNAME | `k8s02-workspace-<key>.privatelink.<region>.prometheus.monitor.azure.com` | -| `k8s02-workspace-<key>.privatelink.<region>.prometheus.monitor.azure.com` | A | \<Private endpoint IP address\> | --This approach enables access to the workspace **using the same query endpoint** for clients on the VNet hosting the private endpoints, as well as clients outside the VNet. --If you're using a custom DNS server on your network, clients must be able to resolve the FQDN for the workspace query endpoint to the private endpoint IP address. You should configure your DNS server to delegate your private link subdomain to the private DNS zone for the VNet, or configure the A records for `k8s02-workspace` with the private endpoint IP address. --> [!TIP] -> When using a custom or on-premises DNS server, you should configure your DNS server to resolve the workspace query endpoint name in the `privatelink` subdomain to the private endpoint IP address. You can do this by delegating the `privatelink` subdomain to the private DNS zone of the VNet or by configuring the DNS zone on your DNS server and adding the DNS A records. --The recommended DNS zone names for private endpoints for an Azure Monitor workspace are: --| Resource | Target sub-resource | Zone name | -| : | : | : | -| Azure Monitor workspace| prometheusMetrics | `privatelink.<region>.prometheus.monitor.azure.com` | --For more information on configuring your own DNS server to support private endpoints, see the following articles: --- [Name resolution for resources in Azure virtual networks](../../virtual-network/virtual-networks-name-resolution-for-vms-and-role-instances.md#name-resolution-that-uses-your-own-dns-server)-- [DNS configuration for private endpoints](../../private-link/private-endpoint-overview.md#dns-configuration)--## Pricing --For pricing details, see [Azure Private Link pricing](https://azure.microsoft.com/pricing/details/private-link). --## Known issues --Keep in mind the following known issues about private endpoints for Azure Monitor workspace. --### Workspace query access constraints for clients in VNets with private endpoints --Clients in VNets with existing private endpoints face constraints when accessing other Azure Monitor workspaces that have private endpoints. For example, suppose a VNet N1 has a private endpoint for a workspace A1. If workspace A2 has a private endpoint in a VNet N2, then clients in VNet N1 must also query workspace data in account A2 using a private endpoint. If workspace A2 doesn't have any private endpoints configured, then clients in VNet N1 can query data from that workspace without a private endpoint. --This constraint is a result of the DNS changes made when workspace A2 creates a private endpoint. --## Next steps --- [Managed Grafana network settings](https://aka.ms/ags/mpe)-- [Azure Private Endpoint DNS configuration](../../private-link/private-endpoint-dns.md) |
| azure-monitor | Azure Monitor Workspace Scaling Best Practice | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/azure-monitor-workspace-scaling-best-practice.md | - Title: Best practices for scaling Azure Monitor Workspaces with Azure Monitor managed service for Prometheus -description: Learn best practices for organizing your Azure Monitor Workspaces to meet your scale and growing volume of data ingestion ---- Previously updated : 07/24/2024--# customer intent: As an azure administrator I want to understand the best practices for scaling Azure Monitor Workspaces to meet a growing volume of data ingestion ----# Best practices for scaling Azure Monitor Workspaces with Azure Monitor managed service for Prometheus --Azure Monitor managed service for Prometheus allows you to collect and analyze metrics at scale. Prometheus metrics are stored in Azure Monitor Workspaces. The workspace supports analysis tools like Azure Managed Grafana, Azure Monitor metrics explorer with PromQL, and open source tools such as PromQL and Grafana. --This article provides best practices for organizing your Azure Monitor Workspaces to meet your scale and growing volume of data ingestion. ---## Topology design criteria --A single Azure Monitor workspace can be sufficient for many use cases. Some organizations create multiple workspaces to better meet their requirements. As you identify the right criteria to create additional workspaces, create the lowest number of workspaces that match your requirements, while optimizing for minimal administrative management overhead. --The following are scenarios that require splitting an Azure Monitor workspace into multiple workspaces: --| Scenario | Best practice | -||| -|Sovereign clouds.| When working with more than one sovereign cloud, create an Azure Monitor workspace in each cloud.| -| Compliance or regulatory requirements.| If you're subject to regulations that mandate the storage of data in specific regions, create an Azure Monitor workspace per region as per your requirements. | -| Regional scaling. | When you're managing metrics for regionally diverse organizations such as large services or financial institutions with regional accounts, create an Azure Monitor workspace per region. -| Azure tenants.| For multiple Azure tenants, create an Azure Monitor workspace in each tenant. Querying data across tenants isn't supported. -| Deployment environments. | Create a separate workspace for each of your deployment environments to maintain discrete metrics for development, test, preproduction, and production environments.| -| Service limits and quotas. | Azure Monitor workspaces have default ingestion limits, which can be increased by opening a support ticket. If you're approaching the limit, or estimate that you'll exceed the ingestion limit, consider requesting an increase, or splitting your workspace into two or more workspaces.| --## Service limits and quotas --Azure Monitor workspaces have default quotas and limitations for metrics of 1 million event ingested per minute. As your usage grows and you need to ingest more metrics, you can request an increase. If your capacity requirements are exceptionally large and your data ingestion needs are exceeding the limits of a single Azure Monitor workspace, consider creating multiple Azure Monitor workspaces. Use the Azure monitor workspace platform metrics to monitor utilization and limits. For more information on limits and quotas, see [Azure Monitor service limits and quotas](/azure/azure-monitor/service-limits#prometheus-metrics). --Consider the following best practices for managing Azure Monitor workspace limits and quotas: --| Best practice | Description | -||| -| Monitor and create an alert on ingestion limits and utilization.| In the Azure portal, navigate to your Azure Monitor Workspace. Go to Metrics and verify that the metrics Active Time Series % Utilization and Events Per Minute Ingested % Utilization are below 100%. Set an Azure Monitor Alert to monitor the utilization and fire when the utilization is greater than 80% of the limit. For more information on monitoring utilization and limits, see [How can I monitor the service limits and quotas](/azure/azure-monitor/essentials/prometheus-metrics-overview#how-can-i-monitor-the-service-limits-and-quota).| -|Request for a limit increase when the utilization exceeds 80% of the current limit.|As your Azure usage grows, the volume of data ingested is likely to increase. We recommend that you request an increase in limits if your data ingestion is exceeding or close to 80% of the ingestion limit. To request a limit increase, open a support ticket. To open a support ticket, see [Create an Azure support request](/azure/azure-supportability/how-to-create-azure-support-request).| -|Estimate your projected scale.|As your usage grows and you ingest more metrics into your workspace, make an estimate of the projected scale and rate of growth. Based on your projections, request an increase in the limit. -|Ingestion with Remote-write using the Azure monitor side-car container. |If you're using the Azure monitor side-car container and remote-write to ingest metrics into an Azure Monitor workspace, consider the following limits: <li>The side-car container can process up to 150,000 unique time series.</li><li> The container might throw errors serving requests over 150,000 due to the high number of concurrent connections. Mitigate this issue by increasing the remote batch size from the 500 default, to 1,000. Changing the remote batch size reduces the number of open connections.</li>| -|DCR/DCE limits. |Limits apply to the data collection rules (DCR) and data collection endpoints (DCE) that send Prometheus metrics to your Azure Monitor workspace. For information on these limits, see [Prometheus Service limits](/azure/azure-monitor/service-limits#prometheus-metrics). These limits can't be increased. <p> Consider creating additional DCRs and DCEs to distribute the ingestion load across multiple endpoints. This approach helps optimize performance and ensures efficient data handling. For more information about creating DCRs and DCEs, see [How to create custom Data collection endpoint(DCE) and custom Data collection rule(DCR) for an existing Azure monitor workspace to ingest Prometheus metrics](https://github.com/Azure/prometheus-collector/tree/main/Azure-ARM-templates/Prometheus-RemoteWrite-DCR-artifacts)| ---## Optimizing performance for high volumes of data --### Ingestion --To optimize ingestion, consider the following best practices: --| Best practice | Description | -||| -| Identify High cardinality Metrics. | Identify metrics that have a high cardinality, or metrics that are generating many time series. Once you identify high-cardinality metrics, optimize them to reduce the number of time series by dropping unnecessary labels.| -| Use Prometheus config to optimize ingestion. | Azure Managed Prometheus provides Configmaps, which have settings that can be configured and used to optimize ingestion. For more information, see [ama-metrics-settings-configmap](https://aka.ms/azureprometheus-addon-settings-configmap) and [ama-metrics-prometheus-config-configmap](https://github.com/Azure/prometheus-collector/blob/main/otelcollector/configmaps/ama-metrics-prometheus-config-configmap.yaml). These configurations follow the same format as the Prometheus configuration file.<br> For information on customizing collection, see [Customize scraping of Prometheus metrics in Azure Monitor managed service for Prometheus](/azure/azure-monitor/containers/prometheus-metrics-scrape-configuration).<p> For example, consider the following: <li> **Tune Scrape Intervals**.</li> The default scrape frequency is 30 seconds, which can be changed per default target using the configmap. To balance the trade-off between data granularity and resource usage, adjust the `scrape_interval` and `scrape_timeout` based on the criticality of metrics. <li> **Drop unnecessary labels for high cardinality metrics**.</li> For high cardinality metrics, identify labels that aren't necessary and drop them to reduce the number of time series. Use the `metric_relabel_configs` to drop specific labels from ingestion. For more information, see [Prometheus Configuration](https://prometheus.io/docs/prometheus/latest/configuration/configuration/#relabel_config).| --Use the configmap, change the settings as required, and apply the configmap to the kube-system namespace for your cluster. If you're using remote-writing into and Azure Monitor workspace, apply the customizations during ingestion directly in your Prometheus configuration. --### Queries --To optimize queries, consider the following best practices: --#### Use Recording rules to optimize query performance --Prometheus recording rules are used to precompute frequently used, or computationally expensive queries, making them more efficient and faster to query. Recording rules are especially useful for high volume metrics where querying raw data can be slow and resource-intensive. For more information, see [Recording rules](https://prometheus.io/docs/prometheus/latest/configuration/recording_rules/#recording-rules). Azure Managed Prometheus provides a managed and scalable way to create and update recording rules with the help of [Azure Managed Prometheus Rule Groups.](/azure/azure-monitor/essentials/prometheus-rule-groups#rule-types) --Once the rule groups are created, Azure Managed Prometheus automatically loads and starts evaluating them. Query rule groups from the Azure Monitor workspace like other Prometheus metrics. --Recording rules have the following benefits: ---- **Improve query performance** - Recording rules can be used to precompute complex queries, making them faster to query later. Precomputing complex queries reduces the load on Prometheus when these metrics are queried. --- **Efficiency and Reduced query time** - Recording rules precompute the query results, reducing the time taken to query the data. This is especially useful for dashboards with multiple panels or high cardinality metrics. --- **Simplicity** - Recording rules simplify queries in Grafana or other visualization tools, as they can reference precomputed metrics. - -The following example shows a recording rule as defined in Azure Managed Prometheus rule group: -``` yaml -"record": "job:request_duration_seconds:avg ", -"expression": "avg(rate(request_duration_seconds_sum[5m])) by (job)", -"labels": { "workload_type": "job" - }, -"enabled": true -``` --For more complex metrics, create recording rules that aggregate multiple metrics or perform more advanced calculations. In the following example, `instance:node_cpu_utilisation:rate5m` computes the cpu utilization when the cpu isn't idle --```yaml -"record": "instance:node_cpu_utilisation:rate5m", - "expression": "1 - avg without (cpu) (sum without (mode)(rate(node_cpu_seconds_total{job=\"node\", mode=~\"idle|iowait|steal\"}[5m])))", -"labels": { - "workload_type": "job" - }, -"enabled": true -``` ---Consider the following best practices for optimizing recording rules: --| Best practice | Description | -||| -| Identify High Volume Metrics. | Focus on metrics that are queried frequently and have a high cardinality. | -| Optimize Rule Evaluation Interval. | To balance between data freshness and computational load, adjust the evaluation interval of your recording rules. | -| Monitor Performance. | Monitor query performance and adjust recording rules as necessary. | -| Optimize rules by limiting scope.|To make recording rules faster, limit them in scope to a specific cluster. For more information, see [Limiting rules to a specific cluster](/azure/azure-monitor/essentials/prometheus-rule-groups#limiting-rules-to-a-specific-cluster).| ---#### Using filters in queries --Optimizing Prometheus queries using filters involves refining the queries to return only the necessary data, reducing the amount of data processed and improving performance. The following are some common techniques to refine Prometheus queries. --| Best practice | Description | -||| -| Use label filters.|Label filters help to narrow down the data to only what you need. Prometheus allows filtering by using `{label_name="label_value"}` syntax. If you have a large number of metrics across multiple clusters, an easy way to limit time series is to use the `cluster` filter. <p> For example, instead of querying `container_cpu_usage_seconds_total`, filter by cluster `container_cpu_usage_seconds_total{cluster="cluster1"}`.| -| Apply time range selectors.|Using specific time ranges can significantly reduce the amount of data queried.<p> For example, instead of querying all data points for the last seven days `http_requests_total{job="myapp"}`, query for the last hour using `http_requests_total{job="myapp"}[1h]`.| -| Use aggregation and grouping.| Aggregation functions can be used to summarize data, which can be more efficient than processing raw data points. When aggregating data, use `by` to group by specific labels, or `without` to exclude specific labels.<p> For example, sum requests grouped by job: `sum(rate(http_requests_total[5m])) by (job)`.| -|Filter early in the query.| To limit the dataset from the start, apply filters as early as possible in your query.<p> For example, instead of `sum(rate(http_requests_total[5m])) by (job)`, filter first, then aggregate as follows: `sum(rate(http_requests_total{job="myapp"}[5m])) by (job)`.| -| Avoid regex where possible.| Regex filters can be powerful but are also computationally expensive. Use exact matches whenever possible.<p> For example, instead of `http_requests_total{job=~"myapp.*"}`, use `http_requests_total{job="myapp"}`.| -| Use offset for historical data.| If you're comparing current data with historical data, use the `offset` modifier.<p> For example, to compare current requests against requests from 24 hours ago, use `rate(http_requests_total[5m]) - rate(http_requests_total[5m] offset 24h)`.| -| Limit data points in charts.| When creating charts, limit the number of data points to improve rendering performance. Use the step parameter to control the resolution.<p> For example, in Grafana: Set a higher step value to reduce data points:`http_requests_total{job="myapp"}[1h:10s]`.| ---#### Parallel queries --Running a high number of parallel queries in Prometheus can lead to performance bottlenecks and can affect the stability of your Prometheus server. To handle a large volume of parallel queries efficiently, follow the best practices below: --| Best practice | Description | -||| -| Query Load Distribution.| Distribute the query load by spreading the queries across different time intervals or Prometheus instances.| -|Staggered Queries.| Schedule queries to run at different intervals to avoid peaks of simultaneous query executions.| --If you're still seeing issues with running many parallel queries, create a support ticket to request an increase in the query limits. --### Alerts and recording rules --#### Optimizing alerts and recording rules for high scale --Prometheus alerts and recording rules can be defined as Prometheus rule groups. One rule group can contain up to 20 alerts or recording rules. Create up to 500 rule groups for each workspace to accommodate the number of alerts/rules required. To raise this limit, open a support ticket --When defining the recording rules, take into account the evaluation interval to optimize the number of time series per rule and the performance of rule evaluations. Evaluation intervals can be between 1 minute and 24 hours. The default is 1 minute. --### Use Resource Health to view queries from recording rule status --Set up Resource Health to view the health of your Prometheus rule group in the portal. Resource Health allows you to detect problems in your recording rules, such as incorrect configuration, or query throttling problems. For more information on setting up Resource Health, see [View the resource health states of your Prometheus rule groups](/azure/azure-monitor/essentials/prometheus-rule-groups#view-the-resource-health-states-of-your-prometheus-rule-groups) |
| azure-monitor | Collect Custom Metrics Guestos Resource Manager Vm | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/collect-custom-metrics-guestos-resource-manager-vm.md | - Title: Collect Windows VM metrics in Azure Monitor with a template -description: Send guest OS metrics to the Azure Monitor metric database store by using a Resource Manager template for a Windows virtual machine. ----- Previously updated : 08/26/2024---# Send guest OS metrics to the Azure Monitor metrics store by using an ARM template for a Windows VM --> [!NOTE] -> Azure Monitor Agent (AMA) collects monitoring data from the guest operating system of Azure and hybrid virtual machines and delivers it to Azure Monitor for use by features, insights, and other services such as [Microsoft Sentinel](../../sentintel/../sentinel/overview.md) and [Microsoft Defender for Cloud](/azure/defender-for-cloud/defender-for-cloud-introduction). -> ->We recommend using the Azure Monitor Agent to collet logs and metrics from Virtual Machines. For more information, see [Azure Monitor Agent overview](../agents/azure-monitor-agent-overview.md). --Performance data from the guest OS of Azure virtual machines (VMs) isn't collected automatically like other [platform metrics](./monitor-azure-resource.md#monitoring-data). Install the Azure Monitor [Diagnostics extension](../agents/diagnostics-extension-overview.md) to collect guest OS metrics into the metrics database so that it can be used with all features of Azure Monitor Metrics. These features include near real time alerting, charting, routing, and access from a REST API. This article describes the process for sending guest OS performance metrics for a Windows VM to the metrics database by using an Azure Resource Manager template (ARM template). --> [!NOTE] -> For details on configuring the diagnostics extension to collect guest OS metrics by using the Azure portal, see [Install and configure the Windows Azure Diagnostics (WAD) extension](../agents/diagnostics-extension-windows-install.md). --If you're new to ARM templates, learn about [template deployments](../../azure-resource-manager/management/overview.md) and their structure and syntax. --## Prerequisites --- Your subscription must be registered with [Microsoft.Insights](../../azure-resource-manager/management/resource-providers-and-types.md).-- You need to have either [Azure PowerShell](/powershell/azure) or [Azure Cloud Shell](../../cloud-shell/overview.md) installed.--## Set up Azure Monitor as a data sink -The Azure Diagnostics extension uses a feature called *data sinks* to route metrics and logs to different locations. The following steps show how to use an ARM template and PowerShell to deploy a VM by using the new Azure Monitor data sink. --## ARM template -For this example, you can use a publicly available sample template. The starting templates are on -[GitHub](https://github.com/Azure/azure-quickstart-templates/tree/master/quickstarts/microsoft.compute/vm-simple-windows). --- **Azuredeploy.json**: A preconfigured ARM template for the deployment of a VM.-- **Azuredeploy.parameters.json**: A parameters file that stores information like what user name and password you want to set for your VM. During deployment, the ARM template uses the parameters that are set in this file.--Download and save both files locally. --### Modify azuredeploy.parameters.json -1. Open the *azuredeploy.parameters.json* file. --1. Enter values for `adminUsername` and `adminPassword` for the VM. These parameters are used for remote access to the VM. To avoid having your VM hijacked, *don't* use the values in this template. Bots scan the internet for user names and passwords in public GitHub repositories. They're likely to be testing VMs with these defaults. --1. Create a unique `dnsname` for the VM. --### Modify azuredeploy.json --1. Open the *azuredeploy.json* file. --1. Add a storage account ID to the `variables` section of the template after the entry for `storageAccountName`. - - ```json - // Find these lines. - "variables": { - "storageAccountName": "[concat(uniquestring(resourceGroup().id), 'sawinvm')]", - - // Add this line directly below. - "accountid": "[resourceId('Microsoft.Storage/storageAccounts', variables('storageAccountName'))]", - ``` - -1. Add this Managed Service Identity (MSI) extension to the template at the top of the `resources` section. The extension ensures that Azure Monitor accepts the metrics that are being emitted. -- ```json - //Find this code. - "resources": [ - // Add this code directly below. - { - "type": "Microsoft.Compute/virtualMachines/extensions", - "name": "[concat(variables('vmName'), '/', 'WADExtensionSetup')]", - "apiVersion": "2017-12-01", - "location": "[resourceGroup().location]", - "dependsOn": [ - "[concat('Microsoft.Compute/virtualMachines/', variables('vmName'))]" ], - "properties": { - "publisher": "Microsoft.ManagedIdentity", - "type": "ManagedIdentityExtensionForWindows", - "typeHandlerVersion": "1.0", - "autoUpgradeMinorVersion": true, - "settings": { - "port": 50342 - } - } - }, - ``` --1. Add the `identity` configuration to the VM resource to ensure that Azure assigns a system identity to the MSI extension. This step ensures that the VM can emit guest metrics about itself to Azure Monitor. -- ```json - // Find this section - "subnet": { - "id": "[variables('subnetRef')]" - } - } - } - ] - } - }, - { - "apiVersion": "2017-03-30", - "type": "Microsoft.Compute/virtualMachines", - "name": "[variables('vmName')]", - "location": "[resourceGroup().location]", - // add these 3 lines below - "identity": { - "type": "SystemAssigned" - }, - //end of added lines - "dependsOn": [ - "[resourceId('Microsoft.Storage/storageAccounts/', variables('storageAccountName'))]", - "[resourceId('Microsoft.Network/networkInterfaces/', variables('nicName'))]" - ], - "properties": { - "hardwareProfile": { - ... - ``` --1. Add the following configuration to enable the diagnostics extension on a Windows VM. For a simple Resource Manager-based VM, you can add the extension configuration to the resources array for the VM. The line `"sinks": "AzMonSink"`, and the corresponding `"SinksConfig"` later in the section, enable the extension to emit metrics directly to Azure Monitor. Feel free to add or remove performance counters as needed. - - ```json - "networkProfile": { - "networkInterfaces": [ - { - "id": "[resourceId('Microsoft.Network/networkInterfaces',variables('nicName'))]" - } - ] - }, - "diagnosticsProfile": { - "bootDiagnostics": { - "enabled": true, - "storageUri": "[reference(resourceId('Microsoft.Storage/storageAccounts/', variables('storageAccountName'))).primaryEndpoints.blob]" - } - } - }, - //Start of section to add - "resources": [ - { - "type": "Microsoft.Compute/virtualMachines/extensions", - "name": "[concat(variables('vmName'), '/', 'Microsoft.Insights.VMDiagnosticsSettings')]", - "apiVersion": "2017-12-01", - "location": "[resourceGroup().location]", - "dependsOn": [ - "[concat('Microsoft.Compute/virtualMachines/', variables('vmName'))]" - ], - "properties": { - "publisher": "Microsoft.Azure.Diagnostics", - "type": "IaaSDiagnostics", - "typeHandlerVersion": "1.12", - "autoUpgradeMinorVersion": true, - "settings": { - "WadCfg": { - "DiagnosticMonitorConfiguration": { - "overallQuotaInMB": 4096, - "DiagnosticInfrastructureLogs": { - "scheduledTransferLogLevelFilter": "Error" - }, - "Directories": { - "scheduledTransferPeriod": "PT1M", - "IISLogs": { - "containerName": "wad-iis-logfiles" - }, - "FailedRequestLogs": { - "containerName": "wad-failedrequestlogs" - } - }, - "PerformanceCounters": { - "scheduledTransferPeriod": "PT1M", - "sinks": "AzMonSink", - "PerformanceCounterConfiguration": [ - { - "counterSpecifier": "\\Memory\\Available Bytes", - "sampleRate": "PT15S" - }, - { - "counterSpecifier": "\\Memory\\% Committed Bytes In Use", - "sampleRate": "PT15S" - }, - { - "counterSpecifier": "\\Memory\\Committed Bytes", - "sampleRate": "PT15S" - } - ] - }, - "WindowsEventLog": { - "scheduledTransferPeriod": "PT1M", - "DataSource": [ - { - "name": "Application!*" - } - ] - }, - "Logs": { - "scheduledTransferPeriod": "PT1M", - "scheduledTransferLogLevelFilter": "Error" - } - }, - "SinksConfig": { - "Sink": [ - { - "name" : "AzMonSink", - "AzureMonitor" : {} - } - ] - } - }, - "StorageAccount": "[variables('storageAccountName')]" - }, - "protectedSettings": { - "storageAccountName": "[variables('storageAccountName')]", - "storageAccountKey": "[listKeys(variables('accountid'),'2015-06-15').key1]", - "storageAccountEndPoint": "https://core.windows.net/" - } - } - } - ] - //End of section to add - ``` --1. Save and close both files. --## Deploy the ARM template --> [!NOTE] -> You must be running Azure Diagnostics extension version 1.5 or higher *and* have the `autoUpgradeMinorVersion:` property set to `true` in your ARM template. Azure then loads the proper extension when it starts the VM. If you don't have these settings in your template, change them and redeploy the template. --To deploy the ARM template, we use Azure PowerShell. --1. Start PowerShell. -1. Sign in to Azure by using `Login-AzAccount`. -1. Get your list of subscriptions by using `Get-AzSubscription`. -1. Set the subscription that you're using to create/update the VM in: -- ```powershell - Select-AzSubscription -SubscriptionName "<Name of the subscription>" - ``` --1. To create a new resource group for the VM that's being deployed, run the following command: -- ```powershell - New-AzResourceGroup -Name "<Name of Resource Group>" -Location "<Azure Region>" - ``` -- > [!NOTE] - > Remember to [use an Azure region that's enabled for custom metrics](./metrics-custom-overview.md). --1. Run the following commands to deploy the VM by using the ARM template. - > [!NOTE] - > If you want to update an existing VM, add *-Mode Incremental* to the end of the following command. -- ```powershell - New-AzResourceGroupDeployment -Name "<NameThisDeployment>" -ResourceGroupName "<Name of the Resource Group>" -TemplateFile "<File path of your Resource Manager template>" -TemplateParameterFile "<File path of your parameters file>" - ``` --1. After your deployment succeeds, the VM should be in the Azure portal, emitting metrics to Azure Monitor. -- > [!NOTE] - > You might run into errors around the selected `vmSkuSize`. If this error happens, go back to your *azuredeploy.json* file and update the default value of the `vmSkuSize` parameter. In this case, we recommend that you try `"Standard_DS1_v2"`). --## Chart your metrics --1. Sign in to the Azure portal. --1. On the left menu, select **Monitor**. --1. On the **Monitor** page, select **Metrics**. -- :::image type="content" source="media/collect-custom-metrics-guestos-resource-manager-vm/metrics.png" lightbox="media/collect-custom-metrics-guestos-resource-manager-vm/metrics.png" alt-text="Screenshot that shows the Metrics page."::: --1. Change the aggregation period to **Last 30 minutes**. --1. In the resource dropdown menu, select the VM that you created. If you didn't change the name in the template, it should be **SimpleWinVM2**. --1. In the namespaces dropdown list, select **azure.vm.windows.guestmetrics**. --1. In the metrics dropdown list, select **Memory\%Committed Bytes in Use**. --## Next steps -Learn more about [custom metrics](./metrics-custom-overview.md). |
| azure-monitor | Collect Custom Metrics Guestos Resource Manager Vmss | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/collect-custom-metrics-guestos-resource-manager-vmss.md | - Title: Collect Windows scale set metrics in Azure Monitor with template -description: Send guest OS metrics to the Azure Monitor metric store by using a Resource Manager template for a Windows virtual machine scale set ---- Previously updated : 08/26/2024--# Send guest OS metrics to the Azure Monitor metric store by using an Azure Resource Manager template for a Windows virtual machine scale set --> [!NOTE] -> Azure Monitor Agent (AMA) collects monitoring data from the guest operating system of Azure and hybrid virtual machines and Virtual Machine Scale Sets and delivers it to Azure Monitor for use by features, insights, and other services such as [Microsoft Sentinel](../../sentintel/../sentinel/overview.md) and [Microsoft Defender for Cloud](/azure/defender-for-cloud/defender-for-cloud-introduction). -> ->We recommend using the Azure Monitor Agent to collet logs and metrics from Virtual Machine Scale Sets. For more information, see [Azure Monitor Agent overview](../agents/azure-monitor-agent-overview.md). ---By using the Azure Monitor [Azure Diagnostics extension for Windows (WAD)](../agents/diagnostics-extension-overview.md), you can collect metrics and logs from the guest operating system (guest OS) that runs as part of a virtual machine, cloud service, or Azure Service Fabric cluster. The extension can send telemetry to many different locations listed in the previously linked article. --This article describes the process to send guest OS performance metrics for a Windows virtual machine scale set to the Azure Monitor data store. Starting with Microsoft Azure Diagnostics version 1.11, you can write metrics directly to the Azure Monitor metrics store, where standard platform metrics are already collected. By storing them in this location, you can access the same actions that are available for platform metrics. Actions include near real-time alerting, charting, routing, access from the REST API, and more. In the past, the Microsoft Azure Diagnostics extension wrote to Azure Storage but not the Azure Monitor data store. --If you're new to Resource Manager templates, learn about [template deployments](../../azure-resource-manager/management/overview.md) and their structure and syntax. ---## Prerequisites --- Your subscription must be registered with [Microsoft.Insights](../../azure-resource-manager/management/resource-providers-and-types.md). --- You need to have [Azure PowerShell](/powershell/azure) installed, or you can use [Azure Cloud Shell](../../cloud-shell/overview.md). --## Set up Azure Monitor as a data sink -The Azure Diagnostics extension uses a feature called **data sinks** to route metrics and logs to different locations. The following steps show how to use a Resource Manager template and PowerShell to deploy a VM by using the new Azure Monitor data sink. --## Author a Resource Manager template -For this example, you can use a publicly available [sample template](https://github.com/Azure/azure-quickstart-templates/tree/master/quickstarts/microsoft.compute/vmss-windows-autoscale): --- **Azuredeploy.json** is a preconfigured Resource Manager template for deployment of a virtual machine scale set.--- **Azuredeploy.parameters.json** is a parameters file that stores information like what username and password you want to set for your VM. During deployment, the Resource Manager template uses the parameters set in this file. --Download and save both files locally. --### Modify azuredeploy.parameters.json --Open the **azuredeploy.parameters.json** file: --- Provide a **vmSKU** you want to deploy. We recommend Standard_D2_v3. -- Specify a **windowsOSVersion** you want for your virtual machine scale set. We recommend 2016-Datacenter. -- Name the virtual machine scale set resource to be deployed by using a **vmssName** property. An example is **VMSS-WAD-TEST**. -- Specify the number of VMs you want to run on the virtual machine scale set by using the **instanceCount** property.-- Enter values for **adminUsername** and **adminPassword** for the virtual machine scale set. These parameters are used for remote access to the VMs in the scale set. To avoid having your VM hijacked, **do not** use the ones in this template. Bots scan the internet for usernames and passwords in public GitHub repositories. They're likely to be testing VMs with these defaults. --### Modify azuredeploy.json --Open the **azuredeploy.json** file. --Add a variable to hold the storage account information in the Resource Manager template. Any logs or performance counters specified in the diagnostics config file are written to both the Azure Monitor metric store and the storage account you specify here: --```json -"variables": { - //add this line - "storageAccountName": "[concat('storage', uniqueString(resourceGroup().id))]", - ... -} -``` - -Find the virtual machine scale set definition in the resources section and add the **identity** section to the configuration. This addition ensures that Azure assigns it a system identity. This step also ensures that the VMs in the scale set can emit guest metrics about themselves to Azure Monitor: --```json -{ - "type": "Microsoft.Compute/virtualMachineScaleSets", - "name": "[variables('namingInfix')]", - "location": "[resourceGroup().location]", - "apiVersion": "2017-03-30", - //add these lines below - "identity": { - "type": "systemAssigned" - }, - //end of lines to add - ... -} -``` --In the virtual machine scale set resource, find the **virtualMachineProfile** section. Add a new profile called **extensionsProfile** to manage extensions. ---In the **extensionProfile**, add a new extension to the template as shown in the **VMSS-WAD-extension** section. This section is the managed identities for Azure resources extension that ensures the metrics being emitted are accepted by Azure Monitor. The **name** field can contain any name. --The following code from the MSI extension also adds the diagnostics extension and configuration as an extension resource to the virtual machine scale set resource. Feel free to add or remove performance counters as needed: --```json - "extensionProfile": { - "extensions": [ - // BEGINNING of added code - // Managed identities for Azure resources - { - "name": "VMSS-WAD-extension", - "properties": { - "publisher": "Microsoft.ManagedIdentity", - "type": "ManagedIdentityExtensionForWindows", - "typeHandlerVersion": "1.0", - "autoUpgradeMinorVersion": true, - "settings": { - "port": 50342 - }, - "protectedSettings": {} - } - }, - // add diagnostic extension. (Remove this comment after pasting.) - { - "name": "[concat('VMDiagnosticsVmExt','_vmNodeType0Name')]", - "properties": { - "type": "IaaSDiagnostics", - "autoUpgradeMinorVersion": true, - "protectedSettings": { - "storageAccountName": "[variables('storageAccountName')]", - "storageAccountKey": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', variables('storageAccountName')),'2015-05-01-preview').key1]", - "storageAccountEndPoint": "https://core.windows.net/" - }, - "publisher": "Microsoft.Azure.Diagnostics", - "settings": { - "WadCfg": { - "DiagnosticMonitorConfiguration": { - "overallQuotaInMB": "50000", - "PerformanceCounters": { - "scheduledTransferPeriod": "PT1M", - "sinks": "AzMonSink", - "PerformanceCounterConfiguration": [ - { - "counterSpecifier": "\\Memory\\% Committed Bytes In Use", - "sampleRate": "PT15S" - }, - { - "counterSpecifier": "\\Memory\\Available Bytes", - "sampleRate": "PT15S" - }, - { - "counterSpecifier": "\\Memory\\Committed Bytes", - "sampleRate": "PT15S" - } - ] - }, - "EtwProviders": { - "EtwEventSourceProviderConfiguration": [ - { - "provider": "Microsoft-ServiceFabric-Actors", - "scheduledTransferKeywordFilter": "1", - "scheduledTransferPeriod": "PT5M", - "DefaultEvents": { - "eventDestination": "ServiceFabricReliableActorEventTable" - } - }, - { - "provider": "Microsoft-ServiceFabric-Services", - "scheduledTransferPeriod": "PT5M", - "DefaultEvents": { - "eventDestination": "ServiceFabricReliableServiceEventTable" - } - } - ], - "EtwManifestProviderConfiguration": [ - { - "provider": "cbd93bc2-71e5-4566-b3a7-595d8eeca6e8", - "scheduledTransferLogLevelFilter": "Information", - "scheduledTransferKeywordFilter": "4611686018427387904", - "scheduledTransferPeriod": "PT5M", - "DefaultEvents": { - "eventDestination": "ServiceFabricSystemEventTable" - } - } - ] - } - }, - "SinksConfig": { - "Sink": [ - { - "name": "AzMonSink", - "AzureMonitor": {} - } - ] - } - }, - "StorageAccount": "[variables('storageAccountName')]" - }, - "typeHandlerVersion": "1.11" - } - } - ] - }, - // end of added code. Be sure that the number and type of brackets match properly when done. - { - "type": "Microsoft.Insights/autoscaleSettings", - ... - } -``` --Add a **dependsOn** for the storage account to ensure it's created in the correct order: --```json -"dependsOn": [ - "[concat('Microsoft.Network/loadBalancers/', variables('loadBalancerName'))]", - "[concat('Microsoft.Network/virtualNetworks/', variables('virtualNetworkName'))]", - //add this line below - "[concat('Microsoft.Storage/storageAccounts/', variables('storageAccountName'))]" -] -``` --Create a storage account if one isn't already created in the template: --```json -"resources": [ - // add this code - { - "type": "Microsoft.Storage/storageAccounts", - "name": "[variables('storageAccountName')]", - "apiVersion": "2015-05-01-preview", - "location": "[resourceGroup().location]", - "properties": { - "accountType": "Standard_LRS" - } - }, - // end added code - { - "type": "Microsoft.Network/virtualNetworks", - "name": "[variables('virtualNetworkName')]", - ... - } -] -``` --Save and close both files. --## Deploy the Resource Manager template --> [!NOTE] -> You must be running the Azure Diagnostics extension version 1.5 or higher **and** have the **autoUpgradeMinorVersion:** property set to **true** in your Resource Manager template. Azure then loads the proper extension when it starts the VM. If you don't have these settings in your template, change them and redeploy the template. --To deploy the Resource Manager template, use Azure PowerShell: --1. Launch PowerShell. --1. Sign in to Azure using `Login-AzAccount`. --1. Get your list of subscriptions by using `Get-AzSubscription`. --1. Set the subscription you'll create, or update the virtual machine: -- ```powershell - Select-AzSubscription -SubscriptionName "<Name of the subscription>" - ``` --1. Create a new resource group for the VM being deployed. Run the following command: -- ```powershell - New-AzResourceGroup -Name "VMSSWADtestGrp" -Location "<Azure Region>" - ``` --1. Run the following commands to deploy the VM: -- > [!NOTE] - > If you want to update an existing scale set, add **-Mode Incremental** to the end of the command. -- ```powershell - New-AzResourceGroupDeployment -Name "VMSSWADTest" -ResourceGroupName "VMSSWADtestGrp" -TemplateFile "<File path of your azuredeploy.JSON file>" -TemplateParameterFile "<File path of your azuredeploy.parameters.JSON file>" - ``` --1. After your deployment succeeds, you should find the virtual machine scale set in the Azure portal. It should emit metrics to Azure Monitor. -- > [!NOTE] - > You might run into errors around the selected **vmSkuSize**. In that case, go back to your **azuredeploy.json** file and update the default value of the **vmSkuSize** parameter. We recommend that you try **Standard_DS1_v2**. --## Chart your metrics --1. Sign in to the Azure portal. --1. In the left-hand menu, select **Monitor**. --1. On the **Monitor** page, select **Metrics**. -- :::image source="media/collect-custom-metrics-guestos-resource-manager-vmss/metrics.png" alt-text="A screenshot showing the metrics menu item on the Azure Monitor menu page." lightbox="media/collect-custom-metrics-guestos-resource-manager-vmss/metrics.png"::: --1. Change the aggregation period to **Last 30 minutes**. --1. In the resource drop-down menu, select the virtual machine scale set you created. --1. In the namespaces drop-down menu, select **Virtual Machine Guest**. --1. In the metrics drop-down menu, select **Memory\%Committed Bytes in Use**. -- :::image source="media/collect-custom-metrics-guestos-resource-manager-vmss/create-metrics-chart.png" alt-text="A screenshot showing the selection of namespace metric and aggregation for a metrics chart." lightbox="media/collect-custom-metrics-guestos-resource-manager-vmss/create-metrics-chart.png"::: --You can then also choose to use the dimensions on this metric to chart it for a particular VM or to plot each VM in the scale set. --## Next steps --- Learn more about [custom metrics](./metrics-custom-overview.md). |
| azure-monitor | Collect Custom Metrics Guestos Vm Classic | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/collect-custom-metrics-guestos-vm-classic.md | - Title: Send classic Windows VM metrics to Azure Monitor metrics database -description: Send Guest OS metrics to the Azure Monitor data store for a Windows virtual machine (classic) --- Previously updated : 05/31/2024---# Send Guest OS metrics to the Azure Monitor metrics database for a Windows virtual machine (classic) ---The Azure Monitor [Diagnostics extension](../agents/diagnostics-extension-overview.md) (known as "WAD" or "Diagnostics") allows you to collect metrics and logs from the guest operating system (Guest OS) running as part of a virtual machine, cloud service, or Service Fabric cluster. The extension can send telemetry to [many different locations.](../data-platform.md?toc=%2fazure%2fazure-monitor%2ftoc.json) --This article describes the process for sending Guest OS performance metrics for a Windows virtual machine (classic) to the Azure Monitor metric database. Starting with Diagnostics version 1.11, you can write metrics directly to the Azure Monitor metrics store, where standard platform metrics are already collected. --Storing them in this location allows you to access the same actions as you do for platform metrics. Actions include near-real time alerting, charting, routing, access from a REST API, and more. In the past, the Diagnostics extension wrote to Azure Storage, but not to the Azure Monitor data store. --The process that's outlined in this article only works on classic virtual machines that are running the Windows operating system. --## Prerequisites --- You must be a [service administrator or co-administrator](../../cost-management-billing/manage/add-change-subscription-administrator.md) on your Azure subscription. --- Your subscription must be registered with [Microsoft.Insights](../../azure-resource-manager/management/resource-providers-and-types.md). --- You need to have either [Azure PowerShell](/powershell/azure) or [Azure Cloud Shell](../../cloud-shell/overview.md) installed.--## Create a classic virtual machine and storage account --1. Create a classic VM by using the Azure portal. - :::image type="content" source="./media/collect-custom-metrics-guestos-vm-classic/create-classic-vm.png" lightbox="./media/collect-custom-metrics-guestos-vm-classic/create-classic-vm.png" alt-text="Create Classic VM"::: --1. When you're creating this VM, choose the option to create a new classic storage account. We use this storage account in later steps. --1. In the Azure portal, go to the **Storage accounts** resource pane. Select **Keys**, and take note of the storage account name and storage account key. You need this information in later steps. - :::image type="content" source="./media/collect-custom-metrics-guestos-vm-classic/storage-access-keys.png" lightbox="./media/collect-custom-metrics-guestos-vm-classic/storage-access-keys.png" alt-text="Storage access keys"::: --## Create a service principal --Create a service principal in your Microsoft Entra tenant by using the instructions at [Create a service principal](../../active-directory/develop/howto-create-service-principal-portal.md). Note the following while going through this process: -- Create new client secret for this app.-- Save the key and the client ID for use in later steps.--Give this app ΓÇ£Monitoring Metrics PublisherΓÇ¥ permissions to the resource that you want to emit metrics against. You can use a resource group or an entire subscription. --> [!NOTE] -> The Diagnostics extension uses the service principal to authenticate against Azure Monitor and emit metrics for your classic VM. --## Author Diagnostics extension configuration --1. Prepare your Diagnostics extension configuration file. This file dictates which logs and performance counters the Diagnostics extension should collect for your classic VM. Following is an example: -- ```xml - <?xml version="1.0" encoding="utf-8"?> - <DiagnosticsConfiguration xmlns="http://schemas.microsoft.com/ServiceHosting/2010/10/DiagnosticsConfiguration"> - <PublicConfig xmlns="http://schemas.microsoft.com/ServiceHosting/2010/10/DiagnosticsConfiguration"> - <WadCfg> - <DiagnosticMonitorConfiguration overallQuotaInMB="4096" sinks="applicationInsights.errors"> - <DiagnosticInfrastructureLogs scheduledTransferLogLevelFilter="Error" /> - <Directories scheduledTransferPeriod="PT1M"> - <IISLogs containerName="wad-iis-logfiles" /> - <FailedRequestLogs containerName="wad-failedrequestlogs" /> - </Directories> - <PerformanceCounters scheduledTransferPeriod="PT1M"> - <PerformanceCounterConfiguration counterSpecifier="\Processor(*)\% Processor Time" sampleRate="PT15S" /> - <PerformanceCounterConfiguration counterSpecifier="\Memory\Available Bytes" sampleRate="PT15S" /> - <PerformanceCounterConfiguration counterSpecifier="\Memory\Committed Bytes" sampleRate="PT15S" /> - <PerformanceCounterConfiguration counterSpecifier="\Memory\% Committed Bytes" sampleRate="PT15S" /> - <PerformanceCounterConfiguration counterSpecifier="\LogicalDisk(*)\Disk Read Bytes/sec" sampleRate="PT15S" /> - </PerformanceCounters> - <WindowsEventLog scheduledTransferPeriod="PT1M"> - <DataSource name="Application!*[System[(Level=1 or Level=2 or Level=3)]]" /> - <DataSource name="Windows Azure!*[System[(Level=1 or Level=2 or Level=3 or Level=4)]]" /> - </WindowsEventLog> - <CrashDumps> - <CrashDumpConfiguration processName="WaIISHost.exe" /> - <CrashDumpConfiguration processName="WaWorkerHost.exe" /> - <CrashDumpConfiguration processName="w3wp.exe" /> - </CrashDumps> - <Logs scheduledTransferPeriod="PT1M" scheduledTransferLogLevelFilter="Error" /> - <Metrics resourceId="/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/MyResourceGroup/providers/Microsoft.ClassicCompute/virtualMachines/MyClassicVM"> - <MetricAggregation scheduledTransferPeriod="PT1M" /> - <MetricAggregation scheduledTransferPeriod="PT1H" /> - </Metrics> - </DiagnosticMonitorConfiguration> - <SinksConfig> - </SinksConfig> - </WadCfg> - <StorageAccount /> - </PublicConfig> - <PrivateConfig xmlns="http://schemas.microsoft.com/ServiceHosting/2010/10/DiagnosticsConfiguration"> - <StorageAccount name="" endpoint="" /> - </PrivateConfig> - <IsEnabled>true</IsEnabled> - </DiagnosticsConfiguration> - ``` -1. In the ΓÇ£SinksConfigΓÇ¥ section of your diagnostics file, define a new Azure Monitor sink, as follows: -- ```xml - <SinksConfig> - <Sink name="AzMonSink"> - <AzureMonitor> - <ResourceId>Provide the resource ID of your classic VM </ResourceId> - <Region>The region your VM is deployed in</Region> - </AzureMonitor> - </Sink> - </SinksConfig> - ``` --1. In the section of your configuration file where the list of performance counters to be collected is listed, route the performance counters to the Azure Monitor sink "AzMonSink". -- ```xml - <PerformanceCounters scheduledTransferPeriod="PT1M" sinks="AzMonSink"> - <PerformanceCounterConfiguration counterSpecifier="\Processor(_Total)\% Processor Time" sampleRate="PT15S" /> - ... - </PerformanceCounters> - ``` --1. In the private configuration, define the Azure Monitor account. Then add the service principal information to use to emit metrics. -- ```xml - <PrivateConfig xmlns="http://schemas.microsoft.com/ServiceHosting/2010/10/DiagnosticsConfiguration"> - <StorageAccount name="" endpoint="" /> - <AzureMonitorAccount> - <ServicePrincipalMeta> - <PrincipalId>clientId for your service principal</PrincipalId> - <Secret>client secret of your service principal</Secret> - </ServicePrincipalMeta> - </AzureMonitorAccount> - </PrivateConfig> - ``` --1. Save this file locally. --## Deploy the Diagnostics extension to your cloud service --1. Launch PowerShell and sign in. -- ```powershell - Login-AzAccount - ``` --1. Start by setting the context for your classic VM. -- ```powershell - $VM = Get-AzureVM -ServiceName <VMΓÇÖs Service_Name> -Name <VM Name> - ``` --1. Set the context of the classic storage account that was created with the VM. -- ```powershell - $StorageContext = New-AzStorageContext -StorageAccountName <name of your storage account from earlier steps> -storageaccountkey "<storage account key from earlier steps>" - ``` --1. Set the Diagnostics file path to a variable by using the following command: -- ```powershell - $diagconfig = ΓÇ£<path of the diagnostics configuration file with the Azure Monitor sink configured>ΓÇ¥ - ``` --1. Prepare the update for your classic VM with the diagnostics file that has the Azure Monitor sink configured. -- ```powershell - $VM_Update = Set-AzureVMDiagnosticsExtension -DiagnosticsConfigurationPath $diagconfig -VM $VM -StorageContext $Storage_Context - ``` --1. Deploy the update to your VM by running the following command: -- ```powershell - Update-AzureVM -ServiceName "ClassicVMWAD7216" -Name "ClassicVMWAD" -VM $VM_Update.VM - ``` --> [!NOTE] -> It is still mandatory to provide a storage account as part of the installation of the Diagnostics extension. Any logs or performance counters that are specified in the Diagnostics config file will be written to the specified storage account. --## Plot the metrics in the Azure portal --1. Go to the Azure portal. --1. On the left menu, select **Monitor.** --1. On the **Monitor** pane on the left, select **Metrics**. -- :::image type="content" source="./media/collect-custom-metrics-guestos-vm-classic/navigate-metrics.png" lightbox="./media/collect-custom-metrics-guestos-vm-classic/navigate-metrics.png" alt-text="Navigate metrics"::: --1. In the resources drop-down menu, select your classic VM. --1. In the namespaces drop-down menu, select **azure.vm.windows.guest**. --1. In the metrics drop-down menu, select **Memory\Committed Bytes in Use**. - :::image type="content" source="./media/collect-custom-metrics-guestos-vm-classic/plot-metrics.png" lightbox="./media/collect-custom-metrics-guestos-vm-classic/plot-metrics.png" alt-text="Plot metrics"::: ---## Next steps -- Learn more about [custom metrics](./metrics-custom-overview.md). |
| azure-monitor | Collect Custom Metrics Guestos Vm Cloud Service Classic | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/collect-custom-metrics-guestos-vm-cloud-service-classic.md | - Title: Send classic Cloud Services metrics to Azure Monitor metrics database -description: Describes the process for sending Guest OS performance metrics for Azure classic Cloud Services to the Azure Monitor metric store. -- Previously updated : 05/31/2024--# Send Guest OS metrics to the Azure Monitor metric store classic Cloud Services ---With the Azure Monitor [Diagnostics extension](../agents/diagnostics-extension-overview.md), you can collect metrics and logs from the guest operating system (Guest OS) running as part of a virtual machine, cloud service, or Service Fabric cluster. The extension can send telemetry to [many different locations.](../data-platform.md?toc=%2fazure%2fazure-monitor%2ftoc.json) --This article describes the process for sending Guest OS performance metrics for Azure classic Cloud Services to the Azure Monitor metric store. Starting with Diagnostics version 1.11, you can write metrics directly to the Azure Monitor metrics store, where standard platform metrics are already collected. --Storing them in this location allows you to access the same actions that you can for platform metrics. Actions include near-real time alerting, charting, routing, access from a REST API, and more. In the past, the Diagnostics extension wrote to Azure Storage, but not to the Azure Monitor data store. --The process that's outlined in this article works only for performance counters in Azure Cloud Services. It doesn't work for other custom metrics. --## Prerequisites --- You must be a [service administrator or co-administrator](../../cost-management-billing/manage/add-change-subscription-administrator.md) on your Azure subscription. --- Your subscription must be registered with [Microsoft.Insights](../../azure-resource-manager/management/resource-providers-and-types.md). --- You need to have either [Azure PowerShell](/powershell/azure) or [Azure Cloud Shell](../../cloud-shell/overview.md) installed.--## Provision a cloud service and storage account --1. Create and deploy a classic cloud service. A sample classic Cloud Services application and deployment can be found at [Get started with Azure Cloud Services and ASP.NET](../../cloud-services/cloud-services-dotnet-get-started.md). --2. You can use an existing storage account or deploy a new storage account. It's best if the storage account is in the same region as the classic cloud service that you created. In the Azure portal, go to the **Storage accounts** resource pane, and then select **Keys**. Take note of the storage account name and the storage account key. You'll need this information in later steps. - <!-- convertborder later --> - :::image type="content" source="./media/collect-custom-metrics-guestos-vm-cloud-service-classic/storage-keys.png" lightbox="./media/collect-custom-metrics-guestos-vm-cloud-service-classic/storage-keys.png" alt-text="Storage account keys" border="false"::: --## Create a service principal --Create a service principal in your Microsoft Entra tenant by using the instructions at [Use portal to create a Microsoft Entra application and service principal that can access resources](../../active-directory/develop/howto-create-service-principal-portal.md). Note the following while you're going through this process: --- You can put in any URL for the sign-in URL. -- Create new client secret for this app. -- Save the key and the client ID for use in later steps. --Give the app created in the previous step *Monitoring Metrics Publisher* permissions to the resource you want to emit metrics against. If you plan to use the app to emit custom metrics against many resources, you can grant these permissions at the resource group or subscription level. --> [!NOTE] -> The Diagnostics extension uses the service principal to authenticate against Azure Monitor and emit metrics for your cloud service. --## Author Diagnostics extension configuration --Prepare your Diagnostics extension configuration file. This file dictates which logs and performance counters the Diagnostics extension should collect for your cloud service. Following is a sample Diagnostics configuration file: --```xml -<?xml version="1.0" encoding="utf-8"?> -<DiagnosticsConfiguration xmlns="http://schemas.microsoft.com/ServiceHosting/2010/10/DiagnosticsConfiguration"> - <PublicConfig xmlns="http://schemas.microsoft.com/ServiceHosting/2010/10/DiagnosticsConfiguration"> - <WadCfg> - <DiagnosticMonitorConfiguration overallQuotaInMB="4096"> - <DiagnosticInfrastructureLogs scheduledTransferLogLevelFilter="Error" /> - <Directories scheduledTransferPeriod="PT1M"> - <IISLogs containerName="wad-iis-logfiles" /> - <FailedRequestLogs containerName="wad-failedrequestlogs" /> - </Directories> - <PerformanceCounters scheduledTransferPeriod="PT1M"> - <PerformanceCounterConfiguration counterSpecifier="\Processor(_Total)\% Processor Time" sampleRate="PT15S" /> - <PerformanceCounterConfiguration counterSpecifier="\Memory\Available MBytes" sampleRate="PT15S" /> - <PerformanceCounterConfiguration counterSpecifier="\Memory\Committed Bytes" sampleRate="PT15S" /> - <PerformanceCounterConfiguration counterSpecifier="\Memory\Page Faults/sec" sampleRate="PT15S" /> - </PerformanceCounters> - <WindowsEventLog scheduledTransferPeriod="PT1M"> - <DataSource name="Application!*[System[(Level=1 or Level=2 or Level=3)]]" /> - <DataSource name="Windows Azure!*[System[(Level=1 or Level=2 or Level=3 or Level=4)]]" /> - </WindowsEventLog> - <CrashDumps> - <CrashDumpConfiguration processName="WaIISHost.exe" /> - <CrashDumpConfiguration processName="WaWorkerHost.exe" /> - <CrashDumpConfiguration processName="w3wp.exe" /> - </CrashDumps> - <Logs scheduledTransferPeriod="PT1M" scheduledTransferLogLevelFilter="Error" /> - </DiagnosticMonitorConfiguration> - <SinksConfig> - </SinksConfig> - </WadCfg> - <StorageAccount /> - </PublicConfig> - <PrivateConfig xmlns="http://schemas.microsoft.com/ServiceHosting/2010/10/DiagnosticsConfiguration"> - <StorageAccount name="" endpoint="" /> -</PrivateConfig> - <IsEnabled>true</IsEnabled> -</DiagnosticsConfiguration> -``` --In the "SinksConfig" section of your diagnostics file, define a new Azure Monitor sink: --```xml - <SinksConfig> - <Sink name="AzMonSink"> - <AzureMonitor> - <ResourceId>-Provide ClassicCloudServiceΓÇÖs Resource ID-</ResourceId> - <Region>-Azure Region your Cloud Service is deployed in-</Region> - </AzureMonitor> - </Sink> - </SinksConfig> -``` --In the section of your configuration file where you list the performance counters to collect, add the Azure Monitor sink. This entry ensures that all the performance counters that you specified are routed to Azure Monitor as metrics. You can add or remove performance counters according to your needs. --```xml - <PerformanceCounters scheduledTransferPeriod="PT1M" sinks="AzMonSink"> - <PerformanceCounterConfiguration counterSpecifier="\Processor(_Total)\% Processor Time" sampleRate="PT15S" /> - ... - </PerformanceCounters> -``` --Finally, in the private configuration, add an *Azure Monitor Account* section. Enter the service principal client ID and secret that you created earlier. --```xml -<PrivateConfig xmlns="http://schemas.microsoft.com/ServiceHosting/2010/10/DiagnosticsConfiguration"> - <StorageAccount name="" endpoint="" /> - <AzureMonitorAccount> - <ServicePrincipalMeta> - <PrincipalId>clientId from step 3</PrincipalId> - <Secret>client secret from step 3</Secret> - </ServicePrincipalMeta> - </AzureMonitorAccount> -</PrivateConfig> -``` --Save this diagnostics file locally. --## Deploy the Diagnostics extension to your cloud service --Launch PowerShell and log in to Azure. --```powershell -Login-AzAccount -``` --Use the following commands to store the details of the storage account that you created earlier. --```powershell -$storage_account = <name of your storage account from step 3> -$storage_keys = <storage account key from step 3> -``` --Similarly, set the diagnostics file path to a variable by using the following command: --```powershell -$diagconfig = ΓÇ£<path of the Diagnostics configuration file with the Azure Monitor sink configured>ΓÇ¥ -``` --Deploy the Diagnostics extension to your cloud service with the diagnostics file with the Azure Monitor sink configured using the following command: --```powershell -Set-AzureServiceDiagnosticsExtension -ServiceName <classicCloudServiceName> -StorageAccountName $storage_account -StorageAccountKey $storage_keys -DiagnosticsConfigurationPath $diagconfig -``` --> [!NOTE] -> It's still mandatory to provide a storage account as part of the installation of the Diagnostics extension. Any logs or performance counters that are specified in the diagnostics config file are written to the specified storage account. --## Plot metrics in the Azure portal --1. Go to the Azure portal. -- :::image type="content" source="./media/collect-custom-metrics-guestos-vm-cloud-service-classic/navigate-metrics.png" lightbox="./media/collect-custom-metrics-guestos-vm-cloud-service-classic/navigate-metrics.png" alt-text="Screenshot shows the Azure portal with Monitor, then Metrics selected."::: --2. On the left menu, select **Monitor.** --3. On the **Monitor** pane, select the **Metrics Preview** tab. --4. In the resources drop-down menu, select your classic cloud service. --5. In the namespaces drop-down menu, select **azure.vm.windows.guest**. --6. In the metrics drop-down menu, select **Memory\Committed Bytes in Use**. --You use the dimension filtering and splitting capabilities to view the total memory that's used by a specific role or role instance. - <!-- convertborder later --> - :::image type="content" source="./media/collect-custom-metrics-guestos-vm-cloud-service-classic/metrics-graph.png" lightbox="./media/collect-custom-metrics-guestos-vm-cloud-service-classic/metrics-graph.png" alt-text="Screenshot shows Metrics data." border="false"::: --## Next steps --- Learn more about [custom metrics](./metrics-custom-overview.md). |
| azure-monitor | Collect Custom Metrics Linux Telegraf | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/collect-custom-metrics-linux-telegraf.md | - Title: Collect custom metrics for Linux Virtual Machines with the InfluxData Telegraf agent -description: Instructions on how to deploy the InfluxData Telegraf agent on a Linux VM in Azure and configure the agent to publish metrics to Azure Monitor. ------ Previously updated : 06/06/2024--# Collect custom metrics for a Linux Virtual Machine with the InfluxData Telegraf agent ---This article explains how to deploy and configure the [InfluxData](https://www.influxdata.com/) Telegraf agent on a Linux virtual machine to send metrics to Azure Monitor. --> [!NOTE] -> InfluxData Telegraf is an open source agent and not officially supported by Azure Monitor. For issues with the Telegraf connector, refer to the Telegraf GitHub page here: [InfluxData](https://github.com/influxdata/telegraf) --## InfluxData Telegraf agent --[Telegraf](https://docs.influxdata.com/telegraf/) is a plug-in-driven agent that enables the collection of metrics from over 150 different sources. Depending on what workloads run on your VM, you can configure the agent to use specialized input plug-ins to collect metrics. Examples are MySQL, NGINX, and Apache. By using output plug-ins, the agent can then write to destinations that you choose. The Telegraf agent integrates directly with the Azure Monitor custom metrics REST API. It supports an Azure Monitor output plug-in. Using this plug-in, the agent can collect workload-specific metrics on your Linux VM and submit them as custom metrics to Azure Monitor. ---## Connect to the VM --Create an SSH connection to the VM where you want to install Telegraf. Select the **Connect** button on the overview page for your virtual machine. ---In the **Connect to virtual machine** page, keep the default options to connect by DNS name over port 22. In **Login using VM local account**, a connection command is shown. Select the button to copy the command. The following example shows what the SSH connection command looks like: --```cmd -ssh azureuser@XXXX.XX.XXX -``` -Paste the SSH connection command into a shell, such as Azure Cloud Shell or Bash on Ubuntu on Windows, or use an SSH client of your choice to create the connection. --## Install and configure Telegraf --To install the Telegraf Debian package onto the VM, run the following commands from your SSH session: --# [Ubuntu, Debian](#tab/ubuntu) --Add the repository: --```bash -# download the package to the VM -curl -s https://repos.influxdata.com/influxdb.key | sudo apt-key add - -source /etc/lsb-release -sudo echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | sudo tee /etc/apt/sources.list.d/influxdb.list -sudo curl -fsSL https://repos.influxdata.com/influxdata-archive_compat.key | sudo apt-key --keyring /etc/apt/trusted.gpg.d/influxdata-archive_compat.gpg add -``` -Install the package: --```bash - sudo apt-get update - sudo apt-get install telegraf -``` -# [RHEL, Oracle Linux](#tab/redhat) --Add the repository: --```bash -cat <<EOF | sudo tee /etc/yum.repos.d/influxdb.repo -[influxdb] -name = InfluxDB Repository - RHEL $releasever -baseurl = https://repos.influxdata.com/rhel/$releasever/$basearch/stable -enabled = 1 -gpgcheck = 1 -gpgkey = https://repos.influxdata.com/influxdata-archive_compat.key -EOF -``` -Install the package: --```bash - sudo yum -y install telegraf -``` --Telegraf's configuration file defines Telegraf's operations. By default, an example configuration file is installed at the path **/etc/telegraf/telegraf.conf**. The example configuration file lists all possible input and output plug-ins. However, we'll create a custom configuration file and have the agent use it by running the following commands: --```bash -# generate the new Telegraf config file in the current directory -telegraf --input-filter cpu:mem --output-filter azure_monitor config > azm-telegraf.conf --# replace the example config with the new generated config -sudo cp azm-telegraf.conf /etc/telegraf/telegraf.conf -``` --> [!NOTE] -> The preceding code enables only two input plug-ins: **cpu** and **mem**. You can add more input plug-ins, depending on the workload that runs on your machine. Examples are Docker, MySQL, and NGINX. For a full list of input plug-ins, see the **Additional configuration** section. --Finally, to have the agent start using the new configuration, we force the agent to stop and start by running the following commands: --```bash -# stop the telegraf agent on the VM -sudo systemctl stop telegraf -# start and enable the telegraf agent on the VM to ensure it picks up the latest configuration -sudo systemctl enable --now telegraf -``` -Now the agent collects metrics from each of the input plug-ins specified and emits them to Azure Monitor. --## Plot your Telegraf metrics in the Azure portal --1. Open the [Azure portal](https://portal.azure.com). --1. Navigate to the new **Monitor** tab. Then select **Metrics**. --1. Select your VM in the resource selector. --1. Select the **Telegraf/CPU** namespace, and select the **usage_system** metric. You can choose to filter by the dimensions on this metric or split on them. -- :::image type="content" source="./media/collect-custom-metrics-linux-telegraf/metric-chart.png" alt-text="A screenshot showing a metric chart with telegraph metrics selected." lightbox="./media/collect-custom-metrics-linux-telegraf/metric-chart.png"::: --## Additional configuration --The preceding walkthrough provides information on how to configure the Telegraf agent to collect metrics from a few basic input plug-ins. The Telegraf agent has support for over 150 input plug-ins, with some supporting additional configuration options. InfluxData has published a [list of supported plugins](https://docs.influxdata.com/telegraf/v1.15/plugins/inputs/) and instructions on [how to configure them](https://docs.influxdata.com/telegraf/v1.15/administration/configuration/). --Additionally, in this walkthrough, you used the Telegraf agent to emit metrics about the VM the agent is deployed on. The Telegraf agent can also be used as a collector and forwarder of metrics for other resources. To learn how to configure the agent to emit metrics for other Azure resources, see [Azure Monitor Custom Metric Output for Telegraf](https://github.com/influxdat). --## Clean up resources --When they're no longer needed, you can delete the resource group, virtual machine, and all related resources. To do so, select the resource group for the virtual machine and select **Delete**. Then confirm the name of the resource group to delete. --## Next steps -- Learn more about [custom metrics](./metrics-custom-overview.md). |
| azure-monitor | Create Diagnostic Settings | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/create-diagnostic-settings.md | - Title: Create diagnostic settings in Azure Monitor -description: Learn how to send Azure Monitor platform metrics and logs to Azure Monitor Logs, Azure Storage, or Azure Event Hubs with diagnostic settings. ----- Previously updated : 08/11/2024----# Create diagnostic settings in Azure Monitor --Create and edit diagnostic settings in Azure Monitor to send Azure platform metrics and logs to different destinations like Azure Monitor Logs, Azure Storage, or Azure Event Hubs. You can use different methods to work with the diagnostic settings, such as the Azure portal, the Azure CLI, PowerShell, and Azure Resource Manager. --> [!IMPORTANT] ->The Retention Policy as set in the Diagnostic Setting settings is now deprecated and can no longer be used. Use the Azure Storage Lifecycle Policy to manage the length of time that your logs are retained. For more information, see [Migrate diagnostic settings storage retention to Azure Storage lifecycle management](./migrate-to-azure-storage-lifecycle-policy.md) --## [Azure portal](#tab/portal) --You can configure diagnostic settings in the Azure portal either from the Azure Monitor menu or from the menu for the resource. --1. Where you configure diagnostic settings in the Azure portal depends on the resource: -- - For a single resource, select **Diagnostic settings** under **Monitoring** on the resource's menu. -- :::image type="content" source="media/diagnostic-settings/menu-resource.png" alt-text="Screenshot that shows the Monitoring section of a resource menu in the Azure portal with Diagnostic settings highlighted." border="false"::: -- - For one or more resources, select **Diagnostic settings** under **Settings** on the Azure Monitor menu and then select the resource. -- :::image type="content" source="media/diagnostic-settings/menu-monitor.png" alt-text="Screenshot that shows the Settings section in the Azure Monitor menu with Diagnostic settings highlighted."border="false"::: -- - For the activity log, select **Activity log** on the **Azure Monitor** menu and then select **Export Activity Logs**. Make sure you disable any legacy configuration for the activity log. For instructions, see [Disable existing settings](./activity-log.md#legacy-collection-methods). -- :::image type="content" source="media/diagnostic-settings/menu-activity-log.png" alt-text="Screenshot that shows the Azure Monitor menu with Activity log selected and Export activity logs highlighted in the Monitor-Activity log menu bar."::: --1. If no settings exist on the resource you select, you're prompted to create a setting. Select **Add diagnostic setting**. -- :::image type="content" source="media/diagnostic-settings/add-setting.png" alt-text="Screenshot that shows the Add diagnostic setting with no existing settings."::: -- If there are existing settings on the resource, you see a list of settings already configured. Select **Add diagnostic setting** to add a new setting. Or select **Edit setting** to edit an existing one. Each setting can have no more than one of each of the destination types. -- :::image type="Add diagnostic setting - existing settings" source="media/diagnostic-settings/edit-setting.png" alt-text="Screenshot that shows adding a diagnostic setting for existing settings."::: --1. Give your setting a name if it doesn't already have one. -- :::image type="Add diagnostic setting" source="media/diagnostic-settings/setting-new-blank.png" alt-text="Screenshot that shows Diagnostic setting name."::: --1. **Logs and metrics to route**: For logs, either choose a category group or select the individual checkboxes for each category of data you want to send to the destinations specified later. The list of categories varies for each Azure service. Select **AllMetrics** if you want to store metrics in Azure Monitor Logs too. --1. **Destination details**: Select the checkbox for each destination. Options appear so that you can add more information. -- :::image type="content" source="media/diagnostic-settings/send-to-log-analytics-event-hubs.png" alt-text="Screenshot that shows the available options under the Destination details section." border="false"::: -- 1. **Send to Log Analytics workspace**: Select your **Subscription** and the **Log Analytics workspace** where you want to send the data. If you don't have a workspace, you must [create one before you proceed](../logs/quick-create-workspace.md). -- 1. **Archive to a storage account**: Select your **Subscription** and the **Storage account** where you want to store the data. -- :::image type="content" source="media/diagnostic-settings/storage-settings-new.png" alt-text="Screenshot that shows storage category and destination details." lightbox="media/diagnostic-settings/storage-settings-new.png"::: -- > [!TIP] - > Use the [Azure Storage Lifecycle Policy](../../storage/blobs/lifecycle-management-policy-configure.md?tabs=azure-portal) to manage the length of time that your logs are retained. The Retention Policy as set in the Diagnostic Setting settings is now deprecated. -- 1. **Stream to an event hub**: Specify the following criteria: -- - **Subscription**: The subscription that the event hub is part of. - - **Event hub namespace**: If you don't have one, you must [create one](../../event-hubs/event-hubs-create.md). - - **Event hub name (optional)**: The name to send all data to. If you don't specify a name, an event hub is created for each log category. If you're sending to multiple categories, you might want to specify a name to limit the number of event hubs created. For more information, see [Azure Event Hubs quotas and limits](../../event-hubs/event-hubs-quotas.md). - - **Event hub policy name** (also optional): A policy defines the permissions that the streaming mechanism has. For more information, see [Event Hubs features](../../event-hubs/event-hubs-features.md#publisher-policy). -- 1. **Send to partner solution**: You must first install Azure Native ISV Services into your subscription. Configuration options vary by partner. For more information, see [Azure Native ISV Services overview](../../partner-solutions/overview.md). --1. If the service supports both [resource-specific](resource-logs.md#resource-specific) and [Azure diagnostics](resource-logs.md#azure-diagnostics-mode) mode, then an option to select the [destination table](resource-logs.md#select-the-collection-mode) displays when you select **Log Analytics workspace** as a destination. You should usually select **Resource specific** since the table structure allows for more flexibility and more efficient queries. -- :::image type="content" source="media/diagnostic-settings/destination-table.png" alt-text="Screenshot of the dialog box to set the destination table."::: --1. Select **Save**. --After a few moments, the new setting appears in your list of settings for this resource. Logs are streamed to the specified destinations as new event data is generated. It might take up to 15 minutes between when an event is emitted and when it [appears in a Log Analytics workspace](../logs/data-ingestion-time.md). ---## [PowerShell](#tab/powershell) --Use the [New-AzDiagnosticSetting](/powershell/module/az.monitor/new-azdiagnosticsetting) cmdlet to create a diagnostic setting with [Azure PowerShell](../powershell-samples.md). See the documentation for this cmdlet for descriptions of its parameters. --> [!IMPORTANT] -> You can't use this method for an activity log. Instead, use [Create diagnostic setting in Azure Monitor by using an Azure Resource Manager template](./resource-manager-diagnostic-settings.md) to create a Resource Manager template and deploy it with PowerShell. --The following example PowerShell cmdlet creates a diagnostic setting for all logs, or for audit logs, and metrics for a key vault by using Log Analytics Workspace. --```powershell -$KV = Get-AzKeyVault -ResourceGroupName <resource group name> -VaultName <key vault name> -$Law = Get-AzOperationalInsightsWorkspace -ResourceGroupName <resource group name> -Name <workspace name> # LAW name is case sensitive --$metric = New-AzDiagnosticSettingMetricSettingsObject -Enabled $true -Category AllMetrics -# For all available logs, use: -$log = New-AzDiagnosticSettingLogSettingsObject -Enabled $true -CategoryGroup allLogs -# or, for audit logs, use: -$log = New-AzDiagnosticSettingLogSettingsObject -Enabled $true -CategoryGroup audit -New-AzDiagnosticSetting -Name 'KeyVault-Diagnostics' -ResourceId $KV.ResourceId -WorkspaceId $Law.ResourceId -Log $log -Metric $metric -Verbose -``` ---## [CLI](#tab/cli) --Use the [az monitor diagnostic-settings create](/cli/azure/monitor/diagnostic-settings#az-monitor-diagnostic-settings-create) command to create a diagnostic setting with the [Azure CLI](/cli/azure/monitor). See the documentation for this command for descriptions of its parameters. --> [!IMPORTANT] -> You can't use this method for an activity log. Instead, use [Create diagnostic setting in Azure Monitor by using a Resource Manager template](./resource-manager-diagnostic-settings.md) to create a Resource Manager template and deploy it with the Azure CLI. --The following example command creates a diagnostic setting by using all three destinations. The syntax is slightly different depending on your client. --To specify [resource-specific mode](resource-logs.md#resource-specific) if the service supports it, add the `export-to-resource-specific` parameter with a value of `true`.` --```azurecli -az monitor diagnostic-settings create \ name KeyVault-Diagnostics \resource /subscriptions/<subscription ID>/resourceGroups/<resource group name>/providers/Microsoft.KeyVault/vaults/mykeyvault \logs '[{"category": "AuditEvent","enabled": true}]' \metrics '[{"category": "AllMetrics","enabled": true}]' \storage-account /subscriptions/<subscription ID>/resourceGroups/<resource group name>/providers/Microsoft.Storage/storageAccounts/<storage account name> \workspace /subscriptions/<subscription ID>/resourcegroups/<resource group name>/providers/microsoft.operationalinsights/workspaces/<log analytics workspace name> \event-hub-rule /subscriptions/<subscription ID>/resourceGroups/<resource group name>/providers/Microsoft.EventHub/namespaces/<event hub namespace>/authorizationrules/RootManageSharedAccessKey \event-hub <event hub name> \export-to-resource-specific true-``` ---## [Resource Manager](#tab/arm) --The following JSON template provides an example for creating a diagnostic setting to send all audit logs to a log analytics workspace. Keep in mind that the `apiVersion` can change depending on the resource in the scope. --**Template file** --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "scope": { - "type": "string" - }, - "workspaceId": { - "type": "string" - }, - "settingName": { - "type": "string" - } -}, - "resources": [ - { - "type": "Microsoft.Insights/diagnosticSettings", - "apiVersion": "2021-05-01-preview", - "scope": "[parameters('scope')]", - "name": "[parameters('settingName')]", - "properties": { - "workspaceId": "[parameters('workspaceId')]", - "logs": [ - { - "category": null, - "categoryGroup": "audit", - "enabled": true - } - ] - } - } - ] - } -``` --**Parameter file** --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "settingName": { - "value": "audit3" - }, - "workspaceId": { - "value": "/subscriptions/<subscription id>/resourcegroups/<resourcegroup name>/providers/microsoft.operationalinsights/workspaces/<workspace name>" - }, - "scope": { - "value": "Microsoft.<resource type>/<resourceName>" - } - } -} -``` --## [REST API](#tab/api) --To create or update diagnostic settings by using the [Azure Monitor REST API](/rest/api/monitor/), see [Diagnostic settings](/rest/api/monitor/diagnosticsettings). ---## [Azure Policy](#tab/policy) --For details on using Azure Policy to create diagnostic settings at scale, see [Create diagnostic settings at scale by using Azure Policy](diagnostic-settings-policy.md). ----## Troubleshooting --Here are some troubleshooting tips. --### Metric category isn't supported --When you deploy a diagnostic setting, you receive an error message similar to "Metric category 'xxxx' isn't supported." You might receive this error even though your previous deployment succeeded. --The problem occurs when you use a Resource Manager template, REST API, the CLI, or Azure PowerShell. Diagnostic settings created via the Azure portal aren't affected because only the supported category names are presented. --The problem occurs because of a recent change in the underlying API. Metric categories other than **AllMetrics** aren't supported and never were except for a few specific Azure services. In the past, other category names were ignored when deploying a diagnostic setting. The Azure Monitor back end redirected these categories to **AllMetrics**. As of February 2021, the back end was updated to specifically confirm the metric category provided is accurate. This change can cause some deployments to fail. --If you receive this error, update your deployments to replace any metric category names with **AllMetrics** to fix the issue. If the deployment was previously adding multiple categories, only keep one with the **AllMetrics** reference. If you continue to have the problem, contact Azure support through the Azure portal. --### Setting disappears because of non-ASCII characters in resourceID --Diagnostic settings don't support resource IDs with non-ASCII characters. For example, consider the term "Preproducci├│n." Because you can't rename resources in Azure, your only option is to create a new resource without the non-ASCII characters. If the characters are in a resource group, you can move the resources under it to a new one. Otherwise, you need to re-create the resource. --### Possibility of duplicated or dropped data --Every effort is made to ensure all log data is sent correctly to your destinations, however it's not possible to guarantee 100% data transfer of logs between endpoints. Retries and other mechanisms are in place to work around these issues and attempt to ensure log data arrives at the endpoint. --### Inactive resources --When a resource is inactive and exporting zero-value metrics, the diagnostic settings export mechanism backs off incrementally to avoid unnecessary costs of exporting and storing zero values. The back-off may lead to a delay in the export of the next non-zero value. --When a resource is inactive for one hour, the export mechanism backs off to 15 minutes. This means that there is a potential latency of up to 15 minutes for the next nonzero value to be exported. The maximum backoff time of two hours is reached after seven days of inactivity. Once the resource starts exporting nonzero values, the export mechanism reverts to the original export latency of three minutes. --This behavior only applies to exported metrics and doesn't affect metrics-based alerts or autosacle. ---## Next steps --- [Review how to work with diagnostic settings in Azure Monitor](./diagnostic-settings.md)-- [Migrate diagnostic settings storage retention to Azure Storage lifecycle management](./migrate-to-azure-storage-lifecycle-policy.md)-- [Read more about Azure platform logs](./platform-logs-overview.md) |
| azure-monitor | Data Collection Endpoint Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/data-collection-endpoint-overview.md | - Title: Data collection endpoints in Azure Monitor -description: Overview of how data collection endpoints work and how to create and set them up based on your deployment. --- Previously updated : 03/18/2024--ms.reviwer: nikeist ----# Data collection endpoints in Azure Monitor --A data collection endpoint (DCE) is a connection where data sources send collected data for processing and ingestion into Azure Monitor. This article provides an overview of data collection endpoints and explains how to create and set them up based on your deployment. --## When is a DCE required? -Prior to March 31, 2024, a DCE was required for all data collection scenarios using a DCR that required an endpoint. Any DCR created after this date includes its own endpoints for logs and metrics. The URL for these endpoints can be found in the [`logsIngestion` and `metricsIngestion`](./data-collection-rule-structure.md#endpoints) properties of the DCR. These endpoints can be used instead of a DCE for any direct ingestion scenarios. --Endpoints cannot be added to an existing DCR, but you can keep using any existing DCRs with existing DCEs. If you want to move to a DCR endpoint, then you must create a new DCR to replace the existing one. A DCR with endpoints can also use a DCE. In this case, you can choose whether to use the DCE or the DCR endpoints for each of the clients that use the DCR. --The following scenarios can currently use DCR endpoints. A DCE required if private link is used. --- [Logs ingestion API](../logs/logs-ingestion-api-overview.md)-- [Container Insights](../containers/container-insights-overview.md)--The following data types still require creating a DCE: --- [AMA Based Custom Logs](../agents/data-collection-text-log.md)-- [Windows IIS Logs](../agents/data-collection-iis.md)-- [Prometheus Metrics](../containers/container-insights-prometheus-logs.md)--## Components of a DCE --A data collection endpoint includes components required to ingest data into Azure Monitor and send configuration files to Azure Monitor Agent. --[How you set up endpoints for your deployment](#how-to-set-up-data-collection-endpoints-based-on-your-deployment) depends on whether your monitored resources and Log Analytics workspaces are in one or more regions. --This table describes the components of a data collection endpoint, related regionality considerations, and how to set up the data collection endpoint when you create a data collection rule using the portal: --| Component | Description | Regionality considerations |Data collection rule configuration | -|:|:|:|:| -| Logs ingestion endpoint | The endpoint that ingests logs into the data ingestion pipeline. Azure Monitor transforms the data and sends it to the defined destination Log Analytics workspace and table based on a DCR ID sent with the collected data.<br>Example: `<unique-dce-identifier>.<regionname>-1.ingest`. |Same region as the destination Log Analytics workspace. |Set on the **Basics** tab when you create a data collection rule using the portal. | -| Metrics ingestion endpoint | The endpoint that ingests metrics into the data ingestion pipeline. Azure Monitor transforms the data and sends it to the defined destination Azure Monitor workspace and table based on a DCR ID sent with the collected data.<br>Example: `<unique-dce-identifier>.<regionname>-1.metrics.ingest`. |Same region as the destination Azure Monitor workspace. |Set on the **Basics** tab when you create a data collection rule using the portal. | -| Configuration access endpoint | The endpoint from which Azure Monitor Agent retrieves data collection rules (DCRs).<br>Example: `<unique-dce-identifier>.<regionname>-1.handler.control`. | Same region as the monitored resources. | Set on the **Resources** tab when you create a data collection rule using the portal.| ---## How to set up data collection endpoints based on your deployment --- **Scenario: All monitored resources are in the same region as the destination Log Analytics workspace**-- Set up one data collection endpoint to send configuration files and receive collected data. - - :::image type="content" source="media/data-collection-endpoint-overview/data-collection-endpoint-one-region.png" alt-text="A diagram that shows resources in a single region sending data and receiving configuration files using a data collection endpoint." lightbox="media/data-collection-endpoint-overview/data-collection-endpoint-one-region.png"::: --- **Scenario: Monitored resources send data to a Log Analytics workspace in a different region**-- - Create a data collection endpoint in each region where you have Azure Monitor Agent deployed to send configuration files to the agents in that region. - - - Send data from all resources to a data collection endpoint in the region where your destination Log Analytics workspaces are located. - - :::image type="content" source="media/data-collection-endpoint-overview/data-collection-endpoint-regionality.png" alt-text="A diagram that shows resources in two regions sending data and receiving configuration files using data collection endpoints." lightbox="media/data-collection-endpoint-overview/data-collection-endpoint-regionality.png"::: --- **Scenario: Monitored resources in one or more regions send data to multiple Log Analytics workspaces in different regions**-- - Create a data collection endpoint in each region where you have Azure Monitor Agent deployed to send configuration files to the agents in that region. - - - Create a data collection endpoint in each region with a destination Log Analytics workspace to send data to the Log Analytics workspaces in that region. - - - Send data from each monitored resource to the data collection endpoint in the region where the destination Log Analytics workspace is located. - - :::image type="content" source="media/data-collection-endpoint-overview/data-collection-endpoint-regionality-multiple-workspaces.png" alt-text="A diagram that shows monitored resources in multiple regions sending data to multiple Log Analytics workspaces in different regions using data collection endpoints." lightbox="media/data-collection-endpoint-overview/data-collection-endpoint-regionality-multiple-workspaces.png"::: --> [!NOTE] -> By default, the Microsoft.Insights resource provider isnt registered in a Subscription. Ensure to register it successfully before trying to create a Data Collection Endpoint. --## Create a data collection endpoint --# [Azure portal](#tab/portal) --1. On the **Azure Monitor** menu in the Azure portal, select **Data Collection Endpoints** under the **Settings** section. Select **Create** to create a new Data Collection Endpoint. - <!-- convertborder later --> - :::image type="content" source="media/data-collection-endpoint-overview/data-collection-endpoint-overview.png" lightbox="media/data-collection-endpoint-overview/data-collection-endpoint-overview.png" alt-text="Screenshot that shows data collection endpoints." border="false"::: --1. Select **Create** to create a new endpoint. Provide a **Rule name** and specify a **Subscription**, **Resource Group**, and **Region**. This information specifies where the DCE will be created. - <!-- convertborder later --> - :::image type="content" source="media/data-collection-endpoint-overview/data-collection-endpoint-basics.png" lightbox="media/data-collection-endpoint-overview/data-collection-endpoint-basics.png" alt-text="Screenshot that shows data collection rule basics." border="false"::: --1. Select **Review + create** to review the details of the DCE. Select **Create** to create it. --# [REST API](#tab/restapi) --Create DCEs by using the [DCE REST APIs](/cli/azure/monitor/data-collection/endpoint). --Create associations between endpoints to your target machines or resources by using the [DCRA REST APIs](/rest/api/monitor/datacollectionruleassociations/create#examples). ----## Sample data collection endpoint -The sample data collection endpoint (DCE) below is for virtual machines with Azure Monitor agent, with public network access disabled so that agent only uses private links to communicate and send data to Azure Monitor/Log Analytics. --```json -{ - "id": "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxx/resourceGroups/myResourceGroup/providers/Microsoft.Insights/dataCollectionEndpoints/myCollectionEndpoint", - "name": "myCollectionEndpoint", - "type": "Microsoft.Insights/dataCollectionEndpoints", - "location": "eastus", - "tags": { - "tag1": "A", - "tag2": "B" - }, - "properties": { - "configurationAccess": { - "endpoint": "https://mycollectionendpoint-abcd.eastus-1.control.monitor.azure.com" - }, - "logsIngestion": { - "endpoint": "https://mycollectionendpoint-abcd.eastus-1.ingest.monitor.azure.com" - }, - "metricsIngestion": { - "endpoint": "https://mycollectionendpoint-abcd.eastus-1.metrics.ingest.monitor.azure.com" - }, - "networkAcls": { - "publicNetworkAccess": "Disabled" - } - }, - "systemData": { - "createdBy": "user1", - "createdByType": "User", - "createdAt": "yyyy-mm-ddThh:mm:ss.sssssssZ", - "lastModifiedBy": "user2", - "lastModifiedByType": "User", - "lastModifiedAt": "yyyy-mm-ddThh:mm:ss.sssssssZ" - }, - "etag": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" -} -``` --## Limitations --- Data collection endpoints only support Log Analytics workspaces and Azure Monitor Workspace as destinations for collected data. [Custom metrics (preview)](../essentials/metrics-custom-overview.md) collected and uploaded via Azure Monitor Agent aren't currently controlled by DCEs.---## Next steps --- [Add an endpoint to an Azure Monitor Private Link Scope resource](../logs/private-link-configure.md#connect-azure-monitor-resources) |
| azure-monitor | Data Collection Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/data-collection-monitor.md | - Title: Monitor and troubleshoot DCR data collection in Azure Monitor -description: Configure log collection for monitoring and troubleshooting of DCR-based data collection in Azure Monitor. --- Previously updated : 03/01/2024---# Monitor and troubleshoot DCR data collection in Azure Monitor -This article provides detailed metrics and logs that you can use to monitor performance and troubleshoot any issues related to data collection in Azure Monitor. This telemetry is currently available for data collection scenarios defined by a [data collection rules (DCR)](./data-collection-rule-overview.md) such as Azure Monitor agent and Logs ingestion API. --> [!IMPORTANT] -> This article only refers to data collection scenarios that use DCRs, including the following: -> -> - Logs collected using [Azure Monitor Agent (AMA)](../agents/agents-overview.md) -> - Logs ingested using [Log Ingestion API](../logs/logs-ingestion-api-overview.md) -> - Logs collected by other methods that use a [workspace transformation DCR](./data-collection-transformations-workspace.md) -> -> See the documentation for other scenarios for any monitoring and troubleshooting information that may be available. --DCR diagnostic features include metrics and error logs emitted during log processing. [DCR metrics](#dcr-metrics) provide information about the volume of data being ingested, the number and nature of any processing errors, and statistics related to data transformation. [DCR error logs](#dcr-metrics) are generated any time data processing is not successful and the data doesnΓÇÖt reach its destination. --## DCR Error Logs --Error logs are generated when data reaches the Azure Monitor ingestion pipeline but fails to reach its destination. Examples of error conditions include: --- Log delivery errors-- [Transformation](./data-collection-transformations.md) errors where the structure of the logs makes the transformation KQL invalid-- Log Ingestion API calls:- - with any HTTP response other than 200/202 - - with payload containing malformed data - - with payload over any [ingestion limits](/azure/azure-monitor/service-limits#logs-ingestion-api) - - throttling due to overage of API call limits --To avoid excessive logging of persistent errors related to the same data flow, some errors will be logged only a limited number of times each hour followed by a summary error message. The error is then muted until the end of the hour. The number of times a given error is logged may vary depending on the region where DCR is deployed. --Some log ingestion errors will not be logged because they can't be associated with a DCR. The following errors may not be logged: --- Failures caused by malformed call URI (HTTP response code 404)-- Certain internal server errors (HTTP response code 500)--### Enable DCR error logs -DCR error logs are implemented as [resource logs](./resource-logs.md) in Azure Monitor. Enable log collection by creating a [diagnostic setting](./diagnostic-settings.md) for the DCR. Each DCR will require its own diagnostic setting. See [Create diagnostic settings in Azure Monitor](./create-diagnostic-settings.md) for the detailed process. Select the category **Log Errors** and **Send to Log Analytics workspace**. You may want to select the same workspace that's used by the DCR, or you may want to consolidate all of your error logs in a single workspace. --### Retrieve DCR error logs -Error logs are written to the [DCRLogErrors](/azure/azure-monitor/reference/tables/dcrlogerrors) table in the Log Analytics workspace you specified in the diagnostic setting. Following are sample queries you can use in [Log Analytics](../logs/log-analytics-overview.md) to retrieve these logs. --**Retrieve all error logs for a particular DCR** --```kusto -DCRLogErrors -| where _ResourceId == "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/microsoft.insights/datacollectionrules/my-dcr" -``` --**Retrieve all error logs for a particular input stream in a particular DCR** --```kusto -DCRLogErrors -| where _ResourceId == "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/microsoft.insights/datacollectionrules/my-dcr" -| where InputStreamId == "Custom-MyTable_CL" -``` ---## DCR Metrics -DCR metrics are collected automatically for all DCRs, and you can analyze them using [metrics explorer](./analyze-metrics.md) like the platform metrics for other Azure resources. *Input stream* is included as a dimension so if you have a DCR with multiple input streams, you can analyze each by [filtering or splitting](./analyze-metrics.md#use-dimension-filters-and-splitting). Some metrics include other dimensions as shown in the table below. ---| Metric | Dimensions | Description | -|||| -| Logs Ingestion Bytes per Min | Input Stream | Total number of bytes received per minute. | -| Logs Ingestion Requests per Min | Input stream<br>HTTP response code | Number of calls received per minute | -| Logs Rows Dropped per Min | Input stream | Number of log rows dropped during processing per minute. This includes rows dropped both due to filtering criteria in KQL transformation and rows dropped due to errors. | -| Logs Rows Received per Min | Input stream | Number of log rows received for processing per minute. | -| Logs Transformation Duration per Min | Input stream | Average KQL transformation runtime per minute. Represents KQL transformation code efficiency. Data flows with longer transformation run time can experience delays in data processing and greater data latency. | -| Logs Transformation Errors per Min | Input stream<br>Error type | Number of processing errors encountered per minute | ---## Troubleshooting common issues -If you're missing expected data in your Log Analytics workspace, follow these basic steps to troubleshoot the issue. This assumes that you enabled DCR logging as described above. --- Check metrics such as `Logs Ingestion Bytes per Min` and `Logs Rows Received per Min` to ensure that the data is reaching Azure Monitor. If not, then check your data source to ensure that it's sending data as expected.-- Check `Logs Rows Dropped per Min` to see if any rows are being dropped. This may not indicate an error since the rows could be dropped by a transformation. If the rows dropped is the same as `Logs Rows Dropped per Min` though, then no data will be ingested in the workspace. Examine the `Logs Transformation Errors per Min` to see if there are any transformation errors.-- Check `Logs Transformation Errors per Min` to determine if there are any errors from transformations applied to the incoming data. This could be due to changes in the data structure or the transformation itself.-- Check `DCRLogErrors` for any ingestion errors that may have been logged. This can provide additional detail in identifying the root cause of the issue.----## Monitoring your log ingestion --The following signals could be useful for monitoring the health of your log collection with DCRs. Create alert rules to identify these conditions. --| Signal | Possible causes and actions | -||| -| New entries in `DCRErrorLogs` or sudden change in `Log Transform Errors`. | - Problems with Log Ingestion API setup such as authentication, access to DCR or DCE, call payload issues.<br>- Changes in data structure causing KQL transformation failures.<br>- Changes in data destination configuration causing data delivery failures. | -| Sudden change in `Logs Ingestion Bytes per Min` | - Changes in configuration of log ingestion on the client, including AMA settings.<br>- Changes in structure of logs sent.| -| Sudden change in ratio between `Logs Ingestion Bytes per Min` and `Logs Rows Received per Min` | - Changes in the structure of logs sent. Examine the changes to make sure the data is properly processed with KQL transformation. | -| Sudden change in `Logs Transformation Duration per Min` | - Changes in the structure of logs affecting the efficiency of log filtering criteria set in KQL transformation. Examine the changes to make sure the data is properly processed with KQL transformation. | -| `Logs Ingestion Requests per Min` or `Logs Ingestion Bytes per Min` approaching Log Ingestion API service limits. | - Examine and optimize your DCR configuration to avoid throttling. | --## Alerts -Rather than reactively troubleshooting issues, create alert rules to be proactively notified when a potential error condition occurs. The following table provides examples of alert rules you can create to monitor your log ingestion. --| Condition | Alert details | -|:|:| -| Sudden changes of rows dropped | Metric alert rule using a dynamic threshold for `Logs Rows Dropped per Min`. | -| Number of API calls approaching service limits | Metric alert rule using a static threshold for `Logs Ingestion Requests per Min`. Set threshold near 12,000, which is the service limit for maximum requests/minute per DCR. | -| Error logs | Log query alert using `DCRLogErrors`. Use a **Table rows** measure and **Threshold value** of **1** to be alerted whenever any errors are logged. | --## Next steps -- [Read more about data collection rules.](./data-collection-rule-overview.md)-- [Read more about ingestion-time transformations.](./data-collection-transformations.md)- |
| azure-monitor | Data Collection Rule Best Practices | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/data-collection-rule-best-practices.md | - Title: Best practices for data collection rule creation and management in Azure Monitor -description: Details on the best practices to be followed to correctly create and maintain data collection rule in Azure Monitor. - Previously updated : 01/08/2024-----# Best practices for data collection rule creation and management in Azure Monitor --[Data Collection Rules (DCRs)](data-collection-rule-overview.md) determine how to collect and process telemetry sent to Azure. Some data collection rules will be created and managed by Azure Monitor, while you may create others to customize data collection for your particular requirements. This article discusses some best practices that should be applied when creating your own DCRs. --When creating a DCR, there are some aspects that need to be considered such as: --- The type of data that will be collected, also known as data source type (performance, events)-- The target Virtual Machines to which the DCR will be associated with-- The destination of collected data--Considering all these factors is critical for a good DCR organization. All the above points impact on DCR management effort as well on resource consumption for configuration transfer and processing. --Given the native granularity, which allows a given DCR to be associated with more than one target virtual machine and vice versa, it's important to keep the DCRs as simple as possible using fewer data sources each. It's also important to keep the list of collected items in each data source lean and oriented to the observability scope. ---To clarify what an *observability scope* could be, think about it as your preferred logical boundary for collecting data. For instance, a possible scope could be a set of virtual machines running software (for example, "SQL Servers") needed for a specific application, or basic operating system counters or events set used by your IT Admins. It's also possible to create similar scopes dedicated to different environments ("Development", "Test", "Production") to specialize even more. --In fact, it's not ideal and even not recommended to create a single DCR containing all the data sources, collection items and destinations to implement the observability. In the following table, there are several recommendations that could help in better planning DCR creation and maintenance: --| Category | Best practice | Explanation | Impact area | -|:|:|:|:| -| Data Collection | Define the observability scope | Defining the observability scope is key to an easier and successful DCR management and organization observability scope. It will help clarifying what the collection need is, and from which target virtual machine it should be performed. As previously explained, an observability scope could be a set of virtual machines running software that is common to a specific application, a set of common information for the IT department, etc. As an example, collecting the basic operating system performance counters, such as CPU utilization, available memory, and free disk space, could be seen as a scope for your Central IT Management. | Not having a clearly defined scope doesn't bring clarity and doesn't allow for a proper management. | -| | Create DCRs specific to the observability scope | Creating separate DCRs based on the observability scope is key for easy maintenance. It will allow you to easily associate the DCRs to the relevant target virtual machines. | Why creating a single DCR that collects operating system performance counters plus web server counters and database counters all together? This approach, not only will force each and every associated virtual machine to transfer, process and execute configuration that is outside of the scope but will also require more effort when the DCR configuration needs to be updated. Think about managing a template that includes unnecessary entries; this situation is less than ideal and leaves room for errors. | -| | Create DCR specific to data source type inside the defined observability scope(s) | Creating separate DCRs for performance and events will help in both managing the configuration and the association with granularity based on the target machines. For instance, creating a DCR to collect both events and performance counters could result in an unoptimal approach. There could be situations in which a given machine (or set of machines) doesn't have the event logs or performance counters configured in the DCR. In this situation, the virtual machine(s) will be forced to process and execute a configuration that isn't necessary according to the software installed on it. | Not using different DCRs will force each and every associated virtual machine to transfer, process and execute configuration that might be not applicable according to the installed software. An excessive compute resource consumption and errors in processing configuration might happen causing the [Azure Monitor Agent (AMA)](../overview.md) becoming unresponsive. Moreover, collecting unnecessary data will increase data ingestion costs. | -| Data destination | Create different DCR based on the destination | DCRs have the capability of sending data to multiple different destinations, like Azure Monitor Metrics and Azure Monitor Logs, simultaneously. Having DCR(s) specific to destination is helpful in managing the data sovereign or law requirements. Since, being compliant might require to send data only to allowed repositories created in allowed regions, having different DCRs allows for a better granular destination targeting | Not separating DCRs based on the data destination, might result in being not compliant with data handling, privacy and access requirements and could make unnecessary data collection resulting in unexpected costs. | --The aforementioned principles provide a foundation for creating your own DCR management approach that balances maintainability, ease of reuse, granularity, and service limits. DCRs also need shared governance, to minimize both the creation of silos and unnecessary duplication of work. --## Next steps --- [Read more about data collection rules and options for creating them.](data-collection-rule-overview.md) |
| azure-monitor | Data Collection Rule Create Edit | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/data-collection-rule-create-edit.md | - Title: Create and edit data collection rules (DCRs) in Azure Monitor -description: Details on creating and editing data collection rules (DCRs) in Azure Monitor. --- Previously updated : 11/15/2023-----# Create and edit data collection rules (DCRs) and associations in Azure Monitor --There are multiple methods for creating a [data collection rule (DCR)](./data-collection-rule-overview.md) in Azure Monitor. In some cases, Azure Monitor can create and manage the DCR according to settings that you configure in the Azure portal. In other cases, you need to create your own DCRs to customize particular scenarios. --This article describes the different methods for creating and editing a DCR. For the contents of the DCR itself, see [Structure of a data collection rule in Azure Monitor](./data-collection-rule-structure.md). --## Permissions -- You require the following permissions to create DCRs and associations: --| Built-in role | Scopes | Reason | -|:|:|:| -| [Monitoring Contributor](../../role-based-access-control/built-in-roles.md#monitoring-contributor) | <ul><li>Subscription and/or</li><li>Resource group and/or </li><li>An existing DCR</li></ul> | Create or edit DCRs, assign rules to the machine, deploy associations. | -| [Virtual Machine Contributor](../../role-based-access-control/built-in-roles.md#virtual-machine-contributor)<br>[Azure Connected Machine Resource Administrator](../../role-based-access-control/built-in-roles.md#azure-connected-machine-resource-administrator)</li></ul> | <ul><li>Virtual machines, virtual machine scale sets</li><li>Azure Arc-enabled servers</li></ul> | Deploy agent extensions on the VM (virtual machine). | -| Any role that includes the action *Microsoft.Resources/deployments/** | <ul><li>Subscription and/or</li><li>Resource group and/or </li><li>An existing DCR</li></ul> | Deploy Azure Resource Manager templates. | --## Automated methods to create a DCR --The following table lists methods to create data collection scenarios using the Azure portal where the DCR is created for you. In these cases, you don't need to interact directly with the DCR itself. --| Scenario | Resources | Description | -|:|:|:| -| Monitor a virtual machine | [Enable VM Insights overview](../vm/vminsights-enable-overview.md) | When you enable VM Insights on a VM, the Azure Monitor agent is installed and a DCR is created and associated with the VM. This DCR collects a predefined set of performance counters and shouldn't be modified. | -| Container insights | [Enable Container Insights](../containers/kubernetes-monitoring-enable.md#enable-prometheus-and-grafana) | When you enable Container Insights on a Kubernetes cluster, a containerized version of the Azure Monitor agent is installed, and a DCR with association to the cluster is created that collects data according to the configuration you selected. You may need to modify this DCR to add a transformation. | -| Workspace transformation | [Add a transformation in a workspace data collection rule using the Azure portal](../logs/tutorial-workspace-transformations-portal.md) | Create a transformation for any supported table in a Log Analytics workspace. This transformation is specified within a DCR, which is linked to the workspace. The transformation is then applied to any data sent to that table from any legacy workloads that don't yet utilize DCR. | --## Create a DCR -To create a data collection rule using the Azure CLI, PowerShell, API, or ARM templates, create a JSON file, starting with one of the [sample DCRs](./data-collection-rule-samples.md). Use information in [Structure of a data collection rule in Azure Monitor](./data-collection-rule-structure.md) to modify the JSON file for your particular environment and requirements. --> [!IMPORTANT] -> Create your data collection rule in the same region as your destination Log Analytics workspace or Azure Monitor workspace. You can associate the data collection rule to machines or containers from any subscription or resource group in the tenant. To send data across tenants, you must first enable [Azure Lighthouse](../../lighthouse/overview.md). --### [Portal](#tab/portal) --### Create with Azure portal -The Azure portal provides a simplified experience for creating a DCR for virtual machines and virtual machine scale sets. Using this method, you don't need to understand the structure of a DCR unless you want to implement an advanced feature such as a transformation. The process for creating this DCR with various data sources is described in [Collect data with Azure Monitor Agent](../agents/azure-monitor-agent-data-collection.md). ---### [CLI](#tab/CLI) --### Create with CLI -Use the [az monitor data-collection rule create](/cli/azure/monitor/data-collection/rule) command to create a DCR from your JSON file. --```azurecli -az monitor data-collection rule create --location 'eastus' --resource-group 'my-resource-group' --name 'my-dcr' --rule-file 'C:\MyNewDCR.json' --description 'This is my new DCR' -``` --Use the [az monitor data-collection rule association create](/cli/azure/monitor/data-collection/rule/association) command to create an association between your DCR and resource. --```azurecli -az monitor data-collection rule association create --name "my-vm-dcr-association" --rule-id "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/Microsoft.Insights/dataCollectionRules/my-dcr" --resource "subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/Microsoft.Compute/virtualMachines/my-vm" -``` --### [PowerShell](#tab/powershell) --### Create with PowerShell -Use the [New-AzDataCollectionRule](/powershell/module/az.monitor/new-azdatacollectionrule) cmdlet to create a DCR from your JSON file. --```powershell -New-AzDataCollectionRule -Name 'my-dcr' -ResourceGroupName 'my-resource-group' -JsonFilePath 'C:\MyNewDCR.json' -``` --Use the [New-AzDataCollectionRuleAssociation](/powershell/module/az.monitor/new-azdatacollectionruleassociation) command to create an association between your DCR and resource. --```powershell - New-AzDataCollectionRuleAssociation -TargetResourceId '/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/Microsoft.Compute/virtualMachines/my-vm' -DataCollectionRuleId '/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/my-resource-group/providers/microsoft.insights/datacollectionrules/my-dcr' -AssociationName 'my-vm-dcr-association' -``` ----### [API](#tab/api) --### Create with API -Use the [DCR create API](/rest/api/monitor/data-collection-rules/create) to create the DCR from your JSON file. You can use any method to call a REST API as shown in the following examples. --```powershell -$ResourceId = "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/Microsoft.Insights/dataCollectionRules/my-dcr" -$FilePath = ".\my-dcr.json" -$DCRContent = Get-Content $FilePath -Raw -Invoke-AzRestMethod -Path ("$ResourceId"+"?api-version=2022-06-01") -Method PUT -Payload $DCRContent -``` --```azurecli -ResourceId="/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/Microsoft.Insights/dataCollectionRules/my-dcr" -FilePath="my-dcr.json" -az rest --method put --url $ResourceId"?api-version=2022-06-01" --body @$FilePath -``` --### [ARM](#tab/arm) ---### Create with ARM template -See the following references for defining DCRs and associations in a template. -* [Data collection rules](/azure/templates/microsoft.insights/datacollectionrules) -* [Data collection rule associations](/azure/templates/microsoft.insights/datacollectionruleassociations) --#### DCR --Use the following template to create a DCR using information from [Structure of a data collection rule in Azure Monitor](./data-collection-rule-structure.md) and [Sample data collection rules (DCRs) in Azure Monitor](./data-collection-rule-samples.md) to define the `dcr-properties`. --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "dataCollectionRuleName": { - "type": "string", - "metadata": { - "description": "Specifies the name of the Data Collection Rule to create." - } - }, - "location": { - "type": "string", - "metadata": { - "description": "Specifies the location in which to create the Data Collection Rule." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/dataCollectionRules", - "name": "[parameters('dataCollectionRuleName')]", - "location": "[parameters('location')]", - "apiVersion": "2021-09-01-preview", - "properties": { - "<dcr-properties>" - } - } - ] -} --``` ---#### DCR Association -Azure VM -The following sample creates an association between an Azure virtual machine and a data collection rule. --**Bicep template file** --```bicep -@description('The name of the virtual machine.') -param vmName string --@description('The name of the association.') -param associationName string --@description('The resource ID of the data collection rule.') -param dataCollectionRuleId string --resource vm 'Microsoft.Compute/virtualMachines@2021-11-01' existing = { - name: vmName -} --resource association 'Microsoft.Insights/dataCollectionRuleAssociations@2021-09-01-preview' = { - name: associationName - scope: vm - properties: { - description: 'Association of data collection rule. Deleting this association will break the data collection for this virtual machine.' - dataCollectionRuleId: dataCollectionRuleId - } -} -``` --**ARM template file** --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "type": "string", - "metadata": { - "description": "The name of the virtual machine." - } - }, - "associationName": { - "type": "string", - "metadata": { - "description": "The name of the association." - } - }, - "dataCollectionRuleId": { - "type": "string", - "metadata": { - "description": "The resource ID of the data collection rule." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/dataCollectionRuleAssociations", - "apiVersion": "2021-09-01-preview", - "scope": "[format('Microsoft.Compute/virtualMachines/{0}', parameters('vmName'))]", - "name": "[parameters('associationName')]", - "properties": { - "description": "Association of data collection rule. Deleting this association will break the data collection for this virtual machine.", - "dataCollectionRuleId": "[parameters('dataCollectionRuleId')]" - } - } - ] -} -``` --**Parameter file** --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "value": "my-azure-vm" - }, - "associationName": { - "value": "my-windows-vm-my-dcr" - }, - "dataCollectionRuleId": { - "value": "/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/my-resource-group/providers/microsoft.insights/datacollectionrules/my-dcr" - } - } -} -``` -### DCR Association -Arc-enabled server -The following sample creates an association between an Azure Arc-enabled server and a data collection rule. --**Bicep template file** --```bicep -@description('The name of the virtual machine.') -param vmName string --@description('The name of the association.') -param associationName string --@description('The resource ID of the data collection rule.') -param dataCollectionRuleId string --resource vm 'Microsoft.HybridCompute/machines@2021-11-01' existing = { - name: vmName -} --resource association 'Microsoft.Insights/dataCollectionRuleAssociations@2021-09-01-preview' = { - name: associationName - scope: vm - properties: { - description: 'Association of data collection rule. Deleting this association will break the data collection for this Arc server.' - dataCollectionRuleId: dataCollectionRuleId - } -} -``` --**ARM template file** --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "type": "string", - "metadata": { - "description": "The name of the virtual machine." - } - }, - "associationName": { - "type": "string", - "metadata": { - "description": "The name of the association." - } - }, - "dataCollectionRuleId": { - "type": "string", - "metadata": { - "description": "The resource ID of the data collection rule." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/dataCollectionRuleAssociations", - "apiVersion": "2021-09-01-preview", - "scope": "[format('Microsoft.HybridCompute/machines/{0}', parameters('vmName'))]", - "name": "[parameters('associationName')]", - "properties": { - "description": "Association of data collection rule. Deleting this association will break the data collection for this Arc server.", - "dataCollectionRuleId": "[parameters('dataCollectionRuleId')]" - } - } - ] -} -``` --**Parameter file** --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmName": { - "value": "my-hybrid-vm" - }, - "associationName": { - "value": "my-windows-vm-my-dcr" - }, - "dataCollectionRuleId": { - "value": "/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/my-resource-group/providers/microsoft.insights/datacollectionrules/my-dcr" - } - } -} -``` ---## Edit a DCR --To edit a DCR, you can use any of the methods described in the previous section to create a DCR using a modified version of the JSON. --If you need to retrieve the JSON for an existing DCR, you can copy it from the **JSON View** for the DCR in the Azure portal. You can also retrieve it using an API call as shown in the following PowerShell example. --```powershell -$ResourceId = "<ResourceId>" # Resource ID of the DCR to edit -$FilePath = "<FilePath>" # Store DCR content in this file -$DCR = Invoke-AzRestMethod -Path ("$ResourceId"+"?api-version=2022-06-01") -Method GET -$DCR.Content | ConvertFrom-Json | ConvertTo-Json -Depth 20 | Out-File -FilePath $FilePath -``` --For a tutorial that walks through the process of retrieving and then editing an existing DCR, see [Tutorial: Edit a data collection rule (DCR)](./data-collection-rule-edit.md). --## Next steps --* [Read about the detailed structure of a data collection rule](data-collection-rule-structure.md) -* [Get details on transformations in a data collection rule](data-collection-transformations.md) |
| azure-monitor | Data Collection Rule Edit | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/data-collection-rule-edit.md | - Title: Tutorial - Editing Data Collection Rules -description: This article describes how to make changes in Data Collection Rule definition using command line tools and simple API calls. ---- Previously updated : 11/03/2023---# Tutorial: Edit a data collection rule (DCR) -This tutorial describes how to edit the definition of Data Collection Rule (DCR) that has been already provisioned using command line tools. --In this tutorial, you learn how to: -> [!div class="checklist"] -> * Leverage existing portal functionality to pre-create DCRs -> * Get the content of a Data Collection Rule using ARM API call -> * Apply changes to a Data Collection Rule using ARM API call -> * Automate the process of DCR update using PowerShell scripts --> [!NOTE] -> This tutorial walks through one method for editing an existing DCR. See [Create and edit data collection rules (DCRs) in Azure Monitor](data-collection-rule-create-edit.md) for other methods. --## Prerequisites -To complete this tutorial you need the following: -- Log Analytics workspace where you have at least [contributor rights](../logs/manage-access.md#azure-rbac).-- [Permissions to create Data Collection Rule objects](data-collection-rule-create-edit.md#permissions) in the workspace.-- Up to date version of PowerShell. Using Azure Cloud Shell is recommended.--## Overview of tutorial -While going through the wizard on the portal is the simplest way to set up the ingestion of your custom data to Log Analytics, in some cases you might want to update your Data Collection Rule later to: -- Change data collection settings (e.g. Data Collection Endpoint, associated with the DCR)-- Update data parsing or filtering logic for your data stream-- Change data destination (e.g. send data to an Azure table, as this option is not directly offered as part of the DCR-based custom log wizard)--In this tutorial, you first set up ingestion of a custom log. Then you modify the KQL transformation for your custom log to include additional filtering and apply the changes to your DCR. Finally, we're going to combine all editing operations into a single PowerShell script, which can be used to edit any DCR for any of the above mentioned reasons. --## Set up new custom log -Start by setting up a new custom log. Follow [Tutorial: Send custom logs to Azure Monitor Logs using the Azure portal (preview)]( ../logs/tutorial-logs-ingestion-portal.md). Note the resource ID of the DCR created. --## Retrieve DCR content -In order to update DCR, we are going to retrieve its content and save it as a file, which can be further edited. -1. Click the **Cloud Shell** button in the Azure portal and ensure the environment is set to **PowerShell**. -- :::image type="content" source="../logs/media/tutorial-workspace-transformations-api/open-cloud-shell.png" lightbox="../logs/media/tutorial-workspace-transformations-api/open-cloud-shell.png" alt-text="Screenshot of opening cloud shell"::: --2. Execute the following commands to retrieve DCR content and save it to a file. Replace `<ResourceId>` with DCR ResourceID and `<FilePath>` with the name of the file to store DCR. -- ```PowerShell - $ResourceId = "<ResourceId>" # Resource ID of the DCR to edit - $FilePath = "<FilePath>" # Store DCR content in this file - $DCR = Invoke-AzRestMethod -Path ("$ResourceId"+"?api-version=2022-06-01") -Method GET - $DCR.Content | ConvertFrom-Json | ConvertTo-Json -Depth 20 | Out-File -FilePath $FilePath - ``` -## Edit DCR -Now, when DCR content is stored as a JSON file, you can use an editor of your choice to make changes in the DCR. You may [prefer to download the file from the Cloud Shell environment](../../cloud-shell/using-the-shell-window.md#upload-and-download-files), if you are using one. --Alternatively you can use code editors supplied with the environment. For example, if you saved your DCR in a file named `temp.dcr` on your Cloud Drive, you could use the following command to open DCR for editing right in the Cloud Shell window: -```PowerShell -code "temp.dcr" -``` --LetΓÇÖs modify the KQL transformation within DCR to drop rows where RequestType is anything, but ΓÇ£GETΓÇ¥. -1. Open the file created in the previous part for editing using an editor of your choice. -2. Locate the line containing `ΓÇ¥transformKqlΓÇ¥` attribute, which, if you followed the tutorial for custom log creation, should look similar to this: - ```json - "transformKql": " source\n | extend TimeGenerated = todatetime(Time)\n | parse RawData with \n ClientIP:string\n ' ' *\n ' ' *\n ' [' * '] \"' RequestType:string\n \" \" Resource:string\n \" \" *\n '\" ' ResponseCode:int\n \" \" *\n | where ResponseCode != 200\n | project-away Time, RawData\n" - ``` -3. Modify KQL transformation to include additional filter by RequestType - ```json - "transformKql": " source\n | where RawData contains \"GET\"\n | extend TimeGenerated = todatetime(Time)\n | parse RawData with \n ClientIP:string\n ' ' *\n ' ' *\n ' [' * '] \"' RequestType:string\n \" \" Resource:string\n \" \" *\n '\" ' ResponseCode:int\n \" \" *\n | where ResponseCode != 200\n | project-away Time, RawData\n" - ``` -4. Save the file with modified DCR content. --## Apply changes -Our final step is to update DCR back in the system. This is accomplished by ΓÇ£PUTΓÇ¥ HTTP call to ARM API, with updated DCR content sent in the HTTP request body. -1. If you are using Azure Cloud Shell, save the file and close the embedded editor, or [upload modified DCR file back to the Cloud Shell environment](../../cloud-shell/using-the-shell-window.md#upload-and-download-files). -2. Execute the following commands to load DCR content from the file and place HTTP call to update the DCR in the system. Replace `<ResourceId>` with DCR ResourceID and `<FilePath>` with the name of the file modified in the previous part of the tutorial. You can omit first two lines if you read and write to the DCR within the same PowerShell session. - ```PowerShell - $ResourceId = "<ResourceId>" # Resource ID of the DCR to edit - $FilePath = "<FilePath>" # Store DCR content in this file - $DCRContent = Get-Content $FilePath -Raw - Invoke-AzRestMethod -Path ("$ResourceId"+"?api-version=2022-06-01") -Method PUT -Payload $DCRContent - ``` -3. Upon successful call, you should get the response with status code ΓÇ£200ΓÇ¥, indicating that your DCR is now updated. -4. You can now navigate to your DCR and examine its content on the portal via ΓÇ£JSON ViewΓÇ¥ function, or you could repeat the first part of the tutorial to retrieve DCR content into a file. --## Putting everything together -Now, when we know how to read and update the content of a DCR, letΓÇÖs put everything together into utility script, which can be used to perform both operations together. --```PowerShell -param ([Parameter(Mandatory=$true)] $ResourceId) --# get DCR content and put into a file -$FilePath = "temp.dcr" -$DCR = Invoke-AzRestMethod -Path ("$ResourceId"+"?api-version=2022-06-01") -Method GET -$DCR.Content | ConvertFrom-Json | ConvertTo-Json -Depth 20 | Out-File $FilePath --# Open DCR in code editor -code $FilePath | Wait-Process --#Wait for confirmation to apply changes -$Output = Read-Host "Apply changes to DCR (Y/N)? " -if ("Y" -eq $Output.toupper()) -{ - #write DCR content back from the file - $DCRContent = Get-Content $FilePath -Raw - Invoke-AzRestMethod -Path ("$ResourceId"+"?api-version=2022-06-01") -Method PUT -Payload $DCRContent -} --#Delete temporary file -Remove-Item $FilePath -``` -### How to use this utility -- Assuming you saved the script as a file, named `DCREditor.ps1` and need to modify a Data Collection Rule with resource ID of `/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/foo/providers/Microsoft.Insights/dataCollectionRules/bar`, this could be accomplished by running the following command: --```PowerShell -.\DCREditor.ps1 "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/foo/providers/Microsoft.Insights/dataCollectionRules/bar" -``` --DCR content opens in embedded code editor. Once editing is complete, entering "Y" on script prompt applies changes back to the DCR. --## Next steps --- [Read more about data collection rules and options for creating them.](data-collection-rule-overview.md) |
| azure-monitor | Data Collection Rule Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/data-collection-rule-overview.md | - Title: Data collection rules in Azure Monitor -description: Overview of data collection rules (DCRs) in Azure Monitor including their contents and structure and how you can create and work with them. --- Previously updated : 03/18/2024-----# Data collection rules (DCRs) in Azure Monitor -*Data collection rules (DCRs)* are part of an [ETL](/azure/architecture/data-guide/relational-data/etl)-like data collection process that improves on legacy data collection methods for Azure Monitor. This process uses a common data ingestion pipeline, the Azure Monitor pipeline, for all data sources and a standard method of configuration that's more manageable and scalable than other methods. Specific advantages of DCR-based data collection include the following: --- Consistent method for configuration of different data sources.-- Ability to apply a transformation to filter or modify incoming data before it's stored.-- Scalable configuration options supporting infrastructure as code and DevOps processes.-- Option of edge pipeline in your own environment to provide high-end scalability, layered network configurations, and periodic connectivity.---Data collection using the Azure Monitor pipeline is shown in the diagram below. Each collection scenario is defined in a DCR that specifies how the data should be processed and where it should be sent. The Azure Monitor pipeline itself consists of two components: --- **Cloud pipeline** is a component of Azure Monitor that's automatically available in your Azure subscription. It requires no configuration, and doesn't appear in the Azure portal. It represents the processing path for data that's sent to Azure Monitor. The DCR provides instructions for how the cloud pipeline should process data it receives.-- **Edge pipeline** is an optional component that extends the Azure Monitor pipeline to your own data center. It enables at-scale collection and routing of telemetry data before it's delivered to the cloud pipeline. See [Edge pipeline](#edge-pipeline) for details on the value of this component.----## Using data collection rules --Data collection rules (DCRs) are stored in Azure so they can be centrally deployed and managed like any other Azure resource. They're sets of instructions supporting data collection using the Azure Monitor pipeline. They provide a consistent and centralized way to define and customize different data collection scenarios. Depending on the scenario, DCRs specify such details as what data should be collected, how to transform that data, and where to send it. --There are two fundamental ways that DCRs are specified for a particular data collection scenario as described in the following sections. --### Data collection rule associations (DCRA) -Data collection rule associations (DCRAs) are used to associate a DCR with a monitored resource. This is a many-to-many relationship, where a single DCR can be associated with multiple resources, and a single resource can be associated with multiple DCRs. This allows you to develop a strategy for maintaining your monitoring across sets of resources with different requirements. ---For example, the following diagram illustrates data collection for [Azure Monitor agent (AMA)](../agents/azure-monitor-agent-overview.md) running on a virtual machine. When the agent is installed, it connects to Azure Monitor to retrieve any DCRs that are associated with it. In this scenario, the DCR specifies events and performance data to collect, which the agent uses to determine what data to collect from the machine and send to Azure Monitor. Once the data is delivered, the cloud pipeline runs any transformation specified in the DCR to filter and modify the data and then sends the data to the specified workspace and table. ---### Direct ingestion -With direct ingestion, a particular DCR is specified to process the incoming data. For example, the following diagram illustrates data from a custom application using [Logs ingestion API](../logs/logs-ingestion-api-overview.md). Each API call specifies the DCR that will process its data. The DCR understands the structure of the incoming data, includes a transformation that ensures that the data is in the format of the target table, and specifies a workspace and table to send the transformed data. ---## Transformations -[Transformations](./data-collection-transformations.md) allow you to modify incoming data before it's stored in Azure Monitor. You may filter unneeded data to reduce your ingestion costs, remove sensitive data that shouldn't be persisted in the Log Analytics workspace, or format data to ensure that it matches the schema of its destination. Transformations are [KQL queries](../logs/log-query-overview.md) defined in the DCR that run in the cloud pipeline. --## Endpoints -Data sent to the cloud pipeline must be sent to the URL of a specific endpoint. Depending on the scenario, this may be a public endpoint, an endpoint provided by the DCR itself, or a data collection endpoint (DCE) that you create in your Azure subscription. See [Data collection endpoints in Azure Monitor](./data-collection-endpoint-overview.md) for details on the endpoints used in different data collection scenarios. --## Edge pipeline -The [edge pipeline](./edge-pipeline-configure.md) extends the Azure Monitor pipeline to your own data center. It enables at-scale collection and routing of telemetry data before it's delivered to Azure Monitor in the Azure cloud. --Specific use cases for Azure Monitor edge pipeline are: --- **Scalability**. The edge pipeline can handle large volumes of data from monitored resources that may be limited by other collection methods such as Azure Monitor agent.-- **Periodic connectivity**. Some environments may have unreliable connectivity to the cloud, or may have long unexpected periods without connection. The edge pipeline can cache data locally and sync with the cloud when connectivity is restored.-- **Layered network**. In some environments, the network is segmented and data cannot be sent directly to the cloud. The edge pipeline can be used to collect data from monitored resources without cloud access and manage the connection to Azure Monitor in the cloud.---## Data collection scenarios -The following table describes the data collection scenarios that are currently supported using DCRs and the Azure Monitor pipeline. See the links in each entry for details on its configuration. --| Scenario | Description | -| | | -| Virtual machines | Install the [Azure Monitor agent](../agents/agents-overview.md) on a VM and associate it with one or more DCRs that define the events and performance data to collect from the client operating system. You can perform this configuration using the Azure portal so you don't have to directly edit the DCR.<br><br>See [Collect data with Azure Monitor Agent](../agents/azure-monitor-agent-data-collection.md). | -| | When you enable [VM insights](../vm/vminsights-overview.md) on a virtual machine, it deploys the Azure Monitor agent to telemetry from the VM client. The DCR is created for you automatically to collect a predefined set of performance data.<br><br>See [Enable VM Insights overview](../vm/vminsights-enable-overview.md). | -| Container insights | When you enable [Container insights](../containers/container-insights-overview.md) on your Kubernetes cluster, it deploys a containerized version of the Azure Monitor agent to send logs from the cluster to a Log Analytics workspace. The DCR is created for you automatically, but you may need to modify it to customize your collection settings.<br><br>See [Configure data collection in Container insights using data collection rule](../containers/container-insights-data-collection-dcr.md). | -| Log ingestion API | The [Logs ingestion API](../logs/logs-ingestion-api-overview.md) allows you to send data to a Log Analytics workspace from any REST client. The API call specifies the DCR to accept its data and specifies the DCR's endpoint. The DCR understands the structure of the incoming data, includes a transformation that ensures that the data is in the format of the target table, and specifies a workspace and table to send the transformed data.<br><br>See [Logs Ingestion API in Azure Monitor](../logs/logs-ingestion-api-overview.md). | -| Azure Event Hubs | Send data to a Log Analytics workspace from [Azure Event Hubs](../../event-hubs/event-hubs-about.md). The DCR defines the incoming stream and defines the transformation to format the data for its destination workspace and table.<br><br>See [Tutorial: Ingest events from Azure Event Hubs into Azure Monitor Logs (Public Preview)](../logs/ingest-logs-event-hub.md). | -| Workspace transformation DCR | The workspace transformation DCR is a special DCR that's associated with a Log Analytics workspace and allows you to perform transformations on data being collected using other methods. You create a single DCR for the workspace and add a transformation to one or more tables. The transformation is applied to any data sent to those tables through a method that doesn't use a DCR.<br><br>See [Workspace transformation DCR in Azure Monitor](./data-collection-transformations-workspace.md). | --## DCR regions -Data collection rules are available in all public regions where Log Analytics workspaces and the Azure Government and China clouds are supported. Air-gapped clouds aren't yet supported. A DCR gets created and stored in a particular region and is backed up to the [paired-region](../../availability-zones/cross-region-replication-azure.md#azure-paired-regions) within the same geography. The service is deployed to all three [availability zones](../../availability-zones/az-overview.md#availability-zones) within the region. For this reason, it's a *zone-redundant service*, which further increases availability. --**Single region data residency** is a preview feature to enable storing customer data in a single region and is currently only available in the Southeast Asia Region (Singapore) of the Asia Pacific Geo and the Brazil South (Sao Paulo State) Region of the Brazil Geo. Single-region residency is enabled by default in these regions. ---## Next steps -See the following articles for additional information on how to work with DCRs. --- [Data collection rule structure](data-collection-rule-structure.md) for a description of the JSON structure of DCRs and the different elements used for different workflows.-- [Sample data collection rules (DCRs)](data-collection-rule-samples.md) for sample DCRs for different data collection scenarios.-- [Create and edit data collection rules (DCRs) in Azure Monitor](./data-collection-rule-create-edit.md) for different methods to create DCRs for different data collection scenarios.-- [Azure Monitor service limits](../service-limits.md#data-collection-rules) for limits that apply to each DCR. |
| azure-monitor | Data Collection Rule Samples | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/data-collection-rule-samples.md | - Title: Sample data collection rules (DCRs) in Azure Monitor -description: Sample data collection rule for different Azure Monitor data collection scenarios. - Previously updated : 03/14/2024------# Sample data collection rules (DCRs) in Azure Monitor -This article includes sample [data collection rules (DCRs)](./data-collection-rule-overview.md) for different scenarios. For descriptions of each of the properties in these DCRs, see [Data collection rule structure](./data-collection-rule-structure.md). --> [!NOTE] -> These samples provide the source JSON of a DCR if you're using an ARM template or REST API to create or modify a DCR. After creation, the DCR will have additional properties as described in [Structure of a data collection rule in Azure Monitor](data-collection-rule-structure.md). --## Azure Monitor agent - events and performance data -The sample [data collection rule](../essentials/data-collection-rule-overview.md) below is for virtual machines with [Azure Monitor agent](../agents/azure-monitor-agent-data-collection.md) and has the following details: --- Performance data- - Collects specific Processor, Memory, Logical Disk, and Physical Disk counters every 15 seconds and uploads every minute. - - Collects specific Process counters every 30 seconds and uploads every 5 minutes. -- Windows events- - Collects Windows security events and uploads every minute. - - Collects Windows application and system events and uploads every 5 minutes. -- Syslog- - Collects Debug, Critical, and Emergency events from cron facility. - - Collects Alert, Critical, and Emergency events from syslog facility. -- Destinations- - Sends all data to a Log Analytics workspace named centralWorkspace. --> [!NOTE] -> For an explanation of XPaths that are used to specify event collection in data collection rules, see [Limit data collection with custom XPath queries](../agents/data-collection-windows-events.md#filter-events-using-xpath-queries). ---```json -{ - "location": "eastus", - "properties": { - "dataSources": { - "performanceCounters": [ - { - "name": "cloudTeamCoreCounters", - "streams": [ - "Microsoft-Perf" - ], - "scheduledTransferPeriod": "PT1M", - "samplingFrequencyInSeconds": 15, - "counterSpecifiers": [ - "\\Processor(_Total)\\% Processor Time", - "\\Memory\\Committed Bytes", - "\\LogicalDisk(_Total)\\Free Megabytes", - "\\PhysicalDisk(_Total)\\Avg. Disk Queue Length" - ] - }, - { - "name": "appTeamExtraCounters", - "streams": [ - "Microsoft-Perf" - ], - "scheduledTransferPeriod": "PT5M", - "samplingFrequencyInSeconds": 30, - "counterSpecifiers": [ - "\\Process(_Total)\\Thread Count" - ] - } - ], - "windowsEventLogs": [ - { - "name": "cloudSecurityTeamEvents", - "streams": [ - "Microsoft-Event" - ], - "scheduledTransferPeriod": "PT1M", - "xPathQueries": [ - "Security!*" - ] - }, - { - "name": "appTeam1AppEvents", - "streams": [ - "Microsoft-Event" - ], - "scheduledTransferPeriod": "PT5M", - "xPathQueries": [ - "System!*[System[(Level = 1 or Level = 2 or Level = 3)]]", - "Application!*[System[(Level = 1 or Level = 2 or Level = 3)]]" - ] - } - ], - "syslog": [ - { - "name": "cronSyslog", - "streams": [ - "Microsoft-Syslog" - ], - "facilityNames": [ - "cron" - ], - "logLevels": [ - "Debug", - "Critical", - "Emergency" - ] - }, - { - "name": "syslogBase", - "streams": [ - "Microsoft-Syslog" - ], - "facilityNames": [ - "syslog" - ], - "logLevels": [ - "Alert", - "Critical", - "Emergency" - ] - } - ] - }, - "destinations": { - "logAnalytics": [ - { - "workspaceResourceId": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/Microsoft.OperationalInsights/workspaces/my-workspace", - "name": "centralWorkspace" - } - ] - }, - "dataFlows": [ - { - "streams": [ - "Microsoft-Perf", - "Microsoft-Syslog", - "Microsoft-Event" - ], - "destinations": [ - "centralWorkspace" - ] - } - ] - } - } -``` --## Azure Monitor agent - text logs -The sample data collection rule below is used to collect [text logs using Azure Monitor agent](../agents/data-collection-text-log.md). Note that the names of streams for custom text logs should begin with the "Custom-" prefix. --```json -{ - "location": "eastus", - "properties": { - "streamDeclarations": { - "Custom-MyLogFileFormat": { - "columns": [ - { - "name": "TimeGenerated", - "type": "datetime" - }, - { - "name": "RawData", - "type": "string" - } - ] - } - }, - "dataSources": { - "logFiles": [ - { - "streams": [ - "Custom-MyLogFileFormat" - ], - "filePatterns": [ - "C:\\JavaLogs\\*.log" - ], - "format": "text", - "settings": { - "text": { - "recordStartTimestampFormat": "ISO 8601" - } - }, - "name": "myLogFileFormat-Windows" - }, - { - "streams": [ - "Custom-MyLogFileFormat" - ], - "filePatterns": [ - "//var//*.log" - ], - "format": "text", - "settings": { - "text": { - "recordStartTimestampFormat": "ISO 8601" - } - }, - "name": "myLogFileFormat-Linux" - } - ] - }, - "destinations": { - "logAnalytics": [ - { - "workspaceResourceId": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/Microsoft.OperationalInsights/workspaces/my-workspace", - "name": "MyDestination" - } - ] - }, - "dataFlows": [ - { - "streams": [ - "Custom-MyLogFileFormat" - ], - "destinations": [ - "MyDestination" - ], - "transformKql": "source", - "outputStream": "Custom-MyTable_CL" - } - ] - } -} -``` --## Event Hubs -The sample data collection rule below is used to collect [data from an event hub](../logs/ingest-logs-event-hub.md). --```json -{ - "location": "eastus", - "properties": { - "streamDeclarations": { - "Custom-MyEventHubStream": { - "columns": [ - { - "name": "TimeGenerated", - "type": "datetime" - }, - { - "name": "RawData", - "type": "string" - }, - { - "name": "Properties", - "type": "dynamic" - } - ] - } - }, - "dataSources": { - "dataImports": { - "eventHub": { - "consumerGroup": "<consumer-group>", - "stream": "Custom-MyEventHubStream", - "name": "myEventHubDataSource1" - } - } - }, - "destinations": { - "logAnalytics": [ - { - "workspaceResourceId": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/Microsoft.OperationalInsights/workspaces/my-workspace", - "name": "MyDestination" - } - ] - }, - "dataFlows": [ - { - "streams": [ - "Custom-MyEventHubStream" - ], - "destinations": [ - "MyDestination" - ], - "transformKql": "source", - "outputStream": "Custom-MyTable_CL" - } - ] - } -} -``` --## Logs ingestion API -The sample [data collection rule](../essentials/data-collection-rule-overview.md) below is used with the [Logs ingestion API](../logs/logs-ingestion-api-overview.md). It has the following details: --- Sends data to a table called MyTable_CL in a workspace called my-workspace.-- Applies a [transformation](../essentials//data-collection-transformations.md) to the incoming data.--> [!NOTE] -> Logs ingestion API requires the [logsIngestion](../essentials/data-collection-rule-structure.md#endpoints) property which includes the URL of the endpoint. This property is added to the DCR after it's created. --```json -{ - "location": "eastus", - "properties": { - "streamDeclarations": { - "Custom-MyTable": { - "columns": [ - { - "name": "Time", - "type": "datetime" - }, - { - "name": "Computer", - "type": "string" - }, - { - "name": "AdditionalContext", - "type": "string" - } - ] - } - }, - "destinations": { - "logAnalytics": [ - { - "workspaceResourceId": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/cefingestion/providers/microsoft.operationalinsights/workspaces/my-workspace", - "name": "LogAnalyticsDest" - } - ] - }, - "dataFlows": [ - { - "streams": [ - "Custom-MyTable" - ], - "destinations": [ - "LogAnalyticsDest" - ], - "transformKql": "source | extend jsonContext = parse_json(AdditionalContext) | project TimeGenerated = Time, Computer, AdditionalContext = jsonContext, ExtendedColumn=tostring(jsonContext.CounterName)", - "outputStream": "Custom-MyTable_CL" - } - ] - } -} -``` --## Workspace transformation DCR -The sample [data collection rule](../essentials/data-collection-rule-overview.md) below is used as a -[workspace transformation DCR](../essentials/data-collection-transformations-workspace.md) to transform all data sent to a table called *LAQueryLogs*. --```json -{ - "location": "eastus", - "properties": { - "destinations": { - "logAnalytics": [ - { - "workspaceResourceId": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/Microsoft.OperationalInsights/workspaces/my-workspace", - "name": "clv2ws1" - } - ] - }, - "dataFlows": [ - { - "streams": [ - "Microsoft-Table-LAQueryLogs" - ], - "destinations": [ - "clv2ws1" - ], - "transformKql": "source |where QueryText !contains 'LAQueryLogs' | extend Context = parse_json(RequestContext) | extend Resources_CF = tostring(Context['workspaces']) |extend RequestContext = ''" - } - ] - } -} -``` ---## Next steps --- [Get details for the different properties in a DCR](../essentials/data-collection-rule-structure.md)-- [See different methods for creating a DCR](../essentials/data-collection-rule-create-edit.md)- |
| azure-monitor | Data Collection Rule Structure | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/data-collection-rule-structure.md | - Title: Structure of a data collection rule in Azure Monitor -description: Details on the structure of different kinds of data collection rule in Azure Monitor. --- Previously updated : 07/26/2024-ms.reviwer: nikeist ---# Structure of a data collection rule in Azure Monitor -[Data collection rules (DCRs)](data-collection-rule-overview.md) are sets of instructions that determine how to collect and process telemetry sent to Azure Monitor. Some DCRs will be created and managed by Azure Monitor. This article describes the JSON properties of DCRs for creating and editing them in those cases where you need to work with them directly. --- See [Create and edit data collection rules (DCRs) in Azure Monitor](data-collection-rule-create-edit.md) for details working with the JSON described here.-- See [Sample data collection rules (DCRs) in Azure Monitor](../essentials/data-collection-rule-samples.md) for sample DCRs for different scenarios.--## Properties -Properties at the top level of the DCR. --| Property | Description | -|:|:| -| `immutableId` | A unique identifier for the data collection rule. Property and value are automatically created when the DCR is created. | -| `description` | A description of the data collection rule. | -| `dataCollectionEndpointId` | Resource ID of the [data collection endpoint (DCE)](data-collection-endpoint-overview.md) used by the DCR if you provided one. Property not present in DCRs that don't use a DCE. | ---## `endpoints` -Contains the URLs of the endpoints for the DCR. This section and its properties are automatically created when the DCR is created. --> [!NOTE] -> These properties weren't created for DCRs created before March 31, 2024. DCRs created before this date required a [data collection endpoint (DCE)](data-collection-endpoint-overview.md) and the `dataCollectionEndpointId` property to be specified. If you want to use these embedded DCEs then you must create a new DCR. --| Property | Description | -|:|:| -| `logsIngestion` | URL for ingestion endpoint for log data. | -| `metricsIngestion` | URL for ingestion endpoint for metric data. | --**Scenarios** -- Logs ingestion API--## `dataCollectionEndpointId` -Specifies the [data collection endpoint (DCE)](data-collection-endpoint-overview.md) used by the DCR. --**Scenarios** -- Azure Monitor agent-- Logs ingestion API-- Events Hubs- --## `streamDeclarations` -Declaration of the different types of data sent into the Log Analytics workspace. Each stream is an object whose key represents the stream name, which must begin with *Custom-*. The stream contains a full list of top-level properties that are contained in the JSON data that will be sent. The shape of the data you send to the endpoint doesn't need to match that of the destination table. Instead, the output of the transform that's applied on top of the input data needs to match the destination shape. --This section isn't used for data sources sending known data types such as events and performance data sent from Azure Monitor agent. --The possible data types that can be assigned to the properties are: --- `string`-- `int`-- `long`-- `real`-- `boolean`-- `dynamic`-- `datetime`.--**Scenarios** -- Azure Monitor agent (text logs only)-- Logs ingestion API -- Event Hubs--## `destinations` -Declaration of all the destinations where the data will be sent. Only `logAnalytics` is currently supported as a destination except for Azure Monitor agent which can also use `azureMonitorMetrics`. Each Log Analytics destination requires the full workspace resource ID and a friendly name that will be used elsewhere in the DCR to refer to this workspace. --**Scenarios** -- Azure Monitor agent (text logs only)-- Logs ingestion API -- Event Hubs-- Workspace transformation DCR--## `dataSources` -Unique source of monitoring data that has its own format and method of exposing its data. Each data source has a data source type, and each type defines a unique set of properties that must be specified for each data source. The data source types currently available are listed in the following table. --| Data source type | Description | -|:|:| -| eventHub | Data from Azure Event Hubs | -| extension | VM extension-based data source, used exclusively by Log Analytics solutions and Azure services ([View agent supported services and solutions](../agents/azure-monitor-agent-overview.md#supported-services-and-features)) | -| logFiles | Text log on a virtual machine | -| performanceCounters | Performance counters for both Windows and Linux virtual machines | -| syslog | Syslog events on Linux virtual machines | -| windowsEventLogs | Windows event log on virtual machines | --**Scenarios** -- Azure Monitor agent-- Event Hubs---## `dataFlows` -Matches streams with destinations and optionally specifies a transformation. --### `dataFlows/Streams` -One or more streams defined in the previous section. You may include multiple streams in a single data flow if you want to send multiple data sources to the same destination. Only use a single stream though if the data flow includes a transformation. One stream can also be used by multiple data flows when you want to send a particular data source to multiple tables in the same Log Analytics workspace. --### `dataFlows/destinations` -One or more destinations from the `destinations` section above. Multiple destinations are allowed for multi-homing scenarios. --### `dataFlows/transformKql` -Optional [transformation](data-collection-transformations.md) applied to the incoming stream. The transformation must understand the schema of the incoming data and output data in the schema of the target table. If you use a transformation, the data flow should only use a single stream. --### `dataFlows/outputStream` -Describes which table in the workspace specified under the `destination` property the data will be sent to. The value of `outputStream` has the format `Microsoft-[tableName]` when data is being ingested into a standard Log Analytics table, or `Custom-[tableName]` when ingesting data into a custom table. Only one destination is allowed per stream.<br><br>This property isn't used for known data sources from Azure Monitor such as events and performance data since these are sent to predefined tables. | --**Scenarios** --- Azure Monitor agent-- Logs ingestion API-- Event Hubs-- Workspace transformation DCR----## Next steps --[Overview of data collection rules and methods for creating them](data-collection-rule-overview.md) - |
| azure-monitor | Data Collection Rule View | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/data-collection-rule-view.md | - Title: Manage data collection rules (DCRs) and associations in Azure Monitor -description: Describes different options for viewing data collection rules (DCRs) and data collection rule associations (DCRA) in Azure Monitor. --- Previously updated : 03/18/2024----# Manage data collection rules (DCRs) and associations in Azure Monitor -[Data collection rules (DCRs)](data-collection-rule-overview.md) are used to specify the data that you want to collect from your Azure resources and the configuration for how that data is collected. This article describes how to view the DCRs in your subscription and the resources that they are associated with. It also provides details on managing [data collection rule associations (DCRAs)](data-collection-rule-overview.md#data-collection-rule-associations-dcra). --> [!NOTE] -> This article describes how to manage DCRs and their associations with resources using the Azure portal. Details for creating the DCR itself are described in [Create and edit data collection rules (DCRs) in Azure Monitor](./data-collection-rule-create-edit.md). -> -> For alternate methods of working with DCRs and associations, see the following: -> - Azure CLI - [az monitor data-collection rule](/cli/azure/monitor/data-collection/rule) -> - PowerShell - [Az.Monitor](/powershell/module/az.monitor) --## View DCRs and add associations --To view your DCRs in the Azure portal, select **Data Collection Rules** under **Settings** on the **Monitor** menu. ---Select a DCR to view its details, including the resources it's associated with. For some DCRs, you may need to use the **JSON view** to view its details. See [Create and edit data collection rules (DCRs) in Azure Monitor](./data-collection-rule-create-edit.md) for details on how you can modify them. --> [!NOTE] -> Although this view shows all DCRs in the specified subscriptions, selecting the **Create** button will create a data collection for Azure Monitor Agent. Similarly, this page will only allow you to modify DCRs for Azure Monitor Agent. For guidance on how to create and update DCRs for other workflows, see [Create and edit data collection rules (DCRs) in Azure Monitor](./data-collection-rule-create-edit.md). --Click the **Resources** tab to view the resources associated with the selected DCR. Click **Add** to add an association to a new resource. You can view and add resources using this feature whether or not you created the DCR in the Azure portal. ----## Preview DCR experience -A preview of the new Azure portal experience for DCRs is now available. The preview experience ties together DCRs and the resources they're associated with. You can either view the list by **Data collection rule**, which shows the number of resources associated with each DCR, or by **Resources**, which shows the count of DCRs associated with each resource. --Select the option on the displayed banner to enable this experience. ----### Data collection rule view -In the **Data collection rule** view, the **Resource count** represents the number of resources that have a [data collection rule association](./data-collection-rule-overview.md#data-collection-rule-associations-dcra) with the DCR. Click this value to open the **Resources** view for that DCR. ---### Resources view -The **Resources** view lists all Azure resources that match the selected filter, whether they have a DCR association or not. Tiles at the top of the view list the count of total resources listed, the number of resources not associated with a DCR, and the total number of DCRs matching the selected filter. ---**View DCRs for a resource** --The **Data collection rules** column represents the number of DCRs that are associated with each resource. Click this value to open a new pane listing the DCRs associated with the resource. ---> [!IMPORTANT] -> Not all DCRs are associated with resources. For example, DCRs used with the [Logs ingestion API](../logs/logs-ingestion-api-overview.md) are specified in the API call and do not use associations. These DCRs still appear in the view, but will have a **Resource Count** of 0. --**Create new DCR or associations with existing DCR** --Using the **Resources** view, you can create a new DCR for the selected resources or associate them with an existing DCR. Select the resources and then click one of the following options. --| Option | Description | -|:|:| -| Create a data collection rule | Launch the process to create a new DCR. The selected resources are automatically added as resources for the new DCR. See [Collect data with Azure Monitor Agent](../agents/azure-monitor-agent-data-collection.md) for details on this process. | -| Associate with existing data collection rule | Associate the selected resources with one or more existing DCRs. This opens a list of DCRs that can be associated with the current resource. This list only includes DCRs that are valid for the particular resource. For example, if the resource is a VM with the Azure Monitor agent (AMA) installed, only DCRs that process AMA data are listed. | -----## Azure Policy -Using [Azure Policy](../../governance/policy/overview.md), you can associate a DCR with multiple resources at scale. When you create an assignment between a resource group and a built-in policy or initiative, associations are created between the DCR and each resource of the assigned type in the resource group, including any new resources as they're created. Azure Monitor provides a simplified user experience to create an assignment for a policy or initiative for a particular DCR, which is an alternate method to creating the assignment using Azure Policy directly. --> [!NOTE] -> A **policy** in Azure Policy is a single rule or condition that resources in Azure must comply with. For example, there is a built-in policy called **Configure Windows Machines to be associated with a Data Collection Rule or a Data Collection Endpoint**. -> -> An **initiative** is a collection of policies that are grouped together to achieve a specific goal or purpose. For example, there is an initiative called **Configure Windows machines to run Azure Monitor Agent and associate them to a Data Collection Rule** that includes multiple policies to install and configure the Azure Monitor agent. --From the DCR in the Azure portal, select **Policies (Preview)**. This will open a page that lists any assignments with the current DCR and the compliance state of included resources. Tiles across the top provide compliance metrics for all resources and assignments. ---To create a new assignment, click either **Assign Policy** or **Assign Initiative**. ---| Setting | Description | -|:|:| -| Subscription | The subscription with the resource group to use as the scope. | -| Resource group | The resource group to use as the scope. The DCR will be assigned to all resource in this resource group, depending on the resource group managed by the definition. | -| Policy/Initiative definition | The definition to assign. The dropdown will include all definitions in the subscription that accept DCR as a parameter. | -| Assignment Name | A name for the assignment. Must be unique in the subscription. | -| Description | Optional description of the assignment. | -| Policy Enforcement | The policy is only actually applied if enforcement is enabled. If disabled, only assessments for the policy are performed. | --Once an assignment is created, you can view its details by clicking on it. This will allow you to edit the details of the assignment and also to create a remediation task. ---> [!IMPORTANT] -> The assignment won't be applied to existing resources until you create a remediation task. For more information, see [Remediate non-compliant resources with Azure Policy](../../governance/policy/how-to/remediate-resources.md). ---## Next steps -See the following articles for additional information on how to work with DCRs. --- [Data collection rule structure](data-collection-rule-structure.md) for a description of the JSON structure of DCRs and the different elements used for different workflows.-- [Sample data collection rules (DCRs)](data-collection-rule-samples.md) for sample DCRs for different data collection scenarios.-- [Create and edit data collection rules (DCRs) in Azure Monitor](./data-collection-rule-create-edit.md) for different methods to create DCRs for different data collection scenarios.-- [Azure Monitor service limits](../service-limits.md#data-collection-rules) for limits that apply to each DCR. |
| azure-monitor | Data Collection Transformations Structure | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/data-collection-transformations-structure.md | - Title: Structure of transformation in Azure Monitor -description: Structure of transformation in Azure Monitor including limitations of KQL allowed in a transformation. --- Previously updated : 06/09/2023-ms.reviwer: nikeist ----# Structure of transformation in Azure Monitor -[Transformations in Azure Monitor](./data-collection-transformations.md) allow you to filter or modify incoming data before it's stored in a Log Analytics workspace. They're implemented as a Kusto Query Language (KQL) statement in a [data collection rule (DCR)](data-collection-rule-overview.md). This article provides details on how this query is structured and limitations on the KQL language allowed. ---## Transformation structure -The KQL statement is applied individually to each entry in the data source. It must understand the format of the incoming data and create output in the structure of the target table. A virtual table named `source` represents the input stream. `source` table columns match the input data stream definition. Following is a typical example of a transformation. This example includes the following functionality: --- Filters the incoming data with a [where](/azure/data-explorer/kusto/query/whereoperator) statement-- Adds a new column using the [extend](/azure/data-explorer/kusto/query/extendoperator) operator-- Formats the output to match the columns of the target table using the [project](/azure/data-explorer/kusto/query/projectoperator) operator--```kusto -source -| where severity == "Critical" -| extend Properties = parse_json(properties) -| project - TimeGenerated = todatetime(["time"]), - Category = category, - StatusDescription = StatusDescription, - EventName = name, - EventId = tostring(Properties.EventId) -``` --## KQL limitations -Since the transformation is applied to each record individually, it can't use any KQL operators that act on multiple records. Only operators that take a single row as input and return no more than one row are supported. For example, [summarize](/azure/data-explorer/kusto/query/summarizeoperator) isn't supported since it summarizes multiple records. See [Supported KQL features](#supported-kql-features) for a complete list of supported features. ----Transformations in a [data collection rule (DCR)](data-collection-rule-overview.md) allow you to filter or modify incoming data before it's stored in a Log Analytics workspace. This article describes how to build transformations in a DCR, including details and limitations of the Kusto Query Language (KQL) used for the transform statement. ----## Required columns -The output of every transformation must contain a valid timestamp in a column called `TimeGenerated` of type `datetime`. Make sure to include it in the final `extend` or `project` block! Creating or updating a DCR without `TimeGenerated` in the output of a transformation will lead to an error. --## Handling dynamic data -Consider the following input with [dynamic data](/azure/data-explorer/kusto/query/scalar-data-types/dynamic): --```json -{ - "TimeGenerated" : "2021-11-07T09:13:06.570354Z", - "Message": "Houston, we have a problem", - "AdditionalContext": { - "Level": 2, - "DeviceID": "apollo13" - } -} -``` --To access the properties in *AdditionalContext*, define it as dynamic-type column in the input stream: --```json -"columns": [ - { - "name": "TimeGenerated", - "type": "datetime" - }, - { - "name": "Message", - "type": "string" - }, - { - "name": "AdditionalContext", - "type": "dynamic" - } -] -``` --The content of the *AdditionalContext* column can now be parsed and used in the KQL transformation: --```kusto -source -| extend parsedAdditionalContext = parse_json(AdditionalContext) -| extend Level = toint (parsedAdditionalContext.Level) -| extend DeviceId = tostring(parsedAdditionalContext.DeviceID) -``` --## Dynamic literals -Use the [parse_json function](/azure/data-explorer/kusto/query/parsejsonfunction) to handle [dynamic literals](/azure/data-explorer/kusto/query/scalar-data-types/dynamic#dynamic-literals). --For example, the following queries provide the same functionality: --```kql -print d=dynamic({"a":123, "b":"hello", "c":[1,2,3], "d":{}}) -``` --```kql -print d=parse_json('{"a":123, "b":"hello", "c":[1,2,3], "d":{}}') -``` --## Supported KQL features --### Supported statements --#### let statement -The right-hand side of [let](/azure/data-explorer/kusto/query/letstatement) can be a scalar expression, a tabular expression or a user-defined function. Only user-defined functions with scalar arguments are supported. --#### tabular expression statements -The only supported data sources for the KQL statement are as follows: --- **source**, which represents the source data. For example:--```kql -source -| where ActivityId == "383112e4-a7a8-4b94-a701-4266dfc18e41" -| project PreciseTimeStamp, Message -``` --- [print](/azure/data-explorer/kusto/query/printoperator) operator, which always produces a single row. For example:- -```kusto -print x = 2 + 2, y = 5 | extend z = exp2(x) + exp2(y) -``` ---### Tabular operators -- [extend](/azure/data-explorer/kusto/query/extendoperator)-- [project](/azure/data-explorer/kusto/query/projectoperator)-- [print](/azure/data-explorer/kusto/query/printoperator)-- [where](/azure/data-explorer/kusto/query/whereoperator)-- [parse](/azure/data-explorer/kusto/query/parseoperator)-- [project-away](/azure/data-explorer/kusto/query/projectawayoperator)-- [project-rename](/azure/data-explorer/kusto/query/projectrenameoperator)-- [datatable](/azure/data-explorer/kusto/query/datatableoperator?pivots=azuremonitor)-- [columnifexists](/azure/data-explorer/kusto/query/columnifexists) (use columnifexists instead of column_ifexists)--### Scalar operators --#### Numerical operators -All [Numerical operators](/azure/data-explorer/kusto/query/numoperators) are supported. --#### Datetime and Timespan arithmetic operators -All [Datetime and Timespan arithmetic operators](/azure/data-explorer/kusto/query/datetime-timespan-arithmetic) are supported. --#### String operators -The following [String operators](/azure/data-explorer/kusto/query/datatypes-string-operators) are supported. --- ==-- !=-- =~-- !~-- contains-- !contains-- contains_cs-- !contains_cs-- has-- !has-- has_cs-- !has_cs-- startswith-- !startswith-- startswith_cs-- !startswith_cs-- endswith-- !endswith-- endswith_cs-- !endswith_cs-- matches regex-- in-- !in---#### Bitwise operators --The following [Bitwise operators](/azure/data-explorer/kusto/query/binoperators) are supported. --- binary_and()-- binary_or()-- binary_xor()-- binary_not()-- binary_shift_left()-- binary_shift_right()--### Scalar functions --#### Bitwise functions --- [binary_and](/azure/data-explorer/kusto/query/binary-andfunction)-- [binary_or](/azure/data-explorer/kusto/query/binary-orfunction)-- [binary_not](/azure/data-explorer/kusto/query/binary-notfunction)-- [binary_shift_left](/azure/data-explorer/kusto/query/binary-shift-leftfunction)-- [binary_shift_right](/azure/data-explorer/kusto/query/binary-shift-rightfunction)-- [binary_xor](/azure/data-explorer/kusto/query/binary-xorfunction)--#### Conversion functions --- [tobool](/azure/data-explorer/kusto/query/toboolfunction)-- [todatetime](/azure/data-explorer/kusto/query/todatetimefunction)-- [todouble/toreal](/azure/data-explorer/kusto/query/todoublefunction)-- [toguid](/azure/data-explorer/kusto/query/toguidfunction)-- [toint](/azure/data-explorer/kusto/query/tointfunction)-- [tolong](/azure/data-explorer/kusto/query/tolongfunction)-- [tostring](/azure/data-explorer/kusto/query/tostringfunction)-- [totimespan](/azure/data-explorer/kusto/query/totimespanfunction)--#### DateTime and TimeSpan functions --- [ago](/azure/data-explorer/kusto/query/agofunction)-- [datetime_add](/azure/data-explorer/kusto/query/datetime-addfunction)-- [datetime_diff](/azure/data-explorer/kusto/query/datetime-difffunction)-- [datetime_part](/azure/data-explorer/kusto/query/datetime-partfunction)-- [dayofmonth](/azure/data-explorer/kusto/query/dayofmonthfunction)-- [dayofweek](/azure/data-explorer/kusto/query/dayofweekfunction)-- [dayofyear](/azure/data-explorer/kusto/query/dayofyearfunction)-- [endofday](/azure/data-explorer/kusto/query/endofdayfunction)-- [endofmonth](/azure/data-explorer/kusto/query/endofmonthfunction)-- [endofweek](/azure/data-explorer/kusto/query/endofweekfunction)-- [endofyear](/azure/data-explorer/kusto/query/endofyearfunction)-- [getmonth](/azure/data-explorer/kusto/query/getmonthfunction)-- [getyear](/azure/data-explorer/kusto/query/getyearfunction)-- [hourofday](/azure/data-explorer/kusto/query/hourofdayfunction)-- [make_datetime](/azure/data-explorer/kusto/query/make-datetimefunction)-- [make_timespan](/azure/data-explorer/kusto/query/make-timespanfunction)-- [now](/azure/data-explorer/kusto/query/nowfunction)-- [startofday](/azure/data-explorer/kusto/query/startofdayfunction)-- [startofmonth](/azure/data-explorer/kusto/query/startofmonthfunction)-- [startofweek](/azure/data-explorer/kusto/query/startofweekfunction)-- [startofyear](/azure/data-explorer/kusto/query/startofyearfunction)-- [todatetime](/azure/data-explorer/kusto/query/todatetimefunction)-- [totimespan](/azure/data-explorer/kusto/query/totimespanfunction)-- [weekofyear](/azure/data-explorer/kusto/query/weekofyearfunction)--#### Dynamic and array functions --- [array_concat](/azure/data-explorer/kusto/query/arrayconcatfunction)-- [array_length](/azure/data-explorer/kusto/query/arraylengthfunction)-- [pack_array](/azure/data-explorer/kusto/query/packarrayfunction)-- [pack](/azure/data-explorer/kusto/query/packfunction)-- [parse_json](/azure/data-explorer/kusto/query/parsejsonfunction)-- [parse_xml](/azure/data-explorer/kusto/query/parse-xmlfunction)-- [zip](/azure/data-explorer/kusto/query/zipfunction)--#### Mathematical functions --- [abs](/azure/data-explorer/kusto/query/abs-function)-- [bin/floor](/azure/data-explorer/kusto/query/binfunction)-- [ceiling](/azure/data-explorer/kusto/query/ceilingfunction)-- [exp](/azure/data-explorer/kusto/query/exp-function)-- [exp10](/azure/data-explorer/kusto/query/exp10-function)-- [exp2](/azure/data-explorer/kusto/query/exp2-function)-- [isfinite](/azure/data-explorer/kusto/query/isfinitefunction)-- [isinf](/azure/data-explorer/kusto/query/isinffunction)-- [isnan](/azure/data-explorer/kusto/query/isnanfunction)-- [log](/azure/data-explorer/kusto/query/log-function)-- [log10](/azure/data-explorer/kusto/query/log10-function)-- [log2](/azure/data-explorer/kusto/query/log2-function)-- [pow](/azure/data-explorer/kusto/query/powfunction)-- [round](/azure/data-explorer/kusto/query/roundfunction)-- [sign](/azure/data-explorer/kusto/query/signfunction)--#### Conditional functions --- [case](/azure/data-explorer/kusto/query/casefunction)-- [iif](/azure/data-explorer/kusto/query/iiffunction)-- [max_of](/azure/data-explorer/kusto/query/max-offunction)-- [min_of](/azure/data-explorer/kusto/query/min-offunction)--#### String functions --- [base64_encodestring](/azure/data-explorer/kusto/query/base64_encode_tostringfunction) (use base64_encodestring instead of base64_encode_tostring)-- [base64_decodestring](/azure/data-explorer/kusto/query/base64_decode_tostringfunction) (use base64_decodestring instead of base64_decode_tostring)-- [countof](/azure/data-explorer/kusto/query/countoffunction)-- [extract](/azure/data-explorer/kusto/query/extractfunction)-- [extract_all](/azure/data-explorer/kusto/query/extractallfunction)-- [indexof](/azure/data-explorer/kusto/query/indexoffunction)-- [isempty](/azure/data-explorer/kusto/query/isemptyfunction)-- [isnotempty](/azure/data-explorer/kusto/query/isnotemptyfunction)-- [parse_json](/azure/data-explorer/kusto/query/parsejsonfunction)-- [replace](https://github.com/microsoft/Kusto-Query-Language/blob/master/doc/replacefunction.md)-- [split](/azure/data-explorer/kusto/query/splitfunction)-- [strcat](/azure/data-explorer/kusto/query/strcatfunction)-- [strcat_delim](/azure/data-explorer/kusto/query/strcat-delimfunction)-- [strlen](/azure/data-explorer/kusto/query/strlenfunction)-- [substring](/azure/data-explorer/kusto/query/substringfunction)-- [tolower](/azure/data-explorer/kusto/query/tolowerfunction)-- [toupper](/azure/data-explorer/kusto/query/toupperfunction)-- [hash_sha256](/azure/data-explorer/kusto/query/sha256hashfunction)--#### Type functions --- [gettype](/azure/data-explorer/kusto/query/gettypefunction)-- [isnotnull](/azure/data-explorer/kusto/query/isnotnullfunction)-- [isnull](/azure/data-explorer/kusto/query/isnullfunction)--#### Special functions --##### parse_cef_dictionary --Given a string containing a CEF message, `parse_cef_dictionary` parses the Extension property of the message into a dynamic key/value object. Semicolon is a reserved character that should be replaced prior to passing the raw message into the method, as shown in the example. --```kusto -| extend cefMessage=iff(cefMessage contains_cs ";", replace(";", " ", cefMessage), cefMessage) -| extend parsedCefDictionaryMessage =parse_cef_dictionary(cefMessage) -| extend parsecefDictionaryExtension = parsedCefDictionaryMessage["Extension"] -| project TimeGenerated, cefMessage, parsecefDictionaryExtension -``` ---##### geo_location --Given a string containing IP address (IPv4 and IPv6 are supported), `geo_location` function returns approximate geographical location, including the following attributes: -* Country -* Region -* State -* City -* Latitude -* Longitude --```kusto -| extend GeoLocation = geo_location("1.0.0.5") -``` ---> [!IMPORTANT] -> Due to nature of IP geolocation service utilized by this function, it may introduce data ingestion latency if used excessively. Exercise caution when using this function more than several times per transformation. --### Identifier quoting -Use [Identifier quoting](/azure/data-explorer/kusto/query/schema-entities/entity-names?q=identifier#identifier-quoting) as required. ---## Next steps --- [Create a data collection rule](../agents/azure-monitor-agent-data-collection.md) and an association to it from a virtual machine using the Azure Monitor agent. |
| azure-monitor | Data Collection Transformations Workspace | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/data-collection-transformations-workspace.md | - Title: Workspace transformation data collection rule (DCR) in Azure Monitor -description: Create a transformation for data not being collected using a data collection rule (DCR). --- Previously updated : 03/22/2024-ms.reviwer: nikeist ---# Workspace transformation data collection rule (DCR) in Azure Monitor --The *workspace transformation data collection rule (DCR)* is a special [DCR](./data-collection-rule-overview.md) that's applied directly to a Log Analytics workspace. The purpose of this DCR is to perform [transformations](./data-collection-transformations.md) on data that does not yet use a DCR for its data collection, and thus has no means to define a transformation. --The workspace transformation DCR includes transformations for one or more supported tables in the workspace. These transformations are applied to any data sent to these tables unless that data came from another DCR. For example, if you create a transformation in the workspace transformation DCR for the Event table, it would be applied to events collected by virtual machines running the Log Analytics agent because this agent doesn't use a DCR. The transformation would be ignored by any data sent from Azure Monitor Agent because it uses a DCR and would be expected to provide its own transformation. --A common use of the workspace transformation DCR is collection of [resource logs](./resource-logs.md) that are configured with a [diagnostic setting](./diagnostic-settings.md). You might want to apply a transformation to this data to filter out records that you don't require. Since diagnostic settings don't have transformations, you can use the workspace transformation DCR to apply a transformation to this data. ---## Supported tables -See [Tables that support transformations in Azure Monitor Logs](../logs/tables-feature-support.md) for a list of the tables that can be used with transformations. You can also use the [Azure Monitor data reference](/azure/azure-monitor/reference/) which lists the attributes for each table, including whether it supports transformations. In addition to these tables, any custom tables (suffix of *_CL*) are also supported. --## Create a workspace transformation --See the following tutorials for creating a workspace transformation DCR: --- [Add workspace transformation to Azure Monitor Logs by using the Azure portal](../logs/tutorial-workspace-transformations-portal.md)-- [Add workspace transformation to Azure Monitor Logs by using Resource Manager templates](../logs/tutorial-workspace-transformations-api.md) ---## Next steps --- [Use the Azure portal to create a workspace transformation DCR.](../logs/tutorial-workspace-transformations-api.md)-- [Use ARM templates to create a workspace transformation DCR.](../logs/tutorial-workspace-transformations-portal.md)- |
| azure-monitor | Data Collection Transformations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/data-collection-transformations.md | - Title: Data collection transformations -description: Use transformations in a data collection rule in Azure Monitor to filter and modify incoming data. --- Previously updated : 03/28/2024-ms.reviwer: nikeist ---# Data collection transformations in Azure Monitor -With transformations in Azure Monitor, you can filter or modify incoming data before it's sent to a Log Analytics workspace. This article provides a basic description of transformations and how they're implemented. It provides links to other content for creating a transformation. --Transformations are performed in Azure Monitor in the data ingestion pipeline after the data source delivers the data and before it's sent to the destination. The data source might perform its own filtering before sending data but then rely on the transformation for further manipulation before it's sent to the destination. --Transformations are defined in a [data collection rule (DCR)](data-collection-rule-overview.md) and use a [Kusto Query Language (KQL) statement](data-collection-transformations-structure.md) that's applied individually to each entry in the incoming data. It must understand the format of the incoming data and create output in the structure expected by the destination. --The following diagram illustrates the transformation process for incoming data and shows a sample query that might be used. See [Structure of transformation in Azure Monitor](./data-collection-transformations-structure.md) for details on building transformation queries. ---## Why to use transformations -The following table describes the different goals that you can achieve by using transformations. --| Category | Details | -|:|:| -| Remove sensitive data | You might have a data source that sends information you don't want stored for privacy or compliancy reasons.<br><br>**Filter sensitive information.** Filter out entire rows or particular columns that contain sensitive information.<br><br>**Obfuscate sensitive information.** Replace information such as digits in an IP address or telephone number with a common character.<br><br>**Send to an alternate table.** Send sensitive records to an alternate table with different role-based access control configuration. | -| Enrich data with more or calculated information | Use a transformation to add information to data that provides business context or simplifies querying the data later.<br><br>**Add a column with more information.** For example, you might add a column identifying whether an IP address in another column is internal or external.<br><br>**Add business-specific information.** For example, you might add a column indicating a company division based on location information in other columns. | -| Reduce data costs | Because you're charged ingestion cost for any data sent to a Log Analytics workspace, you want to filter out any data that you don't require to reduce your costs.<br><br>**Remove entire rows.** For example, you might have a diagnostic setting to collect resource logs from a particular resource but not require all the log entries that it generates. Create a transformation that filters out records that match a certain criteria.<br><br>**Remove a column from each row.** For example, your data might include columns with data that's redundant or has minimal value. Create a transformation that filters out columns that aren't required.<br><br>**Parse important data from a column.** You might have a table with valuable data buried in a particular column. Use a transformation to parse the valuable data into a new column and remove the original.<br><br>**Send certain rows to basic logs.** Send rows in your data that require basic query capabilities to basic logs tables for a lower ingestion cost. | -| Format data for destination | You might have a data source that sends data in a format that doesn't match the structure of the destination table. Use a transformation to reformat the data to the required schema. | --## Supported tables -See [Tables that support transformations in Azure Monitor Logs](../logs/tables-feature-support.md) for a list of the tables that can be used with transformations. You can also use the [Azure Monitor data reference](/azure/azure-monitor/reference/) which lists the attributes for each table, including whether it supports transformations. In addition to these tables, any custom tables (suffix of *_CL*) are also supported. ---- Any Azure table listed in [Tables that support transformations in Azure Monitor Logs](../logs/tables-feature-support.md). You can also use the [Azure Monitor data reference](/azure/azure-monitor/reference/) which lists the attributes for each table, including whether it supports transformations.-- Any custom table created for the Azure Monitor Agent. (MMA custom table can't use transformations)---## Create a transformation -There are multiple methods to create transformations depending on the data collection method. The following table lists guidance for different methods for creating transformations. --| Data collection | Reference | -|:|:| -| Logs ingestion API | [Send data to Azure Monitor Logs by using REST API (Azure portal)](../logs/tutorial-logs-ingestion-portal.md)<br>[Send data to Azure Monitor Logs by using REST API (Azure Resource Manager templates)](../logs/tutorial-logs-ingestion-api.md) | -| Virtual machine with Azure Monitor agent | [Add transformation to Azure Monitor Log](../agents/azure-monitor-agent-transformation.md) | -| Kubernetes cluster with Container insights | [Data transformations in Container insights](../containers/container-insights-transformations.md) | -| Azure Event Hubs | [Tutorial: Ingest events from Azure Event Hubs into Azure Monitor Logs (Public Preview)](../logs/ingest-logs-event-hub.md) | --## Multiple destinations --With transformations, you can send data to multiple destinations in a Log Analytics workspace by using a single DCR. You provide a KQL query for each destination, and the results of each query are sent to their corresponding location. You can send different sets of data to different tables or use multiple queries to send different sets of data to the same table. --For example, you might send event data into Azure Monitor by using the Logs Ingestion API. Most of the events should be sent an analytics table where it could be queried regularly, while audit events should be sent to a custom table configured for [basic logs](../logs/logs-table-plans.md) to reduce your cost. --To use multiple destinations, you must currently either manually create a new DCR or [edit an existing one](data-collection-rule-edit.md). See the [Samples](#samples) section for examples of DCRs that use multiple destinations. --> [!IMPORTANT] -> Currently, the tables in the DCR must be in the same Log Analytics workspace. To send to multiple workspaces from a single data source, use multiple DCRs and configure your application to send the data to each. ----## Monitor transformations -See [Monitor and troubleshoot DCR data collection in Azure Monitor](data-collection-monitor.md) for details on logs and metrics that monitor the health and performance of transformations. This includes identifying any errors that occur in the KQL and metrics to track their running duration. --## Cost for transformations -While transformations themselves don't incur direct costs, the following scenarios can result in additional charges: --- If a transformation increases the size of the incoming data, such as by adding a calculated column, you'll be charged the standard ingestion rate for the extra data.-- If a transformation reduces the ingested data by more than 50%, you'll be charged for the amount of filtered data above 50%.--To calculate the data processing charge resulting from transformations, use the following formula:<br>[GB filtered out by transformations] - ([GB data ingested by pipeline] / 2). The following table shows examples. --| Data ingested by pipeline | Data dropped by transformation | Data ingested by Log Analytics workspace | Data processing charge | Ingestion charge | -|:|:-:|:-:|:-:|:-:| -| 20 GB | 12 GB | 8 GB | 2 GB <sup>1</sup> | 8 GB | -| 20 GB | 8 GB | 12 GB | 0 GB | 12 GB | --<sup>1</sup> This charge excludes the charge for data ingested by Log Analytics workspace. --To avoid this charge, you should filter ingested data using alternative methods before applying transformations. By doing so, you can reduce the amount of data processed by transformations and, therefore, minimize any additional costs. --See [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor) for current charges for ingestion and retention of log data in Azure Monitor. --> [!IMPORTANT] -> If Azure Sentinel is enabled for the Log Analytics workspace, there's no filtering ingestion charge regardless of how much data the transformation filters. --## Samples -The following Resource Manager templates show sample DCRs with different patterns. You can use these templates as a starting point to creating DCRs with transformations for your own scenarios. --### Single destination --The following example is a DCR for Azure Monitor Agent that sends data to the `Syslog` table. In this example, the transformation filters the data for records with `error` in the message. --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "resources" : [ - { - "type": "Microsoft.Insights/dataCollectionRules", - "name": "singleDestinationDCR", - "apiVersion": "2021-09-01-preview", - "location": "eastus", - "properties": { - "dataSources": { - "syslog": [ - { - "name": "sysLogsDataSource", - "streams": [ - "Microsoft-Syslog" - ], - "facilityNames": [ - "auth", - "authpriv", - "cron", - "daemon", - "mark", - "kern", - "mail", - "news", - "syslog", - "user", - "uucp" - ], - "logLevels": [ - "Debug", - "Critical", - "Emergency" - ] - } - ] - }, - "destinations": { - "logAnalytics": [ - { - "workspaceResourceId": "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/my-resource-group/providers/Microsoft.OperationalInsights/workspaces/my-workspace", - "name": "centralWorkspace" - } - ] - }, - "dataFlows": [ - { - "streams": [ - "Microsoft-Syslog" - ], - "transformKql": "source | where message has 'error'", - "destinations": [ - "centralWorkspace" - ] - } - ] - } - } - ] -} -``` --### Multiple Azure tables --The following example is a DCR for data from the Logs Ingestion API that sends data to both the `Syslog` and `SecurityEvent` tables. This DCR requires a separate `dataFlow` for each with a different `transformKql` and `OutputStream` for each. In this example, all incoming data is sent to the `Syslog` table while malicious data is also sent to the `SecurityEvent` table. If you didn't want to replicate the malicious data in both tables, you could add a `where` statement to first query to remove those records. --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "resources" : [ - { - "type": "Microsoft.Insights/dataCollectionRules", - "name": "multiDestinationDCR", - "location": "eastus", - "apiVersion": "2021-09-01-preview", - "properties": { - "dataCollectionEndpointId": "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/my-resource-group/providers//Microsoft.Insights/dataCollectionEndpoints/my-dce", - "streamDeclarations": { - "Custom-MyTableRawData": { - "columns": [ - { - "name": "Time", - "type": "datetime" - }, - { - "name": "Computer", - "type": "string" - }, - { - "name": "AdditionalContext", - "type": "string" - } - ] - } - }, - "destinations": { - "logAnalytics": [ - { - "workspaceResourceId": "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/my-resource-group/providers/Microsoft.OperationalInsights/workspaces/my-workspace", - "name": "clv2ws1" - }, - ] - }, - "dataFlows": [ - { - "streams": [ - "Custom-MyTableRawData" - ], - "destinations": [ - "clv2ws1" - ], - "transformKql": "source | project TimeGenerated = Time, Computer, Message = AdditionalContext", - "outputStream": "Microsoft-Syslog" - }, - { - "streams": [ - "Custom-MyTableRawData" - ], - "destinations": [ - "clv2ws1" - ], - "transformKql": "source | where (AdditionalContext has 'malicious traffic!' | project TimeGenerated = Time, Computer, Subject = AdditionalContext", - "outputStream": "Microsoft-SecurityEvent" - } - ] - } - } - ] -} -``` --### Combination of Azure and custom tables --The following example is a DCR for data from the Logs Ingestion API that sends data to both the `Syslog` table and a custom table with the data in a different format. This DCR requires a separate `dataFlow` for each with a different `transformKql` and `OutputStream` for each. When using custom tables, it is important to ensure that the schema of the destination (your custom table) contains the custom columns ([how-to add or delete custom columns](../logs/create-custom-table.md#add-or-delete-a-custom-column)) that match the schema of the records you are sending. For instance, if your record has a field called SyslogMessage, but the destination custom table only has TimeGenerated and RawData, youΓÇÖll receive an event in the custom table with only the TimeGenerated field populated and the RawData field will be empty. The SyslogMessage field will be dropped because the schema of the destination table doesnΓÇÖt contain a string field called SyslogMessage. --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "resources" : [ - { - "type": "Microsoft.Insights/dataCollectionRules", - "name": "multiDestinationDCR", - "location": "eastus", - "apiVersion": "2021-09-01-preview", - "properties": { - "dataCollectionEndpointId": "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/my-resource-group/providers//Microsoft.Insights/dataCollectionEndpoints/my-dce", - "streamDeclarations": { - "Custom-MyTableRawData": { - "columns": [ - { - "name": "Time", - "type": "datetime" - }, - { - "name": "Computer", - "type": "string" - }, - { - "name": "AdditionalContext", - "type": "string" - } - ] - } - }, - "destinations": { - "logAnalytics": [ - { - "workspaceResourceId": "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/my-resource-group/providers/Microsoft.OperationalInsights/workspaces/my-workspace", - "name": "clv2ws1" - }, - ] - }, - "dataFlows": [ - { - "streams": [ - "Custom-MyTableRawData" - ], - "destinations": [ - "clv2ws1" - ], - "transformKql": "source | project TimeGenerated = Time, Computer, SyslogMessage = AdditionalContext", - "outputStream": "Microsoft-Syslog" - }, - { - "streams": [ - "Custom-MyTableRawData" - ], - "destinations": [ - "clv2ws1" - ], - "transformKql": "source | extend jsonContext = parse_json(AdditionalContext) | project TimeGenerated = Time, Computer, AdditionalContext = jsonContext, ExtendedColumn=tostring(jsonContext.CounterName)", - "outputStream": "Custom-MyTable_CL" - } - ] - } - } - ] -} -``` --## Next steps --- [Read more about data collection rules (DCRs)](./data-collection-rule-overview.md).-- [Create a workspace transformation DCRs that applies to data not collected using a DCR](./data-collection-transformations-workspace.md).- |
| azure-monitor | Data Platform Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/data-platform-metrics.md | - Title: Metrics in Azure Monitor | Microsoft Docs -description: Learn about metrics in Azure Monitor, which are lightweight monitoring data capable of supporting near real-time scenarios. --- Previously updated : 03/10/2024----# Azure Monitor Metrics overview --Azure Monitor Metrics is a feature of Azure Monitor that collects numeric data from monitored resources into a time-series database. Metrics are numerical values that are collected at regular intervals and describe some aspect of a system at a particular time. --> [!NOTE] -> Azure Monitor Metrics is one half of the data platform that supports Azure Monitor. The other half is [Azure Monitor Logs](../logs/data-platform-logs.md), which collects and organizes log and performance data. You can analyze that data by using a rich query language. ---## Types of metrics -There are multiple types of metrics supported by Azure Monitor Metrics: --- Native metrics use tools in Azure Monitor for analysis and alerting.- - Platform metrics are collected from Azure resources. They require no configuration and have no cost. - - Custom metrics are collected from different sources that you configure including applications and agents running on virtual machines. -- Prometheus metrics are collected from Kubernetes clusters including Azure Kubernetes service (AKS) and use industry standard tools for analyzing and alerting such as PromQL and Grafana.---The differences between each of the metrics are summarized in the following table. --| Category | Native platform metrics | Native custom metrics | Prometheus metrics | -|:|:|:|:| -| Sources | Azure resources | Azure Monitor agent<br>Application insights<br>REST API | Azure Kubernetes service (AKS) cluster<br>Any Kubernetes cluster through remote-write | -| Configuration | None | Varies by source | Enable Azure Monitor managed service for Prometheus | -| Stored | Subscription | Subscription | [Azure Monitor workspace](azure-monitor-workspace-overview.md) | -| Cost | No | Yes | Yes (free during preview) | -| Aggregation | preaggregated | preaggregated | raw data | -| Analyze | [Metrics Explorer](metrics-charts.md) | [Metrics Explorer](metrics-charts.md) | PromQL<br>Grafana dashboards | -| Alert | [metrics alert rule](../alerts/tutorial-metric-alert.md) | [metrics alert rule](../alerts/tutorial-metric-alert.md) | [Prometheus alert rule](../essentials/prometheus-rule-groups.md) | -| Visualize | [Workbooks](../visualize/workbooks-overview.md)<br>[Azure dashboards](../app/tutorial-app-dashboards.md)<br>[Grafana](../visualize/grafana-plugin.md) | [Workbooks](../visualize/workbooks-overview.md)<br>[Azure dashboards](../app/tutorial-app-dashboards.md)<br>[Grafana](../visualize/grafana-plugin.md) | [Grafana](../../managed-grafan) | -| Retrieve | [Azure CLI](/cli/azure/monitor/metrics)<br>[Azure PowerShell cmdlets](/powershell/module/az.monitor)<br>[REST API](./rest-api-walkthrough.md) or client library<br>[.NET](/dotnet/api/overview/azure/Monitor.Query-readme)<br>[Go](https://pkg.go.dev/github.com/Azure/azure-sdk-for-go/sdk/monitor/query/azlogs)<br>[Java](/jav) | --## Data collection --Azure Monitor collects metrics from the following sources. After these metrics are collected in the Azure Monitor metric database, they can be evaluated together regardless of their source: --- **Azure resources**: Platform metrics are created by Azure resources and give you visibility into their health and performance. Each type of resource creates a [distinct set of metrics](./metrics-supported.md) without any configuration required. Platform metrics are collected from Azure resources at one-minute frequency unless specified otherwise in the metric's definition. -- **Applications**: Application Insights creates metrics for your monitored applications to help you detect performance issues and track trends in how your application is being used. Values include _Server response time_ and _Browser exceptions_.-- **Virtual machine agents**: Metrics are collected from the guest operating system of a virtual machine. You can enable guest OS metrics for Windows virtual machines by using the [Azure Monitor Agent](/azure/azure-monitor/agents/agents-overview). Azure Monitor Agent replaces the legacy agents - [Windows diagnostic extension](../agents/diagnostics-extension-overview.md) and the [InfluxData Telegraf agent](https://www.influxdata.com/time-series-platform/telegraf/) for Linux virtual machines.-- **Custom metrics**: You can define metrics in addition to the standard metrics that are automatically available. You can [define custom metrics in your application](../app/api-custom-events-metrics.md) that's monitored by Application Insights. You can also create custom metrics for an Azure service by using the [custom metrics API](./metrics-store-custom-rest-api.md).-- **Kubernetes clusters**: Kubernetes clusters typically send metric data to a local Prometheus server that you must maintain. [Azure Monitor managed service for Prometheus ](prometheus-metrics-overview.md) provides a managed service that collects metrics from Kubernetes clusters and store them in Azure Monitor Metrics.--> [!NOTE] -> Metrics collected from different sources and by different methods may be aggregated differently. For example, platform metrics are preaggregated and stored in a time-series database, while Prometheus metrics are stored as raw data.Resource metrics may also have a different latency than other metrics. This can lead to differences in metric values for a specific sample time. Over time when latency ceases to be an issue, and when analyzing the metrics at the same time granularity, these differences disappear. --## REST API --Azure Monitor provides REST APIs that allow you to get data in and out of Azure Monitor Metrics. -- **Custom metrics API** - [Custom metrics](./metrics-custom-overview.md) allow you to load your own metrics into the Azure Monitor Metrics database. Those metrics can then be used by the same analysis tools that process Azure Monitor platform metrics. -- **Azure Monitor Metrics REST API** - Allows you to access Azure Monitor platform metrics definitions and values. For more information, see [Azure Monitor REST API](/rest/api/monitor/metrics/list). For information on how to use the API, see the [Azure monitoring REST API walkthrough](./rest-api-walkthrough.md).-- **Azure Monitor Metrics Batch REST API** - [Azure Monitor Metrics Batch API](/rest/api/monitor/metrics-batch/) is a high-volume API designed for customers with large volume metrics queries. It's similar to the existing standard Azure Monitor Metrics REST API, but provides the capability to retrieve metric data for up to 50 resource IDs in the same subscription and region in a single batch API call. This improves query throughput and reduces the risk of throttling. --## Security --All communication between connected systems and the Azure Monitor service is encrypted using the TLS 1.2 (HTTPS) protocol. The Microsoft SDL process is followed to ensure all Azure services are up-to-date with the most recent advances in cryptographic protocols. --Secure connection is established between the agent and the Azure Monitor service using certificate-based authentication and TLS with port 443. Azure Monitor uses a secret store to generate and maintain keys. Private keys are rotated every 90 days and are stored in Azure and are managed by the Azure operations who follow strict regulatory and compliance practices. For more information on security, see [Encryption of data in transit](../../security/fundamentals/encryption-overview.md#encryption-of-data-in-transit), [Encryption of data at rest](../../security/fundamentals/encryption-atrest.md), and [Azure Monitor Logs data security](../logs/data-security.md) --## Metrics Explorer --Use [Metrics Explorer](metrics-charts.md) to interactively analyze the data in your metric database and chart the values of multiple metrics over time. You can pin the charts to a dashboard to view them with other visualizations. You can also retrieve metrics by using the [Azure monitoring REST API](./rest-api-walkthrough.md). -<!-- convertborder later --> --For more information, see [Analyze metrics with Azure Monitor metrics explorer](./analyze-metrics.md). --## Data structure --Data that Azure Monitor Metrics collects, is stored in a time-series database that's optimized for analyzing time-stamped data. Each set of metric values is a time series with the following properties: --* The time when the value was collected. -* The resource that the value is associated with. -* A namespace that acts like a category for the metric. -* A metric name. -* The value itself. -* [Multiple dimensions](#multi-dimensional-metrics) when they're present. Custom metrics are limited to 10 dimensions. --## Multi-dimensional metrics -One of the challenges to metric data is that it often has limited information to provide context for collected values. Azure Monitor addresses this challenge with multi-dimensional metrics. --Metric dimensions are name/value pairs that carry more data to describe the metric value. For example, a metric called _Available disk space_ might have a dimension called _Drive_ with values _C:_ and _D:_. That dimension would allow viewing available disk space across all drives or for each drive individually. --See [Apply dimension filters and splitting](analyze-metrics.md?#use-dimension-filters-and-splitting) for details on viewing metric dimensions in metrics explorer. --### Nondimensional metric -The following table shows sample data from a nondimensional metric, network throughput. It can only answer a basic question like "What was my network throughput at a given time?" --| Timestamp | Metric value | -| - |:-| -| 8/9/2017 8:14 | 1,331.8 Kbps | -| 8/9/2017 8:15 | 1,141.4 Kbps | -| 8/9/2017 8:16 | 1,110.2 Kbps | ----### Network throughput and two dimensions ("IP" and "Direction") -The following table shows sample data from a multidimensional metric, network throughput with two dimensions called *IP* and *Direction*. It can answer questions such as "What was the network throughput for each IP address?" and "How much data was sent versus received?" --| Timestamp | Dimension "IP" | Dimension "Direction" | Metric value| -| - |:--|:- |:--| -| 8/9/2017 8:14 | IP="192.168.5.2" | Direction="Send" | 646.5 Kbps | -| 8/9/2017 8:14 | IP="192.168.5.2" | Direction="Receive" | 420.1 Kbps | -| 8/9/2017 8:14 | IP="10.24.2.15" | Direction="Send" | 150.0 Kbps | -| 8/9/2017 8:14 | IP="10.24.2.15" | Direction="Receive" | 115.2 Kbps | -| 8/9/2017 8:15 | IP="192.168.5.2" | Direction="Send" | 515.2 Kbps | -| 8/9/2017 8:15 | IP="192.168.5.2" | Direction="Receive" | 371.1 Kbps | -| 8/9/2017 8:15 | IP="10.24.2.15" | Direction="Send" | 155.0 Kbps | -| 8/9/2017 8:15 | IP="10.24.2.15" | Direction="Receive" | 100.1 Kbps | --> [!NOTE] -> Dimension names and dimension values are case-insenstive. ---## Retention of metrics --### Platform and custom metrics -Platform and custom metrics are stored for **93 days** with the following exceptions: --- **Classic guest OS metrics**: These performance counters are collected by the [Windows diagnostic extension](../agents/diagnostics-extension-overview.md) or the [Linux diagnostic extension](/azure/virtual-machines/extensions/diagnostics-linux) and routed to an Azure Storage account. Retention for these metrics is guaranteed to be at least 14 days, although no expiration date is written to the storage account.- - For performance reasons, the portal limits how much data it displays based on volume. So, the actual number of days that the portal retrieves can be longer than 14 days if the volume of data being written isn't large. --- **Guest OS metrics sent to Azure Monitor Metrics**: These performance counters are collected by the [Windows diagnostic extension](../agents/diagnostics-extension-overview.md) and sent to the [Azure Monitor data sink](../agents/diagnostics-extension-overview.md#data-destinations), or the [InfluxData Telegraf agent](https://www.influxdata.com/time-series-platform/telegraf/) on Linux machines, or the newer [Azure Monitor agent](../agents/azure-monitor-agent-overview.md) via data-collection rules. Retention for these metrics is 93 days.--- **Guest OS metrics collected by the Log Analytics agent**: These performance counters are collected by the Log Analytics agent and sent to a Log Analytics workspace. Retention for these metrics is 31 days and can be extended up to 2 years.--- **Application Insights log-based metrics**: Behind the scenes, [log-based metrics](../app/pre-aggregated-metrics-log-metrics.md) translate into log queries. Their retention is variable and matches the retention of events in underlying logs, which is 31 days to 2 years. For Application Insights resources, logs are stored for 90 days.--> [!NOTE] -> You can [send platform metrics for Azure Monitor resources to a Log Analytics workspace](./resource-logs.md#send-to-log-analytics-workspace) for long-term trending. --While platform and custom metrics are stored for 93 days, you can only query (in the **Metrics** tile) for a maximum of 30 days' worth of data on any single chart. This limitation doesn't apply to log-based metrics. If you see a blank chart or your chart displays only part of metric data, verify that the difference between start and end dates in the time picker doesn't exceed the 30-day interval. After you've selected a 30-day interval, you can [pan](./metrics-charts.md#pan) the chart to view the full retention window. --> [!NOTE] -> Moving or renaming an Azure Resource may result in a lost of metric history for that resource. --### Prometheus metrics -Prometheus metrics are stored for **18 months**, but a PromQL query can only span a maximum of 32 days. --## Next steps --- Learn more about the [Azure Monitor data platform](../data-platform.md).-- Learn about [log data in Azure Monitor](../logs/data-platform-logs.md).-- Learn about the [monitoring data available](../data-sources.md) for various resources in Azure. |
| azure-monitor | Diagnostic Settings Policy | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/diagnostic-settings-policy.md | - Title: Create diagnostic settings at scale using Azure policies and initiatives -description: Use Azure Policy to create diagnostic settings in Azure Monitor at scale as each Azure resource is created. ---- Previously updated : 05/30/2024-----# Create diagnostic settings at scale using Azure Policies and Initiatives --In order to monitor Azure resources, it's necessary to create [diagnostic settings](./diagnostic-settings.md) for each resource. This process can be difficult to manage when you have many resources. To simplify the process of creating and applying diagnostic settings at scale, use Azure Policy to automatically generate diagnostic settings for both new and existing resources. --Each Azure resource type has a unique set of categories listed in the diagnostic settings. Each resource type therefore requires a separate policy definition. Some resource types have built-in policy definitions that you can assign without modification. For other resource types, you can create a custom definition. --## Log category groups --Log category groups, group together similar types of logs. Category groups make it easy to refer to multiple logs in a single command. An **allLogs** category group exists containing all of the logs. There's also an **audit** category group that includes all audit logs. By using to a category group, you can define a policy that dynamically updates as new log categories are added to group. --## Built-in policy definitions for Azure Monitor -There are generally three built-in policy definitions for each resource type, corresponding to the three destinations to send diagnostics to: -* Log Analytics workspaces -* Azure Storage accounts -* Event hubs --Assign the policies for the resource type according to which destinations you need. --A set of policies built-in policies and initiatives based on the audit log category groups have been developed to help you apply diagnostics settings with only a few steps. For more information, see [Enable Diagnostics settings by category group using built-in policies.](./diagnostics-settings-policies-deployifnotexists.md) --For a complete list of built-in policies for Azure Monitor, see [Azure Policy built-in definitions for Azure Monitor](../policy-reference.md) --## Custom policy definitions -For resource types that don't have a built-in policy, you need to create a custom policy definition. You could do create a new policy manually in the Azure portal by copying an existing built-in policy and then modifying it for your resource type. Alternatively, create the policy programmatically by using a script in the PowerShell Gallery. --The script [Create-AzDiagPolicy](https://www.powershellgallery.com/packages/Create-AzDiagPolicy) creates policy files for a particular resource type that you can install by using PowerShell or the Azure CLI. Use the following procedure to create a custom policy definition for diagnostic settings: --1. Ensure that you have [Azure PowerShell](/powershell/azure/install-azure-powershell) installed. -2. Install the script by using the following command: - - ```azurepowershell - Install-Script -Name Create-AzDiagPolicy - ``` --3. Run the script by using the parameters to specify where to send the logs. You'll be prompted to specify a subscription and resource type. -- For example, to create a policy definition that sends logs to a Log Analytics workspace and an event hub, use the following command: -- ```azurepowershell - Create-AzDiagPolicy.ps1 -ExportLA -ExportEH -ExportDir ".\PolicyFiles" - ``` -- Alternatively, you can specify a subscription and resource type in the command. For example, to create a policy definition that sends logs to a Log Analytics workspace and an event hub for SQL Server databases, use the following command: -- ```azurepowershell - Create-AzDiagPolicy.ps1 -SubscriptionID xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx -ResourceType Microsoft.Sql/servers/databases -ExportLA -ExportEH -ExportDir ".\PolicyFiles" - ``` --5. The script creates separate folders for each policy definition. Each folder contains three files named *azurepolicy.json*, *azurepolicy.rules.json*, and *azurepolicy.parameters.json*. If you want to create the policy manually in the Azure portal, you can copy and paste the contents of *azurepolicy.json* because it includes the entire policy definition. Use the other two files with PowerShell or the Azure CLI to create the policy definition from a command line. -- The following examples show how to install the policy definition from both PowerShell and the Azure CLI. Each example includes metadata to specify a category of **Monitoring** to group the new policy definition with the built-in policy definitions. -- ```azurepowershell - New-AzPolicyDefinition -name "Deploy Diagnostic Settings for SQL Server database to Log Analytics workspace" -policy .\Apply-Diag-Settings-LA-Microsoft.Sql-servers-databases\azurepolicy.rules.json -parameter .\Apply-Diag-Settings-LA-Microsoft.Sql-servers-databases\azurepolicy.parameters.json -mode All -Metadata '{"category":"Monitoring"}' - ``` -- ```azurecli - az policy definition create --name 'deploy-diag-setting-sql-database--workspace' --display-name 'Deploy Diagnostic Settings for SQL Server database to Log Analytics workspace' --rules 'Apply-Diag-Settings-LA-Microsoft.Sql-servers-databases\azurepolicy.rules.json' --params 'Apply-Diag-Settings-LA-Microsoft.Sql-servers-databases\azurepolicy.parameters.json' --subscription 'AzureMonitor_Docs' --mode All - ``` --## Initiative -Rather than create an assignment for each policy definition, a common strategy is to create an initiative that includes the policy definitions to create diagnostic settings for each Azure service. Create an assignment between the initiative and a management group, subscription, or resource group, depending on how you manage your environment. This strategy offers the following benefits: --- Create a single assignment for the initiative instead of multiple assignments for each resource type. Use the same initiative for multiple monitoring groups, subscriptions, or resource groups.-- Modify the initiative when you need to add a new resource type or destination. For example, your initial requirements might be to send data only to a Log Analytics workspace, but later you want to add an event hub. Modify the initiative instead of creating new assignments.--For details on creating an initiative, see [Create and assign an initiative definition](../../governance/policy/tutorials/create-and-manage.md#create-and-assign-an-initiative-definition). Consider the following recommendations: --- Set **Category** to **Monitoring** to group it with related built-in and custom policy definitions.-- Instead of specifying the details for the Log Analytics workspace and the event hub for policy definitions included in the initiative, use a common initiative parameter. This parameter allows you to easily specify a common value for all policy definitions and change that value if necessary.-<!-- convertborder later --> --## Assignment -Assign the initiative to an Azure management group, subscription, or resource group, depending on the scope of your resources to monitor. A [management group](../../governance/management-groups/overview.md) is useful for scoping policy, especially if your organization has multiple subscriptions. -<!-- convertborder later --> --By using initiative parameters, you can specify the workspace or any other details once for all of the policy definitions in the initiative. -<!-- convertborder later --> --## Remediation -The initiative will be applied to each virtual machine as it's created. A [remediation task](../../governance/policy/how-to/remediate-resources.md) deploys the policy definitions in the initiative to existing resources, so you can create diagnostic settings for any resources that were already created. --When you create the assignment by using the Azure portal, you have the option of creating a remediation task at the same time. See [Remediate non-compliant resources with Azure Policy](../../governance/policy/how-to/remediate-resources.md) for details on the remediation. -<!-- convertborder later --> --## Troubleshooting --### Metric category is not supported --When deploying a diagnostic setting, you receive an error message, similar to *Metric category 'xxxx' is not supported*. You may receive this error even though your previous deployment succeeded. --The problem occurs when using a Resource Manager template, REST API, Azure CLI, or Azure PowerShell. Diagnostic settings created via the Azure portal aren't affected as only the supported category names are presented. --The problem is caused by a recent change in the underlying API. Metric categories other than 'AllMetrics' aren't supported and never were except for a few specific Azure services. In the past, other category names were ignored when deploying a diagnostic setting. The Azure Monitor backend redirected these categories to 'AllMetrics'. As of February 2021, the backend was updated to specifically confirm the metric category provided is accurate. This change has caused some deployments to fail. --If you receive this error, update your deployments to replace any metric category names with 'AllMetrics' to fix the issue. If the deployment was previously adding multiple categories, only one with the 'AllMetrics' reference should be kept. If you continue to have the problem, contact Azure support through the Azure portal. --### Setting disappears due to non-ASCII characters in resourceID --Diagnostic settings don't support resourceIDs with non-ASCII characters (for example, Preproducci├│n). Since you can't rename resources in Azure, your only option is to create a new resource without the non-ASCII characters. If the characters are in a resource group, you can move the resources under it to a new one. Otherwise, you'll need to recreate the resource. --## Next steps --- [Read more about Azure platform Logs](./platform-logs-overview.md)-- [Read more about diagnostic settings](./diagnostic-settings.md) |
| azure-monitor | Diagnostic Settings | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/diagnostic-settings.md | - Title: Diagnostic settings in Azure Monitor -description: Learn about working with diagnostic settings for Azure Monitor platform metrics and logs. ----- Previously updated : 06/13/2024----# Diagnostic settings in Azure Monitor --This article provides details on creating and configuring diagnostic settings to send Azure platform metrics, resource logs, and the activity log to different destinations. --Each Azure resource requires its own diagnostic setting, which defines the following criteria: --- **Sources**: The type of metric and log data to send to the destinations defined in the setting. The available types vary by resource type.-- **Destinations**: One or more destinations to send to.--A single diagnostic setting can define no more than one of each of the destinations. If you want to send data to more than one of a particular destination type (for example, two different Log Analytics workspaces), create multiple settings. Each resource can have up to five diagnostic settings. --> [!WARNING] -> If you need to delete a resource, rename, or move a resource, or migrate it across resource groups or subscriptions, first delete its diagnostic settings. Otherwise, if you recreate this resource, the diagnostic settings for the deleted resource could be included with the new resource, depending on the resource configuration for each resource. If the diagnostics settings are included with the new resource, this resumes the collection of resource logs as defined in the diagnostic setting and sends the applicable metric and log data to the previously configured destination. -> -> Also, it's a good practice to delete the diagnostic settings for a resource you're going to delete and don't plan on using again to keep your environment clean. --The following video walks you through routing resource platform logs with diagnostic settings. The video was done at an earlier time. Be aware of the following changes: --- There are now four destinations. You can send platform metrics and logs to certain Azure Monitor partners.-- A new feature called category groups was introduced in November 2021.--Information on these newer features is included in this article. --> [!VIDEO https://www.microsoft.com/en-us/videoplayer/embed/RE4AvVO] --## Sources --There are three sources for diagnostic information: --- Platform metrics are sent automatically to [Azure Monitor Metrics](./data-platform-metrics.md) by default and without configuration. For more information on supported metrics, see [Supported metrics with Azure Monitor](./metrics-supported.md)-- Platform logs provide detailed diagnostic and auditing information for Azure resources and the Azure platform they depend on.- - **Resource logs** aren't collected until they're routed to a destination. For more information on supported logs, see [Supported Resource log categories for Azure Monitor](/azure/azure-monitor/reference/supported-logs/logs-index) - - The **Activity log** provides information about resources from outside the resource, such as when the resource was created or deleted. Entries exist on their own but can be routed to other locations. --### Metrics --The **AllMetrics** setting routes a resource's platform metrics to other destinations. This option might not be present for all resource providers. --### Resource logs --With resource logs, you can select the log categories you want to route individually or choose a category group. --**Category groups** -> [!NOTE] -> Category groups don't apply to all metric resource providers. If a provider doesn't have them available in the diagnostic settings in the Azure portal, then they also won't be available via Azure Resource Manager templates. --You can use *category groups* to dynamically collect resource logs based on predefined groupings instead of selecting individual log categories. Microsoft defines the groupings to help monitor specific use cases across all Azure services. Over time, the categories in the group might be updated as new logs are rolled out or as assessments change. When log categories are added or removed from a category group, your log collection is modified automatically without you having to update your diagnostic settings. --When you use category groups, you: --- No longer can individually select resource logs based on individual category types.-- No longer can apply retention settings to logs sent to Azure Storage.--Currently, there are two category groups: --- **All**: Every resource log offered by the resource.-- **Audit**: All resource logs that record customer interactions with data or the settings of the service. Audit logs are an attempt by each resource provider to provide the most relevant audit data, but might not be considered sufficient from an auditing standards perspective depending on your use case. As mentioned above, what's collected is dynamic, and Microsoft may change it over time as new resource log categories become available.--The "Audit" category group is a subset of the "All" category group, but the Azure portal and REST API consider them separate settings. Selecting the "All" category group does collect all audit logs even if the "Audit" category group is also selected. --The following image shows the logs category groups on the **Add diagnostics settings** page. ---> [!NOTE] -> Enabling *Audit* for Azure SQL Database does not enable auditing for Azure SQL Database. To enable database auditing, you have to enable it from the auditing blade for Azure Database. --### Activity log --See the [Activity log settings](#activity-log-settings) section. --## Destinations --Platform logs and metrics can be sent to the destinations listed in the following table. - -To ensure the security of data in transit, all destination endpoints are configured to support TLS 1.2. --| Destination | Description | -|:|:| -| [Log Analytics workspace](../logs/workspace-design.md) | Metrics are converted to log form. This option might not be available for all resource types. Sending them to the Azure Monitor Logs store (which is searchable via Log Analytics) helps you to integrate them into queries, alerts, and visualizations with existing log data. -| [Azure Storage account](../../storage/blobs/index.yml) | Archiving logs and metrics to a Storage account is useful for audit, static analysis, or back up. Compared to using Azure Monitor Logs or a Log Analytics workspace, Storage is less expensive, and logs can be kept there indefinitely. | -| [Azure Event Hubs](../../event-hubs/index.yml) | When you send logs and metrics to Event Hubs, you can stream data to external systems such as third-party SIEMs and other Log Analytics solutions. | -| [Azure Monitor partner solutions](../../partner-solutions/overview.md)| Specialized integrations can be made between Azure Monitor and other non-Microsoft monitoring platforms. Integration is useful when you're already using one of the partners. | --## Activity log settings --The activity log uses a diagnostic setting but has its own user interface because it applies to the whole subscription rather than individual resources. The destination information listed here still applies. For more information, see [Azure activity log](activity-log.md). ---## Requirements and limitations --This section discusses requirements and limitations. --### Time before telemetry gets to destination --After you set up a diagnostic setting, data should start flowing to your selected destination(s) within 90 minutes. When sending logs to a Log Analytics workspace, the table is created automatically if it doesn't already exist. The table is only created when the first log records are received. If you get no information within 24 hours, then you might be experiencing one of the following issues: --- No logs are being generated.-- Something is wrong in the underlying routing mechanism.--If you're experiencing an issue, you can try disabling the configuration and then reenabling it. Contact Azure support through the Azure portal if you continue to have issues. --### Metrics as a source --There are certain limitations with exporting metrics: --- **Sending multi-dimensional metrics via diagnostic settings isn't currently supported**. Metrics with dimensions are exported as flattened single-dimensional metrics, aggregated across dimension values. For example, the **IOReadBytes** metric on a blockchain can be explored and charted on a per-node level. However, when exported via diagnostic settings, the metric exported shows all read bytes for all nodes.-- **Not all metrics are exportable with diagnostic settings**. Because of internal limitations, not all metrics are exportable to Azure Monitor Logs or Log Analytics. For more information, see the **Exportable** column in the [list of supported metrics](./metrics-supported.md).--To get around these limitations for specific metrics, you can manually extract them by using the [Metrics REST API](/rest/api/monitor/metrics/list). Then you can import them into Azure Monitor Logs by using the [Azure Monitor Data Collector API](../logs/data-collector-api.md). --### Destination limitations --Any destinations for the diagnostic setting must be created before you create the diagnostic settings. The destination doesn't have to be in the same subscription as the resource sending logs if the user who configures the setting has appropriate Azure role-based access control access to both subscriptions. By using Azure Lighthouse, it's also possible to have diagnostic settings sent to a workspace, storage account, or event hub in another Microsoft Entra tenant. --The following table provides unique requirements for each destination including any regional restrictions. --| Destination | Requirements | -|:|:| -| Log Analytics workspace | The workspace doesn't need to be in the same region as the resource being monitored.| -| Storage account | Don't use an existing storage account that has other, nonmonitoring data stored in it. Splitting the types of data up allow you better control access to the data. If you're archiving the activity log and resource logs together, you might choose to use the same storage account to keep all monitoring data in a central location.<br><br>To prevent modification of the data, send it to immutable storage. Set the immutable policy for the storage account as described in [Set and manage immutability policies for Azure Blob Storage](../../storage/blobs/immutable-policy-configure-version-scope.md). You must follow all steps in this linked article including enabling protected append blobs writes.<br><br>The storage account needs to be in the same region as the resource being monitored if the resource is regional.<br><br> Diagnostic settings can't access storage accounts when virtual networks are enabled. You must enable **Allow trusted Microsoft services** to bypass this firewall setting in storage accounts so that the Azure Monitor diagnostic settings service is granted access to your storage account.<br><br>[Azure DNS zone endpoints (preview)](../../storage/common/storage-account-overview.md#azure-dns-zone-endpoints-preview) and [Azure Premium LRS](../../storage/common/storage-redundancy.md#locally-redundant-storage) (locally redundant storage) storage accounts aren't supported as a log or metric destination.| -| Event Hubs | The shared access policy for the namespace defines the permissions that the streaming mechanism has. Streaming to Event Hubs requires Manage, Send, and Listen permissions. To update the diagnostic setting to include streaming, you must have the ListKey permission on that Event Hubs authorization rule.<br><br>The event hub namespace needs to be in the same region as the resource being monitored if the resource is regional. <br><br> Diagnostic settings can't access Event Hubs resources when virtual networks are enabled. You must enable **Allow trusted Microsoft services** to bypass this firewall setting in Event Hubs so that the Azure Monitor diagnostic settings service is granted access to your Event Hubs resources.| -| Partner solutions | The solutions vary by partner. Check the [Azure Native ISV Services documentation](../../partner-solutions/overview.md) for details.| --### Diagnostic logs for Application Insights --If you want to store diagnostic logs for Application Insights in a Log Analytics workspace, don't send the logs to the same workspace that the Application Insights resource is based on. This configuration can cause duplicate telemetry to be displayed because Application Insights is already storing this data. Send your Application Insights logs to a different Log Analytics workspace. --When sending Application Insights logs to a different workspace, be aware that Application Insights accesses telemetry across Application Insight resources, including multiple Log Analytics workspaces. Restrict the Application Insights user's access to only the Log Analytics workspace linked with the Application Insights resource. Set the access control mode to **Requires workspace permissions** and manage permissions through Azure role-based access control to ensure that Application Insights only has access to the Log Analytics workspace that the Application Insights resource is based on. -- --## Controlling costs --There's a cost for collecting data in a Log Analytics workspace, so only collect the categories you require for each service. The data volume for resource logs varies significantly between services. --You might also not want to collect platform metrics from Azure resources because this data is already being collected in Metrics. Only configure your diagnostic data to collect metrics if you need metric data in the workspace for more complex analysis with log queries. Diagnostic settings don't allow granular filtering of resource logs. ---## Next steps --- [Create diagnostic settings for Azure Monitor platform metrics and logs](./create-diagnostic-settings.md)-- [Migrate diagnostic settings storage retention to Azure Storage lifecycle management](./migrate-to-azure-storage-lifecycle-policy.md)-- [Read more about Azure platform logs](./platform-logs-overview.md) |
| azure-monitor | Diagnostics Settings Policies Deployifnotexists | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/diagnostics-settings-policies-deployifnotexists.md | - Title: Enable diagnostics settings by category group using built-in policies. -description: Use Azure builtin policies to create diagnostic settings in Azure Monitor. ----- Previously updated : 02/25/2024-- --# Built-in policies for Azure Monitor -Policies and policy initiatives provide a simple method to enable logging at-scale via diagnostics settings for Azure Monitor. Using a policy initiative, you can turn on audit logging for all [supported resources](#supported-resources) in your Azure environment. --Enable resource logs to track activities and events that take place on your resources and give you visibility and insights into any changes that occur. -Assign policies to enable resource logs and to send them to destinations according to your needs. Send logs to event hubs for third-party SIEM systems, enabling continuous security operations. Send logs to storage accounts for longer term storage or the fulfillment of regulatory compliance. --A set of built-in policies and initiatives exists to direct resource logs to Log Analytics Workspaces, Event Hubs, and Storage Accounts. The policies enable audit logging, sending logs belonging to the **audit** or the **All logs** log category group, to an event hub, Log Analytics workspace or Storage Account. The policies' `effect` is `DeployIfNotExists`, which deploys the policy as a default if there aren't other settings defined. ---## Deploy policies. -Deploy the policies and initiatives using the Portal, CLI, PowerShell, or Azure Resource Management templates -### [Azure portal](#tab/portal) --The following steps show how to apply the policy to send audit logs to for key vaults to a log analytics workspace. --1. From the Policy page, select **Definitions**. --1. Select your scope. You can apply a policy to the entire subscription, a resource group, or an individual resource. -1. From the **Definition type** dropdown, select **Policy**. -1. Select **Monitoring** from the Category dropdown -1. Enter *keyvault* in the **Search** field. -1. Select the **Enable logging by category group for Key vaults (microsoft.keyvault/vaults) to Log Analytics** policy, - :::image type="content" source="./media/diagnostics-settings-policies-deployifnotexists/policy-definitions.png" lightbox="./media/diagnostics-settings-policies-deployifnotexists/policy-definitions.png" alt-text="A screenshot of the policy definitions page."::: -1. From the policy definition page, select **Assign** -1. Select the **Parameters** tab. -1. Select the Log Analytics Workspace that you want to send the audit logs to. -1. Select the **Remediation** tab. - :::image type="content" source="./media/diagnostics-settings-policies-deployifnotexists/assign-policy-parameters.png" lightbox="./media/diagnostics-settings-policies-deployifnotexists/assign-policy-parameters.png" alt-text="A screenshot of the assign policy page, parameters tab."::: -1. On the remediation tab, select the keyvault policy from the **Policy to remediate** dropdown. -1. Select the **Create a Managed Identity** checkbox. -1. Under **Type of Managed Identity**, select **System assigned Managed Identity**. -1. Select **Review + create**, then select **Create** . - :::image type="content" source="./media/diagnostics-settings-policies-deployifnotexists/assign-policy-remediation.png" lightbox="./media/diagnostics-settings-policies-deployifnotexists/assign-policy-remediation.png" alt-text="A screenshot of the assign policy page, remediation tab."::: ---### [CLI](#tab/cli) -To apply a policy using the CLI, use the following commands: --1. Create a policy assignment using [`az policy assignment create`](/cli/azure/policy/assignment#az-policy-assignment-create). - ```azurecli - az policy assignment create --name <policy assignment name> --policy "6b359d8f-f88d-4052-aa7c-32015963ecc1" --scope <scope> --params "{\"logAnalytics\": {\"value\": \"<log analytics workspace resource ID"}}" --mi-system-assigned --location <location> - ``` - For example, to apply the policy to send audit logs to a log analytics workspace -- ```azurecli - az policy assignment create --name "policy-assignment-1" --policy "6b359d8f-f88d-4052-aa7c-32015963ecc1" --scope /subscriptions/12345678-aaaa-bbbb-cccc-1234567890ab/resourceGroups/rg-001 --params "{\"logAnalytics\": {\"value\": \"/subscriptions/12345678-aaaa-bbbb-cccc-1234567890ab/resourcegroups/rg-001/providers/microsoft.operationalinsights/workspaces/workspace-001\"}}" --mi-system-assigned --location eastus - ``` --1. Assign the required role to the identity created for the policy assignment. -Find the role in the policy definition by searching for *roleDefinitionIds* -- ```json - ...}, - "roleDefinitionIds": [ - "/providers/Microsoft.Authorization/roleDefinitions/92aaf0da-9dab-42b6-94a3-d43ce8d16293" - ], - "deployment": { - "properties": {... - ``` - Assign the required role using [`az policy assignment identity assign`](/cli/azure/policy/assignment/identity): - ```azurecli - az policy assignment identity assign --system-assigned --resource-group <resource group name> --role <role name or ID> --identity-scope </scope> --name <policy assignment name> - ``` - For example: - ```azurecli - az policy assignment identity assign --system-assigned --resource-group rg-001 --role 92aaf0da-9dab-42b6-94a3-d43ce8d16293 --identity-scope /subscriptions/12345678-aaaa-bbbb-cccc-1234567890ab/resourceGroups/rg001 --name policy-assignment-1 - ``` --1. Trigger a scan to find existing resources using [`az policy state trigger-scan`](/cli/azure/policy/state#az-policy-state-trigger-scan). -- ```azurecli - az policy state trigger-scan --resource-group rg-001 - ``` --1. Create a remediation task to apply the policy to existing resources using [`az policy remediation create`](/cli/azure/policy/remediation#az-policy-remediation-create). -- ```azurecli - az policy remediation create -g <resource group name> --policy-assignment <policy assignment name> --name <remediation name> - ``` -- For example, - ```azurecli - az policy remediation create -g rg-001 -n remediation-001 --policy-assignment policy-assignment-1 - ``` --For more information on policy assignment using CLI, see [Azure CLI reference - az policy assignment](/cli/azure/policy/assignment#az-policy-assignment-create) --### [PowerShell](#tab/Powershell) --To apply a policy using the PowerShell, use the following commands: --1. Set up your environment. - Select your subscription and set your resource group - ```azurepowershell - Select-AzSubscription <subscriptionID> - $rg = Get-AzResourceGroup -Name <resource groups name> - ``` --1. Get the policy definition and configure the parameters for the policy. In the example below we assign the policy to send keyVault logs to a Log Analytics workspace - ```azurepowershell - $definition = Get-AzPolicyDefinition |Where-Object Name -eq 6b359d8f-f88d-4052-aa7c-32015963ecc1 - $params = @{"logAnalytics"="/subscriptions/<subscriptionID/resourcegroups/<resourcgroup>/providers/microsoft.operationalinsights/workspaces/<log anlaytics workspace name>"} - ``` --1. Assign the policy - ```azurepowershell - $policyAssignment=New-AzPolicyAssignment -Name <assignment name> -DisplayName "assignment display name" -Scope $rg.ResourceId -PolicyDefinition $definition -PolicyparameterObject $params -IdentityType 'SystemAssigned' -Location <location> - - #To get your assignemnt use: - $policyAssignment=Get-AzPolicyAssignment -Name '<assignment name>' -Scope '/subscriptions/<subscriptionID>/resourcegroups/<resource group name>' -- ``` --1. Assign the required role or roles to the system assigned Managed Identity - ```azurepowershell - $principalID=$policyAssignment.Identity.PrincipalId - $roleDefinitionIds=$definition.Properties.policyRule.then.details.roleDefinitionIds - $roleDefinitionIds | ForEach-Object { - $roleDefId = $_.Split("/") | Select-Object -Last 1 - New-AzRoleAssignment -Scope $rg.ResourceId -ObjectId $policyAssignment.Identity.PrincipalId -RoleDefinitionId $roleDefId - } - ``` --1. Scan for compliance, then create a remediation task to force compliance for existing resources. - ```azurepowershell - Start-AzPolicyComplianceScan -ResourceGroupName $rg.ResourceGroupName - Start-AzPolicyRemediation -Name $policyAssignment.Name -PolicyAssignmentId $policyAssignment.PolicyAssignmentId -ResourceGroupName $rg.ResourceGroupName - ``` --1. Check compliance - ```azurepowershell - Get-AzPolicyState -PolicyAssignmentName $policyAssignment.Name -ResourceGroupName $policyAssignment.ResourceGroupName|select-object IsCompliant, ResourceID - ``` ---The policy is visible in the resources' diagnostic settings after approximately 30 minutes. --## Remediation tasks --Policies are applied to new resources when they're created. To apply a policy to existing resources, create a remediation task. Remediation tasks bring resources into compliance with a policy. --Remediation tasks act for specific policies. For initiatives that contain multiple policies, create a remediation task for each policy in the initiative where you have resources that you want to bring into compliance. -- Define remediation tasks when you first assign the policy, or at any stage after assignment. --To create a remediation task for policies during the policy assignment, select the **Remediation** tab on **Assign policy** page and select the **Create remediation task** checkbox. --To create a remediation task after the policy has been assigned, select your assigned policy from the list on the Policy Assignments page. - --Select **Remediate**. -Track the status of your remediation task in the **Remediation tasks** tab of the Policy Remediation page. ------For more information on remediation tasks, see [Remediate noncompliant resources](../../governance/policy/how-to/remediate-resources.md) --## Assign initiatives --Initiatives are collections of policies. There are two sets of initiatives for Azure Monitor Diagnostics settings: --1. Enable the *audit* category group resource logging - + [Enable audit category group resource logging for supported resources to Event Hubs](https://portal.azure.com/?feature.customportal=false&feature.canmodifystamps=true&Microsoft_Azure_Monitoring_Logs=stage1&Microsoft_OperationsManagementSuite_Workspace=stage1#view/Microsoft_Azure_Policy/InitiativeDetailBlade/id/%2Fproviders%2FMicrosoft.Authorization%2FpolicySetDefinitions%2F1020d527-2764-4230-92cc-7035e4fcf8a7/scopes~/%5B%22%2Fsubscriptions%2F12345678-aaaa-bbbb-cccc-1234567890ab%22%5D) - + [Enable audit category group resource logging for supported resources to Log Analytics](https://portal.azure.com/?feature.customportal=false&feature.canmodifystamps=true&Microsoft_Azure_Monitoring_Logs=stage1&Microsoft_OperationsManagementSuite_Workspace=stage1#view/Microsoft_Azure_Policy/InitiativeDetailBlade/id/%2Fproviders%2FMicrosoft.Authorization%2FpolicySetDefinitions%2Ff5b29bc4-feca-4cc6-a58a-772dd5e290a5/scopes~/%5B%22%2Fsubscriptions%2F12345678-aaaa-bbbb-cccc-1234567890ab%22%5D) - + [Enable audit category group resource logging for supported resources to storage](https://portal.azure.com/?feature.customportal=false&feature.canmodifystamps=true&Microsoft_Azure_Monitoring_Logs=stage1&Microsoft_OperationsManagementSuite_Workspace=stage1#view/Microsoft_Azure_Policy/InitiativeDetailBlade/id/%2Fproviders%2FMicrosoft.Authorization%2FpolicySetDefinitions%2F8d723fb6-6680-45be-9d37-b1a4adb52207/scopes~/%5B%22%2Fsubscriptions%2F12345678-aaaa-bbbb-cccc-1234567890ab%22%5D) --1. Enable the *allLogs* category group resource logging - + [Enable allLogs category group resource logging for supported resources to storage](https://portal.azure.com/#view/Microsoft_Azure_Policy/InitiativeDetail.ReactView/id/%2Fproviders%2FMicrosoft.Authorization%2FpolicySetDefinitions%2Fb6b86da9-e527-49de-ac59-6af0a9db10b8/version~/null/scopes~/) - + [Enable allLogs category group resource logging for supported resources to Event Hubs](https://portal.azure.com/#view/Microsoft_Azure_Policy/InitiativeDetail.ReactView/id/%2Fproviders%2FMicrosoft.Authorization%2FpolicySetDefinitions%2F85175a36-2f12-419a-96b4-18d5b0096531/version~/null/scopes/) - + [Enable allLogs category group resource logging for supported resources to Log Analytics](https://portal.azure.com/#view/Microsoft_Azure_Policy/InitiativeDetail.ReactView/id/%2Fproviders%2FMicrosoft.Authorization%2FpolicySetDefinitions%2F0884adba-2312-4468-abeb-5422caed1038/version~/null/scopes/%5B%22%2Fsubscriptions%2F""%22%22%5D) ---In this example, we assign an initiative for sending audit logs to a Log Analytics workspace. --### [Azure portal](#tab/portal) --1. From the policy **Definitions** page, select your scope. --1. Select *Initiative* in the **Definition type** dropdown. -1. Select *Monitoring* in the **Category** dropdown. -1. Enter *audit* in the **Search** field. -1. Select thee *Enable audit category group resource logging for supported resources to Log Analytics* initiative. -1. On the following page, select **Assign** --1. On the **Basics** tab of the **Assign initiative** page, select a **Scope** that you want the initiative to apply to. -1. Enter a name in the **Assignment name** field. -1. Select the **Parameters** tab. -- The **Parameters** contains the parameters defined in the policy. In this case, we need to select the Log Analytics workspace that we want to send the logs to. For more information in the individual parameters for each policy, see [Policy-specific parameters](#policy-specific-parameters). --1. Select the **Log Analytics workspace** to send your audit logs to. --1. Select **Review + create** then **Create** --To verify that your policy or initiative assignment is working, create a resource in the subscription or resource group scope that you defined in your policy assignment. --After 10 minutes, select the **Diagnostics settings** page for your resource. -Your diagnostic setting appears in the list with the default name *setByPolicy-LogAnalytics* and the workspace name that you configured in the policy. ---Change the default name in the **Parameters** tab of the **Assign initiative** or policy page by unselecting the **Only show parameters that need input or review** checkbox. ---### [PowerShell](#tab/Powershell) ---1. Set up your environment variables - ```azurepowershell - # Set up your environment variables. - $subscriptionId = <your subscription ID>; - $rg = Get-AzResourceGroup -Name <your resource group name>; - Select-AzSubscription $subscriptionId; - $logAnlayticsWorskspaceId=</subscriptions/$subscriptionId/resourcegroups/$rg.ResourceGroupName/providers/microsoft.operationalinsights/workspaces/<your log analytics workspace>; - ``` --1. Get the initiative definition. In this example, we'll use Initiative *Enable audit category group resource logging for supported resources to ` -Log Analytics*, ResourceID "/providers/Microsoft.Authorization/policySetDefinitions/f5b29bc4-feca-4cc6-a58a-772dd5e290a5" - ```azurepowershell - $definition = Get-AzPolicySetDefinition |Where-Object ResourceID -eq /providers/Microsoft.Authorization/policySetDefinitions/f5b29bc4-feca-4cc6-a58a-772dd5e290a5; - ``` --1. Set an assignment name and configure parameters. For this initiative, the parameters include the Log Analytics workspace ID. - ```azurepowershell - $assignmentName=<your assignment name>; - $params = @{"logAnalytics"="/subscriptions/$subscriptionId/resourcegroups/$($rg.ResourceGroupName)/providers/microsoft.operationalinsights/workspaces/<your log analytics workspace>"} - ``` --1. Assign the initiative using the parameters - ```azurepowershell - $policyAssignment=New-AzPolicyAssignment -Name $assignmentName -Scope $rg.ResourceId -PolicySetDefinition $definition -PolicyparameterObject $params -IdentityType 'SystemAssigned' -Location eastus; - ``` --1. Assign the `Contributor` role to the system assigned Managed Identity. For other initiatives, check which roles are required. - ```azurepowershell - New-AzRoleAssignment -Scope $rg.ResourceId -ObjectId $policyAssignment.Identity.PrincipalId -RoleDefinitionName Contributor; - ``` -1. Scan for policy compliance. The `Start-AzPolicyComplianceScan` command takes a few minutes to return - ```azurepowershell - Start-AzPolicyComplianceScan -ResourceGroupName $rg.ResourceGroupName; - ``` --1. Get a list of resources to remediate and the required parameters by calling `Get-AzPolicyState` - ```azurepowershell - $assignmentState=Get-AzPolicyState -PolicyAssignmentName $assignmentName -ResourceGroupName $rg.ResourceGroupName; - $policyAssignmentId=$assignmentState.PolicyAssignmentId[0]; - $policyDefinitionReferenceIds=$assignmentState.PolicyDefinitionReferenceId; - ``` --1. For each resource type with noncompliant resources, start a remediation task. - ```azurepowershell - $policyDefinitionReferenceIds | ForEach-Object { - $referenceId = $_ - Start-AzPolicyRemediation -ResourceGroupName $rg.ResourceGroupName -PolicyAssignmentId $policyAssignmentId -PolicyDefinitionReferenceId $referenceId -Name "$($rg.ResourceGroupName) remediation $referenceId"; - } - ``` --1. Check the compliance state when the remediation tasks have completed. - ```azurepowershell - Get-AzPolicyState -PolicyAssignmentName $assignmentName -ResourceGroupName $rg.ResourceGroupName|select-object IsCompliant, ResourceID - ``` --You can get your policy assignment details using the following command: - ```azurepowershell - $policyAssignment=Get-AzPolicyAssignment -Name $assignmentName -Scope "/subscriptions/$subscriptionId/resourcegroups/$($rg.ResourceGroupName)"; - ``` --### [CLI](#tab/cli) ---1. Sign in to your Azure account using the `az login` command. --1. Select the subscription where you want to apply the policy initiative using the `az account set` command. --1. Assign the initiative using [`az policy assignment create`](/cli/azure/policy/assignment#az-policy-assignment-create). -- ```azurecli - az policy assignment create --name <assignment name> --resource-group <resource group name> --policy-set-definition <initiative name> --params <parameters object> --mi-system-assigned --location <location> - ``` - For example: -- ```azurecli - az policy assignment create --name "assign-cli-example-01" --resource-group "cli-example-01" --policy-set-definition 'f5b29bc4-feca-4cc6-a58a-772dd5e290a5' --params '{"logAnalytics":{"value":"/subscriptions/12345678-aaaa-bbbb-cccc-1234567890ab/resourcegroups/cli-example-01/providers/microsoft.operationalinsights/workspaces/cli-example-01-ws"}, "diagnosticSettingName":{"value":"AssignedBy-cli-example-01"}}' --mi-system-assigned --location eastus - ``` -1. Assign the required role to the system managed identity -- Find the roles to assign in any of the policy definitions in the initiative by searching the definition for *roleDefinitionIds*, for example: -- ```json - ...}, - "roleDefinitionIds": [ - "/providers/Microsoft.Authorization/roleDefinitions/92aaf0da-9dab-42b6-94a3-d43ce8d16293" - ], - "deployment": { - "properties": {... - ``` - Assign the required role using [`az policy assignment identity assign`](/cli/azure/policy/assignment/identity): - ```azurecli - az policy assignment identity assign --system-assigned --resource-group <resource group name> --role <role name or ID> --identity-scope <scope> --name <policy assignment name> - ``` -- For example: - ```azurecli - az policy assignment identity assign --system-assigned --resource-group "cli-example-01" --role 92aaf0da-9dab-42b6-94a3-d43ce8d16293 --identity-scope "/subscriptions/12345678-aaaa-bbbb-cccc-1234567890ab/resourcegroups/cli-example-01" --name assign-cli-example-01 - ``` --1. Create remediation tasks for the policies in the initiative. -- Remediation tasks are created per-policy. Each task is for a specific `definition-reference-id`, specified in the initiative as `policyDefinitionReferenceId`. To find the `definition-reference-id` parameter, use the following command: - ```azurecli - az policy set-definition show --name f5b29bc4-feca-4cc6-a58a-772dd5e290a5 |grep policyDefinitionReferenceId - ``` - Remediate the resources using [`az policy remediation create`](/cli/azure/policy/remediation#az-policy-remediation-create) -- ```azurecli - az policy remediation create --resource-group <resource group name> --policy-assignment <assignment name> --name <remediation task name> --definition-reference-id "policy specific reference ID" --resource-discovery-mode ReEvaluateCompliance - ``` - For example: - ```azurecli - az policy remediation create --resource-group "cli-example-01" --policy-assignment assign-cli-example-01 --name "rem-assign-cli-example-01" --definition-reference-id "keyvault-vaults" --resource-discovery-mode ReEvaluateCompliance - ``` - To create a remediation task for all of the policies in the initiative, use the following example: - ```bash - for policyDefinitionReferenceId in $(az policy set-definition show --name f5b29bc4-feca-4cc6-a58a-772dd5e290a5 |grep policyDefinitionReferenceId |cut -d":" -f2|sed s/\"//g) - do - az policy remediation create --resource-group "cli-example-01" --policy-assignment assign-cli-example-01 --name remediate-$policyDefinitionReferenceId --definition-reference-id $policyDefinitionReferenceId; - done - ``` -----## Common parameters --The following table describes the common parameters for each set of policies. --|Parameter| Description| Valid Values|Default| -||||| -|effect| Enable or disable the execution of the policy|DeployIfNotExists,<br>AuditIfNotExists,<br>Disabled|DeployIfNotExists| -|diagnosticSettingName|Diagnostic Setting Name||setByPolicy-{LogAnalytics\|EventHubs\|Storage}| -|categoryGroup|Diagnostic category group|none,<br>audit,<br>allLogs|audit| -|resourceTypeList|For initiatives, a list of resource types to be evaluated for diagnostic setting existence.|Supported resources|All supported resources| --## Policy-specific parameters -### Log Analytics policy parameters - This policy deploys a diagnostic setting using a category group to route logs to a Log Analytics workspace. --|Parameter| Description| Valid Values|Default| -||||| -|resourceLocationList|Resource Location List to send logs to nearby Log Analytics. <br>"*" selects all locations|Supported locations|\*| -|logAnalytics|Log Analytics Workspace||| --### Event Hubs policy parameters --This policy deploys a diagnostic setting using a category group to route logs to an event hub. --|Parameter| Description| Valid Values|Default| -||||| -|resourceLocation|Resource Location must be the same location as the event hub Namespace|Supported locations|| -|eventHubAuthorizationRuleId|Event hub Authorization Rule ID. The authorization rule is at event hub namespace level. For example, /subscriptions/{subscription ID}/resourceGroups/{resource group}/providers/Microsoft.EventHub/namespaces/{Event Hub namespace}/authorizationrules/{authorization rule}||| -|eventHubName|Event hub name||Monitoring| ---### Storage Accounts policy parameters -This policy deploys a diagnostic setting using a category group to route logs to a Storage Account. --|Parameter| Description| Valid Values|Default| -||||| -|resourceLocation|Resource Location must be in the same location as the Storage Account|Supported locations| -|storageAccount|Storage Account resourceId||| --## Supported resources --Built-in All logs and Audit logs policies for Log Analytics workspaces, Event Hubs, and Storage Accounts exist for the following resources: --|Resource Type| All logs| Audit Logs| -|||| -|microsoft.aad/domainservices|Yes|Yes| -|microsoft.agfoodplatform/farmbeats|Yes|Yes| -|microsoft.analysisservices/servers|Yes|No| -|microsoft.apimanagement/service|Yes|Yes| -|microsoft.app/managedenvironments|Yes|Yes| -|microsoft.appconfiguration/configurationstores|Yes|Yes| -|microsoft.appplatform/spring|Yes|No| -|microsoft.attestation/attestationproviders|Yes|Yes| -|microsoft.automation/automationaccounts|Yes|Yes| -|microsoft.autonomousdevelopmentplatform/workspaces|Yes|No| -|microsoft.avs/privateclouds|Yes|Yes| -|microsoft.azureplaywrightservice/accounts|Yes|Yes| -|microsoft.azuresphere/catalogs|Yes|Yes| -|microsoft.batch/batchaccounts|Yes|Yes| -|microsoft.botservice/botservices|Yes|No| -|microsoft.cache/redis|Yes|Yes| -|microsoft.cache/redisenterprise/databases|Yes|Yes| -|microsoft.cdn/cdnwebapplicationfirewallpolicies|Yes|No| -|microsoft.cdn/profiles|Yes|Yes| -|microsoft.cdn/profiles/endpoints|Yes|No| -|microsoft.chaos/experiments|Yes|Yes| -|microsoft.classicnetwork/networksecuritygroups|Yes|No| -|microsoft.cloudtest/hostedpools|Yes|No| -|microsoft.codesigning/codesigningaccounts|Yes|Yes| -|microsoft.cognitiveservices/accounts|Yes|Yes| -|microsoft.communication/communicationservices|Yes|No| -|microsoft.community/communitytrainings|Yes|Yes| -|microsoft.confidentialledger/managedccfs|Yes|Yes| -|microsoft.connectedcache/enterprisemcccustomers|Yes|No| -|microsoft.connectedcache/ispcustomers|Yes|No| -|microsoft.containerinstance/containergroups|Yes|No| -|microsoft.containerregistry/registries|Yes|Yes| -|microsoft.customproviders/resourceproviders|Yes|No| -|microsoft.d365customerinsights/instances|Yes|No| -|microsoft.dashboard/grafana|Yes|Yes| -|microsoft.databricks/workspaces|Yes|No| -|microsoft.datafactory/factories|Yes|No| -|microsoft.datalakeanalytics/accounts|Yes|No| -|microsoft.datalakestore/accounts|Yes|No| -|microsoft.dataprotection/backupvaults|Yes|No| -|microsoft.datashare/accounts|Yes|No| -|microsoft.dbformariadb/servers|Yes|No| -|microsoft.dbformysql/flexibleservers|Yes|Yes| -|microsoft.dbformysql/servers|Yes|No| -|microsoft.dbforpostgresql/flexibleservers|Yes|Yes| -|microsoft.dbforpostgresql/servergroupsv2|Yes|No| -|microsoft.dbforpostgresql/servers|Yes|No| -|microsoft.desktopvirtualization/applicationgroups|Yes|No| -|microsoft.desktopvirtualization/hostpools|Yes|No| -|microsoft.desktopvirtualization/scalingplans|Yes|No| -|microsoft.desktopvirtualization/workspaces|Yes|No| -|microsoft.devcenter/devcenters|Yes|Yes| -|microsoft.devices/iothubs|Yes|Yes| -|microsoft.devices/provisioningservices|Yes|No| -|microsoft.digitaltwins/digitaltwinsinstances|Yes|No| -|microsoft.documentdb/cassandraclusters|Yes|Yes| -|microsoft.documentdb/databaseaccounts|Yes|Yes| -|microsoft.documentdb/mongoclusters|Yes|Yes| -|microsoft.eventgrid/domains|Yes|Yes| -|microsoft.eventgrid/partnernamespaces|Yes|Yes| -|microsoft.eventgrid/partnertopics|Yes|No| -|microsoft.eventgrid/systemtopics|Yes|No| -|microsoft.eventgrid/topics|Yes|Yes| -|microsoft.eventhub/namespaces|Yes|Yes| -|microsoft.experimentation/experimentworkspaces|Yes|No| -|microsoft.healthcareapis/services|Yes|No| -|microsoft.healthcareapis/workspaces/dicomservices|Yes|No| -|microsoft.healthcareapis/workspaces/fhirservices|Yes|No| -|microsoft.healthcareapis/workspaces/iotconnectors|Yes|No| -|microsoft.insights/autoscalesettings|Yes|No| -|microsoft.insights/components|Yes|No| -|microsoft.insights/datacollectionrules|Yes|No| -|microsoft.keyvault/managedhsms|Yes|Yes| -|microsoft.keyvault/vaults|Yes|Yes| -|microsoft.kusto/clusters|Yes|Yes| -|microsoft.loadtestservice/loadtests|Yes|Yes| -|microsoft.logic/integrationaccounts|Yes|No| -|microsoft.logic/workflows|Yes|No| -|microsoft.machinelearningservices/registries|Yes|Yes| -|microsoft.machinelearningservices/workspaces|Yes|Yes| -|microsoft.machinelearningservices/workspaces/onlineendpoints|Yes|No| -|microsoft.managednetworkfabric/networkdevices|Yes|No| -|microsoft.media/mediaservices|Yes|Yes| -|microsoft.media/mediaservices/liveevents|Yes|Yes| -|microsoft.media/mediaservices/streamingendpoints|Yes|Yes| -|microsoft.netapp/netappaccounts/capacitypools/volumes|Yes|Yes| -|microsoft.network/applicationgateways|Yes|No| -|microsoft.network/azurefirewalls|Yes|No| -|microsoft.network/bastionhosts|Yes|Yes| -|microsoft.network/dnsresolverpolicies|Yes|No| -|microsoft.network/expressroutecircuits|Yes|No| -|microsoft.network/frontdoors|Yes|Yes| -|microsoft.network/loadbalancers|Yes|No| -|microsoft.network/networkmanagers|Yes|Yes| -|microsoft.network/networkmanagers/ipampools|Yes|Yes| -|microsoft.network/networksecuritygroups|Yes|No| -|microsoft.network/networksecurityperimeters|Yes|No| -|microsoft.network/p2svpngateways|Yes|Yes| -|microsoft.network/publicipaddresses|Yes|Yes| -|microsoft.network/publicipprefixes|Yes|Yes| -|microsoft.network/trafficmanagerprofiles|Yes|No| -|microsoft.network/virtualnetworkgateways|Yes|Yes| -|microsoft.network/virtualnetworks|Yes|No| -|microsoft.network/vpngateways|Yes|No| -|microsoft.networkanalytics/dataproducts|Yes|Yes| -|microsoft.networkcloud/baremetalmachines|Yes|No| -|microsoft.networkcloud/clusters|Yes|No| -|microsoft.networkcloud/storageappliances|Yes|No| -|microsoft.networkfunction/azuretrafficcollectors|Yes|No| -|microsoft.notificationhubs/namespaces|Yes|Yes| -|microsoft.notificationhubs/namespaces/notificationhubs|Yes|Yes| -|microsoft.openenergyplatform/energyservices|Yes|No| -|microsoft.operationalinsights/workspaces|Yes|Yes| -|microsoft.powerbi/tenants/workspaces|Yes|No| -|microsoft.powerbidedicated/capacities|Yes|No| -|microsoft.purview/accounts|Yes|Yes| -|microsoft.recoveryservices/vaults|Yes|No| -|microsoft.relay/namespaces|Yes|No| -|microsoft.search/searchservices|Yes|Yes| -|microsoft.servicebus/namespaces|Yes|Yes| -|microsoft.servicenetworking/trafficcontrollers|Yes|No| -|microsoft.signalrservice/signalr|Yes|Yes| -|microsoft.signalrservice/webpubsub|Yes|Yes| -|microsoft.sql/managedinstances|Yes|Yes| -|microsoft.sql/managedinstances/databases|Yes|No| -|microsoft.sql/servers/databases|Yes|Yes| -|microsoft.storagecache/caches|Yes|No| -|microsoft.storagemover/storagemovers|Yes|No| -|microsoft.streamanalytics/streamingjobs|Yes|No| -|microsoft.synapse/workspaces|Yes|Yes| -|microsoft.synapse/workspaces/bigdatapools|Yes|Yes| -|microsoft.synapse/workspaces/kustopools|Yes|Yes| -|microsoft.synapse/workspaces/scopepools|Yes|Yes| -|microsoft.synapse/workspaces/sqlpools|Yes|Yes| -|microsoft.timeseriesinsights/environments|Yes|No| -|microsoft.timeseriesinsights/environments/eventsources|Yes|No| -|microsoft.videoindexer/accounts|Yes|No| -|microsoft.web/hostingenvironments|Yes|Yes| -|microsoft.workloads/sapvirtualinstances|Yes|Yes| --## Next Steps --* [Create diagnostic settings at scale using Azure Policy](./diagnostic-settings-policy.md) -* [Azure Policy built-in definitions for Azure Monitor](../policy-reference.md) -* [Azure Policy Overview](../../governance/policy/overview.md) -* [Azure Enterprise Policy as Code](https://techcommunity.microsoft.com/t5/core-infrastructure-and-security/azure-enterprise-policy-as-code-a-new-approach/ba-p/3607843) |
| azure-monitor | Edge Pipeline Configure | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/edge-pipeline-configure.md | - Title: Configuration of Azure Monitor pipeline at edge and multicloud -description: Configuration of Azure Monitor pipeline for edge and multicloud - Previously updated : 04/25/2024------# Configuration of Azure Monitor pipeline at edge -[Azure Monitor pipeline](./pipeline-overview.md) is a data ingestion pipeline providing consistent and centralized data collection for Azure Monitor. The [pipeline at edge](./pipeline-overview.md#edge-pipeline) enables at-scale collection, and routing of telemetry data before it's sent to the cloud. It can cache data locally and sync with the cloud when connectivity is restored and route telemetry to Azure Monitor in cases where the network is segmented and data cannot be sent directly to the cloud. This article describes how to enable and configure the pipeline at edge in your environment. --## Overview -The Azure Monitor pipeline at edge is a containerized solution that is deployed on an [Arc-enabled Kubernetes cluster](../../azure-arc/kubernetes/overview.md) and leverages OpenTelemetry Collector as a foundation. The following diagram shows the components of the pipeline at edge. One or more data flows listen for incoming data from clients, and the pipeline extension forwards the data to the cloud, using the local cache if necessary. --The pipeline configuration file defines the data flows and cache properties for the pipeline at edge. The [DCR](./pipeline-overview.md#data-collection-rules) defines the schema of the data being sent to the cloud pipeline, a transformation to filter or modify the data, and the destination where the data should be sent. Each data flow definition for the pipeline configuration specifies the DCR and stream within that DCR that will process that data in the cloud pipeline. ---> [!NOTE] -> Private link is supported by pipeline at edge for the connection to the cloud pipeline. --The following components and configurations are required to enable the Azure Monitor pipeline at edge. If you use the Azure portal to configure the pipeline at edge, then each of these components is created for you. With other methods, you need to configure each one. ---| Component | Description | -|:|:| -| Edge pipeline controller extension | Extension added to your Arc-enabled Kubernetes cluster to support pipeline functionality - `microsoft.monitor.pipelinecontroller`. | -| Edge pipeline controller instance | Instance of the edge pipeline running on your Arc-enabled Kubernetes cluster. | -| Data flow | Combination of receivers and exporters that run on the pipeline controller instance. Receivers accept data from clients, and exporters to deliver that data to Azure Monitor. | -| Pipeline configuration | Configuration file that defines the data flows for the pipeline instance. Each data flow includes a receiver and an exporter. The receiver listens for incoming data, and the exporter sends the data to the destination. | -| Data collection endpoint (DCE) | Endpoint where the data is sent to the Azure Monitor pipeline. The pipeline configuration includes a property for the URL of the DCE so the pipeline instance knows where to send the data. | --| Configuration | Description | -|:|:| -| Data collection rule (DCR) | Configuration file that defines how the data is received in the cloud pipeline and where it's sent. The DCR can also include a transformation to filter or modify the data before it's sent to the destination. | -| Pipeline configuration | Configuration that defines the data flows for the pipeline instance, including the data flows and cache. | --## Supported configurations --**Supported distros**<br> -Azure Monitor pipeline at edge is supported on the following Kubernetes distributions: --- Canonical-- Cluster API Provider for Azure-- K3-- Rancher Kubernetes Engine-- VMware Tanzu Kubernetes Grid--**Supported locations**<br> -Azure Monitor pipeline at edge is supported in the following Azure regions: --- East US2-- West US2-- West Europe--## Prerequisites --- [Arc-enabled Kubernetes cluster](../../azure-arc/kubernetes/overview.md ) in your own environment with an external IP address. See [Connect an existing Kubernetes cluster to Azure Arc](../../azure-arc/kubernetes/quickstart-connect-cluster.md) for details on enabling Arc for a cluster.-- The Arc-enabled Kubernetes cluster must have the custom locations features enabled. See [Create and manage custom locations on Azure Arc-enabled Kubernetes](/azure/azure-arc/kubernetes/custom-locations#enable-custom-locations-on-your-cluster).-- Log Analytics workspace in Azure Monitor to receive the data from the pipeline at edge. See [Create a Log Analytics workspace in the Azure portal](../../azure-monitor/logs/quick-create-workspace.md) for details on creating a workspace.-- The following resource providers must be registered in your Azure subscription. See [Azure resource providers and types](/azure/azure-resource-manager/management/resource-providers-and-types).- - Microsoft.Insights - - Microsoft.Monitor ----## Workflow -You don't need a detail understanding of the different steps performed by the Azure Monitor pipeline to configure it using the Azure portal. You may need a more detailed understanding of it though if you use another method of installation or if you need to perform more advanced configuration such as transforming the data before it's stored in its destination. --The following tables and diagrams describe the detailed steps and components in the process for collecting data using the pipeline at edge and passing it to the cloud pipeline for storage in Azure Monitor. Also included in the tables is the configuration required for each of those components. --| Step | Action | Supporting configuration | -|:|:|:| -| 1. | Client sends data to the edge pipeline receiver. | Client is configured with IP and port of the edge pipeline receiver and sends data in the expected format for the receiver type. | -| 2. | Receiver forwards data to the exporter. | Receiver and exporter are configured in the same pipeline. | -| 3. | Exporter tries to send the data to the cloud pipeline. | Exporter in the pipeline configuration includes URL of the DCE, a unique identifier for the DCR, and the stream in the DCR that defines how the data will be processed. | -| 3a. | Exporter stores data in the local cache if it can't connect to the DCE. | Persistent volume for the cache and configuration of the local cache is enabled in the pipeline configuration. | ---| Step | Action | Supporting configuration | -|:|:|:| -| 4. | Cloud pipeline accepts the incoming data. | The DCR includes a schema definition for the incoming stream that must match the schema of the data coming from the pipeline at edge. | -| 5. | Cloud pipeline applies a transformation to the data. | The DCR includes a transformation that filters or modifies the data before it's sent to the destination. The transformation may filter data, remove or add columns, or completely change its schema. The output of the transformation must match the schema of the destination table. | -| 6. | Cloud pipeline sends the data to the destination. | The DCR includes a destination that specifies the Log Analytics workspace and table where the data will be stored. | ---## Segmented network --[Network segmentation](/azure/architecture/networking/guide/network-level-segmentation) is a model where you use software defined perimeters to create a different security posture for different parts of your network. In this model, you may have a network segment that can't connect to the internet or to other network segments. The pipeline at edge can be used to collect data from these network segments and send it to the cloud pipeline. ---To use Azure Monitor pipeline in a layered network configuration, you must add the following entries to the allowlist for the Arc-enabled Kubernetes cluster. See [Configure Azure IoT Layered Network Management Preview on level 4 cluster](/azure/iot-operations/manage-layered-network/howto-configure-l4-cluster-layered-network?tabs=k3s#configure-layered-network-management-preview-service). ---```yml -- destinationUrl: "*.ingest.monitor.azure.com"- destinationType: external -- destinationUrl: "login.windows.net"- destinationType: external -``` ---## Create table in Log Analytics workspace --Before you configure the data collection process for the pipeline at edge, you need to create a table in the Log Analytics workspace to receive the data. This must be a custom table since built-in tables aren't currently supported. The schema of the table must match the data that it receives, but there are multiple steps in the collection process where you can modify the incoming data, so you the table schema doesn't need to match the source data that you're collecting. The only requirement for the table in the Log Analytics workspace is that it has a `TimeGenerated` column. --See [Add or delete tables and columns in Azure Monitor Logs](../logs/create-custom-table.md) for details on different methods for creating a table. For example, use the CLI command below to create a table with the three columns called `Body`, `TimeGenerated`, and `SeverityText`. --```azurecli -az monitor log-analytics workspace table create --workspace-name my-workspace --resource-group my-resource-group --name my-table_CL --columns TimeGenerated=datetime Body=string SeverityText=string -``` ----## Enable cache -Edge devices in some environments may experience intermittent connectivity due to various factors such as network congestion, signal interference, power outage, or mobility. In these environments, you can configure the pipeline at edge to cache data by creating a [persistent volume](https://kubernetes.io) in your cluster. The process for this will vary based on your particular environment, but the configuration must meet the following requirements: -- - Metadata namespace must be the same as the specified instance of Azure Monitor pipeline. - - Access mode must support `ReadWriteMany`. --Once the volume is created in the appropriate namespace, configure it using parameters in the pipeline configuration file below. --> [!CAUTION] -> Each replica of the edge pipeline stores data in a location in the persistent volume specific to that replica. Decreasing the number of replicas while the cluster is disconnected from the cloud will prevent that data from being backfilled when connectivity is restored. --Data is retrieved from the cache using first-in-first-out (FIFO). Any data older than 48 hours will be discarded. --## Enable and configure pipeline -The current options for enabling and configuration are detailed in the tabs below. --### [Portal](#tab/Portal) --### Configure pipeline using Azure portal -When you use the Azure portal to enable and configure the pipeline, all required components are created based on your selections. This saves you from the complexity of creating each component individually, but you made need to use other methods for --Perform one of the following in the Azure portal to launch the installation process for the Azure Monitor pipeline: --- From the **Azure Monitor pipelines (preview)** menu, click **Create**. -- From the menu for your Arc-enabled Kubernetes cluster, select **Extensions** and then add the **Azure Monitor pipeline extension (preview)** extension.--The **Basic** tab prompts you for the following information to deploy the extension and pipeline instance on your cluster. ---The settings in this tab are described in the following table. --| Property | Description | -|:|:| -| Instance name | Name for the Azure Monitor pipeline instance. Must be unique for the subscription. | -| Subscription | Azure subscription to create the pipeline instance. | -| Resource group | Resource group to create the pipeline instance. | -| Cluster name | Select your Arc-enabled Kubernetes cluster that the pipeline will be installed on. | -| Custom Location | Custom location for your Arc-enabled Kubernetes cluster. This will be automatically populated with the name of a custom location that will be created for your cluster or you can select another custom location in the cluster. | --The **Dataflow** tab allows you to create and edit dataflows for the pipeline instance. Each dataflow includes the following details: ---The settings in this tab are described in the following table. --| Property | Description | -|:|:| -| Name | Name for the dataflow. Must be unique for this pipeline. | -| Source type | The type of data being collected. The following source types are currently supported:<br>- Syslog<br>- OTLP | -| Port | Port that the pipeline listens on for incoming data. If two dataflows use the same port, they will both receive and process the data. | -| Log Analytics Workspace | Log Analytics workspace to send the data to. | -| Table Name | The name of the table in the Log Analytics workspace to send the data to. | ---### [CLI](#tab/CLI) --### Configure pipeline using Azure CLI -Following are the steps required to create and configure the components required for the Azure Monitor pipeline at edge using Azure CLI. ---### Edge pipeline extension -The following command adds the edge pipeline extension to your Arc-enabled Kubernetes cluster. --```azurecli -az k8s-extension create --name <pipeline-extension-name> --extension-type microsoft.monitor.pipelinecontroller --scope cluster --cluster-name <cluster-name> --resource-group <resource-group> --cluster-type connectedClusters --release-train Preview --## Example -az k8s-extension create --name my-pipe --extension-type microsoft.monitor.pipelinecontroller --scope cluster --cluster-name my-cluster --resource-group my-resource-group --cluster-type connectedClusters --release-train Preview -``` --### Custom location -The following ARM template creates the custom location for to your Arc-enabled Kubernetes cluster. --```azurecli -az customlocation create --name <custom-location-name> --resource-group <resource-group-name> --namespace <name of namespace> --host-resource-id <connectedClusterId> --cluster-extension-ids <extensionId> --## Example -az customlocation create --name my-cluster-custom-location --resource-group my-resource-group --namespace my-cluster-custom-location --host-resource-id /subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/Microsoft.Kubernetes/connectedClusters/my-cluster --cluster-extension-ids /subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/Microsoft.Kubernetes/connectedClusters/my-cluster/providers/Microsoft.KubernetesConfiguration/extensions/my-cluster -``` ----### DCE -The following ARM template creates the [data collection endpoint (DCE)](./data-collection-endpoint-overview.md) required for the pipeline at edge to connect to the cloud pipeline. You can use an existing DCE if you already have one in the same region. Replace the properties in the following table before deploying the template. --```azurecli -az monitor data-collection endpoint create -g "myResourceGroup" -l "eastus2euap" --name "myCollectionEndpoint" --public-network-access "Enabled" --## Example - az monitor data-collection endpoint create --name strato-06-dce --resource-group strato --public-network-access "Enabled" -``` ----### DCR -The DCR is stored in Azure Monitor and defines how the data will be processed when it's received from the pipeline at edge. The pipeline at edge configuration specifies the `immutable ID` of the DCR and the `stream` in the DCR that will process the data. The `immutable ID` is automatically generated when the DCR is created. --Replace the properties in the following template and save them in a json file before running the CLI command to create the DCR. See [Structure of a data collection rule in Azure Monitor](./data-collection-rule-overview.md) for details on the structure of a DCR. --| Parameter | Description | -|:|:--| -| `name` | Name of the DCR. Must be unique for the subscription. | -| `location` | Location of the DCR. Must match the location of the DCE. | -| `dataCollectionEndpointId` | Resource ID of the DCE. | -| `streamDeclarations` | Schema of the data being received. One stream is required for each dataflow in the pipeline configuration. The name must be unique in the DCR and must begin with *Custom-*. The `column` sections in the samples below should be used for the OLTP and Syslog data flows. If the schema for your destination table is different, then you can modify it using a transformation defined in the `transformKql` parameter. | -| `destinations` | Add additional section to send data to multiple workspaces. | -| - `name` | Name for the destination to reference in the `dataFlows` section. Must be unique for the DCR. | -| - `workspaceResourceId` | Resource ID of the Log Analytics workspace. | -| - `workspaceId` | Workspace ID of the Log Analytics workspace. | -| `dataFlows` | Matches streams and destinations. One entry for each stream/destination combination. | -| - `streams` | One or more streams (defined in `streamDeclarations`). You can include multiple stream if they're being sent to the same destination. | -| - `destinations` | One or more destinations (defined in `destinations`). You can include multiple destinations if they're being sent to the same destination. | -| - `transformKql` | Transformation to apply to the data before sending it to the destination. Use `source` to send the data without any changes. The output of the transformation must match the schema of the destination table. See [Data collection transformations in Azure Monitor](./data-collection-transformations.md) for details on transformations. | -| - `outputStream` | Specifies the destination table in the Log Analytics workspace. The table must already exist in the workspace. For custom tables, prefix the table name with *Custom-*. Built-in tables are not currently supported with pipeline at edge. | ---```json -{ - "properties": { - "dataCollectionEndpointId": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/Microsoft.Insights/dataCollectionEndpoints/my-dce", - "streamDeclarations": { - "Custom-OTLP": { - "columns": [ - { - "name": "Body", - "type": "string" - }, - { - "name": "TimeGenerated", - "type": "datetime" - }, - { - "name": "SeverityText", - "type": "string" - } - ] - }, - "Custom-Syslog": { - "columns": [ - { - "name": "Body", - "type": "string" - }, - { - "name": "TimeGenerated", - "type": "datetime" - }, - { - "name": "SeverityText", - "type": "string" - } - ] - } - }, - "dataSources": {}, - "destinations": { - "logAnalytics": [ - { - "name": "LogAnayticsWorkspace01", - "workspaceResourceId": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/Microsoft.OperationalInsights/workspaces/my-workspace", - "workspaceId": "00000000-0000-0000-0000-000000000000" - } - ] - }, - "dataFlows": [ - { - "streams": [ - "Custom-OTLP" - ], - "destinations": [ - "LogAnayticsWorkspace01" - ], - "transformKql": "source", - "outputStream": "Custom-OTelLogs_CL" - }, - { - "streams": [ - "Custom-Syslog" - ], - "destinations": [ - "LogAnayticsWorkspace01" - ], - "transformKql": "source", - "outputStream": "Custom-Syslog_CL" - } - ] - } -} -``` --Install the DCR using the following command: --```azurecli -az monitor data-collection rule create --name 'myDCRName' --location <location> --resource-group <resource-group> --rule-file '<dcr-file-path.json>' --## Example -az monitor data-collection rule create --name my-pipeline-dcr --location westus2 --resource-group 'my-resource-group' --rule-file 'C:\MyDCR.json' --``` ---### DCR access -The Arc-enabled Kubernetes cluster must have access to the DCR to send data to the cloud pipeline. Use the following command to retrieve the object ID of the System Assigned Identity for your cluster. --```azurecli -az k8s-extension show --name <extension-name> --cluster-name <cluster-name> --resource-group <resource-group> --cluster-type connectedClusters --query "identity.principalId" -o tsv --## Example: -az k8s-extension show --name my-pipeline-extension --cluster-name my-cluster --resource-group my-resource-group --cluster-type connectedClusters --query "identity.principalId" -o tsv -``` --Use the output from this command as input to the following command to give Azure Monitor pipeline the authority to send its telemetry to the DCR. --```azurecli -az role assignment create --assignee "<extension principal ID>" --role "Monitoring Metrics Publisher" --scope "/subscriptions/<subscription-id>/resourceGroups/<resource-group>/providers/Microsoft.Insights/dataCollectionRules/<dcr-name>" --## Example: -az role assignment create --assignee "00000000-0000-0000-0000-000000000000" --role "Monitoring Metrics Publisher" --scope "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/Microsoft.Insights/dataCollectionRules/my-dcr" -``` --### Edge pipeline configuration -The edge pipeline configuration defines the details of the pipeline at edge instance and deploy the data flows necessary to receive and send telemetry to the cloud. --Replace the properties in the following table before deploying the template. --| Property | Description | -|:|:--| -| **General** | | -| `name` | Name of the pipeline instance. Must be unique in the subscription. | -| `location` | Location of the pipeline instance. | -| `extendedLocation` | | -| **Receivers** | One entry for each receiver. Each entry specifies the type of data being received, the port it will listen on, and a unique name that will be used in the `pipelines` section of the configuration. | -| `type` | Type of data received. Current options are `OTLP` and `Syslog`. | -| `name` | Name for the receiver referenced in the `service` section. Must be unique for the pipeline instance. | -| `endpoint` | Address and port the receiver listens on. Use `0.0.0.0` for al addresses. | -| **Processors** | Reserved for future use.| -| **Exporters** | One entry for each destination. | -| `type` | Only currently supported type is `AzureMonitorWorkspaceLogs`. | -| `name` | Must be unique for the pipeline instance. The name is used in the `pipelines` section of the configuration. | -| `dataCollectionEndpointUrl` | URL of the DCE where the pipeline at edge will send the data. You can locate this in the Azure portal by navigating to the DCE and copying the **Logs Ingestion** value. | -| `dataCollectionRule` | Immutable ID of the DCR that defines the data collection in the cloud pipeline. From the JSON view of your DCR in the Azure portal, copy the value of the **immutable ID** in the **General** section. | -| - `stream` | Name of the stream in your DCR that will accept the data. | -| - `maxStorageUsage` | Capacity of the cache. When 80% of this capacity is reached, the oldest data is pruned to make room for more data. | -| - `retentionPeriod` | Retention period in minutes. Data is pruned after this amount of time. | -| - `schema` | Schema of the data being sent to the cloud pipeline. This must match the schema defined in the stream in the DCR. The schema used in the example is valid for both Syslog and OTLP. | -| **Service** | One entry for each pipeline instance. Only one instance for each pipeline extension is recommended. | -| **Pipelines** | One entry for each data flow. Each entry matches a `receiver` with an `exporter`. | -| `name` | Unique name of the pipeline. | -| `receivers` | One or more receivers to listen for data to receive. | -| `processors` | Reserved for future use. | -| `exporters` | One or more exporters to send the data to the cloud pipeline. | -| `persistence` | Name of the persistent volume used for the cache. Remove this parameter if you don't want to enable the cache. | ---```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "metadata": { - "description": "This template deploys an edge pipeline for azure monitor." - }, - "resources": [ - { - "type": "Microsoft.monitor/pipelineGroups", - "location": "eastus", - "apiVersion": "2023-10-01-preview", - "name": "my-pipeline-group-name", - "extendedLocation": { - "name": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/Microsoft.ExtendedLocation/customLocations/my-custom-location", - "type": "CustomLocation" - }, - "properties": { - "receivers": [ - { - "type": "OTLP", - "name": "receiver-OTLP", - "otlp": { - "endpoint": "0.0.0.0:4317" - } - }, - { - "type": "Syslog", - "name": "receiver-Syslog", - "syslog": { - "endpoint": "0.0.0.0:514" - } - } - ], - "processors": [], - "exporters": [ - { - "type": "AzureMonitorWorkspaceLogs", - "name": "exporter-log-analytics-workspace", - "azureMonitorWorkspaceLogs": { - "api": { - "dataCollectionEndpointUrl": "https://my-dce-4agr.eastus-1.ingest.monitor.azure.com", - "dataCollectionRule": "dcr-00000000000000000000000000000000", - "stream": "Custom-OTLP", - "schema": { - "recordMap": [ - { - "from": "body", - "to": "Body" - }, - { - "from": "severity_text", - "to": "SeverityText" - }, - { - "from": "time_unix_nano", - "to": "TimeGenerated" - } - ] - } - }, - "cache": { - "maxStorageUsage": 10000, - "retentionPeriod": 60 - } - } - } - ], - "service": { - "pipelines": [ - { - "name": "DefaultOTLPLogs", - "receivers": [ - "receiver-OTLP" - ], - "processors": [], - "exporters": [ - "exporter-log-analytics-workspace" - ], - "type": "logs" - }, - { - "name": "DefaultSyslogs", - "receivers": [ - "receiver-Syslog" - ], - "processors": [], - "exporters": [ - "exporter-log-analytics-workspace" - ], - "type": "logs" - } - ], - "persistence": { - "persistentVolumeName": "my-persistent-volume" - } - }, - "networkingConfigurations": [ - { - "externalNetworkingMode": "LoadBalancerOnly", - "routes": [ - { - "receiver": "receiver-OTLP" - }, - { - "receiver": "receiver-Syslog" - } - ] - } - ] - } - } - ] -} -``` --Install the template using the following command: --```azurecli -az deployment group create --resource-group <resource-group-name> --template-file <path-to-template> --## Example -az deployment group create --resource-group my-resource-group --template-file C:\MyPipelineConfig.json --``` ---### [ARM](#tab/arm) --### ARM template sample to configure all components --You can deploy all of the required components for the Azure Monitor pipeline at edge using the single ARM template shown below. Edit the parameter file with specific values for your environment. Each section of the template is described below including sections that you must modify before using it. ---| Component | Type | Description | -|:|:|:| -| Log Analytics workspace | `Microsoft.OperationalInsights/workspaces` | Remove this section if you're using an existing Log Analytics workspace. The only parameter required is the workspace name. The immutable ID for the workspace, which is needed for other components, will be automatically created. | -| Data collection endpoint (DCE) | `Microsoft.Insights/dataCollectionEndpoints` | Remove this section if you're using an existing DCE. The only parameter required is the DCE name. The logs ingestion URL for the DCE, which is needed for other components, will be automatically created. | -| Edge pipeline extension | `Microsoft.KubernetesConfiguration/extensions` | The only parameter required is the pipeline extension name. | -| Custom location | `Microsoft.ExtendedLocation/customLocations` | Custom location of the Arc-enabled Kubernetes cluster to create the custom | -| Edge pipeline instance | `Microsoft.monitor/pipelineGroups` | Edge pipeline instance that includes configuration of the listener, exporters, and data flows. You must modify the properties of the pipeline instance before deploying the template. | -| Data collection rule (DCR) | `Microsoft.Insights/dataCollectionRules` | The only parameter required is the DCR name, but you must modify the properties of the DCR before deploying the template. | ---### Template file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "location": { - "type": "string" - }, - "clusterId": { - "type": "string" - }, - "clusterExtensionIds": { - "type": "array" - }, - "customLocationName": { - "type": "string" - }, - "cachePersistentVolume": { - "type": "string" - }, - "cacheMaxStorageUsage": { - "type": "int" - }, - "cacheRetentionPeriod": { - "type": "int" - }, - "dceName": { - "type": "string" - }, - "dcrName": { - "type": "string" - }, - "logAnalyticsWorkspaceName": { - "type": "string" - }, - "pipelineExtensionName": { - "type": "string" - }, - "pipelineGroupName": { - "type": "string" - }, - "tagsByResource": { - "type": "object", - "defaultValue": {} - } - }, - "resources": [ - { - "type": "Microsoft.OperationalInsights/workspaces", - "name": "[parameters('logAnalyticsWorkspaceName')]", - "location": "[parameters('location')]", - "apiVersion": "2017-03-15-preview", - "tags": "[ if(contains(parameters('tagsByResource'), 'Microsoft.OperationalInsights/workspaces'), parameters('tagsByResource')['Microsoft.OperationalInsights/workspaces'], json('{}')) ]", - "properties": { - "sku": { - "name": "pergb2018" - } - } - }, - { - "type": "Microsoft.Insights/dataCollectionEndpoints", - "name": "[parameters('dceName')]", - "location": "[parameters('location')]", - "apiVersion": "2021-04-01", - "tags": "[ if(contains(parameters('tagsByResource'), 'Microsoft.Insights/dataCollectionEndpoints'), parameters('tagsByResource')['Microsoft.Insights/dataCollectionEndpoints'], json('{}')) ]", - "properties": { - "configurationAccess": {}, - "logsIngestion": {}, - "networkAcls": { - "publicNetworkAccess": "Enabled" - } - } - }, - { - "type": "Microsoft.Insights/dataCollectionRules", - "name": "[parameters('dcrName')]", - "location": "[parameters('location')]", - "apiVersion": "2021-09-01-preview", - "dependsOn": [ - "[resourceId('Microsoft.OperationalInsights/workspaces', 'DefaultWorkspace-westus2')]", - "[resourceId('Microsoft.Insights/dataCollectionEndpoints', 'Aep-mytestpl-ZZPXiU05tJ')]" - ], - "tags": "[ if(contains(parameters('tagsByResource'), 'Microsoft.Insights/dataCollectionRules'), parameters('tagsByResource')['Microsoft.Insights/dataCollectionRules'], json('{}')) ]", - "properties": { - "dataCollectionEndpointId": "[resourceId('Microsoft.Insights/dataCollectionEndpoints', 'Aep-mytestpl-ZZPXiU05tJ')]", - "streamDeclarations": { - "Custom-OTLP": { - "columns": [ - { - "name": "Body", - "type": "string" - }, - { - "name": "TimeGenerated", - "type": "datetime" - }, - { - "name": "SeverityText", - "type": "string" - } - ] - }, - "Custom-Syslog": { - "columns": [ - { - "name": "Body", - "type": "string" - }, - { - "name": "TimeGenerated", - "type": "datetime" - }, - { - "name": "SeverityText", - "type": "string" - } - ] - } - }, - "dataSources": {}, - "destinations": { - "logAnalytics": [ - { - "name": "DefaultWorkspace-westus2", - "workspaceResourceId": "[resourceId('Microsoft.OperationalInsights/workspaces', 'DefaultWorkspace-westus2')]", - "workspaceId": "[reference(resourceId('Microsoft.OperationalInsights/workspaces', 'DefaultWorkspace-westus2'))].customerId" - } - ] - }, - "dataFlows": [ - { - "streams": [ - "Custom-OTLP" - ], - "destinations": [ - "localDest-DefaultWorkspace-westus2" - ], - "transformKql": "source", - "outputStream": "Custom-OTelLogs_CL" - }, - { - "streams": [ - "Custom-Syslog" - ], - "destinations": [ - "DefaultWorkspace-westus2" - ], - "transformKql": "source", - "outputStream": "Custom-Syslog_CL" - } - ] - } - }, - { - "type": "Microsoft.KubernetesConfiguration/extensions", - "apiVersion": "2022-11-01", - "name": "[parameters('pipelineExtensionName')]", - "scope": "[parameters('clusterId')]", - "tags": "[ if(contains(parameters('tagsByResource'), 'Microsoft.KubernetesConfiguration/extensions'), parameters('tagsByResource')['Microsoft.KubernetesConfiguration/extensions'], json('{}')) ]", - "identity": { - "type": "SystemAssigned" - }, - "properties": { - "aksAssignedIdentity": { - "type": "SystemAssigned" - }, - "autoUpgradeMinorVersion": false, - "extensionType": "microsoft.monitor.pipelinecontroller", - "releaseTrain": "preview", - "scope": { - "cluster": { - "releaseNamespace": "my-strato-ns" - } - }, - "version": "0.37.3-privatepreview" - } - }, - { - "type": "Microsoft.ExtendedLocation/customLocations", - "apiVersion": "2021-08-15", - "name": "[parameters('customLocationName')]", - "location": "[parameters('location')]", - "tags": "[ if(contains(parameters('tagsByResource'), 'Microsoft.ExtendedLocation/customLocations'), parameters('tagsByResource')['Microsoft.ExtendedLocation/customLocations'], json('{}')) ]", - "dependsOn": [ - "[parameters('pipelineExtensionName')]" - ], - "properties": { - "hostResourceId": "[parameters('clusterId')]", - "namespace": "[toLower(parameters('customLocationName'))]", - "clusterExtensionIds": "[parameters('clusterExtensionIds')]", - "hostType": "Kubernetes" - } - }, - { - "type": "Microsoft.monitor/pipelineGroups", - "location": "[parameters('location')]", - "apiVersion": "2023-10-01-preview", - "name": "[parameters('pipelineGroupName')]", - "tags": "[ if(contains(parameters('tagsByResource'), 'Microsoft.monitor/pipelineGroups'), parameters('tagsByResource')['Microsoft.monitor/pipelineGroups'], json('{}')) ]", - "dependsOn": [ - "[parameters('customLocationName')]", - "[resourceId('Microsoft.Insights/dataCollectionRules','Aep-mytestpl-ZZPXiU05tJ')]" - ], - "extendedLocation": { - "name": "[resourceId('Microsoft.ExtendedLocation/customLocations', parameters('customLocationName'))]", - "type": "CustomLocation" - }, - "properties": { - "receivers": [ - { - "type": "OTLP", - "name": "receiver-OTLP-4317", - "otlp": { - "endpoint": "0.0.0.0:4317" - } - }, - { - "type": "Syslog", - "name": "receiver-Syslog-514", - "syslog": { - "endpoint": "0.0.0.0:514" - } - } - ], - "processors": [], - "exporters": [ - { - "type": "AzureMonitorWorkspaceLogs", - "name": "exporter-lu7mbr90", - "azureMonitorWorkspaceLogs": { - "api": { - "dataCollectionEndpointUrl": "[reference(resourceId('Microsoft.Insights/dataCollectionEndpoints','Aep-mytestpl-ZZPXiU05tJ')).logsIngestion.endpoint]", - "stream": "Custom-DefaultAEPOTelLogs_CL-FqXSu6GfRF", - "dataCollectionRule": "[reference(resourceId('Microsoft.Insights/dataCollectionRules', 'Aep-mytestpl-ZZPXiU05tJ')).immutableId]", - "cache": { - "maxStorageUsage": "[parameters('cacheMaxStorageUsage')]", - "retentionPeriod": "[parameters('cacheRetentionPeriod')]" - }, - "schema": { - "recordMap": [ - { - "from": "body", - "to": "Body" - }, - { - "from": "severity_text", - "to": "SeverityText" - }, - { - "from": "time_unix_nano", - "to": "TimeGenerated" - } - ] - } - } - } - } - ], - "service": { - "pipelines": [ - { - "name": "DefaultOTLPLogs", - "receivers": [ - "receiver-OTLP" - ], - "processors": [], - "exporters": [ - "exporter-lu7mbr90" - ] - } - ], - "persistence": { - "persistentVolume": "[parameters('cachePersistentVolume')]" - } - } - } - } - ], - "outputs": {} -} --``` --### Sample parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "location": { - "value": "eastus" - }, - "clusterId": { - "value": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/Microsoft.Kubernetes/connectedClusters/my-arc-cluster" - }, - "clusterExtensionIds": { - "value": ["/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/Microsoft.KubernetesConfiguration/extensions/my-pipeline-extension"] - }, - "customLocationName": { - "value": "my-custom-location" - }, - "dceName": { - "value": "my-dce" - }, - "dcrName": { - "value": "my-dcr" - }, - "logAnalyticsWorkspaceName": { - "value": "my-workspace" - }, - "pipelineExtensionName": { - "value": "my-pipeline-extension" - }, - "pipelineGroupName": { - "value": "my-pipeline-group" - }, - "tagsByResource": { - "value": {} - } - } -} -``` ----## Verify configuration --### Verify pipeline components running in the cluster -In the Azure portal, navigate to the **Kubernetes services** menu and select your Arc-enabled Kubernetes cluster. Select **Services and ingresses** and ensure that you see the following --- \<pipeline name\>-external-service -- \<pipeline name\>-service ---Click on the entry for **\<pipeline name\>-external-service** and note the IP address and port in the **Endpoints** column. This is the external IP address and port that your clients will send data to. See [Retrieve ingress endpoint](#retrieve-ingress-endpoint) for retrieving this address from the client. --### Verify heartbeat -Each pipeline configured in your pipeline instance will send a heartbeat record to the `Heartbeat` table in your Log Analytics workspace every minute. The contents of the `OSMajorVersion` column should match the name your pipeline instance. If there are multiple workspaces in the pipeline instance, then the first one configured will be used. --Retrieve the heartbeat records using a log query as in the following example: ----## Client configuration -Once your edge pipeline extension and instance are installed, then you need to configure your clients to send data to the pipeline. --### Retrieve ingress endpoint -Each client requires the external IP address of the Azure Monitor pipeline service. Use the following command to retrieve this address: --```azurecli -kubectl get services -n <namespace where azure monitor pipeline was installed> -``` --- If the application producing logs is external to the cluster, copy the *external-ip* value of the service *\<pipeline name\>-service* or *\<pipeline name\>-external-service* with the load balancer type. -- If the application is on a pod within the cluster, copy the *cluster-ip* value. --> [!NOTE] -> If the external-ip field is set to *pending*, you will need to configure an external IP for this ingress manually according to your cluster configuration. --| Client | Description | -|:|:| -| Syslog | Update Syslog clients to send data to the pipeline endpoint and the port of your Syslog dataflow. | -| OTLP | The Azure Monitor edge pipeline exposes a gRPC-based OTLP endpoint on port 4317. Configuring your instrumentation to send to this OTLP endpoint will depend on the instrumentation library itself. See [OTLP endpoint or Collector](https://opentelemetry.io/docs/instrumentation/python/exporters/#otlp-endpoint-or-collector) for OpenTelemetry documentation. The environment variable method is documented at [OTLP Exporter Configuration](https://opentelemetry.io/docs/concepts/sdk-configuration/otlp-exporter-configuration/). | ---## Verify data -The final step is to verify that the data is received in the Log Analytics workspace. You can perform this verification by running a query in the Log Analytics workspace to retrieve data from the table. ---## Next steps --- [Read more about Azure Monitor pipeline](./pipeline-overview.md). |
| azure-monitor | Metric Chart Samples | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/metric-chart-samples.md | - Title: Azure Monitor metric chart example -description: Learn about visualizing your Azure Monitor data. ---- Previously updated : 08/26/2024----# Metric chart examples --The Azure platform offers [over a thousand metrics](/azure/azure-monitor/reference/supported-metrics/metrics-index), many of which have dimensions. By using [dimension filters](./metrics-charts.md), applying [splitting](./metrics-charts.md), controlling chart type, and adjusting chart settings you can create powerful diagnostic views and dashboards that provide insight into the health of your infrastructure and applications. This article shows some examples of the charts that you can build using [Metrics Explorer](./metrics-charts.md), and explains the necessary steps to configure each of these charts. ---## Website CPU utilization by server instances --This chart shows if the CPU usage for an App Service Plan was within the acceptable range and breaks it down by instance to determine whether the load was properly distributed. ---### How to configure this chart -1. Select **Metrics** from the **Monitoring** section of your App service plan's menu -1. Select the **CPU Percentage** metric. -1. Select **Apply splitting** and select the **Instance** dimension. --## Application availability by region --View your application's availability by region to identify which geographic locations are having problems. This chart shows the Application Insights availability metric. The chart shows that the monitored application has no problem with availability from the East US data center, but it's experiencing a partial availability problem from West US, and East Asia. ---### How to configure this chart --1. Turn on [Application Insights availability](/previous-versions/azure/azure-monitor/app/monitor-web-app-availability) monitoring for your website. -1. Select your Application Insights resource. -1. Select the **Availability** metric. -1. Apply splitting on the **Run location** dimension. --## Volume of failed storage account transactions by API name --Your storage account resource is experiencing an excess volume of failed transactions. Use the transactions metric to identify which API is responsible for the excess failure. Notice that the following chart is configured with the same dimension (API name) in splitting and filtered by failed response type: ---### How to configure this chart --1. In the scope dropdown, select your Storage Account -1. In the metric dropdown, select the **Transactions** metric. -1. Select **Add filter** and select **Response type** from the **Property** dropdown. -1. Select **CLientOtherError** from the **Values** dropdown. -1. Select **Apply splitting** and select **API name** from the values dropdown. --## Total requests of Cosmos DB by Database Names and Collection Names --You want to identify which collection in which database of your Cosmos DB instance is having maximum requests to adjust your costs for Cosmos DB. ---### How to configure this chart --1. In the scope dropdown, select your Cosmos DB. -1. In the metric dropdown, select **Total Requests**. -1. Select **Apply splitting** and select the **DatabaseName** and **CollectionName** dimensions from the **Values** dropdown. --## Next steps --* Learn about Azure Monitor [Workbooks](../visualize/workbooks-overview.md) -* Learn more about [Metric Explorer](metrics-charts.md) |
| azure-monitor | Metrics Aggregation Explained | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/metrics-aggregation-explained.md | - Title: Azure Monitor metrics aggregation and display explained -description: Detailed information on how metrics are aggregated in Azure Monitor ---- Previously updated : 09/06/2024----# Azure Monitor Metrics aggregation and display explained --This article explains the aggregation of metrics in the time-series database that backs Azure Monitor [platform metrics](../data-platform.md) and [custom metrics](../essentials/metrics-custom-overview.md). The article also applies to standard [Application Insights metrics](../app/app-insights-overview.md). --This information in this article is complex and is provided for those who want to dig deeper into the metrics system. You do not need to understand it to use Azure Monitor metrics effectively. --## Overview and terms --When you add a metric to a chart, metrics explorer automatically pre-selects its default aggregation. The default makes sense in the basic scenarios, but you can use different aggregations to gain more insights about the metric. Viewing different aggregations on a chart requires that you understand how metrics explorer handles them. --Let's define a few terms clearly first: --- **Metric value** ΓÇô A single measurement value gathered for a specific resource.-- **Time-Series database** - A database optimized for the storage and retrieval of data points all containing a value and a corresponding time-stamp. -- **Time period** ΓÇô A generic period of time.-- **Time interval** ΓÇô The period of time between the gathering of two metric values. -- **Time range** ΓÇô The time period displayed on a chart. Typical default is 24 hours. Only specific ranges are available. -- **Time granularity** or **time grain** ΓÇô The time period used to aggregate values together to allow display on a chart. Only specific ranges are available. Current minimum is 1 minute. The time granularity value should be smaller than the selected time range to be useful, otherwise just one value is shown for the entire chart. -- **Aggregation type** ΓÇô A type of statistic calculated from multiple metric values. -- **Aggregate** ΓÇô The process of taking multiple input values and then using them to produce a single output value via the rules defined by the aggregation type. For example, taking an average of multiple values. --## Summary of process --Metrics are a series of values stored with a time-stamp. In Azure, most metrics are stored in the Azure Metrics time-series database. When you plot a chart, the values of the selected metrics are retrieved from the database and then separately aggregated based on the chosen time granularity (also known as time grain). You select the size of the time granularity using the [metrics explorer time picker](../essentials/analyze-metrics.md#configure-the-time-range). If you donΓÇÖt make an explicit selection, the time granularity is automatically selected based on the currently selected time range. Once selected, the metric values that were captured during each time granularity interval are aggregated and placed onto the chart - one datapoint per interval. --## Aggregation types --There are five basic aggregation types available in the metrics explorer. Metrics explorer hides the aggregations that are irrelevant and can't be used for a given metric. --- **Sum** ΓÇô the sum of all values captured over the aggregation interval. Sometimes referred to as the Total aggregation.-- **Count** ΓÇô the number of measurements captured over the aggregation interval. Count doesn't look at the value of the measurement, only the number of records. -- **Average** ΓÇô the average of the metric values captured over the aggregation interval. For most metrics, this value is Sum/Count. -- **Min** ΓÇô the smallest value captured over the aggregation interval.-- **Max** ΓÇô the largest value captured over the aggregation interval.--For example, suppose a chart is showing the **Network Out Total** metric for a VM using the **SUM** aggregation over the last 24-hour time span. The time range and granularity can be changed from the upper right of the chart as seen in the following screenshot. ---For time granularity = 30 minutes and the time range = 24 hours: --- The chart is drawn from 48 datapoints. That is 24 hours x 2 datapoints per hour (60min/30min) aggregated 1-minute datapoints. -- The line chart connects 48 dots in the chart plot area. -- Each datapoint represents the sum of all network out bytes sent out during each of the relevant 30-min time periods. --- :::image type="content" source="media/metrics-aggregation-explained/24-hour-30-min-gran.png" alt-text="Screenshot showing data on a line graph set to 24-hour time range and 30-minute time granularity" border="true" lightbox="media/metrics-aggregation-explained/24-hour-30-min-gran.png"::: --*Click on the images in this section to see larger versions.* --If you switch the time granularity to 15 minutes, the chart is drawn from 96 aggregated data points. That is, 60min/15min = 4 datapoints per hour x 24 hours. ---For time granularity of 5 minutes, you get 24 x (60/5) = 288 points. ---For time granularity of 1 minute (the smallest possible on the chart), you get 24 x 60/1 = 1440 points. ---The charts look different for these summations as shown in the previous screenshots. Notice how this VM has numerous outputs in a small time period relative to the rest of the time window. --The time granularity allows you to adjust the "signal-to-noise" ratio on a chart. Higher aggregations remove noise and smooth out spikes. Notice the variations at the bottom 1-minute chart and how they smooth out as you go to higher granularity values. --This smoothing behavior is important when you send this data to other systems--for example, alerts. Typically, you usually don't want to be alerted by short spikes in CPU time over 90%. But if the CPU stays at 90% for 5 minutes, that's likely important. If you set up an alert rule on CPU (or any metric), making the time granularity larger can reduce the number of false alerts you receive. --It's important to establish what's "normal" for your workload to know what time interval is best. This is one of the benefits of [dynamic alerts](../alerts/alerts-dynamic-thresholds.md), which is a different topic not covered here. --## How the system collects metrics --Data collection varies by metric. --> [!NOTE] -> The examples below are simplified for illustration, and the actual metric data included in each aggregation is affected by the data available when the evaluation occurs. --### Measurement collection frequency --There are two types of collection periods. --- **Regular** - The metric is gathered at a consistent time interval that doesn't vary.--- **Activity-based** - The metric is gathered based on when a transaction of a certain type occurs. Each transaction has a metric entry and a time stamp. They aren't gathered at regular intervals so there are a varying number of records over a given time period. --### Granularity --The minimum time granularity is 1 minute, but the underlying system may capture data faster depending on the metric. For example, CPU percentage for an Azure VM is captured at a time interval of 15 seconds. Because HTTP failures are tracked as transactions, they can easily exceed many more than one a minute. Other metrics such as SQL Storage are captured at a time interval of every 20 minutes. This choice is up to the individual resource provider and type. Most try to provide the smallest time interval possible. --### Dimensions, splitting, and filtering --Metrics are captured for each individual resource. However, the level at which the metrics are collected, stored, and able to be charted may vary. This level is represented by other metrics available in **metrics dimensions**. Each individual resource provider gets to define how detailed the data they collect is. Azure Monitor only defines how such detail should be presented and stored. --When you chart a metric in metric explorer, you have the option to "split" the chart by a dimension. Splitting a chart means that you're looking into the underlying data for more detail and seeing that data charted or filtered in metric explorer. --For example, [Microsoft.ApiManagement/service](./metrics-supported.md#microsoftapimanagementservice) has *Location* as a dimension for many metrics. --- **Capacity** is one such metric. Having the *Location* dimension implies that the underlying system is storing a metric record for the capacity of each location, rather than just one for the aggregate amount. You can then retrieve or split out that information in a metric chart. --- Looking at **Overall Duration of Gateway Requests**, there are 2 dimensions *Location* and *Hostname*, again letting you know the location of a duration and which hostname it came from. --- One of the more flexible metrics, **Requests**, has 7 different dimensions. - -Check the Azure Monitor [metrics supported](./metrics-supported.md) article for details on each metric and the dimensions available. In addition, the documentation for each resource provider and type may provide additional information on the dimensions and what they measure. --You can use splitting and filtering together to dig into a problem. Below is an example of a graphic showing the *Avg Disk Write Bytes* for a group of VMs in a resource group. We have a rollup of all the VMs with this metric, but we may want to dig into see which are responsible for the peaks around 6AM. Are they the same machine? How many machines are involved? ---*Click on the images in this section to see larger versions.* --When we apply splitting, we can see the underlying data, but it's a bit of a mess. Turns out there are 20 VMs being aggregated into the chart above. In this case, we've used our mouse to hover over the large peak at 6AM that tells us that CH-DCVM11 is the cause. But it's hard to see the rest of the data associated with that VM because of other VMs cluttering the chart. ---Using filtering allows us to clean up the chart to see what's really happening. You can check or uncheck the VMs you want to see. Notice the dotted lines. Those are mentioned in a later section. ---For more information on how to show split dimension data on a metric explorer chart, see [Advanced features of metrics explorer- filters and splitting](../essentials/metrics-charts.md#filters). --### NULL and zero values --When the system expects metric data from a resource but doesn't receive it, it records a NULL value. NULL is different than a zero value, which becomes important in the calculation of aggregations and charting. NULL values aren't counted as valid measurements. --NULLs show up differently on different charts. Scatter plots skip showing a dot on the chart. Bar charts skip showing the bar. On line charts, NULL can show up as [dotted or dashed lines](../essentials/metrics-troubleshoot.md#chart-shows-dashed-line) like those shown in the screenshot in the previous section. When calculating averages that include NULLs, there are fewer data points to take the average from. This behavior can sometimes result in an unexpected drop in values on a chart, though less so than if the value was converted to a zero and used as a valid datapoint. --[Custom metrics](../essentials/metrics-custom-overview.md) always use NULLs when no data is received. With [platform metrics](../data-platform.md), each resource provider decides whether to use zeros or NULLs based on what makes the most sense for a given metric. --Azure Monitor alerts use the values the resource provider writes to the metric database, so it's important to know how the resource provider handles NULLs by viewing the data first. --## How aggregation works --The metrics charts in the previous system show different types of aggregated data. The system preaggregates the data so that the requested charts can show quicker without many repeated computations. --In this example: --- We're collecting a **fictitious** transactional metric called **HTTP failures** -- *Server* is a dimension for the **HTTP failures** metric.-- We have 3 servers - Server A, B, and C.--To simplify the explanation, we start with the SUM aggregation type only. --### Sub minute to 1-minute aggregation --First raw metric data is collected and stored in the Azure Monitor metrics database. In this case, each server has transaction records stored with a timestamp because *Server* is a dimension. Given that the smallest time period you can view as a customer is 1 minute, those timestamps are first aggregated into 1-minute metric values for each individual server. The aggregation process for Server B is shown in the graphic below. Servers A and C are done in the same way and have different data. ---The resulting 1-minute aggregated values are stored as new entries in the metrics database so they can be gathered for later calculations. ---### Dimension aggregation --The 1-minute calculations are then collapsed by dimension and again stored as individual records. In this case, all the data from all the individual servers are aggregated into a 1-minute interval metric and stored in the metrics database for use in later aggregations. ---For clarity, the following table shows the method of aggregation. --| Period | Server A | Server B | Server C | Sum (A+B+C)| -| -- | -- | -- | -- | -- | -| Minute 1 | 1 | 1 | 1 | 3 | -| Minute 2 | 0 | 5 | 1 | 6 | -| Minute 3 | 0 | 5 | 1 | 6 | -| Minute 4 | 2 | 3 | 4 | 9 | -| Minute 5 | 1 | 0 | 3 | 4 | -| Minute 6 | 1 | 0 | 4 | 5 | -| Minute 7 | 1 | 2 | 4 | 7 | -| Minute 8 | 0 | 1 | 0 | 1 | -| Minute 9 | 1 | 1 | 4 | 6 | -| Minute 10| 2 | 1 | 0 | 3 | --Only one dimension is shown above, but this same aggregation and storage process occurs for **all dimensions** that a metric supports. --- Collect values into 1-minute aggregated set by that dimension. Store those values. -- Collapse the dimension into a 1-minute aggregated SUM. Store those values. --Let's introduce another dimension of HTTP failures called NetworkAdapter. Let's say we had a varying number of adapters per server. --- Server A has 1 adapter-- Server B has 2 adapters-- Server C has 3 adapters--We'd collect data for the following transactions separately. They would be marked with: --- A time-- A value-- The server the transaction came from-- The adapter that the transaction came from--Each of those subminute streams would then be aggregated into 1-minute time-series values and stored in the Azure Monitor metric database: --- Server A, Adapter 1-- Server B, Adapter 1-- Server B, Adapter 2-- Server C, Adapter 1-- Server C, Adapter 2-- Server C, Adapter 3--In addition, the following collapsed aggregations would also be stored: --- Server A, Adapter 1 (because there's nothing to collapse, it would be stored again)-- Server B, Adapter 1+2-- Server C, Adapter 1+2+3-- Servers ALL, Adapters ALL--This shows that metrics with large numbers of dimensions have a larger number of aggregations. It's not important to know all the permutations, just understand the reasoning. The system wants to have both the individual data and the aggregated data stored for quick retrieval for access on any chart. The system picks either the most relevant stored aggregation or the underlying raw data depending on what you choose to display. --### Aggregation with no dimensions --Because this metric has a dimension *Server*, you can get to the underlying data for server A, B, and C above via splitting and filtering, as explained earlier in this article. If the metric didn't have *Server* as a dimension, you as a customer could only access the aggregated 1-minute sums shown in black on the diagram. That is, the values of 3, 6, 6, 9, etc. The system also wouldn't do the underlying work to aggregate split values it would never use them in metric explorer or send them out via the metrics REST API. --## Viewing time granularities above 1 minute --If you ask for metrics at a larger granularity, the system uses the 1-minute aggregated sums to calculate the sums for the larger time granularities. Below, dotted lines show the summation method for the 2-minute and 5-minute time granularities. Again, we're showing just the SUM aggregation type for simplicity. ---For the 2-minute time granularity. --| Period | Sums -| -|-| -| Minute 1 & 2 | (3 + 6) = 9 | -| Minute 3 & 4 | (6 + 9) = 15| -| Minute 4 & 5 | (4 + 5) = 9 | -| Minute 6 & 7 | (7 + 1) = 8 | -| Minute 8 & 9 | (6 + 3) = 9 | --For 5-minute time granularity. --| Period | Sums | -||| -| Minute 1 through 5 | 3 + 6 + 6 + 9 + 4 = 28 | -| Minute 6 through 10 | 5 + 7 + 1 + 6 + 3 = 22 | --The system uses the stored aggregated data that gives the best performance. --Below is the larger diagram for the above 1-minute aggregation process, with some of the arrows left out to improve readability. ---## More complex example --Following is a larger example using values for a fictitious metric called HTTP Response time in milliseconds. Here we introduce other levels of complexity. --1. We show aggregation for Sum, Count, Min, and Max and the calculation for Average. -2. We show NULL values and how they affect calculations. --Consider the following example. The boxes and arrows show examples of how the values are aggregated and calculated. --The same 1-minute preaggregation process as described in the previous section occurs for Sums, Count, Minimum, and Maximum. However, Average is NOT preaggregated. It's recalculated using aggregated data to avoid calculation errors. - --Consider minute 6 for the 1-minute aggregation as highlighted above. This minute is the point where Server B went offline and stopped reporting data, perhaps due to a reboot. --From Minute 6 above, the calculated 1-minute aggregation types are: --| Aggregation type | Value | Notes | -||--|-| -| Sum | 53+20=73 | | -| Count | 2 | Shows the effect of NULLs. The value would have been 3 if the server had been online. | -| Minimum | 20 | | -| Maximum | 53 | | -| Average | 73 / 2 | Always the Sum divided by the Count. It's never stored and always recalculated for each time granularity using the aggregated numbers for that granularity. Notice the recalculation for the 5-minute and 10-minute time granularities as highlighted above. | --The red text color indicates values that might be considered out of the normal range and shows how they propagate (or fail to) as the time-granularity goes up. Notice how the *Min* and *Max* indicate there are underlying anomalies while the *Average* and *Sums* lose that information as your time granularity goes up. --You can also see that the NULLs give a better calculation of average than if zeros were used instead. --> [!NOTE] -> Though not the case in this example, *Count* is equal to *Sum* in cases where a metric is always captured with the value of 1. This is common when a metric tracks the occurrence of a transactional event--for example, the number of HTTP failures mentioned in a previous example in this article. --## Next steps --- [Analyze metrics with Azure Monitor metrics explorer](../essentials/analyze-metrics.md) |
| azure-monitor | Metrics Custom Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/metrics-custom-overview.md | - Title: Custom metrics in Azure Monitor (preview) -description: Learn about custom metrics in Azure Monitor and how they're modeled. ---- Previously updated : 01/07/2024---# Custom metrics in Azure Monitor (preview) --Azure makes some metrics available to you out of the box. These metrics are called [standard or platform](./metrics-supported.md). Custom metrics are performance indicators or business-specific metrics that can be collected via your application's telemetry, the Azure Monitor Agent, a diagnostics extension that runs on your Azure resources, or an external monitoring system. Once custom metrics are published to Azure Monitor, you can browse, query, and alert on them along side the standard Azure metrics. --Azure Monitor custom metrics are currently in public preview. --## Methods to send custom metrics --Custom metrics can be sent to Azure Monitor via several methods: --- Use Azure Application Insights SDK to instrument your application by sending custom telemetry to Azure Monitor.-- Install the [Azure Monitor Agent](../agents/azure-monitor-agent-overview.md) on your Windows or Linux Azure virtual machine or virtual machine scale set and use a [data collection rule](../agents/azure-monitor-agent-data-collection.md) to send performance counters to Azure Monitor metrics.-- Install the Azure Diagnostics extension on your [Azure VM](../essentials/collect-custom-metrics-guestos-resource-manager-vm.md), [Virtual Machine Scale Set](../essentials/collect-custom-metrics-guestos-resource-manager-vmss.md), [classic VM](../essentials/collect-custom-metrics-guestos-vm-classic.md), or [classic cloud service](../essentials/collect-custom-metrics-guestos-vm-cloud-service-classic.md). Then send performance counters to Azure Monitor.-- Install the [InfluxData Telegraf agent](../essentials/collect-custom-metrics-linux-telegraf.md) on your Azure Linux VM. Send metrics by using the Azure Monitor output plug-in.-- Send custom metrics [directly to the Azure Monitor REST API](./metrics-store-custom-rest-api.md).--## Pricing model and retention --In general, there's no cost to ingest standard metrics (platform metrics) into an Azure Monitor metrics store, but custom metrics incur costs when they enter general availability. Queries to the metrics API do incur costs. For details on when billing is enabled for custom metrics and metrics queries, check the [Azure Monitor pricing page](https://azure.microsoft.com/pricing/details/monitor/). --Custom metrics are retained for the [same amount of time as platform metrics](../essentials/data-platform-metrics.md#retention-of-metrics). --> [!NOTE] -> To provide a better experience, custom metrics sent to Azure Monitor from the Application Insights Classic API (SDKs) are always stored in both Log Analytics and the Metrics Store. Your cost to store these metrics is only based on the volume ingested by Log Analytics. There is no additional cost for data stored in the Metrics Store. --## Custom metric definitions --Each metric data point published contains a namespace, name, and dimension information. The first time a custom metric is emitted to Azure Monitor, a metric definition is automatically created. This new metric definition is then discoverable on any resource that the metric is emitted from via the metric definitions. There's no need to predefine a custom metric in Azure Monitor before it's emitted. --> [!NOTE] -> Application Insights, the diagnostics extension, and the InfluxData Telegraf agent are already configured to emit metric values against the correct regional endpoint and carry all the preceding properties in each emission. ---## Using custom metrics --After custom metrics are submitted to Azure Monitor, you can browse through them via the Azure portal and query them via the Azure Monitor REST APIs. You can also create alerts on them to notify you when certain conditions are met. --> [!NOTE] -> You need to have a reader or contributor role to view custom metrics. See [Monitoring Reader](../../role-based-access-control/built-in-roles.md#monitoring-reader). --### Browse your custom metrics via the Azure portal --1. Go to the [Azure portal](https://portal.azure.com). -1. Select the **Monitor** pane. -1. Select **Metrics**. -1. Select a resource that you've emitted custom metrics against. -1. Select the metrics namespace for your custom metric. -1. Select the custom metric. --For more information on viewing metrics in the Azure portal, see [Analyze metrics with Azure Monitor metrics explorer](./analyze-metrics.md). ---## Latency and storage retention --A newly added metric or a newly added dimension to a metric might take up to 3 minutes to appear. After the data is in the system, it should appear in less than 30 seconds 99 percent of the time. --If you delete a metric or remove a dimension, the change can take a week to a month to be deleted from the system. --## Quotas and limits --Azure Monitor imposes the following usage limits on custom metrics: --|Category|Limit| -||| -|Total active time series in a subscription per region|50,000| -|Dimension keys per metric|10| -|String length for metric namespaces, metric names, dimension keys, and dimension values|256 characters| -|The combined length of all custom metric names, using utf-8 encoding|64 KB| --An active time series is defined as any unique combination of metric, dimension key, or dimension value that has had metric values published in the past 12 hours. --To understand the limit of 50,000 on time series, consider the following metric: --> *Server response time* with Dimensions: *Region*, *Department*, *CustomerID* --With this metric, if you have 10 regions, 20 departments, and 100 customers that gives you 10 x 20 x 100 = 20,000 time series. --If you have 100 regions, 200 departments, and 2,000 customers, that gives you 100 x 200 x 2,000 = 40 million time series, which is far over the limit just for this metric alone. --Again, this limit isn't for an individual metric. It's for the sum of all such metrics across a subscription and region. --Follow the steps below to see your current total active time series metrics, and more information to assist with troubleshooting. --1. Navigate to the Monitor section of the Azure portal. -1. Select **Metrics** on the left hand side. -1. Under **Select a scope**, check the applicable subscription and resource groups. -1. Under **Refine scope**, choose **Custom Metric Usage** and the desired location. -1. Select the **Apply** button. -1. Choose either **Active Time Series**, **Active Time Series Limit**, or **Throttled Time Series**. --There's a limit of 64 KB on the combined length of all custom metrics names, assuming utf-8 or 1 byte per character. If the 64-KB limit is exceeded, metadata for additional metrics won't be available. The metric names for additional custom metrics won't appear in the Azure portal in selection fields, and won't be returned by the API in requests for metric definitions. The metric data is still available and can be queried. --When the limit has been exceeded, reduce the number of metrics you're sending or shorten the length of their names. It then takes up to two days for the new metrics' names to appear. --To avoid reaching the limit, don't include variable or dimensional aspects in your metric names. -For example, the metrics for server CPU usage,`CPU_server_12345678-319d-4a50-b27e-1234567890ab` and `CPU_server_abcdef01-319d-4a50-b27e-abcdef012345` should be defined as metric `CPU` and with a `Server` dimension. --## Design limitations and considerations --**Using Application Insights for the purpose of auditing.** The Application Insights telemetry pipeline is optimized for minimizing the performance impact and limiting the network traffic from monitoring your application. As such, it throttles or samples (takes only a percentage of your telemetry and ignores the rest) if the initial dataset becomes too large. Because of this behavior, you can't use it for auditing purposes because some records are likely to be dropped. --**Metrics with a variable in the name.** Don't use a variable as part of the metric name. Use a constant instead. Each time the variable changes its value, Azure Monitor generates a new metric. Azure Monitor then quickly hits the limit on the number of metrics. Generally, when developers want to include a variable in the metric name, they really want to track multiple time series within one metric and should use dimensions instead of variable metric names. --**High-cardinality metric dimensions.** Metrics with too many valid values in a dimension (a *high cardinality*) are much more likely to hit the 50,000 limit. In general, you should never use a constantly changing value in a dimension. Timestamp, for example, should never be a dimension. You can use server, customer, or product ID, but only if you have a smaller number of each of those types. --As a test, ask yourself if you would ever chart such data on a graph. If you have 10 or maybe even 100 servers, it might be useful to see them all on a graph for comparison. But if you have 1,000, the resulting graph would likely be difficult or impossible to read. A best practice is to keep it to fewer than 100 valid values. Up to 300 is a gray area. If you need to go over this amount, use Azure Monitor custom logs instead. --If you have a variable in the name or a high-cardinality dimension, the following issues can occur: --- Metrics become unreliable because of throttling.-- Metrics Explorer won't work.-- Alerting and notifications become unpredictable.-- Costs can increase unexpectedly. Microsoft isn't charging for custom metrics with dimensions while this feature is in public preview. After charges start in the future, you'll incur unexpected charges. The plan is to charge for metrics consumption based on the number of time series monitored and number of API calls made.--If the metric name or dimension value is populated with an identifier or high-cardinality dimension by mistake, you can easily fix it by removing the variable part. --But if high cardinality is essential for your scenario, the aggregated metrics are probably not the right choice. Switch to using custom logs (that is, trackMetric API calls with [trackEvent](../app/api-custom-events-metrics.md#trackevent)). However, consider that logs don't aggregate values, so every single entry will be stored. As a result, if you have a large volume of logs in a small time period (1 million a second, for example), it can cause throttling and ingestion delays. --## Next steps --Use custom metrics from various - |
| azure-monitor | Metrics Explorer | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/metrics-explorer.md | - Title: Azure Monitor metrics explorer with PromQL (Preview) -description: Learn about Azure Monitor metrics explorer with Prometheus query language support. ---- Previously updated : 04/24/2024---# Customer intent: As an Azure Monitor user, I want to learn how to use Azure Monitor metrics explorer with PromQL. ----# Azure Monitor metrics explorer with PromQL (Preview) --Azure Monitor metrics explorer with PromQL (Preview) allows you to analyze metrics using Prometheus query language (PromQL) for metrics stored in an Azure Monitor workspace. --Azure Monitor metrics explorer with PromQL (Preview) is available from the **Metrics** menu item of any Azure Monitor workspace. You can query metrics from Azure Monitor workspaces using PromQL or any other Azure resource using the query builder. --> [!NOTE] -> You must have the *Monitoring Reader* role at the subscription level to visualize metrics across multiple resources, resource groups, or a subscription. For more information, see [Assign Azure roles in the Azure portal](/azure/role-based-access-control/role-assignments-portal). ---## Create a chart --The chart pane has two options for charting a metric: -- Add with editor.-- Add with builder.--Adding a chart with the editor allows you to enter a PromQL query to retrieve metrics data. The editor provides syntax highlighting and intellisense for PromQL queries. Currently, queries are limited to the metrics stored in an Azure Monitor workspace. For more information on PromQL, see [Querying Prometheus](https://prometheus.io/docs/prometheus/latest/querying/basics/). --Adding a chart with the builder allows you to select metrics from any of your Azure resources. The builder provides a list of metrics available in the selected scope. Select the metric, aggregation type, and chart type from the builder. The builder can't be used to chart metrics stored in an Azure Monitor workspace. ---### Create a chart with the editor and PromQL --To add a metric using the query editor: --1. Select **Add metric** and select **Add with editor** from the dropdown. --1. Select a **Scope** from the dropdown list. This scope is the Azure Monitor workspace where the metrics are stored. -1. Enter a PromQL query in the editor field, or select a single metric from **Metric** dropdown. -1. Select **Run** to run the query and display the results in the chart. You can customize the chart by selecting the gear-wheel icon. You can change the chart title, add annotations, and set the time range for the chart. ---### Create a chart with the builder --To add a metric with the builder: --1. Select **Add metric** and select **Add with builder** from the dropdown. --1. Select a **Scope**. The scope can be any Azure resource in your subscription. -1. Select a **Metric Namespace** from the dropdown list. The metrics namespace is the category of the metric. -1. Select a **Metric** from the dropdown list. -1. Select the **Aggregation** type from the dropdown list. -- For more information on the selecting scope, metrics, and aggregation, see [Analyze metrics](/azure/azure-monitor/essentials/analyze-metrics#set-the-resource-scope). ---Metrics are displayed by default as a line chart. Select your preferred chart type from the dropdown list in the toolbar. Customize the chart by selecting the gear-wheel icon. You can change the chart title, add annotations, and set the time range for the chart. --## Multiple metrics and charts -Each workspace can host multiple charts. Each chart can contain multiple metrics. --### Add a metric --Add multiple metrics to the chart by selecting **Add metric**. Use either the builder or the editor to add metrics to the chart. --> [!NOTE] -> Using both the code editor and query builder on the same chart is not supported in the Preview release of Azure Monitor metrics explorer and may result in unexpected behavior. ---### Add a new chart --Create additional charts by selecting **New chart**. Each chart can have multiple metrics and different chart types and settings. --Time range and granularity are applied to all the charts in the workspace. ---### Remove a chart --To remove a chart, select the ellipsis (**...**) options icon and select **Remove**. --## Configure time range and granularity --Configure the time range and granularity for your metric chart to view data that's relevant to your monitoring scenario. By default, the chart shows the most recent 24 hours of metrics data. --Set the time range for the chart by selecting the time picker in the toolbar. Select a predefined time range, or set a custom time range. ---Time grain is the frequency of sampling and display of the data points on the chart. Select the time granularity by using the time picker in the metrics explorer. If the data is stored at a lower or more frequent granularity than selected, the metric values displayed are aggregated to the level of granularity selected. The time grain is set to automatic by default. The automatic setting selects the best time grain based on the time range selected. --For more information on configuring time range and granularity, see [Analyze metrics](/azure/azure-monitor/essentials/analyze-metrics#configure-the-time-range). ---## Chart features --Interact with the charts to gain deeper insights into your metrics data. -Interactive features include the following: --- Zoom-in. Select and drag to zoom in on a specific area of the chart. -- Pan. Shift chart left and right along the time axis.-- Change chart settings such as chart type, Y-axis range, and legends.-- Save and share charts--For more information on chart features, see [Interactive chart features](/azure/azure-monitor/essentials/analyze-metrics#interactive-chart-features). ---## Next steps --- [Azure Monitor managed service for Prometheus](/azure/azure-monitor/essentials/prometheus-metrics-overview)-- [Azure Monitor workspace overview](/azure/azure-monitor/essentials/azure-monitor-workspace-overview)-- [Understanding metrics aggregation](/azure/azure-monitor/essentials/metrics-aggregation-explained) |
| azure-monitor | Metrics Store Custom Rest Api | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/metrics-store-custom-rest-api.md | - Title: Send metrics to the Azure Monitor metric database by using a REST API -description: Learn how to send custom metrics for an Azure resource to the Azure Monitor metrics store by using a REST API. ---- Previously updated : 01/07/2024---# Ingest custom metrics for an Azure resource using the REST API --This article shows you how to send custom metrics for Azure resources to the Azure Monitor metrics store via the REST API. When the metrics are in Azure Monitor, you can do all the things with them that you do with standard metrics. For example, you can generate charts and alerts and route the metrics to other external tools. --> [!NOTE] -> The REST API only permits sending custom metrics for Azure resources. To send metrics for resources in other environments or on-premises, use [Application Insights](../app/api-custom-events-metrics.md). --## Send REST requests to ingest custom metrics --When you send custom metrics to Azure Monitor, each data point, or value, reported in the metrics must include the following information. --+ [Authentication token](#authentication) -+ [Subject](#subject) -+ [Region](#region) -+ [Timestamp](#timestamp) -+ [Namespace](#namespace) -+ [Name](#name) -+ [Dimension keys](#dimension-keys) -+ [Dimension values](#dimension-values) -+ [Metric values](#metric-values) ---### Authentication --To submit custom metrics to Azure Monitor, the entity that submits the metric needs a valid Microsoft Entra token in the **Bearer** header of the request. Supported ways to acquire a valid bearer token include: --- [Managed identities for Azure resources](../../active-directory/managed-identities-azure-resources/overview.md). You can use a managed identity to give resources permissions to carry out certain operations. An example is allowing a resource to emit metrics about itself. A resource, or its managed identity, can be granted **Monitoring Metrics Publisher** permissions on another resource. With this permission, the managed identity can also emit metrics for other resources.-- [Microsoft Entra service principal](../../active-directory/develop/app-objects-and-service-principals.md). In this scenario, a Microsoft Entra application, or service, can be assigned permissions to emit metrics about an Azure resource. To authenticate the request, Azure Monitor validates the application token by using Microsoft Entra public keys. The existing **Monitoring Metrics Publisher** role already has this permission. It's available in the Azure portal.-- The service principal, depending on what resources it emits custom metrics for, can be given the **Monitoring Metrics Publisher** role at the scope required. Examples are a subscription, resource group, or specific resource. --> [!TIP] -> When you request a Microsoft Entra token to emit custom metrics, ensure that the audience or resource that the token is requested for is `https://monitoring.azure.com/`. Be sure to include the trailing slash. --### Get an authorization token --Once you have created your managed identity or service principal and assigned **Monitoring Metrics Publisher** permissions, you can get an authorization token. -When requesting a token specify `resource: https://monitoring.azure.com`. ---Save the access token from the response for use in the following HTTP requests. ---### Subject --The subject property captures which Azure resource ID the custom metric is reported for. This information is encoded in the URL of the API call. Each API can submit metric values for only a single Azure resource. --> [!NOTE] -> You can't emit custom metrics against the resource ID of a resource group or subscription. --### Region --The region property captures the Azure region where the resource you're emitting metrics for is deployed. Metrics must be emitted to the same Azure Monitor regional endpoint as the region where the resource is deployed. For example, custom metrics for a VM deployed in West US must be sent to the WestUS regional Azure Monitor endpoint. The region information is also encoded in the URL of the API call. --### Timestamp --Each data point sent to Azure Monitor must be marked with a timestamp. This timestamp captures the date and time at which the metric value is measured or collected. Azure Monitor accepts metric data with timestamps as far as 20 minutes in the past and 5 minutes in the future. The timestamp must be in ISO 8601 format. --### Namespace --Namespaces are a way to categorize or group similar metrics together. By using namespaces, you can achieve isolation between groups of metrics that might collect different insights or performance indicators. For example, you might have a namespace called **contosomemorymetrics** that tracks memory-use metrics which profile your app. Another namespace called **contosoapptransaction** might track all metrics about user transactions in your application. --### Name --The name property is the name of the metric that's being reported. Usually, the name is descriptive enough to help identify what's measured. An example is a metric that measures the number of memory bytes used on a VM. It might have a metric name like **Memory Bytes In Use**. --### Dimension keys --A dimension is a key/value pair that helps describe other characteristics about the metric that's being collected. By using the other characteristics, you can collect more information about the metric, which allows for deeper insights. --For example, the **Memory Bytes In Use** metric might have a dimension key called **Process** that captures how many bytes of memory each process on a VM consumes. By using this key, you can filter the metric to see how much memory specific processes use or to identify the top five processes by memory usage. --Dimensions are optional, and not all metrics have dimensions. A custom metric can have up to 10 dimensions. --### Dimension values --When you're reporting a metric data point, for each dimension key on the reported metric, there's a corresponding dimension value. For example, you might want to report the memory that ContosoApp uses on your VM: --* The metric name would be **Memory Bytes in Use**. -* The dimension key would be **Process**. -* The dimension value would be **ContosoApp.exe**. --When you're publishing a metric value, you can specify only a single dimension value per dimension key. If you collect the same memory utilization for multiple processes on the VM, you can report multiple metric values for that timestamp. Each metric value would specify a different dimension value for the **Process** dimension key. --Although dimensions are optional, if a metric post defines dimension keys, corresponding dimension values are mandatory. --### Metric values --Azure Monitor stores all metrics at 1-minute granularity intervals. During a given minute, a metric might need to be sampled several times. An example is CPU utilization. Or a metric might need to be measured for many discrete events, such as sign-in transaction latencies. --To limit the number of raw values that you have to emit and pay for in Azure Monitor, locally preaggregate and emit the aggregated values: --* **Min**: The minimum observed value from all the samples and measurements during the minute. -* **Max**: The maximum observed value from all the samples and measurements during the minute. -* **Sum**: The summation of all the observed values from all the samples and measurements during the minute. -* **Count**: The number of samples and measurements taken during the minute. ---> [!NOTE] -> Azure Monitor doesn't support defining **Units** for a custom metric. ---For example, if there were four sign-in transactions to your app during a minute, the resulting measured latencies for each might be: --|Transaction 1|Transaction 2|Transaction 3|Transaction 4| -||||| -|7 ms|4 ms|13 ms|16 ms| --Then the resulting metric publication to Azure Monitor would be: --* Min: 4 -* Max: 16 -* Sum: 40 -* Count: 4 --If your application can't preaggregate locally and needs to emit each discrete sample or event immediately upon collection, you can emit the raw measure values. For example, each time a sign-in transaction occurs on your app, you publish a metric to Azure Monitor with only a single measurement. So, for a sign-in transaction that took 12 milliseconds, the metric publication would be: --* Min: 12 -* Max: 12 -* Sum: 12 -* Count: 1 --With this process, you can emit multiple values for the same metric/dimension combination during a given minute. Azure Monitor then takes all the raw values emitted for a given minute and aggregates them. --### Sample custom metric publication --In the following example, create a custom metric called **Memory Bytes in Use** under the metric namespace **Memory Profile** for a virtual machine. The metric has a single dimension called **Process**. For the timestamp, metric values are emitted for two processes. --Store the following JSON in a file called *custommetric.json* on your local computer. Update the time parameter so that it's within the last 20 minutes. You can't put a metric into the store that's more than 20 minutes old. --```json -{ - "time": "2024-01-07T11:25:20-7:00", - "data": { -- "baseData": { -- "metric": "Memory Bytes in Use", - "namespace": "Memory Profile", - "dimNames": [ - "Process" - ], - "series": [ - { - "dimValues": [ - "ContosoApp.exe" - ], - "min": 10, - "max": 89, - "sum": 190, - "count": 4 - }, - { - "dimValues": [ - "SalesApp.exe" - ], - "min": 10, - "max": 23, - "sum": 86, - "count": 4 - } - ] - } - } - } -``` --Submit the following HTTP POST request by using the following variables: -+ `location`: Deployment region of the resource you're emitting metrics for. -+ `resourceId`: Resource ID of the Azure resource you're tracking the metric against. -+ `accessToken`: The authorization token acquired from the *Get an authorization token* step. - - ```console - curl -X POST 'https://<location>.monitoring.azure.com/<resourceId>/metrics' \ - -H 'Content-Type: application/json' \ - -H 'Authorization: Bearer <accessToken>' \ - -d @custommetric.json - ``` ---## View your metrics --1. Sign in to the Azure portal. --1. In the menu on the left, select **Monitor**. --1. On the **Monitor** page, select **Metrics**. -- :::image type="content" source="./media/metrics-store-custom-rest-api/metrics.png" alt-text="Screenshot that shows how to select Metrics in the Azure portal."::: --1. Change the aggregation period to **Last hour**. --1. In the **Scope** dropdown list, select the resource you send the metric for. --1. In the **Metric Namespace** dropdown list, select **Memory Profile**. --1. In the **Metric** dropdown list, select **Memory Bytes in Use**. --## Troubleshooting --If you receive an error message with some part of the process, consider the following troubleshooting information: --- If you can't issue metrics against a subscription or resource group, or resource, check that your application or service principal has the **Monitoring Metrics Publisher** role assigned in **Access control (IAM)**.-- Check that the number of dimension names matches the number of values.-- Check that you're emitting metrics to the correct Azure Monitor regional endpoint. For example, if your resource is deployed in West US, you must emit metrics to the West US regional endpoint.-- Check that the timestamp is within the last 20 minutes.-- Check that the timestamp is in ISO 8601 format.-- Check that the metric name is valid. For example, it can't contain spaces.--## Next steps --Learn more about [custom metrics](./metrics-custom-overview.md). |
| azure-monitor | Metrics Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/metrics-troubleshoot.md | - Title: Troubleshooting Azure Monitor metric charts -description: Troubleshoot the issues with creating, customizing, or interpreting metric charts ---- Previously updated : 01/21/2024---# Troubleshooting metrics charts --Use this article if you run into issues with creating, customizing, or interpreting charts in Azure metrics explorer. If you're new to metrics, learn about [getting started with metrics explorer](metrics-getting-started.md) and [advanced features of metrics explorer](../essentials/metrics-charts.md). You can also see [examples](../essentials/metric-chart-samples.md) of the configured metric charts. --## Chart shows no data --Sometimes the charts might show no data after selecting correct resources and metrics. Several of the following reasons can cause this behavior: --### Microsoft.Insights resource provider isn't registered for your subscription --Exploring metrics requires *Microsoft.Insights* resource provider registered in your subscription. In many cases, it's registered automatically (that is, after you configure an alert rule, customize diagnostic settings for any resource, or configure an autoscale rule). If the Microsoft.Insights resource provider isn't registered, you must manually register it by following steps described in [Azure resource providers and types](../../azure-resource-manager/management/resource-providers-and-types.md). --**Solution:** Open **Subscriptions**, **Resource providers** tab, and verify that *Microsoft.Insights* is registered for your subscription. --### You don't have sufficient access rights to your resource --In Azure, [Azure role-based access control (Azure RBAC)](../../role-based-access-control/overview.md) controls access to metrics. You must be a member of [monitoring reader](../../role-based-access-control/built-in-roles.md#monitoring-reader), [monitoring contributor](../../role-based-access-control/built-in-roles.md#monitoring-contributor), or [contributor](../../role-based-access-control/built-in-roles.md#contributor) to explore metrics for any resource. --**Solution:** Ensure that you have sufficient permissions for the resource from which you're exploring metrics. --### You receive the error message "Access permission denied" --You may encounter this message when querying from an Azure Kubernetes Service (AKS) or Azure Monitor workspace. Since Prometheus metrics for your AKS are stored in Azure Monitor workspaces, this error can be caused by various reasons: --* You may not have the permissions to query from the Azure Monitor workspace being used to emit metrics. -* You may have an adblock software enabled that blocks `monitor.azure.com` traffic. -* Your Azure Monitor workspace Networking settings don't support query access. --**Solution(s):** One or more of the following fixes may be required to fix the error. --* Check that you have sufficient permissions to perform microsoft.monitor/accounts/read assigned through Access Control (IAM) in your Azure Monitor workspace. -* You may need to pause or disable your adblock in order to view data. Or you can set your adblock allow `monitor.azure.com` traffic. -* You might need to enable private access through your private endpoint or change settings to allow public access. --### Your resource didn't emit metrics during the selected time range --Some resources donΓÇÖt constantly emit their metrics. For example, Azure doesn't collect metrics for stopped virtual machines. Other resources might emit their metrics only when some condition occurs. For example, a metric showing processing time of a transaction requires at least one transaction. If there were no transactions in the selected time range, the chart is naturally empty. Additionally, while most of the metrics in Azure are collected every minute, there are some that are collected less frequently. See the metric documentation to get more details about the metric that you're trying to explore. --**Solution:** Change the time of the chart to a wider range. You may start from "Last 30 days" using a larger time granularity (or relying on the "Automatic time granularity" option). --### You picked a time range greater than 30 days --[Most metrics in Azure are stored for 93 days](../essentials/data-platform-metrics.md#retention-of-metrics). However, you can only query for no more than 30 days worth of data on any single chart. This limitation doesn't apply to [log-based metrics](../app/pre-aggregated-metrics-log-metrics.md#log-based-metrics). --**Solution:** If you see a blank chart or your chart only displays part of metric data, verify that the difference between start- and end- dates in the time picker doesn't exceed the 30-day interval. Once you select a 30 day interval, you can [pan](metrics-charts.md#pan) the chart to view the full retention window. --### All metric values were outside of the locked y-axis range --By [locking the boundaries of chart y-axis](../essentials/metrics-charts.md#locking-the-range-of-the-y-axis), you can unintentionally make the chart display area not show the chart line. For example, if the y-axis is locked to a range between 0% and 50%, and the metric has a constant value of 100%, the line is always rendered outside of the visible area, making the chart appear blank. --**Solution:** Verify that the y-axis boundaries of the chart arenΓÇÖt locked outside of the range of the metric values. If the y-axis boundaries are locked, you may want to temporarily reset them to ensure that the metric values donΓÇÖt fall outside of the chart range. Locking the y-axis range isnΓÇÖt recommended with automatic granularity for the charts with **sum**, **min**, and **max** aggregation because their values will change with granularity by resizing browser window or going from one screen resolution to another. Switching granularity may leave the display area of your chart empty. --### You're looking at a Guest (classic) metric but didnΓÇÖt enable Azure Diagnostic Extension --Collection of **Guest (classic)** metrics requires configuring the Azure Diagnostics Extension or enabling it using the **Diagnostic Settings** panel for your resource. --**Solution:** If Azure Diagnostics Extension is enabled but you're still unable to see your metrics, follow steps outlined in [Azure Diagnostics Extension troubleshooting guide](../agents/diagnostics-extension-troubleshooting.md#metric-data-doesnt-appear-in-the-azure-portal). See also the troubleshooting steps for [can't pick Guest (classic) namespace and metrics](#cannot-pick-guest-namespace-and-metrics) --### Chart is segmented by a property that the metric doesn't define --If you segment a chart by a property that the metric doesn't define, the chart displays no content. --**Solution:** Clear the segmentation (splitting), or choose a different property. --### Filter on another chart excludes all data --Filters apply to all of the charts on the pane. If you set a filter on another chart, it could exclude all data from the current chart. --**Solution:** Check the filters for all the charts on the pane. If you want different filters on different charts, create the charts in different panes. Save the charts as separate favorites. If you want, you can pin the charts to the dashboard so you can see them together. --## "Error retrieving data" message on dashboard --This problem may happen when your dashboard was created with a metric that was later deprecated and removed from Azure. To verify that it's the case, open the **Metrics** tab of your resource, and check the available metrics in the metric picker. If the metric isn't shown, the metric has been removed from Azure. Usually, when a metric is deprecated, there's a better new metric that provides with a similar perspective on the resource health. --**Solution:** Update the failing tile by picking an alternative metric for your chart on dashboard. You can [review a list of available metrics for Azure services](./metrics-supported.md). --## Chart shows dashed line --Azure metrics charts use dashed line style to indicate that there's a missing value (also known as "null value") between two known time grain data points. For example, if in the time selector you picked "1 minute" time granularity but the metric was reported at 07:26, 07:27, 07:29, and 07:30 (note a minute gap between second and third data points), then a dashed line connects 07:27 and 07:29 and a solid line connects all other data points. The dashed line drops down to zero when the metric uses **count** and **sum** aggregation. For the **avg**, **min** or **max** aggregations, the dashed line connects two nearest known data points. Also, when the data is missing on the rightmost or leftmost side of the chart, the dashed line expands to the direction of the missing data point. - :::image type="content" source="./media/metrics-troubleshoot/dashed-line.png" lightbox="./media/metrics-troubleshoot/dashed-line.png" alt-text="Screenshot that shows how when the data is missing on the rightmost or leftmost side of the chart, the dashed line expands to the direction of the missing data point."::: --**Solution:** This behavior is by design. It's useful for identifying missing data points. The line chart is a superior choice for visualizing trends of high-density metrics but may be difficult to interpret for the metrics with sparse values, especially when corelating values with time grain is important. The dashed line makes reading of these charts easier but if your chart is still unclear, consider viewing your metrics with a different chart type. For example, a scattered plot chart for the same metric clearly shows each time grain by only visualizing a dot when there's a value and skipping the data point altogether when the value is missing: - <!-- convertborder later --> - :::image type="content" source="./media/metrics-troubleshoot/scatter-plot.png" lightbox="./media/metrics-troubleshoot/scatter-plot.png" alt-text="Screenshot that highlights the Scatter chart menu option." border="false"::: -- > [!NOTE] - > If you still prefer a line chart for your metric, moving mouse over the chart may help to assess the time granularity by highlighting the data point at the location of the mouse pointer. --## Units of measure in metrics charts --Azure monitor metrics uses SI based prefixes. Metrics only use IEC prefixes if the resource provider chooses an appropriate unit for a metric. -For ex: The resource provider Network interface (resource name: rarana-vm816) has no metric unit defined for "Packets Sent". The prefix used for the metric value here's k representing kilo (1000), a SI prefix. --The resource provider Storage account (resource name: ibabichvm) has metric unit defined for "Blob Capacity" as bytes. Hence, the prefix used is mebi (1024^2), an IEC prefix. --SI uses decimal --| Value | abbreviation | SI | -|::|::|:-:| -| 1000 | k | kilo | -| 1000^2 | M | mega | -| 1000^3 | G | giga | -| 1000^4 | T | tera | -| 1000^5 | P | peta | -| 1000^6 | E | exa | -| 1000^7 | Z | zetta | -| 1000^8 | Y | yotta | --IEC uses binary --|Value | abbreviation| IEC |Legacy| SI | -|:-:|:--:|::|:-:|::| -|1024 | Ki |kibi | K | kilo| -|1024^2| Mi |mebi | M | mega| -|1024^3| Gi |gibi | G | giga| -|1024^4| Ti |tebi | T | tera| -|1024^5| Pi |pebi | - | | -|1024^6| Ei |exbi | - | | -|1024^7| Zi |zebi | - | | -|1024^8| Yi |yobi | - | | ---## Chart shows unexpected drop in values --In many cases, the perceived drop in the metric values is a misunderstanding of the data shown on the chart. You can be misled by a drop in sums or counts when the chart shows the most-recent minutes because Azure hasn't received or processed the last metric data points yet. Depending on the service, the latency of processing metrics can be within a couple minutes range. For charts showing a recent time range with a 1- or 5- minute granularity, a drop of the value over the last few minutes becomes more noticeable: - <!-- convertborder later --> - :::image type="content" source="./media/metrics-troubleshoot/unexpected-dip.png" lightbox="./media/metrics-troubleshoot/unexpected-dip.png" alt-text="Screenshot that shows a drop of the value over the last few minutes." border="false"::: --**Solution:** This behavior is by design. We believe that showing data as soon as we receive it's beneficial even when the data is *partial* or *incomplete*. Doing so allows you to make important conclusion sooner and start investigation right away. For example, for a metric that shows the number of failures, seeing a partial value X tells you that there were at least X failures on a given minute. You can start investigating the problem right away, rather than wait to see the exact count of failures that happened on this minute, which might not be as important. The chart updates once we receive the entire set of data, but at that time it may also show new incomplete data points from more recent minutes. --## Cannot pick Guest namespace and metrics --Virtual machines and virtual machine scale sets have two categories of metrics: **Virtual Machine Host** metrics that are collected by the Azure hosting environment, and **Guest (classic)** metrics that are collected by the [monitoring agent](../agents/agents-overview.md) running on your virtual machines. You install the monitoring agent by enabling [Azure Diagnostic Extension](../agents/diagnostics-extension-overview.md). --By default, Guest (classic) metrics are stored in Azure Storage account, which you pick from the **Diagnostic settings** tab of your resource. If Guest metrics aren't collected or metrics explorer can't access them, you'll only see the **Virtual Machine Host** metric namespace: ---**Solution:** If you don't see **Guest (classic)** namespace and metrics in metrics explorer: --1. Confirm that [Azure Diagnostic Extension](../agents/diagnostics-extension-overview.md) is enabled and configured to collect metrics. - > [!WARNING] - > You can't use [Log Analytics agent](../agents/log-analytics-agent.md) (also referred to as the Microsoft Monitoring Agent, or "MMA") to send **Guest (classic)** into a storage account. --1. Ensure that **Microsoft.Insights** resource provider is [registered for your subscription](#microsoftinsights-resource-provider-isnt-registered-for-your-subscription). --1. Verify that storage account isn't protected by the firewall. Azure portal needs access to storage account in order to retrieve metrics data and plot the charts. --1. Use [Azure Storage Explorer](https://azure.microsoft.com/features/storage-explorer/) to validate that metrics are flowing into the storage account. If metrics aren't collected, follow the [Azure Diagnostics Extension troubleshooting guide](../agents/diagnostics-extension-troubleshooting.md#metric-data-doesnt-appear-in-the-azure-portal). --## Log and queries are disabled for Drill into Logs --To view recommended logs and queries, you must route your diagnostic logs to Log Analytics. --**Solution:** To route your diagnostic logs to Log Analytics, see [Diagnostic settings in Azure Monitor](./diagnostic-settings.md). --## Only the Activity logs appear in Drill into Logs --The Drill into Logs feature is only available for select resource providers. By default, activity logs are provided. --**Solution:** This behavior is expected for some resource providers. --## Next steps --* [Learn about getting started with Metric Explorer](metrics-getting-started.md) -* [Learn about advanced features of Metric Explorer](../essentials/metrics-charts.md) -* [See a list of available metrics for Azure services](./metrics-supported.md) -* [See examples of configured charts](../essentials/metric-chart-samples.md) |
| azure-monitor | Migrate To Azure Storage Lifecycle Policy | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/migrate-to-azure-storage-lifecycle-policy.md | - Title: "Migrate diagnostic settings storage retention to Azure Storage lifecycle management" -description: "How to Migrate from diagnostic settings storage retention to Azure Storage lifecycle management" ----- Previously updated : 09/02/2024--#Customer intent: As a dev-ops administrator I want to migrate my retention setting from diagnostic setting retention storage to Azure Storage lifecycle management so that it continues to work after the feature has been deprecated. ---# Migrate from diagnostic settings storage retention to Azure Storage lifecycle management --The Diagnostic Settings Storage Retention feature is being deprecated. To configure retention for logs and metrics sent to an Azure Storage account, use Azure Storage Lifecycle Management. --This guide walks you through migrating from using Azure diagnostic settings storage retention to using [Azure Storage lifecycle management](../../storage/blobs/lifecycle-management-policy-configure.md?tabs=azure-portal) for retention. -For logs sent to a Log Analytics workspace, retention is set for each table on the **Tables** page of your workspace. For more information on Log Analytics workspace retention, see [Manage data retention in a Log Analytics workspace](../logs/data-retention-configure.md). --> [!IMPORTANT] -> **Deprecation Timeline.** -> - March 31, 2023 ΓÇô The Diagnostic Settings Storage Retention feature will no longer be available to configure new retention rules for log data. This includes using the portal, CLI PowerShell, and ARM and Bicep templates. If you have configured retention settings, you'll still be able to see and change them in the portal. -> - September 30, 2025 ΓÇô All retention functionality for the Diagnostic Settings Storage Retention feature will be disabled across all environments. --## Prerequisites --An existing diagnostic setting logging to a storage account. --## Migration procedures --## [Azure portal](#tab/portal) --To migrate your diagnostics settings retention rules, follow the steps below: --1. Go to the Diagnostic Settings page for your logging resource and locate the diagnostic setting you wish to migrate -1. Set the retention for your logged categories to *0* -1. Select **Save** - :::image type="content" source="./media/retention-migration/diagnostics-setting.png" lightbox="./media/retention-migration/diagnostics-setting.png" alt-text="A screenshot showing a diagnostics setting page."::: --1. Navigate to the storage account you're logging to -1. Under **Data management**, select **Lifecycle Management** to view or change lifecycle management policies -1. Select List View, and select **Add a rule** -1. Enter a **Rule name** -1. Under **Rule Scope**, select **Limit blobs with filters** -1. Under **Blob Type**, select **Append Blobs** and **Base blobs** under **Blob subtype**. -1. Select **Next** --1. Set your retention time, then select **Next** --1. On the **Filters** tab, under **Blob prefix** set path or prefix to the container or logs you want the retention rule to apply to. The path or prefix can be at any level within the container and will apply to all blobs under that path or prefix. -For example, for *all* insight activity logs, use the container *insights-activity-logs* to set the retention for all of the logs in that container. -To set the rule for a specific webapp app, use *insights-activity-logs/ResourceId=/SUBSCRIPTIONS/\<your subscription Id\>/RESOURCEGROUPS/\<your resource group\>/PROVIDERS/MICROSOFT.WEB/SITES/\<your webapp name\>*. -- Use the Storage browser to help you find the path or prefix. - The example below shows the prefix for a specific web app: **insights-activity-logs/ResourceId=/SUBSCRIPTIONS/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/RESOURCEGROUPS/rg-001/PROVIDERS/MICROSOFT.WEB/SITES/appfromdocker1*. - To set the rule for all resources in the resource group, use *insights-activity-logs/ResourceId=/SUBSCRIPTIONS/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e7/RESOURCEGROUPS/rg-001*. - :::image type="content" source="./media/retention-migration/blob-prefix.png" alt-text="A screenshot showing the Storage browser and resource path." lightbox="./media/retention-migration/blob-prefix.png"::: --1. Select **Add** to save the rule. ---## [CLI](#tab/cli) --Use the [az storage account management-policy create](/cli/azure/storage/account/management-policy#az-storage-account-management-policy-create) command to create a lifecycle management policy. You must still set the retention in your diagnostic settings to *0*. For more information, see the migration procedures for the Azure Portal. ----```azurecli --az storage account management-policy create --account-name <storage account name> --resource-group <resource group name> --policy @<policy definition file> -``` --The sample policy definition file below sets the retention for all blobs in the container *insights-activity-logs* for the given subscription ID. For more information, see [Lifecycle management policy definition](../../storage/blobs/lifecycle-management-overview.md#lifecycle-management-policy-definition). --```json -{ - "rules": [ - { - "enabled": true, - "name": "Susbcription level lifecycle rule", - "type": "Lifecycle", - "definition": { - "actions": { - "baseBlob": { - "delete": { - "daysAfterModificationGreaterThan": 120 - } - } - }, - "filters": { - "blobTypes": [ - "appendBlob" - ], - "prefixMatch": [ - "insights-activity-logs/ResourceId=/SUBSCRIPTIONS/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e" - ] - } - } - } - ] -} -----``` --## [Templates](#tab/templates) --Apply the following template to create a lifecycle management policy. You must still set the retention in your diagnostic settings to *0*. For more information, see the migration procedures for the Azure Portal. --```azurecli --az deployment group create --resource-group <resource group name> --template-file <template file> --``` --The following template sets the retention for storage account *azmonstorageaccount001* for all blobs in the container *insights-activity-logs* for all resources for the subscription ID *aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e*. --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "resources": [ - { - "type": "Microsoft.Storage/storageAccounts/managementPolicies", - "apiVersion": "2021-02-01", - "name": "azmonstorageaccount001/default", - "properties": { - "policy": { - "rules": [ - { - "enabled": true, - "name": "Susbcription level lifecycle rule", - "type": "Lifecycle", - "definition": { - "actions": { - "baseBlob": { - "delete": { - "daysAfterModificationGreaterThan": 120 - } - } - }, - "filters": { - "blobTypes": [ - "appendBlob" - ], - "prefixMatch": [ - "insights-activity-logs/ResourceId=/SUBSCRIPTIONS/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e" - ] - } - } - } - ] - } - } - } - ] -} -``` ----## Next steps --[Configure a lifecycle management policy](../../storage/blobs/lifecycle-management-policy-configure.md?tabs=azure-portal). |
| azure-monitor | Migrate To Batch Api | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/migrate-to-batch-api.md | - Title: Migrate from the metrics API to the getBatch API -description: How to migrate from the metrics API to the getBatch API --- Previously updated : 06/27/2024----# Customer intent: As a customer, I want to understand how to migrate from the metrics API to the getBatch API --# How to migrate from the metrics API to the getBatch API --Heavy use of the [metrics API](/rest/api/monitor/metrics/list?tabs=HTTP) can result in throttling or performance problems. Migrating to the [`metrics:getBatch`](/rest/api/monitor/metrics-batch/batch?tabs=HTTP) API allows you to query multiple resources in a single REST request. The two APIs share a common set of query parameter and response formats that make migration easy. --## Request format - The `metrics:getBatch` API request has the following format: - ```http -POST /subscriptions/<subscriptionId>/metrics:getBatch?metricNamespace=<resource type namespace>&api-version=2023-10-01 -Host: <region>.metrics.monitor.azure.com -Content-Type: application/json -Authorization: Bearer <token> -{ - "resourceids":[<comma separated list of resource IDs>] -} --``` --For example, -```http -POST /subscriptions/12345678-1234-1234-1234-123456789abc/metrics:getBatch?metricNamespace=microsoft.compute/virtualMachines&api-version=2023-10-01 -Host: eastus.metrics.monitor.azure.com -Content-Type: application/json -Authorization: Bearer eyJ0eXAiOiJKV1QiLCJhb...TaXzf6tmC4jhog -{ - "resourceids":["/subscriptions/12345678-1234-1234-1234-123456789abc/resourceGroups/rg-vms-01/providers/Microsoft.Compute/virtualMachines/vmss-001_41df4bb9", - "/subscriptions/12345678-1234-1234-1234-123456789abc/resourceGroups/rg-vms-02/providers/Microsoft.Compute/virtualMachines/vmss-001_c1187e2f" -] -} - ``` --## Batching restrictions --Consider the following restrictions on which resources can be batched together when deciding if the `metrics:getBatch` API is the correct choice for your scenario. --- All resources in a batch must be in the same subscription.-- All resources in a batch must be in the same Azure region.-- All resources in a batch must be the same resource type.--To help identify groups of resources that meet these criteria, run the following Azure Resource Graph query using the [Azure Resource Graph Explorer](https://portal.azure.com/#view/HubsExtension/ArgQueryBlade), or via the [Azure Resource Manager Resources query API](/rest/api/azureresourcegraph/resourcegraph(2021-03-01)/resources/resources?tabs=HTTP). --``` - resources - | project id, subscriptionId, ['type'], location - | order by subscriptionId, ['type'], location -``` --## Request conversion steps --To convert an existing metrics API call to a metric:getBatch API call, follow these steps: --Assume the following API call is being used to request metrics: --```http -GET https://management.azure.com/subscriptions/12345678-1234-1234-1234-123456789abc/resourceGroups/sample-test/providers/Microsoft.Storage/storageAccounts/testaccount/providers/microsoft.Insights/metrics?timespan=2023-04-20T12:00:00.000Z/2023-04-22T12:00:00.000Z&interval=PT6H&metricNamespace=microsoft.storage%2Fstorageaccounts&metricnames=Ingress,Egress&aggregation=total,average,minimum,maximum&top=10&orderby=total desc&$filter=ApiName eq '*'&api-version=2019-07-01 -``` --1. Change the hostname. - Replace `management.azure.com` with a regional endpoint for the Azure Monitor Metrics data plane using the following format: `<region>.metrics.monitor.azure.com` where `region` is region of the resources you're requesting metrics for. For the example, if the resources are in westus2, the hostname is `westus2.metrics.monitor.azure.com`. --1. Change the API name and path. - The `metrics:getBatch` API is a subscription level POST API. The resources for which the metrics are requested, are specified in the request body rather than in the URL path. - Change the url path as follows: - from `/subscriptions/12345678-1234-1234-1234-123456789abc/resourceGroups/sample-test/providers/Microsoft.Storage/storageAccounts/testaccount/providers/microsoft.Insights/metrics` - to `/subscriptions/12345678-1234-1234-1234-123456789abc/metrics:getBatch` --1. The `metricNamespace` query param is required for metrics:getBatch. For Azure standard metrics, the namespace name is usually the resource type of the resources you specified. To check the namespace value to use, see the [metrics namespaces API](/rest/api/monitor/metric-namespaces/list?tabs=HTTP) -1. Switch from using the `timespan` query param to using `starttime` and `endtime`. For example, `?timespan=2023-04-20T12:00:00.000Z/2023-04-22T12:00:00.000Z` becomes `?startime=2023-04-20T12:00:00.000Z&endtime=2023-04-22T12:00:00.000Z`. -1. Update the api-version query parameter as follows: `&api-version=2023-10-01` -1. The filter query param isn't prefixed with a `$` in the `metrics:getBatch` API. Change the query param from `$filter=` to `filter=`. -1. The `metrics:getBatch` API is a POST call with a body that contains a comma-separated list of resourceIds in the following format: - For example: - ```json - { - "resourceids": [ - // <comma separated list of resource ids> - ] - } - ``` - - For example: - ```json - { - "resourceids": [ - "/subscriptions/12345678-1234-1234-1234-123456789abc/resourceGroups/sample-test/providers/Microsoft.Storage/storageAccounts/testaccount" - ] - } - ``` -- Up to 50 unique resource IDs may be specified in each call. Each resource must belong to the same subscription, region, and be of the same resource type. --> [!IMPORTANT] -> + The `resourceids` object property in the body must be lower case. -> + Ensure that there are no trailing commas on your last resourceid in the array list. --### Converted batch request --The following example shows the converted batch request. -```http - POST https://westus2.metrics.monitor.azure.com/subscriptions/12345678-1234-1234-1234-123456789abc/metrics:getBatch?starttime=2023-04-20T12:00:00.000Z&endtime=2023-04-22T12:00:00.000Z&interval=PT6H&metricNamespace=microsoft.storage%2Fstorageaccounts&metricnames=Ingress,Egress&aggregation=total,average,minimum,maximum&top=10&orderby=total desc&filter=ApiName eq '*'&api-version=2023-10-01 - - { - "resourceids": [ - "/subscriptions/12345678-1234-1234-1234-123456789abc/resourceGroups/sample-test/providers/Microsoft.Storage/storageAccounts/testaccount", - "/subscriptions/12345678-1234-1234-1234-123456789abc/resourceGroups/sample2-test-rg/providers/Microsoft.Storage/storageAccounts/eax252qtemplate", - "/subscriptions/12345678-1234-1234-1234-123456789abc/resourceGroups/sample3/providers/Microsoft.Storage/storageAccounts/sample3diag", - "/subscriptions/12345678-1234-1234-1234-123456789abc/resourceGroups/sample3/providers/Microsoft.Storage/storageAccounts/sample3prefile", - "/subscriptions/12345678-1234-1234-1234-123456789abc/resourceGroups/sample3/providers/Microsoft.Storage/storageAccounts/sample3tipstorage", - "/subscriptions/12345678-1234-1234-1234-123456789abc/resourceGroups/sample3backups/providers/Microsoft.Storage/storageAccounts/pod01account1" - ] - } -``` --## Response Format --The response format of the `metrics:getBatch` API encapsulates a list of individual metrics call responses in the following format: --```json -{ - "values": [ - // <One individual metrics response per requested resourceId> - ] -} -``` --A `resourceid` property was added to each resources' metrics list in the `metrics:getBatch` API response. -- The following show sample response formats. --### [Individual response](#tab/individual-response) --```json -{ - "cost": 11516, - "startime": "2023-04-20T12:00:00Z", - "endtime": "2023-04-22T12:00:00Z", - "interval": "P1D", - "value": [ - { - "id": "/subscriptions/12345678-1234-1234-1234-123456789abc/resourceGroups/sample-test/providers/Microsoft.Storage/storageAccounts/testaccount/providers/Microsoft.Insights/metrics/Ingress", - "type": "Microsoft.Insights/metrics", - "name": { - "value": "Ingress", - "localizedValue": "Ingress" - }, - "displayDescription": "The amount of ingress data, in bytes. This number includes ingress from an external client into Azure Storage as well as ingress within Azure.", - "unit": "Bytes", - "timeseries": [ - { - "metadatavalues": [ - { - "name": { - "value": "apiname", - "localizedValue": "apiname" - }, - "value": "EntityGroupTransaction" - } - ], - "data": [ - { - "timeStamp": "2023-04-20T12:00:00Z", - "total": 1737897, - "average": 5891.17627118644, - "minimum": 1674, - "maximum": 10976 - }, - { - "timeStamp": "2023-04-21T12:00:00Z", - "total": 1712543, - "average": 5946.329861111111, - "minimum": 1674, - "maximum": 10980 - } - ] - }, - { - "metadatavalues": [ - { - "name": { - "value": "apiname", - "localizedValue": "apiname" - }, - "value": "GetBlobServiceProperties" - } - ], - "data": [ - { - "timeStamp": "2023-04-20T12:00:00Z", - "total": 1284, - "average": 321, - "minimum": 321, - "maximum": 321 - }, - { - "timeStamp": "2023-04-21T12:00:00Z", - "total": 1926, - "average": 321, - "minimum": 321, - "maximum": 321 - } - ] - } - ], - "errorCode": "Success" - }, - { - "id": "/subscriptions/12345678-1234-1234-1234-123456789abc/resourceGroups/sample-test/providers/Microsoft.Storage/storageAccounts/testaccount/providers/Microsoft.Insights/metrics/Egress", - "type": "Microsoft.Insights/metrics", - "name": { - "value": "Egress", - "localizedValue": "Egress" - }, - "displayDescription": "The amount of egress data. This number includes egress to external client from Azure Storage as well as egress within Azure. As a result, this number does not reflect billable egress.", - "unit": "Bytes", - "timeseries": [ - { - "metadatavalues": [ - { - "name": { - "value": "apiname", - "localizedValue": "apiname" - }, - "value": "EntityGroupTransaction" - } - ], - "data": [ - { - "timeStamp": "2023-04-20T12:00:00Z", - "total": 249603, - "average": 846.1118644067797, - "minimum": 839, - "maximum": 1150 - }, - { - "timeStamp": "2023-04-21T12:00:00Z", - "total": 244652, - "average": 849.4861111111111, - "minimum": 839, - "maximum": 1150 - } - ] - }, - { - "metadatavalues": [ - { - "name": { - "value": "apiname", - "localizedValue": "apiname" - }, - "value": "GetBlobServiceProperties" - } - ], - "data": [ - { - "timeStamp": "2023-04-20T12:00:00Z", - "total": 3772, - "average": 943, - "minimum": 943, - "maximum": 943 - }, - { - "timeStamp": "2023-04-21T12:00:00Z", - "total": 5658, - "average": 943, - "minimum": 943, - "maximum": 943 - } - ] - } - ], - "errorCode": "Success" - } - ], - "namespace": "microsoft.storage/storageaccounts", - "resourceregion": "westus2" -} -``` -### [metrics:getBatch Response](#tab/batch-response) --```json -{ -"values": [ - { - "cost": 11516, - "starttime": "2023-04-20T12:00:00Z", - "endtime": "2023-04-22T12:00:00Z", - "interval": "P1D", - "value": [ - { - "id": "/subscriptions/12345678-1234-1234-1234-123456789abc/resourceGroups/sample-test/providers/Microsoft.Storage/storageAccounts/testaccount/providers/Microsoft.Insights/metrics/Ingress", - "type": "Microsoft.Insights/metrics", - "name": { - "value": "Ingress", - "localizedValue": "Ingress" - }, - "displayDescription": "The amount of ingress data, in bytes. This number includes ingress from an external client into Azure Storage as well as ingress within Azure.", - "unit": "Bytes", - "timeseries": [ - { - "metadatavalues": [ - { - "name": { - "value": "apiname", - "localizedValue": "apiname" - }, - "value": "EntityGroupTransaction" - } - ], - "data": [ - { - "timeStamp": "2023-04-20T12:00:00Z", - "total": 1737897, - "average": 5891.17627118644, - "minimum": 1674, - "maximum": 10976 - }, - { - "timeStamp": "2023-04-21T12:00:00Z", - "total": 1712543, - "average": 5946.329861111111, - "minimum": 1674, - "maximum": 10980 - } - ] - }, - { - "metadatavalues": [ - { - "name": { - "value": "apiname", - "localizedValue": "apiname" - }, - "value": "GetBlobServiceProperties" - } - ], - "data": [ - { - "timeStamp": "2023-04-20T12:00:00Z", - "total": 1284, - "average": 321, - "minimum": 321, - "maximum": 321 - }, - { - "timeStamp": "2023-04-21T12:00:00Z", - "total": 1926, - "average": 321, - "minimum": 321, - "maximum": 321 - } - ] - } - ], - "errorCode": "Success" - }, - { - "id": "/subscriptions/12345678-1234-1234-1234-123456789abc/resourceGroups/sample-test/providers/Microsoft.Storage/storageAccounts/testaccount/providers/Microsoft.Insights/metrics/Egress", - "type": "Microsoft.Insights/metrics", - "name": { - "value": "Egress", - "localizedValue": "Egress" - }, - "displayDescription": "The amount of egress data. This number includes egress to external client from Azure Storage as well as egress within Azure. As a result, this number does not reflect billable egress.", - "unit": "Bytes", - "timeseries": [ - { - "metadatavalues": [ - { - "name": { - "value": "apiname", - "localizedValue": "apiname" - }, - "value": "EntityGroupTransaction" - } - ], - "data": [ - { - "timeStamp": "2023-04-20T12:00:00Z", - "total": 249603, - "average": 846.1118644067797, - "minimum": 839, - "maximum": 1150 - }, - { - "timeStamp": "2023-04-21T12:00:00Z", - "total": 244652, - "average": 849.4861111111111, - "minimum": 839, - "maximum": 1150 - } - ] - }, - { - "metadatavalues": [ - { - "name": { - "value": "apiname", - "localizedValue": "apiname" - }, - "value": "GetBlobServiceProperties" - } - ], - "data": [ - { - "timeStamp": "2023-04-20T12:00:00Z", - "total": 3772, - "average": 943, - "minimum": 943, - "maximum": 943 - }, - { - "timeStamp": "2023-04-21T12:00:00Z", - "total": 5658, - "average": 943, - "minimum": 943, - "maximum": 943 - } - ] - } - ], - "errorCode": "Success" - } - ], - "namespace": "microsoft.storage/storageaccounts", - "resourceregion": "westus2", - "resourceid": "/subscriptions/12345678-1234-1234-1234-123456789abc/resourceGroups/sample-test/providers/Microsoft.Storage/storageAccounts/testaccount" - }, - { - "cost": 11516, - "starttime": "2023-04-20T12:00:00Z", - "endtime": "2023-04-22T12:00:00Z", - "interval": "P1D", - "value": [ - { - "id": "/subscriptions/12345678-1234-1234-1234-123456789abc/resourceGroups/sample3/providers/Microsoft.Storage/storageAccounts/sample3diag/providers/Microsoft.Insights/metrics/Ingress", - "type": "Microsoft.Insights/metrics", - "name": { - "value": "Ingress", - "localizedValue": "Ingress" - }, - "displayDescription": "The amount of ingress data, in bytes. This number includes ingress from an external client into Azure Storage as well as ingress within Azure.", - "unit": "Bytes", - "timeseries": [ - { - "metadatavalues": [ - { - "name": { - "value": "apiname", - "localizedValue": "apiname" - }, - "value": "EntityGroupTransaction" - } - ], - "data": [ - { - "timeStamp": "2023-04-20T12:00:00Z", - "total": 867509, - "average": 5941.842465753424, - "minimum": 1668, - "maximum": 10964 - }, - { - "timeStamp": "2023-04-21T12:00:00Z", - "total": 861018, - "average": 5979.291666666667, - "minimum": 1668, - "maximum": 10964 - } - ] - }, - { - "metadatavalues": [ - { - "name": { - "value": "apiname", - "localizedValue": "apiname" - }, - "value": "GetBlobServiceProperties" - } - ], - "data": [ - { - "timeStamp": "2023-04-20T12:00:00Z", - "total": 1268, - "average": 317, - "minimum": 312, - "maximum": 332 - }, - { - "timeStamp": "2023-04-21T12:00:00Z", - "total": 1560, - "average": 312, - "minimum": 312, - "maximum": 312 - } - ] - } - ], - "errorCode": "Success" - }, - { - "id": "/subscriptions/12345678-1234-1234-1234-123456789abc/resourceGroups/sample3/providers/Microsoft.Storage/storageAccounts/sample3diag/providers/Microsoft.Insights/metrics/Egress", - "type": "Microsoft.Insights/metrics", - "name": { - "value": "Egress", - "localizedValue": "Egress" - }, - "displayDescription": "The amount of egress data. This number includes egress to external client from Azure Storage as well as egress within Azure. As a result, this number does not reflect billable egress.", - "unit": "Bytes", - "timeseries": [ - { - "metadatavalues": [ - { - "name": { - "value": "apiname", - "localizedValue": "apiname" - }, - "value": "EntityGroupTransaction" - } - ], - "data": [ - { - "timeStamp": "2023-04-20T12:00:00Z", - "total": 124316, - "average": 851.4794520547945, - "minimum": 839, - "maximum": 1150 - }, - { - "timeStamp": "2023-04-21T12:00:00Z", - "total": 122943, - "average": 853.7708333333334, - "minimum": 839, - "maximum": 1150 - } - ] - }, - { - "metadatavalues": [ - { - "name": { - "value": "apiname", - "localizedValue": "apiname" - }, - "value": "GetBlobServiceProperties" - } - ], - "data": [ - { - "timeStamp": "2023-04-20T12:00:00Z", - "total": 3384, - "average": 846, - "minimum": 846, - "maximum": 846 - }, - { - "timeStamp": "2023-04-21T12:00:00Z", - "total": 4230, - "average": 846, - "minimum": 846, - "maximum": 846 - } - ] - } - ], - "errorCode": "Success" - } - ], - "namespace": "microsoft.storage/storageaccounts", - "resourceregion": "westus2", - "resourceid": "/subscriptions/12345678-1234-1234-1234-123456789abc/resourceGroups/sample3/providers/Microsoft.Storage/storageAccounts/sample3diag" - } - ] -} -``` ---## Error response changes --In the `metrics:getBatch` error response, the error content is wrapped inside a top level "error" property on the response. For example, --+ Metrics API error response -- ```json - { - "code": "BadRequest", - "message": "Metric: Ingress does not support requested dimension combination: apiname2, supported ones are: GeoType,ApiName,Authentication, TraceId: {ab11d9c2-b17e-4f75-8986-b314ecacbe11}" - } - ``` --+ Batch API error response: -- ```json - { - "error": { - "code": "BadRequest", - "message": "Metric: Egress does not support requested dimension combination: apiname2, supported ones are: GeoType,ApiName,Authentication, TraceId: {cd77617d-5f11-e50d-58c5-ba2f2cdc38ce}" - } - } - ``` --## Troubleshooting --+ Empty time series returned `"timeseries": []` - - An empty time series is returned when no data is available for the specified time range and filter. The most common cause is specifying a time range that doesn't contain any data. For example, if the time range is set to a future date. - - Another common cause is specifying a filter that doesn't match any resources. For example, if the filter specifies a dimension value that doesn't exist on any resources in the subscription and region combination, `"timeseries": []` is returned. - -+ Wildcard filters - Using a wildcard filter such as `Microsoft.ResourceId eq '*'` causes the API to return a time series for every resourceId in the subscription and region. If the subscription and region combination contains no resources, an empty time series is returned. The same query without the wildcard filter would return a single time series, aggregating the requested metric over the requested dimensions, for example subscription and region. - -+ Custom metrics aren't currently supported. - The `metrics:getBatch` API doesn't support querying custom metrics, or queries where the metric namespace name isn't a resource type. This is the case for VM Guest OS metrics that use the namespace "azure.vm.windows.guestmetrics" or "azure.vm.linux.guestmetrics". --+ The top parameter applies per resource ID specified. -How the top parameter works in the context of the batch API can be a little confusing. Rather than enforcing a limit on the total time series returned by the entire call, it rather enforces the total time series returned *per metric per resource ID*. If you have a batch query with many '*' filters specified, two metrics, and four resource IDs with a top of 5. The maximum possible time series returned by that query is 40, that is 2x4x5 time series. --### 401 authorization errors --The individual metrics API requires a user have the [Monitoring Reader](/azure/role-based-access-control/built-in-roles#monitoring-reader) permission on the resource being queried. Because the `metrics:getBatch` API is a subscription level API, users must have the Monitoring Reader permission for the queried subscription to use the batch API. Even if users have Monitoring Reader on all the resources being queried in the batch API, the request fails if the user doesn't have Monitoring Reader on the subscription itself. --### 529 throttling errors --While the data plane batch API is designed to help mitigate throttling problems, 529 error codes can still occur which indicates that the metrics backend is currently throttling some customers. The recommended action is to implement an exponential backoff retry scheme. --## Paging -Paging isn't supported by the metrics:getBatch API. The most common use-case for this API is frequently calling every few minutes for the same metrics and resources for the latest timeframe. Low latency is an important consideration so many customers parallelize their queries as much as possible. Paging forces customers into a sequential calling pattern that introduces additional query latency. In scenarios where requests return volumes of metric data where paging would be beneficial, it's recommended to split the query into multiple parallel queries. --## Billing -Yes all metrics data plane and batching calls are billed. For more information, see the **Azure Monitor native metrics** section in [Basic Log Search Queries](https://azure.microsoft.com/pricing/details/monitor/#pricing). |
| azure-monitor | Monitor Azure Resource | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/monitor-azure-resource.md | - Title: Monitor Azure resources with Azure Monitor | Microsoft Docs -description: This article describes how to collect and analyze monitoring data from resources in Azure by using Azure Monitor. --- Previously updated : 07/17/2023-----# Monitor Azure resources with Azure Monitor --When you have critical applications and business processes that rely on Azure resources, you want to monitor those resources for their availability, performance, and operation. Azure Monitor is a full-stack monitoring service that provides a complete set of features to monitor your Azure resources. You can also use Azure Monitor to monitor resources in other clouds and on-premises. --In this article, you learn about: --> [!div class="checklist"] -> * Azure Monitor and how it's integrated into the portal for other Azure services. -> * The types of data collected by Azure Monitor for Azure resources. -> * Azure Monitor tools that are used to collect and analyze data. --> [!NOTE] -> This article describes Azure Monitor concepts and walks you through different menu items. To jump right into using Azure Monitor features, start with [Analyze metrics for an Azure resource](../essentials/tutorial-metrics.md). --## Monitoring data --This section discusses collecting and monitoring data. --### Azure Monitor data collection --As soon as you create an Azure resource, Azure Monitor is enabled and starts collecting metrics and activity logs. With some configuration, you can gather more monitoring data and enable other features. The Azure Monitor data platform is made up of Metrics and Logs. Each feature collects different kinds of data and enables different Azure Monitor features. --- [Azure Monitor Metrics](../essentials/data-platform-metrics.md) stores numeric data from monitored resources into a time-series database. The metric database is automatically created for each Azure subscription. Use [Metrics Explorer](../essentials/tutorial-metrics.md) to analyze data from Azure Monitor Metrics.-- [Azure Monitor Logs](../logs/data-platform-logs.md) collects logs and performance data where they can be retrieved and analyzed in different ways by using log queries. You must create a Log Analytics workspace to collect log data. Use [Log Analytics](../logs/log-analytics-tutorial.md) to analyze data from Azure Monitor Logs.--### Monitoring data from Azure resources --While resources from different Azure services have different monitoring requirements, they generate monitoring data in the same formats so that you can use the same Azure Monitor tools to analyze all Azure resources. --Diagnostic settings define where resource logs and metrics for a particular resource should be sent. Possible destinations are: --- [Activity log](./platform-logs-overview.md): Subscription-level events that track operations for each Azure resource, for example, creating a new resource or starting a virtual machine. Activity log events are automatically generated and collected for viewing in the Azure portal. You can create a diagnostic setting to send the activity log to Azure Monitor Logs.-- [Platform metrics](../essentials/data-platform-metrics.md): Numerical values that are automatically collected at regular intervals and describe some aspect of a resource at a particular time. Platform metrics are automatically generated and collected in Azure Monitor Metrics.-- [Resource logs](./platform-logs-overview.md): Provide insight into operations that were performed by an Azure resource. Operation examples might be getting a secret from a key vault or making a request to a database. Resource logs are generated automatically, but you must create a diagnostic setting to send them to Azure Monitor Logs.-- [Virtual machine guest metrics and logs](): Performance and log data from the guest operating system of Azure virtual machines. You must install an agent on the virtual machine to collect this data and send it to Azure Monitor Metrics and Azure Monitor Logs.--## Menu options --You can access Azure Monitor features from the **Monitor** menu in the Azure portal. You can also access Azure Monitor features directly from the menu for different Azure services. Different Azure services might have slightly different experiences, but they share a common set of monitoring options in the Azure portal. These menu items include **Overview** and **Activity log** and multiple options in the **Monitoring** section of the menu. ----## Overview page --The **Overview** page includes details about the resource and often its current state. For example, a virtual machine shows its current running state. Many Azure services have a **Monitoring** tab that includes charts for a set of key metrics. Charts are a quick way to view the operation of the resource. You can select any of the charts to open them in Metrics Explorer for more detailed analysis. --To learn how to use Metrics Explorer, see [Analyze metrics for an Azure resource](../essentials/tutorial-metrics.md). ---### Activity log --The **Activity log** menu item lets you view entries in the [activity log](../essentials/activity-log.md) for the current resource. -<!-- convertborder later --> --## Alerts --The **Alerts** page shows you any recent alerts that were fired for the resource. Alerts proactively notify you when important conditions are found in your monitoring data and can use data from either Metrics or Logs. --To learn how to create alert rules and view alerts, see [Create a metric alert for an Azure resource](../alerts/tutorial-metric-alert.md) or [Create a log search alert for an Azure resource](../alerts/tutorial-log-alert.md). ---## Metrics --The **Metrics** menu item opens [Metrics Explorer](./metrics-getting-started.md). You can use it to work with individual metrics or combine multiple metrics to identify correlations and trends. This is the same Metrics Explorer that opens when you select one of the charts on the **Overview** page. --To learn how to use Metrics Explorer, see [Analyze metrics for an Azure resource](../essentials/tutorial-metrics.md). -<!-- convertborder later --> --## Diagnostic settings --The **Diagnostic settings** page lets you create a [diagnostic setting](../essentials/diagnostic-settings.md) to collect the resource logs for your resource. You can send them to multiple locations, but the most common use is to send them to a Log Analytics workspace so you can analyze them with Log Analytics. --To learn how to create a diagnostic setting, see [Collect and analyze resource logs from an Azure resource](../essentials/tutorial-resource-logs.md). ---## Insights --The **Insights** menu item opens the insight for the resource if the Azure service has one. [Insights](../insights/insights-overview.md) provide a customized monitoring experience built on the Azure Monitor data platform and standard features. --For a list of insights that are available and links to their documentation, see [Insights](../insights/insights-overview.md) and [core solutions](/previous-versions/azure/azure-monitor/insights/solutions). -<!-- convertborder later --> --## Next steps --Now that you have a basic understanding of Azure Monitor, get started analyzing some metrics for an Azure resource. --> [!div class="nextstepaction"] -> [Analyze metrics for an Azure resource](../essentials/tutorial-metrics.md) |
| azure-monitor | Prometheus Api Promql | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/prometheus-api-promql.md | - Title: Query Prometheus metrics using the API and PromQL -description: Describes how to use the API to Query metrics in an Azure Monitor workspace using PromQL. --- Previously updated : 05/31/2024----# Query Prometheus metrics using the API and PromQL --Azure Monitor managed service for Prometheus, collects metrics from Azure Kubernetes clusters and stores them in an Azure Monitor workspace. PromQL (Prometheus query language), is a functional query language that allows you to query and aggregate time series data. Use PromQL to query and aggregate metrics stored in an Azure Monitor workspace. --This article describes how to query an Azure Monitor workspace using PromQL via the REST API. -For more information on PromQL, see [Querying prometheus](https://prometheus.io/docs/prometheus/latest/querying/basics/). --## Prerequisites -To query an Azure monitor workspace using PromQL, you need the following prerequisites: -+ An Azure Kubernetes cluster or remote Kubernetes cluster. -+ Azure Monitor managed service for Prometheus scraping metrics from a Kubernetes cluster. -+ An Azure Monitor workspace where Prometheus metrics are being stored. --## Authentication --To query your Azure Monitor workspace, authenticate using Microsoft Entra ID. -The API supports Microsoft Entra authentication using client credentials. Register a client app with Microsoft Entra ID and request a token. --To set up Microsoft Entra authentication, follow the steps below: --1. Register an app with Microsoft Entra ID. -1. Grant access for the app to your Azure Monitor workspace. -1. Request a token. ---<a name='register-an-app-with-azure-active-directory'></a> --### Register an app with Microsoft Entra ID --1. To register an app, follow the steps in [Register an App to request authorization tokens and work with APIs](../logs/api/register-app-for-token.md?tabs=portal) --### Allow your app access to your workspace -Assign the **Monitoring Data Reader** role your app so it can query data from your Azure Monitor workspace. --1. Open your Azure Monitor workspace in the Azure portal. --1. On the Overview page, take note of your Query endpoint for use in your REST request. --1. Select Access control (IAM). --1. Select **Add**, then **Add role assignment** from the Access Control (IAM) page. -- :::image type="content" source="./media/prometheus-api-promql/access-control.png" lightbox="./media/prometheus-api-promql/access-control.png" alt-text="A screenshot showing the Azure Monitor workspace overview page."::: --1. On the **Add role Assignment page**, search for *Monitoring*. --1. Select **Monitoring Data Reader**, then select the Members tab. -- :::image type="content" source="./media/prometheus-api-promql/add-role-assignment.png" lightbox="./media/prometheus-api-promql/add-role-assignment.png" alt-text="A screenshot showing the Add role assignment page."::: --1. Select **Select members**. --1. Search for the app that you registered and select it. --1. Choose **Select**. --1. Select **Review + assign**. -- :::image type="content" source="./media/prometheus-api-promql/select-members.png" lightbox="./media/prometheus-api-promql/select-members.png" alt-text="A screenshot showing the Add role assignment, select members page."::: --You've created your app registration and have assigned it access to query data from your Azure Monitor workspace. You can now generate a token and use it in a query. ---### Request a token -Send the following request in the command prompt or by using a client like Postman. --```shell -curl -X POST 'https://login.microsoftonline.com/<tennant ID>/oauth2/token' \ --H 'Content-Type: application/x-www-form-urlencoded' \data-urlencode 'grant_type=client_credentials' \data-urlencode 'client_id=<your apps client ID>' \data-urlencode 'client_secret=<your apps client secret>' \data-urlencode 'resource=https://prometheus.monitor.azure.com'-``` --Sample response body: --```JSON -{ - "token_type": "Bearer", - "expires_in": "86399", - "ext_expires_in": "86399", - "expires_on": "1672826207", - "not_before": "1672739507", - "resource": "https:/prometheus.monitor.azure.com", - "access_token": "eyJ0eXAiOiJKV1Qi....gpHWoRzeDdVQd2OE3dNsLIvUIxQ" -} -``` --Save the access token from the response for use in the following HTTP requests. --## Query endpoint --Find your Azure Monitor workspace's query endpoint on the Azure Monitor workspace overview page. ---## Supported APIs -The following queries are supported: --### Instant queries - For more information, see [Instant queries](https://prometheus.io/docs/prometheus/latest/querying/api/#instant-queries) --Path: `/api/v1/query` -Examples: -``` -POST https://k8s-02-workspace-abcd.eastus.prometheus.monitor.azure.com/api/v1/query header 'Authorization: Bearer <access token>'header 'Content-Type: application/x-www-form-urlencoded' data-urlencode 'query=sum( \- container_memory_working_set_bytes \ - * on(namespace,pod) \ - group_left(workload, workload_type) \ - namespace_workload_pod:kube_pod_owner:relabel{ workload_type="deployment"}) by (pod)' --``` -``` -GET 'https://k8s02-workspace-abcd.eastus.prometheus.monitor.azure.com/api/v1/query?query=container_memory_working_set_bytes' header 'Authorization: Bearer <access token>'-``` -### Range queries -For more information, see [Range queries](https://prometheus.io/docs/prometheus/latest/querying/api/#range-queries) -Path: `/api/v1/query_range` -Examples: -``` -GET 'https://k8s02-workspace-abcd.eastus.prometheus.monitor.azure.com/api/v1/query_range?query=container_memory_working_set_bytes&start=2023-03-01T00:00:00.000Z&end=2023-03-20T00:00:00.000Z&step=6h' header 'Authorization: Bearer <access token>-``` --``` -POST 'https://k8s02-workspace-abcd.eastus.prometheus.monitor.azure.com/api/v1/query_range' header 'Authorization: Bearer <access token>'header 'Content-Type: application/x-www-form-urlencoded' data-urlencode 'query=up' data-urlencode 'start=2023-03-01T20:10:30.781Z' data-urlencode 'end=2023-03-20T20:10:30.781Z' data-urlencode 'step=6h'-``` -### Series -For more information, see [Series](https://prometheus.io/docs/prometheus/latest/querying/api/#finding-series-by-label-matchers) --Path: `/api/v1/series` -Examples: -``` -POST 'https://k8s02-workspace-abcd.eastus.prometheus.monitor.azure.com/api/v1/series' header 'Authorization: Bearer <access token>header 'Content-Type: application/x-www-form-urlencoded' data-urlencode 'match[]=kube_pod_info{pod="bestapp-123abc456d-4nmfm"}'--``` -``` -GET 'https://k8s02-workspace-abcd.eastus.prometheus.monitor.azure.com/api/v1/series?match[]=container_network_receive_bytes_total{namespace="default-1669648428598"}' -``` --### Labels --For more information, see [Labels](https://prometheus.io/docs/prometheus/latest/querying/api/#getting-label-names) -Path: `/api/v1/labels` -Examples: -``` -GET 'https://k8s02-workspace-abcd.eastus.prometheus.monitor.azure.com/api/v1/labels' --``` -``` -POST 'https://k8s02-workspace-abcd.eastus.prometheus.monitor.azure.com/api/v1/labels' -``` --### Label values -For more information, see [Label values](https://prometheus.io/docs/prometheus/latest/querying/api/#query.ing-label-values) -Path: `/api/v1/label/__name__/values.` ---> [!NOTE] -> `__name__` is the only supported version of this API and returns all metric names. No other /api/v1/label/<label_name>/values are supported. --Example: -``` -GET 'https://k8s02-workspace-abcd.eastus.prometheus.monitor.azure.com/api/v1/label/__name__/values' -``` --For the full specification of OSS prom APIs, see [Prometheus HTTP API](https://prometheus.io/docs/prometheus/latest/querying/api/#http-api). --## API limitations -The following limitations are in addition to those detailed in the Prometheus specification. --+ Query must be scoped to a metric - Any time series fetch queries (/series or /query or /query_range) must contain a \_\_name\_\_ label matcher. That is, each query must be scoped to a metric. There can only be one \_\_name\_\_ label matcher in a query. -+ Query /series does not support regular expression filter -+ Supported time range - + /query_range API supports a time range of 32 days. This is the maximum time range allowed, including range selectors specified in the query itself. - For example, the query `rate(http_requests_total[1h]` for last the 24 hours would actually mean data is being queried for 25 hours. This comes from the 24-hour range plus the 1 hour specified in query itself. - + /series API fetches data for a maximum 12-hour time range. If `endTime` isn't provided, endTime = time.now(). If the time rage is greater than 12 hours, the `startTime` is set to `endTime ΓÇô 12h` -+ Ignored time range - Start time and end time provided with `/labels` and `/label/__name__/values` are ignored, and all retained data in the Azure Monitor workspace is queried. -+ Experimental features - Experimental features such as exemplars aren't supported. --For more information on Prometheus metrics limits, see [Prometheus metrics](../../azure-monitor/service-limits.md#prometheus-metrics) ---## Frequently asked questions --This section provides answers to common questions. -----## Next steps --[Azure Monitor workspace overview](./azure-monitor-workspace-overview.md) -[Manage an Azure Monitor workspace](./azure-monitor-workspace-manage.md) -[Overview of Azure Monitor Managed Service for Prometheus](./prometheus-metrics-overview.md) -[Query Prometheus metrics using Azure workbooks](./prometheus-workbooks.md) |
| azure-monitor | Prometheus Grafana | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/prometheus-grafana.md | - Title: Use Azure Monitor managed service for Prometheus as data source for Grafana -description: Details on how to configure Azure Monitor managed service for Prometheus as data source for both Azure Managed Grafana and self-hosted Grafana in an Azure virtual machine. -- Previously updated : 01/08/2024---# Use Azure Monitor managed service for Prometheus as data source for Grafana using managed system identity --[Azure Monitor managed service for Prometheus](prometheus-metrics-overview.md) allows you to collect and analyze metrics at scale using a [Prometheus](https://aka.ms/azureprometheus-promio)-compatible monitoring solution. The most common way to analyze and present Prometheus data is with a Grafana dashboard. This article explains how to configure Prometheus as a data source for both [Azure Managed Grafana](../../managed-grafan) and [self-hosted Grafana](https://grafana.com/) running in an Azure virtual machine using managed system identity authentication. --For information on using Grafana with Active Directory, see [Configure self-managed Grafana to use Azure Monitor managed Prometheus with Microsoft Entra ID](./prometheus-self-managed-grafana-azure-active-directory.md). --## Azure Managed Grafana -The following sections describe how to configure Azure Monitor managed service for Prometheus as a data source for Azure Managed Grafana. --> [!IMPORTANT] -> This section describes the manual process for adding an Azure Monitor managed service for Prometheus data source to Azure Managed Grafana. You can achieve the same functionality by linking the Azure Monitor workspace and Grafana workspace as described in [Link a Grafana workspace](./azure-monitor-workspace-manage.md#link-a-grafana-workspace). --### Configure system identity -Your Grafana workspace requires the following settings: --- System managed identity enabled-- **Monitoring Data Reader** role for the Azure Monitor workspace--Both of these settings are configured by default when you created your Grafana workspace and linked it to an Azure Monitor workspace. Verify these settings on the **Identity** page for your Grafana workspace. ----**Configure from Grafana workspace**<br> -Use the following steps to allow access all Azure Monitor workspaces in a resource group or subscription: --1. Open the **Identity** page for your Grafana workspace in the Azure portal. --1. If **Status** is **No**, change it to **Yes**. -1. Select **Azure role assignments** to review the existing access in your subscription. -1. If **Monitoring Data Reader** isn't listed for your subscription or resource group: - 1. Select **+ Add role assignment**. - 1. For **Scope**, select either **Subscription** or **Resource group**. -- 1. For **Role**, select **Monitoring Data Reader**. - 1. Select **Save**. ---**Configure from Azure Monitor workspace**<br> -Use the following steps to allow access to only a specific Azure Monitor workspace: --1. Open the **Access Control (IAM)** page for your Azure Monitor workspace in the Azure portal. --1. Select **Add role assignment**. -1. Select **Monitoring Data Reader** and select **Next**. -1. For **Assign access to**, select **Managed identity**. -1. Select **+ Select members**. -1. For **Managed identity**, select **Azure Managed Grafana**. -1. Select your Grafana workspace and then select **Select**. -1. Select **Review + assign** to save the configuration. --### Create Prometheus data source --Azure Managed Grafana supports Azure authentication by default. --1. Open the **Overview** page for your Azure Monitor workspace in the Azure portal. --1. Copy the **Query endpoint**, which you'll need in a step below. -1. Open your Azure Managed Grafana workspace in the Azure portal. -1. Select on the **Endpoint** to view the Grafana workspace. -1. Select **Configuration** and then **Data source**. -1. Select **Add data source** and then **Prometheus**. -1. For **URL**, paste in the query endpoint for your Azure Monitor workspace. -1. Select **Azure Authentication** to turn it on. -1. For **Authentication** under **Azure Authentication**, select **Managed Identity**. -1. Scroll to the bottom of the page and select **Save & test**. ----## Self-managed Grafana -The following sections describe how to configure Azure Monitor managed service for Prometheus as a data source for self-managed Grafana on an Azure virtual machine. -### Configure system identity -Azure virtual machines support both system assigned and user assigned identity. The following steps configure system assigned identity. --**Configure from Azure virtual machine**<br> -Use the following steps to allow access all Azure Monitor workspaces in a resource group or subscription: --1. Open the **Identity** page for your virtual machine in the Azure portal. --1. If **Status** is **No**, change it to **Yes**. -1. Select **Save**. -1. Select **Azure role assignments** to review the existing access in your subscription. -1. If **Monitoring Data Reader** isn't listed for your subscription or resource group: - 1. Select **+ Add role assignment**. -- 1. For **Scope**, select either **Subscription** or **Resource group**. - 1. For **Role**, select **Monitoring Data Reader**. - 1. Select **Save**. --**Configure from Azure Monitor workspace**<br> -Use the following steps to allow access to only a specific Azure Monitor workspace: --1. Open the **Access Control (IAM)** page for your Azure Monitor workspace in the Azure portal. --1. Select **Add role assignment**. -1. Select **Monitoring Data Reader** and select **Next**. -1. For **Assign access to**, select **Managed identity**. -1. Select **+ Select members**. -1. For **Managed identity**, select **Virtual machine**. -1. Select your Grafana workspace and then click **Select**. -1. Select **Review + assign** to save the configuration. -----### Create Prometheus data source --Versions 9.x and greater of Grafana support Azure Authentication, but it's not enabled by default. To enable this feature, you need to update your Grafana configuration. To determine where your Grafana.ini file is and how to edit your Grafana config, review the [Configure Grafana](https://grafana.com/docs/grafana/v9.0/setup-grafana/configure-grafana/) document from Grafana Labs. Once you know where your configuration file lives on your VM, make the following update: ---1. Locate and open the *Grafana.ini* file on your virtual machine. --1. Under the `[auth]` section of the configuration file, change the `azure_auth_enabled` setting to `true`. -1. Under the `[azure]` section of the configuration file, change the `managed_identity_enabled` setting to `true` -1. Open the **Overview** page for your Azure Monitor workspace in the Azure portal. -1. Copy the **Query endpoint**, which you'll need in a step below. -1. Open your Azure Managed Grafana workspace in the Azure portal. -1. Click on the **Endpoint** to view the Grafana workspace. -1. Select **Configuration** and then **Data source**. -1. Click **Add data source** and then **Prometheus**. -1. For **URL**, paste in the query endpoint for your Azure Monitor workspace. -1. Select **Azure Authentication** to turn it on. -1. For **Authentication** under **Azure Authentication**, select **Managed Identity**. -1. Scroll to the bottom of the page and click **Save & test**. ---## Frequently asked questions --This section provides answers to common questions. -----## Next steps -- [Configure self-managed Grafana to use Azure-managed Prometheus with Microsoft Entra ID](./prometheus-self-managed-grafana-azure-active-directory.md).-- [Collect Prometheus metrics for your AKS cluster](../containers/kubernetes-monitoring-enable.md#enable-prometheus-and-grafana).-- [Configure Prometheus alerting and recording rules groups](prometheus-rule-groups.md).-- [Customize scraping of Prometheus metrics](prometheus-metrics-scrape-configuration.md). |
| azure-monitor | Prometheus Metrics Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/prometheus-metrics-overview.md | - Title: Overview of Azure Monitor Managed Service for Prometheus -description: Overview of Azure Monitor managed service for Prometheus, which provides a Prometheus-compatible interface for storing and retrieving metric data. ---- Previously updated : 01/25/2024---# Azure Monitor managed service for Prometheus --Azure Monitor managed service for Prometheus is a component of [Azure Monitor Metrics](data-platform-metrics.md), providing more flexibility in the types of metric data that you can collect and analyze with Azure Monitor. Prometheus metrics are supported by analysis tool like [Azure Monitor Metrics Explorer with PromQL](./metrics-explorer.md) and open source tools such as [PromQL](https://aka.ms/azureprometheus-promio-promql) and [Grafana](../../managed-grafan). --Azure Monitor managed service for Prometheus allows you to collect and analyze metrics at scale using a Prometheus-compatible monitoring solution, based on the [Prometheus](https://aka.ms/azureprometheus-promio) project from the Cloud Native Computing Foundation. This fully managed service allows you to use the [Prometheus query language (PromQL)](https://aka.ms/azureprometheus-promio-promql) to analyze and alert on the performance of monitored infrastructure and workloads without having to operate the underlying infrastructure. --> [!IMPORTANT] -> Azure Monitor managed service for Prometheus is intended for storing information about service health of customer machines and applications. It is not intended for storing any data classified as Personal Identifiable Information (PII) or End User Identifiable Information (EUII). We strongly recommend that you do not send any sensitive information (usernames, credit card numbers etc.) into Azure Monitor managed service for Prometheus fields like metric names, label names, or label values. --## Data sources -Azure Monitor managed service for Prometheus can currently collect data from any of the following data sources: --- Azure Kubernetes service (AKS)-- Azure Arc-enabled Kubernetes--## Enable -The only requirement to enable Azure Monitor managed service for Prometheus is to create an [Azure Monitor workspace](azure-monitor-workspace-overview.md), which is where Prometheus metrics are stored. Once this workspace is created, you can onboard services that collect Prometheus metrics. --- To collect Prometheus metrics from your Kubernetes cluster, see [Enable monitoring for Kubernetes clusters](../containers/kubernetes-monitoring-enable.md#enable-prometheus-and-grafana).-- To configure remote-write to collect data from your self-managed Prometheus server, see [Azure Monitor managed service for Prometheus remote write](./remote-write-prometheus.md).--## Remote write --In addition to the managed service for Prometheus, you can also use self-managed prometheus and remote-write to collect metrics and store them in an Azure Monitor workspace. --### Kubernetes services --Send metrics from self-managed Prometheus on Kubernetes clusters. For more information on remote-write to Azure Monitor workspaces for Kubernetes services, see the following articles: --- [Send Prometheus data from AKS to Azure Monitor by using managed identity authentication](/azure/azure-monitor/containers/prometheus-remote-write-managed-identity)-- [Send Prometheus data from AKS to Azure Monitor by using Microsoft Entra ID authentication](/azure/azure-monitor/containers/prometheus-remote-write-active-directory)-- [Send Prometheus data to Azure Monitor by using Microsoft Entra ID pod-managed identity (preview) authentication](/azure/azure-monitor/containers/prometheus-remote-write-azure-ad-pod-identity)-- [Send Prometheus data to Azure Monitor by using Microsoft Entra ID Workload ID (preview) authentication](/azure/azure-monitor/containers/prometheus-remote-write-azure-workload-identity)--### Virtual Machines and Virtual Machine Scale sets --Send data from self-managed Prometheus on virtual machines and virtual machine scale sets. Servers can be in an Azure-managed environment or on-premises. Fro more information, see [Send Prometheus metrics from Virtual Machines to an Azure Monitor workspace](/azure/azure-monitor/essentials/prometheus-remote-write-virtual-machines). --## Azure Monitor Metrics Explorer with PromQL --Metrics Explorer with PromQL allows you to analyze and visualize platform metrics, and use Prometheus query language (PromQL) to query Prometheus and other metrics stored in an Azure Monitor workspace. Metrics Explorer with PromQL is available from the **Metrics** menu item of any Azure Monitor workspace in the Azure portal. See [Metrics Explorer with PromQL](./metrics-explorer.md) for more information. --## Grafana integration --The primary method for visualizing Prometheus metrics is [Azure Managed Grafana](../../managed-grafan#link-a-grafana-workspace) so that it can be used as a data source in a Grafana dashboard. You then have access to multiple prebuilt dashboards that use Prometheus metrics and the ability to create any number of custom dashboards. --## Rules and alerts -Azure Monitor managed service for Prometheus supports recording rules and alert rules using PromQL queries. Metrics recorded by recording rules are stored back in the Azure Monitor workspace and can be queried by dashboard or by other rules. Alert rules and recording rules can be created and managed using [Azure Managed Prometheus rule groups](prometheus-rule-groups.md). For your AKS cluster, a set of [predefined Prometheus alert rules](../containers/container-insights-metric-alerts.md) and [recording rules](./prometheus-metrics-scrape-default.md#recording-rules) is provided to allow easy quick start. --Alerts fired by alert rules can trigger actions or notifications, as defined in the [action groups](../alerts/action-groups.md) configured for the alert rule. You can also view fired and resolved Prometheus alerts in the Azure portal along with other alert types. --## Service limits and quotas --Azure Monitor Managed service for Prometheus has default limits and quotas for ingestion. When you reach the ingestion limits throttling can occur. You can request an increase in these limits. For more information on throttling and requesting increased limits, see [Monitoring metrics limits](#how-can-i-monitor-the-service-limits-and-quota). For information on Prometheus metrics limits, see [Azure Monitor service limits](../service-limits.md#prometheus-metrics). --## Limitations/Known issues - Azure Monitor managed Service for Prometheus --- Scraping and storing metrics at frequencies less than 1 second isn't supported.-- Microsoft Azure operated by 21Vianet cloud and Air gapped clouds aren't supported for Azure Monitor managed service for Prometheus.-- To monitor Windows nodes & pods in your clusters, see [Enable monitoring for Azure Kubernetes Service (AKS) cluster](../containers/kubernetes-monitoring-enable.md#enable-windows-metrics-collection-preview).-- Azure Managed Grafana isn't currently available in the Azure US Government cloud.-- Usage metrics (metrics under `Metrics` menu for the Azure Monitor workspace) - Ingestion quota limits and current usage for any Azure monitor Workspace aren't available yet in US Government cloud.-- During node updates, you might experience gaps lasting 1 to 2 minutes in some metric collections from our cluster level collector. This gap is due to a regular action from Azure Kubernetes Service to update the nodes in your cluster. This behavior is expected and occurs due to the node it runs on being updated. None of our recommended alert rules are affected by this behavior. ---## Prometheus references --Following are links to Prometheus documentation. --- [PromQL](https://aka.ms/azureprometheus-promio-promql)-- [Grafana](https://aka.ms/azureprometheus-promio-grafana)-- [Recording rules](https://aka.ms/azureprometheus-promio-recrules)-- [Alerting rules](https://aka.ms/azureprometheus-promio-alertrules)-- [Writing Exporters](https://aka.ms/azureprometheus-promio-exporters)---## Frequently asked questions --This section provides answers to common questions. --### How do I retrieve Prometheus metrics? --All data is retrieved from an Azure Monitor workspace by using queries that are written in Prometheus Query Language (PromQL). You can write your own queries, use queries from the open source community, and use Grafana dashboards that include PromQL queries. See the [Prometheus project](https://prometheus.io/docs/prometheus/latest/querying/basics/). ---### When I use managed service for Prometheus, can I store data for more than one cluster in an Azure Monitor workspace? --Yes. Managed service for Prometheus is intended to enable scenarios where you can store data from several Azure Kubernetes Service clusters in a single Azure Monitor workspace. See [Azure Monitor workspace overview](./azure-monitor-workspace-overview.md?#azure-monitor-workspace-architecture). --### What types of resources can send Prometheus metrics to managed service for Prometheus? --Our agent can be used on Azure Kubernetes Service clusters and Azure Arc-enabled Kubernetes clusters. It's installed as a managed add-on for AKS clusters and an extension for Azure Arc-enabled Kubernetes clusters and you can configure it to collect the data you want. You can also configure remote write on Kubernetes clusters running in Azure, another cloud, or on-premises by following our instructions for enabling remote write. --If you use the Azure portal to enable Prometheus metrics collection and install the AKS add-on or Azure Arc-enabled Kubernetes extension from the Insights page of your cluster, it enables logs collection into Log Analytics and Prometheus metrics collection into managed service for Prometheus. For more information, see [Data sources](#data-sources). --### How can I monitor the service limits and quota? --Azure Monitor Managed service for Prometheus has default limits and quotas for ingestion. For information on Prometheus metrics limits, see [Azure Monitor service limits](../service-limits.md#prometheus-metrics). When you reach the ingestion limits throttling can occur. In order to avoid throttling, you can monitor and set up an alert on Azure Monitor Workspace ingestion limits. --1. In the Azure portal, navigate to your Azure Monitor Workspace, click on **Metrics** under the **Monitoring** section. -2. Select the Azure Monitor Workspace as scope, and in the drop-down for Metric, select *"View standard metrics with the builder"*. -3. In the drop-down for Metric, select **Active Time Series % Utilization** and **Events Per Minute Ingested % Utilization** and verify that they are below 100%. ---4. You can set an Azure Alert to monitor the utilization and fire an alert when the utilization is greater than a certain threshold (eg. 80% of the limit). Click on "**New alert rule**" to create an Azure alert for the same. ---If the alert is fired i.e. the ingestion utilization is more than the threshold, you can request an increase in these limits by creating a support ticket. --1. In the Azure portal, navigate to your Azure Monitor Workspace, click on **Support + Troubleshooting**. -2. Type the issue eg. "Service and subscription limits (quotas)", then select **Service and subscription limits (quotas)** and click "Next". ---3. In the next screen, select your subscription and then select **Managed Prometheus** as the **Quota type**. -4. Provide additional details to create the support ticket. ---## Next steps --- [Enable Azure Monitor managed service for Prometheus on your Kubernetes clusters](../containers/kubernetes-monitoring-enable.md).-- [Configure Prometheus alerting and recording rules groups](prometheus-rule-groups.md).-- [Customize scraping of Prometheus metrics](prometheus-metrics-scrape-configuration.md). |
| azure-monitor | Prometheus Remote Write Virtual Machines | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/prometheus-remote-write-virtual-machines.md | - Title: Send Prometheus metrics from virtual machines, scale sets, or Kubernetes clusters to an Azure Monitor workspace -description: How to configure remote-write to send data from self-managed Prometheus to an Azure Monitor managed service for Prometheus ---- Previously updated : 08/07/2024-#customer intent: As an azure administrator, I want to send Prometheus metrics from my self-managed Prometheus instance to an Azure Monitor workspace. ---# Send Prometheus metrics from virtual machines, scale sets, or Kubernetes clusters to an Azure Monitor workspace --Prometheus isn't limited to monitoring Kubernetes clusters. Use Prometheus to monitor applications and services running on your servers, wherever they're running. For example, you can monitor applications running on Virtual Machines, Virtual Machine Scale Sets, or even on-premises servers. You can also send Prometheus metrics to an Azure Monitor workspace from your self-managed cluster and Prometheus server. Install prometheus on your servers and configure remote-write to send metrics to an Azure Monitor workspace. --This article explains how to configure remote-write to send data from a self-managed Prometheus instance to an Azure Monitor workspace. ---## Remote write options --Self-managed Prometheus can run on Azure and non-Azure environments. The following are authentication options for remote-write to Azure Monitor workspace based on the environment where Prometheus is running. --## Azure-managed Virtual Machines, Virtual Machine Scale Sets, and Kubernetes clusters --Use user-assigned managed identity authentication for services running self managed Prometheus in an Azure environment. Azure-managed services include: --- Azure Virtual Machines-- Azure Virtual Machine Scale Sets-- Azure Kubernetes Service (AKS)--To set up remote write for Azure-managed resources, see [Remote-write using user-assigned managed identity](#remote-write-using-user-assigned-managed-identity-authentication). ---## Virtual machines and Kubernetes clusters running on non-Azure environments. --If you have virtual machines or a Kubernetes cluster in non-Azure environments, or you have onboarded to Azure Arc, install self-managed Prometheus, and configure remote-write using Microsoft Entra ID application authentication. For more information, see [Remote-write using Microsoft Entra ID application authentication](#remote-write-using-microsoft-entra-id-application-authentication). --Onboarding to Azure Arc-enabled services allows you to manage and configure non-Azure virtual machines in Azure. For more Information on onboarding Virtual Machines to Azure Arc-enabled servers, see [Azure Arc-enabled servers](/azure/azure-arc/servers/overview) and [Azure Arc-enabled Kubernetes](/azure/azure-arc/kubernetes/overview). Arc-enabled services only support Microsoft Entra ID authentication. - -> [!NOTE] -> System-assigned managed identity is not supported for remote-write to Azure Monitor workspaces. Use user-assigned managed identity or Microsoft Entra ID application authentication. ---## Prerequisites --### Supported versions --- Prometheus versions greater than v2.45 are required for managed identity authentication.-- Prometheus versions greater than v2.48 are required for Microsoft Entra ID application authentication. --### Azure Monitor workspace --This article covers sending Prometheus metrics to an Azure Monitor workspace. To create an Azure monitor workspace, see [Manage an Azure Monitor workspace](./azure-monitor-workspace-manage.md#create-an-azure-monitor-workspace). --## Permissions --Administrator permissions for the cluster or resource are required to complete the steps in this article. --## Set up authentication for remote-write --Depending on the environment where Prometheus is running, you can configure remote-write to use user-assigned managed identity or Microsoft Entra ID application authentication to send data to Azure Monitor workspace. --Use the Azure portal or CLI to create a user-assigned managed identity or Microsoft Entra ID application. --### [Remote-write using user-assigned managed identity](#tab/managed-identity) --### Remote-write using user-assigned managed identity authentication --User-assigned managed identity authentication can be used in any Azure-managed environment. If your Prometheus service is running in a non-Azure environment, you can use Microsoft Entra ID application authentication. --To configure a user-assigned managed identity for remote-write to Azure Monitor workspace, complete the following steps. --#### Create a user-assigned managed identity --To create a user-managed identity to use in your remote-write configuration, see [Manage user-assigned managed identities](/entra/identity/managed-identities-azure-resources/how-manage-user-assigned-managed-identities#create-a-user-assigned-managed-identity). --Note the value of the `clientId` of the managed identity that you created. This ID is used in the Prometheus remote write configuration. --#### Assign the Monitoring Metrics Publisher role to the application --On the workspace's data collection rule, assign the `Monitoring Metrics Publisher` role to the managed identity. --1. On the Azure Monitor workspace Overview page, select the **Data collection rule** link. -- :::image type="content" source="media/prometheus-remote-write-virtual-machines/select-data-collection-rule.png" lightbox="media/prometheus-remote-write-virtual-machines/select-data-collection-rule.png" alt-text="A screenshot showing the data collection rule link on an Azure Monitor workspace page."::: --1. On the data collection rule page, select **Access control (IAM)**. --1. Select **Add**, and **Add role assignment**. - :::image type="content" source="media/prometheus-remote-write-virtual-machines/data-collection-rule-access-control.png" lightbox="media/prometheus-remote-write-virtual-machines/data-collection-rule-access-control.png" alt-text="A screenshot showing the data collection rule."::: --1. Search for and select for *Monitoring Metrics Publisher*, and then select **Next**. - :::image type="content" source="media/prometheus-remote-write-virtual-machines/add-role-assignment.png" lightbox="media/prometheus-remote-write-virtual-machines/add-role-assignment.png" alt-text="A screenshot showing the role assignment menu for a data collection rule."::: --1. Select **Managed Identity**. -1. Select **Select members**. -1. In the **Managed Entity** dropdown, *User-assigned managed identity*. -1. Select the user-assigned identity that you want to use, then click **Select**. -1. Select **Review + assign** to complete the role assignment. - - :::image type="content" source="media/prometheus-remote-write-virtual-machines/select-members.png" lightbox="media/prometheus-remote-write-virtual-machines/select-members.png" alt-text="A screenshot showing the select members menu for a data collection rule."::: --#### Assign the managed identity to a Virtual Machine or Virtual Machine Scale Set --> [!IMPORTANT] -> To complete the steps in this section, you must have owner or user access administrator permissions for the Virtual Machine or Virtual MAchine Scale Set. - -1. In the Azure portal, go to the cluster, Virtual Machine, or Virtual Machine Scale Set's page. -1. Select **Identity**. -1. Select **User assigned**. -1. Select **Add**. -1. Select the user assigned managed identity that you created, then select **Add**. -- :::image type="content" source="media/prometheus-remote-write-virtual-machines/assign-user-identity.png" lightbox="media/prometheus-remote-write-virtual-machines/assign-user-identity.png" alt-text="A screenshot showing the add user assigned managed identity page."::: --#### Assign the managed identity for an Azure Kubernetes Service --For Azure Kubernetes services (AKS), the managed identity must be assigned to the virtual machine scale sets. --AKS creates a resource group containing the virtual machine scale sets. The resource group name is in the format `MC_<resource group name>_<AKS cluster name>_<region>`. -For each Virtual Machine Scale Set in the resource group, assign the managed identity according to the steps in the previous section, [Assign the managed identity to a Virtual Machine or Virtual Machine Scale Set](#assign-the-managed-identity-to-a-virtual-machine-or-virtual-machine-scale-set). ----### [Microsoft Entra ID application](#tab/entra-application) -### Remote-write using Microsoft Entra ID application authentication --Microsoft Entra ID application authentication can be used in any environment. If your Prometheus service is running in an Azure-managed environment, consider using user-assigned managed identity authentication. --To configure remote-write to Azure Monitor workspace using a Microsoft Entra ID application, create an Entra application. On Azure Monitor workspace's data collection rule, assign the `Monitoring Metrics Publisher` role to the Entra application. --> [!NOTE] -> Your Azure Entra application uses a client secret or password. Client secrets have an expiration date. Make sure to create a new client secret before it expires so you don't lose authenticated access --#### Create a Microsoft Entra ID application --To create a Microsoft Entra ID application using the portal, see [Create a Microsoft Entra ID application and service principal that can access resources](/entra/identity-platform/howto-create-service-principal-portal#register-an-application-with-microsoft-entra-id-and-create-a-service-principal). --When you have created your Entra application, get the client ID and generate a client secret. --1. In the list of applications, copy the value for **Application (client) ID** for the registered application. This value is used in the Prometheus remote write configuration as the value for `client_id`. -- :::image type="content" source="media/prometheus-remote-write-virtual-machines/find-clinet-id.png" alt-text="A screenshot showing the application or client ID of a Microsoft Entra ID application." lightbox="media/prometheus-remote-write-virtual-machines/find-clinet-id.png"::: --1. Select **Certificates and Secrets** -1. Select **Client secrets**, them select **New client secret** to create a new Secret -1. Enter a description, set the expiration date and select **Add**. - - :::image type="content" source="media/prometheus-remote-write-virtual-machines/create-client-secret.png" alt-text="A screenshot showing the add secret page." lightbox="media/prometheus-remote-write-virtual-machines/create-client-secret.png"::: --1. Copy the value of the secret securely. The value is used in the Prometheus remote write configuration as the value for `client_secret`. The client secret value is only visible when created and can't be retrieved later. If lost, you must create a new client secret. -- :::image type="content" source="media/prometheus-remote-write-virtual-machines/copy-client-secret.png" alt-text="A screenshot showing the client secret value." lightbox="media/prometheus-remote-write-virtual-machines/copy-client-secret.png"::: - -#### Assign the Monitoring Metrics Publisher role to the application --Assign the `Monitoring Metrics Publisher` role on the workspace's data collection rule to the application. --1. On the Azure Monitor workspace, overview page, select the **Data collection rule** link. -- :::image type="content" source="media/prometheus-remote-write-virtual-machines/select-data-collection-rule.png" alt-text="A screenshot showing the data collection rule link on the Azure Monitor workspace page." lightbox="media/prometheus-remote-write-virtual-machines/select-data-collection-rule.png"::: --1. On the data collection rule overview page, select **Access control (IAM)**. --1. Select **Add**, and then select **Add role assignment**. -- :::image type="content" source="media/prometheus-remote-write-virtual-machines/data-collection-rule-access-control.png" alt-text="A screenshot showing adding the role add assignment pages." lightbox="media/prometheus-remote-write-virtual-machines/data-collection-rule-access-control.png"::: --1. Select the **Monitoring Metrics Publisher** role, and then select **Next**. -- :::image type="content" source="media/prometheus-remote-write-virtual-machines/add-role-assignment.png" lightbox="media/prometheus-remote-write-virtual-machines/add-role-assignment.png" alt-text="A screenshot showing the role assignment menu for a data collection rule."::: --1. Select **User, group, or service principal**, and then choose **Select members**. Select the application that you created, and then choose **Select**. -- :::image type="content" source="media/prometheus-remote-write-virtual-machines/select-members-apps.png" alt-text="Screenshot that shows selecting the application." lightbox="media/prometheus-remote-write-virtual-machines/select-members-apps.png"::: --1. To complete the role assignment, select **Review + assign**. --### [CLI](#tab/CLI) -## Create user-assigned identities and Microsoft Entra ID apps using CLI --### Create a user-assigned managed identity --Create a user-assigned managed identity for remote-write using the following steps: -1. Create a user-assigned managed identity -1. Assign the `Monitoring Metrics Publisher` role on the workspace's data collection rule to the managed identity -1. Assign the managed identity to a Virtual Machine or Virtual Machine Scale Set. --Note the value of the `clientId` of the managed identity that you create. This ID is used in the Prometheus remote write configuration. --1. Create a user-assigned managed identity using the following CLI command: -- ```azurecli - az account set \ - --subscription <subscription id> -- az identity create \ - --name <identity name> \ - --resource-group <resource group name> - ``` - - The following is an example of the output displayed: -- ```azurecli - { - "clientId": "00001111-aaaa-2222-bbbb-3333cccc4444", - "id": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/rg-001/providers/Microsoft.ManagedIdentity/userAssignedIdentities/PromRemoteWriteIdentity", - "location": "eastus", - "name": "PromRemoteWriteIdentity", - "principalId": "aaaaaaaa-bbbb-cccc-1111-222222222222", - "resourceGroup": "rg-001", - "systemData": null, - "tags": {}, - "tenantId": "ffff5f5f-aa6a-bb7b-cc8c-dddddd9d9d9d", - "type": "Microsoft.ManagedIdentity/userAssignedIdentities" - } - ``` --1. Assign the `Monitoring Metrics Publisher` role on the workspace's data collection rule to the managed identity. - - ```azurecli - az role assignment create \ - --role "Monitoring Metrics Publisher" \ - --assignee <managed identity client ID> \ - --scope <data collection rule resource ID> - ``` - For example, - - ```azurecli - az role assignment create \ - --role "Monitoring Metrics Publisher" \ - --assignee 00001111-aaaa-2222-bbbb-3333cccc4444 \ - --scope /subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/MA_amw-001_eastus_managed/providers/Microsoft.Insights/dataCollectionRules/amw-001 - ``` --1. Assign the managed identity to a Virtual Machine or Virtual Machine Scale Set. -- For Virtual Machines: - ```azurecli - az vm identity assign \ - -g <resource group name> \ - -n <virtual machine name> \ - --identities <user assigned identity resource ID> - ``` - - For Virtual Machine Scale Sets: - - ```azurecli - az vmss identity assign \ - -g <resource group name> \ - -n <VSS name> \ - --identities <user assigned identity resource ID> - ``` -- For example, for a Virtual Machine Scale Set: -- ```azurecli - az vm identity assign \ - -g rg-prom-on-vm \ - -n win-vm-prom \ - --identities /subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/rg-001/providers/Microsoft.ManagedIdentity/userAssignedIdentities/PromRemoteWriteIdentity - ``` -For more information, see [az identity create](/cli/azure/identity#az-identity-create) and [az role assignment create](/cli/azure/role/assignment#az-role-assignment-create). --#### Create a Microsoft Entra ID application -To create a Microsoft Entra ID application using CLI, and assign the `Monitoring Metrics Publisher` role, run the following command: --```azurecli -az ad sp create-for-rbac --name <application name> \ role "Monitoring Metrics Publisher" \scopes <azure monitor workspace data collection rule Id>-``` -For example, -```azurecli -az ad sp create-for-rbac \ name PromRemoteWriteApp \role "Monitoring Metrics Publisher" \scopes /subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/MA_amw-001_eastus_managed/providers/Microsoft.nsights/dataCollectionRules/amw-001-``` -The following is an example of the output displayed: -```azurecli -{ - "appId": "66667777-aaaa-8888-bbbb-9999cccc0000", - "displayName": "PromRemoteWriteApp", - "password": "Aa1Bb~2Cc3.-Dd4Ee5Ff6Gg7Hh8Ii9_Jj0Kk1Ll2", - "tenant": "ffff5f5f-aa6a-bb7b-cc8c-dddddd9d9d9d" -} -``` --The output contains the `appId` and `password` values. Save these values to use in the Prometheus remote write configuration as values for `client_id` and `client_secret` The password or client secret value is only visible when created and can't be retrieved later. If lost, you must create a new client secret. --For more information, see [az ad app create](/cli/azure/ad/app#az-ad-app-create) and [az ad sp create-for-rbac](/cli/azure/ad/sp#az-ad-sp-create-for-rbac). ----## Configure remote-write --Remote-write is configured in the Prometheus configuration file `prometheus.yml`, or in the Prometheus Operator. --For more information on configuring remote-write, see the Prometheus.io article: [Configuration](https://prometheus.io/docs/prometheus/latest/configuration/configuration/#remote_write). For more on tuning the remote write configuration, see [Remote write tuning](https://prometheus.io/docs/practices/remote_write/#remote-write-tuning). --### [Configure remote-write for Prometheus Operator](#tab/prom-operator) --If you are running Prometheus Operator on a Kubernetes cluster, follow the below steps to send data to your Azure Monitor Workspace. --1. If you are using Microsoft Entra ID authentication, convert the secret using base64 encoding, and then apply the secret into your Kubernetes cluster. Save the following into a yaml file. Skip this step if you are using managed identity authentication. --```yaml -apiVersion: v1 -kind: Secret -metadata: - name: remote-write-secret - namespace: monitoring # Replace with namespace where Prometheus Operator is deployed. -type: Opaque -data: - password: <base64-encoded-secret> --``` --Apply the secret. --```azurecli -# set context to your cluster -az aks get-credentials -g <aks-rg-name> -n <aks-cluster-name> --kubectl apply -f <remote-write-secret.yaml> -``` --2. You will need to update the values for remote write section in Prometheus Operator. Copy the following and save it as a yaml file. For the values of the yaml file, see below section. Refer to [Prometheus Operator documentation](https://github.com/prometheus-operator/prometheus-operator/blob/main/Documentation/api.md#azuread) for more details on the Azure Monitor Workspace remote write specification in Prometheus Operator. --```yaml -prometheus: - prometheusSpec: - remoteWrite: - - url: "<metrics ingestion endpoint for your Azure Monitor workspace>" - azureAd: -# AzureAD configuration. -# The Azure Cloud. Options are 'AzurePublic', 'AzureChina', or 'AzureGovernment'. - cloud: 'AzurePublic' - managedIdentity: - clientId: "<clientId of the managed identity>" - oauth: - clientId: "<clientId of the Entra app>" - clientSecret: - name: remote-write-secret - key: password - tenantId: "<Azure subscription tenant Id>" -``` --3. Use helm to update your remote write config using the above yaml file. --```azurecli -helm upgrade -f <YAML-FILENAME>.yml prometheus prometheus-community/kube-prometheus-stack --namespace <namespace where Prometheus Operator is deployed> -``` --### [Configure remote-write for Prometheus running in VMs or other environments](#tab/prom-vm) --To send data to your Azure Monitor Workspace, add the following section to the configuration file (prometheus.yml) of your self-managed Prometheus instance. --```yaml -remote_write: - - url: "<metrics ingestion endpoint for your Azure Monitor workspace>" -# AzureAD configuration. -# The Azure Cloud. Options are 'AzurePublic', 'AzureChina', or 'AzureGovernment'. - azuread: - cloud: 'AzurePublic' - managed_identity: - client_id: "<client-id of the managed identity>" - oauth: - client_id: "<client-id from the Entra app>" - client_secret: "<client secret from the Entra app>" - tenant_id: "<Azure subscription tenant Id>" -``` ----The `url` parameter specifies the metrics ingestion endpoint of the Azure Monitor workspace. It can be found on the Overview page of your Azure Monitor workspace in the Azure portal. ---Use either the `managed_identity`, or `oauth` for Microsoft Entra ID application authentication, depending on your implementation. Remove the object that you're not using. --Find your client ID for the managed identity using the following Azure CLI command: --```azurecli -az identity list --resource-group <resource group name> -``` -For more information, see [az identity list](/cli/azure/identity#az-identity-list). --To find your client for managed identity authentication in the portal, go to the **Managed Identities** page in the Azure portal and select the relevant identity name. Copy the value of the **Client ID** from the **Identity overview** page. ---To find the client ID for the Microsoft Entra ID application, use the following CLI or see the first step in the [Create an Microsoft Entra ID application using the Azure portal](#remote-write-using-microsoft-entra-id-application-authentication) section. --```azurecli -$ az ad app list --display-name < application name> -``` -For more information, see [az ad app list](/cli/azure/ad/app#az-ad-app-list). --->[!NOTE] -> After editing the configuration file, restart Prometheus for the changes to apply. ---## Verify that remote-write data is flowing --Use the following methods to verify that Prometheus data is being sent into your Azure Monitor workspace. --### Azure Monitor metrics explorer with PromQL --To check if the metrics are flowing to the Azure Monitor workspace, from your Azure Monitor workspace in the Azure portal, select **Metrics**. Use the metrics explorer to query the metrics that you're expecting from the self-managed Prometheus environment. For more information, see [Metrics explorer](/azure/azure-monitor/essentials/metrics-explorer). ---### Prometheus explorer in Azure Monitor Workspace --Prometheus Explorer provides a convenient way to interact with Prometheus metrics within your Azure environment, making monitoring and troubleshooting more efficient. To use the Prometheus explorer, go to your Azure Monitor workspace in the Azure portal and select **Prometheus Explorer** to query the metrics that you're expecting from the self-managed Prometheus environment. -For more information, see [Prometheus explorer](/azure/azure-monitor/essentials/prometheus-workbooks). --### Grafana --Use PromQL queries in Grafana to verify that the results return the expected data. To configure Grafana, see [getting Grafana setup with Managed Prometheus](../essentials/prometheus-grafana.md) ---## Troubleshoot remote write --If remote data isn't appearing in your Azure Monitor workspace, see [Troubleshoot remote write](../containers/prometheus-remote-write-troubleshooting.md) for common issues and solutions. ---## Next steps --- [Learn more about Azure Monitor managed service for Prometheus](./prometheus-metrics-overview.md).-- [Learn more about Azure Monitor reverse proxy side car for remote-write from self-managed Prometheus running on Kubernetes](../containers/prometheus-remote-write.md) |
| azure-monitor | Prometheus Rule Groups | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/prometheus-rule-groups.md | - Title: Rule groups in Azure Monitor Managed Service for Prometheus -description: Description of rule groups in Azure Monitor managed service for Prometheus which alerting and data computation. --- Previously updated : 11/09/2023---# Azure Monitor managed service for Prometheus rule groups -Rules in Prometheus act on data as it's collected. They're configured as part of a Prometheus rule group, which is applied to Prometheus metrics in [Azure Monitor workspace](azure-monitor-workspace-overview.md). --## Rule types -There are two types of Prometheus rules as described in the following table. --| Type | Description | -|:|:| -| Alert |[Alert rules ](https://aka.ms/azureprometheus-promio-alertrules)let you create an Azure Monitor alert based on the results of a Prometheus Query Language (Prom QL) query. Alerts fired by Azure Managed Prometheus alert rules are processed and trigger notifications in similar way to other Azure Monitor alerts.| -| Recording |[Recording rules](https://aka.ms/azureprometheus-promio-recrules) allow you to precompute frequently needed or computationally extensive expressions and store their result as a new set of time series. Time series created by recording rules are ingested back to your Azure Monitor workspace as new Prometheus metrics. | --## Create Prometheus rules -Azure Managed Prometheus rule groups, recording rules and alert rules can be created and configured using The Azure resource type **Microsoft.AlertsManagement/prometheusRuleGroups**, where the alert rules and recording rules are defined as part of the rule group properties. Prometheus rule groups are defined with a scope of a specific [Azure Monitor workspace](azure-monitor-workspace-overview.md). Prometheus rule groups can be created using Azure Resource Manager (ARM) templates, API, Azure CLI, or PowerShell. --Azure managed Prometheus rule groups follow the structure and terminology of the open source Prometheus rule groups. Rule names, expression, 'for' clause, labels, annotations are all supported in the Azure version. The following key differences between OSS rule groups and Azure managed Prometheus should be noted: -* Azure managed Prometheus rule groups are managed as Azure resources, and include necessary information for resource management, such as the subscription and resource group where the Azure rule group should reside. -* Azure managed Prometheus alert rules include dedicated properties that allow alerts to be processed like other Azure Monitor alerts. For example, alert severity, action group association, and alert auto resolve configuration are supported as part of Azure managed Prometheus alert rules. --> [!NOTE] -> For your AKS or ARC Kubernetes clusters, you can use some of the recommended alerts rules. See pre-defined alert rules [here](../containers/container-insights-metric-alerts.md#enable-prometheus-alert-rules). --### Limiting rules to a specific cluster --You can optionally limit the rules in a rule group to query data originating from a single specific cluster, by adding a cluster scope to your rule group, and/or by using the rule group `clusterName` property. -You should limit rules to a single cluster if your Azure Monitor workspace contains a large amount of data from multiple clusters. In such a case, there's a concern that running a single set of rules on all the data may cause performance or throttling issues. By using the cluster scope, you can create multiple rule groups, each configured with the same rules, with each group covering a different cluster. --To limit your rule group to a cluster scope [using an ARM template](#creating-prometheus-rule-group-using-resource-manager-template), you should add the Azure Resource ID of your cluster to the rule group **scopes[]** list. **The scopes list must still include the Azure Monitor workspace resource ID**. The following cluster resource types are supported as a cluster scope: -* Azure Kubernetes Service (AKS) clusters (Microsoft.ContainerService/managedClusters) -* Azure Arc-enabled Kubernetes clusters (Microsoft.kubernetes/connectedClusters) -* Azure connected appliances (Microsoft.ResourceConnector/appliances) --In addition to the cluster ID, you can configure the **clusterName** property of your rule group. The 'clusterName' property must match the `cluster` label that is added to your metrics when scraped from a specific cluster. By default, this label is set to the last part (resource name) of your cluster ID. If you've changed this label using the ['cluster_alias'](../essentials/prometheus-metrics-scrape-configuration.md#cluster-alias) setting in your cluster scraping configmap, you must include the updated value in the rule group 'clusterName' property. If your scraping uses the default 'cluster' label value, the 'clusterName' property is optional. --Here's an example of how a rule group is configured to limit query to a specific cluster: --``` json -{ - "name": "sampleRuleGroup", - "type": "Microsoft.AlertsManagement/prometheusRuleGroups", - "apiVersion": "2023-03-01", - "location": "northcentralus", - "properties": { - "description": "Sample Prometheus Rule Group limited to a specific cluster", - "scopes": [ - "/subscriptions/<subscription-id>/resourcegroups/<resource-group-name>/providers/microsoft.monitor/accounts/<azure-monitor-workspace-name>", - "/subscriptions/<subscription-id>/resourcegroups/<resource-group-name>/providers/microsoft.containerservice/managedclusters/<myClusterName>" - ], - "clusterName": "<myCLusterName>", - "rules": [ - { - ... - } - ] - } -} -``` -If both cluster ID scope and `clusterName` aren't specified for a rule group, the rules in the group query data from all the clusters in the workspace from all clusters. --You can also limit your rule group to a cluster scope using the [portal UI](#configure-the-rule-group-scope). --### Create or edit Prometheus rule group in the Azure portal --To create a new rule group from the portal home page: --1. In the [portal](https://portal.azure.com/), select **Monitor** > **Alerts**. -1. Select **Prometheus Rule Groups** -1. Select **+ Create** to open up the rule group creation wizard --To edit a new rule group from the portal home page: --1. In the [portal](https://portal.azure.com/), select **Monitor** > **Alerts**. -1. Select **Prometheus Rule Groups** to see the list of existing rule groups in your subscription -1. Select the desired rule group to go to enter edit mode. - --#### Configure the rule group scope -On the rule group **Scope** tab: -1. Select the **Azure Monitor workspace** from a list of workspaces available in your subscriptions. The rules in this group query data from this workspace. -1. To limit your rule group to a cluster scope, select the **Specific cluster** option: - * Select the **Cluster** from the list of clusters that are already connected to the selected Azure Monitor workspace. - * The default **Cluster name** value is entered for you. You should change this value only if you've changed your cluster label value using [cluster_alias](../essentials/prometheus-metrics-scrape-configuration.md#cluster-alias). -1. Select **Next** to configure the rule group details - --#### Configure the rule group details -On the rule group **Details** tab: -1. Select the **Subscription** and **Resource group** where the rule group should be stored. -1. Enter the rule group **Name** and **Description**. The rule group name can't be changed after the rule group is created. -1. Select the **Evaluate every** period for the rule group. 1 minute is the default. -1. Select if the rule group is to be enabled when created. -1. Select **Next** to configure the rules in the group. - --#### Configure the rules in the group -* On the rule group **Rules** tab you can see the list of recording rules and alert rules in the group. -* You can add rules up to the limit of 20 rules in a single group. -* Rules are evaluated in the order they appear in the group. You can change the order of rules using the **move up** and **move down** options. --* To add a new recording rule: - -1. Select **+ Add recording rule** to open the **Create a recording rule** pane. -2. Enter the **Name** of the rule. This name is the name of the metric created by the rule. -3. Enter the PromQL **Expression** for the rule. -4. Select if the rule is to be enabled when created. -5. You can enter optional **Labels** key/value pairs for the rule. These labels are added to the metric created by the rule. -6. Select **Create** to add the new rule to the rule list. - --* To add a new alert rule: - -1. Select **+ Add alert rule** to open the "Create an alert rule" pane. -2. Select the **Severity** of alerts fired by this rule. -3. Enter the **Name** of the rule. This name is the name of alerts fired by the rule. -4. Enter the PromQL **Expression** for the rule. -5. Select the **For** value for the period between the alert expression first becomes true and until the alert is fired. -6. You can enter optional **Annotations** key/value pairs for the rule. These annotations are added to alerts fired by the rule. -7. You can enter optional **Labels** key/value pairs for the rule. These labels are added to the alerts fired by the rule. -8. Select the [action groups](../alerts/action-groups.md) that the rule triggers. -9. Select **Automatically resolve alert** to automatically resolve alerts if the rule condition is no longer true during the **Time to auto-resolve** period. -10. Select if the rule is to be enabled when created. -11. Select **Create** to add the new rule to the rule list. - --#### Finish creating the rule group -1. On the **Tags** tab, set any required Azure resource tags to be added to the rule group resource. - :::image type="content" source="media/prometheus-metrics-rule-groups/create-new-rule-group-tags.png" alt-text="Screenshot that shows the Tags tab when creating a new alert rule."::: -1. On the **Review + create** tab, the rule group is validated, and lets you know about any issues. On this tab, you can also select the **View automation template** option, and download the template for the group you're about to create. -1. When validation passes and you've reviewed the settings, select the **Create** button. - :::image type="content" source="media/prometheus-metrics-rule-groups/create-new-rule-group-review-create.png" alt-text="Screenshot that shows the Review and create tab when creating a new alert rule."::: -1. You can follow up on the rule group deployment to make sure it completes successfully or be notified on any error. --### Creating Prometheus rule group using Resource Manager template --You can use a Resource Manager template to create and configure Prometheus rule groups, alert rules, and recording rules. Resource Manager templates enable you to programmatically create and configure rule groups in a consistent and reproducible way across all your environments. --The basic steps are as follows: --1. Use the following template as a JSON file that describes how to create the rule group. -2. Deploy the template using any deployment method, such as [Azure portal](../../azure-resource-manager/templates/deploy-portal.md), [Azure CLI](../../azure-resource-manager/templates/deploy-cli.md), [Azure PowerShell](../../azure-resource-manager/templates/deploy-powershell.md), or [Rest API](../../azure-resource-manager/templates/deploy-rest.md). --### Template example for a Prometheus rule group -Following is a sample template that creates a Prometheus rule group, including one recording rule and one alert rule. This template creates a resource of type `Microsoft.AlertsManagement/prometheusRuleGroups`. The scope of this group is limited to a single AKS cluster. The rules are executed in the order they appear within a group. --``` json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": {}, - "variables": {}, - "resources": [ - { - "name": "sampleRuleGroup", - "type": "Microsoft.AlertsManagement/prometheusRuleGroups", - "apiVersion": "2023-03-01", - "location": "northcentralus", - "properties": { - "description": "Sample Prometheus Rule Group", - "scopes": [ - "/subscriptions/<subscription-id>/resourcegroups/<resource-group-name>/providers/microsoft.monitor/accounts/<azure-monitor-workspace-name>", - "/subscriptions/<subscription-id>/resourcegroups/<resource-group-name>/providers/microsoft.containerservice/managedclusters/<myClusterName>" - ], - "enabled": true, - "clusterName": "<myCLusterName>", - "interval": "PT1M", - "rules": [ - { - "record": "instance:node_cpu_utilisation:rate5m", - "expression": "1 - avg without (cpu) (sum without (mode)(rate(node_cpu_seconds_total{job=\"node\", mode=~\"idle|iowait|steal\"}[5m])))", - "labels": { - "workload_type": "job" - }, - "enabled": true - }, - { - "alert": "KubeCPUQuotaOvercommit", - "expression": "sum(min without(resource) (kube_resourcequota{job=\"kube-state-metrics\", type=\"hard\", resource=~\"(cpu|requests.cpu)\"})) / sum(kube_node_status_allocatable{resource=\"cpu\", job=\"kube-state-metrics\"}) > 1.5", - "for": "PT5M", - "labels": { - "team": "prod" - }, - "annotations": { - "description": "Cluster has overcommitted CPU resource requests for Namespaces.", - "runbook_url": "https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubecpuquotaovercommit", - "summary": "Cluster has overcommitted CPU resource requests." - }, - "enabled": true, - "severity": 3, - "resolveConfiguration": { - "autoResolved": true, - "timeToResolve": "PT10M" - }, - "actions": [ - { - "actionGroupID": "/subscriptions/<subscription-id>/resourcegroups/<resource-group-name>/providers/microsoft.insights/actiongroups/<action-group-name>" - } - ] - } - ] - } - } - ] -} -``` --The following tables describe each of the properties in the rule definition. --### Rule group -The rule group contains the following properties. --| Name | Required | Type | Description | -|:|:|:|:| -| `name` | True | string | Prometheus rule group name | -| `type` | True | string | `Microsoft.AlertsManagement/prometheusRuleGroups` | -| `apiVersion` | True | string | `2023-03-01` | -| `location` | True | string | Resource location out of supported regions. | -| `properties.description` | False | string | Rule group description. | -| `properties.scopes` | True | string[] | Must include the target Azure Monitor workspace ID. Can optionally include one more cluster ID, as well. | -| `properties.enabled` | False | boolean | Enable/disable group. Default is true. | -| `properties.clusterName` | False | string | Must match the `cluster` label that is added to metrics scraped from your target cluster. By default, set to the last part (resource name) of cluster ID that appears in scopes[]. | -| `properties.interval` | False | string | Group evaluation interval. Default = PT1M | --### Recording rules -The `rules` section contains the following properties for recording rules. --| Name | Required | Type | Description | -|:|:|:|:| -| `record` | True | string | Recording rule name. This name is used for the new time series. | -| `expression` | True | string | PromQL expression to calculate the new time series value. | -| `labels` | True | string | Prometheus rule labels key-value pairs. These labels are added to the recorded time series. | -| `enabled` | False | boolean | Enable/disable group. Default is true. | --### Alert rules -The `rules` section contains the following properties for alerting rules. --| Name | Required | Type | Description | Notes | -|:|:|:|:|:| -| `alert` | False | string | Alert rule name | -| `expression` | True | string | PromQL expression to evaluate. | -| `for` | False | string | Alert firing timeout. Values - PT1M, PT5M etc. | -| `labels` | False | object | labels key-value pairs | Prometheus alert rule labels. These labels are added to alerts fired by this rule. | -| `rules.annotations` | False | object | Annotations key-value pairs to add to the alert. | -| `enabled` | False | boolean | Enable/disable group. Default is true. | -| `rules.severity` | False | integer | Alert severity. 0-4, default is 3 (informational) | -| `rules.resolveConfigurations.autoResolved` | False | boolean | When enabled, the alert is automatically resolved when the condition is no longer true. Default = true | -| `rules.resolveConfigurations.timeToResolve` | False | string | Alert auto resolution timeout. Default = "PT5M" | -| `rules.action[].actionGroupId` | false | string | One or more action group resource IDs. Each is activated when an alert is fired. | --### Converting Prometheus rules file to a Prometheus rule group ARM template --If you have a [Prometheus rules configuration file](https://prometheus.io/docs/prometheus/latest/configuration/recording_rules/#configuring-rules) (in YAML format), you can now convert it to an Azure Prometheus rule group ARM template, using the [az-prom-rules-converter utility](https://github.com/Azure/prometheus-collector/tree/main/tools/az-prom-rules-converter#az-prom-rules-converter). The rules file can contain definition of one or more rule groups. --In addition to the rules file, you must provide the utility with other properties that are needed to create the Azure Prometheus rule groups, including: subscription, resource group, location, target Azure Monitor workspace, target cluster ID and name, and action groups (used for alert rules). The utility creates a template file that can be deployed directly or within a deployment pipe providing some of these properties as parameters. Properties that you provide to the utility are used for all the rule groups in the template. For example, all rule groups in the file are created in the same subscription, resource group and location, and using the same Azure Monitor workspace. If an action group is provided as a parameter to the utility, the same action group is used in all the alert rules in the template. If you want to change this default configuration (for example, use different action groups in different rules) you can edit the resulting template according to your needs, before deploying it. --> [!NOTE] -> The az-prom-convert-utility is provided as a courtesy tool. We recommend that you review the resulting template and verify it matches your intended configuration. --### Creating Prometheus rule group using Azure CLI --You can use Azure CLI to create and configure Prometheus rule groups, alert rules, and recording rules. The following code examples use [Azure Cloud Shell](../../cloud-shell/overview.md). --1. In the [portal](https://portal.azure.com/), select **Cloud Shell**. At the prompt, use the commands that follow. --2. To create a Prometheus rule group, use the `az alerts-management prometheus-rule-group create` command. You can see detailed documentation on the Prometheus rule group create command in the `az alerts-management prometheus-rule-group create` section of the [Azure CLI commands for creating and managing Prometheus rule groups](/cli/azure/alerts-management/prometheus-rule-group#commands). --Example: Create a new Prometheus rule group with rules --```azurecli - az alerts-management prometheus-rule-group create -n TestPrometheusRuleGroup -g TestResourceGroup -l westus --enabled --description "test" --interval PT10M --scopes "/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/testrg/providers/microsoft.monitor/accounts/testaccount" --rules [{"record":"test","expression":"test","labels":{"team":"prod"}},{"alert":"Billing_Processing_Very_Slow","expression":"test","enabled":"true","severity":2,"for":"PT5M","labels":{"team":"prod"},"annotations":{"annotationName1":"annotationValue1"},"resolveConfiguration":{"autoResolved":"true","timeToResolve":"PT10M"},"actions":[{"actionGroupId":"/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/testrg/providers/microsoft.insights/actionGroups/test-action-group-name1","actionProperties":{"key11":"value11","key12":"value12"}},{"actionGroupId":"/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/testrg/providers/microsoft.insights/actionGroups/test-action-group-name2","actionProperties":{"key21":"value21","key22":"value22"}}]}] -``` --### Create a new Prometheus rule group with PowerShell --To create a Prometheus rule group using PowerShell, use the [new-azprometheusrulegroup](/powershell/module/az.alertsmanagement/new-azprometheusrulegroup) cmdlet. --Example: Create Prometheus rule group definition with rules. --```powershell -$rule1 = New-AzPrometheusRuleObject -Record "job_type:billing_jobs_duration_seconds:99p5m" -$action = New-AzPrometheusRuleGroupActionObject -ActionGroupId /subscriptions/fffffffff-ffff-ffff-ffff-ffffffffffff/resourceGroups/MyresourceGroup/providers/microsoft.insights/actiongroups/MyActionGroup -ActionProperty @{"key1" = "value1"} -$Timespan = New-TimeSpan -Minutes 15 -$rule2 = New-AzPrometheusRuleObject -Alert Billing_Processing_Very_Slow -Expression "job_type:billing_jobs_duration_seconds:99p5m > 30" -Enabled $false -Severity 3 -For $Timespan -Label @{"team"="prod"} -Annotation @{"annotation" = "value"} -ResolveConfigurationAutoResolved $true -ResolveConfigurationTimeToResolve $Timespan -Action $action -$rules = @($rule1, $rule2) -$scope = "/subscriptions/fffffffff-ffff-ffff-ffff-ffffffffffff/resourcegroups/MyresourceGroup/providers/microsoft.monitor/accounts/MyAccounts" -New-AzPrometheusRuleGroup -ResourceGroupName MyresourceGroup -RuleGroupName MyRuleGroup -Location eastus -Rule $rules -Scope $scope -Enabled -``` -## View Prometheus rule groups -You can view your Prometheus rule groups and their included rules in the Azure portal in one of the following ways: -* In the [portal home page](https://portal.azure.com/), in the search box, look for **Prometheus Rule Groups**. -* In the [portal home page](https://portal.azure.com/), select **Monitor** > **Alerts**, then select **Prometheus Rule Groups**. - :::image type="content" source="media/prometheus-metrics-rule-groups/prometheus-rule-groups-from-alerts.png" alt-text="Screenshot that shows how to view Prometheus rule groups from the alerts screen."::: -* In the page of a specific Azure Kubernetes Services (AKS) resource, or a specific Azure Monitor Workspace (AMW), select **Monitor** > **Alerts**, then select **Prometheus Rule Groups**, to view a list of rule groups for this specific resource. -You can select a rule group from the list to view or edit its details. --## View the resource health states of your Prometheus rule groups -You can now view the [resource health state](../../service-health/resource-health-overview.md) of your Prometheus rule group in the portal. This can allow you to detect problems in your rule groups, such as incorrect configuration, or query throttling problems --1. In the [portal](https://portal.azure.com/), go to the overview of your Prometheus rule group you would like to monitors -1. From the left pane, under **Help**, select **Resource health**. - :::image type="content" source="media/prometheus-metrics-rule-groups/prometheus-rule-groups-resource-health.png" alt-text="Screenshot that shows how to view resource health state of a Prometheus rule group."::: -1. In the rule group resource health screen, you can see the current availability state of the rule group, as well as a history of recent resource health events, up to 30 days back. - :::image type="content" source="media/prometheus-metrics-rule-groups/prometheus-rule-groups-resource-health-history.png" alt-text="Screenshot that shows how to view the resource health history of a Prometheus rule group."::: --* If the rule group is marked as **Available**, it is working as expected. -* If the rule group is marked as **Degraded**, one or more rules in the group are not working as expected. This can be due to the rule query being throttled, or to other issues that may cause the rule evaluation to fail. Expand the status entry for more information on the detected problem, as well as suggestions for mitigation or for further troubleshooting. -* If the rule group is marked as **Unavailable**, the entire rule group is not working as expected. This can be due the configuration issue (for example, the Azure Monitor Workspace can't be detected) or due to internal service issues. Expand the status entry for more information on the detected problem, as well as suggestions for mitigation or for further troubleshooting. -* If the rule group is marked as **Unknown**, the entire rule group is disabled or is in an unknown state. - -## Disable and enable rule groups -To enable or disable a rule, select the rule group in the Azure portal. Select either **Enable** or **Disable** to change its status. --## Next steps -- [Learn more about the Azure alerts](../alerts/alerts-types.md).-- [Prometheus documentation for recording rules](https://aka.ms/azureprometheus-promio-recrules).-- [Prometheus documentation for alerting rules](https://aka.ms/azureprometheus-promio-alertrules). |
| azure-monitor | Prometheus Self Managed Grafana Azure Active Directory | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/prometheus-self-managed-grafana-azure-active-directory.md | - Title: Configure self-hosted Grafana to use Azure Monitor managed service for Prometheus as data source using Microsoft Entra ID. -description: How to configure Azure Monitor managed service for Prometheus as data source for both Azure Managed Grafana and self-hosted Grafana using Microsoft Entra ID. --- Previously updated : 08/11/2024---# Configure self-managed Grafana to use Azure Monitor managed service for Prometheus with Microsoft Entra ID. --[Azure Monitor managed service for Prometheus](prometheus-metrics-overview.md) allows you to collect and analyze metrics at scale using a [Prometheus](https://aka.ms/azureprometheus-promio)-compatible monitoring solution. The most common way to analyze and present Prometheus data is with a Grafana dashboard. This article explains how to configure Prometheus as a data source for [self-hosted Grafana](https://grafana.com/) using Microsoft Entra ID. - -For information on using Grafana with managed system identity, see [Configure Grafana using managed system identity](./prometheus-grafana.md). -<a name='azure-active-directory-authentication'></a> --## Microsoft Entra authentication --To set up Microsoft Entra authentication, follow the steps below: -1. Register an app with Microsoft Entra ID. -1. Grant access for the app to your Azure Monitor workspace. -1. Configure your self-hosted Grafana with the app's credentials. -<a name='register-an-app-with-azure-active-directory'></a> --## Register an app with Microsoft Entra ID --1. To register an app, open the Active Directory Overview page in the Azure portal. --1. Select **New registration**. -1. On the Register an application page, enter a **Name** for the application. -1. Select **Register**. -1. Note the **Application (client) ID** and **Directory(Tenant) ID**. They're used in the Grafana authentication settings. - :::image type="content" source="./media/prometheus-self-managed-grafana-azure-active-directory/app-registration-overview.png" lightbox="./media/prometheus-self-managed-grafana-azure-active-directory/app-registration-overview.png" alt-text="A screenshot showing the App registration overview page."::: -1. On the app's overview page, select **Certificates and Secrets**. -1. In the client secrets tab, select **New client secret**. -1. Enter a **Description**. -1. Select an **expiry** period from the dropdown and select **Add**. - > [!NOTE] - > Create a process to renew the secret and update your Grafana data source settings before the secret expires. - > Once the secret expires Grafana will lose the ability to query data from your Azure Monitor workspace. -- :::image type="content" source="./media/prometheus-self-managed-grafana-azure-active-directory/add-a-client-secret.png" lightbox="./media/prometheus-self-managed-grafana-azure-active-directory/add-a-client-secret.png" alt-text="A screenshot showing the Add client secret page."::: - -1. Copy and save the client secret **Value**. - > [!NOTE] - > Client secret values can only be viewed immediately after creation. Be sure to save the secret before leaving the page. -- :::image type="content" source="./media/prometheus-self-managed-grafana-azure-active-directory/client-secret.png" lightbox="./media/prometheus-self-managed-grafana-azure-active-directory/client-secret.png" alt-text="A screenshot showing the client secret page with generated secret value."::: --### Allow your app access to your workspace --Allow your app to query data from your Azure Monitor workspace. --1. Open your Azure Monitor workspace in the Azure portal. --1. On the Overview page, take note of your **Query endpoint**. The query endpoint is used when setting up your Grafana data source. -1. Select **Access control (IAM)**. --1. Select **Add**, then **Add role assignment** from the **Access Control (IAM)** page. --1. On the **Add role Assignment** page, search for **Monitoring**. -1. Select **Monitoring data reader**, then select the **Members** tab. -- :::image type="content" source="./media/prometheus-self-managed-grafana-azure-active-directory/add-role-assignment.png" lightbox="./media/prometheus-self-managed-grafana-azure-active-directory/add-role-assignment.png" alt-text="A screenshot showing the Add role assignment page."::: --1. Select **Select members**. -1. Search for the app that you registered in the [Register an app with Microsoft Entra ID](#register-an-app-with-azure-active-directory) section and select it. -1. Click **Select**. -1. Select **Review + assign**. - :::image type="content" source="./media/prometheus-self-managed-grafana-azure-active-directory/select-members.png" lightbox="./media/prometheus-self-managed-grafana-azure-active-directory/select-members.png" alt-text="A screenshot showing the Add role assignment, select members page."::: --You've created your App registration and have assigned it access to query data from your Azure Monitor workspace. The next step is setting up your Prometheus data source in Grafana. ---## Setup self-managed Grafana to turn on Azure Authentication. --Grafana now supports connecting to Azure Monitor managed Prometheus using the [Prometheus data source](https://grafana.com/docs/grafana/latest/datasources/prometheus/). For self-hosted Grafana instances, a configuration change is needed to use the Azure Authentication option in Grafana. For self-hosted Grafana or any other Grafana instances that are not managed by Azure, make the following changes: --1. Locate the Grafana configuration file. See the [Configure Grafana](https://grafana.com/docs/grafana/v9.0/setup-grafana/configure-grafana/) documentation for details. -1. Identity your Grafana version. -1. Update the Grafana configuration file. -- For Grafana 9.0: -- ``` - [feature_toggles] - # Azure authentication for Prometheus (<=9.0) - prometheus_azure_auth = true - ``` - -- For Grafana 9.1 and later versions: -- ``` - [auth] - # Azure authentication for Prometheus (>=9.1) - azure_auth_enabled = true - ``` -- For Azure Managed Grafana, you don't need to make any configuration changes. Managed Identity is also enabled by default. --## Configure your Prometheus data source in Grafana --1. Sign-in to your Grafana instance. --1. On the configuration page, select the **Data sources** tab. -1. Select **Add data source**. -1. Select **Prometheus**. -1. Enter a **Name** for your Prometheus data source. -1. In the **URL** field, paste the Query endpoint value from the Azure Monitor workspace overview page. -1. Under **Auth**, turn on **Azure Authentication**. -1. In the Azure Authentication section, select **App Registration** from the **Authentication** dropdown. -1. Enter the **Direct(tenant) ID**, **Application (client) ID**, and the **Client secret** from the [Register an app with Microsoft Entra ID](#register-an-app-with-azure-active-directory) section. -1. Select **Save & test** - :::image type="content" source="./media/prometheus-self-managed-grafana-azure-active-directory/configure-grafana.png" lightbox="./media/prometheus-self-managed-grafana-azure-active-directory/configure-grafana.png" alt-text="A screenshot showing the Grafana settings page for adding a data source."::: - -## Frequently asked questions --This section provides answers to common questions. -----## Next steps -- [Configure Grafana using managed system identity](./prometheus-grafana.md).-- [Collect Prometheus metrics for your AKS cluster](../containers/kubernetes-monitoring-enable.md).-- [Configure Prometheus alerting and recording rules groups](prometheus-rule-groups.md).-- [Customize scraping of Prometheus metrics](prometheus-metrics-scrape-configuration.md). |
| azure-monitor | Prometheus Workbooks | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/prometheus-workbooks.md | - Title: Query Prometheus metrics using Azure workbooks -description: Query Prometheus metrics in the portal using Azure Workbooks. -- Previously updated : 07/17/2023----# Query Prometheus metrics using Azure workbooks --Create dashboards powered by Azure Monitor managed service for Prometheus using [Azure Workbooks](../visualize/workbooks-overview.md). -This article introduces workbooks for Azure Monitor workspaces and shows you how to query Prometheus metrics using Azure workbooks and the Prometheus query language (PromQL). --## Prerequisites -To query Prometheus metrics from an Azure Monitor workspace, you need the following: -- An Azure Monitor workspace. To create an Azure Monitor workspace, see [Create an Azure Monitor Workspace](./azure-monitor-workspace-overview.md?tabs=azure-portal.md).-- Your Azure Monitor workspace must be [collecting Prometheus metrics](../containers/kubernetes-monitoring-enable.md#enable-prometheus-and-grafana) from an AKS cluster.-- The user must be assigned role that can perform the **microsoft.monitor/accounts/read** operation on the Azure Monitor workspace.--## Prometheus Explorer workbook -Azure Monitor workspaces include an exploration workbook to query your Prometheus metrics. --1. From the Azure Monitor workspace overview page, select **Prometheus explorer** -- -2. Or the **Workbooks** menu item, and in the Azure Monitor workspace gallery, select the **Prometheus Explorer** workbook tile. ---A workbook has the following input options: -- **Time Range**. Select the period of time that you want to include in your query. Select **Custom** to set a start and end time.-- **PromQL**. Enter the PromQL query to retrieve your data. For more information about PromQL, see [Querying Prometheus](https://prometheus.io/docs/prometheus/latest/querying/basics/#querying-prometheus).-- **Graph**, **Grid**, and **Dimensions** tabs. Switch between a graphic, tabular, and dimensional view of the query output.---## Create a Prometheus workbook --Workbooks support many visualizations and Azure integrations. For more information about Azure Workbooks, see [Creating an Azure Workbook](../visualize/workbooks-create-workbook.md). ----1. From your Azure Monitor workspace, select **Workbooks**. --1. Select **New**. -1. In the new workbook, select **Add**, and select **Add query** from the dropdown. -1. Azure Workbooks use [data sources](../visualize/workbooks-data-sources.md#prometheus) to set the source scope the data they present. To query Prometheus metrics, select the **Data source** dropdown, and choose **Prometheus** . -1. From the **Azure Monitor workspace** dropdown, select your workspace. -1. Select your query type from **Prometheus query type** dropdown. -1. Write your PromQL query in the **Prometheus Query** field. -1. Select **Run Query** button. -1. Select the **Done Editing** at the bottom of the section and save your work ---## Troubleshooting --If you receive a message indicating that "You currently do not have any Prometheus data ingested to this Azure Monitor workspace": --- Verify that you have turned on metrics collection in the Monitored clusters blade of your Azure Monitor workspace.--If your workbook query does not return data with a message "You do not have query access": --- Check that you have sufficient permissions to perform **microsoft.monitor/accounts/read** assigned through Access Control (IAM) in your Azure Monitor workspace.-- Confirm if your Networking settings support query access. You might need to enable private access through your private endpoint or change settings to allow public access.-- If you have ad block enabled in your browser, you might need to pause or disable and refresh the workbook in order to view data.---## Frequently asked questions --This section provides answers to common questions. -----## Next steps -* [Collect Prometheus metrics from AKS cluster](../containers/kubernetes-monitoring-enable.md#enable-prometheus-and-grafana) -* [Azure Monitor workspace](./azure-monitor-workspace-overview.md) -* [Use Azure Monitor managed service for Prometheus as data source for Grafana using managed system identity](./prometheus-grafana.md) |
| azure-monitor | Resource Logs Schema | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/resource-logs-schema.md | - Title: Azure resource logs supported services and schemas -description: Understand the supported services and event schemas for Azure resource logs. - Previously updated : 05/26/2023----# Common and service-specific schemas for Azure resource logs --> [!NOTE] -> Resource logs were previously known as diagnostic logs. The name was changed in October 2019 as the types of logs gathered by Azure Monitor shifted to include more than just the Azure resource. -> -> This article used to list resource log categories that you can collect. That list is now at [Resource log categories](resource-logs-categories.md). --[Azure Monitor resource logs](../essentials/platform-logs-overview.md) are logs emitted by Azure services that describe the operation of those services or resources. All resource logs available through Azure Monitor share a common top-level schema. Each service has the flexibility to emit unique properties for its own events. --A combination of the resource type (available in the `resourceId` property) and the category uniquely identify a schema. This article describes the top-level schemas for resource logs and links to the schemata for each service. ---## Top-level common schema --> [!NOTE] -> The schema described here is valid when resource logs are sent to Azure storage or to an event hub. When the logs are sent to a Log Analytics workspace, the column names may be different. See [Standard columns in Azure Monitor Logs](../logs/log-standard-columns.md) for columns common to all tables in a Log Analytics workspace and [Azure Monitor data reference](/azure/azure-monitor/reference) for a reference of different tables. --| Name | Required or optional | Description | -|||| -| `time` | Required | The timestamp (UTC) of the event being logged. | -| `resourceId` | Required | The resource ID of the resource that emitted the event. For tenant services, this is of the form */tenants/tenant-id/providers/provider-name*. | -| `tenantId` | Required for tenant logs | The tenant ID of the Active Directory tenant that this event is tied to. This property is used only for tenant-level logs. It does not appear in resource-level logs. | -| `operationName` | Required | The name of the operation that this event is logging, for example `Microsoft.Storage/storageAccounts/blobServices/blobs/Read`. The operationName is typically modeled in the form of an Azure Resource Manager operation, `Microsoft.<providerName>/<resourceType>/<subtype>/<Write|Read|Delete|Action>`, even if it's not a documented Resource Manager operation. | -| `operationVersion` | Optional | The API version associated with the operation, if `operationName` was performed through an API (for example, `http://myservice.windowsazure.net/object?api-version=2016-06-01`). If no API corresponds to this operation, the version represents the version of that operation in case the properties associated with the operation change in the future. | -| `category` or `type` | Required | The log category of the event being logged. Category is the granularity at which you can enable or disable logs on a particular resource. The properties that appear within the properties blob of an event are the same within a particular log category and resource type. Typical log categories are `Audit`, `Operational`, `Execution`, and `Request`. <br/><br/> For Application Insights resource, `type` denotes the category of log exported. | -| `resultType` | Optional | The status of the logged event, if applicable. Values include `Started`, `In Progress`, `Succeeded`, `Failed`, `Active`, and `Resolved`. | -| `resultSignature` | Optional | The substatus of the event. If this operation corresponds to a REST API call, this field is the HTTP status code of the corresponding REST call. | -| `resultDescription `| Optional | The static text description of this operation; for example, `Get storage file`. | -| `durationMs` | Optional | The duration of the operation in milliseconds. | -| `callerIpAddress` | Optional | The caller IP address, if the operation corresponds to an API call that would come from an entity with a publicly available IP address. | -| `correlationId` | Optional | A GUID that's used to group together a set of related events. Typically, if two events have the same `operationName` value but two different statuses (for example, `Started` and `Succeeded`), they share the same `correlationID` value. This might also represent other relationships between events. | -| `identity` | Optional | A JSON blob that describes the identity of the user or application that performed the operation. Typically, this field includes the authorization and claims or JWT token from Active Directory. | -| `level` | Optional | The severity level of the event. Must be one of `Informational`, `Warning`, `Error`, or `Critical`. | -| `location` | Optional | The region of the resource emitting the event; for example, `East US` or `France South`. | -| `properties` | Optional | Any extended properties related to this category of events. All custom or unique properties must be put inside this "Part B" of the schema. | --## Service-specific schemas --The schema for resource logs varies depending on the resource and log category. The following list shows Azure services that make available resource logs and links to the service and category-specific schemas (where available). The list changes as new services are added. If you don't see what you need, feel free to open a GitHub issue on this article so we can update it. --| Service or feature | Schema and documentation | -| | | -| Microsoft Entra ID | [Overview](../../active-directory/reports-monitoring/concept-activity-logs-azure-monitor.md), [Audit log schema](../../active-directory/reports-monitoring/overview-reports.md), [Sign-ins schema](../../active-directory/reports-monitoring/reference-azure-monitor-sign-ins-log-schema.md) | -| Azure Analysis Services | [Azure Analysis -| Azure API Management | [API Management resource logs](../../api-management/api-management-howto-use-azure-monitor.md#resource-logs) | -| Azure App Service | [App Service logs](../../app-service/troubleshoot-diagnostic-logs.md) -| Azure Application Gateway |[Logging for Application Gateway](../../application-gateway/application-gateway-diagnostics.md) | -| Azure Automation |[Log Analytics for Azure Automation](../../automation/automation-manage-send-joblogs-log-analytics.md) | -| Azure Batch |[Azure Batch logging](../../batch/batch-diagnostics.md) | -| Azure AI Search | [Cognitive Search monitoring data reference (schemas)](/azure/search/monitor-azure-cognitive-search-data-reference#schemas) | -| Azure AI services | [Logging for Azure AI services](/azure/ai-services/diagnostic-logging) | -| Azure Container Instances | [Logging for Azure Container Instances](/azure/container-instances/container-instances-log-analytics#log-schema) | -| Azure Container Registry | [Logging for Azure Container Registry](../../container-registry/monitor-service.md) | -| Azure Content Delivery Network | [Diagnostic logs for Azure Content Delivery Network](../../cdn/cdn-azure-diagnostic-logs.md) | -| Azure Cosmos DB | [Azure Cosmos DB logging](/azure/cosmos-db/monitor-cosmos-db) | -| Azure Data Explorer | [Azure Data Explorer logs](/azure/data-explorer/using-diagnostic-logs) | -| Azure Data Factory | [Monitor Data Factory by using Azure Monitor](../../data-factory/monitor-using-azure-monitor.md) | -| Azure Data Lake Analytics |[Accessing logs for Azure Data Lake Analytics](../../data-lake-analytics/data-lake-analytics-diagnostic-logs.md) | -| Azure Data Lake Storage |[Accessing logs for Azure Data Lake Storage](../../data-lake-store/data-lake-store-diagnostic-logs.md) | -| Azure Database for MySQL | [Azure Database for MySQL diagnostic logs](/azure/mysql/concepts-server-logs#diagnostic-logs) | -| Azure Database for PostgreSQL | [Azure Database for PostgreSQL logs](/azure/postgresql/concepts-server-logs#resource-logs) | -| Azure Databricks | [Diagnostic logging in Azure Databricks](/azure/databricks/administration-guide/account-settings/azure-diagnostic-logs) | -| Azure DDoS Protection | [Logging for Azure DDoS Protection](../../ddos-protection/ddos-view-diagnostic-logs.md#example-log-queries) | -| Azure Digital Twins | [Set up Azure Digital Twins diagnostics](../../digital-twins/troubleshoot-diagnostics.md#log-schemas) -| Azure Event Hubs |[Azure Event Hubs logs](../../event-hubs/event-hubs-diagnostic-logs.md) | -| Azure ExpressRoute | [Monitoring Azure ExpressRoute](../../expressroute/monitor-expressroute.md#collection-and-routing) | -| Azure Firewall | [Logging for Azure Firewall](../../firewall/diagnostic-logs.md) | -| Azure Front Door | [Logging for Azure Front Door](../../frontdoor/front-door-diagnostics.md) | -| Azure Functions | [Monitoring Azure Functions Data Reference Resource Logs](../../azure-functions/monitor-functions-reference.md#resource-logs) | -| Application Insights | [Application Insights Data Reference Resource Logs](../monitor-azure-monitor-reference.md#supported-resource-logs-for-microsoftinsightscomponents) | -| Azure IoT Hub | [IoT Hub operations](../../iot-hub/monitor-iot-hub-reference.md#resource-logs) | -| Azure IoT Hub Device Provisioning Service| [Device Provisioning Service operations](../../iot-dps/monitor-iot-dps-reference.md#resource-logs) | -| Azure Key Vault |[Azure Key Vault logging](/azure/key-vault/general/logging) | -| Azure Kubernetes Service |[Azure Kubernetes Service logging](/azure/aks/monitor-aks-reference#resource-logs) | -| Azure Load Balancer |[Log Analytics for Azure Load Balancer](../../load-balancer/monitor-load-balancer.md) | -| Azure Load Testing |[Azure Load Testing logs](../../load-testing/monitor-load-testing-reference.md#resource-logs) | -| Azure Logic Apps |[Logic Apps B2B custom tracking schema](../../logic-apps/tracking-schemas-as2-x12-custom.md) | -| Azure Machine Learning | [Diagnostic logging in Azure Machine Learning](/azure/machine-learning/monitor-resource-reference) | -| Azure Media Services | [Media Services monitoring schemas](/azure/media-services/latest/monitoring/monitor-media-services#schemas) | -| Network security groups |[Log Analytics for network security groups (NSGs)](../../virtual-network/virtual-network-nsg-manage-log.md) | -| Azure Operator Insights | [Monitoring Azure Operator Insights data reference](../../operator-insights/monitor-operator-insights-data-reference.md#schemas) | -| Azure Power BI Embedded | [Logging for Power BI Embedded in Azure](/power-bi/developer/azure-pbie-diag-logs) | -| Recovery Services | [Data model for Azure Backup](../../backup/backup-azure-reports-data-model.md)| -| Azure Service Bus |[Azure Service Bus logs](../../service-bus-messaging/service-bus-diagnostic-logs.md) | -| Azure SignalR | [Monitoring Azure SignalR Service data reference](../../azure-signalr/signalr-howto-monitor-reference.md) | -| Azure SQL Database | [Azure SQL Database logging](/azure/azure-sql/database/metrics-diagnostic-telemetry-logging-streaming-export-configure) | -| Azure Storage | [Blobs](../../storage/blobs/monitor-blob-storage-reference.md#resource-logs-preview), [Files](../../storage/files/storage-files-monitoring-reference.md#resource-logs-preview), [Queues](../../storage/queues/monitor-queue-storage-reference.md#resource-logs-preview), [Tables](../../storage/tables/monitor-table-storage-reference.md#resource-logs-preview) | -| Azure Stream Analytics |[Job logs](../../stream-analytics/stream-analytics-job-diagnostic-logs.md) | -| Azure Traffic Manager | [Traffic Manager log schema](../../traffic-manager/traffic-manager-diagnostic-logs.md) | -| Azure Video Indexer|[Monitor Azure Video Indexer data reference](/azure/azure-video-indexer/monitor-video-indexer-data-reference)| -| Azure Virtual Network | Schema not available | -| Azure Web PubSub | [Monitoring Azure Web PubSub data reference](../../azure-web-pubsub/howto-monitor-data-reference.md) | -| Virtual network gateways | [Logging for Virtual Network Gateways](../../vpn-gateway/troubleshoot-vpn-with-azure-diagnostics.md)| ----## Next steps --* [See the resource log categories you can collect](resource-logs-categories.md) -* [Learn more about resource logs](../essentials/platform-logs-overview.md) -* [Stream resource logs to Event Hubs](./resource-logs.md#send-to-azure-event-hubs) -* [Change resource log diagnostic settings by using the Azure Monitor REST API](/rest/api/monitor/diagnosticsettings) -* [Analyze logs from Azure Storage with Log Analytics](./resource-logs.md#send-to-log-analytics-workspace) |
| azure-monitor | Resource Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/resource-logs.md | - Title: Send Azure resource log data -description: Learn how to send Azure resource logs to a Log Analytics workspace, event hub, or Azure Storage in Azure Monitor. -- Previously updated : 08/08/2023----# Send Azure resource log data --Azure resource logs are [platform logs](../essentials/platform-logs-overview.md) that provide insight into operations that were performed within an Azure resource. The content of resource logs varies by the Azure service and resource type. Resource logs aren't collected by default. This article describes the [diagnostic setting](diagnostic-settings.md) required for each Azure resource to send its resource logs to different destinations. --## Send to Log Analytics workspace -- Send resource logs to a Log Analytics workspace to enable the features of [Azure Monitor Logs](../logs/data-platform-logs.md), where you can: --- Correlate resource log data with other monitoring data collected by Azure Monitor.-- Consolidate log entries from multiple Azure resources, subscriptions, and tenants into one location for analysis together.-- Use log queries to perform complex analysis and gain deep insights on log data.-- Use log search alerts with complex alerting logic.--[Create a diagnostic setting](../essentials/diagnostic-settings.md) to send resource logs to a Log Analytics workspace. This data is stored in tables as described in [Structure of Azure Monitor Logs](../logs/data-platform-logs.md). The tables used by resource logs depend on what type of collection the resource is using: --- **Azure diagnostics**: All data is written to the [AzureDiagnostics](/azure/azure-monitor/reference/tables/azurediagnostics) table.-- **Resource-specific**: Data is written to individual tables for each category of the resource.--### Resource-specific --In this mode, individual tables in the selected workspace are created for each category selected in the diagnostic setting. We recommend this method because it: --- Makes it easier to work with the data in log queries.-- Provides better discoverability of schemas and their structure.-- Improves performance across ingestion latency and query times.-- Provides the ability to grant Azure role-based access control rights on a specific table.--All Azure services will eventually migrate to the resource-specific mode. --The example below creates three tables: --- Table `Service1AuditLogs`-- | Resource provider | Category | A | B | C | - |:|::|::|::|::| - | Service 1 | AuditLogs | x1 | y1 | z1 | - | Service 1 | AuditLogs | x5 | y5 | z5 | - | ... | --- Table `Service1ErrorLogs`-- | Resource provider | Category | D | E | F | - |:|::|::|::|::| - | Service 1 | ErrorLogs | q1 | w1 | e1 | - | Service 1 | ErrorLogs | q2 | w2 | e2 | - | ... | --- Table `Service2AuditLogs`-- | Resource provider | Category | G | H | I | - |:|::|::|::|::| - | Service 2 | AuditLogs | j1 | k1 | l1| - | Service 2 | AuditLogs | j3 | k3 | l3| - | ... | --### Azure diagnostics mode --In this mode, all data from any diagnostic setting is collected in the [AzureDiagnostics](/azure/azure-monitor/reference/tables/azurediagnostics) table. This legacy method is used today by most Azure services. Because multiple resource types send data to the same table, its schema is the superset of the schemas of all the different data types being collected. For details on the structure of this table and how it works with this potentially large number of columns, see [AzureDiagnostics reference](/azure/azure-monitor/reference/tables/azurediagnostics). --Consider an example where diagnostic settings are collected in the same workspace for the following data types: --- Audit logs of service 1 have a schema that consists of columns A, B, and C-- Error logs of service 1 have a schema that consists of columns D, E, and F-- Audit logs of service 2 have a schema that consists of columns G, H, and I--The `AzureDiagnostics` table looks like this example: --| ResourceProvider | Category | A | B | C | D | E | F | G | H | I | -|:|::|::|::|::|::|::|::|::||::| -| Microsoft.Service1 | AuditLogs | x1 | y1 | z1 | | | | | | | -| Microsoft.Service1 | ErrorLogs | | | | q1 | w1 | e1 | | | | -| Microsoft.Service2 | AuditLogs | | | | | | | j1 | k1 | l1 | -| Microsoft.Service1 | ErrorLogs | | | | q2 | w2 | e2 | | | | -| Microsoft.Service2 | AuditLogs | | | | | | | j3 | k3 | l3 | -| Microsoft.Service1 | AuditLogs | x5 | y5 | z5 | | | | | | | -| ... | --### Select the collection mode --Most Azure resources write data to the workspace in either **Azure diagnostics** or **resource-specific** mode without giving you a choice. For more information, see [Common and service-specific schemas for Azure resource logs](./resource-logs-schema.md). --All Azure services will eventually use the resource-specific mode. As part of this transition, some resources allow you to select a mode in the diagnostic setting. Specify resource-specific mode for any new diagnostic settings because this mode makes the data easier to manage. It also might help you avoid complex migrations later. - ---> [!NOTE] -> For an example that sets the collection mode by using an Azure Resource Manager template, see [Resource Manager template samples for diagnostic settings in Azure Monitor](./resource-manager-diagnostic-settings.md#diagnostic-setting-for-recovery-services-vault). --You can modify an existing diagnostic setting to resource-specific mode. In this case, data that was already collected remains in the `AzureDiagnostics` table until it's removed according to your retention setting for the workspace. New data is collected in the dedicated table. Use the [union](/azure/kusto/query/unionoperator) operator to query data across both tables. --Continue to watch the [Azure Updates](https://azure.microsoft.com/updates/) blog for announcements about Azure services that support resource-specific mode. --## Send to Azure Event Hubs --Send resource logs to an event hub to send them outside of Azure. For example, resource logs might be sent to a third-party SIEM or other log analytics solutions. Resource logs from event hubs are consumed in JSON format with a `records` element that contains the records in each payload. The schema depends on the resource type as described in [Common and service-specific schema for Azure resource logs](resource-logs-schema.md). --The following sample output data is from Azure Event Hubs for a resource log: --```json -{ - "records": [ - { - "time": "2019-07-15T18:00:22.6235064Z", - "workflowId": "/SUBSCRIPTIONS/00000000-0000-0000-0000-000000000000/RESOURCEGROUPS/JOHNKEMTEST/PROVIDERS/MICROSOFT.LOGIC/WORKFLOWS/JOHNKEMTESTLA", - "resourceId": "/SUBSCRIPTIONS/00000000-0000-0000-0000-000000000000/RESOURCEGROUPS/JOHNKEMTEST/PROVIDERS/MICROSOFT.LOGIC/WORKFLOWS/JOHNKEMTESTLA/RUNS/08587330013509921957/ACTIONS/SEND_EMAIL", - "category": "WorkflowRuntime", - "level": "Error", - "operationName": "Microsoft.Logic/workflows/workflowActionCompleted", - "properties": { - "$schema": "2016-04-01-preview", - "startTime": "2016-07-15T17:58:55.048482Z", - "endTime": "2016-07-15T18:00:22.4109204Z", - "status": "Failed", - "code": "BadGateway", - "resource": { - "subscriptionId": "00000000-0000-0000-0000-000000000000", - "resourceGroupName": "JohnKemTest", - "workflowId": "243aac67fe904cf195d4a28297803785", - "workflowName": "JohnKemTestLA", - "runId": "08587330013509921957", - "location": "westus", - "actionName": "Send_email" - }, - "correlation": { - "actionTrackingId": "29a9862f-969b-4c70-90c4-dfbdc814e413", - "clientTrackingId": "08587330013509921958" - } - } - }, - { - "time": "2019-07-15T18:01:15.7532989Z", - "workflowId": "/SUBSCRIPTIONS/00000000-0000-0000-0000-000000000000/RESOURCEGROUPS/JOHNKEMTEST/PROVIDERS/MICROSOFT.LOGIC/WORKFLOWS/JOHNKEMTESTLA", - "resourceId": "/SUBSCRIPTIONS/00000000-0000-0000-0000-000000000000/RESOURCEGROUPS/JOHNKEMTEST/PROVIDERS/MICROSOFT.LOGIC/WORKFLOWS/JOHNKEMTESTLA/RUNS/08587330012106702630/ACTIONS/SEND_EMAIL", - "category": "WorkflowRuntime", - "level": "Information", - "operationName": "Microsoft.Logic/workflows/workflowActionStarted", - "properties": { - "$schema": "2016-04-01-preview", - "startTime": "2016-07-15T18:01:15.5828115Z", - "status": "Running", - "resource": { - "subscriptionId": "00000000-0000-0000-0000-000000000000", - "resourceGroupName": "JohnKemTest", - "workflowId": "243aac67fe904cf195d4a28297803785", - "workflowName": "JohnKemTestLA", - "runId": "08587330012106702630", - "location": "westus", - "actionName": "Send_email" - }, - "correlation": { - "actionTrackingId": "042fb72c-7bd4-439e-89eb-3cf4409d429e", - "clientTrackingId": "08587330012106702632" - } - } - } - ] -} -``` --## Send to Azure Storage --Send resource logs to Azure Storage to retain them for archiving. After you've created the diagnostic setting, a storage container is created in the storage account as soon as an event occurs in one of the enabled log categories. --> [!NOTE] -> An alternate to archiving is to send the resource log to a table in your Log Analytics workspace with [low-cost, long-term retention](../logs/data-retention-configure.md). --The blobs within the container use the following naming convention: --``` -insights-logs-{log category name}/resourceId=/SUBSCRIPTIONS/{subscription ID}/RESOURCEGROUPS/{resource group name}/PROVIDERS/{resource provider name}/{resource type}/{resource name}/y={four-digit numeric year}/m={two-digit numeric month}/d={two-digit numeric day}/h={two-digit 24-hour clock hour}/m=00/PT1H.json -``` --The blob for a network security group might have a name similar to this example: --``` -insights-logs-networksecuritygrouprulecounter/resourceId=/SUBSCRIPTIONS/00000000-0000-0000-0000-000000000000/RESOURCEGROUPS/TESTRESOURCEGROUP/PROVIDERS/MICROSOFT.NETWORK/NETWORKSECURITYGROUP/TESTNSG/y=2016/m=08/d=22/h=18/m=00/PT1H.json -``` --Each PT1H.json blob contains a JSON object with events from log files that were received during the hour specified in the blob URL. During the present hour, events are appended to the PT1H.json file as they're received, regardless of when they were generated. The minute value in the URL, `m=00` is always `00` as blobs are created on a per hour basis. --Within the PT1H.json file, each event is stored in the following format. It uses a common top-level schema but is unique for each Azure service, as described in [Resource logs schema](./resource-logs-schema.md). --> [!NOTE] -> Logs are written to blobs based on the time that the log was received, regardless of the time it was generated. This means that a given blob can contain log data that is outside the hour specified in the blobΓÇÖs URL. Where a data source like Application insights, supports uploading stale telemetry a blob can contain data from the previous 48 hours. -> At the start of a new hour, it is possible that existing logs are still being written to the previous hourΓÇÖs blob while new logs are written to the new hourΓÇÖs blob. --```json -{"time": "2016-07-01T00:00:37.2040000Z","systemId": "46cdbb41-cb9c-4f3d-a5b4-1d458d827ff1","category": "NetworkSecurityGroupRuleCounter","resourceId": "/SUBSCRIPTIONS/s1id1234-5679-0123-4567-890123456789/RESOURCEGROUPS/TESTRESOURCEGROUP/PROVIDERS/MICROSOFT.NETWORK/NETWORKSECURITYGROUPS/TESTNSG","operationName": "NetworkSecurityGroupCounters","properties": {"vnetResourceGuid": "{12345678-9012-3456-7890-123456789012}","subnetPrefix": "10.3.0.0/24","macAddress": "000123456789","ruleName": "/subscriptions/ s1id1234-5679-0123-4567-890123456789/resourceGroups/testresourcegroup/providers/Microsoft.Network/networkSecurityGroups/testnsg/securityRules/default-allow-rdp","direction": "In","type": "allow","matchedConnections": 1988}} -``` --## Azure Monitor partner integrations --Resource logs can also be sent to partner solutions that are fully integrated into Azure. For a list of these solutions and details on how to configure them, see [Azure Monitor partner integrations](../../partner-solutions/overview.md). --## Next steps --* [Read more about resource logs](../essentials/platform-logs-overview.md). -* [Create diagnostic settings to send platform logs and metrics to different destinations](../essentials/diagnostic-settings.md). |
| azure-monitor | Resource Manager Diagnostic Settings | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/resource-manager-diagnostic-settings.md | - Title: Resource Manager template samples for diagnostic settings -description: Sample Azure Resource Manager templates to apply Azure Monitor diagnostic settings to an Azure resource. ---- Previously updated : 08/26/2024----# Resource Manager template samples for diagnostic settings in Azure Monitor --This article includes sample [Azure Resource Manager templates](../../azure-resource-manager/templates/syntax.md) to create diagnostic settings for an Azure resource. Each sample includes a template file and a parameters file with sample values to provide to the template. --To create a diagnostic setting for an Azure resource, add a resource of type `<resource namespace>/providers/diagnosticSettings` to the template. This article provides examples for some resource types, but the same pattern can be applied to other resource types. The collection of allowed logs and metrics varies for each resource type. ---## Diagnostic setting for an activity log --The following sample creates a diagnostic setting for an activity log by adding a resource of type `Microsoft.Insights/diagnosticSettings` to the template. --> [!IMPORTANT] -> Diagnostic settings for activity logs are created for a subscription, not for a resource group like settings for Azure resources. To deploy the Resource Manager template, use `New-AzSubscriptionDeployment` for PowerShell or `az deployment sub create` for the Azure CLI. --### Template file --# [Bicep](#tab/bicep) --```bicep -targetScope = 'subscription' --@description('The name of the diagnostic setting.') -param settingName string --@description('The resource Id for the workspace.') -param workspaceId string --@description('The resource Id for the storage account.') -param storageAccountId string --@description('The resource Id for the event hub authorization rule.') -param eventHubAuthorizationRuleId string --@description('The name of the event hub.') -param eventHubName string --resource setting 'Microsoft.Insights/diagnosticSettings@2021-05-01-preview' = { - name: settingName - properties: { - workspaceId: workspaceId - storageAccountId: storageAccountId - eventHubAuthorizationRuleId: eventHubAuthorizationRuleId - eventHubName: eventHubName - logs: [ - { - category: 'Administrative' - enabled: true - } - { - category: 'Security' - enabled: true - } - { - category: 'ServiceHealth' - enabled: true - } - { - category: 'Alert' - enabled: true - } - { - category: 'Recommendation' - enabled: true - } - { - category: 'Policy' - enabled: true - } - { - category: 'Autoscale' - enabled: true - } - { - category: 'ResourceHealth' - enabled: true - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2018-05-01/subscriptionDeploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "settingName": { - "type": "string", - "metadata": { - "description": "The name of the diagnostic setting." - } - }, - "workspaceId": { - "type": "string", - "metadata": { - "description": "The resource Id for the workspace." - } - }, - "storageAccountId": { - "type": "string", - "metadata": { - "description": "The resource Id for the storage account." - } - }, - "eventHubAuthorizationRuleId": { - "type": "string", - "metadata": { - "description": "The resource Id for the event hub authorization rule." - } - }, - "eventHubName": { - "type": "string", - "metadata": { - "description": "The name of the event hub." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/diagnosticSettings", - "apiVersion": "2021-05-01-preview", - "name": "[parameters('settingName')]", - "properties": { - "workspaceId": "[parameters('workspaceId')]", - "storageAccountId": "[parameters('storageAccountId')]", - "eventHubAuthorizationRuleId": "[parameters('eventHubAuthorizationRuleId')]", - "eventHubName": "[parameters('eventHubName')]", - "logs": [ - { - "category": "Administrative", - "enabled": true - }, - { - "category": "Security", - "enabled": true - }, - { - "category": "ServiceHealth", - "enabled": true - }, - { - "category": "Alert", - "enabled": true - }, - { - "category": "Recommendation", - "enabled": true - }, - { - "category": "Policy", - "enabled": true - }, - { - "category": "Autoscale", - "enabled": true - }, - { - "category": "ResourceHealth", - "enabled": true - } - ] - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2018-05-01/subscriptionDeploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "settingName": { - "value": "Send to all locations" - }, - "workspaceId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/MyResourceGroup/providers/microsoft.operationalinsights/workspaces/MyWorkspace" - }, - "storageAccountId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/MyResourceGroup/providers/Microsoft.Storage/storageAccounts/mystorageaccount" - }, - "eventHubAuthorizationRuleId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/MyResourceGroup/providers/Microsoft.EventHub/namespaces/MyNameSpace/authorizationrules/RootManageSharedAccessKey" - }, - "eventHubName": { - "value": "my-eventhub" - } - } -} -``` --## Diagnostic setting for Azure Data Explorer --The following sample creates a diagnostic setting for an Azure Data Explorer cluster by adding a resource of type `Microsoft.Kusto/clusters/providers/diagnosticSettings` to the template. --### Template file --# [Bicep](#tab/bicep) --```bicep -param clusterName string -param settingName string -param workspaceId string -param storageAccountId string -param eventHubAuthorizationRuleId string -param eventHubName string --resource cluster 'Microsoft.Kusto/clusters@2022-02-01' existing = { - name: clusterName -} --resource setting 'Microsoft.Insights/diagnosticSettings@2021-05-01-preview' = { - name: settingName - scope: cluster - properties: { - workspaceId: workspaceId - storageAccountId: storageAccountId - eventHubAuthorizationRuleId: eventHubAuthorizationRuleId - eventHubName: eventHubName - metrics: [] - logs: [ - { - category: 'Command' - categoryGroup: null - enabled: true - retentionPolicy: { - enabled: false - days: 0 - } - } - { - category: 'Query' - categoryGroup: null - enabled: true - retentionPolicy: { - enabled: false - days: 0 - } - } - { - category: 'Journal' - categoryGroup: null - enabled: true - retentionPolicy: { - enabled: false - days: 0 - } - } - { - category: 'SucceededIngestion' - categoryGroup: null - enabled: false - retentionPolicy: { - enabled: false - days: 0 - } - } - { - category: 'FailedIngestion' - categoryGroup: null - enabled: false - retentionPolicy: { - enabled: false - days: 0 - } - } - { - category: 'IngestionBatching' - categoryGroup: null - enabled: false - retentionPolicy: { - enabled: false - days: 0 - } - } - { - category: 'TableUsageStatistics' - categoryGroup: null - enabled: false - retentionPolicy: { - enabled: false - days: 0 - } - } - { - category: 'TableDetails' - categoryGroup: null - enabled: false - retentionPolicy: { - enabled: false - days: 0 - } - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "clusterName": { - "type": "string" - }, - "settingName": { - "type": "string" - }, - "workspaceId": { - "type": "string" - }, - "storageAccountId": { - "type": "string" - }, - "eventHubAuthorizationRuleId": { - "type": "string" - }, - "eventHubName": { - "type": "string" - } - }, - "resources": [ - { - "type": "Microsoft.Insights/diagnosticSettings", - "apiVersion": "2021-05-01-preview", - "scope": "[format('Microsoft.Kusto/clusters/{0}', parameters('clusterName'))]", - "name": "[parameters('settingName')]", - "properties": { - "workspaceId": "[parameters('workspaceId')]", - "storageAccountId": "[parameters('storageAccountId')]", - "eventHubAuthorizationRuleId": "[parameters('eventHubAuthorizationRuleId')]", - "eventHubName": "[parameters('eventHubName')]", - "metrics": [], - "logs": [ - { - "category": "Command", - "categoryGroup": null, - "enabled": true, - "retentionPolicy": { - "enabled": false, - "days": 0 - } - }, - { - "category": "Query", - "categoryGroup": null, - "enabled": true, - "retentionPolicy": { - "enabled": false, - "days": 0 - } - }, - { - "category": "Journal", - "categoryGroup": null, - "enabled": true, - "retentionPolicy": { - "enabled": false, - "days": 0 - } - }, - { - "category": "SucceededIngestion", - "categoryGroup": null, - "enabled": false, - "retentionPolicy": { - "enabled": false, - "days": 0 - } - }, - { - "category": "FailedIngestion", - "categoryGroup": null, - "enabled": false, - "retentionPolicy": { - "enabled": false, - "days": 0 - } - }, - { - "category": "IngestionBatching", - "categoryGroup": null, - "enabled": false, - "retentionPolicy": { - "enabled": false, - "days": 0 - } - }, - { - "category": "TableUsageStatistics", - "categoryGroup": null, - "enabled": false, - "retentionPolicy": { - "enabled": false, - "days": 0 - } - }, - { - "category": "TableDetails", - "categoryGroup": null, - "enabled": false, - "retentionPolicy": { - "enabled": false, - "days": 0 - } - } - ] - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "clusterName": { - "value": "kustoClusterName" - }, - "diagnosticSettingName": { - "value": "A new Diagnostic Settings configuration" - }, - "workspaceId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/MyResourceGroup/providers/microsoft.operationalinsights/workspaces/MyWorkspace" - }, - "storageAccountId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/MyResourceGroup/providers/Microsoft.Storage/storageAccounts/mystorageaccount" - }, - "eventHubAuthorizationRuleId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/MyResourceGroup/providers/Microsoft.EventHub/namespaces/MyNameSpace/authorizationrules/RootManageSharedAccessKey" - }, - "eventHubName": { - "value": "myEventhub" - } - } -} -``` --### Template file: Enabling the 'audit' category group --# [Bicep](#tab/bicep) --```bicep -param clusterName string -param settingName string -param workspaceId string -param storageAccountId string -param eventHubAuthorizationRuleId string -param eventHubName string --resource cluster 'Microsoft.Kusto/clusters@2022-02-01' existing = { - name: clusterName -} --resource setting 'Microsoft.Insights/diagnosticSettings@2021-05-01-preview' = { - name: settingName - scope: cluster - properties: { - workspaceId: workspaceId - storageAccountId: storageAccountId - eventHubAuthorizationRuleId: eventHubAuthorizationRuleId - eventHubName: eventHubName - logs: [ - { - category: null - categoryGroup: 'audit' - enabled: true - retentionPolicy: { - enabled: false - days: 0 - } - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "clusterName": { - "type": "string" - }, - "settingName": { - "type": "string" - }, - "workspaceId": { - "type": "string" - }, - "storageAccountId": { - "type": "string" - }, - "eventHubAuthorizationRuleId": { - "type": "string" - }, - "eventHubName": { - "type": "string" - } - }, - "resources": [ - { - "type": "Microsoft.Insights/diagnosticSettings", - "apiVersion": "2021-05-01-preview", - "scope": "[format('Microsoft.Kusto/clusters/{0}', parameters('clusterName'))]", - "name": "[parameters('settingName')]", - "properties": { - "workspaceId": "[parameters('workspaceId')]", - "storageAccountId": "[parameters('storageAccountId')]", - "eventHubAuthorizationRuleId": "[parameters('eventHubAuthorizationRuleId')]", - "eventHubName": "[parameters('eventHubName')]", - "logs": [ - { - "category": null, - "categoryGroup": "audit", - "enabled": true, - "retentionPolicy": { - "enabled": false, - "days": 0 - } - } - ] - } - } - ] -} -``` ----## Diagnostic setting for Azure Key Vault --The following sample creates a diagnostic setting for an instance of Azure Key Vault by adding a resource of type `Microsoft.KeyVault/vaults/providers/diagnosticSettings` to the template. --> [!IMPORTANT] -> For Azure Key Vault, the event hub must be in the same region as the key vault. --### Template file --# [Bicep](#tab/bicep) --```bicep -@description('The name of the diagnostic setting.') -param settingName string --@description('The name of the key vault.') -param vaultName string --@description('The resource Id of the workspace.') -param workspaceId string --@description('The resource Id of the storage account.') -param storageAccountId string --@description('The resource Id for the event hub authorization rule.') -param eventHubAuthorizationRuleId string --@description('The name of the event hub.') -param eventHubName string --resource vault 'Microsoft.KeyVault/vaults@2021-11-01-preview' existing = { - name: vaultName -} --resource setting 'Microsoft.Insights/diagnosticSettings@2021-05-01-preview' = { - name: settingName - scope: vault - properties: { - workspaceId: workspaceId - storageAccountId: storageAccountId - eventHubAuthorizationRuleId: eventHubAuthorizationRuleId - eventHubName: eventHubName - logs: [ - { - category: 'AuditEvent' - enabled: true - } - ] - metrics: [ - { - category: 'AllMetrics' - enabled: true - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "settingName": { - "type": "string", - "metadata": { - "description": "The name of the diagnostic setting." - } - }, - "vaultName": { - "type": "string", - "metadata": { - "description": "The name of the key vault." - } - }, - "workspaceId": { - "type": "string", - "metadata": { - "description": "The resource Id of the workspace." - } - }, - "storageAccountId": { - "type": "string", - "metadata": { - "description": "The resource Id of the storage account." - } - }, - "eventHubAuthorizationRuleId": { - "type": "string", - "metadata": { - "description": "The resource Id for the event hub authorization rule." - } - }, - "eventHubName": { - "type": "string", - "metadata": { - "description": "The name of the event hub." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/diagnosticSettings", - "apiVersion": "2021-05-01-preview", - "scope": "[format('Microsoft.KeyVault/vaults/{0}', parameters('vaultName'))]", - "name": "[parameters('settingName')]", - "properties": { - "workspaceId": "[parameters('workspaceId')]", - "storageAccountId": "[parameters('storageAccountId')]", - "eventHubAuthorizationRuleId": "[parameters('eventHubAuthorizationRuleId')]", - "eventHubName": "[parameters('eventHubName')]", - "logs": [ - { - "category": "AuditEvent", - "enabled": true - } - ], - "metrics": [ - { - "category": "AllMetrics", - "enabled": true - } - ] - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "settingName": { - "value": "Send to all locations" - }, - "vaultName": { - "value": "MyVault" - }, - "workspaceId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/MyResourceGroup/providers/microsoft.operationalinsights/workspaces/MyWorkspace" - }, - "storageAccountId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/MyResourceGroup/providers/Microsoft.Storage/storageAccounts/mystorageaccount" - }, - "eventHubAuthorizationRuleId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/MyResourceGroup/providers/Microsoft.EventHub/namespaces/MyNameSpace/authorizationrules/RootManageSharedAccessKey" - }, - "eventHubName": { - "value": "my-eventhub" - } - } -} -``` --## Diagnostic setting for Azure SQL Database --The following sample creates a diagnostic setting for an instance of Azure SQL Database by adding a resource of type `microsoft.sql/servers/databases/providers/diagnosticSettings` to the template. --### Template file --# [Bicep](#tab/bicep) --```bicep -@description('The name of the diagnostic setting.') -param settingName string --@description('The name of the Azure SQL database server.') -param serverName string --@description('The name of the SQL database.') -param dbName string --@description('The resource Id of the workspace.') -param workspaceId string --@description('The resource Id of the storage account.') -param storageAccountId string --@description('The resource Id of the event hub authorization rule.') -param eventHubAuthorizationRuleId string --@description('The name of the event hub.') -param eventHubName string --resource dbServer 'Microsoft.Sql/servers@2021-11-01-preview' existing = { - name: serverName -} --resource db 'Microsoft.Sql/servers/databases@2021-11-01-preview' existing = { - parent: dbServer - name: dbName -} --resource setting 'Microsoft.Insights/diagnosticSettings@2021-05-01-preview' = { - name: settingName - scope: db - properties: { - workspaceId: workspaceId - storageAccountId: storageAccountId - eventHubAuthorizationRuleId: eventHubAuthorizationRuleId - eventHubName: eventHubName - logs: [ - { - category: 'SQLInsights' - enabled: true - } - { - category: 'AutomaticTuning' - enabled: true - } - { - category: 'QueryStoreRuntimeStatistics' - enabled: true - } - { - category: 'QueryStoreWaitStatistics' - enabled: true - } - { - category: 'Errors' - enabled: true - } - { - category: 'DatabaseWaitStatistics' - enabled: true - } - { - category: 'Timeouts' - enabled: true - } - { - category: 'Blocks' - enabled: true - } - { - category: 'Deadlocks' - enabled: true - } - ] - metrics: [ - { - category: 'Basic' - enabled: true - } - { - category: 'InstanceAndAppAdvanced' - enabled: true - } - { - category: 'WorkloadManagement' - enabled: true - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "settingName": { - "type": "string", - "metadata": { - "description": "The name of the diagnostic setting." - } - }, - "serverName": { - "type": "string", - "metadata": { - "description": "The name of the Azure SQL database server." - } - }, - "dbName": { - "type": "string", - "metadata": { - "description": "The name of the SQL database." - } - }, - "workspaceId": { - "type": "string", - "metadata": { - "description": "The resource Id of the workspace." - } - }, - "storageAccountId": { - "type": "string", - "metadata": { - "description": "The resource Id of the storage account." - } - }, - "eventHubAuthorizationRuleId": { - "type": "string", - "metadata": { - "description": "The resource Id of the event hub authorization rule." - } - }, - "eventHubName": { - "type": "string", - "metadata": { - "description": "The name of the event hub." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/diagnosticSettings", - "apiVersion": "2021-05-01-preview", - "scope": "[format('Microsoft.Sql/servers/{0}/databases/{1}', parameters('serverName'), parameters('dbName'))]", - "name": "[parameters('settingName')]", - "properties": { - "workspaceId": "[parameters('workspaceId')]", - "storageAccountId": "[parameters('storageAccountId')]", - "eventHubAuthorizationRuleId": "[parameters('eventHubAuthorizationRuleId')]", - "eventHubName": "[parameters('eventHubName')]", - "logs": [ - { - "category": "SQLInsights", - "enabled": true - }, - { - "category": "AutomaticTuning", - "enabled": true - }, - { - "category": "QueryStoreRuntimeStatistics", - "enabled": true - }, - { - "category": "QueryStoreWaitStatistics", - "enabled": true - }, - { - "category": "Errors", - "enabled": true - }, - { - "category": "DatabaseWaitStatistics", - "enabled": true - }, - { - "category": "Timeouts", - "enabled": true - }, - { - "category": "Blocks", - "enabled": true - }, - { - "category": "Deadlocks", - "enabled": true - } - ], - "metrics": [ - { - "category": "Basic", - "enabled": true - }, - { - "category": "InstanceAndAppAdvanced", - "enabled": true - }, - { - "category": "WorkloadManagement", - "enabled": true - } - ] - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "settingName": { - "value": "Send to all locations" - }, - "serverName": { - "value": "MySqlServer" - }, - "dbName": { - "value": "MySqlDb" - }, - "workspaceId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/MyResourceGroup/providers/microsoft.operationalinsights/workspaces/MyWorkspace" - }, - "storageAccountId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/MyResourceGroup/providers/Microsoft.Storage/storageAccounts/mystorageaccount" - }, - "eventHubAuthorizationRuleId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/MyResourceGroup/providers/Microsoft.EventHub/namespaces/MyNameSpace/authorizationrules/RootManageSharedAccessKey" - }, - "eventHubName": { - "value": "my-eventhub" - } - } -} -``` --## Diagnostic setting for Azure SQL Managed Instance --The following sample creates a diagnostic setting for an instance of Azure SQL Managed Instance by adding a resource of type `microsoft.sql/managedInstances/providers/diagnosticSettings` to the template. --### Template file --# [Bicep](#tab/bicep) --```bicep -param sqlManagedInstanceName string -param diagnosticSettingName string -param diagnosticWorkspaceId string -param storageAccountId string -param eventHubAuthorizationRuleId string -param eventHubName string --resource instance 'Microsoft.Sql/managedInstances@2021-11-01-preview' existing = { - name: sqlManagedInstanceName -} --resource setting 'Microsoft.Insights/diagnosticSettings@2021-05-01-preview' = { - name: diagnosticSettingName - scope: instance - properties: { - workspaceId: diagnosticWorkspaceId - storageAccountId: storageAccountId - eventHubAuthorizationRuleId: eventHubAuthorizationRuleId - eventHubName: eventHubName - logs: [ - { - category: 'ResourceUsageStats' - enabled: true - } - { - category: 'DevOpsOperationsAudit' - enabled: true - } - { - category: 'SQLSecurityAuditEvents' - enabled: true - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "metadata": { - "parameters": { - "sqlManagedInstanceName": { - "type": "string" - }, - "diagnosticSettingName": { - "type": "string" - }, - "diagnosticWorkspaceId": { - "type": "string" - }, - "storageAccountId": { - "type": "string" - }, - "eventHubAuthorizationRuleId": { - "type": "string" - }, - "eventHubName": { - "type": "string" - } - }, - "resources": [ - { - "type": "Microsoft.Insights/diagnosticSettings", - "apiVersion": "2021-05-01-preview", - "scope": "[format('Microsoft.Sql/managedInstances/{0}', parameters('sqlManagedInstanceName'))]", - "name": "[parameters('diagnosticSettingName')]", - "properties": { - "workspaceId": "[parameters('diagnosticWorkspaceId')]", - "storageAccountId": "[parameters('storageAccountId')]", - "eventHubAuthorizationRuleId": "[parameters('eventHubAuthorizationRuleId')]", - "eventHubName": "[parameters('eventHubName')]", - "logs": [ - { - "category": "ResourceUsageStats", - "enabled": true - }, - { - "category": "DevOpsOperationsAudit", - "enabled": true - }, - { - "category": "SQLSecurityAuditEvents", - "enabled": true - } - ] - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "sqlManagedInstanceName": { - "value": "MyInstanceName" - }, - "diagnosticSettingName": { - "value": "Send to all locations" - }, - "diagnosticWorkspaceId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/MyResourceGroup/providers/microsoft.operationalinsights/workspaces/MyWorkspace" - }, - "storageAccountId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/MyResourceGroup/providers/Microsoft.Storage/storageAccounts/mystorageaccount" - }, - "eventHubAuthorizationRuleId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/MyResourceGroup/providers/Microsoft.EventHub/namespaces/MyNameSpace/authorizationrules/RootManageSharedAccessKey" - }, - "eventHubName": { - "value": "myEventhub" - } - } -} -``` --## Diagnostic setting for a managed instance of Azure SQL Database --The following sample creates a diagnostic setting for a managed instance of Azure SQL Database by adding a resource of type `microsoft.sql/managedInstances/databases/providers/diagnosticSettings` to the template. --### Template file --# [Bicep](#tab/bicep) --```bicep -param sqlManagedInstanceName string -param sqlManagedDatabaseName string -param diagnosticSettingName string -param diagnosticWorkspaceId string -param storageAccountId string -param eventHubAuthorizationRuleId string -param eventHubName string --resource dbInstance 'Microsoft.Sql/managedInstances@2021-11-01-preview' existing = { - name:sqlManagedInstanceName -} --resource db 'Microsoft.Sql/managedInstances/databases@2021-11-01-preview' existing = { - name: sqlManagedDatabaseName - parent: dbInstance -} --resource setting 'Microsoft.Insights/diagnosticSettings@2021-05-01-preview' = { - name: diagnosticSettingName - scope: db - properties: { - workspaceId: diagnosticWorkspaceId - storageAccountId: storageAccountId - eventHubAuthorizationRuleId: eventHubAuthorizationRuleId - eventHubName: eventHubName - logs: [ - { - category: 'SQLInsights' - enabled: true - } - { - category: 'QueryStoreRuntimeStatistics' - enabled: true - } - { - category: 'QueryStoreWaitStatistics' - enabled: true - } - { - category: 'Errors' - enabled: true - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "metadata": { - "_generator": { - "name": "bicep", - "version": "0.5.6.12127", - "templateHash": "10835183659402804631" - } - }, - "parameters": { - "sqlManagedInstanceName": { - "type": "string" - }, - "sqlManagedDatabaseName": { - "type": "string" - }, - "diagnosticSettingName": { - "type": "string" - }, - "diagnosticWorkspaceId": { - "type": "string" - }, - "storageAccountId": { - "type": "string" - }, - "eventHubAuthorizationRuleId": { - "type": "string" - }, - "eventHubName": { - "type": "string" - } - }, - "resources": [ - { - "type": "Microsoft.Insights/diagnosticSettings", - "apiVersion": "2021-05-01-preview", - "scope": "[format('Microsoft.Sql/managedInstances/{0}/databases/{1}', parameters('sqlManagedInstanceName'), parameters('sqlManagedDatabaseName'))]", - "name": "[parameters('diagnosticSettingName')]", - "properties": { - "workspaceId": "[parameters('diagnosticWorkspaceId')]", - "storageAccountId": "[parameters('storageAccountId')]", - "eventHubAuthorizationRuleId": "[parameters('eventHubAuthorizationRuleId')]", - "eventHubName": "[parameters('eventHubName')]", - "logs": [ - { - "category": "SQLInsights", - "enabled": true - }, - { - "category": "QueryStoreRuntimeStatistics", - "enabled": true - }, - { - "category": "QueryStoreWaitStatistics", - "enabled": true - }, - { - "category": "Errors", - "enabled": true - } - ] - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "sqlManagedInstanceName": { - "value": "MyInstanceName" - }, - "sqlManagedDatabaseName": { - "value": "MyManagedDatabaseName" - }, - "diagnosticSettingName": { - "value": "Send to all locations" - }, - "diagnosticWorkspaceId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/MyResourceGroup/providers/microsoft.operationalinsights/workspaces/MyWorkspace" - }, - "storageAccountId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/MyResourceGroup/providers/Microsoft.Storage/storageAccounts/mystorageaccount" - }, - "eventHubAuthorizationRuleId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/MyResourceGroup/providers/Microsoft.EventHub/namespaces/MyNameSpace/authorizationrules/RootManageSharedAccessKey" - }, - "eventHubName": { - "value": "myEventhub" - } - } -} -``` --## Diagnostic setting for Recovery Services vault --The following sample creates a diagnostic setting for an Azure Recovery Services vault by adding a resource of type `microsoft.recoveryservices/vaults/providers/diagnosticSettings` to the template. This example specifies the collection mode as described in [Azure resource logs](./resource-logs.md#send-to-log-analytics-workspace). Specify `Dedicated` or `AzureDiagnostics` for the `logAnalyticsDestinationType` property. --### Template file --# [Bicep](#tab/bicep) --```bicep -param recoveryServicesName string -param settingName string -param workspaceId string -param storageAccountId string -param eventHubAuthorizationRuleId string -param eventHubName string --resource vault 'Microsoft.RecoveryServices/vaults@2021-08-01' existing = { - name: recoveryServicesName -} --resource setting 'Microsoft.Insights/diagnosticSettings@2021-05-01-preview' = { - name: settingName - scope: vault - properties: { - workspaceId: workspaceId - storageAccountId: storageAccountId - eventHubAuthorizationRuleId: eventHubAuthorizationRuleId - eventHubName: eventHubName - logs: [ - { - category: 'AzureBackupReport' - enabled: false - } - { - category: 'CoreAzureBackup' - enabled: true - } - { - category: 'AddonAzureBackupJobs' - enabled: true - } - { - category: 'AddonAzureBackupAlerts' - enabled: true - } - { - category: 'AddonAzureBackupPolicy' - enabled: true - } - { - category: 'AddonAzureBackupStorage' - enabled: true - } - { - category: 'AddonAzureBackupProtectedInstance' - enabled: true - } - { - category: 'AzureSiteRecoveryJobs' - enabled: false - } - { - category: 'AzureSiteRecoveryEvents' - enabled: false - } - { - category: 'AzureSiteRecoveryReplicatedItems' - enabled: false - } - { - category: 'AzureSiteRecoveryReplicationStats' - enabled: false - } - { - category: 'AzureSiteRecoveryRecoveryPoints' - enabled: false - } - { - category: 'AzureSiteRecoveryReplicationDataUploadRate' - enabled: false - } - { - category: 'AzureSiteRecoveryProtectedDiskDataChurn' - enabled: false - } - ] - logAnalyticsDestinationType: 'Dedicated' - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "recoveryServicesName": { - "type": "string" - }, - "settingName": { - "type": "string" - }, - "workspaceId": { - "type": "string" - }, - "storageAccountId": { - "type": "string" - }, - "eventHubAuthorizationRuleId": { - "type": "string" - }, - "eventHubName": { - "type": "string" - } - }, - "resources": [ - { - "type": "Microsoft.Insights/diagnosticSettings", - "apiVersion": "2021-05-01-preview", - "scope": "[format('Microsoft.RecoveryServices/vaults/{0}', parameters('recoveryServicesName'))]", - "name": "[parameters('settingName')]", - "properties": { - "workspaceId": "[parameters('workspaceId')]", - "storageAccountId": "[parameters('storageAccountId')]", - "eventHubAuthorizationRuleId": "[parameters('eventHubAuthorizationRuleId')]", - "eventHubName": "[parameters('eventHubName')]", - "logs": [ - { - "category": "AzureBackupReport", - "enabled": false - }, - { - "category": "CoreAzureBackup", - "enabled": true - }, - { - "category": "AddonAzureBackupJobs", - "enabled": true - }, - { - "category": "AddonAzureBackupAlerts", - "enabled": true - }, - { - "category": "AddonAzureBackupPolicy", - "enabled": true - }, - { - "category": "AddonAzureBackupStorage", - "enabled": true - }, - { - "category": "AddonAzureBackupProtectedInstance", - "enabled": true - }, - { - "category": "AzureSiteRecoveryJobs", - "enabled": false - }, - { - "category": "AzureSiteRecoveryEvents", - "enabled": false - }, - { - "category": "AzureSiteRecoveryReplicatedItems", - "enabled": false - }, - { - "category": "AzureSiteRecoveryReplicationStats", - "enabled": false - }, - { - "category": "AzureSiteRecoveryRecoveryPoints", - "enabled": false - }, - { - "category": "AzureSiteRecoveryReplicationDataUploadRate", - "enabled": false - }, - { - "category": "AzureSiteRecoveryProtectedDiskDataChurn", - "enabled": false - } - ], - "logAnalyticsDestinationType": "Dedicated" - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "settingName": { - "value": "Send to all locations" - }, - "recoveryServicesName": { - "value": "my-vault" - }, - "workspaceId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/MyResourceGroup/providers/microsoft.operationalinsights/workspaces/MyWorkspace" - }, - "storageAccountId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/MyResourceGroup/providers/Microsoft.Storage/storageAccounts/mystorageaccount" - }, - "eventHubAuthorizationRuleId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/MyResourceGroup/providers/Microsoft.EventHub/namespaces/MyNameSpace/authorizationrules/RootManageSharedAccessKey" - }, - "eventHubName": { - "value": "my-eventhub" - } - } -} -``` --## Diagnostic setting for a Log Analytics workspace --The following sample creates a diagnostic setting for a Log Analytics workspace by adding a resource of type `Microsoft.OperationalInsights/workspaces/providers/diagnosticSettings` to the template. This example sends audit data about queries executed in the workspace to the same workspace. --### Template file --# [Bicep](#tab/bicep) --```bicep -param workspaceName string -param settingName string -param workspaceId string -param storageAccountId string -param eventHubAuthorizationRuleId string -param eventHubName string --resource workspace 'Microsoft.OperationalInsights/workspaces@2021-12-01-preview' existing = { - name: workspaceName -} -resource setting 'Microsoft.Insights/diagnosticSettings@2021-05-01-preview' = { - name: settingName - scope: workspace - properties: { - workspaceId: workspaceId - storageAccountId: storageAccountId - eventHubAuthorizationRuleId: eventHubAuthorizationRuleId - eventHubName: eventHubName - logs: [ - { - category: 'Audit' - enabled: true - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceName": { - "type": "string" - }, - "settingName": { - "type": "string" - }, - "workspaceId": { - "type": "string" - }, - "storageAccountId": { - "type": "string" - }, - "eventHubAuthorizationRuleId": { - "type": "string" - }, - "eventHubName": { - "type": "string" - } - }, - "resources": [ - { - "type": "Microsoft.Insights/diagnosticSettings", - "apiVersion": "2021-05-01-preview", - "scope": "[format('Microsoft.OperationalInsights/workspaces/{0}', parameters('workspaceName'))]", - "name": "[parameters('settingName')]", - "properties": { - "workspaceId": "[parameters('workspaceId')]", - "storageAccountId": "[parameters('storageAccountId')]", - "eventHubAuthorizationRuleId": "[parameters('eventHubAuthorizationRuleId')]", - "eventHubName": "[parameters('eventHubName')]", - "logs": [ - { - "category": "Audit", - "enabled": true - } - ] - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "settingName": { - "value": "Send to all locations" - }, - "workspaceName": { - "value": "MyWorkspace" - }, - "workspaceId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/MyResourceGroup/providers/microsoft.operationalinsights/workspaces/MyWorkspace" - }, - "storageAccountId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/MyResourceGroup/providers/Microsoft.Storage/storageAccounts/mystorageaccount" - }, - "eventHubAuthorizationRuleId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/MyResourceGroup/providers/Microsoft.EventHub/namespaces/MyNameSpace/authorizationrules/RootManageSharedAccessKey" - }, - "eventHubName": { - "value": "my-eventhub" - } - } -} -``` --## Diagnostic setting for Azure Storage --The following sample creates a diagnostic setting for each storage service endpoint that's available in the Azure Storage account. A setting is applied to each individual storage service that's available on the account. The storage services that are available depend on the type of storage account. --This template creates a diagnostic setting for a storage service in the account only if it exists for the account. For each available service, the diagnostic setting enables transaction metrics, and the collection of resource logs for read, write, and delete operations. --### Template file --# [Bicep](#tab/bicep) --main.bicep --```bicep -param storageAccountName string -param settingName string -param storageSyncName string -param workspaceId string --module nested './module.bicep' = { - name: 'nested' - params: { - endpoints: reference(resourceId('Microsoft.Storage/storageAccounts', storageAccountName), '2019-06-01', 'Full').properties.primaryEndpoints - settingName: settingName - storageAccountName: storageAccountName - storageSyncName: storageSyncName - workspaceId: workspaceId - } -} -``` --module.bicep --```bicep -param endpoints object -param settingName string -param storageAccountName string -param storageSyncName string -param workspaceId string --var hasblob = contains(endpoints, 'blob') -var hastable = contains(endpoints, 'table') -var hasfile = contains(endpoints, 'file') -var hasqueue = contains(endpoints, 'queue') --resource storageAccount 'Microsoft.Storage/storageAccounts@2021-09-01' existing = { - name: storageAccountName -} --resource diagnosticSetting 'Microsoft.Insights/diagnosticSettings@2021-05-01-preview' = { - name: settingName - scope: storageAccount - properties: { - workspaceId: workspaceId - storageAccountId: resourceId('Microsoft.Storage/storageAccounts', storageSyncName) - metrics: [ - { - category: 'Transaction' - enabled: true - } - ] - } -} --resource blob 'Microsoft.Storage/storageAccounts/blobServices@2021-09-01' existing = { - name:'default' - parent:storageAccount -} --resource blobSetting 'Microsoft.Insights/diagnosticSettings@2021-05-01-preview' = if (hasblob) { - name: settingName - scope: blob - properties: { - workspaceId: workspaceId - storageAccountId: resourceId('Microsoft.Storage/storageAccounts', storageSyncName) - logs: [ - { - category: 'StorageRead' - enabled: true - } - { - category: 'StorageWrite' - enabled: true - } - { - category: 'StorageDelete' - enabled: true - } - ] - metrics: [ - { - category: 'Transaction' - enabled: true - } - ] - } -} --resource table 'Microsoft.Storage/storageAccounts/tableServices@2021-09-01' existing = { - name:'default' - parent:storageAccount -} --resource tableSetting 'Microsoft.Insights/diagnosticSettings@2021-05-01-preview' = if (hastable) { - name: settingName - scope: table - properties: { - workspaceId: workspaceId - storageAccountId: resourceId('Microsoft.Storage/storageAccounts', storageSyncName) - logs: [ - { - category: 'StorageRead' - enabled: true - } - { - category: 'StorageWrite' - enabled: true - } - { - category: 'StorageDelete' - enabled: true - } - ] - metrics: [ - { - category: 'Transaction' - enabled: true - } - ] - } -} --resource file 'Microsoft.Storage/storageAccounts/fileServices@2021-09-01' existing = { - name:'default' - parent:storageAccount -} --resource fileSetting 'Microsoft.Insights/diagnosticSettings@2021-05-01-preview' = if (hasfile) { - name: settingName - scope: file - properties: { - workspaceId: workspaceId - storageAccountId: resourceId('Microsoft.Storage/storageAccounts', storageSyncName) - logs: [ - { - category: 'StorageRead' - enabled: true - } - { - category: 'StorageWrite' - enabled: true - } - { - category: 'StorageDelete' - enabled: true - } - ] - metrics: [ - { - category: 'Transaction' - enabled: true - } - ] - } -} --resource queue 'Microsoft.Storage/storageAccounts/queueServices@2021-09-01' existing = { - name:'default' - parent:storageAccount -} ---resource queueSetting 'Microsoft.Insights/diagnosticSettings@2021-05-01-preview' = if (hasqueue) { - name: settingName - scope: queue - properties: { - workspaceId: workspaceId - storageAccountId: resourceId('Microsoft.Storage/storageAccounts', storageSyncName) - logs: [ - { - category: 'StorageRead' - enabled: true - } - { - category: 'StorageWrite' - enabled: true - } - { - category: 'StorageDelete' - enabled: true - } - ] - metrics: [ - { - category: 'Transaction' - enabled: true - } - ] - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "storageAccountName": { - "type": "string" - }, - "settingName": { - "type": "string" - }, - "storageSyncName": { - "type": "string" - }, - "workspaceId": { - "type": "string" - } - }, - "resources": [ - { - "type": "Microsoft.Resources/deployments", - "apiVersion": "2020-10-01", - "name": "nested", - "properties": { - "expressionEvaluationOptions": { - "scope": "inner" - }, - "mode": "Incremental", - "parameters": { - "endpoints": { - "value": "[reference(resourceId('Microsoft.Storage/storageAccounts', parameters('storageAccountName')), '2019-06-01', 'Full').properties.primaryEndpoints]" - }, - "settingName": { - "value": "[parameters('settingName')]" - }, - "storageAccountName": { - "value": "[parameters('storageAccountName')]" - }, - "storageSyncName": { - "value": "[parameters('storageSyncName')]" - }, - "workspaceId": { - "value": "[parameters('workspaceId')]" - } - }, - "template": { - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "endpoints": { - "type": "object" - }, - "settingName": { - "type": "string" - }, - "storageAccountName": { - "type": "string" - }, - "storageSyncName": { - "type": "string" - }, - "workspaceId": { - "type": "string" - } - }, - "variables": { - "hasblob": "[contains(parameters('endpoints'), 'blob')]", - "hastable": "[contains(parameters('endpoints'), 'table')]", - "hasfile": "[contains(parameters('endpoints'), 'file')]", - "hasqueue": "[contains(parameters('endpoints'), 'queue')]" - }, - "resources": [ - { - "type": "Microsoft.Insights/diagnosticSettings", - "apiVersion": "2021-05-01-preview", - "scope": "[format('Microsoft.Storage/storageAccounts/{0}', parameters('storageAccountName'))]", - "name": "[parameters('settingName')]", - "properties": { - "workspaceId": "[parameters('workspaceId')]", - "storageAccountId": "[resourceId('Microsoft.Storage/storageAccounts', parameters('storageSyncName'))]", - "metrics": [ - { - "category": "Transaction", - "enabled": true - } - ] - } - }, - { - "condition": "[variables('hasblob')]", - "type": "Microsoft.Insights/diagnosticSettings", - "apiVersion": "2021-05-01-preview", - "scope": "[format('Microsoft.Storage/storageAccounts/{0}/blobServices/{1}', split(parameters('storageAccountName'), '/')[0], split(parameters('storageAccountName'), '/')[1])]", - "name": "[parameters('settingName')]", - "properties": { - "workspaceId": "[parameters('workspaceId')]", - "storageAccountId": "[resourceId('Microsoft.Storage/storageAccounts', parameters('storageSyncName'))]", - "logs": [ - { - "category": "StorageRead", - "enabled": true - }, - { - "category": "StorageWrite", - "enabled": true - }, - { - "category": "StorageDelete", - "enabled": true - } - ], - "metrics": [ - { - "category": "Transaction", - "enabled": true - } - ] - } - }, - { - "condition": "[variables('hastable')]", - "type": "Microsoft.Insights/diagnosticSettings", - "apiVersion": "2021-05-01-preview", - "scope": "[format('Microsoft.Storage/storageAccounts/{0}/tableServices/{1}', split(parameters('storageAccountName'), '/')[0], split(parameters('storageAccountName'), '/')[1])]", - "name": "[parameters('settingName')]", - "properties": { - "workspaceId": "[parameters('workspaceId')]", - "storageAccountId": "[resourceId('Microsoft.Storage/storageAccounts', parameters('storageSyncName'))]", - "logs": [ - { - "category": "StorageRead", - "enabled": true - }, - { - "category": "StorageWrite", - "enabled": true - }, - { - "category": "StorageDelete", - "enabled": true - } - ], - "metrics": [ - { - "category": "Transaction", - "enabled": true - } - ] - } - }, - { - "condition": "[variables('hasfile')]", - "type": "Microsoft.Insights/diagnosticSettings", - "apiVersion": "2021-05-01-preview", - "scope": "[format('Microsoft.Storage/storageAccounts/{0}/fileServices/{1}', split(parameters('storageAccountName'), '/')[0], split(parameters('storageAccountName'), '/')[1])]", - "name": "[parameters('settingName')]", - "properties": { - "workspaceId": "[parameters('workspaceId')]", - "storageAccountId": "[resourceId('Microsoft.Storage/storageAccounts', parameters('storageSyncName'))]", - "logs": [ - { - "category": "StorageRead", - "enabled": true - }, - { - "category": "StorageWrite", - "enabled": true - }, - { - "category": "StorageDelete", - "enabled": true - } - ], - "metrics": [ - { - "category": "Transaction", - "enabled": true - } - ] - } - }, - { - "condition": "[variables('hasqueue')]", - "type": "Microsoft.Insights/diagnosticSettings", - "apiVersion": "2021-05-01-preview", - "name": "[parameters('settingName')]", - "properties": { - "workspaceId": "[parameters('workspaceId')]", - "storageAccountId": "[resourceId('Microsoft.Storage/storageAccounts', parameters('storageSyncName'))]", - "logs": [ - { - "category": "StorageRead", - "enabled": true - }, - { - "category": "StorageWrite", - "enabled": true - }, - { - "category": "StorageDelete", - "enabled": true - } - ], - "metrics": [ - { - "category": "Transaction", - "enabled": true - } - ] - } - } - ] - } - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "storageAccountName": { - "value": "mymonitoredstorageaccount" - }, - "settingName": { - "value": "Send to all locations" - }, - "storageSyncName": { - "value": "mystorageaccount" - }, - "workspaceId": { - "value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/MyResourceGroup/providers/microsoft.operationalinsights/workspaces/MyWorkspace" - } - } -} -``` --## Next steps --* [Get other sample templates for Azure Monitor](../resource-manager-samples.md) -* [Learn more about diagnostic settings](../essentials/diagnostic-settings.md) |
| azure-monitor | Rest Activity Log | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/rest-activity-log.md | - Title: Retrieve activity log data using Azure monitor REST API -description: How to retrieve activity log data using Azure monitor REST API. -- Previously updated : 03/10/2024---# customer intent: As a developer, I want to learn how to retrieve activity log data using Azure monitor REST API. ---# Retrieve activity log data using Azure monitor REST API --The Azure Activity Log is a log that provides insight into operations performed on resources in your subscription. Operations include create, update, delete, and other actions taken on resources. The Activity Log is a platform-wide log and isn't limited to a particular service. This article explains how to retrieve activity log data using the Azure Monitor REST API. For more information about the activity log, see [Azure Activity Log event schema](/azure/azure-monitor/essentials/activity-log-schema). ---## Authentication --To retrieve resource logs, you must authenticate with Microsoft Entra. For more information, see [Azure monitoring REST API walkthrough](/azure/azure-monitor/essentials/rest-api-walkthrough?tabs=powershell#authenticate-azure-monitor-requests). --## Retrieve activity log data --Use the Azure Monitor REST API to query [activity log](/rest/api/monitor/activitylogs) data. --The following request format is used to request activity log data. --```curl -GET /subscriptions/<subscriptionId>/providers/Microsoft.Insights/eventtypes/management/values \ -?api-version=2015-04-01 \ -&$filter=<filter> \ -&$select=<select> -host: management.azure.com -authorization: Bearer <token> -``` --### $filter -`$filter` reduces the set of data collected. This argument is required and it also requires at least the start date/time. -The `$filter` argument accepts the following patterns: -- List events for a resource group: `$filter=eventTimestamp ge '2014-07-16T04:36:37.6407898Z' and eventTimestamp le '2014-07-20T04:36:37.6407898Z' and resourceGroupName eq <resourceGroupName>`.-- List events for a specific resource: `$filter=eventTimestamp ge '2014-07-16T04:36:37.6407898Z' and eventTimestamp le '2014-07-20T04:36:37.6407898Z' and resourceUri eq <resourceURI>`.-- List events for a subscription in a time range: `$filter=eventTimestamp ge '2014-07-16T04:36:37.6407898Z' and eventTimestamp le '2014-07-20T04:36:37.6407898Z'`.-- List events for a resource provider: `$filter=eventTimestamp ge '2014-07-16T04:36:37.6407898Z' and eventTimestamp le '2014-07-20T04:36:37.6407898Z' and resourceProvider eq <resourceProviderName>`.-- List events for a correlation ID:` $filter=eventTimestamp ge '2014-07-16T04:36:37.6407898Z' and eventTimestamp le '2014-07-20T04:36:37.6407898Z' and correlationId eq '<correlationID>`.---### $select -`$select` fetches a specified list of properties for the returned events. -The `$select` argument is a comma separated list of property names to be returned. -Valid values are: -`authorization`, `claims`, `correlationId`, `description`, `eventDataId`, `eventName`, `eventTimestamp`, `httpRequest`, `level`, `operationId`, `operationName`, `properties`, `resourceGroupName`, `resourceProviderName`, `resourceId`, `status`, `submissionTimestamp`, `subStatus`, and `subscriptionId`. --The following sample requests use the Azure Monitor REST API to query an activity log. -### Get activity logs with filter: --The following example gets the activity logs for resource group `MSSupportGroup` between the dates `2023-03-21T20:00:00Z` and `2023-03-24T20:00:00Z` --``` HTTP -GET https://management.azure.com/subscriptions/12345678-abcd-98765432-abcdef012345/providers/microsoft.insights/eventtypes/management/values?api-version=2015-04-01&$filter=eventTimestamp ge '2023-03-21T20:00:00Z' and eventTimestamp le '2023-03-24T20:00:00Z' and resourceGroupName eq 'MSSupportGroup' -``` -### Get activity logs with filter and select: --The following example gets the activity logs for resource group `MSSupportGroup`, between the dates `2023-03-21T20:00:00Z` and `2023-03-24T20:00:00Z`, returning the elements eventName, operationName, status, eventTimestamp, correlationId, submissionTimestamp, and level. --```HTTP -GET https://management.azure.com/subscriptions/12345678-abcd-98765432-abcdef012345/providers/microsoft.insights/eventtypes/management/values?api-version=2015-04-01&$filter=eventTimestamp ge '2023-03-21T20:00:00Z' and eventTimestamp le '2023-03-24T20:00:00Z'and resourceGroupName eq 'MSSupportGroup'&$select=eventName,operationName,status,eventTimestamp,correlationId,submissionTimestamp,level -``` --## Next steps -[Stream Azure Monitor activity log data](/azure/azure-monitor/essentials/activity-log). -[Azure Activity Log event schema](/azure/azure-monitor/essentials/activity-log-schema). - |
| azure-monitor | Rest Api Walkthrough | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/rest-api-walkthrough.md | - Title: Azure monitoring REST API walkthrough -description: How to authenticate requests and use the Azure Monitor REST API to retrieve available metric definitions, metric values, and activity logs. -- Previously updated : 06/27/2024------# Azure monitoring REST API walkthrough --This article shows you how to use the [Azure Monitor REST API reference](/rest/api/monitor/). --Retrieve metric definitions, dimension values, and metric values using the Azure Monitor API and use the data in your applications, or store in a database for analysis. You can also list alert rules and view activity logs using the Azure Monitor API. --## Authenticate Azure Monitor requests --Request submitted using the Azure Monitor API use the Azure Resource Manager authentication model. All requests are authenticated with Microsoft Entra ID. One approach to authenticating the client application is to create a Microsoft Entra service principal and retrieve an authentication token. You can create a Microsoft Entra service principal using the Azure portal, CLI, or PowerShell. For more information, see [Register an App to request authorization tokens and work with APIs](../logs/api/register-app-for-token.md). --### Retrieve a token -Once you've created a service principal, retrieve an access token. Specify `resource=https://management.azure.com` in the token request. ----After authenticating and retrieving a token, use the access token in your Azure Monitor API requests by including the header `'Authorization: Bearer <access token>'` --> [!NOTE] -> For more information on working with the Azure REST API, see the [Azure REST API reference](/rest/api/azure/). -> --## Retrieve the resource ID --Using the REST API requires the resource ID of the target Azure resource. -Resource IDs follow the following pattern: --`/subscriptions/<subscription-id>/resourceGroups/<resource-group-name>/providers/<provider>/<resource name>/` --For example --* **Azure IoT Hub**: /subscriptions/\<subscription-id>/resourceGroups/\<resource-group-name>/providers/Microsoft.Devices/IotHubs/\<iot-hub-name> -* **Elastic SQL pool**: /subscriptions/\<subscription-id>/resourceGroups/\<resource-group-name>/providers/Microsoft.Sql/servers/\<pool-db>/elasticpools/\<sql-pool-name> -* **Azure SQL Database (v12)**: /subscriptions/\<subscription-id>/resourceGroups/\<resource-group-name>/providers/Microsoft.Sql/servers/\<server-name>/databases/\<database-name> -* **Azure Service Bus**: /subscriptions/\<subscription-id>/resourceGroups/\<resource-group-name>/providers/Microsoft.ServiceBus/\<namespace>/\<servicebus-name> -* **Azure Virtual Machine Scale Sets**: /subscriptions/\<subscription-id>/resourceGroups/\<resource-group-name>/providers/Microsoft.Compute/virtualMachineScaleSets/\<vm-name> -* **Azure Virtual Machines**: /subscriptions/\<subscription-id>/resourceGroups/\<resource-group-name>/providers/Microsoft.Compute/virtualMachines/\<vm-name> -* **Azure Event Hubs**: /subscriptions/\<subscription-id>/resourceGroups/\<resource-group-name>/providers/Microsoft.EventHub/namespaces/\<eventhub-namespace> --Use the Azure portal, PowerShell, or the Azure CLI to find the resource ID. ---### [Azure portal](#tab/portal) --To find the resourceID in the portal, from the resource's overview page, select **JSON view** ---The Resource JSON page is displayed. The resource ID can be copied using the icon on the right of the ID. ----### [PowerShell](#tab/powershell) --The resource ID can be retrieved by using Azure PowerShell cmdlets too. For example, to obtain the resource ID for an Azure logic app, execute the `Get-AzureLogicApp` cmdlet, as in the following example: --```powershell -Get-AzLogicApp -ResourceGroupName azmon-rest-api-walkthrough -Name contosotweets -``` --The result should be similar to the following example: --```output -Id : /subscriptions/12345678-abcd-98765432-abcdef012345/resourceGroups/azmon-rest-api-walkthrough/providers/Microsoft.Logic/workflows/ContosoTweets -Name : ContosoTweets -Type : Microsoft.Logic/workflows -Location : centralus -ChangedTime : 8/21/2017 6:58:57 PM -CreatedTime : 8/18/2017 7:54:21 PM -AccessEndpoint : https://prod-08.centralus.logic.azure.com:443/workflows/f3a91b352fcc47e6bff989b85446c5db -State : Enabled -Definition : {$schema, contentVersion, parameters, triggers...} -Parameters : {[$connections, Microsoft.Azure.Management.Logic.Models.WorkflowParameter]} -SkuName : -AppServicePlan : -PlanType : -PlanId : -Version : 08586982649483762729 -``` --### [Azure CLI](#tab/cli) --To retrieve the resource ID for an Azure Storage account by using the Azure CLI, execute the `az storage account show` command, as shown in the following example: --```azurecli -az storage account show -g azmon-rest-api-walkthrough -n azmonstorage001 -``` --The result should be similar to the following example: --```json -{ - "accessTier": null, - "creationTime": "2023-08-18T19:58:41.840552+00:00", - "customDomain": null, - "enableHttpsTrafficOnly": false, - "encryption": null, - "id": "/subscriptions/12345678-abcd-98765432-abcdef012345/resourceGroups/azmon-rest-api-walkthrough/providers/Microsoft.Storage/storageAccounts/azmonstorage001", - "identity": null, - "kind": "Storage", - "lastGeoFailoverTime": null, - "location": "centralus", - "name": "azmonstorage001", - "networkAcls": null, - "primaryEndpoints": { - "blob": "https://azmonstorage001.blob.core.windows.net/", - "file": "https://azmonstorage001.file.core.windows.net/", - "queue": "https://azmonstorage001.queue.core.windows.net/", - "table": "https://azmonstorage001.table.core.windows.net/" - }, - "primaryLocation": "centralus", - "provisioningState": "Succeeded", - "resourceGroup": "azmon-rest-api-walkthrough", - "secondaryEndpoints": null, - "secondaryLocation": "eastus2", - "sku": { - "name": "Standard_GRS", - "tier": "Standard" - }, - "statusOfPrimary": "available", - "statusOfSecondary": "available", - "tags": {}, - "type": "Microsoft.Storage/storageAccounts" -} -``` --> [!NOTE] -> Azure logic apps aren't yet available via the Azure CLI. For this reason, an Azure Storage account is shown in the preceding example. -> ---## API endpoints --The API endpoints use the following pattern: -`/<resource URI>/providers/microsoft.insights/<metrics|metricDefinitions>?api-version=<apiVersion>` -The `resource URI` is composed of the following components: -`/subscriptions/<subscription id>/resourcegroups/<resourceGroupName>/providers/<resourceProviderNamespace>/<resourceType>/<resourceName>/` --> [!IMPORTANT] -> Be sure to include `/providers/microsoft.insights/` after the resource URI when you make an API call to retrieve metrics or metric definitions. -## Retrieve metric definitions --Use the [Azure Monitor Metric Definitions REST API](/rest/api/monitor/metricdefinitions) to access the list of metrics that are available for a service. -Use the following request format to retrieve metric definitions. --```HTTP -GET /subscriptions/<subscription id>/resourcegroups/<resourceGroupName>/providers/<resourceProviderNamespace>/<resourceType>/<resourceName>/providers/microsoft.insights/metricDefinitions?api-version=<apiVersion> -Host: management.azure.com -Content-Type: application/json -Authorization: Bearer <access token> --``` --For example, The following request retrieves the metric definitions for an Azure Storage account. --```curl -curl --location --request GET 'https://management.azure.com/subscriptions/12345678-abcd-98765432-abcdef012345/resourceGroups/azmon-rest-api-walkthrough/providers/Microsoft.Storage/storageAccounts/ContosoStorage/providers/microsoft.insights/metricDefinitions?api-version=2018-01-01' header 'Authorization: Bearer eyJ0eXAiOi...xYz-``` --The following JSON shows an example response body. -In this example, only the second metric has dimensions. --```json -{ - "value": [ - { - "id": "/subscriptions/12345678-abcd-98765432-abcdef012345/resourceGroups/azmon-rest-api-walkthrough/providers/Microsoft.Storage/storageAccounts/ContosoStorage/providers/microsoft.insights/metricdefinitions/UsedCapacity", - "resourceId": "/subscriptions/12345678-abcd-98765432-abcdef012345/resourceGroups/azmon-rest-api-walkthrough/providers/Microsoft.Storage/storageAccounts/ContosoStorage", - "namespace": "Microsoft.Storage/storageAccounts", - "category": "Capacity", - "name": { - "value": "UsedCapacity", - "localizedValue": "Used capacity" - }, - "isDimensionRequired": false, - "unit": "Bytes", - "primaryAggregationType": "Average", - "supportedAggregationTypes": [ - "Total", - "Average", - "Minimum", - "Maximum" - ], - "metricAvailabilities": [ - { - "timeGrain": "PT1H", - "retention": "P93D" - }, - ... - { - "timeGrain": "PT12H", - "retention": "P93D" - }, - { - "timeGrain": "P1D", - "retention": "P93D" - } - ] - }, - { - "id": "/subscriptions/12345678-abcd-98765432-abcdef012345/resourceGroups/azmon-rest-api-walkthrough/providers/Microsoft.Storage/storageAccounts/ContosoStorage/providers/microsoft.insights/metricdefinitions/Transactions", - "resourceId": "/subscriptions/12345678-abcd-98765432-abcdef012345/resourceGroups/azmon-rest-api-walkthrough/providers/Microsoft.Storage/storageAccounts/ContosoStorage", - "namespace": "Microsoft.Storage/storageAccounts", - "category": "Transaction", - "name": { - "value": "Transactions", - "localizedValue": "Transactions" - }, - "isDimensionRequired": false, - "unit": "Count", - "primaryAggregationType": "Total", - "supportedAggregationTypes": [ - "Total" - ], - "metricAvailabilities": [ - { - "timeGrain": "PT1M", - "retention": "P93D" - }, - { - "timeGrain": "PT5M", - "retention": "P93D" - }, - ... - { - "timeGrain": "PT30M", - "retention": "P93D" - }, - { - "timeGrain": "PT1H", - "retention": "P93D" - }, - ... - { - "timeGrain": "P1D", - "retention": "P93D" - } - ], - "dimensions": [ - { - "value": "ResponseType", - "localizedValue": "Response type" - }, - { - "value": "GeoType", - "localizedValue": "Geo type" - }, - { - "value": "ApiName", - "localizedValue": "API name" - } - ] - }, - ... - ] -} -``` -> [!NOTE] -> We recommend using API version "2018-01-01" or later. Older versions of the metric definitions API don't support dimensions. --## Retrieve dimension values --After the retrieving the available metric definitions, retrieve the range of values for the metric's dimensions. Use dimension values to filter or segment the metrics in your queries. Use the [Azure Monitor Metrics REST API](/rest/api/monitor/metrics) to find all of the values for a given metric dimension. --Use the metric's `name.value` element in the filter definitions. If no filters are specified, the default metric is returned. The API only allows one dimension to have a wildcard filter. -Specify the request for dimension values using the `"resultType=metadata"` query parameter. The `resultType` is omitted for a metric values request. --> [!NOTE] -> To retrieve dimension values by using the Azure Monitor REST API, use the API version "2019-07-01" or later. -> -Use the following request format to retrieve dimension values. -```HTTP -GET /subscriptions/<subscription-id>/resourceGroups/ -<resource-group-name>/providers/<resource-provider-namespace>/ -<resource-type>/<resource-name>/providers/microsoft.insights/ -metrics?metricnames=<metric> -×pan=<starttime/endtime> -&$filter=<filter> -&resultType=metadata -&api-version=<apiVersion> HTTP/1.1 -Host: management.azure.com -Content-Type: application/json -Authorization: Bearer <access token> -``` -The following example retrieves the list of dimension values that were emitted for the `API Name` dimension of the `Transactions` metric, where the `GeoType` dimension has a value of `Primary`, for the specified time range. --```curl -curl --location --request GET 'https://management.azure.com/subscriptions/12345678-abcd-98765432-abcdef012345/resourceGroups/azmon-rest-api-walkthrough/providers/Microsoft.Storage/storageAccounts/ContosoStorage/providers/microsoft.insights/metrics \ -?metricnames=Transactions \ -×pan=2023-03-01T00:00:00Z/2023-03-02T00:00:00Z \ -&resultType=metadata \ -&$filter=GeoType eq \'Primary\' and ApiName eq \'*\' \ -&api-version=2019-07-01' --header 'Content-Type: application/json' \header 'Authorization: Bearer eyJ0e..meG1lWm9Y'-``` -The following JSON shows an example response body. --```json -{ - "timespan": "2023-03-01T00:00:00Z/2023-03-02T00:00:00Z", - "value": [ - { - "id": "/subscriptions/12345678-abcd-98765432-abcdef012345/resourceGroups/azmon-rest-api-walkthrough/providers/Microsoft.Storage/storageAccounts/ContosoStorage/providers/Microsoft.Insights/metrics/Transactions", - "type": "Microsoft.Insights/metrics", - "name": { - "value": "Transactions", - "localizedValue": "Transactions" - }, - "unit": "Count", - "timeseries": [ - { - "metadatavalues": [ - { - "name": { - "value": "apiname", - "localizedValue": "apiname" - }, - "value": "DeleteBlob" - } - ] - }, - { - "metadatavalues": [ - { - "name": { - "value": "apiname", - "localizedValue": "apiname" - }, - "value": "SetBlobProperties" - } - ] - }, - ... - ] - } - ], - "namespace": "Microsoft.Storage/storageAccounts", - "resourceregion": "eastus" -} -``` --## Retrieve metric values --After retrieving the metric definitions and dimension values, retrieve the metric values. Use the [Azure Monitor Metrics REST API](/rest/api/monitor/metrics) to retrieve the metric values. --Use the metric's `name.value` element in the filter definitions. If no dimension filters are specified, the rolled up, aggregated metric is returned. --### Multiple time series -A time series is a set of data points that are ordered by time for a given combination of dimensions. A dimension is an aspect of the metric that describes the data point such as resource Id, region, or ApiName. -+ To fetch multiple time series with specific dimension values, specify a filter query parameter that specifies both dimension values such as `"&$filter=ApiName eq 'ListContainers' or ApiName eq 'GetBlobServiceProperties'"`. In this example, you get a time series where `ApiName` is `ListContainers` and a second time series where `ApiName` is `GetBlobServiceProperties`. -+ To return a time series for every value of a given dimension, use an `*` filter such as `"&$filter=ApiName eq '*'"`. Use the `Top` and `OrderBy` query parameters to limit and sort the number of time series returned. In this example, you get a time series for every value of `ApiName`in the result set. If no data is returned, the API returns an empty time series `"timeseries": []`. --> [!NOTE] -> To retrieve multi-dimensional metric values using the Azure Monitor REST API, use the API version "2019-07-01" or later. -> --Use the following request format to retrieve metric values. --```HTTP -GET /subscriptions/<subscription-id>/resourceGroups/<resource-group-name>/providers/<resource-provider-namespace>/<resource-type>/<resource-name>/providers/microsoft.insights/metrics?metricnames=<metric>×pan=<starttime/endtime>&$filter=<filter>&interval=<timeGrain>&aggregation=<aggreation>&api-version=<apiVersion> -Host: management.azure.com -Content-Type: application/json -Authorization: Bearer <access token> -``` --The following example retrieves the top three APIs, by the number of `Transactions` in descending value order, during a 5-minute range, where the `GeoType` dimension has a value of `Primary`. --```curl -curl --location --request GET 'https://management.azure.com/subscriptions/12345678-abcd-98765432-abcdef012345/resourceGroups/azmon-rest-api-walkthrough/providers/Microsoft.Storage/storageAccounts/ContosoStorage/providers/microsoft.insights/metrics \ -?metricnames=Transactions \ -×pan=2023-03-01T02:00:00Z/2023-03-01T02:05:00Z \ -& $filter=apiname eq '\''GetBlobProperties'\' -&interval=PT1M \ -&aggregation=Total \ -&top=3 \ -&orderby=Total desc \ -&api-version=2019-07-01"' \ header 'Content-Type: application/json' \header 'Authorization: Bearer yJ0eXAiOi...g1dCI6Ii1LS'-``` -The following JSON shows an example response body. --```json -{ - "cost": 0, - "timespan": "2023-03-01T02:00:00Z/2023-03-01T02:05:00Z", - "interval": "PT1M", - "value": [ - { - "id": "/subscriptions/12345678-abcd-98765432-abcdef012345/resourceGroups/azmon-rest-api-walkthrough/providers/Microsoft.Storage/storageAccounts/ContosoStorage/providers/Microsoft.Insights/metrics/Transactions", - "type": "Microsoft.Insights/metrics", - "name": { - "value": "Transactions", - "localizedValue": "Transactions" - }, - "unit": "Count", - "timeseries": [ - { - "metadatavalues": [ - { - "name": { - "value": "apiname", - "localizedValue": "apiname" - }, - "value": "GetBlobProperties" - } - ], - "data": [ - { - "timeStamp": "2023-09-19T02:00:00Z", - "total": 2 - }, - { - "timeStamp": "2023-09-19T02:01:00Z", - "total": 1 - }, - { - "timeStamp": "2023-09-19T02:02:00Z", - "total": 3 - }, - { - "timeStamp": "2023-09-19T02:03:00Z", - "total": 7 - }, - { - "timeStamp": "2023-09-19T02:04:00Z", - "total": 2 - } - ] - }, - ... - ] - } - ], - "namespace": "Microsoft.Storage/storageAccounts", - "resourceregion": "eastus" -} -``` --## Querying metrics for multiple resources at a time. --In addition to querying for metrics on an individual resource, some resource types also support querying for multiple resources in a single request. These APIs are what power the [Multi-Resource experience in Azure metrics explorer](./metrics-dynamic-scope.md). The set of resources types that support querying for multiple metrics can be seen on the [Metrics blade in Azure monitor](https://portal.azure.com/#view/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/~/metrics) via the resource type drop-down in the scope selector on the context blade. For more information, see the [Multi-Resource UX documentation](./metrics-dynamic-scope.md). --There are some important differences between querying metrics for multiple and individual resources. -+ Metrics multi-resource APIs operate at the subscription level instead of the resource ID level. This restriction means users querying these APIs must have [Monitoring Reader](../../role-based-access-control/built-in-roles.md#monitoring-reader) permissions on the subscription itself. -+ Metrics multi-resource APIs only support a single resourceType per query, which must be specified in the form of a metric namespace query parameter. -+ Metrics multi-resource APIs only support a single Azure region per query, which must be specified in the form of a region query parameter. --### Querying metrics for multiple resources examples --The following example shows an individual metric definitions request: -``` -GET https://management.azure.com/subscriptions/12345678-abcd-98765432-abcdef012345/resourceGroups/EASTUS-TESTING/providers/Microsoft.Compute/virtualMachines/TestVM1/providers/microsoft.insights/metricdefinitions?api-version=2021-05-01 -``` --The following request shows the equivalent metric definitions request for multiple resources. -The only changes are the subscription path instead of a resource ID path, and the addition of `region` and `metricNamespace` query parameters. -``` -GET https://management.azure.com/subscriptions/12345678-abcd-98765432-abcdef012345/providers/microsoft.insights/metricdefinitions?api-version=2021-05-01®ion=eastus&metricNamespace=microsoft.compute/virtualmachines -``` --The following example shows an individual metrics request. -``` -GET https://management.azure.com/subscriptions/12345678-abcd-98765432-abcdef012345/resourceGroups/EASTUS-TESTING/providers/Microsoft.Compute/virtualMachines/TestVM1/providers/microsoft.Insights/metrics?timespan=2023-06-25T22:20:00.000Z/2023-06-26T22:25:00.000Z&interval=PT5M&metricnames=Percentage CPU&aggregation=average&api-version=2021-05-01 -``` --Below is an equivalent metrics request for multiple resources: -``` -GET https://management.azure.com/subscriptions/12345678-abcd-98765432-abcdef012345/providers/microsoft.Insights/metrics?timespan=2023-06-25T22:20:00.000Z/2023-06-26T22:25:00.000Z&interval=PT5M&metricnames=Percentage CPU&aggregation=average&api-version=2021-05-01®ion=eastus&metricNamespace=microsoft.compute/virtualmachines&$filter=Microsoft.ResourceId eq '*' -``` -> [!NOTE] -> A `Microsoft.ResourceId eq '*'` filter is added in the example for the multi resource metrics requests. The `*` filter tells the API to return a separate time series for each virtual machine resource that has data in the subscription and region. Without the filter the API would return a single time series aggregating the average CPU for all VMs. The times series for each resource is differentiated by the `Microsoft.ResourceId` metadata value on each time series entry, as can be seen in the following sample return value. If there are no resourceIds retrieved by this query an empty time series`"timeseries": []` is returned. --```JSON -{ - "timespan": "2023-06-25T22:35:00Z/2023-06-26T22:40:00Z", - "interval": "PT6H", - "value": [ - { - "id": "subscriptions/12345678-abcd-98765432-abcdef012345/providers/Microsoft.Insights/metrics/Percentage CPU", - "type": "Microsoft.Insights/metrics", - "name": { - "value": "Percentage CPU", - "localizedValue": "Percentage CPU" - }, - "displayDescription": "The percentage of allocated compute units that are currently in use by the Virtual Machine(s)", - "unit": "Percent", - "timeseries": [ - { - "metadatavalues": [ - { - "name": { - "value": "Microsoft.ResourceId", - "localizedValue": "Microsoft.ResourceId" - }, - "value": "/subscriptions/12345678-abcd-98765432-abcdef012345/resourceGroups/EASTUS-TESTING/providers/Microsoft.Compute/virtualMachines/TestVM1" - } - ], - "data": [ - { - "timeStamp": "2023-06-25T22:35:00Z", - "average": 3.2618888888888886 - }, - { - "timeStamp": "2023-06-26T04:35:00Z", - "average": 4.696944444444445 - }, - { - "timeStamp": "2023-06-26T10:35:00Z", - "average": 6.19701388888889 - }, - { - "timeStamp": "2023-06-26T16:35:00Z", - "average": 2.630347222222222 - }, - { - "timeStamp": "2023-06-26T22:35:00Z", - "average": 21.288999999999998 - } - ] - }, - { - "metadatavalues": [ - { - "name": { - "value": "Microsoft.ResourceId", - "localizedValue": "Microsoft.ResourceId" - }, - "value": "/subscriptions/12345678-abcd-98765432-abcdef012345/resourceGroups/EASTUS-TESTING/providers/Microsoft.Compute/virtualMachines/TestVM2" - } - ], - "data": [ - { - "timeStamp": "2023-06-25T22:35:00Z", - "average": 7.567069444444444 - }, - { - "timeStamp": "2023-06-26T04:35:00Z", - "average": 5.111835883171071 - }, - { - "timeStamp": "2023-06-26T10:35:00Z", - "average": 10.078277777777778 - }, - { - "timeStamp": "2023-06-26T16:35:00Z", - "average": 8.399097222222222 - }, - { - "timeStamp": "2023-06-26T22:35:00Z", - "average": 2.647 - } - ] - }, - { - "metadatavalues": [ - { - "name": { - "value": "Microsoft.ResourceId", - "localizedValue": "Microsoft.ResourceId" - }, - "value": "/subscriptions/12345678-abcd-98765432-abcdef012345/resourceGroups/Common-TESTING/providers/Microsoft.Compute/virtualMachines/CommonVM1" - } - ], - "data": [ - { - "timeStamp": "2023-06-25T22:35:00Z", - "average": 6.892319444444444 - }, - { - "timeStamp": "2023-06-26T04:35:00Z", - "average": 3.5054305555555554 - }, - { - "timeStamp": "2023-06-26T10:35:00Z", - "average": 8.398817802503476 - }, - { - "timeStamp": "2023-06-26T16:35:00Z", - "average": 6.841666666666667 - }, - { - "timeStamp": "2023-06-26T22:35:00Z", - "average": 3.3850000000000002 - } - ] - } - ], - "errorCode": "Success" - } - ], - "namespace": "microsoft.compute/virtualmachines", - "resourceregion": "eastus" -} -``` - -### Troubleshooting querying metrics for multiple resources --+ Empty time series returned `"timeseries": []` - - An empty time series is returned when no data is available for the specified time range and filter. The most common cause is specifying a time range that doesn't contain any data. For example, if the time range is set to a future date. - - Another common cause is specifying a filter that doesn't match any resources. For example, if the filter specifies a dimension value that doesn't exist on any resources in the subscription and region combination, `"timeseries": []` is returned. - -+ Wildcard filters - Using a wildcard filter such as `Microsoft.ResourceId eq '*'` causes the API to return a time series for every resourceId in the subscription and region. If the subscription and region combination contains no resources, an empty time series is returned. The same query without the wildcard filter would return a single time series, aggregating the requested metric over the requested dimensions, for example subscription and region. - -+ 401 authorization errors: - The individual resource metrics APIs requires a user have the [Monitoring Reader](../../role-based-access-control/built-in-roles.md#monitoring-reader) permission on the resource being queried. Because the multi resource metrics APIs are subscription level APIs, users must have the [Monitoring Reader](../../role-based-access-control/built-in-roles.md#monitoring-reader) permission for the queried subscription to use the multi resource metrics APIs. Even if users have Monitoring Reader on all the resources in a subscription, the request fails if the user doesn't have Monitoring Reader on the subscription itself. ---## Next steps --- Review the [overview of monitoring](../overview.md).-- View the [supported metrics with Azure Monitor](./metrics-supported.md).-- Review the [Microsoft Azure Monitor REST API reference](/rest/api/monitor/).-- Review the new [Azure Monitor Query client libraries](https://devblogs.microsoft.com/azure-sdk/announcing-the-new-azure-monitor-query-client-libraries/)-- Review the [Azure Management Library](/previous-versions/azure/reference/mt417623(v=azure.100)).-- [Retrieve activity log data using Azure monitor REST API](./rest-activity-log.md). |
| azure-monitor | Stream Monitoring Data Event Hubs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/stream-monitoring-data-event-hubs.md | - Title: Stream Azure monitoring data to an event hub and external partners -description: Learn how to stream your Azure monitoring data to an event hub to get the data into a partner SIEM or analytics tool. ---- Previously updated : 08/09/2023---# Stream Azure monitoring data to an event hub or external partner --In most cases, the most effective method to stream data from Azure Monitor to external tools is by using [Azure Event Hubs](../../event-hubs/index.yml). This article provides a brief description on how to stream data and then lists some of the partners where you can send it. Some partners have special integration with Azure Monitor and might be hosted on Azure. --## Create an Event Hubs namespace --Before you configure streaming for any data source, you need to [create an Event Hubs namespace and event hub](../../event-hubs/event-hubs-create.md). This namespace and event hub is the destination for all of your monitoring data. An Event Hubs namespace is a logical grouping of event hubs that share the same access policy, much like a storage account has individual blobs within that storage account. Consider the following details about the Event Hubs namespace and event hubs that you use for streaming monitoring data: --* The number of throughput units allows you to increase throughput scale for your event hubs. Only one throughput unit is typically necessary. If you need to scale up as your log usage increases, you can manually increase the number of throughput units for the namespace or enable auto inflation. -* The number of partitions allows you to parallelize consumption across many consumers. A single partition can support up to 20 MBps or approximately 20,000 messages per second. Depending on the tool consuming the data, it might or might not support consuming from multiple partitions. Four partitions are reasonable to start with if you're not sure about the number of partitions to set. -* You set message retention on your event hub to at least seven days. If your consuming tool goes down for more than a day, this retention ensures that the tool can pick up where it left off for events up to seven days old. -* You should use the default consumer group for your event hub. There's no need to create other consumer groups or use a separate consumer group unless you plan to have two different tools consume the same data from the same event hub. -* For the Azure activity log, you pick an Event Hubs namespace, and Azure Monitor creates an event hub within that namespace called _insights-logs-operational-logs_. For other log types, you can either choose an existing event hub or have Azure Monitor create an event hub per log category. -* Outbound port 5671 and 5672 must typically be opened on the computer or virtual network consuming data from the event hub. --## Monitoring data available -[Sources of monitoring data for Azure Monitor and their data collection methods](../data-sources.md) describes the different kinds of data collected by Azure Monitor and the methods used to collect them. See that article for that data that can be streamed to an event hub and links to configuration details. ---## Stream diagnostics data --Use diagnostics setting to stream logs and metrics to Event Hubs. -For information on how to set up diagnostic settings, see [Create diagnostic settings](./create-diagnostic-settings.md) --The following JSON is an example of metrics data sent to an event hub: --```json -[ - { - "records": [ - { - "count": 2, - "total": 0.217, - "minimum": 0.042, - "maximum": 0.175, - "average": 0.1085, - "resourceId": "/SUBSCRIPTIONS/ABCDEF12-3456-78AB-CD12-34567890ABCD/RESOURCEGROUPS/RG-001/PROVIDERS/MICROSOFT.WEB/SITES/SCALEABLEWEBAPP1", - "time": "2023-04-18T09:03:00.0000000Z", - "metricName": "CpuTime", - "timeGrain": "PT1M" - }, - { - "count": 2, - "total": 0.284, - "minimum": 0.053, - "maximum": 0.231, - "average": 0.142, - "resourceId": "/SUBSCRIPTIONS/ABCDEF12-3456-78AB-CD12-34567890ABCD/RESOURCEGROUPS/RG-001/PROVIDERS/MICROSOFT.WEB/SITES/SCALEABLEWEBAPP1", - "time": "2023-04-18T09:04:00.0000000Z", - "metricName": "CpuTime", - "timeGrain": "PT1M" - }, - { - "count": 1, - "total": 1, - "minimum": 1, - "maximum": 1, - "average": 1, - "resourceId": "/SUBSCRIPTIONS/ABCDEF12-3456-78AB-CD12-34567890ABCD/RESOURCEGROUPS/RG-001/PROVIDERS/MICROSOFT.WEB/SITES/SCALEABLEWEBAPP1", - "time": "2023-04-18T09:03:00.0000000Z", - "metricName": "Requests", - "timeGrain": "PT1M" - }, - ... - ] - } -] -``` --The following JSON is an example of log data sent to an event hub: ---```json -[ - { - "records": [ - { - "time": "2023-04-18T09:39:56.5027358Z", - "category": "AuditEvent", - "operationName": "VaultGet", - "resultType": "Success", - "correlationId": "12345678-abc-4bc5-9f31-950eaf3bfcb4", - "callerIpAddress": "10.0.0.10", - "identity": { - "claim": { - "http://schemas.microsoft.com/identity/claims/objectidentifier": "123abc12-abcd-9876-cdef-123abc456def", - "appid": "12345678-a1a1-b2b2-c3c3-9876543210ab" - } - }, - "properties": { - "id": "https://mykeyvault.vault.azure.net/", - "clientInfo": "AzureResourceGraph.IngestionWorkerService.global/1.23.1.224", - "requestUri": "https://northeurope.management.azure.com/subscriptions/ABCDEF12-3456-78AB-CD12-34567890ABCD/resourceGroups/rg-001/providers/Microsoft.KeyVault/vaults/mykeyvault?api-version=2023-02-01&MaskCMKEnabledProperties=true", - "httpStatusCode": 200, - "properties": { - "sku": { - "Family": "A", - "Name": "Standard", - "Capacity": null - }, - "tenantId": "12345678-abcd-1234-abcd-1234567890ab", - "networkAcls": null, - "enabledForDeployment": 0, - "enabledForDiskEncryption": 0, - "enabledForTemplateDeployment": 0, - "enableSoftDelete": 1, - "softDeleteRetentionInDays": 90, - "enableRbacAuthorization": 0, - "enablePurgeProtection": null - } - }, - "resourceId": "/SUBSCRIPTIONS/ABCDEF12-3456-78AB-CD12-34567890ABCD/RESOURCEGROUPS/RG-001/PROVIDERS/MICROSOFT.KEYVAULT/VAULTS/mykeyvault", - "operationVersion": "2023-02-01", - "resultSignature": "OK", - "durationMs": "16" - } - ], - "EventProcessedUtcTime": "2023-04-18T09:42:07.0944007Z", - "PartitionId": 1, - "EventEnqueuedUtcTime": "2023-04-18T09:41:14.9410000Z" - }, -... -``` --## Manual streaming with a logic app --For data that you can't directly stream to an event hub, you can write to Azure Storage and then you can use a time-triggered logic app that [pulls data from Azure Blob Storage](../../connectors/connectors-create-api-azureblobstorage.md#add-action) and [pushes it as a message to the event hub](../../connectors/connectors-create-api-azure-event-hubs.md#add-action). ---## Partner tools with Azure Monitor integration --Routing your monitoring data to an event hub with Azure Monitor enables you to easily integrate with external SIEM and monitoring tools. The following table lists examples of tools with Azure Monitor integration. --| Tool | Hosted in Azure | Description | -|:|:| :| -| IBM QRadar | No | The Microsoft Azure DSM and Microsoft Azure Event Hubs Protocol are available for download from [the IBM support website](https://www.ibm.com/support). | -| Splunk | No | [Splunk Add-on for Microsoft Cloud Services](https://splunkbase.splunk.com/app/3110/) is an open-source project available in Splunkbase. <br><br> If you can't install an add-on in your Splunk instance and, for example, you're using a proxy or running on Splunk Cloud, you can forward these events to the Splunk HTTP Event Collector by using [Azure Function for Splunk](https://github.com/Microsoft/AzureFunctionforSplunkVS). This tool is triggered by new messages in the event hub. | -| SumoLogic | No | Instructions for setting up SumoLogic to consume data from an event hub are available at [Collect Logs for the Azure Audit App from Event Hubs](https://help.sumologic.com/docs/integrations/microsoft-azure/audit/#collecting-logs-for-the-azure-audit-app-from-event-hub). | -| ArcSight | No | The ArcSight Azure Event Hubs smart connector is available as part of [the ArcSight smart connector collection](https://community.microfocus.com/cyberres/arcsight/f/arcsight-product-announcements/163662/announcing-general-availability-of-arcsight-smart-connectors-7-10-0-8114-0). | -| Syslog server | No | If you want to stream Azure Monitor data directly to a Syslog server, you can use a [solution based on an Azure function](https://github.com/miguelangelopereira/azuremonitor2syslog/). -| LogRhythm | No| Instructions to set up LogRhythm to collect logs from an event hub are available at [this LogRhythm website](https://logrhythm.com/six-tips-for-securing-your-azure-cloud-environment/). -|Logz.io | Yes | For more information, see [Get started with monitoring and logging by using Logz.io for Java apps running on Azure](/azure/developer/java/fundamentals/java-get-started-with-logzio). --## Next steps -* [Read the overview of the Azure activity log](../essentials/platform-logs-overview.md) -* [Set up an alert based on an activity log event](../alerts/alerts-log-webhook.md) |
| azure-monitor | Tutorial Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/tutorial-metrics.md | - Title: Analyze metrics for an Azure resource -description: Learn how to analyze metrics for an Azure resource by using metrics explorer in Azure Monitor. --- Previously updated : 08/08/2023----# Analyze metrics for an Azure resource -Metrics are numerical values that are automatically collected at regular intervals and describe some aspect of a resource. For example, a metric might tell you the processor utilization of a virtual machine, the free space in a storage account, or the incoming traffic for a virtual network. --Metrics explorer is a feature of Azure Monitor in the Azure portal. You can use it to create charts from metric values, visually correlate trends, and investigate spikes and dips in metric values. Use the metrics explorer to plot charts from metrics created by your Azure resources and investigate their health and utilization. --In this tutorial, you learn how to: --> [!div class="checklist"] -> * Open metrics explorer for an Azure resource. -> * Select a metric to plot on a chart. -> * Perform different aggregations of metric values. -> * Modify the time range and granularity for the chart. --The following video shows a more extensive scenario than the procedure outlined in this tutorial. If you're new to metrics, read this article first and then view the video to see more specifics. --> [!VIDEO https://www.microsoft.com/videoplayer/embed/RE4qO59] --## Prerequisites -To complete the steps in this tutorial, you need an Azure resource to monitor. You can use any resource in your Azure subscription that supports metrics. To determine whether a resource supports metrics, go to its menu in the Azure portal. Then verify that a **Metrics** option is in the **Monitoring** section of the menu. --## Open metrics explorer -1. Select **Metrics** under the **Monitoring** section of your resource's menu. The scope is already populated with your resource. The following example is for a storage account, but other Azure services will look similar. -- :::image type="content" source="media/tutorial-metrics/metrics-menu.png" lightbox="media/tutorial-metrics/metrics-menu.png" alt-text="Screenshot that shows a Metrics menu item."::: --1. Select a **Namespace** if the scope has more than one. The namespace is a way to organize metrics so that you can easily find them. For example, storage accounts have separate namespaces for storing Files, Tables, Blobs, and Queues metrics. Many resource types have only one namespace. --1. Select a metric from a list of available metrics for the selected scope and namespace. -- :::image type="content" source="media/tutorial-metrics/metric-picker.png" lightbox="media/tutorial-metrics/metric-picker.png" alt-text="Screenshot that shows selecting a namespace and metric."::: -- Alternatively, change the metric **Aggregation**. This option defines how the metric values will be aggregated across the time granularity for the graph. For example, if the time granularity is set to **15 minutes** and the aggregation is set to **Sum**, each point in the graph will be the sum of all collected values over each 15-minute segment. -- :::image type="content" source="media/tutorial-metrics/chart.png" lightbox="media/tutorial-metrics/chart.png" alt-text="Screenshot that shows a chart titled Sum Ingress for contosoretailweb."::: --1. Select **Add metric** and repeat these steps if you want to see multiple metrics plotted in the same chart. For multiple charts in one view, select **New chart**. --## Select a time range and granularity --By default, the chart shows the most recent 24 hours of metrics data. --1. Use the time picker to change the **Time range** for the chart or the **Time granularity**, which defines the time range for each data point. The chart uses the specified aggregation to calculate all sampled values over the time granularity specified. -- :::image type="content" source="media/tutorial-metrics/time-picker.png" lightbox="media/tutorial-metrics/time-picker.png" alt-text="Screenshot that shows the Change time range pane."::: --1. Use the **time brush** to investigate an interesting area of the chart, such as a spike or a dip. Put the mouse pointer at the beginning of the area, click and hold the left mouse button, drag to the other side of the area, and release the button. The chart will zoom in on that time range. -- :::image type="content" source="media/tutorial-metrics/time-brush.png" lightbox="media/tutorial-metrics/time-brush.png" alt-text="Screenshot that shows the Time brush."::: --## Apply dimension filters and splitting -See the following references for advanced features you can use to perform more analysis on your metrics and identify potential outliers in your data: --- [Filtering](../essentials/metrics-charts.md#filters) lets you choose which dimension values are included in the chart. For example, you might want to show only successful requests when you chart a *server response time* metric.-- [Splitting](../essentials/metrics-charts.md#apply-splitting) controls whether the chart displays separate lines for each value of a dimension or aggregates the values into a single line. For example, you might want to see one line for an average response time across all server instances. Or you might want separate lines for each server.--See [examples of charts](../essentials/metric-chart-samples.md) that have filtering and splitting applied. --## Advanced chart settings --You can customize the chart style and title and modify advanced chart settings. When you're finished with customization, pin the chart to a dashboard to save your work. You can also configure metrics alerts. To learn about these options and other advanced features of Azure Monitor metrics explorer, see [Advanced features of Azure metrics explorer](../essentials/metrics-charts.md#locking-the-range-of-the-y-axis). --## Next steps -Now that you've learned how to work with metrics in Azure Monitor, learn how to create a metric alert rule to be notified when a metric value indicates a potential problem. --> [!div class="nextstepaction"] -> [Create a metric alert in Azure Monitor](../alerts/tutorial-metric-alert.md) |
| azure-monitor | Tutorial Resource Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/essentials/tutorial-resource-logs.md | - Title: Collect resource logs from an Azure resource -description: Learn how to configure diagnostic settings to send resource logs from an Azure resource to a Log Analytics workspace where they can be analyzed with a log query. --- Previously updated : 08/08/2023----# Collect and analyze resource logs from an Azure resource -Resource logs provide insight into the detailed operation of an Azure resource and are useful for monitoring their health and availability. Azure resources generate resource logs automatically, but you must create a diagnostic setting to collect them. This tutorial takes you through the process of creating a diagnostic setting to send resource logs to a Log Analytics workspace where you can analyze them with log queries. --In this tutorial, you learn how to: --> [!div class="checklist"] -> * Create a Log Analytics workspace in Azure Monitor. -> * Create a diagnostic setting to collect resource logs. -> * Create a simple log query to analyze logs. --## Prerequisites --To complete the steps in this tutorial, you need an Azure resource to monitor. --You can use any resource in your Azure subscription that supports diagnostic settings. To determine whether a resource supports diagnostic settings, go to its menu in the Azure portal and verify that there's a **Diagnostic settings** option in the **Monitoring** section of the menu. --> [!NOTE] -> This procedure doesn't apply to Azure virtual machines. Their **Diagnostic settings** menu is used to configure the diagnostic extension. --## Create a Log Analytics workspace --## Create a diagnostic setting -[Diagnostic settings](../essentials/diagnostic-settings.md) define where to send resource logs for a particular resource. A single diagnostic setting can have multiple [destinations](../essentials/diagnostic-settings.md#destinations), but we only use a Log Analytics workspace in this tutorial. --Under the **Monitoring** section of your resource's menu, select **Diagnostic settings**. Then select **Add diagnostic setting**. --> [!NOTE] -> Some resources might require other selections. For example, a storage account requires you to select a resource before the **Add diagnostic setting** option is displayed. You might also notice a **Preview** label for some resources because their diagnostic settings are currently in preview. ---Each diagnostic setting has three basic parts: -- - **Name**: The name has no significant effect and should be descriptive to you. - - **Categories**: Categories of logs to send to each of the destinations. The set of categories varies for each Azure service. - - **Destinations**: One or more destinations to send the logs. All Azure services share the same set of possible destinations. Each diagnostic setting can define one or more destinations but no more than one destination of a particular type. --Enter a name for the diagnostic setting and select the categories that you want to collect. See the documentation for each service for a definition of its available categories. **AllMetrics** sends the same platform metrics available in Azure Monitor Metrics for the resource to the workspace. As a result, you can analyze this data with log queries along with other monitoring data. Select **Send to Log Analytics workspace** and then select the workspace that you created. ---Select **Save** to save the diagnostic settings. -- ## Use a log query to retrieve logs -Data is retrieved from a Log Analytics workspace by using a log query written in Kusto Query Language (KQL). A set of pre-created queries is available for many Azure services, so you don't require knowledge of KQL to get started. --Select **Logs** from your resource's menu. Log Analytics opens with the **Queries** window that includes prebuilt queries for your resource type. --> [!NOTE] -> If the **Queries** window doesn't open, select **Queries** in the upper-right corner. ---Browse through the available queries. Identify one to run and select **Run**. The query is added to the query window and the results are returned. ---## Next steps -Once you're collecting monitoring data for your Azure resources, see your different options for creating alert rules to be proactively notified when Azure Monitor identifies interesting information. --> [!div class="nextstepaction"] -> [Create alert rules for an Azure resource](../alerts/alert-options.md) |
| azure-monitor | Getting Started | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/getting-started.md | - Title: Getting started with Azure Monitor -description: Guidance and recommendations for deploying Azure Monitor. --- Previously updated : 02/11/2024----# Getting started with Azure Monitor --This article helps guide you through getting started with Azure Monitor. It includes an overview of the basic steps you need for a complete Azure Monitor implementation, and recommendations for preparing your environment and configuring Azure Monitor. --Azure Monitor is immediately available when you create an Azure subscription. Some features start working right away, while others require some configuration. For example, the [activity log](./essentials/platform-logs-overview.md) immediately starts collecting events about activity in the subscription, platform [metrics](essentials/data-platform-metrics.md) are collected for any Azure resources you create, and metrics explorer is available to analyze data right out of the box. --Other features require configuration. For example, you need to create [diagnostic settings](essentials/diagnostic-settings.md) to collect detailed data from your resources, and you need to configure alerts to be notified when something important happens. --## Accessing Azure Monitor --- In the Azure portal, - - Access all Azure Monitor features and data from the **Monitor** menu. - - Use the **Monitoring** section in the menu of various Azure services to access the Azure Monitor tools with data filtered to a particular resource. -- Use the Azure CLI, PowerShell, and the REST API to access Azure Monitor data for various scenarios.--## Getting started workflow -These articles provide detailed information about each of the main steps you'll need to do when getting started with Azure Monitor. --| Article | Description | -|:|:| -| [Plan your implementation](best-practices-plan.md)|Things that you should consider before starting your implementation. Includes design decisions and information about your organization and requirements that you should gather.| -| [Configure data collection](best-practices-data-collection.md)|Tasks required to collect monitoring data from your Azure and hybrid applications and resources. To enable Azure Monitor to monitor all of your Azure resources, you need to:</br> - Configure Azure resources to generate monitoring data for Azure Monitor to collect.</br> - Configure Azure Monitor components | -| [Understand the analysis and visualizations tools](best-practices-analysis.md)|Get to know the standard features and additional visualizations that you can create to analyze collected monitoring data. | -| [Configure alerts and automated responses](./alerts/alerts-plan.md) |Configure notifications and processes that are automatically triggered when an alert is fired. | -| [Optimize costs](best-practices-cost.md) |Some data collection and Azure Monitor features are included out of the box at no cost. Some features have costs based on their particular configuration, the amount of data collected, or the frequency at which they're run. Reduce your cloud monitoring costs by implementing and managing Azure Monitor in the most cost-effective manner. See:</br>- [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/)</br> - [Azure Monitor cost and usage](cost-usage.md)| --## Next steps --- [Planning your monitoring strategy and configuration](best-practices-plan.md).-- Start with the [Monitor Azure resources with Azure Monitor tutorial](essentials/monitor-azure-resource.md). |
| azure-monitor | Code Optimizations Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/insights/code-optimizations-troubleshoot.md | - Title: Troubleshoot Code Optimizations (Preview) -description: Learn how to use Application Insights Code Optimizations on Azure. View a checklist of troubleshooting steps. ----- Previously updated : 06/25/2024----# Troubleshoot Code Optimizations (Preview) --This article provides troubleshooting steps and information to use Application Insights Code Optimizations for Microsoft Azure. --## Troubleshooting checklist --### Step 1: View a video about Code Optimizations setup --View the following demonstration video to learn how to set up Code Optimizations correctly. --> [!VIDEO https://www.youtube-nocookie.com/embed/vbi9YQgIgC8] --### Step 2: Make sure that your app is connected to an Application Insights resource --[Create an Application Insights resource](/azure/azure-monitor/app/create-workspace-resource) and verify that it's connected to the correct app. --### Step 3: Verify that Application Insights Profiler is enabled --[Enable Application Insights Profiler](/azure/azure-monitor/profiler/profiler-overview). --### Step 4: Verify that Application Insights Profiler is collecting profiles --To make sure that profiles are uploaded to your Application Insights resource, follow these steps: --1. In the [Azure portal](https://portal.azure.com), search for and select **Application Insights**. -1. In the list of Application Insights resources, select the name of your resource. -1. In the navigation pane of your Application Insights resource, locate the **Investigate** heading, and then select **Performance**. -1. On the **Performance** page of your Application Insights resource, select **Profiler**: -- :::image type="content" source="./media/code-optimizations-troubleshoot/performance-page.png" alt-text="Azure portal screenshot that shows how to navigate to the Application Insights Profiler."::: --1. On the **Application Insights Profiler** page, view the **Recent profiling sessions** section. -- :::image type="content" source="./media/code-optimizations-troubleshoot/profiling-sessions.png" alt-text="Azure portal screenshot of the Application Insights Profiler page." lightbox="./media/code-optimizations-troubleshoot/profiling-sessions.png"::: -- > [!NOTE] - > If you don't see any profiling sessions, see [Troubleshoot Application Insights Profiler](../profiler/profiler-troubleshooting.md). --### Step 5: Regularly check the Profiler --After you successfully complete the previous steps, keep checking the Profiler for insights. Meanwhile, the service continues to analyze your profiles and provide insights as soon as it detects any issues in your code. After you enable the Application Insights Profiler, several hours might be required for you to generate profiles and for the service to analyze them. If the service detects no issues in your code, a message appears that confirms that no insights were found. --## Contact us for help --If you have questions or need help, [create a support request](https://ms.portal.azure.com/#blade/Microsoft_Azure_Support/HelpAndSupportBlade/overview?DMC=troubleshoot), or ask [Azure community support](https://azure.microsoft.com/support/community). You can also submit product feedback to [Azure feedback community](https://feedback.azure.com/d365community). |
| azure-monitor | Code Optimizations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/insights/code-optimizations.md | - Title: Monitor and analyze runtime behavior with Code Optimizations (Preview) -description: Identify and remove CPU and memory bottlenecks using Azure Monitor's Code Optimizations feature ----- Previously updated : 06/25/2024-----# Monitor and analyze runtime behavior with Code Optimizations (Preview) --Code Optimizations, an AI-based service in Azure Application Insights, works in tandem with the Application Insights Profiler to detect CPU and memory usage performance issues at a code level and provide recommendations on how to fix them. Code Optimizations identifies these CPU and memory bottlenecks by: --- Analyzing the runtime behavior of your application.-- Comparing the behavior to performance engineering best practices.--Make informed decisions and optimize your code using real-time performance data and insights gathered from your production environment. --[You can review your Code Optimizations in the Azure portal.](https://aka.ms/codeoptimizations) --## Demo video --> [!VIDEO https://www.youtube-nocookie.com/embed/eu1P_vLTZO0] --## Requirements for using Code Optimizations --Before you can use Code Optimizations on your application: --- [Enable the Application Insights Profiler](../profiler/profiler-overview.md).-- Verify your application:- - Is .NET. - - Uses [Application Insights](../app/app-insights-overview.md). - - Is collecting profiles. --## Application Insights Profiler vs. Code Optimizations --Application Insights Profiler and Code Optimizations work together to provide a holistic approach to performance issue detection. --### Application Insights Profiler -[The Profiler](../profiler/profiler-overview.md) focuses on tracing specific requests, down to the millisecond. It provides an excellent "big picture" view of issues within your application and general best practices to address them. --### Code Optimizations -[Code Optimizations](https://aka.ms/codeoptimizations) analyzes the profiling data collected by the Application Insights Profiler. As the Profiler uploads data to Application Insights, our machine learning model analyzes some of the data to find where the application's code can be optimized. Code Optimizations: --- Displays aggregated data gathered over time.-- Connects data with the methods and functions in your application code.-- Narrows down the culprit by finding bottlenecks within the code.--## Cost and overhead --Code Optimizations are generated automatically after [Application Insights Profiler is enabled](../profiler/profiler-overview.md#sampling-rate-and-overhead). It incurs no extra cost to you as it analyzes performance issues and generates performance recommendations. Some features (such as code-level fix suggestions) require [Copilot for GitHub](https://docs.github.com/copilot/about-github-copilot/what-is-github-copilot) and/or [Copilot for Azure](../../copilot/overview.md). --## Supported regions --Code Optimizations is available in the same regions as Application Insights. You can check the available regions using the following command: --```sh -az account list-locations -o table -``` --You can set an explicit region using connection strings. [Learn more about connection strings with examples.](../app/sdk-connection-string.md#connection-string-examples) --## Next steps --> [!div class="nextstepaction"] -> [Set up Code Optimizations](set-up-code-optimizations.md) ---## Related links --Get started with Code Optimizations by enabling the following features on your application: -- [Application Insights](../app/create-workspace-resource.md)-- [Application Insights Profiler](../profiler/profiler-overview.md)--Running into issues? Check the [Troubleshooting guide](./code-optimizations-troubleshoot.md) |
| azure-monitor | Insights Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/insights/insights-overview.md | - Title: Azure Monitor Insights Overview -description: Lists available Azure Monitor "Insights" and other Azure product integrations --- Previously updated : 09/06/2024----# Azure Monitor Insights overview --Some services have a curated monitoring experience. That is, Microsoft provides customized functionality meant to act as a starting point for monitoring those services. These experiences are collectively known as *curated visualizations* with the larger more complex of them being called *Insights*. --The experiences collect and analyze a subset of available telemetry for a given service(s). Depending on the service, the experiences might also provide out-of-the-box alerting. They present the telemetry in a visual layout. The visualizations vary in size and scale. --Some visualizations are considered part of Azure Monitor and follow the support and service level agreements for Azure. They're supported in all Azure regions where Azure Monitor is available. Other curated visualizations provide less functionality, might not scale, and might have different agreements. Some might be based solely on Azure Monitor Workbooks, while others might have an extensive custom experience. --## Insights and curated visualizations --The following table lists the available curated visualizations and information about them. **Most** of the list below can be found in the [Insights hub in the Azure portal](https://portal.azure.com/#view/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/~/more). The table uses the same grouping as portal. -->[!NOTE] -> Another type of older visualization called *monitoring solutions* is no longer in active development. The replacement technology is the Azure Monitor Insights, as mentioned here. We suggest you use the Insights and not deploy new instances of solutions. For more information on the solutions, see [Monitoring solutions in Azure Monitor](solutions.md). --|Name with docs link| State | [Azure portal link](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/more)| Description | -|:--|:--|:--|:--| -|**Compute**|||| -|[Azure VM Insights](/azure/azure-monitor/insights/vminsights-overview) |General Availability (GA) | [Yes](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/virtualMachines) |Monitors your Azure VMs and Virtual Machine Scale Sets at scale. It analyzes the performance and health of your Windows and Linux VMs and monitors their processes and dependencies on other resources and external processes. | -|[Azure Container Insights](/azure/azure-monitor/insights/container-insights-overview) |GA | [Yes](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/containerInsights) |Monitors the performance of container workloads that are deployed to managed Kubernetes clusters hosted on Azure Kubernetes Service. It gives you performance visibility by collecting metrics from controllers, nodes, and containers that are available in Kubernetes through the Metrics API. Container logs are also collected. After you enable monitoring from Kubernetes clusters, these metrics and logs are automatically collected for you through a containerized version of the Log Analytics agent for Linux. | -|**Networking**|||| -|[Azure Network Insights](../../network-watcher/network-insights-overview.md) | GA | [Yes](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/networkInsights) | Provides a comprehensive view of health and metrics for all your network resources. The advanced search capability helps you identify resource dependencies, enabling scenarios like identifying resources that are hosting your website, by searching for your website name. | -|**Storage**|||| -| [Azure Storage Insights](/azure/azure-monitor/insights/storage-insights-overview) | GA | [Yes](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/storageInsights) | Provides comprehensive monitoring of your Azure Storage accounts by delivering a unified view of your Azure Storage services performance, capacity, and availability. | -| [Azure Backup](../../backup/backup-azure-monitoring-use-azuremonitor.md) | GA | [Yes](https://portal.azure.com/#blade/Microsoft_Azure_DataProtection/BackupCenterMenuBlade/backupReportsConfigure/menuId/backupReportsConfigure) | Provides built-in monitoring and alerting capabilities in a Recovery Services vault. | -|**Databases**|||| -| [Azure Cosmos DB Insights](/azure/cosmos-db/cosmosdb-insights-overview) | GA | [Yes](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/cosmosDBInsights) | Provides a view of the overall performance, failures, capacity, and operational health of all your Azure Cosmos DB resources in a unified interactive experience. | -| [Azure Monitor for Azure Cache for Redis](../../azure-cache-for-redis/redis-cache-insights-overview.md) | GA | [Yes](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/redisCacheInsights) | Provides a unified, interactive view of overall performance, failures, capacity, and operational health. | -|**Analytics**|||| -| [Azure Data Explorer Insights](/azure/data-explorer/data-explorer-insights) | GA | [Yes](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/adxClusterInsights) | Azure Data Explorer Insights provides comprehensive monitoring of your clusters by delivering a unified view of your cluster performance, operations, usage, and failures. | -| [Azure Monitor Log Analytics Workspace](../logs/log-analytics-workspace-insights-overview.md) | GA | [Yes](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/lawsInsights) | Log Analytics Workspace Insights provides comprehensive monitoring of your workspaces through a unified view of your workspace usage, performance, health, agent, queries, and change log. This article will help you understand how to onboard and use Log Analytics Workspace Insights. | -|**Security**|||| -| [Azure Key Vault Insights](/azure/key-vault/key-vault-insights-overview) | GA | [Yes](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/keyvaultsInsights) | Provides comprehensive monitoring of your key vaults by delivering a unified view of your Key Vault requests, performance, failures, and latency. | -|**Monitor**|||| -| [Azure Monitor Application Insights](../app/app-insights-overview.md) | GA | [Yes](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/applicationsInsights) | Extensible application performance management service that monitors the availability, performance, and usage of your web applications whether they're hosted in the cloud or on-premises. It uses the powerful data analysis platform in Azure Monitor to provide you with deep insights into your application's operations. It enables you to diagnose errors without waiting for a user to report them. Application Insights includes connection points to various development tools and integrates with Visual Studio to support your DevOps processes. | -| [Azure Activity Log Insights](../essentials/activity-log-insights.md) | Preview | [Yes](https://portal.azure.com/#blade/Microsoft_Azure_DataProtection/BackupCenterMenuBlade/backupReportsConfigure/menuId/backupReportsConfigure) | Provides built-in monitoring and alerting capabilities in a Recovery Services vault. | -| [Azure Monitor for Resource Groups](../../azure-resource-manager/management/resource-group-insights.md) | GA | No | Triage and diagnose any problems your individual resources encounter, while offering context for the health and performance of the resource group as a whole. | -|**Integration**|||| -| [Azure Service Bus Insights](../../service-bus-messaging/service-bus-insights.md) | Preview | [Yes](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/serviceBusInsights) | Azure Service Bus Insights provide a view of the overall performance, failures, capacity, and operational health of all your Service Bus resources in a unified interactive experience. | -|[Azure IoT Edge](../../iot-edge/how-to-explore-curated-visualizations.md) | GA | No | Visualize and explore metrics collected from the IoT Edge device right in the Azure portal by using Azure Monitor Workbooks-based public templates. The curated workbooks use built-in metrics from the IoT Edge runtime. These views don't need any metrics instrumentation from the workload modules. | -|**Workloads**|||| -| [Azure SQL Insights (preview)](/azure/azure-sql/database/sql-insights-overview) | Preview | [Yes](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/sqlWorkloadInsights) | A comprehensive interface for monitoring any product in the Azure SQL family. SQL Insights uses dynamic management views to expose the data you need to monitor health, diagnose problems, and tune performance. Note: If you're just setting up SQL monitoring, use SQL Insights instead of the SQL Analytics solution. | -| [Azure Monitor for SAP solutions](/azure/virtual-machines/workloads/sap/monitor-sap-on-azure) | GA | No | An Azure-native monitoring product for anyone running their SAP landscapes on Azure. It works with both SAP on Azure Virtual Machines and SAP on Azure Large Instances. Collects telemetry data from Azure infrastructure and databases in one central location and visually correlates the data for faster troubleshooting. You can monitor different components of an SAP landscape, such as Azure virtual machines (VMs), high-availability clusters, SAP HANA database, and SAP NetWeaver, by adding the corresponding provider for that component. | -|**Other**|||| -| [Azure Virtual Desktop Insights](../../virtual-desktop/azure-monitor.md) | GA | [Yes](https://portal.azure.com/#blade/Microsoft_Azure_WVD/WvdManagerMenuBlade/insights/menuId/insights) | Azure Virtual Desktop Insights is a dashboard built on Azure Monitor Workbooks that helps IT professionals understand their Azure Virtual Desktop environments. | -| [Azure Stack HCI Insights](/azure-stack/hci/manage/azure-stack-hci-insights) | GA| [Yes](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/azureStackHCIInsights) | Based on Azure Monitor Workbooks. Provides health, performance, and usage insights about registered Azure Stack HCI version 21H2 clusters that are connected to Azure and enrolled in monitoring. It stores its data in a Log Analytics workspace, which allows it to deliver powerful aggregation and filtering and analyze data trends over time. | -| [Windows Update for Business](/windows/deployment/update/wufb-reports-overview) | GA | [Yes](https://ms.portal.azure.com/#view/AppInsightsExtension/WorkbookViewerBlade/Type/updatecompliance-insights/ComponentId/Azure%20Monitor/GalleryResourceType/Azure%20Monitor/ConfigurationId/community-Workbooks%2FUpdateCompliance%2FUpdateComplianceHub) | Detailed deployment monitoring, compliance assessment and failure troubleshooting for all Windows 10/11 devices.| -|**Not in Azure portal Insight hub**|||| -| [Azure Monitor Workbooks for Microsoft Entra ID](../../active-directory/reports-monitoring/howto-use-azure-monitor-workbooks.md) |GA| [Yes](https://portal.azure.com/#blade/Microsoft_AAD_IAM/ActiveDirectoryMenuBlade/Workbooks) | Microsoft Entra ID provides workbooks to understand the effect of your Conditional Access policies, troubleshoot sign-in failures, and identify legacy authentications. | -| [Azure HDInsight](../../hdinsight/log-analytics-migration.md#insights) | Preview | No | An Azure Monitor workbook that collects important performance metrics from your HDInsight cluster and provides the visualizations and dashboards for most common scenarios. Gives a complete view of a single HDInsight cluster including resource utilization and application status.| --## Next steps --- Reference some of the insights listed above to review their functionality |
| azure-monitor | Resource Manager Sql Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/insights/resource-manager-sql-insights.md | - Title: Resource Manager template samples for SQL Insights (preview) -description: Sample Azure Resource Manager templates to deploy and configure SQL Insights (preview). ---- Previously updated : 08/09/2023---# Resource Manager template samples for SQL Insights (preview) -This article includes sample [Azure Resource Manager templates](../../azure-resource-manager/templates/syntax.md) to enable SQL Insights (preview) for monitoring SQL running in Azure. See the [SQL Insights (preview) documentation](/azure/azure-sql/database/sql-insights-overview) for details on the offering and versions of SQL we support. Each sample includes a template file and a parameters file with sample values to provide to the template. ----## Create a SQL Insights (preview) monitoring profile -The following sample creates a SQL Insights monitoring profile, which includes the SQL monitoring data to collect, frequency of data collection, and specifies the workspace the data will be sent to. ---### Template file --View the [template file on git hub](https://github.com/microsoft/Application-Insights-Workbooks/blob/master/Workbooks/Workloads/SQL/Create%20new%20profile/CreateNewProfile.armtemplate). --### Parameter file --View the [parameter file on git hub](https://github.com/microsoft/Application-Insights-Workbooks/blob/master/Workbooks/Workloads/SQL/Create%20new%20profile/CreateNewProfile.parameters.json). ---## Add a monitoring VM to a SQL Insights monitoring profile -Once you have created a monitoring profile, you need to allocate Azure virtual machines that will be configured to remotely collect data from the SQL resources you specify in the configuration for that VM. Refer to the SQL Insights enable documentation for more details. --The following sample configures a monitoring VM to collect the data from the specified SQL resources. ---### Template file --View the [template file on git hub](https://github.com/microsoft/Application-Insights-Workbooks/blob/master/Workbooks/Workloads/SQL/Add%20monitoring%20virtual%20machine/AddMonitoringVirtualMachine.armtemplate). --### Parameter file --View the [parameter file on git hub](https://github.com/microsoft/Application-Insights-Workbooks/blob/master/Workbooks/Workloads/SQL/Add%20monitoring%20virtual%20machine/AddMonitoringVirtualMachine.parameters.json). ---## Create an alert rule for SQL Insights -The following sample creates an alert rule that will cover the SQL resources within the scope of the specified monitoring profile. This alert rule will appear in the SQL Insights UI in the alerts UI context panel. --The parameter file has values from one of the alert templates we provide in SQL Insights, you can modify it to alert on other data we collect for SQL. The template does not specify an action group for the alert rule. ---### Template file --View the [template file on git hub](https://github.com/microsoft/Application-Insights-Workbooks/blob/master/Workbooks/Workloads/Alerts/log-metric-noag.armtemplate). --### Parameter file --View the [parameter file on git hub](https://github.com/microsoft/Application-Insights-Workbooks/blob/master/Workbooks/Workloads/Alerts/sql-cpu-utilization-percent.parameters.json). ------## Next steps --* [Get other sample templates for Azure Monitor](../resource-manager-samples.md). -* [Learn more about SQL Insights (preview)](/azure/azure-sql/database/sql-insights-overview). |
| azure-monitor | Scom Assessment | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/insights/scom-assessment.md | - Title: Assess System Center Operations Manager with Azure Monitor -description: You can use the System Center Operations Manager Health Check solution to assess the risk and health of your environments on a regular interval. --- Previously updated : 07/26/2024-----# Optimize your environment with the System Center Operations Manager Health Check (Preview) solution ---You can use the System Center Operations Manager Health Check solution to assess the risk and health of your System Center Operations Manager management group on a regular interval. This article helps you install, configure, and use the solution so that you can take corrective actions for potential problems. --This solution provides a prioritized list of recommendations specific to your deployed server infrastructure. The recommendations are categorized across four focus areas, which help you quickly understand the risk and take corrective action. --The recommendations made are based on the knowledge and experience gained by Microsoft engineers from thousands of customer visits. Each recommendation provides guidance about why an issue might matter to you and how to implement the suggested changes. --You can choose focus areas that are most important to your organization and track your progress toward running a risk free and healthy environment. --After you've added the solution and an assessment is performed, summary information for focus areas is shown on the **System Center Operations Manager Health Check** dashboard for your infrastructure. The following sections describe how to use the information on the **System Center Operations Manager Health Check** dashboard, where you can view and then take recommended actions for your Operations Manager environment. -<!-- convertborder later --> -<!-- convertborder later --> --## Installing and configuring the solution --The solution works with Microsoft System Center 2012 Operations Manager Service Pack 1, Microsoft System Center 2012 R2 Operations Manager, Microsoft System Center 2016 Operations Manager, Microsoft System Center 2016 Operations Manager and Microsoft System Center Operations Manager 1807. A supported version of .NET Framework 4.6.2 must be installed on each management server. --Use the following information to install and configure the solution. --- Before you can use the Health Check solution in Log Analytics, you must have the solution installed. Install the solution from [Azure marketplace](https://azuremarketplace.microsoft.com/marketplace/apps/Microsoft.SCOMAssessmentOMS?tab=Overview).--- After adding the solution to the workspace, the **System Center Operations Manager Health Check** tile on the dashboard displays an additional configuration required message. Click on the tile and follow the configuration steps mentioned in the page- <!-- convertborder later --> - :::image type="content" source="./media/scom-assessment/scom-configrequired-tile.png" lightbox="./media/scom-assessment/scom-configrequired-tile.png" alt-text="System Center Operations Manager dashboard tile." border="false"::: --> [!NOTE] -> Configuration of System Center Operations Manager can be done using a script by following the steps mentioned in the configuration page of the solution in Log Analytics. -- To configure the assessment through Operations Manager Operations console, perform the steps below in the following order: -1. [Set the Run As account for System Center Operations Manager Health Check](#operations-manager-run-as-accounts-for-log-analytics) -2. Configure the System Center Operations Manager Health Check rule --## System Center Operations Manager Health Check data collection details --The System Center Operations Manager Health Check solution collects data from the following sources: --* Registry -* Windows Management Instrumentation (WMI) -* Event log -* File data -* Directly from Operations Manager using PowerShell and SQL queries, from a management server that you have specified. --Data is collected on the management server and forwarded to Log Analytics every seven days. --## Operations Manager run-as accounts for Log Analytics --Log Analytics builds on management packs for workloads to provide value-add services. Each workload requires workload-specific privileges to run management packs in a different security context, such as a domain user account. Configure an Operations Manager Run As account with privileged credentials. For additional information, see [How to create a Run As account](/previous-versions/system-center/system-center-2012-R2/hh321655(v=sc.12)) in the Operations Manager documentation. --Use the following information to set the Operations Manager Run As account for System Center Operations Manager Health Check. --### Set the Run As account --The Run As account must meet following requirements before proceeding: --* A domain user account that is a member of the local Administrators group on all servers supporting any Operations Manager role - Management server, SQL Server hosting the operational, data warehouse and ACS database, Reporting, Web console, and Gateway server. -* Operation Manager Administrator Role for the management group being assessed -* If the account does not have SQL sysadmin rights, then execute the [script](#sql-script-to-grant-granular-permissions-to-the-run-as-account) to grant granular permissions to the account on each SQL Server instance hosting one or all of the Operations Manager databases. --1. In the Operations Manager Console, select the **Administration** navigation button. -2. Under **Run As Configuration**, click **Accounts**. -3. In the **Create Run As Account** Wizard, on the **Introduction** page click **Next**. -4. On the **General Properties** page, select **Windows** in the **Run As Account type:** list. -5. Type a display name in the **Display Name** text box and optionally type a description in the **Description** box, and then click **Next**. -6. On the **Distribution Security** page, select **More secure**. -7. Click **Create**. --Now that the Run As account is created, it needs to target management servers in the management group and associated with a pre-defined Run As profile so workflows will run using the credentials. --1. Under **Run As Configuration**, **Accounts**, in the results pane, double-click the account you created earlier. -2. On the **Distribution** tab, click **Add** for the **Selected computers** box and add the management server to distribute the account to. Click **OK** twice to save your changes. -3. Under **Run As Configuration**, click **Profiles**. -4. Search for the *SCOM Assessment Profile*. -5. The profile name should be: *Microsoft System Center Operations Manager Health Check Run As Profile*. -6. Right-click and update its properties and add the recently created Run As Account you created earlier. --### SQL script to grant granular permissions to the Run As account --Execute the following SQL script to grant required permissions to the Run As account on the SQL Server instance used by Operations Manager hosting the operational, data warehouse, and ACS database. --``` Replace <UserName> with the actual user name being used as Run As Account.-USE master - Create login for the user, comment this line if login is already created.-CREATE LOGIN [UserName] FROM WINDOWS --GRANT permissions to user.-GRANT VIEW SERVER STATE TO [UserName] -GRANT VIEW ANY DEFINITION TO [UserName] -GRANT VIEW ANY DATABASE TO [UserName] - Add database user for all the databases on SQL Server Instance, this is required for connecting to individual databases. NOTE: This command must be run anytime new databases are added to SQL Server instances.-EXEC sp_msforeachdb N'USE [?]; CREATE USER [UserName] FOR LOGIN [UserName];' --Use msdb -GRANT SELECT To [UserName] -Go -Give SELECT permission on all Operations Manager related Databases-Replace the Operations Manager database name with the one in your environment-Use [OperationsManager]; -GRANT SELECT To [UserName] -GO -Replace the Operations Manager DatawareHouse database name with the one in your environment-Use [OperationsManagerDW]; -GRANT SELECT To [UserName] -GO -Replace the Operations Manager Audit Collection database name with the one in your environment-Use [OperationsManagerAC]; -GRANT SELECT To [UserName] -GO -Give db_owner on [OperationsManager] DBReplace the Operations Manager database name with the one in your environment-USE [OperationsManager] -GO -ALTER ROLE [db_owner] ADD MEMBER [UserName] --``` --### Configure the health check rule --The System Center Operations Manager Health Check solution’s management pack includes a rule named *Microsoft System Center Operations Manager Run Health Check Rule*. This rule is responsible for running the health check. To enable the rule and configure the frequency, use the procedures below. --By default, the Microsoft System Center Operations Manager Run Health Check Rule is disabled. To run the health check, you must enable the rule on a management server. Use the following steps. --#### Enable the rule for a specific management server --1. In the **Authoring** workspace of the Operations Manager Operations console, search for the rule *Microsoft System Center Operations Manager Run Health Check Rule* in the **Rules** pane. -2. In the search results, select the one that includes the text *Type: Management Server*. -3. Right-click the rule and then click **Overrides** > **For a specific object of class: Management Server**. -4. In the available management servers list, select the management server where the rule should run. This should be the same management server you configured earlier to associate the Run As account with. -5. Ensure that you change override value to **True** for the **Enabled** parameter value. - <!-- convertborder later --> - :::image type="content" source="./media/scom-assessment/rule.png" lightbox="./media/scom-assessment/rule.png" alt-text="override parameter" border="false"::: -- While still in this window, configure the run frequency using the next procedure. --#### Configure the run frequency --The assessment is configured to run every 10,080 minutes (or seven days) by default. You can override the value to a minimum value of 1440 minutes (or one day). The value represents the minimum time gap required between successive assessment runs. To override the interval, use the steps below. --1. In the **Authoring** workspace of the Operations Manager console, search for the rule *Microsoft System Center Operations Manager Run Health Check Rule* in the **Rules** section. -2. In the search results, select the one that includes the text *Type: Management Server*. -3. Right-click the rule and then click **Override the Rule** > **For all objects of class: Management Server**. -4. Change the **Interval** parameter value to your desired interval value. In the example below, the value is set to 1440 minutes (one day). - <!-- convertborder later --> - :::image type="content" source="./media/scom-assessment/interval.png" lightbox="./media/scom-assessment/interval.png" alt-text="interval parameter" border="false"::: -- If the value is set to less than 1440 minutes, then the rule runs on a one day interval. In this example, the rule ignores the interval value and runs at a frequency of one day. ---## Understanding how recommendations are prioritized --Every recommendation made is given a weighting value that identifies the relative importance of the recommendation. Only the 10 most important recommendations are shown. --### How weights are calculated --Weightings are aggregate values based on three key factors: --- The *probability* that an issue identified will cause problems. A higher probability equates to a larger overall score for the recommendation.-- The *impact* of the issue on your organization if it does cause a problem. A higher impact equates to a larger overall score for the recommendation.-- The *effort* required to implement the recommendation. A higher effort equates to a smaller overall score for the recommendation.--The weighting for each recommendation is expressed as a percentage of the total score available for each focus area. For example, if a recommendation in the Availability and Business Continuity focus area has a score of 5%, implementing that recommendation increases your overall Availability and Business Continuity score by 5%. --### Focus areas --**Availability and Business Continuity** - This focus area shows recommendations for service availability, resiliency of your infrastructure, and business protection. --**Performance and Scalability** - This focus area shows recommendations to help your organization's IT infrastructure grow, ensure that your IT environment meets current performance requirements, and is able to respond to changing infrastructure needs. --**Upgrade, Migration, and Deployment** - This focus area shows recommendations to help you upgrade, migrate, and deploy SQL Server to your existing infrastructure. --**Operations and Monitoring** - This focus area shows recommendations to help streamline your IT operations, implement preventative maintenance, and maximize performance. --### Should you aim to score 100% in every focus area? --Not necessarily. The recommendations are based on the knowledge and experiences gained by Microsoft engineers across thousands of customer visits. However, no two server infrastructures are the same, and specific recommendations may be more or less relevant to you. For example, some security recommendations might be less relevant if your virtual machines are not exposed to the Internet. Some availability recommendations may be less relevant for services that provide low priority ad hoc data collection and reporting. Issues that are important to a mature business may be less important to a start-up. You may want to identify which focus areas are your priorities and then look at how your scores change over time. --Every recommendation includes guidance about why it is important. Use this guidance to evaluate whether implementing the recommendation is appropriate for you, given the nature of your IT services and the business needs of your organization. --## Use health check focus area recommendations --Before you can use a health check solution in Log Analytics, you must have the solution installed. To read more about installing solutions, see [Install a management solution](./solutions.md). After it is installed, you can view the summary of recommendations by using the System Center Operations Manager Health Check tile on the **Overview** page for your workspace in the Azure portal. --View the summarized compliance assessments for your infrastructure and then drill-into recommendations. --### To view recommendations for a focus area and take corrective action -1. Log in to the Azure portal at [https://portal.azure.com](https://portal.azure.com). -2. In the Azure portal, click **More services** found on the lower left-hand corner. In the list of resources, type **Log Analytics**. As you begin typing, the list filters based on your input. Select **Log Analytics**. -3. In the Log Analytics subscriptions pane, select a workspace and then click the **Workspace summary (deprecated)** menu item. -4. On the **Overview** page, click the **System Center Operations Manager Health Check** tile. -5. On the **System Center Operations Manager Health Check** page, review the summary information in one of the focus area sections and then click one to view recommendations for that focus area. -6. On any of the focus area pages, you can view the prioritized recommendations made for your environment. Click a recommendation under **Affected Objects** to view details about why the recommendation is made. - <!-- convertborder later --> - :::image type="content" source="./media/scom-assessment/log-analytics-scom-healthcheck-dashboard-02.png" lightbox="./media/scom-assessment/log-analytics-scom-healthcheck-dashboard-02.png" alt-text="focus area" border="false":::<br> -7. You can take corrective actions suggested in **Suggested Actions**. When the item has been addressed, later assessments will record that recommended actions were taken and your compliance score will increase. Corrected items appear as **Passed Objects**. --## Ignore recommendations --If you have recommendations that you want to ignore, you can create a text file that Log Analytics uses to prevent recommendations from appearing in your assessment results. --### To identify recommendations that you want to ignore -1. In the Azure portal on the Log Analytics workspace page for your selected workspace, click the **Log Search** menu item. -2. Use the following query to list recommendations that have failed for computers in your environment. -- ``` - Type=SCOMAssessmentRecommendationRecommendationResult=Failed | select Computer, RecommendationId, Recommendation | sort Computer - ``` -- >[!NOTE] - > If your workspace has been upgraded to the [new Log Analytics query language](../logs/log-query-overview.md), then the above query would change to the following. - > - > `SCOMAssessmentRecommendationRecommendation | where RecommendationResult == "Failed" | sort by Computer asc | project Computer, RecommendationId, Recommendation` -- Here's a screenshot showing the Log Search query: - <!-- convertborder later --> - :::image type="content" source="./media/scom-assessment/scom-log-search.png" lightbox="./media/scom-assessment/scom-log-search.png" alt-text="log search" border="false":::<br> --3. Choose recommendations that you want to ignore. You'll use the values for RecommendationId in the next procedure. --### To create and use an IgnoreRecommendations.txt text file --1. Create a file named IgnoreRecommendations.txt. -2. Paste or type each RecommendationId for each recommendation that you want Log Analytics to ignore on a separate line and then save and close the file. -3. Put the file in the following folder on each computer where you want Log Analytics to ignore recommendations. -4. On the Operations Manager management server - *SystemDrive*:\Program Files\Microsoft System Center 2012 R2\Operations Manager\Server. --### To verify that recommendations are ignored --1. After the next scheduled assessment runs, by default every seven days, the specified recommendations are marked Ignored and will not appear on the health check dashboard. -2. You can use the following Log Search queries to list all the ignored recommendations. -- ``` - Type=SCOMAssessmentRecommendationRecommendationResult=Ignored | select Computer, RecommendationId, Recommendation | sort Computer - ``` -- >[!NOTE] - > If your workspace has been upgraded to the [new Log Analytics query language](../logs/log-query-overview.md), then the above query would change to the following. - > - > `SCOMAssessmentRecommendationRecommendation | where RecommendationResult == "Ignore" | sort by Computer asc | project Computer, RecommendationId, Recommendation` --3. If you decide later that you want to see ignored recommendations, remove any IgnoreRecommendations.txt files, or you can remove RecommendationIDs from them. --## Frequently asked questions --*I added the Health Check solution to my Log Analytics workspace. But I don’t see the recommendations. Why not?* After adding the solution, use the following steps view the recommendations on the Log Analytics dashboard. --- [Set the Run As account for System Center Operations Manager Health Check](#operations-manager-run-as-accounts-for-log-analytics) -- [Configure the System Center Operations Manager Health Check rule](#configure-the-health-check-rule)---*Is there a way to configure how often the check runs?* Yes. See [Configure the run frequency](#configure-the-run-frequency). --*If another server is discovered after I’ve added the System Center Operations Manager Health Check solution, will it be checked?* Yes, after discovery it is checked from then on, by default every seven days. --*What is the name of the process that does the data collection?* AdvisorAssessment.exe --*Where does the AdvisorAssessment.exe process run?* AdvisorAssessment.exe runs under the HealthService process of the management server where the health check rule is enabled. Using that process, discovery of your entire environment is achieved through remote data collection. --*How long does it take for data collection?* Data collection on the server takes about one hour. It may take longer in environments that have many Operations Manager instances or databases. --*What if I set the interval of the assessment to less than 1440 minutes?* The assessment is pre-configured to run at a maximum of once per day. If you override the interval value to a value less than 1440 minutes, then the assessment uses 1440 minutes as the interval value. --*How to know if there are prerequisite failures?* If the health check ran and you don't see results, then it is likely that some of the prerequisites for the check failed. You can execute queries: `Operation Solution=SCOMAssessment` and `SCOMAssessmentRecommendation FocusArea=Prerequisites` in Log Search to see the failed prerequisites. --*There is a `Failed to connect to the SQL Instance (….).` message in prerequisite failures. What is the issue?* AdvisorAssessment.exe, the process that collects data, runs under the HealthService process on the management server. As part of the health check, the process attempts to connect to the SQL Server where the Operations Manager database is present. This error can occur when firewall rules block the connection to the SQL Server instance. --*What type of data is collected?* The following types of data are collected: - WMI data - Registry data - EventLog data - Operations Manager data through Windows PowerShell, SQL Queries and File information collector. --*Why do I have to configure a Run As Account?* With Operations Manager, various SQL queries are run. In order for them to run, you must use a Run As Account with necessary permissions. In addition, local administrator credentials are required to query WMI. --*Why display only the top 10 recommendations?* Instead of giving you an exhaustive, overwhelming list of tasks, we recommend that you focus on addressing the prioritized recommendations first. After you address them, additional recommendations will become available. If you prefer to see the detailed list, you can view all recommendations using Log Search. --*Is there a way to ignore a recommendation?* Yes, see the [Ignore recommendations](#ignore-recommendations). ---## Next steps --- [Search logs](../logs/log-query-overview.md) to learn how to analyze detailed System Center Operations Manager Health Check data and recommendations.- |
| azure-monitor | Set Up Code Optimizations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/insights/set-up-code-optimizations.md | - Title: Set up Code Optimizations (Preview) -description: Learn how to enable and set up Azure Monitor's Code Optimizations feature. ----- Previously updated : 03/08/2024----# Set up Code Optimizations (Preview) --Setting up Code Optimizations to identify and analyze CPU and memory bottlenecks in your web applications is a simple process in the Azure portal. In this guide, you learn how to: --- Connect your web app to Application Insights.-- Enable the Profiler on your web app.--[You can review your Code Optimizations in the Azure portal.](https://aka.ms/codeoptimizations) --## Demo video --> [!VIDEO https://www.youtube-nocookie.com/embed/vbi9YQgIgC8] --## Connect your web app to Application Insights --Before setting up Code Optimizations for your web app, ensure that your app is connected to an Application Insights resource. --1. In the Azure portal, navigate to your web application. -1. From the left menu, select **Settings** > **Application Insights**. -1. In the Application Insights blade for your web application, determine the following options: -- - **If your web app is already connected to an Application Insights resource:** - - A banner at the top of the blade reads: **Your app is connected to Application Insights resource: {NAME-OF-RESOURCE}**. - - :::image type="content" source="media/set-up-code-optimizations/already-enabled-app-insights.png" alt-text="Screenshot of the banner explaining that your app is already connected to App Insights."::: -- - **If your web app still needs to be connected to an Application Insights resource:** - - A banner at the top of the blade reads: **Your app will be connected to an auto-created Application Insights resource: {NAME-OF-RESOURCE}**. -- :::image type="content" source="media/set-up-code-optimizations/need-to-enable-app-insights.png" alt-text="Screenshot of the banner telling you to enable App Insights and the name of the App Insights resource."::: --1. Click **Apply** at the bottom of the Application Insights pane. --## Enable Profiler on your web app --Profiler collects traces on your web app for Code Optimizations to analyze. In a few hours, if Code Optimization notices any performance bottlenecks in your application, you can see and review Code Optimizations insights. --1. Still in the Application Insights blade, under **Instrument your application**, select the **.NET** tab. -1. Under **Profiler**, select the toggle to turn on Profiler for your web app. -- :::image type="content" source="media/set-up-code-optimizations/enable-profiler.png" alt-text="Screenshot of how to enable Profiler for your web app."::: --1. Verify the Profiler is collecting traces. - 1. Navigate to your Application Insights resource. - 1. From the left menu, select **Investigate** > **Performance**. - 1. In the Performance blade, select **Profiler** from the top menu. - 1. Review the profiler traces collected from your web app. [If you don't see any traces, see the troubleshooting guide](../profiler/profiler-troubleshooting.md). --## Next steps --> [!div class="nextstepaction"] -> [View Code Optimizations results](view-code-optimizations.md) |
| azure-monitor | Troubleshoot Workbooks | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/insights/troubleshoot-workbooks.md | - Title: Troubleshooting Azure Monitor workbook-based insights -description: Provides troubleshooting guidance for Azure Monitor workbook-based insights for services like Azure Key Vault, Azure Cosmos DB, Azure Storage, and Azure Cache for Redis. ---- Previously updated : 06/17/2020---# Troubleshooting workbook-based insights --This article will help you with the diagnosis and troubleshooting of some of the common issues you may encounter when using Azure Monitor workbook-based insights. ---## Why can I only see 200 resources --The number of selected resources has a limit of 200, regardless of the number of subscriptions that are selected. --## What happens when I select a recently pinned tile in the dashboard --* If you select anywhere on the tile, it will take you to the tab where the tile was pinned from. For example, if you pin a graph in the "Overview" tab then when you select that tile in the dashboard it will open up that default view, however if you pin a graph from your own saved copy then it will open up your saved copy's view. -* The filter icon in the top left of the title opens the "Configure tile settings" tab. -* The ellipse icon in the top right will give you the options to "Customize title data", "customize", "refresh" and "remove from dashboard". --## What happens when I save a workbook --* When you save a workbook, it lets you create a new copy of the workbook with your edits and changes the title. Saving doesn't overwrite the workbook, the current workbook will always be the default view. -* An **unsaved** workbook is just the default view. --## Why donΓÇÖt I see all my subscriptions in the portal --The portal will show data only for selected subscriptions on portal launch. To change what subscriptions are selected, go to the top right and select the notebook with a filter icon. This option will show the **Directory + subscriptions** tab. -<!-- convertborder later --> --## What is time range --Time range shows you data from a certain time frame. For example, if the time range is 24 hours, then it's showing data from the past 24 hours. --## What is time granularity (time grain) --Time granularity is the time difference between two data points. For example, if the time grain is set to 1 second that means metrics are collected each second. --## What is the time granularity once we pin any part of the workbooks to a dashboard --The default time granularity is set to automatic, it currently can't be changed at this time. --## How do I change the timespan/ time range of the workbook step on my dashboard --By default the timespan/time range on your dashboard tile is set to 24 hours, to change this select the ellipses in the top right, select **Customize tile data**, check "override the dashboard time settings at the title level" box and then pick a timespan using the dropdown menu. -<!-- convertborder later --> -<!-- convertborder later --> --## How do I change the title of the workbook or a workbook step I pinned to a dashboard --The title of the workbook or workbook step that is pinned to a dashboard retains the same name it had in the workbook. To change the title, you must save your own copy of the workbook. Then you'll be able to name the workbook before you press save. -<!-- convertborder later --> --To change the name of a step in your saved workbook, select edit under the step and then select the gear at the bottom of settings. -<!-- convertborder later --> -<!-- convertborder later --> --## Next steps --Learn more about the scenarios workbooks are designed to support, how to author new and customize existing reports, and more by reviewing [Create interactive reports with Azure Monitor workbooks](../visualize/workbooks-overview.md). |
| azure-monitor | View Code Optimizations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/insights/view-code-optimizations.md | - Title: View Code Optimizations results (Preview) -description: Learn how to access the results provided by Azure Monitor's Code Optimizations feature. ----- Previously updated : 06/25/2024----# View Code Optimizations results (Preview) --Now that you set up and configured Code Optimizations on your app, [access and view any insights you received directly via the Azure portal.](https://aka.ms/codeoptimizations) --You can also access Code Optimizations through any of your Application Insights resources from **Performance** pane and select **Code Optimizations (preview)** button from the top menu. ---## Interpret estimated Memory and CPU percentages --The estimated CPU and Memory are determined based on the amount of activity in your application. In addition to the Memory and CPU percentages, Code Optimizations also includes: --- The actual allocation sizes (in bytes)-- A breakdown of the allocated types made within the call--### Memory -For Memory, the number is just a percentage of all allocations made within the trace. For example, if an issue takes 24% memory, you spent 24% of all your allocations within that call. --### CPU -For CPU, the percentage is based on the number of CPUs in your machine (four core, eight core, etc.) and the trace time. For example, let's say your trace is 10 seconds long and you have 4 CPUs: you have a total of 40 seconds of CPU time. If the insight says the line of code is using 5% of the CPU, itΓÇÖs using 5% of 40 seconds, or 2 seconds. --## Filter and sort results --On the Code Optimizations page, you can filter the results by: --- Using the search bar to filter by field.-- Setting the time range via the **Time Range** drop-down menu.-- Selecting the corresponding role from the **Role** drop-down menu.--You can also sort columns in the insights results based on: --- Type (memory or CPU).-- Issue frequency within a specific time period (count).-- Corresponding role, if your service has multiple roles (role).---## View insights --After sorting and filtering the Code Optimizations results, you can then select each insight to view the following details in a pane: --- Detailed description of the performance bug insight.-- The full call stack.-- Recommendations on how to fix the performance issue.---> [!NOTE] -> If you don't see any insights, it's likely that the Code Optimizations service hasn't noticed any performance bottlenecks in your code. Continue to check back to see if any insights pop up. --### Call stack --In the insights details pane, under the **Call Stack** heading, you can: --- Select **Expand** to view the full call stack surrounding the performance issue-- Select **Copy** to copy the call stack.----### Trend impact --You can also view a graph depicting a specific performance issue's impact and threshold. The trend impact results vary depending on the filters you set. For example, a CPU `String.SubString()` performance issue's insights seen over a seven day time frame may look like: ----## Next steps --> [!div class="nextstepaction"] -> [Review Code Optimizations in Azure portal](https://aka.ms/codeoptimizations) - |
| azure-monitor | Ip Addresses | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/ip-addresses.md | - Title: IP addresses used by Azure Monitor | Microsoft Docs -description: This article discusses server firewall exceptions that are required by Azure Monitor - Previously updated : 03/14/2024-ms.servce: azure-monitor ------# IP addresses used by Azure Monitor --[Azure Monitor](.\overview.md) uses several IP addresses. Azure Monitor is made up of core platform metrics and logs in addition to Log Analytics and Application Insights. You might need to know IP addresses if the app or infrastructure that you're monitoring is hosted behind a firewall. --> [!NOTE] -> Although these addresses are static, it's possible that we'll need to change them from time to time. All Application Insights traffic represents outbound traffic with the exception of availability monitoring and webhook action groups, which also require inbound firewall rules. --You can use Azure [network service tags](../virtual-network/service-tags-overview.md) to manage access if you're using Azure network security groups. If you're managing access for hybrid/on-premises resources, you can download the equivalent IP address lists as [JSON files](../virtual-network/service-tags-overview.md#discover-service-tags-by-using-downloadable-json-files), which are updated each week. To cover all the exceptions in this article, use the service tags `ActionGroup`, `ApplicationInsightsAvailability`, and `AzureMonitor`. --> [!NOTE] -> Service tags do not replace validation/authentication checks required for cross-tenant communications between a customer's azure resource and other service tag resources. --## Outgoing ports --You need to open some outgoing ports in your server's firewall to allow the Application Insights SDK or Application Insights Agent to send data to the portal. --> [!NOTE] -> These addresses are listed by using Classless Interdomain Routing notation. As an example, an entry like `51.144.56.112/28` is equivalent to 16 IPs that start at `51.144.56.112` and end at `51.144.56.127`. --| Purpose | URL | Type | IP | Ports | -| | | | | | -| Telemetry | `dc.applicationinsights.azure.com`<br/>`dc.applicationinsights.microsoft.com`<br/>`dc.services.visualstudio.com`<br/>`*.in.applicationinsights.azure.com`<br/><br/> |Global<br/>Global<br/>Global<br/>Regional<br/>|| 443 | -| Live Metrics | `live.applicationinsights.azure.com`<br/>`rt.applicationinsights.microsoft.com`<br/>`rt.services.visualstudio.com`<br/><br/>`{region}.livediagnostics.monitor.azure.com`<br/><br/>*Example for `{region}`: `westus2`|Global<br/>Global<br/>Global<br/><br/>Regional<br/>|20.49.111.32/29<br/>13.73.253.112/29| 443 | --> [!NOTE] -> Application Insights ingestion endpoints are IPv4 only. --## Application Insights Agent --Application Insights Agent configuration is needed only when you're making changes. --| Purpose | URL | Ports | -| | | | -| Configuration |`management.core.windows.net` |`443` | -| Configuration |`management.azure.com` |`443` | -| Configuration |`login.windows.net` |`443` | -| Configuration |`login.microsoftonline.com` |`443` | -| Configuration |`secure.aadcdn.microsoftonline-p.com` |`443` | -| Configuration |`auth.gfx.ms` |`443` | -| Configuration |`login.live.com` |`443` | -| Installation | `globalcdn.nuget.org`, `packages.nuget.org` ,`api.nuget.org/v3/index.json` `nuget.org`, `api.nuget.org`, `dc.services.vsallin.net` |`443` | --## Availability tests --For more information on availability tests, see [Private availability testing](./app/availability-private-test.md). --## Application Insights and Log Analytics APIs --| Purpose | URI | IP | Ports | -| | | | | -| API |`api.applicationinsights.io`<br/>`api1.applicationinsights.io`<br/>`api2.applicationinsights.io`<br/>`api3.applicationinsights.io`<br/>`api4.applicationinsights.io`<br/>`api5.applicationinsights.io`<br/>`dev.applicationinsights.io`<br/>`dev.applicationinsights.microsoft.com`<br/>`dev.aisvc.visualstudio.com`<br/>`www.applicationinsights.io`<br/>`www.applicationinsights.microsoft.com`<br/>`www.aisvc.visualstudio.com`<br/>`api.loganalytics.io`<br/>`*.api.loganalytics.io`<br/>`dev.loganalytics.io`<br>`docs.loganalytics.io`<br/>`www.loganalytics.io`<br/>`api.loganalytics.azure.com` |20.37.52.188 <br/> 20.37.53.231 <br/> 20.36.47.130 <br/> 20.40.124.0 <br/> 20.43.99.158 <br/> 20.43.98.234 <br/> 13.70.127.61 <br/> 40.81.58.225 <br/> 20.40.160.120 <br/> 23.101.225.155 <br/> 52.139.8.32 <br/> 13.88.230.43 <br/> 52.230.224.237 <br/> 52.242.230.209 <br/> 52.173.249.138 <br/> 52.229.218.221 <br/> 52.229.225.6 <br/> 23.100.94.221 <br/> 52.188.179.229 <br/> 52.226.151.250 <br/> 52.150.36.187 <br/> 40.121.135.131 <br/> 20.44.73.196 <br/> 20.41.49.208 <br/> 40.70.23.205 <br/> 20.40.137.91 <br/> 20.40.140.212 <br/> 40.89.189.61 <br/> 52.155.118.97 <br/> 52.156.40.142 <br/> 23.102.66.132 <br/> 52.231.111.52 <br/> 52.231.108.46 <br/> 52.231.64.72 <br/> 52.162.87.50 <br/> 23.100.228.32 <br/> 40.127.144.141 <br/> 52.155.162.238 <br/> 137.116.226.81 <br/> 52.185.215.171 <br/> 40.119.4.128 <br/> 52.171.56.178 <br/> 20.43.152.45 <br/> 20.44.192.217 <br/> 13.67.77.233 <br/> 51.104.255.249 <br/> 51.104.252.13 <br/> 51.143.165.22 <br/> 13.78.151.158 <br/> 51.105.248.23 <br/> 40.74.36.208 <br/> 40.74.59.40 <br/> 13.93.233.49 <br/> 52.247.202.90 |80,443 | -| Azure Pipeline annotations extension | `aigs1.aisvc.visualstudio.com` |dynamic|443 | --## Application Insights analytics --| Purpose | URI | IP | Ports | -| | | | | -| Analytics portal | `analytics.applicationinsights.io` | dynamic | 80,443 | -| CDN | `applicationanalytics.azureedge.net` | dynamic | 80,443 | -| Media CDN | `applicationanalyticsmedia.azureedge.net` | dynamic | 80,443 | --The *.applicationinsights.io domain is owned by the Application Insights team. --## Log Analytics portal --| Purpose | URI | IP | Ports | -| | | | | -| Portal | `portal.loganalytics.io` | dynamic | 80,443 | -| CDN | `applicationanalytics.azureedge.net` | dynamic | 80,443 | --The *.loganalytics.io domain is owned by the Log Analytics team. --## Application Insights Azure portal extension --| Purpose | URI | IP | Ports | -| | | | | -| Application Insights extension | `stamp2.app.insightsportal.visualstudio.com` | dynamic | 80,443 | -| Application Insights extension CDN | `insightsportal-prod2-cdn.aisvc.visualstudio.com`<br/>`insightsportal-prod2-asiae-cdn.aisvc.visualstudio.com`<br/>`insightsportal-cdn-aimon.applicationinsights.io` | dynamic | 80,443 | --## Application Insights SDKs --| Purpose | URI | IP | Ports | -| | | | | -| Application Insights JS SDK CDN | `az416426.vo.msecnd.net`<br/>`js.monitor.azure.com` | dynamic | 80,443 | --## Action group webhooks --You can query the list of IP addresses used by action groups by using the [Get-AzNetworkServiceTag PowerShell command](/powershell/module/az.network/Get-AzNetworkServiceTag). --### Action group service tag --Managing changes to source IP addresses can be time consuming. Using *service tags* eliminates the need to update your configuration. A service tag represents a group of IP address prefixes from a specific Azure service. Microsoft manages the IP addresses and automatically updates the service tag as addresses change, which eliminates the need to update network security rules for an action group. --1. In the Azure portal under **Azure Services**, search for **Network Security Group**. -1. Select **Add** and create a network security group: -- 1. Add the resource group name, and then enter **Instance details** information. - 1. Select **Review + Create**, and then select **Create**. - - :::image type="content" source="alerts/media/action-groups/action-group-create-security-group.png" alt-text="Screenshot that shows how to create a network security group."border="true"::: --1. Go to **Resource Group**, and then select the network security group you created: -- 1. Select **Inbound security rules**. - 1. Select **Add**. - - :::image type="content" source="alerts/media/action-groups/action-group-add-service-tag.png" alt-text="Screenshot that shows how to add inbound security rules." border="true"::: --1. A new window opens in the right pane: -- 1. Under **Source**, enter **Service Tag**. - 1. Under **Source service tag**, enter **ActionGroup**. - 1. Select **Add**. - - :::image type="content" source="alerts/media/action-groups/action-group-service-tag.png" alt-text="Screenshot that shows how to add a service tag." border="true"::: --## Profiler --| Purpose | URI | IP | Ports | -| | | | | -| Agent | `agent.azureserviceprofiler.net`<br/>`*.agent.azureserviceprofiler.net`<br/>`profiler.monitor.azure.com` | 20.190.60.38<br/>20.190.60.32<br/>52.173.196.230<br/>52.173.196.209<br/>23.102.44.211<br/>23.102.45.216<br/>13.69.51.218<br/>13.69.51.175<br/>138.91.32.98<br/>138.91.37.93<br/>40.121.61.208<br/>40.121.57.2<br/>51.140.60.235<br/>51.140.180.52<br/>52.138.31.112<br/>52.138.31.127<br/>104.211.90.234<br/>104.211.91.254<br/>13.70.124.27<br/>13.75.195.15<br/>52.185.132.101<br/>52.185.132.170<br/>20.188.36.28<br/>40.89.153.171<br/>52.141.22.239<br/>52.141.22.149<br/>102.133.162.233<br/>102.133.161.73<br/>191.232.214.6<br/>191.232.213.239 | 443 | -| Portal | `gateway.azureserviceprofiler.net`<br/>`dataplane.diagnosticservices.azure.com` | dynamic | 443 | -| Storage | `*.core.windows.net` | dynamic | 443 | --## Snapshot Debugger --> [!NOTE] -> Profiler and Snapshot Debugger share the same set of IP addresses. --| Purpose | URI | IP | Ports | -| | | | | -| Agent | `agent.azureserviceprofiler.net`<br/>`*.agent.azureserviceprofiler.net`<br/>`snapshot.monitor.azure.com` | 20.190.60.38<br/>20.190.60.32<br/>52.173.196.230<br/>52.173.196.209<br/>23.102.44.211<br/>23.102.45.216<br/>13.69.51.218<br/>13.69.51.175<br/>138.91.32.98<br/>138.91.37.93<br/>40.121.61.208<br/>40.121.57.2<br/>51.140.60.235<br/>51.140.180.52<br/>52.138.31.112<br/>52.138.31.127<br/>104.211.90.234<br/>104.211.91.254<br/>13.70.124.27<br/>13.75.195.15<br/>52.185.132.101<br/>52.185.132.170<br/>20.188.36.28<br/>40.89.153.171<br/>52.141.22.239<br/>52.141.22.149<br/>102.133.162.233<br/>102.133.161.73<br/>191.232.214.6<br/>191.232.213.239 | 443 | -| Portal | `gateway.azureserviceprofiler.net`<br/>`dataplane.diagnosticservices.azure.com` | dynamic | 443 | -| Storage | `*.core.windows.net` | dynamic | 443 | --## Frequently asked questions --This section provides answers to common questions. --### Can I monitor an intranet web server? --Yes, but you need to allow traffic to our services by either firewall exceptions or proxy redirects: --- QuickPulse `https://rt.services.visualstudio.com:443`-- ApplicationIdProvider `https://dc.services.visualstudio.com:443`-- TelemetryChannel `https://dc.services.visualstudio.com:443`- -See [IP addresses used by Azure Monitor](./ip-addresses.md) to review our full list of services and IP addresses. - -### How do I reroute traffic from my server to a gateway on my intranet? - -Route traffic from your server to a gateway on your intranet by overwriting endpoints in your configuration. If the `Endpoint` properties aren't present in your config, these classes use the default values shown in the following ApplicationInsights.config example. - -Your gateway should route traffic to our endpoint's base address. In your configuration, replace the default values with `http://<your.gateway.address>/<relative path>`. - -#### Example ApplicationInsights.config with default endpoints: - -```xml -<ApplicationInsights> -... -<TelemetryModules> - <Add Type="Microsoft.ApplicationInsights.Extensibility.PerfCounterCollector.QuickPulse.QuickPulseTelemetryModule, Microsoft.AI.PerfCounterCollector"> - <QuickPulseServiceEndpoint>https://rt.services.visualstudio.com/QuickPulseService.svc</QuickPulseServiceEndpoint> - </Add> -</TelemetryModules> - ... -<TelemetryChannel> - <EndpointAddress>https://dc.services.visualstudio.com/v2/track</EndpointAddress> -</TelemetryChannel> -... -<ApplicationIdProvider Type="Microsoft.ApplicationInsights.Extensibility.Implementation.ApplicationId.ApplicationInsightsApplicationIdProvider, Microsoft.ApplicationInsights"> - <ProfileQueryEndpoint>https://dc.services.visualstudio.com/api/profiles/{0}/appId</ProfileQueryEndpoint> -</ApplicationIdProvider> -... -</ApplicationInsights> -``` --> [!NOTE] -> `ApplicationIdProvider` is available starting in v2.6.0. |
| azure-monitor | Aiops Machine Learning | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/aiops-machine-learning.md | - Title: AIOps and machine learning in Azure Monitor -description: Use machine learning to improve your ability to predict IT needs and identify and respond to anomalous patterns in log data. ---- Previously updated : 02/14/2024---# Customer intent: As a DevOps manager or data scientist, I want to understand which AIOps features Azure Monitor offers and how to implement a machine learning pipeline on data in Azure Monitor Logs so that I can use artifical intelligence to improve service quality and reliability of my IT environment. ---# Detect and mitigate potential issues using AIOps and machine learning in Azure Monitor -Artificial Intelligence for IT Operations (AIOps) offers powerful ways to improve service quality and reliability by using machine learning to process and automatically act on data you collect from applications, services, and IT resources into Azure Monitor. --Azure Monitor's built-in AIOps capabilities provide insights and help you troubleshoot issues and automate data-driven tasks, such as predicting capacity usage and autoscaling, identifying and analyzing application performance issues, and detecting anomalous behaviors in virtual machines, containers, and other resources. These features boost your IT monitoring and operations, without requiring machine learning knowledge and further investment. --Azure Monitor also provides tools that let you create your own machine learning pipeline to introduce new analysis and response capabilities and act on data in Azure Monitor Logs. --This article describes Azure Monitor's built-in AIOps capabilities and explains how you can create and run customized machine learning models and build an automated machine learning pipeline on data in Azure Monitor Logs. --## Built-in Azure Monitor AIOps and machine learning capabilities --|Monitoring scenario|Capability|Description| -|-|-|-| -|Log monitoring|[Log Analytics Workspace Insights](../logs/log-analytics-workspace-insights-overview.md) | Provides a unified view of your Log Analytics workspaces and uses machine learning to detect ingestion anomalies. | -||[Kusto Query Language (KQL) time series analysis and machine learning functions](../logs/kql-machine-learning-azure-monitor.md)| Easy-to-use tools for generating time series data, detecting anomalies, forecasting, and performing root cause analysis directly in Azure Monitor Logs without requiring in-depth knowledge of data science and programming languages. | -||[Microsoft Copilot in Azure](/azure/copilot/get-monitoring-information)| Helps you use Log Analytics to analyze data and troubleshoot issues. Generates example KQL queries based on prompts, such as "Are there any errors in container logs?". | -|Application performance monitoring|[Application Map Intelligent view](../app/app-map.md)| Maps dependencies between services and helps you spot performance bottlenecks or failure hotspots across all components of your distributed application.| -||[Smart detection](../alerts/proactive-diagnostics.md)|Analyzes the telemetry your application sends to Application Insights, alerts on performance problems and failure anomalies, and identifies potential root causes of application performance issues.| -|Metric alerts|[Dynamic thresholds for metric alerting](../alerts/alerts-dynamic-thresholds.md)| Learns metrics patterns, automatically sets alert thresholds based on historical data, and identifies anomalies that might indicate service issues.| -|Virtual machine scale sets|[Predictive autoscale](../autoscale/autoscale-predictive.md)|Forecasts the overall CPU requirements of a virtual machine scale set, based on historical CPU usage patterns, and automatically scales out to meet these needs.| --## Machine learning in Azure Monitor Logs --Use the Kusto Query Language's [built-in time series analysis and machine learning functions, operators, and plug-ins](/azure/data-explorer/kusto/query/machine-learning-clustering) to gain insights about service health, usage, capacity and other trends, and to generate forecasts and detect anomalies in [Azure Monitor Logs](../logs/data-platform-logs.md). --To gain greater flexibility and expand your ability to analyze and act on data, you can also implement your own machine learning pipeline on data in Azure Monitor Logs. --This table compares the advantages and limitations of using KQL's built-in machine learning capabilities and creating your own machine learning pipeline, and links to tutorials that demonstrate how you can implement each: --||Built-in KQL machine learning capabilities |Create your own machine learning pipeline| -|-|-|-| -|**Scenario**| :white_check_mark: Anomaly detection, root cause, and time series analysis <br> | :white_check_mark: Anomaly detection, root cause, and time series analysis <br> :white_check_mark: [Advanced analysis and AIOPs scenarios](#create-your-own-machine-learning-pipeline-on-data-in-azure-monitor-logs) | -|**Advantages**|🔹Gets you started very quickly.<br>🔹No data science knowledge and programming skills required.<br>🔹 Optimal performance and cost savings. |🔹Supports larger scales.<br>🔹Enables advanced, more complex scenarios.<br>🔹Flexibility in choosing libraries, models, parameters.| -|**Service limits and data volumes** |[Azure portal](../service-limits.md#azure-portal) or [Query API log query limits](../service-limits.md#la-query-api) depending on whether you're working in the portal or using the API, for example, from a notebook.|🔹[Query API log query limits](../service-limits.md#la-query-api) if you query data in Azure Monitor Logs as part of your [machine learning pipeline](#create-your-own-machine-learning-pipeline-on-data-in-azure-monitor-logs). Otherwise, no Azure service limits.<br>🔹Can support larger data volumes.| -|**Integration**|None required. Run using [Log Analytics](../logs/log-analytics-tutorial.md) in the Azure portal or from an [integrated Jupyter Notebook](../logs/notebooks-azure-monitor-logs.md).|Requires integration with a tool, such as [Jupyter Notebook](../logs/notebooks-azure-monitor-logs.md). Typically, you'd also integrate with other Azure services, like [Azure Synapse Analytics](/azure/synapse-analytics/overview-what-is).| -|**Performance**|Optimal performance, using the Azure Data Explorer platform, running at high scales in a distributed manner. |Introduces a small amount of latency when querying or exporting data, depending on how you [implement your machine learning pipeline](#create-your-own-machine-learning-pipeline-on-data-in-azure-monitor-logs). | -|**Model type** |Linear regression model and other models supported by KQL time series functions with a set of configurable parameters.|Completely customizable machine learning model or anomaly detection method. | -|**Cost**|No extra cost.| Depending on how you [implement your machine learning pipeline](#create-your-own-machine-learning-pipeline-on-data-in-azure-monitor-logs), you might incur charges for [exporting data](../logs/logs-data-export.md#pricing-model), ingesting scored data into Azure Monitor Logs, and the use of other Azure services.| -|**Tutorial**|[Detect and analyze anomalies using KQL machine learning capabilities in Azure Monitor](../logs/kql-machine-learning-azure-monitor.md)|[Analyze data in Azure Monitor Logs using a notebook](../logs/notebooks-azure-monitor-logs.md)| --## Create your own machine learning pipeline on data in Azure Monitor Logs --Build your own machine learning pipeline on data in Azure Monitor Logs to introduce new AIOps capabilities and support advanced scenarios, such as: --- Hunting for security attacks with more sophisticated models than those by KQL.-- Detecting performance issues and troubleshooting errors in a web application.-- Creating multi-step flows, running code in each step based on the results of the previous step.-- Automating the analysis of Azure Monitor Log data and providing insights into multiple areas, including infrastructure health and customer behavior.-- Correlating data in Azure Monitor Logs with data from other sources.--There are two approaches to making data in Azure Monitor Logs available to your machine learning pipeline: --- **Query data in Azure Monitor Logs** - [Integrate a notebook with Azure Monitor Logs](../logs/notebooks-azure-monitor-logs.md) or run a script or application on log data using libraries like [Azure Monitor Query client library](/python/api/overview/azure/monitor-query-readme) or [MSTICPY](https://msticpy.readthedocs.io/en/latest/) to retrieve data from Azure Monitor Logs in tabular form; for example, into a [Pandas DataFrame](https://pandas.pydata.org/docs/user_guide/dsintro.html#dataframe). The data you query is retrieved to an in-memory object on your server, without exporting the data out of your Log Analytics workspace. -- > [!NOTE] - > You might need to convert data formats as part of your pipeline. For example, to use libraries built on top of Apache Spark, like [SynapseML](https://microsoft.github.io/SynapseML/), you might need to [convert Pandas to PySpark DataFrame](https://sparkbyexamples.com/pyspark/convert-pandas-to-pyspark-dataframe/). --- **Export data out of Azure Monitor Logs** - [Export data out of your Log Analytics workspace](../logs/logs-data-export.md), usually to a blob storage account, and [implement your machine learning pipeline using a machine learning library](#implement-the-steps-of-the-machine-learning-lifecycle-in-azure-monitor-logs). ---This table compares the advantages and limitations of the approaches to retrieving data for your machine learning pipeline: --| |Query data in Azure Monitor Logs|Export data| -|-|-|-|-| -|**Advantages**|🔹Gets you started quickly.<br>🔹Requires only basic data science and programming skills.<br>🔹Minimal latency and cost savings.|🔹Supports larger scales.<br>🔹No query limitations.| -|**Data exported?**|No|Yes| -|**Service limits**|[Query API log query limits](../service-limits.md#log-analytics-workspaces) and [user query throttling](../service-limits.md#user-query-throttling). You can overcome Query API limits to, a certain degree, by [splitting larger queries into chunks](https://github.com/Azure/azure-sdk-for-python/blob/main/sdk/monitor/azure-monitor-query/samples/notebooks/sample_large_query.ipynb).| None from Azure Monitor. | -|**Data volumes**|Analyze several GBs of data, or a few million records per hour.|Supports large volumes of data.| -|**Machine learning library**|For small to medium-sized datasets, you'd typically use single-node machine learning libraries, like [Scikit Learn](https://scikit-learn.org/stable/).|For large datasets, you'd typically use big data machine learning libraries, like [SynapseML](https://github.com/microsoft/SynapseML).| -|**Latency** | Minimal. | Introduces a small amount of latency in exporting data.| -|**Cost** |No extra charges in Azure Monitor.<br>Cost of Azure Synapse Analytics, Azure Machine Learning, or other service, if used.| [Cost of data export](../logs/logs-data-export.md#pricing-model) and external storage.<br>Cost of Azure Synapse Analytics, Azure Machine Learning, or other service, if used.| --> [!TIP] -> To benefit from the best of both implementation approaches, create a hybrid pipeline. A common hybrid approach is to export data for model training, which involves large volumes of data, and to use the *query data in Azure Monitor Logs* approach to explore data and score new data to reduce latency and costs. -## Implement the steps of the machine learning lifecycle in Azure Monitor Logs --Setting up a machine learning pipeline typically involves all or some of the steps described below. --There are various Azure and open source machine learning libraries you can use to implement your machine learning pipeline, including [Scikit Learn](https://scikit-learn.org/), [PyTorch](https://pytorch.org/), [Tensorflow](https://www.tensorflow.org/), [Spark MLlib](https://spark.apache.org/docs/latest/ml-guide.html), and [SynapseML](https://github.com/microsoft/SynapseML). --This table describes each step and provides high-level guidance and some examples of how to implement these steps based on the implementation approaches described in [Create your own machine learning pipeline on data in Azure Monitor Logs](#create-your-own-machine-learning-pipeline-on-data-in-azure-monitor-logs): --|Step|Description|Query data in Azure Monitor Logs|Export data| -|-|-|-|-| -|**Explore data**| Examine and understand the data you've collected. |The simplest way to explore your data is using [Log Analytics](../logs/log-analytics-tutorial.md), which provides a rich set of tools for exploring and visualizing data in the Azure portal. You can also [analyze data in Azure Monitor Logs using a notebook](../logs/notebooks-azure-monitor-logs.md).|To analyze logs outside of Azure Monitor, [export data out of your Log Analytics workspace](../logs/logs-data-export.md) and set up the environment in the service you choose.<br>For an example of how to explore logs outside of Azure Monitor, see [Analyze data exported from Log Analytics using Synapse](https://techcommunity.microsoft.com/t5/azure-observability-blog/how-to-analyze-data-exported-from-log-analytics-data-using/ba-p/2547888).| -|**Build and training a machine learning model**|Model training is an iterative process. Researchers or data scientists develop a model by fetching and cleaning the training data, engineer features, trying various models and tuning parameters, and repeating this cycle until the model is accurate and robust.|For small to medium-sized datasets, you typically use single-node machine learning libraries, like [Scikit Learn](https://scikit-learn.org/stable/).<br> For an example of how to train a machine learning model on data in Azure Monitor Logs using the Scikit Learn library, see this [sample notebook: Detect anomalies in Azure Monitor Logs using machine learning techniques](https://github.com/Azure/azure-sdk-for-python/blob/main/sdk/monitor/azure-monitor-query/samples/notebooks/sample_machine_learning_sklearn.ipynb).|For large datasets, you typically use big data machine learning libraries, like [SynapseML](/azure/synapse-analytics/machine-learning/synapse-machine-learning-library).| -|**Deploy and score a model**|Scoring is the process of applying a machine learning model on new data to get predictions. Scoring usually needs to be done at scale with minimal latency.|To query new data in Azure Monitor Logs, use [Azure Monitor Query client library](/python/api/overview/azure/monitor-query-readme).<br>For an example of how to score data using open source tools, see this [sample notebook: Detect anomalies in Azure Monitor Logs using machine learning techniques](https://github.com/Azure/azure-sdk-for-python/blob/main/sdk/monitor/azure-monitor-query/samples/notebooks/sample_machine_learning_sklearn.ipynb).| | -|**Run your pipeline on schedule**| Automate your pipeline to retrain your model regularly on current data.| Schedule your machine learning pipeline with [Azure Synapse Analytics](/azure/synapse-analytics/synapse-notebook-activity) or [Azure Machine Learning](/azure/machine-learning/how-to-schedule-pipeline-job).|See the examples in the *Query data in Azure Monitor Logs* column. | --Ingesting scored results to a Log Analytics workspace lets you use the data to get advanced insights, and to create alerts and dashboards. For an example of how to ingest scored results using [Azure Monitor Ingestion client library](/python/api/overview/azure/monitor-ingestion-readme), see [Ingest anomalies into a custom table in your Log Analytics workspace](../logs/notebooks-azure-monitor-logs.md#4-ingest-analyzed-data-into-a-custom-table-in-your-log-analytics-workspace-optional). -## Next steps --Learn more about: --- [Azure Monitor Logs](../logs/data-platform-logs.md).-- [Azure Monitor Insights and curated visualizations](../insights/insights-overview.md). |
| azure-monitor | Analyze Usage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/analyze-usage.md | - Title: Analyze usage in a Log Analytics workspace in Azure Monitor -description: Methods and queries to analyze the data in your Log Analytics workspace to help you understand usage and potential cause for high usage. -- Previously updated : 08/14/2024---# Analyze usage in a Log Analytics workspace -Azure Monitor costs can vary significantly based on the volume of data being collected in your Log Analytics workspace. This volume is affected by the set of solutions using the workspace and the amount of data that each solution collects. This article provides guidance on analyzing your collected data to assist in controlling your data ingestion costs. It helps you determine the cause of higher-than-expected usage. It also helps you to predict your costs as you monitor more resources and configure different Azure Monitor features. ---## Causes for higher-than-expected usage -Each Log Analytics workspace is charged as a separate service and contributes to the bill for your Azure subscription. The amount of data ingestion can be considerable, depending on the: --- Set of insights and services enabled and their configuration.- - Number and type of monitored resources. - - Volume of data collected from each monitored resource. --An unexpected increase in any of these factors can result in increased charges for data retention. The rest of this article provides methods for detecting such a situation and then analyzing collected data to identify and mitigate the source of the increased usage. --## Send alert when data collection is high --To avoid unexpected bills, you should be proactively notified anytime you experience excessive usage. Notification allows you to address any potential anomalies before the end of your billing period. --The following example is a [log search alert rule](../alerts/alerts-types.md#log-alerts) that sends an alert if the billable data volume ingested in the last 24 hours was greater than 50 GB. Modify the **Alert Logic** setting to use a different threshold based on expected usage in your environment. You can also increase the frequency to check usage multiple times every day, but this option will result in a higher charge for the alert rule. --| Setting | Value | -|:|:| -| **Scope** | | -| Target scope | Select your Log Analytics workspace. | -| **Condition** | | -| Query | `Usage | where IsBillable | summarize DataGB = sum(Quantity / 1000)` | -| Measurement | Measure: *DataGB*<br>Aggregation type: Total<br>Aggregation granularity: 1 day | -| Alert Logic | Operator: Greater than<br>Threshold value: 50<br>Frequency of evaluation: 1 day | -| Actions | Select or add an [action group](../alerts/action-groups.md) to notify you when the threshold is exceeded. | -| **Details** | | -| Severity| Warning | -| Alert rule name | Billable data volume greater than 50 GB in 24 hours. | --## Usage analysis in Azure Monitor -Start your analysis with existing tools in Azure Monitor. These tools require no configuration and can often provide the information you need with minimal effort. If you need deeper analysis into your collected data than existing Azure Monitor features, use any of the following [log queries](log-query-overview.md) in [Log Analytics](log-analytics-overview.md). --### Log Analytics Workspace Insights -[Log Analytics Workspace Insights](log-analytics-workspace-insights-overview.md#usage-tab) provides you with a quick understanding of the data in your workspace. For example, you can determine the: --- Data tables that are ingesting the most data volume in the main table.-- Top resources contributing data.-- Trend of data ingestion.--See the **Usage** tab for a breakdown of ingestion by solution and table. This information can help you quickly identify the tables that contribute to the bulk of your data volume. The tab also shows trending of data collection over time. You can determine if data collection steadily increased over time or suddenly increased in response to a configuration change. --Select **Additional Queries** for prebuilt queries that help you further understand your data patterns. --### Usage and estimated costs -The **Data ingestion per solution** chart on the [Usage and estimated costs](../cost-usage.md#usage-and-estimated-costs) page for each workspace shows the total volume of data sent and how much is being sent by each solution over the previous 31 days. This information helps you determine trends such as whether any increase is from overall data usage or usage by a particular solution. --## Querying data volumes from the Usage table --Analyze the amount of billable data collected by a particular service or solution. These queries use the [Usage](/azure/azure-monitor/reference/tables/usage) table that collects usage data for each table in the workspace. --> [!NOTE] -> The clause with `TimeGenerated` is only to ensure that the query experience in the Azure portal looks back beyond the default 24 hours. When you use the **Usage** data type, `StartTime` and `EndTime` represent the time buckets for which results are presented. --**Billable data volume by type over the past month** --```kusto -Usage -| where TimeGenerated > ago(32d) -| where StartTime >= startofday(ago(31d)) and EndTime < startofday(now()) -| where IsBillable == true -| summarize BillableDataGB = sum(Quantity) / 1000. by bin(StartTime, 1d), DataType -| render columnchart -``` --**Billable data volume by solution and type over the past month** --```kusto -Usage -| where TimeGenerated > ago(32d) -| where StartTime >= startofday(ago(31d)) and EndTime < startofday(now()) -| where IsBillable == true -| summarize BillableDataGB = sum(Quantity) / 1000 by Solution, DataType -| sort by Solution asc, DataType asc -``` --## Querying data volume from the events directly --You can use [log queries](log-query-overview.md) in [Log Analytics](log-analytics-overview.md) if you need deeper analysis into your collected data. Each table in a Log Analytics workspace has the following standard columns that can assist you in analyzing billable data: --- [_IsBillable](log-standard-columns.md#_isbillable) identifies records for which there's an ingestion charge. Use this column to filter out non-billable data.-- [_BilledSize](log-standard-columns.md#_billedsize) provides the size in bytes of the record.--**Billable data volume for specific events** --If you find that a particular data type is collecting excessive data, you might want to analyze the data in that table to determine particular records that are increasing. This example filters specific event IDs in the `Event` table and then provides a count for each ID. You can modify this query by using the columns from other tables. --```kusto -Event -| where TimeGenerated > startofday(ago(31d)) and TimeGenerated < startofday(now()) -| where EventID == 5145 or EventID == 5156 -| where _IsBillable == true -| summarize count(), Bytes=sum(_BilledSize) by EventID, bin(TimeGenerated, 1d) -``` --### Data volume by Azure resource, resource group, or subscription -You can analyze the amount of billable data collected from a particular resource or set of resources. These queries use the [_ResourceId](./log-standard-columns.md#_resourceid) and [_SubscriptionId](./log-standard-columns.md#_subscriptionid) columns for data from resources hosted in Azure. --> [!WARNING] -> Use [find](/azure/data-explorer/kusto/query/findoperator?pivots=azuremonitor) queries sparingly because scans across data types are [resource intensive](./query-optimization.md#query-details-pane) to execute. If you don't need results per subscription, resource group, or resource name, use the [Usage](/azure/azure-monitor/reference/tables/usage) table as in the preceding queries. --**Billable data volume by resource ID for the last full day** --```kusto -find where TimeGenerated between(startofday(ago(1d))..startofday(now())) project _ResourceId, _BilledSize, _IsBillable -| where _IsBillable == true -| summarize BillableDataBytes = sum(_BilledSize) by _ResourceId -| sort by BillableDataBytes nulls last -``` --**Billable data volume by resource group for the last full day** --```kusto -find where TimeGenerated between(startofday(ago(1d))..startofday(now())) project _ResourceId, _BilledSize, _IsBillable -| where _IsBillable == true -| summarize BillableDataBytes = sum(_BilledSize) by _ResourceId -| extend resourceGroup = tostring(split(_ResourceId, "/")[4] ) -| summarize BillableDataBytes = sum(BillableDataBytes) by resourceGroup -| sort by BillableDataBytes nulls last -``` --It might be helpful to parse `_ResourceId`: --```Kusto -| parse tolower(_ResourceId) with "/subscriptions/" subscriptionId "/resourcegroups/" - resourceGroup "/providers/" provider "/" resourceType "/" resourceName -``` --**Billable data volume by subscription for the last full day** --```kusto -find where TimeGenerated between(startofday(ago(1d))..startofday(now())) project _BilledSize, _IsBillable, _SubscriptionId -| where _IsBillable == true -| summarize BillableDataBytes = sum(_BilledSize) by _SubscriptionId -| sort by BillableDataBytes nulls last -``` --> [!TIP] -> For workspaces with large data volumes, doing queries such as the ones shown in this section, which query large volumes of raw data, might need to be restricted to a single day. To track trends over time, consider setting up a [Power BI report](./log-powerbi.md) and using [incremental refresh](./log-powerbi.md#collect-data-with-power-bi-dataflows) to collect data volumes per resource once a day. --### Data volume by computer -You can analyze the amount of billable data collected from a virtual machine or a set of virtual machines. The **Usage** table doesn't have the granularity to show data volumes for specific virtual machines, so these queries use the [find operator](/azure/data-explorer/kusto/query/findoperator) to search all tables that include a computer name. The **Usage** type is omitted because this query is only for analytics of data trends. --> [!WARNING] -> Use [find](/azure/data-explorer/kusto/query/findoperator?pivots=azuremonitor) queries sparingly because scans across data types are [resource intensive](./query-optimization.md#query-details-pane) to execute. If you don't need results per subscription, resource group, or resource name, use the [Usage](/azure/azure-monitor/reference/tables/usage) table as in the preceding queries. --**Billable data volume by computer for the last full day** --```kusto -find where TimeGenerated between(startofday(ago(1d))..startofday(now())) project _BilledSize, _IsBillable, Computer, Type -| where _IsBillable == true and Type != "Usage" -| extend computerName = tolower(tostring(split(Computer, '.')[0])) -| summarize BillableDataBytes = sum(_BilledSize) by computerName -| sort by BillableDataBytes desc nulls last -``` --**Count of billable events by computer for the last full day** --```kusto -find where TimeGenerated between(startofday(ago(1d))..startofday(now())) project _IsBillable, Computer, Type -| where _IsBillable == true and Type != "Usage" -| extend computerName = tolower(tostring(split(Computer, '.')[0])) -| summarize eventCount = count() by computerName -| sort by eventCount desc nulls last -``` --## Querying for common data types -If you find that you have excessive billable data for a particular data type, you might need to perform a query to analyze data in that table. The following queries provide samples for some common data types: --**Security** solution --```kusto -SecurityEvent -| summarize AggregatedValue = count() by EventID -| order by AggregatedValue desc nulls last -``` --**Log Management** solution --```kusto -Usage -| where Solution == "LogManagement" and iff(isnotnull(toint(IsBillable)), IsBillable == true, IsBillable == "true") == true -| summarize AggregatedValue = count() by DataType -| order by AggregatedValue desc nulls last -``` --**Perf** data type --```kusto -Perf -| summarize AggregatedValue = count() by CounterPath -``` --```kusto -Perf -| summarize AggregatedValue = count() by CounterName -``` --**Event** data type --```kusto -Event -| summarize AggregatedValue = count() by EventID -``` --```kusto -Event -| summarize AggregatedValue = count() by EventLog, EventLevelName -``` --**Syslog** data type --```kusto -Syslog -| summarize AggregatedValue = count() by Facility, SeverityLevel -``` --```kusto -Syslog -| summarize AggregatedValue = count() by ProcessName -``` --**AzureDiagnostics** data type --```kusto -AzureDiagnostics -| summarize AggregatedValue = count() by ResourceProvider, ResourceId -``` --## Application Insights data -There are two approaches to investigating the amount of data collected for Application Insights, depending on whether you have a classic or workspace-based application. Use the `_BilledSize` property that's available on each ingested event for both workspace-based and classic resources. You can also use aggregated information in the [systemEvents](/azure/azure-monitor/reference/tables/appsystemevents) table for classic resources. --> [!NOTE] -> Queries against Application Insights tables, except `SystemEvents`, will work for both a workspace-based and classic Application Insights resource. [Backward compatibility](../app/convert-classic-resource.md#understand-log-queries) allows you to continue to use [legacy table names](../app/apm-tables.md). For a workspace-based resource, open **Logs** on the **Log Analytics workspace** menu. For a classic resource, open **Logs** on the **Application Insights** menu. --**Dependency operations generate the most data volume in the last 30 days (workspace-based or classic)** --```kusto -dependencies -| where timestamp >= startofday(ago(30d)) -| summarize sum(_BilledSize) by operation_Name -| render barchart -``` --**Daily data volume by type for this Application Insights resource for the last 7 days (classic only)** --```kusto -systemEvents -| where timestamp >= startofday(ago(7d)) and timestamp < startofday(now()) -| where type == "Billing" -| extend BillingTelemetryType = tostring(dimensions["BillingTelemetryType"]) -| extend BillingTelemetrySizeInBytes = todouble(measurements["BillingTelemetrySize"]) -| summarize sum(BillingTelemetrySizeInBytes) by BillingTelemetryType, bin(timestamp, 1d) -``` --### Data volume trends for workspace-based resources -To look at the data volume trends for [workspace-based Application Insights resources](../app/create-workspace-resource.md), use a query that includes all the Application Insights tables. The following queries use the [table names specific to workspace-based resources](../app/apm-tables.md#table-schemas). --**Daily data volume by type for all Application Insights resources in a workspace for 7 days** --```kusto -union AppAvailabilityResults, - AppBrowserTimings, - AppDependencies, - AppExceptions, - AppEvents, - AppMetrics, - AppPageViews, - AppPerformanceCounters, - AppRequests, - AppSystemEvents, - AppTraces -| where TimeGenerated >= startofday(ago(7d)) and TimeGenerated < startofday(now()) -| summarize sum(_BilledSize) by _ResourceId, bin(TimeGenerated, 1d) -``` --To look at the data volume trends for only a single Application Insights resource, add the following line before `summarize` in the preceding query: --```kusto -| where _ResourceId contains "<myAppInsightsResourceName>" -``` --> [!TIP] -> For workspaces with large data volumes, doing queries such as the preceding one, which query large volumes of raw data, might need to be restricted to a single day. To track trends over time, consider setting up a [Power BI report](./log-powerbi.md) and using [incremental refresh](./log-powerbi.md#collect-data-with-power-bi-dataflows) to collect data volumes per resource once a day. --## Understand nodes sending data -If you don't have excessive data from any particular source, you might have an excessive number of agents that are sending data. --**Count of agent nodes that are sending a heartbeat each day in the last month** --```kusto -Heartbeat -| where TimeGenerated > startofday(ago(31d)) -| summarize nodes = dcount(Computer) by bin(TimeGenerated, 1d) -| render timechart -``` --> [!WARNING] -> Use [find](/azure/data-explorer/kusto/query/findoperator?pivots=azuremonitor) queries sparingly because scans across data types are [resource intensive](./query-optimization.md#query-details-pane) to execute. If you don't need results per subscription, resource group, or resource name, use the [Usage](/azure/azure-monitor/reference/tables/usage) table as in the preceding queries. --**Count of nodes sending any data in the last 24 hours** --```kusto -find where TimeGenerated > ago(24h) project Computer -| extend computerName = tolower(tostring(split(Computer, '.')[0])) -| where computerName != "" -| summarize nodes = dcount(computerName) -``` --**Data volume sent by each node in the last 24 hours** --```kusto -find where TimeGenerated > ago(24h) project _BilledSize, Computer -| extend computerName = tolower(tostring(split(Computer, '.')[0])) -| where computerName != "" -| summarize TotalVolumeBytes=sum(_BilledSize) by computerName -``` --## Nodes billed by the legacy Per Node pricing tier -The [legacy Per Node pricing tier](cost-logs.md#legacy-pricing-tiers) bills for nodes with hourly granularity. It also doesn't count nodes that are only sending a set of security data types. To get a list of computers that will be billed as nodes if the workspace is in the legacy Per Node pricing tier, look for nodes that are sending billed data types because some data types are free. In this case, use the leftmost field of the fully qualified domain name. --The following queries return the count of computers with billed data per hour. The number of units on your bill is in units of node months, which is represented by `billableNodeMonthsPerDay` in the query. If the workspace has the Update Management solution installed, add the **Update** and **UpdateSummary** data types to the list in the `where` clause. --```kusto -find where TimeGenerated >= startofday(ago(7d)) and TimeGenerated < startofday(now()) project Computer, _IsBillable, Type, TimeGenerated -| where Type !in ("SecurityAlert", "SecurityBaseline", "SecurityBaselineSummary", "SecurityDetection", "SecurityEvent", "WindowsFirewall", "MaliciousIPCommunication", "LinuxAuditLog", "SysmonEvent", "ProtectionStatus", "WindowsEvent") -| extend computerName = tolower(tostring(split(Computer, '.')[0])) -| where computerName != "" -| where _IsBillable == true -| summarize billableNodesPerHour=dcount(computerName) by bin(TimeGenerated, 1h) -| summarize billableNodesPerDay = sum(billableNodesPerHour)/24., billableNodeMonthsPerDay = sum(billableNodesPerHour)/24./31. by day=bin(TimeGenerated, 1d) -| sort by day asc -``` --> [!NOTE] -> Some complexity in the actual billing algorithm when solution targeting is used isn't represented in the preceding query. --## Security and automation node counts --**Count of distinct security nodes** --```kusto -union -( - Heartbeat - | where (Solutions has 'security' or Solutions has 'antimalware' or Solutions has 'securitycenter') - | project Computer -), -( - ProtectionStatus - | where Computer !in (Heartbeat | project Computer) - | project Computer -) -| distinct Computer -| project lowComputer = tolower(Computer) -| distinct lowComputer -| count -``` --**Number of distinct automation nodes** --```kusto - ConfigurationData - | where (ConfigDataType == "WindowsServices" or ConfigDataType == "Software" or ConfigDataType =="Daemons") - | extend lowComputer = tolower(Computer) | summarize by lowComputer - | join ( - Heartbeat - | where SCAgentChannel == "Direct" - | extend lowComputer = tolower(Computer) | summarize by lowComputer, ComputerEnvironment - ) on lowComputer - | summarize count() by ComputerEnvironment | sort by ComputerEnvironment asc -``` --## Late-arriving data -If you observe high data ingestion reported by using `Usage` records, but you don't observe the same results summing `_BilledSize` directly on the data type, it's possible that you have late-arriving data. This situation occurs when data is ingested with old timestamps. --For example, an agent might have a connectivity issue and send accumulated data when it reconnects. Or a host might have an incorrect time. Either example can result in an apparent discrepancy between the ingested data reported by the [Usage](/azure/azure-monitor/reference/tables/usage) data type and a query summing [_BilledSize](./log-standard-columns.md#_billedsize) over the raw data for a particular day specified by **TimeGenerated**, the timestamp when the event was generated. --To diagnose late-arriving data issues, use the [_TimeReceived](./log-standard-columns.md#_timereceived) column and the [TimeGenerated](./log-standard-columns.md#timegenerated) column. The `_TimeReceived` property is the time when the record was received by the Azure Monitor ingestion point in the Azure cloud. --The following example is in response to high ingested data volumes of [W3CIISLog](/azure/azure-monitor/reference/tables/w3ciislog) data on May 2, 2021, to identify the timestamps on this ingested data. The `where TimeGenerated > datetime(1970-01-01)` statement is included to provide the clue to the Log Analytics user interface to look over all data. --```Kusto -W3CIISLog -| where TimeGenerated > datetime(1970-01-01) -| where _TimeReceived >= datetime(2021-05-02) and _TimeReceived < datetime(2021-05-03) -| where _IsBillable == true -| summarize BillableDataMB = sum(_BilledSize)/1.E6 by bin(TimeGenerated, 1d) -| sort by TimeGenerated asc -``` --## Next steps --- See [Azure Monitor Logs pricing details](cost-logs.md) for information on how charges are calculated for data in a Log Analytics workspace and different configuration options to reduce your charges.-- See [Azure Monitor cost and usage](../cost-usage.md) for a description of the different types of Azure Monitor charges and how to analyze them on your Azure bill.-- See [Azure Monitor best practices - Cost management](../best-practices-cost.md) for best practices on configuring and managing Azure Monitor to minimize your charges.-- See [Data collection transformations in Azure Monitor (preview)](../essentials/data-collection-transformations.md) for information on using transformations to reduce the amount of data you collected in a Log Analytics workspace by filtering unwanted records and columns.- |
| azure-monitor | Access Api | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/api/access-api.md | - Title: API access and authentication -description: Learn how to authenticate and access the Azure Monitor Log Analytics API. Previously updated : 05/30/2024-----# Access the Azure Monitor Log Analytics API --You can submit a query request to a workspace by using the Azure Monitor Log Analytics endpoint `https://api.loganalytics.azure.com`. To access the endpoint, you must authenticate through Microsoft Entra ID. -->[!Note] -> The `api.loganalytics.io` endpoint is being replaced by `api.loganalytics.azure.com`. The `api.loganalytics.io` endpoint will continue to be supported for the forseeable future. --## Authenticate with a demo API key --To quickly explore the API without Microsoft Entra authentication, use the demonstration workspace with sample data, which supports API key authentication. --To authenticate and run queries against the sample workspace, use `DEMO_WORKSPACE` as the {workspace-id} and pass in the API key `DEMO_KEY`. --If either the Application ID or the API key is incorrect, the API service returns a [403](https://en.wikipedia.org/wiki/List_of_HTTP_status_codes#4xx_Client_Error) (Forbidden) error. --The API key `DEMO_KEY` can be passed in three different ways, depending on whether you want to use a header, the URL, or basic authentication: --- **Custom header**: Provide the API key in the custom header `X-Api-Key`.-- **Query parameter**: Provide the API key in the URL parameter `api_key`.-- **Basic authentication**: Provide the API key as either username or password. If you provide both, the API key must be in the username.--This example uses the workspace ID and API key in the header: --``` - POST https://api.loganalytics.azure.com/v1/workspaces/DEMO_WORKSPACE/query - X-Api-Key: DEMO_KEY - Content-Type: application/json - - { - "query": "AzureActivity | summarize count() by Category" - } -``` --## Public API endpoint --The public API endpoint is: --``` - https://api.loganalytics.azure.com/{api-version}/workspaces/{workspaceId} -``` -where: - -The query is passed in the request body. - -For example: - ``` - https://api.loganalytics.azure.com/v1/workspaces/1234abcd-def89-765a-9abc-def1234abcde - - Body: - { - "query": "Usage" - } -``` --## Set up authentication --To access the API, you register a client app with Microsoft Entra ID and request a token. --1. [Register an app in Microsoft Entra ID](./register-app-for-token.md). --1. On the app's overview page, select **API permissions**. -1. Select **Add a permission**. -1. On the **APIs my organization uses** tab, search for **Log Analytics** and select **Log Analytics API** from the list. -- :::image type="content" source="../media/api-register-app/request-api-permissions.png" alt-text="A screenshot that shows the Request API permissions page."::: --1. Select **Delegated permissions**. -1. Select the **Data.Read** checkbox. -1. Select **Add permissions**. -- :::image type="content" source="../media/api-register-app/add-requested-permissions.png" alt-text="A screenshot that shows the continuation of the Request API permissions page."::: --Now that your app is registered and has permissions to use the API, grant your app access to your Log Analytics workspace. --1. From your **Log Analytics workspace** overview page, select **Access control (IAM)**. -1. Select **Add role assignment**. -- :::image type="content" source="../media/api-register-app/workspace-access-control.png" alt-text="A screenshot that shows the Access control page for a Log Analytics workspace."::: --1. Select the **Reader** role and then select **Members**. -- :::image type="content" source="../media/api-register-app/add-role-assignment.png" alt-text="A screenshot that shows the Add role assignment page for a Log Analytics workspace."::: --1. On the **Members** tab, choose **Select members**. -1. Enter the name of your app in the **Select** box. -1. Select your app and choose **Select**. -1. Select **Review + assign**. -- :::image type="content" source="../media/api-register-app/select-members.png" alt-text="A screenshot that shows the Select members pane on the Add role assignment page for a Log Analytics workspace."::: --1. After you finish the Active Directory setup and workspace permissions, request an authorization token. -->[!Note] -> For this example, we applied the Reader role. This role is one of many built-in roles and might include more permissions than you require. More granular roles and permissions can be created. For more information, see [Manage access to Log Analytics workspaces](../../logs/manage-access.md). --## Request an authorization token --Before you begin, make sure you have all the values required to make the request successfully. All requests require: -- Your Microsoft Entra tenant ID.-- Your workspace ID.-- Your Microsoft Entra client ID for the app.-- A Microsoft Entra client secret for the app.--The Log Analytics API supports Microsoft Entra authentication with three different [Microsoft Entra ID OAuth2](/azure/active-directory/develop/active-directory-protocols-oauth-code) flows: -- Client credentials-- Authorization code-- Implicit--### Client credentials flow --In the client credentials flow, the token is used with the Log Analytics endpoint. A single request is made to receive a token by using the credentials provided for your app in the previous step when you [register an app in Microsoft Entra ID](./register-app-for-token.md). --Use `resource=https://api.loganalytics.azure.com`. ----Use the token in requests to the Log Analytics endpoint: --```http - POST /v1/workspaces/your workspace id/query?timespan=P1D - Host: https://api.loganalytics.azure.com - Content-Type: application/json - Authorization: Bearer <your access token> -- Body: - { - "query": "AzureActivity |summarize count() by Category" - } -``` --Example response: --```http - { - "tables": [ - { - "name": "PrimaryResult", - "columns": [ - { - "name": "OperationName", - "type": "string" - }, - { - "name": "Level", - "type": "string" - }, - { - "name": "ActivityStatus", - "type": "string" - } - ], - "rows": [ - [ - "Metric Alert", - "Informational", - "Resolved", - ... - ], - ... - ] - }, - ... - ] - } -``` --### Authorization code flow --The main OAuth2 flow supported is through [authorization codes](/azure/active-directory/develop/active-directory-protocols-oauth-code). This method requires two HTTP requests to acquire a token with which to call the Azure Monitor Log Analytics API. There are two URLs, with one endpoint per request. Their formats are described in the following sections. --#### Authorization code URL (GET request) --```http - GET https://login.microsoftonline.com/YOUR_Azure AD_TENANT/oauth2/authorize? - client_id=<app-client-id> - &response_type=code - &redirect_uri=<app-redirect-uri> - &resource=https://api.loganalytics.io -``` --When a request is made to the authorize URL, the client\_id is the application ID from your Microsoft Entra app, copied from the app's properties menu. The redirect\_uri is the homepage/login URL from the same Microsoft Entra app. When a request is successful, this endpoint redirects you to the sign-in page you provided at sign-up with the authorization code appended to the URL. See the following example: --```http - http://<app-client-id>/?code=AUTHORIZATION_CODE&session_state=STATE_GUID -``` --At this point, you've obtained an authorization code, which you need now to request an access token. --#### Authorization code token URL (POST request) --```http - POST /YOUR_Azure AD_TENANT/oauth2/token HTTP/1.1 - Host: https://login.microsoftonline.com - Content-Type: application/x-www-form-urlencoded - - grant_type=authorization_code - &client_id=<app client id> - &code=<auth code fom GET request> - &redirect_uri=<app-client-id> - &resource=https://api.loganalytics.io - &client_secret=<app-client-secret> -``` --All values are the same as before, with some additions. The authorization code is the same code you received in the previous request after a successful redirect. The code is combined with the key obtained from the Microsoft Entra app. If you didn't save the key, you can delete it and create a new one from the keys tab of the Microsoft Entra app menu. The response is a JSON string that contains the token with the following schema. Types are indicated for the token values. --Response example: --```http - { - "access_token": "eyJ0eXAiOiJKV1QiLCJ.....Ax", - "expires_in": "3600", - "ext_expires_in": "1503641912", - "id_token": "not_needed_for_log_analytics", - "not_before": "1503638012", - "refresh_token": "eyJ0esdfiJKV1ljhgYF.....Az", - "resource": "https://api.loganalytics.io", - "scope": "Data.Read", - "token_type": "bearer" - } -``` --The access token portion of this response is what you present to the Log Analytics API in the `Authorization: Bearer` header. You can also use the refresh token in the future to acquire a new access\_token and refresh\_token when yours have gone stale. For this request, the format and endpoint are: --```http - POST /YOUR_AAD_TENANT/oauth2/token HTTP/1.1 - Host: https://login.microsoftonline.com - Content-Type: application/x-www-form-urlencoded - - client_id=<app-client-id> - &refresh_token=<refresh-token> - &grant_type=refresh_token - &resource=https://api.loganalytics.io - &client_secret=<app-client-secret> -``` --Response example: --```http - { - "token_type": "Bearer", - "expires_in": "3600", - "expires_on": "1460404526", - "resource": "https://api.loganalytics.io", - "access_token": "eyJ0eXAiOiJKV1QiLCJ.....Ax", - "refresh_token": "eyJ0esdfiJKV1ljhgYF.....Az" - } -``` --### Implicit code flow --The Log Analytics API supports the OAuth2 [implicit flow](/azure/active-directory/develop/active-directory-dev-understanding-oauth2-implicit-grant). For this flow, only a single request is required, but no refresh token can be acquired. --#### Implicit code authorize URL --```http - GET https://login.microsoftonline.com/YOUR_AAD_TENANT/oauth2/authorize? - client_id=<app-client-id> - &response_type=token - &redirect_uri=<app-redirect-uri> - &resource=https://api.loganalytics.io -``` --A successful request produces a redirect to your redirect URI with the token in the URL: --```http - http://YOUR_REDIRECT_URI/#access_token=YOUR_ACCESS_TOKEN&token_type=Bearer&expires_in=3600&session_state=STATE_GUID -``` --This access\_token can be used as the `Authorization: Bearer` header value when it's passed to the Log Analytics API to authorize requests. --## More information --You can find documentation about OAuth2 with Microsoft Entra here: --## Next steps --- [Request format](./request-format.md)-- [Response format](./response-format.md)-- [Querying logs for Azure resources](./azure-resource-queries.md)-- [Batch queries](./batch-queries.md) |
| azure-monitor | Azure Resource Queries | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/api/azure-resource-queries.md | - Title: Querying logs for Azure resources -description: In Log Analytics, queries typically execute in the context of a workspace. A workspace may contain data for many resources, making it difficult to isolate data for a particular resource. Previously updated : 08/12/2024-----# Querying logs for Azure resources --In Azure Monitor Log Analytics, queries typically execute in the context of a workspace. A workspace may contain data for many resources, making it difficult to isolate data for a particular resource. Resources may additionally send data to multiple workspaces. To simplify this experience, the REST API permits querying Azure resources directly for their logs. --## Response format --Azure resource queries produce the [same response shape](response-format.md) as queries targeting a Log Analytics workspace. --## URL format --Consider an Azure resource with a fully qualified identifier: --``` - /subscriptions/<sid>/resourceGroups/<rg>/providers/<providerName>/<resourceType>/<resourceName> -``` --A query for this resource's logs against the direct API endpoint would go to the following URL: --``` - https://api.loganalytics.azure.com/v1/subscriptions/<sid>/resourceGroups/<rg>/providers/<providerName>/<resourceType>/<resourceName>/query -``` --A query to the same resource via ARM would use the following URL: --``` - https://management.azure.com/subscriptions/<sid>/resourceGroups/<rg>/providers/<providerName>/<resourceType>/<resourceName>/providers/microsoft.insights/logs?api-version=2018-03-01-preview -``` --Essentially, this URL is the fully qualified Azure resource plus the extension provider: `/providers/microsoft.insights/logs`. --## Table access and RBAC --The `microsoft.insights` resource provider exposes a new set of operations for controlling access to logs at the table level. These operations have the following format for a table named `tableName`. --``` - microsoft.insights/logs/<tableName>/read -``` --This permission can be added to roles using the ΓÇÿactionsΓÇÖ property to allow specified tables and the ΓÇÿnotActionsΓÇÖ property to disallow specified tables. --## Workspace access control --Today, Azure resource queries look over Log Analytics workspaces as possible data sources. However, administrators may have locked down access to the workspace via RBAC roles. By default, the API only returns results from workspaces the user has permissions to access. --Workspace administrators may want to utilize Azure resource queries without breaking existing RBAC, creating a scenario where a user may have access to read the logs for an Azure resource, but may not have permission to query the workspace containing those logs. Workspace administrators resource, to view logs via a boolean property on the workspace. This allows users to access the logs pertaining to the target Azure resource in a particular workspace, so long as the user has access to read the logs for the target Azure resource. --This is the action for scoping access to Tables at the workspace level: --``` - microsoft.operationalinsights/workspaces/query/<tableName>/read -``` --## Error responses --Below is a brief listing of common failure scenarios when querying Azure resources along with a description of symptomatic behavior. --### Azure resource does not exist --``` - HTTP/1.1 404 Not Found - { - "error": { - "message": "The resource /subscriptions/7fd50ca7-1e78-4144-ab9c-0ec2faafa046/resourcegroups/test-rg/providers/microsoft.storage/storageaccounts/exampleResource was not found", - "code": "ResourceNotFoundError" - } - } -``` -### No access to resource --``` - HTTP/1.1 403 Forbidden - { - "error": { - "message": "The provided credentials have insufficient access to perform the requested operation", - "code": "InsufficientAccessError", - "innererror": { - "code": "AuthorizationFailedError", - "message": "User '92eba38a-70da-42b0-ab83-ffe82cce658f' does not have access to read logs for this resource" - } - } -``` --### No logs from resource, or no permission to workspace containing those logs --Depending on the precise combination of data and permissions, the response will either contain a 200 with no resulting data or will throw a syntax error (4xx error). --## Partial access --There are some scenarios where a user may have partial permissions to access a particular resource's logs. When a user is missing either: -- - Access to the workspace containing logs for the Azure resource - - Access to the tables reference in the query --They will see a normal response, with data sources the user does not have permissions to access silently filtered out. To see information about a user's access to an Azure resource, the underlying Log Analytics workspaces, and to specific tables, include the header `Prefer: include-permissions=true` with requests. This will cause the response JSON to include a section like the following: --``` - { - "permissions": { - "resources": [ - { - "resourceId": "/subscriptions/<id>/resourceGroups<id>/providers/Microsoft.Compute/virtualMachines/VM1", - "dataSources": [ - "/subscriptions/<id>/resourceGroups<id>/providers/Microsoft.OperationalInsights/workspaces/WS1" - ] - }, - { - "resourceId": "/subscriptions/<id>/resourceGroups<id>/providers/Microsoft.Compute/virtualMachines/VM2", - "denyTables": [ - "SecurityEvent", - "SecurityBaseline" - ], - "dataSources": [ - "/subscriptions/<id>/resourceGroups<id>/providers/Microsoft.OperationalInsights/workspaces/WS2", - "/subscriptions/<id>/resourceGroups<id>/providers/Microsoft.OperationalInsights/workspaces/WS3" - ] - } - ], - "dataSources": [ - { - "resourceId": "/subscriptions/<id>/resourceGroups<id>/providers/Microsoft.OperationalInsights/workspaces/WS1", - "denyTables": [ - "Tables.Custom" - ] - }, - { - "resourceId": "/subscriptions/<id>/resourceGroups<id>/providers/Microsoft.OperationalInsights/workspaces/WS2" - } - ] - } - } -``` --The `resources` payload describes an attempt to query two VMs. VM1 sends data to workspace WS1, while VM2 sends data to two workspaces: WS2 and WS3. Additionally, the user does not have permission to query the `SecurityEvent` or `SecurityBaseline` tables for the resource. --The `dataSources` payload filters the results further by describing which workspaces the user can query. Here the user does not have permissions to query WS3, and an additional table filtered out of WS1. --To clearly state what data such a query would return: -- - Logs for VM1 in WS1, excluding Tables.Custom from the workspace. - - Logs for VM2, excluding SecurityEvent and SecurityBaseline, in WS2. |
| azure-monitor | Batch Queries | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/api/batch-queries.md | - Title: Batch queries -description: The Azure Monitor Log Analytics API supports batching. Previously updated : 08/12/2024-----# Batch queries --The Azure Monitor Log Analytics API supports batching queries together. Batch queries currently require Microsoft Entra authentication. --## Request format -To batch queries, use the API endpoint, adding $batch at the end of the URL: `https://api.loganalytics.azure.com/v1/$batch`. --If no method is included, batching defaults to the GET method. On GET requests, the API ignores the body parameter of the request object. --The batch request includes regular headers for other operations: --``` - Content-Type: application/json - Authorization: Bearer <user token> -``` --The body of the request is an array of objects containing the following properties: - -Example: --``` - POST https://api.loganalytics.azure.com/v1/$batch - Content-Type: application/json - Authorization: Bearer <user token> - Cache-Control: no-cache - { - "requests": - [ - { - "id": "1", - "headers": { - "Content-Type": "application/json" - }, - "body": { - "query": "AzureActivity | summarize count()", - "timespan": "PT1H" - }, - "method": "POST", - "path": "/query", - "workspace": "workspace-1" - }, - { - "id": "2", - "headers": { - "Content-Type": "application/json" - }, - "body": { - "query": "ApplicationInsights | limit 10", - "timespan": "PT1H" - }, - "method": "POST", - "path": "/fakePath", - "workspace": "workspace-2" - } - ] - } -``` --## Response format --The response format is a similar array of objects. Each object contains: - -If a query doesn't return successfully, the response body contains error messages. The error messages only apply to the individual queries in the batch; the batch itself returns a status code independent of the return values of its members. -The batch returns successfully if the batch is: - The batch returns successfully even when the results of its member queries may be a mix of successes and failures. --Example --``` - { - "responses": - [ - { - "id": "2", - "status": 404, - "body": { - "error": { - "message": "The requested path does not exist", - "code": "PathNotFoundError" - } - } - }, - { - "id": "1", - "status": 200, - "body": { - "tables": [ - { - "name": "PrimaryResult", - "columns": [ - { - "name": "Count", - "type": "long" - } - ], - "rows": [ - [ - 7240 - ] - ] - } - ] - } - } - ] - } -``` --## Behavior and errors -The order of responses inside the returned object isn't related to the order in the request. It is determined by time it takes each individual query to complete. Use IDs to map the query response objects to the original requests. Don't assume that the query responses are in order. --An entire batch request only fails if: ---Under these conditions, the shape of the response will be different from the normal container. The objects contained within the batch object may each fail or succeed independently. See below for an example. -## Example errors --This list is a non-exhaustive list of examples of possible errors and their meanings. --- 400 - Malformed request. The outer request object was not valid JSON.--``` - { - "error": { - "message": "The request had some invalid properties", - "code": "BadArgumentError", - "innererror": { - "code": "QueryValidationError", - "message": "Failed parsing the query", - "details": [ - { - "code": "InvalidJsonBody", - "message": "Unexpected end of JSON input", - "target": null - } - ] - } - } - } -``` --- 403 - Forbidden. The token provided does not have access to the resource you are trying to access. Make sure that your token request has the correct resource, and you have granted permissions for your Microsoft Entra application.--``` - { - "error": { - "message": "The provided authentication is not valid for this resource", - "code": "InvalidTokenError", - "innererror": { - "code": "SignatureVerificationFailed", - "message": "Could not validate the request" - } - } - } -``` --- 204 - Not Placed. You have no data for the API to pull in the backing store. As a 2xx this is technically a successful request. However, in a batch, it's useful to note the error.--``` - { - "responses": [ - { - "id": "2", - "status": 204, - "body": { - "error": { - "code": "WorkspaceNotPlacedError" - } - } - } - ] - } -``` --- 404 - Not found. The query path does not exist. This error can also occur in a batch if you specify an invalid HTTP method in the individual request.--``` - { - "responses": [ - { - "id": "1", - "status": 404, - "body": { - "error": { - "message": "The requested path does not exist", - "code": "PathNotFoundError" - } - } - } - ] - } -``` --- 400 - Failed to resolve resource. The GUID representing the workspace is incorrect.--``` - { - "responses": [ - { - "id": "1", - "status": 400, - "body": { - "error": { - "code": "FailedToResolveResource", - "message": "Resource identity could not be resovled" - } - } - } - ] - } -``` |
| azure-monitor | Cache | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/api/cache.md | - Title: Caching -description: To improve performance, responses can be served from a cache. By default, responses are stored for 2 minutes. Previously updated : 08/12/2024-----# Caching -To improve performance, responses can be served from a cache. By default, responses are stored for 2 minutes. --## Request -Cache options can be set with the `Cache-Control` header in the HTTP request, see [here](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Cache-Control) for more information. --The API supports the standard `max-age`, `no-cache`, and `no-store` directives. --For example, the following request allows a maximum cache age of 30 seconds --``` - POST https://api.loganalytics.azure.com/v1/workspaces/{workspace-id}/query - Authorization: Bearer <access token> - Cache-Control: max-age=30 - - { - "query" : "Heartbeat | count" - } -``` -## Response --If a response is returned from the cache, the `Age` header specifies the staleness of the response in seconds. --For example, the following response is 13 seconds stale. --``` - HTTP/1.1 200 OK - Age: 13 - Content-Type: application/json; charset=utf-8 - - { - "tables": [ - { - "name": "PrimaryResult", - "columns": [ - { - "name": "count_", - "type": "long" - } - ], - "rows": [ - [ - 1939908516 - ] - ] - } - ] - } -``` |
| azure-monitor | Cross Workspace Queries | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/api/cross-workspace-queries.md | - Title: Cross workspace queries -description: The API supports the ability to query across multiple workspaces. Previously updated : 07/21/2024-----# Cross workspace queries --The API allows you to query across multiple workspaces. There are two ways to execute these queries: implicit and explicit. The implicit method performs an automatic union over data in the requested workspace, while the explicit method allows more precision and control over how to access data from each workspace. --The maximum number of resources in any cross-resource query is limited to 10. --## Resource identifiers --For either implicit or explicit cross-workspace queries, you need to specify the resources you will be accessing. There are four types of identifiers: ---> [!NOTE] -> We strongly recommend identifying a workspace by its unique Workspace ID or Azure Resource ID because they remove ambiguity and are more performant. --## Implicit cross workspace queries --For implicit syntax, specify the workspaces that you want to include in your query scope. The API performs a single query over each application provided in your list. The syntax for a cross-workspace POST is: --Example: --``` - POST https://api.loganalytics.azure.com/v1/workspaces/00000000-0000-0000-0000-000000000000/query - - Authorization: Bearer <user token> - Content-Type: application/json - - { - "query": "union * | where TimeGenerated > ago(1d) | summarize count() by Type, TenantId", - "workspaces": ["AIFabrikamDemo1", "AIFabrikamDemo2"] - } -``` --The same request as a GET (line breaks for readability of query parameters): --``` - GET https://api.loganalytics.azure.com/v1/workspaces/00000000-0000-0000-0000-000000000000/query?query=union+*+%7C+where+TimeGenerated+%3E+ago(1d)+%7C+summarize+count()+by+Type%2C+TenantId&workspaces=AIFabrikamDemo1%2CAIFabrikamDemo2 - - - Authorization: Bearer <user token> - Content-Type: application/json -``` --This query would run over AIFabrikamDemo1, AIFabrikamDemo2, and the workspace represented by the GUID 00000000-0000-0000-0000-000000000000, returning the union of the results. In the GET version, the workspaces query parameters is a comma-separated list of resources to query. --## Explicit cross workspace queries --In some cases, you might want the query to operate over a more targeted subset of the data in the workspaces of interest, combining data from multiple workspaces. In these cases, explicitly mention a workspace and table in the query, similar to making cross-cluster or cross-database queries or joins between tables. --The syntax to reference another application is: workspace('identifier').table. --Example: --``` - POST https://api.loganalytics.azure.com/v1/workspaces/00000000-0000-0000-0000-000000000000/query - Content-Type: application/json - Authorization: Bearer <user token> - - { - "query": "union (AzureActivity | where timestamp > ago(1d)), (workspaces('00000000-0000-0000-0000-000000000000').AzureActivity | where timestamp> ago(1d))" - } -``` --You can also URL encode this query and make it a GET request. In this case, there is no query parameter for other workspaces since the workspaces will get referenced from inside the query. --## Throttling --For the purposes of rate limiting, one cross-resource query counts as one API query, regardless of the number of resources in the query. |
| azure-monitor | Errors | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/api/errors.md | - Title: Azure Monitor Log Analytics API errors -description: This section contains a non-exhaustive list of known common errors that can occur in the Azure Monitor Log Analytics API, their causes, and possible solutions. Previously updated : 08/12/2024-----# Azure Monitor Log Analytics API errors --This section contains a non-exhaustive list of known common errors, their causes, and possible solutions. It also contains successful responses, which often indicate an issue with the request (such as a missing header) or otherwise unexpected behavior. --## Query syntax error --400 response: --``` - { - "error": { - "message": "The request had some invalid properties", - "code": "BadArgumentError", - "innererror": { - "code": "SyntaxError", - "message": "Syntax Error" - } - } - } -``` --The query string is malformed. Check for extra spaces, punctuation, or spelling errors. --## No authentication provided --401 response: --``` - { - "error": { - "code": "AuthenticationFailed", - "message": "Authentication failed. The 'Authorization' header is missing." - } - } -``` --Include a form of authentication with your request, such as the header `"Authorization: Bearer \<token\>"`. --## Invalid authentication token --403 response: --``` - { - "error": { - "code": "InvalidAuthenticationToken", - "message": "The access token is invalid." - } - } -``` --The token is malformed or otherwise invalid. This error can occur if you manually copy and paste the token and add or cut characters to the payload. Verify that the token is exactly as received from Microsoft Entra ID. --## Invalid token audience --403 response: --``` - { - "error": { - "code": "InvalidAuthenticationTokenAudience", - "message": "The access token has been obtained from wrong audience or resource 'https://api.loganalytics.io'. It should exactly match (including forward slash) with one of the allowed audiences 'https://management.core.windows.net/','https://management.azure.com/'." - } - } -``` --This error occurs if you try to use the client credentials OAuth2 flow to obtain a token for the API and then use that token via the Azure Resource Manager endpoint. Use one of the indicated URLs as the resource in your token request if you want to use the Azure Resource Manager endpoint. Alternatively, you can use the direct API endpoint with a different OAuth2 flow for authorization. --## Client credentials to direct API --403 response: --``` - { - "error": { - "message": "The provided credentials have insufficient access to perform the requested operation", - "code": "InsufficientAccessError", - "innererror": { - "code": "UnauthorizedClient", - "message": "The service principal does not have sufficient permissions to access this resource: 997631f8-3a55-4bb2-81b2-c0972b222260" - } - } - } -``` --This error can occur if you try to use client credentials via the direct API endpoint. If you're using the direct API endpoint, use a different OAuth2 flow for authorization. If you must use client credentials, use the Azure Resource Manager API endpoint. --## Insufficient permissions --403 response: --``` - { - "error": { - "message": "The provided credentials have insufficient access to perform the requested operation", - "code": "InsufficientAccessError" - } - } -``` --The token you've presented for authorization belongs to a user who doesn't have sufficient access to this privilege. Verify that your workspace GUID and your token request are correct. If necessary, grant IAM privileges in your workspace to the Microsoft Entra application you created as Contributor. --> [!NOTE] -> When you use Microsoft Entra authentication, it might take up to 60 minutes for the Application Insights REST API to recognize new role-based access control permissions. While permissions are propagating, REST API calls might fail with error code 403. --## Bad authorization code --403 response: --``` - { - "error": "invalid_grant", - "error_description": "AADSTS70002: Error validating credentials. AADSTS70008: The provided authorization code or refresh token is expired. Send a new interactive authorization request for this user and resource.", - "error_codes": [ - 70002, - 70008 - ] - } -``` --The authorization code submitted in the token request was either stale or previously used. Reauthorize via the Microsoft Entra authorize endpoint to get a new code. --## Path not found --404 response: --``` - { - "error": { - "message": "The requested path does not exist", - "code": "PathNotFoundError" - } - } -``` --The requested query path doesn't exist. Verify the URL spelling of the endpoint you're hitting and that you're using a supported HTTP verb. --## Missing JSON or Content-Type --200 response: Empty body --If you send a POST request that's missing either JSON body or the `"Content-Type: application/json"` header, we return an empty 200 response. --## No data in workspace --204 response: Empty body --If a workspace has no data in it, we return 204 No Content. |
| azure-monitor | Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/api/overview.md | - Title: Overview -description: This article describes the REST API that makes the data collected by Azure Log Analytics easily available. Previously updated : 05/26/2024-----# Azure Monitor Log Analytics API overview --The Log Analytics Query API is a REST API that you can use to query the full set of data collected by Azure Monitor logs. You can use the same query language that's used throughout the service. Use this API to retrieve data, build new visualizations of your data, and extend the capabilities of Log Analytics. --## Log Analytics API authentication --You must authenticate to access the Log Analytics API: -- To query your workspaces, you must use [Microsoft Entra authentication](../../../active-directory/fundamentals/active-directory-whatis.md).-- To quickly explore the API without using Microsoft Entra authentication, you can use an API key to query sample data in a non-production environment.--<a name='azure-ad-authentication-for-workspace-data'></a> --### Microsoft Entra authentication for workspace data --The Log Analytics API supports Microsoft Entra authentication with three different [Microsoft Entra ID OAuth2](/azure/active-directory/develop/active-directory-protocols-oauth-code) flows: -- Authorization code-- Implicit-- Client credentials--The authorization code flow and implicit flow both require at least one user interactive sign-in to your application. If you need a non-interactive flow, use the client credentials flow. --After you receive a token, the process for calling the Log Analytics API is the same for all flows. Requests require the `Authorization: Bearer` header, populated with the token received from the OAuth2 flow. --### API key authentication for sample data --To quickly explore the API without using Microsoft Entra authentication, we provide a demonstration workspace with sample data. You can [authenticate by using an API key](./access-api.md#authenticate-with-a-demo-api-key). --> [!NOTE] -> When you use Microsoft Entra authentication, it might take up to 60 minutes for the Application Insights REST API to recognize new role-based access control permissions. While permissions are propagating, REST API calls might fail with [error code 403](./errors.md#insufficient-permissions). --## Log Analytics API query limits --For information about query limits, see the [Query API section of this webpage](../../service-limits.md). --## Try the Log Analytics API --To try the API without writing any code, you can use: - - Your favorite client such as [Fiddler](https://www.telerik.com/fiddler) or [Postman](https://www.getpostman.com/) to manually generate queries with a user interface. - - [cURL](https://curl.haxx.se/) from the command line. Then pipe the output into [jsonlint](https://github.com/zaach/jsonlint) to get readable JSON. --Instead of calling the REST API directly, you can use the idiomatic Azure Monitor Query client libraries: --- [.NET](/dotnet/api/overview/azure/Monitor.Query-readme)-- [Go](https://pkg.go.dev/github.com/Azure/azure-sdk-for-go/sdk/monitor/query/azlogs)-- [Java](/java/api/overview/azure/monitor-query-readme)-- [JavaScript](/javascript/api/overview/azure/monitor-query-readme)-- [Python](/python/api/overview/azure/monitor-query-readme)--Each client library is a wrapper around the REST API that allows you to retrieve log data from the workspace. |
| azure-monitor | Prefer Options | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/api/prefer-options.md | - Title: Prefer options -description: The API supports setting some request options using the Prefer header. This section describes how to set each preference and their values. Previously updated : 08/12/2024-----# Prefer options --The API supports setting some request and response options using the `Prefer` header. This section describes how to set each preference and their values. --## Visualization information --In the query language, you can specify different render options. By default, the API doesn't return information about the type of visualization. To include a specific visualization, include this header: --``` - Prefer: include-render=true -``` --The header includes a `render` property in the response that specifies the type of visualization selected by the query and any properties for that visualization. --For example, the following request specifies a visualization of a bar chart with title "Perf events in the last day": --``` - POST https://api.loganalytics.azure.com/v1/workspaces/{workspace-id}/query - Authorization: Bearer <access token> - Prefer: include-render=true - Content-Type: application/json - - { - "query": "Perf | summarize count() by bin(TimeGenerated, 4h) | render barchart title='24H Perf events'", - "timespan": "P1D" - } -``` --The response contains a `render` property, which describes the metadata for the selected visualization. --``` - HTTP/1.1 200 OK - Content-Type: application/json; charset=utf-8 - - { - "tables": [ ...query results... ], - "render": { - "visualization": "barchart", - "title": "24H Perf events", - "accumulate": false, - "isQuerySorted": false, - "kind": "default", - "annotation": "", - "by": null - } - } -``` --## Query statistics --To get information about query statistics, include this header: --``` - Prefer: include-statistics=true -``` --The header includes a `statistics` property in the response that describes various performance statistics such as query execution time and resource usage. --## Query timeout -The default query timeout is 3 minutes. To adjust the query timeout set the `wait` property, as documented [here](timeouts.md). --## Query data sources -To get information about the query data sources - regions, workspaces, clusters and tables, include this header: --``` - Prefer: include-dataSources=true -``` |
| azure-monitor | Register App For Token | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/api/register-app-for-token.md | - Title: Register an App to request authorization tokens and work with APIs -description: How to register an app and assign a role so it can access request a token and work with APIs Previously updated : 05/30/2024------# Register an App to request authorization tokens and work with APIs --To access Azure REST APIs such as the Log analytics API, or to send custom metrics, you can generate an authorization token based on a client ID and secret. The token is then passed in your REST API request. This article shows you how to register a client app and create a client secret so that you can generate a token. --## Register an App --Create a service principal and register an app using the Azure portal, Azure CLI, or PowerShell. -### [Azure portal](#tab/portal) --1. To register an app, open the Active Directory Overview page in the Azure portal. --1. Select **App registrations** from the side bar. --1. Select **New registration** -1. On the Register an application page, enter a **Name** for the application. -1. Select **Register** --1. On the app's overview page, select **Certificates and Secrets** -1. Note the **Application (client) ID**. It's used in the HTTP request for a token. - -1. In the **Client secrets tab** Select **New client secret** -1. Enter a **Description** and select **Add** - :::image type="content" source="../media/api-register-app/add-a-client-secret.png" alt-text="A screenshot showing the Add client secret page."::: - -1. Copy and save the client secret **Value**. -- > [!NOTE] - > Client secret values can only be viewed immediately after creation. Be sure to save the secret before leaving the page. -- :::image type="content" source="../media/api-register-app/client-secret.png" alt-text="A screenshot showing the client secrets page."::: ---### [Azure CLI](#tab/cli) ---Run the following script to create a service principal and app. --```azurecli -az ad sp create-for-rbac -n <Service principal display name> --``` -The response looks as follows: -```JSON -{ - "appId": "0a123b56-c987-1234-abcd-1a2b3c4d5e6f", - "displayName": "AzMonAPIApp", - "password": "123456.ABCDE.~XYZ876123ABcEdB7169", - "tenant": "a1234bcd-5849-4a5d-a2eb-5267eae1bbc7" -} --``` ->[!Important] -> The output includes credentials that you must protect. Be sure that you do not include these credentials in your code or check the credentials into your source control. --Add a role and scope for the resources that you want to access using the API --```azurecli -az role assignment create --assignee <`appId`> --role <Role> --scope <resource URI> -``` --The CLI following example assigns the `Reader` role to the service principal for all resources in the `rg-001`resource group: --```azurecli - az role assignment create --assignee 0a123b56-c987-1234-abcd-1a2b3c4d5e6f --role Reader --scope '\/subscriptions/a1234bcd-5849-4a5d-a2eb-5267eae1bbc7/resourceGroups/rg-001' -``` -For more information on creating a service principal using Azure CLI, see [Create an Azure service principal with the Azure CLI](/cli/azure/create-an-azure-service-principal-azure-cli). --### [PowerShell](#tab/powershell) -The following sample script demonstrates creating a Microsoft Entra service principal via PowerShell. For a more detailed walkthrough, see [using Azure PowerShell to create a service principal to access resources](../../../active-directory/develop/howto-authenticate-service-principal-powershell.md) --```powershell -$subscriptionId = "{azure-subscription-id}" -$resourceGroupName = "{resource-group-name}" --# Authenticate to a specific Azure subscription. -Connect-AzAccount -SubscriptionId $subscriptionId --# Password for the service principal -$pwd = "{service-principal-password}" -$secureStringPassword = ConvertTo-SecureString -String $pwd -AsPlainText -Force --# Create a new Azure Active Directory application -$azureAdApplication = New-AzADApplication ` - -DisplayName "My Azure Monitor" ` - -HomePage "https://localhost/azure-monitor" ` - -IdentifierUris "https://localhost/azure-monitor" ` - -Password $secureStringPassword --# Create a new service principal associated with the designated application -New-AzADServicePrincipal -ApplicationId $azureAdApplication.ApplicationId --# Assign Reader role to the newly created service principal -New-AzRoleAssignment -RoleDefinitionName Reader ` - -ServicePrincipalName $azureAdApplication.ApplicationId.Guid --``` ---## Next steps --Before you can generate a token using your app, client ID, and secret, assign the app to a role using Access control (IAM) for resource that you want to access. The role will depend on the resource type and the API that you want to use. -For example, -- To grant your app read from a Log Analytics Workspace, add your app as a member to the **Reader** role using Access control (IAM) for your Log Analytics Workspace. For more information, see [Access the API](./access-api.md)--- To grant access to send custom metrics for a resource, add your app as a member to the **Monitoring Metrics Publisher** role using Access control (IAM) for your resource. For more information, see [Send metrics to the Azure Monitor metric database using REST API](../../essentials/metrics-store-custom-rest-api.md)--For more information, see [Assign Azure roles using the Azure portal](../../../role-based-access-control/role-assignments-portal.yml) --Once you've assigned a role, you can use your app, client ID, and client secret to generate a bearer token to access the REST API. --> [!NOTE] -> When using Microsoft Entra authentication, it may take up to 60 minutes for the Azure Application Insights REST API to recognize new role-based access control (RBAC) permissions. While permissions are propagating, REST API calls may fail with error code 403. |
| azure-monitor | Request Format | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/api/request-format.md | - Title: Request format -description: The Azure Monitor Log Analytics API request format. Previously updated : 08/12/2024-----# Azure Monitor Log Analytics API request format --There are two endpoints through which you can communicate with the Log Analytics API: -- A direct URL for the API: `https://api.loganalytics.azure.com`-- Through Azure Resource Manager (ARM).--While the URLs are different, the query parameters are the same for each endpoint. Both endpoints require authorization through Microsoft Entra ID. --The API supports the `POST` and `GET` methods. --## Public API format --The Public API format is: --``` - https://api.loganalytics.azure.com/{api-version}/workspaces/{workspaceId}/query?[parameters] -``` -where: --## GET /query --When the HTTP method executed is `GET`, the parameters are included in the query string. --For example, to count AzureActivity events by Category, make this call: --``` - GET https://api.loganalytics.azure.com/v1/workspaces/{workspace-id}/query?query=AzureActivity%20|%20summarize%20count()%20by%20Category - Authorization: Bearer <access token> -``` -## POST /query --When the HTTP method executed is `POST`: - -For example, to count AzureActivity events by Category, make this call: --``` - POST https://api.loganalytics.azure.com/v1/workspaces/{workspace-id}/query - - Authorization: Bearer <access token> - Content-Type: application/json - - { - "query": "AzureActivity | summarize count() by Category" - } -``` |
| azure-monitor | Response Format | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/api/response-format.md | - Title: Azure Monitor Log Analytics API response format -description: The Azure Monitor Log Analytics API response is JSON that contains an array of table objects. Previously updated : 08/12/2024-----# Azure Monitor Log Analytics API response format --The Azure Monitor Log Analytics API response is a JSON string that contains an array of table objects. --The `tables` property is an array of tables that represent the query result. Each table contains `name`, `columns`, and `rows` properties: ---In the following example, we can see that the result contains two columns: `Category` and `count_`. The first column, `Category`, represents the value of the `Category` column in the `AzureActivity` table. The second column, `count_` is the count of the number of events in the `AzureActivity` table for the specific category. --``` - HTTP/1.1 200 OK - Content-Type: application/json; charset=utf-8 - - { - "tables": [ - { - "name": "PrimaryResult", - "columns": [ - { - "name": "Category", - "type": "string" - }, - { - "name": "count_", - "type": "long" - } - ], - "rows": [ - [ - "Administrative", - 20839 - ], - [ - "Recommendation", - 122 - ], - [ - "Alert", - 64 - ], - [ - "ServiceHealth", - 11 - ] - ] - } - ] - } -``` --## Azure Monitor Log Analytics API errors --If a fatal error occurs during query execution, an error status code is returned with a [OneAPI](https://github.com/Microsoft/api-guidelines/blob/vNext/Guidelines.md#errorresponse--object) error object that describes the error. --If a non-fatal error occurs during query execution, the response status code is `200 OK`. It contains the query results in the `tables` property as described. The response also contains an `error` property, which is a OneAPI error object with the code `PartialError`. Details of the error are included in the `details` property. --## Next steps --Get more information about using the [API options](batch-queries.md). |
| azure-monitor | Timeouts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/api/timeouts.md | - Title: Timeouts of query executions -description: Query execution times can vary widely based on the complexity of the query, the amount of data being analyzed, and the load on the system and workspace at the time of the query. Previously updated : 08/12/2024-----# Timeouts --Query execution times can vary widely based on: --- The complexity of the query.-- The amount of data being analyzed.-- The load on the system at the time of the query.-- The load on the workspace at the time of the query.--You might want to customize the timeout for the query. The default timeout is 3 minutes. The maximum timeout is 10 minutes. --## Timeout request header --To set the timeout, use the `Prefer` header in the HTTP request by using the standard `wait` preference. For more information, see [this website](https://tools.ietf.org/html/rfc7240#section-4.3). The `Prefer` header puts an upper limit, in seconds, on how long the client waits for the service to process the query. --## Response --If a query takes longer than the specified timeout (or default timeout, if unspecified), it fails with a status code of 504 Gateway Timeout. --For example, the following request allows a maximum server timeout age of 30 seconds: --``` - POST https://api.loganalytics.azure.com/v1/workspaces/{workspace-id}/query - Authorization: Bearer <access token> - Prefer: wait=30 - - { - "query" : "Heartbeat | count" - } -``` |
| azure-monitor | Availability Zones | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/availability-zones.md | - Title: Availability zones in Azure Monitor -description: Learn about the data and service resilience benefits Azure Monitor availability zones provide to protect against datacenter failure. ---- Previously updated : 07/23/2024---# Customer intent: As an IT manager, I want to understand the data and service resilience benefits Azure Monitor availability zones provide to ensure my data and services are sufficiently protected in the event of datacenter failure. --# Enhance data and service resilience in Azure Monitor Logs with availability zones --[Azure availability zones](../../reliability/availability-zones-overview.md) protect applications and data from datacenter failures and can enhance the resilience of Azure Monitor features that rely on a Log Analytics workspace. This article describes the data and service resilience benefits Azure Monitor availability zones provide in supported regions. --> [!NOTE] -> Application Insights resources can use availability zones only if they're workspace-based. Classic Application Insights resources can't use availability zones. --## Prerequisites --- A Log Analytics workspace linked to a shared or [dedicated cluster](logs-dedicated-clusters.md). Azure Monitor creates Log Analytics workspaces in a shared cluster, unless you set up a dedicated cluster for your workspaces.----## How availability zones enhance data and service resilience in Azure Monitor Logs --Each Azure region that supports availability zones is made of one or more datacenters, or zones, equipped with independent power, cooling, and networking infrastructure. --Azure Monitor Logs availability zones are [zone-redundant](../../reliability/availability-zones-overview.md#zonal-and-zone-redundant-services), which means that Microsoft manages spreading service requests and replicating data across different zones in supported regions. If one zone is affected by an incident, Microsoft manages failover to a different availability zone in the region automatically. You don't need to take any action because switching between zones is seamless. --A subset of the availability zones that support data resilience currently also support service resilience for Azure Monitor Logs. In regions that support **service resilience**, Azure Monitor Logs service operations - for example, log ingestion, queries, and alerts - can continue in the event of a zone failure. In regions that only support **data resilience**, your stored data is protected against zonal failures, but service operations might be impacted by regional incidents. --> [!NOTE] -> Moving to a dedicated cluster in a region that supports availablility zones protects data ingested after the move, not historical data. - -## Supported regions --| Region | Data resilience - Shared clusters (default) | Data resilience - Dedicated clusters | Service resilience | -| | | | | -| **Africa** | | | | -| South Africa North | | :white_check_mark: | | -| **Americas** | | | | -| Brazil South | | :white_check_mark: | | -| Canada Central | :white_check_mark: | :white_check_mark: | | -| Central US | | :white_check_mark: | | -| East US | | :white_check_mark: | | -| East US 2 | | :white_check_mark: | :white_check_mark: | -| South Central US | :white_check_mark: | :white_check_mark: | | -| Spain Central | :white_check_mark: | :white_check_mark: | :white_check_mark: | -| West US 2 | | :white_check_mark: | :white_check_mark: | -| West US 3 | :white_check_mark: | :white_check_mark: | | -| **Asia Pacific** | | | | -| Australia East | :white_check_mark: | :white_check_mark: | | -| Central India | :white_check_mark: | :white_check_mark: | | -| East Asia | | :white_check_mark: | | -| Japan East | | :white_check_mark: | | -| Korea Central | | :white_check_mark: | | -| Southeast Asia | :white_check_mark: | :white_check_mark: | | -| **Europe** | | | | -| France Central | :white_check_mark: | :white_check_mark: | | -| Germany West Central | | :white_check_mark: | | -| Italy North | :white_check_mark: | :white_check_mark: | :white_check_mark: | -| North Europe | :white_check_mark: | :white_check_mark: | :white_check_mark: | -| Norway East | :white_check_mark: | :white_check_mark: | | -| Poland Central | | :white_check_mark: | | -| Sweden Central | :white_check_mark: | :white_check_mark: | | -| Switzerland North | | :white_check_mark: | | -| UK South | :white_check_mark: | :white_check_mark: | | -| West Europe | | :white_check_mark: | | -| **Middle East** | | | | -| Israel Central | :white_check_mark: | :white_check_mark: | :white_check_mark: | -| Qatar Central | | :white_check_mark: | | -| UAE North | :white_check_mark: | :white_check_mark: | | ---## Next steps --Learn more about how to: -- [Set up a dedicated cluster](logs-dedicated-clusters.md).-- [Migrate Log Analytics workspaces to availability zone support](../../availability-zones/migrate-monitor-log-analytics.md). |
| azure-monitor | Azure Ad Authentication Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/azure-ad-authentication-logs.md | - Title: Microsoft Entra authentication for Azure Monitor Logs -description: Learn how to enable Microsoft Entra authentication for Log Analytics in Azure Monitor. - Previously updated : 08/24/2021---# Microsoft Entra authentication for Azure Monitor Logs --Azure Monitor can [collect data in Azure Monitor Logs from multiple sources](data-platform-logs.md#data-collection-routing-and-transformation). These sources include agents on virtual machines, Application Insights, diagnostic settings for Azure resources, and the Data Collector API. --Log Analytics agents use a workspace key as an enrollment key to verify initial access and provision a certificate further used to establish a secure connection between the agent and Azure Monitor. To learn more, see [Send data from agents](data-security.md#2-send-data-from-agents). The Data Collector API uses the same workspace key to [authorize access](data-collector-api.md#authorization). --These options might be cumbersome and pose a risk because it's difficult to manage credentials, specifically workspace keys, at a large scale. You can opt out of local authentication and ensure that only telemetry that's exclusively authenticated by using Managed Identities and Microsoft Entra ID is ingested into Azure Monitor. This feature enhances the security and reliability of the telemetry used to make critical operational and business decisions. --To enable Microsoft Entra integration for Azure Monitor Logs and remove reliance on these shared secrets: --1. [Disable local authentication for Log Analytics workspaces](#disable-local-authentication-for-log-analytics-workspaces). -1. Ensure that only authenticated telemetry is ingested in your Application Insights resources with [Microsoft Entra authentication for Application Insights (preview)](../app/azure-ad-authentication.md). -2. Follow [best practices for using Entra authentication](/entra/identity/managed-identities-azure-resources/managed-identity-best-practice-recommendations). --## Prerequisites --- [Migrate to Azure Monitor Agent](../agents/azure-monitor-agent-migration.md) from the Log Analytics agents. Azure Monitor Agent doesn't require any keys but instead [requires a system-managed identity](../agents/azure-monitor-agent-requirements.md#permissions).-- [Migrate to the Log Ingestion API](./custom-logs-migrate.md) from the HTTP Data Collector API to send data to Azure Monitor Logs.--## Permissions required --To disable local authentication for a Log Analytics workspace, you need `microsoft.operationalinsights/workspaces/write` permissions on the workspace, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example. --## Disable local authentication for Log Analytics workspaces ---Disabling local authentication might limit the availability of some functionality, specifically: --- Existing Log Analytics agents will stop functioning. Only Azure Monitor Agent will be supported. Azure Monitor Agent will be missing some capabilities that are available through the Log Analytics agent. Examples include custom log collection and IIS log collection.-- The Data Collector API (preview) won't support Microsoft Entra authentication and won't be available to ingest data.-- VM insights and Container insights will stop working. Local authorization will be the only authorization method supported by these features.--You can disable local authentication by using Azure Policy. Or you can disable it programmatically through an Azure Resource Manager template, PowerShell, or the Azure CLI. --### [Azure Policy](#tab/azure-policy) --Azure Policy for `DisableLocalAuth` won't allow you to create a new Log Analytics workspace unless this property is set to `true`. The policy name is `Log Analytics Workspaces should block non-Azure Active Directory based ingestion`. To apply this policy definition to your subscription, [create a new policy assignment and assign the policy](../../governance/policy/assign-policy-portal.md). --The policy template definition: --```json -{ - "properties": { - "displayName": "Log Analytics Workspaces should block non-Azure Active Directory based ingestion.", - "policyType": "BuiltIn", - "mode": "Indexed", - "description": "Enforcing log ingestion to require Azure Active Directory authentication prevents unauthenticated logs from an attacker which could lead to incorrect status, false alerts, and incorrect logs stored in the system.", - "metadata": { - "version": "1.0.0", - "category": "Monitoring" - }, - "parameters": { - "effect": { - "type": "String", - "metadata": { - "displayName": "Effect", - "description": "Enable or disable the execution of the policy" - }, - "allowedValues": [ - "Deny", - "Audit", - "Disabled" - ], - "defaultValue": "Audit" - } - }, - "policyRule": { - "if": { - "allOf": [ - { - "field": "type", - "equals": "Microsoft.OperationalInsights/workspaces" - }, - { - "field": "Microsoft.OperationalInsights/workspaces/features.disableLocalAuth", - "notEquals": "true" - } - ] - }, - "then": { - "effect": "[parameters('effect')]" - } - } - }, - "id": "/providers/Microsoft.Authorization/policyDefinitions/e15effd4-2278-4c65-a0da-4d6f6d1890e2", - "type": "Microsoft.Authorization/policyDefinitions", - "name": "e15effd4-2278-4c65-a0da-4d6f6d1890e2" -} -``` --### [Azure Resource Manager](#tab/azure-resource-manager) --The `DisableLocalAuth` property is used to disable any local authentication on your Log Analytics workspace. When set to `true`, this property enforces that Microsoft Entra authentication must be used for all access. --Use the following Azure Resource Manager template to disable local authentication: --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaces_name": { - "defaultValue": "workspace-name", - "type": "string" - }, - "workspace_location": { - "defaultValue": "region-name", - "type": "string" - } - }, - "variables": {}, - "resources": [ - { - "type": "Microsoft.OperationalInsights/workspaces", - "apiVersion": "2020-08-01", - "name": "[parameters('workspaces_name')]", - "location": "[parameters('workspace_location')]", - "properties": { - "sku": { - "name": "PerGB2018" - }, - "retentionInDays": 30, - "features": { - "disableLocalAuth": false, - "enableLogAccessUsingOnlyResourcePermissions": true - } - } - } - ] -} --``` --### [Azure CLI](#tab/azure-cli) --The `DisableLocalAuth` property is used to disable any local authentication on your Log Analytics workspace. When set to `true`, this property enforces that Microsoft Entra authentication must be used for all access. --Use the following Azure CLI commands to disable local authentication: --```azurecli - az resource update --ids "/subscriptions/[Your subscription ID]/resourcegroups/[Your resource group]/providers/microsoft.operationalinsights/workspaces/[Your workspace name]--api-version "2021-06-01" --set properties.features.disableLocalAuth=True -``` --### [PowerShell](#tab/powershell) --The `DisableLocalAuth` property is used to disable any local authentication on your Log Analytics workspace. When set to `true`, this property enforces that Microsoft Entra authentication must be used for all access. --Use the following PowerShell commands to disable local authentication: --```powershell - $workspaceSubscriptionId = "[You subscription ID]" - $workspaceResourceGroup = "[You resource group]" - $workspaceName = "[Your workspace name]" - $disableLocalAuth = $false - - # login - Connect-AzAccount - - # select subscription - Select-AzSubscription -SubscriptionId $workspaceSubscriptionId - - # get private link workspace resource - $workspace = Get-AzResource -ResourceType Microsoft.OperationalInsights/workspaces -ResourceGroupName $workspaceResourceGroup -ResourceName $workspaceName -ApiVersion "2021-06-01" - - # set DisableLocalAuth - $workspace.Properties.Features | Add-Member -MemberType NoteProperty -Name DisableLocalAuth -Value $disableLocalAuth -Force - $workspace | Set-AzResource -Force -``` ----## Next steps -See [Microsoft Entra authentication for Application Insights (preview)](../app/azure-ad-authentication.md). |
| azure-monitor | Azure Monitor Data Explorer Proxy | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/azure-monitor-data-explorer-proxy.md | - Title: Correlate data in Azure Data Explorer and Azure Resource Graph with data in a Log Analytics workspace -description: Run cross-service queries to correlated data in Azure Data Explorer and Azure Resource Graph with data in a Log Analytics workspace. --- Previously updated : 08/12/2024----# Correlate data in Azure Data Explorer and Azure Resource Graph with data in a Log Analytics workspace --You can correlate data in [Azure Data Explorer](/azure/data-explorer/data-explorer-overview) and [Azure Resource Graph](../../governance/resource-graph/overview.md) with data in your Log Analytics workspace and Application Insights resources to enhance your analysis in [Azure Monitor Logs](../logs/data-platform-logs.md). [Microsoft Sentinel](../../sentinel/overview.md), which also stores data in Log Analytics workspaces, supports cross-service queries to Azure Data Explorer but not to Azure Resource Graph. This article explains how to run cross-service queries from any service that stores data in a Log Analytics workspace. --Run cross-service queries by using any client tools that support Kusto Query Language (KQL) queries, including the Log Analytics web UI, workbooks, PowerShell, and the REST API. --## Permissions required --To run a cross-service query that correlates data in Azure Data Explorer or Azure Resource Graph with data in a Log Analytics workspace, you need: --- `Microsoft.OperationalInsights/workspaces/query/*/read` permissions to the Log Analytics workspaces you query, as provided by the [Log Analytics Reader built-in role](../logs/manage-access.md#log-analytics-reader), for example.-- Reader permissions to the resources you query in Azure Resource Graph.-- Viewer permissions to the tables you query in Azure Data Explorer.--## Query data in Azure Data Explorer by using adx() --Enter the identifier for an Azure Data Explorer cluster in a query within the `adx` pattern, followed by the database name and table. --```kusto -adx('https://help.kusto.windows.net/Samples').StormEvents -``` -### Combine Azure Data Explorer cluster tables with a Log Analytics workspace --Use the `union` command to combine cluster tables with a Log Analytics workspace. --For example: --```kusto -union customEvents, adx('https://help.kusto.windows.net/Samples').StormEvents -| take 10 -``` --```kusto -let CL1 = adx('https://help.kusto.windows.net/Samples').StormEvents; -union customEvents, CL1 | take 10 -``` --> [!TIP] -> Shorthand format is allowed: *ClusterName*/*InitialCatalog*. For example, `adx('help/Samples')` is translated to `adx('help.kusto.windows.net/Samples')`. --When you use the [`join` operator](/azure/data-explorer/kusto/query/joinoperator) instead of union, you're required to use a [`hint`](/azure/data-explorer/kusto/query/joinoperator#join-hints) to combine the data in the Azure Data Explorer cluster with the Log Analytics workspace. Use `Hint.remote={Direction of the Log Analytics Workspace}`. --For example: --```kusto -AzureDiagnostics -| join hint.remote=left adx("cluster=ClusterURI").AzureDiagnostics on (ColumnName) -``` --### Join data from an Azure Data Explorer cluster in one tenant with an Azure Monitor resource in another --Cross-tenant queries between the services aren't supported. You're signed in to a single tenant for running the query that spans both resources. --If the Azure Data Explorer resource is in Tenant A and the Log Analytics workspace is in Tenant B, use one of the following methods: --* Use Azure Data Explorer to add roles for principals in different tenants. Add your user ID in Tenant B as an authorized user on the Azure Data Explorer cluster. Validate that the [TrustedExternalTenant](/powershell/module/az.kusto/update-azkustocluster) property on the Azure Data Explorer cluster contains Tenant B. Run the cross query fully in Tenant B. -* Use [Lighthouse](../../lighthouse/index.yml) to project the Azure Monitor resource into Tenant A. --### Connect to Azure Data Explorer clusters from different tenants --Kusto Explorer automatically signs you in to the tenant to which the user account originally belongs. To access resources in other tenants with the same user account, you must explicitly specify `TenantId` in the connection string: --`Data Source=https://ade.applicationinsights.io/subscriptions/SubscriptionId/resourcegroups/ResourceGroupName;Initial Catalog=NetDefaultDB;AAD Federated Security=True;Authority ID=TenantId` --## Query data in Azure Resource Graph by using arg() (Preview) --Enter the `arg("")` pattern, followed by the Azure Resource Graph table name. --For example: --```kusto -arg("").<Azure-Resource-Graph-table-name> -``` --Here are some sample Azure Log Analytics queries that use the new Azure Resource Graph cross-service query capabilities: --- Filter a Log Analytics query based on the results of an Azure Resource Graph query:-- ```kusto - arg("").Resources - | where type == "microsoft.compute/virtualmachines" and properties.hardwareProfile.vmSize startswith "Standard_D" - | join ( - Heartbeat - | where TimeGenerated > ago(1d) - | distinct Computer - ) - on $left.name == $right.Computer - ``` --- Create an alert rule that applies only to certain resources taken from an ARG query:- - Exclude resources based on tags ΓÇô for example, not to trigger alerts for VMs with a ΓÇ£TestΓÇ¥ tag. -- ```kusto - arg("").Resources - | where tags.environment=~'Test' - | project name - ``` -- - Retrieve performance data related to CPU utilization and filter to resources with the ΓÇ£prodΓÇ¥ tag. - - ```kusto - InsightsMetrics - | where Name == "UtilizationPercentage" - | lookup ( - arg("").Resources - | where type == 'microsoft.compute/virtualmachines' - | project _ResourceId=tolower(id), tags - ) - on _ResourceId - | where tostring(tags.Env) == "Prod" - ``` --More use cases: -- Use a tag to determine whether VMs should be running 24x7 or should be shut down at night.-- Show alerts on any server that contains a certain number of cores.--## Create an alert based on a cross-service query from your Log Analytics workspace --To create an alert rule based on a cross-service query from your Log Analytics workspace, follow the steps in [Create or edit a log search alert rule](../alerts/alerts-create-log-alert-rule.md), selecting your Log Analytics workspace, on the **Scope** tab. --> [!NOTE] -> You can also run cross-service queries from Azure Data Explorer and Azure Resource Graph to a Log Analytics workspace, by selecting the relevant resource as the scope of your alert. --## Limitations --### General cross-service query limitations -* Cross-service queries donΓÇÖt support parameterized functions and functions whose definition includes other cross-workspace or cross-service expressions, including `adx()`, `arg()`, `resource()`, `workspace()`, and `app()`. -* Cross-service queries support **only ".show"** functions. - This capability enables cross-cluster queries to reference an Azure Monitor, Azure Data Explorer, or Azure Resource Graph tabular function directly. - The following commands are supported with the cross-service query: - * `.show functions` - * `.show function {FunctionName}` - * `.show database {DatabaseName} schema as json` -* Database names are case sensitive. -* Identifying the Timestamp column in the cluster isn't supported. The Log Analytics Query API won't pass the time filter. -* Cross-service queries support data retrieval only. -* [Private Link](../logs/private-link-security.md) (private endpoints) and [IP restrictions](/azure/data-explorer/security-network-restrict-public-access) don't support cross-service queries. -* `mv-expand` is limited to 2,000 records. -* Azure Monitor Logs doesn't support the `external_table()` function, which lets you query external tables in Azure Data Explorer. To query an external table, define `external_table(<external-table-name>)` as a parameterless function in Azure Data Explorer. You can then call the function using the expression `adx("").<function-name>`. --### Azure Resource Graph cross-service query limitations --* Microsoft Sentinel doesn't support cross-service queries to Azure Resource Graph. -* When you query Azure Resource Graph data from Azure Monitor: - * The query returns the first 1,000 records only. - * Azure Monitor doesn't return Azure Resource Graph query errors. - * The Log Analytics query editor marks valid Azure Resource Graph queries as syntax errors. - * Joins are not supported when not using Hint. - * These operators aren't supported: `smv-apply()`, `rand()`, `arg_max()`, `arg_min()`, `avg()`, `avg_if()`, `countif()`, `sumif()`, `percentile()`, `percentiles()`, `percentilew()`, `percentilesw()`, `stdev()`, `stdevif()`, `stdevp()`, `variance()`, `variancep()`, `varianceif()`. ---### Combine Azure Resource Graph tables with a Log Analytics workspace --Use the `union` command to combine cluster tables with a Log Analytics workspace. --For example: --```kusto -union AzureActivity, arg("").Resources -| take 10 -``` -```kusto -let CL1 = arg("").Resources ; -union AzureActivity, CL1 | take 10 -``` --When you use the [`join` operator](/azure/data-explorer/kusto/query/joinoperator) instead of union, you need to use a [`hint`](/azure/data-explorer/kusto/query/joinoperator#join-hints) to combine the data in Azure Resource Graph with data in the Log Analytics workspace. Use `Hint.remote={Direction of the Log Analytics Workspace}`. For example: --```kusto -Perf | where ObjectName == "Memory" and (CounterName == "Available MBytes Memory") -| extend _ResourceId = replace_string(replace_string(replace_string(_ResourceId, 'microsoft.compute', 'Microsoft.Compute'), 'virtualmachines','virtualMachines'),"resourcegroups","resourceGroups") -| join hint.remote=left (arg("").Resources | where type =~ 'Microsoft.Compute/virtualMachines' | project _ResourceId=id, tags) on _ResourceId | project-away _ResourceId1 | where tostring(tags.env) == "prod" -``` --## Next steps -* [Write queries](/azure/data-explorer/write-queries) -* [Perform cross-resource log queries in Azure Monitor](../logs/cross-workspace-query.md) - |
| azure-monitor | Basic Logs Azure Tables | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/basic-logs-azure-tables.md | - Title: Tables that support the Basic table plan in Azure Monitor Logs -description: This article lists all tables support the Basic table plan in Azure Monitor Logs. ---- Previously updated : 07/22/2024---# Tables that support the Basic table plan in Azure Monitor Logs --All custom tables created with or migrated to the [Logs ingestion API](logs-ingestion-api-overview.md), and the Azure tables listed below support the [Basic table plan](../logs/logs-table-plans.md). --> [!NOTE] -> Tables created with the [Data Collector API](data-collector-api.md) don't support the Basic table plan. ---| Service | Table | -|:|:| -| Azure Active Directory | [AADDomainServicesDNSAuditsGeneral](/azure/azure-monitor/reference/tables/AADDomainServicesDNSAuditsGeneral)<br> [AADDomainServicesDNSAuditsDynamicUpdates](/azure/azure-monitor/reference/tables/AADDomainServicesDNSAuditsDynamicUpdates)<br>[AADManagedIdentitySignInLogs](/azure/azure-monitor/reference/tables/AADManagedIdentitySignInLogs)<br>[AADNonInteractiveUserSignInLogs](/azure/azure-monitor/reference/tables/AADNonInteractiveUserSignInLogs)<br>[AADServicePrincipalSignInLogs](/azure/azure-monitor/reference/tables/AADServicePrincipalSignInLogs) <br>[ADFSSignInLogs](/azure/azure-monitor/reference/tables/ADFSSignInLogs) | -| Azure Cache for Redis | [ACREntraAuthenticationAuditLog](/azure/azure-monitor/reference/tables/ACREntraAuthenticationAuditLog) | -| Azure Load Balancing | [ALBHealthEvent](/azure/azure-monitor/reference/tables/ALBHealthEvent) | -| Azure Databricks | [DatabricksBrickStoreHttpGateway](/azure/azure-monitor/reference/tables/databricksbrickstorehttpgateway)<br>[DatabricksDataMonitoring](/azure/azure-monitor/reference/tables/databricksdatamonitoring)<br>[DatabricksFilesystem](/azure/azure-monitor/reference/tables/databricksfilesystem)<br>[DatabricksDashboards](/azure/azure-monitor/reference/tables/databricksdashboards)<br>[DatabricksCloudStorageMetadata](/azure/azure-monitor/reference/tables/databrickscloudstoragemetadata)<br>[DatabricksPredictiveOptimization](/azure/azure-monitor/reference/tables/databrickspredictiveoptimization)<br>[DatabricksIngestion](/azure/azure-monitor/reference/tables/databricksingestion)<br>[DatabricksMarketplaceConsumer](/azure/azure-monitor/reference/tables/databricksmarketplaceconsumer)<br>[DatabricksLineageTracking](/azure/azure-monitor/reference/tables/databrickslineagetracking) -| API Management | [ApiManagementGatewayLogs](/azure/azure-monitor/reference/tables/ApiManagementGatewayLogs)<br>[ApiManagementWebSocketConnectionLogs](/azure/azure-monitor/reference/tables/ApiManagementWebSocketConnectionLogs) | -| API Management Service| APIMDevPortalAuditDiagnosticLog | -| Application Gateways | [AGWAccessLogs](/azure/azure-monitor/reference/tables/AGWAccessLogs)<br>[AGWPerformanceLogs](/azure/azure-monitor/reference/tables/AGWPerformanceLogs)<br>[AGWFirewallLogs](/azure/azure-monitor/reference/tables/AGWFirewallLogs) | -| Application Gateway for Containers | [AGCAccessLogs](/azure/azure-monitor/reference/tables/AGCAccessLogs) | -| Application Insights | [AppTraces](/azure/azure-monitor/reference/tables/apptraces) | -| Bare Metal Machines | [NCBMSecurityDefenderLogs](/azure/azure-monitor/reference/tables/ncbmsecuritydefenderlogs)<br>[NCBMSystemLogs](/azure/azure-monitor/reference/tables/NCBMSystemLogs)<br>[NCBMSecurityLogs](/azure/azure-monitor/reference/tables/NCBMSecurityLogs) <br>[NCBMBreakGlassAuditLogs](/azure/azure-monitor/reference/tables/ncbmbreakglassauditlogs)| -| Chaos Experiments | [ChaosStudioExperimentEventLogs](/azure/azure-monitor/reference/tables/ChaosStudioExperimentEventLogs) | -| Cloud HSM | [CHSMManagementAuditLogs](/azure/azure-monitor/reference/tables/CHSMManagementAuditLogs)<br>[CHSMServiceOperationAuditLogs](/azure/azure-monitor/reference/tables/chsmserviceoperationauditlogs)| -| Container Apps | [ContainerAppConsoleLogs](/azure/azure-monitor/reference/tables/containerappconsoleLogs) | -| Container Insights | [ContainerLogV2](/azure/azure-monitor/reference/tables/containerlogv2) | -| Container Apps Environments | [AppEnvSpringAppConsoleLogs](/azure/azure-monitor/reference/tables/AppEnvSpringAppConsoleLogs) | -| Communication Services | [ACSAdvancedMessagingOperations](/azure/azure-monitor/reference/tables/acsadvancedmessagingoperations)<br>[ACSCallAutomationIncomingOperations](/azure/azure-monitor/reference/tables/ACSCallAutomationIncomingOperations)<br>[ACSCallAutomationMediaSummary](/azure/azure-monitor/reference/tables/ACSCallAutomationMediaSummary)<br>[ACSCallClientMediaStatsTimeSeries](/azure/azure-monitor/reference/tables/ACSCallClientMediaStatsTimeSeries)<br>[ACSCallClientOperations](/azure/azure-monitor/reference/tables/ACSCallClientOperations)<br>[ACSCallRecordingIncomingOperations](/azure/azure-monitor/reference/tables/ACSCallRecordingIncomingOperations)<br>[ACSCallRecordingSummary](/azure/azure-monitor/reference/tables/ACSCallRecordingSummary)<br>[ACSCallSummary](/azure/azure-monitor/reference/tables/ACSCallSummary)<br>[ACSJobRouterIncomingOperations](/azure/azure-monitor/reference/tables/ACSJobRouterIncomingOperations)<br>[ACSRoomsIncomingOperations](/azure/azure-monitor/reference/tables/acsroomsincomingoperations)<br>[ACSCallClosedCaptionsSummary](/azure/azure-monitor/reference/tables/acscallclosedcaptionssummary) | -| Confidential Ledgers | [CCFApplicationLogs](/azure/azure-monitor/reference/tables/CCFApplicationLogs) | - Cosmos DB | [CDBDataPlaneRequests](/azure/azure-monitor/reference/tables/cdbdataplanerequests)<br>[CDBPartitionKeyStatistics](/azure/azure-monitor/reference/tables/cdbpartitionkeystatistics)<br>[CDBPartitionKeyRUConsumption](/azure/azure-monitor/reference/tables/cdbpartitionkeyruconsumption)<br>[CDBQueryRuntimeStatistics](/azure/azure-monitor/reference/tables/cdbqueryruntimestatistics)<br>[CDBMongoRequests](/azure/azure-monitor/reference/tables/cdbmongorequests)<br>[CDBCassandraRequests](/azure/azure-monitor/reference/tables/cdbcassandrarequests)<br>[CDBGremlinRequests](/azure/azure-monitor/reference/tables/cdbgremlinrequests)<br>[CDBControlPlaneRequests](/azure/azure-monitor/reference/tables/cdbcontrolplanerequests)<br>CDBTableApiRequests | -| Cosmos DB for MongoDB (vCore) | [VCoreMongoRequests](/azure/azure-monitor/reference/tables/VCoreMongoRequests) | -| Kubernetes clusters - Azure Arc | [ArcK8sAudit](/azure/azure-monitor/reference/tables/ArcK8sAudit)<br>[ArcK8sAuditAdmin](/azure/azure-monitor/reference/tables/ArcK8sAuditAdmin)<br>[ArcK8sControlPlane](/azure/azure-monitor/reference/tables/ArcK8sControlPlane) | -| De-identification Services | [AHDSDeidAuditLogs](/azure/azure-monitor/reference/tables/AHDSDeidAuditLogs) | -| Data Manager for Energy | [OEPDataplaneLogs](/azure/azure-monitor/reference/tables/OEPDataplaneLogs) | Dedicated SQL Pool | [SynapseSqlPoolSqlRequests](/azure/azure-monitor/reference/tables/synapsesqlpoolsqlrequests)<br>[SynapseSqlPoolRequestSteps](/azure/azure-monitor/reference/tables/synapsesqlpoolrequeststeps)<br>[SynapseSqlPoolExecRequests](/azure/azure-monitor/reference/tables/synapsesqlpoolexecrequests)<br>[SynapseSqlPoolDmsWorkers](/azure/azure-monitor/reference/tables/synapsesqlpooldmsworkers)<br>[SynapseSqlPoolWaits](/azure/azure-monitor/reference/tables/synapsesqlpoolwaits) | -| DNS Security Policies | [DNSQueryLogs](/azure/azure-monitor/reference/tables/DNSQueryLogs) | -| Dev Centers | [DevCenterDiagnosticLogs](/azure/azure-monitor/reference/tables/DevCenterDiagnosticLogs)<br>[DevCenterResourceOperationLogs](/azure/azure-monitor/reference/tables/DevCenterResourceOperationLogs)<br>[DevCenterBillingEventLogs](/azure/azure-monitor/reference/tables/DevCenterBillingEventLogs) | -| Data Transfer | [DataTransferOperations](/azure/azure-monitor/reference/tables/DataTransferOperations) | -| Event Grid Namespaces | [EGNSuccessfulHttpDataPlaneOperations](/azure/azure-monitor/reference/tables/EGNSuccessfulHttpDataPlaneOperations)<br>[EGNFailedHttpDataPlaneOperations](/azure/azure-monitor/reference/tables/EGNFailedHttpDataPlaneOperations)| -| Event Hubs | [AZMSArchiveLogs](/azure/azure-monitor/reference/tables/AZMSArchiveLogs)<br>[AZMSAutoscaleLogs](/azure/azure-monitor/reference/tables/AZMSAutoscaleLogs)<br>[AZMSCustomerManagedKeyUserLogs](/azure/azure-monitor/reference/tables/AZMSCustomerManagedKeyUserLogs)<br>[AZMSKafkaCoordinatorLogs](/azure/azure-monitor/reference/tables/AZMSKafkaCoordinatorLogs)<br>[AZMSKafkaUserErrorLogs](/azure/azure-monitor/reference/tables/AZMSKafkaUserErrorLogs) | -| Firewalls | [AZFWFlowTrace](/azure/azure-monitor/reference/tables/AZFWFlowTrace) | -| Health Care APIs | [AHDSMedTechDiagnosticLogs](/azure/azure-monitor/reference/tables/AHDSMedTechDiagnosticLogs)<br>[AHDSDicomDiagnosticLogs](/azure/azure-monitor/reference/tables/AHDSDicomDiagnosticLogs)<br>[AHDSDicomAuditLogs](/azure/azure-monitor/reference/tables/AHDSDicomAuditLogs) | -| Key Vault | [AZKVAuditLogs](/azure/azure-monitor/reference/tables/AZKVAuditLogs)<br>[AZKVPolicyEvaluationDetailsLogs](/azure/azure-monitor/reference/tables/AZKVPolicyEvaluationDetailsLogs) | -| Kubernetes services | [AKSAudit](/azure/azure-monitor/reference/tables/AKSAudit)<br>[AKSAuditAdmin](/azure/azure-monitor/reference/tables/AKSAuditAdmin)<br>[AKSControlPlane](/azure/azure-monitor/reference/tables/AKSControlPlane) | -| Log Analytics | [LASummaryLogs](/azure/azure-monitor/reference/tables/LASummaryLogs) | -| Managed Lustre | [AFSAuditLogs](/azure/azure-monitor/reference/tables/AFSAuditLogs) | -| Managed NGINX | [NGXOperationLogs](/azure/azure-monitor/reference/tables/ngxoperationlogs) <br>[NGXSecurityLogs](/azure/azure-monitor/reference/tables/ngxsecuritylogs)| -| MDC | [MDCDetectionFimEvents](/azure/azure-monitor/reference/tables/mdcdetectionfimevents) <br>[MDCDetectionDNSEvents](/azure/azure-monitor/reference/tables/mdcdetectiondnsevents) -| Media Services | [AMSLiveEventOperations](/azure/azure-monitor/reference/tables/AMSLiveEventOperations)<br>[AMSKeyDeliveryRequests](/azure/azure-monitor/reference/tables/AMSKeyDeliveryRequests)<br>[AMSMediaAccountHealth](/azure/azure-monitor/reference/tables/AMSMediaAccountHealth)<br>[AMSStreamingEndpointRequests](/azure/azure-monitor/reference/tables/AMSStreamingEndpointRequests) | -| Microsoft Graph | [MicrosoftGraphActivityLogs](/azure/azure-monitor/reference/tables/microsoftgraphactivitylogs) | -| Monitor | [AzureMetricsV2](/azure/azure-monitor/reference/tables/AzureMetricsV2) | -| Network Devices (Operator Nexus) | [MNFDeviceUpdates](/azure/azure-monitor/reference/tables/MNFDeviceUpdates)<br>[MNFSystemStateMessageUpdates](/azure/azure-monitor/reference/tables/MNFSystemStateMessageUpdates) <br>[MNFSystemSessionHistoryUpdates](/azure/azure-monitor/reference/tables/mnfsystemsessionhistoryupdates) | -| Network Managers | [AVNMConnectivityConfigurationChange](/azure/azure-monitor/reference/tables/AVNMConnectivityConfigurationChange)<br>[AVNMIPAMPoolAllocationChange](/azure/azure-monitor/reference/tables/AVNMIPAMPoolAllocationChange) | -| Nexus Clusters | [NCCKubernetesLogs](/azure/azure-monitor/reference/tables/NCCKubernetesLogs)<br>[NCCVMOrchestrationLogs](/azure/azure-monitor/reference/tables/NCCVMOrchestrationLogs) | -| Nexus Storage Appliances | [NCSStorageLogs](/azure/azure-monitor/reference/tables/NCSStorageLogs)<br>[NCSStorageAlerts](/azure/azure-monitor/reference/tables/NCSStorageAlerts) | -| Operator Insights ΓÇô Data Products | [AOIDatabaseQuery](/azure/azure-monitor/reference/tables/AOIDatabaseQuery)<br>[AOIDigestion](/azure/azure-monitor/reference/tables/AOIDigestion)<br>[AOIStorage](/azure/azure-monitor/reference/tables/AOIStorage) | -| Redis cache | [ACRConnectedClientList](/azure/azure-monitor/reference/tables/ACRConnectedClientList) | -| Redis Cache Enterprise | [REDConnectionEvents](/azure/azure-monitor/reference/tables/REDConnectionEvents) | -| Relays | [AZMSHybridConnectionsEvents](/azure/azure-monitor/reference/tables/AZMSHybridConnectionsEvents) | -| Security | [SecurityAttackPathData](/azure/azure-monitor/reference/tables/SecurityAttackPathData)<br> [MDCFileIntegrityMonitoringEvents](/azure/azure-monitor/reference/tables/mdcfileintegritymonitoringevents) | -| Service Bus | [AZMSApplicationMetricLogs](/azure/azure-monitor/reference/tables/AZMSApplicationMetricLogs)<br>[AZMSOperationalLogs](/azure/azure-monitor/reference/tables/AZMSOperationalLogs)<br>[AZMSRunTimeAuditLogs](/azure/azure-monitor/reference/tables/AZMSRunTimeAuditLogs)<br>[AZMSVNetConnectionEvents](/azure/azure-monitor/reference/tables/AZMSVNetConnectionEvents) | -| Sphere | [ASCAuditLogs](/azure/azure-monitor/reference/tables/ASCAuditLogs)<br>[ASCDeviceEvents](/azure/azure-monitor/reference/tables/ASCDeviceEvents) | -| Storage | [StorageBlobLogs](/azure/azure-monitor/reference/tables/StorageBlobLogs)<br>[StorageFileLogs](/azure/azure-monitor/reference/tables/StorageFileLogs)<br>[StorageQueueLogs](/azure/azure-monitor/reference/tables/StorageQueueLogs)<br>[StorageTableLogs](/azure/azure-monitor/reference/tables/StorageTableLogs) | -| Synapse Analytics | [SynapseSqlPoolExecRequests](/azure/azure-monitor/reference/tables/SynapseSqlPoolExecRequests)<br>[SynapseSqlPoolRequestSteps](/azure/azure-monitor/reference/tables/SynapseSqlPoolRequestSteps)<br>[SynapseSqlPoolDmsWorkers](/azure/azure-monitor/reference/tables/SynapseSqlPoolDmsWorkers)<br>[SynapseSqlPoolWaits](/azure/azure-monitor/reference/tables/SynapseSqlPoolWaits) | -| Storage Mover | [StorageMoverJobRunLogs](/azure/azure-monitor/reference/tables/StorageMoverJobRunLogs)<br>[StorageMoverCopyLogsFailed](/azure/azure-monitor/reference/tables/StorageMoverCopyLogsFailed)<br>[StorageMoverCopyLogsTransferred](/azure/azure-monitor/reference/tables/StorageMoverCopyLogsTransferred)<br> | -| Virtual Network Manager | [AVNMNetworkGroupMembershipChange](/azure/azure-monitor/reference/tables/AVNMNetworkGroupMembershipChange)<br>[AVNMRuleCollectionChange](/azure/azure-monitor/reference/tables/AVNMRuleCollectionChange) | - --## Next steps --- [Manage data retention](../logs/data-retention-configure.md)- |
| azure-monitor | Basic Logs Query | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/basic-logs-query.md | - Title: Query data in a Basic and Auxiliary table in Azure Monitor Logs -description: This article explains how to query data from Basic and Auxiliary logs tables. ---- Previously updated : 07/21/2024---# Query data in a Basic and Auxiliary table in Azure Monitor Logs -Basic and Auxiliary logs tables reduce the cost of ingesting high-volume verbose logs and let you query the data they store with some limitations. This article explains how to query data from Basic and Auxiliary logs tables. --For more information about Basic and Auxiliary table plans, see [Azure Monitor Logs Overview: Table plans](data-platform-logs.md#table-plans). --> [!NOTE] -> Other tools that use the Azure API for querying - for example, Grafana and Power BI - cannot access data in Basic and Auxiliary tables. ---## Limitations --Queries on data in Basic and Auxiliary tables are subject to the following limitations: --#### Kusto Query Language (KQL) language limitations --Queries of data in Basic or Auxiliary tables support all KQL [scalar](/azure/data-explorer/kusto/query/scalar-functions) and [aggregation](/azure/data-explorer/kusto/query/aggregation-functions) functions. However, Basic or Auxiliary table queries are limited to a single table. Therefore, these limitations apply: --- Operators that join data from multiple tables are limited:- - [join](/azure/data-explorer/kusto/query/join-operator?pivots=azuremonitor), [find](/azure/data-explorer/kusto/query/find-operator?pivots=azuremonitor), [search](/azure/data-explorer/kusto/query/search-operator), and [externaldata](/azure/data-explorer/kusto/query/externaldata-operator?pivots=azuremonitor) aren't supported. - - [lookup](/azure/data-explorer/kusto/query/lookup-operator) and [union](/azure/data-explorer/kusto/query/union-operator?pivots=azuremonitor) are supported, but limited to up to five Analytics tables. -- [User-defined functions](/azure/data-explorer/kusto/query/functions/user-defined-functions) aren't supported.-- [Cross-service](/azure/azure-monitor/logs/cross-workspace-query) and [cross-resource](/azure/azure-monitor/logs/cross-workspace-query) queries aren't supported.---#### Time range -Specify the time range in the query header in Log Analytics or in the API call. You can't specify the time range in the query body using a **where** statement. --#### Query scope --Set the Log Analytics workspace as the scope of your query. You can't run queries using another resource for the scope. For more information about query scope, see [Log query scope and time range in Azure Monitor Log Analytics](scope.md). --#### Concurrent queries -You can run two concurrent queries per user. --#### Auxiliary log query performance --Queries of data in Auxiliary tables are unoptimized and might take longer to return results than queries you run on Analytics and Basic tables. --#### Purge -You canΓÇÖt [purge personal data](personal-data-mgmt.md#exporting-and-deleting-personal-data) from Basic and Auxiliary tables. --## Run a query on a Basic or Auxiliary table -Running a query on Basic or Auxiliary tables is the same as querying any other table in Log Analytics. See [Get started with Azure Monitor Log Analytics](./log-analytics-tutorial.md) if you aren't familiar with this process. --# [Portal](#tab/portal-1) --In the Azure portal, select **Monitor** > **Logs** > **Tables**. --In the list of tables, you can identify Basic and Auxiliary tables by their unique icon: ---You can also hover over a table name for the table information view, which specifies that the table has the Basic or Auxiliary table plan: ---When you add a table to the query, Log Analytics identifies a Basic or Auxiliary table and aligns the authoring experience accordingly. ---# [API](#tab/api-1) --Use **/search** from the [Log Analytics API](api/overview.md) to query data in a Basic or Auxiliary table using a REST API. This is similar to the [/query](api/request-format.md) API with the following differences: --- The query is subject to the language limitations described in [KQL language limitations](#kusto-query-language-kql-language-limitations).-- The time span must be specified in the header of the request and not in the query statement.--**Sample Request** --```http -https://api.loganalytics.io/v1/workspaces/{workspaceId}/search?timespan=P1D -``` --**Request body** --```json -{ - "query": "ContainerLogV2 | where Computer == \"some value\"\n", -} -``` ----## Pricing model -The charge for a query on Basic and Auxiliary tables is based on the amount of data the query scans, which depends on the size of the table and the query's time range. For example, a query that scans three days of data in a table that ingests 100 GB each day, would be charged for 300 GB. --For more information, see [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/). ---## Next steps --- [Learn more about Azure Monitor Logs table plans](data-platform-logs.md#table-plans).-- |
| azure-monitor | Change Pricing Tier | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/change-pricing-tier.md | - Title: Change pricing tier for Log Analytics workspace -description: Details on how to change pricing tier for Log Analytics workspace in Azure Monitor. ---- Previously updated : 05/02/2024-- -# Change pricing tier for Log Analytics workspace -Each Log Analytics workspace in Azure Monitor can have a different [pricing tier](cost-logs.md#commitment-tiers). This article describes how to change the pricing tier for a workspace and how to track these changes. --> [!NOTE] -> This article describes how to change the commitment tier for a Log Analytics workspace once you determine which commitment tier you want to use. See [Azure Monitor Logs pricing details](cost-logs.md) for details on how commitment tiers work and [Azure Monitor cost and usage](../cost-usage.md#log-analytics-workspace) for recommendations on the most cost effective commitment based on your observed Azure Monitor usage. --## Permissions required --| Action | Permissions required | -|:-|:| -| Change pricing tier | `Microsoft.OperationalInsights/workspaces/*/write` permissions to the Log Analytics workspace, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example | ---## Changing pricing tier --# [Azure portal](#tab/azure-portal) -Use the following steps to change the pricing tier of your workspace using the Azure portal. --1. From the **Log Analytics workspaces** menu, select your workspace, and open **Usage and estimated costs**. This displays a list of each of the pricing tiers available for this workspace. --2. Review the estimated costs for each pricing tier. This estimate assumes that your usage in the last 31 days is typical. --3. Choose the tier with the lowest estimated cost. This tier is labeled **Recommended Tier**. -- -3. Click **Select** if you decide to change the pricing tier after reviewing the estimated costs. --4. Review the commitment message in the popup that "Commitment Tier pricing has a 31-day commitment period, during which the workspace cannot be moved to a lower Commitment Tier or any Consumption Tier" and select **Change pricing tier** to confirm. --# [Azure Resource Manager](#tab/azure-resource-manager) -To set the pricing tier using an [Azure Resource Manager](./resource-manager-workspace.md), use the `sku` object to set the pricing tier and the `capacityReservationLevel` parameter if the pricing tier is `capacityresrvation`. For details on this template format, see [Microsoft.OperationalInsights workspaces](/azure/templates/microsoft.operationalinsights/workspaces) --The following sample template sets a workspace to a 300 GB/day commitment tier. To set the pricing tier to other values such as Pay-As-You-Go (called `pergb2018` for the SKU), omit the `capacityReservationLevel` property. --``` -{ - "$schema": https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#, - "contentVersion": "1.0.0.0", - "resources": [ - { - "name": "YourWorkspaceName", - "type": "Microsoft.OperationalInsights/workspaces", - "apiVersion": "2020-08-01", - "location": "yourWorkspaceRegion", - "properties": { - "sku": { - "name": "capacityreservation", - "capacityReservationLevel": 300 - } - } - } - ] -} -``` --See [Deploying the sample templates](../resource-manager-samples.md) if you're not familiar with using Resource Manager templates. ----## Tracking pricing tier changes -Changes to a workspace's pricing tier are recorded in the [Activity Log](../essentials/activity-log.md). Filter for events with an **Operation** of *Create Workspace*. The event's **Change history** tab shows the old and new pricing tiers in the `properties.sku.name` row. To monitor changes the pricing tier, [create an alert](../alerts/alerts-activity-log.md) for the *Create Workspace* operation. --## Next steps --- See [Azure Monitor Logs pricing details](cost-logs.md) for details on how charges are calculated for data in a Log Analytics workspace and different configuration options to reduce your charges.-- See [Azure Monitor cost and usage](../cost-usage.md) for a description of the different types of Azure Monitor charges and how to analyze them on your Azure bill. |
| azure-monitor | Computer Groups | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/computer-groups.md | - Title: Computer groups in Azure Monitor log queries -description: Computer groups in Azure Monitor allow you to scope log queries to a particular set of computers. This article describes the different methods you can use to create computer groups and how to use them in a log query. --- Previously updated : 07/26/2024----# Computer groups in Azure Monitor log queries -Computer groups in Azure Monitor allow you to scope [log queries](./log-query-overview.md) to a particular set of computers. Each group is populated with computers using a query that you define. When the group is included in a log query, the results are limited to records that match the computers in the group. --## Permissions required --| Action | Permissions required | -|:|:| -| Create a computer group from a log query. | `microsoft.operationalinsights/workspaces/savedSearches/write` permissions to the Log Analytics workspace where you want to create the computer group, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example. | -| Run a computer group's log search or use a computer group in a log query. | `Microsoft.OperationalInsights/workspaces/query/*/read` permissions to the Log Analytics workspaces you query, as provided by the [Log Analytics Reader built-in role](./manage-access.md#log-analytics-reader), for example. | -| Delete a computer group. | `microsoft.operationalinsights/workspaces/savedSearches/delete` permissions to the Log Analytics workspace where the computer group is saved, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example. | --## Creating a computer group --> [!NOTE] -> While some classic features are being retired with the Log Analytics agent deprecation, there are no current plans to deprecate computer groups. It's typically more effective though to leverage the capabilities of the KQL language to scope log queries. --You can create a computer group in Azure Monitor using the methods in the following table. Details on each method are provided in the sections below. --| Method | Description | -|: |: | -| Log query |Create a log query that returns a list of computers. | -| Active Directory | No longer supported | -| Configuration Manager | No longer supported | -| Windows Server Update Services | No longer supported | --### Log query -Computer groups created from a log query contain all of the computers returned by a query that you define. This query is run every time the computer group is used so that any changes since the group was created is reflected. --You can use any query for a computer group, but it must return a distinct set of computers by using `distinct Computer`. Following is a typical example query that you could use for as a computer group. --```kusto -Heartbeat | where Computer contains "srv" | distinct Computer -``` --Use the following procedure to create a computer group from a log search in the Azure portal. --1. Click **Logs** in the **Azure Monitor** menu in the Azure portal. -1. Create and run a query that returns the computers that you want in the group. -1. Click **Save** at the top of the screen, and select **Save as function** from the dropdown. -1. Select **Save as computer group**. -1. Provide values for each property for the computer group described in the table and click **Save**. --The following table describes the properties that define a computer group. --| Property | Description | -|:|:| -| Function name | Name of the query to display in the portal. | -| Legacy category | Category to organize the queries in the portal. | -| Parameters | Add a parameter for each variable in the function that requires a value when it's used. For more information, see [Function parameters](functions.md#function-parameters). | ---### Active Directory -No longer supported --### Windows Server Update Service -No longer supported --### Configuration Manager -No longer supported --## Managing computer groups -You can view computer groups that were created from a log query from the **Legacy computer groups** menu item in your Log Analytics workspace in the Azure portal. Select the **Saved Groups** tab to view the list of groups. --Click the **Run query** icon for a group to run the group's log search that returns its members. Click the **Delete** icon to delete the computer group. You can't modify a computer group but instead must delete and then recreate it with the modified settings. ---## Using a computer group in a log query -You use a Computer group created from a log query in a query by treating its alias as a function, typically with the following syntax: --```kusto -Table | where Computer in (ComputerGroup) -``` --For example, you could use the following to return UpdateSummary records for only computers in a computer group called mycomputergroup. --```kusto -UpdateSummary | where Computer in (mycomputergroup) -``` --## Next steps -* Learn about [log queries](./log-query-overview.md) to analyze the data collected from data sources and solutions. |
| azure-monitor | Cost Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/cost-logs.md | - Title: Azure Monitor Logs cost calculations and options -description: Cost details for data stored in a Log Analytics workspace in Azure Monitor, including commitment tiers and data size calculation. -- Previously updated : 01/25/2024-ms.reviwer: dalek git ---# Azure Monitor Logs cost calculations and options --The most significant charges for most Azure Monitor implementations are typically ingestion and retention of data in your Log Analytics workspaces. Several features in Azure Monitor don't have a direct cost but add to the workspace data that's collected. This article describes how data charges are calculated for your Log Analytics workspaces and the various configuration options that affect your costs. ----## Pricing model --The default pricing for Log Analytics is a pay-as-you-go model that's based on ingested data volume and data retention. Each Log Analytics workspace is charged as a separate service and contributes to the bill for your Azure subscription. [Pricing for Log Analytics](https://azure.microsoft.com/pricing/details/monitor/) is set regionally. The amount of data ingestion can be considerable, depending on: --- The set of management solutions enabled and their configuration.-- The number and type of monitored resources.-- The types of data collected from each monitored resource.--A list of Azure Monitor billing meter names is available [here](../cost-meters.md). --## Data size calculation --Data volume is measured as the size of the data sent to be stored and is measured in units of GB (10^9 bytes). The data size of a single record is calculated from a string representation of the columns that are stored in the Log Analytics workspace for that record. It doesn't matter whether the data is sent from an agent or added during the ingestion process. This calculation includes any custom columns added by the [logs ingestion API](logs-ingestion-api-overview.md), [transformations](../essentials/data-collection-transformations.md) or [custom fields](custom-fields.md) that are added as data is collected and then stored in the workspace. -->[!NOTE] ->The billable data volume calculation is generally substantially smaller than the size of the entire incoming JSON-packaged event. On average, across all event types, the billed size is around 25 percent less than the incoming data size. It can be up to 50 percent for small events. The percentage includes the effect of the standard columns excluded from billing. It's essential to understand this calculation of billed data size when you estimate costs and compare other pricing models. --### Excluded columns --The following [standard columns](log-standard-columns.md) are common to all tables and are excluded in the calculation of the record size. All other columns stored in Log Analytics are included in the calculation of the record size. The standard columns are: --- `_ResourceId`-- `_SubscriptionId`-- `_ItemId`-- `_IsBillable`-- `_BilledSize`-- `Type`--### Excluded tables --Some tables are free from data ingestion charges altogether, including, for example, [AzureActivity](/azure/azure-monitor/reference/tables/azureactivity), [Heartbeat](/azure/azure-monitor/reference/tables/heartbeat), [Usage](/azure/azure-monitor/reference/tables/usage), and [Operation](/azure/azure-monitor/reference/tables/operation). This information is always indicated by the [_IsBillable](log-standard-columns.md#_isbillable) column, which shows whether a record was excluded from billing for data ingestion and retention. --### Charges for other solutions and services --Some solutions have more specific policies about free data ingestion. For example, [Azure Migrate](https://azure.microsoft.com/pricing/details/azure-migrate/) makes dependency visualization data free for the first 180 days of a Server Assessment. Services such as [Microsoft Defender for Cloud](https://azure.microsoft.com/pricing/details/azure-defender/), [Microsoft Sentinel](https://azure.microsoft.com/pricing/details/azure-sentinel/), and [configuration management](https://azure.microsoft.com/pricing/details/automation/) have their own pricing models. --See the documentation for different services and solutions for any unique billing calculations. --## Commitment tiers --In addition to the pay-as-you-go model, Log Analytics has *commitment tiers*, which can save you as much as 30 percent compared to the pay-as-you-go price. With commitment tier pricing, you can commit to buy data ingestion for a workspace, starting at 100 GB per day, at a lower price than pay-as-you-go pricing. Any usage above the commitment level (overage) is billed at that same price per GB as provided by the current commitment tier. (Overage is billed using the same commitment tier billing meter. For example if a workspace is in the 200 GB/day commitment tier and ingests 300 GB in a day, that usage is billed as 1.5 units of the 200 GB/day commitment tier.) The commitment tiers have a 31-day commitment period from the time a commitment tier is selected or changed. --- During the commitment period, you can change to a higher commitment tier, which restarts the 31-day commitment period. You can't move back to pay-as-you-go or to a lower commitment tier until after you finish the commitment period.-- At the end of the commitment period, the workspace retains the selected commitment tier, and the workspace can be moved to pay-as-you-go or to a lower commitment tier at any time.-- If a workspace is inadvertently moved into a commitment tier, contact Microsoft Support to reset the commitment period so you can move back to the pay-as-you-go pricing tier.--Billing for the commitment tiers is done per workspace on a daily basis. If the workspace is part of a [dedicated cluster](#dedicated-clusters), the billing is done for the cluster. See the following "Dedicated clusters" section. For a list of the commitment tiers and their prices, see [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/). --Azure Commitment Discounts, such as discounts received from [Microsoft Enterprise Agreements](https://www.microsoft.com/licensing/licensing-programs/enterprise), are applied to Azure Monitor Logs commitment-tier pricing just as they are to pay-as-you-go pricing. Discounts are applied whether the usage is being billed per workspace or per dedicated cluster. --> [!TIP] -> The **Usage and estimated costs** menu item for each Log Analytics workspace shows an estimate of what your data ingestion charges would be at each commitment level to help you choose the optimal commitment tier for your data ingestion patterns. Review this information periodically to determine if you can reduce your charges by moving to another tier. For information on this view, see [Usage and estimated costs](../cost-usage.md#usage-and-estimated-costs). To review your actual charges, use [Azure Cost Management = Billing](../cost-usage.md#azure-cost-management--billing). --## Dedicated clusters --An [Azure Monitor Logs dedicated cluster](logs-dedicated-clusters.md) is a collection of workspaces in a single managed Azure Data Explorer cluster. Dedicated clusters support advanced features, such as [customer-managed keys](customer-managed-keys.md), and use the same commitment-tier pricing model as workspaces, although they must have a commitment level of at least 100 GB per day. Any usage above the commitment level (overage) is billed at that same price per GB as provided by the current commitment tier. There's no pay-as-you-go option for clusters. --The cluster commitment tier has a 31-day commitment period after the commitment level is increased. During the commitment period, the commitment tier level can't be reduced, but it can be increased at any time. When workspaces are associated to a cluster, the data ingestion billing for those workspaces is done at the cluster level by using the configured commitment tier level. --There are two modes of billing for a cluster that you specify when you create the cluster: --- **Cluster (default)**: Billing for ingested data is done at the cluster level. The ingested data quantities from each workspace associated to a cluster are aggregated to calculate the daily bill for the cluster. Per-node allocations from [Microsoft Defender for Cloud](../../security-center/index.yml) are applied at the workspace level prior to this aggregation of data across all workspaces in the cluster.--- **Workspaces**: Commitment tier costs for your cluster are attributed proportionately to the workspaces in the cluster, by each workspace's data ingestion volume (after accounting for per-node allocations from [Microsoft Defender for Cloud](../../security-center/index.yml) for each workspace).<br><br>If the total data volume ingested into a cluster for a day is less than the commitment tier, each workspace is billed for its ingested data at the effective per-GB commitment tier rate by billing them a fraction of the commitment tier. The unused part of the commitment tier is then billed to the cluster resource.<br><br>If the total data volume ingested into a cluster for a day is more than the commitment tier, each workspace is billed for a fraction of the commitment tier, based on its fraction of the ingested data that day and each workspace for a fraction of the ingested data above the commitment tier. If the total data volume ingested into a workspace for a day is above the commitment tier, nothing is billed to the cluster resource.--Examples of how cluster billing works in each of these modes can be found [here](/azure/sentinel/enroll-simplified-pricing-tier?tabs=microsoft-sentinel#dedicated-cluster-billing-examples). --Data retention is billed for each workspace, the same as for workspaces not joined to a cluster. --Cluster billing starts when the cluster is created, regardless of whether workspaces are associated with the cluster. --When you link workspaces to a cluster, the pricing tier is changed to cluster, and ingestion is billed based on the cluster's commitment tier. Workspaces associated to a cluster no longer have their own pricing tier. Workspaces can be unlinked from a cluster at any time, and the pricing tier can be changed to per GB. --If your linked workspace is using the legacy Per Node pricing tier, it is billed based on data ingested against the cluster's commitment tier, and no longer Per Node. Per-node data allocations from Microsoft Defender for Cloud will continue to be applied. --If a cluster is deleted, billing for the cluster stops even if the cluster is within its 31-day commitment period. --For more information on how to create a dedicated cluster and specify its billing type, see [Create a dedicated cluster](logs-dedicated-clusters.md#create-a-dedicated-cluster). --## Basic and Auxiliary table plans --You can configure certain tables in a Log Analytics workspace to use [Basic and Auxiliary table plans](logs-table-plans.md). Data in these tables has a significantly reduced ingestion charge. There's a charge to query data in these tables. --The charge for querying data in Basic and Auxiliary tables is based on the GB of data scanned in performing the search. --For more information about the Basic and Auxiliary table plans, see [Azure Monitor Logs overview: Table plans](data-platform-logs.md#table-plans). --## Log data retention --In addition to data ingestion, there's a charge for the retention of data in each Log Analytics workspace. You can set the retention period for the entire workspace or for each table. After this period, the data is either removed or kept in long-term retention. During the long-term retention period, you pay a reduced retention charge, and there's a charge to retrieve the data using a [search job](search-jobs.md). Use long-term retention to reduce your costs for data that you must store for compliance or occasional investigation. --[Deleting a custom table](create-custom-table.md#delete-a-table) doesn't remove data associated with that table, so interactive and long-term retention charges continue to apply. --For more information on data retention, including how to configure these settings and access data in long-term retention, see [Manage data retention in a Log Analytics workspace](data-retention-configure.md). -->[!NOTE] ->Deleting data from your Log Analytics workspace using the Log Analytics Purge feature doesn't affect your retention costs. To lower retention costs, decrease the retention period for the workspace or for specific tables. --## Search jobs --Retrieve data from long-term retention by running [search jobs](search-jobs.md). Search jobs are asynchronous queries that fetch records into a new search table within your workspace for further analytics. Search jobs are billed by the number of GB of data scanned on each day that's accessed to perform the search. --## Log data restore --When you need to intensively queried large volumes of data, or data in long-term retention with the full analytic query capabilities, the [data restore](restore.md) feature is a powerful tool. The restore operation makes a specific time range of data in a table available in the hot cache for high-performance queries. You can later dismiss the data when you're finished. Log data restore is billed by the amount of data restored, and by the time the restore is kept active. The minimal values billed for any data restore are 2 TB and 12 hours. Data restored of more than 2 TB and/or more than 12 hours in duration is billed on a pro-rated basis. --## Log data export --[Data export](logs-data-export.md) in a Log Analytics workspace lets you continuously export data per selected tables in your workspace to an Azure Storage account or Azure Event Hubs as it arrives to an Azure Monitor pipeline. Charges for the use of data export are based on the amount of data exported. The size of data exported is the number of bytes in the exported JSON-formatted data. --## Application Insights billing --Because [workspace-based Application Insights resources](../app/create-workspace-resource.md) store their data in a Log Analytics workspace, the billing for data ingestion and retention is done by the workspace where the Application Insights data is located. For this reason, you can use all options of the Log Analytics pricing model, including [commitment tiers](#commitment-tiers), along with pay-as-you-go. --> [!TIP] -> Looking to adjust retention settings on your Application Insights tables? The table names have changed for workspace based components, see [Application Insights Table Structure](/azure/azure-monitor/app/convert-classic-resource#table-structure) --Data ingestion and data retention for a [classic Application Insights resource](/previous-versions/azure/azure-monitor/app/create-new-resource) follow the same pay-as-you-go pricing as workspace-based resources, but they can't use commitment tiers. --Telemetry from ping tests and multi-step tests is charged the same as data usage for other telemetry from your app. Use of web tests and enabling alerting on custom metric dimensions is still reported through Application Insights. There's no data volume charge for using [Live Metrics Stream](../app/live-stream.md). --For more information about legacy tiers that are available to early adopters of Application Insights, see [Application Insights legacy enterprise (per node) pricing tier](/previous-versions/azure/azure-monitor/app/legacy-pricing). --## Workspaces with Microsoft Sentinel --When Microsoft Sentinel is enabled in a Log Analytics workspace, all data collected in that workspace is subject to Microsoft Sentinel charges along with Log Analytics charges. For this reason, you'll often separate your security and operational data in different workspaces so that you don't incur [Microsoft Sentinel charges](../../sentinel/billing.md) for operational data. --In some scenarios, combining this data can result in cost savings. Typically, this situation occurs when you aren't collecting enough security and operational data for each to reach a commitment tier on their own, but the combined data is enough to reach a commitment tier. For more information, see: --- [Design a Log Analytics workspace architecture](workspace-design.md)-- [Sample Log Analytics workspace designs for Microsoft Sentinel](../../sentinel/sample-workspace-designs.md)--## Workspaces with Microsoft Defender for Cloud --[Microsoft Defender for Servers (part of Defender for Cloud)](../../security-center/index.yml) [bills by the number of monitored services](https://azure.microsoft.com/pricing/details/defender-for-cloud/). It provides 500 MB per server per day of data allocation that's applied to the following subset of [security data types](/azure/azure-monitor/reference/tables/tables-category#security): --- [SecurityAlert](/azure/azure-monitor/reference/tables/securityalert)-- [SecurityBaseline](/azure/azure-monitor/reference/tables/securitybaseline)-- [SecurityBaselineSummary](/azure/azure-monitor/reference/tables/securitybaselinesummary)-- [SecurityDetection](/azure/azure-monitor/reference/tables/securitydetection)-- [SecurityEvent](/azure/azure-monitor/reference/tables/securityevent)-- [WindowsFirewall](/azure/azure-monitor/reference/tables/windowsfirewall)-- [SysmonEvent](/azure/azure-monitor/reference/tables/sysmonevent)-- [ProtectionStatus](/azure/azure-monitor/reference/tables/protectionstatus)-- [Update](/azure/azure-monitor/reference/tables/update) and [UpdateSummary](/azure/azure-monitor/reference/tables/updatesummary) when the Update Management solution isn't running in the workspace or solution targeting is enabled.-- [MDCFileIntegrityMonitoringEvents](/azure/azure-monitor/reference/tables/mdcfileintegritymonitoringevents)--If the workspace is in the legacy Per Node pricing tier, the Defender for Cloud and Log Analytics allocations are combined and applied jointly to all billable ingested data. If the workspace has Sentinel enabled on it, if Sentinel is using a classic pricing tier, the Defender data allocation applies only for the Log Analytics data ingestion billing, but not the classic Sentinel billing. If Sentinel is using a [simplified pricing tier](/azure/sentinel/enroll-simplified-pricing-tier), the Defender data allocation applies to the unified Sentinel billing. To learn more on how Microsoft Sentinel customers can benefit, see the [Microsoft Sentinel Pricing page](https://azure.microsoft.com/pricing/details/microsoft-sentinel/). --The count of monitored servers is calculated on an hourly granularity. The daily data allocation contributions from each monitored server are aggregated at the workspace level. If the workspace is in the legacy Per Node pricing tier, the Microsoft Defender for Cloud and Log Analytics allocations are combined and applied jointly to all billable ingested data. --## Legacy pricing tiers --Subscriptions that contained a Log Analytics workspace or Application Insights resource on April 2, 2018, or are linked to an Enterprise Agreement that started before February 1, 2019, and is still active, will continue to have access to use the following legacy pricing tiers: --- Standalone (Per GB)-- Per Node (Operations Management Suite [OMS]) --Access to the legacy Free Trial pricing tier was limited on July 1, 2022. Pricing information for the Standalone and Per Node pricing tiers is available [here](https://aka.ms/OMSpricing). --A list of Azure Monitor billing meter names, including these legacy tiers, is available [here](../cost-meters.md). --> [!IMPORTANT] -> The legacy pricing tiers do not support access to some of the newest features in Log Analytics such as ingesting data to tables with the cost-effective Basic and Auxiliary table plans. --### Free Trial pricing tier --Workspaces in the Free Trial pricing tier have daily data ingestion limited to 500 MB (except for security data types collected by [Microsoft Defender for Cloud](../../security-center/index.yml)). Data retention is limited to seven days. The Free Trial pricing tier is intended only for evaluation purposes, not production workloads. No SLA is provided for the Free Trial tier. --> [!NOTE] -> Creating new workspaces in, or moving existing workspaces into, the legacy Free Trial pricing tier was possible only until July 1, 2022. --### Standalone pricing tier --Usage on the Standalone pricing tier is billed by the ingested data volume. It's reported in the **Log Analytics** service and the meter is named "Data Analyzed." Workspaces in the Standalone pricing tier have user-configurable retention from 30 to 730 days. Workspaces in the Standalone pricing tier don't support the use of [Basic and Auxiliary table plans](logs-table-plans.md). --### Per Node pricing tier --The Per Node pricing tier charges per monitored VM (node) on an hour granularity. For each monitored node, the workspace is allocated 500 MB of data per day that's not billed. This allocation is calculated with hourly granularity and is aggregated at the workspace level each day. Data ingested above the aggregate daily data allocation is billed per GB as data overage. The Per Node pricing tier is a legacy tier, which is only available to existing Subscriptions fulfilling the requirement for [legacy pricing tiers](#legacy-pricing-tiers). --On your bill, the service is **Insight and Analytics** for Log Analytics usage if the workspace is in the Per Node pricing tier. Workspaces in the Per Node pricing tier have user-configurable retention from 30 to 730 days. Workspaces in the Per Node pricing tier don't support the use of [Basic and Auxiliary table plans](logs-table-plans.md). Usage is reported on three meters: --- **Node**: The usage for the number of monitored nodes (VMs) in units of node months.-- **Data Overage per Node**: The number of GB of data ingested in excess of the aggregated data allocation.-- **Data Included per Node**: The amount of ingested data that was covered by the aggregated data allocation. This meter is also used when the workspace is in all pricing tiers to show the amount of data covered by Microsoft Defender for Cloud.--> [!TIP] -> If your workspace has access to the **Per Node** pricing tier but you're wondering whether it would cost less in a pay-as-you-go tier, [use the following query](#evaluate-the-legacy-per-node-pricing-tier) for a recommendation. --### Standard and Premium pricing tiers --Workspaces can't be created in or moved to the **Standard** or **Premium** pricing tiers since October 1, 2016. Workspaces already in these pricing tiers can continue to use them, but if a workspace is moved out of these tiers, it can't be moved back. The Standard and Premium pricing tiers have fixed data retention of 30 days and 365 days, respectively. Workspaces in these pricing tiers don't support the use of [Basic and Auxiliary table plans](logs-table-plans.md) and long-term data retention. Data ingestion meters on your Azure bill for these legacy tiers are called "Data Analyzed." --### Microsoft Defender for Cloud with legacy pricing tiers --The following considerations pertain to legacy Log Analytics tiers and how usage is billed for [Microsoft Defender for Cloud](../../security-center/index.yml): --- If the workspace is in the legacy Standard or Premium tier, Microsoft Defender for Cloud is billed only for Log Analytics data ingestion, not per node.-- If the workspace is in the legacy Per Node tier, Microsoft Defender for Cloud is billed using the current [Microsoft Defender for Cloud node-based pricing model](https://azure.microsoft.com/pricing/details/security-center/).-- In other pricing tiers (including commitment tiers), if Microsoft Defender for Cloud was enabled before June 19, 2017, Microsoft Defender for Cloud is billed only for Log Analytics data ingestion. Otherwise, Microsoft Defender for Cloud is billed using the current Microsoft Defender for Cloud node-based pricing model.--More information on pricing tier limitations is available at [Azure subscription and service limits, quotas, and constraints](../service-limits.md#log-analytics-workspaces). --None of the legacy pricing tiers have regional-based pricing. --> [!NOTE] -> To use the entitlements that come from purchasing OMS E1 Suite, OMS E2 Suite, or OMS Add-On for System Center, choose the Log Analytics Per Node pricing tier. --## Evaluate the legacy Per Node pricing tier --It's often difficult to determine whether workspaces with access to the legacy Per Node pricing tier are better off in that tier or in a current pay-as-you-go or commitment tier. You need to understand the trade-off between the fixed cost per monitored node in the Per Node pricing tier and its included data allocation of 500 MB per node per day and the cost of paying for ingested data in the pay-as-you-go (per GB) tier. --Use the following query to make a recommendation for the optimal pricing tier based on a workspace's usage patterns. This query looks at the monitored nodes and data ingested into a workspace in the last seven days. For each day, it evaluates which pricing tier would have been optimal. To use the query, you must specify: --- Whether the workspace is using Microsoft Defender for Cloud by setting `workspaceHasSecurityCenter` to `true` or `false`.-- Update the prices if you have specific discounts.-- Specify the number of days to look back and analyze by setting `daysToEvaluate`. This option is useful if the query is taking too long trying to look at seven days of data.--```kusto -// Set these parameters before running query -// For pay-as-you-go (per-GB) and commitment tier pricing details, see https://azure.microsoft.com/pricing/details/monitor/. -// You can see your per-node costs in your Azure usage and charge data. For more information, see https://learn.microsoft.com/azure/cost-management-billing/understand/download-azure-daily-usage. -let workspaceHasSecurityCenter = true; -let daysToEvaluate = 7; -let PerNodePrice = 15.; // Monthly price per monitored node -let PerNodeOveragePrice = 2.30; // Price per GB for data overage in the Per Node pricing tier -let PerGBPrice = 2.30; // Enter the pay-as-you-go price for your workspace's region (from https://azure.microsoft.com/pricing/details/monitor/) -let CommitmentTier100Price = 196.; // Enter your price for the 100 GB/day commitment tier -let CommitmentTier200Price = 368.; // Enter your price for the 200 GB/day commitment tier -let CommitmentTier300Price = 540.; // Enter your price for the 300 GB/day commitment tier -let CommitmentTier400Price = 704.; // Enter your price for the 400 GB/day commitment tier -let CommitmentTier500Price = 865.; // Enter your price for the 500 GB/day commitment tier -let CommitmentTier1000Price = 1700.; // Enter your price for the 1000 GB/day commitment tier -let CommitmentTier2000Price = 3320.; // Enter your price for the 2000 GB/day commitment tier -let CommitmentTier5000Price = 8050.; // Enter your price for the 5000 GB/day commitment tier -// -let SecurityDataTypes=dynamic(["SecurityAlert", "SecurityBaseline", "SecurityBaselineSummary", "SecurityDetection", "SecurityEvent", "WindowsFirewall", "MaliciousIPCommunication", "LinuxAuditLog", "SysmonEvent", "ProtectionStatus", "WindowsEvent", "Update", "UpdateSummary"]); -let StartDate = startofday(datetime_add("Day",-1*daysToEvaluate,now())); -let EndDate = startofday(now()); -union * -| where TimeGenerated >= StartDate and TimeGenerated < EndDate -| extend computerName = tolower(tostring(split(Computer, '.')[0])) -| where computerName != "" -| summarize nodesPerHour = dcount(computerName) by bin(TimeGenerated, 1h) -| summarize nodesPerDay = sum(nodesPerHour)/24. by day=bin(TimeGenerated, 1d) -| join kind=leftouter ( - Heartbeat - | where TimeGenerated >= StartDate and TimeGenerated < EndDate - | where Computer != "" - | summarize ASCnodesPerHour = dcount(Computer) by bin(TimeGenerated, 1h) - | extend ASCnodesPerHour = iff(workspaceHasSecurityCenter, ASCnodesPerHour, 0) - | summarize ASCnodesPerDay = sum(ASCnodesPerHour)/24. by day=bin(TimeGenerated, 1d) -) on day -| join ( - Usage - | where TimeGenerated >= StartDate and TimeGenerated < EndDate - | where IsBillable == true - | extend NonSecurityData = iff(DataType !in (SecurityDataTypes), Quantity, 0.) - | extend SecurityData = iff(DataType in (SecurityDataTypes), Quantity, 0.) - | summarize DataGB=sum(Quantity)/1000., NonSecurityDataGB=sum(NonSecurityData)/1000., SecurityDataGB=sum(SecurityData)/1000. by day=bin(StartTime, 1d) -) on day -| extend AvgGbPerNode = NonSecurityDataGB / nodesPerDay -| extend OverageGB = iff(workspaceHasSecurityCenter, - max_of(DataGB - 0.5*nodesPerDay - 0.5*ASCnodesPerDay, 0.), - max_of(DataGB - 0.5*nodesPerDay, 0.)) -| extend PerNodeDailyCost = nodesPerDay * PerNodePrice / 31. + OverageGB * PerNodeOveragePrice -| extend billableGB = iff(workspaceHasSecurityCenter, - (NonSecurityDataGB + max_of(SecurityDataGB - 0.5*ASCnodesPerDay, 0.)), DataGB ) -| extend PerGBDailyCost = billableGB * PerGBPrice -| extend CommitmentTier100DailyCost = CommitmentTier100Price + max_of(billableGB - 100, 0.)* CommitmentTier100Price/100. -| extend CommitmentTier200DailyCost = CommitmentTier200Price + max_of(billableGB - 200, 0.)* CommitmentTier200Price/200. -| extend CommitmentTier300DailyCost = CommitmentTier300Price + max_of(billableGB - 300, 0.)* CommitmentTier300Price/300. -| extend CommitmentTier400DailyCost = CommitmentTier400Price + max_of(billableGB - 400, 0.)* CommitmentTier400Price/400. -| extend CommitmentTier500DailyCost = CommitmentTier500Price + max_of(billableGB - 500, 0.)* CommitmentTier500Price/500. -| extend CommitmentTier1000DailyCost = CommitmentTier1000Price + max_of(billableGB - 1000, 0.)* CommitmentTier1000Price/1000. -| extend CommitmentTier2000DailyCost = CommitmentTier2000Price + max_of(billableGB - 2000, 0.)* CommitmentTier2000Price/2000. -| extend CommitmentTier5000DailyCost = CommitmentTier5000Price + max_of(billableGB - 5000, 0.)* CommitmentTier5000Price/5000. -| extend MinCost = min_of( - PerNodeDailyCost,PerGBDailyCost,CommitmentTier100DailyCost,CommitmentTier200DailyCost, - CommitmentTier300DailyCost, CommitmentTier400DailyCost, CommitmentTier500DailyCost, CommitmentTier1000DailyCost, CommitmentTier2000DailyCost, CommitmentTier5000DailyCost) -| extend Recommendation = case( - MinCost == PerNodeDailyCost, "Per node tier", - MinCost == PerGBDailyCost, "Pay-as-you-go tier", - MinCost == CommitmentTier100DailyCost, "Commitment tier (100 GB/day)", - MinCost == CommitmentTier200DailyCost, "Commitment tier (200 GB/day)", - MinCost == CommitmentTier300DailyCost, "Commitment tier (300 GB/day)", - MinCost == CommitmentTier400DailyCost, "Commitment tier (400 GB/day)", - MinCost == CommitmentTier500DailyCost, "Commitment tier (500 GB/day)", - MinCost == CommitmentTier1000DailyCost, "Commitment tier (1000 GB/day)", - MinCost == CommitmentTier2000DailyCost, "Commitment tier (2000 GB/day)", - MinCost == CommitmentTier5000DailyCost, "Commitment tier (5000 GB/day)", - "Error" -) -| project day, nodesPerDay, ASCnodesPerDay, NonSecurityDataGB, SecurityDataGB, OverageGB, AvgGbPerNode, PerGBDailyCost, PerNodeDailyCost, - CommitmentTier100DailyCost, CommitmentTier200DailyCost, CommitmentTier300DailyCost, CommitmentTier400DailyCost, CommitmentTier500DailyCost, CommitmentTier1000DailyCost, CommitmentTier2000DailyCost, CommitmentTier5000DailyCost, Recommendation -| sort by day asc -//| project day, Recommendation // Comment this line to see details -| sort by day asc -``` --This query isn't an exact replication of how usage is calculated, but it provides pricing tier recommendations in most cases. --> [!NOTE] -> To use the entitlements that come from purchasing OMS E1 Suite, OMS E2 Suite, or OMS Add-On for System Center, choose the Log Analytics Per Node pricing tier. --## Next steps --- See [Azure Monitor cost and usage](../cost-usage.md) for a description of the different types of Azure Monitor charges and how to analyze them on your Azure bill.-- See [Analyze usage in Log Analytics workspace](analyze-usage.md) for details on analyzing the data in your workspace to determine the source of any higher-than-expected usage and opportunities to reduce your amount of data collected.-- See [Set daily cap on Log Analytics workspace](daily-cap.md) to control your costs by configuring a maximum volume that might be ingested in a workspace each day.-- See [Azure Monitor best practices - Cost management](../best-practices-cost.md) for best practices on configuring and managing Azure Monitor to minimize your charges.- |
| azure-monitor | Create Custom Table Auxiliary | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/create-custom-table-auxiliary.md | - Title: Set up a table with the Auxiliary plan for low-cost data ingestion and retention in your Log Analytics workspace (Preview) -description: Create a custom table with the Auxiliary table plan in your Log Analytics workspace for low-cost ingestion and retention of log data. ------ Previously updated : 07/21/2024-# Customer intent: As a Log Analytics workspace administrator, I want to create a custom table with the Auxiliary table plan, so that I can ingest and retain data at a low cost for auditing and compliance. ---# Set up a table with the Auxiliary plan in your Log Analytics workspace (Preview) --The [Auxiliary table plan](../logs/data-platform-logs.md#table-plans) lets you ingest and retain data in your Log Analytics workspace at a low cost. Azure Monitor Logs currently supports the Auxiliary table plan on [data collection rule (DCR)-based custom tables](../logs/manage-logs-tables.md#table-type-and-schema) to which you send data you collect using [Azure Monitor Agent](../agents/agents-overview.md) or the [Logs ingestion API](../logs/logs-ingestion-api-overview.md). --This article explains how to create a custom table with the Auxiliary plan in your Log Analytics workspace and set up a data collection rule that sends data to this table. --Here's a video that explains some of the uses and benefits of the Auxiliary table plan: --> [!VIDEO https://www.youtube.com/embed/GbD2Q3K_6Vo?cc_load_policy=1&cc_lang_pref=auto] --> [!IMPORTANT] -> See [public preview limitations](#public-preview-limitations) for supported regions and limitations related to Auxiliary tables and data collection rules. --## Prerequisites --To create a custom table and collect log data, you need: --- A Log Analytics workspace where you have at least [contributor rights](../logs/manage-access.md#azure-rbac).-- A [data collection endpoint (DCE)](../essentials/data-collection-endpoint-overview.md).-- All tables in a Log Analytics workspace have a column named `TimeGenerated`. If your raw log data has a `TimeGenerated` property, Azure Monitor uses this value to identify the creation time of the record. For a table with the Auxiliary plan, the `TimeGenerated` column currently supports ISO8601 format only. For information about the `TimeGenerated` format, see [supported ISO 8601 datetime format](/azure/data-explorer/kusto/query/scalar-data-types/datetime#iso-8601).- --## Create a custom table with the Auxiliary plan --To create a custom table, call the [Tables - Create Or Update API](/rest/api/loganalytics/tables/create-or-update) by using this command: --```http -https://management.azure.com/subscriptions/{subscription_id}/resourceGroups/{resource_group}/providers/Microsoft.OperationalInsights/workspaces/{workspace_name}/tables/{table name_CL}?api-version=2023-01-01-preview -``` --Provide this payload - update the table name and adjust the columns based on your table schema: --```json - { - "properties": { - "schema": { - "name": "table_name_CL", - "columns": [ - { - "name": "TimeGenerated", - "type": "datetime" - }, - { - "name": "StringProperty", - "type": "string" - }, - { - "name": "IntProperty", - "type": "int" - }, - { - "name": "LongProperty", - "type": "long" - }, - { - "name": "RealProperty", - "type": "real" - }, - { - "name": "BooleanProperty", - "type": "boolean" - }, - { - "name": "GuidProperty", - "type": "guid" - }, - { - "name": "DateTimeProperty", - "type": "datetime" - } - ] - }, - "totalRetentionInDays": 365, - "plan": "Auxiliary" - } -} -``` --## Send data to a table with the Auxiliary plan --There are currently two ways to ingest data to a custom table with the Auxiliary plan: --- [Collect logs from a text file with Azure Monitor Agent](../agents/data-collection-log-text.md) / [Collect logs from a JSON file with Azure Monitor Agent](../agents/data-collection-log-json.md).-- If you use this method, your custom table must only have two columns - `TimeGenerated` and `RawData` (of type `string`). The data collection rule sends the entirety of each log entry you collect to the `RawData` column, and Azure Monitor Logs automatically populates the `TimeGenerated` column with the time the log is ingested. --- Send data to Azure Monitor using Logs ingestion API. -- To use this method: -- 1. [Create a custom table with the Auxiliary plan](#create-a-custom-table-with-the-auxiliary-plan) as described in this article. - 1. Follow the steps described in [Tutorial: Send data to Azure Monitor using Logs ingestion API](../logs/tutorial-logs-ingestion-api.md) to: - 1. [Create a Microsoft Entra application](../logs/tutorial-logs-ingestion-api.md#create-microsoft-entra-application). - 1. [Create a data collection rule](../logs/tutorial-logs-ingestion-api.md#create-data-collection-rule) using this ARM template. -- ```json - { - "$schema": "https://schema.management.azure.com/schemas/2019-08-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "dataCollectionRuleName": { - "type": "string", - "metadata": { - "description": "Specifies the name of the data collection rule to create." - } - }, - "location": { - "type": "string", - "metadata": { - "description": "Specifies the region in which to create the data collection rule. The must be the same region as the destination Log Analytics workspace." - } - }, - "workspaceResourceId": { - "type": "string", - "metadata": { - "description": "The Azure resource ID of the Log Analytics workspace in which you created a custom table with the Auxiliary plan." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/dataCollectionRules", - "name": "[parameters('dataCollectionRuleName')]", - "location": "[parameters('location')]", - "apiVersion": "2023-03-11", - "kind": "Direct", - "properties": { - "streamDeclarations": { - "Custom-table_name_CL": { - "columns": [ - { - "name": "TimeGenerated", - "type": "datetime" - }, - { - "name": "StringProperty", - "type": "string" - }, - { - "name": "IntProperty", - "type": "int" - }, - { - "name": "LongProperty", - "type": "long" - }, - { - "name": "RealProperty", - "type": "real" - }, - { - "name": "BooleanProperty", - "type": "boolean" - }, - { - "name": "GuidProperty", - "type": "guid" - }, - { - "name": "DateTimeProperty", - "type": "datetime" - } - } - }, - "destinations": { - "logAnalytics": [ - { - "workspaceResourceId": "[parameters('workspaceResourceId')]", - "name": "myworkspace" - } - ] - }, - "dataFlows": [ - { - "streams": [ - "Custom-table_name_CL" - ], - "destinations": [ - "myworkspace" - ] - } - ] - } - } - ], - "outputs": { - "dataCollectionRuleId": { - "type": "string", - "value": "[resourceId('Microsoft.Insights/dataCollectionRules', parameters('dataCollectionRuleName'))]" - } - } - } - ``` -- Where: - - `myworkspace` is the name of your Log Analytics workspace. - - `table_name_CL` is the name of your table. - - `columns` includes the same columns you set in [Create a custom table with the Auxiliary plan](#create-a-custom-table-with-the-auxiliary-plan). - - 1. [Grant your application permission to use your DCR](../logs/tutorial-logs-ingestion-api.md#assign-permissions-to-a-dcr). --## Public preview limitations --During public preview, these limitations apply: --- The Auxiliary plan is gradually being rolled out to all regions and is currently supported in:-- | **Region** | **Locations** | - |--|| - | **Americas** | Canada Central | - | | Central US | - | | East US | - | | East US 2 | - | | West US | - | | South Central US | - | | North Central US | - | **Asia Pacific** | Australia East | - | | Australia South East | - | **Europe** | East Asia | - | | North Europe | - | | UK South | - | | Germany West Central | - | | Switzerland North | - | | France Central | - | **Middle East** | Israel Central | ---- You can set the Auxiliary plan only on data collection rule-based custom tables you create using the [Tables - Create Or Update API](/rest/api/loganalytics/tables/create-or-update).-- Tables with the Auxiliary plan: - - Are currently unbilled. There's currently no charge for ingestion, queries, search jobs, and long-term retention. - - Do not support columns with dynamic data. - - Have a fixed total retention of 365 days. - - Support ISO 8601 datetime format only. -- A data collection rule that sends data to a table with an Auxiliary plan:- - Can only send data to a single table. - - Can't include a [transformation](../essentials/data-collection-transformations.md). -- Ingestion data for Auxiliary tables isn't currently available in the Azure Monitor Logs [Usage table](/azure/azure-monitor/reference/tables/usage). To estimate data ingestion volume, you can count the number of records in your Auxiliary table using this query:-- ```kusto - MyTable_CL - | summarize count() - ``` --## Next steps --Learn more about: --- [Azure Monitor Logs table plans](../logs/data-platform-logs.md#table-plans)-- [Collecting logs with the Log Ingestion API](../logs/logs-ingestion-api-overview.md)-- [Data collection rules](../essentials/data-collection-endpoint-overview.md) |
| azure-monitor | Create Custom Table | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/create-custom-table.md | - Title: Add or delete tables and columns in Azure Monitor Logs -description: Create a table with a custom schema to collect logs from any data source. ------ Previously updated : 01/28/2024-# Customer intent: As a Log Analytics workspace administrator, I want to manage table schemas and be able create a table with a custom schema to store logs from an Azure or non-Azure data source. ---# Add or delete tables and columns in Azure Monitor Logs --[Data collection rules](../essentials/data-collection-rule-overview.md) let you [filter and transform log data](../essentials/data-collection-transformations.md) before sending the data to an [Azure table or a custom table](../logs/manage-logs-tables.md#table-type-and-schema). This article explains how to create custom tables and add custom columns to tables in your Log Analytics workspace. --> [!IMPORTANT] -> Whenever you update a table schema, be sure to [update any data collection rules](../essentials/data-collection-rule-overview.md) that send data to the table. The table schema you define in your data collection rule determines how Azure Monitor streams data to the destination table. Azure Monitor does not update data collection rules automatically when you make table schema changes. --## Prerequisites --To create a custom table, you need: --- A Log Analytics workspace where you have at least [contributor rights](../logs/manage-access.md#azure-rbac).-- A [data collection endpoint (DCE)](../essentials/data-collection-endpoint-overview.md).-- A JSON file with at least one record of sample for your custom table. This will look similar to the following:-- ```json - [ - { - "TimeGenerated": "supported_datetime_format", - "<column_name_1>": "<column_name_1_value>", - "<column_name_2>": "<column_name_2_value>" - }, - { - "TimeGenerated": "supported_datetime_format", - "<column_name_1>": "<column_name_1_value>", - "<column_name_2>": "<column_name_2_value>" - }, - { - "TimeGenerated": "supported_datetime_format", - "<column_name_1>": "<column_name_1_value>", - "<column_name_2>": "<column_name_2_value>" - } - ] - ``` - - All tables in a Log Analytics workspace must have a column named `TimeGenerated`. If your sample data has a column named `TimeGenerated`, then this value will be used to identify the ingestion time of the record. If not, a `TimeGenerated` column will be added to the transformation in your DCR for the table. For information about the `TimeGenerated` format, see [supported datetime formats](/azure/data-explorer/kusto/query/scalar-data-types/datetime#supported-formats). --## Create a custom table --Azure tables have predefined schemas. To store log data in a different schema, use data collection rules to define how to collect, transform, and send the data to a custom table in your Log Analytics workspace. To create a custom table with the Auxiliary plan, see [Set up a table with the Auxiliary plan (Preview)](create-custom-table-auxiliary.md). --> [!IMPORTANT] -> Custom tables have a suffix of **_CL**; for example, *tablename_CL*. The Azure portal adds the **_CL** suffix to the table name automatically. When you create a custom table using a different method, you need to add the **_CL** suffix yourself. The *tablename_CL* in the [DataFlows Streams](../essentials/data-collection-rule-structure.md#dataflows) properties in your data collection rules must match the *tablename_CL* name in the Log Analytics workspace. --> [!WARNING] -> Table names are used for billing purposes so they should not contain sensitive information. --# [Portal](#tab/azure-portal-1) --To create a custom table using the Azure portal: --1. From the **Log Analytics workspaces** menu, select **Tables**. -- :::image type="content" source="media/manage-logs-tables/azure-monitor-logs-table-configuration.png" alt-text="Screenshot that shows the Tables screen for a Log Analytics workspace." lightbox="media/manage-logs-tables/azure-monitor-logs-table-configuration.png"::: --1. Select **Create** and then **New custom log (DCR-based)**. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/new-custom-log.png" lightbox="media/tutorial-logs-ingestion-portal/new-custom-log.png" alt-text="Screenshot showing new DCR-based custom log."::: --1. Specify a name and, optionally, a description for the table. You don't need to add the *_CL* suffix to the custom table's name - this is added automatically to the name you specify in the portal. --1. Select an existing data collection rule from the **Data collection rule** dropdown, or select **Create a new data collection rule** and specify the **Subscription**, **Resource group**, and **Name** for the new data collection rule. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/new-data-collection-rule.png" lightbox="media/tutorial-logs-ingestion-portal/new-data-collection-rule.png" alt-text="Screenshot showing new data collection rule."::: --1. Select a [data collection endpoint](../essentials/data-collection-endpoint-overview.md#create-a-data-collection-endpoint) and select **Next**. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/custom-log-table-name.png" lightbox="media/tutorial-logs-ingestion-portal/custom-log-table-name.png" alt-text="Screenshot showing custom log table name."::: --1. Select **Browse for files** and locate the JSON file with the sample data for your new table. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/custom-log-browse-files.png" lightbox="media/tutorial-logs-ingestion-portal/custom-log-browse-files.png" alt-text="Screenshot showing custom log browse for files."::: -- If your sample data doesn't include a `TimeGenerated` column, then you will receive a message that a transformation is being created with this column. --1. If you want to [transform log data before ingestion](../essentials//data-collection-transformations.md) into your table: -- 1. Select **Transformation editor**. -- The transformation editor lets you create a transformation for the incoming data stream. This is a KQL query that runs against each incoming record. Azure Monitor Logs stores the results of the query in the destination table. - - :::image type="content" source="media/tutorial-logs-ingestion-portal/custom-log-data-preview.png" lightbox="media/tutorial-logs-ingestion-portal/custom-log-data-preview.png" alt-text="Screenshot showing custom log data preview."::: -- 1. Select **Run** to view the results. - - :::image type="content" source="media/tutorial-logs-ingestion-portal/custom-log-query-01.png" lightbox="media/tutorial-logs-ingestion-portal/custom-log-query-01.png" alt-text="Screenshot showing initial custom log data query."::: --1. Select **Apply** to save the transformation and view the schema of the table that's about to be created. Select **Next** to proceed. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/custom-log-final-schema.png" lightbox="media/tutorial-logs-ingestion-portal/custom-log-final-schema.png" alt-text="Screenshot showing custom log final schema."::: --1. Verify the final details and select **Create** to save the custom log. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/custom-log-create.png" lightbox="media/tutorial-logs-ingestion-portal/custom-log-create.png" alt-text="Screenshot showing custom log create."::: --# [API](#tab/api-1) --To create a custom table, call the [Tables - Create Or Update API](/rest/api/loganalytics/tables/create-or-update). --# [CLI](#tab/azure-cli-1) --To create a custom table, run the [az monitor log-analytics workspace table create](/cli/azure/monitor/log-analytics/workspace/table#az-monitor-log-analytics-workspace-table-create) command. -# [PowerShell](#tab/azure-powershell-1) --Use the [Tables - Update PATCH API](/rest/api/loganalytics/tables/update) to create a custom table with the PowerShell code below. This code creates a table called *MyTable_CL* with two columns. Modify this schema to collect a different table. --1. Select the **Cloud Shell** button in the Azure portal and ensure the environment is set to **PowerShell**. -- :::image type="content" source="../logs/media/tutorial-workspace-transformations-api/open-cloud-shell.png" lightbox="../logs/media/tutorial-workspace-transformations-api/open-cloud-shell.png" alt-text="Screenshot of opening Cloud Shell in the Azure portal."::: --1. Copy the following PowerShell code and replace the **Path** parameter with the appropriate values for your workspace in the `Invoke-AzRestMethod` command. Paste it into the Cloud Shell prompt to run it. -- ```PowerShell - $tableParams = @' - { - "properties": { - "schema": { - "name": "MyTable_CL", - "columns": [ - { - "name": "TimeGenerated", - "type": "DateTime" - }, - { - "name": "RawData", - "type": "String" - } - ] - } - } - } - '@ -- Invoke-AzRestMethod -Path "/subscriptions/{subscription}/resourcegroups/{resourcegroup}/providers/microsoft.operationalinsights/workspaces/{workspace}/tables/MyTable_CL?api-version=2021-12-01-preview" -Method PUT -payload $tableParams - ``` ----## Delete a table --There are several types of tables in Azure Monitor Logs. You can delete any table that's not an Azure table, but what happens to the data when you delete the table is different for each type of table. --For more information, see [What happens to data when you delete a table in a Log Analytics workspace](../logs/data-retention-configure.md#what-happens-to-data-when-you-delete-a-table-in-a-log-analytics-workspace). ---# [Portal](#tab/azure-portal-2) --To delete a table from the Azure portal: --1. From the Log Analytics workspace menu, select **Tables**. -1. Search for the tables you want to delete by name, or by selecting **Search results** in the **Type** field. - - :::image type="content" source="media/search-job/search-results-on-log-analytics-tables-screen.png" alt-text="Screenshot that shows the Tables screen for a Log Analytics workspace with the Filter by name and Type fields highlighted." lightbox="media/search-job/search-results-on-log-analytics-tables-screen.png"::: --1. Select the table you want to delete, select the ellipsis ( **...** ) to the right of the table, select **Delete**, and confirm the deletion by typing **yes**. -- :::image type="content" source="media/search-job/delete-table.png" alt-text="Screenshot that shows the Delete Table screen for a table in a Log Analytics workspace." lightbox="media/search-job/delete-table.png"::: - -# [API](#tab/api-2) --To delete a table, call the [Tables - Delete API](/rest/api/loganalytics/tables/delete). --# [CLI](#tab/azure-cli-2) --To delete a table, run the [az monitor log-analytics workspace table delete](/cli/azure/monitor/log-analytics/workspace/table#az-monitor-log-analytics-workspace-table-delete) command. --# [PowerShell](#tab/azure-powershell-2) --To delete a table using PowerShell: --1. Select the **Cloud Shell** button in the Azure portal and ensure the environment is set to **PowerShell**. -- :::image type="content" source="../logs/media/tutorial-workspace-transformations-api/open-cloud-shell.png" lightbox="../logs/media/tutorial-workspace-transformations-api/open-cloud-shell.png" alt-text="Screenshot of opening Cloud Shell in the Azure portal."::: --1. Copy the following PowerShell code and replace the **Path** parameter with the appropriate values for your workspace in the `Invoke-AzRestMethod` command. Paste it into the Cloud Shell prompt to run it. --- ```PowerShell - Invoke-AzRestMethod -Path "/subscriptions/{subscription}/resourcegroups/{resourcegroup}/providers/microsoft.operationalinsights/workspaces/{workspace}/tables/NewCustom_CL?api-version=2021-12-01-preview" -Method DELETE - ``` - --## Add or delete a custom column --You can modify the schema of custom tables and add custom columns to, or delete columns from, a standard table. --> [!NOTE] -> Column names must start with a letter and can consist of up to 45 alphanumeric characters and underscores (`_`). `_ResourceId`, `id`, `_ResourceId`, `_SubscriptionId`, `TenantId`, `Type`, `UniqueId`, and `Title` are reserved column names. --# [Portal](#tab/azure-portal-3) --To add a custom column to a table in your Log Analytics workspace, or delete a column: --1. From the **Log Analytics workspaces** menu, select **Tables**. -1. Select the ellipsis ( **...** ) to the right of the table you want to edit and select **Edit schema**. - This opens the **Schema Editor** screen. -1. Scroll down to the **Custom Columns** section of the **Schema Editor** screen. - - :::image type="content" source="media/create-custom-table/add-or-delete-column-azure-monitor-logs.png" alt-text="Screenshot showing the Schema Editor screen with the Add a column and Delete buttons highlighted." lightbox="media/create-custom-table/add-or-delete-column-azure-monitor-logs.png"::: --1. To add a new column: - 1. Select **Add a column**. - 1. Set the column name and description (optional), and select the expected value type from the **Type** dropdown. - 1. Select **Save** to save the new column. -1. To delete a column, select the **Delete** icon to the left of the column you want to delete. --# [API](#tab/api-3) --To add or delete a custom column, call the [Tables - Create Or Update API](/rest/api/loganalytics/tables/create-or-update). --# [CLI](#tab/azure-cli-3) --To add or delete a custom column, run the [az monitor log-analytics workspace table update](/cli/azure/monitor/log-analytics/workspace/table#az-monitor-log-analytics-workspace-table-update) command. --# [PowerShell](#tab/azure-powershell-3) --To add a new column to an Azure or custom table, run: --```powershell -$tableParams = @' -{ - "properties": { - "schema": { - "name": "<TableName>", - "columns": [ - { - "name": ""<ColumnName>", - "description": "First custom column", - "type": "string", - "isDefaultDisplay": true, - "isHidden": false - } - ] - } - } -} -'@ --Invoke-AzRestMethod -Path "/subscriptions/{subscription}/resourcegroups/{resourcegroup}/providers/microsoft.operationalinsights/workspaces/{workspace}/tables/<TableName>?api-version=2021-12-01-preview" -Method PUT -payload $tableParams -``` --The `PUT` call returns the updated table properties, which should include the newly added column. --**Example** --Run this command to add a custom column, called `Custom1_CF`, to the Azure `Heartbeat` table: --```powershell -$tableParams = @' -{ - "properties": { - "schema": { - "name": "Heartbeat", - "columns": [ - { - "name": "Custom1_CF", - "description": "The second custom column", - "type": "datetime", - "isDefaultDisplay": true, - "isHidden": false - } - ] - } - } -} -'@ --Invoke-AzRestMethod -Path "/subscriptions/{subscription}/resourcegroups/{resourcegroup}/providers/microsoft.operationalinsights/workspaces/{workspace}/tables/Heartbeat?api-version=2021-12-01-preview" -Method PUT -payload $tableParams -``` --Now, to delete the newly added column and add another one instead, run: --```powershell -$tableParams = @' -{ - "properties": { - "schema": { - "name": "Heartbeat", - "columns": [ - { - "name": "Custom2_CF", - "description": "The second custom column", - "type": "datetime", - "isDefaultDisplay": true, - "isHidden": false - } - ] - } - } -} -'@ --Invoke-AzRestMethod -Path "/subscriptions/{subscription}/resourcegroups/{resourcegroup}/providers/microsoft.operationalinsights/workspaces/{workspace}/tables/Heartbeat?api-version=2021-12-01-preview" -Method PUT -payload $tableParams -``` --To delete all custom columns in the table, run: --```powershell -$tableParams = @' -{ - "properties": { - "schema": { - "name": "Heartbeat", - "columns": [ - ] - } - } -} -'@ --Invoke-AzRestMethod -Path "/subscriptions/{subscription}/resourcegroups/{resourcegroup}/providers/microsoft.operationalinsights/workspaces/{workspace}/tables/Heartbeat?api-version=2021-12-01-preview" -Method PUT -payload $tableParams -``` ---## Next steps --Learn more about: --- [Collecting logs with the Log Ingestion API](../logs/logs-ingestion-api-overview.md)-- [Collecting logs with Azure Monitor Agent](../agents/agents-overview.md)-- [Data collection rules](../essentials/data-collection-endpoint-overview.md) |
| azure-monitor | Cross Workspace Query | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/cross-workspace-query.md | - Title: Query across resources with Azure Monitor -description: Query and correlated data from multiple Log Analytics workspaces, applications, or resources using the `workspace()`, `app()`, and `resource()` Kusto Query Language (KQL) expressions. --- Previously updated : 12/28/2023-# Customer intent: As a data analyst, I want to write KQL queries that correlate data from multiple Log Analytics workspaces, applications, or resources, to enable my analysis. ----# Query data across Log Analytics workspaces, applications, and resources in Azure Monitor --There are two ways to query data from multiple workspaces, applications, and resources: --* Explicitly by specifying the workspace, app, or resource information using the [workspace()](#query-across-log-analytics-workspaces-using-workspace), [app()](#query-across-classic-application-insights-applications-using-app), or [resource()](#correlate-data-between-resources-using-resource) expressions, as described in this article. -* Implicitly by using [resource-context queries](manage-access.md#access-mode). When you query in the context of a specific resource, resource group, or a subscription, the query retrieves relevant data from all workspaces that contain data for these resources. Resource-context queries don't retrieve data from classic Application Insights resources. --This article explains how to use the `workspace()`, `app()`, and `resource()` expressions to query data from multiple Log Analytics workspaces, applications, and resources. --If you manage subscriptions in other Microsoft Entra tenants through [Azure Lighthouse](../../lighthouse/overview.md), you can include [Log Analytics workspaces created in those customer tenants](../../lighthouse/how-to/monitor-at-scale.md) in your queries. --> [!IMPORTANT] -> If you're using a [workspace-based Application Insights resource](../app/create-workspace-resource.md), telemetry is stored in a Log Analytics workspace with all other log data. Use the `workspace()` expression to query data from applications in multiple workspaces. You don't need a cross-workspace query to query data from multiple applications in the same workspace. --## Permissions required --| Action | Permissions required | -| | | -| Check workspace state | `Microsoft.OperationalInsights/workspaces/query/*/read` permissions to the Log Analytics workspaces you query, as provided by the [Log Analytics Reader built-in role](./manage-access.md#log-analytics-reader), for example. | -| Save a query | `microsoft.operationalinsights/querypacks/queries/action` permissions to the query pack where you want to save the query, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example. | --## Limitations --* Cross-resource and cross-service queries donΓÇÖt support parameterized functions and functions whose definition includes other cross-workspace or cross-service expressions, including `adx()`, `arg()`, `resource()`, `workspace()`, and `app()`. -* You can include up to 100 Log Analytics workspaces or classic Application Insights resources in a single query. -* Querying across a large number of resources can substantially slow down the query. -* Cross-resource queries in log search alerts are only supported in the current [scheduledQueryRules API](/rest/api/monitor/scheduledqueryrule-2018-04-16/scheduled-query-rules). If you're using the legacy Log Analytics Alerts API, you'll need to [switch to the current API](../alerts/alerts-log-api-switch.md). -* References to a cross resource, such as another workspace, should be explicit and can't be parameterized. --## Query across workspaces, applications, and resources using functions --This section explains how to query workspaces, applications, and resources using functions with and without using a function. --### Query without using a function -You can query multiple resources from any of your resource instances. These resources can be workspaces and apps combined. --Example for a query across three workspaces: --```kusto -union - Update, - workspace("00000000-0000-0000-0000-000000000001").Update, - workspace("00000000-0000-0000-0000-000000000002").Update -| where TimeGenerated >= ago(1h) -| where UpdateState == "Needed" -| summarize dcount(Computer) by Classification -``` --For more information on the union, where, and summarize operators, see [union operator](/azure/data-explorer/kusto/query/unionoperator), [where operator](/azure/data-explorer/kusto/query/summarizeoperator), and [summarize operator](/azure/data-explorer/kusto/query/summarizeoperator). --### Query by using a function -When you use cross-resource queries to correlate data from multiple Log Analytics workspaces and Application Insights components, the query can become complex and difficult to maintain. You should make use of [functions in Azure Monitor log queries](./functions.md) to separate the query logic from the scoping of the query resources. This method simplifies the query structure. The following example demonstrates how you can monitor multiple Application Insights components and visualize the count of failed requests by application name. --Create a query like the following example that references the scope of Application Insights components. The `withsource= SourceApp` command adds a column that designates the application name that sent the log. [Save the query as a function](./functions.md#create-a-function) with the alias `applicationsScoping`. --```Kusto -// crossResource function that scopes my Application Insights components -union withsource= SourceApp -app('00000000-0000-0000-0000-000000000000').requests, -app('00000000-0000-0000-0000-000000000001').requests, -app('00000000-0000-0000-0000-000000000002').requests, -app('00000000-0000-0000-0000-000000000003').requests, -app('00000000-0000-0000-0000-000000000004').requests -``` --You can now [use this function](./functions.md#use-a-function) in a cross-resource query like the following example. The function alias `applicationsScoping` returns the union of the requests table from all the defined applications. The query then filters for failed requests and visualizes the trends by application. The `parse` operator is optional in this example. It extracts the application name from the `SourceApp` property. --```Kusto -applicationsScoping -| where timestamp > ago(12h) -| where success == 'False' -| parse SourceApp with * '(' applicationId ')' * -| summarize count() by applicationId, bin(timestamp, 1h) -| render timechart -``` -->[!NOTE] -> This method can't be used with log search alerts because the access validation of the alert rule resources, including workspaces and applications, is performed at alert creation time. Adding new resources to the function after the alert creation isn't supported. If you prefer to use a function for resource scoping in log search alerts, you must edit the alert rule in the portal or with an Azure Resource Manager template to update the scoped resources. Alternatively, you can include the list of resources in the log search alert query. --## Query across Log Analytics workspaces using workspace() --Use the `workspace()` expression to retrieve data from a specific workspace in the same resource group, another resource group, or another subscription. You can use this expression to include log data in an Application Insights query and to query data across multiple workspaces in a log query. --### Syntax --`workspace(`*Identifier*`)` --### Arguments --`*Identifier*`: Identifies the workspace by using one of the formats in the following table. --| Identifier | Description | Example -|:|:|:| -| ID | GUID of the workspace | workspace("00000000-0000-0000-0000-000000000000") | -| Azure Resource ID | Identifier for the Azure resource | workspace("/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/Contoso/providers/Microsoft.OperationalInsights/workspaces/contosoretail") | --### Examples --```Kusto -workspace("00000000-0000-0000-0000-000000000000").Update | count -``` -```Kusto -workspace("/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/Contoso/providers/Microsoft.OperationalInsights/workspaces/contosoretail").Event | count -``` -```Kusto -union -( workspace("00000000-0000-0000-0000-000000000000").Heartbeat | where Computer == "myComputer"), -(app("00000000-0000-0000-0000-000000000000").requests | where cloud_RoleInstance == "myRoleInstance") -| count -``` -```Kusto -union -(workspace("00000000-0000-0000-0000-000000000000").Heartbeat), (app("00000000-0000-0000-0000-000000000000").requests) | where TimeGenerated between(todatetime("2023-03-08 15:00:00") .. todatetime("2023-04-08 15:05:00")) -``` --## Query across classic Application Insights applications using app() --Use the `app` expression to retrieve data from a specific classic Application Insights resource in the same resource group, another resource group, or another subscription. If you're using a [workspace-based Application Insights resource](../app/create-workspace-resource.md), telemetry is stored in a Log Analytics workspace with all other log data. Use the `workspace()` expression to query data from applications in multiple workspaces. You don't need a cross-workspace query to query data from multiple applications in the same workspace. --### Syntax --`app(`*Identifier*`)` --### Arguments --`*Identifier*`: Identifies the app using one of the formats in the table below. --| Identifier | Description | Example -|:|:|:| -| ID | GUID of the app | app("00000000-0000-0000-0000-000000000000") | -| Azure Resource ID | Identifier for the Azure resource |app("/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/Fabrikam/providers/microsoft.insights/components/fabrikamapp") | --### Examples --```Kusto -app("00000000-0000-0000-0000-000000000000").requests | count -``` -```Kusto -app("/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/Fabrikam/providers/microsoft.insights/components/fabrikamapp").requests | count -``` -```Kusto -union -(workspace("00000000-0000-0000-0000-000000000000").Heartbeat | where Computer == "myComputer"), -(app("00000000-0000-0000-0000-000000000000").requests | where cloud_RoleInstance == "myColumnInstance") -| count -``` -```Kusto -union -(workspace("00000000-0000-0000-0000-000000000000").Heartbeat), (app("00000000-0000-0000-0000-000000000000").requests) -| where TimeGenerated between(todatetime("2023-03-08 15:00:00") .. todatetime("2023-04-08 15:05:00")) -``` --## Correlate data between resources using resource() --The `resource` expression is used in a Azure Monitor query [scoped to a resource](scope.md#query-scope) to retrieve data from other resources. --### Syntax --`resource(`*Identifier*`)` --### Arguments --`*Identifier*`: Identifies the resource, resource group, or subscription from which to correlate data. --| Identifier | Description | Example -|:|:|:| -| Resource | Includes data for the resource. | resource("/subscriptions/xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourcesgroups/myresourcegroup/providers/microsoft.compute/virtualmachines/myvm") | -| Resource Group or Subscription | Includes data for the resource and all resources that it contains. | resource("/subscriptions/xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourcesgroups/myresourcegroup) | --### Examples --```Kusto -union (Heartbeat),(resource("/subscriptions/xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourcesgroups/myresourcegroup/providers/microsoft.compute/virtualmachines/myvm").Heartbeat) | summarize count() by _ResourceId, TenantId -``` -```Kusto -union (Heartbeat),(resource("/subscriptions/xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourcesgroups/myresourcegroup).Heartbeat) | summarize count() by _ResourceId, TenantId -``` --## Next steps --See [Analyze log data in Azure Monitor](./log-query-overview.md) for an overview of log queries and how Azure Monitor log data is structured. |
| azure-monitor | Custom Fields Migrate | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/custom-fields-migrate.md | - Title: Migration of custom fields to KQL-based transformations in Azure Monitor -description: Learn how to migrate custom fields in a Log Analytics workspace in Azure Monitor with KQL-based custom columns using transformations. -- Previously updated : 08/12/2024----# Tutorial: Replace custom fields in Log Analytics workspace with KQL-based custom columns --Custom fields is a feature of Azure Monitor that allows you to extract into a separate column data from a different text column of the same table. Creation of new custom fields will be disabled starting March 31, 2023. Custom fields functionality will be deprecated and existing custom fields will stop functioning on March 31, 2026. --There are several advantages to using DCR-based [ingestion-time transformations](../essentials/data-collection-transformations.md) to accomplish the same result: --- You can apply full set of [string functions](/azure/data-explorer/kusto/query/scalarfunctions#string-functions) to shape your custom columns.-- You can apply multiple operations to the same data. For example, extract a portion of a value to a separate column and remove the original column.-- You can use ingestion-time transformations in your ARM templates to deploy custom columns at scale.--With the introduction of [data collection rules (DCR)](../essentials/data-collection-rule-overview.md), KQL-based transformations are the standard method of table customization, replacing legacy custom fields. --In this tutorial, you learn how to: --> [!div class="checklist"] -> * Locate custom fields that require replacement -> * Understand the content of the custom fields -> * Setup ingestion-time transformation to replace custom fields within the table ---## Prerequisites --- Log Analytics workspace with a table containing custom fields-- Sufficient account privilege to create and modify data collection rules (DCR)----## Locate custom fields for replacement -Start by locating custom fields to replace. If you already know the custom fields you plan to replace, proceed to the next step. --1. Navigate to the Log Analytics workspace where the table with custom fields is located. -2. In the side menu, select **Tables**. Select **Manage table** from the context menu for the table. -- :::image type="content" source="media/custom-fields-migrate/manage-table.png" alt-text="Screenshot showing the manage table option for a table in a Log Analytics workspace" lightbox="media/custom-fields-migrate/manage-table.png"::: --1. Note if any data collection rules (DCRs) are associated with given table. - - - If any DCRs are present in corresponding section, it means that any pre-existing custom fields were either already implemented within these DCRs, or abandoned upon DCR creation. You're going to examine the content of custom fields on the next step of this tutorial and determine whether more updates to DCRs needed. - - If there are no data collection rules associated with the table, then all columns in given table with names ending with "_CF" will be custom fields subject to replacement. -- :::image type="content" source="media/custom-fields-migrate/manage-table-details.png" alt-text="Screenshot showing the properties of a table including data collection rules associated with the table" lightbox="media/custom-fields-migrate/manage-table-details.png"::: --2. Close the table properties dialog and select **Edit schema** from the table context menu. Scroll to the bottom of page where custom columns are listed. These columns end with *_CF*. -- :::image type="content" source="media/custom-fields-migrate/custom-columns.png" alt-text="Screenshot showing the column listing for a table including any custom columns" lightbox="media/custom-fields-migrate/custom-columns.png"::: --1. Note the names of these columns since you'll determine their content in the next step. --## Understand custom field content -Since there is no way to examine the custom field definition directly, you need to query the table to determine the custom field formula. --1. Select **Logs** in the side menu and run a query to get a sample of data from the table. -- :::image type="content" source="media/custom-fields-migrate/log-analytics-sample-data.png" alt-text="Screenshot of Log Analytics with query returning sample data" lightbox="media/custom-fields-migrate/log-analytics-sample-data.png"::: --1. Locate the columns noted in the previous step and examine their content. - - If the column *is not empty* and *there are DCRs* associated with the table, then custom field logic has been already implemented with transformation. No action is required - - If the column *is empty* (or not present in query results) and *there are DCRs* associated with the table, the custom field logic wasn't implemented with the DCR. Add a transformation to the dataflow in the existing DCR. - - If the column *isn't empty* and *there are no DCRs* associated with the table, the custom field logic needs to implemented as a transformation in the [workspace DCR](../essentials/data-collection-transformations-workspace.md). --1. Examine the content of the custom field and determine the logic how it's being calculated. Custom fields usually calculate substrings of other columns in the same table. Determine which column the data comes from and the portion of the string it extracts. --## Create transformation -You're now ready to create the required KQL snippet and add it to a DCR. This logic is applied to each record as it's ingested into the workspace. --1. Modify the query for the table using KQL to replicate the custom field logic. If you have multiple custom fields to replace, you may combine their calculation logic into a single statement. -- - Use [parse](/azure/data-explorer/kusto/query/parseoperator) operator for pattern-based search of a substring within a string. - - Use [extract()](/azure/data-explorer/kusto/query/extractfunction) function for regex-based substring search. - - String functions as [split()](/azure/data-explorer/kusto/query/splitfunction), [substring()](/azure/data-explorer/kusto/query/substringfunction), and [many others](/azure/data-explorer/kusto/query/scalarfunctions#string-functions) may also be useful. -- :::image type="content" source="media/custom-fields-migrate/log-analytics-transformation-query.png" alt-text="Screenshot of Log Analytics with query returning data using transformation query" lightbox="media/custom-fields-migrate/log-analytics-transformation-query.png"::: --2. Determine where your new KQL definition of the custom column needs to be placed. - - - For logs collected using [Azure Monitor Agent (AMA)](../agents/agents-overview.md), [edit the DCR](../essentials/data-collection-rule-edit.md) collecting data for the table, adding a transformation. For an example, see [Samples](../essentials/data-collection-transformations.md#samples). The transformation query is defined in the `transformKql` element. - - For resource logs collected with [diagnostic settings](../essentials/diagnostic-settings.md), add the transformation to the [workspace default DCR](../essentials/data-collection-transformations-workspace.md). The table must [support transformations](../logs/tables-feature-support.md). ----## Frequently Asked Questions --### How do I migrate custom fields for a text log collected with legacy Log Analytics agent (MMA)? --Consider migrating to Azure Monitor Agent (AMA). Log Analytics agent is approaching its end of support, and you should migrate to Azure Monitor Agent (AMA). [Text logs collected with AMA](../agents/data-collection-text-log.md) use log parsing logic defined in form of KQL transformations from the start. Custom fields aren't required and not supported in text logs collected by Azure Monitor Agent. --### Is migration of custom fields to KQL mandatory? --No, you need to migrate your custom fields only if you still want your custom columns populated. If you don't migrate your custom fields, corresponding columns will stop being populated when support of custom fields is ended. Data that has been already processed and stored in the table won't be affected and will remain usable. --### Will I lose my existing data in corresponding columns if I don't migrate my custom fields in time? --No, custom fields are calculated at the time of data ingestion. Deleting the field definition or not migrating them in time won't affect any data previously ingested. --## Next steps --- [Read more about transformations in Azure Monitor.](../essentials/data-collection-transformations.md)- |
| azure-monitor | Custom Fields | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/custom-fields.md | - Title: Custom fields in Azure Monitor (Preview) -description: The Custom Fields feature of Azure Monitor allows you to create your own searchable fields from records in a Log Analytics workspace that add to the properties of a collected record. This article describes the process to create a custom field and provides a detailed walkthrough with a sample event. ---- Previously updated : 08/12/2024----# Create custom fields in a Log Analytics workspace in Azure Monitor (Preview) --> [!IMPORTANT] -> Creation of new custom fields will be disabled starting March 31, 2023. Custom fields functionality will be deprecated, and existing custom fields will stop functioning by March 31, 2026. You should [migrate to ingestion-time transformations](custom-fields-migrate.md) to keep parsing your log records. -> -> Currently, when you add a new custom field, it may take up to 7 days before data starts appearing. --The **Custom Fields** feature of Azure Monitor allows you to extend existing records in your Log Analytics workspace by adding your own searchable fields. Custom fields are automatically populated from data extracted from other properties in the same record. ---For example, the sample record below has useful data buried in the event description. Extracting this data into a separate property makes it available for such actions as sorting and filtering. -<!-- convertborder later --> --> [!NOTE] -> In the Preview, you are limited to 500 custom fields in your workspace. This limit will be expanded when this feature reaches general availability. --## Creating a custom field -When you create a custom field, Log Analytics must understand which data to use to populate its value. It uses a technology from Microsoft Research called FlashExtract to quickly identify this data. Rather than requiring you to provide explicit instructions, Azure Monitor learns about the data you want to extract from examples that you provide. --The following sections provide the procedure for creating a custom field. At the bottom of this article is a walkthrough of a sample extraction. --> [!NOTE] -> The custom field is populated as records matching the specified criteria are added to the Log Analytics workspace, so it will only appear on records collected after the custom field is created. The custom field will not be added to records that are already in the data store when itΓÇÖs created. -> --### Step 1: Identify records that will have the custom field -The first step is to identify the records that will get the custom field. You start with a [standard log query](./log-query-overview.md) and then select a record to act as the model that Azure Monitor will learn from. When you specify that you are going to extract data into a custom field, the **Field Extraction Wizard** is opened where you validate and refine the criteria. --1. Go to **Logs** and use a [query to retrieve the records](./log-query-overview.md) that will have the custom field. -2. Select a record that Log Analytics will use to act as a model for extracting data to populate the custom field. You will identify the data that you want to extract from this record, and Log Analytics will use this information to determine the logic to populate the custom field for all similar records. -3. Right-click on the record, and select **Extract fields from**. -4. The **Field Extraction Wizard** is opened, and the record you selected is displayed in the **Main Example** column. The custom field will be defined for those records with the same values in the properties that are selected. -5. If the selection is not exactly what you want, select additional fields to narrow the criteria. In order to change the field values for the criteria, you must cancel and select a different record matching the criteria you want. --### Step 2: Perform initial extract. -Once youΓÇÖve identified the records that will have the custom field, you identify the data that you want to extract. Log Analytics will use this information to identify similar patterns in similar records. In the step after this you will be able to validate the results and provide further details for Log Analytics to use in its analysis. --1. Highlight the text in the sample record that you want to populate the custom field. You will then be presented with a dialog box to provide a name and data type for the field and to perform the initial extract. The characters **\_CF** will automatically be appended. -2. Click **Extract** to perform an analysis of collected records. -3. The **Summary** and **Search Results** sections display the results of the extract so you can inspect its accuracy. **Summary** displays the criteria used to identify records and a count for each of the data values identified. **Search Results** provides a detailed list of records matching the criteria. --### Step 3: Verify accuracy of the extract and create custom field -Once you have performed the initial extract, Log Analytics will display its results based on data that has already been collected. If the results look accurate then you can create the custom field with no further work. If not, then you can refine the results so that Log Analytics can improve its logic. --1. If any values in the initial extract arenΓÇÖt correct, then click the **Edit** icon next to an inaccurate record and select **Modify this highlight** in order to modify the selection. -2. The entry is copied to the **Additional examples** section underneath the **Main Example**. You can adjust the highlight here to help Log Analytics understand the selection it should have made. -3. Click **Extract** to use this new information to evaluate all the existing records. The results may be modified for records other than the one you just modified based on this new intelligence. -4. Continue to add corrections until all records in the extract correctly identify the data to populate the new custom field. -5. Click **Save Extract** when you are satisfied with the results. The custom field is now defined, but it wonΓÇÖt be added to any records yet. -6. Wait for new records matching the specified criteria to be collected and then run the log search again. New records should have the custom field. -7. Use the custom field like any other record property. You can use it to aggregate and group data and even use it to produce new insights. --## Removing a custom field -There are two ways to remove a custom field. The first is the **Remove** option for each field when viewing the complete list as described above. The other method is to retrieve a record and click the button to the left of the field. The menu will have an option to remove the custom field. --## Sample walkthrough -The following section walks through a complete example of creating a custom field. This example extracts the service name in Windows events that indicate a service changing state. This relies on events created by Service Control Manager during system startup on Windows computers. If you want to follow this example, you must be [collecting Information events for the System log](../agents/data-sources-windows-events.md). --We enter the following query to return all events from Service Control Manager that have an Event ID of 7036 which is the event that indicates a service starting or stopping. -<!-- convertborder later --> --We then right-click on any record with event ID 7036 and select **Extract fields from \`Event`**. -<!-- convertborder later --> --The **Field Extraction Wizard** opens with the **EventLog** and **EventID** fields selected in the **Main Example** column. This indicates that the custom field will be defined for events from the System log with an event ID of 7036. This is sufficient so we donΓÇÖt need to select any other fields. -<!-- convertborder later --> --We highlight the name of the service in the **RenderedDescription** property and use **Service** to identify the service name. The custom field will be called **Service_CF**. The field type in this case is a string, so we can leave that unchanged. -<!-- convertborder later --> --We see that the service name is identified properly for some records but not for others. The **Search Results** show that part of the name for the **WMI Performance Adapter** wasnΓÇÖt selected. The **Summary** shows that one record identified **Modules Installer** instead of **Windows Modules Installer**. -<!-- convertborder later --> --We start with the **WMI Performance Adapter** record. We click its edit icon and then **Modify this highlight**. -<!-- convertborder later --> --We increase the highlight to include the word **WMI** and then rerun the extract. -<!-- convertborder later --> --We can see that the entries for **WMI Performance Adapter** have been corrected, and Log Analytics also used that information to correct the records for **Windows Module Installer**. -<!-- convertborder later --> --We can now run a query that verifies **Service_CF** is created but is not yet added to any records. That's because the custom field doesn't work against existing records so we need to wait for new records to be collected. -<!-- convertborder later --> --After some time has passed so new events are collected, we can see that the **Service_CF** field is now being added to records that match our criteria. -<!-- convertborder later --> --We can now use the custom field like any other record property. To illustrate this, we create a query that groups by the new **Service_CF** field to inspect which services are the most active. -<!-- convertborder later --> --## Next steps -* Learn about [log queries](./log-query-overview.md) to build queries using custom fields for criteria. -* Monitor [custom log files](../agents/data-sources-custom-logs.md) that you parse using custom fields. |
| azure-monitor | Custom Logs Migrate | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/custom-logs-migrate.md | - Title: Migrate from the HTTP Data Collector API to the Log Ingestion API -description: Migrate from the legacy Azure Monitor Data Collector API to the Log Ingestion API, which provides more processing power and greater flexibility. ---- Previously updated : 08/12/2024----# Migrate from the HTTP Data Collector API to the Log Ingestion API to send data to Azure Monitor Logs --The Azure Monitor [Log Ingestion API](../logs/logs-ingestion-api-overview.md) provides more processing power and greater flexibility in ingesting logs and [managing tables](../logs/manage-logs-tables.md) than the legacy [HTTP Data Collector API](../logs/data-collector-api.md). This article describes the differences between the Data Collector API and the Log Ingestion API and provides guidance and best practices for migrating to the new Log Ingestion API. --> [!NOTE] -> As a Microsoft MVP, [Morten Waltorp Knudsen](https://mortenknudsen.net/) contributed to and provided material feedback for this article. For an example of how you can automate the setup and ongoing use of the Log Ingestion API, see Morten's publicly available [AzLogDcrIngestPS PowerShell module](https://github.com/KnudsenMorten/AzLogDcrIngestPS). --## Advantages of the Log Ingestion API --The Log Ingestion API provides the following advantages over the Data Collector API: --- Supports [transformations](../essentials/data-collection-transformations.md), which enable you to modify the data before it's ingested into the destination table, including filtering and data manipulation.-- Lets you send data to multiple destinations. -- Enables you to manage the destination table schema, including column names, and whether to add new columns to the destination table when the source data schema changes.-## Prerequisites --The migration procedure described in this article assumes you have: --- A Log Analytics workspace where you have at least [contributor rights](manage-access.md#azure-rbac).-- [Permissions to create data collection rules](../essentials/data-collection-rule-create-edit.md#permissions) in the Log Analytics workspace.-- [A Microsoft Entra application to authenticate API calls](../logs/tutorial-logs-ingestion-portal.md#create-azure-ad-application) or any other Resource Manager authentication scheme.--## Permissions required --| Action | Permissions required | -|:|:| -| Create a data collection endpoint. | `Microsoft.Insights/dataCollectionEndpoints/write` permissions as provided by the [Monitoring Contributor built-in role](../../role-based-access-control/built-in-roles.md#monitoring-contributor), for example. | -| Create or modify a data collection rule. | `Microsoft.Insights/DataCollectionRules/Write` permissions as provided by the [Monitoring Contributor built-in role](../../role-based-access-control/built-in-roles.md#monitoring-contributor), for example. | -| Convert a table that uses the Data Collector API to data collection rules and the Log Ingestion API. | `Microsoft.OperationalInsights/workspaces/tables/migrate/action` permissions as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example. | -| Create new tables or modify table schemas. | `microsoft.operationalinsights/workspaces/tables/write` permissions as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example. | -| Call the Log Ingestion API. | See [Assign permissions to a DCR](./tutorial-logs-ingestion-api.md#assign-permissions-to-a-dcr). | --## Create new resources required for the Log ingestion API --The Log Ingestion API requires you to create two new types of resources, which the HTTP Data Collector API doesn't require: --- [Data collection endpoints](../essentials/data-collection-endpoint-overview.md), from which the data you collect is ingested into the pipeline for processing.-- [Data collection rules](../essentials/data-collection-rule-overview.md), which define [data transformations](../essentials/data-collection-transformations.md) and the destination table to which the data is ingested.--## Migrate existing custom tables or create new tables --If you have an existing custom table to which you currently send data using the Data Collector API, you can: --- Migrate the table to continue ingesting data into the same table using the Log Ingestion API. -- Maintain the existing table and data and set up a new table into which you ingest data using the Log Ingestion API. You can then delete the old table when you're ready. -- This is the preferred option, especially if you to need to make changes to the existing table. Changes to existing data types and multiple schema changes to existing Data Collector API custom tables can lead to errors. --> [!TIP] -> To identify which tables use the Data Collector API, [view table properties](../logs/manage-logs-tables.md#view-table-properties). The **Type** property of tables that use the Data Collector API is set to **Custom table (classic)**. Note that tables that ingest data using the legacy Log Analytics agent (MMA) also have the **Type** property set to **Custom table (classic)**. Be sure to migrate from Log Analytics agent to Azure Monitor Agent before converting MMA tables. Otherwise, you'll stop ingesting data into custom fields in these tables after the table conversion. --This table summarizes considerations to keep in mind for each option: --||Table migration|Side-by-side implementation| -|-|-|-| -|**Table and column naming**|Reuse existing table name.<br>Column naming options: <br>- Use new column names and define a transformation to direct incoming data to the newly named column.<br>- Continue using old names.|Set the new table name freely.<br>Need to adjust integrations, dashboards, and alerts before switching to the new table.| -|**Migration procedure**|One-off table migration. Not possible to roll back a migrated table. |Migration can be done gradually, per table.| -|**Post-migration**|You can continue to ingest data using the HTTP Data Collector API with existing columns, except custom columns.<br>Ingest data into new columns using the Log Ingestion API only.| Data in the old table is available until the end of retention period.<br>When you first set up a new table or make schema changes, it can take 10-15 minutes for the data changes to start appearing in the destination table.| --To convert a table that uses the Data Collector API to data collection rules and the Log Ingestion API, issue this API call against the table: --```rest -POST https://management.azure.com/subscriptions/{subscriptionId}/resourcegroups/{resourceGroupName}/providers/Microsoft.OperationalInsights/workspaces/{workspaceName}/tables/{tableName}/migrate?api-version=2021-12-01-preview -``` -This call is idempotent, so it has no effect if the table has already been converted. --The API call enables all DCR-based custom logs features on the table. The Data Collector API will continue to ingest data into existing columns, but won't create any new columns. Any previously defined [custom fields](../logs/custom-fields.md) won't continue to be populated. Another way to migrate an existing table to using data collection rules, but not necessarily the Log Ingestion API is applying a [workspace transformation](../logs/tutorial-workspace-transformations-portal.md) to the table. --> [!IMPORTANT] -> - Column names must start with a letter and can consist of up to 45 alphanumeric characters and underscores (`_`). -> - `_ResourceId`, `id`, `_ResourceId`, `_SubscriptionId`, `TenantId`, `Type`, `UniqueId`, and `Title` are reserved column names. -> - Custom columns you add to an Azure table must have the suffix `_CF`. -> - If you update the table schema in your Log Analytics workspace, you must also update the input stream definition in the data collection rule to ingest data into new or modified columns. --## Call the Log Ingestion API --The Log Ingestion API lets you send up to 1 MB of compressed or uncompressed data per call. If you need to send more than 1 MB of data, you can send multiple calls in parallel. This is a change from the Data Collector API, which lets you send up to 32 MB of data per call. --For information about how to call the Log Ingestion API, see [Log Ingestion REST API call](../logs/logs-ingestion-api-overview.md#rest-api-call). --## Modify table schemas and data collection rules based on changes to source data object --While the Data Collector API automatically adjusts the destination table schema when the source data object schema changes, the Log Ingestion API doesn't. This ensures that you don't collect new data into columns that you didn't intend to create. --When the source data schema changes, you can: --- [Modify destination table schemas](../logs/create-custom-table.md) and [data collection rules](../essentials/data-collection-rule-edit.md) to align with source data schema changes.-- [Define a transformation](../essentials/data-collection-transformations.md) in the data collection rule to send the new data into existing columns in the destination table. -- Leave the destination table and data collection rule unchanged. In this case, you won't ingest the new data.--> [!NOTE] -> You can't reuse a column name with a data type that's different to the original data type defined for the column. --## Next steps --- [Walk through a tutorial sending custom logs using the Azure portal.](tutorial-logs-ingestion-portal.md)-- [Walk through a tutorial sending custom logs using Resource Manager templates and REST API.](tutorial-logs-ingestion-api.md) |
| azure-monitor | Customer Managed Keys | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/customer-managed-keys.md | - Title: Azure Monitor customer-managed key -description: Information and steps to configure Customer-managed key to encrypt data in your Log Analytics workspaces using an Azure Key Vault key. -- Previously updated : 01/06/2024 -----# Azure Monitor customer-managed key --Data in Azure Monitor is encrypted with Microsoft-managed keys. You can use your own encryption key to protect the data and saved queries in your workspaces. Customer-managed keys in Azure Monitor give you greater flexibility to manage access controls to logs. Once configure, new data ingested to linked workspaces gets encrypted with your key stored in [Azure Key Vault](/azure/key-vault/general/overview), or [Azure Key Vault Managed "HSM"](/azure/key-vault/managed-hsm/overview). --Review [limitations and constraints](#limitationsandconstraints) before configuration. --## Customer-managed key overview --[Encryption at Rest](../../security/fundamentals/encryption-atrest.md) is a common privacy and security requirement in organizations. You can let Azure completely manage encryption at rest, while you have various options to closely manage encryption and encryption keys. --Azure Monitor ensures that all data and saved queries are encrypted at rest using Microsoft-managed keys (MMK). You can encrypt data using your own key in [Azure Key Vault](/azure/key-vault/general/overview), for control over the key lifecycle, and ability to revoke access to your data. Azure Monitor use of encryption is identical to the way [Azure Storage encryption](../../storage/common/storage-service-encryption.md#about-azure-storage-service-side-encryption) operates. --Customer-managed key is delivered on [dedicated clusters](./logs-dedicated-clusters.md) providing higher protection level and control. Data is encrypted in storage twice, once at the service level using Microsoft-managed keys or Customer-managed keys, and once at the infrastructure level, using two different [encryption algorithms](../../storage/common/storage-service-encryption.md#about-azure-storage-service-side-encryption) and two different keys. [double encryption](../../storage/common/storage-service-encryption.md#doubly-encrypt-data-with-infrastructure-encryption) protects against a scenario where one of the encryption algorithms or keys may be compromised. Dedicated cluster also lets you protect data with [Lockbox](#customer-lockbox). --Data ingested in the last 14 days or recently used in queries is kept in hot-cache (SSD-backed) for query efficiency. SSD data is encrypted with Microsoft keys regardless customer-managed key configuration, but your control over SSD access adheres to [key revocation](#key-revocation) --Log Analytics Dedicated Clusters [pricing model](./logs-dedicated-clusters.md#cluster-pricing-model) requires commitment Tier starting at 100 GB per day. --## How Customer-managed key works in Azure Monitor --Azure Monitor uses managed identity to grant access to your Azure Key Vault. The identity of the Log Analytics cluster is supported at the cluster level. To allow Customer-managed key on multiple workspaces, a Log Analytics Cluster resource performs as an intermediate identity connection between your Key Vault and your Log Analytics workspaces. The cluster's storage uses the managed identity associated with the cluster to authenticate to your Azure Key Vault via Microsoft Entra ID. --Clusters support two [managed identity types](../../active-directory/managed-identities-azure-resources/overview.md#managed-identity-types): System-assigned and User-assigned, while a single identity can be defined in a cluster depending on your scenario. --- System-assigned managed identity is simpler and being generated automatically with the cluster creation when identity `type` is set to "*SystemAssigned*". This identity can be used later to grant storage access to your Key Vault for wrap and unwrap operations.-- User-assigned managed identity lets you configure Customer-managed key at cluster creation, when granting it permissions in your Key Vault before cluster creation.--You can apply Customer-managed key configuration to a new cluster, or existing cluster linked to workspaces and ingesting data. New data ingested to linked workspaces gets encrypted with your key, and older data ingested before the configuration, remains encrypted with Microsoft key. Your queries aren't affected by Customer-managed key configuration and performed across old, and new data seamlessly. You can unlink workspaces from cluster at any time. New data ingested after the unlink gets encrypted with Microsoft key, and queries are performed across old, and new data seamlessly. --> [!IMPORTANT] -> Customer-managed key capability is regional. Your Azure Key Vault, cluster and linked workspaces must be in the same region, but they can be in different subscriptions. -<!-- convertborder later --> --1. Key Vault -2. Log Analytics cluster resource having managed identity with permissions to Key Vault—The identity is propagated to the underlay dedicated cluster storage -3. Dedicated cluster -4. Workspaces linked to dedicated cluster --### Encryption keys operation --There are three types of keys involved in Storage data encryption: --- "**KEK**" - Key Encryption Key (your Customer-managed key)-- "**AEK**" - Account Encryption Key-- "**DEK**" - Data Encryption Key--The following rules apply: --- The cluster storage has unique encryption key for every Storage Account, which is known as the "AEK".-- The "AEK" is used to derive "DEKs, which are the keys that are used to encrypt each block of data written to disk.-- When you configure a key in your Key Vault, and updated the key details in the cluster, the cluster storage performs requests to 'wrap' and 'unwrap' "AEK" for encryption and decryption.-- Your "KEK" never leaves your Key Vault, and in the case of Managed "HSM", it never leaves the hardware.-- Azure Storage uses managed identity associated with the *Cluster* resource for authentication. It accesses Azure Key Vault via Microsoft Entra ID.--### Customer-Managed key provisioning steps --1. Creating Azure Key Vault and storing key -1. Creating cluster -1. Granting permissions to your Key Vault -1. Updating cluster with key identifier details -1. Linking workspaces --Customer-managed key configuration isn't supported in Azure portal currently and provisioning can be performed via [PowerShell](/powershell/module/az.operationalinsights/), [CLI](/cli/azure/monitor/log-analytics), or [REST](/rest/api/loganalytics/) requests. --## Storing encryption key ("KEK") --A [portfolio of Azure Key Management products](/azure/key-vault/managed-hsm/mhsm-control-data#portfolio-of-azure-key-management-products) lists the vaults and managed HSMs that can be used. --Create or use an existing Azure Key Vault in the region that the cluster is planed. In your Key vault, generate or import a key to be used for logs encryption. The Azure Key Vault must be configured as recoverable, to protect your key and the access to your data in Azure Monitor. You can verify this configuration under properties in your Key Vault, both **Soft delete** and **Purge protection** should be enabled. -<!-- convertborder later --> --These settings can be updated in Key Vault via CLI and PowerShell: --- [Soft Delete](/azure/key-vault/general/soft-delete-overview)-- [Purge protection](/azure/key-vault/general/soft-delete-overview#purge-protection) guards against force deletion of the secret, vault even after soft delete--## Create cluster --Clusters use managed identity for data encryption with your Key Vault. Configure identity `type` property to `SystemAssigned` when creating your cluster to allow access to your Key Vault for "wrap" and "unwrap" operations. - - Identity settings in cluster for System-assigned managed identity - ```json - { - "identity": { - "type": "SystemAssigned" - } - } - ``` --Follow the procedure illustrated in [Dedicated Clusters article](./logs-dedicated-clusters.md#create-a-dedicated-cluster). --## Grant Key Vault permissions --There are two permission models in Key Vault to grant access to your cluster and underlay storage—Azure role-based access control (Azure RBAC), and Vault access policies (legacy). --1. Assign Azure RBAC you control (recommended) - - To add role assignments, you must have Microsoft.Authorization/roleAssignments/write and Microsoft.Authorization/roleAssignments/delete permissions, such as [User Access Administrator](../../role-based-access-control/built-in-roles.md#user-access-administrator) or [Owner](../../role-based-access-control/built-in-roles.md#owner). -- Open your Key Vault in Azure portal, **click Access configuration** in **Settings**, and select **Azure role-based access control** option. Then enter **Access control (IAM)** and add **Key Vault Crypto Service Encryption User** role assignment. - <!-- convertborder later --> - :::image type="content" source="media/customer-managed-keys/grant-key-vault-permissions-rbac-8bit.png" lightbox="media/customer-managed-keys/grant-key-vault-permissions-rbac-8bit.png" alt-text="Screenshot of Grant Key Vault RBAC permissions." border="false"::: --1. Assign vault access policy (legacy) -- Open your Key Vault in Azure portal and click **Access Policies**, select **Vault access policy**, then click **+ Add Access Policy** to create a policy with these settings: -- - Key permissions—select **Get**, **Wrap Key** and **Unwrap Key**. - - Select principal—depending on the identity type used in the cluster (system or user assigned managed identity) - - System assigned managed identity - enter the cluster name or cluster principal ID - - User assigned managed identity - enter the identity name - <!-- convertborder later --> - :::image type="content" source="media/customer-managed-keys/grant-key-vault-permissions-8bit.png" lightbox="media/customer-managed-keys/grant-key-vault-permissions-8bit.png" alt-text="Screenshot of Grant Key Vault access policy permissions." border="false"::: -- The **Get** permission is required to verify that your Key Vault is configured as recoverable to protect your key and the access to your Azure Monitor data. --## Update cluster with key identifier details --All operations on the cluster require the `Microsoft.OperationalInsights/clusters/write` action permission. This permission could be granted via the Owner or Contributor that contains the `*/write` action or via the Log Analytics Contributor role that contains the `Microsoft.OperationalInsights/*` action. --This step updates dedicated cluster storage with the key and version to use for "AEK" wrap and unwrap. -->[!IMPORTANT] ->- Key rotation can be automatic or require explicit key update, see [Key rotation](#key-rotation) to determine approach that is suitable for you before updating the key identifier details in cluster. ->- Cluster update should not include both identity and key identifier details in the same operation. If you need to update both, the update should be in two consecutive operations. ---Update KeyVaultProperties in cluster with key identifier details. --The operation is asynchronous and can take a while to complete. --# [Azure portal](#tab/portal) --N/A --# [Azure CLI](#tab/azure-cli) --When entering "''" value for ```key-version```, the cluster always uses the last key version in Key Vault and there is no need to update cluster post key rotation. --```azurecli -az account set --subscription cluster-subscription-id --az monitor log-analytics cluster update --no-wait --name "cluster-name" --resource-group "resource-group-name" --key-name "key-name" --key-vault-uri "key-uri" --key-version "key-version" --$clusterResourceId = az monitor log-analytics cluster list --resource-group "resource-group-name" --query "[?contains(name, "cluster-name")].[id]" --output tsv -az resource wait --created --ids $clusterResourceId --include-response-body true -``` -# [PowerShell](#tab/powershell) --When entering "''" value for ```KeyVersion```, the cluster always uses the last key version in Key Vault and there is no need to update cluster post key rotation. --```powershell -Select-AzSubscription "cluster-subscription-id" --Update-AzOperationalInsightsCluster -ResourceGroupName "resource-group-name" -ClusterName "cluster-name" -KeyVaultUri "key-uri" -KeyName "key-name" -KeyVersion "key-version" -AsJob --# Check when the job is done when `-AsJob` was used -Get-Job -Command "New-AzOperationalInsightsCluster*" | Format-List -Property * -``` --# [REST](#tab/rest) --```rst -PATCH https://management.azure.com/subscriptions/<subscription-id>/resourcegroups/<resource-group-name>/providers/Microsoft.OperationalInsights/clusters/cluster-name?api-version=2022-10-01 -Authorization: Bearer <token> -Content-type: application/json - -{ - "properties": { - "keyVaultProperties": { - "keyVaultUri": "https://key-vault-name.vault.azure.net", - "keyName": "key-name", - "keyVersion": "current-version" - }, - "sku": { - "name": "CapacityReservation", - "capacity": 100 - } -} -``` --**Response** --It takes the propagation of the key a while to complete. You can check the update state by sending GET request on the cluster and look at the **KeyVaultProperties** properties. Your recently updated key should return in the response. --Response to GET request when key update is completed: -202 (Accepted) and header -```json -{ - "identity": { - "type": "SystemAssigned", - "tenantId": "tenant-id", - "principalId": "principal-id" - }, - "sku": { - "name": "capacityreservation", - "capacity": 100 - }, - "properties": { - "keyVaultProperties": { - "keyVaultUri": "https://key-vault-name.vault.azure.net", - "keyName": "key-name", - "keyVersion": "current-version" - }, - "provisioningState": "Succeeded", - "clusterId": "cluster-id", - "billingType": "Cluster", - "lastModifiedDate": "last-modified-date", - "createdDate": "created-date", - "isDoubleEncryptionEnabled": false, - "isAvailabilityZonesEnabled": false, - "capacityReservationProperties": { - "lastSkuUpdate": "last-sku-modified-date", - "minCapacity": 100 - } - }, - "id": "/subscriptions/subscription-id/resourceGroups/resource-group-name/providers/Microsoft.OperationalInsights/clusters/cluster-name", - "name": "cluster-name", - "type": "Microsoft.OperationalInsights/clusters", - "location": "cluster-region" -} -``` ----## Link workspace to cluster --> [!IMPORTANT] -> This step should be performed only after the cluster provisioning. If you link workspaces and ingest data prior to the provisioning, ingested data will be dropped and won't be recoverable. --You need to have "write" permissions on your workspace and cluster to perform this operation. It includes `Microsoft.OperationalInsights/workspaces/write` and `Microsoft.OperationalInsights/clusters/write`. --Follow the procedure illustrated in [Dedicated Clusters article](./logs-dedicated-clusters.md#link-a-workspace-to-a-cluster). --## Key revocation --> [!IMPORTANT] -> - The recommended way to revoke access to your data is by disabling your key, or deleting Access Policy in your Key Vault. -> - Setting the cluster's `identity` `type` to `None` also revokes access to your data, but this approach isn't recommended since you can't revert it without contacting support. --The cluster storage always respect changes in key permissions within an hour or sooner, and storage become unavailable. New data ingested to linked workspaces is dropped and non-recoverable. Data is inaccessible on these workspaces and queries fail. Previously ingested data remains in storage as long as your cluster and your workspaces aren't deleted. Inaccessible data is governed by the data-retention policy and purged when retention is reached. Data ingested in the last 14 days and data recently used in queries is also kept in hot-cache (SSD-backed) for query efficiency. The data on SSD gets deleted on key revocation operation and becomes inaccessible. The cluster storage attempts to reach Key Vault for wrap and unwrap periodically, and once key is enabled, unwrap succeeds, SSD data is reloaded from storage, and data ingestion and query are resumed within 30 minutes. --## Key rotation --Key rotation has two modes: --- Autorotation—update your cluster with ```"keyVaultProperties"``` but omit ```"keyVersion"``` property, or set it to ```""```. Storage automatically uses the latest key version.-- Explicit key version update—update your cluster with key version in ```"keyVersion"``` property. Rotation of keys requires an explicit ```"keyVaultProperties"``` update in cluster, see [Update cluster with Key identifier details](#update-cluster-with-key-identifier-details). If you generate new key version in Key Vault but don't update it in the cluster, the cluster storage keeps using your previous key. If you disable or delete the old key before updating a new one in the cluster, you get into [key revocation](#key-revocation) state.--All your data remains accessible after the key rotation operation. Data always encrypted with the Account Encryption Key ("AEK"), which is encrypted with your new Key Encryption Key ("KEK") version in Key Vault. --## Customer-managed key for saved queries and log search alerts --The query language used in Log Analytics is expressive and can contain sensitive information in comments, or in the query syntax. Some organizations require that such information is kept protected under Customer-managed key policy and you need save your queries encrypted with your key. Azure Monitor enables you to store saved queries and log search alerts encrypted with your key in your own Storage Account when linked to your workspace. --## Customer-managed key for Workbooks --With the considerations mentioned for [Customer-managed key for saved queries and log search alerts](#customer-managed-key-for-saved-queries-and-log-search-alerts), Azure Monitor enables you to store Workbook queries encrypted with your key in your own Storage Account, when selecting **Save content to an Azure Storage Account** in Workbook 'Save' operation. -<!-- convertborder later --> --> [!NOTE] -> Queries remain encrypted with Microsoft key ("MMK") in the following scenarios regardless Customer-managed key configuration: Azure dashboards, Azure Logic App, Azure Notebooks and Automation Runbooks. --When linking your Storage Account for saved queries, the service stores saved queries and log search alert queries in your Storage Account. Having control on your Storage Account [encryption-at-rest policy](../../storage/common/customer-managed-keys-overview.md), you can protect saved queries and log search alerts with Customer-managed key. You will, however, be responsible for the costs associated with that Storage Account. --**Considerations before setting Customer-managed key for queries** -* You need to have "write" permissions on your workspace and Storage Account. -* Make sure to create your Storage Account in the same region as your Log Analytics workspace is located, with Customer-managed key encryption. This is important since saved queries are stored in table storage and it can only be encrypted at Storage Account creation. -* Queries saved in [query pack](./query-packs.md) aren't encrypted with Customer-managed key. Select **Save as Legacy query** when saving queries instead, to protect them with Customer-managed key. -* Saves queries in storage are considered service artifacts and their format may change. -* Linking a Storage Account for queries removes existing saves queries from your workspace. Copy saves queries that you need before this configuration. You can view your saved queries using [PowerShell](/powershell/module/az.operationalinsights/get-azoperationalinsightssavedsearch). -* Query 'history' and 'pin to dashboard' aren't supported when linking Storage Account for queries. -* You can link a single Storage Account to a workspace for both saved queries and log search alert queries. -* Log search alerts are saved in blob storage and Customer-managed key encryption can be configured at Storage Account creation, or later. -* Fired log search alerts won't contain search results or alert query. You can use [alert dimensions](../alerts/alerts-types.md#monitor-the-same-condition-on-multiple-resources-using-splitting-by-dimensions-1) to get context in the fired alerts. --**Configure BYOS for saved queries** --Link a Storage Account for queries to keep saved queries in your Storage Account. --# [Azure portal](#tab/portal) --N/A --# [Azure CLI](#tab/azure-cli) --```azurecli -az account set --subscription "storage-account-subscription-id" --$storageAccountId = '/subscriptions/<subscription-id>/resourceGroups/<resource-group-name>/providers/Microsoft.Storage/storageAccounts/<storage name>' --az account set --subscription "workspace-subscription-id" --az monitor log-analytics workspace linked-storage create --type Query --resource-group "resource-group-name" --workspace-name "workspace-name" --storage-accounts $storageAccountId -``` --# [PowerShell](#tab/powershell) --```powershell -Select-AzSubscription "StorageAccount-subscription-id" --$storageAccountId = (Get-AzStorageAccount -ResourceGroupName "resource-group-name" -Name "storage-account-name").id --Select-AzSubscription "workspace-subscription-id" --New-AzOperationalInsightsLinkedStorageAccount -ResourceGroupName "resource-group-name" -WorkspaceName "workspace-name" -DataSourceType Query -StorageAccountIds $storageAccountId -``` --# [REST](#tab/rest) --```rst -PUT https://management.azure.com/subscriptions/<subscription-id>/resourcegroups/<resource-group-name>/providers/Microsoft.OperationalInsights/workspaces/<workspace-name>/linkedStorageAccounts/Query?api-version=2020-08-01 -Authorization: Bearer <token> -Content-type: application/json - -{ - "properties": { -  "dataSourceType": "Query", -    "storageAccountIds": -   [ -     "/subscriptions/<subscription-id>/resourceGroups/<resource-group-name>/providers/Microsoft.Storage/storageAccounts/<storage-account-name>" -   ] -  } -} -``` ----After the configuration, any new *saved search* query will be saved in your storage. --**Configure BYOS for log search alert queries** --Link a Storage Account for *Alerts* to keep *log search alert* queries in your Storage Account. --# [Azure portal](#tab/portal) --N/A --# [Azure CLI](#tab/azure-cli) --```azurecli -az account set --subscription "storage-account-subscription-id" --$storageAccountId = '/subscriptions/<subscription-id>/resourceGroups/<resource-group-name>/providers/Microsoft.Storage/storageAccounts/<storage name>' --az account set --subscription "workspace-subscription-id" --az monitor log-analytics workspace linked-storage create --type ALerts --resource-group "resource-group-name" --workspace-name "workspace-name" --storage-accounts $storageAccountId -``` --# [PowerShell](#tab/powershell) --```powershell -Select-AzSubscription "StorageAccount-subscription-id" --$storageAccountId = (Get-AzStorageAccount -ResourceGroupName "resource-group-name" -Name "storage-account-name").id --Select-AzSubscription "workspace-subscription-id" --New-AzOperationalInsightsLinkedStorageAccount -ResourceGroupName "resource-group-name" -WorkspaceName "workspace-name" -DataSourceType Alerts -StorageAccountIds $storageAccountId -``` --# [REST](#tab/rest) --```rst -PUT https://management.azure.com/subscriptions/<subscription-id>/resourcegroups/<resource-group-name>/providers/Microsoft.OperationalInsights/workspaces/<workspace-name>/linkedStorageAccounts/Alerts?api-version=2020-08-01 -Authorization: Bearer <token> -Content-type: application/json - -{ - "properties": { -  "dataSourceType": "Alerts", -    "storageAccountIds": -   [ -     "/subscriptions/<subscription-id>/resourceGroups/<resource-group-name>/providers/Microsoft.Storage/storageAccounts/<storage-account-name>" -   ] -  } -} -``` ---After the configuration, any new alert query will be saved in your storage. --## Customer Lockbox --Lockbox gives you the control to approve or reject Microsoft engineer request to access your data during a support request. --Lockbox is provided in dedicated cluster in Azure Monitor, where your permission to access data is granted at the subscription level. --Learn more about [Customer Lockbox for Microsoft Azure](../../security/fundamentals/customer-lockbox-overview.md) --## Customer-Managed key operations --Customer-Managed key is provided on dedicated cluster and these operations are referred in [dedicated cluster article](./logs-dedicated-clusters.md#change-cluster-properties) --- Get all clusters in resource group -- Get all clusters in subscription-- Update *capacity reservation* in cluster-- Update *billingType* in cluster-- Unlink a workspace from cluster-- Delete cluster--## Limitations and constraints --- A maximum of five active clusters can be created in each region and subscription.--- A maximum number of seven reserved clusters (active or recently deleted) can exist in each region and subscription.--- A maximum of 1,000 Log Analytics workspaces can be linked to a cluster.--- A maximum of two workspace link operations on particular workspace is allowed in 30 day period.--- Moving a cluster to another resource group or subscription isn't currently supported.--- Cluster update shouldn't include both identity and key identifier details in the same operation. In case you need to update both, the update should be in two consecutive operations.--- Lockbox isn't available in China currently. --- [Double encryption](../../storage/common/storage-service-encryption.md#doubly-encrypt-data-with-infrastructure-encryption) is configured automatically for clusters created from October 2020 in supported regions. You can verify if your cluster is configured for double encryption by sending a GET request on the cluster and observing that the `isDoubleEncryptionEnabled` value is `true` for clusters with Double encryption enabled. - - If you create a cluster and get an error—"region-name doesn’t support Double Encryption for clusters", you can still create the cluster without Double encryption, by adding `"properties": {"isDoubleEncryptionEnabled": false}` in the REST request body. - - Double encryption settings cannot be changed after the cluster is created. --Deleting a linked workspace is permitted while linked to cluster. If you decide to [recover](./delete-workspace.md#recover-a-workspace-in-a-soft-delete-state) the workspace during the [soft-delete](./delete-workspace.md#delete-a-workspace-into-a-soft-delete-state) period, it returns to previous state and remains linked to cluster. --- Customer-managed key encryption applies to newly ingested data after the configuration time. Data that was ingested prior to the configuration, remains encrypted with Microsoft key. You can query data ingested before and after the Customer-managed key configuration seamlessly.--- The Azure Key Vault must be configured as recoverable. These properties aren't enabled by default and should be configured using CLI or PowerShell:<br>- - [Soft Delete](/azure/key-vault/general/soft-delete-overview). - - [Purge protection](/azure/key-vault/general/soft-delete-overview#purge-protection) should be turned on to guard against force deletion of the secret, vault even after soft delete. --- Your Azure Key Vault, cluster and workspaces must be in the same region and in the same Microsoft Entra tenant, but they can be in different subscriptions.--- Setting the cluster's `identity` `type` to `None` also revokes access to your data, but this approach isn't recommended since you can't revert it without contacting support. The recommended way to revoke access to your data is [key revocation](#key-revocation).--- You can't use Customer-managed key with User-assigned managed identity if your Key Vault is in Private-Link (vNet). You can use System-assigned managed identity in this scenario.--## Troubleshooting --- Behavior per Key Vault availability:- - Normal operation—storage caches "AEK" for short periods of time and goes back to Key Vault to unwrap periodically. - - - Key Vault connection errors—storage handles transient errors (timeouts, connection failures, "DNS" issues), by allowing keys to stay in cache during the availability issue, and it overcomes blips and availability issues. The query and ingestion capabilities continue without interruption. - -- Key Vault access rate—The frequency that Azure the cluster storage accesses Key Vault for wrap and unwrap is between 6 to 60 seconds.--- If you update your cluster while it's at provisioning state, or updating state, the update fails.--- If you get conflict—error when creating a cluster, a cluster with the same name may have been deleted in the last 14 days and kept reserved. Deleted cluster name becomes available 14 days after deletion.--- Workspace link to cluster fails if it is linked to another cluster.--- If you create a cluster and specify the KeyVaultProperties immediately, operation may fail until identity is assigned in cluster, and granted at Key Vault.--- If you update existing cluster with KeyVaultProperties and 'Get' key Access Policy is missing in Key Vault, the operation fails.--- If you fail to deploy your cluster, verify that your Azure Key Vault, cluster and linked workspaces are in the same region. The can be in different subscriptions.--- If you rotate your key in Key Vault and don't update the new key identifier details in the cluster, cluster keep using previous key and your data will become inaccessible. Update new key identifier details in cluster to resume data ingestion and query. You can update key version with "''" to have storage always use lates key version automatically.--- Some operations are long running and can take a while to complete, include cluster create, cluster key update and cluster delete. You can check the operation status by sending GET request to cluster or workspace and observe the response. For example, unlinked workspace won't have the *clusterResourceId* under *features*.--- Error messages- - **Cluster Update** - - 400 — Cluster is in deleting state. Async operation is in progress. Cluster must complete its operation before any update operation is performed. - - 400 — KeyVaultProperties is not empty but has a bad format. See [key identifier update](#update-cluster-with-key-identifier-details). - - 400 — Failed to validate key in Key Vault. Could be due to lack of permissions or when key doesn’t exist. Verify that you [set key and Access Policy](#grant-key-vault-permissions) in Key Vault. - - 400 — Key is not recoverable. Key Vault must be set to Soft-delete and Purge-protection. See [Key Vault documentation](/azure/key-vault/general/soft-delete-overview) - - 400 — Operation cannot be executed now. Wait for the Async operation to complete and try again. - - 400 — Cluster is in deleting state. Wait for the Async operation to complete and try again. -- **Cluster Get** - - 404--Cluster not found, the cluster might have been deleted. If you try to create a cluster with that name and get conflict, the cluster is in deletion process. --## Next steps --- Learn about [Log Analytics dedicated cluster billing](cost-logs.md#dedicated-clusters)-- Learn about [proper design of Log Analytics workspaces](./workspace-design.md) |
| azure-monitor | Daily Cap | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/daily-cap.md | - Title: Set daily cap on Log Analytics workspace -description: Set a -- Previously updated : 10/23/2023---# Set daily cap on Log Analytics workspace -A daily cap on a Log Analytics workspace allows you to avoid unexpected increases in charges for data ingestion by stopping collection of billable data for the rest of the day whenever a specified threshold is reached. This article describes how the daily cap works and how to configure one in your workspace. --> [!IMPORTANT] -> You should use care when setting a daily cap because when data collection stops, your ability to observe and receive alerts when the health conditions of your resources will be impacted. It can also impact other Azure services and solutions whose functionality may depend on up-to-date data being available in the workspace. Your goal shouldn't be to regularly hit the daily limit but rather use it as an infrequent method to avoid unplanned charges resulting from an unexpected increase in the volume of data collected. -> -> For strategies to reduce your Azure Monitor costs, see [Cost optimization and Azure Monitor](../best-practices-cost.md). --## Permissions required --| Action | Permissions or role needed | -||| -| Set the daily cap on a Log Analytics workspace | `Microsoft.OperationalInsights/workspaces/write` permissions to the Log Analytics workspaces you set the daily cap on, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example. | -| Set the daily cap on a classic Application Insights resource | `microsoft.insights/components/CurrentBillingFeatures/write` permissions to the classic Application Insights resources you set the daily cap on, as provided by the [Application Insights Component Contributor built-in role](../../role-based-access-control/built-in-roles.md#application-insights-component-contributor), for example. | -| Create an alert when the daily cap for a Log Analytics workspace is reached | `microsoft.insights/scheduledqueryrules/write` permissions, as provided by the [Monitoring Contributor built-in role](../../role-based-access-control/built-in-roles.md#monitoring-contributor), for example | -| Create an alert when the daily cap for a classic Application Insights resource is reached | `microsoft.insights/activitylogalerts/write` permissions, as provided by the [Monitoring Contributor built-in role](../../role-based-access-control/built-in-roles.md#monitoring-contributor), for example | -| View the effect of the daily cap | `Microsoft.OperationalInsights/workspaces/query/*/read` permissions to the Log Analytics workspaces you query, as provided by the [Log Analytics Reader built-in role](./manage-access.md#log-analytics-reader), for example. | --## How the daily cap works -Each workspace has a daily cap that defines its own data volume limit. When the daily cap is reached, a warning banner appears across the top of the page for the selected Log Analytics workspace in the Azure portal, and an operation event is sent to the *Operation* table under the **LogManagement** category. You can optionally create an alert rule to send an alert when this event is created. --The data size used for the daily cap is the size after customer-defined data transformations. (Learn more about data [transformations in Data Collection Rules](../essentials/data-collection-transformations.md).) --Data collection resumes at the reset time which is a different hour of the day for each workspace. This reset hour can't be configured. You can optionally create an alert rule to send an alert when this event is created. --> [!NOTE] -> The daily cap can't stop data collection at precisely the specified cap level and some excess data is expected. The data collection beyond the daily cap can be particularly large if the workspace is receiving high rates of data. If data is collected above the cap, it's still billed. See [View the effect of the Daily Cap](#view-the-effect-of-the-daily-cap) for a query that is helpful in studying the daily cap behavior. -## When to use a daily cap -Daily caps are typically used by organizations that are particularly cost conscious. They shouldn't be used as a method to reduce costs, but rather as a preventative measure to ensure that you don't exceed a particular budget. --When data collection stops, you effectively have no monitoring of features and resources relying on that workspace. Instead of relying on the daily cap alone, you can [create an alert rule](#alert-when-daily-cap-is-reached) to notify you when data collection reaches some level before the daily cap. Notification allows you to address any increases before data collection shuts down, or even to temporarily disable collection for less critical resources. --## Application Insights -You should configure the daily cap setting for both Application Insights and Log Analytics to limit the amount of telemetry data ingested by your service. For workspace-based Application Insights resources, the effective daily cap is the minimum of the two settings. For classic Application Insights resources, only the Application Insights daily cap applies since their data doesnΓÇÖt reside in a Log Analytics workspace. --> [!TIP] -> If you're concerned about the amount of billable data collected by Application Insights, you should configure [sampling](../app/sampling.md) to tune its data volume to the level you want. Use the daily cap as a safety method in case your application unexpectedly begins to send much higher volumes of telemetry. --The maximum cap for an Application Insights classic resource is 1,000 GB/day unless you request a higher maximum for a high-traffic application. When you create a resource in the Azure portal, the daily cap is set to 100 GB/day. When you create a resource in Visual Studio, the default is small (only 32.3 MB/day). The daily cap default is set to facilitate testing. It's intended that the user will raise the daily cap before deploying the app into production. --> [!NOTE] -> If you are using connection strings to send data to Application Insights using [regional ingestion endpoints](../ip-addresses.md#outgoing-ports), then the Application Insights and Log Analytics daily cap settings are effective per region. If you are using only instrumentation key (ikey) to send data to Application Insights using the [global ingestion endpoint](../ip-addresses.md#outgoing-ports), then the Application Insights daily cap setting may not be effective across regions, but the Log Analytics daily cap setting will still apply. --We've removed the restriction on some subscription types that have credit that couldn't be used for Application Insights. Previously, if the subscription has a spending limit, the daily cap dialog has instructions to remove the spending limit and enable the daily cap to be raised beyond 32.3 MB/day. --## Determine your daily cap -To help you determine an appropriate daily cap for your workspace, see [Azure Monitor cost and usage](../cost-usage.md) to understand your data ingestion trends. You can also review [Analyze usage in Log Analytics workspace](analyze-usage.md) which provides methods to analyze your workspace usage in more detail. ----## Workspaces with Microsoft Defender for Cloud --> [!IMPORTANT] -> Starting September 18, 2023, Azure Monitor caps all billable data types -> when the daily cap is met. There is no special behavior for any data types when [Microsoft Defender for Servers](/azure/defender-for-cloud/plan-defender-for-servers-select-plan) is enabled on your workspace. -> This change improves your ability to fully contain costs from higher-than-expected data ingestion. -> If you have a daily cap set on a workspace that has Microsoft Defender for Servers enabled, -> be sure that the cap is high enough to accommodate this change. -> Also, be sure to set an alert (see below) so that you are notified as soon as your daily cap is met. --Until September 18, 2023, if a workspace enabled the [Microsoft Defenders for Servers](/azure/defender-for-cloud/plan-defender-for-servers-select-plan) solution after June 19, 2017, some security related data types are collected for Microsoft Defender for Cloud or Microsoft Sentinel despite any daily cap configured. The following data types will be subject to this special exception from the daily cap WindowsEvent, SecurityAlert, SecurityBaseline, SecurityBaselineSummary, SecurityDetection, SecurityEvent, WindowsFirewall, MaliciousIPCommunication, LinuxAuditLog, SysmonEvent, ProtectionStatus, Update, UpdateSummary, CommonSecurityLog and Syslog --## Set the daily cap -### Log Analytics workspace -To set or change the daily cap for a Log Analytics workspace in the Azure portal: --1. From the **Log Analytics workspaces** menu, select your workspace, and then **Usage and estimated costs**. -2. Select **Daily Cap** at the top of the page. -3. Select **ON** and then set the data volume limit in GB/day. ---> [!NOTE] -> The reset hour for the workspace is displayed but cannot be configured. --To configure the daily cap with Azure Resource Manager, set the `dailyQuotaGb` parameter under `WorkspaceCapping` as described at [Workspaces - Create Or Update](/rest/api/loganalytics/workspaces/createorupdate#workspacecapping). ---### Classic Applications Insights resource -To set or change the daily cap for a classic Application Insights resource in the Azure portal: --1. From the **Monitor** menu, select **Applications**, your application, and then **Usage and estimated costs**. -2. Select **Data Cap** at the top of the page. -3. Set the data volume limit in GB/day. -4. If you want an email sent to the subscription administrator when the daily limit is reached, then select that option. -3. Set the daily cap warning level in percentage of the data volume limit. -4. If you want an email sent to the subscription administrator when the daily cap warning level is reached, then select that option. ---To configure the daily cap with Azure Resource Manager, set the `dailyQuota`, `dailyQuotaResetTime` and `warningThreshold` parameters as described at [Workspaces - Create Or Update](../app/powershell.md#set-the-daily-cap). ---## Alert when daily cap is reached -When the daily cap is reached for a Log Analytics workspace, a banner is displayed in the Azure portal, and an event is written to the **Operations** table in the workspace. You should create an alert rule to proactively notify you when this occurs. --To receive an alert when the daily cap is reached, create a [log search alert rule](../alerts/alerts-types.md#log-alerts) with the following details. --| Setting | Value | -|:|:| -| **Scope** | | -| Target scope | Select your Log Analytics workspace. | -| **Condition** | | -| Signal type | Log | -| Signal name | Custom log search | -| Query | `_LogOperation | where Category =~ "Ingestion" | where Detail contains "OverQuota"` | -| Measurement | Measure: *Table rows*<br>Aggregation type: Count<br>Aggregation granularity: 5 minutes | -| Alert Logic | Operator: Greater than<br>Threshold value: 0<br>Frequency of evaluation: 5 minutes | -| Actions | Select or add an [action group](../alerts/action-groups.md) to notify you when the threshold is exceeded. | -| **Details** | | -| Severity| Warning | -| Alert rule name | Daily data limit reached | ---### Classic Application Insights resource -When the daily cap is reach for a classic Application Insights resource, an event is created in the Azure Activity log with the following signal names. You can also optionally have an email sent to the subscription administrator both when the cap is reached and when a specified percentage of the daily cap has been reached. --* Application Insights component daily cap warning threshold reached -* Application Insights component daily cap reached --To create an alert when the daily cap is reached, create an [Activity log alert rule](../alerts/alerts-activity-log.md#azure-portal) with the following details. ---| Setting | Value | -|:|:| -| **Scope** | | -| Target scope | Select your application. | -| **Condition** | | -| Signal type | Activity Log | -| Signal name | Application Insights component daily cap reached<br>Or<br>Application Insights component daily cap warning threshold reached | -| Severity| Warning | -| Alert rule name | Daily data limit reached | ----## View the effect of the daily cap -The following query can be used to track the data volumes that are subject to the daily cap for a Log Analytics workspace between daily cap resets. In this example, the workspace's reset hour is 14:00. Change `DailyCapResetHour` to match the reset hour of your workspace which you can see on the Daily Cap configuration page. --```kusto -let DailyCapResetHour=14; -Usage -| where TimeGenerated > ago(32d) -| extend StartTime=datetime_add("hour",-1*DailyCapResetHour,StartTime) -| where StartTime > startofday(ago(31d)) -| where IsBillable -| summarize IngestedGbBetweenDailyCapResets=sum(Quantity)/1000. by day=bin(StartTime , 1d) // Quantity in units of MB -| render areachart -``` -Add `Update` and `UpdateSummary` data types to the `where Datatype` line when the Update Management solution is not running on the workspace or solution targeting is enabled ([learn more](../../security-center/security-center-pricing.md#what-data-types-are-included-in-the-500-mb-data-daily-allowance).) --## Next steps --- See [Azure Monitor Logs pricing details](cost-logs.md) for details on how charges are calculated for data in a Log Analytics workspace and different configuration options to reduce your charges.-- See [Azure Monitor Logs pricing details](cost-logs.md) for details on how charges are calculated for data in a Log Analytics workspace and different configuration options to reduce your charges.-- See [Analyze usage in Log Analytics workspace](analyze-usage.md) for details on analyzing the data in your workspace to determine to source of any higher than expected usage and opportunities to reduce your amount of data collected. |
| azure-monitor | Data Collection Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/data-collection-troubleshoot.md | - Title: Troubleshoot why data is no longer being collected in Azure Monitor -description: Steps to take if data is no longer being collected in Log Analytics workspace in Azure Monitor. - Previously updated : 08/06/2024-- -# Troubleshoot why data is no longer being collected in Azure Monitor -This article explains how to detect when data collection in Azure Monitor stops and details steps you can take to address data collection issues. --> [!IMPORTANT] -> If you're troubleshooting data collection for a scenario that uses a data collection rule (DCR) such as Azure Monitor agent or Logs ingestion API, see [Monitor and troubleshoot DCR data collection in Azure Monitor](../essentials/data-collection-monitor.md) for additional troubleshooting information. --## Daily cap reached --The [daily cap](daily-cap.md) limits the amount of data that a Log Analytics workspace can collect in a day. When the daily cap is reached, data collection stops until the reset time. You can either wait for collection to automatically restart, or increase the daily data volume limit. --#### Check Log Analytics workspace data collection status --When data collection in a Log Analytics workspace stops, an event with a type of **Operation** is created in the workspace. Run the following query to check whether you're reaching the daily limit and missing data: --```kusto -Operation | where OperationCategory == 'Data Collection Status' -``` --When data collection stops, the **OperationStatus** is **Warning**. When data collection starts, the **OperationStatus** is **Succeeded**. --To be notified when data collection stops, use the steps described in the [Alert when daily cap is reached](daily-cap.md#alert-when-daily-cap-is-reached) section. To configure an e-mail, webhook, or runbook action for the alert rule, use the steps described in [create an action group](../alerts/action-groups.md). --## Ingestion volume rate limit reached -The [default ingestion volume rate limit](../service-limits.md#log-analytics-workspaces) for data sent from Azure resources using diagnostic settings is approximately 6 GB/min per workspace. This is an approximate value because the actual size can vary between data types, depending on the log length and its compression ratio. This limit doesn't apply to data that's sent from agents or the [Logs ingestion API](logs-ingestion-api-overview.md). --If you send data at a higher rate to a single workspace, some data is dropped, and an event is sent to the **Operation** table in your workspace every six hours while the threshold continues to be exceeded. If your ingestion volume continues to exceed the rate limit or you're expecting to reach it sometime soon, you can request an increase to your workspace by sending an email to LAIngestionRate@microsoft.com or by opening a support request. --#### Check whether your workspace reached its data ingestion rate limit --Use this query to retrieve the record that indicates the data ingestion rate limit was reached. --```kusto -Operation -| where OperationCategory == "Ingestion" -| where Detail startswith "The rate of data crossed the threshold" -``` -## Legacy free pricing tier daily ingestion limit reached -If your Log Analytics workspace is in the [legacy Free pricing tier](cost-logs.md#legacy-pricing-tiers) and has collected more than 500 MB of data in a day, data collection stops for the rest of the day. Wait until the following day for collection to automatically restart, or change to a paid pricing tier. --## Azure Monitor Agent not sending data --[Azure Monitor Agent](../agents/azure-monitor-agent-overview.md) collects data from virtual machines and sends the data to Azure Monitor. An agent might stop sending data to your Log Analytics workspace in various scenarios. For example, when [Azure Site Recovery](/azure/site-recovery/site-recovery-overview) recovers a virtual machine in a disaster recovery scenario, the resource ID of the machine changes, requiring reinstallation of Azure Monitor Agent on the machine. --#### Check the health of agents sending data to your workspace --Azure Monitor Agent instances installed on all virtual machines that send data to your Log Analytics workspace send a heartbeat to the [Heartbeat table](/azure/azure-monitor/reference/tables/heartbeat) every minute. --Run this query to list VMs that haven't reported a heartbeat in the last five minutes: --```kusto -Heartbeat -| where TimeGenerated > ago(24h) -| summarize LastCall = max(TimeGenerated) by Computer, _ResourceId -| where LastCall < ago(5m) -``` --## Azure subscription is suspended -Your Azure subscription could be in a suspended state for one of the following reasons: --- Free trial ended-- Azure pass expired-- Monthly spending limit reached (such as on an MSDN or Visual Studio subscription)--## Other Log Analytics workspace limits --There are other Log Analytics limits, some of which depend on the Log Analytics pricing tier. For more information, see [Azure subscription and service limits, quotas, and constraints](../service-limits.md#log-analytics-workspaces). ---## Next steps --- See [Analyze usage in Log Analytics workspace](../logs/analyze-usage.md) for details on analyzing the data in your workspace to determine to source of any higher than expected usage and opportunities to reduce your amount of data collected. |
| azure-monitor | Data Collector Api | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/data-collector-api.md | - Title: Azure Monitor HTTP Data Collector API | Microsoft Docs -description: You can use the Azure Monitor HTTP Data Collector API to add POST JSON data to a Log Analytics workspace from any client that can call the REST API. This article describes how to use the API, and it has examples of how to publish data by using various programming languages. --- Previously updated : 08/08/2023---# Send log data to Azure Monitor by using the HTTP Data Collector API (deprecated) --This article shows you how to use the HTTP Data Collector API to send log data to Azure Monitor from a REST API client. It describes how to format data that's collected by your script or application, include it in a request, and have that request authorized by Azure Monitor. We provide examples for Azure PowerShell, C#, and Python. --> [!NOTE] -> The Azure Monitor HTTP Data Collector API has been deprecated and will no longer be functional as of 9/14/2026. It's been replaced by the [Logs ingestion API](logs-ingestion-api-overview.md). --## Concepts -You can use the HTTP Data Collector API to send log data to a Log Analytics workspace in Azure Monitor from any client that can call a REST API. The client might be a runbook in Azure Automation that collects management data from Azure or another cloud, or it might be an alternative management system that uses Azure Monitor to consolidate and analyze log data. --All data in the Log Analytics workspace is stored as a record with a particular record type. You format your data to send to the HTTP Data Collector API as multiple records in JavaScript Object Notation (JSON). When you submit the data, an individual record is created in the repository for each record in the request payload. ---## Create a request -To use the HTTP Data Collector API, you create a POST request that includes the data to send in JSON. The next three tables list the attributes that are required for each request. We describe each attribute in more detail later in the article. --### Request URI -| Attribute | Property | -|: |: | -| Method |POST | -| URI |https://\<CustomerId\>.ods.opinsights.azure.com/api/logs?api-version=2016-04-01 | -| Content type |application/json | -| | | --### Request URI parameters -| Parameter | Description | -|: |: | -| CustomerID |The unique identifier for the Log Analytics workspace. | -| Resource |The API resource name: /api/logs. | -| API Version |The version of the API to use with this request. Currently, the version is 2016-04-01. | -| | | --### Request headers -| Header | Description | -|: |: | -| Authorization |The authorization signature. Later in the article, you can read about how to create an HMAC-SHA256 header. | -| Log-Type |Specify the record type of the data that's being submitted. It can contain only letters, numbers, and the underscore (_) character, and it can't exceed 100 characters. | -| x-ms-date |The date that the request was processed, in RFC [1123](/dotnet/api/system.globalization.datetimeformatinfo.rfc1123pattern) format. | -| x-ms-AzureResourceId | The resource ID of the Azure resource that the data should be associated with. It populates the [_ResourceId](./log-standard-columns.md#_resourceid) property and allows the data to be included in [resource-context](manage-access.md#access-mode) queries. If this field isn't specified, the data won't be included in resource-context queries. | -| time-generated-field | The name of a field in the data that contains the timestamp of the data item. If you specify a field, its contents are used for **TimeGenerated**. If you don't specify this field, the default for **TimeGenerated** is the time that the message is ingested. The contents of the message field should follow the ISO 8601 format YYYY-MM-DDThh:mm:ssZ. The Time Generated value cannot be older than 2 days before received time or more than a day in the future. In such case, the time that the message is ingested will be used.| -| | | --## Authorization -Any request to the Azure Monitor HTTP Data Collector API must include an authorization header. To authenticate a request, sign the request with either the primary or the secondary key for the workspace that's making the request. Then, pass that signature as part of the request. --Here's the format for the authorization header: ---```sql -Authorization: SharedKey <WorkspaceID>:<Signature> -``` --*WorkspaceID* is the unique identifier for the Log Analytics workspace. *Signature* is a [Hash-based Message Authentication Code (HMAC)](/dotnet/api/system.security.cryptography.hmacsha256) that's constructed from the request and then computed by using the [SHA256 algorithm](/dotnet/api/system.security.cryptography.sha256). Then, you encode it by using Base64 encoding. --Use this format to encode the **SharedKey** signature string: ---```ruby -StringToSign = VERB + "\n" + - Content-Length + "\n" + - Content-Type + "\n" + - "x-ms-date:" + x-ms-date + "\n" + - "/api/logs"; -``` --Here's an example of a signature string: ---```ruby -POST\n1024\napplication/json\nx-ms-date:Mon, 04 Apr 2016 08:00:00 GMT\n/api/logs -``` --When you have the signature string, encode it by using the HMAC-SHA256 algorithm on the UTF-8-encoded string, and then encode the result as Base64. Use this format: ---```sql -Signature=Base64(HMAC-SHA256(UTF8(StringToSign))) -``` --The samples in the next sections have sample code to help you create an authorization header. --## Request body -The body of the message must be in JSON. It must include one or more records with the property name and value pairs in the following format. The property name can contain only letters, numbers, and the underscore (_) character. --```json -[ - { - "property 1": "value1", - "property 2": "value2", - "property 3": "value3", - "property 4": "value4" - } -] -``` --You can batch multiple records together in a single request by using the following format. All the records must be the same record type. --```json -[ - { - "property 1": "value1", - "property 2": "value2", - "property 3": "value3", - "property 4": "value4" - }, - { - "property 1": "value1", - "property 2": "value2", - "property 3": "value3", - "property 4": "value4" - } -] -``` --## Record type and properties -You define a custom record type when you submit data through the Azure Monitor HTTP Data Collector API. Currently, you can't write data to existing record types that were created by other data types and solutions. Azure Monitor reads the incoming data and then creates properties that match the data types of the values that you enter. --Each request to the Data Collector API must include a **Log-Type** header with the name for the record type. The suffix **_CL** is automatically appended to the name you enter to distinguish it from other log types as a custom log. For example, if you enter the name **MyNewRecordType**, Azure Monitor creates a record with the type **MyNewRecordType_CL**. This helps ensure that there are no conflicts between user-created type names and those shipped in current or future Microsoft solutions. --To identify a property's data type, Azure Monitor adds a suffix to the property name. If a property contains a null value, the property isn't included in that record. This table lists the property data type and corresponding suffix: --| Property data type | Suffix | -|: |: | -| String |_s | -| Boolean |_b | -| Double |_d | -| Date/time |_t | -| GUID (stored as a string) |_g | -| | | --> [!NOTE] -> String values that appear to be GUIDs are given the _g suffix and formatted as a GUID, even if the incoming value doesn't include dashes. For example, both "8145d822-13a7-44ad-859c-36f31a84f6dd" and "8145d82213a744ad859c36f31a84f6dd" are stored as "8145d822-13a7-44ad-859c-36f31a84f6dd". The only differences between this and another string are the _g in the name and the insertion of dashes if they aren't provided in the input. --The data type that Azure Monitor uses for each property depends on whether the record type for the new record already exists. --* If the record type doesn't exist, Azure Monitor creates a new one by using the JSON type inference to determine the data type for each property for the new record. -* If the record type does exist, Azure Monitor attempts to create a new record based on existing properties. If the data type for a property in the new record doesnΓÇÖt match and canΓÇÖt be converted to the existing type, or if the record includes a property that doesnΓÇÖt exist, Azure Monitor creates a new property that has the relevant suffix. --For example, the following submission entry would create a record with three properties, **number_d**, **boolean_b**, and **string_s**: -<!-- convertborder later --> --If you were to submit this next entry, with all values formatted as strings, the properties wouldn't change. You can convert the values to existing data types. -<!-- convertborder later --> --But, if you then make this next submission, Azure Monitor would create the new properties **boolean_d** and **string_d**. You can't convert these values. -<!-- convertborder later --> --If you then submit the following entry, before the record type is created, Azure Monitor would create a record with three properties, **number_s**, **boolean_s**, and **string_s**. In this entry, each of the initial values is formatted as a string: -<!-- convertborder later --> --## Reserved properties -The following properties are reserved and shouldn't be used in a custom record type. You'll receive an error if your payload includes any of these property names: --- tenant-- TimeGenerated-- RawData--## Data limits -The data posted to the Azure Monitor Data collection API is subject to certain constraints: --* Maximum of 30 MB per post to Azure Monitor Data Collector API. This is a size limit for a single post. If the data from a single post exceeds 30 MB, you should split the data into smaller sized chunks and send them concurrently. -* Maximum of 32 KB for field values. If the field value is greater than 32 KB, the data will be truncated. -* Recommended maximum of 50 fields for a given type. This is a practical limit from a usability and search experience perspective. -* Tables in Log Analytics workspaces support only up to 500 columns (referred to as fields in this article). -* Maximum of 45 characters for column names. --## Return codes -The HTTP status code 200 means that the request has been received for processing. This indicates that the operation finished successfully. --The complete set of status codes that the service might return is listed in the following table: --| Code | Status | Error code | Description | -|: |: |: |: | -| 200 |OK | |The request was successfully accepted. | -| 400 |Bad request |InactiveCustomer |The workspace has been closed. | -| 400 |Bad request |InvalidApiVersion |The API version that you specified wasn't recognized by the service. | -| 400 |Bad request |InvalidCustomerId |The specified workspace ID is invalid. | -| 400 |Bad request |InvalidDataFormat |An invalid JSON was submitted. The response body might contain more information about how to resolve the error. | -| 400 |Bad request |InvalidLogType |The specified log type contained special characters or numerics. | -| 400 |Bad request |MissingApiVersion |The API version wasnΓÇÖt specified. | -| 400 |Bad request |MissingContentType |The content type wasnΓÇÖt specified. | -| 400 |Bad request |MissingLogType |The required value log type wasnΓÇÖt specified. | -| 400 |Bad request |UnsupportedContentType |The content type wasn't set to **application/json**. | -| 403 |Forbidden |InvalidAuthorization |The service failed to authenticate the request. Verify that the workspace ID and connection key are valid. | -| 404 |Not Found | | Either the provided URL is incorrect or the request is too large. | -| 429 |Too Many Requests | | The service is experiencing a high volume of data from your account. Please retry the request later. | -| 500 |Internal Server Error |UnspecifiedError |The service encountered an internal error. Please retry the request. | -| 503 |Service Unavailable |ServiceUnavailable |The service currently is unavailable to receive requests. Please retry your request. | -| | | --## Query data -To query data submitted by the Azure Monitor HTTP Data Collector API, search for records whose **Type** is equal to the **LogType** value that you specified and appended with **_CL**. For example, if you used **MyCustomLog**, you would return all records with `MyCustomLog_CL`. --## Sample requests -In this section are samples that demonstrate how to submit data to the Azure Monitor HTTP Data Collector API by using various programming languages. --For each sample, set the variables for the authorization header by doing the following: --1. In the Azure portal, locate your Log Analytics workspace. -2. Select **Agents**. -2. To the right of **Workspace ID**, select the **Copy** icon, and then paste the ID as the value of the **Customer ID** variable. -3. To the right of **Primary Key**, select the **Copy** icon, and then paste the ID as the value of the **Shared Key** variable. --Alternatively, you can change the variables for the log type and JSON data. --### [PowerShell](#tab/powershell) --```powershell -# Replace with your Workspace ID -$CustomerId = "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" --# Replace with your Primary Key -$SharedKey = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" --# Specify the name of the record type that you'll be creating -$LogType = "MyRecordType" --# Optional name of a field that includes the timestamp for the data. If the time field is not specified, Azure Monitor assumes the time is the message ingestion time -$TimeStampField = "" ---# Create two records with the same set of properties to create -$json = @" -[{ "StringValue": "MyString1", - "NumberValue": 42, - "BooleanValue": true, - "DateValue": "2019-09-12T20:00:00.625Z", - "GUIDValue": "9909ED01-A74C-4874-8ABF-D2678E3AE23D" -}, -{ "StringValue": "MyString2", - "NumberValue": 43, - "BooleanValue": false, - "DateValue": "2019-09-12T20:00:00.625Z", - "GUIDValue": "8809ED01-A74C-4874-8ABF-D2678E3AE23D" -}] -"@ --# Create the function to create the authorization signature -Function Build-Signature ($customerId, $sharedKey, $date, $contentLength, $method, $contentType, $resource) -{ - $xHeaders = "x-ms-date:" + $date - $stringToHash = $method + "`n" + $contentLength + "`n" + $contentType + "`n" + $xHeaders + "`n" + $resource -- $bytesToHash = [Text.Encoding]::UTF8.GetBytes($stringToHash) - $keyBytes = [Convert]::FromBase64String($sharedKey) -- $sha256 = New-Object System.Security.Cryptography.HMACSHA256 - $sha256.Key = $keyBytes - $calculatedHash = $sha256.ComputeHash($bytesToHash) - $encodedHash = [Convert]::ToBase64String($calculatedHash) - $authorization = 'SharedKey {0}:{1}' -f $customerId,$encodedHash - return $authorization -} --# Create the function to create and post the request -Function Post-LogAnalyticsData($customerId, $sharedKey, $body, $logType) -{ - $method = "POST" - $contentType = "application/json" - $resource = "/api/logs" - $rfc1123date = [DateTime]::UtcNow.ToString("r") - $contentLength = $body.Length - $signature = Build-Signature ` - -customerId $customerId ` - -sharedKey $sharedKey ` - -date $rfc1123date ` - -contentLength $contentLength ` - -method $method ` - -contentType $contentType ` - -resource $resource - $uri = "https://" + $customerId + ".ods.opinsights.azure.com" + $resource + "?api-version=2016-04-01" -- $headers = @{ - "Authorization" = $signature; - "Log-Type" = $logType; - "x-ms-date" = $rfc1123date; - "time-generated-field" = $TimeStampField; - } -- $response = Invoke-WebRequest -Uri $uri -Method $method -ContentType $contentType -Headers $headers -Body $body -UseBasicParsing - return $response.StatusCode --} --# Submit the data to the API endpoint -Post-LogAnalyticsData -customerId $customerId -sharedKey $sharedKey -body ([System.Text.Encoding]::UTF8.GetBytes($json)) -logType $logType -``` --### [C#](#tab/c-sharp) -```csharp -using System; -using System.Net; -using System.Net.Http; -using System.Net.Http.Headers; -using System.Security.Cryptography; -using System.Text; -using System.Threading.Tasks; --namespace OIAPIExample -{ - class ApiExample - { - // An example JSON object, with key/value pairs - static string json = @"[{""DemoField1"":""DemoValue1"",""DemoField2"":""DemoValue2""},{""DemoField3"":""DemoValue3"",""DemoField4"":""DemoValue4""}]"; -- // Update customerId to your Log Analytics workspace ID - static string customerId = "xxxxxxxx-xxx-xxx-xxx-xxxxxxxxxxxx"; -- // For sharedKey, use either the primary or the secondary Connected Sources client authentication key - static string sharedKey = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"; -- // LogName is name of the event type that is being submitted to Azure Monitor - static string LogName = "DemoExample"; -- // You can use an optional field to specify the timestamp from the data. If the time field is not specified, Azure Monitor assumes the time is the message ingestion time - static string TimeStampField = ""; -- static void Main() - { - // Create a hash for the API signature - var datestring = DateTime.UtcNow.ToString("r"); - var jsonBytes = Encoding.UTF8.GetBytes(json); - string stringToHash = "POST\n" + jsonBytes.Length + "\napplication/json\n" + "x-ms-date:" + datestring + "\n/api/logs"; - string hashedString = BuildSignature(stringToHash, sharedKey); - string signature = "SharedKey " + customerId + ":" + hashedString; -- PostData(signature, datestring, json); - } -- // Build the API signature - public static string BuildSignature(string message, string secret) - { - var encoding = new System.Text.ASCIIEncoding(); - byte[] keyByte = Convert.FromBase64String(secret); - byte[] messageBytes = encoding.GetBytes(message); - using (var hmacsha256 = new HMACSHA256(keyByte)) - { - byte[] hash = hmacsha256.ComputeHash(messageBytes); - return Convert.ToBase64String(hash); - } - } -- // Send a request to the POST API endpoint - public static void PostData(string signature, string date, string json) - { - try - { - string url = "https://" + customerId + ".ods.opinsights.azure.com/api/logs?api-version=2016-04-01"; -- System.Net.Http.HttpClient client = new System.Net.Http.HttpClient(); - client.DefaultRequestHeaders.Add("Accept", "application/json"); - client.DefaultRequestHeaders.Add("Log-Type", LogName); - client.DefaultRequestHeaders.Add("Authorization", signature); - client.DefaultRequestHeaders.Add("x-ms-date", date); - client.DefaultRequestHeaders.Add("time-generated-field", TimeStampField); -- // If charset=utf-8 is part of the content-type header, the API call may return forbidden. - System.Net.Http.HttpContent httpContent = new StringContent(json, Encoding.UTF8); - httpContent.Headers.ContentType = new MediaTypeHeaderValue("application/json"); - Task<System.Net.Http.HttpResponseMessage> response = client.PostAsync(new Uri(url), httpContent); -- System.Net.Http.HttpContent responseContent = response.Result.Content; - string result = responseContent.ReadAsStringAsync().Result; - Console.WriteLine("Return Result: " + result); - } - catch (Exception excep) - { - Console.WriteLine("API Post Exception: " + excep.Message); - } - } - } -} --``` --### [Python](#tab/python) -->[!NOTE] -> If using Python 2, you may need to change the line: -> `bytes_to_hash = bytes(string_to_hash, encoding="utf-8")` -> to -> `bytes_to_hash = bytes(string_to_hash).encode("utf-8")` --```python -import json -import requests -import datetime -import hashlib -import hmac -import base64 --# Update the customer ID to your Log Analytics workspace ID -customer_id = 'xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx' --# For the shared key, use either the primary or the secondary Connected Sources client authentication key -shared_key = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" --# The log type is the name of the event that is being submitted -log_type = 'WebMonitorTest' --# An example JSON web monitor object -json_data = [{ - "slot_ID": 12345, - "ID": "5cdad72f-c848-4df0-8aaa-ffe033e75d57", - "availability_Value": 100, - "performance_Value": 6.954, - "measurement_Name": "last_one_hour", - "duration": 3600, - "warning_Threshold": 0, - "critical_Threshold": 0, - "IsActive": "true" -}, -{ - "slot_ID": 67890, - "ID": "b6bee458-fb65-492e-996d-61c4d7fbb942", - "availability_Value": 100, - "performance_Value": 3.379, - "measurement_Name": "last_one_hour", - "duration": 3600, - "warning_Threshold": 0, - "critical_Threshold": 0, - "IsActive": "false" -}] -body = json.dumps(json_data) --##################### -######Functions###### -##################### --# Build the API signature -def build_signature(customer_id, shared_key, date, content_length, method, content_type, resource): - x_headers = 'x-ms-date:' + date - string_to_hash = method + "\n" + str(content_length) + "\n" + content_type + "\n" + x_headers + "\n" + resource - bytes_to_hash = bytes(string_to_hash, encoding="utf-8") - decoded_key = base64.b64decode(shared_key) - encoded_hash = base64.b64encode(hmac.new(decoded_key, bytes_to_hash, digestmod=hashlib.sha256).digest()).decode() - authorization = "SharedKey {}:{}".format(customer_id,encoded_hash) - return authorization --# Build and send a request to the POST API -def post_data(customer_id, shared_key, body, log_type): - method = 'POST' - content_type = 'application/json' - resource = '/api/logs' - rfc1123date = datetime.datetime.utcnow().strftime('%a, %d %b %Y %H:%M:%S GMT') - content_length = len(body) - signature = build_signature(customer_id, shared_key, rfc1123date, content_length, method, content_type, resource) - uri = 'https://' + customer_id + '.ods.opinsights.azure.com' + resource + '?api-version=2016-04-01' -- headers = { - 'content-type': content_type, - 'Authorization': signature, - 'Log-Type': log_type, - 'x-ms-date': rfc1123date - } -- response = requests.post(uri,data=body, headers=headers) - if (response.status_code >= 200 and response.status_code <= 299): - print('Accepted') - else: - print("Response code: {}".format(response.status_code)) --post_data(customer_id, shared_key, body, log_type) -``` ---### [Java](#tab/java) --```java --import org.apache.http.HttpResponse; -import org.apache.http.client.methods.HttpPost; -import org.apache.http.entity.StringEntity; -import org.apache.http.impl.client.CloseableHttpClient; -import org.apache.http.impl.client.HttpClients; -import org.springframework.http.MediaType; --import javax.crypto.Mac; -import javax.crypto.spec.SecretKeySpec; -import java.io.IOException; -import java.nio.charset.StandardCharsets; -import java.security.InvalidKeyException; -import java.security.NoSuchAlgorithmException; -import java.text.SimpleDateFormat; -import java.util.Base64; -import java.util.Calendar; -import java.util.TimeZone; -import java.util.Locale; --import static org.springframework.http.HttpHeaders.CONTENT_TYPE; --public class ApiExample { -- private static final String workspaceId = "xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx"; - private static final String sharedKey = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"; - private static final String logName = "DemoExample"; - /* - You can use an optional field to specify the timestamp from the data. If the time field is not specified, - Azure Monitor assumes the time is the message ingestion time - */ - private static final String timestamp = ""; - private static final String json = "{\"name\": \"test\",\n" + " \"id\": 1\n" + "}"; - private static final String RFC_1123_DATE = "EEE, dd MMM yyyy HH:mm:ss z"; -- public static void main(String[] args) throws IOException, NoSuchAlgorithmException, InvalidKeyException { - String dateString = getServerTime(); - String httpMethod = "POST"; - String contentType = "application/json"; - String xmsDate = "x-ms-date:" + dateString; - String resource = "/api/logs"; - String stringToHash = String - .join("\n", httpMethod, String.valueOf(json.getBytes(StandardCharsets.UTF_8).length), contentType, - xmsDate , resource); - String hashedString = getHMAC256(stringToHash, sharedKey); - String signature = "SharedKey " + workspaceId + ":" + hashedString; -- postData(signature, dateString, json); - } -- private static String getServerTime() { - Calendar calendar = Calendar.getInstance(); - SimpleDateFormat dateFormat = new SimpleDateFormat(RFC_1123_DATE, Locale.US); - dateFormat.setTimeZone(TimeZone.getTimeZone("GMT")); - return dateFormat.format(calendar.getTime()); - } -- private static void postData(String signature, String dateString, String json) throws IOException { - String url = "https://" + workspaceId + ".ods.opinsights.azure.com/api/logs?api-version=2016-04-01"; - HttpPost httpPost = new HttpPost(url); - httpPost.setHeader("Authorization", signature); - httpPost.setHeader(CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE); - httpPost.setHeader("Log-Type", logName); - httpPost.setHeader("x-ms-date", dateString); - httpPost.setHeader("time-generated-field", timestamp); - httpPost.setEntity(new StringEntity(json)); - try(CloseableHttpClient httpClient = HttpClients.createDefault()){ - HttpResponse response = httpClient.execute(httpPost); - int statusCode = response.getStatusLine().getStatusCode(); - System.out.println("Status code: " + statusCode); - } - } -- private static String getHMAC256(String input, String key) throws InvalidKeyException, NoSuchAlgorithmException { - String hash; - Mac sha256HMAC = Mac.getInstance("HmacSHA256"); - Base64.Decoder decoder = Base64.getDecoder(); - SecretKeySpec secretKey = new SecretKeySpec(decoder.decode(key.getBytes(StandardCharsets.UTF_8)), "HmacSHA256"); - sha256HMAC.init(secretKey); - Base64.Encoder encoder = Base64.getEncoder(); - hash = new String(encoder.encode(sha256HMAC.doFinal(input.getBytes(StandardCharsets.UTF_8)))); - return hash; - } --} ---``` -----## Alternatives and considerations --Although the Data Collector API should cover most of your needs as you collect free-form data into Azure Logs, you might require an alternative approach to overcome some of the limitations of the API. Your options, including major considerations, are listed in the following table: --| Alternative | Description | Best suited for | -|||| -| [Custom events](../app/api-custom-events-metrics.md?toc=%2Fazure%2Fazure-monitor%2Ftoc.json#properties): Native SDK-based ingestion in Application Insights | Application Insights, usually instrumented through an SDK within your application, gives you the ability to send custom data through Custom Events. | <ul><li> Data that's generated within your application, but not picked up by the SDK through one of the default data types (requests, dependencies, exceptions, and so on).</li><li> Data that's most often correlated with other application data in Application Insights. </li></ul> | -| Data Collector API in Azure Monitor Logs | The Data Collector API in Azure Monitor Logs is a completely open-ended way to ingest data. Any data that's formatted in a JSON object can be sent here. After it's sent, it's processed and made available in Monitor Logs to be correlated with other data in Monitor Logs or against other Application Insights data. <br/><br/> It's fairly easy to upload the data as files to an Azure Blob Storage blob, where the files will be processed and then uploaded to Log Analytics. For a sample implementation, see [Create a data pipeline with the Data Collector API](./create-pipeline-datacollector-api.md). | <ul><li> Data that isn't necessarily generated within an application that's instrumented within Application Insights.<br>Examples include lookup and fact tables, reference data, preaggregated statistics, and so on. </li><li> Data that will be cross-referenced against other Azure Monitor data (Application Insights, other Monitor Logs data types, Defender for Cloud, Container insights and virtual machines, and so on). </li></ul> | -| [Azure Data Explorer](/azure/data-explorer/ingest-data-overview) | Azure Data Explorer, now generally available to the public, is the data platform that powers Application Insights Analytics and Azure Monitor Logs. By using the data platform in its raw form, you have complete flexibility (but require the overhead of management) over the cluster (Kubernetes role-based access control (RBAC), retention rate, schema, and so on). Azure Data Explorer provides many [ingestion options](/azure/data-explorer/ingest-data-overview#ingestion-methods), including [CSV, TSV, and JSON](/azure/kusto/management/mappings) files. | <ul><li> Data that won't be correlated with any other data under Application Insights or Monitor Logs. </li><li> Data that requires advanced ingestion or processing capabilities that aren't available today in Azure Monitor Logs. </li></ul> | ----## Next steps -- Use the [Log Search API](./log-query-overview.md) to retrieve data from the Log Analytics workspace.--- Learn more about how to [create a data pipeline with the Data Collector API](create-pipeline-datacollector-api.md) by using a Logic Apps workflow to Azure Monitor.- |
| azure-monitor | Data Ingestion Time | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/data-ingestion-time.md | - Title: Log data ingestion time in Azure Monitor | Microsoft Docs -description: This article explains the different factors that affect latency in collecting log data in Azure Monitor. ---- Previously updated : 03/21/2022----# Log data ingestion time in Azure Monitor -Azure Monitor is a high-scale data service that serves thousands of customers that send terabytes of data each month at a growing pace. There are often questions about the time it takes for log data to become available after it's collected. This article explains the different factors that affect this latency. --## Average latency -Latency refers to the time that data is created on the monitored system and the time that it becomes available for analysis in Azure Monitor. The average latency to ingest log data is *between 20 seconds and 3 minutes*. The specific latency for any particular data will vary depending on several factors that are explained in this article. --## Factors affecting latency -The total ingestion time for a particular set of data can be broken down into the following high-level areas: --- **Agent time**: The time to discover an event, collect it, and then send it to a [data collection endpoint](../essentials/data-collection-endpoint-overview.md) as a log record. In most cases, this process is handled by an agent. More latency might be introduced by the network.-- **Pipeline time**: The time for the ingestion pipeline to process the log record. This time period includes parsing the properties of the event and potentially adding calculated information.-- **Indexing time**: The time spent to ingest a log record into an Azure Monitor big data store.--Details on the different latency introduced in this process are described in the following sections. --### Agent collection latency --**Time varies** --Agents and management solutions use different strategies to collect data from a virtual machine, which might affect the latency. Some specific examples are listed in the following table. --| Type of data | Collection frequency | Notes | -|:--|:-|:| -| Windows events, Syslog events, and performance metrics | Collected immediately| | -| Linux performance counters | Polled at 30-second intervals| | -| IIS logs and text logs | Collected after their timestamp changes | For IIS logs, this schedule is influenced by the [rollover schedule configured on IIS](../agents/data-sources-iis-logs.md). | -| Active Directory Replication solution | Assessment every five days | The agent collects the logs only when assessment is complete.| -| Active Directory Assessment solution | Weekly assessment of your Active Directory infrastructure | The agent collects the logs only when assessment is complete.| --### Agent upload frequency --**Under 1 minute** --To ensure the Log Analytics agent is lightweight, the agent buffers logs and periodically uploads them to Azure Monitor. Upload frequency varies between 30 seconds and 2 minutes depending on the type of data. Most data is uploaded in under 1 minute. --### Network --**Varies** --Network conditions might negatively affect the latency of this data to reach a data collection endpoint. --### Azure metrics, resource logs, activity log --**30 seconds to 15 minutes** --Azure data adds more time to become available at a data collection endpoint for processing: --- **Azure platform metrics** are available in under a minute in the metrics database, but they take another 3 minutes to be exported to the data collection endpoint.-- **Resource logs** typically add 30 to 90 seconds, depending on the Azure service. Some Azure services (specifically, Azure SQL Database and Azure Virtual Network) currently report their logs at 5-minute intervals. Work is in progress to improve this time further. To examine this latency in your environment, see the [query that follows](#check-ingestion-time).-- **Activity logs** are available for analysis in 3 to 10 minutes.--### Management solutions collection --**Varies** --Some solutions don't collect their data from an agent and might use a collection method that introduces more latency. Some solutions collect data at regular intervals without attempting near real time collection. Specific examples include: --- Microsoft 365 solution polls activity logs by using the Management Activity API, which currently doesn't provide any near real time latency guarantees.-- Windows Analytics solutions (Update Compliance, for example) data is collected by the solution at a daily frequency.--To determine a solution's collection frequency, see the [documentation for each solution](/previous-versions/azure/azure-monitor/insights/solutions). --### Pipeline-process time --**30 to 60 seconds** --After the data is available at the data collection endpoint, it takes another 30 to 60 seconds to be available for querying. --After log records are ingested into the Azure Monitor pipeline (as identified in the [_TimeReceived](./log-standard-columns.md#_timereceived) property), they're written to temporary storage to ensure tenant isolation and to make sure that data isn't lost. This process typically adds 5 to 15 seconds. --Some solutions implement heavier algorithms to aggregate data and derive insights as data is streaming in. For example, Application Insights calculates application map data; Azure Network Performance Monitoring aggregates incoming data over 3-minute intervals, which effectively adds 3-minute latency. --If the data collection includes an [ingestion-time transformation](../essentials/data-collection-transformations.md), then this will add some latency to the pipeline. Use the metric [Logs Transformation Duration per Min](../essentials/data-collection-monitor.md) to monitor the efficiency of the transformation query. --Another process that adds latency is the process that handles custom logs. In some cases, this process might add a few minutes of latency to logs that are collected from files by the agent. --### New custom data types provisioning --When a new type of custom data is created from a [custom log](../agents/data-sources-custom-logs.md) or the [Data Collector API](../logs/data-collector-api.md), the system creates a dedicated storage container. This one-time overhead occurs only on the first appearance of this data type. --### Surge protection --**Typically less than 1 minute, but can be more** --The top priority of Azure Monitor is to ensure that no customer data is lost, so the system has built-in protection for data surges. This protection includes buffers to ensure that even under immense load, the system will keep functioning. Under normal load, these controls add less than a minute. In extreme conditions and failures, they could add significant time while ensuring data is safe. --### Indexing time --**5 minutes or less** --There's a built-in balance for every big data platform between providing analytics and advanced search capabilities as opposed to providing immediate access to the data. With Azure Monitor, you can run powerful queries on billions of records and get results within a few seconds. This performance is made possible because the infrastructure transforms the data dramatically during its ingestion and stores it in unique compact structures. The system buffers the data until enough of it is available to create these structures. This process must be completed before the log record appears in search results. --This process currently takes about 5 minutes when there's a low volume of data, but it can take less time at higher data rates. This behavior seems counterintuitive, but this process allows optimization of latency for high-volume production workloads. --## Check ingestion time -Ingestion time might vary for different resources under different circumstances. You can use log queries to identify specific behavior of your environment. The following table specifies how you can determine the different times for a record as it's created and sent to Azure Monitor. --| Step | Property or function | Comments | -|:|:|:| -| Record created at data source | [TimeGenerated](./log-standard-columns.md#timegenerated) <br>If the data source doesn't set this value, it will be set to the same time as _TimeReceived. | If at processing time the Time Generated value is older than two days, the row will be dropped. | -| Record received by the data collection endpoint | [_TimeReceived](./log-standard-columns.md#_timereceived) | This field isn't optimized for mass processing and shouldn't be used to filter large datasets. | -| Record stored in workspace and available for queries | [ingestion_time()](/azure/kusto/query/ingestiontimefunction) | We recommend using `ingestion_time()` if there's a need to filter only records that were ingested in a certain time window. In such cases, we recommend also adding a `TimeGenerated` filter with a larger range. | --### Ingestion latency delays -You can measure the latency of a specific record by comparing the result of the [ingestion_time()](/azure/kusto/query/ingestiontimefunction) function to the `TimeGenerated` property. This data can be used with various aggregations to discover how ingestion latency behaves. Examine some percentile of the ingestion time to get insights for large amounts of data. --For example, the following query will show you which computers had the highest ingestion time over the prior 8 hours: --``` Kusto -Heartbeat -| where TimeGenerated > ago(8h) -| extend E2EIngestionLatency = ingestion_time() - TimeGenerated -| extend AgentLatency = _TimeReceived - TimeGenerated -| summarize percentiles(E2EIngestionLatency,50,95), percentiles(AgentLatency,50,95) by Computer -| top 20 by percentile_E2EIngestionLatency_95 desc -``` --The preceding percentile checks are good for finding general trends in latency. To identify a short-term spike in latency, using the maximum (`max()`) might be more effective. --If you want to drill down on the ingestion time for a specific computer over a period of time, use the following query, which also visualizes the data from the past day in a graph: --``` Kusto -Heartbeat -| where TimeGenerated > ago(24h) //and Computer == "ContosoWeb2-Linux" -| extend E2EIngestionLatencyMin = todouble(datetime_diff("Second",ingestion_time(),TimeGenerated))/60 -| extend AgentLatencyMin = todouble(datetime_diff("Second",_TimeReceived,TimeGenerated))/60 -| summarize percentiles(E2EIngestionLatencyMin,50,95), percentiles(AgentLatencyMin,50,95) by bin(TimeGenerated,30m) -| render timechart -``` --Use the following query to show computer ingestion time by the country/region where they're located, which is based on their IP address: --``` Kusto -Heartbeat -| where TimeGenerated > ago(8h) -| extend E2EIngestionLatency = ingestion_time() - TimeGenerated -| extend AgentLatency = _TimeReceived - TimeGenerated -| summarize percentiles(E2EIngestionLatency,50,95),percentiles(AgentLatency,50,95) by RemoteIPCountry -``` --Different data types originating from the agent might have different ingestion latency time, so the previous queries could be used with other types. Use the following query to examine the ingestion time of various Azure ---``` Kusto -AzureDiagnostics -| where TimeGenerated > ago(8h) -| extend E2EIngestionLatency = ingestion_time() - TimeGenerated -| extend AgentLatency = _TimeReceived - TimeGenerated -| summarize percentiles(E2EIngestionLatency,50,95), percentiles(AgentLatency,50,95) by ResourceProvider -``` --Use the same query logic to diagnose latency conditions for Application Insights data: ---```kusto -// Classic Application Insights schema -let start=datetime("2023-08-21 05:00:00"); -let end=datetime("2023-08-23 05:00:00"); -requests -| where timestamp > start and timestamp < end -| extend TimeEventOccurred = timestamp -| extend TimeRequiredtoGettoAzure = _TimeReceived - timestamp -| extend TimeRequiredtoIngest = ingestion_time() - _TimeReceived -| extend EndtoEndTime = ingestion_time() - timestamp -| project timestamp, TimeEventOccurred, _TimeReceived, TimeRequiredtoGettoAzure , ingestion_time(), TimeRequiredtoIngest, EndtoEndTime -| sort by EndtoEndTime desc -``` ---```kusto -// Workspace-based Application Insights schema -let start=datetime("2023-08-21 05:00:00"); -let end=datetime("2023-08-23 05:00:00"); -AppRequests -| where TimeGenerated > start and TimeGenerated < end -| extend TimeEventOccurred = TimeGenerated -| extend TimeRequiredtoGettoAzure = _TimeReceived - TimeGenerated -| extend TimeRequiredtoIngest = ingestion_time() - _TimeReceived -| extend EndtoEndTime = ingestion_time() - TimeGenerated -| project TimeGenerated, TimeEventOccurred, _TimeReceived, TimeRequiredtoGettoAzure , ingestion_time(), TimeRequiredtoIngest, EndtoEndTime -| sort by EndtoEndTime desc -``` --The two queries above can be paired with any other Application Insights table other than "requests". --### Resources that stop responding -In some cases, a resource could stop sending data. To understand if a resource is sending data or not, look at its most recent record, which can be identified by the standard `TimeGenerated` field. --Use the `Heartbeat` table to check the availability of a VM because a heartbeat is sent once a minute by the agent. Use the following query to list the active computers that havenΓÇÖt reported heartbeat recently: --``` Kusto -Heartbeat -| where TimeGenerated > ago(1d) //show only VMs that were active in the last day -| summarize NoHeartbeatPeriod = now() - max(TimeGenerated) by Computer -| top 20 by NoHeartbeatPeriod desc -``` --## Next steps --Read the [service-level agreement](https://azure.microsoft.com/support/legal/sla/monitor/v1_3/) for Azure Monitor. |
| azure-monitor | Data Platform Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/data-platform-logs.md | - Title: Azure Monitor Logs -description: This article explains how Azure Monitor Logs works and how people with different monitoring needs and skills can use the basic and advanced capabilities that Azure Monitor Logs offers. - Previously updated : 07/07/2024---# Customer intent: As new user or decision-maker evaluating Azure Monitor Logs, I want to understand how Azure Monitor Logs addresses my monitoring and analysis needs. ---# Azure Monitor Logs overview --Azure Monitor Logs is a centralized software as a service (SaaS) platform for collecting, analyzing, and acting on telemetry data generated by Azure and non-Azure resources and applications. --You can collect logs, manage log data and costs, and consume different types of data in one [Log Analytics workspace](#log-analytics-workspace), the primary Azure Monitor Logs resource. This means you never have to move data or manage other storage, and you can retain different data types for as long or as little as you need. --This article provides an overview of how Azure Monitor Logs works and explains how it addresses the needs and skills of different personas in an organization. --> [!NOTE] -> Azure Monitor Logs is one half of the data platform that supports Azure Monitor. The other is [Azure Monitor Metrics](../essentials/data-platform-metrics.md), which stores numeric data in a time-series database. --## How Azure Monitor Logs works --Azure Monitor Logs provides you with the tools to: --* **Collect any data** by using Azure Monitor data collection methods. Transform data based on your needs to optimize costs, remove personal data, and so on, and route data to tables in your Log Analytics workspace. -* **Manage and optimize log data and costs** by configuring your Log Analytics workspace and log tables, including table schemas, table plans, data retention, data aggregation, who has access to which data, and log-related costs. -* **Retrieve data in near-real time** by using Kusto Query language (KQL), or KQL-based tools and features that don't require KQL knowledge, such as Simple mode in the Log Analytics user interface, prebuilt curated monitoring experiences called Insights, and predefined queries. -* **Use data flexibly** for a range of use cases, including data analysis, troubleshooting, alerting, dashboards and reports, custom applications, and other Azure or non-Azure services. ---## Data collection, routing, and transformation --Azure Monitor's data collection capabilities let you collect data from all of your applications and resources running in Azure, other clouds, and on-premises. A powerful ingestion pipeline enables filtering, transforming, and routing data to destination tables in your Log Analytics workspace to optimize costs, analytics capabilities, and query performance. ---For more information on data collection and transformation, see [Azure Monitor data sources and data collection methods](../data-sources.md) and [Data collection transformations in Azure Monitor](../essentials/data-collection-transformations.md). --## Log Analytics workspace --A [Log Analytics workspace](../logs/log-analytics-workspace-overview.md) is a data store that holds tables into which you collect data. --To address the data storage and consumption needs of various personas who use a Log Analytics workspace, you can: --- [Define table plans](#table-plans) based on your data consumption and cost management needs.-- [Manage low-cost long-term retention and interactive retention](../logs/data-retention-configure.md) for each table.-- [Manage access](../logs/manage-access.md) to the workspace and to specific tables.-- [Use summary rules to aggregate critical data](../logs/summary-rules.md) in summary tables. This lets you optimize data for ease of use and actionable insights, and store raw data in a table with a low-cost table plan for however long you need it.-- Create ready-to-run [saved queries](../logs/save-query.md), [visualizations](../best-practices-analysis.md#built-in-visualization-tools), and [alerts](../alerts/alerts-create-log-alert-rule.md) tailored to specific personas. ---You can also configure network isolation, replicate your workspace across regions, and [design a workspace architecture based on your business needs](../logs/workspace-design.md). ---## Table plans --You can use one Log Analytics workspace to store any type of log required for any purpose. For example: --- High-volume, verbose data that requires **cheap long-term storage for audit and compliance**-- App and resource data for **troubleshooting** by developers-- Key event and performance data for scaling and alerting to ensure ongoing **operational excellence and security**-- Aggregated long-term data trends for **advanced analytics and machine learning** --Table plans let you manage data costs based on how often you use the data in a table and the type of analysis you need the data for. --This video provides an overview of how table plans enable multi-tier logging in Azure Monitor Logs: --> [!VIDEO https://www.youtube.com/embed/sn5-c8wYJcw?cc_load_policy=1&cc_lang_pref=auto] ---The diagram and table below compare the Analytics, Basic, and Auxiliary table plans. For information about interactive and long-term retention, see [Manage data retention in a Log Analytics workspace](../logs/data-retention-configure.md). For information about how to select or modify a table plan, see [Select a table plan](logs-table-plans.md). ---| Features | Analytics | Basic | Auxiliary (Preview) | -| | | | | -| Best for | High-value data used for continuous monitoring, real-time detection, and performance analytics. | Medium-touch data needed for troubleshooting and incident response. | Low-touch data, such as verbose logs, and data required for auditing and compliance. | -| Supported [table types](../logs/manage-logs-tables.md) | All table types | [Azure tables that support Basic logs](basic-logs-azure-tables.md) and DCR-based custom tables | DCR-based custom tables | -|Ingestion cost |Standard | Reduced | Minimal | -|Query price included |✅ | ❌ | ❌ | -| Optimized query performance | ✅ | ✅ | ❌ Slower queries.<br>Good for auditing. Not optimized for real-time analysis. | -| Query capabilities | [Full query capabilities](../logs/get-started-queries.md). | [Full Kusto Query Language (KQL) on a single table](basic-logs-query.md), which you can extend with data from an Analytics table using [lookup](/azure/data-explorer/kusto/query/lookup-operator). | [Full KQL on a single table](basic-logs-query.md), which you can extend with data from an Analytics table using [lookup](/azure/data-explorer/kusto/query/lookup-operator). | -| [Alerts](../alerts/alerts-overview.md) | ✅ | ❌ | ❌ | -| [Insights](../insights/insights-overview.md) | ✅ | ❌ | ❌ | -| [Dashboards](../visualize/tutorial-logs-dashboards.md) | ✅ | ✅ Cost per query for dashboard refreshes not included. | Possible, but slow to refresh, cost per query for dashboard refreshes not included. | -| [Data export](logs-data-export.md) | ✅ | ❌ | ❌ | -| [Microsoft Sentinel](../../sentinel/overview.md) | ✅ | ✅ | ✅ | -| [Search jobs](../logs/search-jobs.md) | ✅ | ✅ | ✅ | -| [Summary rules](../logs/summary-rules.md) | ✅ | ✅ KQL limited to a single table | ✅ KQL limited to a single table | -| [Restore](../logs/restore.md) | ✅ | ✅ | ❌ | -| Interactive retention | 30 days (90 days for Microsoft Sentinel and Application Insights).<br> Can be extended to up to two years at a prorated monthly long-term retention charge. | 30 days | 30 days | -| Total retention | Up to 12 years | Up to 12 years | Up to 12 years*<br>*Public preview limitation: Auxiliary plan total retention is currently fixed at 365 days. | --> [!NOTE] -> The Auxiliary table plan is in public preview. For current limitations and supported regions, see [Public preview limitations](create-custom-table-auxiliary.md#public-preview-limitations).<br> The Basic and Auxiliary table plans aren't available for workspaces in [legacy pricing tiers](cost-logs.md#legacy-pricing-tiers). --## Kusto Query Language (KQL) and Log Analytics --You retrieve data from a Log Analytics workspace using a [Kusto Query Language (KQL)](/azure/data-explorer/kusto/query/) query, which is a read-only request to process data and return results. KQL is a powerful tool that can analyze millions of records quickly. Use KQL to explore your logs, transform and aggregate data, discover patterns, identify anomalies and outliers, and more. --Log Analytics is a tool in the Azure portal for running log queries and analyzing their results. [Log Analytics Simple mode](log-analytics-simple-mode.md) lets any user, regardless of their knowledge of KQL, retrieve data from one or more tables with one click. A set of controls lets you explore and analyze the retrieved data using the most popular Azure Monitor Logs functionality in an intuitive, spreadsheet-like experience. ---If you're familiar with KQL, you can use Log Analytics KQL mode to edit and create queries, which you can then use in Azure Monitor features such as alerts and workbooks, or share with other users. --For more information about Log Analytics, see [Overview of Log Analytics in Azure Monitor](./log-analytics-overview.md). --## Built-in insights and custom dashboards, workbooks, and reports --Many of Azure Monitor's [ready-to-use, curated Insights experiences](../insights/insights-overview.md) store data in Azure Monitor Logs, and present this data in an intuitive way so you can monitor the performance and availability of your cloud and hybrid applications and their supporting components. ---You can also [create your own visualizations and reports](../best-practices-analysis.md#built-in-visualization-tools) using workbooks, dashboards, and Power BI. --## Use cases --This table describes some of the ways that you can use the data you collect in Azure Monitor Logs to derive operational and business value. --| Capability | Description | -|:|:| -| Analyze | Use [Log Analytics](./log-analytics-tutorial.md) in the Azure portal to write [log queries](./log-query-overview.md) and interactively analyze log data by using a powerful analysis engine. | -| Aggregate| Use [summary rules](./summary-rules.md) to aggregate information you need for alerting and analysis from the raw log data you ingest. This lets you optimize your costs, analysis capabilities, and query performance. | -| Detect and analyze anomalies | [Use built-in or custom anomaly detection algorithms](./kql-machine-learning-azure-monitor.md) to identify unusual patterns or behaviors in your log data. This helps in early detection of potential issues. | -| Alert | Configure a [log search alert rule](../alerts/alerts-log.md) or [metric alert for logs](../alerts/alerts-metric-logs.md) to send a notification or take [automated action](../alerts/action-groups.md) when a particular condition occurs. | -| Visualize | Pin query results rendered as tables or charts to an [Azure dashboard](../../azure-portal/azure-portal-dashboards.md).<br>Create a [workbook](../visualize/workbooks-overview.md) to combine with multiple sets of data in an interactive report. <br>Export the results of a query to [Power BI](./log-powerbi.md) to use different visualizations and share with people outside Azure.<br>Export the results of a query to [Grafana](../visualize/grafana-plugin.md) to use its dashboarding and combine with other data sources.| -| Get insights | [Insights](../insights/insights-overview.md) provide a customized monitoring experience for particular resources and services. | -| Retrieve | Access log query results from:<ul><li>The command line using [Azure CLI](/cli/azure/monitor/log-analytics) or [Azure PowerShell cmdlets](/powershell/module/az.operationalinsights).</li><li>A custom app using the [REST API](/rest/api/loganalytics/) or client library for [.NET](/dotnet/api/overview/azure/Monitor.Query-readme), [Go](https://pkg.go.dev/github.com/Azure/azure-sdk-for-go/sdk/monitor/azquery), [Java](/java/api/overview/azure/monitor-query-readme), [JavaScript](/javascript/api/overview/azure/monitor-query-readme), or [Python](/python/api/overview/azure/monitor-query-readme).</li></ul> | -| Import | Upload logs from a custom app via the [REST API](/azure/azure-monitor/logs/logs-ingestion-api-overview) or client library for [.NET](/dotnet/api/overview/azure/Monitor.Ingestion-readme), [Go](https://pkg.go.dev/github.com/Azure/azure-sdk-for-go/sdk/monitor/ingestion/azlogs), [Java](/java/api/overview/azure/monitor-ingestion-readme), [JavaScript](/javascript/api/overview/azure/monitor-ingestion-readme), or [Python](/python/api/overview/azure/monitor-ingestion-readme). | -| Export | Configure [automated export of log data](./logs-data-export.md) to an Azure Storage account or Azure Event Hubs.<br>Build a workflow to retrieve log data and copy it to an external location by using [Azure Logic Apps](../../connectors/connectors-azure-monitor-logs.md). | -| Bring your own analysis | [Analyze data in Azure Monitor Logs using a notebook](../logs/notebooks-azure-monitor-logs.md) to create streamlined, multi-step processes on top of data you collect in Azure Monitor Logs. This is especially useful for purposes such as [building and running machine learning pipelines](../logs/aiops-machine-learning.md#create-your-own-machine-learning-pipeline-on-data-in-azure-monitor-logs), advanced analysis, and troubleshooting guides (TSGs) for Support needs. | -| Retain data for auditing and compliance | [Send data directly to a table with the Auxiliary plan](./create-custom-table-auxiliary.md) and [extend retention of data in any table](./data-retention-configure.md) to keep data for auditing and compliance to up to 12 years. The low-cost Auxiliary table plan and in-workspace, long-term retention let you reduce costs and use your data quickly and easily when you need it.| --## Working with Microsoft Sentinel and Microsoft Defender for Cloud --[Microsoft Sentinel](../../sentinel/overview.md) and [Microsoft Defender for Cloud](/azure/defender-for-cloud/defender-for-cloud-introduction) perform [Security monitoring](../best-practices-plan.md#security-monitoring-solutions) in Azure. --These services store their data in Azure Monitor Logs so that it can be analyzed with other log data collected by Azure Monitor. --### Learn more --| Service | More information | -|:--|:--| -| Microsoft Sentinel | <ul><li>[Where Microsoft Sentinel data is stored](../../sentinel/geographical-availability-data-residency.md#where-microsoft-sentinel-data-is-stored)</li><li>[Design a Log Analytics workspace architecture](./workspace-design.md)</li><li>s[Microsoft Sentinel sample workspace designs](../../sentinel/sample-workspace-designs.md)</li><li>[Prepare for multiple workspaces and tenants in Microsoft Sentinel](../../sentinel/prepare-multiple-workspaces.md)</li><li>[Enable Microsoft Sentinel on your Log Analytics workspace](../../sentinel/quickstart-onboard.md).</li><li>[Log management in Microsoft Sentinel](../../sentinel/log-plans.md)</li><li>[Microsoft Sentinel pricing](https://azure.microsoft.com/pricing/details/microsoft-sentinel/)</li><li>[Charges for workspaces with Microsoft Sentinel](./cost-logs.md#workspaces-with-microsoft-sentinel)</li></ul> | -| Microsoft Defender for Cloud | <ul><li>[Continuously export Microsoft Defender for Cloud data](/azure/defender-for-cloud/continuous-export)</li><li>[Data consumption](/azure/defender-for-cloud/data-security#data-consumption)</li><li>[Frequently asked questions about Log Analytics workspaces used with Microsoft Defender for Cloud](/azure/defender-for-cloud/faq-data-collection-agents)</li><li>[Microsoft Defender for Cloud pricing](https://azure.microsoft.com/pricing/details/defender-for-cloud/)</li><li>[Charges for workspaces with Microsoft Defender for Cloud](./cost-logs.md#workspaces-with-microsoft-defender-for-cloud)</li></ul> | --## Next steps --- Learn about [log queries](./log-query-overview.md) to retrieve and analyze data from a Log Analytics workspace.-- Learn about [metrics in Azure Monitor](../essentials/data-platform-metrics.md).-- Learn about the [monitoring data available](../data-sources.md) for various resources in Azure. |
| azure-monitor | Data Retention Configure | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/data-retention-configure.md | - Title: Manage data retention in a Log Analytics workspace -description: Configure retention settings for a table in a Log Analytics workspace in Azure Monitor. -- Previously updated : 7/22/2024-# Customer intent: As an Azure account administrator, I want to manage data retention for each table in my Log Analytics workspace based on my account's data usage and retention needs. ---# Manage data retention in a Log Analytics workspace --A Log Analytics workspace retains data in two states: --* **Interactive retention**: In this state, data is available for monitoring, troubleshooting, and near-real-time analytics. -* **Long-term retention**: In this low-cost state, data isn't available for table plan features, but can be accessed through [search jobs](../logs/search-jobs.md). --This article explains how Log Analytics workspaces retain data and how to manage the data retention of tables in your workspace. --## Interactive, long-term, and total retention --By default, all tables in a Log Analytics workspace retain data for 30 days, except for [log tables with 90-day default retention](#log-tables-with-90-day-default-retention). During this period - the interactive retention period - you can retrieve the data from the table through queries, and the data is available for visualizations, alerts, and other features and services, based on the table plan. --You can extend the interactive retention period of tables with the Analytics plan to up to two years. The Basic and Auxiliary plans have a fixed interactive retention period of 30 days. --> [!NOTE] -> You can reduce the interactive retention period of Analytics tables to as little as four days using the API or CLI. However, since 31 days of interactive retention are included in the ingestion price, lowering the retention period below 31 days doesn't reduce costs. ---To retain data in the same table beyond the interactive retention period, extend the table's total retention to up to 12 years. At the end of the interactive retention period, the data stays in the table for the remainder of the total retention period you configure. During this period - the long-term retention period - run a search job to retrieve the specific data you need from the table and make it available for interactive queries in a search results table. ----## How retention modifications work --When you shorten a table's total retention, Azure Monitor Logs waits 30 days before removing the data, so you can revert the change and avoid data loss if you made an error in configuration. --When you increase total retention, the new retention period applies to all data that was already ingested into the table and wasn't yet removed. --When you change the long-term retention settings of a table with existing data, the change takes effect immediately. --***Example***: --- You have an existing Analytics table with 180 days of interactive retention and no long-term retention. -- You change the interactive retention to 90 days without changing the total retention period of 180 days. -- Azure Monitor automatically treats the remaining 90 days of total retention as low-cost, long-term retention, so that data that's 90-180 days old isn't lost.---## Permissions required --| Action | Permissions required | -|:-|:| -| Configure default interactive retention for Analytics tables in a Log Analytics workspace | `Microsoft.OperationalInsights/workspaces/write` and `microsoft.operationalinsights/workspaces/tables/write` permissions to the Log Analytics workspace, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example | -| Get retention setting by table for a Log Analytics workspace | `Microsoft.OperationalInsights/workspaces/tables/read` permissions to the Log Analytics workspace, as provided by the [Log Analytics Reader built-in role](./manage-access.md#log-analytics-reader), for example | --## Configure the default interactive retention period of Analytics tables --The default interactive retention period of all tables in a Log Analytics workspace is 30 days. You can change the default interactive period of Analytics tables to up to two years by modifying the workspace-level data retention setting. Basic and Auxiliary tables have a fixed interactive retention period of 30 days. --Changing the default workspace-level data retention setting automatically affects all Analytics tables to which the default setting still applies in your workspace. If you've already changed the interactive retention of a particular table, that table isn't affected when you change the workspace default data retention setting. --> [!IMPORTANT] -> Workspaces with 30-day retention might keep data for 31 days. If you need to retain data for 30 days only to comply with a privacy policy, configure the default workspace retention to 30 days using the API and update the `immediatePurgeDataOn30Days` workspace property to `true`. This operation is currently only supported using the [Workspaces - Update API](/rest/api/loganalytics/workspaces/update). --# [Portal](#tab/portal-3) --To set the default interactive retention period of Analytics tables within a Log Analytics workspace: --1. From the **Log Analytics workspaces** menu in the Azure portal, select your workspace. -1. Select **Usage and estimated costs** in the left pane. -1. Select **Data Retention** at the top of the page. - - :::image type="content" source="media/manage-cost-storage/manage-cost-change-retention-01.png" lightbox="media/manage-cost-storage/manage-cost-change-retention-01.png" alt-text="Screenshot that shows changing the workspace data retention setting."::: --1. Move the slider to increase or decrease the number of days, and then select **OK**. --# [API](#tab/api-3) --To set the default interactive retention period of Analytics tables within a Log Analytics workspace, call the [Workspaces - Create Or Update API](/rest/api/loganalytics/workspaces/create-or-update): --```http -PATCH https://management.azure.com/subscriptions/{subscriptionId}/resourcegroups/{resourceGroupName}/providers/Microsoft.OperationalInsights/workspaces/{workspaceName}?api-version=2023-09-01 -``` --**Request body** --The request body includes the values in the following table. --|Name | Type | Description | -| | | | -|`properties.retentionInDays` | integer | The workspace data retention in days. Allowed values are per pricing plan. See pricing tiers documentation for details. | -|`location`|string| The geo-location of the resource.| -|`immediatePurgeDataOn30Days`|boolean|Flag that indicates whether data is immediately removed after 30 days and is nonrecoverable. Applicable only when workspace retention is set to 30 days.| ---**Example** --This example sets the workspace's retention to the workspace default of 30 days and ensures that data is immediately removed after 30 days and is nonrecoverable. --**Request** --```http -PATCH https://management.azure.com/subscriptions/{subscriptionId}/resourcegroups/{resourceGroupName}/providers/Microsoft.OperationalInsights/workspaces/{workspaceName}?api-version=2023-09-01 --{ - "properties": { - "retentionInDays": 30, - "features": {"immediatePurgeDataOn30Days": true} - }, -"location": "australiasoutheast" -} --**Response** --Status code: 200 --```http -{ - "properties": { - ... - "retentionInDays": 30, - "features": { - "legacy": 0, - "searchVersion": 1, - "immediatePurgeDataOn30Days": true, - ... - }, - ... -``` ---# [CLI](#tab/cli-3) --To set the default interactive retention period of Analytics tables within a Log Analytics workspace, run the [az monitor log-analytics workspace update](/cli/azure/monitor/log-analytics/workspace/#az-monitor-log-analytics-workspace-update) command and pass the `--retention-time` parameter. --This example sets the table's interactive retention to 30 days: --```azurecli -az monitor log-analytics workspace update --resource-group myresourcegroup --retention-time 30 --workspace-name myworkspace -``` --# [PowerShell](#tab/PowerShell-3) --Use the [Set-AzOperationalInsightsWorkspace](/powershell/module/az.operationalinsights/Set-AzOperationalInsightsWorkspace) cmdlet to set the default interactive retention period of Analytics tables within a Log Analytics workspace. This example sets the default interactive retention period to 30 days: --```powershell -Set-AzOperationalInsightsWorkspace -ResourceGroupName "myResourceGroup" -Name "MyWorkspace" -RetentionInDays 30 -``` ---## Configure table-level retention --By default, all tables with the Analytics data plan inherit the [Log Analytics workspace's default interactive retention setting](#configure-the-default-interactive-retention-period-of-analytics-tables) and have no long-term retention. You can increase the interactive retention period of Analytics tables to up to 730 days at an [extra cost](https://azure.microsoft.com/pricing/details/monitor/). --To add long-term retention to a table with any data plan, set **total retention** to up to 12 years (4,383 days). The Auxiliary table plan is currently in public preview, during which the plan's total retention is fixed at 365 days. --> [!NOTE] -> Currently, you can set total retention to up to 12 years through the Azure portal and API. CLI and PowerShell are limited to seven years; support for 12 years will follow. --# [Portal](#tab/portal-1) --To modify the retention setting for a table in the Azure portal: --1. From the **Log Analytics workspaces** menu, select **Tables**. -- The **Tables** screen lists all the tables in the workspace. --1. Select the context menu for the table you want to configure and select **Manage table**. -- :::image type="content" source="media/basic-logs-configure/log-analytics-table-configuration.png" lightbox="media/basic-logs-configure/log-analytics-table-configuration.png" alt-text="Screenshot that shows the Manage table button for one of the tables in a workspace."::: --1. Configure the interactive retention and total retention settings in the **Data retention settings** section of the table configuration screen. -- :::image type="content" source="media/data-retention-configure/log-analytics-configure-table-retention-auxiliary.png" lightbox="media/data-retention-configure/log-analytics-configure-table-retention-auxiliary.png" alt-text="Screenshot that shows the data retention settings on the table configuration screen."::: --# [API](#tab/api-1) --To modify the retention setting for a table, call the [Tables - Update API](/rest/api/loganalytics/tables/update): --```http -PATCH https://management.azure.com/subscriptions/{subscriptionId}/resourcegroups/{resourceGroupName}/providers/Microsoft.OperationalInsights/workspaces/{workspaceName}/tables/{tableName}?api-version=2022-10-01 -``` --You can use either PUT or PATCH, with the following difference: --- The **PUT** API sets `retentionInDays` and `totalRetentionInDays` to the default value if you don't set non-null values.-- The **PATCH** API doesn't change the `retentionInDays` or `totalRetentionInDays` values if you don't specify values.--**Request body** --The request body includes the values in the following table. --|Name | Type | Description | -| | | | -|properties.retentionInDays | integer | The table's data retention in days. This value can be between 4 and 730. <br/>Setting this property to null applies the workspace retention period. For a Basic Logs table, the value is always 8. | -|properties.totalRetentionInDays | integer | The table's total data retention including long-term retention. This value can be between 4 and 730; or 1095, 1460, 1826, 2191, 2556, 2922, 3288, 3653, 4018, or 4383. Set this property to null if you don't want long-term retention. | --**Example** --This example sets the table's interactive retention to the workspace default of 30 days, and the total retention to two years, which means that the long-term retention period is 23 months. --**Request** --```http -PATCH https://management.azure.com/subscriptions/00000000-0000-0000-0000-00000000000/resourcegroups/testRG/providers/Microsoft.OperationalInsights/workspaces/testWS/tables/CustomLog_CL?api-version=2022-10-01 -``` --**Request body** --```http -{ - "properties": { - "retentionInDays": null, - "totalRetentionInDays": 730 - } -} -``` --**Response** --Status code: 200 --```http -{ - "properties": { - "retentionInDays": 30, - "totalRetentionInDays": 730, - "archiveRetentionInDays": 700, - ... - }, - ... -} -``` --# [CLI](#tab/cli-1) --To modify a table's retention settings, run the [az monitor log-analytics workspace table update](/cli/azure/monitor/log-analytics/workspace/table#az-monitor-log-analytics-workspace-table-update) command and pass the `--retention-time` and `--total-retention-time` parameters. --This example sets the table's interactive retention to 30 days, and the total retention to two years, which means that the long-term retention period is 23 months: --```azurecli -az monitor log-analytics workspace table update --subscription ContosoSID --resource-group ContosoRG --workspace-name ContosoWorkspace --name AzureMetrics --retention-time 30 --total-retention-time 730 -``` --To reapply the workspace's default interactive retention value to the table and reset its total retention to 0, run the [az monitor log-analytics workspace table update](/cli/azure/monitor/log-analytics/workspace/table#az-monitor-log-analytics-workspace-table-update) command with the `--retention-time` and `--total-retention-time` parameters set to `-1`. --For example: --```azurecli -az monitor log-analytics workspace table update --subscription ContosoSID --resource-group ContosoRG --workspace-name ContosoWorkspace --name Syslog --retention-time -1 --total-retention-time -1 -``` --# [PowerShell](#tab/PowerShell-1) --Use the [Update-AzOperationalInsightsTable](/powershell/module/az.operationalinsights/Update-AzOperationalInsightsTable) cmdlet to modify a table's retention settings. This example sets the table's interactive retention to 30 days, and the total retention to two years, which means that the long-term retention period is 23 months: --```powershell -Update-AzOperationalInsightsTable -ResourceGroupName ContosoRG -WorkspaceName ContosoWorkspace -TableName AzureMetrics -RetentionInDays 30 -TotalRetentionInDays 730 -``` --To reapply the workspace's default interactive retention value to the table and reset its total retention to 0, run the [Update-AzOperationalInsightsTable](/powershell/module/az.operationalinsights/Update-AzOperationalInsightsTable) cmdlet with the `-RetentionInDays` and `-TotalRetentionInDays` parameters set to `-1`. --For example: --```powershell -Update-AzOperationalInsightsTable -ResourceGroupName ContosoRG -WorkspaceName ContosoWorkspace -TableName Syslog -RetentionInDays -1 -TotalRetentionInDays -1 -``` -----## Get retention settings by table --# [Portal](#tab/portal-2) --To view a table's retention settings in the Azure portal, from the **Log Analytics workspaces** menu, select **Tables**. --The **Tables** screen shows the interactive retention and total retention periods for all the tables in the workspace. -----# [API](#tab/api-2) --To get the retention setting of a particular table (in this example, `SecurityEvent`), call the **Tables - Get** API: --```JSON -GET /subscriptions/00000000-0000-0000-0000-00000000000/resourceGroups/MyResourceGroupName/providers/Microsoft.OperationalInsights/workspaces/MyWorkspaceName/Tables/SecurityEvent?api-version=2022-10-01 -``` --To get all table-level retention settings in your workspace, don't set a table name. --For example: --```JSON -GET /subscriptions/00000000-0000-0000-0000-00000000000/resourceGroups/MyResourceGroupName/providers/Microsoft.OperationalInsights/workspaces/MyWorkspaceName/Tables?api-version=2022-10-01 -``` --# [CLI](#tab/cli-2) --To get the retention setting of a particular table, run the [az monitor log-analytics workspace table show](/cli/azure/monitor/log-analytics/workspace/table#az-monitor-log-analytics-workspace-table-show) command. --For example: --```azurecli -az monitor log-analytics workspace table show --subscription ContosoSID --resource-group ContosoRG --workspace-name ContosoWorkspace --name SecurityEvent -``` --# [PowerShell](#tab/PowerShell-2) --To get the retention setting of a particular table, run the [Get-AzOperationalInsightsTable](/powershell/module/az.operationalinsights/get-azoperationalinsightstable) cmdlet. --For example: --```powershell -Get-AzOperationalInsightsTable -ResourceGroupName ContosoRG -WorkspaceName ContosoWorkspace -tableName SecurityEvent -``` -----## What happens to data when you delete a table in a Log Analytics workspace? --A Log Analytics workspace can contain several [types of tables](../logs/manage-logs-tables.md#table-type-and-schema). What happens when you delete the table is different for each: --|Table type|Data retention|Recommendations| -|-|-|-| -|Azure table |An Azure table holds logs from an Azure resource or data required by an Azure service or solution and can't be deleted. When you stop streaming data from the resource, service, or solution, data remains in the workspace until the end of the retention period defined for the table. |To minimize charges, set [table-level retention](#configure-table-level-retention) to four days before you stop streaming logs to the table.| -|[Custom log table](./create-custom-table.md#create-a-custom-table) (`table_CL`)| Soft deletes the table until the end of the table-level retention or default workspace retention period. During the soft delete period, you continue to pay for data retention and can recreate the table and access the data by setting up a table with the same name and schema. Fourteen days after you delete a custom table, Azure Monitor removes the table-level retention configuration and applies the default workspace retention.|To minimize charges, set [table-level retention](#configure-table-level-retention) to four days before you delete the table.| -|[Search results table](./search-jobs.md) (`table_SRCH`)| Deletes the table and data immediately and permanently.|| -|[Restored table](./restore.md) `(table_RST`)| Deletes the hot cache provisioned for the restore, but source table data isn't deleted.|| --## Log tables with 90-day default retention --By default, the `Usage` and `AzureActivity` tables keep data for at least 90 days at no charge. When you increase the workspace retention to more than 90 days, you also increase the retention of these tables. These tables are also free from data ingestion charges. --Tables related to Application Insights resources also keep data for 90 days at no charge. You can adjust the retention of each of these tables individually: --- `AppAvailabilityResults`-- `AppBrowserTimings`-- `AppDependencies`-- `AppExceptions`-- `AppEvents`-- `AppMetrics`-- `AppPageViews`-- `AppPerformanceCounters`-- `AppRequests`-- `AppSystemEvents`-- `AppTraces`--## Pricing model --The charge for adding interactive retention and long-term retention is calculated based on the volume of data you retain, in GB, and the number or days for which you retain the data. Log data that has `_IsBillable == false` isn't subject to ingestion or retention charges. --For more information, see [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/). --## Next steps --Learn more about: --- [Managing personal data in Azure Monitor Logs](../logs/personal-data-mgmt.md)-- [Creating a search job to retrieve auxiliary data matching particular criteria](search-jobs.md)-- [Restore data from the auxiliary tier for a specific time range](restore.md) |
| azure-monitor | Data Security | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/data-security.md | - Title: Azure Monitor Logs data security | Microsoft Docs -description: Learn about how Azure Monitor Logs protects your privacy and secures your data. ---- Previously updated : 07/02/2023----# Azure Monitor Logs data security --This article explains how Azure Monitor collects, processes, and secures log data, and describes security features you can use to further secure your Azure Monitor environment. The information in this article is specific to [Azure Monitor Logs](../logs/data-platform-logs.md) and supplements the information on [Azure Trust Center](https://www.microsoft.com/en-us/trust-center?rtc=1). --Azure Monitor Logs manages your cloud-based data securely using: --* Data segregation -* Data retention -* Physical security -* Incident management -* Compliance -* Security standards certifications --Contact us with any questions, suggestions, or issues about any of the following information, including our security policies at [Azure support options](https://azure.microsoft.com/support/options/). --## Sending data securely using TLS --To ensure the security of data in transit to Azure Monitor, we strongly encourage you to configure the agent to use at least Transport Layer Security (TLS) 1.3. Older versions of TLS/Secure Sockets Layer (SSL) have been found to be vulnerable and while they still currently work to allow backwards compatibility, they are **not recommended**, and the industry is quickly moving to abandon support for these older protocols. --The [PCI Security Standards Council](https://www.pcisecuritystandards.org/) has set a [deadline of June 30, 2018](https://www.pcisecuritystandards.org/pdfs/PCI_SSC_Migrating_from_SSL_and_Early_TLS_Resource_Guide.pdf) to disable older versions of TLS/SSL and upgrade to more secure protocols. Once Azure drops legacy support, if your agents can't communicate over at least TLS 1.3 you won't be able to send data to Azure Monitor Logs. --We recommend you do NOT explicit set your agent to only use TLS 1.3 unless necessary. Allowing the agent to automatically detect, negotiate, and take advantage of future security standards is preferable. Otherwise you might miss the added security of the newer standards and possibly experience problems if TLS 1.3 is ever deprecated in favor of those newer standards. --### Platform-specific guidance --|Platform/Language | Support | More Information | -| | | | -|Linux | Linux distributions tend to rely on [OpenSSL](https://www.openssl.org) for TLS 1.2 support. | Check the [OpenSSL Changelog](https://www.openssl.org/news/changelog.html) to confirm your version of OpenSSL is supported.| -| Windows 8.0 - 10 | Supported, and enabled by default. | To confirm that you're still using the [default settings](/windows-server/security/tls/tls-registry-settings). | -| Windows Server 2012 - 2016 | Supported, and enabled by default. | To confirm that you're still using the [default settings](/windows-server/security/tls/tls-registry-settings) | -| Windows 7 SP1 and Windows Server 2008 R2 SP1 | Supported, but not enabled by default. | See the [Transport Layer Security (TLS) registry settings](/windows-server/security/tls/tls-registry-settings) page for details on how to enable. | --## Data segregation -After your data is ingested by Azure Monitor, the data is kept logically separate on each component throughout the service. All data is tagged per workspace. This tagging persists throughout the data lifecycle, and it's enforced at each layer of the service. Your data is stored in a dedicated database in the storage cluster in the region you've selected. --## Data retention -Indexed log search data is stored and retained according to your pricing plan. For more information, see [Log Analytics Pricing](https://azure.microsoft.com/pricing/details/log-analytics/). --As part of your [subscription agreement](https://azure.microsoft.com/support/legal/subscription-agreement/), Microsoft retains your data per the terms of the agreement. When customer data is removed, no physical drives are destroyed. --The following table lists some of the available solutions and provides examples of the type of data they collect. --| **Solution** | **Data types** | -| | | -| Capacity and Performance |Performance data and metadata | -| Update Management |Metadata and state data | -| Log Management |User-defined event logs, Windows Event Logs and/or IIS Logs | -| Change Tracking |Software inventory, Windows service and Linux daemon metadata, and Windows/Linux file metadata | -| SQL and Active Directory Assessment |WMI data, registry data, performance data, and SQL Server dynamic management view results | --The following table shows examples of data types: --| **Data type** | **Fields** | -| | | -| Alert |Alert Name, Alert Description, BaseManagedEntityId, Problem ID, IsMonitorAlert, RuleId, ResolutionState, Priority, Severity, Category, Owner, ResolvedBy, TimeRaised, TimeAdded, LastModified, LastModifiedBy, LastModifiedExceptRepeatCount, TimeResolved, TimeResolutionStateLastModified, TimeResolutionStateLastModifiedInDB, RepeatCount | -| Configuration |CustomerID, AgentID, EntityID, ManagedTypeID, ManagedTypePropertyID, CurrentValue, ChangeDate | -| Event |EventId, EventOriginalID, BaseManagedEntityInternalId, RuleId, PublisherId, PublisherName, FullNumber, Number, Category, ChannelLevel, LoggingComputer, EventData, EventParameters, TimeGenerated, TimeAdded <br>**Note:** When you write events with custom fields in to the Windows event log, Log Analytics collects them. | -| Metadata |BaseManagedEntityId, ObjectStatus, OrganizationalUnit, ActiveDirectoryObjectSid, PhysicalProcessors, NetworkName, IPAddress, ForestDNSName, NetbiosComputerName, VirtualMachineName, LastInventoryDate, HostServerNameIsVirtualMachine, IP Address, NetbiosDomainName, LogicalProcessors, DNSName, DisplayName, DomainDnsName, ActiveDirectorySite, PrincipalName, OffsetInMinuteFromGreenwichTime | -| Performance |ObjectName, CounterName, PerfmonInstanceName, PerformanceDataId, PerformanceSourceInternalID, SampleValue, TimeSampled, TimeAdded | -| State |StateChangeEventId, StateId, NewHealthState, OldHealthState, Context, TimeGenerated, TimeAdded, StateId2, BaseManagedEntityId, MonitorId, HealthState, LastModified, LastGreenAlertGenerated, DatabaseTimeModified | --## Physical security -Azure Monitor is managed by Microsoft personnel and all activities are logged and can be audited. Azure Monitor is operated as an Azure Service and meets all Azure Compliance and Security requirements. You can view details about the physical security of Azure assets on page 18 of the [Microsoft Azure Security Overview](https://download.microsoft.com/download/6/0/2/6028B1AE-4AEE-46CE-9187-641DA97FC1EE/Windows%20Azure%20Security%20Overview%20v1.01.pdf). Physical access rights to secure areas are changed within one business day for anyone who no longer has responsibility for the Azure Monitor service, including transfer and termination. You can read about the global physical infrastructure we use at [Microsoft Datacenters](https://azure.microsoft.com/global-infrastructure/). --## Incident management -Azure Monitor has an incident management process that all Microsoft services adhere to. To summarize, we: --* Use a shared responsibility model where a portion of security responsibility belongs to Microsoft and a portion belongs to the customer -* Manage Azure security incidents: - * Start an investigation upon detection of an incident - * Assess the impact and severity of an incident by an on-call incident response team member. Based on evidence, the assessment might or might not result in further escalation to the security response team. - * Diagnose an incident by security response experts to conduct the technical or forensic investigation, identify containment, mitigation, and work around strategies. If the security team believes that customer data could have become exposed to an unlawful or unauthorized individual, parallel execution of the Customer Incident Notification process begins in parallel. - * Stabilize and recover from the incident. The incident response team creates a recovery plan to mitigate the issue. Crisis containment steps such as quarantining impacted systems can occur immediately and in parallel with diagnosis. Longer term mitigations can be planned which occur after the immediate risk has passed. - * Close the incident and conduct a post-mortem. The incident response team creates a post-mortem that outlines the details of the incident, with the intention to revise policies, procedures, and processes to prevent a recurrence of the event. -* Notify customers of security incidents: - * Determine the scope of impacted customers and to provide anybody who is impacted as detailed a notice as possible - * Create a notice to provide customers with detailed enough information so that they can perform an investigation on their end and meet any commitments they have made to their end users while not unduly delaying the notification process. - * Confirm and declare the incident, as necessary. - * Notify customers with an incident notification without unreasonable delay and in accordance with any legal or contractual commitment. Notifications of security incidents are delivered to one or more of a customer's administrators by any means Microsoft selects, including via email. -* Conduct team readiness and training: - * Microsoft personnel are required to complete security and awareness training, which helps them to identify and report suspected security issues. - * Operators working on the Microsoft Azure service have addition training obligations surrounding their access to sensitive systems hosting customer data. - * Microsoft security response personnel receive specialized training for their roles --While rare, Microsoft notifies each customer within one day if significant loss of any customer data occurs. --For more information about how Microsoft responds to security incidents, see [Microsoft Azure Security Response in the Cloud](/compliance/assurance/assurance-incident-management). --## Compliance -The Azure Monitor software development and service team's information security and governance program supports its business requirements and adheres to laws and regulations as described at [Microsoft Azure Trust Center](https://azure.microsoft.com/support/trust-center/) and [Microsoft Trust Center Compliance](https://www.microsoft.com/en-us/trustcenter/compliance/default.aspx). How Azure Monitor Logs establishes security requirements, identifies security controls, manages, and monitors risks are also described there. Annually, we review policies, standards, procedures, and guidelines. --Each development team member receives formal application security training. Internally, we use a version control system for software development. Each software project is protected by the version control system. --Microsoft has a security and compliance team that oversees and assesses all services at Microsoft. Information security officers make up the team and they aren't associated with the engineering teams that develop Log Analytics. The security officers have their own management chain and conduct independent assessments of products and services to ensure security and compliance. --Microsoft's board of directors is notified by an annual report about all information security programs at Microsoft. --The Log Analytics software development and service team are actively working with the Microsoft Legal and Compliance teams and other industry partners to acquire various certifications. --## Certifications and attestations -Azure Log Analytics meets the following requirements: --* [ISO/IEC 27001](https://www.iso.org/standard/27001) -* [ISO/IEC 27018:2014](https://www.iso.org/iso/home/store/catalogue_tc/catalogue_detail.htm?csnumber=61498) -* [ISO 22301](https://azure.microsoft.com/blog/iso22301/) -* [Payment Card Industry (PCI Compliant) Data Security Standard (PCI DSS)](https://www.microsoft.com/en-us/TrustCenter/Compliance/PCI) by the PCI Security Standards Council. -* [Service Organization Controls (SOC) 1 Type 1 and SOC 2 Type 1](https://www.microsoft.com/en-us/TrustCenter/Compliance/SOC1-and-2) compliant -* [HIPAA and HITECH](/compliance/regulatory/offering-hipaa-hitech) for companies that have a HIPAA Business Associate Agreement -* Windows Common Engineering Criteria -* Microsoft Trustworthy Computing -* As an Azure service, the components that Azure Monitor uses adhere to Azure compliance requirements. You can read more at [Microsoft Trust Center Compliance](https://www.microsoft.com/en-us/trustcenter/compliance/default.aspx). --> [!NOTE] -> In some certifications/attestations, Azure Monitor Logs is listed under its former name of *Operational Insights*. -> -> --## Cloud computing security data flow -The following diagram shows a cloud security architecture as the flow of information from your company and how it's secured as is moves to Azure Monitor, ultimately seen by you in the Azure portal. More information about each step follows the diagram. -<!-- convertborder later --> --### 1. Sign up for Azure Monitor and collect data -For your organization to send data to Azure Monitor Logs, you configure a Windows or Linux agent running on Azure virtual machines, or on virtual or physical computers in your environment or other cloud provider. If you use Operations Manager, from the management group you configure the Operations Manager agent. Users (which might be you, other individual users, or a group of people) create one or more Log Analytics workspaces, and register agents by using one of the following accounts: --* [Organizational ID](../../active-directory/fundamentals/sign-up-organization.md) -* [Microsoft Account - Outlook, Office Live, MSN](https://account.microsoft.com/account) --A Log Analytics workspace is where data is collected, aggregated, analyzed, and presented. A workspace is primarily used as a means to partition data, and each workspace is unique. For example, you might want to have your production data managed with one workspace and your test data managed with another workspace. Workspaces also help an administrator control user access to the data. Each workspace can have multiple user accounts associated with it, and each user account can access multiple Log Analytics workspaces. You create workspaces based on datacenter region. --For Operations Manager, the Operations Manager management group establishes a connection with the Azure Monitor service. You then configure which agent-managed systems in the management group are allowed to collect and send data to the service. Depending on the solution you've enabled, data from these solutions are either sent directly from an Operations Manager management server to the Azure Monitor service, or because of the volume of data collected by the agent-managed system, are sent directly from the agent to the service. For systems not monitored by Operations Manager, each connects securely to the Azure Monitorservice directly. --All communication between connected systems and the Azure Monitor service is encrypted. The TLS (HTTPS) protocol is used for encryption. The Microsoft SDL process is followed to ensure Log Analytics is up-to-date with the most recent advances in cryptographic protocols. --Each type of agent collects log data for Azure Monitor. The type of data that is collected depends on the configuration of your workspace and other features of Azure Monitor. --### 2. Send data from agents -You register all agent types with an enrollment key and a secure connection is established between the agent and the Azure Monitor service using certificate-based authentication and TLS with port 443. Azure Monitor uses a secret store to generate and maintain keys. Private keys are rotated every 90 days and are stored in Azure and are managed by the Azure operations who follow strict regulatory and compliance practices. --With Operations Manager, the management group registered with a Log Analytics workspace establishes a secure HTTPS connection with an Operations Manager management server. --For Windows or Linux agents running on Azure virtual machines, a read-only storage key is used to read diagnostic events in Azure tables. --With any agent reporting to an Operations Manager management group that is integrated with Azure Monitor, if the management server is unable to communicate with the service for any reason, the collected data is stored locally in a temporary cache on the management server. They try to resend the data every eight minutes for two hours. For data that bypasses the management server and is sent directly to Azure Monitor, the behavior is consistent with the Windows agent. --The Windows or management server agent cached data is protected by the operating system's credential store. If the service can't process the data after two hours, the agents will queue the data. If the queue becomes full, the agent starts dropping data types, starting with performance data. The agent queue limit is a registry key so you can modify it, if necessary. Collected data is compressed and sent to the service, bypassing the Operations Manager management group databases, so it doesn't add any load to them. After the collected data is sent, it's removed from the cache. --As described above, data from the management server or direct-connected agents is sent over TLS to Microsoft Azure datacenters. Optionally, you can use ExpressRoute to provide extra security for the data. ExpressRoute is a way to directly connect to Azure from your existing WAN network, such as a multi-protocol label switching (MPLS) VPN, provided by a network service provider. For more information, see [ExpressRoute](https://azure.microsoft.com/services/expressroute/) and [Does my agent traffic use my Azure ExpressRoute connection?](#does-my-agent-traffic-use-my-azure-expressroute-connection). --### 3. The Azure Monitor service receives and processes data -The Azure Monitor service ensures that incoming data is from a trusted source by validating certificates and the data integrity with Azure authentication. The unprocessed raw data is then stored in an Azure Event Hubs in the region the data will eventually be stored at rest. The type of data that is stored depends on the types of solutions that were imported and used to collect data. Then, the Azure Monitor service processes the raw data and ingests it into the database. --The retention period of collected data stored in the database depends on the selected pricing plan. For the *Free* tier, collected data is available for seven days. For the *Paid* tier, collected data is available for 31 days by default, but can be extended to 730 days. Data is stored encrypted at rest in Azure storage, to ensure data confidentiality, and the data is replicated within the local region using locally redundant storage (LRS), or zone-redundant storage (ZRS) in [supported regions](../logs/availability-zones.md). The last two weeks of data are also stored in SSD-based cache and this cache is encrypted. --Data in database storage can't be altered once ingested but can be deleted via [*purge* API path](personal-data-mgmt.md#delete). Although data can't be altered, some certifications require that data is kept immutable and can't be changed or deleted in storage. Data immutability can be achieved using [data export](logs-data-export.md) to a storage account that is configured as [immutable storage](../../storage/blobs/immutable-policy-configure-version-scope.md). --### 4. Use Azure Monitor to access the data -To access your Log Analytics workspace, you sign in to the Azure portal using the organizational account or Microsoft account that you set up previously. All traffic between the portal and Azure Monitor service is sent over a secure HTTPS channel. When using the portal, a session ID is generated on the user client (web browser) and data is stored in a local cache until the session is terminated. When terminated, the cache is deleted. Client-side cookies, which don't contain personally identifiable information, aren't automatically removed. Session cookies are marked HTTPOnly and are secured. After a predetermined idle period, the Azure portal session is terminated. ---## Customer-managed security keys --Data in Azure Monitor is encrypted with Microsoft-managed keys. You can use [customer-managed encryption keys](../logs/customer-managed-keys.md) to protect the data and saved queries in your workspaces. Customer-managed keys in Azure Monitor give you greater flexibility to manage access controls to your logs. --Once configure, new data ingested to linked workspaces gets encrypted with your key stored in [Azure Key Vault](/azure/key-vault/general/overview), or [Azure Key Vault Managed "HSM"](/azure/key-vault/managed-hsm/overview). --## Private storage --Azure Monitor Logs relies on Azure Storage in specific scenarios. Use [private/customer-managed storage](./private-storage.md) to manage your personally encrypted storage account. --## Private Link networking -[Azure Private Link networking](./private-link-security.md) lets you securely link Azure platform as a service (PaaS) services, including Azure Monitor, to your virtual network using private endpoints. --## Customer Lockbox for Microsoft Azure --[Customer Lockbox for Microsoft Azure](../../security/fundamentals/customer-lockbox-overview.md) provides you with an interface to review and approve or reject customer data access requests. It's used when a Microsoft engineer needs to access customer data, whether in response to a customer-initiated support ticket or a problem identified by Microsoft. To enable Customer Lockbox, you need a [dedicated cluster](../logs/logs-dedicated-clusters.md). --## Tamper-proofing and immutability --Azure Monitor is an append-only data platform, but includes provisions to delete data for compliance purposes. You can [set a lock on your Log Analytics workspace](../../azure-resource-manager/management/lock-resources.md) to block all activities that could delete data: purge, table delete, and table- or workspace-level data retention changes. However, this lock can still be removed. --To fully tamper-proof your monitoring solution, we recommend you [export your data to an immutable storage solution](../../storage/blobs/immutable-storage-overview.md). --## Frequently asked questions --This section provides answers to common questions. --### Does my agent traffic use my Azure ExpressRoute connection? --Traffic to Azure Monitor uses the Microsoft peering ExpressRoute circuit. See [ExpressRoute documentation](../../expressroute/expressroute-faqs.md#supported-services) for a description of the different types of ExpressRoute traffic. |
| azure-monitor | Delete Workspace | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/delete-workspace.md | - Title: Delete and recover an Azure Log Analytics workspace | Microsoft Docs -description: Learn how to delete your Log Analytics workspace if you created one in a personal subscription or restructure your workspace model. ---- Previously updated : 08/12/2024---# Delete and recover an Azure Log Analytics workspace --This article explains the concept of Azure Log Analytics workspace soft-delete and how to recover a deleted workspace in a soft-delete state. It also explains how to delete a workspace permanently instead of deleting it into a soft-delete state. --## Permissions required --- To delete a Log Analytics workspace into a soft-delete state or permanently, you need `microsoft.operationalinsights/workspaces/delete` permissions to the workspace, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example.-- To recover a Log Analytics workspace in a soft-delete state, you need `Microsoft.OperationalInsights/workspaces/write` permissions to the workspace, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example.--## Considerations when you delete a workspace --When you delete a Log Analytics workspace into a soft-delete state, a soft-delete operation is performed to allow the recovery of the workspace, including its data and connected agents, within 14 days. This process occurs whether the deletion was accidental or intentional. --After the soft-delete period, the workspace resource and its data are nonrecoverable and queued for purge completely within 30 days. The workspace name is released and you can use it to create a new workspace. --> [!NOTE] -> If you want to override the soft-delete behavior and permanently delete your workspace, follow the steps in [Delete a workspace permanently](#delete-a-workspace-permanently). --The soft-delete operation deletes the workspace resource, and any associated users' permission is broken. If users are associated with other workspaces, they can continue using Log Analytics with those other workspaces. --Be careful when you delete a workspace because there might be important data and configuration that might negatively affect your service operation. Review what agents, solutions, and other Azure services store their data in Log Analytics, such as: --* Management solutions. -* Azure Automation. -* Agents running on Windows and Linux virtual machines. -* Agents running on Windows and Linux computers in your environment. -* System Center Operations Manager. --## Delete a workspace into a soft-delete state --The workspace delete operation removes the workspace Azure Resource Manager resource. Its configuration and data are kept for 14 days, although it will look as if the workspace is deleted. Any agents and System Center Operations Manager management groups configured to report to the workspace remain in an orphaned state during the soft-delete period. The service provides a mechanism for [recovering the deleted workspace](#recover-a-workspace-in-a-soft-delete-state), including its data and connected resources, essentially undoing the deletion. --> [!NOTE] -> Installed solutions and linked services like your Azure Automation account are permanently removed from the workspace at deletion time and can't be recovered. These resources should be reconfigured after the recovery operation to bring the workspace back to its previously configured state. --### [Azure portal](#tab/azure-portal) --1. Sign in to the [Azure portal](https://portal.azure.com). -1. In the Azure portal, select **All services**. In the list of resources, enter **Log Analytics**. As you begin typing, the list filters based on your input. Select **Log Analytics workspaces**. -1. In the list of Log Analytics workspaces, select a workspace. Select **Delete**. -1. A confirmation page appears that shows the data ingestion to the workspace over the past week. -1. Enter the name of the workspace to confirm and then select **Delete**. -- :::image type="content" source="media/delete-workspace/workspace-delete.png" alt-text="Screenshot that shows confirming the deletion of a workspace." lightbox="media/delete-workspace/workspace-delete.png"::: --### [REST API](#tab/rest-api) --To delete a workspace into a soft-delete state, call the [Workspaces - Delete API](/rest/api/loganalytics/workspaces/delete): --```http -DELETE https://management.azure.com/subscriptions/{subscriptionId}/resourcegroups/{resourceGroupName}/providers/Microsoft.OperationalInsights/workspaces/{workspaceName}?api-version=2022-10-01 -``` --### [PowerShell](#tab/powershell) --To delete a workspace into a soft-delete state, run the [Remove-AzOperationalInsightsWorkspace](/powershell/module/az.operationalinsights/remove-azoperationalinsightsworkspace) cmdlet. --```PowerShell -PS C:\>Remove-AzOperationalInsightsWorkspace -ResourceGroupName "resource-group-name" -Name "workspace-name" -``` --### [CLI](#tab/cli) --To delete a workspace into a soft-delete state, run the [az monitor log-analytics workspace delete](/cli/azure/monitor/log-analytics/workspace#az-monitor-log-analytics-workspace-delete) command. --```azurecli -az monitor log-analytics workspace delete --resource-group MyResourceGroup --workspace-name MyWorkspace -``` ----## Recover a workspace in a soft-delete state --When you delete a Log Analytics workspace accidentally or intentionally, the service places the workspace in a soft-delete state and makes it inaccessible to any operation. The name of the deleted workspace is preserved during the soft-delete period. It can't be used to create a new workspace. After the soft-delete period, the workspace is nonrecoverable and scheduled for permanent deletion, and its name is released and can be used when creating a new workspace. --You can recover your workspace during the soft-delete period, including its data, configuration, and connected agents. The workspace recovery is performed by re-creating the Log Analytics workspace with the details of the deleted workspace, including: --- Subscription ID-- Resource group name-- Workspace name-- Region--> [!IMPORTANT] -> If your workspace was deleted as part of a resource group delete operation, you must first re-create the resource group. --The workspace and all its data are brought back after the recovery operation. However, solutions and linked services were permanently removed from the workspace when it was deleted into a soft-delete state. These resources should be reconfigured to bring the workspace to its previously configured state. After you recover the workspace, some of the data might not be available for query until the associated solutions are reinstalled and their schemas are added to the workspace. --### [Azure portal](#tab/azure-portal) --1. Sign in to the [Azure portal](https://portal.azure.com). -1. In the Azure portal, select **All services**. In the list of resources, enter **Log Analytics**. As you begin typing, the list filters based on your input. Select **Log Analytics workspaces**. You see the list of workspaces you have in the selected scope. -1. Select **Open recycle bin** on the top left menu to open a page with workspaces in a soft-delete state that can be recovered. -- <!-- convertborder later --> - :::image type="content" source="media/delete-workspace/recover-menu.png" lightbox="media/delete-workspace/recover-menu.png" alt-text="Screenshot that shows the Log Analytics workspaces screen and Open recycle bin on the menu bar." border="false"::: --1. Select the workspace. Then select **Recover** to recover the workspace. - <!-- convertborder later --> - :::image type="content" source="media/delete-workspace/recover-workspace.png" lightbox="media/delete-workspace/recover-workspace.png" alt-text="Screenshot that shows the Recycle bin with a workspace and the Recover button." border="false"::: --### [REST API](#tab/rest-api) --To recover the workspace, create it again with the same name, in the same subscription, resource group and location by calling the [Workspaces - Create Or Update API](/rest/api/loganalytics/workspaces/create-or-update). --```http -PUT https://management.azure.com/subscriptions/{subscriptionId}/resourcegroups/{resourceGroupName}/providers/Microsoft.OperationalInsights/workspaces/{workspaceName}?api-version=2022-10-01 -``` --### [PowerShell](#tab/powershell) --To recover a workspace in a soft delete state, run the [Restore-AzOperationalInsightsWorkspace](/powershell/module/az.operationalinsights/restore-azoperationalinsightsworkspace) cmdlet. --```PowerShell -PS C:\>Select-AzSubscription "subscription-name-the-workspace-was-in" -PS C:\>Restore-AzOperationalInsightsWorkspace -ResourceGroupName "resource-group-name-the-workspace-was-in" -Name "deleted-workspace-name" -Location "region-name-the-workspace-was-in" -``` --### [CLI](#tab/cli) --To recover a workspace in a soft delete state, run the [az monitor log-analytics workspace recover](/cli/azure/monitor/log-analytics/workspace#az-monitor-log-analytics-workspace-recover) command: ---```azurecli -az monitor log-analytics workspace recover --resource-group MyResourceGroup --workspace-name MyWorkspace -``` ----## Delete a workspace permanently -The soft-delete method might not fit in some scenarios, such as development and testing, where you need to repeat a deployment with the same settings and workspace name. In such cases, you can permanently delete your workspace and "override" the soft-delete period. The permanent workspace delete operation releases the workspace name. You can create a new workspace by using the same name. --> [!IMPORTANT] -> - Use the permanent workspace delete operation with caution because it's irreversible. You won't be able to recover your workspace and its data. -> - If the workspace you want to delete permanently is in a soft-delete state, you must first [recover the workspace](#recover-a-workspace-in-a-soft-delete-state) before you can delete it permanently. --### [Azure portal](#tab/azure-portal) --To permanently delete a workspace by using the Azure portal: --1. Sign in to the [Azure portal](https://portal.azure.com). -1. In the Azure portal, select **All services**. In the list of resources, enter **Log Analytics**. As you begin typing, the list filters based on your input. Select **Log Analytics workspaces**. -1. In the list of Log Analytics workspaces, select a workspace. Select **Delete**. -1. A confirmation page appears that shows the data ingestion to the workspace over the past week. -1. Select the **Delete the workspace permanently** checkbox. -1. Enter the name of the workspace to confirm and then select **Delete**. -- :::image type="content" source="media/delete-workspace/workspace-delete.png" alt-text="Screenshot that shows confirming the deletion of a workspace." lightbox="media/delete-workspace/workspace-delete.png"::: --### [REST API](#tab/rest-api) --To delete a workspace permanently, call the [Workspaces - Delete API](/rest/api/loganalytics/workspaces/delete) and add the `force` URI parameter: --```http -DELETE https://management.azure.com/subscriptions/{subscriptionId}/resourcegroups/{resourceGroupName}/providers/Microsoft.OperationalInsights/workspaces/{workspaceName}?api-version=2022-10-01&force=true -``` --### [PowerShell](#tab/powershell) --To delete a workspace permanently, run the [Remove-AzOperationalInsightsWorkspace](/powershell/module/az.operationalinsights/remove-azoperationalinsightsworkspace) cmdlet and add the `-ForceDelete` tag. The `-ForceDelete` option is currently available with Az.OperationalInsights 2.3.0 or higher. --```powershell -PS C:\>Remove-AzOperationalInsightsWorkspace -ResourceGroupName "resource-group-name" -Name "workspace-name" -ForceDelete -``` --### [CLI](#tab/cli) --To delete a workspace permanently, run the [az monitor log-analytics workspace delete](/cli/azure/monitor/log-analytics/workspace#az-monitor-log-analytics-workspace-delete) command and add the `--force` parameter. --```azurecli -az monitor log-analytics workspace delete --force --resource-group MyResourceGroup --workspace-name MyWorkspace -``` ----## Troubleshooting --Use the following section to troubleshoot issues with deleting or recovering a Log Analytics workspace. --### I'm not sure if the workspace I deleted can be recovered --If you aren't sure if a deleted workspace is in a soft-delete state and can be recovered, in the Azure portal, select [Open recycle bin](?tabs=azure-portal#recover-a-workspace-in-a-soft-delete-state) on the **Log Analytics workspaces** page to see a list of soft-deleted workspaces per subscription. Permanently deleted workspaces aren't included in the list. --### Resolve the "This workspace name is already in use" or "conflict" error message --If you receive one of these error messages when you create a workspace, it could be because: --* The workspace name isn't available because it's being used by someone in your organization or another customer. -* The workspace was deleted in the last 14 days and its name was kept reserved for the soft-delete period. To resolve, follow these steps: -- 1. [Recover](#recover-a-workspace-in-a-soft-delete-state) your workspace in a soft-delete state, which allows you to delete it permanently. - 1. [Permanently delete](#delete-a-workspace-permanently) the workspace you recovered. When you delete a workspace permanently, its name is no longer reserved. - 1. [Create a new workspace](./quick-create-workspace.md) by using the same workspace name. -- After the deletion call is successfully completed on the back end, you can restore the workspace and finish the permanent delete operation by using one of the methods suggested earlier. --### I'm receiving 204 response code with "Resource not found" when deleting a workspace --If you get a 204 response code with "Resource not found" when you delete a workspace, consecutive retries operations might have occurred. The 204 code is an empty response, which usually means that the resource doesn't exist, so the delete finished without doing anything. --### I'm receiving error code 404 when attempting to recover my workspace --If you deleted your resource group and your workspace was included, you can see the deleted workspace on the [Open recycle bin](?tabs=azure-portal#recover-a-workspace-in-a-soft-delete-state) page in the Azure portal. The recovery operation will fail with the error code 404 because the resource group doesn't exist. [Re-create your resource group](../../azure-resource-manager/management/manage-resource-groups-portal.md) and try the recovery again. --## Next steps --If you need to create a new Log Analytics workspace, see [Create a Log Analytics workspace](./quick-create-workspace.md). |
| azure-monitor | Functions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/functions.md | - Title: Functions in Azure Monitor log queries -description: This article describes how to use functions to call a query from another log query in Azure Monitor. ---- Previously updated : 06/22/2022----# Functions in Azure Monitor log queries -A function is a log query in Azure Monitor that can be used in other log queries as though it's a command. You can use functions to provide solutions to different customers and also reuse query logic in your own environment. This article describes how to use functions and how to create your own. --## Permissions required --- To view or use functions, you need `Microsoft.OperationalInsights/workspaces/query/*/read` permissions to the Log Analytics workspace, as provided by the [Log Analytics Reader built-in role](./manage-access.md#log-analytics-reader), for example.--- To create or edit functions, you need `microsoft.operationalinsights/workspaces/savedSearches/write` permissions to the Log Analytics workspace, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example.--## Types of functions -There are two types of functions in Azure Monitor: --- **Solution functions:** Prebuilt functions are included with Azure Monitor. These functions are available in all Log Analytics workspaces and can't be modified.-- **Workspace functions:** These functions are installed in a particular Log Analytics workspace. They can be modified and controlled by the user.--## View functions -You can view solution functions and workspace functions in the current workspace on the **Functions** tab in the left pane of a Log Analytics workspace. Use **Filter** to filter the functions included in the list. Use **Group by** to change their grouping. Enter a string in the **Search** box to locate a particular function. Hover over a function to view details about it, including a description and parameters. ---## Use a function -Use a function in a query by typing its name with values for any parameters the same as you would type in a command. The output of the function can either be returned as results or piped to another command. --Add a function to the current query by double-clicking on its name or hovering over it and selecting **Use in editor**. Functions in the workspace will also be included in IntelliSense as you type in a query. --If a query requires parameters, provide them by using the syntax `function_name(param1,param2,...)`. ---## Create a function -To create a function from the current query in the editor, select **Save** > **Save as function**. ---Create a function with Log Analytics in the Azure portal by selecting **Save** and then providing the information in the following table: --| Setting | Description | -|:|:| -| Function name | Name for the function. The name may not include a space or any special characters. It also may not start with an underscore (_) because this character is reserved for solution functions. | -| Legacy category | User-defined category to help filter and group functions. | -| Save as computer group | Save the query as a [computer group](computer-groups.md). | -| Parameters | Add a parameter for each variable in the function that requires a value when it's used. For more information, see [Function parameters](#function-parameters). | ---## Function parameters -You can add parameters to a function so that you can provide values for certain variables when you call it. As a result, the same function can be used in different queries, each providing different values for the parameters. Parameters are defined by the following properties: --| Setting | Description | -|:|:| -| Type | Data type for the value. | -| Name | Name for the parameter. This name must be used in the query to replace with the parameter value. | -| Default value | Value to be used for the parameter if a value isn't provided. | --Parameters are ordered as they're created. Parameters that have no default value are positioned in front of parameters that have a default value. --> [!NOTE] -> Classic Application Insights resources don't support parameterized functions. If you have a [workspace-based Application Insights resource](../app/create-workspace-resource.md), you can create parameterized functions from your Log Analytics workspace. For information on migrating your Classic Application Insights resource to a workspace-based resource, see [Migrate to workspace-based Application Insights resources](../app/convert-classic-resource.md). --## Work with function code -You can view the code of a function either to gain insight into how it works or to modify the code for a workspace function. Select **Load the function code** to add the function code to the current query in the editor. --If you add the function code to an empty query or the first line of an existing query, the function name is added to the tab. A workspace function enables the option to edit the function details. ---## Edit a function -Edit the properties or the code of a function by creating a new query. Hover over the name of the function and select **Load function code**. Make any modifications that you want to the code and select **Save**. Then select **Edit function details**. Make any changes you want to the properties and parameters of the function and select **Save**. ---## Example -The following sample function returns all events in the Azure activity log since a particular date and that match a particular category. --Start with the following query by using hardcoded values to verify that the query works as expected. --```Kusto -AzureActivity -| where CategoryValue == "Administrative" -| where TimeGenerated > todatetime("2021/04/05 5:40:01.032 PM") -``` ---Next, replace the hardcoded values with parameter names. Then save the function by selecting **Save** > **Save as function**. --```Kusto -AzureActivity -| where CategoryValue == CategoryParam -| where TimeGenerated > DateParam -``` --- Provide the following values for the function properties: --| Property | Value | -|:|:| -| Function name | AzureActivityByCategory | -| Legacy category | Demo functions | --Define the following parameters before you save the function: --| Type | Name | Default value | -|:|:|:| -| string | CategoryParam | "Administrative" | -| datetime | DateParam | | ---Create a new query and view the new function by hovering over it. Look at the order of the parameters. They must be specified in this order when you use the function. ---Select **Use in editor** to add the new function to a query. Then add values for the parameters. You don't need to specify a value for `CategoryParam` because it has a default value. ---## Next steps -See [String operations](/azure/data-explorer/kusto/query/samples?&pivots=azuremonitor#string-operations) for more information on how to write Azure Monitor log queries. |
| azure-monitor | Get Started Queries | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/get-started-queries.md | - Title: Get started with log queries in Azure Monitor | Microsoft Docs -description: This article provides a tutorial for getting started writing log queries in Azure Monitor. ---- Previously updated : 10/31/2023----# Get started with log queries in Azure Monitor --> [!NOTE] -> If you're collecting data from at least one virtual machine, you can work through this exercise in your own environment. For other scenarios, use our [demo environment](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring_Logs/DemoLogsBlade), which includes plenty of sample data. -> -> If you already know how to query in Kusto Query Language (KQL) but need to quickly create useful queries based on resource types, see the saved example queries pane in [Use queries in Azure Monitor Log Analytics](../logs/queries.md). --In this tutorial, you learn to write log queries in Azure Monitor. The article shows you how to: --- Understand query structure.-- Sort query results.-- Filter query results.-- Specify a time range.-- Select which fields to include in the results.-- Define and use custom fields.-- Aggregate and group results.--For a tutorial on using Log Analytics in the Azure portal, see [Get started with Azure Monitor Log Analytics](./log-analytics-tutorial.md). --For more information about log queries in Azure Monitor, see [Overview of log queries in Azure Monitor](../logs/log-query-overview.md). --Here's a video version of this tutorial: --> [!VIDEO https://www.microsoft.com/videoplayer/embed/RE42pGX] ---## Write a new query --Queries can start with either a table name or the `search` command. It's a good idea to start with a table name because it defines a clear scope for the query. It also improves query performance and the relevance of the results. --> [!NOTE] -> KQL, which is used by Azure Monitor, is case sensitive. Language keywords are usually written in lowercase. When you use names of tables or columns in a query, be sure to use the correct case, as shown on the schema pane. --### Table-based queries --Azure Monitor organizes log data in tables, each composed of multiple columns. All tables and columns are shown on the schema pane in Log Analytics in the Analytics portal. Identify a table that you're interested in, and then take a look at a bit of data: --```Kusto -SecurityEvent -| take 10 -``` --The preceding query returns 10 results from the `SecurityEvent` table, in no specific order. This common way to get a glance at a table helps you to understand its structure and content. Let's examine how it's built: --* The query starts with the table name `SecurityEvent`, which defines the scope of the query. -* The pipe (|) character separates commands, so the output of the first command is the input of the next. You can add any number of piped elements. -* Following the pipe is the [`take` operator](#take). -- We could run the query even without adding `| take 10`. The command would still be valid, but it could return up to 30,000 results. --#### Take --Use the [`take` operator](/azure/data-explorer/kusto/query/takeoperator) to view a small sample of records by returning up to the specified number of records. The selected results are arbitrary and displayed in no particular order. If you need to return results in a particular order, use the [`sort` and `top` operators](#sort-and-top). --### Search queries --Search queries are less structured. They're better suited for finding records that include a specific value in any of their columns: --```Kusto -search in (SecurityEvent) "Cryptographic" -| take 10 -``` --This query searches the `SecurityEvent` table for records that contain the phrase "Cryptographic." Of those records, 10 records are returned and displayed. If you omit the `in (SecurityEvent)` part and run only `search "Cryptographic"`, the search goes over *all* tables. The process would then take longer and be less efficient. --> [!IMPORTANT] -> Search queries are ordinarily slower than table-based queries because they have to process more data. --## Sort and top --This section describes the `sort` and `top` operators and their `desc` and `asc` arguments. Although [`take`](#take) is useful for getting a few records, you can't select or sort the results in any particular order. To get an ordered view, use `sort` and `top`. --### Desc and asc --#### Desc --Use the `desc` argument to sort records in descending order. Descending is the default sorting order for `sort` and `top`, so you can usually omit the `desc` argument. --For example, the data returned by both of the following queries is sorted by the [TimeGenerated column](./log-standard-columns.md#timegenerated), in descending order: --- ```Kusto- SecurityEvent - | sort by TimeGenerated desc - ``` --- ```Kusto- SecurityEvent - | sort by TimeGenerated - ``` - -#### Asc --To sort in ascending order, specify `asc`. --### Sort --You can use the [`sort` operator](/azure/data-explorer/kusto/query/sort-operator). `sort` sorts the query results by the column you specify. However, `sort` doesn't limit the number of records that are returned by the query. --For example, the following query returns all available records for the `SecurityEvent` table, which is up to a maximum of 30,000 records, and sorts them by the TimeGenerated column. --```Kusto -SecurityEvent -| sort by TimeGenerated -``` --The preceding query could return too many results. Also, it might also take some time to return the results. The query sorts the entire `SecurityEvent` table by the `TimeGenerated` column. The Analytics portal then limits the display to only 30,000 records. This approach isn't optimal. The best way to only get the latest records is to use the [`top` operator](#top). --### Top --Use the [`top` operator](/azure/data-explorer/kusto/query/topoperator) to sort the entire table on the server side and then only return the top records. --For example, the following query returns the latest 10 records: --```Kusto -SecurityEvent -| top 10 by TimeGenerated -``` --The output looks like this example. -<!-- convertborder later --> --## The where operator: Filter on a condition -Filters, as indicated by their name, filter the data by a specific condition. Filtering is the most common way to limit query results to relevant information. --To add a filter to a query, use the [`where` operator](/azure/data-explorer/kusto/query/whereoperator) followed by one or more conditions. For example, the following query returns only `SecurityEvent` records where `Level equals _8`: --```Kusto -SecurityEvent -| where Level == 8 -``` --When you write filter conditions, you can use the following expressions: --| Expression | Description | Example | -|:|:|:| -| == | Check equality<br>(case-sensitive) | `Level == 8` | -| =~ | Check equality<br>(case-insensitive) | `EventSourceName =~ "microsoft-windows-security-auditing"` | -| !=, <> | Check inequality<br>(both expressions are identical) | `Level != 4` | -| `and`, `or` | Required between conditions| `Level == 16 or CommandLine != ""` | --To filter by multiple conditions, you can use either of the following approaches: --Use `and`, as shown here: --```Kusto -SecurityEvent -| where Level == 8 and EventID == 4672 -``` --Pipe multiple `where` elements, one after the other, as shown here: --```Kusto -SecurityEvent -| where Level == 8 -| where EventID == 4672 -``` --> [!NOTE] -> Values can have different types, so you might need to cast them to perform comparisons on the correct type. For example, the `SecurityEvent Level` column is of type String, so you must cast it to a numerical type, such as `int` or `long`, before you can use numerical operators on it, as shown here: -> `SecurityEvent | where toint(Level) >= 10` --## Specify a time range --You can specify a time range by using the time picker or a time filter. --### Use the time picker --The time picker is displayed next to the **Run** button and indicates that you're querying records from only the last 24 hours. This default time range is applied to all queries. To get records from only the last hour, select **Last hour** and then run the query again. -<!-- convertborder later --> --### Add a time filter to the query --You can also define your own time range by adding a time filter to the query. Adding a time filter overrides the time range selected in the [time picker](#use-the-time-picker). --It's best to place the time filter immediately after the table name: --```Kusto -SecurityEvent -| where TimeGenerated > ago(30m) -| where toint(Level) >= 10 -``` --In the preceding time filter, `ago(30m)` means "30 minutes ago." This query returns records from only the last 30 minutes, which is expressed as, for example, 30m. Other units of time include days (for example, 2d) and seconds (for example, 10s). --## Use project and extend to select and compute columns --Use `project` to select specific columns to include in the results: --```Kusto -SecurityEvent -| top 10 by TimeGenerated -| project TimeGenerated, Computer, Activity -``` --The preceding example generates the following output: -<!-- convertborder later --> --You can also use `project` to rename columns and define new ones. The next example uses `project` to do the following: --* Select only the `Computer` and `TimeGenerated` original columns. -* Display the `Activity` column as `EventDetails`. -* Create a new column named `EventCode`. The `substring()` function is used to get only the first four characters from the `Activity` field. --```Kusto -SecurityEvent -| top 10 by TimeGenerated -| project Computer, TimeGenerated, EventDetails=Activity, EventCode=substring(Activity, 0, 4) -``` --You can use `extend` to keep all original columns in the result set and define other ones. The following query uses `extend` to add the `EventCode` column. This column might not be displayed at the end of the table results. You would need to expand the details of a record to view it. --```Kusto -SecurityEvent -| top 10 by TimeGenerated -| extend EventCode=substring(Activity, 0, 4) -``` --## Use summarize to aggregate groups of rows -Use `summarize` to identify groups of records according to one or more columns and apply aggregations to them. The most common use of `summarize` is `count`, which returns the number of results in each group. --The following query reviews all `Perf` records from the last hour, groups them by `ObjectName`, and counts the records in each group: --```Kusto -Perf -| where TimeGenerated > ago(1h) -| summarize count() by ObjectName -``` --Sometimes it makes sense to define groups by multiple dimensions. Each unique combination of these values defines a separate group: --```Kusto -Perf -| where TimeGenerated > ago(1h) -| summarize count() by ObjectName, CounterName -``` --Another common use is to perform mathematical or statistical calculations on each group. The following example calculates the average `CounterValue` for each computer: --```Kusto -Perf -| where TimeGenerated > ago(1h) -| summarize avg(CounterValue) by Computer -``` --Unfortunately, the results of this query are meaningless because we mixed together different performance counters. To make the results more meaningful, calculate the average separately for each combination of `CounterName` and `Computer`: --```Kusto -Perf -| where TimeGenerated > ago(1h) -| summarize avg(CounterValue) by Computer, CounterName -``` --### Summarize by a time column -Grouping results can also be based on a time column or another continuous value. Simply summarizing `by TimeGenerated`, though, would create groups for every single millisecond over the time range because these values are unique. --To create groups based on continuous values, it's best to break the range into manageable units by using `bin`. The following query analyzes `Perf` records that measure free memory (`Available MBytes`) on a specific computer. It calculates the average value of each 1-hour period over the last 7 days: --```Kusto -Perf -| where TimeGenerated > ago(7d) -| where Computer == "ContosoAzADDS2" -| where CounterName == "Available MBytes" -| summarize avg(CounterValue) by bin(TimeGenerated, 1h) -``` --To make the output clearer, you can select to display it as a time chart, which shows the available memory over time. -<!-- convertborder later --> --## Frequently asked questions --This section provides answers to common questions. --### Why am I seeing duplicate records in Azure Monitor Logs? --Occasionally, you might notice duplicate records in Azure Monitor Logs. This duplication is typically from one of the following two conditions: - -- Components in the pipeline have retries to ensure reliable delivery at the destination. Occasionally, this capability might result in duplicates for a small percentage of telemetry items.-- If the duplicate records come from a virtual machine, you might have both the Log Analytics agent and Azure Monitor Agent installed. If you still need the Log Analytics agent installed, configure the Log Analytics workspace to no longer collect data that's also being collected by the data collection rule used by Azure Monitor Agent.---## Next steps --- To learn more about using string data in a log query, see [Work with strings in Azure Monitor log queries](/azure/data-explorer/kusto/query/samples?&pivots=azuremonitor#string-operations).-- To learn more about aggregating data in a log query, see [Advanced aggregations in Azure Monitor log queries](/azure/data-explorer/write-queries#advanced-aggregations).-- To learn how to join data from multiple tables, see [Joins in Azure Monitor log queries](/azure/data-explorer/kusto/query/samples?&pivots=azuremonitor#joins).-- Get documentation on the entire Kusto Query Language in the [KQL language reference](/azure/kusto/query/). |
| azure-monitor | Ingest Logs Event Hub | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/ingest-logs-event-hub.md | - Title: Ingest events from Azure Event Hubs into Azure Monitor Logs (Preview) -description: Ingest logs from Event Hubs into Azure Monitor Logs ----- Previously updated : 12/28/2023---# Customer intent: As a DevOps engineer, I want to ingest data from an event hub into a Log Analytics workspace so that I can monitor logs that I send to Azure Event Hubs. ---# Tutorial: Ingest events from Azure Event Hubs into Azure Monitor Logs (Public Preview) --[Azure Event Hubs](../../event-hubs/event-hubs-about.md) is a big data streaming platform that collects events from multiple sources to be ingested by Azure and external services. This article explains how to ingest data directly from an event hub into a Log Analytics workspace. ---In this tutorial, you learn how to: --> [!div class="checklist"] -> * Create a destination table for event hub data in your Log Analytics workspace -> * Create a data collection endpoint -> * Create a data collection rule -> * Grant the data collection rule permissions to the event hub -> * Associate the data collection rule with the event hub --## Prerequisites --To send events from Azure Event Hubs to Azure Monitor Logs, you need these resources, *all in the same region*: --- [Log Analytics workspace](../logs/quick-create-workspace.md) where you have at least [contributor rights](../logs/manage-access.md#azure-rbac).-- Your Log Analytics workspace needs to be [linked to a dedicated cluster](../logs/logs-dedicated-clusters.md#link-a-workspace-to-a-cluster) or to have a [commitment tier](../logs/cost-logs.md#commitment-tiers).-- [Event Hubs namespace](/azure/event-hubs/event-hubs-features#namespace) that permits public network access. Private Link and Network Security Perimeters (NSP) are currently not supported.-- [Event hub](/azure/event-hubs/event-hubs-create) with events. You can send events to your event hub by following the steps in [Send and receive events in Azure Event Hubs tutorials](../../event-hubs/event-hubs-create.md#next-steps) or by [configuring the diagnostic settings of Azure resources](../essentials/create-diagnostic-settings.md).--## Supported regions --Azure Monitor currently supports ingestion from Event Hubs in these regions: --| Americas | Europe | Middle East | Africa | Asia Pacific | -| - | - | - | - | - | -| Brazil South | France Central | UAE North | South Africa North | Australia Central | -| Brazil Southeast | North Europe | | | Australia East | -| Canada Central | Norway East | | | Australia Southeast | -| Canada East | Switzerland North | | | Central India | -| East US | Switzerland West | | | East Asia | -| East US 2 | UK South | | | Japan East | -| South Central US | UK West | | | Jio India West | -| West US | West Europe | | | Korea Central | -| West US 3 | | | | Southeast Asia | --## Collect required information --You need your subscription ID, resource group name, workspace name, workspace resource ID, and event hub instance resource ID in subsequent steps: --1. Navigate to your workspace in the **Log Analytics workspaces** menu and select **Properties** and copy your **Subscription ID**, **Resource group**, and **Workspace name**. You'll need these details to create resources in this tutorial. -- :::image type="content" source="media/ingest-logs-event-hub/create-custom-table-prepare.png" lightbox="media/ingest-logs-event-hub/create-custom-table-prepare.png" alt-text="Screenshot showing Log Analytics workspace overview screen with subscription ID, resource group name, and workspace name highlighted."::: --1. Select **JSON** to open the **Resource JSON** screen and copy the workspace's **Resource ID**. You'll need the workspace resource ID to create a data collection rule. -- :::image type="content" source="media/ingest-logs-event-hub/log-analytics-workspace-id.png" lightbox="media/ingest-logs-event-hub/log-analytics-workspace-id.png" alt-text="Screenshot showing the Resource JSON screen with the workspace resource ID highlighted."::: --1. Navigate to your event hub instance, select **JSON** to open the **Resource JSON** screen, and copy the event hub instance's **Resource ID**. You'll need the event hub instance's resource ID to associate the data collection rule with the event hub. -- :::image type="content" source="media/ingest-logs-event-hub/event-hub-resource-id.png" lightbox="media/ingest-logs-event-hub/event-hub-resource-id.png" alt-text="Screenshot showing the Resource JSON screen with the event hub resource ID highlighted."::: -## Create a destination table in your Log Analytics workspace --Before you can ingest data, you need to set up a destination table. You can ingest data into custom tables and [supported Azure tables](../logs/logs-ingestion-api-overview.md#supported-tables). --To create a custom table into which to ingest events, in the Azure portal: --1. Select the **Cloud Shell** button and ensure the environment is set to **PowerShell**. -- :::image type="content" source="media/ingest-logs-event-hub/create-custom-table-open-cloud-shell.png" lightbox="media/ingest-logs-event-hub/create-custom-table-open-cloud-shell.png" alt-text="Screenshot showing how to open Cloud Shell."::: ---1. Run this PowerShell command to create the table, providing the table name (`<table_name>`) in the JSON (that too with suffix *_CL* in case of custom table), and setting the `<subscription_id>`, `<resource_group_name>`, `<workspace_name>`, and `<table_name>` values in the `Invoke-AzRestMethod -Path` command: -- ```PowerShell - $tableParams = @' - { - "properties": { - "schema": { - "name": "<table_name>", - "columns": [ - { - "name": "TimeGenerated", - "type": "datetime", - "description": "The time at which the data was ingested." - }, - { - "name": "RawData", - "type": "string", - "description": "Body of the event." - }, - { - "name": "Properties", - "type": "dynamic", - "description": "Additional message properties." - } - ] - } - } - } - '@ - - Invoke-AzRestMethod -Path "/subscriptions/<subscription_id>/resourcegroups/<resource_group_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>/tables/<table_name>?api-version=2021-12-01-preview" -Method PUT -payload $tableParams - ``` --> [!IMPORTANT] -> - Column names must start with a letter and can consist of up to 45 alphanumeric characters and underscores (`_`). -> - `_ResourceId`, `id`, `_ResourceId`, `_SubscriptionId`, `TenantId`, `Type`, `UniqueId`, and `Title` are reserved column names. -> - Column names are case-sensitive. Make sure to use the correct case in your data collection rule. --## Create a data collection endpoint --To collect data with a data collection rule, you need a data collection endpoint: --1. [Create a data collection endpoint](../essentials/data-collection-endpoint-overview.md#create-a-data-collection-endpoint). -- > [!IMPORTANT] - > Create the data collection endpoint in the same region as your Log Analytics workspace. --1. From the data collection endpoint's Overview screen, select **JSON View**. -- :::image type="content" source="media/ingest-logs-event-hub/data-collection-endpoint-details.png" lightbox="media/ingest-logs-event-hub/data-collection-rule-details.png" alt-text="Screenshot that shows the data collection endpoint Overview screen."::: --1. Copy the **Resource ID** for the data collection rule. You'll use this information in the next step. -- :::image type="content" source="media/ingest-logs-event-hub/data-collection-rule-json-view.png" lightbox="media/ingest-logs-event-hub/data-collection-rule-json-view.png" alt-text="Screenshot that shows the data collection endpoint JSON view."::: - -## Create a data collection rule --Azure Monitor uses [data collection rules](../essentials/data-collection-rule-overview.md) to define which data to collect, how to transform that data, and where to send the data. --To create a data collection rule in the Azure portal: --1. In the portal's search box, type in *template* and then select **Deploy a custom template**. -- :::image type="content" source="media/tutorial-workspace-transformations-api/deploy-custom-template.png" lightbox="media/tutorial-workspace-transformations-api/deploy-custom-template.png" alt-text="Screenshot to deploy custom template."::: --1. Select **Build your own template in the editor**. -- :::image type="content" source="media/tutorial-workspace-transformations-api/build-custom-template.png" lightbox="media/tutorial-workspace-transformations-api/build-custom-template.png" alt-text="Screenshot to build template in the editor."::: --1. Paste the Resource Manager template below into the editor and then select **Save**. -- :::image type="content" source="media/tutorial-workspace-transformations-api/edit-template.png" lightbox="media/tutorial-workspace-transformations-api/edit-template.png" alt-text="Screenshot to edit Resource Manager template."::: -- Notice the following details in the data collection rule below: -- - `identity` - Defines which type of [managed identity](../../active-directory/managed-identities-azure-resources/overview.md) to use. In our example, we use system-assigned identity. You can also [configure user-assigned managed identity](#configure-user-assigned-managed-identity-optional). - - - `dataCollectionEndpointId` - Resource ID of the data collection endpoint. - - `streamDeclarations` - Defines which data to ingest from the event hub (incoming data). The stream declaration can't be modified. - - - `TimeGenerated` - The time at which the data was ingested from event hub to Azure Monitor Logs. - - `RawData` - Body of the event. For more information, see [Read events](../../event-hubs/event-hubs-features.md#read-events). - - `Properties` - User properties from the event. For more information, see [Read events](../../event-hubs/event-hubs-features.md#read-events). - - - `datasources` - Specifies the [event hub consumer group](../../event-hubs/event-hubs-features.md#consumer-groups) and the stream to which you ingest the data. - - `destinations` - Specifies all of the destinations where the data will be sent. You can [ingest data to one or more Log Analytics workspaces](../essentials/data-collection-transformations.md#). - - `dataFlows` - Matches the stream with the destination workspace and specifies the transformation query and the destination table. In our example, we ingest data to the custom table we created previously. You can also [ingest into a supported Azure table](#ingest-log-data-into-an-azure-table-optional). - - `transformKql` - Specifies a transformation to apply to the incoming data (stream declaration) before it's sent to the workspace. In our example, we set `transformKql` to `source`, which doesn't modify the data from the source in any way, because we're mapping incoming data to a custom table we've created specifically with the corresponding schema. If you're ingesting data to a table with a different schema or to filter data before ingestion, [define a data collection transformation](../essentials/data-collection-transformations.md#multiple-destinations). -- ```json - { - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "dataCollectionRuleName": { - "type": "string", - "metadata": { - "description": "Specifies the name of the data collection Rule to create." - } - }, - "workspaceResourceId": { - "type": "string", - "metadata": { - "description": "Specifies the Azure resource ID of the Log Analytics workspace to use." - } - }, - "endpointResourceId": { - "type": "string", - "metadata": { - "description": "Specifies the Azure resource ID of the data collection endpoint to use." - } - }, - "tableName": { - "type": "string", - "metadata": { - "description": "Specifies the name of the table in the workspace." - } - }, - "consumerGroup": { - "type": "string", - "metadata": { - "description": "Specifies the consumer group of event hub." - }, - "defaultValue": "$Default" - } - }, - "resources": [ - { - "type": "Microsoft.Insights/dataCollectionRules", - "name": "[parameters('dataCollectionRuleName')]", - "location": "[resourceGroup().location]", - "apiVersion": "2022-06-01", - "identity": { - "type": "systemAssigned" - }, - "properties": { - "dataCollectionEndpointId": "[parameters('endpointResourceId')]", - "streamDeclarations": { - "Custom-MyEventHubStream": { - "columns": [ - { - "name": "TimeGenerated", - "type": "datetime" - }, - { - "name": "RawData", - "type": "string" - }, - { - "name": "Properties", - "type": "dynamic" - } - ] - } - }, - "dataSources": { - "dataImports": { - "eventHub": { - "consumerGroup": "[parameters('consumerGroup')]", - "stream": "Custom-MyEventHubStream", - "name": "myEventHubDataSource1" - } - } - }, - "destinations": { - "logAnalytics": [ - { - "workspaceResourceId": "[parameters('workspaceResourceId')]", - "name": "MyDestination" - } - ] - }, - "dataFlows": [ - { - "streams": [ - "Custom-MyEventHubStream" - ], - "destinations": [ - "MyDestination" - ], - "transformKql": "source", - "outputStream": "[concat('Custom-', parameters('tableName'))]" - } - ] - } - } - ] - } - ``` -1. On the **Custom deployment** screen, specify a **Subscription** and **Resource group** to store the data collection rule and then provide values for the parameters defined in the template, including: -- - **Region** - Region for the data collection rule. Populated automatically based on the resource group you select. - - **Data Collection Rule Name** - Give the rule a name. - - **Workspace Resource ID** - See [Collect required information](#collect-required-information). - - **Endpoint Resource ID** - Generated when you [create the data collection endpoint](#create-a-data-collection-endpoint). - - **Table Name** - The name of the destination table. In our example, and whenever you use a custom table, the table name must end with the suffix *_CL*. If you're ingesting data to an Azure table, enter the table name - for example, `Syslog` - without the suffix. - - **Consumer Group** - By default, the consumer group is set to `$Default`. If needed, change the value to a different [event hub consumer group](../../event-hubs/event-hubs-features.md#consumer-groups). -- :::image type="content" source="media/ingest-logs-event-hub/data-collection-rule-custom-template-deployment.png" lightbox="media/ingest-logs-event-hub/data-collection-rule-custom-template-deployment.png" alt-text="Screenshot showing the Custom Template Deployment screen with the deployment values for the data collection rule set up in this tutorial."::: --1. Select **Review + create** and then **Create** when you review the details. --1. When the deployment is complete, expand the **Deployment details** box, and select your data collection rule to view its details. Select **JSON View**. -- :::image type="content" source="media/ingest-logs-event-hub/data-collection-rule-details.png" lightbox="media/ingest-logs-event-hub/data-collection-rule-details.png" alt-text="Screenshot that shows the Data Collection Rule Overview screen."::: --1. Copy the **Resource ID** for the data collection rule. You'll use this information in the next step. -- :::image type="content" source="media/ingest-logs-event-hub/data-collection-rule-json-view.png" lightbox="media/ingest-logs-event-hub/data-collection-rule-json-view.png" alt-text="Screenshot that shows the data collection rule JSON view."::: --### Configure user-assigned managed identity (optional) --To configure your data collection rule to support [user-assigned identity](../../active-directory/managed-identities-azure-resources/how-manage-user-assigned-managed-identities.md), in the example above, replace: --```json - "identity": { - "type": "systemAssigned" - }, -``` --with: --```json - "identity": { - "type": "userAssigned", - "userAssignedIdentities": { - "<identity_resource_Id>": { - } - } - }, -``` --To find the `<identity_resource_Id>` value, navigate to your user-assigned managed identity resource in the Azure portal, select **JSON** to open the **Resource JSON** screen and copy the managed identity's **Resource ID**. ---### Ingest log data into an Azure table (optional) --To ingest data into a [supported Azure table](../logs/logs-ingestion-api-overview.md#supported-tables): --1. In the data collection rule, change `outputStream`: -- From: `"outputStream": "[concat('Custom-', parameters('tableName'))]"` - - To: `"outputStream": "outputStream": "[concat(Microsoft-', parameters('tableName'))]"` - -1. In `transformKql`, [define a transformation](../essentials/data-collection-transformations-structure.md#transformation-structure) that sends the ingested data into the target columns in the destination Azure table. --## Grant the event hub permission to the data collection rule --With [managed identity](../../active-directory/managed-identities-azure-resources/overview.md), you can give any event hub, or Event Hubs namespace, permission to send events to the data collection rule and data collection endpoint you created. When you grant the permissions to the Event Hubs namespace, all event hubs within the namespace inherit the permissions. --1. From the event hub or Event Hubs namespace in the Azure portal, select **Access Control (IAM)** > **Add role assignment**. -- :::image type="content" source="media/ingest-logs-event-hub/event-hub-add-role-assignment.png" lightbox="media/ingest-logs-event-hub/event-hub-add-role-assignment.png" alt-text="Screenshot that shows the Access control screen for the data collection rule."::: --1. Select **Azure Event Hubs Data Receiver** and select **Next**. -- :::image type="content" source="media/ingest-logs-event-hub/event-hub-data-receiver-role-assignment.png" lightbox="media/ingest-logs-event-hub/event-hub-data-receiver-role-assignment.png" alt-text="Screenshot that shows the Add Role Assignment screen for the event hub with the Azure Event Hubs Data Receiver role highlighted."::: --1. Select **Managed identity** for **Assign access to** and click **Select members**. Select **Data collection rule**, search for your data collection rule by name, and click **Select**. -- :::image type="content" source="media/ingest-logs-event-hub/assign-access-to-managed-identity.png" lightbox="media/ingest-logs-event-hub/assign-access-to-managed-identity.png" alt-text="Screenshot that shows how to assign access to managed identity."::: --1. Select **Review + assign** and verify the details before saving your role assignment. -- :::image type="content" source="media/ingest-logs-event-hub/event-hub-add-role-assignment-save.png" lightbox="media/ingest-logs-event-hub/event-hub-add-role-assignment-save.png" alt-text="Screenshot that shows the Review and Assign tab of the Add Role Assignment screen."::: --## Associate the data collection rule with the event hub --The final step is to associate the data collection rule to the event hub from which you want to collect events. --You can associate a single data collection rule with multiple event hubs that share the same [consumer group](../../event-hubs/event-hubs-features.md#consumer-groups) and ingest data to the same stream. Alternatively, you can associate a unique data collection rule to each event hub. --> [!IMPORTANT] -> You must associate at least one data collection rule to the event hub to ingest data from an event hub. When you delete all data collection rule associations related to the event hub, you'll stop ingesting data from the event hub. --To create a data collection rule association in the Azure portal: --1. In the Azure portal's search box, type in *template* and then select **Deploy a custom template**. --1. Select **Build your own template in the editor**. --1. Paste the Resource Manager template below into the editor and then select **Save**. -- ```JSON - { - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "eventHubResourceID": { - "type": "string", - "metadata": { - "description": "Specifies the Azure resource ID of the event hub to use." - } - }, - "associationName": { - "type": "string", - "metadata": { - "description": "The name of the association." - } - }, - "dataCollectionRuleID": { - "type": "string", - "metadata": { - "description": "The resource ID of the data collection rule." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/dataCollectionRuleAssociations", - "apiVersion": "2021-09-01-preview", - "scope": "[parameters('eventHubResourceId')]", - "name": "[parameters('associationName')]", - "properties": { - "description": "Association of data collection rule. Deleting this association will break the data collection for this event hub.", - "dataCollectionRuleId": "[parameters('dataCollectionRuleId')]" - } - } - ] - } - ``` --1. On the **Custom deployment** screen, specify a **Subscription** and **Resource group** to store the data collection rule association and then provide values for the parameters defined in the template, including: -- - **Region** - Populated automatically based on the resource group you select. - - **Event Hub Instance Resource ID** - See [Collect required information](#collect-required-information). - - **Association Name** - Give the association a name. - - **Data Collection Rule ID** - Generated when you [create the data collection rule](#create-a-data-collection-rule). - - :::image type="content" source="media/ingest-logs-event-hub/data-collection-rule-association-custom-template-deployment.png" lightbox="media/ingest-logs-event-hub/data-collection-rule-association-custom-template-deployment.png" alt-text="Screenshot showing the Custom Template Deployment screen with the deployment values for the data collection rule association set up in this tutorial."::: --1. Select **Review + create** and then **Create** when you review the details. --## Check your destination table for ingested events --Now that you've associated the data collection rule with your event hub, Azure Monitor Logs will ingest all existing events whose [retention period](/azure/event-hubs/event-hubs-features#event-retention) hasn't expired and all new events. --To check your destination table for ingested events: --1. Navigate to your workspace and select **Logs**. -1. Write a simple query in the query editor and select **Run**: -- ```kusto - <table_name> - ``` - - You should see events from your event hub. --## Clean up resources --In this tutorial, you created the following resources: --- Custom table -- Data collection endpoint-- Data collection rule-- Data collection rule association--Evaluate whether you still need these resources. Delete the resources you don't need individually, or delete all of these resources at once by deleting the resource group. Resources you leave running can cost you money. --To stop ingesting data from the event hub, [delete all data collection rule associations](/rest/api/monitor/data-collection-rule-associations/delete) related to the event hub, or [delete the data collection rules](/rest/api/monitor/data-collection-rules/delete) themselves. These actions also reset event hub [checkpointing](/azure/event-hubs/event-hubs-features#checkpointing). --## Known issues and limitations --- If you transfer a subscription between Microsoft Entra directories, you need to follow the steps described in [Known issues with managed identities for Azure resources](/azure/active-directory/managed-identities-azure-resources/known-issues#transferring-a-subscription-between-azure-ad-directories) to continue ingesting data.-- You can ingest messages of up to 64 KB from Event Hubs to Azure Monitor Logs.--## Next steps --Learn more about to: --- [Create a custom table](../logs/create-custom-table.md#create-a-custom-table).-- [Create a data collection endpoint](../essentials/data-collection-endpoint-overview.md#create-a-data-collection-endpoint).-- [Update an existing data collection rule](../essentials/data-collection-rule-edit.md). |
| azure-monitor | Kql Machine Learning Azure Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/kql-machine-learning-azure-monitor.md | - Title: Detect and analyze anomalies with KQL in Azure Monitor -description: Learn how to use KQL machine learning tools for time series analysis and anomaly detection in Azure Monitor Log Analytics. ----- Previously updated : 08/12/2024-# Customer intent: As a data analyst, I want to use the native machine learning capabilities of Azure Monitor Logs to gain insights from my log data without having to export data outside of Azure Monitor. ---# Tutorial: Detect and analyze anomalies using KQL machine learning capabilities in Azure Monitor --The Kusto Query Language (KQL) includes machine learning operators, functions and plugins for time series analysis, anomaly detection, forecasting, and root cause analysis. Use these KQL capabilities to perform advanced data analysis in Azure Monitor without the overhead of exporting data to external machine learning tools. --In this tutorial, you learn how to: --> [!div class="checklist"] -> * Create a time series -> * Identify anomalies in a time series -> * Tweak anomaly detection settings to refine results -> * Analyze the root cause of anomalies --> [!NOTE] -> This tutorial provides links to a Log Analytics demo environment in which you can run the KQL query examples. The data in the demo environment is dynamic, so the query results aren't the same as the query results shown in this article. However, you can implement the same KQL queries and principals in your own environment and all [Azure Monitor tools that use KQL](log-query-overview.md). --## Prerequisites --- An Azure account with an active subscription. [Create an account for free](https://azure.microsoft.com/free/?WT.mc_id=A261C142F).-- A workspace with log data.---## Create a time series --Use the KQL `make-series` operator to create a time series. --Let's create a time series based on logs in the [Usage table](/azure/azure-monitor/reference/tables/usage), which holds information about how much data each table in a workspace ingests every hour, including billable and non-billable data. --This query uses `make-series` to chart the total amount of billable data ingested by each table in the workspace every day, over the past 21 days: --<a href="https://portal.azure.com#@ec7cb332-9a0a-4569-835a-ce7658e8444e/blade/Microsoft_Azure_Monitoring_Logs/DemoLogsBlade/resourceId/%2FDemo/source/LogsBlade.AnalyticsShareLinkToQuery/q/H4sIAAAAAAAAA6VSu04DMRDs8xWrVHdSyKsEpQggQQoKUPiAvfNecorPF%252By1IiMKfoPf40tYO5cEBaWiHY9nd2ZWE4NjtMx1QzCD6UTdwGgEyzXtcVDIBG0FLEgiObI1uQGUrTdcmxUUWG6gsm2TOKW3lsz%252BX0%252BLPBnViY9P2gL%252BXzl%252Bqiwm7W7vx3YnkkwGuAWHzVZT5GPv1eGKDtMZC8F39P35ZQnQoA7vMq%252F3Abs1CbIU4QcyZGWSgoJ4R6KYpUDaSmHIcNVmx9zyfDg8e%252BtM53meZkZ3Fo1sULU2mXnzZMNAtFe1MdErMkym1%252BMxzJ8OoVS1ddFukBVVjOwCT2NHq80pzDTu6Gjhbmutk%252B3ZDPpsPfXjZgtTaq%252BkBqMDFAdKTOwgZsl5LUdCLGINbuhqXxPMS%252FaoU64z55vs2aO0xiEHRRXGP9K4CJ%252Blmeq8nGTq7UKW8kDbX60XAe5l02XYpmbvLMkE9%252FeedO1Sj2FvjCNfzMgxKbKJWq7jqYvGS8Jc59rFEPDE%252BAERMgnLLgMAAA%253D%253D" target="_blank">Click to run query</a> --```kusto -let starttime = 21d; // The start date of the time series, counting back from the current date -let endtime = 0d; // The end date of the time series, counting back from the current date -let timeframe = 1d; // How often to sample data -Usage // The table weΓÇÖre analyzing -| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range -| where IsBillable == "true" // Include only billable data in the result set -| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type -| render timechart // Renders results in a timechart -``` --In the resulting chart, you can clearly see some anomalies - for example, in the `AzureDiagnostics` and `SecurityEvent` data types: ---Next, we'll use a KQL function to list all of the anomalies in a time series. --> [!NOTE] -> For more information about `make-series` syntax and usage, see [make-series operator](/azure/data-explorer/kusto/query/make-seriesoperator). --## Find anomalies in a time series --The `series_decompose_anomalies()` function takes a series of values as input and extracts anomalies. --Let's give the result set of our time series query as input to the `series_decompose_anomalies()` function: --<a href="https://portal.azure.com#@ec7cb332-9a0a-4569-835a-ce7658e8444e/blade/Microsoft_Azure_Monitoring_Logs/DemoLogsBlade/resourceId/%2FDemo/source/LogsBlade.AnalyticsShareLinkToQuery/q/H4sIAAAAAAAAA61Uu3LUQBDM%252FRWDI6lKfoZQFxjsAgcEYBO75rQj3eLVrtiH70QR8Bv8Hl%252FC7Ejn09mYiExa9fRMd8%252FKUIQQ0ceoO4IFnJ%252BpN3ByAjf5DBRGgsZ5iCsCQQTymkIFtUs2atvCEut7aLzrBFMn78mOhQeGucmqifl0JL6y6j%252FQ5qLGoxBPE39wa3BNJAvRQcCuN5TxePAlYEsZcZu74ZLP1%252FT75y9PgBbN8J37HfyA9Yr45JaJ35Mlz50ULCmuiRkLscg1CocCW1c8OlaWx8dPvk2Ky7KUnlmdR9vuBH9L5IeKuVttbdaKEc7OX5%252BewsVHViCYRvuQ5Q48osomvoAzOMG03Zkp7R4VXYe32hiRvVjAYfSJDvNk17Y2SVEAZ80Ayy0mW7Zl8xSS4f2gyGwd3tPRmBNc1DGhEWMXIXXFp4QcWxxKUNRgruG8mfiJnZLny1ZKcC%252BYyR%252Bon8W%252BHOCSJ70deon2nSfuEJ4vlNFBghxGYZHxrIU2vCequLCuQyO48XG4qZ2nCq42PdVcJwpLFjPS3SmqXde7QHe4LS1mXkjiQhHG3DbRYx3zy4TmvQ48jhv9dSn2KeYs5%252BZmrx%252BOaNNnihl7tifP75pCucRZldUTf2cAfhfjtsoy8fP6ueq%252F0e%252F5MAMYZ1sReyVTjr6j97yItSQhjv%252FDtPJxPXfjvco7k0k%252FU0zesmvGANfpqB9I%252FLTUorwoetD85BgkO0XTnJDyoMzde%252FeVT%252Fb9qWZmVnvS9oyodmsxX7FLarTlMdcrXa%252F4R2VSZ8VTL%252BPm2ILjfyYLx2Uo5oz5WoRaloMRYbpXQaAjDIJEwPcuI6f77rxiB237B35S8SykBQAA" target="_blank">Click to run query</a> --```kusto -let starttime = 21d; // Start date for the time series, counting back from the current date -let endtime = 0d; // End date for the time series, counting back from the current date -let timeframe = 1d; // How often to sample data -Usage // The table weΓÇÖre analyzing -| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range -| where IsBillable == "true" // Includes only billable data in the result set -| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type -| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage) // Scores and extracts anomalies based on the output of make-series -| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies() -| where Anomalies != 0 // Returns all positive and negative deviations from expected usage -| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return -| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering -``` --This query returns all usage anomalies for all tables in the last three weeks: ---Looking at the query results, you can see that the function: --- Calculates an expected daily usage for each table.-- Compares actual daily usage to expected usage.-- Assigns an anomaly score to each data point, indicating the extent of the deviation of actual usage from expected usage.-- Identifies positive (`1`) and negative (`-1`) anomalies in each table. --> [!NOTE] -> For more information about `series_decompose_anomalies()` syntax and usage, see [series_decompose_anomalies()](/azure/data-explorer/kusto/query/series-decompose-anomaliesfunction). --## Tweak anomaly detection settings to refine results --It's good practice to review initial query results and make tweaks to the query, if necessary. Outliers in input data can affect the function's learning, and you might need to adjust the function's anomaly detection settings to get more accurate results. --Filter the results of the `series_decompose_anomalies()` query for anomalies in the `AzureDiagnostics` data type: ---The results show two anomalies on June 14 and June 15. Compare these results with the chart from our first `make-series` query, where you can see other anomalies on May 27 and 28: ---The difference in results occurs because the `series_decompose_anomalies()` function scores anomalies relative to the expected usage value, which the function calculates based on the full range of values in the input series. --To get more refined results from the function, exclude the usage on the June 15 - which is an outlier compared to the other values in the series - from the function's learning process. --The [syntax of the `series_decompose_anomalies()` function](/azure/data-explorer/kusto/query/series-decompose-anomaliesfunction) is: --`series_decompose_anomalies (Series[Threshold,Seasonality,Trend,Test_points,AD_method,Seasonality_threshold])` --`Test_points` specifies the number of points at the end of the series to exclude from the learning (regression) process. --To exclude the last data point, set `Test_points` to `1`: --<a href="https://portal.azure.com#@ec7cb332-9a0a-4569-835a-ce7658e8444e/blade/Microsoft_Azure_Monitoring_Logs/DemoLogsBlade/resourceId/%2FDemo/source/LogsBlade.AnalyticsShareLinkToQuery/q/H4sIAAAAAAAAA61Uy27UQBC85yuaXGJLzmMjcQHtISgR5IAiIJyjXk%252FbazKeMfPYXSMO%252FAa%252Fx5fQ0%252FbuegPhxM0eV1dXV%252FVYUwAf0IXQtARzuJyp13B%252BDp%252FSGSgMBJV1EJYEgvDkGvIFlDaa0JgaFlg%252BQuVsK5gyOkdmKDzSzE1GjcwXA%252FGNUf%252BBNhVVDoV4VPzOrsFWgQwECx7bTlPC49FnjzUlxH3qhgs%252BX9OvHz8dARrU%252FTfud%252FQd1kvik3smfkuGHHdSsKCwJmbMxCJbKewzrG22cyzPz86efBsnzvNceqbpHJp6P%252FDXSK4vmLtujEmzYoDZ5auLC7h6zxMIpmqcT%252BP2LFElE5%252FBaRxhjdmbKe12E936N43WMvZ8DsfBRTpOym5NqaMiD9boHhZbTLJsy%252BbIR837QYHZWnyk0yEnuCpDRC3Gzn1ssw8RObbQ56CowlTDeTPxEzslz%252BetlOCeMZM%252FUDeJfdHDNSu977sh2rvrO9ZIG85fZVfGtqhloYbH%252FlNpHRVws%252BmoZCWiPGeRwzwPikrbdtbTA25Ls8mMxezsZXE6K05wVZ8UMwlWGP0QzyY4LEN6GYt5fT3PawcbbQxdDCmyiYcFl6UAUrC7JFeoI23dH71O1q9OadOlVhNRya3A49sqUzZydHnxxO4JgN%252FFx60hifjP%252BqlZf6M%252FsG8C0NbUYsqNqPQiH53jvSwdDTep%252F5fX%252BW5b9%252FJepBVKpB8pRGfYXa2B65rQrEh8N1SjvChaNfxkGSQrRqNOiEkoc3fOfuGTQ3%252BKacIHox0YUey3abpx11Q1hmWul0255P%252BWjq0RT53ITbF5y79QHhwXPpsyplviS1kiRvjxmnmBDjDwEgEvQkKO1986xQ6a%252BjfngHTtswUAAA%253D%253D" target="_blank">Click to run query</a> --```kusto -let starttime = 21d; // Start date for the time series, counting back from the current date -let endtime = 0d; // End date for the time series, counting back from the current date -let timeframe = 1d; // How often to sample data -Usage // The table weΓÇÖre analyzing -| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range -| where IsBillable == "true" // Includes only billable data in the result set -| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type -| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage,1.5,-1,'avg',1) // Scores and extracts anomalies based on the output of make-series, excluding the last value in the series - the Threshold, Seasonality, and Trend input values are the default values for the function -| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies() -| where Anomalies != 0 // Returns all positive and negative deviations from expected usage -| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return -| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering -``` --Filter the results for the `AzureDiagnostics` data type: ---All of the anomalies in the chart from our first `make-series` query now appear in the result set. --## Analyze the root cause of anomalies --Comparing expected values to anomalous values helps you understand the cause of the differences between the two sets. --The KQL `diffpatterns()` plugin compares two data sets of the same structure and finds patterns that characterize differences between the two data sets. --This query compares `AzureDiagnostics` usage on June 15, the extreme outlier in our example, with the table usage on other days: --<a href="https://portal.azure.com#@ec7cb332-9a0a-4569-835a-ce7658e8444e/blade/Microsoft_Azure_Monitoring_Logs/DemoLogsBlade/resourceId/%2FDemo/source/LogsBlade.AnalyticsShareLinkToQuery/q/H4sIAAAAAAAAA61SwY7UMAw9M19hzWVbqbvLckVzGDGIIxJwX3kTtw2bJiVxKEUc%252BAf%252BkC%252FBaTu77SBu9JLGdp793rMlhsgYmE1HcIBXd%252Fo13N7CxxwDjUxQ%252BwDcEkwVkYKhWIHyybFxDTygeoQ6%252BG6qUSkEcvPDnRVscnpBfjkDv3X6P8Ci8x3a8ZSBDlM4w9yj1sWVxvGqur6roMNHuj%252FniomlryVbYOOLZbBSvhVhXwvYmI%252Fcduky4VcwtEa1YOKUshgZ6mTtVG%252FcM5WArqEc8SkAfcOutwTF6BModBCot6iktBWgwXALCLEnZWqjoMWgr5XXpDety93xewp0Mtg4H9mo%252BGL3Q6BZOMBxo4Sp6zXRTzLQO3IUJKtLOBzWwlWwXz3ey%252FW9kAj5Evdl1uSodZSprUo2A4g7NnUuRyxtOp%252FFib01PAsUKCYruyVmGcceePCZDOZIhN8%252Ff20mR2Hy3F3YDfJPsJkfHogHIgeXVj7tb1ne3PzT5kzoRLVxFC%252FNOq%252Fil0RhlOZ98J9J8ZbhB4riqFi3wplZz7IIqhfWnILL7nxFmzIzLZb0yEzBxWIDuJb7wotp2De%252B61FkhBRRhvTur52cF2hWuxGPwlK69PsDddtehdwDAAA%253D" target="_blank">Click to run query</a> --```kusto -let starttime = 21d; // Start date for the time series, counting back from the current date -let endtime = 0d; // End date for the time series, counting back from the current date -let anomalyDate = datetime_add('day',-1, make_datetime(startofday(ago(endtime)))); // Start of day of the anomaly date, which is the last full day in the time range in our example (you can replace this with a specific hard-coded anomaly date) -AzureDiagnostics -| extend AnomalyDate = iff(startofday(TimeGenerated) == anomalyDate, "AnomalyDate", "OtherDates") // Adds calculated column called AnomalyDate, which splits the result set into two data sets ΓÇô AnomalyDate and OtherDates -| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Defines the time range for the query -| project AnomalyDate, Resource // Defines which columns to return -| evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate") // Compares usage on the anomaly date with the regular usage pattern -``` --The query identifies each entry in the table as occurring on *AnomalyDate* (June 15) or *OtherDates*. The `diffpatterns()` plugin then splits these data sets - called A (*OtherDates* in our example) and B (*AnomalyDate* in our example) - and returns a few patterns that contribute to the differences in the two sets: ---Looking at the query results, you can see the following differences: --- There are 24,892,147 instances of ingestion from the *CH1-GEARAMAAKS* resource on all other days in the query time range, and no ingestion of data from this resource on June 15. Data from the *CH1-GEARAMAAKS* resource accounts for 73.36% of the total ingestion on other days in the query time range and 0% of the total ingestion on June 15.-- There are 2,168,448 instances of ingestion from the *NSG-TESTSQLMI519* resource on all other days in the query time range, and 110,544 instances of ingestion from this resource on June 15. Data from the *NSG-TESTSQLMI519* resource accounts for 6.39% of the total ingestion on other days in the query time range and 25.61% of ingestion on June 15. - -Notice that, on average, there are 108,422 instances of ingestion from the *NSG-TESTSQLMI519* resource during the 20 days that make up the *other days* period (divide 2,168,448 by 20). Therefore, the ingestion from the *NSG-TESTSQLMI519* resource on June 15 isn't significantly different from the ingestion from this resource on other days. However, because there's no ingestion from *CH1-GEARAMAAKS* on June 15, the ingestion from *NSG-TESTSQLMI519* makes up a significantly greater percentage of the total ingestion on the anomaly date as compared to other days. --The *PercentDiffAB* column shows the absolute percentage point difference between A and B (|PercentA - PercentB|), which is the main measure of the difference between the two sets. By default, the `diffpatterns()` plugin returns difference of over 5% between the two data sets, but you can tweak this threshold. For example, to return only differences of 20% or more between the two data sets, you can set `| evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate", "~", 0.20)` in the query above. The query now returns only one result: ---> [!NOTE] -> For more information about `diffpatterns()` syntax and usage, see [diff patterns plugin](/azure/data-explorer/kusto/query/diffpatternsplugin). --## Next steps --Learn more about: --- [Log queries in Azure Monitor](log-query-overview.md).-- [How to use Kusto queries](/azure/data-explorer/kusto/query/tutorial?pivots=azuremonitor).-- [Analyze logs in Azure Monitor with KQL](/training/modules/analyze-logs-with-kql/) |
| azure-monitor | Log Analytics Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/log-analytics-overview.md | - Title: Overview of Log Analytics in Azure Monitor -description: This overview describes Log Analytics, which is a tool in the Azure portal used to edit and run log queries for analyzing data in Azure Monitor logs. - Previously updated : 12/28/2023----# Overview of Log Analytics in Azure Monitor --Log Analytics is a tool in the Azure portal that's used to edit and run log queries against data in the Azure Monitor Logs store. --You might write a simple query that returns a set of records and then use features of Log Analytics to sort, filter, and analyze them. Or you might write a more advanced query to perform statistical analysis and visualize the results in a chart to identify a particular trend. --Whether you work with the results of your queries interactively or use them with other Azure Monitor features, such as log search alerts or workbooks, Log Analytics is the tool that you'll use to write and test them. ---> [!TIP] -> This article describes Log Analytics and its features. If you want to jump right into a tutorial, see [Log Analytics tutorial](./log-analytics-tutorial.md). --Here's a video version of this tutorial: --> [!VIDEO https://www.youtube.com/embed/-aMecR2Nrfc] --## Start Log Analytics --To start Log Analytics in the Azure portal, on the **Azure Monitor** menu select **Logs**. You'll also see this option on the menu for most Azure resources. No matter where you start Log Analytics, the tool is the same. But the menu you use to start Log Analytics determines the data that's available. --If you start Log Analytics from the **Azure Monitor** menu or the **Log Analytics workspaces** menu, you'll have access to all the records in a workspace. If you select **Logs** from another type of resource, your data will be limited to log data for that resource. For more information, see [Log query scope and time range in Azure Monitor Log Analytics](./scope.md). -<!-- convertborder later --> --When you start Log Analytics, a dialog appears that contains [example queries](../logs/queries.md). The queries are categorized by solution. Browse or search for queries that match your requirements. You might find one that does exactly what you need. You can also load one to the editor and modify it as required. Browsing through example queries is a good way to learn how to write your own queries. --If you want to start with an empty script and write it yourself, close the example queries. Select **Queries** at the top of the screen to get them back. --> [!TIP] -> [Log Analytics simple mode](../logs/log-analytics-simple-mode.md) is currently in preview and available to a limited number of customers. To try it, select **Try Log Analytics simple mode** at the top right corner of the Log Analytics query editor. -> :::image type="content" source="media/log-analytics-explorer/try-new-log-analytics.png" alt-text="A GIF showing the Try new Log Analytics button."::: --## Log Analytics interface --The following image identifies four Log Analytics components. These four Log Analytics components are: --1. [Top action bar](#top-action-bar) -1. [Left sidebar](#left-sidebar) -1. [Query window](#query-window) -1. [Results window](#results-window) ---### Top action bar --The top bar has controls for working with a query in the query window. --| Option | Description | -|:|:| -| Scope | Specifies the scope of data used for the query. This could be all the data in a Log Analytics workspace or data for a particular resource across multiple workspaces. See [Query scope](./scope.md). | -| Run button | Run the selected query in the query window. You can also select **Shift+Enter** to run a query. | -| Time picker | Select the time range for the data available to the query. This action is overridden if you include a time filter in the query. See [Log query scope and time range in Azure Monitor Log Analytics](./scope.md). | -| Save button | Save the query to a [query pack](./query-packs.md). Saved queries are available from: <ul><li> The **Other** section in the **Queries** dialog for the workspace</li><li>The **Other** section in the **Queries** tab in the [left sidebar](#left-sidebar) for the workspace</ul> | - Share button | Copy a link to the query, the query text, or the query results to the clipboard. | -| New alert rule button | Open the Create an alert rule page. Use this page to [create an alert rule](../alerts/alerts-create-new-alert-rule.md?tabs=log) with an alert type of [log search alert](../alerts/alerts-types.md#log-alerts). The page opens with the [Conditions tab](../alerts/alerts-create-new-alert-rule.md?tabs=log#set-the-alert-rule-conditions) selected, and your query is added to the **Search query** field. | -| Export button | Export the results of the query to a CSV file or the query to Power Query Formula Language format for use with Power BI. | -| Pin to button | Pin the results of the query to an Azure dashboard or add them to an Azure workbook. | -| Format query button | Arrange the selected text for readability. | -| Search job mode toggle | [Run search jobs](./search-jobs.md). -| Queries button | Open the **Queries** dialog, which provides access to saved queries in the workspace. | --### Left sidebar --The sidebar on the left lists tables in the workspace, sample queries, functions, and filter options for the current query. --| Tab | Description | -|:|:| -| Tables | Lists the tables that are part of the selected scope. Select **Group by** to change the grouping of the tables. Hover over a table name to display a dialog with a description of the table and options to view its documentation and preview its data. Expand a table to view its columns. Double-click a table or column name to add it to the query. | -| Queries | List of example queries that you can open in the query window. This list is the same one that appears when you open Log Analytics. Select **Group by** to change the grouping of the queries. Double-click a query to add it to the query window or hover over it for other options. | -| Functions | Lists the [functions](./functions.md) in the workspace. | -| Filter | Creates filter options based on the results of a query. After you run a query, columns appear with different values from the results. Select one or more values, and then select **Apply & Run** to add a **where** command to the query and run it again. | --### Query window --The query window is where you edit your query. IntelliSense is used for KQL commands and color coding enhances readability. Select **+** at the top of the window to open another tab. --A single window can include multiple queries. A query can't include any blank lines, so you can separate multiple queries in a window with one or more blank lines. The current query is the one with the cursor positioned anywhere in it. --To run the current query, select the **Run** button or select **Shift+Enter**. --### Results window --The results of a query appear in the results window. By default, the results are displayed as a table. To display the results as a chart, select **Chart** in the results window. You can also add a **render** command to your query. --#### Results view --The results view displays query results in a table organized by columns and rows. Click to the left of a row to expand its values. Select the **Columns** dropdown to change the list of columns. Sort the results by selecting a column name. Filter the results by selecting the funnel next to a column name. Clear the filters and reset the sorting by running the query again. --Select **Group columns** to display the grouping bar above the query results. Group the results by any column by dragging it to the bar. Create nested groups in the results by adding more columns. --#### Chart view --The chart view displays the results as one of multiple available chart types. You can specify the chart type in a **render** command in your query. You can also select it from the **Visualization Type** dropdown. --| Option | Description | -|:|:| -| Visualization type | Type of chart to display. | -| X-axis | Column in the results to use for the x-axis. -| Y-axis | Column in the results to use for the y-axis. Typically, this is a numeric column. | -| Split by | Column in the results that defines the series in the chart. A series is created for each value in the column. | -| Aggregation | Type of aggregation to perform on the numeric values in the y-axis. | --## Relationship to Azure Data Explorer --If you've worked with the Azure Data Explorer web UI, Log Analytics should look familiar. That's because it's built on top of Azure Data Explorer and uses the same Kusto Query Language. --Log Analytics adds features specific to Azure Monitor, such as filtering by time range and the ability to create an alert rule from a query. Both tools include an explorer that lets you scan through the structure of available tables. The Azure Data Explorer web UI primarily works with tables in Azure Data Explorer databases. Log Analytics works with tables in a Log Analytics workspace. --## Next steps --- Walk through a [tutorial on using Log Analytics in the Azure portal](./log-analytics-tutorial.md).-- Walk through a [tutorial on writing queries](./get-started-queries.md). |
| azure-monitor | Log Analytics Simple Mode | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/log-analytics-simple-mode.md | - Title: Analyze data using Log Analytics Simple mode (Preview) -description: This article explains how to use Log Analytics Simple mode to explore and analyze data in Azure Monitor Logs. ---- Previously updated : 05/19/2024--# Customer intent: As an analyst or DevOps troubleshooter, I want to get insights from log data without using Kusto Query Language (KQL). ----# Analyze data using Log Analytics Simple mode (Preview) --Log Analytics now offers two modes that make log data simpler to explore and analyze for both basic and advanced users: --- **Simple mode** provides the most commonly used Azure Monitor Logs functionality in an intuitive, spreadsheet-like experience. Just point and click to filter, sort, and aggregate data to get to the insights you need 80% of the time. -- **KQL mode** gives advanced users the full power of Kusto Query Language (KQL) to derive deeper insights from their logs using the [Log Analytics query editor](log-analytics-overview.md).--You can switch seamlessly between Simple and KQL modes, and advanced users can share complex queries that anyone can continue working with in Simple mode. --This article explains how to use Log Analytics Simple mode to explore and analyze data in Azure Monitor Logs. --Here's a video that provides a quick overview of how to query logs in Log Analytics using both Simple and KQL modes: -<br> -->[!VIDEO https://www.youtube.com/embed/85Xxj5FhTk0?cc_load_policy=1&cc_lang_pref=auto] --## Try Log Analytics Simple mode --Simple mode is currently an opt-in experience. To try it, select **Try the new Log Analytics** at the top right corner of the Log Analytics query editor. You can switch back to the classic Log Analytics experience at any time. ---## How Simple mode works --Simple mode lets you [get started quickly by retrieving data from one or more tables with one click](#get-started-in-simple-mode). You then use a set of intuitive controls to [explore and analyze the retrieved data](#explore-and-analyze-data-in-simple-mode). --This section orients you with the controls available in Log Analytics Simple mode. ---### Top query bar --In Simple mode, the top bar has controls for working with data and switching to KQL mode. ---| Option | Description | -|:|:| -| **Time range** | Select the [time range](./scope.md) for the data available to the query. In KQL mode, if you set a different time range in your query, the time range you set in the time picker is overridden. | -|**Limit**|Configure the number of entries Log Analytics retrieves in Simple mode. The default limit is 1000. For more information on query limits, see [Configure query results limit](#configure-query-result-limit).| -|**Add**|Add filters, and apply Simple mode operators, as described in [Explore and analyze data in Simple mode](#explore-and-analyze-data-in-simple-mode).| -|**Simple/KQL mode**|Switch between Simple and KQL mode.| --### Left pane --The collapsible left pane gives you access to tables, example and saved queries, functions, and query history. --Pin the left pane to keep it open while you work, or maximize your query window by selecting an icon from the left pane only when you need it. ---| Option | Description | -|:|:| -| **Tables** | Lists the tables that are part of the selected scope. Select **Group by** to change the grouping of the tables. Hover over a table name to view the table's description and a link to its documentation. Expand a table to view its columns. Select a table to run a query on it. | -| **Queries** | Lists example and saved queries. This is the same list that's in the Queries Hub. Select **Group by** to change the grouping of the queries. Hover over a query to view the query's description. Select a query to run it.| -|**Functions**|Lists [functions](../logs/functions.md), which allow you to reuse predefined query logic in your log queries. | -|**Query history**|Lists your query history. Select a query to rerun it.| --### More tools --This section describes more tools available above the query area of the screen, as shown in this screenshot, from left to right. ---| Option | Description | -|:|:| -| **Tab context menu**|[Change query scope](scope.md) or rename, duplicate, or close tab. | -| **Save** | [Save a query to a query pack](../logs/save-query.md) or as a [function](functions.md), or pin your query to a [workbook](../visualize/workbooks-overview.md), an [Azure dashboard](../visualize/tutorial-logs-dashboards.md), or [Grafana dashboard](../visualize/grafana-plugin.md#pin-charts-from-the-azure-portal-to-azure-managed-grafana). | -| **Share** | Copy a link to your query, the query text, or query results, or [export data to Excel](../logs/log-excel.md), CSV, or [Power BI](../logs/log-powerbi.md). | -| **New alert rule** | [Create a new alert rule](../alerts/alerts-create-new-alert-rule.md#create-or-edit-an-alert-rule-in-the-azure-portal). | -| **Search job mode** | [Run a search job](../logs/search-jobs.md). | -| **Log Analytics settings**| Define default Log Analytics settings, including time zone, whether Log Analytics first opens in Simple or KQL mode, and whether to display tables with no data.| -| **Switch back to classic Logs** | Switch back to the [classic Log Analytics user interface](../logs/log-analytics-overview.md). | -| **Queries Hub** | Open the example queries dialog that appears when you first open Log Analytics. | --## Get started in Simple mode --When you select a table or a predefined query or function in Simple mode, Log Analytics automatically retrieves the relevant data for you to explore and analyze. --This lets you retrieve logs with one click whether you open Log Analytics in resource or workspace context. --To get started, you can: --- Click **Select a table** and select a table from the **Tables** tab to view table data.-- :::image type="content" source="media/log-analytics-explorer/log-analytics-select-table.png" alt-text="Screenshot that shows the Select a table button in Log Analytics." lightbox="media/log-analytics-explorer/log-analytics-select-table.png"::: -- Alternatively, select **Tables** from the left pane to view the list of tables in the workspace. -- :::image type="content" source="media/log-analytics-explorer/log-analytics-tables.png" alt-text="Screenshot that shows the Tables tab in Log Analytics." lightbox="media/log-analytics-explorer/log-analytics-tables.png"::: --- Use an existing query, such as a shared or [saved query](../logs/save-query.md), or an example query.-- :::image type="content" source="media/log-analytics-explorer/log-analytics-simple-mode-example-query.png" alt-text="Screenshot that shows an example query in Log Analytics." lightbox="media/log-analytics-explorer/log-analytics-simple-mode-example-query.png"::: --- Select a query from your query history.-- :::image type="content" source="media/log-analytics-explorer/log-analytics-query-history.png" alt-text="Screenshot that shows the query history in Log Analytics." lightbox="media/log-analytics-explorer/log-analytics-query-history.png"::: --- Select a [function](../logs/functions.md).-- :::image type="content" source="media/log-analytics-explorer/log-analytics-functions.png" alt-text="Screenshot that shows the functions tab in Log Analytics." lightbox="media/log-analytics-explorer/log-analytics-functions.png"::: -- > [!IMPORTANT] - > Functions let you reuse query logic and often require input parameters or additional context. In such cases, the function won't run until you switch to KQL mode and provide the required input. - -## Explore and analyze data in Simple mode --After you [get started in Simple mode](#get-started-in-simple-mode), you can explore and analyze data using the [top query bar](#top-query-bar). --> [!NOTE] -> The order in which you apply filters and operators affects your query and results. For example, if you apply a filter and then aggregate, Log Analytics applies the aggregation to the filtered data. If you aggregate and then filter, the aggregation is applied to the unfiltered data. --#### Change time range and number of records displayed --By default, Simple mode lists the latest 1,000 entries in the table from the last 24 hours. --To change the time range and number of records displayed, use the **Time range** and **Limit** selectors. For more information about result limit, see [Configure query result limit](#configure-query-result-limit). - ---#### Filter by column --1. Select **Add** and choose a column. -- :::image type="content" source="media/log-analytics-explorer/log-analytics-add-filter.png" alt-text="Screenshot that shows the Add filters menu that opens when you select Add in Log Analytics Simple mode." lightbox="media/log-analytics-explorer/log-analytics-add-filter.png"::: --1. Select a value to filter by, or enter text or numbers in the **Search** box. -- If you filter by selecting values from a list, you can select multiple values. If the list is long, you'll see a **Not all results are shown** message. Scroll to the bottom of the list and select **Load more results** to retrieve more values. - - :::image type="content" source="media/log-analytics-explorer/log-analytics-filter.png" alt-text="Screenshot that shows filter values for the OperationId column in Log Analytics Simple mode." lightbox="media/log-analytics-explorer/log-analytics-filter.png"::: --#### Search for entries that have a specific value in the table --1. Select **Search**. -- :::image type="content" source="media/log-analytics-explorer/log-analytics-search.png" alt-text="Screenshot that shows the Search option in Log Analytics Simple mode." lightbox="media/log-analytics-explorer/log-analytics-search.png"::: --1. Enter a string in the **Search this table** box and select **Apply**. -- Log Analytics filters the table to show only entries that contain the string you entered. --> [!IMPORTANT] -> We recommend using **Filter** if you know which column holds the data you're searching for. The [search operator is substantially less performant](../logs/query-optimization.md#avoid-unnecessary-use-of-search-and-union-operators) than filtering, and might not function well on large volumes of data. --#### Aggregate data --1. Select **Aggregate**. -1. Select a column to aggregate by and select an operator to aggregate by, as described in [Use aggregation operators](#use-aggregation-operators). -- :::image type="content" source="media/log-analytics-explorer/log-analytics-aggregate.png" alt-text="Screenshot that shows the aggregation operators in the Aggregate table window in Log Analytics." lightbox="media/log-analytics-explorer/log-analytics-aggregate.png"::: --#### Show or hide columns --1. Select **Show columns**. -1. Select or clear columns to show or hide them, then select **Apply**. -- :::image type="content" source="media/log-analytics-explorer/log-analytics-show-column.png" alt-text="Screenshot that shows the Show columns window in Log Analytics." lightbox="media/log-analytics-explorer/log-analytics-show-column.png"::: --#### Sort by column --1. Select **Sort**. -1. Select a column to sort by. -1. Select **Ascending** or **Descending**, then select **Apply**. -- :::image type="content" source="media/log-analytics-explorer/log-analytics-sort.png" alt-text="Screenshot that shows the Sort by column window in Log Analytics." lightbox="media/log-analytics-explorer/log-analytics-sort.png"::: --1. Select **Sort** again to sort by another column. --### Use aggregation operators --Use aggregation operators to summarize data from multiple rows, as described in this table. --| Operator | Description | -|:|:| -|[count](/azure/data-explorer/kusto/query/count-operator)|Counts the number of times each distinct value exists in the column.| -|[dcount](/azure/data-explorer/kusto/query/dcount-aggfunction)|For the `dcount` operator, you select two columns. The operator counts the total number of distinct values in the second column correlated to each value in the first column. For example, this shows the distinct number of result codes for successful and failed operations:<br/> :::image type="content" source="media/log-analytics-explorer/log-analytics-dcount.png" alt-text="Screenshot that shows the result of an aggregation using the dcount operator in Azure Monitor Log Analytics." lightbox="media/log-analytics-explorer/log-analytics-dcount.png"::: | -|[sum](/azure/data-explorer/kusto/query/sum-aggregation-function)<br/>[avg](/azure/data-explorer/kusto/query/avg-aggregation-function)<br/>[max](/azure/data-explorer/kusto/query/max-aggregation-function)<br/>[min](/azure/data-explorer/kusto/query/min-aggregation-function)|For these operators, you select two columns. The operators calculate the sum, average, maximum, or minimum of all values in the second column for each value in the first column. For example, this shows the total duration of each operation in milliseconds for the past 24 hours:<br/>:::image type="content" source="media/log-analytics-explorer/log-analytics-sum.png" alt-text="Screenshot that shows the results of an aggregation using the sum operator in Azure Monitor Log Analytics." lightbox="media/log-analytics-explorer/log-analytics-sum.png"::: | --> [!IMPORTANT] -> Basic logs tables don't support aggregation using the `avg` and `sum` operators. -## Switch modes --To switch modes, select **Simple mode** or **KQL mode** from the dropdown in the top right corner of the query editor. ---When you begin to query logs in Simple mode and then switch to KQL mode, the query editor is prepopulated with the KQL query related to your Simple mode analysis. You can then edit and continue working with the query. ---For straightforward queries on a single table, Log Analytics displays the table name at the right of the top query bar in Simple mode. For more complex queries, Log Analytics displays **User Query** at the left of the top query bar. Select **User Query** to return to the query editor and modify your query at any time. ---## Configure query result limit --1. Select **Limit** to open the **Limit results** window. -- :::image type="content" source="media/log-analytics-explorer/log-analytics-result-limits.png" alt-text="Screenshot that shows the limit results window in Log Analytics." lightbox="media/log-analytics-explorer/log-analytics-result-limits.png"::: --1. Select one of the preset limits, or enter a custom limit. - - The maximum number of results that you can retrieve in the Log Analytics portal experience, in both Simple mode and KQL mode, is 30,000. However, when you [share a Log Analytics query](#more-tools) with an integrated tool, or use the query in a [search job](search-jobs.md), the query limit is set based on the tools you choose. -- Select **Max. limit** to return the maximum number of results provided by any of the tools available on the **Share** window or using a search job. -- :::image type="content" source="media/log-analytics-explorer/log-analytics-share-query.png" alt-text="Screenshot that shows the Share window in Log Analytics." lightbox="media/log-analytics-explorer/log-analytics-share-query.png"::: -- This table lists the maximum result limits of Azure Monitor log queries using the various tools: -- |Tool|Description|Max. limit| - |||| - |Log Analytics|Queries you run in the Azure portal.|30,000| - |[Excel](../logs/log-excel.md), [Power BI](../logs/log-powerbi.md), [Log Analytics Query API](../logs/api/overview.md)|Queries you use in Excel and Power BI, which are integrated with Log Analytics, and queries you run using the API.|500,000| - |[Search job](search-jobs.md)|Azure Monitor reingests the results of a query your run in search job mode into a new table in your Log Analytics.|1,000,000| ---## Next steps -- Walk through a [tutorial on using KQL mode in Log Analytics](../logs/log-analytics-tutorial.md).-- Access the complete [reference documentation for KQL](/azure/kusto/query/). |
| azure-monitor | Log Analytics Tutorial | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/log-analytics-tutorial.md | - Title: "Log Analytics tutorial" -description: Learn how to use Log Analytics in Azure Monitor to build and run a log query and analyze its results in the Azure portal. ---- Previously updated : 09/05/2024----# Log Analytics tutorial --Log Analytics is a tool in the Azure portal to edit and run log queries from data collected by Azure Monitor logs and interactively analyze their results. You can use Log Analytics queries to retrieve records that match particular criteria, identify trends, analyze patterns, and provide various insights into your data. --This tutorial walks you through the Log Analytics interface, gets you started with some basic queries, and shows you how you can work with the results. You learn how to: --> [!div class="checklist"] -> * Understand the log data schema. -> * Write and run simple queries, and modify the time range for queries. -> * Filter, sort, and group query results. -> * View, modify, and share visuals of query results. -> * Load, export, and copy queries and results. --> [!IMPORTANT] -> In this tutorial, you use Log Analytics features to build one query and use another example query. When you're ready to learn the syntax of queries and start directly editing the query itself, read the [Kusto Query Language tutorial](/azure/data-explorer/kusto/query/tutorial?pivots=azuremonitor). That tutorial walks you through example queries that you can edit and run in Log Analytics. It uses several of the features that you learn in this tutorial. --## Prerequisites --This tutorial uses the [Log Analytics demo environment](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring_Logs/DemoLogsBlade), which includes plenty of sample data that supports the sample queries. You can also use your own Azure subscription, but you might not have data in the same tables. --> [!NOTE] -> Log Analytics has two modes - Simple and KQL. *This tutorial walks you through KQL mode.* For information on Simple mode, see [Analyze data using Log Analytics Simple mode (Preview)](log-analytics-simple-mode.md). --## Open Log Analytics --Open the [Log Analytics demo environment](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring_Logs/DemoLogsBlade), or select **Logs** from the Azure Monitor menu in your subscription. This step sets the initial scope to a Log Analytics workspace so that your query selects from all data in that workspace. If you select **Logs** from an Azure resource's menu, the scope is set to only records from that resource. For details about the scope, see [Log query scope](./scope.md). --You can view the scope in the upper-left corner of the Logs experience, below the name of your active query tab. If you're using your own environment, you see an option to select a different scope. This option isn't available in the demo environment. ---## View table information --The left side of the screen includes the **Tables** tab, where you can inspect the tables that are available in the current scope. These tables are grouped by **Solution** by default, but you can change their grouping or filter them. --Expand the **Log Management** solution and locate the **AppRequests** table. You can expand the table to view its schema, or hover over its name to show more information about it. ---* Select the link below **Useful links** (in this example [AppRequests](/azure/azure-monitor/reference/tables/AppRequests)) to go to the table reference that documents each table and its columns. --* Select **Preview data** to have a quick look at a few recent records in the table. This preview can be useful to ensure it's the data you're expecting before you run a query with it. ---## Write a query --Let's write a query by using the **AppRequests** table. Double-click its name or hover over it and click on **Use in editor** to add it to the query window. You can also type directly in the window. You can even get IntelliSense which helps completing the names of tables in the current scope and Kusto Query Language (KQL) commands. --This is the simplest query that we can write. It just returns all the records in a table. Run it by selecting the **Run** button or by selecting **Shift+Enter** with the cursor positioned anywhere in the query text. ---You can see that we do have results. The number of records that the query returns appears in the lower-right corner. The maximum number of results that you can retrieve in the Log Analytics portal experience is 30,000. --### Time range --All queries return records generated within a set time range. By default, the query returns records generated in the last 24 hours. --You can set a different time range by using the [where operator](/azure/data-explorer/kusto/query/tutorial?pivots=azuremonitor#filter-by-boolean-expression-where-1) in the query. You can also use the **Time range** dropdown list at the top of the screen. --Let's change the time range of the query by selecting **Last 12 hours** from the **Time range** dropdown. Select **Run** to return the results. --> [!NOTE] -> Changing the time range by using the **Time range** dropdown doesn't change the query in the query editor. ---### Multiple filters --Let's reduce our results further by adding another filter condition. A query can include any number of filters to target exactly the set of records that you want. On the left side of the screen where the **Tables** tab is active, select the **Filter** tab instead. If you can't find it, click on the ellipsis to view more tabs. --On the **Filter** tab, select **Load old filters** to view the top 10 values for each filter. ---Select **Get Home/Index** under **Name**, then click on **Apply & Run**. ---## Analyze results --In addition to helping you write and run queries, Log Analytics provides features for working with the results. Start by expanding a record to view the values for all of its columns by clicking the chevron on the left side of the row. ---Select the name of any column to sort the results by that column. Select the filter icon next to it to provide a filter condition. This action is similar to adding a filter condition to the query itself, except that this filter is cleared if the query is run again. Use this method if you want to quickly analyze a set of records as part of interactive analysis. --Set a filter on the **DurationMs** column to limit the records to those that took more than **150** milliseconds. --1. The results table allows you to filter just like in Excel. Select the ellipsis in the **Name** column header. -1. Uncheck **Select All**, then search for **Get Home/Index** and check it. Filters are automatically applied to your results. ---### Search through query results --Let's search through the query results by using the search box at the top right of the results pane. --Enter **Chicago** in the query results search box, and select the arrows to find all instances of this string in your search results. ---### Reorganize and summarize data --To better visualize your data, you can reorganize and summarize the data in the query results based on your needs. --Select **Columns** to the right of the results pane to open the **Columns** sidebar. ---In the sidebar, you see a list of all available columns. Drag the **Url** column into the **Row Groups** section. Results are now organized by that column, and you can collapse each group to help you with your analysis. This action is similar to adding a filter condition to the query, but instead of refetching data from the server, you're processing the data your original query returned. When you run the query again, Log Analytics retrieves data based on your original query. Use this method if you want to quickly analyze a set of records as part of interactive analysis. ---### Create a pivot table --To analyze the performance of your pages, create a pivot table. --In the **Columns** sidebar, select **Pivot Mode**. --Select **Url** and **DurationMs** to show the total duration of all calls to each URL. --To view the maximum call duration to each URL, select **sum(DurationMs)** > **max**. ---Now let's sort the results by longest maximum call duration by selecting the **max(DurationMs)** column in the results pane. ---## Work with charts --Let's look at a query that uses numerical data that we can view in a chart. Instead of building a query, we select an example query. --Select **Queries** on the left pane. This pane includes example queries that you can add to the query window. If you're using your own workspace, you should have various queries in multiple categories.<!-- If you're using the demo environment, you might see only a single **Log Analytics workspaces** category. Expand that to view the queries in the category. --> --Load the **Function Error rate** query in the **Applications** category to the editor. To do so, double-click the query or hover over the query name to show more information, then select **Load to editor**. ---Notice that the new query is separated from the other by a blank line. A query in KQL ends when it encounters a blank line, making them separate queries. ---Click anywhere in a query to select it, then click on the **Run** button to run it. ---To view the results in a graph, select **Chart** on the results pane. Notice that there are various options for working with the chart, such as changing it to another type. ---## Next steps --Now that you know how to use Log Analytics, complete the tutorial on using log queries: -> [!div class="nextstepaction"] -> [Write Azure Monitor log queries](get-started-queries.md) |
| azure-monitor | Log Analytics Workspace Health | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/log-analytics-workspace-health.md | - Title: Monitor Log Analytics workspace health -description: This article how to monitor the health of a Log Analytics workspace and set up alerts about latency issues specific to the Log Analytics workspace or related to known Azure service issues. ---- Previously updated : 11/23/2023--#Customer-intent: As a Log Analytics workspace administrator, I want to know when there are latency issues in a Log Analytics workspace, so I can act to resolve the issue, contact Microsoft for support, or track that is Azure is meeting its SLA. ---# Monitor Log Analytics workspace health --[Azure Service Health](../../service-health/overview.md) monitors the health of your cloud resources, including Log Analytics workspaces. When a Log Analytics workspace is healthy, data you collect from resources in your IT environment is available for querying and analysis in a relatively short period of time, known as [latency](../logs/data-ingestion-time.md). This article explains how to view the health status of your Log Analytics workspace, set up workspace health status alerts, and view workspace health metrics. --Azure Service Health monitors: --- [Resource health](../../service-health/resource-health-overview.md): information about the health of your individual cloud resources, such as a specific Log Analytics workspace. -- [Service health](../../service-health/service-health-overview.md): information about the health of the Azure services and regions you're using, which might affect your Log Analytics workspace, including communications about outages, planned maintenance activities, and other health advisories.--## Permissions required --- To view Log Analytics workspace health, you need `*/read` permissions to the Log Analytics workspace, as provided by the [Log Analytics Reader built-in role](./manage-access.md#log-analytics-reader), for example.-- To set up health status alerts, you need `Microsoft.Insights/ActivityLogAlerts/Write` permissions to the Log Analytics workspace, as provided by the [Monitoring Contributor built-in role](../roles-permissions-security.md#monitoring-contributor), for example.--## View Log Analytics workspace health and set up health status alerts ---To view your Log Analytics workspace health and set up health status alerts: - -1. Select **Resource health** from the Log Analytics workspace menu. -- The **Resource health** screen shows: -- - **Health history**: Indicates whether Azure Service Health has detected latency or query execution issues in the specific Log Analytics workspace. To further investigate latency issues related to your workspace, see [Investigate latency](#investigate-log-analytics-workspace-health-issues). - - **Azure service issues**: Displayed when a known issue with an Azure service might affect latency in the Log Analytics workspace. Select the message to view details about the service issue in Azure Service Health. - - > [!NOTE] - > - Service health notifications do not indicate that your Log Analytics workspace is necessarily affected by the know service issue. If your Log Analytics workspace resource health status is **Available**, Azure Service Health did not detect issues in your workspace. - > - Resource Health excludes data types for which long ingestion latency is expected. For example, Application Insights data types that calculate the application map data and are known to add latency. -- - :::image type="content" source="media/data-ingestion-time/log-analytics-workspace-latency.png" lightbox="media/data-ingestion-time/log-analytics-workspace-latency.png" alt-text="Screenshot that shows the Resource health screen for a Log Analytics workspace."::: -- This table describes the possible resource health status values for a Log Analytics workspace: -- | Resource health status | Description | - |-|-| - |Available| [Average latency](../logs/data-ingestion-time.md#average-latency) and no query execution issues detected.| - |Unavailable|Higher than average latency detected.| - |Degraded|Query failures detected.| - |Unknown|Currently unable to determine Log Analytics workspace health because you haven't run queries or ingested data to this workspace recently.| - -1. To set up health status alerts, you can either [enable recommended out-of-the-box alert](../alerts/alerts-overview.md#recommended-alert-rules) rules, or manually create new alert rules. - - To enable the recommended alert rules: - 1. Select **Alerts** > **Enable recommended alert rules**. - - The **Enable recommended alert rules** pane opens with a list of recommended alert rules for your Log Analytics workspace. - - :::image type="content" source="media/data-ingestion-time/log-analytics-workspace-recommended-alerts.png" alt-text="Screenshot of recommended alert rules pane."::: -- 1. In the **Alert me if** section, select all of the rules you want to enable. - 1. In the **Notify me by** section, select the way you want to be notified if an alert is triggered. - 1. Select **Use an existing action group**, and enter the details of the existing action group if you want to use an action group that already exists. - 1. Select **Enable**. -- - To create a new alert rule: - 1. Select **Add resource health alert**. - - The **Create alert rule** wizard opens, with the **Scope** and **Condition** panes prepopulated. By default, the rule triggers alerts all status changes in all Log Analytics workspaces in the subscription. If necessary, you can edit and modify the scope and condition at this stage. - - :::image type="content" source="media/data-ingestion-time/log-analytics-workspace-latency-alert-rule.png" lightbox="media/data-ingestion-time/log-analytics-workspace-latency-alert-rule.png" alt-text="Screenshot that shows the Create alert rule wizard for Log Analytics workspace latency issues."::: -- 1. Follow the rest of the steps in [Create a new alert rule in the Azure portal](../alerts/alerts-create-new-alert-rule.md#create-or-edit-an-alert-rule-in-the-azure-portal). --## View Log Analytics workspace health metrics --Azure Monitor exposes a set of metrics that provide insight into Log Analytics workspace health. --To view Log Analytics workspace health metrics: --1. Select **Metrics** from the Log Analytics workspace menu. This opens [Metrics Explorer](../essentials/metrics-charts.md) in context of your Log Analytics workspace. -1. In the **Metric** field, select one of the Log Analytics workspace health metrics: -- | Category | Metric name | Scope | Description | - | - | - | - | - | - | SLI | AvailabilityRate_Query | Workspace | Percentage of successful user queries in the Log Analytics workspace within the selected time range.<br>This number includes all queries that return 2XX, 4XX, and 504 response codes; in other words, all user queries that don't result in a service error. | - | SLI | Ingestion Time | Workspace or table | Time in seconds it took since record recieved in Azure Monitor Logs cloud service until it was available for queries. It is recommended to examine ingestion time for specific tables. See more details [here](./data-ingestion-time.md). | - | SLI | Ingestion Volume | Workspace or table | Number of records ingested into a workspace or a table. | - | User Queries | Query count | Workspace | Total number of user queries in the Log Analytics workspace within the selected time range.<br>This number includes only user-initiated queries, and doesn't include queries initiated by Sentinel rules and alert-related queries. | - | User Queries | Query failure count | Workspace | Total number of failed user queries in the Log Analytics workspace within the selected time range.<br>This number includes all queries that return 5XX response codes - except 504 *Gateway Timeout* - which indicate an error related to the application gateway or the backend server.| - | [Data Export](./logs-data-export.md) | Bytes Exported | Workspace | Total number of bytes exported to destination from Log Analytics workspace within the selected time range. The size of data exported is the number of bytes in the exported JSON formatted data. 1 GB = 10^9 bytes. | - | [Data Export](./logs-data-export.md) | Export Failures | Workspace | Total number of failed export requests in the Log Analytics workspace within the selected time range. <br>This number includes export failures that can result by Azure Monitor, destination resource availability, or throttling. | - | [Data Export](./logs-data-export.md) | Records exported | Workspace | Total number of records exported from Log Analytics workspace within the selected time range. | --## Investigate Log Analytics workspace health issues --To investigate Log Analytics workspace health issues: --- Use [Log Analytics Workspace Insights](../logs/log-analytics-workspace-insights-overview.md), which provides a unified view of your workspace usage, performance, health, agent, queries, and change log.-- [Query](./queries.md) the data in your Log Analytics workspace to [understand which factors are contributing greater than expected latency in your workspace](../logs/data-ingestion-time.md). -- [Use the `_LogOperation` function to view and set up alerts about operational issues](../logs/monitor-workspace.md) logged in your Log Analytics workspace.-- --## Next steps --Learn more about: --- [Log Analytics Workspace Insights](../logs/log-analytics-workspace-insights-overview.md).-- [Querying log data in Azure Monitor Logs](../logs/get-started-queries.md).- |
| azure-monitor | Log Analytics Workspace Insights Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/log-analytics-workspace-insights-overview.md | - Title: Log Analytics Workspace Insights -description: An overview of Log Analytics Workspace Insights usage, performance, health, agents, queries, and change log. ----- Previously updated : 12/28/2023----# Log Analytics Workspace Insights --Log Analytics Workspace Insights provides comprehensive monitoring of your workspaces through a unified view of your workspace usage, performance, health, agent, queries, and change log. This article helps you understand how to onboard and use Log Analytics Workspace Insights. --## Permissions required --- You need `Microsoft.OperationalInsights/workspaces/read` permissions to the Log Analytics workspace whose insights you want to see, as provided by the [Log Analytics Reader built-in role](./manage-access.md#log-analytics-reader), for example..-- To run the additional usage queries, you need `*/read` permissions, as provided by the [Log Analytics Reader built-in role](./manage-access.md#log-analytics-reader), for example.---## Overview of your Log Analytics workspaces --When you access Log Analytics Workspace Insights through Azure Monitor Insights, the **At scale** perspective is shown. Here you can: --- See how your workspaces are spread across the globe.-- Review their retention.-- See color-coded capping and license details.-- Choose a workspace to see its insights.---To start Log Analytics Workspace Insights at scale: --1. Sign in to the [Azure portal](https://portal.azure.com/). --1. Select **Monitor** from the left pane in the Azure portal. Under the **Insights Hub** section, select **Log Analytics Workspace Insights**. --## View insights for a Log Analytics workspace --You can use insights in the context of a specific workspace to display rich data and analytics of the workspace performance, usage, health, agents, queries, and changes. ---To access Log Analytics Workspace Insights: --1. Open Log Analytics Workspace Insights from Azure Monitor (as previously explained). --1. Select a workspace to drill into. --Or use these steps: --1. In the Azure portal, select **Log Analytics Workspaces**. --1. Choose a Log Analytics workspace. --1. Under **Monitoring**, select **Insights** on the workspace menu. --The data is organized in tabs. The time range on top defaults to 24 hours and applies to all tabs. Some charts and tables use a different time range, as indicated in their titles. --## Overview tab --On the **Overview** tab, you can see: --* **Main statistics and settings**: - - The monthly ingestion volume of the workspace. - - How many machines sent heartbeats. That is, the machines that are connected to this workspace in the selected time range. - - Machines that haven't sent heartbeats in the last hour in the selected time range. - - The data retention period set. - - The daily cap set and how much data was already ingested on the recent day. --* **Top five tables**: Charts that analyze the five most-ingested tables over the past month: - - The volume of data ingested to each table. - - The daily ingestion to each of them to visually display spikes or dips. - - Ingestion anomalies: A list of identified spikes and dips in ingestion to these tables. --## Usage tab --This tab provides a dashboard display. --### Usage dashboard --This tab provides information on the workspace's usage. The dashboard subtab shows ingestion data displayed in tables. It defaults to the five most-ingested tables in the selected time range. These same tables are displayed on the **Overview** page. Use the **Workspace Tables** dropdown to choose which tables to display. ---* **Main grid**: Tables are grouped by solutions with information about each table: - - How much data was ingested to it during the selected time range. - - The percentage this table takes from the entire ingestion volume during the selected time range: This information helps identify the tables that affect your ingestion the most. In the following screenshot, you can see `AzureDiagnostics` and `ContainerLog` alone stand for more than two-thirds (64%) of the data ingested to this workspace. - - The last update of usage statistics regarding each table: We normally expect usage statistics to refresh hourly. Refreshing usage statistics is a recurrent service-internal operation. A delay in refreshing that data is only noted so that you know to interpret the data correctly. There's no action you should take. - - **Billable**: Indicates which tables are billed for and which are free. --* **Table-specific details**: At the bottom of the page, you can see detailed information on the table selected in the main grid: - - **Ingestion volume**: How much data was ingested to the table from each resource and how it spreads over time. Resources ingesting more than 30% of the total volume sent to this table are marked with a warning sign. - - **Ingestion latency**: How much time ingestion took, analyzed for the 50th, 90th, or 95th percentiles of requests sent to this table. The top chart in this area depicts the total ingestion time of the requests for the selected percentile from end to end. It spans from the time the event occurred until it was ingested to the workspace. - - The chart below it shows separately the latency of the agent, which is the time it took the agent to send the log to the workspace. The chart also shows the latency of the pipeline, which is the time it took the service to process the data and push it to the workspace. - :::image type="content" source="media/log-analytics-workspace-insights-overview/workspace-usage-ingestion-latency.png" alt-text="Screenshot that shows the workspace Usage tab Ingestion Latency subtab." lightbox="media/log-analytics-workspace-insights-overview/workspace-usage-ingestion-latency.png"::: --### Additional usage queries --The **Additional Queries** subtab exposes queries that run across all workspace tables (instead of relying on the usage metadata, which is refreshed hourly). Because the queries are much more extensive and less efficient, they don't run automatically. They can reveal interesting information about which resources send the most logs to the workspace and perhaps affect billing. ---One such query is **What Azure resources send most logs to this workspace** (showing the top 50). -In the demo workspace, you can clearly see that three Kubernetes clusters send far more data than all other resources combined. One cluster loads the workspace the most. ---## Health tab --This tab shows the workspace health state, when it was last reported, and operational [errors and warnings](../logs/monitor-workspace.md) retrieved from the `_LogOperation` table. For more information on the listed issues and mitigation steps, see [Monitor health of a Log Analytics workspace in Azure Monitor](../logs/monitor-workspace.md#categories). ---## Agents tab --This tab provides information on the agents that send logs to this workspace. --* **Operation errors and warnings**: These errors and warnings are related specifically to agents. They're grouped by the error/warning title to help you get a clearer view of different issues that might occur. They can be expanded to show the exact times and resources to which they refer. You can select **Run query in Logs** to query the `_LogOperation` table through the Logs experience to see the raw data and analyze it further. -* **Workspace agents**: These agents are the ones that sent logs to the workspace during the selected time range. You can see the types and health state of the agents. Agents marked **Healthy** aren't necessarily working well. This designation only indicates that they sent a heartbeat during the last hour. A more detailed health state is described in the grid. -* **Agents activity**: This grid shows information on either all agents or healthy or unhealthy agents. Here too **Healthy** only indicates that the agent sent a heartbeat during the last hour. To understand its state better, review the trend shown in the grid. It shows how many heartbeats this agent sent over time. The true health state can only be inferred if you know how the monitored resource operates. For example, if a computer is intentionally shut down at particular times, you can expect the agent's heartbeats to appear intermittently, in a matching pattern. --## Query Audit tab --Query auditing creates logs about the execution of queries on the workspace. If enabled, this data is beneficial to understanding and improving the performance, efficiency, and load for queries. To enable query auditing on your workspace or learn more about it, see [Audit queries in Azure Monitor Logs](../logs/query-audit.md). --#### Performance --This tab shows: --* **Query duration**: The 95th percentile and 50th percentile (median) duration in ms, over time. -* **Number of rows returned**: The 95th percentile and 50th percentile (median) of rows count, over time. -* **The volume of data processed**: The 95th percentile, 50th percentile, and the total of processed data in all requests, over time. -* **Response code**s: The distribution of response codes to all queries in the selected time range. ---### Slow and inefficient queries -The **Slow & Inefficient Queries** subtab shows two grids to help you identify slow and inefficient queries you might want to rethink. These queries shouldn't be used in dashboards or alerts because they'll create unneeded chronic load on your workspace. -* **Most resource-intensive queries**: The 10 most CPU-demanding queries, along with the volume of data processed (KB), the time range, and the text of each query. -* **Slowest queries**: The 10 slowest queries, along with the time range and text of each query. ---### Query users -The **Users** subtab shows user activity against this workspace: --* **Queries by user**: How many queries each user ran in the selected time range. -* **Throttled users**: Users that ran queries that were throttled because of over-querying the workspace. --## Change Log tab --This tab shows configuration changes made on the workspace during the last 90 days regardless of the time range selected. It also shows who made the changes. It's intended to help you monitor who changes important workspace settings, such as data capping or workspace license. ---## Next steps --To learn the scenarios that workbooks are designed to support and how to author new and customize existing reports, see [Create interactive reports with Azure Monitor workbooks](../visualize/workbooks-overview.md). |
| azure-monitor | Log Analytics Workspace Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/log-analytics-workspace-overview.md | - Title: Log Analytics workspace overview -description: Overview of Log Analytics workspace, which stores data for Azure Monitor Logs. - Previously updated : 07/20/2024--# Customer intent: As a Log Analytics administrator, I want to understand to set up and manage my workspace, so that I can best address my business needs, including data access, cost management, and workspace health. As a Log Analytics user, I want to understand the workspace configuration options available to me, so I can best address my analysis. ---# Log Analytics workspace overview --A Log Analytics workspace is a data store into which you can collect any type of log data from all of your Azure and non-Azure resources and applications. Workspace configuration options let you manage all of your log data in one workspace to meet the operations, analysis, and auditing needs of different personas in your organization through: --- Azure Monitor features, such as built-in [insights experiences](../insights/insights-overview.md), [alerts](../alerts/alerts-create-log-alert-rule.md), and [automatic actions](../autoscale/autoscale-overview.md)-- Other Azure services, such as [Microsoft Sentinel](/azure/sentinel/overview), [Microsoft Defender for Cloud](/azure/defender-for-cloud/defender-for-cloud-introduction), and [Logic Apps](/azure/connectors/connectors-azure-monitor-logs)-- Microsoft tools, such as [Power BI](log-powerbi.md) and [Excel](log-excel.md)-- Integration with custom and third-party applications--This article provides an overview of concepts related to Log Analytics workspaces. --> [!IMPORTANT] -> [Microsoft Sentinel](../../sentinel/overview.md) documentation uses the term *Microsoft Sentinel workspace*. This workspace is the same Log Analytics workspace described in this article, but it's enabled for Microsoft Sentinel. All data in the workspace is subject to Microsoft Sentinel pricing. --## Log tables --Each Log Analytics workspace contains multiple tables in which Azure Monitor Logs stores data you collect. --Azure Monitor Logs automatically creates tables required to store monitoring data you collect from your Azure environment. You [create custom tables](create-custom-table.md) to store data you collect from non-Azure resources and applications, based on the data model of the log data you collect and how you want to store and use the data. --Table management settings let you control access to specific tables, and manage the data model, retention, and cost of data in each table. For more information, see [Manage tables in a Log Analytics workspace](manage-logs-tables.md). ----## Data retention --A Log Analytics workspace retains data in two states - **interactive retention** and **long-term retention**. --During the interactive retention period, you retrieve the data from the table through queries, and the data is available for visualizations, alerts, and other features and services, based on the table plan. - -Each table in your Log Analytics workspace lets you retain data up to 12 years in low-cost, long-term retention. Retrieve specific data you need from long-term retention to interactive retention using a search job. This means that you manage your log data in one place, without moving data to external storage, and you get the full analytics capabilities of Azure Monitor on older data, when you need it. --For more information, see [Manage data retention in a Log Analytics workspace](data-retention-configure.md). --## Data access --Permission to access data in a Log Analytics workspace is defined by the [access control mode](manage-access.md#access-control-mode) setting on each workspace. You can give users explicit access to the workspace by using a [built-in or custom role](../roles-permissions-security.md). Or, you can allow access to data collected for Azure resources to users with access to those resources. --For more information, see [Manage access to log data and workspaces in Azure Monitor](manage-access.md). --## View Log Analytics workspace insights --[Log Analytics Workspace Insights](log-analytics-workspace-insights-overview.md) helps you manage and optimize your Log Analytics workspaces with a comprehensive view of your workspace usage, performance, health, ingestion, queries, and change log. ---## Transform data you ingest into your Log Analytics workspace --[Data collection rules (DCRs)](../essentials/data-collection-rule-overview.md) that define data coming into Azure Monitor can include transformations that allow you to filter and transform data before it's ingested into the workspace. Since all data sources don't yet support DCRs, each workspace can have a [workspace transformation DCR](../essentials/data-collection-transformations-workspace.md). --[Transformations](../essentials/data-collection-transformations.md) in the workspace transformation DCR are defined for each table in a workspace and apply to all data sent to that table, even if sent from multiple sources. These transformations only apply to workflows that don't already use a DCR. For example, [Azure Monitor agent](../agents/azure-monitor-agent-overview.md) uses a DCR to define data collected from virtual machines. This data won't be subject to any ingestion-time transformations defined in the workspace. --For example, you might have [diagnostic settings](../essentials/diagnostic-settings.md) that send [resource logs](../essentials/resource-logs.md) for different Azure resources to your workspace. You can create a transformation for the table that collects the resource logs that filters this data for only records that you want. This method saves you the ingestion cost for records you don't need. You might also want to extract important data from certain columns and store it in other columns in the workspace to support simpler queries. --## Cost --There's no direct cost for creating or maintaining a workspace. You're charged for the data you ingest into the workspace and for data retention, based on each table's [table plan](data-platform-logs.md#table-plans). --For information on pricing, see [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/). For guidance on how to reduce your costs, see [Azure Monitor best practices - Cost management](../best-practices-cost.md). If you're using your Log Analytics workspace with services other than Azure Monitor, see the documentation for those services for pricing information. --## Design a Log Analytics workspace architecture to address specific business needs --You can use a single workspace for all your data collection. However, you can also create multiple workspaces based on specific business requirements such as regulatory or compliance requirements to store data in specific locations, split billing, and resilience. --For considerations related to creating multiple workspaces, see [Design a Log Analytics workspace configuration](./workspace-design.md). ---## Next steps --- [Create a new Log Analytics workspace](quick-create-workspace.md).-- See [Design a Log Analytics workspace configuration](workspace-design.md) for considerations on creating multiple workspaces.-- [Learn about log queries to retrieve and analyze data from a Log Analytics workspace](./log-query-overview.md). |
| azure-monitor | Log Excel | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/log-excel.md | - Title: Integrate Log Analytics and Excel -description: Get a Log Analytics query into Excel and refresh results inside Excel. ---- Previously updated : 06/22/2022----# Integrate Log Analytics and Excel --You can integrate Azure Monitor Log Analytics and Microsoft Excel using M query and the Log Analytics API. This integration allows you to send up a certain number of records and MB of data. These limits are documented in the [Azure Monitor Log Analytics workspace limits](../service-limits.md#log-analytics-workspaces) in the Azure portal section. --> [!NOTE] -> Because Excel is a local client application, local hardware and software limitations impact it's performance and ability to process large sets of data. --## Prerequisites --To integrate Log Analytics and Excel, you need: --- [Excel](https://www.microsoft.com/en-us/microsoft-365/excel) local client application.-- A Log Analytics workspace that has some data. If needed, [create a diagnostic setting to send data to a Log Analytics workspace](../essentials/create-diagnostic-settings.md).---## Create your M query in Log Analytics --1. **Create and run your query** in Log analytics as you normally would. DonΓÇÖt worry if you hit the number of records limitation in the user interface. We recommend you use relative dates - like the ΓÇÿagoΓÇÖ function or the UI time picker - so Excel refreshes the right set of data. - -2. **Export Query** - Once you are happy with the query and its results, export the query to M using Log Analytics **Export to Power BI (M query)** menu choice under the *Export* menu: -- :::image type="content" source="media/log-excel/export-query.png" alt-text="Screenshot of Log Analytics query with the data and export option." border="true"::: ----Choosing this option downloads a .txt file containing the M code you can use in Excel. --The query shown above exports the following M code. HereΓÇÖs an example of the M code exported for the query in our example: --```m -/* -The exported Power Query Formula Language (M Language ) can be used with Power Query in Excel -and Power BI Desktop. -For Power BI Desktop follow the instructions below: -1) Download Power BI Desktop from https://powerbi.microsoft.com/desktop/ -2) In Power BI Desktop select: 'Get Data' -> 'Blank Query'->'Advanced Query Editor' -3) Paste the M Language script into the Advanced Query Editor and select 'Done' -*/ --let AnalyticsQuery = -let Source = Json.Document(Web.Contents("https://api.loganalytics.io/v1/workspaces/ddcfc599-cae0-48ee-9026-fffffffffffff/query", -[Query=[#"query"=" --Heartbeat -| summarize dcount(ComputerIP) by bin(TimeGenerated, 1h) -| render timechart -",#"x-ms-app"="OmsAnalyticsPBI",#"timespan"="P1D",#"prefer"="ai.response-thinning=true"],Timeout=#duration(0,0,4,0)])), -TypeMap = #table( -{ "AnalyticsTypes", "Type" }, -{ -{ "string", Text.Type }, -{ "int", Int32.Type }, -{ "long", Int64.Type }, -{ "real", Double.Type }, -{ "timespan", Duration.Type }, -{ "datetime", DateTimeZone.Type }, -{ "bool", Logical.Type }, -{ "guid", Text.Type }, -{ "dynamic", Text.Type } -}), -DataTable = Source[tables]{0}, -Columns = Table.FromRecords(DataTable[columns]), -ColumnsWithType = Table.Join(Columns, {"type"}, TypeMap , {"AnalyticsTypes"}), -Rows = Table.FromRows(DataTable[rows], Columns[name]), -Table = Table.TransformColumnTypes(Rows, Table.ToList(ColumnsWithType, (c) => { c{0}, c{3}})) -in -Table -in AnalyticsQuery -``` --## Connect Query to Excel --To import the query. --1. Open Microsoft Excel. -1. In the ribbon, go to the **Data** menu. Select **get data**. From **other sources**, select **blank query**: - - :::image type="content" source="media/log-excel/excel-import-blank-query.png" alt-text="Import from blank in Excel option" border="true"::: --1. In the Power query window select **Advanced editor**: -- :::image type="content" source="media/log-excel/advanced-editor.png" alt-text="Excel Advanced query editor" border="true"::: -- -1. Replace the text in the advanced editor with the query exported from Log Analytics: -- :::image type="content" source="media/log-excel/advanced-editor-2.png" alt-text="Creating a blank query" border="true"::: - -1. Select **Done**, and then **Load and close**. Excel executes the query using the Log analytics API and the result set then shown. - -- :::image type="content" source="media/log-excel/excel-query-result.png" alt-text="Query results in Excel" border="true"::: --> [!Note] -> If the number of records is less than expected, the volume of the results might exceeded the 61MiB limit. Try using `project` or `project-away` in your query to limit the columns to the one you need. --## Refreshing data --You can refresh your data directly from Excel. In the **Data** menu group in the Excel ribbon, select the **Refresh** button. - -## Next steps --For more information about ExcelΓÇÖs integrations with external data sources, see [Import data from external data sources (Power Query)](https://support.office.com/article/import-data-from-external-data-sources-power-query-be4330b3-5356-486c-a168-b68e9e616f5a) |
| azure-monitor | Log Powerbi | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/log-powerbi.md | - Title: Log Analytics integration with Power BI and Excel -description: Learn how to send results from a query in Log Analytics to Power BI. ---- Previously updated : 05/26/2024---# Integrate Log Analytics with Power BI --[Azure Monitor Logs](../logs/data-platform-logs.md) provides an end-to-end solution for ingesting logs. From [Log Analytics](../data-platform.md), Azure Monitor's user interface for querying logs, you can connect log data to Microsoft's [Power BI](https://powerbi.microsoft.com/) data visualization platform. --This article explains how to feed data from Log Analytics into Power BI to produce reports and dashboards based on log data. --> [!NOTE] -> You can use free Power BI features to integrate and create reports and dashboards. More advanced features, such as sharing your work, scheduled refreshes, dataflows, and incremental refresh might require purchasing a Power BI Pro or Premium account. For more information, see [Learn more about Power BI pricing and features](https://powerbi.microsoft.com/pricing/). --## Prerequisites --- To export the query to a .txt file that you can use in Power BI Desktop, you need [Power BI Desktop](https://powerbi.microsoft.com/desktop/).-- To create a new dataset based on your query directly in the Power BI service:- - You need a Power BI account. - - You must give permission in Azure for the Power BI service to write logs. For more information, see [Prerequisites to configure Azure Log Analytics for Power BI](/power-bi/transform-model/log-analytics/desktop-log-analytics-configure#prerequisites). --## Permissions required --- To export the query to a .txt file that you can use in Power BI Desktop, you need `Microsoft.OperationalInsights/workspaces/query/*/read` permissions to the Log Analytics workspaces you query, as provided by the [Log Analytics Reader built-in role](./manage-access.md#log-analytics-reader), for example.-- To create a new dataset based on your query directly in the Power BI service, you need `Microsoft.OperationalInsights/workspaces/write` permissions to the Log Analytics workspaces you query, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example.--## Create Power BI datasets and reports from Log Analytics queries --From the **Export** menu in Log Analytics, select one of the two options for creating Power BI datasets and reports from your Log Analytics queries: -- -- **Power BI (as an M query)**: This option exports the query (together with the connection string for the query) to a .txt file that you can use in Power BI Desktop. Use this option if you need to model or transform the data in ways that aren't available in the Power BI service. Otherwise, consider exporting the query as a new dataset.-- **Power BI (new Dataset)**: This option creates a new dataset based on your query directly in the Power BI service. After the dataset has been created, you can create reports, use Analyze in Excel, share it with others, and use other Power BI features. For more information, see [Create a Power BI dataset directly from Log Analytics](/power-bi/connect-data/create-dataset-log-analytics).--> [!NOTE] -> The export operation is subject to the [Log Analytics Query API limits](../service-limits.md#la-query-api). If your query results exceed the maximum size of data returned by the Query API, the operation exports partial results. --## Collect data with Power BI dataflows --[Power BI dataflows](/power-bi/service-dataflows-overview) also allow you to collect and store data. A dataflow is a type of cloud ETL (extract, transform, and load) process that helps you collect and prepare your data. A dataset is the "model" designed to help you connect different entities and model them for your needs. --## Incremental refresh --Both Power BI datasets and Power BI dataflows have an incremental refresh option. Power BI dataflows and Power BI datasets support this feature. To use incremental refresh on dataflows, you need Power BI Premium. --Incremental refresh runs small queries and updates smaller amounts of data per run instead of ingesting all the data again and again when you run the query. You can save large amounts of data but add a new increment of data every time the query is run. This behavior is ideal for longer-running reports. --Power BI incremental refresh relies on the existence of a **datetime** field in the result set. Before you configure incremental refresh, make sure your Log Analytics query result set includes at least one **datetime** field. --To learn more and how to configure incremental refresh, see [Power BI datasets and incremental refresh](/power-bi/service-premium-incremental-refresh) and [Power BI dataflows and incremental refresh](/power-bi/service-dataflows-incremental-refresh). --## Reports and dashboards --After your data is sent to Power BI, you can continue to use Power BI to create reports and dashboards. --For more information, see [Create and share your first Power BI report](/training/modules/build-your-first-power-bi-report/). --## Next steps --Learn how to: -- [Get started with Log Analytics queries](./log-query-overview.md).-- [Integrate Log Analytics and Excel](log-excel.md). |
| azure-monitor | Log Query Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/log-query-overview.md | - Title: Log queries in Azure Monitor -description: This reference information for Kusto Query Language used by Azure Monitor includes elements specific to Azure Monitor and elements not supported in Azure Monitor log queries. ---- Previously updated : 05/26/2024----# Log queries in Azure Monitor -Azure Monitor Logs is based on Azure Data Explorer, and log queries are written by using the same Kusto Query Language (KQL). This rich language is designed to be easy to read and author, so you should be able to start writing queries with some basic guidance. --Areas in Azure Monitor where you'll use queries include: --- [Log Analytics](../logs/log-analytics-overview.md): Use this primary tool in the Azure portal to edit log queries and interactively analyze their results. Even if you intend to use a log query elsewhere in Azure Monitor, you'll typically write and test it in Log Analytics before you copy it to its final location.-- [Log search alert rules](../alerts/alerts-overview.md): Proactively identify issues from data in your workspace. Each alert rule is based on a log query that's automatically run at regular intervals. The results are inspected to determine if an alert should be created.-- [Workbooks](../visualize/workbooks-overview.md): Include the results of log queries by using different visualizations in interactive visual reports in the Azure portal.-- [Azure dashboards](../visualize/tutorial-logs-dashboards.md): Pin the results of any query into an Azure dashboard, which allows you to visualize log and metric data together and optionally share with other Azure users.-- [Azure Logic Apps](../../connectors/connectors-azure-monitor-logs.md): Use the results of a log query in an automated workflow by using a logic app workflow.-- [PowerShell](/powershell/module/az.operationalinsights/invoke-azoperationalinsightsquery): Use the results of a log query in a PowerShell script from a command line or an Azure Automation runbook that uses `Invoke-AzOperationalInsightsQuery`.-- [Log Analytics Query API](/rest/api/loganalytics/query): Retrieve log data from the workspace from any REST API client. The API request includes a query that's run against Azure Monitor to determine the data to retrieve.-- **Azure Monitor Query client libraries**: Retrieve log data from the workspace via an idiomatic client library for the following ecosystems:- - [.NET](/dotnet/api/overview/azure/Monitor.Query-readme) - - [Go](https://pkg.go.dev/github.com/Azure/azure-sdk-for-go/sdk/monitor/query/azlogs) - - [Java](/java/api/overview/azure/monitor-query-readme) - - [JavaScript](/javascript/api/overview/azure/monitor-query-readme) - - [Python](/python/api/overview/azure/monitor-query-readme) - - For an example of how to implement the Azure Monitor Query client library for Python, see [Analyze data in Azure Monitor Logs using a notebook](../logs/notebooks-azure-monitor-logs.md). --## Get started -The best way to get started learning to write log queries by using KQL is to use available tutorials and samples: --- [Log Analytics tutorial](./log-analytics-tutorial.md): Tutorial on using the features of Log Analytics, which is the tool that you'll use in the Azure portal to edit and run queries. It also allows you to write simple queries without directly working with the query language. If you haven't used Log Analytics before, start here so that you understand the tool you'll use with the other tutorials and samples.-- [KQL tutorial](/azure/data-explorer/kusto/query/tutorial?pivots=azuremonitor): Guided walk through basic KQL concepts and common operators. This is the best place to start to come up to speed with the language itself and the structure of log queries.-- [Example queries](../logs/queries.md): Description of the example queries available in Log Analytics. You can use the queries without modification or use them as samples to learn KQL.--## Reference documentation -[Documentation for KQL](/azure/data-explorer/kusto/query/), including the reference for all commands and operators, is available in the Azure Data Explorer documentation. Even as you get proficient at using KQL, you'll still regularly use the reference to investigate new commands and scenarios that you haven't used before. --## Language differences -Although Azure Monitor uses the same KQL as Azure Data Explorer, there are some differences. The KQL documentation will specify those operators that aren't supported by Azure Monitor or that have different functionality. Operators specific to Azure Monitor are documented in the Azure Monitor content. The following sections list the differences between versions of the language for quick reference. --### Statements not supported in Azure Monitor --* [Alias](/azure/kusto/query/aliasstatement) -* [Query parameters](/azure/kusto/query/queryparametersstatement) --### Functions not supported in Azure Monitor --* [cluster()](/azure/kusto/query/clusterfunction) -* [cursor_after()](/azure/kusto/query/cursorafterfunction) -* [cursor_before_or_at()](/azure/kusto/query/cursorbeforeoratfunction) -* [cursor_current(), current_cursor()](/azure/kusto/query/cursorcurrent) -* [database()](/azure/kusto/query/databasefunction) -* [current_principal()](/azure/kusto/query/current-principalfunction) -* [extent_id()](/azure/kusto/query/extentidfunction) -* [extent_tags()](/azure/kusto/query/extenttagsfunction) --### Operator not supported in Azure Monitor --[Cross-Cluster Join](/azure/kusto/query/joincrosscluster) --### Plug-ins not supported in Azure Monitor --* [Python plugin](/azure/kusto/query/pythonplugin) -* [sql_request plugin](/azure/kusto/query/sqlrequestplugin) --### Other operators in Azure Monitor -The following operators support specific Azure Monitor features and aren't available outside of Azure Monitor: --* [workspace()](../logs/cross-workspace-query.md#query-across-log-analytics-workspaces-using-workspace) -* [app()](../logs/cross-workspace-query.md#query-across-classic-application-insights-applications-using-app) -* [resource()](../logs/cross-workspace-query.md#correlate-data-between-resources-using-resource) ---## Next steps -- Walk through a [tutorial on writing queries](/azure/data-explorer/kusto/query/tutorial?pivots=azuremonitor).-- Access the complete [reference documentation for KQL](/azure/kusto/query/). |
| azure-monitor | Log Standard Columns | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/log-standard-columns.md | - Title: Standard columns in Azure Monitor log records | Microsoft Docs -description: Describes columns that are common to multiple data types in Azure Monitor logs. --- Previously updated : 05/26/2024----# Standard columns in Azure Monitor Logs -Data in Azure Monitor Logs is [stored as a set of records in either a Log Analytics workspace or Application Insights application](../logs/data-platform-logs.md), each with a particular data type that has a unique set of columns. Many data types will have standard columns that are common across multiple types. This article describes these columns and provides examples of how you can use them in queries. --Workspace-based applications in Application Insights store their data in a Log Analytics workspace and use the same standard columns as other tables in the workspace. Classic applications store their data separately and have different standard columns as specified in this article. --> [!NOTE] -> Some of the standard columns will not show in the schema view or intellisense in Log Analytics, and they won't show in query results unless you explicitly specify the column in the output. -> --## TenantId -The **TenantId** column holds the workspace ID for the Log Analytics workspace. --## TimeGenerated -The **TimeGenerated** column contains the date and time that the record was created by the data source. See [Log data ingestion time in Azure Monitor](../logs/data-ingestion-time.md) for more details. --**TimeGenerated** provides a common column to use for filtering or summarizing by time. When you select a time range for a view or dashboard in the Azure portal, it uses **TimeGenerated** to filter the results. --> [!NOTE] -> Tables supporting classic Application Insights resources use the **Timestamp** column instead of the **TimeGenerated** column. --> [!NOTE] -> The **TimeGenerated** value cannot be older than 2 days before received time or more than a day in the future. If in some situation, the value is older than 2 days or more than a day in the future, it would be replaced with the actual recieved time. --### Examples --The following query returns the number of error events created for each day in the previous week. --```Kusto -Event -| where EventLevelName == "Error" -| where TimeGenerated between(startofweek(ago(7days))..endofweek(ago(7days))) -| summarize count() by bin(TimeGenerated, 1day) -| sort by TimeGenerated asc -``` -## \_TimeReceived -The **\_TimeReceived** column contains the date and time that the record was received by the Azure Monitor ingestion point in the Azure cloud. This can be useful for identifying latency issues between the data source and the cloud. An example would be a networking issue causing a delay with data being sent from an agent. See [Log data ingestion time in Azure Monitor](../logs/data-ingestion-time.md) for more details. --> [!NOTE] -> The **\_TimeReceived** column is calculate each time it is used. This process is resource intensive. Refrain from using it to filter large number of records. Using this function recurrently can lead to increased query execution duration. ---The following query gives the average latency by hour for event records from an agent. This includes the time from the agent to the cloud and the total time for the record to be available for log queries. --```Kusto -Event -| where TimeGenerated > ago(1d) -| project TimeGenerated, TimeReceived = _TimeReceived, IngestionTime = ingestion_time() -| extend AgentLatency = toreal(datetime_diff('Millisecond',TimeReceived,TimeGenerated)) / 1000 -| extend TotalLatency = toreal(datetime_diff('Millisecond',IngestionTime,TimeGenerated)) / 1000 -| summarize avg(AgentLatency), avg(TotalLatency) by bin(TimeGenerated,1hr) -``` --## Type -The **Type** column holds the name of the table that the record was retrieved from which can also be thought of as the record type. This column is useful in queries that combine records from multiple tables, such as those that use the `search` operator, to distinguish between records of different types. **$table** can be used in place of **Type** in some queries. --> [!NOTE] -> Tables supporting classic Application Insights resources use the **itemType** column instead of the **Type** column. --### Examples -The following query returns the count of records by type collected over the past hour. --```Kusto -search * -| where TimeGenerated > ago(1h) -| summarize count() by Type --``` -## \_ItemId -The **\_ItemId** column holds a unique identifier for the record. ---## \_ResourceId -The **\_ResourceId** column holds a unique identifier for the resource that the record is associated with. This gives you a standard column to use to scope your query to only records from a particular resource, or to join related data across multiple tables. --For Azure resources, the value of **_ResourceId** is the [Azure resource ID URL](../../azure-resource-manager/templates/template-functions-resource.md). The column is limited to Azure resources, including [Azure Arc](../../azure-arc/overview.md) resources, or to custom logs that indicated the Resource ID during ingestion. --> [!NOTE] -> Some data types already have fields that contain Azure resource ID or at least parts of it like subscription ID. While these fields are kept for backward compatibility, it is recommended to use the _ResourceId to perform cross correlation since it will be more consistent. --### Examples -The following query joins performance and event data for each computer. It shows all events with an ID of _101_ and processor utilization over 50%. --```Kusto -Perf -| where CounterName == "% User Time" and CounterValue > 50 and _ResourceId != "" -| join kind=inner ( - Event - | where EventID == 101 -) on _ResourceId -``` --The following query joins _AzureActivity_ records with _SecurityEvent_ records. It shows all activity operations with users that were logged in to these machines. --```Kusto -AzureActivity -| where - OperationName in ("Restart Virtual Machine", "Create or Update Virtual Machine", "Delete Virtual Machine") - and ActivityStatus == "Succeeded" -| join kind= leftouter ( - SecurityEvent - | where EventID == 4624 - | summarize LoggedOnAccounts = makeset(Account) by _ResourceId -) on _ResourceId -``` --The following query parses **_ResourceId** and aggregates billed data volumes per Azure Resource Group. --```Kusto -union withsource = tt * -| where _IsBillable == true -| parse tolower(_ResourceId) with "/subscriptions/" subscriptionId "/resourcegroups/" - resourceGroup "/providers/" provider "/" resourceType "/" resourceName -| summarize Bytes=sum(_BilledSize) by resourceGroup | sort by Bytes nulls last -``` --Use these `union withsource = tt *` queries sparingly as scans across data types are expensive to execute. --It is always more efficient to use the \_SubscriptionId column than extracting it by parsing the \_ResourceId column. --## \_SubscriptionId -The **\_SubscriptionId** column holds the subscription ID of the resource that the record is associated with. This gives you a standard column to use to scope your query to only records from a particular subscription, or to compare different subscriptions. --For Azure resources, the value of **__SubscriptionId** is the subscription part of the [Azure resource ID URL](../../azure-resource-manager/templates/template-functions-resource.md). The column is limited to Azure resources, including [Azure Arc](../../azure-arc/overview.md) resources, or to custom logs that indicated the Subscription ID during ingestion. --> [!NOTE] -> Some data types already have fields that contain Azure subscription ID . While these fields are kept for backward compatibility, it is recommended to use the \_SubscriptionId column to perform cross correlation since it will be more consistent. -### Examples -The following query examines performance data for computers of a specific subscription. --```Kusto -Perf -| where TimeGenerated > ago(24h) and CounterName == "memoryAllocatableBytes" -| where _SubscriptionId == "ebb79bc0-aa86-44a7-8111-cabbe0c43993" -| summarize avgMemoryAllocatableBytes = avg(CounterValue) by Computer -``` --The following query parses **_ResourceId** and aggregates billed data volumes per Azure subscription. --```Kusto -union withsource = tt * -| where _IsBillable == true -| summarize Bytes=sum(_BilledSize) by _SubscriptionId | sort by Bytes nulls last -``` --Use these `union withsource = tt *` queries sparingly as scans across data types are expensive to execute. ---## \_IsBillable -The **\_IsBillable** column specifies whether ingested data is considered billable. Data with **\_IsBillable** equal to `false` does not incur data ingestion, retention or archive charges. --### Examples -To get a list of computers sending billed data types, use the following query: --> [!NOTE] -> Use queries with `union withsource = tt *` sparingly as scans across data types are expensive to execute. --```Kusto -union withsource = tt * -| where _IsBillable == true -| extend computerName = tolower(tostring(split(Computer, '.')[0])) -| where computerName != "" -| summarize TotalVolumeBytes=sum(_BilledSize) by computerName -``` --This can be extended to return the count of computers per hour that are sending billed data types: --```Kusto -union withsource = tt * -| where _IsBillable == true -| extend computerName = tolower(tostring(split(Computer, '.')[0])) -| where computerName != "" -| summarize dcount(computerName) by bin(TimeGenerated, 1h) | sort by TimeGenerated asc -``` --## \_BilledSize -The **\_BilledSize** column specifies the size in bytes of data that will be billed to your Azure account if **\_IsBillable** is true. See [Data size calculation](cost-logs.md#data-size-calculation) to learn more about the details of how the billed size is calculated. ---### Examples -To see the size of billable events ingested per computer, use the `_BilledSize` column which provides the size in bytes: --```Kusto -union withsource = tt * -| where _IsBillable == true -| summarize Bytes=sum(_BilledSize) by Computer | sort by Bytes nulls last -``` --To see the size of billable events ingested per subscription, use the following query: --```Kusto -union withsource=table * -| where _IsBillable == true -| summarize Bytes=sum(_BilledSize) by _SubscriptionId | sort by Bytes nulls last -``` --To see the size of billable events ingested per resource group, use the following query: --```Kusto -union withsource=table * -| where _IsBillable == true -| parse _ResourceId with "/subscriptions/" SubscriptionId "/resourcegroups/" ResourceGroupName "/" * -| summarize Bytes=sum(_BilledSize) by _SubscriptionId, ResourceGroupName | sort by Bytes nulls last --``` ---To see the count of events ingested per computer, use the following query: --```Kusto -union withsource = tt * -| summarize count() by Computer | sort by count_ nulls last -``` --To see the count of billable events ingested per computer, use the following query: --```Kusto -union withsource = tt * -| where _IsBillable == true -| summarize count() by Computer | sort by count_ nulls last -``` --To see the count of billable data types from a specific computer, use the following query: --```Kusto -union withsource = tt * -| where Computer == "computer name" -| where _IsBillable == true -| summarize count() by tt | sort by count_ nulls last -``` --## Next steps --- Read more about how [Azure Monitor log data is stored](./log-query-overview.md).-- Get a lesson on [writing log queries](./get-started-queries.md).-- Get a lesson on [joining tables in log queries](/azure/data-explorer/kusto/query/samples?&pivots=azuremonitor#joins). |
| azure-monitor | Logs Data Export | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/logs-data-export.md | - Title: Log Analytics workspace data export in Azure Monitor -description: Log Analytics workspace data export in Azure Monitor lets you continuously export data per selected tables in your workspace. You can export to an Azure Storage Account or Azure Event Hubs as it's collected. --- Previously updated : 06/14/2024---# Log Analytics workspace data export in Azure Monitor -Data export in a Log Analytics workspace lets you continuously export data per selected tables in your workspace. You can export to an Azure Storage Account or Azure Event Hubs as the data arrives to an Azure Monitor pipeline. This article provides details on this feature and steps to configure data export in your workspaces. --## Overview -Data in Log Analytics is available for the retention period defined in your workspace. It's used in various experiences provided in Azure Monitor and Azure services. There are cases where you need to use other tools: --* **Tamper-protected store compliance:** Data can't be altered in Log Analytics after it's ingested, but it can be purged. Export to a Storage Account set with [immutability policies](../../storage/blobs/immutable-policy-configure-version-scope.md) to keep data tamper protected. -* **Integration with Azure services and other tools:** Export to Event Hubs as data arrives and is processed in Azure Monitor. -* **Long-term retention of audit and security data:** Export to a Storage Account in the workspace's region. Or you can replicate data to other regions by using any of the [Azure Storage redundancy options](../../storage/common/storage-redundancy.md#redundancy-in-a-secondary-region) including GRS and GZRS. --After you've configured data export rules in a Log Analytics workspace, new data for tables in rules is exported from the Azure Monitor pipeline to your Storage Account or Event Hubs as it arrives. Data export traffic is in Azure backbone network and doesn't leave the Azure network. ---Data is exported without a filter. For example, when you configure a data export rule for a *SecurityEvent* table, all data sent to the *SecurityEvent* table is exported starting from the configuration time. Alternatively, you can filter or modify exported data by configuring [transformations](./../essentials/data-collection-transformations.md) in your workspace, which apply to incoming data, before it's sent to your Log Analytics workspaces and to export destinations. --## Other export options -Log Analytics workspace data export continuously exports data that's sent to your Log Analytics workspace. There are other options to export data for particular scenarios: --- Configure diagnostic settings in Azure resources. Logs are sent to a destination directly. This approach has lower latency compared to data export in Log Analytics.-- Schedule export of data based on a log query you define with the [Log Analytics query API](/rest/api/loganalytics/dataaccess/query/execute). Use Azure Data Factory, Azure Functions, or Azure Logic Apps to orchestrate queries in your workspace and export data to a destination. This method is similar to the data export feature, but you can use it to export historical data from your workspace by using filters and aggregation. This method is subject to [log query limits](../service-limits.md#log-analytics-workspaces) and isn't intended for scale. For more information, see [Export data from a Log Analytics workspace to a Storage Account by using Logic Apps](logs-export-logic-app.md).-- One-time export to a local machine by using a PowerShell script. For more information, see [Invoke-AzOperationalInsightsQueryExport](https://www.powershellgallery.com/packages/Invoke-AzOperationalInsightsQueryExport).--## Limitations --- Custom logs created using the [HTTP Data Collector API](./data-collector-api.md) can't be exported, including text-based logs consumed by Log Analytics agent. Custom logs created using [data collection rules](./logs-ingestion-api-overview.md), including text-based logs, can be exported. -- Data export will gradually support more tables, but is currently limited to tables specified in the [supported tables](#supported-tables) section. You can include tables that aren't yet supported in rules, but no data will be exported for them until the tables are supported.-- You can define up to 10 enabled rules in your workspace, each can include multiple tables. You can create more rules in workspace in disabled state. -- Destinations must be in the same region as the Log Analytics workspace.-- The Storage Account must be unique across rules in the workspace.-- Table names can be 60 characters long when you're exporting to a Storage Account. They can be 47 characters when you're exporting to Event Hubs. Tables with longer names won't be exported.-- Export to Premium Storage Account isn't supported.--## Data completeness -Data export is optimized to move large data volume to your destinations. The export operation might fail if the destination doesn't have sufficient capacity or is unavailable. In the event of failure, the retry process continues for up to 12 hours. For more information about destination limits and recommended alerts, see [Create or update a data export rule](#create-or-update-a-data-export-rule). If the destinations are still unavailable after the retry period, the data is discarded. In certain cases, retry can cause duplication of a fraction of the exported records. --## Pricing model -Data export charges are based on the number of bytes exported to destinations in JSON formatted data, and measured in GB (10^9 bytes). Size calculation in workspace query can't correspond with export charges since doesn't include the JSON formatted data. You can use PowerShell to [calculate the total billing size of a blob container](../../storage/scripts/storage-blobs-container-calculate-billing-size-powershell.md). --For more information, including the data export billing timeline, see [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/). Billing for Data Export was enabled in early October 2023. --## Export destinations --The data export destination must be available before you create export rules in your workspace. Destinations don't have to be in the same subscription as your workspace. When you use Azure Lighthouse, it's also possible to send data to destinations in another Microsoft Entra tenant. --You need to have write permissions to both workspace and destination to configure a data export rule on any table in a workspace. The shared access policy for the Event Hubs namespace defines the permissions that the streaming mechanism has. Streaming to Event Hubs requires manage, send, and listen permissions. To update the export rule, you must have the ListKey permission on that Event Hubs authorization rule. --### Storage Account --Avoid using existing Storage Account that has other non-monitoring data, to better control access to the data, prevent reaching storage ingress rate limit failures, and latency. --To send data to an immutable Storage Account, set the immutable policy for the Storage Account as described in [Set and manage immutability policies for Azure Blob Storage](../../storage/blobs/immutable-policy-configure-version-scope.md). You must follow all steps in this article, including enabling protected append blobs writes. --The Storage Account can't be Premium, must be StorageV1 or later, and located in the same region as your workspace. If you need to replicate your data to other Storage Accounts in other regions, you can use any of the [Azure Storage redundancy options](../../storage/common/storage-redundancy.md#redundancy-in-a-secondary-region), including GRS and GZRS. --Data is sent to Storage Accounts as it reaches Azure Monitor and exported to destinations located in a workspace region. A container is created for each table in the Storage Account with the name *am-* followed by the name of the table. For example, the table *SecurityEvent* would send to a container named *am-SecurityEvent*. --Blobs are stored in 5-minute folders in the following path structure: *WorkspaceResourceId=/subscriptions/subscription-id/resourcegroups/\<resource-group\>/providers/microsoft.operationalinsights/workspaces/\<workspace\>/y=\<four-digit numeric year\>/m=\<two-digit numeric month\>/d=\<two-digit numeric day\>/h=\<two-digit 24-hour clock hour\>/m=\<two-digit 60-minute clock minute\>/PT05M.json*. Appends to blobs are limited to 50-K writes. More blobs will be added in the folder as *PT05M_#.json**, where '#' is the incremental blob count. --> [!NOTE] -> Appends to blobs are written based on the "TimeGenerated" field and occur when receiving source data. Data arriving to Azure Monitor with delay, or retried following destinations throttling, is written to blobs according to its TimeGenerated. --The format of blobs in a Storage Account is in [JSON lines](/previous-versions/azure/azure-monitor/essentials/resource-logs-blob-format), where each record is delimited by a new line, with no outer records array and no commas between JSON records. ---### Event Hubs --Avoid using existing Event Hub that has non-monitoring data to prevent reaching the Event Hubs namespace ingress rate limit failures, and latency. --Data is sent to your Event Hub as it reaches Azure Monitor and is exported to destinations located in a workspace region. You can create multiple export rules to the same Event Hubs namespace by providing a different `Event Hub name` in the rule. When an `Event Hub name` isn't provided, a default Event Hub is created for tables that you export with the name *am-* followed by the name of the table. For example, the table *SecurityEvent* would be sent to an Event Hub named *am-SecurityEvent*. --The [number of supported Event Hubs in Basic and Standard namespace tiers is 10](../../event-hubs/event-hubs-quotas.md#common-limits-for-all-tiers). When you're exporting more than 10 tables to these tiers, either split the tables between several export rules to different Event Hubs namespaces or provide an Event Hub name to export all tables to it. --> [!NOTE] -> - The Basic Event Hubs namespace tier is limited. It supports [lower event size](../../event-hubs/event-hubs-quotas.md#basic-vs-standard-vs-premium-vs-dedicated-tiers) and no [Auto-inflate](../../event-hubs/event-hubs-auto-inflate.md) option to automatically scale up and increase the number of throughput units. Because data volume to your workspace increases over time and as a consequence Event Hub scaling is required, use Standard, Premium, or Dedicated Event Hubs tiers with the **Auto-inflate** feature enabled. For more information, see [Automatically scale up Azure Event Hubs throughput units](../../event-hubs/event-hubs-auto-inflate.md). -> - Data export can't reach Event Hubs resources when virtual networks are enabled. You have to select the **Allow Azure services on the trusted services list to access this Storage Account** checkbox to bypass this firewall setting in an Event Hub to grant access to your Event Hubs. --## Query exported data --Exporting data from workspaces to Storage Accounts help satisfy various scenarios mentioned in [overview](#overview), and can be consumed by tools that can read blobs from Storage Accounts. The following methods let you query data using Log Analytics query language, which is the same for Azure Data Explorer. -1. Use Azure Data Explorer to [query data in Azure Data Lake](/azure/data-explorer/data-lake-query-data). -2. Use Azure Data Explorer to [ingest data from a Storage Account](/azure/data-explorer/ingest-from-container). -3. Use Log Analytics workspace to query [ingested data using Logs Ingestion API ](./logs-ingestion-api-overview.md). Ingested data is to a custom log table and not to the original table. - --## Enable data export -The following steps must be performed to enable Log Analytics data export. For more information on each, see the following sections: --- Register the resource provider-- Allow trusted Microsoft services-- Create or update a data export rule--### Register the resource provider -The Azure resource provider **Microsoft.Insights** needs to be registered in your subscription to enable Log Analytics data export. --This resource provider is probably already registered for most Azure Monitor users. To verify, go to **Subscriptions** in the Azure portal. Select your subscription and then select **Resource providers** under the **Settings** section of the menu. Locate **Microsoft.Insights**. If its status is **Registered**, then it's already registered. If not, select **Register** to register it. --You can also use any of the available methods to register a resource provider as described in [Azure resource providers and types](../../azure-resource-manager/management/resource-providers-and-types.md). The following sample command uses the Azure CLI: --```azurecli -az provider register --namespace 'Microsoft.insights' -``` --The following sample command uses PowerShell: --```PowerShell -Register-AzResourceProvider -ProviderNamespace Microsoft.insights -``` --### Allow trusted Microsoft services -If you've configured your Storage Account to allow access from selected networks, you need to add an exception to allow Azure Monitor to write to the account. From **Firewalls and virtual networks** for your Storage Account, select **Allow Azure services on the trusted services list to access this Storage Account**. -<!-- convertborder later --> --### Monitor destinations --> [!IMPORTANT] -> Export destinations have limits and should be monitored to minimize throttling, failures, and latency. For more information, see [Storage Account scalability](../../storage/common/scalability-targets-standard-account.md#scale-targets-for-standard-storage-accounts) and [Event Hubs namespace quotas](../../event-hubs/event-hubs-quotas.md). --The following metrics are available for data export operation and alerts --| Metric name | Description | -|:|:| -| Bytes Exported | Total number of bytes exported to destination from Log Analytics workspace within the selected time range. The size of data exported is the number of bytes in the exported JSON formatted data. 1 GB = 10^9 bytes. | -| Export Failures | Total number of failed export requests to destination from Log Analytics workspace within the selected time range. This number includes export attempts failures due to destination resource throttling, forbidden access error, or any server error. A retry process handles failed attempts and the number isn’t an indication for missing data. | -| Records exported | Total number of records exported from Log Analytics workspace within the selected time range. This number counts records for operations that ended with success. | ---#### Monitor a Storage Account --1. Use a separate Storage Account for export. -1. Configure an alert on the metric: -- | Scope | Metric namespace | Metric | Aggregation | Threshold | - |:|:|:|:|:| - | storage-name | Account | Ingress | Sum | 80% of maximum ingress per alert evaluation period. For example, the limit is 60 Gbps for general-purpose v2 in West US. The alert threshold is 1676 GiB per 5-minute evaluation period. | - -1. Alert remediation actions: - - Use a separate Storage Account for export that isn't shared with non-monitoring data. - - Azure Storage Standard accounts support higher ingress limit by request. To request an increase, contact [Azure Support](https://azure.microsoft.com/support/faq/). - - Split tables between more Storage Accounts. --#### Monitor Event Hubs --1. Configure alerts on the [metrics](../../event-hubs/monitor-event-hubs-reference.md): - - | Scope | Metric namespace | Metric | Aggregation | Threshold | - |:|:|:|:|:| - | namespaces-name | Event Hubs standard metrics | Incoming bytes | Sum | 80% of maximum ingress per alert evaluation period. For example, the limit is 1 MB/s per unit (TU or PU) and five units used. The threshold is 228 MiB per 5-minute evaluation period. | - | namespaces-name | Event Hubs standard metrics | Incoming requests | Count | 80% of maximum events per alert evaluation period. For example, the limit is 1,000/s per unit (TU or PU) and five units used. The threshold is 1,200,000 per 5-minute evaluation period. | - | namespaces-name | Event Hubs standard metrics | Quota exceeded errors | Count | Between 1% of request. For example, requests per 5 minutes is 600,000. The threshold is 6,000 per 5-minute evaluation period. | --1. Alert remediation actions: - - Use a separate Event Hubs namespace for export that isn't shared with non-monitoring data. - - Configure the [Auto-inflate](../../event-hubs/event-hubs-auto-inflate.md) feature to automatically scale up and increase the number of throughput units to meet usage needs. - - Verify the increase of throughput units to accommodate data volume. - - Split tables between more namespaces. - - Use Premium or Dedicated tiers for higher throughput. --### Create or update a data export rule -A data export rule defines the destination and tables for which data is exported. The rule provisioning takes about 30 minutes before the export operation initiated. Data export rules considerations: -- The Storage Account must be unique across rules in the workspace.-- Multiple rules can use the same Event Hubs namespace when you're sending to separate Event Hubs.-- Export to a Storage Account: A separate container is created in the Storage Account for each table.-- Export to Event Hubs: If an Event Hub name isn't provided, a separate Event Hub is created for each table. The [number of supported Event Hubs in Basic and Standard namespace tiers is 10](../../event-hubs/event-hubs-quotas.md#common-limits-for-all-tiers). When you're exporting more than 10 tables to these tiers, either split the tables between several export rules to different Event Hubs namespaces or provide an Event Hub name in the rule to export all tables to it.--# [Azure portal](#tab/portal) --1. On the **Log Analytics workspace** menu in the Azure portal, select **Data Export** under the **Settings** section. Select **New export rule** at the top of the pane. -- :::image type="content" source="media/logs-data-export/export-create-1.png" lightbox="media/logs-data-export/export-create-1.png" alt-text="Screenshot that shows the data export entry point."::: --1. Follow the steps, and then select **Create**. Only the tables with data in them are displayed under "Source" tab. - <!-- convertborder later --> - :::image type="content" source="media/logs-data-export/export-create-2.png" lightbox="media/logs-data-export/export-create-2.png" alt-text="Screenshot of export rule configuration." border="false"::: --# [PowerShell](#tab/powershell) --Use the following command to create a data export rule to a Storage Account by using PowerShell. A separate container is created for each table. --```powershell -$storageAccountResourceId = '/subscriptions/subscription-id/resourceGroups/resource-group-name/providers/Microsoft.Storage/storageAccounts/storage-account-name' -New-AzOperationalInsightsDataExport -ResourceGroupName resourceGroupName -WorkspaceName workspaceName -DataExportName 'ruleName' -TableName 'SecurityEvent,Heartbeat' -ResourceId $storageAccountResourceId -``` --Use the following command to create a data export rule to a specific Event Hub by using PowerShell. All tables are exported to the provided Event Hub name and can be filtered by the **Type** field to separate tables. --```powershell -$eventHubResourceId = '/subscriptions/subscription-id/resourceGroups/resource-group-name/providers/Microsoft.EventHub/namespaces/namespaces-name/eventhubs/eventhub-name' -New-AzOperationalInsightsDataExport -ResourceGroupName resourceGroupName -WorkspaceName workspaceName -DataExportName 'ruleName' -TableName 'SecurityEvent,Heartbeat' -ResourceId $eventHubResourceId -EventHubName EventhubName -``` --Use the following command to create a data export rule to an Event Hub by using PowerShell. When a specific Event Hub name isn't provided, a separate container is created for each table, up to the [number of Event Hubs supported in each Event Hubs tier](../../event-hubs/event-hubs-quotas.md#common-limits-for-all-tiers). To export more tables, provide an Event Hub name in the rule. Or you can set another rule and export the remaining tables to another Event Hubs namespace. --```powershell -$eventHubResourceId = '/subscriptions/subscription-id/resourceGroups/resource-group-name/providers/Microsoft.EventHub/namespaces/namespaces-name' -New-AzOperationalInsightsDataExport -ResourceGroupName resourceGroupName -WorkspaceName workspaceName -DataExportName 'ruleName' -TableName 'SecurityEvent,Heartbeat' -ResourceId $eventHubResourceId -``` --# [Azure CLI](#tab/azure-cli) --Use the following command to create a data export rule to a Storage Account by using the CLI. A separate container is created for each table. --```azurecli -$storageAccountResourceId = '/subscriptions/subscription-id/resourceGroups/resource-group-name/providers/Microsoft.Storage/storageAccounts/storage-account-name' -az monitor log-analytics workspace data-export create --resource-group resourceGroupName --workspace-name workspaceName --name ruleName --tables SecurityEvent Heartbeat --destination $storageAccountResourceId -``` --Use the following command to create a data export rule to a specific Event Hub by using the CLI. All tables are exported to the provided Event Hub name and can be filtered by the **Type** field to separate tables. --```azurecli -$eventHubResourceId = '/subscriptions/subscription-id/resourceGroups/resource-group-name/providers/Microsoft.EventHub/namespaces/namespaces-name/eventhubs/eventhub-name' -az monitor log-analytics workspace data-export create --resource-group resourceGroupName --workspace-name workspaceName --name ruleName --tables SecurityEvent Heartbeat --destination $eventHubResourceId -``` --Use the following command to create a data export rule to an Event Hub by using the CLI. When a specific Event Hub name isn't provided, a separate container is created for each table up to the [number of supported Event Hubs for your Event Hubs tier](../../event-hubs/event-hubs-quotas.md#common-limits-for-all-tiers). If you have more tables to export, provide an Event Hub name to export any number of tables. Or you can set another rule to export the remaining tables to another Event Hubs namespace. --```azurecli -$eventHubsNamespacesResourceId = '/subscriptions/subscription-id/resourceGroups/resource-group-name/providers/Microsoft.EventHub/namespaces/namespaces-name' -az monitor log-analytics workspace data-export create --resource-group resourceGroupName --workspace-name workspaceName --name ruleName --tables SecurityEvent Heartbeat --destination $eventHubsNamespacesResourceId -``` --# [REST](#tab/rest) --Use the following request to create a data export rule to a Storage Account by using the REST API. A separate container is created for each table. The request should use bearer token authorization and content type application/json. --```rest -PUT https://management.azure.com/subscriptions/<subscription-id>/resourcegroups/<resource-group-name>/providers/Microsoft.operationalInsights/workspaces/<workspace-name>/dataexports/<data-export-name>?api-version=2020-08-01 -``` --The body of the request specifies the table's destination. The following example is a sample body for the REST request. --```json -{ - "properties": { - "destination": { - "resourceId": "/subscriptions/subscription-id/resourcegroups/resource-group-name/providers/Microsoft.Storage/storageAccounts/storage-account-name" - }, - "tablenames": [ - "table1", - "table2" - ], - "enable": true - } -} -``` --The following example is a sample body for the REST request for an Event Hub. --```json -{ - "properties": { - "destination": { - "resourceId": "/subscriptions/subscription-id/resourcegroups/resource-group-name/providers/Microsoft.EventHub/namespaces/eventhub-namespaces-name" - }, - "tablenames": [ - "table1", - "table2" - ], - "enable": true - } -} -``` --The following example is a sample body for the REST request for an Event Hub where the Event Hub name is provided. In this case, all exported data is sent to it. --```json -{ - "properties": { - "destination": { - "resourceId": "/subscriptions/subscription-id/resourcegroups/resource-group-name/providers/Microsoft.EventHub/namespaces/eventhub-namespaces-name", - "metaData": { - "EventHubName": "eventhub-name" - }, - "tablenames": [ - "table1", - "table2" - ], - "enable": true - } - } -} -``` --# [Template](#tab/json) --Use the following command to create a data export rule to a Storage Account by using an Azure Resource Manager template. --``` -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceName": { - "defaultValue": "workspace-name", - "type": "String" - }, - "workspaceLocation": { - "defaultValue": "workspace-region", - "type": "string" - }, - "storageAccountRuleName": { - "defaultValue": "storage-account-rule-name", - "type": "string" - }, - "storageAccountResourceId": { - "defaultValue": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/resource-group-name/providers/Microsoft.Storage/storageAccounts/storage-account-name", - "type": "String" - } - }, - "variables": {}, - "resources": [ - { - "type": "microsoft.operationalinsights/workspaces", - "apiVersion": "2020-08-01", - "name": "[parameters('workspaceName')]", - "location": "[parameters('workspaceLocation')]", - "resources": [ - { - "type": "microsoft.operationalinsights/workspaces/dataexports", - "apiVersion": "2020-08-01", - "name": "[concat(parameters('workspaceName'), '/' , parameters('storageAccountRuleName'))]", - "dependsOn": [ - "[resourceId('microsoft.operationalinsights/workspaces', parameters('workspaceName'))]" - ], - "properties": { - "destination": { - "resourceId": "[parameters('storageAccountResourceId')]" - }, - "tableNames": [ - "Heartbeat", - "InsightsMetrics", - "VMConnection", - "Usage" - ], - "enable": true - } - } - ] - } - ] -} -``` --Use the following command to create a data export rule to an Event Hub by using a Resource Manager template. A separate Event Hub is created for each table. --``` -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceName": { - "defaultValue": "workspace-name", - "type": "String" - }, - "workspaceLocation": { - "defaultValue": "workspace-region", - "type": "string" - }, - "eventhubRuleName": { - "defaultValue": "event-hub-rule-name", - "type": "string" - }, - "namespacesResourceId": { - "defaultValue": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/resource-group-name/providers/microsoft.eventhub/namespaces/namespaces-name", - "type": "String" - } - }, - "variables": {}, - "resources": [ - { - "type": "microsoft.operationalinsights/workspaces", - "apiVersion": "2020-08-01", - "name": "[parameters('workspaceName')]", - "location": "[parameters('workspaceLocation')]", - "resources": [ - { - "type": "microsoft.operationalinsights/workspaces/dataexports", - "apiVersion": "2020-08-01", - "name": "[concat(parameters('workspaceName'), '/', parameters('eventhubRuleName'))]", - "dependsOn": [ - "[resourceId('microsoft.operationalinsights/workspaces', parameters('workspaceName'))]" - ], - "properties": { - "destination": { - "resourceId": "[parameters('namespacesResourceId')]" - }, - "tableNames": [ - "Usage", - "Heartbeat" - ], - "enable": true - } - } - ] - } - ] -} -``` --Use the following command to create a data export rule to a specific Event Hub by using a Resource Manager template. All tables are exported to it. --``` -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceName": { - "defaultValue": "workspace-name", - "type": "String" - }, - "workspaceLocation": { - "defaultValue": "workspace-region", - "type": "string" - }, - "eventhubRuleName": { - "defaultValue": "event-hub-rule-name", - "type": "string" - }, - "namespacesResourceId": { - "defaultValue": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/resource-group-name/providers/microsoft.eventhub/namespaces/namespaces-name", - "type": "String" - }, - "eventhubName": { - "defaultValue": "event-hub-name", - "type": "string" - } - }, - "variables": {}, - "resources": [ - { - "type": "microsoft.operationalinsights/workspaces", - "apiVersion": "2020-08-01", - "name": "[parameters('workspaceName')]", - "location": "[parameters('workspaceLocation')]", - "resources": [ - { - "type": "microsoft.operationalinsights/workspaces/dataexports", - "apiVersion": "2020-08-01", - "name": "[concat(parameters('workspaceName'), '/', parameters('eventhubRuleName'))]", - "dependsOn": [ - "[resourceId('microsoft.operationalinsights/workspaces', parameters('workspaceName'))]" - ], - "properties": { - "destination": { - "resourceId": "[parameters('namespacesResourceId')]", - "metaData": { - "eventHubName": "[parameters('eventhubName')]" - } - }, - "tableNames": [ - "Usage", - "Heartbeat" - ], - "enable": true - } - } - ] - } - ] -} -``` -----## View data export rule configuration --# [Azure portal](#tab/portal) --1. On the **Log Analytics workspace** menu in the Azure portal, select **Data Export** under the **Settings** section. -- :::image type="content" source="media/logs-data-export/export-view-1.png" lightbox="media/logs-data-export/export-view-1.png" alt-text="Screenshot that shows the Data Export screen."::: --1. Select a rule for a configuration view. - <!-- convertborder later --> - :::image type="content" source="media/logs-data-export/export-view-2.png" lightbox="media/logs-data-export/export-view-2.png" alt-text="Screenshot of data export rule view." border="false"::: --# [PowerShell](#tab/powershell) --Use the following command to view the configuration of a data export rule by using PowerShell. --```powershell -Get-AzOperationalInsightsDataExport -ResourceGroupName resourceGroupName -WorkspaceName workspaceName -DataExportName 'ruleName' -``` --# [Azure CLI](#tab/azure-cli) --Use the following command to view the configuration of a data export rule by using the CLI. --```azurecli -az monitor log-analytics workspace data-export show --resource-group resourceGroupName --workspace-name workspaceName --name ruleName -``` --# [REST](#tab/rest) --Use the following request to view the configuration of a data export rule by using the REST API. The request should use bearer token authorization. --```rest -GET https://management.azure.com/subscriptions/<subscription-id>/resourcegroups/<resource-group-name>/providers/Microsoft.operationalInsights/workspaces/<workspace-name>/dataexports/<data-export-name>?api-version=2020-08-01 -``` --# [Template](#tab/json) --The template option doesn't apply. ----## Disable or update an export rule --# [Azure portal](#tab/portal) --You can disable export rules to stop the export for a certain period, such as when testing is being held. On the **Log Analytics workspace** menu in the Azure portal, select **Data Export** under the **Settings** section. Select the **Status** toggle to disable or enable the export rule. ---# [PowerShell](#tab/powershell) --You can disable export rules to stop the export for a certain period, such as when testing is being held. Use the following command to disable or update rule parameters by using PowerShell. --```powershell -Update-AzOperationalInsightsDataExport -ResourceGroupName resourceGroupName -WorkspaceName workspaceName -DataExportName 'ruleName' -TableName 'SecurityEvent,Heartbeat' -Enable: $false -``` --# [Azure CLI](#tab/azure-cli) --You can disable export rules to stop the export for a certain period, such as when testing is being held. Use the following command to disable or update rule parameters by using the CLI. --```azurecli -az monitor log-analytics workspace data-export update --resource-group resourceGroupName --workspace-name workspaceName --name ruleName --tables SecurityEvent Heartbeat --enable false -``` --# [REST](#tab/rest) --You can disable export rules to stop the export for a certain period, such as when testing is being held. Use the following command to disable or update rule parameters by using the REST API. The request should use bearer token authorization. --```rest -PUT https://management.azure.com/subscriptions/<subscription-id>/resourcegroups/<resource-group-name>/providers/Microsoft.operationalInsights/workspaces/<workspace-name>/dataexports/<data-export-name>?api-version=2020-08-01 -Authorization: Bearer <token> -Content-type: application/json --{ - "properties": { - "destination": { - "resourceId": "/subscriptions/subscription-id/resourcegroups/resource-group-name/providers/Microsoft.Storage/storageAccounts/storage-account-name" - }, - "tablenames": [ -"table1", - "table2" - ], - "enable": false - } -} -``` --# [Template](#tab/json) --You can disable export rules to stop export when testing is performed and you don't need data sent to a destination. Set ```"enable": false``` in the template to disable a data export. ----## Delete an export rule --# [Azure portal](#tab/portal) --On the **Log Analytics workspace** menu in the Azure portal, select **Data Export** under the **Settings** section. Select the ellipsis to the right of the rule and select **Delete**. ---# [PowerShell](#tab/powershell) --Use the following command to delete a data export rule by using PowerShell. --```powershell -Remove-AzOperationalInsightsDataExport -ResourceGroupName resourceGroupName -WorkspaceName workspaceName -DataExportName 'ruleName' -``` --# [Azure CLI](#tab/azure-cli) --Use the following command to delete a data export rule by using the CLI. --```azurecli -az monitor log-analytics workspace data-export delete --resource-group resourceGroupName --workspace-name workspaceName --name ruleName -``` --# [REST](#tab/rest) --Use the following request to delete a data export rule by using the REST API. The request should use bearer token authorization. --```rest -DELETE https://management.azure.com/subscriptions/<subscription-id>/resourcegroups/<resource-group-name>/providers/Microsoft.operationalInsights/workspaces/<workspace-name>/dataexports/<data-export-name>?api-version=2020-08-01 -``` --# [Template](#tab/json) --The template option doesn't apply. ----## View all data export rules in a workspace --# [Azure portal](#tab/portal) --On the **Log Analytics workspace** menu in the Azure portal, select **Data Export** under the **Settings** section to view all export rules in the workspace. ---# [PowerShell](#tab/powershell) --Use the following command to view all the data export rules in a workspace by using PowerShell. --```powershell -Get-AzOperationalInsightsDataExport -ResourceGroupName resourceGroupName -WorkspaceName workspaceName -``` --# [Azure CLI](#tab/azure-cli) --Use the following command to view all data export rules in a workspace by using the CLI. --```azurecli -az monitor log-analytics workspace data-export list --resource-group resourceGroupName --workspace-name workspaceName -``` --# [REST](#tab/rest) --Use the following request to view all data export rules in a workspace by using the REST API. The request should use bearer token authorization. --```rest -GET https://management.azure.com/subscriptions/<subscription-id>/resourcegroups/<resource-group-name>/providers/Microsoft.operationalInsights/workspaces/<workspace-name>/dataexports?api-version=2020-08-01 -``` --# [Template](#tab/json) --The template option doesn't apply. ----## Unsupported tables -If the data export rule includes an unsupported table, the configuration will succeed, but no data will be exported for that table. If the table is later supported, then its data will be exported at that time. --## Supported tables --> [!NOTE] -> We are in a process of adding support for more tables. Please check this article regularly. --| Table | Limitations | -||| -| AACAudit | | -| AACHttpRequest | | -| AADB2CRequestLogs | | -| AADCustomSecurityAttributeAuditLogs | | -| AADDomainServicesAccountLogon | | -| AADDomainServicesAccountManagement | | -| AADDomainServicesDirectoryServiceAccess | | -| AADDomainServicesDNSAuditsDynamicUpdates | | -| AADDomainServicesDNSAuditsGeneral | | -| AADDomainServicesLogonLogoff | | -| AADDomainServicesPolicyChange | | -| AADDomainServicesPrivilegeUse | | -| AADManagedIdentitySignInLogs | | -| AADNonInteractiveUserSignInLogs | | -| AADProvisioningLogs | | -| AADRiskyServicePrincipals | | -| AADRiskyUsers | | -| AADServicePrincipalRiskEvents | | -| AADServicePrincipalSignInLogs | | -| AADUserRiskEvents | | -| ABSBotRequests | | -| ACICollaborationAudit | | -| ACRConnectedClientList | | -| ACSAuthIncomingOperations | | -| ACSBillingUsage | | -| ACSCallAutomationIncomingOperations | | -| ACSCallAutomationMediaSummary | | -| ACSCallClientMediaStatsTimeSeries | | -| ACSCallClientOperations | | -| ACSCallClosedCaptionsSummary | | -| ACSCallDiagnostics | | -| ACSCallRecordingIncomingOperations | | -| ACSCallRecordingSummary | | -| ACSCallSummary | | -| ACSCallSurvey | | -| ACSChatIncomingOperations | | -| ACSEmailSendMailOperational | | -| ACSEmailStatusUpdateOperational | | -| ACSEmailUserEngagementOperational | | -| ACSJobRouterIncomingOperations | | -| ACSNetworkTraversalDiagnostics | | -| ACSNetworkTraversalIncomingOperations | | -| ACSRoomsIncomingOperations | | -| ACSSMSIncomingOperations | | -| ADAssessmentRecommendation | | -| AddonAzureBackupAlerts | | -| AddonAzureBackupJobs | | -| AddonAzureBackupPolicy | | -| AddonAzureBackupProtectedInstance | | -| AddonAzureBackupStorage | | -| ADFActivityRun | | -| ADFAirflowSchedulerLogs | | -| ADFAirflowTaskLogs | | -| ADFAirflowWebLogs | | -| ADFAirflowWorkerLogs | | -| ADFPipelineRun | | -| ADFSandboxActivityRun | | -| ADFSandboxPipelineRun | | -| ADFSSignInLogs | | -| ADFSSISIntegrationRuntimeLogs | | -| ADFSSISPackageEventMessageContext | | -| ADFSSISPackageEventMessages | | -| ADFSSISPackageExecutableStatistics | | -| ADFSSISPackageExecutionComponentPhases | | -| ADFSSISPackageExecutionDataStatistics | | -| ADFTriggerRun | | -| ADPAudit | | -| ADPDiagnostics | | -| ADPRequests | | -| ADReplicationResult | | -| ADSecurityAssessmentRecommendation | | -| ADTDataHistoryOperation | | -| ADTDigitalTwinsOperation | | -| ADTEventRoutesOperation | | -| ADTModelsOperation | | -| ADTQueryOperation | | -| ADXCommand | | -| ADXIngestionBatching | | -| ADXJournal | | -| ADXQuery | | -| ADXTableDetails | | -| ADXTableUsageStatistics | | -| AegDataPlaneRequests | | -| AegDeliveryFailureLogs | | -| AegPublishFailureLogs | | -| AEWAssignmentBlobLogs | | -| AEWAuditLogs | | -| AEWComputePipelinesLogs | | -| AFSAuditLogs | | -| AGCAccessLogs | | -| AgriFoodApplicationAuditLogs | | -| AgriFoodFarmManagementLogs | | -| AgriFoodFarmOperationLogs | | -| AgriFoodInsightLogs | | -| AgriFoodJobProcessedLogs | | -| AgriFoodModelInferenceLogs | | -| AgriFoodProviderAuthLogs | | -| AgriFoodSatelliteLogs | | -| AgriFoodSensorManagementLogs | | -| AgriFoodWeatherLogs | | -| AGSGrafanaLoginEvents | | -| AGWAccessLogs | | -| AGWFirewallLogs | | -| AGWPerformanceLogs | | -| AHDSDicomAuditLogs | | -| AHDSDicomDiagnosticLogs | | -| AHDSMedTechDiagnosticLogs | | -| AirflowDagProcessingLogs | | -| AKSAudit | | -| AKSAuditAdmin | | -| AKSControlPlane | | -| ALBHealthEvent | | -| Alert | Partial support. Data ingestion for Zabbix alerts isn't supported. | -| AlertEvidence | | -| AlertInfo | | -| AmlComputeClusterEvent | | -| AmlComputeCpuGpuUtilization | | -| AmlComputeInstanceEvent | | -| AmlComputeJobEvent | | -| AmlDataLabelEvent | | -| AmlDataSetEvent | | -| AmlDataStoreEvent | | -| AmlDeploymentEvent | | -| AmlEnvironmentEvent | | -| AmlInferencingEvent | | -| AmlModelsEvent | | -| AmlOnlineEndpointConsoleLog | | -| AmlOnlineEndpointEventLog | | -| AmlOnlineEndpointTrafficLog | | -| AmlPipelineEvent | | -| AmlRegistryReadEventsLog | | -| AmlRegistryWriteEventsLog | | -| AmlRunEvent | | -| AmlRunStatusChangedEvent | | -| AMSKeyDeliveryRequests | | -| AMSLiveEventOperations | | -| AMSMediaAccountHealth | | -| AMSStreamingEndpointRequests | | -| AMWMetricsUsageDetails | | -| ANFFileAccess | | -| Anomalies | | -| AOIDatabaseQuery | | -| AOIDigestion | | -| AOIStorage | | -| ApiManagementGatewayLogs | | -| ApiManagementWebSocketConnectionLogs | | -| AppAvailabilityResults | | -| AppBrowserTimings | | -| AppCenterError | | -| AppDependencies | | -| AppEnvSpringAppConsoleLogs | | -| AppEvents | | -| AppExceptions | | -| AppMetrics | | -| AppPageViews | | -| AppPerformanceCounters | | -| AppPlatformBuildLogs | | -| AppPlatformContainerEventLogs | | -| AppPlatformIngressLogs | | -| AppPlatformLogsforSpring | | -| AppPlatformSystemLogs | | -| AppRequests | | -| AppServiceAntivirusScanAuditLogs | | -| AppServiceAppLogs | | -| AppServiceAuditLogs | | -| AppServiceAuthenticationLogs | | -| AppServiceConsoleLogs | | -| AppServiceEnvironmentPlatformLogs | | -| AppServiceFileAuditLogs | | -| AppServiceHTTPLogs | | -| AppServiceIPSecAuditLogs | | -| AppServicePlatformLogs | | -| AppServiceServerlessSecurityPluginData | | -| AppSystemEvents | | -| AppTraces | | -| ArcK8sAudit | | -| ArcK8sAuditAdmin | | -| ArcK8sControlPlane | | -| ASCAuditLogs | | -| ASCDeviceEvents | | -| ASimAuditEventLogs | | -| ASimAuthenticationEventLogs | | -| ASimDhcpEventLogs | | -| ASimDnsActivityLogs | | -| ASimFileEventLogs | | -| ASimNetworkSessionLogs | | -| ASimProcessEventLogs | | -| ASimRegistryEventLogs | | -| ASimUserManagementActivityLogs | | -| ASimWebSessionLogs | | -| ASRJobs | | -| ASRReplicatedItems | | -| ATCExpressRouteCircuitIpfix | | -| AuditLogs | | -| AutoscaleEvaluationsLog | | -| AutoscaleScaleActionsLog | | -| AVNMConnectivityConfigurationChange | | -| AVNMIPAMPoolAllocationChange | | -| AVNMNetworkGroupMembershipChange | | -| AVNMRuleCollectionChange | | -| AVSSyslog | | -| AWSCloudTrail | | -| AWSCloudWatch | | -| AWSGuardDuty | | -| AWSVPCFlow | | -| AZFWApplicationRule | | -| AZFWApplicationRuleAggregation | | -| AZFWDnsQuery | | -| AZFWFatFlow | | -| AZFWFlowTrace | | -| AZFWIdpsSignature | | -| AZFWInternalFqdnResolutionFailure | | -| AZFWNatRule | | -| AZFWNatRuleAggregation | | -| AZFWNetworkRule | | -| AZFWNetworkRuleAggregation | | -| AZFWThreatIntel | | -| AZKVAuditLogs | | -| AZKVPolicyEvaluationDetailsLogs | | -| AZMSApplicationMetricLogs | | -| AZMSArchiveLogs | | -| AZMSAutoscaleLogs | | -| AZMSCustomerManagedKeyUserLogs | | -| AZMSDiagnosticErrorLogs | | -| AZMSHybridConnectionsEvents | | -| AZMSKafkaCoordinatorLogs | | -| AZMSKafkaUserErrorLogs | | -| AZMSOperationalLogs | | -| AZMSRunTimeAuditLogs | | -| AZMSVnetConnectionEvents | | -| AzureAssessmentRecommendation | | -| AzureAttestationDiagnostics | | -| AzureBackupOperations | | -| AzureDevOpsAuditing | | -| AzureLoadTestingOperation | | -| AzureMetricsV2 | | -| BehaviorAnalytics | | -| CassandraAudit | | -| CassandraLogs | | -| CCFApplicationLogs | | -| CDBCassandraRequests | | -| CDBControlPlaneRequests | | -| CDBDataPlaneRequests | | -| CDBGremlinRequests | | -| CDBMongoRequests | | -| CDBPartitionKeyRUConsumption | | -| CDBPartitionKeyStatistics | | -| CDBQueryRuntimeStatistics | | -| ChaosStudioExperimentEventLogs | | -| CHSMManagementAuditLogs | | -| CIEventsAudit | | -| CIEventsOperational | | -| CloudAppEvents | | -| CommonSecurityLog | | -| ComputerGroup | | -| ConfidentialWatchlist | | -| ConfigurationData | Partial support. Some of the data is ingested through internal services that aren't supported in export. Currently, this portion is missing in export. | -| ContainerAppConsoleLogs | | -| ContainerAppSystemLogs | | -| ContainerEvent | | -| ContainerImageInventory | | -| ContainerInstanceLog | | -| ContainerInventory | | -| ContainerLog | | -| ContainerLogV2 | | -| ContainerNodeInventory | | -| ContainerRegistryLoginEvents | | -| ContainerRegistryRepositoryEvents | | -| ContainerServiceLog | | -| CoreAzureBackup | | -| DatabricksAccounts | | -| DatabricksBrickStoreHttpGateway | | -| DatabricksCapsule8Dataplane | | -| DatabricksClamAVScan | | -| DatabricksCloudStorageMetadata | | -| DatabricksClusterLibraries | | -| DatabricksClusters | | -| DatabricksDashboards | | -| DatabricksDataMonitoring | | -| DatabricksDBFS | | -| DatabricksDeltaPipelines | | -| DatabricksFeatureStore | | -| DatabricksFilesystem | | -| DatabricksGenie | | -| DatabricksGitCredentials | | -| DatabricksGlobalInitScripts | | -| DatabricksIAMRole | | -| DatabricksIngestion | | -| DatabricksInstancePools | | -| DatabricksJobs | | -| DatabricksLineageTracking | | -| DatabricksMarketplaceConsumer | | -| DatabricksMLflowAcledArtifact | | -| DatabricksMLflowExperiment | | -| DatabricksModelRegistry | | -| DatabricksNotebook | | -| DatabricksPartnerHub | | -| DatabricksPredictiveOptimization | | -| DatabricksRemoteHistoryService | | -| DatabricksRepos | | -| DatabricksSecrets | | -| DatabricksServerlessRealTimeInference | | -| DatabricksSQLPermissions | | -| DatabricksSSH | | -| DatabricksUnityCatalog | | -| DatabricksWebTerminal | | -| DatabricksWorkspace | | -| DatabricksWorkspaceLogs | | -| DataTransferOperations | | -| DataverseActivity | | -| DCRLogErrors | | -| DCRLogTroubleshooting | | -| DevCenterBillingEventLogs | | -| DevCenterDiagnosticLogs | | -| DevCenterResourceOperationLogs | | -| DeviceEvents | | -| DeviceFileCertificateInfo | | -| DeviceFileEvents | | -| DeviceImageLoadEvents | | -| DeviceInfo | | -| DeviceLogonEvents | | -| DeviceNetworkEvents | | -| DeviceNetworkInfo | | -| DeviceProcessEvents | | -| DeviceRegistryEvents | | -| DeviceTvmSecureConfigurationAssessment | | -| DeviceTvmSecureConfigurationAssessmentKB | | -| DeviceTvmSoftwareInventory | | -| DeviceTvmSoftwareVulnerabilities | | -| DeviceTvmSoftwareVulnerabilitiesKB | | -| DnsEvents | | -| DnsInventory | | -| DNSQueryLogs | | -| DSMAzureBlobStorageLogs | | -| DSMDataClassificationLogs | | -| DSMDataLabelingLogs | | -| Dynamics365Activity | | -| DynamicSummary | | -| EGNFailedMqttConnections | | -| EGNFailedMqttPublishedMessages | | -| EGNFailedMqttSubscriptions | | -| EGNMqttDisconnections | | -| EGNSuccessfulMqttConnections | | -| EmailAttachmentInfo | | -| EmailEvents | | -| EmailPostDeliveryEvents | | -| EmailUrlInfo | | -| EnrichedMicrosoft365AuditLogs | | -| ETWEvent | Partial support. Data arriving from the Log Analytics agent or Azure Monitor Agent is fully supported in export. Data arriving via the Diagnostics extension agent is collected through storage. This path isn't supported in export. | -| Event | Partial support. Data arriving from the Log Analytics agent or Azure Monitor Agent is fully supported in export. Data arriving via the Diagnostics extension agent is collected through storage. This path isn't supported in export. | -| ExchangeAssessmentRecommendation | | -| ExchangeOnlineAssessmentRecommendation | | -| FailedIngestion | | -| FunctionAppLogs | | -| GCPAuditLogs | | -| GoogleCloudSCC | | -| HDInsightAmbariClusterAlerts | | -| HDInsightAmbariSystemMetrics | | -| HDInsightGatewayAuditLogs | | -| HDInsightHadoopAndYarnLogs | | -| HDInsightHadoopAndYarnMetrics | | -| HDInsightHBaseLogs | | -| HDInsightHBaseMetrics | | -| HDInsightHiveAndLLAPLogs | | -| HDInsightHiveAndLLAPMetrics | | -| HDInsightHiveQueryAppStats | | -| HDInsightHiveTezAppStats | | -| HDInsightJupyterNotebookEvents | | -| HDInsightKafkaLogs | | -| HDInsightKafkaMetrics | | -| HDInsightOozieLogs | | -| HDInsightRangerAuditLogs | | -| HDInsightSecurityLogs | | -| HDInsightSparkApplicationEvents | | -| HDInsightSparkBlockManagerEvents | | -| HDInsightSparkEnvironmentEvents | | -| HDInsightSparkExecutorEvents | | -| HDInsightSparkExtraEvents | | -| HDInsightSparkJobEvents | | -| HDInsightSparkLogs | | -| HDInsightSparkSQLExecutionEvents | | -| HDInsightSparkStageEvents | | -| HDInsightSparkStageTaskAccumulables | | -| HDInsightSparkTaskEvents | | -| HDInsightStormLogs | | -| HDInsightStormMetrics | | -| HDInsightStormTopologyMetrics | | -| HealthStateChangeEvent | | -| Heartbeat | | -| HuntingBookmark | | -| IdentityDirectoryEvents | | -| IdentityInfo | | -| IdentityLogonEvents | | -| IdentityQueryEvents | | -| InsightsMetrics | Partial support. Some of the data is ingested through internal services that aren't supported in export. Currently, this portion is missing in export. | -| IntuneAuditLogs | | -| IntuneDeviceComplianceOrg | | -| IntuneDevices | | -| IntuneOperationalLogs | | -| KubeEvents | | -| KubeHealth | | -| KubeMonAgentEvents | | -| KubeNodeInventory | | -| KubePodInventory | | -| KubePVInventory | | -| KubeServices | | -| LAQueryLogs | | -| LASummaryLogs | | -| LinuxAuditLog | | -| LogicAppWorkflowRuntime | | -| McasShadowItReporting | | -| MCCEventLogs | | -| MCVPAuditLogs | | -| MCVPOperationLogs | | -| MDCFileIntegrityMonitoringEvents | | -| MDECustomCollectionDeviceFileEvents | | -| MicrosoftAzureBastionAuditLogs | | -| MicrosoftDataShareReceivedSnapshotLog | | -| MicrosoftDataShareSentSnapshotLog | | -| MicrosoftDataShareShareLog | | -| MicrosoftGraphActivityLogs | | -| MicrosoftHealthcareApisAuditLogs | | -| MicrosoftPurviewInformationProtection | | -| MNFDeviceUpdates | | -| MNFSystemSessionHistoryUpdates | | -| MNFSystemStateMessageUpdates | | -| NCBMBreakGlassAuditLogs | | -| NCBMSecurityDefenderLogs | | -| NCBMSecurityLogs | | -| NCBMSystemLogs | | -| NCCKubernetesLogs | | -| NCCVMOrchestrationLogs | | -| NCSStorageAlerts | | -| NCSStorageLogs | | -| NetworkAccessTraffic | | -| NetworkMonitoring | | -| NGXOperationLogs | | -| NSPAccessLogs | | -| NTAInsights | | -| NTAIpDetails | | -| NTANetAnalytics | | -| NTATopologyDetails | | -| NWConnectionMonitorDestinationListenerResult | | -| NWConnectionMonitorDNSResult | | -| NWConnectionMonitorPathResult | | -| NWConnectionMonitorTestResult | | -| OEPAirFlowTask | | -| OEPAuditLogs | | -| OEPDataplaneLogs | | -| OEPElasticOperator | | -| OEPElasticsearch | | -| OfficeActivity | | -| OLPSupplyChainEntityOperations | | -| OLPSupplyChainEvents | | -| Operation | Partial support. Some of the data is ingested through internal services that aren't supported in export. Currently, this portion is missing in export. | -| Perf | | -| PFTitleAuditLogs | | -| PowerAppsActivity | | -| PowerAutomateActivity | | -| PowerBIActivity | | -| PowerBIAuditTenant | | -| PowerBIDatasetsTenant | | -| PowerBIDatasetsWorkspace | | -| PowerBIReportUsageWorkspace | | -| PowerPlatformAdminActivity | | -| PowerPlatformConnectorActivity | | -| PowerPlatformDlpActivity | | -| ProjectActivity | | -| PurviewDataSensitivityLogs | | -| PurviewScanStatusLogs | | -| PurviewSecurityLogs | | -| REDConnectionEvents | | -| RemoteNetworkHealthLogs | | -| ResourceManagementPublicAccessLogs | | -| SCCMAssessmentRecommendation | | -| SCOMAssessmentRecommendation | | -| SecureScoreControls | | -| SecureScores | | -| SecurityAlert | | -| SecurityAttackPathData | | -| SecurityBaseline | | -| SecurityBaselineSummary | | -| SecurityDetection | | -| SecurityEvent | | -| SecurityIncident | | -| SecurityIoTRawEvent | | -| SecurityNestedRecommendation | | -| SecurityRecommendation | | -| SecurityRegulatoryCompliance | | -| SentinelAudit | | -| SentinelHealth | | -| ServiceFabricOperationalEvent | Partial support. Data arriving from the Log Analytics agent or Azure Monitor Agent is fully supported in export. Data arriving via the Diagnostics extension agent is collected through storage. This path isn't supported in export. | -| ServiceFabricReliableActorEvent | Partial support. Data arriving from the Log Analytics agent or Azure Monitor Agent is fully supported in export. Data arriving via the Diagnostics extension agent is collected through storage. This path isn't supported in export. | -| ServiceFabricReliableServiceEvent | Partial support. Data arriving from the Log Analytics agent or Azure Monitor Agent is fully supported in export. Data arriving via the Diagnostics extension agent is collected through storage. This path isn't supported in export. | -| SfBAssessmentRecommendation | | -| SharePointOnlineAssessmentRecommendation | | -| SignalRServiceDiagnosticLogs | | -| SigninLogs | | -| SPAssessmentRecommendation | | -| SQLAssessmentRecommendation | | -| SqlAtpStatus | | -| SQLSecurityAuditEvents | | -| SqlVulnerabilityAssessmentScanStatus | | -| StorageBlobLogs | | -| StorageCacheOperationEvents | | -| StorageCacheUpgradeEvents | | -| StorageCacheWarningEvents | | -| StorageFileLogs | | -| StorageMalwareScanningResults | | -| StorageMoverCopyLogsFailed | | -| StorageMoverCopyLogsTransferred | | -| StorageMoverJobRunLogs | | -| StorageQueueLogs | | -| StorageTableLogs | | -| SucceededIngestion | | -| SynapseBigDataPoolApplicationsEnded | | -| SynapseBuiltinSqlPoolRequestsEnded | | -| SynapseDXCommand | | -| SynapseDXFailedIngestion | | -| SynapseDXIngestionBatching | | -| SynapseDXQuery | | -| SynapseDXSucceededIngestion | | -| SynapseDXTableDetails | | -| SynapseDXTableUsageStatistics | | -| SynapseGatewayApiRequests | | -| SynapseIntegrationActivityRuns | | -| SynapseIntegrationPipelineRuns | | -| SynapseIntegrationTriggerRuns | | -| SynapseLinkEvent | | -| SynapseRbacOperations | | -| SynapseScopePoolScopeJobsEnded | | -| SynapseScopePoolScopeJobsStateChange | | -| SynapseSqlPoolDmsWorkers | | -| SynapseSqlPoolExecRequests | | -| SynapseSqlPoolRequestSteps | | -| SynapseSqlPoolSqlRequests | | -| SynapseSqlPoolWaits | | -| Syslog | | -| ThreatIntelligenceIndicator | | -| TSIIngress | | -| UCClient | | -| UCClientReadinessStatus | | -| UCClientUpdateStatus | | -| UCDeviceAlert | | -| UCDOAggregatedStatus | | -| UCDOStatus | | -| UCServiceUpdateStatus | | -| UCUpdateAlert | | -| Update | Partial support. Some of the data is ingested through internal services that aren't supported in export. Currently, this portion is missing in export. | -| UpdateRunProgress | | -| UpdateSummary | | -| UrlClickEvents | | -| Usage | | -| UserAccessAnalytics | | -| UserPeerAnalytics | | -| VCoreMongoRequests | | -| VIAudit | | -| VIIndexing | | -| VMConnection | Partial support. Some of the data is ingested through internal services that aren't supported in export. Currently, this portion is missing in export. | -| W3CIISLog | Partial support. Data arriving from the Log Analytics agent or Azure Monitor Agent is fully supported in export. Data arriving via the Diagnostics extension agent is collected through storage. This path isn't supported in export. | -| WaaSDeploymentStatus | | -| WaaSInsiderStatus | | -| WaaSUpdateStatus | | -| Watchlist | | -| WebPubSubConnectivity | | -| WebPubSubHttpRequest | | -| WebPubSubMessaging | | -| Windows365AuditLogs | | -| WindowsClientAssessmentRecommendation | | -| WindowsEvent | | -| WindowsFirewall | | -| WindowsServerAssessmentRecommendation | | -| WireData | Partial support. Some of the data is ingested through internal services that aren't supported in export. Currently, this portion is missing in export. | -| WorkloadDiagnosticLogs | | -| WUDOAggregatedStatus | | -| WUDOStatus | | -| WVDAgentHealthStatus | | -| WVDAutoscaleEvaluationPooled | | -| WVDCheckpoints | | -| WVDConnectionGraphicsDataPreview | | -| WVDConnectionNetworkData | | -| WVDConnections | | -| WVDErrors | | -| WVDFeeds | | -| WVDHostRegistrations | | -| WVDManagement | | -| WVDSessionHostManagement | | --## Next steps --[Query the exported data from Azure Data Explorer](../logs/azure-data-explorer-query-storage.md) - |
| azure-monitor | Logs Dedicated Clusters | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/logs-dedicated-clusters.md | - Title: Azure Monitor Logs Dedicated Clusters -description: Customers meeting the minimum commitment tier could use dedicated clusters -- Previously updated : 04/21/2024----# Create and manage a dedicated cluster in Azure Monitor Logs --Linking a Log Analytics workspace to a dedicated cluster in Azure Monitor provides advanced capabilities and higher query utilization. Clusters require a minimum ingestion commitment of 100 GB per day. You can link and unlink workspaces from a dedicated cluster without any data loss or service interruption. --## Advanced capabilities -Capabilities that require dedicated clusters: --- **[Customer-managed keys](../logs/customer-managed-keys.md)** - Encrypt cluster data using keys that you provide and control.-- **[Lockbox](../logs/customer-managed-keys.md#customer-lockbox)** - Control Microsoft support engineer access requests to your data.-- **[Double encryption](../../storage/common/storage-service-encryption.md#doubly-encrypt-data-with-infrastructure-encryption)** - Protect against a scenario where one of the encryption algorithms or keys may be compromised. In this case, the extra layer of encryption continues to protect your data.-- **[Cross-query optimization](../logs/cross-workspace-query.md)** - Cross-workspace queries run faster when workspaces are on the same cluster.-- **Cost optimization** - Link your workspaces in same region to cluster to get commitment tier discount to all workspaces, even to ones with low ingestion that -eligible for commitment tier discount. -- **[Availability zones](../../availability-zones/az-overview.md)** - Protect your data from datacenter failures by relying on datacenters in different physical locations, equipped with independent power, cooling, and networking. The physical separation in zones and independent infrastructure makes an incident far less likely since the workspace can rely on the resources from any of the zones. [Azure Monitor availability zones](./availability-zones.md#supported-regions) covers broader parts of the service and when available in your region, extends your Azure Monitor resilience automatically. Azure Monitor creates dedicated clusters as availability-zone-enabled (`isAvailabilityZonesEnabled`: 'true') by default in supported regions. [Dedicated clusters Availability zones](./availability-zones.md#supported-regions) aren't supported in all regions currently.-- **[Ingest from Azure Event Hubs](../logs/ingest-logs-event-hub.md)** - Lets you ingest data directly from an event hub into a Log Analytics workspace. Dedicated cluster lets you use capability when ingestion from all linked workspaces combined meet commitment tier. --## Cluster pricing model -Log Analytics Dedicated Clusters use a commitment tier pricing model of at least 100 GB/day. Any usage above the tier level incurs charges based on the per-GB rate of that commitment tier. See [Azure Monitor Logs pricing details](cost-logs.md#dedicated-clusters) for pricing details for dedicated clusters. The commitment tiers have a 31-day commitment period from the time a commitment tier is selected. --## Prerequisites --- Dedicated clusters require a minimum ingestion commitment of 100 GB per day.-- When creating a dedicated cluster, you can't name it with the same name as a cluster that was deleted within the past two weeks.--## Required permissions --To perform cluster-related actions, you need these permissions: --| Action | Permissions or role needed | -|-|-| -| Create a dedicated cluster |`Microsoft.Resources/deployments/*`and `Microsoft.OperationalInsights/clusters/write` permissions, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example | -| Change cluster properties |`Microsoft.OperationalInsights/clusters/write` permissions, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example | -| Link workspaces to a cluster | `Microsoft.OperationalInsights/clusters/write`, `Microsoft.OperationalInsights/workspaces/write`, and `Microsoft.OperationalInsights/workspaces/linkedservices/write` permissions, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example | -| Check workspace link status | `Microsoft.OperationalInsights/workspaces/read` permissions to the workspace, as provided by the [Log Analytics Reader built-in role](./manage-access.md#log-analytics-reader), for example | -| Get clusters or check a cluster's provisioning status | `Microsoft.OperationalInsights/clusters/read` permissions, as provided by the [Log Analytics Reader built-in role](./manage-access.md#log-analytics-reader), for example | -| Update commitment tier or billingType in a cluster | `Microsoft.OperationalInsights/clusters/write` permissions, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example | -| Grant the required permissions | Owner or Contributor role that has `*/write` permissions, or the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), which has `Microsoft.OperationalInsights/*` permissions | -| Unlink a workspace from cluster | `Microsoft.OperationalInsights/workspaces/linkedServices/delete` permissions, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example | -| Delete a dedicated cluster | `Microsoft.OperationalInsights/clusters/delete` permissions, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example | --For more information on Log Analytics permissions, see [Manage access to log data and workspaces in Azure Monitor](./manage-access.md). --## Resource Manager template samples --This article includes sample [Azure Resource Manager (ARM) templates](../../azure-resource-manager/templates/syntax.md) to create and configure Log Analytics clusters in Azure Monitor. Each sample includes a template file and a parameters file with sample values to provide to the template. ---### Template references --- [Microsoft.OperationalInsights clusters](/azure/templates/microsoft.operationalinsights/2020-03-01-preview/clusters)--## Create a dedicated cluster --Provide the following properties when creating new dedicated cluster: --- **ClusterName**: Must be unique for the resource group.-- **ResourceGroupName**: Use a central IT resource group because many teams in the organization usually share clusters. For more design considerations, review [Design a Log Analytics workspace configuration](../logs/workspace-design.md).-- **Location**-- **SkuCapacity**: You can set the commitment tier to 100, 200, 300, 400, 500, 1000, 2000, 5000, 10000, 25000, 50000 GB per day. The minimum commitment tier supported in CLI is 500 currently. Use REST to configure lower commitment tiers with minimum of 100. For more information on cluster costs, see [Dedicate clusters](./cost-logs.md#dedicated-clusters). -- **Managed identity**: Clusters support two [managed identity types](../../active-directory/managed-identities-azure-resources/overview.md#managed-identity-types): - - System-assigned managed identity - Generated automatically with the cluster creation when identity `type` is set to "*SystemAssigned*". This identity can be used later to grant storage access to your Key Vault for wrap and unwrap operations. -- *Identity in Cluster's REST Call* - ```json - { - "identity": { - "type": "SystemAssigned" - } - } - ``` - - User-assigned managed identity - Lets you configure a customer-managed key at cluster creation, when granting it permissions in your Key Vault before cluster creation. -- *Identity in Cluster's REST Call* - ```json - { - "identity": { - "type": "UserAssigned", - "userAssignedIdentities": { - "subscriptions/<subscription-id>/resourcegroups/<resource-group-name>/providers/Microsoft.ManagedIdentity/UserAssignedIdentities/<cluster-assigned-managed-identity>" - } - } - } - ``` --After you create your cluster resource, you can edit properties such as *sku*, *keyVaultProperties, or *billingType*. See more details below. --Deleted clusters take two weeks to be completely removed. You can have up to seven clusters per subscription and region, five active, and two deleted in past two weeks. --> [!NOTE] -> Creating a cluster involves multiple resources and operation typically complete in two hours. -> Dedicated cluster is billed once provisioned regardless data ingestion and it's recommended to prepare the deployment to expedite the provisioning and workspaces link to cluster. Verify the following: -> - A list of initial workspace to be linked to cluster is identified -> - You have permissions to subscription intended for the cluster and any workspace to be linked --#### [Portal](#tab/azure-portal) --Click **Create** in the **Log Analytics dedicated clusters** menu in the Azure portal. You will be prompted for details such as the name of the cluster and the commitment tier. ----#### [CLI](#tab/cli) --> [!NOTE] -> The minimum commitment tier supported in CLI is 500 currently. Use REST to configure lower commitment tiers with minimum of 100. --```azurecli -az account set --subscription "cluster-subscription-id" --az monitor log-analytics cluster create --no-wait --resource-group "resource-group-name" --name "cluster-name" --location "region-name" --sku-capacity "daily-ingestion-gigabyte" --# Wait for job completion when `--no-wait` was used -$clusterResourceId = az monitor log-analytics cluster list --resource-group "resource-group-name" --query "[?contains(name, 'cluster-name')].[id]" --output tsv -az resource wait --created --ids $clusterResourceId --include-response-body true -``` --#### [PowerShell](#tab/powershell) --> [!NOTE] -> The minimum commitment tier supported in PowerShell is 500 currently. Use REST to configure lower commitment tiers with minimum of 100. --```powershell -Select-AzSubscription "cluster-subscription-id" --New-AzOperationalInsightsCluster -ResourceGroupName "resource-group-name" -ClusterName "cluster-name" -Location "region-name" -SkuCapacity "daily-ingestion-gigabyte" -AsJob --# Check when the job is done when `-AsJob` was used -Get-Job -Command "New-AzOperationalInsightsCluster*" | Format-List -Property * -``` --#### [REST API](#tab/restapi) --*Call* --```rest -PUT https://management.azure.com/subscriptions/<subscription-id>/resourceGroups/<resource-group-name>/providers/Microsoft.OperationalInsights/clusters/<cluster-name>?api-version=2022-10-01 -Authorization: Bearer <token> -Content-type: application/json --{ - "identity": { - "type": "systemAssigned" - }, - "sku": { - "name": "capacityReservation", - "Capacity": 100 - }, - "properties": { - "billingType": "Cluster", - }, - "location": "<region>", -} -``` --*Response* --Should be 202 (Accepted) and a header. --#### [ARM template (Bicep)](#tab/bicep) --The following sample creates a new empty Log Analytics cluster. --```bicep -@description('Specify the name of the Log Analytics cluster.') -param clusterName string --@description('Specify the location of the resources.') -param location string = resourceGroup().location --@description('Specify the capacity reservation value.') -@allowed([ - 100 - 200 - 300 - 400 - 500 - 1000 - 2000 - 5000 -]) -param CommitmentTier int --@description('Specify the billing type settings. Can be \'Cluster\' (default) or \'Workspaces\' for proportional billing on workspaces.') -@allowed([ - 'Cluster' - 'Workspaces' -]) -param billingType string --resource cluster 'Microsoft.OperationalInsights/clusters@2021-06-01' = { - name: clusterName - location: location - identity: { - type: 'SystemAssigned' - } - sku: { - name: 'CapacityReservation' - capacity: CommitmentTier - } - properties: { - billingType: billingType - } -} -``` --**Parameter file** --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-08-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "clusterName": { - "value": "MyCluster" - }, - "CommitmentTier": { - "value": 500 - }, - "billingType": { - "value": "Cluster" - } - } -} -``` --#### [ARM template (JSON)](#tab/json) --The following sample creates a new empty Log Analytics cluster. --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "clusterName": { - "type": "string", - "metadata": { - "description": "Specify the name of the Log Analytics cluster." - } - }, - "location": { - "type": "string", - "defaultValue": "[resourceGroup().location]", - "metadata": { - "description": "Specify the location of the resources." - } - }, - "CommitmentTier": { - "type": "int", - "allowedValues": [ - 100, - 200, - 300, - 400, - 500, - 1000, - 2000, - 5000 - ], - "metadata": { - "description": "Specify the capacity reservation value." - } - }, - "billingType": { - "type": "string", - "allowedValues": [ - "Cluster", - "Workspaces" - ], - "metadata": { - "description": "Specify the billing type settings. Can be 'Cluster' (default) or 'Workspaces' for proportional billing on workspaces." - } - } - }, - "resources": [ - { - "type": "Microsoft.OperationalInsights/clusters", - "apiVersion": "2021-06-01", - "name": "[parameters('clusterName')]", - "location": "[parameters('location')]", - "identity": { - "type": "SystemAssigned" - }, - "sku": { - "name": "CapacityReservation", - "capacity": "[parameters('CommitmentTier')]" - }, - "properties": { - "billingType": "[parameters('billingType')]" - } - } - ] -} -``` --**Parameter file** --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-08-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "clusterName": { - "value": "MyCluster" - }, - "CommitmentTier": { - "value": 500 - }, - "billingType": { - "value": "Cluster" - } - } -} -``` ----### Check cluster provisioning status --The provisioning of the Log Analytics cluster takes a while to complete. Use one of the following methods to check the *ProvisioningState* property. The value is *ProvisioningAccount* while provisioning and *Succeeded* when completed. --#### [Portal](#tab/azure-portal) --The portal will provide a status as the cluster is being provisioned. --#### [CLI](#tab/cli) --```azurecli -az account set --subscription "cluster-subscription-id" --az monitor log-analytics cluster show --resource-group "resource-group-name" --name "cluster-name" -``` --#### [PowerShell](#tab/powershell) --```powershell -Select-AzSubscription "cluster-subscription-id" --Get-AzOperationalInsightsCluster -ResourceGroupName "resource-group-name" -ClusterName "cluster-name" -``` - -#### [REST API](#tab/restapi) --Send a GET request on the cluster resource and look at the *provisioningState* value. The value is *ProvisioningAccount* while provisioning and *Succeeded* when completed. -- ```rest - GET https://management.azure.com/subscriptions/subscription-id/resourceGroups/resource-group-name/providers/Microsoft.OperationalInsights/clusters/cluster-name?api-version=2022-10-01 - Authorization: Bearer <token> - ``` -- **Response** -- ```json - { - "identity": { - "type": "SystemAssigned", - "tenantId": "tenant-id", - "principalId": "principal-id" - }, - "sku": { - "name": "capacityreservation", - "capacity": 100 - }, - "properties": { - "provisioningState": "ProvisioningAccount", - "clusterId": "cluster-id", - "billingType": "Cluster", - "lastModifiedDate": "last-modified-date", - "createdDate": "created-date", - "isDoubleEncryptionEnabled": false, - "isAvailabilityZonesEnabled": false, - "capacityReservationProperties": { - "lastSkuUpdate": "last-sku-modified-date", - "minCapacity": 100 - } - }, - "id": "/subscriptions/subscription-id/resourceGroups/resource-group-name/providers/Microsoft.OperationalInsights/clusters/cluster-name", - "name": "cluster-name", - "type": "Microsoft.OperationalInsights/clusters", - "location": "cluster-region" - } - ``` --The managed identity service generates the *principalId* GUID when you create the cluster. --#### [ARM template (Bicep)](#tab/bicep) --N/A --#### [ARM template (JSON)](#tab/json) --N/A ----## Link a workspace to a cluster --> [!NOTE] -> - Linking a workspace can be performed only after the completion of the Log Analytics cluster provisioning. -> - Linking a workspace to a cluster involves syncing multiple backend components and cache hydration, which typically complete in two hours. -> - When linking a Log Analytics workspace workspace, the workspace billing plan in changed to *LACluster*, and you should remove SKU in workspace template to prevent conflict during workspace deployment. -> - Other than the billing aspects that is governed by the cluster plan, all workspace configurations and query aspects remain unchanged during and after the link. --You need 'write' permissions to both the workspace and the cluster resource for workspace link operation: --- In the workspace: *Microsoft.OperationalInsights/workspaces/write*-- In the cluster resource: *Microsoft.OperationalInsights/clusters/write*--Once Log Analytics workspace linked to a dedicated cluster, new data sent to workspace is ingested to your dedicated cluster, while previously ingested data remains in Log Analytics cluster. Linking a workspace has no effect on workspace operation, including ingestion and query experiences. Log Analytics query engine stitches data from old and new clusters automatically, and the results of queries are complete. --Clusters are regional and can be linked to up to 1,000 workspaces located in the same region as the cluster. A workspace can't be linked to a cluster more than twice a month, to prevent data fragmentation. --Linked workspaces can be in different subscriptions than the subscription the cluster is located in. The workspace and cluster can be in different tenants if Azure Lighthouse is used to map both of them to a single tenant. --When a dedicated cluster is configured with a customer-managed key (CMK), the newly ingested data is encrypted with your key, while older data remains encrypted with a Microsoft-managed key (MMK). The key configuration is abstracted by Log Analytics and the query across old and new data encryptions is performed seamlessly. --Use the following steps to link a workspace to a cluster. You can use automation for linking multiple workspaces: --#### [Portal](#tab/azure-portal) --Select your cluster from **Log Analytics dedicated clusters** menu in the Azure portal and then click **Linked workspaces** to view all workspaces currently linked to the dedicated cluster. Click **Link workspaces** to link additional workspaces. ---#### [CLI](#tab/cli) --> [!NOTE] -> Use **cluster** value for linked-service ```name```. --```azurecli -# Find cluster resource ID -az account set --subscription "cluster-subscription-id" -$clusterResourceId = az monitor log-analytics cluster list --resource-group "resource-group-name" --query "[?contains(name, 'cluster-name')].[id]" --output tsv --# Link workspace -az account set --subscription "workspace-subscription-id" -az monitor log-analytics workspace linked-service create --no-wait --name cluster --resource-group "resource-group-name" --workspace-name "workspace-name" --write-access-resource-id $clusterResourceId --# Wait for job completion when `--no-wait` was used -$workspaceResourceId = az monitor log-analytics workspace list --resource-group "resource-group-name" --query "[?contains(name, 'workspace-name')].[id]" --output tsv -az resource wait --deleted --ids $workspaceResourceId --include-response-body true -``` --#### [PowerShell](#tab/powershell) --> [!NOTE] -> Use **cluster** value for ```LinkedServiceName```. --```powershell -Select-AzSubscription "cluster-subscription-id" --# Find cluster resource ID -$clusterResourceId = (Get-AzOperationalInsightsCluster -ResourceGroupName "resource-group-name" -ClusterName "cluster-name").id --Select-AzSubscription "workspace-subscription-id" --# Link the workspace to the cluster -Set-AzOperationalInsightsLinkedService -ResourceGroupName "resource-group-name" -WorkspaceName "workspace-name" -LinkedServiceName cluster -WriteAccessResourceId $clusterResourceId -AsJob --# Check when the job is done -Get-Job -Command "Set-AzOperationalInsightsLinkedService" | Format-List -Property * -``` --#### [REST API](#tab/restapi) --Use the following REST call to link to a cluster: --*Send* --```rest -PUT https://management.azure.com/subscriptions/<subscription-id>/resourcegroups/<resource-group-name>/providers/microsoft.operationalinsights/workspaces/<workspace-name>/linkedservices/cluster?api-version=2020-08-01 -Authorization: Bearer <token> -Content-type: application/json --{ - "properties": { - "WriteAccessResourceId": "/subscriptions/<subscription-id>/resourcegroups/<resource-group-name>/providers/microsoft.operationalinsights/clusters/<cluster-name>" - } -} -``` --*Response* --202 (Accepted) and header. --#### [ARM template (Bicep)](#tab/bicep) --N/A --#### [ARM template (JSON)](#tab/json) --N/A ----### Check workspace link status --The workspace link operation can take up to 90 minutes to complete. You can check the status on both the linked workspaces and the cluster. When completed, the workspace resources will include `clusterResourceId` property under `features`, and the cluster will include linked workspaces under `associatedWorkspaces` section. --When a cluster is configured with a customer managed key, data ingested to the workspaces after the link operation is complete will be stored encrypted with your key. --#### [Portal](#tab/azure-portal) --On the **Overview** page for your dedicated cluster, select **JSON View**. The `associatedWorkspaces` section lists the workspaces linked to the cluster. ---#### [CLI](#tab/cli) --```azurecli -az account set --subscription "workspace-subscription-id" --az monitor log-analytics workspace show --resource-group "resource-group-name" --workspace-name "workspace-name" -``` --#### [PowerShell](#tab/powershell) --```powershell -Select-AzSubscription "workspace-subscription-id" --Get-AzOperationalInsightsWorkspace -ResourceGroupName "resource-group-name" -Name "workspace-name" -``` --#### [REST API](#tab/restapi) --*Call* --```rest -GET https://management.azure.com/subscriptions/<subscription-id>/resourcegroups/<resource-group-name>/providers/microsoft.operationalinsights/workspaces/<workspace-name>?api-version=2023-09-01 -Authorization: Bearer <token> -``` --*Response* --```json -{ - "properties": { - "source": "Azure", - "customerId": "workspace-name", - "provisioningState": "Succeeded", - "sku": { - "name": "pricing-tier-name", - "lastSkuUpdate": "Tue, 28 Jan 2020 12:26:30 GMT" - }, - "retentionInDays": 31, - "features": { - "legacy": 0, - "searchVersion": 1, - "enableLogAccessUsingOnlyResourcePermissions": true, - "clusterResourceId": "/subscriptions/subscription-id/resourceGroups/resource-group-name/providers/Microsoft.OperationalInsights/clusters/cluster-name" - }, - "workspaceCapping": { - "dailyQuotaGb": -1.0, - "quotaNextResetTime": "Tue, 28 Jan 2020 14:00:00 GMT", - "dataIngestionStatus": "RespectQuota" - } - }, - "id": "/subscriptions/subscription-id/resourcegroups/resource-group-name/providers/microsoft.operationalinsights/workspaces/workspace-name", - "name": "workspace-name", - "type": "Microsoft.OperationalInsights/workspaces", - "location": "region" -} -``` --#### [ARM template (Bicep)](#tab/bicep) --N/A --#### [ARM template (JSON)](#tab/json) --N/A ----## Change cluster properties --After you create your cluster resource and it's fully provisioned, you can edit cluster properties using CLI, PowerShell or REST API. Properties you can set after the cluster is provisioned include: --- **keyVaultProperties** - Contains the key in Azure Key Vault with the following parameters: *KeyVaultUri*, *KeyName*, *KeyVersion*. See [Update cluster with Key identifier details](../logs/customer-managed-keys.md#update-cluster-with-key-identifier-details).-- **Identity** - The identity used to authenticate to your Key Vault. This can be System-assigned or User-assigned.-- **billingType** - Billing attribution for the cluster resource and its data. Includes on the following values:- - **Cluster (default)** - The costs for your cluster are attributed to the cluster resource. - - **Workspaces** - The costs for your cluster are attributed proportionately to the workspaces in the Cluster, with the cluster resource being billed some of the usage if the total ingested data for the day is under the commitment tier. See [Log Analytics Dedicated Clusters](./cost-logs.md#dedicated-clusters) to learn more about the cluster pricing model. -->[!IMPORTANT] ->Cluster update should not include both identity and key identifier details in the same operation. If you need to update both, the update should be in two consecutive operations. --#### [Portal](#tab/azure-portal) --N/A --#### [CLI](#tab/cli) --The following sample updates the billing type. --```azurecli -az account set --subscription "cluster-subscription-id" --az monitor log-analytics cluster update --resource-group "resource-group-name" --name "cluster-name" --billing-type {Cluster, Workspaces} -``` --#### [PowerShell](#tab/powershell) --The following sample updates the billing type. --```powershell -Select-AzSubscription "cluster-subscription-id" --Update-AzOperationalInsightsCluster -ResourceGroupName "resource-group-name" -ClusterName "cluster-name" -BillingType "Workspaces" -``` --#### [REST API](#tab/restapi) --The following sample updates the billing type. --*Call* --```rest -PATCH https://management.azure.com/subscriptions/<subscription-id>/resourceGroups/<resource-group-name>/providers/Microsoft.OperationalInsights/clusters/<cluster-name>?api-version=2022-10-01 -Authorization: Bearer <token> -Content-type: application/json --{ - "properties": { - "billingType": "Workspaces" - }, - "location": "region" -} -``` --#### [ARM template (Bicep)](#tab/bicep) --The following sample updates a Log Analytics cluster to use customer-managed key. --```bicep -@description('Specify the name of the Log Analytics cluster.') -param clusterName string -@description('Specify the location of the resources') -param location string = resourceGroup().location -@description('Specify the key vault name.') -param keyVaultName string -@description('Specify the key name.') -param keyName string -@description('Specify the key version. When empty, latest key version is used.') -param keyVersion string -var keyVaultUri = format('{0}{1}', keyVaultName, environment().suffixes.keyvaultDns) -resource cluster 'Microsoft.OperationalInsights/clusters@2021-06-01' = { - name: clusterName - location: location - identity: { - type: 'SystemAssigned' - } - properties: { - keyVaultProperties: { - keyVaultUri: keyVaultUri - keyName: keyName - keyVersion: keyVersion - } - } -} -``` --**Parameter file** --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-08-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "clusterName": { - "value": "MyCluster" - }, - "keyVaultUri": { - "value": "https://key-vault-name.vault.azure.net" - }, - "keyName": { - "value": "MyKeyName" - }, - "keyVersion": { - "value": "" - } - } -} -``` --#### [ARM template (JSON)](#tab/json) --The following sample updates a Log Analytics cluster to use customer-managed key. --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "clusterName": { - "type": "string", - "metadata": { - "description": "Specify the name of the Log Analytics cluster." - } - }, - "location": { - "type": "string", - "defaultValue": "[resourceGroup().location]", - "metadata": { - "description": "Specify the location of the resources" - } - }, - "keyVaultName": { - "type": "string", - "metadata": { - "description": "Specify the key vault name." - } - }, - "keyName": { - "type": "string", - "metadata": { - "description": "Specify the key name." - } - }, - "keyVersion": { - "type": "string", - "metadata": { - "description": "Specify the key version. When empty, latest key version is used." - } - } - }, - "variables": { - "keyVaultUri": "[format('{0}{1}', parameters('keyVaultName'), environment().suffixes.keyvaultDns)]" - }, - "resources": [ - { - "type": "Microsoft.OperationalInsights/clusters", - "apiVersion": "2021-06-01", - "name": "[parameters('clusterName')]", - "location": "[parameters('location')]", - "identity": { - "type": "SystemAssigned" - }, - "properties": { - "keyVaultProperties": { - "keyVaultUri": "[variables('keyVaultUri')]", - "keyName": "[parameters('keyName')]", - "keyVersion": "[parameters('keyVersion')]" - } - } - } - ] -} -``` --**Parameter file** --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-08-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "clusterName": { - "value": "MyCluster" - }, - "keyVaultUri": { - "value": "https://key-vault-name.vault.azure.net" - }, - "keyName": { - "value": "MyKeyName" - }, - "keyVersion": { - "value": "" - } - } -} -``` ----## Get all clusters in resource group --#### [Portal](#tab/azure-portal) --From the **Log Analytics dedicated clusters** menu in the Azure portal, select the **Resource group** filter. ---#### [CLI](#tab/cli) --```azurecli -az account set --subscription "cluster-subscription-id" --az monitor log-analytics cluster list --resource-group "resource-group-name" -``` --#### [PowerShell](#tab/powershell) --```powershell -Select-AzSubscription "cluster-subscription-id" --Get-AzOperationalInsightsCluster -ResourceGroupName "resource-group-name" -``` --#### [REST API](#tab/restapi) --*Call* --```rest -GET https://management.azure.com/subscriptions/<subscription-id>/resourcegroups/<resource-group-name>/providers/Microsoft.OperationalInsights/clusters?api-version=2022-10-01 -Authorization: Bearer <token> -``` --*Response* - -```json -{ - "value": [ - { - "identity": { - "type": "SystemAssigned", - "tenantId": "tenant-id", - "principalId": "principal-id" - }, - "sku": { - "name": "capacityreservation", - "capacity": 100 - }, - "properties": { - "provisioningState": "Succeeded", - "clusterId": "cluster-id", - "billingType": "Cluster", - "lastModifiedDate": "last-modified-date", - "createdDate": "created-date", - "isDoubleEncryptionEnabled": false, - "isAvailabilityZonesEnabled": false, - "capacityReservationProperties": { - "lastSkuUpdate": "last-sku-modified-date", - "minCapacity": 100 - } - }, - "id": "/subscriptions/subscription-id/resourceGroups/resource-group-name/providers/Microsoft.OperationalInsights/clusters/cluster-name", - "name": "cluster-name", - "type": "Microsoft.OperationalInsights/clusters", - "location": "cluster-region" - } - ] -} -``` --#### [ARM template (Bicep)](#tab/bicep) --N/A --#### [ARM template (JSON)](#tab/json) --N/A ----## Get all clusters in subscription --#### [Portal](#tab/azure-portal) --From the **Log Analytics dedicated clusters** menu in the Azure portal, select the **Subscription** filter. ---#### [CLI](#tab/cli) --```azurecli -az account set --subscription "cluster-subscription-id" --az monitor log-analytics cluster list -``` --#### [PowerShell](#tab/powershell) --```powershell -Select-AzSubscription "cluster-subscription-id" --Get-AzOperationalInsightsCluster -``` -#### [REST API](#tab/restapi) --*Call* --```rest -GET https://management.azure.com/subscriptions/<subscription-id>/providers/Microsoft.OperationalInsights/clusters?api-version=2022-10-01 -Authorization: Bearer <token> -``` - -*Response* - -The same as for 'clusters in a resource group', but in subscription scope. --#### [ARM template (Bicep)](#tab/bicep) --N/A --#### [ARM template (JSON)](#tab/json) --N/A ----## Update commitment tier in cluster --When the data volume to linked workspaces changes over time, you can update the Commitment Tier level appropriately to optimize cost. The tier is specified in units of Gigabytes (GB) and can have values of 100, 200, 300, 400, 500, 1000, 2000, 5000, 10000, 25000, 50000 GB per day. You don't have to provide the full REST request body, but you must include the sku. --During the commitment period, you can change to a higher commitment tier, which restarts the 31-day commitment period. You can't move back to pay-as-you-go or to a lower commitment tier until after you finish the commitment period. --#### [Portal](#tab/azure-portal) --Select your cluster from **Log Analytics dedicated clusters** menu in the Azure portal and then click **Change** next to **Commitment tier** ---#### [CLI](#tab/cli) --```azurecli -az account set --subscription "cluster-subscription-id" --az monitor log-analytics cluster update --resource-group "resource-group-name" --name "cluster-name" --sku-capacity 500 -``` --#### [PowerShell](#tab/powershell) --```powershell -Select-AzSubscription "cluster-subscription-id" --Update-AzOperationalInsightsCluster -ResourceGroupName "resource-group-name" -ClusterName "cluster-name" -SkuCapacity 500 -``` --#### [REST API](#tab/restapi) --*Call* --```rest -PATCH https://management.azure.com/subscriptions/<subscription-id>/resourceGroups/<resource-group-name>/providers/Microsoft.OperationalInsights/clusters/<cluster-name>?api-version=2022-10-01 -Authorization: Bearer <token> -Content-type: application/json --{ - "sku": { - "name": "capacityReservation", - "Capacity": 2000 - } -} -``` --#### [ARM template (Bicep)](#tab/bicep) --N/A --#### [ARM template (JSON)](#tab/json) --N/A ----### Unlink a workspace from cluster --You can unlink a workspace from a cluster at any time. The workspace pricing tier is changed to per-GB, data ingested to cluster before the unlink operation remains in the cluster, and new data to workspace get ingested to Log Analytics. --> [!WARNING] -> Unlinking a workspace does not move workspace data out of the cluster. Any data collected for workspace while linked to cluster, remains in cluster for the retention period defined in workspace, and accessible as long as cluster isn't deleted. --Queries aren't affected when workspace is unlinked and service performs cross-cluster queries seamlessly. If cluster was configured with Customer-managed key (CMK), data ingested to workspace while was linked, remains encrypted with your key and accessible, while your key and permissions to Key Vault remain. --> [!NOTE] -> - There is a limit of two link operations for a specific workspace within a month to prevent data distribution across clusters. Contact support if you reach the limit. -> - Unlinked workspaces are moved to Pay-As-You-Go pricing tier. --Use the following commands to unlink a workspace from cluster: --#### [Portal](#tab/azure-portal) --Select your cluster from **Log Analytics dedicated clusters** menu in the Azure portal and then click **Linked workspaces** to view all workspaces currently linked to the dedicated cluster. Select any workspaces you want to unlink and click **Unlink**. ---#### [CLI](#tab/cli) --```azurecli -az account set --subscription "workspace-subscription-id" --az monitor log-analytics workspace linked-service delete --resource-group "resource-group-name" --workspace-name "workspace-name" --name cluster -``` --#### [PowerShell](#tab/powershell) --```powershell -Select-AzSubscription "workspace-subscription-id" --# Unlink a workspace from cluster -Remove-AzOperationalInsightsLinkedService -ResourceGroupName "resource-group-name" -WorkspaceName {workspace-name} -LinkedServiceName cluster -``` --#### [REST API](#tab/restapi) --```rest -DELETE https://management.azure.com/subscriptions/{subscriptionId}/resourcegroups/{resourceGroupName}/providers/Microsoft.OperationalInsights/workspaces/{workspaceName}/linkedServices/{linkedServiceName}?api-version=2020-08-01 -``` --#### [ARM template (Bicep)](#tab/bicep) --N/A --#### [ARM template (JSON)](#tab/json) --N/A ----## Delete cluster --You need to have *write* permissions on the cluster resource. --Cluster deletion operation should be done with caution, since operation is non-recoverable. All ingested data to cluster from linked workspaces, gets permanently deleted. --The cluster's billing stops when cluster is deleted, regardless of the 31-days commitment tier defined in cluster. --If you delete a cluster that has linked workspaces, workspaces get automatically unlinked from the cluster, workspaces are moved to pay-as-you-go pricing tier, and new data to workspaces is ingested to Log Analytics clusters instead. You can query workspace for the time range before it was linked to the cluster, and after the unlink, and the service performs cross-cluster queries seamlessly. --> [!NOTE] -> - There is a limit of seven clusters per subscription and region, five active, plus two that were deleted in past two weeks. -> - Cluster's name remain reserved two weeks after deletion, and can't be used for creating a new cluster. --Use the following commands to delete a cluster: --#### [Portal](#tab/azure-portal) --Select your cluster from **Log Analytics dedicated clusters** menu in the Azure portal and then click **Delete**. ---#### [CLI](#tab/cli) --```azurecli -az account set --subscription "cluster-subscription-id" --az monitor log-analytics cluster delete --resource-group "resource-group-name" --name $clusterName -``` --#### [PowerShell](#tab/powershell) --```powershell -Select-AzSubscription "cluster-subscription-id" --Remove-AzOperationalInsightsCluster -ResourceGroupName "resource-group-name" -ClusterName "cluster-name" -``` --#### [REST API](#tab/restapi) --Use the following REST call to delete a cluster: --```rest -DELETE https://management.azure.com/subscriptions/<subscription-id>/resourceGroups/<resource-group-name>/providers/Microsoft.OperationalInsights/clusters/<cluster-name>?api-version=2022-10-01 -Authorization: Bearer <token> -``` -- **Response** -- 200 OK --#### [ARM template (Bicep)](#tab/bicep) --N/A --#### [ARM template (JSON)](#tab/json) --N/A ----## Limits and constraints --- A maximum of five active clusters can be created in each region and subscription.--- A maximum of seven clusters allowed per subscription and region, five active, plus two that were deleted in past 2 weeks.--- A maximum of 1,000 Log Analytics workspaces can be linked to a cluster.--- A maximum of two workspace link operations on particular workspace is allowed in 30 day period.--- Moving a cluster to another resource group or subscription isn't currently supported.--- Moving a cluster to another region isn't supported.--- Cluster update shouldn't include both identity and key identifier details in the same operation. In case you need to update both, the update should be in two consecutive operations.--- Lockbox isn't currently available in China. --- [Double encryption](../../storage/common/storage-service-encryption.md#doubly-encrypt-data-with-infrastructure-encryption) is configured automatically for clusters created from October 2020 in supported regions. You can verify if your cluster is configured for double encryption by sending a GET request on the cluster and observing that the `isDoubleEncryptionEnabled` value is `true` for clusters with Double encryption enabled. - - If you create a cluster and get an error "region-name doesn't support Double Encryption for clusters.", you can still create the cluster without Double encryption by adding `"properties": {"isDoubleEncryptionEnabled": false}` in the REST request body. - - Double encryption setting can't be changed after the cluster has been created. --- Deleting a workspace is permitted while linked to cluster. If you decide to [recover](./delete-workspace.md#recover-a-workspace-in-a-soft-delete-state) the workspace during the [soft-delete](./delete-workspace.md#delete-a-workspace-into-a-soft-delete-state) period, workspace returns to previous state and remains linked to cluster.--- During the commitment period, you can change to a higher commitment tier, which restarts the 31-day commitment period. You can't move back to pay-as-you-go or to a lower commitment tier until after you finish the commitment period.--## Troubleshooting --- If you get conflict error when creating a cluster, it might have been deleted in past 2 weeks and in deletion process yet. The cluster name remains reserved during the 2 weeks deletion period and you can't create a new cluster with that name.--- If you update your cluster while the cluster is at provisioning or updating state, the update will fail.--- Some operations are long and can take a while to complete. These are *cluster create*, *cluster key update* and *cluster delete*. You can check the operation status by sending GET request to cluster or workspace and observe the response. For example, unlinked workspace won't have the *clusterResourceId* under *features*.--- If you attempt to link a Log Analytics workspace that's already linked to another cluster, the operation will fail.--## Error messages - -### Cluster Create --- 400--Cluster name isn't valid. Cluster name can contain characters a-z, A-Z, 0-9 and length of 3-63.-- 400--The body of the request is null or in bad format.-- 400--SKU name is invalid. Set SKU name to capacityReservation.-- 400--Capacity was provided but SKU isn't capacityReservation. Set SKU name to capacityReservation.-- 400--Missing Capacity in SKU. Set Capacity value to 100, 200, 300, 400, 500, 1000, 2000, 5000, 10000, 25000, 50000 GB per day.-- 400--Capacity is locked for 30 days. Decreasing capacity is permitted 30 days after update.-- 400--No SKU was set. Set the SKU name to capacityReservation and Capacity value to 100, 200, 300, 400, 500, 1000, 2000, 5000, 10000, 25000, 50000 GB per day.-- 400--Identity is null or empty. Set Identity with systemAssigned type.-- 400--KeyVaultProperties are set on creation. Update KeyVaultProperties after cluster creation.-- 400--Operation can't be executed now. Async operation is in a state other than succeeded. Cluster must complete its operation before any update operation is performed.--### Cluster Update --- 400--Cluster is in deleting state. Async operation is in progress. Cluster must complete its operation before any update operation is performed.-- 400--KeyVaultProperties isn't empty but has a bad format. See [key identifier update](../logs/customer-managed-keys.md#update-cluster-with-key-identifier-details).-- 400--Failed to validate key in Key Vault. Could be due to lack of permissions or when key doesn't exist. Verify that you [set key and access policy](../logs/customer-managed-keys.md#grant-key-vault-permissions) in Key Vault.-- 400--Key isn't recoverable. Key Vault must be set to Soft-delete and Purge-protection. See [Key Vault documentation](/azure/key-vault/general/soft-delete-overview)-- 400--Operation can't be executed now. Wait for the Async operation to complete and try again.-- 400--Cluster is in deleting state. Wait for the Async operation to complete and try again.--### Cluster Get --- 404--Cluster not found, the cluster might have been deleted. If you try to create a cluster with that name and get conflict, the cluster is in deletion process.--### Cluster Delete --- 409--Can't delete a cluster while in provisioning state. Wait for the Async operation to complete and try again.--### Workspace link --- 404--Workspace not found. The workspace you specified doesn't exist or was deleted.-- 409--Workspace link or unlink operation in process.-- 400--Cluster not found, the cluster you specified doesn't exist or was deleted.--### Workspace unlink -- 404--Workspace not found. The workspace you specified doesn't exist or was deleted.-- 409--Workspace link or unlink operation in process.--## Next steps --- Learn about [Log Analytics dedicated cluster billing](cost-logs.md#dedicated-clusters).-- Learn about [proper design of Log Analytics workspaces](../logs/workspace-design.md).-- Get other [sample templates for Azure Monitor](../resource-manager-samples.md). |
| azure-monitor | Logs Export Logic App | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/logs-export-logic-app.md | - Title: Export data from a Log Analytics workspace to a storage account by using Logic Apps -description: This article describes a method to use Azure Logic Apps to query data from a Log Analytics workspace and send it to Azure Storage. --- Previously updated : 08/12/2024----# Export data from a Log Analytics workspace to a storage account by using Logic Apps -This article describes a method to use [Azure Logic Apps](../../logic-apps/index.yml) to query data from a Log Analytics workspace in Azure Monitor and send it to Azure Storage. Use this process when you need to export your Azure Monitor Logs data for auditing and compliance scenarios or to allow another service to retrieve this data. --## Other export methods -The method discussed in this article describes a scheduled export from a log query by using a logic app. Other options to export data for particular scenarios include: --- To export data from your Log Analytics workspace to a storage account or Azure Event Hubs, use the Log Analytics workspace data export feature of Azure Monitor Logs. See [Log Analytics workspace data export in Azure Monitor](logs-data-export.md).-- One-time export by using a logic app. See [Azure Monitor Logs connector for Logic Apps](../../connectors/connectors-azure-monitor-logs.md).-- One-time export to a local machine by using a PowerShell script. See [Invoke-AzOperationalInsightsQueryExport](https://www.powershellgallery.com/packages/Invoke-AzOperationalInsightsQueryExport).--## Overview -This procedure uses the [Azure Monitor Logs connector](/connectors/azuremonitorlogs), which lets you run a log query from a logic app and use its output in other actions in the workflow. The [Azure Blob Storage connector](/connectors/azureblob) is used in this procedure to send the query output to storage. -<!-- convertborder later --> --When you export data from a Log Analytics workspace, limit the amount of data processed by your Logic Apps workflow. Filter and aggregate your log data in the query to reduce the required data. For example, if you need to export sign-in events, filter for required events and project only the required fields. For example: --```Kusto -SecurityEvent -| where EventID == 4624 or EventID == 4625 -| project TimeGenerated , Account , AccountType , Computer -``` --When you export the data on a schedule, use the `ingestion_time()` function in your query to ensure that you don't miss late-arriving data. If data is delayed because of network or platform issues, using the ingestion time ensures that data is included in the next Logic Apps execution. For an example, see the step "Add Azure Monitor Logs action" in the [Logic Apps procedure](#logic-apps-procedure) section. --## Prerequisites -The following prerequisites must be completed before you start this procedure: --- **Log Analytics workspace**: The user who creates the logic app must have at least read permission to the workspace.-- **Storage account**: The storage account doesn't have to be in the same subscription as your Log Analytics workspace. The user who creates the logic app must have write permission to the storage account.--## Connector limits -Log Analytics workspace and log queries in Azure Monitor are multitenancy services that include limits to protect and isolate customers and maintain quality of service. When you query for a large amount of data, consider the following limits, which can affect how you configure the Logic Apps recurrence and your log query: --- Log queries can't return more than 500,000 rows.-- Log queries can't return more than 64,000,000 bytes.-- Log queries can't run longer than 10 minutes.-- Log Analytics connector is limited to 100 calls per minute.--## Logic Apps procedure --The following sections walk you through the procedure. --### Create a container in the storage account --Use the procedure in [Create a container](../../storage/blobs/storage-quickstart-blobs-portal.md#create-a-container) to add a container to your storage account to hold the exported data. The name used for the container in this article is **loganalytics-data**, but you can use any name. --### Create a logic app workflow --1. Go to **Logic Apps** in the Azure portal and select **Add**. Select a **Subscription**, **Resource group**, and **Region** to store the new logic app. Then give it a unique name. You can turn on the **Log Analytics** setting to collect information about runtime data and events as described in [Set up Azure Monitor Logs and collect diagnostics data for Azure Logic Apps](../../logic-apps/monitor-workflows-collect-diagnostic-data.md). This setting isn't required for using the Azure Monitor Logs connector. - <!-- convertborder later --> - :::image type="content" source="media/logs-export-logic-app/create-logic-app.png" lightbox="media/logs-export-logic-app/create-logic-app.png" alt-text="Screenshot that shows creating a logic app." border="false"::: --1. Select **Review + create** and then select **Create**. After the deployment is finished, select **Go to resource** to open the **Logic Apps Designer**. --### Create a trigger for the workflow --Under **Start with a common trigger**, select **Recurrence**. This setting creates a logic app workflow that automatically runs at a regular interval. In the **Frequency** box of the action, select **Day**. In the **Interval** box, enter **1** to run the workflow once per day. -<!-- convertborder later --> --### Add an Azure Monitor Logs action --The Azure Monitor Logs action lets you specify the query to run. The log query used in this example is optimized for hourly recurrence. It collects the data ingested for the particular execution time. For example, if the workflow runs at 4:35, the time range would be 3:00 to 4:00. If you change the logic app to run at a different frequency, you need to change the query too. For example, if you set the recurrence to run daily, you set `startTime` in the query to `startofday(make_datetime(year,month,day,0,0))`. --You're prompted to select a tenant to grant access to the Log Analytics workspace with the account that the workflow will use to run the query. --1. Select **+ New step** to add an action that runs after the recurrence action. Under **Choose an action**, enter **azure monitor**. Then select **Azure Monitor Logs**. - <!-- convertborder later --> - :::image type="content" source="media/logs-export-logic-app/select-azure-monitor-connector.png" lightbox="media/logs-export-logic-app/select-azure-monitor-connector.png" alt-text="Screenshot that shows an Azure Monitor Logs action." border="false"::: --1. Select **Azure Log Analytics ΓÇô Run query and list results**. - <!-- convertborder later --> - :::image type="content" source="media/logs-export-logic-app/select-query-action-list.png" lightbox="media/logs-export-logic-app/select-query-action-list.png" alt-text="Screenshot that shows Azure Monitor Logs is highlighted under Choose an action." border="false"::: --1. Select the **Subscription** and **Resource Group** for your Log Analytics workspace. Select **Log Analytics Workspace** for the **Resource Type**. Then select the workspace name under **Resource Name**. --1. Add the following log query to the **Query** window: -- ```Kusto - let dt = now(); - let year = datetime_part('year', dt); - let month = datetime_part('month', dt); - let day = datetime_part('day', dt); - let hour = datetime_part('hour', dt); - let startTime = make_datetime(year,month,day,hour,0)-1h; - let endTime = startTime + 1h - 1tick; - AzureActivity - | where ingestion_time() between(startTime .. endTime) - | project - TimeGenerated, - BlobTime = startTime, - OperationName , - OperationNameValue , - Level , - ActivityStatus , - ResourceGroup , - SubscriptionId , - Category , - EventSubmissionTimestamp , - ClientIpAddress = parse_json(HTTPRequest).clientIpAddress , - ResourceId = _ResourceId - ``` --1. The **Time Range** specifies the records that will be included in the query based on the **TimeGenerated** column. The value should be greater than the time range selected in the query. Because this query isn't using the **TimeGenerated** column, the **Set in query** option isn't available. For more information about the time range, see [Query scope](./scope.md). Select **Last 4 hours** for the **Time Range**. This setting ensures that any records with an ingestion time larger than **TimeGenerated** will be included in the results. - <!-- convertborder later --> - :::image type="content" source="media/logs-export-logic-app/run-query-list-action.png" lightbox="media/logs-export-logic-app/run-query-list-action.png" alt-text="Screenshot that shows the settings for the new Azure Monitor Logs action named Run query and visualize results." border="false"::: --### Add a Parse JSON action (optional) --The output from the **Run query and list results** action is formatted in JSON. You can parse this data and manipulate it as part of the preparation for the **Compose** action. --You can provide a JSON schema that describes the payload you expect to receive. The designer parses JSON content by using this schema and generates user-friendly tokens that represent the properties in your JSON content. You can then easily reference and use those properties throughout your Logic App's workflow. --You can use a sample output from the **Run query and list results** step. --1. Select **Run Trigger** in the Logic Apps ribbon. Then select **Run** and download and save an output record. For the sample query in the previous stem, you can use the following sample output: -- ```json - { - "TimeGenerated": "2020-09-29T23:11:02.578Z", - "BlobTime": "2020-09-29T23:00:00Z", - "OperationName": "Returns Storage Account SAS Token", - "OperationNameValue": "MICROSOFT.RESOURCES/DEPLOYMENTS/WRITE", - "Level": "Informational", - "ActivityStatus": "Started", - "ResourceGroup": "monitoring", - "SubscriptionId": "00000000-0000-0000-0000-000000000000", - "Category": "Administrative", - "EventSubmissionTimestamp": "2020-09-29T23:11:02Z", - "ClientIpAddress": "192.168.1.100", - "ResourceId": "/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/monitoring/providers/microsoft.storage/storageaccounts/my-storage-account" - } - ``` --1. Select **+ New step** and then select **+ Add an action**. Under **Choose an operation**, enter **json** and then select **Parse JSON**. - <!-- convertborder later --> - :::image type="content" source="media/logs-export-logic-app/select-parse-json.png" lightbox="media/logs-export-logic-app/select-parse-json.png" alt-text="Screenshot that shows selecting a Parse JSON operator." border="false"::: --1. Select the **Content** box to display a list of values from previous activities. Select **Body** from the **Run query and list results** action. This output is from the log query. - <!-- convertborder later --> - :::image type="content" source="media/logs-export-logic-app/select-body.png" lightbox="media/logs-export-logic-app/select-body.png" alt-text="Screenshot that shows selecting a Body." border="false"::: --1. Copy the sample record saved earlier. Select **Use sample payload to generate schema** and paste. - <!-- convertborder later --> - :::image type="content" source="media/logs-export-logic-app/parse-json-payload.png" lightbox="media/logs-export-logic-app/parse-json-payload.png" alt-text="Screenshot that shows parsing a JSON payload." border="false"::: --### Add the Compose action --The **Compose** action takes the parsed JSON output and creates the object that you need to store in the blob. --1. Select **+ New step**, and then select **+ Add an action**. Under **Choose an operation**, enter **compose**. Then select the **Compose** action. - <!-- convertborder later --> - :::image type="content" source="media/logs-export-logic-app/select-compose.png" lightbox="media/logs-export-logic-app/select-compose.png" alt-text="Screenshot that shows selecting a Compose action." border="false"::: --1. Select the **Inputs** box to display a list of values from previous activities. Select **Body** from the **Parse JSON** action. This parsed output is from the log query. - <!-- convertborder later --> - :::image type="content" source="media/logs-export-logic-app/select-body-compose.png" lightbox="media/logs-export-logic-app/select-body-compose.png" alt-text="Screenshot that shows selecting a body for a Compose action." border="false"::: --### Add the Create blob action --The **Create blob** action writes the composed JSON to storage. --1. Select **+ New step**, and then select **+ Add an action**. Under **Choose an operation**, enter **blob**. Then select the **Create blob** action. - <!-- convertborder later --> - :::image type="content" source="media/logs-export-logic-app/select-create-blob.png" lightbox="media/logs-export-logic-app/select-create-blob.png" alt-text="Screenshot that shows selecting the Create Blob action." border="false"::: --1. Enter a name for the connection to your storage account in **Connection Name**. Then select the folder icon in the **Folder path** box to select the container in your storage account. Select **Blob name** to see a list of values from previous activities. Select **Expression** and enter an expression that matches your time interval. For this query, which is run hourly, the following expression sets the blob name per previous hour: -- ```json - subtractFromTime(formatDateTime(utcNow(),'yyyy-MM-ddTHH:00:00'), 1,'Hour') - ``` - <!-- convertborder later --> - :::image type="content" source="media/logs-export-logic-app/blob-expression.png" lightbox="media/logs-export-logic-app/blob-expression.png" alt-text="Screenshot that shows a blob expression." border="false"::: --1. Select the **Blob content** box to display a list of values from previous activities. Then select **Outputs** in the **Compose** section. - <!-- convertborder later --> - :::image type="content" source="media/logs-export-logic-app/create-blob.png" lightbox="media/logs-export-logic-app/create-blob.png" alt-text="Screenshot that shows creating a blob expression." border="false"::: --### Test the workflow --To test the workflow, select **Run**. If the workflow has errors, they're indicated on the step with the problem. You can view the executions and drill in to each step to view the input and output to investigate failures. See [Troubleshoot and diagnose workflow failures in Azure Logic Apps](../../logic-apps/logic-apps-diagnosing-failures.md), if necessary. -<!-- convertborder later --> --### View logs in storage --Go to the **Storage accounts** menu in the Azure portal and select your storage account. Select the **Blobs** tile. Then select the container you specified in the **Create blob** action. Select one of the blobs and then select **Edit blob**. -<!-- convertborder later --> --### Logic App template --The optional Parse JSON step isn't included in template --```json -{ - "definition": { - "$schema": "https://schema.management.azure.com/providers/Microsoft.Logic/schemas/2016-06-01/workflowdefinition.json#", - "actions": { - "Compose": { - "inputs": "@body('Run_query_and_list_results')", - "runAfter": { - "Run_query_and_list_results": [ - "Succeeded" - ] - }, - "type": "Compose" - }, - "Create_blob_(V2)": { - "inputs": { - "body": "@outputs('Compose')", - "headers": { - "ReadFileMetadataFromServer": true - }, - "host": { - "connection": { - "name": "@parameters('$connections')['azureblob']['connectionId']" - } - }, - "method": "post", - "path": "/v2/datasets/@{encodeURIComponent(encodeURIComponent('AccountNameFromSettings'))}/files", - "queries": { - "folderPath": "/logicappexport", - "name": "@{utcNow()}", - "queryParametersSingleEncoded": true - } - }, - "runAfter": { - "Compose": [ - "Succeeded" - ] - }, - "runtimeConfiguration": { - "contentTransfer": { - "transferMode": "Chunked" - } - }, - "type": "ApiConnection" - }, - "Run_query_and_list_results": { - "inputs": { - "body": "let dt = now();\nlet year = datetime_part('year', dt);\nlet month = datetime_part('month', dt);\nlet day = datetime_part('day', dt);\n let hour = datetime_part('hour', dt);\nlet startTime = make_datetime(year,month,day,hour,0)-1h;\nlet endTime = startTime + 1h - 1tick;\nAzureActivity\n| where ingestion_time() between(startTime .. endTime)\n| project \n TimeGenerated,\n BlobTime = startTime, \n OperationName ,\n OperationNameValue ,\n Level ,\n ActivityStatus ,\n ResourceGroup ,\n SubscriptionId ,\n Category ,\n EventSubmissionTimestamp ,\n ClientIpAddress = parse_json(HTTPRequest).clientIpAddress ,\n ResourceId = _ResourceId ", - "host": { - "connection": { - "name": "@parameters('$connections')['azuremonitorlogs']['connectionId']" - } - }, - "method": "post", - "path": "/queryData", - "queries": { - "resourcegroups": "resource-group-name", - "resourcename": "workspace-name", - "resourcetype": "Log Analytics Workspace", - "subscriptions": "workspace-subscription-id", - "timerange": "Set in query" - } - }, - "runAfter": {}, - "type": "ApiConnection" - } - }, - "contentVersion": "1.0.0.0", - "outputs": {}, - "parameters": { - "$connections": { - "defaultValue": {}, - "type": "Object" - } - }, - "triggers": { - "Recurrence": { - "evaluatedRecurrence": { - "frequency": "Day", - "interval": 1 - }, - "recurrence": { - "frequency": "Day", - "interval": 1 - }, - "type": "Recurrence" - } - } - }, - "parameters": { - "$connections": { - "value": { - "azureblob": { - "connectionId": "/subscriptions/logic-app-subscription-id/resourceGroups/logic-app-resource-group-name/providers/Microsoft.Web/connections/blob-connection-name", - "connectionName": "blob-connection-name", - "id": "/subscriptions/logic-app-subscription-id/providers/Microsoft.Web/locations/canadacentral/managedApis/azureblob" - }, - "azuremonitorlogs": { - "connectionId": "/subscriptions/blob-connection-name/resourceGroups/logic-app-resource-group-name/providers/Microsoft.Web/connections/azure-monitor-logs-connection-name", - "connectionName": "azure-monitor-logs-connection-name", - "id": "/subscriptions/blob-connection-name/providers/Microsoft.Web/locations/canadacentral/managedApis/azuremonitorlogs" - } - } - } - } -} -``` --## Next steps --- Learn more about [log queries in Azure Monitor](./log-query-overview.md).-- Learn more about [Logic Apps](../../logic-apps/index.yml).-- Learn more about [Power Automate](https://make.powerautomate.com). |
| azure-monitor | Logs Ingestion Api Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/logs-ingestion-api-overview.md | - Title: Logs Ingestion API in Azure Monitor -description: Send data to a Log Analytics workspace using REST API or client libraries. - Previously updated : 04/15/2024---# Logs Ingestion API in Azure Monitor -The Logs Ingestion API in Azure Monitor lets you send data to a Log Analytics workspace using either a [REST API call](#rest-api-call) or [client libraries](#client-libraries). The API allows you to send data to [supported Azure tables](#supported-tables) or to [custom tables that you create](../logs/create-custom-table.md#create-a-custom-table). You can also [extend the schema of Azure tables with custom columns](../logs/create-custom-table.md#add-or-delete-a-custom-column) to accept additional data. --## Basic operation -Data can be sent to the Logs Ingestion API from any application that can make a REST API call. This may be a custom application that you create, or it may be an application or agent that understands how to send data to the API. It specifies a [data collection rule (DCR)](../essentials/data-collection-rule-overview.md) that includes the target table and workspace and the credentials of an app registration with access to the specified DCR. It sends the data to an endpoint specified by the DCR, or to a [data collection endpoint (DCE)](../essentials/data-collection-endpoint-overview.md) if you're using private link. --The data sent by your application to the API must be formatted in JSON and match the structure expected by the DCR. It doesn't necessarily need to match the structure of the target table because the DCR can include a [transformation](../essentials//data-collection-transformations.md) to convert the data to match the table's structure. You can modify the target table and workspace by modifying the DCR without any change to the API call or source data. ---## Configuration -The following table describes each component in Azure that you must configure before you can use the Logs Ingestion API. --> [!NOTE] -> For a PowerShell script that automates the configuration of these components, see [Sample code to send data to Azure Monitor using Logs ingestion API](../logs/tutorial-logs-ingestion-code.md). --| Component | Function | -|:|:| -| App registration and secret | The application registration is used to authenticate the API call. It must be granted permission to the DCR described below. The API call includes the **Application (client) ID** and **Directory (tenant) ID** of the application and the **Value** of an application secret.<br><br>See [Create a Microsoft Entra application and service principal that can access resources](../../active-directory/develop/howto-create-service-principal-portal.md#register-an-application-with-azure-ad-and-create-a-service-principal) and [Create a new application secret](../../active-directory/develop/howto-create-service-principal-portal.md#option-3-create-a-new-application-secret). | -| Data collection endpoint (DCE) | The DCE is only required if private link is being used. It provides an endpoint for the application to send to. A single DCE can support multiple DCRs, so you can use an existing DCE if you already have one in the same region as your Log Analytics workspace. If you aren't using private link, then you can use the DCR endpoint.<br><br>See [Create a data collection endpoint](../essentials/data-collection-endpoint-overview.md#create-a-data-collection-endpoint). | -| Table in Log Analytics workspace | The table in the Log Analytics workspace must exist before you can send data to it. You can use one of the [supported Azure tables](#supported-tables) or create a custom table using any of the available methods. If you use the Azure portal to create the table, then the DCR is created for you, including a transformation if it's required. With any other method, you need to create the DCR manually as described in the next section.<br><br>See [Create a custom table](create-custom-table.md#create-a-custom-table). | -| Data collection rule (DCR) | Azure Monitor uses the [Data collection rule (DCR)](../essentials/data-collection-rule-overview.md) to understand the structure of the incoming data and what to do with it. If the structure of the table and the incoming data don't match, the DCR can include a [transformation](../essentials/data-collection-transformations.md) to convert the source data to match the target table. You can also use the transformation to filter source data and perform any other calculations or conversions.<br><br>If you create a custom table using the Azure portal, the DCR and the transformation are created for you based on sample data that you provide. If you use an existing table or create a custom table using another method, then you must manually create the DCR using details in the following section.<br><br>Once your DCR is created, you must grant access to it for the application that you created in the first step. From the **Monitor** menu in the Azure portal, select **Data Collection rules** and then the DCR that you created. Select **Access Control (IAM)** for the DCR and then select **Add role assignment** to add the **Monitoring Metrics Publisher** role. | ---## **Manually create DCR** -If you're sending data to a table that already exists, then you must create the DCR manually. Start with the [Sample DCR for Logs Ingestion API](../essentials/data-collection-rule-samples.md#logs-ingestion-api) and modify the following parameters in the template. Then use any of the methods described in [Create and edit data collection rules (DCRs) in Azure Monitor](../essentials/data-collection-rule-create-edit.md) to create the DCR. --| Parameter | Description | -|:|:| -| `region` | Region to create your DCR. This must match the region of the DCE and the Log Analytics workspace. | -| `dataCollectionEndpointId` | Resource ID of your DCE. | -| `streamDeclarations` | Change the column list to the columns in your incoming data. You don't need to change the name of the stream since this just needs to match the `streams` name in `dataFlows`. | -| `workspaceResourceId` | Resource ID of your Log Analytics workspace. You don't need to change the name since this just needs to match the `destinations` name in `dataFlows`. | -| `transformKql` | KQL query to be applied to the incoming data. If the schema of the incoming data matches the schema of the table, then you can use `source` for the transformation which will pass on the incoming data unchanged. Otherwise, use a query that will transform the data to match the table schema. | -| `outputStream` | Name of the table to send the data. For a custom table, add the prefix *Custom-\<table-name\>*. For a built-in table, add the prefix *Microsoft-\<table-name\>*. | --## Client libraries --In addition to making a REST API call, you can use the following client libraries to send data to the Logs ingestion API. The libraries require the same components described in [Configuration](#configuration). For examples using each of these libraries, see [Sample code to send data to Azure Monitor using Logs ingestion API](../logs/tutorial-logs-ingestion-code.md). --- [.NET](/dotnet/api/overview/azure/Monitor.Ingestion-readme)-- [Go](https://pkg.go.dev/github.com/Azure/azure-sdk-for-go/sdk/monitor/ingestion/azlogs)-- [Java](/java/api/overview/azure/monitor-ingestion-readme)-- [JavaScript](/javascript/api/overview/azure/monitor-ingestion-readme)-- [Python](/python/api/overview/azure/monitor-ingestion-readme)--## REST API call -To send data to Azure Monitor with a REST API call, make a POST call over HTTP. Details required for this call are described in this section. --### Endpoint URI --The endpoint URI uses the following format, where the `Data Collection Endpoint` and `DCR Immutable ID` identify the DCE and DCR. The immutable ID is generated for the DCR when it's created. You can retrieve it from the [Overview page for the DCR in the Azure portal](../essentials/data-collection-rule-view.md). ---`Stream Name` refers to the [stream](../essentials/data-collection-rule-structure.md#streamdeclarations) in the DCR that should handle the custom data. --``` -{Data Collection Endpoint URI}/dataCollectionRules/{DCR Immutable ID}/streams/{Stream Name}?api-version=2023-01-01 -``` --For example: --``` -https://my-dce-5kyl.eastus-1.ingest.monitor.azure.com/dataCollectionRules/dcr-000a00a000a00000a000000aa000a0aa/streams/Custom-MyTable?api-version=2023-01-01 -``` --### Headers --The following table describes that headers for your API call. ---| Header | Required? |Description | -|:|:|:| -| Authorization | Yes | Bearer token obtained through the client credentials flow. Use the token audience value for your cloud:<br><br>Azure public cloud - `https://monitor.azure.com`<br>Microsoft Azure operated by 21Vianet cloud - `https://monitor.azure.cn`<br>Azure US Government cloud - `https://monitor.azure.us` | -| Content-Type | Yes | `application/json` | -| Content-Encoding | No | `gzip` | -| x-ms-client-request-id | No | String-formatted GUID. This is a request ID that can be used by Microsoft for any troubleshooting purposes. | --### Body --The body of the call includes the custom data to be sent to Azure Monitor. The shape of the data must be a JSON array with item structure that matches the format expected by the stream in the DCR. If it is needed to send a single item within API call, the data should be sent as a single-item array. --For example: --```json -[ -{ - "TimeGenerated": "2023-11-14 15:10:02", - "Column01": "Value01", - "Column02": "Value02" -} -] -``` --Ensure that the request body is properly encoded in UTF-8 to prevent any issues with data transmission. --### Example --See [Sample code to send data to Azure Monitor using Logs ingestion API](tutorial-logs-ingestion-code.md?tabs=powershell#sample-code) for an example of the API call using PowerShell. ---## Supported tables --Data sent to the ingestion API can be sent to the following tables: --| Tables | Description | -|:|:| -| Custom tables | Any custom table that you create in your Log Analytics workspace. The target table must exist before you can send data to it. Custom tables must have the `_CL` suffix. | -| Azure tables | The following Azure tables are currently supported. Other tables may be added to this list as support for them is implemented.<br><br> -- [ADAssessmentRecommendation](/azure/azure-monitor/reference/tables/adassessmentrecommendation)<br>-- [ADSecurityAssessmentRecommendation](/azure/azure-monitor/reference/tables/adsecurityassessmentrecommendation)<br>-- [Anomalies](/azure/azure-monitor/reference/tables/anomalies)<br>-- [ASimAuditEventLogs](/azure/azure-monitor/reference/tables/asimauditeventlogs)<br>-- [ASimAuthenticationEventLogs](/azure/azure-monitor/reference/tables/asimauthenticationeventlogs)<br>-- [ASimDhcpEventLogs](/azure/azure-monitor/reference/tables/asimdhcpeventlogs)<br>-- [ASimDnsActivityLogs](/azure/azure-monitor/reference/tables/asimdnsactivitylogs)<br>-- ASimDnsAuditLogs<br>-- [ASimFileEventLogs](/azure/azure-monitor/reference/tables/asimfileeventlogs)<br>-- [ASimNetworkSessionLogs](/azure/azure-monitor/reference/tables/asimnetworksessionlogs)<br>-- [ASimProcessEventLogs](/azure/azure-monitor/reference/tables/asimprocesseventlogs)<br>-- [ASimRegistryEventLogs](/azure/azure-monitor/reference/tables/asimregistryeventlogs)<br>-- [ASimUserManagementActivityLogs](/azure/azure-monitor/reference/tables/asimusermanagementactivitylogs)<br>-- [ASimWebSessionLogs](/azure/azure-monitor/reference/tables/asimwebsessionlogs)<br>-- [AWSCloudTrail](/azure/azure-monitor/reference/tables/awscloudtrail)<br>-- [AWSCloudWatch](/azure/azure-monitor/reference/tables/awscloudwatch)<br>-- [AWSGuardDuty](/azure/azure-monitor/reference/tables/awsguardduty)<br>-- [AWSVPCFlow](/azure/azure-monitor/reference/tables/awsvpcflow)<br>-- [AzureAssessmentRecommendation](/azure/azure-monitor/reference/tables/azureassessmentrecommendation)<br>-- [CommonSecurityLog](/azure/azure-monitor/reference/tables/commonsecuritylog)<br>-- [DeviceTvmSecureConfigurationAssessmentKB](/azure/azure-monitor/reference/tables/devicetvmsecureconfigurationassessmentkb)<br>-- [DeviceTvmSoftwareVulnerabilitiesKB](/azure/azure-monitor/reference/tables/devicetvmsoftwarevulnerabilitieskb)<br>-- [ExchangeAssessmentRecommendation](/azure/azure-monitor/reference/tables/exchangeassessmentrecommendation)<br>-- [ExchangeOnlineAssessmentRecommendation](/azure/azure-monitor/reference/tables/exchangeonlineassessmentrecommendation)<br>-- [GCPAuditLogs](/azure/azure-monitor/reference/tables/gcpauditlogs)<br>-- [GoogleCloudSCC](/azure/azure-monitor/reference/tables/googlecloudscc)<br>-- [SCCMAssessmentRecommendation](/azure/azure-monitor/reference/tables/sccmassessmentrecommendation)<br>-- [SCOMAssessmentRecommendation](/azure/azure-monitor/reference/tables/scomassessmentrecommendation)<br>-- [SecurityEvent](/azure/azure-monitor/reference/tables/securityevent)<br>-- [SfBAssessmentRecommendation](/azure/azure-monitor/reference/tables/sfbassessmentrecommendation)<br>-- [SfBOnlineAssessmentRecommendation](/azure/azure-monitor/reference/tables/sfbonlineassessmentrecommendation)<br>-- [SharePointOnlineAssessmentRecommendation](/azure/azure-monitor/reference/tables/sharepointonlineassessmentrecommendation)<br>-- [SPAssessmentRecommendation](/azure/azure-monitor/reference/tables/spassessmentrecommendation)<br>-- [SQLAssessmentRecommendation](/azure/azure-monitor/reference/tables/sqlassessmentrecommendation)<br>-- StorageInsightsAccountPropertiesDaily<br>-- StorageInsightsDailyMetrics<br>-- StorageInsightsHourlyMetrics<br>-- StorageInsightsMonthlyMetrics<br>-- StorageInsightsWeeklyMetrics<br>-- [Syslog](/azure/azure-monitor/reference/tables/syslog)<br>-- [UCClient](/azure/azure-monitor/reference/tables/ucclient)<br>-- [UCClientReadinessStatus](/azure/azure-monitor/reference/tables/ucclientreadinessstatus)<br>-- [UCClientUpdateStatus](/azure/azure-monitor/reference/tables/ucclientupdatestatus)<br>-- [UCDeviceAlert](/azure/azure-monitor/reference/tables/ucdevicealert)<br>-- [UCDOAggregatedStatus](/azure/azure-monitor/reference/tables/ucdoaggregatedstatus)<br>-- [UCDOStatus](/azure/azure-monitor/reference/tables/ucdostatus)<br>-- [UCServiceUpdateStatus](/azure/azure-monitor/reference/tables/ucserviceupdatestatus)<br>-- [UCUpdateAlert](/azure/azure-monitor/reference/tables/ucupdatealert)<br>-- [WindowsClientAssessmentRecommendation](/azure/azure-monitor/reference/tables/windowsclientassessmentrecommendation)<br>-- [WindowsEvent](/azure/azure-monitor/reference/tables/windowsevent)<br>-- [WindowsServerAssessmentRecommendation](/azure/azure-monitor/reference/tables/windowsserverassessmentrecommendation)<br>---> [!NOTE] -> Column names must start with a letter and can consist of up to 45 alphanumeric characters and underscores (`_`). `_ResourceId`, `id`, `_ResourceId`, `_SubscriptionId`, `TenantId`, `Type`, `UniqueId`, and `Title` are reserved column names. Custom columns you add to an Azure table must have the suffix `_CF`. --## Limits and restrictions --For limits related to the Logs Ingestion API, see [Azure Monitor service limits](../service-limits.md#logs-ingestion-api). --## Next steps --- [Walk through a tutorial sending data to Azure Monitor Logs with Logs ingestion API on the Azure portal](tutorial-logs-ingestion-portal.md)-- [Walk through a tutorial sending custom logs using Resource Manager templates and REST API](tutorial-logs-ingestion-api.md)-- Get guidance on using the client libraries for the Logs ingestion API for [.NET](/dotnet/api/overview/azure/Monitor.Ingestion-readme), [Java](/java/api/overview/azure/monitor-ingestion-readme), [JavaScript](/javascript/api/overview/azure/monitor-ingestion-readme), or [Python](/python/api/overview/azure/monitor-ingestion-readme). |
| azure-monitor | Logs Table Plans | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/logs-table-plans.md | - Title: Select a table plan based on data usage in a Log Analytics workspace -description: Use the Auxiliary, Basic, and Analytics Logs plans to reduce costs and take advantage of advanced analytics capabilities in Azure Monitor Logs. ---- Previously updated : 07/04/2024--# Customer intent: As a Log Analytics workspace administrator, I want to manage configure the plans of tables in my Log Analytics workspace so that I pay less for data I use less frequently. ---# Select a table plan based on data usage in a Log Analytics workspace --You can use one Log Analytics workspace to store any type of log required for any purpose. For example: --* High-volume, verbose data that requires **cheap long-term storage for audit and compliance** -* App and resource data for **troubleshooting** by developers -* Key event and performance data for scaling and alerting to ensure ongoing **operational excellence and security** -* Aggregated long-term data trends for **advanced analytics and machine learning** --Table plans let you manage data costs based on how often you use the data in a table and the type of analysis you need the data for. This article explains and how to set a table's plan. --For information about what each table plan offers and which use cases it's optimal for, see [Table plans](data-platform-logs.md#table-plans). --## Permissions required --| Action | Permissions required | -|:-|:| -| View table plan | `Microsoft.OperationalInsights/workspaces/tables/read` permissions to the Log Analytics workspace, as provided by the [Log Analytics Reader built-in role](./manage-access.md#log-analytics-reader), for example | -| Set table plan | `Microsoft.OperationalInsights/workspaces/write` and `microsoft.operationalinsights/workspaces/tables/write` permissions to the Log Analytics workspace, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example | - -## Set the table plan --You can set the table plan to Auxiliary only when you [create a custom table](../logs/create-custom-table.md#create-a-custom-table) by using the API. Built-in Azure tables don't currently support the Auxiliary plan. After you create a table with an Auxiliary plan, you can't switch the table's plan. --All tables support the Analytics plan and all DCR-based custom tables and [some Azure tables support the Basic log plan](basic-logs-azure-tables.md). You can switch between the Analytics and Basic plans, the change takes effect on existing data in the table immediately. --When you change a table's plan from Analytics to Basic, Azure monitor treats any data that's older than 30 days as long-term retention data based on the total retention period set for the table. In other words, the total retention period of the table remains unchanged, unless you explicitly [modify the long-term retention period](../logs/data-retention-configure.md). --> [!NOTE] -> You can switch a table's plan once a week. --### [Portal](#tab/portal-1) --Analytics is the default table plan of all tables you create in the portal. You can switch between the Analytics and Basic plans, as described in this section. --To switch a table's plan in the Azure portal: --1. From the **Log Analytics workspaces** menu, select **Tables**. -- The **Tables** screen lists all the tables in the workspace. --1. Select the context menu for the table you want to configure and select **Manage table**. -- :::image type="content" source="media/basic-logs-configure/log-analytics-table-configuration.png" lightbox="media/basic-logs-configure/log-analytics-table-configuration.png" alt-text="Screenshot that shows the Manage table button for one of the tables in a workspace."::: --1. From the **Table plan** dropdown on the table configuration screen, select **Basic** or **Analytics**. -- The **Table plan** dropdown is enabled only for [tables that support Basic logs](basic-logs-azure-tables.md). -- :::image type="content" source="media/data-retention-configure/log-analytics-configure-table-retention-auxiliary.png" lightbox="media/data-retention-configure/log-analytics-configure-table-retention-auxiliary.png" alt-text="Screenshot that shows the data retention settings on the table configuration screen."::: --1. Select **Save**. --### [API](#tab/api-1) --To configure a table for Basic logs or Analytics logs, call the [Tables - Update API](/rest/api/loganalytics/tables/create-or-update): --```http -PATCH https://management.azure.com/subscriptions/<subscriptionId>/resourcegroups/<resourceGroupName>/providers/Microsoft.OperationalInsights/workspaces/<workspaceName>/tables/<tableName>?api-version=2021-12-01-preview -``` --**Request body** --| Name | Type | Description | -|--|--|--| -| properties.plan | string | The table plan. Possible values are `Analytics` and `Basic`. | --> [!IMPORTANT] -> Use the bearer token for authentication. Learn more about [using bearer tokens](https://social.technet.microsoft.com/wiki/contents/articles/51140.azure-rest-management-api-the-quickest-way-to-get-your-bearer-token.aspx). --#### Example --This example configures the `ContainerLogV2` table for Basic logs. --Container Insights uses `ContainerLog` by default. To switch to using `ContainerLogV2` for Container insights, [enable the ContainerLogV2 schema](../containers/container-insights-logging-v2.md) before you convert the table to Basic logs. --**Sample request** --```http -PATCH https://management.azure.com/subscriptions/ContosoSID/resourcegroups/ContosoRG/providers/Microsoft.OperationalInsights/workspaces/ContosoWorkspace/tables/ContainerLogV2?api-version=2021-12-01-preview -``` --* Use this request body to change to Basic logs: -- ```http - { - "properties": { - "plan": "Basic" - } - } - ``` --* Use this request body to change to Analytics Logs: -- ```http - { - "properties": { - "plan": "Analytics" - } - } - ``` --**Sample response** --* This sample is the response for a table changed to Basic logs: - - Status code: 200 - - ```http - { - "properties": { - "retentionInDays": 30, - "totalRetentionInDays": 30, - "archiveRetentionInDays": 22, - "plan": "Basic", - "lastPlanModifiedDate": "2022-01-01T14:34:04.37", - "schema": {...} - }, - "id": "subscriptions/ContosoSID/resourcegroups/ContosoRG/providers/Microsoft.OperationalInsights/workspaces/ContosoWorkspace", - "name": "ContainerLogV2" - } - ``` --### [CLI](#tab/cli-1) --To configure a table for Basic logs or Analytics logs, run the [az monitor log-analytics workspace table update](/cli/azure/monitor/log-analytics/workspace/table#az-monitor-log-analytics-workspace-table-update) command and set the `--plan` parameter to `Basic` or `Analytics`. --#### Examples --* To set Basic logs: -- ```azurecli - az monitor log-analytics workspace table update --subscription ContosoSID --resource-group ContosoRG --workspace-name ContosoWorkspace --name ContainerLogV2 --plan Basic - ``` --* To set Analytics Logs: -- ```azurecli - az monitor log-analytics workspace table update --subscription ContosoSID --resource-group ContosoRG --workspace-name ContosoWorkspace --name ContainerLogV2 --plan Analytics - ``` --### [PowerShell](#tab/azure-powershell) --To configure a table's plan, use the [Update-AzOperationalInsightsTable](/powershell/module/az.operationalinsights/Update-AzOperationalInsightsTable) cmdlet: --```powershell -Update-AzOperationalInsightsTable -ResourceGroupName RG-NAME -WorkspaceName WORKSPACE-NAME -TableName TABLE-NAME -Plan Basic|Analytics -``` --#### Examples --* To set Basic logs: -- ```powershell - Update-AzOperationalInsightsTable -ResourceGroupName ContosoRG -WorkspaceName ContosoWorkspace -TableName ContainerLogV2 -Plan Basic - ``` --* To set Analytics Logs: -- ```powershell - Update-AzOperationalInsightsTable -ResourceGroupName ContosoRG -WorkspaceName ContosoWorkspace -TableName ContainerLogV2 -Plan Analytics - ``` ----## Related content --* [Manage data retention](../logs/data-retention-configure.md). -* [Tables that support the Basic table plan in Azure Monitor Logs](basic-logs-azure-tables.md). - |
| azure-monitor | Manage Access | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/manage-access.md | - Title: Manage access to Log Analytics workspaces -description: This article explains how you can manage access to data stored in a Log Analytics workspace in Azure Monitor by using resource, workspace, or table-level permissions. ---- Previously updated : 03/20/2024-----# Manage access to Log Analytics workspaces --The factors that determine which data you can access in a Log Analytics workspace are: --- The settings on the workspace itself.-- Your access permissions to resources that send data to the workspace.-- The method used to access the workspace.--This article describes how to manage access to data in a Log Analytics workspace. --## Overview --The factors that define the data you can access are described in the following table. Each factor is further described in the sections that follow. --| Factor | Description | -|:|:| -| [Access mode](#access-mode) | Method used to access the workspace. Defines the scope of the data available and the access control mode that's applied. | -| [Access control mode](#access-control-mode) | Setting on the workspace that defines whether permissions are applied at the workspace or resource level. | -| [Azure role-based access control (RBAC)](#azure-rbac) | Permissions applied to individuals or groups of users for the workspace or resource sending data to the workspace. Defines what data you have access to. | -| [Table-level Azure RBAC](#set-table-level-read-access) | Optional permissions that define specific data types in the workspace that you can access. Can be applies to all access modes or access control modes. | --## Access mode --The *access mode* refers to how you access a Log Analytics workspace and defines the data you can access during the current session. The mode is determined according to the [scope](scope.md) you select in Log Analytics. --There are two access modes: --- **Workspace-context**: You can view all logs in the workspace for which you have permission. Queries in this mode are scoped to all data in tables that you have access to in the workspace. This access mode is used when logs are accessed with the workspace as the scope, such as when you select **Logs** on the **Azure Monitor** menu in the Azure portal.--Records are only available in resource-context queries if they're associated with the relevant resource. To check this association, run a query and verify that the [_ResourceId](./log-standard-columns.md#_resourceid) column is populated. --There are known limitations with the following resources: --- **Computers outside of Azure**: Resource-context is only supported with [Azure Arc for servers](../../azure-arc/servers/index.yml).-- **Application Insights**: Supported for resource-context only when using a [workspace-based Application Insights resource](../app/create-workspace-resource.md).-- **Azure Service Fabric**--### Compare access modes --The following table summarizes the access modes: --| Issue | Workspace-context | Resource-context | -|:|:|:| -| Who is each model intended for? | Central administration.<br>Administrators who need to configure data collection and users who need access to a wide variety of resources. Also currently required for users who need to access logs for resources outside of Azure. | Application teams.<br>Administrators of Azure resources being monitored. Allows them to focus on their resource without filtering. | -| What does a user require to view logs? | Permissions to the workspace.<br>See "Workspace permissions" in [Manage access using workspace permissions](./manage-access.md#azure-rbac). | Read access to the resource.<br>See "Resource permissions" in [Manage access using Azure permissions](./manage-access.md#azure-rbac). Permissions can be inherited from the resource group or subscription or directly assigned to the resource. Permission to the logs for the resource will be automatically assigned. The user doesn't require access to the workspace.| -| What is the scope of permissions? | Workspace.<br>Users with access to the workspace can query all logs in the workspace from tables they have permissions to. See [Set table-level read access](./manage-access.md#set-table-level-read-access). | Azure resource.<br>Users can query logs for specific resources, resource groups, or subscriptions they have access to in any workspace, but they can't query logs for other resources. | -| How can a user access logs? | On the **Azure Monitor** menu, select **Logs**.<br><br>Select **Logs** from **Log Analytics workspaces**.<br><br>From Azure Monitor [workbooks](../best-practices-analysis.md#azure-workbooks). | Select **Logs** on the menu for the Azure resource. Users will have access to data for that resource.<br><br>Select **Logs** on the **Azure Monitor** menu. Users will have access to data for all resources they have access to.<br><br>Select **Logs** from **Log Analytics workspaces**, if users have access to the workspace.<br><br>From Azure Monitor [workbooks](../best-practices-analysis.md#azure-workbooks). | --## Access control mode --The *access control mode* is a setting on each workspace that defines how permissions are determined for the workspace. --* **Require workspace permissions**. This control mode doesn't allow granular Azure RBAC. To access the workspace, the user must be [granted permissions to the workspace](#azure-rbac) or to [specific tables](#set-table-level-read-access). -- If a user accesses the workspace in [workspace-context mode](#access-mode), they have access to all data in any table they've been granted access to. If a user accesses the workspace in [resource-context mode](#access-mode), they have access to only data for that resource in any table they've been granted access to. -- This setting is the default for all workspaces created before March 2019. --* **Use resource or workspace permissions**. This control mode allows granular Azure RBAC. Users can be granted access to only data associated with resources they can view by assigning Azure `read` permission. -- When a user accesses the workspace in [workspace-context mode](#access-mode), workspace permissions apply. When a user accesses the workspace in [resource-context mode](#access-mode), only resource permissions are verified, and workspace permissions are ignored. Enable Azure RBAC for a user by removing them from workspace permissions and allowing their resource permissions to be recognized. -- This setting is the default for all workspaces created after March 2019. -- > [!NOTE] - > If a user has only resource permissions to the workspace, they can only access the workspace by using resource-context mode assuming the workspace access mode is set to **Use resource or workspace permissions**. --### Configure access control mode for a workspace --# [Azure portal](#tab/portal) --View the current workspace access control mode on the **Overview** page for the workspace in the **Log Analytics workspace** menu. ---Change this setting on the **Properties** page of the workspace. If you don't have permissions to configure the workspace, changing the setting is disabled. ---# [PowerShell](#tab/powershell) --Use the following command to view the access control mode for all workspaces in the subscription: --```powershell -Get-AzResource -ResourceType Microsoft.OperationalInsights/workspaces -ExpandProperties | foreach {$_.Name + ": " + $_.Properties.features.enableLogAccessUsingOnlyResourcePermissions} -``` --The output should resemble the following: --``` -DefaultWorkspace38917: True -DefaultWorkspace21532: False -``` --A value of `False` means the workspace is configured with *workspace-context* access mode. A value of `True` means the workspace is configured with *resource-context* access mode. --> [!NOTE] -> If a workspace is returned without a Boolean value and is blank, this result also matches the results of a `False` value. -> --Use the following script to set the access control mode for a specific workspace to *resource-context* permission: --```powershell -$WSName = "my-workspace" -$Workspace = Get-AzResource -Name $WSName -ExpandProperties -if ($Workspace.Properties.features.enableLogAccessUsingOnlyResourcePermissions -eq $null) - { $Workspace.Properties.features | Add-Member enableLogAccessUsingOnlyResourcePermissions $true -Force } -else - { $Workspace.Properties.features.enableLogAccessUsingOnlyResourcePermissions = $true } -Set-AzResource -ResourceId $Workspace.ResourceId -Properties $Workspace.Properties -Force -``` --Use the following script to set the access control mode for all workspaces in the subscription to *resource-context* permission: --```powershell -Get-AzResource -ResourceType Microsoft.OperationalInsights/workspaces -ExpandProperties | foreach { -if ($_.Properties.features.enableLogAccessUsingOnlyResourcePermissions -eq $null) - { $_.Properties.features | Add-Member enableLogAccessUsingOnlyResourcePermissions $true -Force } -else - { $_.Properties.features.enableLogAccessUsingOnlyResourcePermissions = $true } -Set-AzResource -ResourceId $_.ResourceId -Properties $_.Properties -Force -} -``` --# [Resource Manager](#tab/arm) --To configure the access mode in an Azure Resource Manager template, set the **enableLogAccessUsingOnlyResourcePermissions** feature flag on the workspace to one of the following values: --* **false**: Set the workspace to *workspace-context* permissions. This setting is the default if the flag isn't set. -* **true**: Set the workspace to *resource-context* permissions. ----## Azure RBAC --Access to a workspace is managed by using [Azure RBAC](../../role-based-access-control/role-assignments-portal.yml). To grant access to the Log Analytics workspace by using Azure permissions, follow the steps in [Assign Azure roles to manage access to your Azure subscription resources](../../role-based-access-control/role-assignments-portal.yml). --### Workspace permissions --Each workspace can have multiple accounts associated with it. Each account can have access to multiple workspaces. The following table lists the Azure permissions for different workspace actions: --|Action |Azure permissions needed |Notes | -|-|-|| -| Change the pricing tier. | `Microsoft.OperationalInsights/workspaces/*/write` | -| Create a workspace in the Azure portal. | `Microsoft.Resources/deployments/*` <br> `Microsoft.OperationalInsights/workspaces/*` | -| View workspace basic properties and enter the workspace pane in the portal. | `Microsoft.OperationalInsights/workspaces/read` | -| Query logs by using any interface. | `Microsoft.OperationalInsights/workspaces/query/read` | -| Access all log types by using queries. | `Microsoft.OperationalInsights/workspaces/query/*/read` | -| Access a specific log table - legacy method | `Microsoft.OperationalInsights/workspaces/query/<table_name>/read` | -| Read the workspace keys to allow sending logs to this workspace. | `Microsoft.OperationalInsights/workspaces/sharedKeys/action` | -| Create or update a summary rule | `Microsoft.Operationalinsights/workspaces/summarylogs/write`| -| Add and remove monitoring solutions. | `Microsoft.Resources/deployments/*` <br> `Microsoft.OperationalInsights/*` <br> `Microsoft.OperationsManagement/*` <br> `Microsoft.Automation/*` <br> `Microsoft.Resources/deployments/*/write`<br><br>These permissions need to be granted at resource group or subscription level. | -| View data in the **Backup** and **Site Recovery** solution tiles. | Administrator/Co-administrator<br><br>Accesses resources deployed by using the classic deployment model. | -| Run a search job. | `Microsoft.OperationalInsights/workspaces/tables/write` <br> `Microsoft.OperationalInsights/workspaces/searchJobs/write`| -| Restore data from long-term retention. | `Microsoft.OperationalInsights/workspaces/tables/write` <br> `Microsoft.OperationalInsights/workspaces/restoreLogs/write`| --### Built-in roles --Assign users to these roles to give them access at different scopes: --* **Subscription**: Access to all workspaces in the subscription -* **Resource group**: Access to all workspaces in the resource group -* **Resource**: Access to only the specified workspace --Create assignments at the resource level (workspace) to assure accurate access control. Use [custom roles](../../role-based-access-control/custom-roles.md) to create roles with the specific permissions needed. --> [!NOTE] -> To add and remove users to a user role, you must have `Microsoft.Authorization/*/Delete` and `Microsoft.Authorization/*/Write` permission. --#### Log Analytics Reader --Members of the Log Analytics Reader role can view all monitoring data and monitoring settings, including the configuration of Azure diagnostics on all Azure resources. --Members of the Log Analytics Reader role can: --- View and search all monitoring data.-- View monitoring settings, including viewing the configuration of Azure diagnostics on all Azure resources.--The Log Analytics Reader role includes the following Azure actions: --| Type | Permission | Description | -| - | - | -- | -| Action | `*/read` | Ability to view all Azure resources and resource configuration.<br>Includes viewing:<br>- Virtual machine extension status.<br>- Configuration of Azure diagnostics on resources.<br>- All properties and settings of all resources.<br><br>For workspaces, allows full unrestricted permissions to read the workspace settings and query data. See more granular options in the preceding list. | -| Action | `Microsoft.Support/*` | Ability to open support cases. | -|Not Action | `Microsoft.OperationalInsights/workspaces/sharedKeys/read` | Prevents reading of workspace key required to use the data collection API and to install agents. This prevents the user from adding new resources to the workspace. | --#### Log Analytics Contributor --Members of the Log Analytics Contributor role can: --- Read all monitoring data granted by the Log Analytics Reader role.-- Edit monitoring settings for Azure resources, including:- - Adding the VM extension to VMs. - - Configuring Azure diagnostics on all Azure resources. -- Create and configure Automation accounts. Permission must be granted at the resource group or subscription level.-- Add and remove management solutions. Permission must be granted at the resource group or subscription level.-- Read storage account keys.-- Configure the collection of logs from Azure Storage.-- Configure data export rules.-- [Run a search job.](search-jobs.md)-- [Restore data from long-term retention.](restore.md)--> [!WARNING] -> You can use the permission to add a virtual machine extension to a virtual machine to gain full control over a virtual machine. --The Log Analytics Contributor role includes the following Azure actions: --| Permission | Description | -| - | -- | -| `*/read` | Ability to view all Azure resources and resource configuration.<br><br>Includes viewing:<br>- Virtual machine extension status.<br>- Configuration of Azure diagnostics on resources.<br>- All properties and settings of all resources.<br><br>For workspaces, allows full unrestricted permissions to read the workspace settings and query data. See more granular options in the preceding list. | -| `Microsoft.Automation/automationAccounts/*` | Ability to create and configure Azure Automation accounts, including adding and editing runbooks. | -| `Microsoft.ClassicCompute/virtualMachines/extensions/*` <br> `Microsoft.Compute/virtualMachines/extensions/*` | Add, update, and remove virtual machine extensions, including the Microsoft Monitoring Agent extension and the OMS Agent for Linux extension. | -| `Microsoft.ClassicStorage/storageAccounts/listKeys/action` <br> `Microsoft.Storage/storageAccounts/listKeys/action` | View the storage account key. Required to configure Log Analytics to read logs from Azure Storage accounts. | -| `Microsoft.Insights/alertRules/*` | Add, update, and remove alert rules. | -| `Microsoft.Insights/diagnosticSettings/*` | Add, update, and remove diagnostics settings on Azure resources. | -| `Microsoft.OperationalInsights/*` | Add, update, and remove configuration for Log Analytics workspaces. To edit workspace advanced settings, user needs `Microsoft.OperationalInsights/workspaces/write`. | -| `Microsoft.OperationsManagement/*` | Add and remove management solutions. | -| `Microsoft.Resources/deployments/*` | Create and delete deployments. Required for adding and removing solutions, workspaces, and automation accounts. | -| `Microsoft.Resources/subscriptions/resourcegroups/deployments/*` | Create and delete deployments. Required for adding and removing solutions, workspaces, and automation accounts. | --### Resource permissions --To read data from or send data to a workspace in the [resource context](#access-mode), you need these permissions on the resource: --| Permission | Description | -| - | -- | -| `Microsoft.Insights/logs/*/read` | Ability to view all log data for the resource | -| `Microsoft.Insights/logs/<tableName>/read`<br>Example:<br>`Microsoft.Insights/logs/Heartbeat/read` | Ability to view specific table for this resource - legacy method | -| `Microsoft.Insights/diagnosticSettings/write` | Ability to configure diagnostics setting to allow setting up logs for this resource | --The `/read` permission is usually granted from a role that includes _\*/read or_ _\*_ permissions, such as the built-in [Reader](../../role-based-access-control/built-in-roles.md#reader) and [Contributor](../../role-based-access-control/built-in-roles.md#contributor) roles. Custom roles that include specific actions or dedicated built-in roles might not include this permission. --### Custom role examples --In addition to using the built-in roles for a Log Analytics workspace, you can create custom roles to assign more granular permissions. Here are some common examples. --**Example 1: Grant a user permission to read log data from their resources.** --- Configure the workspace access control mode to *use workspace or resource permissions*.-- Grant users `*/read` or `Microsoft.Insights/logs/*/read` permissions to their resources. If they're already assigned the [Log Analytics Reader](../../role-based-access-control/built-in-roles.md#reader) role on the workspace, it's sufficient.---**Example 2: Grant a user permission to read log data from their resources and run a search job.** --- Configure the workspace access control mode to *use workspace or resource permissions*.-- Grant users `*/read` or `Microsoft.Insights/logs/*/read` permissions to their resources. If they're already assigned the [Log Analytics Reader](../../role-based-access-control/built-in-roles.md#reader) role on the workspace, it's sufficient.-- Grant users the following permissions on the workspace:- - `Microsoft.OperationalInsights/workspaces/tables/write`: Required to be able to create the search results table (_SRCH). - - `Microsoft.OperationalInsights/workspaces/searchJobs/write`: Required to allow executing the search job operation. ---**Example 3: Grant a user permission to read log data from their resources and configure their resources to send logs to the Log Analytics workspace.** --- Configure the workspace access control mode to *use workspace or resource permissions*.-- Grant users the following permissions on the workspace: `Microsoft.OperationalInsights/workspaces/read` and `Microsoft.OperationalInsights/workspaces/sharedKeys/action`. With these permissions, users can't perform any workspace-level queries. They can only enumerate the workspace and use it as a destination for diagnostic settings or agent configuration.-- Grant users the following permissions to their resources: `Microsoft.Insights/logs/*/read` and `Microsoft.Insights/diagnosticSettings/write`. If they're already assigned the [Log Analytics Contributor](../../role-based-access-control/built-in-roles.md#contributor) role, assigned the Reader role, or granted `*/read` permissions on this resource, it's sufficient.--**Example 4: Grant a user permission to read log data from their resources, but not to send logs to the Log Analytics workspace or read security events.** --- Configure the workspace access control mode to *use workspace or resource permissions*.-- Grant users the following permissions to their resources: `Microsoft.Insights/logs/*/read`.-- Add the following NonAction to block users from reading the SecurityEvent type: `Microsoft.Insights/logs/SecurityEvent/read`. The NonAction shall be in the same custom role as the action that provides the read permission (`Microsoft.Insights/logs/*/read`). If the user inherits the read action from another role that's assigned to this resource or to the subscription or resource group, they could read all log types. This scenario is also true if they inherit `*/read` that exists, for example, with the Reader or Contributor role.--**Example 5: Grant a user permission to read log data from their resources and all Microsoft Entra sign-in and read Update Management solution log data in the Log Analytics workspace.** --- Configure the workspace access control mode to *use workspace or resource permissions*.-- Grant users the following permissions on the workspace:- - `Microsoft.OperationalInsights/workspaces/read`: Required so the user can enumerate the workspace and open the workspace pane in the Azure portal - - `Microsoft.OperationalInsights/workspaces/query/read`: Required for every user that can execute queries - - `Microsoft.OperationalInsights/workspaces/query/SigninLogs/read`: To be able to read Microsoft Entra sign-in logs - - `Microsoft.OperationalInsights/workspaces/query/Update/read`: To be able to read Update Management solution logs - - `Microsoft.OperationalInsights/workspaces/query/UpdateRunProgress/read`: To be able to read Update Management solution logs - - `Microsoft.OperationalInsights/workspaces/query/UpdateSummary/read`: To be able to read Update Management logs - - `Microsoft.OperationalInsights/workspaces/query/Heartbeat/read`: Required to be able to use Update Management solutions - - `Microsoft.OperationalInsights/workspaces/query/ComputerGroup/read`: Required to be able to use Update Management solutions -- Grant users the following permissions to their resources: `*/read`, assigned to the Reader role, or `Microsoft.Insights/logs/*/read`--**Example 6: Restrict a user from restoring data from long-term retention.** --- Configure the workspace access control mode to *use workspace or resource permissions*.-- Assign the user to the [Log Analytics Contributor](../../role-based-access-control/built-in-roles.md#contributor) role.-- Add the following NonAction to block users from restoring data from long-term retention: `Microsoft.OperationalInsights/workspaces/restoreLogs/write`---## Set table-level read access --See [Manage table-level read access](manage-table-access.md). --## Next steps --* See [Log Analytics agent overview](../agents/log-analytics-agent.md) to gather data from computers in your datacenter or other cloud environment. -* See [Collect data about Azure virtual machines](../vm/monitor-virtual-machine.md) to configure data collection from Azure VMs. |
| azure-monitor | Manage Logs Tables | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/manage-logs-tables.md | - Title: Manage tables in a Log Analytics workspace -description: Learn how to manage table settings in a Log Analytics workspace based on your data analysis and cost management needs. --- Previously updated : 07/21/2024-# Customer intent: As a Log Analytics workspace administrator, I want to understand how table properties work and how to view and manage table properties so that I can manage the data and costs related to a Log Analytics workspace effectively. ----# Manage tables in a Log Analytics workspace --A Log Analytics workspace lets you collect log data from Azure and non-Azure resources into one space for analysis, use by other services, such as [Sentinel](../../../articles/sentinel/overview.md), and to trigger alerts and actions, for example, using [Azure Logic Apps](../../connectors/connectors-azure-monitor-logs.md). The Log Analytics workspace consists of tables, which you can configure to manage your data model, data access, and log-related costs. This article explains the table configuration options in Azure Monitor Logs and how to set table properties based on your data analysis and cost management needs. --## Table properties --This diagram provides an overview of the table configuration options in Azure Monitor Logs: ---### Table type and schema --A table's schema is the set of columns that make up the table, into which Azure Monitor Logs collects log data from one or more data sources. --Your Log Analytics workspace can contain the following types of tables: --| Table type | Data source | Schema | -|--|-|-| -| Azure table | Logs from Azure resources or required by Azure services and solutions. | Azure Monitor Logs creates Azure tables automatically based on Azure services you use and [diagnostic settings](../essentials/diagnostic-settings.md) you configure for specific resources. Each Azure table has a predefined schema. You can [add columns to an Azure table](../logs/create-custom-table.md#add-or-delete-a-custom-column) to store transformed log data or enrich data in the Azure table with data from another source.| -| Custom table | Non-Azure resources and any other data source, such as file-based logs. | You can [define a custom table's schema](../logs/create-custom-table.md) based on how you want to store data you collect from a given data source. | -| Search results | All data stored in a Log Analytics workspace. | The schema of a search results table is based on the query you define when you [run the search job](../logs/search-jobs.md). You can't edit the schema of existing search results tables. | -| Restored logs | Data stored in a specific table in a Log Analytics workspace. | A restored logs table has the same schema as the table from which you [restore logs](../logs/restore.md). You can't edit the schema of existing restored logs tables. | --### Table plan --[Configure a table's plan](../logs/logs-table-plans.md) based on how often you access the data in the table: -- The **Analytics** plan is suited for continuous monitoring, real-time detection, and performance analytics. This plan makes log data available for interactive multi-table queries and use by features and services for 30 days to two years. -- The **Basic** plan is suited for troubleshooting and incident response. This plan offers discounted ingestion and optimized single-table queries for 30 days. -- The **Auxiliary** plan is suited for low-touch data, such as verbose logs, and data required for auditing and compliance. This plan offers low-cost ingestion and unoptimized single-table queries for 30 days.--For full details about Azure Monitor Logs table plans, see [Azure Monitor Logs: Table plans](../logs/data-platform-logs.md#table-plans). --### Long-term retention --Long-term retention is a low-cost solution for keeping data that you don't use regularly in your workspace for compliance or occasional investigation. Use [table-level retention settings](../logs/data-retention-configure.md) to add or extend long-term retention. --To access data in long-term retention, [run a search job](../logs/search-jobs.md). --### Ingestion-time transformations --Reduce costs and analysis effort by using data collection rules to [filter out and transform data before ingestion](../essentials/data-collection-transformations.md) based on the schema you define for your custom table. --> [!NOTE] -> Tables with the [Auxiliary table plan](data-platform-logs.md) do not currently support data transformation. For more details, see [Auxiliary table plan public preview limitations](create-custom-table-auxiliary.md#public-preview-limitations). --## View table properties --> [!NOTE] -> The table name is case sensitive. --# [Portal](#tab/azure-portal) --To view and set table properties in the Azure portal: --1. From your Log Analytics workspace, select **Tables**. -- The **Tables** screen presents table configuration information for all tables in your Log Analytics workspace. -- :::image type="content" source="media/manage-logs-tables/azure-monitor-logs-table-configuration.png" alt-text="Screenshot that shows the Tables screen for a Log Analytics workspace." lightbox="media/manage-logs-tables/azure-monitor-logs-table-configuration.png"::: --1. Select the ellipsis (**...**) to the right of a table to open the table management menu. -- The available table management options vary based on the table type. -- 1. Select **Manage table** to edit the table properties. - - 1. Select **Edit schema** to view and edit the table schema. --# [API](#tab/api) --To view table properties, call the [Tables - Get API](/rest/api/loganalytics/tables/get): --```http -GET https://management.azure.com/subscriptions/{subscriptionId}/resourcegroups/{resourceGroupName}/providers/Microsoft.OperationalInsights/workspaces/{workspaceName}/tables/{tableName}?api-version=2021-12-01-preview -``` --**Response body** --|Name | Type | Description | -| | | | -|properties.plan | string | The table plan. `Analytics`, `Basic`, or `Auxiliary`. | -|properties.retentionInDays | integer | The table's interactive retention in days. For `Basic` and `Auxiliiary`, this value is 30 days. For `Analytics`, the value is between four and 730 days.| -|properties.totalRetentionInDays | integer | The table's total data retention, including interactive and long-term retention.| -|properties.archiveRetentionInDays|integer|The table's long-term retention period (read-only, calculated).| -|properties.lastPlanModifiedDate|String|Last time when the plan was set for this table. Null if no change was ever done from the default settings (read-only). --**Sample request** --```http -GET https://management.azure.com/subscriptions/ContosoSID/resourcegroups/ContosoRG/providers/Microsoft.OperationalInsights/workspaces/ContosoWorkspace/tables/ContainerLogV2?api-version=2021-12-01-preview -``` --**Sample response** - -Status code: 200 -```http -{ - "properties": { - "retentionInDays": 8, - "totalRetentionInDays": 8, - "archiveRetentionInDays": 0, - "plan": "Basic", - "lastPlanModifiedDate": "2022-01-01T14:34:04.37", - "schema": {...}, - "provisioningState": "Succeeded" - }, - "id": "subscriptions/ContosoSID/resourcegroups/ContosoRG/providers/Microsoft.OperationalInsights/workspaces/ContosoWorkspace", - "name": "ContainerLogV2" -} -``` --To set table properties, call the [Tables - Create Or Update API](/rest/api/loganalytics/tables/create-or-update). --# [Azure CLI](#tab/azure-cli) --To view table properties using Azure CLI, run the [az monitor log-analytics workspace table show](/cli/azure/monitor/log-analytics/workspace/table#az-monitor-log-analytics-workspace-table-show) command. --For example: --```azurecli -az monitor log-analytics workspace table show --subscription ContosoSID --resource-group ContosoRG --workspace-name ContosoWorkspace --name Syslog --output table -``` --To set table properties using Azure CLI, run the [az monitor log-analytics workspace table update](/cli/azure/monitor/log-analytics/workspace/table#az-monitor-log-analytics-workspace-table-update) command. --# [PowerShell](#tab/azure-powershell) --To view table properties using PowerShell, run: --```powershell -Invoke-AzRestMethod -Path "/subscriptions/ContosoSID/resourcegroups/ContosoRG/providers/microsoft.operationalinsights/workspaces/ContosoWorkspace/tables/Heartbeat?api-version=2021-12-01-preview" -Method GET -``` --**Sample response** --```json -{ - "properties": { - "totalRetentionInDays": 30, - "archiveRetentionInDays": 0, - "plan": "Analytics", - "retentionInDaysAsDefault": true, - "totalRetentionInDaysAsDefault": true, - "schema": { - "tableSubType": "Any", - "name": "Heartbeat", - "tableType": "Microsoft", - "standardColumns": [ - { - "name": "TenantId", - "type": "guid", - "description": "ID of the workspace that stores this record.", - "isDefaultDisplay": true, - "isHidden": true - }, - { - "name": "SourceSystem", - "type": "string", - "description": "Type of agent the data was collected from. Possible values are OpsManager (Windows agent) or Linux.", - "isDefaultDisplay": true, - "isHidden": false - }, - { - "name": "TimeGenerated", - "type": "datetime", - "description": "Date and time the record was created.", - "isDefaultDisplay": true, - "isHidden": false - }, - <OMITTED> - { - "name": "ComputerPrivateIPs", - "type": "dynamic", - "description": "The list of private IP addresses of the computer.", - "isDefaultDisplay": true, - "isHidden": false - } - ], - "solutions": [ - "LogManagement" - ], - "isTroubleshootingAllowed": false - }, - "provisioningState": "Succeeded", - "retentionInDays": 30 - }, - "id": "/subscriptions/{guid}/resourceGroups/{rg name}/providers/Microsoft.OperationalInsights/workspaces/{ws id}/tables/Heartbeat", - "name": "Heartbeat" -} -``` --Use the [Update-AzOperationalInsightsTable](/powershell/module/az.operationalinsights/Update-AzOperationalInsightsTable) cmdlet to set table properties. ----## Next steps --Learn how to: --- [Set a table's log data plan](../logs/logs-table-plans.md)-- [Add custom tables and columns](../logs/create-custom-table.md)-- [Configure data retention](../logs/data-retention-configure.md)-- [Design a workspace architecture](../logs/workspace-design.md) |
| azure-monitor | Manage Table Access | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/manage-table-access.md | - Title: Manage read access to tables in a Log Analytics workspace -description: This article explains how you to manage read access to specific tables in a Log Analytics workspace. ---- Previously updated : 07/22/2024-----# Manage table-level read access in a Log Analytics workspace --Table-level access settings let you grant specific users or groups read-only permission to data in a table. Users with table-level read access can read data from the specified table in both the workspace and the resource context. --This article describes two ways to manage table-level read access. --> [!NOTE] -> We recommend using the first method described here, which is currently in **preview**. During preview, the recommended method described here does not apply to Microsoft Sentinel Detection Rules, which might have access to more tables than intended. -Alternatively, you can use the [legacy method of setting table-level read access](#legacy-method-of-setting-table-level-read-access), which has some limitations related to custom log tables. Before using either method, see [Table-level access considerations and limitations](#table-level-access-considerations-and-limitations). --## Set table-level read access (preview) --Granting table-level read access involves assigning a user two roles: --- At the workspace level - a custom role that provides limited permissions to read workspace details and run a query in the workspace, but not to read data from any tables. -- At the table level - a **Reader** role, scoped to the specific table. --**To grant a user or group limited permissions to the Log Analytics workspace:** --1. Create a [custom role](../../role-based-access-control/custom-roles.md) at the workspace level to let users read workspace details and run a query in the workspace, without providing read access to data in any tables: -- 1. Navigate to your workspace and select **Access control (IAM)** > **Roles**. -- 1. Right-click the **Reader** role and select **Clone**. -- :::image type="content" source="media/manage-access/access-control-clone-role.png" alt-text="Screenshot that shows the Roles tab of the Access control screen with the clone button highlighted for the Reader role." lightbox="media/manage-access/access-control-clone-role.png"::: -- This opens the **Create a custom role** screen. -- 1. On the **Basics** tab of the screen: - 1. Enter a **Custom role name** value and, optionally, provide a description. - 1. Set **Baseline permissions** to **Start from scratch**. -- :::image type="content" source="media/manage-access/manage-access-create-custom-role.png" alt-text="Screenshot that shows the Basics tab of the Create a custom role screen with the Custom role name and Description fields highlighted." lightbox="media/manage-access/manage-access-create-custom-role.png"::: -- 1. Select the **JSON** tab > **Edit**: -- 1. In the `"actions"` section, add these actions: -- ```json - "Microsoft.OperationalInsights/workspaces/read", - "Microsoft.OperationalInsights/workspaces/query/read" - ``` -- 1. In the `"not actions"` section, add: - - ```json - "Microsoft.OperationalInsights/workspaces/sharedKeys/read" - ``` -- :::image type="content" source="media/manage-access/manage-access-create-custom-role-json.png" alt-text="Screenshot that shows the JSON tab of the Create a custom role screen with the actions section of the JSON file highlighted." lightbox="media/manage-access/manage-access-create-custom-role-json.png"::: -- 1. Select **Save** > **Review + Create** at the bottom of the screen, and then **Create** on the next page. --1. Assign your custom role to the relevant user: - 1. Select **Access control (AIM)** > **Add** > **Add role assignment**. -- :::image type="content" source="media/manage-access/manage-access-add-role-assignment-button.png" alt-text="Screenshot that shows the Access control screen with the Add role assignment button highlighted." lightbox="media/manage-access/manage-access-add-role-assignment-button.png"::: -- 1. Select the custom role you created and select **Next**. -- :::image type="content" source="media/manage-access/manage-access-add-role-assignment-screen.png" alt-text="Screenshot that shows the Add role assignment screen with a custom role and the Next button highlighted." lightbox="media/manage-access/manage-access-add-role-assignment-screen.png"::: --- This opens the **Members** tab of the **Add custom role assignment** screen. -- 1. Click **+ Select members** to open the **Select members** screen. -- :::image type="content" source="media/manage-access/manage-access-add-role-assignment-select-members.png" alt-text="Screenshot that shows the Select members screen." lightbox="media/manage-access/manage-access-add-role-assignment-select-members.png"::: -- 1. Search for and select a user and click **Select**. - 1. Select **Review and assign**. - -The user can now read workspace details and run a query, but can't read data from any tables. --**To grant the user read access to a specific table:** --1. From the **Log Analytics workspaces** menu, select **Tables**. -1. Select the ellipsis ( **...** ) to the right of your table and select **Access control (IAM)**. - - :::image type="content" source="media/manage-access/table-level-access-control.png" alt-text="Screenshot that shows the Log Analytics workspace table management screen with the table-level access control button highlighted." lightbox="media/manage-access/table-level-access-control.png"::: --1. On the **Access control (IAM)** screen, select **Add** > **Add role assignment**. -1. Select the **Reader** role and select **Next**. -1. Click **+ Select members** to open the **Select members** screen. -1. Search for and select the user and click **Select**. -1. Select **Review and assign**. --The user can now read data from this specific table. Grant the user read access to other tables in the workspace, as needed. - -## Legacy method of setting table-level read access --The legacy method of table-level also uses [Azure custom roles](../../role-based-access-control/custom-roles.md) to let you grant specific users or groups access to specific tables in the workspace. Azure custom roles apply to workspaces with either workspace-context or resource-context [access control modes](manage-access.md#access-control-mode) regardless of the user's [access mode](manage-access.md#access-mode). --To define access to a particular table, create a [custom role](../../role-based-access-control/custom-roles.md): --* Set the user permissions in the **Actions** section of the role definition. -* Use `Microsoft.OperationalInsights/workspaces/query/*` to grant access to all tables. -* To exclude access to specific tables when you use a wildcard in **Actions**, list the tables excluded tables in the **NotActions** section of the role definition. --Here are examples of custom role actions to grant and deny access to specific tables. --Grant access to the _Heartbeat_ and _AzureActivity_ tables: --``` -"Actions": [ - "Microsoft.OperationalInsights/workspaces/read", - "Microsoft.OperationalInsights/workspaces/query/read", - "Microsoft.OperationalInsights/workspaces/query/Heartbeat/read", - "Microsoft.OperationalInsights/workspaces/query/AzureActivity/read" - ], -``` --Grant access to only the _SecurityBaseline_ table: --``` -"Actions": [ - "Microsoft.OperationalInsights/workspaces/read", - "Microsoft.OperationalInsights/workspaces/query/read", - "Microsoft.OperationalInsights/workspaces/query/SecurityBaseline/read" -], -``` ---Grant access to all tables except the _SecurityAlert_ table: --``` -"Actions": [ - "Microsoft.OperationalInsights/workspaces/read", - "Microsoft.OperationalInsights/workspaces/query/read", - "Microsoft.OperationalInsights/workspaces/query/*/read" -], -"notActions": [ - "Microsoft.OperationalInsights/workspaces/query/SecurityAlert/read" -], -``` --### Limitations of the legacy method related to custom tables --Custom tables store data you collect from data sources such as [text logs](../agents/data-sources-custom-logs.md) and the [HTTP Data Collector API](data-collector-api.md). To identify the table type, [view table information in Log Analytics](./log-analytics-tutorial.md#view-table-information). --Using the legacy method of table-level access, you can't grant access to individual custom log tables at the table level, but you can grant access to all custom log tables. To create a role with access to all custom log tables, create a custom role by using the following actions: --``` -"Actions": [ - "Microsoft.OperationalInsights/workspaces/read", - "Microsoft.OperationalInsights/workspaces/query/read", - "Microsoft.OperationalInsights/workspaces/query/Tables.Custom/read" -], -``` --## Table-level access considerations and limitations --- In the Log Analytics UI, users with table-level can see the list of all tables in the workspace, but can only retrieve data from tables to which they have access.-- The standard Reader or Contributor roles, which include the _\*/read_ action, override table-level access control and give users access to all log data.-- A user with table-level access but no workspace-level permissions can access log data from the API but not from the Azure portal. -- Administrators and owners of the subscription have access to all data types regardless of any other permission settings.-- Workspace owners are treated like any other user for per-table access control.-- Assign roles to security groups instead of individual users to reduce the number of assignments. This practice will also help you use existing group management tools to configure and verify access.--## Next steps --* Learn more about [managing access to Log Analytics workspaces](manage-access.md). |
| azure-monitor | Migrate Splunk To Azure Monitor Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/migrate-splunk-to-azure-monitor-logs.md | - Title: Migrate from Splunk to Azure Monitor Logs - Get started -description: Plan the phases of your migration from Splunk to Azure Monitor Logs and get started importing, collecting, and analyzing log data. ---- Previously updated : 03/20/2024--# Customer intent: As an IT manager, I want to understand the steps required to migrate my Splunk deployment to Azure Monitor Logs so that I can decide whether to migrate and plan and execute my migration. ----# Migrate from Splunk to Azure Monitor Logs --[Azure Monitor Logs](../logs/data-platform-logs.md) is a cloud-based managed monitoring and observability service that provides many advantages in terms of cost management, scalability, flexibility, integration, and low maintenance overhead. The service is designed to handle large amounts of data and scale easily to meet the needs of organizations of all sizes. --Azure Monitor Logs collects data from a wide variety of sources, including Windows Event logs, Syslog, and custom logs, to provide a unified view of all Azure and non-Azure resources. Using a sophisticated query language and curated visualization you can quickly analyze millions of records to identify, understand, and respond to critical patterns in your monitoring data. --This article explains how to migrate your Splunk Observability deployment to Azure Monitor Logs for logging and log data analysis. --For information on migrating your Security Information and Event Management (SIEM) deployment from Splunk Enterprise Security to Azure Sentinel, see [Plan your migration to Microsoft Sentinel](../../sentinel/migration.md). --## Why migrate to Azure Monitor? --The benefits of migrating to Azure Monitor include: --- Fully managed, Software as a Service (SaaS) platform with:- - Automatic upgrades and scaling. - - [Simple per-GB pay-as-you-go pricing](https://azure.microsoft.com/pricing/details/monitor/). - - [Cost optimization and monitoring features](../../azure-monitor/best-practices-cost.md) and low-cost [Basic and Auxiliary table plans](../logs/data-platform-logs.md#table-plans). -- Cloud-native monitoring and observability, including:- - [End-to-end, at-scale monitoring](../overview.md). - - [Native monitoring of Azure resources](../essentials/platform-logs-overview.md). - - [Privacy and compliance](../security-controls-policy.md). -- Native integration with a range of complementary Azure services, such as [Microsoft Sentinel](../../sentinel/overview.md) for security information and event management, [Azure Logic Apps](../../logic-apps/logic-apps-overview.md) for automation, [Azure Managed Grafana](../../managed-grafan) for dashboarding, and [Azure Machine Learning](/azure/machine-learning/overview-what-is-azure-machine-learning) for advanced analysis and response capabilities.--## Compare offerings --|Splunk offering| Product |Azure offering| -|||| -|Splunk Platform|<ul><li>Splunk Cloud Platform</li><li>Splunk Enterprise</li></ul>|[Azure Monitor Logs](../logs/data-platform-logs.md) is a centralized software as a service (SaaS) platform for collecting, analyzing, and acting on telemetry data generated by Azure and non-Azure resources and applications.| -|Splunk Observability|<ul><li>Splunk Infrastructure Monitoring</li><li>Splunk Application Performance Monitoring</li><li>Splunk IT Service Intelligence</li></ul>|[Azure Monitor](../overview.md) is an end-to-end solution for collecting, analyzing, and acting on telemetry from your cloud, multicloud, and on-premises environments, built over a powerful data ingestion pipeline that's shared with Microsoft Sentinel. Azure Monitor offers enterprises a comprehensive solution for monitoring cloud, hybrid, and on-premises environments, with [network isolation](../logs/private-link-security.md), [resilience features and protection from data center failures](../logs/availability-zones.md), [reporting](../overview.md#insights), and [alerts and response](../overview.md#respond) capabilities.<br>Azure Monitor's built-in features include:<ul><li>[Azure Monitor Insights](../insights/insights-overview.md) - ready-to-use, curated monitoring experiences with preconfigured data inputs, searches, alerts, and visualizations.</li><li>[Application Insights](../app/app-insights-overview.md) - provides Application Performance Management (APM) for live web applications.</li><li>[Azure Monitor AIOps and built-in machine learning capabilities](../logs/aiops-machine-learning.md) - provide insights and help you troubleshoot issues and automate data-driven tasks, such as predicting capacity usage and autoscaling, identifying and analyzing application performance issues, and detecting anomalous behaviors in virtual machines, containers, and other resources.</li></ul> These features are free of installation fees.| -|Splunk Security|<ul><li>Splunk Enterprise Security</li><li>Splunk Mission Control<br>Splunk SOAR</li></ul>|[Microsoft Sentinel](../../sentinel/overview.md) is a cloud-native solution that runs over the Azure Monitor platform to provide intelligent security analytics and threat intelligence across the enterprise.| --## Introduction to key concepts ---|Azure Monitor Logs|Similar Splunk concept|Description| -|||| -|[Log Analytics workspace](../logs/log-analytics-workspace-overview.md)|Namespace|A Log Analytics workspace is an environment in which you can collect log data from all Azure and non-Azure monitored resources. The data in the workspace is available for querying and analysis, Azure Monitor features, and other Azure services. Similar to a Splunk namespace, you can manage access to the data and artifacts, such as alerts and workbooks, in your Log Analytics workspace.<br/>[Design your Log Analytics workspace architecture](../logs/workspace-design.md) based on your needs - for example, split billing, regional data storage requirements, and resilience considerations.| -|[Table management](../logs/manage-logs-tables.md)|Indexing|Azure Monitor Logs ingests log data into tables in a managed [Azure Data Explorer](/azure/data-explorer/data-explorer-overview) database. During ingestion, the service automatically indexes and timestamps the data, which means you can store various types of data and access the data quickly using Kusto Query Language (KQL) queries.<br/>Use table properties to manage the table schema, data retention, and whether to store the data for occasional auditing and troubleshooting or for ongoing analysis and use by features and services.<br/>For a comparison of Splunk and Azure Data Explorer data handling and querying concepts, see [Splunk to Kusto Query Language map](/azure/data-explorer/kusto/query/splunk-cheat-sheet). | -|[Analytics, Basic, and Auxiliary table plans](../logs/data-platform-logs.md#table-plans)| |Azure Monitor Logs offers three table plans that let you reduce log ingestion and retention costs and take advantage of Azure Monitor's advanced features and analytics capabilities based on your needs.<br/>The **Analytics** plan makes log data available for interactive queries and use by features and services.<br/>The **Basic** plan lets you ingest and retain logs at a reduced cost for troubleshooting and incident response.<br/>The **Auxiliary** plan is a low-cost way to ingest and retain logs low-touch data, such as verbose logs, and data required for auditing and compliance.| -|[Long-term retention](../logs/data-retention-configure.md)|Data bucket states (hot, warm, cold, thawed), archiving, Dynamic Data Active Archive (DDAA)|The cost-effective long-term retention option keeps your logs in your Log Analytics workspace and lets you access this data immediately, when you need it. Retention configuration changes are effective immediately because data isn't physically transferred to external storage. You can [restore data in long-term retention](../logs/restore.md) or run a [search job](../logs/search-jobs.md) to make a specific time range of data available for real-time analysis. | -|[Access control](../logs/manage-access.md)|Role-based user access, permissions|Define which people and resources can read, write, and perform operations on specific resources using [Azure role-based access control (RBAC)](../../role-based-access-control/overview.md). A user with access to a resource has access to the resource's logs.<br/>Azure facilitates data security and access management with features such as [built-in roles](../../role-based-access-control/built-in-roles.md), [custom roles](../../role-based-access-control/custom-roles.md), [inheritance of role permission](../../role-based-access-control/scope-overview.md), and [audit history](/entr#set-table-level-read-access) for granular access control to specific data types. | -|[Data transformations](../essentials/data-collection-transformations.md)|Transforms, field extractions|Transformations let you filter or modify incoming data before it's sent to a Log Analytics workspace. Use transformations to remove sensitive data, enrich data in your Log Analytics workspace, perform calculations, and filter out data you don't need to reduce data costs.| -|[Data collection rules](../essentials/data-collection-rule-overview.md)|Data inputs, data pipeline|Define which data to collect, how to transform that data, and where to send the data.| -|[Kusto Query Language (KQL)](/azure/kusto/query/)|Splunk Search Processing Language (SPL)|Azure Monitor Logs uses a large subset of KQL that's suitable for simple log queries but also includes advanced functionality such as aggregations, joins, and smart analytics. Use the [Splunk to Kusto Query Language map](/azure/data-explorer/kusto/query/splunk-cheat-sheet) to translate your Splunk SPL knowledge to KQL. You can also [learn KQL with tutorials](../logs/get-started-queries.md) and [KQL training modules](/training/modules/analyze-logs-with-kql/). | -|[Log Analytics](../logs/log-analytics-tutorial.md)|Splunk Web, Search app, Pivot tool|A tool in the Azure portal for editing and running log queries in Azure Monitor Logs. Log Analytics also provides a rich set of tools for exploring and visualizing data without using KQL.| -|[Cost optimization](../../azure-monitor/best-practices-cost.md)| |Azure Monitor provides [tools and best practices to help you understand, monitor, and optimize your costs](../../azure-monitor/best-practices-cost.md) based on your needs.| --## 1. Understand your current usage --Your current usage in Splunk will help you decide which [pricing tier](../logs/change-pricing-tier.md) to select in Azure Monitor and estimate your future costs: --- [Follow Splunk guidance](https://docs.splunk.com/Documentation/Splunk/latest/Admin/AboutSplunksLicenseUsageReportView) to view your usage report.-- [Azure Monitor cost estimates](../cost-estimate.md) using the [Pricing Calculator](https://azure.microsoft.com/pricing/calculator/?service=monitor). --## 2. Set up a Log Analytics workspace --Your Log Analytics workspace is where you collect log data from all of your monitored resources. You can retain data in a Log Analytics workspace for up to seven years. Low-cost data archiving within the workspace lets you access data in long-term retention quickly and easily when you need it, without the overhead of managing an external data store. --We recommend collecting all of your log data in a single Log Analytics workspace for ease of management. If you're considering using multiple workspaces, see [Design a Log Analytics workspace architecture](../logs/workspace-design.md). --To set up a Log Analytics workspace for data collection: --1. [Create a Log Analytics workspace](../logs/quick-create-workspace.md). - - Azure Monitor Logs creates Azure tables in your workspace automatically based on Azure services you use and [data collection settings](#4-collect-data) you define for Azure resources. --1. Configure your Log Analytics workspace, including: - 1. [Pricing tier](../logs/change-pricing-tier.md). - 1. [Link your Log Analytics workspace to a dedicated cluster](../logs/availability-zones.md) to take advantage of advanced capabilities, if you're eligible, based on pricing tier. - 1. [Daily cap](../logs/daily-cap.md). - 1. [Data retention](../logs/data-retention-configure.md). - 1. [Network isolation](../logs/private-link-security.md). - 1. [Access control](../logs/manage-access.md). --1. Use [table-level configuration settings](../logs/manage-logs-tables.md) to: - 1. [Define each table's log data plan](../logs/logs-table-plans.md). - - The default log data plan is Analytics, which lets you take advantage of Azure Monitor's rich monitoring and analytics capabilities. - - 1. [Set a data retention and archiving policy for specific tables](../logs/data-retention-configure.md), if you need them to be different from the workspace-level data retention and archiving policy. - 1. [Modify the table schema](../logs/create-custom-table.md) based on your data model. --## 3. Migrate Splunk artifacts to Azure Monitor --To migrate most Splunk artifacts, you need to translate Splunk Processing Language (SPL) to Kusto Query Language (KQL). For more information, see the [Splunk to Kusto Query Language map](/azure/data-explorer/kusto/query/splunk-cheat-sheet) and [Get started with log queries in Azure Monitor](../logs/get-started-queries.md). --This table lists Splunk artifacts and links to guidance for setting up the equivalent artifacts in Azure Monitor: --|Splunk artifact| Azure Monitor artifact| -||| -|Alerts|[Alert rules](../alerts/alerts-create-new-alert-rule.md)| -|Alert actions|[Action groups](../alerts/action-groups.md)| -|Infrastructure Monitoring|[Azure Monitor Insights](../insights/insights-overview.md) are a set of ready-to-use, curated monitoring experiences with preconfigured data inputs, searches, alerts, and visualizations to get you started analyzing data quickly and effectively. | -|Dashboards|[Workbooks](../visualize/workbooks-overview.md)| -|Lookups|Azure Monitor provides various ways to enrich data, including:<br>- [Data collection rules](../essentials/data-collection-rule-overview.md), which let you send data from multiple sources to a Log Analytics workspace, and perform calculations and transformations before ingesting the data.<br>- KQL operators, such as the [join operator](/azure/data-explorer/kusto/query/joinoperator), which combines data from different tables, and the [externaldata operator](/azure/data-explorer/kusto/query/externaldata-operator?pivots=azuremonitor), which returns data from external storage.<br>- Integration with services, such as [Azure Machine Learning](/azure/machine-learning/overview-what-is-azure-machine-learning) or [Azure Event Hubs](../../event-hubs/event-hubs-about.md), to apply advanced machine learning and stream in more data.| -|Namespaces|You can grant or limit permission to artifacts in Azure Monitor based on [access control](../logs/manage-access.md) you define on your [Log Analytics workspace](../logs/log-analytics-workspace-overview.md) or [Azure resource groups](../../azure-resource-manager/management/manage-resource-groups-portal.md).| -|Permissions|[Access management](../logs/manage-access.md)| -|Reports|Azure Monitor offers a range of options for analyzing, visualizing, and sharing data, including:<br>- [Integration with Grafana](../visualize/grafana-plugin.md)<br>- [Insights](../insights/insights-overview.md)<br>- [Workbooks](../visualize/workbooks-overview.md)<br>- [Dashboards](../visualize/tutorial-logs-dashboards.md)<br>- [Integration with Power BI](../logs/log-powerbi.md)<br>- [Integration with Excel](../logs/log-excel.md)| -|Searches|[Queries](../logs/log-query-overview.md)| -|Source types|[Define your data model in your Log Analytics workspace](../logs/manage-logs-tables.md). Use [ingestion-time transformations](../essentials/data-collection-transformations.md) to filter, format, or modify incoming data.| -|Data collections methods| See [Collect data](#4-collect-data) for Azure Monitor tools designed for specific resources.| --For information on migrating Splunk SIEM artifacts, including detection rules and SOAR automation, see [Plan your migration to Microsoft Sentinel](../../sentinel/migration.md). --## 4. Collect data --Azure Monitor provides tools for collecting data from log [data sources](../data-sources.md) on Azure and non-Azure resources in your environment. --To collect data from a resource: --1. Set up the relevant data collection tool based on the table below. -1. Decide which data you need to collect from the resource. -1. Use [transformations](../essentials/data-collection-transformations.md) to remove sensitive data, enrich data or perform calculations, and filter out data you don't need, to reduce costs. --This table lists the tools Azure Monitor provides for collecting data from various resource types. --| Resource type | Data collection tool |Similar Splunk tool| Collected data | -| | | | | -| **Azure** | [Diagnostic settings](../essentials/diagnostic-settings.md) | | **Azure tenant** - Microsoft Entra audit logs provide sign-in activity history and audit trail of changes made within a tenant.<br/>**Azure resources** - Logs and performance counters.<br/>**Azure subscription** - Service health records along with records on any configuration changes made to the resources in your Azure subscription. | -| **Application** | [Application insights](../app/app-insights-overview.md) |Splunk Application Performance Monitoring| Application performance monitoring data. | -| **Container** |[Container insights](../containers/container-insights-overview.md)|Container Monitoring| Container performance data. | -| **Operating system** | [Azure Monitor Agent](../vm/monitor-virtual-machine-agent.md) |Universal Forwarder, Heavy Forwarder | Monitoring data from the guest operating system of Azure and non-Azure virtual machines.| -| **Non-Azure source** | [Logs Ingestion API](../logs/logs-ingestion-api-overview.md) |HTTP Event Collector (HEC)| File-based logs and any data you send to a [data collection endpoint](../essentials/data-collection-endpoint-overview.md) on a monitored resource.| ---## 5. Transition to Azure Monitor Logs --A common approach is to transition to Azure Monitor Logs gradually, while maintaining historical data in Splunk. During this period, you can: --- Use the [Log ingestion API](../logs/logs-ingestion-api-overview.md) to ingest data from Splunk. -- Use [Log Analytics workspace data export](../logs/logs-data-export.md) to export data out of Azure Monitor. --To export your historical data from Splunk: --1. Use one of the [Splunk export methods](https://docs.splunk.com/Documentation/Splunk/8.2.5/Search/Exportsearchresults) to export data in CSV format. -1. To collect the exported data: - 1. Use Azure Monitor Agent to collect the data you export from Splunk, as described in [Collect text logs with Azure Monitor Agent](../agents/data-collection-text-log.md). - - or - - 1. Collect the exported data directly with the Logs Ingestion API, as described in [Send data to Azure Monitor Logs by using a REST API](../logs/tutorial-logs-ingestion-api.md). ---## Next steps --- Learn more about using [Log Analytics](../logs/log-analytics-overview.md) and the [Log Analytics Query API](../logs/api/overview.md).-- [Enable Microsoft Sentinel on your Log Analytics workspace](../../sentinel/quickstart-onboard.md).-- Take the [Analyze logs in Azure Monitor with KQL training module](/training/modules/analyze-logs-with-kql/). |
| azure-monitor | Monitor Workspace | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/monitor-workspace.md | - Title: Monitor operational issues logged in your Azure Monitor Log Analytics workspace -description: The article describes how to monitor the health of your Log Analytics workspace by using data in the Operation table. -- Previously updated : 07/02/2023----# Monitor operational issues in your Azure Monitor Log Analytics workspace --To maintain the performance and availability of your Log Analytics workspace in Azure Monitor, you need to be able to proactively detect any issues that arise. This article describes how to monitor the health of your Log Analytics workspace by using data in the [Operation](/azure/azure-monitor/reference/tables/operation) table. This table is included in every Log Analytics workspace. It contains error messages and warnings that occur in your workspace. We recommend that you create alerts for issues with the level of Warning and Error. ---## _LogOperation function --Azure Monitor Logs sends information on any issues to the [Operation](/azure/azure-monitor/reference/tables/operation) table in the workspace where the issue occurred. The `_LogOperation` system function is based on the **Operation** table and provides a simplified set of information for analysis and alerting. --## Columns --The `_LogOperation` function returns the columns in the following table. --| Column | Description | -|:|:| -| TimeGenerated | Time that the incident occurred in UTC. | -| Category | Operation category group. Can be used to filter on types of operations and help create more precise system auditing and alerts. See the following section for a list of categories. | -| Operation | Description of the operation type. The operation can indicate that one of the Log Analytics limits was reached, a back-end process related issue, or any other service message. | -| Level | Severity level of the issue:<br>- Info: No specific attention needed.<br>- Warning: Process wasn't completed as expected, and attention is needed.<br>- Error: Process failed, and attention is needed. -| Detail | Detailed description of the operation, includes the specific error message. | -| _ResourceId | Resource ID of the Azure resource related to the operation. | -| Computer | Computer name if the operation is related to an Azure Monitor agent. | -| CorrelationId | Used to group consecutive related operations. | --## Categories --The following table describes the categories from the `_LogOperation` function. --| Category | Description | -|:|:| -| Ingestion | Operations that are part of the data ingestion process. | -| Agent | Indicates an issue with agent installation. | -| Data collection | Operations related to data collection processes. | -| Solution targeting | Operation of type `ConfigurationScope` was processed. | -| Assessment solution | An assessment process was executed. | --### Ingestion --Ingestion operations are issues that occurred during data ingestion and include notification about reaching the Log Analytics workspace limits. Error conditions in this category might suggest data loss, so they're important to monitor. For service limits for Log Analytics workspaces, see [Azure Monitor service limits](../service-limits.md#log-analytics-workspaces). --> [!IMPORTANT] -> If you're troubleshooting data collection for a scenario that uses a data collection rule (DCR) such as Azure Monitor agent or Logs ingestion API, see [Monitor and troubleshoot DCR data collection in Azure Monitor](../essentials/data-collection-monitor.md) for additional troubleshooting information. --#### Operation: Data collection stopped --"Data collection stopped due to daily limit of free data reached. Ingestion status = OverQuota" --In the past seven days, logs collection reached the daily set limit. The limit is set either as the workspace is set to **Free tier** or the daily collection limit was configured for this workspace. -After your data collection reaches the set limit, it automatically stops for the day and will resume only during the next collection day. --Recommended actions: --* Check the `_LogOperation` table for collection stopped and collection resumed events:</br> -`_LogOperation | where TimeGenerated >= ago(7d) | where Category == "Ingestion" | where Detail has "Data collection"` -* [Create an alert](daily-cap.md#alert-when-daily-cap-is-reached) on the "Data collection stopped" Operation event. This alert notifies you when the collection limit is reached. -* Data collected after the daily collection limit is reached will be lost. Use the **Workspace insights** pane to review usage rates from each source. Or you can decide to [manage your maximum daily data volume](daily-cap.md) or [change the pricing tier](cost-logs.md#commitment-tiers) to one that suits your collection rates pattern. -* The data collection rate is calculated per day and resets at the start of the next day. You can also monitor a collection resume event by [creating an alert](./daily-cap.md#alert-when-daily-cap-is-reached) on the "Data collection resumed" Operation event. --#### Operation: Ingestion rate --"The data ingestion volume rate crossed the threshold in your workspace: {0:0.00} MB per one minute and data has been dropped." --Recommended actions: --* Check the `_LogOperation` table for an ingestion rate event:</br> -`_LogOperation | where TimeGenerated >= ago(7d) | where Category == "Ingestion" | where Operation has "Ingestion rate"` - </br>An event is sent to the **Operation** table in the workspace every six hours while the threshold continues to be exceeded. -* [Create an alert](daily-cap.md#alert-when-daily-cap-is-reached) on the "Data collection stopped" Operation event. This alert notifies you when the limit is reached. -* Data collected while the ingestion rate reached 100 percent will be dropped and lost. Use the **Workspace insights** pane to review your usage patterns and try to reduce them.</br> -For more information, see: </br> - - [Azure Monitor service limits](../service-limits.md#data-ingestion-volume-rate) </br> - - [Analyze usage in Log Analytics workspace](analyze-usage.md) --#### Operation: Maximum table column count --"Data of type \<**table name**\> was dropped because number of fields \<**new fields count**\> is above the limit of \<**current field count limit**\> custom fields per data type." --Recommended action: For custom tables, you can move to [parsing the data](./parse-text.md) in queries. --#### Operation: Field content validation --"The following fields' values \<**field name**\> of type \<**table name**\> have been trimmed to the max allowed size, \<**field size limit**\> bytes. Please adjust your input accordingly." --A field larger than the limit size was processed by Azure logs. The field was trimmed to the allowed field limit. We don't recommend sending fields larger than the allowed limit because it results in data loss. --Recommended actions: --Check the source of the affected data type: --* If the data is being sent through the HTTP Data Collector API, you need to change your code\script to split the data before it's ingested. -* For custom logs, collected by a Log Analytics agent, change the logging settings of the application or tool. -* For any other data type, raise a support case. For more information, see [Azure Monitor service limits](../service-limits.md#data-ingestion-volume-rate). --### Data collection --The following section provides information on data collection. --#### Operation: Azure Activity Log collection --"Access to the subscription was lost. Ensure that the \<**subscription id**\> subscription is in the \<**tenant id**\> Microsoft Entra tenant. If the subscription is transferred to another tenant, there's no impact to the services, but information for the tenant could take up to an hour to propagate." --In some situations, like moving a subscription to a different tenant, the Azure activity logs might stop flowing into the workspace. In those situations, you need to reconnect the subscription following the process described in this article. --Recommended actions: --* If the subscription mentioned in the warning message no longer exists, go to the **Legacy activity log connector** pane under **Classic**. Select the relevant subscription, and then select the **Disconnect** button. -* If you no longer have access to the subscription mentioned in the warning message: - * Follow the preceding step to disconnect the subscription. - * To continue collecting logs from this subscription, contact the subscription owner to fix the permissions and re-enable activity log collection. -* [Create a diagnostic setting](../essentials/activity-log.md#send-to-log-analytics-workspace) to send the activity log to a Log Analytics workspace. --### Agent --The following section provides information on agents. --#### Operation: Linux Agent --"Two successive configuration applications from OMS Settings failed." --Configuration settings on the portal have changed. --Recommended action: -This issue is raised in case there's an issue for the agent to retrieve the new config settings. To mitigate this issue, reinstall the agent. -Check the `_LogOperation` table for the agent event:</br> -- `_LogOperation | where TimeGenerated >= ago(6h) | where Category == "Agent" | where Operation == "Linux Agent" | distinct _ResourceId` --The list shows the resource IDs where the agent has the wrong configuration. To mitigate the issue, reinstall the agents listed. --## Alert rules --Use [log search alerts](../alerts/alerts-log-query.md) in Azure Monitor to be proactively notified when an issue is detected in your Log Analytics workspace. Use a strategy that allows you to respond in a timely manner to issues while minimizing your costs. Your subscription will be charged for each alert rule as listed in [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/#platform-logs). --A recommended strategy is to start with two alert rules based on the level of the issue. Use a short frequency such as every 5 minutes for Errors and a longer frequency such as 24 hours for Warnings. Because Errors indicate potential data loss, you want to respond to them quickly to minimize any loss. Warnings typically indicate an issue that doesn't require immediate attention, so you can review them daily. --Use the process in [Create, view, and manage log search alerts by using Azure Monitor](../alerts/alerts-log.md) to create the log search alert rules. The following sections describe the details for each rule. --| Query | Threshold value | Period | Frequency | -|:|:|:|:| -| `_LogOperation | where Level == "Error"` | 0 | 5 | 5 | -| `_LogOperation | where Level == "Warning"` | 0 | 1,440 | 1,440 | --These alert rules respond the same to all operations with Error or Warning. As you become more familiar with the operations that are generating alerts, you might want to respond differently for particular operations. For example, you might want to send notifications to different people for particular operations. --To create an alert rule for a specific operation, use a query that includes the **Category** and **Operation** columns. --The following example creates a Warning alert when the ingestion volume rate has reached 80 percent of the limit: --- Target: Select your Log Analytics workspace-- Criteria:- - Signal name: Custom log search - - Search query: `_LogOperation | where Category == "Ingestion" | where Operation == "Ingestion rate" | where Level == "Warning"` - - Based on: Number of results - - Condition: Greater than - - Threshold: 0 - - Period: 5 (minutes) - - Frequency: 5 (minutes) -- Alert rule name: Daily data limit reached-- Severity: Warning (Sev 1)--The following example creates a Warning alert when the data collection has reached the daily limit: --- Target: Select your Log Analytics workspace-- Criteria:- - Signal name: Custom log search - - Search query: `_LogOperation | where Category == "Ingestion" | where Operation == "Data collection Status" | where Level == "Warning"` - - Based on: Number of results - - Condition: Greater than - - Threshold: 0 - - Period: 5 (minutes) - - Frequency: 5 (minutes) -- Alert rule name: Daily data limit reached-- Severity: Warning (Sev 1)--## Next steps --- Learn more about [log search alerts](../alerts/alerts-log.md).-- [Collect query audit data](./query-audit.md) for your workspace. |
| azure-monitor | Move Workspace | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/move-workspace.md | - Title: Move a Log Analytics workspace in Azure Monitor | Microsoft Docs -description: Learn how to move your Log Analytics workspace to another subscription or resource group. --- Previously updated : 08/12/2024-----# Move a Log Analytics workspace to a different subscription or resource group --In this article, you'll learn the steps to move a Log Analytics workspace to another resource group or subscription in the same region. To move a workspace across regions, see [Move a Log Analytics workspace to another region](./move-workspace-region.md). --> [!TIP] -> To learn more about how to move Azure resources through the Azure portal, PowerShell, the Azure CLI, or the REST API, see [Move resources to a new resource group or subscription](../../azure-resource-manager/management/move-resource-group-and-subscription.md). --## Prerequisites --- The subscription or resource group where you want to move your Log Analytics workspace must be located in the same region as the Log Analytics workspace you're moving.-- The move operation requires that no services can be linked to the workspace. Prior to the move, delete solutions that rely on linked services, including an Azure Automation account. These solutions must be removed before you can unlink your Automation account. Data collection for the solutions will stop and their tables will be removed from the UI, but data remains in workspace for the retention period defined for table. When you add solutions back after the move, ingestion restored and tables become visible with data. Linked services include:- - Update management - - Change tracking - - Start/Stop VMs during off-hours - - Microsoft Defender for Cloud -- Connected [Log Analytics agents](../agents/log-analytics-agent.md) and [Azure Monitor Agent](../agents/azure-monitor-agent-overview.md) remain connected to the workspace after the move with no interruption to ingestion.-- Alerts should be re-created after the move, since permissions for alerts is based on workspace resource ID, which changes with the move. Alerts created after June 1, 2019, or in workspaces that were [upgraded from the legacy Log Analytics Alert API to the scheduledQueryRules API](../alerts/alerts-log-api-switch.md) can be exported in templates and deployed after the move. You can [check if the scheduledQueryRules API is used for alerts in your workspace](../alerts/alerts-log-api-switch.md#check-switching-status-of-workspace). Alternatively, you can configure alerts manually in the target workspace.-- Update resource paths after a workspace move for Azure or external resources that point to the workspace. For example: [Azure Monitor alert rules](../alerts/alerts-resource-move.md), Third-party applications, Custom scripting, etc.--## Permissions required --| Action | Permissions required | -|:|:| -| Verify the Microsoft Entra tenant. | `Microsoft.AzureActiveDirectory/b2cDirectories/read` permissions, as provided by the [Log Analytics Reader built-in role](./manage-access.md#log-analytics-reader), for example. | -| Delete a solution. | `Microsoft.OperationsManagement/solutions/delete` permissions on the solution, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example. | -| Remove alert rules for the Start/Stop VMs solution. | `microsoft.insights/scheduledqueryrules/delete` permissions, as provided by the [Monitoring Contributor built-in role](../../role-based-access-control/built-in-roles.md#monitoring-contributor), for example. | -| Unlink the Automation account | `Microsoft.OperationalInsights/workspaces/linkedServices/delete` permissions on the linked Log Analytics workspace, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example. | -| Move a Log Analytics workspace. | `Microsoft.OperationalInsights/workspaces/delete` and `Microsoft.OperationalInsights/workspaces/write` permissions on the Log Analytics workspace, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example. | --## Considerations and limits --Consider these points before you move a Log Analytics workspace: --- It can take Azure Resource Manager a few hours to complete. Solutions might be unresponsive during the operation.-- Managed solutions that are installed in the workspace, will be moved as well.-- Managed solutions are workspace's objects and can't be moved independently.-- Workspace keys (both primary and secondary) are regenerated with a workspace move operation. If you keep a copy of your workspace keys in Azure Key Vault, update them with the new keys generated after the workspace is moved.-->[!IMPORTANT] -> **Microsoft Sentinel customers** -> - Currently, after Microsoft Sentinel is deployed on a workspace, moving the workspace to another resource group or subscription isn't supported. -> - If you've already moved the workspace, disable all active rules under **Analytics** and reenable them after five minutes. This solution should be effective in most cases, although it's unsupported and undertaken at your own risk. --## Verify the Microsoft Entra tenant -The workspace source and destination subscriptions must exist within the same Microsoft tenant. Use Azure PowerShell to verify that both subscriptions have the same Entra tenant ID. --### [Portal](#tab/azure-portal) --[Find your Microsoft Entra tenant](../../azure-portal/get-subscription-tenant-id.md#find-your-azure-ad-tenant) for the source and destination subscriptions. --### [REST API](#tab/rest-api) --To fetch the tenant ID for the source and destination subscriptions, call the [Subscriptions - Get API](/rest/api/resources/subscriptions/get): --```http -GET https://management.azure.com/subscriptions/{subscriptionId}?api-version=2020-01-01 -``` --### [CLI](#tab/cli) --Run the [az account tenant](/cli/azure/account/tenant) command: --```azurecli -az account tenant list --subscription <your-source-subscription> -az account tenant list --subscription <your-destination-subscription> -``` --### [PowerShell](#tab/PowerShell) --Run the [Get-AzSubscription](/powershell/module/az.accounts/get-azsubscription/) command: --```powershell -(Get-AzSubscription -SubscriptionName <your-source-subscription>).TenantId -(Get-AzSubscription -SubscriptionName <your-destination-subscription>).TenantId -``` ----## Delete solutions --### [Portal](#tab/azure-portal) --1. Open the menu for the resource group where any solutions are installed. -1. Select the solutions to remove. -1. Select **Delete Resources** and then confirm the resources to be removed by selecting **Delete**. - <!-- convertborder later --> - :::image type="content" source="media/move-workspace/delete-solutions.png" lightbox="media/move-workspace/delete-solutions.png" alt-text="Screenshot that shows deleting solutions." border="false"::: --### [REST API](#tab/rest-api) --To delete the solution, call the [Resources - Delete API](/rest/api/resources/resources/delete): --```http -DELETE https://management.azure.com/subscriptions/{subscriptionId}/resourcegroups/{resourceGroupName}/providers/{resourceProviderNamespace}/{parentResourcePath}/{resourceType}/{resourceName}?api-version=2021-04-01 -``` --### [CLI](#tab/cli) --To remove solutions, run the [az resource delete](/cli/azure/resource#az-resource-delete) command. You need to specify the name of the resource, resource type, and resource group for the solution you want to delete: --```azurecli -az resource delete --name <resource-name> --resource-type <resource-type> --resource-group <resource-group-name> -``` --### [PowerShell](#tab/PowerShell) --To remove solutions, use the [Remove-AzResource](/powershell/module/az.resources/remove-azresource) cmdlet as shown in the following example: --```powershell -Remove-AzResource -ResourceType 'Microsoft.OperationsManagement/solutions' -ResourceName "ChangeTracking(<workspace-name>)" -ResourceGroupName <resource-group-name> -Remove-AzResource -ResourceType 'Microsoft.OperationsManagement/solutions' -ResourceName "Updates(<workspace-name>)" -ResourceGroupName <resource-group-name> -Remove-AzResource -ResourceType 'Microsoft.OperationsManagement/solutions' -ResourceName "Start-Stop-VM(<workspace-name>)" -ResourceGroupName <resource-group-name> -``` ----### Remove alert rules for the Start/Stop VMs solution --To remove the **Start/Stop VMs** solution, you also need to remove the alert rules created by the solution. --### [Portal](#tab/azure-portal) --1. Open the **Monitor** menu and then select **Alerts**. -1. Select **Manage alert rules**. -1. Select the following three alert rules, and then select **Delete**: -- - AutoStop_VM_Child - - ScheduledStartStop_Parent - - SequencedStartStop_Parent - <!-- convertborder later --> - :::image type="content" source="media/move-workspace/delete-rules.png" lightbox="media/move-workspace/delete-rules.png" alt-text="Screenshot that shows deleting rules." border="false"::: --### [REST API](#tab/rest-api) --Delete the following alert rules by calling the Scheduled Query Rules - Delete API: -- - AutoStop_VM_Child - - ScheduledStartStop_Parent - - SequencedStartStop_Parent --```http -DELETE https://management.azure.com/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Insights/scheduledQueryRules/{ruleName}?api-version=2023-03-15-preview -``` --### [CLI](#tab/cli) --Delete the following alert rules by running the [az monitor scheduled-query delete](/cli/azure/monitor/scheduled-query#az-monitor-scheduled-query-delete) command: --- AutoStop_VM_Child-- ScheduledStartStop_Parent-- SequencedStartStop_Parent--```azurecli -az monitor scheduled-query delete [--ids] - [--name] - [--resource-group] - [--subscription] - [--yes] -``` --### [PowerShell](#tab/PowerShell) --Delete the following alert rules by running the [Remove-AzScheduledQueryRule](/powershell/module/az.monitor/remove-azscheduledqueryrule) command: --- AutoStop_VM_Child-- ScheduledStartStop_Parent-- SequencedStartStop_Parent----## Unlink the Automation account --### [Portal](#tab/azure-portal) --See [Delete a standalone Automation account linked to workspace](../../automation/delete-account.md#delete-a-standalone-automation-account-linked-to-workspace). --### [REST API](#tab/rest-api) --Call the [Linked Services - Delete API](/rest/api/loganalytics/linked-services/delete). --```http -DELETE https://management.azure.com/subscriptions/{subscriptionId}/resourcegroups/{resourceGroupName}/providers/Microsoft.OperationalInsights/workspaces/{workspaceName}/linkedServices/{linkedServiceName}?api-version=2020-08-01 -``` --### [CLI](#tab/cli) --Not supported. --### [PowerShell](#tab/PowerShell) --Not supported. ----## Move your workspace --### [Portal](#tab/azure-portal) --1. Open the **Log Analytics workspaces** menu and then select your workspace. -1. On the **Overview** page, select **change** next to either **Resource group** or **Subscription name**. -1. A new page opens with a list of resources related to the workspace. Select the resources to move to the same destination subscription and resource group as the workspace. -1. Select a destination **Subscription** and **Resource group**. If you're moving the workspace to another resource group in the same subscription, you won't see the **Subscription** option. -1. Select **OK** to move the workspace and selected resources. -- :::image type="content" source="media/move-workspace/portal.png" lightbox="media/move-workspace/portal.png" alt-text="Screenshot that shows the Overview pane in the Log Analytics workspace with options to change the resource group and subscription name."::: --### [REST API](#tab/rest-api) --To move your workspace, call the [Resources - Move Resources API](/rest/api/resources/resources/move-resources). --```http -POST https://management.azure.com/subscriptions/{subscriptionId}/resourceGroups/{sourceResourceGroupName}/moveResources?api-version=2021-04-01 -``` --### [CLI](#tab/cli) --To move your workspace, run the [az resource move](/cli/azure/resource#az-resource-move) command: --```azurecli -az resource move --destination-group - --ids - [--destination-subscription-id] -``` --### [PowerShell](#tab/PowerShell) --To move your workspace, run the [Move-AzResource](/powershell/module/AzureRM.Resources/Move-AzureRmResource) cmdlet as shown in the following example: --```powershell -Move-AzResource -ResourceId "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/MyResourceGroup01/providers/Microsoft.OperationalInsights/workspaces/MyWorkspace" -DestinationSubscriptionId "00000000-0000-0000-0000-000000000000" -DestinationResourceGroupName "MyResourceGroup02" -``` ----> [!IMPORTANT] -> After the move operation, removed solutions and the Automation account link should be reconfigured to bring the workspace back to its previous state. --## Next steps -For a list of which resources support the move operation, see [Move operation support for resources](../../azure-resource-manager/management/move-support-resources.md). |
| azure-monitor | Notebooks Azure Monitor Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/notebooks-azure-monitor-logs.md | - Title: Analyze data in Azure Monitor Logs using a notebook -description: Learn how to integrate a notebook with a Log Analytics workspace to create a machine learning pipeline or perform advanced analysis on data in Azure Monitor Logs. ----- Previously updated : 08/12/2024--# Customer intent: As a data scientist, I want to run custom code on data in Azure Monitor Logs to gain insights without having to export data outside of Azure Monitor. ---# Tutorial: Analyze data in Azure Monitor Logs using a notebook --Notebooks are integrated environments that let you create and share documents with live code, equations, visualizations, and text. Integrating a notebook with a Log Analytics workspace lets you create a multi-step process that runs code in each step based on the results of the previous step. You can use such streamlined processes to build machine learning pipelines, advanced analysis tools, troubleshooting guides (TSGs) for support needs, and more. --Integrating a notebook with a Log Analytics workspace also lets you: --- Run KQL queries and custom code in any language.-- Introduce new analytics and visualization capabilities, such as new machine learning models, custom timelines, and process trees.-- Integrate data sets outside of Azure Monitor Logs, such as an on-premises data sets.-- Take advantage of increased service limits using the Query API limits compared to the Azure portal.--In this tutorial, you learn how to: -> [!div class="checklist"] -> * Integrate a notebook with your Log Analytics workspace using the [Azure Monitor Query client library](/python/api/overview/azure/monitor-query-readme) and the [Azure Identity client library](https://pypi.org/project/azure-identity/) -> * Explore and visualize data from your Log Analytics workspace in a notebook -> * Ingest data from your notebook into a custom table in your Log Analytics workspace (optional) --For an example of how to build a machine learning pipeline to analyze data in Azure Monitor Logs using a notebook, see this [sample notebook: Detect anomalies in Azure Monitor Logs using machine learning techniques](https://github.com/Azure/azure-sdk-for-python/blob/main/sdk/monitor/azure-monitor-query/samples/notebooks/sample_machine_learning_sklearn.ipynb). --> [!TIP] -> To work around [API-related limitations](/azure/azure-monitor/service-limits#la-query-api), [split larger queries into multiple smaller queries](https://github.com/Azure/azure-sdk-for-python/blob/main/sdk/monitor/azure-monitor-query/samples/notebooks/sample_large_query.ipynb). ---## Prerequisites -For this tutorial, you need: --- An [Azure Machine Learning workspace with a CPU compute instance](/azure/machine-learning/quickstart-create-resources) with:-- - [A notebook](/azure/machine-learning/quickstart-run-notebooks#start-with-notebooks). - - A kernel set to Python 3.8 or higher. --- The following roles and permissions: -- - In **Azure Monitor Logs**: The **Logs Analytics Contributor** role to read data from and send data to your Logs Analytics workspace. For more information, see [Manage access to Log Analytics workspaces](../logs/manage-access.md#log-analytics-contributor). - - In **Azure Machine Learning**: - - A resource group-level **Owner** or **Contributor** role, to create a new Azure Machine Learning workspace if needed. - - A **Contributor** role on the Azure Machine Learning workspace where you run your notebook. - - For more information, see [Manage access to an Azure Machine Learning workspace](/azure/machine-learning/how-to-assign-roles). -## Tools and notebooks --In this tutorial, you use these tools: --| Tool | Description | -| | | -|[Azure Monitor Query client library](/python/api/overview/azure/monitor-query-readme) |Lets you run read-only queries on data in Azure Monitor Logs. | -|[Azure Identity client library](/python/api/overview/azure/identity-readme)|Enables Azure SDK clients to authenticate with Microsoft Entra ID.| -|[Azure Monitor Ingestion client library](/python/api/overview/azure/monitor-ingestion-readme)| Lets you send custom logs to Azure Monitor using the Logs Ingestion API. Required to [ingest analyzed data into a custom table in your Log Analytics workspace (optional)](#4-ingest-analyzed-data-into-a-custom-table-in-your-log-analytics-workspace-optional)| -|[Data collection rule](../essentials/data-collection-rule-overview.md), [data collection endpoint](../essentials/data-collection-endpoint-overview.md), and a [registered application](../logs/tutorial-logs-ingestion-portal.md#create-azure-ad-application) | Required to [ingest analyzed data into a custom table in your Log Analytics workspace (optional)](#4-ingest-analyzed-data-into-a-custom-table-in-your-log-analytics-workspace-optional) | ---Other query libraries you can use include: --- [Kqlmagic library](https://pypi.org/project/Kqlmagic/) lets you run KQL queries directly inside a notebook in the same way you run KQL queries from the Log Analytics tool.-- [MSTICPY library](https://msticpy.readthedocs.io/en/latest/https://docsupdatetracker.net/index.html) provides templated queries that invoke built-in KQL time series and machine learning capabilities, and provides advanced visualization tools and analyses of data in Log Analytics workspace.--Other Microsoft notebook experiences for advanced analysis include: --- [Azure Synapse Analytics notebooks](/azure/synapse-analytics/spark/apache-spark-notebook-concept)-- [Microsoft Fabric notebooks](/fabric/data-engineering/how-to-use-notebook)-- [Visual Studio Code Notebooks](https://code.visualstudio.com/docs/datascience/jupyter-notebooks)--## 1. Integrate your Log Analytics workspace with your notebook --Set up your notebook to query your Log Analytics workspace: --1. Install the Azure Monitor Query, Azure Identity and Azure Monitor Ingestion client libraries along with the Pandas data analysis library, Plotly visualization library: -- ```python - import sys - - !{sys.executable} -m pip install --upgrade azure-monitor-query azure-identity azure-monitor-ingestion - - !{sys.executable} -m pip install --upgrade pandas plotly - ``` --1. Set the `LOGS_WORKSPACE_ID` variable below to the ID of your Log Analytics workspace. The variable is currently set to use the [Azure Monitor Demo workspace](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring_Logs/DemoLogsBlade), which you can use to demo the notebook. -- ```python - LOGS_WORKSPACE_ID = "DEMO_WORKSPACE" - ``` - -1. Set up `LogsQueryClient` to authenticate and query Azure Monitor Logs. -- This code sets up `LogsQueryClient` to authenticate using `DefaultAzureCredential`: - - ```python - from azure.core.credentials import AzureKeyCredential - from azure.core.pipeline.policies import AzureKeyCredentialPolicy - from azure.identity import DefaultAzureCredential - from azure.monitor.query import LogsQueryClient - - if LOGS_WORKSPACE_ID == "DEMO_WORKSPACE": - credential = AzureKeyCredential("DEMO_KEY") - authentication_policy = AzureKeyCredentialPolicy(name="X-Api-Key", credential=credential) - else: - credential = DefaultAzureCredential() - authentication_policy = None - - logs_query_client = LogsQueryClient(credential, authentication_policy=authentication_policy) - ``` -- `LogsQueryClient` typically only supports authentication with Microsoft Entra token credentials. However, we can pass a custom authentication policy to enable the use of API keys. This allows the client to [query the demo workspace](../logs/api/access-api.md#authenticate-with-a-demo-api-key). The availability and access to this demo workspace is subject to change, so we recommend using your own Log Analytics workspace. --1. Define a helper function, called `query_logs_workspace`, to run a given query in the Log Analytics workspace and return the results as a Pandas DataFrame. - -- ```python - import pandas as pd - import plotly.express as px - - from azure.monitor.query import LogsQueryStatus - from azure.core.exceptions import HttpResponseError - - - def query_logs_workspace(query): - try: - response = logs_query_client.query_workspace(LOGS_WORKSPACE_ID, query, timespan=None) - if response.status == LogsQueryStatus.PARTIAL: - error = response.partial_error - data = response.partial_data - print(error.message) - elif response.status == LogsQueryStatus.SUCCESS: - data = response.tables - for table in data: - my_data = pd.DataFrame(data=table.rows, columns=table.columns) - except HttpResponseError as err: - print("something fatal happened") - print (err) - return my_data - ``` --## 2. Explore and visualize data from your Log Analytics workspace in your notebook --Let's look at some data in the workspace by running a query from the notebook: --1. This query checks how much data (in Megabytes) you ingested into each of the tables (data types) in your Log Analytics workspace each hour over the past week: -- ```python - TABLE = "Usage" - - QUERY = f""" - let starttime = 7d; // Start date for the time series, counting back from the current date - let endtime = 0d; // today - {TABLE} | project TimeGenerated, DataType, Quantity - | where TimeGenerated between (ago(starttime)..ago(endtime)) - | summarize ActualUsage=sum(Quantity) by TimeGenerated=bin(TimeGenerated, 1h), DataType - """ - - df = query_logs_workspace(QUERY) - display(df) - ``` -- The resulting DataFrame shows the hourly ingestion in each of the tables in the Log Analytics workspace: - - :::image type="content" source="media/jupyter-notebook-ml-azure-monitor-logs/machine-learning-azure-monitor-logs-ingestion-all-tables-dataframe.png" alt-text="Screenshot of a DataFrame generated in a notebook with log ingestion data retrieved from a Log Analytics workspace." --1. Now, let's view the data as a graph that shows hourly usage for various data types over time, based on the Pandas DataFrame: -- ```python - df = df.sort_values(by="TimeGenerated") - graph = px.line(df, x='TimeGenerated', y="ActualUsage", color='DataType', title="Usage in the last week - All data types") - graph.show() - ``` -- The resulting graph looks like this: -- :::image type="content" source="media/jupyter-notebook-ml-azure-monitor-logs/machine-learning-azure-monitor-logs-ingestion-all-tables.png" alt-text="A graph that shows the amount of data ingested into each of the tables in a Log Analytics workspace over seven days." lightbox="media/jupyter-notebook-ml-azure-monitor-logs/machine-learning-azure-monitor-logs-ingestion-all-tables.png"::: -- You've successfully queried and visualized log data from your Log Analytics workspace in your notebook. --## 3. Analyze data --As a simple example, let's take the first five rows: --``` -analyzed_df = df.head(5) -``` --For an example of how to implement machine learning techniques to analyze data in Azure Monitor Logs, see this [sample notebook: Detect anomalies in Azure Monitor Logs using machine learning techniques](https://github.com/Azure/azure-sdk-for-python/blob/main/sdk/monitor/azure-monitor-query/samples/notebooks/sample_machine_learning_sklearn.ipynb). - -## 4. Ingest analyzed data into a custom table in your Log Analytics workspace (optional) --Send your analysis results to a custom table in your Log Analytics workspace to trigger alerts or to make them available for further analysis. --1. To send data to your Log Analytics workspace, you need a custom table, data collection endpoint, data collection rule, and a registered Microsoft Entra application with permission to use the data collection rule, as explained in [Tutorial: Send data to Azure Monitor Logs with Logs ingestion API (Azure portal)](../logs/tutorial-logs-ingestion-portal.md). -- When you create your custom table: -- 1. Upload this sample file to define the table schema: - - ```json - [ - { - "TimeGenerated": "2023-03-19T19:56:43.7447391Z", - "ActualUsage": 40.1, - "DataType": "AzureDiagnostics" - } - ] - ``` - -1. Define the constants you need for the Logs Ingestion API: -- ```python - os.environ['AZURE_TENANT_ID'] = "<Tenant ID>"; #ID of the tenant where the data collection endpoint resides - os.environ['AZURE_CLIENT_ID'] = "<Application ID>"; #Application ID to which you granted permissions to your data collection rule - os.environ['AZURE_CLIENT_SECRET'] = "<Client secret>"; #Secret created for the application - - - - os.environ['LOGS_DCR_STREAM_NAME'] = "<Custom stream name>" ##Name of the custom stream from the data collection rule - os.environ['LOGS_DCR_RULE_ID'] = "<Data collection rule immutableId>" # immutableId of your data collection rule - os.environ['DATA_COLLECTION_ENDPOINT'] = "<Logs ingestion URL of your endpoint>" # URL that looks like this: https://xxxx.ingest.monitor.azure.com - ``` -1. Ingest the data into the custom table in your Log Analytics workspace: -- ```python - from azure.core.exceptions import HttpResponseError - from azure.identity import ClientSecretCredential - from azure.monitor.ingestion import LogsIngestionClient - import json - - - credential = ClientSecretCredential( - tenant_id=AZURE_TENANT_ID, - client_id=AZURE_CLIENT_ID, - client_secret=AZURE_CLIENT_SECRET - ) - - client = LogsIngestionClient(endpoint=DATA_COLLECTION_ENDPOINT, credential=credential, logging_enable=True) - - body = json.loads(analyzed_df.to_json(orient='records', date_format='iso')) - - try: - response = client.upload(rule_id=LOGS_DCR_RULE_ID, stream_name=LOGS_DCR_STREAM_NAME, logs=body) - print("Upload request accepted") - except HttpResponseError as e: - print(f"Upload failed: {e}") - ``` -- > [!NOTE] - > When you create a table in your Log Analytics workspace, it can take up to 15 minutes for ingested data to appear in the table. --1. Verify that the data now appears in your custom table. -- :::image type="content" source="media/jupyter-notebook-ml-azure-monitor-logs/machine-learning-anomalies-in-azure-monitor-log-analytics-workspace.png" alt-text="Screenshot that shows a query in Log Analytics on a custom table into which the analysis results from the notebook were ingested." lightbox="media/jupyter-notebook-ml-azure-monitor-logs/machine-learning-anomalies-in-azure-monitor-log-analytics-workspace.png"::: --## Next steps --Learn more about how to: --- [Schedule a machine learning pipeline](/azure/machine-learning/how-to-schedule-pipeline-job).-- [Detect and analyze anomalies using KQL](../logs/kql-machine-learning-azure-monitor.md). |
| azure-monitor | Parse Text | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/parse-text.md | - Title: Parse text data in Azure Monitor logs | Microsoft Docs -description: This article describes options for parsing log data in Azure Monitor records when the data is ingested and when it's retrieved in a query and compares the relative advantages for each. --- Previously updated : 08/12/2024----# Parse text data in Azure Monitor logs -Some log data collected by Azure Monitor will include multiple pieces of information in a single property. Parsing this data into multiple properties makes it easier to use in queries. A common example is a [custom log](../agents/data-sources-custom-logs.md) that collects an entire log entry with multiple values into a single property. By creating separate properties for the different values, you can search and aggregate on each one. --This article describes different options for parsing log data in Azure Monitor when the data is ingested and when it's retrieved in a query, comparing the relative advantages for each. --## Permissions required --- To parse data at collection time, you need `Microsoft.Insights/dataCollectionRuleAssociations/*` permissions, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example.-- To parse data at query time, you need `Microsoft.OperationalInsights/workspaces/query/*/read` permissions, as provided by the [Log Analytics Reader built-in role](./manage-access.md#log-analytics-reader), for example.--## Parsing methods -You can parse data either at ingestion time when the data is collected or at query time when you analyze the data with a query. Each strategy has unique advantages. --### Parse data at collection time -Use [transformations](../essentials/data-collection-transformations.md) to parse data at collection time and define which columns to send the parsed data to. --**Advantages:** --- Easier to query the collected data because you don't need to include parse commands in the query.-- Better query performance because the query doesn't need to perform parsing.--**Disadvantages:** --- Must be defined in advance. Can't include data that's already been collected.-- If you change the parsing logic, it will only apply to new data.-- Increases latency time for collecting data.-- Errors can be difficult to handle.--### Parse data at query time -When you parse data at query time, you include logic in your query to parse data into multiple fields. The actual table itself isn't modified. --**Advantages:** --- Applies to any data, including data that's already been collected.-- Changes in logic can be applied immediately to all data.-- Flexible parsing options, including predefined logic for particular data structures.--**Disadvantages:** --- Requires more complex queries. This drawback can be mitigated by using [functions to simulate a table](#use-a-function-to-simulate-a-table).-- Must replicate parsing logic in multiple queries. Can share some logic through functions.-- Can create overhead when you run complex logic against very large record sets (billions of records).--## Parse data as it's collected -For more information on parsing data as it's collected, see [Structure of transformation in Azure Monitor](../essentials/data-collection-transformations-structure.md). This approach creates custom properties in the table that can be used by queries like any other property. --## Parse data in a query by using patterns -When the data you want to parse can be identified by a pattern repeated across records, you can use different operators in the [Kusto Query Language](/azure/kusto/query/) to extract the specific piece of data into one or more new properties. --### Simple text patterns --Use the [parse](/azure/kusto/query/parseoperator) operator in your query to create one or more custom properties that can be extracted from a string expression. You specify the pattern to be identified and the names of the properties to create. This approach is useful for data with key-value strings with a form similar to `key=value`. --Consider a custom log with data in the following format: --``` -Time=2018-03-10 01:34:36 Event Code=207 Status=Success Message=Client 05a26a97-272a-4bc9-8f64-269d154b0e39 connected -Time=2018-03-10 01:33:33 Event Code=208 Status=Warning Message=Client ec53d95c-1c88-41ae-8174-92104212de5d disconnected -Time=2018-03-10 01:35:44 Event Code=209 Status=Success Message=Transaction 10d65890-b003-48f8-9cfc-9c74b51189c8 succeeded -Time=2018-03-10 01:38:22 Event Code=302 Status=Error Message=Application could not connect to database -Time=2018-03-10 01:31:34 Event Code=303 Status=Error Message=Application lost connection to database -``` --The following query would parse this data into individual properties. The line with `project` is added to only return the calculated properties and not `RawData`, which is the single property that holds the entire entry from the custom log. --```Kusto -MyCustomLog_CL -| parse RawData with * "Time=" EventTime " Event Code=" Code " Status=" Status " Message=" Message -| project EventTime, Code, Status, Message -``` --This example breaks out the user name of a UPN in the `AzureActivity` table. --```Kusto -AzureActivity -| parse Caller with UPNUserPart "@" * -| where UPNUserPart != "" //Remove non UPN callers (apps, SPNs, etc) -| distinct UPNUserPart, Caller -``` --### Regular expressions -If your data can be identified with a regular expression, you can use [functions that use regular expressions](/azure/kusto/query/re2) to extract individual values. The following example uses [extract](/azure/kusto/query/extractfunction) to break out the `UPN` field from `AzureActivity` records and then return distinct users. --```Kusto -AzureActivity -| extend UPNUserPart = extract("([a-z.]*)@", 1, Caller) -| distinct UPNUserPart, Caller -``` --To enable efficient parsing at large scale, Azure Monitor uses the re2 version of Regular Expressions, which is similar but not identical to some of the other regular expression variants. For more information, see the [re2 expression syntax](https://aka.ms/kql_re2syntax). --## Parse delimited data in a query -Delimited data separates fields with a common character, like a comma in a CSV file. Use the [split](/azure/kusto/query/splitfunction) function to parse delimited data by using a delimiter that you specify. You can use this approach with the [extend](/azure/kusto/query/extendoperator) operator to return all fields in the data or to specify individual fields to be included in the output. --> [!NOTE] -> Because split returns a dynamic object, the results might need to be explicitly cast to data types, such as string to be used in operators and filters. --Consider a custom log with data in the following CSV format: --``` -2018-03-10 01:34:36, 207,Success,Client 05a26a97-272a-4bc9-8f64-269d154b0e39 connected -2018-03-10 01:33:33, 208,Warning,Client ec53d95c-1c88-41ae-8174-92104212de5d disconnected -2018-03-10 01:35:44, 209,Success,Transaction 10d65890-b003-48f8-9cfc-9c74b51189c8 succeeded -2018-03-10 01:38:22, 302,Error,Application could not connect to database -2018-03-10 01:31:34, 303,Error,Application lost connection to database -``` --The following query would parse this data and summarize by two of the calculated properties. The first line splits the `RawData` property into a string array. Each of the next lines gives a name to individual properties and adds them to the output by using functions to convert them to the appropriate data type. --```Kusto -MyCustomCSVLog_CL -| extend CSVFields = split(RawData, ',') -| extend EventTime = todatetime(CSVFields[0]) -| extend Code = toint(CSVFields[1]) -| extend Status = tostring(CSVFields[2]) -| extend Message = tostring(CSVFields[3]) -| where getyear(EventTime) == 2018 -| summarize count() by Status,Code -``` --## Parse predefined structures in a query -If your data is formatted in a known structure, you might be able to use one of the functions in the [Kusto Query Language](/azure/kusto/query/) for parsing predefined structures: --- [JSON](/azure/kusto/query/parsejsonfunction)-- [XML](/azure/kusto/query/parse-xmlfunction)-- [IPv4](/azure/kusto/query/parse-ipv4function)-- [URL](/azure/kusto/query/parseurlfunction)-- [URL query](/azure/kusto/query/parseurlqueryfunction)-- [File path](/azure/kusto/query/parsepathfunction)-- [User agent](/azure/kusto/query/parse-useragentfunction)-- [Version string](/azure/kusto/query/parse-versionfunction)--The following example query parses the `Properties` field of the `AzureActivity` table, which is structured in JSON. It saves the results to a dynamic property called `parsedProp`, which includes the individual named value in the JSON. These values are used to filter and summarize the query results. --```Kusto -AzureActivity -| extend parsedProp = parse_json(Properties) -| where parsedProp.isComplianceCheck == "True" -| summarize count() by ResourceGroup, tostring(parsedProp.tags.businessowner) -``` --These parsing functions can be processor intensive. Only use them when your query uses multiple properties from the formatted data. Otherwise, simple pattern matching processing is faster. --The following example shows the breakdown of the domain controller `TGT Preauth` type. The type exists only in the `EventData` field, which is an XML string. No other data from this field is needed. In this case, [parse](/azure/kusto/query/parseoperator) is used to pick out the required piece of data. --```Kusto -SecurityEvent -| where EventID == 4768 -| parse EventData with * 'PreAuthType">' PreAuthType '</Data>' * -| summarize count() by PreAuthType -``` --## Use a function to simulate a table -You might have multiple queries that perform the same parsing of a particular table. In this case, [create a function](../logs/functions.md) that returns the parsed data instead of replicating the parsing logic in each query. You can then use the function alias in place of the original table in other queries. --Consider the preceding comma-delimited custom log example. To use the parsed data in multiple queries, create a function by using the following query and save it with the alias `MyCustomCSVLog`. --```Kusto -MyCustomCSVLog_CL -| extend CSVFields = split(RawData, ',') -| extend DateTime = tostring(CSVFields[0]) -| extend Code = toint(CSVFields[1]) -| extend Status = tostring(CSVFields[2]) -| extend Message = tostring(CSVFields[3]) -``` --You can now use the alias `MyCustomCSVLog` in place of the actual table name in queries like the following example: --```Kusto -MyCustomCSVLog -| summarize count() by Status,Code -``` --## Next steps -Learn about [log queries](./log-query-overview.md) to analyze the data collected from data sources and solutions. |
| azure-monitor | Personal Data Mgmt | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/personal-data-mgmt.md | - Title: Managing personal data in Azure Monitor Logs and Application Insights -description: This article describes how to manage personal data stored in Azure Monitor Log Analytics and the methods to identify and remove it. ---- Previously updated : 06/28/2022-# Customer intent: As an Azure Monitor admin user, I want to understand how to manage personal data in logs that Azure Monitor collects. ----# Managing personal data in Azure Monitor Logs and Application Insights --Log Analytics is a data store where personal data is likely to be found. Application Insights stores its data in a Log Analytics partition. This article explains where Log Analytics and Application Insights store personal data and how to manage this data. --In this article, _log data_ refers to data sent to a Log Analytics workspace, while _application data_ refers to data collected by Application Insights. If you're using a workspace-based Application Insights resource, the information on log data applies. If you're using a classic Application Insights resource, the application data applies. ---## Permissions required --| Action | Permissions required | -|:-|:| -| Purge data from a Log Analytics workspace | `Microsoft.OperationalInsights/workspaces/purge/action` permissions to the Log Analytics workspace, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example | ---## Strategy for personal data handling --While it's up to you and your company to define a strategy for handling personal data, here are a few approaches, listed from most to least preferable from a technical point of view: --* Stop collecting personal data, or obfuscate, anonymize, or adjust collected data to exclude it from being considered "personal". This is _by far_ the preferred approach, which saves you the need to create a costly and impactful data handling strategy. -* Normalize the data to reduce negative affects on the data platform and performance. For example, instead of logging an explicit User ID, create a lookup to correlate the username and their details to an internal ID that can then be logged elsewhere. That way, if a user asks you to delete their personal information, you can delete only the row in the lookup table that corresponds to the user. -* If you need to collect personal data, build a process using the purge API path and the existing query API to meet any obligations to export and delete any personal data associated with a user. --## Where to look for personal data in Log Analytics --Log Analytics prescribes a schema to your data, but allows you to override every field with custom values. You can also ingest custom schemas. As such, it's impossible to say exactly where personal data will be found in your specific workspace. The following locations, however, are good starting points in your inventory. --> [!NOTE] -> Some of the queries below use `search *` to query all tables in a workspace. We highly recommend you avoid using `search *`, which creates a highly inefficient query, whenever possible. Instead, query a specific table. --### Log data --* **IP addresses**: Log Analytics collects various IP information in multiple tables. For example, the following query shows all tables that collected IPv4 addresses in the last 24 hours: - ``` - search * - | where * matches regex @'\b((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)(\.|$)){4}\b' //RegEx originally provided on https://stackoverflow.com/questions/5284147/validating-ipv4-addresses-with-regexp - | summarize count() by $table - ``` - -* **User IDs**: You'll find user usernames and user IDs in various solutions and tables. You can look for a particular username or user ID across your entire dataset using the search command: - ``` - search "<username or user ID>" - ``` - - Remember to look not only for human-readable usernames but also for GUIDs that can be traced back to a particular user. -* **Device IDs**: Like user IDs, device IDs are sometimes considered personal data. Use the approach listed above for user IDs to identify tables that hold personal data. -* **Custom data**: Log Analytics lets you collect custom data through custom logs, custom fields, the [HTTP Data Collector API](../logs/data-collector-api.md), and as part of system event logs. Check all custom data for personal data. -* **Solution-captured data**: Because the solution mechanism is open-ended, we recommend reviewing all tables generated by solutions to ensure compliance. --### Application data --* **IP addresses**: While Application Insights obfuscates all IP address fields to `0.0.0.0` by default, it's fairly common to override this value with the actual user IP to maintain session information. Use the query below to find any table that contains values in the *IP address* column other than `0.0.0.0` in the last 24 hours: - ``` - search client_IP != "0.0.0.0" - | where timestamp > ago(1d) - | summarize numNonObfuscatedIPs_24h = count() by $table - ``` - -* **User IDs**: By default, Application Insights uses randomly generated IDs for user and session tracking in fields such as *session_Id*, *user_Id*, *user_AuthenticatedId*, *user_AccountId*, and *customDimensions*. However, it's common to override these fields with an ID that's more relevant to the application, such as usernames or Microsoft Entra GUIDs. These IDs are often considered to be personal data. We recommend obfuscating or anonymizing these IDs. -* **Custom data**: Application Insights allows you to append a set of custom dimensions to any data type. Use the following query to identify custom dimensions collected in the last 24 hours: - ``` - search * - | where isnotempty(customDimensions) - | where timestamp > ago(1d) - | project $table, timestamp, name, customDimensions - ``` - -* **In-memory and in-transit data**: Application Insights tracks exceptions, requests, dependency calls, and traces. You'll often find personal data at the code and HTTP call level. Review exceptions, requests, dependencies, and traces tables to identify any such data. Use [telemetry initializers](../app/api-filtering-sampling.md) where possible to obfuscate this data. -* **Snapshot Debugger captures**: The [Snapshot Debugger](../app/snapshot-debugger.md) feature in Application Insights lets you collect debug snapshots when Application Insights detects an exception on the production instance of your application. Snapshots expose the full stack trace leading to the exceptions and the values for local variables at every step in the stack. Unfortunately, this feature doesn't allow selective deletion of snap points or programmatic access to data within the snapshot. Therefore, if the default snapshot retention rate doesn't satisfy your compliance requirements, we recommend you turn off the feature. --## Exporting and deleting personal data --We __strongly__ recommend you restructure your data collection policy to stop collecting personal data, obfuscate or anonymize personal data, or otherwise modify such data until it's no longer considered personal. In handling personal, data you'll incur costs in defining and automating a strategy, building an interface through which your customers interact with their data, and ongoing maintenance. It's also computationally costly for Log Analytics and Application Insights, and a large volume of concurrent Query or Purge API calls can negatively affect all other interactions with Log Analytics functionality. However, if you have to collect personal data, follow the guidelines in this section. --> [!IMPORTANT] -> While most purge operations complete much quicker, **the formal SLA for the completion of purge operations is set at 30 days** due to their heavy impact on the data platform. This SLA meets GDPR requirements. It's an automated process, so there's no way to expedite the operation. --### View and export --Use the [Log Analytics query API](/rest/api/loganalytics/dataaccess/query) or the [Application Insights query API](/rest/api/application-insights/query) for view and export data requests. --> [!NOTE] -> You can't use the Log Analytics query API on that have the [Basic and Auxiliary table plans](data-platform-logs.md#table-plans). Instead, use the [Log Analytics /search API](basic-logs-query.md#run-a-query-on-a-basic-or-auxiliary-table). --You need to implement the logic for converting the data to an appropriate format for delivery to your users. [Azure Functions](https://azure.microsoft.com/services/functions/) is a great place to host such logic. ---### Delete --> [!WARNING] -> Deletes in Log Analytics are destructive and non-reversible! Please use extreme caution in their execution. --Azure Monitor's [Purge API](/rest/api/loganalytics/workspacepurge/purge) lets you delete personal data. Use the purge operation sparingly to avoid potential risks, performance impact, and the potential to skew all-up aggregations, measurements, and other aspects of your Log Analytics data. See the [Strategy for personal data handling](#strategy-for-personal-data-handling) section for alternative approaches to handling personal data. --Purge is a highly privileged operation. Grant the _Data Purger_ role in Azure Resource Manager cautiously due to the potential for data loss. --To manage system resources, we limit purge requests to 50 requests an hour. Batch the execution of purge requests by sending a single command whose predicate includes all user identities that require purging. Use the [in operator](/azure/kusto/query/inoperator) to specify multiple identities. Run the query before executing the purge request to verify the expected results. --> [!IMPORTANT] -> Use of the Log Analytics or Application Insights Purge API does not affect your retention costs. To lower retention costs, you must decrease your data retention period. --#### Log data --* The [Workspace Purge POST API](/rest/api/loganalytics/workspacepurge/purge) takes an object specifying parameters of data to delete and returns a reference GUID. -* The [Get Purge Status POST API](/rest/api/loganalytics/workspace-purge/get-purge-status) returns an 'x-ms-status-location' header that includes a URL you can call to determine the status of your purge operation. For example: -- ``` - x-ms-status-location: https://management.azure.com/subscriptions/[SubscriptionId]/resourceGroups/[ResourceGroupName]/providers/Microsoft.OperationalInsights/workspaces/[WorkspaceName]/operations/purge-[PurgeOperationId]?api-version=2015-03-20 - ``` --> [!NOTE] -> You can't purge data from tables that have the [Basic and Auxiliary table plans](data-platform-logs.md#table-plans). --#### Application data --* The [Components - Purge POST API](/rest/api/application-insights/components/purge) takes an object specifying parameters of data to delete and returns a reference GUID. -* The [Components - Get Purge Status GET API](/rest/api/application-insights/components/get-purge-status) returns an 'x-ms-status-location' header that includes a URL you can call to determine the status of your purge operation. For example: -- ``` - x-ms-status-location: https://management.azure.com/subscriptions/[SubscriptionId]/resourceGroups/[ResourceGroupName]/providers/microsoft.insights/components/[ComponentName]/operations/purge-[PurgeOperationId]?api-version=2015-05-01 - ``` --## Next steps -- Learn more about [how Log Analytics collects, processes, and secures data](../logs/data-security.md).-- Learn more about [how Application Insights collects, processes, and secures data](/previous-versions/azure/azure-monitor/app/data-retention-privacy). |
| azure-monitor | Private Link Configure | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/private-link-configure.md | - Title: Configure your private link -description: This article shows the steps to configure a private link. -- Previously updated : 07/25/2023---# Configure your private link -Configuring an instance of Azure Private Link requires you to: --* Create an Azure Monitor Private Link Scope (AMPLS) with resources. -* Create a private endpoint on your network and connect it to the scope. -* Configure the required access on your Azure Monitor resources. --This article reviews how configuration is done through the Azure portal. It provides an example Azure Resource Manager template (ARM template) to automate the process. --## Create a private link connection through the Azure portal -In this section, we review the step-by-step process of setting up a private link through the Azure portal. To create and manage a private link by using the command line or an ARM template, see [Use APIs and the command line](#use-apis-and-the-command-line). --### Create an Azure Monitor Private Link Scope --1. Go to **Create a resource** in the Azure portal and search for **Azure Monitor Private Link Scope**. -- :::image type="content" source="./media/private-link-security/ampls-find-1c.png" lightbox="./media/private-link-security/ampls-find-1c.png" alt-text="Screenshot showing finding Azure Monitor Private Link Scope."::: --1. Select **Create**. -1. Select a subscription and resource group. -1. Give the AMPLS a name. Use a meaningful and clear name like *AppServerProdTelem*. -1. Select **Review + create**. -- :::image type="content" source="./media/private-link-security/ampls-create-1d.png" lightbox="./media/private-link-security/ampls-create-1d.png" alt-text="Screenshot that shows creating an Azure Monitor Private Link Scope."::: --1. Let the validation pass and select **Create**. --### Connect Azure Monitor resources --Connect Azure Monitor resources like Log Analytics workspaces, Application Insights components, and [data collection endpoints](../essentials/data-collection-endpoint-overview.md)) to your Azure Monitor Private Link Scope (AMPLS). --1. In your AMPLS, select **Azure Monitor Resources** in the menu on the left. Select **Add**. -1. Add the workspace or component. Selecting **Add** opens a dialog where you can select Azure Monitor resources. You can browse through your subscriptions and resource groups. You can also enter their names to filter down to them. Select the workspace or component and select **Apply** to add them to your scope. -- :::image type="content" source="./media/private-link-security/ampls-select-2.png" lightbox="./media/private-link-security/ampls-select-2.png" alt-text="Screenshot that shows selecting a scope."::: --> [!NOTE] -> Deleting Azure Monitor resources requires that you first disconnect them from any AMPLS objects they're connected to. It's not possible to delete resources connected to an AMPLS. --### Connect to a private endpoint --Now that you have resources connected to your AMPLS, create a private endpoint to connect your network. You can do this task in the [Azure portal Private Link Center](https://portal.azure.com/#blade/Microsoft_Azure_Network/PrivateLinkCenterBlade/privateendpoints) or inside your AMPLS, as done in this example. --1. In your scope resource, select **Private Endpoint connections** from the resource menu on the left. Select **Private Endpoint** to start the endpoint creation process. You can also approve connections that were started in the Private Link Center here by selecting them and selecting **Approve**. -- :::image type="content" source="./media/private-link-security/ampls-select-private-endpoint-connect-3.png" lightbox="./media/private-link-security/ampls-select-private-endpoint-connect-3.png" alt-text="Screenshot that shows Private Endpoint connections."::: --1. On the **Basics** tab, select the **Subscription** and **Resource group** --1. Enter the **Name** of the endpoint, and **Network Interface Name** -1. Select the **Region** the private endpoint should live in. The region must be the same region as the virtual network to which you connect it. -1. Select **Next: Resource**. -- :::image type="content" source="./media/private-link-security/create-private-endpoint-basics.png" alt-text="A screenshot showing the create private endpoint basics tab." lightbox="./media/private-link-security/create-private-endpoint-basics.png"::: --1. On the **Resource** tab,select the *Subscription* that contains your Azure Monitor Private Link Scope resource. -1. For **Resource type**, select *Microsoft.insights/privateLinkScopes*. -1. From the **Resource** dropdown, select the Private Link Scope you created earlier. --1. Select **Next: Virtual Network**. -- :::image type="content" source="./media/private-link-security/create-private-endpoint-resource.png" alt-text="Screenshot that shows the Create a private endpoint page in the Azure portal with the Resource tab selected." lightbox="./media/private-link-security/create-private-endpoint-resource.png"::: --1. On the **Virtual Network** tab, select the **Virtual network** and **Subnet** that you want to connect to your Azure Monitor resources. -1. For **Network policy for private endpoints**, select **edit** if you want to apply network security groups or Route tables to the subnet that contains the private endpoint. -- In **Edit subnet network policy**, select the checkboxes next to **Network security groups** and **Route tables**, and select **Save**. For more information, see [Manage network policies for private endpoints](../../private-link/disable-private-endpoint-network-policy.md). --1. For **Private IP configuration**, by default, **Dynamically allocate IP address** is selected. If you want to assign a static IP address, select **Statically allocate IP address**. Then enter a name and private IP. - Optionally, you can select or create an **Application security group**. You can use application security groups to group virtual machines and define network security policies based on those groups. -1. Select **Next: DNS**. - - :::image type="content" source="./media/private-link-security/create-private-endpoint-virtual-network.png" alt-text="Screenshot that shows the Create a private endpoint page in the Azure portal with the Virtual Network tab selected." lightbox="./media/private-link-security/create-private-endpoint-virtual-network.png"::: --1. On the **DNS** tab, select **Yes** for **Integrate with private DNS zone**, and let it automatically create a new private DNS zone. The actual DNS zones might be different from what's shown in the following screenshot. -- > [!NOTE] - > If you select **No** and prefer to manage DNS records manually, first finish setting up your private link. Include this private endpoint and the AMPLS configuration. Then, configure your DNS according to the instructions in [Azure private endpoint DNS configuration](../../private-link/private-endpoint-dns.md). Make sure not to create empty records as preparation for your private link setup. The DNS records you create can override existing settings and affect your connectivity with Azure Monitor. - > - > Additionally, if you select **Yes** or **No** and you're using your own custom DNS servers, you need to set up conditional forwarders for the Public DNS zone forwarders mentioned in [Azure private endpoint DNS configuration](../../private-link/private-endpoint-dns.md). - > The conditional forwarders need to forward the DNS queries to [Azure DNS](/azure/virtual-network/what-is-ip-address-168-63-129-16). --1. Select **Next: Tags**, then select **Review + create**. -- :::image type="content" source="./media/private-link-security/create-private-endpoint-dns.png" alt-text="Screenshot that shows the Create a private endpoint page in the Azure portal with the DNS tab selected." lightbox="./media/private-link-security/create-private-endpoint-dns.png"::: --1. On the **Review + create** , once the validation passes select **Create**. --You've now created a new private endpoint that's connected to this AMPLS. --## Configure access to your resources -So far we've covered the configuration of your network. But you should also consider how you want to configure network access to your monitored resources like Log Analytics workspaces, Application Insights components, and [data collection endpoints](../essentials/data-collection-endpoint-overview.md). --Go to the Azure portal. On your resource's menu, find **Network Isolation** on the left side. This page controls which networks can reach the resource through a private link and whether other networks can reach it or not. ---### Connected Azure Monitor Private Link Scopes -Here you can review and configure the resource's connections to an AMPLS. Connecting to an AMPLS allows traffic from the virtual network connected to each AMPLS to reach the resource. It has the same effect as connecting it from the scope as we did in the section [Connect Azure Monitor resources](#connect-azure-monitor-resources). --To add a new connection, select **Add** and select the AMPLS. Select **Apply** to connect it. Your resource can connect to five AMPLS objects, as mentioned in [Consider AMPLS limits](./private-link-design.md#consider-ampls-limits). --### Virtual networks access configuration: Manage access from outside of a Private Link Scope -The settings on the bottom part of this page control access from public networks, meaning networks not connected to the listed scopes. --If you set **Accept data ingestion from public networks not connected through a Private Link Scope** to **No**, clients like machines or SDKs outside of the connected scopes can't upload data or send logs to the resource. --If you set **Accept queries from public networks not connected through a Private Link Scope** to **No**, clients like machines or SDKs outside of the connected scopes can't query data in the resource. --That data includes access to logs, metrics, and the live metrics stream. It also includes experiences built on top such as workbooks, dashboards, query API-based client experiences, and insights in the Azure portal. Experiences running outside the Azure portal and that query Log Analytics data also have to be running within the private-linked virtual network. --## Use APIs and the command line --You can automate the process described earlier by using ARM templates, REST, and command-line interfaces. --### Create and manage Private Link Scopes -To create and manage Private Link Scopes, use the [REST API](/rest/api/monitor/privatelinkscopes(preview)/private%20link%20scoped%20resources%20(preview)) or the [Azure CLI (az monitor private-link-scope)](/cli/azure/monitor/private-link-scope). --#### Create an AMPLS with Open access modes: CLI example -The following CLI command creates a new AMPLS resource named `"my-scope"`, with both query and ingestion access modes set to `Open`. --``` -az resource create -g "my-resource-group" --name "my-scope" -l global --api-version "2021-07-01-preview" --resource-type Microsoft.Insights/privateLinkScopes --properties "{\"accessModeSettings\":{\"queryAccessMode\":\"Open\", \"ingestionAccessMode\":\"Open\"}}" -``` --#### Create an AMPLS with mixed access modes: PowerShell example -The following PowerShell script creates a new AMPLS resource named `"my-scope"`, with the query access mode set to `Open` but the ingestion access modes set to `PrivateOnly`. This setting means it will allow ingestion only to resources in the AMPLS. --``` -# scope details -$scopeSubscriptionId = "ab1800bd-ceac-48cd-...-..." -$scopeResourceGroup = "my-resource-group" -$scopeName = "my-scope" -$scopeProperties = @{ - accessModeSettings = @{ - queryAccessMode = "Open"; - ingestionAccessMode = "PrivateOnly" - } -} --# login -Connect-AzAccount --# select subscription -Select-AzSubscription -SubscriptionId $scopeSubscriptionId --# create private link scope resource -$scope = New-AzResource -Location "Global" -Properties $scopeProperties -ResourceName $scopeName -ResourceType "Microsoft.Insights/privateLinkScopes" -ResourceGroupName $scopeResourceGroup -ApiVersion "2021-07-01-preview" -Force -``` --#### Create an AMPLS: ARM template -The following ARM template creates: --* An AMPLS named `"my-scope"`, with query and ingestion access modes set to `Open`. -* A Log Analytics workspace named `"my-workspace"`. -* And adds a scoped resource to the `"my-scope"` AMPLS named `"my-workspace-connection"`. --> [!NOTE] -> Make sure you use a new API version (2021-07-01-preview or later) for the creation of the AMPLS object (type `microsoft.insights/privatelinkscopes` as follows). The ARM template documented in the past used an old API version, which results in an AMPLS set with `QueryAccessMode="Open"` and `IngestionAccessMode="PrivateOnly"`. --``` -{ - "$schema": https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#, - "contentVersion": "1.0.0.0", - "parameters": { - "private_link_scope_name": { - "defaultValue": "my-scope", - "type": "String" - }, - "workspace_name": { - "defaultValue": "my-workspace", - "type": "String" - } - }, - "variables": {}, - "resources": [ - { - "type": "microsoft.insights/privatelinkscopes", - "apiVersion": "2021-07-01-preview", - "name": "[parameters('private_link_scope_name')]", - "location": "global", - "properties": { - "accessModeSettings":{ - "queryAccessMode":"Open", - "ingestionAccessMode":"Open" - } - } - }, - { - "type": "microsoft.operationalinsights/workspaces", - "apiVersion": "2020-10-01", - "name": "[parameters('workspace_name')]", - "location": "westeurope", - "properties": { - "sku": { - "name": "pergb2018" - }, - "publicNetworkAccessForIngestion": "Enabled", - "publicNetworkAccessForQuery": "Enabled" - } - }, - { - "type": "microsoft.insights/privatelinkscopes/scopedresources", - "apiVersion": "2019-10-17-preview", - "name": "[concat(parameters('private_link_scope_name'), '/', concat(parameters('workspace_name'), '-connection'))]", - "dependsOn": [ - "[resourceId('microsoft.insights/privatelinkscopes', parameters('private_link_scope_name'))]", - "[resourceId('microsoft.operationalinsights/workspaces', parameters('workspace_name'))]" - ], - "properties": { - "linkedResourceId": "[resourceId('microsoft.operationalinsights/workspaces', parameters('workspace_name'))]" - } - } - ] -} -``` --### Set AMPLS access modes: PowerShell example -To set the access mode flags on your AMPLS, you can use the following PowerShell script. The following script sets the flags to `Open`. To use the Private Only mode, use the value `"PrivateOnly"`. --Allow about 10 minutes for the AMPLS access modes update to take effect. --``` -# scope details -$scopeSubscriptionId = "ab1800bd-ceac-48cd-...-..." -$scopeResourceGroup = "my-resource-group-name" -$scopeName = "my-scope" --# login -Connect-AzAccount --# select subscription -Select-AzSubscription -SubscriptionId $scopeSubscriptionId --# get private link scope resource -$scope = Get-AzResource -ResourceType Microsoft.Insights/privateLinkScopes -ResourceGroupName $scopeResourceGroup -ResourceName $scopeName -ApiVersion "2021-07-01-preview" --# set access mode settings -$scope.Properties.AccessModeSettings.QueryAccessMode = "Open"; -$scope.Properties.AccessModeSettings.IngestionAccessMode = "Open"; -$scope | Set-AzResource -Force -``` --### Set resource access flags -To manage the workspace or component access flags, use the flags `[--ingestion-access {Disabled, Enabled}]` and `[--query-access {Disabled, Enabled}]`on [az monitor log-analytics workspace](/cli/azure/monitor/log-analytics/workspace) or [az monitor app-insights component](/cli/azure/monitor/app-insights/component). --## Review and validate your private link setup --Follow the steps in this section to review and validate your private link setup. --### Review your endpoint's DNS settings -The private endpoint you created should now have five DNS zones configured: --* `privatelink.monitor.azure.com` -* `privatelink.oms.opinsights.azure.com` -* `privatelink.ods.opinsights.azure.com` -* `privatelink.agentsvc.azure-automation.net` -* `privatelink.blob.core.windows.net` --Each of these zones maps specific Azure Monitor endpoints to private IPs from the virtual network's pool of IPs. The IP addresses shown in the following images are only examples. Your configuration should instead show private IPs from your own network. --> [!IMPORTANT] -> AMPLS and private endpoint resources created starting December 1, 2021, use a mechanism called Endpoint Compression. Now resource-specific endpoints, such as the OMS, ODS, and AgentSVC endpoints, share the same IP address, per region and per DNS zone. This mechanism means fewer IPs are taken from the virtual network's IP pool, and many more resources can be added to the AMPLS. --#### Privatelink-monitor-azure-com -This zone covers the global endpoints used by Azure Monitor, which means endpoints serve requests globally/regionally and not resource-specific requests. This zone should have endpoints mapped for: --* **in.ai**: Application Insights ingestion endpoint (both a global and a regional entry). -* **api**: Application Insights and Log Analytics API endpoint. -* **live**: Application Insights live metrics endpoint. -* **profiler**: Application Insights profiler endpoint. -* **snapshot**: Application Insights snapshot endpoint. -* **diagservices-query**: Application Insights Profiler and Snapshot Debugger (used when accessing profiler/debugger results in the Azure portal). --This zone also covers the resource-specific endpoints for [data collection endpoints (DCEs)](../essentials/data-collection-endpoint-overview.md): --* `<unique-dce-identifier>.<regionname>.handler.control`: Private configuration endpoint, part of a DCE resource. -* `<unique-dce-identifier>.<regionname>.ingest`: Private ingestion endpoint, part of a DCE resource. -<!-- convertborder later --> --#### Log Analytics endpoints -> [!IMPORTANT] -> AMPLSs and private endpoints created starting December 1, 2021, use a mechanism called Endpoint Compression. Now each resource-specific endpoint, such as OMS, ODS, and AgentSVC, uses a single IP address, per region and per DNS zone, for all workspaces in that region. This mechanism means fewer IPs are taken from the virtual network's IP pool, and many more resources can be added to the AMPLS. --Log Analytics uses four DNS zones: --* **privatelink-oms-opinsights-azure-com**: Covers workspace-specific mapping to OMS endpoints. You should see an entry for each workspace linked to the AMPLS connected with this private endpoint. -* **privatelink-ods-opinsights-azure-com**: Covers workspace-specific mapping to ODS endpoints, which are the ingestion endpoints of Log Analytics. You should see an entry for each workspace linked to the AMPLS connected with this private endpoint. -* **privatelink-agentsvc-azure-automation-net**: Covers workspace-specific mapping to the agent service automation endpoints. You should see an entry for each workspace linked to the AMPLS connected with this private endpoint. -* **privatelink-blob-core-windows-net**: Configures connectivity to the global agents' solution packs storage account. Through it, agents can download new or updated solution packs, which are also known as management packs. Only one entry is required to handle all Log Analytics agents, no matter how many workspaces are used. This entry is only added to private link setups created at or after April 19, 2021 (or starting June 2021 on Azure sovereign clouds). --The following screenshot shows endpoints mapped for an AMPLS with two workspaces in East US and one workspace in West Europe. Notice the East US workspaces share the IP addresses. The West Europe workspace endpoint is mapped to a different IP address. The blob endpoint doesn't appear in this image but it's configured. ---### Validate that you're communicating over a private link --Make sure that your private link is in good working order: --* To validate that your requests are now sent through the private endpoint, you can review them with a network tracking tool or even your browser. For example, when you attempt to query your workspace or application, make sure the request is sent to the private IP mapped to the API endpoint. In this example, it's *172.17.0.9*. -- > [!Note] - > Some browsers might use other DNS settings. For more information, see [Browser DNS settings](./private-link-design.md#browser-dns-settings). Make sure your DNS settings apply. --* To make sure your workspaces or components aren't receiving requests from public networks (not connected through AMPLS), set the resource's public ingestion and query flags to **No** as explained in [Configure access to your resources](#configure-access-to-your-resources). -* From a client on your protected network, use `nslookup` to any of the endpoints listed in your DNS zones. It should be resolved by your DNS server to the mapped private IPs instead of the public IPs used by default. --## Next steps --- Learn about [private storage](private-storage.md) for custom logs and customer-managed keys.-- Learn about [Private Link for Azure Automation](../../automation/how-to/private-link-security.md).-- Learn about the new [data collection endpoints](../essentials/data-collection-endpoint-overview.md). |
| azure-monitor | Private Link Design | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/private-link-design.md | - Title: Design your Azure Private Link setup -description: This article shows how to design your Azure Private Link setup ---- Previously updated : 05/07/2023---# Design your Azure Private Link setup --Before you set up your instance of Azure Private Link, consider your network topology and your DNS routing topology. --As discussed in [Use Azure Private Link to connect networks to Azure Monitor](private-link-security.md), setting up a private link affects traffic to all Azure Monitor resources. That's especially true for Application Insights resources. It also affects not only the network connected to the private endpoint but also all other networks that share the same DNS. --The simplest and most secure approach: -1. Create a single private link connection, with a single private endpoint and a single Azure Monitor Private Link Scope (AMPLS). If your networks are peered, create the private link connection on the shared (or hub) virtual network. -1. Add *all* Azure Monitor resources like Application Insights components, Log Analytics workspaces, and [data collection endpoints](../essentials/data-collection-endpoint-overview.md) to the AMPLS. -1. Block network egress traffic as much as possible. --If you can't add all Azure Monitor resources to your AMPLS, you can still apply your private link to some resources, as explained in [Control how private links apply to your networks](./private-link-design.md#control-how-private-links-apply-to-your-networks). We don't recommend this approach because it doesn't prevent data exfiltration. --## Plan by network topology --Consider network topology in your planning process. --### Guiding principle: Avoid DNS overrides by using a single AMPLS -Some networks are composed of multiple virtual networks or other connected networks. If these networks share the same DNS, setting up a private link on any of them would update the DNS and affect traffic across all networks. --In the following diagram, virtual network 10.0.1.x connects to AMPLS1, which creates DNS entries that map Azure Monitor endpoints to IPs from range 10.0.1.x. Later, virtual network 10.0.2.x connects to AMPLS2, which overrides the same DNS entries by mapping *the same global/regional endpoints* to IPs from the range 10.0.2.x. Because these virtual networks aren't peered, the first virtual network now fails to reach these endpoints. --To avoid this conflict, create only a single AMPLS object per DNS. ---### Hub-and-spoke networks -Hub-and-spoke networks should use a single private link connection set on the hub (main) network, and not on each spoke virtual network. ---> [!NOTE] -> You might prefer to create separate private links for your spoke virtual networks, for example, to allow each virtual network to access a limited set of monitoring resources. In such cases, you can create a dedicated private endpoint and AMPLS for each virtual network. *You must also verify they don't share the same DNS zones to avoid DNS overrides*. --### Peered networks -Network peering is used in various topologies, other than hub and spoke. Such networks can share each other's IP addresses, and most likely share the same DNS. In such cases, create a single private link on a network that's accessible to your other networks. Avoid creating multiple private endpoints and AMPLS objects because ultimately only the last one set in the DNS applies. --### Isolated networks -If your networks aren't peered, *you must also separate their DNS to use private links*. After that's done, create a separate private endpoint for each network, and a separate AMPLS object. Your AMPLS objects can link to the same workspaces/components or to different ones. --### Testing locally: Edit your machine's hosts file instead of the DNS -To test private links locally without affecting other clients on your network, make sure not to update your DNS when you create your private endpoint. Instead, edit the hosts file on your machine so that it will send requests to the private link endpoints: --* Set up a private link, but when you connect to a private endpoint, choose *not* to auto-integrate with the DNS (step 5b). -* Configure the relevant endpoints on your machines' hosts files. To review the Azure Monitor endpoints that need mapping, see [Review your endpoint's DNS settings](./private-link-configure.md#review-your-endpoints-dns-settings). --We don't recommend that approach for production environments. --## Control how private links apply to your networks -By using private link access modes, you can control how private links affect your network traffic. These settings can apply to your AMPLS object (to affect all connected networks) or to specific networks connected to it. --Choosing the proper access mode is critical to ensuring continuous, uninterrupted network traffic. Each of these modes can be set for ingestion and queries, separately: --* **Private Only**: Allows the virtual network to reach only private link resources (resources in the AMPLS). That's the most secure mode of work. It prevents data exfiltration by blocking traffic out of the AMPLS to Azure Monitor resources. -* **Open**: Allows the virtual network to reach both private link resources and resources not in the AMPLS (if they [accept traffic from public networks](./private-link-design.md#control-network-access-to-your-resources)). The Open access mode doesn't prevent data exfiltration, but it still offers the other benefits of private links. Traffic to private link resources is sent through private endpoints, validated, and sent over the Microsoft backbone. The Open mode is useful for a mixed mode of work (accessing some resources publicly and others over a private link) or during a gradual onboarding process. -Access modes are set separately for ingestion and queries. For example, you can set the Private Only mode for ingestion and the Open mode for queries. --Apply caution when you select your access mode. Using the Private Only access mode will block traffic to resources not in the AMPLS across all networks that share the same DNS, regardless of subscription or tenant. The exception is Log Analytics ingestion requests, which is explained. If you can't add all Azure Monitor resources to the AMPLS, start by adding select resources and applying the Open access mode. Switch to the Private Only mode for maximum security *only after you've added all Azure Monitor resources to your AMPLS*. --For configuration details and examples, see [Use APIs and the command line](./private-link-configure.md#use-apis-and-the-command-line). --> [!NOTE] -> Log Analytics ingestion uses resource-specific endpoints. As such, it doesn't adhere to AMPLS access modes. To assure Log Analytics ingestion requests can't access workspaces out of the AMPLS, set the network firewall to block traffic to public endpoints, regardless of the AMPLS access modes. --### Set access modes for specific networks -The access modes set on the AMPLS resource affect all networks, but you can override these settings for specific networks. --In the following diagram, VNet1 uses the Open mode and VNet2 uses the Private Only mode. Requests from VNet1 can reach Workspace 1 and Component 2 over a private link. Requests can reach Component 3 only if it [accepts traffic from public networks](./private-link-design.md#control-network-access-to-your-resources). VNet2 requests can't reach Component 3. --## Consider AMPLS limits ---In the following diagram: -* Each virtual network connects to only *one* AMPLS object. -* AMPLS A connects to two workspaces and one Application Insight component by using two of the possible 300 Log Analytics workspaces and one of the possible 1,000 Application Insights components it can connect to. -* Workspace 2 connects to AMPLS A and AMPLS B by using two of the five possible AMPLS connections. -* AMPLS B is connected to private endpoints of two virtual networks (VNet2 and VNet3) by using two of the 10 possible private endpoint connections. ---## Control network access to your resources -Your Log Analytics workspaces or Application Insights components can be set to: -* Accept or block ingestion from public networks (networks not connected to the resource AMPLS). -* Accept or block queries from public networks (networks not connected to the resource AMPLS). --That granularity allows you to set access according to your needs, per workspace. For example, you might accept ingestion only through private link-connected networks (meaning specific virtual networks) but still choose to accept queries from all networks, public and private. --Blocking queries from public networks means clients like machines and SDKs outside of the connected AMPLSs can't query data in the resource. That data includes logs, metrics, and the live metrics stream. Blocking queries from public networks affects all experiences that run these queries, such as workbooks, dashboards, insights in the Azure portal, and queries run from outside the Azure portal. --> [!NOTE] -> There are certain exceptions where these settings do not apply. You can find details in [the following section](#exceptions). --Your [data collection endpoints](../essentials/data-collection-endpoint-overview.md) can be set to accept or block access from public networks (networks not connected to the resource AMPLS). --For configuration information, see [Set resource access flags](./private-link-configure.md#set-resource-access-flags). --### Exceptions --Note the following exceptions. --#### Diagnostic logs -Logs and metrics uploaded to a workspace via [diagnostic settings](../essentials/diagnostic-settings.md) go over a secure private Microsoft channel and aren't controlled by these settings. --#### Custom metrics or Azure Monitor guest metrics -[Custom metrics (preview)](../essentials/metrics-custom-overview.md) collected and uploaded via Azure Monitor Agent aren't controlled by data collection endpoints. They can't be configured over private links. --#### Azure Resource Manager -Restricting access as previously explained applies to data in the resource. However, configuration changes like turning these access settings on or off are managed by Azure Resource Manager. To control these settings, restrict access to resources by using the appropriate roles, permissions, network controls, and auditing. For more information, see [Azure Monitor roles, permissions, and security](../roles-permissions-security.md). --> [!NOTE] -> Queries sent through the Resource Manager API can't use Azure Monitor private links. These queries can only go through if the target resource allows queries from public networks (set through the **Network Isolation** pane or [by using the CLI](./private-link-configure.md#set-resource-access-flags)). -> -> The following experiences are known to run queries through the Resource Manager API: -> * LogicApp connector -> * Update Management solution -> * Change Tracking solution -> * VM Insights -> * Container Insights -> * Log Analytics **Workspace Summary (deprecated)** pane (that shows the solutions dashboard) --## Application Insights considerations -* You'll need to add resources hosting the monitored workloads to a private link. For example, see [Using private endpoints for Azure Web App](../../app-service/networking/private-endpoint.md). -* Non-portal consumption experiences must also run on the private-linked virtual network that includes the monitored workloads. -* To support private links for the Profiler and Debugger, you'll need to [provide your own storage account](../app/profiler-bring-your-own-storage.md). --> [!NOTE] -> To fully secure workspace-based Application Insights, you need to lock down access to the Application Insights resource and the underlying Log Analytics workspace. --## Log Analytics considerations --Note the following Log Analytics considerations. --### Log Analytics solution packs download -Log Analytics agents need to access a global storage account to download solution packs. Private link setups created at or after April 19, 2021 (or starting June 2021 on Azure sovereign clouds) can reach the agents' solution packs storage over the private link. This capability is made possible through a DNS zone created for `blob.core.windows.net`. --If your private link setup was created before April 19, 2021, it won't reach the solution packs storage over a private link. To handle that, you can either: -* Re-create your AMPLS and the private endpoint connected to it. -* Allow your agents to reach the storage account through its public endpoint by adding the following rules to your firewall allowlist: -- | Cloud environment | Agent resource | Ports | Direction | - |:--|:--|:--|:--| - |Azure Public | scadvisorcontent.blob.core.windows.net | 443 | Outbound - |Azure Government | usbn1oicore.blob.core.usgovcloudapi.net | 443 | Outbound - |Microsoft Azure operated by 21Vianet | mceast2oicore.blob.core.chinacloudapi.cn| 443 | Outbound --### Collect custom logs and IIS log over a private link -Storage accounts are used in the ingestion process of custom logs. By default, service-managed storage accounts are used. To ingest custom logs on private links, you must use your own storage accounts and associate them with Log Analytics workspaces. --For more information on how to connect your own storage account, see [Customer-owned storage accounts for log ingestion](private-storage.md) and specifically [Use private links](private-storage.md#private-links) and [Link storage accounts to your Log Analytics workspace](private-storage.md#link-storage-accounts-to-your-log-analytics-workspace). --### Automation -If you use Log Analytics solutions that require an Azure Automation account (such as Update Management, Change Tracking, or Inventory), you should also create a private link for your Automation account. For more information, see [Use Azure Private Link to securely connect networks to Azure Automation](../../automation/how-to/private-link-security.md). --> [!NOTE] -> Some products and Azure portal experiences query data through Resource Manager. In this case, they won't be able to query data over a private link unless private link settings are applied to Resource Manager too. To overcome this restriction, you can configure your resources to accept queries from public networks as explained in [Controlling network access to your resources](./private-link-design.md#control-network-access-to-your-resources). (Ingestion can remain limited to private link networks.) -We've identified the following products and experiences query workspaces through Resource -> * LogicApp connector -> * Update Management solution -> * Change Tracking solution -> * The **Workspace Summary (deprecated)** pane in the portal (that shows the solutions dashboard) -> * VM Insights -> * Container Insights --## Managed Prometheus considerations -* Private Link ingestion settings are made using AMPLS and settings on the Data Collection Endpoints (DCEs) that reference the Azure Monitor workspace used to store your Prometheus metrics. -* Private Link query settings are made directly on the Azure Monitor workspace used to store your Prometheus metrics and aren't handled via AMPLS. --## Requirements --Note the following requirements. --### Network subnet size -The smallest supported IPv4 subnet is /27 (using CIDR subnet definitions). Although Azure virtual networks [can be as small as /29](../../virtual-network/virtual-networks-faq.md#how-small-and-how-large-can-virtual-networks-and-subnets-be), Azure [reserves five IP addresses](../../virtual-network/virtual-networks-faq.md#are-there-any-restrictions-on-using-ip-addresses-within-these-subnets). The Azure Monitor private link setup requires at least 11 more IP addresses, even if you're connecting to a single workspace. [Review your endpoint's DNS settings](./private-link-configure.md#review-your-endpoints-dns-settings) for the list of Azure Monitor private link endpoints. --### Agents -The latest versions of the Windows and Linux agents must be used to support secure ingestion to Log Analytics workspaces. Older versions can't upload monitoring data over a private network. --#### Azure Monitor Windows agents --Azure Monitor Windows agent version 1.1.1.0 or higher (by using [data collection endpoints](../essentials/data-collection-endpoint-overview.md)). --#### Azure Monitor Linux agents --Azure Monitor Linux agent version 1.10.5.0 or higher (by using [data collection endpoints](../essentials/data-collection-endpoint-overview.md)). --#### Log Analytics Windows agent (on deprecation path) --Use the Log Analytics agent version 10.20.18038.0 or later. --#### Log Analytics Linux agent (on deprecation path) --Use agent version 1.12.25 or later. If you can't, run the following commands on your VM: --```cmd -$ sudo /opt/microsoft/omsagent/bin/omsadmin.sh -X -$ sudo /opt/microsoft/omsagent/bin/omsadmin.sh -w <workspace id> -s <workspace key> -``` --### Azure portal -To use Azure Monitor portal experiences such as Application Insights, Log Analytics, and [data collection endpoints](../essentials/data-collection-endpoint-overview.md), you need to allow the Azure portal and Azure Monitor extensions to be accessible on the private networks. Add **AzureActiveDirectory**, **AzureResourceManager**, **AzureFrontDoor.FirstParty**, and **AzureFrontdoor.Frontend** [service tags](../../firewall/service-tags.md) to your network security group. --### Programmatic access -To use the REST API, the Azure [CLI](/cli/azure/monitor), or PowerShell with Azure Monitor on private networks, add the [service tags](../../virtual-network/service-tags-overview.md) **AzureActiveDirectory** and **AzureResourceManager** to your firewall. --### Application Insights SDK downloads from a content delivery network -Bundle the JavaScript code in your script so that the browser doesn't attempt to download code from a CDN. An example is provided on [GitHub](https://github.com/microsoft/ApplicationInsights-JS#npm-setup-ignore-if-using-snippet-setup). --### Browser DNS settings -If you're connecting to your Azure Monitor resources over a private link, traffic to these resources must go through the private endpoint that's configured on your network. To enable the private endpoint, update your DNS settings as explained in [Connect to a private endpoint](./private-link-configure.md#connect-to-a-private-endpoint). Some browsers use their own DNS settings instead of the ones you set. The browser might attempt to connect to Azure Monitor public endpoints and bypass the private link entirely. Verify that your browser settings don't override or cache old DNS settings. --### Querying limitation: externaldata operator -* The [`externaldata` operator](/azure/data-explorer/kusto/query/externaldata-operator?pivots=azuremonitor) isn't supported over a private link because it reads data from storage accounts but doesn't guarantee the storage is accessed privately. -* The [Azure Data Explorer proxy (ADX proxy)](azure-monitor-data-explorer-proxy.md) allows log queries to query Azure Data Explorer. The ADX proxy isn't supported over a private link because it doesn't guarantee the targeted resource is accessed privately. --## Next steps -- Learn how to [configure your private link](private-link-configure.md).-- Learn about [private storage](private-storage.md) for custom logs and customer-managed keys.-- Learn about [Private Link for Automation](../../automation/how-to/private-link-security.md). |
| azure-monitor | Private Link Security | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/private-link-security.md | - Title: Use Azure Private Link to connect networks to Azure Monitor -description: Set up an Azure Monitor Private Link Scope to securely connect networks to Azure Monitor. -- Previously updated : 07/25/2023---# Use Azure Private Link to connect networks to Azure Monitor --With [Azure Private Link](../../private-link/private-link-overview.md), you can securely link Azure platform as a service (PaaS) resources to your virtual network by using private endpoints. Azure Monitor is a constellation of different interconnected services that work together to monitor your workloads. An Azure Monitor private link connects a private endpoint to a set of Azure Monitor resources to define the boundaries of your monitoring network. That set is called an Azure Monitor Private Link Scope (AMPLS). --> [!NOTE] -> Azure Monitor private links are structured differently from private links to other services you might use. Instead of creating multiple private links, one for each resource the virtual network connects to, Azure Monitor uses a single private link connection, from the virtual network to an AMPLS. AMPLS is the set of all Azure Monitor resources to which a virtual network connects through a private link. --## Advantages --With Private Link you can: --- Connect privately to Azure Monitor without opening up any public network access.-- Ensure your monitoring data is only accessed through authorized private networks.-- Prevent data exfiltration from your private networks by defining specific Azure Monitor resources that connect through your private endpoint.-- Securely connect your private on-premises network to Azure Monitor by using Azure ExpressRoute and Private Link.-- Keep all traffic inside the Azure backbone network.--For more information, see [Key benefits of Private Link](../../private-link/private-link-overview.md#key-benefits). --## How it works: Main principles -An Azure Monitor private link connects a private endpoint to a set of Azure Monitor resources made up of Log Analytics workspaces and Application Insights resources. That set is called an Azure Monitor Private Link Scope. ---An AMPLS: --* **Uses private IPs**: The private endpoint on your virtual network allows it to reach Azure Monitor endpoints through private IPs from your network's pool, instead of using the public IPs of these endpoints. For this reason, you can keep using your Azure Monitor resources without opening your virtual network to unrequired outbound traffic. -* **Runs on the Azure backbone**: Traffic from the private endpoint to your Azure Monitor resources will go over the Azure backbone and not be routed to public networks. -* **Controls which Azure Monitor resources can be reached**: Configure your AMPLS to your preferred access mode. You can either allow traffic only to Private Link resources or to both Private Link and non-Private-Link resources (resources out of the AMPLS). -* **Controls network access to your Azure Monitor resources**: Configure each of your workspaces or components to accept or block traffic from public networks. You can apply different settings for ingestion and query requests. --## Azure Monitor private links rely on your DNS -When you set up a private link connection, your DNS zones map Azure Monitor endpoints to private IPs to send traffic through the private link. Azure Monitor uses both resource-specific endpoints and shared global/regional endpoints to reach the workspaces and components in your AMPLS. --> [!WARNING] -> Because Azure Monitor uses some shared endpoints (meaning endpoints that aren't resource specific), setting up a private link even for a single resource changes the DNS configuration that affects traffic to *all resources*. In other words, traffic to all workspaces or components is affected by a single private link setup. --The use of shared endpoints also means you should use a single AMPLS for all networks that share the same DNS. Creating multiple AMPLS resources will cause Azure Monitor DNS zones to override each other and break existing environments. To learn more, see [Plan by network topology](./private-link-design.md#plan-by-network-topology). --### Shared global and regional endpoints -When you configure Private Link even for a single resource, traffic to the following endpoints will be sent through the allocated private IPs: --* **All Application Insights endpoints**: Endpoints handling ingestion, live metrics, the Profiler, and the debugger to Application Insights endpoints are global. -* **The query endpoint**: The endpoint handling queries to both Application Insights and Log Analytics resources is global. --> [!IMPORTANT] -> Creating a private link affects traffic to *all* monitoring resources, not only resources in your AMPLS. Effectively, it will cause all query requests and ingestion to Application Insights components to go through private IPs. It doesn't mean the private link validation applies to all these requests.</br> -> -> Resources not added to the AMPLS can only be reached if the AMPLS access mode is Open and the target resource accepts traffic from public networks. When you use the private IP, *private link validations don't apply to resources not in the AMPLS*. To learn more, see [Private Link access modes](#private-link-access-modes-private-only-vs-open). -> -> Private Link settings for Managed Prometheus and ingesting data into your Azure Monitor workspace are configured on the Data Collection Endpoints for the referenced resource. Settings for querying your Azure Monitor workspace over Private Link are made directly on the Azure Monitor workspace and are not handled via AMPLS. --### Resource-specific endpoints -Log Analytics endpoints are workspace specific, except for the query endpoint discussed earlier. As a result, adding a specific Log Analytics workspace to the AMPLS will send ingestion requests to this workspace over the private link. Ingestion to other workspaces will continue to use the public endpoints. --[Data collection endpoints](../essentials/data-collection-endpoint-overview.md) are also resource specific. You can use them to uniquely configure ingestion settings for collecting guest OS telemetry data from your machines (or set of machines) when you use the new [Azure Monitor Agent](../agents/azure-monitor-agent-overview.md) and [data collection rules](../essentials/data-collection-rule-overview.md). Configuring a data collection endpoint for a set of machines doesn't affect ingestion of guest telemetry from other machines that use the new agent. --> [!IMPORTANT] -> Starting December 1, 2021, the private endpoints DNS configuration will use the Endpoint Compression mechanism, which allocates a single private IP address for all workspaces in the same region. It improves the supported scale (up to 300 workspaces and 1,000 components per AMPLS) and reduces the total number of IPs taken from the network's IP pool. --## Private Link access modes: Private Only vs. Open -As discussed in [Azure Monitor private links rely on your DNS](#azure-monitor-private-links-rely-on-your-dns), only a single AMPLS resource should be created for all networks that share the same DNS. As a result, organizations that use a single global or regional DNS have a single private link to manage traffic to all Azure Monitor resources, across all global or regional networks. --For private links created before September 2021, that means: --* Log ingestion works only for resources in the AMPLS. Ingestion to all other resources is denied (across all networks that share the same DNS), regardless of subscription or tenant. -* Queries have a more open behavior that allows query requests to reach even resources not in the AMPLS. The intention here was to avoid breaking customer queries to resources not in the AMPLS and allow resource-centric queries to return the complete result set. --This behavior proved to be too restrictive for some customers because it breaks ingestion to resources not in the AMPLS. But it was too permissive for others because it allows querying resources not in the AMPLS. --Starting September 2021, private links have new mandatory AMPLS settings that explicitly set how they should affect network traffic. When you create a new AMPLS resource, you're now required to select the access modes you want for ingestion and queries separately: --* **Private Only mode**: Allows traffic only to Private Link resources. -* **Open mode**: Uses Private Link to communicate with resources in the AMPLS, but also allows traffic to continue to other resources. To learn more, see [Control how private links apply to your networks](./private-link-design.md#control-how-private-links-apply-to-your-networks). --Although Log Analytics query requests are affected by the AMPLS access mode setting, Log Analytics ingestion requests use resource-specific endpoints and aren't controlled by the AMPLS access mode. To ensure Log Analytics ingestion requests can't access workspaces out of the AMPLS, set the network firewall to block traffic to public endpoints, regardless of the AMPLS access modes. --> [!NOTE] -> If you've configured Log Analytics with Private Link by initially setting the network security group rules to allow outbound traffic by `ServiceTag:AzureMonitor`, the connected VMs send the logs through a public endpoint. Later, if you change the rules to deny outbound traffic by `ServiceTag:AzureMonitor`, the connected VMs keep sending logs until you reboot the VMs or cut the sessions. To make sure the desired configuration takes immediate effect, reboot the connected VMs. -> --## Next steps -- [Design your Azure Private Link setup](private-link-design.md).-- Learn how to [configure your private link](private-link-configure.md).-- Learn about [private storage](private-storage.md) for custom logs and customer-managed keys.-<h3><a id="connect-to-a-private-endpoint"></a></h3> |
| azure-monitor | Private Storage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/private-storage.md | - Title: Use customer-managed storage accounts in Azure Monitor Logs -description: Use your own Azure Storage account to ingest logs into Azure Monitor Logs. ---- Previously updated : 11/26/2023---# Use customer-managed storage accounts in Azure Monitor Logs --Azure Monitor Logs relies on Azure Storage in various scenarios. Azure Monitor typically manages this type of storage automatically, but some cases require you to provide and manage your own storage account, also known as a customer-managed storage account. This article describes the use cases and requirements for setting up customer-managed storage for Azure Monitor Logs and explains how to link a storage account to a Log Analytics workspace. --> [!NOTE] -> We recommend that you don't take a dependency on the contents that Azure Monitor Logs uploads to customer-managed storage because formatting and content might change. --## Private links -Customer-managed storage accounts are used to ingest custom logs when private links are used to connect to Azure Monitor resources. The ingestion process of these data types first uploads logs to an intermediary Azure Storage account, and only then ingests them to a workspace. --### Workspace requirements -When you connect to Azure Monitor over a private link, Azure Monitor Agent can only send logs to workspaces accessible over a private link. This requirement means you should: --* Configure an Azure Monitor Private Link Scope (AMPLS) object. -* Connect it to your workspaces. -* Connect the AMPLS to your network over a private link. --For more information on the AMPLS configuration procedure, see [Use Azure Private Link to securely connect networks to Azure Monitor](./private-link-security.md). --### Storage account requirements -For the storage account to connect to your private link, it must: --* Be located on your virtual network or a peered network and connected to your virtual network over a private link. -* Be located on the same region as the workspace it's linked to. -* Allow Azure Monitor to access the storage account. To allow only specific networks to access your storage account, select the exception **Allow trusted Microsoft services to access this storage account**. -- :::image type="content" source="./media/private-storage/storage-trust.png" lightbox="./media/private-storage/storage-trust.png" alt-text="Screenshot that shows Storage account trust Microsoft services."::: --If your workspace handles traffic from other networks, configure the storage account to allow incoming traffic coming from the relevant networks/internet. --Coordinate the TLS version between the agents and the storage account. We recommend that you send data to Azure Monitor Logs by using TLS 1.2 or higher. Review the [platform-specific guidance](./data-security.md#sending-data-securely-using-tls). If necessary, [configure your agents to use TLS](../agents/agent-windows.md#configure-agent-to-use-tls-12). If that's not possible, configure the storage account to accept TLS 1.0. --## Customer-managed key data encryption -Azure Storage encrypts all data at rest in a storage account. By default, it uses Microsoft-managed keys (MMKs) to encrypt the data. However, Azure Storage also allows you to use customer-managed keys (CMKs) from Azure Key Vault to encrypt your storage data. You can either import your own keys into Key Vault or use the Key Vault APIs to generate keys. --### CMK scenarios that require a customer-managed storage account --A customer-managed storage account is required for: --* Encrypting log-alert queries with CMKs. -* Encrypting saved queries with CMKs. --### Apply CMKs to customer-managed storage accounts --Follow this guidance to apply CMKs to customer-managed storage accounts. --#### Storage account requirements -The storage account and the key vault must be in the same region, but they also can be in different subscriptions. For more information about Azure Storage encryption and key management, see [Azure Storage encryption for data at rest](../../storage/common/storage-service-encryption.md). --#### Apply CMKs to your storage accounts -To configure your Azure Storage account to use CMKs with Key Vault, use the [Azure portal](../../storage/common/customer-managed-keys-configure-key-vault.md?toc=%252fazure%252fstorage%252fblobs%252ftoc.json), [PowerShell](../../storage/common/customer-managed-keys-configure-key-vault.md?toc=%252fazure%252fstorage%252fblobs%252ftoc.json), or the [Azure CLI](../../storage/common/customer-managed-keys-configure-key-vault.md?toc=%252fazure%252fstorage%252fblobs%252ftoc.json). --> [!NOTE] -> - When linking Storage Account for query, existing saved queries in workspace are deleted permanently for privacy. You can copy existing saved queries before storage link using [PowerShell](/powershell/module/az.operationalinsights/get-azoperationalinsightssavedsearch). -> - Queries saved in [query pack](./query-packs.md) aren't encrypted with Customer-managed key. Select **Save as Legacy query** when saving queries instead, to protect them with Customer-managed key. -> - Saved queries are stored in table storage and encrypted with Customer-managed key when encryption is configured at Storage Account creation. -> - Log search alerts are saved in blob storage where configuration of Customer-managed key encryption can be at Storage Account creation, or later. -> - You can use a single Storage Account for all purposes, query, alert, custom log and IIS logs. Linking storage for custom log and IIS logs might require more Storage Accounts for scale, depending on the ingestion rate and storage limits. You can link up to five Storage Accounts to a workspace. --## Link storage accounts to your Log Analytics workspace --### Use the Azure portal -On the Azure portal, open your workspace menu and select **Linked storage accounts**. A pane shows the linked storage accounts by the use cases previously mentioned (ingestion over Private Link, applying CMKs to saved queries or to alerts). ---Selecting an item on the table opens its storage account details, where you can set or update the linked storage account for this type. --You can use the same account for different use cases if you prefer. --### Use the Azure CLI or REST API -You can also link a storage account to your workspace via the [Azure CLI](/cli/azure/monitor/log-analytics/workspace/linked-storage) or [REST API](/rest/api/loganalytics/linkedstorageaccounts). --The applicable `dataSourceType` values are: --* `CustomLogs`: To use the storage account for custom logs and IIS logs ingestion. -* `Query`: To use the storage account to store saved queries (required for CMK encryption). -* `Alerts`: To use the storage account to store log-based alerts (required for CMK encryption). --## Manage linked storage accounts --Follow this guidance to manage your linked storage accounts. --### Create or modify a link -When you link a storage account to a workspace, Azure Monitor Logs starts using it instead of the storage account owned by the service. You can: --* Register multiple storage accounts to spread the load of logs between them. -* Reuse the same storage account for multiple workspaces. --### Unlink a storage account -To stop using a storage account, unlink the storage from the workspace. When you unlink all storage accounts from a workspace, Azure Monitor Logs uses service-managed storage accounts. If your network has limited access to the internet, these storage accounts might not be available and any scenario that relies on storage will fail. --### Replace a storage account -To replace a storage account used for ingestion: --1. **Create a link to a new storage account**. The logging agents will get the updated configuration and start sending data to the new storage. The process could take a few minutes. -2. **Unlink the old storage account so agents will stop writing to the removed account**. The ingestion process keeps reading data from this account until it's all ingested. Don't delete the storage account until you see that all logs were ingested. --### Maintain storage accounts --Follow this guidance to maintain your storage accounts. --#### Manage log retention -When you use your own storage account, retention is up to you. Azure Monitor Logs doesn't delete logs stored on your private storage. Instead, you should set up a policy to handle the load according to your preferences. --#### Consider load -Storage accounts can handle a certain load of read and write requests before they start throttling requests. For more information, see [Scalability and performance targets for Azure Blob Storage](../../storage/common/scalability-targets-standard-account.md). --Throttling affects the time it takes to ingest logs. If your storage account is overloaded, register another storage account to spread the load between them. To monitor your storage account's capacity and performance, review its [Insights in the Azure portal](../../storage/common/storage-insights-overview.md?toc=%2fazure%2fazure-monitor%2ftoc.json). --### Related charges -You're charged for storage accounts based on the volume of stored data, the type of storage, and the type of redundancy. For more information, see [Block blob pricing](https://azure.microsoft.com/pricing/details/storage/blobs) and [Azure Table Storage pricing](https://azure.microsoft.com/pricing/details/storage/tables). --## Next steps --- Learn about [using Private Link to securely connect networks to Azure Monitor](private-link-security.md).-- Learn about [Azure Monitor customer-managed keys](../logs/customer-managed-keys.md). |
| azure-monitor | Queries | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/queries.md | - Title: Use queries in Azure Monitor Log Analytics -description: Overview of log queries in Azure Monitor Log Analytics including different types of queries and sample queries that you can use. ----- Previously updated : 12/28/2023---# Use queries in Log Analytics -When you open Log Analytics, you can access existing log queries. You can either run these queries without modification or use them as a starting point for your own queries. The available queries include examples provided by Azure Monitor and queries saved by your organization. This article describes the queries that are available and how you can discover and use them. ---## Queries interface -Select queries from the query interface, which is available from two different locations in Log Analytics. --### Queries dialog --When you open Log Analytics, the **Queries** dialog automatically appears. If you don't want this dialog to automatically appear, turn off the **Always show Queries** toggle. ---Each query is represented by a card. You can quickly scan through the queries to find what you need. You can run the query directly from the dialog or choose to load it to the query editor for modification. --You can also access it by selecting **Queries** in the upper-right corner. -<!-- convertborder later --> --### Query sidebar --You can access the same functionality of the dialog experience from the **Queries** pane on the left sidebar of Log Analytics. Hover over a query name to get the query description and more functionality. -<!-- convertborder later --> --## Find and filter queries --The options in this section are available in both the dialog and sidebar query experience, but with a slightly different user interface. --### [Group by](#tab/groupby) --Change the grouping of the queries by selecting the **group by** dropdown list. The grouping values also act as an active table of contents. Selecting one of the values on the left side of the screen scrolls the **Queries** view directly to the item selected. If your organization created query packs with tags, the custom tags will be included in this list. ---### [Filter](#tab/filter) --You can also filter the queries according to the **group by** values mentioned earlier. In the **Example queries** dialog, the filters are found at the top. ---### [Combine group by and filter](#tab/combinegroupbyandfilter) --The filter and group by functionalities are designed to work in tandem. They provide flexibility in how queries are arranged. For example, if you're using a resource group with multiple resources, you might want to filter down to a specific resource type and arrange the resulting queries by topic. ----## Query properties -Each query has multiple properties that help you group and find them. These properties are available for sorting and filtering. For more information, see [Find and filter queries](#find-and-filter-queries). --You can define several of them when you [save your own query](save-query.md). The types of properties are: --| Query property | Description | -| : | : | -| Resource type | A resource as defined in Azure, such as a virtual machine. For a full mapping of Azure Monitor Logs and Log Analytics tables to resource type, see the [Azure Monitor table reference](/azure/azure-monitor/reference/tables/tables-resourcetype). | -| Category | A type of information, such as Security or Audit. Categories are identical to the categories defined in the Tables side pane. For a full list of categories, see the [Azure Monitor table reference](/azure/azure-monitor/reference/tables/tables-category). | -| Solution | An Azure Monitor solution associated with the queries. | -| Topic | The topic of the example query, such as Activity logs or App logs. The topic property is unique to example queries and might differ according to the specific resource type. | -| Query type | Defines the type of the query. Query type might be Example queries, Query pack queries, or Legacy queries. | -| Labels | Custom labels that you can define and assign when you [save your own query](save-query.md). | -| Tags | Custom properties that you can define when you [create a query pack](query-packs.md). You can use tags to create your own taxonomies for organizing queries. | --### View query properties --From the **Queries** pane on the left sidebar of Log Analytics, hover over a query name to see its properties. ---## Favorites -You can identify frequently used queries as favorites to give you quicker access. Select the star next to the query to add it to **Favorites**. View your favorite queries from the **Favorites** option in the query interface. --## Types of queries -The query interface is populated with the following types of queries: --| Type | Description | -| : | : | -| Example queries | Example queries can provide instant insight into a resource and offer a way to start learning and using Kusto Query Language (KQL). They can help you shorten the time it takes to start using Log Analytics. We've collected and curated more than 500 example queries to provide you with instant value. The number of example queries is continually growing. | -| Query packs | A [query pack](query-packs.md) holds a collection of log queries. Queries that you save yourself, the [default query pack](query-packs.md#default-query-pack), and query packs that your organization might have created in the subscription are included. To view and manage query packs, see [View query packs](./query-packs.md#view-query-packs). To add query packs to your Log Analytics workspace. see [Use multiple query packs](./query-packs.md#use-multiple-query-packs). | -| Legacy queries | Log queries previously saved in the query explorer experience are legacy queries. Also, queries associated with Azure solutions that are installed in the workspace are legacy queries. These queries are listed in the **Queries** dialog under **Legacy queries**. | -->[!TIP] -> Legacy queries are only available in a Log Analytics workspace. --## Effect of query scope -The queries that are available when you open Log Analytics are determined by the current [query scope](scope.md). For example: --| Query scope | Description | -| : | : | -| Workspace | All example queries and queries from query packs. Legacy queries in the workspace. | -| Single resource | Example queries and queries from query packs for the resource type. | -| Resource group | Example queries and queries from query packs for resource types in the resource. | --> [!TIP] -> The more resources you have in your scope, the longer the time it takes for the portal to filter and show the **Queries** dialog. --## Next steps --[Get started with KQL queries](get-started-queries.md) |
| azure-monitor | Query Audit | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/query-audit.md | - Title: Audit queries in Azure Monitor log queries -description: Details of log query audit logs which provide telemetry about log queries run in Azure Monitor. --- Previously updated : 10/20/2021----# Audit queries in Azure Monitor Logs -Log query audit logs provide telemetry about log queries run in Azure Monitor. This includes information such as when a query was run, who ran it, what tool was used, the query text, and performance statistics describing the query's execution. ---## Configure query auditing -Query auditing is enabled with a [diagnostic setting](../essentials/diagnostic-settings.md) on the Log Analytics workspace. This allows you to send audit data to the current workspace or any other workspace in your subscription, to Azure Event Hubs to send outside of Azure, or to Azure Storage for archiving. --### Azure portal -Access the diagnostic setting for a Log Analytics workspace in the Azure portal in either of the following locations: --- From the **Azure Monitor** menu, select **Diagnostic settings**, and then locate and select the workspace.- <!-- convertborder later --> - :::image type="content" source="media/query-audit/diagnostic-setting-monitor.png" lightbox="media/query-audit/diagnostic-setting-monitor.png" alt-text="Screenshot of diagnostic settings Azure Monitor." border="false"::: --- From the **Log Analytics workspaces** menu, select the workspace, and then select **Diagnostic settings**.-- :::image type="content" source="media/query-audit/diagnostic-setting-workspace.png" lightbox="media/query-audit/diagnostic-setting-workspace.png" alt-text="Screenshot of diagnostic settings Log Analytics workspace."::: --### Resource Manager template -You can get an example Resource Manager template from [Diagnostic setting for Log Analytics workspace](../essentials/resource-manager-diagnostic-settings.md#diagnostic-setting-for-a-log-analytics-workspace). --## Audit data -An audit record is created each time a query is run. If you send the data to a Log Analytics workspace, it's stored in a table called *LAQueryLogs*. The following table describes the properties in each record of the audit data. --| Field | Description | -|:|:| -| TimeGenerated | UTC time when query was submitted. | -| CorrelationId | Unique ID to identify the query. Can be used in troubleshooting scenarios when contacting Microsoft for assistance. | -| AADObjectId | Microsoft Entra ID of the user account that started the query. | -| AADTenantId | ID of the tenant of the user account that started the query. | -| AADEmail | Email of the tenant of the user account that started the query. | -| AADClientId | ID and resolved name of the application used to start the query. | -| RequestClientApp | Resolved name of the application used to start the query. For more information, see [request client app.](#request-client-app).| -| QueryTimeRangeStart | Start of the time range selected for the query. This may not be populated in certain scenarios such as when the query is started from Log Analytics, and time range is specified inside the query rather than the time picker. | -| QueryTimeRangeEnd | End of the time range selected for the query. This may not be populated in certain scenarios such as when the query is started from Log Analytics, and time range is specified inside the query rather than the time picker. | -| QueryText | Text of the query that was run. | -| RequestTarget | API URL was used to submit the query. | -| RequestContext | List of resources that the query was requested to run against. Contains up to three string arrays: workspaces, applications, and resources. Subscription or resource group-targeted queries will show as *resources*. Includes the target implied by RequestTarget.<br>The resource ID for each resource will be included if it can be resolved. It may not be able to resolved if an error is returned in accessing the resource. In this case, the specific text from the query will be used.<br>If the query uses an ambiguous name, such as a workspace name existing in multiple subscriptions, this ambiguous name will be used. | -| RequestContextFilters | Set of filters specified as part of the query invocation. Includes up to three possible string arrays:<br>- ResourceTypes - type of resource to limit the scope of the query<br>- Workspaces - list of workspaces to limit the query to<br>- WorkspaceRegions - list of workspace regions to limit the query | -| ResponseCode | HTTP response code returned when the query was submitted. | -| ResponseDurationMs | Time for the response to be returned. | -| ResponseRowCount | Total number of rows returned by the query. | -| StatsCPUTimeMs | Total compute time used for computing, parsing and data fetching. Only populated if query returns with status code 200. | -| StatsDataProcessedKB | Amount of data that was accessed to process the query. Influenced by the size of the target table, time span used, filters applied, and the number of columns referenced. Only populated if query returns with status code 200. | -| StatsDataProcessedStart | Time of oldest data that was accessed to process the query. Influenced by the query explicit time span and filters applied. This might be larger than the explicit time span due to data partitioning. Only populated if query returns with status code 200. | -| StatsDataProcessedEnd |Time of newest data that was accessed to process the query. Influenced by the query explicit time span and filters applied. This might be larger than the explicit time span due to data partitioning. Only populated if query returns with status code 200. | -| StatsWorkspaceCount | Number of workspaces accessed by the query. Only populated if query returns with status code 200. | -| StatsRegionCount | Number of regions accessed by the query. Only populated if query returns with status code 200. | --### Request Client App -| RequestClientApp | Description | -|:|:| -|AAPBI|[Log Analytics integration with Power BI](../logs/log-powerbi.md).| -|AppAnalytics|Experiences of Log Analytics in the Azure portal.| -|AppInsightsPortalExtension|[Workbooks](../visualize/workbooks-data-sources.md#logs-analytics-tables-application-insights) or [Application insights](../app/app-insights-overview.md).| -|ASC_Portal|Microsoft Defender for Cloud.| -|ASI_Portal|Sentinel.| -|AzureAutomation|[Azure Automation.](../../automation/overview.md)| -|AzureMonitorLogsConnector|[Azure Monitor Logs Connector](../../connectors/connectors-azure-monitor-logs.md).| -|csharpsdk|[Log Analytics Query API.](../logs/api/overview.md)| -|Draft-Monitor|[Log search alert creation in the Azure portal.](../alerts/alerts-create-new-alert-rule.md?tabs=log)| -|Grafana|[Grafana connector.](../visualize/grafana-plugin.md)| -|IbizaExtension|Experiences of Log Analytics in the Azure portal.| -|infraInsights/container|[Container insights.](../containers/container-insights-overview.md)| -|infraInsights/vm|[VM insights.](../vm/vminsights-overview.md)| -|LogAnalyticsExtension|[Azure Dashboard](../../azure-portal/azure-portal-dashboards.md).| -|LogAnalyticsPSClient|[Log Analytics Query API.](../logs/api/overview.md)| -|OmsAnalyticsPBI|Log Analytics integration with [Power BI.](../logs/log-powerbi.md)| -|PowerBIConnector|Log Analytics integration with [Power BI.](../logs/log-powerbi.md)| -|Sentinel-Investigation-Queries|Sentinel.| -|Sentinel-DataCollectionAggregator|Sentinel.| -|Sentinel-analyticsManagement-customerQuery|Sentinel.| -|Unknown|[Log Analytics Query API.](../logs/api/overview.md)| -|UpdateManagement|[Update Management.](../../automation/update-management/overview.md)| ---## Considerations --- Queries are only logged when executed in a user context. No Service-to-Service within Azure will be logged. The two primary sets of queries this exclusion encompasses are billing calculations and automated alert executions. In the case of alerts, only the scheduled alert query itself won't be logged; the initial execution of the alert in the alert creation screen is executed in a user context, and will be available for audit purposes. -- Performance statistics aren't available for queries coming from the Azure Data Explorer proxy. All other data for these queries will still be populated.-- The *h* hint on strings that [obfuscates string literals](/azure/data-explorer/kusto/query/scalar-data-types/string#obfuscated-string-literals) won't have an effect on the query audit logs. The queries will be captured exactly as submitted without the string being obfuscated. You should ensure that only users who have compliance rights to see this data are able to do so using the various Kubernetes RBAC or Azure RBAC modes available in Log Analytics workspaces.-- For queries that include data from multiple workspaces, the query will only be captured in those workspaces to which the user has access.--## Costs -There's no cost for Azure Diagnostic Extension, but you may incur charges for the data ingested. Check [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/) for the destination where you're collecting data. --## Next steps --- Learn more about [diagnostic settings](../essentials/diagnostic-settings.md).-- Learn more about [optimizing log queries](query-optimization.md). |
| azure-monitor | Query Optimization | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/query-optimization.md | - Title: Optimize log queries in Azure Monitor -description: Best practices for optimizing log queries in Azure Monitor. ---- Previously updated : 03/22/2022-----# Optimize log queries in Azure Monitor -Azure Monitor Logs uses [Azure Data Explorer](/azure/data-explorer/) to store log data and run queries for analyzing that data. It creates, manages, and maintains the Azure Data Explorer clusters for you, and optimizes them for your log analysis workload. When you run a query, it's optimized and routed to the appropriate Azure Data Explorer cluster that stores the workspace data. --Azure Monitor Logs and Azure Data Explorer use many automatic query optimization mechanisms. Automatic optimizations provide significant boost, but there are some cases where you can dramatically improve your query performance. This article explains the performance considerations and several techniques to fix them. --Most of the techniques are common to queries that are run directly on Azure Data Explorer and Azure Monitor Logs. Several unique Azure Monitor Logs considerations are also discussed. For more Azure Data Explorer optimization tips, see [Query best practices](/azure/kusto/query/best-practices). --Optimized queries will: --- Run faster and reduce overall duration of the query execution.-- Have smaller chance of being throttled or rejected.--Pay particular attention to queries that are used for recurrent and simultaneous usage, such as dashboards, alerts, Azure Logic Apps, and Power BI. The impact of an ineffective query in these cases is substantial. --Here's a detailed video walkthrough on optimizing queries. --> [!VIDEO https://www.microsoft.com/en-us/videoplayer/embed/RE4NUH0] --## Query Details pane -After you run a query in Log Analytics, select **Query details** at the bottom right corner of the screen to open the **Query Details** pane. This pane shows the results of several performance indicators for the query. These performance indicators are described in the following section. ---## Query performance indicators --The following query performance indicators are available for every query that's executed: --- [Total CPU](#total-cpu): Overall compute used to process the query across all compute nodes. It represents time used for computing, parsing, and data fetching.-- [Data used for processed query](#data-used-for-processed-query): Overall data that was accessed to process the query. Influenced by the size of the target table, time span used, filters applied, and the number of columns referenced.-- [Time span of the processed query](#time-span-of-the-processed-query): The gap between the newest and the oldest data that was accessed to process the query. Influenced by the explicit time range specified for the query.-- [Age of processed data](#age-of-processed-data): The gap between now and the oldest data that was accessed to process the query. It highly influences the efficiency of data fetching.-- [Number of workspaces](#number-of-workspaces): How many workspaces were accessed during the query processing based on implicit or explicit selection.-- [Number of regions](#number-of-regions): How many regions were accessed during the query processing based on implicit or explicit selection of workspaces. Multi-region queries are much less efficient, and performance indicators present partial coverage.-- [Parallelism](#parallelism): Indicates how much the system was able to execute this query on multiple nodes. Relevant only to queries that have high CPU consumption. Influenced by usage of specific functions and operators.--## Total CPU -The actual compute CPU that was invested to process this query across all the query processing nodes. Because most queries are executed on large numbers of nodes, this total will usually be much larger than the duration the query took to execute. --A query that uses more than 100 seconds of CPU is considered a query that consumes excessive resources. A query that uses more than 1,000 seconds of CPU is considered an abusive query and might be throttled. --Query processing time is spent on: --- **Data retrieval**: Retrieval of old data will consume more time than retrieval of recent data.-- **Data processing**: Logic and evaluation of the data.--In addition to the time spent in the query processing nodes, Azure Monitor Logs spends time in: --- Authenticating the user and verifying they're permitted to access this data.-- Locating the data store.-- Parsing the query.-- Allocating the query processing nodes.--This time isn't included in the query total CPU time. --### Early filtering of records prior to using high CPU functions --Some of the query commands and functions are heavy in their CPU consumption. This case is especially true for commands that parse JSON and XML or extract complex regular expressions. Such parsing can happen explicitly via [parse_json()](/azure/kusto/query/parsejsonfunction) or [parse_xml()](/azure/kusto/query/parse-xmlfunction) functions or implicitly when it refers to dynamic columns. --These functions consume CPU in proportion to the number of rows they're processing. The most efficient optimization is to add `where` conditions early in the query. In this way, they can filter out as many records as possible before the CPU-intensive function is executed. --For example, the following queries produce exactly the same result. But the second one is the most efficient because the [where](/azure/kusto/query/whereoperator) condition before parsing excludes many records: --```Kusto -//less efficient -SecurityEvent -| extend Details = parse_xml(EventData) -| extend FilePath = tostring(Details.UserData.RuleAndFileData.FilePath) -| extend FileHash = tostring(Details.UserData.RuleAndFileData.FileHash) -| where FileHash != "" and FilePath !startswith "%SYSTEM32" // Problem: irrelevant results are filtered after all processing and parsing is done -| summarize count() by FileHash, FilePath -``` -```Kusto -//more efficient -SecurityEvent -| where EventID == 8002 //Only this event have FileHash -| where EventData !has "%SYSTEM32" //Early removal of unwanted records -| extend Details = parse_xml(EventData) -| extend FilePath = tostring(Details.UserData.RuleAndFileData.FilePath) -| extend FileHash = tostring(Details.UserData.RuleAndFileData.FileHash) -| where FileHash != "" and FilePath !startswith "%SYSTEM32" // exact removal of results. Early filter is not accurate enough -| summarize count() by FileHash, FilePath -| where FileHash != "" // No need to filter out %SYSTEM32 here as it was removed before -``` --### Avoid using evaluated where clauses --Queries that contain [where](/azure/kusto/query/whereoperator) clauses on an evaluated column rather than on columns that are physically present in the dataset lose efficiency. Filtering on evaluated columns prevents some system optimizations when large sets of data are handled. --For example, the following queries produce exactly the same result. But the second one is more efficient because the [where](/azure/kusto/query/whereoperator) condition refers to a built-in column: --```Kusto -//less efficient -Syslog -| extend Msg = strcat("Syslog: ",SyslogMessage) -| where Msg has "Error" -| count -``` -```Kusto -//more efficient -Syslog -| where SyslogMessage has "Error" -| count -``` --In some cases, the evaluated column is created implicitly by the query processing engine because the filtering is done not just on the field: --```Kusto -//less efficient -SecurityEvent -| where tolower(Process) == "conhost.exe" -| count -``` -```Kusto -//more efficient -SecurityEvent -| where Process =~ "conhost.exe" -| count -``` --### Use effective aggregation commands and dimensions in summarize and join --Some aggregation commands like [max()](/azure/kusto/query/max-aggfunction), [sum()](/azure/kusto/query/sum-aggfunction), [count()](/azure/kusto/query/count-aggfunction), and [avg()](/azure/kusto/query/avg-aggfunction) have low CPU impact because of their logic. Other commands are more complex and include heuristics and estimations that allow them to be executed efficiently. For example, [dcount()](/azure/kusto/query/dcount-aggfunction) uses the HyperLogLog algorithm to provide close estimation to a distinct count of large sets of data without actually counting each value. --The percentile functions are doing similar approximations by using the nearest rank percentile algorithm. Several of the commands include optional parameters to reduce their impact. For example, the [makeset()](/azure/kusto/query/makeset-aggfunction) function has an optional parameter to define the maximum set size, which significantly affects the CPU and memory. --[Join](/azure/kusto/query/joinoperator?pivots=azuremonitor) and [summarize](/azure/kusto/query/summarizeoperator) commands might cause high CPU utilization when they're processing a large set of data. Their complexity is directly related to the number of possible values, referred to as *cardinality*, of the columns that are used as the `by` in `summarize` or as the `join` attributes. For explanation and optimization of `join` and `summarize`, see their documentation articles and optimization tips. --For example, the following queries produce exactly the same result because `CounterPath` is always one-to-one mapped to `CounterName` and `ObjectName`. The second one is more efficient because the aggregation dimension is smaller: --```Kusto -//less efficient -Perf -| summarize avg(CounterValue) -by CounterName, CounterPath, ObjectName -``` -```Kusto -//make the group expression more compact improve the performance -Perf -| summarize avg(CounterValue), any(CounterName), any(ObjectName) -by CounterPath -``` --CPU consumption might also be affected by `where` conditions or extended columns that require intensive computing. All trivial string comparisons, such as [equal ==](/azure/kusto/query/datatypes-string-operators) and [startswith](/azure/kusto/query/datatypes-string-operators), have roughly the same CPU impact. Advanced text matches have more impact. Specifically, the [has](/azure/kusto/query/datatypes-string-operators) operator is more efficient than the [contains](/azure/kusto/query/datatypes-string-operators) operator. Because of string handling techniques, it's more efficient to look for strings that are longer than four characters than short strings. --For example, the following queries produce similar results, depending on `Computer` naming policy. But the second one is more efficient: --```Kusto -//less efficient ΓÇô due to filter based on contains -Heartbeat -| where Computer contains "Production" -| summarize count() by ComputerIP -``` -```Kusto -//less efficient ΓÇô due to filter based on extend -Heartbeat -| extend MyComputer = Computer -| where MyComputer startswith "Production" -| summarize count() by ComputerIP -``` -```Kusto -//more efficient -Heartbeat -| where Computer startswith "Production" -| summarize count() by ComputerIP -``` --> [!NOTE] -> This indicator presents only CPU from the immediate cluster. In a multi-region query, it would represent only one of the regions. In a multi-workspace query, it might not include all workspaces. --### Avoid full XML and JSON parsing when string parsing works -Full parsing of an XML or JSON object might consume high CPU and memory resources. In many cases, when only one or two parameters are needed and the XML or JSON objects are simple, it's easier to parse them as strings. Use the [parse operator](/azure/kusto/query/parseoperator) or other [text parsing techniques](./parse-text.md). The performance boost will be more significant because the number of records in the XML or JSON object increases. It's essential when the number of records reaches tens of millions. --For example, the following query returns exactly the same results as the preceding queries without performing full XML parsing. The query makes some assumptions about the XML file structure, like the `FilePath` element comes after `FileHash` and none of them has attributes: --```Kusto -//even more efficient -SecurityEvent -| where EventID == 8002 //Only this event have FileHash -| where EventData !has "%SYSTEM32" //Early removal of unwanted records -| parse EventData with * "<FilePath>" FilePath "</FilePath>" * "<FileHash>" FileHash "</FileHash>" * -| summarize count() by FileHash, FilePath -| where FileHash != "" // No need to filter out %SYSTEM32 here as it was removed before -``` --## Data used for processed query --A critical factor in the processing of the query is the volume of data that's scanned and used for the query processing. Azure Data Explorer uses aggressive optimizations that dramatically reduce the data volume compared to other data platforms. Still, there are critical factors in the query that can affect the data volume that's used. --A query that processes more than 2,000 KB of data is considered a query that consumes excessive resources. A query that's processing more than 20,000 KB of data is considered an abusive query and might be throttled. --In Azure Monitor Logs, the `TimeGenerated` column is used as a way to index the data. Restricting the `TimeGenerated` values to as narrow a range as possible will improve query performance. The narrow range significantly limits the amount of data that has to be processed. --### Avoid unnecessary use of search and union operators --Another factor that increases the data that's processed is the use of a large number of tables. This scenario usually happens when `search *` and `union *` commands are used. These commands force the system to evaluate and scan data from all tables in the workspace. In some cases, there might be hundreds of tables in the workspace. Try to avoid using `search *` or any search without scoping it to a specific table. --For example, the following queries produce exactly the same result, but the last one is the most efficient: --```Kusto -// This version scans all tables though only Perf has this kind of data -search "Processor Time" -| summarize count(), avg(CounterValue) by Computer -``` -```Kusto -// This version scans all strings in Perf tables ΓÇô much more efficient -Perf -| search "Processor Time" -| summarize count(), avg(CounterValue) by Computer -``` -```Kusto -// This is the most efficient version -Perf -| where CounterName == "% Processor Time" -| summarize count(), avg(CounterValue) by Computer -``` --### Add early filters to the query --Another method to reduce the data volume is to have [where](/azure/kusto/query/whereoperator) conditions early in the query. The Azure Data Explorer platform includes a cache that lets it know which partitions include data that's relevant for a specific `where` condition. For example, if a query contains `where EventID == 4624`, then it would distribute the query only to nodes that handle partitions with matching events. --The following example queries produce exactly the same result, but the second one is more efficient: --```Kusto -//less efficient -SecurityEvent -| summarize LoginSessions = dcount(LogonGuid) by Account -``` -```Kusto -//more efficient -SecurityEvent -| where EventID == 4624 //Logon GUID is relevant only for logon event -| summarize LoginSessions = dcount(LogonGuid) by Account -``` --### Avoid multiple scans of the same source data by using conditional aggregation functions and the materialize function -When a query has several subqueries that are merged by using join or union operators, each subquery scans the entire source separately. Then it merges the results. This action multiplies the number of times that data is scanned, which is a critical factor in large datasets. --A technique to avoid this scenario is by using the conditional aggregation functions. Most of the [aggregation functions](/azure/data-explorer/kusto/query/summarizeoperator#list-of-aggregation-functions) that are used in a summary operator have a conditioned version that you can use for a single summarize operator with multiple conditions. --For example, the following queries show the number of login events and the number of process execution events for each account. They return the same results, but the first query scans the data twice. The second query scans it only once: --```Kusto -//Scans the SecurityEvent table twice and perform expensive join -SecurityEvent -| where EventID == 4624 //Login event -| summarize LoginCount = count() by Account -| join -( - SecurityEvent - | where EventID == 4688 //Process execution event - | summarize ExecutionCount = count(), ExecutedProcesses = make_set(Process) by Account -) on Account -``` --```Kusto -//Scan only once with no join -SecurityEvent -| where EventID == 4624 or EventID == 4688 //early filter -| summarize LoginCount = countif(EventID == 4624), ExecutionCount = countif(EventID == 4688), ExecutedProcesses = make_set_if(Process,EventID == 4688) by Account -``` --Another case where subqueries are unnecessary is pre-filtering for a [parse operator](/azure/data-explorer/kusto/query/parseoperator?pivots=azuremonitor) to make sure that it processes only records that match a specific pattern. They're unnecessary because the parse operator and other similar operators return empty results when the pattern doesn't match. The following two queries return exactly the same results, but the second query scans the data only once. In the second query, each parse command is relevant only for its events. The `extend` operator afterward shows how to refer to an empty data situation: --```Kusto -//Scan SecurityEvent table twice -union( -SecurityEvent -| where EventID == 8002 -| parse EventData with * "<FilePath>" FilePath "</FilePath>" * "<FileHash>" FileHash "</FileHash>" * -| distinct FilePath -),( -SecurityEvent -| where EventID == 4799 -| parse EventData with * "CallerProcessName\">" CallerProcessName1 "</Data>" * -| distinct CallerProcessName1 -) -``` --```Kusto -//Single scan of the SecurityEvent table -SecurityEvent -| where EventID == 8002 or EventID == 4799 -| parse EventData with * "<FilePath>" FilePath "</FilePath>" * "<FileHash>" FileHash "</FileHash>" * //Relevant only for event 8002 -| parse EventData with * "CallerProcessName\">" CallerProcessName1 "</Data>" * //Relevant only for event 4799 -| extend FilePath = iif(isempty(CallerProcessName1),FilePath,"") -| distinct FilePath, CallerProcessName1 -``` --When the preceding query doesn't allow you to avoid using subqueries, another technique is to hint to the query engine that there's a single source of data used in each one of them by using the [materialize() function](/azure/data-explorer/kusto/query/materializefunction?pivots=azuremonitor). This technique is useful when the source data is coming from a function that's used several times within the query. `Materialize` is effective when the output of the subquery is much smaller than the input. The query engine will cache and reuse the output in all occurrences. --### Reduce the number of columns that's retrieved --Because Azure Data Explorer is a columnar data store, retrieval of every column is independent of the others. The number of columns that are retrieved directly influences the overall data volume. You should only include the columns in the output that are needed by [summarizing](/azure/kusto/query/summarizeoperator) the results or [projecting](/azure/kusto/query/projectoperator) the specific columns. --Azure Data Explorer has several optimizations to reduce the number of retrieved columns. If it determines that a column isn't needed, for example, if it's not referenced in the [summarize](/azure/kusto/query/summarizeoperator) command, it won't retrieve it. --For example, the second query might process three times more data because it needs to fetch not one column but three: --```Kusto -//Less columns --> Less data -SecurityEvent -| summarize count() by Computer -``` -```Kusto -//More columns --> More data -SecurityEvent -| summarize count(), dcount(EventID), avg(Level) by Computer -``` --## Time span of the processed query --All logs in Azure Monitor Logs are partitioned according to the `TimeGenerated` column. The number of partitions that are accessed are directly related to the time span. Reducing the time range is the most efficient way of assuring a prompt query execution. --A query with a time span of more than 15 days is considered a query that consumes excessive resources. A query with a time span of more than 90 days is considered an abusive query and might be throttled. --You can set the time range by using the time range selector in the Log Analytics screen as described in [Log query scope and time range in Azure Monitor Log Analytics](./scope.md#time-range). This method is recommended because the selected time range is passed to the back end by using the query metadata. --An alternative method is to explicitly include a [where](/azure/kusto/query/whereoperator) condition on `TimeGenerated` in the query. Use this method because it assures that the time span is fixed, even when the query is used from a different interface. --Make sure that all parts of the query have `TimeGenerated` filters. When a query has subqueries fetching data from various tables or the same table, each query has to include its own [where](/azure/kusto/query/whereoperator) condition. --### Make sure all subqueries have the TimeGenerated filter --For example, in the following query, the `Perf` table will be scanned only for the last day. The `Heartbeat` table will be scanned for all of its history, which might be up to two years: --```Kusto -Perf -| where TimeGenerated > ago(1d) -| summarize avg(CounterValue) by Computer, CounterName -| join kind=leftouter ( - Heartbeat - //No time span filter in this part of the query - | summarize IPs = makeset(ComputerIP, 10) by Computer -) on Computer -``` --A common case where such a mistake occurs is when [arg_max()](/azure/kusto/query/arg-max-aggfunction) is used to find the most recent occurrence. For example: --```Kusto -Perf -| where TimeGenerated > ago(1d) -| summarize avg(CounterValue) by Computer, CounterName -| join kind=leftouter ( - Heartbeat - //No time span filter in this part of the query - | summarize arg_max(TimeGenerated, *), min(TimeGenerated) -by Computer -) on Computer -``` --You can easily correct this situation by adding a time filter in the inner query: --```Kusto -Perf -| where TimeGenerated > ago(1d) -| summarize avg(CounterValue) by Computer, CounterName -| join kind=leftouter ( - Heartbeat - | where TimeGenerated > ago(1d) //filter for this part - | summarize arg_max(TimeGenerated, *), min(TimeGenerated) -by Computer -) on Computer -``` --Another example of this fault is when you perform the time scope filtering just after a [union](/azure/kusto/query/unionoperator?pivots=azuremonitor) over several tables. When you perform the union, each subquery should be scoped. You can use a [let](/azure/kusto/query/letstatement) statement to ensure scoping consistency. --For example, the following query will scan all the data in the `Heartbeat` and `Perf` tables, not just the last day: --```Kusto -Heartbeat -| summarize arg_min(TimeGenerated,*) by Computer -| union ( - Perf - | summarize arg_min(TimeGenerated,*) by Computer) -| where TimeGenerated > ago(1d) -| summarize min(TimeGenerated) by Computer -``` --To fix the query: --```Kusto -let MinTime = ago(1d); -Heartbeat -| where TimeGenerated > MinTime -| summarize arg_min(TimeGenerated,*) by Computer -| union ( - Perf - | where TimeGenerated > MinTime - | summarize arg_min(TimeGenerated,*) by Computer) -| summarize min(TimeGenerated) by Computer -``` --### Time span measurement limitations --The measurement is always larger than the actual time specified. For example, if the filter on the query is 7 days, the system might scan 7.5 or 8.1 days. This variance is because the system is partitioning the data into chunks of variable sizes. To ensure that all relevant records are scanned, the system scans the entire partition. This process might cover several hours and even more than a day. --There are several cases where the system can't provide an accurate measurement of the time range. This situation happens in most cases where the query's span is less than a day or in multi-workspace queries. --> [!IMPORTANT] -> This indicator presents only data processed in the immediate cluster. In a multi-region query, it would represent only one of the regions. In a multi-workspace query, it might not include all workspaces. --## Age of processed data -Azure Data Explorer uses several storage tiers: in-memory, local SSD disks, and much slower Azure Blobs. The newer the data, the higher the chance that it's stored in a more performant tier with smaller latency, which reduces the query duration and CPU. Other than the data itself, the system also has a cache for metadata. The older the data, the less chance its metadata will be in a cache. --A query that processes data that's more than 14 days old is considered a query that consumes excessive resources. --Some queries require the use of old data, but there are also cases where old data is used by mistake. This scenario happens when queries are executed without providing a time range in their metadata and not all table references include a filter on the `TimeGenerated` column. In these cases, the system will scan all the data that's stored in the table. When the data retention is long, it can cover long time ranges. As a result, data that's as old as the data retention period is scanned. --Such cases can be, for example: --- Not setting the time range in Log Analytics with a subquery that isn't limited. See the preceding example.-- Using the API without the time range optional parameters.-- Using a client that doesn't force a time range, for example, like the Power BI connector.--See examples and notes in the previous section because they're also relevant in this case. --## Number of regions -There are situations where a single query might be executed across different regions. For example: --- When several workspaces are explicitly listed and they're located in different regions.-- When a resource-scoped query is fetching data and the data is stored in multiple workspaces that are located in different regions.--Cross-region query execution requires the system to serialize and transfer in the back end large chunks of intermediate data that are usually much larger than the query final results. It also limits the system's ability to perform optimizations and heuristics and use caches. --If there's no reason to scan all these regions, adjust the scope so that it covers fewer regions. If the resource scope is minimized but many regions are still used, it might happen because of misconfiguration. For example, audit logs and diagnostic settings might be sent to different workspaces in different regions or there might be multiple diagnostic settings configurations. --A query that spans more than three regions is considered a query that consumes excessive resources. A query that spans more than six regions is considered an abusive query and might be throttled. --> [!IMPORTANT] -> When a query is run across several regions, the CPU and data measurements won't be accurate and will represent the measurement of only one of the regions. --## Number of workspaces -Workspaces are logical containers that are used to segregate and administer logs data. The back end optimizes workspace placements on physical clusters within the selected region. --Use of multiple workspaces can result from instances when: --- Several workspaces are explicitly listed.-- A resource-scoped query is fetching data and the data is stored in multiple workspaces.--Cross-region and cross-cluster execution of queries requires the system to serialize and transfer in the back end large chunks of intermediate data that are usually much larger than the query final results. It also limits the system's ability to perform optimizations and heuristics and use caches. --A query that spans more than five workspaces is considered a query that consumes excessive resources. Queries can't span more than 100 workspaces. --> [!IMPORTANT] -> - In some multi-workspace scenarios, the CPU and data measurements won't be accurate and will represent the measurement of only a few of the workspaces. -> - Cross workspace queries having an explicit identifier: workspace ID, or workspace Azure Resource ID, consume less resources and are more performant. --## Parallelism -Azure Monitor Logs uses large clusters of Azure Data Explorer to run queries. These clusters vary in scale and potentially get up to dozens of compute nodes. The system automatically scales the clusters according to workspace placement logic and capacity. --To efficiently execute a query, it's partitioned and distributed to compute nodes based on the data that's required for its processing. In some situations, the system can't do this step efficiently, which can lead to a long duration of the query. --Query behaviors that can reduce parallelism include: --- Use of serialization and window functions, such as the [serialize operator](/azure/kusto/query/serializeoperator), [next()](/azure/kusto/query/nextfunction), [prev()](/azure/kusto/query/prevfunction), and the [row](/azure/kusto/query/rowcumsumfunction) functions. Time series and user analytics functions can be used in some of these cases. Inefficient serialization might also happen if the following operators aren't used at the end of the query: [range](/azure/kusto/query/rangeoperator), [sort](/azure/data-explorer/kusto/query/sort-operator), [order](/azure/kusto/query/orderoperator), [top](/azure/kusto/query/topoperator), [top-hitters](/azure/kusto/query/tophittersoperator), and [getschema](/azure/kusto/query/getschemaoperator).-- Use of the [dcount()](/azure/kusto/query/dcount-aggfunction) aggregation function forces the system to have a central copy of the distinct values. When the scale of data is high, consider using the `dcount` function optional parameters to reduce accuracy.-- In many cases, the [join](/azure/kusto/query/joinoperator?pivots=azuremonitor) operator lowers overall parallelism. Examine `shuffle join` as an alternative when performance is problematic.-- In resource-scope queries, the pre-execution Kubernetes role-based access control (RBAC) or Azure RBAC checks might linger in situations where there's a large number of Azure role assignments. This situation might lead to longer checks that would result in lower parallelism. For example, a query might be executed on a subscription where there are thousands of resources and each resource has many role assignments on the resource level, not on the subscription or resource group.-- If a query is processing small chunks of data, its parallelism will be low because the system won't spread it across many compute nodes.--## Next steps --[Reference documentation for the Kusto Query Language](/azure/kusto/query/) |
| azure-monitor | Query Packs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/query-packs.md | - Title: Query packs in Azure Monitor -description: Query packs in Azure Monitor provide a way to share collections of log queries in multiple Log Analytics workspaces. ----- Previously updated : 12/11/2023----# Query packs in Azure Monitor Logs -Query packs act as containers for log queries in Azure Monitor. They let you save log queries and share them across workspaces and other contexts in Log Analytics. --## Permissions -You can set the permissions on a query pack when you view it in the Azure portal. You need the following permissions to use query packs: --- **Reader**: Users can see and run all queries in the query pack.-- **Contributor**: Users can modify existing queries and add new queries to the query pack.-- > [!IMPORTANT] - > When a user needs to create a query pack assign the user Log Analytics Contributor at the Resource Group level. -## View query packs -You can view and manage query packs in the Azure portal from the **Log Analytics query packs** menu. Select a query pack to view and edit its permissions. This article describes how to create a query pack by using the API. -<!-- convertborder later --> --## Default query pack -Azure Monitor automatically creates a query pack called `DefaultQueryPack` in each subscription in a resource group called `LogAnalyticsDefaultResources` when you save your first query. You can save queries to this query pack or create other query packs depending on your requirements. --## Use multiple query packs --The default query pack is sufficient for most users to save and reuse queries. You might want to create multiple query packs for users in your organization if, for example, you want to load different sets of queries in different Log Analytics sessions and provide different permissions for different collections of queries. --When you [create a new query pack](#create-a-query-pack), you can add tags that classify queries based on your business needs. For example, you could tag a query pack to relate it to a particular department in your organization or to severity of issues that the included queries are meant to address. By using tags, you can create different sets of queries intended for different sets of users and different situations. --To add query packs to your Log Analytics workspace: --1. Open Log Analytics and select **Queries** in the upper-right corner. -1. In the upper-left corner on the **Queries** dialog, next to **Query packs**, click **Select query packs** or **0 selected**. -1. Select the query packs that you want to add to the workspace. ---> [!IMPORTANT] -> You can add up to five query packs to a Log Analytics workspace. --## Create a query pack -You can create a query pack by using the REST API or from the **Log Analytics query packs** pane in the Azure portal. To open the **Log Analytics query packs** pane in the portal, select **All services** > **Other**. --> [!NOTE] -> Queries saved in [query pack](./query-packs.md) aren't encrypted with Customer-managed key. Select **Save as Legacy query** when saving queries instead, to protect them with Customer-managed key. --### Create a token -You must have a token for authentication of the API request. There are multiple methods to get a token. One method is to use `armclient`. --First, sign in to Azure by using the following command: --``` -armclient login -``` --Then create the token by using the following command. The token is automatically copied to the clipboard so that you can paste it into another tool. --``` -armclient token -``` --### Create a payload -The payload of the request is the JSON that defines one or more queries and the location where the query pack should be stored. The name of the query pack is specified in the API request described in the next section. --```json -{ - "location": "eastus", - "properties": - { - "displayName": "Query name that will be displayed in the UI", - "description": "Query description that will be displayed in the UI", - "body": "<<query text, standard KQL code>>", - "related": { - "categories": [ - "workloads" - ], - "resourceTypes": [ - "microsoft.insights/components" - ], - "solutions": [ - "logmanagement" - ] - }, - "tags": { - "Tag1": [ - "Value1", - "Value2" - ] - } - } -} -``` --Each query in the query pack has the following properties: --| Property | Description | -|:|:| -| `displayName` | Display name listed in Log Analytics for each query. | -| `description` | Description of the query displayed in Log Analytics for each query. | -| `body` | Query written in Kusto Query Language. | -| `related` | Related categories, resource types, and solutions for the query. Used for grouping and filtering in Log Analytics by the user to help locate their query. Each query can have up to 10 of each type. Retrieve allowed values from https://api.loganalytics.io/v1/metadata?select=resourceTypes, solutions, and categories. | -| `tags` | Other tags used by the user for sorting and filtering in Log Analytics. Each tag will be added to Category, Resource Type, and Solution when you [group and filter queries](queries.md#find-and-filter-queries). | --### Create a request -Use the following request to create a new query pack by using the REST API. The request should use bearer token authorization. The content type should be `application/json`. --```rest -POST https://management.azure.com/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/Microsoft.Insights/querypacks/my-query-pack?api-version=2019-09-01 -``` --Use a tool that can submit a REST API request, such as Fiddler or Postman, to submit the request by using the payload described in the previous section. The query ID will be generated and returned in the payload. --## Update a query pack -To update a query pack, submit the following request with an updated payload. This command requires the query pack ID. --```rest -POST https://management.azure.com/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/my-resource-group/providers/Microsoft.Insights/querypacks/my-query-pack/queries/query-id/?api-version=2019-09-01 -``` --## Next steps --See [Using queries in Azure Monitor Log Analytics](queries.md) to see how users interact with query packs in Log Analytics. |
| azure-monitor | Quick Create Workspace | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/quick-create-workspace.md | - Title: Create Log Analytics workspaces -description: Learn how to create a Log Analytics workspace to enable management solutions and data collection from your cloud and on-premises environments. --- Previously updated : 08/12/2024---# Customer intent: As a DevOps engineer or IT expert, I want to set up a workspace to collect logs from multiple data sources from Azure, on-premises, and third-party cloud deployments. --# Create a Log Analytics workspace --A Log Analytics workspace is a data store into which you can collect any type of log data from all of your Azure and non-Azure resources and applications. We recommend that you send all log data to one Log Analytics workspace, unless you have specific business needs that require you to create multiple workspaces, as described in [Design a Log Analytics workspace architecture](./workspace-design.md). --This article explains how to create a Log Analytics workspace. --## Prerequisites --To create a Log Analytics workspace, you need an Azure account with an active subscription. You can [create an account for free](https://azure.microsoft.com/free). --## Permissions required --You need `Microsoft.OperationalInsights/workspaces/write` permissions to the resource group where you want to create the Log Analytics workspace, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example. --## Create a workspace --## [Portal](#tab/azure-portal) --Use the **Log Analytics workspaces** menu to create a workspace. --1. In the [Azure portal](https://portal.azure.com), enter **Log Analytics** in the search box. As you begin typing, the list filters based on your input. Select **Log Analytics workspaces**. -- :::image type="content" source="media/quick-create-workspace/azure-portal-01.png" alt-text="Screenshot that shows the search bar at the top of the Azure home screen. As you begin typing, the list of search results filters based on your input."::: --1. Select **Add**. --1. Select a **Subscription** from the dropdown. -1. Use an existing **Resource Group** or create a new one. -1. Provide a name for the new **Log Analytics workspace**, such as *DefaultLAWorkspace*. This name must be unique per resource group. -1. Select an available **Region**. For more information, see which [regions Log Analytics is available in](https://azure.microsoft.com/regions/services/). Search for Azure Monitor in the **Search for a product** box. -- :::image type="content" source="media/quick-create-workspace/create-workspace.png" alt-text="Screenshot that shows the boxes that need to be populated on the Basics tab of the Create Log Analytics workspace screen."::: --1. Select **Review + Create** to review the settings. Then select **Create** to create the workspace. A default pricing tier of pay-as-you-go is applied. No charges will be incurred until you start collecting enough data. For more information about other pricing tiers, see [Log Analytics pricing details](https://azure.microsoft.com/pricing/details/log-analytics/). --## [PowerShell](#tab/azure-powershell) --The following sample script creates a workspace with no data source configuration. --```powershell -$ResourceGroup = <"my-resource-group"> -$WorkspaceName = <"log-analytics-workspace-name"> -$Location = <"westeurope"> --# Create the resource group if needed -try { - Get-AzResourceGroup -Name $ResourceGroup -ErrorAction Stop -} catch { - New-AzResourceGroup -Name $ResourceGroup -Location $Location -} --# Create the workspace -New-AzOperationalInsightsWorkspace -Location $Location -Name $WorkspaceName -ResourceGroupName $ResourceGroup -``` --> [!NOTE] -> Log Analytics was previously called Operational Insights. The PowerShell cmdlets use Operational Insights in Log Analytics commands. - -After you've created a workspace, [configure a Log Analytics workspace in Azure Monitor by using PowerShell](./powershell-workspace-configuration.md). --## [Azure CLI](#tab/azure-cli) --Run the [az group create](/cli/azure/group#az-group-create) command to create a resource group or use an existing resource group. To create a workspace, use the [az monitor log-analytics workspace create](/cli/azure/monitor/log-analytics/workspace#az-monitor-log-analytics-workspace-create) command. --```Azure CLI - az group create --name <myGroup> --location <myLocation> - az monitor log-analytics workspace create --resource-group <myGroup> \ - --workspace-name <myWorkspace> -``` --For more information about Azure Monitor Logs in Azure CLI, see [Managing Azure Monitor Logs in Azure CLI](./azure-cli-log-analytics-workspace-sample.md). --## [Bicep](#tab/bicep) --The following sample uses [Microsoft.OperationalInsights workspaces](/azure/templates/microsoft.operationalinsights/workspaces?tabs=bicep&pivots=deployment-language-bicep) to create a Log Analytics workspace in Azure Monitor. For more information about Bicep, see [Bicep overview](../../azure-resource-manager/bicep/overview.md). ---### Bicep file --```bicep -@description('Name of the workspace.') -param workspaceName string --@description('Pricing tier: PerGB2018 or legacy tiers (Free, Standalone, PerNode, Standard or Premium) which are not available to all customers.') -@allowed([ - 'pergb2018' - 'Free' - 'Standalone' - 'PerNode' - 'Standard' - 'Premium' -]) -param sku string = 'pergb2018' --@description('Specifies the location for the workspace.') -param location string --@description('Number of days to retain data.') -param retentionInDays int = 120 --@description('true to use resource or workspace permissions. false to require workspace permissions.') -param resourcePermissions bool --@description('Number of days to retain data in Heartbeat table.') -param heartbeatTableRetention int --resource workspace 'Microsoft.OperationalInsights/workspaces@2023-09-01' = { - name: workspaceName - location: location - properties: { - sku: { - name: sku - } - retentionInDays: retentionInDays - features: { - enableLogAccessUsingOnlyResourcePermissions: resourcePermissions - } - } -} --resource workspaceName_Heartbeat 'Microsoft.OperationalInsights/workspaces/tables@2022-10-01' = { - parent: workspace - name: 'Heartbeat' - properties: { - retentionInDays: heartbeatTableRetention - } -} -``` --> [!NOTE] -> If you specify a pricing tier of **Free**, then remove the **retentionInDays** element. --### Parameter file --```bicepparam -using './main.bicep' --param workspaceName = 'MyWorkspace' -param sku = 'pergb2018' -param location = 'eastus' -param retentionInDays = 120 -param resourcePermissions = true -param heartbeatTableRetention = 30 -``` --## [Resource Manager template](#tab/azure-resource-manager) --The following sample uses the [Microsoft.OperationalInsights workspaces](/azure/templates/microsoft.operationalinsights/workspaces?tabs=bicep) template to create a Log Analytics workspace in Azure Monitor. -For more information about Azure Resource Manager templates, see [Azure Resource Manager templates](../../azure-resource-manager/templates/syntax.md). ---### Template file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceName": { - "type": "string", - "metadata": { - "description": "Name of the workspace." - } - }, - "sku": { - "type": "string", - "defaultValue": "pergb2018", - "allowedValues": [ - "pergb2018", - "Free", - "Standalone", - "PerNode", - "Standard", - "Premium" - ], - "metadata": { - "description": "Pricing tier: PerGB2018 or legacy tiers (Free, Standalone, PerNode, Standard or Premium) which are not available to all customers." - } - }, - "location": { - "type": "string", - "metadata": { - "description": "Specifies the location for the workspace." - } - }, - "retentionInDays": { - "type": "int", - "defaultValue": 120, - "metadata": { - "description": "Number of days to retain data." - } - }, - "resourcePermissions": { - "type": "bool", - "metadata": { - "description": "true to use resource or workspace permissions. false to require workspace permissions." - } - }, - "heartbeatTableRetention": { - "type": "int", - "metadata": { - "description": "Number of days to retain data in Heartbeat table." - } - } - }, - "resources": [ - { - "type": "Microsoft.OperationalInsights/workspaces", - "apiVersion": "2023-09-01", - "name": "[parameters('workspaceName')]", - "location": "[parameters('location')]", - "properties": { - "sku": { - "name": "[parameters('sku')]" - }, - "retentionInDays": "[parameters('retentionInDays')]", - "features": { - "enableLogAccessUsingOnlyResourcePermissions": "[parameters('resourcePermissions')]" - } - } - }, - { - "type": "Microsoft.OperationalInsights/workspaces/tables", - "apiVersion": "2022-10-01", - "name": "[format('{0}/{1}', parameters('workspaceName'), 'Heartbeat')]", - "properties": { - "retentionInDays": "[parameters('heartbeatTableRetention')]" - }, - "dependsOn": [ - "workspace" - ] - } - ] -} -``` --> [!NOTE] -> If you specify a pricing tier of **Free**, then remove the **retentionInDays** element. --### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-08-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceName": { - "value": "MyWorkspace" - }, - "sku": { - "value": "pergb2018" - }, - "location": { - "value": "eastus" - }, - "resourcePermissions": { - "value": true - }, - "heartbeatTableRetention": { - "value": 30 - } - } -} -``` ----## Troubleshooting --When you create a workspace that was deleted in the last 14 days and in [soft-delete state](../logs/delete-workspace.md#delete-a-workspace-into-a-soft-delete-state), the operation could have a different outcome depending on your workspace configuration: --1. If you provide the same workspace name, resource group, subscription, and region as in the deleted workspace, your workspace will be recovered including its data, configuration, and connected agents. -1. Workspace names must be unique for a resource group. If you use a workspace name that already exists, or is soft deleted, an error is returned. To permanently delete your soft-deleted name and create a new workspace with the same name, follow these steps: -- 1. [Recover](../logs/delete-workspace.md#recover-a-workspace-in-a-soft-delete-state) your workspace. - 1. [Permanently delete](../logs/delete-workspace.md#delete-a-workspace-permanently) your workspace. - 1. Create a new workspace by using the same workspace name. - -## Next steps --Now that you have a workspace available, you can configure collection of monitoring telemetry, run log searches to analyze that data, and add a management solution to provide more data and analytic insights. To learn more: --* See [Monitor health of Log Analytics workspace in Azure Monitor](../logs/monitor-workspace.md) to create alert rules to monitor the health of your workspace. -* See [Collect Azure service logs and metrics for use in Log Analytics](../essentials/resource-logs.md#send-to-log-analytics-workspace) to enable data collection from Azure resources with Azure Diagnostics or Azure Storage. |
| azure-monitor | Resource Manager Log Queries | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/resource-manager-log-queries.md | - Title: Resource Manager template samples for log queries -description: Sample Azure Resource Manager templates to deploy Azure Monitor log queries. ---- Previously updated : 08/12/2024---# Resource Manager template samples for log queries in Azure Monitor --This article includes sample [Azure Resource Manager templates](../../azure-resource-manager/templates/syntax.md) to create and configure log queries in Azure Monitor. Each sample includes a template file and a parameters file with sample values to provide to the template. ---## Template references --- [Microsoft.OperationalInsights workspaces/savedSearches](/azure/templates/microsoft.operationalinsights/2020-03-01-preview/workspaces/savedsearches)--## Simple log query --The following sample adds a log query to a Log Analytics workspace. --### Template file --# [Bicep](#tab/bicep) --```bicep -@description('The name of the workspace.') -param workspaceName string --@description('The location of the resources.') -param location string = resourceGroup().location --resource workspace 'Microsoft.OperationalInsights/workspaces@2021-12-01-preview' = { - name: workspaceName - location: location -} --resource savedSearch 'Microsoft.OperationalInsights/workspaces/savedSearches@2020-08-01' = { - parent: workspace - name: 'VMSS query' - properties: { - etag: '*' - displayName: 'VMSS Instance Count' - category: 'VMSS' - query: 'Event | where Source == "ServiceFabricNodeBootstrapAgent" | summarize AggregatedValue = count() by Computer' - version: 1 - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceName": { - "type": "string", - "metadata": { - "description": "The name of the workspace." - } - }, - "location": { - "type": "string", - "defaultValue": "[resourceGroup().location]", - "metadata": { - "description": "The location of the resources." - } - } - }, - "resources": [ - { - "type": "Microsoft.OperationalInsights/workspaces", - "apiVersion": "2021-12-01-preview", - "name": "[parameters('workspaceName')]", - "location": "[parameters('location')]" - }, - { - "type": "Microsoft.OperationalInsights/workspaces/savedSearches", - "apiVersion": "2020-08-01", - "name": "[format('{0}/{1}', parameters('workspaceName'), 'VMSS query')]", - "properties": { - "etag": "*", - "displayName": "VMSS Instance Count", - "category": "VMSS", - "query": "Event | where Source == \"ServiceFabricNodeBootstrapAgent\" | summarize AggregatedValue = count() by Computer", - "version": 1 - }, - "dependsOn": [ - "[resourceId('Microsoft.OperationalInsights/workspaces', parameters('workspaceName'))]" - ] - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceName": { - "value": "MyWorkspace" - }, - "location": { - "value": "eastus" - } - } -} -``` --## Log query as a function --The following sample adds a log query as a function to a Log Analytics workspace. --### Template file --# [Bicep](#tab/bicep) --```bicep -@description('The name of the workspace.') -param workspaceName string --@description('The location of the resources.') -param location string = resourceGroup().location --resource workspace 'Microsoft.OperationalInsights/workspaces@2021-12-01-preview' = { - name: workspaceName - location: location -} --resource savedSearch 'Microsoft.OperationalInsights/workspaces/savedSearches@2020-08-01' = { - parent: workspace - name: 'VMSS query' - properties: { - etag: '*' - displayName: 'VMSS Instance Count' - category: 'VMSS' - query: 'Event | where Source == "ServiceFabricNodeBootstrapAgent" | summarize AggregatedValue = count() by Computer' - version: 1 - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceName": { - "type": "string" - }, - "location": { - "type": "string" - } - }, - "resources": [ - { - "type": "Microsoft.OperationalInsights/workspaces", - "apiVersion": "2017-03-15-preview", - "name": "[parameters('workspaceName')]", - "location": "[parameters('location')]", - "resources": [ - { - "type": "savedSearches", - "apiVersion": "2020-08-01", - "name": "Cross workspace query", - "dependsOn": [ - "[concat('Microsoft.OperationalInsights/workspaces/', parameters('workspaceName'))]" - ], - "properties": { - "etag": "*", - "displayName": "Failed Logon Events", - "category": "Security", - "FunctionAlias": "failedlogonsecurityevents", - "query": " - union withsource=SourceWorkspace - workspace('workspace1').SecurityEvent, - workspace('workspace2').SecurityEvent, - workspace('workspace3').SecurityEvent, - | where EventID == 4625", - "version": 1 - } - } - ] - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceName": { - "value": "MyWorkspace" - }, - "location": { - "value": "eastus" - } - } -} -``` --## Parameterized function --The following sample adds a log query as a function that uses a parameter to a Log Analytics workspace. A second log query is included that uses the parameterized function. --> [!NOTE] -> Resource template is currently the only method that can be used to parameterized functions. Any log query can use the function once it's installed in the workspace. --### Template file --# [Bicep](#tab/bicep) --```bicep -param workspaceName string -param location string --resource workspace 'Microsoft.OperationalInsights/workspaces@2021-12-01-preview' = { - name: workspaceName - location: location -} --resource parameterizedFunctionSavedSearch 'Microsoft.OperationalInsights/workspaces/savedSearches@2020-08-01' = { - parent: workspace - name: 'Parameterized function' - properties: { - etag: '*' - displayName: 'Unavailable computers function' - category: 'Samples' - functionAlias: 'UnavailableComputers' - functionParameters: 'argSpan: timespan' - query: ' Heartbeat | summarize LastHeartbeat=max(TimeGenerated) by Computer| where LastHeartbeat < ago(argSpan)' - } -} --resource queryUsingFunctionSavedSearch 'Microsoft.OperationalInsights/workspaces/savedSearches@2020-08-01' = { - parent: workspace - name: 'Query using function' - properties: { - etag: '*' - displayName: 'Unavailable computers' - category: 'Samples' - query: 'UnavailableComputers(7days)' - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceName": { - "type": "string" - }, - "location": { - "type": "string" - } - }, - "resources": [ - { - "type": "Microsoft.OperationalInsights/workspaces", - "apiVersion": "2021-12-01-preview", - "name": "[parameters('workspaceName')]", - "location": "[parameters('location')]" - }, - { - "type": "Microsoft.OperationalInsights/workspaces/savedSearches", - "apiVersion": "2020-08-01", - "name": "[format('{0}/{1}', parameters('workspaceName'), 'Parameterized function')]", - "properties": { - "etag": "*", - "displayName": "Unavailable computers function", - "category": "Samples", - "functionAlias": "UnavailableComputers", - "functionParameters": "argSpan: timespan", - "query": " Heartbeat | summarize LastHeartbeat=max(TimeGenerated) by Computer| where LastHeartbeat < ago(argSpan)" - }, - "dependsOn": [ - "[resourceId('Microsoft.OperationalInsights/workspaces', parameters('workspaceName'))]" - ] - }, - { - "type": "Microsoft.OperationalInsights/workspaces/savedSearches", - "apiVersion": "2020-08-01", - "name": "[format('{0}/{1}', parameters('workspaceName'), 'Query using function')]", - "properties": { - "etag": "*", - "displayName": "Unavailable computers", - "category": "Samples", - "query": "UnavailableComputers(7days)" - }, - "dependsOn": [ - "[resourceId('Microsoft.OperationalInsights/workspaces', parameters('workspaceName'))]" - ] - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceName": { - "value": "MyWorkspace" - }, - "location": { - "value": "eastus" - } - } -} -``` --## Next steps --- [Get other sample templates for Azure Monitor](../resource-manager-samples.md).-- [Learn more about log queries](../logs/log-query-overview.md).-- [Learn more about functions](../logs/functions.md). |
| azure-monitor | Resource Manager Workspace | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/resource-manager-workspace.md | - Title: Resource Manager template samples for Log Analytics workspaces -description: Sample Azure Resource Manager templates to deploy Log Analytics workspaces and configure data sources in Azure Monitor. ---- Previously updated : 08/08/2023---# Resource Manager template samples for Log Analytics workspaces in Azure Monitor --This article includes sample [Azure Resource Manager templates](../../azure-resource-manager/templates/syntax.md) to create and configure [Log Analytics workspaces](./log-analytics-workspace-overview.md) in Azure Monitor. Each sample includes a template file and a parameters file with sample values to provide to the template. ---## Prerequisites --Verify that your Azure subscription allows you to create Log Analytics workspaces in the target region. --## Permissions required --| Action | Permissions required | -|:|:| -| Deploy ARM templates. | `Microsoft.Resources/deployments/*` permissions, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example. | -| Create a Log Analytics workspace. | `Microsoft.OperationalInsights/workspaces/write` permissions, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example. | -| Configure data collection for Log Analytics workspace. | `Microsoft.OperationalInsights/workspaces/write` and `Microsoft.OperationalInsights/workspaces/dataSources/write` permissions, as provided by the [Log Analytics Contributor built-in role](./manage-access.md#log-analytics-contributor), for example. | --## Template references --- [Microsoft.OperationalInsights workspaces](/azure/templates/microsoft.operationalinsights/2020-03-01-preview/workspaces)-- [Microsoft.OperationalInsights workspaces/dataSources](/azure/templates/microsoft.operationalinsights/2020-03-01-preview/workspaces/datasources)--## Create a Log Analytics workspace --The following sample creates a new empty [Log Analytics workspace](./log-analytics-workspace-insights-overview.md). A workspace has unique workspace ID and resource ID. You can reuse the same workspace name when in different [resource groups](../../azure-resource-manager/management/manage-resource-groups-portal.md#what-is-a-resource-group). --### Notes --- If you specify a pricing tier of **Free**, then remove the **retentionInDays** element.--### Template file --# [Bicep](#tab/bicep) --```bicep -@description('Specify the name of the workspace.') -param workspaceName string --@description('Specify the location for the workspace.') -param location string --@description('Specify the pricing tier: PerGB2018 or legacy tiers (Free, Standalone, PerNode, Standard or Premium) which are not available to all customers.') -@allowed([ - 'CapacityReservation' - 'Free' - 'LACluster' - 'PerGB2018' - 'PerNode' - 'Premium' - 'Standalone' - 'Standard' -]) -param sku string = 'PerGB2018' --@description('Specify the number of days to retain data.') -param retentionInDays int = 120 --@description('Specify true to use resource or workspace permissions, or false to require workspace permissions.') -param resourcePermissions bool --@description('Specify the number of days to retain data in Heartbeat table.') -param heartbeatTableRetention int --resource workspace 'Microsoft.OperationalInsights/workspaces@2021-12-01-preview' = { - name: workspaceName - location: location - properties: { - sku: { - name: sku - } - retentionInDays: retentionInDays - features: { - enableLogAccessUsingOnlyResourcePermissions: resourcePermissions - } - } -} --resource table 'Microsoft.OperationalInsights/workspaces/tables@2021-12-01-preview' = { - parent: workspace - name: 'Heartbeat' - properties: { - retentionInDays: heartbeatTableRetention - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceName": { - "type": "string", - "metadata": { - "description": "Specify the name of the workspace." - } - }, - "location": { - "type": "string", - "metadata": { - "description": "Specify the location for the workspace." - } - }, - "sku": { - "type": "string", - "defaultValue": "PerGB2018", - "allowedValues": [ - "CapacityReservation", - "Free", - "LACluster", - "PerGB2018", - "PerNode", - "Premium", - "Standalone", - "Standard" - ], - "metadata": { - "description": "Specify the pricing tier: PerGB2018 or legacy tiers (Free, Standalone, PerNode, Standard or Premium) which are not available to all customers." - } - }, - "retentionInDays": { - "type": "int", - "defaultValue": 120, - "metadata": { - "description": "Specify the number of days to retain data." - } - }, - "resourcePermissions": { - "type": "bool", - "metadata": { - "description": "Specify true to use resource or workspace permissions, or false to require workspace permissions." - } - }, - "heartbeatTableRetention": { - "type": "int", - "metadata": { - "description": "Specify the number of days to retain data in Heartbeat table." - } - } - }, - "resources": [ - { - "type": "Microsoft.OperationalInsights/workspaces", - "apiVersion": "2021-12-01-preview", - "name": "[parameters('workspaceName')]", - "location": "[parameters('location')]", - "properties": { - "sku": { - "name": "[parameters('sku')]" - }, - "retentionInDays": "[parameters('retentionInDays')]", - "features": { - "enableLogAccessUsingOnlyResourcePermissions": "[parameters('resourcePermissions')]" - } - } - }, - { - "type": "Microsoft.OperationalInsights/workspaces/tables", - "apiVersion": "2021-12-01-preview", - "name": "[format('{0}/{1}', parameters('workspaceName'), 'Heartbeat')]", - "properties": { - "retentionInDays": "[parameters('heartbeatTableRetention')]" - }, - "dependsOn": [ - "[resourceId('Microsoft.OperationalInsights/workspaces', parameters('workspaceName'))]" - ] - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceName": { - "value": "MyWorkspace" - }, - "sku": { - "value": "PerGB2018" - }, - "location": { - "value": "eastus" - }, - "resourcePermissions": { - "value": true - }, - "heartbeatTableRetention": { - "value": 30 - } - } -} -``` --## Deploy the sample templates --See [Deploy the sample templates](../resource-manager-samples.md). --## Next steps --- [Get other sample templates for Azure Monitor](../resource-manager-samples.md).-- [Learn more about Log Analytics workspaces](./quick-create-workspace.md).-- [Learn more about agent data sources](../agents/agent-data-sources.md). |
| azure-monitor | Restore | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/restore.md | - Title: Restore logs in Azure Monitor -description: Restore a specific time range of data in a Log Analytics workspace for high-performance queries. - Previously updated : 08/12/2024-----# Restore logs in Azure Monitor -The restore operation makes a specific time range of data in a table available in the hot cache for high-performance queries. This article describes how to restore data, query that data, and then dismiss the data when you're done. --> [!NOTE] -> Tables with the [Auxiliary table plan](data-platform-logs.md) do not support data restore. Use a [search job](search-jobs.md) to retrieve data that's in long-term retention from an Auxiliary table. --## Permissions --To restore data from long-term retention, you need `Microsoft.OperationalInsights/workspaces/tables/write` and `Microsoft.OperationalInsights/workspaces/restoreLogs/write` permissions to the Log Analytics workspace, for example, as provided by the [Log Analytics Contributor built-in role](../logs/manage-access.md#built-in-roles). --## When to restore logs -Use the restore operation to query data in [long-term retention](data-retention-configure.md). You can also use the restore operation to run powerful queries within a specific time range on any Analytics table when the log queries you run on the source table can't complete within the log query timeout of 10 minutes. --> [!NOTE] -> Restore is one method for accessing data in long-term retention. Use restore to run queries against a set of data within a particular time range. Use [Search jobs](search-jobs.md) to access data based on specific criteria. --## What does restore do? -When you restore data, you specify the source table that contains the data you want to query and the name of the new destination table to be created. --The restore operation creates the restore table and allocates extra compute resources for querying the restored data using high-performance queries that support full KQL. --The destination table provides a view of the underlying source data, but doesn't affect it in any way. The table has no retention setting, and you must explicitly [dismiss the restored data](#dismiss-restored-data) when you no longer need it. --## Restore data --# [API](#tab/api-1) -To restore data from a table, call the **Tables - Create or Update** API. The name of the destination table must end with *_RST*. --```http -PUT https://management.azure.com/subscriptions/{subscriptionId}/resourcegroups/{resourceGroupName}/providers/Microsoft.OperationalInsights/workspaces/{workspaceName}/tables/{user defined name}_RST?api-version=2021-12-01-preview -``` --**Request body** --The body of the request must include the following values: --|Name | Type | Description | -|:|:|:| -|properties.restoredLogs.sourceTable | string | Table with the data to restore. | -|properties.restoredLogs.startRestoreTime | string | Start of the time range to restore. | -|properties.restoredLogs.endRestoreTime | string | End of the time range to restore. | --**Restore table status** --The **provisioningState** property indicates the current state of the restore table operation. The API returns this property when you start the restore, and you can retrieve this property later using a GET operation on the table. The **provisioningState** property has one of the following values: --| Value | Description -|:|:| -| Updating | Restore operation in progress. | -| Succeeded | Restore operation completed. | -| Deleting | Deleting the restored table. | --**Sample request** --This sample restores data from the month of January 2020 from the *Usage* table to a table called *Usage_RST*. --**Request** --```http -PUT https://management.azure.com/subscriptions/00000000-0000-0000-0000-00000000000/resourcegroups/testRG/providers/Microsoft.OperationalInsights/workspaces/testWS/tables/Usage_RST?api-version=2021-12-01-preview -``` --**Request body:** -```http -{ - "properties": { - "restoredLogs": { - "startRestoreTime": "2020-01-01T00:00:00Z", - "endRestoreTime": "2020-01-31T00:00:00Z", - "sourceTable": "Usage" - } - } -} -``` -# [CLI](#tab/cli-1) --To restore data from a table, run the [az monitor log-analytics workspace table restore create](/cli/azure/monitor/log-analytics/workspace/table/restore#az-monitor-log-analytics-workspace-table-restore-create) command. --For example: --```azurecli -az monitor log-analytics workspace table restore create --subscription ContosoSID --resource-group ContosoRG --workspace-name ContosoWorkspace --name Heartbeat_RST --restore-source-table Heartbeat --start-restore-time "2022-01-01T00:00:00.000Z" --end-restore-time "2022-01-08T00:00:00.000Z" --no-wait -``` -----## Query restored data --Restored logs retain their original timestamps. When you run a query on restored logs, set the query time range based on when the data was originally generated. --Set the query time range by either: --- Selecting **Custom** in the **Time range** dropdown at the top of the query editor and setting **From** and **To** values.<br> - or -- Specifying the time range in the query. For example:-- ```kusto - let startTime =datetime(01/01/2022 8:00:00 PM); - let endTime =datetime(01/05/2022 8:00:00 PM); - TableName_RST - | where TimeGenerated between(startTime .. endTime) - ``` --## Dismiss restored data --To save costs, we recommend you [delete the restored table](../logs/create-custom-table.md#delete-a-table) to dismiss restored data when you no longer need it. --Deleting the restored table doesn't delete the data in the source table. --> [!NOTE] -> Restored data is available as long as the underlying source data is available. When you delete the source table from the workspace or when the source table's retention period ends, the data is dismissed from the restored table. However, the empty table will remain if you do not delete it explicitly. --## Limitations -Restore is subject to the following limitations. --You can: --- Restore data from a period of at least two days.--- Restore up to 60 TB.-- Run up to two restore processes in a workspace concurrently.-- Run only one active restore on a specific table at a given time. Executing a second restore on a table that already has an active restore fails. -- Perform up to four restores per table per week. --## Pricing model --The charge for restored logs is based on the volume of data you restore, and the duration for which the restore is active. Thus, the units of price are *per GB per day*. Data restores are billed on each UTC-day that the restore is active. --- Charges are subject to a minimum restored data volume of 2 TB per restore. If you restore less data, you will be charged for the 2 TB minimum each day until the [restore is dismissed](#dismiss-restored-data).-- On the first and last days that the restore is active, you're only billed for the part of the day the restore was active. --- The minimum charge is for a 12-hour restore duration, even if the restore is active for less than 12-hours.--- For more information on your data restore price, see [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/) on the Logs tab.--Here are some examples to illustrate data restore cost calculations: --1. If your table holds 500 GB a day and you restore 10 days data from that table, your total restore size is 5 TB. You are charged for this 5 TB of restored data each day until you [dismiss the restored data](#dismiss-restored-data). Your daily cost is 5,000 GB multiplied by your data restore price (see [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/).) --1. If instead, only 700 GB of data is restored, each day that the restore is active is billed for the 2 TB minimum restore level. Your daily cost is 2,000 GB multiplied by your data restore price. --1. If a 5 TB data restore is only kept active for 1 hour, it is billed for 12-hour minimum. The cost for this data restore is 5,000 GB multiplied by your data restore price multiplied by 0.5 days (the 12-hour minimum). --1. If a 700 GB data restore is only kept active for 1 hour, it is billed for 12-hour minimum. The cost for this data restore is 2,000 GB (the minimum billed restore size) multiplied by your data restore price multiplied by 0.5 days (the 12-hour minimum). --> [!NOTE] -> There is no charge for querying restored logs since they are Analytics logs. --## Next steps --- [Learn more about data retention.](data-retention-configure.md)--- [Learn about Search jobs, which is another method for retrieving data from long-term retention.](search-jobs.md)- |
| azure-monitor | Save Query | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/save-query.md | - Title: Save a query in Azure Monitor Log Analytics -description: This article describes how to save a query in Log Analytics. ----- Previously updated : 06/22/2022---# Save a query in Azure Monitor Log Analytics -[Log queries](log-query-overview.md) are requests in Azure Monitor that you can use to process and retrieve data in a Log Analytics workspace. Saving a log query allows you to: --- Use the query in all Log Analytics contexts, including workspace and resource centric.-- Allow other users to run the same query.-- Create a library of common queries for your organization.--## Permissions -- To save a query, you need the **Log Analytics Contributor** role.-- To view a saved query, you need the **Log Analytics Reader** role.--## Save options -When you save a query, it's stored in a query pack, which has benefits over the previous method of storing the query in a workspace, including: --- Easier discoverability with the ability to filter and group queries by different properties.-- Queries are available when you use a resource scope in Log Analytics.-- Queries are made available across subscriptions.-- More data is available to describe and categorize the query.--## Save a query -To save a query to a query pack, select **Save as query** from the **Save** dropdown in Log Analytics. -<!-- convertborder later --> --When you save a query to a query pack, the following dialog box appears where you can provide values for the query properties. The query properties are used for filtering and grouping of similar queries to help you find the query you're looking for. For a detailed description of each property, see [Query properties](queries.md#query-properties). --Most users should leave the option to **Save to the default query pack**, which will save the query in the [default query pack](query-packs.md#default-query-pack). Clear this checkbox if there are other query packs in your subscription. For information on how to create a new query pack, see [Query packs in Azure Monitor Logs](query-packs.md). -<!-- convertborder later --> --## Edit a query -You might want to edit a query that you've already saved. You might want to change the query itself or modify any of its properties. After you open an existing query in Log Analytics and make changes, you can save the edited query with the same properties or modify any properties before saving. --If you want to save the query with a different name, select **Save as query** as if you were creating a new query. --## Save as a legacy query -We don't recommend saving as a legacy query because of the advantages of query packs. You can save a query to the workspace to combine it with other queries that were saved to the workspace before the release of query packs. --To save a legacy query, select **Save as query** from the **Save** dropdown in Log Analytics. Choose the **Save as Legacy query** option. The only option available will be the legacy category. --## Troubleshooting --### Can't select the option to save to the default query pack --This error can occur when the subscription you try to save the query to doesn't have a default query pack. -If you clear the option to **Save to the default query pack**, select a subscription that doesn't have a default query pack, and then select a subscription that has a default query pack, you won't be able to select this option. --To resolve this error, close the **Save as query** dialog box, save the query again, and only select a subscription that has a default query pack. --### Fix the "You need permissions to create resource groups in subscription 'xxxx'" error message --When you attempt to save a query to the default query pack, the following error message may appear on the screen: *You need permissions to create resource groups in subscription 'xxxx'*. --This error can occur when the [default query pack](query-packs.md#default-query-pack) doesn't exist and you don't have the Contributor permission for the subscription. --To resolve this error, someone with Contributor permissions for the subscription needs to save the first query to the default query pack. --## Next steps --[Get started with KQL queries](get-started-queries.md) |
| azure-monitor | Scope | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/scope.md | - Title: Log query scope in Azure Monitor Log Analytics -description: Describes the scope and time range for a log query in Azure Monitor Log Analytics. ---- Previously updated : 12/28/2023----# Log query scope and time range in Azure Monitor Log Analytics -When you run a [log query](../logs/log-query-overview.md) in [Log Analytics in the Azure portal](../logs/log-analytics-tutorial.md), the set of data evaluated by the query depends on the scope and the time range that you select. This article describes the scope and time range and how you can set each depending on your requirements. It also describes the behavior of different types of scopes. ---## Query scope -The query scope defines the records that the query evaluates. This definition will usually include all records in a single Log Analytics workspace or Application Insights application. Log Analytics also allows you to set a scope for a particular monitored Azure resource. This allows a resource owner to focus only on their data, even if that resource writes to multiple workspaces. --The scope is always displayed at the top left of the Log Analytics window. An icon indicates whether the scope is a Log Analytics workspace or an Application Insights application. No icon indicates another Azure resource. ---The method you use to start Log Analytics determines the scope, and in some cases you can change the scope by clicking on it. The following table lists the different types of scope used and different details for each. --> [!IMPORTANT] -> If you're using a workspace-based application in Application Insights, then its data is stored in a Log Analytics workspace with all other log data. For backward compatibility you will get the classic Application Insights experience when you select the application as your scope. To see this data in the Log Analytics workspace, set the scope to the workspace. --| Query scope | Records in scope | How to select | Changing Scope | -|:|:|:|:| -| Log Analytics workspace | All records in the Log Analytics workspace. | Select **Logs** from the **Azure Monitor** menu or the **Log Analytics workspaces** menu. | Can change scope to any other resource type. | -| Application Insights application | All records in the Application Insights application. | Select **Logs** from the **Application Insights** menu for the application. | Can only change scope to another Application Insights application. | -| Resource group | Records created by all resources in the resource group. Can include data from multiple Log Analytics workspaces. | Select **Logs** from the resource group menu. | Can't change scope.| -| Subscription | Records created by all resources in the subscription. Can include data from multiple Log Analytics workspaces. | Select **Logs** from the subscription menu. | Can't change scope. | -| Other Azure resources | Records created by the resource. Can include data from multiple Log Analytics workspaces. | Select **Logs** from the resource menu.<br>OR<br>Select **Logs** from the **Azure Monitor** menu and then select a new scope. | Can only change scope to same resource type. | --### Limitations when scoped to a resource --When the query scope is a Log Analytics workspace or an Application Insights application, all options in the portal and all query commands are available. When scoped to a resource though, the following options in the portal not available because they're associated with a single workspace or application: --- Save-- Query explorer-- New alert rule--You can't use the following commands in a query when scoped to a resource since the query scope already includes any workspaces with data for that resource or set of resources: --- [app](../logs/app-expression.md)-- [workspace](../logs/workspace-expression.md)- --## Query scope limits -Setting the scope to a resource or set of resources is a powerful feature of Log Analytics since it allows you to automatically consolidate distributed data in a single query. It can significantly affect performance though if data needs to be retrieved from workspaces across multiple Azure regions. --Log Analytics helps protect against excessive overhead from queries that span workspaces in multiple regions by issuing a warning or error when a certain number of regions are being used. -Your query receives a warning if the scope includes workspaces in 5 or more regions. it will still run, but it might take excessive time to complete. -<!-- convertborder later --> --Your query will be blocked from running if the scope includes workspaces in 20 or more regions. In this case, you'll be prompted to reduce the number of workspace regions and attempt to run the query again. The dropdown will display all of the regions in the scope of the query, and you should reduce the number of regions before attempting to run the query again. -<!-- convertborder later --> ---## Time range -The time range specifies the set of records that are evaluated for the query based on when the record was created. This is defined by the **TimeGenerated** column on every record in the workspace or application as specified in the following table. For a classic Application Insights application, the **timestamp** column is used for the time range. ---Set the time range by selecting it from the time picker at the top of the Log Analytics window. You can select a predefined period or select **Custom** to specify a specific time range. -<!-- convertborder later --> --If you set a filter in the query that uses the standard time column as shown in the table above, the time picker changes to **Set in query**, and the time picker is disabled. In this case, it's most efficient to put the filter at the top of the query so that any subsequent processing only needs to work with the filtered records. -<!-- convertborder later --> --If you use the [workspace](../logs/workspace-expression.md) or [app](../logs/app-expression.md) command to retrieve data from another workspace or classic application, the time picker might behave differently. If the scope is a Log Analytics workspace and you use **app**, or if the scope is a classic Application Insights application and you use **workspace**, then Log Analytics might not understand that the column used in the filter should determine the time filter. --In the following example, the scope is set to a Log Analytics workspace. The query uses **workspace** to retrieve data from another Log Analytics workspace. The time picker changes to **Set in query** because it sees a filter that uses the expected **TimeGenerated** column. -<!-- convertborder later --> --If the query uses **app** to retrieve data from a classic Application Insights application though, Log Analytics doesn't recognize the **timestamp** column in the filter, and the time picker remains unchanged. In this case, both filters are applied. In the example, only records created in the last 24 hours are included in the query even though it specifies 7 days in the **where** clause. -<!-- convertborder later --> --## Next steps --- Walk through a [tutorial on using Log Analytics in the Azure portal](../logs/log-analytics-tutorial.md).-- Walk through a [tutorial on writing queries](../logs/get-started-queries.md). |
| azure-monitor | Search Jobs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/search-jobs.md | - Title: Run search jobs in Azure Monitor -description: Search jobs are asynchronous log queries in Azure Monitor that make results available as a table for further analytics. - Previously updated : 07/22/2024-----# Customer intent: As a data scientist or workspace administrator, I want an efficient way to search through large volumes of data in a table, including data in long-term retention. ---# Run search jobs in Azure Monitor --Search jobs are asynchronous queries that fetch records into a new search table within your workspace for further analytics. The search job uses parallel processing and can run for hours across large datasets. This article describes how to create a search job and how to query its resulting data. --This video explains when and how to use search jobs: - -> [!VIDEO https://www.youtube.com/embed/5iShgXRu1sU?cc_load_policy=1&cc_lang_pref=auto] --## Permissions required --| Action | Permissions required | -|:-|:| -| Run a search job | `Microsoft.OperationalInsights/workspaces/tables/write` and `Microsoft.OperationalInsights/workspaces/searchJobs/write` permissions to the Log Analytics workspace, for example, as provided by the [Log Analytics Contributor built-in role](../logs/manage-access.md#built-in-roles). | --> [!NOTE] -> Cross-tenant search jobs are not currently supported, even when Entra ID tenants are managed through Azure Lighthouse. --## When to use search jobs --Use a search job when the log query timeout of 10 minutes isn't sufficient to search through large volumes of data or if you're running a slow query. --Search jobs also let you retrieve records from [long-term retention](data-retention-configure.md) and [tables with the Basic and Auxiliary plans](data-platform-logs.md#table-plans) into a new Analytics table where you can take advantage of Azure Monitor Log's full analytics capabilities. In this way, running a search job can be an alternative to: --- [Restoring data from long-term retention](restore.md) for a specific time range. --- Querying Basic and Auxiliary tables directly and paying for each query.<br/>- To determine which alternative is more cost-effective, compare the cost of querying Basic and Auxiliary tables with the cost of running a search job and storing the search job results. --## What does a search job do? --A search job sends its results to a new table in the same workspace as the source data. The results table is available as soon as the search job begins, but it may take time for results to begin to appear. --The search job results table is an [Analytics table](../logs/logs-table-plans.md) that is available for log queries and other Azure Monitor features that use tables in a workspace. The table uses the [retention value](data-retention-configure.md) set for the workspace, but you can modify this value after the table is created. --The search results table schema is based on the source table schema and the specified query. The following other columns help you track the source records: --| Column | Value | -|:--|:--| -| _OriginalType | *Type* value from source table. | -| _OriginalItemId | *_ItemID* value from source table. | -| _OriginalTimeGenerated | *TimeGenerated* value from source table. | -| TimeGenerated | Time at which the search job ran. | --Queries on the results table appear in [log query auditing](query-audit.md) but not the initial search job. --## Run a search job --Run a search job to fetch records from large datasets into a new search results table in your workspace. --> [!TIP] -> You incur charges for running a search job. Therefore, write and optimize your query in interactive query mode before running the search job. --### [Portal](#tab/portal-1) --To run a search job, in the Azure portal: --1. From the **Log Analytics workspace** menu, select **Logs**. --1. Select the ellipsis menu on the right-hand side of the screen and toggle **Search job mode** on. -- :::image type="content" source="media/search-job/switch-to-search-job-mode.png" alt-text="Screenshot of the Logs screen with the Search job mode switch highlighted." lightbox="media/search-job/switch-to-search-job-mode.png"::: -- Azure Monitor Logs intellisense supports [KQL query limitations in search job mode](#kql-query-limitations) to help you write your search job query. --1. Specify the search job date range using the time picker. --1. Type the search job query and select the **Search Job** button. -- Azure Monitor Logs prompts you to provide a name for the result set table and informs you that the search job is subject to billing. - - :::image type="content" source="media/search-job/run-search-job.png" alt-text="Screenshot that shows the Azure Monitor Logs prompt to provide a name for the search job results table." lightbox="media/search-job/run-search-job.png"::: --1. Enter a name for the search job result table and select **Run a search job**. -- Azure Monitor Logs runs the search job and creates a new table in your workspace for your search job results. -- :::image type="content" source="media/search-job/search-job-execution-1.png" alt-text="Screenshot that shows an Azure Monitor Logs message that the search job is running and the search job results table will be available shortly." lightbox="media/search-job/search-job-execution-1.png"::: --1. When the new table is ready, select **View tablename_SRCH** to view the table in Log Analytics. -- :::image type="content" source="media/search-job/search-job-execution-2.png" alt-text="Screenshot that shows an Azure Monitor Logs message that the search job results table is available to view." lightbox="media/search-job/search-job-execution-2.png"::: -- You can see the search job results as they begin flowing into the newly created search job results table. -- :::image type="content" source="media/search-job/search-job-execution-3.png" alt-text="Screenshot that shows search job results table with data." lightbox="media/search-job/search-job-execution-3.png"::: -- Azure Monitor Logs shows a **Search job is done** message at the end of the search job. The results table is now ready with all the records that match the search query. -- :::image type="content" source="media/search-job/search-job-done.png" alt-text="Screenshot that shows an Azure Monitor Logs message that the search job is done." lightbox="media/search-job/search-job-done.png"::: --### [API](#tab/api-1) --To run a search job, call the **Tables - Create or Update** API. The call includes the name of the results table to be created. The name of the results table must end with *_SRCH*. - -```http -PUT https://management.azure.com/subscriptions/{subscriptionId}/resourcegroups/{resourceGroupName}/providers/Microsoft.OperationalInsights/workspaces/{workspaceName}/tables/<TableName>_SRCH?api-version=2021-12-01-preview -``` --**Request body** --Include the following values in the body of the request: --| Name | Type | Description | -| - | - | - | -| properties.searchResults.query | string | Log query written in KQL to retrieve data. | -| properties.searchResults.limit | integer | Maximum number of records in the result set, up to one million records. (Optional) | -| properties.searchResults.startSearchTime | string | Start of the time range to search. | -| properties.searchResults.endSearchTime | string | End of the time range to search. | --**Sample request** --This example creates a table called *Syslog_suspected_SRCH* with the results of a query that searches for particular records in the *Syslog* table. --**Request** --```http -PUT https://management.azure.com/subscriptions/00000000-0000-0000-0000-00000000000/resourcegroups/testRG/providers/Microsoft.OperationalInsights/workspaces/testWS/tables/Syslog_suspected_SRCH?api-version=2021-12-01-preview -``` --**Request body** --```json -{ - "properties": { - "searchResults": { - "query": "Syslog | where * has 'suspected.exe'", - "limit": 1000, - "startSearchTime": "2020-01-01T00:00:00Z", - "endSearchTime": "2020-01-31T00:00:00Z" - } - } -} -``` --**Response** --Status code: 202 accepted. --### [CLI](#tab/cli-1) --To run a search job, run the [az monitor log-analytics workspace table search-job create](/cli/azure/monitor/log-analytics/workspace/table/search-job#az-monitor-log-analytics-workspace-table-search-job-create) command. The name of the results table, which you set using the `--name` parameter, must end with *_SRCH*. --**Example** --```azurecli -az monitor log-analytics workspace table search-job create --subscription ContosoSID --resource-group ContosoRG --workspace-name ContosoWorkspace --name HeartbeatByIp_SRCH --search-query 'Heartbeat | where ComputerIP has "00.000.00.000"' --limit 1500 --start-search-time "2022-01-01T00:00:00.000Z" --end-search-time "2022-01-08T00:00:00.000Z" --no-wait -``` --### [PowerShell](#tab/powershell-1) --To run a search job, run the [New-AzOperationalInsightsSearchTable](/powershell/module/az.operationalinsights/new-azoperationalinsightssearchtable) command. The name of the results table, which you set using the `TableName` parameter, must end with *_SRCH*. --**Example** --```powershell -New-AzOperationalInsightsSearchTable -ResourceGroupName ContosoRG -WorkspaceName ContosoWorkspace -TableName HeartbeatByIp_SRCH -SearchQuery "Heartbeat" -StartSearchTime "01-01-2022 00:00:00" -EndSearchTime "01-01-2022 00:00:00" -``` ----## Get search job status and details --### [Portal](#tab/portal-2) --1. From the **Log Analytics workspace** menu, select **Logs**. --1. From the Tables tab, select **Search results** to view all search job results tables. -- The icon on the search job results table displays an update indication until the search job is completed. - - :::image type="content" source="media/search-job/search-results-tables.png" alt-text="Screenshot that shows the Tables tab on Logs screen in the Azure portal with the search results tables listed under Search results." lightbox="media/search-job/search-results-tables.png"::: --### [API](#tab/api-2) --Call the **Tables - Get** API to get the status and details of a search job: -```http -GET https://management.azure.com/subscriptions/{subscriptionId}/resourcegroups/{resourceGroupName}/providers/Microsoft.OperationalInsights/workspaces/{workspaceName}/tables/<TableName>_SRCH?api-version=2021-12-01-preview -``` --**Table status** --Each search job table has a property called *provisioningState*, which can have one of the following values: --| Status | Description | -|:--|:--| -| Updating | Populating the table and its schema. | -| InProgress | Search job is running, fetching data. | -| Succeeded | Search job completed. | -| Deleting | Deleting the search job table. | --**Sample request** --This example retrieves the table status for the search job in the previous example. --**Request** --```http -GET https://management.azure.com/subscriptions/00000000-0000-0000-0000-00000000000/resourcegroups/testRG/providers/Microsoft.OperationalInsights/workspaces/testWS/tables/Syslog_SRCH?api-version=2021-12-01-preview -``` --**Response** --```json -{ - "properties": { - "retentionInDays": 30, - "totalRetentionInDays": 30, - "archiveRetentionInDays": 0, - "plan": "Analytics", - "lastPlanModifiedDate": "Mon, 01 Nov 2021 16:38:01 GMT", - "schema": { - "name": "Syslog_SRCH", - "tableType": "SearchResults", - "description": "This table was created using a Search Job with the following query: 'Syslog | where * has 'suspected.exe'.'", - "columns": [...], - "standardColumns": [...], - "solutions": [ - "LogManagement" - ], - "searchResults": { - "query": "Syslog | where * has 'suspected.exe'", - "limit": 1000, - "startSearchTime": "Wed, 01 Jan 2020 00:00:00 GMT", - "endSearchTime": "Fri, 31 Jan 2020 00:00:00 GMT", - "sourceTable": "Syslog" - } - }, - "provisioningState": "Succeeded" - }, - "id": "subscriptions/00000000-0000-0000-0000-00000000000/resourcegroups/testRG/providers/Microsoft.OperationalInsights/workspaces/testWS/tables/Syslog_SRCH", - "name": "Syslog_SRCH" -} -``` --### [CLI](#tab/cli-2) --To check the status and details of a search job table, run the [az monitor log-analytics workspace table show](/cli/azure/monitor/log-analytics/workspace/table#az-monitor-log-analytics-workspace-table-show) command. --**Example** --```azurecli -az monitor log-analytics workspace table show --subscription ContosoSID --resource-group ContosoRG --workspace-name ContosoWorkspace --name HeartbeatByIp_SRCH --output table \ -``` --### [PowerShell](#tab/powershell-2) --To check the status and details of a search job table, run the [Get-AzOperationalInsightsTable](/powershell/module/az.operationalinsights/get-azoperationalinsightstable) command. --**Example** --```powershell -Get-AzOperationalInsightsTable -ResourceGroupName "ContosoRG" -WorkspaceName "ContosoWorkspace" -tableName "HeartbeatByIp_SRCH" -``` --> [!NOTE] -> When "-TableName" is not provided, the command will instead list all tables associated with a workspace. ----## Delete a search job table --We recommend you [delete the search job table](../logs/create-custom-table.md#delete-a-table) when you're done querying the table. This reduces workspace clutter and extra charges for data retention. --## Limitations --Search jobs are subject to the following limitations: --* Optimized to query one table at a time. -* Search date range is up to one year. -* Supports long running searches up to a 24-hour time-out. -* Results are limited to one million records in the record set. -* Concurrent execution is limited to five search jobs per workspace. -* Limited to 100 search results tables per workspace. -* Limited to 100 search job executions per day per workspace. --When you reach the record limit, Azure aborts the job with a status of *partial success*, and the table will contain only records ingested up to that point. --### KQL query limitations --Search jobs are intended to scan large volumes of data in a specific table. Therefore, search job queries must always start with a table name. To enable asynchronous execution using distribution and segmentation, the query supports a subset of KQL, including the operators: --* [where](/azure/data-explorer/kusto/query/whereoperator) -* [extend](/azure/data-explorer/kusto/query/extendoperator) -* [project](/azure/data-explorer/kusto/query/projectoperator) -* [project-away](/azure/data-explorer/kusto/query/projectawayoperator) -* [project-keep](/azure/data-explorer/kusto/query/project-keep-operator) -* [project-rename](/azure/data-explorer/kusto/query/projectrenameoperator) -* [project-reorder](/azure/data-explorer/kusto/query/projectreorderoperator) -* [parse](/azure/data-explorer/kusto/query/parse-operator) -* [parse-where](/azure/data-explorer/kusto/query/parse-where-operator) --You can use all functions and binary operators within these operators. --## Pricing model -The charge for a search job is based on: --* Search job execution - the amount of data the search job scans. -* Search job results - the amount of data the search job finds and is ingested into the results table, based on the regular log data ingestion prices. --For example, if your table holds 500 GB per day, for a search over 30 days, you'll be charged for 15,000 GB of scanned data. -If the search job finds 1,000 records that match the search query, you'll be charged for ingesting these 1,000 records into the results table. --For more information, see [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/). --## Next steps --- [Learn more about data retention and archiving data.](data-retention-configure.md)-- [Learn about restoring data, which is another method for retrieving data from long-term retention.](restore.md)-- [Learn about directly querying Basic and Auxiliary tables.](basic-logs-query.md) |
| azure-monitor | Set Up Logs Ingestion Api Prerequisites | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/set-up-logs-ingestion-api-prerequisites.md | - Title: Set up resources required to send data to Azure Monitor Logs using the Logs Ingestion API -description: Run a PowerShell script to set up all resources required to send data to Azure Monitor using the Logs Ingestion API. ----- Previously updated : 08/12/2024---# Set up resources required to send data to Azure Monitor Logs using the Logs Ingestion API --This article provides a PowerShell script that sets up all of the resources you need before you can send data to Azure Monitor Logs using the [Logs ingestion API](logs-ingestion-api-overview.md). --> [!NOTE] -> As a Microsoft MVP, [Morten Waltorp Knudsen](https://mortenknudsen.net/) contributed to and provided material feedback for this article. For an example of how you can automate the setup and ongoing use of the Log Ingestion API, see Morten's [AzLogDcrIngestPS PowerShell module](https://github.com/KnudsenMorten/AzLogDcrIngestPS). --## Create resources and permissions -The script creates these resources, if they don't already exist: --- A Log Analytics workspace and a resource group for the Log Analytics workspace. - - You probably already have a Log Analytics workspace, in which case, provide the workspace details so the script sets up the other resources in the same region as the workspace. --- A Microsoft Entra application to authenticate against the API and:- - A service principal on the Microsoft Entra application - - A secret for the Microsoft Entra application -- A data collection endpoint (DCE) and a resource group for the data collection endpoint, in same region as Log Analytics workspace, to receive data. -- A resource group for data collection rules (DCR) in the same region as the Log Analytics workspace.--The script also grants the app `Contributor` permissions to: --- The Log Analytics workspace -- The resource group for data collection rules -- The resource group for data collection endpoints--## PowerShell script ----```powershell -# -# Prerequisite functions -# --Write-Output "Checking needed functions ... Please Wait !" -$ModuleCheck = Get-Module -Name Az.Resources -ListAvailable -ErrorAction SilentlyContinue -If (!($ModuleCheck)) - { - Write-Output "Installing Az-module in CurrentUser scope ... Please Wait !" - Install-module -Name Az -Force -Scope CurrentUser - } --$ModuleCheck = Get-Module -Name Microsoft.Graph -ListAvailable -ErrorAction SilentlyContinue -If (!($ModuleCheck)) - { - Write-Output "Installing Microsoft.Graph in CurrentUser scope ... Please Wait !" - Install-module -Name Microsoft.Graph -Force -Scope CurrentUser - } --<# - Install-module Az -Scope CurrentUser - Install-module Microsoft.Graph -Scope CurrentUser - install-module Az.portal -Scope CurrentUser -- Import-module Az -Scope CurrentUser - Import-module Az.Accounts -Scope CurrentUser - Import-module Az.Resources -Scope CurrentUser - Import-module Microsoft.Graph.Applications -Scope CurrentUser - Import-Module Microsoft.Graph.DeviceManagement.Enrolment -Scope CurrentUser -#> ---#- -# (1) Variables (Prerequisites, environment setup) -#- -$TenantId = "<your tenant ID>" --# Azure app registration -$AzureAppName = "Log-Ingestion-App" -$AzAppSecretName = "Log-Ingestion-App secret" --# Log Analytics workspace -$LogAnalyticsSubscription = "<Log Analytics workspace ID>" -$LogAnalyticsResourceGroup = "<Log Analytics workspace resource group>" -$LoganalyticsWorkspaceName = "<Log Analytics workspace name>" -$LoganalyticsLocation = "<Log Analytics workspace location>" --# Data collection endpoint -$AzDceName = "dce-log-ingestion-demo" -$AzDceResourceGroup = "rg-dce-log-ingestion-demo" --# Data collection rule -$AzDcrResourceGroup = "rg-dcr-log-ingestion-demo" -$AzDcrPrefix = "demo" --$VerbosePreference = "SilentlyContinue" # "Continue" --#- -# (2) Connectivity -#- - # Connect to Azure - Connect-AzAccount -Tenant $TenantId -WarningAction SilentlyContinue -- # Get access token - $AccessToken = Get-AzAccessToken -ResourceUrl https://management.azure.com/ - $AccessToken = $AccessToken.Token -- # Build headers for Azure REST API with access token - $Headers = @{ - "Authorization"="Bearer $($AccessToken)" - "Content-Type"="application/json" - } --- # Connect to Microsoft Graph - $MgScope = @( - "Application.ReadWrite.All",` - "Directory.Read.All",` - "Directory.AccessAsUser.All", - "RoleManagement.ReadWrite.Directory" - ) - Connect-MgGraph -TenantId $TenantId -Scopes $MgScope --#- -# (3) Prerequisites - deployment of environment (if missing) -#- -- <# - This section deploys all resources needed for ingesting logs using the Log Ingestion API. -- The deployment includes the following steps: -- (1) Create a resource group for the Log Analytics workspace - (2) Create the Log Analytics workspace - (3) Create an Azure App registration to send data to Azure Monitor Logs - (4) Create a service principal on the app - (5) Create a secret for the app - (6) Create a resource group for the data collection endpoint (DCE) in the same region as the Log Analytics workspace - (7) Create a resource group for data collection rules (DCR) in the same region as the Log Analytics workspace - (8) Create data collection endpoint (DCE) in same region as Log Analytics workspace - (9) Grant the Azure app permissions to the Log Analytics workspace - (10) Grant the Azure app permissions to the resource group for data collection rules (DCR) - (11) Grant the Azure app permissions to the resource group for data collection endpoints (DCE) - #> -- #- - # Azure context - #- -- Write-Output "" - Write-Output "Validating Azure context is subscription [ $($LogAnalyticsSubscription) ]" - $AzContext = Get-AzContext - If ($AzContext.Subscription -ne $LogAnalyticsSubscription ) - { - Write-Output "" - Write-Output "Switching Azure context to subscription [ $($LogAnalyticsSubscription) ]" - $AzContext = Set-AzContext -Subscription $LogAnalyticsSubscription -Tenant $TenantId - } -- #- - # Create the resource group for Log Analytics workspace - #- -- Write-Output "" - Write-Output "Validating Azure resource group exist [ $($LogAnalyticsResourceGroup) ]" - try { - Get-AzResourceGroup -Name $LogAnalyticsResourceGroup -ErrorAction Stop - } catch { - Write-Output "" - Write-Output "Creating Azure resource group [ $($LogAnalyticsResourceGroup) ]" - New-AzResourceGroup -Name $LogAnalyticsResourceGroup -Location $LoganalyticsLocation - } -- #- - # Create the workspace - #- -- Write-Output "" - Write-Output "Validating Log Analytics workspace exist [ $($LoganalyticsWorkspaceName) ]" - try { - $LogWorkspaceInfo = Get-AzOperationalInsightsWorkspace -Name $LoganalyticsWorkspaceName -ResourceGroupName $LogAnalyticsResourceGroup -ErrorAction Stop - } catch { - Write-Output "" - Write-Output "Creating Log Analytics workspace [ $($LoganalyticsWorkspaceName) ] in $LogAnalyticsResourceGroup" - New-AzOperationalInsightsWorkspace -Location $LoganalyticsLocation -Name $LoganalyticsWorkspaceName -Sku PerGB2018 -ResourceGroupName $LogAnalyticsResourceGroup - } -- #- - # Get workspace details - #- -- $LogWorkspaceInfo = Get-AzOperationalInsightsWorkspace -Name $LoganalyticsWorkspaceName -ResourceGroupName $LogAnalyticsResourceGroup -- $LogAnalyticsWorkspaceResourceId = $LogWorkspaceInfo.ResourceId -- #- - # Create Azure app registration - #- -- Write-Output "" - Write-Output "Validating Azure App [ $($AzureAppName) ]" - $AppCheck = Get-MgApplication -Filter "DisplayName eq '$AzureAppName'" -ErrorAction Stop - If ($AppCheck -eq $null) - { - Write-Output "" - Write-host "Creating Azure App [ $($AzureAppName) ]" - $AzureApp = New-MgApplication -DisplayName $AzureAppName - } -- #- - # Create service principal on Azure app - #- -- Write-Output "" - Write-Output "Validating Azure Service Principal on App [ $($AzureAppName) ]" - $AppInfo = Get-MgApplication -Filter "DisplayName eq '$AzureAppName'" -- $AppId = $AppInfo.AppId - $ObjectId = $AppInfo.Id -- $ServicePrincipalCheck = Get-MgServicePrincipal -Filter "AppId eq '$AppId'" - If ($ServicePrincipalCheck -eq $null) - { - Write-Output "" - Write-host "Creating Azure Service Principal on App [ $($AzureAppName) ]" - $ServicePrincipal = New-MgServicePrincipal -AppId $AppId - } -- #- - # Create secret on Azure app - #- -- Write-Output "" - Write-Output "Validating Azure Secret on App [ $($AzureAppName) ]" - $AppInfo = Get-MgApplication -Filter "AppId eq '$AppId'" -- $AppId = $AppInfo.AppId - $ObjectId = $AppInfo.Id -- If ($AzAppSecretName -notin $AppInfo.PasswordCredentials.DisplayName) - { - Write-Output "" - Write-host "Creating Azure Secret on App [ $($AzureAppName) ]" -- $passwordCred = @{ - displayName = $AzAppSecretName - endDateTime = (Get-Date).AddYears(1) - } -- $AzAppSecret = (Add-MgApplicationPassword -applicationId $ObjectId -PasswordCredential $passwordCred).SecretText - Write-Output "" - Write-Output "Secret with name [ $($AzAppSecretName) ] created on app [ $($AzureAppName) ]" - Write-Output $AzAppSecret - Write-Output "" - Write-Output "AppId for app [ $($AzureAppName) ] is" - Write-Output $AppId - } -- #- - # Create a resource group for data collection endpoints (DCE) in the same region as the Log Analytics workspace - #- -- Write-Output "" - Write-Output "Validating Azure resource group exist [ $($AzDceResourceGroup) ]" - try { - Get-AzResourceGroup -Name $AzDceResourceGroup -ErrorAction Stop - } catch { - Write-Output "" - Write-Output "Creating Azure resource group [ $($AzDceResourceGroup) ]" - New-AzResourceGroup -Name $AzDceResourceGroup -Location $LoganalyticsLocation - } -- #- - # Create a resource group for data collection rules (DCR) in the same region as the Log Analytics workspace - #- -- Write-Output "" - Write-Output "Validating Azure resource group exist [ $($AzDcrResourceGroup) ]" - try { - Get-AzResourceGroup -Name $AzDcrResourceGroup -ErrorAction Stop - } catch { - Write-Output "" - Write-Output "Creating Azure resource group [ $($AzDcrResourceGroup) ]" - New-AzResourceGroup -Name $AzDcrResourceGroup -Location $LoganalyticsLocation - } -- #- - # Create data collection endpoint - #- -- Write-Output "" - Write-Output "Validating data collection endpoint exist [ $($AzDceName) ]" - - $DceUri = "https://management.azure.com" + "/subscriptions/" + $LogAnalyticsSubscription + "/resourceGroups/" + $AzDceResourceGroup + "/providers/Microsoft.Insights/dataCollectionEndpoints/" + $AzDceName + "?api-version=2022-06-01" - Try - { - Invoke-RestMethod -Uri $DceUri -Method GET -Headers $Headers - } - Catch - { - Write-Output "" - Write-Output "Creating/updating DCE [ $($AzDceName) ]" -- $DceObject = [pscustomobject][ordered]@{ - properties = @{ - description = "DCE for LogIngest to LogAnalytics $LoganalyticsWorkspaceName" - networkAcls = @{ - publicNetworkAccess = "Enabled" -- } - } - location = $LogAnalyticsLocation - name = $AzDceName - type = "Microsoft.Insights/dataCollectionEndpoints" - } -- $DcePayload = $DceObject | ConvertTo-Json -Depth 20 -- $DceUri = "https://management.azure.com" + "/subscriptions/" + $LogAnalyticsSubscription + "/resourceGroups/" + $AzDceResourceGroup + "/providers/Microsoft.Insights/dataCollectionEndpoints/" + $AzDceName + "?api-version=2022-06-01" -- Try - { - Invoke-WebRequest -Uri $DceUri -Method PUT -Body $DcePayload -Headers $Headers - } - Catch - { - } - } - - #- - # Sleeping 1 min to let Azure AD replicate before delegation - #- -- # Write-Output "Sleeping 1 min to let Azure AD replicate before doing delegation" - # Start-Sleep -s 60 -- #- - # Grant the Azure app permissions to the Log Analytics workspace - # Needed for table management - not needed for log ingestion - for simplicity, it's set up when there's one app - #- -- Write-Output "" - Write-Output "Setting Contributor permissions for app [ $($AzureAppName) ] on the Log Analytics workspace [ $($LoganalyticsWorkspaceName) ]" -- $LogWorkspaceInfo = Get-AzOperationalInsightsWorkspace -Name $LoganalyticsWorkspaceName -ResourceGroupName $LogAnalyticsResourceGroup -- $LogAnalyticsWorkspaceResourceId = $LogWorkspaceInfo.ResourceId -- $ServicePrincipalObjectId = (Get-MgServicePrincipal -Filter "AppId eq '$AppId'").Id - $DcrRgResourceId = (Get-AzResourceGroup -Name $AzDcrResourceGroup).ResourceId -- # Contributor on Log Analytics workspace - $guid = (new-guid).guid - $ContributorRoleId = "b24988ac-6180-42a0-ab88-20f7382dd24c" # Contributor - $roleDefinitionId = "/subscriptions/$($LogAnalyticsSubscription)/providers/Microsoft.Authorization/roleDefinitions/$($ContributorRoleId)" - $roleUrl = "https://management.azure.com" + $LogAnalyticsWorkspaceResourceId + "/providers/Microsoft.Authorization/roleAssignments/$($Guid)?api-version=2018-07-01" - $roleBody = @{ - properties = @{ - roleDefinitionId = $roleDefinitionId - principalId = $ServicePrincipalObjectId - scope = $LogAnalyticsWorkspaceResourceId - } - } - $jsonRoleBody = $roleBody | ConvertTo-Json -Depth 6 -- $result = try - { - Invoke-RestMethod -Uri $roleUrl -Method PUT -Body $jsonRoleBody -headers $Headers -ErrorAction SilentlyContinue - } - catch - { - } --- #- - # Grant the Azure app permissions to the DCR resource group - #- -- Write-Output "" - Write-Output "Setting Contributor permissions for app [ $($AzureAppName) ] on resource group [ $($AzDcrResourceGroup) ]" -- $ServicePrincipalObjectId = (Get-MgServicePrincipal -Filter "AppId eq '$AppId'").Id - $AzDcrRgResourceId = (Get-AzResourceGroup -Name $AzDcrResourceGroup).ResourceId -- # Contributor - $guid = (new-guid).guid - $ContributorRoleId = "b24988ac-6180-42a0-ab88-20f7382dd24c" # Contributor - $roleDefinitionId = "/subscriptions/$($LogAnalyticsSubscription)/providers/Microsoft.Authorization/roleDefinitions/$($ContributorRoleId)" - $roleUrl = "https://management.azure.com" + $AzDcrRgResourceId + "/providers/Microsoft.Authorization/roleAssignments/$($Guid)?api-version=2018-07-01" - $roleBody = @{ - properties = @{ - roleDefinitionId = $roleDefinitionId - principalId = $ServicePrincipalObjectId - scope = $AzDcrRgResourceId - } - } - $jsonRoleBody = $roleBody | ConvertTo-Json -Depth 6 -- $result = try - { - Invoke-RestMethod -Uri $roleUrl -Method PUT -Body $jsonRoleBody -headers $Headers -ErrorAction SilentlyContinue - } - catch - { - } -- Write-Output "" - Write-Output "Setting Monitoring Metrics Publisher permissions for app [ $($AzureAppName) ] on RG [ $($AzDcrResourceGroup) ]" -- # Monitoring Metrics Publisher - $guid = (new-guid).guid - $monitorMetricsPublisherRoleId = "3913510d-42f4-4e42-8a64-420c390055eb" - $roleDefinitionId = "/subscriptions/$($LogAnalyticsSubscription)/providers/Microsoft.Authorization/roleDefinitions/$($monitorMetricsPublisherRoleId)" - $roleUrl = "https://management.azure.com" + $AzDcrRgResourceId + "/providers/Microsoft.Authorization/roleAssignments/$($Guid)?api-version=2018-07-01" - $roleBody = @{ - properties = @{ - roleDefinitionId = $roleDefinitionId - principalId = $ServicePrincipalObjectId - scope = $AzDcrRgResourceId - } - } - $jsonRoleBody = $roleBody | ConvertTo-Json -Depth 6 -- $result = try - { - Invoke-RestMethod -Uri $roleUrl -Method PUT -Body $jsonRoleBody -headers $Headers -ErrorAction SilentlyContinue - } - catch - { - } -- #- - # Grant the Azure app permissions to the DCE resource group - #- -- Write-Output "" - Write-Output "Setting Contributor permissions for app [ $($AzDceName) ] on RG [ $($AzDceResourceGroup) ]" -- $ServicePrincipalObjectId = (Get-MgServicePrincipal -Filter "AppId eq '$AppId'").Id - $AzDceRgResourceId = (Get-AzResourceGroup -Name $AzDceResourceGroup).ResourceId -- # Contributor - $guid = (new-guid).guid - $ContributorRoleId = "b24988ac-6180-42a0-ab88-20f7382dd24c" # Contributor - $roleDefinitionId = "/subscriptions/$($LogAnalyticsSubscription)/providers/Microsoft.Authorization/roleDefinitions/$($ContributorRoleId)" - $roleUrl = "https://management.azure.com" + $AzDceRgResourceId + "/providers/Microsoft.Authorization/roleAssignments/$($Guid)?api-version=2018-07-01" - $roleBody = @{ - properties = @{ - roleDefinitionId = $roleDefinitionId - principalId = $ServicePrincipalObjectId - scope = $AzDceRgResourceId - } - } - $jsonRoleBody = $roleBody | ConvertTo-Json -Depth 6 -- $result = try - { - Invoke-RestMethod -Uri $roleUrl -Method PUT -Body $jsonRoleBody -headers $Headers -ErrorAction SilentlyContinue - } - catch - { - } -- #-- - # Summarize environment details - #-- -- # Azure App - Write-Output "" - Write-Output "Tenant Id:" - Write-Output $TenantId -- # Azure App - $AppInfo = Get-MgApplication -Filter "DisplayName eq '$AzureAppName'" - $AppId = $AppInfo.AppId - $ObjectId = $AppInfo.Id -- Write-Output "" - Write-Output "Log Ingestion Azure App name:" - Write-Output $AzureAppName -- Write-Output "" - Write-Output "Log Ingestion Azure App ID:" - Write-Output $AppId - Write-Output "" --- If ($AzAppSecret) - { - Write-Output "LogIngestion Azure App secret:" - Write-Output $AzAppSecret - } - Else - { - Write-Output "Log Ingestion Azure App secret:" - Write-Output "N/A (new secret must be made)" - } -- # Azure Service Principal for App - $ServicePrincipalObjectId = (Get-MgServicePrincipal -Filter "AppId eq '$AppId'").Id - Write-Output "" - Write-Output "Log Ingestion service principal Object ID for app:" - Write-Output $ServicePrincipalObjectId -- # Azure Loganalytics - Write-Output "" - $LogWorkspaceInfo = Get-AzOperationalInsightsWorkspace -Name $LoganalyticsWorkspaceName -ResourceGroupName $LogAnalyticsResourceGroup - $LogAnalyticsWorkspaceResourceId = $LogWorkspaceInfo.ResourceId -- Write-Output "" - Write-Output "Log Analytics workspace resource ID:" - Write-Output $LogAnalyticsWorkspaceResourceId -- # DCE - $DceUri = "https://management.azure.com" + "/subscriptions/" + $LogAnalyticsSubscription + "/resourceGroups/" + $AzDceResourceGroup + "/providers/Microsoft.Insights/dataCollectionEndpoints/" + $AzDceName + "?api-version=2022-06-01" - $DceObj = Invoke-RestMethod -Uri $DceUri -Method GET -Headers $Headers -- $AzDceLogIngestionUri = $DceObj.properties.logsIngestion[0].endpoint -- Write-Output "" - Write-Output "Data collection endpoint name:" - Write-Output $AzDceName -- Write-Output "" - Write-Output "Data collection endpoint Log Ingestion URI:" - Write-Output $AzDceLogIngestionUri - Write-Output "" - Write-Output "-" -``` --## Next steps --- [Learn more about data collection rules](../essentials/data-collection-rule-overview.md)-- [Learn more about writing transformation queries](../essentials//data-collection-transformations.md) |
| azure-monitor | Summary Rules | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/summary-rules.md | - Title: Aggregate data in a Log Analytics workspace by using summary rules (Preview) -description: Aggregate data in Log Analytics workspace with summary rules feature in Azure Monitor, including creating, starting, stopping, and troubleshooting rules. ------ Previously updated : 04/23/2024--# Customer intent: As a Log Analytics workspace administrator or developer, I want to optimize my query performance, cost-effectiveness, security, and analysis capabilities by using summary rules to aggregate data I ingest to specific tables. ---# Aggregate data in a Log Analytics workspace by using summary rules (Preview) --A summary rule lets you aggregate log data at a regular cadence and send the aggregated results to a custom log table in your Log Analytics workspace. Use summary rules to optimize your data for: --- **Analysis and reports**, especially over large data sets and time ranges, as required for security and incident analysis, month-over-month or annual business reports, and so on. Complex queries on a large data set often time out. It's easier and more efficient to analyze and report on _cleaned_ and _aggregated_ summarized data. --- **Cost savings** on verbose logs, which you can retain for as little or as long as you need in a cheap Basic log table, and send summarized data to an Analytics table for analysis and reports. --- **Security and data privacy** by removing or obfuscating privacy details in summarized shareable data and limiting access to tables with raw data.--This article describes how summary rules work and how to define and view summary rules, and provides some examples of the use and benefits of summary rules. --Here's a video that provides an overview of some of the benefits of summary rules: --> [!VIDEO https://www.youtube.com/embed/uuZlOps42LE?cc_load_policy=1&cc_lang_pref=auto] --## How summary rules work --Summary rules perform batch processing directly in your Log Analytics workspace. The summary rule aggregates chunks of data, defined by bin size, based on a KQL query, and reingests the summarized results into a custom table with an [Analytics log plan](logs-table-plans.md) in your Log Analytics workspace. ---You can aggregate data from any table, regardless of whether the table has an [Analytics or Basic data plan](basic-logs-query.md). Azure Monitor creates the destination table schema based on the query you define. If the destination table already exists, Azure Monitor adds any columns required to support the query results. All destination tables also include a set of standard fields with summary rule information, including: --- `_RuleName`: The summary rule that generated the aggregated log entry.-- `_RuleLastModifiedTime`: When the rule was last modified. -- `_BinSize`: The aggregation interval. -- `_BinStartTime` The aggregation start time.--You can configure up to 30 active rules to aggregate data from multiple tables and send the aggregated data to separate destination tables or the same table. --You can export summarized data from a custom log table to a storage account or Event Hubs for further integrations by defining a [data export rule](logs-data-export.md). --### Example: Summarize ContainerLogsV2 data --If you're monitoring containers, you ingest a large volume of verbose logs into the `ContainerLogsV2` table. --You might use this query in your summary rule to aggregate all unique log entries within 60 minutes, keeping the data that's useful for analysis and dropping data you don't need: --```kusto -ContainerLogV2 | summarize Count = count() by Computer, ContainerName, PodName, PodNamespace, LogSource, LogLevel, Message = tostring(LogMessage.Message) -``` --Here's the raw data in the `ContainerLogsV2` table: ---Here's the aggregated data that the summary rule sends to the destination table: ---Instead of logging hundreds of similar entries within an hour, the destination table shows the count of each unique entry, as defined in the KQL query. Set the [Basic data plan](logs-table-plans.md) on the `ContainerLogsV2` table for cheap retention of the raw data, and use the summarized data in the destination table for your analysis needs. --## Permissions required --| Action | Permissions required | -| | | -| Create or update summary rule | `Microsoft.Operationalinsights/workspaces/summarylogs/write` permissions to the Log Analytics workspace, as provided by the [Log Analytics Contributor built-in role](manage-access.md#log-analytics-contributor), for example | -| Create or update destination table | `Microsoft.OperationalInsights/workspaces/tables/write` permissions to the Log Analytics workspace, as provided by the [Log Analytics Contributor built-in role](manage-access.md#log-analytics-contributor), for example | -| Enable query in workspace | `Microsoft.OperationalInsights/workspaces/query/read` permissions to the Log Analytics workspace, as provided by the [Log Analytics Reader built-in role](manage-access.md#log-analytics-reader), for example | -| Query all logs in workspace | `Microsoft.OperationalInsights/workspaces/query/*/read` permissions to the Log Analytics workspace, as provided by the [Log Analytics Reader built-in role](manage-access.md#log-analytics-reader), for example | -| Query logs in table | `Microsoft.OperationalInsights/workspaces/query/<table>/read` permissions to the Log Analytics workspace, as provided by the [Log Analytics Reader built-in role](manage-access.md#log-analytics-reader), for example | -| Query logs in table (table action) | `Microsoft.OperationalInsights/workspaces/tables/query/read` permissions to the Log Analytics workspace, as provided by the [Log Analytics Reader built-in role](manage-access.md#log-analytics-reader), for example | -| Use queries encrypted in a customer-managed storage account|`Microsoft.Storage/storageAccounts/*` permissions to the storage account, as provided by the [Storage Account Contributor built-in role](/azure/role-based-access-control/built-in-roles/storage#storage-account-contributor), for example| ---## Restrictions and limitations --| Category | Limit | -|:|:| -| Maximum number of active rules in a workspace | 30 | -| Maximum number of results per bin | 500,000 | -| Maximum results set volume | 100 MB | -| Query time-out for bin processing | 10 minutes | --- Summary rules are currently only available in the public cloud. -- The summary rule processes incoming data and can't be configured on a historical time range. -- When bin execution retries are exhausted, the bin is skipped and can't be re-executed.-- Querying a Log Analytics workspace in another tenant by using Lighthouse isn't supported.-- KQL limits depend on the table plan of the source table. -- - Analytics: Supports all KQL commands, except for: - - - [Cross-resource queries](cross-workspace-query.md), using the `workspaces()`, `app()`, and `resource()` expressions, and [cross-service queries](azure-monitor-data-explorer-proxy.md), using the `ADX()` and `ARG()` expressions. - - Plugins that reshape the data schema, including [bag unpack](/azure/data-explorer/kusto/query/bag-unpack-plugin), [narrow](/azure/data-explorer/kusto/query/narrow-plugin), and [pivot](/azure/data-explorer/kusto/query/pivot-plugin). - - Basic: Supports all KQL commands on a single table. You can join up to five Analytics tables using the [lookup](/azure/data-explorer/kusto/query/lookup-operator) operator. - - Functions: User-defined functions aren't supported. System functions provided by Microsoft are supported. --## Pricing model --There's no extra cost for Summary rules. You only pay for the query and the ingestion of results to the destination table, based on the table plan of the source table on which you run the query: --| Source table plan | Query cost | Summary results ingestion cost | -| | | | -| Analytics | No cost | Analytics ingested GB | -| Basic and Auxiliary | Scanned GB | Analytics ingested GB | --For example, the cost calculation for an hourly rule that returns 100 records per bin is: --| Source table plan | Monthly price calculation -| | | -| Analytics | Ingestion price x record size x number of records x 24 hours x 30 days | -| Basic and Auxiliary | Scanned GB price x scanned size + Ingestion price x record size x number of records x 24 hours x 30 days | --For more information, see [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/). --## Create or update a summary rule --Before you create a rule, experiment with the query in [Log Analytics](log-analytics-overview.md). Verify that the query doesn't reach or near the query limit. Check that the query produces the intended schema and expected results. If the query is close to the query limits, consider using a smaller `binSize` to process less data per bin. You can also modify the query to return fewer records or remove fields with higher volume. --> [!NOTE] -> Summary rules are most beneficial in term of cost and results consumption when reduced significantly. For example, results volume is 0.01% or less than source. --When you update a query and remove output fields from the results set, Azure Monitor doesn't automatically remove the columns from the destination table. You need to [delete columns from your table](create-custom-table.md#add-or-delete-a-custom-column) manually. ---### [API](#tab/api) --To create or update a summary rule, make this `PUT` API call: --```kusto -PUT https://management.azure.com/subscriptions/{subscriptionId}/resourceGroups/{resourcegroup}/providers/Microsoft.OperationalInsights/workspaces/{workspace}/summarylogs/{ruleName}?api-version=2023-01-01-preview -Authorization: {credential} --{ - "properties": { - "ruleType": "User", - "description": "My test rule", - "ruleDefinition": { - "query": "StorageBlobLogs | summarize count() by AccountName", - "binSize": 30, - "destinationTable": "MySummaryLogs_CL" - } - } -} -``` --### [Azure Resource Manager template](#tab/azure-resource-manager) --Use this template to create or update a summary rule. For more information about using and deploying Azure Resource Manager templates, see [Azure Resource Manager templates](../../azure-resource-manager/templates/syntax.md). --#### Template file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceName": { - "type": "String", - "metadata": { - "description": "The workspace name where summary rule is deployed." - } - }, - "summaryRuleName": { - "type": "String", - "metadata": { - "description": "The summary rule name." - } - }, - "description": { - "type": "String", - "metadata": { - "description": "A description of the rule." - } - }, - "location": { - "defaultValue": "[resourceGroup().location]", - "type": "String", - "metadata": { - "description": "The Location of the workspace summary rule is deployed." - } - }, - "ruleType": { - "defaultValue": "User", - "allowedValues": [ - "User" - ], - "type": "String", - "metadata": { - "description": "The summary rule type (User,System). Should be 'User' for and rule with query that you define." - } - }, - "query": { - "type": "String", - "metadata": { - "description": "The query used in summary rules." - } - }, - "binSize": { - "defaultValue": 60, - "allowedValues": [ - 20, - 30, - 60, - 120, - 180, - 360, - 720, - 1440 - ], - "type": "Int", - "metadata": { - "description": "The execution interval in minutes, and the lookback time range." - } - }, - "destinationTable": { - "type": "String", - "metadata": { - "description": "The name of the custom log table that the summary results are sent to. Name must end with '_CL'." - } - } - // -- optional -- - // "binDelay": { - // "type": "Int", - // "metadata": { - // "description": "Optional - The minimum wait time in minutes before bin execution. For example, value of '10' cause bin (01:00-02:00) to be executed after 02:10." - // } - // }, - // "timeSelector": { - // "defaultValue": "TimeGenerated", - // "allowedValues": [ - // "TimeGenerated" - // ], - // "type": "String", - // "metadata": { - // "description": "Optional - The time field to be used by the summary rule. Must be 'TimeGenerated'." - // } - // }, - // "binStartTime": { - // "type": "String", - // "metadata": { - // "description": "Optional - The Time of initial bin. Can start at current time minus binSize, or future, and in whole hours. For example: '2024-01-01T08:00'." - // } - // } - }, - "variables": {}, - "resources": [ - { - "type": "Microsoft.OperationalInsights/workspaces/summaryLogs", - "apiVersion": "2023-01-01-preview", - //"name": "[format('{0}/{1}', parameters('workspaceName'), parameters('summaryRuleName'))]", - "name": "[concat(parameters('workspaceName'), '/', parameters('summaryRuleName'))]", - "properties": { - "ruleType": "[parameters('ruleType')]", - "description": "[parameters('description')]", - "ruleDefinition": { - "query": "[parameters('query')]", - "binSize": "[parameters('binSize')]", - "destinationTable": "[parameters('destinationTable')]" - // -- optional -- - //"binDelay": "[parameters('binDelay')]", - //"timeSelector": "[parameters('timeSelector')]", - //"binStartTime": "[parameters('binStartTime')]" - } - } - } - ] -} -``` ---#### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceName": { - "value": "myworkspace" - }, - "summaryRuleName": { - "value": "myrulename" - }, - "description": { - "value": "My rule description." - }, - "location": { - "value": "eastus" //Log Analytics workspace region - }, - "ruleType": { - "value": "User" - }, - "query": { - "value": "StorageBlobLogs | summarize Count = count(), DurationMs98 = percentile(DurationMs, 90) by StatusCode, CallerIpAddress, OperationName" - }, - "binSize": { - "value": 20 - }, - "destinationTable": { - "value": "MySummaryLogs_CL" - } - } -} -``` ---This table describes the summary rule parameters: --| Parameter | Valid values | Description | -| | | -| `ruleType` | `User` or `System` | Specifies the type of rule. <br> - `User`: Rules you define. <br> - `System`: Predefined rules managed by Azure services. | -| `description` | String | Describes the rule and its function. This parameter is helpful when you have several rules and can help with rule management. | -| `binSize` |`20`, `30`, `60`, `120`, `180`, `360`, `720`, or `1,440` (minutes) | Defines the aggregation interval and lookback time range. For example, if you set `"binSize": 120`, you might get entries for `02:00 to 04:00` and `04:00 to 06:00`.| -| `query` | [Kusto Query Language (KQL) query](get-started-queries.md) | Defines the query to execute in the rule. You don't need to specify a time range because the `binSize` parameter determines the aggregation interval - for example, `02:00 to 03:00` if `"binSize": 60`. If you add a time filter in the query, the time rage used in the query is the intersection between the filter and the bin size. | -| `destinationTable` | `tablename_CL` | Specifies the name of the destination custom log table. The name value must have the suffix `_CL`. Azure Monitor creates the table in the workspace, if it doesn't already exist, based on the query you set in the rule. If the table already exists in the workspace, Azure Monitor adds any new columns introduced in the query. <br><br> If the summary results include a reserved column name - such as `TimeGenerated`, `_IsBillable`, `_ResourceId`, `TenantId`, or `Type` - Azure Monitor appends the `_Original` prefix to the original fields to preserve their original values.| -| `binDelay` (optional) | Integer (minutes) | Sets a time to delay before bin execution for late arriving data, also known as [ingestion latency](data-ingestion-time.md). The delay allows for most data to arrive and for service load distribution. The default delay is from three and a half minutes to 10% of the `binSize` value. <br><br> If you know that the data you query is typically ingested with delay, set the `binDelay` parameter with the known delay value or greater. For more information, see [Configure the aggregation timing](#configure-the-aggregation-timing).<br>In some cases, Azure Monitor might begin bin execution slightly after the set bin delay to ensure service reliability and query success.| -| `binStartTime` (optional) | Datetime in<br>`%Y-%n-%eT%H:%M %Z` format | Specifies the date and time for the initial bin execution. The value can start at rule creation datetime minus the `binSize` value, or later and in whole hours. For example, if the datetime is `2023-12-03T12:13Z` and `binSize` is 1,440, the earliest valid `binStartTime` value is `2023-12-02T13:00Z`, and the aggregation includes data logged between 02T13:00 and 03T13:00. In this scenario, the rules start aggregating a 03T13:00 plus the default or specified delay. <br><br> The `binStartTime` parameter is useful in daily summary scenarios. Suppose you're in the UTC-8 time zone and you create a daily rule at `2023-12-03T12:13Z`. You want the rule to complete before you start your day at 8:00 (00:00 UTC). Set the `binStartTime` parameter to `2023-12-02T22:00Z`. The first aggregation includes all data logged between 02T:06:00 and 03T:06:00 local time, and the rule runs at the same time daily. For more information, see [Configure the aggregation timing](#configure-the-aggregation-timing).<br><br> When you update rules, you can either: <br> - Use the existing `binStartTime` value or remove the `binStartTime` parameter, in which case execution continues based on the initial definition.<br> - Update the rule with a new `binStartTime` value to set a new datetime value. | -| `timeSelector` (optional) | `TimeGenerated` | Defines the timestamp field that Azure Monitor uses to aggregate data. For example, if you set `"binSize": 120`, you might get entries with a `TimeGenerated` value between `02:00` and `04:00`. | ---### Configure the aggregation timing --By default, the summary rule creates the first aggregation shortly after the next whole hour. --The short delay Azure Monitor adds accounts for ingestion latency - or the time between when the data is created in the monitored system and the time that it becomes available for analysis in Azure Monitor. By default, this delay is between three and a half minutes to 10% of the `binSize` value before aggregating each chunk of data. In most cases, this delay ensures that Azure Monitor aggregates all data logged within each bin period. --For example: --- You create a summary rule with a bin size of 30 minutes at 14:44. -- The rule creates the first aggregation shortly after 15:00 - for example, at 15:04 - for data logged between 14:30 and 15:00. -- You create a summary rule with a bin size of 720 minutes (12 hours) at 14:44. -- The rule creates the first aggregation at 16:12 - 72 minutes (10% of the 720 bin size) after 13:00 - for data logged between 03:00 and 15:00. --Use the `binStartTime` and `binDelay` parameters to change the timing of the first aggregation and the delay Azure Monitor adds before each aggregation. --The next sections provide examples of the default aggregation timing and the more advanced aggregation timing options. --#### Use default aggregation timing --In this example, the summary rule is created at on 2023-06-07 at 14:44, and Azure Monitor adds a default delay of **four minutes**. --| binSize (minutes) | Initial rule run | First aggregation | Second aggregation | -| | | | | -| 1440 | 2023-06-07 15:04 | 2023-06-06 15:00 - 2023-06-07 15:00 | 2023-06-07 15:00 - 2023-06-08 15:00 | -| 720 | 2023-06-07 15:04 | 2023-06-07 03:00 - 2023-06-07 15:00 | 2023-06-07 15:00 - 2023-06-08 03:00 | -| 360 | 2023-06-07 15:04 | 2023-06-07 09:00 - 2023-06-07 15:00 | 2023-06-07 15:00 - 2023-06-07 21:00 | -| 180 | 2023-06-07 15:04 | 2023-06-07 12:00 - 2023-06-07 15:00 | 2023-06-07 15:00 - 2023-06-07 18:00 | -| 120 | 2023-06-07 15:04 | 2023-06-07 13:00 - 2023-06-07 15:00 | 2023-06-07 15:00 - 2023-06-07 17:00 | -| 60 | 2023-06-07 15:04 | 2023-06-07 14:00 - 2023-06-07 15:00 | 2023-06-07 15:00 - 2023-06-07 16:00 | -| 30 | 2023-06-07 15:04 | 2023-06-07 14:30 - 2023-06-07 15:00 | 2023-06-07 15:00 - 2023-06-07 15:30 | -| 20 | 2023-06-07 15:04 | 2023-06-07 14:40 - 2023-06-07 15:00 | 2023-06-07 15:00 - 2023-06-07 15:20 | --#### Set optional aggregation timing parameters --In this example, the summary rule is created at on 2023-06-07 at 14:44, and the rule includes these advanced configuration settings: -- `binStartTime`: 2023-06-08 07:00-- `binDelay`: **8 minutes**--| binSize (minutes) | Initial rule run | First aggregation | Second aggregation | -| | | | | -| 1440 | 2023-06-09 07:08 | 2023-06-08 07:00 - 2023-06-09 07:00 | 2023-06-09 07:00 - 2023-06-10 07:00 | -| 720 | 2023-06-08 19:08 | 2023-06-08 07:00 - 2023-06-08 19:00 | 2023-06-08 19:00 - 2023-06-09 07:00 | -| 360 | 2023-06-08 13:08 | 2023-06-08 07:00 - 2023-06-08 13:00 | 2023-06-08 13:00 - 2023-06-08 19:00 | -| 180 | 2023-06-08 10:08 | 2023-06-08 07:00 - 2023-06-08 10:00 | 2023-06-08 10:00 - 2023-06-08 13:00 | -| 120 | 2023-06-08 09:08 | 2023-06-08 07:00 - 2023-06-08 09:00 | 2023-06-08 09:00 - 2023-06-08 11:00 | -| 60 | 2023-06-08 08:08 | 2023-06-08 07:00 - 2023-06-08 08:00 | 2023-06-08 08:00 - 2023-06-08 09:00 | -| 30 | 2023-06-08 07:38 | 2023-06-08 07:00 - 2023-06-08 07:30 | 2023-06-08 07:30 - 2023-06-08 08:00 | -| 20 | 2023-06-08 07:28 | 2023-06-08 07:00 - 2023-06-08 07:20 | 2023-06-08 07:20 - 2023-06-08 07:40 | --## View summary rules --Use this `GET` API call to view the configuration for a specific summary rule: --```kusto -GET https://management.azure.com/subscriptions/{subscriptionId}/resourceGroups/{resourcegroup}/providers/Microsoft.OperationalInsights/workspaces/{workspace}/summarylogs/{ruleName1}?api-version=2023-01-01-preview -Authorization: {credential} -``` --Use this `GET` API call to view the configuration to view the configuration of all summary rules in your Log Analytics workspace: --```kusto -GET https://management.azure.com/subscriptions/{subscriptionId}/resourceGroups/{resourcegroup}/providers/Microsoft.OperationalInsights/workspaces/{workspace}/summarylogs?api-version=2023-01-01-preview -Authorization: {credential} -``` --## Stop and restart a summary rule --You can stop a rule for a period of time - for example, if you want to verify that data is ingested to a table and you don't want to affect the summarized table and reports. When you restart the rule, Azure Monitor starts processing data from the next whole hour or based on the defined `binStartTime` (optional) parameter. --To stop a rule, use this `POST` API call: --```kusto -POST https://management.azure.com/subscriptions/{subscriptionId}/resourceGroups/{resourcegroup}/providers/Microsoft.OperationalInsights/workspaces/{workspace}/summarylogs/{ruleName}/stop?api-version=2023-01-01-preview -Authorization: {credential} -``` --To restart the rule, use this `POST` API call: --```kusto -POST https://management.azure.com/subscriptions/{subscriptionId}/resourceGroups/{resourcegroup}/providers/Microsoft.OperationalInsights/workspaces/{workspace}/summarylogs/{ruleName}/start?api-version=2023-01-01-preview -Authorization: {credential} -``` --## Delete a summary rule --You can have up to 30 active summary rules in your Log Analytics workspace. If you want to create a new rule, but you already have 30 active rules, you must stop or delete an active summary rule. --To delete a rule, use this `DELETE` API call: --```kusto -DELETE https://management.azure.com/subscriptions/{subscriptionId}/resourceGroups/{resourcegroup}/providers/Microsoft.OperationalInsights/workspaces/{workspace}/summarylogs/{ruleName}?api-version=2023-01-01-preview -Authorization: {credential} -``` --## Monitor summary rules --To monitor summary rules, enable the **Summary Logs** category in the [diagnostic settings](../essentials/create-diagnostic-settings.md) of your Log Analytics workspace. Azure Monitor sends summary rule execution details, including summary rule run Start, Succeeded, and Failed information, to the [LASummaryLogs](/azure/azure-monitor/reference/tables/lasummarylogs) table in your workspace. --We recommend you that you [set up log alert rules](../alerts/alerts-create-log-alert-rule.md) to receive notification of bin failures, or when bin execution is nearing time-out, as shown below. Depending on the failure reason, you can either reduce the bin size to process less data on each execution, or modify the query to return fewer records or fields with higher volume. --This query returns failed runs: --```kusto -LASummaryLogs | where Status == "Failed" -``` --This query returns bin runs where the `QueryDurationMs` value is greater than 0.9 x 600,000 milliseconds: --```kusto -LASummaryLogs | where QueryDurationMs > 0.9 * 600000 -``` --### Verify data completeness --Summary rules are designed for scale, and include a retry mechanism to overcome transient service or query failures related to [query limits](../service-limits.md#log-analytics-workspaces), for example. The retry mechanism makes 10 attempts to aggregate a failed bin within eight hours, and skips a bin, if exhausted. The rule is set to `isActive: false` and put on hold after eight consecutive bin retries. If you enable [monitor summary rules](#monitor-summary-rules), Azure Monitor logs an event in the `LASummaryLogs` table in your workspace. --You can't rerun a failed bin run, but you can use the following query to view failed runs: --```kusto -let startTime = datetime("2024-02-16"); -let endtTime = datetime("2024-03-03"); -let ruleName = "myRuleName"; -let stepSize = 20m; // The stepSize value is equal to the bin size defined in the rule -LASummaryLogs -| where RuleName == ruleName -| where Status == 'Succeeded' -| make-series dcount(BinStartTime) default=0 on BinStartTime from startTime to endtTime step stepSize -| render timechart -``` -This query renders the results as a timechart: ---See the [Monitor summary rules](#monitor-summary-rules) section for rule remediation options and proactive alerts. ---## Encrypt summary rule queries by using customer-managed keys --A KQL query can contain sensitive information in comments or in the query syntax. To encrypt summary rule queries, [link a storage account to your Log Analytics workspace and use customer-managed keys](private-storage.md). --Considerations when you work with encrypted queries: --- Linking a storage account to encrypt your queries doesnΓÇÖt interrupt existing rules.-- By default, Azure Monitor stores summary rule queries in Log Analytics storage. If you have existing summary rules before you link a storage account to your Log Analytics workspace, update your summary rules so the queries to save the existing queries in the storage account.-- Queries that you save in a storage account are located in the `CustomerConfigurationStoreTable` table. These queries are considered service artifacts and their format might change.-- You can use the same storage account for summary rule queries, [saved queries in Log Analytics](save-query.md), and [log alerts](../alerts/alerts-types.md#log-alerts).--## Troubleshoot summary rules --This section provides tips for troubleshooting summary rules. --### Summary rule destination table accidentally deleted --If you delete the destination table while the summary rule is active, the rule gets suspended and Azure Monitor sends an event to the `LASummaryLogs` table with a message indicating that the rule was suspended. --If you don't need the summary results in the destination table, delete the rule and table. If you need to recover summary results, follow the steps in Create or update summary rules section to recreate the table. The destination table is restored, including the data ingested before the delete, depending on the retention policy in the table. --If you don't need the summary results in the destination table, delete the rule and table. If you need the summary results, follow the steps in the [Create or update summary rules](#create-or-update-a-summary-rule) section to recreate the destination table and restore all data, including the data ingested before the delete, depending on the retention policy in the table. --### Query uses operators that create new columns in the destination table --The destination table schema is defined when you create or update a summary rule. If the query in the summary rule includes operators that allow output schema expansion based on incoming data - for example, if the query uses the `arg_max(expression, *)` function - Azure Monitor doesn't add new columns to the destination table after you create or update the summary rule, and the output data that requires these columns will be dropped. To add the new fields to the destination table, [update the summary rule](#create-or-update-a-summary-rule) or [add a column to your table manually](create-custom-table.md#add-or-delete-a-custom-column). --### Data in removed columns remains in the workspace based on the table's retention settings --When you remove columns in the query, the columns and data remain in the destination and based on the [retention period](data-retention-configure.md) defined on the table or workspace. If you don't need the removed in destination table, [delete the columns from the table schema](create-custom-table.md#add-or-delete-a-custom-column). If you then add columns with the same name, any data that's not older that the retention period appears again. --## Related content --- Learn more about [Azure Monitor Logs data plans](logs-table-plans.md).-- Walk through a [tutorial on using KQL mode in Log Analytics](../logs/log-analytics-tutorial.md).-- Access the complete [reference documentation for KQL](/azure/kusto/query/).- |
| azure-monitor | Tables Feature Support | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/tables-feature-support.md | - Title: Tables that support ingestion-time transformations in Azure Monitor Logs -description: Reference for tables that support ingestion-time transformations in Azure Monitor Logs. --- Previously updated : 07/10/2022---# Tables that support transformations in Azure Monitor Logs --The following list identifies the tables in a [Log Analytics workspace](log-analytics-workspace-overview.md) that support [transformations](../essentials/data-collection-transformations.md). --> [!NOTE] -> We are in a process of adding support for more tables. Please check this article regularly. --| Table | Limitations | -|:|:| -| [AACAudit](/azure/azure-monitor/reference/tables/aacaudit) | | -| [AACHttpRequest](/azure/azure-monitor/reference/tables/aachttprequest) | | -| [AADDomainServicesAccountLogon](/azure/azure-monitor/reference/tables/aaddomainservicesaccountlogon) | | -| [AADDomainServicesAccountManagement](/azure/azure-monitor/reference/tables/aaddomainservicesaccountmanagement) | | -| [AADDomainServicesDirectoryServiceAccess](/azure/azure-monitor/reference/tables/aaddomainservicesdirectoryserviceaccess) | | -| [AADDomainServicesLogonLogoff](/azure/azure-monitor/reference/tables/aaddomainserviceslogonlogoff) | | -| [AADDomainServicesPolicyChange](/azure/azure-monitor/reference/tables/aaddomainservicespolicychange) | | -| [AADDomainServicesPrivilegeUse](/azure/azure-monitor/reference/tables/aaddomainservicesprivilegeuse) | | -| [AADManagedIdentitySignInLogs](/azure/azure-monitor/reference/tables/aadmanagedidentitysigninlogs) | | -| [AADNonInteractiveUserSignInLogs](/azure/azure-monitor/reference/tables/aadnoninteractiveusersigninlogs) | | -| [AADProvisioningLogs](/azure/azure-monitor/reference/tables/aadprovisioninglogs) | | -| [AADRiskyUsers](/azure/azure-monitor/reference/tables/aadriskyusers) | | -| [AADServicePrincipalSignInLogs](/azure/azure-monitor/reference/tables/aadserviceprincipalsigninlogs) | | -| [AADUserRiskEvents](/azure/azure-monitor/reference/tables/aaduserriskevents) | | -| ABAPAuditLog | | -| [ABSBotRequests](/azure/azure-monitor/reference/tables/absbotrequests) | | -| [ACSAuthIncomingOperations](/azure/azure-monitor/reference/tables/acsauthincomingoperations) | | -| [ACSBillingUsage](/azure/azure-monitor/reference/tables/acsbillingusage) | | -| [ACSChatIncomingOperations](/azure/azure-monitor/reference/tables/acschatincomingoperations) | | -| [ACSSMSIncomingOperations](/azure/azure-monitor/reference/tables/acssmsincomingoperations) | | -| [ADAssessmentRecommendation](/azure/azure-monitor/reference/tables/adassessmentrecommendation) | | -| [AddonAzureBackupAlerts](/azure/azure-monitor/reference/tables/addonazurebackupalerts) | | -| [AddonAzureBackupJobs](/azure/azure-monitor/reference/tables/addonazurebackupjobs) | | -| [AddonAzureBackupPolicy](/azure/azure-monitor/reference/tables/addonazurebackuppolicy) | | -| [AddonAzureBackupProtectedInstance](/azure/azure-monitor/reference/tables/addonazurebackupprotectedinstance) | | -| [AddonAzureBackupStorage](/azure/azure-monitor/reference/tables/addonazurebackupstorage) | | -| [ADFActivityRun](/azure/azure-monitor/reference/tables/adfactivityrun) | | -| [ADFAirflowSchedulerLogs](/azure/azure-monitor/reference/tables/adfairflowschedulerlogs) | | -| [ADFAirflowTaskLogs](/azure/azure-monitor/reference/tables/adfairflowtasklogs) | | -| [ADFAirflowWebLogs](/azure/azure-monitor/reference/tables/adfairflowweblogs) | | -| [ADFAirflowWorkerLogs](/azure/azure-monitor/reference/tables/adfairflowworkerlogs) | | -| [ADFPipelineRun](/azure/azure-monitor/reference/tables/adfpipelinerun) | | -| [ADFSandboxActivityRun](/azure/azure-monitor/reference/tables/adfsandboxactivityrun) | | -| [ADFSandboxPipelineRun](/azure/azure-monitor/reference/tables/adfsandboxpipelinerun) | | -| [ADFSSignInLogs](/azure/azure-monitor/reference/tables/adfssigninlogs) | | -| [ADFSSISIntegrationRuntimeLogs](/azure/azure-monitor/reference/tables/adfssisintegrationruntimelogs) | | -| [ADFSSISPackageEventMessageContext](/azure/azure-monitor/reference/tables/adfssispackageeventmessagecontext) | | -| [ADFSSISPackageEventMessages](/azure/azure-monitor/reference/tables/adfssispackageeventmessages) | | -| [ADFSSISPackageExecutableStatistics](/azure/azure-monitor/reference/tables/adfssispackageexecutablestatistics) | | -| [ADFSSISPackageExecutionComponentPhases](/azure/azure-monitor/reference/tables/adfssispackageexecutioncomponentphases) | | -| [ADFSSISPackageExecutionDataStatistics](/azure/azure-monitor/reference/tables/adfssispackageexecutiondatastatistics) | | -| [ADFTriggerRun](/azure/azure-monitor/reference/tables/adftriggerrun) | | -| [ADPAudit](/azure/azure-monitor/reference/tables/adpaudit) | | -| [ADPDiagnostics](/azure/azure-monitor/reference/tables/adpdiagnostics) | | -| [ADPRequests](/azure/azure-monitor/reference/tables/adprequests) | | -| [ADReplicationResult](/azure/azure-monitor/reference/tables/adreplicationresult) | | -| [ADSecurityAssessmentRecommendation](/azure/azure-monitor/reference/tables/adsecurityassessmentrecommendation) | | -| [ADTDigitalTwinsOperation](/azure/azure-monitor/reference/tables/adtdigitaltwinsoperation) | | -| [ADTModelsOperation](/azure/azure-monitor/reference/tables/adtmodelsoperation) | | -| [ADTQueryOperation](/azure/azure-monitor/reference/tables/adtqueryoperation) | | -| [ADXCommand](/azure/azure-monitor/reference/tables/adxcommand) | | -| [ADXJournal](/azure/azure-monitor/reference/tables/adxjournal) | | -| [ADXQuery](/azure/azure-monitor/reference/tables/adxquery) | | -| [ADXTableDetails](/azure/azure-monitor/reference/tables/adxtabledetails) | | -| [ADXTableUsageStatistics](/azure/azure-monitor/reference/tables/adxtableusagestatistics) | | -| [AegDeliveryFailureLogs](/azure/azure-monitor/reference/tables/aegdeliveryfailurelogs) | | -| [AegPublishFailureLogs](/azure/azure-monitor/reference/tables/aegpublishfailurelogs) | | -| [AirflowDagProcessingLogs](/azure/azure-monitor/reference/tables/airflowdagprocessinglogs) | | -| [Alert](/azure/azure-monitor/reference/tables/alert) | | -| [AlertEvidence](/azure/azure-monitor/reference/tables/alertevidence) | | -| [AlertInfo](/azure/azure-monitor/reference/tables/alertinfo) | | -| [AmlComputeClusterEvent](/azure/azure-monitor/reference/tables/amlcomputeclusterevent) | | -| [AmlComputeCpuGpuUtilization](/azure/azure-monitor/reference/tables/amlcomputecpugpuutilization) | | -| [AmlComputeInstanceEvent](/azure/azure-monitor/reference/tables/amlcomputeinstanceevent) | | -| [AmlComputeJobEvent](/azure/azure-monitor/reference/tables/amlcomputejobevent) | | -| [AmlDataLabelEvent](/azure/azure-monitor/reference/tables/amldatalabelevent) | | -| [AmlDataSetEvent](/azure/azure-monitor/reference/tables/amldatasetevent) | | -| [AmlDataStoreEvent](/azure/azure-monitor/reference/tables/amldatastoreevent) | | -| [AmlDeploymentEvent](/azure/azure-monitor/reference/tables/amldeploymentevent) | | -| [AmlEnvironmentEvent](/azure/azure-monitor/reference/tables/amlenvironmentevent) | | -| [AmlInferencingEvent](/azure/azure-monitor/reference/tables/amlinferencingevent) | | -| [AmlModelsEvent](/azure/azure-monitor/reference/tables/amlmodelsevent) | | -| [AmlOnlineEndpointConsoleLog](/azure/azure-monitor/reference/tables/amlonlineendpointconsolelog) | | -| [AmlPipelineEvent](/azure/azure-monitor/reference/tables/amlpipelineevent) | | -| [AmlRunEvent](/azure/azure-monitor/reference/tables/amlrunevent) | | -| [AmlRunStatusChangedEvent](/azure/azure-monitor/reference/tables/amlrunstatuschangedevent) | | -| [Anomalies](/azure/azure-monitor/reference/tables/anomalies) | | -| [ApiManagementGatewayLogs](/azure/azure-monitor/reference/tables/apimanagementgatewaylogs) | | -| [AppAvailabilityResults](/azure/azure-monitor/reference/tables/appavailabilityresults) | | -| [AppBrowserTimings](/azure/azure-monitor/reference/tables/appbrowsertimings) | | -| [AppCenterError](/azure/azure-monitor/reference/tables/appcentererror) | | -| [AppDependencies](/azure/azure-monitor/reference/tables/appdependencies) | | -| [AppEvents](/azure/azure-monitor/reference/tables/appevents) | | -| [AppExceptions](/azure/azure-monitor/reference/tables/appexceptions) | | -| [AppMetrics](/azure/azure-monitor/reference/tables/appmetrics) | | -| [AppPageViews](/azure/azure-monitor/reference/tables/apppageviews) | | -| [AppPerformanceCounters](/azure/azure-monitor/reference/tables/appperformancecounters) | | -| [AppPlatformIngressLogs](/azure/azure-monitor/reference/tables/appplatformingresslogs) | | -| [AppPlatformLogsforSpring](/azure/azure-monitor/reference/tables/appplatformlogsforspring) | | -| [AppPlatformSystemLogs](/azure/azure-monitor/reference/tables/appplatformsystemlogs) | | -| [AppRequests](/azure/azure-monitor/reference/tables/apprequests) | | -| [AppServiceAntivirusScanAuditLogs](/azure/azure-monitor/reference/tables/appserviceantivirusscanauditlogs) | | -| [AppServiceAppLogs](/azure/azure-monitor/reference/tables/appserviceapplogs) | | -| [AppServiceAuditLogs](/azure/azure-monitor/reference/tables/appserviceauditlogs) | | -| [AppServiceConsoleLogs](/azure/azure-monitor/reference/tables/appserviceconsolelogs) | | -| [AppServiceEnvironmentPlatformLogs](/azure/azure-monitor/reference/tables/appserviceenvironmentplatformlogs) | | -| [AppServiceFileAuditLogs](/azure/azure-monitor/reference/tables/appservicefileauditlogs) | | -| [AppServiceHTTPLogs](/azure/azure-monitor/reference/tables/appservicehttplogs) | | -| [AppServiceIPSecAuditLogs](/azure/azure-monitor/reference/tables/appserviceipsecauditlogs) | | -| [AppServicePlatformLogs](/azure/azure-monitor/reference/tables/appserviceplatformlogs) | | -| [AppSystemEvents](/azure/azure-monitor/reference/tables/appsystemevents) | | -| [AppTraces](/azure/azure-monitor/reference/tables/apptraces) | | -| [ASimAuditEventLogs](/azure/azure-monitor/reference/tables/asimauditeventlogs) | | -| [ASimAuthenticationEventLogs](/azure/azure-monitor/reference/tables/asimauthenticationeventlogs) | | -| [ASimDhcpEventLogs](/azure/azure-monitor/reference/tables/asimdhcpeventlogs) | | -| [ASimDnsActivityLogs](/azure/azure-monitor/reference/tables/asimdnsactivitylogs) | | -| ASimDnsAuditLogs | | -| [ASimFileEventLogs](/azure/azure-monitor/reference/tables/asimfileeventlogs) | | -| [ASimNetworkSessionLogs](/azure/azure-monitor/reference/tables/asimnetworksessionlogs) | | -| [ASimProcessEventLogs](/azure/azure-monitor/reference/tables/asimprocesseventlogs) | | -| [ASimRegistryEventLogs](/azure/azure-monitor/reference/tables/asimregistryeventlogs) | | -| [ASimUserManagementActivityLogs](/azure/azure-monitor/reference/tables/asimusermanagementactivitylogs) | | -| [ASimWebSessionLogs](/azure/azure-monitor/reference/tables/asimwebsessionlogs) | | -| [AuditLogs](/azure/azure-monitor/reference/tables/auditlogs) | | -| [AutoscaleEvaluationsLog](/azure/azure-monitor/reference/tables/autoscaleevaluationslog) | | -| [AutoscaleScaleActionsLog](/azure/azure-monitor/reference/tables/autoscalescaleactionslog) | | -| [AWSCloudTrail](/azure/azure-monitor/reference/tables/awscloudtrail) | | -| [AWSCloudWatch](/azure/azure-monitor/reference/tables/awscloudwatch) | | -| [AWSGuardDuty](/azure/azure-monitor/reference/tables/awsguardduty) | | -| [AWSVPCFlow](/azure/azure-monitor/reference/tables/awsvpcflow) | | -| [AzureAssessmentRecommendation](/azure/azure-monitor/reference/tables/azureassessmentrecommendation) | | -| [AzureDevOpsAuditing](/azure/azure-monitor/reference/tables/azuredevopsauditing) | | -| [BehaviorAnalytics](/azure/azure-monitor/reference/tables/behavioranalytics) | | -| [BlockchainApplicationLog](/azure/azure-monitor/reference/tables/blockchainapplicationlog) | | -| [BlockchainProxyLog](/azure/azure-monitor/reference/tables/blockchainproxylog) | | -| [CDBCassandraRequests](/azure/azure-monitor/reference/tables/cdbcassandrarequests) | | -| [CDBControlPlaneRequests](/azure/azure-monitor/reference/tables/cdbcontrolplanerequests) | | -| [CDBDataPlaneRequests](/azure/azure-monitor/reference/tables/cdbdataplanerequests) | | -| [CDBGremlinRequests](/azure/azure-monitor/reference/tables/cdbgremlinrequests) | | -| [CDBMongoRequests](/azure/azure-monitor/reference/tables/cdbmongorequests) | | -| [CDBPartitionKeyRUConsumption](/azure/azure-monitor/reference/tables/cdbpartitionkeyruconsumption) | | -| [CDBPartitionKeyStatistics](/azure/azure-monitor/reference/tables/cdbpartitionkeystatistics) | | -| [CDBQueryRuntimeStatistics](/azure/azure-monitor/reference/tables/cdbqueryruntimestatistics) | | -| [CloudAppEvents](/azure/azure-monitor/reference/tables/cloudappevents) | | -| [CommonSecurityLog](/azure/azure-monitor/reference/tables/commonsecuritylog) | | -| [ComputerGroup](/azure/azure-monitor/reference/tables/computergroup) | | -| [ConfigurationChange](/azure/azure-monitor/reference/tables/configurationchange) | | -| [ConfigurationData](/azure/azure-monitor/reference/tables/configurationdata) | Partial support – some of the data is ingested through internal services that aren't supported. | -| [ContainerImageInventory](/azure/azure-monitor/reference/tables/containerimageinventory) | | -| [ContainerInventory](/azure/azure-monitor/reference/tables/containerinventory) | | -| [ContainerLog](/azure/azure-monitor/reference/tables/containerlog) | | -| [ContainerLogV2](/azure/azure-monitor/reference/tables/containerlogv2) | | -| [ContainerNodeInventory](/azure/azure-monitor/reference/tables/containernodeinventory) | | -| [ContainerRegistryLoginEvents](/azure/azure-monitor/reference/tables/containerregistryloginevents) | | -| [ContainerRegistryRepositoryEvents](/azure/azure-monitor/reference/tables/containerregistryrepositoryevents) | | -| [ContainerServiceLog](/azure/azure-monitor/reference/tables/containerservicelog) | | -| [CoreAzureBackup](/azure/azure-monitor/reference/tables/coreazurebackup) | | -| [DatabricksAccounts](/azure/azure-monitor/reference/tables/databricksaccounts) | | -| [DatabricksClusters](/azure/azure-monitor/reference/tables/databricksclusters) | | -| [DatabricksDBFS](/azure/azure-monitor/reference/tables/databricksdbfs) | | -| [DatabricksFeatureStore](/azure/azure-monitor/reference/tables/databricksfeaturestore) | | -| [DatabricksGenie](/azure/azure-monitor/reference/tables/databricksgenie) | | -| [DatabricksGlobalInitScripts](/azure/azure-monitor/reference/tables/databricksglobalinitscripts) | | -| [DatabricksInstancePools](/azure/azure-monitor/reference/tables/databricksinstancepools) | | -| [DatabricksJobs](/azure/azure-monitor/reference/tables/databricksjobs) | | -| [DatabricksMLflowAcledArtifact](/azure/azure-monitor/reference/tables/databricksmlflowacledartifact) | | -| [DatabricksMLflowExperiment](/azure/azure-monitor/reference/tables/databricksmlflowexperiment) | | -| [DatabricksNotebook](/azure/azure-monitor/reference/tables/databricksnotebook) | | -| [DatabricksRemoteHistoryService](/azure/azure-monitor/reference/tables/databricksremotehistoryservice) | | -| [DatabricksSecrets](/azure/azure-monitor/reference/tables/databrickssecrets) | | -| [DatabricksSQLPermissions](/azure/azure-monitor/reference/tables/databrickssqlpermissions) | | -| [DatabricksSSH](/azure/azure-monitor/reference/tables/databricksssh) | | -| [DatabricksWorkspace](/azure/azure-monitor/reference/tables/databricksworkspace) | | -| [DataverseActivity](/azure/azure-monitor/reference/tables/dataverseactivity) | | -| DefenderForSqlAlerts | | -| DefenderForSqlTelemetry | | -| [DeviceEvents](/azure/azure-monitor/reference/tables/deviceevents) | | -| [DeviceFileCertificateInfo](/azure/azure-monitor/reference/tables/devicefilecertificateinfo) | | -| [DeviceFileEvents](/azure/azure-monitor/reference/tables/devicefileevents) | | -| [DeviceImageLoadEvents](/azure/azure-monitor/reference/tables/deviceimageloadevents) | | -| [DeviceInfo](/azure/azure-monitor/reference/tables/deviceinfo) | | -| [DeviceLogonEvents](/azure/azure-monitor/reference/tables/devicelogonevents) | | -| [DeviceNetworkEvents](/azure/azure-monitor/reference/tables/devicenetworkevents) | | -| [DeviceNetworkInfo](/azure/azure-monitor/reference/tables/devicenetworkinfo) | | -| [DeviceProcessEvents](/azure/azure-monitor/reference/tables/deviceprocessevents) | | -| [DeviceRegistryEvents](/azure/azure-monitor/reference/tables/deviceregistryevents) | | -| [DeviceTvmSecureConfigurationAssessment](/azure/azure-monitor/reference/tables/devicetvmsecureconfigurationassessment) | | -| [DeviceTvmSecureConfigurationAssessmentKB](/azure/azure-monitor/reference/tables/devicetvmsecureconfigurationassessmentkb) | | -| [DeviceTvmSoftwareInventory](/azure/azure-monitor/reference/tables/devicetvmsoftwareinventory) | | -| [DeviceTvmSoftwareVulnerabilities](/azure/azure-monitor/reference/tables/devicetvmsoftwarevulnerabilities) | | -| [DeviceTvmSoftwareVulnerabilitiesKB](/azure/azure-monitor/reference/tables/devicetvmsoftwarevulnerabilitieskb) | | -| [DnsEvents](/azure/azure-monitor/reference/tables/dnsevents) | | -| [DnsInventory](/azure/azure-monitor/reference/tables/dnsinventory) | | -| DummyHydrationFact | | -| [DynamicEventCollection](/azure/azure-monitor/reference/tables/dynamiceventcollection) | | -| [Dynamics365Activity](/azure/azure-monitor/reference/tables/dynamics365activity) | | -| [EmailAttachmentInfo](/azure/azure-monitor/reference/tables/emailattachmentinfo) | | -| [EmailEvents](/azure/azure-monitor/reference/tables/emailevents) | | -| [EmailPostDeliveryEvents](/azure/azure-monitor/reference/tables/emailpostdeliveryevents) | | -| [EmailUrlInfo](/azure/azure-monitor/reference/tables/emailurlinfo) | | -| [Event](/azure/azure-monitor/reference/tables/event) | Partial support . Data arriving from Log Analytics agent (MMA) or Azure Monitor Agent (AMA) is fully supported. Data arriving from Diagnostics Extension  is collected through Azure storage. This path isn’t supported. | -| [ExchangeAssessmentRecommendation](/azure/azure-monitor/reference/tables/exchangeassessmentrecommendation) | | -| [ExchangeOnlineAssessmentRecommendation](/azure/azure-monitor/reference/tables/exchangeonlineassessmentrecommendation) | | -| [FailedIngestion](/azure/azure-monitor/reference/tables/failedingestion) | | -| [FunctionAppLogs](/azure/azure-monitor/reference/tables/functionapplogs) | | -| [GCPAuditLogs](/azure/azure-monitor/reference/tables/gcpauditlogs) | | -| [GoogleCloudSCC](/azure/azure-monitor/reference/tables/googlecloudscc) | | -| [HDInsightAmbariClusterAlerts](/azure/azure-monitor/reference/tables/hdinsightambariclusteralerts) | | -| [HDInsightAmbariSystemMetrics](/azure/azure-monitor/reference/tables/hdinsightambarisystemmetrics) | | -| [HDInsightHadoopAndYarnLogs](/azure/azure-monitor/reference/tables/hdinsighthadoopandyarnlogs) | | -| [HDInsightHadoopAndYarnMetrics](/azure/azure-monitor/reference/tables/hdinsighthadoopandyarnmetrics) | | -| [HDInsightHBaseLogs](/azure/azure-monitor/reference/tables/hdinsighthbaselogs) | | -| [HDInsightHBaseMetrics](/azure/azure-monitor/reference/tables/hdinsighthbasemetrics) | | -| [HDInsightHiveAndLLAPLogs](/azure/azure-monitor/reference/tables/hdinsighthiveandllaplogs) | | -| [HDInsightHiveAndLLAPMetrics](/azure/azure-monitor/reference/tables/hdinsighthiveandllapmetrics) | | -| [HDInsightHiveTezAppStats](/azure/azure-monitor/reference/tables/hdinsighthivetezappstats) | | -| [HDInsightKafkaLogs](/azure/azure-monitor/reference/tables/hdinsightkafkalogs) | | -| [HDInsightKafkaMetrics](/azure/azure-monitor/reference/tables/hdinsightkafkametrics) | | -| [HDInsightOozieLogs](/azure/azure-monitor/reference/tables/hdinsightoozielogs) | | -| [HDInsightSecurityLogs](/azure/azure-monitor/reference/tables/hdinsightsecuritylogs) | | -| [HDInsightSparkApplicationEvents](/azure/azure-monitor/reference/tables/hdinsightsparkapplicationevents) | | -| [HDInsightSparkBlockManagerEvents](/azure/azure-monitor/reference/tables/hdinsightsparkblockmanagerevents) | | -| [HDInsightSparkEnvironmentEvents](/azure/azure-monitor/reference/tables/hdinsightsparkenvironmentevents) | | -| [HDInsightSparkExecutorEvents](/azure/azure-monitor/reference/tables/hdinsightsparkexecutorevents) | | -| [HDInsightSparkJobEvents](/azure/azure-monitor/reference/tables/hdinsightsparkjobevents) | | -| [HDInsightSparkLogs](/azure/azure-monitor/reference/tables/hdinsightsparklogs) | | -| [HDInsightSparkSQLExecutionEvents](/azure/azure-monitor/reference/tables/hdinsightsparksqlexecutionevents) | | -| [HDInsightSparkStageEvents](/azure/azure-monitor/reference/tables/hdinsightsparkstageevents) | | -| [HDInsightSparkStageTaskAccumulables](/azure/azure-monitor/reference/tables/hdinsightsparkstagetaskaccumulables) | | -| [HDInsightSparkTaskEvents](/azure/azure-monitor/reference/tables/hdinsightsparktaskevents) | | -| [HealthStateChangeEvent](/azure/azure-monitor/reference/tables/healthstatechangeevent) | | -| [HuntingBookmark](/azure/azure-monitor/reference/tables/huntingbookmark) | | -| [IdentityDirectoryEvents](/azure/azure-monitor/reference/tables/identitydirectoryevents) | | -| [IdentityInfo](/azure/azure-monitor/reference/tables/identityinfo) | | -| [IdentityLogonEvents](/azure/azure-monitor/reference/tables/identitylogonevents) | | -| [IdentityQueryEvents](/azure/azure-monitor/reference/tables/identityqueryevents) | | -| [InsightsMetrics](/azure/azure-monitor/reference/tables/insightsmetrics) | Partial support – some of the data is ingested through internal services that aren't supported. | -| [IntuneAuditLogs](/azure/azure-monitor/reference/tables/intuneauditlogs) | | -| [IntuneDevices](/azure/azure-monitor/reference/tables/intunedevices) | | -| [IntuneOperationalLogs](/azure/azure-monitor/reference/tables/intuneoperationallogs) | | -| [KubeEvents](/azure/azure-monitor/reference/tables/kubeevents) | | -| [KubeHealth](/azure/azure-monitor/reference/tables/kubehealth) | | -| [KubeMonAgentEvents](/azure/azure-monitor/reference/tables/kubemonagentevents) | | -| [KubeNodeInventory](/azure/azure-monitor/reference/tables/kubenodeinventory) | | -| [KubePodInventory](/azure/azure-monitor/reference/tables/kubepodinventory) | | -| [KubePVInventory](/azure/azure-monitor/reference/tables/kubepvinventory) | | -| [KubeServices](/azure/azure-monitor/reference/tables/kubeservices) | | -| [LAQueryLogs](/azure/azure-monitor/reference/tables/laquerylogs) | | -| [LinuxAuditLog](/azure/azure-monitor/reference/tables/linuxauditlog) | | -| [McasShadowItReporting](/azure/azure-monitor/reference/tables/mcasshadowitreporting) | | -| [MCCEventLogs](/azure/azure-monitor/reference/tables/mcceventlogs) | | -| [MicrosoftAzureBastionAuditLogs](/azure/azure-monitor/reference/tables/microsoftazurebastionauditlogs) | | -| [MicrosoftDataShareReceivedSnapshotLog](/azure/azure-monitor/reference/tables/microsoftdatasharereceivedsnapshotlog) | | -| [MicrosoftDataShareSentSnapshotLog](/azure/azure-monitor/reference/tables/microsoftdatasharesentsnapshotlog) | | -| [MicrosoftGraphActivityLogs](/azure/azure-monitor/reference/tables/microsoftgraphactivitylogs) | | -| [MicrosoftHealthcareApisAuditLogs](/azure/azure-monitor/reference/tables/microsofthealthcareapisauditlogs) | | -| [MicrosoftPurviewInformationProtection](/azure/azure-monitor/reference/tables/microsoftpurviewinformationprotection) | | -| [NetworkAccessTraffic](/azure/azure-monitor/reference/tables/networkaccesstraffic) | | -| [NetworkMonitoring](/azure/azure-monitor/reference/tables/networkmonitoring) | | -| [NTAIpDetails](/azure/azure-monitor/reference/tables/ntaipdetails) | | -| [NTANetAnalytics](/azure/azure-monitor/reference/tables/ntanetanalytics) | | -| [NTATopologyDetails](/azure/azure-monitor/reference/tables/ntatopologydetails) | | -| [NWConnectionMonitorPathResult](/azure/azure-monitor/reference/tables/nwconnectionmonitorpathresult) | | -| [NWConnectionMonitorTestResult](/azure/azure-monitor/reference/tables/nwconnectionmonitortestresult) | | -| [OfficeActivity](/azure/azure-monitor/reference/tables/officeactivity) | | -| [Perf](/azure/azure-monitor/reference/tables/perf) | Partial support – only windows perf data is currently supported. | -| [PowerAppsActivity](/azure/azure-monitor/reference/tables/powerappsactivity) | | -| [PowerAutomateActivity](/azure/azure-monitor/reference/tables/powerautomateactivity) | | -| [PowerBIActivity](/azure/azure-monitor/reference/tables/powerbiactivity) | | -| [PowerBIDatasetsWorkspace](/azure/azure-monitor/reference/tables/powerbidatasetsworkspace) | | -| [PowerPlatformAdminActivity](/azure/azure-monitor/reference/tables/powerplatformadminactivity) | | -| [PowerPlatformConnectorActivity](/azure/azure-monitor/reference/tables/powerplatformconnectoractivity) | | -| [PowerPlatformDlpActivity](/azure/azure-monitor/reference/tables/powerplatformdlpactivity) | | -| ProcessInvestigator | | -| [ProjectActivity](/azure/azure-monitor/reference/tables/projectactivity) | | -| [ProtectionStatus](/azure/azure-monitor/reference/tables/protectionstatus) | | -| [PurviewScanStatusLogs](/azure/azure-monitor/reference/tables/purviewscanstatuslogs) | | -| RomeDetectionEvent | | -| [SCCMAssessmentRecommendation](/azure/azure-monitor/reference/tables/sccmassessmentrecommendation) | | -| [SCOMAssessmentRecommendation](/azure/azure-monitor/reference/tables/scomassessmentrecommendation) | | -| [SecureScoreControls](/azure/azure-monitor/reference/tables/securescorecontrols) | | -| [SecureScores](/azure/azure-monitor/reference/tables/securescores) | | -| [SecurityAlert](/azure/azure-monitor/reference/tables/securityalert) | | -| [SecurityBaseline](/azure/azure-monitor/reference/tables/securitybaseline) | | -| [SecurityBaselineSummary](/azure/azure-monitor/reference/tables/securitybaselinesummary) | | -| [SecurityDetection](/azure/azure-monitor/reference/tables/securitydetection) | | -| [SecurityEvent](/azure/azure-monitor/reference/tables/securityevent) | Partial support – data arriving from Log Analytics agent (MMA) or Azure Monitor Agent (AMA) is fully supported. Data arriving via Diagnostics Extension agent is collected though storage while this path isn’t supported. | -| [SecurityIncident](/azure/azure-monitor/reference/tables/securityincident) | | -| [SecurityIoTRawEvent](/azure/azure-monitor/reference/tables/securityiotrawevent) | | -| [SecurityNestedRecommendation](/azure/azure-monitor/reference/tables/securitynestedrecommendation) | | -| [SecurityRecommendation](/azure/azure-monitor/reference/tables/securityrecommendation) | | -| [SecurityRegulatoryCompliance](/azure/azure-monitor/reference/tables/securityregulatorycompliance) | | -| [SentinelHealth](/azure/azure-monitor/reference/tables/sentinelhealth) | | -| ServiceMap | | -| [SfBAssessmentRecommendation](/azure/azure-monitor/reference/tables/sfbassessmentrecommendation) | | -| [SfBOnlineAssessmentRecommendation](/azure/azure-monitor/reference/tables/sfbonlineassessmentrecommendation) | | -| [SharePointOnlineAssessmentRecommendation](/azure/azure-monitor/reference/tables/sharepointonlineassessmentrecommendation) | | -| [SignalRServiceDiagnosticLogs](/azure/azure-monitor/reference/tables/signalrservicediagnosticlogs) | | -| [SigninLogs](/azure/azure-monitor/reference/tables/signinlogs) | | -| [SPAssessmentRecommendation](/azure/azure-monitor/reference/tables/spassessmentrecommendation) | | -| [SQLAssessmentRecommendation](/azure/azure-monitor/reference/tables/sqlassessmentrecommendation) | | -| [SqlAtpStatus](/azure/azure-monitor/reference/tables/sqlatpstatus) | | -| [SQLSecurityAuditEvents](/azure/azure-monitor/reference/tables/sqlsecurityauditevents) | | -| [SqlThreatProtectionLoginAudits](/azure/azure-monitor/reference/tables/sqlthreatprotectionloginaudits) | | -| [SqlVulnerabilityAssessmentResult](/azure/azure-monitor/reference/tables/sqlvulnerabilityassessmentresult) | | -| [SqlVulnerabilityAssessmentScanStatus](/azure/azure-monitor/reference/tables/sqlvulnerabilityassessmentscanstatus) | | -| [StorageBlobLogs](/azure/azure-monitor/reference/tables/storagebloblogs) | | -| [StorageFileLogs](/azure/azure-monitor/reference/tables/storagefilelogs) | | -| StorageInsightsAccountPropertiesDaily | | -| StorageInsightsDailyMetrics | | -| StorageInsightsHourlyMetrics | | -| StorageInsightsMonthlyMetrics | | -| StorageInsightsWeeklyMetrics | | -| [StorageQueueLogs](/azure/azure-monitor/reference/tables/storagequeuelogs) | | -| [StorageTableLogs](/azure/azure-monitor/reference/tables/storagetablelogs) | | -| [SucceededIngestion](/azure/azure-monitor/reference/tables/succeededingestion) | | -| [SynapseBigDataPoolApplicationsEnded](/azure/azure-monitor/reference/tables/synapsebigdatapoolapplicationsended) | | -| [SynapseBuiltinSqlPoolRequestsEnded](/azure/azure-monitor/reference/tables/synapsebuiltinsqlpoolrequestsended) | | -| [SynapseDXFailedIngestion](/azure/azure-monitor/reference/tables/synapsedxfailedingestion) | | -| [SynapseDXSucceededIngestion](/azure/azure-monitor/reference/tables/synapsedxsucceededingestion) | | -| [SynapseGatewayApiRequests](/azure/azure-monitor/reference/tables/synapsegatewayapirequests) | | -| [SynapseIntegrationActivityRuns](/azure/azure-monitor/reference/tables/synapseintegrationactivityruns) | | -| [SynapseIntegrationPipelineRuns](/azure/azure-monitor/reference/tables/synapseintegrationpipelineruns) | | -| [SynapseIntegrationTriggerRuns](/azure/azure-monitor/reference/tables/synapseintegrationtriggerruns) | | -| [SynapseRbacOperations](/azure/azure-monitor/reference/tables/synapserbacoperations) | | -| [SynapseSqlPoolDmsWorkers](/azure/azure-monitor/reference/tables/synapsesqlpooldmsworkers) | | -| [SynapseSqlPoolExecRequests](/azure/azure-monitor/reference/tables/synapsesqlpoolexecrequests) | | -| [SynapseSqlPoolRequestSteps](/azure/azure-monitor/reference/tables/synapsesqlpoolrequeststeps) | | -| [SynapseSqlPoolSqlRequests](/azure/azure-monitor/reference/tables/synapsesqlpoolsqlrequests) | | -| [SynapseSqlPoolWaits](/azure/azure-monitor/reference/tables/synapsesqlpoolwaits) | | -| [Syslog](/azure/azure-monitor/reference/tables/syslog) | Partial support – data arriving from Log Analytics agent (MMA) or Azure Monitor Agent (AMA) is fully supported. Data arriving via Diagnostics Extension agent is collected though storage while this path isn’t supported. | -| [ThreatIntelligenceIndicator](/azure/azure-monitor/reference/tables/threatintelligenceindicator) | | -| [TSIIngress](/azure/azure-monitor/reference/tables/tsiingress) | | -| [UCClient](/azure/azure-monitor/reference/tables/ucclient) | | -| [UCClientReadinessStatus](/azure/azure-monitor/reference/tables/ucclientreadinessstatus) | | -| [UCClientUpdateStatus](/azure/azure-monitor/reference/tables/ucclientupdatestatus) | | -| [UCDeviceAlert](/azure/azure-monitor/reference/tables/ucdevicealert) | | -| [UCDOAggregatedStatus](/azure/azure-monitor/reference/tables/ucdoaggregatedstatus) | | -| [UCDOStatus](/azure/azure-monitor/reference/tables/ucdostatus) | | -| [UCServiceUpdateStatus](/azure/azure-monitor/reference/tables/ucserviceupdatestatus) | | -| [UCUpdateAlert](/azure/azure-monitor/reference/tables/ucupdatealert) | | -| [Update](/azure/azure-monitor/reference/tables/update) | Partial support – some of the data is ingested through internal services that aren't supported. | -| [UpdateRunProgress](/azure/azure-monitor/reference/tables/updaterunprogress) | | -| [UpdateSummary](/azure/azure-monitor/reference/tables/updatesummary) | | -| [UrlClickEvents](/azure/azure-monitor/reference/tables/urlclickevents) | | -| [W3CIISLog](/azure/azure-monitor/reference/tables/w3ciislog) | Partial support – data arriving from Log Analytics agent (MMA) or Azure Monitor Agent (AMA) is fully supported. Data arriving via Diagnostics Extension agent is collected though storage while this path isn’t supported. | -| [WaaSDeploymentStatus](/azure/azure-monitor/reference/tables/waasdeploymentstatus) | | -| [WaaSInsiderStatus](/azure/azure-monitor/reference/tables/waasinsiderstatus) | | -| [WaaSUpdateStatus](/azure/azure-monitor/reference/tables/waasupdatestatus) | | -| [Watchlist](/azure/azure-monitor/reference/tables/watchlist) | | -| [WebPubSubConnectivity](/azure/azure-monitor/reference/tables/webpubsubconnectivity) | | -| [WebPubSubHttpRequest](/azure/azure-monitor/reference/tables/webpubsubhttprequest) | | -| [WebPubSubMessaging](/azure/azure-monitor/reference/tables/webpubsubmessaging) | | -| [WindowsClientAssessmentRecommendation](/azure/azure-monitor/reference/tables/windowsclientassessmentrecommendation) | | -| [WindowsEvent](/azure/azure-monitor/reference/tables/windowsevent) | | -| [WindowsFirewall](/azure/azure-monitor/reference/tables/windowsfirewall) | | -| [WindowsServerAssessmentRecommendation](/azure/azure-monitor/reference/tables/windowsserverassessmentrecommendation) | | -| [WireData](/azure/azure-monitor/reference/tables/wiredata) | Partial support – some of the data is ingested through internal services that aren't supported. | -| [WorkloadDiagnosticLogs](/azure/azure-monitor/reference/tables/workloaddiagnosticlogs) | | -| [WUDOAggregatedStatus](/azure/azure-monitor/reference/tables/wudoaggregatedstatus) | | -| [WUDOStatus](/azure/azure-monitor/reference/tables/wudostatus) | | -| [WVDAgentHealthStatus](/azure/azure-monitor/reference/tables/wvdagenthealthstatus) | | -| [WVDCheckpoints](/azure/azure-monitor/reference/tables/wvdcheckpoints) | | -| [WVDConnectionNetworkData](/azure/azure-monitor/reference/tables/wvdconnectionnetworkdata) | | -| [WVDConnections](/azure/azure-monitor/reference/tables/wvdconnections) | | -| [WVDErrors](/azure/azure-monitor/reference/tables/wvderrors) | | -| [WVDFeeds](/azure/azure-monitor/reference/tables/wvdfeeds) | | -| [WVDHostRegistrations](/azure/azure-monitor/reference/tables/wvdhostregistrations) | | -| [WVDManagement](/azure/azure-monitor/reference/tables/wvdmanagement) | | - |
| azure-monitor | Tutorial Logs Ingestion Api | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/tutorial-logs-ingestion-api.md | - Title: 'Tutorial: Send data to Azure Monitor Logs with Logs ingestion API (Resource Manager templates)' -description: Tutorial on how sending data to a Log Analytics workspace in Azure Monitor using the Logs ingestion API. Supporting components configured using Resource Manager templates. ---- Previously updated : 03/13/2024---# Tutorial: Send data to Azure Monitor using Logs ingestion API (Resource Manager templates) -The [Logs Ingestion API](logs-ingestion-api-overview.md) in Azure Monitor allows you to send custom data to a Log Analytics workspace. This tutorial uses Azure Resource Manager templates (ARM templates) to walk through configuration of the components required to support the API and then provides a sample application using both the REST API and client libraries for [.NET](/dotnet/api/overview/azure/Monitor.Ingestion-readme), [Go](https://pkg.go.dev/github.com/Azure/azure-sdk-for-go/sdk/monitor/ingestion/azlogs), [Java](/java/api/overview/azure/monitor-ingestion-readme), [JavaScript](/javascript/api/overview/azure/monitor-ingestion-readme), and [Python](/python/api/overview/azure/monitor-ingestion-readme). --> [!NOTE] -> This tutorial uses ARM templates to configure the components required to support the Logs ingestion API. See [Tutorial: Send data to Azure Monitor Logs with Logs ingestion API (Azure portal)](tutorial-logs-ingestion-portal.md) for a similar tutorial that uses the Azure portal UI to configure these components. --The steps required to configure the Logs ingestion API are as follows: --1. [Create a Microsoft Entra application](#create-azure-ad-application) to authenticate against the API. -2. [Create a custom table in a Log Analytics workspace](#create-new-table-in-log-analytics-workspace). This is the table you'll be sending data to. -4. [Create a data collection rule (DCR)](#create-data-collection-rule) to direct the data to the target table. -5. [Give the Microsoft Entra application access to the DCR](#assign-permissions-to-a-dcr). -6. See [Sample code to send data to Azure Monitor using Logs ingestion API](tutorial-logs-ingestion-code.md) for sample code to send data to using the Logs ingestion API. --> [!NOTE] -> This article includes options for using a DCR ingestion endpoint or a data collection endpoint (DCE). You can choose to user either one, but a DCE is required with Logs ingestion API if private link is used. See [When is a DCE required?](../essentials/data-collection-endpoint-overview.md#when-is-a-dce-required). --## Prerequisites -To complete this tutorial, you need: --- A Log Analytics workspace where you have at least [contributor rights](manage-access.md#azure-rbac).-- [Permissions to create DCR objects](../essentials/data-collection-rule-create-edit.md#permissions) in the workspace.---## Collect workspace details -Start by gathering information that you'll need from your workspace. --Go to your workspace in the **Log Analytics workspaces** menu in the Azure portal. On the **Properties** page, copy the **Resource ID** and save it for later use. ---<a name='create-azure-ad-application'></a> --## Create Microsoft Entra application -Start by registering a Microsoft Entra application to authenticate against the API. Any Resource Manager authentication scheme is supported, but this tutorial follows the [Client Credential Grant Flow scheme](../../active-directory/develop/v2-oauth2-client-creds-grant-flow.md). --1. On the **Microsoft Entra ID** menu in the Azure portal, select **App registrations** > **New registration**. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/new-app-registration.png" lightbox="media/tutorial-logs-ingestion-portal/new-app-registration.png" alt-text="Screenshot that shows the app registration screen."::: --1. Give the application a name and change the tenancy scope if the default isn't appropriate for your environment. A **Redirect URI** isn't required. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/new-app-name.png" lightbox="media/tutorial-logs-ingestion-portal/new-app-name.png" alt-text="Screenshot that shows app details."::: --1. After registration, you can view the details of the application. Note the **Application (client) ID** and the **Directory (tenant) ID**. You'll need these values later in the process. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/new-app-id.png" lightbox="media/tutorial-logs-ingestion-portal/new-app-id.png" alt-text="Screenshot that shows the app ID."::: --1. Generate an application client secret, which is similar to creating a password to use with a username. Select **Certificates & secrets** > **New client secret**. Give the secret a name to identify its purpose and select an **Expires** duration. The option **12 months** is selected here. For a production implementation, you would follow best practices for a secret rotation procedure or use a more secure authentication mode, such as a certificate. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/new-app-secret.png" lightbox="media/tutorial-logs-ingestion-portal/new-app-secret.png" alt-text="Screenshot that shows the secret for the new app."::: --1. Select **Add** to save the secret and then note the **Value**. Ensure that you record this value because you can't recover it after you leave this page. Use the same security measures as you would for safekeeping a password because it's the functional equivalent. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/new-app-secret-value.png" lightbox="media/tutorial-logs-ingestion-portal/new-app-secret-value.png" alt-text="Screenshot that shows the secret value for the new app."::: --## Create data collection endpoint --## [DCR endpoint](#tab/dcr) -A DCE isn't required if you use the DCR ingestion endpoint. --## [DCE](#tab/dce) --A [DCE](../essentials/data-collection-endpoint-overview.md) is required to accept the data being sent to Azure Monitor. After you configure the DCE and link it to a DCR, you can send data over HTTP from your application. The DCE must be located in the same region as the DCR and the Log Analytics workspace where the data will be sent. --1. In the Azure portal's search box, enter **template** and then select **Deploy a custom template**. -- :::image type="content" source="media/tutorial-workspace-transformations-api/deploy-custom-template.png" lightbox="media/tutorial-workspace-transformations-api/deploy-custom-template.png" alt-text="Screenshot that shows how to deploy a custom template."::: --1. Select **Build your own template in the editor**. -- :::image type="content" source="media/tutorial-workspace-transformations-api/build-custom-template.png" lightbox="media/tutorial-workspace-transformations-api/build-custom-template.png" alt-text="Screenshot that shows how to build a template in the editor."::: --1. Paste the following ARM template into the editor and then select **Save**. You don't need to modify this template because you'll provide values for its parameters. -- :::image type="content" source="media/tutorial-workspace-transformations-api/edit-template.png" lightbox="media/tutorial-workspace-transformations-api/edit-template.png" alt-text="Screenshot that shows how to edit an ARM template."::: --- ```json - { - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "dataCollectionEndpointName": { - "type": "string", - "metadata": { - "description": "Specifies the name of the Data Collection Endpoint to create." - } - }, - "location": { - "type": "string", - "defaultValue": "westus2", - "metadata": { - "description": "Specifies the location for the Data Collection Endpoint." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/dataCollectionEndpoints", - "name": "[parameters('dataCollectionEndpointName')]", - "location": "[parameters('location')]", - "apiVersion": "2021-04-01", - "properties": { - "networkAcls": { - "publicNetworkAccess": "Enabled" - } - } - } - ], - "outputs": { - "dataCollectionEndpointId": { - "type": "string", - "value": "[resourceId('Microsoft.Insights/dataCollectionEndpoints', parameters('dataCollectionEndpointName'))]" - } - } - } - ``` --1. On the **Custom deployment** screen, specify a **Subscription** and **Resource group** to store the DCR and then provide values like a **Name** for the DCE. The **Location** should be the same location as the workspace. The **Region** will already be populated and will be used for the location of the DCE. -- :::image type="content" source="media/tutorial-logs-ingestion-api/data-collection-endpoint-custom-deploy.png" lightbox="media/tutorial-logs-ingestion-api/data-collection-endpoint-custom-deploy.png" alt-text="Screenshot to edit custom deployment values."::: --1. Select **Review + create** and then select **Create** after you review the details. --1. Select **JSON View** to view other details for the DCE. Copy the **Resource ID** and the **logsIngestion endpoint** which you'll need in a later step. -- :::image type="content" source="media/tutorial-logs-ingestion-api/data-collection-endpoint-json.png" lightbox="media/tutorial-logs-ingestion-api/data-collection-endpoint-json.png" alt-text="Screenshot that shows the DCE resource ID."::: ----## Create new table in Log Analytics workspace -The custom table must be created before you can send data to it. The table for this tutorial will include five columns shown in the schema below. The `name`, `type`, and `description` properties are mandatory for each column. The properties `isHidden` and `isDefaultDisplay` both default to `false` if not explicitly specified. Possible data types are `string`, `int`, `long`, `real`, `boolean`, `dateTime`, `guid`, and `dynamic`. --> [!NOTE] -> This tutorial uses PowerShell from Azure Cloud Shell to make REST API calls by using the Azure Monitor **Tables** API. You can use any other valid method to make these calls. --> [!IMPORTANT] -> Custom tables must use a suffix of `_CL`. --1. Select the **Cloud Shell** button in the Azure portal and ensure the environment is set to **PowerShell**. -- :::image type="content" source="media/tutorial-workspace-transformations-api/open-cloud-shell.png" lightbox="media/tutorial-workspace-transformations-api/open-cloud-shell.png" alt-text="Screenshot that shows opening Cloud Shell."::: --1. Copy the following PowerShell code and replace the variables in the **Path** parameter with the appropriate values for your workspace in the `Invoke-AzRestMethod` command. Paste it into the Cloud Shell prompt to run it. -- ```PowerShell - $tableParams = @' - { - "properties": { - "schema": { - "name": "MyTable_CL", - "columns": [ - { - "name": "TimeGenerated", - "type": "datetime", - "description": "The time at which the data was generated" - }, - { - "name": "Computer", - "type": "string", - "description": "The computer that generated the data" - }, - { - "name": "AdditionalContext", - "type": "dynamic", - "description": "Additional message properties" - }, - { - "name": "CounterName", - "type": "string", - "description": "Name of the counter" - }, - { - "name": "CounterValue", - "type": "real", - "description": "Value collected for the counter" - } - ] - } - } - } - '@ -- Invoke-AzRestMethod -Path "/subscriptions/{subscription}/resourcegroups/{resourcegroup}/providers/microsoft.operationalinsights/workspaces/{workspace}/tables/MyTable_CL?api-version=2022-10-01" -Method PUT -payload $tableParams - ``` --## Create data collection rule -The [DCR](../essentials/data-collection-rule-overview.md) defines how the data will be handled once it's received. This includes: --- Schema of data that's being sent to the endpoint-- [Transformation](../essentials/data-collection-transformations.md) that will be applied to the data before it's sent to the workspace-- Destination workspace and table the transformed data will be sent to--1. In the Azure portal's search box, enter **template** and then select **Deploy a custom template**. -- :::image type="content" source="media/tutorial-workspace-transformations-api/deploy-custom-template.png" lightbox="media/tutorial-workspace-transformations-api/deploy-custom-template.png" alt-text="Screenshot that shows how to deploy a custom template."::: --2. Select **Build your own template in the editor**. -- :::image type="content" source="media/tutorial-workspace-transformations-api/build-custom-template.png" lightbox="media/tutorial-workspace-transformations-api/build-custom-template.png" alt-text="Screenshot that shows how to build a template in the editor."::: --3. Paste the following ARM template into the editor and then select **Save**. -- :::image type="content" source="media/tutorial-workspace-transformations-api/edit-template.png" lightbox="media/tutorial-workspace-transformations-api/edit-template.png" alt-text="Screenshot that shows how to edit an ARM template."::: -- ## [DCR endpoint](#tab/dcr) -- Notice the following details in the DCR defined in this template: -- - `streamDeclarations`: Column definitions of the incoming data. - - `destinations`: Destination workspace. - - `dataFlows`: Matches the stream with the destination workspace and specifies the transformation query and the destination table. The output of the destination query is what will be sent to the destination table. -- ```json - { - "$schema": "https://schema.management.azure.com/schemas/2019-08-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "dataCollectionRuleName": { - "type": "string", - "metadata": { - "description": "Specifies the name of the Data Collection Rule to create." - } - }, - "location": { - "type": "string", - "metadata": { - "description": "Specifies the location in which to create the Data Collection Rule." - } - }, - "workspaceResourceId": { - "type": "string", - "metadata": { - "description": "Specifies the Azure resource ID of the Log Analytics workspace to use." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/dataCollectionRules", - "name": "[parameters('dataCollectionRuleName')]", - "location": "[parameters('location')]", - "apiVersion": "2023-03-11", - "kind": "Direct", - "properties": { - "streamDeclarations": { - "Custom-MyTableRawData": { - "columns": [ - { - "name": "Time", - "type": "datetime" - }, - { - "name": "Computer", - "type": "string" - }, - { - "name": "AdditionalContext", - "type": "string" - }, - { - "name": "CounterName", - "type": "string" - }, - { - "name": "CounterValue", - "type": "real" - } - ] - } - }, - "destinations": { - "logAnalytics": [ - { - "workspaceResourceId": "[parameters('workspaceResourceId')]", - "name": "myworkspace" - } - ] - }, - "dataFlows": [ - { - "streams": [ - "Custom-MyTableRawData" - ], - "destinations": [ - "myworkspace" - ], - "transformKql": "source | extend jsonContext = parse_json(AdditionalContext) | project TimeGenerated = Time, Computer, AdditionalContext = jsonContext, CounterName=tostring(jsonContext.CounterName), CounterValue=toreal(jsonContext.CounterValue)", - "outputStream": "Custom-MyTable_CL" - } - ] - } - } - ], - "outputs": { - "dataCollectionRuleId": { - "type": "string", - "value": "[resourceId('Microsoft.Insights/dataCollectionRules', parameters('dataCollectionRuleName'))]" - } - } - } - ``` - - ## [DCE](#tab/dce) -- Notice the following details in the DCR defined in this template: -- - `dataCollectionEndpointId`: Resource ID of the data collection endpoint. - - `streamDeclarations`: Column definitions of the incoming data. - - `destinations`: Destination workspace. - - `dataFlows`: Matches the stream with the destination workspace and specifies the transformation query and the destination table. The output of the destination query is what will be sent to the destination table. -- ```json - { - "$schema": "https://schema.management.azure.com/schemas/2019-08-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "dataCollectionRuleName": { - "type": "string", - "metadata": { - "description": "Specifies the name of the Data Collection Rule to create." - } - }, - "location": { - "type": "string", - "metadata": { - "description": "Specifies the location in which to create the Data Collection Rule." - } - }, - "workspaceResourceId": { - "type": "string", - "metadata": { - "description": "Specifies the Azure resource ID of the Log Analytics workspace to use." - } - }, - "endpointResourceId": { - "type": "string", - "metadata": { - "description": "Specifies the Azure resource ID of the Data Collection Endpoint to use." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/dataCollectionRules", - "name": "[parameters('dataCollectionRuleName')]", - "location": "[parameters('location')]", - "apiVersion": "2023-03-11", - "kind": "Direct", - "properties": { - "dataCollectionEndpointId": "[parameters('endpointResourceId')]", - "streamDeclarations": { - "Custom-MyTableRawData": { - "columns": [ - { - "name": "Time", - "type": "datetime" - }, - { - "name": "Computer", - "type": "string" - }, - { - "name": "AdditionalContext", - "type": "string" - }, - { - "name": "CounterName", - "type": "string" - }, - { - "name": "CounterValue", - "type": "real" - } - ] - } - }, - "destinations": { - "logAnalytics": [ - { - "workspaceResourceId": "[parameters('workspaceResourceId')]", - "name": "myworkspace" - } - ] - }, - "dataFlows": [ - { - "streams": [ - "Custom-MyTableRawData" - ], - "destinations": [ - "myworkspace" - ], - "transformKql": "source | extend jsonContext = parse_json(AdditionalContext) | project TimeGenerated = Time, Computer, AdditionalContext = jsonContext, CounterName=tostring(jsonContext.CounterName), CounterValue=toreal(jsonContext.CounterValue)", - "outputStream": "Custom-MyTable_CL" - } - ] - } - } - ], - "outputs": { - "dataCollectionRuleId": { - "type": "string", - "value": "[resourceId('Microsoft.Insights/dataCollectionRules', parameters('dataCollectionRuleName'))]" - } - } - } - ``` ---4. On the **Custom deployment** screen, specify a **Subscription** and **Resource group** to store the DCR. Then provide values defined in the template. The values include a **Name** for the DCR and the **Workspace Resource ID** that you collected in a previous step. The **Location** should be the same location as the workspace. The **Region** will already be populated and will be used for the location of the DCR. -- :::image type="content" source="media/tutorial-workspace-transformations-api/custom-deployment-values.png" lightbox="media/tutorial-workspace-transformations-api/custom-deployment-values.png" alt-text="Screenshot that shows how to edit custom deployment values."::: --5. Select **Review + create** and then select **Create** after you review the details. --6. When the deployment is complete, expand the **Deployment details** box and select your DCR to view its details. Select **JSON View**. -- :::image type="content" source="media/tutorial-workspace-transformations-api/data-collection-rule-details.png" lightbox="media/tutorial-workspace-transformations-api/data-collection-rule-details.png" alt-text="Screenshot that shows DCR details."::: --1. Copy the **Immutable ID** and **Logs ingestion URI** for the DCR. You'll use these when you [send data to Azure Monitor using the API](./tutorial-logs-ingestion-code.md). -- :::image type="content" source="media/tutorial-logs-ingestion-api/data-collection-rule-json-view.png" lightbox="media/tutorial-logs-ingestion-api/data-collection-rule-json-view.png" alt-text="Screenshot that shows DCR JSON view."::: --## Assign permissions to a DCR -After the DCR has been created, the application needs to be given permission to it. Permission will allow any application using the correct application ID and application key to send data to the new DCR. --1. From the DCR in the Azure portal, select **Access Control (IAM)** > **Add role assignment**. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/add-role-assignment.png" lightbox="media/tutorial-logs-ingestion-portal/custom-log-create.png" alt-text="Screenshot that shows adding a custom role assignment to DCR."::: --1. Select **Monitoring Metrics Publisher** and select **Next**. You could instead create a custom action with the `Microsoft.Insights/Telemetry/Write` data action. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/add-role-assignment-select-role.png" lightbox="media/tutorial-logs-ingestion-portal/add-role-assignment-select-role.png" alt-text="Screenshot that shows selecting a role for DCR role assignment."::: --1. Select **User, group, or service principal** for **Assign access to** and choose **Select members**. Select the application that you created and choose **Select**. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/add-role-assignment-select-member.png" lightbox="media/tutorial-logs-ingestion-portal/add-role-assignment-select-member.png" alt-text="Screenshot that shows selecting members for the DCR role assignment."::: --1. Select **Review + assign** and verify the details before you save your role assignment. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/add-role-assignment-save.png" lightbox="media/tutorial-logs-ingestion-portal/add-role-assignment-save.png" alt-text="Screenshot that shows saving the DCR role assignment."::: ---## Sample code -See [Sample code to send data to Azure Monitor using Logs ingestion API](tutorial-logs-ingestion-code.md) for sample code using the components created in this tutorial. ---## Next steps --- [Complete a similar tutorial using the Azure portal](tutorial-logs-ingestion-portal.md)-- [Read more about custom logs](logs-ingestion-api-overview.md)-- [Learn more about writing transformation queries](../essentials//data-collection-transformations.md) |
| azure-monitor | Tutorial Logs Ingestion Code | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/tutorial-logs-ingestion-code.md | - Title: 'Sample code to send data to Azure Monitor using Logs ingestion API' -description: Sample code using REST API and client libraries for Logs ingestion API in Azure Monitor. - Previously updated : 04/15/2024---# Sample code to send data to Azure Monitor using Logs ingestion API --This article provides sample code using the [Logs ingestion API](logs-ingestion-api-overview.md). Each sample requires the following components to be created before the code is run. See [Tutorial: Send data to Azure Monitor using Logs ingestion API (Resource Manager templates)](tutorial-logs-ingestion-api.md) for a complete walkthrough of creating these components configured to support each of these samples. --- Custom table in a Log Analytics workspace-- Data collection rule (DCR) to direct the data to the target table-- Microsoft Entra application with access to the DCR-- Data collection endpoint (DCE) if you're using private link. Otherwise, use the DCR logs endpoint.---## Sample code --## [.NET](#tab/net) --The following script uses the [Azure Monitor Ingestion client library for .NET](/dotnet/api/overview/azure/Monitor.Ingestion-readme). --1. Install the Azure Monitor Ingestion client library and the Azure Identity library. The Azure Identity library is required for the authentication used in this sample. - - ```dotnetcli - dotnet add package Azure.Identity - dotnet add package Azure.Monitor.Ingestion - ``` --3. Create the following environment variables with values for your Microsoft Entra application. These values are used by `DefaultAzureCredential` in the Azure Identity library. -- - `AZURE_TENANT_ID` - - `AZURE_CLIENT_ID` - - `AZURE_CLIENT_SECRET` --2. Replace the variables in the following sample code with values from your DCR. You may also want to replace the sample data with your own. -- ```csharp - using Azure; - using Azure.Core; - using Azure.Identity; - using Azure.Monitor.Ingestion; -- // Initialize variables - var endpoint = new Uri("https://my-url.monitor.azure.com"); - var ruleId = "dcr-00000000000000000000000000000000"; - var streamName = "Custom-MyTableRawData"; - - // Create credential and client - var credential = new DefaultAzureCredential(); - LogsIngestionClient client = new(endpoint, credential); - - DateTimeOffset currentTime = DateTimeOffset.UtcNow; - - // Use BinaryData to serialize instances of an anonymous type into JSON - BinaryData data = BinaryData.FromObjectAsJson( -     new[] { -         new -         { -             Time = currentTime, -             Computer = "Computer1", -             AdditionalContext = new -             { -                 InstanceName = "user1", -                 TimeZone = "Pacific Time", -                 Level = 4, -                 CounterName = "AppMetric1", -                 CounterValue = 15.3 -             } -         }, -         new -         { -             Time = currentTime, -             Computer = "Computer2", -             AdditionalContext = new -             { -                 InstanceName = "user2", -                 TimeZone = "Central Time", -                 Level = 3, -                 CounterName = "AppMetric1", -                 CounterValue = 23.5 -             } -         }, -     }); - - // Upload logs - try - { - var response = await client.UploadAsync(ruleId, streamName, RequestContent.Create(data)).ConfigureAwait(false); - if (response.IsError) - { - throw new Exception(response.ToString()); - } - - Console.WriteLine("Log upload completed using content upload"); - } - catch (Exception ex) - { - Console.WriteLine("Upload failed with Exception: " + ex.Message); - } - - // Logs can also be uploaded in a List - var entries = new List<object>(); - for (int i = 0; i < 10; i++) - { - entries.Add( - new - { - Time = currentTime, - Computer = "Computer" + i.ToString(), - AdditionalContext = new - { - InstanceName = "user" + i.ToString(), - TimeZone = "Central Time", - Level = 3, - CounterName = "AppMetric1" + i.ToString(), - CounterValue = i - } - } - ); - } - - // Make the request - try - { - var response = await client.UploadAsync(ruleId, streamName, entries).ConfigureAwait(false); - if (response.IsError) - { - throw new Exception(response.ToString()); - } - - Console.WriteLine("Log upload completed using list of entries"); - } - catch (Exception ex) - { - Console.WriteLine("Upload failed with Exception: " + ex.Message); - } - ``` --3. Execute the code, and the data should arrive in your Log Analytics workspace within a few minutes. --## [Go](#tab/go) --The following sample code uses the [Azure Monitor Ingestion Logs client module for Go](https://pkg.go.dev/github.com/Azure/azure-sdk-for-go/sdk/monitor/ingestion/azlogs). --1. Use `go get` to install the Azure Monitor Ingestion Logs and Azure Identity client modules for Go. The Azure Identity module is required for the authentication used in this sample. -- ```bash - go get github.com/Azure/azure-sdk-for-go/sdk/monitor/ingestion/azlogs - go get github.com/Azure/azure-sdk-for-go/sdk/azidentity - ``` --1. Create the following environment variables with values for your Microsoft Entra application. These values are used by `DefaultAzureCredential` in the Azure Identity module. -- - `AZURE_TENANT_ID` - - `AZURE_CLIENT_ID` - - `AZURE_CLIENT_SECRET` --1. Replace the variables in the following sample code with values from your DCR. You might also want to replace the sample data with your own. -- ```go - package main - - import ( - "context" - "encoding/json" - "strconv" - "time" - - "github.com/Azure/azure-sdk-for-go/sdk/azidentity" - "github.com/Azure/azure-sdk-for-go/sdk/monitor/ingestion/azlogs" - ) - - // logs ingestion URI - const endpoint = "https://my-url.monitor.azure.com" - // data collection rule (DCR) immutable ID - const ruleID = "dcr-00000000000000000000000000000000" - // stream name in the DCR that represents the destination table - const streamName = "Custom-MyTableRawData" - - type Computer struct { - Time time.Time - Computer string - AdditionalContext string - } - - func main() { - // creating the client using DefaultAzureCredential - cred, err := azidentity.NewDefaultAzureCredential(nil) - - if err != nil { - //TODO: handle error - } - - client, err := azlogs.NewClient(endpoint, cred, nil) - - if err != nil { - //TODO: handle error - } - - // generating logs - // logs should match the schema defined by the provided stream - var data []Computer - - for i := 0; i < 10; i++ { - data = append(data, Computer{ - Time: time.Now().UTC(), - Computer: "Computer" + strconv.Itoa(i), - AdditionalContext: "context", - }) - } - - // marshal data into []byte - logs, err := json.Marshal(data) - - if err != nil { - panic(err) - } - - // upload logs - _, err = client.Upload(context.TODO(), ruleID, streamName, logs, nil) - - if err != nil { - //TODO: handle error - } - } - ``` --1. Execute the code, and the data should arrive in your Log Analytics workspace within a few minutes. --## [Java](#tab/java) --The following sample code uses the [Azure Monitor Ingestion client library for Java](/java/api/overview/azure/monitor-ingestion-readme). --1. Include the Logs ingestion package and the `azure-identity` package from the [Azure Identity library](https://github.com/Azure/azure-sdk-for-java/tree/azure-monitor-ingestion_1.0.1/sdk/identity/azure-identity). The Azure Identity library is required for the authentication used in this sample. -- > [!NOTE] - > See the Maven repositories for [Microsoft Azure Client Library For Identity](https://mvnrepository.com/artifact/com.azure/azure-identity) and [Microsoft Azure SDK For Azure Monitor Data Ingestion](https://mvnrepository.com/artifact/com.azure/azure-monitor-ingestion) for the latest versions. -- ```xml - <dependency> - <groupId>com.azure</groupId> - <artifactId>azure-monitor-ingestion</artifactId> - <version>{get-latest-version}</version> - <dependency> - <groupId>com.azure</groupId> - <artifactId>azure-identity</artifactId> - <version>{get-latest-version}</version> - </dependency> - ``` --1. Create the following environment variables with values for your Microsoft Entra application. These values are used by `DefaultAzureCredential` in the Azure Identity library. -- - `AZURE_TENANT_ID` - - `AZURE_CLIENT_ID` - - `AZURE_CLIENT_SECRET` --1. Replace the variables in the following sample code with values from your DCR. You may also want to replace the sample data with your own. -- ```java - import com.azure.identity.DefaultAzureCredentialBuilder; - import com.azure.monitor.ingestion.models.LogsUploadException; -- import java.time.OffsetDateTime; - import java.util.Arrays; - import java.util.List; -- public class LogsUploadSample { - public static void main(String[] args) { - - LogsIngestionClient client = new LogsIngestionClientBuilder() - .endpoint("https://my-url.monitor.azure.com") - .credential(new DefaultAzureCredentialBuilder().build()) - .buildClient(); - - List<Object> dataList = Arrays.asList( - new Object() { - OffsetDateTime time = OffsetDateTime.now(); - String computer = "Computer1"; - Object additionalContext = new Object() { - String instanceName = "user4"; - String timeZone = "Pacific Time"; - int level = 4; - String counterName = "AppMetric1"; - double counterValue = 15.3; - }; - }, - new Object() { - OffsetDateTime time = OffsetDateTime.now(); - String computer = "Computer2"; - Object additionalContext = new Object() { - String instanceName = "user2"; - String timeZone = "Central Time"; - int level = 3; - String counterName = "AppMetric2"; - double counterValue = 43.5; - }; - }); - - try { - client.upload("dcr-00000000000000000000000000000000", "Custom-MyTableRawData", dataList); - System.out.println("Logs uploaded successfully"); - } catch (LogsUploadException exception) { - System.out.println("Failed to upload logs "); - exception.getLogsUploadErrors() - .forEach(httpError -> System.out.println(httpError.getMessage())); - } - } - } - ``` --1. Execute the code, and the data should arrive in your Log Analytics workspace within a few minutes. --## [JavaScript](#tab/javascript) --The following sample code uses the [Azure Monitor Ingestion client library for JavaScript](/javascript/api/overview/azure/monitor-ingestion-readme). --1. Use [npm](https://www.npmjs.com/) to install the Azure Monitor Ingestion and Azure Identity client libraries for JavaScript. The Azure Identity library is required for the authentication used in this sample. -- ```bash - npm install --save @azure/monitor-ingestion - npm install --save @azure/identity - ``` --1. Create the following environment variables with values for your Microsoft Entra application. These values are used by `DefaultAzureCredential` in the Azure Identity library. -- - `AZURE_TENANT_ID` - - `AZURE_CLIENT_ID` - - `AZURE_CLIENT_SECRET` --1. Replace the variables in the following sample code with values from your DCR. You might also want to replace the sample data with your own. -- ```javascript - const { DefaultAzureCredential } = require("@azure/identity"); - const { LogsIngestionClient, isAggregateLogsUploadError } = require("@azure/monitor-ingestion"); - - require("dotenv").config(); - - async function main() { - const logsIngestionEndpoint = "https://my-url.monitor.azure.com"; - const ruleId = "dcr-00000000000000000000000000000000"; - const streamName = "Custom-MyTableRawData"; - const credential = new DefaultAzureCredential(); - const client = new LogsIngestionClient(logsIngestionEndpoint, credential); - const logs = [ - { - Time: "2021-12-08T23:51:14.1104269Z", - Computer: "Computer1", - AdditionalContext: { - "InstanceName": "user1", - "TimeZone": "Pacific Time", - "Level": 4, - "CounterName": "AppMetric2", - "CounterValue": 35.3 - } - }, - { - Time: "2021-12-08T23:51:14.1104269Z", - Computer: "Computer2", - AdditionalContext: { - "InstanceName": "user2", - "TimeZone": "Pacific Time", - "Level": 4, - "CounterName": "AppMetric2", - "CounterValue": 43.5 - } - }, - ]; - try{ - await client.upload(ruleId, streamName, logs); - } - catch(e){ - let aggregateErrors = isAggregateLogsUploadError(e) ? e.errors : []; - if (aggregateErrors.length > 0) { - console.log("Some logs have failed to complete ingestion"); - for (const error of aggregateErrors) { - console.log(`Error - ${JSON.stringify(error.cause)}`); - console.log(`Log - ${JSON.stringify(error.failedLogs)}`); - } - } else { - console.log(e); - } - } - } - - main().catch((err) => { - console.error("The sample encountered an error:", err); - process.exit(1); - }); - ``` --1. Execute the code, and the data should arrive in your Log Analytics workspace within a few minutes. --## [PowerShell](#tab/powershell) --The following PowerShell code sends data to the endpoint by using HTTP REST fundamentals. --> [!NOTE] -> This sample requires PowerShell v7.0 or later. --1. Run the following sample PowerShell command, which adds a required assembly for the script. -- ```powershell - Add-Type -AssemblyName System.Web - ``` --1. Replace the parameters in the **Step 0** section with values from your application and DCR. You might also want to replace the sample data in the **Step 2** section with your own. -- ```powershell - ### Step 0: Set variables required for the rest of the script. - - # information needed to authenticate to AAD and obtain a bearer token - $tenantId = "00000000-0000-0000-00000000000000000" #Tenant ID the data collection endpoint resides in - $appId = " 000000000-0000-0000-00000000000000000" #Application ID created and granted permissions - $appSecret = "0000000000000000000000000000000000000000" #Secret created for the application - - # information needed to send data to the DCR endpoint - $endpoint_uri = "https://my-url.monitor.azure.com" #Logs ingestion URI for the DCR - $dcrImmutableId = "dcr-00000000000000000000000000000000" #the immutableId property of the DCR object - $streamName = "Custom-MyTableRawData" #name of the stream in the DCR that represents the destination table - - - ### Step 1: Obtain a bearer token used later to authenticate against the DCR. - - $scope= [System.Web.HttpUtility]::UrlEncode("https://monitor.azure.com//.default") - $body = "client_id=$appId&scope=$scope&client_secret=$appSecret&grant_type=client_credentials"; - $headers = @{"Content-Type"="application/x-www-form-urlencoded"}; - $uri = "https://login.microsoftonline.com/$tenantId/oauth2/v2.0/token" - - $bearerToken = (Invoke-RestMethod -Uri $uri -Method "Post" -Body $body -Headers $headers).access_token - - - ### Step 2: Create some sample data. - - $currentTime = Get-Date ([datetime]::UtcNow) -Format O - $staticData = @" - [ - { - "Time": "$currentTime", - "Computer": "Computer1", - "AdditionalContext": { - "InstanceName": "user1", - "TimeZone": "Pacific Time", - "Level": 4, - "CounterName": "AppMetric1", - "CounterValue": 15.3 - } - }, - { - "Time": "$currentTime", - "Computer": "Computer2", - "AdditionalContext": { - "InstanceName": "user2", - "TimeZone": "Central Time", - "Level": 3, - "CounterName": "AppMetric1", - "CounterValue": 23.5 - } - } - ] - "@; - - - ### Step 3: Send the data to the Log Analytics workspace. - - $body = $staticData; - $headers = @{"Authorization"="Bearer $bearerToken";"Content-Type"="application/json"}; - $uri = "$endpoint_uri/dataCollectionRules/$dcrImmutableId/streams/$($streamName)?api-version=2023-01-01" - - $uploadResponse = Invoke-RestMethod -Uri $uri -Method "Post" -Body $body -Headers $headers - ``` -- > [!NOTE] - > If you receive an `Unable to find type [System.Web.HttpUtility].` error, run the last line in section 1 of the script for a fix and execute it. Executing it uncommented as part of the script won't resolve the issue. The command must be executed separately. --1. Execute the script, and you should see an `HTTP - 204` response. The data should arrive in your Log Analytics workspace within a few minutes. --## [Python](#tab/python) --The following sample code uses the [Azure Monitor Ingestion client library for Python](/python/api/overview/azure/monitor-ingestion-readme). --1. Use [pip](https://pypi.org/project/pip/) to install the Azure Monitor Ingestion and Azure Identity client libraries for Python. The Azure Identity library is required for the authentication used in this sample. -- ```bash - pip install azure-monitor-ingestion - pip install azure-identity - ``` --1. Create the following environment variables with values for your Microsoft Entra application. These values are used by `DefaultAzureCredential` in the Azure Identity library. -- - `AZURE_TENANT_ID` - - `AZURE_CLIENT_ID` - - `AZURE_CLIENT_SECRET` --1. Replace the variables in the following sample code with values from your DCR. You might also want to replace the sample data in the **Step 2** section with your own. -- ```python - # information needed to send data to the DCR endpoint - endpoint_uri = "https://my-url.monitor.azure.com" # logs ingestion endpoint of the DCR - dcr_immutableid = "dcr-00000000000000000000000000000000" # immutableId property of the Data Collection Rule - stream_name = "Custom-MyTableRawData" #name of the stream in the DCR that represents the destination table - - # Import required modules - import os - from azure.identity import DefaultAzureCredential - from azure.monitor.ingestion import LogsIngestionClient - from azure.core.exceptions import HttpResponseError - - credential = DefaultAzureCredential() - client = LogsIngestionClient(endpoint=endpoint_uri, credential=credential, logging_enable=True) - - body = [ - { - "Time": "2023-03-12T15:04:48.423211Z", - "Computer": "Computer1", - "AdditionalContext": { - "InstanceName": "user1", - "TimeZone": "Pacific Time", - "Level": 4, - "CounterName": "AppMetric2", - "CounterValue": 35.3 - } - }, - { - "Time": "2023-03-12T15:04:48.794972Z", - "Computer": "Computer2", - "AdditionalContext": { - "InstanceName": "user2", - "TimeZone": "Central Time", - "Level": 3, - "CounterName": "AppMetric2", - "CounterValue": 43.5 - } - } - ] - - try: - client.upload(rule_id=dcr_immutableid, stream_name=stream_name, logs=body) - except HttpResponseError as e: - print(f"Upload failed: {e}") - ``` --1. Execute the code, and the data should arrive in your Log Analytics workspace within a few minutes. ----## Troubleshooting -This section describes different error conditions you might receive and how to correct them. --### Script returns error code 403 -Ensure that you have the correct permissions for your application to the DCR. You might also need to wait up to 30 minutes for permissions to propagate. --### Script returns error code 413 or warning of TimeoutExpired with the message ReadyBody_ClientConnectionAbort in the response -The message is too large. The maximum message size is currently 1 MB per call. --### Script returns error code 429 -API limits have been exceeded. The limits are currently set to 500 MB of data per minute for both compressed and uncompressed data and 300,000 requests per minute. Retry after the duration listed in the `Retry-After` header in the response. --### Script returns error code 503 -Ensure that you have the correct permissions for your application to the DCR. You might also need to wait up to 30 minutes for permissions to propagate. --### You don't receive an error, but data doesn't appear in the workspace -The data might take some time to be ingested, especially the first time data is being sent to a particular table. It shouldn't take longer than 15 minutes. --### IntelliSense in Log Analytics doesn't recognize the new table -The cache that drives IntelliSense might take up to 24 hours to update. --## Next steps --- [Learn more about data collection rules](../essentials/data-collection-rule-overview.md)-- [Learn more about writing transformation queries](../essentials//data-collection-transformations.md) |
| azure-monitor | Tutorial Logs Ingestion Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/tutorial-logs-ingestion-portal.md | - Title: 'Tutorial: Send data to Azure Monitor Logs with Logs ingestion API (Azure portal)' -description: Tutorial on how sending data to a Log Analytics workspace in Azure Monitor using the Logs ingestion API. Supporting components configured using the Azure portal. - Previously updated : 09/14/2023--------# Tutorial: Send data to Azure Monitor Logs with Logs ingestion API (Azure portal) -The [Logs Ingestion API](logs-ingestion-api-overview.md) in Azure Monitor allows you to send external data to a Log Analytics workspace with a REST API. This tutorial uses the Azure portal to walk through configuration of a new table and a sample application to send log data to Azure Monitor. The sample application collects entries from a text file and either converts the plain log to JSON format generating a resulting .json file, or sends the content to the data collection endpoint. --> [!NOTE] -> This tutorial uses the Azure portal to configure the components to support the Logs ingestion API. See [Tutorial: Send data to Azure Monitor using Logs ingestion API (Resource Manager templates)](tutorial-logs-ingestion-api.md) for a similar tutorial that uses Azure Resource Manager templates to configure these components and that has sample code for client libraries for [.NET](/dotnet/api/overview/azure/Monitor.Ingestion-readme), [Go](https://pkg.go.dev/github.com/Azure/azure-sdk-for-go/sdk/monitor/ingestion/azlogs), [Java](/java/api/overview/azure/monitor-ingestion-readme), [JavaScript](/javascript/api/overview/azure/monitor-ingestion-readme), and [Python](/python/api/overview/azure/monitor-ingestion-readme). ---The steps required to configure the Logs ingestion API are as follows: --1. [Create a Microsoft Entra application](#create-azure-ad-application) to authenticate against the API. -3. [Create a data collection endpoint (DCE)](#create-data-collection-endpoint) to receive data. -2. [Create a custom table in a Log Analytics workspace](#create-new-table-in-log-analytics-workspace). This is the table you'll be sending data to. As part of this process, you will create a data collection rule (DCR) to direct the data to the target table. -5. [Give the AD application access to the DCR](#assign-permissions-to-the-dcr). -6. [Use sample code to send data to using the Logs ingestion API](#send-sample-data). ---## Prerequisites -To complete this tutorial, you need: --- A Log Analytics workspace where you have at least [contributor rights](manage-access.md#azure-rbac).-- [Permissions to create DCR objects](../essentials/data-collection-rule-create-edit.md#permissions) in the workspace.-- PowerShell 7.2 or later.--## Overview of the tutorial -In this tutorial, you'll use a PowerShell script to send sample Apache access logs over HTTP to the API endpoint. This approach requires a script to convert this data to the JSON format that's required for the Azure Monitor Logs Ingestion API. The data will further be converted with a transformation in a DCR that filters out records that shouldn't be ingested. It also creates the columns required for the table where the data will be sent. --After the configuration is finished, you'll send sample data from the command line, and then inspect the results in Log Analytics. --<a name='create-azure-ad-application'></a> --## Create Microsoft Entra application -Start by registering a Microsoft Entra application to authenticate against the API. Any Resource Manager authentication scheme is supported, but this tutorial will follow the [Client Credential Grant Flow scheme](../../active-directory/develop/v2-oauth2-client-creds-grant-flow.md). --1. On the **Microsoft Entra ID** menu in the Azure portal, select **App registrations** > **New registration**. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/new-app-registration.png" lightbox="media/tutorial-logs-ingestion-portal/new-app-registration.png" alt-text="Screenshot that shows the app registration screen."::: --1. Give the application a name and change the tenancy scope if the default isn't appropriate for your environment. A **Redirect URI** isn't required. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/new-app-name.png" lightbox="media/tutorial-logs-ingestion-portal/new-app-name.png" alt-text="Screenshot that shows app details."::: --1. After registration, you can view the details of the application. Note the **Application (client) ID** and the **Directory (tenant) ID**. You'll need these values later in the process. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/new-app-id.png" lightbox="media/tutorial-logs-ingestion-portal/new-app-id.png" alt-text="Screenshot that shows the app ID."::: --1. You now need to generate an application client secret, which is similar to creating a password to use with a username. Select **Certificates & secrets** > **New client secret**. Give the secret a name to identify its purpose and select an **Expires** duration. The value **1 year** is selected here. For a production implementation, you would follow best practices for a secret rotation procedure or use a more secure authentication mode, such as a certificate. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/new-app-secret.png" lightbox="media/tutorial-logs-ingestion-portal/new-app-secret.png" alt-text="Screenshot that shows a secret for a new app."::: --1. Select **Add** to save the secret and then note the **Value**. Ensure that you record this value because you can't recover it after you move away from this page. Use the same security measures as you would for safekeeping a password because it's the functional equivalent. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/new-app-secret-value.png" lightbox="media/tutorial-logs-ingestion-portal/new-app-secret-value.png" alt-text="Screenshot that shows the secret value for the new app."::: --## Create data collection endpoint --> [!NOTE] -> A DCE is no longer required in most cases since you can use the endpoint of the DCR. The Azure portal though has not yet been updated to reflect this change and currently requires a DCE when you create the custom log. If you use [other methods to create the custom table and DCR](./tutorial-logs-ingestion-api.md), you can use the DCR endpoint instead of a DCE. ---A [data collection endpoint](../essentials/data-collection-endpoint-overview.md) is required to accept the data from the script. After you configure the DCE and link it to a DCR, you can send data over HTTP from your application. The DCE needs to be in the same region as the Log Analytics workspace where the data will be sent or the data collection rule being used. --1. To create a new DCE, go to the **Monitor** menu in the Azure portal. Select **Data Collection Endpoints** and then select **Create**. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/new-data-collection-endpoint.png" lightbox="media/tutorial-logs-ingestion-portal/new-data-collection-endpoint.png" alt-text="Screenshot that shows new DCE."::: --1. Provide a name for the DCE and ensure that it's in the same region as your workspace. Select **Create** to create the DCE. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/data-collection-endpoint-details.png" lightbox="media/tutorial-logs-ingestion-portal/data-collection-endpoint-details.png" alt-text="Screenshot that shows DCE details."::: --1. After the DCE is created, select it so that you can view its properties. Note the **Logs ingestion** URI because you'll need it in a later step. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/data-collection-endpoint-uri.png" lightbox="media/tutorial-logs-ingestion-portal/data-collection-endpoint-uri.png" alt-text="Screenshot that shows DCE URI."::: ---## Create new table in Log Analytics workspace -Before you can send data to the workspace, you need to create the custom table where the data will be sent. --> [!NOTE] -> The table creation for a log ingestion API custom log below can't be used to create a [agent custom log table](../agents/data-collection-text-log.md). You must use the CLI or custom template process to create the table. If you do not have sufficient rights to run CLI or custom template you must ask your administrator to add the table for you. --1. Go to the **Log Analytics workspaces** menu in the Azure portal and select **Tables**. The tables in the workspace will appear. Select **Create** > **New custom log (DCR based)**. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/new-custom-log.png" lightbox="media/tutorial-logs-ingestion-portal/new-custom-log.png" alt-text="Screenshot that shows the new DCR-based custom log."::: --1. Specify a name for the table. You don't need to add the *_CL* suffix required for a custom table because it will be automatically added to the name you specify. --1. Select **Create a new data collection rule** to create the DCR that will be used to send data to this table. If you have an existing DCR, you can choose to use it instead. Specify the **Subscription**, **Resource group**, and **Name** for the DCR that will contain the custom log configuration. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/new-data-collection-rule.png" lightbox="media/tutorial-logs-ingestion-portal/new-data-collection-rule.png" alt-text="Screenshot that shows the new DCR."::: --1. Select the DCR that you created, and then select **Next**. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/custom-log-table-name.png" lightbox="media/tutorial-logs-ingestion-portal/custom-log-table-name.png" alt-text="Screenshot that shows the custom log table name."::: --## Parse and filter sample data -Instead of directly configuring the schema of the table, you can upload a file with a sample JSON array of data through the portal, and Azure Monitor will set the schema automatically. The sample JSON file must contain one or more log records structured as an array, in the same way the data is sent in the body of an HTTP request of the logs ingestion API call. --1. Follow the instructions in [generate sample data](#generate-sample-data) to create the *data_sample.json* file. --1. Select **Browse for files** and locate the *data_sample.json* file that you previously created. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/custom-log-browse-files.png" lightbox="media/tutorial-logs-ingestion-portal/custom-log-browse-files.png" alt-text="Screenshot that shows custom log browse for files."::: --1. Data from the sample file is displayed with a warning that `TimeGenerated` isn't in the data. All log tables within Azure Monitor Logs are required to have a `TimeGenerated` column populated with the timestamp of the logged event. In this sample, the timestamp of the event is stored in the field called `Time`. You'll add a transformation that will rename this column in the output. --1. Select **Transformation editor** to open the transformation editor to add this column. You'll add a transformation that will rename this column in the output. The transformation editor lets you create a transformation for the incoming data stream. This is a KQL query that's run against each incoming record. The results of the query will be stored in the destination table. For more information on transformation queries, see [Data collection rule transformations in Azure Monitor](../essentials//data-collection-transformations.md). -- :::image type="content" source="media/tutorial-logs-ingestion-portal/custom-log-data-preview.png" lightbox="media/tutorial-logs-ingestion-portal/custom-log-data-preview.png" alt-text="Screenshot that shows the custom log data preview."::: --1. Add the following query to the transformation editor to add the `TimeGenerated` column to the output: -- ```kusto - source - | extend TimeGenerated = todatetime(Time) - ``` --1. Select **Run** to view the results. You can see that the `TimeGenerated` column is now added to the other columns. Most of the interesting data is contained in the `RawData` column, though. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/custom-log-query-01.png" lightbox="media/tutorial-logs-ingestion-portal/custom-log-query-01.png" alt-text="Screenshot that shows the initial custom log data query."::: --1. Modify the query to the following example, which extracts the client IP address, the HTTP method, the address of the page being accessed, and the response code from each log entry. -- ```kusto - source - | extend TimeGenerated = todatetime(Time) - | parse RawData with - ClientIP:string - ' ' * - ' ' * - ' [' * '] "' RequestType:string - ' ' Resource:string - ' ' * - '" ' ResponseCode:int - ' ' * - ``` --1. Select **Run** to view the results. This action extracts the contents of `RawData` into the separate columns `ClientIP`, `RequestType`, `Resource`, and `ResponseCode`. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/custom-log-query-02.png" lightbox="media/tutorial-logs-ingestion-portal/custom-log-query-02.png" alt-text="Screenshot that shows the custom log data query with parse command."::: --1. The query can be optimized more though by removing the `RawData` and `Time` columns because they aren't needed anymore. You can also filter out any records with `ResponseCode` of 200 because you're only interested in collecting data for requests that weren't successful. This step reduces the volume of data being ingested, which reduces its overall cost. -- ```kusto - source - | extend TimeGenerated = todatetime(Time) - | parse RawData with - ClientIP:string - ' ' * - ' ' * - ' [' * '] "' RequestType:string - ' ' Resource:string - ' ' * - '" ' ResponseCode:int - ' ' * - | project-away Time, RawData - | where ResponseCode != 200 - ``` --1. Select **Run** to view the results. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/custom-log-query-03.png" lightbox="media/tutorial-logs-ingestion-portal/custom-log-query-03.png" alt-text="Screenshot that shows a custom log data query with a filter."::: --1. Select **Apply** to save the transformation and view the schema of the table that's about to be created. Select **Next** to proceed. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/custom-log-final-schema.png" lightbox="media/tutorial-logs-ingestion-portal/custom-log-final-schema.png" alt-text="Screenshot that shows a custom log final schema."::: --1. Verify the final details and select **Create** to save the custom log. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/custom-log-create.png" lightbox="media/tutorial-logs-ingestion-portal/custom-log-create.png" alt-text="Screenshot that shows custom log create."::: --## Collect information from the DCR -With the DCR created, you need to collect its ID, which is needed in the API call. --1. On the **Monitor** menu in the Azure portal, select **Data collection rules** and select the DCR you created. From **Overview** for the DCR, select **JSON View**. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/data-collection-rule-json-view.png" lightbox="media/tutorial-logs-ingestion-portal/data-collection-rule-json-view.png" alt-text="Screenshot that shows the DCR JSON view."::: --1. Copy the **immutableId** value. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/data-collection-rule-immutable-id.png" lightbox="media/tutorial-logs-ingestion-portal/data-collection-rule-immutable-id.png" alt-text="Screenshot that shows collecting the immutable ID from the JSON view."::: --## Assign permissions to the DCR -The final step is to give the application permission to use the DCR. Any application that uses the correct application ID and application key can now send data to the new DCE and DCR. --1. Select **Access Control (IAM)** for the DCR and then select **Add role assignment**. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/add-role-assignment.png" lightbox="media/tutorial-logs-ingestion-portal/custom-log-create.png" alt-text="Screenshot that shows adding the custom role assignment to the DCR."::: --1. Select **Monitoring Metrics Publisher** > **Next**. You could instead create a custom action with the `Microsoft.Insights/Telemetry/Write` data action. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/add-role-assignment-select-role.png" lightbox="media/tutorial-logs-ingestion-portal/add-role-assignment-select-role.png" alt-text="Screenshot that shows selecting the role for the DCR role assignment."::: --1. Select **User, group, or service principal** for **Assign access to** and choose **Select members**. Select the application that you created and then choose **Select**. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/add-role-assignment-select-member.png" lightbox="media/tutorial-logs-ingestion-portal/add-role-assignment-select-member.png" alt-text="Screenshot that shows selecting members for the DCR role assignment."::: --1. Select **Review + assign** and verify the details before you save your role assignment. -- :::image type="content" source="media/tutorial-logs-ingestion-portal/add-role-assignment-save.png" lightbox="media/tutorial-logs-ingestion-portal/add-role-assignment-save.png" alt-text="Screenshot that shows saving the DCR role assignment."::: --## Generate sample data --The following PowerShell script generates sample data to configure the custom table and sends sample data to the logs ingestion API to test the configuration. --> [!NOTE] -> This sample script requires PowerShell v7.2 or later. --1. Run the following PowerShell command, which adds a required assembly for the script: -- ```powershell - Add-Type -AssemblyName System.Web - ``` --1. Update the values of `$tenantId`, `$appId`, and `$appSecret` with the values you noted for **Directory (tenant) ID**, **Application (client) ID**, and secret **Value**. Then save it with the file name *LogGenerator.ps1*. -- ``` PowerShell - param ([Parameter(Mandatory=$true)] $Log, $Type="file", $Output, $DcrImmutableId, $DceURI, $Table) - ################ - ##### Usage - ################ - # LogGenerator.ps1 - # -Log <String> - Log file to be forwarded - # [-Type "file|API"] - Whether the script should generate sample JSON file or send data via - # API call. Data will be written to a file by default. - # [-Output <String>] - Path to resulting JSON sample - # [-DcrImmutableId <string>] - DCR immutable ID - # [-DceURI] - Data collection endpoint URI - # [-Table] - The name of the custom log table, including "_CL" suffix --- ##### >>>> PUT YOUR VALUES HERE <<<<< - # Information needed to authenticate to Azure Active Directory and obtain a bearer token - $tenantId = "<put tenant ID here>"; #the tenant ID in which the Data Collection Endpoint resides - $appId = "<put application ID here>"; #the app ID created and granted permissions - $appSecret = "<put secret value here>"; #the secret created for the above app - never store your secrets in the source code - ##### >>>> END <<<<< --- $file_data = Get-Content $Log - if ("file" -eq $Type) { - ############ - ## Convert plain log to JSON format and output to .json file - ############ - # If not provided, get output file name - if ($null -eq $Output) { - $Output = Read-Host "Enter output file name" - }; -- # Form file payload - $payload = @(); - $records_to_generate = [math]::min($file_data.count, 500) - for ($i=0; $i -lt $records_to_generate; $i++) { - $log_entry = @{ - # Define the structure of log entry, as it will be sent - Time = Get-Date ([datetime]::UtcNow) -Format O - Application = "LogGenerator" - RawData = $file_data[$i] - } - $payload += $log_entry - } - # Write resulting payload to file - New-Item -Path $Output -ItemType "file" -Value ($payload | ConvertTo-Json -AsArray) -Force -- } else { - ############ - ## Send the content to the data collection endpoint - ############ - if ($null -eq $DcrImmutableId) { - $DcrImmutableId = Read-Host "Enter DCR Immutable ID" - }; -- if ($null -eq $DceURI) { - $DceURI = Read-Host "Enter data collection endpoint URI" - } -- if ($null -eq $Table) { - $Table = Read-Host "Enter the name of custom log table" - } -- ## Obtain a bearer token used to authenticate against the data collection endpoint - $scope = [System.Web.HttpUtility]::UrlEncode("https://monitor.azure.com//.default") - $body = "client_id=$appId&scope=$scope&client_secret=$appSecret&grant_type=client_credentials"; - $headers = @{"Content-Type" = "application/x-www-form-urlencoded" }; - $uri = "https://login.microsoftonline.com/$tenantId/oauth2/v2.0/token" - $bearerToken = (Invoke-RestMethod -Uri $uri -Method "Post" -Body $body -Headers $headers).access_token -- ## Generate and send some data - foreach ($line in $file_data) { - # We are going to send log entries one by one with a small delay - $log_entry = @{ - # Define the structure of log entry, as it will be sent - Time = Get-Date ([datetime]::UtcNow) -Format O - Application = "LogGenerator" - RawData = $line - } - # Sending the data to Log Analytics via the DCR! - $body = $log_entry | ConvertTo-Json -AsArray; - $headers = @{"Authorization" = "Bearer $bearerToken"; "Content-Type" = "application/json" }; - $uri = "$DceURI/dataCollectionRules/$DcrImmutableId/streams/Custom-$Table"+"?api-version=2023-01-01"; - $uploadResponse = Invoke-RestMethod -Uri $uri -Method "Post" -Body $body -Headers $headers; -- # Let's see how the response looks - Write-Output $uploadResponse - Write-Output "" -- # Pausing for 1 second before processing the next entry - Start-Sleep -Seconds 1 - } - } - ``` --1. Copy the sample log data from [sample data](#sample-data) or copy your own Apache log data into a file called `sample_access.log`. --1. To read the data in the file and create a JSON file called `data_sample.json` that you can send to the logs ingestion API, run: -- ```PowerShell - .\LogGenerator.ps1 -Log "sample_access.log" -Type "file" -Output "data_sample.json" - ``` ---## Send sample data -Allow at least 30 minutes for the configuration to take effect. You might also experience increased latency for the first few entries, but this activity should normalize. --1. Run the following command providing the values that you collected for your DCR and DCE. The script will start ingesting data by placing calls to the API at the pace of approximately one record per second. -- ```PowerShell - .\LogGenerator.ps1 -Log "sample_access.log" -Type "API" -Table "ApacheAccess_CL" -DcrImmutableId <immutable ID> -DceUri <data collection endpoint URL> - ``` --1. From Log Analytics, query your newly created table to verify that data arrived and that it's transformed properly. --## Troubleshooting -See the [Troubleshooting](tutorial-logs-ingestion-code.md#troubleshooting) section of the sample code article if your code doesn't work as expected. --## Sample data -You can use the following sample data for the tutorial. Alternatively, you can use your own data if you have your own Apache access logs. --``` -0.0.139.0 -0.0.153.185 -0.0.153.185 -0.0.66.230 -0.0.148.92 -0.0.35.224 -0.0.162.225 -0.0.162.225 -0.0.148.108 -0.0.148.1 -0.0.203.24 -0.0.4.214 -0.0.10.125 -0.0.10.125 -0.0.10.125 -0.0.10.125 -0.0.10.117 -0.0.10.114 -0.0.10.114 -0.0.10.125 -0.0.10.117 -0.0.10.117 -0.0.10.114 -0.0.10.114 -0.0.10.125 -0.0.10.114 -0.0.10.114 -0.0.10.125 -0.0.10.117 -0.0.10.117 -0.0.10.114 -0.0.10.125 -0.0.10.117 -0.0.10.114 -0.0.10.117 -0.0.10.125 -0.0.10.125 -0.0.10.125 -0.0.10.125 -0.0.10.125 -0.0.10.125 -0.0.10.114 -0.0.10.117 -0.0.167.138 -0.0.149.55 -0.0.229.86 -0.0.117.249 -0.0.117.249 -0.0.117.249 -0.0.64.41 -0.0.208.79 -0.0.208.79 -0.0.208.79 -0.0.208.79 -0.0.196.129 -0.0.196.129 -0.0.66.158 -0.0.161.12 -0.0.161.12 -0.0.51.36 -0.0.51.36 -0.0.145.131 -0.0.145.131 -0.0.0.179 -0.0.0.179 -0.0.145.131 -0.0.145.131 -0.0.95.52 -0.0.95.52 -0.0.51.36 -0.0.51.36 -0.0.227.31 -0.0.227.31 -0.0.51.36 -0.0.51.36 -0.0.51.36 -0.0.51.36 -0.0.4.22 -0.0.4.22 -0.0.143.24 -0.0.143.24 -0.0.0.98 -0.0.0.98 -0.0.51.62 -0.0.51.62 -0.0.51.36 -0.0.51.36 -0.0.0.98 -0.0.0.98 -0.0.58.254 -0.0.58.254 -0.0.51.62 -0.0.51.62 -0.0.227.31 -0.0.227.31 -0.0.0.179 -0.0.0.179 -0.0.58.254 -0.0.58.254 -0.0.95.52 -0.0.95.52 -0.0.0.98 -0.0.0.98 -0.0.58.90 -0.0.58.90 -0.0.51.36 -0.0.51.36 -0.0.207.154 -0.0.207.154 -0.0.95.52 -0.0.95.52 -0.0.51.62 -0.0.51.62 -0.0.145.131 -0.0.145.131 -0.0.58.90 -0.0.58.90 -0.0.227.55 -0.0.227.55 -0.0.95.52 -0.0.95.52 -0.0.161.12 -0.0.161.12 -0.0.227.55 -0.0.227.55 -0.0.143.30 -0.0.143.30 -0.0.227.31 -0.0.227.31 -0.0.161.6 -0.0.161.6 -0.0.161.6 -0.0.227.31 -0.0.227.31 -0.0.51.62 -0.0.51.62 -0.0.227.31 -0.0.227.31 -0.0.95.20 -0.0.95.20 -0.0.207.154 -0.0.207.154 -0.0.0.98 -0.0.0.98 -0.0.51.36 -0.0.51.36 -0.0.227.55 -0.0.227.55 -0.0.207.154 -0.0.207.154 -0.0.51.36 -0.0.51.36 -0.0.51.36 -0.0.51.36 -0.0.207.221 -0.0.207.221 -0.0.0.179 -0.0.0.179 -0.0.161.12 -0.0.161.12 -0.0.58.90 -0.0.58.90 -0.0.145.106 -0.0.145.106 -0.0.145.106 -0.0.145.106 -0.0.0.179 -0.0.0.179 -0.0.149.8 -0.0.207.154 -0.0.207.154 -0.0.227.31 -0.0.227.31 -0.0.51.62 -0.0.51.62 -0.0.227.55 -0.0.227.55 -0.0.143.30 -0.0.143.30 -0.0.95.52 -0.0.95.52 -0.0.145.131 -0.0.145.131 -0.0.51.62 -0.0.51.62 -0.0.0.98 -0.0.0.98 -0.0.207.221 -0.0.145.131 -0.0.207.221 -0.0.145.131 -0.0.51.62 -0.0.51.62 -0.0.51.36 -0.0.51.36 -0.0.145.131 -0.0.145.131 -0.0.58.254 -0.0.58.254 -0.0.145.106 -0.0.145.106 -0.0.207.221 -0.0.207.221 -0.0.227.31 -0.0.227.31 -0.0.145.106 -0.0.145.106 -0.0.145.131 -0.0.145.131 -0.0.0.179 -0.0.0.179 -0.0.227.31 -0.0.227.31 -0.0.227.55 -0.0.227.55 -0.0.95.52 -0.0.95.52 -0.0.0.98 -0.0.0.98 -0.0.4.35 -0.0.4.35 -0.0.4.22 -0.0.4.22 -0.0.58.90 -0.0.58.90 -0.0.145.106 -0.0.145.106 -0.0.143.24 -0.0.143.24 -0.0.227.55 -0.0.227.55 -0.0.207.154 -0.0.207.154 -0.0.143.30 -0.0.143.30 -0.0.227.31 -0.0.227.31 -0.0.0.179 -0.0.0.179 -0.0.0.98 -0.0.0.98 -0.0.207.221 -0.0.207.221 -0.0.0.179 -0.0.0.179 -0.0.0.98 -0.0.0.98 -0.0.207.221 -0.0.207.221 -0.0.207.154 -0.0.207.154 -0.0.58.254 -0.0.58.254 -0.0.51.36 -0.0.51.36 -0.0.51.36 -0.0.51.36 -0.0.207.154 -0.0.207.154 -0.0.161.6 -0.0.145.131 -0.0.145.131 -0.0.207.221 -0.0.207.221 -0.0.95.20 -0.0.95.20 -0.0.183.233 -0.0.183.233 -0.0.51.36 -0.0.51.36 -0.0.95.52 -0.0.95.52 -0.0.227.31 -0.0.227.31 -0.0.51.62 -0.0.51.62 -0.0.95.52 -0.0.95.52 -0.0.207.154 -0.0.207.154 -0.0.51.36 -0.0.51.36 -0.0.58.90 -0.0.58.90 -0.0.4.35 -0.0.4.35 -0.0.95.52 -0.0.95.52 -0.0.167.138 -0.0.51.36 -0.0.51.36 -0.0.161.6 -0.0.161.6 -0.0.58.254 -0.0.58.254 -0.0.207.154 -0.0.207.154 -0.0.58.90 -0.0.58.90 -0.0.51.62 -0.0.51.62 -0.0.58.90 -0.0.58.90 -0.0.81.164 -0.0.81.164 -0.0.207.221 -0.0.207.221 -0.0.227.55 -0.0.227.55 -0.0.227.55 -0.0.227.55 -0.0.207.221 -0.0.207.154 -0.0.207.154 -0.0.207.221 -0.0.143.30 -0.0.143.30 -0.0.0.179 -0.0.0.179 -0.0.51.62 -0.0.51.62 -0.0.4.35 -0.0.4.35 -0.0.207.221 -0.0.207.221 -0.0.51.62 -0.0.51.62 -0.0.51.62 -0.0.51.62 -0.0.95.20 -0.0.4.35 -0.0.4.35 -0.0.58.254 -0.0.58.254 -0.0.145.106 -0.0.145.106 -0.0.0.98 -0.0.0.98 -0.0.95.52 -0.0.95.52 -0.0.51.62 -0.0.51.62 -0.0.207.221 -0.0.207.221 -0.0.143.30 -0.0.143.30 -0.0.207.154 -0.0.207.154 -0.0.143.30 -0.0.95.20 -0.0.95.20 -0.0.0.98 -0.0.0.98 -0.0.145.131 -0.0.145.131 -0.0.161.12 -0.0.161.12 -0.0.95.52 -0.0.95.52 -0.0.161.12 -0.0.161.12 -0.0.0.179 -0.0.0.179 -0.0.4.35 -0.0.4.35 -0.0.164.246 -0.0.161.12 -0.0.161.12 -0.0.161.12 -0.0.161.12 -0.0.207.221 -0.0.207.221 -0.0.4.35 -0.0.4.35 -0.0.207.221 -0.0.207.221 -0.0.145.106 -0.0.145.106 -0.0.4.22 -0.0.4.22 -0.0.161.12 -0.0.161.12 -0.0.58.254 -0.0.58.254 -0.0.161.12 -0.0.161.12 -0.0.66.216 -0.0.0.179 -0.0.0.179 -0.0.145.131 -0.0.145.131 -0.0.4.35 -0.0.4.35 -0.0.58.254 -0.0.58.254 -0.0.143.24 -0.0.143.24 -0.0.143.24 -0.0.143.24 -0.0.207.221 -0.0.207.221 -0.0.58.254 -0.0.58.254 -0.0.145.131 -0.0.145.131 -0.0.51.36 -0.0.51.36 -0.0.227.31 -0.0.161.12 -0.0.227.31 -0.0.161.6 -0.0.161.6 -0.0.207.221 -0.0.207.221 -0.0.161.12 -0.0.145.106 -0.0.145.106 -0.0.161.6 -0.0.161.6 -0.0.95.20 -0.0.95.20 -0.0.4.35 -0.0.4.35 -0.0.95.52 -0.0.95.52 -0.0.128.50 -0.0.227.31 -0.0.227.31 -0.0.227.31 -0.0.227.31 -0.0.227.55 -0.0.227.55 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -0.0.29.211 -``` --## Next steps --- [Complete a similar tutorial by using ARM templates](tutorial-logs-ingestion-api.md)-- [Read more about custom logs](logs-ingestion-api-overview.md)-- [Learn more about writing transformation queries](../essentials//data-collection-transformations.md) |
| azure-monitor | Tutorial Workspace Transformations Api | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/tutorial-workspace-transformations-api.md | - Title: Tutorial - Add ingestion-time transformation to Azure Monitor Logs using Resource Manager templates -description: Describes how to add a custom transformation to data flowing through Azure Monitor Logs using Resource Manager templates. --- Previously updated : 08/12/2024---# Tutorial: Add transformation in workspace data collection rule to Azure Monitor using Resource Manager templates -This tutorial walks you through configuration of a sample [transformation in a workspace data collection rule](../essentials/data-collection-transformations.md) using Resource Manager templates. [Transformations](../essentials/data-collection-transformations.md) in Azure Monitor allow you to filter or modify incoming data before it's sent to its destination. Workspace transformations provide support for [ingestion-time transformations](../essentials/data-collection-transformations.md) for workflows that don't yet use the [Azure Monitor data ingestion pipeline](../essentials/data-collection.md). --Workspace transformations are stored together in a single [data collection rule (DCR)](../essentials/data-collection-rule-overview.md) for the workspace, called the workspace DCR. Each transformation is associated with a particular table. The transformation is applied to all data sent to this table from any workflow not using a DCR. --> [!NOTE] -> This tutorial uses Resource Manager templates and REST API to configure a workspace transformation. See [Tutorial: Add transformation in workspace data collection rule to Azure Monitor using the Azure portal](tutorial-workspace-transformations-portal.md) for the same tutorial using the Azure portal. --In this tutorial, you learn to: --> [!div class="checklist"] -> * Configure [workspace transformation](../essentials/data-collection-transformations-workspace.md) for a table in a Log Analytics workspace. -> * Write a log query for an ingestion-time transform. ---> [!NOTE] -> This tutorial uses PowerShell from Azure Cloud Shell to make REST API calls using the Azure Monitor **Tables** API and the Azure portal to install Resource Manager templates. You can use any other method to make these calls. --## Prerequisites -To complete this tutorial, you need the following: --- Log Analytics workspace where you have at least [contributor rights](manage-access.md#azure-rbac).-- [Permissions to create Data Collection Rule objects](../essentials/data-collection-rule-create-edit.md#permissions) in the workspace.-- The table must already have some data.-- The table can't already be linked to the [workspace transformation DCR](../essentials/data-collection-transformations-workspace.md).---## Overview of tutorial -In this tutorial, you'll reduce the storage requirement for the `LAQueryLogs` table by filtering out certain records. You'll also remove the contents of a column while parsing the column data to store a piece of data in a custom column. The [LAQueryLogs table](query-audit.md#audit-data) is created when you enable [log query auditing](query-audit.md) in a workspace, but this is only used as a sample for the tutorial. You can use this same basic process to create a transformation for any [supported table](tables-feature-support.md) in a Log Analytics workspace. ---## Enable query audit logs -You need to enable [query auditing](query-audit.md) for your workspace to create the `LAQueryLogs` table that you'll be working with. This is not required for all ingestion time transformations. It's just to generate the sample data that this sample transformation will use. --1. From the **Log Analytics workspaces** menu in the Azure portal, select **Diagnostic settings** and then **Add diagnostic setting**. -- :::image type="content" source="media/tutorial-workspace-transformations-portal/diagnostic-settings.png" lightbox="media/tutorial-workspace-transformations-portal/diagnostic-settings.png" alt-text="Screenshot of diagnostic settings."::: --2. Provide a name for the diagnostic setting and select the workspace so that the auditing data is stored in the same workspace. Select the **Audit** category and then click **Save** to save the diagnostic setting and close the diagnostic setting page. -- :::image type="content" source="media/tutorial-workspace-transformations-portal/new-diagnostic-setting.png" lightbox="media/tutorial-workspace-transformations-portal/new-diagnostic-setting.png" alt-text="Screenshot of new diagnostic setting."::: --3. Select **Logs** and then run some queries to populate `LAQueryLogs` with some data. These queries don't need to actually return any data. -- :::image type="content" source="media/tutorial-workspace-transformations-portal/sample-queries.png" lightbox="media/tutorial-workspace-transformations-portal/sample-queries.png" alt-text="Screenshot of sample log queries."::: --## Update table schema -Before you can create the transformation, the following two changes must be made to the table: --- The table must be enabled for workspace transformation. This is required for any table that will have a transformation, even if the transformation doesn't modify the table's schema.-- Any additional columns populated by the transformation must be added to the table.--Use the **Tables - Update** API to configure the table with the PowerShell code below. Calling the API enables the table for workspace transformations, whether or not custom columns are defined. In this sample, it includes a custom column called *Resources_CF* that will be populated with the transformation query. --> [!IMPORTANT] -> Any custom columns added to a built-in table must end in *_CF*. Columns added to a custom table (a table with a name that ends in *_CL*) does not need to have this suffix. --1. Click the **Cloud Shell** button in the Azure portal and ensure the environment is set to **PowerShell**. -- :::image type="content" source="media/tutorial-workspace-transformations-api/open-cloud-shell.png" lightbox="media/tutorial-workspace-transformations-api/open-cloud-shell.png" alt-text="Screenshot of opening Cloud Shell."::: --2. Copy the following PowerShell code and replace the **Path** parameter with the details for your workspace. -- ```PowerShell - $tableParams = @' - { - "properties": { - "schema": { - "name": "LAQueryLogs", - "columns": [ - { - "name": "Resources_CF", - "description": "The list of resources, this query ran against", - "type": "string", - "isDefaultDisplay": true, - "isHidden": false - } - ] - } - } - } - '@ -- Invoke-AzRestMethod -Path "/subscriptions/{subscription}/resourcegroups/{resourcegroup}/providers/microsoft.operationalinsights/workspaces/{workspace}/tables/LAQueryLogs?api-version=2021-12-01-preview" -Method PUT -payload $tableParams - ``` --3. Paste the code into the Cloud Shell prompt to run it. -- :::image type="content" source="media/tutorial-workspace-transformations-api/cloud-shell-script.png" lightbox="media/tutorial-workspace-transformations-api/cloud-shell-script.png" alt-text="Screenshot of script in Cloud Shell."::: --4. You can verify that the column was added by going to the **Log Analytics workspace** menu in the Azure portal. Select **Logs** to open Log Analytics and then expand the `LAQueryLogs` table to view its columns. -- :::image type="content" source="media/tutorial-workspace-transformations-portal/verify-table.png" lightbox="media/tutorial-workspace-transformations-portal/verify-table.png" alt-text="Screenshot of Log Analytics with new column."::: --## Define transformation query -Use Log Analytics to test the transformation query before adding it to a data collection rule. --1. Open your workspace in the **Log Analytics workspaces** menu in the Azure portal and select **Logs** to open Log Analytics. --2. Run the following query to view the contents of the `LAQueryLogs` table. Notice the contents of the `RequestContext` column. The transformation will retrieve the workspace name from this column and remove the rest of the data in it. -- ```kusto - LAQueryLogs - | take 10 - ``` -- :::image type="content" source="media/tutorial-workspace-transformations-portal/initial-query.png" lightbox="media/tutorial-workspace-transformations-portal/initial-query.png" alt-text="Screenshot of initial query in Log Analytics."::: --3. Modify the query to the following: -- ``` kusto - LAQueryLogs - | where QueryText !contains 'LAQueryLogs' - | extend Context = parse_json(RequestContext) - | extend Workspace_CF = tostring(Context['workspaces'][0]) - | project-away RequestContext, Context - ``` - This makes the following changes: -- - Drop rows related to querying the `LAQueryLogs` table itself to save space since these log entries aren't useful. - - Add a column for the name of the workspace that was queried. - - Remove data from the `RequestContext` column to save space. --- :::image type="content" source="media/tutorial-workspace-transformations-portal/modified-query.png" lightbox="media/tutorial-workspace-transformations-portal/modified-query.png" alt-text="Screenshot of modified query in Log Analytics."::: ---1. Make the following changes to the query to use it in the transformation: -- - Instead of specifying a table name (`LAQueryLogs` in this case) as the source of data for this query, use the `source` keyword. This is a virtual table that always represents the incoming data in a transformation query. - - Remove any operators that aren't supported by transform queries. See [Supported KQL features](/azure/azure-monitor/essentials/data-collection-transformations-structure) for a detail list of operators that are supported. - - Flatten the query to a single line so that it can fit into the DCR JSON. -- Following is the query that you will use in the transformation after these modifications: -- ```kusto - source | where QueryText !contains 'LAQueryLogs' | extend Context = parse_json(RequestContext) | extend Resources_CF = tostring(Context['workspaces']) |extend RequestContext = '' - ``` --## Create data collection rule (DCR) -Since this is the first transformation in the workspace, you need to create a [workspace transformation DCR](../essentials/data-collection-transformations-workspace.md). If you create workspace transformations for other tables in the same workspace, they must be stored in this same DCR. --1. In the Azure portal's search box, type in *template* and then select **Deploy a custom template**. -- :::image type="content" source="media/tutorial-workspace-transformations-api/deploy-custom-template.png" lightbox="media/tutorial-workspace-transformations-api/deploy-custom-template.png" alt-text="Screenshot to deploy custom template."::: --2. Click **Build your own template in the editor**. -- :::image type="content" source="media/tutorial-workspace-transformations-api/build-custom-template.png" lightbox="media/tutorial-workspace-transformations-api/build-custom-template.png" alt-text="Screenshot to build template in the editor."::: --3. Paste the Resource Manager template below into the editor and then click **Save**. This template defines the DCR and contains the transformation query. You don't need to modify this template since it will collect values for its parameters. -- :::image type="content" source="media/tutorial-workspace-transformations-api/edit-template.png" lightbox="media/tutorial-workspace-transformations-api/edit-template.png" alt-text="Screenshot to edit Resource Manager template."::: --- ```json - { -     "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", -     "contentVersion": "1.0.0.0", -     "parameters": { -         "dataCollectionRuleName": { -             "type": "string", -             "metadata": { -                 "description": "Specifies the name of the Data Collection Rule to create." -             } -         }, -         "location": { -             "type": "string", -             "defaultValue": "westus2", -             "allowedValues": [ -                 "westus2", - "eastus2", -                 "eastus2euap" -             ], -             "metadata": { -                 "description": "Specifies the location in which to create the Data Collection Rule." -             } -         }, -         "workspaceResourceId": { -             "type": "string", -             "metadata": { -                 "description": "Specifies the Azure resource ID of the Log Analytics workspace to use." -             } -         } -     }, -     "resources": [ -         { -             "type": "Microsoft.Insights/dataCollectionRules", -             "name": "[parameters('dataCollectionRuleName')]", -             "location": "[parameters('location')]", -             "apiVersion": "2021-09-01-preview", -             "kind": "WorkspaceTransforms", -             "properties": { - "destinations": { - "logAnalytics": [ - { - "workspaceResourceId": "[parameters('workspaceResourceId')]", - "name": "clv2ws1" - } - ] - }, - "dataFlows": [ - { - "streams": [ - "Microsoft-Table-LAQueryLogs" - ], - "destinations": [ - "clv2ws1" - ], - "transformKql": "source |where QueryText !contains 'LAQueryLogs' | extend Context = parse_json(RequestContext) | extend Resources_CF = tostring(Context['workspaces']) |extend RequestContext = ''" - } - ] -             } -         } -     ], -     "outputs": { -         "dataCollectionRuleId": { -             "type": "string", -             "value": "[resourceId('Microsoft.Insights/dataCollectionRules', parameters('dataCollectionRuleName'))]" -         } -     } - } - ``` --4. On the **Custom deployment** screen, specify a **Subscription** and **Resource group** to store the data collection rule and then provide values defined in the template. This includes a **Name** for the data collection rule and the **Workspace Resource ID** that you collected in a previous step. The **Location** should be the same location as the workspace. The **Region** will already be populated and is used for the location of the data collection rule. -- :::image type="content" source="media/tutorial-workspace-transformations-api/custom-deployment-values.png" lightbox="media/tutorial-workspace-transformations-api/custom-deployment-values.png" alt-text="Screenshot to edit custom deployment values."::: --5. Click **Review + create** and then **Create** when you review the details. --6. When the deployment is complete, expand the **Deployment details** box and click on your data collection rule to view its details. Click **JSON View**. -- :::image type="content" source="media/tutorial-workspace-transformations-api/data-collection-rule-details.png" lightbox="media/tutorial-workspace-transformations-api/data-collection-rule-details.png" alt-text="Screenshot for data collection rule details."::: --7. Copy the **Resource ID** for the data collection rule. You'll use this in the next step. -- :::image type="content" source="media/tutorial-workspace-transformations-api/data-collection-rule-json-view.png" lightbox="media/tutorial-workspace-transformations-api/data-collection-rule-json-view.png" alt-text="Screenshot for data collection rule JSON view."::: --## Link workspace to DCR -The final step to enable the transformation is to link the DCR to the workspace. --> [!IMPORTANT] -> A workspace can only be connected to a single DCR, and the linked DCR must contain this workspace as a destination. --Use the **Workspaces - Update** API to configure the table with the PowerShell code below. --1. Click the **Cloud Shell** button to open Cloud Shell again. Copy the following PowerShell code and replace the parameters with values for your workspace and DCR. -- ```PowerShell - $defaultDcrParams = @' - { - "properties": { - "defaultDataCollectionRuleResourceId": "/subscriptions/{subscription}/resourceGroups/{resourcegroup}/providers/Microsoft.Insights/dataCollectionRules/{DCR}" - } - } - '@ -- Invoke-AzRestMethod -Path "/subscriptions/{subscription}/resourcegroups/{resourcegroup}/providers/microsoft.operationalinsights/workspaces/{workspace}?api-version=2021-12-01-preview" -Method PATCH -payload $defaultDcrParams - ``` --2. Paste the code into the Cloud Shell prompt to run it. -- :::image type="content" source="media/tutorial-workspace-transformations-api/cloud-shell-script-link-workspace.png" lightbox="media/tutorial-workspace-transformations-api/cloud-shell-script-link-workspace.png" alt-text="Screenshot of script to link workspace to DCR."::: --## Test transformation -Allow about 30 minutes for the transformation to take effect, and you can then test it by running a query against the table. Only data sent to the table after the transformation was applied will be affected. --For this tutorial, run some sample queries to send data to the `LAQueryLogs` table. Include some queries against `LAQueryLogs` so you can verify that the transformation filters these records. Notice that the output has the new `Workspace_CF` column, and there are no records for `LAQueryLogs`. ---## Troubleshooting -This section describes different error conditions you may receive and how to correct them. --### IntelliSense in Log Analytics not recognizing new columns in the table -The cache that drives IntelliSense may take up to 24 hours to update. --### Transformation on a dynamic column isn't working -There is currently a known issue affecting dynamic columns. A temporary workaround is to explicitly parse dynamic column data using `parse_json()` prior to performing any operations against them. --## Next steps --- [Read more about transformations](../essentials/data-collection-transformations.md)-- [See which tables support workspace transformations](tables-feature-support.md)-- [Learn more about writing transformation queries](../essentials/data-collection-transformations-structure.md) |
| azure-monitor | Tutorial Workspace Transformations Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/tutorial-workspace-transformations-portal.md | - Title: 'Tutorial: Add a workspace transformation to Azure Monitor Logs by using the Azure portal' -description: Describes how to add a custom transformation to data flowing through Azure Monitor Logs by using the Azure portal. --- Previously updated : 08/12/2024---# Tutorial: Add a transformation in a workspace data collection rule by using the Azure portal -This tutorial walks you through configuration of a sample [transformation in a workspace data collection rule (DCR)](../essentials/data-collection-transformations.md) by using the Azure portal. [Transformations](../essentials/data-collection-transformations.md) in Azure Monitor allow you to filter or modify incoming data before it's sent to its destination. Workspace transformations provide support for [ingestion-time transformations](../essentials/data-collection-transformations.md) for workflows that don't yet use the [Azure Monitor data ingestion pipeline](../essentials/data-collection.md). --Workspace transformations are stored together in a single [DCR](../essentials/data-collection-rule-overview.md) for the workspace, which is called the workspace DCR. Each transformation is associated with a particular table. The transformation will be applied to all data sent to this table from any workflow not using a DCR. --> [!NOTE] -> This tutorial uses the Azure portal to configure a workspace transformation. For the same tutorial using Azure Resource Manager templates and REST API, see [Tutorial: Add transformation in workspace data collection rule to Azure Monitor using resource manager templates](tutorial-workspace-transformations-api.md). --In this tutorial, you learn how to: --> [!div class="checklist"] -> * Configure a [workspace transformation](../essentials/data-collection-transformations-workspace.md) for a table in a Log Analytics workspace. -> * Write a log query for a workspace transformation. --## Prerequisites -To complete this tutorial, you need: --- A Log Analytics workspace where you have at least [contributor rights](manage-access.md#azure-rbac).-- [Permissions to create DCR objects](../essentials/data-collection-rule-create-edit.md#permissions) in the workspace.-- A table that already has some data.-- The table can't be linked to the [workspace transformation DCR](../essentials/data-collection-transformations-workspace.md).--## Overview of the tutorial -In this tutorial, you'll reduce the storage requirement for the `LAQueryLogs` table by filtering out certain records. You'll also remove the contents of a column while parsing the column data to store a piece of data in a custom column. The [LAQueryLogs table](query-audit.md#audit-data) is created when you enable [log query auditing](query-audit.md) in a workspace. You can use this same basic process to create a transformation for any [supported table](tables-feature-support.md) in a Log Analytics workspace. --This tutorial uses the Azure portal, which provides a wizard to walk you through the process of creating an ingestion-time transformation. After you finish the steps, you'll see that the wizard: --- Updates the table schema with any other columns from the query.-- Creates a `WorkspaceTransforms` DCR and links it to the workspace if a default DCR isn't already linked to the workspace.-- Creates an ingestion-time transformation and adds it to the DCR.--## Enable query audit logs -You need to enable [query auditing](query-audit.md) for your workspace to create the `LAQueryLogs` table that you'll be working with. This step isn't required for all ingestion time transformations. It's just to generate the sample data that we'll be working with. --1. On the **Log Analytics workspaces** menu in the Azure portal, select **Diagnostic settings** > **Add diagnostic setting**. -- :::image type="content" source="media/tutorial-workspace-transformations-portal/diagnostic-settings.png" lightbox="media/tutorial-workspace-transformations-portal/diagnostic-settings.png" alt-text="Screenshot that shows diagnostic settings."::: --1. Enter a name for the diagnostic setting. Select the workspace so that the auditing data is stored in the same workspace. Select the **Audit** category and then select **Save** to save the diagnostic setting and close the **Diagnostic setting** page. -- :::image type="content" source="media/tutorial-workspace-transformations-portal/new-diagnostic-setting.png" lightbox="media/tutorial-workspace-transformations-portal/new-diagnostic-setting.png" alt-text="Screenshot that shows the new diagnostic setting."::: --1. Select **Logs** and then run some queries to populate `LAQueryLogs` with some data. These queries don't need to return data to be added to the audit log. -- :::image type="content" source="media/tutorial-workspace-transformations-portal/sample-queries.png" lightbox="media/tutorial-workspace-transformations-portal/sample-queries.png" alt-text="Screenshot that shows sample log queries."::: --## Add a transformation to the table -Now that the table's created, you can create the transformation for it. --1. On the **Log Analytics workspaces** menu in the Azure portal, select **Tables**. Locate the `LAQueryLogs` table and select **Create transformation**. -- :::image type="content" source="media/tutorial-workspace-transformations-portal/create-transformation.png" lightbox="media/tutorial-workspace-transformations-portal/create-transformation.png" alt-text="Screenshot that shows creating a new transformation."::: --1. Because this transformation is the first one in the workspace, you must create a [workspace transformation DCR](../essentials/data-collection-transformations-workspace.md). If you create transformations for other tables in the same workspace, they'll be stored in this same DCR. Select **Create a new data collection rule**. The **Subscription** and **Resource group** will already be populated for the workspace. Enter a name for the DCR and select **Done**. -- :::image type="content" source="media/tutorial-workspace-transformations-portal/new-data-collection-rule.png" lightbox="media/tutorial-workspace-transformations-portal/new-data-collection-rule.png" alt-text="Screenshot that shows creating a new data collection rule."::: --1. Select **Next** to view sample data from the table. As you define the transformation, the result will be applied to the sample data. For this reason, you can evaluate the results before you apply it to actual data. Select **Transformation editor** to define the transformation. -- :::image type="content" source="media/tutorial-workspace-transformations-portal/sample-data.png" lightbox="media/tutorial-workspace-transformations-portal/sample-data.png" alt-text="Screenshot that shows sample data from the log table."::: --1. In the transformation editor, you can see the transformation that will be applied to the data prior to its ingestion into the table. The incoming data is represented by a virtual table named `source`, which has the same set of columns as the destination table itself. The transformation initially contains a simple query that returns the `source` table with no changes. --1. Modify the query to the following example: -- ``` kusto - source - | where QueryText !contains 'LAQueryLogs' - | extend Context = parse_json(RequestContext) - | extend Workspace_CF = tostring(Context['workspaces'][0]) - | project-away RequestContext, Context - ``` -- The modification makes the following changes: -- - Rows related to querying the `LAQueryLogs` table itself were dropped to save space because these log entries aren't useful. - - A column for the name of the workspace that was queried was added. - - Data from the `RequestContext` column was removed to save space. -- > [!Note] - > Using the Azure portal, the output of the transformation will initiate changes to the table schema if required. Columns will be added to match the transformation output if they don't already exist. Make sure that your output doesn't contain any columns that you don't want added to the table. If the output doesn't include columns that are already in the table, those columns won't be removed, but data won't be added. - > - > Any custom columns added to a built-in table must end in `_CF`. Columns added to a custom table don't need to have this suffix. A custom table has a name that ends in `_CL`. --1. Copy the query into the transformation editor and select **Run** to view results from the sample data. You can verify that the new `Workspace_CF` column is in the query. -- :::image type="content" source="media/tutorial-workspace-transformations-portal/transformation-editor.png" lightbox="media/tutorial-workspace-transformations-portal/transformation-editor.png" alt-text="Screenshot that shows the transformation editor."::: --1. Select **Apply** to save the transformation and then select **Next** to review the configuration. Select **Create** to update the DCR with the new transformation. -- :::image type="content" source="media/tutorial-workspace-transformations-portal/save-transformation.png" lightbox="media/tutorial-workspace-transformations-portal/save-transformation.png" alt-text="Screenshot that shows saving the transformation."::: --## Test the transformation -Allow about 30 minutes for the transformation to take effect and then test it by running a query against the table. Only data sent to the table after the transformation was applied will be affected. --For this tutorial, run some sample queries to send data to the `LAQueryLogs` table. Include some queries against `LAQueryLogs` so that you can verify that the transformation filters these records. Now the output has the new `Workspace_CF` column, and there are no records for `LAQueryLogs`. --## Troubleshooting -This section describes different error conditions you might receive and how to correct them. --### IntelliSense in Log Analytics not recognizing new columns in the table -The cache that drives IntelliSense might take up to 24 hours to update. --### Transformation on a dynamic column isn't working -A known issue currently affects dynamic columns. A temporary workaround is to explicitly parse dynamic column data by using `parse_json()` prior to performing any operations against them. --## Next steps --- [Read more about transformations](../essentials/data-collection-transformations.md)-- [See which tables support workspace transformations](tables-feature-support.md)-- [Learn more about writing transformation queries](../essentials/data-collection-transformations-structure.md) |
| azure-monitor | Workspace Design | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/workspace-design.md | - Title: Design a Log Analytics workspace architecture -description: The article describes the considerations and recommendations for customers preparing to deploy a workspace in Azure Monitor. - Previously updated : 08/15/2024---# Design a Log Analytics workspace architecture --A single [Log Analytics workspace](log-analytics-workspace-overview.md) might be sufficient for many environments that use Azure Monitor and Microsoft Sentinel. But many organizations create multiple workspaces to optimize costs and better meet different business requirements. This article presents a set of criteria for determining whether to use a single workspace or multiple workspaces. It also discusses the configuration and placement of those workspaces to meet your requirements while optimizing your costs. --> [!NOTE] -> This article discusses Azure Monitor and Microsoft Sentinel because many customers need to consider both in their design. Most of the decision criteria apply to both services. If you use only one of these services, you can ignore the other in your evaluation. --Here's a video about the fundamentals of Azure Monitor Logs and best practices and design considerations for designing your Azure Monitor Logs deployment: --> [!VIDEO https://www.youtube.com/embed/7RBp9j0P_Ao?cc_load_policy=1&cc_lang_pref=auto] --## Design strategy -Your design should always start with a single workspace to reduce the complexity of managing multiple workspaces and in querying data from them. There are no performance limitations from the amount of data in your workspace. Multiple services and data sources can send data to the same workspace. As you identify criteria to create more workspaces, your design should use the fewest number of workspace to meet your requirements. --Designing a workspace configuration includes evaluation of multiple criteria. But some of the criteria might be in conflict. For example, you might be able to reduce egress charges by creating a separate workspace in each Azure region. Consolidating into a single workspace might allow you to reduce charges even more with a commitment tier. Evaluate each of the criteria independently. Consider your requirements and priorities to determine which design is most effective for your environment. --## Design criteria -The following table presents criteria to consider when you design your workspace architecture. The sections that follow describe the criteria. --| Criteria | Description | -|:|:| -| [Operational and security data](#operational-and-security-data) | You may choose to combine operational data from Azure Monitor in the same workspace as security data from Microsoft Sentinel or separate each into their own workspace. Combining them gives you better visibility across all your data, while your security standards might require separating them so that your security team has a dedicated workspace. You may also have cost implications to each strategy. | -| [Azure tenants](#azure-tenants) | If you have multiple Azure tenants, you'll usually create a workspace in each one. Several data sources can only send monitoring data to a workspace in the same Azure tenant. | -| [Azure regions](#azure-regions) | Each workspace resides in a particular Azure region. You might have regulatory or compliance requirements to store data in specific locations. | -| [Data ownership](#data-ownership) | You might choose to create separate workspaces to define data ownership. For example, you might create workspaces by subsidiaries or affiliated companies. | -| [Split billing](#split-billing) | By placing workspaces in separate subscriptions, they can be billed to different parties. | -| [Data retention](#data-retention) | You can set different retention settings for each workspace and each table in a workspace. You need a separate workspace if you require different retention settings for different resources that send data to the same tables. | -| [Commitment tiers](#commitment-tiers) | Commitment tiers allow you to reduce your ingestion cost by committing to a minimum amount of daily data in a single workspace. | -| [Legacy agent limitations](#legacy-agent-limitations) | Legacy virtual machine agents have limitations on the number of workspaces they can connect to. | -| [Data access control](#data-access-control) | Configure access to the workspace and to different tables and data from different resources. | -|[Resilience](#resilience)| To ensure that data in your workspace is available in the event of a region failure, you can ingest data into multiple workspaces in different regions.| --### Operational and security data -The decision whether to combine your operational data from Azure Monitor in the same workspace as security data from Microsoft Sentinel or separate each into their own workspace depends on your security requirements and the potential cost implications for your environment. --**Dedicated workspaces** -Creating dedicated workspaces for Azure Monitor and Microsoft Sentinel will allow you to segregate ownership of data between operational and security teams. This approach may also help to optimize costs since when Microsoft Sentinel is enabled in a workspace, all data in that workspace is subject to Microsoft Sentinel pricing even if it's operational data collected by Azure Monitor. --A workspace with Microsoft Sentinel gets three months of free data retention instead of 31 days. This scenario typically results in higher costs for operational data in a workspace without Microsoft Sentinel. See [Azure Monitor Logs pricing details](cost-logs.md#workspaces-with-microsoft-sentinel). ---**Combined workspace** -Combining your data from Azure Monitor and Microsoft Sentinel in the same workspace gives you better visibility across all of your data allowing you to easily combine both in queries and workbooks. If access to the security data should be limited to a particular team, you can use [table level RBAC](../logs/manage-access.md#set-table-level-read-access) to block particular users from tables with security data or limit users to accessing the workspace using [resource-context](../logs/manage-access.md#access-mode). --This configuration may result in cost savings if it helps you reach a [commitment tier](#commitment-tiers), which provides a discount to your ingestion charges. For example, consider an organization that has operational data and security data each ingesting about 50 GB per day. Combining the data in the same workspace would allow a commitment tier at 100 GB per day. That scenario would provide a 15% discount for Azure Monitor and a 50% discount for Microsoft Sentinel. --If you create separate workspaces for other criteria, you'll usually create more workspace pairs. For example, if you have two Azure tenants, you might create four workspaces with an operational and security workspace in each tenant. --- **If you use both Azure Monitor and Microsoft Sentinel:** Consider separating each in a dedicated workspace if required by your security team or if it results in a cost savings. Consider combining the two for better visibility of your combined monitoring data or if it helps you reach a commitment tier.-- **If you use both Microsoft Sentinel and Microsoft Defender for Cloud:** Consider using the same workspace for both solutions to keep security data in one place.--### Azure tenants -Most resources can only send monitoring data to a workspace in the same Azure tenant. Virtual machines that use [Azure Monitor Agent](../agents/azure-monitor-agent-overview.md) or the [Log Analytics agents](../agents/log-analytics-agent.md) can send data to workspaces in separate Azure tenants. You might consider this scenario as a [service provider](#multiple-tenant-strategies). --- **If you have a single Azure tenant:** Create a single workspace for that tenant.-- **If you have multiple Azure tenants:** Create a workspace for each tenant. For other options including strategies for service providers, see [Multiple tenant strategies](#multiple-tenant-strategies).--### Azure regions -Each Log Analytics workspace resides in a [particular Azure region](https://azure.microsoft.com/global-infrastructure/geographies/). You might have regulatory or compliance purposes for keeping data in a particular region. For example, an international company might locate a workspace in each major geographical region, such as the United States and Europe. --- **If you have requirements for keeping data in a particular geography:** Create a separate workspace for each region with such requirements.-- **If you don't have requirements for keeping data in a particular geography:** Use a single workspace for all regions.-- **If you are sending data to a geography or region that outside of your workspace's region, whether or not the sending resource resides in Azure**: Consider using a workspace in the same geography or region as your data.--Also consider potential [bandwidth charges](https://azure.microsoft.com/pricing/details/bandwidth/) that might apply when you're sending data to a workspace from a resource in another region. These charges are usually minor relative to data ingestion costs for most customers. These charges typically result from sending data to the workspace from a virtual machine. Monitoring data from other Azure resources by using [diagnostic settings](../essentials/diagnostic-settings.md) doesn't [incur egress charges](../cost-usage.md#data-transfer-charges). --Use the [Azure pricing calculator](https://azure.microsoft.com/pricing/calculator) to estimate the cost and determine which regions you need. Consider workspaces in multiple regions if bandwidth charges are significant. --- **If bandwidth charges are significant enough to justify the extra complexity:** Create a separate workspace for each region with virtual machines.-- **If bandwidth charges aren't significant enough to justify the extra complexity:** Use a single workspace for all regions.--### Data ownership -You might have a requirement to segregate data or define boundaries based on ownership. For example, you might have different subsidiaries or affiliated companies that require delineation of their monitoring data. --- **If you require data segregation:** Use a separate workspace for each data owner.-- **If you don't require data segregation:** Use a single workspace for all data owners.--### Split billing -You might need to split billing between different parties or perform charge back to a customer or internal business unit. You can use [Azure Cost Management + Billing](../cost-usage.md#azure-cost-management--billing) to view charges by workspace. You can also use a log query to view [billable data volume by Azure resource, resource group, or subscription](analyze-usage.md#data-volume-by-azure-resource-resource-group-or-subscription). This approach might be sufficient for your billing requirements. --- **If you don't need to split billing or perform charge back:** Use a single workspace for all cost owners.-- **If you need to split billing or perform charge back:** Consider whether [Azure Cost Management + Billing](../cost-usage.md#azure-cost-management--billing) or a log query provides cost reporting that's granular enough for your requirements. If not, use a separate workspace for each cost owner.--### Data retention -You can configure default [data retention settings](data-retention-configure.md) for a workspace or [configure different settings for each table](data-retention-configure.md#configure-table-level-retention). You might require different settings for different sets of data in a particular table. If so, you need to separate that data into different workspaces, each with unique retention settings. --- **If you can use the same retention settings for all data in each table:** Use a single workspace for all resources.-- **If you require different retention settings for different resources in the same table:** Use a separate workspace for different resources.--### Commitment tiers -[Commitment tiers](../logs/cost-logs.md#commitment-tiers) provide a discount to your workspace ingestion costs when you commit to a specific amount of daily data. You might choose to consolidate data in a single workspace to reach the level of a particular tier. This same volume of data spread across multiple workspaces wouldn't be eligible for the same tier, unless you have a dedicated cluster. --If you can commit to daily ingestion of at least 100 GB per day, you should implement a [dedicated cluster](../logs/cost-logs.md#dedicated-clusters) that provides extra functionality and performance. Dedicated clusters also allow you to combine the data from multiple workspaces in the cluster to reach the level of a commitment tier. --- **If you'll ingest at least 100 GB per day across all resources:** Create a dedicated cluster and set the appropriate commitment tier.-- **If you'll ingest at least 100 GB per day across resources:** Consider combining them into a single workspace to take advantage of a commitment tier.--### Legacy agent limitations -You should avoid sending duplicate data to multiple workspaces because of the extra charges, but you might have virtual machines connected to multiple workspaces. The most common scenario is an agent connected to separate workspaces for Azure Monitor and Microsoft Sentinel. -- [Azure Monitor Agent](../agents/azure-monitor-agent-overview.md) and the [Log Analytics agent for Windows](../agents/log-analytics-agent.md) can connect to multiple workspaces. The [Log Analytics agent for Linux](../agents/log-analytics-agent.md) can only connect to a single workspace. --- **If you use the Log Analytics agent for Linux:** Migrate to [Azure Monitor Agent](../agents/azure-monitor-agent-overview.md) or ensure that your Linux machines only require access to a single workspace.--### Data access control -When you grant a user [access to a workspace](manage-access.md#azure-rbac), the user has access to all data in that workspace. This access is appropriate for a member of a central administration or security team who must access data for all resources. Access to the workspace is also determined by resource-context role-based access control (RBAC) and table-level RBAC. --[Resource-context RBAC](manage-access.md#access-mode): By default, if a user has read access to an Azure resource, they inherit permissions to any of that resource's monitoring data sent to the workspace. This level of access allows users to access information about resources they manage without being granted explicit access to the workspace. If you need to block this access, you can change the [access control mode](manage-access.md#access-control-mode) to require explicit workspace permissions. --- **If you want users to be able to access data for their resources:** Keep the default access control mode of **Use resource or workspace permissions**.-- **If you want to explicitly assign permissions for all users:** Change the access control mode to **Require workspace permissions**.--[Table-level RBAC](manage-access.md#set-table-level-read-access): With table-level RBAC, you can grant or deny access to specific tables in the workspace. In this way, you can implement granular permissions required for specific situations in your environment. --For example, you might grant access to only specific tables collected by Microsoft Sentinel to an internal auditing team. Or you might deny access to security-related tables to resource owners who need operational data related to their resources. --- **If you don't require granular access control by table:** Grant the operations and security team access to their resources and allow resource owners to use resource-context RBAC for their resources.-- **If you require granular access control by table:** Grant or deny access to specific tables by using table-level RBAC.--For more information, see [Manage access to Microsoft Sentinel data by resource](../../sentinel/resource-context-rbac.md). --### Resilience --To ensure that critical data in your workspace is available in the event of a region failure, you can ingest some or all of your data into multiple workspaces in different regions. --This option requires managing integration with other services and products separately for each workspace. Even though the data will be available in the alternate workspace in case of failure, resources that rely on the data, such as alerts and workbooks, won't know to switch over to the alternate workspace. Consider storing ARM templates for critical resources with configuration for the alternate workspace in Azure DevOps, or as disabled policies that can quickly be enabled in a failover scenario. --## Work with multiple workspaces -Many designs include multiple workspaces. For example, a central security operations team might use its own Microsoft Sentinel workspaces to manage centralized artifacts like analytics rules or workbooks. --Both Azure Monitor and Microsoft Sentinel include features to assist you in analyzing this data across workspaces. For more information, see: --- [Create a log query across multiple workspaces and apps in Azure Monitor](cross-workspace-query.md)-- [Extend Microsoft Sentinel across workspaces and tenants](../../sentinel/extend-sentinel-across-workspaces-tenants.md)--When naming each workspace, we recommend including a meaningful indicator in the name so that you can easily identity the purpose of each workspace. --## Multiple tenant strategies -Environments with multiple Azure tenants, including Microsoft service providers (MSPs), independent software vendors (ISVs), and large enterprises, often require a strategy where a central administration team has access to administer workspaces located in other tenants. Each of the tenants might represent separate customers or different business units. --> [!NOTE] -> For partners and service providers who are part of the [Cloud Solution Provider (CSP) program](https://partner.microsoft.com/membership/cloud-solution-provider), Log Analytics in Azure Monitor is one of the Azure services available in Azure CSP subscriptions. --Two basic strategies for this functionality are described in the following sections. --### Distributed architecture -In a distributed architecture, a Log Analytics workspace is created in each Azure tenant. This option is the only one you can use if you're monitoring Azure services other than virtual machines. --There are two options to allow service provider administrators to access the workspaces in the customer tenants: --- Use [Azure Lighthouse](../../lighthouse/overview.md) to access each customer tenant. The service provider administrators are included in a Microsoft Entra user group in the service provider's tenant. This group is granted access during the onboarding process for each customer. The administrators can then access each customer's workspaces from within their own service provider tenant instead of having to sign in to each customer's tenant individually. For more information, see [Monitor customer resources at scale](../../lighthouse/how-to/monitor-at-scale.md).-- Add individual users from the service provider as [Microsoft Entra guest users (B2B)](../../active-directory/external-identities/what-is-b2b.md). The customer tenant administrators manage individual access for each service provider administrator. The service provider administrators must sign in to the directory for each tenant in the Azure portal to access these workspaces.--Advantages to this strategy: --- Logs can be collected from all types of resources.-- The customer can confirm specific levels of permissions with [Azure delegated resource management](../../lighthouse/concepts/architecture.md). Or the customer can manage access to the logs by using their own [Azure RBAC](../../role-based-access-control/overview.md).-- Each customer can have different settings for their workspace, such as retention and data cap.-- Isolation between customers for regulatory and compliance.-- The charge for each workspace is included in the bill for the customer's subscription.--Disadvantages to this strategy: --- Centrally visualizing and analyzing data across customer tenants with tools such as Azure Monitor workbooks can result in slower experiences. This is the case especially when analyzing data across more than 50 workspaces.-- If customers aren't onboarded for Azure delegated resource management, service provider administrators must be provisioned in the customer directory. This requirement makes it more difficult for the service provider to manage many customer tenants at once.--### Centralized -A single workspace is created in the service provider's subscription. This option can only collect data from customer virtual machines. Agents installed on the virtual machines are configured to send their logs to this central workspace. --Advantages to this strategy: --- It's easy to manage many customers.-- The service provider has full ownership over the logs and the various artifacts, such as functions and saved queries.-- A service provider can perform analytics across all of its customers.--Disadvantages to this strategy: --- Logs can only be collected from virtual machines with an agent. It won't work with PaaS, SaaS, or Azure Service Fabric data sources.-- It might be difficult to separate data between customers because their data shares a single workspace. Queries need to use the computer's fully qualified domain name or the Azure subscription ID.-- All data from all customers will be stored in the same region with a single bill and the same retention and configuration settings.--### Hybrid -In a hybrid model, each tenant has its own workspace. A mechanism is used to pull data into a central location for reporting and analytics. This data could include a small number of data types or a summary of the activity, such as daily statistics. --There are two options to implement logs in a central location: --- **Central workspace**: The service provider creates a workspace in its tenant and uses a script that utilizes the [Query API](api/overview.md) with the [logs ingestion API](logs-ingestion-api-overview.md) to bring the data from the tenant workspaces to this central location. Another option is to use [Azure Logic Apps](../../logic-apps/logic-apps-overview.md) to copy data to the central workspace.-- **Power BI**: The tenant workspaces export data to Power BI by using the integration between the [Log Analytics workspace and Power BI](log-powerbi.md).--## Next steps --- Learn more about [designing and configuring data access in a workspace](manage-access.md).-- Get [sample workspace architectures for Microsoft Sentinel](../../sentinel/sample-workspace-designs.md).-- Here's a video on designing the proper structure for your Log Analytics workspace: [ITOps Talk:Log Analytics workspace design deep dive](/shows/it-ops-talk/ops115-log-analytics-workspace-design-deep-dive) |
| azure-monitor | Workspace Replication | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/logs/workspace-replication.md | - Title: Enhance resilience by replicating your Log Analytics workspace across regions (Preview) -description: Use the workspace replication feature in Log Analytics to create copies of a workspace in different regions for data resiliency. --- Previously updated : 05/18/2024---# Customer intent: As a Log Analytics workspace administrator, I want to replicate my workspace across regions to protect and continue to access my log data in the event of a regional failure. ---# Enhance resilience by replicating your Log Analytics workspace across regions (Preview) --Replicating your Log Analytics workspace across regions enhances resilience by letting you switch over to the replicated workspace and continue operations if there's a regional failure. This article explains how Log Analytics workspace replication works, how to replicate your workspace, how to switch over and back, and how to decide when to switch between your replicated workspaces. --Here's a video that provides a quick overview of how Log Analytics workspace replication works: -->[!VIDEO https://www.youtube.com/embed/9t7T7D4oVMk?cc_load_policy=1&cc_lang_pref=auto] --> [!IMPORTANT] -> Although we sometimes use the term failover, for example in the API call, failover is also commonly used to describe an automatic process. Therefore, this article uses the term switchover to emphasize that the switch to the replicated workspace is an action you trigger manually. --## Permissions required --| Action | Permissions required | -| | | -| Enable workspace replication | `Microsoft.OperationalInsights/workspaces/write` permissions to the Log Analytics workspace, as provided by the [Log Analytics Contributor built-in role](manage-access.md#log-analytics-contributor), for example | -| Switch over and switch back (trigger failover and failback) | `Microsoft.OperationalInsights/workspaces/write` permissions to the Log Analytics workspace at the **resource group level**, as provided by the [Log Analytics Contributor built-in role](manage-access.md#log-analytics-contributor), for example | -| Check workspace state | `Microsoft.OperationalInsights/workspaces/read` permissions to the Log Analytics workspace, as provided by the [Log Analytics Reader built-in role](manage-access.md#log-analytics-reader), for example | --## How Log Analytics workspace replication works --Your original workspace and region are referred to as the **primary**. The replicated workspace and alternate region are referred to as the **secondary**. --The workspace replication process creates an instance of your workspace in the secondary region. The process creates the secondary workspace with the same configuration as your primary workspace, and Azure Monitor automatically updates the secondary workspace with any future changes you make to your primary workspace configuration. --The secondary workspace is a "shadow" workspace for resiliency purposes only. You canΓÇÖt see the secondary workspace in the Azure portal, and you can't manage or access it directly. --When you enable workspace replication, Azure Monitor sends new logs ingested to your primary workspace to your secondary region also. Logs you ingest to the workspace before you enable workspace replication arenΓÇÖt copied over. --If an outage affects your primary region, you can switch over and reroute all ingestion and query requests to your secondary region. After Azure mitigates the outage and your primary workspace is healthy again, you can switch back over to your primary region. --When you switch over, the secondary workspace becomes active and your primary becomes inactive. Azure Monitor then ingests new data through the ingestion pipeline in your secondary region, rather than the primary region. When you switch over to your secondary region, Azure Monitor replicates all data you ingest from the secondary region to the primary region. The process is asynchronous and doesn't affect your ingestion latency. --> [!IMPORTANT] -> After you switch over to the secondary region, if the primary region can't process incoming log data, Azure Monitor buffers the data in the secondary region for up to 11 days. During the first four days, Azure Monitor automatically reattempts to replicate the data periodically. ----### Supported regions --Workspace replication is currently supported for workspaces in a limited set of regions, organized by region groups (groups of geographically adjacent regions). When you enable replication, select a secondary location from the list of supported regions in the same region group as the workspace primary location. For example, a workspace in West Europe can be replicated in North Europe, but not in West US 2, since these regions are in different region groups. --These region groups and regions are currently supported: --| Region group | Regions | Notes | -| | | | -| **North America** | East US | Replication isn't supported to or from the East US 2 region. | -| | East US 2 | Replication isn't supported to or from the East US region. | -| | West US | | -| | West US 2 | | -| | Central US | | -| | South Central US | | -| | Central Canada | | -| **Europe** | West Europe | | -| | North Europe | | -| | South UK | | -| | West UK | | -| | Germany West Central | | -| | France Central | | --### Data residency requirements --Different customers have different data residency requirements, so it's important that you control where your data is stored. Azure Monitor processes and stores logs in the primary and secondary regions that you choose. For more information, see [Supported regions](#supported-regions). --### Support for Sentinel and other services --Various services and features that use Log Analytics workspaces are compatible with workspace replication and switchover. These services and features continue to work when you switch over to the secondary workspace. --For example, regional network issues that cause log ingestion latency can impact Sentinel customers. Customers that use replicated workspaces can switch over to their secondary region to continue working with their Log Analytics workspace and Sentinel. However, if the network issue impacts the Sentinel service health, switching to another region doesn't mitigate the issue. --Some Azure Monitor experiences, including Application Insights and VM Insights, are currently only partially compatible with workspace replication and switchover. For the full list, see [Restrictions and limitations](#restrictions-and-limitations). --## Enable and disable workspace replication --You enable and disable workspace replication by using a REST command. The command triggers a long running operation, which means that it can take a few minutes for the new settings to apply. After you enable replication, it can take up to one hour for all tables (data types) to begin replicating, and some data types might start replicating before others. Changes you make to table schemas after you enable workspace replication - for example, new custom log tables or custom fields you create, or diagnostic logs set up for new resource types - can take up to one hour to start replicating. --> [!IMPORTANT] -> Replication of Log Analytics workspaces linked to a dedicated cluster is currently not supported. --### Enable workspace replication --To enable replication on your Log Analytics workspace, use this `PUT` command: --```http -PUT --https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview --body: -{ - "properties": { - "replication": { - "enabled": true, - "location": "<secondary_region>" - } - }, - "location": "<primary_region>" -} -``` --Where: --- `<subscription_id>`: The subscription ID related to your workspace.-- `<resourcegroup_name>` : The resource group that contains your Log Analytics workspace resource.-- `<workspace_name>`: The name of your workspace.-- `<primary_region>`: The primary region for your Log Analytics workspace.-- `<secondary_region>`: The region in which Azure Monitor creates the secondary workspace.--For the supported `location` values, see [Supported regions](#supported-regions). --The `PUT` command is a long running operation that can take some time to complete. A successful call returns a `200` status code. You can track the provisioning state of your request, as described in [Check request provisioning state](#check-request-provisioning-state). --### Check request provisioning state --To check the provisioning state of your request, run this `GET` command: --```http -GET --https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>?api-version=2023-01-01-preview -``` --Where: --- `<subscription_id>`: The subscription ID related to your workspace.-- `<resourcegroup_name>`: The resource group that contains your Log Analytics workspace resource.-- `<workspace_name>`: The name of your Log Analytics workspace.- -Use the `GET` command to verify that the workspace provisioning state changes from `Updating` to `Succeeded`, and the secondary region is set as expected. ---> [!NOTE] -> When you enable replication for workspaces that interact with Sentinel, it can take up to 12 days to fully replicate Watchlist and Threat Intelligence data to the secondary workspace. --### Associate data collection rules with the system data collection endpoint --You use [data collection rules (DCR)](../essentials/data-collection-rule-overview.md) to collect log data using Azure Monitor Agent and the Logs Ingestion API. --If you have data collection rules that send data to your primary workspace, you need to associate the rules to a system [data collection endpoint (DCE)](../essentials/data-collection-endpoint-overview.md), which Azure Monitor creates when you enable workspace replication. The name of the system data collection endpoint is identical to your workspace ID. Only data collection rules you associate to the workspace's system data collection endpoint enable replication and switchover. This behavior lets you specify the set of log streams to replicate, which helps you control your replication costs. --To replicate data you collect using data collection rules, associate your data collection rules to the system data collection endpoint for your Log Analytics workspace: --1. In the Azure portal, select **Data collection rules**. -1. From the **Data collection rules** screen, select a data collection rule that sends data to your primary Log Analytics workspace. -1. On the data collection rule **Overview** page, select **Configure DCE** and select the system data collection endpoint from the available list: -- :::image type="content" source="media/workspace-replication/configure-dce.png" alt-text="Screenshot that shows how to configure a data collection endpoint for an existing data collection rule in the Azure portal." lightbox="media/workspace-replication/configure-dce.png"::: - For details about the System DCE, check the workspace object properties. --> [!IMPORTANT] -> Data collection rules connected to a workspace's system data collection endpoint can target only that specific workspace. The data collection rules **must not** target other destinations, such as other workspaces or Azure Storage accounts. --### Disable workspace replication --To disable replication for a workspace, use this `PUT` command: --```http -PUT --https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview --body: -{ - "properties": { - "replication": { - "enabled": false - } - }, - "location": "<primary_region>" -} -``` --Where: --- `<subscription_id>`: The subscription ID related to your workspace.-- `<resourcegroup_name>` : The resource group that contains your workspace resource.-- `<workspace_name>`: The name of your workspace.-- `<primary_region>`: The primary region for your workspace.--The `PUT` command is a long running operation that can take some time to complete. A successful call returns a `200` status code. You can track the provisioning state of your request, as described in [Check request provisioning state](#check-request-provisioning-state). --## Monitor workspace and service health --Ingestion latency or query failures are examples of issues that can often be handled by failing over to your secondary region. Such issues can be detected by using Service Health notifications and log queries. --Service Health notifications are useful for service-related issues. To identify issues impacting your specific workspace (and possibly not the entire service), you can use other measures: --- [Create alerts based on the workspace resource health](log-analytics-workspace-health.md#view-log-analytics-workspace-health-and-set-up-health-status-alerts)-- Set your own thresholds for [workspace health metrics](log-analytics-workspace-health.md#view-log-analytics-workspace-health-metrics)-- Create your own monitoring queries to serve as custom health indicators for your workspace, as described in [Monitor workspace performance using queries](#monitor-workspace-performance-using-queries), to:- - Measure ingestion latency per table - - Identify whether the source of latency is the collection agents or the ingestion pipeline - - Monitor ingestion volume anomalies per table and resource - - Monitor query success rate per table, user, or resource - - Create alerts based on your queries --> [!NOTE] -> You can also use log queries to monitor your secondary workspace, but keep in mind that logs replication is done in batch operations. The measured latency can fluctuate and doesn't indicate any health issue with your secondary workspace. For more information, see [Audit the inactive workspace](#audit-the-inactive-workspace). --## Switch over to your secondary workspace --During switchover, most operations work the same as when you use the primary workspace and region. However, some operations have slightly different behavior or are blocked. For more information, see [Restrictions and limitations](#restrictions-and-limitations). --### When should I switch over? --You decide when to switch over to your secondary workspace and switch back to your primary workspace based on ongoing performance and health monitoring and your system standards and requirements. --There are several points to consider in your plan for switchover, as described in the following subsections. --#### Issue type and scope --The switchover process routes ingestion and query requests to your secondary region, which usually bypasses any faulty component that's causing latency or failure in your primary region. As a result, switchover isn't likely to help if: --- There's a cross-regional issue with an underlying resource. For example, if the same resource types fail in both your primary and secondary regions.-- You experience an issue related to workspace management, such as changing workspace retention. Workspace management operations are always handled in your primary region. During switchover, workspace management operations are blocked.--#### Issue duration --Switchover isn't instantaneous. The process of rerouting requests relies on DNS updates, which some clients pick up within minutes while others can take more time. Therefore, it's helpful to understand whether the issue can be resolved within a few minutes. If the observed issue is consistent or continuous, don't wait to switch over. Here are some examples: --- **Ingestion**: Issues with the ingestion pipeline in your primary region can affect data replication to your secondary workspace. During switchover, logs are instead sent to the ingestion pipeline in the secondary region.--- **Query**: If queries in your primary workspace fail or timeout, Log search alerts can be affected. In this scenario, switch over to your secondary workspace to make sure all your alerts are triggered correctly.--#### Secondary workspace data --Logs ingested to your primary workspace before you enable replication aren't copied to the secondary workspace. If you enabled workspace replication three hours ago and you now switch over to your secondary workspace, your queries can only return data from the last three hours. --Before you switch regions during switchover, your secondary workspace needs to contain a useful volume of logs. We recommend waiting at least one week after you enable replication before you trigger switchover. The seven days allow for sufficient data to be available in your secondary region. --### Trigger switchover --Before you switch over, [confirm that the workspace replication operation completed successfully](#check-request-provisioning-state). Switchover only succeeds when the secondary workspace is configured correctly. --To switch over to your secondary workspace, use this `POST` command: --```http -POST -https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/locations/<secondary_region>/workspaces/<workspace_name>/failover?api-version=2023-01-01-preview -``` --Where: --- `<subscription_id>`: The subscription ID related to your workspace.-- `<resourcegroup_name>` : The resource group that contains your workspace resource.-- `<secondary_region>`: The region to switch to during switchover.-- `<workspace_name>`: The name of the workspace to switch to during switchover.--The `POST` command is a long running operation that can take some time to complete. A successful call returns a `202` status code. You can track the provisioning state of your request, as described in [Check request provisioning state](#check-request-provisioning-state). --## Switch back to your primary workspace --The switchback process cancels the rerouting of queries and log ingestion requests to the secondary workspace. When you switch back, Azure Monitor goes back to routing queries and log ingestion requests to your primary workspace. --When you switch over to your secondary region, Azure Monitor replicates logs from your secondary workspace to your primary workspace. If an outage impacts the log ingestion process in the primary region, it can take time for Azure Monitor to complete the ingestion of the replicated logs to your primary workspace. --### When should I switch back? --There are several points to consider in your plan for switchback, as described in the following subsections. --#### Log replication state --Before you switch back, verify that Azure Monitor has completed replicating all logs ingested during switchover to the primary region. If you switch back before all logs replicate to the primary workspace, your queries might return partial results until log ingestion completes. --You can query your primary workspace in the Azure portal for the inactive region, as described in [Audit the inactive workspace](#audit-the-inactive-workspace). --#### Primary workspace health --There are two important health items to check in preparation for switchback to your primary workspace: --- Confirm there are no outstanding Service Health notifications for the primary workspace and region.-- Confirm your primary workspace is ingesting logs and processing queries as expected.--For examples of how to query your primary workspace when your secondary workspace is active and bypass the rerouting of requests to your secondary workspace, see [Audit the inactive workspace](#audit-the-inactive-workspace). --### Trigger switchback --Before you switch back, confirm the [Primary workspace health](#primary-workspace-health) and complete [replication of logs](#log-replication-state). --The switchback process updates your DNS records. After the DNS records update, it can take time for all clients to receive the updated DNS settings and resume routing to the primary workspace. --To switch back to your primary workspace, use this `POST` command: --```http -POST --https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>/failback?api-version=2023-01-01-preview -``` --Where: --- `<subscription_id>`: The subscription ID related to your workspace.-- `<resourcegroup_name>` : The resource group that contains your workspace resource.-- `<workspace_name>`: The name of the workspace to switch to during switchback.--The `POST` command is a long running operation that can take some time to complete. A successful call returns a `202` status code. You can track the provisioning state of your request, as described in [Check request provisioning state](#check-request-provisioning-state). --## Audit the inactive workspace --By default, Azure Monitor run queries in your _active_ region. The active region is typically your primary region in your primary workspace. During switchover, the secondary workspace becomes _active_ and the primary region is _inactive_. --In some cases, you might want to query the _inactive_ region. For example, you might want to ensure that your secondary workspace has complete replication of ingested logs before you switch over. --### Query inactive region --To query the available logs on the inactive workspace: --1. In the Azure portal, go to your Log Analytics workspace. -1. On the left, select **Logs**. -1. On the query toolbar, select **More tools** (...) at the right. -1. Enable **Query inactive region**. -- :::image type="content" source="media/workspace-replication/query-inactive-region.png" alt-text="Screenshot that shows how to query the inactive region through the workspace Logs page in the Azure portal." lightbox="media/workspace-replication/query-inactive-region.png"::: --After you enable the **Query inactive region** option, Log Analytics shows query results for the inactive region rather than the active region. --You can confirm that Azure Monitor runs your query in the intended region by checking these fields in the `LAQueryLogs` table, which is created when you [enable query auditing in your Log Analytics workspace](query-audit.md): --- `isWorkspaceInFailover`: Indicates whether the workspace was in switchover mode during the query. The data type is Boolean (True, False).-- `workspaceRegion`: The region of the workspace targeted by the query. The data type is String.--## Monitor workspace performance using queries --We recommend using the queries in this section to create alert rules that notify you of possible workspace health or performance issues. However, the decision to switch over requires your careful consideration, and shouldn't be done automatically. --In the query rule, you can define a condition to switch over to your secondary workspace after a specified number of violations. For more information, see [Create or edit a log search alert rule](../alerts/alerts-create-activity-log-alert-rule.md). --Two significant measurements of workspace performance include _ingestion latency_ and _ingestion volume_. The following sections explore these monitoring options. --### Monitor end-to-end ingestion latency --Ingestion latency measures the time it takes to ingest logs to the workspace. The time measurement starts when the initial logged event occurs and ends when the log is stored in your workspace. The total ingestion latency is composed of two parts: --- **Agent latency**: The time required by the agent to report an event.-- **Ingestion pipeline (backend) latency**: The time required for the ingestion pipeline to process the logs and write them to your workspace.--Different data types have different ingestion latency. You can measure ingestion for each data type separately, or create a generic query for all types, and a more fine-grained query for specific types that are of higher importance to you. We suggest you measure the 90th percentile of the ingestion latency, which is more sensitive to change than the average or the 50th percentile (median). --The following sections show how to use queries to check the ingestion latency for your workspace. --#### Evaluate baseline ingestion latency of specific tables --Begin by determining the baseline latency of specific tables over several days. --This example query creates a chart of the 90th percentile of ingestion latency on the Perf table: --```kusto -// Assess the ingestion latency baseline for a specific data type -Perf -| where TimeGenerated > ago(3d) -| project TimeGenerated, -IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s -| summarize LatencyIngestion90Percentile=percentile(IngestionDurationSeconds, 90) by bin(TimeGenerated, 1h) -| render timechart -``` --After you run the query, review the results and rendered chart to determine the expected latency for that table. --#### Monitor and alert on current ingestion latency --After you establish the baseline ingestion latency for a specific table, [create a log search alert rule](../alerts/alerts-create-log-alert-rule.md) for the table based on changes in latency over a short period of time. --This query calculates ingestion latency over the past 20 minutes: --```kusto -// Track the recent ingestion latency (in seconds) of a specific table -Perf -| where TimeGenerated > ago(20m) -| extend IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s -| summarize Ingestion90Percent_seconds=percentile(IngestionDurationSeconds, 90) -``` --Because you can expect some fluctuations, create an alert rule condition to check if the query returns a value significantly greater than the baseline. --#### Determine the source of ingestion latency --When you notice your total ingestion latency is going up, you can use queries to determine whether the source of the latency is the agents or the ingestion pipeline. --This query charts the 90th percentile latency of the agents and of the pipeline, separately: --```kusto -// Assess agent and pipeline (backend) latency -Perf -| where TimeGenerated > ago(1h) -| extend AgentLatencySeconds = (_TimeReceived-TimeGenerated)/1s, - PipelineLatencySeconds=(ingestion_time()-_TimeReceived)/1s -| summarize percentile(AgentLatencySeconds,90), percentile(PipelineLatencySeconds,90) by bin(TimeGenerated,5m) -| render columnchart -``` --> [!NOTE] -> Although the chart displays the 90th percentile data as stacked columns, the sum of the data in the two charts doesn't equal the _total_ ingestion 90th percentile. --### Monitor ingestion volume --Ingestion volume measurements can help identify unexpected changes to the total or table-specific ingestion volume for your workspace. The query volume measurements can help you identify performance issues with log ingestion. Some useful volume measurements include: --- Total ingestion volume per table-- Constant ingestion volume (standstill)-- Ingestion anomalies - spikes and dips in ingestion volume--The following sections show how to use queries to check the ingestion volume for your workspace. --#### Monitor total ingestion volume per table --You can define a query to monitor the ingestion volume per table in your workspace. The query can include an alert that checks for unexpected changes to the total or table-specific volumes. --This query calculates the total ingestion volume over the past hour per table in megabytes per second (MBs): --```kusto -// Calculate total ingestion volume over the past hour per table -Usage -| where TimeGenerated > ago(1h) -| summarize BillableDataMB = sum(_BilledSize)/1.E6 by bin(TimeGenerated,1h), DataType -``` --#### Check for ingestion standstill --If you ingest logs through agents, you can use the agent's _heartbeat_ to detect connectivity. A still heartbeat can reveal a stop in logs ingestion to your workspace. When the query data reveals an ingestion standstill, you can define a condition to trigger a desired response. --The following query checks the agent heartbeat to detect connectivity issues: --```kusto -// Count agent heartbeats in the last ten minutes -Heartbeat -| where TimeGenerated>ago(10m) -| count -``` --#### Monitor ingestion anomalies --You can identify spikes and dips in your workspace ingestion volume data in various ways. Use the [series_decompose_anomalies()](/azure/data-explorer/kusto/query/series-decompose-anomaliesfunction) function to extract anomalies from the ingestion volumes you monitor in your workspace, or create your own anomaly detector to support your unique workspace scenarios. --##### Identify anomalies using series_decompose_anomalies --The `series_decompose_anomalies()` function identifies anomalies in a series of data values. This query calculates the hourly ingestion volume of each table in your Log Analytics workspace, and uses `series_decompose_anomalies()` to identify anomalies: --```kusto -// Calculate hourly ingestion volume per table and identify anomalies -Usage -| where TimeGenerated > ago(24h) -| project TimeGenerated, DataType, Quantity -| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType -| summarize - Timestamp=make_list(TimeGenerated), - IngestionVolumeMB=make_list(IngestionVolumeMB) - by DataType -| extend series_decompose_anomalies(IngestionVolumeMB) -| mv-expand - Timestamp, - IngestionVolumeMB, - series_decompose_anomalies_IngestionVolumeMB_ad_flag, - series_decompose_anomalies_IngestionVolumeMB_ad_score, - series_decompose_anomalies_IngestionVolumeMB_baseline -| where series_decompose_anomalies_IngestionVolumeMB_ad_flag != 0 -``` --For more information about how to use `series_decompose_anomalies()` to detect anomalies in log data, see [Detect and analyze anomalies using KQL machine learning capabilities in Azure Monitor](kql-machine-learning-azure-monitor.md). --##### Create your own anomaly detector --You can create a custom anomaly detector to support the scenario requirements for your workspace configuration. This section provides an example to demonstrate the process. --The following query calculates: --- **Expected ingestion volume**: Per hour, by table (based on the median of medians, but you can customize the logic)-- **Actual ingestion volume**: Per hour, by table--To filter out insignificant differences between the expected and the actual ingestion volume, the query applies two filters: --- **Rate of change**: Over 150% or under 66% of the expected volume, per table-- **Volume of change**: Indicates whether the increased or decreased volume is more than 0.1% of the monthly volume of that table--```kusto -// Calculate expected vs actual hourly ingestion per table -let TimeRange=24h; -let MonthlyIngestionByType= - Usage - | where TimeGenerated > ago(30d) - | summarize MonthlyIngestionMB=sum(Quantity) by DataType; -// Calculate the expected ingestion volume by median of hourly medians -let ExpectedIngestionVolumeByType= - Usage - | where TimeGenerated > ago(TimeRange) - | project TimeGenerated, DataType, Quantity - | summarize IngestionMedian=percentile(Quantity, 50) by bin(TimeGenerated, 1h), DataType - | summarize ExpectedIngestionVolumeMB=percentile(IngestionMedian, 50) by DataType; -Usage -| where TimeGenerated > ago(TimeRange) -| project TimeGenerated, DataType, Quantity -| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType -| join kind=inner (ExpectedIngestionVolumeByType) on DataType -| extend GapVolumeMB = round(IngestionVolumeMB-ExpectedIngestionVolumeMB,2) -| where GapVolumeMB != 0 -| extend Trend=iff(GapVolumeMB > 0, "Up", "Down") -| extend IngestedVsExpectedAsPercent = round(IngestionVolumeMB * 100 / ExpectedIngestionVolumeMB, 2) -| join kind=inner (MonthlyIngestionByType) on DataType -| extend GapAsPercentOfMonthlyIngestion = round(abs(GapVolumeMB) * 100 / MonthlyIngestionMB, 2) -| project-away DataType1, DataType2 -// Determine whether the spike/deep is substantial: over 150% or under 66% of the expected volume for this data type -| where IngestedVsExpectedAsPercent > 150 or IngestedVsExpectedAsPercent < 66 -// Determine whether the gap volume is significant: over 0.1% of the total monthly ingestion volume to this workspace -| where GapAsPercentOfMonthlyIngestion > 0.1 -| project - Timestamp=format_datetime(todatetime(TimeGenerated), 'yyyy-MM-dd HH:mm:ss'), - Trend, - IngestionVolumeMB, - ExpectedIngestionVolumeMB, - IngestedVsExpectedAsPercent, - GapAsPercentOfMonthlyIngestion -``` --### Monitor query success and failure --Each query returns a response code that indicates success or failure. When the query fails, the response also includes the error types. A high surge of errors can indicate a problem with the workspace availability or service performance. --This query counts how many queries returned a server error code: --```kusto -// Count query errors -LAQueryLogs -| where ResponseCode>=500 and ResponseCode<600 -| count -``` -## Restrictions and limitations --- Replication of Log Analytics workspaces linked to a dedicated cluster is currently not supported. -- The [purge operation](personal-data-mgmt.md#delete), which deletes records from a workspace, removes the relevant records from both the primary and the secondary workspaces. If one of the workspace instances isn't available, the purge operation fails.-- Replication of alert rules across regions is currently not supported. Since Azure Monitor supports querying the inactive region, query-based alerts continue to work when you switch between regions unless the Alerts service in the active region isn't working properly or the alert rules aren't available.-- When you enable replication for workspaces that interact with Sentinel, it can take up to 12 days to fully replicate Watchlist and Threat Intelligence data to the secondary workspace.-- During switchover, workspace management operations aren't supported, including:- - Change workspace retention, pricing tier, daily cap, and so on - - Change network settings - - Change schema through new custom logs or connecting platform logs from new resource providers, such as sending diagnostic logs from a new resource type -- The solution targeting capability of the legacy Log Analytics agent isn't supported during switchover. Therefore, during switchover, solution data is ingested from **all** agents.-- The failover process updates your Domain Name System (DNS) records to reroute all ingestion requests to your secondary region for processing. Some HTTP clients have "sticky connections" and might take longer to pick up the DNS updated DNS. During switchover, these clients might attempt to ingest logs through the primary region for some time. You might be ingesting logs to your primary workspace using various clients, including the legacy Log Analytics Agent, Azure Monitor Agent, code (using the Logs Ingestion API or the legacy HTTP data collection API), and other services, such as Sentinel. - -The following features are partially supported or not currently supported: --| Feature | Support | -| | | -| Search jobs, Restore | Partially supported - Search job and restore operations create tables and populate them with search results or restored data. After you enable workspace replication, new tables created for these operations replicate to your secondary workspace. Tables populated **before** you enable replication aren't replicated. If these operations are in progress when you switch over, the outcome is unexpected. It might complete successfully but not replicate, or it might fail, depending on your workspace health and the exact timing.| -| Application Insights over Log Analytics workspaces | Not supported | -| VM Insights | Not supported | -| Container Insights | Not supported | -| Private links | Not supported during failover | --## Related content --- [Monitor Log Analytics workspace health](../logs/log-analytics-workspace-health.md)-- [Monitor operational issues in your Azure Monitor Log Analytics workspace](../logs/monitor-workspace.md) |
| azure-monitor | Monitor Azure Monitor Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/monitor-azure-monitor-reference.md | - Title: Monitoring data reference for Azure Monitor -description: This article contains important reference material you need when you monitor Azure Monitor. Previously updated : 03/31/2024--------# Azure Monitor monitoring data reference ---See [Monitor Azure Monitor](monitor-azure-monitor.md) for details on the data you can collect for Azure Monitor and how to use it. --<!-- ## Metrics. Required section. --> --<!-- Repeat the following section for each resource type/namespace in your service. For each ### section, replace the <ResourceType/namespace> placeholder, add the metrics-tableheader #include, and add the table #include. --To add the table #include, find the table(s) for the resource type in the Metrics column at https://review.learn.microsoft.com/en-us/azure/azure-monitor/reference/supported-metrics/metrics-index?branch=main#supported-metrics-and-log-categories-by-resource-type, which is autogenerated from underlying systems. --> --### Supported metrics for Microsoft.Monitor/accounts -The following table lists the metrics available for the Microsoft.Monitor/accounts resource type. --### Supported metrics for microsoft.insights/autoscalesettings -The following table lists the metrics available for the microsoft.insights/autoscalesettings resource type. --### Supported metrics for microsoft.insights/components -The following table lists the metrics available for the microsoft.insights/components resource type. --### Supported metrics for Microsoft.Insights/datacollectionrules -The following table lists the metrics available for the Microsoft.Insights/datacollectionrules resource type. --### Supported metrics for Microsoft.operationalinsight/workspaces --Azure Monitor Logs / Log Analytics workspaces ---<!-- ## Metric dimensions. Required section. --> ---Microsoft.Monitor/accounts: --- `Stamp color`--microsoft.insights/autoscalesettings: --- `MetricTriggerRule`-- `MetricTriggerSource`-- `ScaleDirection`--microsoft.insights/components: --- `availabilityResult/name`-- `availabilityResult/location`-- `availabilityResult/success`-- `dependency/type`-- `dependency/performanceBucket`-- `dependency/success`-- `dependency/target`-- `dependency/resultCode`-- `operation/synthetic`-- `cloud/roleInstance`-- `cloud/roleName`-- `client/isServer`-- `client/type`--Microsoft.Insights/datacollectionrules: --- `InputStreamId`-- `ResponseCode`-- `ErrorType`---### Supported resource logs for Microsoft.Monitor/accounts --### Supported resource logs for microsoft.insights/autoscalesettings --### Supported resource logs for microsoft.insights/components --### Supported resource logs for Microsoft.Insights/datacollectionrules ---### Application Insights -microsoft.insights/components --- [AzureActivity](/azure/azure-monitor/reference/tables/AzureActivity#columns)-- [AzureMetrics](/azure/azure-monitor/reference/tables/AzureMetrics#columns)-- [AppAvailabilityResults](/azure/azure-monitor/reference/tables/AppAvailabilityResults#columns)-- [AppBrowserTimings](/azure/azure-monitor/reference/tables/AutoscaleScaleActionsLog#columns)-- [AppDependencies](/azure/azure-monitor/reference/tables/AppDependencies#columns)-- [AppEvents](/azure/azure-monitor/reference/tables/AppEvents#columns)-- [AppPageViews](/azure/azure-monitor/reference/tables/AppPageViews#columns)-- [AppPerformanceCounters](/azure/azure-monitor/reference/tables/AppPerformanceCounters#columns)-- [AppRequests](/azure/azure-monitor/reference/tables/AppRequests#columns)-- [AppSystemEvents](/azure/azure-monitor/reference/tables/AppSystemEvents#columns)-- [AppTraces](/azure/azure-monitor/reference/tables/AppTraces#columns)-- [AppExceptions](/azure/azure-monitor/reference/tables/AppExceptions#columns)--### Azure Monitor autoscale settings -Microsoft.Insights/AutoscaleSettings --- [AzureActivity](/azure/azure-monitor/reference/tables/AzureActivity#columns)-- [AzureMetrics](/azure/azure-monitor/reference/tables/AzureMetrics#columns)-- [AutoscaleEvaluationsLog](/azure/azure-monitor/reference/tables/AutoscaleEvaluationsLog#columns)-- [AutoscaleScaleActionsLog](/azure/azure-monitor/reference/tables/AutoscaleScaleActionsLog#columns)--### Azure Monitor Workspace -Microsoft.Monitor/accounts --- [AMWMetricsUsageDetails](/azure/azure-monitor/reference/tables/AMWMetricsUsageDetails#columns)--### Data Collection Rules -Microsoft.Insights/datacollectionrules --- [DCRLogErrors](/azure/azure-monitor/reference/tables/DCRLogErrors#columns)--### Workload Monitoring of Azure Monitor Insights -Microsoft.Insights/WorkloadMonitoring --- [InsightsMetrics](/azure/azure-monitor/reference/tables/InsightsMetrics#columns)--- [Monitor resource provider operations](/azure/role-based-access-control/resource-provider-operations#monitor)--## Related content --- See [Monitor Azure Monitor](monitor-azure-monitor.md) for a description of monitoring Azure Monitor.-- See [Monitor Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) for details on monitoring Azure resources. |
| azure-monitor | Monitor Azure Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/monitor-azure-monitor.md | - Title: Monitor Azure Monitor -description: Start here to learn how to monitor Azure Monitor. Previously updated : 03/31/2024--------# Monitor Azure Monitor ---Azure Monitor has many separate larger components. Information on monitoring each of these components follows. --## Azure Monitor core --**Autoscale** - Azure Monitor Autoscale has a diagnostics feature that provides insights into the performance of your autoscale settings. For more information, see [Azure Monitor Autoscale diagnostics](autoscale/autoscale-diagnostics.md) and [Troubleshooting using autoscale metrics](autoscale/autoscale-troubleshoot.md#autoscale-metrics). --**Agent Monitoring** - You can now monitor the health of your agents easily and seamlessly across Azure, on premises and other clouds using this interactive experience. For more information, see [Azure Monitor Agent Health](agents/azure-monitor-agent-health.md). --**Data Collection Rules(DCRs)** - Use [detailed metrics and log](essentials/data-collection-monitor.md) to monitor the performance of your DCRs. --## Azure Monitor Logs and Log Analytics --**[Log Analytics Workspace Insights](logs/log-analytics-workspace-insights-overview.md)** provides a dashboard that shows you the volume of data going through your workspace(s). You can calculate the cost of your workspace based on the data volume. - -**[Log Analytics workspace health](logs/log-analytics-workspace-health.md)** provides a set of queries that you can use to monitor the health of your workspace. --**Optimizing and troubleshooting log queries** - Sometimes Azure Monitor KQL Log queries can take more time to run than needed or never return at all. By monitoring the various aspects of the query, you can troubleshoot and optimize them. For more information, see [Audit queries in Azure Monitor Logs](logs/query-audit.md) and [Optimize log queries](logs/query-optimization.md). --**Log Ingestion pipeline latency** - Azure Monitor provides a highly scalable log ingestion pipeline that can ingest logs from any source. You can monitor the latency of this pipeline using Kusto queries. For more information, see [Log data ingestion time in Azure Monitor](logs/data-ingestion-time.md#check-ingestion-time). --**Log Analytics usage** - You can monitor the data ingestion for your Log Analytics workspace. For more information, see [Analyze usage in Log Analytics](logs/analyze-usage.md). --## All resources --**Health of any Azure resource** - Azure Monitor resources are tied into the resource health feature, which provides insights into the health of any Azure resource. For more information, see [Resource health](/azure/service-health/resource-health-overview/). ----For more information about the resource types for Azure Monitor, see [Azure Monitor monitoring data reference](monitor-azure-monitor-reference.md). ----For a list of available metrics for Azure Monitor, see [Azure Monitor monitoring data reference](monitor-azure-monitor-reference.md#metrics). ---For the available resource log categories, their associated Log Analytics tables, and the logs schemas for Azure Monitor, see [Azure Monitor monitoring data reference](monitor-azure-monitor-reference.md#resource-logs). -------Refer to the links in the beginning of this article for specific Kusto queries for each of the Azure Monitor components. ---## Related content --- See [Azure Monitor monitoring data reference](monitor-azure-monitor-reference.md) for a reference of the metrics, logs, and other important values created for Azure Monitor.-- See [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) for general details on monitoring Azure resources. |
| azure-monitor | Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/overview.md | - Title: Azure Monitor overview -description: Overview of Microsoft services and functionalities that contribute to a complete monitoring strategy for your Azure services and applications. --- Previously updated : 07/15/2024---# Azure Monitor overview --Azure Monitor is a comprehensive monitoring solution for collecting, analyzing, and responding to monitoring data from your cloud and on-premises environments. You can use Azure Monitor to maximize the availability and performance of your applications and services. It helps you understand how your applications are performing and allows you to manually and programmatically respond to system events. --Azure Monitor collects and aggregates the data from every layer and component of your system across multiple Azure and non-Azure subscriptions and tenants. It stores it in a common data platform for consumption by a common set of tools that can correlate, analyze, visualize, and/or respond to the data. You can also integrate other Microsoft and non-Microsoft tools. ---The diagram above shows an abstracted view of the monitoring process. A more detailed breakdown of the Azure Monitor architecture is shown in the [High level architecture](#high-level-architecture) section below. ---## High level architecture --Azure Monitor can monitor these types of resources in Azure, other clouds, or on-premises: --- Applications-- Virtual machines-- Guest operating systems-- Containers including Prometheus metrics-- Databases-- Security events in combination with Azure Sentinel-- Networking events and health in combination with Network Watcher-- Custom sources that use the APIs to get data into Azure Monitor--You can also export monitoring data from Azure Monitor into other systems so you can: --- Integrate with other third-party and open-source monitoring and visualization tools-- Integrate with ticketing and other ITSM systems--If you're a System Center Operations Manager (SCOM) user, Azure Monitor now includes Azure Monitor [SCOM Managed Instance (SCOM MI)](./vm/scom-managed-instance-overview.md). Operations Manager MI is a cloud-hosted version of Operations Manager and allows you to move your on-premises Operations Manager installation to Azure. --The following diagram shows a high-level architecture view of Azure Monitor. ---Click on the diagram to see a more detailed expanded version showing a larger breakdown of data sources and data collection methods. --The diagram depicts the Azure Monitor system components: --- **[Data sources](data-sources.md)** are the types of resources being monitored. -- The data is **collected and routed** to the data platform. Clicking on the diagram shows these options, which are also called out in detail later in this article. -- The **[data platform](data-platform.md)** stores the collected monitoring data. Azure Monitor's core data platform has stores for metrics, logs, traces, and changes. System Center Operations Manager MI uses its own database hosted in SQL Managed Instance.-- The **consumption** section shows the components that use data from the data platform. - - Azure Monitor's core consumption methods include tools to provide **insights**, **visualize**, and **analyze** data. The visualization tools build on the analysis tools and the insights build on top of both the visualization and analysis tools. - - There are additional mechanisms to help you **respond** to incoming monitoring data. --- The **SCOM MI** path uses the traditional Operations Manager console that SCOM customers are already familiar with. --- Interoperability options are shown in the **integrate** section. Not all services integrate at all levels. SCOM MI only integrates with Power BI. --## Data sources --Azure Monitor can collect [data from multiple sources](data-sources.md). --The diagram below shows an expanded version of the data source types that Azure Monitor can gather monitoring data from. ---Click on the diagram above to see a larger version of the data sources diagram in context. --You can integrate application, infrastructure, and custom data source monitoring data from outside Azure, including from on-premises, and non-Microsoft clouds. --Azure Monitor collects these types of data: --|Data Type|Description and subtypes| -||--| -|App/Workloads |**App**- Application performance, health, and activity data. <br/><br/>**Workloads** - IaaS workloads such as SQL server, Oracle or SAP running on a hosted Virtual Machine.| -|Infrastructure|**Container** - Data about containers, such as [Azure Kubernetes Service](/azure/aks/intro-kubernetes), [Prometheus](./essentials/prometheus-metrics-overview.md), and the applications running inside containers.<br><br>**Operating system** - Data about the guest operating system on which your application is running.| -|Azure Platform|**Azure resource** - Data about the operation of an Azure resource from inside the resource, including changes. Resource Logs are one example. <br><br>**Azure subscription** - The operation and management of an Azure subscription, and data about the health and operation of Azure itself. The activity log is one example.<br><br>**Azure tenant** - Data about the operation of tenant-level Azure services, such as Microsoft Entra ID.<br> | -|Custom Sources| Data that gets into the system using the <br/> - Azure Monitor REST API <br/> - Data Collection API | --For detailed information about each of the data sources, see [data sources](./data-sources.md). --SCOM MI (like on premises SCOM) collects only IaaS Workload and Operating System sources. --## Data collection and routing --Azure Monitor collects and routes monitoring data using a few different mechanisms depending on the data being routed and the destination. Much like a road system improved over the years, not all roads lead to all locations. Some are legacy, some new, and some are better to take than others given how Azure Monitor has evolved over time. For more information, see **[data sources](data-sources.md)**. ---Click on the diagram to see a larger version of the data collection in context. --|Collection method|Description | -||| -|[Application instrumentation](app/app-insights-overview.md)| Application Insights is enabled through either [Auto-Instrumentation (agent)](app/codeless-overview.md) or by adding the Application Insights SDK to your application code. In addition, Application Insights is in process of implementing [Open Telemetry](./app/opentelemetry-overview.md). For more information, reference [How do I instrument an application?](app/app-insights-overview.md#how-do-i-instrument-an-application).| -|[Agents](agents/agents-overview.md)|Agents can collect monitoring data from the guest operating system of Azure and hybrid virtual machines.| -|[Data collection rules](essentials/data-collection-rule-overview.md)|Use data collection rules to specify what data should be collected, how to transform it, and where to send it.| -|Zero Config| Data is automatically sent to a destination without user configuration. Platform metrics are the most common example. | -|[Diagnostic settings](essentials/diagnostic-settings.md)|Use diagnostic settings to determine where to send resource log and activity log data on the data platform.| -|[Azure Monitor REST API](logs/logs-ingestion-api-overview.md)|The Logs Ingestion API in Azure Monitor lets you send data to a Log Analytics workspace in Azure Monitor Logs. You can also send metrics into the Azure Monitor Metrics store using the custom metrics API.| --A common way to route monitoring data to other non-Microsoft tools is using *Event hubs*. See more in the [Integrate](#integrate) section below. --SCOM MI (like on-premises SCOM) uses an agent to collect data, which it sends to a management server running in a SCOM MI on Azure. --For detailed information about data collection, see [data collection](./best-practices-data-collection.md). --## Data platform --Azure Monitor stores data in data stores for each of the three pillars of observability, plus an additional one: -- metrics -- Each store is optimized for specific types of data and monitoring scenarios. ---Select the preceding diagram to see the Data Platform in the context of the whole of Azure Monitor. --|Pillar of Observability/<br>Data Store|Description| -||| -|[Azure Monitor Metrics](essentials/data-platform-metrics.md)|Metrics are numerical values that describe an aspect of a system at a particular point in time. [Azure Monitor Metrics](./essentials/data-platform-metrics.md) is a time-series database, optimized for analyzing time-stamped data. Azure Monitor collects metrics at regular intervals. Metrics are identified with a timestamp, a name, a value, and one or more defining labels. They can be aggregated using algorithms, compared to other metrics, and analyzed for trends over time. It supports native Azure Monitor metrics and [Prometheus metrics](essentials/prometheus-metrics-overview.md).| -|[Azure Monitor Logs](logs/data-platform-logs.md)|Logs are recorded system events. Logs can contain different types of data, be structured or free-form text, and they contain a timestamp. Azure Monitor stores structured and unstructured log data of all types in [Azure Monitor Logs](./logs/data-platform-logs.md). You can route data to [Log Analytics workspaces](./logs/log-analytics-overview.md) for querying and analysis.| -|Traces|[Distributed tracing](app/distributed-tracing.md) allows you to see the path of a request as it travels through different services and components. Azure Monitor gets distributed trace data from [instrumented applications](app/app-insights-overview.md#how-do-i-instrument-an-application). The trace data is stored in a separate workspace in Azure Monitor Logs.| -|Changes|Changes are a series of events in your application and resources. They're tracked and stored when you use the [Change Analysis](./change/change-analysis.md) service, which uses [Azure Resource Graph](../governance/resource-graph/overview.md) as its store. Change Analysis helps you understand which changes, such as deploying updated code, may have caused issues in your systems.| --Distributed tracing is a technique used to trace requests as they travel through a distributed system. It allows you to see the path of a request as it travels through different services and components. It helps you to identify performance bottlenecks and troubleshoot issues in a distributed system. --For less expensive, long-term archival of monitoring data for auditing or compliance purposes, you can export to [Azure Storage](/azure/storage/). --SCOM MI is similar to SCOM on-premises. It stores its information in an SQL Database, but uses SQL Managed Instance because it's in Azure. ---## Consumption --The following sections outline methods and services that consume monitoring data from the Azure Monitor data platform. --All areas in the *consumption* section of the diagram have a user interface that appears in the Azure portal. --The top part of the consumption section applies to Azure Monitor core only. SCOM MI uses the traditional Ops Console running in the cloud. It can also send monitoring data to Power BI for visualization. --### The Azure portal --The Azure portal is a web-based, unified console that provides an alternative to command-line tools. With the Azure portal, you can manage your Azure subscription using a graphical user interface. You can build, manage, and monitor everything from simple web apps to complex cloud deployments in the portal. The *Monitor* section of the Azure portal provides a visual interface that gives you access to the data collected for Azure resources and an easy way to access the tools, insights, and visualizations in Azure Monitor. ---### Insights --Some Azure resource providers have curated visualizations that provide a customized monitoring experience and require minimal configuration. Insights are large, scalable, curated visualizations. ---The following table describes some of the larger insights: --|Insight |Description | -||| -|[Application Insights](app/app-insights-overview.md)|Application Insights monitors the availability, performance, and usage of your web applications.| -|[Container Insights](containers/container-insights-overview.md)|Container Insights gives you performance visibility into container workloads that are deployed to managed Kubernetes clusters hosted on Azure Kubernetes Service. Container Insights collects container logs and metrics from controllers, nodes, and containers that are available in Kubernetes through the Metrics API. After you enable monitoring from Kubernetes clusters, these metrics and logs are automatically collected for you through a containerized version of the Log Analytics agent for Linux.| -|[VM Insights](vm/vminsights-overview.md)|VM Insights monitors your Azure VMs. It analyzes the performance and health of your Windows and Linux VMs and identifies their different processes and interconnected dependencies on external processes. The solution includes support for monitoring performance and application dependencies for VMs hosted on-premises or another cloud provider.| -|[Network Insights](../network-watcher/network-insights-overview.md)|Network Insights provides a comprehensive and visual representation through topologies, of health and metrics for all deployed network resources, without requiring any configuration. It also provides access to network monitoring capabilities like Connection Monitor, flow logging for network security groups (NSGs), and Traffic Analytics and other diagnostic features. | --For more information, see the [list of insights and curated visualizations in the Azure Monitor Insights overview](insights/insights-overview.md). --### Visualize ---Visualizations such as charts and tables are effective tools for summarizing monitoring data and presenting it to different audiences. Azure Monitor has its own features for visualizing monitoring data and uses other Azure services for publishing it to different audiences. Power BI and Grafana are not officially part of the Azure Monitor product, but they're a core integration and part of the Azure Monitor story. --|Visualization|Description | -||| -|[Dashboards](visualize/tutorial-logs-dashboards.md)|Azure dashboards allow you to combine different kinds of data into a single pane in the Azure portal. You can optionally share the dashboard with other Azure users. You can add the output of any log query or metrics chart to an Azure dashboard. For example, you could create a dashboard that combines tiles that show a graph of metrics, a table of activity logs, a usage chart from Application Insights, and the output of a log query.| -|[Workbooks](visualize/workbooks-overview.md)|Workbooks provide a flexible canvas for data analysis and the creation of rich visual reports in the Azure portal. You can use them to query data from multiple data sources. Workbooks can combine and correlate data from multiple data sets in one visualization giving you easy visual representation of your system. Workbooks are interactive and can be shared across teams with data updating in real time. Use workbooks provided with Insights, utilize the library of templates, or create your own.| -|[Power BI](logs/log-powerbi.md)|Power BI is a business analytics service that provides interactive visualizations across various data sources. It's an effective means of making data available to others within and outside your organization. You can configure Power BI to automatically import log data from Azure Monitor to take advantage of these visualizations. | -|[Grafana](visualize/grafana-plugin.md)|Grafana is an open platform that excels in operational dashboards. All versions of Grafana include the Azure Monitor data source plug-in to visualize your Azure Monitor metrics and logs. Azure Managed Grafana also optimizes this experience for Azure-native data stores such as Azure Monitor and Azure Data Explorer. In this way, you can easily connect to any resource in your subscription and view all resulting monitoring data in a familiar Grafana dashboard. It also supports pinning charts from Azure Monitor metrics and logs to Grafana dashboards. <br/><br/> Grafana has popular plug-ins and dashboard templates for non-Microsoft APM tools such as Dynatrace, New Relic, and AppDynamics as well. You can use these resources to visualize Azure platform data alongside other metrics from higher in the stack collected by these other tools. It also has AWS CloudWatch and GCP BigQuery plug-ins for multicloud monitoring in a single pane of glass.| --For a more extensive discussion of the recommended visualization tools and when to use them, see [Analyze and visualize monitoring data](best-practices-analysis.md) --### Analyze --The Azure portal contains built-in tools that allow you to analyze monitoring data. ---|Tool |Description | -||| -|[Metrics explorer](essentials/analyze-metrics.md)|Use the Azure Monitor metrics explorer user interface in the Azure portal to investigate the health and utilization of your resources. Metrics explorer helps you plot charts, visually correlate trends, and investigate spikes and dips in metric values. Metrics explorer contains features for applying dimensions and filtering, and for customizing charts. These features help you analyze exactly the data you need in a visually intuitive way.| -|[Log Analytics](logs/log-analytics-overview.md)|The Log Analytics user interface in the Azure portal helps you query the log data collected by Azure Monitor so that you can quickly retrieve, consolidate, and analyze collected data. After creating test queries, you can then directly analyze the data with Azure Monitor tools, or you can save the queries for use with visualizations or alert rules. Log Analytics workspaces are based on Azure Data Explorer, using a powerful analysis engine and the rich Kusto query language (KQL).Azure Monitor Logs uses a version of the Kusto Query Language suitable for simple log queries, and advanced functionality such as aggregations, joins, and smart analytics. You can [get started with KQL](logs/get-started-queries.md) quickly and easily. NOTE: The term "Log Analytics" is sometimes used to mean both the Azure Monitor Logs data platform store and the UI that accesses that store. Previous to 2019, the term "Log Analytics" did refer to both. It's still common to find content using that framing in various blogs and documentation on the internet. | -|[Change Analysis](change/change-analysis.md)| Change Analysis is a subscription-level Azure resource provider that checks resource changes in the subscription and provides data for diagnostic tools to help users understand what changes might have caused issues. The Change Analysis user interface in the Azure portal gives you insight into the cause of live site issues, outages, or component failures. Change Analysis uses the [Azure Resource Graph](../governance/resource-graph/overview.md) to detect various types of changes, from the infrastructure layer through application deployment.| --### Respond --An effective monitoring solution proactively responds to critical events, without the need for an individual or team to notice the issue. The response could be a text or email to an administrator, or an automated process that attempts to correct an error condition. ----[**Artificial Intelligence for IT Operations (AIOps)**](logs/aiops-machine-learning.md) can improve service quality and reliability by using machine learning to process and automatically act on data you collect from applications, services, and IT resources into Azure Monitor. It automates data-driven tasks, predicts capacity usage, identifies performance issues, and detects anomalies across applications, services, and IT resources. These features simplify IT monitoring and operations without requiring machine learning expertise. --**[Azure Monitor Alerts](alerts/alerts-overview.md)** notify you of critical conditions and can take corrective action. Alert rules can be based on metric or log data. - -- Metric alert rules provide near-real-time alerts based on collected metrics. -- Log search alert rules based on logs allow for complex logic across data from multiple sources.--Alert rules use [action groups](alerts/action-groups.md), which can perform actions such as sending email or SMS notifications. Action groups can send notifications using webhooks to trigger external processes or to integrate with your IT service management tools. Action groups, actions, and sets of recipients can be shared across multiple rules. ---SCOM MI currently uses its own separate traditional SCOM alerting mechanism in the Ops Console. --**[Autoscale](autoscale/autoscale-overview.md)** allows you to dynamically control the number of resources running to handle the load on your application. You can create rules that use Azure Monitor metrics to determine when to automatically add resources when the load increases or remove resources that are sitting idle. You can specify a minimum and maximum number of instances, and the logic for when to increase or decrease resources to save money and to increase performance. ---**[Azure Logic Apps](../logic-apps/logic-apps-overview.md)** is also an option. For more information, see the [Integrate](#integrate) section below. --## Integrate --You may need to integrate Azure Monitor with other systems or to build custom solutions that use your monitoring data. These Azure services work with Azure Monitor to provide integration capabilities. Below are only a few of the possible integrations. ---|Azure service |Description | -||| -|[Event Hubs](../event-hubs/event-hubs-about.md)|Azure Event Hubs is a streaming platform and event ingestion service. It can transform and store data by using any real-time analytics provider or batching/storage adapters. Use Event Hubs to stream Azure Monitor data to partner SIEM and monitoring tools.| -|[Azure Storage](../storage/common/storage-introduction.md)| Export data to Azure storage for less expensive, long-term archival of monitoring data for auditing or compliance purposes. -|[Hosted and Managed Partners](/azure/partner-solutions/partners##observability) | Many external partners integrate with Azure Monitor. Azure Monitor has also partnered with a few monitoring providers to provide an [Azure-hosted version of their products](/azure/partner-solutions/partners#observability) to make interoperability easier. Examples include Elastic, Datadog, Logz.io, and Dynatrace. -|[API](/rest/api/monitor/)|Multiple APIs are available to read and write metrics and logs to and from Azure Monitor in addition to accessing generated alerts. You can also configure and retrieve alerts. With APIs, you have unlimited possibilities to build custom solutions that integrate with Azure Monitor.| -|[Azure Logic Apps](../logic-apps/logic-apps-overview.md)|Azure Logic Apps is a service you can use to automate tasks and business processes by using workflows that integrate with different systems and services with little or no code. Activities are available that read and write metrics and logs in Azure Monitor. You can use Logic Apps to [customize responses and perform other actions in response to Azure Monitor alerts](alerts/alerts-logic-apps.md). You can also perform other [more complex actions](logs/logicapp-flow-connector.md) when the Azure Monitor infrastructure doesn't already supply a built-it method.| -|[Azure Functions](../azure-functions/functions-overview.md)| Similar to Azure Logic Apps, Azure Functions give you the ability to preprocess and post process monitoring data and perform complex action beyond the scope of typical Azure Monitor alerts. Azure Functions uses code however providing additional flexibility over Logic Apps. -|Azure DevOps and GitHub | Azure Monitor Application Insights gives you the ability to create [Work Item Integration](app/release-and-work-item-insights.md?tabs=work-item-integration) with monitoring data embedding in it. Additional options include [release annotations](app/release-and-work-item-insights.md?tabs=release-annotations) and [continuous monitoring](app/release-and-work-item-insights.md?tabs=continuous-monitoring). | ---Additional integrations not shown in the diagram that may be of interest. --| Integration | Description | -|-|-| -| [Defender for the Cloud](/azure/defender-for-cloud/defender-for-cloud-introduction) | Collect and analyze security events and perform threat analysis. See [Data collection in Defender for the Cloud](/azure/defender-for-cloud/monitoring-components). | -| [Microsoft Sentinel](../sentinel/index.yml) | Connect to different sources including Office 365 and Amazon Web Services Cloud Trail. See [Connect data sources](../sentinel/connect-data-sources.md). | -| [Microsoft Intune](/mem/intune/fundamentals/what-is-intune) | Create a diagnostic setting to send logs to Azure Monitor. See [Send log data to storage, Event Hubs, or log analytics in Intune (preview)](/mem/intune/fundamentals/review-logs-using-azure-monitor). | -| [ITSM](alerts/itsmc-overview.md) | The [IT Service Management (ITSM) Connector](./alerts/itsmc-overview.md) allows you to connect Azure and a supported ITSM product/service. | --These are just a few options. There are many more third party companies that integrate with Azure and Azure Monitor at various levels. Use your favorite search engine to locate them. --## Frequently asked questions --This section provides answers to common questions. --### What's the difference between Azure Monitor, Log Analytics, and Application Insights? --In September 2018, Microsoft combined Azure Monitor, Log Analytics, and Application Insights into a single service to provide powerful end-to-end monitoring of your applications and the components they rely on. Features in Log Analytics and Application Insights haven't changed, although some features have been rebranded to Azure Monitor to better reflect their new scope. The log data engine and query language of Log Analytics is now referred to as Azure Monitor Logs. --### How much does Azure Monitor cost? --The cost of Azure Monitor is based on your usage of different features and is primarily determined by the amount of data you collect. See [Azure Monitor cost and usage](./usage-estimated-costs.md) for details on how costs are determined and [Cost optimization in Azure Monitor](./best-practices-cost.md) for recommendations on reducing your overall spend. --### Is there an on-premises version of Azure Monitor? --No. Azure Monitor is a scalable cloud service that processes and stores large amounts of data, although Azure Monitor can monitor resources that are on-premises and in other clouds. --### Does Azure Monitor integrate with System Center Operations Manager? --You can connect your existing System Center Operations Manager management group to Azure Monitor to collect data from agents into Azure Monitor Logs. This capability allows you to use log queries and solutions to analyze data collected from agents. You can also configure existing System Center Operations Manager agents to send data directly to Azure Monitor. See [Connect Operations Manager to Azure Monitor](agents/om-agents.md). --Microsoft also offers System Center Operations Manager Managed Instance (SCOM MI) as an option to migrate a traditional SCOM setup into the cloud with minimal changes. For more information see [About Azure Monitor SCOM Managed Instance](/system-center/scom/operations-manager-managed-instance-overview). - --## Next steps -- [Getting started with Azure Monitor](getting-started.md)-- [Sources of monitoring data for Azure Monitor](data-sources.md)-- [Data collection in Azure Monitor](essentials/data-collection.md) |
| azure-monitor | Policy Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/policy-reference.md | - Title: Built-in policy definitions for Azure Monitor -description: Lists Azure Policy built-in policy definitions for Azure Monitor. These built-in policy definitions provide common approaches to managing your Azure resources. Previously updated : 02/06/2024-------# Azure Policy built-in definitions for Azure Monitor --This page is an index of [Azure Policy](../governance/policy/overview.md) built-in policy -definitions for Azure Monitor. For additional Azure Policy built-ins for other services, see -[Azure Policy built-in definitions](../governance/policy/samples/built-in-policies.md). --The name of each built-in policy definition links to the policy definition in the Azure portal. Use -the link in the **Version** column to view the source on the -[Azure Policy GitHub repo](https://github.com/Azure/azure-policy). --## Azure Monitor ---## Next steps --- See the built-ins on the [Azure Policy GitHub repo](https://github.com/Azure/azure-policy).-- Review the [Azure Policy definition structure](../governance/policy/concepts/definition-structure.md).-- Review [Understanding policy effects](../governance/policy/concepts/effects.md). |
| azure-monitor | Profiler Aspnetcore Linux | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/profiler/profiler-aspnetcore-linux.md | - Title: Enable Profiler for ASP.NET Core web apps hosted in Linux -description: Learn how to enable Profiler on your ASP.NET Core web application hosted in Linux on Azure App Service. -- Previously updated : 08/19/2024--# Customer Intent: As a .NET developer, I'd like to enable Application Insights Profiler for my .NET web application hosted in Linux ---# Enable Profiler for ASP.NET Core web apps hosted in Linux --By using Profiler, you can track how much time is spent in each method of your live ASP.NET Core web apps that are hosted in Linux on Azure App Service. This article focuses on web apps hosted in Linux. You can also experiment by using Linux, Windows, and Mac development environments. --In this article, you: -> [!div class="checklist"] -> - Set up and deploy an ASP.NET Core web application hosted on Linux. -> - Add Application Insights Profiler to the ASP.NET Core web application. --## Prerequisites --- Install the [latest .NET Core SDK](https://dotnet.microsoft.com/download/dotnet).-- Install Git by following the instructions at [Getting started: Installing Git](https://git-scm.com/book/en/v2/Getting-Started-Installing-Git).-- Review the following samples for context:- - [Enable Service Profiler for containerized ASP.NET Core Application (.NET 6)](https://github.com/microsoft/ApplicationInsights-Profiler-AspNetCore/tree/main/examples/EnableServiceProfilerForContainerAppNet6) - - [Application Insights Profiler for Worker Service example](https://github.com/microsoft/ApplicationInsights-Profiler-AspNetCore/tree/main/examples/ServiceProfilerInWorkerNet6) --## Set up the project locally --1. Open a command prompt window on your machine. --1. Create an ASP.NET Core MVC web application: -- ```console - dotnet new mvc -n LinuxProfilerTest - ``` --1. Change the working directory to the root folder for the project. --1. Add the NuGet package to collect the Profiler traces: -- ```console - dotnet add package Microsoft.ApplicationInsights.Profiler.AspNetCore - ``` --1. In your preferred code editor, enable Application Insights and Profiler in `Program.cs`. [Add custom Profiler settings, if applicable](https://github.com/microsoft/ApplicationInsights-Profiler-AspNetCore/blob/main/Configurations.md). -- For `WebAPI`: -- ```csharp - // Add services to the container. - builder.Services.AddApplicationInsightsTelemetry(); - builder.Services.AddServiceProfiler(); - ``` -- For `Worker`: -- ```csharp - IHost host = Host.CreateDefaultBuilder(args) - .ConfigureServices(services => - { - services.AddApplicationInsightsTelemetryWorkerService(); - services.AddServiceProfiler(); - - // Assuming Worker is your background service class. - services.AddHostedService<Worker>(); - }) - .Build(); - - await host.RunAsync(); - ``` --1. Save and commit your changes to the local repository: -- ```console - git init - git add . - git commit -m "first commit" - ``` --## Create the Linux web app to host your project --1. In the Azure portal, create a web app environment by using App Service on Linux. -- :::image type="content" source="./media/profiler-aspnetcore-linux/create-web-app.png" alt-text="Screenshot that shows creating the Linux web app."::: --1. Go to your new web app resource and select **Deployment Center** > **FTPS credentials** to create the deployment credentials. Make a note of your credentials to use later. -- :::image type="content" source="./media/profiler-aspnetcore-linux/credentials.png" alt-text="Screenshot that shows creating the deployment credentials."::: --1. Select **Save**. -1. Select the **Settings** tab. -1. In the dropdown, select **Local Git** to set up a local Git repository in the web app. -- :::image type="content" source="./media/profiler-aspnetcore-linux/deployment-options.png" alt-text="Screenshot that shows view deployment options in a dropdown."::: --1. Select **Save** to create a Git repository with a Git clone URI. -- :::image type="content" source="./media/profiler-aspnetcore-linux/local-git-repo.png" alt-text="Screenshot that shows setting up the local Git repository."::: -- For more deployment options, see the [App Service documentation](../../app-service/deploy-best-practices.md). --## Deploy your project --1. In your command prompt window, browse to the root folder for your project. Add a Git remote repository to point to the repository on App Service: -- ```console - git remote add azure https://<username>@<app_name>.scm.azurewebsites.net:443/<app_name>.git - ``` -- - Use the **username** that you used to create the deployment credentials. - - Use the **app name** that you used to create the web app by using App Service on Linux. --1. Deploy the project by pushing the changes to Azure: -- ```console - git push azure main - ``` -- You should see output similar to the following example: -- ```output - Counting objects: 9, done. - Delta compression using up to 8 threads. - Compressing objects: 100% (8/8), done. - Writing objects: 100% (9/9), 1.78 KiB | 911.00 KiB/s, done. - Total 9 (delta 3), reused 0 (delta 0) - remote: Updating branch 'main'. - remote: Updating submodules. - remote: Preparing deployment for commit id 'd7369a99d7'. - remote: Generating deployment script. - remote: Running deployment command... - remote: Handling ASP.NET Core Web Application deployment. - remote: ...... - remote: Restoring packages for /home/site/repository/EventPipeExampleLinux.csproj... - remote: . - remote: Installing Newtonsoft.Json 10.0.3. - remote: Installing Microsoft.ApplicationInsights.Profiler.Core 1.1.0-LKG - ... - ``` --## Add Application Insights to monitor your web app --You have three options to add Application Insights to your web app: --- By using the **Application Insights** pane in the Azure portal.-- By using the **Configuration** pane in the Azure portal.-- By manually adding to your web app settings.--# [Application Insights pane](#tab/enablement) --1. In your web app on the Azure portal, select **Application Insights** on the left pane. -1. Select **Turn on Application Insights**. -- :::image type="content" source="./media/profiler-aspnetcore-linux/turn-on-app-insights.png" alt-text="Screenshot that shows turning on Application Insights."::: --1. Under **Application Insights**, select **Enable**. -- :::image type="content" source="./media/profiler-aspnetcore-linux/enable-app-insights.png" alt-text="Screenshot that shows enabling Application Insights."::: --1. Under **Link to an Application Insights resource**, either create a new resource or select an existing resource. For this example, we create a new resource. -- :::image type="content" source="./media/profiler-aspnetcore-linux/link-app-insights.png" alt-text="Screenshot that shows linking Application Insights to a new or existing resource."::: --1. Select **Apply** > **Yes** to apply and confirm. --# [Configuration pane](#tab/config) --1. [Create an Application Insights resource](../app/create-workspace-resource.md) in the same Azure subscription as your App Service instance. -1. Go to the Application Insights resource. -1. Copy the **Instrumentation Key** (iKey). -1. In your web app in the Azure portal, select **Configuration** on the left pane. -1. Select **New application setting**. -- :::image type="content" source="./media/profiler-aspnetcore-linux/new-setting-configuration.png" alt-text="Screenshot that shows adding a new application setting in the Configuration pane."::: --1. Add the following settings in the **Add/Edit application setting** pane by using your saved iKey: -- | Name | Value | - | - | -- | - | APPINSIGHTS_INSTRUMENTATIONKEY | [YOUR_APPINSIGHTS_KEY] | -- :::image type="content" source="./media/profiler-aspnetcore-linux/add-ikey-settings.png" alt-text="Screenshot that shows adding the iKey to the Settings pane."::: --1. Select **OK**. -- :::image type="content" source="./media/profiler-aspnetcore-linux/save-app-insights-key.png" alt-text="Screenshot that shows saving the Application Insights key settings."::: --1. Select **Save**. --# [Web app settings](#tab/appsettings) --1. [Create an Application Insights resource](../app/create-workspace-resource.md) in the same Azure subscription as your App Service instance. -1. Go to the Application Insights resource. -1. Copy the **Instrumentation Key** (iKey). -1. In your preferred code editor, go to your ASP.NET Core project's `appsettings.json` file. -1. Add the following code and insert your copied iKey: -- ```json - "ApplicationInsights": - { - "InstrumentationKey": "<your-instrumentation-key>" - } - ``` --1. Save `appsettings.json` to apply the settings change. ----## Next steps --> [!div class="nextstepaction"] -> [Generate load and view Profiler traces](./profiler-data.md) |
| azure-monitor | Profiler Azure Functions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/profiler/profiler-azure-functions.md | - Title: Enable Profiler for Azure Functions apps -description: Enable Application Insights Profiler for Azure Functions app. -ms.contributor: charles.weininger - Previously updated : 08/16/2024----# Enable Profiler for Azure Functions apps --In this article, you'll use the Azure portal to: -- View the current app settings for your Functions app. -- Add two new app settings to enable Profiler on the Functions app. -- Navigate to the Profiler for your Functions app to view data.--> [!NOTE] -> You can enable the Application Insights Profiler for Azure Functions apps on the **App Service** plan. --## Prerequisites --- [An Azure Functions app](../../azure-functions/functions-create-function-app-portal.md). Verify your Functions app is on the **App Service** plan. - - :::image type="content" source="./media/profiler-azure-functions/choose-plan.png" alt-text="Screenshot of where to select App Service plan from drop-down in Functions app creation."::: --- Linked to [an Application Insights resource](/previous-versions/azure/azure-monitor/app/create-new-resource). Make note of the instrumentation key.--## App settings for enabling Profiler --|App Setting | Value | -||-| -|APPINSIGHTS_PROFILERFEATURE_VERSION | 1.0.0 | -|DiagnosticServices_EXTENSION_VERSION | ~3 | -|APPINSIGHTS_INSTRUMENTATIONKEY | Unique value from your App Insights resource. | --## Add app settings to your Azure Functions app --From your Functions app overview page in the Azure portal: --1. Under **Settings**, select **Configuration**. -- :::image type="content" source="./media/profiler-azure-functions/configuration-menu.png" alt-text="Screenshot of selecting Configuration from under the Settings section of the left side menu."::: --1. In the **Application settings** tab, verify the `APPINSIGHTS_INSTRUMENTATIONKEY` setting is included in the settings list. -- :::image type="content" source="./media/profiler-azure-functions/app-insights-key.png" alt-text="Screenshot showing the App Insights Instrumentation Key setting in the list."::: --1. Select **New application setting**. -- :::image type="content" source="./media/profiler-azure-functions/new-setting-button.png" alt-text="Screenshot outlining the new application setting button."::: --1. Copy the **App Setting** and its **Value** from the [table above](#app-settings-for-enabling-profiler) and paste into the corresponding fields. -- :::image type="content" source="./media/profiler-azure-functions/app-setting-1.png" alt-text="Screenshot adding the app insights profiler feature version setting."::: -- :::image type="content" source="./media/profiler-azure-functions/app-setting-2.png" alt-text="Screenshot adding the diagnostic services extension version setting."::: -- Leave the **Deployment slot setting** blank for now. --1. Click **OK**. --1. Click **Save** in the top menu, then **Continue**. -- :::image type="content" source="./media/profiler-azure-functions/save-button.png" alt-text="Screenshot outlining the save button in the top menu of the configuration pane."::: -- :::image type="content" source="./media/profiler-azure-functions/continue-button.png" alt-text="Screenshot outlining the continue button in the dialog after saving."::: --The app settings now show up in the table: ----> [!NOTE] -> You can also enable Profiler using: -> - [Azure Resource Manager Templates](../app/azure-web-apps-net-core.md#app-service-application-settings-with-azure-resource-manager) -> - [Azure PowerShell](/powershell/module/az.websites/set-azwebapp) -> - [Azure CLI](/cli/azure/webapp/config/appsettings) ---## Next Steps -Learn how to... -> [!div class="nextstepaction"] -> [Generate load and view Profiler traces](./profiler-data.md) |
| azure-monitor | Profiler Bring Your Own Storage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/profiler/profiler-bring-your-own-storage.md | - Title: Configure BYOS for Profiler and Snapshot Debugger -description: Configure Bring Your Own Storage (BYOS) for Azure Application Insights Profiler and Snapshot Debugger. ----reviewer: cweining - Previously updated : 08/19/2024----# Configure BYOS for Application Insights Profiler and Snapshot Debugger --When you use [Application Insights Profiler](./profiler-overview.md) or [Snapshot Debugger](../snapshot-debugger/snapshot-debugger.md), artifacts generated by your application are uploaded by default into Azure Storage accounts over the public internet. For these artifacts and storage accounts, Microsoft controls and covers the cost for: --- Processing and analysis.-- Encryption-at-rest and lifetime management policies.--Meanwhile, when you "bring your own storage" (BYOS), artifacts are uploaded into a storage account that only you control and cover the cost for: --- The encryption-at-rest policy and the Lifetime management policy.-- Network access.--> [!NOTE] -> BYOS is required if you're enabling Azure Private Link or customer-managed keys. -> -> - [Learn more about Private Link for Application Insights](../logs/private-link-security.md). -> - [Learn more about customer-managed keys for Application Insights](../logs/customer-managed-keys.md). --In this guide, you learn how to: -> [!div class="checklist"] -> - Grant Diagnostic Services access to your storage account. -> - Link your storage account with your Application Insights resource. -> - Learn how your storage account is accessed. --## Prerequisites --- Verify you created your storage account in the same location as your Application Insights resource.-- If you enabled [Private Link](../logs/private-link-security.md), allow connection to our Trusted Microsoft Service from your virtual network.--## Grant Diagnostic Services access to your storage account --A BYOS storage account is linked to an Application Insights resource. Start by granting the `Storage Blob Data Contributor` role to the Microsoft Entra application named `Diagnostic Services Trusted Storage Access` via the [Access Control (IAM)](../../role-based-access-control/role-assignments-portal.yml) page in your storage account. --1. Select **Access control (IAM)**. --1. Select **Add** > **Add role assignment** to open the **Add role assignment** page. --1. Assign the following role. - - | Setting | Value | - | | | - | Role | Storage Blob Data Contributor | - | Assign access to | User, group, or service principal | - | Members | Diagnostic Services Trusted Storage Access | -- :::image type="content" source="media/profiler-bring-your-own-storage/add-role-assignment-page.png" alt-text="Screenshot that shows the role assignment page in the Azure portal."::: - - Once assigned, you can see the role under the **Role assignments** section. - :::image type="content" source="media/profiler-bring-your-own-storage/figure-11.png" alt-text="Screenshot that shows the IAM screen after Role assignments."::: --> [!NOTE] -> If you're also using Private Link, one more configuration is required to allow connection to our Trusted Microsoft Service from your virtual network. For more information, see [Storage network security documentation](../../storage/common/storage-network-security.md#trusted-microsoft-services). --## Link your storage account with your Application Insights resource --You have three options for configuring BYOS for code-level diagnostics like Profiler and Snapshot Debugger: --- Azure PowerShell cmdlets-- The Azure CLI-- Azure Resource Manager templates--#### [PowerShell](#tab/azure-powershell) --Before you begin, [install Azure PowerShell 4.2.0 or greater](/powershell/azure/install-azure-powershell). --1. Install the Application Insights PowerShell extension. -- ```powershell - Install-Module -Name Az.ApplicationInsights -Force - ``` --1. Sign in with your Azure account subscription. -- ```powershell - Connect-AzAccount -Subscription "{subscription_id}" - ``` -- For more information on how to sign in, see the [Connect-AzAccount documentation](/powershell/module/az.accounts/connect-azaccount). --1. Remove any previous storage account linked to your Application Insights resource. -- Pattern: -- ```powershell - Get-AzApplicationInsights -ResourceGroupName "{resource_group_name}" -Name "{application_insights_name}" | Remove-AzApplicationInsightsLinkedStorageAccount - ``` -- Example: -- ```powershell - Get-AzApplicationInsights -ResourceGroupName "byos-test" -Name "byos-test-westus2-ai" | Remove-AzApplicationInsightsLinkedStorageAccount - ``` --1. Connect your storage account with your Application Insights resource. - - Pattern: -- ```powershell - $storageAccount = Get-AzStorageAccount -ResourceGroupName "{resource_group_name}" -Name "{storage_account_name}" - Get-AzApplicationInsights -ResourceGroupName "{resource_group_name}" -Name "{application_insights_name}" | New-AzApplicationInsightsLinkedStorageAccount -LinkedStorageAccountResourceId $storageAccount.Id - ``` -- Example: -- ```powershell - $storageAccount = Get-AzStorageAccount -ResourceGroupName "byos-test" -Name "byosteststoragewestus2" - Get-AzApplicationInsights -ResourceGroupName "byos-test" -Name "byos-test-westus2-ai" | New-AzApplicationInsightsLinkedStorageAccount -LinkedStorageAccountResourceId $storageAccount.Id - ``` --#### [Azure CLI](#tab/azure-cli) --Before you begin, [install the Azure CLI](/cli/azure/install-azure-cli). --1. Install the Application Insights CLI extension. -- ```azurecli - az extension add -n application-insights - ``` --1. Connect your storage account with your Application Insights resource. -- Pattern: -- ```azurecli - az monitor app-insights component linked-storage link --resource-group "{resource_group_name}" --app "{application_insights_name}" --storage-account "{storage_account_name}" - ``` - - Example: -- ```azurecli - az monitor app-insights component linked-storage link --resource-group "byos-test" --app "byos-test-westus2-ai" --storage-account "byosteststoragewestus2" - ``` - - Expected output: -- ```powershell - { - "id": "/subscriptions/{subscription}/resourcegroups/byos-test/providers/microsoft.insights/components/byos-test-westus2-ai/linkedstorageaccounts/serviceprofiler", - "linkedStorageAccount": "/subscriptions/{subscription}/resourceGroups/byos-test/providers/Microsoft.Storage/storageAccounts/byosteststoragewestus2", - "name": "serviceprofiler", - "resourceGroup": "byos-test", - "type": "microsoft.insights/components/linkedstorageaccounts" - } - ``` -- > [!NOTE] - > For performing updates on the linked storage accounts to your Application Insights resource, see the [Application Insights CLI documentation](/cli/azure/monitor/app-insights/component/linked-storage). --#### [Resource Manager template](#tab/azure-resource-manager) --1. Create an Azure Resource Manager template file with the following content (*byos.template.json*): -- ```json - { - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "applicationinsights_name": { - "type": "String" - }, - "storageaccount_name": { - "type": "String" - } - }, - "variables": {}, - "resources": [ - { - "name": "[concat(parameters('applicationinsights_name'), '/serviceprofiler')]", - "type": "Microsoft.Insights/components/linkedStorageAccounts", - "apiVersion": "2020-03-01-preview", - "properties": { - "linkedStorageAccount": "[resourceId('Microsoft.Storage/storageAccounts', parameters('storageaccount_name'))]" - } - } - ], - "outputs": {} - } - ``` --1. Run the following PowerShell command to deploy the preceding template: -- Syntax: -- ```powershell - New-AzResourceGroupDeployment -ResourceGroupName "{your_resource_name}" -TemplateFile "{local_path_to_arm_template}" - ``` -- Example: -- ```powershell - New-AzResourceGroupDeployment -ResourceGroupName "byos-test" -TemplateFile "D:\Docs\byos.template.json" - ``` --1. Provide the following parameters when you're prompted in the PowerShell console: - - | Parameter | Description | - |-|--| - | `application_insights_name` | The name of the Application Insights resource to enable BYOS. | - | `storage_account_name` | The name of the storage account resource that you use as your BYOS. | - - Expected output: -- ```powershell - Supply values for the following parameters: - (Type !? for Help.) - application_insights_name: byos-test-westus2-ai - storage_account_name: byosteststoragewestus2 - - DeploymentName : byos.template - ResourceGroupName : byos-test - ProvisioningState : Succeeded - Timestamp : 4/16/2020 1:24:57 AM - Mode : Incremental - TemplateLink : - Parameters : - Name Type Value - ============================== ========================= ========== - application_insights_name String byos-test-westus2-ai - storage_account_name String byosteststoragewestus2 - - Outputs : - DeploymentDebugLogLevel : - ``` --1. Enable Profiler or Snapshot Debugger on the workload of interest through the Azure portal. In this example, it's **App Service** > **Application Insights**. -- :::image type="content" source="media/profiler-bring-your-own-storage/figure-20.png" alt-text="Screenshot that shows the code-level diagnostics in the Azure portal."::: ----## Troubleshooting --Troubleshoot common issues in configuring BYOS. --- For general Profiler troubleshooting, see the [Profiler troubleshooting documentation](profiler-troubleshooting.md).-- For general Snapshot Debugger troubleshooting, see the [Snapshot Debugger troubleshooting documentation](/troubleshoot/azure/azure-monitor/app-insights/snapshot-debugger-troubleshoot).--### Scenario: Template schema '{schema_uri}' isn't supported --You received an error similar to the following example: --```powershell -New-AzResourceGroupDeployment : 11:53:49 AM - Error: Code=InvalidTemplate; Message=Deployment template validation failed: 'Template schema -'https://schema.management.azure.com/schemas/2020-01-01/deploymentTemplate.json#' is not supported. Supported versions are -'2014-04-01-preview,2015-01-01,2018-05-01,2019-04-01,2019-08-01'. Please see https://aka.ms/arm-template for usage details.'. -``` --#### Solutions --- Make sure that the `$schema` property of the template is valid. It must follow this pattern:- ``` - https://schema.management.azure.com/schemas/{schema_version}/deploymentTemplate.json# - ``` --- Make sure that the `schema_version` of the template is within valid values: `2014-04-01-preview, 2015-01-01, 2018-05-01, 2019-04-01, 2019-08-01`.- -### Scenario: No registered resource provider found for location '{location}' --You received an error similar to the following example: --```powershell -New-AzResourceGroupDeployment : 6:18:03 PM - Resource microsoft.insights/components 'byos-test-westus2-ai' failed with message '{ - "error": { - "code": "NoRegisteredProviderFound", - "message": "No registered resource provider found for location 'westus2' and API version '2020-03-01-preview' for type 'components'. The supported api-versions are '2014-04-01, -2014-08-01, 2014-12-01-preview, 2015-05-01, 2018-05-01-preview'. The supported locations are ', eastus, southcentralus, northeurope, westeurope, southeastasia, westus2, uksouth, -canadacentral, centralindia, japaneast, australiaeast, koreacentral, francecentral, centralus, eastus2, eastasia, westus, southafricanorth, northcentralus, brazilsouth, switzerlandnorth, -australiasoutheast'." - } -}' -``` --#### Solutions --- Make sure that the `apiVersion` of the resource `microsoft.insights/components` is `2015-05-01`.-- Make sure that the `apiVersion` of the resource `linkedStorageAccount` is `2020-03-01-preview`.- -### Scenario: Storage account location should match Application Insights component location --You received an error similar to the following example: --```powershell -New-AzResourceGroupDeployment : 1:01:12 PM - Resource microsoft.insights/components/linkedStorageAccounts 'byos-test-centralus-ai/serviceprofiler' failed with message '{ - "error": { - "code": "BadRequest", - "message": "Storage account location should match AI component location", - "innererror": { - "trace": [ - "System.ArgumentException" - ] - } - } -}' -``` --#### Solution --Make sure that the location of the Application Insights resource is the same as the storage account. - -## Frequently asked questions --This section provides answers to common questions about configuring BYOS for Profiler and Snapshot Debugger. --### If I enabled Profiler/Snapshot Debugger and BYOS, is my data migrated into my storage account? -- No, it won't. --### Does BYOS work with encryption-at-rest and customer-managed keys? - - Yes. To be precise, BYOS is a requirement to have Profiler/Snapshot Debugger enabled with customer-manager keys. --### Does BYOS work in an environment isolated from the internet? - - Yes. BYOS is a requirement for isolated network scenarios. --### Does BYOS work with both customer-managed keys and Private Link enabled? - - Yes, it's possible. --### If I enabled BYOS, can I go back to using Diagnostic Services storage accounts to store my collected data? - - Yes, you can, but we don't currently support data migration from your BYOS. --### After I enable BYOS, do I take over all the related costs of storage and networking? -- Yes. --### How is my storage account accessed? --1. Agents running in your virtual machines or Azure App Service upload artifacts (profiles, snapshots, and symbols) to blob containers in your account. -- This process involves contacting Profiler or Snapshot Debugger to obtain a shared access signature token to a new blob in your storage account. --1. Profiler or Snapshot Debugger: -- - Analyzes the incoming blob. - - Write back the analysis results and log files into blob storage. - - Depending on available compute capacity, this process might occur anytime after upload. --1. When you view Profiler traces or Snapshot Debugger analysis, the service fetches the analysis results from blob storage. --## Next steps --- [Learn more about Application Insights Profiler](./profiler-overview.md)-- [Learn more about Snapshot Debugger](../snapshot-debugger/snapshot-debugger.md) |
| azure-monitor | Profiler Cloudservice | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/profiler/profiler-cloudservice.md | - Title: Enable Profiler for Azure Cloud Services -description: Profile Azure Cloud Services in real time with Application Insights Profiler. -- Previously updated : 08/16/2024---# Enable Profiler for Azure Cloud Services --You can receive performance traces for your instance of [Azure Cloud Services](../../cloud-services-extended-support/overview.md) by enabling the Application Insights Profiler. Profiler is installed on your instance of Azure Cloud Services via the [Azure Diagnostics extension](../agents/diagnostics-extension-overview.md). --In this guide, you learn how to: -> [!div class="checklist"] -> - Enable your instance of Azure Cloud Services to send diagnostics data to Application Insights. -> - Configure the Azure Diagnostics extension within your solution to install Profiler. -> - Deploy your service and generate traffic to view Profiler traces. --## Prerequisites --- Make sure you've [set up diagnostics for your instance of Azure Cloud Services](/visualstudio/azure/vs-azure-tools-diagnostics-for-cloud-services-and-virtual-machines).-- Use [.NET Framework 4.6.1](/dotnet/framework/migration-guide/how-to-determine-which-versions-are-installed) or newer.- - If you're using [OS Family 4](../../cloud-services/cloud-services-guestos-update-matrix.md#family-4-releases), install .NET Framework 4.6.1 or newer with a [startup task](../../cloud-services/cloud-services-dotnet-install-dotnet.md). - - [OS Family 5](../../cloud-services/cloud-services-guestos-update-matrix.md#family-5-releases) includes a compatible version of .NET Framework by default. --## Track requests with Application Insights --When you publish your instance of Azure Cloud Services to the Azure portal, add the [Application Insights SDK to Azure Cloud Services](../app/azure-web-apps-net-core.md). ---After you've added the SDK and published your instance of Azure Cloud Services to the Azure portal, track requests by using Application Insights: --- **For ASP.NET web roles**: Application Insights tracks the requests automatically.-- **For worker roles**: You need to [add code manually to your application to track requests](profiler-trackrequests.md).--## Configure the Azure Diagnostics extension --Locate the Azure Diagnostics *diagnostics.wadcfgx* file for your application role. ---Add the following `SinksConfig` section as a child element of `WadCfg`: --```xml -<WadCfg> - <DiagnosticMonitorConfiguration>...</DiagnosticMonitorConfiguration> - <SinksConfig> - <Sink name="MyApplicationInsightsProfiler"> - <!-- Replace with your own Application Insights instrumentation key. --> - <ApplicationInsightsProfiler>00000000-0000-0000-0000-000000000000</ApplicationInsightsProfiler> - </Sink> - </SinksConfig> -</WadCfg> -``` --> [!NOTE] -> The instrumentation keys that are used by the application and the `ApplicationInsightsProfiler` sink must match. --Deploy your service with the new Diagnostics configuration. Application Insights Profiler is now configured to run on your instance of Azure Cloud Services. --## Next steps --> [!div class="nextstepaction"] -> [Generate load and view Profiler traces](./profiler-data.md) - |
| azure-monitor | Profiler Containers | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/profiler/profiler-containers.md | - Title: Profile Azure containers with Application Insights Profiler -description: Learn how to enable the Application Insights Profiler for your ASP.NET Core application running in Azure containers. -ms.contributor: charles.weininger - Previously updated : 08/19/2024--# Customer Intent: As a .NET developer, I'd like to learn how to enable Profiler on my ASP.NET Core application running in my container. ---# Profile live Azure containers with Application Insights --You can enable the Application Insights Profiler for ASP.NET Core application running in your container almost without code. To enable the Application Insights Profiler on your container instance, you need to: --- Add the reference to the `Microsoft.ApplicationInsights.Profiler.AspNetCore` NuGet package.-- Update the code to enable the Profiler.-- Set up the Application Insights instrumentation key.--In this article, you learn about the various ways that you can: -> [!div class="checklist"] -> - Install the NuGet package in the project. -> - Set the environment variable via the orchestrator (like Kubernetes). -> - Learn security considerations around production deployment, like protecting your Application Insights instrumentation key. --## Prerequisites --- [An Application Insights resource](/previous-versions/azure/azure-monitor/app/create-new-resource). Make note of the instrumentation key.-- [Docker Desktop](https://www.docker.com/products/docker-desktop/) to build Docker images.-- [.NET 6 SDK](https://dotnet.microsoft.com/download/dotnet/6.0) installed.--## Set up the environment --1. Clone and use the following [sample project](https://github.com/microsoft/ApplicationInsights-Profiler-AspNetCore/tree/main/examples/EnableServiceProfilerForContainerAppNet6): - - ```bash - git clone https://github.com/microsoft/ApplicationInsights-Profiler-AspNetCore.git - ``` --1. Go to the Container App example: -- ```bash - cd examples/EnableServiceProfilerForContainerAppNet6 - ``` --1. This example is a barebones project created by calling the following CLI command: -- ```powershell - dotnet new mvc -n EnableServiceProfilerForContainerApp - ``` -- We've added delay in the `Controllers/WeatherForecastController.cs` project to simulate the bottleneck. -- ```csharp - [HttpGet(Name = "GetWeatherForecast")] - public IEnumerable<WeatherForecast> Get() - { - SimulateDelay(); - ... - // Other existing code. - } - private void SimulateDelay() - { - // Delay for 500ms to 2s to simulate a bottleneck. - Thread.Sleep((new Random()).Next(500, 2000)); - } - ``` --1. Add the NuGet package to collect the Profiler traces: -- ```console - dotnet add package Microsoft.ApplicationInsights.Profiler.AspNetCore - ``` --1. Enable Application Insights and Profiler. -- ### [ASP.NET Core 6 and later](#tab/net-core-new) - - Add `builder.Services.AddApplicationInsightsTelemetry()` and `builder.Services.AddServiceProfiler()` after the `WebApplication.CreateBuilder()` method in `Program.cs`: - - ```csharp - var builder = WebApplication.CreateBuilder(args); -- builder.Services.AddApplicationInsightsTelemetry(); // Add this line of code to enable Application Insights. - builder.Services.AddServiceProfiler(); // Add this line of code to enable Profiler - builder.Services.AddControllersWithViews(); -- var app = builder.Build(); - ``` -- ### [ASP.NET Core 5 and earlier](#tab/net-core-old) - - Add `services.AddApplicationInsightsTelemetry()` and `services.AddServiceProfiler()` to the `ConfigureServices()` method in `Startup.cs`: -- ```csharp - public void ConfigureServices(IServiceCollection services) - { - services.AddApplicationInsightsTelemetry(); // Add this line of code to enable Application Insights. - services.AddServiceProfiler(); // Add this line of code to enable Profiler - services.AddControllersWithViews(); - } - ``` - - --## Pull the latest ASP.NET Core build/runtime images --1. Go to the .NET Core 6.0 example directory: -- ```bash - cd examples/EnableServiceProfilerForContainerAppNet6 - ``` --1. Pull the latest ASP.NET Core images: -- ```shell - docker pull mcr.microsoft.com/dotnet/sdk:6.0 - docker pull mcr.microsoft.com/dotnet/aspnet:6.0 - ``` --> [!TIP] -> Find the official images for the Docker [SDK](https://hub.docker.com/_/microsoft-dotnet-sdk) and [runtime](https://hub.docker.com/_/microsoft-dotnet-aspnet). --## Add your Application Insights key --1. Via your Application Insights resource in the Azure portal, take note of your Application Insights instrumentation key. -- :::image type="content" source="./media/profiler-containerinstances/application-insights-key.png" alt-text="Screenshot that shows finding the instrumentation key in the Azure portal."::: --1. Open `appsettings.json` and add your Application Insights instrumentation key to this code section: -- ```json - { - "ApplicationInsights": - { - "InstrumentationKey": "Your instrumentation key" - } - } - ``` --## Build and run the Docker image --1. Review the Docker file. --1. Build the example image: -- ```bash - docker build -t profilerapp . - ``` --1. Run the container: -- ```bash - docker run -d -p 8080:80 --name testapp profilerapp - ``` --## View the container via your browser --To hit the endpoint, you have two options: --- Visit `http://localhost:8080/weatherforecast` in your browser.-- Use curl:- - ```terraform - curl http://localhost:8080/weatherforecast - ``` --## Inspect the logs --Optionally, inspect the local log to see if a session of profiling finished: --```bash -docker logs testapp -``` --In the local logs, note the following events: - -```output -Starting application insights profiler with instrumentation key: your-instrumentation key # Double check the instrumentation key -Service Profiler session started. # Profiler started. -Finished calling trace uploader. Exit code: 0 # Uploader is called with exit code 0. -Service Profiler session finished. # A profiling session is completed. -``` --## View the Service Profiler traces --1. Wait for 2 to 5 minutes so that the events can be aggregated to Application Insights. -1. Open the **Performance** pane in your Application Insights resource. -1. After the trace process is finished, the **Profiler Traces** button appears. -- :::image type="content" source="./media/profiler-containerinstances/profiler-traces.png" alt-text="Screenshot that shows the Profiler traces button in the Performance pane."::: --## Clean up resources --Run the following command to stop the example project: --```bash -docker rm -f testapp -``` --## Next steps --> [!div class="nextstepaction"] -> [Generate load and view Profiler traces](./profiler-data.md) |
| azure-monitor | Profiler Data | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/profiler/profiler-data.md | - Title: Generate load and view Application Insights Profiler data -description: Generate load to your Azure service to view the Profiler data -ms.contributor: charles.weininger - Previously updated : 07/11/2024----# View Application Insights Profiler data --Let's say you're running a web performance test. You'll need traces to understand how your web app is running under load. In this article, you'll: --> [!div class="checklist"] -> - Generate traffic to your web app by starting a web performance test or starting a Profiler on-demand session. -> - View the Profiler traces after your load test or Profiler session. -> - Learn how to read the Profiler performance data and call stack. --## Generate traffic to your Azure service --For Profiler to upload traces, your service must be actively handling requests. --If you've newly enabled Profiler, run a short [load test with Azure Load Testing](/azure/load-testing/quickstart-create-and-run-load-test). --If your Azure service already has incoming traffic or if you just want to manually generate traffic, skip the load test and start a **Profiler on-demand session**: --1. From the Application Insights overview page for your Azure service, select **Performance** from the left menu. -1. On the **Performance** pane, select **Profiler** from the top menu for Profiler settings. -- :::image type="content" source="./media/profiler-overview/profiler-button-inline.png" alt-text="Screenshot of the Profiler button from the Performance pane." lightbox="media/profiler-settings/profiler-button.png"::: --1. Once the Profiler settings page loads, select **Profile Now**. -- :::image type="content" source="./media/profiler-settings/configure-blade-inline.png" alt-text="Screenshot of Profiler page features and settings." lightbox="media/profiler-settings/configure-blade.png"::: --## View traces --1. After the Profiler sessions finish running, return to the **Performance** pane. -1. Under **Drill into...**, select **Profiler traces** to view the traces. -- :::image type="content" source="./media/profiler-overview/trace-explorer-inline.png" alt-text="Screenshot of trace explorer page." lightbox="media/profiler-overview/trace-explorer.png"::: --The trace explorer displays the following information: --| Filter | Description | -| | -- | -| Profile tree v. Flame graph | View the traces as either a tree or in graph form. | -| Hot path | Select to open the biggest leaf node. In most cases, this node is near a performance bottleneck. | -| Framework dependencies | Select to view each of the traced framework dependencies associated with the traces. | -| Hide events | Type in strings to hide from the trace view. Select *Suggested events* for suggestions. | -| Event | Event or function name. The tree displays a mix of code and events that occurred, such as SQL and HTTP events. The top event represents the overall request duration. | -| Module | The module where the traced event or function occurred. | -| Thread time | The time interval between the start of the operation and the end of the operation. | -| Timeline | The time when the function or event was running in relation to other functions. | --## How to read performance data --Profiler uses a combination of sampling methods and instrumentation to analyze your application's performance. While performing detailed collection, the Profiler: --- Samples the instruction pointer of each machine CPU every millisecond. - - Each sample captures the complete call stack of the thread, giving detailed information at both high and low levels of abstraction. -- Collects events to track activity correlation and causality, including:- - Context switching events - - Task Parallel Library (TPL) events - - Thread pool events --The call stack displayed in the timeline view is the result of the sampling and instrumentation. Because each sample captures the complete call stack of the thread, it includes code from Microsoft .NET Framework, and any other frameworks that you reference. --### Object allocation (clr!JIT\_New or clr!JIT\_Newarr1) --**clr!JIT\_New** and **clr!JIT\_Newarr1** are helper functions in .NET Framework that allocate memory from a managed heap. -- **clr!JIT\_New** is invoked when an object is allocated. -- **clr!JIT\_Newarr1** is invoked when an object array is allocated. --These two functions usually work quickly. If **clr!JIT\_New** or **clr!JIT\_Newarr1** take up time in your timeline, the code might be allocating many objects and consuming significant amounts of memory. --### Loading code (clr!ThePreStub) --**clr!ThePreStub** is a helper function in .NET Framework that prepares the code for initial execution, which usually includes just-in-time (JIT) compilation. For each C# method, **clr!ThePreStub** should be invoked, at most, once during a process. --If **clr!ThePreStub** takes extra time for a request, it's the first request to execute that method. The .NET Framework runtime takes a significant amount of time to load the first method. Consider: -- Using a warmup process that executes that portion of the code before your users access it.-- Running Native Image Generator (ngen.exe) on your assemblies.--### Lock contention (clr!JITutil\_MonContention or clr!JITutil\_MonEnterWorker) --**clr!JITutil\_MonContention** or **clr!JITutil\_MonEnterWorker** indicate that the current thread is waiting for a lock to be released. This text is often displayed when you: -- Execute a C# **LOCK** statement,-- Invoke the **Monitor.Enter** method, or-- Invoke a method with the **MethodImplOptions.Synchronized** attribute. --Lock contention usually occurs when thread _A_ acquires a lock and thread _B_ tries to acquire the same lock before thread _A_ releases it. --### Loading code ([COLD]) --If the .NET Framework runtime is executing [unoptimized code](/cpp/build/profile-guided-optimizations) for the first time, the method name will contain **[COLD]**: --`mscorlib.ni![COLD]System.Reflection.CustomAttribute.IsDefined` --For each method, it should be displayed once during the process, at most. --If loading code takes a substantial amount of time for a request, it's the request's initiate execute of the unoptimized portion of the method. Consider using a warmup process that executes that portion of the code before your users access it. --### Send HTTP request --Methods such as **HttpClient.Send** indicate that the code is waiting for an HTTP request to be completed. --### Database operation --Methods such as **SqlCommand.Execute** indicate that the code is waiting for a database operation to finish. --### Waiting (AWAIT\_TIME) --**AWAIT\_TIME** indicates that the code is waiting for another task to finish. This delay occurs with the C# **AWAIT** statement. When the code does a C# **AWAIT**: -- The thread unwinds and returns control to the thread pool.-- There's no blocked thread waiting for the **AWAIT** to finish. --However, logically, the thread that did the **AWAIT** is "blocked", waiting for the operation to finish. The **AWAIT\_TIME** statement indicates the blocked time, waiting for the task to finish. --If the **AWAIT_TIME** appears to be in framework code instead of your code, the Profiler could be showing: -- The framework code used to execute the **AWAIT** -- Code used for recording telemetry about the **AWAIT** --You can uncheck the **Framework dependencies** checkbox at the top of the page to show only your code and make it easier to see where the **AWAIT** originates. --### Blocked time --**BLOCKED_TIME** indicates that the code is waiting for another resource to be available. For example, it might be waiting for: -- A synchronization object-- A thread to be available-- A request to finish--### Unmanaged Async --In order for async calls to be tracked across threads, .NET Framework emits ETW events and passes activity IDs between threads. Since unmanaged (native) code and some older styles of asynchronous code lack these events and activity IDs, the Profiler can't track the thread and functions running on the thread. This item is labeled **Unmanaged Async** in the call stack. Download the ETW file to use [PerfView](https://github.com/Microsoft/perfview/blob/master/documentation/Downloading.md) for more insight. --### CPU time --The CPU is busy executing the instructions. --### Disk time --The application is performing disk operations. --### Network time --The application is performing network operations. --### When column --The **When** column is a visualization of the variety of _inclusive_ samples collected for a node over time. The total range of the request is divided into 32 time buckets, where the node's inclusive samples accumulate. Each bucket is represented as a bar. The height of the bar represents a scaled value. For the following nodes, the bar represents the consumption of one of the resources during the bucket: -- Nodes marked **CPU_TIME** or **BLOCKED_TIME**.-- Nodes with an obvious relationship to consuming a resource (for example, a CPU, disk, or thread). --For these metrics, you can get a value of greater than 100% by consuming multiple resources. For example, if you use two CPUs during an interval on average, you get 200%. --## Next steps -Learn how to... -> [!div class="nextstepaction"] -> [Configure Profiler settings](./profiler-settings.md) ---[performance-blade]: ./media/profiler-overview/performance-blade-v2-examples.png -[trace-explorer]: ./media/profiler-overview/trace-explorer.png |
| azure-monitor | Profiler Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/profiler/profiler-overview.md | - Title: Analyze application performance traces with Application Insights Profiler -description: Identify the hot path in your web server code with a low-footprint profiler. -ms.contributor: charles.weininger - Previously updated : 08/15/2024----# Profile production applications in Azure with Application Insights Profiler --Diagnosing your application's performance issues can be difficult, especially when running on a production environment in the dynamic cloud. Slow responses in your application could be caused by infrastructure, framework, or application code handling the request in the pipeline. --With Application Insights Profiler, you can capture, identify, and view performance traces for your application running in Azure, regardless of the scenario. The Profiler trace process occurs automatically, at scale, and doesn't negatively affect your users. The Profiler identifies: --- The median, fastest, and slowest response times for each web request made by your customers.-- The "hot" code path spending the most time handling a particular web request.--Enable the Profiler on all your Azure applications to gather data with the following triggers: --- **Sampling trigger**: Starts Profiler randomly about once an hour for two minutes.-- **CPU trigger**: Starts Profiler when the CPU usage percentage is over 80 percent.-- **Memory trigger**: Starts Profiler when memory usage is above 80 percent.--Each of these triggers can be [configured, enabled, or disabled](./profiler-settings.md#trigger-settings). --## Sampling rate and overhead --Profiler randomly runs two minutes per hour on each virtual machine hosting applications with Profiler enabled. ---## Supported in Profiler --Profiler works with .NET applications deployed on the following Azure services. View specific instructions for enabling Profiler for each service type in the following links. --| Compute platform | .NET (>= 4.6) | .NET Core | -| - | - | | -| [Azure App Service](profiler.md) | Yes | Yes | -| [Azure Virtual Machines and Virtual Machine Scale Sets for Windows](profiler-vm.md) | Yes | Yes | -| [Azure Virtual Machines and Virtual Machine Scale Sets for Linux](profiler-aspnetcore-linux.md) | No | Yes | -| [Azure Cloud Services](profiler-cloudservice.md) | Yes | Yes | -| [Azure Container Instances for Windows](profiler-containers.md) | No | Yes | -| [Azure Container Instances for Linux](profiler-containers.md) | No | Yes | -| Kubernetes | No | Yes | -| [Azure Functions](./profiler-azure-functions.md) | Yes | Yes | -| [Azure Service Fabric](profiler-servicefabric.md) | Yes | Yes | --> [!NOTE] -> You can also use the [Java Profiler for Azure Monitor Application Insights](../app/java-standalone-profiler.md), currently in preview. --If you've enabled Profiler but aren't seeing traces, see the [Troubleshooting guide](profiler-troubleshooting.md). --## Limitations --- **Data retention**: The default data retention period is five days.-- **Profiling web apps**:- - Although you can use Profiler at no extra cost, your web app must be hosted in the basic tier of the Web Apps feature of Azure App Service, at minimum. - - You can attach only one profiler to each web app. - - Profiler on Linux is only supported on Windows-based web apps. --## Next steps -Learn how to enable Profiler on your Azure service: -- [Azure App Service](./profiler.md)-- [Azure Functions app](./profiler-azure-functions.md)-- [Azure Cloud Services](./profiler-cloudservice.md)-- [Azure Service Fabric app](./profiler-servicefabric.md)-- [Azure Virtual Machines](./profiler-vm.md)-- [ASP.NET Core application hosted in Linux on Azure App Service](./profiler-aspnetcore-linux.md)-- [ASP.NET Core application running in containers](./profiler-containers.md) |
| azure-monitor | Profiler Servicefabric | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/profiler/profiler-servicefabric.md | - Title: Enable Profiler for Azure Service Fabric applications -description: Profile live Azure Service Fabric apps with Application Insights. -- Previously updated : 08/16/2024---# Enable Profiler for Azure Service Fabric applications --Application Insights Profiler is included with Azure Diagnostics. You can install the Azure Diagnostics extension by using an Azure Resource Manager template (ARM template) for your Azure Service Fabric cluster. Get a [template that installs Azure Diagnostics on a Service Fabric cluster](https://github.com/Azure/azure-docs-json-samples/blob/master/application-insights/ServiceFabricCluster.json). --In this guide, you learn how to: -> [!div class="checklist"] -> - Add the Application Insights Profiler property to your ARM template. -> - Deploy your Service Fabric cluster with the Application Insights Profiler instrumentation key. -> - Enable Application Insights on your Service Fabric application. -> - Redeploy your Service Fabric cluster to enable Profiler. --## Prerequisites --- Profiler supports .NET Framework and .NET applications.- - Verify you're using [.NET Framework 4.6.2](/dotnet/framework/migration-guide/how-to-determine-which-versions-are-installed) or later. - - Confirm that the deployed OS is `Windows Server 2012 R2` or later. -- [An Azure Service Fabric managed cluster](/azure/service-fabric/quickstart-managed-cluster-portal).--## Create a deployment template --1. In your Service Fabric managed cluster, go to where you implemented the [ARM template](https://github.com/Azure/azure-docs-json-samples/blob/master/application-insights/ServiceFabricCluster.json). --1. Locate the `WadCfg` tags in the [Azure Diagnostics](../agents/diagnostics-extension-overview.md) extension in the deployment template file. --1. Add the following `SinksConfig` section as a child element of `WadCfg`. Replace the `ApplicationInsightsProfiler` property value with your own Application Insights instrumentation key: - - ```json - "settings": { - "WadCfg": { - "SinksConfig": { - "Sink": [ - { - "name": "MyApplicationInsightsProfilerSinkVMSS", - "ApplicationInsightsProfiler": "YOUR_APPLICATION_INSIGHTS_INSTRUMENTATION_KEY" - } - ] - }, - }, - } - ``` -- For information about how to add the Diagnostics extension to your deployment template, see [Use monitoring and diagnostics with a Windows VM and Azure Resource Manager templates](/azure/virtual-machines/extensions/diagnostics-template). --## Deploy your Service Fabric cluster --After you update `WadCfg` with your instrumentation key, deploy your Service Fabric cluster. --Application Insights Profiler is installed and enabled when the Azure Diagnostics extension is installed. --## Enable Application Insights on your Service Fabric application --For Profiler to collect profiles for your requests, your application must be tracking operations with Application Insights. --- **For stateless APIs**: See the instructions for [tracking requests for profiling](./profiler-trackrequests.md).-- **For tracking custom operations in other kinds of apps**: See [Track custom operations with Application Insights .NET SDK](../app/custom-operations-tracking.md).--After you enable Application Insights, redeploy your application. --## Generate traffic and view Profiler traces --1. Launch an [availability test](/previous-versions/azure/azure-monitor/app/monitor-web-app-availability) to generate traffic to your application. -1. Wait 10 to 15 minutes for traces to be sent to the Application Insights instance. -1. View the [Profiler traces](./profiler-overview.md) via the Application Insights instance in the Azure portal. --## Next steps --> [!div class="nextstepaction"] -> [Generate load and view Profiler traces](./profiler-data.md) - |
| azure-monitor | Profiler Settings | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/profiler/profiler-settings.md | - Title: Configure Application Insights Profiler | Microsoft Docs -description: Use the Application Insights Profiler settings pane to see Profiler status and start profiling sessions -ms.contributor: Charles.Weininger - Previously updated : 08/23/2024---# Configure Application Insights Profiler --After you enable Application Insights Profiler, you can: --- Start a new profiling session.-- Configure Profiler triggers.-- View recent profiling sessions.--To open the Application Insights Profiler settings pane, select **Performance** on the left pane on your Application Insights page. ---You can view Profiler traces across your Azure resources via two methods: --- The **Profiler** button:-- Select **Profiler**. -- :::image type="content" source="./media/profiler-overview/profiler-button-inline.png" alt-text="Screenshot that shows the Profiler button on the Performance pane." lightbox="media/profiler-settings/profiler-button.png"::: --- Operations:-- 1. Select an operation from the **Operation name** list. **Overall** is highlighted by default. - 1. Select **Profiler traces**. - - :::image type="content" source="./media/profiler-settings/operation-entry-inline.png" alt-text="Screenshot that shows selecting operation and Profiler traces to view all Profiler traces." lightbox="media/profiler-settings/operation-entry.png"::: -- 1. Select one of the requests from the list on the left. - 1. Select **Configure Profiler**. -- :::image type="content" source="./media/profiler-settings/configure-profiler-inline.png" alt-text="Screenshot that shows the overall selection and clicking Profiler traces to view all profiler traces." lightbox="media/profiler-settings/configure-profiler.png"::: --Within Profiler, you can configure and view Profiler. The **Application Insights Profiler** page has the following features. ---| Feature | Description | -|-|-| -**Profile now** | Starts profiling sessions for all apps that are linked to this instance of Application Insights. -**Triggers** | Allows you to configure triggers that cause Profiler to run. -**Recent profiling sessions** | Displays information about past profiling sessions, which you can sort by using the filters at the top of the page. --## Profile now --Select **Profile now** to start a profiling session on demand. When you select this link, all Profiler agents that are sending data to this Application Insights instance start to capture a profile. After 5 to 10 minutes, the profile session is shown in the list. --To manually trigger a Profiler session, you need, at minimum, *write* access on your role for the Application Insights component. In most cases, you get write access automatically. If you're having issues, you need the **Application Insights Component Contributor** subscription scope role added. For more information, see [Roles, permissions, and security in Azure Monitor](../roles-permissions-security.md). --## Trigger settings --Select **Triggers** to open the **Trigger Settings** pane that has the **CPU**, **Memory**, and **Sampling** trigger tabs. --### CPU or Memory triggers --You can set up a trigger to start profiling when the percentage of CPU or memory use hits the level you set. ---| Setting | Description | -|-|-| -On/Off button | On: Starts Profiler. Off: Doesn't start Profiler. -Memory threshold | When this percentage of memory is in use, Profiler is started. -Duration | Sets the length of time Profiler runs when triggered. -Cooldown | Sets the length of time Profiler waits before checking for the memory or CPU usage again after it's triggered. --### Sampling trigger --Unlike CPU or Memory triggers, an event doesn't trigger the Sampling trigger. Instead, it's triggered randomly to get a truly random sample of your application's performance. -You can: -- Turn this trigger off to disable random sampling.-- Set how often profiling occurs and the duration of the profiling session.---| Setting | Description | -|-|-| -On/Off button | On: Starts Profiler. Off: Doesn't start Profiler. -Sample rate | The rate at which Profiler can occur. </br> <ul><li>The **Normal** setting collects data 5% of the time, which is about 2 minutes per hour.</li><li>The **High** setting profiles 50% of the time.</li><li>The **Maximum** setting profiles 75% of the time.</li></ul> </br> We recommend the **Normal** setting for production environments. -Duration | Sets the length of time Profiler runs when triggered. --## Recent profiling sessions -This section of the **Profiler** page displays recent profiling session information. A profiling session represents the time taken by the Profiler agent while profiling one of the machines that hosts your application. Open the profiles from a session by selecting one of the rows. For each session, we show the following settings. --| Setting | Description | -|-|-| -Triggered by | How the session was started, either by a trigger, Profile now, or default sampling. -App Name | Name of the application that was profiled. -Machine Instance | Name of the machine the Profiler agent ran on. -Timestamp | Time when the profile was captured. -CPU % | Percentage of CPU used while Profiler was running. -Memory % | Percentage of memory used while Profiler was running. --## Next steps --[Enable Profiler and view traces](profiler.md?toc=/azure/azure-monitor/toc.json) --[profiler-on-demand]: ./media/profiler-settings/profiler-on-demand.png -[performance-blade]: ./media/profiler-settings/performance-blade.png -[configure-profiler-page]: ./media/profiler-settings/configureBlade.png -[trigger-settings-flyout]: ./media/profiler-settings/trigger-central-p-u.png -[create-performance-test]: ./media/profiler-settings/new-performance-test.png -[configure-performance-test]: ./media/profiler-settings/configure-performance-test.png -[load-test-queued]: ./media/profiler-settings/load-test-queued.png -[load-test-in-progress]: ./media/profiler-settings/load-test-in-progress.png -[enable-app-insights]: ./media/profiler-settings/enable-app-insights-blade-01.png -[update-site-extension]: ./media/profiler-settings/update-site-extension-01.png -[change-and-save-appinsights]: ./media/profiler-settings/change-and-save-app-insights-01.png -[check-for-extension-update]: ./media/profiler-settings/check-extension-update-01.png -[profiler-timeout]: ./media/profiler-settings/profiler-time-out.png |
| azure-monitor | Profiler Trackrequests | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/profiler/profiler-trackrequests.md | - Title: Write code to track requests with Application Insights | Microsoft Docs -description: Write code to track requests with Application Insights so you can get profiles for your requests. -- Previously updated : 08/19/2024----# Write code to track requests with Application Insights --Application Insights needs to track requests for your application to provide profiles for your application on the **Performance** page in the Azure portal. For applications built on already-instrumented frameworks (like ASP.NET and ASP.NET Core), Application Insights can automatically track requests. --For other applications (like Azure Cloud Services worker roles and Azure Service Fabric stateless APIs), you need to track requests with code that tells Application Insights where your requests begin and end. Requests telemetry is then sent to Application Insights, which you can view on the **Performance** page. Profiles are collected for those requests. --To manually track requests: --1. Early in the application lifetime, add the following code: -- ```csharp - using Microsoft.ApplicationInsights.Extensibility; - ... - // Replace with your own Application Insights instrumentation key. - TelemetryConfiguration.Active.InstrumentationKey = "00000000-0000-0000-0000-000000000000"; - ``` - - For more information about this global instrumentation key configuration, see [Use Service Fabric with Application Insights](https://github.com/Azure-Samples/service-fabric-dotnet-getting-started/blob/dev/appinsights/ApplicationInsights.md). --1. For any piece of code that you want to instrument, add a `StartOperation<RequestTelemetry>` **using** statement around it, as shown in the following example: -- ```csharp - using Microsoft.ApplicationInsights; - using Microsoft.ApplicationInsights.DataContracts; - ... - var client = new TelemetryClient(); - ... - using (var operation = client.StartOperation<RequestTelemetry>("Insert_Your_Custom_Event_Unique_Name")) - { - // ... Code I want to profile. - } - ``` --1. Calling `StartOperation<RequestTelemetry>` within another `StartOperation<RequestTelemetry>` scope isn't supported. You can use `StartOperation<DependencyTelemetry>` in the nested scope instead. For example: - - ```csharp - using (var getDetailsOperation = client.Operation<RequestTelemetry>("GetProductDetails")) - { - try - { - ProductDetail details = new ProductDetail() { Id = productId }; - getDetailsOperation.Telemetry.Properties["ProductId"] = productId.ToString(); - - // By using DependencyTelemetry, 'GetProductPrice' is correctly linked as part of the 'GetProductDetails' request. - using (var getPriceOperation = client.StartOperation<DependencyTelemetry>("GetProductPrice")) - { - double price = await _priceDataBase.GetAsync(productId); - if (IsTooCheap(price)) - { - throw new PriceTooLowException(productId); - } - details.Price = price; - } - - // Similarly, note how 'GetProductReviews' doesn't establish another RequestTelemetry. - using (var getReviewsOperation = client.StartOperation<DependencyTelemetry>("GetProductReviews")) - { - details.Reviews = await _reviewDataBase.GetAsync(productId); - } - - getDetailsOperation.Telemetry.Success = true; - return details; - } - catch(Exception ex) - { - getDetailsOperation.Telemetry.Success = false; - - // This exception gets linked to the 'GetProductDetails' request telemetry. - client.TrackException(ex); - throw; - } - } - ``` ---## Next steps --Troubleshoot the [Application Insights Profiler](./profiler-troubleshooting.md). |
| azure-monitor | Profiler Troubleshooting | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/profiler/profiler-troubleshooting.md | - Title: Troubleshoot Application Insights Profiler -description: Walk through troubleshooting steps and information to enable and use Application Insights Profiler. - Previously updated : 08/19/2024----# Troubleshoot Application Insights Profiler --This article presents troubleshooting steps and information to enable you to use Application Insights Profiler. --## Are you using the appropriate Profiler endpoint? --Currently, the only regions that require endpoint modifications are [Azure Government](../../azure-government/compare-azure-government-global-azure.md#application-insights) and [Microsoft Azure operated by 21Vianet](/azure/china/resources-developer-guide). --|App setting | US Government Cloud | China Cloud | -|||-| -|ApplicationInsightsProfilerEndpoint | `https://profiler.monitor.azure.us` | `https://profiler.monitor.azure.cn` | -|ApplicationInsightsEndpoint | `https://dc.applicationinsights.us` | `https://dc.applicationinsights.azure.cn` | --## Is your app running on the right version? --Profiler is supported on the [.NET Framework later than 4.6.2](https://dotnet.microsoft.com/download/dotnet-framework). --If your web app is an ASP.NET Core application, it must be running on the [latest supported ASP.NET Core runtime](https://dotnet.microsoft.com/download/dotnet/8.0). --## Are you using the right Azure service plan? --Profiler isn't currently supported on free or shared app service plans. Upgrade to one of the basic plans for Profiler to start working. --> [!NOTE] -> The Azure Functions consumption plan isn't supported. See [Profile live Azure Functions app with Application Insights](./profiler-azure-functions.md). --## Are you searching for Profiler data within the right time frame? --If the data you're trying to view is older than two weeks, try limiting your time filter and try again. Traces are deleted after seven days. --## Are you aware of the Profiler sampling rate and overhead? --Profiler randomly runs two minutes per hour on each virtual machine hosting applications with Profiler enabled. ---## Can you access the gateway? --Check that a firewall or proxies aren't blocking your access to [this webpage](https://gateway.azureserviceprofiler.net). --## Are you seeing timeouts or do you need to check to see if Profiler is running? --Profiling data is uploaded only when it can be attached to a request that happened while Profiler was running. Profiler collects data for two minutes each hour. You can also trigger Profiler by [starting a profiling session](./profiler-settings.md#profile-now). --Profiler writes trace messages and custom events to your Application Insights resource. You can use these events to see how Profiler is running. --Search for trace messages and custom events sent by Profiler to your Application Insights resource. --1. In your Application Insights resource, select **Search** from the top menu. -- :::image type="content" source="./media/profiler-troubleshooting/search-trace-messages.png" lightbox="./media/profiler-troubleshooting/search-trace-messages.png" alt-text="Screenshot that shows selecting the Search button from the Application Insights resource."::: --1. Use the following search string to find the relevant data: -- ``` - stopprofiler OR startprofiler OR upload OR ServiceProfilerSample - ``` -- :::image type="content" source="./media/profiler-troubleshooting/search-results.png" lightbox="./media/profiler-troubleshooting/search-results.png" alt-text="Screenshot that shows the search results from aforementioned search string."::: -- The preceding search results include two examples of searches from two AI resources: -- - If the application isn't receiving requests while Profiler is running, the message explains that the upload was canceled because of no activity. -- - Profiler started and sent custom events when it detected requests that happened while Profiler was running. If the `ServiceProfilerSample` custom event is displayed, it means that a profile was captured and is available in the **Application Insights Performance** pane. -- If no records are displayed, Profiler isn't running or took too long to respond. Make sure [Profiler is enabled on your Azure service](./profiler.md). --## Profiler is on, but no traces captured --Even when the Profiler is enabled, it may not capture or upload traces, especially in these situations: --1. **No incoming requests to your application:** - You can manually invoke your application or create an [availability test](../app/availability.md), or a [load test](../../load-testing/overview-what-is-azure-load-testing.md). --1. **No incoming telemetry acknowledged by Application Insights:** - - If there is traffic coming to your application: validate that there are incoming requests showing in Application Insights [Live Metrics](../app/live-stream.md). - - If the `Incoming Requests` charts are empty (no data or showing zero): [troubleshoot Application Insights](/troubleshoot/azure/azure-monitor/app-insights/telemetry/asp-net-troubleshoot-no-data). - - If you are hosting your .NET application on Azure App Service: [try the App Service .NET troubleshooting steps](../app/azure-web-apps-net.md#troubleshooting). --1. **Profiler setting for Sampling is turned off:** - If still no profiler traces are available, check the Profiler Sampling setting. - 1. Open **Application Insights** > **Performance** blade. - 1. Click on **Profiler**. - 1. Click on the **Triggers** button. - 1. In the Trigger Settings, ensure the **Sampling** toggle is on. --1. **Still no traces uploaded?** - [Create a support request](https://ms.portal.azure.com/#blade/Microsoft_Azure_Support/HelpAndSupportBlade/overview?DMC=troubleshoot), or ask [Azure community support](/answers/products/azure?product=all). You can also submit product feedback to [Azure feedback community](https://feedback.azure.com/d365community). --## Double counting in parallel threads --When two or more parallel threads are associated with a request, the total time metric in the stack viewer might be more than the duration of the request. In that case, the total thread time is more than the actual elapsed time. --For example, one thread might be waiting on the other to be completed. The viewer tries to detect this situation and omits the uninteresting wait. In doing so, it errs on the side of displaying too much information rather than omitting what might be critical information. --When you see parallel threads in your traces, determine which threads are waiting so that you can identify the hot path for the request. Usually, the thread that quickly goes into a wait state is waiting on the other threads. Concentrate on the other threads and ignore the time in the waiting threads. --## Troubleshoot Profiler on your specific Azure service --The following sections walk you through troubleshooting steps for using Profiler on Azure App Service or Azure Cloud Services. --### Azure App Service --For Profiler to work properly, make sure: --- Your web app has [Application Insights enabled](./profiler.md) with the [right settings](./profiler.md#for-application-insights-and-app-service-in-different-subscriptions).--- The [**ApplicationInsightsProfiler3** WebJob]() is running. To check the webjob:- 1. Go to [Kudu](https://github.com/projectkudu/kudu/wiki/Accessing-the-kudu-service). In the Azure portal: - 1. In your App Service instance, select **Advanced Tools** on the left pane. - 1. Select **Go**. - 1. On the top menu, select **Tools** > **WebJobs dashboard**. - The **WebJobs** pane opens. -- If **ApplicationInsightsProfiler3** doesn't show up, restart your App Service application. -- :::image type="content" source="./media/profiler-troubleshooting/profiler-web-job.png" lightbox="./media/profiler-troubleshooting/profiler-web-job.png" alt-text="Screenshot that shows the WebJobs pane, which displays the name, status, and last runtime of jobs."::: -- 1. To view the details of the WebJob, including the log, select the **ApplicationInsightsProfiler3** link. - The **Continuous WebJob Details** pane opens. -- :::image type="content" source="./media/profiler-troubleshooting/profiler-web-job-log.png" lightbox="./media/profiler-troubleshooting/profiler-web-job-log.png" alt-text="Screenshot that shows the Continuous WebJob Details pane."::: --If Profiler still isn't working for you, download the log and [submit an Azure support ticket](https://azure.microsoft.com/support/). --#### Check the Diagnostic Services site extension status page --If you enabled Profiler through the [Application Insights pane](profiler.md) in the portal, it's managed by the Diagnostic Services site extension. You can check the status page of this extension by going to -`https://{site-name}.scm.azurewebsites.net/DiagnosticServices`. --> [!NOTE] -> The domain of the status page link varies depending on the cloud. This domain is the same as the Kudu management site for App Service. --The status page shows the installation state of the Profiler and [Snapshot Debugger](../snapshot-debugger/snapshot-debugger.md) agents. If there was an unexpected error, it appears along with steps on how to fix it. --You can use the Kudu management site for App Service to get the base URL of this status page: --1. Open your App Service application in the Azure portal. -1. Select **Advanced Tools**. -1. Select **Go**. -1. On the Kudu management site: - 1. Append `/DiagnosticServices` to the URL. - 1. Select Enter. --It ends like `https://<kudu-url>/DiagnosticServices`. --A status page appears similar to the following example. ---> [!NOTE] -> Codeless installation of Application Insights Profiler follows the .NET Core support policy. For more information about supported runtimes, see [.NET Core support policy](https://dotnet.microsoft.com/platform/support/policy/dotnet-core). --#### Manual installation --When you configure Profiler, updates are made to the web app's settings. If necessary, you can [apply the updates manually](./profiler.md#verify-the-always-on-setting-is-enabled). --#### Too many active profiling sessions --In Azure App Service, there's a limit of only **one profiling session at a time**. This limit is enforced at the VM level across all applications and deployment slots running in an App Service Plan. -This limit applies equally to profiling sessions started via *Diagnose and solve problems*, Kudu, and Application Insights Profiler. -If Profiler tries to start a session when another is already running, an error is logged in the Application Log and also the continuous WebJob log for ApplicationInsightsProfiler3. --You may see one of the following messages in the logs: --- `Microsoft.ServiceProfiler.Exceptions.TooManyETWSessionException`-- `Error: StartProfiler failed. Details: System.Runtime.InteropServices.COMException (0xE111005E): Exception from HRESULT: 0xE111005E`--The error code 0xE111005E indicates that a profiling session couldn't start because another session is already running. --To avoid the error, move some web apps to a different App Service Plan or disable Profiler on some of the applications. If you use deployment slots, be sure to stop any unused slots. --#### Deployment error: Directory Not Empty 'D:\\home\\site\\wwwroot\\App_Data\\jobs' --If you're redeploying your web app to a Web Apps resource with Profiler enabled, you might see the following message: --"Directory Not Empty 'D:\\home\\site\\wwwroot\\App_Data\\jobs'" --This error occurs if you run Web Deploy from scripts or from Azure Pipelines. Resolve it by adding the following deployment parameters to the Web Deploy task: --``` --skip:Directory='.*\\App_Data\\jobs\\continuous\\ApplicationInsightsProfiler.*' -skip:skipAction=Delete,objectname='dirPath',absolutepath='.*\\App_Data\\jobs\\continuous$' -skip:skipAction=Delete,objectname='dirPath',absolutepath='.*\\App_Data\\jobs$' -skip:skipAction=Delete,objectname='dirPath',absolutepath='.*\\App_Data$'-``` --These parameters delete the folder used by Application Insights Profiler and unblock the redeploy process. They don't affect the Profiler instance that's currently running. --#### Is Application Insights Profiler running? --Profiler runs as a continuous WebJob in the web app. You can open the web app resource in the [Azure portal](https://portal.azure.com). In the **WebJobs** pane, check the status of **ApplicationInsightsProfiler**. If it isn't running, open **Logs** to get more information. --### VMs and Azure Cloud Services --To see whether Profiler is configured correctly by Azure Diagnostics: --1. Verify that the content of the Azure Diagnostics configuration deployed is what you expect. --1. Make sure Azure Diagnostics passes the proper iKey on the Profiler command line. --1. Check the Profiler log file to see whether Profiler ran but returned an error. --To check the settings that were used to configure Azure Diagnostics: --1. Sign in to the virtual machine (VM). --1. Open the log file at this location. The plug-in version might be newer on your machine. -- For VMs: - ``` - c:\WindowsAzure\logs\Plugins\Microsoft.Azure.Diagnostics.PaaSDiagnostics\1.11.3.12\DiagnosticsPlugin.log - ``` -- For Azure Cloud - ``` - c:\logs\Plugins\Microsoft.Azure.Diagnostics.PaaSDiagnostics\1.11.3.12\DiagnosticsPlugin.log - ``` --1. In the file, search for the string `WadCfg` to find the settings that were passed to the VM to configure Azure Diagnostics. --1. Check to see whether the iKey used by the Profiler sink is correct. --1. Check the command line that starts Profiler. The command line arguments are in the following file (the drive could be `c:` or `d:` and the directory might be hidden): -- For VMs: - ``` - C:\ProgramData\ApplicationInsightsProfiler\config.json - ``` -- For Azure Cloud - ``` - D:\ProgramData\ApplicationInsightsProfiler\config.json - ``` --1. Make sure that the iKey on the Profiler command line is correct. --1. By using the path found in the preceding *config.json* file, check the Profiler log file, called `BootstrapN.log`. It displays: -- - The debug information that indicates the settings that Profiler is using. - - Status and error messages from Profiler. -- You can find the file: -- For VMs: - ``` - C:\WindowsAzure\Logs\Plugins\Microsoft.Azure.Diagnostics.IaaSDiagnostics\1.17.0.6\ApplicationInsightsProfiler - ``` -- For Azure Cloud - ``` - C:\Logs\Plugins\Microsoft.Azure.Diagnostics.IaaSDiagnostics\1.17.0.6\ApplicationInsightsProfiler - ``` --1. If Profiler is running while your application is receiving requests, the following message appears: "Activity detected from iKey." --1. When the trace is being uploaded, the following message appears: "Start to upload trace." --### Edit network proxy or firewall rules --If your application connects to the internet via a proxy or a firewall, you might need to update the rules to communicate with Profiler. --The IPs used by Application Insights Profiler are included in the Azure Monitor service tag. For more information, see [Service tags documentation](../../virtual-network/service-tags-overview.md). --## Support --If you still need help, submit a support ticket in the Azure portal. Include the correlation ID from the error message. |
| azure-monitor | Profiler Vm | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/profiler/profiler-vm.md | - Title: Enable Profiler for web apps on an Azure virtual machine -description: Profile web apps running on an Azure virtual machine or a virtual machine scale set by using Application Insights Profiler - Previously updated : 08/19/2024----# Enable Profiler for web apps on an Azure virtual machine ---In this article, you learn how to run Application Insights Profiler on your Azure virtual machine (VM) or Azure virtual machine scale set via three different methods: --- Visual Studio and Azure Resource Manager-- PowerShell-- Azure Resource Explorer--Select your preferred method tab to: --In this guide, you learn how to: -> [!div class="checklist"] -> - Configure the Azure Diagnostics extension to run Profiler. -> - Install the Application Insights SDK on a VM. -> - Deploy your application. -> - View Profiler traces via the Application Insights instance in the Azure portal. --## Prerequisites --- A functioning [ASP.NET Core application](/aspnet/core/getting-started).-- An [Application Insights resource](../app/create-workspace-resource.md).-- To review the Azure Resource Manager templates (ARM templates) for the Azure Diagnostics extension:- - [VM](https://github.com/Azure/azure-docs-json-samples/blob/master/application-insights/WindowsVirtualMachine.json) - - [Virtual machine scale set](https://github.com/Azure/azure-docs-json-samples/blob/master/application-insights/WindowsVirtualMachineScaleSet.json) --## Add the Application Insights SDK to your application --1. Open your ASP.NET core project in Visual Studio. --1. Select **Project** > **Add Application Insights Telemetry**. --1. Select **Azure Application Insights** > **Next**. --1. Select the subscription where your Application Insights resource lives and select **Next**. --1. Select where to save the connection string and select **Next**. --1. Select **Finish**. --> [!NOTE] -> For full instructions, including how to enable Application Insights on your ASP.NET Core application without Visual Studio, see the [Application Insights for ASP.NET Core applications](../app/asp-net-core.md). --## Confirm the latest stable release of the Application Insights SDK --1. Go to **Project** > **Manage NuGet Packages**. --1. Select **Microsoft.ApplicationInsights.AspNetCore**. --1. On the side pane, select the latest version of the SDK from the dropdown. --1. Select **Update**. -- :::image type="content" source="../app/media/asp-net-core/update-nuget-package.png" alt-text="Screenshot that shows where to select the Application Insights package for update."::: --## Enable Profiler --You can enable Profiler by any of three ways: --- Within your ASP.NET Core application by using an Azure Resource Manager template and Visual Studio. **Recommended.**-- By using a PowerShell command via the Azure CLI.-- By using Azure Resource Explorer.--# [Visual Studio and ARM template](#tab/vs-arm) --### Install the Azure Diagnostics extension --1. Choose which ARM template to use: - - [VM](https://github.com/Azure/azure-docs-json-samples/blob/master/application-insights/WindowsVirtualMachine.json) - - [Virtual machine scale set](https://github.com/Azure/azure-docs-json-samples/blob/master/application-insights/WindowsVirtualMachineScaleSet.json) --1. In the template, locate the resource of type `extension`. --1. In Visual Studio, go to the `arm.json` file in your ASP.NET Core application that was added when you installed the Application Insights SDK. --1. Add the resource type `extension` from the template to the `arm.json` file to set up a VM or virtual machine scale set with Azure Diagnostics. --1. Within the `WadCfg` tag, add your Application Insights instrumentation key to `MyApplicationInsightsProfilerSink`. -- - ```json - "WadCfg": { - "SinksConfig": { - "Sink": [ - { - "name": "MyApplicationInsightsProfilerSink", - "ApplicationInsightsProfiler": "YOUR_APPLICATION_INSIGHTS_INSTRUMENTATION_KEY" - } - ] - } - } - ``` --1. Deploy your application. --# [PowerShell](#tab/powershell) --The following PowerShell commands are an approach for existing VMs that touch only the Azure Diagnostics extension. --> [!NOTE] -> If you deploy the VM again, the sink will be lost. You need to update the config you use when you deploy the VM to preserve this setting. --### Install Application Insights via the Azure Diagnostics config --1. Export the currently deployed Azure Diagnostics config to a file: -- ```powershell - $ConfigFilePath = [IO.Path]::GetTempFileName() - ``` --1. Add the Application Insights Profiler sink to the config returned by the following command: -- ```powershell - (Get-AzVMDiagnosticsExtension -ResourceGroupName "YOUR_RESOURCE_GROUP" -VMName "YOUR_VM").PublicSettings | Out-File -Verbose $ConfigFilePath - ``` -- Application Insights Profiler `WadCfg`: - - ```json - "WadCfg": { - "SinksConfig": { - "Sink": [ - { - "name": "MyApplicationInsightsProfilerSink", - "ApplicationInsightsProfiler": "YOUR_APPLICATION_INSIGHTS_INSTRUMENTATION_KEY" - } - ] - } - } - ``` - -1. Run the following command to pass the updated config to the `Set-AzVMDiagnosticsExtension` command. -- ```powershell - Set-AzVMDiagnosticsExtension -ResourceGroupName "YOUR_RESOURCE_GROUP" -VMName "YOUR_VM" -DiagnosticsConfigurationPath $ConfigFilePath - ``` -- > [!NOTE] - > `Set-AzVMDiagnosticsExtension` might require the `-StorageAccountName` argument. If your original diagnostics configuration had the `storageAccountName` property in the `protectedSettings` section (which isn't downloadable), be sure to pass the same original value you had in this cmdlet call. --### IIS Http Tracing feature --If the intended application is running through [IIS](https://www.microsoft.com/web/downloads/platform.aspx), enable the `IIS Http Tracing` Windows feature: --1. Establish remote access to the environment. --1. Use the [Add Windows features](/iis/configuration/system.webserver/tracing/) window, or run the following command in PowerShell (as administrator): -- ```powershell - Enable-WindowsOptionalFeature -FeatureName IIS-HttpTracing -Online -All - ``` -- If establishing remote access is a problem, you can use the [Azure CLI](/cli/azure/get-started-with-azure-cli) to run the following command: -- ```cli - az vm run-command invoke -g MyResourceGroupName -n MyVirtualMachineName --command-id RunPowerShellScript --scripts "Enable-WindowsOptionalFeature -FeatureName IIS-HttpTracing -Online -All" - ``` --1. Deploy your application. --# [Azure Resource Explorer](#tab/azure-resource-explorer) --### Set the Profiler sink by using Azure Resource Explorer --Because the Azure portal doesn't provide a way to set the Application Insights Profiler sink, you can use [Azure Resource Explorer](https://resources.azure.com) to set the sink. --> [!NOTE] -> If you deploy the VM again, the sink will be lost. You need to update the config you use when you deploy the VM to preserve this setting. --1. Verify that the Microsoft Azure Diagnostics extension is installed by viewing the extensions installed for your virtual machine. -- :::image type="content" source="./media/profiler-vm/wad-extension.png" alt-text="Screenshot that shows checking if the WAD extension is installed."::: --1. Find the VM Diagnostics extension for your VM: - 1. Go to [Azure Resource Explorer](https://resources.azure.com). - 1. Expand **subscriptions** and find the subscription that holds the resource group with your VM. - 1. Drill down to your VM extensions by selecting your resource group. Then select **Microsoft.Compute** > **virtualMachines** > **[your virtual machine]** > **extensions**. -- :::image type="content" source="./media/profiler-vm/azure-resource-explorer.png" alt-text="Screenshot that shows going to WAD config in Azure Resource Explorer."::: --1. Add the Application Insights Profiler sink to the `SinksConfig` node under `WadCfg`. If you don't already have a `SinksConfig` section, you might need to add one. To add the sink: -- - Specify the proper Application Insights iKey in your settings. - - Switch the Explorer mode to **Read/Write** in the upper-right corner. - - Select **Edit**. -- :::image type="content" source="./media/profiler-vm/resource-explorer-sinks-config.png" alt-text="Screenshot that shows adding the Application Insights Profiler sink."::: -- ```json - "WadCfg": { - "SinksConfig": { - "Sink": [ - { - "name": "MyApplicationInsightsProfilerSink", - "ApplicationInsightsProfiler": "YOUR_APPLICATION_INSIGHTS_INSTRUMENTATION_KEY" - } - ] - } - } - ``` --1. After you've finished editing the config, select **PUT**. --1. If the `put` is successful, a green check mark appears in the middle of the screen. -- :::image type="content" source="./media/profiler-vm/resource-explorer-put.png" alt-text="Screenshot that shows sending the PUT request to apply changes."::: ----## Can Profiler run on on-premises servers? --Currently, Application Insights Profiler isn't supported for on-premises servers. --## Next steps --> [!div class="nextstepaction"] -> [Generate load and view Profiler traces](./profiler-data.md) |
| azure-monitor | Profiler | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/profiler/profiler.md | - Title: Enable Profiler for Azure App Service apps | Microsoft Docs -description: Profile live apps on Azure App Service with Application Insights Profiler. - Previously updated : 08/15/2024----# Enable Profiler for Azure App Service apps --[Application Insights Profiler](./profiler-overview.md) is preinstalled as part of the Azure App Service runtime. You can run Profiler on ASP.NET and ASP.NET Core apps running on App Service by using the Basic service tier or higher. --Codeless installation of Application Insights Profiler: -- Follows [the .NET Core support policy](https://dotnet.microsoft.com/platform/support/policy/dotnet-core).-- Is only supported on *Windows-based* web apps.--To enable Profiler on Linux, walk through the [ASP.NET Core Azure Linux web apps instructions](profiler-aspnetcore-linux.md). --## Prerequisites --- An [Azure App Service ASP.NET/ASP.NET Core app](../../app-service/quickstart-dotnetcore.md).-- An [Application Insights resource](/previous-versions/azure/azure-monitor/app/create-new-resource) connected to your App Service app.--## Verify the "Always on" setting is enabled --1. In the Azure portal, go to your App Service instance. -1. Under **Settings** on the left pane, select **Configuration**. -- :::image type="content" source="./media/profiler/configuration-menu.png" alt-text="Screenshot that shows selecting Configuration on the left pane."::: --1. Select the **General settings** tab. -1. Verify that **Always on** > **On** is selected. -- :::image type="content" source="./media/profiler/always-on.png" alt-text="Screenshot that shows the General tab on the Configuration pane showing that Always On is enabled."::: --1. Select **Save** if you made changes. --## Enable Application Insights and Profiler --You can enable Profiler either when: -- [Your Application Insights resource and App Service resource are in the same subscription](#for-application-insights-and-app-service-in-the-same-subscription), or-- [Your Application Insights resource and App Service resource are in separate subscriptions.](#for-application-insights-and-app-service-in-different-subscriptions)--### For Application Insights and App Service in the same subscription --If your Application Insights resource is in the same subscription as your instance of App Service: --1. Under **Settings** on the left pane, select **Application Insights**. -- :::image type="content" source="./media/profiler/app-insights-menu.png" alt-text="Screenshot that shows selecting Application Insights on the left pane."::: --1. Under **Application Insights**, select **Enable**. -1. Verify that you connected an Application Insights resource to your app. -- :::image type="content" source="./media/profiler/enable-app-insights.png" alt-text="Screenshot that shows enabling Application Insights on your app."::: --1. Scroll down and select the **.NET** or **.NET Core** tab, depending on your app. -1. Verify that **Collection level** > **Recommended** is selected. -1. Under **Profiler**, select **On**. -- If you chose the **Basic** collection level earlier, the Profiler setting is disabled. -1. Select **Apply** > **Yes** to confirm. -- :::image type="content" source="./media/profiler/enable-profiler.png" alt-text="Screenshot that shows enabling Profiler on your app."::: --### For Application Insights and App Service in different subscriptions --If your Application Insights resource is in a different subscription from your instance of App Service, you need to enable Profiler manually by creating app settings for your App Service instance. You can automate the creation of these settings by using a template or other means. Here are the settings you need to enable Profiler. --|App setting | Value | -||-| -|APPINSIGHTS_INSTRUMENTATIONKEY | iKey for your Application Insights resource | -|APPINSIGHTS_PROFILERFEATURE_VERSION | 1.0.0 | -|DiagnosticServices_EXTENSION_VERSION | ~3 | --Set these values by using: -- [Azure Resource Manager templates](../app/azure-web-apps-net-core.md#app-service-application-settings-with-azure-resource-manager)-- [Azure PowerShell](/powershell/module/az.websites/set-azwebapp)-- [Azure CLI](/cli/azure/webapp/config/appsettings)--## Enable Profiler for regional clouds --Currently, the only regions that require endpoint modifications are [Azure Government](../../azure-government/compare-azure-government-global-azure.md#application-insights) and [Microsoft Azure operated by 21Vianet](/azure/china/resources-developer-guide). --|App setting | US Government Cloud | China Cloud | -|||-| -|ApplicationInsightsProfilerEndpoint | `https://profiler.monitor.azure.us` | `https://profiler.monitor.azure.cn` | -|ApplicationInsightsEndpoint | `https://dc.applicationinsights.us` | `https://dc.applicationinsights.azure.cn` | --<a name='enable-azure-active-directory-authentication-for-profile-ingestion'></a> --## Enable Microsoft Entra authentication for profile ingestion --Application Insights Profiler supports Microsoft Entra authentication for profile ingestion. For all profiles of your application to be ingested, your application must be authenticated and provide the required application settings to the Profiler agent. --Profiler only supports Microsoft Entra authentication when you reference and configure Microsoft Entra ID by using the [Application Insights SDK](../app/asp-net-core.md#configure-the-application-insights-sdk) in your application. --To enable Microsoft Entra ID for profile ingestion: --1. Create and add the managed identity to authenticate against your Application Insights resource to your App Service: -- 1. [System-assigned managed identity documentation](../../app-service/overview-managed-identity.md?tabs=portal%2chttp#add-a-system-assigned-identity) -- 1. [User-assigned managed identity documentation](../../app-service/overview-managed-identity.md?tabs=portal%2chttp#add-a-user-assigned-identity) --1. [Configure and enable Microsoft Entra ID](../app/azure-ad-authentication.md?tabs=net#configure-and-enable-azure-ad-based-authentication) in your Application Insights resource. --1. Add the following application setting to let the Profiler agent know which managed identity to use. -- - For system-assigned identity: -- | App setting | Value | - | -- | | - | APPLICATIONINSIGHTS_AUTHENTICATION_STRING | `Authorization=AAD` | -- - For user-assigned identity: -- | App setting | Value | - | - | -- | - | APPLICATIONINSIGHTS_AUTHENTICATION_STRING | `Authorization=AAD;ClientId={Client id of the User-Assigned Identity}` | --## Disable Profiler --To stop or restart Profiler for an individual app's instance: --1. Under **Settings** on the left pane, select **WebJobs**. -- :::image type="content" source="./media/profiler/web-jobs-menu.png" alt-text="Screenshot that shows selecting web jobs on the left pane."::: --1. Select the webjob named `ApplicationInsightsProfiler3`. --1. Select **Stop**. -- :::image type="content" source="./media/profiler/stop-web-job.png" alt-text="Screenshot that shows selecting stop for stopping the webjob."::: --1. Select **Yes** to confirm. --We recommend that you have Profiler enabled on all your apps to discover any performance issues as early as possible. --You can delete Profiler's files when you use WebDeploy to deploy changes to your web application. You can prevent the deletion by excluding the *App_Data* folder from being deleted during deployment. --## Next steps -- Learn how to [generate load and view Profiler traces](./profiler-data.md)-- Learn how to use the [Code Optimizations feature](../insights/code-optimizations.md) alongside the Application Insights Profiler |
| azure-monitor | Resource Graph Samples | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/resource-graph-samples.md | - Title: Azure Resource Graph sample queries for Azure Monitor -description: Sample Azure Resource Graph queries for Azure Monitor showing the use of resource types and tables to access Azure Monitor-related resources and properties. Previously updated : 08/09/2023------# Azure Resource Graph sample queries for Azure Monitor --This page is a collection of [Azure Resource Graph](../governance/resource-graph/overview.md) sample queries -for Azure Monitor. --## Azure Monitor ---## Next steps --- Learn more about the [query language](../governance/resource-graph/concepts/query-language.md).-- Learn more about how to [explore resources](../governance/resource-graph/concepts/explore-resources.md). |
| azure-monitor | Resource Manager Samples | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/resource-manager-samples.md | - Title: Resource Manager template samples for Azure Monitor -description: Deploy and configure Azure Monitor features by using Resource Manager templates. ---- Previously updated : 08/09/2023---# Resource Manager template samples for Azure Monitor --You can deploy and configure Azure Monitor at scale by using [Azure Resource Manager templates](../azure-resource-manager/templates/syntax.md). This article lists sample templates for Azure Monitor features. You can modify these samples for your particular requirements and deploy them by using any standard method for deploying Resource Manager templates. --## Deploy the sample templates --The basic steps to use one of the template samples are: --1. Copy the template and save it as a JSON file. -2. Modify the parameters for your environment and save the JSON file. -3. Deploy the template by using [any deployment method for Resource Manager templates](../azure-resource-manager/templates/deploy-portal.md). --Following are basic steps for using different methods to deploy the sample templates. Follow the included links for more details. --## [Azure portal](#tab/portal) --For more details, see [Deploy resources with ARM templates and Azure portal](../azure-resource-manager/templates/deploy-portal.md). --1. In the Azure portal, select **Create a resource**, search for **template**. and then select **Template deployment**. -2. Select **Create**. -4. Select **Build your own template in editor**. -5. Click **Load file** and select your template file. -6. Click **Save**. -7. Fill in parameter values. -8. Click **Review + Create**. --## [CLI](#tab/cli) --For more details, see [How to use Azure Resource Manager (ARM) deployment templates with Azure CLI](../azure-resource-manager/templates/deploy-cli.md). --```azurecli -az login -az deployment group create \ - --name AzureMonitorDeployment \ - --resource-group <resource-group> \ - --template-file azure-monitor-deploy.json \ - --parameters azure-monitor-deploy.parameters.json -``` --## [PowerShell](#tab/powershell) --For more details, see [Deploy resources with ARM templates and Azure PowerShell](../azure-resource-manager/templates/deploy-powershell.md). --```powershell -Connect-AzAccount -Select-AzSubscription -SubscriptionName <subscription> -New-AzResourceGroupDeployment -Name AzureMonitorDeployment -ResourceGroupName <resource-group> -TemplateFile azure-monitor-deploy.json -TemplateParameterFile azure-monitor-deploy.parameters.json -``` --## [REST API](#tab/api) --For more details, see [Deploy resources with ARM templates and Azure Resource Manager REST API](../azure-resource-manager/templates/deploy-rest.md). --```rest -PUT https://management.azure.com/subscriptions/{subscriptionId}/resourcegroups/{resourceGroupName}/providers/Microsoft.Resources/deployments/{deploymentName}?api-version=2020-10-01 -``` --In the request body, provide a link to your template and parameter file. --```json -{ - "properties": { - "templateLink": { - "uri": "http://mystorageaccount.blob.core.windows.net/templates/template.json", - "contentVersion": "1.0.0.0" - }, - "parametersLink": { - "uri": "http://mystorageaccount.blob.core.windows.net/templates/parameters.json", - "contentVersion": "1.0.0.0" - }, - "mode": "Incremental" - } -} -``` ----## List of sample templates --- [Agents](agents/resource-manager-agent.md): Deploy and configure the Log Analytics agent and a diagnostic extension.-- Alerts:- - [Log search alert rules](alerts/resource-manager-alerts-log.md): Configure alerts from log queries and Azure Activity Log. - - [Metric alert rules](alerts/resource-manager-alerts-metric.md): Configure alerts from metrics that use different kinds of logic. -- [Application Insights](app/create-workspace-resource.md)-- [Diagnostic settings](essentials/resource-manager-diagnostic-settings.md): Create diagnostic settings to forward logs and metrics from different resource types.-- [Enable Prometheus metrics](containers/kubernetes-monitoring-enable.md?tabs=arm#enable-prometheus-and-grafana): Install the Azure Monitor agent on your AKS cluster and send Prometheus metrics to your Azure Monitor workspace.-- [Log queries](logs/resource-manager-log-queries.md): Create saved log queries in a Log Analytics workspace.-- [Log Analytics workspace](logs/resource-manager-workspace.md): Create a Log Analytics workspace and configure a collection of data sources from the Log Analytics agent.-- [Workbooks](visualize/resource-manager-workbooks.md): Create workbooks.-- [Azure Monitor for VMs](vm/resource-manager-vminsights.md): Onboard virtual machines to Azure Monitor for VMs.--## Next steps --Learn more about [Resource Manager templates](../azure-resource-manager/templates/overview.md). |
| azure-monitor | Roles Permissions Security | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/roles-permissions-security.md | - Title: Roles, permissions, and security in Azure Monitor -description: Learn how to use roles and permissions in Azure Monitor to restrict access to monitoring resources. --- Previously updated : 05/31/2024----# Roles, permissions, and security in Azure Monitor --This article shows how to apply [role-based access control (RBAC)](../role-based-access-control/overview.md) monitoring roles to grant or limit access, and discusses security considerations for your Azure Monitor-related resources. --## Built-in monitoring roles --[Azure role-based access control (Azure RBAC)](../role-based-access-control/overview.md) provides built-in roles for monitoring that you can assign to users, groups, service principals, and managed identities. The most common roles are [*Monitoring Reader*](#monitoring-reader) and [*Monitoring Contributor*](#monitoring-contributor) for read and write permissions, respectively. --For more detailed information on the monitoring roles, see [RBAC Monitoring Roles](../role-based-access-control/built-in-roles.md#monitor). --### Monitoring Reader --People assigned the Monitoring Reader role can view all monitoring data in a subscription but can't modify any resource or edit any settings related to monitoring resources. This role is appropriate for users in an organization, such as support or operations engineers, who need to: --* View monitoring dashboards in the Azure portal. -* View alert rules defined in [Azure alerts](alerts/alerts-overview.md). -* Query Azure Monitor Metrics by using the [Azure Monitor REST API](/rest/api/monitor/metrics), [PowerShell cmdlets](powershell-samples.md), or [cross-platform CLI](cli-samples.md). -* Query the Activity log by using the portal, Azure Monitor REST API, PowerShell cmdlets, or cross-platform CLI. -* View the [diagnostic settings](essentials/diagnostic-settings.md) for a resource. -* View the [log profile](essentials/activity-log.md#legacy-collection-methods) for a subscription. -* View autoscale settings. -* View alert activity and settings. -* Search Log Analytics workspace data, including usage data for the workspace. -* Retrieve the table schemas in a Log Analytics workspace. -* Retrieve and execute log queries in a Log Analytics workspace. -* Access Application Insights data. --> [!NOTE] -> This role doesn't give read access to log data that has been streamed to an event hub or stored in a storage account. For information on how to configure access to these resources, see the [Security considerations for monitoring data](#security-considerations-for-monitoring-data) section later in this article. --### Monitoring Contributor --People assigned the Monitoring Contributor role can view all monitoring data in a subscription. They can also create or modify monitoring settings, but they can't modify any other resources. --This role is a superset of the Monitoring Reader role. It's appropriate for members of an organization's monitoring team or managed service providers who, in addition to the permissions mentioned earlier, need to: --* View monitoring dashboards in the portal and create their own private monitoring dashboards. -* Create and edit [diagnostic settings](essentials/diagnostic-settings.md) for a resource. <sup>1</sup> -* Set alert rule activity and settings using [Azure alerts](alerts/alerts-overview.md). -* List shared keys for a Log Analytics workspace. -* Create, delete, and execute saved searches in a Log Analytics workspace. -* Create and delete the workspace storage configuration for Log Analytics. -* Create web tests and components for Application Insights. --<sup>1</sup> To create or edit a diagnostic setting, users must also separately be granted ListKeys permission on the target resource (storage account or event hub namespace). --> [!NOTE] -> This role doesn't give read access to log data that has been streamed to an event hub or stored in a storage account. For information on how to configure access to these resources, see the [Security considerations for monitoring data](#security-considerations-for-monitoring-data) section later in this article. --## Monitor permissions and Azure custom roles --If the built-in roles don't meet the needs of your team, you can [create an Azure custom role](../role-based-access-control/custom-roles.md) with [granular permissions](../role-based-access-control/permissions/monitor.md). --For example, you can use granular permissions to create an Azure custom role for an Activity Log Reader with the following PowerShell script. --```powershell -$role = Get-AzRoleDefinition "Reader" -$role.Id = $null -$role.Name = "Activity Log Reader" -$role.Description = "Can view activity logs." -$role.Actions.Clear() -$role.Actions.Add("Microsoft.Insights/eventtypes/*") -$role.AssignableScopes.Clear() -$role.AssignableScopes.Add("/subscriptions/mySubscription") -New-AzRoleDefinition -Role $role -``` --> [!NOTE] -> Access to alerts, diagnostic settings, and metrics for a resource requires that the user has read access to the resource type and scope of that resource. Creating a diagnostic setting that sends data to a storage account or streams to event hubs requires the user to also have ListKeys permission on the target resource. --## Assign a role ---To assign a role, see [Assign Azure roles using Azure PowerShell](../role-based-access-control/role-assignments-powershell.md). --For example, the following PowerShell script assigns a role to a specified user. --Replace `<RoleId>` with the [RBAC Monitoring Role](../role-based-access-control/built-in-roles.md#monitor) ID you want to assign. --Replace `<SubscriptionID>`, `<ResourceGroupName>`, and `<UserPrincipalName>` with the appropriate values for your environment. --```powershell -# Define variables -$SubscriptionId = "<SubscriptionID>" -$ResourceGroupName = "<ResourceGroupName>" -$UserPrincipalName = "<UserPrincipalName>" # The UPN of the user to whom you want to assign the role -$RoleId = "<RoleId>" # The ID of the role --# Get the user object -$User = Get-AzADUser -UserPrincipalName $UserPrincipalName --# Define the scope (e.g., subscription or resource group level) -$Scope = "/subscriptions/$SubscriptionId/resourceGroups/$ResourceGroupName" --# Assign the role -New-AzRoleAssignment -ObjectId $User.Id -RoleDefinitionId $RoleId -Scope $Scope -``` --You can also [Assign Azure roles by using the Azure portal](../role-based-access-control/role-assignments-portal.yml). --> [!IMPORTANT] -> - Ensure you have the necessary permissions to assign roles in the specified scope. You must have *Owner* rights to the subscription or the resource group. -> - Assign access in the resource group or subscription to which your resource belongs, not in the resource itself. --## PowerShell query to determine role membership --It can be helpful to generate lists of users who belong to a given role. To help with generating these types of lists, the following sample queries can be adjusted to fit your specific needs. --### Query entire subscription for Admin roles + Contributor roles --```powershell -(Get-AzRoleAssignment -IncludeClassicAdministrators | Where-Object {$_.RoleDefinitionName -in @('ServiceAdministrator', 'CoAdministrator', 'Owner', 'Contributor') } | Select -ExpandProperty SignInName | Sort-Object -Unique) -Join ", " -``` --### Query within the context of a specific Application Insights resource for owners and contributors --```powershell -$resourceGroup = "ResourceGroupName" -$resourceName = "AppInsightsName" -$resourceType = "microsoft.insights/components" -(Get-AzRoleAssignment -ResourceGroup $resourceGroup -ResourceType $resourceType -ResourceName $resourceName | Where-Object {$_.RoleDefinitionName -in @('Owner', 'Contributor') } | Select -ExpandProperty SignInName | Sort-Object -Unique) -Join ", " -``` --### Query within the context of a specific resource group for owners and contributors --```powershell -$resourceGroup = "ResourceGroupName" -(Get-AzRoleAssignment -ResourceGroup $resourceGroup | Where-Object {$_.RoleDefinitionName -in @('Owner', 'Contributor') } | Select -ExpandProperty SignInName | Sort-Object -Unique) -Join ", " -``` --## Security considerations for monitoring data --[Data in Azure Monitor](data-platform.md) can be sent in a storage account or streamed to an event hub, both of which are general-purpose Azure resources. Being general-purpose resources, creating, deleting, and accessing them is a privileged operation reserved for an administrator. Since this data can contain sensitive information such as IP addresses or user names, use the following practices for monitoring-related resources to prevent misuse: --* Use a single, dedicated storage account for monitoring data. If you need to separate monitoring data into multiple storage accounts, always use different storage accounts for monitoring data and other types of data. If you share storage accounts for monitoring and other types of data, you might inadvertently grant access to other data to organizations that should only access monitoring data. For example, a non-Microsoft organization for security information and event management should need only access to monitoring data. -* Use a single, dedicated service bus or event hub namespace across all diagnostic settings for the same reason described in the previous point. -* Limit access to monitoring-related storage accounts or event hubs by keeping them in a separate resource group. [Use scope](../role-based-access-control/overview.md#scope) on your monitoring roles to limit access to only that resource group. -* You should never grant the ListKeys permission for either storage accounts or event hubs at subscription scope when a user only needs access to monitoring data. Instead, give these permissions to the user at a resource or resource group scope (if you have a dedicated monitoring resource group). --### Limit access to monitoring-related storage accounts --When a user or application needs access to monitoring data in a storage account, [generate a shared access signature (SAS)](/rest/api/storageservices/create-account-sas) on the storage account that contains monitoring data with service-level read-only access to blob storage. In PowerShell, the account SAS might look like the following code: --```powershell -$context = New-AzStorageContext -ConnectionString "[connection string for your monitoring Storage Account]" -$token = New-AzStorageAccountSASToken -ResourceType Service -Service Blob -Permission "rl" -Context $context -``` --You can then give the token to the entity that needs to read from that storage account. The entity can list and read from all blobs in that storage account. --Alternatively, if you need to control this permission with Azure RBAC, you can grant that entity the `Microsoft.Storage/storageAccounts/listkeys/action` permission on that particular storage account. This permission is necessary for users who need to set a diagnostic setting to send data to a storage account. For example, you can create the following Azure custom role for a user or application that needs to read from only one storage account: --```powershell -$role = Get-AzRoleDefinition "Reader" -$role.Id = $null -$role.Name = "Monitoring Storage Account Reader" -$role.Description = "Can get the storage account keys for a monitoring storage account." -$role.Actions.Clear() -$role.Actions.Add("Microsoft.Storage/storageAccounts/listkeys/action") -$role.Actions.Add("Microsoft.Storage/storageAccounts/Read") -$role.AssignableScopes.Clear() -$role.AssignableScopes.Add("/subscriptions/mySubscription/resourceGroups/myResourceGroup/providers/Microsoft.Storage/storageAccounts/myMonitoringStorageAccount") -New-AzRoleDefinition -Role $role -``` --> [!WARNING] -> The ListKeys permission enables the user to list the primary and secondary storage account keys. These keys grant the user all signed permissions (such as read, write, create blobs, and delete blobs) across all signed services (blob, queue, table, file) in that storage account. We recommend using an account SAS when possible. --### Limit access to monitoring-related event hubs --You can follow a similar pattern with event hubs, but first you need to create a dedicated authorization rule for listening. If you want to grant access to an application that only needs to listen to monitoring-related event hubs, follow these steps: --1. In the portal, create a shared access policy on the event hubs that were created for streaming monitoring data with only listening claims. For example, you might call it "monitoringReadOnly." If possible, give that key directly to the consumer and skip the next step. -1. If the consumer needs to get the key on demand, grant the user the ListKeys action for that event hub. This step is also necessary for users who need to set a diagnostic setting or a log profile to stream to event hubs. For example, you might create an Azure RBAC rule: - - ```powershell - $role = Get-AzRoleDefinition "Reader" - $role.Id = $null - $role.Name = "Monitoring Event Hub Listener" - $role.Description = "Can get the key to listen to an event hub streaming monitoring data." - $role.Actions.Clear() - $role.Actions.Add("Microsoft.EventHub/namespaces/authorizationrules/listkeys/action") - $role.Actions.Add("Microsoft.EventHub/namespaces/Read") - $role.AssignableScopes.Clear() - $role.AssignableScopes.Add("/subscriptions/mySubscription/resourceGroups/myResourceGroup/providers/Microsoft.ServiceBus/namespaces/mySBNameSpace") - New-AzRoleDefinition -Role $role - ``` -## Next steps --* [Read about Azure RBAC and permissions in Azure Resource Manager](../role-based-access-control/overview.md) -* [Read the overview of monitoring in Azure](overview.md) |
| azure-monitor | Configure Log Analytics For Scom Managed Instance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/configure-log-analytics-for-scom-managed-instance.md | - Title: Configure Log Analytics for Azure Monitor SCOM Managed Instance -description: This article details about the Integration of Azure Monitor SCOM Managed Instance with Log Analytics and how to configure Azure Monitor SCOM Managed Instance with Azure Log Analytics. --- Previously updated : 05/22/2024------# Configure Log Analytics for Azure Monitor SCOM Managed Instance --The integration of Azure Monitor SCOM Managed Instance with Azure Log Analytics (LA) is a mechanism to synchronize the monitoring data from individual SCOM Managed Instances to the respective LA workspace with a predefined frequency, enabling retention and advanced user actions such as visualization and reporting. --Synchronization of SCOM Managed Instance workload's monitoring data to a common data source (LA) helps to centralize all monitoring logs and prevents data fragmentation. With LA retention policies, longer-term trend analysis is possible in LA. --This article details about the Integration of Azure Monitor SCOM Managed Instance with Log Analytics and how to configure Azure Monitor SCOM Managed Instance with Azure Log Analytics. --Before you configure Log Analytics workspace for SCOM Managed Instance, ensure you have a Log Analytics workspace available for integration or create a Log Analytics workspace. For more information on how to create Log Analytics workspace, see [Create a Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace?tabs=azure-portal). --## General guidelines --Following are the general guidelines for the location and existence of LA workspaces and SCOM Managed Instance: --- To reduce latency in data synchronization, we recommend that you keep the SCOM Managed Instance and LA workspace in the same region.--- To reduce management (RBAC, policies, NSG) activities, we recommend that you keep SCOM Managed Instance and LA workspace in the same subscription and resource group.--- To onboard Azure Log Analytics workspace to SCOM Managed Instance, you must have required level of permissions, at least **Log Analytics Contributor**. You must assign **Log Analytics Contributor** permissions on the resource group of the workspace to **Microsoft.SCOM Resource Provider**. For more information, see [Manage access to Log Analytics workspace](/azure/azure-monitor/logs/manage-access?tabs=portal).--## Data types synchronized to Log Analytics workspace --The prioritized list of SCOM Managed Instance monitored data that synchronizes to LA workspace are --- **EVENT**: Table consists of Event log data collected by management pack rules and monitors.-- **STATE**: Table consists of current and past health states of monitored resources.-- **PERFORMANCE**: Table consists of Performance metric data collected by management pack rules and monitors.-- **AUDIT**: Table consists of management pack related audit (change tracking) data.--## Data Retention in Log Analytics --The retention policy application on Log Analytic workspace is default value, which is 30 days. Azure Monitor SCOM Managed Instance doesn't change this value. For more information on Data retention, see [Data retention and archive in Azure Monitor Logs](/azure/azure-monitor/logs/data-retention-archive?tabs=portal-1%2Cportal-2) ---## Configure Log Analytics Workspace for SCOM Managed Instance --### Prerequisites --Ensure to provide Log Analytics Contributor permissions on the Log Analytics Workspace's Resource Group for *Microsoft.SCOM* Resource Provider (RP). --To provide the permissions, follow these steps: --1. Navigate to the resource group of respective Log analytics workspace > **Access Control** > **Add Role Assignment** > **Choose Log Analytics Contributor** and select **Next**. --2. Search for **Microsoft.SCOM Resource provider** and select **Assign**. --### Integrate SCOM Managed Instance with Log Analytics --To integrate SCOM Managed Instance with Log Analytics, follow these steps: --1. Sign in to theΓÇ»[Azure portal](https://ms.portal.azure.com/#home). Search for and selectΓÇ»**SCOM Managed Instance**. --2. On the **Overview** page, select **View Instances**. --3. On the **SCOM managed instances** page, select the desired SCOM managed instance. --4. On the left pane, select **Log Analytics workspace**. --5. On the **Log Analytics workspace** page, select **Link Log Analytics workspace**. --6. On the **Configure Log Analytics Workspace for SCOM managed instance** page, do the following: -- 1. **Destination details**: - - **Subscription**: Select the desired subscription. - - **Log Analytics workspace**: Select the desired Log Analytics workspace. -- >[!NOTE] - >Ensure to provide Log Analytics Contributor permissions on the resource group. -- 2. **Log data types**: - - **Data types**: Select the desired date type. -- 3. **Historic data**: - - **Enable historic data for last 7 days**: Select this checkbox if you wish to synchronize the last seven days of historic data. --7. Select **Save**. --The Integration of SCOM Managed Instance with Log Analytics takes few minutes to complete. --## View Logs --To view the integrated logs, follow these steps: --1. Post successful configuration, wait for a few minutes, and sign in to theΓÇ»[Azure portal](https://ms.portal.azure.com/#home). Search for and selectΓÇ»**Log Analytic workspace**. --2. On the **Overview** page, select **Logs**. - On the Query page, under **Custom Logs**, SCOM Managed Instance related data tables such as State, Performance, Event, and Management pack (ending with CL) are created. --3. Select the desired custom table (State, Performance, Event and Management pack) and select **Run** to view the results. --Optionally, you can create a new workbook, query the data from this LA workspace, and visualize the monitored data. --For more information on Log Analytics workspaces, see the following articles: --- [Log Analytics workspace overview](/azure/azure-monitor/logs/log-analytics-workspace-overview).-- [Monitor Log Analytics workspace health](/azure/azure-monitor/logs/log-analytics-workspace-health). |
| azure-monitor | Configure Network Firewall | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/configure-network-firewall.md | - Title: Configure the network firewall for Azure Monitor SCOM Managed Instance -description: This article describes how to configure the network firewall. --- Previously updated : 05/22/2024------# Configure the network firewall for Azure Monitor SCOM Managed Instance --This article describes how to configure the network firewall and Azure network security group (NSG) rules. --> [!NOTE] -> To learn about the Azure Monitor SCOM Managed Instance architecture, see [Azure Monitor SCOM Managed Instance](overview.md). --## Network prerequisites --This section discusses network prerequisites with three network model examples. --### Establish direct connectivity (line of sight) between your domain controller and the Azure network --Ensure that there's direct network connectivity (line of sight) between the network of your desired domain controller and the Azure subnet (virtual network) where you want to deploy an instance of SCOM Managed Instance. Ensure that there's direct network connectivity (line of sight) between the workloads/agents and the Azure subnet in which the SCOM Managed Instance is deployed. --Direct connectivity is required so that all your following resources can communicate with each other over the network: --- Domain controller-- Agents-- System Center Operations Manager components, such as the Operations console-- SCOM Managed Instance components, such as management servers--The following three distinct network models are visually represented to create the SCOM Managed Instance. --#### Network model 1: The domain controller is located on-premises --In this model, the desired domain controller is located within your on-premises network. You must establish an Azure ExpressRoute connection between your on-premises network and the Azure subnet used for the SCOM Managed Instance. --If your domain controller and other component are on-premises, you must establish the line of sight through ExpressRoute or a virtual private network (VPN). For more information, see [ExpressRoute documentation](/azure/expressroute/) and [Azure VPN Gateway documentation](/azure/vpn-gateway/). --The following network model shows where the desired domain controller is situated within the on-premises network. A direct connection exists (via ExpressRoute or VPN) between the on-premises network and the Azure subnet that's used for SCOM Managed Instance creation. ---#### Network model 2: The domain controller is hosted in Azure --In this configuration, the designated domain controller is hosted in Azure, and you must establish an ExpressRoute or VPN connection between your on-premises network and the Azure subnet. It's used for the SCOM Managed Instance creation and the Azure subnet that's used for the designated domain controller. For more information, see [ExpressRoute](/azure/expressroute/) and [VPN Gateway](/azure/vpn-gateway/). --In this model, the desired domain controller remains integrated into your on-premises domain forest. However, you chose to create a dedicated Active Directory controller in Azure to support Azure resources that rely on the on-premises Active Directory infrastructure. ---### Network model 3: The domain controller and SCOM Managed Instances are in Azure virtual networks --In this model, both the desired domain controller and the SCOM Managed Instances are placed in separate and dedicated virtual networks in Azure. --If the domain controller you want and all other components are in the same virtual network of Azure (a conventional active domain controller) with no presence on-premises, you already have a line of sight between all your components. --If the domain controller you want and all other components are in different virtual networks of Azure (a conventional active domain controller) with no presence on-premises, you need to do virtual network peering between all the virtual networks that are in your network. For more information, see [Virtual network peering in Azure](/azure/virtual-network/virtual-network-peering-overview). ---Take care of the following issues for all three networking models mentioned earlier: --1. Ensure that the SCOM Managed Instance subnet can establish connectivity to the designated domain controller configured for Azure or SCOM Managed Instance. Also, ensure that domain name resolution within the SCOM Managed Instance subnet lists the designated domain controller as the top entry among the resolved domain controllers to avoid network latency or performance and firewall issues. --1. The following ports on the designated domain controller and Domain Name System (DNS) must be accessible from the SCOM Managed Instance subnet: - - TCP port 389 or 636 for LDAP - - TCP port 3268 or 3269 for global catalog - - TCP and UDP port 88 for Kerberos - - TCP and UDP port 53 for DNS - - TCP 9389 for Active Directory web service - - TCP 445 for SMB - - TCP 135 for RPC -- The internal firewall rules and NSG must allow communication from the SCOM Managed Instance virtual network and the designated domain controller/DNS for all the ports listed earlier. --1. The Azure SQL Managed Instance virtual network and SCOM Managed Instance must be peered to establish connectivity. Specifically, the port 1433 (private port) or 3342 (public port) must be reachable from the SCOM Managed Instance to the SQL managed instance. Configure the NSG rules and firewall rules on both virtual networks to allow ports 1433 and 3342. --1. Allow communication on ports 5723, 5724, and 443 from the machine being monitored to SCOM Managed Instance. -- - If the machine is on-premises, set up the NSG rules and firewall rules on the SCOM Managed Instance subnet and on the on-premises network where the monitored machine is located to ensure specified essential ports (5723, 5724, and 443) are reachable from the monitored machine to the SCOM Managed Instance subnet. - - - If the machine is in Azure, set up the NSG rules and firewall rules on the SCOM Managed Instance virtual network and on the virtual network where the monitored machine is located to ensure specified essential ports (5723, 5724, and 443) are reachable from the monitored machine to the SCOM Managed Instance subnet. --## Firewall requirements --To function properly, SCOM Managed Instance must have access to the following port number and URLs. Configure the NSG and firewall rules to allow this communication. --|Resource|Port|Direction|Service Tags|Purpose| -|||||| -|*.blob.core.windows.net|443|Outbound|Storage|Azure Storage| -|management.azure.com|443|Outbound|AzureResourceManager|Azure Resource Manager| -|gcs.prod.monitoring.core.windows.net <br/> *.prod.warm.ingest.monitor.core.windows.net|443|Outbound|AzureMonitor|SCOM MI Logs| -|*.prod.microsoftmetrics.com <br/> *.prod.hot.ingest.monitor.core.windows.net <br/> *.prod.hot.ingestion.msftcloudes.com|443|Outbound|AzureMonitor|SCOM MI Metrics| -|*.workloadnexus.azure.com|443|Outbound| |Nexus Service| -|*.azuremonitor-scommiconnect.azure.com|443|Outbound| |Bridge Service| --> [!IMPORTANT] -> To minimize the need for extensive communication with both your Active Directory admin and the network admin, see [Self-verification](self-verification-steps.md). The article outlines the procedures that the Active Directory admin and the network admin use to validate their configuration changes and ensure their successful implementation. This process reduces unnecessary back-and-forth interactions from the Operations Manager admin to the Active Directory admin and the network admin. This configuration saves time for the admins. --## Next steps --- [Verify Azure and internal GPO policies](verify-azure-internal-group-policy-object-policies.md) |
| azure-monitor | Connect Managed Instance Ops Console | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/connect-managed-instance-ops-console.md | - Title: Connect the Azure Monitor SCOM Managed Instance to Operations console -description: This article describes how to connect the Azure Monitor SCOM Managed Instance to Operations console. --- Previously updated : 05/22/2024------# Connect the Azure Monitor SCOM Managed Instance to Operations console --Azure Monitor SCOM Managed Instance is compatible with [System Center Operations Manager 2022](https://www.microsoft.com/download/details.aspx?id=104038). --After you create the SCOM Managed Instance in Azure, connect the instance to Operations console to configure the workloads and monitor. --## Connect SCOM Managed Instance to Operations console --Follow the below steps to connect a SCOM Managed Instance to Operations console: --1. **Identify server to install Ops Console**: Identify a server where you want to install the Operations console. - >[!Note] - >Don't perform this on a SCOM Managed Instance VM; do it on a separate VM. The VM needs to be a Windows Server. This server can be on-premises or on Azure. - >- If the VM/machine is on-premises, set the NSG rules and firewall rules on the SCOM Managed Instance VNet and on the on-premises network where the VM/machine is located to ensure specified essential port (5724) is reachable. - >- If the VM/machine is in Azure, set the NSG rules and firewall rules on the SCOM Managed Instance VNet and on the Virtual network (VNET) where the VM/machine is located to ensure specified essential port (5724) is reachable. -1. **Install the Ops Console**: From the [executable file](https://go.microsoft.com/fwlink/?linkid=2212475), install the Operations console and follow the installation wizard to successfully install the Operations console. -1. **Connect SCOM Managed Instance to Ops Console**: Sign in to the Operations console and select **Connect To Server**. Add the DNS name displayed at SCOM Managed Instance > **Overview** > **Properties** > **Load Balancer**. --## Next step --[Migrate from Operations Manager on-premises to Azure Monitor SCOM Managed Instance](migrate-to-operations-manager-managed-instance.md) -- |
| azure-monitor | Create Group Managed Service Account | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/create-group-managed-service-account.md | - Title: Create a computer group and group-managed service account for Azure Monitor SCOM Managed Instance -description: This article describes how to create a group-managed service account, computer group, and domain user account in on-premises Active Directory. --- Previously updated : 05/22/2024------# Create a computer group and group-managed service account for Azure Monitor SCOM Managed Instance --This article describes how to create a group-managed service account (gMSA) account, computer group, and domain user account in on-premises Active Directory. --> [!NOTE] -> To learn about the Azure Monitor SCOM Managed Instance architecture, see [Azure Monitor SCOM Managed Instance](overview.md). --## Active Directory prerequisites --To perform Active Directory operations, install the **RSAT: Active Directory Domain Services and Lightweight Directory Tools** feature. Then install the **Active Directory Users and Computers** tool. You can install this tool on any machine that has domain connectivity. You must sign in to this tool with admin permissions to perform all Active Directory operations. --### Configure a domain account in Active Directory --Create a domain account in your Active Directory instance. The domain account is a typical Active Directory account. (It can be a nonadmin account.) You use this account to add the System Center Operations Manager management servers to your existing domain. ---Ensure that this account has the [permissions](/windows/security/threat-protection/security-policy-settings/add-workstations-to-domain) to join other servers to your domain. You can use an existing domain account if it has these permissions. --You use the configured domain account in later steps to create an instance of SCOM Managed Instance and subsequent steps. --### Create and configure a computer group --Create a computer group in your Active Directory instance. For more information, see [Create a group account in Active Directory](/windows/security/threat-protection/windows-firewall/create-a-group-account-in-active-directory). All the management servers that you create will be a part of this group so that all the members of the group can retrieve gMSA credentials. (You create these credentials in later steps.) The group name can't contain spaces and must have alphabet characters only. ---To manage this computer group, provide permissions to the domain account that you created. --1. Select the group properties, and then select **Managed By**. -1. For **Name**, enter the name of the domain account. -1. Select the **Manager can update membership list** checkbox. -- :::image type="Server group properties" source="media/create-gmsa-account/server-group-properties.png" alt-text="Screenshot that shows server group properties."::: --### Create and configure a gMSA account --Create a gMSA to run the management server services and to authenticate the services. Use the following PowerShell command to create a gMSA service account. The DNS host name can also be used to configure the static IP and associate the same DNS name to the static IP as in [step 8](create-static-ip.md). --```powershell -New-ADServiceAccount ContosogMSA -DNSHostName "ContosoLB.aquiladom.com" -PrincipalsAllowedToRetrieveManagedPassword "ContosoServerGroup" -KerberosEncryptionType AES128, AES256ΓÇ»-ServicePrincipalNames MSOMHSvc/ContosoLB.aquiladom.com, MSOMHSvc/ContosoLB, MSOMSdkSvc/ContosoLB.aquiladom.com, MSOMSdkSvc/ContosoLB -``` --In that command: --- `ContosogMSA` is the gMSA name.-- `ContosoLB.aquiladom.com` is the DNS name for the load balancer. Use the same DNS name to create the static IP and associate the same DNS name to the static IP as in [step 8](create-static-ip.md).-- `ContosoServerGroup` is the computer group created in Active Directory (specified previously).-- `MSOMHSvc/ContosoLB.aquiladom.com`, `SMSOMHSvc/ContosoLB`, `MSOMSdkSvc/ContosoLB.aquiladom.com`, and `MSOMSdkSvc/ContosoLB` are service principal names.--> [!NOTE] -> If the gMSA name is longer than 14 characters, ensure that you set `SamAccountName` at less than 15 characters, including the `$` sign. --If the root key isn't effective, use the following command: --```powershell -Add-KdsRootKey -EffectiveTime ((get-date).addhours(-10)) -``` --Ensure that the created gMSA account is a local admin account. If there are any Group Policy Object policies on the local admins at the Active Directory level, ensure that they have the gMSA account as the local admin. --> [!IMPORTANT] -> To minimize the need for extensive communication with both your Active Directory admin and the network admin, see [Self-verification](self-verification-steps.md). The article outlines the procedures that the Active Directory admin and network admin use to validate their configuration changes and ensure their successful implementation. This process reduces unnecessary back-and-forth interactions from the Operations Manager admin to the Active Directory admin and the network admin. This configuration saves time for the admins. --## Next steps --[Store domain credentials in Azure Key Vault](store-domain-credentials-key-vault.md) |
| azure-monitor | Create Key Vault | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/create-key-vault.md | - Title: Create an Azure key vault -description: This article describes how to create a key vault to store domain credentials. --- Previously updated : 05/22/2024------# Create an Azure key vault --This article describes how to create a key vault to store domain credentials. -->[!NOTE] -> To learn about the Azure Monitor SCOM Managed Instance architecture, see [Azure Monitor SCOM Managed Instance](overview.md). --## Create a key vault to store secrets --For security, you can store domain account credentials in key vault secrets. Later, you can use these secrets in SCOM Managed Instance creation. --Azure Key Vault is a cloud service that provides a secure store for keys, secrets, and certificates. For more information, see [About Azure Key Vault](/azure/key-vault/general/overview). --1. In the Azure portal, search for and select **Key vaults**. -- :::image type="Key vaults in portal" source="media/create-key-vault/azure-portal-key-vaults.png" alt-text="Screenshot that shows the icon for key vaults in the Azure portal."::: -- The **Key vaults** page opens. --1. Select **Create**. --1. For **Basics**, do the following: - - **Project details**: - - **Subscription**: Select the subscription. - - **Resource group**: Select the resource group you want. - - **Instance details**: - - **Key vault name**: Enter the name of your key vault. There are no added restrictions, except for those that apply to names in other Azure services. - - **Region**: Choose the region that you're going to select for your other resources. - - **Pricing tier**: Select **Standard** or **Premium** as required. - - **Recovery options**: - - **Days to retain deleted vaults**: Enter a value from 7 to 90. - - **Purge protection**: We recommend enabling this feature to have a mandatory retention period. -- :::image type="Create a key vault" source="media/create-key-vault/create-a-key-vault.png" alt-text="Screenshot that shows basic information for creating a key vault."::: --1. Select **Next**. For now, no change is required in access configuration. Access configuration is done in the [step 5](create-user-assigned-identity.md). --1. For **Networking**, do the following: - - Select **Enable public access**. - - Under **Public Access**, for **Allow access from**, select **All networks**. -- :::image type="Networking tab" source="media/create-key-vault/networking-inline.png" alt-text="Screenshot that shows selections for enabling public access on the Networking tab." lightbox="media/create-key-vault/networking-expanded.png"::: --1. Select **Next**. -1. For **Tags**, select the tags if required and select **Next**. -1. For **Review + create**, review the selections and select **Create** to create the key vault. - -## Next steps --- [Create a user-assigned identity](create-user-assigned-identity.md) |
| azure-monitor | Create Operations Manager Managed Instance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/create-operations-manager-managed-instance.md | - Title: Create an instance of Azure Monitor SCOM Managed Instance -description: This article describes how to create a SCOM Managed Instance to monitor workloads by using System Center Operations Manager functionality on Azure. --- Previously updated : 05/22/2024-------# Create an instance of Azure Monitor SCOM Managed Instance --Azure Monitor SCOM Managed Instance provides System Center Operations Manager functionality in Azure. It helps you monitor all your workloads, whether they're on-premises, in Azure, or in any other cloud services. --This article describes how to create an instance of the service (a SCOM Managed Instance) with System Center Operations Manager functionality in Azure. --## Supported regions --- Australia East-- Canada Central-- East US-- East US 2-- Germany West Central-- Italy North-- North Europe-- South India-- Southeast Asia-- Sweden Central-- UK South-- West Europe-- West US-- West US 2-- West US 3--## Create a SCOM Managed Instance --To create a SCOM Managed Instance, follow these steps: --1. Sign in to the [Azure portal](https://portal.azure.com). Search for and select **SCOM Managed Instance**. -1. On the **Overview** page, you have three options: - - **Pre-requisites**: Allows you to view the prerequisites. - - **SCOM managed instance**: Allows you to create a SCOM Managed Instance. - - **Manage your SCOM managed instance**: Allows you to view the list of created instances. -- :::image type="SCOM Managed Instance overview" source="media/create-operations-manager-managed-instance/scom-managed-instance-overview-inline.png" alt-text="Screenshot that shows options on the Overview page for SCOM Managed Instance." lightbox="media/create-operations-manager-managed-instance/scom-managed-instance-overview-expanded.png"::: -- Select **Create SCOM managed instance**. -1. The **Prerequisites to create SCOM managed instance** page opens. Download the script and run it on a domain-joined machine to validate the prerequisites. -- :::image type="Script download" source="media/create-operations-manager-managed-instance/script-download-inline.png" alt-text="Screenshot that shows the button for downloading a script." lightbox="media/create-operations-manager-managed-instance/script-download-expanded.png"::: -1. Under **Basics**, do the following: - - **Project details**: - - **Subscription**: Select the Azure subscription in which you want to place the SCOM Managed Instance. - - **Resource group**: Select the resource group in which you want to place the SCOM Managed Instance. We recommend that you have a new resource group exclusively for SCOM Managed Instance. -- :::image type="Project details" source="media/create-operations-manager-managed-instance/project-details-inline.png" alt-text="Screenshot that shows project details for creating a SCOM Managed Instance." lightbox="media/create-operations-manager-managed-instance/project-details-expanded.png"::: -- - **Instance details**: - - **SCOM managed instance name**: Enter a name for your SCOM Managed Instance. - >[!NOTE] - >- The name of a SCOM Managed Instance can have only alphanumeric characters and be up to 9 characters. - >- A SCOM Managed Instance is equivalent to a System Center Operations Manager management group, so choose a name accordingly. - - **Region**: Select a region near to you geographically so that latency between your agents and the SCOM Managed Instance is as low as possible. This region must also contain the virtual network. -- :::image type="Instance details" source="media/create-operations-manager-managed-instance/instance-details-inline.png" alt-text="Screenshot that shows instance details for creating a SCOM Managed Instance." lightbox="media/create-operations-manager-managed-instance/instance-details-expanded.png"::: -- - **Active directory details**: - - **Domain name**: Enter the name of the domain that the domain controller is administering. - - **DNS server IP**: Enter the IP address of the Domain Name System (DNS) server that's providing the IP addresses to the resources in the domain from the previous step. - - **OU Path**: Enter the organizational unit (OU) path to where you want to join the servers. This field isn't a necessary. If you leave it blank, it assumes the default value. Ensure that the value you enter is in the distinguished name format. For example: **OU=testOU,DC=domain,DC=Domain,DC=com**. -- :::image type="Active Directory details" source="media/create-operations-manager-managed-instance/active-directory-details-inline.png" alt-text="Screenshot that shows Active Directory details for creating a SCOM Managed Instance." lightbox="media/create-operations-manager-managed-instance/active-directory-details-expanded.png"::: -- - **Domain account details**: - - **Security key vault**: Select the key vault that has the secret username and secret password of the domain account's user credentials. - - **Username secret**: Enter the secret name for the user under the selected key vault. - - **Password secret**: Enter the secret name for the password under the selected key vault. -- >[!NOTE] - >Ensure that you provide the secret names created in the *selected key vault* and not the actual domain username and password. -- :::image type="content" source="./media/create-operations-manager-managed-instance/secret-password-mapping-inline.png" alt-text="Screenshot that shows password mapping for creating a secret." lightbox="./media/create-operations-manager-managed-instance/secret-password-mapping-expanded.png"::: -- - **Azure hybrid benefit**: By default, **No** is selected. Select **Yes** if you're using a Windows Server license for your existing servers. This license is applicable only for the Windows servers that are used while you create a virtual machine for the SCOM Managed Instance. It won't apply to the existing Windows servers. -- :::image type="Azure hybrid benefit" source="media/create-operations-manager-managed-instance/azure-hybrid-benefit.png" alt-text="Screenshot that shows options for Azure hybrid benefit."::: -1. Select **Next**. -1. Under **Networking**, do the following: - - **Virtual network**: - - **Virtual network**: Select the virtual network that has direct connectivity to the workloads that you want to monitor and to your domain controller and DNS server. - - **Subnet**: Select a subnet that has at least 32 IP addresses to house the instance. The minimum address space is 28. -- The subnet can have existing resources in it. However, don't choose the subnet that houses the SQL managed instance because it won't contain enough IP addresses to house the SCOM Managed Instance components. -- - **SCOM managed instance interface**: - - **Static IP**: Enter the static IP for the load balancer. This IP should be in the selected subnet range for SCOM Managed Instance. Ensure that the IP is in the IPv4 format, and create it in your routing table. - - **DNS name**: Enter the DNS name that you attached to the static IP from the preceding step. The DNS name is mapped to the static IP that's previously defined. - - **gMSA details**: - - **Computer group name**: Enter the name of the computer group that you create after creation of the group managed service account (gMSA) account. - - **gMSA account name**: Enter the gMSA name. It must end with **$**. -- :::image type="gMSA details" source="media/create-operations-manager-managed-instance/gmsa-details.png" alt-text="Screenshot that shows gMSA details."::: -1. Select **Next**. -1. Under **Database**, do the following: - - **SQL managed instance**: For **Resource Name**, select the Azure SQL Managed Instance resource name for the instance that you want to associate with this SCOM Managed Instance. Use only the SQL managed instance that has given permissions to the SCOM Managed Instance. For more information, see [SQL managed instance creation and permission](/system-center/scom/create-operations-manager-managed-instance?view=sc-om-2022&tabs=prereqs-portal#create-and-configure-a-sql-mi&preserve-view=true). - - **User managed identity**: For **User managed identity account**, provide a user managed identity with system admin privileges on the SQL managed instance and **Get** and **List** permissions on key vault secrets that were selected on the **Basics** tab. Ensure that the same MSI has read permissions on the key vault for domain account credentials. -1. Select **Next**. -1. Under **Validate**, all the prerequisites are validated. It takes 10 minutes to finish the validation. -- :::image type="Validate tab" source="media/create-operations-manager-managed-instance/validate-inline.png" alt-text="Screenshot that shows the Validate tab." lightbox="media/create-operations-manager-managed-instance/validate-expanded.png"::: -- After the validation is finished, check the results and revalidate if needed. -- :::image type="Validation complete" source="media/create-operations-manager-managed-instance/validation-complete-inline.png" alt-text="Screenshot that shows Validation status: Completed." lightbox="media/create-operations-manager-managed-instance/validation-complete-expanded.png"::: --1. Select **Next: Tags**. -1. Under **Tags**, enter the **Name** and **Value** information, and then select the resource. -- Tags help you categorize resources and view consolidated billing by applying the same tags to multiple resources and resource groups. For more information, see [Use tags to organize your Azure resources and management hierarchy](/azure/azure-resource-manager/management/tag-resources?wt.mc_id=azuremachinelearning_inproduct_portal_utilities-tags-tab&tabs=json). -1. Select **Next**. -1. Under **Review + create**, review all the inputs given so far, and then select **Create**. Your deployment is created on Azure. Creation of a SCOM Managed Instance takes up to an hour. -- >[!NOTE] - >If the deployment fails, delete the instance and all the associated resources, and then create the instance again. For more information, see [Delete an instance](./scom-managed-instance-faq.yml#other-queries). --1. After the deployment is finished, select **Go to resource**. -- On the instance page, you can view some of the essential details and instructions for post-deployment steps and reporting bugs. --## Next steps --- [Troubleshoot commonly encountered errors while validating input parameters](troubleshooting-input-parameters-scom-managed-instance.md)-- [Troubleshoot issues with Azure Monitor SCOM Managed Instance](troubleshoot-scom-managed-instance.md)-- [Azure Monitor SCOM Managed Instance frequently asked questions](scom-managed-instance-faq.yml) |
| azure-monitor | Create Reports Power Bi | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/create-reports-power-bi.md | - Title: Create reports on Power BI -description: This article describes how to create reports on Power BI for Azure Monitor SCOM Managed Instance. --- Previously updated : 05/24/2024-------# Create reports on Power BI --This article describes how to create reports on Power BI for Azure Monitor SCOM Managed Instance. --> [!VIDEO https://www.youtube.com/embed/MG5kGoe1zj0?start=215] --## Prerequisites --- Azure Active Directory based authentication: -- 1. [Create an Azure Active Directory group](/azure/active-directory/roles/groups-create-eligible) for the users to whom you want to provide permissions to read data from the SQL Managed Instance through this Power BI report. -- 2. Create login credentials for the Azure Active Directory group in the SQL Managed Instance, which adds the user principal of the group in the SQL Managed Instance. To create a login, see [Create Login (Transact-SQL)](/sql/t-sql/statements/create-login-transact-sql?view=azuresqldb-mi-current&preserve-view=true). - :::image type="Create login" source="media/operations-manager-managed-instance-create-reports-on-power-bi/create-login.png" alt-text="Screenshot showing create login option."::: - 3. Provide **db_datareader** permission to the Login on Data warehouse database. - :::image type="Login properties" source="media/operations-manager-managed-instance-create-reports-on-power-bi/login-properties.png" alt-text="Screenshot showing login properties."::: - 4. [Download the supported SSMS](/sql/ssms/download-sql-server-management-studio-ssms?view=sql-server-ver16&preserve-view=true) and add login to SSMS. - 5. In the network security group of the subnet where the Azure SQL Managed Instance is hosted, create an NSG rule to allow public endpoint traffic on port number 3342. For more information about how to configure public endpoint, see [Configure public endpoint](/azure/azure-sql/managed-instance/public-endpoint-configure?view=azuresql&preserve-view=true). - :::image type="Destination port range" source="media/operations-manager-managed-instance-create-reports-on-power-bi/destination-port-range.png" alt-text="Screenshot showing destination port range."::: -- SQL based authentication: -- - You need the username and password of the SQL Managed Instance. --## Create reports through public endpoint of SQL MI --1. Sign in to the [Azure portal](https://portal.azure.com/) and search for SCOM Managed Instance. -1. On the **Overview** page, under **Reports**, select **Power BI**. You have three options on the Power BI page. - 1. **Prerequisite**: Allows you to manage endpoints. - 1. **Configure and install Power BI**: Allows you to install and configure the SCOM Managed Instance dashboard in Power BI. - 1. **View Power BI dashboard**: Allows you to visualize the SCOM Managed Instance dashboard in Power BI after the configuration. -1. Review the **Prerequisites** to ensure Public endpoint of SQL MI is enabled. You'll notice the Database Host URL and Database name are displayed. - :::image type="Public endpoints" source="media/operations-manager-managed-instance-create-reports-on-power-bi/public-endpoints.png" alt-text="Screenshot showing public endpoints."::: -1. Select **Configure Dashboard**, **Powerbi.com** opens in a new browser. Select **Get it now** to install **Microsoft SCOM managed instance reports** Power BI app in your workspace. - :::image type="Power BI app" source="media/operations-manager-managed-instance-create-reports-on-power-bi/power-bi-app.png" alt-text="Screenshot showing Power BI app."::: -1. The app displays sample data. You can edit the parameter values **Data-Warehouse DB host URL** and **Data-Warehouse Name**. - >[!Note] - >To update the parameters, go to **Settings** of the dataset, and edit the parameters or select **Connect your data** in the banner. - :::image type="Connect your data" source="media/operations-manager-managed-instance-create-reports-on-power-bi/connect-your-data.png" alt-text="Screenshot showing Connect your data option."::: -1. After you enter the parameters, select any one of the following authentication methods: - - SQL username and password-based method - - Azure Active Directory-based method - - The dataset and reports will be refreshed. -- >[!Note] - >To view Power BI reports of multiple SCOM Managed Instances, **Microsoft SCOM managed instance reports** app must be installed individually in a different Power BI workspace. --## Next steps --[Connect the Azure Monitor SCOM Managed Instance to Ops console](connect-managed-instance-ops-console.md). |
| azure-monitor | Create Separate Subnet In Vnet | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/create-separate-subnet-in-vnet.md | - Title: Create a separate subnet in a VNet for SCOM Managed Instance -description: This article describes how to create a separate subnet in a virtual network for Azure Monitor SCOM Managed Instance. --- Previously updated : 05/22/2024------# Create a separate subnet in a virtual network for Azure Monitor SCOM Managed Instance --This article describes how to create a separate subnet in a virtual network for a managed instance of Azure Monitor SCOM Managed Instance and enable Azure NAT Gateway on a SCOM Managed Instance subnet. -->[!NOTE] -> To learn about the SCOM Managed Instance architecture, see [Azure Monitor SCOM Managed Instance](overview.md#architecture). --## Create a separate subnet in a virtual network --For more information on how to create a virtual network, see [Quickstart: Use the Azure portal to create a virtual network](/azure/virtual-network/quick-create-portal). --After a SCOM Managed Instance subnet is created, we need a NAT gateway for outbound internet access from the SCOM Managed Instance subnet. Edit the subnet to add a NAT gateway. In Azure, add a NAT gateway to the subnet where the SCOM managed instance is created. A NAT gateway is needed for outbound internet access from the SCOM Managed Instance subnet. For more information, see [What is Virtual Network NAT?](/azure/virtual-network/nat-gateway/nat-overview). -->[!NOTE] ->The SCOM Managed Instance requires outbound Internet access for communication with dependent endpoints. We recommend to use a NAT Gateway for this purpose. However, if there is an already established outbound internet access through a firewall, you can skip the creation of a NAT Gateway. --To create a NAT gateway for a SCOM Managed Instance subnet, follow these steps: --1. Create a NAT gateway in the same region where the virtual network is present. -1. Create a NAT gateway in the same subscription that you use for SCOM Managed Instance. -1. Create a public IP. -- :::image type="NAT gateway" source="media/create-separate-subnet-in-vnet/nat-gateway-inline.png" alt-text="Screenshot that shows public IP information for a NAT gateway." lightbox="media/create-separate-subnet-in-vnet/nat-gateway-expanded.png"::: --1. In the subnet section, select a virtual network and subnet for SCOM Managed Instance. --## Next steps --- [Create SQL Managed Instance](create-sql-managed-instance.md) |
| azure-monitor | Create Sql Managed Instance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/create-sql-managed-instance.md | - Title: Create an Azure SQL managed instance -description: This article describes how to create a SQL managed instance in a dedicated subnet of a virtual network. --- Previously updated : 05/22/2024------# Create an Azure SQL managed instance --This article describes how to create a SQL managed instance in a dedicated subnet of a virtual network. Peer your Azure Monitor SCOM Managed Instance subnet and Azure SQL Managed Instance subnet. -->[!NOTE] -> To learn about the SCOM Managed Instance architecture, see [Azure Monitor SCOM Managed Instance](overview.md). --## Create and configure a SQL managed instance --Before you create a SCOM Managed Instance, create a SQL managed instance. For more information, see [Create a SQL managed instance](/azure/azure-sql/managed-instance/instance-create-quickstart?view=azuresql&preserve-view=true). -->[!NOTE] ->You can reuse your existing SQL managed instance if that matches the requirement. However, you need to configure it to work for SCOM Managed Instance. --We recommend the following settings for creating a SQL managed instance: --- **Resource Group**: Create a new resource group for SQL Managed Instance. A best practice is to create a new resource group for large Azure resources.-- **Managed Instance name**: Choose a unique name. This name is used while you create a SCOM Managed Instance to refer to this SQL managed instance.-- **Region**: Choose the region close to you. There's no strict requirement on region for the instance, but we recommend the closest region for latency purposes.-- **Compute+Storage**: General Purpose (Gen5) with eight cores is the default. However, customers with less than 2000 workloads or customers who are validating SCOM Managed Instance in their test environments can use a SQL MI instance with four vCores.-- **Authentication Method**: Select **SQL Authentication**. Enter the credentials that you want to use for accessing the SQL managed instance. These credentials don't refer to any that you've created so far.-- >[!Note] - >Choosing SQL Authentication mode is temporary. Later in [Step 5](/system-center/scom/create-user-assigned-identity?view=sc-om-2022#set-the-microsoft-entra-admin-value-in-the-sql-managed-instance&preserve-view=true) it will be updated to use Microsoft Entra ID with MSI. --- **VNet**: This SQL managed instance needs to have direct connectivity (line of sight) to the SCOM Managed Instance that you create in the future. Choose a virtual network that you'll eventually use for your SCOM Managed Instance. If you choose a different virtual network, ensure that it has connectivity to the SCOM Managed Instance virtual network by peering both the SCOM Managed Instance virtual network and the SQL Managed Instance virtual network.-- The subnet that you provide to SQL Managed Instance has to be dedicated (delegated) to the SQL managed instance. The provided subnet can't be used to house any other resources. -- By design, a managed instance needs a minimum of 32 IP addresses in a subnet. As a result, you can use a minimum subnet mask of /27 when you define your subnet IP ranges. For more information, see [Determine required subnet size and range for Azure SQL Managed Instance](/azure/azure-sql/managed-instance/vnet-subnet-determine-size?view=azuresql&preserve-view=true). -- **Connection Type**: By default, the connection type is **Proxy**.-- **Public Endpoint**: This setting can be either **Enabled** or **Disabled**. To use Power BI reporting, you need to enable the public endpoint.-- If the SQL Managed Instance virtual network is different from the SCOM Managed Instance virtual network: -- - Create an inbound NSG rule on the SQL Managed Instance subnet to allow traffic from the SCOM Managed Instance subnet to port 3342 and 1433 on the SQL Managed Instance subnet. For more information, see [Configure a public endpoint in Azure SQL Managed Instance](/azure/azure-sql/managed-instance/public-endpoint-configure?view=azuresql&preserve-view=true). - - Peer your SQL Managed Instance virtual network with the one in which SCOM Managed Instance is present. --For the rest of the settings on the other tabs, you can leave them as default or change them according to your requirements. --> [!NOTE] -> Creation of a new SQL managed instance can take up to six hours. --## Next steps --- [Create a key vault ](create-key-vault.md) |
| azure-monitor | Create Static Ip | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/create-static-ip.md | - Title: Create a static IP for Azure Monitor SCOM Managed Instance -description: This article describes how to create a static IP for load balancer in a dedicated subnet of SCOM Managed Instance. --- Previously updated : 05/22/2024------# Create a static IP for Azure Monitor SCOM Managed Instance --This article describes how to create a static IP for a load balancer in a dedicated subnet of Azure Monitor SCOM Managed Instance. Additionally, insert an entry into the Domain Name System (DNS) server, and ensure that the DNS name resolves to the DNS name (`DNSHostName`) of the group managed service account (gMSA). Get the DNS host name of the gMSA account from [step 6](create-group-managed-service-account.md). -->[!NOTE] -> To learn about the SCOM Managed Instance architecture, see [Azure Monitor SCOM Managed Instance](overview.md). --## Create a static IP and configure the DNS name --For all the System Center Operations Manager components to communicate with the load balancer that the SCOM Managed Instance service creates, you need a static IP and DNS name for the load balancer's front-end configuration. --Ensure that the static IP is in the subnet that you created for SCOM Managed Instance. Create a DNS name (according to your organization's policy) for the static IP. The DNS name must resolve to the gMSA account DNS Host name. For the DNS Host name of the gMSA account, run the following command: --```powershell -Get-ADServiceAccount -Identity <gMSA Account Name> -Properties DNSHostName,Enabled,PrincipalsAllowedToRetrieveManagedPassword,SamAccountName,ServicePrincipalNames -Credential <DomainUserCredentials> -``` --Replace the gMSA account name and domain credentials with the right values in the preceding command. --Create the forward lookup entry in DNS by creating an association between the IP and the DNS name. --- If you use the DNS infrastructure of an Active Directory domain, open the DNS manager, connect to the DNS server, and create an association between the IP and the DNS name (forward lookup).-- If you use a different DNS software, create the forward lookup entry in the DNS server to create an association between the IP and the DNS name (forward lookup).---> [!IMPORTANT] -> To minimize the need for extensive communication with both your Active Directory admin and the network admin, see [Self-verification](self-verification-steps.md). The article outlines the procedures that the Active Directory admin and the network admin use to validate their configuration changes and ensure their successful implementation. This process reduces unnecessary back-and-forth interactions from the Operations Manager admin to the Active Directory admin and the network admin. This configuration saves time for the admins. --## Next steps --- [Configure the network firewall](configure-network-firewall.md) |
| azure-monitor | Create User Assigned Identity | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/create-user-assigned-identity.md | - Title: Create a user-assigned identity for SCOM Managed Instance -description: This article describes how to create a user-assigned identity, provide admin access to Azure SQL Managed Instance, and grant get and list access on a key vault. --- Previously updated : 05/22/2024------# Create a user-assigned identity for Azure Monitor SCOM Managed Instance --This article describes how to create a user-assigned identity, provide admin access to Azure SQL Managed Instance, and grant **Get** and **List** access on a key vault. -->[!NOTE] -> To learn about the Azure Monitor SCOM Managed Instance architecture, see [Azure Monitor SCOM Managed Instance](overview.md). --## Create a managed service identity --The managed service identity (MSI) provides an identity for applications to use when they're connecting to resources that support Microsoft Entra ID authentication. For SCOM Managed Instance, a managed identity replaces the traditional four System Center Operations Manager service accounts. It's used to access the Azure SQL Managed Instance database. It's also used to access the key vault. --> [!NOTE] -> - Ensure that you're a contributor in the subscription where you create the MSI. -> - The MSI must have admin permission on SQL Managed Instance and read permission on the key vault that you use to store the domain account credentials. --1. Sign in to the [Azure portal](https://portal.azure.com). Search for and select **Managed Identities**. -- :::image type="Managed Identity in Azure portal" source="media/create-user-assigned-identity/azure-portal-managed-identity.png" alt-text="Screenshot that shows the icon for managed identities in the Azure portal."::: -1. On the **Managed Identities** page, select **Create**. -- :::image type="Managed Identity" source="media/create-user-assigned-identity/managed-identities.png" alt-text="Screenshot that shows Managed Identity."::: -- The **Create User Assigned Managed Identity** pane opens. -1. Under **Basics**, do the following: - - **Project details**: - - **Subscription**: Select the Azure subscription in which you want to create the SCOM Managed Instance. - - **Resource group**: Select the resource group in which you want to create the SCOM Managed Instance. - - **Instance details**: - - **Region**: Select the region in which you want to create the SCOM Managed Instance. - - **Name**: Enter a name for the instance. -- :::image type="Create user assigned managed identity" source="media/create-user-assigned-identity/create-user-assigned-managed-identity.png" alt-text="Screenshot that shows project and instance details for a user-assigned managed identity."::: -1. Select **Next: Tags**. -1. On the **Tags** tab, enter the **Name** value and select the resource. -- Tags help you categorize resources and view consolidated billing by applying the same tags to multiple resources and resource groups. For more information, see [Use tags to organize your Azure resources and management hierarchy](/azure/azure-resource-manager/management/tag-resources?wt.mc_id=azuremachinelearning_inproduct_portal_utilities-tags-tab&tabs=json). -1. Select **Next: Review + create**. -1. On the **Review + create** tab, review all the information that you provided and select **Create**. -- :::image type="Managed identity review" source="media/create-user-assigned-identity/managed-identity-review.png" alt-text="Screenshot that shows the tab for reviewing a managed identity before creation."::: --Your deployment is now created on Azure. You can access the resource and view its details. --### Set the Microsoft Entra admin value in the SQL managed instance --To set the Microsoft Entra admin value in the SQL managed instance that you created in [step 3](create-sql-managed-instance.md), follow these steps: -->[!NOTE] ->You must have Global Administrator or Privileged Role Administrator permissions for the subscription to perform the following operations. -->[!Important] ->Using Groups as Microsoft Entra admin is currently not supported. --1. Open the SQL managed instance. Under **Settings**, select **Microsoft Entra admin**. -- :::image type="Microsoft Entra admin" source="media/create-user-assigned-identity/microsoft-entra-admin.png" alt-text="Screenshot of the pane for Microsoft Entra admin information."::: --1. Select the error-box message to provide **Read** permissions to the SQL managed instance on Microsoft Entra ID. **Grant permissions** pane opens to grant the permissions. -- :::image type="Grant permissions" source="media/create-user-assigned-identity/grant-permissions.png" alt-text="Screenshot of grant permissions."::: --1. Select **Grant Permissions** to initiate the operation and once it is completed, you can find a notification for successfully updating the Microsoft Entra read permissions. -- :::image type="read permissions" source="media/create-user-assigned-identity/read-permissions.png" alt-text="Screenshot of read permissions."::: --1. Select **Set admin**, and search for your MSI. This MSI is the same one that you provided during the SCOM Managed Instance creation flow. You find the admin added to the SQL managed instance. -- :::image type="Microsoft Entra admin" source="media/create-user-assigned-identity/microsoft-entra-inline.png" alt-text="Screenshot of MSI information for Microsoft Entra." lightbox="media/create-user-assigned-identity/microsoft-entra-expanded.png"::: --1. If you get an error after you add a managed identity account, it indicates that read permissions aren't yet provided to your identity. Be sure to provide the necessary permissions before you create your SCOM Managed Instance or else your SCOM Managed Instance creation fails. -- :::image type="SQL Microsoft Entra admin" source="media/create-user-assigned-identity/sql-microsoft-entra-inline.png" alt-text="Screenshot that shows successful Microsoft Entra authentication." lightbox="media/create-user-assigned-identity/sql-microsoft-entra-expanded.png"::: --For more information about permissions, see [Directory Readers role in Microsoft Entra ID for Azure SQL](/azure/azure-sql/database/authentication-aad-directory-readers-role?view=azuresql&preserve-view=true). --## Grant permission on the key vault --To grant permission on the key vault that you created in [step 4](create-key-vault.md), follow these steps: --1. Go to the key vault resource that you created in [step 4](create-key-vault.md) and select **Access policies**. --1. On theΓÇ»**Access policies** page, select **Create**. -- :::image type="Access Policies" source="media/create-user-assigned-identity/access-policies.png" alt-text="Screenshot that shows the Access policies page."::: --1. On the **Permissions** tab, select the **Get** and **List** options. -- :::image type="Create Access policy" source="media/create-user-assigned-identity/create-access-policy.png" alt-text="Screenshot that shows the Create access policy page."::: --1. Select **Next**. --1. On the **Principal** tab, enter the name of the MSI you created. --1. Select **Next**. Select the same MSI that you used in the SQL Managed Instance admin configuration. -- :::image type="Principal tab" source="media/create-user-assigned-identity/principal.png" alt-text="Screenshot that shows the Principal tab."::: --1. SelectΓÇ»**Next** > **Create**. --## Next steps --- [Create a gMSA account](create-group-managed-service-account.md) |
| azure-monitor | Customizations On Scom Managed Instance Management Servers | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/customizations-on-scom-managed-instance-management-servers.md | - Title: Customizations on Azure Monitor SCOM Managed Instance management servers -description: This article describes about the Customizations on Azure Monitor SCOM Managed Instance management servers. --- Previously updated : 05/22/2024------# Customizations on Azure Monitor SCOM Managed Instance management servers --Azure Monitor SCOM Managed Instance is a PaaS service hosted on Azure. As part of instance creation, Azure creates a Virtual machine scale set cluster and commissions VMs inside that Virtual machine scale set cluster. However, if you have a requirement to access the management server and customize some aspect of it, such as applying a post-deployment configuration, installing a Management Pack or software, or carry out any other management operation, use the [Script for Customization](https://download.microsoft.com/download/0/1/5/015ee8fc-e3ab-4842-8c2a-3acebb0e54f5/RunCustomizations.zip). --The script internally uses Azure custom script extensions for making the customizations. Once you run the script, it downloads and executes the customization script on the SCOM Managed Instance Management Servers. --## Requirements to run the script --- Azure CLI (Installed and Logged In)-- PowerShell 5.1 or later--You can run the script on a machine, which has PowerShell running. Sign into the Azure portal Microsoft account that is a part of the SCOM Managed Instance subscription. Run the following cmdlets in the PowerShell console: --```powershell -ΓÇ£az loginΓÇ¥ -ΓÇ£az account set ΓÇôsubscription ΓÇ£NameOf SubscriptionΓÇ¥ -``` --The script needs the following inputs: --|Input | Description | -||| -| **ResourceGroupName** | The name of the resource group that contains the SCOM Managed Instance management servers Virtual machine scale set. | -| **VMSSName** | The name of the SCOM Managed Instance management servers Virtual machine scale set to apply customizations to. | -| **FileURI** | The parameter should point to an accessible URI where the PowerShell script to be executed is hosted. You can upload the customization script to sources such as Azure Blob Storage, GitHub, or any other platform that provides storage. For example, see https://raw.githubusercontent.com/Azure-Samples/compute-automation-configurations/master/automate-iis.ps1. | -| **CommandToExecute** | This parameter specifies the command to execute the customization script file. For example, you can use a command such as: PowerShell `ExecutionPolicy Unrestricted -File automate-iis.ps1`. | --Here's an example of a command to run the script (replace the parameters in quotation marks with your own values): --``` -.\RunCustomization.ps1 ΓÇô ResourceGroupName ΓÇ£myResourceGroupΓÇ¥ -VMSSName ΓÇ£myVMSSΓÇ¥ -FileURI ΓÇ£https://example.com/myscript.ps1ΓÇ¥ -CommandToExecute ΓÇ£powershell.exe -ExecutionPolicy Unrestricted -File myscript.ps1ΓÇ¥ -``` --If the script runs successfully, deployment gets successful and displays **Deployment finished Successfully** message. --If there's an error in the script, you see **An error occurred during deployment. Please check the above logs for debugging** message. --## Next steps --[Create a SCOM Managed Instance](create-operations-manager-managed-instance.md). |
| azure-monitor | Dashboards On Azure Managed Grafana | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/dashboards-on-azure-managed-grafana.md | - Title: Dashboards on Azure Managed Grafana -description: This article describes how to create a SCOM Managed Instance dashboard on Azure Managed Grafana. --- Previously updated : 05/22/2024------# Dashboards on Azure Managed Grafana --Azure Managed Grafana (AMG) is a data visualization platform, built on top of the Grafana software by Grafana Labs. Grafana helps you bring together metrics, logs, and traces into a single user interface. --Azure Managed Grafana is optimized for the Azure environment and works seamlessly, providing the following integration features: --- Built-in support for [Azure Monitor](/azure/azure-monitor/) and [Azure Data Explorer](/azure/data-explorer/).-- User authentication and access control using Microsoft Entra identities.-- Direct import of existing charts from the Azure portal.--This article describes how to create a SCOM Managed Instance dashboard on Azure Managed Grafana. --## Steps to create a SCOM Managed Instance dashboard on Azure Managed Grafana --To create a SCOM Managed Instance dashboard on Azure Managed Grafana, follow these steps: --### Get started with Azure Managed Grafana (AMG) --1. Create or reuse an Azure Managed Grafana (AMG) with a version 10 on the Azure portal. To create an AMG instance, follow [these steps](/azure/managed-grafana/quickstart-managed-grafana-portal). -2. Enable System assigned managed identity on the AMG instance. -- :::image type="Permissions" source="media/dashboards-on-azure-managed-grafana/grafana-permissions.png" alt-text="Screenshot of grafana permissions."::: -3. Browse to SQL managed instance where SCOM Managed Instance databases are created. Note the SQL managed instance public endpoints and the Database name. --### Assign Permissions --1. On the AMG instance, provide **Grafana Admin** permissions to the users who need access to create dashboards. - >[!NOTE] - >After you set up a dashboard, assign **Grafana Editor** user permission to view, edit and create additional dashboards. -1. Grant permissions to the System managed identity of the Grafana instance on the SQL managed instance database by downloading and running the [PowerShell script](https://go.microsoft.com/fwlink/?linkid=2252607). This script creates a SQL user for Azure Managed Grafana identity. -1. The script accepts details of **Azure Managed Grafana Instance name**, **SCOM MI instance name**, SQL managed instance **Public endpoint** and **Server admin login** credentials of SQL managed instance. --### Configure Data source on AMG --1. Browse to the AMG portal by selecting the AMG instance endpoint. -2. Navigate to **Connections** > **Data sources** and add a data source of type **Microsoft SQL Server**. -3. On the **Settings** page, enter the Database endpoint URL in the **Host** field. -4. Enter the Database name (noted above) in **Database** field. -5. Use **Azure Managed Identity** as the authentication method. -6. Select **Save and test**. --### Import SCOM Managed Instance dashboards in AMG instance --1. Navigate to AMG instance endpoint > **Dashboards** > **New** > **Import** > **Import via grafana.com** > **Enter 19919** and select **Import**. -2. Browse to the imported dashboards. -3. On the top of the dashboard, choose the created Data source and the respective database in the dashboard settings. |
| azure-monitor | Migrate To Operations Manager Managed Instance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/migrate-to-operations-manager-managed-instance.md | - Title: Migrate from Operations Manager on-premises to Azure Monitor SCOM Managed Instance -description: This quickstart describes how to migrate from Operations Manager on-premises to Azure Monitor SCOM Managed Instance. --- Previously updated : 05/22/2024------# Quickstart: Migrate from Operations Manager on-premises to Azure Monitor SCOM Managed Instance --This quickstart provides the process of migration from Operations Manager on-premises to Azure Monitor SCOM Managed Instance. --## Prerequisites --1. Verify that your current Operations Manager agent version is supported to multi-homed with SCOM Managed Instance. -- >[!Note] - >Agent versions 2022 and 2019 are supported. -2. Deploy a SCOM Managed Instance instance. --3. Configure user roles and permissions in SCOM Managed Instance. --4. Import management packs and overrides from your current Operations Manager environment. --5. Configure Run-As account for management packs. --6. If you use multiple management servers in SCOM Managed Instance, deploy a small set of pilot agents and verify failover behavior between management servers in SCOM Managed Instance. --7. Identify an application or service that is currently monitored by Operations Manager on-premises. Multihome its agents to start reporting to SCOM Managed Instance and Operations Manager on-premises and perform the following steps: -- - Verify that you see the same monitoring data for the service in both your current Operations Manager environment and SCOM Managed Instance. - - Configure groups. - - Configure notification subscriptions. - - Configure reporting. - - Configure Dashboards. - - Configure agent-specific settings. - - Configure Agent primary and failover management server. -- Repeat the service-based migration according to step 6 for each application/service. --8. Configure and verify connectors. - For example: Configure and verify connectors for ITSM tools and automation. --9. Once all the monitoring data, reporting, notification, connectors, permissions, and groups are verified in SCOM Managed Instance, uninstall agent configuration for the old Operations Manager environment. -->[!Note] ->Overrides target a specific instance of a class and may not work after migration of management packs, as instance ID might change between management groups. Group membership configured on specific instances might not work either. --Provided the migration details for the following artifacts as an example: --- Management Packs and Overrides -- Dashboard-- User roles and permissions -- Notification subscriptions -- Groups -- 1P Integrations -- Agent mapping and configuration--[Here's](#supported-artifacts-for-migration) the complete list of supported artifacts. --## Migrate from on-premises to SCOM Managed Instance --Select the required artifact to view the migration details from on-premises to SCOM Managed Instance: --# [Management Packs and Overrides](#tab/mp-overrides) --1. Run the below script to create an inventory of all existing Management Packs deployed in Operations -- ```powershell - Get-SCOMManagementPack | Select-Object DisplayName, Name, Sealed, Version, LastModified | Sort-Object DisplayName | Format-Table - ``` --2. Export [unsealed Management Packs](/system-center/scom/manage-mp-import-remove-delete?#how-to-export-an-operations-manager-management-pack): -- ```powershell - Get-SCOMManagementPack | Where{ $_.Sealed -eq $false } | Export-SCOMManagementPack -Path "C:\Temp\Unsealed Management Packs" - ``` --3. Import [Sealed Management Packs in SCOM Managed Instance](/system-center/scom/manage-mp-import-remove-delete?#importing-a-management-pack). -- - You must have a copy of any custom sealed Management Packs that you need to import. --4. Import [unsealed (exported) Management Packs in SCOM Managed Instance](/system-center/scom/manage-mp-import-remove-delete?#import-a-management-pack-from-disk). --### Post migration validation --Follow these steps to validate the migration of Groups and Data collection. --1. **In Groups**: Go to **Authoring** workspace in the Operations Manager console and select **Groups**. Review the membership of any groups created by the Management Packs and verify that they've been populated with the correct objects. --1. **In Data collection**: To verify that the intended objects are discovered, go to **Monitoring** in the Operations Manager console and review the views for each Management Pack. -- 1. Verify that the state views are populated with the correct objects (Servers, Databases, Websites, and so on) and they're being monitored (Health State isn't **Unmonitored**). -- 1. Check the performance views and verify that the performance data has been collected. --# [Dashboard](#tab/dashboard) --Operations Manager supports the following four types of data visualizations. -Below is a quick summary of what can be migrated: --| Types of data visualizations | Can be migrated to SCOM Managed Instance | Recommendations | -|||||| -| Dashboards/Views that are available in Management Pack | Yes | Operations console | -| Dashboards/Views created on Operations console | Yes | Operations console | -| Reports that are available in Management Pack | No | Power BI reports | -| Reports that are created on Operations console | No | Power BI reports | --- For Dashboards/Views that's available in Management Pack, you can view the data similar to the one in Operations Manager on-premises (as they're built into Management Pack).-- For Dashboards/Views created on the Operations console, you need to reconfigure custom dashboards and views in SCOM Managed Instance.-- For (SSRS) reports that are available in Management Pack and on the Operations console, you need to reconfigure all reports on Power BI as the Reporting Server doesn't exist in SCOM Managed Instance. --# [User roles and permissions](#tab/userrole-permission) -->[!Note] -> No 1:1 mapping is permitted between user roles in SCOM Managed Instance to Operations Manager on-premises. --In SCOM Managed Instance, only two user roles are available, whereas Operations Manager on-premises has 10 user profile roles. For more information, see [Operations associated with user role profiles](/system-center/scom/manage-security-create-runas-account). --Use the following mapping chart to provide access on SCOM Managed Instance with appropriate permissions: --### Mapping chart --| Operations Manager on-premises | SCOM Managed Instance | -||--| -| Report Operator | Reader | -| Read-Only Operator | Reader | -| Operator | Reader | -| Advanced Operator | Reader | -| Application Monitoring Operator | Reader | -| Author | Contributor | -| Administrator | Contributor | -| Report Security Administrator | Contributor | -| Read-only Administrator | Contributor | -| Delegated administrator | Contributor | --1. Export the list of user roles and users in each role. -- ```powershell - # This script will export the SCOM User Roles to CSV and Text File Format. - # -- - # Outputs the file to the current users desktop - # -- - $UserRoles = @() - $UserRoleList = Get-SCOMUserRole - Write-Output "Processing User Role: " - foreach ($UserRole in $UserRoleList) - { - Write-Output " $UserRole" - $UserRoles += New-Object -TypeName psobject -Property @{ - Name = $UserRole.Name; - DisplayName = $UserRole.DisplayName; - Description = $UserRole.Description; - Users = ($UserRole.Users -join "; "); - } - } - $UserRolesOutput = $UserRoles | Select-Object Name, DisplayName, Description, Users - # Table Output - $UserRolesOutput | Format-Table -AutoSize - # CSV Output - $UserRolesOutput | Export-CSV -Path "$env:USERPROFILE`\Desktop\UserRoles.csv" -NoTypeInformation - # Text File Output - $UserRolesOutput | Out-File "$env:USERPROFILE`\Desktop\UserRoles.txt" -Width 4096 - ``` --2. With the exported list and mapping recommendations, manually add the users to the respective Azure (SCOM Managed Instance) user roles. --# [Notification subscriptions](#tab/notification-subscriptions) --SCOM Managed Instance supports the following notification channels: --- Emails-- SMS/Text--Export the **Notifications Internal Library** Management pack from the Operations Manager Management Group to migrate all your notification settings and import them to SCOM Managed Instance. --After you migrate the notification configuration to SCOM Managed Instance, copy the local files that are used in Command Channels to the same path on all Management Servers in the Notification Resource Pool. If you migrate from Operations Manager 2016, configuring Notification Channel requires more steps. --Metadata for all notifications/subscriptions is stored under the unsealed management pack. If you migrate the management pack, the notifications and subscriptions are also migrated. --Microsoft.SystemCenter.Notifications.Internal - 10.22.10113.0 - Notifications Internal Library -->[!Note] ->Notifications/Subscriptions depend on Run as account. Configure the accounts/profiles in a newer environment before you migrate the management pack. --# [Groups](#tab/groups) --Groups are migrated as part of Management Packs. For more information, see **step 5** in the **Management Packs and Overrides** tab. --# [1P Integrations](#tab/integrations) --The following integrations are supported: --- Service Manager -- System Center Virtual Machine Manager-- Azure Monitor --System Center Orchestrator to Azure Automation is the recommendation on Azure equivalent services. --# [Agent mapping and configuration](#tab/agent-mapping-config) --To migrate from System Center Operations Manager agent to SCOM Managed Instance, see [High level overview of upgrading agents and running two environments](/system-center/scom/deploy-upgrade-overview#high-level-overview-of-upgrading-agents-and-running-two-environments-1). -- --### Supported artifacts for migration --- Management Packs and Overrides -- Dashboard-- User roles and permissions -- Notification subscriptions -- Groups -- 1P Integrations -- Agent mapping and configuration-- Gateways -- Custom and 3P Solutions --## Next steps --[Create a SCOM Managed Instance on Azure](create-operations-manager-managed-instance.md). |
| azure-monitor | Monitor Azure Off Azure Vm With Scom Managed Instance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/monitor-azure-off-azure-vm-with-scom-managed-instance.md | - Title: Monitor Azure and Off-Azure Virtual machines with Azure Monitor SCOM Managed Instance extensions. -description: Azure Monitor SCOM Managed Instance provides a cloud-based alternative for Operations Manager users providing monitoring continuity for cloud and on-premises environments across the cloud adoption journey. --- Previously updated : 07/05/2024------# Monitor Azure and Off-Azure Virtual machines with Azure Monitor SCOM Managed Instance extensions --Azure Monitor SCOM Managed Instance provides a cloud-based alternative for Operations Manager users providing monitoring continuity for cloud and on-premises environments across the cloud adoption journey. --## SCOM Managed Instance Agent --In Azure Monitor SCOM Managed Instance, an agent is a service that is installed on a computer that looks for configuration data and proactively collects information for analysis and reporting, measures the health state of monitored objects like an SQL database or logical disk, and executes tasks on demand by an operator or in response to a condition. It allows SCOM Managed Instance to monitor Windows operating systems and the components installed on them, such as a website or an Active Directory domain controller. --In Azure Monitor SCOM Managed Instance, monitoring agent is installed and managed by Azure Virtual Machine Extensions, named **SCOMMI-Agent-Windows**. For more information on VM extensions, see [Azure Virtual Machine extensions and features](/azure/virtual-machines/extensions/overview). --## Supported Windows versions for monitoring --Following are the supported Windows versions that can be monitored using SCOM Managed Instance: --- Windows 2022-- Windows 2019-- Windows 2016-- Windows 2012 R2-- Windows 2012--For more information, see [Operations Manager System requirements](/system-center/scom/system-requirements). --## Use Arc channel for Agent configuration and monitoring data --Azure Arc can unlock connectivity and monitor on-premises workloads. Azure based manageability of monitoring agents for SCOM Managed Instance helps you to reduce operations cost and simplify agent configuration. The following are the key capabilities of SCOM Managed Instance monitoring over Arc channel: --- Discover and Install SCOM Managed Instance agent as a VM extension for Arc connected servers.-- Monitor Arc connected servers and hosted applications by reusing existing System Center Operations Manager management packs.-- Monitor Arc connected servers and applications, which are in untrusted domain/workgroup. -- Azure based SCOM Managed Instance agent management (such as patch, push management pack rules and monitors) via Arc connectivity.--## Prerequisites --Following are the prerequisites required to monitor Virtual machines: --1. Line of sight to Nexus endpoint. - For example, `Test-NetConnection -ComputerName westus.workloadnexus.azure.com -Port 443` -2. Line of sight to SCOMMI LB - For example, `Test-NetConnection -ComputerName <LBDNS> -Port 5723` -3. Ensure to install [.NET Framework 4.7.2](https://support.microsoft.com/topic/microsoft-net-framework-4-7-2-offline-installer-for-windows-05a72734-2127-a15d-50cf-daf56d5faec2) or higher on desired monitoring endpoints. --To Troubleshooting connectivity problems, see [Troubleshoot issues with Azure Monitor SCOM Managed Instance](/system-center/scom/troubleshoot-scom-managed-instance?view=sc-om-2022#scenario-agent-connectivity-failing&preserve-view=true). --## Install an agent to monitor Azure and Arc-enabled servers -->[!NOTE] ->Agent doesn't support multihoming to multiple SCOM Managed Instances. --To install SCOM Managed Instance agent, follow these steps: --1. On the desired SCOM Managed Instance **Overview** page, under Manage, select **Monitored Resources**. --2. On the **Monitored Resources** page, select **New Monitored Resource**. -- :::image type="content" source="media/monitor-azure-off-azure-vm-with-scom-managed-instance/monitored-resources-inline.png" alt-text="Screenshot that shows the Monitored Resource page." lightbox="media/monitor-azure-off-azure-vm-with-scom-managed-instance/monitored-resources-expanded.png"::: -- **Add a Monitored Resource** page opens listing all the unmonitored virtual machines. - - :::image type="content" source="media/monitor-azure-off-azure-vm-with-scom-managed-instance/add-monitored-resource-inline.png" alt-text="Screenshot that shows add a monitored resource page." lightbox="media/monitor-azure-off-azure-vm-with-scom-managed-instance/add-monitored-resource-expanded.png"::: --3. Select the desired resource and then select **Add**. -- :::image type="content" source="media/monitor-azure-off-azure-vm-with-scom-managed-instance/add-resource-inline.png" alt-text="Screenshot that shows the Add a resource option." lightbox="media/monitor-azure-off-azure-vm-with-scom-managed-instance/add-resource-expanded.png"::: --4. On the **Add Monitored Resources** window, enable **Auto upgrade**, review the selections and select **Add**. - - :::image type="content" source="media/monitor-azure-off-azure-vm-with-scom-managed-instance/install-inline.png" alt-text="Screenshot that shows Install option." lightbox="media/monitor-azure-off-azure-vm-with-scom-managed-instance/install-expanded.png"::: --## Manage agent configuration installed on Azure and Arc-enabled servers --### Upgrade an agent -->[!NOTE] ->Upgrading an agent is a one time effort for existing monitored resources. Further updates will be applied automatically to these resources. For new resources, you can choose this option when you add them to the SCOM Managed Instance. --To upgrade the agent version, follow these steps: --1. Sign in to the [Azure portal](https://portal.azure.com/). Search and select **SCOM Managed Instance**. -2. On the **Overview** page, under **Manage**, select **SCOM managed instances**. -3. On the **SCOM managed instances** page, select the desired SCOM managed instance. -4. On the desired SCOM Managed Instance **Overview** page, under **Manage**, select **Monitored Resources**. -5. On the **Monitored Resources** page, select Ellipsis button **(…)**, which is next to your desired monitored resource, and select **Configure**. - - :::image type="content" source="media/monitor-azure-off-azure-vm-with-scom-managed-instance/resource-inline.png" alt-text="Screenshot that shows monitored resources." lightbox="media/monitor-azure-off-azure-vm-with-scom-managed-instance/resource-expanded.png"::: -- :::image type="content" source="media/monitor-azure-off-azure-vm-with-scom-managed-instance/configure-agent-inline.png" alt-text="Screenshot that shows agent configuration option." lightbox="media/monitor-azure-off-azure-vm-with-scom-managed-instance/configure-agent-expanded.png"::: --6. On the **Configure Monitored Resource** page, enable **Auto upgrade** and then select **Configure**. -- :::image type="content" source="media/monitor-azure-off-azure-vm-with-scom-managed-instance/configure-monitored-resource-inline.png" alt-text="Screenshot that shows configuration option." lightbox="media/monitor-azure-off-azure-vm-with-scom-managed-instance/configure-monitored-resource-expanded.png"::: --### Remove an agent --To remove the agent version, follow these steps: --1. Sign in to the [Azure portal](https://portal.azure.com/). Search and select **SCOM Managed Instance**. -2. On the **Overview** page, under **Manage**, select **SCOM managed instances**. -3. On the **SCOM managed instances** page, select the desired SCOM Managed Instance. -4. On the desired SCOM Managed Instance **Overview** page, under **Manage**, select **Monitored Resources**. -5. On the **Monitored Resources** page, select Ellipsis button **(…)**, which is next to your desired monitored resource, and select **Remove**. -- :::image type="content" source="media/monitor-azure-off-azure-vm-with-scom-managed-instance/delete-agent-inline.png" alt-text="Screenshot that shows delete agent option." lightbox="media/monitor-azure-off-azure-vm-with-scom-managed-instance/delete-agent-expanded.png"::: --6. On the **Remove Monitored Resources** page, enter *remove* under **Enter "remove" to confirm "removal"** and then select **Remove**. -- :::image type="content" source="media/monitor-azure-off-azure-vm-with-scom-managed-instance/delete-monitored-resource-inline.png" alt-text="Screenshot that shows delete option." lightbox="media/monitor-azure-off-azure-vm-with-scom-managed-instance/delete-monitored-resource-expanded.png"::: --## Multihome On-premises virtual machines --Multihoming allows you to monitor on-premises virtual machines by retaining the existing connection with Operations Manager (On-premises) and establishing a new connection with SCOM Managed Instance. When a virtual machine that is monitored by Operations Manager (on-premises) is multihomed with SCOM Managed Instance, the Azure extensions replace existing monitoring agent (*Monagent.msi*) with the latest version of SCOM Managed Instance agent. During this operation, the connection to Operations Manager (on-premises) is retained automatically to ensure continuity in monitoring process. -->[!Note] ->- To multihome your on-premises your virtual machines, they must be Arc-enabled. ->- Multihome with Operations Manager is supported only using Kerberos authentication. ->- Multihome is limited only to two connections, one with SCOM Managed Instance and another with Operations Manager. A virtual machine cannot be multihomed to multiple Operations Manager Management Groups or multiple SCOM Managed Instances. --### Multihome supported scenarios --Multihome is supported with the following Operations Manager versions using the SCOM Managed Instance extension-based agent: --| -|Operations Manager 2012|Operations Manager 2016|Operations Manager 2019|Operations Manager 2022| -|||||| -|Supported |✅|✅|✅|✅| -->[!NOTE] ->Agents (Monagent) that are installed by Operations Manager (on-premises) aren't supported to multihome with SCOM Managed Instance. |
| azure-monitor | Monitor Health Scom Managed Instance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/monitor-health-scom-managed-instance.md | - Title: Azure Monitor SCOM Managed Instance Service Health Dashboard -description: With Azure Monitor SCOM Managed Instance Service Health Dashboard, you can now view the health of SCOM Managed Instance service in real-time. --- Previously updated : 05/22/2024------# Azure Monitor SCOM Managed Instance Service Health Dashboard --With Azure Monitor SCOM Managed Instance Service Health Dashboard, you can now view the health of SCOM Managed Instance service in real-time. --## Key capabilities --Resource Health capability allows you to do the following: --- Monitors your resource and lets you know if itΓÇÖs running as expected.-- Help you diagnose and get support for service problems that affect your Azure resources.-- Reports on the current and past health of your resources.--For more information, see [Azure Resource Health overview](/azure/service-health/resource-health-overview?WT.mc_id=Portal-Microsoft_Azure_Health). --To troubleshoot the problems in your service, see the following: --- [Troubleshoot issues with Azure Monitor SCOM Managed Instance](./troubleshoot-scom-managed-instance.md).-- [Troubleshoot commonly encountered errors while validating input parameters](./troubleshooting-input-parameters-scom-managed-instance.md).-- Use the [troubleshooting tool](https://portal.azure.com/#view/Microsoft_Azure_Support/TroubleshootV2Blade/assetId/%2Fsubscriptions%2F5a87dd7e-200a-4e94-8cd6-a9461de63755%2FresourceGroups%2Fsaipwus2rg1%2Fproviders%2FMicrosoft.Scom%2FmanagedInstances%2Fsaipscom1) to get recommended solutions. |
| azure-monitor | Monitor Linux Machines | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/monitor-linux-machines.md | - Title: Monitor Linux machines -description: This article describes how it monitor Linux machines. --- Previously updated : 06/10/2024------# Monitor Linux machines --Azure Monitor SCOM Managed Instance provides a cloud-based alternative for Operations Manager users providing monitoring continuity for cloud and on-premises environments across the cloud adoption journey. -->[!NOTE] ->- Linux monitoring is supported only via Managed Gateways. ->- Azure and Arc-enabled Linux machines aren't supported. --With SCOM Managed Instance, you can monitor Linux workloads that are on-premises and behind a gateway server. At this stage, we don't support monitoring Linux VMs hosted in Azure. For more information, see [How to monitor on-premises Linux VMs](/system-center/scom/manage-deploy-crossplat-agent-console). |
| azure-monitor | Monitor Off Azure Vm With Scom Managed Instance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/monitor-off-azure-vm-with-scom-managed-instance.md | - Title: Monitor Off-Azure Virtual machines with Azure Monitor SCOM Managed Instance -description: This article describes how it monitor Azure and Off-Azure virtual machines with SCOM Managed Instance. --- Previously updated : 07/17/2024------# Monitor Off-Azure Virtual machines with Azure Monitor SCOM Managed Instance --Azure Monitor SCOM Managed Instance provides a cloud-based alternative for Operations Manager users providing monitoring continuity for cloud and on-premises environments across the cloud adoption journey. --## SCOM Managed Instance Agent --In Azure Monitor SCOM Managed Instance, an agent is a service that is installed on a computer that looks for configuration data and proactively collects information for analysis and reporting, measures the health state of monitored objects like an SQL database or logical disk, and executes tasks on demand by an operator or in response to a condition. It allows SCOM Managed Instance to monitor Windows operating systems and the components installed on them, such as a website or an Active Directory domain controller. --## Support for Azure and Off-Azure workloads --One of the most important monitoring scenarios is that of on-premises (off-Azure) workloads that unlock SCOM Managed Instance as a true **Hybrid monitoring solution**. --The following are the supported monitoring scenarios: --|Type of endpoint|Trust|Experience| -|||| -|Line of sight on-premises agent|Trusted|OpsConsole| -|Line of sight on-premises agent|Untrusted|Managed Gateway and OpsConsole| -|No Line of sight on-premises agent|Trusted/Untrusted|Managed Gateway and OpsConsole| --SCOM Managed Instance users will be able to: --- Set up and manage Gateways on Arc-enabled servers from SCOM Managed Instance portal.-- Set high availability at Gateway plane for agent failover as described in [Designing for High Availability and Disaster Recovery](/system-center/scom/plan-hadr-design).---## Supported scenarios --The following are the supported monitoring scenarios: --- On-premises virtual machines with no Line of sight connectivity (must use managed Gateway) to Azure-- On-premises virtual machines that have Line of sight connectivity to Azure--## Prerequisites --Following are the prerequisites required on desired monitoring endpoints: --1. Confirm the Line of sight between SCOM Managed Instance and desired monitoring endpoints by running the following command. Obtain LB DNS (Load balancer DNS) information by navigating to SCOM Managed Instance > **Overview** > **Properties** > **Load balancer** > **DNS Name**. -- ``` - Test-NetConnection -ComputerName <Load balancer DNS> -Port 5723 - ``` -2. Ensure to install [.NET Framework 4.7.2](https://support.microsoft.com/topic/microsoft-net-framework-4-7-2-offline-installer-for-windows-05a72734-2127-a15d-50cf-daf56d5faec2) or higher on desired monitoring endpoints. -3. Ensure TLS 1.2 or higher is enabled. --To Troubleshooting connectivity problems, see [Troubleshoot issues with Azure Monitor SCOM Managed Instance](troubleshoot-scom-managed-instance.md). --## Install SCOM Managed Instance Gateway --Managed Gateway can be installed on Arc-enabled servers enabling it to relay monitoring data from air-gapped and network isolated servers to SCOM Managed Instance. --To install SCOM Managed Instance gateway, follow these steps: --1. Sign in to the [Azure portal](https://portal.azure.com/). Search and select **SCOM Managed Instance**. -2. On the **Overview** page, under **Manage**, select **SCOM managed instances**. -3. On the **SCOM managed instances** page, select the desired SCOM managed instance. -4. On the desired SCOM managed instance **Overview** page, under **Manage**, select **Managed Gateway**. -5. On the **Managed Gateways** page, select **New Managed Gateway**. -- :::image type="content" source="media/monitor-off-azure-vm-with-scom-managed-instance/new-managed-gateway-inline.png" alt-text="Screenshot that shows new managed gateway." lightbox="media/monitor-off-azure-vm-with-scom-managed-instance/new-managed-gateway-expanded.png"::: -- **Add a Managed Gateway** page opens listing all the Azure arc virtual machines. -- >[!NOTE] - >SCOM Managed Instance Managed Gateway can be configured on Arc-enabled machines only. -- :::image type="content" source="media/monitor-off-azure-vm-with-scom-managed-instance/add-managed-gateway-inline.png" alt-text="Screenshot that shows add a managed gateway option." lightbox="media/monitor-off-azure-vm-with-scom-managed-instance/add-managed-gateway-expanded.png"::: --6. Select the desired virtual machine and then select **Add**. -- :::image type="content" source="media/monitor-off-azure-vm-with-scom-managed-instance/add-inline.png" alt-text="Screenshot that shows Add managed gateway." lightbox="media/monitor-off-azure-vm-with-scom-managed-instance/add-expanded.png"::: --7. On the **Add Monitored Resources** window, review the selections and select **Add**. -- :::image type="content" source="media/monitor-off-azure-vm-with-scom-managed-instance/install-gateway-inline.png" alt-text="Screenshot that shows Install managed gateway page." lightbox="media/monitor-off-azure-vm-with-scom-managed-instance/install-gateway-expanded.png"::: --### Delete a Gateway --To delete a Gateway, follow these steps: --1. Sign in to the [Azure portal](https://portal.azure.com/). Search and select **SCOM Managed Instance**. -2. On the **Overview** page, under **Manage**, select **SCOM managed instances**. -3. On the **SCOM managed instances** page, select the desired SCOM managed instance. -4. On the desired SCOM managed instance **Overview** page, under **Manage**, select **Managed Gateways**. -5. On the **Managed Gateways** page, select Ellipsis button **(…)**, which is next to your desired gateway, and select **Delete**. -- :::image type="content" source="media/monitor-off-azure-vm-with-scom-managed-instance/delete-gateway-inline.png" alt-text="Screenshot that shows delete gateway option." lightbox="media/monitor-off-azure-vm-with-scom-managed-instance/delete-gateway-expanded.png"::: --6. On the **Delete SCOM MI Gateway** page, check **Are you sure that you want to delete Managed Gateway?** and then select **Delete**. -- :::image type="content" source="media/monitor-off-azure-vm-with-scom-managed-instance/delete-managed-gateway-inline.png" alt-text="Screenshot that shows delete managed gateway option." lightbox="media/monitor-off-azure-vm-with-scom-managed-instance/delete-managed-gateway-expanded.png"::: --## Managed Gateway configuration --### Configure monitoring of servers via SCOM Managed Instance Gateway --To configure monitoring of air-gapped and network isolated servers through Managed Gateway, follow the steps mentioned in [Install an agent on a computer running Windows by using the Discovery Wizard](/system-center/scom/manage-deploy-windows-agent-console#install-an-agent-on-a-computer-running-windows-by-using-the-discovery-wizard) section. Download and install agent from [here](https://go.microsoft.com/fwlink/?linkid=2251996). -->[!NOTE] ->Operations Manager Console is required for this action. For more information, see [Connect the Azure Monitor SCOM Managed Instance to Ops console](connect-managed-instance-ops-console.md). --## Install agent for Windows virtual machine --To install agent for Windows virtual machine, [download](https://go.microsoft.com/fwlink/?linkid=2251996) and follow these steps. --Before you use either method to manually deploy the agent, ensure the following conditions are met: --- The account that is used to run MSI must have administrative privileges on the computer on which you're installing agent.--- Each agent that is installed with the Setup Wizard or from the command line must be approved by a management group. For more information, see [Process Manual Agent Installations](/system-center/scom/manage-process-manual-agent-install).--- SCOM Managed Instance must be configured to accept agents installed with MSI, or they'll be automatically rejected and therefore not display in the Operations console. For more information, see [Process Manual Agent Installations](/system-center/scom/manage-process-manual-agent-install). If the managed instance is configured to accept manually installed agents after the agents have been manually installed, the agents will display in the console after approximately one hour.--Follow these steps to deploy the SCOM Managed Instance agent with the Agent Setup Wizard: --1. Use local administrator privileges to sign in to the computer where you want to install the agent. --2. On the Operations Manager installation media, double-click **Setup.exe**. --3. In **Optional Installations**, select **Local agent**. --4. On the **Welcome** page, select **Next**. --5. On the **Important Notice** page, review the Microsoft software license terms and select **I Agree**. --6. On the **Destination Folder** page, leave the installation folder set to the default, or select **Change** and type a path, and select **Next**. --7. On the **Agent Setup Options** page, you can choose whether you want to **connect the agent to Operations Manager**. --8. On the **Management Group Configuration** page, do the following: -- a. Enter the name of the SCOM Managed Instance name in the **Management Group Name** field and the Load Balancer DNS name in the **Management Server** field. -- > [!NOTE] - > To use a gateway server, enter the gateway server name in the **Management Server** text box. -- b. Enter a value for **Management Server Port**, or leave the default of 5723. -- c. Enter **Next**. --9. On the **Agent Action Account** page, leave it set to the default of **Local System**, or select **Domain or Local Computer Account**; enter the **User Account**, **Password**, and **Domain or local computer**; and select **Next**. --10. On the **Ready to Install** page, review the settings and select **Install** to display the **Installing Microsoft Monitoring Agent** page. --11. When the **Completing the Microsoft Monitoring Agent Setup Wizard** page appears, select **Finish**. --## Configure monitoring of on-premises servers --To configure monitoring of on-premises servers that have direct connectivity (VPN/ER) with Azure, follow the steps mentioned in [Install an agent on a computer running Windows by using the Discovery Wizard](/system-center/scom/manage-deploy-windows-agent-console#install-an-agent-on-a-computer-running-windows-by-using-the-discovery-wizard) section. -->[!NOTE] ->Operations Manager Console is required for this action. For more information, see [Connect the Azure Monitor SCOM Managed Instance to Ops console](connect-managed-instance-ops-console.md). |
| azure-monitor | Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/overview.md | - Title: About Azure Monitor SCOM Managed Instance -description: This article describes about Azure Monitor SCOM Managed Instance. --- Previously updated : 05/22/2024------# About Azure Monitor SCOM Managed Instance --This article provides you with a quick service overview of Azure Monitor SCOM Managed Instance. --With the integration of SCOM Managed Instance, System Center Operations Manager functionality is now available on Azure. --SCOM Managed Instance is a cloud-based alternative for System Center Operations Manager customers. SCOM Managed Instance provides you with continuous monitoring of your workloads with minimal infrastructure management through migrations or after you enable Azure connectivity for your on-premises environments. --To know about the SCOM Managed Instance Architecture, see [Azure Monitor SCOM Managed Instance](overview.md#architecture). --## Key benefits --The key benefits of SCOM Managed Instance are: --- **Preserves investments in SCOM**: Allows you to preserve your existing System Center Operations Manager investments. SCOM Managed Instance is compatible with all the existing System Center Operations Manager management packs and provides a means to migrate management pack configurations from the on-premises setup. --- **Simplifies System Center Operations Manager infrastructure management**: All the cloud connected System Center Operations Manager components are managed by Microsoft; removes the responsibility of hardware/software updates and security patches. --- **Continues monitoring through migration**: Won't cause disruptions in monitoring while you migrate infrastructure or workloads from on-premises to the cloud. As you migrate from one UR to the next, you can migrate from your existing System Center Operations Manager setup.--- **Monitors workloads everywhere**: SCOM Managed Instance is hosted in Azure with the capability of monitoring workloads running wherever they are (in Azure or on-premises) without the need for modification.--## Features --SCOM Managed Instance functionality allows you to: --- Configure an E2E System Center Operations Manager setup (SCOM Managed Instance) on Azure.-- Manage (view, delete) your SCOM Managed Instance in Azure.-- Connect to your SCOM Managed Instance using the System Center Operations Manager Ops console.-- Monitor workloads (wherever they're located) using the Ops, and while using your existing management packs.-- Incur zero database maintenance (Ops database and Data warehouse database) because of the offloading of database management to SQL Managed Instance (SQL MI).-- Scale your instance immediately without the need to add/delete physical servers.-- View your SCOM Managed Instance reports in Power BI.-- Patch your instance in one click with the latest bug fixes and features.-->[!NOTE] ->Azure Monitor SCOM Managed Instance doesn't support **Move Resource** functionality. --## Comparison of System Center Operations Manager on-premises with SCOM Managed Instance --SCOM Managed Instance has all the capabilities of System Center Operations Manager on-premises in a cloud-native way. --The following table highlights the key differences between System Center Operations Manager on-premises and SCOM Managed Instance:ΓÇ» --|Scenario|Feature|Operations Manager on-premises|SCOM Managed Instance| -||||| -|Manageability of monitoring infrastructure|Patching|Update RollUps (URs) released every 6-7 months. Customer must spend days to update all the System Center Operations Manager components.|Auto operating system patches; System Center Operations Manager patches every 15-20 days. Patching done at the click of a button.| -|Manageability of monitoring infrastructure|Agent management|Manually managed by the customer.|Azure managed through VM extensions.| -|Manageability of monitoring infrastructure|Availability, Reliability, and Fault-Tolerance|Customer responsibility. No HA or BCDR promised by the product.|Instance-level availability and tolerance.| -|Manageability of monitoring infrastructure|Optimization and Scaling|Customer responsibility and heavy infrastructure.|Manually initiated from the portal at the click of a button.| -|Workload monitoring|Reuse of System Center Operations Manager management packs|All agent-based management packs are supported.|All agent-based management packs are supported.| -|Workload monitoring|Monitoring non-domain workloads|Supported via gateway servers.|Via gateway servers for off-Azure endpoints and via managed identify for Azure endpoints.| -|Workload monitoring|Monitoring Arc and multicloud workloads|Arc is not supported. Availability of Azure management pack.|Azure-based, Arc connected, and on-premises workloads.| -|Log collection and analysis|Query and analysis of observability data|Querying is possible.|Maintained in SQL managed instance. <br/> <br/> A first-class ability to channel data into the log analytics workspace to maintain a central data plane. -|Alerting|Real-time alerts for infra and apps|Alerting through System Center Operations Manager Ops console.|Integrated alerting with Azure Monitor.| -|Dashboarding|Basic reports about monitoring setup|SSRS-based reporting.|Built-in templates on Azure workbooks and dashboards for Azure Managed Grafana.| -|Dashboarding|App-specific reports|Customers must manually integrate with SquaredUp.|Partner published library of dashboards for Azure Managed Grafana.| --## Architecture ---A SCOM Managed Instance consists of two parts: - - A Microsoft-managed part - - A customer-managed part --### A Microsoft-managed part --A Microsoft-managed part consists of Management Servers and the [Azure SQL Managed Instance](/azure/azure-sql/managed-instance/sql-managed-instance-paas-overview?view=azuresql&preserve-view=true) hosting an Operations database and Data Warehouse database. The Azure-hosted components can be managed directly from the Azure portal. At the backend, the components interact continuously with ARM and the RP to carry out Azure-based operations. ---The databases hosted in the SQL MI allow formation and to view reports in Power BI. The Management Servers can be scaled up/down based on your requirements. When you create a new instance, you get one management server. The number changes depending on how you decide to scale your instance. You can update your management servers at the click of a button. --### A customer-managed part --A customer-managed part consists of Ops that are used to monitor and administer the instance. The agents to be monitored are under the customer domain, and if they are in another domain, a gateway server is needed to carry out the authentication. The customer-managed part hosts a DNS with a static IP that is provided to the Management Servers hosted in Azure. --**Detailed Architecture of SCOM Managed Instance** ---SCOM Managed Instance deploys and manages Operations Manager in customer subscription. It establishes connectivity to the on-premises monitored agents through VPN/Express Route. --In customer subscription, SCOM Managed Instance, creates a Virtual Machine Scale Set in a managed resource group and deploys Operations Manager on the Virtual Machine Scale Sets, which is front-loaded with Load Balancer for resiliency and elasticity. Operations Manager Management server connects to customer provided SQL MI for Database operations. Both SQL managed instance and Virtual Machine Scale Sets are created in different VNets and are joined to establish line of sight. --Operations Manager Management server and monitored agents are connected through ER/VPN. Agents establish session with Operations Manager Management server using the Kerberos authentication, where Operations Manager Virtual Machine Scale Sets VMs are joined to the AD domain of the monitored agents. --## Next steps -- To create SCOM Managed Instance, follow these steps: -- - [Step 1. Register the SCOM Managed Instance resource provider](register-scom-managed-instance-resource-provider.md). - - [Step 2. Create separate subnet in a VNet](create-separate-subnet-in-vnet.md). - - [Step 3. Create a SQL Managed Instance](create-sql-managed-instance.md). - - [Step 4. Create a Key vault](create-key-vault.md). - - [Step 5. Create a user assigned identity](create-user-assigned-identity.md). - - [Step 6. Create a computer group and gMSA account](create-group-managed-service-account.md). - - [Step 7. Store domain credentials in Key vault](store-domain-credentials-key-vault.md). - - [Step 8. Create a static IP](create-static-ip.md). - - [Step 9. Configure the network firewall](configure-network-firewall.md). - - [Step 10. Verify Azure and internal GPO policies](verify-azure-internal-group-policy-object-policies.md). - - [Step 11. SCOM Managed Instance self-verification of steps](self-verification-steps.md). - - [Step 12. Create a SCOM Managed Instance](create-operations-manager-managed-instance.md). --[Migrate from Operations Manager on-premises to Azure Monitor SCOM Managed Instance](migrate-to-operations-manager-managed-instance.md). |
| azure-monitor | Patch Scom Managed Instance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/patch-scom-managed-instance.md | - Title: Patch Azure Monitor SCOM Managed Instance -description: This article provides information on how to patch your Azure Monitor SCOM Managed Instance. --- Previously updated : 05/22/2024------# Patch Azure Monitor SCOM Managed Instance --Azure Monitor SCOM Managed Instance offers a convenient patching experience compared to on-premises System Center Operations Manager. --Following are the key highlights: --- No update rollup in SCOM Managed Instance. A patch is released as and when there are significant fixes and updates made to the product. They're released at a frequency of as often as two weeks or two months.-- Patching is quick and convenient and happens at the click of a button.-- All newer patches are backward compatible with the older versions. --This article provides information on how to patch your SCOM Managed Instance. --## Pre-Patching checklist --Before you proceed with the patching process, complete the following prechecks to ensure a successful patching operation: --1. **SQL managed instance status**: Verify that the SQL managed instance is operational and running, and not in a shutdown state. --2. **Management server health**: Confirm the health of existing Management Servers. --3. **Domain credentials verification**: Validate the status of the domain credentials used in the key vault. If the credentials have expired, update the password to ensure they're active and functional. --4. **NAT Gateway association**: Ensure that the NAT Gateway is still associated with the subnet and hasn't been removed. --5. **VNET connectivity requirements**: Ensure that VNet to VNet communication is allowed to enable communication between the newly added managed servers and the existing ones. Additionally, verify that the connectivity from the VNet to the SQL managed instance and Domain Controller is operational. --## Patch SCOM Managed Instance --To patch SCOM Managed Instance, follow these steps: --1. Sign in to the [Azure portal](https://portal.azure.com/) and search for **SCOM Managed Instance**. -1. On the **Overview** page, under **Configuration**, select **Patching**. -1. On the **Patching** page, you see the status of the updates available for your instance. -- :::image type="Patching" source="media/patch-scom-managed-instance/scom-mi-patching.png" alt-text="Screenshot of Patching."::: --1. Select **Update instance** to update your instance. -- :::image type="Update Instance" source="media/patch-scom-managed-instance/update-instance.png" alt-text="Screenshot of Update Instance."::: - -It takes 30 mins to 1 hour to successfully update the instance. -- :::image type="Instance updated" source="media/patch-scom-managed-instance/instance-updated.png" alt-text="Screenshot of Instance updated."::: -->[!NOTE] ->To run custom configurations in your SCOM Managed Instance management servers, see [Customizations on Azure Monitor SCOM managed instance management servers](customizations-on-scom-managed-instance-management-servers.md). ---## Troubleshoot patching issues --### Issue: In rare cases, after patching, stale Management Servers are visible on console --**Cause**: Occurs if a patching operation has left an inconsistent state after completion. --**Resolution**: Microsoft Azure Virtual Machine Scale Sets is used to provision the management servers for SCOM Managed Instances. To remove the stale management server from the system, follow these steps: --1. Access the Azure Virtual Machine Scale Sets and log in to one of the management servers for the SCOM Managed Instance. --2. Launch PowerShell in administrative mode and navigate to the following directory. -- `C:\Packages\Plugins\Microsoft.Azure.SCOMMIServer.ScomServerForWindows\<version>\bin\troubleshooter` -- >[!Note] - >To find the version, go to `C:\Packages\Plugins\Microsoft.Azure.SCOMMIServer.ScomServerForWindows` and review all available versions and then select the latest one. --3. Execute the following script: -- ```powershell - .\RemoveStaleManagementServers.ps1 - ``` -- The script is interactive and prompts you for the FQDN of the stale server. --4. Provide the accurate FQDN of the stale management server you wish to remove. -- For example, FQDN: SCOMMI2000001.contoso.com. --## Next steps --[Connect the Azure Monitor SCOM Managed Instance to Ops console](connect-managed-instance-ops-console.md) |
| azure-monitor | Query Scom Managed Instance Data On Grafana | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/query-scom-managed-instance-data-on-grafana.md | - Title: Query Azure Monitor SCOM Managed Instance data from Azure Managed Grafana dashboards. -description: This article describes how to query monitoring data from Operational database and create dashboards on Azure Managed Grafana. --- Previously updated : 05/22/2024------# Query Azure Monitor SCOM Managed Instance data from Azure Managed Grafana dashboards --This article describes how to query monitoring data from Operational database and create dashboards on Azure Managed Grafana. --From Azure Managed Grafana linked to Azure Monitor SCOM Managed Instance, you can use SQL queries to get the monitored data from Operational database stored on Azure Managed SQL Managed Instance. --## Prerequisites --Before you query monitoring data from Azure Managed Grafana portal, ensure that SCOM Managed Instance is linked to Azure Managed Grafana. For more information, see [Dashboards on Azure Managed Grafana](./dashboards-on-azure-managed-grafana.md). --Few ready-to-use dashboards are available at [Azure/SCOM Managed Instance/Operational Dashboard](https://grafana.com/grafana/dashboards/19919-azure-scom-managed-instance-operational-dashboard/), which can be imported and edited as per your requirement on Azure Managed Grafana instance. --## Create a dashboard on Azure Managed Grafana --To create a dashboard, follow these steps: --1. Navigate to Grafana and select **Add visualization**. You can choose the type of visualization based on the available options. - :::image type="Add visualization" source="media/query-scom-managed-instance-data-on-grafana/add-visualization.png" alt-text="Screenshot of Add visualization."::: -1. Under **Panel options**, enter **Title** and **Description**. - :::image type="panel options" source="media/query-scom-managed-instance-data-on-grafana/panel-options.png" alt-text="Screenshot of panel options."::: -1. Under **Query**, select **Code** and enter the query. - :::image type="code option" source="media/query-scom-managed-instance-data-on-grafana/code.png" alt-text="Screenshot of code options."::: -1. Select **Run query**. --## Sample queries --Following are few helpful sample queries and dashboards to get started on using Azure Managed Grafana with SCOM Managed Instance: --- Health state of workload -- Workload health and the number of new alerts on them -- Top events on workload-- Top alerts from workload -- Performance data query for workload counter--The following queries help you to build Health, Alerts, and Top events from a particular workload/monitoring object: -->[!NOTE] ->- Replace the \<Management pack name prefix\> with the actual management pack name, say **Microsoft.SQL%** for SQL workload. ->- Replace the \<Monitoring Object Type\> with component class, say, **%.DBEngine** for SQL server role. --### Health state of workload --``` -SELECT HealthState = -- CASE -- WHEN MEV.HealthState = 1 THEN 'Healthy' -- WHEN MEV.HealthState = 2 THEN 'Warning' -- WHEN MEV.HealthState = 3 THEN 'Critical' -- ELSE 'Uninitialized' -- END, -- CAST(COUNT(*) AS DECIMAL(5, 2)) AS servers -- FROM ${Database}.[dbo].[ManagedEntityGenericView] MEV -- INNER JOIN ${Database}.[dbo].[ManagedTypeView] MTV ON MTV.Id = MEV.MonitoringClassId and MTV.name like '%.<Monitoring Object Type>' -- INNER JOIN ${Database}.[dbo].[ManagementPackView] MPV ON MPV.Id = MTV.ManagementPackId and MPV.name like '<MP name Prefix>' -- GROUP BY MEV.HealthState -- ORDER BY MEV.HealthState -``` --### Workload health and the number of new alerts on them --``` -SELECT MEV.Name -- ,HealthState = -- CASE -- WHEN MEV.HealthState = 1 THEN 'Healthy' -- WHEN MEV.HealthState = 2 THEN 'Warning' -- WHEN MEV.HealthState = 3 THEN 'Critical' -- ELSE 'Uninitialized' -- END -- ,NewAlerts = COUNT(AV.ResolutionState) -- FROM ${Database}.[dbo].[ManagedEntityGenericView] MEV -- INNER JOIN ${Database}.[dbo].[ManagedTypeView] MTV ON MTV.Id = MEV.MonitoringClassId and MTV.name like '%.<Monitoring Object Type>' -- INNER JOIN ${Database}.[dbo].[ManagementPackView] MPV ON MPV.Id = MTV.ManagementPackId and MPV.name like '%<MP name prefix>%' -- INNER JOIN ${Database}.[dbo].[AlertView] AV ON AV.MonitoringClassId = MTV.Id and AV.ResolutionState = 0 AND $__timeFilter(TimeRaised) -- GROUP BY MEV.Name, HealthState, AV.ResolutionState -``` --### Top events on workload --``` -SELECT EventDescription = LT5.LTValue -- ,Count(*) Occurences -- ,AffectedSQLServers = Count(DISTINCT(EV.LoggingComputer)) -- FROM ${Database}.[dbo].[EventView] EV -- INNER JOIN ${Database}.[dbo].[ManagedTypeView] MTV ON MTV.Id = EV.ClassId -- INNER JOIN ${Database}.[dbo].[ManagementPackView] MPV ON MPV.Id = MTV.ManagementPackId and MPV.name like '%<MP Name Prefix>%' -- INNER JOIN ${Database}.dbo.LocalizedText LT5 ON EV.EventNumberStringId = LT5.LTStringId AND LT5.LanguageCode = 'ENU' -- WHERE $__timeFilter(TimeGenerated) AND LevelId < 3 --GROUP BY Number, LT5.LTValue --ORDER BY Occurences, AffectedSQLServers DESC; -``` --### Top alerts from workload --``` -SELECT AV.AlertStringName AS Alert -- ,Occurrence = COUNT(AV.ResolutionState) -- ,AffectedServers = COUNT(MEV.name) -- FROM ${Database}.[dbo].[AlertView] AV -- INNER JOIN ${Database}.[dbo].[ManagedTypeView] MTV ON MTV.Id = AV.MonitoringClassId and MTV.name like '%<Monitoring Object Type>' -- INNER JOIN ${Database}.[dbo].[ManagementPackView] MPV ON MPV.Id = MTV.ManagementPackId and MPV.name like '%M<MP Name Prefix>%' -- INNER JOIN ${Database}.[dbo].[ManagedEntityGenericView] MEV ON MTV.Id = MEV.MonitoringClassId -- where AV.ResolutionState = 0 and $__timeFilter(TimeRaised) -- GROUP BY AV.AlertStringName, AV.ResolutionState -``` --### Performance data query for workload counter --``` -SELECT PD.TimeSampled -- ,CASE -- WHEN BME.Path IS NOT NULL AND BME.Path <> '' THEN CONCAT(BME.Path, '\', COALESCE(BME.Name, '')) -- ELSE COALESCE(BME.Name, '') END AS TagetObjectPath -- ,ObjectName = PC.ObjectName -- ,CounterName = PC.CounterName -- ,Value = PD.SampleValue -- FROM dbo.PerformanceDataAllView PD -- INNER JOIN dbo.PerformanceSource PS ON PD.PerformanceSourceInternalId = PS.PerformanceSourceInternalId -- INNER JOIN dbo.PerformanceCounter PC ON PS.PerformanceCounterId = PC.PerformanceCounterId and CounterName = 'Receive I/Os/sec' -- INNER JOIN dbo.BaseManagedEntity BME ON PS.BaseManagedEntityId = BME.BaseManagedEntityId AND BME.IsDeleted = 0 -- INNER JOIN [dbo].[ManagedTypeView] MTV ON MTV.Id = BME.BaseManagedTypeId -- INNER JOIN [dbo].[ManagementPackView] MPV ON MPV.Id = MTV.ManagementPackId and MPV.name like 'Microsoft.SQL%' -``` --## Next steps --[Troubleshoot issues with Azure Monitor SCOM Managed Instance](troubleshoot-scom-managed-instance.md). |
| azure-monitor | Register Scom Managed Instance Resource Provider | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/register-scom-managed-instance-resource-provider.md | - Title: Register the Azure Monitor SCOM Managed Instance resource provider -description: This article describes how to register the SCOM Managed Instance resource provider. --- Previously updated : 05/22/2024------# Register the Azure Monitor SCOM Managed Instance resource provider --This article describes how to register the Azure Monitor SCOM Managed Instance resource provider. -->[!NOTE] -> To learn about the SCOM Managed Instance architecture, see [Azure Monitor SCOM Managed Instance](overview.md). --## Register the SCOM Managed Instance resource provider --To register the SCOM Managed Instance resource provider, follow these steps: --1. Sign in to the [Azure portal](https://portal.azure.com) and select **Subscriptions**. -1. Select the subscription where you want to deploy SCOM Managed Instance. -1. On the **Subscription** page, under **Settings**, select **Resource providers** and search for **Microsoft.Scom**. If the **Microsoft.Scom** provider isn't registered, select the provider, and then select **Register**. -- :::image type="Microsoft resource provider" source="media/register-scom-managed-instance-resource-provider/resource-providers-inline.png" alt-text="Screenshot that shows the Microsoft provider." lightbox="media/register-scom-managed-instance-resource-provider/resource-providers-expanded.png"::: --1. On the **Subscription** page, under **Settings**, select **Resource providers** and search for **microsoft.insights**. If the **microsoft.insights** provider isn't registered, select the provider, and then select **Register**. -- :::image type="Microsoft Insights resource provider" source="media/register-scom-managed-instance-resource-provider/resource-provider-insights-inline.png" alt-text="Screenshot that shows the Microsoft insights provider." lightbox="media/register-scom-managed-instance-resource-provider/resource-provider-insights-expanded.png"::: --1. On the **Subscription** page, under **Settings**, select **Resource providers** and search for **Microsoft.Compute**. If the **Microsoft.Compute** provider isn't registered, select the provider, and then select **Register**. -- :::image type="Microsoft compute resource provider" source="media/register-scom-managed-instance-resource-provider/resource-provider-compute-inline.png" alt-text="Screenshot that shows the Microsoft compute provider." lightbox="media/register-scom-managed-instance-resource-provider/resource-provider-compute-expanded.png"::: --## Next steps --- [Create a separate subnet in a virtual network](create-separate-subnet-in-vnet.md) |
| azure-monitor | Scale Scom Managed Instance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/scale-scom-managed-instance.md | - Title: Scale Azure Monitor SCOM Managed Instance -description: This article provides information on how to scale your Azure Monitor SCOM Managed Instance. --- Previously updated : 05/22/2024------# Scale Azure Monitor SCOM Managed Instance --Addition or deletion of a management server to the existing System Center Operations Manager Infrastructure automatically links or delinks it from the existing Operational database, Data warehouse, and endpoints in SCOM Managed Instance. --This article provides information on how to scale your SCOM Managed Instance. --> [!VIDEO https://www.youtube.com/embed/MG5kGoe1zj0?start=63] --## Pre-Scaling checklist --Before you proceed with the scaling process, complete the following prechecks to ensure a successful scaling operation: --1. **SQL managed instance status**: Verify that the SQL managed instance is operational and running, and not in a shutdown state. --2. **Management server health**: Confirm the health of the existing Management Servers. --3. **Domain credentials verification**: Validate the status of the domain credentials used in the key vault. If the credentials have expired, update the password to ensure they're active and functional. --4. **NAT Gateway association**: Ensure that the NAT Gateway is still associated with the subnet and hasn't been removed. --5. **VNet connectivity requirements**: Ensure that VNet to VNet communication is allowed to enable communication between the newly added managed servers and the existing ones. Additionally, verify that the connectivity from the VNet to the SQL managed instance and Domain Controller is operational. --## Scale In/Out the management servers --To scale In/Out the management servers, follow these steps: --1. Sign in to the [Azure portal](https://portal.azure.com/) and search for **SCOM Managed Instance**. -1. On the **Overview** page, under **Configuration**, select **Scaling**. - :::image type="Scaling" source="media/scale-scom-managed-instance/scaling.png" alt-text="Screenshot of Scaling."::: -1. On the **Scaling** page, - 1. **Current**: Displays the existing number of management servers that are a part of the SCOM Managed Instance. - 1. **Scale In/Out management servers**: - 1. **Total Endpoints to be monitored**: Enter the total number of endpoints you would like to monitor using a specific SCOM Managed Instance. - 1. **Recommended Management servers**: Depending on the number of endpoints you enter, the ideal number of management servers to be provisioned will be recommended. You can change the recommended value as desired. -- >[!Note] - >A Management server can monitor up to 1000 endpoints. -- :::image type="Scaling SCOM Managed Instance" source="media/scale-scom-managed-instance/scaling-scom-mi.png" alt-text="Screenshot of Scaling SCOM Managed Instance."::: - -1. Select **Save** to trigger the Scale In or Scale Out operation. --## Troubleshoot scaling issues --### Issue: In rare cases, after scaling, stale Management Servers are visible on console --**Cause**: Occurs if a scaling operation has left an inconsistent state after completion. --**Resolution**: Microsoft Azure Virtual Machine Scale Sets is used to provision the management servers for SCOM Managed Instances. To remove the stale management server from the system, follow these steps: --1. Access the Azure Virtual Machine Scale Sets and log in to one of the management servers for the SCOM Managed Instance. --2. Launch PowerShell in administrative mode and navigate to the following directory. -- `C:\Packages\Plugins\Microsoft.Azure.SCOMMIServer.ScomServerForWindows\<version>\bin\troubleshooter` -- >[!Note] - >To find the version, go to `C:\Packages\Plugins\Microsoft.Azure.SCOMMIServer.ScomServerForWindows` and review all available versions and then select the latest one. --3. Execute the following script: -- ```powershell - .\RemoveStaleManagementServers.ps1 - ``` -- The script is interactive and prompts you for the FQDN of the stale server. --4. Provide the accurate FQDN of the stale management server you wish to remove. -- For example, FQDN: SCOMMI2000001.contoso.com. --## Next steps --[Patch SCOM Managed Instance](patch-scom-managed-instance.md) |
| azure-monitor | Scom Mi Activity Log | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/scom-mi-activity-log.md | - Title: Azure Monitor SCOM Managed Instance activity log -description: This article provides information on how to view the activity log. --- Previously updated : 05/22/2024-------# Azure Monitor SCOM Managed Instance activity log --The Azure Monitor SCOM Managed Instance activity log is a platform log in Azure that provides insight into subscription-level events. The activity log includes information such as when a SCOM Managed Instance resource is created or modified or patched with new software and scaled or deleted. This article provides information on how to view the activity log. -->[!Note] ->- Entries in the Activity Log are system generated and can't be changed or deleted. ->- Entries in the Activity Log represent control plane changes such as create, update, scale, patch, or delete SCOM Managed Instance. --## Retention period --Activity log events are retained in Azure for 90 days and then deleted. There's no charge for entries during this time regardless of volume. For more functionality, such as longer retention, create a diagnostic setting and route the entries to another location based on your needs. --## View the activity log --You can access the activity log from the Azure portal. The menu that you open it from determines its initial filter. You can change the filter to view all other entries. Select **Add Filter**  to add more properties to the filter. --For more information on activity log categories, see [Azure activity log event schema](/azure/azure-monitor/essentials/activity-log-schema#categories). --## Download the activity log --Select **Download as CSV** to download the events in the current view. ---### View change history --You can view the change history of an event and get the details of changes occurred during the event time. Select an event from the activity log and then select the  **Change history** to view any associated changes with that event. ---If any changes are associated with the event, you'll see a list of changes that you can select. To view details, select a change. The **Change history** page opens and displays the changes to the resource. In the following example, you can see that the SCOM Managed Instance tags and provision state changes. - |
| azure-monitor | Scom Mi Data Encryption At Rest | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/scom-mi-data-encryption-at-rest.md | - Title: Azure Monitor SCOM Managed Instance Data Encryption at Rest -description: This article provides an overview of SCOM Managed Instance Data Encryption at Rest. --- Previously updated : 05/22/2024------# Azure Monitor SCOM Managed Instance Data Encryption at Rest --Microsoft Azure includes tools to safeguard the data according to your company's security and compliance needs. Encryption at Rest is a common security requirement. --In Azure, organizations can encrypt data at rest without the risk or cost of a custom key management solution. Organizations have the option of letting Azure completely manage Encryption at Rest. Additionally, organizations have various options to closely manage encryption or encryption keys. For more information, see [Azure Data Encryption at rest](/azure/security/fundamentals/encryption-atrest). --This article discusses the SCOM Managed Instance components protecting the data at various levels. --## SCOM Managed Instance components for Azure Encryption at Rest --The goal of encryption at rest is that data that is persisted on disk is encrypted with a secret encryption key. To achieve that goal, secure key creation, storage, access control, and management of the encryption keys must be provided. --SCOM Managed Instance service doesn't store any customer details. SCOM Managed Instance uses different persistence storage, such as Key vault, Storage account, and Cosmos Database, to store service metadata. --### Azure Key Vault --The storage location of the encryption keys and access control to those keys is central to an Encryption at Rest model. The keys need to be highly secure but manageable by specified users and available to specific services. SCOM Managed Instance uses Azure Key Vault to store service configurations, certificates, and secrets. SCOM Managed Instance uses the Encryption at Rest capability of Azure Key Vault. --### Azure Storage account --SCOM Managed Instance uses a storage account to hold service configurations, scripts, and System Center Operations Manager runtime bits. It's also used to exchange messages (actions on SCOM Managed Instance) between System Center Operations Manager RP web service and the worker role service. SCOM Managed Instance metadata that is stored in Azure storage blob/Queue uses 256-bit AES encryption. --## Cosmos database --SCOM Managed Instance uses RPaaS Cosmos database to store SCOM Managed Instance resource details. Azure Cosmos database uses AES-256 encryption on all regions where the account is running. --## Encryption at Compute --Though SCOM Managed Instance doesn't store any customer details, it takes domain user details from your key vault secrets. These domain user details are used for adding System Center Operations Manager management servers to on-premises Domain controller. To avoid any data leak at compute, encrypt it using the VM extension `AzureDiskEncryption`. |
| azure-monitor | Self Verification Steps | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/self-verification-steps.md | - Title: Azure Monitor SCOM Managed Instance self-verification of steps -description: This article describes the self-verification processes of the Operations Manager admin, Active Directory admin, and network admin. --- Previously updated : 05/22/2024------# Azure Monitor SCOM Managed Instance self-verification of steps --This article describes the self-verification processes of the Operations Manager admin, Active Directory admin, and network admin. --> [!NOTE] -> To learn about the Azure Monitor SCOM Managed Instance architecture, see [Azure Monitor SCOM Managed Instance](overview.md). --After you set up the required parameters, run the self-validation tool. Based on the experience and data collected from telemetry, Operations Manager administrators have spent considerable time validating the accuracy of parameters. Running this tool helps to identify any issues with your environment or parameters before you proceed with the deployment. --Many customers benefit from this tool because it saves time that would otherwise be spent troubleshooting issues with parameters later on. We recommend running this tool before deployment to avoid spending excessive time diagnosing and troubleshooting on-premises parameters in the future. --In the process of creating an instance of SCOM Managed Instance, three primary personas are involved. The following flow is typical of how the Operations Manager admin sets up the steps in enterprise organizations: --1. The Operations Manager admin initiates communication with the Active Directory admin to configure all the Active Directory-related settings. --1. The Operations Manager admin then communicates with the network admin to establish the virtual network and configure the necessary firewalls, network security groups, and DNS resolution to connect to the designated Active Directory controller, as outlined in the network prerequisites. --1. After all the configurations are implemented, the Operations Manager admin proceeds with thorough testing on a test virtual machine (VM) to ensure that everything functions as expected. This testing phase helps to proactively identify and address any potential issues. --If the Operations Manager admin plays all three roles, they can independently handle and manage all the tasks without requiring the involvement of different personnel for each specific area. --With the steps provided for each persona to validate the parameters, we aim to streamline the process of setting up the parameters to reduce the time required for creating the SCOM managed instance. --By empowering each persona to verify their respective parameters, we can expedite the overall setup process and achieve faster SCOM managed instance deployment. --## Operations Manager admin self-verification of steps --Running Operations Manager admin self-verification is essential to understand the accuracy of the parameters. --> [!VIDEO de6cac42-06ca-4517-bb99-9438ce2b8fa5] --> [!IMPORTANT] -> Initially, create a new test Windows Server (2022/2019) VM in the same subnet selected for the SCOM managed instance creation. Subsequently, both your Active Directory admin and network admin can individually use this VM to verify the effectiveness of their respective changes. This approach saves time spent on back-and-forth communication between the Active Directory admin and the network admin. --Follow these steps to run the validation script: --1. Generate a new VM running on Windows Server 2022 or 2019 within the chosen subnet for the SCOM managed instance creation. Sign in to the VM and configure its DNS server to use the same DNS server IP that you plan to use during the creation of the SCOM managed instance. For example, see the following screenshot to set the DNS server IP. -- :::image type="DNS server IP" source="media/scom-managed-instance-self-verification-of-steps/dns-server-ip.png" alt-text="Screenshot that shows the DNS server IP."::: --1. [Download the validation script](https://download.microsoft.com/download/2/3/a/23a14c00-8adf-4aba-99ea-6c80fb321f3b/SCOMMI%20Validation%20and%20Troubleshooter.zip) to the test VM and extract. It consists of five files: - - `Readme.txt` - - `ScomValidation.ps1` - - `RunValidationAsSCOMAdmin.ps1` - - `RunValidationAsActiveDirectoryAdmin.ps1` - - `RunValidationAsNetworkAdmin.ps1` --1. Follow the steps mentioned in the `Readme.txt` file to run `RunValidationAsSCOMAdmin.ps1`. Make sure to fill in the settings value in `RunValidationAsSCOMAdmin.ps1` with applicable values before you run it. -- ```powershell - # $settings = @{ - # Configuration = @{ - # DomainName="test.com" - # OuPath= "DC=test,DC=com" - # DNSServerIP = "000.00.0.00" - # UserName="test\testuser" - # Password = "password" - # SqlDatabaseInstance= "test-sqlmi-instance.023a29518976.database.windows.net" - # ManagementServerGroupName= "ComputerMSG" - # GmsaAccount= "test\testgMSA$" - # DnsName= "lbdsnname.test.com" - # LoadBalancerIP = "00.00.00.000" - # } - # } - # Note : Before running this script, please make sure you have provided all the parameters in the settings - $settings = @{ - Configuration = @{ - DomainName="<domain name>" - OuPath= "<OU path>" - DNSServerIP = "<DNS server IP>" - UserName="<domain user name>" - Password = "<domain user password>" - SqlDatabaseInstance= "<SQL MI Host name>" - ManagementServerGroupName= "<Computer Management server group name>" - GmsaAccount= "<GMSA account>" - DnsName= "<DNS name associated with the load balancer IP address>" - LoadBalancerIP = "<Load balancer IP address>" - } - } - ``` --1. In general, `RunValidationAsSCOMAdmin.ps1` runs all the validations. If you want to run a specific check, open `ScomValidation.ps1` and comment all other checks, which are at the end of the file. You can also add a breakpoint in the specific check to debug the check and understand the issues better. -- ```powershell - # Default mode is - SCOMAdmin, by default if mode is not passed then it will run all the validations - # adding all the checks to result set - try { - # Connectivity checks - $validationResults += Invoke-ValidateStorageConnectivity $settings - $results = ConvertTo-Json $validationResults -Compress - - $validationResults += Invoke-ValidateSQLConnectivity $settings - $results = ConvertTo-Json $validationResults -Compress - - $validationResults += Invoke-ValidateDnsIpAddress $settings - $results = ConvertTo-Json $validationResults -Compress - - $validationResults += Invoke-ValidateDomainControllerConnectivity $settings - $results = ConvertTo-Json $validationResults -Compress - - # Parameter validations - $validationResults += Invoke-ValidateDomainJoin $settings - $results = ConvertTo-Json $validationResults -Compress - - $validationResults += Invoke-ValidateStaticIPAddressAndDnsname $settings - $results = ConvertTo-Json $validationResults -Compress - - $validationResults += Invoke-ValidateComputerGroup $settings - $results = ConvertTo-Json $validationResults -Compress - - $validationResults += Invoke-ValidategMSAAccount $settings - $results = ConvertTo-Json $validationResults -Compress - - $validationResults += Invoke-ValidateLocalAdminOverideByGPO $settings - $results = ConvertTo-Json $validationResults -Compress - } - catch { - Write-Verbose -Verbose $_ - } - ``` -- > [!NOTE] - > Operations Manager admin validations include a check for any GPO policies that override the local administrator group. It might take a long time to finish because the check queries all the policies for assessment. --1. The validation script displays all the validation checks and their respective errors, which helps in resolving the validation issues. For fast resolution, run the script in PowerShell ISE with a breakpoint, which can speed up the debugging process. -- If all the checks pass successfully, return to the onboarding page and start the onboarding process. --## Active Directory admin self-verification of steps --To minimize back-and-forth communication with the Operations Manager admin, it's a good practice for the Active Directory admin to independently assess the Active Directory parameters. If needed, you can seek assistance from the Operations Manager admin to run the validation tool to ensure a smoother and more efficient process of parameter evaluation. --Performing Active Directory admin self-verification is an optional step. We provide the flexibility for each organization to decide whether to undertake this process based on their convenience and specific requirements. --Follow these steps to run the validation script: --1. Generate a new VM running on Windows Server 2022 or 2019 within the chosen subnet for the SCOM managed instance creation. Sign in to the VM and configure its DNS server to use the same DNS server IP that you plan to use during the creation of the SCOM managed instance. If the test VM is already created by Operations Manager admin, then use the test VM. For example, see the following screenshot to set the DNS server IP. -- :::image type="DNS server IP" source="media/scom-managed-instance-self-verification-of-steps/dns-server-ip.png" alt-text="Screenshot that shows the DNS server IP."::: --1. [Download the validation script](https://download.microsoft.com/download/2/3/a/23a14c00-8adf-4aba-99ea-6c80fb321f3b/SCOMMI%20Validation%20and%20Troubleshooter.zip) to the test VM and extract. It consists of five files: - - `Readme.txt` - - `ScomValidation.ps1` - - `RunValidationAsSCOMAdmin.ps1` - - `RunValidationAsActiveDirectoryAdmin.ps1` - - `RunValidationAsNetworkAdmin.ps1` --1. Follow the steps mentioned in the `Readme.txt` file to run `RunValidationAsActiveDirectoryAdmin.ps1`. Make sure to fill in the settings value in `RunValidationAsActiveDirectoryAdmin.ps1` with applicable values before you run it. -- ```powershell - # $settings = @{ - # Configuration = @{ - # DomainName="test.com" - # OuPath= "DC=test,DC=com" - # DNSServerIP = "000.00.0.00" - # UserName="test\testuser" - # Password = "password" - # ManagementServerGroupName= "ComputerMSG" - # GmsaAccount= "test\testgMSA$" - # DnsName= "lbdsnname.test.com" - # LoadBalancerIP = "00.00.00.000" - # } - # } - # Note : Before running this script, please make sure you have provided all the parameters in the settings - $settings = @{ - Configuration = @{ - DomainName="<domain name>" - OuPath= "<OU path>" - DNSServerIP = "<DNS server IP>" - UserName="<domain user name>" - Password = "<domain user password>" - ManagementServerGroupName= "<Computer Management server group name>" - GmsaAccount= "<GMSA account>" - DnsName= "<DNS name associated with the load balancer IP address>" - LoadBalancerIP = "<Load balancer IP address>" - } - } - ``` --1. In general, `RunValidationAsActiveDirectoryAdmin.ps1` runs all the validations. If you want to run a specific check, open `ScomValidation.ps1` and comment all other checks, which are under Active Directory admin checks. You can also add a breakpoint in the specific check to debug the check and understand the issues better. -- ```powershell - # Mode is AD admin then following validations/test will be performed - if ($mode -eq "ADAdmin") { -- try { - # Mode is AD admin then following validations/test will be performed - $validationResults += Invoke-ValidateDnsIpAddress $settings - $results = ConvertTo-Json $validationResults -Compress -- $validationResults += Invoke-ValidateDomainControllerConnectivity $settings - $results = ConvertTo-Json $validationResults -Compress -- # Parameter validations - $validationResults += Invoke-ValidateDomainJoin $settings - $results = ConvertTo-Json $validationResults -Compress -- $validationResults += Invoke-ValidateStaticIPAddressAndDnsname $settings - $results = ConvertTo-Json $validationResults -Compress -- $validationResults += Invoke-ValidateComputerGroup $settings - $results = ConvertTo-Json $validationResults -Compress -- $validationResults += Invoke-ValidategMSAAccount $settings - $results = ConvertTo-Json $validationResults -Compress - - $validationResults += Invoke-ValidateLocalAdminOverideByGPO $settings - $results = ConvertTo-Json $validationResults -Compress - } - catch { - Write-Verbose -Verbose $_ - } - } - ``` -- > [!NOTE] - > Active Directory admin validations include a check for any GPO policies that override the local administrator group. It might take a long time to finish because the check queries all the policies for assessment. --1. The validation script displays all the validation checks and their respective errors, which helps in resolving validation issues. For fast resolution, run the script in PowerShell ISE with a breakpoint, which can speed up the debugging process. -- If all the checks pass successfully, there are no issues with the Active Directory parameters. --## Network admin self-verification of steps --To minimize back-and-forth communication with the Operations Manager admin, the network admin must independently assess the network configuration. If needed, they can seek assistance from the Operations Manager admin to run the validation tool to ensure a smoother and more efficient process of parameter evaluation. --Performing network admin self-verification is an optional step. We provide the flexibility for each organization to decide whether to undertake this process based on their convenience and specific requirements. --Follow these steps to run the validation script: --1. Generate a new VM running on Windows Server 2022 or 2019 within the chosen subnet for the SCOM managed instance creation. Sign in to the VM and configure its DNS server to use the same DNS server IP that you plan to use during the creation of the SCOM managed instance. If the test VM is already created by the Operations Manager admin, use the test VM. For example, see the following screenshot to set the DNS server IP. -- :::image type="DNS server IP" source="media/scom-managed-instance-self-verification-of-steps/dns-server-ip.png" alt-text="Screenshot of the DNS server IP."::: --1. [Download the validation script](https://download.microsoft.com/download/2/3/a/23a14c00-8adf-4aba-99ea-6c80fb321f3b/SCOMMI%20Validation%20and%20Troubleshooter.zip) to the test VM and extract. It consists of five files: - - `Readme.txt` - - `ScomValidation.ps1` - - `RunValidationAsSCOMAdmin.ps1` - - `RunValidationAsActiveDirectoryAdmin.ps1` - - `RunValidationAsNetworkAdmin.ps1` --1. Follow the steps mentioned in the `Readme.txt` file to run `RunValidationAsNetworkAdmin.ps1`. Make sure to fill in the settings value in `RunValidationAsNetworkAdmin.ps1` with applicable values before you run it. -- ```powershell - # $settings = @{ - # Configuration = @{ - # DomainName="test.com" - # DNSServerIP = "000.00.0.00" - # SqlDatabaseInstance= "<SQL MI Host name>" - # } - # } - # Note : Before running this script, please make sure you have provided all the parameters in the settings - $settings = @{ - Configuration = @{ - DomainName="<domain name>" - DNSServerIP = "<DNS server IP>" - SqlDatabaseInstance= "<SQL MI Host name>" - } - } - ``` --1. In general, `RunValidationAsNetworkAdmin.ps1` runs all the validations related to network configuration. If you want to run a specific check, open `ScomValidation.ps1` and comment all other checks, which are under network admin checks. You can also add a breakpoint in the specific check to debug the check and understand the issues better. -- ```powershell - # Mode is Network admin then following validations/test will be performed - try { - $validationResults += Invoke-ValidateStorageConnectivity $settings - $results = ConvertTo-Json $validationResults -Compress - - $validationResults += Invoke-ValidateSQLConnectivity $settings - $results = ConvertTo-Json $validationResults -Compress - - $validationResults += Invoke-ValidateDnsIpAddress $settings - $results = ConvertTo-Json $validationResults -Compress - - $validationResults += Invoke-ValidateDomainControllerConnectivity $settings - $results = ConvertTo-Json $validationResults -Compress - } - catch { - Write-Verbose -Verbose $_ - } - ``` --1. The validation script displays all the validation checks and their respective errors, which helps in resolving validation issues. For fast resolution, run the script in PowerShell ISE with a breakpoint, which can speed up the debugging process. -- If all the checks pass successfully, there are no issues with the network configuration. --## Next steps --- [Create an instance of Azure Monitor SCOM Managed Instance](create-operations-manager-managed-instance.md) |
| azure-monitor | Store Domain Credentials Key Vault | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/store-domain-credentials-key-vault.md | - Title: Store domain credentials in Azure Key Vault -description: This article describes how to store domain credentials in Azure Key Vault. --- Previously updated : 05/22/2024------# Store domain credentials in Azure Key Vault --This article describes how to store domain credentials in Azure Key Vault. --## To store domain credentials in a key vault --1. Go to the key vault resource created in [step 4](create-key-vault.md). --1. On the left pane, under **Objects**, select **Secrets**. - - > [!NOTE] - > You must create two secrets to store the domain account credentials: - > - Username - > - Password --1. Select **Generate/Import**. -1. On the **Create a secret** page, do the following: - 1. **Upload options**: Select **Manual**. - 1. **Name**: Enter the name of the secret. For example, you can use **Username** for the username secret and **Password** for the password secret. - 1. **Secret value**: For the username value (in the format **domain\username**), enter the domain account username. For the password value, enter the domain account password. For example, if the domain is contoso.com, the username should be in the format **contoso\username**. - 1. Leave the **Content type (optional)**, **Set activation date**, **Set expiration date**, **Enabled**, and **Tags** areas as default. Select **Create** to create the secret. --## Next steps --- [Create a static IP](create-static-ip.md) |
| azure-monitor | Troubleshoot Scom Managed Instance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/troubleshoot-scom-managed-instance.md | - Title: Troubleshoot issues with Azure Monitor SCOM Managed Instance -description: This article describes the errors that might occur when you deploy or use Azure Monitor SCOM Managed Instance and how to resolve them. --- Previously updated : 06/19/2024------# Troubleshoot issues with Azure Monitor SCOM Managed Instance --This article describes the errors that might occur when you deploy or use Azure Monitor SCOM Managed Instance and how to resolve them. --## Scenario: SCOM Managed Instance creation/deployment --### General troubleshooting --1. Ensure all the prerequisites are met. Creation issues may arise due to improper/incomplete prerequisites. -2. Ensure you read/check the error message carefully. The error messages capture the issue/error in creation. -3. Check the **SCOM Setup logs** link provided in the error message. Select the link to download the System Center Operations Manager setup logs. Analyze the logs to identify and resolve errors/failures. -4. If you're unable to identify the issue with the above steps, sign in to the Virtual Machine Scale Sets instance and check the logs under *C:\WindowsAzure\Logs\Plugins\Microsoft.Azure.SCOMMIServer.ScomServerForWindows\<version>*, which helps you identify the issue. -5. If the issue persists, raise a support ticket with all relevant details [`correlation-id`, `subscription-id`, and so on] ---### Issue: Resource group `%ResourceGroupName%` is managed by other Azure resource --**Cause**: Occurs when the *ManagedBy* property is set for the resource group. --**Resolution**: Provide another resource group with *ManagedBy* property as empty. --### Issue: The subnet `%SubnetName%` selected is dedicated to another service --**Cause**: Occurs when the subnet has delegations. --**Resolution**: Provide a subnet, which isn't delegated to any other service. --### Issue: Error when SCOM Managed Instance is unable to reach SQL Managed Instance `%instance%` --**Cause**: This error can be caused by any of the following reasons: - - Missing Line-of-sight visibility from SCOM Managed Instance VNet to SQL Managed Instance endpoint. - - Missing the right level of NSG rules to allow traffic over SQL Managed Instance public endpoint. - - MSI isn't added as Active Directory admin. - - SCOM Managed Instance might not have read permissions on the SQL Managed Instance. - - There might be an issue with your VNet/Region. ---**Resolution:** - - Provide read permission to the SQL Managed Instance. - - MSI must be added as Active Directory admin on the SQL Managed Instance. - - Ensure connectivity between SCOM Managed Instance and SQL Managed Instance networks. For more information, see [Create and configure an SQL Managed Instance](/system-center/scom/create-operations-manager-managed-instance?tabs=prereqs-portal#create-and-configure-an-sql-mi-instance). --### Issue: Not enough cores to create `%instance%` in the given region --**Cause**: Occurs when there aren't enough cores to create an instance in the given region. --**Resolution**: Check the quota section on Azure portal and allocate more cores of type Standard Ds3v2 in the region if needed. --### Issue: Secret key with same name is already present in the Key vault --**Cause**: Occurs when another secret key with the same name is already present in the Key vault. --**Resolution**: Change the name of the instance. --### Issue: VM has reported a failure when processing extension `joindomain` to join to the domain `%DomainName%` --**Cause**: Occurs due to the following reasons: -1. Line-of-sight visibility from SCOM Managed Instance Server to Domain Controller. -2. Domain User Credentials aren't provided or incorrect. -3. OU Path for AD Domain isn't provided. --**Resolution**: Check the cause and accordingly try to resolve the issue. --### Issue: Static IP already in use --**Cause**: Occurs if the static IP is being used by another instance. --**Resolution**: Use another static IP. --### Issue: Invalid Identity Type `%identityType%` --**Cause**: Occurs due to incorrect Managed identity. --**Resolution**: Provide one of the possible Identity types ((None), (SystemAssigned,UserAssigned)) and try again. --### Issue: Private static IP address `%LbIpAddr%` doesn't belong to the range of subnet `%subnet%` --**Cause**: Occurs as the IP address isn't in the subnet range. --**Resolution**: Provide an available IP from the subnet range and retry the operation. --### Issue: Identity isnΓÇÖt a system admin on SQL Managed Instance: '%instance'. --**Cause**: Occurs due to the following reasons: --1. User Managed Identity isnΓÇÖt SQL Admin on the SQL MI. -2. User Managed Identity is confirmed as SQL Admin on the SQL MI, and this is deployed using ARM, BICEP, Terraform or other deployment solution. --**Resolution**: Ensure that the User Managed Identity is deployed using the AppId and not the ObjectId. You can confirm if this is applicable by navigating to the SQL MI, Microsoft Entra ID admin pane. Check if the guid that is listed with the User Managed Identity is the ObjectId or AppId of the Service Principal. When this is the ObjectId: --- Set it using the portal-- Redeploy with your preferred solution using the AppId.--## Scenario: Deploy Reports on Power BI --### Issue: SQL Managed Instance isn't reachable --**Cause**: Occurs if the public endpoint isn't enabled. Power BI won't be able to reach SQL Managed Instance. --**Resolution**: Check the user permissions on SQL Managed Instance and provide the required permissions. --### Issue: Unable to refresh dataset credentials --**Cause**: Occurs if the user doesn't have appropriate permissions on the SQL Managed Instance. --**Resolution**: Check the user permissions on SQL Managed Instance and provide the required permissions. --### Issue: Report unable to refresh --**Cause**: Occurs due to large data size. The report might not refresh. --**Resolution**: If the Power BI workspace is in *pro* tier, change it to *premium* tier or change the capacity of the workspace. --## Scenario: Manual Scale up/down --### Issue: Internet connectivity test failed. Required endpoints are not reachable from the VNet --**Cause**: Network issue. --**Resolution**: Ensure that the SCOM Managed Instance has outbound Internet access and NSG/Firewall is properly configured to allow access to the required endpoints as described in [firewall requirements](configure-network-firewall.md#firewall-requirements). --### Issue: Quota Exceeded --**Cause**: Occurs if there are no cores available for scaling. --**Resolution**: Increase the number of cores in the subscription. --Check the quota section on Azure portal and allocate more cores of type Standard Ds3v2 in the region if needed. --### Issue: Extension provisioning error --**Cause**: This error might occur during the provisioning of System Center Operations Manager extension or System Center Operations Manager installation. --**Resolution**: Check the [general troubleshooting](./troubleshoot-scom-managed-instance.md#general-troubleshooting), try to identify the issue, and resolve it accordingly. --### Issue: Conflict --**Cause**: Occurs if patching or scaling is in progress. A new operation can't be triggered. --**Resolution**: Wait for the ongoing process to complete and try again. --## Scenario: Patching --### Issue: Internet connectivity test failed. Required endpoints are not reachable from the VNet --**Cause**: Network issue. --**Resolution**: Ensure that the SCOM Managed Instance has outbound Internet access and NSG/Firewall is properly configured to allow access to the required endpoints as described in [firewall requirements](configure-network-firewall.md#firewall-requirements). --### Issue: Notification is stuck at *Fetching updates* even though the update operation is complete --**Cause**: Network issue/development issue. --**Resolution**: Try refreshing for updates. If not resolved, contact Microsoft support. --### Issue: Update state isn't reflected correctly on the card --**Cause**: Network issue/development issue. --**Resolution**: Try refreshing for updates. If not resolved, contact Microsoft support. --### Issue: Inconsistency in the controls within the card --**Cause**: Consistency Issue. -For example, the update button is enabled even though the title of the card reads **SCOM is up to date**. --**Resolution**: Try refreshing. If not resolved, contact Microsoft support. --### Issue: Warning message pops up for updates --**Cause**: Occurs due to any of the following reasons: -1. New update is available, and the user hasn't triggered the update instance; or -2. Last update failed, and the user hasn't triggered another update instance. --**Resolution**: Trigger an *update instance*. --### Issue: Update fails after multiple retries - -**Resolution**: To resolve, contact Microsoft support. --### Issue: Update fails, and rollback fails to leave an inconsistent state where the number of VMs on the Virtual Machine Scale Sets instance has been modified --**Resolution**: Go to System Center Operations Manager console and remove inconsistent nodes. --### Issue: Update fails but database update is successful --**Cause**: Occurs due to failed update after the successful database update. --**Resolution**: Retry after some time. --### Issue: After successful update, System Center Operations Manager console isn't functioning properly on the instance --**Cause**: Occurs if System Center Operations Manager isn't installed properly or some process might be stuck. --**Resolution**: Try to restart the instance. If the issue persists, contact Microsoft support. --### Issue: Update is taking more than 3 hours and fails eventually --**Cause**: Occurs when the update takes more than 3 hours. --**Resolution**: Contact Microsoft support. --### Issue: Some intermittent issue during update --**Cause**: Occurs if the service fabric or RP crashes or restarts. --**Resolution**: Restart the update. --### Issue: Scaling and Patching triggered simultaneously and then fails --**Cause**: Occurs if scaling and patching requests are sent and accepted at the same time. --**Resolution**: In case you've triggered a scaling operation, wait for the operation to complete before you try to update operation. --### Issue: Extension takes more time to update and fails --**Cause**: Occurs if SQL Managed Instance and SCOM Managed Instance are in different regions due to which the extension takes more time to update and eventually fails. --**Resolution**: Have SQL Managed Instance and SCOM Managed Instance in the same region. --### Issue: After patching, user data in the database is altered or not retained properly --**Cause**: Occurs if update wasn't done properly. --**Resolution**: Restart the update. --### Issue: Patching request fails --**Cause**: Occurs due to portal or ARM issue. --**Resolution**: Wait for some time and retry. If the issue exists even after fixing the portal/ARM issue, contact Microsoft support. --### Issue: Patching or scaling operation is already in progress, try again after some time. --**Cause**: Occurs if a patching or scaling operation is already in progress. --**Resolution**: Wait for the existing operation to complete and try after some time. --### Issue: Stale Management Servers visible on console --**Cause**: Occurs if a patching or scaling operation has left an inconsistent state after completion. --**Resolution**: Microsoft Azure Virtual Machine Scale Sets is used to provision the management servers for SCOM Managed Instances. To remove the stale management server from the system, follow these steps: --1. Access the Azure Virtual Machine Scale Sets and log in to one of the management servers for the SCOM Managed Instance. --2. Launch PowerShell in administrative mode and navigate to the following directory. -- `C:\Packages\Plugins\Microsoft.Azure.SCOMMIServer.ScomServerForWindows\<version>\bin\troubleshooter` -- >[!Note] - >To find the version, go to `C:\Packages\Plugins\Microsoft.Azure.SCOMMIServer.ScomServerForWindows` and review all available versions and then select the latest one. --3. Execute the following script: -- ```powershell - .\RemoveStaleManagementServers.ps1 - ``` -- The script is interactive and prompts you for the FQDN of the stale server. --4. Provide the accurate FQDN of the stale management server you wish to remove. -- For example, FQDN: SCOMMI2000001.contoso.com. |
| azure-monitor | Troubleshooting Input Parameters Scom Managed Instance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/troubleshooting-input-parameters-scom-managed-instance.md | - Title: Troubleshoot commonly encountered errors while validating input parameters -description: This article describes the errors that might occur while validating input parameters and how to resolve them. --- Previously updated : 05/22/2024------# Troubleshoot commonly encountered errors while validating input parameters --This article describes the errors that might occur while validating input parameters and how to resolve them. --If you encounter any issues while creating on-premises parameters, use [this script](https://go.microsoft.com/fwlink/?linkid=2221732) for assistance. --This script is designed to help troubleshoot and resolve issues related to on-premises parameter creation. Access the script and utilize its functionalities to address any difficulties you might encounter during the creation of on-premises parameters. --Follow these steps to run the script: --1. Download the script and run it with the **-Help** option to get the parameters. -2. Sign in with domain credentials to a domain joined machine. The machine must be in a domain used for SCOM Managed Instance. After you sign in, run the script with the specified parameters. -3. If any validation fails, take the corrective actions as suggested by the script and rerun the script until it passes all the validations. -4. Once all the validations are successful, use the same parameters used in the script, for instance creation. --## Validation checks and details --| Validation| Description| -|-|-| -|Azure input validation checks| | -|Setting up prerequisites on the test machine| 1. Install AD PowerShell module. </br>2. Install Group Policy PowerShell module.| -|Internet connectivity| Checks if outbound internet connectivity is available on the test servers.| -|SQL MI connectivity| Checks if the provided SQL MI is reachable from the network on which the test servers are created.| -|DNS Server connectivity| Checks if the provided DNS Server IP is reachable and resolved to a valid DNS Server.| -|Domain connectivity| Checks if the provided domain name is reachable and resolved to a valid domain.| -|Domain join validation| Checks if domain join succeeds using provided OU Path and domain credentials.| -|Static IP and LB FQDN association| Checks if a DNS record has been created for the provided static IP against the provided DNS name.| -|Computer group validations| Checks if the provided computer group is managed by the provided domain user, and the manager can update group membership.| -|gMSA account validations| Checks if the provided gMSA: </br>- Is enabled. </br>- Has its DNS Host Name set to the provided DNS name of the LB. </br>- Has a SAM Account Name length of 15 characters or less. </br>- Has the right SPNs' set. </br> The password can be retrieved by members of the provided computer group. -|Group policy validations| Checks if the domain (or the OU Path, which hosts the management servers) is affected by any group policy, which will alter the local Administrators group.| -|Post validation clean-up| Unjoin from the domain.| --## General guidelines for running validation script --During the onboarding process, a validation is conducted at the validation stage/tab. If all the validations are successful, you can proceed to the final stage of creating SCOM Managed Instance. However, if any validations fails, you can't proceed with the creation. --In cases where multiple validations fail, the best approach is to address all the issues at once by manually running a [validation script](https://download.microsoft.com/download/2/3/a/23a14c00-8adf-4aba-99ea-6c80fb321f3b/SCOMMI%20Validation%20and%20Troubleshooter.zip) on a test machine. --> [!Important] -> Initially, create a new test Windows Server (2022/2019) virtual machine (VM) in the same subnet selected for SCOM Managed Instance creation. Subsequently, both your AD admin and Network admin can individually utilize this VM to verify the effectiveness of their respective changes. This approach significantly saves time spent on back-and-forth communication between the AD admin and Network admin. --Follow these steps to run the validation script: --1. Generate a new virtual machine (VM) running on Windows Server 2022 or 2019 within the chosen **subnet** for SCOM Managed Instance creation. Sign in to the VM and configure its DNS server to use the same DNS IP that was utilized during the creation of the SCOM Managed Instance. For example, see below: - - :::image type="Properties" source="media/troubleshooting-input-parameters-scom-managed-instance/properties.png" alt-text="Screenshot of properties."::: --2. Download the validation script to the test VM and extract. It consists of five files: - - ScomValidation.ps1 - - RunValidationAsSCOMAdmin.ps1 - - RunValidationAsActiveDirectoryAdmin.ps1 - - RunValidationAsNetworkAdmin.ps1 - - Readme.txt --3. Follow the steps mentioned in the Readme.txt file to run the *RunValidationAsSCOMAdmin.ps1*. Ensure to fill the settings value in *RunValidationAsSCOMAdmin.ps1* with applicable values before running it. -- ```powershell - # $settings = @{ - # Configuration = @{ - # DomainName="test.com" - # OuPath= "DC=test,DC=com" - # DNSServerIP = "190.36.1.55" - # UserName="test\testuser" - # Password = "password" - # SqlDatabaseInstance= "test-sqlmi-instance.023a29518976.database.windows.net" - # ManagementServerGroupName= "ComputerMSG" - # GmsaAccount= "test\testgMSA$" - # DnsName= "lbdsnname.test.com" - # LoadBalancerIP = "10.88.78.200" - # } - # } - # Note : Before running this script, please make sure you have provided all the parameters in the settings - $settings = @{ - Configuration = @{ - DomainName="<domain name>" - OuPath= "<OU path>" - DNSServerIP = "<DNS server IP>" - UserName="<domain user name>" - Password = "<domain user password>" - SqlDatabaseInstance= "<SQL MI Host name>" - ManagementServerGroupName= "<Computer Management server group name>" - GmsaAccount= "<GMSA account>" - DnsName= "<DNS name associated with the load balancer IP address>" - LoadBalancerIP = "<Load balancer IP address>" - } - } - ``` --4. In general, *RunValidationAsSCOMAdmin.ps1* runs all the validations. If you wish to run a specific check, then open *ScomValidation.ps1* and comment all other checks, which are at the end of the file. You can also add break point in the specific check to debug the check and understand the issues better. --```powershell -   # Default mode is - SCOMAdmin, by default if mode is not passed then it will run all the validations --    # adding all the checks to result set --    try { --        # Connectivity checks --        $validationResults += Invoke-ValidateStorageConnectivity $settings --        $results = ConvertTo-Json $validationResults -Compress --        --        $validationResults += Invoke-ValidateSQLConnectivity $settings --        $results = ConvertTo-Json $validationResults -Compress -- --        $validationResults += Invoke-ValidateDnsIpAddress $settings --        $results = ConvertTo-Json $validationResults -Compress -- --        $validationResults += Invoke-ValidateDomainControllerConnectivity $settings --        $results = ConvertTo-Json $validationResults -Compress -- --        # Parameter validations --        $validationResults += Invoke-ValidateDomainJoin $settings --        $results = ConvertTo-Json $validationResults -Compress -- --        $validationResults += Invoke-ValidateStaticIPAddressAndDnsname $settings --        $results = ConvertTo-Json $validationResults -Compress -- --        $validationResults += Invoke-ValidateComputerGroup $settings --        $results = ConvertTo-Json $validationResults -Compress -- --        $validationResults += Invoke-ValidategMSAAccount $settings --        $results = ConvertTo-Json $validationResults -Compress --            --        $validationResults += Invoke-ValidateLocalAdminOverideByGPO $settings --        $results = ConvertTo-Json $validationResults -Compress --    } --    catch { --        Write-Verbose -Verbose  $_ --    } -``` --5. The validation script displays all the validation checks and their respective errors, which will help resolving the validation issues. For fast resolution, run the script in PowerShell ISE with break point, which can speed up the debugging process. -- If all the checks pass successfully, return to the onboarding page and restart the onboarding process again. --## Internet connectivity --### Issue: Outbound internet connectivity doesn't exist on the test servers --**Cause:** Occurs due to an incorrect DNS Server IP or an incorrect network configuration. --**Resolution:** --1. Check the DNS Server IP, and ensure that DNS Server is up and running. -2. Ensure that the VNet, which is being used for SCOM Managed Instance creation has line-of-sight to the DNS Server. --### Issue: Unable to connect to the storage account to download SCOM Managed Instance product bits --**Cause:** Occurs due to a problem with your internet connectivity. --**Resolution:** Verify that the VNet being used for SCOM Managed Instance creation has outbound internet access by creating test virtual machine on the same subnet as SCOM Managed Instance and test outbound connectivity from test virtual machine. --### Issue: Internet connectivity test failed. Required endpoints are not reachable from the VNet --**Cause**: Occurs due to an incorrect DNS Server IP or an incorrect network configuration. --**Resolution**: --- Check the DNS Server IP, and ensure that the DNS Server is up and running.--- Ensure that the VNet, which is being used for SCOM Managed Instance creation has line-of-sight to the DNS Server.--- Ensure that the SCOM Managed Instance has outbound Internet access and NSG/Firewall is properly configured to allow access to the required endpoints as described in [firewall requirements](configure-network-firewall.md#firewall-requirements).--### General troubleshooting steps for [internet connectivity](https://download.microsoft.com/download/2/3/a/23a14c00-8adf-4aba-99ea-6c80fb321f3b/SCOMMI%20Validation%20and%20Troubleshooter.zip) --1. Generate a new virtual machine (VM) running on Windows Server 2022 or 2019 within the chosen subnet for SCOM Managed Instance creation. Sign in to the VM and configure its DNS server to use the same DNS IP that was utilized during the creation of the SCOM Managed Instance. --2. You can either follow the step-by-step instructions provided below, or if you're familiar with PowerShell, execute the specific check called `Invoke-ValidateStorageConnectivity` in the *[ScomValidation.ps1](https://download.microsoft.com/download/2/3/a/23a14c00-8adf-4aba-99ea-6c80fb321f3b/SCOMMI%20Validation%20and%20Troubleshooter.zip)* script. For more information on running the validation script independently on your test machine, see **[General guidelines for running the validation script](#general-guidelines-for-running-validation-script)**. --3. Open the PowerShell ISE in admin mode and set *Set-ExecutionPolicy* as *Unrestricted*. --4. To check the Internet connectivity, run the following command: -- ```powershell - Test-NetConnection www.microsoft.com -Port 80 - ``` -- This command verifies the connectivity to *[www.microsoft.com](https://www.microsoft.com/)* on port 80. If this fails, it indicates an issue with outbound internet connectivity. --5. To verify the DNS settings, run the following command: -- ```powershell - Get-DnsClientServerAddress - ``` -- This command retrieves the DNS server IP addresses configured on the machine. Ensure that the DNS settings are correct and accessible. --6. To check the network configuration, run the following command: -- ```powershell - Get-NetIPConfiguration - ``` -- This command displays the network configuration details. Verify that the network settings are accurate and match your network environment. --## SQL MI connectivity --### Issue: Outbound Internet connectivity doesn't exist on the test servers --**Cause:** Occurs due to an incorrect DNS Server IP, or an incorrect network configuration. --**Resolution:** --1. Check the DNS Server IP and ensure that the DNS Server is up and running. -2. Ensure that the VNet, which is being used for SCOM Managed Instance creation has line-of-sight to the DNS Server. --### Issue: Failed to configure DB login for MSI on SQL managed instance --**Cause**: Occurs when MSI is not properly configured to access SQL managed instance. --**Resolution**: Check if MSI is configured as Microsoft Entra Admin on SQL managed instance. Ensure that required [Microsoft Entra ID permissions](/system-center/scom/create-user-assigned-identity?view=sc-om-2022#set-the-active-directory-admin-value-in-the-sql-managed-instance&preserve-view=true) are provided to SQL managed instance for MSI authentication to work. --### Issue: Failed to connect to SQL MI from this instance --**Cause:** Occurs as the SQL MI VNet isn't delegated or isn't properly peered with the SCOM Managed Instance VNet. --**Resolution:** --1. Verify that the SQL MI is correctly configured. -2. Ensure that the VNet, which is being used for SCOM Managed Instance creation has line-of-sight to the SQL MI, either by being in the same VNet or by VNet peering. --### General troubleshooting steps for SQL MI connectivity --1. Generate a new virtual machine (VM) running on Windows Server 2022 or 2019 within the chosen subnet for SCOM Managed Instance creation. Sign in to the VM and configure its DNS server to use the same DNS IP that was utilized during the creation of the SCOM Managed Instance. --2. You can either follow the step-by-step instructions provided below, or if you're familiar with PowerShell, execute the specific check called `Invoke-ValidateSQLConnectivity` in the *[ScomValidation.ps1](https://download.microsoft.com/download/2/3/a/23a14c00-8adf-4aba-99ea-6c80fb321f3b/SCOMMI%20Validation%20and%20Troubleshooter.zip)* script. For more information on running the validation script independently on your test machine, see **[General guidelines for running the validation script](#general-guidelines-for-running-validation-script)**. --3. Open the PowerShell ISE in admin mode and set *Set-ExecutionPolicy* as *Unrestricted*. --4. To check the outbound internet connectivity, run the following command: -- ```powershell - Test-NetConnection -ComputerName "www.microsoft.com" -Port 80 - ``` -- This command verifies the outbound internet connectivity by attempting to establish a connection to *[www.microsoft.com](https://www.microsoft.com/)* on port 80. If the connection fails, it indicates a potential issue with the internet connectivity. --5. To verify the DNS settings and network configuration, ensure that the DNS server IP addresses are correctly configured and validate the network configuration settings on the machine where the validation is being performed. --6. To test the SQL MI connection, run the following command: -- ```powershell - Test-NetConnection -ComputerName $sqlMiName -Port 1433 - ``` -- Replace `$sqlMiName` with the name of the SQL MI host name. -- This command tests the connection to the SQL MI instance. If the connection is successful, it indicates that the SQL MI is reachable. --## DNS Server connectivity --### Issue: DNS IP provided (\<DNS IP\>) is incorrect, or the DNS Server isn't reachable --**Resolution:** Check the DNS Server IP, and ensure that DNS Server is up and running. --### General troubleshooting for DNS server connectivity --1. Generate a new virtual machine (VM) running on Windows Server 2022 or 2019 within the chosen subnet for SCOM Managed Instance creation. Sign in to the VM and configure its DNS server to use the same DNS IP that was utilized during the creation of the SCOM Managed Instance. --2. You can either follow the step-by-step instructions provided below, or if you're familiar with PowerShell, execute the specific check called `Invoke-ValidateDnsIpAddress` in the *[ScomValidation.ps1](https://download.microsoft.com/download/2/3/a/23a14c00-8adf-4aba-99ea-6c80fb321f3b/SCOMMI%20Validation%20and%20Troubleshooter.zip)* script. For more information on running the validation script independently on your test machine, see **[General guidelines for running the validation script](#general-guidelines-for-running-validation-script)**. --3. Open the PowerShell ISE in admin mode and set *Set-ExecutionPolicy* as *Unrestricted*. --4. To check the DNS resolution for the specified IP address, run the following command: -- ```powershell - Resolve-DnsName -Name $ipAddress -IssueAction SilentlyContinue - ``` -- Replace `$ipAddress` with the IP address you want to validate. -- This command checks the DNS resolution for the provided IP address. If the command doesn't return any results or throws an error, it indicates a potential issue with DNS resolution. --5. To verify the network connectivity to the IP address, run the following command: -- ```powershell - Test-NetConnection -ComputerName $ipAddress -Port 80 - ``` -- Replace `$ipAddress` with the IP address you want to test. -- This command checks the network connectivity to the specified IP address on port 80. If the connection fails, it suggests a network connectivity issue. --## Domain connectivity --### Issue: Domain controller for domain \<domain name\> isn't reachable from this network, or port isn't open on at least one domain controller --**Cause:** Occurs due to an issue with the provided DNS Server IP or your network configuration. --**Resolution:** --1. Check the DNS Server IP and ensure that DNS Server is up and running. -2. Ensure that the domain name resolution is correctly directed to the designated Domain Controller (DC) configured for either Azure or SCOM Managed Instance. Confirm that this DC is listed at the top among the resolved DCs. If the resolution is directed to different DC servers, it indicates a problem with AD domain resolution. -3. Check the domain name and ensure that domain controller configure for Azure and SCOM Managed Instance is up and running. - >[!Note] - >Ports 9389, 389/636, 88, 3268/3269, 135, 445 should be open on DC configured for Azure or SCOM Managed Instance, and all services on the DC should be running. --### General troubleshooting steps for domain connectivity --1. Generate a new virtual machine (VM) running on Windows Server 2022 or 2019 within the chosen subnet for SCOM Managed Instance creation. Sign in to the VM and configure its DNS server to use the same DNS IP that was utilized during the creation of the SCOM Managed Instance. --2. You can either follow the step-by-step instructions provided below, or if you're familiar with PowerShell, execute the specific check called `Invoke-ValidateDomainControllerConnectivity` in the *[ScomValidation.ps1](https://download.microsoft.com/download/2/3/a/23a14c00-8adf-4aba-99ea-6c80fb321f3b/SCOMMI%20Validation%20and%20Troubleshooter.zip)* script. For more information on running the validation script independently on your test machine, see **[General guidelines for running the validation script](#general-guidelines-for-running-validation-script)**. --3. Open the PowerShell ISE in admin mode and set *Set-ExecutionPolicy* as *Unrestricted*. --4. To check the domain controller reachability, run the following command: - ```powershell - Resolve-DnsName -Name $domainName - ``` -- Replace `$domainName` with the name of the domain you want to test. -- Ensure that the domain name resolution is correctly directed to the designated Domain Controller (DC) configured for either Azure or SCOM Managed Instance. Confirm that this DC is listed at the top among the resolved DCs. If the resolution is directed to different DC servers, it indicates a problem with AD domain resolution. --5. To verify DNS server settings: -- - Ensure that the DNS server settings on the machine running the validation are correctly configured. - - Verify if the DNS server IP addresses are accurate and accessible. --6. To validate network configuration: -- - Verify the network configuration settings on the machine where the validation is being performed. - - Ensure that the machine is connected to the correct network and has the necessary network settings to communicate with the domain controller. --7. To test the required port on the domain controller, run the following command: -- ```powershell - Test-NetConnection -ComputerName $domainName -Port $portToCheck - ``` -- Replace `$domainName` with the name of the domain you want to test, and `$portToCheck` with each port from the following list number: - - 389/636 - - 88 - - 3268/3269 - - 135 - - 445 - - Execute the provided command for all the above ports. -- This command checks if the specified port is open on the designated domain controller that is configured for Azure or SCOM Managed Instance creation. If the command shows a successful connection, it indicates that the necessary ports are open. --## Domain join validation --### Issue: Test management servers failed to join the domain --**Cause:** Occurs because of an incorrect OU path, incorrect credentials, or a problem in the network connectivity. --**Resolution:** --1. Check the credentials created in your Key vault. The username and password secret must reflect the correct username and format of the username value must be *domain\username* and password, which have permissions to join a machine to the domain. By default, user accounts can only add up to 10 computers to the domain. To configure, see [Default limit to number if workstations a user can join to the domain](/troubleshoot/windows-server/identity/default-workstation-numbers-join-domain). -2. Verify that the OU Path is correct and doesn't block new computers from joining the domain. --### General troubleshooting steps for Domain join validation --1. Generate a new virtual machine (VM) running on Windows Server 2022 or 2019 within the chosen subnet for SCOM Managed Instance creation. Sign in to the VM and configure its DNS server to use the same DNS IP that was utilized during the creation of the SCOM Managed Instance. --2. You can either follow the step-by-step instructions provided below, or if you're familiar with PowerShell, execute the specific check called `Invoke-ValidateDomainJoin` in the *[ScomValidation.ps1](https://download.microsoft.com/download/2/3/a/23a14c00-8adf-4aba-99ea-6c80fb321f3b/SCOMMI%20Validation%20and%20Troubleshooter.zip)* script. For more information on running the validation script independently on your test machine, see **[General guidelines for running the validation script](#general-guidelines-for-running-validation-script)**. --3. Open the PowerShell ISE in admin mode and set *Set-ExecutionPolicy* as *Unrestricted*. --4. Join the VM to a domain using the domain account that is used in SCOM Managed Instance creation. - For joining the domain to a machine using credentials, run the following command: - ```powershell -- $domainName = "<domainname>" --- $domainJoinCredentials = New-Object pscredential -ArgumentList ("<username>", (ConvertTo-SecureString "password" -AsPlainText -Force)) ---- $ouPath = "<OU path>" - if (![String]::IsNullOrWhiteSpace($ouPath)) { - $domainJoinResult = Add-Computer -DomainName $domainName -Credential $domainJoinCredentials -OUPath $ouPath -Force -WarningAction SilentlyContinue -ErrorAction SilentlyContinue - } - else { - $domainJoinResult = Add-Computer -DomainName $domainName -Credential $domainJoinCredentials -Force -WarningAction SilentlyContinue -ErrorAction SilentlyContinue - } - ``` -- Replace the username, password, $domainName, $ouPath with the right values. -- After you run the above command, run the following command to check if the machine joined the domain successfully: -- ```powershell - Get-WmiObject -Class Win32_ComputerSystem | Select-Object -ExpandProperty PartOfDomain - ``` --## Static IP and LB FQDN association --### Issue: Tests couldn't be run since the servers failed to join the domain --**Resolution:** Ensure that the machines can join the domain. Follow the troubleshooting steps from the [Domain join validation section](#domain-join-validation). --### Issue: DNS Name \<DNS Name\> couldn't be resolved --**Resolution:** The DNS Name provided doesn't exist in the DNS records. Check the DNS name and ensure it is correctly associated with the Static IP provided. --### Issue: The provided static IP \<static IP\> and Load Balancer DNS \<DNS Name\> doesn't match --**Resolution:** Check the DNS records and provide the correct DNS Name/Static IP combination. For more information, see [Create a static IP and configure the DNS name](/system-center/scom/create-operations-manager-managed-instance?&tabs=prereqs-active#create-a-static-ip-and-configure-the-dns-name). --### General troubleshooting steps for Static IP and LB FQDN association --1. Generate a new virtual machine (VM) running on Windows Server 2022 or 2019 within the chosen subnet for SCOM Managed Instance creation. Sign in to the VM and configure its DNS server to use the same DNS IP that was utilized during the creation of the SCOM Managed Instance. --2. You can either follow the step-by-step instructions provided below, or if you're familiar with PowerShell, execute the specific check called `Invoke-ValidateStaticIPAddressAndDnsname` in the *[ScomValidation.ps1](https://download.microsoft.com/download/2/3/a/23a14c00-8adf-4aba-99ea-6c80fb321f3b/SCOMMI%20Validation%20and%20Troubleshooter.zip)* script. For more information on running the validation script independently on your test machine, see **[General guidelines for running the validation script](#general-guidelines-for-running-validation-script)**. --3. Open the PowerShell ISE in admin mode and set *Set-ExecutionPolicy* as *Unrestricted*. --4. Join the virtual machine to a domain using the domain account that is used in SCOM Managed Instance creation. - To join the virtual machine to domain, follow the steps provided in the [Domain join validation section](#domain-join-validation). --5. Get IP address and associated DNS name and run the following commands to see if they match. - Resolve the DNS name and fetch the actual IP address: -- ```powershell - $DNSRecord = Resolve-DnsName -Name $DNSName - $ActualIP = $DNSRecord.IPAddress - ``` - - If the DNS name can't be resolved, ensure that the DNS name is valid and associated with the actual IP address. --## Computer group validations --### Issue: Test couldn't be run since the servers failed to join the domain --**Resolution:** Ensure that the machines can join the domain. Follow the troubleshooting steps specified in the [Domain join validation section](#domain-join-validation). --### Issue: Computer group with name \<computer group name\> couldn't be found in your domain --**Resolution:** Verify the existence of the group and check the name provided or create a new one if not created already. --### Issue: The input computer group \<computer group name\> isn't managed by the user \<domain username\> --**Resolution:** Navigate to the group properties and set this user as the manager. For more information, see [Create and configure a computer group](/system-center/scom/create-gmsa-account). --### Issue: The manager \<domain username\> of the input computer group \<computer group name\> doesn't have the necessary permissions to manage group membership --**Resolution:** Navigate to the **Group properties** and check the **Manage can update membership list** checkbox. For more information, see [Create and configure a computer group](/system-center/scom/create-gmsa-account). --### General troubleshooting steps for Computer group validations --1. Generate a new virtual machine (VM) running on Windows Server 2022 or 2019 within the chosen subnet for SCOM Managed Instance creation. Sign in to the VM and configure its DNS server to use the same DNS IP that was utilized during the creation of the SCOM Managed Instance. --2. You can either follow the step-by-step instructions provided below, or if you're familiar with PowerShell, execute the specific check called `Invoke-ValidateComputerGroup` in the *[ScomValidation.ps1](https://download.microsoft.com/download/2/3/a/23a14c00-8adf-4aba-99ea-6c80fb321f3b/SCOMMI%20Validation%20and%20Troubleshooter.zip)* script. For more information on running the validation script independently on your test machine, see **[General guidelines for running the validation script](#general-guidelines-for-running-validation-script)**. --3. Join the VM to a domain using the domain account that is used in SCOM Managed Instance creation. To join the virtual machine to domain, follow the steps provided in the [Domain join validation section](#domain-join-validation). --4. Open the PowerShell ISE in admin mode and set *Set-ExecutionPolicy* as *Unrestricted*. --5. Run the following command to import modules: -- ```powershell - Add-WindowsFeature RSAT-AD-PowerShell -ErrorAction SilentlyContinue - Add-WindowsFeature GPMC -ErrorAction SilentlyContinue - ``` --6. To verify if the VM is joined to the domain, run the following command: -- ```powershell - Get-WmiObject -Class Win32_ComputerSystem | Select-Object -ExpandProperty PartOfDomain - ``` --7. To verify the domain existence and if the current machine is already joined- to the domain, run the following command: -- ```powershell - $domainJoinCredentials = New-Object pscredential -ArgumentList ("<username>", (ConvertTo-SecureString "password" -AsPlainText -Force)) - $Domain = Get-ADDomain -Current LocalComputer -Credential $domainUserCredentials - ``` -- Replace `$username`, `password` with applicable values. --8. To verify the existence of the user in the domain, run the following command: -- ```powershell - $DomainUser = Get-ADUser -Identity $username -Credential $domainUserCredentials - ``` -- Replace `$username`, `$domainUserCredentials` with applicable values --9. To verify the existence of the computer group in the domain, run the following command: -- ```powershell - $ComputerGroup = Get-ADGroup -Identity $computerGroupName -Properties ManagedBy,DistinguishedName -Credential $domainUserCredentials - ``` -- Replace `$computerGroupName`, `$domainUserCredentials` with applicable values. --10. If the user and computer group exist, determine if the user is the manager of the computer group. -- ```powershell - Import-Module ActiveDirectory - $DomainDN = $Domain.DistinguishedName - $GroupDN = $ComputerGroup.DistinguishedName - $RightsGuid = [GUID](Get-ItemProperty "AD:\CN=Self-Membership,CN=Extended-Rights,CN=Configuration,$DomainDN" -Name rightsGuid -Credential $domainUserCredentials | Select-Object -ExpandProperty rightsGuid) -- # Run Get ACL under the give credentials - $job = Start-Job -ScriptBlock { - param ( - [Parameter(Mandatory = $true)] - [string] $GroupDN, - [Parameter(Mandatory = $true)] - [GUID] $RightsGuid - ) -- Import-Module ActiveDirectory - $AclRule = (Get-Acl -Path "AD:\$GroupDN").GetAccessRules($true,$true,[System.Security.Principal.SecurityIdentifier]) | Where-Object {($_.ObjectType -eq $RightsGuid) -and ($_.ActiveDirectoryRights -like '*WriteProperty*')} - return $AclRule -- } -ArgumentList $GroupDN, $RightsGuid -Credential $domainUserCredentials -- $timeoutSeconds = 20 - $jobResult = Wait-Job $job -Timeout $timeoutSeconds -- # Job did not complete within the timeout - if ($null -eq $jobResult) { - Write-Host "Checking permissions, timeout after 10 seconds." - Remove-Job $job -Force - } else { - # Job completed within the timeout - $AclRule = Receive-Job $job - Remove-Job $job -Force - } - - $managerCanUpdateMembership = $false - if (($null -ne $AclRule) -and ($AclRule.AccessControlType -eq 'Allow') -and ($AclRule.IdentityReference -eq $DomainUser.SID)) { - $managerCanUpdateMembership = $true -- ``` -- If `managerCanUpdateMembership` is **True**, then the domain user has update membership permission on the computer group. - If `managerCanUpdateMembership` is **False**, then give the computer group manage permission to the domain user. --## gMSA account validations --### Issue: Test doesn't run since the servers failed to join the domain --**Resolution:** Ensure that the machines can join the domain. Follow the troubleshooting steps specified in the [Domain join validation section](#domain-join-validation). --### Issue: Computer group with name \<computer group name\> isn't found in your domain. The members of this group must be able to retrieve the gMSA password --**Resolution:** Verify the existence of the group and check the name provided. --### Issue: gMSA with name \<domain gMSA\> couldn't be found in your domain --**Resolution:** Verify the existence of the gMSA account and check the name provided or create a new one if it hasn't been created already. --### Issue: gMSA \<domain gMSA\> isn't enabled --**Resolution:** Enable it using the following command: --```powershell -Set-ADServiceAccount -Identity <domain gMSA> -Enabled $true -``` --### Issue: gMSA \<domain gMSA\> needs to have its DNS Host Name set to \<DNS Name\> --**Resolution:** The gMSA doesn't have the `DNSHostName` property set correctly. Set the `DNSHostName` property using the following command: --```powershell -Set-ADServiceAccount -Identity <domain gMSA> -DNSHostName <DNS Name> -``` --### Issue: The Sam Account Name for gMSA \<domain gMSA\> exceeds the limit of 15 characters --**Resolution:** Set the `SamAccountName` using the following command: --```powershell -Set-ADServiceAccount -Identity <domain gMSA> -SamAccountName <shortname$> -``` --### Issue: Computer Group \<computer group name\> needs to be set as the PrincipalsAllowedToRetrieveManagedPassword for gMSA \<domain gMSA\> --**Resolution:** The gMSA doesn't have `PrincipalsAllowedToRetrieveManagedPassword` set correctly. Set the `PrincipalsAllowedToRetrieveManagedPassword` using the following command: --```powershell -Set-ADServiceAccount -Identity <domain gMSA> - PrincipalsAllowedToRetrieveManagedPassword <computer group name> -``` --### Issue: The SPNs haven't been set correctly for the gMSA \<domain gMSA\> --**Resolution:** The gMSA doesn't have correct Service Principal Names set. Set the Service Principal Names using the following command: --```powershell -Set-ADServiceAccount -Identity <domain gMSA> -ServicePrincipalNames <set of SPNs> -``` --### General troubleshooting steps for gMSA account validations --1. Generate a new virtual machine (VM) running on Windows Server 2022 or 2019 within the chosen subnet for SCOM Managed Instance creation. Sign in to the VM and configure its DNS server to use the same DNS IP that was utilized during the creation of the SCOM Managed Instance. --2. You can either follow the step-by-step instructions provided below, or if you're familiar with PowerShell, execute the specific check called `Invoke-ValidategMSAAccount` in the *[ScomValidation.ps1](https://download.microsoft.com/download/2/3/a/23a14c00-8adf-4aba-99ea-6c80fb321f3b/SCOMMI%20Validation%20and%20Troubleshooter.zip)* script. For more information on running the validation script independently on your test machine, see **[General guidelines for running the validation script](#general-guidelines-for-running-validation-script)**. --3. Join the VM to a domain using the domain account that is used in SCOM Managed Instance creation. To join the virtual machine to domain, follow the steps provided in the [Domain join validation section](#domain-join-validation). --4. Open the PowerShell ISE in admin mode and set *Set-ExecutionPolicy* as *Unrestricted*. --5. Run following command to import modules: -- ```powershell - Add-WindowsFeature RSAT-AD-PowerShell -ErrorAction SilentlyContinue - Add-WindowsFeature GPMC -ErrorAction SilentlyContinue - ``` --6. To verify that the servers have successfully joined the domain, run the following command: -- ```powershell - (Get-WmiObject -Class Win32_ComputerSystem).PartOfDomain - ``` --7. To check the existence of the computer group, run the following command: -- ```powershell - $Credentials = New-Object pscredential -ArgumentList ("<username>", (ConvertTo-SecureString "password" -AsPlainText -Force)) - $adGroup = Get-ADGroup -Identity $computerGroupName -Properties ManagedBy,DistinguishedName -Credential $Credentials - ``` -- Replace username, password and computerGroupName with applicable values. - -8. To check the existence of the gMSA account, run the following command: -- ```powershell - $adServiceAccount = Get-ADServiceAccount -Identity gMSAAccountName -Properties DNSHostName,Enabled,PrincipalsAllowedToRetrieveManagedPassword,SamAccountName,ServicePrincipalNames -Credential $Credentials - ``` --9. To validate the gMSA account properties, check if the gMSA account is enabled: -- ```powershell - (Get-ADServiceAccount -Identity <GmsaAccount>).Enabled - ``` -- If the command returns **False**, enable the account in the domain. --10. To verify that the DNS Host Name of the gMSA account matches the provided DNS name (LB DNS name), run the following commands: -- ```powershell - (Get-ADServiceAccount -Identity <GmsaAccount>).DNSHostName - ``` -- If the command doesn't return the expected DNS name, update the DNS Host Name of gMsaAccount to LB DNS name. --11. Ensure that the Sam Account Name for the gMSA account doesn't exceed the limit of 15 characters: -- ```powershell - (Get-ADServiceAccount -Identity <GmsaAccount>).SamAccountName.Length - ``` --12. To validate the `PrincipalsAllowedToRetrieveManagedPassword` property, run the following commands: -- Check if the Computer Group specified is set as the `PrincipalsAllowedToRetrieveManagedPassword`` for the gMSA account: -- ```powershell - (Get-ADServiceAccount -Identity <GmsaAccount>).PrincipalsAllowedToRetrieveManagedPassword -contains (Get-ADGroup -Identity <ComputerGroupName>).DistinguishedName - ``` -- Replace `gMSAAccount` and `ComputerGroupName` with applicable values. --13. To validate the Service Principal Names (SPNs) for the gMSA account, run the following command: -- ```powershell - $CorrectSPNs = @("MSOMSdkSvc/$dnsHostName", "MSOMSdkSvc/$dnsName", "MSOMHSvc/$dnsHostName", "MSOMHSvc/$dnsName") - (Get-ADServiceAccount -Identity <GmsaAccount>).ServicePrincipalNames - ``` -- Check if the results have Correct SPNs. Replace `$dnsName` with LB DNS name given in the SCOM Managed Instance creation. Replace `$dnsHostName` with LB DNS short name. - For example: MSOMHSvc/ContosoLB.domain.com, MSOMHSvc/ContosoLB, MSOMSdkSvc/ContosoLB.domain.com, and MSOMSdkSvc/ContosoLB are service principal names. --## Group policy validations -->[!Important] ->To fix GPO policies, collaborate with your active directory admin and exclude System Center Operations Manager from the below policies: ->- GPOs that modify or override local administrator group configurations. ->- GPOs that deactivate network authentication. ->- Evaluate GPOs impeding remote sign in for local administrators. --### Issue: This test couldn't be run since the servers failed to join the domain --**Resolution:** Ensure that the machines join the domain. Follow the troubleshooting steps from the [Domain join validation section](#domain-join-validation). --### Issue: gMSA with name \<domain gMSA\> couldn't be found in your domain. This account needs to be a local administrator on the server --**Resolution:** Verify the existence of the account and ensure that the gMSA and domain user are part of local administrator group. --### Issue: The accounts \<domain username\> and \<domain gMSA\> couldn't be added to the local Administrators group on the test management servers or didn't persist in the group after group policy update --**Resolution:** Ensure that the domain username and gMSA inputs provided are correct, including the full name (domain\account). Also check if there are any group policies on your test machine overriding the local Administrators group because of policies created at OU or Domain level. gMSA and domain user must be a part of the local administrator group for SCOM Managed Instance to work. SCOM Managed Instance machines must be excluded from any policy overriding the local administrator group (work with AD admin). --### Issue: SCOM Managed Instance failed --**Cause:** A group policy in your domain (name: \<group policy name\>) is overriding the local Administrators group on test management servers, either on the OU containing the servers or the root of the domain. --**Resolution:** Ensure that the OU for SCOM Managed Instance Management Servers (\<OU Path\>) isn't affected by *no policies override the group*. --### General troubleshooting steps for Group policy validations --1. Generate a new virtual machine (VM) running on Windows Server 2022 or 2019 within the chosen subnet for SCOM Managed Instance creation. Sign in to the VM and configure its DNS server to use the same DNS IP that was utilized during the creation of the SCOM Managed Instance. --2. You can either follow the step-by-step instructions provided below, or if you're familiar with PowerShell, execute the specific check called `Invoke-ValidateLocalAdminOverideByGPO` in the *[ScomValidation.ps1](https://download.microsoft.com/download/2/3/a/23a14c00-8adf-4aba-99ea-6c80fb321f3b/SCOMMI%20Validation%20and%20Troubleshooter.zip)* script. For more information on running the validation script independently on your test machine, see **[General guidelines for running the validation script](#general-guidelines-for-running-validation-script)**. --3. Join the VM to a domain using the domain account that is used in SCOM Managed Instance creation. To join the virtual machine to domain, follow the steps provided in the [Domain join validation section](#domain-join-validation). --4. Open the PowerShell ISE in admin mode and set *Set-ExecutionPolicy* as *Unrestricted*. --5. Run the following commands to import modules: -- ```powershell - Add-WindowsFeature RSAT-AD-PowerShell -ErrorAction SilentlyContinue - Add-WindowsFeature GPMC -ErrorAction SilentlyContinue - ``` --6. To verify if the servers have successfully joined the domain, run the following command: -- ```powershell - (Get-WmiObject -Class Win32_ComputerSystem).PartOfDomain - ``` -- The command must return **True**. --7. To check the existence of the gMSA account, run the following command: -- ```powershell - Get-ADServiceAccount -Identity <GmsaAccount> - ``` --8. To validate the presence of user accounts in the local Administrators group, run the following command: -- ```powershell - $domainJoinCredentials = New-Object pscredential -ArgumentList ("<username>", (ConvertTo-SecureString "password" -AsPlainText -Force)) - $addToAdminResult = Add-LocalGroupMember -Group "Administrators" -Member $userName, $gMSAccount -ErrorAction SilentlyContinue - $gpUpdateResult = gpupdate /force - $LocalAdmins = Get-LocalGroupMember -Group 'Administrators' | Select-Object -ExpandProperty Name - ``` -- Replace the `<UserName>` and `<GmsaAccount>` with the actual values. --9. To determine the domain and organizational unit (OU) details, run the following command: -- ```powershell - Get-ADOrganizationalUnit -Filter "DistinguishedName -like '$ouPathDN'" -Properties CanonicalName -Credential $domainUserCredentials - ``` -- Replace the \<OuPathDN\> with the actual OU path. --10. To get the GPO (Group Policy Object) report from the domain and check for overriding policies on the local Administrators group, run the following command: -- ```powershell - [xml]$gpoReport = Get-GPOReport -All -ReportType Xml -Domain <domain name> - foreach ($GPO in $gpoReport.GPOS.GPO) { - # Check if the GPO links to the entire domain, or the input OU if provided - if (($GPO.LinksTo.SOMPath -eq $domainName) -or ($GPO.LinksTo.SOMPath -eq $ouPathCN)) { - # Check if there is a policy overriding the Local Users and Groups - if ($GPO.Computer.ExtensionData.Extension.LocalUsersAndGroups.Group) { - $GroupPolicy = $GPO.Computer.ExtensionData.Extension.LocalUsersAndGroups.Group | Select-Object @{Name='RemoveUsers';Expression={$_.Properties.deleteAllUsers}},@{Name='RemoveGroups';Expression={$_.Properties.deleteAllGroups}},@{Name='GroupName';Expression={$_.Properties.groupName}} - # Check if the policy is acting on the BUILTIN\Administrators group, and whether it is removing other users or groups - if (($GroupPolicy.groupName -eq "Administrators (built-in)") -and (($GroupPolicy.RemoveUsers -eq 1) -or ($GroupPolicy.RemoveGroups -eq 1))) { - $overridingPolicyFound = $true - $overridingPolicyName = $GPO.Name - } - } - } - } - if($overridingPolicyFound) { - Write-Warning "Validation failed. A group policy in your domain (name: $overridingPolicyName) is overriding the local Administrators group on this machine. This will cause SCOM MI installation to fail. Please ensure that the OU for SCOM MI Management Servers is not affected by this policy" - } - else { - Write-Output "Validation suceeded. No group policy found in your domain which overrides local Administrators. " - } - ``` --If the script execution gives a warning as **Validation Failed**, then there is policy (name as in the warning message) that overrides local administrator group. Check with active directory administrator and exclude the System Center Operations Manager management server from the policy. |
| azure-monitor | Tutorial Create Scom Managed Instance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/tutorial-create-scom-managed-instance.md | - Title: Tutorial - Create an instance of Azure Monitor SCOM Managed Instance -description: This article describes how to create an Azure Monitor SCOM Managed Instance to monitor workloads by using System Center Operations Manager functionality on Azure. --- Previously updated : 05/22/2024-------# Tutorial: Create an instance of Azure Monitor SCOM Managed Instance --Azure Monitor SCOM Managed Instance provides System Center Operations Manager functionality in Azure. It helps you monitor all your workloads, whether they're on-premises, in Azure, or in any other cloud services. --This tutorial describes how to create an instance of the service (a SCOM Managed Instance) with System Center Operations Manager functionality in Azure. --## Supported regions --- Australia East-- Canada Central-- East US-- East US 2-- Germany West Central-- Italy North-- North Europe-- South India-- Southeast Asia-- Sweden Central-- UK South-- West Europe-- West US-- West US 2-- West US 3--## Prerequisites --Before you create a SCOM Managed Instance, follow these steps: --- [Step 1. Register the SCOM Managed Instance resource provider](register-scom-managed-instance-resource-provider.md).-- [Step 2. Create separate subnet in a VNet](create-separate-subnet-in-vnet.md).-- [Step 3. Create a SQL Managed Instance](create-sql-managed-instance.md).-- [Step 4. Create a Key vault](create-key-vault.md).-- [Step 5. Create a user assigned identity](create-user-assigned-identity.md).-- [Step 6. Create a computer group and gMSA account](create-group-managed-service-account.md).-- [Step 7. Store domain credentials in Key vault](store-domain-credentials-key-vault.md).-- [Step 8. Create a static IP](create-static-ip.md).-- [Step 9. Configure the network firewall](configure-network-firewall.md).-- [Step 10. Verify Azure and internal GPO policies](verify-azure-internal-group-policy-object-policies.md).-- [Step 11. SCOM Managed Instance self-verification of steps](self-verification-steps.md).--## Create a SCOM Managed Instance --To create a SCOM Managed Instance, follow these steps: --1. Sign in to the [Azure portal](https://portal.azure.com). Search for and select **SCOM Managed Instance**. -1. On the **Overview** page, you have three options: - - **Pre-requisites**: Allows you to view the prerequisites. - - **SCOM managed instance**: Allows you to create a SCOM Managed Instance. - - **Manage your SCOM managed instance**: Allows you to view the list of created instances. -- :::image type="SCOM Managed Instance overview" source="media/create-operations-manager-managed-instance/scom-managed-instance-overview-inline.png" alt-text="Screenshot that shows options on the Overview page for SCOM Managed Instance." lightbox="media/create-operations-manager-managed-instance/scom-managed-instance-overview-expanded.png"::: -- Select **Create SCOM managed instance**. -1. The **Prerequisites to create SCOM managed instance** page opens. Download the script and run it on a domain-joined machine to validate the prerequisites. -- :::image type="Script download" source="media/create-operations-manager-managed-instance/script-download-inline.png" alt-text="Screenshot that shows the button for downloading a script." lightbox="media/create-operations-manager-managed-instance/script-download-expanded.png"::: -1. Under **Basics**, do the following: - - **Project details**: - - **Subscription**: Select the Azure subscription in which you want to place the SCOM Managed Instance. - - **Resource group**: Select the resource group in which you want to place the SCOM Managed Instance. We recommend that you have a new resource group exclusively for SCOM Managed Instance. -- :::image type="Project details" source="media/create-operations-manager-managed-instance/project-details-inline.png" alt-text="Screenshot that shows project details for creating a SCOM Managed Instance." lightbox="media/create-operations-manager-managed-instance/project-details-expanded.png"::: -- - **Instance details**: - - **SCOM managed instance name**: Enter a name for your SCOM Managed Instance. - >[!NOTE] - >- The name of a SCOM Managed Instance can have only alphanumeric characters and be up to 10 characters. - >- A SCOM Managed Instance is equivalent to a System Center Operations Manager management group, so choose a name accordingly. - - **Region**: Select a region near to you geographically so that latency between your agents and the SCOM Managed Instance is as low as possible. This region must also contain the virtual network. -- :::image type="Instance details" source="media/create-operations-manager-managed-instance/instance-details-inline.png" alt-text="Screenshot that shows instance details for creating a SCOM Managed Instance." lightbox="media/create-operations-manager-managed-instance/instance-details-expanded.png"::: -- - **Active directory details**: - - **Domain name**: Enter the name of the domain that the domain controller is administering. - - **DNS server IP**: Enter the IP address of the Domain Name System (DNS) server that's providing the IP addresses to the resources in the domain from the previous step. - - **OU Path**: Enter the organizational unit (OU) path to where you want to join the servers. This field isn't a necessary. If you leave it blank, it assumes the default value. Ensure that the value you enter is in the distinguished name format. For example: **OU=testOU,DC=domain,DC=Domain,DC=com**. -- :::image type="Active Directory details" source="media/create-operations-manager-managed-instance/active-directory-details-inline.png" alt-text="Screenshot that shows Active Directory details for creating a SCOM Managed Instance." lightbox="media/create-operations-manager-managed-instance/active-directory-details-expanded.png"::: -- - **Domain account details**: - - **Security key vault**: Select the key vault that has the secret username and secret password of the domain account's user credentials. - - **Username secret**: Enter the secret name for the user under the selected key vault. - - **Password secret**: Enter the secret name for the password under the selected key vault. -- >[!NOTE] - >Ensure that you provide the secret names created in the *selected key vault* and not the actual domain username and password. -- :::image type="content" source="./media/create-operations-manager-managed-instance/secret-password-mapping-inline.png" alt-text="Screenshot that shows password mapping for creating a secret." lightbox="./media/create-operations-manager-managed-instance/secret-password-mapping-expanded.png"::: -- - **Azure hybrid benefit**: By default, **No** is selected. Select **Yes** if you're using a Windows Server license for your existing servers. This license is applicable only for the Windows servers that are used while you create a virtual machine for the SCOM Managed Instance. It won't apply to the existing Windows servers. -- :::image type="Azure hybrid benefit" source="media/create-operations-manager-managed-instance/azure-hybrid-benefit.png" alt-text="Screenshot that shows options for Azure hybrid benefit."::: -1. Select **Next**. -1. Under **Networking**, do the following: - - **Virtual network**: - - **Virtual network**: Select the virtual network that has direct connectivity to the workloads that you want to monitor and to your domain controller and DNS server. - - **Subnet**: Select a subnet that has at least 32 IP addresses to house the instance. The minimum address space is 28. -- The subnet can have existing resources in it. However, don't choose the subnet that houses the SQL managed instance because it won't contain enough IP addresses to house the SCOM Managed Instance components. -- - **SCOM managed instance interface**: - - **Static IP**: Enter the static IP for the load balancer. This IP should be in the selected subnet range for SCOM Managed Instance. Ensure that the IP is in the IPv4 format, and create it in your routing table. - - **DNS name**: Enter the DNS name that you attached to the static IP from the preceding step. The DNS name is mapped to the static IP that's previously defined. - - **gMSA details**: - - **Computer group name**: Enter the name of the computer group that you create after creation of the group managed service account (gMSA) account. - - **gMSA account name**: Enter the gMSA name. It must end with **$**. -- :::image type="gMSA details" source="media/create-operations-manager-managed-instance/gmsa-details.png" alt-text="Screenshot that shows gMSA details."::: -1. Select **Next**. -1. Under **Database**, do the following: - - **SQL managed instance**: For **Resource Name**, select the Azure SQL Managed Instance resource name for the instance that you want to associate with this SCOM Managed Instance. Use only the SQL managed instance that has given permissions to the SCOM Managed Instance. For more information, see [SQL managed instance creation and permission](/system-center/scom/create-operations-manager-managed-instance?view=sc-om-2022&tabs=prereqs-portal#create-and-configure-a-sql-mi&preserve-view=true). - - **User managed identity**: For **User managed identity account**, provide a user managed identity with system admin privileges on the SQL managed instance and **Get** and **List** permissions on key vault secrets that were selected on the **Basics** tab. Ensure that the same MSI has read permissions on the key vault for domain account credentials. -1. Select **Next**. -1. Under **Validate**, all the prerequisites are validated. It takes 10 minutes to finish the validation. -- :::image type="Validate tab" source="media/create-operations-manager-managed-instance/validate-inline.png" alt-text="Screenshot that shows the Validate tab." lightbox="media/create-operations-manager-managed-instance/validate-expanded.png"::: -- After the validation is finished, check the results and revalidate if needed. -- :::image type="Validation complete" source="media/create-operations-manager-managed-instance/validation-complete-inline.png" alt-text="Screenshot that shows Validation status: Completed." lightbox="media/create-operations-manager-managed-instance/validation-complete-expanded.png"::: --1. Select **Next: Tags**. -1. Under **Tags**, enter the **Name** and **Value** information, and then select the resource. -- Tags help you categorize resources and view consolidated billing by applying the same tags to multiple resources and resource groups. For more information, see [Use tags to organize your Azure resources and management hierarchy](/azure/azure-resource-manager/management/tag-resources?wt.mc_id=azuremachinelearning_inproduct_portal_utilities-tags-tab&tabs=json). -1. Select **Next**. -1. Under **Review + create**, review all the inputs given so far, and then select **Create**. Your deployment is created on Azure. Creation of a SCOM Managed Instance takes up to an hour. -- >[!NOTE] - >If the deployment fails, delete the instance and all the associated resources, and then create the instance again. For more information, see [Delete an instance](./scom-managed-instance-faq.yml#other-queries). --1. After the deployment is finished, select **Go to resource**. -- On the instance page, you can view some of the essential details and instructions for post-deployment steps and reporting bugs. --## Next steps --- [Troubleshoot commonly encountered errors while validating input parameters](troubleshooting-input-parameters-scom-managed-instance.md)-- [Troubleshoot issues with Azure Monitor SCOM Managed Instance](troubleshoot-scom-managed-instance.md)-- [Azure Monitor SCOM Managed Instance frequently asked questions](scom-managed-instance-faq.yml) |
| azure-monitor | Use Managed Identities With Scom Mi | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/use-managed-identities-with-scom-mi.md | - Title: Use Managed identities for Azure with Azure Monitor SCOM Managed Instance -description: This article describes how to use Managed identities for Azure with Azure Monitor SCOM Managed Instance. --- Previously updated : 05/24/2024-------# Use Managed identities for Azure with Azure Monitor SCOM Managed Instance --A common challenge when building cloud applications is how to securely manage the credentials in your code for authenticating various services without saving them locally on a developer workstation or in source control.  --*Managed identities for Azure* solve this problem for all your resources in Azure Active Directory by providing them with automatically managed identities. You can use a service's identity to authenticate any service that supports Azure Active Directory authentication, including Key vault, without sorting any credentials in your code. -->[!Note] ->- *Managed identities for Azure* are the new name for the service formerly known as Managed Service Identity (MSI). ->- *Managed identities for Azure resources* are free with Azure Active Directory for Azure subscriptions. There's no extra cost. --## Concepts --Managed identities for Azure are based on several key concepts: --- **Client ID** - A unique identifier generated by Azure Active Directory that is tied to an application and service principal during its initial provisioning. For more information, see  [Application (client) ID](/azure/active-directory/develop/developer-glossary#application-client-id).--- **Principal ID** - The object ID of the service principal object for your managed identity that is used to grant role-based access to an Azure resource. --- **Service Principal** - An Azure Active Directory object, which represents the projection of an Azure Active Directory application on a given tenant. For more information, see  [Service principal](/azure/active-directory/develop/developer-glossary#service-principal-object).--## Managed identity types --There are two types of managed identities: --- **System-assigned managed identity**: Enabled directly on an Azure service instance. The lifecycle of a system-assigned identity is unique to the Azure service instance that it's enabled on. --- **User-assigned managed identity**: Created as a standalone Azure resource. The identity can be assigned to one or more Azure service instances and is managed separately from the lifecycles of those instances. --For more information on Managed identity types, see  [How do managed identities for Azure resources work?](/azure/active-directory/managed-identities-azure-resources/overview#managed-identity-types). --## Supported scenarios for SCOM Managed Instance --SCOM Managed Instance supports both System Assigned Managed Identity and User Assigned Managed Identity for the SCOM Managed Instances deployed in Azure. SCOM Managed Instance creates other dependency resources like Virtual Machine Scale Sets (VMSS) cluster to host management servers. SCOM Managed Instance onboarded the Managed identities with HOBO v2 so that the assigned Identity will be delegated to the underlying infrastructure for authenticating with sink resources. These Identities are used to authenticate other Azure services in different scenarios. --- System Assigned Managed Identity-- - SCOM Managed Instance will send different health or performance metrics to Geneva Cluster services, monitoring the instance behavior at run time. The system Assigned Identity, which is delegated to SCOM Managed Instance resource, will be used to authenticate with Azure Geneva Cluster services. --- User Assigned Managed Identity -- - For SCOM Managed Instance, a Managed Identity will replace the traditional four System Center Operations Manager service accounts and will be used to access the SQL Managed Instance database. SCOM Managed Instance reads/writes customer workload monitoring data to SQL managed instance databases. The User Assigned Identity assigned to SCOM Managed Instance resource will be used for authenticating from System Center Operations Manager servers to SQL Managed instance. -- - SCOM Managed Instance onboarding process takes the domain user credentials stored in Customer Key vault. The secrets in the Customer Key vault are accessed using the managed identity assigned to SCOM Managed Instance. -- During SCOM Managed Instance onboarding, you must provide the User Managed Identity, which has access to Customer Key vault and SQL Managed Instance. --## Create a Managed Service Identity (MSI) --Create a [Managed Service identity](/system-center/scom/create-operations-manager-managed-instance?view=sc-om-2022&tabs=prereqs-portal#create-a-managed-service-identity-msi&preserve-view=true) and provide it with the right access level on Azure resource. --## Create a Key vault and add Credentials as a secret in the Key vault  --Store the domain account you create in the Active Directory in a Key vault account for security. Azure Key Vault is a cloud service that provides a secure store for keys, secrets, and certificates. For more information, see [Azure Key vault](/azure/key-vault/general/overview). --- Create a [Key vault](/azure/key-vault/general/quick-create-portal).-- Create a [Secret for the domain account](/azure/key-vault/secrets/quick-create-portal).-- Assign a Reader role on this key vault to the Managed Service Identity (MSI). For more information, see  [Assign a Key vault access policy](/azure/key-vault/general/assign-access-policy?tabs=azure-portal).--## Set the Active Directory Admin value in the SQL Managed Instance --[Set the Active Directory Admin value](/system-center/scom/create-operations-manager-managed-instance?view=sc-om-2022&tabs=prereqs-portal#set-the-active-directory-admin-value-in-the-sql-mi&preserve-view=true) in the SQL Managed Instance. |
| azure-monitor | Verify Azure Internal Group Policy Object Policies | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/verify-azure-internal-group-policy-object-policies.md | - Title: Verify Azure and internal GPO policies for Azure Monitor SCOM Managed Instance -description: This article describes how to verify Azure and internal GPO policies. --- Previously updated : 05/22/2024------# Verify Azure and internal GPO policies for Azure Monitor SCOM Managed Instance --This article describes how to verify Azure and internal Group Policy Object (GPO) policies. --> [!NOTE] -> To learn about the Azure Monitor SCOM Managed Instance architecture, see [Azure Monitor SCOM Managed Instance](overview.md). --## Verify Azure policies --If any Azure policies are aimed at constraining the creation of managed resource groups, virtual machine scale sets, load balancers, managed identities, and metric alerts, make an exception for the subscription that's associated with the instance of Azure Monitor SCOM Managed Instance. This exception is necessary because the SCOM managed instance creates all these resources within the managed resource group. --Follow these steps to view the policies that are applied on a subscription: --1. Go to the specific subscription, and on the left menu under **Subscription**, select the policies. -1. On the **Policies** page, select the policy assignments and find the policy that's causing the issue. -1. Open the specific assignment and select the exemption. -- :::image type="create exemption" source="media/verify-azure-and-internal-gpo-policies/create-exemption.png" alt-text="Screenshot that shows the Create exemption page."::: --## Verify internal GPO policies --As SCOM managed instances become part of the designated domain or organizational unit (OU), any GPO policies come into play at the OU or domain level and affect the local administrators group. Consider the exclusion of the SCOM managed instance from those GPO policies. --The following policies could potentially influence the local administrator groups. Customized policies might also be in effect. -- - Review any GPO policies that might alter the configuration of the local administrator group. - - Examine whether there are any GPO policies intended to deactivate network authentication. - - Assess whether any policies are obstructing remote logins to the local administrator group. --> [!IMPORTANT] -> To minimize the need for extensive communication with both your Active Directory admin and network admin, see [Self-verification](self-verification-steps.md). The article outlines the procedures that the Active Directory admin and network admin use to validate their configuration changes and ensure their successful implementation. This process reduces unnecessary back-and-forth interactions from the Operations Manager admin to the Active Directory admin and the network admin. This configuration saves time for the admins. --## Next step --- [SCOM Managed Instance self-verification of steps](self-verification-steps.md) |
| azure-monitor | View Operations Manager Alerts Azure Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/view-operations-manager-alerts-azure-monitor.md | - Title: View System Center Operations ManagerΓÇÖs alerts in Azure Monitor -description: This article describes the recent feature addition that allows Azure Monitor SCOM Managed Instance customers to view Operations ManagerΓÇÖs alerts in Azure Monitor. --- Previously updated : 05/22/2024------# View System Center Operations ManagerΓÇÖs alerts in Azure Monitor --This article describes the recent feature addition that allows Azure Monitor SCOM Managed Instance customers to view Operations ManagerΓÇÖs alerts in Azure Monitor. --> [!VIDEO 09a0b07e-c50c-4ee4-b0a7-43d8ca6bb847] --## Alert --An alert is an object that is generated in System Center Operations Manager when one of the rules or monitors that are set in an Operations Manager management pack is triggered. In System Center - Operations Manager, an alert can be generated by a rule or a monitor. For more information on rules and monitors, seeΓÇ»[Operations Manager management pack](/system-center/scom/manage-overview-management-pack). --For detailed information on how an alert is produced in Operations Manager, see [How an alert is produced](/system-center/scom/manage-alert-generation-overview). --## View and manage alerts in Operations Manager on-premises --In System Center Operations Manager, alerts matching a specific criterion and related to an object or group of objects are presented in an alerts view. From this view, you can review alerts that have been generated by rules and monitors, which are still active and haven't been closed automatically or manually by an operator. For more information on how alerts are viewed, see [View Active Alerts and Details](/system-center/scom/manage-alert-view-alerts-details). --Each alert has specific properties that inform the user about different factors such as the history of the alert, how it's generated, what are the objects affected etc. For a complete list of all the properties of a rule/monitor alert, see [Examining Properties of Alerts, Rules, and Monitors](/system-center/scom/manage-examine-properties-of-workflows). --## View Operations ManagerΓÇÖs alerts in Azure Monitor --For SCOM Managed Instance, the alerts that are generated in the workload can now be seen in Azure Monitor. --Log in to the Azure portal, access the Azure Monitor service, and select **Alerts** tab to see a list of all the alerts that the service has generated. ---To view the alerts that are generated by your SCOM Managed Instance service, select **SCOM Managed Instance** in the **Monitor service** filter. ---Select an alert to view its details. Details include: --- Severity of the alert-- Fired Time-- Affected Resource-- Hierarchy of the affected resource group-- User Response-- Alert Condition-- Is it a monitor alert-- Operations Manager resolution state-- Priority-- Last Modified Time-- Category-- Last Modified By-- Operations Manager severity-- Description-- Monitor service-- Alert ID-- Suppression Status-- Target Resource Type-- History of the alert---## Compare Operations Manager Ops console and Azure Monitor alerts data --The alerts moving from System Center Operations Manager to Azure Monitor SCOM Managed Instance must match the Azure Monitor alert schema to be displayed properly in the portal. --The following translations are made to the Operations Manager alert schema when moving to Azure Monitor alerts schema: --|Alert property|Representation in Operations Console|Representation in Azure Monitor| -|||| -| State | Seven predefined Alert states, which can be extended to 255 user-defined states. <br/> <br/> New, Acknowledged, Scheduled, Assigned to Engineering, Awaiting Evidence, Resolved and Closed.| Two distinct properties: Alert monitoring Condition and User state. <br/> <br/> The new alert from Operations Manager to Azure is represented as **Fired** and **New**, respectively. <br/> <br/> The closed alert from SCOM Managed Instance is represented as **Resolved** and **New** or **Resolved** and **Closed**. | -|Severity|Critical, Warning, Informational|Critical, Error, Warning, Informational and Verbose <br/> <br/> SCOM Managed Instance alerts are represented with the corresponding Alert severity in Azure.| -|Signal Type| |All SCOM Managed Instance alerts are represented as Custom signal type in Azure.| -|Monitoring Service| |**SCOM Managed Instance**| -|Effected resource| |If the alert is from Azure native/Arc resource, then it is represented with its corresponding ARM resource ID. <br/> <br/> If the alert is from on-premises workload, it is represented with SCOM Managed Instance resource ARM ID.| -|Additional properties|Priority, Category, Owner, Repeat count, alert context, and parameters. <br/> <br/> The management pack discovered object for the alert.|All these properties are represented in Azure alert context to enhance it with SCOM Managed Instance alerts information.| --## Integrate Azure Monitor alerts with ITSM tools --Azure Monitor allows integration with ITSM tools such as ServiceNow so that alerts can be forwarded to the tools in the form of incidents. Using Azure Monitor AlertsΓÇÖ concept of [Action Groups](/azure/azure-monitor/alerts/action-groups) and [Alert Processing Rules](/azure/azure-monitor/alerts/alerts-processing-rules?tabs=portal), you can create the necessary actions to link alerts from SCOM Managed Instance with an ITSM connector such as ServiceNow. --For more information, see [Connect ServiceNow with IT Service Management Connector](/azure/azure-monitor/alerts/itsmc-connections-servicenow). --Once the ITSM connector is created and connected to the ServiceNow instance, follow these steps: --1. After you create the ITSM connector, create an **Action Group** in the **Azure Monitor Alerts** page with an ITSM action type created. -- :::image type="content" source="media/view-operations-manager-alerts-azure-monitor/action-group-inline.png" alt-text="Screenshot showing Action group." lightbox="media/view-operations-manager-alerts-azure-monitor/action-group-expanded.png"::: --2. Create an Alert Processing Rule with the filter **Monitor Service equals SCOM Managed Instance**. - :::image type="content" source="media/view-operations-manager-alerts-azure-monitor/alert-processing-rule-inline.png" alt-text="Screenshot showing Alert processing rule." lightbox="media/view-operations-manager-alerts-azure-monitor/alert-processing-rule-expanded.png"::: --3. In the **Rule settings** tab, under **Rule type**, select **Apply action group** option. -- :::image type="content" source="media/view-operations-manager-alerts-azure-monitor/rule-settings-inline.png" alt-text="Screenshot showing Rule settings tab." lightbox="media/view-operations-manager-alerts-azure-monitor/rule-settings-expanded.png"::: --Now, the connection to the ServiceNow instance is successfully established and the alerts reflect in the portal as incidents. --In the ServiceNow portal, you can see your list of incidents under the **Microsoft OMS Integrator ΓÇô OMS Incidents** tab. ---## Status of an alert when itΓÇÖs closed --Irrespective of the alert being a rule or monitor alert, if the alert is closed in the System Center Operations Manager Ops Console, the closed state of the alert will be reflected in the Azure Monitor portal with the **Alert condition** changing from **Fired** to **Resolved**. --->[!NOTE] ->- We donΓÇÖt recommend closing a monitor alert manually in the Azure Monitor portal. For more information, see [How to Close an Alert Generated by a Monitor](/system-center/scom/manage-alert-created-by-monitor). ->- If you close a rule-based alert in the Azure Monitor portal, the change will not be reflected in the System Center Operations Manager Ops Console. |
| azure-monitor | Whats New Scom Managed Instance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/scom-manage-instance/whats-new-scom-managed-instance.md | - Title: WhatΓÇÖs new in Azure Monitor SCOM Managed Instance -description: This article provides details of what's new in each version of Azure Monitor SCOM Managed Instance. --- Previously updated : 08/12/2024------# WhatΓÇÖs new in Azure Monitor SCOM Managed Instance --This article provides details of what's new in each version of Azure Monitor SCOM Managed Instance. --## Version 1.0.103 --- Bug fix in domain connectivity checks of validation to prevent timeouts.--## Version 1.0.100 --- Bug fix in pre-patch/pre-scale validations.--## Version 1.0.99 --- Enhanced checks for domain connectivity to handle multiple domain controllers during onboarding, pre-patching, and pre-scaling validations.--## Version 1.0.98 --- Improved onboarding telemetry and bug fixes in prerequisite validations.--- Improved reliability of clean-up actions after update and scale-down operations.--- Updated troubleshooting script.--## Version 1.0.97 --- Improved onboarding telemetry.--- Bug fix to remove stale AD objects associated with deallocated VMs after the scale down/update operation.--## Version 1.0.96 --- Pre-patch validation bug fix for machines that have unresolved accounts in the admin group.--## Version 1.0.95 --- Enhance onboarding/pre-patching/pre-scaling validations to check the connectivity to required endpoints as described in [firewall requirements](configure-network-firewall.md#firewall-requirements).--## Version 1.0.94 --- Installation bug fix for domain joined machines.--- Fixed issue in scale down operation where incorrect management server was being assigned as RMS.--- Enhanced system resiliency by executing the SCOM managed gateway onboard and offboard commands exclusively on the present RMS.--- Bug fix in scale management server script to handle right reallocation of agents.--## Version 1.0.91 --- **Implemented pre-patching validations**: Conducted essential checks before initiating the patching operation, ensuring optimal conditions for existing management servers, verifying SQL connectivity, confirming active directory accessibility, and validating the accuracy of domain account credentials.--- Bug fix to handle the concurrency in extension installation.--## Version 1.0.89 --- The Log Analytics workspace feature is available for existing and new SCOM Managed Instances.--## Version 1.0.88 --- Bug fixes for onboarding validation.--- Fixed issue where Static IP and LB association check fails with error **The property `IP4Address` cannot be found on this object**.--## Version 1.0.87 --- Bug fixes for onboarding validation.--- Fixed issue where Domain Connectivity check fails with error **The property `TcpTestSucceeded` cannot be found on this object**.--## Version 1.0.86 --- Introduced [Resource Health feature](/azure/service-health/resource-health-overview?WT.mc_id=Portal-Microsoft_Azure_Health) for SCOM Managed Instance.--- Introduced Log Analytics Integration feature for SCOM Managed Instance.--## Version 1.0.85 --- Improved performance of extension for onboarding, scaling, and patching operations.--## Next steps --[Migrate from Operations Manager on-premises to Azure Monitor SCOM Managed Instance](migrate-to-operations-manager-managed-instance.md) |
| azure-monitor | Security Controls Policy | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/security-controls-policy.md | - Title: Azure Policy Regulatory Compliance controls for Azure Monitor -description: Lists Azure Policy Regulatory Compliance controls available for Azure Monitor. These built-in policy definitions provide common approaches to managing the compliance of your Azure resources. Previously updated : 02/06/2024--------# Azure Policy Regulatory Compliance controls for Azure Monitor --[Regulatory Compliance in Azure Policy](../governance/policy/concepts/regulatory-compliance.md) -provides Microsoft created and managed initiative definitions, known as _built-ins_, for the -**compliance domains** and **security controls** related to different compliance standards. This -page lists the **compliance domains** and **security controls** for Azure Monitor. You can assign -the built-ins for a **security control** individually to help make your Azure resources compliant -with the specific standard. ----## Next steps --- Learn more about [Azure Policy Regulatory Compliance](../governance/policy/concepts/regulatory-compliance.md).-- See the built-ins on the [Azure Policy GitHub repo](https://github.com/Azure/azure-policy). |
| azure-monitor | Service Limits | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/service-limits.md | - Title: Azure Monitor service limits | Microsoft Docs -description: This article lists limits in different areas of Azure Monitor. --- Previously updated : 07/26/2024---# Azure Monitor service limits --This article lists limits in different areas of Azure Monitor. --## Alerts ---## Action groups ---## Autoscale ---## Prometheus metrics ---## Logs Ingestion API ---## Data collection rules ---## Diagnostic settings ---## Log queries and language ---## Log Analytics workspaces ---## Application Insights ---## Azure Monitor Private Link Scope (AMPLS) ---## Next steps --- [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/)-- [Azure Monitor cost and usage](cost-usage.md) |
| azure-monitor | Snapshot Debugger App Service | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/snapshot-debugger/snapshot-debugger-app-service.md | - Title: Enable Snapshot Debugger for .NET apps in Azure App Service | Microsoft Docs -description: Enable Snapshot Debugger for .NET apps in Azure App Service -----reviewer: cweining Previously updated : 11/17/2023----# Enable Snapshot Debugger for .NET apps in Azure App Service --> [!NOTE] -> If you're using a preview version of .NET Core, or your application references Application Insights SDK (directly or indirectly via a dependent assembly), follow the instructions for [Enable Snapshot Debugger for other environments](snapshot-debugger-vm.md) to include the [`Microsoft.ApplicationInsights.SnapshotCollector`](https://www.nuget.org/packages/Microsoft.ApplicationInsights.SnapshotCollector) NuGet package with the application. --Snapshot Debugger currently supports ASP.NET and ASP.NET Core apps running on Azure App Service on Windows service plans. --We recommend that you run your application on the Basic or higher service tiers when using Snapshot Debugger. For most applications: -- The Free and Shared service tiers don't have enough memory or disk space to save snapshots. -- The Consumption tier isn't currently available for Snapshot Debugger.--Although Snapshot Debugger is preinstalled as part of the App Services runtime, you need to turn it on to get snapshots for your App Service app. Codeless installation of Snapshot Debugger follows [the .NET Core support policy.](https://dotnet.microsoft.com/platform/support/policy/dotnet-core). --# [Azure portal](#tab/portal) --After you've deployed your .NET App Services web app: --1. Navigate to your App Service in the Azure portal. -1. In the left-side menu, select **Settings** > **Application Insights**. -- :::image type="content" source="./media/snapshot-debugger/application-insights-app-services.png" alt-text="Screenshot showing the Enable App Insights on App Services portal."::: --1. Click **Turn on Application Insights**. - - If you have an existing Application Insights resource you'd rather use, select that option under **Change your resource**. -1. Under **Instrument your application**, select the **.NET** tab. -1. Switch both Snapshot Debugger toggles to **On**. - - :::image type="content" source="./media/snapshot-debugger/enablement-ui.png" alt-text="Screenshot showing how to add App Insights site extension."::: - -1. Snapshot Debugger is now enabled. --## Disable Snapshot Debugger --To disable Snapshot Debugger for your App Services resource: -1. Navigate to your App Service in the Azure portal. -1. In the left-side menu, select **Settings** > **Application Insights**. -1. Switch the Snapshot Debugger toggles to **Off**. --# [Azure Resource Manager](#tab/arm) --You can also set app settings within the Azure Resource Manager template to enable Snapshot Debugger and Profiler. For example: --```json -{ - "apiVersion": "2023-12-01", - "name": "[parameters('webSiteName')]", - "type": "Microsoft.Web/sites", - "location": "[resourceGroup().location]", - "dependsOn": [ - "[variables('hostingPlanName')]" - ], - "tags": { - "[concat('hidden-related:', resourceId('Microsoft.Web/serverfarms', variables('hostingPlanName')))]": "empty", - "displayName": "Website" - }, - "properties": { - "name": "[parameters('webSiteName')]", - "serverFarmId": "[resourceId('Microsoft.Web/serverfarms', variables('hostingPlanName'))]" - }, - "resources": [ - { - "apiVersion": "2015-08-01", - "name": "appsettings", - "type": "config", - "dependsOn": [ - "[parameters('webSiteName')]", - "[concat('AppInsights', parameters('webSiteName'))]" - ], - "properties": { - "APPINSIGHTS_INSTRUMENTATIONKEY": "[reference(resourceId('Microsoft.Insights/components', concat('AppInsights', parameters('webSiteName'))), '2014-04-01').InstrumentationKey]", - // "Turn on" a Snapshot Debugger version - "APPINSIGHTS_SNAPSHOTFEATURE_VERSION": "1.0.0", - "DiagnosticServices_EXTENSION_VERSION": "~3", - "ApplicationInsightsAgent_EXTENSION_VERSION": "~2" - } - } - ] -}, -``` ----Generate traffic to your application that can trigger an exception. Then, wait 10 to 15 minutes for snapshots to be sent to the Application Insights instance. --## Enable Snapshot Debugger for other cloud regions --Currently the only regions that require endpoint modifications are [Azure Government](../../azure-government/compare-azure-government-global-azure.md#application-insights) and [Microsoft Azure operated by 21Vianet](/azure/china/resources-developer-guide) through the Application Insights Connection String. --|Connection String Property | US Government Cloud | China Cloud | -|||-| -|SnapshotEndpoint | `https://snapshot.monitor.azure.us` | `https://snapshot.monitor.azure.cn` | --For more information about other connection overrides, see [Application Insights documentation](../app/sdk-connection-string.md?tabs=net#connection-string-with-explicit-endpoint-overrides). --## Configure Snapshot Debugger --### Enable Microsoft Entra authentication for snapshot ingestion --Snapshot Debugger supports Microsoft Entra authentication for snapshot ingestion. For all snapshots of your application to be ingested, your application must be authenticated and provide the required application settings to the Snapshot Debugger agent. --As of today, Snapshot Debugger only supports Microsoft Entra authentication when you reference and configure Microsoft Entra ID using the Application Insights SDK in your application. --To turn on Microsoft Entra ID for snapshot ingestion in your App Services resource: --1. Add the managed identity that authenticates against your Application Insights resource to your App Service. You can create either: -- - [Add a System-Assigned Managed identity](../../app-service/overview-managed-identity.md?tabs=portal%2chttp#add-a-system-assigned-identity). - - [Add a User-Assigned Managed identity](../../app-service/overview-managed-identity.md?tabs=portal%2chttp#add-a-user-assigned-identity). --1. Configure and turn on Microsoft Entra ID in your Application Insights resource. For more information, see the following [documentation](../app/azure-ad-authentication.md?tabs=net#configure-and-enable-azure-ad-based-authentication) --1. Add the following application setting. This setting tells the Snapshot Debugger agent which managed identity to use: --For System-Assigned Identity: --|App Setting | Value | -||-| -|APPLICATIONINSIGHTS_AUTHENTICATION_STRING | Authorization=AD | --For User-Assigned Identity: --|App Setting | Value | -||-| -|APPLICATIONINSIGHTS_AUTHENTICATION_STRING | Authorization=AD;ClientID={Client ID of the User-Assigned Identity} | --## Unsupported scenarios --Below you can find scenarios where Snapshot Collector isn't supported: --|Scenario | Side Effects | Recommendation | -||--|-| -|You're using the Snapshot Collector SDK in your application directly (*.csproj*) and enabled the advanced option "Interop".| The local Application Insights SDK (including Snapshot Collector telemetry) are lost and no Snapshots are available. <br/> Your application could crash at startup with `System.ArgumentException: telemetryProcessorTypedoes not implement ITelemetryProcessor.` <br/> [Learn more about the Application Insights feature "Interop".](../app/azure-web-apps-net-core.md#troubleshooting) | If you're using the advanced option "Interop", use the codeless Snapshot Collector injection (enabled through the Azure portal). | --## Next steps --- View [snapshots](snapshot-debugger-data.md?toc=/azure/azure-monitor/toc.json#access-debug-snapshots-in-the-portal) in the Azure portal.-- [Troubleshoot Snapshot Debugger issues](snapshot-debugger-troubleshoot.md).--[Enablement UI]: ./media/snapshot-debugger/enablement-ui.png -[snapshot-debugger-app-setting]:./media/snapshot-debugger/snapshot-debugger-app-setting.png |
| azure-monitor | Snapshot Debugger Data | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/snapshot-debugger/snapshot-debugger-data.md | - Title: View Application Insights Snapshot Debugger data -description: View snapshots collected by the Snapshot Debugger in either the Azure portal or Visual Studio ----reviewer: cweining -- Previously updated : 11/17/2023---# View Application Insights Snapshot Debugger data --Snapshots appear as [**Exceptions**](../app/asp-net-exceptions.md) in the Application Insights pane of the Azure portal. View debug snapshots in the portal to examine the call stack and inspect variables at each call stack frame. --For a more powerful debugging experience with source code, open snapshots with Visual Studio Enterprise. You can also [set SnapPoints to interactively take snapshots](/visualstudio/debugger/debug-live-azure-applications) without waiting for an exception. --## Prerequisites --Snapshots might include sensitive information. You can only view snapshots if you are assigned the `Application Insights Snapshot Debugger` role. --## Access debug snapshots in the portal --After an exception has occurred in your application and a snapshot is created, you can view snapshots in the Azure portal within 5 to 10 minutes. --1. In your Application Insights resource, select **Investigate** > **Failures** from the left-side menu. --1. In the **Failures** pane, select either: - - The **Operations** tab, or - - The **Exceptions** tab. --1. Select the **[x] Samples** in the center column of the page to generate a list of sample operations or exceptions to the right. -- :::image type="content" source="./media/snapshot-debugger/failures-page.png" alt-text="Screenshot showing the Failures Page in Azure portal."::: --1. From the list of samples, select an operation or exception to open the **End-to-End Transaction Details** page. From here, select the exception event you'd like to investigate. - - If a snapshot is available for the given exception, select the **Open debug snapshot** button in the right pane to view the **Debug Snapshot** page. - - [If you do not see this button, no snapshot may be available. See the troubleshooting guide.](./snapshot-debugger-troubleshoot.md#use-the-snapshot-health-check) -- :::image type="content" source="./media/snapshot-debugger/e2e-transaction-page.png" alt-text="Screenshot showing the Open Debug Snapshot button on exception."::: --1. In the **Debug Snapshot** page, you see a call stack with a local variables pane. Select a call stack frame to view local variables and parameters for that function call in the variables pane. -- :::image type="content" source="./media/snapshot-debugger/open-snapshot-portal.png" alt-text="Screenshot showing the Open debug snapshot highlighted in the Azure portal."::: --## Download snapshots to view in Visual Studio --To view snapshots in Visual Studio 2017 Enterprise or greater: --1. Click the **Download Snapshot** button in the **Debug Snapshot** page to download a `.diagsession` file, which can be opened by Visual Studio Enterprise. --1. In Visual Studio, make sure you have the Snapshot Debugger Visual Studio component installed. - - **For Visual Studio 2017 Enterprise and greater:** The required Snapshot Debugger component can be selected from the **Individual Component** list in the Visual Studio installer. - - **For a version older than Visual Studio 2017 version 15.5:** Install the extension from the [Visual Studio Marketplace](https://aka.ms/snapshotdebugger). --1. Open the `.diagsession` file. The Minidump Debugging page in Visual Studio appears. --1. Click **Debug Managed Code** to start debugging the snapshot. The snapshot opens to the line of code where the exception was thrown. -- :::image type="content" source="./media/snapshot-debugger/open-snapshot-visual-studio.png" alt-text="Screenshot showing the debug snapshot in Visual Studio."::: --The downloaded snapshot includes any symbol files found on your web application server. These symbol files are required to associate snapshot data with source code. For App Service apps, make sure to enable symbol deployment when you publish your web apps. --## Next steps --Enable the Snapshot Debugger in your: -- [App Service](./snapshot-debugger-app-service.md)-- [Function App](./snapshot-debugger-function-app.md)-- [Virtual machine or other Azure service](./snapshot-debugger-vm.md) |
| azure-monitor | Snapshot Debugger Function App | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/snapshot-debugger/snapshot-debugger-function-app.md | - Title: Enable Snapshot Debugger for .NET and .NET Core apps in Azure Functions | Microsoft Docs -description: Enable Snapshot Debugger for .NET and .NET Core apps in Azure Functions. ----reviewer: cweining - Previously updated : 11/17/2023----# Enable Snapshot Debugger for .NET and .NET Core apps in Azure Functions --Snapshot Debugger currently works for ASP.NET and ASP.NET Core apps that are running on Azure Functions on Windows service plans. --We recommend that you run your application on the Basic or higher service tiers when using Snapshot Debugger. For most applications: -- The Free and Shared service tiers don't have enough memory or disk space to save snapshots. -- The Consumption tier isn't currently available for Snapshot Debugger.--Snapshot Debugger is preinstalled as part of the Azure Functions runtime, so you don't need to add extra NuGet packages or application settings. --## Prerequisite --[Enable Application Insights monitoring in your Functions app](../../azure-functions/configure-monitoring.md#new-function-app-in-the-portal). --## Enable Snapshot Debugger --To enable Snapshot Debugger in your Functions app, add the `snapshotConfiguration` property to your *host.json* file and redeploy your function. For example: --```json -{ - "version": "2.0", - "logging": { - "applicationInsights": { - "snapshotConfiguration": { - "isEnabled": true - } - } - } -} -``` -Generate traffic to your application that can trigger an exception. Then wait 10 to 15 minutes for snapshots to be sent to the Application Insights instance. --You can verify that Snapshot Debugger has been enabled by checking your .NET function app files. For example, in the following simple .NET function app, the `.csproj`, `{Your}Function.cs`, and `host.json` of your .NET application show Snapshot Debugger as enabled: --`Project.csproj` --```xml -<Project Sdk="Microsoft.NET.Sdk"> -<PropertyGroup> - <TargetFramework>netcoreapp2.1</TargetFramework> - <AzureFunctionsVersion>v2</AzureFunctionsVersion> -</PropertyGroup> -<ItemGroup> - <PackageReference Include="Microsoft.NET.Sdk.Functions" Version="1.0.31" /> -</ItemGroup> -<ItemGroup> - <None Update="host.json"> - <CopyToOutputDirectory>PreserveNewest</CopyToOutputDirectory> - </None> - <None Update="local.settings.json"> - <CopyToOutputDirectory>PreserveNewest</CopyToOutputDirectory> - <CopyToPublishDirectory>Never</CopyToPublishDirectory> - </None> -</ItemGroup> -</Project> -``` --`{Your}Function.cs` --```csharp -using System; -using System.Threading.Tasks; -using Microsoft.AspNetCore.Mvc; -using Microsoft.Azure.WebJobs; -using Microsoft.Azure.WebJobs.Extensions.Http; -using Microsoft.AspNetCore.Http; -using Microsoft.Extensions.Logging; --namespace SnapshotCollectorAzureFunction -{ - public static class ExceptionFunction - { - [FunctionName("ExceptionFunction")] - public static Task<IActionResult> Run( - [HttpTrigger(AuthorizationLevel.Function, "get", Route = null)] HttpRequest req, - ILogger log) - { - log.LogInformation("C# HTTP trigger function processed a request."); -- throw new NotImplementedException("Dummy"); - } - } -} -``` --`Host.json` --```json -{ - "version": "2.0", - "logging": { - "applicationInsights": { - "samplingExcludedTypes": "Request", - "samplingSettings": { - "isEnabled": true - }, - "snapshotConfiguration": { - "isEnabled": true - } - } - } -} -``` --## Enable Snapshot Debugger for other clouds --Currently, the only regions that require endpoint modifications are [Azure Government](../../azure-government/compare-azure-government-global-azure.md#application-insights) and [Microsoft Azure operated by 21Vianet](/azure/china/resources-developer-guide). --The following example shows the `host.json` updated with the US Government Cloud agent endpoint: --```json -{ - "version": "2.0", - "logging": { - "applicationInsights": { - "samplingExcludedTypes": "Request", - "samplingSettings": { - "isEnabled": true - }, - "snapshotConfiguration": { - "isEnabled": true, - "agentEndpoint": "https://snapshot.monitor.azure.us" - } - } - } -} -``` --Here are the supported overrides of the Snapshot Debugger agent endpoint: --|Property | US Government Cloud | China Cloud | -|||-| -|AgentEndpoint | `https://snapshot.monitor.azure.us` | `https://snapshot.monitor.azure.cn` | --## Disable Snapshot Debugger --To disable Snapshot Debugger in your Functions app, update your `host.json` file by setting the `snapshotConfiguration.isEnabled` property to `false`. --```json -{ - "version": "2.0", - "logging": { - "applicationInsights": { - "snapshotConfiguration": { - "isEnabled": false - } - } - } -} -``` --## Next steps --- [View snapshots](snapshot-debugger-data.md?toc=/azure/azure-monitor/toc.json#access-debug-snapshots-in-the-portal) in the Azure portal.-- Customize Snapshot Debugger configuration based on your use case on your Functions app. For more information, see [Snapshot configuration in host.json](../../azure-functions/functions-host-json.md#applicationinsightssnapshotconfiguration).-- [Troubleshoot Snapshot Debugger issues](snapshot-debugger-troubleshoot.md). |
| azure-monitor | Snapshot Debugger Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/snapshot-debugger/snapshot-debugger-troubleshoot.md | - Title: Troubleshoot Azure Application Insights Snapshot Debugger -description: This article presents troubleshooting steps and information to help developers enable and use Application Insights Snapshot Debugger. ----reviewer: cweining - Previously updated : 08/21/2024----# <a id="troubleshooting"></a> Troubleshoot problems enabling Application Insights Snapshot Debugger or viewing snapshots --If you enabled Application Insights Snapshot Debugger for your application, but aren't seeing snapshots for exceptions, you can use these instructions to troubleshoot. --There can be many different reasons why snapshots aren't generated. You can start by running the snapshot health check to identify some of the possible common causes. --## Not Supported Scenarios --Below you can find scenarios where Snapshot Collector isn't supported: --|Scenario | Side Effects | Recommendation | -||--|-| -|When using the Snapshot Collector SDK in your application directly (*.csproj*) and you have enabled the advance option "Interop".| The local Application Insights SDK (including Snapshot Collector telemetry) will be lost, therefore, no Snapshots will be available. <br/> Your application could crash at startup with `System.ArgumentException: telemetryProcessorTypedoes not implement ITelemetryProcessor` <br/> For more information about the Application Insights feature "Interop", see the [documentation.](../app/azure-web-apps-net-core.md#troubleshooting) | If you're using the advance option "Interop", use the codeless Snapshot Collector injection (enabled thru the Azure portal UX) | --## Make sure you're using the appropriate Snapshot Debugger Endpoint --Currently the only regions that require endpoint modifications are [Azure Government](../../azure-government/compare-azure-government-global-azure.md#application-insights) and [Microsoft Azure operated by 21Vianet](/azure/china/resources-developer-guide). --For App Service and applications using the Application Insights SDK, you have to update the connection string using the supported overrides for Snapshot Debugger as defined below: --|Connection String Property | US Government Cloud | China Cloud | -|||-| -|SnapshotEndpoint | `https://snapshot.monitor.azure.us` | `https://snapshot.monitor.azure.cn` | --For more information about other connection overrides, see [Application Insights documentation](../app/sdk-connection-string.md?tabs=net#connection-string-with-explicit-endpoint-overrides). --For Function App, you have to update the `host.json` using the supported overrides below: --|Property | US Government Cloud | China Cloud | -|||-| -|AgentEndpoint | `https://snapshot.monitor.azure.us` | `https://snapshot.monitor.azure.cn` | --Below is an example of the `host.json` updated with the US Government Cloud agent endpoint: --```json -{ - "version": "2.0", - "logging": { - "applicationInsights": { - "samplingExcludedTypes": "Request", - "samplingSettings": { - "isEnabled": true - }, - "snapshotConfiguration": { - "isEnabled": true, - "agentEndpoint": "https://snapshot.monitor.azure.us" - } - } - } -} -``` --## Use the snapshot health check --Several common problems result in the Open Debug Snapshot not showing up. Using an outdated Snapshot Collector, for example; reaching the daily upload limit; or perhaps the snapshot is just taking a long time to upload. Use the Snapshot Health Check to troubleshoot common problems. --There's a link in the exception pane of the end-to-end trace view that takes you to the Snapshot Health Check. ---The interactive, chat-like interface looks for common problems and guides you to fix them. ---If that doesn't solve the problem, then refer to the following manual troubleshooting steps. --## Verify the instrumentation key --Make sure you're using the correct instrumentation key in your published application. Usually, the instrumentation key is read from the *ApplicationInsights.config* file. Verify the value is the same as the instrumentation key for the Application Insights resource that you see in the portal. ---## <a id="SSL"></a>Check TLS/SSL client settings (ASP.NET) --If you have an ASP.NET application that's hosted in Azure App Service or in IIS on a virtual machine, your application could fail to connect to the Snapshot Debugger service due to a missing SSL security protocol. --[The Snapshot Debugger endpoint requires TLS version 1.2](snapshot-debugger-upgrade.md?toc=/azure/azure-monitor/toc.json). The set of SSL security protocols is one of the quirks enabled by the `httpRuntime targetFramework` value in the `system.web` section of `web.config`. -If the `httpRuntime targetFramework` is 4.5.2 or lower, then TLS 1.2 isn't included by default. --> [!NOTE] -> The `httpRuntime targetFramework` value is independent of the target framework used when building your application. -To check the setting, open your *web.config* file and find the system.web section. Ensure that the `targetFramework` for `httpRuntime` is set to 4.6 or above. -- ```xml - <system.web> - ... - <httpRuntime targetFramework="4.7.2" /> - ... - </system.web> - ``` --> [!NOTE] -> Modifying the `httpRuntime targetFramework` value changes the runtime quirks applied to your application and can cause other, subtle behavior changes. Be sure to test your application thoroughly after making this change. For a full list of compatibility changes, see [Re-targeting changes](/dotnet/framework/migration-guide/application-compatibility#retargeting-changes). -> [!NOTE] -> If the `targetFramework` is 4.7 or above then Windows determines the available protocols. In Azure App Service, TLS 1.2 is available. However, if you're using your own virtual machine, you may need to enable TLS 1.2 in the OS. --## Snapshot Debugger overhead scenarios --The Snapshot Debugger is designed for use in production environments. The default settings include rate limits to minimize the impact on your applications. --However, you may experience small CPU, memory, and I/O overhead associated with the Snapshot Debugger, like in the following scenarios. --**When an exception is thrown in your application:** --- Creating a signature for the problem type and deciding whether to create a snapshot adds a very small CPU and memory overhead.-- If de-optimization is enabled, there is an overhead for re-JITting the method that threw the exception. This will be incurred the next time that method executes. Depending on the size of the method, this could be between 1ms and 100ms of CPU time.--**If the exception handler decides to create a snapshot:** --- Creating the process snapshot takes about half a second (P50=0.3s, P90=1.2s, P95=1.9s) during which time, the thread that threw the exception is paused. Other threads are not blocked.--- Converting the process snapshot to a minidump and uploading it to Application Insights takes several minutes. - - Convert: P50=63s, P90=187s, P95=275s. - - Upload: P50=31s, P90=75s, P95=98s. -- This is done in Snapshot Uploader, which runs in a separate process. The Snapshot Uploader process runs at below normal CPU priority and uses low priority I/O. -- The minidump is first written to disk and the amount of disk spaced is roughly the same as the working set of the original process. Writing the minidump can induce page faults as memory is read. -- The minidump is compressed during upload, which consumes both CPU and memory in the Snapshot Uploader process. The CPU, memory, and disk overhead for this is proportional to the size of the process snapshot. Snapshot Uploader processes snapshots serially. --**When `TrackException` is called:** --The Snapshot Debugger checks if the exception is new or if a snapshot has been created for it. This adds a very small CPU overhead. --## Preview Versions of .NET Core --If you're using a preview version of .NET Core or your application references Application Insights SDK, directly or indirectly via a dependent assembly, follow the instructions for [Enable Snapshot Debugger for other environments](snapshot-debugger-vm.md?toc=/azure/azure-monitor/toc.json). --## Check the Diagnostic Services site extension' Status Page --If Snapshot Debugger was enabled through the [Application Insights pane](snapshot-debugger-app-service.md?toc=/azure/azure-monitor/toc.json) in the portal, it was enabled by the Diagnostic Services site extension. --> [!NOTE] -> Codeless installation of Application Insights Snapshot Debugger follows the .NET Core support policy. -> For more information about supported runtimes, see [.NET Core Support Policy](https://dotnet.microsoft.com/platform/support/policy/dotnet-core). -You can check the Status Page of this extension by going to the following url: -`https://{site-name}.scm.azurewebsites.net/DiagnosticServices` --> [!NOTE] -> The domain of the Status Page link will vary depending on the cloud. -This domain will be the same as the Kudu management site for App Service. -This Status Page shows the installation state of the Profiler and Snapshot Collector agents. If there was an unexpected error, it will be displayed and show how to fix it. --You can use the Kudu management site for App Service to get the base url of this Status Page: --1. Open your App Service application in the Azure portal. -1. Select **Advanced Tools**, or search for **Kudu**. -1. Select **Go**. -1. Once you are on the Kudu management site, in the URL, **append the following `/DiagnosticServices` and press enter**. - It will end like this: `https://<kudu-url>/DiagnosticServices` --## Upgrade to the latest version of the NuGet package --Based on how Snapshot Debugger was enabled, see the following options: --* If Snapshot Debugger was enabled through the [Application Insights pane in the portal](snapshot-debugger-app-service.md?toc=/azure/azure-monitor/toc.json), then your application should already be running the latest NuGet package. --* If Snapshot Debugger was enabled by including the [Microsoft.ApplicationInsights.SnapshotCollector](https://www.nuget.org/packages/Microsoft.ApplicationInsights.SnapshotCollector) NuGet package, use Visual Studio's NuGet Package Manager to make sure you're using the latest version of `Microsoft.ApplicationInsights.SnapshotCollector`. --For the latest updates and bug fixes [consult the release notes](https://github.com/microsoft/ApplicationInsights-SnapshotCollector/blob/main/CHANGELOG.md). --## Check the uploader logs --After a snapshot is created, a minidump file (*.dmp*) is created on disk. A separate uploader process creates that minidump file and uploads it, along with any associated PDBs, to Application Insights Snapshot Debugger storage. After the minidump has uploaded successfully, it's deleted from disk. The log files for the uploader process are kept on disk. In an App Service environment, you can find these logs in `D:\Home\LogFiles`. Use the Kudu management site for App Service to find these log files. --1. Open your App Service application in the Azure portal. -1. Select **Advanced Tools**, or search for **Kudu**. -1. Select **Go**. -1. In the **Debug console** drop-down list, select **CMD**. -1. Select **LogFiles**. --You should see at least one file with a name that begins with `Uploader_` or `SnapshotUploader_` and a `.log` extension. Select the appropriate icon to download any log files or open them in a browser. -The file name includes a unique suffix that identifies the App Service instance. If your App Service instance is hosted on more than one machine, there are separate log files for each machine. When the uploader detects a new minidump file, it's recorded in the log file. Here's an example of a successful snapshot and upload: --``` -SnapshotUploader.exe Information: 0 : Received Fork request ID 139e411a23934dc0b9ea08a626db16c5 from process 6368 (Low pri) - DateTime=2018-03-09T01:42:41.8571711Z -SnapshotUploader.exe Information: 0 : Creating minidump from Fork request ID 139e411a23934dc0b9ea08a626db16c5 from process 6368 (Low pri) - DateTime=2018-03-09T01:42:41.8571711Z -SnapshotUploader.exe Information: 0 : Dump placeholder file created: 139e411a23934dc0b9ea08a626db16c5.dm_ - DateTime=2018-03-09T01:42:41.8728496Z -SnapshotUploader.exe Information: 0 : Dump available 139e411a23934dc0b9ea08a626db16c5.dmp - DateTime=2018-03-09T01:42:45.7525022Z -SnapshotUploader.exe Information: 0 : Successfully wrote minidump to D:\local\Temp\Dumps\c12a605e73c44346a984e00000000000\139e411a23934dc0b9ea08a626db16c5.dmp - DateTime=2018-03-09T01:42:45.7681360Z -SnapshotUploader.exe Information: 0 : Uploading D:\local\Temp\Dumps\c12a605e73c44346a984e00000000000\139e411a23934dc0b9ea08a626db16c5.dmp, 214.42 MB (uncompressed) - DateTime=2018-03-09T01:42:45.7681360Z -SnapshotUploader.exe Information: 0 : Upload successful. Compressed size 86.56 MB - DateTime=2018-03-09T01:42:59.6184651Z -SnapshotUploader.exe Information: 0 : Extracting PDB info from D:\local\Temp\Dumps\c12a605e73c44346a984e00000000000\139e411a23934dc0b9ea08a626db16c5.dmp. - DateTime=2018-03-09T01:42:59.6184651Z -SnapshotUploader.exe Information: 0 : Matched 2 PDB(s) with local files. - DateTime=2018-03-09T01:42:59.6809606Z -SnapshotUploader.exe Information: 0 : Stamp does not want any of our matched PDBs. - DateTime=2018-03-09T01:42:59.8059929Z -SnapshotUploader.exe Information: 0 : Deleted D:\local\Temp\Dumps\c12a605e73c44346a984e00000000000\139e411a23934dc0b9ea08a626db16c5.dmp - DateTime=2018-03-09T01:42:59.8530649Z -``` --> [!NOTE] -> The example above is from version 1.2.0 of the `Microsoft.ApplicationInsights.SnapshotCollector` NuGet package. In earlier versions, the uploader process is called `MinidumpUploader.exe` and the log is less detailed. -In the previous example, the instrumentation key is `c12a605e73c44346a984e00000000000`. This value should match the instrumentation key for your application. -The minidump is associated with a snapshot with the ID `139e411a23934dc0b9ea08a626db16c5`. You can use this ID later to locate the associated exception record in Application Insights Analytics. --The uploader scans for new PDBs about once every 15 minutes. Here's an example: --``` -SnapshotUploader.exe Information: 0 : PDB rescan requested. - DateTime=2018-03-09T01:47:19.4457768Z -SnapshotUploader.exe Information: 0 : Scanning D:\home\site\wwwroot for local PDBs. - DateTime=2018-03-09T01:47:19.4457768Z -SnapshotUploader.exe Information: 0 : Local PDB scan complete. Found 2 PDB(s). - DateTime=2018-03-09T01:47:19.4614027Z -SnapshotUploader.exe Information: 0 : Deleted PDB scan marker : D:\local\Temp\Dumps\c12a605e73c44346a984e00000000000\6368.pdbscan - DateTime=2018-03-09T01:47:19.4614027Z -``` --For applications that *aren't* hosted in App Service, the uploader logs are in the same folder as the minidumps: `%TEMP%\Dumps\<ikey>` (where `<ikey>` is your instrumentation key). --## Troubleshooting Cloud Services --In Cloud Services, the default temporary folder could be too small to hold the minidump files, leading to lost snapshots. --The space needed depends on the total working set of your application and the number of concurrent snapshots. --The working set of a 32-bit ASP.NET web role is typically between 200 MB and 500 MB. Allow for at least two concurrent snapshots. --For example, if your application uses 1 GB of total working set, you should make sure there is at least 2 GB of disk space to store snapshots. --Follow these steps to configure your Cloud Service role with a dedicated local resource for snapshots. --1. Add a new local resource to your Cloud Service by editing the Cloud Service definition (.csdef) file. The following example defines a resource called `SnapshotStore` with a size of 5 GB. -- ```xml - <LocalResources> - <LocalStorage name="SnapshotStore" cleanOnRoleRecycle="false" sizeInMB="5120" /> - </LocalResources> - ``` --1. Modify your role's startup code to add an environment variable that points to the `SnapshotStore` local resource. For Worker Roles, the code should be added to your role's `OnStart` method: -- ```csharp - public override bool OnStart() - { - Environment.SetEnvironmentVariable("SNAPSHOTSTORE", RoleEnvironment.GetLocalResource("SnapshotStore").RootPath); - return base.OnStart(); - } - ``` -- For Web Roles (ASP.NET), the code should be added to your web application's `Application_Start` method: -- ```csharp - using Microsoft.WindowsAzure.ServiceRuntime; - using System; - namespace MyWebRoleApp - { - public class MyMvcApplication : System.Web.HttpApplication - { - protected void Application_Start() - { - Environment.SetEnvironmentVariable("SNAPSHOTSTORE", RoleEnvironment.GetLocalResource("SnapshotStore").RootPath); - // TODO: The rest of your application startup code - } - } - } - ``` --1. Update your role's *ApplicationInsights.config* file to override the temporary folder location used by `SnapshotCollector` -- ```xml - <TelemetryProcessors> - <Add Type="Microsoft.ApplicationInsights.SnapshotCollector.SnapshotCollectorTelemetryProcessor, Microsoft.ApplicationInsights.SnapshotCollector"> - <!-- Use the SnapshotStore local resource for snapshots --> - <TempFolder>%SNAPSHOTSTORE%</TempFolder> - <!-- Other SnapshotCollector configuration options --> - </Add> - </TelemetryProcessors> - ``` --## Overriding the Shadow Copy folder --When the Snapshot Collector starts up, it tries to find a folder on disk that is suitable for running the Snapshot Uploader process. The chosen folder is known as the Shadow Copy folder. --The Snapshot Collector checks a few well-known locations, making sure it has permissions to copy the Snapshot Uploader binaries. The following environment variables are used: --* Fabric_Folder_App_Temp -* LOCALAPPDATA -* APPDATA -* TEMP --If a suitable folder can't be found, Snapshot Collector reports an error saying *"Couldn't find a suitable shadow copy folder."* --If the copy fails, Snapshot Collector reports a `ShadowCopyFailed` error. --If the uploader can't be launched, Snapshot Collector reports an `UploaderCannotStartFromShadowCopy` error. The body of the message often contains `System.UnauthorizedAccessException`. This error usually occurs because the application is running under an account with reduced permissions. The account has permission to write to the shadow copy folder, but it doesn't have permission to execute code. --Since these errors usually happen during startup, they'll usually be followed by an `ExceptionDuringConnect` error saying *Uploader failed to start*." --To work around these errors, you can specify the shadow copy folder manually via the `ShadowCopyFolder` configuration option. For example, using *ApplicationInsights.config*: -- ```xml - <TelemetryProcessors> - <Add Type="Microsoft.ApplicationInsights.SnapshotCollector.SnapshotCollectorTelemetryProcessor, Microsoft.ApplicationInsights.SnapshotCollector"> - <!-- Override the default shadow copy folder. --> - <ShadowCopyFolder>D:\SnapshotUploader</ShadowCopyFolder> - <!-- Other SnapshotCollector configuration options --> - </Add> - </TelemetryProcessors> - ``` --Or, if you're using *appsettings.json* with a .NET Core application: -- ```json - { - "ApplicationInsights": { - "InstrumentationKey": "<your instrumentation key>" - }, - "SnapshotCollectorConfiguration": { - "ShadowCopyFolder": "D:\\SnapshotUploader" - } - } - ``` --## Use Application Insights search to find exceptions with snapshots --When a snapshot is created, the throwing exception is tagged with a snapshot ID. That snapshot ID is included as a custom property when the exception is reported to Application Insights. Using **Search** in Application Insights, you can find all records with the `ai.snapshot.id` custom property. --1. Browse to your Application Insights resource in the Azure portal. -1. Select **Search**. -1. Type `ai.snapshot.id` in the Search text box and press Enter. ---If this search returns no results, then, no snapshots were reported to Application Insights in the selected time range. --To search for a specific snapshot ID from the Uploader logs, type that ID in the Search box. If you can't find records for a snapshot that you know was uploaded, follow these steps: --1. Double-check that you're looking at the right Application Insights resource by verifying the instrumentation key. --1. Using the timestamp from the Uploader log, adjust the Time Range filter of the search to cover that time range. --If you still don't see an exception with that snapshot ID, then the exception record wasn't reported to Application Insights. This situation can happen if your application crashed after it took the snapshot but before it reported the exception record. In this case, check the App Service logs under `Diagnose and solve problems` to see if there were unexpected restarts or unhandled exceptions. --## Edit network proxy or firewall rules --If your application connects to the Internet via a proxy or a firewall, you may need to update the rules to communicate with the Snapshot Debugger service. --The IPs used by Application Insights Snapshot Debugger are included in the Azure Monitor service tag. For more information, see [Service Tags documentation](../../virtual-network/service-tags-overview.md). --## Are there any billing costs when using snapshots? --There are no charges against your subscription specific to Snapshot Debugger. The snapshot files collected are stored separately from the telemetry collected by the Application Insights SDKs and there are no charges for the snapshot ingestion or storage. |
| azure-monitor | Snapshot Debugger Vm | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/snapshot-debugger/snapshot-debugger-vm.md | - Title: Enable Snapshot Debugger for .NET apps in Azure Service Fabric, Cloud Services, and Virtual Machines | Microsoft Docs -description: Enable Snapshot Debugger for .NET apps in Azure Service Fabric, Azure Cloud Services, and Azure Virtual Machines. ----reviewer: cweining - Previously updated : 11/17/2023----# Enable Snapshot Debugger for .NET apps in Azure Service Fabric, Cloud Services, and Virtual Machines --If your ASP.NET or ASP.NET Core application runs in Azure App Service and requires a customized Snapshot Debugger configuration, or a preview version of .NET Core, start with [Enable Snapshot Debugger for .NET apps in Azure App Service](snapshot-debugger-app-service.md). --If your application runs in Azure Service Fabric, Azure Cloud Services, Azure Virtual Machines, or on-premises machines, you can skip enabling Snapshot Debugger on App Service and follow the guidance in this article. --## Prerequisites --- [Enable Application Insights in your .NET resource](../app/asp-net.md).-- Include the [Microsoft.ApplicationInsights.SnapshotCollector](https://www.nuget.org/packages/Microsoft.ApplicationInsights.SnapshotCollector) NuGet package version 1.4.2 or above in your app.-- Understand that snapshots may take 10 to 15 minutes to be sent to the Application Insights instance after an exception has been triggered. --## Configure snapshot collection for ASP.NET applications --When you add the [Microsoft.ApplicationInsights.SnapshotCollector](https://www.nuget.org/packages/Microsoft.ApplicationInsights.SnapshotCollector) NuGet package to your application, the `SnapshotCollectorTelemetryProcessor` is added automatically to the `TelemetryProcessors` section of [`ApplicationInsights.config`](../app/configuration-with-applicationinsights-config.md). --If you don't see `SnapshotCollectorTelemetryProcessor` in `ApplicationInsights.config`, or if you want to customize the Snapshot Debugger configuration, you can edit it manually. --> [!NOTE] -> Any manual configurations may get overwritten when upgrading to a newer version of the [Microsoft.ApplicationInsights.SnapshotCollector](https://www.nuget.org/packages/Microsoft.ApplicationInsights.SnapshotCollector) NuGet package. --Snapshot Collector's default configuration looks similar to the following example: --```xml -<TelemetryProcessors> - <Add Type="Microsoft.ApplicationInsights.SnapshotCollector.SnapshotCollectorTelemetryProcessor, Microsoft.ApplicationInsights.SnapshotCollector"> - <!-- The default is true, but you can disable Snapshot Debugging by setting it to false --> - <IsEnabled>true</IsEnabled> - <!-- Snapshot Debugging is usually disabled in developer mode, but you can enable it by setting this to true. --> - <!-- DeveloperMode is a property on the active TelemetryChannel. --> - <IsEnabledInDeveloperMode>false</IsEnabledInDeveloperMode> - <!-- How many times we need to see an exception before we ask for snapshots. --> - <ThresholdForSnapshotting>1</ThresholdForSnapshotting> - <!-- The maximum number of examples we create for a single problem. --> - <MaximumSnapshotsRequired>3</MaximumSnapshotsRequired> - <!-- The maximum number of problems that we can be tracking at any time. --> - <MaximumCollectionPlanSize>50</MaximumCollectionPlanSize> - <!-- How often we reconnect to the stamp. The default value is 15 minutes.--> - <ReconnectInterval>00:15:00</ReconnectInterval> - <!-- How often to reset problem counters. --> - <ProblemCounterResetInterval>1.00:00:00</ProblemCounterResetInterval> - <!-- The maximum number of snapshots allowed in ten minutes.The default value is 1. --> - <SnapshotsPerTenMinutesLimit>3</SnapshotsPerTenMinutesLimit> - <!-- The maximum number of snapshots allowed per day. --> - <SnapshotsPerDayLimit>30</SnapshotsPerDayLimit> - <!-- Whether or not to collect snapshot in low IO priority thread. The default value is true. --> - <SnapshotInLowPriorityThread>true</SnapshotInLowPriorityThread> - <!-- Agree to send anonymous data to Microsoft to make this product better. --> - <ProvideAnonymousTelemetry>true</ProvideAnonymousTelemetry> - <!-- The limit on the number of failed requests to request snapshots before the telemetry processor is disabled. --> - <FailedRequestLimit>3</FailedRequestLimit> - </Add> -</TelemetryProcessors> -``` --Snapshots are collected _only_ on exceptions reported to Application Insights. In some cases (for example, older versions of the .NET platform), you might need to [configure exception collection](../app/asp-net-exceptions.md#exceptions) to see exceptions with snapshots in the portal. --## Configure snapshot collection for ASP.NET Core applications or Worker Services --### Prerequisites --Your application should already reference one of the following Application Insights NuGet packages: -- [Microsoft.ApplicationInsights.AspNetCore](https://www.nuget.org/packages/Microsoft.ApplicationInsights.AspNetCore)-- [Microsoft.ApplicationInsights.WorkerService](https://www.nuget.org/packages/Microsoft.ApplicationInsights.WorkerService)--### Add the NuGet package --Add the [Microsoft.ApplicationInsights.SnapshotCollector](https://www.nuget.org/packages/Microsoft.ApplicationInsights.SnapshotCollector) NuGet package to your app. --### Update the services collection --In your application's startup code, where services are configured, add a call to the `AddSnapshotCollector` extension method. We suggest adding this line immediately after the call to `AddApplicationInsightsTelemetry`. For example: --```csharp -var builder = WebApplication.CreateBuilder(args); --// Add services to the container. -builder.Services.AddApplicationInsightsTelemetry(); -builder.Services.AddSnapshotCollector(); -``` --### Customize the Snapshot Collector --For most scenarios, Snapshot Collector's default settings are sufficient. However, you can customize the settings by adding the following code before the call to `AddSnapshotCollector()`: --```csharp -using Microsoft.ApplicationInsights.SnapshotCollector; -... -builder.Services.Configure<SnapshotCollectorConfiguration>(builder.Configuration.GetSection("SnapshotCollector")); -``` --Next, add a `SnapshotCollector` section to _`appsettings.json`_ where you can override the defaults. --Snapshot Collector's default `appsettings.json` configuration looks similar to the following example: --```json -{ - "SnapshotCollector": { - "IsEnabledInDeveloperMode": false, - "ThresholdForSnapshotting": 1, - "MaximumSnapshotsRequired": 3, - "MaximumCollectionPlanSize": 50, - "ReconnectInterval": "00:15:00", - "ProblemCounterResetInterval":"1.00:00:00", - "SnapshotsPerTenMinutesLimit": 1, - "SnapshotsPerDayLimit": 30, - "SnapshotInLowPriorityThread": true, - "ProvideAnonymousTelemetry": true, - "FailedRequestLimit": 3 - } -} -``` --If you need to customize the Snapshot Collector's behavior manually, without using _appsettings.json_, use the overload of `AddSnapshotCollector` that takes a delegate. For example: --```csharp -builder.Services.AddSnapshotCollector(config => config.IsEnabledInDeveloperMode = true); -``` --## Configure snapshot collection for other .NET applications --Snapshots are collected only on exceptions that are reported to Application Insights. --For ASP.NET and ASP.NET Core applications, the Application Insights SDK automatically reports unhandled exceptions that escape a controller method or endpoint route handler. --For other applications, you might need to modify your code to report them. The exception handling code depends on the structure of your application. For example: --```csharp -using Microsoft.ApplicationInsights; -using Microsoft.ApplicationInsights.DataContracts; -using Microsoft.ApplicationInsights.Extensibility; --internal class ExampleService -{ - private readonly TelemetryClient _telemetryClient; -- public ExampleService(TelemetryClient telemetryClient) - { - // Obtain the TelemetryClient via dependency injection. - _telemetryClient = telemetryClient; - } -- public void HandleExampleRequest() - { - using IOperationHolder<RequestTelemetry> operation = - _telemetryClient.StartOperation<RequestTelemetry>("Example"); - try - { - // TODO: Handle the request. - operation.Telemetry.Success = true; - } - catch (Exception ex) - { - // Report the exception to Application Insights. - operation.Telemetry.Success = false; - _telemetryClient.TrackException(ex); - // TODO: Rethrow the exception if desired. - } - } -} -``` --The following example uses `ILogger` instead of `TelemetryClient`. This example assumes you're using the [Application Insights Logger Provider](../app/ilogger.md#console-application). As the example shows, when handling an exception, be sure to pass the exception as the first parameter to `LogError`. --```csharp -using Microsoft.Extensions.Logging; --internal class LoggerExample -{ - private readonly ILogger _logger; -- public LoggerExample(ILogger<LoggerExample> logger) - { - _logger = logger; - } -- public void HandleExampleRequest() - { - using IDisposable scope = _logger.BeginScope("Example"); - try - { - // TODO: Handle the request - } - catch (Exception ex) - { - // Use the LogError overload with an Exception as the first parameter. - _logger.LogError(ex, "An error occurred."); - } - } -} -``` --By default, the Application Insights Logger (`ApplicationInsightsLoggerProvider`) forwards exceptions to the Snapshot Debugger via `TelemetryClient.TrackException`. This behavior is controlled via the `TrackExceptionsAsExceptionTelemetry` property on the `ApplicationInsightsLoggerOptions` class. --If you set `TrackExceptionsAsExceptionTelemetry` to `false` when configuring the Application Insights Logger, the preceding example will not trigger the Snapshot Debugger. In this case, modify your code to call `TrackException` manually. ---## Next steps --- View [snapshots](snapshot-debugger-data.md?toc=/azure/azure-monitor/toc.json#access-debug-snapshots-in-the-portal) in the Azure portal.-- [Troubleshoot Snapshot Debugger issues](snapshot-debugger-troubleshoot.md). |
| azure-monitor | Snapshot Debugger | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/snapshot-debugger/snapshot-debugger.md | - Title: Debug exceptions in .NET applications using Snapshot Debugger -description: Use Snapshot Debugger to automatically collect snapshots and debug exceptions in .NET apps. ----reviewer: cweining -- Previously updated : 08/14/2024---# Debug exceptions in .NET applications using Snapshot Debugger --When enabled, Snapshot Debugger automatically collects a debug snapshot of the source code and variables when an exception occurs in your live .NET application. The Snapshot Debugger in [Application Insights](../app/app-insights-overview.md): --- Monitors system-generated logs from your web app.-- Collects snapshots on your top-throwing exceptions.-- Provides information you need to diagnose issues in production.--[Learn more about the Snapshot Debugger and Snapshot Uploader processes.](#how-snapshot-debugger-works) --## Supported applications and environments --This section lists the applications and environments that are supported. --### Applications --Snapshot collection is available for: --- .NET Framework 4.6.2 and newer versions.-- [.NET 6.0 or later](https://dotnet.microsoft.com/download) on Windows.--### Environments --The following environments are supported: --- [Azure App Service](snapshot-debugger-app-service.md?toc=/azure/azure-monitor/toc.json)-- [Azure Functions](snapshot-debugger-function-app.md?toc=/azure/azure-monitor/toc.json)-- [Azure Cloud Services](snapshot-debugger-vm.md?toc=/azure/azure-monitor/toc.json) running OS family 4 or later-- [Azure Service Fabric](snapshot-debugger-vm.md?toc=/azure/azure-monitor/toc.json) running on Windows Server 2012 R2 or later-- [Azure Virtual Machines and Azure Virtual Machine Scale Sets](snapshot-debugger-vm.md?toc=/azure/azure-monitor/toc.json) running Windows Server 2012 R2 or later-- [On-premises virtual or physical machines](snapshot-debugger-vm.md?toc=/azure/azure-monitor/toc.json) running Windows Server 2012 R2 or later or Windows 8.1 or later--> [!NOTE] -> Client applications (for example, WPF, Windows Forms, or UWP) aren't supported. --## Prerequisites for using Snapshot Debugger --### Packages and configurations --- Include the [Snapshot Collector NuGet package](https://www.nuget.org/packages/Microsoft.ApplicationInsights.SnapshotCollector) in your application.-- Configure collection parameters in [`ApplicationInsights.config`](../app/configuration-with-applicationinsights-config.md).--### Permissions --- Verify you're added to the [Application Insights Snapshot Debugger](../../role-based-access-control/role-assignments-portal.yml) role for the target **Application Insights Snapshot**.--## How Snapshot Debugger works --The Snapshot Debugger is implemented as an [Application Insights telemetry processor](../app/configuration-with-applicationinsights-config.md#telemetry-processors-aspnet). When your application runs, the Snapshot Debugger telemetry processor is added to your application's system-generated logs pipeline. --> [!IMPORTANT] -> Snapshots might contain personal data or other sensitive information in variable and parameter values. Snapshot data is stored in the same region as your Application Insights resource. --### Snapshot Debugger process --The Snapshot Debugger process starts and ends with the `TrackException` method. A process snapshot is a suspended clone of the running process, so that your users experience little to no interruption. In a typical scenario: --1. Your application throws the [`TrackException`](../app/asp-net-exceptions.md#exceptions). --1. The Snapshot Debugger monitors exceptions as they're thrown by subscribing to the [`AppDomain.CurrentDomain.FirstChanceException`](/dotnet/api/system.appdomain.firstchanceexception) event. --1. A counter is incremented for the problem ID. - - When the counter reaches the `ThresholdForSnapshotting` value, the problem ID is added to a collection plan. - - > [!NOTE] - > The `ThresholdForSnapshotting` default minimum value is 1. With this value, your app has to trigger the same exception *twice* before a snapshot is created. --1. The exception event's problem ID is computed and compared against the problem IDs in the collection plan. --1. If there's a match between problem IDs, a **snapshot** of the running process is created. - - The snapshot is assigned a unique identifier and the exception is stamped with that identifier. - - > [!NOTE] - > The snapshot creation rate is limited by the `SnapshotsPerTenMinutesLimit` setting. By default, the limit is one snapshot every 10 minutes. - -1. After the `FirstChanceException` handler returns, the thrown exception is processed as normal. --1. The exception reaches the `TrackException` method again and is reported to Application Insights, along with the snapshot identifier. --> [!NOTE] -> Set `IsEnabledInDeveloperMode` to `true` if you want to generate snapshots while you debug in Visual Studio. --### Snapshot Uploader process --While the Snapshot Debugger process continues to run and serve traffic to users with little interruption, the snapshot is handed off to the Snapshot Uploader process. In a typical scenario, the Snapshot Uploader: --1. Creates a minidump. --1. Uploads the minidump to Application Insights, along with any relevant symbol (*.pdb*) files. --> [!NOTE] -> No more than 50 snapshots per day can be uploaded. --If you enabled the Snapshot Debugger but you aren't seeing snapshots, see the [Troubleshooting guide](snapshot-debugger-troubleshoot.md). --## Upgrading Snapshot Debugger --Snapshot Debugger auto-upgrades via the built-in, preinstalled Application Insights site extension. --Manually adding an Application Insights site extension to keep Snapshot Debugger up-to-date is deprecated. --## Overhead --The Snapshot Debugger is designed for use in production environments. The default settings include rate limits to minimize the impact on your applications. --However, you may experience small CPU, memory, and I/O overhead associated with the Snapshot Debugger, such as: -- When an exception is thrown in your application-- If the exception handler decides to create a snapshot-- When `TrackException` is called--There is **no additional cost** for storing data captured by Snapshot Debugger. --[See example scenarios in which you may experience Snapshot Debugger overhead.](./snapshot-debugger-troubleshoot.md#snapshot-debugger-overhead-scenarios) --## Limitations --This section discusses limitations for the Snapshot Debugger. --- **Data retention**-- Debug snapshots are stored for 15 days. The default data retention policy is set on a per-application basis. If you need to increase this value, you can request an increase by opening a support case in the Azure portal. For each Application Insights instance, a maximum number of 50 snapshots are allowed per day. --- **Publish symbols**-- The Snapshot Debugger requires symbol files on the production server to: - - Decode variables - - Provide a debugging experience in Visual Studio -- By default, Visual Studio 2017 versions 15.2+ publishes symbols for release builds when it publishes to App Service. -- In prior versions, you must add the following line to your publish profile `.pubxml` file so that symbols are published in release mode: -- ```xml - <ExcludeGeneratedDebugSymbol>False</ExcludeGeneratedDebugSymbol> - ``` -- For Azure Compute and other types, make sure that the symbol files are either: - - In the same folder of the main application `.dll` (typically, `wwwroot/bin`), or - - Available on the current path. -- For more information on the different symbol options that are available, see the [Visual Studio documentation](/visualstudio/ide/reference/advanced-build-settings-dialog-box-csharp). For best results, we recommend that you use *Full*, *Portable*, or *Embedded*. --- **Optimized builds**-- In some cases, local variables can't be viewed in release builds because of optimizations applied by the JIT compiler. -- However, in App Service, the Snapshot Debugger can deoptimize throwing methods that are part of its collection plan. -- > [!TIP] - > Install the Application Insights Site extension in your instance of App Service to get deoptimization support. --## Next steps --Enable the Application Insights Snapshot Debugger for your application: --- [Azure App Service](snapshot-debugger-app-service.md?toc=/azure/azure-monitor/toc.json)-- [Azure Functions](snapshot-debugger-function-app.md?toc=/azure/azure-monitor/toc.json)-- [Azure Cloud Services](snapshot-debugger-vm.md?toc=/azure/azure-monitor/toc.json)-- [Azure Service Fabric](snapshot-debugger-vm.md?toc=/azure/azure-monitor/toc.json)-- [Azure Virtual Machines and Virtual Machine Scale Sets](snapshot-debugger-vm.md?toc=/azure/azure-monitor/toc.json)-- [On-premises virtual or physical machines](snapshot-debugger-vm.md?toc=/azure/azure-monitor/toc.json) |
| azure-monitor | Grafana Plugin | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/grafana-plugin.md | - Title: Monitor Azure services and applications by using Grafana -description: Route Azure Monitor and Application Insights data so that you can view it in Grafana. - Previously updated : 06/21/2023----# Monitor your Azure services in Grafana -You can monitor Azure services and applications by using [Grafana](https://grafana.com/) and the included [Azure Monitor data source plug-in](https://grafana.com/docs/grafana/latest/datasources/azuremonitor/). The plug-in retrieves data from these Azure --- [Azure Monitor Metrics](../essentials/data-platform-metrics.md) for numeric time series data from Azure resources.-- [Azure Monitor Logs](../logs/data-platform-logs.md) for log and performance data from Azure resources that enables you to query by using the powerful Kusto Query Language (KQL). You can use Application Insights log queries to retrieve Application Insights log based metrics- - [Application Insights log based metrics](../essentials/app-insights-metrics.md) to let you analyze the health of your monitored apps. You can use Application Insights log queries in Grafana to use the Application Insights log metrics data. -- [Azure Resource Graph](../../governance/resource-graph/overview.md) to quickly query and identify Azure resources across subscriptions.---You can then display this performance and availability data on your Grafana dashboard. --Use the following steps to set up a Grafana server and build dashboards for metrics and logs from Azure Monitor. --## Set up Grafana --Follow these steps to set up Grafana. --### Set up Azure Managed Grafana -Azure Managed Grafana is optimized for the Azure environment and works seamlessly with Azure Monitor. You can: --- Manage user authentication and access control by using Microsoft Entra identities.-- Pin charts from the Azure portal directly to Azure Managed Grafana dashboards.--Use this [quickstart guide](../../managed-grafan) to create an Azure Managed Grafana workspace by using the Azure portal. --### Set up Grafana locally -To set up a local Grafana server, [download and install Grafana in your local environment](https://grafana.com/grafana/download). --## Sign in to Grafana --> [!IMPORTANT] -> Internet Explorer and the older Microsoft Edge browsers aren't compatible with Grafana. You must use a chromium-based browser including Microsoft Edge. For more information, see [Supported web browsers for Grafana](https://grafana.com/docs/grafana/latest/installation/requirements/#supported-web-browsers). --Sign in to Grafana by using the endpoint URL of your Azure Managed Grafana workspace or your server's IP address. --## Configure an Azure Monitor data source plug-in --Azure Managed Grafana includes an Azure Monitor data source plug-in. By default, the plug-in is preconfigured with a managed identity that can query and visualize monitoring data from all resources in the subscription in which the Grafana workspace was deployed. Skip ahead to the section "Build a Grafana dashboard." ---You can expand the resources that can be viewed by your Azure Managed Grafana workspace by [configuring additional permissions](../../managed-grafan) on other subscriptions or resources. -- If you're using an instance that isn't Azure Managed Grafana, you have to set up an Azure Monitor data source. --1. Select **Add data source**, filter by the name **Azure**, and select the **Azure Monitor** data source. -- :::image type="content" source="./media/grafana-plugin/azure-monitor-data-source-list.png" lightbox="./media/grafana-plugin/azure-monitor-data-source-list.png" alt-text="Screenshot that shows Azure Monitor data source selection."::: --1. Pick a name for the data source and choose between managed identity or app registration for authentication. --If you're hosting Grafana on your own Azure Virtual Machines or Azure App Service instance with managed identity enabled, you can use this approach for authentication. However, if your Grafana instance isn't hosted on Azure or doesn't have managed identity enabled, you'll need to use app registration with an Azure service principal to set up authentication. --### Use managed identity --1. Enable managed identity on your VM or App Service instance and change the Grafana server managed identity support setting to **true**. - * The managed identity of your hosting VM or App Service instance needs to have the [Monitoring Reader role](../roles-permissions-security.md) assigned for the subscription, resource group, or resources of interest. - * You'll also need to update the setting `managed_identity_enabled = true` in the Grafana server config. For more information, see [Grafana configuration](https://grafana.com/docs/grafana/latest/administration/configuration/). After both steps are finished, you can then save and test access. --1. Select **Save & test** and Grafana will test the credentials. You should see a message similar to the following one. - - :::image type="content" source="./media/grafana-plugin/managed-identity.png" lightbox="./media/grafana-plugin/managed-identity.png" alt-text="Screenshot that shows Azure Monitor data source with config-approved managed identity."::: --### Use app registration --1. Create a service principal. Grafana uses a Microsoft Entra service principal to connect to Azure Monitor APIs and collect data. You must create, or use an existing service principal, to manage access to your Azure resources: - * See [Create a Microsoft Entra app and service principal in the portal](../../active-directory/develop/howto-create-service-principal-portal.md) to create a service principal. Copy and save your tenant ID (Directory ID), client ID (Application ID), and client secret (Application key value). - * View [Assign application to role](../../active-directory/develop/howto-create-service-principal-portal.md) to assign the [Monitoring Reader role](../roles-permissions-security.md) to the Microsoft Entra application on the subscription, resource group, or resource you want to monitor. - -1. Provide the connection details you want to use: - * When you configure the plug-in, you can indicate which Azure Cloud you want the plug-in to monitor: Public, Azure US Government, Azure Germany, or Microsoft Azure operated by 21Vianet. - > [!NOTE] - > Some data source fields are named differently than their correlated Azure settings: - > * Tenant ID is the Azure Directory ID. - > * Client ID is the Microsoft Entra Application ID. - > * Client Secret is the Microsoft Entra Application key value. --1. Select **Save & test** and Grafana will test the credentials. You should see a message similar to the following one. - - :::image type="content" source="./media/grafana-plugin/app-registration.png" lightbox="./media/grafana-plugin/app-registration.png" alt-text="Screenshot that shows Azure Monitor data source configuration with the approved app registration."::: --## Use out-of-the-box dashboards --Azure Monitor contains out-of-the-box dashboards to use with Azure Managed Grafana and the Azure Monitor plugin. -- -Azure Monitor also supports out-of-the-box dashboards for seamless integration with Azure Monitor managed service for Prometheus. These dashboards are automatically deployed to Azure Managed Grafana when linked to Azure Monitor managed service for Prometheus. --## Build a Grafana dashboard --1. Go to the Grafana home page and select **New Dashboard**. --1. In the new dashboard, select **Graph**. You can try other charting options, but this article uses **Graph** as an example. --1. A blank graph shows up on your dashboard. Select the panel title and select **Edit** to enter the details of the data you want to plot in this graph chart. -- :::image type="content" source="./media/grafana-plugin/grafana-new-graph-dark.png" lightbox="./media/grafana-plugin/grafana-new-graph-dark.png" alt-text="Screenshot that shows Grafana new panel dropdown list options."::: --1. Select the Azure Monitor data source you've configured. - * Visualizing Azure Monitor metrics: Select **Azure Monitor** in the service dropdown list. A list of selectors shows up where you can select the resources and metric to monitor in this chart. To collect metrics from a VM, use the namespace `Microsoft.Compute/VirtualMachines`. After you've selected VMs and metrics, you can start viewing their data in the dashboard. -- :::image type="content" source="./media/grafana-plugin/grafana-graph-config-for-azure-monitor-dark.png" lightbox="./media/grafana-plugin/grafana-graph-config-for-azure-monitor-dark.png" alt-text="Screenshot that shows Grafana panel config for Azure Monitor metrics."::: - * Visualizing Azure Monitor log data: Select **Azure Log Analytics** in the service dropdown list. Select the workspace you want to query and set the query text. You can copy here any log query you already have or create a new one. As you enter your query, IntelliSense suggests autocomplete options. Select the visualization type, **Time series** > **Table**, and run the query. - - > [!NOTE] - > - > The default query provided with the plug-in uses two macros: `$__timeFilter()` and `$__interval`. - > These macros allow Grafana to dynamically calculate the time range and time grain, when you zoom in on part of a chart. You can remove these macros and use a standard time filter, such as `TimeGenerated > ago(1h)`, but that means the graph wouldn't support the zoom-in feature. - - :::image type="content" source="./media/grafana-plugin/grafana-graph-config-for-azure-log-analytics-dark.png" lightbox="./media/grafana-plugin/grafana-graph-config-for-azure-log-analytics-dark.png" alt-text="Screenshot of Grafana panel config for Azure Monitor logs."::: --1. The following dashboard has two charts. The one on the left shows the CPU percentage of two VMs. The chart on the right shows the transactions in an Azure Storage account broken down by the Transaction API type. -- :::image type="content" source="media/grafana-plugin/grafana6.png" lightbox="media/grafana-plugin/grafana6.png" alt-text="Screenshot of Grafana dashboards with two panels."::: --## Pin charts from the Azure portal to Azure Managed Grafana --In addition to building your panels in Grafana, you can also quickly pin Azure Monitor visualizations from the Azure portal to new or existing Grafana dashboards by adding panels to your Grafana dashboard directly from Azure Monitor. Go to **Metrics** for your resource. Create a chart and select **Save to dashboard**, followed by **Pin to Grafana**. Choose the workspace and dashboard and select **Pin** to complete the operation. ---## Advanced Grafana features --Grafana has advanced features. --### Variables -Some query values can be selected through UI dropdowns and updated in the query. Consider the following query as an example: --``` -Usage -| where $__timeFilter(TimeGenerated) -| summarize total_KBytes=sum(Quantity)*1024 by bin(TimeGenerated, $__interval) -| sort by TimeGenerated -``` --You can configure a variable that will list all available **Solution** values and then update your query to use it. To create a new variable, select the dashboard's **Settings** button in the top right area, select **Variables**, and then select **New**. On the variable page, define the data source and query to run to get the list of values. ---After it's created, adjust the query to use the selected values, and your charts will respond accordingly: --``` -Usage -| where $__timeFilter(TimeGenerated) and Solution in ($Solutions) -| summarize total_KBytes=sum(Quantity)*1024 by bin(TimeGenerated, $__interval) -| sort by TimeGenerated -``` ---### Create dashboard playlists --One of the many useful features of Grafana is the dashboard playlist. You can create multiple dashboards and add them to a playlist configuring an interval for each dashboard to show. Select **Play** to see the dashboards cycle through. You might want to display them on a large wall monitor to provide a status board for your group. --## Optional: Monitor other datasources in the same Grafana dashboards --There are many data source plug-ins that you can use to bring these metrics together in a dashboard. --Here are good reference articles on how to use Telegraf, InfluxDB, Azure Monitor managed service for Prometheus, and Docker: --Here's an image of a full Grafana dashboard that has metrics from Azure Monitor and Application Insights. --## Clean up resources --If you've set up a Grafana environment on Azure, you're charged when resources are running whether you're using them or not. To avoid incurring additional charges, clean up the resource group created in this article. --1. On the left menu in the Azure portal, select **Resource groups** > **Grafana**. -1. On your resource group page, select **Delete**, enter **Grafana** in the text box, and then select **Delete**. --## Next steps -[Overview of Azure Monitor metrics](../data-platform.md) |
| azure-monitor | Resource Manager Workbooks | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/resource-manager-workbooks.md | - Title: Resource Manager template samples for workbooks -description: Sample Azure Resource Manager templates to deploy Azure Monitor workbooks. ---- Previously updated : 06/13/2022---# Resource Manager template samples for workbooks in Azure Monitor --This article includes sample [Azure Resource Manager templates](../../azure-resource-manager/templates/syntax.md) to create workbooks in Azure Monitor. Each sample includes a template file and a parameters file with sample values to provide to the template. ---Workbooks can be complex, so a typical strategy is to create the workbook in the Azure portal and then generate a Resource Manager template. See details of this method in [Azure Resource Manager template for deploying workbooks](../visualize/workbooks-automate.md). --## Create a workbook --The following sample creates a simple workbook. --### Template file --# [Bicep](#tab/bicep) --```bicep -@description('The unique guid for this workbook instance.') -param workbookId string = newGuid() --@description('The location of the resource.') -param location string = resourceGroup().location --@description('The friendly name for the workbook that is used in the Gallery or Saved List. Needs to be unique in the scope of the resource group and source.') -param workbookDisplayName string = 'My Workbook' --@description('The gallery that the workbook will been shown under. Supported values include workbook, `tsg`, Azure Monitor, etc.') -param workbookType string = 'tsg' --@description('The id of resource instance to which the workbook will be associated.') -param workbookSourceId string = '<insert-your-resource-id-here>' ---resource workbook 'Microsoft.Insights/workbooks@2018-06-17-preview' = { - name: workbookId - location: location - kind: 'shared' - properties: { - displayName: workbookDisplayName - serializedData: '{"version":"Notebook/1.0","items":[{"type":1,"content":"{\\"json\\":\\"Hello World!\\"}","conditionalVisibility":null}],"isLocked":false}' - version: '1.0' - sourceId: workbookSourceId - category: workbookType - } -} --output workbookId string = workbook.id -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workbookId": { - "type": "string", - "defaultValue": "[newGuid()]", - "metadata": { - "description": "The unique guid for this workbook instance." - } - }, - "location": { - "type": "string", - "defaultValue": "[resourceGroup().location]", - "metadata": { - "description": "The location of the resource." - } - }, - "workbookDisplayName": { - "type": "string", - "defaultValue": "My Workbook", - "metadata": { - "description": "The friendly name for the workbook that is used in the Gallery or Saved List. Needs to be unique in the scope of the resource group and source." - } - }, - "workbookType": { - "type": "string", - "defaultValue": "tsg", - "metadata": { - "description": "The gallery that the workbook will been shown under. Supported values include workbook, `tsg`, Azure Monitor, etc." - } - }, - "workbookSourceId": { - "type": "string", - "defaultValue": "<insert-your-resource-id-here>", - "metadata": { - "description": "The id of resource instance to which the workbook will be associated." - } - } - }, - "resources": [ - { - "type": "microsoft.insights/workbooks", - "apiVersion": "2018-06-17-preview", - "name": "[parameters('workbookId')]", - "location": "[parameters('location')]", - "kind": "shared", - "properties": { - "displayName": "[parameters('workbookDisplayName')]", - "serializedData": "{\"version\":\"Notebook/1.0\",\"items\":[{\"type\":1,\"content\":\"{\\\"json\\\":\\\"Hello World!\\\"}\",\"conditionalVisibility\":null}],\"isLocked\":false}", - "version": "1.0", - "sourceId": "[parameters('workbookSourceId')]", - "category": "[parameters('workbookType')]" - } - } - ], - "outputs": { - "workbookId": { - "type": "string", - "value": "[resourceId('microsoft.insights/workbooks', parameters('workbookId'))]" - } - } -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workbookDisplayName": { - "value": "Sample Hello World workbook" - }, - "workbookType": { - "value": "workbook" - }, - "workbookSourceId": { - "value": "Azure Monitor" - } - } -} -``` --## Next steps --* [Get other sample templates for Azure Monitor](../resource-manager-samples.md). -* [Learn more about action groups](../visualize/workbooks-overview.md). |
| azure-monitor | Tutorial Logs Dashboards | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/tutorial-logs-dashboards.md | - Title: Create and share dashboards of Azure Log Analytics data | Microsoft Docs -description: This tutorial helps you understand how Log Analytics dashboards can visualize all of your saved log queries, giving you a single lens to view your environment. --- Previously updated : 11/07/2023-----# Create and share dashboards of Log Analytics data --Log Analytics dashboards can visualize all of your saved log queries. Visualizations give you the ability to find, correlate, and share IT operational data in your organization. This tutorial covers creating a log query that will be used to support a shared dashboard that can be accessed by your IT operations support team. You learn how to: --> [!div class="checklist"] -> * Create a shared dashboard in the Azure portal. -> * Visualize a performance log query. -> * Add a log query to a shared dashboard. -> * Customize a tile in a shared dashboard. --To complete the example in this tutorial, you must have an existing virtual machine [connected to the Log Analytics workspace](../vm/monitor-virtual-machine.md). --## Sign in to the Azure portal -Sign in to the [Azure portal](https://portal.azure.com). --## Create a shared dashboard -Select **Dashboard** to open your default [dashboard](../../azure-portal/azure-portal-dashboards.md). Your dashboard will look different from the following example. -<!-- convertborder later --> --Here you can bring together operational data that's most important to IT across all your Azure resources, including telemetry from Azure Log Analytics. Before we visualize a log query, let's first create a dashboard and share it. We can then focus on our example performance log query, which will render as a line chart, and add it to the dashboard. --> [!NOTE] -> The following chart types are supported in Azure dashboards by using log queries: -> - `areachart` -> - `columnchart` -> - `piechart` (will render in dashboard as a donut) -> - `scatterchart` -> - `timechart` --To create a dashboard, select **New dashboard**. -<!-- convertborder later --> --This action creates a new, empty, private dashboard. It opens in a customization mode where you can name your dashboard and add or rearrange tiles. Edit the name of the dashboard and specify **Sample Dashboard** for this tutorial. Then select **Done customizing**.<br><br> <!-- convertborder later -->:::image type="content" source="media/tutorial-logs-dashboards/log-analytics-create-dashboard-02.png" lightbox="media/tutorial-logs-dashboards/log-analytics-create-dashboard-02.png" alt-text="Screenshot that shows saving a customized Azure dashboard." border="false"::: --When you create a dashboard, it's private by default, so you're the only person who can see it. To make it visible to others, select **Share**. -<!-- convertborder later --> --Choose a subscription and resource group for your dashboard to be published to. For convenience, you're guided toward a pattern where you place dashboards in a resource group called **dashboards**. Verify the subscription selected and then select **Publish**. Access to the information displayed in the dashboard is controlled with [Azure role-based access control](../../role-based-access-control/role-assignments-portal.yml). --## Visualize a log query -[Log Analytics](../logs/log-analytics-tutorial.md) is a dedicated portal used to work with log queries and their results. Features include the ability to edit a query on multiple lines and selectively execute code. Log Analytics also uses context-sensitive IntelliSense and Smart Analytics. --In this tutorial, you'll use Log Analytics to create a performance view in graphical form and save it for a future query. Then you'll pin it to the shared dashboard you created earlier. --Open Log Analytics by selecting **Logs** on the Azure Monitor menu. It starts with a new blank query. -<!-- convertborder later --> --Enter the following query to return processor utilization records for both Windows and Linux computers. The records are grouped by `Computer` and `TimeGenerated` and displayed in a visual chart. Select **Run** to run the query and view the resulting chart. --```Kusto -Perf -| where CounterName == "% Processor Time" and ObjectName == "Processor" and InstanceName == "_Total" -| summarize AggregatedValue = avg(CounterValue) by bin(TimeGenerated, 1hr), Computer -| render timechart -``` --Save the query by selecting **Save**. ---In the **Save Query** control panel, provide a name such as **Azure VMs - Processor Utilization** and a category such as **Dashboards**. Select **Save**. This way you can create a library of common queries that you can use and modify. Finally, pin this query to the shared dashboard you created earlier. Select the **Pin to dashboard** button in the upper-right corner of the page and then select the dashboard name. --Now that we have a query pinned to the dashboard, you'll notice that it has a generic title and comment underneath it. --- Rename the query with a meaningful name that can be easily understood by anyone who views it. Select **Edit** to customize the title and subtitle for the tile, and then select **Update**. A banner appears that asks you to publish changes or discard. Select **Save a copy**. ---## Next steps -In this tutorial, you learned how to create a dashboard in the Azure portal and add a log query to it. Follow this link to see prebuilt Log Analytics script samples. --> [!div class="nextstepaction"] -> [Log Analytics script samples](../logs/queries.md) |
| azure-monitor | Workbook Templates Move Region | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbook-templates-move-region.md | - Title: Move and Azure Workbook template to another region -description: How to move a workbook template to a different region ---- Previously updated : 06/21/2023---#Customer intent: As an Azure service administrator, I want to move my resources to another Azure region --# Move an Azure Workbook Template to another region --This article describes how to move Azure Workbook Template resources to a different Azure region. You might move your resources to another region for a number of reasons. For example, to take advantage of a new Azure region, to deploy features or services available in specific regions only, to meet internal policy and governance requirements, or in response to capacity planning requirements. --There currently is no portal UI to create Workbook Template resources, the only current way to create them is [via Azure Resource Manager Template (ARM template) deployments](../visualize/workbooks-automate.md). As such, the easiest way to move a template is to reuse the previous ARM template and update it to be deployed to the new region. --## Prerequisites --* Ensure that workbook templates are supported in the target region. --## Prepare --* Identify the previously used ARM Template for the workbook template. --## Move --1. Update the previously used template to reference the new region. -- > [!NOTE] - > You may need to use a new name for the workbook template to avoid any duplicate names. --2. Deploy the updated template via ARM template deployment to create a new workbook template in the desired region. --## Verify --Use the Azure Workbooks browse UI to locate the newly deployed workbook template. Ensure the location is the target location. --## Clean up --Once your workbook template has been created in the new region, delete the original workbook template in the previous region. -1. Find the workbook template in the Azure Workbooks browse UI. -2. Select the workbook template to delete. -3. Select the "Delete" command. --If you renamed your workbook template to import it into a new region, you can rename the workbook template to the previous name after the original item has been deleted by using the "Rename" command in the Azure Workbook Template resource view. --## Next Steps --Need to move a workbook instead of a template? See how to [move an Azure Workbook to another region](./workbooks-move-region.md). - |
| azure-monitor | Workbooks Access Troubleshooting Guide | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-access-troubleshooting-guide.md | - Title: Access Troubleshooting Guides in Azure Workbooks -description: Learn how to access the deprecated troubleshooting guides in Azure Workbooks. -- Previously updated : 06/21/2023---# Access deprecated Troubleshooting guides in Azure Workbooks --Troubleshooting guides are now deprecated, and the **Troubleshooting guides** menu item is no longer available. You can still access the troubleshooting guides in the Azure Workbooks menu on the left. -- :::image type="content" source="media/workbooks-access-troubleshooting-guides/workbooks-tsg-menu.png" alt-text="Screenshot of Troubleshooting guides icon in the menu. "::: --Use the 'Change Type' feature to change workbook types and move them from the Troubleshooting Guide gallery to the Workbook gallery. --## Change the workbook type using the Change Type toolbar item --1. Switch the workbook to edit mode by selecting **Edit**. -1. Select the **Edit** icon, and then **Change Type**. -- :::image type="content" source="media/workbooks-access-troubleshooting-guides/workbooks-tsg-change-type-menu.png" alt-text="Screenshot of icon to change the workbooks type. "::: --1. A window opens with a dropdown with a workbook type to which you can change. Select **Workbook** and then **OK**. -- :::image type="content" source="media/workbooks-access-troubleshooting-guides/workbooks-tsg-select-type.png" alt-text="Screenshot of window to select new workbook type. "::: --1. A success status popup window appears in the top right corner. It may take up to a minute for the change to be reflected in the gallery. --1. The workbook that was previously a `Troubleshooting guide` and resided in the Troubleshooting guides gallery is now in the Workbooks gallery. -- :::image type="content" source="media/workbooks-access-troubleshooting-guides/workbooks-tsg-done.png" alt-text="Screenshot showing the troubleshooting guide in the Workbooks gallery. "::: ---## Change the workbook type using the browse pane --1. Open up the workbooks browse pane and select the workbook that you want to change by clicking on the workbook name. -- :::image type="content" source="media/workbooks-access-troubleshooting-guides/workbooks-tsg-browse.png" alt-text="Screenshot of the Workbooks browse pane. "::: --1. Notice the current workbook type is labeled as "tsg". Select **Change type** -- :::image type="content" source="media/workbooks-access-troubleshooting-guides/workbooks-tsg-browse-change-type.png" alt-text="Screenshot of changing the workbook type in the browse pane."::: --1. A success status popup window appears in the top right corner. It may take up to a minute for the change to be reflected in the gallery. - --## Change the workbook type using the gallery card '...' menu -1. Navigate to the gallery containing the workbook that you'd like to change the type for. -1. Select the **...** button on the gallery card item, and then select **Change Type**. -- :::image type="content" source="media/workbooks-access-troubleshooting-guides/workbooks-tsg-gallery-change-type.png" alt-text="Screenshot of changing the Workbook type from the gallery. "::: ---## Next steps --Learn how to create [Honeycomb visualizations](workbooks-honey-comb.md). |
| azure-monitor | Workbooks Automate | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-automate.md | - Title: Azure Monitor workbooks and Azure Resource Manager templates -description: Simplify complex reporting with prebuilt and custom parameterized Azure Monitor workbooks deployed via Azure Resource Manager templates. --- Previously updated : 06/21/2023---# Programmatically manage workbooks --Resource owners can create and manage their workbooks programmatically via Azure Resource Manager templates (ARM templates). --This capability can be useful in scenarios like: -* Deploying org- or domain-specific analytics reports along with resources deployments. For instance, you can deploy org-specific performance and failure workbooks for your new apps or virtual machines. -* Deploying standard reports or dashboards by using workbooks for existing resources. --The workbook will be created in the desired sub/resource-group and with the content specified in the ARM templates. --Two types of workbook resources can be managed programmatically: -* [Workbook templates](#arm-template-for-deploying-a-workbook-template) -* [Workbook instances](#arm-template-for-deploying-a-workbook-instance) --## ARM template for deploying a workbook template --1. Open a workbook you want to deploy programmatically. -1. Switch the workbook to edit mode by selecting **Edit**. -1. Open the **Advanced Editor** by using the **</>** button on the toolbar. -1. Ensure you're on the **Gallery Template** tab. - <!-- convertborder later --> - :::image type="content" source="./media/workbooks-automate/gallery-template.png" lightbox="./media/workbooks-automate/gallery-template.png" alt-text="Screenshot that shows the Gallery Template tab." border="false"::: --1. Copy the JSON in the gallery template to the clipboard. -1. The following sample ARM template deploys a workbook template to the Azure Monitor workbook gallery. Paste the JSON you copied in place of `<PASTE-COPIED-WORKBOOK_TEMPLATE_HERE>`. For a reference ARM template that creates a workbook template, see [this GitHub repository](https://github.com/microsoft/Application-Insights-Workbooks/blob/master/Documentation/ARM-template-for-creating-workbook-template). -- ```json - { - "$schema": "http://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "resourceName": { - "type": "string", - "defaultValue": "my-workbook-template", - "metadata": { - "description": "The unique name for this workbook template instance" - } - } - }, - "resources": [ - { - "name": "[parameters('resourceName')]", - "type": "microsoft.insights/workbooktemplates", - "location": "[resourceGroup().location]", - "apiVersion": "2019-10-17-preview", - "dependsOn": [], - "properties": { - "galleries": [ - { - "name": "A Workbook Template", - "category": "Deployed Templates", - "order": 100, - "type": "workbook", - "resourceType": "Azure Monitor" - } - ], - "templateData": <PASTE-COPIED-WORKBOOK_TEMPLATE_HERE> - } - } - ] - } - ``` -1. In the `galleries` object, fill in the `name` and `category` keys with your values. Learn more about [parameters](#parameters) in the next section. -1. Deploy this ARM template by using either the [Azure portal](../../azure-resource-manager/templates/deploy-portal.md#deploy-resources-from-custom-template), the [command-line interface](../../azure-resource-manager/templates/deploy-cli.md), or [PowerShell](../../azure-resource-manager/templates/deploy-powershell.md). -1. Open the Azure portal and go to the workbook gallery chosen in the ARM template. In the example template, go to the Azure Monitor workbook gallery: - 1. Open the Azure portal and go to Azure Monitor. - 1. Open `Workbooks` from the table of contents. - 1. Find your template in the gallery under the category `Deployed Templates`. (It will be one of the purple items.) --### Parameters --|Parameters |Explanation | -|:-|:-| -| `name` | The name of the workbook template resource in Azure Resource Manager. | -|`type` | Always microsoft.insights/workbooktemplates. | -| `location` | The Azure location where the workbook will be created. | -| `apiVersion` | 2019-10-17 preview. | -| `type` | Always microsoft.insights/workbooktemplates. | -| `galleries` | The set of galleries in which to show this workbook template. | -| `gallery.name` | The friendly name of the workbook template in the gallery. | -| `gallery.category` | The group in the gallery in which to place the template. | -| `gallery.order` | A number that decides the order to show the template within a category in the gallery. Lower order implies higher priority. | -| `gallery.resourceType` | The resource type corresponding to the gallery. This type is usually the resource type string corresponding to the resource (for example, microsoft.operationalinsights/workspaces). | -|`gallery.type` | Referred to as workbook type. This unique key differentiates the gallery within a resource type. Application Insights, for example, has the types `workbook` and `tsg` that correspond to different workbook galleries. | --### Galleries --| Gallery | Resource type | Workbook type | -|:--|:-|:--| -| Workbooks in Azure Monitor | `Azure Monitor` | `workbook` | -| VM Insights in Azure Monitor | `Azure Monitor` | `vm-insights` | -| Workbooks in Log Analytics workspace | `microsoft.operationalinsights/workspaces` | `workbook` | -| Workbooks in Application Insights | `microsoft.insights/components` | `workbook` | -| Troubleshooting guides in Application Insights | `microsoft.insights/components` | `tsg` | -| Usage in Application Insights | `microsoft.insights/components` | `usage` | -| Workbooks in Kubernetes service | `Microsoft.ContainerService/managedClusters` | `workbook` | -| Workbooks in resource groups | `microsoft.resources/subscriptions/resourcegroups` | `workbook` | -| Workbooks in Microsoft Entra ID | `microsoft.aadiam/tenant` | `workbook` | -| VM Insights in virtual machines | `microsoft.compute/virtualmachines` | `insights` | -| VM Insights in virtual machine scale sets | `microsoft.compute/virtualmachinescalesets` | `insights` | --## ARM template for deploying a workbook instance --1. Open a workbook that you want to deploy programmatically. -1. Switch the workbook to edit mode by selecting **Edit**. -1. Open the **Advanced Editor** by selecting **</>**. -1. In the editor, switch **Template Type** to **ARM template**. -1. The ARM template for creating shows up in the editor. Copy the content and use as-is or merge it with a larger template that also deploys the target resource. - <!-- convertborder later --> - :::image type="content" source="./media/workbooks-automate/programmatic-template.png" lightbox="./media/workbooks-automate/programmatic-template.png" alt-text="Screenshot that shows how to get the ARM template from within the workbook UI." border="false"::: --## Sample ARM template -This template shows how to deploy a workbook that displays `Hello World!`. --```json -{ - "$schema": "http://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workbookDisplayName": { - "type":"string", - "defaultValue": "My Workbook", - "metadata": { - "description": "The friendly name for the workbook that is used in the Gallery or Saved List. Needs to be unique in the scope of the resource group and source" - } - }, - "workbookType": { - "type":"string", - "defaultValue": "tsg", - "metadata": { - "description": "The gallery that the workbook will be shown under. Supported values include workbook, `tsg`, Azure Monitor, etc." - } - }, - "workbookSourceId": { - "type":"string", - "defaultValue": "<insert-your-resource-id-here>", - "metadata": { - "description": "The id of resource instance to which the workbook will be associated" - } - }, - "workbookId": { - "type":"string", - "defaultValue": "[newGuid()]", - "metadata": { - "description": "The unique guid for this workbook instance" - } - } - }, - "resources": [ - { - "name": "[parameters('workbookId')]", - "type": "Microsoft.Insights/workbooks", - "location": "[resourceGroup().location]", - "kind": "shared", - "apiVersion": "2018-06-17-preview", - "dependsOn": [], - "properties": { - "displayName": "[parameters('workbookDisplayName')]", - "serializedData": "{\"version\":\"Notebook/1.0\",\"items\":[{\"type\":1,\"content\":\"{\\\"json\\\":\\\"Hello World!\\\"}\",\"conditionalVisibility\":null}],\"isLocked\":false}", - "version": "1.0", - "sourceId": "[parameters('workbookSourceId')]", - "category": "[parameters('workbookType')]" - } - } - ], - "outputs": { - "workbookId": { - "type": "string", - "value": "[resourceId( 'Microsoft.Insights/workbooks', parameters('workbookId'))]" - } - } -} -``` --### Template parameters --| Parameter | Description | -| :- |:-| -| `workbookDisplayName` | The friendly name for the workbook that's used in the **Gallery** or **Saved List**. Needs to be unique in the scope of the resource group and source. | -| `workbookType` | The gallery where the workbook appears. Supported values include workbook, `tsg`, and Azure Monitor. | -| `workbookSourceId` | The ID of the resource instance to which the workbook will be associated. The new workbook will show up related to this resource instance, for example, in the resource's table of contents under **Workbook**. If you want your workbook to show up in the **Workbooks** gallery in Azure Monitor, use the string **Azure Monitor** instead of a resource ID. | -| `workbookId` | The unique guid for this workbook instance. Use `[newGuid()]` to automatically create a new guid. | -| `kind` | Used to specify if the created workbook is shared. All new workbooks will use the value **shared**. | -| `location` | The Azure location where the workbook will be created. Use `[resourceGroup().location]` to create it in the same location as the resource group. | -| `serializedData` | Contains the content or payload to be used in the workbook. Use the ARM template from the workbooks UI to get the value. | --### Workbook types -Workbook types specify the workbook gallery type where the new workbook instance appears. Options include: --| Type | Gallery location | -| :- |:-| -| `workbook` | The default used in most reports, including the **Workbooks** gallery of Application Insights and Azure Monitor. | -| `tsg` | The **Troubleshooting Guides** gallery in Application Insights. | -| `usage` | The **More** gallery under **Usage** in Application Insights. | --### Work with JSON-formatted workbook data in the serializedData template parameter --When you export an ARM template for an Azure workbook, there are often fixed resource links embedded within the exported `serializedData` template parameter. These links include potentially sensitive values such as subscription ID and resource group name, and other types of resource IDs. --The following example demonstrates the customization of an exported workbook ARM template, without resorting to string manipulation. The pattern shown in this example is intended to work with the unaltered data as exported from the Azure portal. It's also a best practice to mask out any embedded sensitive values when you manage workbooks programmatically. For this reason, the subscription ID and resource group have been masked here. No other modifications were made to the raw incoming `serializedData` value. --```json -{ - "contentVersion": "1.0.0.0", - "parameters": { - "workbookDisplayName": { - "type": "string" - }, - "workbookSourceId": { - "type": "string", - "defaultValue": "[resourceGroup().id]" - }, - "workbookId": { - "type": "string", - "defaultValue": "[newGuid()]" - } - }, - "variables": { - // serializedData from original exported Azure Resource Manager template - "serializedData": "{\"version\":\"Notebook/1.0\",\"items\":[{\"type\":1,\"content\":{\"json\":\"Replace with Title\"},\"name\":\"text - 0\"},{\"type\":3,\"content\":{\"version\":\"KqlItem/1.0\",\"query\":\"{\\\"version\\\":\\\"ARMEndpoint/1.0\\\",\\\"data\\\":null,\\\"headers\\\":[],\\\"method\\\":\\\"GET\\\",\\\"path\\\":\\\"/subscriptions/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX/resourceGroups\\\",\\\"urlParams\\\":[{\\\"key\\\":\\\"api-version\\\",\\\"value\\\":\\\"2019-06-01\\\"}],\\\"batchDisabled\\\":false,\\\"transformers\\\":[{\\\"type\\\":\\\"jsonpath\\\",\\\"settings\\\":{\\\"tablePath\\\":\\\"$..*\\\",\\\"columns\\\":[]}}]}\",\"size\":0,\"queryType\":12,\"visualization\":\"map\",\"tileSettings\":{\"showBorder\":false},\"graphSettings\":{\"type\":0},\"mapSettings\":{\"locInfo\":\"AzureLoc\",\"locInfoColumn\":\"location\",\"sizeSettings\":\"location\",\"sizeAggregation\":\"Count\",\"opacity\":0.5,\"legendAggregation\":\"Count\",\"itemColorSettings\":null}},\"name\":\"query - 1\"}],\"isLocked\":false,\"fallbackResourceIds\":[\"/subscriptions/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX/resourceGroups/XXXXXXX\"]}", -- // parse the original into a JSON object, so that it can be manipulated - "parsedData": "[json(variables('serializedData'))]", -- // create new JSON objects that represent only the items/properties to be modified - "updatedTitle": { - "content":{ - "json": "[concat('Resource Group Regions in subscription \"', subscription().displayName, '\"')]" - } - }, - "updatedMap": { - "content": { - "path": "[concat('/subscriptions/', subscription().subscriptionId, '/resourceGroups')]" - } - }, -- // the union function applies the updates to the original data - "updatedItems": [ - "[union(variables('parsedData')['items'][0], variables('updatedTitle'))]", - "[union(variables('parsedData')['items'][1], variables('updatedMap'))]" - ], -- // copy to a new workbook object, with the updated items - "updatedWorkbookData": { - "version": "[variables('parsedData')['version']]", - "items": "[variables('updatedItems')]", - "isLocked": "[variables('parsedData')['isLocked']]", - "fallbackResourceIds": ["[parameters('workbookSourceId')]"] - }, -- // convert back to an encoded string - "reserializedData": "[string(variables('updatedWorkbookData'))]" - }, - "resources": [ - { - "name": "[parameters('workbookId')]", - "type": "microsoft.insights/workbooks", - "location": "[resourceGroup().location]", - "apiVersion": "2018-06-17-preview", - "dependsOn": [], - "kind": "shared", - "properties": { - "displayName": "[parameters('workbookDisplayName')]", - "serializedData": "[variables('reserializedData')]", - "version": "1.0", - "sourceId": "[parameters('workbookSourceId')]", - "category": "workbook" - } - } - ], - "outputs": { - "workbookId": { - "type": "string", - "value": "[resourceId( 'microsoft.insights/workbooks', parameters('workbookId'))]" - } - }, - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#" -} -``` --In this example, the following steps facilitate the customization of an exported ARM template: --1. Export the workbook as an ARM template as explained in the preceding section. -1. In the template's `variables` section: - 1. Parse the `serializedData` value into a JSON object variable, which creates a JSON structure including an array of items that represent the content of the workbook. - 1. Create new JSON objects that represent only the items/properties to be modified. - 1. Project a new set of JSON content items (`updatedItems`) by using the `union()` function to apply the modifications to the original JSON items. - 1. Create a new workbook object, `updatedWorkbookData`, that contains `updatedItems` and the `version`/`isLocked` data from the original parsed data and a corrected set of `fallbackResourceIds`. - 1. Serialize the new JSON content back into a new string variable, `reserializedData`. -1. Use the new `reserializedData` variable in place of the original `serializedData` property. -1. Deploy the new workbook resource by using the updated ARM template. --## Next steps --Explore how workbooks are being used to power the new [Storage insights experience](../../storage/common/storage-insights-overview.md?toc=%2fazure%2fazure-monitor%2ftoc.json). |
| azure-monitor | Workbooks Bring Your Own Storage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-bring-your-own-storage.md | - Title: Azure Monitor workbooks bring your own storage -description: Learn how to secure your workbook by saving the workbook content to your storage. -- Previously updated : 06/21/2023---# Bring your own storage to save workbooks --There are times when you might have a query or some business logic that you want to secure. You can help secure workbooks by saving their content to your storage. The storage account can then be encrypted with Microsoft-managed keys, or you can manage the encryption by supplying your own keys. For more information, see Azure documentation on [storage service encryption](../../storage/common/storage-service-encryption.md). --## Save a workbook with managed identities --1. Before you can save the workbook to your storage, you'll need to create a managed identity by selecting **All Services** > **Managed Identities**. Then give it **Storage Blob Data Contributor** access to your storage account. For more information, see [Azure documentation on managed identities](../../active-directory/managed-identities-azure-resources/how-to-manage-ua-identity-portal.md). - <!-- convertborder later --> - :::image type="content" source="./media/workbooks-bring-your-own-storage/add-identity-role-assignment.png" lightbox="./media/workbooks-bring-your-own-storage/add-identity-role-assignment.png" alt-text="Screenshot that shows adding a role assignment." border="false"::: --1. Create a new workbook. -1. Select **Save** to save the workbook. -1. Select the **Save content to an Azure Storage Account** checkbox to save to an Azure Storage account. - <!-- convertborder later --> - :::image type="content" source="./media/workbooks-bring-your-own-storage/saved-dialog-default.png" lightbox="./media/workbooks-bring-your-own-storage/saved-dialog-default.png" alt-text="Screenshot that shows the Save dialog." border="false"::: --1. Select the storage account and container you want. The **Storage account** list is from the subscription selected previously. - <!-- convertborder later --> - :::image type="content" source="./media/workbooks-bring-your-own-storage/save-dialog-with-storage.png" lightbox="./media/workbooks-bring-your-own-storage/save-dialog-with-storage.png" alt-text="Screenshot that shows the Save dialog with a storage option." border="false"::: --1. Select **(change)** to select a managed identity previously created. - <!-- convertborder later --> - :::image type="content" source="./media/workbooks-bring-your-own-storage/change-managed-identity.png" lightbox="./media/workbooks-bring-your-own-storage/change-managed-identity.png" alt-text="Screenshot that shows the Change identity dialog." border="false"::: --1. After you've selected your storage options, select **Save** to save your workbook. --## Limitations --- When you save to custom storage, you can't pin individual parts of the workbook to a dashboard because the individual pins would contain protected information in the dashboard itself. When you use custom storage, you can only pin links to the workbook itself to dashboards.-- After a workbook has been saved to custom storage, it will always be saved to custom storage, and this feature can't be turned off. To save elsewhere, you can use **Save As** and elect to not save the copy to custom storage.-- Workbooks saved to custom storage can't be recovered by the support team. Users might be able to recover the workbook content if soft-delete or blob versioning is enabled on the underlying storage account. See [recovering a deleted workbook](workbooks-manage.md#recover-a-deleted-workbook).-- Workbooks saved to custom storage don't support versioning. Only the most recent version is stored. Other versions might be available in storage if blob versioning is enabled on the underlying storage account. See [manage workbook versions](workbooks-manage.md#manage-workbook-versions).--## Next steps --- Learn how to create a [Map](workbooks-map-visualizations.md) visualization in workbooks.-- Learn how to use [groups in workbooks](../visualize/workbooks-groups.md). |
| azure-monitor | Workbooks Chart Visualizations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-chart-visualizations.md | - Title: Azure Monitor workbook chart visualizations -description: Learn about all the Azure Monitor workbook chart visualizations. -- Previously updated : 06/21/2023---# Chart visualizations --Workbooks can take the data returned from queries in various formats to create different visualizations from that data, such as area, line, bar, or time visualizations. --You can present monitoring data as charts. Supported chart types include: --- Line-- Bar-- Bar categorical-- Area-- Scatter plot-- Pie-- Time--You can choose to customize the: --- Height-- Width-- Color palette-- Legend-- Titles-- No-data message-- Other characteristics--You can also customize axis types and series colors by using chart settings. --Workbooks support charts for both logs and metric data sources. --## Log charts --Azure Monitor logs give you detailed information about your apps and infrastructure. Log information isn't collected by default, and you have to configure data collection. Logs provide information about the state of the resource and data that's useful for diagnostics. You can use workbooks to present log data as visual charts for user analysis. --### Add a log chart --The following example shows the trend of requests to an app over the previous days. --1. Switch the workbook to edit mode by selecting **Edit** on the toolbar. -1. Use the **Add query** link to add a log query control to the workbook. -1. For **Query type**, select **Log**. For **Resource type**, select, for example, **Application Insights**, and select the resources to target. -1. Use the query editor to enter the [KQL](/azure/kusto/query/) for your analysis. An example is trend of requests. -1. Set **Visualization** to **Area**, **Bar**, **Bar (categorical)**, **Line**, **Pie**, **Scatter**, or **Time**. -1. Set other parameters like time range, visualization, size, color palette, and legend, if needed. -<!-- convertborder later --> --### Log chart parameters --| Parameter | Description | Examples | -| - |:-|:-| -| Query type | The type of query to use. | Logs, Azure Resource Graph | -| Resource type | The resource type to target. | Application Insights, Log Analytics, or Azure-first | -| Resources | A set of resources to get the metrics value from. | MyApp1 | -| Time range | The time window to view the log chart. | Last hour, last 24 hours | -| Visualization | The visualization to use. | Area, bar, line, pie, scatter, time, bar (categorical) | -| Size | The vertical size of the control. | Small, medium, large, or full | -| Color palette | The color palette to use in the chart. Ignored in multi-metric or segmented mode. | Blue, green, red | -| Legend | The aggregation function to use for the legend. | Sum or average of values or max, min, first, last value | -| Query | Any KQL query that returns data in the format expected by the chart visualization. | _requests \| make-series Requests = count() default = 0 on timestamp from ago(1d) to now() step 1h_ | --### Time-series charts --You can use the workbook's query control to create time-series charts such as area, bar, line, scatter, and time. You must have time and metric information in the result set to create a time-series chart. --#### Simple time series --The following query returns a table with two columns: `timestamp` and `Requests`. The query control uses `timestamp` for the x-axis and `Requests` for the y-axis. --```kusto -requests -| summarize Requests = count() by bin(timestamp, 1h) -``` -<!-- convertborder later --> --#### Time series with multiple metrics --The following query returns a table with three columns: `timestamp`, `Requests`, and `Users`. The query control uses `timestamp` for the x-axis and `Requests` and `Users` as separate series on the y-axis. --```kusto -requests -| summarize Requests = count(), Users = dcount(user_Id) by bin(timestamp, 1h) -``` -<!-- convertborder later --> --#### Segmented time series --The following query returns a table with three columns: `timestamp`, `Requests`, and `RequestName`, where `RequestName` is a categorical column with the names of requests. The query control here uses `timestamp` for the x-axis and adds a series per value of `RequestName`. --``` -requests -| summarize Request = count() by bin(timestamp, 1h), RequestName = name -``` -<!-- convertborder later --> --### Summarize vs. make-series --The examples in the previous section use the `summarize` operator because it's easier to understand. The `summarize` operator's major limitation is that it omits the results row if there are no items in the bucket. If the results row is omitted, depending on where the empty buckets are in the time range, the chart time window might shift. --We recommend using the `make-series` operator to create time-series data. You can provide default values for empty buckets. --The following query uses the `make-series` operator: --```kusto -requests -| make-series Requests = count() default = 0 on timestamp from ago(1d) to now() step 1h by RequestName = name -``` --The following query shows a similar chart with the `summarize` operator: --```kusto -requests -| summarize Request = count() by bin(timestamp, 1h), RequestName = name -``` -<!-- convertborder later --> --### Categorical bar chart or histogram --You can represent a dimension or column on the x-axis by using categorical charts. Categorical charts are useful for histograms. The following example shows the distribution of requests by their result code: --```kusto -requests -| summarize Requests = count() by Result = strcat('Http ', resultCode) -| order by Requests desc -``` --The query returns two columns: `Requests` metric and `Result` category. Each value of the `Result` column is represented by a bar in the chart with height proportional to the `Requests metric`. -<!-- convertborder later --> --### Pie charts --Pie charts allow the visualization of numerical proportion. The following example shows the proportion of requests by their result code: --```kusto -requests -| summarize Requests = count() by Result = strcat('Http ', resultCode) -| order by Requests desc -``` --The query returns two columns: `Requests` metric and `Result` category. Each value of the `Result` column gets its own slice in the pie with size proportional to the `Requests` metric. -<!-- convertborder later --> --## Metric charts --Most Azure resources emit metric data about their state and health. Examples include CPU utilization, storage availability, count of database transactions, and failing app requests. You can use workbooks to create visualizations of this data as time-series charts. --### Add a metric chart --The following example shows the number of transactions in a storage account over the prior hour. This information allows the storage owner to see the transaction trend and look for anomalies in behavior. --1. Switch the workbook to edit mode by selecting **Edit** on the toolbar. -1. Use the **Add metric** link to add a metric control to the workbook. -1. Select a resource type, for example, **Storage account**. Select the resources to target, the metric namespace and name, and the aggregation to use. -1. Set other parameters like time range, split by, visualization, size, and color palette, if needed. -<!-- convertborder later --> --### Metric chart parameters --| Parameter | Description | Examples | -| - |:-|:-| -| Resource type | The resource type to target. | Storage or virtual machine | -| Resources | A set of resources to get the metrics value from. | MyStorage1 | -| Namespace | The namespace with the metric. | Storage > Blob | -| Metric | The metric to visualize. | Storage > Blob > Transactions | -| Aggregation | The aggregation function to apply to the metric. | Sum, count, average | -| Time range | The time window to view the metric in. | Last hour, last 24 hours | -| Visualization | The visualization to use. | Area, bar, line, scatter, grid | -| Split by | Optionally split the metric on a dimension. | Transactions by geo type | -| Size | The vertical size of the control. | Small, medium, or large | -| Color palette | The color palette to use in the chart. Ignored if the `Split by` parameter is used. | Blue, green, red | --### Examples --Transactions split by API name as a line chart: -<!-- convertborder later --> --Transactions split by response type as a large bar chart: -<!-- convertborder later --> --Average latency as a scatter chart: -<!-- convertborder later --> --## Chart settings --You can use chart settings to customize which fields are used in the: --- Chart axes-- Axis units-- Custom formatting-- Ranges-- Grouping behaviors-- Legends-- Series colors--### Settings tab --The **Settings** tab controls: --- **X-axis Settings**, **Y-axis Settings**: Includes which fields. You can use custom formatting to set the number formatting to the axis values and custom ranges.-- **Grouping Settings**: Includes which field. Sets the limits before an "Others" group is created.-- **Legend Settings**: Shows metrics like series name, colors, and numbers at the bottom, and a legend like series names and colors.-<!-- convertborder later --> --#### Custom formatting --Number formatting options are shown in this table. --| Formatting option | Description | -|:- |:-| -| Units | The units for the column, such as various options for percentage, counts, time, byte, count/time, and bytes/time. For example, the unit for a value of 1234 can be set to milliseconds and it's rendered as 1.234s. | -| Style | The format to render it as, such as decimal, currency, and percent. | -| Show grouping separators | Checkbox to show group separators. Renders 1234 as 1,234 in the US. | -| Minimum integer digits | Minimum number of integer digits to use (default 1). | -| Minimum fractional digits | Minimum number of fractional digits to use (default 0). | -| Maximum fractional digits | Maximum number of fractional digits to use. | -| Minimum significant digits | Minimum number of significant digits to use (default 1). | -| Maximum significant digits | Maximum number of significant digits to use. | -<!-- convertborder later --> --### Series Settings tab --You can adjust the labels and colors shown for series in the chart with the **Series Settings** tab: --- **Series name**: This field is used to match a series in the data and, if matched, the display label and color are displayed.-- **Comment**: This field is useful for template authors because this comment might be used by translators to localize the display labels.-<!-- convertborder later --> --## Next steps --- Learn how to create a [tile in workbooks](workbooks-tile-visualizations.md).-- Learn how to create [interactive workbooks](workbooks-interactive.md). |
| azure-monitor | Workbooks Composite Bar | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-composite-bar.md | - Title: Azure Workbooks composite bar renderer -description: Learn about all the Azure Workbooks composite bar renderer visualizations. -- Previously updated : 06/21/2023---# Composite bar renderer --With Azure Workbooks, data can be rendered by using the composite bar. This bar is made up of multiple bars. --The following image shows the composite bar for database status. It shows how many servers are online, offline, and in a recovering state. -<!-- convertborder later --> --The composite bar renderer is supported for grid, tile, and graph visualizations. --## Add the composite bar renderer --1. Switch the workbook to edit mode by selecting **Edit**. -1. Select **Add** > **Add query**. -1. Set **Data source** to `JSON` and set **Visualization** to `Grid`. -1. Add the following JSON data: -- ```json - [ - {"sub":"X", "server": "A", "online": 20, "recovering": 3, "offline": 4, "total": 27}, - {"sub":"X", "server": "B", "online": 15, "recovering": 8, "offline": 5, "total": 28}, - {"sub":"Y", "server": "C", "online": 25, "recovering": 4, "offline": 5, "total": 34}, - {"sub":"Y", "server": "D", "online": 18, "recovering": 6, "offline": 9, "total": 33} - ] - ``` --1. Run the query. -1. Select **Column Settings** to open the settings pane. -1. Under **Columns**, select `total`. For **Column renderer**, select `Composite Bar`. -1. Under **Composite Bar Settings**, set the following settings: -- | Column Name | Color | - |-|--| - | online | Green | - | recovering | Yellow | - | offline | Red (Bright) | --1. For **Label**, enter `["online"] of ["total"] are healthy`. -1. In the column settings for **online**, **offline**, and **recovering**, you can set **Column renderer** to `Hidden` (optional). -1. Select the **Labels** tab and update the label for the total column as `Database Status` (optional). -1. Select **Apply**. --The composite bar settings will look like the following screenshot: -<!-- convertborder later --> --The composite bar with the preceding settings: -<!-- convertborder later --> --## Composite bar settings --Select the column name and corresponding color to render the column in that color as part of a composite bar. You can insert, delete, and move rows up and down. --### Label --The composite bar label is displayed at the top of the composite bar. You can use a mix of static text, columns, and parameters. If **Label** is empty, the value of the current columns is displayed as the label. In the previous example, if we left the **Label** field blank, the value of total columns would be displayed. --Refer to columns with `["columnName"]`. --Refer to parameters with `{paramName}`. --Both the column name and parameter name are case sensitive. You can also make labels a link by selecting **Make this item a link** and then adding link settings. --### Aggregation --Aggregations are useful for Tree/Group By visualizations. The data for a column for the group row is decided by the aggregation set for that column. Three types of aggregations are applicable for composite bars: None, Sum, and Inherit. --To add Group By settings: --1. In column settings, go to the column you want to add settings to. -1. In **Tree/Group By Settings**, under **Tree type**, select **Group By**. -1. Select the field you want to group by. - <!-- convertborder later --> - :::image type="content" source="./media/workbooks-composite-bar/group-by-settings.png" lightbox="./media/workbooks-composite-bar/group-by-settings.png" alt-text="Screenshot that shows Group By settings." border="false"::: --#### None --The setting of **None** for aggregation means that no results are displayed for that column for the group rows. -<!-- convertborder later --> --#### Sum --If aggregation is set as **Sum**, the column in the group row shows the composite bar by using the sum of the columns used to render it. The label will also use the sum of the columns referred to in it. --In the following example, **online**, **offline**, and **recovering** all have max aggregation set to them and the aggregation for the total column is **Sum**. -<!-- convertborder later --> --#### Inherit --If aggregation is set as **Inherit**, the column in the group row shows the composite bar by using the aggregation set by users for the columns used to render it. The columns used in **Label** also use the aggregation set by the user. If the current column renderer is **Composite Bar** and is referred to in the label (like **total** in the preceding example), then **Sum** is used as the aggregation for that column. --In the following example, **online**, **offline**, and **recovering** all have max aggregation set to them and the aggregation for total column is **Inherit**. -<!-- convertborder later --> --## Sorting --For grid visualizations, the sorting of the rows for the column with the composite bar renderer works based on the value that's the sum of the columns used to render the composite bar computer dynamically. In the previous examples, the value used for sorting is the sum of the **online**, **recovering**, and **offline** columns for that particular row. --## Tile visualizations --To make a composite bar renderer for a tile visualization: --1. Select **Add** > **Add query**. -1. Change the data source to `JSON`. Enter the data from the [previous example](#add-the-composite-bar-renderer). -1. Change **Visualization** to `Tiles`. -1. Run the query. -1. Select **Tile Settings**. -1. Under **Tile fields**, select **Left**. -1. Under **Field settings**, set the following settings: - 1. **Use column**: `server` - 1. **Column renderer**: `Text` -1. Under **Tile fields**, select **Bottom**. -1. Under **Field settings**, set the following settings: - 1. **Use column**: `total` - 1. **Column renderer**: `Composite Bar` - 1. Under **Composite Bar Settings**, set the following settings: -- | Column Name | Color | - |-|--| - | online | Green | - | recovering | Yellow | - | offline | Red (Bright) | -- 1. For **Label**, enter `["online"] of ["total"] are healthy`. -1. Select **Apply**. --Composite bar settings for tiles: -<!-- convertborder later --> --The composite bar view for tiles with the preceding settings will look like this example: -<!-- convertborder later --> --## Graph visualizations --To make a composite bar renderer for a graph visualization (type Hive Clusters): --1. Select **Add** > **Add query**. -2. Change **Data source** to `JSON`. Enter the data from the [previous example](#add-the-composite-bar-renderer). -1. Change **Visualization** to `Graphs`. -1. Run the query. -1. Select **Graph Settings**. -1. Under **Node Format Settings**, select **Center Content**. -1. Under **Field settings**, set the following settings: - 1. **Use column**: `total` - 1. **Column renderer**: `Composite Bar` - 1. Under **Composite Bar Settings**, set the following settings: -- |Column Name | Color | - |-|--| - | online | Green | - | recovering | Yellow | - | offline | Red (Bright) | -- 1. For **Label**, enter `["online"] of ["total"] are healthy`. -1. Under **Layout Settings**, set the following settings: - 1. **Graph Type**: `Hive Clusters` - 1. **Node ID**: `server` - 1. **Group By Field**: `None` - 1. **Node Size**: `100` - 1. **Margin between hexagons**: `5` - 1. **Coloring Type**: `None` -1. Select **Apply**. --Composite bar settings for graphs: -<!-- convertborder later --> --The composite bar view for a graph with the preceding settings will look like this example: -<!-- convertborder later --> --## Next steps --[Get started with Azure Workbooks](workbooks-overview.md) |
| azure-monitor | Workbooks Create Workbook | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-create-workbook.md | - Title: Create or edit an Azure Workbook -description: Learn how to create an Azure Workbook. ---- Previously updated : 01/08/2024----# Create or edit an Azure Workbook -This article describes how to create a new workbook and how to add elements to your Azure Workbook. --This video walks you through creating workbooks. --> [!VIDEO https://www.microsoft.com/en-us/videoplayer/embed/RE4B4Ap] --## Create a new Azure Workbook --To create a new Azure workbook: -1. From the Azure Workbooks page, select an empty template or select **New** in the top toolbar. -1. Combine any of these elements to add to your workbook: - - [Text](#add-text) - - [Parameters](#add-parameters) - - [Queries](#add-queries) - - [Metric charts](#add-metric-charts) - - [Links](#add-links) - - [Groups](#add-groups) - - Configuration options --## Add text --Workbooks allow authors to include text blocks in their workbooks. The text can be human analysis of the data, information to help users interpret the data, section headings, etc. -- :::image type="content" source="media/workbooks-create-workbook/workbooks-text-example.png" lightbox="media/workbooks-create-workbook/workbooks-text-example.png" alt-text="Screenshot of adding text to a workbook."::: --Text is added through a markdown control into which an author can add their content. An author can use the full formatting capabilities of markdown. These include different heading and font styles, hyperlinks, tables, etc. Markdown allows authors to create rich Word- or Portal-like reports or analytic narratives. Text can contain parameter values in the markdown text, and those parameter references are updated as the parameters change. --**Edit mode**: - <!-- convertborder later --> - :::image type="content" source="media/workbooks-create-workbook/workbooks-text-control-edit-mode.png" lightbox="media/workbooks-create-workbook/workbooks-text-control-edit-mode.png" alt-text="Screenshot showing adding text to a workbook in edit mode." border="false"::: --**Preview mode**: - <!-- convertborder later --> - :::image type="content" source="media/workbooks-create-workbook/workbooks-text-control-edit-mode-preview.png" lightbox="media/workbooks-create-workbook/workbooks-text-control-edit-mode-preview.png" alt-text="Screenshot showing adding text to a workbook in preview mode." border="false"::: --To add text to an Azure workbook: --1. Make sure you are in **Edit** mode by selecting the **Edit** in the toolbar. Add a query by doing either of these steps: - - Select **Add**, and **Add text** below an existing element, or at the bottom of the workbook. - - Select the ellipses (...) to the right of the **Edit** button next to one of the elements in the workbook, then select **Add** and then **Add text**. -1. Enter markdown text into the editor field. -1. Use the **Text Style** option to switch between plain markdown, and markdown wrapped with the Azure portal's standard info/warning/success/error styling. -- > [!TIP] - > Use this [markdown cheat sheet](https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet) to see the different formatting options. --1. Use the **Preview** tab to see how your content looks. The preview shows the content inside a scrollable area to limit its size, but when displayed at runtime, the markdown content expands to fill whatever space it needs, without a scrollbar. -1. Select **Done Editing**. --### Text styles -These text styles are available: --| Style | Description | -| | | -| plain| No formatting is applied | -|info| The portal's "info" style, with a `ℹ` or similar icon and blue background | -|error| The portal's "error" style, with a `❌` or similar icon and red background | -|success| The portal's "success" style, with a `✔` or similar icon and green background | -|upsell| The portal's "upsell" style, with a `🚀` or similar icon and purple background | -|warning| The portal's "warning" style, with a `⚠` or similar icon and blue background | ---You can also choose a text parameter as the source of the style. The parameter value must be one of the above text values. The absence of a value, or any unrecognized value will be treated as `plain` style. --### Text style examples --**Info style example**: - <!-- convertborder later --> - :::image type="content" source="media/workbooks-create-workbook/workbooks-text-control-edit-mode-preview.png" lightbox="media/workbooks-create-workbook/workbooks-text-control-edit-mode-preview.png" alt-text="Screenshot of adding text to a workbook in preview mode showing info style." border="false"::: --**Warning style example**: -- :::image type="content" source="media/workbooks-create-workbook/workbooks-text-example-warning.png" lightbox="media/workbooks-create-workbook/workbooks-text-example-warning.png" alt-text="Screenshot of a text visualization in warning style."::: --## Add queries --Azure Workbooks allow you to query any of the supported workbook [data sources](workbooks-data-sources.md). --For example, you can query Azure Resource Health to help you view any service problems affecting your resources. You can also query Azure Monitor metrics, which is numeric data collected at regular intervals. Azure Monitor metrics provide information about an aspect of a system at a particular time. --To add a query to an Azure Workbook: --1. Make sure you are in **Edit** mode by selecting the **Edit** in the toolbar. Add a query by doing either of these steps: - - Select **Add**, and **Add query** below an existing element, or at the bottom of the workbook. - - Select the ellipses (...) to the right of the **Edit** button next to one of the elements in the workbook, then select **Add** and then **Add query**. -1. Select the [data source](workbooks-data-sources.md) for your query. The other fields are determined based on the data source you choose. -1. Select any other values that are required based on the data source you selected. -1. Select the [visualization](workbooks-visualizations.md) for your workbook. -1. In the query section, enter your query, or select from a list of sample queries by selecting **Samples**, and then edit the query to your liking. -1. Select **Run Query**. -1. When you're sure you have the query you want in your workbook, select **Done editing**. ---### Best practices for querying logs - The log analytics query language doesn't have a **table_ifexists** function like the function for testing for columns. However, there are some ways to check if a table exists. For example, you can use a [fuzzy union](/azure/kusto/query/unionoperator?pivots=azuredataexplorer). When doing a union, you can use the **isfuzzy=true** setting to let the union continue if some of the tables don't exist. You can add a parameter query in your workbook that checks for existence of the table, and hides some content if it doesn't. Items that aren't visible aren't run, so you can design your template so that other queries in the workbook that would fail if the table doesn't exist, don't run until after the test verifies that the table exists. -- For example: -- ``` - let MissingTable = view () { print isMissing=1 }; - union isfuzzy=true MissingTable, (AzureDiagnostics | getschema | summarize c=count() | project isMissing=iff(c > 0, 0, 1)) - | top 1 by isMissing asc - ``` -- This query returns a **1** if the **AzureDiagnostics** table doesn't exist in the workspace. If the real table doesn't exist, the fake row of the **MissingTable** will be returned. If any columns exist in the schema for the **AzureDiagnostics** table, a **0** is returned. You could use this as a parameter value, and conditionally hide your query steps unless the parameter value is 0. You could also use conditional visibility to show text that says that the current workspace doesn't have the missing table, and send the user to documentation on how to onboard. -- Instead of hiding steps, you may just want to have no rows as a result. You can change the **MissingTable** to be an empty data table with the appropriate matching schema: -- ``` - let MissingTable = datatable(ResourceId: string) []; - union isfuzzy=true MissingTable, (AzureDiagnostics - | extend ResourceId = column_ifexists('ResourceId', '') - ``` -- In this case, the query returns no rows if the **AzureDiagnostics** table is missing, or if the **ResourceId** column is missing from the table. --### Tutorial - resource centric logs queries in workbooks --This video shows you how to use resource level logs queries in Azure Workbooks. It also has tips and tricks on how to enable advanced scenarios and improve performance. --[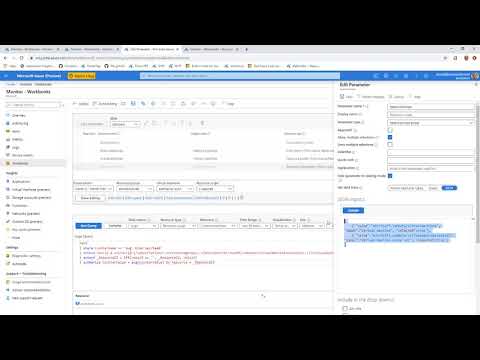](https://youtu.be/8CvjM0VvOA8 "Video showing how to make resource centric log queries in workbooks") --#### Dynamic resource type parameter -Uses dynamic scopes for more efficient querying. The snippet below uses this heuristic: -1. _Individual resources_: if the count of selected resource is less than or equal to 5 -2. _Resource groups_: if the number of resources is over 5 but the number of resource groups the resources belong to is less than or equal to 3 -3. _Subscriptions_: otherwise --``` -Resources -| take 1 -| project x = dynamic(["microsoft.compute/virtualmachines", "microsoft.compute/virtualmachinescalesets", "microsoft.resources/resourcegroups", "microsoft.resources/subscriptions"]) -| mvexpand x to typeof(string) -| extend jkey = 1 -| join kind = inner (Resources -| where id in~ ({VirtualMachines}) -| summarize Subs = dcount(subscriptionId), resourceGroups = dcount(resourceGroup), resourceCount = count() -| extend jkey = 1) on jkey -| project x, label = 'x', - selected = case( - x in ('microsoft.compute/virtualmachinescalesets', 'microsoft.compute/virtualmachines') and resourceCount <= 5, true, - x == 'microsoft.resources/resourcegroups' and resourceGroups <= 3 and resourceCount > 5, true, - x == 'microsoft.resources/subscriptions' and resourceGroups > 3 and resourceCount > 5, true, - false) -``` -#### Static resource scope for querying multiple resource types -```json -[ - { "value":"microsoft.compute/virtualmachines", "label":"Virtual machine", "selected":true }, - { "value":"microsoft.compute/virtualmachinescaleset", "label":"Virtual machine scale set", "selected":true } -] -``` -#### Resource parameter grouped by resource type -``` -Resources -| where type =~ 'microsoft.compute/virtualmachines' or type =~ 'microsoft.compute/virtualmachinescalesets' -| where resourceGroup in~({ResourceGroups}) -| project value = id, label = id, selected = false, - group = iff(type =~ 'microsoft.compute/virtualmachines', 'Virtual machines', 'Virtual machine scale sets') -``` --## Add parameters --You can collect input from consumers and reference it in other parts of the workbook using parameters. Use parameters to scope the result set or to set the right visual. Parameters help you build interactive reports and experiences. For more information on how parameters can be used, see [workbook parameters](workbooks-parameters.md). --Workbooks allow you to control how your parameter controls are presented to consumers – text box vs. drop down, single- vs. multi-select, values from text, JSON, KQL, or Azure Resource Graph, etc. --Watch this video to learn how to use parameters and log data in Azure Workbooks. -> [!VIDEO https://www.microsoft.com/en-us/videoplayer/embed/RE59Wee] --To add a parameter to an Azure Workbook: --1. Make sure you are in **Edit** mode by selecting the **Edit** in the toolbar. Add a parameter by doing either of these steps: - - Select **Add**, and **Add parameter** below an existing element, or at the bottom of the workbook. - - Select the ellipses (...) to the right of the **Edit** button next to one of the elements in the workbook, then select **Add** and then **Add parameter**. -1. In the new parameter pane that pops up enter values for these fields: -- - Parameter name: Parameter names can't include spaces or special characters - - Display name: Display names can include spaces, special characters, emoji, etc. - - Parameter type: - - Required: --1. Select **Done editing**. - <!-- convertborder later --> - :::image type="content" source="media/workbooks-parameters/workbooks-time-settings.png" lightbox="media/workbooks-parameters/workbooks-time-settings.png" alt-text="Screenshot showing the creation of a time range parameter." border="false"::: --## Add metric charts --Most Azure resources emit metric data about state and health such as CPU utilization, storage availability, count of database transactions, failing app requests, etc. Using workbooks, you can create visualizations of the metric data as time-series charts. --The example below shows the number of transactions in a storage account over the prior hour. This allows the storage owner to see the transaction trend and look for anomalies in behavior. -- :::image type="content" source="media/workbooks-create-workbook/workbooks-metric-chart-storage-area.png" lightbox="media/workbooks-create-workbook/workbooks-metric-chart-storage-area.png" alt-text="Screenshot showing a metric area chart for storage transactions in a workbook."::: --To add a metric chart to an Azure Workbook: --1. Make sure you are in **Edit** mode by selecting the **Edit** in the toolbar. Add a metric chart by doing either of these steps: - - Select **Add**, and **Add metric** below an existing element, or at the bottom of the workbook. - - Select the ellipses (...) to the right of the **Edit** button next to one of the elements in the workbook, then select **Add** and then **Add metric**. -1. Select a **resource type**, the resources to target, the metric namespace and name, and the aggregation to use. -1. Set other parameters if needed such time range, split-by, visualization, size and color palette. -1. Select **Done Editing**. --This is a metric chart in edit mode: -<!-- convertborder later --> --### Metric chart parameters --| Parameter | Explanation | Example | -| - |:-|:-| -| Resource Type| The resource type to target | Storage or Virtual Machine. | -| Resources| A set of resources to get the metrics value from | MyStorage1 | -| Namespace | The namespace with the metric | Storage > Blob | -| Metric| The metric to visualize | Storage > Blob > Transactions | -| Aggregation | The aggregation function to apply to the metric | Sum, Count, Average, etc. | -| Time Range | The time window to view the metric in | Last hour, Last 24 hours, etc. | -| Visualization | The visualization to use | Area, Bar, Line, Scatter, Grid | -| Split By| Optionally split the metric on a dimension | Transactions by Geo type | -| Size | The vertical size of the control | Small, medium or large | -| Color palette | The color palette to use in the chart. Ignored if the `Split by` parameter is used | Blue, green, red, etc. | --### Metric chart examples --**Transactions split by API name as a line chart** - <!-- convertborder later --> - :::image type="content" source="media/workbooks-create-workbook/workbooks-metric-chart-storage-split-line.png" lightbox="media/workbooks-create-workbook/workbooks-metric-chart-storage-split-line.png" alt-text="Screenshot showing a metric line chart for Storage transactions split by API name." border="false"::: ---**Transactions split by response type as a large bar chart** - <!-- convertborder later --> - :::image type="content" source="media/workbooks-create-workbook/workbooks-metric-chart-storage-bar-large.png" lightbox="media/workbooks-create-workbook/workbooks-metric-chart-storage-bar-large.png" alt-text="Screenshot showing a large metric bar chart for Storage transactions split by response type." border="false"::: --**Average latency as a scatter chart** - <!-- convertborder later --> - :::image type="content" source="media/workbooks-create-workbook/workbooks-metric-chart-storage-scatter.png" lightbox="media/workbooks-create-workbook/workbooks-metric-chart-storage-scatter.png" alt-text="Screenshot showing a metric scatter chart for storage latency." border="false"::: --## Add links --You can use links to create links to other views, workbooks, other items inside a workbook, or to create tabbed views within a workbook. The links can be styled as hyperlinks, buttons, and tabs. - <!-- convertborder later --> - :::image type="content" source="media/workbooks-create-workbook/workbooks-empty-links.png" lightbox="media/workbooks-create-workbook/workbooks-empty-links.png" alt-text="Screenshot of adding a link to a workbook." border="false"::: --Watch this video to learn how to use tabs, groups, and contextual links in Azure Workbooks: -> [!VIDEO https://www.microsoft.com/en-us/videoplayer/embed/RE59YTe] -### Link styles -You can apply styles to the link element itself and to individual links. --**Link element styles** ---|Style |Sample |Notes | -|||| -|Bullet List | :::image type="content" source="media/workbooks-create-workbook/workbooks-link-style-bullet.png" alt-text="Screenshot of bullet style workbook link."::: | The default, links, appears as a bulleted list of links, one on each line. The **Text before link** and **Text after link** fields can be used to add more text before or after the link items. | -|List |:::image type="content" source="media/workbooks-create-workbook/workbooks-link-style-list.png" alt-text="Screenshot of list style workbook link."::: | Links appear as a list of links, with no bullets. | -|Paragraph | :::image type="content" source="media/workbooks-create-workbook/workbooks-link-style-paragraph.png" alt-text="Screenshot of paragraph style workbook link."::: |Links appear as a paragraph of links, wrapped like a paragraph of text. | -|Navigation | :::image type="content" source="media/workbooks-create-workbook/workbooks-link-style-navigation.png" alt-text="Screenshot of navigation style workbook link."::: | Links appear as links, with vertical dividers, or pipes (`|`) between each link. | -|Tabs | :::image type="content" source="media/workbooks-create-workbook/workbooks-link-style-tabs.png" alt-text="Screenshot of tabs style workbook link."::: |Links appear as tabs. Each link appears as a tab, no link styling options apply to individual links. See the [tabs](#tabs) section below for how to configure tabs. | -|Toolbar | :::image type="content" source="media/workbooks-create-workbook/workbooks-link-style-toolbar.png" alt-text="Screenshot of toolbar style workbook link."::: | Links appear an Azure portal styled toolbar, with icons and text. Each link appears as a toolbar button. See the [toolbar](#toolbars) section below for how to configure toolbars. | ---**Link styles** --| Style | Description | -|:- |:-| -| Link | By default links appear as a hyperlink. URL links can only be link style. | -| Button (Primary) | The link appears as a "primary" button in the portal, usually a blue color | -| Button (Secondary) | The links appear as a "secondary" button in the portal, usually a "transparent" color, a white button in light themes and a dark gray button in dark themes. | --If required parameters are used in button text, tooltip text, or value fields, and the required parameter is unset when using buttons, the button is disabled. You can use this capability, for example, to disable buttons when no value is selected in another parameter or control. --### Link actions -Links can use all of the link actions available in [link actions](workbooks-link-actions.md), and have two more available actions: --| Action | Description | -|:- |:-| -|Set a parameter value | A parameter can be set to a value when selecting a link, button, or tab. Tabs are often configured to set a parameter to a value, which hides and shows other parts of the workbook based on that value.| -|Scroll to a step| When selecting a link, the workbook will move focus and scroll to make another step visible. This action can be used to create a "table of contents", or a "go back to the top" style experience.| --### Tabs --Most of the time, tab links are combined with the **Set a parameter value** action. Here's an example showing the links step configured to create 2 tabs, where selecting either tab sets a **selectedTab** parameter to a different value (the example shows a third tab being edited to show the parameter name and parameter value placeholders): - <!-- convertborder later --> - :::image type="content" source="media/workbooks-create-workbook/workbooks-creating-tabs.png" lightbox="media/workbooks-create-workbook/workbooks-creating-tabs.png" alt-text="Screenshot of creating tabs in workbooks." border="false"::: ---You can then add other items in the workbook that are conditionally visible if the **selectedTab** parameter value is "1" by using the advanced settings: - <!-- convertborder later --> - :::image type="content" source="media/workbooks-create-workbook/workbooks-selected-tab.png" lightbox="media/workbooks-create-workbook/workbooks-selected-tab.png" alt-text="Screenshot of conditionally visible tab in workbooks." border="false"::: --The first tab is selected by default, initially setting **selectedTab** to 1, and making that step visible. Selecting the second tab changes the value of the parameter to "2", and different content is displayed: -- :::image type="content" source="media/workbooks-create-workbook/workbooks-selected-tab2.png" lightbox="media/workbooks-create-workbook/workbooks-selected-tab2.png" alt-text="Screenshot of workbooks with content displayed when selected tab is 2."::: --A sample workbook with the above tabs is available in [sample Azure Workbooks with links](workbooks-sample-links.md#sample-workbook-with-links). -g -### Tabs limitations ---### Toolbars --Use the Toolbar style to have your links appear styled as a toolbar. In toolbar style, the author must fill in fields for: --<!-- convertborder later --> - :::image type="content" source="media/workbooks-create-workbook/workbooks-links-create-toolbar.png" lightbox="media/workbooks-create-workbook/workbooks-links-create-toolbar.png" alt-text="Screenshot of creating links styled as a toolbar in workbooks." border="false"::: --If any required parameters are used in button text, tooltip text, or value fields, and the required parameter is unset, the toolbar button is disabled. For example, this can be used to disable toolbar buttons when no value is selected in another parameter/control. --A sample workbook with toolbars, globals parameters, and ARM Actions is available in [sample Azure Workbooks with links](workbooks-sample-links.md#sample-workbook-with-toolbar-links). --## Add groups --A group item in a workbook allows you to logically group a set of steps in a workbook. --Groups in workbooks are useful for several things: -- - **Layout**: When you want items to be organized vertically, you can create a group of items that will all stack up and set the styling of the group to be a percentage width instead of setting percentage width on all the individual items. - - **Visibility**: When you want several items to hide or show together, you can set the visibility of the entire group of items, instead of setting visibility settings on each individual item. This can be useful in templates that use tabs, as you can use a group as the content of the tab, and the entire group can be hidden/shown based on a parameter set by the selected tab. - - **Performance**: When you have a large template with many sections or tabs, you can convert each section into its own subtemplate, and use groups to load all the subtemplates within the top-level template. The content of the subtemplates won't load or run until a user makes those groups visible. Learn more about [how to split a large template into many templates](#splitting-a-large-template-into-many-templates). --To add a group to your workbook: --1. Make sure you are in **Edit** mode by selecting the **Edit** in the toolbar. Add a parameter by doing either of these steps: - - Select **Add**, and **Add group** below an existing element, or at the bottom of the workbook. - - Select the ellipses (...) to the right of the **Edit** button next to one of the elements in the workbook, then select **Add** and then **Add group**. - <!-- convertborder later --> - :::image type="content" source="media/workbooks-create-workbook/workbooks-add-group.png" lightbox="media/workbooks-create-workbook/workbooks-add-group.png" alt-text="Screenshot showing selecting adding a group to a workbook. " border="false"::: -1. Select items for your group. -1. Select **Done editing.** -- This is a group in read mode with two items inside: a text item and a query item. - <!-- convertborder later --> - :::image type="content" source="media/workbooks-create-workbook/workbooks-groups-view.png" lightbox="media/workbooks-create-workbook/workbooks-groups-view.png" alt-text="Screenshot showing a group in read mode in a workbook." border="false"::: -- In edit mode, you can see those two items are actually inside a group item. In the screenshot below, the group is in edit mode. The group contains two items inside the dashed area. Each item can be in edit or read mode, independent of each other. For example, the text step is in edit mode while the query step is in read mode. - <!-- convertborder later --> - :::image type="content" source="media/workbooks-create-workbook/workbooks-groups-edit.png" lightbox="media/workbooks-create-workbook/workbooks-groups-edit.png" alt-text="Screenshot of a group in edit mode in a workbook." border="false"::: --### Scoping a group --A group is treated as a new scope in the workbook. Any parameters created in the group are only visible inside the group. This is also true for merge - you can only see data inside their group or at the parent level. --### Group types --You can specify which type of group to add to your workbook. There are two types of groups: ---### Load types --You can specify how and when the contents of a group are loaded. --#### Lazy loading --Lazy loading is the default. In lazy loading, the group is only loaded when the item is visible. This allows a group to be used by tab items. If the tab is never selected, the group never becomes visible and therefore the content isn't loaded. --For groups created from a template, the content of the template isn't retrieved and the items in the group aren't created until the group becomes visible. Users see progress spinners for the whole group while the content is retrieved. --#### Explicit loading --In this mode, a button is displayed where the group would be, and no content is retrieved or created until the user explicitly selects the button to load the content. This is useful in scenarios where the content might be expensive to compute or rarely used. The author can specify the text to appear on the button. --This screenshot shows explicit load settings with a configured "Load more" button. - <!-- convertborder later --> - :::image type="content" source="media/workbooks-create-workbook/workbooks-groups-explicitly-loaded.png" lightbox="media/workbooks-create-workbook/workbooks-groups-explicitly-loaded.png" alt-text="Screenshot of explicit load settings for a group in workbooks." border="false"::: --This is the group before being loaded in the workbook: - <!-- convertborder later --> - :::image type="content" source="media/workbooks-create-workbook/workbooks-groups-explicitly-loaded-before.png" lightbox="media/workbooks-create-workbook/workbooks-groups-explicitly-loaded-before.png" alt-text="Screenshot showing an explicit group before being loaded in the workbook." border="false"::: ---The group after being loaded in the workbook: -- :::image type="content" source="media/workbooks-create-workbook/workbooks-groups-explicitly-loaded-after.png" lightbox="media/workbooks-create-workbook/workbooks-groups-explicitly-loaded-after.png" alt-text="Screenshot showing an explicit group after being loaded in the workbook."::: --#### Always mode --In **Always** mode, the content of the group is always loaded and created as soon as the workbook loads. This is most frequently used when you're using a group only for layout purposes, where the content will always be visible. --### Using templates inside a group --When a group is configured to load from a template, by default, that content is loaded in lazy mode, and it will only load when the group is visible. --When a template is loaded into a group, the workbook attempts to merge any parameters declared in the template with parameters that already exist in the group. Any parameters that already exist in the workbook with identical names will be merged out of the template being loaded. If all parameters in a parameter step are merged out, the entire parameters step disappears. --#### Example 1: All parameters have identical names --Suppose you have a template that has two parameters at the top, a time range parameter and a text parameter named "**Filter**": - <!-- convertborder later --> - :::image type="content" source="media/workbooks-create-workbook/workbooks-groups-top-level-params.png" lightbox="media/workbooks-create-workbook/workbooks-groups-top-level-params.png" alt-text="Screenshot showing top level parameters in a workbook." border="false"::: --Then a group item loads a second template that has its own two parameters and a text step, where the parameters are named the same: - <!-- convertborder later --> - :::image type="content" source="media/workbooks-create-workbook/workbooks-groups-merged-away.png" lightbox="media/workbooks-create-workbook/workbooks-groups-merged-away.png" alt-text="Screenshot of a workbook template with top level parameters." border="false"::: --When the second template is loaded into the group, the duplicate parameters are merged out. Since all of the parameters are merged away, the inner parameters step is also merged out, resulting in the group containing only the text step. --### Example 2: One parameter has an identical name --Suppose you have a template that has two parameters at the top, a **time range** parameter and a text parameter named "**FilterB**" (): - <!-- convertborder later --> - :::image type="content" source="media/workbooks-create-workbook/workbooks-groups-wont-merge-away.png" lightbox="media/workbooks-create-workbook/workbooks-groups-wont-merge-away.png" alt-text="Screenshot of a group item with the result of parameters merged away." border="false"::: --When the group's item's template is loaded, the **TimeRange** parameter is merged out of the group. The workbook contains the initial parameters step with **TimeRange** and **Filter**, and the group's parameter only includes **FilterB**. - <!-- convertborder later --> - :::image type="content" source="media/workbooks-create-workbook/workbooks-groups-wont-merge-away-result.png" lightbox="media/workbooks-create-workbook/workbooks-groups-wont-merge-away-result.png" alt-text="Screenshot of workbook group where parameters won't merge away." border="false"::: --If the loaded template had contained **TimeRange** and **Filter** (instead of **FilterB**), then the resulting workbook would have a parameters step and a group with only the text step remaining. --### Splitting a large template into many templates --To improve performance, it's helpful to break up a large template into multiple smaller templates that loads some content in lazy mode or on demand by the user. This makes the initial load faster since the top-level template can be smaller. --When splitting a template into parts, you'll basically need to split the template into many templates (subtemplates) that all work individually. If the top-level template has a **TimeRange** parameter that other items use, the subtemplate will need to also have a parameters item that defines a parameter with same exact name. The subtemplates will work independently and can load inside larger templates in groups. --To turn a larger template into multiple subtemplates: --1. Create a new empty group near the top of the workbook, after the shared parameters. This new group will eventually become a subtemplate. -1. Create a copy of the shared parameters step, and then use **move into group** to move the copy into the group created in step 1. This parameter allows the subtemplate to work independently of the outer template, and will get merged out when loaded inside the outer template. -- > [!NOTE] - > Subtemplates don't technically need to have the parameters that get merged out if you never plan on the sub-templates being visible by themselves. However, if the sub-templates do not have the parameters, it will make them very hard to edit or debug if you need to do so later. --1. Move each item in the workbook you want to be in the subtemplate into the group created in step 1. -1. If the individual steps moved in step 3 had conditional visibilities, that becomes the visibility of the outer group (like used in tabs). Remove them from the items inside the group and add that visibility setting to the group itself. Save here to avoid losing changes and/or export and save a copy of the json content. -1. If you want that group to be loaded from a template, you can use the **Edit** toolbar button in the group. This opens just the content of that group as a workbook in a new window. You can then save it as appropriate and close this workbook view (don't close the browser, just that view to go back to the previous workbook you were editing). -1. You can then change the group step to load from template and set the template ID field to the workbook/template you created in step 5. To work with workbooks IDs, the source needs to be the full Azure Resource ID of a shared workbook. Press *Load* and the content of that group will now be loaded from that subtemplate instead of saved inside this outer workbook. -- |
| azure-monitor | Workbooks Criteria | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-criteria.md | - Title: Azure Workbooks criteria parameters -description: Learn about adding criteria parameters to your workbook. ---- Previously updated : 06/21/2023----# Text parameter criteria --When a query depends on many parameters, the query will be stalled until each of its parameters has been resolved. Sometimes a parameter could have a simple query that concatenates a string or performs a conditional evaluation. These queries still make network calls to services that perform these basic operations, and that process increases the time it takes for a parameter to resolve a value. The result is long load times for complex workbooks. --When you use criteria parameters, you can define a set of criteria based on previously specified parameters that will be evaluated to provide a dynamic value. The main benefit of using criteria parameters is that criteria parameters can resolve values of previously specified parameters and perform simple conditional operations without making any network calls. The following example is a criteria-parameters use case. --## Example --Consider the following conditional query: ---``` -let metric = dynamic({Counter}); -print tostring((metric.object == 'Network Adapter' and (metric.counter == 'Bytes Received/sec' or metric.counter == 'Bytes Sent/sec')) or (metric.object == 'Network' and (metric.counter == 'Total Bytes Received' or metric.counter == 'Total Bytes Transmitted'))) -``` --If you're focused on the `metric.counter` object, the value of the parameter `isNetworkCounter` should be true if the parameter `Counter` has `Bytes Received/sec`, `Bytes Sent/sec`, `Total Bytes Received`, or `Total Bytes Transmitted`. --This can be translated to a criteria text parameter: ---In the preceding screenshot, the conditions will be evaluated from top to bottom and the value of the parameter `isNetworkCounter` will take the value of whichever condition evaluates to true first. All conditions except for the default condition (the "else" condition) can be reordered to get the desired outcome. --## Set up criteria --1. Start with a workbook with at least one existing parameter in edit mode. - 1. Select **Add parameters** > **Add Parameter**. - 1. In the new parameter pane that opens, enter: - - **Parameter name**: `rand` - - **Parameter type**: `Text` - - **Required**: `checked` - - **Get data from**: `Query` - - Enter `print rand(0-1)` in the query editor. This parameter will output a value between 0-1. - 1. Select **Save** to create the parameter. -- > [!NOTE] - > The first parameter in the workbook won't show the **Criteria** tab. -- :::image type="content" source="media/workbooks-criteria/workbooks-criteria-first-param.png" alt-text="Screenshot that shows the first parameter."::: --1. In the table with the `rand` parameter, select **Add Parameter**. -1. In the new parameter pane that opens, enter: - - **Parameter name**: `randCriteria` - - **Parameter type**: `Text` - - **Required**: `checked` - - **Get data from**: `Criteria` -1. A grid appears. Select **Edit** next to the blank text box to open the **Criteria Settings** form. For a description of each field, see [Criteria Settings form](#criteria-settings-form). -- :::image type="content" source="media/workbooks-criteria/workbooks-criteria-setting.png" alt-text="Screenshot that shows the Criteria Settings form."::: --1. Enter the following data to populate the first criteria, and then select **OK**: - - **First operand**: `rand` - - **Operator**: `>` - - **Value from**: `Static Value` - - **Second operand**: `0.25` - - **Value from**: `Static Value` - - **Result is**: `is over 0.25` -- :::image type="content" source="media/workbooks-criteria/workbooks-criteria-setting-filled.png" alt-text="Screenshot that shows the Criteria Settings form filled in."::: --1. Select **Edit** next to the condition `Click edit to specify a result for the default condition` to edit the default condition. -- > [!NOTE] - > For the default condition, everything should be disabled except for the last `Value from` and `Result is` fields. --1. Enter the following data to populate the default condition, and then select **OK**: - - **Value from**: Static Value - - **Result is**: is 0.25 or under -- :::image type="content" source="media/workbooks-criteria/workbooks-criteria-default.png" alt-text="Screenshot that shows the Criteria Settings default form filled."::: --1. Save the parameter. -1. Refresh the workbook to see the `randCriteria` parameter in action. Its value will be based on the value of `rand`. --## Criteria Settings form --|Form fields|Description| -|--|-| -|First operand| This dropdown list consists of parameter names that have already been created. The value of the parameter will be used on the left side of the comparison. | -|Operator|The operator used to compare the first and second operands. Can be a numerical or string evaluation. The operator `is empty` will disable the `Second operand` because only the `First operand` is required.| -|Value from|If set to `Parameter`, a dropdown list consisting of parameters that have already been created appears. The value of that parameter will be used on the right side of the comparison.<br/> If set to `Static Value`, a text box appears where you can enter a value for the right side of the comparison.| -|Second operand| Will be either a dropdown menu consisting of created parameters or a text box depending on the preceding `Value from` selection.| -|Value from|If set to `Parameter`, a dropdown list consisting of parameters that have already been created appears. The value of that parameter will be used for the return value of the current parameter.<br/> If set to `Static Value`:<br>- A text box appears where you can enter a value for the result.<br>- You can also dereference other parameters by using curly braces around the parameter name.<br>- It's possible to concatenate multiple parameters and create a custom string, for example, "`{paramA}`, `{paramB}`, and some string." <br><br>If set to `Expression`:<br> - A text box appears where you can enter a mathematical expression that will be evaluated as the result.<br>- Like the `Static Value` case, multiple parameters might be dereferenced in this text box.<br>- If the parameter value referenced in the text box isn't a number, it will be treated as the value `0`.| -|Result is| Will be either a dropdown menu consisting of created parameters or a textbox depending on the preceding `Value from` selection. The text box will be evaluated as the final result of this **Criteria Settings** form. |
| azure-monitor | Workbooks Data Sources | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-data-sources.md | - Title: Azure Workbooks data sources | Microsoft docs -description: Simplify complex reporting with prebuilt and custom parameterized workbooks built from multiple data sources. ----- Previously updated : 08/14/2024----# Azure Workbooks data sources --Workbooks can extract data from these data sources: ---## Logs (Analytics Tables, Application Insights) --With workbooks, you can use the `Logs (Analytics)` data source query logs from the following sources: --* Azure Monitor Logs (Application Insights resources and Log Analytics workspaces analytics tables) -* Resource-centric data (activity logs) --You can use Kusto query language (KQL) queries that transform the underlying resource data to select a result set that can be visualized as text, charts, or grids. -<!-- convertborder later --> --You can easily query across multiple resources to create a unified rich reporting experience. --See also: [Log Analytics query optimization tips](../logs/query-optimization.md) --See also: [Workbooks best practices and hints for logs queries](workbooks-create-workbook.md#best-practices-for-querying-logs) --Tutorial: [Making resource centric log queries in workbooks](workbooks-create-workbook.md#tutorialresource-centric-logs-queries-in-workbooks) --## Logs (Basic and Auxiliary Tables) --Workbooks also supports querying Log Analytics Basic and Auxiliary tables through a separate `Logs (Basic)` data source. Basic and Auxiliary logs tables reduce the cost of ingesting high-volume verbose logs and let you query the data they store with some limitations. ---> [!NOTE] -> Basic and Auxiliary logs and the workbook `Logs (Basic)` data source have limitations compared to the `Log (Analytics)` data source, most notably -> * *Extra cost*, including per-query costs. See [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/) for details. -> * Basic logs does not support the full KQL language -> * Basic logs only operates on single Log Analyics Workspace, it does not have cross-resource or resource centric query support. -> * Basic logs does not support "set in query" style time ranges, an explicit time range (or parameter) must be specified. --For a full list of details and limitations, see [Query data in a Basic and Auxiliary table in Azure Monitor Logs](../logs/basic-logs-query.md) --See also: [Log Analytics query optimization tips](../logs/query-optimization.md) --## Metrics --Azure resources emit [metrics](../essentials/data-platform-metrics.md) that can be accessed via workbooks. Metrics can be accessed in workbooks through a specialized control that allows you to specify the target resources, the desired metrics, and their aggregation. You can then plot this data in charts or grids. -<!-- convertborder later --> -<!-- convertborder later --> --## Azure Resource Graph --Workbooks support querying for resources and their metadata by using Azure Resource Graph. This functionality is primarily used to build custom query scopes for reports. The resource scope is expressed via a KQL subset that Resource Graph supports, which is often sufficient for common use cases. --To make a query control that uses this data source, use the **Query type** dropdown and select **Azure Resource Graph**. Then choose at which level of data you wish to target, either Subscriptions, Management groups, or the entire Tenant/Directory. Then select the subscriptions to target. Use **Query control** to add the Resource Graph KQL query that selects an interesting resource subset. -<!-- convertborder later --> --## Azure Resource Manager --Azure Workbooks supports Azure Resource Manager REST operations so that you can query the management.azure.com endpoint without providing your own authorization header token. --To make a query control that uses this data source, use the **Data source** dropdown and select **Azure Resource Manager**. Provide the appropriate parameters, such as **Http method**, **url path**, **headers**, **url parameters**, and **body**. Azure Resource Manager data source is intended to be used as a data source to power data *visualizations*; as such, it does not support `PUT` or `PATCH` operations. The data source supports the following HTTP methods, with these expecations and limitations: --* `GET` - the most common operation for visualization, execute a query and parse the `JSON` result using settings in the "Result Settings" tab. -* `GETARRAY` - for ARM APIs that may return multiple "pages" of results using the ARM standard `nextLink` or `@odata.nextLink` style response (See [Async operations, throttling, and paging](/rest/api/azure/#async-operations-throttling-and-paging), this method makes followup calls to the API for each `nextLink` result, and merge those results into an array of results. -* `POST` - This method is used for APIs that pass information in a POST body. - -> [!NOTE] -> The Azure Resource Manager data source only supports results that return a 200 `OK` response, indicating the result is synchronous. APIs returning asynchronous results with 202 `ACCEPTED` asynchronous result and a header with a result URL are not supported. --## Azure Data Explorer --Workbooks now have support for querying from [Azure Data Explorer](/azure/data-explorer/) clusters with the powerful [Kusto](/azure/kusto/query/index) query language. -For the **Cluster Name** field, add the region name following the cluster name. An example is *mycluster.westeurope*. -<!-- convertborder later --> --See also: [Azure Data Explorer query best practices](/azure/data-explorer/kusto/query/best-practices) --## JSON --The JSON provider allows you to create a query result from static JSON content. It's most commonly used in parameters to create dropdown parameters of static values. Simple JSON arrays or objects are converted into grid rows and columns. For more specific behaviors, you can use the **Results** tab and JSONPath settings to configure columns. --> [!NOTE] -> Do *not* include sensitive information in fields like headers, parameters, body, and URL, because they'll be visible to all the workbook users. --This provider supports [JSONPath](workbooks-jsonpath.md). --## Merge --Merging data from different sources can enhance the insights experience. An example is augmenting active alert information with related metric data. Merging data allows users to see not just the effect (an active alert) but also potential causes, for example, high CPU usage. The monitoring domain has numerous such correlatable data sources that are often critical to the triage and diagnostic workflow. --With workbooks, you can query different data sources. Workbooks also provide simple controls that you can use to merge or join data to provide rich insights. The *merge* control is the way to achieve it. A single merge data source can do many merges in one step. For example, a *single* merge data source can merge results from a step using Azure Resource Graph with Azure Metrics, and then merge that result with another step using the Azure Resource Manager data source in one query item. --> [!NOTE] -> Although hidden query and metrics steps run if they're referenced by a merge step, hidden query items that use the merge data source don't run while hidden. -> A step that uses merge and attempts to reference a hidden step by using merge data source won't run until that hidden step becomes visible. -> A single merge step can merge many data sources at once. There's rarely a case where a merge data source will reference another merge data source. ---### Combine alerting data with Log Analytics Virtual Machine (VM) performance data --The following example combines alerting data with Log Analytics VM performance data to get a rich insights grid. -<!-- convertborder later --> --### Use merge control to combine Resource Graph and Log Analytics data --Watch this tutorial on using the merge control to combine Resource Graph and Log Analytics data: --[](https://www.youtube.com/watch?v=7nWP_YRzxHg "Video showing how to combine data from different sources in workbooks.") --Workbooks support these merges: --* Inner unique join -* Full inner join -* Full outer join -* Left outer join -* Right outer join -* Left semi-join -* Right semi-join -* Left anti-join -* Right anti-join -* Union -* Duplicate table --### Merge examples --[Using the Duplicate Table option to reuse queried data](workbooks-commonly-used-components.md#reuse-query-data-in-different-visualizations) --## Custom endpoint --Workbooks support getting data from any external source. If your data lives outside Azure, you can bring it to workbooks by using this data source type. --To make a query control that uses this data source, use the **Data source** dropdown and select **Custom Endpoint**. Provide the appropriate parameters, such as **Http method**, **url**, **headers**, **url parameters**, and **body**. Make sure your data source supports [CORS](https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS). Otherwise, the request will fail. --To avoid automatically making calls to untrusted hosts when you use templates, you need to mark the used hosts as trusted. You can either select **Add as trusted** or add it as a trusted host in workbook settings. These settings are saved locally in [browsers that support IndexDb with web workers](https://caniuse.com/#feat=indexeddb). --This provider supports [JSONPath](workbooks-jsonpath.md). --## Workload health --Azure Monitor has functionality that proactively monitors the availability and performance of Windows or Linux guest operating systems. Azure Monitor models key components and their relationships, criteria for how to measure the health of those components, and can alert you when an unhealthy condition is detected. With workbooks, you can use this information to create rich interactive reports. --To make a query control that uses this data source, use the **Query type** dropdown to select **Workload Health**. Then select subscription, resource group, or VM resources to target. Use the health filter dropdowns to select an interesting subset of health incidents for your analytic needs. -<!-- convertborder later --> --## Azure resource health --Workbooks support getting Azure resource health and combining it with other data sources to create rich, interactive health reports. --To make a query control that uses this data source, use the **Query type** dropdown and select **Azure health**. Then select the resources to target. Use the health filter dropdowns to select an interesting subset of resource issues for your analytic needs. -<!-- convertborder later --> --## Azure RBAC --The Azure role-based access control (RBAC) provider allows you to check permissions on resources. It's can be used in parameters to check if the correct RBACs are set up. A use case would be to create a parameter to check deployment permission and then notify the user if they don't have deployment permission. --Simple JSON arrays or objects are converted into grid rows and columns or text with a `hasPermission` column with either true or false. The permission is checked on each resource and then either `or` or `and` to get the result. The [operations or actions](../../role-based-access-control/resource-provider-operations.md) can be a string or an array. -- **String:** - ``` - "Microsoft.Resources/deployments/validate/action" - ``` -- **Array:** - ``` - ["Microsoft.Resources/deployments/read","Microsoft.Resources/deployments/write","Microsoft.Resources/deployments/validate/action","Microsoft.Resources/operations/read"] - ``` --## Change Analysis --To make a query control that uses [Application Change Analysis](../app/change-analysis.md) as the data source, use the **Data source** dropdown and select **Change Analysis**. Then select a single resource. Changes for up to the last 14 days can be shown. Use the **Level** dropdown to filter between **Important**, **Normal**, and **Noisy** changes. This dropdown supports workbook parameters of the type [drop down](workbooks-dropdowns.md). -<!-- convertborder later --> -> [!div class="mx-imgBorder"] -> :::image type="content" source="./media/workbooks-data-sources/change-analysis-data-source.png" lightbox="./media/workbooks-data-sources/change-analysis-data-source.png" alt-text="A screenshot that shows a workbook with Change Analysis." border="false"::: ---## Prometheus --With [Azure Monitor managed service for Prometheus](../essentials/prometheus-metrics-overview.md), you can collect Prometheus metrics for your Kubernetes clusters. To query Prometheus metrics, select **Prometheus** from the data source dropdown, followed by where the metrics are stored in [Azure Monitor workspace](../essentials/azure-monitor-workspace-overview.md) and the [Prometheus query type](https://prometheus.io/docs/prometheus/latest/querying/api/) for the PromQL query. --<!-- convertborder later; border-bottom is missing, so applying the Learn formatting border --> --> [!NOTE] -> Querying from an Azure Monitor workspace is a data plane action and requires an explicit role assignment of Monitoring Data Reader, which is not assigned by default -> Learn more about [Azure control and data plane](../../azure-resource-manager/management/control-plane-and-data-plane.md) --## Next steps - |
| azure-monitor | Workbooks Dropdowns | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-dropdowns.md | - Title: Azure Monitor workbook dropdown parameters -description: Use dropdown parameters to simplify complex reporting with prebuilt and custom parameterized workbooks. -- Previously updated : 08/14/2024---# Workbook dropdown parameters --By using dropdown parameters, you can collect one or more input values from a known set. For example, you can use a dropdown parameter to select one of your app's requests. Dropdown parameters also provide a user-friendly way to collect arbitrary inputs from users. Dropdown parameters are especially useful in enabling filtering in your interactive reports. --The easiest way to specify a dropdown parameter is by providing a static list in the parameter setting. A more interesting way is to get the list dynamically via a KQL query. You can also specify whether it's single or multi-select by using parameter settings. If it's multi-select, you can specify how the result set should be formatted, for example, as delimiter or quotation. --## Dropdown parameter components -When using either static JSON content or getting dynamic values from queries, dropdown parameters allow up to four fields of information, in this specific order: --1. `value` (required): the first column / field in the data is used as the literal value of the parameter. In the case of simple static JSON parameters, it can be as simple as the JSON content `["dev", "test", "prod"]`, which would create a dropdown of three items with those values as both the value and the label in the dropdown. The name of this field doesn't need to be `value`, the dropdown will use the first field in the data no matter the name. -1. `label` (optional): the second column / field in the data is used as the display name/label of the parameter in the dropdown. If not specified, the value is used as the label. The name of this field doesn't need to be `label`, the dropdown will use the second field in the data no matter the name. -1. `selected` (optional): the third column / field in the data is used to specify which value should be selected by default. If not specified, no items are selected by default. The selection behavior is based on the JavaScript "falsy" concept, so values like `0`, `false`, `null`, or empty strings are treated as not selected. The name of this field doesn't need to be `selected`, the dropdown will use the third field in the data no matter the name. -- > [!NOTE] - > This only controls *default* selection, once a user has selected values in the dropdown, those user selected values are used. Even if a subsequent query for the parameter runs and returns new default values. To return to the default selection, the use can use the "Default Items" option in the dropdown, which will re-query the default values and apply them. - > - > Default values are only applied if no items have been selected by the user. - > - > If a subsequent query returns items that do *not* include previously selected values, the missing values are removed from the selection. The selected items in the dropdown will become the intersection of the items returned by the query and the items that were previously selected. --1. `group` (optional): unlike the other fields, the grouping column *must* be named `group` and appear after `value`, `label` and `selected`. This field in the data is used to group the items in the dropdown. If not specified, no grouping is used. If default selection isn't needed, the data/query must still return a `selected` field in at least one object/row, even if all the values are `false`. --> [!NOTE] -> Any other fields in the data are ignored by the dropdown parameter. It is suggested to limit the content to just those fields used by the dropdown to avoid complicated queries returning data that is ignored. --## Create a static dropdown parameter --1. Start with an empty workbook in edit mode. -1. Select **Add parameters** > **Add Parameter**. -1. In the new parameter pane that opens, enter: - 1. **Parameter name**: `Environment` - 1. **Parameter type**: `Drop down` - 1. **Required**: `checked` - 1. **Allow multiple selections**: `unchecked` - 1. **Get data from**: `JSON` or, select `Query` and select the `JSON` data source. - - The JSON data source allows the JSON content to reference any existing parameters. -1. In the **JSON Input** text block, insert this JSON snippet: -- ```json - [ - { "value":"dev", "label":"Development" }, - { "value":"ppe", "label":"Pre-production" }, - { "value":"prod", "label":"Production", "selected":true } - ] - ``` --1. Select **Update**. -1. Select **Save** to create the parameter. -1. The **Environment** parameter is a dropdown list with the three values. - <!-- convertborder later --> - :::image type="content" source="./media/workbooks-dropdowns/dropdown-create.png" lightbox="./media/workbooks-dropdowns/dropdown-create.png" alt-text="Screenshot that shows the creation of a static dropdown parameter." border="false"::: --## Create a static dropdown list with groups of items --If your query result/JSON contains a `group` field, the dropdown list displays groups of values. Follow the preceding sample, but use the following JSON instead: --```json -[ - { "value":"dev", "label":"Development", "group":"Development" }, - { "value":"dev-cloud", "label":"Development (Cloud)", "group":"Development" }, - { "value":"ppe", "label":"Pre-production", "group":"Test" }, - { "value":"ppe-test", "label":"Pre-production (Test)", "group":"Test" }, - { "value":"prod1", "label":"Prod 1", "selected":true, "group":"Production" }, - { "value":"prod2", "label":"Prod 2", "group":"Production" } -] -``` -<!-- convertborder later --> --> [!NOTE] -> When using a `group` field in your query, you must also supply a value for `label` and `selected` fields. --## Create a dynamic dropdown parameter --1. Start with an empty workbook in edit mode. -1. Select **Add parameters** > **Add Parameter**. -1. In the new parameter pane that opens, enter: - 1. **Parameter name**: `RequestName` - 1. **Parameter type**: `Drop down` - 1. **Required**: `checked` - 1. **Allow multiple selections**: `unchecked` - 1. **Get data from**: `Query` -1. In the **JSON Input** text block, insert this JSON snippet: -- ```kusto - requests - | summarize by name - | order by name asc - ``` --1. Select **Run Query**. -1. Select **Save** to create the parameter. -1. The **RequestName** parameter is a dropdown list with the names of all requests in the app. - <!-- convertborder later --> - :::image type="content" source="./media/workbooks-dropdowns/dropdown-dynamic.png" lightbox="./media/workbooks-dropdowns/dropdown-dynamic.png" alt-text="Screenshot that shows the creation of a dynamic dropdown parameter." border="false"::: --## Example: Custom labels, selecting the first item by default, and grouping by operation name -The query used in the preceding dynamic dropdown parameter returns a list of values that are rendered in the dropdown list. -If you want a different display name, or to allow the user to select the display name, use the value, label, selection, and group columns. --The following sample shows how to get a list of distinct Application Insights dependencies. The display names are styled with an emoji, the first item is selected by default, and the items are grouped by operation names: --```kusto -dependencies -| summarize by operation_Name, name -| where name !contains ('.') -| order by name asc -| serialize Rank = row_number() -| project value = name, label = strcat('🌐 ', name), selected = iff(Rank == 1, true, false), group = operation_Name -``` -<!-- convertborder later --> --## Reference a dropdown parameter --You can reference dropdown parameters anywhere that parameters can be used, including replacing the parameter value into queries, visualization settings, Markdown text content, or other places where you can select a parameter as an option. --### In KQL --1. Select **Add query** to add a query control, and then select an Application Insights resource. -1. In the KQL editor, enter this snippet: -- ```kusto - requests - | where name == '{RequestName}' - | summarize Requests = count() by bin(timestamp, 1h) -- ``` --1. The snippet expands on query evaluation time to: -- ```kusto - requests - | where name == 'GET Home/Index' - | summarize Requests = count() by bin(timestamp, 1h) - ``` --1. Select the **Run query** to see the results. Optionally, render it as a chart. - <!-- convertborder later --> - :::image type="content" source="./media/workbooks-dropdowns/dropdown-reference.png" lightbox="./media/workbooks-dropdowns/dropdown-reference.png" alt-text="Screenshot that shows a dropdown parameter referenced in KQL." border="false"::: --## Dropdown parameter options --| Parameter | Description | Example | -| - |:-|:-| -| `{DependencyName}` | The selected value | GET fabrikamaccount | -| `{DependencyName:value}` | The selected value (same as above) | GET fabrikamaccount | -| `{DependencyName:label}` | The selected label | 🌐 GET fabrikamaccount | -| `{DependencyName:escape}` | The selected value, with any common quote characters replaced when formatted into queries | GET fabrikamaccount | --## Multiple selection --The examples so far explicitly set the parameter to select only one value in the dropdown list. Dropdown parameters also support *multiple selection*. To enable this option, select the **Allow multiple selections** checkbox. --You can specify the format of the result set via the **Delimiter** and **Quote with** settings. By default, `,` (comma) is used as the delimiter, and `'` (single quote) is used as the quote character. The default returns the values as a collection in the form of `'a', 'b', 'c'` when formatted into the query. You can also limit the maximum number of selections. --When using a multiple select parameter in a query, make sure that the KQL referencing the parameter works with the format of the result. For example: -- a single value parameter doesn't include any quotes when formatted into a query, so make sure to include the quotes in the query itself, for example: `where name == '{parameter}'`. -- quotes are included in the formatted parameter when using a multiple select parameter, so make sure that the query doesn't include quotes. For example, `where name in ({parameter})`. --Note how this example also switched from `name ==` to `name in`. The `==` operator only allows a single value, while the `in` operator allows multiple values. --```kusto -dependencies -| where name in ({DependencyName}) -| summarize Requests = count() by bin(timestamp, 1h), name -``` --This example shows the multi-select dropdown parameter at work: -<!-- convertborder later --> --## Dropdown special selections --Dropdown parameters also allow you to specify special values that also appear in the dropdown: -* Any one -* Any three -* ... -* Any 100 -* Any custom limit -* All --When these special items are selected, the parameter value is automatically set to the specific number of items, or all values. --### Special casing All, and allowing an empty selection to be treated as All --When you select **All**, an additional field appears, which allows you to specify a special value for the **All** parameter. This is useful when "All" could be a large number of items and could generate a very large query. ---In this specific case, the string `[]` is used instead of a value. This string can be used to generate an empty array in the logs query, like: --```kusto -let selection = dynamic([{Selection}]); -SomeQuery -| where array_length(selection) == 0 or SomeField in (selection) -``` --If all items are selected, the value of `Selection` is `[]`, producing an empty array for the `selection` variable in the query. If no values are selected, the value of `Selection` is formatted as empty string, also resulting in an empty array. If any values are selected, they're formatted inside the dynamic part of the query, causing the array to have those values. You can then test for `array_length` of 0 to have the filter not apply or use the `in` operator to filter on the values in the array. --Other common examples use '*' as the special marker value when a parameter is required, and then test with: --```kusto -| where "*" in ({Selection}) or SomeField in ({Selection}) -``` --## Next steps --[Learn about the types of visualizations you can use to create rich visual reports with Azure Workbooks](workbooks-visualizations.md). |
| azure-monitor | Workbooks Graph Visualizations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-graph-visualizations.md | - Title: Azure Workbooks graph visualizations -description: Learn about all the Azure Workbooks graph visualizations. -- Previously updated : 06/21/2023---# Graph visualizations --Azure Workbooks graph visualizations support visualizing arbitrary graphs based on data from logs to show the relationships between monitoring entities. --The following graph shows data flowing in and out of a computer via various ports to and from external computers. It's colored by type, for example, computer vs. port vs. external IP. The edge sizes correspond to the amount of data flowing in between. The underlying data comes from KQL query targeting VM connections. -<!-- convertborder later --> --## Add a graph --1. Switch the workbook to edit mode by selecting **Edit**. -1. Use the **Add query** link to add a log query control to the workbook. -1. For **Query type**, select **Logs**. For **Resource type**, select, for example, **Application Insights**, and select the resources to target. -1. Use the query editor to enter the KQL for your analysis. -- ```kusto - let data = dependencies - | summarize Calls = count() by App = appName, Request = operation_Name, Dependency = name - | extend RequestId = strcat(App, '::', Request); - let links = data - | summarize Calls = sum(Calls) by App, RequestId - | project SourceId = App, TargetId = RequestId, Calls, Kind = 'App -> Request' - | union (data - | project SourceId = RequestId, TargetId = Dependency, Calls, Kind = 'Request -> Dependency'); - let nodes = data - | summarize Calls = sum(Calls) by App - | project Id = App, Name = App, Calls, Kind = 'App' - | union (data - | summarize Calls = sum(Calls) by RequestId, Request - | project Id = RequestId, Name = Request, Calls, Kind = 'Request') - | union (data - | summarize Calls = sum(Calls) by Dependency - | project Id = Dependency, Name = Dependency, Calls, Kind = 'Dependency'); - nodes - | union (links) - ``` --1. Set **Visualization** to **Graph**. -1. Select **Graph Settings** to open the **Graph Settings** pane. -1. In **Node Format Settings** at the top, set: - * **Top Content** - - **Use column**: `Name` - * **Column renderer**: `Text` - * **Center Content** - - **Use column**: `Calls` - * **Column renderer**: `Big Number` - * **Color palette**: `None` - * **Bottom Content** - - **Use column**: `Kind` - * **Column renderer**: `Text` -1. In **Layout Settings** at the bottom, set: - * **Node ID**: `Id` - * **Source ID**: `SourceId` - * **Target ID**: `TargetId` - * **Edge Label**: `None` - * **Edge Size**: `Calls` - * **Node Size**: `None` - * **Coloring Type**: `Categorical` - * **Node Color Field**: `Kind` - * **Color palette**: `Pastel` -1. Select **Save and Close** at the bottom of the pane. -<!-- convertborder later --> --## Graph settings --| Setting | Description | -|:-|:-| -| `Node ID` | Selects a column that provides the unique ID of nodes on the graph. The value of the column can be a string or a number. | -| `Source ID` | Selects a column that provides the IDs of source nodes for edges on the graph. Values must map to a value in the `Node Id` column. | -| `Target ID` | Selects a column that provides the IDs of target nodes for edges on the graph. Values must map to a value in the `Node Id` column. | -| `Edge Label` | Selects a column that provides edge labels on the graph. | -| `Edge Size` | Selects a column that provides the metric on which the edge widths will be based. | -| `Node Size` | Selects a column that provides the metric on which the node areas will be based. | -| `Coloring Type` | Used to choose the node coloring scheme. | --## Node coloring types --| Coloring type | Description | -|:- |:| -| `None` | All nodes have the same color. | -| `Categorical` | Nodes are assigned colors based on the value or category from a column in the result set. In the preceding example, the coloring is based on the column `Kind` of the result set. Supported palettes are `Default`, `Pastel`, and `Cool tone`. | -| `Field Based` | In this type, a column provides specific RGB values to use for the node. Provides the most flexibility but usually requires more work to enable. | --## Node format settings --You can specify what content goes to the different parts of a node: top, left, center, right, and bottom. Graphs can use any renderers' workbook supports like text, big numbers, spark lines, and icons. --## Field-based node coloring --1. Switch the workbook to edit mode by selecting **Edit**. -1. Use the **Add query** link to add a log query control to the workbook. -1. For **Query type**, select **Logs**. For **Resource type**, select, for example, **Application Insights**, and select the resources to target. -1. Use the query editor to enter the KQL for your analysis. -- ```kusto - let data = dependencies - | summarize Calls = count() by App = appName, Request = operation_Name, Dependency = name - | extend RequestId = strcat(App, '::', Request); - let links = data - | summarize Calls = sum(Calls) by App, RequestId - | project SourceId = App, TargetId = RequestId, Calls, Kind = 'App -> Request' - | union (data - | project SourceId = RequestId, TargetId = Dependency, Calls, Kind = 'Request -> Dependency'); - let nodes = data - | summarize Calls = sum(Calls) by App - | project Id = App, Name = App, Calls, Color = 'FD7F23' - | union (data - | summarize Calls = sum(Calls) by RequestId, Request - | project Id = RequestId, Name = Request, Calls, Color = 'B3DE8E') - | union (data - | summarize Calls = sum(Calls) by Dependency - | project Id = Dependency, Name = Dependency, Calls, Color = 'C9B3D5'); - nodes - | union (links) - ``` --1. Set **Visualization** to `Graph`. -1. Select **Graph Settings** to open the **Graph Settings** pane. -1. In **Node Format Settings** at the top, set: - * **Top Content**: - * **Use column**: `Name` - * **Column renderer**: `Text` - * **Center Content**: - * **Use column**: `Calls` - * **Column renderer**: `Big Number` - * **Color palette**: `None` - * **Bottom Content**: - * **Use column**: `Kind` - * **Column renderer**: `Text` -1. In **Layout Settings** at the bottom, set: - * **Node ID**:`Id` - * **Source ID**: `SourceId` - * **Target ID**: `TargetId` - * **Edge Label**: `None` - * **Edge Size**: `Calls` - * **Node Size**: `Node` - * **Coloring Type**: `Field Based` - * **Node Color Field**: `Color` -1. Select **Save and Close** at the bottom of the pane. -<!-- convertborder later --> --## Next steps --* Graphs also support the composite bar renderer. To learn more, see [Composite bar renderer](workbooks-composite-bar.md). -* Learn more about the [data sources](workbooks-data-sources.md) you can use in workbooks. |
| azure-monitor | Workbooks Grid Visualizations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-grid-visualizations.md | - Title: Azure Monitor workbook grid visualizations -description: Learn about all the Azure Monitor workbook grid visualizations. -- Previously updated : 06/21/2023----# Grid visualizations --Grids or tables are a common way to present data to users. You can individually style the columns of grids in workbooks to provide a rich UI for your reports. While a plain table shows data, it's hard to read and insights won't always be apparent. Styling the grid can help make it easier to read and interpret the data. --The following example shows a grid that combines icons, heatmaps, and spark bars to present complex information. The workbook also provides sorting, a search box, and a go-to-analytics button. -<!-- convertborder later; applied Learn formatting border because the border created manually is thin. --> --## Add a log-based grid --1. Switch the workbook to edit mode by selecting **Edit** on the toolbar. -1. Select **Add query** to add a log query control to the workbook. -1. For **Query type**, select **Log**. For **Resource type**, select, for example, **Application Insights**, and select the resources to target. -1. Use the query editor to enter the KQL for your analysis. An example is VMs with memory below a threshold. -1. Set **Visualization** to **Grid**. -1. Set parameters like time range, size, color palette, and legend, if needed. -<!-- convertborder later --> --## Log chart parameters --| Parameter | Description | Examples | -| - |:-|:-| -|Query type| The type of query to use. | Logs, Azure Resource Graph | -|Resource type| The resource type to target. | Application Insights, Log Analytics, or Azure-first | -|Resources| A set of resources to get the metrics value from. | MyApp1 | -|Time range| The time window to view the log chart. | Last hour, last 24 hours | -|Visualization| The visualization to use. | Grid | -|Size| The vertical size of the control. | Small, medium, large, or full | -|Query| Any KQL query that returns data in the format expected by the chart visualization. | _requests \| summarize Requests = count() by name_ | --## Simple grid --Workbooks can render KQL results as a simple table. The following grid shows the count of requests and unique users per request type in an app: --```kusto -requests -| where name !endswith('.eot') -| summarize Requests = count(), Users = dcount(user_Id) by name -| order by Requests desc -``` -<!-- convertborder later --> --## Grid styling --Columns styled as heatmaps: -<!-- convertborder later --> --Columns styled as bars: -<!-- convertborder later --> --### Style a grid column --1. Select the **Column Setting** button on the query control toolbar. -1. In the **Edit column settings** pane, select the column to style. -1. In **Column renderer**, select **Heatmap**, **Bar**, or **Bar underneath** and select related settings to style your column. --The following example shows the **Requests** column styled as a bar: -<!-- convertborder later --> --This option usually takes you to some other view with context coming from the cell, or it might open a URL. --### Custom formatting --You can also set the number formatting of your cell values in workbooks. To set this formatting, select the **Custom formatting** checkbox when it's available. --| Formatting option | Description | -|:- |:-| -|Units| The units for the column with various options for percentage, counts, time, byte, count/time, and bytes/time. For example, the unit for a value of 1234 can be set to milliseconds and it's rendered as 1.234 s. | -|Style| The format used to render it, such as decimal, currency, percent. | -|Show group separator| Checkbox to show group separators. Renders 1234 as 1,234 in the US. | -|Minimum integer digits| Minimum number of integer digits to use (default 1). | -|Minimum fractional digits| Minimum number of fractional digits to use (default 0). | -|Maximum fractional digits| Maximum number of fractional digits to use. | -|Minimum significant digits| Minimum number of significant digits to use (default 1). | -|Maximum significant digits| Maximum number of significant digits to use. | -|Custom text for missing values| When a data point doesn't have a value, show this custom text instead of a blank. | --### Custom date formatting --When you've specified that a column is set to the date/time renderer, you can specify custom date formatting options by using the **Custom date formatting** checkbox. --| Formatting option | Description | -|:- |:-| -|Style| The format to render a date as short, long, or full, or a time as short or long. | -|Show time as| Allows you to decide between showing the time in local time (default) or as UTC. Depending on the date format style selected, the UTC/time zone information might not be displayed. | --## Custom column width setting --You can customize the width of any column in the grid by using the **Custom Column Width** field in **Column Settings**. -<!-- convertborder later --> --If the field is left blank, the width is automatically determined based on the number of characters in the column and the number of visible columns. The default unit is "ch," which is an abbreviation for "characters." --Selecting the **(Current Width)** button in the label fills the text field with the selected column's current width. If a value is present in the **Custom Column Width** field with no unit of measurement, the default is used. --The units of measurement available are: --| Unit of measurement | Definition | -|:--|:| -| ch | characters (default) | -| px | pixels | -| fr | fractional units | -| % | percentage | --**Input validation**: If validation fails, a red guidance message appears underneath the field, but you can still apply the width. If a value is present in the input, it's parsed out. If no valid unit of measure is found, the default is used. --You can set the width to any value. There's no minimum or maximum width. The **Custom Column Width** field is disabled for hidden columns. --## Examples --Here are some examples. --### Spark lines and bar underneath --The following example shows request counts and the trend by request name: --```kusto -requests -| make-series Trend = count() default = 0 on timestamp from ago(1d) to now() step 1h by name -| project-away timestamp -| join kind = inner (requests - | summarize Requests = count() by name - ) on name -| project name, Requests, Trend -| order by Requests desc -``` -<!-- convertborder later --> --### Heatmap with shared scales and custom formatting --This example shows various request duration metrics and the counts. The heatmap renderer uses the minimum values set in settings or calculates a minimum and maximum value for the column. It assigns a background color from the selected palette for the cell. The color is based on the value of the cell relative to the minimum and maximum value of the column. --``` -requests -| summarize Mean = avg(duration), (Median, p80, p95, p99) = percentiles(duration, 50, 80, 95, 99), Requests = count() by name -| order by Requests desc -``` -<!-- convertborder later --> --In the preceding example, a shared palette in green or red and a scale are used to color the columns **Mean**, **Median**, **p80**, **p95**, and **p99**. A separate palette in blue is used for the **Requests** column. --#### Shared scale --To get a shared scale: --1. Use regular expressions to select more than one column to apply a setting to. For example, set the column name to **Mean|Median|p80|p95|p99** to select them all. -1. Delete default settings for the individual columns. --The new multi-column setting applies its settings to include a shared scale. -<!-- convertborder later --> --### Icons to represent status --The following example shows custom status of requests based on the p95 duration: --``` -requests -| summarize p95 = percentile(duration, 95) by name -| order by p95 desc -| project Status = case(p95 > 5000, 'critical', p95 > 1000, 'error', 'success'), name, p95 -``` -<!-- convertborder later --> --Supported icon names: --- cancelled-- critical-- disabled-- error-- failed-- info-- none-- pending-- stopped-- question-- success-- unknown-- warning-- uninitialized-- resource-- up-- down-- left-- right-- trendup-- trenddown-- 4-- 3-- 2-- 1-- Sev0-- Sev1-- Sev2-- Sev3-- Sev4-- Fired-- Resolved-- Available-- Unavailable-- Degraded-- Unknown-- Blank--## Fractional unit percentages --The fractional unit, abbreviated as "fr," is a commonly used dynamic unit of measurement in various types of grids. As the window size or resolution changes, the fr width changes too. --The following screenshot shows a table with eight columns that are 1fr width each and all are equal widths. As the window size changes, the width of each column changes proportionally. -<!-- convertborder later --> --The following image shows the same table, except the first column is set to 50% width. This setting dynamically sets the column to half of the total grid width. Resizing the window continues to retain the 50% width unless the window size gets too small. These dynamic columns have a minimum width based on their contents. --The remaining 50% of the grid is divided up by the eight total fractional units. The **Kind** column is set to 2fr, so it takes up one-fourth of the remaining space. Because the other columns are 1fr each, they each take up one-eighth of the right half of the grid. -<!-- convertborder later --> --Combining fr, %, px, and ch widths is possible and works similarly to the previous examples. The widths that are set by the static units (ch and px) are hard constants that won't change even if the window or resolution is changed. --The columns set by % take up their percentage based on the total grid width. This width might not be exact because of previously minimum widths. --The columns set with fr split up the remaining grid space based on the number of fractional units they're allotted. -<!-- convertborder later --> --## Next steps --* Learn how to create a [graph in workbooks](workbooks-graph-visualizations.md). -* Learn how to create a [tile in workbooks](workbooks-tile-visualizations.md). |
| azure-monitor | Workbooks Honey Comb | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-honey-comb.md | - Title: Azure Workbooks honeycomb visualizations -description: Learn about Azure Workbooks honeycomb visualizations. -- Previously updated : 06/21/2023---# Honeycomb visualizations --Azure Workbooks honeycomb visualizations provide high-density views of metrics or categories that can optionally be grouped as clusters. They're useful for visually identifying hotspots and drilling in further. --The following image shows the CPU utilization of virtual machines across two subscriptions. Each cell represents a virtual machine. The color/label represents its average CPU utilization. Red cells are hot machines. The virtual machines are clustered by subscription. -<!-- convertborder later --> --Watch this video to learn how to build a hive cluster. --> [!VIDEO https://www.microsoft.com/en-us/videoplayer/embed/RE5ah5O] --## Add a honeycomb --1. Switch the workbook to edit mode by selecting **Edit**. -1. Select **Add** > **Add query** to add a log query control to the workbook. -1. For **Data source**, select **Logs**. For **Resource type**, select **Log Analytics**. For **Resource**, point to a workspace that has a virtual machine performance log. -1. Use the query editor to enter the KQL for your analysis. -- ```kusto - Perf - | where CounterName == 'Available MBytes' - | summarize CounterValue = avg(CounterValue) by Computer, _ResourceId - | extend ResourceGroup = extract(@'/subscriptions/.+/resourcegroups/(.+)/providers/microsoft.compute/virtualmachines/.+', 1, _ResourceId) - | extend ResourceGroup = iff(ResourceGroup == '', 'On-premises computers', ResourceGroup), Id = strcat(_ResourceId, '::', Computer) - ``` --1. Run the query. -1. Set **Visualization** to `Graph`. -1. Select **Graph Settings**. - 1. In **Node Format Settings** at the top, set: - 1. **Top Content** - - **Use column**: `Computer` - - **Column renderer**: `Text` - 1. **Center Content** - - **Use column**: `CounterValue` - - **Column renderer**: `Big Number` - - **Color palette**: `None` - - Select the **Custom number formatting** checkbox. - - **Units**: `Megabytes` - - **Maximum fractional digits**: `1` - 1. In **Layout Settings** at the bottom, set: - - **Graph Type**: `Hive Clusters` - - **Node ID**: `Id` - - **Group By Field**: `None` - - **Node Size**: 100 - - **Margin between hexagons**: `5` - - **Coloring Type**: `Heatmap` - - **Node Color Field**: `CounterValue` - - **Color palette**: `Red to Green` - - **Minimum value**: `100` - - **Maximum value**: `2000` --1. Select **Save and Close** at the bottom of the pane. -<!-- convertborder later --> --## Honeycomb layout settings --| Setting | Description | -|:- |:-| -| `Node ID` | Selects a column that provides the unique ID of nodes. The value of the column can be a string or a number. | -| `Group By Field` | Select the column to cluster the nodes on. | -| `Node Size` | Sets the size of the hexagonal cells. Use with the `Margin between hexagons` property to customize the look of the honeycomb chart. | -| `Margin between hexagons` | Sets the gap between the hexagonal cells. Use with the `Node size` property to customize the look of the honeycomb chart. | -| `Coloring Type` | Selects the scheme to use to color the node. | -| `Node Color Field` | Selects a column that provides the metric on which the node areas will be based. | --## Node coloring types --| Coloring type | Description | -|:- |:-| -| `None` | All nodes have the same color. | -| `Categorical` | Nodes are assigned colors based on the value or category from a column in the result set. In the preceding example, the coloring is based on the column `Kind` of the result set. Supported palettes are `Default`, `Pastel`, and `Cool tone`. | -| `Heatmap` | In this type, the cells are colored based on a metric column and a color palette. Color coding provides a simple way to highlight metrics spread across cells. | -| `Thresholds` | In this type, cell colors are set by threshold rules, for example, _CPU > 90% => Red, 60% > CPU > 90% => Yellow, CPU < 60% => Green_. | -| `Field Based` | In this type, a column provides specific RGB values to use for the node. Provides the most flexibility but usually requires more work to enable. | --## Node format settings --You can specify what content goes to the different parts of a node: top, left, center, right, and bottom. You're free to use any of the renderers supported by workbooks like text, big numbers, spark lines, and icons. --## Next steps --- Learn how to create a [composite bar renderer in workbooks](workbooks-composite-bar.md).-- Learn how to [import Azure Monitor log data into Power BI](../logs/log-powerbi.md). |
| azure-monitor | Workbooks Interactive Reports | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-interactive-reports.md | - Title: Create interactive reports with Azure Monitor Workbooks -description: This article explains how to create interactive reports in Azure Workbooks. -- Previously updated : 01/08/2024-----# Create interactive reports with Azure Monitor Workbooks --There are several ways that you can create interactive reports and experiences in workbooks: ---## Set up a grid row click --1. Make sure you're in edit mode by selecting **Edit**. -1. Select **Add query** to add a log query control to the workbook. -1. Select the log query type, the resource type, and the target resources. -1. Use the query editor to enter the KQL for your analysis: -- ```kusto - requests - | summarize AllRequests = count(), FailedRequests = countif(success == false) by Request = name - | order by AllRequests desc - ``` --1. Select **Run query** to see the results. -1. Select **Advanced Settings** to open the **Advanced Settings** pane. -1. Select the **When an item is selected, export a parameter** checkbox. -1. Select **Add Parameter** and fill in the following information: - - **Field to export**: `Request` - - **Parameter name**: `SelectedRequest` - - **Default value**: `All requests` - - :::image type="content" source="media/workbooks-configurations/workbooks-export-parameters-add.png" alt-text="Screenshot that shows the Advanced Settings workbook editor with settings for exporting fields as parameters."::: --1. Optional. If you want to export the entire contents of the selected row instead of a specific column, leave **Field to export** unset. The entire row's contents are exported as JSON to the parameter. On the referencing KQL control, use the `todynamic` function to parse the JSON and access the individual columns. -1. Select **Save**. -1. Select **Done Editing**. -1. Add another query control as in the preceding steps. -1. Use the query editor to enter the KQL for your analysis. -- ```kusto - requests - | where name == '{SelectedRequest}' or 'All Requests' == '{SelectedRequest}' - | summarize ['{SelectedRequest}'] = count() by bin(timestamp, 1h) - ``` --1. Select **Run query** to see the results. -1. Change **Visualization** to **Area chart**. -1. Choose a row to select in the first grid. Note how the area chart below filters to the selected request. --The resulting report looks like this example in edit mode: - - :::image type="content" source="media/workbooks-configurations/workbooks-interactivity-grid-create.png" alt-text="Screenshot that shows workbooks with the first two queries in edit mode."::: --The following image shows a more elaborate interactive report in read mode based on the same principles. The report uses grid clicks to export parameters, which in turn are used in two charts and a text block. -- :::image type="content" source="media/workbooks-configurations/workbooks-interactivity-grid-read.png" alt-text="Screenshot that shows a workbook report using grid clicks."::: --## Set up grid cell clicks --1. Make sure you're in edit mode by selecting **Edit**. -1. Select **Add query** to add a log query control to the workbook. -1. Select the log query type, resource type, and target resources. -1. Use the query editor to enter the KQL for your analysis: -- ```kusto - requests - | summarize Count = count(), Sample = any(pack_all()) by Request = name - | order by Count desc - ``` --1. Select **Run query** to see the results. -1. Select **Column Settings** to open the settings pane. -1. In the **Columns** section, set: - - **Sample** - - **Column renderer**: `Link` - - **View to open**: `Cell Details` - - **Link label**: `Sample` - - **Count** - - **Column renderer**: `Bar` - - **Color palette**: `Blue` - - **Minimum value**: `0` - - **Request** - - **Column renderer**: `Automatic` -1. Select **Save and Close** to apply changes. -- :::image type="content" source="media/workbooks-configurations/workbooks-column-settings.png" alt-text="Screenshot that shows the Edit column settings pane."::: --1. Select a **Sample** link in the grid to open a pane with the details of a sampled request. -- :::image type="content" source="media/workbooks-configurations/workbooks-grid-link-details.png" alt-text="Screenshot that shows the Details pane of the sample request."::: --## Link renderer actions --Learn about how [link actions](workbooks-link-actions.md) work to enhance workbook interactivity. --## Set conditional visibility --1. Follow the steps in the [Set up a grid row click](#set-up-a-grid-row-click) section to set up two interactive controls. -1. Add a new parameter with these values: - - **Parameter name**: `ShowDetails` - - **Parameter type**: `Drop down` - - **Required**: `checked` - - **Get data from**: `JSON` - - **JSON Input**: `["Yes", "No"]` -1. Select **Save** to commit changes. -- :::image type="content" source="media/workbooks-configurations/workbooks-edit-parameter.png" alt-text="Screenshot that shows editing an interactive parameter in workbooks."::: --1. Set the parameter value to `Yes`. - - :::image type="content" source="media/workbooks-configurations/workbooks-set-parameter.png" alt-text="Screenshot that shows setting an interactive parameter value in a workbook."::: --1. In the query control with the area chart, select **Advanced Settings** (the gear icon). -1. If **ShowDetails** is set to `Yes`, select **Make this item conditionally visible**. -1. Select **Done Editing** to commit the changes. -1. On the workbook toolbar, select **Done Editing**. -1. Switch the value of **ShowDetails** to `No`. Notice that the chart below disappears. --The following image shows the case where **ShowDetails** is `Yes`: -- :::image type="content" source="media/workbooks-configurations/workbooks-conditional-visibility-visible.png" alt-text="Screenshot that shows a workbook with a conditional component that's visible."::: --The following image shows the hidden case where **ShowDetails** is `No`: ---## Set up multi-selects in grids and charts --Query and metrics components can export parameters when a row or multiple rows are selected. ---1. In the query component that displays the grid, select **Advanced settings**. -1. Select the **When items are selected, export parameters** checkbox. -1. Select the **Allow selection of multiple values** checkbox. - - The displayed visualization allows multi-selecting and the exported parameter's values will be arrays of values, like when using multi-select dropdown parameters. - - If cleared, the display visualization only captures the last selected item and exports only a single value at a time. -1. Use **Add Parameter** for each parameter you want to export. A pop-up window appears with the settings for the parameter to be exported. --When you enable single selection, you can specify which field of the original data to export. Fields include parameter name, parameter type, and default value to use if nothing is selected. --When you enable multi-selection, you specify which field of the original data to export. Fields include parameter name, parameter type, quote with, and delimiter. The quote with and delimiter values are used when turning arrow values into text when they're being replaced in a query. In multi-selection, if no values are selected, the default value is an empty array. --> [!NOTE] -> For multi-selection, only unique values are exported. For example, you won't see output array values like "1,1,2,1". The array output will be "1,2". --If you leave the **Field to export** setting empty in the export settings, all the available fields in the data will be exported as a stringified JSON object of key:value pairs. For grids and titles, the string includes the fields in the grid. For charts, the available fields are x,y,series, and label, depending on the type of chart. --While the default behavior is to export a parameter as text, if you know the field is a subscription or resource ID, use that information as the export parameter type. Then the parameter can be used downstream in places that require those types of parameters. --## Capture user input to use in a query --You can capture user input by using dropdown lists and use the selections in your queries. For example, you can have a dropdown list to accept a set of virtual machines and then filter your KQL to include just the selected machines. In most cases, this step is as simple as including the parameter's value in the query: --```sql - Perf - | where Computer in ({Computers}) - | take 5 -``` --In more advanced scenarios, you might need to transform the parameter results before they can be used in queries. Take this OData filter payload: --```json -{ - "name": "deviceComplianceTrend", - "filter": "(OSFamily eq 'Android' or OSFamily eq 'OS X') and (ComplianceState eq 'Compliant')" -} -``` --The following example shows how to enable this scenario. Let's say you want the values of the `OSFamily` and `ComplianceState` filters to come from dropdown lists in the workbook. The filter could include multiple values as in the preceding `OsFamily` case. It needs to also support the case where you want to include all dimension values, that is to say, with no filters. --### Set up parameters --1. [Create a new empty workbook](workbooks-create-workbook.md) and [add a parameter component](workbooks-create-workbook.md#add-parameters). -1. Select **Add parameter** to create a new parameter. Use the following settings: - - **Parameter name**: `OsFilter` - - **Display name**: `Operating system` - - **Parameter type**: `drop-down` - - **Allow multiple selections**: `Checked` - - **Delimiter**: `or` (with spaces before and after) - - **Quote with**: `<empty>` - - **Get data from**: `JSON` - - **JSON Input**: -- ```json - [ - { "value": "OSFamily eq 'Android'", "label": "Android" }, - { "value": "OSFamily eq 'OS X'", "label": "OS X" } - ] - ``` -- - In the **Include in the drop down** section: - - Select the **All** checkbox. - - **Select All value**: `OSFamily ne '#@?'` - - Select **Save** to save this parameter. -1. Add another parameter with these settings: - - **Parameter name**: `ComplianceStateFilter` - - **Display name**: `Compliance State` - - **Parameter type**: `drop-down` - - **Allow multiple selections**: `Checked` - - **Delimiter**: `or` (with spaces before and after) - - **Quote with**: `<empty>` - - **Get data from**: `JSON` - - **JSON Input**: -- ```json - [ - { "value": "ComplianceState eq 'Compliant'", "label": "Compliant" }, - { "value": "ComplianceState eq 'Non-compliant'", "label": "Non compliant" } - ] - ``` - - In the **Include in the drop down** section: - - Select the **All** checkbox. - - **Select All value**: `ComplianceState ne '#@?'` - - Select **Save** to save this parameter. --1. Select **Add text** to add a text block. In the **Markdown text to display** block, add: -- ```json - { - "name": "deviceComplianceTrend", - "filter": "({OsFilter}) and ({ComplianceStateFilter})" - } - ``` -- This screenshot shows the parameter settings: -- :::image type="content" source="media/workbooks-commonly-used-components/workbooks-odata-parameters-settings.png" alt-text="Screenshot that shows parameter settings for dropdown lists with parameter values."::: --### Single filter value --The simplest case is the selection of a single filter value in each of the dimensions. The dropdown control uses the JSON input field's value as the parameter's value. --```json -{ - "name": "deviceComplianceTrend", - "filter": "(OSFamily eq 'OS X') and (ComplianceState eq 'Compliant')" -} -``` ---### Multiple filter values --If you choose multiple filter values, for example, both Android and OS X operating systems, the `Delimiter` and `Quote with` parameter settings kick in and produce this compound filter: --```json -{ - "name": "deviceComplianceTrend", - "filter": "(OSFamily eq 'OS X' or OSFamily eq 'Android') and (ComplianceState eq 'Compliant')" -} -``` ---### No filter case --Another common case is having no filter for that dimension. This scenario is equivalent to including all values of the dimensions as part of the result set. The way to enable it is by having an `All` option on the dropdown and have it return a filter expression that always evaluates to `true`. An example is _ComplianceState eq '#@?'_. --```json -{ - "name": "deviceComplianceTrend", - "filter": "(OSFamily eq 'OS X' or OSFamily eq 'Android') and (ComplianceState ne '#@?')" -} -``` ---## Reuse query data in different visualizations --There are times where you want to visualize the underlying dataset in different ways without having to pay the cost of the query each time. This sample shows you how to do so by using the `Merge` option in the query control. --### Set up the parameters --1. [Create a new empty workbook](workbooks-create-workbook.md). -1. Select **Add query** to create a query control, and enter these values: - - **Data source**: `Logs` - - **Resource type**: `Log Analytics` - - **Log Analytics workspace**: _Pick one of your workspaces that has performance data_ - - **Log Analytics workspace logs query**: -- ```sql - Perf - | where CounterName == '% Processor Time' - | summarize CpuAverage = avg(CounterValue), CpuP95 = percentile(CounterValue, 95) by Computer - | order by CpuAverage desc - ``` --1. Select **Run Query** to see the results. -- This result dataset is the one we want to reuse in multiple visualizations. -- :::image type="content" source="media/workbooks-commonly-used-components/workbooks-reuse-data-resultset.png" alt-text="Screenshot that shows the result of a workbooks query." lightbox="media/workbooks-commonly-used-components/workbooks-reuse-data-resultset.png"::: --1. Go to the **Advanced settings** tab, and for the name, enter `Cpu data`. -1. Select **Add query** to create another query control. -1. For **Data source**, select `Merge`. -1. Select **Add Merge**. -1. In the settings pane, set: - - **Merge Type**: `Duplicate table` - - **Table**: `Cpu data` -1. Select **Run Merge**. You'll get the same result as the preceding. -- :::image type="content" source="media/workbooks-commonly-used-components/workbooks-reuse-data-duplicate.png" alt-text=" Screenshot that shows duplicate query results in a workbook." lightbox="media/workbooks-commonly-used-components/workbooks-reuse-data-duplicate.png"::: --1. Set the table options: - - Use the **Name After Merge** column to set friendly names for your result columns. For example, you can rename `CpuAverage` to `CPU utilization (avg)`, and then use **Run Merge** to update the result set. - - Use **Delete** to remove a column. - - Select the `[Cpu data].CpuP95` row. - - Use **Delete** in the query control toolbar. - - Use **Run Merge** to see the result set without the CpuP95 column -1. Change the order of the columns by selecting **Move up** or **Move down**. -1. Add new columns based on values of other columns by selecting **Add new item**. -1. Style the table by using the options in **Column settings** to get the visualization you want. -1. Add more query controls working against the `Cpu data` result set if needed. --This example shows Average and P95 CPU utilization side by side: ---## Use Azure Resource Manager to retrieve alerts in a subscription --This sample shows you how to use the Azure Resource Manager query control to list all existing alerts in a subscription. This guide will also use JSON Path transformations to format the results. See the [list of supported Resource Manager calls](/rest/api/azure/). --### Set the parameters --1. [Create a new empty workbook](workbooks-create-workbook.md). -1. Select **Add parameter**, and set: - - **Parameter name**: `Subscription` - - **Parameter type**: `Subscription picker` - - **Required**: `Checked` - - **Get data from**: `Default Subscriptions` -1. Select **Save**. -1. Select **Add query** to create a query control, and use these settings. For this example, we're using the [Alerts Get All REST call](/rest/api/monitor/alertsmanagement/alerts/getall) to get a list of existing alerts for a subscription. For supported api-versions, see the [Azure REST API reference](/rest/api/azure/). - - **Data source**: `Azure Resource Manager (Preview)` - - **Http Method**: `GET` - - **Path**: `/subscriptions/{Subscription:id}/providers/Microsoft.AlertsManagement/alerts` - - Add the api-version parameter on the **Parameters** tab and set: - - **Parameter**: `api-version` - - **Value**: `2018-05-05` --1. Select a subscription from the created subscription parameter, and select **Run Query** to see the results. -- This raw JSON is returned from Resource -- :::image type="content" source="media/workbooks-commonly-used-components/workbooks-arm-alerts-query-no-formatting.png" alt-text="Screenshot that shows an alert data JSON response in workbooks by using a Resource Manager provider." lightbox="media/workbooks-commonly-used-components/workbooks-arm-alerts-query-no-formatting.png"::: --### Format the response --You might be satisfied with the information here. But let's extract some interesting properties and format the response in a way that's easy to read. --1. Go to the **Result Settings** tab. -1. Switch **Result Format** from `Content` to `JSON Path`. [JSON Path](workbooks-jsonpath.md) is a workbook transformer. -1. In the JSON Path settings, set **JSON Path Table** to `$.value.[*].properties.essentials`. This extracts all `"value.*.properties.essentials"` fields from the returned JSON. -1. Select **Run Query** to see the grid. -- :::image type="content" source="media/workbooks-commonly-used-components/workbooks-arm-alerts-query-grid.png" alt-text="Screenshot that shows alert data in a workbook in grid format by using a Resource Manager provider." lightbox="media/workbooks-commonly-used-components/workbooks-arm-alerts-query-grid.png"::: --### Filter the results --JSON Path also allows you to choose information from the generated table to show as columns. --For example, if you want to filter the results to the columns **TargetResource**, **Severity**, **AlertState**, **AlertRule**, **Description**, **StartTime**, and **ResolvedTime**, you could add the following rows in the columns table in JSON Path: --| Column ID | Column JSON Path | -| :- | :-: | -| TargetResource | $.targetResource | -| Severity | $.severity | -| AlertState | $.alertState | -| AlertRule | $.alertRule | -| Description | $.description | -| StartTime | $.startDateTime | -| ResolvedTime | $.monitorConditionResolvedDateTime | ---## Next steps --* [Learn about the types of visualizations you can use to create rich visual reports with Azure Workbooks](workbooks-visualizations.md). -* [Use drop down parameters to simplify complex reporting](workbooks-dropdowns.md). |
| azure-monitor | Workbooks Jsonpath | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-jsonpath.md | - Title: Azure Monitor workbooks - Transform JSON data with JSONPath -description: Use JSONPath in Azure Monitor workbooks to transform the JSON data results to a different data format. -- Previously updated : 06/21/2023---# Use JSONPath to transform JSON data in workbooks --Workbooks can query data from many sources. Some endpoints, such as [Azure Resource Manager](../../azure-resource-manager/management/overview.md) or custom endpoints can return results in JSON. If the JSON data returned by the queried endpoint is in a format that you don't want, you can use JSONPath transformation to convert the JSON to a table structure. You can then use the table to plot [workbook visualizations](./workbooks-overview.md#visualizations). --JSONPath is a query language for JSON that's similar to XPath for XML. Like XPath, JSONPath allows for the extraction and filtration of data out of the JSON structure. --## Use JSONPath --In this example, the JSON object represents a store's inventory. We're going to create a table of the store's available books listing their titles, authors, and prices. --1. Switch the workbook to edit mode by selecting **Edit**. -1. Use the **Add** > **Add query** link to add a query control to the workbook. -1. Select the data source as **JSON**. -1. Use the JSON editor to enter the following JSON snippet: -- ```json - { "store": { - "books": [ - { "category": "reference", - "author": "Nigel Rees", - "title": "Sayings of the Century", - "price": 8.95 - }, - { "category": "fiction", - "author": "Evelyn Waugh", - "title": "Sword of Honour", - "price": 12.99 - }, - { "category": "fiction", - "author": "Herman Melville", - "title": "Moby Dick", - "isbn": "0-553-21311-3", - "price": 8.99 - }, - { "category": "fiction", - "author": "J. R. R. Tolkien", - "title": "The Lord of the Rings", - "isbn": "0-395-19395-8", - "price": 22.99 - } - ], - "bicycle": { - "color": "red", - "price": 19.95 - } - } - } - ``` -1. Select the **Result Settings** tab and switch the result format to **JSON Path**. -1. Apply the following JSON path settings: -- - **JSON Path Table**: `$.store.books`. This field represents the path of the root of the table. In this case, we care about the store's book inventory. The table path filters the JSON to the book information. -- | Column IDs | Column JSON paths | - |:--|:--| - | Title | `$.title` | - | Author | `$.author` | - | Price | `$.price` | -- Column IDs are the column headers. Column JSON paths fields represent the path from the root of the table to the column value. --1. Select **Run Query**. -- :::image type="content" source="media/workbooks-jsonpath/query-jsonpath.png" alt-text="Screenshot that shows editing a query item with JSON data source and JSON path result format."::: --## Use regular expressions to convert values --You may have some data that isn't in a standard format. To use that data effectively, you would want to convert that data into a standard format. --In this example, the published date is in YYYMMMDD format. The code interprets this value as a numeric value, not text, resulting in right-justified numbers, instead of as a date. --You can use the **Type**, **RegEx Match** and **Replace With** fields in the result settings to convert the result into true dates. --|Result setting field |Description | -||| -|Type|Allows you to explicitly change the type of the value returned by the API. This field us usually left unset, but you can use this field to force the value to a different type. | -|Regex Match|Allows you to enter a regular expression to take part (or parts) of the value returned by the API instead of the whole value. This field is usually combined with the **Replace With** field. | -|Replace With|Use this field to create the new value along with the regular expression. If this value is empty, the default is `$&`, which is the match result of the expression. See string.replace documentation to see other values that you can use to generate other output.| ---To convert YYYMMDD format into YYYY-MM-DD format: --1. Select the Published row in the grid. -1. In the **Type** field, select Date/Time so that the column is usable in charts. -1. In the **Regex Match** field, use this regular expression: `([0-9]{4})([0-9]{2})([0-9]{2})`. This regular expression: - - matches a four digit number, then a two digit number, then another two digit number. - - The parentheses form capture groups to use in the next step. -1. In the **Replace With**, use this regular expression: `$1-$2-$3`. This expression creates a new string with each captured group, with a hyphen between them, turning "12345678" into "1234-56-78"). -1. Run the query again. -- :::image type="content" source="media/workbooks-jsonpath/workbooks-jsonpath-convert-date-time.png" alt-text="Screenshot that shows JSONpath converted to date-time format."::: -## Next steps --- [Workbooks overview](./workbooks-overview.md)-- [Groups in Azure Monitor Workbooks](workbooks-groups.md) |
| azure-monitor | Workbooks Limits | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-limits.md | - Title: Azure Workbooks data source limits | Microsoft docs -description: Learn about the limits of each type of workbook data source. ---- Previously updated : 01/08/2024----# Workbooks result limits --Data source, visualization, and parameter limits have some points in common: --- In general, Azure Workbooks limits the results of queries to no more than 10,000 results. Any results after that point are truncated.-- Each data source might have its own specific limits based on the limits of the service it queries.-- Those limits might be on the numbers of resources, regions, results returned, and time ranges. Consult the documentation for each service to find those limits.--## Data source limits --This table lists the limits of specific data sources. --|Data source|Limits | -||| -|Log-based queries|Log Analytics [has limits](../service-limits.md#log-queries-and-language) for the number of resources, workspaces, and regions involved in queries.| -|Metrics|Metrics grids are limited to querying 200 resources at a time. | -|Azure Resource Graph|Resource Graph limits queries to 1,000 subscriptions at a time.| --## Visualization limits --This table lists the limits of specific data visualizations. --|Visualization|Limits | -||| -|Grid|By default, grids only display the first 250 rows of data. This setting can be changed in the query component's advanced settings to display up to 10,000 rows. Any further items are ignored, and a warning appears.<br>The checkbox for toggling the selection of all items is available only when the grid displays 150 rows of data or fewer.| -|Charts|Charts are limited to 100 series.<br>Charts are limited to 10,000 data points. | -|Tiles|Tiles is limited to displaying 100 tiles. Any further items are ignored, and a warning appears.| -|Maps|Maps are limited to displaying 100 points. Any further items are ignored, and a warning appears.| -|Text|Text visualization only displays the first cell of data returned by a query. Any other data is ignored.| --## Parameter limits --This table lists the limits of specific data parameters. --|Parameter|Limits | -||| -|Drop down|Drop-down-based parameters are limited to 1,000 items. Any items returned by a query after that are ignored.<br>When based on a query, only the first four columns of data produced by the query are used. Any other columns are ignored.| -|Multi-value|Multi-value parameters are limited to 100 items. Any items returned by a query after that are ignored.<br>When based on a query, only the first column of data produced by the query is used. Any other columns are ignored. | -|Options group|Options group parameters are limited to 1,000 items. Any items returned by a query after that are ignored. <br>When based on a query, only the first column of data produced by the query is used. Any other columns are ignored.| -|Text|Text parameters that retrieve their value based on a query will only display the first cell returned by the query (row 1, column 1). Any other data is ignored.| |
| azure-monitor | Workbooks Link Actions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-link-actions.md | - Title: Azure Workbooks link actions -description: This article explains how to use link actions in Azure Workbooks. -- Previously updated : 05/29/2024-----# Link actions --Link actions can be accessed through workbook link components or through column settings of [grids](../visualize/workbooks-grid-visualizations.md), [tiles](../visualize/workbooks-tile-visualizations.md), or [graphs](../visualize/workbooks-graph-visualizations.md). --## General link actions --| Link action | Action on select | -|:- |:-| -|Generic Details| Shows the row values in a property grid context view. | -|Cell Details| Shows the cell value in a property grid context view. Useful when the cell contains a dynamic type with information, for example, JSON with request properties like location and role instance. | -|URL| The value of the cell is expected to be a valid HTTP URL. The cell is a link that opens that URL in a new tab.| --## Application Insights --| Link action | Action on select | -|:- |:-| -|Custom Event Details| Opens the Application Insights search details with the custom event ID ("itemId") in the cell. | -|Details| Similar to Custom Event Details except for dependencies, exceptions, page views, requests, and traces. | -|Custom Event User Flows| Opens the Application Insights User Flows experience pivoted on the custom event name in the cell. | -|User Flows| Similar to Custom Event User Flows except for exceptions, page views, and requests. | -|User Timeline| Opens the user timeline with the user ID ("user_Id") in the cell. | -|Session Timeline| Opens the Application Insights search experience for the value in the cell, for example, search for text *abc* where abc is the value in the cell. | --## Azure resource --| Link action | Action on select | -|:- |:-| -|ARM Deployment| Deploys an Azure Resource Manager (ARM) template. When this item is selected, more fields are displayed to let you configure which ARM template to open and parameters for the template. [See Azure Resource Manager deployment link settings](#azure-resource-manager-deployment-link-settings). | -|Create Alert Rule| Creates an alert rule for a resource. | -|Custom View| Opens a custom view. When this item is selected, more fields appear where you can configure the view extension, view name, and any parameters used to open the view. [See custom view link settings](#custom-view-link-settings). | -|Metrics| Opens a metrics view. | -|Resource Overview| Opens the resource's view in the portal based on the resource ID value in the cell. You can also optionally set a submenu value that opens a specific menu item in the resource view. | -|Workbook (Template)| Opens a workbook template. When this item is selected, more fields appear where you can configure what template to open. | --## Link settings --When you use the link renderer, the following settings are available: -<!-- convertborder later --> --| Setting | Description | -|:- |:-| -|View to open| Allows you to select one of the actions. | -|Menu item| If **Resource Overview** is selected, this menu item is in the resource's overview. You can use it to open alerts or activity logs instead of the "overview" for the resource. Menu item values are different for each Azure Resource type.| -|Link label| If specified, this value appears in the grid column. If this value isn't specified, the value of the cell appears. If you want another value to appear, like a heatmap or icon, don't use the link renderer. Instead, use the appropriate renderer and select the **Make this item a link** option. | -|Open link in Context pane| If specified, the link is opened as a pop-up "context" view on the right side of the window instead of opening as a full view. | --When you use the **Make this item a link** option, the following settings are available: --| Setting | Description | -|:- |:-| -|Link value comes from| When a cell is displayed as a renderer with a link, this field specifies where the "link" value to be used in the link comes from. You can select from a dropdown of the other columns in the grid. For example, the cell might be a heatmap value. But perhaps you want the link to open the **Resource Overview** for the resource ID in the row. In that case, you would set the link value to come from the **Resource ID** field. -|View to open| Same as above. | -|Menu item| Same as above. | -|Open link in Context pane| Same as above. | --## ARM Action Settings --Use this setting to invoke an ARM action by specifying the ARM API details. The documentation for ARM REST APIs can be found [here](https://aka.ms/armrestapi). In all of the UX fields, you can resolve parameters using `{paramName}`. You can also resolve columns using `["columnName"]`. In the example images below, we can reference the column `id` by writing `["id"]`. If the column is an Azure Resource ID, you can get a friendly name of the resource using the formatter `label`. This is similar to [parameter formatting](workbooks-parameters.md#parameter-formatting-options). --### ARM Action Settings Tab --This section defines the ARM action API. --| Source | Explanation | -|:- |:-| -|ARM Action path| The ARM action path. For example: "/subscriptions/:subscription/resourceGroups/:resourceGroup/someAction?api-version=:apiversion".| -|Http Method| Select an HTTP method. The available choices are: `POST`, `PUT`, `PATCH`, `DELETE`| -|Long Operation| Long Operations poll the URI from the `Azure-AsyncOperation` or the `Location` response header from the original operation. Learn more about [tracking asynchronous Azure operations](../../azure-resource-manager/management/async-operations.md). -|Parameters| URL parameters grid with the key and value.| -|Headers| Headers grid with the key and value.| -|Body| Editor for the request payload in JSON.| ---### ARM Action UX Settings --This section configures what the users see before they run the ARM action. --| Source | Explanation | -|:- |:-| -|Title| Title used on the run view. | -|Customize ARM Action name| Authors can customize the ARM action displayed on the notification after the action is triggered.| -|Description of ARM Action| The markdown text used to provide a helpful description to users when they want to run the ARM action. | -|Run button text from| Label used on the run (execute) button to trigger the ARM action.| ---After these configurations are set, when the user selects the link, the view opens with the UX described here. If the user selects the button specified by **Run button text from**, it runs the ARM action using the configured values. On the bottom of the context pane, you can select **View Request Details** to inspect the HTTP method and the ARM API endpoint used for the ARM action. ---The progress and result of the ARM Action is shown as an Azure portal notification. ----## Azure Resource Manager deployment link settings --If the link type is **ARM Deployment**, you must specify more settings to open a Resource Manager deployment. There are two main tabs for configurations: **Template Settings** and **UX Settings**. --### Template settings --This section defines where the template should come from and the parameters used to run the Resource Manager deployment. --| Source | Description | -|:- |:-| -|Resource group ID comes from| The resource ID is used to manage deployed resources. The subscription is used to manage deployed resources and costs. The resource groups are used like folders to organize and manage all your resources. If this value isn't specified, the deployment fails. Select from **Cell**, **Column**, **Parameter**, and **Static Value** in [Link sources](#link-sources).| -|ARM template URI from| The URI to the ARM template itself. The template URI needs to be accessible to the users who deploy the template. Select from **Cell**, **Column**, **Parameter**, and **Static Value** in [Link sources](#link-sources). For more information, see [Azure Quickstart Templates](https://azure.microsoft.com/resources/templates/).| -|ARM Template Parameters|Defines the template parameters used for the template URI defined earlier. These parameters are used to deploy the template on the run page. The grid contains an **Expand** toolbar button to help fill the parameters by using the names defined in the template URI and set to static empty values. This option can only be used when there are no parameters in the grid and the template URI is set. The lower section is a preview of what the parameter output looks like. Select **Refresh** to update the preview with current changes. Parameters are typically values. References are something that could point to key vault secrets that the user has access to. <br/><br/> **Template Viewer pane limitation** doesn't render reference parameters correctly and shows as a null/value. As a result, users won't be able to correctly deploy reference parameters from the **Template Viewer** tab.| -<!-- convertborder later --> --### UX settings --This section configures what you see before you run the Resource Manager deployment. --| Source | Description | -|:- |:-| -|Title from| Title used on the run view. Select from **Cell**, **Column**, **Parameter**, and **Static Value** in [Link sources](#link-sources).| -|Description from| The Markdown text used to provide a helpful description to users when they want to deploy the template. Select from **Cell**, **Column**, **Parameter**, and **Static Value** in [Link sources](#link-sources). <br/><br/> If you select **Static Value**, a multi-line text box appears. In this text box, you can resolve parameters by using `"{paramName}"`. Also, you can treat columns as parameters by appending `"_column"` after the column name like `{columnName_column}`. In the following example image, you can reference the column `"VMName"` by writing `"{VMName_column}"`. The value after the colon is the [parameter formatter](../visualize/workbooks-parameters.md#parameter-formatting-options). In this case, it's **value**.| -|Run button text from| Label used on the run (execute) button to deploy the ARM template. Users select this button to start deploying the ARM template.| -<!-- convertborder later --> --After these configurations are set, when you select the link, the view opens with the UX described in the UX settings. If you select **Run button text from**, an ARM template is deployed by using the values from [Template Settings](#template-settings). **View template** opens the **Template Viewer** tab so that you can examine the template and the parameters before you deploy. -<!-- convertborder later --> --## Custom view link settings --Use this setting to open **Custom Views** in the Azure portal. You can configure the settings using the form or URL. --<!-- convertborder later --> --> [!NOTE] -> Views with a menu can't be opened in a context tab. If a view with a menu is configured to open in a context tab, no context tab is shown when the link is selected. --### Form --| Source | Description | -|:- |:-| -|Extension name| The name of the extension that hosts the name of the view.| -|View name| The name of the view to open.| ---There are two types of inputs: grids and JSON. Use a grid for simple key and value tab inputs. Use JSON to specify a nested JSON input. ---#### Grid --- **Parameter Name**: The name of the View input parameter.-- **Parameter Comes From**: Where the value of the View parameter should come from. Select from **Cell**, **Column**, **Parameter**, and **Static Value** in [Link sources](#link-sources).- > [!NOTE] - > If you select **Static Value**, the parameters can be resolved by using brackets to link `"{paramName}"` in the text box. Columns can be treated as parameters columns by appending `_column` after the column name like `"{columnName_column}"`. -- **Parameter Value**: Depending on the value in **Parameter Comes From**, this dropdown contains available parameters, columns, or a static value.--<!-- convertborder later --> --#### JSON --- Specify your tab input in a JSON format on the editor. Like the **Grid** mode, parameters and columns can be referenced by using `{paramName}` for parameters and `{columnName_column}` for columns. Selecting **Show JSON Sample** shows the expected output of all resolved parameters and columns used for the view input.----### URL --Paste a portal URL that contains the extension, name of the view, and any inputs needed to open the view. After you select **Initialize Settings**, the form is populated so that you can add, modify, or remove any of the view inputs. -<!-- convertborder later --> --## Workbook (Template) link settings --If the selected link type is **Workbook (Template)**, you must specify more settings to open the correct workbook template. The following settings have options for how the grid finds the appropriate value for each of the settings. --| Setting | Description | -|:- |:-| -|Workbook owner Resource ID comes from| This value is the Resource ID of the Azure resource that "owns" the workbook. Commonly, it's an Application Insights resource or a Log Analytics workspace. Inside of Azure Monitor, this value might also be the literal string `"Azure Monitor"`. When the workbook is saved, this value is what the workbook is linked to. | -|Workbook resources come from| An array of Azure Resource IDs that specify the default resource used in the workbook. For example, if the template being opened shows virtual machine metrics, the values here would be virtual machine resource IDs. Many times, the owner and resources are set to the same settings. | -|Template ID comes from| Specify the ID of the template to be opened. A community template from the gallery is the most common case. Prefix the path to the template with `Community-`, like `Community-Workbooks/Performance/Apdex` for the `Workbooks/Performance/Apdex` template. If it's a link to a saved workbook or template, use the full path to the Azure resource ID of that item, for example, "/subscriptions/12345678-a1b2-1234-a1b2-c3d4e5f6/resourceGroups/rgname/providers/microsoft.insights/workbooks/1a2b3c4d-5678-abcd-xyza-1a2b3c4d5e6f. | -|Workbook Type comes from| Specify the kind of workbook template to open. The most common cases use the default or workbook option to use the value in the current workbook. | -|Gallery Type comes from| This value specifies the gallery type that's displayed in the **Gallery** view of the template that opens. The most common cases use the default or workbook option to use the value in the current workbook. | -|Location comes from| The location field should be specified if you're opening a specific workbook resource. If location isn't specified, finding the workbook content is slower. If you know the location, specify it. If you don't know the location or are opening a template with no specific location, leave this field as `Default`.| -|Pass specific parameters to template| Select to pass specific parameters to the template. If selected, only the specified parameters are passed to the template or else all the parameters in the current workbook are passed to the template. In that case, the parameter *names* must be the same in both workbooks for this parameter value to work.| -|Workbook Template Parameters| This section defines the parameters that are passed to the target template. The name should match with the name of the parameter in the target template. Select from **Cell**, **Column**, **Parameter**, and **Static Value**. The name and value must not be empty to pass that parameter to the target template.| --For each of the preceding settings, you must choose where the value in the linked workbook comes from. See [Link sources](#link-sources). --When the workbook link is opened, the new workbook view is passed to all the values configured from the preceding settings. -<!-- convertborder later --> -<!-- convertborder later --> --## Link sources --| Source | Description | -|:- |:-| -|Cell| Use the value in that cell in the grid as the link value. | -|Column| When selected, a field appears where you can select another column in the grid. The value of that column for the row is used in the link value. This link value is commonly used to enable each row of a grid to open a different template by setting the **Template Id** field to **column**. Or it's used to open the same workbook template for different resources, if the **Workbook resources** field is set to a column that contains an Azure Resource ID. | -|Parameter| When selected, a field appears where you can select a parameter. The value of that parameter is used for the value when the link is selected. | -|Static Value| When selected, a field appears where you can enter a static value that's used in the linked workbook. This value is commonly used when all the rows in the grid use the same value for a field. | -|Component| Use the value set in the current component of the workbook. It's common in query and metrics components to set the workbook resources in the linked workbook to those resources used in the query/metrics component, not the current workbook. | -|Workbook| Use the value set in the current workbook. | -|Default| Use the default value that would be used if no value were specified. This situation is common for **Gallery Type comes from**, where the default gallery would be set by the type of the owner resource. | |
| azure-monitor | Workbooks Manage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-manage.md | - Title: Manage Azure Monitor workbooks -description: Understand how to Manage Azure Workbooks -- Previously updated : 01/08/2024---# Manage Azure Monitor Workbooks -This article describes how to manage Azure Workbooks in the Azure portal. --## Save a workbook --Workbooks are shared resources. They require write access to the parent resource group to be saved. --1. In the Azure portal, select the workbook. -2. Select **Save**. -1. Enter the **title**, **subscription**, **resource group**, and **location**. -1. Select **Save**. --By default, the workbook is auto-filled with the same settings, subscription and resource group as the LA workspace. -You can save the workbook directly to shared reports or share the workbook. Keep in mind that the person you want to share with must have permissions to access the workbook as well as to all of the resources referenced in the workbook. --## Share a workbook --When you want to share a workbook or template, keep in mind that the person you want to share with must have permissions to access the workbook as well as to all of the resources referenced in the workbook. They must have an Azure account, and **Monitoring Reader** permissions. -To share a workbook or workbook template: --1. In the Azure portal, select **Monitor**, and then select **Workbooks** from the left pane. -1. Select the checkbox next to the workbook or template you want to share. -1. Select the **Share** icon from the top toolbar. -1. The **Share workbook** or **Share template** window opens with a URL to use for sharing the workbook. -1. Copy the link to share the workbook, or select **Share link via email** to open your default mail app. ---## Delete a workbook --1. In the Azure portal, select **Monitor**, and then select **Workbooks** from the left pane. -1. Select the checkbox next to the Workbook you want to delete. -1. Select **Delete** from the top toolbar. --## Recover a deleted workbook -When you delete an Azure Workbook, it is soft-deleted and can be recovered by contacting support. After the soft-delete period, the workbook and its content are nonrecoverable and queued for purge completely within 30 days. - -> [!NOTE] -> Workbooks that were saved using bring your own storage cannot be recovered by support. You may be able to recover the workbook content from the storage account if the storage account used has enabled soft delete. --## Set up Auto refresh --1. In the Azure portal, select the workbook. -1. Select **Auto refresh**, and then to select from a list of intervals for the auto-refresh. The workbook will start refreshing after the selected time interval. --- Auto refresh only applies when the workbook is in read mode. If a user sets an interval of 5 minutes and after 4 minutes switches to edit mode, refreshing doesn't occur if the user is still in edit mode. But if the user returns to read mode, the interval of 5 minutes resets and the workbook will be refreshed after 5 minutes.-- Selecting **Auto refresh** in read mode also resets the interval. If a user sets the interval to 5 minutes and after 3 minutes the user selects **Auto refresh** to manually refresh the workbook, the **Auto refresh** interval resets and the workbook will be auto-refreshed after 5 minutes.-- The **Auto refresh** setting isn't saved with the workbook. Every time a user opens a workbook, **Auto refresh** is **Off** and needs to be set again.-- Switching workbooks and going out of the gallery clears the **Auto refresh** interval.----## Manage workbook resources --In the **Resources** section of the **Settings** tab, you can manage the resources in your workbook. --- The workbook is saved in the resource marked as the **Owner**. When you browse workbooks, this is the location of the workbooks and templates you see when browsing. Select **Browse across galleries** to see the workbooks for all your resources.-- The owner resource can't be removed.-- Select **Add Resources** to add a default resource. -- Select **Remove Selected Resources** to remove resources by selecting a resource or several resources. -- When you're finished adding and removing resources, select **Apply Changes**.--## Manage workbook versions ---The versions tab contains a list of all the available versions of this workbook. Select a version and use the toolbar to compare, view, or restore versions. Previous workbook versions are available for 90 days. -- **Compare**: Compares the JSON of the previous workbook to the most recently saved version.-- **View**: Opens the selected version of the workbook in a context pane.-- **Restore**: Saves a new copy of the workbook with the contents of the selected version and overwrites any existing current content. You're prompted to confirm this action.--### Compare versions ---> [!NOTE] -> Version history isn't available for [bring-your-own-storage](workbooks-bring-your-own-storage.md) workbooks. --## Manage workbook styles -On this tab, you can set a padding and spacing style for the whole workbook. The possible options are **Wide**, **Standard**, **Narrow**, and **None**. The default style setting is **Standard**. --## Pinning workbooks --You can pin text, query, or metrics components in a workbook by using the **Pin** button on those items while the workbook is in pin mode. Or you can use the **Pin** button if the workbook author enabled settings for that element to make it visible. --While in pin mode, you can select **Pin Workbook** to pin a component from this workbook to a dashboard. Select **Link to Workbook** to pin a static link to this workbook on your dashboard. You can choose a specific component in your workbook to pin. --To access pin mode, select **Edit** to enter editing mode. Select **Pin** on the top bar. An individual **Pin** then appears above each corresponding workbook part's **Edit** button on the right side of the screen. ---> [!NOTE] -> The state of the workbook is saved at the time of the pin. Pinned workbooks on a dashboard won't update if the underlying workbook is modified. To update a pinned workbook part, you must delete and re-pin that part. --### Time ranges for pinned queries --Pinned workbook query parts respect the dashboard's time range if the pinned item is configured to use a *TimeRange* parameter. The dashboard's time range value is used as the time range parameter's value. Any change of the dashboard time range causes the pinned item to update. If a pinned part is using the dashboard's time range, the subtitle of the pinned part updates to show the dashboard's time range whenever the time range changes. --Pinned workbook parts using a time range parameter auto-refresh at a rate determined by the dashboard's time range. The last time the query ran appears in the subtitle of the pinned part. --If a pinned component has an explicitly set time range and doesn't use a time range parameter, that time range is always used for the dashboard, regardless of the dashboard's settings. The subtitle of the pinned part doesn't show the dashboard's time range. The query doesn't auto-refresh on the dashboard. The subtitle shows the last time the query executed. --> [!NOTE] -> Queries that use the *merge* data source aren't currently supported when pinning to dashboards. --### Enable Trusted hosts --Enable a trusted source or mark this workbook as trusted in this browser. --| Control | Definition | -| -- | -- | -| Mark workbook as trusted | If enabled, this workbook can call any endpoint, whether the host is marked as trusted or not. A workbook is trusted if it's a new workbook, an existing workbook that's saved, or is explicitly marked as a trusted workbook. | -| URL grid | A grid to explicitly add trusted hosts. | |
| azure-monitor | Workbooks Map Visualizations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-map-visualizations.md | - Title: Azure Workbooks map visualizations -description: Learn about Azure Workbooks map visualizations. -- Previously updated : 06/21/2023---# Map visualization --Azure Workbooks map visualizations aid in pinpointing issues in specific regions and showing high-level aggregated views of the monitoring data. Maps aggregate all the data mapped to each location or country/region. --The following screenshot shows the total transactions and end-to-end latency for different storage accounts. Here the size is determined by the total number of transactions. The color metrics below the map show the end-to-end latency. --At first glance, the number of transactions in the **West US** region is small compared to the **East US** region. But the end-to-end latency for the **West US** region is higher than the **East US** region. This information provides initial insight that something is amiss for **West US**. -<!-- convertborder later --> --## Add a map --A map can be visualized if the underlying data or metrics have: --- Latitude/longitude information.-- Azure resource information.-- Azure location information.-- Country/region, name, or country/region code.--### Use an Azure location --1. Switch the workbook to edit mode by selecting **Edit**. -1. Select **Add** > **Add query**. -1. Change **Data Source** to **Azure Resource Graph**. Then select any subscription that has a storage account. -1. Enter the following query for your analysis and then select **Run Query**. -- ```kusto - where type =~ 'microsoft.storage/storageaccounts' - | summarize count() by location - ``` --1. Set **Size** to `Large`. -1. Set **Visualization** to `Map`. -1. All the settings will be autopopulated. For custom settings, select **Map Settings** to open the settings pane. -1. The following screenshot of the map visualization shows storage accounts for each Azure region for the selected subscription. -<!-- convertborder later --> --### Use an Azure resource --1. Switch the workbook to edit mode by selecting **Edit**. -1. Select **Add** > **Add Metric**. -1. Use a subscription that has storage accounts. -1. Change **Resource Type** to `storage account`. In **Resource**, select multiple storage accounts. -1. Select **Add Metric** and add a transaction metric: - 1. **Namespace**: `Account` - 1. **Metric**: `Transactions` - 1. **Aggregation**: `Sum` - <!-- convertborder later --> - :::image type="content" source="./media/workbooks-map-visualizations/map-transaction-metric.png" lightbox="./media/workbooks-map-visualizations/map-transaction-metric.png" alt-text="Screenshot that shows a transaction metric." border="false"::: -1. Select **Add Metric** and add the **Success E2E Latency** metric. - 1. **Namespace**: `Account` - 1. **Metric**: `Success E2E Latency` - 1. **Aggregation**: `Average` - <!-- convertborder later --> - :::image type="content" source="./media/workbooks-map-visualizations/map-e2e-latency-metric.png" lightbox="./media/workbooks-map-visualizations/map-e2e-latency-metric.png" alt-text="Screenshot that shows a success end-to-end latency metric." border="false"::: -1. Set **Size** to `Large`. -1. Set **Visualization** to `Map`. -1. In **Map Settings**, set: - 1. **Location info using**: `Azure Resource` - 1. **Azure resource field**: `Name` - 1. **Size by**: `microsoft.storage/storageaccounts-Transaction-Transactions` - 1. **Aggregation for location**: `Sum of values` - 1. **Coloring type**: `Heatmap` - 1. **Color by**: `microsoft.storage/storageaccounts-Transaction-SuccessE2ELatency` - 1. **Aggregation for color**: `Sum of values` - 1. **Color palette**: `Green to Red` - 1. **Minimum value**: `0` - 1. **Metric value**: `microsoft.storage/storageaccounts-Transaction-SuccessE2ELatency` - 1. **Aggregate other metrics by**: `Sum of values` - 1. Select the **Custom formatting** checkbox. - 1. **Unit**: `Milliseconds` - 1. **Style**: `Decimal` - 1. **Maximum fractional digits**: `2` --### Use country/region --1. Switch the workbook to edit mode by selecting **Edit**. -1. Select **Add** > **Add query**. -1. Change **Data source** to `Log`. -1. Select **Resource type** as `Application Insights`. Then select any Application Insights resource that has `pageViews` data. -1. Use the query editor to enter the KQL for your analysis and select **Run Query**. -- ```kusto - pageViews - | project duration, itemCount, client_CountryOrRegion - | limit 20 - ``` --1. Set **Size** to `Large`. -1. Set **Visualization** to `Map`. -1. All the settings will be autopopulated. For custom settings, select **Map Settings**. --### Use latitude/location --1. Switch the workbook to edit mode by selecting **Edit**. -1. Select **Add** > **Add query**. -1. Change **Data source** to `JSON`. -1. Enter the JSON data in the query editor and select **Run Query**. -1. Set **Size** values to `Large`. -1. Set **Visualization** to `Map`. -1. In **Map Settings** under **Metric Settings**, set **Metric Label** to `displayName`. Then select **Save and Close**. --The following map visualization shows users for each latitude and longitude location with the selected label for metrics. -<!-- convertborder later --> --## Map settings --Map settings include layout, color, and metrics. --### Layout settings --| Setting | Description | -|:-|:-| -| `Location info using` | Select a way to get the location of items shown on the map. <br> **Latitude/Longitude**: Select this option if there are columns with latitude and longitude information. Each row with latitude and longitude data will be shown as a distinct item on the map. <br> **Azure location**: Select this option if there's a column that has Azure location (eastus, westeurope, centralindia) information. Specify that column and it will fetch the corresponding latitude and longitude for each Azure location. It will group the same location rows together based on the aggregation specified to show the locations on the map. <br> **Azure resource**: Select this option if there's a column that has Azure resource information such as an Azure Storage account and an Azure Cosmos DB account. Specify that column and it will fetch the corresponding latitude and longitude for each Azure resource. It will group the same location (Azure location) rows together based on the aggregation specified to show the locations on the map. <br> **Country/Region**: Select this option if there's a column that has country/region name/code (US, United States, IN, India, CN, China) information. Specify that column and it will fetch the corresponding latitude and longitude for each country/region/code. It will group rows together with the same Country-Region Code/Country-Region Name to show the locations on the map. Country Name and Country Code won't be grouped together as a single entity on the map. -| `Latitude/Longitude` | These two options will be visible if the `Location Info` field value is **Latitude/Longitude**. Select the column that has latitude in the `Latitude` field and longitude in the `Longitude` field, respectively. | -| `Azure location field` | This option will be visible if the `Location Info` field value is **Azure location**. Select the column that has the Azure location information. | -| `Azure resource field` | This option will be visible if the `Location Info` field value is **Azure resource**. Select the column that has the Azure resource information. | -| `Country/Region field` | This option will be visible if the `Location Info` field value is **Country/Region**. Select the column that has the country/region information. | -| `Size by` | This option controls the size of the items shown on the map. Size depends on the value in the column specified by the user. Currently, the radius of the circle is directly proportional to the square root of the column's value. If **None** is selected, all the circles will show the default region size.| -| `Aggregation for location` | This field specifies how to aggregate the `Size by` columns that have the same Azure Location/Azure Resource/Country-Region. | -| `Minimum region size` | This field specifies the minimum radius of the item shown on the map. It's used when there's a significant difference between the `Size by` column's values, which causes smaller items to be hardly visible on the map. | -| `Maximum region size` | This field specifies the maximum radius of the item shown on the map. It's used when the `Size by` column's values are extremely large and they're covering a huge area of the map.| -| `Default region size` | This field specifies the default radius of the item shown on the map. The default radius is used when the `Size by` column is **None** or the value is 0.| -| `Minimum value` | The minimum value used to compute region size. If not specified, the minimum value will be the smallest value after aggregation. | -| `Maximum value` | The maximum value used to compute region size. If not specified, the maximum value will be the largest value after aggregation.| -| `Opacity of items on Map` | This field specifies the transparency of items shown on the map. Opacity of 1 means no transparency. Opacity of 0 means that items won't be visible on the map. If there are too many items on the map, opacity can be set to a low value so that all the overlapping items are visible.| --### Color settings --| Coloring type | Description | -|:- |:-| -| `None` | All nodes have the same color. | -| `Thresholds` | In this type, cell colors are set by threshold rules, for example, _CPU > 90% => Red, 60% > CPU > 90% => Yellow, CPU < 60% => Green_. <ul><li> `Color by`: The value of this column will be used by Thresholds/Heatmap logic.</li> <li>`Aggregation for color`: This field specifies how to aggregate the `Color by` columns that have the same Azure Location/Azure Resource/Country-Region. </li> <ul> | -| `Heatmap` | In this type, the cells are colored based on the color palette and `Color by` field. This type will also have the same `Color by` and `Aggregation for color` options as thresholds. | --### Metric settings --| Setting | Description | -|:- |:-| -| `Metric Label` | This option will be visible if the `Location Info` field value is **Latitude/Longitude**. With this feature, you can pick the label to show for the metrics shown below the map. | -| `Metric Value` | This field specifies a metric value to be shown below the map. | -| `Create 'Others' group after` | This field specifies the limit before an "Others" group is created. | -| `Aggregate 'Others' metrics by` | This field specifies the aggregation used for an "Others" group if it's shown. | -| `Custom formatting` | Use this field to set units, style, and formatting options for number values. This setting is the same as a [grid's custom formatting](../visualize/workbooks-grid-visualizations.md#custom-formatting).| --## Next steps --Learn how to create [honeycomb visualizations in workbooks](../visualize/workbooks-honey-comb.md). |
| azure-monitor | Workbooks Move Region | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-move-region.md | - Title: Azure Monitor Workbooks - Move Regions -description: How to move a workbook to a different region --- Previously updated : 06/21/2023---#Customer intent: As an Azure service administrator, I want to move my resources to another Azure region ---# Move an Azure Workbook to another region --This article describes how to move Azure Workbook resources to a different Azure region. You might move your resources to another region for a number of reasons. For example, to take advantage of a new Azure region, to deploy features or services available in specific regions only, to meet internal policy and governance requirements, or in response to capacity planning requirements. --## Prerequisites --* Ensure that workbooks are supported in the target region. --* These instructions apply to workbooks (`microsoft.insights/workbooks`) saved in Azure Monitor and on most resource types. -- However, for workbooks specifically linked to the Application Insights resource type, those workbooks are stored in the Azure region where the Application Insights resource is saved. -- Those workbooks cannot be individually moved to another region. --## Move --The simplest way to move an Azure Workbook is to use "Save as" in the Workbooks tool in the Portal UI: --1. Open the target workbook in the workbook viewer. -2. Use the "Edit" toolbar button to enter edit mode. -3. Use the "Save As" toolbar button. -4. In the Save form, choose a name and the desired region for the workbook. Ensure the other fields for subscription, resource group, and sharing are appropriate. -- > [!NOTE] - > You may need to use a new name for the workbook to avoid any duplicate names. --5. Save. --## Verify --Use the Azure Workbooks browse UI to locate the new workbook. Ensure the location is the target location. --## Clean up --Once your workbook has been created in the new region, delete the original workbook in the previous region. -1. Open the original workbook in the workbook viewer. -2. Use the "Edit" toolbar button to enter edit mode. -3. From the edit tools dropdown (pencil icon), choose "Delete Workbook". --If you renamed your workbook to import it into a new region, you can rename the workbook to the previous name after the original workbook has been deleted by using the Edit Mode toolbar's edit tools dropdown "Rename" item. --## Next Steps --Need to move a workbook template instead of a workbook? See how to [move an Azure Workbook Template to another region](./workbook-templates-move-region.md). --See how to [deploy Workbooks and Workbook Templates](../visualize/workbooks-automate.md) via ARM Templates. |
| azure-monitor | Workbooks Multi Value | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-multi-value.md | - Title: Azure Workbooks multi-value parameters -description: Learn about adding multi-value parameters to your workbook. ---- Previously updated : 06/21/2023----# Multi-value parameters --A multi-value parameter allows the user to set one or more arbitrary text values. Multi-value parameters are commonly used for filtering, often when a dropdown control might contain too many values to be useful. --## Create a static multi-value parameter --1. Start with an empty workbook in edit mode. -1. Select **Add parameters** > **Add Parameter**. -1. In the new parameter pane that opens, enter: - - **Parameter name**: `Filter` - - **Parameter type**: `Multi-value` - - **Required**: `unchecked` - - **Get data from**: `None` -1. Select **Save** to create the parameter. -1. The **Filter** parameter will be a multi-value parameter, initially with no values. -- :::image type="content" source="media/workbooks-multi-value/workbooks-multi-value-create.png" alt-text="Screenshot that shows the creation of a multi-value parameter in a workbook."::: --1. You can then add multiple values. -- :::image type="content" source="media/workbooks-multi-value/workbooks-multi-value-third-value.png" alt-text="Screenshot that shows adding a third value in a workbook."::: --A multi-value parameter behaves similarly to a multi-select [dropdown parameter](workbooks-dropdowns.md) and is commonly used in an "in"-like scenario. --``` - let computerFilter = dynamic([{Computer}]); - Heartbeat - | where array_length(computerFilter) == 0 or Computer in (computerFilter) - | summarize Heartbeats = count() by Computer - | order by Heartbeats desc -``` --## Parameter field style --A multi-value parameter supports the following field styles: --1. **Standard**: Allows you to add or remove arbitrary text items. -- :::image type="content" source="media/workbooks-multi-value/workbooks-multi-value-standard.png" alt-text="Screenshot that shows the workbook standard multi-value field."::: --1. **Password**: Allows you to add or remove arbitrary password fields. The password values are only hidden in the UI when you type. The values are still fully accessible as a parameter value when referred. They're stored unencrypted when the workbook is saved. -- :::image type="content" source="media/workbooks-multi-value/workbooks-multi-value-password.png" alt-text="Screenshot that shows a workbook password multi-value field."::: --## Create a multi-value parameter with initial values --You can use a query to seed the multi-value parameter with initial values. You can then manually remove values or add more values. If a query is used to populate the multi-value parameter, a restore defaults button appears on the parameter to restore back to the originally queried values. --1. Start with an empty workbook in edit mode. -1. Select **Add parameters** > **Add Parameter**. -1. In the new parameter pane that opens, enter: - - **Parameter name**: `Filter` - - **Parameter type**: `Multi-value` - - **Required**: `unchecked` - - **Get data from**: `JSON` -1. In the **JSON Input** text block, insert this JSON snippet: -- ``` - ["apple", "banana", "carrot" ] - ``` -- All the items that are the result of the query are shown as multi-value items. - You aren't limited to JSON. You can use any query provider to provide initial values, but you'll be limited to the first 100 results. -1. Select **Run Query**. -1. Select **Save** to create the parameter. -1. The **Filter** parameter will be a multi-value parameter with three initial values. -- :::image type="content" source="media/workbooks-multi-value/workbooks-multi-value-initial-values.png" alt-text="Screenshot that shows the creation of a dynamic dropdown in a workbook."::: --## Next steps --- [Workbook parameters](workbooks-parameters.md)-- [Workbook dropdown parameters](workbooks-dropdowns.md) |
| azure-monitor | Workbooks Options Group | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-options-group.md | - Title: Azure Workbooks options group parameters -description: Learn about adding options group parameters to your Azure workbook. ---- Previously updated : 06/21/2023----# Options group parameters --When you use an options group parameter, you can select one value from a known set. For example, you can select one of your app's requests. If you're working with a few values, an options group can be a better choice than a [dropdown parameter](workbooks-dropdowns.md). You can see all the possible values and see which one is selected. --Options groups are commonly used for yes/no or on/off style choices. When there are many possible values, using a dropdown list is a better choice. Unlike dropdown parameters, an options group always allows only one selected value. --You can specify the list by: --- Providing a static list in the parameter setting.-- Using a KQL query to retrieve the list dynamically.--## Create a static options group parameter --1. Start with an empty workbook in edit mode. -1. Select **Add parameters** > **Add Parameter**. -1. In the new parameter pane that opens, enter: - - **Parameter name**: `Environment` - - **Parameter type**: `Options Group` - - **Required**: `checked` - - **Get data from**: `JSON` -1. In the **JSON Input** text block, insert this JSON snippet: -- ```json - [ - { "value":"dev", "label":"Development" }, - { "value":"ppe", "label":"Pre-production" }, - { "value":"prod", "label":"Production", "selected":true } - ] - ``` -- You aren't limited to JSON. You can use any query provider to provide initial values, but you'll be limited to the first 100 results. -1. Select **Update**. -1. Select **Save** to create the parameter. -1. The **Environment** parameter will be an options group control with the three values. -- :::image type="content" source="media/workbooks-options-group/workbooks-options-group-create.png" alt-text="Screenshot that shows the creation of a static options group in a workbook."::: --## Next steps --- [Workbook parameters](workbooks-parameters.md)-- [Workbook dropdown parameters](workbooks-dropdowns.md) |
| azure-monitor | Workbooks Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-overview.md | - Title: Azure Workbooks overview -description: Learn how workbooks provide a flexible canvas for data analysis and the creation of rich visual reports within the Azure portal. ---- Previously updated : 06/21/2023----# Azure Workbooks --Workbooks provide a flexible canvas for data analysis and the creation of rich visual reports within the Azure portal. They allow you to tap into multiple data sources from across Azure and combine them into unified interactive experiences. Workbooks let you combine multiple kinds of visualizations and analyses, making them great for freeform exploration. --Workbooks combine text,ΓÇ»[log queries](/azure/data-explorer/kusto/query/), metrics, and parameters into rich interactive reports. --Workbooks are helpful for scenarios such as: --- Exploring the usage of your virtual machine when you don't know the metrics of interest in advance. You can discover metrics for CPU utilization, disk space, memory, and network dependencies.-- Explaining to your team how a recently provisioned VM is performing. You can show metrics for key counters and other log events.-- Sharing the results of a resizing experiment of your VM with other members of your team. You can explain the goals for the experiment with text. Then you can show each usage metric and the analytics queries used to evaluate the experiment, along with clear call-outs for whether each metric was above or below target.-- Reporting the impact of an outage on the usage of your VM. You can combine data, text explanation, and a discussion of next steps to prevent outages in the future.--Watch this video to see how you can use Azure Workbooks to get insights and visualize your data. -> [!VIDEO https://www.microsoft.com/en-us/videoplayer/embed/RE5a1su] --## Accessing Azure Workbooks --You can get to Azure workbooks in a few ways: --- In the [Azure portal](https://portal.azure.com), select **Monitor** > **Workbooks** from the menu bars on the left.-- :::image type="content" source="./media/workbooks-overview/workbooks-menu.png" alt-text="Screenshot that shows Workbooks in the menu."::: --- In a **Log Analytics workspaces** page, select **Workbooks** at the top of the page.-- :::image type="content" source="media/workbooks-overview/workbooks-log-analytics-icon.png" alt-text="Screenshot of Workbooks on the Log Analytics workspaces page."::: --When the gallery opens, select a saved workbook or a template. You can also search for a name in the search box. --## The gallery --The gallery lists all the saved workbooks and templates in your current environment. Select **Browse across galleries** to see the workbooks for all your resources. ---#### Gallery tabs --There are four tabs in the gallery to help organize workbook types. --| Tab | Description | -||| -| All | Shows the top four items for workbooks, public templates, and my templates. Workbooks are sorted by modified date, so you'll see the most recent eight modified workbooks.| -| Workbooks | Shows the list of all the available workbooks that you created or are shared with you. | -| Public Templates | Shows the list of all the available ready to use, get started functional workbook templates published by Microsoft. Grouped by category. | -| My Templates | Shows the list of all the available deployed workbook templates that you created or are shared with you. Grouped by category. | --## Data sources --Workbooks can query data from multiple Azure sources. You can transform this data to provide insights into the availability, performance, usage, and overall health of the underlying components. For example, you can: --- Analyze performance logs from virtual machines to identify high CPU or low memory instances and display the results as a grid in an interactive report.-- Combine data from several different sources within a single report. You can create composite resource views or joins across resources to gain richer data and insights that would otherwise be impossible.--For more information about the supported data sources, see [Azure Workbooks data sources](workbooks-data-sources.md). --## Visualizations --Workbooks provide a rich set of capabilities for visualizing your data. Each data source and result set support visualizations that are most useful for that data. For more information about the visualizations, see [Workbook visualizations](workbooks-visualizations.md). ---## Access control --Users must have the appropriate permissions to view or edit a workbook. Workbook permissions are based on the permissions the user has for the resources included in the workbooks. --Standard Azure roles that provide access to workbooks: --- [Monitoring Reader](../../role-based-access-control/built-in-roles.md#monitoring-reader) includes standard `/read` privileges that would be used by monitoring tools (including workbooks) to read data from resources.--For custom roles, you must add `microsoft.insights/workbooks/write` to the user's permissions to edit and save a workbook. For more information, see the [Workbook Contributor](../../role-based-access-control/built-in-roles.md#monitoring-contributor) role. ---## Next steps --[Create an Azure Workbook](workbooks-create-workbook.md) |
| azure-monitor | Workbooks Parameters | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-parameters.md | - Title: Create workbook parameters -description: Learn how to add parameters to your workbook to collect input from the consumers and reference it in other parts of the workbook. -- Previously updated : 06/21/2023---# Workbook parameters --By using parameters, you can collect input from consumers and reference it in other parts of a workbook. It's usually used to scope the result set or set the right visual. You can build interactive reports and experiences by using this key capability. --When you use workbooks, you can control how your parameter controls are presented to consumers. They can be text box versus dropdown list, single- versus multi-select, and values from text, JSON, KQL, or Azure Resource Graph. --Supported parameter types include: --* [Time](workbooks-time.md): Allows you to select from pre-populated time ranges or select a custom range -* [Drop down](workbooks-dropdowns.md): Allows you to select from a value or set of values -* [Options group](workbooks-options-group.md): Allows you to select one value from a known set -* [Text](workbooks-text.md): Allows you to enter arbitrary text -* [Criteria](workbooks-criteria.md): Allows you to define a set of criteria based on previously specified parameters, which will be evaluated to provide a dynamic value -* [Resource](workbooks-resources.md): Allows you to select one or more Azure resources -* [Subscription](workbooks-resources.md): Allows you to select one or more Azure subscription resources -* [Multi-value](workbooks-multi-value.md): Allows you to set one or more arbitrary text values -* Resource type: Allows you to select one or more Azure resource type values -* Location: Allows you to select one or more Azure location values --## Reference a parameter --You can reference parameter values from other parts of workbooks either by using bindings or value expansions. --### Reference a parameter with bindings --This example shows how to reference a time range parameter with bindings: --1. Select **Add query** to add a query control, and then select an Application Insights resource. -1. Open the **Time Range** dropdown list and select the **Time Range** option from the **Parameters** section at the bottom: - - This option binds the time range parameter to the time range of the chart. - - The time scope of the sample query is now **Last 24 hours**. -1. Run the query to see the results. -- :::image type="content" source="media/workbooks-parameters/workbooks-time-binding.png" alt-text="Screenshot that shows a time range parameter referenced via bindings."::: --### Reference a parameter with KQL --This example shows how to reference a time range parameter with KQL: --1. Select **Add query** to add a query control, and then select an Application Insights resource. -1. In the KQL, enter a time scope filter by using the parameter `| where timestamp {TimeRange}`: - - This parameter expands on query evaluation time to `| where timestamp > ago(1d)`. - - This option is the time range value of the parameter. -1. Run the query to see the results. -- :::image type="content" source="media/workbooks-parameters/workbooks-time-in-code.png" alt-text="Screenshot that shows a time range referenced in the KQL query."::: --### Reference a parameter with text --This example shows how to reference a time range parameter with text: --1. Add a text control to the workbook. -1. In the Markdown, enter `The chosen time range is {TimeRange:label}`. -1. Select **Done Editing**. -1. The text control shows the text *The chosen time range is Last 24 hours*. --## Parameter formatting options - -Each parameter type has its own formatting options. Use the **Previews** section of the **Edit Parameter** pane to see the formatting expansion options for your parameter. -- :::image type="content" source="media/workbooks-parameters/workbooks-time-settings.png" alt-text="Screenshot that shows time range parameter options."::: --You can use these options to format all parameter types except for **Time range picker**. For examples of formatting times, see [Time parameter options](workbooks-time.md#time-parameter-options). --Other parameter types include: -- - **Resource picker**: Resource IDs are formatted. - - **Subscription picker**: Subscription values are formatted. --### Convert toml to json --**Syntax**: `{param:tomltojson}` --**Original value**: --``` -name = "Sam Green" --[address] -state = "New York" -country = "USA" -``` --**Formatted value**: --``` -{ - "name": "Sam Green", - "address": { - "state": "New York", - "country": "USA" - } -} -``` --### Escape JSON --**Syntax**: `{param:escapejson}` --**Original value**: --``` -{ - "name": "Sam Green", - "address": { - "state": "New York", - "country": "USA" - } -} -``` --**Formatted value**: --``` -{\r\n\t\"name\": \"Sam Green\",\r\n\t\"address\": {\r\n\t\t\"state\": \"New York\",\r\n\t\t\"country\": \"USA\"\r\n }\r\n} -``` --### Encode text to base64 --**Syntax**: `{param:base64}` --**Original value**: --``` -Sample text to test base64 encoding -``` --**Formatted value**: --``` -U2FtcGxlIHRleHQgdG8gdGVzdCBiYXNlNjQgZW5jb2Rpbmc= -``` --## Format parameters by using JSONPath --For string parameters that are JSON content, you can use [JSONPath](workbooks-jsonpath.md) in the parameter format string. --For example, you might have a string parameter named `selection` that was the result of a query or selection in a visualization that has the following value: --```json -{ "series":"Failures", "x": 5, "y": 10 } -``` --By using JSONPath, you could get individual values from that object: --Format | Result -| -`{selection:$.series}` | `Failures` -`{selection:$.x}` | `5` -`{selection:$.y}`| `10` --> [!NOTE] -> If the parameter value isn't valid JSON, the result of the format will be an empty value. --## Parameter style --The following styles are available for the parameters. --### Pills --Pills style is the default style. The parameters look like text and require the user to select them once to go into the edit mode. -- :::image type="content" source="media/workbooks-parameters/workbooks-pills-read-mode.png" alt-text="Screenshot that shows Azure Workbooks pills-style read mode."::: -- :::image type="content" source="media/workbooks-parameters/workbooks-pills-edit-mode.png" alt-text="Screenshot that shows Azure Workbooks pills-style edit mode."::: --### Standard --In standard style, the controls are always visible, with a label above the control. -- :::image type="content" source="media/workbooks-parameters/workbooks-standard.png" alt-text="Screenshot that shows Azure Workbooks standard style."::: --### Form horizontal --In form horizontal style, the controls are always visible, with the label on the left side of the control. -- :::image type="content" source="media/workbooks-parameters/workbooks-form-horizontal.png" alt-text="Screenshot that shows Azure Workbooks form horizontal style."::: --### Form vertical --In form vertical style, the controls are always visible, with the label above the control. Unlike standard style, there's only one label or control in one row. -- :::image type="content" source="media/workbooks-parameters/workbooks-form-vertical.png" alt-text="Screenshot that shows Azure Workbooks form vertical style."::: - -> [!NOTE] -> In standard, form horizontal, and form vertical layouts, there's no concept of inline editing. The controls are always in edit mode. --## Global parameters --Now that you've learned how parameters work, and the limitations about only being able to use a parameter "downstream" of where it's set, it's time to learn about global parameters, which change those rules. --With a global parameter, the parameter must still be declared before it can be used. But any step that sets a value to that parameter will affect all instances of that parameter in the workbook. --> [!NOTE] -> Because changing a global parameter has this "update all" behavior, the global setting should only be turned on for parameters that require this behavior. A combination of global parameters that depend on each other can create a cycle or oscillation where the competing globals change each other over and over. To avoid cycles, you can't "redeclare" a parameter that's been declared as global. Any subsequent declarations of a parameter with the same name will create a read-only parameter that can't be edited in that place. --Common uses of global parameters: --1. Synchronize time ranges between many charts: - - Without a global parameter, any time range brush in a chart will only be exported after that chart. So, selecting a time range in the third chart will only update the fourth chart. - - With a global parameter, you can create a global **timeRange** parameter, give it a default value, and have all the other charts use that as their bound time range and time brush output. In addition, set the **Only export the parameter when a range is brushed** setting. Any change of time range in any chart updates the global **timeRange** parameter at the top of the workbook. This functionality can be used to make a workbook act like a dashboard. --1. Allow changing the selected tab in a links step via links or buttons: - - Without a global parameter, the links step only outputs a parameter for the selected tab. - - With a global parameter, you can create a global **selectedTab** parameter. Then you can use that parameter name in the tab selections in the links step. You can pass that parameter value into the workbook from a link or by using another button or link to change the selected tab. Using buttons from a links step in this way can make a wizard-like experience, where buttons at the bottom of a step can affect the visible sections above it. --### Create a global parameter --When you create the parameter in a parameters step, use the **Treat this parameter as a global** option in **Advanced Settings**. The only way to make a global parameter is to declare it with a parameters step. The other methods of creating parameters, via selections, brushing, links, buttons, and tabs, can only update a global parameter. They can't declare one themselves. -- :::image type="content" source="media/workbooks-parameters/workbooks-parameters-global-setting.png" alt-text="Screenshot that shows setting global parameters in a workbook."::: --The parameter will be available and function as normal parameters do. --### Update the value of an existing global parameter --For the chart example, the most common way to update a global parameter is by using time brushing. --In this example, the **timerange** parameter is declared as global. In a query step below that, create and run a query that uses that **timerange** parameter in the query and returns a time chart result. In **Advanced Settings** for the query step, enable the time range brushing setting. Use the same parameter name as the output for the time brush parameter. Also, select the **Only export the parameter when a range is brushed** option. -- :::image type="content" source="media/workbooks-parameters/workbooks-global-time-range-brush.png" alt-text="Screenshot that shows the global time brush setting in a workbook."::: --Whenever a time range is brushed in this chart, it also updates the **timerange** parameter above this query, and the query step itself, because it also depends on **timerange**. -- 1. Before brushing: - - - The time range is shown as **Last hour**. - - The chart shows the last hour of data. -- :::image type="content" source="media/workbooks-parameters/workbooks-global-before-brush.png" alt-text="Screenshot that shows setting global parameters before brushing."::: -- 1. During brushing: - - - The time range is still the last hour, and the brushing outlines are drawn. - - No parameters have changed. After you let go of the brush, the time range is updated. -- :::image type="content" source="media/workbooks-parameters/workbooks-global-during-brush.png" alt-text="Screenshot that shows setting global parameters during brushing."::: -- - 1. After brushing: -- - The time range specified by the time brush is set by this step. It overrides the global value. The **timerange** dropdown list now displays that custom time range. - - Because the global value at the top has changed, and because this chart depends on **timerange** as an input, the time range of the query used in the chart also updates. As a result, the query and the chart will update. - - Any other steps in the workbook that depend on **timerange** will also update. -- :::image type="content" source="media/workbooks-parameters/workbooks-global-after-brush.png" alt-text="Screenshot that shows setting global parameters after brushing."::: -- > [!NOTE] - > If you don't use a global parameter, the **timerange** parameter value will only change below this query step. Things above this step or this item itself won't update. |
| azure-monitor | Workbooks Renderers | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-renderers.md | - Title: Azure Workbooks rendering options -description: Learn about all the Azure Monitor workbook rendering options. -- Previously updated : 06/21/2023----# Rendering options --This article describes the Azure Workbooks rendering options you can use with grids, tiles, and graphs to produce visualizations in optimal format. --## Column renderers --| Column renderer | Description | More options | -|:- |:-|:-| -| Automatic | The default. Uses the most appropriate renderer based on the column type. | | -| Text| Renders the column values as text. | | -| Right aligned| Renders the column values as right-aligned text. | | -| Date/Time| Renders a readable date/time string. | | -| Heatmap| Colors the grid cells based on the value of the cell. | Color palette and min/max value used for scaling. | -| Bar| Renders a bar next to the cell based on the value of the cell. | Color palette and min/max value used for scaling. | -| Bar underneath | Renders a bar near the bottom of the cell based on the value of the cell. | Color palette and min/max value used for scaling. | -| Composite bar| Renders a composite bar by using the specified columns in that row. For more information, see [Composite bar](workbooks-composite-bar.md). | Columns with corresponding colors to render the bar and a label to display at the top of the bar. | -|Spark bars| Renders a spark bar in the cell based on the values of a dynamic array in the cell. An example is the Trend column from the screenshot at the top. | Color palette and min/max value used for scaling. | -|Spark lines| Renders a spark line in the cell based on the values of a dynamic array in the cell. | Color palette and min/max value used for scaling. | -|Icon| Renders icons based on the text values in the cell. Supported values include:<br><ul><li>canceled</li><li>critical</li><li>disabled</li><li>error</li><li>failed</li> <li>info</li><li>none</li><li>pending</li><li>stopped</li><li>question</li><li>success</li><li>unknown</li><li>warning</li><li>uninitialized</li><li>resource</li><li>up</li> <li>down</li><li>left</li><li>right</li><li>trendup</li><li>trenddown</li><li>4</li><li>3</li><li>2</li><li>1</li><li>Sev0</li><li>Sev1</li><li>Sev2</li><li>Sev3</li><li>Sev4</li><li>Fired</li><li>Resolved</li><li>Available</li><li>Unavailable</li><li>Degraded</li><li>Unknown</li><li>Blank</li></ul>| | -| Link | Renders a link when selected or performs a configurable action. Use this setting if you *only* want the item to be a link. Any of the other types of renderers can also be a link by using the **Make this item a link** setting. For more information, see [Link actions](#link-actions). | | -| Location | Renders a friendly Azure region name based on a region ID. | | -| Resource type | Renders a friendly resource type string based on a resource type ID. | | -| Resource| Renders a friendly resource name and link based on a resource ID. | Option to show the resource type icon. | -| Resource group | Renders a friendly resource group name and link based on a resource group ID. If the value of the cell isn't a resource group, it will be converted to one. | Option to show the resource group icon. | -|Subscription| Renders a friendly subscription name and link based on a subscription ID. If the value of the cell isn't a subscription, it will be converted to one. | Option to show the subscription icon. | -|Hidden| Hides the column in the grid. Useful when the default query returns more columns than needed but a project-away isn't desired. | | --## Link actions --If the **Link** renderer is selected or the **Make this item a link** checkbox is selected, you can configure a link action. The action can occur when the user selects the cell to take the user to another view with context coming from the cell or to open a URL. For more information, see link renderer actions. --## Use thresholds with links --The following instructions show you how to use thresholds with links to assign icons and open different workbooks. Each link in the grid opens a different workbook template for that Application Insights resource. --1. Switch the workbook to edit mode by selecting **Edit**. -1. Select **Add** > **Add query**. -1. Change **Data source** to **JSON** and change **Visualization** to **Grid**. -1. Enter this query: -- ```json - [ - { "name": "warning", "link": "Community-Workbooks/Performance/Performance Counter Analysis" }, - { "name": "info", "link": "Community-Workbooks/Performance/Performance Insights" }, - { "name": "error", "link": "Community-Workbooks/Performance/Apdex" } - ] - ``` --1. Run the query. -1. Select **Column Settings** to open the settings. -1. Under **Columns**, select **name**. -1. Under **Column renderer**, select **Thresholds**. -1. Enter and choose the following **Threshold Settings**: -- 1. Keep the **Default** row as is. - 1. Enter whatever text you like. - 1. The **Text** column takes a string format as an input and populates it with the column value and unit if specified. For example, if **warning** is the column value, the text can be `{0} {1} link!`. It will be displayed as `warning link!`. - - | Operator | Value | Icons | - |-||| - | == | warning | Warning | - | == | error | Failed | - <!-- convertborder later --> - :::image type="content" source="./media/workbooks-grid-visualizations/column-settings.png" lightbox="./media/workbooks-grid-visualizations/column-settings.png" alt-text="Screenshot that shows the Edit column settings tab with the preceding settings." border="false"::: - -1. Select the **Make this item a link** checkbox. - - Under **View to open**, select **Workbook (Template)**. - - Under **Link value comes from**, select **link**. - - Select the **Open link in Context pane** checkbox. - - Choose the following settings in **Workbook Link Settings**: - - Under **Template Id comes from**, select **Column**. - - Under **Column**, select **link**. - <!-- convertborder later --> - :::image type="content" source="./media/workbooks-grid-visualizations/make-this-item-a-link.png" lightbox="./media/workbooks-grid-visualizations/make-this-item-a-link.png" alt-text="Screenshot that shows link settings with the preceding settings." border="false"::: --1. Under **Columns**, select **link**. Under **Settings**, next to **Column renderer**, select **(Hide column)**. -1. To change the display name of the **name** column, select the **Labels** tab. On the row with **name** as its **Column ID**, under **Column Label**, enter the name you want displayed. -1. Select **Apply**. - <!-- convertborder later --> - :::image type="content" source="./media/workbooks-grid-visualizations/thresholds-workbooks-links.png" lightbox="./media/workbooks-grid-visualizations/thresholds-workbooks-links.png" alt-text="Screenshot that shows thresholds in a grid with the preceding settings." border="false"::: |
| azure-monitor | Workbooks Resources | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-resources.md | - Title: Azure Monitor workbook resource parameters -description: Learn how to use resource parameters to allow picking of resources in workbooks. Use the resource parameters to set the scope from which to get the data. -- Previously updated : 06/21/2023---# Workbook resource parameters --Resource parameters allow picking of resources in workbooks. This functionality is useful in setting the scope from which to get the data. An example would be allowing you to select the set of VMs, which charts use later when presenting the data. --Values from resource pickers can come from the workbook context, static list, or Azure Resource Graph queries. --> [!NOTE] -> The label for each resource in the resource parameter list is based on the resource id. You cannot replace that name with another value. For clarity, the examples in this document show the label field set to the id, but that value isn't used in the actual parameter. ---## Create a resource parameter (workbook resources) --1. Start with an empty workbook in edit mode. -1. Select **Add parameters** > **Add Parameter**. -1. In the new parameter pane that opens, enter: - 1. **Parameter name**: `Applications` - 1. **Parameter type**: `Resource picker` - 1. **Required**: `checked` - 1. **Allow multiple selections**: `checked` - 1. **Get data from**: `Workbook Resources` - 1. **Include only resource types**: `Application Insights` -1. Select **Save** to create the parameter. -- :::image type="content" source="./media/workbooks-resources/resource-create.png" lightbox="./media/workbooks-resources/resource-create.png" alt-text="Screenshot that shows the creation of a resource parameter by using workbook resources."::: --## Create an Azure Resource Graph resource parameter --1. Start with an empty workbook in edit mode. -1. Select **Add parameters** > **Add Parameter**. -1. In the new parameter pane that opens, enter: - 1. **Parameter name**: `Applications` - 1. **Parameter type**: `Resource picker` - 1. **Required**: `checked` - 1. **Allow multiple selections**: `checked` - 1. **Get data from**: `Query` - 1. **Query Type**: `Azure Resource Graph` - 1. **Subscriptions**: `Use default subscriptions` - 1. In the query control, add this snippet: -- ```kusto - where type == 'microsoft.insights/components' - | project value = id, label = id, selected = false, group = resourceGroup - ``` --1. Select **Save** to create the parameter. -- :::image type="content" source="./media/workbooks-resources/resource-query.png" lightbox="./media/workbooks-resources/resource-query.png" alt-text="Screenshot that shows the creation of a resource parameter by using Azure Resource Graph."::: ---For more information on Azure Resource Graph, see [What is Azure Resource Graph?](../../governance/resource-graph/overview.md). --## Create a JSON list resource parameter --1. Start with an empty workbook in edit mode. -1. Select **Add parameters** > **Add Parameter**. -1. In the new parameter pane that opens, enter: - 1. **Parameter name**: `Applications` - 1. **Parameter type**: `Resource picker` - 1. **Required**: `checked` - 1. **Allow multiple selections**: `checked` - 1. **Get data from**: `JSON` - 1. In the content control, add this JSON snippet: -- ```json - [ - { "value":"/subscriptions/<sub-id>/resourceGroups/<resource-group>/providers/<resource-type>/acmeauthentication", "selected":true, "group":"Acme Backend" }, - { "value":"/subscriptions/<sub-id>/resourceGroups/<resource-group>/providers/<resource-type>/acmeweb", "selected":false, "group":"Acme Frontend" } - ] - ``` -- 1. Select **Update**. -1. Optionally, set `Include only resource types` to **Application Insights**. -1. Select **Save** to create the parameter. --## Reference a resource parameter --1. Select **Add query** to add a query control, and then select an Application Insights resource. -1. Use the **Application Insights** dropdown list to bind the parameter to the control. This step sets the scope of the query to the resources returned by the parameter at runtime. -1. In the KQL control, add this snippet: -- ```kusto - requests - | summarize Requests = count() by appName, name - | order by Requests desc - ``` --1. Run the query to see the results. -- :::image type="content" source="./media/workbooks-resources/resource-reference.png" lightbox="./media/workbooks-resources/resource-reference.png" alt-text="Screenshot that shows a resource parameter referenced in a query control."::: --This approach can be used to bind resources to other controls like metrics. --## Resource parameter options --| Parameter | Description | Example | -| - |:-|:-| -| `{Applications}` | The selected resource ID. | _/subscriptions/\<sub-id\>/resourceGroups/\<resource-group\>/providers/\<resource-type\>/acmeauthentication_ | -| `{Applications:label}` | The label of the selected resource. | `acmefrontend` Note: for multi-value resource parameters, this label may be shortened like `acmefrontend (+3 others)` and may not include all labels of all selected values | -| `{Applications:value}` | The value of the selected resource. | _'/subscriptions/\<sub-id\>/resourceGroups/\<resource-group\>/providers/\<resource-type\>/acmeauthentication'_ | -| `{Applications:name}` | The name of the selected resource. | `acmefrontend` | -| `{Applications:resourceGroup}` | The resource group of the selected resource. | `acmegroup` | -| `{Applications:resourceType}` | The type of the selected resource. | _microsoft.insights/components_ | -| `{Applications:subscription}` | The subscription of the selected resource. | | -| `{Applications:grid}` | A grid that shows the resource properties. Useful to render in a text block while debugging. | | --## Next steps --[Getting started with Azure Workbooks](workbooks-overview.md) |
| azure-monitor | Workbooks Samples | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-samples.md | - Title: Sample Azure Workbooks with links -description: See sample Azure Workbooks. ----- Previously updated : 06/21/2023----# Sample Azure Workbooks -This article includes sample Azure Workbooks. ---## Sample JSON Path parameter workbook -```json -{ - "version": "Notebook/1.0", - "items": [ - { - "type": 9, - "content": { - "version": "KqlParameterItem/1.0", - "parameters": [ - { - "id": "f2552663-d809-40da-93c4-9618dfde9b1d", - "version": "KqlParameterItem/1.0", - "name": "selection", - "type": 1, - "value": "{ \"series\":\"Failures\", \"x\": 5, \"y\": 10}" - } - ], - "style": "above", - "queryType": 0, - "resourceType": "microsoft.operationalinsights/workspaces" - }, - "name": "parameters - 1" - }, - { - "type": 1, - "content": { - "json": "For example, you may have a string parameter named `selection` that was the result of a query or selection in a visualization that has the following value \r\n```json\r\n{selection:json}\r\n```\r\n\r\nUsing JSONPath, you could get individual values from that object:\r\n\r\nformat | result\r\n|\r\n`selection:$.series` | `{selection:$..series}`\r\n`selection:$.x` | `{selection:$..x}`\r\n`selection$.y`| `{selection:$..y}`" - }, - "name": "text - 0" - } - ], - "$schema": "https://github.com/Microsoft/Application-Insights-Workbooks/blob/master/schema/workbook.json" -} -``` -## Sample ARM template for creating a workbook template -```json -{ - "$schema": "http://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "resourceName": { - "type": "string", - "defaultValue": "test-template", - "metadata": { - "description": "The unique name for this workbook template instance" - } - } - }, - "resources": [ - { - "name": "[parameters('resourceName')]", - "type": "microsoft.insights/workbooktemplates", - "location": "[resourceGroup().location]", - "apiVersion": "2019-10-17-preview", - "dependsOn": [], - "properties": { - "priority": 1, - "galleries": [ - { - "name": "A Workbook Template", - "category": "Deployed Templates", - "order": 100, - "type": "workbook", - "resourceType": "Azure Monitor" - } - ], - "templateData": { - "version": "Notebook/1.0", - "items": [ - { - "type": 1, - "content": { - "json": "## New workbook\n\n\nWelcome to your new workbook. This area will display text formatted as markdown.\n\n\nWe've included a basic analytics query to get you started. Use the `Edit` button below each section to configure it or add more sections." - }, - "name": "text - 2" - }, - { - "type": 3, - "content": { - "version": "KqlItem/1.0", - "query": "union withsource=[\"$TableName\"] *\n| summarize Count=count() by TableName=[\"$TableName\"]\n| render barchart", - "size": 1, - "exportToExcelOptions": "visible", - "queryType": 0, - "resourceType": "microsoft.operationalinsights/workspaces" - }, - "name": "query - 2" - } - ], - "styleSettings": {}, - "$schema": "https://github.com/Microsoft/Application-Insights-Workbooks/blob/master/schema/workbook.json" - } - } - } - ] -} -``` --## Sample workbook with links --```json -{ - "version": "Notebook/1.0", - "items": [ - { - "type": 11, - "content": { - "version": "LinkItem/1.0", - "style": "tabs", - "links": [ - { - "cellValue": "selectedTab", - "linkTarget": "parameter", - "linkLabel": "Tab 1", - "subTarget": "1", - "style": "link" - }, - { - "cellValue": "selectedTab", - "linkTarget": "parameter", - "linkLabel": "Tab 2", - "subTarget": "2", - "style": "link" - } - ] - }, - "name": "links - 0" - }, - { - "type": 1, - "content": { - "json": "# selectedTab is {selectedTab}\r\n(this text step is always visible, but shows the value of the `selectedtab` parameter)" - }, - "name": "always visible text" - }, - { - "type": 1, - "content": { - "json": "## content only visible when `selectedTab == 1`" - }, - "conditionalVisibility": { - "parameterName": "selectedTab", - "comparison": "isEqualTo", - "value": "1" - }, - "name": "selectedTab 1 text" - }, - { - "type": 1, - "content": { - "json": "## content only visible when `selectedTab == 2`" - }, - "conditionalVisibility": { - "parameterName": "selectedTab", - "comparison": "isEqualTo", - "value": "2" - }, - "name": "selectedTab 2" - } - ], - "styleSettings": {}, - "$schema": "https://github.com/Microsoft/Application-Insights-Workbooks/blob/master/schema/workbook.json" -} -``` --## Sample workbook with toolbar links --```json -{ - "version": "Notebook/1.0", - "items": [ - { - "type": 9, - "content": { - "version": "KqlParameterItem/1.0", - "crossComponentResources": [ - "value::all" - ], - "parameters": [ - { - "id": "eddb3313-641d-4429-b467-4793d6ed3575", - "version": "KqlParameterItem/1.0", - "name": "Subscription", - "type": 6, - "isRequired": true, - "multiSelect": true, - "quote": "'", - "delimiter": ",", - "query": "where type =~ \"microsoft.web/sites\"\r\n| summarize count() by subscriptionId\r\n| order by subscriptionId asc\r\n| project subscriptionId, label=subscriptionId, selected=row_number()==1", - "crossComponentResources": [ - "value::all" - ], - "value": [], - "typeSettings": { - "additionalResourceOptions": [], - "showDefault": false - }, - "timeContext": { - "durationMs": 86400000 - }, - "queryType": 1, - "resourceType": "microsoft.resourcegraph/resources" - }, - { - "id": "8beaeea6-9550-4574-a51e-bb0c16e68e84", - "version": "KqlParameterItem/1.0", - "name": "site", - "type": 5, - "description": "global parameter set by selection in the grid", - "isRequired": true, - "isGlobal": true, - "query": "where type =~ \"microsoft.web/sites\"\r\n| project id", - "crossComponentResources": [ - "{Subscription}" - ], - "isHiddenWhenLocked": true, - "typeSettings": { - "additionalResourceOptions": [], - "showDefault": false - }, - "timeContext": { - "durationMs": 86400000 - }, - "queryType": 1, - "resourceType": "microsoft.resourcegraph/resources" - }, - { - "id": "0311fb5a-33ca-48bd-a8f3-d3f57037a741", - "version": "KqlParameterItem/1.0", - "name": "properties", - "type": 1, - "isRequired": true, - "isGlobal": true, - "isHiddenWhenLocked": true - } - ], - "style": "above", - "queryType": 1, - "resourceType": "microsoft.resourcegraph/resources" - }, - "name": "parameters - 0" - }, - { - "type": 11, - "content": { - "version": "LinkItem/1.0", - "style": "toolbar", - "links": [ - { - "id": "7ea6a29e-fc83-40cb-a7c8-e57f157b1811", - "cellValue": "{site}", - "linkTarget": "ArmAction", - "linkLabel": "Start", - "postText": "Start website {site:name}", - "style": "primary", - "icon": "Start", - "linkIsContextBlade": true, - "armActionContext": { - "pathSource": "static", - "path": "{site}/start", - "headers": [], - "params": [ - { - "key": "api-version", - "value": "2019-08-01" - } - ], - "isLongOperation": false, - "httpMethod": "POST", - "titleSource": "static", - "title": "Start {site:name}", - "descriptionSource": "static", - "description": "Attempt to start:\n\n{site:grid}", - "resultMessage": "Start {site:name} completed", - "runLabelSource": "static", - "runLabel": "Start" - } - }, - { - "id": "676a0860-6ec8-4c4f-a3b8-a98af422ae47", - "cellValue": "{site}", - "linkTarget": "ArmAction", - "linkLabel": "Stop", - "postText": "Stop website {site:name}", - "style": "primary", - "icon": "Stop", - "linkIsContextBlade": true, - "armActionContext": { - "pathSource": "static", - "path": "{site}/stop", - "headers": [], - "params": [ - { - "key": "api-version", - "value": "2019-08-01" - } - ], - "isLongOperation": false, - "httpMethod": "POST", - "titleSource": "static", - "title": "Stop {site:name}", - "descriptionSource": "static", - "description": "# Attempt to Stop:\n\n{site:grid}", - "resultMessage": "Stop {site:name} completed", - "runLabelSource": "static", - "runLabel": "Stop" - } - }, - { - "id": "5e48925f-f84f-4a2d-8e69-6a4deb8a3007", - "cellValue": "{properties}", - "linkTarget": "CellDetails", - "linkLabel": "Properties", - "postText": "View the properties for Start website {site:name}", - "style": "secondary", - "icon": "Properties", - "linkIsContextBlade": true - } - ] - }, - "name": "site toolbar" - }, - { - "type": 3, - "content": { - "version": "KqlItem/1.0", - "query": "where type =~ \"microsoft.web/sites\"\r\n| extend properties=tostring(properties)\r\n| project-away name, type", - "size": 0, - "showAnalytics": true, - "title": "Web Apps in Subscription {Subscription:name}", - "showRefreshButton": true, - "exportedParameters": [ - { - "fieldName": "id", - "parameterName": "site" - }, - { - "fieldName": "", - "parameterName": "properties", - "parameterType": 1 - } - ], - "showExportToExcel": true, - "queryType": 1, - "resourceType": "microsoft.resourcegraph/resources", - "crossComponentResources": [ - "{Subscription}" - ], - "gridSettings": { - "formatters": [ - { - "columnMatch": "properties", - "formatter": 5 - } - ], - "filter": true, - "sortBy": [ - { - "itemKey": "subscriptionId", - "sortOrder": 1 - } - ] - }, - "sortBy": [ - { - "itemKey": "subscriptionId", - "sortOrder": 1 - } - ] - }, - "name": "query - 1" - }, - { - "type": 1, - "content": { - "json": "## How this workbook works\r\n1. The parameters step declares a `site` resource parameter that is hidden in reading mode, but uses the same query as the grid. this parameter is marked `global`, and has no default selection. The parameters also declares a `properties` hidden text parameter. These parameters are [declared global](https://github.com/microsoft/Application-Insights-Workbooks/blob/master/Documentation/Parameters/Parameters.md#global-parameters) so they can be set by the grid below, but the toolbar can appear *above* the grid.\r\n\r\n2. The workbook has a links step, that renders as a toolbar. This toolbar has items to start a website, stop a website, and show the Azure Resourcve Graph properties for that website. The toolbar buttons all reference the `site` parameter, which by default has no selection, so the toolbar buttons are disabled. The start and stop buttons use the [ARM Action](https://github.com/microsoft/Application-Insights-Workbooks/blob/master/Documentation/Links/LinkActions.md#arm-action-settings) feature to run an action against the selected resource.\r\n\r\n3. The workbook has an Azure Resource Graph (ARG) query step, which queries for web sites in the selected subscriptions, and displays them in a grid. When a row is selected, the selected resource is exported to the `site` global parameter, causing start and stop buttons to become enabled. The ARG properties are also exported to the `properties` parameter, causing the poperties button to become enabled.", - "style": "info" - }, - "conditionalVisibility": { - "parameterName": "debug", - "comparison": "isEqualTo", - "value": "true" - }, - "name": "text - 3" - } - ], - "fallbackResourceIds": [ - "Azure Monitor" - ], - "$schema": "https://github.com/Microsoft/Application-Insights-Workbooks/blob/master/schema/workbook.json" -} -``` |
| azure-monitor | Workbooks Templates | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-templates.md | - Title: Azure Workbooks templates -description: Learn how to use Azure Workbooks templates. ---- Previously updated : 06/21/2023----# Azure Workbooks templates --Azure Workbooks templates are curated reports designed for flexible reuse by multiple users and teams. When you open a template, a transient workbook is created and populated with the content of the template. Workbooks are visible in green. Workbook templates are visible in purple. --You can adjust the template-based workbook parameters and perform analysis without fear of breaking the future reporting experience for colleagues. If you open a template, make some adjustments, and save it, the template is saved as a workbook. This workbook appears in green. The original template is left untouched. --The design and architecture of templates is also different from saved workbooks. Saving a workbook creates an associated Azure Resource Manager resource. But the transient workbook that's created when you open a template doesn't have a unique resource associated with it. The resources associated with a workbook affect who has access to that workbook. Learn more about [Azure Workbooks access control](workbooks-overview.md#access-control). --## Explore a workbook template --Select **Application Failure Analysis** to see one of the default application workbook templates. -- :::image type="content" source="./media/workbooks-overview/failure-analysis.png" alt-text="Screenshot that shows the Application Failure Analysis template." border="false" lightbox="./media/workbooks-overview/failure-analysis.png"::: --When you open the template, a temporary workbook is created that you can interact with. By default, the workbook opens in read mode. Read mode displays only the information for the intended analysis experience that was created by the original template author. --You can adjust the subscription, targeted apps, and the time range of the data you want to display. After you make those selections, the grid of HTTP Requests is also interactive. Selecting an individual row changes the data rendered in the two charts at the bottom of the report. --## Edit a template --To understand how this workbook template is put together, switch to edit mode by selecting **Edit**. -- :::image type="content" source="./media/workbooks-overview/edit.png" alt-text="Screenshot that shows the Edit button." border="false" ::: --**Edit** buttons on the right correspond with each individual aspect of your workbook. -- :::image type="content" source="./media/workbooks-overview/edit-mode.png" alt-text="Screenshot that shows Edit buttons." border="false" lightbox="./media/workbooks-overview/edit-mode.png"::: --If you select the **Edit** button immediately under the grid of requested data, you can see that this part of the workbook consists of a Kusto query against data from an Application Insights resource. -- :::image type="content" source="./media/workbooks-overview/kusto.png" alt-text="Screenshot that shows the underlying Kusto query." border="false" lightbox="./media/workbooks-overview/kusto.png"::: --Select the other **Edit** buttons on the right to see some of the core components that make up workbooks, like: --- Markdown-based [text boxes](../visualize/workbooks-create-workbook.md#add-text).-- [Parameter selection](../visualize/workbooks-parameters.md) UI elements.-- Other [chart/visualization types](workbooks-visualizations.md).--Exploring the prebuilt templates in edit mode, modifying them to fit your needs, and saving your own custom workbook is a good way to start to learn about what's possible with Azure Workbooks. |
| azure-monitor | Workbooks Text Visualizations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-text-visualizations.md | - Title: Azure Monitor workbook text visualizations -description: Learn about all the Azure Monitor workbook text visualizations. -- Previously updated : 06/21/2023---# Text Visualization --The text *visualization* in query steps is different from the [text *step*](workbooks-create-workbook.md#add-text). A text step is a top level item in a workbook, and supports replacing parameters in the content, and allows for error/warning styling. --The text *visualization* is similar to the Azure Data Explorer [`render card`](/azure/data-explorer/kusto/query/renderoperator?pivots=azuredataexplorer) behavior, where the first cell value returned by the query (and *only* the first cell value: row 0, column 0) is displayed in the visualization. --The text visualization has a style setting to change the style of the text displayed in the workbook. --### Text styles -The following text styles are available for text steps: --|Style |Explanation | -|-|--| -|`plain` |No additional formatting is applied, the text value is presumed to be plain text and no special formatting is applied | -|`header`|The text is formatted with the same styling as step headers | -|`bignumber` |The text is formatted in the "big number" style used in [Tile](workbooks-tile-visualizations.md) and [Graph](workbooks-graph-visualizations.md) based visualizations. | -|`markdown`|The text value is rendered in a markdown section, any markdown content in the text content will be interpreted as such and used for formatting. | -|`editor` |The text value is displayed in an editor control, respecting newlines, tab formatting. | --### Examples --Given a query that returns text in a cell, showing in the standard grid visualization: ---You can see that this query returned a single column of data, which appears to be a very long string. In all examples the query step has the same header set. --### Plain example -When the visualization is set to `Text` and the `Plain` style is selected, the text appears as a standard portal text block: ---Text will wrap, and any special formatting values will be displayed as is, with no formatting. --### Header example --Text will be displayed in the same style as step headers. --### Big Number example --Text will be displayed in big number style. ---### Markdown example -For the markdown example, the query response has been adjusted to have markdown formatting elements inside. Without any markdown formatting in the text, the display will be similar to the plain style. ---### Editor example: -For the editor example, newline `\n` and tab `\t` characters have been added to the text to create multiple lines. ---Notice how in this example, the editor has horizontal scrollbar, indicating that some of the lines in this text are wider than the control. |
| azure-monitor | Workbooks Text | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-text.md | - Title: Azure Monitor workbook text parameters -description: Simplify complex reporting with prebuilt and custom parameterized workbooks. Learn more about workbook text parameters. --- Previously updated : 06/21/2023---# Workbook text parameters --Text box parameters provide a simple way to collect text input from workbook users. They're used when it isn't practical to use a dropdown list to collect the input, for example, with an arbitrary threshold or generic filters. By using a workbook, you can get the default value of the text box from a query. This functionality allows for interesting scenarios like setting the default threshold based on the p95 of the metric. --A common use of text boxes is as internal variables used by other workbook controls. You use a query for default values and make the input control invisible in read mode. For example, you might want a threshold to come from a formula, not a user, and then use the threshold in subsequent queries. --## Create a text parameter --1. Start with an empty workbook in edit mode. -1. Select **Add parameters** > **Add Parameter**. -1. In the new parameter pane that opens, enter: - 1. **Parameter name**: `SlowRequestThreshold` - 1. **Parameter type**: `Text` - 1. **Required**: `checked` - 1. **Get data from**: `None` -1. Select **Save** to create the parameter. -- :::image type="content" source="./media/workbooks-text/text-create.png" alt-text="Screenshot that shows the creation of a text parameter."::: --This screenshot shows how the workbook looks in read mode: ---## Parameter field style --The text parameter supports the following field styles: --- **Standard**: A single line text field.-- :::image type="content" source="./media/workbooks-text/standard-text.png" alt-text="Screenshot that shows a standard text field."::: --- **Password**: A single line password field. The password value is only hidden in the UI when you type. The value is fully accessible as a parameter value when referred. It's stored unencrypted when the workbook is saved.-- :::image type="content" source="./media/workbooks-text/password-text.png" alt-text="Screenshot that shows a password field."::: --- **Multiline**: A multiline text field with support of rich IntelliSense and syntax colorization for the following languages:-- - Text - - Markdown - - JSON - - SQL - - TypeScript - - KQL - - TOML -- You can also specify the height for the multiline editor. -- :::image type="content" source="./media/workbooks-text/kql-text.png" alt-text="Screenshot that shows a multiline text field."::: --## Reference a text parameter --1. Select **Add query** to add a query control, and then select an Application Insights resource. -1. In the KQL box, add this snippet: -- ```kusto - requests - | summarize AllRequests = count(), SlowRequests = countif(duration >= {SlowRequestThreshold}) by name - | extend SlowRequestPercent = 100.0 * SlowRequests / AllRequests - | order by SlowRequests desc - ``` --1. By using the text parameter with a value of 500 coupled with the query control, you effectively run the following query: -- ```kusto - requests - | summarize AllRequests = count(), SlowRequests = countif(duration >= 500) by name - | extend SlowRequestPercent = 100.0 * SlowRequests / AllRequests - | order by SlowRequests desc - ``` --1. Run the query to see the results. -- :::image type="content" source="./media/workbooks-text/text-reference.png" alt-text="Screenshot that shows a text parameter referenced in KQL."::: --> [!NOTE] -> In the preceding example, `{SlowRequestThreshold}` represents an integer value. If you were querying for a string like `{ComputerName}`, you would need to modify your Kusto query to add quotation marks `"{ComputerName}"` in order for the parameter field to accept an input without quotation marks. --## Set the default values using queries --1. Start with an empty workbook in edit mode. -1. Select **Add parameters** > **Add Parameter**. -1. In the new parameter pane that opens, enter: - 1. **Parameter name**: `SlowRequestThreshold` - 1. **Parameter type**: `Text` - 1. **Required**: `checked` - 1. **Get data from**: `Query` -1. In the KQL box, add this snippet: -- ```kusto - requests - | summarize round(percentile(duration, 95), 2) - ``` -- This query sets the default value of the text box to the 95th percentile duration for all requests in the app. -1. Run the query to see the results. -1. Select **Save** to create the parameter. -- :::image type="content" source="./media/workbooks-text/text-default-value.png" alt-text="Screenshot that shows a text parameter with a default value from KQL."::: --> [!NOTE] -> While this example queries Application Insights data, the approach can be used for any log-based data source, such as Log Analytics and Azure Resource Graph. --## Add validations --For standard and password text parameters, you can add validation rules that are applied to the text field. Add a valid regex with an error message. If the message is set, it's shown as an error when the field is invalid. --If the match is selected, the field is valid if the value matches the regex. If the match isn't selected, the field is valid if it doesn't match the regex. ---## Format JSON data --If JSON is selected as the language for the multiline text field, the field will have a button that formats the JSON data of the field. You can also use the shortcut Ctrl + \ to format the JSON data. --If data is coming from a query, you can select the option to pre-format the JSON data that's returned by the query. ---## Next steps --[Get started with Azure Workbooks](workbooks-overview.md) |
| azure-monitor | Workbooks Tile Visualizations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-tile-visualizations.md | - Title: Azure Monitor workbook tile visualizations -description: Learn about all the Azure Monitor workbook tile visualizations. -- Previously updated : 06/21/2023---# Tile visualizations --Tiles are a useful way to present summary data in workbooks. The following example shows a common use case of tiles with app-level summary on top of a detailed grid. ---Workbook tiles support showing items like a title, subtitle, large text, icons, metric-based gradients, spark lines or bars, and footers. --## Add a tile --1. Switch the workbook to edit mode by selecting the **Edit** toolbar button. -1. Select **Add** > **Add query** to add a log query control to the workbook. -1. For **Query type**, select **Logs**. For **Resource type**, select, for example, **Application Insights**, and select the resources to target. -1. Use the query editor to enter the KQL for your analysis. -- ```kusto - requests - | summarize Requests = count() by appName, name - | top 7 by Requests desc - ``` --1. Set **Size** to **Full**. -1. Set **Visualization** to **Tiles**. -1. Select the **Tile Settings** button to open the **Tile Settings** pane: - 1. In **Title**, set: - * **Use column**: `name` - 1. In **Left**, set: - * **Use column**: `Requests` - * **Column renderer**: `Big Number` - * **Color palette**: `Green to Red` - * **Minimum value**: `0` - 1. In **Bottom**, set: - * **Use column**: `appName` -1. Select the **Save and Close** button at the bottom of the pane. -<!-- convertborder later; applied Learn formatting border because the border created manually is thin. --> --The tiles in read mode: -<!-- convertborder later; applied Learn formatting border because the border created manually is thin. --> --## Spark lines in tiles --1. Switch the workbook to edit mode by selecting **Edit** on the toolbar. -1. Add a time range parameter called `TimeRange`. - 1. Select **Add** > **Add parameters**. - 1. In the parameter control, select **Add Parameter**. - 1. In the **Parameter name** field, enter `TimeRange`. For **Parameter type**, choose `Time range picker`. - 1. Select **Save** at the top of the pane and then select **Done Editing** in the parameter control. -1. Select **Add** > **Add query** to add a log query control under the parameter control. -1. For **Query type**, select **Logs**. For **Resource type**, select, for example, **Application Insights**, and select the resources to target. -1. Use the query editor to enter the KQL for your analysis. -- ```kusto - let topRequests = requests - | summarize Requests = count() by appName, name - | top 7 by Requests desc; - let topRequestNames = topRequests | project name; - requests - | where name in (topRequestNames) - | make-series Trend = count() default = 0 on timestamp from {TimeRange:start} to {TimeRange:end} step {TimeRange:grain} by name - | join (topRequests) on name - | project-away name1, timestamp - ``` --1. Select **Run Query**. Set `TimeRange` to a value of your choosing before you run the query. -1. Set **Visualization** to **Tiles**. -1. Set **Size** to **Full**. -1. Select **Tile Settings**: - 1. In **Tile**, set: - * **Use column**: `name` - 1. In **Subtile**, set: - * **Use column**: `appNAme` - 1. In **Left**, set: - * **Use column**:`Requests` - * **Column renderer**: `Big Number` - * **Color palette**: `Green to Red` - * **Minimum value**: `0` - 1. In **Bottom**, set: - * **Use column**:`Trend` - * **Column renderer**: `Spark line` - * **Color palette**: `Green to Red` - * **Minimum value**: `0` -1. Select **Save and Close** at the bottom of the pane. -<!-- convertborder later --> --## Tile sizes --You have an option to set the tile width in the tile settings: --* `fixed` (default) -- The default behavior of tiles is to be the same fixed width, approximately 160 pixels wide, plus the space around the tiles. - <!-- convertborder later --> - :::image type="content" source="./media/workbooks-tile-visualizations/tiles-fixed.png" lightbox="./media/workbooks-tile-visualizations/tiles-fixed.png" alt-text="Screenshot that shows fixed-width tiles." border="false"::: -* `auto` -- Each title shrinks or grows to fit their contents. The tiles are limited to the width of the tiles' view (no horizontal scrolling). - <!-- convertborder later --> - :::image type="content" source="./media/workbooks-tile-visualizations/tiles-auto.png" lightbox="./media/workbooks-tile-visualizations/tiles-auto.png" alt-text="Screenshot that shows auto-width tiles." border="false"::: -* `full size` -- Each title is always the full width of the tiles' view, with one title per line. - <!-- convertborder later --> - :::image type="content" source="./media/workbooks-tile-visualizations/tiles-full.png" lightbox="./media/workbooks-tile-visualizations/tiles-full.png" alt-text="Screenshot that shows full-size-width tiles." border="false"::: --## Next steps --* Tiles also support the composite bar renderer. To learn more, see [Composite bar documentation](workbooks-composite-bar.md). -* To learn more about time parameters like `TimeRange`, see [Workbook time parameters documentation](workbooks-time.md). |
| azure-monitor | Workbooks Time Brushing | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-time-brushing.md | - Title: Azure Workbooks time brushing -description: Learn about time brushing in Azure Monitor workbooks. -- Previously updated : 01/08/2024----# Time range brushing --Time range brushing allows a user to "brush" or "scrub" a range on a chart and have that range output as a parameter value. ---You can also choose to only export a parameter when a range is explicitly brushed: ---## Brushing in a metrics chart --When you enable time brushing on a metrics chart, you can "brush" a time by dragging the mouse on the time chart. ---After the brush has stopped, the metrics chart zooms in to that range and exports the range as a time range parameter. -An icon on the toolbar in the upper-right corner is active to reset the time range back to its original, unzoomed time range. --## Brushing in a query chart --When you enable time brushing on a query chart, indicators appear that you can drag, or you can brush a range on the time chart. ---After the brush has stopped, the query chart shows that range as a time range parameter but won't zoom in. This behavior is different than the behavior of metrics charts. Because of the complexity of user-written queries, it might not be possible for workbooks to correctly update the range used by the query in the query content directly. If the query is using a time range parameter, it's possible to get this behavior by using a [global parameter](workbooks-parameters.md#global-parameters) instead. --An icon on the toolbar in the upper-right corner is active to reset the time range back to its original, un-zoomed time range. |
| azure-monitor | Workbooks Time | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-time.md | - Title: Azure Monitor workbook time parameters -description: Learn how to set time parameters to allow users to set the time context of analysis. The time parameters are used by almost all reports. --- Previously updated : 06/21/2023---# Workbook time parameters --With time parameters, you can set the time context of analysis, which is used by almost all reports. Time parameters are simple to set up and use. You can use them to specify the time ranges to show in a dropdown list. You can also create custom time ranges. --## Create a time parameter --1. Start with an empty workbook in edit mode. -1. Select **Add parameters** > **Add Parameter**. -1. In the new parameter pane that opens, enter: - - **Parameter name**: `TimeRange` - - **Parameter type**: `Time range picker` - - **Required**: `checked` - - **Available time ranges**: `Last hour`, `Last 12 hours`, `Last 24 hours`, `Last 48 hours`, `Last 3 days`, `Last 7 days`, and `Allow custom time range selection`. -1. Select **Save** to create the parameter. -- :::image type="content" source="media/workbooks-time/parameters-time.png" alt-text="Screenshot that shows a time range parameter in read mode."::: --This is what the workbook looks like in read mode. --## Reference a time parameter --You can reference time parameters with bindings, KQL, or text. --### Reference a time parameter with bindings --1. Select **Add query** to add a query control, and then select an Application Insights resource. -1. Most workbook controls support a **Time Range** scope picker. Open the **Time Range** dropdown list and select the `{TimeRange}` in the **Time Range Parameters** group at the bottom: -- * This control binds the time range parameter to the time range of the chart. - * The time scope of the sample query is now **Last 24 hours**. -1. Run the query to see the results. -- :::image type="content" source="media/workbooks-time/time-binding.png" alt-text="Screenshot that shows a time range parameter referenced via bindings."::: --### Reference a time parameter with KQL --1. Select **Add query** to add a query control, and then select an Application Insights resource. -1. Open the **Time Range** dropdown list and select the `Set in query` in the **Time Range** group. In the KQL, enter a time scope filter by using the parameter `| where timestamp {TimeRange}`: - * This parameter expands on the query evaluation time to `| where timestamp > ago(1d)`. - * This option is the time range value of the parameter. --1. Run the query to see the results. -- :::image type="content" source="media/workbooks-time/time-in-code.png" alt-text="Screenshot that shows a time range referenced in KQL."::: --### Reference a time parameter in text --1. Add a text control to the workbook. -1. In the Markdown, enter `The chosen time range is {TimeRange:label}`. -1. Select **Done Editing**. -1. The text control shows the text *The chosen time range is Last 24 hours*. --## Time parameter options --| Parameter | Description | Example | -| - |:-|:-| -| `{TimeRange}` | Time range label | Last 24 hours | -| `{TimeRange:label}` | Time range label | Last 24 hours | -| `{TimeRange:value}` | Time range value | > ago (1d) | -| `{TimeRange:query}` | Time range query | > ago (1d) | -| `{TimeRange:start}` | Time range start time | 3/20/2019 4:18 PM | -| `{TimeRange:end}` | Time range end time | 3/21/2019 4:18 PM | -| `{TimeRange:grain}` | Time range grain | 30 m | --### Use parameter options in a query --```kusto -requests -| make-series Requests = count() default = 0 on timestamp from {TimeRange:start} to {TimeRange:end} step {TimeRange:grain} -``` --## Next steps --[Getting started with Azure Workbooks](workbooks-getting-started.md) |
| azure-monitor | Workbooks Traffic Lights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-traffic-lights.md | - Title: Azure Workbooks visual indicators and icons -description: Learn about all how to create visual indicators and icons, such as traffic lights in Azure Monitor Workbooks. ---- Previously updated : 01/08/2024---# Visual indicators and icons --You can summarize status by using a simple visual indication instead of presenting the full range of data values. For example, you can categorize your computers by CPU utilization as cold, warm, or hot and categorize performance as satisfied, tolerated, or frustrated. You can use an indicator or icon that represents the status next to the underlying metric. ---## Create a traffic light icon --The following example shows how to set up a traffic light icon per computer based on the CPU utilization metric. --1. [Create a new empty workbook](workbooks-create-workbook.md). -1. [Add a parameter](workbooks-create-workbook.md#add-parameters), make it a [time range parameter](workbooks-time.md), and name it **TimeRange**. -1. Select **Add query** to add a log query control to the workbook. -1. For **Query type**, select `Logs`, and for **Resource type**, select `Log Analytics`. Select a Log Analytics workspace in your subscription that has VM performance data as a resource. -1. In the query editor, enter: -- ``` - Perf - | where ObjectName == 'Processor' and CounterName == '% Processor Time' - | summarize Cpu = percentile(CounterValue, 95) by Computer - | join kind = inner (Perf - | where ObjectName == 'Processor' and CounterName == '% Processor Time' - | make-series Trend = percentile(CounterValue, 95) default = 0 on TimeGenerated from {TimeRange:start} to {TimeRange:end} step {TimeRange:grain} by Computer - ) on Computer - | project-away Computer1, TimeGenerated - | order by Cpu desc - ``` --1. Set **Visualization** to `Grid`. -1. Select **Column Settings**. -1. In the **Columns** section, set: - - **Cpu** - - **Column renderer**: `Thresholds` - - **Custom number formatting**: `checked` - - **Units**: `Percentage` - - **Threshold settings** (last two need to be in order): - - **Icon**: `Success`, **Operator**: `Default` - - **Icon**: `Critical`, **Operator**: `>`, **Value**: `80` - - **Icon**: `Warning`, **Operator**: `>`, **Value**: `60` - - **Trend** - - **Column renderer**: `Spark line` - - **Color palette**: `Green to Red` - - **Minimum value**: `60` - - **Maximum value**: `80` -1. Select **Save and Close** to commit the changes. ---You can also pin this grid to a dashboard by using **Pin to dashboard**. The pinned grid automatically binds to the time range in the dashboard. ---## Next Steps --[Learn about the types of visualizations you can use to create rich visual reports with Azure Workbooks](workbooks-visualizations.md). |
| azure-monitor | Workbooks Tree Visualizations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-tree-visualizations.md | - Title: Azure Monitor workbook tree visualizations -description: Learn about all the Azure Monitor workbook tree visualizations. -- Previously updated : 06/21/2023---# Tree visualizations --Workbooks support hierarchical views via tree grids. Trees allow some rows to be expandable into the next level for a drill-down experience. --The following example shows container health metrics of a working set size that are visualized as a tree grid. The top-level nodes here are Azure Kubernetes Service (AKS) nodes. The next-level nodes are pods, and the final-level nodes are containers. Notice that you can still format your columns like you do in a grid with heatmaps, icons, and links. The underlying data source in this case is a Log Analytics workspace with AKS logs. -<!-- convertborder later --> --## Add a tree grid --1. Switch the workbook to edit mode by selecting **Edit** on the toolbar. -1. Select **Add** > **Add query** to add a log query control to the workbook. -1. For **Query type**, select **Logs**. For **Resource type**, select, for example, **Application Insights**, and select the resources to target. -1. Use the query editor to enter the KQL for your analysis. -- ```kusto - requests - | summarize Requests = count() by ParentId = appName, Id = name - | extend Kind = 'Request', Name = strcat('🌐 ', Id) - | union (requests - | summarize Requests = count() by Id = appName - | extend Kind = 'Request', ParentId = '', Name = strcat('📱 ', Id)) - | project Name, Kind, Requests, Id, ParentId - | order by Requests desc - ``` --1. Set **Visualization** to **Grid**. -1. Select the **Column Settings** button to open the **Edit column settings** pane. -1. In the **Columns** section at the top, set: - * **Id - Column renderer**: `Hidden` - * **Parent Id - Column renderer**: `Hidden` - * **Requests - Column renderer**: `Bar` - * **Color palette**: `Blue` - * **Minimum value**: `0` -1. In the **Tree/Group By Settings** section at the bottom, set: - * **Tree type**: `Parent/Child` - * **Id Field**: `Id` - * **Parent Id Field**: `ParentId` - * **Show the expander on**: `Name` - * Select the **Expand the top level of the tree** checkbox. -1. Select the **Save and Close** button at the bottom of the pane. -<!-- convertborder later --> --## Tree settings --| Setting | Description | -|:- |:-| -| `Id Field` | The unique ID of every row in the grid. | -| `Parent Id Field` | The ID of the parent of the current row. | -| `Show the expander on` | The column on which to show the tree expander. It's common for tree grids to hide their ID and parent ID fields because they aren't very readable. Instead, the expander appears on a field with a more readable value like the name of the entity. | -| `Expand the top level of the tree` | If selected, the tree grid expands at the top level. This option is useful if you want to show more information by default. | --## Grouping in a grid --You can use grouping to build hierarchical views similar to the ones shown in the preceding example with simpler queries. You do lose aggregation at the inner nodes of the tree, but that's acceptable for some scenarios. Use **Group By** to build tree views when the underlying result set can't be transformed into a proper tree form. Examples are alert, health, and metric data. --## Add a tree by using grouping --1. Switch the workbook to edit mode by selecting **Edit** on the toolbar. -1. Select **Add** > **Add query** to add a log query control to the workbook. -1. For **Query type**, select **Logs**. For **Resource type**, select, for example, **Application Insights**, and select the resources to target. -1. Use the query editor to enter the KQL for your analysis. -- ```kusto - requests - | summarize Requests = count() by App = appName, RequestName = name - | order by Requests desc - ``` --1. Set **Visualization** to **Grid**. -1. Select the **Column Settings** button to open the **Edit column settings** pane. -1. In the **Columns** section at the top, set: - * **App - Column renderer**: `Hidden` - * **Requests - Column renderer**: `Bar` - * **Color palette**: `Blue` - * **Minimum value**: `0` -1. In the **Tree/Group By Settings** section at the bottom, set: - * **Tree type**: `Group By` - * **Group by**: `App` - * **Then by**: `None` - * Select the **Expand the top level of the tree** checkbox. -1. Select the **Save and Close** button at the bottom of the pane. -<!-- convertborder later --> --## Next steps --* Learn how to create a [graph in workbooks](workbooks-graph-visualizations.md). -* Learn how to create a [tile in workbooks](workbooks-tile-visualizations.md). |
| azure-monitor | Workbooks Visualizations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/visualize/workbooks-visualizations.md | - Title: Workbook visualizations -description: Learn about the types of visualizations you can use to create rich visual reports with Azure Workbooks. ---- Previously updated : 06/21/2023-----# Workbook visualizations --Workbooks provide a rich set of capabilities for visualizing Azure Monitor data. The exact set of capabilities depends on the data sources and result sets, but you can expect them to converge over time. These controls allow you to present your analysis in rich interactive reports. --Workbooks support these kinds of visual components: --* [Text parameters](#text-parameters) -* Using queries: - * [Charts](#charts) - * [Grids](#grids) - * [Tiles](#tiles) - * [Trees](#trees) - * [Honeycomb](#honeycomb) - * [Graphs](#graphs) - * [Maps](#maps) - * [Text visualization](#text-visualizations) --> [!NOTE] -> Each visualization and data source might have its own [limits](workbooks-limits.md). --## Examples --### [Text parameters](workbooks-text.md) ---### [Charts](workbooks-chart-visualizations.md) ---### [Grids](workbooks-grid-visualizations.md) ---### [Tiles](workbooks-tile-visualizations.md) ---### [Trees](workbooks-tree-visualizations.md) ---### [Honeycomb](workbooks-honey-comb.md) ---### [Graphs](workbooks-graph-visualizations.md) ---### [Maps](workbooks-map-visualizations.md) ---### [Text visualizations](workbooks-text-visualizations.md) ---## Next steps --[Get started with Azure Workbooks](workbooks-overview.md) |
| azure-monitor | Monitor Virtual Machine Agent | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/monitor-virtual-machine-agent.md | - Title: 'Monitor virtual machines with Azure Monitor: Deploy agent' -description: Learn how to deploy the Azure Monitor agent to your virtual machines for monitoring in Azure Monitor. Monitor virtual machines and their workloads with an Azure Monitor guide. ---- Previously updated : 02/15/2024-----# Monitor virtual machines with Azure Monitor: Deploy agent -This article is part of the guide [Monitor virtual machines and their workloads in Azure Monitor](monitor-virtual-machine.md). It describes how to deploy the Azure Monitor agent to your Azure and hybrid virtual machines in Azure Monitor. --> [!NOTE] -> This scenario describes how to implement complete monitoring of your Azure and hybrid virtual machine environment. To get started monitoring your first Azure virtual machine, see [Monitor Azure virtual machines](/azure/virtual-machines/monitor-vm). --Any monitoring tool like Azure Monitor, requires an agent installed on a machine to collect data from its guest operating system. Azure Monitor uses the [Azure Monitor agent](../agents/agents-overview.md), which supports virtual machines in Azure, other cloud environments, and on-premises. --## Prerequisites -### Create a Log Analytics workspace -You don't need a Log Analytics workspace to deploy the Azure Monitor agent, but you will need one to collect the data that it sends. There's no cost for the workspace, but you do incur ingestion and retention costs when you collect data. --Many environments use a single workspace for all their virtual machines and other Azure resources they monitor. You can even share a workspace used by [Microsoft Defender for Cloud and Microsoft Sentinel](monitor-virtual-machine-security.md), although many customers choose to segregate their availability and performance telemetry from security data. If you're getting started with Azure Monitor, start with a single workspace and consider creating more workspaces as your requirements evolve. [VM insights]() will create a default workspace which you can use to get started quickly. --For complete details on logic that you should consider for designing a workspace configuration, see [Design a Log Analytics workspace configuration](../logs/workspace-design.md). --### Workspace permissions -The access mode of the workspace defines which users can access different sets of data. For details on how to define your access mode and configure permissions, see [Manage access to log data and workspaces in Azure Monitor](../logs/manage-access.md). If you're just getting started with Azure Monitor, consider accepting the defaults when you create your workspace and configure its permissions later. --> [!TIP] -> Multihoming refers to a virtual machine that connects to multiple workspaces. There's typically little reason to multihome agents for Azure Monitor alone. Having an agent send data to multiple workspaces most likely creates duplicate data in each workspace, which increases your overall cost. You can combine data from multiple workspaces by using [cross-workspace queries](../logs/cross-workspace-query.md) and [workbooks](../visualizations/../visualize/workbooks-overview.md). One reason you might consider multihoming is if you have an environment with Microsoft Defender for Cloud or Microsoft Sentinel stored in a workspace that's separate from Azure Monitor. A machine being monitored by each service needs to send data to each workspace. --## Prepare hybrid machines -A hybrid machine is any machine not running in Azure. It's a virtual machine running in another cloud or hosted provider or a virtual or physical machine running on-premises in your datacenter. Use [Azure Arc-enabled servers](../../azure-arc/servers/overview.md) on hybrid machines so you can manage them similarly to your Azure virtual machines. You can use VM insights in Azure Monitor to use the same process to enable monitoring for Azure Arc-enabled servers as you do for Azure virtual machines. For a complete guide on preparing your hybrid machines for Azure, see [Plan and deploy Azure Arc-enabled servers](../../azure-arc/servers/plan-at-scale-deployment.md). This task includes enabling individual machines and using [Azure Policy](../../governance/policy/overview.md) to enable your entire hybrid environment at scale. --There's no additional cost for Azure Arc-enabled servers, but there might be some cost for different options that you enable. For details, see [Azure Arc pricing](https://azure.microsoft.com/pricing/details/azure-arc/). There is a cost for the data collected in the workspace after your hybrid machines are onboarded, but this is the same as for an Azure virtual machine. --### Network requirements -The Azure Monitor agent for both Linux and Windows communicates outbound to the Azure Monitor service over TCP port 443. The Dependency agent uses the Azure Monitor agent for all communication, so it doesn't require any another ports. For details on how to configure your firewall and proxy, see [Network requirements](../agents/azure-monitor-agent-data-collection-endpoint.md). --There are three different options for connect your hybrid virtual machines to Azure Monitor: --- **Public internet**. If your hybrid servers are allowed to communicate with the public internet, then they can connect to a global Azure Monitor endpoint. This is the simplest configuration but also the least secure. - -- **Log Analytics gateway**. With the Log Analytics gateway, you can channel communications from your on-premises machines through a single gateway. Azure Arc doesn't use the gateway, but its Connected Machine agent is required to install Azure Monitor agent. For details on how to configure and use the Log Analytics gateway, see [Log Analytics gateway](../agents/gateway.md).--- **Azure Private Link**. By using Azure Private Link, you can create a private endpoint for your Log Analytics workspace. After it's configured, any connections to the workspace must be made through this private endpoint. Private Link works by using DNS overrides, so there's no configuration requirement on individual agents. For details on Private Link, see [Use Azure Private Link to securely connect networks to Azure Monitor](../logs/private-link-security.md). For specific guidance on configuring private link for your virtual machines, see [Enable network isolation for the Azure Monitor agent](../agents/azure-monitor-agent-data-collection-endpoint.md).----## Agent deployment options -The Azure Monitor agent is implemented as a [virtual machine extension](/azure/virtual-machines/extensions/overview), so you can install it using a variety of standard methods including PowerShell, CLI, and Resource Manager templates. See [Manage Azure Monitor Agent](../agents/azure-monitor-agent-manage.md) for details on each. Other notable methods for installation are described below. --| Method | Scenarios | Details | -|:|:|:| -| Azure Policy | Production deployment at scale | If you have a significant number of virtual machines, you should deploy the agent using Azure Policy as described in [Manage Azure Monitor Agent](../agents/azure-monitor-agent-policy.md) or [Enable VM insights by using Azure Policy](vminsights-enable-policy.md). This will ensure that the agent is automatically added to existing virtual machines and any new ones that you deploy. | -| Data collection rule in Azure portal | Testing and simple deployments | When you create a data collection rule in the Azure portal as described in [Collect data with Azure Monitor Agent](../agents/azure-monitor-agent-data-collection.md), you have the option of specifying virtual machines to receive it. The Azure Monitor agent will be automatically installed on any machines that don't already have it. | -| VM insights in Azure portal | Testing and simple deployments with preconfigured monitoring | VM insights provides [simplified onboarding of agents in the Azure portal](vminsights-enable-portal.md). With a single click for a particular machine, it installs the Azure Monitor agent, connects to a workspace, and starts collecting performance data. You can optionally have it install the dependency agent and collect processes and dependency data to enable the map feature of VM insights. | -| Windows client installer | Client machines | Use the [Windows client installer](../agents/azure-monitor-agent-windows-client.md) to install the agent on Windows clients such as Windows 11. For different options deploying the agent on a single machine or as part of a script, see [Manage Azure Monitor Agent](../agents/azure-monitor-agent-manage.md?tabs=azure-portal#installation-options). | ---## Legacy agents -The Azure Monitor agent replaces legacy agents that are still available but should only be used if you require particular functionality not yet available with Azure Monitor agent. Most users will be able to use Azure Monitor without the legacy agents. --The legacy agents include the following: --- [Log Analytics agent](../agents/log-analytics-agent.md): Supports virtual machines in Azure, other cloud environments, and on-premises. Sends data to Azure Monitor Logs. This agent is the same agent used for System Center Operations Manager.-- [Azure Diagnostic extension](../agents/diagnostics-extension-overview.md): Supports Azure Monitor virtual machines only. Sends data to Azure Monitor Metrics, Azure Event Hubs, and Azure Storage.--See [Supported services and features](../agents/agents-overview.md#supported-services-and-features) for the current features supported by Azure Monitor agent. See [Migrate to Azure Monitor Agent from Log Analytics agent](../agents/azure-monitor-agent-migration.md) for details on migrating to the Azure Monitor agent if you already have the Log Analytics agent deployed. --## Next steps --* [Configure data collection for machines with the Azure Monitor agent](monitor-virtual-machine-data-collection.md). |
| azure-monitor | Monitor Virtual Machine Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/monitor-virtual-machine-alerts.md | - Title: 'Monitor virtual machines with Azure Monitor: Alerts' -description: Learn how to create alerts from virtual machines and their guest workloads by using Azure Monitor. ---- Previously updated : 02/15/2024-----# Monitor virtual machines with Azure Monitor: Alerts --This article is part of the guide [Monitor virtual machines and their workloads in Azure Monitor](monitor-virtual-machine.md). [Alerts in Azure Monitor](../alerts/alerts-overview.md) proactively notify you of interesting data and patterns in your monitoring data. There are no preconfigured alert rules for virtual machines, but you can create your own based on data you collect from Azure Monitor Agent. This article presents alerting concepts specific to virtual machines and common alert rules used by other Azure Monitor customers. --This scenario describes how to implement complete monitoring of your Azure and hybrid virtual machine environment: --- To get started monitoring your first Azure virtual machine, see [Monitor Azure virtual machines](/azure/virtual-machines/monitor-vm). --- To quickly enable a recommended set of alerts, see [Enable recommended alert rules for an Azure virtual machine](tutorial-monitor-vm-alert-recommended.md).--> [!IMPORTANT] -> Most alert rules have a cost that's dependent on the type of rule, how many dimensions it includes, and how frequently it's run. Before you create any alert rules, see the **Alert rules** section in [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/). --## Data collection -Alert rules inspect data that's already been collected in Azure Monitor. You need to ensure that data is being collected for a particular scenario before you can create an alert rule. See [Monitor virtual machines with Azure Monitor: Collect data](monitor-virtual-machine-data-collection.md) for guidance on configuring data collection for various scenarios, including all the alert rules in this article. --## Recommended alert rules -Azure Monitor provides a set of [recommended alert rules](tutorial-monitor-vm-alert-availability.md) that you can quickly enable for any Azure virtual machine. These rules are a great starting point for basic monitoring. But alone, they won't provide sufficient alerting for most enterprise implementations for the following reasons: --- Recommended alerts only apply to Azure virtual machines and not hybrid machines.-- Recommended alerts only include host metrics and not guest metrics or logs. These metrics are useful to monitor the health of the machine itself. But they give you minimal visibility into the workloads and applications running on the machine.-- Recommended alerts are associated with individual machines that create an excessive number of alert rules. Instead of relying on this method for each machine, see [Scaling alert rules](#scaling-alert-rules) for strategies on using a minimal number of alert rules for multiple machines.--## Alert types --The most common types of alert rules in Azure Monitor are [metric alerts](../alerts/alerts-metric.md) and [log search alerts](../alerts/alerts-log-query.md). The type of alert rule that you create for a particular scenario depends on where the data that you're alerting on is located. --You might have cases where data for a particular alerting scenario is available in both Metrics and Logs. If so, you need to determine which rule type to use. You might also have flexibility in how you collect certain data and let your decision of alert rule type drive your decision for data collection method. --### Metric alerts -Common uses for metric alerts: -- Alert when a particular metric exceeds a threshold. An example is when the CPU of a machine is running high.--Data sources for metric alerts: -- Host metrics for Azure virtual machines, which are collected automatically-- Metrics collected by Azure Monitor Agent from the guest operating system--### Log search alerts -Common uses for log search alerts: -- Alert when a particular event or pattern of events from Windows event log or Syslog are found. These alert rules typically measure table rows returned from the query.-- Alert based on a calculation of numeric data across multiple machines. These alert rules typically measure the calculation of a numeric column in the query results.--Data sources for log search alerts: -- All data collected in a Log Analytics workspace--## Scaling alert rules -Because you might have many virtual machines that require the same monitoring, you don't want to have to create individual alert rules for each one. You also want to ensure there are different strategies to limit the number of alert rules you need to manage, depending on the type of rule. Each of these strategies depends on understanding the target resource of the alert rule. --### Metric alert rules -Virtual machines support multiple resource metric alert rules as described in [Monitor multiple resources](../alerts/alerts-types.md#metric-alerts). This capability allows you to create a single metric alert rule that applies to all virtual machines in a resource group or subscription within the same region. --Start with the [recommended alerts](#recommended-alert-rules) and create a corresponding rule for each by using your subscription or a resource group as the target resource. You need to create duplicate rules for each region if you have machines in multiple regions. --As you identify requirements for more metric alert rules, follow this same strategy by using a subscription or resource group as the target resource to: -- Minimize the number of alert rules you need to manage.-- Ensure that they're automatically applied to any new machines.--### Log search alert rules --If you set the target resource of a log search alert rule to a specific machine, queries are limited to data associated with that machine, which gives you individual alerts for it. This arrangement requires a separate alert rule for each machine. --If you set the target resource of a log search alert rule to a Log Analytics workspace, you have access to all data in that workspace. For this reason, you can alert on data from all machines in the workgroup with a single rule. This arrangement gives you the option of creating a single alert for all machines. You can then use dimensions to create a separate alert for each machine. --For example, you might want to alert when an error event is created in the Windows event log by any machine. You first need to create a data collection rule as described in [Collect data with Azure Monitor Agent](../agents/azure-monitor-agent-data-collection.md) to send these events to the `Event` table in the Log Analytics workspace. Then you create an alert rule that queries this table by using the workspace as the target resource and the condition shown in the following image. --The query returns a record for any error messages on any machine. Use the **Split by dimensions** option and specify **_ResourceId** to instruct the rule to create an alert for each machine if multiple machines are returned in the results. ---#### Dimensions --Depending on the information you want to include in the alert, you might need to split by using different dimensions. In this case, make sure the necessary dimensions are projected in the query by using the [project](/azure/data-explorer/kusto/query/projectoperator) or [extend](/azure/data-explorer/kusto/query/extendoperator) operator. Set the **Resource ID column** field to **Don't split** and include all the meaningful dimensions in the list. Make sure **Include all future values** is selected so that any value returned from the query is included. ---#### Dynamic thresholds -Another benefit of using log search alert rules is the ability to include complex logic in the query for determining the threshold value. You can hardcode the threshold, apply it to all resources, or calculate it dynamically based on some field or calculated value. The threshold is applied to resources only according to specific conditions. For example, you might create an alert based on available memory but only for machines with a particular amount of total memory. --## Common alert rules --The following section lists common alert rules for virtual machines in Azure Monitor. Details for metric alerts and log search alerts are provided for each. For guidance on which type of alert to use, see [Alert types](#alert-types). If you're unfamiliar with the process for creating alert rules in Azure Monitor, see the [instructions to create a new alert rule](../alerts/alerts-create-new-alert-rule.md). --> [!NOTE] -> The details for log search alerts provided here are using data collected by using [VM Insights](vminsights-overview.md), which provides a set of common performance counters for the client operating system. This name is independent of the operating system type. --### Machine availability -One of the most common monitoring requirements for a virtual machine is to create an alert if it stops running. The best method is to create a metric alert rule in Azure Monitor by using the VM availability metric, which is currently in public preview. For a walk-through on this metric, see [Create availability alert rule for Azure virtual machine](tutorial-monitor-vm-alert-availability.md). --An alert rule is limited to one activity log signal. So for every condition, one alert rule must be created. For example, "starts or stops the virtual machine" requires two alert rules. However, to be alerted when VM is restarted, only one alert rule is needed. --As described in [Scaling alert rules](#scaling-alert-rules), create an availability alert rule by using a subscription or resource group as the target resource. The rule applies to multiple virtual machines, including new machines that you create after the alert rule. --### Agent heartbeat -The agent heartbeat is slightly different than the machine unavailable alert because it relies on Azure Monitor Agent to send a heartbeat. The agent heartbeat can alert you if the machine is running but the agent is unresponsive. --#### Metric alert rules --A metric called **Heartbeat** is included in each Log Analytics workspace. Each virtual machine connected to that workspace sends a heartbeat metric value each minute. Because the computer is a dimension on the metric, you can fire an alert when any computer fails to send a heartbeat. Set the **Aggregation type** to **Count** and the **Threshold** value to match the **Evaluation granularity**. --#### Log search alert rules --Log search alerts use the [Heartbeat table](/azure/azure-monitor/reference/tables/heartbeat), which should have a heartbeat record every minute from each machine. --Use a rule with the following query: ---```kusto -Heartbeat -| summarize TimeGenerated=max(TimeGenerated) by Computer, _ResourceId -| extend Duration = datetime_diff('minute',now(),TimeGenerated) -| summarize MinutesSinceLastHeartbeat = min(Duration) by Computer, bin(TimeGenerated,5m), _ResourceId -``` --### CPU alerts --This section describes CPU alerts. --#### Metric alert rules --| Target | Metric | -|:|:| -| Host | Percentage CPU (included in recommended alerts) | -| Windows guest | \Processor Information(_Total)\% Processor Time | -| Linux guest | cpu/usage_active | --#### Log search alert rules --**CPU utilization** ---```kusto -InsightsMetrics -| where Origin == "vm.azm.ms" -| where Namespace == "Processor" and Name == "UtilizationPercentage" -| summarize CPUPercentageAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId -``` --### Memory alerts --This section describes memory alerts. --#### Metric alert rules --| Target | Metric | -|:|:| -| Host | Available Memory Bytes (preview) (included in recommended alerts) | -| Windows guest | \Memory\% Committed Bytes in Use<br>\Memory\Available Bytes | -| Linux guest | mem/available<br>mem/available_percent | --#### Log search alert rules --**Available memory in MB** ---```kusto -InsightsMetrics -| where Origin == "vm.azm.ms" -| where Namespace == "Memory" and Name == "AvailableMB" -| summarize AvailableMemoryInMBAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId -``` --**Available memory in percentage** ---```kusto -InsightsMetrics -| where Origin == "vm.azm.ms" -| where Namespace == "Memory" and Name == "AvailableMB" -| extend TotalMemory = toreal(todynamic(Tags)["vm.azm.ms/memorySizeMB"]) | extend AvailableMemoryPercentage = (toreal(Val) / TotalMemory) * 100.0 -| summarize AvailableMemoryInPercentageAverage = avg(AvailableMemoryPercentage) by bin(TimeGenerated, 15m), Computer, _ResourceId -``` --### Disk alerts --This section describes disk alerts. --#### Metric alert rules --| Target | Metric | -|:|:| -| Windows guest | \Logical Disk\(_Total)\% Free Space<br>\Logical Disk\(_Total)\Free Megabytes | -| Linux guest | disk/free<br>disk/free_percent | --#### Log search alert rules --**Logical disk used - all disks on each computer** ---```kusto -InsightsMetrics -| where Origin == "vm.azm.ms" -| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage" -| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId -``` --**Logical disk used - individual disks** ---```kusto -InsightsMetrics -| where Origin == "vm.azm.ms" -| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage" -| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"]) -| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk -``` --**Logical disk IOPS** ---```kusto -InsightsMetrics -| where Origin == "vm.azm.ms" -| where Namespace == "LogicalDisk" and Name == "TransfersPerSecond" -| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"]) -| summarize DiskIOPSAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk -``` --**Logical disk data rate** ---```kusto -InsightsMetrics -| where Origin == "vm.azm.ms" -| where Namespace == "LogicalDisk" and Name == "BytesPerSecond" -| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"]) -| summarize DiskBytesPerSecondAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk -``` --### Network alerts --#### Metric alert rules --| Target | Metric | -|:|:| -| Host | Network In Total, Network Out Total (included in recommended alerts) | -| Windows guest | \Network Interface\Bytes Sent/sec<br>\Logical Disk\(_Total)\Free Megabytes | -| Linux guest | disk/free<br>disk/free_percent | --#### Log search alert rules --**Network interfaces bytes received - all interfaces** ---```kusto -InsightsMetrics -| where Origin == "vm.azm.ms" -| where Namespace == "Network" and Name == "ReadBytesPerSecond" -| summarize BytesReceivedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId -``` --**Network interfaces bytes received - individual interfaces** ---```kusto -InsightsMetrics -| where Origin == "vm.azm.ms" -| where Namespace == "Network" and Name == "ReadBytesPerSecond" -| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"]) -| summarize BytesReceievedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface -``` --**Network interfaces bytes sent - all interfaces** ---```kusto -InsightsMetrics -| where Origin == "vm.azm.ms" -| where Namespace == "Network" and Name == "WriteBytesPerSecond" -| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId -``` --**Network interfaces bytes sent - individual interfaces** ---```kusto -InsightsMetrics -| where Origin == "vm.azm.ms" -| where Namespace == "Network" and Name == "WriteBytesPerSecond" -| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"]) -| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface -``` --### Windows and Linux events -The following sample creates an alert when a specific Windows event is created. It uses a metric measurement alert rule to create a separate alert for each computer. --- **Create an alert rule on a specific Windows event.**- This example shows an event in the Application log. Specify a threshold of 0 and consecutive breaches greater than 0. -- - ```kusto - Event - | where EventLog == "Application" - | where EventID == 123 - | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m) - ``` --- **Create an alert rule on Syslog events with a particular severity.**- The following example shows error authorization events. Specify a threshold of 0 and consecutive breaches greater than 0. -- - ```kusto - Syslog - | where Facility == "auth" - | where SeverityLevel == "err" - | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m) - ``` --### Custom performance counters --- **Create an alert on the maximum value of a counter.**- - ```kusto - Perf - | where CounterName == "My Counter" - | summarize AggregatedValue = max(CounterValue) by Computer - ``` --- **Create an alert on the average value of a counter.**-- ```kusto - Perf - | where CounterName == "My Counter" - | summarize AggregatedValue = avg(CounterValue) by Computer - ``` --## Next steps --[Analyze monitoring data collected for virtual machines](monitor-virtual-machine-analyze.md) |
| azure-monitor | Monitor Virtual Machine Analyze | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/monitor-virtual-machine-analyze.md | - Title: 'Monitor virtual machines with Azure Monitor: Analyze monitoring data' -description: Learn about the different features of Azure Monitor that you can use to analyze the health and performance of your virtual machines. ---- Previously updated : 02/15/2024-----# Monitor virtual machines with Azure Monitor: Analyze monitoring data -This article is part of the guide [Monitor virtual machines and their workloads in Azure Monitor](monitor-virtual-machine.md). It describes how to analyze monitoring data for your virtual machines after you've completed their configuration. --> [!NOTE] -> This scenario describes how to implement complete monitoring of your Azure and hybrid virtual machine environment. To get started monitoring your first Azure virtual machine, see [Monitor Azure virtual machines](/azure/virtual-machines/monitor-vm) or [Tutorial: Collect guest logs and metrics from Azure virtual machine](tutorial-monitor-vm-guest.md). --After you've [configured data collection](monitor-virtual-machine-data-collection.md) for your virtual machines, data will be available for analysis. This article describes the different features of Azure Monitor that you can use to analyze the health and performance of your virtual machines. Several of these features provide a different experience depending on whether you're analyzing a single machine or multiple. Each experience is described here with any unique behavior of each feature depending on which experience is being used. ---## Single machine experience -Access the single machine analysis experience from the **Monitoring** section of the menu in the Azure portal for each Azure virtual machine and Azure Arc-enabled server. These options either limit the data that you're viewing to that machine or at least set an initial filter for it. In this way, you can focus on a particular machine, view its current performance and its trending over time, and help to identify any issues it might be experiencing. ----| Option | Description | -|:|:| -| Overview page | Select the **Monitoring** tab to display alerts, [platform metrics](../essentials/data-platform-metrics.md), and other monitoring information for the virtual machine host. You can see the number of active alerts on the tab. In the **Monitoring** tab, you get a quick view of:<br><br>**Alerts:** the alerts fired in the last 24 hours, with some important statistics about those alerts. If you do not have any alerts set up for this VM, there is a link to help you quickly create new alerts for your VM.<br><br>**Key metrics:** the trend over different time periods for important metrics, such as CPU, network, and disk. Because these are host metrics though, counters from the guest operating system such as memory aren't included. Select a graph to work with this data in [metrics explorer](../essentials/analyze-metrics.md) where you can perform different aggregations, and add more counters for analysis. | -| Activity log | See [activity log](../essentials/activity-log-insights.md#view-the-activity-log) entries filtered for the current virtual machine. Use this log to view the recent activity of the machine, such as any configuration changes and when it was stopped and started. -| Insights | Displays VM insights views if the VM is enabled for [VM insights](../vm/vminsights-overview.md).<br><br>Select the **Performance** tab to view trends of critical performance counters over different periods of time. When you open VM insights from the virtual machine menu, you also have a table with detailed metrics for each disk. For details on how to use the Map view for a single machine, see [Chart performance with VM insights](vminsights-performance.md#view-performance-directly-from-an-azure-vm).<br><br>If *processes and dependencies* is enabled for the VM, select the **Map** tab to view the running processes on the machine, dependencies on other machines, and external processes. For details on how to use the Map view for a single machine, see [Use the Map feature of VM insights to understand application components](vminsights-maps.md#view-a-map-from-a-vm).<br><br>If the VM is not enabled for VM insights, it offers the option to enable VM insights. | -| Alerts | View [alerts](../alerts/alerts-overview.md) for the current virtual machine. These alerts only use the machine as the target resource, so there might be other alerts associated with it. You might need to use the **Alerts** option in the Azure Monitor menu to view alerts for all resources. For details, see [Monitor virtual machines with Azure Monitor - Alerts](monitor-virtual-machine-alerts.md). | -| Metrics | Open metrics explorer with the scope set to the machine. This option is the same as selecting one of the performance charts from the **Overview** page except that the metric isn't already added. | -| Diagnostic settings | Enable and configure the [diagnostics extension](../agents/diagnostics-extension-overview.md) for the current virtual machine. This option is different than the **Diagnostic settings** option for other Azure resources. This is a [legacy agent](monitor-virtual-machine-agent.md#legacy-agents) that has been replaced by the [Azure Monitor agent](monitor-virtual-machine-agent.md). | -| Advisor recommendations | See recommendations for the current virtual machine from [Azure Advisor](../../advisor/index.yml). | -| Logs | Open [Log Analytics](../logs/log-analytics-overview.md) with the [scope](../logs/scope.md) set to the current virtual machine. You can select from a variety of existing queries to drill into log and performance data for only this machine. | -| Connection monitor | Open [Network Watcher Connection Monitor](../../network-watcher/connection-monitor-overview.md) to monitor connections between the current virtual machine and other virtual machines. | -| Workbooks | Open the workbook gallery with the VM insights workbooks for single machines. For a list of the VM insights workbooks designed for individual machines, see [VM insights workbooks](vminsights-workbooks.md#vm-insights-workbooks). | --## Multiple machine experience -Access the multiple machine analysis experience from the **Monitor** menu in the Azure portal for each Azure virtual machine and Azure Arc-enabled server. This will include only VMs that are enabled for VM insights. These options provide access to all data so that you can select the virtual machines that you're interested in comparing. ---| Option | Description | -|:|:| -| Activity log | See [activity log](../essentials/activity-log-insights.md#view-the-activity-log) entries filtered for all resources. Create a filter for a **Resource Type** of virtual machines or Virtual Machine Scale Sets to view events for all your machines. | -| Alerts | View [alerts](../alerts/alerts-overview.md) for all resources. This includes alerts related to all virtual machines in the workspace. Create a filter for a **Resource Type** of virtual machines or Virtual Machine Scale Sets to view alerts for all your machines. | -| Metrics | Open [metrics explorer](../essentials/analyze-metrics.md) with no scope selected. This feature is particularly useful when you want to compare trends across multiple machines. Select a subscription or a resource group to quickly add a group of machines to analyze together. | -| Logs | Open [Log Analytics](../logs/log-analytics-overview.md) with the [scope](../logs/scope.md) set to the workspace. You can select from a variety of existing queries to drill into log and performance data for all machines. Or you can create a custom query to perform additional analysis. | -| Workbooks | Open the workbook gallery with the VM insights workbooks for multiple machines. For a list of the VM insights workbooks designed for multiple machines, see [VM insights workbooks](vminsights-workbooks.md#vm-insights-workbooks). | ----## VM insights experience -VM insights includes multiple performance charts that help you quickly get a status of the operation of your monitored machines, their trending performance over time, and dependencies between machines and processes. It also offers a consolidated view of different aspects of any monitored machine, such as its properties and events collected in the Log Analytics workspace. --The **Get Started** tab displays all machines in your Azure subscription and identifies which ones are being monitored. Use this view to quickly identify which machines aren't being monitored and to onboard individual machines that aren't already being monitored. ---The **Performance** view includes multiple charts with several key performance indicators (KPIs) to help you determine how well machines are performing. The charts show resource utilization over a period of time. You can use them to identify bottlenecks, see anomalies, or switch to a perspective listing each machine to view resource utilization based on the metric selected. For details on how to use the Performance view, see [Chart performance with VM insights](vminsights-performance.md). ---Use the **Map** view to see running processes on machines and their dependencies on other machines and external processes. You can change the time window for the view to determine if these dependencies have changed from another time period. For details on how to use the Map view, see [Use the Map feature of VM insights to understand application components](vminsights-maps.md). -----## Compare Metrics and Logs -For many features of Azure Monitor, you don't need to understand the different types of data it uses and where it's stored. You can use VM insights, for example, without any understanding of what data is being used to populate the Performance view, Map view, and workbooks. You just focus on the logic that you're analyzing. As you dig deeper, you'll need to understand the difference between [Azure Monitor Metrics](../essentials/data-platform-metrics.md) and [Azure Monitor Logs](../logs/data-platform-logs.md). Different features of Azure Monitor use different kinds of data. The type of alerting that you use for a particular scenario depends on having that data available in a particular location. --This level of detail can be confusing if you're new to Azure Monitor. The following information helps you understand the differences between the types of data: --- Any non-numeric data, such as events, is stored in Logs. Metrics can only include numeric data that's sampled at regular intervals.-- Numeric data can be stored in both Metrics and Logs so that it can be analyzed in different ways and support different types of alerts.-- Performance data from the guest operating system is sent to either Metrics or Logs or both by the Azure Monitor agent.-- Performance data from the guest operating system is sent to Logs by VM insights.---## Analyze metric data with metrics explorer -By using metrics explorer, you can plot charts, visually correlate trends, and investigate spikes and dips in metrics' values. For details on how to use this tool, see [Analyze metrics with Azure Monitor metrics explorer](../essentials/analyze-metrics.md). --The following namespaces are used by virtual machines. --| Namespace | Description | Requirement | -|:|:|:| -| Virtual Machine Host | Host metrics automatically collected for all Azure virtual machines. Detailed list of metrics at [Microsoft.Compute/virtualMachines](../essentials/metrics-supported.md#microsoftcomputevirtualmachines). | Collected automatically with no configuration required. | -| Virtual Machine Guest | Guest operating system and application performance data on Windows machines. | Azure Monitor agent installed with a [Data Collection Rule](monitor-virtual-machine-data-collection.md#collect-performance-counters). | -| azure.vm.linux.guestmetrics | Guest operating system and application performance data on Linux machines. | Azure Monitor agent installed with a [Data Collection Rule](monitor-virtual-machine-data-collection.md#collect-performance-counters). | ----## Analyze log data with Log Analytics -Use Log Analytics to perform custom analysis of your log data and when you want to dig deeper into the data used to create the views in workbooks and VM insights. You might want to analyze different logic and aggregations of that data or correlate security data collected by Microsoft Defender for Cloud and Microsoft Sentinel with your [health and availability data](monitor-virtual-machine-data-collection.md). --You don't necessarily need to understand how to write a log query to use Log Analytics. There are multiple prebuilt queries that you can select and either run without modification or use as a start to a custom query. Select **Queries** at the top of the Log Analytics screen, and view queries with a **Resource type** of **Virtual machines** or **Virtual machine scale sets**. For information on how to use these queries, see [Using queries in Azure Monitor Log Analytics](../logs/queries.md). For a tutorial on how to use Log Analytics to run queries and work with their results, see [Log Analytics tutorial](../logs/log-analytics-tutorial.md). ---When you start Log Analytics from the **Logs** menu for a machine, its [scope](../logs/scope.md) is set to that computer. Any queries will only return records associated with that computer. For a simple query that returns all records in a table, double-click a table in the left pane. Work with these results or modify the query for more complex analysis. To set the scope to all records in a workspace, change the scope or select **Logs** from the **Monitor** menu. -----## Visualize data with workbooks -[Workbooks](../visualize/workbooks-overview.MD) provide interactive reports in the Azure portal and combine different kinds of data into a single view. Workbooks combine text,ΓÇ»[log queries](/azure/data-explorer/kusto/query/), metrics, and parameters into rich interactive reports. Workbooks are editable by any other team members who have access to the same Azure resources. --Workbooks are helpful for scenarios such as: --* Exploring the usage of your virtual machine when you don't know the metrics of interest in advance like CPU utilization, disk space, memory, and network dependencies. Unlike other usage analytics tools, workbooks let you combine multiple kinds of visualizations and analyses, which make them great for this kind of free-form exploration. -* Explaining to your team how a recently provisioned VM is performing, by showing metrics for key counters and other log events. -* Sharing the results of a resizing experiment of your VM with other members of your team. You can explain the goals for the experiment with text. Then you can show each usage metric and analytics queries used to evaluate the experiment, along with clear call-outs for whether each metric was above or below target. -* Reporting the impact of an outage on the usage of your VM, combining data, text explanation, and a discussion of next steps to prevent outages in the future. --VM insights include the following workbooks. You can use these workbooks or use them as a start to create custom workbooks to address your particular requirements. --### Single virtual machine --| Workbook | Description | -|-|-| -| Performance | Provides a customizable version of the Performance view that uses all the Log Analytics performance counters that you have enabled. | -| Connections | Provides an in-depth view of the inbound and outbound connections from your VM. | --### Multiple virtual machines --| Workbook | Description | -|-|-| -| Performance | Provides a customizable version of the Top N List and Charts view in a single workbook that uses all the Log Analytics performance counters that you have enabled.| -| Performance counters | Provides a Top N Chart view across a wide set of performance counters. | -| Connections | Provides an in-depth view of the inbound and outbound connections from your monitored machines. | -| Active Ports | Provides a list of the processes that have bound to the ports on the monitored machines and their activity in the chosen timeframe. | -| Open Ports | Provides the number of ports open on your monitored machines and the details on those open ports. | -| Failed Connections | Displays the count of failed connections on your monitored machines, the failure trend, and if the percentage of failures is increasing over time. | -| Security and Audit | Provides an analysis of your TCP/IP traffic that reports on overall connections, malicious connections, and where the IP endpoints reside globally. To enable all features, you'll need to enable Security Detection. | -| TCP Traffic | Provides a ranked report for your monitored machines and their sent, received, and total network traffic in a grid and displayed as a trend line. | -| Traffic Comparison | Compares network traffic trends for a single machine or a group of machines. | -| AMA Migration Helper | Helps you discover what to migrate and track progress as you move from Log Analytics Agent to Azure Monitor Agent. This workbook isn't available from VM insights like the other workbooks. On the Azure Monitor menu, go to **Workbooks** and select **Public Templates**. See [Tools for migrating from Log Analytics Agent to Azure Monitor Agent](../agents/azure-monitor-agent-migration-tools.md#using-ama-migration-helper) | --For instructions on how to create your own custom workbooks, see [Create interactive reports VM insights with workbooks](vminsights-workbooks.md). ----## Next steps --* [Create alerts from collected data](monitor-virtual-machine-alerts.md) - |
| azure-monitor | Monitor Virtual Machine Data Collection | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/monitor-virtual-machine-data-collection.md | - Title: 'Monitor virtual machines with Azure Monitor: Collect data' -description: Learn how to configure data collection for virtual machines for monitoring in Azure Monitor. Monitor virtual machines and their workloads with an Azure Monitor guide. ---- Previously updated : 02/15/2024----# Monitor virtual machines with Azure Monitor: Collect data -This article is part of the guide [Monitor virtual machines and their workloads in Azure Monitor](monitor-virtual-machine.md). It describes how to configure collection of data after you deploy Azure Monitor Agent to your Azure and hybrid virtual machines in Azure Monitor. --This article provides guidance on collecting the most common types of telemetry from virtual machines. The exact configuration that you choose depends on the workloads that you run on your machines. Included in each section are sample log search alerts that you can use with that data. --- For more information about analyzing telemetry collected from your virtual machines, see [Monitor virtual machines with Azure Monitor: Analyze monitoring data](monitor-virtual-machine-analyze.md).-- For more information about using telemetry collected from your virtual machines to create alerts in Azure Monitor, see [Monitor virtual machines with Azure Monitor: Alerts](monitor-virtual-machine-alerts.md).--> [!NOTE] -> This scenario describes how to implement complete monitoring of your Azure and hybrid virtual machine environment. To get started monitoring your first Azure virtual machine, see [Monitor Azure virtual machines](/azure/virtual-machines/monitor-vm). --## Data collection rules -Data collection from Azure Monitor Agent is defined by one or more [data collection rules (DCRs)](../essentials/data-collection-rule-overview.md) that are stored in your Azure subscription and associated with your virtual machines. --For virtual machines, DCRs define data such as events and performance counters to collect and specify the Log Analytics workspaces where data should be sent. The DCR can also use [transformations](../essentials/data-collection-transformations.md) to filter out unwanted data and to add calculated columns. A single machine can be associated with multiple DCRs, and a single DCR can be associated with multiple machines. DCRs are delivered to any machines they're associated with where Azure Monitor Agent processes them. --### View data collection rules -You can view the DCRs in your Azure subscription from **Data Collection Rules** on the **Monitor** menu in the Azure portal. DCRs support other data collection scenarios in Azure Monitor, so all of your DCRs aren't necessarily for virtual machines. ---### Create data collection rules -There are multiple methods to create DCRs depending on the data collection scenario. In some cases, the Azure portal walks you through the configuration. Other scenarios require you to edit a DCR directly. When you configure VM insights, it creates a preconfigured DCR for you automatically. The following sections identify common data to collect and how to configure data collection. --In some cases, you might need to [edit an existing DCR](../essentials/data-collection-rule-edit.md) to add functionality. For example, you might use the Azure portal to create a DCR that collects Windows or Syslog events. You then want to add a transformation to that DCR to filter out columns in the events that you don't want to collect. --As your environment matures and grows in complexity, you should implement a strategy for organizing your DCRs to help their management. For guidance on different strategies, see [Best practices for data collection rule creation and management in Azure Monitor](../essentials/data-collection-rule-best-practices.md). --## Control costs -Because your Azure Monitor cost is dependent on how much data you collect, ensure that you're not collecting more than you need to meet your monitoring requirements. Your configuration is a balance between your budget and how much insight you want into the operation of your virtual machines. ---A typical virtual machine generates between 1 GB and 3 GB of data per month. This data size depends on the configuration of the machine, the workloads running on it, and the configuration of your DCRs. Before you configure data collection across your entire virtual machine environment, begin collection on some representative machines to better predict your expected costs when deployed across your environment. Use [Log Analytics workspace insights](../logs/log-analytics-workspace-insights-overview.md) or log queries in [Data volume by computer](../logs/analyze-usage.md#data-volume-by-computer) to determine the amount of billable data collected for each machine and adjust accordingly. --Evaluate collected data and filter out any that meets the following criteria to reduce your costs. Each data source that you collect may have a different method for filtering out unwanted data. See the sections below for the details each of the common data sources. -- Not used for alerting.-- No known forensic or diagnostic value.-- Not required by regulators.-- Not used in any dashboards or workbooks.---You can also use [transformations](../essentials/data-collection-transformations.md) to implement more granular filtering and also to filter data from columns that provide little value. For example, you might have a Windows event that's valuable for alerting, but it includes columns with redundant or excessive data. You can create a transformation that allows the event to be collected but removes this excessive data. --Filter data as much as possible before it's sent to Azure Monitor to avoid a [potential charge for filtering too much data using transformations](../essentials/data-collection-transformations.md#cost-for-transformations). Use [transformations](../essentials/data-collection-transformations.md) for record filtering using complex logic and for filtering columns with data that you don't require. --## Default data collection -Azure Monitor automatically performs the following data collection without requiring any other configuration. --### Platform metrics -Platform metrics for Azure virtual machines include important host metrics such as CPU, network, and disk utilization. They can be: --- Viewed on the [Overview page](monitor-virtual-machine-analyze.md#single-machine-experience).-- Analyzed with [metrics explorer](../essentials/tutorial-metrics.md) for the machine in the Azure portal.-- Used for [metric alerts](tutorial-monitor-vm-alert-recommended.md).--### Activity log -The [activity log](../essentials/activity-log.md) is collected automatically. It includes the recent activity of the machine, such as any configuration changes and when it was stopped and started. You can view the platform metrics and activity log collected for each virtual machine host in the Azure portal. --You can [view the activity log](../essentials/activity-log-insights.md#view-the-activity-log) for an individual machine or for all resources in a subscription. [Create a diagnostic setting](../essentials/diagnostic-settings.md) to send this data into the same Log Analytics workspace used by Azure Monitor Agent to analyze it with the other monitoring data collected for the virtual machine. There's no cost for ingestion or retention of activity log data. --### VM availability information in Azure Resource Graph -With [Azure Resource Graph](../../governance/resource-graph/overview.md), you can use the same Kusto Query Language used in log queries to query your Azure resources at scale with complex filtering, grouping, and sorting by resource properties. You can use [VM health annotations](../../service-health/resource-health-vm-annotation.md) to Resource Graph for detailed failure attribution and downtime analysis. --For information on what data is collected and how to view it, see [Monitor virtual machines with Azure Monitor: Analyze monitoring data](monitor-virtual-machine-analyze.md). --### VM insights -When you enable VM insights, it creates a DCR with the *_MSVMI-_* prefix that collects the following information. You can use this same DCR with other machines as opposed to creating a new one for each VM. --- Common performance counters for the client operating system are sent to the [InsightsMetrics](/azure/azure-monitor/reference/tables/insightsmetrics) table in the Log Analytics workspace. Counter names are normalized to use the same common name regardless of the operating system type. For a list of performance counters that are collected, see [How to query logs from VM insights](vminsights-log-query.md#performance-records).-- If you specified processes and dependencies to be collected, the following tables are populated:- - - [VMBoundPort](/azure/azure-monitor/reference/tables/vmboundport): Traffic for open server ports on the machine - - [VMComputer](/azure/azure-monitor/reference/tables/vmcomputer): Inventory data for the machine - - [VMConnection](/azure/azure-monitor/reference/tables/vmconnection): Traffic for inbound and outbound connections to and from the machine - - [VMProcess](/azure/azure-monitor/reference/tables/vmprocess): Processes running on the machine --By default, [VM insights](../vm/vminsights-overview.md) won't enable collection of processes and dependencies to save data ingestion costs. This data is required for the Map feature and also deploys the dependency agent to the machine. [Enable this collection](vminsights-enable-portal.md#enable-vm-insights-for-azure-monitor-agent) if you want to use this feature. --## Collect Windows and Syslog events -The operating system and applications in virtual machines often write to the Windows event log or Syslog. You might create an alert as soon as a single event is found or wait for a series of matching events within a particular time window. You might also collect events for later analysis, such as identifying particular trends over time, or for performing troubleshooting after a problem occurs. --For guidance on how to create a DCR to collect Windows and Syslog events, see [Collect data with Azure Monitor Agent](../agents/azure-monitor-agent-data-collection.md). You can quickly create a DCR by using the most common Windows event logs and Syslog facilities filtering by event level. --For more granular filtering by criteria such as event ID, you can create a custom filter by using [XPath queries](../agents/data-collection-windows-events.md#filter-events-using-xpath-queries). You can further filter the collected data by [editing the DCR](../essentials/data-collection-rule-edit.md) to add a [transformation](../essentials/data-collection-transformations.md). --Use the following guidance as a recommended starting point for event collection. Modify the DCR settings to filter unneeded events and add other events depending on your requirements. --| Source | Strategy | -|:|:| -| Windows events | Collect at least **Critical**, **Error**, and **Warning** events for the **System** and **Application** logs to support alerting. Add **Information** events to analyze trends and support troubleshooting. **Verbose** events are rarely useful and typically shouldn't be collected. | -| Syslog events | Collect at least **LOG_WARNING** events for each facility to support alerting. Add **Information** events to analyze trends and support troubleshooting. **LOG_DEBUG** events are rarely useful and typically shouldn't be collected. | --### Sample log queries: Windows events --| Query | Description | -|:|:| -| `Event` | All Windows events | -| `Event | where EventLevelName == "Error"` |All Windows events with severity of error | -| `Event | summarize count() by Source` |Count of Windows events by source | -| `Event | where EventLevelName == "Error" | summarize count() by Source` |Count of Windows error events by source | --### Sample log queries: Syslog events --| Query | Description | -|:|:| -| `Syslog` |All Syslogs | -| `Syslog | where SeverityLevel == "error"` |All Syslog records with severity of error | -| `Syslog | summarize AggregatedValue = count() by Computer` |Count of Syslog records by computer | -| `Syslog | summarize AggregatedValue = count() by Facility` |Count of Syslog records by facility | --## Collect performance counters -Performance data from the client can be sent to either [Azure Monitor Metrics](../essentials/data-platform-metrics.md) or [Azure Monitor Logs](../logs/data-platform-logs.md), and you typically send them to both destinations. If you enabled VM insights, a common set of performance counters is collected in Logs to support its performance charts. You can't modify this set of counters, but you can create other DCRs to collect more counters and send them to different destinations. --There are multiple reasons why you would want to create a DCR to collect guest performance: --- You aren't using VM insights, so client performance data isn't already being collected.-- Collect other performance counters that VM insights isn't collecting.-- Collect performance counters from other workloads running on your client.-- Send performance data to [Azure Monitor Metrics](../essentials/data-platform-metrics.md) where you can use them with metrics explorer and metrics alerts.--For guidance on creating a DCR to collect performance counters, see [Collect events and performance counters from virtual machines with Azure Monitor Agent](../agents/azure-monitor-agent-data-collection.md). You can quickly create a DCR by using the most common counters. For more granular filtering by criteria such as event ID, you can create a custom filter by using [XPath queries](../agents/data-collection-windows-events.md#filter-events-using-xpath-queries). --> [!NOTE] -> You might choose to combine performance and event collection in the same DCR. -- Destination | Description | -|:|:| -| Metrics | Host metrics are automatically sent to Azure Monitor Metrics. You can use a DCR to collect client metrics so that they can be analyzed together with [metrics explorer](../essentials/metrics-getting-started.md) or used with [metrics alerts](../alerts/alerts-create-new-alert-rule.md?tabs=metric). This data is stored for 93 days. | -| Logs | Performance data stored in Azure Monitor Logs can be stored for extended periods. The data can be analyzed along with your event data by using [log queries](../logs/log-query-overview.md) with [Log Analytics](../logs/log-analytics-overview.md) or [log search alerts](../alerts/alerts-create-new-alert-rule.md?tabs=log). You can also correlate data by using complex logic across multiple machines, regions, and subscriptions.<br><br>Performance data is sent to the following tables:<br>- VM insights: [InsightsMetrics](/azure/azure-monitor/reference/tables/insightsmetrics)<br>- Other performance data: [Perf](/azure/azure-monitor/reference/tables/perf) | --### Sample log queries -The following samples use the `Perf` table with custom performance data. For information on performance data collected by VM insights, see [How to query logs from VM insights](../vm/vminsights-log-query.md#performance-records). --| Query | Description | -|:|:| -| `Perf` | All Performance data | -| `Perf | where Computer == "MyComputer"` |All Performance data from a particular computer | -| `Perf | where CounterName == "Current Disk Queue Length"` |All Performance data for a particular counter | -| `Perf | where ObjectName == "Processor" and CounterName == "% Processor Time" and InstanceName == "_Total" | summarize AVGCPU = avg(CounterValue) by Computer` |Average CPU Utilization across all computers | -| `Perf | where CounterName == "% Processor Time" | summarize AggregatedValue = max(CounterValue) by Computer` |Maximum CPU Utilization across all computers | -| `Perf | where ObjectName == "LogicalDisk" and CounterName == "Current Disk Queue Length" and Computer == "MyComputerName" | summarize AggregatedValue = avg(CounterValue) by InstanceName` |Average Current Disk Queue length across all the instances of a given computer | -| `Perf | where CounterName == "Disk Transfers/sec" | summarize AggregatedValue = percentile(CounterValue, 95) by Computer` |95th Percentile of Disk Transfers/Sec across all computers | -| `Perf | where CounterName == "% Processor Time" and InstanceName == "_Total" | summarize AggregatedValue = avg(CounterValue) by bin(TimeGenerated, 1h), Computer` |Hourly average of CPU usage across all computers | -| `Perf | where Computer == "MyComputer" and CounterName startswith_cs "%" and InstanceName == "_Total" | summarize AggregatedValue = percentile(CounterValue, 70) by bin(TimeGenerated, 1h), CounterName` | Hourly 70 percentile of every % percent counter for a particular computer | -| `Perf | where CounterName == "% Processor Time" and InstanceName == "_Total" and Computer == "MyComputer" | summarize ["min(CounterValue)"] = min(CounterValue), ["avg(CounterValue)"] = avg(CounterValue), ["percentile75(CounterValue)"] = percentile(CounterValue, 75), ["max(CounterValue)"] = max(CounterValue) by bin(TimeGenerated, 1h), Computer` |Hourly average, minimum, maximum, and 75-percentile CPU usage for a specific computer | -| `Perf | where ObjectName == "MSSQL$INST2:Databases" and InstanceName == "master"` | All Performance data from the Database performance object for the master database from the named SQL Server instance INST2. | -| `Perf | where TimeGenerated >ago(5m) | where ObjectName == "Process" and InstanceName != "_Total" and InstanceName != "Idle" | where CounterName == "% Processor Time" | summarize cpuVal=avg(CounterValue) by Computer,InstanceName | join (Perf| where TimeGenerated >ago(5m)| where ObjectName == "Process" and CounterName == "ID Process" | summarize arg_max(TimeGenerated,*) by ProcID=CounterValue ) on Computer,InstanceName | sort by TimeGenerated desc | summarize AvgCPU = avg(cpuVal) by InstanceName,ProcID` | Average of CPU over last 5 min for each Process ID. | ---## Collect text logs -Some applications write events written to a text log stored on the virtual machine. Create a [custom table and DCR](../agents/data-collection-text-log.md) to collect this data. You define the location of the text log, its detailed configuration, and the schema of the custom table. There's a cost for the ingestion and retention of this data in the workspace. --### Sample log queries -The column names used here are examples only. The column names for your log will most likely be different. --| Query | Description | -|:|:| -| `MyApp_CL | summarize count() by code` | Count the number of events by code. | -| `MyApp_CL | where status == "Error" | summarize AggregatedValue = count() by Computer, bin(TimeGenerated, 15m)` | Create an alert rule on any error event. | --## Collect IIS logs -IIS running on Windows machines writes logs to a text file. Configure IIS log collection by using [Collect IIS logs with Azure Monitor Agent](../agents/data-collection-iis.md). There's a cost for the ingestion and retention of this data in the workspace. --Records from the IIS log are stored in the [W3CIISLog](/azure/azure-monitor/reference/tables/w3ciislog) table in the Log Analytics workspace. There's a cost for the ingestion and retention of this data in the workspace. --### Sample log queries --| Query | Description | -|:|:| -| `W3CIISLog | where csHost=="www.contoso.com" | summarize count() by csUriStem` | Count the IIS log entries by URL for the host www.contoso.com. | -| `W3CIISLog | summarize sum(csBytes) by Computer` | Review the total bytes received by each IIS machine. | --## Monitor a service or daemon -To monitor the status of a Windows service or Linux daemon, enable the [Change Tracking and Inventory](../../automation/change-tracking/overview.md) solution in [Azure Automation](../../automation/automation-intro.md). --Azure Monitor has no ability on its own to monitor the status of a service or daemon. There are some possible methods to use, such as looking for events in the Windows event log, but this method is unreliable. You can also look for the process associated with the service running on the machine from the [VMProcess](/azure/azure-monitor/reference/tables/vmprocess) table populated by VM insights. This table only updates every hour, which isn't typically sufficient if you want to use this data for alerting. --> [!NOTE] -> The Change Tracking and Analysis solution is different from the [Change Analysis](vminsights-change-analysis.md) feature in VM insights. This feature is in public preview and not yet included in this scenario. --For different options to enable the Change Tracking solution on your virtual machines, see [Enable Change Tracking and Inventory](../../automation/change-tracking/overview.md#enable-change-tracking-and-inventory). This solution includes methods to configure virtual machines at scale. You have to [create an Azure Automation account](../../automation/quickstarts/create-azure-automation-account-portal.md) to support the solution. --When you enable Change Tracking and Inventory, two new tables are created in your Log Analytics workspace. Use these tables for logs queries and log search alert rules. --| Table | Description | -|:|:| -| [ConfigurationChange](/azure/azure-monitor/reference/tables/configurationdata) | Changes to in-guest configuration data | -| [ConfigurationData](/azure/azure-monitor/reference/tables/configurationdata) | Last reported state for in-guest configuration data | --### Sample log queries --- **List all services and daemons that have recently started.**- - ```kusto - ConfigurationChange - | where ConfigChangeType == "Daemons" or ConfigChangeType == "WindowsServices" - | where SvcState == "Running" - | sort by Computer, SvcName - ``` --- **Alert when a specific service stops.** Use this query in a log search alert rule.- - ```kusto - ConfigurationData - | where SvcName == "W3SVC" - | where SvcState == "Stopped" - | where ConfigDataType == "WindowsServices" - | where SvcStartupType == "Auto" - | summarize AggregatedValue = count() by Computer, SvcName, SvcDisplayName, SvcState, bin(TimeGenerated, 15m) - ``` --- **Alert when one of a set of services stops.** Use this query in a log search alert rule.-- ```kusto - let services = dynamic(["omskd","cshost","schedule","wuauserv","heathservice","efs","wsusservice","SrmSvc","CertSvc","wmsvc","vpxd","winmgmt","netman","smsexec","w3svc","sms_site_vss_writer","ccmexe","spooler","eventsystem","netlogon","kdc","ntds","lsmserv","gpsvc","dns","dfsr","dfs","dhcp","DNSCache","dmserver","messenger","w32time","plugplay","rpcss","lanmanserver","lmhosts","eventlog","lanmanworkstation","wnirm","mpssvc","dhcpserver","VSS","ClusSvc","MSExchangeTransport","MSExchangeIS"]); - ConfigurationData - | where ConfigDataType == "WindowsServices" - | where SvcStartupType == "Auto" - | where SvcName in (services) - | where SvcState == "Stopped" - | project TimeGenerated, Computer, SvcName, SvcDisplayName, SvcState - | summarize AggregatedValue = count() by Computer, SvcName, SvcDisplayName, SvcState, bin(TimeGenerated, 15m) - ``` --## Monitor a port -Port monitoring verifies that a machine is listening on a particular port. Two potential strategies for port monitoring are described here. --### Dependency agent tables -If you're using VM insights with **Processes and dependencies collection** enabled, you can use [VMConnection](/azure/azure-monitor/reference/tables/vmconnection) and [VMBoundPort](/azure/azure-monitor/reference/tables/vmboundport) to analyze connections and ports on the machine. The `VMBoundPort` table is updated every minute with each process running on the computer and the port it's listening on. You can create a log search alert similar to the missing heartbeat alert to find processes that have stopped or to alert when the machine isn't listening on a particular port. --- **Review the count of ports open on your VMs to assess which VMs have configuration and security vulnerabilities.**-- ```kusto - VMBoundPort - | where Ip != "127.0.0.1" - | summarize by Computer, Machine, Port, Protocol - | summarize OpenPorts=count() by Computer, Machine - | order by OpenPorts desc - ``` --- **List the bound ports on your VMs to assess which VMs have configuration and security vulnerabilities.**-- ```kusto - VMBoundPort - | distinct Computer, Port, ProcessName - ``` --- **Analyze network activity by port to determine how your application or service is configured.**-- ```kusto - VMBoundPort - | where Ip != "127.0.0.1" - | summarize BytesSent=sum(BytesSent), BytesReceived=sum(BytesReceived), LinksEstablished=sum(LinksEstablished), LinksTerminated=sum(LinksTerminated), arg_max(TimeGenerated, LinksLive) by Machine, Computer, ProcessName, Ip, Port, IsWildcardBind - | project-away TimeGenerated - | order by Machine, Computer, Port, Ip, ProcessName - ``` --- **Review bytes sent and received trends for your VMs.**-- ```kusto - VMConnection - | summarize sum(BytesSent), sum(BytesReceived) by bin(TimeGenerated,1hr), Computer - | order by Computer desc - | render timechart - ``` --- **Use connection failures over time to determine if the failure rate is stable or changing.**-- ```kusto - VMConnection - | where Computer == <replace this with a computer name, e.g. 'acme-demo'> - | extend bythehour = datetime_part("hour", TimeGenerated) - | project bythehour, LinksFailed - | summarize failCount = count() by bythehour - | sort by bythehour asc - | render timechart - ``` --- **Link status trends to analyze the behavior and connection status of a machine.**-- ```kusto - VMConnection - | where Computer == <replace this with a computer name, e.g. 'acme-demo'> - | summarize dcount(LinksEstablished), dcount(LinksLive), dcount(LinksFailed), dcount(LinksTerminated) by bin(TimeGenerated, 1h) - | render timechart - ``` --### Connection Manager -The [Connection Monitor](../../network-watcher/connection-monitor-overview.md) feature of [Network Watcher](../../network-watcher/network-watcher-monitoring-overview.md) is used to test connections to a port on a virtual machine. A test verifies that the machine is listening on the port and that it's accessible on the network. --Connection Manager requires the Network Watcher extension on the client machine initiating the test. It doesn't need to be installed on the machine being tested. For more information, see [Tutorial: Monitor network communication using the Azure portal](../../network-watcher/connection-monitor.md). --There's an extra cost for Connection Manager. For more information, see [Network Watcher pricing](https://azure.microsoft.com/pricing/details/network-watcher/). --## Run a process on a local machine -Monitoring of some workloads requires a local process. An example is a PowerShell script that runs on the local machine to connect to an application and collect or process data. You can use [Hybrid Runbook Worker](../../automation/automation-hybrid-runbook-worker.md), which is part of [Azure Automation](../../automation/automation-intro.md), to run a local PowerShell script. There's no direct charge for Hybrid Runbook Worker, but there's a cost for each runbook that it uses. --The runbook can access any resources on the local machine to gather required data. It can't send data directly to Azure Monitor or create an alert. To create an alert, have the runbook write an entry to a custom log. Then configure that log to be collected by Azure Monitor. Create a log search alert rule that fires on that log entry. --## Next steps --* [Analyze monitoring data collected for virtual machines](monitor-virtual-machine-analyze.md) -* [Create alerts from collected data](monitor-virtual-machine-alerts.md) -- |
| azure-monitor | Monitor Virtual Machine | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/monitor-virtual-machine.md | - Title: Monitor virtual machines with Azure Monitor -description: Learn how to use Azure Monitor to monitor the health and performance of virtual machines and their workloads. ---- Previously updated : 02/15/2024-----# Monitor virtual machines with Azure Monitor --This guide describes how to use Azure Monitor to monitor the health and performance of virtual machines and their workloads. It includes collection of telemetry critical for monitoring and analysis and visualization of collected data to identify trends. It also shows you how to configure alerting to be proactively notified of critical issues. --> [!NOTE] -> This guide describes how to implement complete monitoring of your enterprise Azure and hybrid virtual machine environment. To get started monitoring your first Azure virtual machine, see [Monitor Azure virtual machines](/azure/virtual-machines/monitor-vm). --## Types of machines --This guide includes monitoring of the following types of machines using Azure Monitor. Many of the processes described here are the same regardless of the type of machine. Considerations for different types of machines are clearly identified where appropriate. The types of machines include: --- Azure virtual machines.-- Azure Virtual Machine Scale Sets.-- Hybrid machines, which are virtual machines running in other clouds, with a managed service provider, or on-premises. They also include physical machines running on-premises.--## Layers of monitoring --There are fundamentally four layers to a virtual machine that require monitoring. Each layer has a distinct set of telemetry and monitoring requirements. ---| Layer | Description | -|:|:| -| Virtual machine host | The host virtual machine in Azure. Azure Monitor has no access to the host in other clouds but must rely on information collected from the guest operating system. The host can be useful for tracking activity such as configuration changes, and basic alerting such as processor utilization and whether the machine is running. | -| Guest operating system | The operating system running on the virtual machine, which is some version of either Windows or Linux. A significant amount of monitoring data is available from the guest operating system, such as performance data and events. You must install Azure Monitor agent to retrieve this telemetry. | -| Workloads | Workloads running in the guest operating system that support your business applications. These will typically generate performance data and events similar to the operating system that you can retrieve. You must install Azure Monitor agent to retrieve this telemetry. | -| Application | The business application that depends on your virtual machines. This will typically be monitored by Application insights. | --## Configuration steps -The following table lists the different steps for configuration of VM monitoring. Each one links to an article with the detailed description of that configuration step. --| Step | Description | -|:|:| -| [Deploy Azure Monitor agent](monitor-virtual-machine-agent.md) | Deploy the Azure Monitor agent to your Azure and hybrid virtual machines to collect data from the guest operating system and workloads. | -| [Configure data collection](monitor-virtual-machine-data-collection.md) | Create data collection rules to instruct the Azure Monitor agent to collect telemetry from the guest operating system. | -| [Analyze collected data](monitor-virtual-machine-analyze.md) | Analyze monitoring data collected by Azure Monitor from virtual machines and their guest operating systems and applications to identify trends and critical information. | -| [Create alert rules](monitor-virtual-machine-alerts.md) | Create alerts to proactively identify critical issues in your monitoring data. | -| [Migrate management pack logic](monitor-virtual-machine-management-packs.md) | General guidance for translation the logic from your System Center Operations Manager management packs to Azure Monitor. | -- -## VM insights -[VM insights](../vm/vminsights-overview.md) is a feature in Azure Monitor that allows you to quickly get started monitoring your virtual machines. While it's not required to take advantage of most Azure Monitor features for monitoring your VMs, it provides the following value: --- Simplified onboarding of the Azure Monitor agent to enable monitoring of a virtual machine guest operating system and workloads.-- Preconfigured data collection rule that collects the most common set of performance counters for Windows and Linux.-- Predefined trending performance charts and workbooks that you can use to analyze core performance metrics from the virtual machine's guest operating system.-- Optional collection of details for each virtual machine, the processes running on it, and dependencies with other services.-- Optional dependency map that displays interconnected components with other machines and external sources.--The articles in this guide provide guidance on configuring VM insights and using the data it collects with other Azure Monitor features. They also identify alternatives if you choose not to use VM insights. ---## Security monitoring -Azure Monitor focuses on operational data, while security monitoring in Azure is performed by other services such as [Microsoft Defender for Cloud](/azure/defender-for-cloud/) and [Microsoft Sentinel](../../sentinel/index.yml). Configuration of these services is not included in this guide. --> [!IMPORTANT] -> The security services have their own cost independent of Azure Monitor. Before you configure these services, refer to their pricing information to determine your appropriate investment in their usage. --The following table lists the integration points for Azure Monitor with the security services. All the services use the same Azure Monitor agent, which reduces complexity because there are no other components being deployed to your virtual machines. Defender for Cloud and Microsoft Sentinel store their data in a Log Analytics workspace so that you can use log queries to correlate data collected by the different services. Or you can create a custom workbook that combines security data and availability and performance data in a single view. --See [Design a Log Analytics workspace architecture](../logs/workspace-design.md) for guidance on the most effective workspace design for your requirements taking into account all your services that use them. --| Integration point | Azure Monitor | Microsoft<br>Defender for Cloud | Microsoft<br>Sentinel | Microsoft<br>Defender for Endpoint | -|:|::|::|::|::| -| Collects security events | X<sup>1</sup> | X | X | X | -| Stores data in Log Analytics workspace | X | X | X | | -| Uses Azure Monitor agent | X | X | X | X | --<sup>1</sup> Azure Monitor agent can collect security events but will send them to the [Event table](/azure/azure-monitor/reference/tables/event) with other events. Microsoft Sentinel provides additional features to collect and analyze these events. --> [!IMPORTANT] -> Azure Monitor agent is in preview for some service features. See [Supported services and features](../agents/agents-overview.md#supported-services-and-features) for current details. --## Troubleshoot VM performance issues with Performance Diagnostics --[The Performance Diagnostics tool](/troubleshoot/azure/virtual-machines/performance-diagnostics?toc=/azure/azure-monitor/toc.json) helps troubleshoot performance issues on Windows or Linux virtual machines by quickly diagnosing and providing insights on issues it currently finds on your machines. The tool does not analyze historical monitoring data you collect, but rather checks the current state of the machine for known issues, implementation of best practices, and complex problems that involve slow VM performance or high usage of CPU, disk space, or memory. ---## Next steps --[Deploy the Azure Monitor agent to your virtual machines](monitor-virtual-machine-agent.md) |
| azure-monitor | Resource Manager Vminsights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/resource-manager-vminsights.md | - Title: Resource Manager template samples for VM insights -description: Sample Azure Resource Manager templates to deploy and configureVM insights. ---- Previously updated : 09/28/2023---# Resource Manager template samples for VM insights --This article includes sample [Azure Resource Manager templates](../../azure-resource-manager/templates/syntax.md) to enable VM insights on virtual machines. Each sample includes a template file and a parameters file with sample values to provide to the template. ---## Configure workspace --The following sample enables VM insights for a Log Analytics workspace. --### Template file --# [Bicep](#tab/bicep) --main.bicep --```bicep -@description('Resource ID of the workspace.') -param workspaceResourceId string --@description('Location of the workspace.') -param workspaceLocation string --module VMISolutionDeployment './nested_VMISolutionDeployment.bicep' = { - name: 'VMISolutionDeployment' - scope: resourceGroup(split(workspaceResourceId, '/')[2], split(workspaceResourceId, '/')[4]) - params: { - workspaceLocation: workspaceLocation - workspaceResourceId: workspaceResourceId - } -} -``` --nested_VMISolutionDeployment.bicep --```bicep -@description('Location of the workspace.') -param workspaceLocation string --@description('Resource ID of the workspace.') -param workspaceResourceId string --resource solution 'Microsoft.OperationsManagement/solutions@2015-11-01-preview' = { - location: workspaceLocation - name: 'VMInsights(${split(workspaceResourceId, '/')[8]})' - properties: { - workspaceResourceId: workspaceResourceId - } - plan: { - name: 'VMInsights(${split(workspaceResourceId, '/')[8]})' - product: 'OMSGallery/VMInsights' - promotionCode: '' - publisher: 'Microsoft' - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceResourceId": { - "type": "string", - "metadata": { - "description": "Resource ID of the workspace." - } - }, - "workspaceLocation": { - "type": "string", - "metadata": { - "description": "Location of the workspace." - } - } - }, - "resources": [ - { - "type": "Microsoft.Resources/deployments", - "apiVersion": "2020-10-01", - "name": "VMISolutionDeployment", - "subscriptionId": "[split(parameters('workspaceResourceId'), '/')[2]]", - "resourceGroup": "[split(parameters('workspaceResourceId'), '/')[4]]", - "properties": { - "expressionEvaluationOptions": { - "scope": "inner" - }, - "mode": "Incremental", - "parameters": { - "workspaceLocation": { - "value": "[parameters('workspaceLocation')]" - }, - "workspaceResourceId": { - "value": "[parameters('workspaceResourceId')]" - } - }, - "template": { - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceLocation": { - "type": "string", - "metadata": { - "description": "Location of the workspace." - } - }, - "workspaceResourceId": { - "type": "string", - "metadata": { - "description": "Resource ID of the workspace." - } - } - }, - "resources": [ - { - "type": "Microsoft.OperationsManagement/solutions", - "apiVersion": "2015-11-01-preview", - "name": "[format('VMInsights({0})', split(parameters('workspaceResourceId'), '/')[8])]", - "location": "[parameters('workspaceLocation')]", - "properties": { - "workspaceResourceId": "[parameters('workspaceResourceId')]" - }, - "plan": { - "name": "[format('VMInsights({0})', split(parameters('workspaceResourceId'), '/')[8])]", - "product": "OMSGallery/VMInsights", - "promotionCode": "", - "publisher": "Microsoft" - } - } - ] - } - } - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "workspaceResourceId": { - "value": "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourcegroups/my-resource-group/providers/microsoft.operationalinsights/workspaces/my-workspace" - }, - "workspaceLocation": { - "value": "eastus" - } - } -} -``` --## Onboard an Azure virtual machine --The following sample adds an Azure virtual machine to VM insights. --### Template file --# [Bicep](#tab/bicep) --```bicep -@description('VM Resource ID.') -param VmResourceId string --@description('The Virtual Machine Location.') -param VmLocation string --@description('OS Type, Example: Linux / Windows') -param osType string --@description('Workspace Resource ID.') -param WorkspaceResourceId string --var VmName_var = split(VmResourceId, '/')[8] -var DaExtensionName = ((toLower(osType) == 'windows') ? 'DependencyAgentWindows' : 'DependencyAgentLinux') -var DaExtensionType = ((toLower(osType) == 'windows') ? 'DependencyAgentWindows' : 'DependencyAgentLinux') -var DaExtensionVersion = '9.5' -var MmaExtensionName = ((toLower(osType) == 'windows') ? 'MMAExtension' : 'OMSExtension') -var MmaExtensionType = ((toLower(osType) == 'windows') ? 'MicrosoftMonitoringAgent' : 'OmsAgentForLinux') -var MmaExtensionVersion = ((toLower(osType) == 'windows') ? '1.0' : '1.4') ---resource vm 'Microsoft.Compute/virtualMachines@2021-11-01' = { - name: VmName_var - location: VmLocation -} --resource daExtension 'Microsoft.Compute/virtualMachines/extensions@2021-11-01' = { - parent: vm - name: DaExtensionName - location: VmLocation - properties: { - publisher: 'Microsoft.Azure.Monitoring.DependencyAgent' - type: DaExtensionType - typeHandlerVersion: DaExtensionVersion - autoUpgradeMinorVersion: true - } -} --resource mmaExtension 'Microsoft.Compute/virtualMachines/extensions@2021-11-01' = { - parent: vm - name: MmaExtensionName - location: VmLocation - properties: { - publisher: 'Microsoft.EnterpriseCloud.Monitoring' - type: MmaExtensionType - typeHandlerVersion: MmaExtensionVersion - autoUpgradeMinorVersion: true - settings: { - workspaceId: reference(WorkspaceResourceId, '2021-12-01-preview').customerId - azureResourceId: VmResourceId - stopOnMultipleConnections: true - } - protectedSettings: { - workspaceKey: listKeys(WorkspaceResourceId, '2021-12-01-preview').primarySharedKey - } - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "metadata": { - "_generator": { - "name": "bicep", - "version": "0.5.6.12127", - "templateHash": "5890554597225741728" - } - }, - "parameters": { - "VmResourceId": { - "type": "string", - "metadata": { - "description": "VM Resource ID." - } - }, - "VmLocation": { - "type": "string", - "metadata": { - "description": "The Virtual Machine Location." - } - }, - "osType": { - "type": "string", - "metadata": { - "description": "OS Type, Example: Linux / Windows" - } - }, - "WorkspaceResourceId": { - "type": "string", - "metadata": { - "description": "Workspace Resource ID." - } - } - }, - "variables": { - "VmName_var": "[split(parameters('VmResourceId'), '/')[8]]", - "DaExtensionName": "[if(equals(toLower(parameters('osType')), 'windows'), 'DependencyAgentWindows', 'DependencyAgentLinux')]", - "DaExtensionType": "[if(equals(toLower(parameters('osType')), 'windows'), 'DependencyAgentWindows', 'DependencyAgentLinux')]", - "DaExtensionVersion": "9.5", - "MmaExtensionName": "[if(equals(toLower(parameters('osType')), 'windows'), 'MMAExtension', 'OMSExtension')]", - "MmaExtensionType": "[if(equals(toLower(parameters('osType')), 'windows'), 'MicrosoftMonitoringAgent', 'OmsAgentForLinux')]", - "MmaExtensionVersion": "[if(equals(toLower(parameters('osType')), 'windows'), '1.0', '1.4')]" - }, - "resources": [ - { - "type": "Microsoft.Compute/virtualMachines", - "apiVersion": "2021-11-01", - "name": "[variables('VmName_var')]", - "location": "[parameters('VmLocation')]" - }, - { - "type": "Microsoft.Compute/virtualMachines/extensions", - "apiVersion": "2021-11-01", - "name": "[format('{0}/{1}', variables('VmName_var'), variables('DaExtensionName'))]", - "location": "[parameters('VmLocation')]", - "properties": { - "publisher": "Microsoft.Azure.Monitoring.DependencyAgent", - "type": "[variables('DaExtensionType')]", - "typeHandlerVersion": "[variables('DaExtensionVersion')]", - "autoUpgradeMinorVersion": true - }, - "dependsOn": [ - "[resourceId('Microsoft.Compute/virtualMachines', variables('VmName_var'))]" - ] - }, - { - "type": "Microsoft.Compute/virtualMachines/extensions", - "apiVersion": "2021-11-01", - "name": "[format('{0}/{1}', variables('VmName_var'), variables('MmaExtensionName'))]", - "location": "[parameters('VmLocation')]", - "properties": { - "publisher": "Microsoft.EnterpriseCloud.Monitoring", - "type": "[variables('MmaExtensionType')]", - "typeHandlerVersion": "[variables('MmaExtensionVersion')]", - "autoUpgradeMinorVersion": true, - "settings": { - "workspaceId": "[reference(parameters('WorkspaceResourceId'), '2021-12-01-preview').customerId]", - "azureResourceId": "[parameters('VmResourceId')]", - "stopOnMultipleConnections": true - }, - "protectedSettings": { - "workspaceKey": "[listKeys(parameters('WorkspaceResourceId'), '2021-12-01-preview').primarySharedKey]" - } - }, - "dependsOn": [ - "[resourceId('Microsoft.Compute/virtualMachines', variables('VmName_var'))]" - ] - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "vmResourceId": { - "value": "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/my-resource-group/providers/Microsoft.Compute/virtualMachines/my-linux-vm" - }, - "vmLocation": { - "value": "westus" - }, - "osType": { - "value": "linux" - }, - "workspaceResourceId": { - "value": "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourcegroups/my-resource-group/providers/microsoft.operationalinsights/workspaces/my-workspace" - } - } -} --``` --## Onboard an Azure virtual machine scale set --The following sample adds an Azure virtual machine scale set to VM insights. --### Template file --# [Bicep](#tab/bicep) --```bicep -@description('VM Resource ID.') -param VmssResourceId string --@description('The Virtual Machine Location.') -param VmssLocation string --@description('OS Type, Example: Linux / Windows') -param osType string --@description('Workspace Resource ID.') -param WorkspaceResourceId string --var VmssName_var = split(VmssResourceId, '/')[8] -var DaExtensionName = ((toLower(osType) == 'windows') ? 'DependencyAgentWindows' : 'DependencyAgentLinux') -var DaExtensionType = ((toLower(osType) == 'windows') ? 'DependencyAgentWindows' : 'DependencyAgentLinux') -var DaExtensionVersion = '9.5' -var MmaExtensionName = ((toLower(osType) == 'windows') ? 'MMAExtension' : 'OMSExtension') -var MmaExtensionType = ((toLower(osType) == 'windows') ? 'MicrosoftMonitoringAgent' : 'OmsAgentForLinux') -var MmaExtensionVersion = ((toLower(osType) == 'windows') ? '1.0' : '1.4') --resource vmss 'Microsoft.Compute/virtualMachineScaleSets@2021-11-01' = { - name: VmssName_var - location: VmssLocation - properties:{} -} --resource daExtension 'Microsoft.Compute/virtualMachineScaleSets/extensions@2018-10-01' = { - parent: vmss - name: DaExtensionName - properties: { - publisher: 'Microsoft.Azure.Monitoring.DependencyAgent' - type: DaExtensionType - typeHandlerVersion: DaExtensionVersion - autoUpgradeMinorVersion: true - } -} --resource mmaExtension 'Microsoft.Compute/virtualMachineScaleSets/extensions@2018-10-01' = { - parent: vmss - name: MmaExtensionName - properties: { - publisher: 'Microsoft.EnterpriseCloud.Monitoring' - type: MmaExtensionType - typeHandlerVersion: MmaExtensionVersion - autoUpgradeMinorVersion: true - settings: { - workspaceId: reference(WorkspaceResourceId, '2021-12-01-preview').customerId - azureResourceId: VmssResourceId - stopOnMultipleConnections: true - } - protectedSettings: { - workspaceKey: listKeys(WorkspaceResourceId, '2021-12-01-preview').primarySharedKey - } - } -} -``` --# [JSON](#tab/json) --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "VmssResourceId": { - "type": "string", - "metadata": { - "description": "VM Resource ID." - } - }, - "VmssLocation": { - "type": "string", - "metadata": { - "description": "The Virtual Machine Location." - } - }, - "osType": { - "type": "string", - "metadata": { - "description": "OS Type, Example: Linux / Windows" - } - }, - "WorkspaceResourceId": { - "type": "string", - "metadata": { - "description": "Workspace Resource ID." - } - } - }, - "variables": { - "VmssName_var": "[split(parameters('VmssResourceId'), '/')[8]]", - "DaExtensionName": "[if(equals(toLower(parameters('osType')), 'windows'), 'DependencyAgentWindows', 'DependencyAgentLinux')]", - "DaExtensionType": "[if(equals(toLower(parameters('osType')), 'windows'), 'DependencyAgentWindows', 'DependencyAgentLinux')]", - "DaExtensionVersion": "9.5", - "MmaExtensionName": "[if(equals(toLower(parameters('osType')), 'windows'), 'MMAExtension', 'OMSExtension')]", - "MmaExtensionType": "[if(equals(toLower(parameters('osType')), 'windows'), 'MicrosoftMonitoringAgent', 'OmsAgentForLinux')]", - "MmaExtensionVersion": "[if(equals(toLower(parameters('osType')), 'windows'), '1.0', '1.4')]" - }, - "resources": [ - { - "type": "Microsoft.Compute/virtualMachineScaleSets", - "apiVersion": "2021-11-01", - "name": "[variables('VmssName_var')]", - "location": "[parameters('VmssLocation')]", - "properties": {} - }, - { - "type": "Microsoft.Compute/virtualMachineScaleSets/extensions", - "apiVersion": "2018-10-01", - "name": "[format('{0}/{1}', variables('VmssName_var'), variables('DaExtensionName'))]", - "properties": { - "publisher": "Microsoft.Azure.Monitoring.DependencyAgent", - "type": "[variables('DaExtensionType')]", - "typeHandlerVersion": "[variables('DaExtensionVersion')]", - "autoUpgradeMinorVersion": true - }, - "dependsOn": [ - "[resourceId('Microsoft.Compute/virtualMachineScaleSets', variables('VmssName_var'))]" - ] - }, - { - "type": "Microsoft.Compute/virtualMachineScaleSets/extensions", - "apiVersion": "2018-10-01", - "name": "[format('{0}/{1}', variables('VmssName_var'), variables('MmaExtensionName'))]", - "properties": { - "publisher": "Microsoft.EnterpriseCloud.Monitoring", - "type": "[variables('MmaExtensionType')]", - "typeHandlerVersion": "[variables('MmaExtensionVersion')]", - "autoUpgradeMinorVersion": true, - "settings": { - "workspaceId": "[reference(parameters('WorkspaceResourceId'), '2021-12-01-preview').customerId]", - "azureResourceId": "[parameters('VmssResourceId')]", - "stopOnMultipleConnections": true - }, - "protectedSettings": { - "workspaceKey": "[listKeys(parameters('WorkspaceResourceId'), '2021-12-01-preview').primarySharedKey]" - } - }, - "dependsOn": [ - "[resourceId('Microsoft.Compute/virtualMachineScaleSets', variables('VmssName_var'))]" - ] - } - ] -} -``` ----### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "VmssResourceId": { - "value": "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/my-resource-group/providers/Microsoft.Compute/virtualMachines/my-windows-vmss" - }, - "VmssLocation": { - "value": "westus" - }, - "OsType": { - "value": "windows" - }, - "WorkspaceResourceId": { - "value": "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourcegroups/my-resource-group/providers/microsoft.operationalinsights/workspaces/my-workspace" - } - } -} -``` --## Next steps --* [Get other sample templates for Azure Monitor](../resource-manager-samples.md). -* [Learn more about VM insights](vminsights-overview.md). |
| azure-monitor | Tutorial Monitor Vm Alert Availability | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/tutorial-monitor-vm-alert-availability.md | - Title: Create availability alert rule for multiple Azure virtual machines (preview) -description: Create a single alert rule in Azure Monitor to proactively notify you if any virtual machine in a subscription or resource group is unavailable. --- Previously updated : 07/26/2024----# Tutorial: Create availability alert rule for multiple Azure virtual machines -One of the most common monitoring requirements for a virtual machine is to create an alert if it stops running. The best method for this is to create a metric alert rule in Azure Monitor using the [VM availability](/azure/virtual-machines/monitor-vm-reference#vm-availability-metric-preview) metric which is currently in public preview. --You can create an availability alert rule for a single VM using the VM Availability metric with [recommended alerts](tutorial-monitor-vm-alert-recommended.md). This tutorial shows how to create a single rule that will apply to all virtual machines in a subscription or resource group in a particular region. --> [!TIP] -> While this article uses the metric value *VM availability metric,* you can use the same process to alert on any metric value. --In this article, you learn how to: --> [!div class="checklist"] -> * View the VM availability metric in metrics explorer. -> * Create an alert rule targeting a subscription or resources group. -> * Create an action group to be proactively notified when an alert is created. -- --## Prerequisites -To complete the steps in this article you need the following: --- At least one Azure virtual machine to monitor.--## View VM availability metric in metrics explorer -There are multiple methods to create an alert rule in Azure Monitor. In this tutorial, we'll create it from [metrics explorer](../essentials/metrics-getting-started.md), which will prefill required values such as the scope and metric we want to monitor. You'll just need to provide the detailed logic for the alert rule. ---1. Select **Metrics** from the **Monitor** menu in the Azure portal. -2. In **Select a scope**, select either a subscription or a resource group with VMs to monitor. -3. Under **Refine scope**, for **Resource type**, select *Virtual machines*, and select the **Location** with VMs to monitor. -5. Click **Apply** to set the scope for metrics explorer. -- :::image type="content" source="media/tutorial-monitor-vm/metric-explorer-scope.png" alt-text="Screenshot of metrics explorer scope selection." lightbox="media/tutorial-monitor-vm/metric-explorer-scope.png"::: ---6. Select *VM Availability metric (preview)* for **Metric**. The value is displayed for each VM in the selected scope. -- :::image type="content" source="media/tutorial-monitor-vm/vm-availability-metric-explorer.png" alt-text="Screenshot of VM Availability metric in metrics explorer." lightbox="media/tutorial-monitor-vm/vm-availability-metric-explorer.png"::: --7. Click **New Alert Rule** to create an alert rule and open its configuration. --8. Set the following values for the **Alert logic**. This specifies that the alert will fire whenever the average value of the availability metric falls below 1, which indicates that one of the VMs in the selected scope isn't running. -- | Setting | Value | - |:|:| - | Threshold | Static | - | Aggregation Type | Average | - | Operator | Less than | - | Unit | Count | - | Threshold value | 1 | --9. Set the following values for **When to evaluate**. This specifies that the rule will run every minute, using the collected values from the previous minute. -- | Setting | Value | - |:|:| - | Check every | 1 minute | - | Loopback period | 1 minute | --- :::image type="content" source="media/tutorial-monitor-vm/vm-availability-metric-alert-logic.png" alt-text="Screenshot of alert rule details for VM Availability metric." lightbox="media/tutorial-monitor-vm/vm-availability-metric-alert-logic.png"::: ----## Configure action group -The **Actions** page allows you to add one or more [action groups](../alerts/action-groups.md) to the alert rule. Action groups define a set of actions to take when an alert is fired such as sending an email or an SMS message. --> [!TIP] -> If you already have an action group, click **Add action group** to add an existing group to the alert rule instead of creating a new one. --1. Click **Create action group** to create a new one. -- :::image type="content" source="media/tutorial-monitor-vm/vm-availability-metric-create-action-group.png" alt-text="Screenshot of option to create new action group." lightbox="media/tutorial-monitor-vm/vm-availability-metric-create-action-group.png"::: --2. Select a **Subscription** and **Resource group** for the action group and give it an **Action group name** that will appear in the portal and a **Display name** that will appear in email and SMS notifications. -- :::image type="content" source="media/tutorial-monitor-vm/vm-availability-metric-action-group-basics.png" lightbox="./media/tutorial-monitor-vm/vm-availability-metric-action-group-basics.png" alt-text="Screenshot of action group basics."::: --3. Select **Notifications** and add one or more methods to notify appropriate people when the alert is fired. -- :::image type="content" source="media/tutorial-monitor-vm/action-group-notifications.png" lightbox="./media/tutorial-monitor-vm/action-group-notifications.png" alt-text="Screenshot showing action group notifications."::: --## Configure details --1. Configure different settings for the alert rule on the **Details** page. -- | Setting | Description | - |:|:| - | Subscription | Subscription where the alert rule will be stored. | - | Resource group | Resource group where the alert rule will be stored. This doesn't need to be in the same resource group as the resource that you're monitoring. | - | Severity | The severity allows you to group alerts with a similar relative importance. A severity of **Error** is appropriate for an unresponsive virtual machine. | - | Alert rule name | Name of the alert that's displayed when it fires. | - | Alert rule description | Optional description of the alert rule. | - -- :::image type="content" source="media/tutorial-monitor-vm/alert-rule-details.png" lightbox="media/tutorial-monitor-vm/alert-rule-details.png" alt-text="Screenshot showing alert rule details."::: --2. Click **Review + create** to create the alert rule. --## View the alert -To test the alert rule, stop one or more virtual machines in the scope you specified. If you configured a notification in your action group, then you should receive that notification within a few seconds. You'll also see an alert for each VM on the **Alerts** page. ----## Next steps -Now that you have alerting in place when the VM goes down, enable VM insights to install the Azure Monitor agent which collects additional data from the client and provides additional analysis tools. --> [!div class="nextstepaction"] -> [Collect guest logs and metrics from Azure virtual machine](tutorial-monitor-vm-guest.md) --- |
| azure-monitor | Tutorial Monitor Vm Alert Recommended | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/tutorial-monitor-vm-alert-recommended.md | - Title: Enable recommended alert rules for Azure virtual machine -description: Enable set of recommended metric alert rules for an Azure virtual machine. --- Previously updated : 01/14/2024----# Tutorial: Enable recommended alert rules for Azure virtual machine -[Alerts in Azure Monitor](../alerts/alerts-overview.md) identify when a resource isn't healthy. When you create a new Azure virtual machine, you can quickly enable a set of recommended alert rules that will provide you with initial monitoring for a common set of metrics including CPU percentage and available memory. --> [!NOTE] -> If you selected the **Enable recommended alert rules** option when you created your virtual machine, then the recommended alert rules described in this tutorial will already exist. --In this article, you learn how to: --> [!div class="checklist"] -> * Enable recommended alerts for a new Azure virtual machine. -> * Specify an email address to be notified when an alert files. -> * View the resulting alert rules. --## Prerequisites -To complete the steps in this article you need the following: --- An Azure virtual machine to monitor.--## Create recommended alert rules --1. From the menu for the VM, select **Alerts** in the **Monitoring** section. Select **View + set up**. -- :::image type="content" source="media/tutorial-monitor-vm/enable-recommended-alerts.png" alt-text="Screenshot of option to enable recommended alerts for a virtual machine." lightbox="media/tutorial-monitor-vm/enable-recommended-alerts.png"::: -- A list of recommended alert rules is displayed. You can select which rules to create. You can also change the recommended threshold. Ensure that **Email** is enabled and provide an email address to be notified when any of the alerts fire. An [action group](../alerts/action-groups.md) will be created with this address. If you already have an action group that you want to use, you can specify it instead. -- :::image type="content" source="media/tutorial-monitor-vm/set-up-recommended-alerts.png" alt-text="Screenshot of recommended alert rule configuration." lightbox="media/tutorial-monitor-vm/set-up-recommended-alerts.png"::: -1. Expand each of the alert rules to see its details. By default, the severity for each is **Informational**. You might want to change to another severity such as **Error**. -- :::image type="content" source="media/tutorial-monitor-vm/configure-alert-severity.png" alt-text="Screenshot of recommended alert rule severity configuration." lightbox="media/tutorial-monitor-vm/configure-alert-severity.png"::: --1. Select **Save** to create the alert rules. --## View created alert rules --When the alert rule creation is complete, you'll see the alerts screen for the VM. ---Click **Alert rules** to view the rules you just created. You can click on any of the rules to view their details and to modify their threshold if you want. ----## Next steps -Now that you know have alerting for common VM metrics, create an alert rule to detect when the VM goes offline. --> [!div class="nextstepaction"] -> [Create availability alert rule for Azure virtual machine (preview)](tutorial-monitor-vm-alert-availability.md) - |
| azure-monitor | Tutorial Monitor Vm Enable Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/tutorial-monitor-vm-enable-insights.md | - Title: Enable monitoring with VM insights for an Azure virtual machine -description: Enable monitoring with VM insights in Azure Monitor to monitor an Azure virtual machine. --- Previously updated : 09/28/2023----# Tutorial: Enable monitoring with VM insights for an Azure virtual machine -VM insights is a feature of Azure Monitor that quickly gets you started monitoring your virtual machines. You can view trends of performance data, running processes on individual machines, and dependencies between machines. VM insights installs [Azure Monitor Agent](../agents/azure-monitor-agent-overview.md). It's required to collect the guest operating system and prepares you to configure more monitoring from your VMs according to your requirements. --In this tutorial, you learn how to: --> [!div class="checklist"] -> * Enable VM insights for a virtual machine, which installs Azure Monitor Agent and begins data collection. -> * Enable optional collection of detailed process and telemetry to enable the Map feature of VM insights. -> * Inspect graphs analyzing performance data collected from the virtual machine. -> * Inspect a map showing processes running on the virtual machine and dependencies with other systems. --## Prerequisites -To complete this tutorial, you need an Azure virtual machine to monitor. --> [!NOTE] -> If you selected the option to **Enable virtual machine insights** when you created your virtual machine, VM insights is already enabled. If the machine was previously enabled for VM insights by using the Log Analytics agent, see [Enable VM insights in the Azure portal](vminsights-enable-portal.md) for upgrading to Azure Monitor Agent. --## Enable VM insights -Select **Insights** from your virtual machine's menu in the Azure portal. If VM insights isn't enabled, you see a short description of it and an option to enable it. Select **Enable** to open the **Monitoring configuration** pane. Leave the default option of **Azure Monitor agent**. --To reduce cost for data collection, VM insights creates a default [data collection rule](../essentials/data-collection-rule-overview.md) that doesn't include collection of processes and dependencies. To enable this collection, select **Create New** to create a new data collection rule. ---Provide a **Data collection rule name** and then select **Enable processes and dependencies (Map)**. You can't disable collection of guest performance because it's required for VM insights. --Keep the default Log Analytics workspace for the subscription unless you have another workspace that you want to use. Select **Create** to create the new data collection rule. Select **Configure** to start VM insights configuration. ---A message says that monitoring is being enabled. It might take several minutes for the agent to be installed and for data collection to begin. --## View performance -When the deployment is finished, you see views on the **Performance** tab in VM insights with performance data for the machine. This data shows you the values of key guest metrics over time. ---## View processes and dependencies -Select the **Map** tab to view processes and dependencies for the virtual machine. The current machine is at the center of the view. View the processes running on it by expanding **Processes**. ---## View machine details -The **Map** view provides different tabs with information collected about the virtual machine. Select the tabs to see what's available. ---## Next steps -VM insights collects performance data from the VM guest operating system, but it doesn't collect log data such as Windows event log or Syslog. Now that you have the machine monitored with Azure Monitor Agent, you can create another data collection rule to perform this collection. --> [!div class="nextstepaction"] -> [Collect guest logs and metrics from Azure virtual machine](tutorial-monitor-vm-guest.md) |
| azure-monitor | Tutorial Monitor Vm Guest | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/tutorial-monitor-vm-guest.md | - Title: 'Tutorial: Collect guest logs and metrics from an Azure virtual machine' -description: Create a data collection rule to collect guest logs and metrics from Azure virtual machine. --- Previously updated : 09/28/2023----# Tutorial: Collect guest logs and metrics from an Azure virtual machine -To monitor the guest operating system and workloads on an Azure virtual machine, install [Azure Monitor Agent](../agents/azure-monitor-agent-overview.md) and create a [data collection rule (DCR)](../essentials/data-collection-rule-overview.md) that specifies which data to collect. VM insights installs the agent and collection performance data, but you need to create more DCRs to collect log data such as Windows event logs and Syslog. VM insights also doesn't send guest performance data to Azure Monitor Metrics where it can be analyzed with metrics explorer and used with metrics alerts. --In this tutorial, you learn how to: --> [!div class="checklist"] -> * Create a DCR that sends guest performance data to Azure Monitor Metrics and log events to Azure Monitor Logs. -> * View guest logs in Log Analytics. -> * View guest metrics in metrics explorer. --## Prerequisites -To complete this tutorial, you need an Azure virtual machine to monitor. --> [!IMPORTANT] -> This tutorial doesn't require VM insights to be enabled for the virtual machine. Azure Monitor Agent is installed on the VM if it isn't already installed. --## Create a data collection rule -[Data collection rules](../essentials/data-collection-rule-overview.md) in Azure Monitor define data to collect and where it should be sent. When you define the DCR by using the Azure portal, you specify the virtual machines it should be applied to. Azure Monitor Agent is automatically installed on any virtual machines that don't already have it. --> [!NOTE] -> You must currently install Azure Monitor Agent from the **Monitor** menu in the Azure portal. This functionality isn't yet available from the virtual machine's menu. --On the **Monitor** menu in the Azure portal, select **Data Collection Rules**. Then select **Create** to create a new DCR. ---On the **Basics** tab, enter a **Rule Name**, which is the name of the rule displayed in the Azure portal. Select a **Subscription**, **Resource Group**, and **Region** where the DCR and its associations are stored. These resources don't need to be the same as the resources being monitored. The **Platform Type** defines the options that are available as you define the rest of the DCR. Select **Windows** or **Linux** if the rule is associated only with those resources or select **Custom** if it's associated with both types. ---## Select resources -On the **Resources** tab, identify one or more virtual machines to which the DCR applies. Azure Monitor Agent is installed on any VMs that don't already have it. Select **Add resources** and select either your virtual machines or the resource group or subscription where your virtual machine is located. The DCR applies to all virtual machines in the selected scope. ---## Select data sources -A single DCR can have multiple data sources. For this tutorial, we use the same rule to collect both guest metrics and guest logs. We send metrics to Azure Monitor Metrics and to Azure Monitor Logs so that they can both be analyzed with metrics explorer and Log Analytics. --On the **Collect and deliver** tab, select **Add data source**. For the **Data source type**, select **Performance counters**. Leave the **Basic** setting and select the counters that you want to collect. Use **Custom** to select individual metric values. ---Select the **Destination** tab. **Azure Monitor Metrics** should already be listed. Select **Add destination** to add another. Select **Azure Monitor Logs** for **Destination type**. Select your Log Analytics workspace for **Account or namespace**. Select **Add data source** to save the data source. ---Select **Add data source** again to add logs to the DCR. For the **Data source type**, select **Windows event logs** or **Linux syslog**. Select the types of log data that you want to collect. ----Select the **Destination** tab. **Azure Monitor Logs** should already be selected for **Destination type**. Select your Log Analytics workspace for **Account or namespace**. If you don't already have a workspace, you can select the default workspace for your subscription, which is automatically created. Select **Add data source** to save the data source. ---Select **Review + create** to create the DCR and install the Azure Monitor agent on the selected virtual machines. ---## View logs -Data is retrieved from a Log Analytics workspace by using a log query written in Kusto Query Language. Although a set of precreated queries are available for virtual machines, we use a simple query to have a look at the events that we're collecting. --Select **Logs** from your virtual machine's menu. Log Analytics opens with an empty query window with the scope set to that machine. Any queries include only records collected from that machine. --> [!NOTE] -> The **Queries** window might open when you open Log Analytics. It includes precreated queries that you can use. For now, close this window because we're going to manually create a simple query. ---In the empty query window, enter either **Event** or **Syslog** depending on whether your machine is running Windows or Linux. Then select **Run**. The events collected within the **Time range** are displayed. --> [!NOTE] -> If the query doesn't return any data, you might need to wait a few minutes until events are created on the virtual machine to be collected. You might also need to modify the data source in the DCR to include other categories of events. ---For a tutorial on using Log Analytics to analyze log data, see [Log Analytics tutorial](../logs/log-analytics-tutorial.md). For a tutorial on creating alert rules from log data, see [Tutorial: Create a log search alert for an Azure resource](../alerts/tutorial-log-alert.md). --## View guest metrics -You can view metrics for your host virtual machine with metrics explorer without a DCR like [any other Azure resource](../essentials/tutorial-metrics.md). With the DCR, you can use metrics explorer to view guest metrics and host metrics. --Select **Metrics** from your virtual machine's menu. Metrics explorer opens with the scope set to your virtual machine. Select **Metric Namespace** > **Virtual Machine Guest**. --> [!NOTE] -> If you don't see **Virtual Machine Guest**, you might need to wait a few minutes for the agent to deploy and data to begin collecting. ---The available guest metrics are displayed. Select a metric to add to the chart. ---For a tutorial on how to view and analyze metric data by using metrics explorer, see [Tutorial: Analyze metrics for an Azure resource](../essentials/tutorial-metrics.md). For a tutorial on how to create metrics alerts, see [Tutorial: Create a metric alert for an Azure resource](../alerts/tutorial-metric-alert.md). --## Next steps -[Recommended alerts](tutorial-monitor-vm-alert-recommended.md) and the [VM Availability metric](tutorial-monitor-vm-alert-availability.md) alert from the virtual machine host but don't have any visibility into the guest operating system and its workloads. Now that you're collecting guest metrics for the virtual machine, you can create metric alerts based on guest metrics such as logical disk space. --> [!div class="nextstepaction"] -> [Create a metric alert in Azure Monitor](../alerts/tutorial-metric-alert.md) |
| azure-monitor | Vminsights Change Analysis | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/vminsights-change-analysis.md | - Title: Change analysis in VM insights -description: VM insights integration with Application Change Analysis integration allows you to view any changes made to a virtual machine that might have affected it performance. --- Previously updated : 09/28/2023----# Change analysis in VM insights -VM insights integration with [Application Change Analysis](../app/change-analysis.md) integration allows you to view any changes made to a virtual machine that might have affected its performance. --## Overview -Suppose you have a VM that's running slow and you want to investigate whether recent changes to its configuration could have affected its performance. You view the performance of the VM by using VM insights and find that there's an increase in memory usage in the past hour. Change analysis can help you determine whether any configuration changes made around this time were the cause of the increase. --The Application Change Analysis service aggregates changes from [Azure Resource Graph](../../governance/resource-graph/how-to/get-resource-changes.md) and nested properties changes like network security rules from Azure Resource Manager. --## Enable change analysis -To onboard change analysis in VM insights, you must register the *Microsoft.ChangeAnalysis* resource provider. The first time you start VM insights or Application Change Analysis in the Azure portal, this resource provider is automatically registered for you. Application Change Analysis is a free service that has no performance overhead on resources. --## View change analysis -Change analysis is available from the **Performance** or **Map** tab of VM insights by selecting the **Change** option. -<!-- convertborder later --> --Select **Investigate Changes** to open the Application Change Analysis page filtered for the VM. Review the listed changes to see if there are any that could have caused the issue. If you're unsure about a particular change, look at the **Changed by** column to identify the person who made the change. -<!-- convertborder later --> --## Next steps -- Learn more about [Application Change Analysis](../app/change-analysis.md).-- Learn more about [Azure Resource Graph](../../governance/resource-graph/how-to/get-resource-changes.md).- |
| azure-monitor | Vminsights Dependency Agent Maintenance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/vminsights-dependency-agent-maintenance.md | - Title: VM Insights Dependency Agent -description: This article describes how to upgrade the VM Insights Dependency Agent using command-line, setup wizard, and other methods. ---- Previously updated : 09/28/2023---# Dependency Agent --> [!CAUTION] -> This article references CentOS, a Linux distribution that is End Of Life (EOL) status. Please consider your use and planning accordingly. For more information, see the [CentOS End Of Life guidance](/azure/virtual-machines/workloads/centos/centos-end-of-life). --Dependency Agent collects data about processes running on the virtual machine and external process dependencies. Updates include bug fixes or support of new features or functionality. This article describes Dependency Agent requirements and how to upgrade it manually or through automation. -->[!NOTE] -> Dependency Agent sends heartbeat data to the [InsightsMetrics](/azure/azure-monitor/reference/tables/insightsmetrics) table, for which you incur data ingestion charges. This behavior is different from Azure Monitor Agent, which sends agent health data to the [Heartbeat](/azure/azure-monitor/reference/tables/heartbeat) table, which is free from data collection charges. --## Dependency Agent requirements --> [!div class="checklist"] -> * Requires the Azure Monitor Agent to be installed on the same machine. -> * Collects data using a user-space service and a kernel driver on both Windows and Linux. -> * Supports the same [Windows versions that Azure Monitor Agent supports](../agents/agents-overview.md#supported-operating-systems), except Windows Server 2008 SP2 and Azure Stack HCI. For Linux, see [Dependency Agent Linux support](#dependency-agent-linux-support). --## Install or upgrade Dependency Agent --You can upgrade Dependency Agent for Windows and Linux manually or automatically, depending on the deployment scenario and environment the machine is running in, using these methods: --| Environment | Installation method | Upgrade method | -|-||-| -| Azure VM | Dependency Agent VM extension for [Windows](/azure/virtual-machines/extensions/agent-dependency-windows) and [Linux](/azure/virtual-machines/extensions/agent-dependency-linux) | Agent is automatically upgraded by default unless you configured your Azure Resource Manager template to opt out by setting the property `autoUpgradeMinorVersion` to **false**. The upgrade for minor version where auto upgrade is disabled, and a major version upgrade follow the same method - uninstall and reinstall the extension. | -| Custom Azure VM images | Manual install of Dependency Agent for Windows/Linux | Updating VMs to the newest version of the agent needs to be performed from the command line running the Windows installer package or Linux self-extracting and installable shell script bundle. | -| Non-Azure VMs | Manual install of Dependency Agent for Windows/Linux | Updating VMs to the newest version of the agent needs to be performed from the command line running the Windows installer package or Linux self-extracting and installable shell script bundle. | --> [!NOTE] -> Dependency Agent is installed automatically when VM Insights is enabled for process and connection data via the [Azure portal](vminsights-enable-portal.md), [PowerShell](vminsights-enable-powershell.md), [ARM template deployment](vminsights-enable-resource-manager.md), or [Azure policy](vminsights-enable-policy.md). -> -> If VM Insights is enabled exclusively for performance data, Dependency Agent won't be installed. --### Manually install or upgrade Dependency Agent on Windows --Update the agent on a Windows VM from the command prompt, with a script or other automation solution, or by using the InstallDependencyAgent-Windows.exe Setup Wizard. --#### Prerequisites --> [!div class="checklist"] -> * Download the latest version of the Windows agent from [aka.ms/dependencyagentwindows](https://aka.ms/dependencyagentwindows). --#### Using the Setup Wizard --1. Sign on to the computer with an account that has administrative rights. --1. Execute **InstallDependencyAgent-Windows.exe** to start the Setup Wizard. - -1. Follow the **Dependency Agent Setup** wizard to uninstall the previous version of Dependency Agent and then install the latest version. --#### From the command line --1. Sign in on the computer using an account with administrative rights. --1. Run the following command: -- ```cmd - InstallDependencyAgent-Windows.exe /S /RebootMode=manual - ``` -- The `/RebootMode=manual` parameter prevents the upgrade from automatically rebooting the machine if some processes are using files from the previous version and have a lock on them. --1. To confirm the upgrade was successful, check the `install.log` for detailed setup information. The log directory is *%Programfiles%\Microsoft Dependency Agent\logs*. --### Manually install or upgrade Dependency Agent on Linux --Upgrading from prior versions of Dependency Agent on Linux is supported and performed following the same command as a new installation. --#### Prerequisites --> [!div class="checklist"] -> * Download the latest version of the Linux agent from [aka.ms/dependencyagentlinux](https://aka.ms/dependencyagentlinux) or via curl: --```bash -curl -L -o DependencyAgent-Linux64.bin https://aka.ms/dependencyagentlinux -``` --> [!NOTE] -> Curl doesn't automatically set execution permissions. You need to manually set them using chmod: -> -> ```bash -> chmod +x DependencyAgent-Linux64.bin -> ``` --#### From the command line --1. Sign in on the computer with a user account that has sudo privileges to execute commands as root. --1. Run the following command: -- ```bash - sudo <path>/InstallDependencyAgent-Linux64.bin - ``` --If Dependency Agent fails to start, check the logs for detailed error information. On Linux agents, the log directory is */var/opt/microsoft/dependency-agent/log*. --## Uninstall Dependency Agent --> [!NOTE] -> If Dependency Agent was installed manually, it wonΓÇÖt show in the Azure portal and has to be uninstalled manually. It will only show if it was installed via the [Azure portal](vminsights-enable-portal.md), [PowerShell](vminsights-enable-powershell.md), [ARM template deployment](vminsights-enable-resource-manager.md), or [Azure policy](vminsights-enable-policy.md). --1. From the **Virtual Machines** menu in the Azure portal, select your virtual machine. --1. Select **Extensions + applications** > **DependencyAgentWindows** or **DependencyAgentLinux** > **Uninstall**. -- :::image type="content" source="media/vminsights-dependency-agent-maintenance/azure-monitor-uninstall-dependency-agent.png" alt-text="Screenshot showing the Extensions and applications screen for a virtual machine." lightbox="media/vminsights-dependency-agent-maintenance/azure-monitor-uninstall-dependency-agent.png"::: --### Manually uninstall Dependency Agent on Windows --**Method 1:** In Windows, go to **Add and remove programs**, find Microsoft Dependency Agent, click on the ellipsis to open the context menu, and select **Uninstall**. --**Method 2:** Use the uninstaller located in the Microsoft Dependency Agent folder, for example, `C:\Program Files\Microsoft Dependency Agent"\Uninstall_v.w.x.y.exe` (where v.w.x.y is the version number). --### Manually uninstall Dependency Agent on Linux --1. Sign in on the computer with a user account that has sudo privileges to execute commands as root. --1. Run the following command: -- ```bash - sudo /opt/microsoft/dependency-agent/uninstall -s - ``` --## Dependency Agent Linux support --Since Dependency Agent works at the kernel level, support is also dependent on the kernel version. As of Dependency Agent version 9.10.* the agent supports * kernels. The following table lists the major and minor Linux OS release and supported kernel versions for Dependency Agent. ---## Next steps --If you want to stop monitoring your VMs for a while or remove VM Insights entirely, see [Disable monitoring of your VMs in VM Insights](../vm/vminsights-optout.md). |
| azure-monitor | Vminsights Enable Hybrid | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/vminsights-enable-hybrid.md | - Title: Enable VM Insights on a Windows client machine -description: This article describes how you enable VM Insights on a Windows client machine that's not always online. --- Previously updated : 12/11/2023-# Customer-intent: As a cloud administrator, I want to enable VM Insights on a Windows client machine that's not always online, so that I can collect performance and dependency data when the machine comes online. ----# Enable VM Insights on a Windows client machine --For Windows 10 and 11 client machines that are always powered on and connected to the internet, use [Azure Arc for servers](../../azure-arc/servers/overview.md) and follow the same process as [enabling VM insights on Azure VMs](vminsights-enable-portal.md). --This article describes how to enable VM Insights on a [Windows client machine that's online intermittently and not managed using Azure Arc](/azure/azure-arc/servers/prerequisites#client-operating-system-guidance). --## Prerequisites --- [Log Analytics workspace](../logs/quick-create-workspace.md).-- A Windows device that's domain joined to your Microsoft Entra tenant. The device must be able to connect to the internet.-- See [Supported operating systems](./vminsights-enable-overview.md#supported-operating-systems) to ensure that the operating system of the virtual machine or virtual machine scale set you're enabling is supported.--### Firewall requirements --- For Azure Monitor Agent firewall requirements, see [Define Azure Monitor Agent network settings](../agents/azure-monitor-agent-data-collection-endpoint.md#firewall-requirements). -- The VM Insights Map Dependency agent doesn't transmit any data itself, and it doesn't require any changes to firewalls or ports.--Azure Monitor Agent transmits data to Azure Monitor directly or through the [Log Analytics gateway](../../azure-monitor/agents/gateway.md) if your IT security policies don't allow computers on the network to connect to the internet. --## Limitations ---## Deploy VM Insights data collection rule and install agents --To enable VM Insights on a Windows client machine: --1. If you don't have an existing VM Insights data collection rule, [deploy a VM Insights data collection rule using ARM templates](vminsights-enable-resource-manager.md#deploy-data-collection-rule). The data collection rule must be in the same region as your Log Analytics workspace. -1. Follow the steps described in [Install Azure Monitor Agent on Windows client devices](../agents/azure-monitor-agent-windows-client.md) to: -- - Install Azure Monitor Agent on your machine using the client installer. - - Create a monitored object. - - Associate the monitored object to your VM Insights data collection rule. - - The monitored object automatically associates your VM Insights data collection rule to all Windows devices in your tenant on which you install the Azure Monitor Agent using the client installer. - -1. To use the [Map feature of VM Insights](vminsights-maps.md), install [Dependency Agent on your machine manually](vminsights-dependency-agent-maintenance.md#install-or-upgrade-dependency-agent). - -## Troubleshooting --This section offers troubleshooting tips for common issues. --### Machine doesn't appear on the map --If your Dependency agent installation succeeded but you don't see your computer on the map, diagnose the problem by following these steps: --1. Is the Dependency agent installed successfully? Check to see if the service is installed and running. Look for the service named "Microsoft Dependency agent." --1. Are you on the [Free pricing tier of Log Analytics](/previous-versions/azure/azure-monitor/insights/solutions)? The Free plan allows for up to five unique computers. Any subsequent computers won't show up on the map, even if the prior five are no longer sending data. --1. Is the computer sending log and performance data to Azure Monitor Logs? Run this query for your computer: -- ```Kusto - Usage | where Computer == "computer-name" | summarize sum(Quantity), any(QuantityUnit) by DataType - ``` -- Did it return one or more results? Is the data recent? If so, the agent is operating correctly and communicating with the service. If not, check the agent on your server. See [Troubleshooting Azure Monitor Agent on Windows virtual machines and scale sets](../agents/azure-monitor-agent-troubleshoot-windows-vm.md) or [Log Analytics agent for Linux troubleshooting](../agents/agent-linux-troubleshoot.md). --#### Machine appears on the map but has no processes --You see your server on the map, but it has no process or connection data. In this case, the Dependency agent is installed and running, but the kernel driver didn't load. --Check the *C:\Program Files\Microsoft Dependency Agent\logs\wrapper.log* file . The last lines of the file should indicate why the kernel didn't load. --## Next steps --Now that monitoring is enabled for your virtual machines, this information is available for analysis with VM Insights. --- To view discovered application dependencies, see [View VM Insights Map](vminsights-maps.md).-- To identify bottlenecks and overall utilization with your VM's performance, see [View Azure VM performance](vminsights-performance.md). |
| azure-monitor | Vminsights Enable Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/vminsights-enable-overview.md | - Title: Enable VM Insights overview -description: Learn how to deploy and configure VM Insights and find out about the system requirements. ---- Previously updated : 09/28/2023-----# Enable VM Insights overview --This article provides an overview of how to enable VM Insights to monitor the health and performance of: --- Azure virtual machines.-- Azure Virtual Machine Scale Sets.-- Hybrid virtual machines connected with Azure Arc.-- On-premises virtual machines.-- Virtual machines hosted in another cloud environment.--> [!NOTE] -> Configuring a Log Analytics workspace for using VM Insights by using the Log Analytics agent is no longer supported. --## Installation options and supported machines --The following table shows the installation methods available for enabling VM Insights on supported machines. --| Method | Scope | -|:|:| -| [Azure portal](vminsights-enable-portal.md) | Enable individual machines with the Azure portal. | -| [Azure Policy](vminsights-enable-policy.md) | Create policy to automatically enable when a supported machine is created. | -| [Azure Resource Manager templates](../vm/vminsights-enable-resource-manager.md) | Enable multiple machines by using any of the supported methods to deploy a Resource Manager template, such as the Azure CLI and PowerShell. | -| [PowerShell](vminsights-enable-powershell.md) | Use a PowerShell script to enable multiple machines. | -| [Manual install](vminsights-enable-hybrid.md) | Virtual machines or physical computers on-premises with other cloud environments.| --### Supported Azure Arc machines --VM Insights is available for Azure Arc-enabled servers in regions where the Arc extension service is available. You must be running version 0.9 or above of the Azure Arc agent. --## Supported operating systems --VM Insights supports all operating systems supported by the Dependency agent and either Azure Monitor Agent or Log Analytics agent. For a complete list of operating systems supported by Azure Monitor Agent and Log Analytics agent, see [Azure Monitor agent overview](../agents/agents-overview.md#supported-operating-systems). --Dependency Agent supports the same [Windows versions that Azure Monitor Agent supports](../agents/agents-overview.md#supported-operating-systems), except Windows Server 2008 SP2 and Azure Stack HCI. -For Dependency Agent Linux support, see [Dependency Agent Linux support](../vm/vminsights-dependency-agent-maintenance.md#dependency-agent-linux-support). --> [!IMPORTANT] -> If the Ethernet device for your virtual machine has more than nine characters, it won't be recognized by VM Insights and data won't be sent to the InsightsMetrics table. The agent will collect data from [other sources](../agents/agent-data-sources.md). --### Linux considerations --Consider the following before you install Dependency agent for VM Insights on a Linux machine: --- Only default and SMP Linux kernel releases are supported.-- Nonstandard kernel releases, such as physical address extension (PAE) and Xen, aren't supported for any Linux distribution. For example, a system with the release string of *2.6.16.21-0.8-xen* isn't supported.-- Custom kernels, including recompilations of standard kernels, aren't supported.-- For Debian distros other than version 9.4, the Map feature isn't supported. The Performance feature is available only from the Azure Monitor menu. It isn't available directly from the left pane of the Azure VM.-- CentOSPlus kernel is supported.-- Installing Dependency agent taints the Linux kernel and you might lose support from your Linux distribution until the machine resets.--The Linux kernel must be patched for the Spectre and Meltdown vulnerabilities. For more information, consult with your Linux distribution vendor. Run the following command to check for availability if Spectre/Meltdown has been mitigated: --``` -$ grep . /sys/devices/system/cpu/vulnerabilities/* -``` --Output for this command looks similar to the following and specify whether a machine is vulnerable to either issue. If these files are missing, the machine is unpatched. --``` -/sys/devices/system/cpu/vulnerabilities/meltdown:Mitigation: PTI -/sys/devices/system/cpu/vulnerabilities/spectre_v1:Vulnerable -/sys/devices/system/cpu/vulnerabilities/spectre_v2:Vulnerable: Minimal generic ASM retpoline -``` --## Agents --When you enable VM Insights for a machine, the following agents are installed. --> [!IMPORTANT] -> Azure Monitor Agent has several advantages over the legacy Log Analytics agent, which will be deprecated by August 2024. After this date, Microsoft will no longer provide any support for the Log Analytics agent. [Migrate to Azure Monitor agent](../agents/azure-monitor-agent-migration.md) before August 2024 to continue ingesting data. ---- **[Azure Monitor agent](../agents/azure-monitor-agent-overview.md) or [Log Analytics agent](../agents/log-analytics-agent.md):** Collects data from the virtual machine or Virtual Machine Scale Set and delivers it to the Log Analytics workspace.-- **Dependency agent**: Collects discovered data about processes running on the virtual machine and external process dependencies, which are used by the [Map feature in VM Insights](../vm/vminsights-maps.md). The Dependency agent relies on the Azure Monitor Agent or Log Analytics agent to deliver its data to Azure Monitor. If you use Azure Monitor Agent, the Dependency agent is required for the Map feature. If you don't need the map feature, you don't need to install the Dependency agent.--### Network requirements --- For Azure Monitor Agent, the machine must have access to the following HTTPS endpoints:- - global.handler.control.monitor.azure.com - - `<virtual-machine-region-name>`.handler.control.monitor.azure.com (example: westus.handler.control.azure.com) - - `<log-analytics-workspace-id>`.ods.opinsights.azure.com (example: 12345a01-b1cd-1234-e1f2-1234567g8h99.ods.opinsights.azure.com) - (If using private links on the agent, you must also add the [data collection endpoints](../essentials/data-collection-endpoint-overview.md#components-of-a-dce)) -- For more information, see [Define Azure Monitor Agent network settings](../agents/azure-monitor-agent-data-collection-endpoint.md). --- The Dependency agent requires a connection from the virtual machine to the address 169.254.169.254. This address identifies the Azure metadata service endpoint. Ensure that firewall settings allow connections to this endpoint.--## VM Insights data collection rule --To enable VM Insights on a machine with Azure Monitor Agent, associate a VM insights [data collection rule (DCR)](../essentials/data-collection-rule-overview.md) with the agent. VM Insights creates a default data collection rule if one doesn't already exist. --The data collection rule specifies the data to collect and the workspace to use: --| Option | Description | -|:|:| -| Guest performance | Specifies whether to collect [performance data](/azure/azure-monitor/vm/vminsights-performance) from the guest operating system. This option is required for all machines. The collection interval for performance data is every 60 seconds.| -| Processes and dependencies | Collects information about processes running on the virtual machine and dependencies between machines. This information enables the [Map feature in VM Insights](vminsights-maps.md). This is optional and enables the [VM Insights Map feature](vminsights-maps.md) for the machine. | -| Log Analytics workspace | Workspace to store the data. Only workspaces with VM Insights are listed. | --> [!IMPORTANT] -> VM Insights automatically creates a data collection rule that includes a special data stream required for its operation. Do not modify the VM Insights data collection rule or create your own data collection rule to support VM Insights. To collect additional data, such as Windows and Syslog events, create separate data collection rules and associate them with your machines. --If you associate a data collection rule with the Map feature enabled to a machine on which Dependency Agent isn't installed, the Map view won't be available. To enable the Map view, set `enableAMA property = true` in the Dependency Agent extension when you install Dependency Agent. We recommend following the procedure described in [Enable VM Insights for Azure Monitor Agent](vminsights-enable-portal.md#enable-vm-insights-for-azure-monitor-agent). --## Enable network isolation using Private Link --By default, Azure Monitor Agent connects to a public endpoint to connect to your Azure Monitor environment. To enable network isolation for VM Insights, associate your VM Insights data collection rule to a data collection endpoint linked to an Azure Monitor Private Link Scope, as described in [Enable network isolation for Azure Monitor Agent by using Private Link](../agents/azure-monitor-agent-private-link.md). ---## Diagnostic and usage data --Microsoft automatically collects usage and performance data through your use of Azure Monitor. Microsoft uses this data to improve the quality, security, and integrity of the service. --To provide accurate and efficient troubleshooting capabilities, the Map feature includes data about the configuration of your software. The data provides information such as the operating system and version, IP address, DNS name, and workstation name. Microsoft doesn't collect names, addresses, or other contact information. --For more information about data collection and usage, see the [Microsoft Online Services Privacy Statement](https://go.microsoft.com/fwlink/?LinkId=512132). ---## Next steps --To learn how to use the Performance monitoring feature, see [View VM Insights Performance](../vm/vminsights-performance.md). To view discovered application dependencies, see [View VM Insights Map](../vm/vminsights-maps.md). |
| azure-monitor | Vminsights Enable Policy | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/vminsights-enable-policy.md | - Title: Enable VM insights by using Azure Policy -description: This article describes how you enable VM insights for multiple Azure virtual machines or virtual machine scale sets by using Azure Policy. ---- Previously updated : 07/09/2023----# Enable VM insights by using Azure Policy --[Azure Policy](../../governance/policy/overview.md) lets you set and enforce requirements for all new resources you create and resources you modify. VM insights policy initiatives, which are predefined sets of policies created for VM insights, install the agents required for VM insights and enable monitoring on all new virtual machines in your Azure environment. --This article explains how to enable VM insights for Azure virtual machines, virtual machine scale sets, and hybrid virtual machines connected with Azure Arc by using predefined VM insights policy initiates. ---## VM insights initiatives -VM insights policy initiatives install Azure Monitor Agent and the Dependency agent on new virtual machines in your Azure environment. Assign these initiatives to a management group, subscription, or resource group to install the agents on Windows or Linux Azure virtual machines in the defined scope automatically. --> [!NOTE] -> The VM Insights initiatives listed below don't update a Dependency Agent extension that already exists on your VM with Azure Monitoring Agent settings. Make sure to uninstall the Dependency Agent extension from your VM before deploying these initiatives. --Enable Azure Monitor for VMs with Azure Monitoring Agent -Enable Azure Monitor for virtual machine scale sets with Azure Monitoring Agent -Enable Azure Monitor for Hybrid VMs with Azure Monitoring Agent ---The initiatives apply to new machines you create and machines you modify, but not to existing VMs. --|Name |Description | -|--|| -| Enable Azure Monitor for VMs with Azure Monitoring Agent | Installs Azure Monitor Agent and the Dependency agent on Azure VMs. | -| Enable Azure Monitor for virtual machine scale sets with Azure Monitoring Agent | Installs Azure Monitor Agent and the Dependency agent on virtual machine scale sets. | -| Enable Azure Monitor for Hybrid VMs with Azure Monitoring Agent | Installs Azure Monitor Agent and Dependency agent on hybrid VMs connected with Azure Arc. | -| Legacy: Enable Azure Monitor for VMs | Installs the Log Analytics agent and Dependency agent on virtual machine scale sets. | -| Legacy: Enable Azure Monitor for virtual machine scale sets | Installs the Log Analytics agent and Dependency agent on virtual machine scale sets. | ---## Support for custom images --Azure Monitor Agent-based VM insights policy and initiative definitions have a `scopeToSupportedImages` parameter that's set to `true` by default to enable onboarding Dependency Agent on supported images only. Set this parameter to `false`to allow onboarding Dependency Agent on custom images. --## Assign a VM insights policy initiative --To assign a VM insights policy initiative to a subscription or management group from the Azure portal: --1. Search for and open **Policy**. -1. Select **Assignments** > **Assign initiative**. -- :::image type="content" source="media/vminsights-enable-policy/vm-insights-assign-initiative.png" lightbox="media/vminsights-enable-policy/vm-insights-assign-initiative.png" alt-text="Screenshot that shows the Policy Assignments screen with the Assign initiative button highlighted."::: -- The **Assign initiative** screen appears. -- :::image type="content" source="media/vminsights-enable-policy/assign-initiative.png" lightbox="media/vminsights-enable-policy/assign-initiative.png" alt-text="Screenshot that shows Assign initiative."::: --1. Configure the initiative assignment: -- 1. In the **Scope** field, select the management group or subscription to which you'll assign the initiative. - 1. (Optional) Select **Exclusions** to exclude specific resources from the initiative assignment. For example, if your scope is a management group, you might specify a subscription in that management group to be excluded from the assignment. - 1. Select the ellipsis (**...**) next to **Initiative assignment** to start the policy definition picker. Select one of the VM insights initiatives. - 1. (Optional) Change the **Assignment name** and add a **Description**. - 1. On the **Parameters** tab, select a **Log Analytics workspace** to which all virtual machines in the assignment will send data. For virtual machines to send data to different workspaces, create multiple assignments, each with their own scope. - - :::image type="content" source="media/vminsights-enable-policy/assignment-workspace.png" lightbox="media/vminsights-enable-policy/assignment-workspace.png" alt-text="Screenshot that shows a workspace."::: - - > [!NOTE] - > If you select a workspace that's not within the scope of the assignment, grant *Log Analytics Contributor* permissions to the policy assignment's principal ID. Otherwise, you might get a deployment failure like: - > - > `The client '343de0fe-e724-46b8-b1fb-97090f7054ed' with object id '343de0fe-e724-46b8-b1fb-97090f7054ed' does not have authorization to perform action 'microsoft.operationalinsights/workspaces/read' over scope ...` --1. Select **Review + create** to review the initiative assignment details. Select **Create** to create the assignment. -- Don't create a remediation task at this point because you'll probably need multiple remediation tasks to enable existing virtual machines. For more information about how to create remediation tasks, see [Remediate compliance results](#create-a-remediation-task). --## Review compliance for a VM insights policy initiative --After you assign an initiative, you can review and manage compliance for the initiative across your management groups and subscriptions. --To see how many virtual machines exist in each of the management groups or subscriptions and their compliance status: --1. Search for and open **Azure Monitor**. -1. Select **Virtual machines** > **Overview** > **Other onboarding options**. Then under **Enable using policy**, select **Enable**. -- :::image type="content" source="media/vminsights-enable-policy/other-onboarding-options.png" lightbox="media/vminsights-enable-policy/other-onboarding-options.png" alt-text="Screenshot that shows other onboarding options page of VM insights with the Enable using policy option."::: -- The **Azure Monitor for VMs Policy Coverage** page appears. - <!-- convertborder later --> - :::image type="content" source="media/vminsights-enable-policy/manage-policy-page-01.png" lightbox="media/vminsights-enable-policy/manage-policy-page-01.png" alt-text="Screenshot that shows the VM insights Azure Monitor for VMs Policy Coverage page." border="false"::: -- The following table describes the compliance information presented on the **Azure Monitor for VMs Policy Coverage** page. - - | Function | Description | - |-|-| - | **Scope** | Management group or subscription to which the initiative applies.| - | **My Role** | Your role in the scope. The role can be Reader, Owner, Contributor, or blank if you have access to the subscription but not to the management group to which it belongs. Your role determines which data you can see and whether you can assign policies or initiatives (owner), edit them, or view compliance. | - | **Total VMs** | Total number of VMs in the scope, regardless of their status. For a management group, this number is the sum total of VMs in all related subscriptions or child management groups. | - | **Assignment Coverage** | Percentage of VMs covered by the initiative. When you assign the initiative, the scope you select in the assignment could be the scope listed or a subset of it. For instance, if you create an assignment for a subscription (initiative scope) and not a management group (coverage scope), the value of **Assignment Coverage** indicates the VMs in the initiative scope divided by the VMs in coverage scope. In another case, you might exclude some VMs, resource groups, or a subscription from the policy scope. If the value is blank, it indicates that either the policy or initiative doesn't exist or you don't have permission.| - | **Assignment Status** | **Success**: Azure Monitor Agent or the Log Analytics agent and Dependency agent deployed on all machines in scope.<br>**Warning**: The subscription isn't under a management group.<br>**Not Started**: A new assignment was added.<br>**Lock**: You don't have sufficient privileges to the management group.<br>**Blank**: No VMs exist or a policy isn't assigned. | - | **Compliant VMs** | Number of VMs that have both Azure Monitor Agent or Log Analytics agent and Dependency agent installed. This field is blank if there are no assignments, no VMs in the scope, or if you don't have the relevant permissions. | - | **Compliance** | The overall compliance number is the sum of distinct compliant resources divided by the sum of all distinct resources. | - | **Compliance State** | **Compliant**: All VMs in the scope have Azure Monitor Agent or the Log Analytics agent and Dependency agent deployed to them, or any new VMs in the scope haven't yet been evaluated.<br>**Noncompliant**: There are VMs that aren't enabled and might need remediation.<br>**Not Started**: A new assignment was added.<br>**Lock**: You don't have sufficient privileges to the management group.<br>**Blank**: No policy assigned. | --1. Select the ellipsis (**...**) > **View Compliance**. - <!-- convertborder later --> - :::image type="content" source="media/vminsights-enable-policy/view-compliance.png" lightbox="media/vminsights-enable-policy/view-compliance.png" alt-text="Screenshot that shows View Compliance." border="false"::: -- The **Compliance** page appears. It lists assignments that match the specified filter and indicates whether they're compliant. -- :::image type="content" source="./media/vminsights-enable-policy/policy-view-compliance.png" lightbox="./media/vminsights-enable-policy/policy-view-compliance.png" alt-text="Screenshot that shows Policy compliance for Azure VMs."::: --1. Select an assignment to view its details. The **Initiative compliance** page appears. It lists the policy definitions in the initiative and whether each is in compliance. -- :::image type="content" source="media/vminsights-enable-policy/compliance-details.png" lightbox="media/vminsights-enable-policy/compliance-details.png" alt-text="Screenshot that shows Compliance details."::: -- Policy definitions are considered noncompliant if: -- * Azure Monitor Agent, the Log Analytics agent, or the Dependency agent aren't deployed. Create a remediation task to mitigate. - * VM image (OS) isn't identified in the policy definition. Policies can only verify well-known Azure VM images. Check the documentation to see whether the VM OS is supported. - * Some VMs in the initiative scope are connected to a Log Analytics workspace other than the one that's specified in the policy assignment. --1. Select a policy definition to open the **Policy compliance** page. --## Create a remediation task --If your assignment doesn't show 100% compliance, create remediation tasks to evaluate and enable existing VMs. You'll most likely need to create multiple remediation tasks, one for each policy definition. You can't create a remediation task for an initiative. --To create a remediation task: --1. On the **Initiative compliance** page, select **Create Remediation Task**. -- :::image type="content" source="media/vminsights-enable-policy/policy-compliance-details.png" lightbox="media/vminsights-enable-policy/policy-compliance-details.png" alt-text="Screenshot that shows Policy compliance details."::: -- The **New remediation task** page appears. -- :::image type="content" source="media/vminsights-enable-policy/new-remediation-task.png" lightbox="media/vminsights-enable-policy/new-remediation-task.png" alt-text="Screenshot that shows the New remediation task page."::: --1. Review **Remediation settings** and **Resources to remediate** and modify as necessary. Then select **Remediate** to create the task. -- After the remediation tasks are finished, your VMs should be compliant with agents installed and enabled for VM insights. --## Track remediation tasks --To track the progress of remediation tasks, on the **Policy** menu, select **Remediation** and select the **Remediation tasks** tab. ---## Next steps --Learn how to: -- [View VM insights Map](vminsights-maps.md) to see application dependencies. -- [View Azure VM performance](vminsights-performance.md) to identify bottlenecks and overall utilization of your VM's performance. |
| azure-monitor | Vminsights Enable Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/vminsights-enable-portal.md | - Title: Enable VM insights in the Azure portal -description: Learn how to enable VM insights on a single Azure virtual machine or Virtual Machine Scale Set using the Azure portal. ---- Previously updated : 09/28/2023----# Enable VM insights in the Azure portal -This article describes how to enable VM insights using the Azure portal for Azure virtual machines, Azure Virtual Machine Scale Sets, and hybrid virtual machines connected with [Azure Arc](../../azure-arc/overview.md). --> [!NOTE] -> Azure portal no longer supports enabling VM insights using the legacy Log Analytics agent. --## Prerequisites --- [Log Analytics workspace](../logs/quick-create-workspace.md).-- See [Supported operating systems](./vminsights-enable-overview.md#supported-operating-systems) to ensure that the operating system of the virtual machine or Virtual Machine Scale Set you're enabling is supported. -- See [Manage the Azure Monitor agent](../agents/azure-monitor-agent-manage.md#prerequisites) for prerequisites related to Azure Monitor agent.-- To enable network isolation for Azure Monitor Agent, see [Enable network isolation for Azure Monitor Agent by using Private Link](../agents/azure-monitor-agent-private-link.md).--## View monitored and unmonitored machines --To see which virtual machines in your directory are monitored using VM insights: --1. From the **Monitor** menu in the Azure portal, select **Virtual Machines** > **Overview**. -- The **Overview** page lists all of the virtual machines and Virtual Machine Scale Sets in the selected subscriptions. --1. Select the **Monitored** tab for the list of machines that have VM insights enabled. - -1. Select the **Not monitored** tab for the list of machines that don't have VM insights enabled. -- The **Not monitored** tab includes all machines that don't have VM insights enabled, even if the machines have Azure Monitor Agent or Log Analytics agent installed. If a virtual machine has the Log Analytics agent installed but not the Dependency agent, it will be listed as not monitored. In this case, Azure Monitor Agent will be started without being given the option for the Log Analytics agent. --## Enable VM insights for Azure Monitor Agent -> [!NOTE] -> As part of the Azure Monitor Agent installation process, Azure assigns a [system-assigned managed identity](../../app-service/overview-managed-identity.md?tabs=portal%2chttp#add-a-system-assigned-identity) to the machine if such an identity doesn't already exist. --To enable VM insights on an unmonitored virtual machine or Virtual Machine Scale Set using Azure Monitor Agent: --1. From the **Monitor** menu in the Azure portal, select **Virtual Machines** > **Not Monitored**. - -1. Select **Enable** next to any machine that you want to enable. If a machine is currently not running, you must start it to enable it. -- :::image type="content" source="media/vminsights-enable-portal/enable-unmonitored.png" lightbox="media/vminsights-enable-portal/enable-unmonitored.png" alt-text="Screenshot with unmonitored machines in V M insights."::: --1. On the **Insights Onboarding** page, select **Enable**. - -1. On the **Monitoring configuration** page, select **Azure Monitor agent** and select a [data collection rule](vminsights-enable-overview.md#vm-insights-data-collection-rule) from the **Data collection rule** dropdown. - --1. The **Data collection rule** dropdown lists only rules configured for VM insights. If a data collection rule hasn't already been created for VM insights, Azure Monitor creates a rule with: -- - **Guest performance** enabled. - - **Processes and dependencies** disabled. - 1. Select **Create new** to create a new data collection rule. This lets you select a workspace and specify whether to collect processes and dependencies using the [VM insights Map feature](vminsights-maps.md). -- :::image type="content" source="media/vminsights-enable-portal/create-data-collection-rule.png" lightbox="media/vminsights-enable-portal/create-data-collection-rule.png" alt-text="Screenshot showing screen for creating new data collection rule."::: -- > [!NOTE] - > If you select a data collection rule with Map enabled and your virtual machine is not [supported by the Dependency Agent](../vm/vminsights-dependency-agent-maintenance.md), Dependency Agent will be installed and will run in degraded mode. --1. Select **Configure** to start the configuration process. It takes several minutes to install the agent and start collecting data. You'll receive status messages as the configuration is performed. - -1. If you use a manual upgrade model for your Virtual Machine Scale Set, upgrade the instances to complete the setup. You can start the upgrades from the **Instances** page, in the **Settings** section. --## Enable VM Insights for Azure Monitor Agent on machines monitored with Log Analytics agent --To add Azure Monitor Agent to machines that are already enabled with the Log Analytics agent: --1. From the **Monitor** menu in the Azure portal, select **Virtual Machines** > **Overview** > **Monitored**. - -1. Select **Configure using Azure Monitor agent** next to any machine that you want to enable. If a machine is currently running, you must start it to enable it. -- :::image type="content" source="media/vminsights-enable-portal/add-azure-monitor-agent.png" lightbox="media/vminsights-enable-portal/add-azure-monitor-agent.png" alt-text="Screenshot showing monitoring configuration to Azure Monitor agent to monitored machine."::: --1. On the **Monitoring configuration** page, select **Azure Monitor agent** and select a rule from the **Data collection rule** dropdown. - ---1. The **Data collection rule** dropdown lists only rules configured for VM insights. If a data collection rule hasn't already been created for VM insights, Azure Monitor creates a rule with: -- - **Guest performance** enabled. - - **Processes and dependencies** enabled for backward compatibility with the Log Analytics agent. - 1. Select **Create new** to create a new data collection rule. This lets you select a workspace and specify whether to collect processes and dependencies using the [VM insights Map feature](vminsights-maps.md). -- > [!NOTE] - > Selecting a data collection rule that does not use the Map feature does not uninstall Dependency Agent from the machine. If you do not need the Map feature, [uninstall Dependency Agent manually](../vm/vminsights-dependency-agent-maintenance.md#uninstall-dependency-agent). - 1. With both agents installed, Azure Monitor displays a warning that you may be collecting duplicate data. -- [Screenshot showing warning message for both agents installed]:::image type="content" source="media/vminsights-enable-portal/both-agents-installed.png" lightbox="media/vminsights-enable-portal/both-agents-installed.png" alt-text="Screenshot showing warning message for both agents installed."::: -- > [!WARNING] - > Collecting duplicate data from a single machine with both the Azure Monitor agent and Log Analytics agent can result in: - > - Additional cost of ingestion duplicate data to the Log Analytics workspace. - > - The map feature of VM insights may be inaccurate since it does not check for duplicate data. For more information about - -1. Once you've verified that the Azure Monitor agent has been enabled, remove the Log Analytics agent from the machine to prevent duplicate data collection. --## Next steps --* See [Use VM insights Map](vminsights-maps.md) to view discovered application dependencies. -* See [View Azure VM performance](vminsights-performance.md) to identify bottlenecks, overall utilization, and your VM's performance. - |
| azure-monitor | Vminsights Enable Powershell | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/vminsights-enable-powershell.md | - Title: Enable VM insights by using PowerShell -description: This article describes how to enable VM insights for Azure virtual machines or virtual machine scale sets by using Azure PowerShell. ---- Previously updated : 05/20/2024---# Enable VM insights by using PowerShell -This article describes how to enable VM insights on Azure virtual machines by using PowerShell. This procedure can be used for: --- Azure Virtual Machines-- Azure Virtual Machine Scale Sets--This script installs VM extensions for Azure Monitoring Agent (AMA) and, if necessary, the Dependency Agent to enable VM Insights. If AMA is onboarded, a Data Collection Rule (DCR) and a User Assigned Managed Identity (UAMI) is also associated with the virtual machines and virtual machine scale sets. --> [!NOTE] -> Azure Monitor Agent is supported from version 1.10.1. --## Prerequisites --You need to: --- See [Manage Azure Monitor Agent](../agents/azure-monitor-agent-manage.md#prerequisites) for prerequisites related to Azure Monitor Agent.-- See [Supported operating systems](./vminsights-enable-overview.md#supported-operating-systems) to ensure that the operating system of the virtual machine or virtual machine scale set you're enabling is supported.-- To enable network isolation for Azure Monitor Agent, see [Enable network isolation for Azure Monitor Agent by using Private Link](../agents/azure-monitor-agent-private-link.md).---## PowerShell script --To enable VM insights for multiple VMs or virtual machine scale set, use the PowerShell script [Install-VMInsights.ps1](https://www.powershellgallery.com/packages/Install-VMInsights). The script is available from the Azure PowerShell Gallery. This script iterates through the virtual machines or virtual machine scale sets according to the parameters that you specify. The script can be used to enable VM insights for: --- Every virtual machine and virtual machine scale set in your subscription.-- The scoped resource groups specified by `-ResourceGroup`.-- A VM or virtual machine scale set specified by `-Name`.- You can specify multiple resource groups, VMs, or scale sets by using wildcards. ---Verify that you're using Az PowerShell module version 1.0.0 or later with `Enable-AzureRM` compatibility aliases enabled. Run `Get-Module -ListAvailable Az` to find the version. To upgrade, see [Install Azure PowerShell module](/powershell/azure/install-azure-powershell). If you're running PowerShell locally, run `Connect-AzAccount` to create a connection with Azure. --For a list of the script's argument details and example usage, run `Get-Help`. --```powershell -Get-Help Install-VMInsights.ps1 -Detailed -``` --Use the script to enable VM insights using Azure Monitoring Agent and Dependency Agent. --When you enable VM insights using Azure Monitor Agent, the script associates a Data Collection Rule (DCR) and a User Assigned Managed Identity (UAMI) to the VM/Virtual Machine Scale Set. The UAMI settings are passed to the Azure Monitor Agent extension. --```powershell -Install-VMInsights.ps1 -SubscriptionId <SubscriptionId> ` -[-ResourceGroup <ResourceGroup>] ` -[-ProcessAndDependencies ] ` -[-Name <VM or Virtual Machine Scale Set name>] ` --DcrResourceId <DataCollectionRuleResourceId> `--UserAssignedManagedIdentityName <UserAssignedIdentityName> `--UserAssignedManagedIdentityResourceGroup <UserAssignedIdentityResourceGroup> --``` --Required Arguments: -+ `-SubscriptionId <String>` Azure subscription ID. -+ `-DcrResourceId <String> ` Data Collection Rule (DCR) Azure resource ID identifier. You can specify DCRs from different subscriptions to the VMs or virtual machine scale sets being enabled with Vm-Insights. -+ `-UserAssignedManagedIdentityResourceGroup <String> ` Name of User Assigned Managed Identity (UAMI) resource group. -+ `-UserAssignedManagedIdentityName <String> ` Name of User Assigned Managed Identity (UAMI). ---Optional Arguments: -+ `-ProcessAndDependencies` Set this flag to onboard the Dependency Agent with Azure Monitoring Agent (AMA) settings. If not specified, only the Azure Monitoring Agent (AMA) is onboarded. -+ `-Name <String>` Name of the VM or Virtual Machine Scale Set to be onboarded. If not specified, all VMs and Virtual Machine Scale Set in the subscription or resource group are onboarded. Use wildcards to specify multiple VMs or Virtual Machine Scale Sets. -+ `-ResourceGroup <String>` Name of the resource group containing the VM or Virtual Machine Scale Set to be onboarded. If not specified, all VMs and Virtual Machine Scale Set in the subscription are onboarded. Use wildcards to specify multiple resource groups. -+ `-PolicyAssignmentName <String>` Only include VMs associated with this policy. When the PolicyAssignmentName parameter is specified, the VMs part of the parameter SubscriptionId are considered. -+ `-TriggerVmssManualVMUpdate [<SwitchParameter>]` Trigger the update of VM instances in a scale set whose upgrade policy is set to Manual. -+ `-WhatIf [<SwitchParameter>]` Get info about expected effect of the commands in the script. -+ `-Confirm [<SwitchParameter>]` Confirm each action in the script. -+ `-Approve [<SwitchParameter>]` Provide the approval for the installation to start with no confirmation prompt for the listed VM's/Virtual Machine Scale Sets. - -The script supports wildcards for `-Name` and `-ResourceGroup`. For example, `-Name vm*` enables VM insights for all VMs and Virtual Machine Scale Sets that start with "vm". For more information, see [Wildcards in Windows PowerShell](/powershell/module/microsoft.powershell.core/about/about_wildcards). --Example: -```azurepowershell -Install-VMInsights.ps1 -SubscriptionId 12345678-abcd-abcd-1234-12345678 ` --ResourceGroup rg-AMAPowershell `--ProcessAndDependencies `--Name vmAMAPowershellWindows `--DcrResourceId /subscriptions/12345678-abcd-abcd-1234-12345678/resourceGroups/rg-AMAPowershell/providers/Microsoft.Insights/dataCollectionRules/MSVMI-ama-vmi-default-dcr `--UserAssignedManagedIdentityName miamatest1 `--UserAssignedManagedIdentityResourceGroup amapowershell-``` --The output has the following format: --```powershell -Name Account SubscriptionName Environment TenantId -- - - -- ---AzMon001 12345678-abcd-123… MSI@9876 AzMon001 AzureCloud abcd1234-9876-abcd-1234-1234abcd5648 --Getting list of VMs or VM Scale Sets matching specified criteria. -VMs and Virtual Machine Scale Sets matching selection criteria : --ResourceGroup : rg-AMAPowershell - vmAMAPowershellWindows ---Confirm -Continue? -[Y] Yes [N] No [S] Suspend [?] Help (default is "Y"): --(rg-AMAPowershell) : Assigning roles --(rg-AMAPowershell) vmAMAPowershellWindows : Assigning User Assigned Managed Identity edsMIAMATest -(rg-AMAPowershell) vmAMAPowershellWindows : Successfully assigned User Assigned Managed Identity edsMIAMATest -(rg-AMAPowershell) vmAMAPowershellWindows : Data Collection Rule Id /subscriptions/12345678-abcd-abcd-1234-12345678/resourceGroups/rg-AMAPowershell/providers/Microsoft.Insights/dataCollectionRules/MSVMI-ama-vmi-default-dcr already associated with the VM. -(rg-AMAPowershell) vmAMAPowershellWindows : Extension AzureMonitorWindowsAgent, type = Microsoft.Azure.Monitor.AzureMonitorWindowsAgent already installed. Provisioning State : Succeeded -(rg-AMAPowershell) vmAMAPowershellWindows : Installing/Updating extension AzureMonitorWindowsAgent, type = Microsoft.Azure.Monitor.AzureMonitorWindowsAgent -(rg-AMAPowershell) vmAMAPowershellWindows : Successfully installed/updated extension AzureMonitorWindowsAgent, type = Microsoft.Azure.Monitor.AzureMonitorWindowsAgent -(rg-AMAPowershell) vmAMAPowershellWindows : Installing/Updating extension DA-Extension, type = Microsoft.Azure.Monitoring.DependencyAgent.DependencyAgentWindows -(rg-AMAPowershell) vmAMAPowershellWindows : Successfully installed/updated extension DA-Extension, type = Microsoft.Azure.Monitoring.DependencyAgent.DependencyAgentWindows -(rg-AMAPowershell) vmAMAPowershellWindows : Successfully onboarded VM insights --Summary : -Total VM/VMSS to be processed : 1 -Succeeded : 1 -Skipped : 0 -Failed : 0 -VMSS Instance Upgrade Failures : 0 -``` --Check your VM/Virtual Machine Scale Set in Azure portal to see if the extensions are installed or use the following command: --```powershell --az vm extension list --resource-group <resource group> --vm-name <VM name> -o table ---Name ProvisioningState Publisher Version AutoUpgradeMinorVersion - - - -AzureMonitorWindowsAgent Succeeded Microsoft.Azure.Monitor 1.16 True -DA-Extension Succeeded Microsoft.Azure.Monitoring.DependencyAgent 9.10 True -``` --## Next steps --* See [Use VM insights Map](vminsights-maps.md) to view discovered application dependencies. -* See [View Azure VM performance](vminsights-performance.md) to identify bottlenecks, overall utilization, and your VM's performance. |
| azure-monitor | Vminsights Enable Resource Manager | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/vminsights-enable-resource-manager.md | - Title: Enable VM insights using Resource Manager templates -description: This article describes how you enable VM insights for one or more Azure virtual machines or Virtual Machine Scale Sets by using Azure PowerShell or Azure Resource Manager templates. ---- Previously updated : 05/20/2024---# Enable VM insights using Resource Manager templates -This article describes how to enable VM insights for a virtual machine or Virtual Machine Scale Set using Resource Manager templates. This procedure can be used for: --- Azure virtual machines-- Azure Virtual Machine Scale Sets-- Hybrid virtual machines connected with Azure Arc--If you aren't familiar with how to deploy a Resource Manager template, see [Deploy templates](#deploy-templates). --## Prerequisites --- See [Supported operating systems](./vminsights-enable-overview.md#supported-operating-systems) to ensure that the operating system of the virtual machine or Virtual Machine Scale Set you're enabling is supported. -- See [Manage the Azure Monitor agent](../agents/azure-monitor-agent-manage.md#prerequisites) for prerequisites related to Azure Monitor agent.-- To enable network isolation for Azure Monitor Agent, see [Enable network isolation for Azure Monitor Agent by using Private Link](../agents/azure-monitor-agent-private-link.md).--## Resource Manager templates -Use the Azure Resource Manager templates provided in this article to onboard virtual machines and Virtual Machine Scale Sets using Azure Monitor agent. The templates install the required agents and perform the configuration required to onboard to machine to VM insights. -->[!NOTE] -> Deploy the template in the same resource group as the virtual machine or virtual machine scale set being enabled. --## Enable VM insights using Azure Monitor Agent -First deploy the data collection rule, and then install agents to use that data collection rule. --### Deploy data collection rule --This step installs a data collection rule, named `MSVMI-{WorkspaceName}`, in the same resource group as your Log Analytics workspace: --1. Download the [VM insights data collection rule templates](https://github.com/Azure/AzureMonitorForVMs-ArmTemplates/releases/download/vmi_ama_ga/DeployDcr.zip). -1. [Deploy a template](#deploy-templates) from the downloaded zip file. The following table describes the templates available: -- | Folder | File | Description | - |:|:| - | DeployDcr\\<br>PerfAndMapDcr | DeployDcrTemplate<br>DeployDcrParameters | Enable both Performance and Map experience of VM Insights. | - | DeployDcr\\<br>PerfOnlyDcr | DeployDcrTemplate<br>DeployDcrParameters | Enable only Performance experience of VM Insights. | --### Deploy agents to machines --After you create the data collection rule, deploy: --- [Azure Monitor Agent for Linux or Windows](../agents/resource-manager-agent.md#azure-monitor-agent).-- [Dependency agent for Linux](/azure/virtual-machines/extensions/agent-dependency-linux) or [Dependency agent or Windows](/azure/virtual-machines/extensions/agent-dependency-windows) if you want to enable the Map feature. - -> [!NOTE] -> If your virtual machines scale sets have an upgrade policy set to manual, VM insights will not be enabled for instances by default after installing the template. You must manually upgrade the instances. --## Deploy templates -Each folder in the download has a template and a parameters file. Modify the parameters file with required details such as Virtual Machine Resource ID, Workspace resource ID, data collection rule resource ID, Location, and OS Type. Don't modify the template file unless you need to customize it for your particular scenario. --### Deploy with the Azure portal -See [Quickstart: Create and deploy ARM templates by using the Azure portal](../../azure-resource-manager/resource-manager-quickstart-create-templates-use-the-portal.md) for details on deploying a template from the Azure portal. --### Deploy with PowerShell -Use the following command to deploy the template with PowerShell. --```PowerShell -New-AzResourceGroupDeployment -Name OnboardCluster -ResourceGroupName <ResourceGroupName> -TemplateFile <Template.json> -TemplateParameterFile <Parameters.json> -``` --### Azure CLI -Use the following command to deploy the template with Azure CLI. --```sh -az login -az account set --subscription "Subscription Name" -az deployment group create --resource-group <ResourceGroupName> --template-file <Template.json> --parameters <Parameters.json> -``` --## Next steps --Now that monitoring is enabled for your virtual machines, this information is available for analysis with VM insights. --- To view discovered application dependencies, see [View VM insights Map](vminsights-maps.md).--- To identify bottlenecks and overall utilization with your VM's performance, see [View Azure VM Performance](vminsights-performance.md). |
| azure-monitor | Vminsights Log Query | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/vminsights-log-query.md | - Title: How to Query Logs from VM insights -description: VM insights solution collects metrics and log data to and this article describes the records and includes sample queries. --- Previously updated : 09/28/2023---# How to query logs from VM insights --> [!CAUTION] -> This article references CentOS, a Linux distribution that is End Of Life (EOL) status. Please consider your use and planning accordingly. For more information, see the [CentOS End Of Life guidance](/azure/virtual-machines/workloads/centos/centos-end-of-life). --VM insights collects performance and connection metrics, computer and process inventory data, and health state information and forwards it to the Log Analytics workspace in Azure Monitor. This data is available for [query](../logs/log-query-overview.md) in Azure Monitor. You can apply this data to scenarios that include migration planning, capacity analysis, discovery, and on-demand performance troubleshooting. --## Map records --> [!IMPORTANT] -> If your virtual machine is using VM insights with Azure Monitor agent, then you must have [processes and dependencies enabled](vminsights-enable-portal.md#enable-vm-insights-for-azure-monitor-agent) for these tables to be created. --One record is generated per hour for each unique computer and process, in addition to the records that are generated when a process or computer starts or is added to VM insights. The fields and values in the VMComputer table map to fields of the Machine resource in the ServiceMap Azure Resource Manager API. The fields and values in the VMProcess table map to the fields of the Process resource in the ServiceMap Azure Resource Manager API. The _ResourceId field matches the name field in the corresponding Resource Manager resource. --There are internally generated properties you can use to identify unique processes and computers: --- Computer: Use *_ResourceId* to uniquely identify a computer within a Log Analytics workspace.-- Process: Use *_ResourceId* to uniquely identify a process within a Log Analytics workspace.--Because multiple records can exist for a specified process and computer in a specified time range, queries can return more than one record for the same computer or process. To include only the most recent record, add `| summarize arg_max(TimeGenerated, *) by ResourceId` to the query. --### Connections and ports --The Connection Metrics feature introduces two new tables in Azure Monitor logs - VMConnection and VMBoundPort. These tables provide information about the connections for a machine (inbound and outbound) and the server ports that are open/active on them. ConnectionMetrics are also exposed via APIs that provide the means to obtain a specific metric during a time window. TCP connections resulting from *accepting* on a listening socket are inbound, while those created by *connecting* to a given IP and port are outbound. The direction of a connection is represented by the Direction property, which can be set to either **inbound** or **outbound**. --Records in these tables are generated from data reported by the Dependency Agent. Every record represents an observation over a 1-minute time interval. The TimeGenerated property indicates the start of the time interval. Each record contains information to identify the respective entity, that is, connection or port, as well as metrics associated with that entity. Currently, only network activity that occurs using TCP over IPv4 is reported. --#### Common fields and conventions --The following fields and conventions apply to both VMConnection and VMBoundPort: --- Computer: Fully-qualified domain name of reporting machine -- AgentId: The unique identifier for a machine running Azure Monitor Agent or the Log Analytics agent -- Machine: Name of the Azure Resource Manager resource for the machine exposed by ServiceMap. It's of the form *m-{GUID}*, where *GUID* is the same GUID as AgentId -- Process: Name of the Azure Resource Manager resource for the process exposed by ServiceMap. It's of the form *p-{hex string}*. Process is unique within a machine scope and to generate a unique process ID across machines, combine Machine and Process fields. -- ProcessName: Executable name of the reporting process.-- All IP addresses are strings in IPv4 canonical format, for example *13.107.3.160* --To manage cost and complexity, connection records don't represent individual physical network connections. Multiple physical network connections are grouped into a logical connection, which is then reflected in the respective table. Meaning, records in *VMConnection* table represent a logical grouping and not the individual physical connections that are being observed. Physical network connection sharing the same value for the following attributes during a given one-minute interval, are aggregated into a single logical record in *VMConnection*. --| Property | Description | -|:--|:--| -|Direction |Direction of the connection, value is *inbound* or *outbound* | -|Machine |The computer FQDN | -|Process |Identity of process or groups of processes, initiating/accepting the connection | -|SourceIp |IP address of the source | -|DestinationIp |IP address of the destination | -|DestinationPort |Port number of the destination | -|Protocol |Protocol used for the connection. Values is *tcp*. | --To account for the impact of grouping, information about the number of grouped physical connections is provided in the following properties of the record: --| Property | Description | -|:--|:--| -|LinksEstablished |The number of physical network connections that have been established during the reporting time window | -|LinksTerminated |The number of physical network connections that have been terminated during the reporting time window | -|LinksFailed |The number of physical network connections that have failed during the reporting time window. This information is currently available only for outbound connections. | -|LinksLive |The number of physical network connections that were open at the end of the reporting time window| --#### Metrics --In addition to connection count metrics, information about the volume of data sent and received on a given logical connection or network port are also included in the following properties of the record: --| Property | Description | -|:--|:--| -|BytesSent |Total number of bytes that have been sent during the reporting time window | -|BytesReceived |Total number of bytes that have been received during the reporting time window | -|Responses |The number of responses observed during the reporting time window. -|ResponseTimeMax |The largest response time (milliseconds) observed during the reporting time window. If no value, the property is blank.| -|ResponseTimeMin |The smallest response time (milliseconds) observed during the reporting time window. If no value, the property is blank.| -|ResponseTimeSum |The sum of all response times (milliseconds) observed during the reporting time window. If no value, the property is blank.| --The third type of data being reported is response time - how long does a caller spend waiting for a request sent over a connection to be processed and responded to by the remote endpoint. The response time reported is an estimation of the true response time of the underlying application protocol. It's computed using heuristics based on the observation of the flow of data between the source and destination end of a physical network connection. Conceptually, it's the difference between the time the last byte of a request leaves the sender, and the time when the last byte of the response arrives back to it. These two timestamps are used to delineate request and response events on a given physical connection. The difference between them represents the response time of a single request. --In this first release of this feature, our algorithm is an approximation that may work with varying degree of success depending on the actual application protocol used for a given network connection. For example, the current approach works well for request-response based protocols such as HTTP(S), but doesn't work with one-way or message queue-based protocols. --Here are some important points to consider: --1. If a process accepts connections on the same IP address but over multiple network interfaces, a separate record for each interface will be reported. -2. Records with wildcard IP will contain no activity. They're included to represent the fact that a port on the machine is open to inbound traffic. -3. To reduce verbosity and data volume, records with wildcard IP will be omitted when there's a matching record (for the same process, port, and protocol) with a specific IP address. When a wildcard IP record is omitted, the IsWildcardBind record property with the specific IP address, will be set to "True" to indicate that the port is exposed over every interface of the reporting machine. -4. Ports that are bound only on a specific interface have IsWildcardBind set to *False*. --#### Naming and Classification --For convenience, the IP address of the remote end of a connection is included in the RemoteIp property. For inbound connections, RemoteIp is the same as SourceIp, while for outbound connections, it's the same as DestinationIp. The RemoteDnsCanonicalNames property represents the DNS canonical names reported by the machine for RemoteIp. The RemoteDnsQuestions property represents the DNS questions reported by the machine for RemoteIp. The RemoveClassification property is reserved for future use. --#### Geolocation --*VMConnection* also includes geolocation information for the remote end of each connection record in the following properties of the record: --| Property | Description | -|:--|:--| -|RemoteCountry |The name of the country/region hosting RemoteIp. For example, *United States* | -|RemoteLatitude |The geolocation latitude. For example, *47.68* | -|RemoteLongitude |The geolocation longitude. For example, *-122.12* | --#### Malicious IP --Every RemoteIp property in *VMConnection* table is checked against a set of IPs with known malicious activity. If the RemoteIp is identified as malicious the following properties will be populated (they're empty, when the IP isn't considered malicious) in the following properties of the record: --| Property | Description | -|:--|:--| -|MaliciousIp |The RemoteIp address | -|IndicatorThreadType |Threat indicator detected is one of the following values, *Botnet*, *C2*, *CryptoMining*, *Darknet*, *DDos*, *MaliciousUrl*, *Malware*, *Phishing*, *Proxy*, *PUA*, *Watchlist*. | -|Description |Description of the observed threat. | -|TLPLevel |Traffic Light Protocol (TLP) Level is one of the defined values, *White*, *Green*, *Amber*, *Red*. | -|Confidence |Values are *0 ΓÇô 100*. | -|Severity |Values are *0 ΓÇô 5*, where *5* is the most severe and *0* isn't severe at all. Default value is *3*. | -|FirstReportedDateTime |The first time the provider reported the indicator. | -|LastReportedDateTime |The last time the indicator was seen by Interflow. | -|IsActive |Indicates indicators are deactivated with *True* or *False* value. | -|ReportReferenceLink |Links to reports related to a given observable. To report a false alert or get more details about the malicious IP, open a Support case and provide this link. | -|AdditionalInformation |Provides additional information, if applicable, about the observed threat. | --### Ports --Ports on a machine that actively accept incoming traffic or could potentially accept traffic, but are idle during the reporting time window, are written to the VMBoundPort table. --Every record in VMBoundPort is identified by the following fields: --| Property | Description | -|:--|:--| -|Process | Identity of process (or groups of processes) with which the port is associated with.| -|Ip | Port IP address (can be wildcard IP, *0.0.0.0*) | -|Port |The Port number | -|Protocol | The protocol. Example, *tcp* or *udp* (only *tcp* is currently supported).| --The identity a port is derived from the above five fields and is stored in the PortId property. This property can be used to quickly find records for a specific port across time. --#### Metrics --Port records include metrics representing the connections associated with them. Currently, the following metrics are reported (the details for each metric are described in the previous section): --- BytesSent and BytesReceived -- LinksEstablished, LinksTerminated, LinksLive -- ResposeTime, ResponseTimeMin, ResponseTimeMax, ResponseTimeSum --Here are some important points to consider: --- If a process accepts connections on the same IP address but over multiple network interfaces, a separate record for each interface will be reported. -- Records with wildcard IP will contain no activity. They're included to represent the fact that a port on the machine is open to inbound traffic. -- To reduce verbosity and data volume, records with wildcard IP will be omitted when there's a matching record (for the same process, port, and protocol) with a specific IP address. When a wildcard IP record is omitted, the *IsWildcardBind* property for the record with the specific IP address, will be set to *True*. This indicates the port is exposed over every interface of the reporting machine. -- Ports that are bound only on a specific interface have IsWildcardBind set to *False*. --### VMComputer records --Records with a type of *VMComputer* have inventory data for servers with the Dependency agent. These records have the properties in the following table: --| Property | Description | -|:--|:--| -|TenantId | The unique identifier for the workspace | -|SourceSystem | *Insights* | -|TimeGenerated | Timestamp of the record (UTC) | -|Computer | The computer FQDN | -|AgentId | The unique identifier for a machine running Azure Monitor Agent or the Log Analytics agent | -|Machine | Name of the Azure Resource Manager resource for the machine exposed by ServiceMap. It's of the form *m-{GUID}*, where *GUID* is the same GUID as AgentId. | -|DisplayName | Display name | -|FullDisplayName | Full display name | -|HostName | The name of machine without domain name | -|BootTime | The machine boot time (UTC) | -|TimeZone | The normalized time zone | -|VirtualizationState | *virtual*, *hypervisor*, *physical* | -|Ipv4Addresses | Array of IPv4 addresses | -|Ipv4SubnetMasks | Array of IPv4 subnet masks (in the same order as Ipv4Addresses). | -|Ipv4DefaultGateways | Array of IPv4 gateways | -|Ipv6Addresses | Array of IPv6 addresses | -|MacAddresses | Array of MAC addresses | -|DnsNames | Array of DNS names associated with the machine. | -|DependencyAgentVersion | The version of the Dependency agent running on the machine. | -|OperatingSystemFamily | *Linux*, *Windows* | -|OperatingSystemFullName | The full name of the operating system | -|PhysicalMemoryMB | The physical memory in megabytes | -|Cpus | The number of processors | -|CpuSpeed | The CPU speed in MHz | -|VirtualMachineType | *hyperv*, *vmware*, *xen* | -|VirtualMachineNativeId | The VM ID as assigned by its hypervisor | -|VirtualMachineNativeName | The name of the VM | -|VirtualMachineHypervisorId | The unique identifier of the hypervisor hosting the VM | -|HypervisorType | *hyperv* | -|HypervisorId | The unique ID of the hypervisor | -|HostingProvider | *azure* | -|_ResourceId | The unique identifier for an Azure resource | -|AzureSubscriptionId | A globally unique identifier that identifies your subscription | -|AzureResourceGroup | The name of the Azure resource group the machine is a member of. | -|AzureResourceName | The name of the Azure resource | -|AzureLocation | The location of the Azure resource | -|AzureUpdateDomain | The name of the Azure update domain | -|AzureFaultDomain | The name of the Azure fault domain | -|AzureVmId | The unique identifier of the Azure virtual machine | -|AzureSize | The size of the Azure VM | -|AzureImagePublisher | The name of the Azure VM publisher | -|AzureImageOffering | The name of the Azure VM offer type | -|AzureImageSku | The SKU of the Azure VM image | -|AzureImageVersion | The version of the Azure VM image | -|AzureCloudServiceName | The name of the Azure cloud service | -|AzureCloudServiceDeployment | Deployment ID for the Cloud Service | -|AzureCloudServiceRoleName | Cloud Service role name | -|AzureCloudServiceRoleType | Cloud Service role type: *worker* or *web* | -|AzureCloudServiceInstanceId | Cloud Service role instance ID | -|AzureVmScaleSetName | The name of the virtual machine scale set | -|AzureVmScaleSetDeployment | Virtual machine scale set deployment ID | -|AzureVmScaleSetResourceId | The unique identifier of the virtual machine scale set resource.| -|AzureVmScaleSetInstanceId | The unique identifier of the virtual machine scale set | -|AzureServiceFabricClusterId | The unique identifer of the Azure Service Fabric cluster | -|AzureServiceFabricClusterName | The name of the Azure Service Fabric cluster | --### VMProcess records --Records with a type of *VMProcess* have inventory data for TCP-connected processes on servers with the Dependency agent. These records have the properties in the following table: --| Property | Description | -|:--|:--| -|TenantId | The unique identifier for the workspace | -|SourceSystem | *Insights* | -|TimeGenerated | Timestamp of the record (UTC) | -|Computer | The computer FQDN | -|AgentId | The unique identifier for a machine running Azure Monitor Agent or the Log Analytics agent | -|Machine | Name of the Azure Resource Manager resource for the machine exposed by ServiceMap. It's of the form *m-{GUID}*, where *GUID* is the same GUID as AgentId. | -|Process | The unique identifier of the Service Map process. It's in the form of *p-{GUID}*. -|ExecutableName | The name of the process executable | -|DisplayName | Process display name | -|Role | Process role: *webserver*, *appServer*, *databaseServer*, *ldapServer*, *smbServer* | -|Group | Process group name. Processes in the same group are logically related, e.g., part of the same product or system component. | -|StartTime | The process pool start time | -|FirstPid | The first PID in the process pool | -|Description | The process description | -|CompanyName | The name of the company | -|InternalName | The internal name | -|ProductName | The name of the product | -|ProductVersion | The version of the product | -|FileVersion | The version of the file | -|ExecutablePath |The path of the executable | -|CommandLine | The command line | -|WorkingDirectory | The working directory | -|Services | An array of services under which the process is executing | -|UserName | The account under which the process is executing | -|UserDomain | The domain under which the process is executing | -|_ResourceId | The unique identifier for a process within the workspace | ---## Sample map queries --### List all known machines --```kusto -VMComputer | summarize arg_max(TimeGenerated, *) by _ResourceId -``` --### When was the VM last rebooted --```kusto -let Today = now(); VMComputer | extend DaysSinceBoot = Today - BootTime | summarize by Computer, DaysSinceBoot, BootTime | sort by BootTime asc -``` --### Summary of Azure VMs by image, location, and SKU --```kusto -VMComputer | where AzureLocation != "" | summarize by Computer, AzureImageOffering, AzureLocation, AzureImageSku -``` --### List the physical memory capacity of all managed computers --```kusto -VMComputer | summarize arg_max(TimeGenerated, *) by _ResourceId | project PhysicalMemoryMB, Computer -``` --### List computer name, DNS, IP, and OS --```kusto -VMComputer | summarize arg_max(TimeGenerated, *) by _ResourceId | project Computer, OperatingSystemFullName, DnsNames, Ipv4Addresses -``` --### Find all processes with "sql" in the command line --```kusto -VMProcess | where CommandLine contains_cs "sql" | summarize arg_max(TimeGenerated, *) by _ResourceId -``` --### Find a machine (most recent record) by resource name --```kusto -search in (VMComputer) "m-4b9c93f9-bc37-46df-b43c-899ba829e07b" | summarize arg_max(TimeGenerated, *) by _ResourceId -``` --### Find a machine (most recent record) by IP address --```kusto -search in (VMComputer) "10.229.243.232" | summarize arg_max(TimeGenerated, *) by _ResourceId -``` --### List all known processes on a specified machine --```kusto -VMProcess | where Machine == "m-559dbcd8-3130-454d-8d1d-f624e57961bc" | summarize arg_max(TimeGenerated, *) by _ResourceId -``` --### List all computers running SQL Server --```kusto -VMComputer | where AzureResourceName in ((search in (VMProcess) "*sql*" | distinct Machine)) | distinct Computer -``` --### List all unique product versions of curl in my datacenter --```kusto -VMProcess | where ExecutableName == "curl" | distinct ProductVersion -``` --### Create a computer group of all computers running CentOS --```kusto -VMComputer | where OperatingSystemFullName contains_cs "CentOS" | distinct Computer -``` --### Bytes sent and received trends --```kusto -VMConnection | summarize sum(BytesSent), sum(BytesReceived) by bin(TimeGenerated,1hr), Computer | order by Computer desc | render timechart -``` --### Which Azure VMs are transmitting the most bytes --```kusto -VMConnection | join kind=fullouter(VMComputer) on $left.Computer == $right.Computer | summarize count(BytesSent) by Computer, AzureVMSize | sort by count_BytesSent desc -``` --### Link status trends --```kusto -VMConnection | where TimeGenerated >= ago(24hr) | where Computer == "acme-demo" | summarize dcount(LinksEstablished), dcount(LinksLive), dcount(LinksFailed), dcount(LinksTerminated) by bin(TimeGenerated, 1h) | render timechart -``` --### Connection failures trend --```kusto -VMConnection | where Computer == "acme-demo" | extend bythehour = datetime_part("hour", TimeGenerated) | project bythehour, LinksFailed | summarize failCount = count() by bythehour | sort by bythehour asc | render timechart -``` --### Bound Ports --```kusto -VMBoundPort -| where TimeGenerated >= ago(24hr) -| where Computer == 'admdemo-appsvr' -| distinct Port, ProcessName -``` --### Number of open ports across machines --```kusto -VMBoundPort -| where Ip != "127.0.0.1" -| summarize by Computer, Machine, Port, Protocol -| summarize OpenPorts=count() by Computer, Machine -| order by OpenPorts desc -``` --### Score processes in your workspace by the number of ports they have open --```kusto -VMBoundPort -| where Ip != "127.0.0.1" -| summarize by ProcessName, Port, Protocol -| summarize OpenPorts=count() by ProcessName -| order by OpenPorts desc -``` --### Aggregate behavior for each port --This query can then be used to score ports by activity, e.g., ports with most inbound/outbound traffic, ports with most connections -```kusto -// -VMBoundPort -| where Ip != "127.0.0.1" -| summarize BytesSent=sum(BytesSent), BytesReceived=sum(BytesReceived), LinksEstablished=sum(LinksEstablished), LinksTerminated=sum(LinksTerminated), arg_max(TimeGenerated, LinksLive) by Machine, Computer, ProcessName, Ip, Port, IsWildcardBind -| project-away TimeGenerated -| order by Machine, Computer, Port, Ip, ProcessName -``` --### Summarize the outbound connections from a group of machines --```kusto -// the machines of interest -let machines = datatable(m: string) ["m-82412a7a-6a32-45a9-a8d6-538354224a25"]; -// map of ip to monitored machine in the environment -let ips=materialize(VMComputer -| summarize ips=makeset(todynamic(Ipv4Addresses)) by MonitoredMachine=AzureResourceName -| mvexpand ips to typeof(string)); -// all connections to/from the machines of interest -let out=materialize(VMConnection -| where Machine in (machines) -| summarize arg_max(TimeGenerated, *) by ConnectionId); -// connections to localhost augmented with RemoteMachine -let local=out -| where RemoteIp startswith "127." -| project ConnectionId, Direction, Machine, Process, ProcessName, SourceIp, DestinationIp, DestinationPort, Protocol, RemoteIp, RemoteMachine=Machine; -// connections not to localhost augmented with RemoteMachine -let remote=materialize(out -| where RemoteIp !startswith "127." -| join kind=leftouter (ips) on $left.RemoteIp == $right.ips -| summarize by ConnectionId, Direction, Machine, Process, ProcessName, SourceIp, DestinationIp, DestinationPort, Protocol, RemoteIp, RemoteMachine=MonitoredMachine); -// the remote machines to/from which we have connections -let remoteMachines = remote | summarize by RemoteMachine; -// all augmented connections -(local) -| union (remote) -//Take all outbound records but only inbound records that come from either //unmonitored machines or monitored machines not in the set for which we are computing dependencies. -| where Direction == 'outbound' or (Direction == 'inbound' and RemoteMachine !in (machines)) -| summarize by ConnectionId, Direction, Machine, Process, ProcessName, SourceIp, DestinationIp, DestinationPort, Protocol, RemoteIp, RemoteMachine -// identify the remote port -| extend RemotePort=iff(Direction == 'outbound', DestinationPort, 0) -// construct the join key we'll use to find a matching port -| extend JoinKey=strcat_delim(':', RemoteMachine, RemoteIp, RemotePort, Protocol) -// find a matching port -| join kind=leftouter (VMBoundPort -| where Machine in (remoteMachines) -| summarize arg_max(TimeGenerated, *) by PortId -| extend JoinKey=strcat_delim(':', Machine, Ip, Port, Protocol)) on JoinKey -// aggregate the remote information -| summarize Remote=makeset(iff(isempty(RemoteMachine), todynamic('{}'), pack('Machine', RemoteMachine, 'Process', Process1, 'ProcessName', ProcessName1))) by ConnectionId, Direction, Machine, Process, ProcessName, SourceIp, DestinationIp, DestinationPort, Protocol -``` --## Performance records -Records with a type of *InsightsMetrics* have performance data from the guest operating system of the virtual machine. These records are collected at 60 second intervals and have the properties in the following table: ----| Property | Description | -|:--|:--| -|TenantId | Unique identifier for the workspace | -|SourceSystem | *Insights* | -|TimeGenerated | Time the value was collected (UTC) | -|Computer | The computer FQDN | -|Origin | *vm.azm.ms* | -|Namespace | Category of the performance counter | -|Name | Name of the performance counter | -|Val | Collected value | -|Tags | Related details about the record. See the table below for tags used with different record types. | -|AgentId | Unique identifier for each computer's agent | -|Type | *InsightsMetrics* | -|_ResourceId_ | Resource ID of the virtual machine | --The performance counters currently collected into the *InsightsMetrics* table are listed in the following table: --| Namespace | Name | Description | Unit | Tags | -|:|:|:|:|:| -| Computer | Heartbeat | Computer Heartbeat | | | -| Memory | AvailableMB | Memory Available Bytes | Megabytes | memorySizeMB - Total memory size| -| Network | WriteBytesPerSecond | Network Write Bytes Per Second | BytesPerSecond | NetworkDeviceId - ID of the device<br>bytes - Total sent bytes | -| Network | ReadBytesPerSecond | Network Read Bytes Per Second | BytesPerSecond | networkDeviceId - ID of the device<br>bytes - Total received bytes | -| Processor | UtilizationPercentage | Processor Utilization Percentage | Percent | totalCpus - Total CPUs | -| LogicalDisk | WritesPerSecond | Logical Disk Writes Per Second | CountPerSecond | mountId - Mount ID of the device | -| LogicalDisk | WriteLatencyMs | Logical Disk Write Latency Millisecond | MilliSeconds | mountId - Mount ID of the device | -| LogicalDisk | WriteBytesPerSecond | Logical Disk Write Bytes Per Second | BytesPerSecond | mountId - Mount ID of the device | -| LogicalDisk | TransfersPerSecond | Logical Disk Transfers Per Second | CountPerSecond | mountId - Mount ID of the device | -| LogicalDisk | TransferLatencyMs | Logical Disk Transfer Latency Millisecond | MilliSeconds | mountId - Mount ID of the device | -| LogicalDisk | ReadsPerSecond | Logical Disk Reads Per Second | CountPerSecond | mountId - Mount ID of the device | -| LogicalDisk | ReadLatencyMs | Logical Disk Read Latency Millisecond | MilliSeconds | mountId - Mount ID of the device | -| LogicalDisk | ReadBytesPerSecond | Logical Disk Read Bytes Per Second | BytesPerSecond | mountId - Mount ID of the device | -| LogicalDisk | FreeSpacePercentage | Logical Disk Free Space Percentage | Percent | mountId - Mount ID of the device | -| LogicalDisk | FreeSpaceMB | Logical Disk Free Space Bytes | Megabytes | mountId - Mount ID of the device<br>diskSizeMB - Total disk size | -| LogicalDisk | BytesPerSecond | Logical Disk Bytes Per Second | BytesPerSecond | mountId - Mount ID of the device | ------## Next steps --* If you're new to writing log queries in Azure Monitor, review [how to use Log Analytics](../logs/log-analytics-tutorial.md) in the Azure portal to write log queries. --* Learn about [writing search queries](../logs/get-started-queries.md). -- |
| azure-monitor | Vminsights Maps | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/vminsights-maps.md | - Title: View app dependencies with VM insights -description: This article shows how to use the VM insights Map feature. It discovers application components on Windows and Linux systems and maps the communication between services. ---- Previously updated : 09/28/2023---# Use the Map feature of VM insights to understand application components -In VM insights, you can view discovered application components on Windows and Linux virtual machines (VMs) that run in Azure or your environment. You can observe the VMs in two ways. You can view a map directly from a VM. You can also view a map from Azure Monitor to see the components across groups of VMs. This article helps you to understand these two viewing methods and how to use the Map feature. --For information about configuring VM insights, see [Enable VM insights](vminsights-enable-overview.md). --## Limitations --- If you're duplicating IP ranges either with VMs or Azure Virtual Machine Scale Sets across subnets and virtual networks, VM insights Map might display incorrect information. This issue is known. We're investigating options to improve this experience.-- The Map feature currently only supports IPv4. We're investigating support for IPv6. We also support IPv4 that's tunnelled inside IPv6.-- A map for a resource group or other large group might be difficult to view. Although we've made improvements to Map to handle large and complex configurations, we realize a map can have many nodes, connections, and nodes working as a cluster. We're committed to continuing to enhance support to increase scalability.-- In the Free pricing tier, the VM insights Map feature supports only five machines that are connected to a Log Analytics workspace.--## Prerequisites -To enable the Map feature in VM insights, the virtual machine requires one of the following agents: --- Azure Monitor Agent with processes and dependencies enabled.-- The Log Analytics agent enabled for VM insights.---For more information, see [Enable VM insights on unmonitored machine](vminsights-enable-overview.md). --> [!WARNING] -> Collecting duplicate data from a single machine with both Azure Monitor Agent and the Log Analytics agent can result in the Map feature of VM insights being inaccurate because it doesn't check for duplicate data. ---## Introduction to the Map experience -Before diving into the Map experience, you should understand how it presents and visualizes information. --Whether you select the Map feature directly from a VM or from Azure Monitor, the Map feature presents a consistent experience. The only difference is that from Azure Monitor, one map shows all the members of a multiple-tier application or cluster. --The Map feature visualizes the VM dependencies by discovering running processes that have: --- Active network connections between servers.-- Inbound and outbound connection latency.-- Ports across any TCP-connected architecture over a specified time range.--Expand a VM to show process details and only those processes that communicate with the VM. The client group shows the count of front-end clients that connect into the VM. The server-port groups show the count of back-end servers the VM connects to. Expand a server-port group to see the detailed list of servers that connect over that port. --When you select the VM, the **Properties** pane shows the VM's properties. Properties include system information reported by the operating system, properties of the Azure VM, and a doughnut chart that summarizes the discovered connections. -<!-- convertborder later --> --On the right side of the pane, select **Log Events** to show a list of data that the VM has sent to Azure Monitor. This data is available for querying. Select any record type to open the **Logs** page, where you see the results for that record type. You also see a preconfigured query that's filtered against the VM. -<!-- convertborder later --> --Close the **Logs** page and return to the **Properties** pane. There, select **Alerts** to view VM health-criteria alerts. The Map feature integrates with Azure alerts to show alerts for the selected server in the selected time range. The server displays an icon for current alerts, and the **Machine Alerts** pane lists the alerts. -<!-- convertborder later --> --To make the Map feature display relevant alerts, create an alert rule that applies to a specific computer: --- Include a clause to group alerts by computer (for example, **by Computer interval 1 minute**).-- Base the alert on a metric.--For more information about Azure alerts and how to create alert rules, see [Unified alerts in Azure Monitor](../alerts/alerts-overview.md). --In the upper-right corner, the **Legend** option describes the symbols and roles on the map. For a closer look at your map and to move it around, use the zoom controls in the lower-right corner. You can set the zoom level and fit the map to the size of the page. --## Connection metrics -The **Connections** pane displays standard metrics for the selected connection from the VM over the TCP port. The metrics include response time, requests per minute, traffic throughput, and links. -<!-- convertborder later --> --### Failed connections -The map shows failed connections for processes and computers. A dashed red line indicates a client system is failing to reach a process or port. For systems that use the Dependency agent, the agent reports on failed connection attempts. The Map feature monitors a process by observing TCP sockets that fail to establish a connection. This failure could result from a firewall, a misconfiguration in the client or server, or an unavailable remote service. ---Understanding failed connections can help you troubleshoot, validate migration, analyze security, and understand the overall architecture of the service. Failed connections are sometimes harmless, but they often point to a problem. Connections might fail, for example, when a failover environment suddenly becomes unreachable or when two application tiers can't communicate with each other after a cloud migration. --### Client groups -On the map, client groups represent client machines that connect to the mapped machine. A single client group represents the clients for an individual process or machine. ---To see the monitored clients and IP addresses of the systems in a client group, select the group. The contents of the group appear in the following image. ---If the group includes monitored and unmonitored clients, you can select the appropriate section of the group's doughnut chart to filter the clients. --### Server-port groups -Server-port groups represent ports on servers that have inbound connections from the mapped machine. The group contains the server port and a count of the number of servers that have connections to that port. Select the group to see the individual servers and connections. ---If the group includes monitored and unmonitored servers, you can select the appropriate section of the group's doughnut chart to filter the servers. --## View a map from a VM --To access VM insights directly from a VM: --1. In the Azure portal, select **Virtual Machines**. -1. From the list, select a VM. In the **Monitoring** section, select **Insights**. -1. Select the **Map** tab. --The map visualizes the VM's dependencies by discovering running process groups and processes that have active network connections over a specified time range. --By default, the map shows the last 30 minutes. If you want to see how dependencies looked in the past, you can query for historical time ranges of up to one hour. To run the query, use the **TimeRange** selector in the upper-left corner. You might run a query, for example, during an incident or to see the status before a change. -<!-- convertborder later --> --## View a map from a virtual machine scale set --To access VM insights directly from a virtual machine scale set: --1. In the Azure portal, select **Virtual machine scale sets**. -1. From the list, select a VM. Then in the **Monitoring** section, select **Insights**. -1. Select the **Map** tab. --The map visualizes all instances in the scale set as a group node along with the group's dependencies. The expanded node lists the instances in the scale set. You can scroll through these instances 10 at a time. --To load a map for a specific instance, first select that instance on the map. Then select the **ellipsis** button **(...**) and select **Load Server Map**. In the map that appears, you see process groups and processes that have active network connections over a specified time range. --By default, the map shows the last 30 minutes. If you want to see how dependencies looked in the past, you can query for historical time ranges of up to one hour. To run the query, use the **TimeRange** selector. You might run a query, for example, during an incident or to see the status before a change. -<!-- convertborder later --> -->[!NOTE] ->You can also access a map for a specific instance from the **Instances** view for your virtual machine scale set. In the **Settings** section, go to **Instances** > **Insights**. --## View a map from Azure Monitor --In Azure Monitor, the Map feature provides a global view of your VMs and their dependencies. To access the Map feature in Azure Monitor: --1. In the Azure portal, select **Monitor**. -1. In the **Insights** section, select **Virtual Machines**. -1. Select the **Map** tab. - <!-- convertborder later --> - :::image type="content" source="./media/vminsights-maps/map-multivm-azure-monitor-01.png" lightbox="./media/vminsights-maps/map-multivm-azure-monitor-01.png" alt-text="Screenshot that shows an Azure Monitor overview map of multiple VMs." border="false"::: --Choose a workspace by using the **Workspace** selector at the top of the page. If you have more than one Log Analytics workspace, choose the workspace that's enabled with the solution and that has VMs reporting to it. --The **Group** selector returns subscriptions, resource groups, [computer groups](../logs/computer-groups.md), and virtual machine scale sets of computers that are related to the selected workspace. Your selection applies only to the Map feature and doesn't carry over to Performance or Health. --By default, the map shows the last 30 minutes. If you want to see how dependencies looked in the past, you can query for historical time ranges of up to one hour. To run the query, use the **TimeRange** selector. You might run a query, for example, during an incident or to see the status before a change. --## Next steps --To identify bottlenecks, check performance, and understand overall utilization of your VMs, see [View performance status for VM insights](vminsights-performance.md). |
| azure-monitor | Vminsights Migrate Deprecated Policies | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/vminsights-migrate-deprecated-policies.md | - Title: Migrate from deprecated VM insights policies -description: This article explains how to migrate from deprecated VM insights policies to their replacement policies. ---- Previously updated : 07/09/2023----# Migrate from deprecated VM insights policies --We're deprecating the VM insights DCR deployment policies and replacing them with new policies because of a race condition issue. The deprecated policies will continue to work on existing assignments, but will no longer be available for new assignments. If you're using deprecated policies, we recommend you migrate to the new policies as soon as possible. --This article explains how to migrate from deprecated VM insights policies to their replacement policies. --## Prerequisites --- An existing user-assigned managed identity. --## Deprecated VM insights policies --These policies are deprecated and will be removed in 2026. We recommend you migrate to the replacement policies as soon as possible: --- [[Preview]: Deploy a VMInsights Data Collection Rule and Data Collection Rule Association for Arc Machines in the Resource Group](https://ms.portal.azure.com/#view/Microsoft_Azure_Policy/PolicyDetailBlade/definitionId/%2fproviders%2fMicrosoft.Authorization%2fpolicyDefinitions%2f7c4214e9-ea57-487a-b38e-310ec09bc21d)-- [[Preview]: Deploy a VMInsights Data Collection Rule and Data Collection Rule Association for all the VMs in the Resource Group](https://ms.portal.azure.com/#view/Microsoft_Azure_Policy/PolicyDetailBlade/definitionId/%2fproviders%2fMicrosoft.Authorization%2fpolicyDefinitions%2fa0f27bdc-5b15-4810-b81d-7c4df9df1a37) -- [[Preview]: Deploy a VMInsights Data Collection Rule and Data Collection Rule Association for all the virtual machine scale sets in the Resource Group](https://ms.portal.azure.com/#view/Microsoft_Azure_Policy/PolicyDetailBlade/definitionId/%2fproviders%2fMicrosoft.Authorization%2fpolicyDefinitions%2fc7f3bf36-b807-4f18-82dc-f480ad713635) ---## New VM insights policies --These policies replace the deprecated policies: --- [Configure Linux Machines to be associated with a Data Collection Rule or a Data Collection Endpoint](https://ms.portal.azure.com/#view/Microsoft_Azure_Policy/PolicyDetailBlade/definitionId/%2fproviders%2fMicrosoft.Authorization%2fpolicyDefinitions%2f2ea82cdd-f2e8-4500-af75-67a2e084ca74) -- [Configure Windows Machines to be associated with a Data Collection Rule or a Data Collection Endpoint](https://ms.portal.azure.com/#view/Microsoft_Azure_Policy/PolicyDetailBlade/definitionId/%2fproviders%2fMicrosoft.Authorization%2fpolicyDefinitions%2feab1f514-22e3-42e3-9a1f-e1dc9199355c)--## Migrate from deprecated VM insights policies to replacement policies --1. [Download the Azure Monitor Agent-based VM insights data collection rule templates](https://github.com/Azure/AzureMonitorForVMs-ArmTemplates/releases/download/vmi_ama_ga/DeployDcr.zip). --1. Deploy the VM insights data collection rule using an ARM template, as described in [Quickstart: Create and deploy ARM templates by using the Azure portal](../../azure-resource-manager/templates/quickstart-create-templates-use-the-portal.md#edit-and-deploy-the-template). -- 1. Select **Build your own template in the editor** > **Load file** to upload the template you downloaded in the previous step. -- - To collect only VM insights performance metrics, deploy the `ama-vmi-default-perf-dcr` data collection rule by uploading the **DeployDcr**>**PerfOnlyDcr**>**DeployDcrTemplate** file. - - To collect VM insights performance metrics and Service Map data, deploy the `ama-vmi-default-perfAndda-dcr` data collection rule by uploading the **DeployDcr**>**PerfAndMapDcr**>**DeployDcrTemplate** file. -- 1. When the data collection rule deployment is complete, select **Go to resource** > **JSON View** and copy the data collection rule's **Resource ID**. --1. Select one of the [new VM insights policies for Windows and Linux VMs](#new-vm-insights-policies). -1. Select **Assign**. -1. In the **Scope** field on the **Basics** tab, select your subscription and the resource group that contains the VMs you want to monitor. -1. In the **Data Collection Rule Resource Id** field on the **Parameters** tab, paste the resource ID of the data collection rule you created in the previous step. -1. On the **Remediation** tab: - 1. In the **Scope** field, select your subscription and the resource group that contains your user-assigned managed identity. - 2. Set **Type of managed identity** to **User Assigned Managed Identity** and select your user-assigned identity. --## Next steps --Learn how to: -- [View VM insights Map](vminsights-maps.md) to see application dependencies. -- [View Azure VM performance](vminsights-performance.md) to identify bottlenecks and overall utilization of your VM's performance. |
| azure-monitor | Vminsights Migrate From Service Map | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/vminsights-migrate-from-service-map.md | - Title: Migrate from Service Map to Azure Monitor VM insights -description: Migrate from Service Map to Azure Monitor VM insights to monitor the performance and health of virtual machines and scale sets, including their running processes and dependencies on other resources. --- Previously updated : 09/28/2023-----# Migrate from Service Map to Azure Monitor VM insights --[Azure Monitor VM insights](../vm/vminsights-overview.md) monitors the performance and health of your virtual machines and virtual machine scale sets, including their running processes and dependencies on other resources. This article explains how to migrate from [Service Map](../vm/service-map.md) to Azure Monitor VM insights, which provides a map feature similar to Service Map, along with other benefits. --> [!NOTE] -> Service Map will be retired on 30 September 2025. Be sure to migrate to VM insights before this date to continue monitoring processes and dependencies for your virtual machines. --The map feature of VM insights visualizes virtual machine dependencies by discovering running processes that have active network connection between servers, inbound and outbound connection latency, or ports across any TCP-connected architecture over a specified time range. --## Enable VM insights using Azure Monitor Agent --VM insights uses [Azure Monitor Agent](../agents/agents-overview.md), which replaces the Log Analytics agent used by Service map. For more information about how to enable VM insights for Azure virtual machines and on-premises machines, see [How to enable VM insights using Azure Monitor Agent for Azure virtual machines](../vm/vminsights-enable-overview.md#agents). --If you have on-premises machines, we recommend enabling [Azure Arc for servers](../../azure-arc/servers/overview.md) so that you enable the virtual machines for VM insights using processes similar to Azure virtual machines. --VM insights also collects per-machine performance counters, which provide visibility into the health of your virtual machines. Azure Monitor Log ingests these performance counters every minute, which slightly increases monitoring costs per machine. [Learn more about the pricing](../vm/vminsights-overview.md#pricing). ---## Remove the Service Map solution from the workspace --Once you migrate to VM insights, remove the Service Map solution from the workspace to avoid data duplication and incurring extra costs: --1. Sign in to the [Azure portal](https://portal.azure.com/). -1. In the search bar, type *Log Analytics workspaces*. As you begin typing, the list filters suggestions based on your input. -1. Select **Log Analytics workspaces**. -1. From your list of Log Analytics workspaces, select the workspace you chose when you enabled Service Map. -1. On the left, select **Legacy solutions**. -1. From the list of solutions, select **ServiceMap(workspace name)**. -1. On the **Overview** page for the solution, select **Delete**. -1. When prompted to confirm, select **Yes**. --> [!IMPORTANT] -> You won't be able to onboard new subscriptions to service map after 31 August 2024. The Service Map UI won't be available after 30 September 2025. |
| azure-monitor | Vminsights Optout | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/vminsights-optout.md | - Title: Disable monitoring in VM insights -description: This article describes how to stop monitoring your virtual machines in VM insights. --- Previously updated : 09/28/2023----# Disable monitoring of your VMs in VM insights --After you enable monitoring of your virtual machines (VMs), you can later choose to disable monitoring in VM insights. This article shows how to disable monitoring for one or more VMs. --Currently, VM insights doesn't support selective disabling of VM monitoring. Your Log Analytics workspace might support VM insights and other solutions. It might also collect other monitoring data. If your Log Analytics workspace provides these services, you need to understand the effect and methods of disabling monitoring before you start. --VM insights relies on the following components to deliver its experience: --* A Log Analytics workspace, which stores monitoring data from VMs and other sources. -* A collection of performance counters configured in the workspace. The collection updates the monitoring configuration on all VMs connected to the workspace. -* The `VMInsights` monitoring solution is configured in the workspace. This solution updates the monitoring configuration on all VMs connected to the workspace. -* Azure VM extensions `MicrosoftMonitoringAgent` (for Windows) or `OmsAgentForLinux` (for Linux) and `DependencyAgent`. These extensions collect and send data to the workspace. --As you prepare to disable monitoring of your VMs, keep these considerations in mind: --* If you evaluated with a single VM and used the preselected default Log Analytics workspace, you can disable monitoring by uninstalling the Dependency agent from the VM and disconnecting the Log Analytics agent from this workspace. This approach is appropriate if you intend to use the VM for other purposes and decide later to reconnect it to a different workspace. -* If you selected a preexisting Log Analytics workspace that supports other monitoring solutions and data collection from other sources, you can remove solution components from the workspace without interrupting or affecting your workspace. -->[!NOTE] -> After you remove the solution components from your workspace, you might continue to see performance and map data for your Azure VMs. Data eventually stops appearing in the **Performance** and **Map** views. The **Enable** option is available from the selected Azure VM so that you can reenable monitoring in the future. --## Remove VM insights completely --If you still need the Log Analytics workspace, you can remove the `VMInsights` solution from the workspace. --1. Sign in to the [Azure portal](https://portal.azure.com). -1. In the Azure portal, select **All services**. In the list of resources, enter **Log Analytics**. As you begin typing, the list filters suggestions based on your input. Select **Log Analytics**. -1. In your list of Log Analytics workspaces, select the workspace you chose when you enabled VM insights. -1. On the left, select **Legacy solutions**. -1. In the list of solutions, select **VMInsights(workspace name)**. On the **Overview** page for the solution, select **Delete**. When you're prompted to confirm, select **Yes**. --## Disable monitoring and keep the workspace --If your Log Analytics workspace still needs to support monitoring from other sources, you can disable monitoring on the VM that you used to evaluate VM insights. For Azure VMs, you remove the dependency agent VM extension and the Log Analytics agent VM extension for Windows or Linux directly from the VM. -->[!NOTE] ->Don't remove the Log Analytics agent if: -> -> * Azure Automation manages the VM to orchestrate processes or to manage configuration or updates. -> * Microsoft Defender for Cloud manages the VM for security and threat detection. -> -> If you do remove the Log Analytics agent, you'll prevent those services and solutions from proactively managing your VM. --1. Sign in to the [Azure portal](https://portal.azure.com). -1. In the Azure portal, select **Virtual Machines**. -1. From the list, select a VM. -1. On the left, select **Extensions**. On the **Extensions** page, select **DependencyAgent**. -1. On the extension properties page, select **Uninstall**. -1. On the **Extensions** page, select **MicrosoftMonitoringAgent**. On the extension properties page, select **Uninstall**. |
| azure-monitor | Vminsights Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/vminsights-overview.md | - Title: What is VM insights? -description: Overview of VM insights, which monitors the health and performance of Azure VMs and automatically discovers and maps application components and their dependencies. --- Previously updated : 09/28/2023---# Overview of VM insights --VM insights provides a quick and easy method for getting started monitoring the client workloads on your virtual machines and virtual machine scale sets. It displays an inventory of your existing VMs and provides a guided experience to enable base monitoring for them. It also monitors the performance of your virtual machines and virtual machine scale sets by collecting data on their running processes and dependencies on other resources. --VM insights supports Windows and Linux operating systems on: --- Azure virtual machines.-- Azure virtual machine scale sets.-- Hybrid virtual machines connected with Azure Arc.-- On-premises virtual machines.-- Virtual machines hosted in another cloud environment.--VM insights provides a set of predefined workbooks that allow you to view trending of [collected performance data](vminsights-log-query.md#performance-records) over time. You can view this data in a single VM from the virtual machine directly, or you can use Azure Monitor to deliver an aggregated view of multiple VMs. ----## Pricing --There's no direct cost for VM insights, but you're charged for its activity in the Log Analytics workspace. Based on the pricing that's published on the [Azure Monitor pricing page](https://azure.microsoft.com/pricing/details/monitor/), VM insights is billed for: --- Data ingested from agents and stored in the workspace.-- Alert rules based on log data.-- Notifications sent from alert rules.--The log size varies by the string lengths of performance counters. It can increase with the number of logical disks and network adapters allocated to the VM. If you're already using Service Map, the only change you'll see is the extra performance data that's sent to the Azure Monitor `InsightsMetrics` data type.ΓÇï --## Access VM insights --Access VM insights for all your virtual machines and virtual machine scale sets by selecting **Virtual Machines** from the **Monitor** menu in the Azure portal. To access VM insights for a single virtual machine or virtual machine scale set, select **Insights** from the machine's menu in the Azure portal. --## Limitations --- VM insights collects a predefined set of metrics from the VM client and doesn't collect any event data. You can use the Azure portal to [create data collection rules](../agents/azure-monitor-agent-data-collection.md) to collect events and additional performance counters using the same Azure Monitor agent used by VM insights.-- VM insights doesn't support sending data to multiple Log Analytics workspaces (multi-homing).--## Next steps --- [Enable and configure VM insights](./vminsights-enable-overview.md).- |
| azure-monitor | Vminsights Performance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/vminsights-performance.md | - Title: Chart performance with VM insights -description: This article discusses the VM insights Performance feature that discovers application components on Windows and Linux systems and maps the communication between services. ---- Previously updated : 09/28/2023---# Chart performance with VM insights --> [!CAUTION] -> This article references CentOS, a Linux distribution that is End Of Life (EOL) status. Please consider your use and planning accordingly. For more information, see the [CentOS End Of Life guidance](/azure/virtual-machines/workloads/centos/centos-end-of-life). --VM insights includes a set of performance charts that target several key [performance indicators](vminsights-log-query.md#performance-records) to help you determine how well a virtual machine is performing. The charts show resource utilization over a period of time. You can use them to identify bottlenecks and anomalies. You can also switch to a perspective that lists each machine to view resource utilization based on the metric selected. --VM insights monitors key operating system performance indicators related to processor, memory, network adapter, and disk utilization. Performance helps to: --- Expose issues that indicate a possible system component failure.-- Support tuning and optimization to achieve efficiency.-- Support capacity planning.--> [!NOTE] -> The network chart on the Performance tab looks different from the network chart on the Azure VM overview page because the overview page displays charts based on the host's measurement of activity in the guest VM. The network chart on the Azure VM overview only displays network traffic that will be billed. Inter-virtual network traffic isn't included. The data and charts shown for VM insights are based on data from the guest VM. The network chart displays all TCP/IP traffic that's inbound and outbound to that VM, including inter-virtual network traffic. ---## Limitations -Limitations in performance collection with VM insights: --- Available memory isn't available in all Linux versions, including Red Hat Linux (RHEL) 6 and CentOS 6. It will be available in Linux versions that use [kernel version 3.14](http://www.man7.org/linux/man-pages/man1/free.1.html) or higher. It might be available in some kernel versions between 3.0 and 3.14.-- Metrics are only available for data disks on Linux virtual machines that use XFS filesystem or EXT filesystem family (EXT2, EXT3, EXT4).-- Collecting performance metrics from network shared drives is unsupported.--## Multi-VM perspective from Azure Monitor --From Azure Monitor, the Performance feature provides a view of all monitored VMs deployed across work groups in your subscriptions or in your environment. --To access from Azure Monitor: --1. In the Azure portal, select **Monitor**. -1. In the **Solutions** section, select **Virtual Machines**. -1. Select the **Performance** tab. -<!-- convertborder later --> --On the **Top N Charts** tab, if you have more than one Log Analytics workspace, select the workspace enabled with the solution from the **Workspace** selector at the top of the page. The **Group** selector returns subscriptions, resource groups, [computer groups](../logs/computer-groups.md), and virtual machine scale sets of computers related to the selected workspace that you can use to further filter results presented in the charts on this page and across the other pages. Your selection only applies to the Performance feature and doesn't carry over to Map. --By default, the charts show performance counters for the last hour. By using the **TimeRange** selector, you can query for historical time ranges of up to 30 days to show how performance looked in the past. --Five capacity utilization charts are shown on the page: --* **CPU Utilization %**: Shows the top five machines with the highest average processor utilization. -* **Available Memory**: Shows the top five machines with the lowest average amount of available memory. -* **Logical Disk Space Used %**: Shows the top five machines with the highest average disk space used percent across all disk volumes. -* **Bytes Sent Rate**: Shows the top five machines with the highest average of bytes sent. -* **Bytes Receive Rate**: Shows the top five machines with the highest average of bytes received. -->[!NOTE] ->Each chart described above only shows the top 5 machines. -> --Selecting the pushpin icon in the upper-right corner of a chart pins it to the last Azure dashboard you viewed. From the dashboard, you can resize and reposition the chart. Selecting the chart from the dashboard redirects you to VM insights and loads the correct scope and view. --Select the icon to the left of the pushpin icon on a chart to open the **Top N List** view. This list view shows the resource utilization for a performance metric by individual VM. It also shows which machine is trending the highest. -<!-- convertborder later --> --When you select the virtual machine, the **Properties** pane opens on the right side. It shows properties like system information reported by the operating system and the properties of the Azure VM. Selecting an option under the **Quick Links** section redirects you to that feature directly from the selected VM. -<!-- convertborder later --> --You can switch to the **Aggregated Charts** tab to view the performance metrics filtered by average or percentiles measured. -<!-- convertborder later --> --The following capacity utilization charts are provided: --* **CPU Utilization %**: Defaults show the average and top 95th percentile. -* **Available Memory**: Defaults show the average, top 5th, and 10th percentile. -* **Logical Disk Space Used %**: Defaults show the average and 95th percentile. -* **Bytes Sent Rate**: Defaults show the average bytes sent. -* **Bytes Receive Rate**: Defaults show the average bytes received. --You can also change the granularity of the charts within the time range by selecting **Avg**, **Min**, **Max**, **50th**, **90th**, and **95th** in the percentile selector. --To view the resource utilization by individual VM and see which machine is trending with highest utilization, select the **Top N List** tab. The **Top N List** page shows the top 20 machines sorted by the most utilized by 95th percentile for the metric *CPU Utilization %*. To see more machines, select **Load More**. The results expand to show the top 500 machines. -->[!NOTE] ->The list can't show more than 500 machines at a time. -> -<!-- convertborder later --> --To filter the results on a specific virtual machine in the list, enter its computer name in the **Search by name** text box. --If you want to view utilization from a different performance metric, from the **Metric** dropdown list, select **Available Memory**, **Logical Disk Space Used %**, **Network Received Byte/s**, or **Network Sent Byte/s**. The list updates to show utilization scoped to that metric. --Selecting a virtual machine from the list opens the **Properties** pane on the right side of the page. From here, you can select **Performance detail**. The **Virtual Machine Detail** page opens and is scoped to that VM. The experience is similar to accessing VM Insights Performance directly from the Azure VM. --## View performance directly from an Azure VM --To access directly from a virtual machine: --1. In the Azure portal, select **Virtual Machines**. -1. From the list, select a VM. In the **Monitoring** section, select **Insights**. -1. Select the **Performance** tab. --This page shows performance utilization charts. It also shows a table for each logical disk discovered with its capacity, utilization, and total average by each measure. --The following capacity utilization charts are provided: --* **CPU Utilization %**: Defaults show the average and top 95th percentile. -* **Available Memory**: Defaults show the average, top 5th, and 10th percentile. -* **Logical Disk Space Used %**: Defaults show the average and 95th percentile. -* **Logical Disk IOPS**: Defaults show the average and 95th percentile. -* **Logical Disk MB/s**: Defaults show the average and 95th percentile. -* **Max Logical Disk Used %**: Defaults show the average and 95th percentile. -* **Bytes Sent Rate**: Defaults show the average bytes sent. -* **Bytes Receive Rate**: Defaults show the average bytes received. --Selecting the pushpin icon in the upper-right corner of a chart pins it to the last Azure dashboard you viewed. From the dashboard, you can resize and reposition the chart. Selecting the chart from the dashboard redirects you to VM insights and loads the performance detail view for the VM. ---## Troubleshoot VM performance issues with Performance Diagnostics --[The Performance Diagnostics tool](/troubleshoot/azure/virtual-machines/performance-diagnostics?toc=/azure/azure-monitor/toc.json) helps troubleshoot performance issues on Windows or Linux virtual machines by quickly diagnosing and providing insights on issues it currently finds on your machines. The tool does not analyze historical monitoring data you collect, but rather checks the current state of the machine for known issues, implementation of best practices, and complex problems that involve slow VM performance or high usage of CPU, disk space, or memory. --To install and run the Performance Diagnostics tool, select the **Performance Diagnostics** button from the VM Insights Performance screen > **Install performance diagnostics** and [select an analysis scenario](/troubleshoot/azure/virtual-machines/performance-diagnostics#select-an-analysis-scenario-to-run?toc=/azure/azure-monitor/toc.json) ----## View performance directly from an Azure virtual machine scale set --To access directly from an Azure virtual machine scale set: --1. In the Azure portal, select **Virtual machine scale sets**. -1. From the list, select a VM. -1. In the **Monitoring** section, select **Insights** to view the **Performance** tab. --This page loads the Azure Monitor performance view scoped to the selected scale set. This view enables you to see the Top N instances in the scale set across the set of monitored metrics. You can also view the aggregate performance across the scale set. And you can see the trends for selected metrics across the individual instances in the scale set. Selecting an instance from the list view lets you load its map or move into a detailed performance view for that instance. --Selecting the pushpin icon in the upper-right corner of a chart pins it to the last Azure dashboard you viewed. From the dashboard, you can resize and reposition the chart. Selecting the chart from the dashboard redirects you to VM insights and loads the performance detail view for the VM. --->[!NOTE] ->You can also access a detailed performance view for a specific instance from the **Instances** view for your scale set. Under the **Settings** section, go to **Instances** and select **Insights**. --## Next steps --- Learn how to use [workbooks](vminsights-workbooks.md) that are included with VM insights to further analyze performance and network metrics.-- To learn about discovered application dependencies, see [View VM insights Map](vminsights-maps.md). |
| azure-monitor | Vminsights Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/vminsights-troubleshoot.md | - Title: Troubleshoot VM Insights -description: Get troubleshooting information about agent installation and the use of the VM Insights feature in Azure Monitor. --- Previously updated : 09/28/2023-----# Troubleshoot VM Insights --This article provides troubleshooting information to help you with problems that you might experience when you try to enable or use the VM Insights feature in Azure Monitor. --## Can't enable VM Insights on a machine --When you onboard an Azure virtual machine (VM) from the Azure portal, the following actions occur: --* A default Log Analytics workspace is created if you selected that option. -* The Azure Monitor Agent is installed on the virtual machine through an extension, if the agent isn't already installed. -* The Dependency Agent is installed on the virtual machine through an extension, if it's required. --During the onboarding process, each of these steps is verified and a notification status appears in the portal. Configuration of the workspace and the agent installation typically takes 5 to 10 minutes. It takes another 5 to 10 minutes for data to become available to view in the portal. --If you receive a message that the virtual machine needs to be onboarded after you perform the onboarding process, allow up to 30 minutes for the process to finish. If the problem persists, see the following sections for possible causes. --### Is the virtual machine running? --If the virtual machine has been turned off for a while, is off currently, or was only recently turned on, you won't have data to display until data arrives. --### Is the operating system supported? --If the operating system isn't in the [list of supported operating systems](vminsights-enable-overview.md#supported-operating-systems), installation of the extension fails and you get a message about waiting for data to arrive. --> [!IMPORTANT] -> If a virtual machine that you onboarded on or after April 11, 2022, doesn't appear in VM Insights, you might be running an older version of the Dependency Agent. For more information, see the blog post [Potential breaking changes for VM Insights Linux customers](https://techcommunity.microsoft.com/t5/azure-monitor-status/potential-breaking-changes-for-vm-insights-linux-customers/ba-p/3271989). This consideration doesn't apply for Windows machines and for virtual machines that you onboarded before April 11, 2022. --### Was the extension installed properly? --If you still see a message that the virtual machine needs to be onboarded, it might mean that one or both of the extensions failed to be installed correctly. In the Azure portal, on the **Extensions** pane for your virtual machine, check whether the following extensions appear: --| Operating system | Agents | -|:|:| -| Windows | MicrosoftMonitoringAgent<br>Microsoft.Azure.Monitoring.DependencyAgent | -| Linux | OMSAgentForLinux<br>DependencyAgentLinux | --If you don't see both extensions for your operating system in the list of installed extensions, you must install them. If the extensions are listed but their status doesn't appear as **Provisioning succeeded**, remove the extensions and reinstall them. --### Do you have connectivity problems? --For Windows machines, you can use the TestCloudConnectivity tool to identify a connectivity problem. This tool is installed by default with the agent in the folder *%SystemDrive%\Program Files\Microsoft Monitoring Agent\Agent*. --Run the tool from an elevated command prompt. It returns results and highlights where the test fails. ---## DCR created by the VM Insights process was modified and now data is missing --### Identify the problem --To identify whether a data collection rule (DCR) was modified, go to the Azure Monitor dashboard and locate the DCR. View the JSON properties by using the **JSON View** link on the upper-right side of the overview pane. ---In this example, the original stream name was changed to reflect the name of the performance counter stream. ---Although the counter sections point to the `Microsoft-Perf` table, the stream dataflow is still configured for the proper destination `Microsoft-InsightsMetrics`. --### Resolve the problem --You can't resolve this problem by using the Azure Monitor dashboard directly. But you can resolve it by exporting the template, normalizing the name, and then importing the modified rule over itself. --#### Export the DCR and save locally --1. On the Azure Monitor dashboard, go to the DCR. --2. Select **Export template**. -- :::image type="content" source="media/vminsights-troubleshoot/dcr-export.png" lightbox="media/vminsights-troubleshoot/dcr-export.png" alt-text="Screenshot of the menu option to export a template for a data collection rule."::: --3. On the **Export template** pane for the selected DCR, the portal creates the template file and a matching parameter file. After this process is complete, select **Download** to download the template package and save it locally. -- :::image type="content" source="media/vminsights-troubleshoot/template-download.png" lightbox="media/vminsights-troubleshoot/template-download.png" alt-text="Screenshot that shows the button for downloading a template for a data collection rule."::: --4. Select **Open file**. -- :::image type="content" source="media/vminsights-troubleshoot/downloads.png" lightbox="media/vminsights-troubleshoot/downloads.png" alt-text="Screenshot that shows the link for opening a downloaded file package."::: --5. Copy the two files to a local folder. -- :::image type="content" source="media/vminsights-troubleshoot/copy-file.png" lightbox="media/vminsights-troubleshoot/copy-file.png" alt-text="Screenshot that shows parameter and template files copied to a local folder."::: --#### Modify the template --1. Open the template file in the editor of your choice. Then locate the invalid stream name under the performance counter data source. -- :::image type="content" source="media/vminsights-troubleshoot/update-template.png" lightbox="media/vminsights-troubleshoot/update-template.png" alt-text="Screenshot of a template file."::: --2. By using the valid stream name from the dataflow node, fix the invalid reference. Then save and close your file. -- :::image type="content" source="media/vminsights-troubleshoot/correct-template.png" lightbox="media/vminsights-troubleshoot/correct-template.png" alt-text="Screenshot that shows an updated stream name in a template file."::: --#### Import the template by using the custom deployment feature --1. Back in the portal, search for and then select **Deploy a custom template**. -- :::image type="content" source="media/vminsights-troubleshoot/deploy-template.png" lightbox="media/vminsights-troubleshoot/deploy-template.png" alt-text="Screenshot of search results for the service that deploys a custom template."::: --2. On the **Custom deployment** pane, select **Build your own template in the editor**. -- :::image type="content" source="media/vminsights-troubleshoot/build-template.png" lightbox="media/vminsights-troubleshoot/build-template.png" alt-text="Screenshot that shows the option to build a template in the editor."::: --3. Select **Load file**, and then browse to your saved template and parameter files. -- :::image type="content" source="media/vminsights-troubleshoot/load-file.png" lightbox="media/vminsights-troubleshoot/load-file.png" alt-text="Screenshot that shows the button for loading a file."::: --4. Visually inspect the template to validate that the change is in place, and then select **Save**. -- :::image type="content" source="media/vminsights-troubleshoot/save-template.png" lightbox="media/vminsights-troubleshoot/save-template.png" alt-text="Screenshot of the pane for editing a template."::: --5. The portal uses the parameter file to fill in the deployment options (which can be changed or left intact to overwrite the existing DCR). When the portal completes the process, select **Review + create**. -- :::image type="content" source="media/vminsights-troubleshoot/deploy.png" lightbox="media/vminsights-troubleshoot/deploy.png" alt-text="Screenshot of the pane for custom deployment."::: --6. After validation, select **Create** to finish the deployment. -- :::image type="content" source="media/vminsights-troubleshoot/create-deployment.png" lightbox="media/vminsights-troubleshoot/create-deployment.png" alt-text="Screenshot that shows the button for creating a custom deployment."::: --7. After the deployment is complete, browse to the DCR again and review the JSON in the overview pane. -- :::image type="content" source="media/vminsights-troubleshoot/updated-json.png" lightbox="media/vminsights-troubleshoot/updated-json.png" alt-text="Screenshot that shows the pane for reviewing JSON."::: --8. The agent detects the change and downloads the new configuration, which restores ingestion to the `Microsoft-InsightsMetrics` table. --## Performance view has no data --If the agents appear to be installed correctly but no data appears in the **Performance** view, see the following sections for possible causes. --### Has your Log Analytics workspace reached its data limit? --Check the [capacity reservations and the pricing for data ingestion](https://azure.microsoft.com/pricing/details/monitor/). --### Is your virtual machine agent connected to Azure Monitor Logs? --In the Azure portal, on the **Azure Monitor** menu, select **Logs** to open the Log Analytics workspace. Run the following query for your computer: --```kusto -Heartbeat -| where Computer == "my-computer" -| sort by TimeGenerated desc -``` --If no data appears or if the computer didn't send a heartbeat recently, you might have problems with your agent. For agent troubleshooting information, see these articles: --* [Troubleshoot issues with the Log Analytics agent for Windows](../agents/agent-windows-troubleshoot.md) -* [Troubleshoot issues with the Log Analytics agent for Linux](../agents/agent-linux-troubleshoot.md) --## Virtual machine doesn't appear in the Map view --The following sections help you resolve problems with the **Map** view. --### Is the Dependency Agent installed? --Use the information in the preceding sections to determine if the Dependency Agent is installed and working properly. --### Are you on the Log Analytics free tier? --The [Log Analytics free tier](https://azure.microsoft.com/pricing/details/monitor/) is a legacy pricing plan that allows for up to five unique Service Map machines. Any subsequent machines won't appear in Service Map, even if the prior five are no longer sending data. --### Is your virtual machine sending log and performance data to Azure Monitor Logs? --Use the log query in the [Performance view has no data](#performance-view-has-no-data) section to determine if data is being collected for the virtual machine. If no data is being collected, use the TestCloudConnectivity tool to determine if you have connectivity problems. --## Virtual machine appears in the Map view but has missing data --If the virtual machine is in the **Map** view and the Dependency Agent is installed and running, but the kernel driver didn't load, check the log file at the following locations: --| Operating system | Log | -|:--|:-| -| Windows | C:\Program Files\Microsoft Dependency Agent\logs\wrapper.log | -| Linux | /var/opt/microsoft/dependency-agent/log/service.log | --The last lines of the file should indicate why the kernel didn't load. For example, the kernel might not be supported on Linux if you updated your kernel. --## Related content --* For more information on installing VM Insights agents, see [Enable VM Insights overview](vminsights-enable-overview.md) |
| azure-monitor | Vminsights Workbooks | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/vm/vminsights-workbooks.md | - Title: Create interactive reports with VM insights workbooks -description: Simplify complex reporting with predefined and custom parameterized workbooks for VM insights. --- Previously updated : 09/28/2023----# Create interactive reports with VM insights workbooks --Workbooks combine text,ΓÇ»[log queries](/azure/data-explorer/kusto/query/), metrics, and parameters into rich interactive reports. Workbooks can be edited by any other team members who have access to the same Azure resources. --Workbooks help you to: --* Explore the usage of your virtual machine (VM) when you don't know the metrics of interest in advance, like CPU utilization, disk space, memory, and network dependencies. Unlike other usage analytics tools, workbooks let you combine multiple kinds of visualizations and analyses, making them great for this kind of freeform exploration. -* Explain to your team how a recently provisioned VM is performing by showing metrics for key counters and other log events. -* Share the results of a resizing experiment of your VM with other members of your team. You can explain the goals for the experiment with text. Then you can show each usage metric and the analytics queries used to evaluate the experiment, along with clear call-outs for whether each metric was above or below target. -* Report the impact of an outage on the usage of your VM. You can combine data, text explanation, and a discussion of next steps to prevent outages in the future. --## VM insights workbooks -VM insights includes the following workbooks. You can use these workbooks or use them as a starting point to create custom workbooks to address your particular requirements. --### Single virtual machine --| Workbook | Description | -|-|-| -| Performance | Provides a customizable version of the **Performance** view that uses all the Log Analytics performance counters that you've enabled. | -| Connections | Provides an in-depth view of the inbound and outbound connections from your VM. | --### Multiple virtual machines --| Workbook | Description | -|-|-| -| Performance | Provides a customizable version of the **Top N List and Charts** view in a single workbook that uses all the Log Analytics performance counters that you've enabled.| -| Performance counters | Provides a **Top N Chart** view across a wide set of performance counters. | -| Connections | Provides an in-depth view of the inbound and outbound connections from your monitored VMs. | -| Active Ports | Provides a list of the processes that have bound to the ports on the monitored VMs and their activity in the chosen time frame. | -| Open Ports | Provides the number of ports open on your monitored VMs and the details on those open ports. | -| Failed Connections | Displays the count of failed connections on your monitored VMs, the failure trend, and if the percentage of failures is increasing over time. | -| Security and Audit | An analysis of your TCP/IP traffic that reports on overall connections, malicious connections, and where the IP endpoints reside globally. To enable all features, you must enable **Security Detection**. | -| TCP Traffic | A ranked report for your monitored VMs and their sent, received, and total network traffic in a grid and displayed as a trend line. | -| Traffic Comparison | Lets you compare network traffic trends for a single machine or a group of machines. | --## Create a new workbook --A workbook is made up of sections that consist of independently editable charts, tables, text, and input controls. To better understand workbooks, let's open a template and create a custom workbook. --1. Go to the **Monitor** menu in the Azure portal. --1. Select a VM. --1. On the VM insights page, select the **Performance** or **Map** tab and then select **View Workbooks** from the link on the page. From the dropdown list, select **Go To Gallery**. - <!-- convertborder later --> - :::image type="content" source="media/vminsights-workbooks/workbook-dropdown-gallery-01.png" lightbox="media/vminsights-workbooks/workbook-dropdown-gallery-01.png" alt-text="Screenshot that shows a workbook dropdown list in V M insights." border="false"::: -- The workbook gallery opens with prebuilt workbooks to help you get started. --1. Create a new workbook by selecting **New**. -- :::image type="content" source="media/vminsights-workbooks/workbook-gallery-01.png" lightbox="media/vminsights-workbooks/workbook-gallery-01.png" alt-text="Screenshot that shows a workbook gallery in V M insights."::: --## Edit workbook sections --Workbooks have two modes: editing and reading. A new workbook opens in editing mode. This mode shows all the content of the workbook, including any steps and parameters that are otherwise hidden. Reading mode presents a simplified report-style view. Reading mode allows you to abstract away the complexity that went into creating a report while still having the underlying mechanics only a few clicks away when needed for modification. -<!-- convertborder later --> --1. After you finish editing a section, select **Done Editing** in the lower-left corner of the section. --1. To create a duplicate of a section, select the **Clone this section** icon. Creating duplicate sections is a great way to iterate on a query without losing previous iterations. --1. To move up a section in a workbook, select the **Move up** or **Move down** icon. --1. To remove a section permanently, select the **Remove** icon. --## Add text and Markdown sections --Adding headings, explanations, and commentary to your workbooks helps turn a set of tables and charts into a narrative. Text sections in workbooks support the [Markdown syntax](https://daringfireball.net/projects/markdown/) for text formatting like headings, bold, italics, and bulleted lists. --To add a text section to your workbook, select **Add text** in the lower left of the workbook or section. --## Add query sections -<!-- convertborder later --> --To add a query section to your workbook, select **Add query** in the lower left of the workbook or section. --Query sections are highly flexible and can be used to answer questions like: --* How was my CPU utilization during the same time period as an increase in network traffic? -* What was the trend in available disk space over the last month? -* How many network connection failures did my VM experience over the last two weeks? --You also aren't limited to querying from the context of the VM from which you opened the workbook. To query across multiple VMs and Log Analytics workspaces, you must have access permission to those resources. --To include data from other Log Analytics workspaces or from a specific Application Insights app, use the workspace identifier. To learn more about cross-resource queries, see the [official guidance](../logs/cross-workspace-query.md). --### Advanced analytic query settings --Each section has its own advanced settings, which are accessible via the settings :::image type="content" source="media/vminsights-workbooks/006-settings.png" alt-text="Workbooks section editing controls"::: icon located to the right of **Add parameters**. -<!-- convertborder later --> --| Setting | Description | -| - |:--| -| Custom width | Makes an item an arbitrary size so that you can fit many items on a single line to organize your charts and tables into rich interactive reports. | -| Conditionally visible | Specifies to hide steps based on a parameter when in reading mode. | -| Export a parameter| Allows a selected row in the grid or chart to cause later steps to change values or become visible. | -| Show query when not editing | Displays the query that precedes the chart or table even when in reading mode. -| Show open in analytics button when not editing | Adds the **Analytics** icon to the right corner of the chart to allow one-click access.| --Most of these settings are fairly intuitive, but to understand **Export a parameter** it's better to examine a workbook that makes use of this functionality. --One of the prebuilt workbooks, **TCP Traffic**, provides information on connection metrics from a VM. --The first section of the workbook is based on log query data. The second section is also based on log query data, but selecting a row in the first table interactively updates the contents of the charts. -<!-- convertborder later --> --The behavior is possible through use of the **When an item is selected, export a parameter** advanced settings, which are enabled in the table's log query. -<!-- convertborder later --> --The second log query then utilizes the exported values when a row is selected to create a set of values that are used by the section heading and charts. If no row is selected, it hides the section heading and charts. --For example, the hidden parameter in the second section uses the following reference from the row selected in the grid: --``` -VMConnection -| where TimeGenerated {TimeRange} -| where Computer in ("{ComputerName}") or '*' in ("{ComputerName}") -| summarize Sent = sum(BytesSent), Received = sum(BytesReceived) by bin(TimeGenerated, {TimeRange:grain}) -``` --## Add metrics sections --Metrics sections give you full access to incorporate Azure Monitor metrics data into your interactive reports. In VM insights, the prebuilt workbooks typically contain analytic query data rather than metric data. You can create workbooks with metric data, which allows you to take full advantage of the best of both features all in one place. You also have the ability to pull in metric data from resources in any of the subscriptions to which you have access. --Here's an example of VM data being pulled into a workbook to provide a grid visualization of CPU performance. -<!-- convertborder later --> --## Add parameter sections --Workbook parameters allow you to change values in the workbook without having to manually edit the query or text sections. This removes the requirement of needing to understand the underlying analytics query language and greatly expands the potential audience of workbook-based reporting. --The values of parameters are replaced in query, text, or other parameter sections by putting the name of the parameter in braces, like ``{parameterName}``. Parameter names are limited to similar rules as JavaScript identifiers, alphabetic characters, or underscores, followed by alphanumeric characters or underscores. For example, *a1* is allowed but *1a* isn't allowed. --Parameters are linear, starting from the top of a workbook and flowing down to later steps. Parameters declared later in a workbook can override parameters that were declared earlier. Parameters that use queries can access the values from parameters defined earlier. Within a parameter's step itself, parameters are also linear, left to right, where parameters to the right can depend on a parameter declared earlier in that same step. --Four different types of parameters are currently supported: --| Parameter | Description | -| - |:--| -| Text | Allows the user to edit a text box. You can optionally supply a query to fill in the default value. | -| Drop down | Allows the user to choose from a set of values. | -| Time range picker| Allows the user to choose from a predefined set of time range values or pick from a custom time range.| -| Resource picker | Allows the user to choose from the resources selected for the workbook.| --### Use a text parameter --The value a user enters in the text box is replaced directly in the query, with no escaping or quoting. If the value you need is a string, the query should have single quotation marks around the parameter. An example is **'{parameter}'**. --The text parameter allows the value in a text box to be used anywhere. It can be a table name, column name, function name, or operator. The text parameter type has a setting **Get default value from analytics query**, which allows the workbook author to use a query to populate the default value for that text box. --When the default value is used from a log query, only the first value of the first row (row 0, column 0) is used as the default value. For this reason, we recommend that you limit your query to return only one row and one column. Any other data returned by the query is ignored. --Whatever value the query returns is replaced directly with no escaping or quoting. If the query returns no rows, the result of the parameter is either an empty string (if the parameter isn't required) or undefined (if the parameter is required). --### Use a dropdown --The dropdown parameter type lets you create a dropdown control, which is used to select one or many values. --The dropdown is populated by a log query or JSON. If the query returns one column, the values in that column are both the value and the label in the dropdown control. If the query returns two columns, the first column is the value, and the second column is the label shown in the dropdown. If the query returns three columns, the third column is used to indicate the default selection in that dropdown. This column can be any type, but the simplest is to use bool or numeric types, where 0 is false and 1 is true. --If the column is a string type, null/empty string is considered false. Any other value is considered true. For single-selection dropdowns, the first value with a true value is used as the default selection. For multiple-selection dropdowns, all values with a true value are used as the default selected set. The items in the dropdown are shown in whatever order the query returned rows. --Let's look at the parameters present in the Connections Overview report. Select the edit symbol next to **Direction**. -<!-- convertborder later --> --This action opens the **Edit Parameter** pane. -<!-- convertborder later --> --The JSON lets you generate an arbitrary table populated with content. For example, the following JSON generates two values in the dropdown: --``` -[ - { "value": "inbound", "label": "Inbound"}, - { "value": "outbound", "label": "Outbound"} -] -``` --A more applicable example is using a dropdown list to pick from a set of performance counters by name: --``` -Perf -| summarize by CounterName, ObjectName -| order by ObjectName asc, CounterName asc -| project Counter = pack('counter', CounterName, 'object', ObjectName), CounterName, group = ObjectName -``` --The query shows the following results: -<!-- convertborder later --> --Dropdown lists are powerful tools you can use to customize and create interactive reports. --### Time range parameters --You can make your own custom time range parameter via the dropdown parameter type. You can also use the out-of-box time range parameter type if you don't need the same degree of flexibility. --Time range parameter types have 15 default ranges that go from five minutes to the last 90 days. There's also an option to allow custom time range selection. The operator of the report can choose explicit start and stop values for the time range. --### Resource picker --The resource picker parameter type gives you the ability to scope your report to certain types of resources. An example of a prebuilt workbook that uses the resource picker type is the **Performance** workbook. -<!-- convertborder later --> --## Save and share workbooks with your team --Workbooks are saved within a Log Analytics workspace or a VM resource, depending on how you access the workbooks gallery. The workbook can be saved to the **My Reports** section that's private to you or in the **Shared Reports** section that's accessible to everyone with access to the resource. To view all the workbooks in the resource, select **Open**. --To share a workbook that's currently in **My Reports**: --1. Select **Open**. -1. Select the ellipsis (**...**) next to the workbook you want to share. -1. Select **Move to Shared Reports**. --To share a workbook with a link or via email, select **Share**. Keep in mind that recipients of the link need access to this resource in the Azure portal to view the workbook. To make edits, recipients need at least Contributor permissions for the resource. --To pin a link to a workbook to an Azure dashboard: --1. Select **Open**. -1. Select the ellipsis (**...**) next to the workbook you want to pin. -1. Select **Pin to dashboard**. --## Next steps --- To identify limitations and overall VM performance, see [View Azure VM performance](vminsights-performance.md).-- To learn about discovered application dependencies, see [View VM insights map](vminsights-maps.md). |
| azure-monitor | Whats New | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-monitor/whats-new.md | - Title: "What's new in Azure Monitor documentation" -description: "What's new in Azure Monitor documentation" -- Previously updated : 09/06/2024----# What's new in Azure Monitor documentation --This article lists significant changes to Azure Monitor documentation. --> [!TIP] -> Get notified when this page is updated by copying and pasting the following URL into your feed reader: -> -> :::image type="content" source="./media//whats-new/rss.png" alt-text="An rss icon."::: https://aka.ms/azmon/rss ---## [2024](#tab/2024) --## August 2024 --|Subservice | Article | Description | -|||| -|Agents|[MM)|New Removal Tool| -|Application-Insights|[Migrate to workspace-based Application Insights resources](app/convert-classic-resource.md)|We've updated the table that converts values used in Classic AI resources to Workspace-based resources.| -|Application-Insights|[Application Insights for ASP.NET Core applications](app/asp-net-core.md)|The option to disable telemetry correlation has been documented for ASP.NET Core.| -|Application-Insights|[Configure Application Insights for your ASP.NET website](app/asp-net.md)|The option to disable telemetry correlation has been documented for ASP.NET.| -|Application-Insights|[Configuration options: Azure Monitor Application Insights for Java](app/java-standalone-config.md)|The option to disable telemetry correlation has been documented for Java.| -|Application-Insights|[Monitor your Node.js services and apps with Application Insights](app/nodejs.md)|The option to disable telemetry correlation has been documented for Node.js.| -|Application-Insights|[What is autoinstrumentation for Azure Monitor Application Insights?](app/codeless-overview.md)|Further "autoinstrumentation" explanation has been added, alongside an example, to better convey the meaning of this term.| -|Application-Insights|[Microsoft Entra authentication for Application Insights](app/azure-ad-authentication.md)|Options to enable Entra authentication for .NET and Node.js autoinstrumentation are documented.| -|Application-Insights|[Application Insights availability tests](app/availability.md)|We clarified information about using a "availability test string identifier", which previously caused some confusion when referred to as a "GUID".| -|Containers|[Optimize monitoring costs for Container insights](containers/container-insights-cost.md)|Rewritten to consolidate cost saving options and analysis.| -|Containers|[Configure log collection in Container insights](containers/container-insights-data-collection-configure.md)|New article to consolidate all guidance for container location.| -|Containers|[Filter log collection in Container insights](containers/container-insights-data-collection-filter.md)|New article to describe all options to filter container logs.| -|Containers|[Container insights log schema](containers/container-insights-logs-schema.md)|Rewritten to focus on definition and configuration of log schema, including metadata option.| -|Containers|[Access Syslog data in Container Insights](containers/container-insights-syslog.md)|Removed duplicate information on configuration.| -|Containers|[Data transformations in Container insights](containers/container-insights-transformations.md)|Added details to filtering example and added a new example to send data to multiple tables.| -|Containers|[Enable private link for Kubernetes monitoring in Azure Monitor](containers/container-insights-private-link.md)|New article to consolidate private link guidance for Container insights.| -|Containers|[High scale logs collection in Container Insights (Preview)](containers/container-insights-high-scale.md)|New feature.| -|Containers|[Monitor your Kubernetes cluster performance with Container insights](containers/container-insights-analyze.md)|Added explanation of "Other processes" column.| -|Essentials |[Manage data collection rules (DCRs) and associations in Azure Monitor](essentials/data-collection-rule-view.md)|Added guidance for new UI feature to manage DCR associations.| -|Essentials|[Use Azure Policy to install and manage the Azure Monitor agent](agents/azure-monitor-agent-policy.md)|Added information on new UI feature to create associations.| -|Essentials|[Create and edit data collection rules (DCRs) and associations in Azure Monitor](essentials/data-collection-rule-create-edit.md)|Removed duplicate information.| -|Essentials|[Data collection rules (DCRs) in Azure Monitor](essentials/data-collection-rule-overview.md)|Added diagram.| -|Essentials|[Monitor and troubleshoot DCR data collection in Azure Monitor](essentials/data-collection-monitor.md)|Corrected error in KQL using InputStreamId.| -|General|[Analyze and visualize monitoring data](best-practices-analysis.md)|We've updated our visualization recommendations to better guide customers when to use Azure Managed Grafana and when to use Azure Workbooks.| -|Logs|[Best practices for Azure Monitor Logs](best-practices-logs.md)|Updated overview of features that enhance resilience of your Log Analytics workspace, including a new video. | -|Logs|[Set up a table with the Auxiliary plan in your Log Analytics workspace (Preview)](logs/create-custom-table-auxiliary.md)|New article that explains how to set up a table with the Auxiliary plan. | -|Logs|[Azure Monitor Logs overview](logs/data-platform-logs.md)|Updated Azure Monitor Logs overview provides a high-level overview of data collection, management, retrieval, and consumption for a range of use cases.| -|Logs|[Run search jobs in Azure Monitor](logs/search-jobs.md)|New video that explains how to use search jobs in Azure Monitor Logs.| -|Logs|[Aggregate data in a Log Analytics workspace by using summary rules (Preview)](logs/summary-rules.md)|New video that explains how to use summary rules to optimize data in your Log Analytics workspace.| ----## July 2024 --|Subservice | Article | Description | -|||| -|Agents|[Collect firewall logs with Azure Monitor Agent (Preview)](agents/data-sources-firewall-logs.md)|New article that explains how to collect Windows Firewall logs with Azure Monitor Agent.| -|Agents|[AMA agent data field differences from MMA](agents/azure-monitor-agent-data-field-differences.md)|New article that describes differences between the data collected by Log Analytics agent and Azure Monitor Agent. This information is important when you migrate from the legacy agent to Azure Monitor Agent, especially for migrating queries.| -|Agents|[Collect data with Azure Monitor Agent](agents/azure-monitor-agent-data-collection.md)|Rewritten to describe basic process for all data sources.| -|Agents|[Install and manage Azure Monitor Agent](agents/azure-monitor-agent-manage.md)|Rewritten to simplify agent onboarding guidance.| -|Agents|[Azure Monitor Agent overview](agents/azure-monitor-agent-overview.md)|Rewritten to better describe core concepts including DCR associations.| -|Agents|[Use Azure Policy to install and manage the Azure Monitor agent](agents/azure-monitor-agent-policy.md)|New article to break Azure Policy guidance out from onboarding guidance.| -|Agents|[Azure Monitor agent requirements](agents/azure-monitor-agent-requirements.md)|New article to break agent requirements out from onboarding guidance.| -|Agents|[Azure Monitor Agent supported operating systems](agents/azure-monitor-agent-supported-operating-systems.md)|New article to break supported OS out from onboarding guidance.| -|Agents|[Collect Windows events from virtual machines with Azure Monitor Agent](agents/data-collection-windows-events.md)|Rewritten for consistency with other data collection articles.| -|Agents|[Collect Syslog events with Azure Monitor Agent](agents/data-collection-syslog.md)|Rewritten for consistency with other data collection articles.| -|Agents|[Collect IIS logs with Azure Monitor Agent](agents/data-collection-iis.md)|Rewritten for consistency with other data collection articles.| -|Agents|[Collect performance counters with Azure Monitor Agent](agents/data-collection-performance.md)|Rewritten for consistency with other data collection articles.| -|Agents|[Collect logs from a text file with Azure Monitor Agent](agents/data-collection-log-text.md)|Rewritten for consistency with other data collection articles and to better describe configuration options.| -|Agents|[Collect logs from a JSON file with Azure Monitor Agent](agents/data-collection-log-json.md)|Rewritten for consistency with other data collection articles and to better describe configuration options.| -|Agents|[Collect SNMP trap data with Azure Monitor Agent](agents/data-collection-snmp-data.md)|Rewritten to better describe fundamental strategy.| -|Agents|[Create and edit data collection rules (DCRs) in Azure Monitor](essentials/data-collection-rule-create-edit.md)|Rewritten for consistency with rewritten agent DCR articles.| -|Application-Insights|[Migrate from .NET Application Insights SDKs to Azure Monitor OpenTelemetry](app/opentelemetry-dotnet-migrate.md)|Migrate .NET applications from the SDK Classic API to OpenTelemetry using our new step-by-step guide.| -|Application-Insights|[Configure Azure Monitor OpenTelemetry](app/opentelemetry-configuration.md)|The .NET example under Set the Cloud Role Name and the Cloud Role Instance now shows how to configure all signals.| -|Application-Insights|[Configure Azure Monitor OpenTelemetry](app/opentelemetry-configuration.md)|Node.js guidance is available for using each of the credential classes.| -|Application-Insights|[Monitor Azure Functions with Azure Monitor Application Insights](app/monitor-functions.md)|New configuration guidance added for Functions both on and off a consumption plan.| -|Application-Insights|[Configure Azure Monitor OpenTelemetry](app/opentelemetry-configuration.md)|Updated instructions and code sample for using Entra with Python.| -|Containers|[Monitor Kubernetes clusters using Azure services and cloud native tools](containers/monitor-kubernetes.md)|Updated for Prometheus experience for Container insights.| -|Essentials|[Azure monitoring REST API walkthrough](essentials/rest-api-walkthrough.md)|Get an API token using Python, JavaScript C# and Azure CLI.| -|Essentials|[Best practices for scaling Azure Monitor Workspaces with Azure Monitor managed service for Prometheus](essentials/azure-monitor-workspace-scaling-best-practice.md)|New article: Best practices for Azure Monitor workspaces with Azure Managed Prometheus| -|Logs|[Log Analytics workspace overview](logs/log-analytics-workspace-overview.md)|Public preview of the Auxiliary table plan - a new low-cost plan for verbose logs used in compliance and security scenarios. We've also upgraded the Basic table plan to include 30 days of interactive retention and full KQL on a single table.| -|Logs|[Enhance data and service resilience in Azure Monitor Logs with availability zones](logs/availability-zones.md)|Added availability zone support in Spain Central.| -|Operations-Manager-Managed-Instance|[Monitor Azure and Off-Azure Virtual machines with Azure Monitor SCOM Managed Instance extensions](scom-manage-instance/monitor-arc-enabled-vm-with-scom-managed-instance.md)|Added new monitor doc| -|Operations-Manager-Managed-Instance|[Monitor Off-Azure Virtual machines with Azure Monitor SCOM Managed Instance](scom-manage-instance/monitor-off-azure-vm-with-scom-managed-instance.md)|added new docs| -|Optimization-Insights|[Monitor and analyze runtime behavior with Code Optimizations (Preview)](insights/code-optimizations.md)|Clarify expected CPU/memory overhead when using Profiler/Code Optimizations| -|Profiler|[View Application Insights Profiler data](profiler/profiler-data.md)|Clarify expected CPU/memory overhead when using Profiler| -|Profiler|[Profile production applications in Azure with Application Insights Profiler](profiler/profiler-overview.md)|Clarify expected CPU/memory overhead when using Profiler| -|Profiler|[Configure Application Insights Profiler](profiler/profiler-settings.md)|Clarify expected CPU/memory overhead when using Profiler| -|Profiler|[Troubleshoot Application Insights Profiler](profiler/profiler-troubleshooting.md)|Clarify expected CPU/memory overhead when using Profiler| -|Profiler|[Enable Profiler for Azure App Service apps](profiler/profiler.md)|Clarify expected CPU/memory overhead when using Profiler| -|Snapshot-Debugger|[ Troubleshoot problems enabling Application Insights Snapshot Debugger or viewing snapshots](snapshot-debugger/snapshot-debugger-troubleshoot.md)|Clarify expected CPU/memory overhead when using Snapshot Debugger| -|Snapshot-Debugger|[Debug exceptions in .NET applications using Snapshot Debugger](snapshot-debugger/snapshot-debugger.md)|Clarify expected CPU/memory overhead when using Snapshot Debugger| ----## June 2024 --|Subservice | Article | Description | -|||| -|Agents|[Azure Monitor Agent Migration Helper workbook](agents/azure-monitor-agent-migration-helper-workbook.md)|Guidance for using the AMA migration workbook.| -|Agents|[Migrate to Azure Monitor Agent from Log Analytics agent](agents/azure-monitor-agent-migration.md)|Refreshed guidance for migrating to Azure Monitor Agent.| -|Alerts|[Action groups](alerts/action-groups.md)|Added list of supported roles to which action groups can send emails.| -|Alerts|[Action groups](alerts/action-groups.md)|Updated PowerShell script for action groups using secure webhook.| -|Alerts|[Create or edit a log search alert rule](alerts/alerts-create-log-alert-rule.md)|Added limitation of log search alert rules to indicate that log search alert rules don't support linked storage.| -|Alerts|[Common alert schema](alerts/alerts-common-schema.md)|A link to Azure Monitor Investigator was added to the alerts common schema.| -|App|[Live metrics: Monitor and diagnose with 1-second latency](app/live-stream.md)|Update Distro Feature Matrix| -|Application-Insights|[Migrate to workspace-based Application Insights resources](app/convert-classic-resource.md)|Migration guidance for Classic to Workspace-based resources has been updated. Classic Application Insights resources are fully retired and Continuous Export is disabled.| -|Application-Insights|[OpenTelemetry on Azure](app/opentelemetry.md)|Our OpenTelemetry on Azure offerings are fully documented here, as well as a link to our OpenTelemetry roadmap.| -|Application-Insights|[Application Insights availability tests](app/availability-overview.md)|Availability Test TLS support is now fully documented.| -|Application-Insights|[Enable Azure Monitor OpenTelemetry for .NET, Node.js, Python, and Java applications](app/opentelemetry-enable.md)|A tab for Azure Monitor Application Insights OpenTelemetry support of Java Native images is available.| -|Application-Insights|[Live metrics: Monitor and diagnose with 1-second latency](app/live-stream.md)|We've updated our Live Metrics documentation so that it links out to both OpenTelemetry and the Classic API code.| -|Application-Insights|[Configuration options: Azure Monitor Application Insights for Java](app/java-standalone-config.md)|For Java OpenTelemetry, we've documented how to locally disable ingestion sampling. (preview feature)| -|Containers|[Enable private link with Container insights](containers/container-insights-private-link.md)|Added guidance for CLI.| -|Containers|[Customize scraping of Prometheus metrics in Azure Monitor managed service for Prometheus](containers/prometheus-metrics-scrape-configuration.md)|Updated and refreshed| -|Containers|[Use Prometheus exporters for common workloads with Azure Managed Prometheus](containers/prometheus-exporters.md)|New article listing supported exporters.| -|Essentials|[Send Prometheus metrics from virtual machines, scale sets, or Kubernetes clusters to an Azure Monitor workspace](essentials/prometheus-remote-write-virtual-machines.md)|Configure remote write for self-managed Prometheus on a Kubernetes cluster| -|General|[Create a metric alert with dynamic thresholds](alerts/alerts-dynamic-thresholds.md)|Added possible values for alert User Response field.| -|Logs|[Tutorial: Send data to Azure Monitor using Logs ingestion API (Resource Manager templates)](logs/tutorial-logs-ingestion-api.md)|Updated to use DCR endpoint instead of DCE.| -|Logs|[Create and manage a dedicated cluster in Azure Monitor Logs](logs/logs-dedicated-clusters.md)|Added new process for configuring dedicated clusters in Azure portal.| -|Logs|[Set a table's log data plan to Basic or Analytics](logs/logs-table-plans.md)|The Basic Logs table plan now includes 30 days of interactive retention.| -|Logs|[Aggregate data in a Log Analytics workspace by using summary rules (Preview)](logs/summary-rules.md)|Summary rules final 2| -|Visualizations|[Link actions](visualize/workbooks-link-actions.md)|Added clarification that the user must have permissions to all resources referenced in a workbook as well as to the workbook itself.<p>Updated process and screenshots for custom views in workbook link actions.| ---## May 2024 --|Subservice | Article | Description | -|||| -|Agents|[Migrate to Azure Monitor Agent from Log Analytics agent](agents/azure-monitor-agent-migration.md)|Updated support policy for the legacy Log Analytics agent, which will be retired on August 31, 2024.| -|Alerts|[Create a metric alert with dynamic thresholds](alerts/alerts-dynamic-thresholds.md)|Clarify look-back period| -|Alerts|[Action groups](alerts/action-groups.md)|Updated the description of action groups to clarify that you can use automatic workflows for any scenario, not only to let users know that alert has been raised.| -|Alerts|[Supported resources for Azure Monitor metric alerts](alerts/alerts-metric-near-real-time.md)|Removed references to the deprecated Microsoft.Web/containerApps namespace, and replaced with Microsoft.app/containerApps namespace.| -|Alerts|[Action groups](alerts/action-groups.md)|Updated action group ARM role group notification functionality.| -|Alerts|[Create or edit a log search alert rule](alerts/alerts-create-log-alert-rule.md)|Updated article to indicate that log search alert rule queries support 'ago()' with timespan literals only.| -|Application-Insights|[Configure Azure Monitor OpenTelemetry](app/opentelemetry-configuration.md)|The OpenTelemetry live metrics feature preview is available for .NET Core, Node.js, and Python.| -|Application-Insights|[Testing behind a firewall](app/availability-private-test.md)|New guidance is available for availability testing behind firewalls.| -|Application-Insights|[Application Insights availability tests](app/availability-overview.md)|We added clarification on both running availability tests on an intranet server and the user agent string used for availability tests.| -|Application-Insights|[Application map: Triage distributed applications](app/app-map.md)|This article has been refreshed with all new screenshots.| -|Application-Insights|[Downtime, SLA, and outages workbook](app/sla-report.md)|This article has been refreshed with all new screenshots.| -|Application-Insights|[Application Insights API for custom events and metrics](app/api-custom-events-metrics.md)|Clarification added for Java and JavaScript automatic flushing behavior and configuration.| -|Containers|[Switch to using managed Prometheus visualizations for Container Insights (preview)](containers/container-insights-experience-v2.md)|V2 docs updates| -|Essentials|[Built-in policies for Azure Monitor](essentials/diagnostics-settings-policies-deployifnotexists.md)|New built-in policies for "allLogs" category | -|Logs|[Define Azure Monitor Agent network settings](agents/azure-monitor-agent-data-collection-endpoint.md)|When you create a data collection rule, Azure Monitor now automatically creates a data collection endpoint and associates it to the data collection rule.| -|Logs|[Azure Monitor customer-managed key](logs/customer-managed-keys.md)|Azure Monitor Logs now supports running search jobs in Log Analytics workspaces with customer managed keys.| -|Logs|[Enhance resilience by replicating your Log Analytics workspace across regions (Preview)](logs/workspace-replication.md)|You can now replicate your Log Analytics workspace across regions and switch over to the replicated workspace if there's a regional failure.| -|Logs|[Analyze data using Log Analytics Simple mode (Preview)](logs/log-analytics-simple-mode.md)|Simple mode provides the most commonly used Azure Monitor Logs functionality in an intuitive, spreadsheet-like experience. Just point and click to filter, sort, and aggregate data to get to the insights you need 80% of the time.| -|Profiler|[Troubleshoot Application Insights Profiler](profiler/profiler-troubleshooting.md)|Update Troubleshooting guide with instructions for stopping unused slots.| -|Profiler|[Troubleshoot Application Insights Profiler](profiler/profiler-troubleshooting.md)|Update Troubleshooting guide with prerequisite for latest ASP.NET Core runtime and explanation for limit on active profiling sessions.| ---## April 2024 --|Subservice | Article | Description | -|||| -|Alerts|[Understand the automatic migration process for your classic alert rules](alerts/alerts-automatic-migration.md)|Azure Monitor classic alerts are officially retired, replaced by the newer alerts experience.| -|Alerts|[Troubleshooting problems in Azure Monitor alerts](alerts/alerts-troubleshoot.md)|Update alerts-troubleshoot.md| -|Alerts|[Tutorial: Create a log search alert for an Azure resource](alerts/tutorial-log-alert.md)|Added note to indicate that The combined size of all data in the log alert rule properties can't exceed 64 KB. This can be caused by too many dimensions, the query being too large, too many action groups, or a long description. Remember to optimize these areas when creating log search alert rules.| -|Application-Insights|[Migrate to workspace-based Application Insights resources](app/convert-classic-resource.md)|Continuous Export within Classic Application Insights will be shut down on May 15, 2024. After this date, your Continuous Export configurations will no longer be available.| -|Application-Insights|[Migrate from the Node.js Application Insights SDK 2.X to Azure Monitor OpenTelemetry](app/opentelemetry-nodejs-migrate.md)|Node.js OpenTelemetry migration guidance is available, providing a choice of either clean installing our Distro (recommended) or upgrading to Node.js SDK 3.X as an interim solution.| -|Application-Insights|[Application monitoring for Azure App Service and Python (Preview)](app/azure-web-apps-python.md)|Codeless OpenTelemetry automatic instrumentation for Python is available in preview.| -|Application-Insights|[Configuration options: Azure Monitor Application Insights for Java](app/java-standalone-config.md)|Java Custom Instrumentation (preview) is available. Starting from version 3.3.1, you can capture spans for a method in your application.| -|Application-Insights|[Sampling in Application Insights](app/sampling-classic-api.md)|Conflicting`ExcludedTypes` and `IncludedTypes` guidance has been added.| -|Change-Analysis|[Enable Change Analysis](change/change-analysis-enable.md)|Add note to AzMon Change Analysis documentation to point users to the new ARG Change Analysis public preview, which will replace AzMon Change Analysis in GA.| -|Change-Analysis|[Tutorial: Track a web app outage using Change Analysis](change/change-analysis-track-outages.md)|Add note to AzMon Change Analysis documentation to point users to the new ARG Change Analysis public preview, which will replace AzMon Change Analysis in GA.| -|Change-Analysis|[Troubleshoot Azure Monitor's Change Analysis](change/change-analysis-troubleshoot.md)|Add note to AzMon Change Analysis documentation to point users to the new ARG Change Analysis public preview, which will replace AzMon Change Analysis in GA.| -|Change-Analysis|[Use Change Analysis in Azure Monitor](change/change-analysis.md)|Add note to AzMon Change Analysis documentation to point users to the new ARG Change Analysis public preview, which will replace AzMon Change Analysis in GA.| -|Containers|[Data transformations in Container insights](containers/container-insights-transformations.md)|Fixed syntax errors in transformation examples.| -|Containers|[Recommended alert rules for Kubernetes clusters](containers/kubernetes-metric-alerts.md)|Updated to include new portal experience for enabling Prometheus alerts.| -|Containers|[Customize scraping of Prometheus metrics in Azure Monitor managed service for Prometheus](containers/prometheus-metrics-scrape-configuration.md)|Updated basic authentication| -|Containers|[Argo CD](containers/prometheus-argo-cd-integration.md)|Argo CD Prometheus integration| -|Containers|[Elasticsearch](containers/prometheus-elasticsearch-integration.md)|Elastic search Prometheus integration| -|Containers|[Apache Kafka](containers/prometheus-kafka-integration.md)|Kafka Prometheus integration| -|Essentials|[Data collection rules in Azure Monitor](essentials/data-collection-rule-overview.md)|Rewritten for consistency with new Azure Monitor pipeline content.| -|Essentials|[Configuration of Azure Monitor edge pipeline](essentials/edge-pipeline-configure.md)|New article for edge pipeline.| -|Essentials|[Overview of Azure Monitor pipeline](essentials/pipeline-overview.md)|New article to introduce Azure Monitor pipeline, which includes edge pipeline and cloud pipeline.| -|Essentials|[Azure Monitor metrics explorer with PromQL (Preview)](essentials/metrics-explorer.md)|New metrics explorer with PromQL support for Azure Monitor workspaces.| -|Essentials|[Send Prometheus metrics from Virtual Machines to an Azure Monitor workspace](essentials/prometheus-remote-write-virtual-machines.md)|How to send prometheus metrics from a Virtual machine or Virtual Machine Scale Set.| -|General|[Azure Monitor data sources and data collection methods](data-sources.md)|We've edited the article describing the Azure Monitor data sources to be more consistent with the overall Azure Monitor story.| -|General|[Azure Monitor cost and usage](cost-usage.md)|Updated information about costs associated with Azure Migrate.| -|General|[Azure Monitor monitoring data reference](monitor-azure-monitor-reference.md)|Updated to list the latest metrics, log categories, and Log Analytics tables related to monitoring Azure Monitor.| -|General|[Monitor Azure Monitor](monitor-azure-monitor.md)|How to monitor Azure Monitor article updated to list all the ways you can monitor parts of Azure Monitor. | -|Logs|[Azure Monitor customer-managed key](logs/customer-managed-keys.md)|Updated the management API versions used for managing customer managed keys and dedicated clusters.| ---## March 2024 --|Subservice | Article | Description | -|||| -|Alerts|[Improve the reliability of your application by using Azure Advisor](../../articles/advisor/advisor-high-availability-recommendations.md)|We’ve updated the alerts troubleshooting articles to remove out of date content and include common support issues.| -|Application-Insights|[Enable Azure Monitor OpenTelemetry for .NET, Node.js, Python, and Java applications](app/opentelemetry-enable.md)|OpenTelemetry sample applications are now provided in a centralized location.| -|Application-Insights|[Migrate to workspace-based Application Insights resources](app/convert-classic-resource.md)|Classic Application Insights resources have been retired. For more information, see this article for migration information and frequently asked questions.| -|Application-Insights|[Sampling overrides - Azure Monitor Application Insights for Java](app/java-standalone-sampling-overrides.md)|The sampling overrides feature has reached general availability (GA), starting from 3.5.0.| -|Containers|[Configure data collection and cost optimization in Container insights using data collection rule](containers/container-insights-data-collection-dcr.md)|Updated to include new Logs and Events cost preset.| -|Containers|[Enable private link with Container insights](containers/container-insights-private-link.md)|Updated with ARM templates.| -|Essentials|[Data collection rules in Azure Monitor](essentials/data-collection-rule-overview.md)|Rewritten to consolidate previous data collection article.| -|Essentials|[Workspace transformation data collection rule (DCR) in Azure Monitor](essentials/data-collection-transformations-workspace.md)|Content moved to a new article dedicated to workspace transformation DCR.| -|Essentials|[Data collection transformations in Azure Monitor](essentials/data-collection-transformations.md)|Rewritten to remove redundancy and make the article more consistent with related articles.| -|Essentials|[Create and edit data collection rules (DCRs) in Azure Monitor](essentials/data-collection-rule-create-edit.md)|Updated API version in REST API calls.| -|Essentials|[Tutorial: Edit a data collection rule (DCR)](essentials/data-collection-rule-edit.md)|Updated API version in REST API calls.| -|Essentials|[Monitor and troubleshoot DCR data collection in Azure Monitor](essentials/data-collection-monitor.md)|New article documenting new DCR monitoring feature.| -|Logs|[Monitor Log Analytics workspace health](logs/log-analytics-workspace-health.md)|Added new metrics for monitoring data export from a Log Analytics workspace.| -|Logs|[Set a table's log data plan to Basic or Analytics](logs/logs-table-plans.md)|Azure Databricks logs tables now support the basic logs data plan.| --## February 2024 --|Subservice | Article | Description | -|||| -|Agents|[Manage Azure Monitor Agent](agents/azure-monitor-agent-manage.md)|Added Azure Monitor Agent disk space requirements.| -|Alerts|[Monitor the health of log search alert rules](alerts/log-alert-rule-health.md)|Added documentation for new feature - resource health for log search alert rules.| -|Application-Insights|[Failures and Performance views](app/failures-and-performance-views.md)|A new article was added with current information on both the Performance and Failures views.| -|Application-Insights|[Release and work item insights](app/release-and-work-item-insights.md)|We've modified our Annotations script to support unicode characters.| -|Application-Insights|[Migrate to workspace-based Application Insights resources](app/convert-classic-resource.md)|The FAQ section was updated with information on what happens if you choose not to manually migrate and similar question/answer pairs related to Classic App Insights resource retirement.| -|Containers|[Transition from the Container Monitoring Solution to using Container Insights](containers/container-insights-transition-solution.md)|Changed date for Container Monitoring Solution retirement.| -|Essentials|[Create alert rules for Azure resources](alerts/alert-options.md)|New article summarizing alert options including Azure Monitor Baseline Alerts (AMBA).| -|Essentials|[Structure of transformation in Azure Monitor](essentials/data-collection-transformations-structure.md)|Added | -|General|[Sources of monitoring data for Azure Monitor and their data collection methods](data-sources.md)|Rewritten to simplify list of Azure Monitor data sources.| -|Logs|[Logs Ingestion API in Azure Monitor](logs/logs-ingestion-api-overview.md)|Add new tables that now support ingestion time transformations.| -|Logs|[Plan alerts and automated actions](alerts/alerts-plan.md)|The Getting Started section was edited to make the documentation cleaner and more efficient.| -|Logs|[Enhance data and service resilience in Azure Monitor Logs with availability zones](logs/availability-zones.md)|Updated the list of supported regions for Availability Zones.| -|Logs|[Set a table's log data plan to Basic or Analytics](logs/logs-table-plans.md)|Bare Metal Machines and Microsoft Graph tables now support Basic logs.| -|Virtual-Machines|[Monitor virtual machines with Azure Monitor](vm/monitor-virtual-machine.md)|Added information on using Performance Diagnostics to troubleshoot performance issues on Windows or Linux virtual machines.| --## January 2024 --|Subservice | Article | Description | -|||| -|Agents|[MMA Discovery and Removal Utility](agents/azure-monitor-agent-mma-removal-tool.md)|Added a PowerShell script that discovers and removes the Log Analytics agent from machines as part of the migration to Azure Monitor Agent.| -|Agents|[Send data to Event Hubs and Storage (Preview)](agents/azure-monitor-agent-send-data-to-event-hubs-and-storage.md)|Update azure-monitor-agent-send-data-to-event-hubs-and-storage.md| -|Alerts|[Resource Manager template samples for metric alert rules in Azure Monitor](alerts/resource-manager-alerts-metric.md)|We added a clarification about the parameters used when creating metric alert rules programatically.| -|Alerts|[Manage your alert instances](alerts/alerts-manage-alert-instances.md)|We've added documentation about the new alerts timeline view.| -|Alerts|[Create or edit a log search alert rule](alerts/alerts-create-log-alert-rule.md)|Added limitations to log search alert queries.| -|Alerts|[Create or edit a log search alert rule](alerts/alerts-create-log-alert-rule.md)|We've added samples of log search alert rule queries that use Azure Data Explorer and Azure Resource Graph.| -|Application-Insights|[Data Collection Basics of Azure Monitor Application Insights](app/opentelemetry-overview.md)|We've provided information on how to get a list of Application Insights SDK versions and their names.| -|Application-Insights|[Application Insights logging with .NET](app/ilogger.md)|We've clarified steps to view ILogger telemetry.| -|Application-Insights|[Migrate to workspace-based Application Insights resources](app/convert-classic-resource.md)|The script to discover classic resources has been updated.| -|Application-Insights|[Migrate to workspace-based Application Insights resources](app/convert-classic-resource.md)|Extra details are now available on migrating from Continuous Export to Diagnostic Settings.| -|Application-Insights|[Telemetry processors (preview) - Azure Monitor Application Insights for Java](app/java-standalone-telemetry-processors.md)|Sample metrics filters have been added.| -|Application-Insights|[Log-based and preaggregated metrics in Application Insights](app/pre-aggregated-metrics-log-metrics.md)|We've clarified how custom metrics work.| -|Containers|[Default Prometheus metrics configuration in Azure Monitor](containers/prometheus-metrics-scrape-default.md)|Added default targets for Control Plane to minimal ingestion profile| -|Containers|[Azure Monitor features for Kubernetes monitoring](containers/container-insights-overview.md)|Rewritten to focus on role of log collection and added agent details.| -|Containers|[Configure data collection in Container insights using ConfigMap](containers/container-insights-data-collection-configmap.md)|New article to consolidate ConfigMap configuration of all cluster configurations.| -|Containers|[Configure data collection in Container insights using data collection rule](containers/container-insights-data-collection-dcr.md)|New article to consolidate DCR configuration of all cluster configurations.| -|Containers|[Container insights log schema](containers/container-insights-logs-schema.md)|Combine Prometheus and Container insights| -|Containers|[Enable monitoring for Kubernetes clusters](containers/container-insights-enable-aks.md)|New article to consolidate onboarding process for all container configurations and for both Prometheus and Container insights.| -|Containers|[Customize scraping of Prometheus metrics in Azure Monitor managed service for Prometheus](containers/prometheus-metrics-scrape-configuration.md)|[Azure Monitor Managed Prometheus] Docs for pod annotation scraping through configmap| -|Essentials|[Custom metrics in Azure Monitor (preview)](essentials/metrics-custom-overview.md)|Article refreshed an updated| -|General|[Disable monitoring of your Kubernetes cluster](containers/kubernetes-monitoring-disable.md)|New article to consolidate process for all container configurations and for both Prometheus and Container insights.| -|Logs|[Best practices for Azure Monitor Logs](best-practices-logs.md)|Dedicated clusters are now available in all commitment tiers, with a minimum daily ingestion of 100 GB.| -|Logs|[Enhance data and service resilience in Azure Monitor Logs with availability zones](logs/availability-zones.md)|Availability zones are now supported in the Israel Central, Poland Central, and Italy North regions.| -|Virtual-Machines|[Dependency Agent](vm/vminsights-dependency-agent-maintenance.md)|VM Insights Dependency Agent now supports RHEL 8.6 Linux.| -|Visualizations|[Composite bar renderer](visualize/workbooks-composite-bar.md)|We've edited the Workbooks content to make some features and functionality easier to find based on customer feedback. We've also removed legacy content.| -----## [2023](#tab/2023) --## December 2023 --|Subservice | Article | Description | -|||| -Alerts|[Noncommon alert schema definitions](alerts/alerts-non-common-schema-definitions.md)|Added recommendation for using the common schema| -Alerts|[Create a metric alert in Azure Monitor Logs](alerts/alerts-metric-logs.md)|Add recommendations for alerting at scale| -Alerts|[Create or edit an activity log, service health, or resource health alert rule](alerts/alerts-create-activity-log-alert-rule.md)|Restructured articles about creating new alert rules for better clarity. There are now separate articles dedicated to each alert rule type, and dedicated articles for specific alert rule configurations.| -Alerts|[Create or edit a metric alert rule](alerts/alerts-create-new-alert-rule.md)|Added limitations for use of custom properties in alert rules. Added list of query plugins not supported by log alert rule queries.| -Application-Insights|[Add, modify, and filter OpenTelemetry](app/opentelemetry-add-modify.md)|Custom events code samples and instructions have been added to .NET Core / .NET tabs.| -Application-Insights|[Migrate availability tests](app/availability-test-migration.md)|We've clarified the URL ping tests retirement statement. Migrate your URL ping tests as soon as possible using the PowerShell scripts provided in this article.| -Application-Insights|[Enable Azure Monitor Application Insights Real User Monitoring](app/javascript-sdk.md)|More guidance has been added on when to use the npm package.| -Application-Insights|[Migrate to workspace-based Application Insights resources](app/convert-classic-resource.md)|We confirmed that migrating from classic to workspace-based resources doesn't introduce application downtime or restarts, and it doesn't change your existing instrumentation key or connection string.| -Logs|[Correlate data in Azure Data Explorer and Azure Resource Graph with data in a Log Analytics workspace](logs/azure-monitor-data-explorer-proxy.md)|Explained how to query Azure Data Explorer external tables using the `adx("")` expression. | -Logs|[Logs Ingestion API in Azure Monitor](logs/logs-ingestion-api-overview.md)|Updated Log Ingestion API version.| -Profiler|[Profile production applications in Azure with Application Insights Profiler](profiler/profiler-overview.md)|Add support for Java profiler and link to docs from .NET profiler overview.| -Virtual-Machines|[Enable VM insights by using PowerShell](vm/vminsights-enable-powershell.md)|Enable VM insights with Azure monitor agent by using PowerShell| ---## November 2023 --|Subservice | Article | Description | -|||| -Agents|[Migrate to Azure Monitor Agent from Log Analytics agent](agents/azure-monitor-agent-migration.md)|Container Insights is now generally available with Azure Monitor Agent.| -Agents|[Azure Monitor Agent overview](agents/agents-overview.md)|Azure Monitor Agent now supports AlmaLinux 9, Oracle Linux 9, and Rocky Linux 9.| -Alerts|[Create or edit an alert rule](alerts/alerts-create-new-alert-rule.md)|Added limitations of stateful log alerts.| -Alerts|[Troubleshoot Azure Monitor metric alerts](alerts/alerts-troubleshoot-metric.md)|Documented network error that can occur if you create a metric alert rule that uses a large number of dimensions, creating a payload that is too large for the network. We also documented possible workarounds for this issue.| -Alerts|[Create a metric alert with dynamic thresholds](alerts/alerts-dynamic-thresholds.md)|We restructured the section on Azure Monitor alerts, so that the content is more easily findable and usable.| -Alerts|[Create or edit an alert rule](alerts/alerts-create-new-alert-rule.md)|Corrected information about dimensions. Dimensions are retrieved from the last 24 hours, not 48 hours.| -Alerts|[Connect Azure to ITSM tools by using IT Service Management](alerts/itsmc-definition.md)|Added documentation to note that as of October 2023, we don't support the using ITSM actions to send alerts and events to ServiceNow in the Azure portal.| -Alerts|[Create or edit an alert rule](alerts/alerts-create-new-alert-rule.md)|When you create a log alert rule, if you're querying an ADX or ARG cluster, the data sources accessed by the query, must have the Reader role.| -Application-Insights|[Application Insights overview](app/app-insights-overview.md)|OpenTelemetry for .NET Core reached general availability and is now fully supported.| -Application-Insights|[Enable Azure Monitor OpenTelemetry for .NET, Node.js, Python and Java applications](app/opentelemetry-enable.md)|Our OpenTelemetry FAQ section has been updated to reflect the general availability status of OpenTelemetry for .NET Core.| -Application-Insights|[Monitor your Node.js services and apps with Application Insights](app/nodejs.md)|A dedicated troubleshooting article is now available to assist with issues related to monitoring Node.js apps.| -Application-Insights|[Application Insights availability tests](app/availability-overview.md)|We enabled TLS 1.3 in Availability Tests and updated our troubleshooting information.| -Containers|[Data transformations in Container insights](containers/container-insights-transformations.md)|New article describes how to transform data using a DCR transformation in Container insights| -Containers|[Enable Container insights](containers/container-insights-onboard.md)|New article: Enable private link with Container insights| -Essentials|[Azure Monitor managed service for Prometheus rule groups](essentials/prometheus-rule-groups.md)|Create or edit Prometheus rule group in the Azure portal (preview)| -Logs|[Detect and mitigate potential issues using AIOps and machine learning in Azure Monitor](logs/aiops-machine-learning.md)|Microsoft Copilot in Azure now helps you write KQL queries to analyze data and troubleshoot issues based on prompts, such as "Are there any errors in container logs?". | -Logs|[Best practices for Azure Monitor Logs](./best-practices-logs.md)|More guidance on Azure Monitor Logs features that provide enhanced resilience.| -Logs|[Data retention and archive in Azure Monitor Logs](logs/data-retention-configure.md)|Azure Monitor Logs extended archiving of data to up to 12 years.| -Logs|[Set a table's log data plan to Basic or Analytics](logs/logs-table-plans.md)|Added Basic logs support for Network managers tables.| -Virtual-Machines|[Enable VM insights in the Azure portal](vm/vminsights-enable-portal.md)|Azure portal no longer supports enabling VM insights using Log Analytics agent.| -Virtual-Machines|[Azure Monitor SCOM Managed Instance](vm/scom-managed-instance-overview.md)|Azure Monitor SCOM Managed Instance is now generally available.| -Visualizations|[Azure Workbooks](visualize/workbooks-overview.md)|We clarified that when you're viewing Azure workbooks, you can see all of the workbooks that are in your current view. In order to see all of your existing workbooks of any kind, you must Browse across galleries. | ---## October 2023 --|Subservice | Article | Description | -|||| -General|[Best practices for monitoring Kubernetes with Azure Monitor](best-practices-containers.md)|New article.| -General|[Estimate Azure Monitor costs](cost-estimate.md)|New article describing use of Azure Monitor pricing calculator.| -General|[Azure Monitor billing meter names](cost-meters.md)|Billing meters moved into dedicated reference article.| -General|[Azure Monitor cost and usage](cost-usage.md)|Rewritten.| -Agents|[Collect logs from a text or JSON file with Azure Monitor Agent](agents/data-collection-text-log.md)|Added the ability to collect logs from a JSON file with Azure Monitor Agent.| -Alerts|[Create or edit an alert rule](alerts/alerts-create-new-alert-rule.md)|Custom properties for Azure Monitor alerts are now located in the Details tab when creating or editing an alert rule. | -Alerts|[Create or edit an alert rule](alerts/alerts-create-new-alert-rule.md)|Added note clarifying the limitations of setting the frequency of alert rules to one minute. | -Application-Insights|[IP addresses used by Azure Monitor](app/ip-addresses.md)|A logic model diagram is available to assist with troubleshooting scenarios.| -Application-Insights|[Application Insights Overview dashboard](app/overview-dashboard.md)|All of the Application Insights experiences are now defined in a manner that mirrors the Azure portal experience. We've included a logic model diagram to visually convey how Application Insights works at a high level.| -Application-Insights|[Enable Azure Monitor OpenTelemetry for .NET, Node.js, Python, and Java applications](app/opentelemetry-enable.md)|Our OpenTelemetry Distro released for .NET, Java, Python, and Node.js. This is a replacement for classic Application Insights SDKs.| -Essentials|[Collect IIS logs with Azure Monitor Agent](agents/data-collection-iis.md)|Added guidance on setting up data collection endpoints based on deployment.| -Logs|[Restore logs in Azure Monitor](logs/restore.md)|Updated information about the cost of restoring logs. | -Logs|[Log Analytics workspace data export in Azure Monitor](logs/logs-data-export.md)|Billing for Data Export was enabled in early October 2023.| -Logs|[Analyze usage in a Log Analytics workspace](logs/analyze-usage.md)|Added support for querying data volume from events directly, and by computer.| ---## September 2023 --|Subservice | Article | Description | -|||| -Agents|[Define Azure Monitor Agent network settings](agents/azure-monitor-agent-data-collection-endpoint.md)|Added an example of Azure Monitor Agent deployment with an Azure Resource Manager policy template.| -Agents|[Migrate to Azure Monitor Agent from Log Analytics agent](agents/azure-monitor-agent-migration.md)|VM Insights with Azure Monitor Agent is now generally available.| -Alerts|[Manage your alert instances](alerts/alerts-manage-alert-instances.md)|Updated documentation to clarify that Azure Monitor alerts are stored for 30 days and are deleted after the 30-day retention period. For stateful alerts, while the alert itself is deleted after 30 days, and isn't viewable on the alerts page, the alert condition is stored until the alert is resolved, to prevent firing another alert, and so that notifications can be sent when the alert is resolved.| -Alerts|[Troubleshooting problems in Azure Monitor alerts](alerts/alerts-troubleshoot.md)|Added a new article describing the process for migrating from the alertsSummary API, which is being deprecated in September 2026. You can use Azure Resource Graph's functionality to get the same information returned by the alertsSummary API.| -Alerts|[Troubleshoot log alerts in Azure Monitor](alerts/alerts-troubleshoot-log.md)|Added clarification about the limitations of the override time query setting when creating a new alert rule. The alert time range is limited to a maximum of two days, no matter what override time is set in the query.| -Application-Insights|[Migrate availability tests](app/availability-test-migration.md)|Updated PowerShell script for quick migration of URL Ping Tests to Standard Tests.| -Application-Insights|[Application Insights overview](app/app-insights-overview.md)|We've updated the Supported Languages section to provide more information about the OpenTelemetry Distro.| -Application-Insights|[Migrating from OpenCensus Python SDK and Azure Monitor OpenCensus exporter for Python to Azure Monitor OpenTelemetry Python Distro](app/opentelemetry-python-opencensus-migrate.md)|Follow this guide to migrate Python apps from OpenCensus solutions to the OpenTelemetry Distro.| -Application-Insights|[Enable Azure Monitor OpenTelemetry for .NET, Node.js, Python and Java applications](app/opentelemetry-enable.md)|The OpenTelemetry Distro is fully released and generally available for Node.js, Python, and Java. An OpenTelemetry Exporter is also released and generally available for .NET and .NET Core.| -Application-Insights|[What is autoinstrumentation for Azure Monitor Application Insights?](app/codeless-overview.md)|Automatic instrumentation, which enables Application Insights without code changes, is now released and generally available for App Service on Linux - Publish as Docker.| -Containers|[Migrate from ContainerLog to ContainerLogV2](containers/container-insights-v2-migration.md)|New article.| -Containers|[Configure remote write for Azure managed service for Prometheus using Azure Active Directory workload identity (preview)](containers/prometheus-remote-write-azure-workload-identity.md)|New article Configure remote write for Azure Monitor managed service …| -Essentials|[Migrate from diagnostic settings storage retention to Azure Storage lifecycle management](essentials/migrate-to-azure-storage-lifecycle-policy.md)|Added CLI and template tabs showing storage lifecycle setting.| -General|[Plan your alerts and automated actions](alerts/alerts-plan.md)|Add alerts best practices article| -General|[Azure Monitor cost and usage](cost-usage.md)|Updated information about the Cost Analysis usage report which contains both the cost for your usage, and the number of units of usage. You can use this export to see the amount of benefit you're receiving from various offers such as the [Defender for Servers data allowance](logs/cost-logs.md#workspaces-with-microsoft-defender-for-cloud) and the [Microsoft Sentinel benefit for Microsoft 365 E5, A5, F5, and G5 customers](https://azure.microsoft.com/offers/sentinel-microsoft-365-offer/). | -Logs|[Send log data to Azure Monitor by using the HTTP Data Collector API (deprecated)](logs/data-collector-api.md)|Added deprecation notice.| -Logs|[Azure Monitor Logs overview](logs/data-platform-logs.md)|Added code samples for the Azure Monitor Ingestion client module for Go.| -Logs|[Set a table's log data plan to Basic or Analytics](logs/logs-table-plans.mdVirtual Network Manager, Dev Center, and Communication Services tables that now support Basic logs.| --## August 2023 --|Subservice| Article | Description | -|||| -General|[Azure Monitor cost and usage](cost-usage.md)|Added section detailing billing meter names.| -Application-Insights|[Add, modify, and filter OpenTelemetry](app/opentelemetry-add-modify.md)|A caution has been added about using community libraries with additional information on how to request we include them in our distro.| -Application-Insights|[Add, modify, and filter OpenTelemetry](app/opentelemetry-add-modify.md)|Support and feedback options are now available across all of our OpenTelemetry pages.| -Application-Insights|[How many Application Insights resources should I deploy?](app/create-workspace-resource.md#how-many-application-insights-resources-should-i-deploy)|We added an important warning about additional network costs when monitoring across regions.| -Application-Insights|[Use Search in Application Insights](app/transaction-search-and-diagnostics.md?tabs=transaction-search)|We clarified that URL query strings are not logged by Azure Functions and that URL query strings won't show up in searches.| -Application-Insights|[Migrating from OpenCensus Python SDK and Azure Monitor OpenCensus exporter for Python to Azure Monitor OpenTelemetry Python Distro](app/opentelemetry-python-opencensus-migrate.md)|Migrate from OpenCensus to OpenTelemetry with this step-by-step guidance.| -Application-Insights|[Application Insights overview](app/app-insights-overview.md)|We've added an illustration to convey how Azure Monitor Application Insights works at a high level.| -Containers|[Troubleshoot collection of Prometheus metrics in Azure Monitor](containers/prometheus-metrics-troubleshoot.md)|Added the *Troubleshoot using PowerShell script* section.| -Containers|[Monitor Kubernetes clusters using Azure services and cloud native tools](containers/monitor-kubernetes.md)|Updated previous scenario for hybrid Kubernetes clusters and managed Prometheus.| -Containers|[Monitor Azure Kubernetes Service (AKS)](/azure/aks/monitor-aks)|New article providing simplified introduction to monitoring AKS cluster.| -Containers|[Container insights overview](containers/container-insights-overview.md)|Rewritten for to include new features and managed services.| -Essentials|[Send Prometheus metrics to Log Analytics workspace with Container insights](containers/container-insights-prometheus-logs.md)|Updated to simplify article to only legacy method of sending Prometheus metrics to Log Analytics workspace.| -Essentials|[Collect Prometheus metrics from an AKS cluster](containers/kubernetes-monitoring-enable.md#enable-prometheus-and-grafana)|Updated to include additional onboarding methods.| -Essentials|[Azure Monitor managed service for Prometheus rule groups](essentials/prometheus-rule-groups.md)|Expanded "Limiting rules to a specific cluster"| -Logs|[Enable cost optimization settings](containers/container-insights-cost-config.md)|Updated for portal updates and additional details on workspace tables.| -Logs|[Enable the ContainerLogV2 schema](containers/container-insights-logs-schema.md)|Updated configuration section.| -Logs|[Manage access to Log Analytics workspaces](logs/manage-access.md)|Simplified flow for setting table-level access.| -Logs|[Query data in Azure Data Explorer and Azure Resource Graph from Azure Monitor](logs/azure-monitor-data-explorer-proxy.md)|Azure Monitor now lets you query data in Azure Resource Graph from your Log Analytics workspace. | ---## July 2023 --|Subservice| Article | Description | -|||| -Agents|[Azure Monitor Agent Health (Preview)](agents/azure-monitor-agent-health.md)|Introduced a new Azure Monitor Agent Health workbook, which monitors the health of agents deployed across your organization. | -Alerts|[Manage your alert instances](alerts/alerts-manage-alert-instances.md)|View alerts as a timeline (preview)| -Alerts|[Upgrade to the Scheduled Query Rules API from the legacy Log Analytics alerts API](alerts/alerts-log-api-switch.md)|Changes to the log alert rule creation experience| -Application-Insights|[Migrate to workspace-based Application Insights resources](app/convert-classic-resource.md)|We now support migrating classic components to workspace-based components via PowerShell cmdlet. | -Application-Insights|[EventCounters introduction](app/eventcounters.md)|Code samples have been provided for the latest .NET versions.| -Application-Insights|[Enable a framework extension for Application Insights JavaScript SDK](app/javascript-framework-extensions.md)|We've added a section for the React Native Manual Device Plugin, and clarified exception tracking and device info collection.| -Application-Insights|[Migrate availability tests](app/availability-test-migration.md)|Migrate your classic URL ping tests to the new standard availability tests using this prescriptive guidance.| -Application-Insights|[Enable a framework extension for Application Insights JavaScript SDK](app/javascript-framework-extensions.md)|The 'What does the plug-in enable?' and 'Add configuration' sections have been rewritten to align across all of our JavaScript documentation.| -Application-Insights|[Microsoft Azure Monitor Application Insights JavaScript SDK configuration](app/javascript-sdk-configuration.md)|The 'What does the plug-in enable?' and 'Add configuration' sections have been rewritten to align across all of our JavaScript documentation.| -Application-Insights|[Enable Azure Monitor OpenTelemetry for .NET, Node.js, Python and Java applications](app/opentelemetry-enable.md)|Clarification of the term "Distro" has been provided.| -Application-Insights|[Data Collection Basics of Azure Monitor Application Insights](app/opentelemetry-overview.md)|We've added a new article to clarify both manual and automatic instrumentation options to enable Application Insights.| -Application-Insights|[Enable a framework extension for Application Insights JavaScript SDK](app/javascript-framework-extensions.md)|The "Explore your data" section has been improved.| -Application-Insights|[Sampling overrides (preview) - Azure Monitor Application Insights for Java](app/java-standalone-sampling-overrides.md)|We've documented steps for troubleshooting sampling.| -Logs|[Set a table's log data plan to Basic or Analytics](logs/logs-table-plans.md)|Additional Azure tables now support low-cost basic logs, including tables for the Bare Metal Machines, Managed Lustre, Nexus Clusters, and Nexus Storage Appliances services. | -Logs|[Query Basic Logs in Azure Monitor](logs/basic-logs-query.md)|Basic log queries are now billable.| -Logs|[Restore logs in Azure Monitor](logs/restore.md)|Restored logs are now billable.| -Logs|[Run search jobs in Azure Monitor](logs/search-jobs.md)|Search jobs are now billable.| -Logs|[Tutorial: Ingest events from Azure Event Hubs into Azure Monitor Logs (Preview)](logs/ingest-logs-event-hub.md)|New article that explains how to ingest data directly from Azure Event Hubs, Azure's big data streaming platform, into Azure Monitor Logs.| -Optimization-Insights|[Monitor and analyze runtime behavior with Code Optimizations (Preview)](insights/code-optimizations.md)|PM added a demo video for Code Optimizations| -Virtual-Machines|[Migrate from deprecated VM insights policies](vm/vminsights-migrate-deprecated-policies.md)|We're deprecating the VM insights DCR deployment policies and replacing them with new policies because of a race condition issue. This article explains how to migrate from deprecated VM insights policies to their replacement policies.| --## June 2023 --|Subservice| Article | Description | -|||| -General|[What's new in Azure Monitor documentation](whats-new.md)| Subscribe to "What's New" using the new RSS link| -Application-Insights|[Filter and preprocess telemetry in the Application Insights SDK](app/api-filtering-sampling.md)|An Azure Monitor Telemetry Data Types Reference has been added for quick reference.| -Application-Insights|[Add and modify OpenTelemetry](app/opentelemetry-add-modify.md)|We've simplified the OpenTelemetry onboarding process by moving instructions to add and modify telemetry in this new document.| -Application-Insights|[Application Map: Triage distributed applications](app/app-map.md)|Application Map Intelligent View has reached general availability. Enjoy this powerful tool that harnesses machine learning to aid in service health investigations.| -Application-Insights|[Usage analysis with Application Insights](app/usage.md)|Code samples have been updated for the latest versions of .NET.| -Application-Insights|[Enable a framework extension for Application Insights JavaScript SDK](app/javascript-framework-extensions.md)|All JavaScript SDK documentation has been updated and simplified, including documentation for feature and framework extensions.| -Autoscale|[Use autoscale actions to send email and webhook alert notifications in Azure Monitor](autoscale/autoscale-webhook-email.md)|Article updated and refreshed| -Containers|[Query logs from Container insights](containers/container-insights-log-query.md#container-logs)|New section: Container logs, with sample queries| -Containers|[Authentication for Container Insights](containers/container-insights-authentication.md)|New article: Configure agent authentication for the Container Insights agent| -Essentials|[Azure monitoring REST API walkthrough](essentials/rest-api-walkthrough.md)|Added multi resource request examples| -Essentials|[Azure Monitor managed service for Prometheus rule groups](essentials/prometheus-rule-groups.md)| Added CLI & PowerShell reference and examples| -Logs|[Set up resources required to send data to Azure Monitor Logs using the Logs Ingestion API](logs/set-up-logs-ingestion-api-prerequisites.md)|New article. Run a PowerShell script to set up resources required to send data to Azure Monitor using the Logs Ingestion API.| -Logs|[Migrate from the HTTP Data Collector API to the Log Ingestion API to send data to Azure Monitor Logs](logs/custom-logs-migrate.md)|Updated guidance for migrating from the legacy Azure Monitor Data Collector API to the Log Ingestion API.| -Logs|[Detect and mitigate potential issues using AIOps and machine learning in Azure Monitor](logs/aiops-machine-learning.md)|New article. Lists Azure Monitor AIOps features and explains how to implement a machine learning pipeline on data in Azure Monitor Logs.| -Logs|[Tutorial: Analyze data in Azure Monitor Logs using a notebook](logs/notebooks-azure-monitor-logs.md)|New tutorial. Explains how to integrate a notebook with a Log Analytics workspace to create a machine learning pipeline or perform advanced analysis on data in Azure Monitor Logs. | -Virtual-Machines|[Tutorial: Create availability alert rule for multiple Azure virtual machines (preview)](vm/tutorial-monitor-vm-alert-availability.md)|New article with consolidated list of best practices for monitoring VMs organized by WAF pillar.| --## May 2023 --|Subservice| Article | Description | -|||| -Agents|[Azure Monitor Agent overview](agents/agents-overview.md)|Mma ama migration update| -Agents|[Azure Monitor Agent overview](agents/agents-overview.md)|Azure Monitoring Agent for Linux now officially supports various hardening standards for Linux operating systems and distros.| -Agents|[Migrate from MMA custom text log to AMA DCR based custom text logs](agents/azure-monitor-agent-custom-text-log-migration.md)|New article that explains how to migrate from the HTTP Data Collector API to the Log Ingestion API.| -Agents|[Azure Monitor Agent overview](agents/agents-overview.md)|Azure Monitor Agent now supports Azure Stack HCI. | -Alerts|[Create a new alert rule](alerts/alerts-create-new-alert-rule.md)|Log alert rules support using managed identities to send the log query.| -Alerts|[Monitor Azure AD B2C with Azure Monitor](/azure/active-directory-b2c/azure-monitor)|Articles on action groups have been updated.| -Alerts|[Create a new alert rule](alerts/alerts-create-new-alert-rule.md)|Alert rules that use action groups support custom properties to add custom information to the alert notification payload.| -Application-Insights|[Feature extensions for the Application Insights JavaScript SDK (Click Analytics)](app/javascript-feature-extensions.md)|Most of our JavaScript SDK documentation has been updated and overhauled.| -Application-Insights|[Analyze product usage with HEART](app/usage.md#heartfive-dimensions-of-customer-experience)|Updated and overhauled HEART framework documentation.| -Application-Insights|[Dependency tracking in Application Insights](app/asp-net-dependencies.md)|All new documentation supports the Azure Monitor OpenTelemetry Distro public preview release announced on May 10, 2023. [Public Preview: Azure Monitor OpenTelemetry Distro for ASP.NET Core, JavaScript (Node.js), Python](https://azure.microsoft.com/updates/public-preview-azure-monitor-opentelemetry-distro-for-aspnet-core-javascript-nodejs-python)| -Application-Insights|[Application Monitoring for Azure App Service and Java](app/azure-web-apps-java.md)|Added CATALINA_OPTS for Tomcat.| -Essentials|[Configure remote write for Azure Monitor managed service for Prometheus using Microsoft Azure Active Directory pod identity (preview)](essentials/prometheus-remote-write-azure-ad-pod-identity.md)|New article: Configure remote write for Azure Monitor managed service for Prometheus using Microsoft Azure Active Directory pod identity| -Essentials|[Use private endpoints for Managed Prometheus and Azure Monitor workspace](essentials/azure-monitor-workspace-private-endpoint.md)|New article: Use private endpoints for Managed Prometheus and Azure Monitor workspace| -Essentials|[Private Link for data ingestion for Managed Prometheus and Azure Monitor workspace](essentials/private-link-data-ingestion.md)|New article: Private Link for data ingestion for Managed Prometheus and Azure Monitor workspace| -Essentials|[Collect Prometheus metrics from an Arc-enabled Kubernetes cluster (preview)](essentials/prometheus-metrics-from-arc-enabled-cluster.md)|New article: Collect Prometheus metrics from an Arc-enabled Kubernetes cluster (preview)| -Essentials|[How to migrate from the metrics API to the getBatch API](essentials/migrate-to-batch-api.md)|Migrate from the metrics API to the getBatch API| -Essentials|[Azure Active Directory authorization proxy](essentials/prometheus-authorization-proxy.md)|Microsoft Azure Active Directory (Azure AD) auth proxy| -Essentials|[Integrate KEDA with your Azure Kubernetes Service cluster](essentials/integrate-keda.md)|New Article: Integrate KEDA with AKS and Prometheus| -Essentials|[General Availability: Azure Monitor managed service for Prometheus](https://techcommunity.microsoft.com/t5/azure-observability-blog/general-availability-azure-monitor-managed-service-for/ba-p/3817973)|General Availability: Azure Monitor managed service for Prometheus | -Insights|[Monitor and analyze runtime behavior with Code Optimizations (Preview)](insights/code-optimizations.md)|New doc for public preview release of Code Optimizations feature.| -Logs|[Set a table's log data plan to Basic or Analytics](logs/logs-table-plans.md)|Added Azure Active Directory, Communication Services, Container Apps Environments, and Data Manager for Energy to the list of tables that support Basic logs.| -Logs|[Export data from a Log Analytics workspace to a storage account by using Logic Apps](logs/logs-export-logic-app.md)|Added an Azure Resource Manager template for exporting data from a Log Analytics workspace to a storage account by using Logic Apps.| -Logs|[Set daily cap on Log Analytics workspace](logs/daily-cap.md)|Starting September 18, 2023, the Log Analytics Daily Cap will no longer exclude a set of data types from the daily cap, and all billable data types will be capped if the daily cap is met.| ---## April 2023 --|Subservice| Article | Description | -|||| -Agents|[Azure Monitor Agent Performance Benchmark](agents/azure-monitor-agent-performance.md)|Added performance benchmark data for the scenario of using Azure Monitor Agent to forward data to a gateway.| -Agents|[Troubleshoot issues with the Log Analytics agent for Windows](agents/agent-windows-troubleshoot.md)|Log Analytics will no longer accept connections from MMA versions that use old root CAs (MMA versions prior to the Winter 2020 release for Log Analytics agent, and prior to Microsoft System Center Operations Manager 2019 UR3 for Operations Manager). | -Agents|[Azure Monitor Agent overview](agents/agents-overview.md)|Log Analytics agent supports Windows Server 2022. | -Alerts|[Common alert schema](alerts/alerts-common-schema.md)|Updated alert payload common schema to include custom properties.| -Alerts|[Create and manage action groups in the Azure portal](alerts/action-groups.md)|Clarified use of basic auth in webhook.| -Application-Insights|[Application Insights logging with .NET](app/ilogger.md)|We've made it easier to understand where to find iLogger telemetry.| -Application-Insights|[Set up Azure Monitor for your Python application](/previous-versions/azure/azure-monitor/app/opencensus-python)|Updated telemetry type mappings code sample.| -Application-Insights|[Feature extensions for the Application Insights JavaScript SDK (Click Analytics)](app/javascript-feature-extensions.md)|Code samples updated to use connection strings.| -Application-Insights|[Connection strings](app/sdk-connection-string.md)|Code samples updated for .NET 6/7.| -Application-Insights|[Live Metrics: Monitor and diagnose with 1-second latency](app/live-stream.md)|Code samples updated for .NET 6/7.| -Application-Insights|[Geolocation and IP address handling](app/ip-collection.md)|The PowerShell 'Update-AzApplicationInsights' code sample to disable IP masking has been updated.| -Application-Insights|[Application Insights for Worker Service applications (non-HTTP applications)](app/worker-service.md)|The .NET Core app scenario chart has been updated.| -Application-Insights|[Azure AD authentication for Application Insights](app/azure-ad-authentication.md)|Linked information on how to query Application Insights using Azure AD Authentication.| -Application-Insights|[Enable Azure Monitor OpenTelemetry for .NET, Node.js, Python and Java applications](app/opentelemetry-enable.md)|Java guidance and code samples have been updated.| -Autoscale|[Configure autoscale with PowerShell](autoscale/autoscale-using-powershell.md)|New Article: Configure autoscale using PowerShell| -Autoscale|[Get started with autoscale in Azure](autoscale/autoscale-get-started.md)|Refreshed article| -Containers|[Monitor an Azure Kubernetes Service cluster using Container insights in Azure Monitor](/training/modules/aks-monitor/)|New Learn module: Monitor an Azure Kubernetes Service cluster using Container insights in Azure Monitor.| -Containers|[Manage the Container insights agent](containers/container-insights-manage-agent.md)|Semantic version update of container insights agent version| -Essentials|[Azure Monitor Metrics overview](essentials/data-platform-metrics.md)|New Batch Metrics API that allows multiple resource requests and reducing throttling found in the non-batch version. | -General|[Cost optimization in Azure Monitor](best-practices-cost.md)|Rewritten to match organization of Well Architected Framework service guides| -General|[Best practices for Azure Monitor Logs](best-practices-logs.md)|New article with consolidated list of best practices for Logs organized by WAF pillar.| -General|[Migrate from Operations Manager to Azure Monitor](azure-monitor-operations-manager.md)|Migrate from Operations Manager to Azure Monitor| -Logs|[Application Insights API Access with Microsoft Azure Active Directory (Azure AD) Authentication](app/app-insights-azure-ad-api.md)|New article that explains how to authenticate and access the Azure Monitor Application Insights APIs using Azure AD.| -Logs|[Tutorial: Replace custom fields in Log Analytics workspace with KQL-based custom columns](logs/custom-fields-migrate.md)|Guidance for migrate legacy custom fields to KQL-based custom columns using transformations.| -Logs|[Monitor Log Analytics workspace health](logs/log-analytics-workspace-health.md)|View Log Analytics workspace health metrics, including query success metrics, directly from the Log Analytics workspace screen in the Azure portal.| -Logs|[Set a table's log data plan to Basic or Analytics](logs/logs-table-plans.md)|Dedicated SQL Pool tables and Kubernetes services tables now support Basic logs.| -Logs|[Set daily cap on Log Analytics workspace](logs/daily-cap.md)|Updated daily cap functionality for workspace-based Application Insights.| -Profiler|[View Application Insights Profiler data](profiler/profiler-data.md)|Clarified this section based on user feedback.| -Snapshot-Debugger|[Debug snapshots on exceptions in .NET apps](snapshot-debugger/snapshot-collector-release-notes.md)|Removed "how to view" sections and move into its own doc.| -Snapshot-Debugger|[Enable Snapshot Debugger for .NET apps in Azure App Service](snapshot-debugger/snapshot-debugger-app-service.md)|Updated link for release notes to the "Release notes" section in the Snapshot Debugger overview.| -Snapshot-Debugger|[View Application Insights Snapshot Debugger data](snapshot-debugger/snapshot-debugger-data.md)|Created this new doc for viewing snapshots from content taken from the overview.| -Snapshot-Debugger|[Enable Snapshot Debugger for .NET and .NET Core apps in Azure Functions](snapshot-debugger/snapshot-debugger-function-app.md)|Updated link for release notes to the "Release notes" section in the Snapshot Debugger overview.| -Snapshot-Debugger|[Troubleshoot problems enabling Application Insights Snapshot Debugger or viewing snapshots](snapshot-debugger/snapshot-debugger-troubleshoot.md)|Updated link for release notes to the "Release notes" section in the Snapshot Debugger overview.| -Snapshot-Debugger|[Enable Snapshot Debugger for .NET apps in Azure Service Fabric, Cloud Service, and Virtual Machines](snapshot-debugger/snapshot-debugger-vm.md)|Updated link for release notes to the "Release notes" section in the Snapshot Debugger overview.| -Snapshot-Debugger|[Debug snapshots on exceptions in .NET apps](snapshot-debugger/snapshot-debugger.md)|Moved the release notes to the end of the Snapshot Debugger overview doc to improve page metrics.| -Snapshot-Debugger|[What's new in Azure Monitor documentation](whats-new.md)|Updated link for release notes to the "Release notes" section in the Snapshot Debugger overview.| -Snapshot-Debugger|[Debug snapshots on exceptions in .NET apps](snapshot-debugger/snapshot-debugger.md)|Updated .NET availability for Snapshot Debugger to avoid ".NET Core" and "LTS" language.| -Snapshot-Debugger|[Debug snapshots on exceptions in .NET apps](snapshot-debugger/snapshot-debugger.md)|Added release notes for the 1.4.4 point release addressing user-reported bugs.| --## March 2023 - -|Subservice| Article | Description | -|||| -Alerts|[Manage your alert rules](alerts/alerts-manage-alert-rules.md)|Updated article to reflect that the user can duplicate an existing alert rule.| -Alerts|[Quickstart: Deploy an Azure Kubernetes Service (AKS) cluster by using the Azure portal](/azure/aks/learn/quick-kubernetes-deploy-portal)|You can enable recommended alert rules when you create an AKS cluster in the Azure portal. | -Alerts|[Monitor Log Analytics workspace health](logs/log-analytics-workspace-health.md)|If you have a Log Analytics workspace without any configured alert rules, you can enable recommended alert rules from the **Alerts** page of a Log Analytics workspace.| -Alerts|[Connect Azure to ITSM tools by using IT Service Management](alerts/itsmc-definition.md)|Updated the workflow for creating ServiceNow ITSM tickets from an Azure Monitor alert. The article now specifies separate workflows for ITSM actions, incidents, and events.| -Alerts|[Manage your alert rules](alerts/alerts-manage-alert-rules.md)|Recommended alert rules are now enabled for all customers and are no longer in public preview.| -Alerts|[Create a new alert rule](alerts/alerts-create-new-alert-rule.md)|Updated to reflect the updated **Create new alert rule** UI. The alert rule creation wizard clearly indicates the most commonly used resources and signals for their alerts to help users more easily create alert rules.| -Alerts|[Understanding Azure Active Directory Application Proxy Complex application scenario (preview)](../active-directory/app-proxy/application-proxy-configure-complex-application.md)| Updated the documentation for the common schema used in the alerts payload to contain the detailed information about the fields in the payload of each alert type. | -Alerts|[Supported resources for metric alerts in Azure Monitor](alerts/alerts-metric-near-real-time.md)|Updated list of metrics supported by metric alert rules.| -Alerts|[Create and manage action groups in the Azure portal](alerts/action-groups.md)|Updated the documentation explaining the retry logic used in action groups that use webhooks.| -Alerts|[Create and manage action groups in the Azure portal](alerts/action-groups.md)|Added list of countries/regions supported by voice notifications.| -Alerts|[Connect ServiceNow to Azure Monitor](alerts/itsmc-secure-webhook-connections-servicenow.md)|Added Tokyo to list of supported ServiceNow webhook integrations.| -Application-Insights|[Application Insights SDK support guidance](app/sdk-support-guidance.md)|Release notes are now available for each SDK.| -Application-Insights|[What is distributed tracing and telemetry correlation?](app/distributed-trace-data.md)|Merged our documents related to distributed tracing and telemetry correlation.| -Application-Insights|[Application Insights availability tests](app/availability-overview.md)|Separated and called out the two Classic Tests, which are older versions of availability tests.| -Application-Insights|[Microsoft Azure Monitor Application Insights JavaScript SDK configuration](app/javascript-sdk-configuration.md)|JavaScript SDK configuration now includes npm setup, cookie configuration and management, source map un-minify support, and tree shaking optimized code.| -Application-Insights|[Microsoft Azure Monitor Application Insights JavaScript SDK](app/javascript-sdk.md)|Our introductory article to the JavaScript SDK now provides only the fast and easy code-snippet method of getting started.| -Application-Insights|[Geolocation and IP address handling](app/ip-collection.md)|Updated code samples for .NET 6/7.| -Application-Insights|[Application Insights logging with .NET](app/ilogger.md)|Updated code samples for .NET 6/7.| -Application-Insights|[Azure Monitor overview](overview.md)|Updated Azure Monitor overview graphics along with related content.| -Containers|[Metric alert rules in Container insights (preview)](containers/container-insights-metric-alerts.md)|Updated to indicate deprecation of metric alerts.| -Containers|[Azure Monitor Container insights for Azure Arc-enabled Kubernetes clusters](containers/container-insights-enable-arc-enabled-clusters.md)|Added option for Azure Monitor Private Link Scope (AMPLS) + Proxy.| -Essentials|[Collect Prometheus metrics from an AKS cluster (preview)](containers/kubernetes-monitoring-enable.md#enable-prometheus-and-grafana)|Enabled Windows metric collection metrics add-on.| -Essentials|[Query Prometheus metrics by using the API and PromQL](essentials/prometheus-api-promql.md)|New article: Query Azure Monitor workspaces by using REST and PromQL.| -Essentials|[Configure remote write for Azure Monitor managed service for Prometheus by using Azure Active Directory authentication (preview)](essentials/prometheus-remote-write-active-directory.md)|Added Prometheus remote write Active Directory relabel.| -Essentials|[Built-in policies for Azure Monitor](essentials/diagnostics-settings-policies-deployifnotexists.md)|Added new built-in policies to create diagnostic settings in Azure Monitor with deploy-if-not-exists defaults.| -Logs|[Logs Ingestion API in Azure Monitor](logs/logs-ingestion-api-overview.md)|Updated to include client libraries.| -Logs|[Tutorial: Send data to Azure Monitor by using the Logs Ingestion API (Azure Resource Manager templates)](logs/tutorial-logs-ingestion-api.md)|Rewritten to be more consistent with related tutorial.| -Logs|[Sample code to send data to Azure Monitor by using the Logs Ingestion API](logs/tutorial-logs-ingestion-code.md)|New article: Sample code to send data by using the Logs Ingestion API, including new client ingestion libraries for Python, .NET, Java, and JavaScript.| -Logs|[Tutorial: Send data to Azure Monitor Logs with the Logs Ingestion API (Azure portal)](logs/tutorial-logs-ingestion-portal.md)|Rewritten to be more consistent with related tutorial.| -Snapshot-Debugger|[Enable Profiler for ASP.NET Core web applications hosted in Linux on Azure App Service](profiler/profiler-aspnetcore-linux.md)|Updated code snippets from .NET 5 to .NET 6.| -Snapshot-Debugger|[Enable Snapshot Debugger for .NET apps in Azure Service Fabric, Azure Cloud Services, and Azure Virtual Machines](snapshot-debugger/snapshot-debugger-vm.md)|Updated code snippets from .NET 5 to .NET 6.| --|Subservice| Article | Description | -|||| -Agents|[Azure Monitor Agent extension versions](agents/azure-monitor-agent-extension-versions.md)|Added release notes for the Azure Monitor Agent Linux 1.25 release.| -Agents|[Migrate to Azure Monitor Agent from the Log Analytics agent](agents/azure-monitor-agent-migration.md)|Updated guidance for migrating from Log Analytics agent to Azure Monitor Agent.| -Alerts|[Manage your alert rules](alerts/alerts-manage-alert-rules.md)|Included limitation and workaround for resource health alerts. If you apply a target resource type scope filter to the **Alerts rules** page, the alerts rules list doesn’t include resource health alert rules.| -Alerts|[Customize alert notifications by using Azure Logic Apps](alerts/alerts-logic-apps.md)|Added instructions for other customizations that you can include when you use Logic Apps to create alert notifications. You can extract information about the affected resource from the resource's tags. Then you can include the resource tags in the alert payload and use the information in your logical expressions that are used for creating the notifications.| -Alerts|[Create and manage action groups in the Azure portal](alerts/action-groups-create-resource-manager-template.md)|Combined two articles about creating action groups into one article.| -Alerts|[Create and manage action groups in the Azure portal](alerts/action-groups.md)|Clarified that you can't pass security certificates in a webhook action in action groups.| -Alerts|[Create a new alert rule](alerts/alerts-create-new-alert-rule.md)|Added information about adding custom properties to the alert payload when you use action groups.| -Alerts|[Manage your alert instances](alerts/alerts-manage-alert-instances.md)|Removed option for managing alert instances by using the Azure CLI.| -Application-Insights|[Migrate to workspace-based Application Insights resources](app/convert-classic-resource.md)|Added the continuous export deprecation notice to this article for more visibility. We recommend migrating to workspace-based Application Insights resources as soon as possible to take advantage of new features.| -Application-Insights|[Application Insights API for custom events and metrics](app/api-custom-events-metrics.md)|Consolidated client-side JavaScript SDK extensions into two new articles called *Framework extensions* and *Feature extensions*. We've also created new standalone *Upgrade* and *Troubleshooting* articles.| -Application-Insights|[Monitor Azure Functions with Azure Monitor Application Insights](app/monitor-functions.md)|Overhauled the documentation on Azure Functions integration with Application Insights.| -Application-Insights|[Enable Azure Monitor OpenTelemetry for .NET, Node.js, Python, and Java applications](app/opentelemetry-enable.md)|Updated Java OpenTelemetry examples.| -Application-Insights|[Application monitoring for Azure App Service and Java](app/azure-web-apps-java.md)|Updated and separated out the instructions to manually deploy the latest Application Insights Java version.| -Containers|[Enable Container insights for Azure Kubernetes Service (AKS) clusters](containers/container-insights-enable-aks.md)|Added a section for enabling a private link without managed identity authentication.| -Containers|[Syslog collection with Container insights (preview)](containers/container-insights-syslog.md)|Added use of Azure Resource Manager templates for enabling Syslog collection.| -Containers|[Enable cost-optimization settings (preview)](containers/container-insights-cost-config.md)|New article: Enable cost-optimization settings.| -Essentials|[Data collection transformations in Azure Monitor](essentials/data-collection-transformations.md)|Added section and sample for using transformations to send to multiple destinations.| -Essentials|[Custom metrics in Azure Monitor (preview)](essentials/metrics-custom-overview.md)|Added reference to the limit of 64 KB on the combined length of all custom metrics names.| -Essentials|[Azure monitoring REST API walkthrough](essentials/rest-api-walkthrough.md)|Refreshed REST API walkthrough.| -Essentials|[Collect Prometheus metrics from AKS cluster (preview)](containers/kubernetes-monitoring-enable.md#enable-prometheus-and-grafana)|Added enabling Prometheus metric collection by using Azure Policy and Bicep.| -Essentials|[Send Prometheus metrics to multiple Azure Monitor workspaces (preview)](essentials/prometheus-metrics-multiple-workspaces.md)|Updated sending metrics to multiple Azure Monitor workspaces.| -General|[Analyze and visualize data](best-practices-analysis.md)|Revised the article about analyzing and visualizing monitoring data to provide a comparison of the different visualization tools and guide customers on when to choose each tool for their implementation. | -Logs|[Tutorial: Send data to Azure Monitor Logs by using the REST API (Resource Manager templates)](logs/tutorial-logs-ingestion-api.md)|Made minor fixes and updated sample data.| -Logs|[Analyze usage in a Log Analytics workspace](logs/analyze-usage.md)|Added query for data that has the IsBillable indicator set incorrectly, which could result in incorrect billing.| -Logs|[Add or delete tables and columns in Azure Monitor Logs](logs/create-custom-table.md)|Added custom column naming limitations.| -Logs|[Enhance data and service resilience in Azure Monitor Logs with availability zones](logs/availability-zones.md)|Clarified availability zone support for data resilience and service resilience and added new supported regions.| -Logs|[Monitor Log Analytics workspace health](logs/log-analytics-workspace-health.md)|New article: Explains how to monitor the service and resource health of a Log Analytics workspace.| -Logs|[Feature extensions for Application Insights JavaScript SDK (Click Analytics)](app/javascript-click-analytics-plugin.md)|You can now launch Power BI and create a dataset and report connected to a Log Analytics query with one click.| -Logs|[Set a table's log data plan to Basic or Analytics](logs/logs-table-plans.md)|Added new tables to the list of tables that support Basic Logs.| -Logs|[Manage tables in a Log Analytics workspace]()|Refreshed all Log Analytics workspace images with the new TOC on the left.| -Security-Fundamentals|[Monitoring Azure App Service](../../articles/app-service/monitor-app-service.md)|Revised the Azure Monitor overview to improve usability. The article is cleaned up, streamlined, and better reflects the product architecture and the customer experience. | -Snapshot-Debugger|[host.json reference for Azure Functions 2.x and later](../../articles/azure-functions/functions-host-json.md)|Removing the TSG from the Azure Monitor TOC and adding to the support TOC.| -Snapshot-Debugger|[Configure Bring Your Own Storage (BYOS) for Application Insights Profiler and Snapshot Debugger](profiler/profiler-bring-your-own-storage.md)|Removing the TSG from the Azure Monitor TOC and adding to the support TOC.| -Snapshot-Debugger|[Release notes for Microsoft.ApplicationInsights.SnapshotCollector](https://github.com/microsoft/ApplicationInsights-SnapshotCollector/blob/main/CHANGELOG.md)|Removing the TSG from the Azure Monitor TOC and adding to the support TOC.| -Snapshot-Debugger|[Enable Snapshot Debugger for .NET apps in Azure App Service](snapshot-debugger/snapshot-debugger-app-service.md)|Removing the TSG from the Azure Monitor TOC and adding to the support TOC.| -Snapshot-Debugger|[Enable Snapshot Debugger for .NET and .NET Core apps in Azure Functions](snapshot-debugger/snapshot-debugger-function-app.md)|Removing the TSG from the Azure Monitor TOC and adding to the support TOC.| -Snapshot-Debugger|[Troubleshoot problems enabling Application Insights Snapshot Debugger or viewing snapshots](/troubleshoot/azure/azure-monitor/app-insights/snapshot-debugger-troubleshoot)|Removing the TSG from the Azure Monitor TOC and adding to the support TOC.| -Snapshot-Debugger|[Enable Snapshot Debugger for .NET apps in Azure Service Fabric, Azure Cloud Services, and Virtual Machines](snapshot-debugger/snapshot-debugger-vm.md)|Removing the TSG from the Azure Monitor TOC and adding to the support TOC.| -Snapshot-Debugger|[Debug snapshots on exceptions in .NET apps](snapshot-debugger/snapshot-debugger.md)|Removing the TSG from the Azure Monitor TOC and adding to the support TOC.| -Virtual-Machines|[Monitor virtual machines with Azure Monitor: Analyze monitoring data](vm/monitor-virtual-machine-analyze.md)|New article.| -Visualizations|[Use JSONPath to transform JSON data in workbooks](visualize/workbooks-jsonpath.md)|Added information about using JSONPath to convert data types in Azure Workbooks.| -Containers|[Configure Container insights cost-optimization data collection rules](containers/container-insights-cost-config.md)|New article: Preview of cost-optimization settings.| --## January 2023 --|Subservice| Article | Description | -|||| -Agents|[Tutorial: Transform text logs during ingestion in Azure Monitor Logs](agents/azure-monitor-agent-transformation.md)|New tutorial: How to write a KQL query that transforms text log data and add the transformation to a data collection rule.| -Agents|[Azure Monitor Agent overview](agents/agents-overview.md)|SQL Best Practices Assessment now available with Azure Monitor Agent.| -Alerts|[Create a new alert rule](alerts/alerts-create-new-alert-rule.md)|Streamlined alerts documentation added the common schema definition to the common schema article, and moved sample Resource Manager templates for alerts to the "Samples" section.| -Alerts|[Non-common alert schema definitions for Test Action Group (preview)](alerts/alerts-non-common-schema-definitions.md)|Added a sample payload for the Actual Cost and Forecasted Budget schemas.| -Application-Insights|[Live Metrics: Monitor and diagnose with 1-second latency](app/live-stream.md)|Updated Live Metrics "Troubleshooting" section.| -Application-Insights|[Application Insights for Azure Virtual Machines and Azure Virtual Machine Scale Sets](app/azure-vm-vmss-apps.md)|Easily monitor your IIS-hosted .NET Framework and .NET Core applications running on Azure Virtual Machines and Azure Virtual Machine Scale Sets by using a new App Insights extension.| -Application-Insights|[Sampling in Application Insights](app/sampling.md)|Added embedded links to assist with looking up type definitions (dependency, event, exception, PageView, request, and trace).| -Application-Insights|[Configuration options: Azure Monitor Application Insights for Java](app/java-standalone-config.md)|Instructions are now available on how to set the HTTP proxy by using an environment variable, which overrides the JSON configuration. We've also provided a sample to configure connection string at runtime.| -Application-Insights|[Application Insights for Java 2.x](/previous-versions/azure/azure-monitor/app/deprecated-java-2x)|The Java 2.x retirement notice is available at [https://azure.microsoft.com/updates/application-insights-java-2x-retirement](https://azure.microsoft.com/updates/application-insights-java-2x-retirement).| -Autoscale|[Diagnostic settings in autoscale](autoscale/autoscale-diagnostics.md)|Updated and expanded content.| -Autoscale|[Overview of common autoscale patterns](autoscale/autoscale-common-scale-patterns.md)|Clarification of weekend profiles.| -Autoscale|[Autoscale with multiple profiles](autoscale/autoscale-multiprofile.md)|Added clarifications for profile end times.| -Change-Analysis|[Scenarios for using Change Analysis in Azure Monitor](change/change-analysis-custom-filters.md)|Merged two low-engagement docs into Visualizations article and removed from TOC.| -Change-Analysis|[Scenarios for using Change Analysis in Azure Monitor](change/change-analysis-query.md)|Merged two low-engagement docs into Visualizations article and removed from TOC.| -Change-Analysis|[Scenarios for using Change Analysis in Azure Monitor](change/change-analysis-visualizations.md)|Merged two low-engagement docs into Visualizations article and removed from TOC.| -Change-Analysis|[Track a web app outage by using Change Analysis](change/tutorial-outages.md)|Added new section on virtual network changes to the tutorial.| -Containers|[Azure Monitor container insights for Azure Kubernetes Service hybrid clusters (preview)](containers/kubernetes-monitoring-enable.md?tabs=cli)|New article.| -Containers|[Syslog collection with Container insights (preview)](containers/container-insights-syslog.md)|New article.| -Essentials|[Query Prometheus metrics by using Azure Workbooks (preview)](essentials/prometheus-workbooks.md)|New article.| -Essentials|[Azure Workbooks data sources](visualize/workbooks-data-sources.md)|Added section for Prometheus metrics.| -Essentials|[Query Prometheus metrics by using Azure Workbooks (preview)](essentials/prometheus-workbooks.md)|New article.| -Essentials|[Azure Monitor workspace (preview)](essentials/azure-monitor-workspace-overview.md)|Updated design considerations.| -Essentials|[Supported metrics with Azure Monitor](essentials/metrics-supported.md)|Updated and refreshed the list of supported metrics.| -Essentials|[Supported categories for Azure Monitor resource logs](essentials/resource-logs-categories.md)|Updated and refreshed the list of supported logs.| -General|[Multicloud monitoring with Azure Monitor](best-practices-multicloud.md)|New article.| -Logs|[Set daily cap on Log Analytics workspace](logs/daily-cap.md)|Clarified special case for daily cap logic.| -Logs|[Send custom metrics for an Azure resource to the Azure Monitor metric store by using a REST API](essentials/metrics-store-custom-rest-api.md)|Updated and refreshed how to send custom metrics.| -Logs|[Migrate from Splunk to Azure Monitor Logs](logs/migrate-splunk-to-azure-monitor-logs.md)|New article: Explains how to migrate your Splunk Observability deployment to Azure Monitor Logs for logging and log data analysis.| -Logs|[Manage access to Log Analytics workspaces](logs/manage-access.md)|Added permissions required to run a search job and restore archived data.| -Logs|[Set a table's log data plan to Basic or Analytics](logs/logs-table-plans.md)|Added information about how to modify a table schema by using the API.| -Snapshot-Debugger|[Enable Snapshot Debugger for .NET apps in Azure App Service](snapshot-debugger/snapshot-debugger-app-service.md)|Per customer feedback, added new note that Consumption plan isn't supported.| -Virtual-Machines|[Collect IIS logs with Azure Monitor Agent](agents/data-collection-iis.md)|Added sample log queries.| -Virtual-Machines|[Collect text logs with Azure Monitor Agent](agents/data-collection-text-log.md)|Added sample log queries.| -Virtual-Machines|[Monitor virtual machines with Azure Monitor: Deploy agent](vm/monitor-virtual-machine-agent.md)|Rewritten for Azure Monitor Agent.| -Virtual-Machines|[Monitor virtual machines with Azure Monitor: Alerts](vm/monitor-virtual-machine-alerts.md)|Rewritten for Azure Monitor Agent.| -Virtual-Machines|[Monitor virtual machines with Azure Monitor: Analyze monitoring data](vm/monitor-virtual-machine-analyze.md)|Rewritten for Azure Monitor Agent.| -Virtual-Machines|[Monitor virtual machines with Azure Monitor: Collect data](vm/monitor-virtual-machine-data-collection.md)|Rewritten for Azure Monitor Agent.| -Virtual-Machines|[Monitor virtual machines with Azure Monitor: Migrate management pack logic](vm/monitor-virtual-machine-management-packs.md)|Rewritten for Azure Monitor Agent.| -Virtual-Machines|[Monitor virtual machines with Azure Monitor](vm/monitor-virtual-machine.md)|Rewritten for Azure Monitor Agent.| -Virtual-Machines|[Monitor Azure virtual machines](/azure/virtual-machines/monitor-vm)|VM scenario updates for Azure Monitor Agent.| ---## [2022](#tab/2022) --## December 2022 --|Subservice| Article | Description | -|||| -General|[Azure Monitor for existing Operations Manager customers](azure-monitor-operations-manager.md)|Updated for Azure Monitor Agent and System Center Operations Manager managed instance.| -Application-Insights|[Create an Application Insights resource](/previous-versions/azure/azure-monitor/app/create-new-resource)|Classic Application Insights resources are deprecated. Support ends on February 29, 2024. Migrate to workspace-based resources to take advantage of new capabilities.| -Application-Insights|[Enable Azure Monitor OpenTelemetry for .NET, Node.js, and Python applications (preview)](app/opentelemetry-enable.md)|Updated Node.js sample code for JavaScript and TypeScript.| -Application-Insights|[System performance counters in Application Insights](app/performance-counters.md)|Updated code samples for .NET 6/7.| -Application-Insights|[Sampling in Application Insights](app/sampling.md)|Updated code samples for .NET 6/7.| -Application-Insights|[Availability alerts](app/availability-alerts.md)|Rewritten with new guidance and screenshots.| -Change-Analysis|[Tutorial: Track a web app outage by using Change Analysis](change/tutorial-outages.md)|Changed tutorial content to reflect changes to repo and removed and replaced sections.| -Containers|[Configure Azure CNI networking in Azure Kubernetes Service](/azure/aks/configure-azure-cni)|Added steps to enable IP subnet usage.| -Containers|[Reports in Container insights](containers/container-insights-reports.md)|Updated to reflect the steps to enable IP subnet usage.| -Essentials|[Best practices for data collection rule creation and management in Azure Monitor](essentials/data-collection-rule-best-practices.md)|New article.| -Essentials|[Configure self-managed Grafana to use Azure Monitor managed service for Prometheus (preview) with Azure Active Directory](essentials/prometheus-self-managed-grafana-azure-active-directory.md)|New article: Configured self-managed Grafana to use Azure Monitor managed service for Prometheus (preview) with Azure Active Directory.| -Logs|[Azure Monitor SCOM Managed Instance (preview)](vm/scom-managed-instance-overview.md)|New article.| -Logs|[Set a table's log data plan to Basic or Analytics](logs/logs-table-plans.md)|Updated the list of tables that support Basic Logs.| -Virtual-Machines|[Tutorial: Create availability alert rule for Azure virtual machine (preview)](vm/tutorial-monitor-vm-alert-availability.md)|New article.| -Virtual-Machines|[Tutorial: Enable recommended alert rules for Azure virtual machine](vm/tutorial-monitor-vm-alert-recommended.md)|New article.| -Virtual-Machines|[Tutorial: Enable monitoring with VM insights for Azure virtual machine](vm/tutorial-monitor-vm-enable-insights.md)|New article.| -Virtual-Machines|[Monitor Azure virtual machines](/azure/virtual-machines/monitor-vm)|Updated for Azure Monitor Agent and availability metric.| -Virtual-Machines|[Enable VM insights by using Azure Policy](vm/vminsights-enable-policy.md)|Updated flow for enabling VM insights with Azure Monitor Agent by using Azure Policy.| -Visualizations|[Creating an Azure Workbook](visualize/workbooks-create-workbook.md)|Added tutorial on resource-centric log queries in workbooks.| --## November 2022 --|Subservice| Article | Description | -|||| -General|[Cost optimization and Azure Monitor](best-practices-cost.md)|Rewritten to align with Azure Well-Architected Framework. Moved detailed content to other articles and linked from here.| -Agents|[Collect SNMP trap data with Azure Monitor Agent](agents/data-collection-snmp-data.md)|New tutorial: Explains how to collect Simple Network Management Protocol (SNMP) traps by using Azure Monitor Agent.| -Alerts|[Create a new alert rule](alerts/alerts-create-new-alert-rule.md)|Resource Health alerts and Service Health alerts are created by using the same simplified workflow as all other alert types.| -Alerts|[Manage your alert rules](alerts/alerts-manage-alert-rules.md)|Recommended alert rules are enabled for Azure Kubernetes Service and Log Analytics workspace resources in addition to VMs.| -Application-insights|[Sampling in Application Insights](app/sampling.md)|ASP.NET Core applications can be configured in code or through the `appsettings.json` file. Removed conflicting information.| -Application-insights|[How many Application Insights resources should I deploy?](app/create-workspace-resource.md#how-many-application-insights-resources-should-i-deploy)|Added clarification on setting iKey dynamically in code.| -Application-insights|[Application Map: Triage distributed applications](app/app-map.md)|Documented App Map Filters, an exciting new feature.| -Application-insights|[Enable Application Insights for ASP.NET Core applications](/previous-versions/azure/azure-monitor/app/tutorial-asp-net-core)|The Azure Café sample app is now hosted and linked on Git.| -Application-insights|[What is auto-instrumentation for Azure Monitor Application Insights?](app/codeless-overview.md)|Updated the auto-instrumentation supported languages chart.| -Application-insights|[Application monitoring for Azure App Service and ASP.NET](app/azure-web-apps-net.md)|Corrected links to check versions.| -Application-insights|[Sampling overrides (preview) - Azure Monitor Application Insights for Java](app/java-standalone-sampling-overrides.md)|Updated OpenTelemetry Span information for Java.| -Autoscale|[Understand autoscale settings](autoscale/autoscale-understanding-settings.md)|Refreshed and updated.| -Autoscale|[Overview of common autoscale patterns](autoscale/autoscale-common-scale-patterns.md)|Refreshed and updated.| -Essentials|[Azure Monitor managed service for Prometheus (preview)](essentials/prometheus-metrics-scrape-default.md)|Restructured Prometheus content.| -Essentials|[Configure remote write for Azure Monitor managed service for Prometheus by using Azure Active Directory authentication (preview)](essentials/prometheus-remote-write.md)|New article.| -Essentials|[Azure Monitor workspace (preview)](essentials/azure-monitor-workspace-overview.md)|Added Bicep example.| -Essentials|[Migrate from diagnostic settings storage retention to Azure Storage lifecycle management](essentials/migrate-to-azure-storage-lifecycle-policy.md)|Added deprecation note.| -Essentials|[Diagnostic settings in Azure Monitor](essentials/diagnostic-settings.md)|All destination endpoints support TLS 1.2.| -Logs|[Cost optimization and Azure Monitor](best-practices-cost.md)|Added cost information and removed preview label.| -Logs|[Diagnostic settings in Azure Monitor](essentials/diagnostic-settings.md)|Added section on controlling costs with transformations.| -Logs|[Analyze usage in a Log Analytics workspace](logs/analyze-usage.md)|Added Kusto Query Language query that retrieves data volumes for charged data types.| -Logs|[Access the Azure Monitor Log Analytics API](logs/api/timeouts.md)|Refreshed and updated.| -Logs|[Collect text logs with the Log Analytics agent in Azure Monitor](agents/data-sources-custom-logs.md)|Added new table management section with new articles on table configuration options, schema management, and custom table creation.| -Logs|[Azure Monitor Metrics overview](essentials/data-platform-metrics.md)| Added a new Azure SDK client library for Go.| -Logs|[Azure Monitor Log Analytics API overview](logs/api/overview.md)| Added a new Azure SDK client library for Go.| -Logs|[Azure Monitor Logs overview](logs/data-platform-logs.md)| Added a new Azure SDK client library for Go.| -Logs|[Log queries in Azure Monitor](logs/log-query-overview.md)| Added a new Azure SDK client library for Go.| -Logs|[Set a table's log data plan to Basic or Analytics](logs/logs-table-plans.md)|Added new tables to the list of tables that support the Basic Log data plan.| -Visualizations|[Monitor your Azure services in Grafana](visualize/grafana-plugin.md)|The Grafana integration is generally available and is no longer in preview.| -Visualizations|[Get started with Azure Workbooks](visualize/workbooks-getting-started.md)|Added instructions for how to share workbooks.| --## October 2022 --|Subservice| Article | Description | -|||| -|General|Table of contents|Updated the Azure Monitor table of contents (TOC). The new TOC structure better reflects the customer experience and makes it easier for users to navigate and discover our content.| -Alerts|[Connect Azure to ITSM tools by using IT Service Management](./alerts/itsmc-definition.md)|Deprecating support for sending ITSM actions and events to ServiceNow. Instead, use ITSM actions in action groups based on Azure alerts to create work items in your ITSM tool.| -Alerts|[Create a new alert rule](./alerts/alerts-create-new-alert-rule.md)|New PowerShell commands to create and manage log alerts.| -Alerts|[Types of Azure Monitor alerts](alerts/alerts-types.md)|Updated to include Prometheus alerts.| -Alerts|[Customize alert notifications by using Logic Apps](./alerts/alerts-logic-apps.md)|New article: Use alerts to send emails or Teams posts by using Logic Apps.| -Application-insights|[Sampling in Application Insights](./app/sampling.md)|Prioritized the "When to use sampling" and "How sampling works" sections as prerequisite information for the article.| -Application-insights|[What is auto-instrumentation for Azure Monitor Application Insights?](./app/codeless-overview.md)|Overhauled the auto-instrumentation overview with links and footnotes.| -Application-insights|[Enable Azure Monitor OpenTelemetry for .NET, Node.js, and Python applications (preview)](./app/opentelemetry-enable.md)|Open Telemetry Metrics are now available for .NET, Node.js and Python applications.| -Application-insights|[Find and diagnose performance issues with Application Insights](./app/tutorial-performance.md)|Replaced the URL Ping (Classic) Test with Standard Test step-by-step instructions.| -Application-insights|[Application Insights API for custom events and metrics](./app/api-custom-events-metrics.md)|Added flushing information to the FAQ.| -Application-insights|[Azure AD authentication for Application Insights](./app/azure-ad-authentication.md)|Updated the `TelemetryConfiguration` code sample by using .NET.| -Application-insights|[Using Azure Monitor Application Insights with Spring Boot](./app/java-spring-boot.md)|Updated the Spring Boot information to 3.4.2.| -Application-insights|[Configuration options: Azure Monitor Application Insights for Java](./app/java-standalone-config.md)|Added new features on Capture Log4j Markers and Logback Markers as custom properties on the corresponding trace (log message) telemetry.| -Application-insights|[Create custom KPI dashboards by using Application Insights](./app/overview-dashboard.md#create-custom-kpi-dashboards-using-application-insights)|Refreshed with new screenshots and instructions.| -Application-insights|[Share Azure dashboards by using Azure role-based access control](../azure-portal/azure-portal-dashboard-share-access.md)|Refreshed with new screenshots and instructions.| -Application-insights|[Application monitoring for Azure App Service and ASP.NET](./app/azure-web-apps-net.md)|Added important notes about System.IO.FileNotFoundException after an 2.8.44 auto-instrumentation upgrade.| -Application-insights|[Geolocation and IP address handling](./app/ip-collection.md)| Updated geolocation lookup information.| -Containers|[Metric alert rules in Container insights (preview)](./containers/container-insights-metric-alerts.md)|Updated to include Container insights metric alerts.| -Containers|[Custom metrics collected by Container insights](/previous-versions/azure/azure-monitor/containers/container-insights-custom-metrics)|New article.| -Containers|[Overview of Container insights in Azure Monitor](containers/container-insights-overview.md)|Rewritten to simplify onboarding options.| -Containers|[Enable Container insights for Azure Kubernetes Service cluster](containers/container-insights-enable-aks.md?tabs=azure-cli)|Updated to combine new and existing clusters.| -Containers Prometheus|[Query logs from Container insights](containers/container-insights-log-query.md)|Updated to include log queries for Prometheus data.| -Containers Prometheus|[Collect Prometheus metrics with Container insights](containers/container-insights-prometheus.md?tabs=cluster-wide)|Updated to include Azure Monitor managed service for Prometheus.| -Essentials Prometheus|[Metrics in Azure Monitor](essentials/data-platform-metrics.md)|Updated to include Azure Monitor managed service for Prometheus.| -Essentials Prometheus|<ul> <li> [Azure Monitor workspace overview (preview)](essentials/azure-monitor-workspace-overview.md?tabs=azure-portal) </li><li> [Overview of Azure Monitor managed service for Prometheus (preview)](essentials/prometheus-metrics-overview.md) </li><li>[Rule groups in Azure Monitor managed service for Prometheus (preview)](essentials/prometheus-rule-groups.md)</li><li>[Remote-write in Azure Monitor managed service for Prometheus (preview)](essentials/prometheus-remote-write-managed-identity.md) </li><li>[Use Azure Monitor managed service for Prometheus (preview) as data source for Grafana](essentials/prometheus-grafana.md)</li><li>[Troubleshoot collection of Prometheus metrics in Azure Monitor (preview)](essentials/prometheus-metrics-troubleshoot.md)</li><li>[Default Prometheus metrics configuration in Azure Monitor (preview)](essentials/prometheus-metrics-scrape-default.md)</li><li>[Scrape Prometheus metrics at scale in Azure Monitor (preview)](essentials/prometheus-metrics-scrape-scale.md)</li><li>[Customize scraping of Prometheus metrics in Azure Monitor (preview)](essentials/prometheus-metrics-scrape-configuration.md)</li><li>[Create, validate, and troubleshoot custom configuration file for Prometheus metrics in Azure Monitor (preview)](essentials/prometheus-metrics-scrape-validate.md)</li><li>[Minimal Prometheus ingestion profile in Azure Monitor (preview)](essentials/prometheus-metrics-scrape-configuration-minimal.md)</li><li>[Collect Prometheus metrics from AKS cluster (preview)](containers/kubernetes-monitoring-enable.md#enable-prometheus-and-grafana)</li><li>[Send Prometheus metrics to multiple Azure Monitor workspaces (preview)](essentials/prometheus-metrics-multiple-workspaces.md) </li></ul> |New articles: Public preview of Azure Monitor managed service for Prometheus.| -Essentials Prometheus|[Azure Monitor managed service for Prometheus remote write - managed identity (preview)](./essentials/prometheus-remote-write-managed-identity.md)|Added information that verifies Prometheus remote write is working correctly.| -Essentials|[Azure resource logs](./essentials/resource-logs.md)|Clarified which blob's logs are written to, and when.| -Essentials|[Resource Manager template samples for Azure Monitor](resource-manager-samples.md?tabs=portal)|Added template deployment methods.| -Essentials|[Azure Monitor service limits](service-limits.md)|Added Azure Monitor managed service for Prometheus.| -Logs|[Manage access to Log Analytics workspaces](./logs/manage-access.md)|Table-level role-based access control lets you give specific users or groups read access to particular tables.| -Logs|[Configure Basic Logs in Azure Monitor](./logs/logs-table-plans.md)|Added information on general availability of the Basic Logs data plan, retention and archiving, search job, and the table management user experience in the Azure portal.| -Logs|[Guided project - Analyze logs in Azure Monitor with KQL - Training](/training/modules/analyze-logs-with-kql/)|New Learn module: Learn to write KQL queries to retrieve and transform log data to answer common business and operational questions.| -Logs|[Detect and analyze anomalies with KQL in Azure Monitor](logs/kql-machine-learning-azure-monitor.md)|New tutorial: Walkthrough of how to use KQL for time-series analysis and anomaly detection in Azure Monitor Log Analytics. | -Virtual-machines|[Enable VM insights for a hybrid virtual machine](./vm/vminsights-enable-hybrid.md)|Updated versions of standalone installers.| -Visualizations|[Retrieve legacy Application Insights workbooks](./visualize/workbooks-retrieve-legacy-workbooks.md)|New article: Access legacy workbooks in the Azure portal.| -Visualizations|[Azure Workbooks](./visualize/workbooks-overview.md)|New video to see how you can use Azure Workbooks to get insights and visualize your data. | --## September 2022 --### Agents --| Article | Description | -||| -|[Azure Monitor Agent overview](./agents/agents-overview.md)|Added Azure Monitor Agent support for Arm64-based virtual machines for a number of distributions. <br><br>Azure Monitor Agent and legacy agents don't support machines and appliances that run heavily customized or stripped-down versions of operating system distributions. <br><br>Azure Monitor Agent versions 1.15.2 and higher now support Syslog RFC formats, including Cisco Meraki, Cisco ASA, Cisco FTD, Sophos XG, Juniper Networks, Corelight Zeek, CipherTrust, NXLog, McAfee, and Common Event Format (CEF).| --### Alerts --| Article | Description | -||| -|[Convert ITSM actions that send events to ServiceNow to Secure Webhook actions](./alerts/itsm-convert-servicenow-to-webhook.md)|As of September 2022, we're starting the three-year process of deprecating support of using ITSM actions to send events to ServiceNow. Learn how to convert ITSM actions that send events to ServiceNow to Secure Webhook actions.| -|[Create a new alert rule](./alerts/alerts-create-new-alert-rule.md)|Added description of all available monitoring services to **Create a new alert rule** and **Alert processing rules** pages. <br><br>Added support for regional processing for metric alert rules that monitor a custom metric with the scope defined as one of the supported regions. <br><br> Clarified that selecting the **Automatically resolve alerts** setting makes log alerts stateful.| -|[Types of Azure Monitor alerts](alerts/alerts-types.md)|Azure Database for PostgreSQL - Flexible Servers is supported for monitoring multiple resources.| -|[Upgrade legacy rules management to the current Scheduled Query Rules API from legacy Log Analytics Alert API](./alerts/alerts-log-api-switch.md)|The process of moving legacy log alert rules management from the legacy API to the current API is now supported by the government cloud.| --### Application Insights --| Article | Description | -||| -|[Azure Monitor OpenTelemetry-based auto-instrumentation for Java applications](./app/opentelemetry-enable.md?tabs=java)|Added new OpenTelemetry `@WithSpan` annotation guidance.| -|[Capture Application Insights custom metrics with .NET and .NET Core](/previous-versions/azure/azure-monitor/app/tutorial-asp-net-custom-metrics)|Updated tutorial steps and images.| -|[Configuration options: Azure Monitor Application Insights for Java](./app/opentelemetry-enable.md)|Updated connection string guidance.| -|[Enable Application Insights for ASP.NET Core applications](/previous-versions/azure/azure-monitor/app/tutorial-asp-net-core)|Updated tutorial steps and images.| -|[Enable Azure Monitor OpenTelemetry Exporter for .NET, Node.js, and Python applications (preview)](./app/opentelemetry-enable.md)|Fixed the product feedback link at the bottom of each document.| -|[Filter and preprocess telemetry in the Application Insights SDK](./app/api-filtering-sampling.md)|Added sample initializer to control which client IP gets used as part of geo-location mapping.| -|[Java Profiler for Azure Monitor Application Insights](./app/java-standalone-profiler.md)|Announced the new Java Profiler at Ignite. Read all about it.| -|[Release notes for Azure Web App extension for Application Insights](./app/web-app-extension-release-notes.md)|Added release notes for 2.8.44 and 2.8.43.| -|[Resource Manager template samples for creating Application Insights resources](./app/create-workspace-resource.md)|Fixed inaccurate tagging of workspace-based resources as still in preview.| -|[Unified cross-component transaction diagnostics](./app/transaction-search-and-diagnostics.md?tabs=transaction-diagnostics)|Added a FAQ section to help troubleshoot Azure portal errors like "error retrieving data."| -|[Upgrading from Application Insights Java 2.x SDK](./app/java-standalone-upgrade-from-2x.md)|Added more upgrade guidance. Java 2.x is deprecated.| -|[Using Azure Monitor Application Insights with Spring Boot](./app/java-spring-boot.md)|Updated configuration options.| --### Autoscale -| Article | Description | -||| -|[Autoscale with multiple profiles](./autoscale/autoscale-multiprofile.md)|New article: Using multiple profiles in autoscale with CLI PowerShell and templates.| -|[Flapping in autoscale](./autoscale/autoscale-flapping.md)|New article: Flapping in autoscale.| -|[Understand autoscale settings](./autoscale/autoscale-understanding-settings.md)|Clarified how often autoscale runs.| --### Change Analysis -| Article | Description | -||| -|[Troubleshoot Azure Monitor's Change Analysis](./change/change-analysis-troubleshoot.md)|Added section about partial data and how to mitigate to the troubleshooting guide.| --### Essentials -| Article | Description | -||| -|[Structure of transformation in Azure Monitor (preview)](./essentials/data-collection-transformations-structure.md)|Added information about new KQL functions that are supported.| --### Virtual machines -| Article | Description | -||| -|[Migrate from Service Map to Azure Monitor VM insights](./vm/vminsights-migrate-from-service-map.md)|Added a new article with guidance for migrating from the Service Map solution to Azure Monitor VM insights.| --### Network Insights --| Article | Description | -||| -|[Network Insights](../network-watcher/network-insights-overview.md)| Onboarded the new topology experience to Network Insights in Azure Monitor.| --### Visualizations -| Article | Description | -||| -|[Access deprecated troubleshooting guides in Azure Workbooks](./visualize/workbooks-access-troubleshooting-guide.md)|New article: Access deprecated troubleshooting guides in Azure Workbooks.| --## August 2022 --### Agents --| Article | Description | -||| -|[Log Analytics agent overview](agents/log-analytics-agent.md)|Restructured the "Agents" section and rewrote the *Agents overview* article to reflect that Azure Monitor Agent is the primary agent for collecting monitoring data.| -|[Dependency analysis in Azure Migrate Discovery and assessment - Azure Migrate](../migrate/concepts-dependency-visualization.md)|Revamped the guidance for migrating from the Log Analytics agent to Azure Monitor Agent.| --### Alerts --| Article | Description | -|:|:| -|[Create Azure Monitor alert rules](alerts/alerts-create-new-alert-rule.md)|Added support for data processing in a specified region, for action groups, and for metric alert rules that monitor a custom metric.| --### Application Insights --| Article | Description | -||| -|[Application Insights Overview dashboard](app/overview-dashboard.md)|Added important information clarifying that moving or renaming resources breaks dashboards, with more instructions on how to resolve this scenario.| -|[Application Insights override default SDK endpoints](/previous-versions/azure/azure-monitor/app/create-new-resource#override-default-endpoints)|Clarified that endpoint modification isn't recommended and to use connection strings instead.| -|[Continuous export of telemetry from Application Insights](/previous-versions/azure/azure-monitor/app/export-telemetry)|Added important information about avoiding duplicates when you save diagnostic logs in a Log Analytics workspace.| -|[Dependency tracking in Application Insights with OpenCensus Python](/previous-versions/azure/azure-monitor/app/opencensus-python-dependency)|Updated Django sample application and documentation in the Azure Monitor OpenCensus Python samples repository.| -|[Incoming request tracking in Application Insights with OpenCensus Python](/previous-versions/azure/azure-monitor/app/opencensus-python-request)|Updated Django sample application and documentation in the Azure Monitor OpenCensus Python samples repository.| -|[Monitor Python applications with Azure Monitor](/previous-versions/azure/azure-monitor/app/opencensus-python)|Updated Django sample application and documentation in the Azure Monitor OpenCensus Python samples repository.| -|[Configuration options: Azure Monitor Application Insights for Java](app/java-standalone-config.md)|Updated connection string overrides example.| -|[Application Insights SDK for ASP.NET Core applications](/previous-versions/azure/azure-monitor/app/tutorial-asp-net-core)|Added a new tutorial with step-by-step instructions on how to use the Application Insights SDK with .NET Core applications.| -|[Application Insights SDK support guidance](app/sdk-support-guidance.md)|Updated and clarified the SDK support guidance.| -|[Application Insights: Dependency autocollection](app/asp-net-dependencies.md#dependency-auto-collection)|Updated the latest currently supported node.js modules.| -|[Application Insights custom metrics with .NET and .NET Core](/previous-versions/azure/azure-monitor/app/tutorial-asp-net-custom-metrics)|Added a new tutorial with step-by-step instructions on how to enable custom metrics with .NET applications.| -|[Migrate an Application Insights classic resource to a workspace-based resource](app/convert-classic-resource.md)|Added a comprehensive FAQ section to assist with migration to workspace-based resources.| -|[Configuration options: Azure Monitor Application Insights for Java](app/java-standalone-config.md)| Updated this article for 3.4.0-BETA.| --### Autoscale --| Article | Description | -||| -|[Autoscale in Microsoft Azure](autoscale/autoscale-overview.md)|Updated conceptual diagrams.| -|[Use predictive autoscale to scale out before load demands in Virtual Machine Scale Sets (preview)](autoscale/autoscale-predictive.md)|Predictive autoscale (preview) is now available in all regions.| --### Change Analysis --| Article | Description | -||| -|[Enable Change Analysis](change/change-analysis-enable.md)| Added a note for slot-level enablement.| -|[Tutorial: Track a web app outage by using Change Analysis](change/tutorial-outages.md)| Added setup steps to the tutorial.| -|[Use Change Analysis in Azure Monitor to find web-app issues](change/change-analysis.md)|Updated limitations.| -|[Observability data in Azure Monitor](observability-data.md)| Added a "Changes" section.| --### Containers --| Article | Description | -||| -|[Monitor a deployed Azure Kubernetes Service cluster](containers/container-insights-enable-existing-clusters.md)|Added section on using a private link with Container insights.| --### Essentials --| Article | Description | -||| -|[Azure activity log](essentials/activity-log.md)|Added instructions for how to stop collecting activity logs by using the legacy collection method.| -|[Azure activity log insights](essentials/activity-log-insights.md)|Created a separate activity log insights article in the "Insights" section.| --### Logs --| Article | Description | -||| -|[Configure data retention and archive in Azure Monitor Logs (preview)](logs/data-retention-configure.md)|Clarified how data retention and archiving work in Azure Monitor Logs to address repeated customer inquiries.| --## July 2022 -### General --| Article | Description | -|:|:| -|[Sources of data in Azure Monitor](data-sources.md)|Updated with Azure Monitor Agent and the Logs Ingestion API.| --### Agents --| Article | Description | -|:|:| -|[Azure Monitor Agent overview](agents/agents-overview.md)| Restructured the "Agents" section. A single Azure Monitor Agent is replacing all of Azure Monitor's legacy monitoring agents. -|[Enable network isolation for Azure Monitor Agent](agents/azure-monitor-agent-data-collection-endpoint.md)|Rewritten to better describe configuration of network isolation. --### Alerts --| Article | Description | -|:|:| -|[Azure Monitor alerts overview](alerts/alerts-overview.md)|Updated the logic for the time to resolve behavior in stateful log alerts. --### Application Insights --| Article | Description | -|:|:| -|[Azure Monitor Application Insights Java](app/opentelemetry-enable.md?tabs=java)|Updated the Supported Custom Telemetry table in OpenTelemetry-based auto-instrumentation for Java applications. -|[Application Insights API for custom events and metrics](app/api-custom-events-metrics.md)|Added clarification that valueCount and itemCount have a minimum value of 1. -|[Telemetry sampling in Application Insights](app/sampling.md)|Updated sampling documentation to warn of the potential impact on alerting accuracy. -|[Azure Monitor Application Insights Java (redirect to OpenTelemetry)](app/java-in-process-agent-redirect.md)|Java auto-instrumentation now redirects to OpenTelemetry documentation. -|[Application Insights for ASP.NET Core applications](app/asp-net-core.md)|Updated .NET Core FAQ. -|[Create a new Azure Monitor Application Insights workspace-based resource](app/create-workspace-resource.md)|Linked to Microsoft Insights components for more information on properties. -|[Application Insights SDK support guidance](app/sdk-support-guidance.md)|Updated and clarified SDK support guidance. -|[Azure Monitor Application Insights Java](app/opentelemetry-enable.md?tabs=java)|Updated example code. -|[IP addresses used by Azure Monitor](app/ip-addresses.md)|Updated the IP/FQDN table. -|[Continuous export of telemetry from Application Insights](/previous-versions/azure/azure-monitor/app/export-telemetry)|Updated and clarified the continuous export notice. -|[Set up availability alerts with Application Insights](app/availability-alerts.md)|Added "Custom Alert Rule" and "Alert Frequency" sections. --### Autoscale --| Article | Description | -|:|:| -| [Set up autoscale for a web app with a custom metric](autoscale/autoscale-custom-metric.md) |Rewritten to improve clarity.| -[Overview of autoscale in Azure](autoscale/autoscale-overview.md)|Rewritten to improve clarity.| --### Containers --| Article | Description | -|:|:| -|[Overview of Container insights](containers/container-insights-overview.md)|Added information about deprecation of Docker support.| -|[Enable Container insights](containers/container-insights-onboard.md)|Updated all Container insights content for new support of managed identity authentication by using Azure Monitor Agent.| --### Essentials --| Article | Description | -|:|:| -|[Tutorial: Editing data collection rules](essentials/data-collection-rule-edit.md)|New article.| -|[Data collection rules in Azure Monitor](essentials/data-collection-rule-overview.md)|Rewritten to improve clarity.| -|[Data collection transformations](essentials/data-collection-transformations.md)|Rewritten to improve clarity.| -|[Data collection in Azure Monitor](essentials/data-collection.md)|New article.| -|[Migrate from diagnostic settings storage retention to Azure Storage lifecycle policy](essentials/migrate-to-azure-storage-lifecycle-policy.md)|New article.| --### Logs --| Article | Description | -|:|:| -|[Logs Ingestion API in Azure Monitor (preview)](logs/logs-ingestion-api-overview.md)|Custom logs API renamed to Logs Ingestion API. -|[Tutorial: Send data to Azure Monitor Logs by using the REST API (Resource Manager templates)](logs/tutorial-logs-ingestion-api.md)|Custom logs API renamed to Logs Ingestion API. -|[Tutorial: Send data to Azure Monitor Logs by using the REST API (Azure portal)](logs/tutorial-logs-ingestion-portal.md)|Custom logs API renamed to Logs Ingestion API. --### Virtual machines --| Article | Description | -|:|:| -|[What is VM insights?](vm/vminsights-overview.md)|Updated all VM insights content for new support of Azure Monitor Agent. --## June 2022 --### General --| Article | Description | -|:|:| -| [Tutorial: Editing data collection rules](essentials/data-collection-rule-edit.md) | New article.| --### Application Insights --| Article | Description | -|:|:| -| [Application Insights logging with .NET](app/ilogger.md) | Added connection string sample code.| -| [Application Insights SDK support guidance](app/sdk-support-guidance.md) | Updated SDK supportability guidance. | -| [Azure AD authentication for Application Insights](app/azure-ad-authentication.md) | Azure AD authenticated telemetry ingestion reached general availability.| -| [Application Insights for JavaScript web apps](app/javascript.md) | Our Java on-premises page is retired and redirected to [Azure Monitor OpenTelemetry-based auto-instrumentation for Java applications](app/opentelemetry-enable.md?tabs=java).| -| [Application Insights Telemetry Data Model: Telemetry context](app/data-model-complete.md#context) | Clarified that Anonymous User ID is simply User.Id for easy selection in IntelliSense.| -| [Continuous export of telemetry from Application Insights](/previous-versions/azure/azure-monitor/app/export-telemetry) | On February 29, 2024, continuous export will be deprecated as part of the classic Application Insights deprecation.| -| [Dependency tracking in Application Insights](app/asp-net-dependencies.md) | Updated the Azure Event Hubs Client SDK and Azure Service Bus Client SDK information.| -| [Monitor Azure App Service performance and .NET Core](app/azure-web-apps-net-core.md) | Updated Linux troubleshooting guidance. | -| [Performance counters in Application Insights](app/performance-counters.md) | Added a prerequisite section to ensure performance counter data is accessible.| --### Agents --| Article | Description | -|:|:| -| [Collect text and IIS logs with Azure Monitor Agent (preview)](agents/data-collection-text-log.md) | Added "Troubleshooting" section.| -| [Tools for migrating to Azure Monitor Agent from legacy agents](agents/azure-monitor-agent-migration-tools.md) | New article: Explains how to install and use tools for migrating from legacy agents to the new Azure Monitor Agent.| --### Visualizations -Azure Monitor Workbooks documentation previously resided on an external GitHub repository. We've migrated all Azure Workbooks content to the same repo as all other Azure Monitor content. --## May 2022 --### General --| Article | Description | -|:|:| -| [Azure Monitor cost and usage](cost-usage.md) | Added standard web tests to table.<br>Added explanation of billable GB calculation. | -| [Azure Monitor overview](overview.md) | Updated overview diagram. | --### Agents --| Article | Description | -|:|:| -| [Azure Monitor Agent extension versions](agents/azure-monitor-agent-extension-versions.md) | Updated to latest extension version. | -| [Azure Monitor Agent overview](agents/azure-monitor-agent-overview.md) | Added supported resource types. | -| [Collect text and IIS logs with Azure Monitor Agent (preview)](agents/data-collection-text-log.md) | Corrected error in data collection rule. | -| [Overview of the Azure monitoring agents](agents/agents-overview.md) | Added new OS supported for agent. | -| [Resource Manager template samples for agents](agents/resource-manager-agent.md) | Added Bicep examples. | -| [Rsyslog data not uploaded due to Full Disk space issue on Azure Monitor Agent Linux Agent](agents/azure-monitor-agent-troubleshoot-linux-vm-rsyslog.md) | New article. | -| [Troubleshoot the Azure Monitor Agent on Linux virtual machines and scale sets](agents/azure-monitor-agent-troubleshoot-linux-vm.md) | New article. | -| [Troubleshoot the Azure Monitor Agent on Windows Arc-enabled server](agents/azure-monitor-agent-troubleshoot-windows-arc.md) | New article. | -| [Troubleshoot the Azure Monitor Agent on Windows virtual machines and scale sets](agents/azure-monitor-agent-troubleshoot-windows-vm.md) | New article. | --### Alerts --| Article | Description | -|:|:| -| [Configure Azure to connect ITSM tools by using Secure Webhook](alerts/itsm-connector-secure-webhook-connections-azure-configuration.md) | Added the workflow for ITSM management and removed all references to System Center Service Manager. | -| [Overview of Azure Monitor Alerts](alerts/alerts-overview.md) | Complete rewrite. | -| [Resource Manager template samples for log search alerts](alerts/resource-manager-alerts-log.md) | Added Bicep samples for alerting to the Resource Manager template samples articles. | -| [Supported resources for metric alerts in Azure Monitor](alerts/alerts-metric-near-real-time.md) | Added a newly supported resource type. | --### Application Insights --| Article | Description | -|:|:| -| [Application Map in Application Insights](app/app-map.md) | Application Maps Intelligent View feature. | -| [Application Insights for ASP.NET Core applications](app/asp-net-core.md) | The `telemetry.Flush()` guidance is now available. | -| [Diagnose with Live Metrics Stream](app/live-stream.md) | Updated information on using unsecure control channel. | -| [Migrate an Azure Monitor Application Insights classic resource to a workspace-based resource](app/convert-classic-resource.md) | Schema change documentation is now available. | -| [Profile production apps in Azure with Application Insights Profiler](profiler/profiler-overview.md) | Profiler documentation now has a new home in the TOC. | --All references to unsupported versions of .NET and .NET CORE are scrubbed from Application Insights product documentation. See [.NET and .NET Core Support Policy](https://dotnet.microsoft.com/platform/support/policy/dotnet-core). --### Change Analysis --| Article | Description | -|:|:| -| [Navigate to a change by using custom filters in Change Analysis](change/change-analysis-custom-filters.md) | New article. | -| [Pin and share a Change Analysis query to the Azure dashboard](change/change-analysis-query.md) | New article. | -| [Use Change Analysis in Azure Monitor to find web app issues](change/change-analysis.md) | Added details for enabling web app in-guest changes. | --### Containers --| Article | Description | -|:|:| -| [Configure ContainerLogv2 schema (preview) for Container insights](containers/container-insights-logs-schema.md) | New article: Describes new schema for container logs. | -| [Enable Container insights](containers/container-insights-onboard.md) | Rewritten to improve clarity. | -| [Resource Manager template samples for Container insights](/azure/azure-monitor/containers/kubernetes-monitoring-enable?tabs=arm#enable-container-insights) | Added Bicep examples. | --### Insights --| Article | Description | -|:|:| -| [Troubleshoot SQL Insights (preview)](/azure/azure-sql/database/sql-insights-troubleshoot) | Added known issue for OS computer name. | -### Logs --| Article | Description | -|:|:| -| [Azure Monitor customer-managed key](logs/customer-managed-keys.md) | Updated limitations and constraint. | -| [Design a Log Analytics workspace architecture](logs/workspace-design.md) | Rewritten to better describe decision criteria and include Microsoft Sentinel considerations. | -| [Manage access to Log Analytics workspaces](logs/manage-access.md) | Consolidated and rewrote all content on configuring workspace access. | -| [Restore logs in Azure Monitor (preview)](logs/restore.md) | Documented new Log Analytics table management configuration UI, which lets you configure a table's log plan and archive and retention policies. | --### Virtual machines --| Article | Description | -|:|:| -| [Migrate from VM insights guest health (preview) to Azure Monitor log alerts](vm/vminsights-health-migrate.md) | New article: Describes process to replace VM guest health with alert rules. | -| [VM insights guest health (preview)](vm/vminsights-health-overview.md) | Added deprecation statement. | -- |
| azure-netapp-files | Application Volume Group Introduction | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-netapp-files/application-volume-group-introduction.md | Application volume group for SAP HANA extension one offers support for: * [Standard network features](azure-netapp-files-network-topologies.md) - Application volume group for SAP HANA now supports selecting Standard network features for all volumes in the volume group. The availability of Standard network features simplifies deployment, avoiding the manual process for AvSet pinning and eliminating the need for availability sets. - + Application volume group for SAP HANA now supports selecting Standard network features for all volumes in the volume group. Standard network features support enhanced security including [network security groups (NSGs)](../virtual-network/network-security-group-how-it-works.md) ## Next steps |
| azure-netapp-files | Azure Netapp Files Performance Considerations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-netapp-files/azure-netapp-files-performance-considerations.md | Throughput limits are a combination of read and write speed. The throughput limi Typical storage performance considerations contribute to the total performance delivered. The considerations include read and write mix, the transfer size, random or sequential patterns, and many other factors. -Metrics are reported as aggregates of multiple data points collected during a five-minute interval. For more information about metrics aggregation, see [Azure Monitor Metrics aggregation and display explained](../azure-monitor/essentials/metrics-aggregation-explained.md). +Metrics are reported as aggregates of multiple data points collected during a five-minute interval. For more information about metrics aggregation, see [Azure Monitor Metrics aggregation and display explained](/azure/azure-monitor/essentials/metrics-aggregation-explained). The maximum empirical throughput that has been observed in testing is 4,500 MiB/s. At the Premium storage tier, an automatic QoS volume quota of 70.31 TiB provisions a throughput limit high enough to achieve this performance level. |
| azure-netapp-files | Azure Netapp Files Performance Metrics Volumes | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-netapp-files/azure-netapp-files-performance-metrics-volumes.md | You can also create a dashboard in Azure Monitor for Azure NetApp Files by going ### Azure Monitor API access -You can access Azure NetApp Files counters by using REST API calls. See [Supported metrics with Azure Monitor: Microsoft.NetApp/netAppAccounts/capacityPools/Volumes](../azure-monitor/essentials/metrics-supported.md#microsoftnetappnetappaccountscapacitypoolsvolumes) for counters for capacity pools and volumes. +You can access Azure NetApp Files counters by using REST API calls. See [Supported metrics with Azure Monitor: Microsoft.NetApp/netAppAccounts/capacityPools/Volumes](/azure/azure-monitor/essentials/metrics-supported#microsoftnetappnetappaccountscapacitypoolsvolumes) for counters for capacity pools and volumes. The following example shows a GET URL for viewing logical volume size: |
| azure-netapp-files | Cross Region Replication Display Health Status | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-netapp-files/cross-region-replication-display-health-status.md | You can view replication status on the source volume or the destination volume. ## Set alert rules to monitor replication -Create [alert rules in Azure Monitor](../azure-monitor/alerts/alerts-overview.md) to help you monitor the status of cross-region replication: +Create [alert rules in Azure Monitor](/azure/azure-monitor/alerts/alerts-overview) to help you monitor the status of cross-region replication: 1. In Azure Monitor, select **Alerts**. 2. From the **Alerts** window, select the **Create** dropdown then **Alert rule**. |
| azure-netapp-files | Faq Application Volume Group | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-netapp-files/faq-application-volume-group.md | Title: FAQs About Azure NetApp Files application volume groups | Microsoft Docs -description: answers frequently asked questions (FAQs) about Azure NetApp Files application volume groups. +description: Learn answers to frequently asked questions (FAQs) about Azure NetApp Files application volume groups. Previously updated : 05/19/2022 Last updated : 09/11/2024 # Azure NetApp Files application volume group FAQs -This article answers frequently asked questions (FAQs) about Azure NetApp Files application volume group. +Find answers to frequently asked questions (FAQs) about Azure NetApp Files application volume group. ## Generic FAQs NFSv4.1 is the supported protocol for SAP HANA and Oracle. As such, one TCP/IP s ### How do I size Azure NetApp Files volumes for use with SAP HANA for optimal performance and cost-effectiveness? -For optimal sizing, it's important to size for the complete landscape including snapshots and backup. Decide your volume layout for production, HA, and data protection, and perform your sizing using the [Azure NetApp Files sizing calculator for SAP HANA deployments](https://aka.ms/anfsapcalc). +For optimal sizing, it's important to size for the complete landscape including snapshots and backups. Decide your volume layout for production, HA, and data protection, and perform your sizing using the [Azure NetApp Files sizing calculator for SAP HANA deployments](https://aka.ms/anfsapcalc). ### I received a warning message `"Not enough pool capacity"`. What can I do? Database volume throughput mostly affects the time it takes to read data into me Azure NetApp Files performance of each volume can be adjusted at runtime. As such, at any time, you can adjust the performance of your database by adjusting the data and log volume throughput to your specific requirements. For instance, you can fine-tune performance and reduce costs by allowing higher throughput at startup while reducing to KPIs during normal operation. -### Will all the volumes be provisioned in close proximity to my SAP HANA servers? +### Are all the volumes provisioned in close proximity to my SAP HANA servers? -Using the proximity placement group (PPG) that you created for your SAP HANA servers ensures that the data, log, and shared volumes are created close to the SAP HANA servers to achieve the best latency and throughput. However, log-backup and data-backup volumes donΓÇÖt require low latency. From a protection perspective, it makes sense to store these backup volumes in a different location from the data, log, and shared volumes. Therefore, application volume group places the backup volumes on a different storage location inside the region that has sufficient capacity and throughput available. +With an application volume group, you have the option to deploy volumes with an availability zone or proximity placement group volume placement. Both methods ensure that the data volumes are placed in close proximity to the HANA VMs, but using different principles. ++Using availability zone volume placement (available with extension 1) places the volumes in the same availability zone as the application VMs. Using availability zones also supports Standard network features, which support enhanced security via network security group support. This method doesn't require manual pinning. It'ss therefore easier and faster to use. ++Using proximity placement group requires the creation of a proximity placement group (PPG) for your SAP HANA servers. This placement ensures the data, log, and shared volumes are created close to the SAP HANA servers to achieve the best latency and throughput. This method requires manual pinning of the proximity placement group, which application volume group uses to find the optimal location for deploying the volumes. This method only supports Basic network features. Note that log-backup and data-backup volumes donΓÇÖt require low latency. From a protection perspective, it makes sense to store these backup volumes in a different location from the data, log, and shared volumes. Therefore, the application volume group places the backup volumes on a different storage location inside the region that has sufficient capacity and throughput availability. ### What is the relationship between AVset, VM, PPG, and Azure NetApp Files volumes? A proximity placement group (PPG) needs to have at least one VM assigned to it, either directly or via an AVset. The purpose of the PPG is to extract the exact location of a VM and pass this information to application volume group to search for Azure NetApp Files resources in the very same data center. This setting only works when at least ONE VM in the PPG is started. Typically, you can add your database servers to the PPG. -PPGs have the side effect that if all VMs are shut down, a following restart of VMs DOES NOT guarantee that they will start in the same data center as before. To prevent this situation from happening, it's strongly recommended to use an AVset where all VMs and the PPG are associated to and use the [HANA pinning workflow](https://aka.ms/HANAPINNING). The workflow not only ensures that the VMs aren't moving when restarted, it also ensures that locations are selected where enough compute and Azure NetApp Files resources are available. +PPGs have the side effect that if all VMs are shut down, a following restart of VMs DOES NOT guarantee that they'll start in the same data center as before. To prevent this situation from happening, it's strongly recommended to use an AVset where all VMs and the PPG are associated to and use the [HANA pinning workflow](https://aka.ms/HANAPINNING). The workflow not only ensures that the VMs aren't moving when restarted, it also ensures that locations are selected where enough compute and Azure NetApp Files resources are available. ### For a multi-host SAP HANA system, will the shared volume be resized when I add additional HANA hosts? No. This scenario is currently one of the very few cases where you need to manua Log-back and data-backup volumes are optional, and they don't require close proximity. The best way to achieve the intended outcome is to remove the data-backup or log-backup volume when you create the first volume from the application volume group for SAP HANA. You can then create your own volume as a single, independent volume using standard volume provisioning and selecting the proper capacity and throughput to meet your needs. You should use a naming convention that indicates a data-backup volume and that it's used for multiple SIDs. - ## FAQs about application volume group for Oracle This section answers questions about Azure NetApp Files application volume group for Oracle. The deployment workflow ensures that all volumes are placed in the availability ### How do I size Azure NetApp Files volumes for use with Oracle for optimal performance and cost-effectiveness? -For optimal sizing, it's important to size for the complete database landscape including HA, snapshots, and backup. Decide your volume layout for production, HA and data protection, and perform your sizing according to [Run Your Most Demanding Oracle Workloads in Azure without Sacrificing Performance or Scalability](https://techcommunity.microsoft.com/t5/azure-architecture-blog/run-your-most-demanding-oracle-workloads-in-azure-without/ba-p/3264545) and [Estimate Tool for Sizing Oracle Workloads to Azure IaaS VMs](https://techcommunity.microsoft.com/t5/data-architecture-blog/estimate-tool-for-sizing-oracle-workloads-to-azure-iaas-vms/ba-p/1427183). You can also use the [SAP on Azure NetApp Files Sizing Estimator](https://aka.ms/anfsapcalc) by using the **Add Single Volume** input option. +For optimal sizing, it's important to size for the complete database landscape including HA, snapshots, and backups. Decide your volume layout for production, HA and data protection, and perform your sizing according to [Run Your Most Demanding Oracle Workloads in Azure without Sacrificing Performance or Scalability](https://techcommunity.microsoft.com/t5/azure-architecture-blog/run-your-most-demanding-oracle-workloads-in-azure-without/ba-p/3264545) and [Estimate Tool for Sizing Oracle Workloads to Azure IaaS VMs](https://techcommunity.microsoft.com/t5/data-architecture-blog/estimate-tool-for-sizing-oracle-workloads-to-azure-iaas-vms/ba-p/1427183). You can also use the [SAP on Azure NetApp Files Sizing Estimator](https://aka.ms/anfsapcalc) by using the **Add Single Volume** input option. Important information you need to provide for sizing each of the volumes includes: SID, role (production, Dev, pre-prod/QA), snapshot reserve in percentage, number of days for local snapshot retention, number of file-based backups, single-host/multiple-host with the number of hosts, and Data Guard requirements (primary, secondary). Contact an Oracle on Azure NetApp Files sizing expert to help you plan the overall Oracle system sizing. |
| azure-netapp-files | Monitor Azure Netapp Files | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-netapp-files/monitor-azure-netapp-files.md | This article describes ways to monitor Azure NetApp Files. The Activity log provides insight into subscription-level events. For instance, you can get information about when a resource is modified or when a virtual machine is started. You can view the activity log in the Azure portal or retrieve entries with PowerShell and CLI. This article provides details on viewing the Activity log and sending it to different destinations. -To understand how Activity log works, see [Azure Activity log](../azure-monitor/essentials/activity-log.md). +To understand how Activity log works, see [Azure Activity log](/azure/azure-monitor/essentials/activity-log). For Activity log warnings for Azure NetApp Files volumes, see [Activity log warnings for Azure NetApp Files volumes](troubleshoot-volumes.md#activity-log-warnings-for-volumes). For more information about Azure NetApp Files metrics, see [Metrics for Azure Ne The [Azure Service Health dashboard](https://azure.microsoft.com/features/service-health) keeps you informed about the health of your environment. It provides a personalized view of the status of your Azure services in the regions where they are used. The dashboard provides upcoming planned maintenance and relevant health advisories while allowing you to manage service health alerts. -For more information, see [Azure Service Health dashboard](../service-health/service-health-overview.md) documentation. +For more information, see [Azure Service Health dashboard](/azure/service-health/service-health-overview) documentation. ## Capacity utilization monitoring For more information, see [Monitor capacity utilization](volume-hard-quota-guide ## Next steps -* [Azure Activity log](../azure-monitor/essentials/activity-log.md) +* [Azure Activity log](/azure/azure-monitor/essentials/activity-log) * [Activity log warnings for Azure NetApp Files volumes](troubleshoot-volumes.md#activity-log-warnings-for-volumes) * [Metrics for Azure NetApp Files](azure-netapp-files-metrics.md) * [Monitor capacity utilization](volume-hard-quota-guidelines.md#how-to-operationalize-the-volume-hard-quota-change) |
| azure-netapp-files | Monitor Volume Capacity | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-netapp-files/monitor-volume-capacity.md | The *available space* is accurate using the `df` command. However, the *consumed > The `du` command doesnΓÇÖt account for the space used by snapshots generated in the volume. As such, itΓÇÖs not recommended for determining the available capacity in a volume. ## Using Azure portal-Azure NetApp Files leverages the standard [Azure Monitor](../azure-monitor/overview.md) functionality. As such, you can use Azure Monitor to monitor Azure NetApp Files volumes. +Azure NetApp Files leverages the standard [Azure Monitor](/azure/azure-monitor/overview) functionality. As such, you can use Azure Monitor to monitor Azure NetApp Files volumes. ## Using Azure CLI |
| azure-portal | Set Preferences | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-portal/set-preferences.md | To read all notifications received during your current session, select the **Not :::image type="content" source="media/set-preferences/read-notifications.png" alt-text="Screenshot showing the Notifications icon in the global header."::: -To view notifications from previous sessions, look for events in the Activity log. For more information, see [View the Activity log](../azure-monitor/essentials/activity-log-insights.md#view-the-activity-log). +To view notifications from previous sessions, look for events in the Activity log. For more information, see [View the Activity log](/azure/azure-monitor/essentials/activity-log-insights#view-the-activity-log). ### Enable or disable teaching bubbles |
| azure-relay | Diagnostic Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-relay/diagnostic-logs.md | When you start using your Azure Relay Hybrid Connections, you might want to moni You can view two types of logs for Azure Relay: -- [Activity logs](../azure-monitor/essentials/platform-logs-overview.md): These logs have information about operations performed against your namespace in the Azure portal or through Azure Resource Manager template. These logs are always enabled. For example: "Create or update namespace", "Create or update hybrid connection". -- [Diagnostic logs](../azure-monitor/essentials/platform-logs-overview.md): You can configure diagnostic logs for a richer view of everything that happens with operations and actions that are conducted against your namespace by using the API, or through language SDK.+- [Activity logs](/azure/azure-monitor/essentials/platform-logs-overview): These logs have information about operations performed against your namespace in the Azure portal or through Azure Resource Manager template. These logs are always enabled. For example: "Create or update namespace", "Create or update hybrid connection". +- [Diagnostic logs](/azure/azure-monitor/essentials/platform-logs-overview): You can configure diagnostic logs for a richer view of everything that happens with operations and actions that are conducted against your namespace by using the API, or through language SDK. ## View activity logs To view activity logs for your Azure Relay namespace, switch to the **Activity log** page in the Azure portal. To enable diagnostics logs, do the following steps:  1. Select **Save** on the toolbar to save the settings. -The new settings take effect in about 10 minutes. The logs are displayed in the configured archival target, in the **Diagnostics logs** pane. For more information about configuring diagnostics settings, see the [overview of Azure diagnostics logs](../azure-monitor/essentials/platform-logs-overview.md). +The new settings take effect in about 10 minutes. The logs are displayed in the configured archival target, in the **Diagnostics logs** pane. For more information about configuring diagnostics settings, see the [overview of Azure diagnostics logs](/azure/azure-monitor/essentials/platform-logs-overview). ## Schema for hybrid connections events |
| azure-relay | Relay Metrics Azure Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-relay/relay-metrics-azure-monitor.md | Last updated 08/10/2023 # Azure Relay metrics in Azure Monitor Azure Relay metrics give you the state of resources in your Azure subscription. With a rich set of metrics data, you can assess the overall health of your Relay resources, not only at the namespace level, but also at the entity level. These statistics can be important as they help you to monitor the state of Azure Relay. Metrics can also help troubleshoot root-cause issues without needing to contact Azure support. -Azure Monitor provides unified user interfaces for monitoring across various Azure services. For more information, see [Monitoring in Microsoft Azure](../azure-monitor/overview.md) and the [Retrieve Azure Monitor metrics with .NET](https://github.com/Azure-Samples/monitor-dotnet-metrics-api) sample on GitHub. +Azure Monitor provides unified user interfaces for monitoring across various Azure services. For more information, see [Monitoring in Microsoft Azure](/azure/azure-monitor/overview) and the [Retrieve Azure Monitor metrics with .NET](https://github.com/Azure-Samples/monitor-dotnet-metrics-api) sample on GitHub. > [!IMPORTANT] > This article applies only to the Hybrid Connections feature of Azure Relay, not to the WCF Relay. ## Access metrics -Azure Monitor provides multiple ways to access metrics. You can either access metrics through the [Azure portal](https://portal.azure.com), or use the Azure Monitor APIs (REST and .NET) and analysis solutions such as Operation Management Suite and Event Hubs. For more information, see [Monitoring data collected by Azure Monitor](../azure-monitor/data-platform.md). +Azure Monitor provides multiple ways to access metrics. You can either access metrics through the [Azure portal](https://portal.azure.com), or use the Azure Monitor APIs (REST and .NET) and analysis solutions such as Operation Management Suite and Event Hubs. For more information, see [Monitoring data collected by Azure Monitor](/azure/azure-monitor/data-platform). -Metrics are enabled by default, and you can access the most recent 30 days of data. If you need to retain data for a longer period of time, you can archive metrics data to an Azure Storage account. It's configured in [diagnostic settings](../azure-monitor/essentials/diagnostic-settings.md) in Azure Monitor. +Metrics are enabled by default, and you can access the most recent 30 days of data. If you need to retain data for a longer period of time, you can archive metrics data to an Azure Storage account. It's configured in [diagnostic settings](/azure/azure-monitor/essentials/diagnostic-settings) in Azure Monitor. ## Access metrics in the portal Azure Relay supports the following dimensions for metrics in Azure Monitor. Addi ## Next steps -See the [Azure Monitoring overview](../azure-monitor/overview.md). +See the [Azure Monitoring overview](/azure/azure-monitor/overview). [1]: ./media/relay-metrics-azure-monitor/relay-monitor1.png |
| azure-resource-manager | Scenarios Monitoring | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-resource-manager/bicep/scenarios-monitoring.md | You can create Log Analytics workspaces with the resource type [Microsoft.Operat Diagnostic settings enable you to configure Azure Monitor to export your logs and metrics to a number of destinations, including Log Analytics and Azure Storage. -When creating [diagnostic settings](../../azure-monitor/essentials/diagnostic-settings.md) in Bicep, remember that this resource is an [extension resource](scope-extension-resources.md), which means it's applied to another resource. You can create diagnostic settings in Bicep by using the resource type [Microsoft.Insights/diagnosticSettings](/azure/templates/microsoft.insights/diagnosticsettings?tabs=bicep). +When creating [diagnostic settings](/azure/azure-monitor/essentials/diagnostic-settings) in Bicep, remember that this resource is an [extension resource](scope-extension-resources.md), which means it's applied to another resource. You can create diagnostic settings in Bicep by using the resource type [Microsoft.Insights/diagnosticSettings](/azure/templates/microsoft.insights/diagnosticsettings?tabs=bicep). When creating diagnostic settings in Bicep, you need to apply the scope of the diagnostic setting. The diagnostic setting can be applied at the management, subscription, or resource group level. [Use the scope property on this resource to set the scope for this resource](../../azure-resource-manager/bicep/scope-extension-resources.md). resource subscriptionActivityLog 'Microsoft.Insights/diagnosticSettings@2021-05- Alerts proactively notify you when issues are found within your Azure infrastructure and applications by monitoring data within Azure Monitor. By configuring your monitoring and alerting configuration within your Bicep code, you can automate the creation of these alerts alongside the infrastructure that you are provisioning in Azure. -For more information about how alerts work in Azure see [Overview of alerts in Microsoft Azure](../../azure-monitor/alerts/alerts-overview.md). +For more information about how alerts work in Azure see [Overview of alerts in Microsoft Azure](/azure/azure-monitor/alerts/alerts-overview). The following sections demonstrate how you can configure different types of alerts using Bicep code. Metric alerts notify you when one of your metrics crosses a defined threshold. Y ### Activity log alerts -The [Azure activity log](../../azure-monitor/essentials/activity-log.md) is a platform log in Azure that provides insights into events at the subscription level. This includes information such as when a resource in Azure is modified. +The [Azure activity log](/azure/azure-monitor/essentials/activity-log) is a platform log in Azure that provides insights into events at the subscription level. This includes information such as when a resource in Azure is modified. Activity log alerts are alerts that are activated when a new activity log event occurs that matches the conditions that are specified in the alert. resource scaleOutRule 'Microsoft.Insights/autoscalesettings@2022-10-01' = { ``` > [!NOTE]-> When defining autoscaling rules, keep best practices in mind to avoid issues when attempting to autoscale, such as flapping. For more information, see the following documentation on [best practices for Autoscale](../../azure-monitor/autoscale/autoscale-best-practices.md). +> When defining autoscaling rules, keep best practices in mind to avoid issues when attempting to autoscale, such as flapping. For more information, see the following documentation on [best practices for Autoscale](/azure/azure-monitor/autoscale/autoscale-best-practices). ## Related resources |
| azure-resource-manager | Concepts View Definition | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-resource-manager/managed-applications/concepts-view-definition.md | When you provide this view in _viewDefinition.json_, it overrides the default Ov `"kind": "Metrics"` -The metrics view enables you to collect and aggregate data from your managed application resources in [Azure Monitor Metrics](../../azure-monitor/essentials/data-platform-metrics.md). +The metrics view enables you to collect and aggregate data from your managed application resources in [Azure Monitor Metrics](/azure/azure-monitor/essentials/data-platform-metrics). ```json { The metrics view enables you to collect and aggregate data from your managed app |||| | `displayName` |Yes | The displayed title of the chart. | | `chartType` | No | The visualization to use for this chart. By default, it uses a line chart. Supported chart types: `Bar, Line, Area, Scatter`. |-| `metrics` | Yes | The array of metrics to plot on this chart. To learn more about metrics supported in Azure portal, see [Supported metrics with Azure Monitor](../../azure-monitor/essentials/metrics-supported.md). | +| `metrics` | Yes | The array of metrics to plot on this chart. To learn more about metrics supported in Azure portal, see [Supported metrics with Azure Monitor](/azure/azure-monitor/essentials/metrics-supported). | ### Metric |
| azure-resource-manager | Monitor Managed Application Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-resource-manager/managed-applications/monitor-managed-application-portal.md | After you deploy a managed application to your Azure subscription, you might wan  -You can create alerts for your managed application instance or the resources in the managed application. For information about creating alerts, see [Overview of alerts in Microsoft Azure](../../azure-monitor/alerts/alerts-overview.md). +You can create alerts for your managed application instance or the resources in the managed application. For information about creating alerts, see [Overview of alerts in Microsoft Azure](/azure/azure-monitor/alerts/alerts-overview). ## Next steps |
| azure-resource-manager | Azure Services Resource Providers | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-resource-manager/management/azure-services-resource-providers.md | The resource providers for management services are: | Resource provider namespace | Azure service | | | - |-| Microsoft.Advisor | [Azure Advisor](../../advisor/index.yml) | +| Microsoft.Advisor | [Azure Advisor](/azure/advisor/) | | Microsoft.Authorization - [registered by default](#registration) | [Azure Resource Manager](../index.yml) | | Microsoft.Automation | [Automation](../../automation/index.yml) | | Microsoft.Billing - [registered by default](#registration) | [Cost Management and Billing](/azure/billing/) | The resource providers for management services are: | Microsoft.Portal - [registered by default](#registration) | [Azure portal](../../azure-portal/index.yml) | | Microsoft.RecoveryServices | [Azure Site Recovery](../../site-recovery/index.yml) | | Microsoft.ResourceGraph - [registered by default](#registration) | [Azure Resource Graph](../../governance/resource-graph/index.yml) |-| Microsoft.ResourceHealth | [Azure Service Health](../../service-health/index.yml) | +| Microsoft.ResourceHealth | [Azure Service Health](/azure/service-health/) | | Microsoft.Resources - [registered by default](#registration) | [Azure Resource Manager](../index.yml) | | Microsoft.Scheduler | [Scheduler](../../scheduler/index.yml) | | Microsoft.SoftwarePlan | License | The resource providers for monitoring services are: | Resource provider namespace | Azure service | | | - |-| Microsoft.AlertsManagement | [Azure Monitor](../../azure-monitor/index.yml) | -| Microsoft.ChangeAnalysis | [Azure Monitor](../../azure-monitor/index.yml) | -| Microsoft.Insights | [Azure Monitor](../../azure-monitor/index.yml) | -| Microsoft.Intune | [Azure Monitor](../../azure-monitor/index.yml) | -| Microsoft.OperationalInsights | [Azure Monitor](../../azure-monitor/index.yml) | -| Microsoft.OperationsManagement | [Azure Monitor](../../azure-monitor/index.yml) | -| Microsoft.WorkloadMonitor | [Azure Monitor](../../azure-monitor/index.yml) | +| Microsoft.AlertsManagement | [Azure Monitor](/azure/azure-monitor/) | +| Microsoft.ChangeAnalysis | [Azure Monitor](/azure/azure-monitor/) | +| Microsoft.Insights | [Azure Monitor](/azure/azure-monitor/) | +| Microsoft.Intune | [Azure Monitor](/azure/azure-monitor/) | +| Microsoft.OperationalInsights | [Azure Monitor](/azure/azure-monitor/) | +| Microsoft.OperationsManagement | [Azure Monitor](/azure/azure-monitor/) | +| Microsoft.WorkloadMonitor | [Azure Monitor](/azure/azure-monitor/) | ## Network resource providers |
| azure-resource-manager | Azure Subscription Service Limits | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-resource-manager/management/azure-subscription-service-limits.md | To learn more about limits on a more granular level, such as document size, quer ## Azure Chaos Studio limits -For Azure Chaos Studio limits, see [Azure Chaos Studio service limits](../../chaos-studio/chaos-studio-service-limits.md). +For Azure Chaos Studio limits, see [Azure Chaos Studio service limits](/azure/chaos-studio/chaos-studio-service-limits). ## Azure Communications Gateway limits The latest values for Azure Machine Learning Compute quotas can be found in the ## Azure Monitor limits -For Azure Monitor limits, see [Azure Monitor service limits](../../azure-monitor/service-limits.md). +For Azure Monitor limits, see [Azure Monitor service limits](/azure/azure-monitor/service-limits). ## Azure Data Factory limits |
| azure-resource-manager | Control Plane And Data Plane | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-resource-manager/management/control-plane-and-data-plane.md | Azure Resource Manager handles all control plane requests. It automatically appl * [Azure role-based access control (Azure RBAC)](../../role-based-access-control/overview.md) * [Azure Policy](../../governance/policy/overview.md) * [Management Locks](lock-resources.md)-* [Activity Logs](../../azure-monitor/essentials/activity-log.md) +* [Activity Logs](/azure/azure-monitor/essentials/activity-log) After authenticating the request, Azure Resource Manager sends it to the resource provider, which completes the operation. Even during periods of unavailability for the control plane, you can still access the data plane of your Azure resources. For instance, you can continue to access and operate on data in your storage account resource via its separate storage URI `https://myaccount.blob.core.windows.net` even when `https://management.azure.com` is not available. |
| azure-resource-manager | Lock Resources | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-resource-manager/management/lock-resources.md | Applying locks can lead to unexpected results. Some operations, which don't seem - A read-only lock on a **Log Analytics workspace** prevents **User and Entity Behavior Analytics (UEBA)** from being enabled. -- A cannot-delete lock on a **Log Analytics workspace** doesn't prevent [data purge operations](../../azure-monitor/logs/personal-data-mgmt.md#delete). Instead, remove the [data purge](../../role-based-access-control/built-in-roles.md#data-purger) role from the user.+- A cannot-delete lock on a **Log Analytics workspace** doesn't prevent [data purge operations](/azure/azure-monitor/logs/personal-data-mgmt#delete). Instead, remove the [data purge](../../role-based-access-control/built-in-roles.md#data-purger) role from the user. - A read-only lock on a **subscription** prevents **Azure Advisor** from working correctly. Advisor is unable to store the results of its queries. |
| azure-resource-manager | Monitor Resource Manager | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-resource-manager/management/monitor-resource-manager.md | The metrics are available for up to three months (93 days) and only track synchr ### Accessing Azure Resource Manager metrics -You can access control plane metrics by using the Azure Monitor REST APIs, SDKs, and the Azure portal by selecting the **Azure Resource Manager** metric. For an overview on Azure Monitor, see [Azure Monitor Metrics](../../azure-monitor/data-platform.md). +You can access control plane metrics by using the Azure Monitor REST APIs, SDKs, and the Azure portal by selecting the **Azure Resource Manager** metric. For an overview on Azure Monitor, see [Azure Monitor Metrics](/azure/azure-monitor/data-platform). There's no opt-in or sign-up process to access control plane metrics. |
| azure-resource-manager | Move Support Resources | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-resource-manager/management/move-support-resources.md | Before starting your move operation, review the [checklist](./move-resource-grou > [!div class="mx-tableFixed"] > | Resource type | Resource group | Subscription | Region move | > | - | -- | - | -- |-> | accounts | **Yes** | **Yes** | No. [Learn more](../../azure-monitor/app/create-workspace-resource.md#how-do-i-move-an-application-insights-resource-to-a-new-region). | +> | accounts | **Yes** | **Yes** | No. [Learn more](/azure/azure-monitor/app/create-workspace-resource#how-do-i-move-an-application-insights-resource-to-a-new-region). | > | actiongroups | No | No | No | > | activitylogalerts | No | No | No | > | alertrules | **Yes** | **Yes** | No | |
| azure-resource-manager | Resource Group Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-resource-manager/management/resource-group-insights.md | The resource group insights page provides several other tools scoped to help you | Tool | Description | | - |:--|- | [**Alerts**](../../azure-monitor/alerts/alerts-overview.md) | View, create, and manage your alerts. | - | [**Metrics**](../../azure-monitor/data-platform.md) | Visualize and explore your metric based data. | - | [**Activity logs**](../../azure-monitor/essentials/platform-logs-overview.md) | Subscription level events that have occurred in Azure. | - | [**Application map**](../../azure-monitor/app/app-map.md) | Navigate your distributed application's topology to identify performance bottlenecks or failure hotspots. | + | [**Alerts**](/azure/azure-monitor/alerts/alerts-overview) | View, create, and manage your alerts. | + | [**Metrics**](/azure/azure-monitor/data-platform) | Visualize and explore your metric based data. | + | [**Activity logs**](/azure/azure-monitor/essentials/platform-logs-overview) | Subscription level events that have occurred in Azure. | + | [**Application map**](/azure/azure-monitor/app/app-map) | Navigate your distributed application's topology to identify performance bottlenecks or failure hotspots. | ## Failures and performance Resource Group insights relies on the Azure Monitor Alerts Management system to ## Next steps -- [Azure Monitor Workbooks](../../azure-monitor/visualize/workbooks-overview.md)-- [Azure Resource Health](../../service-health/resource-health-overview.md)-- [Azure Monitor Alerts](../../azure-monitor/alerts/alerts-overview.md)+- [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview) +- [Azure Resource Health](/azure/service-health/resource-health-overview) +- [Azure Monitor Alerts](/azure/azure-monitor/alerts/alerts-overview) |
| azure-signalr | Signalr Concept Messages And Connections | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-signalr/signalr-concept-messages-and-connections.md | The service and the application server keep syncing connection status and making ## Related resources -* [Aggregation types in Azure Monitor](../azure-monitor/essentials/metrics-supported.md#microsoftsignalrservicesignalr) +* [Aggregation types in Azure Monitor](/azure/azure-monitor/essentials/metrics-supported#microsoftsignalrservicesignalr) * [ASP.NET Core SignalR configuration](/aspnet/core/signalr/configuration) * [JSON](https://www.json.org/) * [MessagePack](/aspnet/core/signalr/messagepackhubprotocol) |
| azure-signalr | Signalr Howto Diagnostic Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-signalr/signalr-howto-diagnostic-logs.md | You can enable other types of data collection after some configuration. This art To enable resource logs, you need to set up a place to store your log data, such as Azure Storage or Log Analytics. -- [Azure storage](../azure-monitor/essentials/resource-logs.md#send-to-azure-storage) retains resource logs for policy audit, static analysis, or back up.-- [Log Analytics](../azure-monitor/essentials/resource-logs.md#send-to-log-analytics-workspace) is a flexible log search and analytics tool that allows for analysis of raw logs generated by an Azure resource.+- [Azure storage](/azure/azure-monitor/essentials/resource-logs#send-to-azure-storage) retains resource logs for policy audit, static analysis, or back up. +- [Log Analytics](/azure/azure-monitor/essentials/resource-logs#send-to-log-analytics-workspace) is a flexible log search and analytics tool that allows for analysis of raw logs generated by an Azure resource. ## Enable resource logs To query resource logs, follow these steps: :::image type="content" alt-text="Log Analytics menu item" source="./media/signalr-tutorial-diagnostic-logs/log-analytics-menu-item.png"::: -2. Enter *SignalRServiceDiagnosticLogs* and select time range. For advanced query, see [Get started with Log Analytics in Azure Monitor](../azure-monitor/logs/log-analytics-tutorial.md) +2. Enter *SignalRServiceDiagnosticLogs* and select time range. For advanced query, see [Get started with Log Analytics in Azure Monitor](/azure/azure-monitor/logs/log-analytics-tutorial) :::image type="content" alt-text="Query log in Log Analytics" source="./media/signalr-tutorial-diagnostic-logs/query-log-in-log-analytics.png" lightbox="./media/signalr-tutorial-diagnostic-logs/query-log-in-log-analytics.png"::: |
| azure-signalr | Signalr Howto Scale Autoscale | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-signalr/signalr-howto-scale-autoscale.md | -Azure SignalR Service Premium tier supports an *autoscale* feature, which is an implementation of [Azure Monitor autoscale](../azure-monitor/autoscale/autoscale-overview.md). Autoscale allows you to automatically scale the unit count for your SignalR Service to match the actual load on the service. Autoscale can help you optimize performance and cost for your application. +Azure SignalR Service Premium tier supports an *autoscale* feature, which is an implementation of [Azure Monitor autoscale](/azure/azure-monitor/autoscale/autoscale-overview). Autoscale allows you to automatically scale the unit count for your SignalR Service to match the actual load on the service. Autoscale can help you optimize performance and cost for your application. -Azure SignalR adds its own [service metrics](concept-metrics.md). However, most of the user interface is shared and common to other [Azure services that support autoscaling](../azure-monitor/autoscale/autoscale-overview.md#supported-services-for-autoscale). If you're new to the subject of Azure Monitor Metrics, review [Azure Monitor Metrics aggregation and display explained](../azure-monitor/essentials/metrics-aggregation-explained.md) before digging into SignalR Service Metrics. +Azure SignalR adds its own [service metrics](concept-metrics.md). However, most of the user interface is shared and common to other [Azure services that support autoscaling](/azure/azure-monitor/autoscale/autoscale-overview#supported-services-for-autoscale). If you're new to the subject of Azure Monitor Metrics, review [Azure Monitor Metrics aggregation and display explained](/azure/azure-monitor/essentials/metrics-aggregation-explained) before digging into SignalR Service Metrics. ## Understanding autoscale in SignalR Service |
| azure-vmware | Azure Security Integration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-vmware/azure-security-integration.md | The diagram shows the integrated monitoring architecture of integrated security - [Review the supported platforms in Defender for Cloud](../security-center/security-center-os-coverage.md). -- [Create a Log Analytics workspace](../azure-monitor/logs/quick-create-workspace.md) to collect data from various sources.+- [Create a Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace) to collect data from various sources. - [Enable Microsoft Defender for Cloud in your subscription](../security-center/security-center-get-started.md). You can create queries or use the available predefined query in Microsoft Sentin Now that you covered how to protect your Azure VMware Solution VMs, you can learn more about: - [Using the workload protection dashboard](../security-center/azure-defender-dashboard.md)-- [Advanced multistage attack detection in Microsoft Sentinel](../azure-monitor/logs/quick-create-workspace.md)+- [Advanced multistage attack detection in Microsoft Sentinel](/azure/azure-monitor/logs/quick-create-workspace) - [Integrating Azure native services in Azure VMware Solution](integrate-azure-native-services.md) |
| azure-vmware | Azure Vmware Solution Platform Updates | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-vmware/azure-vmware-solution-platform-updates.md | Microsoft regularly applies important updates to the Azure VMware Solution for n All new Azure VMware Solution private clouds are being deployed with VMware vSphere 8.0 version in Azure Commercial. [Learn more](architecture-private-clouds.md#vmware-software-versions) -Azure VMware Solution was approved to be added as a service within the [DoD SRG Impact Level 4 (IL4)](https://learn.microsoft.com/azure/azure-government/compliance/azure-services-in-fedramp-auditscope#azure-government-services-by-audit-scope) Provisional Authorization (PA) in [Microsoft Azure Government](https://azure.microsoft.com/explore/global-infrastructure/government/#why-azure). +Azure VMware Solution was approved to be added as a service within the [DoD SRG Impact Level 4 (IL4)](/azure/azure-government/compliance/azure-services-in-fedramp-auditscope#azure-government-services-by-audit-scope) Provisional Authorization (PA) in [Microsoft Azure Government](https://azure.microsoft.com/explore/global-infrastructure/government/#why-azure). ## May 2024 |
| azure-vmware | Configure Alerts For Azure Vmware Solution | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-vmware/configure-alerts-for-azure-vmware-solution.md | Last updated 12/05/2023 # Configure Azure Alerts in Azure VMware Solution -In this article, learn how to configure [Azure Action Groups](../azure-monitor/alerts/action-groups.md) in [Microsoft Azure Alerts](../azure-monitor/alerts/alerts-overview.md) to receive notifications of triggered events that you define. Also learn about using [Azure Monitor Metrics](../azure-monitor/essentials/data-platform-metrics.md) to gain deeper insights into your Azure VMware Solution private cloud. +In this article, learn how to configure [Azure Action Groups](/azure/azure-monitor/alerts/action-groups) in [Microsoft Azure Alerts](/azure/azure-monitor/alerts/alerts-overview) to receive notifications of triggered events that you define. Also learn about using [Azure Monitor Metrics](/azure/azure-monitor/essentials/data-platform-metrics) to gain deeper insights into your Azure VMware Solution private cloud. >[!NOTE] >Incidents affecting the availability of an Azure VMware Solution host and its corresponding restoration are sent automatically to the Account Administrator, Service Administrator (Classic Permission), Co-Admins (Classic Permission), and Owners (RBAC Role) of the subscription(s) containing Azure VMware Solution private clouds. The following metrics are visible through Azure Monitor Metrics. ## Next steps Now that you configured an alert rule for your Azure VMware Solution private cloud, you can learn more about:-- [Azure Monitor Metrics](../azure-monitor/essentials/data-platform-metrics.md)-- [Azure Monitor Alerts](../azure-monitor/alerts/alerts-overview.md)-- [Azure Action Groups](../azure-monitor/alerts/action-groups.md)+- [Azure Monitor Metrics](/azure/azure-monitor/essentials/data-platform-metrics) +- [Azure Monitor Alerts](/azure/azure-monitor/alerts/alerts-overview) +- [Azure Action Groups](/azure/azure-monitor/alerts/action-groups) You can also continue with one of the other [Azure VMware Solution](index.yml) how-to guides. |
| azure-vmware | Ecosystem App Monitoring Solutions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-vmware/ecosystem-app-monitoring-solutions.md | A key objective of Azure VMware Solution is to maintain the performance and secu ## Microsoft solutions -Microsoft recommends [Application Insights](../azure-monitor/app/app-insights-overview.md#application-insights-overview), a feature of [Azure Monitor](../azure-monitor/overview.md#azure-monitor-overview), to maximize the availability and performance of your applications and services. +Microsoft recommends [Application Insights](/azure/azure-monitor/app/app-insights-overview#application-insights-overview), a feature of [Azure Monitor](/azure/azure-monitor/overview#azure-monitor-overview), to maximize the availability and performance of your applications and services. Learn how modern monitoring with Azure Monitor can transform your business by reviewing the [product overview, features, getting started guide and more](https://azure.microsoft.com/services/monitor). |
| azure-vmware | Integrate Azure Native Services | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-vmware/integrate-azure-native-services.md | When the extension installation steps are completed, they trigger deployment and Now that you covered how to integrate services and monitor VMware Solution VMs, you can also learn about: - [Using the workload protection dashboard](../security-center/azure-defender-dashboard.md)-- [Advanced multistage attack detection in Microsoft Sentinel](../azure-monitor/logs/quick-create-workspace.md)+- [Advanced multistage attack detection in Microsoft Sentinel](/azure/azure-monitor/logs/quick-create-workspace) |
| azure-vmware | Introduction | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-vmware/introduction.md | Regular upgrades of the Azure VMware Solution private cloud and VMware software ## Monitoring your private cloud -Once you deployed Azure VMware Solution into your subscription, [Azure Monitor logs](../azure-monitor/overview.md) are generated automatically. +Once you deployed Azure VMware Solution into your subscription, [Azure Monitor logs](/azure/azure-monitor/overview) are generated automatically. In your private cloud, you can: - Collect logs on each of your VMs.-- [Download and install the MMA agent](../azure-monitor/agents/log-analytics-agent.md#installation-options) on Linux and Windows VMs.-- Enable the [Azure diagnostics extension](../azure-monitor/agents/diagnostics-extension-overview.md).-- [Create and run new queries](../azure-monitor/logs/data-platform-logs.md#kusto-query-language-kql-and-log-analytics).+- [Download and install the MMA agent](/azure/azure-monitor/agents/log-analytics-agent#installation-options) on Linux and Windows VMs. +- Enable the [Azure diagnostics extension](/azure/azure-monitor/agents/diagnostics-extension-overview). +- [Create and run new queries](/azure/azure-monitor/logs/data-platform-logs#kusto-query-language-kql-and-log-analytics). - Run the same queries you usually run on your VMs. -Monitoring patterns inside the Azure VMware Solution are similar to Azure VMs within the IaaS platform. For more information and how-tos, see [Monitoring Azure VMs with Azure Monitor](../azure-monitor/vm/monitor-vm-azure.md). +Monitoring patterns inside the Azure VMware Solution are similar to Azure VMs within the IaaS platform. For more information and how-tos, see [Monitoring Azure VMs with Azure Monitor](/azure/azure-monitor/vm/monitor-vm-azure). ## Customer communication |
| azure-web-pubsub | Concept Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-web-pubsub/concept-metrics.md | -Azure Web PubSub service has some built-in metrics and you and sets up [alerts](../azure-monitor/alerts/alerts-overview.md) base on metrics. +Azure Web PubSub service has some built-in metrics and you and sets up [alerts](/azure/azure-monitor/alerts/alerts-overview) base on metrics. ## Understand metrics The dimension available in some metrics: - ServiceReload: Triggered when a connection is dropped due to an internal service component reload. This event doesn't indicate a malfunction and is part of normal service operation. - Unauthorized: The connection is unauthorized. -Learn more about [multi-dimensional metrics](../azure-monitor/essentials/data-platform-metrics.md#multi-dimensional-metrics) +Learn more about [multi-dimensional metrics](/azure/azure-monitor/essentials/data-platform-metrics#multi-dimensional-metrics) ## Related resources -- [Aggregation types in Azure Monitor](../azure-monitor/essentials/metrics-supported.md#microsoftsignalrservicewebpubsub)+- [Aggregation types in Azure Monitor](/azure/azure-monitor/essentials/metrics-supported#microsoftsignalrservicewebpubsub) |
| azure-web-pubsub | Howto Azure Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-web-pubsub/howto-azure-monitor.md | The **Overview** page in the Azure portal for each Azure Web PubSub includes a b ## What is Azure Monitor? -Azure Web PubSub creates monitoring data using [Azure Monitor](../azure-monitor/overview.md). Monitor is a full stack monitoring service in Azure that provides a complete set of features to monitor your Azure resources in addition to resources in other clouds and on-premises. +Azure Web PubSub creates monitoring data using [Azure Monitor](/azure/azure-monitor/overview). Monitor is a full stack monitoring service in Azure that provides a complete set of features to monitor your Azure resources in addition to resources in other clouds and on-premises. -If you're not already familiar with monitoring Azure services, start with [Monitoring Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md), which describes the following concepts: +If you're not already familiar with monitoring Azure services, start with [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource), which describes the following concepts: - What is Azure Monitor? - Costs associated with monitoring The following sections build on this article. They describe the specific data ga ## Monitoring data -Azure Web PubSub collects the same kinds of monitoring data as other Azure resources that are described in [Azure Monitor data collection](../azure-monitor/essentials/monitor-azure-resource.md#monitoring-data-from-azure-resources). +Azure Web PubSub collects the same kinds of monitoring data as other Azure resources that are described in [Azure Monitor data collection](/azure/azure-monitor/essentials/monitor-azure-resource#monitoring-data-from-azure-resources). See [Monitor Azure Web PubSub data reference](howto-monitor-data-reference.md) for detailed information on the metrics and logs metrics created by Azure Web PubSub. Platform metrics and the Activity log are collected and stored automatically, bu Resource Logs aren't collected and stored until you create a diagnostic setting and route them to one or more locations. -See [Create diagnostic setting to collect platform logs and metrics in Azure](../azure-monitor/essentials/diagnostic-settings.md) for the detailed process for creating a diagnostic setting using the Azure portal, CLI, or PowerShell. When you create a diagnostic setting, you specify which categories of logs to collect. +See [Create diagnostic setting to collect platform logs and metrics in Azure](/azure/azure-monitor/essentials/diagnostic-settings) for the detailed process for creating a diagnostic setting using the Azure portal, CLI, or PowerShell. When you create a diagnostic setting, you specify which categories of logs to collect. The metrics and logs you can collect are discussed in the following sections. ## Analyzing metrics -You can analyze metrics for Azure Web PubSub with metrics from other Azure services using metrics explorer by opening **Metrics** from the **Azure Monitor** menu. See [Analyze metrics with Azure Monitor metrics explorer](../azure-monitor/essentials/analyze-metrics.md) for details on using this tool. +You can analyze metrics for Azure Web PubSub with metrics from other Azure services using metrics explorer by opening **Metrics** from the **Azure Monitor** menu. See [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics) for details on using this tool. For a list of the platform metrics collected for Azure Web PubSub, see [Metrics](concept-metrics.md). -For reference, you can see a list of [all resource metrics supported in Azure Monitor](../azure-monitor/essentials/metrics-supported.md). +For reference, you can see a list of [all resource metrics supported in Azure Monitor](/azure/azure-monitor/essentials/metrics-supported). ## Analyzing logs Data in Azure Monitor Logs is stored in tables where each table has its own set of unique properties. -All resource logs in Azure Monitor have the same fields followed by service-specific fields. The common schema is outlined in [Azure Monitor resource log schema](../azure-monitor/essentials/resource-logs-schema.md). +All resource logs in Azure Monitor have the same fields followed by service-specific fields. The common schema is outlined in [Azure Monitor resource log schema](/azure/azure-monitor/essentials/resource-logs-schema). Azure Web PubSub collects three types of resource logs: *Connectivity*, *Messaging*, and *HTTP requests*. - **Connectivity** logs provide detailed information for Azure Web PubSub hub connections. For example, basic information (user ID, connection ID, and so on) and event information (connect, disconnect, and so on). Azure Web PubSub collects three types of resource logs: *Connectivity*, *Messagi ### How to enable resource logs -Currently Azure Web PubSub supports integration with [Azure Storage](../azure-monitor/essentials/resource-logs.md#send-to-azure-storage). +Currently Azure Web PubSub supports integration with [Azure Storage](/azure/azure-monitor/essentials/resource-logs#send-to-azure-storage). 1. Go to Azure portal. 1. On **Diagnostic settings** page of your Azure Web PubSub service instance, select **+ Add diagnostic setting**. To view the resource logs, follow these steps: :::image type="content" alt-text="Screenshot showing Log Analytics menu item." source="./media/howto-troubleshoot-diagnostic-logs/log-analytics-menu-item.png" lightbox="./media/howto-troubleshoot-diagnostic-logs/log-analytics-menu-item.png"::: -1. Enter `WebPubSubConnectivity`, `WebPubSubMessaging` or `WebPubSubHttpRequest`, and then select the time range to query the log. For advanced queries, see [Get started with Log Analytics in Azure Monitor](../azure-monitor/logs/log-analytics-tutorial.md). +1. Enter `WebPubSubConnectivity`, `WebPubSubMessaging` or `WebPubSubHttpRequest`, and then select the time range to query the log. For advanced queries, see [Get started with Log Analytics in Azure Monitor](/azure/azure-monitor/logs/log-analytics-tutorial). :::image type="content" alt-text="Screenshot showing query log in Log Analytics." source="./media/howto-troubleshoot-diagnostic-logs/query-log-in-log-analytics.png" lightbox="./media/howto-troubleshoot-diagnostic-logs/query-log-in-log-analytics.png"::: To use a sample query for SignalR service, follow the steps below. ## Alerts -Azure Monitor alerts proactively notify you when important conditions are found in your monitoring data. They allow you to identify and address issues in your system before your customers notice them. You can set alerts on [metrics](../azure-monitor/alerts/alerts-metric-overview.md), [logs](../azure-monitor/alerts/alerts-unified-log.md), and the [activity log](../azure-monitor/alerts/activity-log-alerts.md). Different types of alerts have benefits and drawbacks. +Azure Monitor alerts proactively notify you when important conditions are found in your monitoring data. They allow you to identify and address issues in your system before your customers notice them. You can set alerts on [metrics](/azure/azure-monitor/alerts/alerts-metric-overview), [logs](/azure/azure-monitor/alerts/alerts-unified-log), and the [activity log](/azure/azure-monitor/alerts/activity-log-alerts). Different types of alerts have benefits and drawbacks. The following table lists common and recommended alert rules for Azure Web PubSub. The following table lists common and recommended alert rules for Azure Web PubSu For more information about monitoring Azure Functions, see the following articles: * [Monitor Azure Web PubSub data reference](howto-monitor-data-reference.md) - reference of the metrics, logs, and other important values created by your function app.-* [Monitoring Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md) - details monitoring Azure resources. +* [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) - details monitoring Azure resources. |
| azure-web-pubsub | Howto Generate Client Access Url | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-web-pubsub/howto-generate-client-access-url.md | Title: How to generate client access URL for Azure Web PubSub clients description: How to generate client access URL for Azure Web PubSub clients. Previously updated : 04/25/2023 Last updated : 09/06/2024 The same Client Access URL can be generated by using the Web PubSub server SDK. 2. Generate Client Access URL by calling `WebPubSubServiceClient.getClientAccessToken`: - - Generate MQTT client access token + - Generate client access token ```js+ // for web pubsub native clients + let token = await serviceClient.getClientAccessToken(); ++ // for mqtt clients let token = await serviceClient.getClientAccessToken({ clientProtocol: "mqtt" }); ``` The same Client Access URL can be generated by using the Web PubSub server SDK. 2. Generate Client Access URL by calling `WebPubSubServiceClient.GetClientAccessUri`: - - Generate MQTT client access token + - Generate client access token ```csharp+ // for web pubsub native clients + var url = service.GetClientAccessUri(); + + // for mqtt clients var url = service.GetClientAccessUri(clientProtocol: WebPubSubClientProtocol.Mqtt); ``` The same Client Access URL can be generated by using the Web PubSub server SDK. 2. Generate Client Access URL by calling `WebPubSubServiceClient.get_client_access_token`: - - Generate MQTT client access token + - Generate client access token ```python+ # for web pubsub native clients + token = service.get_client_access_token(); + + # for mqtt clients token = service.get_client_access_token(client_protocol="MQTT") ``` The same Client Access URL can be generated by using the Web PubSub server SDK. 2. Generate Client Access URL by calling `WebPubSubServiceClient.getClientAccessToken`: - - Generate MQTT client access token + - Generate client access token for Web PubSub native clients ++ ```java + GetClientAccessTokenOptions option = new GetClientAccessTokenOptions(); + WebPubSubClientAccessToken token = service.getClientAccessToken(option); + ``` ++ - Generate client access token for MQTT clients ```java GetClientAccessTokenOptions option = new GetClientAccessTokenOptions(); The same Client Access URL can be generated by using the Web PubSub server SDK. In real-world code, we usually have a server side to host the logic generating the Client Access URL. When a client request comes in, the server side can use the general authentication/authorization workflow to validate the client request. Only valid client requests can get the Client Access URL back. -## Invoke the "Generate Client Token" REST API --You can enable Microsoft Entra ID in your service and use the Microsoft Entra token to invoke [Generate Client Token rest API](/rest/api/webpubsub/dataplane/web-pub-sub/generate-client-token) to get the token for the client to use. --1. Follow [Authorize from application](./howto-authorize-from-application.md) to enable Microsoft Entra ID. -2. Follow [Get Microsoft Entra token](./howto-authorize-from-application.md#use-postman-to-get-the-microsoft-entra-token) to get the Microsoft Entra token with Postman. -3. Use the Microsoft Entra token to invoke `:generateToken` with Postman: -- > [!NOTE] - > Please use the latest version of Postman. Old versions of Postman have [some issue](https://github.com/postmanlabs/postman-app-support/issues/3994#issuecomment-893453089) supporting colon `:` in path. -- 1. For the URI, enter `https://{Endpoint}/api/hubs/{hub}/:generateToken?api-version=2024-01-01`. If you'd like to generate token for MQTT clients, append query parameter `&clientType=mqtt` to the URL. - 2. On the **Auth** tab, select **Bearer Token** and paste the Microsoft Entra token fetched in the previous step - 3. Select **Send** and you see the Client Access Token in the response: -- ```json - { - "token": "ABCDEFG.ABC.ABC" - } - ``` +## Generate from REST API `:generateToken` +You could also use Microsoft Entra ID and generate the token by invoking [Generate Client Token REST API](/rest/api/webpubsub/dataplane/web-pub-sub/generate-client-token). ++> [!NOTE] +> Web PubSub does not recommend that you create Microsoft Entra ID tokens for Microsoft Entra ID service principals manually. This is because each Microsoft Entra ID token is short-lived, typically expiring within one hour. After this time, you must manually generate a replacement Microsoft Entra ID token. Instead, use [our SDKs](#generate-from-service-sdk) that automatically generate and replace expired Microsoft Entra ID tokens for you. ++1. Follow [Authorize from application ](./howto-authorize-from-application.md#add-a-client-secret) to enable Microsoft Entra ID and add a client secret. ++1. Gather the following information: + + | Value name | How to get the value | + | | | + | TenantId | TenantId is the value of **Directory (tenant) ID** on the **Overview** pane of the application you registered. | + | ClientId | ClientId is the value of **Application (client) ID** from the **Overview** pane of the application you registered. | + | ClientSecret | ClientSecret is the value of the client secret you just added in step #1 | + +1. Get the Microsoft Entra ID token from Microsoft identity platform + + We use [CURL](https://curl.se/) tool to show how to invoke the REST APIs. The tool is bundled into Windows 10/11, and you could install the tool following [Install CURL](https://curl.se/download.html). ++ ```bash + # set neccessory values, replace the placeholders with your actual values + export TenantId=<your_tenant_id> + export ClientId=<your_client_id> + export ClientSecret=<your_client_secret> ++ curl -X POST "https://login.microsoftonline.com/$TenantId/oauth2/v2.0/token" \ + -H "Content-Type: application/x-www-form-urlencoded" \ + --data-urlencode "grant_type=client_credentials" \ + --data-urlencode "client_id=$ClientId" \ + --data-urlencode "client_secret=$ClientSecret" \ + --data-urlencode "scope=https://webpubsub.azure.com/.default" ++ ``` + The above curl command sends a POST request to Microsoft identity endpoint to get the [Microsoft Entra ID token](/entra/identity-platform/id-tokens) back. + In the response you see the Microsoft Entra ID token in `access_token` field. Copy and store it for later use. ++1. Use the Microsoft Entra ID token to invoke `:generateToken` ++ ```bash + # Replace the values in {} with your actual values. + export Hostname={your_service_hostname} + export Hub={your_hub} + export Microsoft_Entra_Token={Microsoft_entra_id_token_from_previous_step} + curl -X POST "https://$Hostname/api/hubs/$Hub/:generateToken?api-version=2024-01-01" \ + -H "Authorization: Bearer $Microsoft_Entra_Token" \ + -H "Content-Type: application/json" + ``` ++ If you need to generate the token for MQTT clients, append the `clientType=mqtt` parameter to the URL: ++ ```bash + export Hostname={your_service_hostname} + export Hub={your_hub} + export Microsoft_Entra_Token={Microsoft_entra_id_token_from_previous_step} + curl -X POST "https://$Hostname/api/hubs/$Hub/:generateToken?api-version=2024-01-01&clientType=mqtt" \ + -H "Authorization: Bearer $Microsoft_Entra_Token" \ + -H "Content-Type: application/json" + ``` ++ After running the `cURL` command, you should get a response like this: ++ ```json + { + "token": "ABCDEFG.ABC.ABC" + } + ``` |
| azure-web-pubsub | Howto Monitor Data Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-web-pubsub/howto-monitor-data-reference.md | Azure Web PubSub uses Kusto tables from Azure Monitor Logs. You can query these - See [Monitoring Azure Web PubSub](howto-azure-monitor.md) for a description of monitoring Azure Web PubSub.-- See [Monitoring Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md) for details on monitoring Azure resources.+- See [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) for details on monitoring Azure resources. |
| azure-web-pubsub | Howto Scale Autoscale | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-web-pubsub/howto-scale-autoscale.md | -Azure WebPubSub service Premium tier supports an *autoscale* feature, which is an implementation of [Azure Monitor autoscale](../azure-monitor/autoscale/autoscale-overview.md). Autoscale allows you to automatically scale the unit count for your WebPubSub service to match the actual load on the service. Autoscale can help you optimize performance and cost for your application. +Azure WebPubSub service Premium tier supports an *autoscale* feature, which is an implementation of [Azure Monitor autoscale](/azure/azure-monitor/autoscale/autoscale-overview). Autoscale allows you to automatically scale the unit count for your WebPubSub service to match the actual load on the service. Autoscale can help you optimize performance and cost for your application. -Azure WebPubSub adds its own [service metrics](concept-metrics.md). However, most of the user interface is shared and common to other [Azure services that support autoscaling](../azure-monitor/autoscale/autoscale-overview.md#supported-services-for-autoscale). If you're new to the subject of Azure Monitor Metrics, review [Azure Monitor Metrics aggregation and display explained](../azure-monitor/essentials/metrics-aggregation-explained.md) before digging into WebPubSub service Metrics. +Azure WebPubSub adds its own [service metrics](concept-metrics.md). However, most of the user interface is shared and common to other [Azure services that support autoscaling](/azure/azure-monitor/autoscale/autoscale-overview#supported-services-for-autoscale). If you're new to the subject of Azure Monitor Metrics, review [Azure Monitor Metrics aggregation and display explained](/azure/azure-monitor/essentials/metrics-aggregation-explained) before digging into WebPubSub service Metrics. ## Understanding autoscale in WebPubSub service |
| azure-web-pubsub | Howto Troubleshoot Resource Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/azure-web-pubsub/howto-troubleshoot-resource-logs.md | The real-time resource logs captured by live trace tool contain detailed informa ### How to enable resource logs -Currently Azure Web PubSub supports integration with [Azure Storage](../azure-monitor/essentials/resource-logs.md#send-to-azure-storage). +Currently Azure Web PubSub supports integration with [Azure Storage](/azure/azure-monitor/essentials/resource-logs#send-to-azure-storage). 1. Go to Azure portal. 1. On **Diagnostic settings** page of your Azure Web PubSub service instance, select **+ Add diagnostic setting**. To view the resource logs, follow these steps: :::image type="content" alt-text="Log Analytics menu item" source="./media/howto-troubleshoot-diagnostic-logs/log-analytics-menu-item.png" lightbox="./media/howto-troubleshoot-diagnostic-logs/log-analytics-menu-item.png"::: -1. Enter `WebPubSubConnectivity`, `WebPubSubMessaging` or `WebPubSubHttpRequest`, and then select the time range to query the log. For advanced queries, see [Get started with Log Analytics in Azure Monitor](../azure-monitor/logs/log-analytics-tutorial.md). +1. Enter `WebPubSubConnectivity`, `WebPubSubMessaging` or `WebPubSubHttpRequest`, and then select the time range to query the log. For advanced queries, see [Get started with Log Analytics in Azure Monitor](/azure/azure-monitor/logs/log-analytics-tutorial). :::image type="content" alt-text="Query log in Log Analytics" source="./media/howto-troubleshoot-diagnostic-logs/query-log-in-log-analytics.png" lightbox="./media/howto-troubleshoot-diagnostic-logs/query-log-in-log-analytics.png"::: |
| backup | Back Up Azure Stack Hyperconverged Infrastructure Virtual Machines | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/back-up-azure-stack-hyperconverged-infrastructure-virtual-machines.md | Title: Back up Azure Stack HCI virtual machines with MABS description: This article contains the procedures to back up and recover virtual machines using Microsoft Azure Backup Server (MABS).- Previously updated : 05/06/2024+ Last updated : 09/11/2024 |
| backup | Back Up File Data | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/back-up-file-data.md | Title: Back up file data with MABS description: You can back up file data on server and client computers with MABS.- Previously updated : 08/19/2021+ Last updated : 09/11/2024 |
| backup | Backup Azure Diagnostic Events | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-azure-diagnostic-events.md | Data for these events can be sent to either a storage account, a Log Analytics w ## Use diagnostics settings with Log Analytics -You can now use Azure Backup to send vault diagnostics data to dedicated Log Analytics tables for backup. These tables are called [resource-specific tables](../azure-monitor/essentials/resource-logs.md#send-to-log-analytics-workspace). +You can now use Azure Backup to send vault diagnostics data to dedicated Log Analytics tables for backup. These tables are called [resource-specific tables](/azure/azure-monitor/essentials/resource-logs#send-to-log-analytics-workspace). To send your vault diagnostics data to Log Analytics: |
| backup | Backup Azure Diagnostics Mode Data Model | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-azure-diagnostics-mode-data-model.md | To update your queries to remove dependency on V1 schema, follow these steps: ## Next step -After the data model review is complete, start [creating custom queries](../azure-monitor/visualize/tutorial-logs-dashboards.md) in Azure Monitor logs to build your own dashboard. +After the data model review is complete, start [creating custom queries](/azure/azure-monitor/visualize/tutorial-logs-dashboards) in Azure Monitor logs to build your own dashboard. |
| backup | Backup Azure Linux Database Consistent Enhanced Pre Post | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-azure-linux-database-consistent-enhanced-pre-post.md | Title: Database consistent snapshots using enhanced pre-post script framework -description: Learn how Azure Backup allows you to take database consistent snapshots, leveraging Azure VM backup and using packaged pre-post scripts -+ Title: Database consistent snapshots using enhanced prepost script framework +description: Learn how Azure Backup allows you to take database consistent snapshots, leveraging Azure Virtual Machine (VM) backup and using packaged prepost scripts + Previously updated : 09/16/2021 Last updated : 09/11/2024 -# Enhanced pre-post scripts for database consistent snapshot +# Enhanced prepost scripts for database consistent snapshot -Azure Backup service already provides a [_pre-post_ script framework](./backup-azure-linux-app-consistent.md) to achieve application consistency in Linux VMs using Azure Backup. This involves invoking a pre-script (to quiesce the applications) before taking +Azure Backup service already provides a [_prepost_ script framework](./backup-azure-linux-app-consistent.md) to achieve application consistency in Linux VMs using Azure Backup. This process involves invoking a pre-script (to quiesce the applications) before taking snapshot of disks and calling post-script (commands to un-freeze the applications) after the snapshot is completed to return the applications to the normal mode. Authoring, debugging and maintenance of e pre/post scripts could be challenging. To remove this complexity, Azure Backup provides simplified pre/post-script experience for marquee databases to get application consistent snapshot with least overhead. Authoring, debugging and maintenance of e pre/post scripts could be challenging. The new _enhanced_ pre-post script framework has the following key benefits: -- These pre-post scripts are directly installed in Azure VMs along with the backup extension. This helps to eliminate authoring and download them from an external location.+- These pre-post scripts are directly installed in Azure VMs along with the backup extension, which helps to eliminate authoring and download them from an external location. - You can view the definition and content of pre-post scripts in [GitHub](https://github.com/Azure/azure-linux-extensions/tree/master/VMBackup/main/workloadPatch/DefaultScripts), even submit suggestions and changes. You can even submit suggestions and changes via GitHub, which will be triaged and added to benefit the broader community. - You can even add new pre-post scripts for other databases via [GitHub](https://github.com/Azure/azure-linux-extensions/tree/master/VMBackup/main/workloadPatch/DefaultScripts), _which will be triaged and addressed to benefit the broader community_. - The robust framework is efficient to handle scenarios, such as pre-script execution failure or crashes. In any event, the post-script automatically runs to roll back all changes done in the pre-script. The following table describes the parameters: |Parameter |Mandatory |Explanation | |||| |workload_name | Yes | This will contain the name of the database for which you need application consistent backup. The current supported values are `oracle` or `mysql`. |-|command_path/configuration_path | | This will contain path to the workload binary. This is not a mandatory field if the workload binary is set as path variable. | +|command_path/configuration_path | | This will contain path to the workload binary. This isn't a mandatory field if the workload binary is set as path variable. | |linux_user | Yes | This will contain the username of the Linux user with access to the database user login. If this value isn't set, then root is considered as the default user. | |credString | | This stands for credential string to connect to the database. This will contain the entire login string. | |ipc_folder | | The workload can only write to certain file system paths. You need to provide here this folder path so that the pre-script can write the states to this folder path. | Therefore, a daily snapshot + logs with occasional full backup for long-term ret ### Log backup strategy -The enhanced pre-post script framework is built on Azure VM backup that schedules backup once per day. So, the data loss window with RPO as 24 hours isnΓÇÖt suitable for production databases. This solution is complemented with a log backup strategy where log backups are streamed out explicitly. +The enhanced pre-post script framework is built on Azure VM backup that schedules backup once per day. So, the data loss window with Recovery Point Objective (RPO) as 24 hours isnΓÇÖt suitable for production databases. This solution is complemented with a log backup strategy where log backups are streamed out explicitly. -[NFS on blob](../storage/blobs/network-file-system-protocol-support.md) and [NFS on AFS (Preview)](../storage/files/files-nfs-protocol.md) help in easy mounting of volumes directly on database VMs and use database clients to transfer log backups. The data loss window, that is RPO, falls to the frequency of log backups. Also, NFS targets don't need to be highly performant as you might not need to trigger regular streaming (full and incremental) for operational backups after you have a database consistent snapshots. +[NFS on blob](../storage/blobs/network-file-system-protocol-support.md) and [NFS on AFS (Preview)](../storage/files/files-nfs-protocol.md) help in easy mounting of volumes directly on database VMs and use database clients to transfer log backups. The data loss window that is RPO, falls to the frequency of log backups. Also, NFS targets don't need to be highly performant as you might not need to trigger regular streaming (full and incremental) for operational backups after you have a database consistent snapshots. >[!NOTE] >The enhanced pre- script usually takes care to flush all the log transactions in transit to the log backup destination, before quiescing the database to take a snapshot. Therefore, the snapshots are database consistent and reliable during recovery. |
| backup | Backup Azure Manage Vms | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-azure-manage-vms.md | Title: Manage and monitor Azure VM backups description: Learn how to manage and monitor Azure VM backups by using the Azure Backup service.- Previously updated : 07/05/2022+ Last updated : 09/11/2024 |
| backup | Backup Azure Manage Windows Server | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-azure-manage-windows-server.md | Title: Manage Azure Recovery Services vaults and servers description: In this article, learn how to use the Recovery Services vault Overview dashboard to monitor and manage your Recovery Services vaults. - Previously updated : 07/08/2019+ Last updated : 09/11/2024 |
| backup | Backup Azure Monitoring Built In Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-azure-monitoring-built-in-monitor.md | Title: Monitor Azure Backup protected workloads description: In this article, learn about the monitoring and notification capabilities for Azure Backup workloads using the Azure portal.- Previously updated : 09/14/2022+ Last updated : 09/11/2024 ms.assetid: 86ebeb03-f5fa-4794-8a5f-aa5cbbf68a81 Azure Backup also provides alerts via Azure Monitor that enables you to have a c Currently, Azure Backup provides two main types of built-in alerts: -* **Security Alerts**: For scenarios, such as deletion of backup data, or disabling of soft-delete functionality for vault, security alerts (of severity Sev 0) are fired, and displayed in the Azure portal or consumed via other clients (PowerShell, CLI, and REST API). Security alerts are generated by default and can't be turned off. However, you can control the scenarios for which the notifications (for example, emails) should be fired. For more information on how to configure notifications, see [Action rules](../azure-monitor/alerts/alerts-action-rules.md). +* **Security Alerts**: For scenarios, such as deletion of backup data, or disabling of soft-delete functionality for vault, security alerts (of severity Sev 0) are fired, and displayed in the Azure portal or consumed via other clients (PowerShell, CLI, and REST API). Security alerts are generated by default and can't be turned off. However, you can control the scenarios for which the notifications (for example, emails) should be fired. For more information on how to configure notifications, see [Action rules](/azure/azure-monitor/alerts/alerts-action-rules). * **Job Failure Alerts**: For scenarios, such as backup failure and restore failure, Azure Backup provides built-in alerts via Azure Monitor (of Severity Sev 1). Unlike security alerts, you can choose to turn off Azure Monitor alerts for job failure scenarios. For example, you've already configured custom alert rules for job failures via Log Analytics, and don't need built-in alerts to be fired for every job failure. By default, alerts for job failures are turned on. For more information, see the [section on turning on alerts for these scenarios](#turning-on-azure-monitor-alerts-for-job-failure-scenarios). The following table summarizes the different backup alerts currently available via Azure Monitor and the supported workload/vault types: You can change the state of an alert to **Acknowledged** or **Closed** by select > [!NOTE] > - In Backup center, only alerts for Azure-based workloads currently appear. To view alerts for on-premises resources, go to the Recovery Services vault and select the **Alerts** menu item.-> - Only Azure Monitor alerts appear in Backup center. Alerts raised by the older alerting solution (accessed via the [Backup Alerts](#backup-alerts-in-recovery-services-vault) tab in Recovery Services vault) don't appear in Backup center. For more information about Azure Monitor alerts, see [Overview of alerts in Azure](../azure-monitor/alerts/alerts-overview.md). +> - Only Azure Monitor alerts appear in Backup center. Alerts raised by the older alerting solution (accessed via the [Backup Alerts](#backup-alerts-in-recovery-services-vault) tab in Recovery Services vault) don't appear in Backup center. For more information about Azure Monitor alerts, see [Overview of alerts in Azure](/azure/azure-monitor/alerts/alerts-overview). > - Currently, for blob restore alerts, alerts appear under datasource alerts only if you select both the dimensions - *datasourceId* and *datasourceType* while creating the alert rule. If any dimensions aren't selected, the alerts appear under global alerts. ### Configuring notifications for alerts -To configure notifications for Azure Monitor alerts, create an [alert processing rule](../azure-monitor/alerts/alerts-action-rules.md). To create an alert processing rule (earlier called *action rule*) to send email notifications to a given email address, follow these steps. Also, follow these steps to route these alerts to other notification channels, such as ITSM, webhook, logic app, and so on. +To configure notifications for Azure Monitor alerts, create an [alert processing rule](/azure/azure-monitor/alerts/alerts-action-rules). To create an alert processing rule (earlier called *action rule*) to send email notifications to a given email address, follow these steps. Also, follow these steps to route these alerts to other notification channels, such as ITSM, webhook, logic app, and so on. 1. Go to **Backup center** in the Azure portal. To configure notifications for Azure Monitor alerts, create an [alert processing 1. Save the action rule. -[Learn more](../azure-monitor/alerts/alerts-action-rules.md) about Action Rules in Azure Monitor. +[Learn more](/azure/azure-monitor/alerts/alerts-action-rules) about Action Rules in Azure Monitor. ## Backup alerts in Recovery Services vault |
| backup | Backup Azure Monitoring Use Azuremonitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-azure-monitoring-use-azuremonitor.md | Title: Monitor Azure Backup with Azure Monitor description: Monitor Azure Backup workloads and create custom alerts by using Azure Monitor.- Previously updated : 08/01/2023+ Last updated : 09/11/2024 ms.assetid: 01169af5-7eb0-4cb0-bbdb-c58ac71bf48b Use an action group to specify a notification channel. To see the available noti You can satisfy all alerting and monitoring requirements from Log Analytics alone, or you can use Log Analytics to supplement built-in notifications. -For more information, see [Create, view, and manage log alerts by using Azure Monitor](../azure-monitor/alerts/alerts-log.md) and [Create and manage action groups in the Azure portal](../azure-monitor/alerts/action-groups.md). +For more information, see [Create, view, and manage log alerts by using Azure Monitor](/azure/azure-monitor/alerts/alerts-log) and [Create and manage action groups in the Azure portal](/azure/azure-monitor/alerts/action-groups). ### Sample Kusto queries To identify the appropriate log and create an alert: 2. Select the operation name to see the relevant details. 3. Select **New alert rule** to open the **Create rule** page.-4. Create an alert by following the steps in [Create, view, and manage activity log alerts by using Azure Monitor](../azure-monitor/alerts/alerts-activity-log.md). +4. Create an alert by following the steps in [Create, view, and manage activity log alerts by using Azure Monitor](/azure/azure-monitor/alerts/alerts-activity-log).  You can view all alerts created from activity logs and Log Analytics workspaces Although you can get notifications through activity logs, we highly recommend using Log Analytics rather than activity logs for monitoring at scale. Here's why: - **Limited scenarios**: Notifications through activity logs apply only to Azure VM backups. The notifications must be set up for every Recovery Services vault.-- **Definition fit**: The scheduled backup activity doesn't fit with the latest definition of activity logs. Instead, it aligns with [resource logs](../azure-monitor/essentials/resource-logs.md#send-to-log-analytics-workspace). This alignment causes unexpected effects when the data that flows through the activity log channel changes.-- **Problems with the activity log channel**: In Recovery Services vaults, activity logs that are pumped from Azure Backup follow a new model. Unfortunately, this change affects the generation of activity logs in Azure Government, Azure Germany, and Microsoft Azure operated by 21Vianet. If users of these cloud services create or configure any alerts from activity logs in Azure Monitor, the alerts aren't triggered. Also, in all Azure public regions, if a user [collects Recovery Services activity logs into a Log Analytics workspace](../azure-monitor/essentials/activity-log.md), these logs don't appear.+- **Definition fit**: The scheduled backup activity doesn't fit with the latest definition of activity logs. Instead, it aligns with [resource logs](/azure/azure-monitor/essentials/resource-logs#send-to-log-analytics-workspace). This alignment causes unexpected effects when the data that flows through the activity log channel changes. +- **Problems with the activity log channel**: In Recovery Services vaults, activity logs that are pumped from Azure Backup follow a new model. Unfortunately, this change affects the generation of activity logs in Azure Government, Azure Germany, and Microsoft Azure operated by 21Vianet. If users of these cloud services create or configure any alerts from activity logs in Azure Monitor, the alerts aren't triggered. Also, in all Azure public regions, if a user [collects Recovery Services activity logs into a Log Analytics workspace](/azure/azure-monitor/essentials/activity-log), these logs don't appear. Use a Log Analytics workspace for monitoring and alerting at scale for all your workloads that are protected by Azure Backup. |
| backup | Backup Azure Mysql Flexible Server Support Matrix | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-azure-mysql-flexible-server-support-matrix.md | Title: Support matrix for Azure Database for MySQL - Flexible Server retention for long term by using Azure Backup description: Provides a summary of support settings and limitations when backing up Azure Database for MySQL - Flexible Server.- Previously updated : 03/08/2024+ Last updated : 09/11/2024 |
| backup | Backup Azure Policy Supported Skus | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-azure-policy-supported-skus.md | Title: Supported VM SKUs for Azure Policy description: 'An article describing the supported VM SKUs (by Publisher, Image Offer and Image SKU) which are supported for the built-in Azure Policies provided by Backup'- Previously updated : 04/08/2022+ Last updated : 09/11/2024 |
| backup | Backup Azure Recovery Services Vault Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-azure-recovery-services-vault-overview.md | Read more about how to encrypt your backup data [using customer-managed keys](en ## Azure Advisor -[Azure Advisor](../advisor/index.yml) is a personalized cloud consultant that helps optimize the use of Azure. It analyzes your Azure usage and provides timely recommendations to help optimize and secure your deployments. It provides recommendations in four categories: High Availability, Security, Performance, and Cost. +[Azure Advisor](/azure/advisor/) is a personalized cloud consultant that helps optimize the use of Azure. It analyzes your Azure usage and provides timely recommendations to help optimize and secure your deployments. It provides recommendations in four categories: High Availability, Security, Performance, and Cost. -Azure Advisor provides hourly [recommendations](../advisor/advisor-high-availability-recommendations.md#protect-your-virtual-machine-data-from-accidental-deletion) for VMs that aren't backed up, so you never miss backing up important VMs. You can also control the recommendations by snoozing them. You can select the recommendation and enable backup on VMs in-line by specifying the vault (where backups will be stored) and the backup policy (schedule of backups and retention of backup copies). +Azure Advisor provides hourly [recommendations](/azure/advisor/advisor-high-availability-recommendations#protect-your-virtual-machine-data-from-accidental-deletion) for VMs that aren't backed up, so you never miss backing up important VMs. You can also control the recommendations by snoozing them. You can select the recommendation and enable backup on VMs in-line by specifying the vault (where backups will be stored) and the backup policy (schedule of backups and retention of backup copies).  |
| backup | Backup Azure Reports Data Model | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-azure-reports-data-model.md | Title: Data model for Azure Backup diagnostics events description: This data model is in reference to the Resource Specific Mode of sending diagnostic events to Log Analytics (LA). - Previously updated : 05/13/2024+ Last updated : 09/11/2024 |
| backup | Backup Azure Reserved Pricing Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-azure-reserved-pricing-overview.md | Title: Reservation discounts for Azure Backup storage description: This article explains about how reservation discounts are applied to Azure Backup storage.-+ Previously updated : 09/09/2022 Last updated : 09/11/2024 |
| backup | Backup Azure Restore System State | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-azure-restore-system-state.md | Title: Restore System State to a Windows Server description: Step-by-step explanation for restoring Windows Server System State from a backup in Azure.- Previously updated : 08/14/2023+ Last updated : 09/11/2024 |
| backup | Backup Azure Security Feature | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-azure-security-feature.md | Title: Security features that protect hybrid backups description: Learn how to use security features in Azure Backup to make backups more secure Previously updated : 11/07/2023 Last updated : 09/10/2024 |
| backup | Backup Azure Sql Database | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-azure-sql-database.md | Title: Back up SQL Server databases to Azure description: This article explains how to back up SQL Server to Azure. The article also explains SQL Server recovery.- Previously updated : 08/08/2024+ Last updated : 09/11/2024 |
| backup | Backup Azure Vms Agentless Multi Disk Crash Consistent Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-azure-vms-agentless-multi-disk-crash-consistent-overview.md | Title: About agentless multi-disk crash-consistent backup for Azure Virtual Machines by using Azure Backup description: Learn about agentless multi-disk crash-consistent backup for Azure VMs by using Azure Backup via Azure portal.- Previously updated : 03/14/2024+ Last updated : 09/11/2024 |
| backup | Backup Azure Vms Introduction | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-azure-vms-introduction.md | Title: About Azure VM backup description: In this article, learn how the Azure Backup service backs up Azure Virtual machines, and how to follow best practices.- Previously updated : 03/14/2024+ Last updated : 09/11/2024 |
| backup | Backup Center Govern Environment | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-center-govern-environment.md | Title: Govern your backup estate using Backup Center description: Learn how to govern your Azure environment to ensure that all your resources are compliant from a backup perspective with Backup Center.- Previously updated : 09/01/2020+ Last updated : 09/11/2024 |
| backup | Backup Center Monitor Operate | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-center-monitor-operate.md | Currently, the following types of alerts are displayed in Backup center: >- Currently, Backup center displays only alerts for Azure-based workloads. To view alerts for on-premises resources, go to the Recovery Services vault and click **Alerts** from the menu. >- Backup center displays only Azure Monitor alerts. Alerts raised by the older alerting solution (accessed under the [Backup Alerts](backup-azure-monitoring-built-in-monitor.md#backup-alerts-in-recovery-services-vault) tab in Recovery Services vault) aren't displayed in Backup center. -For more information about Azure Monitor alerts, see [Overview of alerts in Azure](../azure-monitor/alerts/alerts-overview.md). +For more information about Azure Monitor alerts, see [Overview of alerts in Azure](/azure/azure-monitor/alerts/alerts-overview). ### Datasource and Global Alerts |
| backup | Backup Center Obtain Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-center-obtain-insights.md | Title: Obtain insights using Backup center description: Learn how to analyze historical trends and gain deeper insights on your backups with Backup center. - Previously updated : 10/19/2021+ Last updated : 09/11/2024 # Obtain Insights using Backup center -For analyzing historical trends and gaining deeper insights on your backups, Backup Center provides an interface to [Backup Reports](configure-reports.md), which uses [Azure Monitor Logs](../azure-monitor/logs/data-platform-logs.md) and [Azure Workbooks](../azure-monitor/visualize/workbooks-overview.md). Backup Reports offers the following capabilities: +For analyzing historical trends and gaining deeper insights on your backups, Backup Center provides an interface to [Backup Reports](configure-reports.md), which uses [Azure Monitor Logs](/azure/azure-monitor/logs/data-platform-logs) and [Azure Workbooks](/azure/azure-monitor/visualize/workbooks-overview). Backup Reports offers the following capabilities: - Allocating and forecasting of cloud storage consumed. |
| backup | Backup Center Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-center-overview.md | Some of the key benefits of Backup center include: - **Single pane of glass to manage backups**: Backup center is designed to function well across a large and distributed Azure environment. You can use Backup center to efficiently manage backups spanning multiple workload types, vaults, subscriptions, regions, and [Azure Lighthouse](../lighthouse/overview.md) tenants. - **Datasource-centric management**: Backup center provides views and filters that are centered on the datasources that you're backing up (for example, VMs and databases). This allows a resource owner or a backup admin to monitor and operate backups of items without needing to focus on which vault an item is backed up to. A key feature of this design is the ability to filter views by datasource-specific properties, such as datasource subscription, datasource resource group, and datasource tags. For example, if your organization follows a practice of assigning different tags to VMs belonging to different departments, you can use Backup center to filter backup information based on the tags of the underlying VMs being backed up without needing to focus on the tag of the vault.-- **Connected experiences**: Backup center provides native integrations to existing Azure services that enable management at scale. For example, Backup center uses the [Azure Policy](../governance/policy/overview.md) experience to help you govern your backups. It also leverages [Azure workbooks](../azure-monitor/visualize/workbooks-overview.md) and [Azure Monitor Logs](../azure-monitor/logs/data-platform-logs.md) to help you view detailed reports on backups. So, you don't need to learn any new principles to use the varied features that the Backup center offers. You can also [discover community resources from the Backup center](#access-community-resources-on-community-hub).+- **Connected experiences**: Backup center provides native integrations to existing Azure services that enable management at scale. For example, Backup center uses the [Azure Policy](../governance/policy/overview.md) experience to help you govern your backups. It also leverages [Azure workbooks](/azure/azure-monitor/visualize/workbooks-overview) and [Azure Monitor Logs](/azure/azure-monitor/logs/data-platform-logs) to help you view detailed reports on backups. So, you don't need to learn any new principles to use the varied features that the Backup center offers. You can also [discover community resources from the Backup center](#access-community-resources-on-community-hub). - **At-scale monitoring capabilities**: Backup center now provides at-scale monitoring capabilities that help you to view replicated items and jobs across all vaults and manage them across subscriptions, resource groups, and regions from a single view for Azure Site Recovery. ## Supported scenarios |
| backup | Backup Encryption | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-encryption.md | Title: Encryption in Azure Backup description: Learn how encryption features in Azure Backup help you protect your backup data and meet the security needs of your business.- Previously updated : 10/28/2022+ Last updated : 09/11/2024 |
| backup | Backup Instant Restore Capability | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-instant-restore-capability.md | Title: Azure Instant Restore Capability description: Azure Instant Restore Capability and FAQs for VM backup stack, Resource Manager deployment model- Previously updated : 04/03/2024+ Last updated : 09/11/2024 |
| backup | Backup Mabs Files Applications Azure Stack | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-mabs-files-applications-azure-stack.md | Title: Back up files in Azure Stack VMs description: Use Azure Backup to back up and recover Azure Stack files and applications to your Azure Stack environment.- Previously updated : 11/11/2021+ Last updated : 09/11/2024 |
| backup | Backup Mabs Protection Matrix | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-mabs-protection-matrix.md | Title: MABS (Azure Backup Server) V4 protection matrix description: This article provides a support matrix listing all workloads, data types, and installations that Azure Backup Server v4 protects. Previously updated : 07/05/2024- Last updated : 09/11/2024+ |
| backup | Backup Mabs Whats New Mabs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-mabs-whats-new-mabs.md | Title: What's new in Microsoft Azure Backup Server description: Microsoft Azure Backup Server gives you enhanced backup capabilities for protecting VMs, files and folders, workloads, and more. - Previously updated : 01/09/2024+ Last updated : 09/11/2024 |
| backup | Backup Managed Disks | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-managed-disks.md | Title: Back up Azure Managed Disks description: Learn how to back up Azure Managed Disks from the Azure portal.- Previously updated : 05/09/2024+ Last updated : 09/11/2024 |
| backup | Backup Rbac Rs Vault | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-rbac-rs-vault.md | Title: Manage Backups with Azure role-based access control description: Use Azure role-based access control to manage access to backup management operations in Recovery Services vault. - Previously updated : 01/24/2024+ Last updated : 09/11/2024 |
| backup | Backup Reports Email | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-reports-email.md | Title: Email Azure Backup Reports description: Create automated tasks to receive periodic reports via email- Previously updated : 04/29/2024+ Last updated : 09/11/2024 |
| backup | Backup Reports System Functions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-reports-system-functions.md | Title: System functions on Azure Monitor Logs description: Write custom queries on Azure Monitor Logs using system functions - Previously updated : 04/30/2024+ Last updated : 09/11/2024 We recommend you to use system functions for querying your backup data in LA wor * **Reduces possibility of custom queries breaking**: If Azure Backup introduces improvements to the schema of the underlying LA tables to accommodate future reporting scenarios, the definition of the functions will also be updated to take into account the schema changes. Thus, if you use system functions for creating custom queries, your queries won't break, even if there are changes in the underlying schema of the tables. > [!NOTE]-> System functions are maintained by Microsoft and their definitions cannot be edited by users. If you require editable functions, you can create [saved functions](../azure-monitor/logs/functions.md) in LA. +> System functions are maintained by Microsoft and their definitions cannot be edited by users. If you require editable functions, you can create [saved functions](/azure/azure-monitor/logs/functions) in LA. ## Types of system functions offered by Azure Backup |
| backup | Backup Sql Server On Availability Groups | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-sql-server-on-availability-groups.md | Title: Back up SQL Server always on availability groups description: In this article, learn how to back up SQL Server on availability groups.- Previously updated : 01/25/2024+ Last updated : 09/11/2024 The backup preference used by Azure Backup SQL AG supports full and differential | Prefer Secondary | Primary replica | Secondary replicas are preferred, but backups can run on primary replica also. | | None/Any | Primary replica | Any replica | -The workload backup extension gets installed on the node when it's registered with the Azure Backup service. When an AG database is configured for backup, the backup schedules are pushed to all the registered nodes of the AG. The schedules fire on all the AG nodes and the workload backup extensions on these nodes synchronize between themselves to decide which node will perform the backup. The node selection depends on the backup type and the backup preference as explained in section 1. +The workload backup extension is installed on the node when you register it with the Azure Backup service. When an AG database is configured for backup, the backup schedules are pushed to all the registered nodes of the AG. The schedules fire on all the AG nodes and the workload backup extensions on these nodes synchronize between themselves to decide which node can perform the backup. The node selection depends on the backup type and the backup preference as explained in section 1. The selected node proceeds with the backup job, whereas the job triggered on the other nodes bails out, that is, it skips the job. The selected node proceeds with the backup job, whereas the job triggered on the ## Register AG nodes to the Recovery Services vault -A Recovery Services vault supports backup of databases only from VMs in the same region and subscription as that of the vault. +A Recovery Services vault supports backup of databases only from VMs in the same region and subscription as of the vault. -- You must register the primary node to the vault (otherwise, full backups can't happen).-- If the backup preference is _secondary only_, then you need to register at least one secondary node to the vault (otherwise, log/copy-only full backups can't happen).+- Register the primary node to the vault (otherwise, full backups can't happen). +- Register at least one secondary node to the vault (otherwise, log/copy-only full backups can't happen) if the backup preference is _secondary only_. -Configuring backups for AG databases will fail with the error code _FabricSvcBackupPreferenceCheckFailedUserError_ if the above conditions aren't met. +Configuring backups for AG databases fail with the error code _FabricSvcBackupPreferenceCheckFailedUserError_ if the above conditions aren't met. LetΓÇÖs consider the following AG deployment as a reference. :::image type="content" source="./media/backup-sql-server-on-availability-groups/ag-deployment.png" alt-text="Diagram for AG deployment as reference."::: -Based on the above sample AG deployment, following are various considerations: +Based on the given sample AG deployment, following are various considerations: - As the primary node is in region 1 and subscription 1, the Recovery Services vault (Vault 1) must be in Region 1 and Subscription 1 for protecting this AG.-- VM3 can't be registered to Vault 1 as it's in a different subscription.-- VM4 can't be registered to Vault 1 as it's in a different region.+- `VM3` can't be registered to Vault 1 as it's in a different subscription. +- `VM4` can't be registered to Vault 1 as it's in a different region. - If the backup preference is _secondary only_, VM1 (Primary) and VM2 (Secondary) must be registered to the Vault 1 (because full backups require the primary node and logs require a secondary node). For other backup preferences, VM1 (Primary) must be registered to Vault 1, VM2 is optional (because all backups can run on primary node). - While VM3 could be registered to vault 2 in subscription 2 and the AG databases would then show up for protection in vault 2 but due to absence of the primary node in vault 2, configuring backups would fail. - Similarly, while VM4 could be registered to vault 4 in region 2, configuring backups would fail since the primary node isn't registered in vault 4. Recovery services vault doesnΓÇÖt support cross-subscription or cross-region bac - Full/differential backups will happen successfully only in the vault that has the primary node. These backups in other vaults will keep failing. -- Log backups will keep working in the previous vault till a log backup runs in the new vault (that's, in the vault where the new primary node is present) and _breaks_ the log chain for old vault.+- Log backups will keep working in the previous vault until a log backup runs in the new vault (that's, in the vault where the new primary node is present) and _breaks_ the log chain for old vault. >[!Note] >There's a hard limit of 15 days beyond which log backups will start failing. As the primary node is in region and subscription, the usual steps to enable bac 1. Configure backups for the AG databases in Vault 2. 1. At this point: 1. The full/differential backups will fail in Vault 1 as none of the registered nodes can take this backup.- 1. The log backups will succeed in Vault 1 till a log backup runs in Vault 2 and _breaks_ the log chain for Vault 1. + 1. The log backups will succeed in Vault 1 until a log backup runs in Vault 2 and _breaks_ the log chain for Vault 1. 1. Failback the AG to VM1. ### Step 3: Enable backups in Region 2, Subscription 1 (Vault 4) Same as Step 2. ## Backup an AG that spans Azure and on-premises Azure Backup for SQL Server canΓÇÖt be run on-premises. If the primary node is in Azure and the backup preference is satisfied by the nodes in Azure, you can follow the above guidance for multi-region AG to enable backups for the replicas in Azure. -If a failover to on-premises node happens, the full and differential backups in Azure will start failing. Log backups may continue till the log chain break happens/15 days pass. +If a failover to on-premises node happens, the full and differential backups in Azure will start failing. Log backups may continue until the log chain break happens/15 days pass. ## Throttling for backup jobs in an AG database |
| backup | Backup Support Automation | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-support-automation.md | Title: Automation in Azure Backup support matrix description: This article summarizes automation tasks related to Azure Backup support. Previously updated : 05/30/2024- Last updated : 09/11/2024+ You can automate most backup related tasks using programmatic methods in Azure | Restore | Restore to a point in time | Supported <br><br> [See the examples](./backup-azure-sql-automation.md#original-restore-with-log-point-in-time). | Supported | Supported | N/A | N/A | N/A | N/A | | Restore | Cross-region restore | Supported <br><br> [See the examples](./backup-azure-sql-automation.md#alternate-workload-restore-to-a-vault-in-secondary-region). | Supported | Supported | N/A | N/A | N/A | N/A | | Manage | Monitor jobs | Supported <br><br> [See the examples](./backup-azure-sql-automation.md#track-azure-backup-jobs). | Supported | Supported | N/A | N/A | N/A | N/A |-| Manage | Manage Azure Monitor Alerts (preview) | Supported <br><br> [See the examples](../azure-monitor/powershell-samples.md). | Supported | Supported | N/A | N/A | N/A | N/A | -| Manage | Manage Azure Monitor Metrics (preview) | Supported <br><br> [See the examples](../azure-monitor/powershell-samples.md). | Supported | Supported | N/A | N/A | N/A | N/A | +| Manage | Manage Azure Monitor Alerts (preview) | Supported <br><br> [See the examples](/azure/azure-monitor/powershell-samples). | Supported | Supported | N/A | N/A | N/A | N/A | +| Manage | Manage Azure Monitor Metrics (preview) | Supported <br><br> [See the examples](/azure/azure-monitor/powershell-samples). | Supported | Supported | N/A | N/A | N/A | N/A | | Manage | Modify backup policy | Supported <br><br> [See the examples](./backup-azure-sql-automation.md#change-policy-for-backup-items). | Supported | Supported | N/A | N/A | N/A | N/A | | Manage | Stop protection and retain backup data | Supported <br><br> [See the examples](./backup-azure-sql-automation.md#retain-data). | Supported | Supported | N/A | N/A | N/A | N/A | | Manage | Stop protection and delete backup data | Supported <br><br> [See the examples](./backup-azure-sql-automation.md#delete-backup-data). | Supported | Supported | N/A | N/A | N/A | N/A | |
| backup | Backup Support Matrix Iaas | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-support-matrix-iaas.md | Title: Support matrix for Azure VM backups description: Get a summary of support settings and limitations for backing up Azure VMs by using the Azure Backup service.- Previously updated : 08/09/2024+ Last updated : 09/11/2024 Back up VMs that are deployed from [Azure Marketplace](https://azuremarketplace. Back up VMs that are deployed from a custom image (third-party) |Supported.<br/><br/> The VMs must be running a supported operating system.<br/><br/> When you're recovering files on VMs, you can restore only to a compatible OS (not an earlier or later OS). Back up VMs that are migrated to Azure| Supported.<br/><br/> To back up a VM, make sure that the VM agent is installed on the migrated machine. Back up multiple VMs and provide consistency | Azure Backup doesn't provide data and application consistency across multiple VMs.-Back up a VM with [diagnostic settings](../azure-monitor/essentials/platform-logs-overview.md) | Not supported. <br/><br/> If the restore of the Azure VM with diagnostic settings is triggered via the [Create new](backup-azure-arm-restore-vms.md#create-a-vm) option, the restore fails. +Back up a VM with [diagnostic settings](/azure/azure-monitor/essentials/platform-logs-overview) | Not supported. <br/><br/> If the restore of the Azure VM with diagnostic settings is triggered via the [Create new](backup-azure-arm-restore-vms.md#create-a-vm) option, the restore fails. Restore zone-pinned VMs | Supported (where [availability zones](https://azure.microsoft.com/global-infrastructure/availability-zones/) are available).<br/><br/>Azure Backup now supports [restoring Azure VMs to a any availability zones](backup-azure-arm-restore-vms.md#restore-options) other than the zone that's pinned in VMs. This support enables you to restore VMs when the primary zone is unavailable. Back up Gen2 VMs | Supported. <br><br/> Azure Backup supports backup and restore of [Gen2 VMs](https://azure.microsoft.com/updates/generation-2-virtual-machines-in-azure-public-preview/). When these VMs are restored from a recovery point, they're restored as [Gen2 VMs](https://azure.microsoft.com/updates/generation-2-virtual-machines-in-azure-public-preview/). Back up Azure VMs with locks | Supported for managed VMs. <br><br> Not supported for unmanaged VMs. |
| backup | Backup Support Matrix Mabs Dpm | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-support-matrix-mabs-dpm.md | Title: MABS & System Center DPM support matrix description: This article summarizes Azure Backup support when you use Microsoft Azure Backup Server (MABS) or System Center DPM to back up on-premises and Azure VM resources. Previously updated : 05/27/2024- Last updated : 09/11/2024+ |
| backup | Backup Support Matrix Mars Agent | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-support-matrix-mars-agent.md | Title: Support matrix for the MARS agent description: This article summarizes Azure Backup support when you back up machines that are running the Microsoft Azure Recovery Services (MARS) agent. Previously updated : 09/07/2023- Last updated : 09/11/2024+ |
| backup | Backup Support Matrix | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-support-matrix.md | Title: Azure Backup support matrix description: Provides a summary of support settings and limitations for the Azure Backup service.- Previously updated : 09/04/2024+ Last updated : 09/11/2024 |
| backup | Backup The Mabs Server | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/backup-the-mabs-server.md | Title: Back up the MABS server description: Learn how to back up the Microsoft Azure Backup Server (MABS).- Previously updated : 09/24/2020+ Last updated : 09/11/2024 |
| backup | Blob Backup Support Matrix | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/blob-backup-support-matrix.md | Title: Support matrix for Azure Blobs backup description: Provides a summary of support settings and limitations when backing up Azure Blobs.- Previously updated : 07/31/2024+ Last updated : 09/11/2024 |
| backup | Configure Reports | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/configure-reports.md | A common requirement for backup admins is to obtain insights on backups based on - Auditing of backups and restores. - Identifying key trends at different levels of granularity. -Azure Backup provides a reporting solution that uses [Azure Monitor logs](../azure-monitor/logs/log-analytics-tutorial.md) and [Azure workbooks](../azure-monitor/visualize/workbooks-overview.md). These resources help you get rich insights on your backups across your entire backup estate. +Azure Backup provides a reporting solution that uses [Azure Monitor logs](/azure/azure-monitor/logs/log-analytics-tutorial) and [Azure workbooks](/azure/azure-monitor/visualize/workbooks-overview). These resources help you get rich insights on your backups across your entire backup estate. ## Supported scenarios To start using the reports, follow these steps: Set up one or more Log Analytics workspaces to store your Backup reporting data. The location and subscription where this Log Analytics workspace can be created is independent of the location and subscription where your vaults exist. -To set up a Log Analytics workspace, see [Create a Log Analytics workspace in the Azure portal](../azure-monitor/logs/quick-create-workspace.md). +To set up a Log Analytics workspace, see [Create a Log Analytics workspace in the Azure portal](/azure/azure-monitor/logs/quick-create-workspace). -By default, the data in a Log Analytics workspace is retained for 30 days. To see data for a longer time horizon, change the retention period of the Log Analytics workspace. To change the retention period, see [Configure data retention and archive policies in Azure Monitor Logs](../azure-monitor/logs/data-retention-configure.md). +By default, the data in a Log Analytics workspace is retained for 30 days. To see data for a longer time horizon, change the retention period of the Log Analytics workspace. To change the retention period, see [Configure data retention and archive policies in Azure Monitor Logs](/azure/azure-monitor/logs/data-retention-configure). ### 2. Configure diagnostics settings for your vaults Once the logic app is created, you'll need to authorize connections to Azure Mon Backup Reports uses [system functions on Azure Monitor logs](backup-reports-system-functions.md). These functions operate on data in the raw Azure Backup tables in LA and return formatted data that helps you easily retrieve information of all your backup-related entities, using simple queries. -To create your own reporting workbooks using Backup Reports as a base, you can go to **Backup Reports**, click **Edit** at the top of the report, and view/edit the queries being used in the reports. Refer to [Azure workbooks documentation](../azure-monitor/visualize/workbooks-overview.md) to learn more about how to create custom reports. +To create your own reporting workbooks using Backup Reports as a base, you can go to **Backup Reports**, click **Edit** at the top of the report, and view/edit the queries being used in the reports. Refer to [Azure workbooks documentation](/azure/azure-monitor/visualize/workbooks-overview) to learn more about how to create custom reports. ## Export to Excel |
| backup | Disk Backup Support Matrix | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/disk-backup-support-matrix.md | Title: Azure Disk Backup support matrix description: Provides a summary of support settings and limitations Azure Disk Backup.- Previously updated : 05/09/2024+ Last updated : 09/11/2024 |
| backup | Guidance Best Practices | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/guidance-best-practices.md | Title: Guidance and best practices description: Discover the best practices and guidance for backing up cloud and on-premises workload to the cloud- Previously updated : 03/12/2024+ Last updated : 09/11/2024 Azure Backup provides you with the [Multi-User Authorization (MUA)](./multi-user You may encounter scenarios where someone tries to breach into your system and maliciously turn off the security mechanisms, such as disabling Soft Delete or attempts to perform destructive operations, such as deleting the backup resources. -Azure Backup provides security against such incidents by sending you critical alerts over your preferred notification channel (email, ITSM, Webhook, runbook, and sp pn) by creating an [Action Rule](../azure-monitor/alerts/alerts-action-rules.md) on top of the alert. [Learn more](./security-overview.md#monitoring-and-alerts-of-suspicious-activity) +Azure Backup provides security against such incidents by sending you critical alerts over your preferred notification channel (email, ITSM, Webhook, runbook, and sp pn) by creating an [Action Rule](/azure/azure-monitor/alerts/alerts-action-rules) on top of the alert. [Learn more](./security-overview.md#monitoring-and-alerts-of-suspicious-activity) ### Security features to help protect hybrid backups To fulfill all these needs, use [Azure Private Endpoint](../private-link/private ## Governance considerations -Governance in Azure is primarily implemented with [Azure Policy](../governance/policy/overview.md) and [Azure Cost Management](../cost-management-billing/cost-management-billing-overview.md). [Azure Policy](../governance/policy/overview.md) allows you to create, assign, and manage policy definitions to enforce rules for your resources. This feature keeps those resources in compliance with your corporate standards. [Azure Cost Management](../cost-management-billing/cost-management-billing-overview.md) allows you to track cloud usage and expenditures for your Azure resources and other cloud providers. Also, the following tools such as [Azure Price Calculator](https://azure.microsoft.com/pricing/calculator/) and [Azure Advisor](../advisor/advisor-overview.md) play an important role in the cost management process. +Governance in Azure is primarily implemented with [Azure Policy](../governance/policy/overview.md) and [Azure Cost Management](../cost-management-billing/cost-management-billing-overview.md). [Azure Policy](../governance/policy/overview.md) allows you to create, assign, and manage policy definitions to enforce rules for your resources. This feature keeps those resources in compliance with your corporate standards. [Azure Cost Management](../cost-management-billing/cost-management-billing-overview.md) allows you to track cloud usage and expenditures for your Azure resources and other cloud providers. Also, the following tools such as [Azure Price Calculator](https://azure.microsoft.com/pricing/calculator/) and [Azure Advisor](/azure/advisor/advisor-overview) play an important role in the cost management process. ### Auto-configure newly provisioned backup infrastructure with Azure Policy at Scale As a backup user or administrator, you should be able to monitor all backup solu * Identifying key trends at different levels of granularity. * In addition,- * You can send data (for example, jobs, policies, and so on) to the **Log Analytics** workspace. This will enable the features of Azure Monitor Logs to enable correlation of data with other monitoring data collected by Azure Monitor, consolidate log entries from multiple Azure subscriptions and tenants into one location for analysis together, use log queries to perform complex analysis and gain deep insights on Log entries. [Learn more here](../azure-monitor/essentials/activity-log.md#send-to-log-analytics-workspace). - * You can send data to an Azure event hub to send entries outside of Azure, for example to a third-party SIEM (Security Information and Event Management) or other log analytics solution. [Learn more here](../azure-monitor/essentials/activity-log.md#send-to-azure-event-hubs). - * You can send data to an Azure Storage account if you want to retain your log data longer than 90 days for audit, static analysis, or back up. If you only need to retain your events for 90 days or less, you don't need to set up archives to a storage account, since Activity Log events are kept in the Azure platform for 90 days. [Learn more](../azure-monitor/essentials/activity-log.md#send-to-azure-storage). + * You can send data (for example, jobs, policies, and so on) to the **Log Analytics** workspace. This will enable the features of Azure Monitor Logs to enable correlation of data with other monitoring data collected by Azure Monitor, consolidate log entries from multiple Azure subscriptions and tenants into one location for analysis together, use log queries to perform complex analysis and gain deep insights on Log entries. [Learn more here](/azure/azure-monitor/essentials/activity-log#send-to-log-analytics-workspace). + * You can send data to an Azure event hub to send entries outside of Azure, for example to a third-party SIEM (Security Information and Event Management) or other log analytics solution. [Learn more here](/azure/azure-monitor/essentials/activity-log#send-to-azure-event-hubs). + * You can send data to an Azure Storage account if you want to retain your log data longer than 90 days for audit, static analysis, or back up. If you only need to retain your events for 90 days or less, you don't need to set up archives to a storage account, since Activity Log events are kept in the Azure platform for 90 days. [Learn more](/azure/azure-monitor/essentials/activity-log#send-to-azure-storage). ### Alerts |
| backup | Manage Afs Backup Cli | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/manage-afs-backup-cli.md | Title: Manage Azure file share backups with the Azure CLI description: Learn how to use the Azure CLI to manage and monitor Azure file shares backed up by Azure Backup.-+ Previously updated : 02/09/2022 Last updated : 09/11/2024 |
| backup | Manage Afs Backup | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/manage-afs-backup.md | Title: Manage Azure File share backups description: This article describes common tasks for managing and monitoring the Azure File shares that are backed up by Azure Backup.- Previously updated : 03/04/2024+ Last updated : 09/11/2024 To open the **Backup Jobs** blade: ## Monitor Azure File share backup operations by using Azure Backup reports -Azure Backup provides a reporting solution that uses [Azure Monitor logs](../azure-monitor/logs/log-analytics-tutorial.md) and [Azure workbooks](../azure-monitor/visualize/workbooks-overview.md). These resources help you get rich insights into your backups. You can leverage these reports to gain visibility into Azure Files backup items, jobs at item level and details of active policies. Using the Email Report feature available in Backup Reports, you can create automated tasks to receive periodic reports via email. [Learn](./configure-reports.md#get-started) how to configure and view Azure Backup reports. +Azure Backup provides a reporting solution that uses [Azure Monitor logs](/azure/azure-monitor/logs/log-analytics-tutorial) and [Azure workbooks](/azure/azure-monitor/visualize/workbooks-overview). These resources help you get rich insights into your backups. You can leverage these reports to gain visibility into Azure Files backup items, jobs at item level and details of active policies. Using the Email Report feature available in Backup Reports, you can create automated tasks to receive periodic reports via email. [Learn](./configure-reports.md#get-started) how to configure and view Azure Backup reports. ## Create a new policy |
| backup | Manage Azure Database Postgresql | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/manage-azure-database-postgresql.md | Title: Manage Azure Database for PostgreSQL server description: Learn about managing Azure Database for PostgreSQL server.- Previously updated : 01/24/2022+ Last updated : 09/11/2024 |
| backup | Manage Azure File Share Rest Api | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/manage-azure-file-share-rest-api.md | Title: Manage Azure File share backup with REST API description: Learn how to use REST API to manage and monitor Azure file shares that are backed up by Azure Backup.- Previously updated : 02/17/2020+ Last updated : 09/11/2024 |
| backup | Manage Azure Sql Vm Rest Api | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/manage-azure-sql-vm-rest-api.md | Title: Manage SQL server databases in Azure VMs with REST API description: Learn how to use REST API to manage and monitor SQL server databases in Azure VM that are backed up by Azure Backup.- Previously updated : 08/11/2022+ Last updated : 09/11/2024 |
| backup | Manage Monitor Sql Database Backup | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/manage-monitor-sql-database-backup.md | Title: Manage and monitor SQL Server DBs on an Azure VM description: This article describes how to manage and monitor SQL Server databases that are running on an Azure VM.- Previously updated : 03/05/2024+ Last updated : 09/11/2024 |
| backup | Manage Recovery Points | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/manage-recovery-points.md | Title: Manage recovery points description: Learn how the Azure Backup service manages recovery points for virtual machines- Previously updated : 06/17/2021+ Last updated : 09/11/2024 |
| backup | Metrics Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/metrics-overview.md | Title: Monitor the health of your backups using Azure Backup Metrics (preview) description: In this article, learn about the metrics available for Azure Backup to monitor your backup health- Previously updated : 07/13/2022+ Last updated : 09/11/2024 Azure Backup offers the following key capabilities: * Ability to write custom alert rules on these metrics to efficiently monitor the health of your backup items * Ability to route fired metric alerts to different notification channels supported by Azure Monitor, such as email, ITSM, webhook, logic apps, and so on. -[Learn more about Azure Monitor metrics](../azure-monitor/essentials/data-platform-metrics.md). +[Learn more about Azure Monitor metrics](/azure/azure-monitor/essentials/data-platform-metrics). ## Supported scenarios To configure alerts and notifications on your metrics, follow these steps: 1. To configure notifications for these alerts using Action Groups, configure an Action Group as part of the alert rule, or create a separate action rule. - We support various notification channels, such as email, ITSM, webhook, Logic App, SMS. [Learn more about Action Groups](../azure-monitor/alerts/action-groups.md). + We support various notification channels, such as email, ITSM, webhook, Logic App, SMS. [Learn more about Action Groups](/azure/azure-monitor/alerts/action-groups). :::image type="content" source="./media/metrics-overview/action-group-inline.png" alt-text="Screenshot showing the process to configure notifications for these alerts using Action Groups." lightbox="./media/metrics-overview/action-group-expanded.png"::: To configure alerts and notifications on your metrics, follow these steps: - To generate an alert on every job failure irrespective of the failure is due to the same underlying cause (stateless behavior), deselect the **Automatically resolve alerts** option in the alert rule. - Alternately, to configure the alerts as stateful, select the same checkbox. Therefore, when a metric alert is fired on the scope, another failure won't create a new metric alert. The alert gets auto-resolved if the alert generation condition evaluates to false for three successive evaluation cycles. New alerts are generated if the condition evaluates to true again. -[Learn more about stateful and stateless behavior of Azure Monitor metric alerts](../azure-monitor/alerts/alerts-troubleshoot-metric.md#the-metric-alert-is-not-triggered-every-time-the-condition-is-met). +[Learn more about stateful and stateless behavior of Azure Monitor metric alerts](/azure/azure-monitor/alerts/alerts-troubleshoot-metric#the-metric-alert-is-not-triggered-every-time-the-condition-is-met). :::image type="content" source="./media/metrics-overview/auto-resolve-alert-inline.png" alt-text="Screenshot showing the process to configure auto-resolution behavior." lightbox="./media/metrics-overview/auto-resolve-alert-expanded.png"::: Based on the alert rules configuration, the fired alert appears under the **Data ### Accessing metrics programmatically -You can use the different programmatic clients, such as PowerShell, CLI, or REST API, to access the metrics functionality. See [Azure Monitor REST API documentation](../azure-monitor/essentials/rest-api-walkthrough.md) for more details. +You can use the different programmatic clients, such as PowerShell, CLI, or REST API, to access the metrics functionality. See [Azure Monitor REST API documentation](/azure/azure-monitor/essentials/rest-api-walkthrough) for more details. ### Sample alert scenarios Dimensions["DatasourceId"]= "All current and future values" ## Next steps - [Learn more about monitoring and reporting in Azure Backup](monitoring-and-alerts-overview.md).-- [Learn more about Azure Monitor metrics](../azure-monitor/essentials/data-platform-metrics.md).-- [Learn more about Azure alerts](../azure-monitor/alerts/alerts-overview.md).+- [Learn more about Azure Monitor metrics](/azure/azure-monitor/essentials/data-platform-metrics). +- [Learn more about Azure alerts](/azure/azure-monitor/alerts/alerts-overview). |
| backup | Microsoft Azure Backup Server Protection V3 Ur1 | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/microsoft-azure-backup-server-protection-v3-ur1.md | Title: MABS (Azure Backup Server) V3 UR1 protection matrix description: This article provides a support matrix listing all workloads, data types, and installations that Azure Backup Server protects. Previously updated : 03/25/2024- Last updated : 09/11/2024+ |
| backup | Microsoft Azure Backup Server Protection V3 | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/microsoft-azure-backup-server-protection-v3.md | Title: What Azure Backup Server V3 RTM can back up description: This article provides a protection matrix listing all workloads, data types, and installations that Azure Backup Serve V3 RTM protects. Previously updated : 10/11/2023- Last updated : 09/11/2024+ |
| backup | Monitor Azure Backup With Backup Explorer | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/monitor-azure-backup-with-backup-explorer.md | Title: Monitor your backups with Backup Explorer description: This article describes how to use Backup Explorer to perform real-time monitoring of backups across vaults, subscriptions, regions, and tenants.- Previously updated : 02/03/2020+ Last updated : 09/11/2024 |
| backup | Monitoring And Alerts Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/monitoring-and-alerts-overview.md | Title: Monitoring and reporting solutions for Azure Backup description: Learn about different monitoring and reporting solutions provided by Azure Backup.- Previously updated : 10/21/2022+ Last updated : 09/11/2024 The following table provides a summary of the different monitoring and reporting | Scenario | Solutions available | | | | | Monitor backup jobs and backup instances | - **Built-in monitoring**: You can monitor backup jobs and backup instances in real time via the [Backup center](./backup-center-overview.md) dashboard. <br><br> - **Customized monitoring dashboards**: Azure Backup allows you to use non-portal clients, such as [PowerShell](./backup-azure-vms-automation.md), [CLI](./create-manage-azure-services-using-azure-command-line-interface.md), and [REST API](./backup-azure-arm-userestapi-managejobs.md), to query backup monitoring data for use in your custom dashboards. In addition, you can query your backups at scale (across vaults, subscriptions, regions, and Lighthouse tenants) using [Azure Resource Graph (ARG)](./query-backups-using-azure-resource-graph.md). [Backup Explorer](./monitor-azure-backup-with-backup-explorer.md) is one sample monitoring workbook, which uses data in ARG that you can use as a reference to create your own dashboards. |-| Monitor overall backup health | - **Resource Health**: You can monitor the health of your Recovery Services vault and Backup vaults, and troubleshoot events causing the resource health issues. [Learn more](../service-health/resource-health-overview.md). You can view the health history and identify events affecting the health of your resource. You can also trigger alerts related to the resource health events. <br><br> - **Azure Monitor Metrics**: Azure Backup also offers the above health metrics via Azure Monitor, which provides you more granular details about the health of your backups. This also allows you to configure alerts and notifications on these metrics. [Learn more](./metrics-overview.md). | -| Get alerted to critical backup incidents | - **Built-in alerts using Azure Monitor**: Azure Backup provides an [alerting solution based on Azure Monitor](./backup-azure-monitoring-built-in-monitor.md#azure-monitor-alerts-for-azure-backup) for scenarios, such as deletion of backup data, disabling of soft-delete, backup failures, and restore failures. You can view and manage these alerts via Backup center. To [configure notifications](./backup-azure-monitoring-built-in-monitor.md#configuring-notifications-for-alerts) for these alerts (for example, emails), you can use Azure Monitor's [Action rules](../azure-monitor/alerts/alerts-action-rules.md?tabs=portal) and [Action groups](../azure-monitor/alerts/action-groups.md) to route alerts to a wide range of notification channels. <br><br> - **Azure Backup Metric Alerts using Azure Monitor (preview)**: You can write custom alert rules using Azure Monitor metrics to monitor the health of your backup items across different KPIs. [Learn more](./metrics-overview.md) <br><br> - **Classic Alerts**: This is the older alerting solution, which you can [access using the Backup Alerts tab](./backup-azure-monitoring-built-in-monitor.md#backup-alerts-in-recovery-services-vault) in the Recovery Services vault blade. These alerts don't appear in Backup center. If you're using classic alerts, we recommend to start using one or more of the Azure Monitor based alert solutions (described above) as it's the forward-looking solution for alerting. <br><br> - **Custom log alerts**: If you've scenarios where an alert needs to be generated based on custom logic, you can use [Log Analytics based alerts](./backup-azure-monitoring-use-azuremonitor.md#create-alerts-by-using-log-analytics) for such scenarios, provided you've configured your vaults to send diagnostics data to a Log Analytics (LA) workspace. Due to the current [frequency at which data in an LA workspace is updated](./backup-azure-monitoring-use-azuremonitor.md#diagnostic-data-update-frequency), this solution is typically used for scenarios where it's acceptable to have a short time difference between the occurrence of the actual incident and the generation of the alert. | +| Monitor overall backup health | - **Resource Health**: You can monitor the health of your Recovery Services vault and Backup vaults, and troubleshoot events causing the resource health issues. [Learn more](/azure/service-health/resource-health-overview). You can view the health history and identify events affecting the health of your resource. You can also trigger alerts related to the resource health events. <br><br> - **Azure Monitor Metrics**: Azure Backup also offers the above health metrics via Azure Monitor, which provides you more granular details about the health of your backups. This also allows you to configure alerts and notifications on these metrics. [Learn more](./metrics-overview.md). | +| Get alerted to critical backup incidents | - **Built-in alerts using Azure Monitor**: Azure Backup provides an [alerting solution based on Azure Monitor](./backup-azure-monitoring-built-in-monitor.md#azure-monitor-alerts-for-azure-backup) for scenarios, such as deletion of backup data, disabling of soft-delete, backup failures, and restore failures. You can view and manage these alerts via Backup center. To [configure notifications](./backup-azure-monitoring-built-in-monitor.md#configuring-notifications-for-alerts) for these alerts (for example, emails), you can use Azure Monitor's [Action rules](/azure/azure-monitor/alerts/alerts-action-rules?tabs=portal) and [Action groups](/azure/azure-monitor/alerts/action-groups) to route alerts to a wide range of notification channels. <br><br> - **Azure Backup Metric Alerts using Azure Monitor (preview)**: You can write custom alert rules using Azure Monitor metrics to monitor the health of your backup items across different KPIs. [Learn more](./metrics-overview.md) <br><br> - **Classic Alerts**: This is the older alerting solution, which you can [access using the Backup Alerts tab](./backup-azure-monitoring-built-in-monitor.md#backup-alerts-in-recovery-services-vault) in the Recovery Services vault blade. These alerts don't appear in Backup center. If you're using classic alerts, we recommend to start using one or more of the Azure Monitor based alert solutions (described above) as it's the forward-looking solution for alerting. <br><br> - **Custom log alerts**: If you've scenarios where an alert needs to be generated based on custom logic, you can use [Log Analytics based alerts](./backup-azure-monitoring-use-azuremonitor.md#create-alerts-by-using-log-analytics) for such scenarios, provided you've configured your vaults to send diagnostics data to a Log Analytics (LA) workspace. Due to the current [frequency at which data in an LA workspace is updated](./backup-azure-monitoring-use-azuremonitor.md#diagnostic-data-update-frequency), this solution is typically used for scenarios where it's acceptable to have a short time difference between the occurrence of the actual incident and the generation of the alert. | | Analyze historical trends | - **Built-in reports**: You can use [Backup Reports](./configure-reports.md) (based on Azure Monitor Logs) to analyze historical trends related to job success and backup usage, and discover optimization opportunities for your backups. You can also [configure periodic emails](./backup-reports-email.md) of these reports. <br><br> - **Customized reporting dashboards**: You can also query the data in Azure Monitor Logs (LA) using the documented [system functions](./backup-reports-system-functions.md) to create your own dashboards to analyze historical information related to your backups. |-| Audit user triggered actions on vaults | **Activity Logs**: You can use standard [Activity Logs](../azure-monitor/essentials/activity-log.md) for your vaults to view information on various user-triggered actions, such as modification of backup policies, restoration of a backup item, and so on. You can also configure alerts on Activity Logs, or export these logs to a Log Analytics workspace for long-term retention. | +| Audit user triggered actions on vaults | **Activity Logs**: You can use standard [Activity Logs](/azure/azure-monitor/essentials/activity-log) for your vaults to view information on various user-triggered actions, such as modification of backup policies, restoration of a backup item, and so on. You can also configure alerts on Activity Logs, or export these logs to a Log Analytics workspace for long-term retention. | ## Next steps - [Learn more](./backup-center-overview.md) about Backup center. - [Learn more](./backup-azure-monitoring-built-in-monitor.md#azure-monitor-alerts-for-azure-backup) about Azure Monitor Alerts.-- [Learn more](../service-health/resource-health-overview.md) about Azure Resource Health.+- [Learn more](/azure/service-health/resource-health-overview) about Azure Resource Health. |
| backup | Multi User Authorization Concept | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/multi-user-authorization-concept.md | Title: Multi-user authorization using Resource Guard description: An overview of Multi-user authorization using Resource Guard.- Previously updated : 06/11/2024+ Last updated : 09/11/2024 |
| backup | Offline Backup Azure Data Box Dpm Mabs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/offline-backup-azure-data-box-dpm-mabs.md | Title: Offline Backup with Azure Data Box for DPM and MABS description: You can use Azure Data Box to seed initial Backup data offline from DPM and MABS.- Previously updated : 05/24/2024+ Last updated : 09/11/2024 |
| backup | Query Backups Using Azure Resource Graph | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/query-backups-using-azure-resource-graph.md | To get started with querying your backups using ARG, follow these steps: 1. To explore the data in any of these tables, write **Kusto** queries in the query editor and click **Run Query**. - You can download the output of these queries as CSV from the **Resource Graph Explorer**. You can also use these queries in custom automation using any automation clients supported by ARG, such as [PowerShell](../governance/resource-graph/first-query-powershell.md), [CLI](../governance/resource-graph/first-query-azurecli.md), or [SDK](../governance/resource-graph/first-query-python.md). You can also create [custom workbooks](../azure-monitor/visualize/workbooks-overview.md) in the Azure portal using ARG as a data source. + You can download the output of these queries as CSV from the **Resource Graph Explorer**. You can also use these queries in custom automation using any automation clients supported by ARG, such as [PowerShell](../governance/resource-graph/first-query-powershell.md), [CLI](../governance/resource-graph/first-query-azurecli.md), or [SDK](../governance/resource-graph/first-query-python.md). You can also create [custom workbooks](/azure/azure-monitor/visualize/workbooks-overview) in the Azure portal using ARG as a data source. >[!NOTE] >- Backup/Restore jobs that are up to 14 days old are available in ARG for query. If you want to query historical records, we recommend you to use **Azure Monitor Logs**. |
| backup | Restore Azure File Share Rest Api | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/restore-azure-file-share-rest-api.md | Title: Restore Azure file shares with REST API description: Learn how to use REST API to restore Azure file shares or specific files from a restore point created by Azure Backup - Previously updated : 02/17/2020+ Last updated : 09/11/2024 -By the end of this article, you'll learn how to perform the following operations using REST API: +By the end of this article, you learn how to perform the following operations using REST API: * View restore points for a backed-up Azure file share. * Restore a full Azure file share. By the end of this article, you'll learn how to perform the following operations We assume that you already have a backed-up file share you want to restore. If you donΓÇÖt, check [Backup Azure file share using REST API](backup-azure-file-share-rest-api.md) to learn how to create one. -For this article, we'll use the following resources: +For this article, we use the following resources: * **RecoveryServicesVault**: *azurefilesvault* * **Resource group**: *azurefiles* |
| backup | Restore Azure Sql Vm Rest Api | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/restore-azure-sql-vm-rest-api.md | Title: Restore SQL server databases in Azure VMs with REST API description: Learn how to use REST API to restore SQL server databases in Azure VM from a restore point created by Azure Backup- Previously updated : 08/11/2022+ Last updated : 09/11/2024 |
| backup | Restore Postgresql Database Use Rest Api | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/restore-postgresql-database-use-rest-api.md | Title: Restore Azure PostgreSQL databases via Azure data protection REST API description: Learn how to restore Azure PostGreSQL databases using Azure Data Protection REST API.- Previously updated : 01/24/2022+ Last updated : 09/11/2024 There're various restore options for a PostgreSQL database. You can restore the #### Restore as database -Construct the Azure Resource Manager ID (ARM ID) of the new PostgreSQL database to be created with the target PostgreSQL server, to which permissions were assigned as detailed [above](#set-up-permissions), and the required PostgreSQL database name. For example, a PostgreSQL database can be named **emprestored21** under a target PostgreSQL server **targetossserver** in resource group **targetrg** with a different subscription. +Construct the Azure Resource Manager ID (ARM ID) of the new PostgreSQL database to be created with the target PostgreSQL server, to which permissions were assigned as detailed [above](#set-up-permissions), and the required PostgreSQL database name. For example, a PostgreSQL database can be named `emprestored21` under a target PostgreSQL server `targetossserver` in resource group `targetrg` with a different subscription. ```http "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx/resourceGroups/targetrg/providers/providers/Microsoft.DBforPostgreSQL/servers/targetossserver/databases/emprestored21" |
| backup | Restore Sql Database Azure Vm | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/restore-sql-database-azure-vm.md | Title: Restore SQL Server databases on an Azure VM description: This article describes how to restore SQL Server databases that are running on an Azure VM and that are backed up with Azure Backup. You can also use Cross Region Restore to restore your databases to a secondary region.- Previously updated : 01/24/2024+ Last updated : 09/11/2024 |
| backup | Sap Hana Backup Support Matrix | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/sap-hana-backup-support-matrix.md | Title: SAP HANA Backup support matrix description: In this article, learn about the supported scenarios and limitations when you use Azure Backup to back up SAP HANA databases on Azure VMs.- Previously updated : 01/30/2024+ Last updated : 09/11/2024 |
| backup | Sap Hana Database About | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/sap-hana-database-about.md | Title: About the SAP HANA database backup on Azure VMs description: In this article, you'll learn about backing up SAP HANA databases that are running on Azure virtual machines.- Previously updated : 11/02/2023+ Last updated : 09/11/2024 |
| backup | Sap Hana Database Instances Backup | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/sap-hana-database-instances-backup.md | Title: Back up SAP HANA database instances on Azure VMs description: In this article, you'll learn how to back up SAP HANA database instances that are running on Azure virtual machines.- Previously updated : 11/02/2023+ Last updated : 09/11/2024 |
| backup | Sap Hana Database Instances Restore | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/sap-hana-database-instances-restore.md | Title: Restore SAP HANA database instances on Azure VMs description: In this article, you'll learn how to restore SAP HANA database instances on Azure virtual machines.- Previously updated : 11/02/2023+ Last updated : 09/11/2024 |
| backup | Soft Delete Azure File Share | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/soft-delete-azure-file-share.md | Title: Accidental Delete Protection for Azure file shares description: Learn how to soft delete can protect your Azure File Shares from accidental deletion. - Previously updated : 02/02/2020+ Last updated : 09/11/2024 |
| backup | Soft Delete Virtual Machines | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/soft-delete-virtual-machines.md | Title: Soft delete for virtual machines description: Learn how soft delete for virtual machines makes backups more secure.- Previously updated : 08/10/2022+ Last updated : 09/11/2024 -Soft delete for VMs protects the backups of your VMs from unintended deletion. Even after the backups are deleted, they're preserved in soft-delete state for 14 additional days. +Soft delete for VMs protects the backups of your VMs from unintended deletion. Even after the backups are deleted, they're preserved in soft-delete state for 14 more days. > [!NOTE]-> Soft delete only protects deleted backup data. If a VM is deleted without a backup, the soft-delete feature won't preserve the data. All resources should be protected with Azure Backup to ensure full resilience. +> Soft delete only protects deleted backup data. If a VM is deleted without a backup, the soft delete feature won't preserve the data. All resources should be protected with Azure Backup to ensure full resilience. > ## Supported regions Soft delete is available in all Azure Public and National regions. ## Soft delete for VMs using Azure portal -1. To delete the backup data of a VM, the backup must be stopped. In the Azure portal, go to your Recovery Services vault, right-click on the backup item and choose **Stop backup**. +1. To delete the backup data of a Virtual Machine (VM), the backup must be stopped. In the Azure portal, go to your Recovery Services vault, right-click on the backup item and choose **Stop backup**.  -2. In the following window, you'll be given a choice to delete or retain the backup data. If you choose **Retain backup data** and then **Stop backup**, the VM backup won't be permanently deleted. Rather, this stops all scheduled backup jobs and retains backup data. In this scenario, retention range set in the policy does not apply to the backup data. It continues the pricing as is until you remove the data manually. If **Delete backup data** is chosen, a delete email alert is sent to the configured email ID informing the user that 14 days remain of extended retention for backup data. Also, an email alert is sent on the 12th day informing that there are two more days left to resurrect the deleted data. The deletion is deferred until the 15th day, when permanent deletion will occur and a final email alert is sent informing about the permanent deletion of the data. +2. In the following window, you're given a choice to delete or retain the backup data. If you choose **Retain backup data** and then **Stop backup**, the VM backup won't be permanently deleted. Rather, this stops all scheduled backup jobs and retains backup data. In this scenario, retention range set in the policy does not apply to the backup data. It continues the pricing as is until you remove the data manually. If **Delete backup data** is chosen, a delete email alert is sent to the configured email ID informing the user that 14 days remain of extended retention for backup data. Also, an email alert is sent on the 12th day informing that there are two more days left to resurrect the deleted data. The deletion is deferred until the 15th day, when permanent deletion will occur and a final email alert is sent informing about the permanent deletion of the data.  Soft delete is available in all Azure Public and National regions.  - A window will appear warning that if undelete is chosen, all restore points for the VM will be undeleted and available for performing a restore operation. The VM will be retained in a "stop protection with retain data" state with backups paused and backup data retained forever with no backup policy effective. + A window will appear warning that if the undelete option is chosen, all restore points for the VM will be undeleted and available for performing a restore operation. The VM will be retained in a "stop protection with retain data" state with backups paused and backup data retained forever with no backup policy effective.  |
| backup | Sql Support Matrix | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/sql-support-matrix.md | Title: Azure Backup support matrix for SQL Server Backup in Azure VMs description: Provides a summary of support settings and limitations when backing up SQL Server in Azure VMs with the Azure Backup service.- Previously updated : 08/06/2024+ Last updated : 09/11/2024 |
| backup | Transport Layer Security | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/transport-layer-security.md | Title: Transport Layer Security in Azure Backup description: Learn how to enable Azure Backup to use the encryption protocol Transport Layer Security (TLS) to keep data secure when being transferred over a network.- Previously updated : 09/20/2022+ Last updated : 09/11/2024 |
| backup | Use Archive Tier Support | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/use-archive-tier-support.md | Title: Use Archive tier description: Learn about using Archive tier Support for Azure Backup.- Previously updated : 10/03/2022+ Last updated : 09/11/2024 zone_pivot_groups: backup-client-portaltier-powershelltier-clitier |
| backup | Whats New | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/backup/whats-new.md | Title: What's new in the Azure Backup service description: Learn about the new features in the Azure Backup service.- Previously updated : 07/24/2024+ Last updated : 09/11/2024 - ignite-2023 For more information, see [how to configure multiple backups per day via backup ## Azure Backup metrics and metrics alerts (in preview) -Azure Backup now provides a set of built-in metrics via [Azure Monitor](../azure-monitor/essentials/data-platform-metrics.md) that allows you to monitor the health of your backups. You can also configure alert rules that trigger alerts when metrics exceed the defined thresholds. +Azure Backup now provides a set of built-in metrics via [Azure Monitor](/azure/azure-monitor/essentials/data-platform-metrics) that allows you to monitor the health of your backups. You can also configure alert rules that trigger alerts when metrics exceed the defined thresholds. Azure Backup offers the following key capabilities: |
| batch | Create Pool Extensions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/batch/create-pool-extensions.md | The following extensions can currently be installed when creating a Batch pool: - [HPC GPU driver extension for Windows on NVIDIA](/azure/virtual-machines/extensions/hpccompute-gpu-windows) - [HPC GPU driver extension for Linux on NVIDIA](/azure/virtual-machines/extensions/hpccompute-gpu-linux) - [Microsoft Antimalware extension for Windows](/azure/virtual-machines/extensions/iaas-antimalware-windows)-- [Azure Monitor agent for Linux](../azure-monitor/agents/azure-monitor-agent-manage.md)-- [Azure Monitor agent for Windows](../azure-monitor/agents/azure-monitor-agent-manage.md)+- [Azure Monitor agent for Linux](/azure/azure-monitor/agents/azure-monitor-agent-manage) +- [Azure Monitor agent for Windows](/azure/azure-monitor/agents/azure-monitor-agent-manage) You can request support for other publishers and/or extension types by opening a support request. |
| batch | Job Pool Lifetime Statistics Migration Guide | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/batch/job-pool-lifetime-statistics-migration-guide.md | The Azure portal has various options to enable monitoring and logs. System logs ## Next steps -For more information, see the Batch [Job](/rest/api/batchservice/job) or [Pool](/rest/api/batchservice/pool) API. For Azure Monitor logs, see [this article](../azure-monitor/logs/data-platform-logs.md). +For more information, see the Batch [Job](/rest/api/batchservice/job) or [Pool](/rest/api/batchservice/pool) API. For Azure Monitor logs, see [this article](/azure/azure-monitor/logs/data-platform-logs). |
| batch | Monitor Application Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/batch/monitor-application-insights.md | Last updated 06/13/2024 # Monitor and debug an Azure Batch .NET application with Application Insights -[Application Insights](../azure-monitor/app/app-insights-overview.md) provides an elegant and powerful way for developers to monitor and debug applications deployed to Azure services. Use Application Insights to monitor performance counters and exceptions as well as instrument your code with custom metrics and tracing. Integrating Application Insights with your Azure Batch application allows you to gain deep insights into behaviors and investigate issues in near-real time. +[Application Insights](/azure/azure-monitor/app/app-insights-overview) provides an elegant and powerful way for developers to monitor and debug applications deployed to Azure services. Use Application Insights to monitor performance counters and exceptions as well as instrument your code with custom metrics and tracing. Integrating Application Insights with your Azure Batch application allows you to gain deep insights into behaviors and investigate issues in near-real time. -This article shows how to add and configure the Application Insights library into your Azure Batch .NET solution and instrument your application code. It also shows ways to monitor your application via the Azure portal and build custom dashboards. For Application Insights support in other languages, see the [languages, platforms, and integrations documentation](../azure-monitor/app/app-insights-overview.md#supported-languages). +This article shows how to add and configure the Application Insights library into your Azure Batch .NET solution and instrument your application code. It also shows ways to monitor your application via the Azure portal and build custom dashboards. For Application Insights support in other languages, see the [languages, platforms, and integrations documentation](/azure/azure-monitor/app/app-insights-overview#supported-languages). A sample C# solution with code to accompany this article is available on [GitHub](https://github.com/Azure/azure-batch-samples/tree/master/CSharp/ArticleProjects/ApplicationInsights). This example adds Application Insights instrumentation code to the [TopNWords](https://github.com/Azure/azure-batch-samples/tree/master/CSharp/TopNWords) example. If you're not familiar with that example, try building and running TopNWords first. Doing this will help you understand a basic Batch workflow of processing a set of input blobs in parallel on multiple compute nodes. Reference Application Insights from your .NET application by using the **Microso ## Instrument your code -To instrument your code, your solution needs to create an Application Insights [TelemetryClient](/dotnet/api/microsoft.applicationinsights.telemetryclient). In the example, the TelemetryClient loads its configuration from the [ApplicationInsights.config](../azure-monitor/app/configuration-with-applicationinsights-config.md) file. Be sure to update ApplicationInsights.config in the following projects with your Application Insights instrumentation key: Microsoft.Azure.Batch.Samples.TelemetryStartTask and TopNWordsSample. +To instrument your code, your solution needs to create an Application Insights [TelemetryClient](/dotnet/api/microsoft.applicationinsights.telemetryclient). In the example, the TelemetryClient loads its configuration from the [ApplicationInsights.config](/azure/azure-monitor/app/configuration-with-applicationinsights-config) file. Be sure to update ApplicationInsights.config in the following projects with your Application Insights instrumentation key: Microsoft.Azure.Batch.Samples.TelemetryStartTask and TopNWordsSample. ```xml <InstrumentationKey>YOUR-IKEY-GOES-HERE</InstrumentationKey> To instrument your code, your solution needs to create an Application Insights [ Also add the instrumentation key in the file TopNWords.cs. -The example in TopNWords.cs uses the following [instrumentation calls](../azure-monitor/app/api-custom-events-metrics.md) from the Application Insights API: +The example in TopNWords.cs uses the following [instrumentation calls](/azure/azure-monitor/app/api-custom-events-metrics) from the Application Insights API: - `TrackMetric()` - Tracks how long, on average, a compute node takes to download the required text file. - `TrackTrace()` - Adds debugging calls to your code. public void CountWords(string blobName, int numTopN, string storageAccountName, ### Azure Batch telemetry initializer helper -When reporting telemetry for a given server and instance, Application Insights uses the Azure VM Role and VM name for the default values. In the context of Azure Batch, the example shows how to use the pool name and compute node name instead. Use a [telemetry initializer](../azure-monitor/app/api-filtering-sampling.md#add-properties) to override the default values. +When reporting telemetry for a given server and instance, Application Insights uses the Azure VM Role and VM name for the default values. In the context of Azure Batch, the example shows how to use the pool name and compute node name instead. Use a [telemetry initializer](/azure/azure-monitor/app/api-filtering-sampling#add-properties) to override the default values. ```csharp using Microsoft.ApplicationInsights.Channel; pool.StartTask = new StartTask() ## Throttle and sample data -Due to the large-scale nature of Azure Batch applications running in production, you might want to limit the amount of data collected by Application Insights to manage costs. See [Sampling in Application Insights](../azure-monitor/app/sampling.md) for some mechanisms to achieve this. +Due to the large-scale nature of Azure Batch applications running in production, you might want to limit the amount of data collected by Application Insights to manage costs. See [Sampling in Application Insights](/azure/azure-monitor/app/sampling) for some mechanisms to achieve this. ## Next steps -- Learn more about [Application Insights](../azure-monitor/app/app-insights-overview.md).-- For Application Insights support in other languages, see the [languages, platforms, and integrations documentation](../azure-monitor/app/app-insights-overview.md#supported-languages).+- Learn more about [Application Insights](/azure/azure-monitor/app/app-insights-overview). +- For Application Insights support in other languages, see the [languages, platforms, and integrations documentation](/azure/azure-monitor/app/app-insights-overview#supported-languages). |
| business-continuity-center | Business Continuity Center Support Matrix | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/business-continuity-center/business-continuity-center-support-matrix.md | Title: Azure Business Continuity Center support matrix description: Provides a summary of support settings and limitations for the Azure Business Continuity center service.- Previously updated : 01/29/2024+ Last updated : 09/11/2024 - references_regions - ignite-2023 -You can use [Azure Business Continuity Center](business-continuity-center-overview.md), a cloud-native unified business continuity and disaster recovery (BCDR) management platform in Azure to manage your protection estate across solutions and environments. This helps enterprises to govern, monitor, operate, and analyze backups and replication at scale. This article summarizes the solutions and scenarios that ABC center supports for each workload type. +You can use [Azure Business Continuity Center](business-continuity-center-overview.md), a cloud-native unified business continuity and disaster recovery (BCDR) management platform in Azure to manage your protection estate across solutions and environments. This solution helps enterprises to govern, monitor, operate, and analyze backups and replication at scale. This article summarizes the solutions and scenarios that ABC center supports for each workload type. ## Supported regions The following table lists all supported scenarios: | | | | | | Monitoring | View all backup and site recovery jobs. | All Solutions and datasource types from above table. | - Seven daysΓÇÖ worth of jobs available out of the box. <br><br> - Each filter/drop-down supports a maximum of 1000 items. Hence, if you want to filter the grid for a particular vault, there might be scenarios where you might not see the desired vault if you have more than 1000 vaults. In these cases, choosing the ΓÇÿAllΓÇÖ option in filter helps you aggregate data across your entire set of subscriptions and vaults that you have access to. | | Monitoring | View Azure Monitor alerts at scale | **Azure Backup**: <br><br> - Azure Virtual Machine <br> - Azure Database for PostgreSQL server <br> - SQL in Azure VM <br> - SAP HANA in Azure VM <br> - Azure Files <br> - Azure Blobs <br> - Azure Disks <br><br> **Azure Site Recovery**: <br><br> - Azure to Azure disaster recovery <br> - VMware and Physical to Azure disaster recovery | See [Alerts documentation](/azure/backup/backup-azure-monitoring-built-in-monitor#azure-monitor-alerts-for-azure-backup). |-| Monitoring | View Azure Backup metrics and write metric alert rules. | **Azure Backup**: <br><br> - Azure Virtual Machine <br> - SQL in Azure VM <br> - SAP HANA in Azure VM <br> - Azure Files <br> - Azure Blobs (Restore Health Events metric only) <br> - Azure Kubernetes Services | See [Metrics documentation](/azure/backup/metrics-overview#supported-scenarios). | +| Monitoring | View the Azure Backup metrics and write metric alert rules. | **Azure Backup**: <br><br> - Azure Virtual Machine <br> - SQL in Azure VM <br> - SAP HANA in Azure VM <br> - Azure Files <br> - Azure Blobs (Restore Health Events metric only) <br> - Azure Kubernetes Services | See [Metrics documentation](/azure/backup/metrics-overview#supported-scenarios). | | Security | View security level | Only for the Azure Backup supported datasources given in the above table, and vaults. | | | Governance | View resources not configured for protection. | **Azure Backup**: <br><br> - Azure VM backup <br> - Azure Storage account (with no file or blobs protected) <br> - Azure Managed Disks backup <br> - Azure Database for PostgreSQL Server backup <br> - Azure Kubernetes services <br><br> **Azure Site Recovery**: <br><br> - Azure to Azure disaster recovery | | | Governance | View all protected items across solutions. | All solutions and datasource types as given in the above table. | Same as previous. | |
| business-continuity-center | Security Levels Concept | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/business-continuity-center/security-levels-concept.md | Title: Security levels in Azure Business Continuity center description: An overview of the levels of Security available in Azure Business Continuity center.- Previously updated : 11/15/2023+ Last updated : 09/11/2024 - ignite-2023 |
| business-process-tracking | Deploy Business Process | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/business-process-tracking/deploy-business-process.md | After the mapped Standard logic app workflows run and emit the data that you spe :::image type="content" source="media/deploy-business-process/transaction-details.png" alt-text="Screenshot shows transactions page and transaction details for a specific stage." lightbox="media/deploy-business-process/transaction-details.png"::: -1. To create custom experiences for the data provided here, check out [Azure Workbooks](../azure-monitor/visualize/workbooks-overview.md) or [Azure Data Explorer with Power BI](/azure/data-explorer/power-bi-data-connector?tabs=web-ui). +1. To create custom experiences for the data provided here, check out [Azure Workbooks](/azure/azure-monitor/visualize/workbooks-overview) or [Azure Data Explorer with Power BI](/azure/data-explorer/power-bi-data-connector?tabs=web-ui). ## Next step |
| cdn | Cdn Azure Diagnostic Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cdn/cdn-azure-diagnostic-logs.md | To use a storage account to store the logs, follow these steps: To use Log Analytics for the logs, follow these steps: >[!NOTE]-> A Log Analytics workspace is required to complete these steps. Refer to: **[Create a Log Analytics workspace in the Azure portal](../azure-monitor/logs/quick-create-workspace.md)** for more information. +> A Log Analytics workspace is required to complete these steps. Refer to: **[Create a Log Analytics workspace in the Azure portal](/azure/azure-monitor/logs/quick-create-workspace)** for more information. 1. For **Diagnostic setting name**, enter a name for your diagnostic log settings. Example properties: ## More resources -- [Azure Diagnostic logs](../azure-monitor/essentials/platform-logs-overview.md)+- [Azure Diagnostic logs](/azure/azure-monitor/essentials/platform-logs-overview) - [Core analytics via Azure Content Delivery Network supplemental portal](./cdn-analyze-usage-patterns.md)-- [Azure Monitor logs](../azure-monitor/logs/log-query-overview.md)+- [Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview) - [Azure Log Analytics REST API](/rest/api/loganalytics) |
| cdn | Cdn Resource Health | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cdn/cdn-resource-health.md | -Azure Content Delivery Network Resource health is a subset of [Azure resource health](../service-health/resource-health-overview.md). You can use Azure resource health to monitor the health of Content Delivery Network resources and receive actionable guidance to troubleshoot problems. +Azure Content Delivery Network Resource health is a subset of [Azure resource health](/azure/service-health/resource-health-overview). You can use Azure resource health to monitor the health of Content Delivery Network resources and receive actionable guidance to troubleshoot problems. >[!IMPORTANT] > Azure Content Delivery Network resource health only currently accounts for the health of global content delivery networking delivery and API capabilities. Azure Content Delivery Network resource health does not verify individual Content Delivery Network endpoints. We're sorry, we're experiencing issues with some of our Content Delivery Network ## Next steps -- [Read an overview of Azure resource health](../service-health/resource-health-overview.md)+- [Read an overview of Azure resource health](/azure/service-health/resource-health-overview) - [Troubleshoot issues with Content Delivery Network compression](./cdn-troubleshoot-compression.md) - [Troubleshoot issues with 404 errors](./cdn-troubleshoot-endpoint.md) |
| cdn | Monitoring And Access Log | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cdn/monitoring-and-access-log.md | The Metrics are displayed in charts and accessible via PowerShell, CLI, and API. Azure CDN from Microsoft measures and sends its metrics in 60-second intervals. The metrics can take up to 3 mins to appear in the portal. -For more information, see [Azure Monitor metrics](../azure-monitor/essentials/data-platform-metrics.md). +For more information, see [Azure Monitor metrics](/azure/azure-monitor/essentials/data-platform-metrics). **Metrics supported by Azure CDN from Microsoft** Select **New alert rule** for metrics listed in Metrics section: :::image type="content" source="./media/cdn-raw-logs/raw-logs-08.png" alt-text="Configure alerts for CDN endpoint." border="true"::: -Alert is charged based on Azure Monitor. For more information about alerts, see [Azure Monitor alerts](../azure-monitor/alerts/alerts-overview.md). +Alert is charged based on Azure Monitor. For more information about alerts, see [Azure Monitor alerts](/azure/azure-monitor/alerts/alerts-overview). ### More Metrics For more information on Azure CDN and the other Azure services mentioned in this - [Analyze](cdn-log-analysis.md) Azure CDN usage patterns. -- Learn more about [Azure Monitor](../azure-monitor/overview.md).+- Learn more about [Azure Monitor](/azure/azure-monitor/overview). -- Configure [Log Analytics in Azure Monitor](../azure-monitor/logs/log-analytics-tutorial.md).+- Configure [Log Analytics in Azure Monitor](/azure/azure-monitor/logs/log-analytics-tutorial). |
| chaos-studio | Chaos Studio Bicep | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-bicep.md | - Title: Use Bicep to create an experiment in Azure Chaos Studio -description: Sample Bicep templates to create Azure Chaos Studio experiments. --- Previously updated : 06/09/2023-------# Use Bicep to create an experiment in Azure Chaos Studio ---This article includes a sample Bicep file to get started in Azure Chaos Studio, including: --* Onboarding a resource as a target (for example, a Virtual Machine) -* Enabling capabilities on the target (for example, Virtual Machine Shutdown) -* Creating a Chaos Studio experiment -* Assigning the necessary permissions for the experiment to execute ---## Build a Virtual Machine Shutdown experiment --In this sample, we create a chaos experiment with a single target resource and a single virtual machine shutdown fault. You can modify the experiment by referencing the [fault library](chaos-studio-fault-library.md) and [recommended role assignments](chaos-studio-fault-providers.md). --### Prerequisites --This sample assumes: -* The Chaos Studio resource provider is already registered with your Azure subscription -* You already have a resource group in a region supported by Chaos Studio -* A virtual machine is deployed in the resource group --### Review the Bicep file --```bicep -@description('The existing virtual machine resource you want to target in this experiment') -param targetName string --@description('Desired name for your Chaos Experiment') -param experimentName string --@description('Desired region for the experiment, targets, and capabilities') -param location string = resourceGroup().location --// Define Chaos Studio experiment steps for a basic Virtual Machine Shutdown experiment -param experimentSteps array = [ - { - name: 'Step1' - branches: [ - { - name: 'Branch1' - actions: [ - { - name: 'urn:csci:microsoft:virtualMachine:shutdown/1.0' - type: 'continuous' - duration: 'PT10M' - parameters: [ - { - key: 'abruptShutdown' - value: 'true' - } - ] - selectorId: 'Selector1' - } - ] - } - ] - } -] --// Reference the existing Virtual Machine resource -resource vm 'Microsoft.Compute/virtualMachines@2023-03-01' existing = { - name: targetName -} --// Deploy the Chaos Studio target resource to the Virtual Machine -resource chaosTarget 'Microsoft.Chaos/targets@2024-01-01' = { - name: 'Microsoft-VirtualMachine' - location: location - scope: vm - properties: {} -- // Define the capability -- in this case, VM Shutdown - resource chaosCapability 'capabilities' = { - name: 'Shutdown-1.0' - } -} --// Define the role definition for the Chaos experiment -resource chaosRoleDefinition 'Microsoft.Authorization/roleDefinitions@2022-04-01' existing = { - scope: vm - // In this case, Virtual Machine Contributor role -- see https://learn.microsoft.com/azure/role-based-access-control/built-in-roles - name: '9980e02c-c2be-4d73-94e8-173b1dc7cf3c' -} --// Define the role assignment for the Chaos experiment -resource chaosRoleAssignment 'Microsoft.Authorization/roleAssignments@2022-04-01' = { - name: guid(vm.id, chaosExperiment.id, chaosRoleDefinition.id) - scope: vm - properties: { - roleDefinitionId: chaosRoleDefinition.id - principalId: chaosExperiment.identity.principalId - principalType: 'ServicePrincipal' - } -} --// Deploy the Chaos Studio experiment resource -resource chaosExperiment 'Microsoft.Chaos/experiments@2024-01-01' = { - name: experimentName - location: location // Doesn't need to be the same as the Targets & Capabilities location - identity: { - type: 'SystemAssigned' - } - properties: { - selectors: [ - { - id: 'Selector1' - type: 'List' - targets: [ - { - id: chaosTarget.id - type: 'ChaosTarget' - } - ] - } - ] - steps: experimentSteps - } -} -``` --## Deploy the Bicep file --1. Save the Bicep file as `chaos-vm-shutdown.bicep` to your local computer. -1. Deploy the Bicep file using either Azure CLI or Azure PowerShell, replacing `exampleRG` with the existing resource group that includes the virtual machine you want to target. -- # [CLI](#tab/CLI) -- ```azurecli - az deployment group create --resource-group exampleRG --template-file chaos-vm-shutdown.bicep - ``` -- # [PowerShell](#tab/PowerShell) -- ```azurepowershell - New-AzResourceGroupDeployment -ResourceGroupName exampleRG -TemplateFile ./chaos-vm-shutdown.bicep - ``` --1. When prompted, enter the following values: - * **targetName**: the name of an existing Virtual Machine within your resource group that you want to target - * **experimentName**: the desired name for your Chaos Experiment -1. The template should deploy within a few minutes. Once the deployment is complete, navigate to Chaos Studio in the Azure portal, select **Experiments**, and find the experiment created by the template. Select it, then **Start** the experiment. --## Next steps --* [Learn more about Chaos Studio](chaos-studio-overview.md) -* [Learn more about chaos experiments](chaos-studio-chaos-experiments.md) |
| chaos-studio | Chaos Studio Chaos Engineering Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-chaos-engineering-overview.md | - Title: Understand chaos engineering and resilience with Chaos Studio -description: Understand the concepts of chaos engineering and resilience. --- Previously updated : 11/01/2021------# Understand chaos engineering and resilience --Before you start using Azure Chaos Studio, it's useful to understand the core site reliability engineering concepts being applied. --## What is resilience? --It's never been easier to create large-scale, distributed applications. Infrastructure is hosted in the cloud, and programming language support is diverse. There are also many open-source and hosted components and services to build on. --Unfortunately, there's no reliability guarantee for these underlying components and dependencies, or for systems built on them. Infrastructure can go offline, and service disruptions or outages can occur at any time. Minor disruptions in one area can be magnified and have longstanding side effects in another. --Applications and services must plan for and accommodate issues like: --- Service outages.-- Disruptions to known and unknown dependencies.-- Sudden unexpected load.-- Latencies throughout the system.--Applications and services must be designed to handle failure and be hardened against disruptions. --Applications and services that deal with stresses and issues gracefully are *resilient*. Individual component reliability is good, but *resilience is a property of the entire system*. End-to-end system resilience must be validated in an integrated, production-like environment with the conditions and load that's faced in production. --## What are chaos engineering and fault injection? --- **Chaos engineering**: The practice of subjecting applications and services to real-world stresses and failures. The goal is to build and validate resilience to unreliable conditions and missing dependencies.-- **Fault injection**: The act of introducing an error to a system. You can use different faults, such as network latency or loss of access to storage, to target system components. You can create scenarios that an application or service must be able to handle or recover from.--A chaos experiment is the application of faults individually, in parallel, or sequentially against one or more subscription resources or dependencies. The goal is to monitor system behavior and health so that you can act on any issues that arise. --An experiment can represent a real-world scenario, such as a datacenter power outage or network latency to a DNS server. It can also be used to simulate edge conditions that occur. Examples are Black Friday shopping sprees or when concert tickets go on sale for a popular band. |
| chaos-studio | Chaos Studio Chaos Experiments | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-chaos-experiments.md | - Title: Chaos experiments in Azure Chaos Studio -description: Understand the concept of a chaos experiment in Azure Chaos Studio. What are the parts of a chaos experiment? How can you create a chaos experiment? ----- Previously updated : 11/01/2021----# Chaos experiments --In Azure Chaos Studio, you create and run chaos experiments. A chaos experiment is an Azure resource that describes the faults that should be run and the resources those faults should be run against. --An experiment is divided into two sections: --- **Selectors**: Selectors are groups of target resources that have faults or other actions run against them. A selector allows you to logically group resources for reuse across multiple actions.-- For example, you might have a selector named `AllNonProdEastUSVMs`, in which you've added all the nonproduction virtual machines in East US. You could then apply CPU pressure followed by virtual memory pressure to those virtual machines by referencing the selector. -- **Logic**: The rest of the experiment describes how and when to run faults. An experiment is organized into *steps* that run one after the other. Each step has one or more *branches* that run at the same time. Steps and branches allow you to inject multiple faults across resources in your environment in parallel.-- Each branch has one or more *actions*, which are either the faults you want to run or time delays. *Faults* are actions that cause some disruption. Most faults take one or more *parameters*, such as the duration to run the fault or the amount of stress to apply. -- --## Cross-subscription and cross-tenant experiments --A chaos experiment is an Azure resource deployed to a subscription, resource group, and region. You can use the Azure portal or the Chaos Studio REST API to create, update, start, cancel, and view the status of an experiment. --Chaos experiments can target resources in a different subscription than the experiment if the subscription is within the same Azure tenant. Chaos experiments can target resources in a different region than the experiment if the region is a supported region for Chaos Studio. --## Documenting chaos experiments --There are several key aspects of your chaos experimentation process you can track and modify over time. One approach is to use work items in Azure Boards or in GitHub Projects. By creating dedicated work items for each experiment, you can track the details, progress, and outcomes of your experiments in a structured manner. This documentation can include information such as the purpose of the experiment, the expected outcomes, the steps followed, the resources involved, and any observations or learnings from the experiment. --| Item | Details | -|-|-| -| Hypothesis | Define the objective and expected outcomes of the experiment | -| Target Scope | Identify which part of the system will be subjected to chaos experiments (e.g., network, database, application layer). | -| Duration | Specify the time frame for the chaos experiment. | -| Target | Determine the specific targets or components within the system. | -| Environment | Define whether the experiment will be conducted in a production, staging, or development environment. | -| Observations | Record any data or behavior observed during the experiment. | -| Results | Summarize the findings and outcomes of the experiment. | -| Action Items | List any action items or steps to be taken based on the results. | -| | | --The **hypothesis** is a crucial aspect of a chaos experiment as it defines the objective and expected outcomes of the experiment. It helps in testing the system's ability to handle unexpected disruptions effectively. By formulating a clear hypothesis, you can focus your experiment on specific areas of the system and gather meaningful data to evaluate its resilience. By leveraging the features of Azure Boards or GitHub Projects, you can collaborate with your team, assign tasks, set due dates, and track the overall progress of your chaos engineering initiatives. --## Next steps -Now that you understand what a chaos experiment is you're ready to: --- [Learn about faults and actions](chaos-studio-faults-actions.md)-- [Create and run your first experiment](chaos-studio-tutorial-service-direct-portal.md) |
| chaos-studio | Chaos Studio Configure Customer Managed Keys | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-configure-customer-managed-keys.md | - Title: Configure customer-managed keys (preview) for experiment encryption- -description: Learn how to configure customer-managed keys (preview) for your Azure Chaos Studio experiment resource by using Azure Blob Storage. ------ Previously updated : 10/06/2023--- -# Configure customer-managed keys (preview) for Azure Chaos Studio by using Azure Blob Storage --Azure Chaos Studio automatically encrypts all data stored in your experiment resource with service-managed keys that Microsoft provides. As an optional feature, you can add a second layer of security by also providing your own customer-managed encryption keys. Customer-managed keys (CMKs) offer greater flexibility for controlling access and key-rotation policies. --When you use CMKs, you need to specify a user-assigned managed identity (UMI) to retrieve the key. The UMI you create must match the UMI that you use for the Chaos Studio experiment. --When configured, Chaos Studio uses Azure Storage, which uses the CMK to encrypt all your experiment execution and result data within your own storage account. --## Prerequisites --- An Azure account with an active subscription. If you don't have an Azure subscription, create a [free account](https://azure.microsoft.com/free/?WT.mc_id=A261C142F) before you begin.-- An existing UMI. For more information about how to create a UMI, see [Manage user-assigned managed identities](../active-directory/managed-identities-azure-resources/how-manage-user-assigned-managed-identities.md?pivots=identity-mi-methods-azp#create-a-user-assigned-managed-identity).-- A public-access-enabled storage account.--## Limitations --- Azure Chaos Studio experiments can't automatically rotate the CMK to use the latest version of the encryption key. You do key rotation directly in your chosen storage account.-- You need to use our *2023-10-27-preview REST API* to create and use CMK-enabled experiments only. There's *no* support for CMK-enabled experiments in our general availability-stable REST API until H1 2024.-- Chaos Studio currently *only supports creating Chaos Studio CMK experiments via the command line by using our 2023-10-27-preview REST API*. As a result, you *can't* create a Chaos Studio experiment with CMK enabled via the Azure portal. We plan to add this functionality in H1 of 2024.-- The storage account must have *public access from all networks* enabled for Chaos Studio experiments to be able to use it. If you have a hard requirement from your organization, reach out to your CSA for potential solutions.-- Experiment data will appear in ARG even after using CMK. This is a known issue, but the visbility is limited to only the active subcription using CMK. --## Configure your storage account --When you create or update your storage account to use it for a CMK experiment, you need to go to the **Encryption** tab and set **Encryption type** to **Customer-managed keys (CMK)** and fill out all the required information. -> [!NOTE] -> The UMI that you use should match the one you use for the corresponding Chaos Studio CMK-enabled experiment. --## Use customer-managed keys with Chaos Studio --You can only configure customer-managed encryption keys when you create a new Chaos Studio experiment resource. When you specify the encryption key details, you also have to select a UMI to retrieve the key from Azure Key Vault. --> [!NOTE] -> The UMI should be the *same* UMI you use with your Chaos Studio experiment resource. Otherwise, the Chaos Studio CMK experiment fails to create or update. --## Azure CLI --The following code sample shows an example `PUT` command for creating or updating a Chaos Studio experiment resource to enable CMKs. --> [!NOTE] ->The two parameters specific to CMK experiments are under the `CustomerDataStorage` block, in which we ask for the subscription ID of the Azure Blob Storage account that you want to use to store your experiment data and the name of the Blob Storage container to use or create. --```HTTP -PUT https://management.azure.com/subscriptions/<yourSubscriptionID>/resourceGroups/exampleRG/providers/Microsoft.Chaos/experiments/exampleExperiment?api-version=2023-10-27-preview --{ - "location": "eastus2euap", - "identity": { - "type": "SystemAssigned" - }, - "properties": { - "steps": [ - { - "name": "step1", - "branches": [ - { - "name": "branch1", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:virtualMachine:shutdown/1.0", - "selectorId": "selector1", - "duration": "PT10M", - "parameters": [ - { - "key": "abruptShutdown", - "value": "false" - } - ] - } - ] - } - ] - } - ], - "selectors": [ - { - "type": "List", - "id": "selector1", - "targets": [ - { - "type": "ChaosTarget", - "id": "/subscriptions/6b052e15-03d3-4f17-b2e1-be7f07588291/resourceGroups/exampleRG/providers/Microsoft.Compute/virtualMachines/exampleVM/providers/Microsoft.Chaos/targets/Microsoft-VirtualMachine" - } - ] - } - ], - "customerDataStorage": { - "storageAccountResourceId": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/exampleRG/providers/Microsoft.Storage/storageAccounts/exampleStorage", - "blobContainerName": "azurechaosstudioexperiments" - } - } -} -``` -## Disable CMK on a Chaos Studio experiment --If you run the same `PUT` command from the previous example on an existing CMK-enabled experiment resource, but you leave the fields in `customerDataStorage` empty, CMK is disabled on an experiment. --## Reenable CMK on a Chaos Studio experiment --If you run the same `PUT` command from the previous example on an existing experiment resource by using the 2023-10-27-preview REST API and populate the fields in `customerDataStorage`, CMK is reenabled on an experiment. --## Change the user-assigned managed identity for retrieving the encryption key --You can change the managed identity for CMKs for an existing Chaos Studio experiment at any time. The outcome would be identical to updating the UMI for any Chaos Studio experiment. -> [!NOTE] ->If the UMI does *not* have the correct permissions to retrieve the CMK from your key vault and write to Blob Storage, the `PUT` command to update the UMI fails. --### List whether an experiment is CMK-enabled or not --When you use the `Get Experiment` command from the 2023-10-27-preview REST API, the response shows you whether the `CustomerDataStorage` properties were populated or not. In this way, you can tell whether an experiment is CMK enabled or not. --## Update the customer-managed encryption key being used by your storage account --You can change the key that you're using at any time because Chaos Studio is using your own storage account for encryption by using your CMK. --## Frequently asked questions --Here are some answers to common questions. --### Is there an extra charge to enable customer-managed keys? --There's no charge associated directly from Chaos Studio. The use of Blob Storage and Key Vault might carry extra cost subject to those services' individual pricing. --### Are customer-managed keys supported for existing Chaos Studio experiments? --This feature is currently only available for Chaos Studio experiments created by using our 2023-10-27-preview REST API. |
| chaos-studio | Chaos Studio Fault Library | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-fault-library.md | - Title: Azure Chaos Studio fault and action library -description: Understand the available actions you can use with Azure Chaos Studio, including any prerequisites and parameters. --- Previously updated : 01/02/2024-------# Azure Chaos Studio fault and action library --This article lists the faults you can use in Chaos Studio, organized by the applicable resource type. To understand which role assignments are recommended for each resource type, see [Supported resource types and role assignments for Azure Chaos Studio](./chaos-studio-fault-providers.md). --## Agent-based faults --Agent-based faults are injected into **Azure Virtual Machines** or **Virtual Machine Scale Set** instances by installing the Chaos Studio Agent. Find the service-direct fault options for these resources below in the [Virtual Machine](#virtual-machines-service-direct) and [Virtual Machine Scale Set](#virtual-machine-scale-set) tables. --| Applicable OS types | Fault name | Applicable scenarios | -||--|-| -| Windows, Linux | [CPU Pressure](#cpu-pressure) | Compute capacity loss, resource pressure | -| Windows, Linux | [Kill Process](#kill-process) | Dependency disruption | -| Windows | [Pause Process](#pause-process) | Dependency disruption, service disruption | -| Windows<sup>1</sup>, Linux<sup>2</sup> | [Network Disconnect](#network-disconnect) | Network disruption | -| Windows<sup>1</sup>, Linux<sup>2</sup> | [Network Latency](#network-latency) | Network performance degradation | -| Windows<sup>1</sup>, Linux<sup>2</sup> | [Network Packet Loss](#network-packet-loss) | Network reliability issues | -| Windows, Linux<sup>2</sup> | [Network Isolation](#network-isolation) | Network disruption | -| Windows | [DNS Failure](#dns-failure) | DNS resolution issues | -| Windows | [Network Disconnect (Via Firewall)](#network-disconnect-via-firewall) | Network disruption | -| Windows, Linux | [Physical Memory Pressure](#physical-memory-pressure) | Memory capacity loss, resource pressure | -| Windows, Linux | [Stop Service](#stop-service) | Service disruption/restart | -| Windows | [Time Change](#time-change) | Time synchronization issues | -| Windows | [Virtual Memory Pressure](#virtual-memory-pressure) | Memory capacity loss, resource pressure | -| Linux | [Arbitrary Stress-ng Stressor](#arbitrary-stress-ng-stressor) | General system stress testing | -| Linux | [Linux DiskIO Pressure](#linux-disk-io-pressure) | Disk I/O performance degradation | -| Windows | [DiskIO Pressure](#disk-io-pressure) | Disk I/O performance degradation | --<sup>1</sup> TCP/UDP packets only. <sup>2</sup> Outbound network traffic only. --## App Service --This section applies to the `Microsoft.Web/sites` resource type. [Learn more about App Service](../app-service/overview.md). --| Fault name | Applicable scenarios | -||-| -| [Stop App Service](#stop-app-service) | Service disruption | --## Autoscale Settings --This section applies to the `Microsoft.Insights/autoscaleSettings` resource type. [Learn more about Autoscale Settings](../azure-monitor/autoscale/autoscale-overview.md). --| Fault name | Applicable scenarios | -||-| -| [Disable Autoscale](#disable-autoscale) | Compute capacity loss (when used with VMSS Shutdown) | --## Azure Kubernetes Service --This section applies to the `Microsoft.ContainerService/managedClusters` resource type. [Learn more about Azure Kubernetes Service](/azure/aks/intro-kubernetes). --| Fault name | Applicable scenarios | -||-| -| [AKS Chaos Mesh DNS Chaos](#aks-chaos-mesh-dns-chaos) | DNS resolution issues | -| [AKS Chaos Mesh HTTP Chaos](#aks-chaos-mesh-http-chaos) | Network disruption | -| [AKS Chaos Mesh IO Chaos](#aks-chaos-mesh-io-chaos) | Disk degradation/pressure | -| [AKS Chaos Mesh Kernel Chaos](#aks-chaos-mesh-kernel-chaos) | Kernel disruption | -| [AKS Chaos Mesh Network Chaos](#aks-chaos-mesh-network-chaos) | Network disruption | -| [AKS Chaos Mesh Pod Chaos](#aks-chaos-mesh-pod-chaos) | Container disruption | -| [AKS Chaos Mesh Stress Chaos](#aks-chaos-mesh-stress-chaos) | System stress testing | -| [AKS Chaos Mesh Time Chaos](#aks-chaos-mesh-time-chaos) | Time synchronization issues | --## Cloud Services (Classic) --This section applies to the `Microsoft.ClassicCompute/domainNames` resource type. [Learn more about Cloud Services (Classic)](../cloud-services/cloud-services-choose-me.md). --| Fault name | Applicable scenarios | -||-| -| [Cloud Service Shutdown](#cloud-services-classic-shutdown) | Compute loss | --## Clustered Cache for Redis --This section applies to the `Microsoft.Cache/redis` resource type. [Learn more about Clustered Cache for Redis](../azure-cache-for-redis/cache-overview.md). --| Fault name | Applicable scenarios | -||-| -| [Azure Cache for Redis (Reboot)](#azure-cache-for-redis-reboot) | Dependency disruption (caches) | --## Cosmos DB --This section applies to the `Microsoft.DocumentDB/databaseAccounts` resource type. [Learn more about Cosmos DB](/azure/cosmos-db/introduction). --| Fault name | Applicable scenarios | -||-| -| [Cosmos DB Failover](#cosmos-db-failover) | Database failover | --## Event Hubs --This section applies to the `Microsoft.EventHub/namespaces` resource type. [Learn more about Event Hubs](../event-hubs/event-hubs-about.md). --| Fault name | Applicable scenarios | -||-| -| [Change Event Hub State](#change-event-hub-state) | Messaging infrastructure misconfiguration/disruption | --## Key Vault --This section applies to the `Microsoft.KeyVault/vaults` resource type. [Learn more about Key Vault](/azure/key-vault/general/basic-concepts). --| Fault name | Applicable scenarios | -||-| -| [Key Vault: Deny Access](#key-vault-deny-access) | Certificate denial | -| [Key Vault: Disable Certificate](#key-vault-disable-certificate) | Certificate disruption | -| [Key Vault: Increment Certificate Version](#key-vault-increment-certificate-version) | Certificate version increment | -| [Key Vault: Update Certificate Policy](#key-vault-update-certificate-policy) | Certificate policy changes/misconfigurations | --## Network Security Groups --This section applies to the `Microsoft.Network/networkSecurityGroups` resource type. [Learn more about network security groups](../virtual-network/network-security-groups-overview.md). --| Fault name | Applicable scenarios | -||-| -| [NSG Security Rule](#nsg-security-rule) | Network disruption (for many Azure services) | --## Service Bus --This section applies to the `Microsoft.ServiceBus/namespaces` resource type. [Learn more about Service Bus](../service-bus-messaging/service-bus-messaging-overview.md). --| Fault name | Applicable scenarios | -||-| -| [Change Queue State](#service-bus-change-queue-state) | Messaging infrastructure misconfiguration/disruption | -| [Change Subscription State](#service-bus-change-subscription-state) | Messaging infrastructure misconfiguration/disruption | -| [Change Topic State](#service-bus-change-topic-state) | Messaging infrastructure misconfiguration/disruption | --## Virtual Machines (service-direct) --This section applies to the `Microsoft.Compute/virtualMachines` resource type. [Learn more about Virtual Machines](/azure/virtual-machines/overview). --| Fault name | Applicable scenarios | -||-| -| [VM Redeploy](#vm-redeploy) | Compute disruption, maintenance events | -| [VM Shutdown](#vm-shutdown) | Compute loss/disruption | --## Virtual Machine Scale Set --This section applies to the `Microsoft.Compute/virtualMachineScaleSets` resource type. [Learn more about Virtual Machine Scale Sets](/azure/virtual-machine-scale-sets/overview). --| Fault name | Applicable scenarios | -||-| -| [VMSS Shutdown](#vmss-shutdown-version-10) | Compute loss/disruption | -| [VMSS Shutdown (2.0)](#vmss-shutdown-version-20) | Compute loss/disruption (by Availability Zone) | --## Orchestration actions --These actions are building blocks for constructing effective experiments. Use them in combination with other faults, such as running a load test while in parallel shutting down compute instances in a zone. --| Action category | Fault name | -|--|| -| Load | [Start load test (Azure Load Testing)](#start-load-test-azure-load-testing) | -| Load | [Stop load test (Azure Load Testing)](#stop-load-test-azure-load-testing) | -| Time delay | [Delay](#delay) | --## Details: Agent-based faults --### Network Disconnect --| Property | Value | -|-|-| -| Capability name | NetworkDisconnect-1.1 | -| Target type | Microsoft-Agent | -| Supported OS types | Windows, Linux (outbound traffic only) | -| Description | Blocks network traffic for specified port range and network block. At least one destinationFilter or inboundDestinationFilter array must be provided. | -| Prerequisites | **Windows:** The agent must run as administrator, which happens by default if installed as a VM extension. | -| | **Linux:** The `tc` (Traffic Control) package is used for network faults. If it isn't already installed, the agent automatically attempts to install it from the default package manager. | -| Urn | urn:csci:microsoft:agent:networkDisconnect/1.1 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| destinationFilters | Delimited JSON array of packet filters defining which outbound packets to target. Maximum of 16.| -| inboundDestinationFilters | Delimited JSON array of packet filters defining which inbound packets to target. Maximum of 16. | -| virtualMachineScaleSetInstances | An array of instance IDs when you apply this fault to a virtual machine scale set. Required for virtual machine scale sets in uniform orchestration mode. [Learn more about instance IDs](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-instance-ids#scale-set-instance-id-for-uniform-orchestration-mode). | --The parameters **destinationFilters** and **inboundDestinationFilters** use the following array of packet filters. --| Property | Value | -|-|-| -| address | IP address that indicates the start of the IP range. | -| subnetMask | Subnet mask for the IP address range. | -| portLow | (Optional) Port number of the start of the port range. | -| portHigh | (Optional) Port number of the end of the port range. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:agent:networkDisconnect/1.1", - "parameters": [ - { - "key": "destinationFilters", - "value": "[ { \"address\": \"23.45.229.97\", \"subnetMask\": \"255.255.255.224\", \"portLow\": \"5000\", \"portHigh\": \"5200\" } ]" - }, - { - "key": "inboundDestinationFilters", - "value": "[ { \"address\": \"23.45.229.97\", \"subnetMask\": \"255.255.255.224\", \"portLow\": \"5000\", \"portHigh\": \"5200\" } ]" - }, - { - "key": "virtualMachineScaleSetInstances", - "value": "[0,1,2]" - } - ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --#### Limitations --* The agent-based network faults currently only support IPv4 addresses. -* The network disconnect fault only affects new connections. Existing active connections continue to persist. You can restart the service or process to force connections to break. -* When running on Windows, the network disconnect fault currently only works with TCP or UDP packets. -* When running on Linux, this fault can only affect **outbound** traffic, not inbound traffic. The fault can affect **both inbound and outbound** traffic on Windows environments (via the `inboundDestinationFilters` and `destinationFilters` parameters). --### Network Disconnect (Via Firewall) --| Property | Value | -|-|-| -| Capability name | NetworkDisconnectViaFirewall-1.0 | -| Target type | Microsoft-Agent | -| Supported OS types | Windows | -| Description | Applies a Windows firewall rule to block outbound traffic for specified port range and network block. | -| Prerequisites | Agent must run as administrator. If the agent is installed as a VM extension, it runs as administrator by default. | -| Urn | urn:csci:microsoft:agent:networkDisconnectViaFirewall/1.0 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| destinationFilters | Delimited JSON array of packet filters that define which outbound packets to target for fault injection. | -| address | IP address that indicates the start of the IP range. | -| subnetMask | Subnet mask for the IP address range. | -| portLow | (Optional) Port number of the start of the port range. | -| portHigh | (Optional) Port number of the end of the port range. | -| virtualMachineScaleSetInstances | An array of instance IDs when you apply this fault to a virtual machine scale set. Required for virtual machine scale sets in uniform orchestration mode. [Learn more about instance IDs](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-instance-ids#scale-set-instance-id-for-uniform-orchestration-mode). | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:agent:networkDisconnectViaFirewall/1.0", - "parameters": [ - { - "key": "destinationFilters", - "value": "[ { \"Address\": \"23.45.229.97\", \"SubnetMask\": \"255.255.255.224\", \"PortLow\": \"5000\", \"PortHigh\": \"5200\" } ]" - }, - { - "key": "virtualMachineScaleSetInstances", - "value": "[0,1,2]" - } - ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --#### Limitations --* The agent-based network faults currently only support IPv4 addresses. -* This fault currently only affects new connections. Existing active connections are unaffected. You can restart the service or process to force connections to break. --### Network Latency --| Property | Value | -|-|-| -| Capability name | NetworkLatency-1.1 | -| Target type | Microsoft-Agent | -| Supported OS types | Windows, Linux (outbound traffic only) | -| Description | Increases network latency for a specified port range and network block. At least one destinationFilter or inboundDestinationFilter array must be provided. | -| Prerequisites | **Windows:** The agent must run as administrator, which happens by default if installed as a VM extension. | -| | **Linux:** The `tc` (Traffic Control) package is used for network faults. If it isn't already installed, the agent automatically attempts to install it from the default package manager. | -| Urn | urn:csci:microsoft:agent:networkLatency/1.1 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| latencyInMilliseconds | Amount of latency to be applied in milliseconds. | -| destinationFilters | Delimited JSON array of packet filters defining which outbound packets to target. Maximum of 16.| -| inboundDestinationFilters | Delimited JSON array of packet filters defining which inbound packets to target. Maximum of 16. | -| virtualMachineScaleSetInstances | An array of instance IDs when you apply this fault to a virtual machine scale set. Required for virtual machine scale sets in uniform orchestration mode. [Learn more about instance IDs](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-instance-ids#scale-set-instance-id-for-uniform-orchestration-mode). | --The parameters **destinationFilters** and **inboundDestinationFilters** use the following array of packet filters. --| Property | Value | -|-|-| -| address | IP address that indicates the start of the IP range. | -| subnetMask | Subnet mask for the IP address range. | -| portLow | (Optional) Port number of the start of the port range. | -| portHigh | (Optional) Port number of the end of the port range. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:agent:networkLatency/1.1", - "parameters": [ - { - "key": "destinationFilters", - "value": "[ { \"address\": \"23.45.229.97\", \"subnetMask\": \"255.255.255.224\", \"portLow\": \"5000\", \"portHigh\": \"5200\" } ]" - }, - { - "key": "inboundDestinationFilters", - "value": "[ { \"address\": \"23.45.229.97\", \"subnetMask\": \"255.255.255.224\", \"portLow\": \"5000\", \"portHigh\": \"5200\" } ]" - }, - { - "key": "latencyInMilliseconds", - "value": "100", - }, - { - "key": "virtualMachineScaleSetInstances", - "value": "[0,1,2]" - } - ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --#### Limitations --* The agent-based network faults currently only support IPv4 addresses. -* When running on Linux, the network latency fault can only affect **outbound** traffic, not inbound traffic. The fault can affect **both inbound and outbound** traffic on Windows environments (via the `inboundDestinationFilters` and `destinationFilters` parameters). -* When running on Windows, the network latency fault currently only works with TCP or UDP packets. -* This fault currently only affects new connections. Existing active connections are unaffected. You can restart the service or process to force connections to break. --### Network Packet Loss --| Property | Value | -|-|-| -| Capability name | NetworkPacketLoss-1.0 | -| Target type | Microsoft-Agent | -| Supported OS types | Windows, Linux (outbound traffic only) | -| Description | Introduces packet loss for outbound traffic at a specified rate, between 0.0 (no packets lost) and 1.0 (all packets lost). This action can help simulate scenarios like network congestion or network hardware issues. | -| Prerequisites | **Windows:** The agent must run as administrator, which happens by default if installed as a VM extension. | -| | **Linux:** The `tc` (Traffic Control) package is used for network faults. If it isn't already installed, the agent automatically attempts to install it from the default package manager. | -| Urn | urn:csci:microsoft:agent:networkPacketLoss/1.0 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| packetLossRate | The rate at which packets matching the destination filters will be lost, ranging from 0.0 to 1.0. | -| virtualMachineScaleSetInstances | An array of instance IDs when you apply this fault to a virtual machine scale set. Required for virtual machine scale sets in uniform orchestration mode. [Learn more about instance IDs](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-instance-ids#scale-set-instance-id-for-uniform-orchestration-mode). | -| destinationFilters | Delimited JSON array of packet filters (parameters below) that define which outbound packets to target for fault injection. Maximum of three.| -| address | IP address that indicates the start of the IP range. | -| subnetMask | Subnet mask for the IP address range. | -| portLow | (Optional) Port number of the start of the port range. | -| portHigh | (Optional) Port number of the end of the port range. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:agent:networkPacketLoss/1.0", - "parameters": [ - { - "key": "destinationFilters", - "value": "[{\"address\":\"23.45.229.97\",\"subnetMask\":\"255.255.255.224\",\"portLow\":5000,\"portHigh\":5200}]" - }, - { - "key": "packetLossRate", - "value": "0.5" - }, - { - "key": "virtualMachineScaleSetInstances", - "value": "[0,1,2]" - } - ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --#### Limitations --* The agent-based network faults currently only support IPv4 addresses. -* When running on Windows, the network packet loss fault currently only works with TCP or UDP packets. -* When running on Linux, this fault can only affect **outbound** traffic, not inbound traffic. The fault can affect **both inbound and outbound** traffic on Windows environments (via the `inboundDestinationFilters` and `destinationFilters` parameters). -* This fault currently only affects new connections. Existing active connections are unaffected. You can restart the service or process to force connections to break. --### Network Isolation --| Property | Value | -|-|-| -| Capability name | NetworkIsolation-1.0 | -| Target type | Microsoft-Agent | -| Supported OS types | Windows, Linux (outbound only) | -| Description | Fully isolate the virtual machine from network connections by dropping all IP-based inbound (on Windows) and outbound (on Windows and Linux) packets for the specified duration. At the end of the duration, network connections will be re-enabled. Because the agent depends on network traffic, this action cannot be cancelled and will run to the specified duration. | -| Prerequisites | **Windows:** The agent must run as administrator, which happens by default if installed as a VM extension. | -| | **Linux:** The `tc` (Traffic Control) package is used for network faults. If it isn't already installed, the agent automatically attempts to install it from the default package manager. | -| Urn | urn:csci:microsoft:agent:networkIsolation/1.0 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| virtualMachineScaleSetInstances | An array of instance IDs when you apply this fault to a virtual machine scale set. Required for virtual machine scale sets in uniform orchestration mode, optional otherwise. [Learn more about instance IDs](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-instance-ids#scale-set-instance-id-for-uniform-orchestration-mode). | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:agent:networkIsolation/1.0", - "parameters": [], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --#### Limitations --* Because the agent depends on network traffic, **this action cannot be cancelled** and will run to the specified duration. Use with caution. -* This fault currently only affects new connections. Existing active connections are unaffected. You can restart the service or process to force connections to break. -* When running on Linux, this fault can only affect **outbound** traffic, not inbound traffic. The fault can affect **both inbound and outbound** traffic on Windows environments. ---### DNS Failure --| Property | Value | -|-|-| -| Capability name | DnsFailure-1.0 | -| Target type | Microsoft-Agent | -| Supported OS types | Windows | -| Description | Substitutes DNS lookup request responses with a specified error code. DNS lookup requests that are substituted must:<ul><li>Originate from the VM.</li><li>Match the defined fault parameters.</li></ul>DNS lookups that aren't made by the Windows DNS client aren't affected by this fault. | -| Prerequisites | None. | -| Urn | urn:csci:microsoft:agent:dnsFailure/1.0 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| hosts | Delimited JSON array of host names to fail DNS lookup request for.<br><br>This property accepts wildcards (`*`), but only for the first subdomain in an address and only applies to the subdomain for which they're specified. For example:<ul><li>\*.microsoft.com is supported.</li><li>subdomain.\*.microsoft isn't supported.</li><li>\*.microsoft.com doesn't work for multiple subdomains in an address, such as subdomain1.subdomain2.microsoft.com.</li></ul> | -| dnsFailureReturnCode | DNS error code to be returned to the client for the lookup failure (FormErr, ServFail, NXDomain, NotImp, Refused, XDomain, YXRRSet, NXRRSet, NotAuth, NotZone). For more information on DNS return codes, see the [IANA website](https://www.iana.org/assignments/dns-parameters/dns-parameters.xml#dns-parameters-6). | -| virtualMachineScaleSetInstances | An array of instance IDs when you apply this fault to a virtual machine scale set. Required for virtual machine scale sets in uniform orchestration mode. [Learn more about instance IDs](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-instance-ids#scale-set-instance-id-for-uniform-orchestration-mode). | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:agent:dnsFailure/1.0", - "parameters": [ - { - "key": "hosts", - "value": "[ \"www.bing.com\", \"msdn.microsoft.com\" ]" - }, - { - "key": "dnsFailureReturnCode", - "value": "ServFail" - }, - { - "key": "virtualMachineScaleSetInstances", - "value": "[0,1,2]" - } - ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --#### Limitations --* The DNS Failure fault requires Windows 2019 RS5 or newer. -* DNS Cache is ignored during the duration of the fault for the host names defined in the fault. --### CPU Pressure --| Property | Value | -|-|-| -| Capability name | CPUPressure-1.0 | -| Target type | Microsoft-Agent | -| Supported OS types | Windows, Linux | -| Description | Adds CPU pressure, up to the specified value, on the VM where this fault is injected during the fault action. The artificial CPU pressure is removed at the end of the duration or if the experiment is canceled. On Windows, the **% Processor Utility** performance counter is used at fault start to determine current CPU percentage, which is subtracted from the `pressureLevel` defined in the fault so that **% Processor Utility** hits approximately the `pressureLevel` defined in the fault parameters. | -| Prerequisites | **Linux**: The **stress-ng** utility needs to be installed. Installation happens automatically as part of agent installation, using the default package manager, on several operating systems including Debian-based (like Ubuntu), Red Hat Enterprise Linux, and OpenSUSE. For other distributions, including Azure Linux, you must install **stress-ng** manually. For more information, see the [upstream project repository](https://github.com/ColinIanKing/stress-ng). | -| | **Windows**: None. | -| Urn | urn:csci:microsoft:agent:cpuPressure/1.0 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| pressureLevel | An integer between 1 and 99 that indicates how much CPU pressure (%) is applied to the VM in terms of **% CPU Usage** | -| virtualMachineScaleSetInstances | An array of instance IDs when you apply this fault to a virtual machine scale set. Required for virtual machine scale sets in uniform orchestration mode. [Learn more about instance IDs](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-instance-ids#scale-set-instance-id-for-uniform-orchestration-mode). | --#### Sample JSON -```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:agent:cpuPressure/1.0", - "parameters": [ - { - "key": "pressureLevel", - "value": "95" - }, - { - "key": "virtualMachineScaleSetInstances", - "value": "[0,1,2]" - } - ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --#### Limitations -Known issues on Linux: -* The stress effect might not be terminated correctly if `AzureChaosAgent` is unexpectedly killed. --### Physical Memory Pressure --| Property | Value | -|-|-| -| Capability name | PhysicalMemoryPressure-1.0 | -| Target type | Microsoft-Agent | -| Supported OS types | Windows, Linux | -| Description | Adds physical memory pressure, up to the specified value, on the VM where this fault is injected during the fault action. The artificial physical memory pressure is removed at the end of the duration or if the experiment is canceled. | -| Prerequisites | **Linux**: The **stress-ng** utility needs to be installed. Installation happens automatically as part of agent installation, using the default package manager, on several operating systems including Debian-based (like Ubuntu), Red Hat Enterprise Linux, and OpenSUSE. For other distributions, including Azure Linux, you must install **stress-ng** manually. For more information, see the [upstream project repository](https://github.com/ColinIanKing/stress-ng). | -| | **Windows**: None. | -| Urn | urn:csci:microsoft:agent:physicalMemoryPressure/1.0 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| pressureLevel | An integer between 1 and 99 that indicates how much physical memory pressure (%) is applied to the VM. | -| virtualMachineScaleSetInstances | An array of instance IDs when you apply this fault to a virtual machine scale set. Required for virtual machine scale sets in uniform orchestration mode. [Learn more about instance IDs](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-instance-ids#scale-set-instance-id-for-uniform-orchestration-mode). | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:agent:physicalMemoryPressure/1.0", - "parameters": [ - { - "key": "pressureLevel", - "value": "95" - }, - { - "key": "virtualMachineScaleSetInstances", - "value": "[0,1,2]" - } - ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --#### Limitations -Currently, the Windows agent doesn't reduce memory pressure when other applications increase their memory usage. If the overall memory usage exceeds 100%, the Windows agent might crash. --### Virtual Memory Pressure --| Property | Value | -|-|-| -| Capability name | VirtualMemoryPressure-1.0 | -| Target type | Microsoft-Agent | -| Supported OS types | Windows | -| Description | Adds virtual memory pressure, up to the specified value, on the VM where this fault is injected during the fault action. The artificial virtual memory pressure is removed at the end of the duration or if the experiment is canceled. | -| Prerequisites | None. | -| Urn | urn:csci:microsoft:agent:virtualMemoryPressure/1.0 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| pressureLevel | An integer between 1 and 99 that indicates how much physical memory pressure (%) is applied to the VM. | -| virtualMachineScaleSetInstances | An array of instance IDs when you apply this fault to a virtual machine scale set. Required for virtual machine scale sets in uniform orchestration mode. [Learn more about instance IDs](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-instance-ids#scale-set-instance-id-for-uniform-orchestration-mode). | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:agent:virtualMemoryPressure/1.0", - "parameters": [ - { - "key": "pressureLevel", - "value": "95" - }, - { - "key": "virtualMachineScaleSetInstances", - "value": "[0,1,2]" - } - ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --### Disk IO Pressure --| Property | Value | -|-|-| -| Capability name | DiskIOPressure-1.1 | -| Target type | Microsoft-Agent | -| Supported OS types | Windows | -| Description | Uses the [diskspd utility](https://github.com/Microsoft/diskspd/wiki) to add disk pressure to a Virtual Machine. Pressure is added to the primary disk by default, or the disk specified with the targetTempDirectory parameter. This fault has five different modes of execution. The artificial disk pressure is removed at the end of the duration or if the experiment is canceled. | -| Prerequisites | None. | -| Urn | urn:csci:microsoft:agent:diskIOPressure/1.1 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| pressureMode | The preset mode of disk pressure to add to the primary storage of the VM. Must be one of the `PressureModes` in the following table. | -| targetTempDirectory | (Optional) The directory to use for applying disk pressure. For example, `D:/Temp`. If the parameter is not included, pressure is added to the primary disk. | -| virtualMachineScaleSetInstances | An array of instance IDs when you apply this fault to a virtual machine scale set. Required for virtual machine scale sets in uniform orchestration mode. [Learn more about instance IDs](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-instance-ids#scale-set-instance-id-for-uniform-orchestration-mode). | --#### Pressure modes --| PressureMode | Description | -| -- | -- | -| PremiumStorageP10IOPS | numberOfThreads = 1<br/>randomBlockSizeInKB = 64<br/>randomSeed = 10<br/>numberOfIOperThread = 25<br/>sizeOfBlocksInKB = 8<br/>sizeOfWriteBufferInKB = 64<br/>fileSizeInGB = 2<br/>percentOfWriteActions = 50 | -| PremiumStorageP10Throttling |<br/>numberOfThreads = 2<br/>randomBlockSizeInKB = 64<br/>randomSeed = 10<br/>numberOfIOperThread = 25<br/>sizeOfBlocksInKB = 64<br/>sizeOfWriteBufferInKB = 64<br/>fileSizeInGB = 1<br/>percentOfWriteActions = 50 | -| PremiumStorageP50IOPS | numberOfThreads = 32<br/>randomBlockSizeInKB = 64<br/>randomSeed = 10<br/>numberOfIOperThread = 32<br/>sizeOfBlocksInKB = 8<br/>sizeOfWriteBufferInKB = 64<br/>fileSizeInGB = 1<br/>percentOfWriteActions = 50 | -| PremiumStorageP50Throttling | numberOfThreads = 2<br/>randomBlockSizeInKB = 1024<br/>randomSeed = 10<br/>numberOfIOperThread = 2<br/>sizeOfBlocksInKB = 1024<br/>sizeOfWriteBufferInKB = 1024<br/>fileSizeInGB = 20<br/>percentOfWriteActions = 50| -| Default | numberOfThreads = 2<br/>randomBlockSizeInKB = 64<br/>randomSeed = 10<br/>numberOfIOperThread = 2<br/>sizeOfBlocksInKB = 64<br/>sizeOfWriteBufferInKB = 64<br/>fileSizeInGB = 1<br/>percentOfWriteActions = 50 | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:agent:diskIOPressure/1.1", - "parameters": [ - { - "key": "pressureMode", - "value": "PremiumStorageP10IOPS" - }, - { - "key": "targetTempDirectory", - "value": "C:/temp/" - }, - { - "key": "virtualMachineScaleSetInstances", - "value": "[0,1,2]" - } - ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --### Linux Disk IO Pressure --| Property | Value | -|-|-| -| Capability name | LinuxDiskIOPressure-1.1 | -| Target type | Microsoft-Agent | -| Supported OS types | Linux | -| Description | Uses stress-ng to apply pressure to the disk. One or more worker processes are spawned that perform I/O processes with temporary files. Pressure is added to the primary disk by default, or the disk specified with the targetTempDirectory parameter. For information on how pressure is applied, see the [stress-ng](https://wiki.ubuntu.com/Kernel/Reference/stress-ng) article. | -| Prerequisites | **Linux**: The **stress-ng** utility needs to be installed. Installation happens automatically as part of agent installation, using the default package manager, on several operating systems including Debian-based (like Ubuntu), Red Hat Enterprise Linux, and OpenSUSE. For other distributions, including Azure Linux, you must install **stress-ng** manually. For more information, see the [upstream project repository](https://github.com/ColinIanKing/stress-ng). | -| Urn | urn:csci:microsoft:agent:linuxDiskIOPressure/1.1 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| workerCount | Number of worker processes to run. Setting `workerCount` to 0 generates as many worker processes as there are number of processors. | -| fileSizePerWorker | Size of the temporary file that a worker performs I/O operations against. Integer plus a unit in bytes (b), kilobytes (k), megabytes (m), or gigabytes (g) (for example, `4m` for 4 megabytes and `256g` for 256 gigabytes). | -| blockSize | Block size to be used for disk I/O operations, greater than 1 byte and less than 4 megabytes (maximum value is `4095k`). Integer plus a unit in bytes, kilobytes, or megabytes (for example, `512k` for 512 kilobytes). | -| targetTempDirectory | (Optional) The directory to use for applying disk pressure. For example, `/tmp/`. If the parameter is not included, pressure is added to the primary disk. | -| virtualMachineScaleSetInstances | An array of instance IDs when you apply this fault to a virtual machine scale set. Required for virtual machine scale sets in uniform orchestration mode. [Learn more about instance IDs](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-instance-ids#scale-set-instance-id-for-uniform-orchestration-mode). | --#### Sample JSON --These sample values produced ~100% disk pressure when tested on a `Standard_D2s_v3` virtual machine with Premium SSD LRS. A large fileSizePerWorker and smaller blockSize help stress the disk fully. --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:agent:linuxDiskIOPressure/1.1", - "parameters": [ - { - "key": "workerCount", - "value": "4" - }, - { - "key": "fileSizePerWorker", - "value": "2g" - }, - { - "key": "blockSize", - "value": "64k" - }, - { - "key": "targetTempDirectory", - "value": "/tmp/" - } - ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` ---### Stop Service --| Property | Value | -|-|-| -| Capability name | StopService-1.0 | -| Target type | Microsoft-Agent | -| Supported OS types | Windows, Linux | -| Description | Stops a Windows service or a Linux systemd service during the fault. Restarts it at the end of the duration or if the experiment is canceled. | -| Prerequisites | None. | -| Urn | urn:csci:microsoft:agent:stopService/1.0 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| serviceName | Name of the Windows service or Linux systemd service you want to stop. | -| virtualMachineScaleSetInstances | An array of instance IDs when you apply this fault to a virtual machine scale set. Required for virtual machine scale sets in uniform orchestration mode. [Learn more about instance IDs](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-instance-ids#scale-set-instance-id-for-uniform-orchestration-mode). | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:agent:stopService/1.0", - "parameters": [ - { - "key": "serviceName", - "value": "nvagent" - }, - { - "key": "virtualMachineScaleSetInstances", - "value": "[0,1,2]" - } - ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --#### Limitations -* **Windows**: Display names for services aren't supported. Use `sc.exe query` in the command prompt to explore service names. -* **Linux**: Other service types besides systemd, like sysvinit, aren't supported. ---### Kill Process --| Property | Value | -|-|-| -| Capability name | KillProcess-1.0 | -| Target type | Microsoft-Agent | -| Supported OS types | Windows, Linux | -| Description | Kills all the running instances of a process that matches the process name sent in the fault parameters. Within the duration set for the fault action, a process is killed repetitively based on the value of the kill interval specified. This fault is a destructive fault where system admin would need to manually recover the process if self-healing is configured for it. | -| Prerequisites | None. | -| Urn | urn:csci:microsoft:agent:killProcess/1.0 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| processName | Name of a process to continuously kill (without the .exe). The process does not need to be running when the fault begins executing. | -| killIntervalInMilliseconds | Amount of time the fault waits in between successive kill attempts in milliseconds. | -| virtualMachineScaleSetInstances | An array of instance IDs when you apply this fault to a virtual machine scale set. Required for virtual machine scale sets in uniform orchestration mode. [Learn more about instance IDs](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-instance-ids#scale-set-instance-id-for-uniform-orchestration-mode). | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:agent:killProcess/1.0", - "parameters": [ - { - "key": "processName", - "value": "myapp" - }, - { - "key": "killIntervalInMilliseconds", - "value": "1000" - }, - { - "key": "virtualMachineScaleSetInstances", - "value": "[0,1,2]" - } - ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --### Pause Process --| Property | Value | -|-|-| -| Capability name | PauseProcess-1.0 | -| Target type | Microsoft-Agent | -| Supported OS types | Windows | -| Description | Pauses (suspends) the specified processes for the specified duration. If there are multiple processes with the same name, this fault suspends all of those processes. Within the fault's duration, the processes are paused repetitively at the specified interval. At the end of the duration or if the experiment is canceled, the processes will resume. | -| Prerequisites | None. | -| Urn | urn:csci:microsoft:agent:pauseProcess/1.0 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| processNames | Delimited JSON array of process names defining which processes are to be paused. Maximum of 4. The process name can optionally include the ".exe" extension. | -| pauseIntervalInMilliseconds | Amount of time the fault waits between successive pausing attempts, in milliseconds. | -| virtualMachineScaleSetInstances | An array of instance IDs when you apply this fault to a virtual machine scale set. Required for virtual machine scale sets in uniform orchestration mode. [Learn more about instance IDs](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-instance-ids#scale-set-instance-id-for-uniform-orchestration-mode). | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:agent:pauseProcess/1.0", - "parameters": [ - { - "key": "processNames", - "value": "[ \"test-0\", \"test-1.exe\" ]" - }, - { - "key": "pauseIntervalInMilliseconds", - "value": "1000" - } - ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --#### Limitations --Currently, a maximum of 4 process names can be listed in the processNames parameter. --### Time Change --| Property | Value | -|-|-| -| Capability name | TimeChange-1.0 | -| Target type | Microsoft-Agent | -| Supported OS types | Windows | -| Description | Changes the system time of the virtual machine and resets the time at the end of the experiment or if the experiment is canceled. | -| Prerequisites | None. | -| Urn | urn:csci:microsoft:agent:timeChange/1.0 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| dateTime | A DateTime string in [ISO8601 format](https://www.cryptosys.net/pki/manpki/pki_iso8601datetime.html). If `YYYY-MM-DD` values are missing, they're defaulted to the current day when the experiment runs. If Thh:mm:ss values are missing, the default value is 12:00:00 AM. If a 2-digit year is provided (`YY`), it's converted to a 4-digit year (`YYYY`) based on the current century. If the timezone `<Z>` is missing, the default offset is the local timezone. `<Z>` must always include a sign symbol (negative or positive). | -| virtualMachineScaleSetInstances | An array of instance IDs when you apply this fault to a virtual machine scale set. Required for virtual machine scale sets in uniform orchestration mode. [Learn more about instance IDs](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-instance-ids#scale-set-instance-id-for-uniform-orchestration-mode). | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:agent:timeChange/1.0", - "parameters": [ - { - "key": "dateTime", - "value": "2038-01-01T03:14:07" - }, - { - "key": "virtualMachineScaleSetInstances", - "value": "[0,1,2]" - } - ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --### Arbitrary Stress-ng Stressor --| Property | Value | -|-|-| -| Capability name | StressNg-1.0 | -| Target type | Microsoft-Agent | -| Supported OS types | Linux | -| Description | Runs any stress-ng command by passing arguments directly to stress-ng. Useful when one of the predefined faults for stress-ng doesn't meet your needs. | -| Prerequisites | **Linux**: The **stress-ng** utility needs to be installed. Installation happens automatically as part of agent installation, using the default package manager, on several operating systems including Debian-based (like Ubuntu), Red Hat Enterprise Linux, and OpenSUSE. For other distributions, including Azure Linux, you must install **stress-ng** manually. For more information, see the [upstream project repository](https://github.com/ColinIanKing/stress-ng). | -| Urn | urn:csci:microsoft:agent:stressNg/1.0 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| stressNgArguments | One or more arguments to pass to the stress-ng process. For information on possible stress-ng arguments, see the [stress-ng](https://wiki.ubuntu.com/Kernel/Reference/stress-ng) article. **NOTE: Do NOT include the "-t " argument because it will cause an error. Experiment length is defined directly in the Azure chaos experiment UI, NOT in the stressNgArguments.** | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:agent:stressNg/1.0", - "parameters": [ - { - "key": "stressNgArguments", - "value": "--random 64" - }, - { - "key": "virtualMachineScaleSetInstances", - "value": "[0,1,2]" - } - ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` ---## Details: Service-direct faults ---### Stop App Service - -| Property | Value | -| - | | -| Capability name | Stop-1.0 | -| Target type | Microsoft-AppService | -| Description | Stops the targeted App Service applications, then restarts them at the end of the fault duration. This action applies to resources of the "Microsoft.Web/sites" type, including App Service, API Apps, Mobile Apps, and Azure Functions. | -| Prerequisites | None. | -| Urn | urn:csci:microsoft:appService:stop/1.0 | -| Fault type | Continuous. | -| Parameters (key, value) | None. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:appService:stop/1.0", - "duration": "PT10M", - "parameters":[], - "selectorid": "myResources" - } - ] -} -``` ---### Disable Autoscale --| Property | Value | -| | | -| Capability name | DisableAutoscale | -| Target type | Microsoft-AutoscaleSettings | -| Description | Disables the [autoscale service](/azure/azure-monitor/autoscale/autoscale-overview). When autoscale is disabled, resources such as virtual machine scale sets, web apps, service bus, and [more](/azure/azure-monitor/autoscale/autoscale-overview#supported-services-for-autoscale) aren't automatically added or removed based on the load of the application. | -| Prerequisites | The autoScalesetting resource that's enabled on the resource must be onboarded to Chaos Studio. | -| Urn | urn:csci:microsoft:autoscalesettings:disableAutoscale/1.0 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| enableOnComplete | Boolean. Configures whether autoscaling is reenabled after the action is done. Default is `true`. | --#### Sample JSON -```json -{ -  "name": "BranchOne", -  "actions": [ -    { -    "type": "continuous", - "name": "urn:csci:microsoft:autoscaleSetting:disableAutoscale/1.0", - "parameters": [ -     { -      "key": "enableOnComplete", -      "value": "true" -     }                 -  ],                                 - "duration": "PT2M", -   "selectorId": "Selector1",      -  } - ] -} -``` ---### AKS Chaos Mesh Network Chaos --| Property | Value | -|-|-| -| Capability name | NetworkChaos-2.1 | -| Target type | Microsoft-AzureKubernetesServiceChaosMesh | -| Supported node pool OS types | Linux | -| Description | Causes a network fault available through [Chaos Mesh](https://chaos-mesh.org/docs/simulate-network-chaos-on-kubernetes/) to run against your Azure Kubernetes Service (AKS) cluster. Useful for re-creating AKS incidents that result from network outages, delays, duplications, loss, and corruption. | -| Prerequisites | The AKS cluster must [have Chaos Mesh deployed](chaos-studio-tutorial-aks-portal.md). | -| Urn | urn:csci:microsoft:azureKubernetesServiceChaosMesh:networkChaos/2.1 | -| Parameters (key, value) | | -| jsonSpec | A JSON-formatted Chaos Mesh spec that uses the [NetworkChaos kind](https://chaos-mesh.org/docs/simulate-network-chaos-on-kubernetes/#create-experiments-using-the-yaml-files). You can use a YAML-to-JSON converter like [Convert YAML To JSON](https://www.convertjson.com/yaml-to-json.htm) to convert the Chaos Mesh YAML to JSON and minify it. Use single-quotes within the JSON or escape the quotes with a backslash character. Only include the YAML under the `jsonSpec` property. Don't include information like metadata and kind. Specifying duration within the `jsonSpec` isn't necessary, but it's used if available. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:azureKubernetesServiceChaosMesh:networkChaos/2.1", - "parameters": [ - { - "key": "jsonSpec", - "value": "{\"action\":\"delay\",\"mode\":\"one\",\"selector\":{\"namespaces\":[\"default\"]},\"delay\":{\"latency\":\"200ms\",\"correlation\":\"100\",\"jitter\":\"0ms\"}}}" - } - ], - "selectorid": "myResources" - } - ] -} -``` --### AKS Chaos Mesh Pod Chaos --| Property | Value | -|-|-| -| Capability name | PodChaos-2.1 | -| Target type | Microsoft-AzureKubernetesServiceChaosMesh | -| Supported node pool OS types | Linux | -| Description | Causes a pod fault available through [Chaos Mesh](https://chaos-mesh.org/docs/simulate-pod-chaos-on-kubernetes/) to run against your AKS cluster. Useful for re-creating AKS incidents that are a result of pod failures or container issues. | -| Prerequisites | The AKS cluster must [have Chaos Mesh deployed](chaos-studio-tutorial-aks-portal.md). | -| Urn | urn:csci:microsoft:azureKubernetesServiceChaosMesh:podChaos/2.1 | -| Parameters (key, value) | | -| jsonSpec | A JSON-formatted Chaos Mesh spec that uses the [PodChaos kind](https://chaos-mesh.org/docs/simulate-pod-chaos-on-kubernetes/#create-experiments-using-yaml-configuration-files). You can use a YAML-to-JSON converter like [Convert YAML To JSON](https://www.convertjson.com/yaml-to-json.htm) to convert the Chaos Mesh YAML to JSON and minify it. Use single-quotes within the JSON or escape the quotes with a backslash character. Only include the YAML under the `jsonSpec` property. Don't include information like metadata and kind. Specifying duration within the `jsonSpec` isn't necessary, but it's used if available. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:azureKubernetesServiceChaosMesh:podChaos/2.1", - "parameters": [ - { - "key": "jsonSpec", - "value": "{\"action\":\"pod-failure\",\"mode\":\"all\",\"selector\":{\"namespaces\":[\"default\"]}}" - } - ], - "selectorid": "myResources" - } - ] -} -``` --### AKS Chaos Mesh Stress Chaos --| Property | Value | -|-|-| -| Capability name | StressChaos-2.1 | -| Target type | Microsoft-AzureKubernetesServiceChaosMesh | -| Supported node pool OS types | Linux | -| Description | Causes a stress fault available through [Chaos Mesh](https://chaos-mesh.org/docs/simulate-heavy-stress-on-kubernetes/) to run against your AKS cluster. Useful for re-creating AKS incidents because of stresses over a collection of pods, for example, due to high CPU or memory consumption. | -| Prerequisites | The AKS cluster must [have Chaos Mesh deployed](chaos-studio-tutorial-aks-portal.md). | -| Urn | urn:csci:microsoft:azureKubernetesServiceChaosMesh:stressChaos/2.1 | -| Parameters (key, value) | | -| jsonSpec | A JSON-formatted Chaos Mesh spec that uses the [StressChaos kind](https://chaos-mesh.org/docs/simulate-heavy-stress-on-kubernetes/#create-experiments-using-the-yaml-file). You can use a YAML-to-JSON converter like [Convert YAML To JSON](https://www.convertjson.com/yaml-to-json.htm) to convert the Chaos Mesh YAML to JSON and minify it. Use single-quotes within the JSON or escape the quotes with a backslash character. Only include the YAML under the `jsonSpec` property. Don't include information like metadata and kind. Specifying duration within the `jsonSpec` isn't necessary, but it's used if available. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:azureKubernetesServiceChaosMesh:stressChaos/2.1", - "parameters": [ - { - "key": "jsonSpec", - "value": "{\"mode\":\"one\",\"selector\":{\"namespaces\":[\"default\"]},\"stressors\":{\"cpu\":{\"workers\":1,\"load\":50},\"memory\":{\"workers\":4,\"size\":\"256MB\"}}" - } - ], - "selectorid": "myResources" - } - ] -} -``` --### AKS Chaos Mesh IO Chaos --| Property | Value | -|-|-| -| Capability name | IOChaos-2.1 | -| Target type | Microsoft-AzureKubernetesServiceChaosMesh | -| Supported node pool OS types | Linux | -| Description | Causes an IO fault available through [Chaos Mesh](https://chaos-mesh.org/docs/simulate-io-chaos-on-kubernetes/) to run against your AKS cluster. Useful for re-creating AKS incidents because of IO delays and read/write failures when you use IO system calls such as `open`, `read`, and `write`. | -| Prerequisites | The AKS cluster must [have Chaos Mesh deployed](chaos-studio-tutorial-aks-portal.md). | -| Urn | urn:csci:microsoft:azureKubernetesServiceChaosMesh:IOChaos/2.1 | -| Parameters (key, value) | | -| jsonSpec | A JSON-formatted Chaos Mesh spec that uses the [IOChaos kind](https://chaos-mesh.org/docs/simulate-io-chaos-on-kubernetes/#create-experiments-using-the-yaml-files). You can use a YAML-to-JSON converter like [Convert YAML To JSON](https://www.convertjson.com/yaml-to-json.htm) to convert the Chaos Mesh YAML to JSON and minify it. Use single-quotes within the JSON or escape the quotes with a backslash character. Only include the YAML under the `jsonSpec` property. Don't include information like metadata and kind. Specifying duration within the `jsonSpec` isn't necessary, but it's used if available. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:azureKubernetesServiceChaosMesh:IOChaos/2.1", - "parameters": [ - { - "key": "jsonSpec", - "value": "{\"action\":\"latency\",\"mode\":\"one\",\"selector\":{\"app\":\"etcd\"},\"volumePath\":\"\/var\/run\/etcd\",\"path\":\"\/var\/run\/etcd\/**\/*\",\"delay\":\"100ms\",\"percent\":50}" - } - ], - "selectorid": "myResources" - } - ] -} -``` --### AKS Chaos Mesh Time Chaos --| Property | Value | -|-|-| -| Capability name | TimeChaos-2.1 | -| Target type | Microsoft-AzureKubernetesServiceChaosMesh | -| Supported node pool OS types | Linux | -| Description | Causes a change in the system clock on your AKS cluster by using [Chaos Mesh](https://chaos-mesh.org/docs/simulate-time-chaos-on-kubernetes/). Useful for re-creating AKS incidents that result from distributed systems falling out of sync, missing/incorrect leap year/leap second logic, and more. | -| Prerequisites | The AKS cluster must [have Chaos Mesh deployed](chaos-studio-tutorial-aks-portal.md). | -| Urn | urn:csci:microsoft:azureKubernetesServiceChaosMesh:timeChaos/2.1 | -| Parameters (key, value) | | -| jsonSpec | A JSON-formatted Chaos Mesh spec that uses the [TimeChaos kind](https://chaos-mesh.org/docs/simulate-time-chaos-on-kubernetes/#create-experiments-using-the-yaml-file). You can use a YAML-to-JSON converter like [Convert YAML To JSON](https://www.convertjson.com/yaml-to-json.htm) to convert the Chaos Mesh YAML to JSON and minify it. Use single-quotes within the JSON or escape the quotes with a backslash character. Only include the YAML under the `jsonSpec` property. Don't include information like metadata and kind. Specifying duration within the `jsonSpec` isn't necessary, but it's used if available. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:azureKubernetesServiceChaosMesh:timeChaos/2.1", - "parameters": [ - { - "key": "jsonSpec", - "value": "{\"mode\":\"one\",\"selector\":{\"namespaces\":[\"default\"]},\"timeOffset\":\"-10m100ns\"}" - } - ], - "selectorid": "myResources" - } - ] -} -``` --### AKS Chaos Mesh Kernel Chaos --| Property | Value | -|-|-| -| Capability name | KernelChaos-2.1 | -| Target type | Microsoft-AzureKubernetesServiceChaosMesh | -| Supported node pool OS types | Linux | -| Description | Causes a kernel fault available through [Chaos Mesh](https://chaos-mesh.org/docs/simulate-kernel-chaos-on-kubernetes/) to run against your AKS cluster. Useful for re-creating AKS incidents because of Linux kernel-level errors, such as a mount failing or memory not being allocated. | -| Prerequisites | The AKS cluster must [have Chaos Mesh deployed](chaos-studio-tutorial-aks-portal.md). | -| Urn | urn:csci:microsoft:azureKubernetesServiceChaosMesh:kernelChaos/2.1 | -| Parameters (key, value) | | -| jsonSpec | A JSON-formatted Chaos Mesh spec that uses the [KernelChaos kind](https://chaos-mesh.org/docs/simulate-kernel-chaos-on-kubernetes/#configuration-file). You can use a YAML-to-JSON converter like [Convert YAML To JSON](https://www.convertjson.com/yaml-to-json.htm) to convert the Chaos Mesh YAML to JSON and minify it. Use single-quotes within the JSON or escape the quotes with a backslash character. Only include the YAML under the `jsonSpec` property. Don't include information like metadata and kind. Specifying duration within the `jsonSpec` isn't necessary, but it's used if available. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:azureKubernetesServiceChaosMesh:kernelChaos/2.1", - "parameters": [ - { - "key": "jsonSpec", - "value": "{\"mode\":\"one\",\"selector\":{\"namespaces\":[\"default\"]},\"failKernRequest\":{\"callchain\":[{\"funcname\":\"__x64_sys_mount\"}],\"failtype\":0}}" - } - ], - "selectorid": "myResources" - } - ] -} -``` --### AKS Chaos Mesh HTTP Chaos --| Property | Value | -|-|-| -| Capability name | HTTPChaos-2.1 | -| Target type | Microsoft-AzureKubernetesServiceChaosMesh | -| Supported node pool OS types | Linux | -| Description | Causes an HTTP fault available through [Chaos Mesh](https://chaos-mesh.org/docs/simulate-http-chaos-on-kubernetes/) to run against your AKS cluster. Useful for re-creating incidents because of HTTP request and response processing failures, such as delayed or incorrect responses. | -| Prerequisites | The AKS cluster must [have Chaos Mesh deployed](chaos-studio-tutorial-aks-portal.md). | -| Urn | urn:csci:microsoft:azureKubernetesServiceChaosMesh:httpChaos/2.1 | -| Parameters (key, value) | | -| jsonSpec | A JSON-formatted Chaos Mesh spec that uses the [HTTPChaos kind](https://chaos-mesh.org/docs/simulate-http-chaos-on-kubernetes/#create-experiments). You can use a YAML-to-JSON converter like [Convert YAML To JSON](https://www.convertjson.com/yaml-to-json.htm) to convert the Chaos Mesh YAML to JSON and minify it. Use single-quotes within the JSON or escape the quotes with a backslash character. Only include the YAML under the `jsonSpec` property. Don't include information like metadata and kind. Specifying duration within the `jsonSpec` isn't necessary, but it's used if available. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:azureKubernetesServiceChaosMesh:httpChaos/2.1", - "parameters": [ - { - "key": "jsonSpec", - "value": "{\"mode\":\"all\",\"selector\":{\"namespaces\":[\"default\"]},\"target\":\"Request\",\"port\":80,\"method\":\"GET\",\"path\":\"/api\",\"abort\":true}" - } - ], - "selectorid": "myResources" - } - ] -} -``` --### AKS Chaos Mesh DNS Chaos --| Property | Value | -|-|-| -| Capability name | DNSChaos-2.1 | -| Target type | Microsoft-AzureKubernetesServiceChaosMesh | -| Supported node pool OS types | Linux | -| Description | Causes a DNS fault available through [Chaos Mesh](https://chaos-mesh.org/docs/simulate-dns-chaos-on-kubernetes/) to run against your AKS cluster. Useful for re-creating incidents because of DNS failures. | -| Prerequisites | The AKS cluster must [have Chaos Mesh deployed](chaos-studio-tutorial-aks-portal.md) and the [DNS service must be installed](https://chaos-mesh.org/docs/simulate-dns-chaos-on-kubernetes/#deploy-chaos-dns-service). | -| Urn | urn:csci:microsoft:azureKubernetesServiceChaosMesh:dnsChaos/2.1 | -| Parameters (key, value) | | -| jsonSpec | A JSON-formatted Chaos Mesh spec that uses the [DNSChaos kind](https://chaos-mesh.org/docs/simulate-dns-chaos-on-kubernetes/#create-experiments-using-the-yaml-file). You can use a YAML-to-JSON converter like [Convert YAML To JSON](https://www.convertjson.com/yaml-to-json.htm) to convert the Chaos Mesh YAML to JSON and minify it. Use single-quotes within the JSON or escape the quotes with a backslash character. Only include the YAML under the `jsonSpec` property. Don't include information like metadata and kind. Specifying duration within the `jsonSpec` isn't necessary, but it's used if available. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:azureKubernetesServiceChaosMesh:dnsChaos/2.1", - "parameters": [ - { - "key": "jsonSpec", - "value": "{\"action\":\"random\",\"mode\":\"all\",\"patterns\":[\"google.com\",\"chaos-mesh.*\",\"github.?om\"],\"selector\":{\"namespaces\":[\"default\"]}}" - } - ], - "selectorid": "myResources" - } - ] -} -``` --### Cloud Services (Classic) Shutdown --| Property | Value | -|-|-| -| Capability name | Shutdown-1.0 | -| Target type | Microsoft-DomainName | -| Description | Stops a deployment during the fault. Restarts the deployment at the end of the fault duration or if the experiment is canceled. | -| Prerequisites | None. | -| Urn | urn:csci:microsoft:domainName:shutdown/1.0 | -| Fault type | Continuous. | -| Parameters | None. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:domainName:shutdown/1.0", - "parameters": [], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --### Azure Cache for Redis (Reboot) --| Property | Value | -|-|-| -| Capability name | Reboot-1.0 | -| Target type | Microsoft-AzureClusteredCacheForRedis | -| Description | Causes a forced reboot operation to occur on the target to simulate a brief outage. | -| Prerequisites | N/A | -| Urn | urn:csci:microsoft:azureClusteredCacheForRedis:reboot/1.0 | -| Fault type | Discrete. | -| Parameters (key, value) | | -| rebootType | The node types where the reboot action is to be performed, which can be specified as PrimaryNode, SecondaryNode, or AllNodes. | -| shardId | The ID of the shard to be rebooted. Only relevant for Premium tier caches. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "discrete", - "name": "urn:csci:microsoft:azureClusteredCacheForRedis:reboot/1.0", - "parameters": [ - { - "key": "RebootType", - "value": "AllNodes" - }, - { - "key": "ShardId", - "value": "0" - } - ], - "selectorid": "myResources" - } - ] -} -``` --#### Limitations --* The reboot fault causes a forced reboot to better simulate an outage event, which means there's the potential for data loss to occur. -* The reboot fault is a **discrete** fault type. Unlike continuous faults, it's a one-time action and has no duration. ---### Cosmos DB Failover --| Property | Value | -|-|-| -| Capability name | Failover-1.0 | -| Target type | Microsoft-CosmosDB | -| Description | Causes an Azure Cosmos DB account with a single write region to fail over to a specified read region to simulate a [write region outage](/azure/cosmos-db/high-availability). | -| Prerequisites | None. | -| Urn | `urn:csci:microsoft:cosmosDB:failover/1.0` | -| Fault type | Continuous. | -| Parameters (key, value) | | -| readRegion | The read region that should be promoted to write region during the failover, for example, `East US 2`. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:cosmosDB:failover/1.0", - "parameters": [ - { - "key": "readRegion", - "value": "West US 2" - } - ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --### Change Event Hub State - -| Property | Value | -| - | | -| Capability name | ChangeEventHubState-1.0 | -| Target type | Microsoft-EventHub | -| Description | Sets individual event hubs to the desired state within an Azure Event Hubs namespace. You can affect specific event hub names or use “*” to affect all within the namespace. This action can help test your messaging infrastructure for maintenance or failure scenarios. This is a discrete fault, so the entity will not be returned to the starting state automatically. | -| Prerequisites | An Azure Event Hubs namespace with at least one [event hub entity](../event-hubs/event-hubs-create.md). | -| Urn | urn:csci:microsoft:eventHub:changeEventHubState/1.0 | -| Fault type | Discrete. | -| Parameters (key, value) | | -| desiredState | The desired state for the targeted event hubs. The possible states are Active, Disabled, and SendDisabled. | -| eventHubs | A comma-separated list of the event hub names within the targeted namespace. Use "*" to affect all entities within the namespace. | --#### Sample JSON --```json -{ - "name": "Branch1", - "actions": [ - { - "selectorId": "Selector1", - "type": "discrete", - "parameters": [ - { - "key": "eventhubs", - "value": "[\"*\"]" - }, - { - "key": "desiredState", - "value": "Disabled" - } - ], - "name": "urn:csci:microsoft:eventHub:changeEventHubState/1.0" - } - ] -} -``` ---### Key Vault: Deny Access --| Property | Value | -|-|-| -| Capability name | DenyAccess-1.0 | -| Target type | Microsoft-KeyVault | -| Description | Blocks all network access to a key vault by temporarily modifying the key vault network rules. This action prevents an application dependent on the key vault from accessing secrets, keys, and/or certificates. If the key vault allows access to all networks, this setting is changed to only allow access from selected networks. No virtual networks are in the allowed list at the start of the fault. All networks are allowed access at the end of the fault duration. If the key vault is set to only allow access from selected networks, any virtual networks in the allowed list are removed at the start of the fault. They're restored at the end of the fault duration. | -| Prerequisites | The target key vault can't have any firewall rules and must not be set to allow Azure services to bypass the firewall. If the target key vault is set to only allow access from selected networks, there must be at least one virtual network rule. The key vault can't be in recover mode. | -| Urn | urn:csci:microsoft:keyVault:denyAccess/1.0 | -| Fault type | Continuous. | -| Parameters (key, value) | None. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:keyvault:denyAccess/1.0", - "parameters": [], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --### Key Vault: Disable Certificate --| Property | Value | -| - | | -| Capability name | DisableCertificate-1.0 | -| Target type | Microsoft-KeyVault | -| Description | By using certificate properties, the fault disables the certificate for a specific duration (provided by the user). It enables the certificate after this fault duration. | -| Prerequisites | None. | -| Urn | urn:csci:microsoft:keyvault:disableCertificate/1.0 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| certificateName | Name of Azure Key Vault certificate on which the fault is executed. | -| version | Certificate version that should be disabled. If not specified, the latest version is disabled. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:keyvault:disableCertificate/1.0", - "parameters": [ - { - "key": "certificateName", - "value": "<name of AKV certificate>" - }, - { - "key": "version", - "value": "<certificate version>" - } --], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --### Key Vault: Increment Certificate Version - -| Property | Value | -| - | | -| Capability name | IncrementCertificateVersion-1.0 | -| Target type | Microsoft-KeyVault | -| Description | Generates a new certificate version and thumbprint by using the Key Vault Certificate client library. Current working certificate is upgraded to this version. Certificate version is not reverted after the fault duration. | -| Prerequisites | None. | -| Urn | urn:csci:microsoft:keyvault:incrementCertificateVersion/1.0 | -| Fault type | Discrete. | -| Parameters (key, value) | | -| certificateName | Name of Azure Key Vault certificate on which the fault is executed. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "discrete", - "name": "urn:csci:microsoft:keyvault:incrementCertificateVersion/1.0", - "parameters": [ - { - "key": "certificateName", - "value": "<name of AKV certificate>" - } - ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --### Key Vault: Update Certificate Policy --| Property | Value | -| - | | -| Capability name | UpdateCertificatePolicy-1.0 | -| Target type | Microsoft-KeyVault | -| Description | Certificate policies (for example, certificate validity period, certificate type, key size, or key type) are updated based on user input and reverted after the fault duration. | -| Prerequisites | None. | -| Urn | urn:csci:microsoft:keyvault:updateCertificatePolicy/1.0 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| certificateName | Name of Azure Key Vault certificate on which the fault is executed. | -| version | Certificate version that should be updated. If not specified, the latest version is updated. | -| enabled | Boolean. Value that indicates if the new certificate version is enabled. | -| validityInMonths | Validity period of the certificate in months. | -| certificateTransparency | Indicates whether the certificate should be published to the certificate transparency list when created. | -| certificateType | Certificate type. | -| contentType | Content type of the certificate. For example, it's Pkcs12 when the certificate contains raw PFX bytes or Pem when it contains ASCII PEM-encoded bytes. Pkcs12 is the default value assumed. | -| keySize | Size of the RSA key: 2048, 3072, or 4096. | -| exportable | Boolean. Value that indicates if the certificate key is exportable from the vault or secure certificate store. | -| reuseKey | Boolean. Value that indicates if the certificate key should be reused when the certificate is rotated.| -| keyType | Type of backing key generated when new certificates are issued, such as RSA or EC. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:keyvault:updateCertificatePolicy/1.0", - "parameters": [ - { - "key": "certificateName", - "value": "<name of AKV certificate>" - }, - { - "key": "version", - "value": "<certificate version>" - }, - { - "key": "enabled", - "value": "True" - }, - { - "key": "validityInMonths", - "value": "12" - }, - { - "key": "certificateTransparency", - "value": "True" - }, - { - "key": "certificateType", - "value": "<certificate type>" - }, - { - "key": "contentType", - "value": "Pem" - }, - { - "key": "keySize", - "value": "4096" - }, - { - "key": "exportable", - "value": "True" - }, - { - "key": "reuseKey", - "value": "False" - }, - { - "key": "keyType", - "value": "RSA" - } -- ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` ---### NSG Security Rule --| Property | Value | -|-|-| -| Capability name | SecurityRule-1.0, SecurityRule-1.1 | -| Target type | Microsoft-NetworkSecurityGroup | -| Description | Enables manipulation or rule creation in an existing Azure network security group (NSG) or set of Azure NSGs, assuming the rule definition is applicable across security groups. Useful for: <ul><li>Simulating an outage of a downstream or cross-region dependency/nondependency.<li>Simulating an event that's expected to trigger a logic to force a service failover.<li>Simulating an event that's expected to trigger an action from a monitoring or state management service.<li>Using as an alternative for blocking or allowing network traffic where Chaos Agent can't be deployed. | -| Prerequisites | None. | -| Urn | urn:csci:microsoft:networkSecurityGroup:securityRule/1.0, urn:csci:microsoft:networkSecurityGroup:securityRule/1.1 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| name | A unique name for the security rule that's created. The fault fails if another rule already exists on the NSG with the same name. Must begin with a letter or number. Must end with a letter, number, or underscore. May contain only letters, numbers, underscores, periods, or hyphens. | -| protocol | Protocol for the security rule. Must be Any, TCP, UDP, or ICMP. | -| sourceAddresses | A string that represents a JSON-delimited array of CIDR-formatted IP addresses. Can also be a [service tag name](../virtual-network/service-tags-overview.md) for an inbound rule, for example, `AppService`. An asterisk `*` can also be used to match all source IPs. | -| destinationAddresses | A string that represents a JSON-delimited array of CIDR-formatted IP addresses. Can also be a [service tag name](../virtual-network/service-tags-overview.md) for an outbound rule, for example, `AppService`. An asterisk `*` can also be used to match all destination IPs. | -| action | Security group access type. Must be either Allow or Deny. | -| destinationPortRanges | A string that represents a JSON-delimited array of single ports and/or port ranges, such as 80 or 1024-65535. | -| sourcePortRanges | A string that represents a JSON-delimited array of single ports and/or port ranges, such as 80 or 1024-65535. | -| priority | A value between 100 and 4096 that's unique for all security rules within the NSG. The fault fails if another rule already exists on the NSG with the same priority. | -| direction | Direction of the traffic affected by the security rule. Must be either Inbound or Outbound. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:networkSecurityGroup:securityRule/1.0", - "parameters": [ - { - "key": "name", - "value": "Block_SingleHost_to_Networks" -- }, - { - "key": "protocol", - "value": "Any" - }, - { - "key": "sourceAddresses", - "value": "[\"10.1.1.128/32\"]" - }, - { - "key": "destinationAddresses", - "value": "[\"10.20.0.0/16\",\"10.30.0.0/16\"]" - }, - { - "key": "access", - "value": "Deny" - }, - { - "key": "destinationPortRanges", - "value": "[\"80-8080\"]" - }, - { - "key": "sourcePortRanges", - "value": "[\"*\"]" - }, - { - "key": "priority", - "value": "100" - }, - { - "key": "direction", - "value": "Outbound" - } - ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --#### Limitations --* The fault can only be applied to an existing NSG. -* When an NSG rule that's intended to deny traffic is applied, existing connections won't be broken until they've been **idle** for 4 minutes. One workaround is to add another branch in the same step that uses a fault that would cause existing connections to break when the NSG fault is applied. For example, killing the process, temporarily stopping the service, or restarting the VM would cause connections to reset. -* Rules are applied at the start of the action. Any external changes to the rule during the duration of the action cause the experiment to fail. -* Creating or modifying Application Security Group rules isn't supported. -* Priority values must be unique on each NSG targeted. Attempting to create a new rule that has the same priority value as another causes the experiment to fail. -* The NSG Security Rule **version 1.1** fault supports an additional `flushConnection` parameter. This functionality has an **active known issue**: if `flushConnection` is enabled, the fault may result in a "FlushingNetworkSecurityGroupConnectionIsNotEnabled" error. To avoid this error temporarily, disable the `flushConnection` parameter or use the NSG Security Rule version **1.0** fault. ---### Service Bus: Change Queue State - -| Property | Value | -| - | | -| Capability name | ChangeQueueState-1.0 | -| Target type | Microsoft-ServiceBus | -| Description | Sets Queue entities within a Service Bus namespace to the desired state. You can affect specific entity names or use “*” to affect all. This action can help test your messaging infrastructure for maintenance or failure scenarios. This is a discrete fault, so the entity will not be returned to the starting state automatically. | -| Prerequisites | A Service Bus namespace with at least one [Queue entity](../service-bus-messaging/service-bus-quickstart-portal.md). | -| Urn | urn:csci:microsoft:serviceBus:changeQueueState/1.0 | -| Fault type | Discrete. | -| Parameters (key, value) | | -| desiredState | The desired state for the targeted queues. The possible states are Active, Disabled, SendDisabled, and ReceiveDisabled. | -| queues | A comma-separated list of the queue names within the targeted namespace. Use "*" to affect all queues within the namespace. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "discrete", - "name": "urn:csci:microsoft:serviceBus:changeQueueState/1.0", - "parameters":[ - { - "key": "desiredState", - "value": "Disabled" - }, - { - "key": "queues", - "value": "samplequeue1,samplequeue2" - } - ], - "selectorid": "myServiceBusSelector" - } - ] -} -``` --#### Limitations --* A maximum of 1000 queue entities can be passed to this fault. --### Service Bus: Change Subscription State - -| Property | Value | -| - | | -| Capability name | ChangeSubscriptionState-1.0 | -| Target type | Microsoft-ServiceBus | -| Description | Sets Subscription entities within a Service Bus namespace and Topic to the desired state. You can affect specific entity names or use “*” to affect all. This action can help test your messaging infrastructure for maintenance or failure scenarios. This is a discrete fault, so the entity will not be returned to the starting state automatically. | -| Prerequisites | A Service Bus namespace with at least one [Subscription entity](../service-bus-messaging/service-bus-quickstart-topics-subscriptions-portal.md). | -| Urn | urn:csci:microsoft:serviceBus:changeSubscriptionState/1.0 | -| Fault type | Discrete. | -| Parameters (key, value) | | -| desiredState | The desired state for the targeted subscriptions. The possible states are Active and Disabled. | -| topic | The parent topic containing one or more subscriptions to affect. | -| subscriptions | A comma-separated list of the subscription names within the targeted namespace. Use "*" to affect all subscriptions within the namespace. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "discrete", - "name": "urn:csci:microsoft:serviceBus:changeSubscriptionState/1.0", - "parameters":[ - { - "key": "desiredState", - "value": "Disabled" - }, - { - "key": "topic", - "value": "topic01" - }, - { - "key": "subscriptions", - "value": "*" - } - ], - "selectorid": "myServiceBusSelector" - } - ] -} -``` --#### Limitations --* A maximum of 1000 subscription entities can be passed to this fault. --### Service Bus: Change Topic State - -| Property | Value | -| - | | -| Capability name | ChangeTopicState-1.0 | -| Target type | Microsoft-ServiceBus | -| Description | Sets the specified Topic entities within a Service Bus namespace to the desired state. You can affect specific entity names or use “*” to affect all. This action can help test your messaging infrastructure for maintenance or failure scenarios. This is a discrete fault, so the entity will not be returned to the starting state automatically. | -| Prerequisites | A Service Bus namespace with at least one [Topic entity](../service-bus-messaging/service-bus-quickstart-topics-subscriptions-portal.md). | -| Urn | urn:csci:microsoft:serviceBus:changeTopicState/1.0 | -| Fault type | Discrete. | -| Parameters (key, value) | | -| desiredState | The desired state for the targeted topics. The possible states are Active and Disabled. | -| topics | A comma-separated list of the topic names within the targeted namespace. Use "*" to affect all topics within the namespace. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "discrete", - "name": "urn:csci:microsoft:serviceBus:changeTopicState/1.0", - "parameters":[ - { - "key": "desiredState", - "value": "Disabled" - }, - { - "key": "topics", - "value": "*" - } - ], - "selectorid": "myServiceBusSelector" - } - ] -} -``` --#### Limitations --* A maximum of 1000 topic entities can be passed to this fault. --### VM Redeploy - -| Property | Value | -| - | | -| Capability name | Redeploy-1.0 | -| Target type | Microsoft-VirtualMachine | -| Description | Redeploys a VM by shutting it down, moving it to a new node in the Azure infrastructure, and powering it back on. This helps validate your workload's resilience to maintenance events. | -| Prerequisites | None. | -| Urn | urn:csci:microsoft:virtualMachine:redeploy/1.0 | -| Fault type | Discrete. | -| Parameters (key, value) | None. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "discrete", - "name": "urn:csci:microsoft:virtualMachine:redeploy/1.0", - "parameters":[], - "selectorid": "myResources" - } - ] -} -``` --#### Limitations --* The Virtual Machine Redeploy operation is throttled within an interval of 10 hours. If your experiment fails with a "Too many redeploy requests" error, wait for 10 hours to retry the experiment. ---### VM Shutdown -| Property | Value | -|-|-| -| Capability name | Shutdown-1.0 | -| Target type | Microsoft-VirtualMachine | -| Supported OS types | Windows, Linux. | -| Description | Shuts down a VM for the duration of the fault. Restarts it at the end of the experiment or if the experiment is canceled. Only Azure Resource Manager VMs are supported. | -| Prerequisites | None. | -| Urn | urn:csci:microsoft:virtualMachine:shutdown/1.0 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| abruptShutdown | (Optional) Boolean that indicates if the VM should be shut down gracefully or abruptly (destructive). | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:virtualMachine:shutdown/1.0", - "parameters": [ - { - "key": "abruptShutdown", - "value": "false" - } - ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` ---### VMSS Shutdown --This fault has two available versions that you can use, Version 1.0 and Version 2.0. The main difference is that Version 2.0 allows you to filter by availability zones, only shutting down instances within a specified zone or zones. --#### VMSS Shutdown Version 1.0 --| Property | Value | -|-|-| -| Capability name | Version 1.0 | -| Target type | Microsoft-VirtualMachineScaleSet | -| Supported OS types | Windows, Linux. | -| Description | Shuts down or kills a virtual machine scale set instance during the fault and restarts the VM at the end of the fault duration or if the experiment is canceled. | -| Prerequisites | None. | -| Urn | urn:csci:microsoft:virtualMachineScaleSet:shutdown/1.0 | -| Fault type | Continuous. | -| Parameters (key, value) | | -| abruptShutdown | (Optional) Boolean that indicates if the virtual machine scale set instance should be shut down gracefully or abruptly (destructive). | -| instances | A string that's a delimited array of virtual machine scale set instance IDs to which the fault is applied. | --##### Version 1.0 sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "continuous", - "name": "urn:csci:microsoft:virtualMachineScaleSet:shutdown/1.0", - "parameters": [ - { - "key": "abruptShutdown", - "value": "true" - }, - { - "key": "instances", - "value": "[\"1\",\"3\"]" - } - ], - "duration": "PT10M", - "selectorid": "myResources" - } - ] -} -``` --#### VMSS Shutdown Version 2.0 --| Property | Value | -|-|-| -| Capability name | Shutdown-2.0 | -| Target type | Microsoft-VirtualMachineScaleSet | -| Supported OS types | Windows, Linux. | -| Description | Shuts down or kills a virtual machine scale set instance during the fault. Restarts the VM at the end of the fault duration or if the experiment is canceled. Supports [dynamic targeting](chaos-studio-tutorial-dynamic-target-cli.md). | -| Prerequisites | None. | -| Urn | urn:csci:microsoft:virtualMachineScaleSet:shutdown/2.0 | -| Fault type | Continuous. | -| [filter](/azure/templates/microsoft.chaos/experiments?pivots=deployment-language-arm-template#filter-objects-1) | (Optional) Available starting with Version 2.0. Used to filter the list of targets in a selector. Currently supports filtering on a list of zones. The filter is only applied to virtual machine scale set resources within a zone:<ul><li>If no filter is specified, this fault shuts down all instances in the virtual machine scale set.</li><li>The experiment targets all virtual machine scale set instances in the specified zones.</li><li>If a filter results in no targets, the experiment fails.</li></ul> | -| Parameters (key, value) | | -| abruptShutdown | (Optional) Boolean that indicates if the virtual machine scale set instance should be shut down gracefully or abruptly (destructive). | --##### Version 2.0 sample JSON snippets --The following snippets show how to configure both [dynamic filtering](chaos-studio-tutorial-dynamic-target-cli.md) and the shutdown 2.0 fault. --Configure a filter for dynamic targeting: --```json -{ - "type": "List", - "id": "myResources", - "targets": [ - { - "id": "<targetResourceId>", - "type": "ChaosTarget" - } - ], - "filter": { - "type": "Simple", - "parameters": { - "zones": [ - "1" - ] - } - } -} -``` --Configure the shutdown fault: --```json -{ - "name": "branchOne", - "actions": [ - { - "name": "urn:csci:microsoft:virtualMachineScaleSet:shutdown/2.0", - "type": "continuous", - "selectorId": "myResources", - "duration": "PT10M", - "parameters": [ - { - "key": "abruptShutdown", - "value": "false" - } - ] - } - ] -} -``` --#### Limitations -Currently, only virtual machine scale sets configured with the **Uniform** orchestration mode are supported. If your virtual machine scale set uses **Flexible** orchestration, you can use the Azure Resource Manager virtual machine shutdown fault to shut down selected instances. -----## Details: Orchestration actions --### Delay --| Property | Value | -|-|-| -| Fault provider | N/A | -| Supported OS types | N/A | -| Description | Adds a time delay before, between, or after other experiment actions. This action isn't a fault and is used to synchronize actions within an experiment. Use this action to wait for the impact of a fault to appear in a service, or wait for an activity outside of the experiment to complete. For example, your experiment could wait for autohealing to occur before injecting another fault. | -| Prerequisites | N/A | -| Urn | urn:csci:microsoft:chaosStudio:timedDelay/1.0 | -| Duration | The duration of the delay in ISO 8601 format (for example, PT10M). | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "delay", - "name": "urn:csci:microsoft:chaosStudio:timedDelay/1.0", - "duration": "PT10M" - } - ] -} -``` --### Start Load Test (Azure Load Testing) - -| Property | Value | -| - | | -| Capability name | Start-1.0 | -| Target type | Microsoft-AzureLoadTest | -| Description | Starts a load test (from Azure Load Testing) based on the provided load test ID. | -| Prerequisites | A load test with a valid load test ID must be created in the [Azure Load Testing service](../load-testing/quickstart-create-and-run-load-test.md). | -| Urn | urn:csci:microsoft:azureLoadTest:start/1.0 | -| Fault type | Discrete. | -| Parameters (key, value) | | -| testID | The ID of a specific load test created in the Azure Load Testing service. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "discrete", - "name": "urn:csci:microsoft:azureLoadTest:start/1.0", - "parameters": [ - { - "key": "testID", - "value": "0" - } - ], - "selectorid": "myResources" - } - ] -} -``` --### Stop Load Test (Azure Load Testing) - -| Property | Value | -| - | | -| Capability name | Stop-1.0 | -| Target type | Microsoft-AzureLoadTest | -| Description | Stops a load test (from Azure Load Testing) based on the provided load test ID. | -| Prerequisites | A load test with a valid load test ID must be created in the [Azure Load Testing service](../load-testing/quickstart-create-and-run-load-test.md). | -| Urn | urn:csci:microsoft:azureLoadTest:stop/1.0 | -| Fault type | Discrete. | -| Parameters (key, value) | | -| testID | The ID of a specific load test created in the Azure Load Testing service. | --#### Sample JSON --```json -{ - "name": "branchOne", - "actions": [ - { - "type": "discrete", - "name": "urn:csci:microsoft:azureLoadTest:stop/1.0", - "parameters": [ - { - "key": "testID", - "value": "0" - } - ], - "selectorid": "myResources" - } - ] -} -``` |
| chaos-studio | Chaos Studio Fault Providers | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-fault-providers.md | - Title: Supported resource types and role assignments for Chaos Studio -description: Understand the list of supported resource types and which role assignment is needed to enable an experiment to run a fault against that resource type. --- Previously updated : 11/01/2021------# Supported resource types and role assignments for Chaos Studio --The following table lists the supported resource types for faults, the target types, and suggested roles to use when you give an experiment permission to a resource of that type. --More information about role assignments can be found on the [Azure built-in roles page](../role-based-access-control/built-in-roles.md). --| Resource type | Target name/type | Suggested role assignment | -|-|--|-| -| Microsoft.Cache/Redis (service-direct) | Microsoft-AzureCacheForRedis | [Redis Cache Contributor](../role-based-access-control/built-in-roles.md#redis-cache-contributor) | -| Microsoft.ClassicCompute/domainNames (service-direct) | Microsoft-DomainNames | [Classic Virtual Machine Contributor](../role-based-access-control/built-in-roles.md#classic-virtual-machine-contributor) | -| Microsoft.Compute/virtualMachines (agent-based) | Microsoft-Agent | [Reader](../role-based-access-control/built-in-roles.md#reader) | -| Microsoft.Compute/virtualMachineScaleSets (agent-based) | Microsoft-Agent | [Reader](../role-based-access-control/built-in-roles.md#reader) | -| Microsoft.Compute/virtualMachines (service-direct) | Microsoft-VirtualMachine | [Virtual Machine Contributor](../role-based-access-control/built-in-roles.md#virtual-machine-contributor) | -| Microsoft.Compute/virtualMachineScaleSets (service-direct) | Microsoft-VirtualMachineScaleSet | [Virtual Machine Contributor](../role-based-access-control/built-in-roles.md#virtual-machine-contributor) | -| Microsoft.ContainerService/managedClusters (service-direct) | Microsoft-AzureKubernetesServiceChaosMesh | [Azure Kubernetes Service Cluster Admin Role](../role-based-access-control/built-in-roles.md#azure-kubernetes-service-cluster-admin-role) | -| Microsoft.DocumentDb/databaseAccounts (Cosmos DB, service-direct) | Microsoft-Cosmos DB | [Azure Cosmos DB Operator](../role-based-access-control/built-in-roles.md#cosmos-db-operator) | -| Microsoft.Insights/autoscalesettings (service-direct) | Microsoft-AutoScaleSettings | [Web Plan Contributor](../role-based-access-control/built-in-roles.md#web-plan-contributor) | -| Microsoft.KeyVault/vaults (service-direct) | Microsoft-KeyVault | [Azure Key Vault Contributor](../role-based-access-control/built-in-roles.md#key-vault-contributor) | -| Microsoft.Network/networkSecurityGroups (service-direct) | Microsoft-NetworkSecurityGroup | [Network Contributor](../role-based-access-control/built-in-roles.md#network-contributor) | -| Microsoft.Web/sites (service-direct) | Microsoft-AppService | [Website Contributor](../role-based-access-control/built-in-roles.md#website-contributor) | -| Microsoft.ServiceBus/namespaces (service-direct) | Microsoft-ServiceBus | [Azure Service Bus Data Owner](../role-based-access-control/built-in-roles.md#azure-service-bus-data-owner) | -| Microsoft.EventHub/namespaces (service-direct) | Microsoft-EventHub | [Azure Event Hubs Data Owner](../role-based-access-control/built-in-roles.md#azure-event-hubs-data-owner) | -| Microsoft.LoadTestService/loadtests (service-direct) | Microsoft-AzureLoadTest | [Load Test Contributor](../role-based-access-control/built-in-roles.md#load-test-contributor) | |
| chaos-studio | Chaos Studio Faults Actions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-faults-actions.md | - Title: Faults and actions in Azure Chaos Studio -description: Understand what faults and actions are in Azure Chaos Studio. What is the difference between a fault and an action? How do you define a fault? ----- Previously updated : 11/01/2021----# Faults and actions in Azure Chaos Studio --In Azure Chaos Studio, every activity that happens as part of an experiment is called an *action*. The most common type of action is a *fault*. This article describes actions and faults and the properties of each. --## Experiment actions --An action is any activity that's orchestrated as part of a chaos experiment. Actions are organized into steps and branches, enabling actions to run either sequentially or in parallel. Every action has the following properties: --* **Name**: The specific action that takes place. A name usually takes the form of a URN for the action, for example, `urn`. -* **Type**: The way that the action executes. Actions can be either *continuous* or *discrete*. A continuous action runs nonstop over a period of time. An example is applying CPU pressure for 10 minutes. A discrete action occurs only once. An example is rebooting an Azure Cache for Redis instance. --## Types of actions --There are two varieties of actions in Chaos Studio: --- **Faults**: This action causes a disruption in one or more resources.-- **Time delays**: This action "waits" without affecting any resources. It's useful for pausing in between faults to wait for a system to be affected by the previous fault.--## Faults --Faults are the most common action in Chaos Studio. Faults cause a disruption in a system, allowing you to verify that the system effectively handles that disruption without affecting availability. --Faults can: --- Be destructive. For example, a fault can kill a process.-- Apply pressure. For example, a fault can add virtual memory pressure.-- Add latency.-- Cause a configuration change.--In addition to a name and type, faults might also have a *duration*, if continuous, and *parameters*. Parameters describe how the fault should be applied and are specific to the fault name. For example, a parameter for the Azure Cosmos DB failover fault is the read region that will be promoted to the write region during the write region failure. Some parameters are required while others are optional. --Faults are either *agent-based* or *service-direct* depending on the target type. An agent-based fault requires the Chaos Studio agent to be installed on a virtual machine or virtual machine scale set. The agent is available for both Windows and Linux, but not all faults are available on both operating systems. For information on which faults are supported on each operating system, see [Chaos Studio fault and action library](chaos-studio-fault-library.md). Service-direct faults don't require any agent. They run directly against an Azure resource. --Faults also include the name of the selector that describes the resources that the fault runs against. To learn more about selectors, see [Chaos experiments](chaos-studio-chaos-experiments.md). A fault can only affect a resource if the resource has been onboarded as a target and has the corresponding fault capability enabled on the resource. --## Next steps -Now that you understand actions and faults you're ready to: -- [Create and run your first experiment](chaos-studio-tutorial-service-direct-portal.md) |
| chaos-studio | Chaos Studio Limitations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-limitations.md | - Title: Azure Chaos Studio limitations and known issues -description: Understand current limitations and known issues when you use Azure Chaos Studio. --- Previously updated : 11/02/2021------# Azure Chaos Studio limitations and known issues --The following are known limitations in Chaos Studio. --## Limitations --- **Supported regions** - The target resources must be in [one of the regions supported by the Azure Chaos Studio](https://azure.microsoft.com/global-infrastructure/services/?products=chaos-studio).-- **Resource Move not supported** - Azure Chaos Studio tracked resources (for example, Experiments) currently do NOT support Resource Move. Experiments can be easily copied (by copying Experiment JSON) for use in other subscriptions, resource groups, or regions. Experiments can also already target resources across regions. Extension resources (Targets and Capabilities) do support Resource Move. -- **VMs require network access to Chaos studio** - For agent-based faults, the virtual machine must have outbound network access to the Chaos Studio agent service:- - Regional endpoints to allowlist are listed in [Permissions and security in Azure Chaos Studio](chaos-studio-permissions-security.md#network-security). - - If you're sending telemetry data to Application Insights, the IPs in [IP addresses used by Azure Monitor](../azure-monitor/ip-addresses.md) are also required. -- **Network Disconnect Fault** - The agent-based "Network Disconnect" fault only affects new connections. Existing active connections continue to persist. You can restart the service or process to force connections to break.-- **Version support** - Review the [Azure Chaos Studio version compatibility](chaos-studio-versions.md) page for more information on operating system, browser, and integration version compatibility.-- **PowerShell modules** - Chaos Studio doesn't have dedicated PowerShell modules at this time. For PowerShell, use our REST API-- **Azure CLI** - Chaos Studio doesn't have dedicated AzCLI modules at this time. Use our REST API from AzCLI-- **Azure Policy** - Chaos Studio doesn't support the applicable built-in policies for our service (audit policy for customer-managed keys and Private Link) at this time. -- **Private Link** - We don't support Azure portal UI experiments for Agent-based experiments using Private Link. These restrictions do NOT apply to our Service-direct faults-- **Customer-Managed Keys** You need to use our 2023-10-27-preview REST API via a CLI to create CMK-enabled experiments. We don't support portal UI experiments using CMK at this time. Experiment info will appear in ARG within the subscription - this is a known issue today, but is limited to only ARG and only viewable by the subscription. -- **Java SDK** At present, we don't have a dedicated Java SDK. If this is something you would use, reach out to us with your feature request. -- **Built-in roles** - Chaos Studio doesn't currently have its own built-in roles. Permissions can be attained to run a chaos experiment by either assigning an [Azure built-in role](chaos-studio-fault-providers.md) or a created custom role to the experiment's identity.-- **Agent Service Tags** Currently we don't have service tags available for our Agent-based faults.-- **Chaos Studio Private Accesses (CSPA)** - For the CSPA resource type, there is a **strict 1:1 mapping of Chaos Target:CSPA Resource (abstraction for private endpoint).** We only allow **5 CSPA resources to be created per Subscription** to maintain the expected experience for all of our customers. --## Known issues -- When selecting target resources for an agent-based fault in the experiment designer, it's possible to select virtual machines or virtual machine scale sets with an operating system not supported by the fault selected.-- When running in a Linux environment, the agent-based network latency fault (NetworkLatency-1.1) can only affect **outbound** traffic, not inbound traffic. The fault can affect **both inbound and outbound** traffic on Windows environments (via the `inboundDestinationFilters` and `destinationFilters` parameters).-- When filtering by Azure subscriptions from the Targets and/or Experiments page, you may experience long load times if you have many subscriptions with large numbers of Azure resources. As a workaround, filter down to the single specific subscription in question to quickly find your desired Targets and/or Experiments.-- The NSG Security Rule **version 1.1** fault supports an additional `flushConnection` parameter. This functionality has an **active known issue**: if `flushConnection` is enabled, the fault may result in a "FlushingNetworkSecurityGroupConnectionIsNotEnabled" error. To avoid this error temporarily, disable the `flushConnection` parameter or use the NSG Security Rule version **1.0** fault.---## Next steps -Get started creating and running chaos experiments to improve application resilience with Chaos Studio by using the following links: -- [Create and run your first experiment](chaos-studio-tutorial-service-direct-portal.md)-- [Learn more about chaos engineering](chaos-studio-chaos-engineering-overview.md) |
| chaos-studio | Chaos Studio Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-overview.md | - Title: What is Azure Chaos Studio? -description: Measure, understand, and build resilience to incidents by using chaos engineering to inject faults and monitor how your application responds. --- Previously updated : 09/05/2024-------# What is Azure Chaos Studio? --[Azure Chaos Studio](https://azure.microsoft.com/services/chaos-studio) is a managed service that uses chaos engineering to help you measure, understand, and improve your cloud application and service resilience. [Chaos engineering](/azure/well-architected/reliability/testing-strategy) is a methodology by which you inject real-world faults into your application to run controlled fault injection experiments. --Resilience is the capability of a system to handle and recover from disruptions. Application disruptions can cause errors and failures that can adversely affect your business or mission. Whether you're developing, migrating, or operating Azure applications, it's important to validate and improve your application's resilience. --Chaos Studio helps you avoid negative consequences by validating that your application responds effectively to disruptions and failures. You can use Chaos Studio to test resilience against real-world incidents, like outages or high CPU utilization on virtual machines (VMs). --The following video provides more background about Chaos Studio: --> [!VIDEO https://aka.ms/docs/player?id=29017ee4-bdfa-491e-acfe-8876e93c505b] --## Chaos Studio scenarios --You can use chaos engineering for various resilience validation scenarios that span the service development and operations lifecycle. There are two types of scenarios: --- **Shift right**: These scenarios use a production or preproduction environment. Usually, you do shift-right scenarios with real customer traffic or simulated load.-- **Shift left**: These scenarios can use a development or shared test environment. You can do shift-left scenarios without any real customer traffic.--You can use Chaos Studio for the following common chaos engineering scenarios: --- Reproduce an incident that affected your application to better understand the failure. Ensure that post-incident repairs prevent the incident from recurring.-- Prepare for a major event or season with "game day" load, scale, performance, and resilience validation.-- Do business continuity and disaster recovery drills to ensure that your application can recover quickly and preserve critical data in a disaster.-- Run high-availability drills to test application resilience against region outages, network configuration errors, high-stress events, or noisy neighbor issues.-- Develop application performance benchmarks.-- Plan capacity needs for production environments.-- Run stress tests or load tests.-- Ensure that services migrated from an on-premises or other cloud environment remain resilient to known failures.-- Build confidence in services built on cloud-native architectures.-- Validate that live site tooling, observability data, and on-call processes still work in unexpected conditions.--For many of these scenarios, you first build resilience by using ad-hoc chaos experiments. Then, you continuously validate that new deployments won't regress resilience. To check, you run chaos experiments as deployment gates in your continuous integration/continuous deployment pipelines. --## How Chaos Studio works --With Chaos Studio, you can orchestrate safe, controlled fault injection on your Azure resources. Chaos experiments are the core of Chaos Studio. A chaos experiment describes the faults to run and the resources to run against. You can organize faults to run in parallel or sequence, depending on your needs. --Chaos Studio supports two types of faults: --- **Service-direct**: These faults run directly against an Azure resource, without any installation or instrumentation. Examples include rebooting an Azure Cache for Redis cluster or adding network latency to Azure Kubernetes Service pods.-- **Agent-based**: These faults run in VMs or virtual machine scale sets to do in-guest failures. Examples include applying virtual memory pressure or killing a process.--Each fault has specific parameters you can configure, like which process to kill or how much memory pressure to generate. --When you build a chaos experiment, you define one or more *steps* that execute sequentially. Each step contains one or more *branches* that run in parallel within the step. Each branch contains one or more *actions*, such as injecting a fault or waiting for a certain duration. --You organize resource *targets* to run faults against into groups called *selectors* so that you can easily reference a group of resources in each action. --The following diagram shows the layout of a chaos experiment in Chaos Studio: -- --A chaos experiment is an Azure resource in a subscription and resource group. You can use the Azure portal or the [Chaos Studio REST API](/rest/api/chaosstudio) to create, update, start, cancel, and view the status of experiments. --## Next steps -Now that you understand how to use chaos engineering, you're ready to: --- [Create and run your first experiment](chaos-studio-tutorial-service-direct-portal.md)-- [Learn more about chaos engineering](chaos-studio-chaos-engineering-overview.md) |
| chaos-studio | Chaos Studio Permissions Security | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-permissions-security.md | - Title: Permissions and security for Azure Chaos Studio -description: Understand how permissions work in Azure Chaos Studio and how you can secure resources from accidental fault injection. ----- Previously updated : 05/06/2024----# Permissions and security in Azure Chaos Studio --Azure Chaos Studio enables you to improve service resilience by systematically injecting faults into your Azure resources. Fault injection is a powerful way to improve service resilience, but it can also be dangerous. Causing failures in your application can have more impact than originally intended and open opportunities for malicious actors to infiltrate your applications. --Chaos Studio has a robust permission model that prevents faults from being run unintentionally or by a bad actor. In this article, you learn how you can secure resources that are targeted for fault injection by using Chaos Studio. --## How can I restrict the ability to inject faults with Chaos Studio? --Chaos Studio has three levels of security to help you control how and when fault injection can occur against a resource: --* First, a chaos experiment is an Azure resource that's deployed to a region, resource group, and subscription. Users must have appropriate Azure Resource Manager permissions to create, update, start, cancel, delete, or view an experiment. -- Each permission is a Resource Manager operation that can be granularly assigned to an identity or assigned as part of a role with wildcard permissions. For example, the Contributor role in Azure has `*/write` permission at the assigned scope, which includes `Microsoft.Chaos/experiments/write` permission. -- When you attempt to control the ability to inject faults against a resource, the most important operation to restrict is `Microsoft.Chaos/experiments/start/action`. This operation starts a chaos experiment that injects faults. --* Second, a chaos experiment has a [system-assigned managed identity](../active-directory/managed-identities-azure-resources/overview.md) or a [user-assigned managed identity](../active-directory/managed-identities-azure-resources/overview.md) that executes faults on a resource. If you choose to use a system-assigned managed identity for your experiment, the identity is created at experiment creation time in your Microsoft Entra tenant. User-assigned managed identites may be used across any number of experiments. -- Within a chaos experiment, you can choose to enable custom role assignment on either your system-assigned or user-assigned managed identity selection. Enabling this functionality allows Chaos Studio to create and assign a custom role containing any necessary experiment action capabilities to your experiment's identity (that do not already exist in your identity selection). If a chaos experiment is using a user-assigned managed identity, any custom roles assigned to the experiment identity by Chaos Studio will persist after experiment deletion. - - If you choose to grant your experiment permissions manually, you must grant its identity [appropriate permissions](chaos-studio-fault-providers.md) to all target resources. If the experiment identity doesn't have appropriate permission to a resource, it can't execute a fault against that resource. --* Third, each resource must be onboarded to Chaos Studio as [a target with corresponding capabilities enabled](chaos-studio-targets-capabilities.md). If a target or the capability for the fault being executed doesn't exist, the experiment fails without affecting the resource. --## User-assigned Managed Identity --A chaos experiment can utilize a [user-assigned managed identity](../active-directory/managed-identities-azure-resources/overview.md) to obtain sufficient permissions to inject faults on the experiment's target resources. Additionally, user-assigned managed identities may be used across any number of experiments in Chaos Studio. To utilize this functionality, you must: -* First, create a user-assigned managed identity within the [Managed Identities](../active-directory/managed-identities-azure-resources/overview.md) service. You may assign your user-assigned managed identity required permissions to run your chaos experiment(s) at this point. -* Second, when creating your chaos experiment, select a user-assigned managed identity from your Subscription. You can choose to enable custom role assignment at this step. Enabling this functionality would grant your identity selection any required permissions it may need based on the faults contained in your experiment. -* Third, after you've added all of your faults to your chaos experiment, review if your identity configuration contains all the necessary actions for your chaos experiment to run successfully. If it does not, contact your system administrator for access or edit your experiment's fault selections. --## Agent authentication --When you run agent-based faults, you must install the Chaos Studio agent on your virtual machine (VM) or virtual machine scale set. The agent uses a [user-assigned managed identity](../active-directory/managed-identities-azure-resources/overview.md) to authenticate to Chaos Studio and an *agent profile* to establish a relationship to a specific VM resource. --When you onboard a VM or virtual machine scale set for agent-based faults, you first create an agent target. The agent target must have a reference to the user-assigned managed identity that's used for authentication. The agent target contains an *agent profile ID*, which is provided as configuration when you install the agent. Agent profiles are unique to each target and targets are unique per resource. --## Azure Resource Manager operations and roles --Chaos Studio has the following operations: --| Operation | Description | -||| -| Microsoft.Chaos/targets/[Read,Write,Delete] | Get, create, update, or delete a target. | -| Microsoft.Chaos/targets/capabilities/[Read,Write,Delete] | Get, create, update, or delete a capability. | -| Microsoft.Chaos/locations/targetTypes/Read | Get all target types. | -| Microsoft.Chaos/locations/targetTypes/capabilityTypes/Read | Get all capability types. | -| Microsoft.Chaos/experiments/[Read,Write,Delete] | Get, create, update, or delete a chaos experiment. | -| Microsoft.Chaos/experiments/start/action | Start a chaos experiment. | -| Microsoft.Chaos/experiments/cancel/action | Stop a chaos experiment. | -| Microsoft.Chaos/experiments/executions/Read | Get the execution status for a run of a chaos experiment. | -| Microsoft.Chaos/experiments/executions/getExecutionDetails/action | Get the execution details (status and errors for each action) for a run of a chaos experiment. | --To assign these permissions granularly, you can [create a custom role](../role-based-access-control/custom-roles.md). --## Network security --All user interactions with Chaos Studio happen through Azure Resource Manager. If a user starts an experiment, the experiment might interact with endpoints other than Resource Manager, depending on the fault: --* **Service-direct faults**: Most service-direct faults are executed through Azure Resource Manager and don't require any allowlisted network endpoints. -* **Service-direct AKS Chaos Mesh faults:** Service-direct faults for Azure Kubernetes Service that use Chaos Mesh require access to the AKS cluster's Kubernetes API server. - * [Learn how to limit AKS network access to a set of IP ranges here](/azure/aks/api-server-authorized-ip-ranges). You can obtain Chaos Studio's IP ranges by querying the `ChaosStudio` [service tag with the Service Tag Discovery API or downloadable JSON files](../virtual-network/service-tags-overview.md). - * Currently, Chaos Studio can't execute Chaos Mesh faults if the AKS cluster has [local accounts disabled](/azure/aks/manage-local-accounts-managed-azure-ad). -* **Agent-based faults**: To use agent-based faults, the agent needs access to the Chaos Studio agent service. A VM or virtual machine scale set must have outbound access to the agent service endpoint for the agent to connect successfully. The agent service endpoint is `https://acs-prod-<region>.chaosagent.trafficmanager.net`. You must replace the `<region>` placeholder with the region where your VM is deployed. An example is `https://acs-prod-eastus.chaosagent.trafficmanager.net` for a VM in East US. -* **Agent-based private networking**: The Chaos Studio agent now supports private networking. Please see [Private networking for Chaos Agent](chaos-studio-private-link-agent-service.md). --## Service tags -A [service tag](../virtual-network/service-tags-overview.md) is a group of IP address prefixes that can be assigned to inbound and outbound rules for network security groups. It automatically handles updates to the group of IP address prefixes without any intervention. Since service tags primarily enable IP address filtering, service tags alone arenΓÇÖt sufficient to secure traffic. --You can use service tags to explicitly allow inbound traffic from Chaos Studio without the need to know the IP addresses of the platform. Chaos Studio's service tag is `ChaosStudio`. --A limitation of service tags is that they can only be used with applications that have a public IP address. If a resource only has a private IP address, service tags can't route traffic to it. --### Use cases -Chaos Studio uses Service Tags for several use cases. --* To use [agent-based faults](chaos-studio-fault-library.md#agent-based-faults), the Chaos Studio agent running inside customer virtual machines must communicate with the Chaos Studio backend service. The Service Tag lets customers allow-list the traffic from the virtual machine to the Chaos Studio service. -* To use certain faults that require communication outside the `management.azure.com` namespace, like [Chaos Mesh faults](chaos-studio-fault-library.md#azure-kubernetes-service) for Azure Kubernetes Service, traffic comes from the Chaos Studio service to the customer resource. The Service Tag lets customers allow-list the traffic from the Chaos Studio service to the targeted resource. -* Customers can use other Service Tags as part of the Network Security Group Rules fault to affect traffic to/from certain Azure services. --By specifying the `ChaosStudio` Service Tag in security rules, traffic can be allowed or denied for the Chaos Studio service without the need to specify individual IP addresses. --### Security considerations --When evaluating and using service tags, itΓÇÖs important to note that they donΓÇÖt provide granular control over individual IP addresses and shouldnΓÇÖt be relied on as the sole method for securing a network. They arenΓÇÖt a replacement for proper network security measures. --## Data encryption --Chaos Studio encrypts all data by default. Chaos Studio only accepts input for system properties like managed identity object IDs, experiment/step/branch names, and fault parameters. An example is the network port range to block in a network disconnect fault. --These properties shouldn't be used to store sensitive data, such as payment information or passwords. For more information on how Chaos Studio protects your data, see [Azure customer data protection](../security/fundamentals/protection-customer-data.md). --## Customer Lockbox --Lockbox gives you the control to approve or reject Microsoft engineer request to access your experiment data during a support request. --Lockbox can be enabled for chaos experiment information, and permission to access data is granted by the customer at the subscription level if lockbox is enabled. --Learn more about [Customer Lockbox for Microsoft Azure](../security/fundamentals/customer-lockbox-overview.md) --## Next steps -Now that you understand how to secure your chaos experiment, you're ready to: --- [Create and run your first experiment](chaos-studio-tutorial-service-direct-portal.md)-- [Create and run your first Azure Kubernetes Service experiment](chaos-studio-tutorial-aks-portal.md) |
| chaos-studio | Chaos Studio Private Link Agent Service | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-private-link-agent-service.md | - Title: Set up Private Link for a Chaos Studio agent-based experiment (preview) -description: Understand the steps to set up a chaos experiment by using Azure Private Link for agent-based experiments. --- Previously updated : 12/04/2023-------# Configure Private Link for agent-based experiments (preview) --This article explains the steps needed to configure Azure Private Link for an Azure Chaos Studio agent-based experiment (preview). The current user experience is based on the private endpoints support that's enabled as part of the public preview of the private endpoints feature. Expect this experience to evolve with time as the feature is enhanced to general availability (GA) quality. It's currently in preview. ---## Prerequisites --- An Azure account with an active subscription. If you don't have an Azure subscription, create a [free account](https://azure.microsoft.com/free/?WT.mc_id=A261C142F) before you begin.-- Define your agent-based experiment by following the steps in [Create a chaos experiment that uses an agent-based fault with the Azure portal](chaos-studio-tutorial-agent-based-portal.md).--> [!NOTE] -> If the target resource was created by using the Azure portal, the Chaos Agent virtual machine (VM) extension is automatically installed on the host VM. If the target is enabled by using the Azure CLI, follow the Chaos Studio documentation to install the VM extension first on the VM. Until you finish the private endpoint setup, the VM extension reports an unhealthy state. This behavior is expected. --<br/> --## Limitations --- You need to use our *2023-10-27-preview REST API* to create and use Private Link for agent-based experiments only. There's *no* support for Private Link for agent-based experiments in our GA-stable REST API until H1 2024.-- The entire end-to-end experience for this flow requires some use of the CLI. The current end-to-end experience can't be done from the Azure portal.-- The **Chaos Studio Private Accesses (CSPA)** resource type has a strict 1:1 mapping of Chaos Target:CSPA Resource (abstraction for private endpoint). We allow only *five CSPA resources to be created per subscription* to maintain the expected experience for all our customers. --## Create a Chaos Studio Private Access resource --To use private endpoints for agent-based chaos experiments, you need to create a new resource type called Chaos Studio Private Accesses. CSPA is the resource against which the private endpoints are created. --Currently, this resource can *only be created from the CLI*. See the following example code for how to create this resource type: -- ```AzCLI -az rest --verbose --skip-authorization-header --header "Authorization=Bearer $accessToken" --method PUT --uri "https://centraluseuap.management.azure.com/subscriptions/<subscriptionID>/resourceGroups/<resourceGroupName>/providers/Microsoft.Chaos/privateAccesses/<CSPAResourceName>?api-version=2023-10-27-preview" --body ' --{ -- "location": "<resourceLocation>", -- "properties": { -- "id": "<CSPAResourceName>", -- "name": "<CSPAResourceName>", -- "location": "<resourceLocation>", -- "type": "Microsoft.Chaos/privateAccesses", -- "resourceId": "subscriptions/<subscriptionID>/resourceGroups/<resourceGroupName>/providers/Microsoft.Chaos/privateAccesses/<CSPAResourceName>" -- } --}' - ``` --| Name |Required | Type | Description | -|-|-|-|-| -|subscriptionID|True|String|GUID that represents an Azure subscription ID.| -|resourceGroupName|True|String|String that represents an Azure resource group.| -|CSPAResourceName|True|String|String that represents the name you want to give your Chaos Studio Private Access resource.| -|resourceLocation|True|String|Location where you want the resource to be hosted (must be a support region by Chaos Studio).| --## Create your virtual network, subnet, and private endpoint --[Set up your desired virtual network, subnet, and endpoint](../private-link/create-private-endpoint-portal.md) for the experiment if you haven't already. --Make sure you attach it to the same VM's virtual network. Screenshots provide examples of creating the virtual network, subnet, and private endpoint. You need to set **Resource type** to **Microsoft.Chaos/privateAccesses** as seen in the screenshot. --[](images/resource-private-endpoint.png#lightbox) --[](images/resource-vnet-cspa.png#lightbox) --## Map the agent host VM to the CSPA resource --Find the target `Resource ID` by making a `GetTarget` call: --```AzCLI -GET https://management.azure.com/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/{parentProviderNamespace}/{parentResourceType}/{parentResourceName}/providers/Microsoft.Chaos/targets/{targetName}?api-version=2023-10-27-preview -``` --<br/> --The `GET` command returns a large response. Note this response. We use this response and modify it before running a `PUT Target` command to map the two resources. --<br/> --Invoke a `PUT Target` command by using this response. You need to append *two more fields* to the body of the `PUT` command before you run it. --These extra fields are shown here: --``` -"privateAccessId": "subscriptions/<subID>/... -"allowPublicAccess": false --}, -``` --Here's an example block for what the `PUT Target` command should look like and the fields that you would need to fill out: --> [!NOTE] -> Copy the body from the previous `GET` command. You need to manually append the `privateAccessID` and `allowPublicAccess` fields. --```AzCLI --az rest --verbose --skip-authorization-header --header "Authorization=Bearer $accessToken" --method PUT --uri "https://management.azure.com/subscriptions/<subscriptionID>/resourceGroups/<resourceGroup>/providers/Microsoft.Compute/virtualMachines/<VMSSname>/providers/Microsoft.Chaos/targets/Microsoft-Agent?api-version=2023-10-27-preview " --body ' { - "id": "/subscriptions/<subscriptionID>/resourceGroups/<resourceGroupName>/providers/microsoft.compute/virtualmachines/<VMSSName>/providers/Microsoft.Chaos/targets/Microsoft-Agent", - "type": "Microsoft.Chaos/targets", - "name": "Microsoft-Agent", - "location": "<resourceLocation>", - "properties": { - "agentProfileId": "<from target resource>", - "identities": [ - { - "type": "AzureManagedIdentity", - "clientId": "<clientID>", - "tenantId": "<tenantID>" - } - ], - "agentTenantId": "CHAOSSTUDIO", - "privateAccessId": "subscriptions/<subscriptionID>/resourceGroups/<resourceGroupName>/providers/Microsoft.Chaos/privateAccesses/<CSPAresourceName>", - "allowPublicAccess": false - }} ' --``` --> [!NOTE] -> The `PrivateAccessID` value should exactly match the `resourceID` value that you used to create the CSPA resource in the earlier section **Create a Chaos Studio Private Access resource**. --## Restart the Azure Chaos Agent service in the VM --After you make all the required changes to the host, restart the Azure Chaos Agent service in the VM. --### Windows --[](images/restart-windows-vm.png#lightbox) --### Linux --For Linux, run the following command from the CLI: --``` -Systemctl restart azure-chaos-agent -``` --[](images/restart-linux-vm.png#lightbox) --## Run your agent-based experiment by using private endpoints --After the restart, Azure Chaos Agent should be able to communicate with the Agent Communication data plane service, and the agent registration to the data plane should be successful. After successful registration, the agent can indicate its status with a heartbeat. Then you can proceed to run the Azure Chaos Agent-based experiments by using private endpoints. |
| chaos-studio | Chaos Studio Private Networking | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-private-networking.md | - Title: Integration of virtual network injection with Chaos Studio -description: Learn how to use virtual network injection with Azure Chaos Studio. --- Previously updated : 10/26/2022-------# Virtual network injection in Azure Chaos Studio --Azure [Virtual Network](../virtual-network/virtual-networks-overview.md) is the fundamental building block for your private network in Azure. A virtual network enables many types of Azure resources to securely communicate with each other, the internet, and on-premises networks. A virtual network is similar to a traditional network that you operate in your own datacenter. It brings other benefits of Azure's infrastructure, such as scale, availability, and isolation. --Virtual network injection allows an Azure Chaos Studio resource provider to inject containerized workloads into your virtual network so that resources without public endpoints can be accessed via a private IP address on the virtual network. After you've configured virtual network injection for a resource in a virtual network and enabled the resource as a target, you can use it in multiple experiments. An experiment can target a mix of private and nonprivate resources if the private resources are configured according to the instructions in this article. --We are also now excited to share that Chaos Studio supports running **agent-based experiments** using Private Endpoints! Chaos Studio now supports Private Link for **both** service-direct and agent-based experiments. If you would like to use Private-Link for agent-based experiments, please reach out to your CSA or visit [How to: Setup private link for agent-based experiments](chaos-studio-private-link-agent-service.md). For private link for service-direct faults, read the following sections for instructions on how to use them. --## Resource type support -Currently, you can only enable certain resource types for Chaos Studio virtual network injection: --* **Azure Kubernetes Service (AKS)** targets can be enabled with virtual network injection through the Azure portal and the Azure CLI. All AKS Chaos Mesh faults can be used. -* **Azure Key Vault** targets can be enabled with virtual network injection through the Azure CLI. The faults that can be used with virtual network injection are Disable Certificate, Increment Certificate Version, and Update Certificate Policy. --## Enable virtual network injection -To use Chaos Studio with virtual network injection, you must meet the following requirements. -1. The `Microsoft.ContainerInstance` and `Microsoft.Relay` resource providers must be registered with your subscription. -1. The virtual network where Chaos Studio resources will be injected must have two subnets: a container subnet and a relay subnet. A container subnet is used for the Chaos Studio containers that will be injected into your private network. A relay subnet is used to forward communication from Chaos Studio to the containers inside the private network. - 1. Both subnets need at least `/28` for the size of the address space (in this case `/27` is larger than `/28`, for example). An example is an address prefix of `10.0.0.0/28` or `10.0.0.0/24`. - 1. The container subnet must be delegated to `Microsoft.ContainerInstance/containerGroups`. - 1. The subnets can be arbitrarily named, but we recommend `ChaosStudioContainerSubnet` and `ChaosStudioRelaySubnet`. -1. When you enable the desired resource as a target so that you can use it in Chaos Studio experiments, the following properties must be set: - 1. Set `properties.subnets.containerSubnetId` to the ID for the container subnet. - 1. Set `properties.subnets.relaySubnetId` to the ID for the relay subnet. --If you're using the Azure portal to enable a private resource as a Chaos Studio target, Chaos Studio currently only recognizes subnets named `ChaosStudioContainerSubnet` and `ChaosStudioRelaySubnet`. If these subnets don't exist, the portal workflow can create them automatically. --If you're using the CLI, the container and relay subnets can have any name (subject to the resource naming guidelines). Specify the appropriate IDs when you enable the resource as a target. --## Example: Use Chaos Studio with a private AKS cluster --This example shows how to configure a private AKS cluster to use with Chaos Studio. It assumes you already have a private AKS cluster within your Azure subscription. To create one, see [Create a private Azure Kubernetes Service cluster](/azure/aks/private-clusters). --### [Azure portal](#tab/azure-portal) --1. In the Azure portal, go to **Subscriptions** > **Resource providers** in your subscription. -1. Register the `Microsoft.ContainerInstance` and `Microsoft.Relay` resource providers, if they aren't already registered, by selecting the provider and then selecting **Register**. Reregister the `Microsoft.Chaos` resource provider. -- :::image type="content" source="images/vnet-register-resource-provider.png" alt-text="Screenshot that shows how to register a resource provider." lightbox="images/vnet-register-resource-provider.png"::: --1. Go to Chaos Studio and select **Targets**. Find your desired AKS cluster and select **Enable targets** > **Enable service-direct targets**. -- :::image type="content" source="images/vnet-enable-targets.png" alt-text="Screenshot that shows how to enable targets in Chaos Studio." lightbox="images/vnet-enable-targets.png"::: --1. Select the cluster's virtual network. If the virtual network already includes subnets named `ChaosStudioContainerSubnet` and `ChaosStudioRelaySubnet`, select them. If they don't already exist, they're automatically created for you. -- :::image type="content" source="images/vnet-select-subnets.png" alt-text="Screenshot that shows how to select the virtual network and subnets." lightbox="images/vnet-select-subnets.png"::: --1. Select **Review + Enable** > **Enable**. -- :::image type="content" source="images/vnet-review.png" alt-text="Screenshot that shows how to review the target enablement." lightbox="images/vnet-review.png"::: --Now you can use your private AKS cluster with Chaos Studio. To learn how to install Chaos Mesh and run the experiment, see [Create a chaos experiment that uses a Chaos Mesh fault with the Azure portal](chaos-studio-tutorial-aks-portal.md). --### [Azure CLI](#tab/azure-cli) --1. Register the `Microsoft.ContainerInstance` and `Microsoft.Relay` resource providers with your subscription by running the following commands. If they're both already registered, you can skip this step. For more information, see the [Register resource provider](../azure-resource-manager/management/resource-providers-and-types.md) instructions. -- ```azurecli - az provider register --namespace 'Microsoft.ContainerInstance' --wait - ``` -- ```azurecli - az provider register --namespace 'Microsoft.Relay' --wait - ``` -- Verify the registration by running the following commands: -- ```azurecli - az provider show --namespace 'Microsoft.ContainerInstance' | grep registrationState - ``` -- ```azurecli - az provider show --namespace 'Microsoft.Relay' | grep registrationState - ``` -- In the output, you should see something similar to: -- ```azurecli - "registrationState": "Registered", - ``` --1. Reregister the `Microsoft.Chaos` resource provider with your subscription. -- ```azurecli - az provider register --namespace 'Microsoft.Chaos' --wait - ``` -- Verify the registration by running the following command: -- ```azurecli - az provider show --namespace 'Microsoft.Chaos' | grep registrationState - ``` -- In the output, you should see something similar to: -- ```azurecli - "registrationState": "Registered", - ``` --1. Create two subnets in the virtual network you want to inject Chaos Studio resources into (in this case, the private AKS cluster's virtual network): -- - Container subnet (example name: `ChaosStudioContainerSubnet`) - - Delegate the subnet to the `Microsoft.ContainerInstance/containerGroups` service. - - This subnet must have at least `/28` in the address space. - - Relay subnet (example name: `ChaosStudioRelaySubnet`) - - This subnet must have at least `/28` in the address space. - - ```azurecli - az network vnet subnet create -g MyResourceGroup --vnet-name MyVnetName --name ChaosStudioContainerSubnet --address-prefixes "10.0.0.0/28" --delegations "Microsoft.ContainerInstance/containerGroups" - ``` - ```azurecli - az network vnet subnet create -g MyResourceGroup --vnet-name MyVnetName --name ChaosStudioRelaySubnet --address-prefixes "10.0.0.0/28" - ``` --1. When you enable targets for the AKS cluster so that you can use it in chaos experiments, set the `properties.subnets.containerSubnetId` and `properties.subnets.relaySubnetId` properties by using the new subnets you created in step 3. -- Replace `$SUBSCRIPTION_ID` with your Azure subscription ID. Replace `$RESOURCE_GROUP` and `$AKS_CLUSTER` with the resource group name and your AKS cluster resource name. Also, replace `$AKS_INFRA_RESOURCE_GROUP` and `$AKS_VNET` with your AKS infrastructure resource group name and virtual network name. Replace `$URL` with the corresponding `https://management.azure.com/` URL used for onboarding the target. -- ```azurecli - CONTAINER_SUBNET_ID=/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$AKS_INFRA_RESOURCE_GROUP/providers/Microsoft.Network/virtualNetworks/$AKS_VNET/subnets/ChaosStudioContainerSubnet - RELAY_SUBNET_ID=/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$AKS_INFRA_RESOURCE_GROUP/providers/Microsoft.Network/virtualNetworks/$AKS_VNET/subnets/ChaosStudioRelaySubnet - BODY="{ \"properties\": { \"subnets\": { \"containerSubnetId\": \"$CONTAINER_SUBNET_ID\", \"relaySubnetId\": \"$RELAY_SUBNET_ID\" } } }" - az rest --method put --url $URL --body "$BODY" - ``` - <!-- - After you create a Target resource with virtual network injection enabled, the resource's properties will include: - - ```json - { - "properties": { - "subnets": { - "containerSubnetId": "/subscriptions/.../subnets/ChaosStudioContainerSubnet", - "relaySubnetId": "/subscriptions/.../subnets/ChaosStudioRelaySubnet" - } - } - } - ``` - --> --Now you can use your private AKS cluster with Chaos Studio. To learn how to install Chaos Mesh and run the experiment, see [Create a chaos experiment that uses a Chaos Mesh fault with the Azure CLI](chaos-studio-tutorial-aks-cli.md). ----## Limitations -* Virtual network injection is currently only possible in subscriptions/regions where Azure Container Instances and Azure Relay are available. -* When you create a Target resource that you enable with virtual network injection, you need `Microsoft.Network/virtualNetworks/subnets/write` access to the virtual network. For example, if the AKS cluster is deployed to virtual network_A, then you must have permissions to create subnets in virtual network_A to enable virtual network injection for the AKS cluster. --<!-- - >--## Next steps -Now that you understand how virtual network injection can be achieved for Chaos Studio, you're ready to: -- [Create and run your first experiment](chaos-studio-tutorial-service-direct-portal.md)-- [Create and run your first Azure Kubernetes Service experiment](chaos-studio-tutorial-aks-portal.md) |
| chaos-studio | Chaos Studio Quickstart Azure Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-quickstart-azure-portal.md | - Title: Create and run a chaos experiment by using Azure Chaos Studio -description: Understand the steps to create and run an Azure Chaos Studio experiment in 10 minutes. --- Previously updated : 11/10/2021------# Quickstart: Create and run a chaos experiment by using Azure Chaos Studio --Get started with Azure Chaos Studio by using a virtual machine (VM) shutdown service-direct experiment to make your service more resilient to that failure in real-world scenarios. --## Prerequisites -- An Azure subscription. [!INCLUDE [quickstarts-free-trial-note](~/reusable-content/ce-skilling/azure/includes/quickstarts-free-trial-note.md)] -- A Linux VM running an operating system in the [Azure Chaos Studio version compatibility](chaos-studio-versions.md) list. If you don't have a VM, [follow these steps to create one](/azure/virtual-machines/linux/quick-create-portal).--## Register the Chaos Studio resource provider -If it's your first time using Chaos Studio, you must first register the Chaos Studio resource provider before you onboard the resources and create an experiment. You must do these steps for each subscription where you use Chaos Studio: --1. Open the [Azure portal](https://portal.azure.com). -1. Search for **Subscriptions** and open the subscription management page. -1. Select the subscription where you want to use Chaos Studio. -1. In the pane on the left, select **Resource providers**. -1. In the list of resource providers that appears, search for **Microsoft.Chaos**. -1. Select the Microsoft.Chaos provider and select the **Register** button. --## Create an Azure resource supported by Chaos Studio --Create an Azure resource and ensure that it's one of the supported [fault providers](chaos-studio-fault-providers.md). Also validate if this resource is being created in the [region](https://azure.microsoft.com/global-infrastructure/services/?products=chaos-studio) where Chaos Studio is available. In this experiment, we choose an Azure VM, which is one of the supported fault providers for Chaos Studio. --## Enable Chaos Studio on the VM you created -1. Open the [Azure portal](https://portal.azure.com). -1. Search for **Chaos Studio** in the search bar. -1. Select **Targets** and go to the VM you created. --1. Select the checkbox next to your VM. Select **Enable targets** > **Enable service-direct targets** from the dropdown menu. --  --1. Confirm that the desired resource is listed. Select **Review + Enable**, then **Enable**. --1. A notification appears and indicates that the resource selected was successfully enabled. - -  --## Create an experiment --1. Select **Experiments**. --  --1. Select **Create** > **New experiment**. --1. Fill in the **Subscription**, **Resource Group**, and **Location** boxes where you want to deploy the chaos experiment. Give your experiment a name. Select **Next: Experiment designer**. --  --1. In the Chaos Studio experiment designer, give a friendly name to your **Step** and **Branch**. Select **Add action > Add fault**. --  --1. Select **VM Shutdown** from the dropdown list. Then fill in the **Duration** box with the number of minutes you want the failure to last. --  --1. Select **Next: Target resources**. --  --1. Select **Add**. --  --1. Verify that your experiment looks correct and then select **Review + create** > **Create**. --  --## Give experiment permission to your VM -1. Go to your VM and select **Access control (IAM)**. --  -1. Select **Add**. --  --1. Select **Add role assignment**. --  --1. Search for **Virtual Machine Contributor** and select the role. Select **Next**. --  --1. Select **Managed identity** option - -1. Choose **Select members** and search for your experiment name. Select your experiment and choose **Select**. --  --1. Select **Review + assign**. --## Run the chaos experiment --1. Open the Azure portal: - * If you're using an @microsoft.com account, go to [this website](https://portal.azure.com/?microsoft_azure_chaos_assettypeoptions={%22chaosStudio%22:{%22options%22:%22%22},%22chaosExperiment%22:{%22options%22:%22%22}}µsoft_azure_chaos=true). - * If you're using an external account, go to [this website](https://portal.azure.com/?feature.customPortal=falseµsoft_azure_chaos_assettypeoptions={%22chaosStudio%22:{%22options%22:%22%22},%22chaosExperiment%22:{%22options%22:%22%22}}). -1. Select the checkbox next to the experiment name and select **Start Experiment**. --  --1. Select **Yes** to confirm you want to start the chaos experiment. --  -1. (Optional) Select the experiment name to see a detailed view of the execution status of the experiment. --## Clean up resources --1. Select the checkbox next to the experiment name and select **Delete**. --  --1. Select **Yes** to confirm that you want to delete the experiment. --1. Search the VM that you created on the Azure portal search bar. --  --1. Select **Delete** to avoid being charged for the resource. --  --## Next steps --Now that you've run a VM shutdown service-direct experiment, you're ready to: --- [Create an experiment that uses agent-based faults](chaos-studio-tutorial-agent-based-portal.md) |
| chaos-studio | Chaos Studio Quickstart Dns Outage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-quickstart-dns-outage.md | - Title: Use Chaos Studio to replicate a DNS outage by using the NSG fault -description: Get started with Azure Chaos Studio by creating a DNS outage by using the network security group fault. --- Previously updated : 08/26/2021------# Replicate a DNS outage by using the NSG fault --The network security group (NSG) fault enables you to modify your existing NSG rules as part of a chaos experiment in Azure Chaos Studio. By using this fault, you can block network traffic to your Azure resources and simulate a loss of connectivity or outages of dependent resources. --This article walks you through creating a chaos experiment that blocks all traffic to external (internet) DNS servers for 15 minutes. You can validate that resources connected to the Azure virtual network associated with the target NSG don't have a dependency on external DNS servers. In this way, you can validate one of the risk-threat model requirements. --## Prerequisites --- An NSG that's associated with the Azure resource you want to target in your experiment.-- Use the Bash environment in [Azure Cloud Shell](../cloud-shell/quickstart.md).--## Create the NSG fault provider --First, you register a fault provider on the subscription where your NSG is hosted for Chaos Studio to interact with it. --1. Create a file named *AzureNetworkSecurityGroupChaos.json* with the following contents and save it to your local machine: -- ```json - { - "properties": { - "enabled": true, - "providerConfiguration": { - "type": "AzureNetworkSecurityGroupChaos" - } - } - } - ``` --1. Open an instance of [Cloud Shell](https://shell.azure.com/). -1. Replace `$SUBSCRIPTION_ID` with the Azure subscription ID that contains the NSG you want to use in your experiment. Run the following command to ensure that the provider is registered on the correct subscription: -- ```azurecli - az account set --subscription $SUBSCRIPTION_ID - ``` --1. Drag and drop *AzureNetworkSecurityGroupChaos.json* into the Cloud Shell window to upload the file. -1. Replace `$SUBSCRIPTION_ID` used in the prior step and execute the following command to register the `AzureNetworkSecurityGroupChaos` fault provider: -- ```azurecli - az rest --method put --url "https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/providers/microsoft.chaos/chaosProviderConfigurations/AzureNetworkSecurityGroupChaos?api-version=2023-11-01" --body @AzureNetworkSecurityGroupChaos.json --resource "https://management.azure.com" - ``` --1. (Optional) Delete the *AzureNetworkSecurityGroupChaos.json* file you previously created because it's no longer required. Close Cloud Shell. --## Create a chaos experiment --After the NSG fault provider is created, you can start to create experiments in Chaos Studio. --1. Open the Azure portal with the Chaos Studio feature flag: - * If you're using an @microsoft.com account, go to [this website](https://portal.azure.com/?microsoft_azure_chaos_assettypeoptions={%22chaosStudio%22:{%22options%22:%22%22},%22chaosExperiment%22:{%22options%22:%22%22}}µsoft_azure_chaos=true). - * If you're using an external account, go to [this website](https://portal.azure.com/?feature.customPortal=falseµsoft_azure_chaos_assettypeoptions={%22chaosStudio%22:{%22options%22:%22%22},%22chaosExperiment%22:{%22options%22:%22%22}}). -1. Select **Add an experiment**. --  --1. Enter the name you want to give the experiment and select the **Subscription**, **Resource group**, and **Location** (region) where you want to create the experiment. -1. Select **Next: Experiment designer**. --  --1. Select **Add fault**. -1. Select **Network Security Group Fault** from the **Faults** dropdown list. --  --1. Populate the following parameters. -- | Parameter | Value | - |--|--| - | Duration | `15` | - | Name | `block_internet_dns` | - | Source Address Prefix | `*` | - | Destination Address Prefix | `Internet` | - | Access | `Deny` | - | Source Port Range | `*` | - | Destination Port Range | `53` | - | Priority | `1001` | - | Direction | `Outbound` | --  -- The **Name** and **Priority** fields might need to be adjusted if either one already exists in a preexisting rule on the target NSG. -- > [!NOTE] - > The priority might need to be lowered if there are any rules that explicitly allow port 53 traffic to the internet. --1. Select **Next: Target resources**. -1. Select the NSGs to be targeted by this experiment. -1. Select **Add**. --  --1. Select **Review + Create**. --  --1. Select **Create**. --  --## Grant the chaos experiment access to the network security group --As a safety precaution, all chaos experiments must be granted access to the Azure resources targeted in the experiment. --1. Go to the resources targeted in the experiment. -1. Select **Access Control (IAM)**. --  --1. Select **Add**. --  --1. Select **Add role assignment**. --  --1. In **Role**, select `Network Contributor`. --  --1. In **Select**, enter the name of the chaos experiment and then select it. --  --1. Select **Save**. --  --## Run the chaos experiment --1. Open the Azure portal with the Chaos Studio feature flag: - * If you're using an @microsoft.com account, go to [this website](https://portal.azure.com/?microsoft_azure_chaos_assettypeoptions={%22chaosStudio%22:{%22options%22:%22%22},%22chaosExperiment%22:{%22options%22:%22%22}}µsoft_azure_chaos=true). - * If you're using an external account, go to [this website](https://portal.azure.com/?feature.customPortal=falseµsoft_azure_chaos_assettypeoptions={%22chaosStudio%22:{%22options%22:%22%22},%22chaosExperiment%22:{%22options%22:%22%22}}). -1. Select the checkbox next to the experiment name and select **Start Experiment**. --  --1. Select **Yes** to confirm you want to start the chaos experiment. --  -1. (Optional) Select the experiment name to see a detailed view of the execution status of the experiment. -1. After the experiment starts, you can use your existing monitoring, telemetry, or logging tools to confirm what effect the execution chaos experiment has had on your service. --## Clean up resources --If you're not going to continue to use this experiment and want to delete it: --1. Open the Azure portal with the Chaos Studio feature flag: -- * If you're using an @microsoft.com account, go to [this website](https://portal.azure.com/?microsoft_azure_chaos_assettypeoptions={%22chaosStudio%22:{%22options%22:%22%22},%22chaosExperiment%22:{%22options%22:%22%22}}µsoft_azure_chaos=true). - * If you're using an external account, go to [this website](https://portal.azure.com/?feature.customPortal=falseµsoft_azure_chaos_assettypeoptions={%22chaosStudio%22:{%22options%22:%22%22},%22chaosExperiment%22:{%22options%22:%22%22}}). -1. Select the checkbox next to the experiment name and select **Delete**. -1. Select **Yes** to confirm that you want to delete the experiment. --If you're not going to continue using any faults related to NSGs: --1. Open an instance of [Cloud Shell](https://shell.azure.com/). -1. Replace **$SUBSCRIPTION_ID** with the Azure subscription ID where the NSG fault provider was provisioned. Run the following command: -- ```azurecli - az rest --method delete --url "https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/providers/microsoft.chaos/chaosProviderConfigurations/AzureNetworkSecurityGroupChaos?api-version=2023-11-01" --resource "https://management.azure.com" - ``` |
| chaos-studio | Chaos Studio Region Availability | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-region-availability.md | - Title: Regional availability of Azure Chaos Studio -description: Understand how Azure Chaos Studio makes chaos experiments and chaos targets available in Azure regions. ----- Previously updated : 09/05/2024----# Regional availability of Azure Chaos Studio --This article describes the regional availability model for Azure Chaos Studio. It explains the difference between a region where experiments can be deployed and one where resources can be targeted. It also provides an overview of the Chaos Studio high-availability model. --Chaos Studio is a regional Azure service, which means that the service is deployed and run within an Azure region. Chaos Studio has two regional components: the region where an experiment is deployed and the region where a resource is targeted. --A chaos experiment can target a resource in a different region than the experiment. This process is called cross-region targeting. To enable chaos experimentation on targets in more regions, Chaos Studio has a set of regions in which you can do *resource targeting*. This set is a superset of the regions in which you can create and manage *experiments*. --To view the list of regions where Chaos Studio and resource targeting are available, see [Products available by region](https://azure.microsoft.com/global-infrastructure/services/?products=chaos-studio). --## Regional availability of chaos experiments -A [chaos experiment](chaos-studio-chaos-experiments.md) is an Azure resource that describes the faults that should be run and the resources those faults should be run against. An experiment is deployed to a single region. The following information and operations stay in that region: --* **Experiment definition**. The definition includes the hierarchy of steps, branches, and actions, the faults and parameters defined, and the resource IDs of target resources. Open-ended properties in the experiment resource JSON including the step name, branch name, and any fault parameters are stored in region and treated as system metadata. -* **Experiment execution**. The execution includes each time an experiment is run or the activity that orchestrates the execution of steps, branches, and actions. -* **Experiment history**. The history includes details such as the step, branch, and action timestamps, status, IDs, and any error messages for each historical experiment run. This data is treated as system metadata. --Any experiment data stored in Chaos Studio is deleted when an experiment is deleted. --## Regional availability of chaos targets (resource targeting) -A [chaos target](chaos-studio-targets-capabilities.md) enables Chaos Studio to interact with an Azure resource. Faults in a chaos experiment run against a chaos target, but the target resource can be in a different region than the experiment. A resource can only be onboarded as a chaos target if Chaos Studio resource targeting is available in that region. --The list of regions where resource targeting is available is a superset of the regions where you can create experiments. A chaos target is deployed to the same region as the target resource. The following information and operations stay in that region: --* **Target definition**. The definition includes basic metadata about the target. Agent-based targets have one user-configurable property: the [identity that's used to connect the agent to the chaos agent service](chaos-studio-permissions-security.md#agent-authentication). -* **Capability definitions**. The definitions include basic metadata about the capabilities enabled on a target. -* **Action execution**. When an experiment runs a fault, the fault itself (for example, shutting down a VM) happens within the target region. --Any target or capability metadata is deleted when a target is deleted. --## High availability with Chaos Studio --For information on high availability with Chaos Studio, see [Reliability in Chaos Studio](../reliability/reliability-chaos-studio.md). --## Data Residency -Azure Chaos Studio doesn't store customer data outside the region the customer deploys the service instance in. --## Next steps -Now that you understand the region availability model for Chaos Studio, you're ready to: -- [Review the availability of Chaos Studio per region](https://azure.microsoft.com/global-infrastructure/services/?products=chaos-studio)-- [Create and run your first experiment](chaos-studio-tutorial-service-direct-portal.md) |
| chaos-studio | Chaos Studio Run Experiment | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-run-experiment.md | - Title: Run and manage a chaos experiment in Azure Chaos Studio -description: Learn how to start, stop, view details, and view history for a chaos experiment in Azure Chaos Studio. --- Previously updated : 11/01/2021------# Run and manage an experiment in Azure Chaos Studio --You can use a chaos experiment to verify that your application is resilient to failures by causing those failures in a controlled environment. This article provides an overview of how to use Azure Chaos Studio with a chaos experiment that you've previously created. --## Start an experiment --1. Open the [Azure portal](https://portal.azure.com). --1. Search for **Chaos Studio** in the search bar. --1. Select **Experiments**. This experiment list view is where you can start, stop, or delete experiments in bulk. You can also create a new experiment. --  --1. Select your experiment. On the experiment **Overview** page, you can start, stop, and edit your experiment. You can also view essential details about the resource and its history. Select **Start** and then select **OK** to start your experiment. --  --1. The experiment status shows as *PreProcessingQueued*, then *WaitingToStart*, and finally *Running*. --## View experiment history and details --1. After the experiment is running, under **History**, select **Details** on the current run to see status and errors. --  --1. The experiment **Details** view shows the execution status of each step, branch, and fault. Select a fault. --  --1. **Fault details** shows other information about the fault execution. It includes which targets have failed or succeeded and why. If there's an error running your experiment, debugging information appears here. --  --## Edit an experiment --1. Return to the experiment **Overview** page and select **Edit**. --  --1. This experiment designer is the same as the one you used to create the experiment. You can add or remove steps, branches, and faults. You can also edit fault parameters and targets. To edit a fault, select **...** next to the fault. --  --1. When you're finished editing, select **Save**. If you want to discard your changes without saving, select the **Close** button in the upper-right corner. -  --> [!WARNING] -> If you added targets to your experiment, remember to add a role assignment on the target resource for your experiment identity. --## Delete an experiment --1. Return to the **Experiments** list and select the checkbox next to the experiment you want to delete. Select **Delete**. You might need to select **...** to see the delete option depending on your screen resolution. --  --1. Select **Yes** to confirm that you want to delete the resource. --1. Alternatively, you can open an experiment and select **Delete**. |
| chaos-studio | Chaos Studio Samples Rest Api | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-samples-rest-api.md | - Title: Use REST APIs to interact with Chaos Studio -description: Create, view, and manage Azure Chaos Studio experiments, targets, and capabilities with REST APIs. --- Previously updated : 11/01/2021-------# Use REST APIs to interact with Chaos Studio --If you're integrating Azure Chaos Studio into your CI/CD pipelines, or you simply prefer to use direct API calls to interact with your Azure resources, you can use Chaos Studio's REST API. For the full API reference, visit the [Azure Chaos Studio REST API reference](/rest/api/chaosstudio/). This page provides samples for using the REST API effectively, and is not intended as a comprehensive reference. --This article assumes you're using [Azure CLI](/cli/azure/install-azure-cli) to execute these commands, but you can adapt them to other standard REST clients. ---You can use the Chaos Studio REST APIs to: -* Create, modify, and delete experiments -* View, start, and stop experiment executions -* View and manage targets -* Register and unregister your subscription with the Chaos Studio resource provider -* View available resource provider operations. --Use the `az cli` utility to perform these actions from the command line. --> [!TIP] -> To get more verbose output with Azure CLI, append `--verbose` to the end of each command. This variable returns more metadata when commands execute, including `x-ms-correlation-request-id`, which aids in debugging. --These examples have been reviewed with the generally available Chaos Studio API version `2023-11-01`. --## Resource provider commands --This section lists the Chaos Studio provider commands, which help you understand the resource provider's status and available operations. --### List details about the Microsoft.Chaos resource provider --This shows information such as available API versions for the Chaos resource provider and region availability. The most recent `api-version` required for this may differ from the `api-version` for Chaos resource provider operations. --```azurecli -az rest --method get --url "https://management.azure.com/subscriptions/{subscriptionId}/providers/Microsoft.Chaos?api-version={apiVersion}" -``` --### List all the operations of the Microsoft.Chaos resource provider --```azurecli -az rest --method get --url "https://management.azure.com/providers/Microsoft.Chaos/operations?api-version={apiVersion}" -``` --## Targets and capabilities --These operations help you see what [targets and capabilities](chaos-studio-targets-capabilities.md) are available, and add them to a target. --### List all target types available in a region --```azurecli -az rest --method get --url "https://management.azure.com/subscriptions/{subscriptionId}/providers/Microsoft.Chaos/locations/{locationName}/targetTypes?api-version={apiVersion}" -``` --### List all capabilities available for a target type --```azurecli -az rest --method get --url "https://management.azure.com/subscriptions/{subscriptionId}/providers/Microsoft.Chaos/locations/{locationName}/targetTypes/{targetType}/capabilityTypes?api-version={apiVersion}" -``` --### Enable a resource as a target --To use a resource in an experiment, you need to enable it as a target. --```azurecli -az rest --method put --url "https://management.azure.com/{resourceId}/providers/Microsoft.Chaos/targets/{targetType}?api-version={apiVersion}" --body "{'properties':{}}" -``` --### Enable capabilities for a target --Once a resource has been enabled as a target, you need to specify what capabilities (corresponding to faults) are allowed. --```azurecli -az rest --method put --url "https://management.azure.com/{resourceId}/providers/Microsoft.Chaos/targets/{targetType}/capabilities/{capabilityName}?api-version={apiVersion}" --body "{'properties':{}}" -``` --### See what capabilities are enabled for a target --Once a target and capabilities have been enabled, you can view the enabled capabilities. This is useful for constructing your chaos experiment, since it includes the parameter schema for each fault. --```azurecli -az rest --method get --url "https://management.azure.com/{resourceId}/providers/Microsoft.Chaos/targets/{targetType}/capabilities?api-version={apiVersion}" -``` --## Experiments --These operations help you view, run, and manage experiments. --### List all the experiments in a resource group --```azurecli -az rest --method get --url "https://management.azure.com/subscriptions/{subscriptionId}/resourceGroups/{resourceGroup}/providers/Microsoft.Chaos/experiments?api-version={apiVersion}" -``` --### Get an experiment's configuration details by name --```azurecli -az rest --method get --url "https://management.azure.com/{experimentId}?api-version={apiVersion}" -``` --### Create or update an experiment --```azurecli -az rest --method put --url "https://management.azure.com/{experimentId}?api-version={apiVersion}" --body @{experimentName.json} -``` --Note: if you receive an `UnsupportedMediaType` error, make sure your referenced JSON file is valid, and try other ways to reference the `.json` file. Different command-line interpreters may require different methods of file referencing. Another common syntax is `--body "@experimentName.json"`. --### Delete an experiment --```azurecli -az rest --method delete --url "https://management.azure.com/{experimentId}?api-version={apiVersion}" -``` --### Start an experiment --```azurecli -az rest --method post --url "https://management.azure.com/{experimentId}/start?api-version={apiVersion}" -``` --### Get all executions of an experiment --```azurecli -az rest --method get --url "https://management.azure.com/{experimentId}/executions?api-version={apiVersion}" -``` --### List the details of a specific experiment execution --If an experiment has failed, this can be used to find error messages and specific targets, branches, steps, or actions that failed. --```azurecli -az rest --method post --url "https://management.azure.com/{experimentId}/executions/{executionDetailsId}/getExecutionDetails?api-version={apiVersion}" -``` --### Cancel (stop) an experiment --```azurecli -az rest --method post --url "https://management.azure.com/{experimentId}/cancel?api-version={apiVersion}" -``` --## Other helpful commands and tips --While these commands don't use the Chaos Studio API specifically, they can be helpful for using Chaos Studio effectively. --### View Chaos Studio resources with Azure Resource Graph --You can use the Azure Resource Graph [REST API](../governance/resource-graph/first-query-rest-api.md) to query resources associated with Chaos Studio, like targets and capabilities. --```azurecli - az rest --method post --url "https://management.azure.com/providers/Microsoft.ResourceGraph/resources?api-version=2021-03-01" --body "{'query':'chaosresources'}" -``` --Alternatively, you can use Azure Resource Graph's `az cli` [extension](../governance/resource-graph/first-query-azurecli.md). --```azurecli-interactive -az graph query -q "chaosresources | summarize count() by type" -``` --For example, if you want a summary of all the Chaos Studio targets active in your subscription by resource group, you can use: --```azurecli-interactive -az graph query -q "chaosresources | where type == 'microsoft.chaos/targets' | summarize count() by resourceGroup" -``` --### Filtering and querying --Like other Azure CLI commands, you can use the `--query` and `--filter` parameters with the Azure CLI `rest` commands. For example, to see a table of available capability types for a specific target type, use the following command: --```azurecli -az rest --method get --url "https://management.azure.com/subscriptions/{subscriptionId}/providers/Microsoft.Chaos/locations/{locationName}/targetTypes/{targetType}/capabilityTypes?api-version=2023-11-01" --output table --query 'value[].{name:name, faultType:properties.runtimeProperties.kind, urn:properties.urn}' -``` --## Parameter definitions --This section describes the parameters used throughout this document and how you can fill them in. --| Parameter name | Definition | Lookup | Example | -| | | | | -| {apiVersion} | Version of the API to use when you execute the command provided | Can be found in the [API documentation](/rest/api/chaosstudio/) | `2023-11-01` | -| {experimentId} | Azure Resource ID for the experiment | Can be found on the [Chaos Studio Experiment page](https://portal.azure.com/#blade/HubsExtension/BrowseResource/resourceType/Microsoft.chaos%2Fchaosexperiments) or with a [GET call](#list-all-the-experiments-in-a-resource-group) to the `/experiments` endpoint | `/subscriptions/6b052e15-03d3-4f17-b2e1-be7f07588291/resourceGroups/my-resource-group/providers/Microsoft.Chaos/experiments/my-chaos-experiment` | -| {experimentName.json} | JSON that contains the configuration of the chaos experiment | Generated by the user | `experiment.json` (See [a CLI tutorial](chaos-studio-tutorial-service-direct-cli.md) for a full example file) | -| {subscriptionId} | Subscription ID where the target resource is located | Find in the [Azure portal Subscriptions page](https://portal.azure.com/#blade/Microsoft_Azure_Billing/SubscriptionsBlade) or by running `az account list --output table` | `6b052e15-03d3-4f17-b2e1-be7f07588291` | -| {resourceGroupName} | Name of the resource group where the target resource is located | Find in the [Resource Groups page](https://portal.azure.com/#blade/HubsExtension/BrowseResourceGroups) or by running `az group list --output table` | `my-resource-group` | -| {executionDetailsId} | Execution ID of an experiment execution | Find in the [Chaos Studio Experiment page](https://portal.azure.com/#blade/HubsExtension/BrowseResource/resourceType/Microsoft.chaos%2Fchaosexperiments) or with a [GET call](#get-all-executions-of-an-experiment) to the `/executions` endpoint | `C69E7FCD-1548-47E5-9DDA-92A5DD60E610` | -| {targetType} | Type of target for the corresponding resource | Find in the [Fault providers list](chaos-studio-fault-providers.md) or a [GET call](#list-all-target-types-available-in-a-region) to the `/locations/{locationName}/targetTypes` endpoint | `Microsoft-VirtualMachine` | -| {capabilityName} | Name of an individual capability resource, extending a target resource | Find in the [fault reference documentation](chaos-studio-fault-library.md) or with a [GET call](#list-all-capabilities-available-for-a-target-type) to the `capabilityTypes` endpoint | `Shutdown-1.0` | -| {locationName} | Azure region for a resource or regional endpoint | Find all possible regions for your account with `az account list-locations --output table` | `eastus` | |
| chaos-studio | Chaos Studio Service Limits | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-service-limits.md | - Title: Azure Chaos Studio service limits -description: Understand the throttling and usage limits for Azure Chaos Studio. ---- Previously updated : 11/01/2021----# Azure Chaos Studio service limits --This article provides service limits for Azure Chaos Studio. For more information about Azure-wide service limits and quotas, see [Azure subscription and service limits, quotas, and constraints](../azure-resource-manager/management/azure-subscription-service-limits.md). --## Experiment and target limits --Chaos Studio applies limits to the number of resources, duration of activities, and retention of data. --| Limit | Value | Description | -|--|--|--| -| Actions per experiment | 9 | The maximum number of actions (such as faults or time delays) in an experiment. | -| Branches per experiment | 9 | The maximum number of parallel tracks that can execute within an experiment. | -| Steps per experiment | 4 | The maximum number of steps that execute in series within an experiment. | -| Action duration (hours) | 12 | The maximum time duration of an individual action. | -| Total experiment duration (hours) | 12 | The maximum duration of an individual experiment, including all actions. | -| Concurrent experiments executing per region and subscription | 5 | The number of experiments that can run at the same time within a region and subscription. | -| Experiment history retention time (days) | 120 | The time period after which individual results of experiment executions are automatically removed. | -| Number of experiment resources per region and subscription | 500 | The maximum number of experiment resources a subscription can store in a given region. | -| Number of targets per action | 50 | The maximum number of resources an individual action can target for execution. For example, the maximum Virtual Machines that can be shut down by a single Virtual Machine Shutdown fault. | -| Number of agents per target | 1,000 | The maximum number of running agents that can be associated with a single target. For example, the agents running on all instances within a single Virtual Machine Scale Set. | -| Number of targets per region and subscription | 10,000 | The maximum number of target resources within a single subscription and region. | --## API throttling limits --Chaos Studio applies limits to all Azure Resource Manager operations. Requests made over the limit are throttled. All request limits are applied for a **five-minute interval** unless otherwise specified. For more information about Azure Resource Manager requests, see [Throttling Resource Manager requests](../azure-resource-manager/management/request-limits-and-throttling.md). --| Operation | Requests | -|--|--| -| Microsoft.Chaos/experiments/write | 100 | -| Microsoft.Chaos/experiments/read | 300 | -| Microsoft.Chaos/experiments/delete | 100 | -| Microsoft.Chaos/experiments/start/action | 20 | -| Microsoft.Chaos/experiments/cancel/action | 100 | -| Microsoft.Chaos/experiments/statuses/read | 100 | -| Microsoft.Chaos/experiments/executionDetails/read | 100 | -| Microsoft.Chaos/targets/write | 200 | -| Microsoft.Chaos/targets/read | 600 | -| Microsoft.Chaos/targets/delete | 200 | -| Microsoft.Chaos/targets/capabilities/write | 600 | -| Microsoft.Chaos/targets/capabilities/read | 1,800 | -| Microsoft.Chaos/targets/capabilities/delete | 600 | -| Microsoft.Chaos/locations/targetTypes/read | 50 | -| Microsoft.Chaos/locations/targetTypes/capabilityTypes/read | 50 | --## Recommended actions -If you have feedback on the current quotas and limits, submit a feedback request in [Community Feedback](https://feedback.azure.com/d365community/forum/18f8dc01-dc37-ec11-b6e6-000d3a9c7101). --Currently, you can't request increases to Chaos Studio quotas, but a request process is in development. --If you expect to exceed the maximum concurrent experiments executing per region and subscription: -* Split your experiments across regions. Experiments can target resources outside the experiment resource's region or target multiple resources across different regions. -* Test more scenarios in each experiment by using more actions, steps, and/or branches (up to the maximum current limits). --If your testing requires longer experiments than the currently supported duration: -* Run multiple experiments in sequence. - -If you want to see experiment execution history: -* Use Chaos Studio's [REST API](../chaos-studio/chaos-studio-samples-rest-api.md) with the "executionDetails" endpoint, for each experiment ID. |
| chaos-studio | Chaos Studio Set Up App Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-set-up-app-insights.md | - Title: Set up App Insights for a Chaos Studio agent-based experiment -description: Understand the steps to connect App Insights to your Chaos Studio Agent-Based Experiment --- Previously updated : 09/27/2023-------# How-to: Configure your experiment to emit Experiment Fault Events to App Insights --In this guide, we'll show you the steps needed to configure a Chaos Studio **Agent-based** Experiment to emit telemetry to App Insights. These events show the start and stop of each fault as well as the type of fault executed and the resource the fault was executed against. App Insights is the primary recommended logging solution for **Agent-based** experiments in Chaos Studio. --## Prerequisites -- An Azure subscription-- An existing Chaos Studio [**Agent-based** Experiment](chaos-studio-tutorial-agent-based-portal.md)-- [Required for Application Insights Resource as well] An existing [Log Analytics Workspace](../azure-monitor/logs/quick-create-workspace.md)-- An existing [Application Insights Resource](../azure-monitor/app/create-workspace-resource.md)-- [Required for Agent-based Chaos Experiments] A [User-Assigned Managed Identity](../active-directory/managed-identities-azure-resources/how-manage-user-assigned-managed-identities.md)--## Step 1: Copy the Instrumentation Key from your Application Insights Resource -Once you have met all the prerequisite steps, copy the **Instrumentation Key** found in the overview page of your Application Insights Resource (see screenshot) --<br/> --[](images/step-1a-app-insights.png#lightbox) --## Step 2: Enable the Target Platform for your Agent-Based Fault with Application Insights -Navigate to the Chaos Studio overview page and click on the **Targets** blade under the "Experiments Management" section. Find the target platform. If it is already enabled as a target for agent-based experiments, you will need to disable it as a target and then "enable for agent-based targets" to bring up the Chaos Studio agent target configuration pane. -See screenshot below for an example: -<br/> --<br/> --[](images/step-2a-app-insights.png#lightbox) --## Step 3: Add your Application Insights account and Instrumentation key -At this point, the Agent target configuration page seen in the screenshot should come up . After configuring your managed identity, make sure Application Insights is "Enabled" and then select your desired Application Insights Account and enter the Instrumentation Key you copied in Step 1. Once you have filled out the required information, you can click "Review+Create" to deploy your resource. --<br/> --[](images/step-3a-app-insights.png#lightbox) --## Step 4: Run the chaos experiment -At this point, your Chaos Target is now configured to emit telemetry to the App Insights Resource you configured! If you navigate to your specific Application Insights Resource and open the "Logs" blade under the "Monitoring" section, you should see the Agent health status and any actions the Agent is taking on your Target Platform. You can now run your experiment and see logging in your Application Insights Resource. See screenshot for example of App Insights Resource running successfully on an Agent-based Chaos Target platform. --<br/> --To query your logs, navigate to the "Logs" tab in the Application Insights Resource to get your desired logging information your desired format. --<br/> --[](images/step-4a-app-insights.png#lightbox) |
| chaos-studio | Chaos Studio Set Up Azure Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-set-up-azure-monitor.md | - Title: Set up Azure monitor for a Chaos Studio experiment -description: Understand the steps to connect Azure Monitor to your Chaos Studio Experiment --- Previously updated : 09/27/2023-------# How-to: Configure your experiment to emit Experiment Fault Events to Azure Monitor --In this guide, we'll show you the steps needed to integrate an Experiment to emit telemetry to Azure Monitor. These events show the start and stop of each fault as well as the type of fault executed and the resource the fault was executed against. You can overlay this data on top of your existing Azure Monitor or external monitoring dashboards. --## Prerequisites -- An Azure subscription-- An existing Chaos Studio Experiment [How to create your first Chaos Experiment](chaos-studio-quickstart-azure-portal.md)-- An existing Log Analytics Workspace [How to Create a Log Analytics Workspace](../azure-monitor/logs/quick-create-workspace.md)--## Step 1: Navigate to Diagnostic Settings tab in your Chaos Experiment -Navigate to the Chaos Experiment you want to emit telemetry to Azure Monitor and open it. Then navigate to the "Diagnostic settings" tab under the "Monitoring" section as shown in the below screenshot: --<br/> --[](images/step-1a.png#lightbox) --## Step 2: Connect your Chaos Experiment to your desired Log Analytics Workspace -Once you are in the "Diagnostic Settings" tab within your Chaos Experiment, select "Add Diagnostic Setting." -Enter the following details: -1. **Diagnostic Setting Name**: Any String you want, much like a Resource Group Name -2. **Category Groups**:Choose which category of logging you want to output to the Log Analytics workspace. -3. **Subscription**: The subscription which includes the Log Analytics Workspace you would like to use -4. **Log Analytics Workspace**: Where you'll select your desired Log Analytics Workspace -<br/> -All the other settings are optional -<br/> --<br/> --[](images/step-2a.png#lightbox) --## Step 3: Run the chaos experiment -Once you have completed Step 2, your experiment is now configured to emit telemetry to Azure Monitor upon the next Chaos Experiment execution! It typically takes time (20 minutes) for the logs to populate. Once populated you can view the log events from the logs tab. Events include experiment start, stop, and details about the faults executed. You can even turn the logs into chart visualizations or overlay your existing live site visualizations with chaos metadata. --<br/> --To query your logs, navigate to the "Logs" tab in your Chaos Experiment Resource to get your desired logging information in your desired format. --<br/> --[](images/step-3a.png#lightbox) |
| chaos-studio | Chaos Studio Target Selection | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-target-selection.md | - Title: Target selection in Azure Chaos Studio -description: Understand two different ways to select experiment targets and target scoping in Azure Chaos Studio. ----- Previously updated : 09/25/2023----# Target selection in Azure Chaos Studio --Every chaos experiment is made up of a different combination of faults and targets, building up to a unique outage scenario to test your system's resilience against. You can select a fixed set of targets for your chaos experiment, or provide a rule in which all matching fault-onboarded resources are included as targets in your experiment. Chaos Studio enables you to do both by providing both manual and query-based target selection. --## List-based manual target selection --List-based manual target selection allows you to select a fixed set of onboarded targets for a particular fault in your chaos experiment. Depending on the selected fault, you can select one or more onboarded resources to target. The aforementioned resources are added to the experiment upon creation time. In order to modify the list, you must navigate to the experiment's page and add or remove fault targets manually. An example of manual target selection is shown below. --[  ](images/manual-target-selection.png#lightbox) --## Query-based dynamic target selection --Query-based dynamic target selection allows you to input a KQL query that selects all onboarded targets that match the query result set. Using your query, you can filter targets based on common Azure resource parameters including type, region, name, and more. Upon experiment creation time, only the query itself is added to your chaos experiment. --The inputted query runs and adds onboarded targets to your experiment that match its result set upon experiment execution time. Thus, any resources onboarded to Chaos Studio after experiment creation time that match the query result set upon experiment execution time are targeted by your experiment. You can preview your query's result set when adding it to your experiment, but it may not match the result set at experiment execution time. An example of a possible dynamic target query is shown below. --[  ](images/dynamic-target-selection-preview.png#lightbox) --## Target scoping --Certain faults in Chaos Studio allow you to further target specific functionality within your Azure resources. If scope selection is available for a target and not configured, the resource will be targeted fully by the selected fault. An example of scope selection on a Virtual Machine Scale Sets instance being targeted by the **VMSS Shutdown (version 2.0)** fault is shown below. --[  ](images/tutorial-dynamic-targets-fault-zones.png#lightbox) --## Next steps -Now that you understand both ways to select targets within a chaos experiment, you're ready to: --- [Create and run your first experiment](chaos-studio-tutorial-service-direct-portal.md) |
| chaos-studio | Chaos Studio Targets Capabilities | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-targets-capabilities.md | - Title: Targets and capabilities in Azure Chaos Studio -description: Understand how to control resource onboarding in Azure Chaos Studio by using targets and capabilities. ----- Previously updated : 11/01/2021----# Targets and capabilities in Azure Chaos Studio --Before you can inject a fault against an Azure resource, the resource must first have corresponding targets and capabilities enabled. Targets and capabilities control which resources are enabled for fault injection and which faults can run against those resources. --By using targets and capabilities [along with other security measures](chaos-studio-permissions-security.md), you can avoid accidental or malicious fault injection with Azure Chaos Studio. For example, with targets and capabilities, you can allow the CPU pressure fault to run against your production virtual machines while preventing the kill process fault from running against them. --## Targets --A chaos *target* enables Chaos Studio to interact with a resource for a particular target type. A *target type* represents the method of injecting faults against a resource. Resource types that only support service-direct faults have one target type. An example is the `Microsoft-CosmosDB` type for Azure Cosmos DB. --Resource types that support service-direct and agent-based faults have two target types. One target type is for service-direct faults (for example, `Microsoft-VirtualMachine`). The other target type is for agent-based faults (always `Microsoft-Agent`). --A target is an extension resource created as a child of the resource that's being onboarded to Chaos Studio. Examples are a virtual machine or a network security group. A target defines the target type that's enabled on the resource. For example, if you're onboarding an Azure Cosmos DB instance with this resource ID: --``` -/subscriptions/fd9ccc83-faf6-4121-9aff-2a2d685ca2a2/resourceGroups/chaosstudiodemo/providers/Microsoft.DocumentDB/databaseAccounts/myDB -``` --The Azure Cosmos DB resource has a child resource formatted like this example: --``` -/subscriptions/fd9ccc83-faf6-4121-9aff-2a2d685ca2a2/resourceGroups/chaosstudiodemo/providers/Microsoft.DocumentDB/databaseAccounts/myDB/providers/Microsoft.Chaos/targets/Microsoft-CosmosDB -``` --Only resources with a target created off of them are targetable for fault injection with Chaos Studio. --## Capabilities --A *capability* enables Chaos Studio to run a particular fault against a resource, such as shutting down a virtual machine. Capabilities are unique per target type. They represent the fault that they enable, for example, `CPUPressure-1.0`. To understand all available faults and their corresponding capability names and target types, see the [Chaos Studio fault library](chaos-studio-fault-library.md). --A capability is an extension resource created as a child of a target. For example, if you're enabling the shutdown fault on a virtual machine with a service-direct target ID: --``` -/subscriptions/fd9ccc83-faf6-4121-9aff-2a2d685ca2a2/resourceGroups/myRG/providers/Microsoft.Compute/virtualMachines/myVM/providers/Microsoft.Chaos/targets/Microsoft-VirtualMachine -``` --The target resource has a child resource formatted like this example: --``` -/subscriptions/fd9ccc83-faf6-4121-9aff-2a2d685ca2a2/resourceGroups/myRG/providers/Microsoft.Compute/virtualMachines/myVM/providers/Microsoft.Chaos/targets/Microsoft-VirtualMachine/capabilities/shutdown-1.0 -``` --An experiment can only inject faults on onboarded targets with the corresponding capabilities enabled. --## List capability names and parameters -For reference, a list of capability names, fault URNs, and parameters is available [in our fault library](chaos-studio-fault-library.md). You can use the HTTP response to create a capability or do a GET on an existing capability to get this information on demand. For example, to do a GET on a VM shutdown capability: --```azurecli -az rest --method get --url "https://management.azure.com/subscriptions/fd9ccc83-faf6-4121-9aff-2a2d685ca2a2/resourceGroups/myRG/providers/Microsoft.Compute/virtualMachines/myVM/providers/Microsoft.Chaos/targets/Microsoft-VirtualMachine/capabilities/shutdown-1.0?api-version=2023-11-01" -``` --Returns the following JSON: --```JSON -{ - "id": "/subscriptions/fd9ccc83-faf6-4121-9aff-2a2d685ca2a2/myRG/providers/Microsoft.Compute/virtualMachines/myVM/providers/Microsoft.Chaos/targets/Microsoft-VirtualMachine/capabilities/shutdown-1.0", - "name": "shutdown-1.0", - "properties": { - "description": null, - "name": "shutdown-1.0", - "parametersSchema": "https://schema-tc.eastus.chaos-prod.azure.com/targetTypes/Microsoft-VirtualMachine/capabilityTypes/Shutdown-1.0/parametersSchema.json", - "publisher": "Microsoft", - "targetType": "VirtualMachine", - "type": "shutdown", - "urn": "urn:csci:microsoft:virtualMachine:shutdown/1.0", - "version": "1.0" - }, - "resourceGroup": "myRG", - "systemData": { - "createdAt": "2021-09-15T23:00:00.826575+00:00", - "lastModifiedAt": "2021-09-15T23:00:00.826575+00:00" - }, - "type": "Microsoft.Chaos/targets/capabilities" -} -``` --The `properties.urn` property is used to define the fault you want to run in a chaos experiment. To understand the schema for this fault's parameters, you can GET the schema referenced by `properties.parametersSchema`: --```azurecli -az rest --method get --url "https://schema-tc.eastus.chaos-prod.azure.com/targetTypes/Microsoft-VirtualMachine/capabilityTypes/Shutdown-1.0/parametersSchema.json" -``` --Returns the following JSON: -```JSON -{ - "$schema": "https://json-schema.org/draft-07/schema", - "properties": { - "abruptShutdown": { - "type": "boolean" - }, - "restartWhenComplete": { - "type": "boolean" - } - }, - "type": "object" -} -``` --## Next steps -Now that you understand what targets and capabilities are, you're ready to: -- [Learn about faults and actions](chaos-studio-faults-actions.md)-- [Learn about target selection and scoping](chaos-studio-target-selection.md)-- [Create and run your first experiment](chaos-studio-tutorial-service-direct-portal.md) |
| chaos-studio | Chaos Studio Tutorial Aad Outage Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-tutorial-aad-outage-portal.md | - Title: Use a chaos experiment template to induce an outage on a Microsoft Entra ID instance -description: Use the Azure portal to create an experiment from the Microsoft Entra ID outage experiment template. ----- Previously updated : 09/27/2023----# Use a chaos experiment template to induce an outage on a Microsoft Entra ID instance --You can use a chaos experiment to verify that your application is resilient to failures by causing those failures in a controlled environment. In this article, you induce an outage on a Microsoft Entra ID resource using a pre-populated experiment template and Azure Chaos Studio. --## Prerequisites --- An Azure subscription. [!INCLUDE [quickstarts-free-trial-note](~/reusable-content/ce-skilling/azure/includes/quickstarts-free-trial-note.md)]-- A network security group.--## Enable Chaos Studio on your network security group --Azure Chaos Studio can't inject faults against a resource until that resource is added to Chaos Studio. To add a resource to Chaos Studio, create a [target and capabilities](chaos-studio-targets-capabilities.md) on the resource. Network security groups have only one target type (service-direct) and one capability (set rules). Other resources might have up to two target types. One target type is for service-direct faults. Another target type is for agent-based faults. Other resources might have many other capabilities. --1. Open the [Azure portal](https://portal.azure.com). -1. Search for **Chaos Studio** in the search bar. -1. Select **Targets** and find your network security group resource. -1. Select the network security group resource and select **Enable targets** > **Enable service-direct targets**. -- [ ](images/tutorial-aad-outage-enable.png#lightbox) -1. Select **Review + Enable** > **Enable**. --You've now successfully added your network security group to Chaos Studio. --## Create an experiment from a template --Now you can create your experiment from a pre-filled experiment template. A chaos experiment defines the actions you want to take against target resources. The actions are organized and run in sequential steps. The chaos experiment also defines the actions you want to take against branches, which run in parallel. --1. In Chaos Studio, go to **Experiments** > **Create** > **New from template**. -- [](images/tutorial-aad-outage-create.png#lightbox) -1. Select **Microsoft Entra ID Outage**. -- [](images/tutorial-aad-outage-select.png#lightbox) -1. Add a name for your experiment that complies with resource naming guidelines. Select **Next: Permissions**. -- [](images/tutorial-aad-outage-basics.png#lightbox) -1. For your chaos experiment to run successfully, it must have [sufficient permissions on target resources](chaos-studio-permissions-security.md). Select a system-assigned managed identity or a user-assigned managed identity for your experiment. You can choose to enable custom role assignment if you would like Chaos Studio to add the necessary permissions to run (in the form of a custom role) to your experiment's identity. Select **Next: Experiment designer**. -- [](images/tutorial-aad-outage-permissions.png#lightbox) -1. Within the **NSG Security Rule (version 1.1)** fault, select **Edit**. -- [](images/tutorial-aad-outage-edit-fault.png#lightbox) -1. Review fault parameters and select **Next: Target resources**. -- [](images/tutorial-aad-outage-fault-params.png#lightbox) -1. Select the network security group resource that you want to use in the experiment. Select **Save**. -- [](images/tutorial-aad-outage-targets.png#lightbox) -1. Select **Review + create** > **Create** to save the experiment. --## Run your experiment -You're now ready to run your experiment. --1. In the **Experiments** view, select your experiment. Select **Start** > **OK**. -1. When **Status** changes to *Running*, select **Details** for the latest run under **History** to see details for the running experiment. --## Next steps -Now that you've run a Microsoft Entra ID outage template experiment, you're ready to: -- [Manage your experiment](chaos-studio-run-experiment.md)-- [Create an experiment that shut down all targets in a zone](chaos-studio-tutorial-dynamic-target-portal.md) |
| chaos-studio | Chaos Studio Tutorial Agent Based Cli | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-tutorial-agent-based-cli.md | - Title: Create an experiment using an agent-based fault with Azure CLI -description: Create an experiment that uses an agent-based fault and configure the chaos agent with the Azure CLI. -- Previously updated : 11/10/2021-------# Create a chaos experiment that uses an agent-based fault with the Azure CLI --You can use a chaos experiment to verify that your application is resilient to failures by causing those failures in a controlled environment. In this article, you cause a high % of CPU utilization event on a Linux virtual machine (VM) by using a chaos experiment and Azure Chaos Studio. Run this experiment to help you defend against an application from becoming resource starved. --You can use these same steps to set up and run an experiment for any agent-based fault. An *agent-based* fault requires setup and installation of the chaos agent. A service-direct fault runs directly against an Azure resource without any need for instrumentation. --## Prerequisites --- An Azure subscription. [!INCLUDE [quickstarts-free-trial-note](~/reusable-content/ce-skilling/azure/includes/quickstarts-free-trial-note.md)]-- A virtual machine running an operating system in the [version compatibility](chaos-studio-versions.md) list. If you don't have a VM, you can [create one](/azure/virtual-machines/linux/quick-create-portal).-- A network setup that permits you to [SSH into your VM](/azure/virtual-machines/ssh-keys-portal).-- A user-assigned managed identity. If you don't have a user-assigned managed identity, you can [create one](../active-directory/managed-identities-azure-resources/how-manage-user-assigned-managed-identities.md).--## Open Azure Cloud Shell --Azure Cloud Shell is a free interactive shell that you can use to run the steps in this article. It has common Azure tools preinstalled and configured to use with your account. --To open Cloud Shell, select **Try it** in the upper-right corner of a code block. You can also open Cloud Shell in a separate browser tab by going to [Bash](https://shell.azure.com/bash). Select **Copy** to copy the blocks of code, paste it into Cloud Shell, and select **Enter** to run it. --If you prefer to install and use the CLI locally, this tutorial requires Azure CLI version 2.0.30 or later. Run `az --version` to find the version. If you need to install or upgrade, see [Install Azure CLI]( /cli/azure/install-azure-cli). --> [!NOTE] -> These instructions use a Bash terminal in Cloud Shell. Some commands might not work as described if you run the CLI locally or in a PowerShell terminal. --## Assign managed identity to the virtual machine --Before you set up Chaos Studio on the VM, assign a user-assigned managed identity to each VM or virtual machine scale set where you plan to install the agent. Use the `az vm identity assign` or `az vmss identity assign` command. Replace `$VM_RESOURCE_ID`/`$VMSS_RESOURCE_ID` with the resource ID of the VM you're adding as a chaos target. Replace `$MANAGED_IDENTITY_RESOURCE_ID` with the resource ID of the user-assigned managed identity. --Virtual machine --```azurecli-interactive -az vm identity assign --ids $VM_RESOURCE_ID --identities $MANAGED_IDENTITY_RESOURCE_ID -``` --Virtual machine scale set --```azurecli-interactive -az vmss identity assign --ids $VMSS_RESOURCE_ID --identities $MANAGED_IDENTITY_RESOURCE_ID -``` --## Enable Chaos Studio on your virtual machine --Chaos Studio can't inject faults against a VM unless that VM was added to Chaos Studio first. To add a VM to Chaos Studio, create a [target and capabilities](chaos-studio-targets-capabilities.md) on the resource. Then you install the chaos agent. --Virtual machines have two target types. One target type enables service-direct faults (where no agent is required). The other target type enables agent-based faults (which requires the installation of an agent). The chaos agent is an application installed on your VM as a [VM extension](/azure/virtual-machines/extensions/overview). You use it to inject faults in the guest operating system. --### Enable the chaos target and capabilities --Next, set up a Microsoft-Agent target on each VM or virtual machine scale set that specifies the user-assigned managed identity that the agent uses to connect to Chaos Studio. In this example, we use one managed identity for all VMs. A target must be created via REST API. In this example, we use the `az rest` CLI command to execute the REST API calls. --1. Modify the following JSON by replacing `$USER_IDENTITY_CLIENT_ID` with the client ID of your managed identity. You can find the client ID in the Azure portal overview of the user-assigned managed identity you created. Replace `$USER_IDENTITY_TENANT_ID` with your Azure tenant ID. You can find it in the Azure portal under **Microsoft Entra ID** under **Tenant information**. Save the JSON as a file in the same location where you're running the Azure CLI. In Cloud Shell, you can drag and drop the JSON file to upload it. -- ```json - { - "properties": { - "identities": [ - { - "clientId": "$USER_IDENTITY_CLIENT_ID", - "tenantId": "$USER_IDENTITY_TENANT_ID", - "type": "AzureManagedIdentity" - } - ] - } - } - ``` --1. Create the target by replacing `$RESOURCE_ID` with the resource ID of the target VM or virtual machine scale set. Replace `target.json` with the name of the JSON file you created in the previous step. -- ```azurecli-interactive - az rest --method put --uri https://management.azure.com/$RESOURCE_ID/providers/Microsoft.Chaos/targets/Microsoft-Agent?api-version=2023-11-01 --body @target.json --query properties.agentProfileId -o tsv - ``` - - If you receive a PowerShell parsing error, switch to a Bash terminal as recommended for this tutorial or surround the referenced JSON file in single quotes (`--body '@target.json'`). --1. Copy down the GUID for the **agentProfileId** returned by this command for use in a later step. --1. Create the capabilities by replacing `$RESOURCE_ID` with the resource ID of the target VM or virtual machine scale set. Replace `$CAPABILITY` with the [name of the fault capability you're enabling](chaos-studio-fault-library.md) (for example, `CPUPressure-1.0`). - - ```azurecli-interactive - az rest --method put --url "https://management.azure.com/$RESOURCE_ID/providers/Microsoft.Chaos/targets/Microsoft-Agent/capabilities/$CAPABILITY?api-version=2023-11-01" --body "{\"properties\":{}}" - ``` -- For example, if you're enabling the CPU Pressure capability: -- ```azurecli-interactive - az rest --method put --url "https://management.azure.com/subscriptions/b65f2fec-d6b2-4edd-817e-9339d8c01dc4/resourceGroups/myRG/providers/Microsoft.Compute/virtualMachines/myVM/providers/Microsoft.Chaos/targets/Microsoft-Agent/capabilities/CPUPressure-1.0?api-version=2023-11-01" --body "{\"properties\":{}}" - ``` --### Install the Chaos Studio virtual machine extension --The chaos agent is an application that runs in your VM or virtual machine scale set instances to execute agent-based faults. During installation, you configure: --- The agent with the managed identity that the agent should use to authenticate to Chaos Studio.-- The profile ID of the Microsoft-Agent target that you created.-- Optionally, an Application Insights instrumentation key that enables the agent to send diagnostic events to Application Insights.--1. Before you begin, make sure you have the following details: - * **agentProfileId**: The property returned when you create the target. If you don't have this property, you can run `az rest --method get --uri https://management.azure.com/$RESOURCE_ID/providers/Microsoft.Chaos/targets/Microsoft-Agent?api-version=2023-11-01` and copy the `agentProfileId` property. - * **ClientId**: The client ID of the user-assigned managed identity used in the target. If you don't have this property, you can run `az rest --method get --uri https://management.azure.com/$RESOURCE_ID/providers/Microsoft.Chaos/targets/Microsoft-Agent?api-version=2023-11-01` and copy the `clientId` property. - * **(Optionally) AppInsightsKey**: The instrumentation key for your Application Insights component, which you can find on the Application Insights page in the portal under **Essentials**. --1. Install the Chaos Studio VM extension. Replace `$VM_RESOURCE_ID` with the resource ID of your VM or replace `$SUBSCRIPTION_ID`, `$RESOURCE_GROUP`, and `$VMSS_NAME` with those properties for your virtual machine scale set. Replace `$AGENT_PROFILE_ID` with the agent Profile ID. Replace `$USER_IDENTITY_CLIENT_ID` with the client ID of your managed identity. Replace `$APP_INSIGHTS_KEY` with your Application Insights instrumentation key. If you aren't using Application Insights, remove that key/value pair. -- #### Full list of default Agent virtual machine extension configuration -- Here is the **minimum agent vm extension configuration** required by the user: -- ```azcli-interactive - { - "profile": "$AGENT_PROFILE_ID", - "auth.msi.clientid": "$USER_IDENTITY_CLIENT_ID" - } - ``` -- Here is **all values for agent vm extension configuration** - - ```azcli-interactive - { - "profile": "$AGENT_PROFILE_ID", - "auth.msi.clientid": "$USER_IDENTITY_CLIENT_ID", - "appinsightskey": "$APP_INSIGHTS_KEY", - "overrides": { - "region": string, default to be null - "logLevel": { - "default" : string , default to be Information - }, - "checkCertRevocation": boolean, default to be false. - } - } - ``` --- #### Install the agent on a virtual machine -- Windows -- ```azurecli-interactive - az vm extension set --ids $VM_RESOURCE_ID --name ChaosWindowsAgent --publisher Microsoft.Azure.Chaos --version 1.1 --settings '{"profile": "$AGENT_PROFILE_ID", "auth.msi.clientid":"$USER_IDENTITY_CLIENT_ID", "appinsightskey":"$APP_INSIGHTS_KEY","Overrides":{"CheckCertRevocation":true}}' - ``` -- Linux -- ```azurecli-interactive - az vm extension set --ids $VM_RESOURCE_ID --name ChaosLinuxAgent --publisher Microsoft.Azure.Chaos --version 1.0 --settings '{"profile": "$AGENT_PROFILE_ID", "auth.msi.clientid":"$USER_IDENTITY_CLIENT_ID", "appinsightskey":"$APP_INSIGHTS_KEY","Overrides":{"CheckCertRevocation":true}}' - ``` -- #### Install the agent on a virtual machine scale set -- Windows -- ```azurecli-interactive - az vmss extension set --subscription $SUBSCRIPTION_ID --resource-group $RESOURCE_GROUP --vmss-name $VMSS_NAME --name ChaosWindowsAgent --publisher Microsoft.Azure.Chaos --version 1.1 --settings '{"profile": "$AGENT_PROFILE_ID", "auth.msi.clientid":"$USER_IDENTITY_CLIENT_ID", "appinsightskey":"$APP_INSIGHTS_KEY","Overrides":{"CheckCertRevocation":true}}' - ``` -- Linux -- ```azurecli-interactive - az vmss extension set --subscription $SUBSCRIPTION_ID --resource-group $RESOURCE_GROUP --vmss-name $VMSS_NAME --name ChaosLinuxAgent --publisher Microsoft.Azure.Chaos --version 1.0 --settings '{"profile": "$AGENT_PROFILE_ID", "auth.msi.clientid":"$USER_IDENTITY_CLIENT_ID", "appinsightskey":"$APP_INSIGHTS_KEY","Overrides":{"CheckCertRevocation":true}}' - ``` -1. If you're setting up a virtual machine scale set, verify that the instances were upgraded to the latest model. If needed, upgrade all instances in the model. -- ```azurecli-interactive - az vmss update-instances -g $RESOURCE_GROUP -n $VMSS_NAME --instance-ids * - ``` --## Create an experiment --After you've successfully deployed your VM, now you can create your experiment. A chaos experiment defines the actions you want to take against target resources. The actions are organized and run in sequential steps. The chaos experiment also defines the actions you want to take against branches, which run in parallel. --1. Formulate your experiment JSON starting with the following JSON sample. Modify the JSON to correspond to the experiment you want to run by using the [Create Experiment API](/rest/api/chaosstudio/experiments/create-or-update) and the [fault library](chaos-studio-fault-library.md). -- ```json - { - "identity": { - "type": "SystemAssigned" - }, - "location": "centralus", - "properties": { - "selectors": [ - { - "id": "Selector1", - "targets": [ - { - "id": "/subscriptions/b65f2fec-d6b2-4edd-817e-9339d8c01dc4/resourceGroups/myRG/providers/Microsoft.Compute/virtualMachines/myWindowsVM/providers/Microsoft.Chaos/targets/Microsoft-Agent", - "type": "ChaosTarget" - }, - { - "id": "/subscriptions/b65f2fec-d6b2-4edd-817e-9339d8c01dc4/resourceGroups/myRG/providers/Microsoft.Compute/virtualMachines/myLinuxVM/providers/Microsoft.Chaos/targets/Microsoft-Agent", - "type": "ChaosTarget" - } - ], - "type": "List" - } - ], - "steps": [ - { - "branches": [ - { - "actions": [ - { - "duration": "PT10M", - "name": "urn:csci:microsoft:agent:cpuPressure/1.0", - "parameters": [ - { - "key": "pressureLevel", - "value": "95" - } - ], - "selectorId": "Selector1", - "type": "continuous" - } - ], - "name": "Branch 1" - } - ], - "name": "Step 1" - } - ] - } - } - ``` -- If you're running against a virtual machine scale set, modify the fault parameters to include the instance numbers to target: -- ```json - "parameters": [ - { - "key": "pressureLevel", - "value": "95" - }, - { - "key": "virtualMachineScaleSetInstances", - "value": "[0,1,2]" - } - ] - ``` -- You can identify scale set instance numbers in the Azure portal by going to your virtual machine scale set and selecting **Instances**. The instance name ends in the instance number. - -1. Create the experiment by using the Azure CLI. Replace `$SUBSCRIPTION_ID`, `$RESOURCE_GROUP`, and `$EXPERIMENT_NAME` with the properties for your experiment. Make sure you've saved and uploaded your experiment JSON. Update `experiment.json` with your JSON filename. -- ```azurecli-interactive - az rest --method put --uri https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.Chaos/experiments/$EXPERIMENT_NAME?api-version=2023-11-01 --body @experiment.json - ``` -- Each experiment creates a corresponding system-assigned managed identity. Note the principal ID for this identity in the response for the next step. --## Give the experiment permission to your virtual machine -When you create a chaos experiment, Chaos Studio creates a system-assigned managed identity that executes faults against your target resources. This identity must be given [appropriate permissions](chaos-studio-fault-providers.md) to the target resource for the experiment to run successfully. The Reader role is required for agent-based faults. Other roles that don't have */Read permission, such as Virtual Machine Contributor, won't grant appropriate permission for agent-based faults. --Give the experiment access to your VM or virtual machine scale set by using the following command. Replace `$EXPERIMENT_PRINCIPAL_ID` with the principal ID from the previous step. Replace `$RESOURCE_ID` with the resource ID of the target VM or virtual machine scale set. Be sure to use the resource ID of the VM, not the resource ID of the chaos agent used in the experiment definition. Run this command for each VM or virtual machine scale set targeted in your experiment. --```azurecli-interactive -az role assignment create --role "Reader" --assignee-principal-type "ServicePrincipal" --assignee-object-id $EXPERIMENT_PRINCIPAL_ID --scope $RESOURCE_ID -``` --## Run your experiment -You're now ready to run your experiment. To see the effect, we recommend that you open [an Azure Monitor metrics chart](../azure-monitor/essentials/tutorial-metrics.md) with your VM's CPU pressure in a separate browser tab. --1. Start the experiment by using the Azure CLI. Replace `$SUBSCRIPTION_ID`, `$RESOURCE_GROUP`, and `$EXPERIMENT_NAME` with the properties for your experiment. -- ```azurecli-interactive - az rest --method post --uri https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.Chaos/experiments/$EXPERIMENT_NAME/start?api-version=2023-11-01 - ``` --1. The response includes a status URL that you can use to query experiment status as the experiment runs. --## Next steps -Now that you've run an agent-based experiment, you're ready to: -- [Create an experiment that uses service-direct faults](chaos-studio-tutorial-service-direct-portal.md)-- [Manage your experiment](chaos-studio-run-experiment.md) |
| chaos-studio | Chaos Studio Tutorial Agent Based Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-tutorial-agent-based-portal.md | - Title: Create an experiment using an agent-based fault with the portal -description: Create an experiment that uses an agent-based fault and configure the chaos agent with the portal. -- Previously updated : 11/01/2021-------# Create a chaos experiment that uses an agent-based fault with the Azure portal --You can use a chaos experiment to verify that your application is resilient to failures by causing those failures in a controlled environment. In this article, you cause a high % of CPU utilization event on a Linux virtual machine (VM) by using a chaos experiment and Azure Chaos Studio. Running this experiment can help you defend against an application from becoming resource starved. --You can use these same steps to set up and run an experiment for any agent-based fault. An *agent-based* fault requires setup and installation of the chaos agent. A service-direct fault runs directly against an Azure resource without any need for instrumentation. --## Prerequisites --- An Azure subscription. [!INCLUDE [quickstarts-free-trial-note](~/reusable-content/ce-skilling/azure/includes/quickstarts-free-trial-note.md)]-- A Linux VM running an operating system in the [version compatibility](chaos-studio-versions.md) list. If you don't have a VM, you can [create one](/azure/virtual-machines/linux/quick-create-portal).-- A network setup that permits you to [SSH into your VM](/azure/virtual-machines/ssh-keys-portal).-- A user-assigned managed identity *that was assigned to the target VM or virtual machine scale set*. If you don't have a user-assigned managed identity, you can [create one](../active-directory/managed-identities-azure-resources/how-manage-user-assigned-managed-identities.md).--## Enable Chaos Studio on your virtual machine --Chaos Studio can't inject faults against a VM unless that VM was added to Chaos Studio first. To add a VM to Chaos Studio, create a [target and capabilities](chaos-studio-targets-capabilities.md) on the resource. Then you install the chaos agent. --Virtual machines have two target types. One target type enables service-direct faults (where no agent is required). Another target type enables agent-based faults (which requires the installation of an agent). The chaos agent is an application installed on your VM as a [VM extension](/azure/virtual-machines/extensions/overview). You use it to inject faults in the guest operating system. --### Enable the chaos target, capabilities, and agent --> [!IMPORTANT] -> Prior to finishing the next steps, you must [create a user-assigned managed identity](../active-directory/managed-identities-azure-resources/how-manage-user-assigned-managed-identities.md). Then you assign it to the target VM or virtual machine scale set. --1. Open the [Azure portal](https://portal.azure.com). -1. Search for **Chaos Studio** in the search bar. -1. Select **Targets** and move to your VM. --  -1. Select the checkbox next to your VM and select **Enable targets**. Then select **Enable agent-based targets** from the dropdown menu. --  -1. Select the **Managed Identity** to use to authenticate the chaos agent and optionally enable Application Insights to see experiment events and agent logs. --  -1. Select **Review + Enable** > **Enable**. --  -1. After a few minutes, a notification appears that indicates that the resources selected were successfully enabled. The Azure portal adds the user-assigned identity to the VM. The portal enables the agent target and capabilities and installs the chaos agent as a VM extension. --  -1. If you're enabling a virtual machine scale set, upgrade instances to the latest model by going to the virtual machine scale set resource pane. Select **Instances**, and then select all instances. Select **Upgrade** if you're not on the latest model. --You've now successfully added your Linux VM to Chaos Studio. In the **Targets** view, you can also manage the capabilities enabled on this resource. Select the **Manage actions** link next to a resource to display the capabilities enabled for that resource. --## Create an experiment -Now you can create your experiment. A chaos experiment defines the actions you want to take against target resources. The actions are organized and run in sequential steps. The chaos experiment also defines the actions you want to take against branches, which run in parallel. --1. Select the **Experiments** tab in Chaos Studio. In this view, you can see and manage all your chaos experiments. Select **Create** > **New experiment**. --  -1. Fill in the **Subscription**, **Resource Group**, and **Location** where you want to deploy the chaos experiment. Give your experiment a name. Select **Next: Experiment designer**. --  -1. You're now in the Chaos Studio experiment designer. You can build your experiment by adding steps, branches, and faults. Give a friendly name to your **Step** and **Branch**. Then select **Add action > Add fault**. --  -1. Select **CPU Pressure** from the dropdown list. Fill in **Duration** with the number of minutes to apply pressure. Fill in **pressureLevel** with the % of CPU utilization pressure that you want to apply. Leave **virtualMachineScaleSetInstances** blank. Select **Next: Target resources**. --  -1. Select your VM and select **Next**. --  -1. Verify that your experiment looks correct. Then select **Review + create** > **Create**. --  --## Give the experiment permission to your virtual machine -When you create a chaos experiment, Chaos Studio creates a system-assigned managed identity that executes faults against your target resources. This identity must be given [appropriate permissions](chaos-studio-fault-providers.md) to the target resource for the experiment to run successfully. --1. Go to your VM and select **Access control (IAM)**. --  -1. Select **Add** > **Add role assignment**. --  -1. Search for **Reader** and select the role. Select **Next**. --  -1. Choose **Select members** and search for your experiment name. Select your experiment and choose **Select**. If there are multiple experiments in the same tenant with the same name, your experiment name is truncated with random characters added. --  -1. Select **Review + assign** > **Review + assign**. --## Run your experiment -You're now ready to run your experiment. To see the impact, we recommend that you open an [Azure Monitor metrics chart](../azure-monitor/essentials/tutorial-metrics.md) with your VM's CPU pressure in a separate browser tab. --1. In the **Experiments** view, select your experiment. Select **Start** > **OK**. --  -1. After the **Status** changes to *Running*, under **History**, select **Details** for the latest run to see details for the running experiment. --## Next steps -Now that you've run an agent-based experiment, you're ready to: -- [Create an experiment that uses service-direct faults](chaos-studio-tutorial-service-direct-portal.md)-- [Manage your experiment](chaos-studio-run-experiment.md) |
| chaos-studio | Chaos Studio Tutorial Aks Cli | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-tutorial-aks-cli.md | - Title: Create a chaos experiment using a Chaos Mesh fault with Azure CLI -description: Create an experiment that uses an AKS Chaos Mesh fault by using Azure Chaos Studio with the Azure CLI. -- Previously updated : 04/25/2024-------# Create a chaos experiment that uses a Chaos Mesh fault with the Azure CLI --You can use a chaos experiment to verify that your application is resilient to failures by causing those failures in a controlled environment. In this article, you cause periodic Azure Kubernetes Service (AKS) pod failures on a namespace by using a chaos experiment and Azure Chaos Studio. Running this experiment can help you defend against service unavailability when there are sporadic failures. --Chaos Studio uses [Chaos Mesh](https://chaos-mesh.org/), a free, open-source chaos engineering platform for Kubernetes, to inject faults into an AKS cluster. Chaos Mesh faults are [service-direct](chaos-studio-tutorial-aks-portal.md) faults that require Chaos Mesh to be installed on the AKS cluster. You can use these same steps to set up and run an experiment for any AKS Chaos Mesh fault. --## Prerequisites --- An Azure subscription. [!INCLUDE [quickstarts-free-trial-note](~/reusable-content/ce-skilling/azure/includes/quickstarts-free-trial-note.md)]-- An AKS cluster with Linux node pools. If you don't have an AKS cluster, see the AKS quickstart that uses the [Azure CLI](/azure/aks/learn/quick-kubernetes-deploy-cli), [Azure PowerShell](/azure/aks/learn/quick-kubernetes-deploy-powershell), or the [Azure portal](/azure/aks/learn/quick-kubernetes-deploy-portal).--## Limitations --* You can use Chaos Mesh faults with private clusters by configuring [VNet Injection in Chaos Studio](chaos-studio-private-networking.md). Any commands issued to the private cluster, including the steps in this article to set up Chaos Mesh, need to follow the [private cluster guidance](/azure/aks/private-clusters). Recommended methods include connecting from a VM in the same virtual network or using the [AKS command invoke](/azure/aks/access-private-cluster) feature. -* AKS Chaos Mesh faults are only supported on Linux node pools. -* Currently, Chaos Mesh faults don't work if the AKS cluster has [local accounts disabled](/azure/aks/manage-local-accounts-managed-azure-ad). -* If your AKS cluster is configured to only allow authorized IP ranges, you need to allow Chaos Studio's IP ranges. You can find them by querying the `ChaosStudio` [service tag with the Service Tag Discovery API or downloadable JSON files](../virtual-network/service-tags-overview.md). --## Open Azure Cloud Shell --Azure Cloud Shell is a free interactive shell that you can use to run the steps in this article. It has common Azure tools preinstalled and configured to use with your account. --To open Cloud Shell, select **Try it** in the upper-right corner of a code block. You can also open Cloud Shell in a separate browser tab by going to [Bash](https://shell.azure.com/bash). Select **Copy** to copy the blocks of code, paste it into Cloud Shell, and select **Enter** to run it. --If you prefer to install and use the CLI locally, this tutorial requires Azure CLI version 2.0.30 or later. Run `az --version` to find the version. If you need to install or upgrade, see [Install Azure CLI](/cli/azure/install-azure-cli). --> [!NOTE] -> These instructions use a Bash terminal in Cloud Shell. Some commands might not work as described if you run the CLI locally or in a PowerShell terminal. --## Set up Chaos Mesh on your AKS cluster --Before you can run Chaos Mesh faults in Chaos Studio, you must install Chaos Mesh on your AKS cluster. --1. Run the following commands in a [Cloud Shell](../cloud-shell/overview.md) window where you have the active subscription set to be the subscription where your AKS cluster is deployed. Replace `$RESOURCE_GROUP` and `$CLUSTER_NAME` with the resource group and name of your cluster resource. -- ```azurecli-interactive - az aks get-credentials -g $RESOURCE_GROUP -n $CLUSTER_NAME - helm repo add chaos-mesh https://charts.chaos-mesh.org - helm repo update - kubectl create ns chaos-testing - helm install chaos-mesh chaos-mesh/chaos-mesh --namespace=chaos-testing --set chaosDaemon.runtime=containerd --set chaosDaemon.socketPath=/run/containerd/containerd.sock - ``` --1. Verify that the Chaos Mesh pods are installed by running the following command: -- ```azurecli-interactive - kubectl get po -n chaos-testing - ``` --You should see output similar to the following example (a chaos-controller-manager and one or more chaos-daemons): --```bash -NAME READY STATUS RESTARTS AGE -chaos-controller-manager-69fd5c46c8-xlqpc 1/1 Running 0 2d5h -chaos-daemon-jb8xh 1/1 Running 0 2d5h -chaos-dashboard-98c4c5f97-tx5ds 1/1 Running 0 2d5h -``` --You can also [use the installation instructions on the Chaos Mesh website](https://chaos-mesh.org/docs/production-installation-using-helm/). --## Enable Chaos Studio on your AKS cluster --Chaos Studio can't inject faults against a resource unless that resource is added to Chaos Studio first. To add a resource to Chaos Studio, create a [target and capabilities](chaos-studio-targets-capabilities.md) on the resource. AKS clusters have only one target type (service-direct), but other resources might have up to two target types. One target type is for service-direct faults. Another target type is for agent-based faults. Each type of Chaos Mesh fault is represented as a capability like PodChaos, NetworkChaos, and IOChaos. --1. Create a target by replacing `$SUBSCRIPTION_ID`, `$resourceGroupName`, and `$AKS_CLUSTER_NAME` with the relevant strings of the AKS cluster you're adding. -- ```azurecli-interactive - az rest --method put --url "https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$resourceGroupName/providers/Microsoft.ContainerService/managedClusters/$AKS_CLUSTER_NAME/providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh?api-version=2024-01-01" --body "{\"properties\":{}}" - ``` --2. Create the capabilities on the target by replacing `$SUBSCRIPTION_ID`, `$resourceGroupName`, and `$AKS_CLUSTER_NAME` with the relevant strings of the AKS cluster you're adding. --Replace `$CAPABILITY` with the ["Capability Name" of the fault you're adding](chaos-studio-fault-library.md). - -```azurecli-interactive -az rest --method put --url "https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$resourceGroupName/providers/Microsoft.ContainerService/managedClusters/$AKS_CLUSTER_NAME/providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh/capabilities/$CAPABILITY?api-version=2024-01-01" --body "{\"properties\":{}}" -``` --**Here's an example of enabling the `PodChaos` capability for your reference:** --```azurecli-interactive -az rest --method put --url "https://management.azure.com/subscriptions/b65f2fec-d6b2-4edd-817e-9339d8c01dc4/resourceGroups/myRG/providers/Microsoft.ContainerService/managedClusters/myCluster/providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh/capabilities/PodChaos-2.1?api-version=2024-01-01" --body "{\"properties\":{}}" -``` --This step must be done for **each*** capability you want to enable on the cluster. --You've now successfully added your AKS cluster to Chaos Studio. --## Create an experiment -Now you can create your experiment. A chaos experiment defines the actions you want to take against target resources. The actions are organized and run in sequential steps. The chaos experiment also defines the actions you want to take against branches, which run in parallel. --1. Create a Chaos Mesh `jsonSpec`: - 1. See the Chaos Mesh documentation for a fault type, [for example, the PodChaos type](https://chaos-mesh.org/docs/simulate-pod-chaos-on-kubernetes/#create-experiments-using-yaml-configuration-files). - 1. Formulate the YAML configuration for that fault type by using the Chaos Mesh documentation. -- ```yaml - apiVersion: chaos-mesh.org/v1alpha1 - kind: PodChaos - metadata: - name: pod-failure-example - namespace: chaos-testing - spec: - action: pod-failure - mode: all - duration: '600s' - selector: - namespaces: - - default - ``` - 1. Remove any YAML outside of the `spec`, including the spec property name. Remove the indentation of the spec details. The `duration` parameter isn't necessary, but is used if provided. In this case, remove it. -- ```yaml - action: pod-failure - mode: all - selector: - namespaces: - - default - ``` - 1. Use a [YAML-to-JSON converter like this one](https://www.convertjson.com/yaml-to-json.htm) to convert the Chaos Mesh YAML to JSON and minimize it. -- ```json - {"action":"pod-failure","mode":"all","selector":{"namespaces":["default"]}} - ``` - 1. Use a [JSON string escape tool like this one](https://www.freeformatter.com/json-escape.html) to escape the JSON spec, or change the double-quotes to single-quotes. - - ```json - {\"action\":\"pod-failure\",\"mode\":\"all\",\"selector\":{\"namespaces\":[\"default\"]}} - ``` -- ```json - {'action':'pod-failure','mode':'all','selector':{'namespaces':['default']}} - ``` --1. Create your experiment JSON by starting with the following JSON sample. Modify the JSON to correspond to the experiment you want to run by using the [Create Experiment API](/rest/api/chaosstudio/experiments/create-or-update), the [fault library](chaos-studio-fault-library.md), and the `jsonSpec` created in the previous step. -- ```json - { - "location": "centralus", - "identity": { - "type": "SystemAssigned" - }, - "properties": { - "steps": [ - { - "name": "AKS pod kill", - "branches": [ - { - "name": "AKS pod kill", - "actions": [ - { - "type": "continuous", - "selectorId": "Selector1", - "duration": "PT10M", - "parameters": [ - { - "key": "jsonSpec", - "value": "{\"action\":\"pod-failure\",\"mode\":\"all\",\"selector\":{\"namespaces\":[\"default\"]}}" - } - ], - "name": "urn:csci:microsoft:azureKubernetesServiceChaosMesh:podChaos/2.1" - } - ] - } - ] - } - ], - "selectors": [ - { - "id": "Selector1", - "type": "List", - "targets": [ - { - "type": "ChaosTarget", - "id": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/myRG/providers/Microsoft.ContainerService/managedClusters/myCluster/providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh" - } - ] - } - ] - } - } - ``` - -1. Create the experiment by using the Azure CLI. Replace `$SUBSCRIPTION_ID`, `$RESOURCE_GROUP`, and `$EXPERIMENT_NAME` with the properties for your experiment. Make sure you've saved and uploaded your experiment JSON. Update `experiment.json` with your JSON filename. -- ```azurecli-interactive - az rest --method put --uri https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.Chaos/experiments/$EXPERIMENT_NAME?api-version=2023-11-01 --body @experiment.json - ``` -- Each experiment creates a corresponding system-assigned managed identity. Note the principal ID for this identity in the response for the next step. --## Give the experiment permission to your AKS cluster -When you create a chaos experiment, Chaos Studio creates a system-assigned managed identity that executes faults against your target resources. This identity must be given [appropriate permissions](chaos-studio-fault-providers.md) to the target resource for the experiment to run successfully. --1. Retrieve the `$EXPERIMENT_PRINCIPAL_ID` by running the following command and copying the `PrincipalID` from the response. Replace `$SUBSCRIPTION_ID`, `$RESOURCE_GROUP`, and `$EXPERIMENT_NAME` with the properties for your experiment. --```azurecli-interactive -az rest --method get --uri https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.Chaos/experiments/$EXPERIMENT_NAME?api-version=2024-01-01 -``` --2. Give the experiment access to your resources by using the following command. Replace `$EXPERIMENT_PRINCIPAL_ID` with the principal ID from the previous step. Replace `$SUBSCRIPTION_ID`, `$resourceGroupName`, and `$AKS_CLUSTER_NAME` with the relevant strings of the AKS cluster. ---```azurecli-interactive -az role assignment create --role "Azure Kubernetes Service Cluster Admin Role" --assignee-principal-type "ServicePrincipal" --assignee-object-id $EXPERIMENT_PRINCIPAL_ID --scope subscriptions/$SUBSCRIPTION_ID/resourceGroups/$resourceGroupName/providers/Microsoft.ContainerService/managedClusters/$AKS_CLUSTER_NAME -``` --## Run your experiment -You're now ready to run your experiment. To see the effect, we recommend that you open your AKS cluster overview and go to **Insights** in a separate browser tab. Live data for the **Active Pod Count** shows the effect of running your experiment. --1. Start the experiment by using the Azure CLI. Replace `$SUBSCRIPTION_ID`, `$RESOURCE_GROUP`, and `$EXPERIMENT_NAME` with the properties for your experiment. -- ```azurecli-interactive - az rest --method post --uri https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.Chaos/experiments/$EXPERIMENT_NAME/start?api-version=2024-01-01 - ``` --1. The response includes a status URL that you can use to query experiment status as the experiment runs. --## Next steps -Now that you've run an AKS Chaos Mesh service-direct experiment, you're ready to: -- [Create an experiment that uses agent-based faults](chaos-studio-tutorial-agent-based-portal.md)-- [Manage your experiment](chaos-studio-run-experiment.md) |
| chaos-studio | Chaos Studio Tutorial Aks Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-tutorial-aks-portal.md | - Title: Create an experiment using a Chaos Mesh fault with the Azure portal -description: Create an experiment that uses an AKS Chaos Mesh fault by using Azure Chaos Studio with the Azure portal. -- Previously updated : 04/21/2022-------# Create a chaos experiment that uses a Chaos Mesh fault to kill AKS pods with the Azure portal --You can use a chaos experiment to verify that your application is resilient to failures by causing those failures in a controlled environment. In this article, you cause periodic Azure Kubernetes Service (AKS) pod failures on a namespace by using a chaos experiment and Azure Chaos Studio. Running this experiment can help you defend against service unavailability when there are sporadic failures. --Chaos Studio uses [Chaos Mesh](https://chaos-mesh.org/), a free, open-source chaos engineering platform for Kubernetes, to inject faults into an AKS cluster. Chaos Mesh faults are [service-direct](chaos-studio-tutorial-aks-portal.md) faults that require Chaos Mesh to be installed on the AKS cluster. You can use these same steps to set up and run an experiment for any AKS Chaos Mesh fault. --## Prerequisites --- An Azure subscription. [!INCLUDE [quickstarts-free-trial-note](~/reusable-content/ce-skilling/azure/includes/quickstarts-free-trial-note.md)]-- An AKS cluster with a Linux node pool. If you don't have an AKS cluster, see the AKS quickstart that uses the [Azure CLI](/azure/aks/learn/quick-kubernetes-deploy-cli), [Azure PowerShell](/azure/aks/learn/quick-kubernetes-deploy-powershell), or the [Azure portal](/azure/aks/learn/quick-kubernetes-deploy-portal).--## Limitations --* You can use Chaos Mesh faults with private clusters by configuring [VNet Injection in Chaos Studio](chaos-studio-private-networking.md). Any commands issued to the private cluster, including the steps in this article to set up Chaos Mesh, need to follow the [private cluster guidance](/azure/aks/private-clusters). Recommended methods include connecting from a VM in the same virtual network or using the [AKS command invoke](/azure/aks/access-private-cluster) feature. -* AKS Chaos Mesh faults are only supported on Linux node pools. -* Currently, Chaos Mesh faults don't work if the AKS cluster has [local accounts disabled](/azure/aks/manage-local-accounts-managed-azure-ad). -* If your AKS cluster is configured to only allow authorized IP ranges, you need to allow Chaos Studio's IP ranges. You can find them by querying the `ChaosStudio` [service tag with the Service Tag Discovery API or downloadable JSON files](../virtual-network/service-tags-overview.md). --## Set up Chaos Mesh on your AKS cluster --Before you can run Chaos Mesh faults in Chaos Studio, you must install Chaos Mesh on your AKS cluster. --1. Run the following commands in an [Azure Cloud Shell](../cloud-shell/overview.md) window where you have the active subscription set to be the subscription where your AKS cluster is deployed. Replace `MyManagedCluster` and `MyResourceGroup` with the name of your cluster and resource group. -- ```azurecli - az aks get-credentials --admin --name MyManagedCluster --resource-group MyResourceGroup - ``` - - ```bash - helm repo add chaos-mesh https://charts.chaos-mesh.org - helm repo update - kubectl create ns chaos-testing - helm install chaos-mesh chaos-mesh/chaos-mesh --namespace=chaos-testing --set chaosDaemon.runtime=containerd --set chaosDaemon.socketPath=/run/containerd/containerd.sock - ``` --1. Verify that the Chaos Mesh pods are installed by running the following command: -- ```bash - kubectl get po -n chaos-testing - ``` -- You should see output similar to the following example (a chaos-controller-manager and one or more chaos-daemons): - - ```bash - NAME READY STATUS RESTARTS AGE - chaos-controller-manager-69fd5c46c8-xlqpc 1/1 Running 0 2d5h - chaos-daemon-jb8xh 1/1 Running 0 2d5h - chaos-dashboard-98c4c5f97-tx5ds 1/1 Running 0 2d5h - ``` --You can also [use the installation instructions on the Chaos Mesh website](https://chaos-mesh.org/docs/production-installation-using-helm/). --## Enable Chaos Studio on your AKS cluster --Chaos Studio can't inject faults against a resource unless that resource is added to Chaos Studio first. You add a resource to Chaos Studio by creating a [target and capabilities](chaos-studio-targets-capabilities.md) on the resource. AKS clusters have only one target type (service-direct), but other resources might have up to two target types. One target type is for service-direct faults. Another target type is for agent-based faults. Each type of Chaos Mesh fault is represented as a capability like PodChaos, NetworkChaos, and IOChaos. --1. Open the [Azure portal](https://portal.azure.com). -1. Search for **Chaos Studio** in the search bar. -1. Select **Targets** and go to your AKS cluster. --  -1. Select the checkbox next to your AKS cluster. Select **Enable targets** and then select **Enable service-direct targets** from the dropdown menu. --  --1. Confirm that the desired resource is listed. Select **Review + Enable**, then **Enable**. --1. A notification appears that indicates that the resources you selected were successfully enabled. --  --You've now successfully added your AKS cluster to Chaos Studio. In the **Targets** view, you can also manage the capabilities enabled on this resource. Select the **Manage actions** link next to a resource to display the capabilities enabled for that resource. --## Create an experiment -Now you can create your experiment. A chaos experiment defines the actions you want to take against target resources. The actions are organized and run in sequential steps. The chaos experiment also defines the actions you want to take against branches, which run in parallel. --1. Select the **Experiments** tab in Chaos Studio. In this view, you can see and manage all your chaos experiments. Select **Create** > **New experiment**. --  -1. Fill in the **Subscription**, **Resource Group**, and **Location** where you want to deploy the chaos experiment. Give your experiment a name. Select **Next: Experiment designer**. --  -1. You're now in the Chaos Studio experiment designer. The experiment designer allows you to build your experiment by adding steps, branches, and faults. Give a friendly name to your **Step** and **Branch** and select **Add action > Add fault**. --  -1. Select **AKS Chaos Mesh Pod Chaos** from the dropdown list. Fill in **Duration** with the number of minutes you want the failure to last and **jsonSpec** with the following information: -- To formulate your Chaos Mesh `jsonSpec`: - 1. See the Chaos Mesh documentation for a fault type, [for example, the PodChaos type](https://chaos-mesh.org/docs/simulate-pod-chaos-on-kubernetes/#create-experiments-using-yaml-configuration-files). - 1. Formulate the YAML configuration for that fault type by using the Chaos Mesh documentation. -- ```yaml - apiVersion: chaos-mesh.org/v1alpha1 - kind: PodChaos - metadata: - name: pod-failure-example - namespace: chaos-testing - spec: - action: pod-failure - mode: all - duration: '600s' - selector: - namespaces: - - default - ``` - 1. Remove any YAML outside of the `spec` (including the spec property name) and remove the indentation of the spec details. The `duration` parameter isn't necessary, but is used if provided. In this case, remove it. -- ```yaml - action: pod-failure - mode: all - selector: - namespaces: - - default - ``` - 1. Use a [YAML-to-JSON converter like this one](https://www.convertjson.com/yaml-to-json.htm) to convert the Chaos Mesh YAML to JSON and minimize it. -- ```json - {"action":"pod-failure","mode":"all","selector":{"namespaces":["default"]}} - ``` - 1. Paste the minimized JSON into the **jsonSpec** field in the portal. --1. Select **Next: Target resources**. --  -1. Select your AKS cluster and select **Next**. --  -1. Verify that your experiment looks correct and select **Review + create** > **Create**. --  --## Give the experiment permission to your AKS cluster -When you create a chaos experiment, Chaos Studio creates a system-assigned managed identity that executes faults against your target resources. This identity must be given [appropriate permissions](chaos-studio-fault-providers.md) to the target resource for the experiment to run successfully. --1. Go to your AKS cluster and select **Access control (IAM)**. --  -1. Select **Add** > **Add role assignment**. --  -1. Search for **Azure Kubernetes Service Cluster Admin Role** and select the role. Select **Next**. --  -1. Choose **Select members** and search for your experiment name. Select your experiment and choose **Select**. If there are multiple experiments in the same tenant with the same name, your experiment name is truncated with random characters added. --  -1. Select **Review + assign** > **Review + assign**. --## Run your experiment -You're now ready to run your experiment. To see the effect, we recommend that you open your AKS cluster overview and go to **Insights** in a separate browser tab. Live data for the **Active Pod Count** shows the effect of running your experiment. --1. In the **Experiments** view, select your experiment. Select **Start** > **OK**. --  -1. When the **Status** changes to *Running*, select **Details** for the latest run under **History** to see details for the running experiment. --## Next steps -Now that you've run an AKS Chaos Mesh service-direct experiment, you're ready to: -- [Create an experiment that uses agent-based faults](chaos-studio-tutorial-agent-based-portal.md)-- [Manage your experiment](chaos-studio-run-experiment.md) |
| chaos-studio | Chaos Studio Tutorial Availability Zone Down Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-tutorial-availability-zone-down-portal.md | - Title: Use an Azure Chaos Studio experiment template to take down Virtual Machine Scale Set availability zones with autoscale disabled -description: Use the Azure portal to create an experiment from the Availability Zone Down experiment template. ----- Previously updated : 09/27/2023----# Use a chaos experiment template to take down Virtual Machine Scale Set availability zones with autoscale disabled --You can use a chaos experiment to verify that your application is resilient to failures by causing those failures in a controlled environment. In this article, you take down an availability zone (with autoscale disabled) of a Virtual Machine Scale Sets instance using a pre-populated experiment template and Azure Chaos Studio. --## Prerequisites --- An Azure subscription. [!INCLUDE [quickstarts-free-trial-note](~/reusable-content/ce-skilling/azure/includes/quickstarts-free-trial-note.md)]-- A Virtual Machine Scale Sets instance.-- An Autoscale Settings instance.--## Enable Chaos Studio on your Virtual Machine Scale Sets and Autoscale Settings instances --Azure Chaos Studio can't inject faults against a resource until that resource is added to Chaos Studio. To add a resource to Chaos Studio, create a [target and capabilities](chaos-studio-targets-capabilities.md) on the resource. Virtual Machine Scale Sets has only one target type (`Microsoft-VirtualMachineScaleSet`) and one capability (`shutdown`). Autoscale Settings has only one target type (`Microsoft-AutoScaleSettings`) and one capability (`disableAutoscale`). Other resources might have up to two target types. One target type is for service-direct faults. Another target type is for agent-based faults. Other resources might have many other capabilities. --1. Open the [Azure portal](https://portal.azure.com). -1. Search for **Chaos Studio** in the search bar. -1. Select **Targets** and find your autoscale setting resource. -1. Select the autoscale setting resource and select **Enable targets** > **Enable service-direct targets**. -- [ ](images/chaos-studio-tutorial-availability-zone-down-portal/target-enable-one.png#lightbox) -1. Select **Review + Enable** > **Enable**. -1. Find your virtual machine scale set resource. -1. Select the virtual machine scale set resource and select **Enable targets** > **Enable service-direct targets**. -- [ ](images/chaos-studio-tutorial-availability-zone-down-portal/target-enable-two.png#lightbox) -1. Select **Review + Enable** > **Enable**. --You've now successfully added your autoscale setting and virtual machine scale set to Chaos Studio. --## Create an experiment from a template --Now you can create your experiment from a pre-filled experiment template. A chaos experiment defines the actions you want to take against target resources. The actions are organized and run in sequential steps. The chaos experiment also defines the actions you want to take against branches, which run in parallel. --1. In Chaos Studio, go to **Experiments** > **Create** > **New from template**. -- [](images/chaos-studio-tutorial-availability-zone-down-portal/create-from.png#lightbox) -1. Select **Availability Zone Down**. -- [](images/chaos-studio-tutorial-availability-zone-down-portal/template-selection.png#lightbox) -1. Add a name for your experiment that complies with resource naming guidelines. Select **Next: Permissions**. -- [](images/chaos-studio-tutorial-availability-zone-down-portal/basics.png#lightbox) -1. For your chaos experiment to run successfully, it must have [sufficient permissions on target resources](chaos-studio-permissions-security.md). Select a system-assigned managed identity or a user-assigned managed identity for your experiment. You can choose to enable custom role assignment if you would like Chaos Studio to add the necessary permissions to run (in the form of a custom role) to your experiment's identity. Select **Next: Experiment designer**. -- [](images/chaos-studio-tutorial-availability-zone-down-portal/permissions-page.png#lightbox) -1. Within the **Disable Autoscale** fault, select **Edit**. -- [](images/chaos-studio-tutorial-availability-zone-down-portal/fault-one-edit.png#lightbox) -1. Review fault parameters and select **Next: Target resources**. -- [](images/chaos-studio-tutorial-availability-zone-down-portal/fault-one-details.png#lightbox) -1. Select the autoscale setting resource that you want to use in the experiment. Select **Save**. -- [](images/chaos-studio-tutorial-availability-zone-down-portal/fault-one-target.png#lightbox) -1. Within the **VMSS Shutdown (version 2.0)** fault, select **Edit**. -- [](images/chaos-studio-tutorial-availability-zone-down-portal/fault-two-edit.png#lightbox) -1. Review fault parameters and select **Next: Target resources**. -- [](images/chaos-studio-tutorial-availability-zone-down-portal/fault-two-details.png#lightbox) -1. Select the virtual machine scale set resource that you want to use in the experiment. Select **Next: Scope**. -- [](images/chaos-studio-tutorial-availability-zone-down-portal/fault-two-target.png#lightbox) -1. Select the zone(s) within your virtual machine scale set you would like to take down. Select **Save**. -- [](images/chaos-studio-tutorial-availability-zone-down-portal/scope.png#lightbox) -1. Select **Review + create** > **Create** to save the experiment. --## Run your experiment -You're now ready to run your experiment. --1. In the **Experiments** view, select your experiment. Select **Start** > **OK**. -1. When **Status** changes to *Running*, select **Details** for the latest run under **History** to see details for the running experiment. --## Next steps -Now that you've run an Availability Zone Down template experiment, you're ready to: -- [Manage your experiment](chaos-studio-run-experiment.md)-- [Create an experiment that induces an outage on an Azure Active Directory instance](chaos-studio-tutorial-aad-outage-portal.md) |
| chaos-studio | Chaos Studio Tutorial Dynamic Target Cli | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-tutorial-dynamic-target-cli.md | - Title: Create a chaos experiment that uses dynamic targeting to select hosts -description: Create an experiment that uses dynamic targeting with the Azure CLI. ----- Previously updated : 12/12/2022----# Create a chaos experiment that uses dynamic targeting to select hosts --You can use dynamic targeting in a chaos experiment to choose a set of targets to run an experiment against. In this article, we show you how to dynamically target virtual machine scale sets to shut down based on availability zone. Running this experiment can help you test failover to an Azure Virtual Machine Scale Sets instance in a different region if there's an outage. --You can use these same steps to set up and run an experiment for any fault that supports dynamic targeting. Currently, only virtual machine scale set shutdown supports dynamic targeting. --## Prerequisites --- An Azure subscription. [!INCLUDE [quickstarts-free-trial-note](~/reusable-content/ce-skilling/azure/includes/quickstarts-free-trial-note.md)]-- An Azure Virtual Machine Scale Sets instance.--## Open Azure Cloud Shell --Azure Cloud Shell is a free interactive shell that you can use to run the steps in this article. It has common Azure tools preinstalled and configured to use with your account. --To open Cloud Shell, select **Try it** in the upper-right corner of a code block. You can also open Cloud Shell in a separate browser tab by going to [Bash](https://shell.azure.com/bash). Select **Copy** to copy the blocks of code, paste it into Cloud Shell, and select **Enter** to run it. --If you want to install and use the CLI locally, this tutorial requires Azure CLI version 2.0.30 or later. Run `az --version` to find the version. If you need to install or upgrade, see [Install Azure CLI]( /cli/azure/install-azure-cli). --> [!NOTE] -> These instructions use a Bash terminal in Cloud Shell. Some commands might not work as described if you're running the CLI locally or in a PowerShell terminal. --## Enable Chaos Studio on your Virtual Machine Scale Sets instance --Azure Chaos Studio can't inject faults against a resource unless that resource was added to Chaos Studio first. To add a resource to Chaos Studio, create a [target and capabilities](chaos-studio-targets-capabilities.md) on the resource. --Virtual Machine Scale Sets has only one target type (`Microsoft-VirtualMachineScaleSet`) and one capability (`shutdown`). Other resources might have up to two target types. One target type is for service-direct faults. Another target type is for agent-based faults. Other resources also might have many other capabilities. --1. Create a [target for your virtual machine scale set](chaos-studio-fault-providers.md) resource. Replace `$RESOURCE_ID` with the resource ID of the virtual machine scale set you're adding: -- ```azurecli-interactive - az rest --method put --url "https://management.azure.com/$RESOURCE_ID/providers/Microsoft.Chaos/targets/Microsoft-VirtualMachineScaleSet?api-version=2023-11-01" --body "{\"properties\":{}}" - ``` --1. Create the capabilities on the virtual machine scale set target. Replace `$RESOURCE_ID` with the resource ID of the resource you're adding. Specify the `VirtualMachineScaleSet` target and the `Shutdown-2.0` capability. -- ```azurecli-interactive - az rest --method put --url "https://management.azure.com/$RESOURCE_ID/providers/Microsoft.Chaos/targets/Microsoft-VirtualMachineScaleSet/capabilities/Shutdown-2.0?api-version=2023-11-01" --body "{\"properties\":{}}" - ``` --You've now successfully added your virtual machine scale set to Chaos Studio. --## Create an experiment --Now you can create your experiment. A chaos experiment defines the actions you want to take against target resources. The actions are organized and run in sequential steps. The chaos experiment also defines the actions you want to take against branches, which run in parallel. --1. Formulate your experiment JSON starting with the following [Virtual Machine Scale Sets Shutdown 2.0](chaos-studio-fault-library.md#vmss-shutdown-version-20) JSON sample. Modify the JSON to correspond to the experiment you want to run by using the [Create Experiment API](/rest/api/chaosstudio/experiments/create-or-update) and the [fault library](chaos-studio-fault-library.md). At this time, dynamic targeting is only available with the Virtual Machine Scale Sets Shutdown 2.0 fault and can only filter on availability zones. -- - Use the `filter` element to configure the list of Azure availability zones to filter targets by. If you don't provide a `filter`, the fault shuts down all instances in the virtual machine scale set. - - The experiment targets all Virtual Machine Scale Sets instances in the specified zones. -- ```json - { - "location": "westus2", - "identity": { - "type": "SystemAssigned" - }, - "properties": { - "selectors": [ - { - "type": "List", - "id": "Selector1", - "targets": [ - { - "id": "/subscriptions/581d4e64-0ad7-495b-bff4-347a5944a2e1/resourceGroups/rg-demo/providers/Microsoft.Compute/virtualMachineScaleSets/vmss-demo/providers/Microsoft.Chaos/targets/Microsoft-VirtualMachineScaleSet", - "type": "ChaosTarget" - } - ], - "filter": { - "type": "Simple", - "parameters": { - "zones": [ - "1" - ] - } - } - } - ], - "steps": [ - { - "name": "Step1", - "branches": [ - { - "name": "Branch1", - "actions": [ - { - "name": "urn:csci:microsoft:virtualMachineScaleSet:shutdown/2.0", - "type": "continuous", - "selectorId": "Selector1", - "duration": "PT2M", - "parameters": [ - { - "key": "abruptShutdown", - "value": "false" - } - ] - } - ] - } - ] - } - ] - } - } - ``` - -1. Create the experiment by using the Azure CLI. Replace `$SUBSCRIPTION_ID`, `$RESOURCE_GROUP`, and `$EXPERIMENT_NAME` with the properties for your experiment. Make sure that you saved and uploaded your experiment JSON. Update `experiment.json` with your JSON filename. -- ```azurecli-interactive - az rest --method put --uri https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.Chaos/experiments/$EXPERIMENT_NAME?api-version=2023-11-01 --body @experiment.json - ``` -- Each experiment creates a corresponding system-assigned managed identity. Note the principal ID for this identity in the response for the next step. --## Give experiment permission to your virtual machine scale sets --When you create a chaos experiment, Chaos Studio creates a system-assigned managed identity that executes faults against your target resources. This identity must be given [appropriate permissions](chaos-studio-fault-providers.md) to the target resource for the experiment to run successfully. --Give the experiment access to your resources by using the following command. Replace `$EXPERIMENT_PRINCIPAL_ID` with the principal ID from the previous step. Replace `$RESOURCE_ID` with the resource ID of the target resource. Change the role to the appropriate [built-in role for that resource type](chaos-studio-fault-providers.md). Run this command for each resource targeted in your experiment. --```azurecli-interactive -az role assignment create --role "Virtual Machine Contributor" --assignee-object-id $EXPERIMENT_PRINCIPAL_ID --scope $RESOURCE_ID -``` --## Run your experiment --You're now ready to run your experiment. To see the effect, check the portal to see if your virtual machine scale sets targets are shut down. If they're shut down, check to see that the services running on your virtual machine scale sets are still running as expected. --1. Start the experiment by using the Azure CLI. Replace `$SUBSCRIPTION_ID`, `$RESOURCE_GROUP`, and `$EXPERIMENT_NAME` with the properties for your experiment. -- ```azurecli-interactive - az rest --method post --uri https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.Chaos/experiments/$EXPERIMENT_NAME/start?api-version=2023-11-01 - ``` --1. The response includes a status URL that you can use to query experiment status as the experiment runs. --## Next steps -Now that you've run a dynamically targeted virtual machine scale set shutdown experiment, you're ready to: -- [Create an experiment that uses agent-based faults](chaos-studio-tutorial-agent-based-portal.md)-- [Manage your experiment](chaos-studio-run-experiment.md) |
| chaos-studio | Chaos Studio Tutorial Dynamic Target Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-tutorial-dynamic-target-portal.md | - Title: Create a chaos experiment to shut down all targets in a zone -description: Use the Azure portal to create an experiment that uses dynamic targeting to select hosts in a zone. ----- Previously updated : 4/19/2023----# Create a chaos experiment to shut down all targets in a zone --You can use dynamic targeting in a chaos experiment to choose a set of targets to run an experiment against, based on criteria evaluated at experiment runtime. This article shows how you can dynamically target a virtual machine scale set to shut down instances based on availability zone. Running this experiment can help you test failover to an Azure Virtual Machine Scale Sets instance in a different region if there's an outage. --You can use these same steps to set up and run an experiment for any fault that supports dynamic targeting. Currently, only virtual machine scale set shutdown supports dynamic targeting. --## Prerequisites --- An Azure subscription. [!INCLUDE [quickstarts-free-trial-note](~/reusable-content/ce-skilling/azure/includes/quickstarts-free-trial-note.md)]-- An Azure Virtual Machine Scale Sets instance.--## Enable Chaos Studio on your virtual machine scale sets --Azure Chaos Studio can't inject faults against a resource until that resource is added to Chaos Studio. To add a resource to Chaos Studio, create a [target and capabilities](chaos-studio-targets-capabilities.md) on the resource. --Virtual Machine Scale Sets has only one target type (`Microsoft-VirtualMachineScaleSet`) and one capability (`shutdown`). Other resources might have up to two target types. One target type is for service-direct faults. Another target type is for agent-based faults. Other resources also might have many other capabilities. --1. Open the [Azure portal](https://portal.azure.com). -1. Search for **Chaos Studio** in the search bar. -1. Select **Targets** and find your virtual machine scale set resource. -1. Select the virtual machine scale set resource and select **Enable targets** > **Enable service-direct targets**. -- [ ](images/tutorial-dynamic-targets-enable.png#lightbox) -1. Select **Review + Enable** > **Enable**. --You've now successfully added your virtual machine scale set to Chaos Studio. --## Create an experiment --Now you can create your experiment. A chaos experiment defines the actions you want to take against target resources. The actions are organized and run in sequential steps. The chaos experiment also defines the actions you want to take against branches, which run in parallel. --1. In Chaos Studio, go to **Experiments** > **Create** > **New experiment**. -- [](images/tutorial-dynamic-targets-experiment-browse.png#lightbox) -1. Add a name for your experiment that complies with resource naming guidelines. Select **Next: Experiment designer**. -- [](images/tutorial-dynamic-targets-create-exp.png#lightbox) -1. In **Step 1** and **Branch 1**, select **Add action** > **Add fault**. -- [](images/tutorial-dynamic-targets-experiment-fault.png#lightbox) -1. Select the **VMSS Shutdown (version 2.0)** fault. Select your desired duration and if you want the shutdown to be abrupt. Select **Next: Target resources**. -- [](images/tutorial-dynamic-targets-fault-details.png#lightbox) -1. Select the virtual machine scale set resource that you want to use in the experiment. Select **Next: Scope**. -- [](images/tutorial-dynamic-targets-fault-resources.png#lightbox) -1. In the **Zones** dropdown list, select the zone where you want virtual machines (VMs) in the Virtual Machine Scale Sets instance to be shut down. Select **Add**. -- [](images/tutorial-dynamic-targets-fault-zones.png#lightbox) -1. Select **Review + create** > **Create** to save the experiment. --## Give the experiment permission to your virtual machine scale sets --When you create a chaos experiment, Chaos Studio creates a system-assigned managed identity that executes faults against your target resources. This identity must be given [appropriate permissions](chaos-studio-fault-providers.md) to the target resource for the experiment to run successfully. To use these steps for any resource and target type, modify the role assignment in step 3 to match the [appropriate role for that resource and target type](chaos-studio-fault-providers.md). --1. Go to your virtual machine scale set resource and select **Access control (IAM)** > **Add role assignment**. -- [](images/tutorial-dynamic-targets-vmss-iam.png#lightbox) -1. On the **Role** tab, select **Virtual Machine Contributor** and select **Next**. -- [](images/tutorial-dynamic-targets-role-selection.png#lightbox) -1. Choose **Select members** and search for your experiment name. Select your experiment and then choose **Select**. If there are multiple experiments in the same tenant with the same name, your experiment name is truncated with random characters added. -- [](images/tutorial-dynamic-targets-role-assignment.png#lightbox) -1. Select **Review + assign** > **Review + assign**. -- [](images/tutorial-dynamic-targets-role-confirmation.png#lightbox) --## Run your experiment --You're now ready to run your experiment. --1. In **Chaos Studio**, go to the **Experiments** view, select your experiment, and select **Start experiment(s)**. -- [](images/tutorial-dynamic-targets-start-experiment.png#lightbox) -1. Select **OK** to confirm that you want to start the experiment. -1. When the **Status** changes to *Running*, select **Details** for the latest run under **History** to see details for the running experiment. If any errors occur, you can view them in **Details**. Select a failed action and expand **Failed targets**. --To see the effect, use a tool like **Azure Monitor** or the **Virtual Machine Scale Sets** section of the portal to check if your virtual machine scale set targets are shut down. If they're shut down, check to see that the services running on your virtual machine scale sets are still running as expected. --In this example, the chaos experiment successfully shut down the instance in Zone 1, as expected. --[](images/tutorial-dynamic-targets-view-vmss.png#lightbox) --## Next steps --> [!TIP] -> If your virtual machine scale set uses an autoscale policy, the policy provisions new VMs after this experiment shuts down existing VMs. To prevent this action, add a parallel branch in your experiment that includes the **Disable Autoscale** fault against the virtual machine scale set `microsoft.insights/autoscaleSettings` resource. Remember to add the `autoscaleSettings` resource as a target and assign the role. --Now that you've run a dynamically targeted virtual machine scale set shutdown experiment, you're ready to: -- [Create an experiment that uses agent-based faults](chaos-studio-tutorial-agent-based-portal.md)-- [Manage your experiment](chaos-studio-run-experiment.md) |
| chaos-studio | Chaos Studio Tutorial Service Direct Cli | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-tutorial-service-direct-cli.md | - Title: Create an experiment using a service-direct fault with Azure CLI -description: Create an experiment that uses a service-direct fault with the Azure CLI. ----- Previously updated : 11/10/2021----# Create a chaos experiment that uses a service-direct fault with the Azure CLI --You can use a chaos experiment to verify that your application is resilient to failures by causing those failures in a controlled environment. In this article, you cause a multi-read, single-write Azure Cosmos DB failover by using a chaos experiment and Azure Chaos Studio. Running this experiment can help you defend against data loss when a failover event occurs. --You can use these same steps to set up and run an experiment for any service-direct fault. A *service-direct* fault runs directly against an Azure resource without any need for instrumentation, unlike agent-based faults, which require installation of the chaos agent. --## Prerequisites --- An Azure subscription. [!INCLUDE [quickstarts-free-trial-note](~/reusable-content/ce-skilling/azure/includes/quickstarts-free-trial-note.md)]-- An Azure Cosmos DB account. If you don't have an Azure Cosmos DB account, you can [create one](/azure/cosmos-db/sql/create-cosmosdb-resources-portal).-- At least one read and one write region setup for your Azure Cosmos DB account.--## Open Azure Cloud Shell --Azure Cloud Shell is a free interactive shell that you can use to run the steps in this article. It has common Azure tools preinstalled and configured to use with your account. --To open Cloud Shell, select **Try it** in the upper-right corner of a code block. You can also open Cloud Shell in a separate browser tab by going to [Bash](https://shell.azure.com/bash). Select **Copy** to copy the blocks of code, paste it into Cloud Shell, and select **Enter** to run it. --If you want to install and use the CLI locally, this tutorial requires Azure CLI version 2.0.30 or later. Run `az --version` to find the version. If you need to install or upgrade, see [Install Azure CLI]( /cli/azure/install-azure-cli). --> [!NOTE] -> These instructions use a Bash terminal in Cloud Shell. Some commands might not work as described if you're running the CLI locally or in a PowerShell terminal. --## Enable Chaos Studio on your Azure Cosmos DB account --Chaos Studio can't inject faults against a resource unless that resource was added to Chaos Studio first. You add a resource to Chaos Studio by creating a [target and capabilities](chaos-studio-targets-capabilities.md) on the resource. Azure Cosmos DB accounts have only one target type (service-direct) and one capability (failover). Other resources might have up to two target types. One target type is for service-direct faults. Another target type is for agent-based faults. Other resources might have many other capabilities. --1. Create a target by replacing `$RESOURCE_ID` with the resource ID of the resource you're adding. Replace `$TARGET_TYPE` with the [target type you're adding](chaos-studio-fault-providers.md): -- ```azurecli-interactive - az rest --method put --url "https://management.azure.com/$RESOURCE_ID/providers/Microsoft.Chaos/targets/$TARGET_TYPE?api-version=2023-11-01" --body "{\"properties\":{}}" - ``` -- For example, if you're adding a virtual machine as a service-direct target: -- ```azurecli-interactive - az rest --method put --url "https://management.azure.com/subscriptions/b65f2fec-d6b2-4edd-817e-9339d8c01dc4/resourceGroups/myRG/providers/Microsoft.Compute/virtualMachines/myVM/providers/Microsoft.Chaos/targets/Microsoft-VirtualMachine?api-version=2023-11-01" --body "{\"properties\":{}}" - ``` --1. Create the capabilities on the target by replacing `$RESOURCE_ID` with the resource ID of the resource you're adding. Replace `$TARGET_TYPE` with the [target type you're adding](chaos-studio-fault-providers.md). Replace `$CAPABILITY` with the [name of the fault capability you're enabling](chaos-studio-fault-library.md). - - ```azurecli-interactive - az rest --method put --url "https://management.azure.com/$RESOURCE_ID/providers/Microsoft.Chaos/targets/$TARGET_TYPE/capabilities/$CAPABILITY?api-version=2023-11-01" --body "{\"properties\":{}}" - ``` -- For example, if you're enabling the virtual machine shutdown capability: -- ```azurecli-interactive - az rest --method put --url "https://management.azure.com/subscriptions/b65f2fec-d6b2-4edd-817e-9339d8c01dc4/resourceGroups/myRG/providers/Microsoft.Compute/virtualMachines/myVM/providers/Microsoft.Chaos/targets/Microsoft-VirtualMachine/capabilities/shutdown-1.0?api-version=2023-11-01" --body "{\"properties\":{}}" - ``` --You've now successfully added your Azure Cosmos DB account to Chaos Studio. --## Create an experiment -Now you can create your experiment. A chaos experiment defines the actions you want to take against target resources. The actions are organized and run in sequential steps. The chaos experiment also defines the actions you want to take against branches, which run in parallel. --1. Formulate your experiment JSON starting with the following JSON sample. Modify the JSON to correspond to the experiment you want to run by using the [Create Experiment API](/rest/api/chaosstudio/experiments/create-or-update) and the [fault library](chaos-studio-fault-library.md). -- ```json - { - "location": "eastus", - "identity": { - "type": "SystemAssigned" - }, - "properties": { - "steps": [ - { - "name": "Step1", - "branches": [ - { - "name": "Branch1", - "actions": [ - { - "type": "continuous", - "selectorId": "Selector1", - "duration": "PT10M", - "parameters": [ - { - "key": "readRegion", - "value": "East US 2" - } - ], - "name": "urn:csci:microsoft:cosmosDB:failover/1.0" - } - ] - } - ] - } - ], - "selectors": [ - { - "id": "Selector1", - "type": "List", - "targets": [ - { - "type": "ChaosTarget", - "id": "/subscriptions/b65f2fec-d6b2-4edd-817e-9339d8c01dc4/resourceGroups/chaosstudiodemo/providers/Microsoft.DocumentDB/databaseAccounts/myDB/providers/Microsoft.Chaos/targets/Microsoft-CosmosDB" - } - ] - } - ] - } - } - ``` - -1. Create the experiment by using the Azure CLI. Replace `$SUBSCRIPTION_ID`, `$RESOURCE_GROUP`, and `$EXPERIMENT_NAME` with the properties for your experiment. Make sure that you've saved and uploaded your experiment JSON. Update `experiment.json` with your JSON filename. -- ```azurecli-interactive - az rest --method put --uri https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.Chaos/experiments/$EXPERIMENT_NAME?api-version=2023-11-01 --body @experiment.json - ``` -- Each experiment creates a corresponding system-assigned managed identity. Note the principal ID for this identity in the response for the next step. --## Give the experiment permission to your Azure Cosmos DB account -When you create a chaos experiment, Chaos Studio creates a system-assigned managed identity that executes faults against your target resources. This identity must be given [appropriate permissions](chaos-studio-fault-providers.md) to the target resource for the experiment to run successfully. --Give the experiment access to your resources by using the following command. Replace `$EXPERIMENT_PRINCIPAL_ID` with the principal ID from the previous step. Replace `$RESOURCE_ID` with the resource ID of the target resource. In this case, it's the Azure Cosmos DB instance resource ID. Change the role to the appropriate [built-in role for that resource type](chaos-studio-fault-providers.md). Run this command for each resource targeted in your experiment. --```azurecli-interactive -az role assignment create --role "Cosmos DB Operator" --assignee-object-id $EXPERIMENT_PRINCIPAL_ID --scope $RESOURCE_ID -``` --## Run your experiment -You're now ready to run your experiment. To see the effect, we recommend that you open your Azure Cosmos DB account overview and go to **Replicate data globally** in a separate browser tab. Refresh periodically during the experiment to show the region swap. --1. Start the experiment by using the Azure CLI. Replace `$SUBSCRIPTION_ID`, `$RESOURCE_GROUP`, and `$EXPERIMENT_NAME` with the properties for your experiment. -- ```azurecli-interactive - az rest --method post --uri https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.Chaos/experiments/$EXPERIMENT_NAME/start?api-version=2023-11-01 - ``` --1. The response includes a status URL that you can use to query experiment status as the experiment runs. --## Next steps -Now that you've run an Azure Cosmos DB service-direct experiment, you're ready to: -- [Create an experiment that uses agent-based faults](chaos-studio-tutorial-agent-based-portal.md)-- [Manage your experiment](chaos-studio-run-experiment.md) |
| chaos-studio | Chaos Studio Tutorial Service Direct Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-tutorial-service-direct-portal.md | - Title: Create an experiment using a service-direct fault with Chaos Studio -description: Create an experiment that uses a service-direct fault with Azure Chaos Studio to fail over an Azure Cosmos DB instance. ----- Previously updated : 11/01/2021----# Create a chaos experiment that uses a service-direct fault to fail over an Azure Cosmos DB instance --You can use a chaos experiment to verify that your application is resilient to failures by causing those failures in a controlled environment. In this article, you cause a multi-read, single-write Azure Cosmos DB failover by using a chaos experiment and Azure Chaos Studio. Running this experiment can help you defend against data loss when a failover event occurs. --You can use these same steps to set up and run an experiment for any service-direct fault. A *service-direct* fault runs directly against an Azure resource without any need for instrumentation. Agent-based faults require installation of the chaos agent. --## Prerequisites --- An Azure subscription. [!INCLUDE [quickstarts-free-trial-note](~/reusable-content/ce-skilling/azure/includes/quickstarts-free-trial-note.md)]-- An Azure Cosmos DB account. If you don't have an Azure Cosmos DB account, follow these steps to [create one](/azure/cosmos-db/sql/create-cosmosdb-resources-portal).-- At least one read and one write region setup for your Azure Cosmos DB account.--## Enable Chaos Studio on your Azure Cosmos DB account --Chaos Studio can't inject faults against a resource unless that resource is added to Chaos Studio first. You add a resource to Chaos Studio by creating a [target and capabilities](chaos-studio-targets-capabilities.md) on the resource. Azure Cosmos DB accounts have only one target type (service-direct) and one capability (failover). Other resources might have up to two target types. One target type is for service-direct faults. Another target type is for agent-based faults. Other resources might have many other capabilities. --1. Open the [Azure portal](https://portal.azure.com). -1. Search for **Chaos Studio** in the search bar. -1. Select **Targets** and go to your Azure Cosmos DB account. --  -1. Select the checkbox next to your Azure Cosmos DB account. Select **Enable targets** and then select **Enable service-direct targets** from the dropdown menu. --  --1. Confirm that the desired resource is listed. Select **Review + Enable**, then **Enable**. --1. A notification appears that indicates that the resources selected were successfully enabled. --  --You've now successfully added your Azure Cosmos DB account to Chaos Studio. In the **Targets** view, you can also manage the capabilities enabled on this resource. Selecting the **Manage actions** link next to a resource displays the capabilities enabled for that resource. --## Create an experiment -Now you can create your experiment. A chaos experiment defines the actions you want to take against target resources. The actions are organized and run in sequential steps. The chaos experiment also defines the actions you want to take against branches, which run in parallel. --1. Select the **Experiments** tab in Chaos Studio. In this view, you can see and manage all your chaos experiments. Select **Create** > **New experiment**. --  -1. Fill in the **Subscription**, **Resource Group**, and **Location** where you want to deploy the chaos experiment. Give your experiment a name. Select **Next: Experiment designer**. --  -1. You're now in the Chaos Studio experiment designer. The experiment designer allows you to build your experiment by adding steps, branches, and faults. Give a friendly name to your **Step** and **Branch** and select **Add action > Add fault**. --  -1. Select **CosmosDB Failover** from the dropdown list. Fill in **Duration** with the number of minutes you want the failure to last and **readRegion** with the read region of your Azure Cosmos DB account. Select **Next: Target resources**. --  -1. Select your Azure Cosmos DB account and select **Next**. --  -1. Verify that your experiment looks correct and select **Review + create** > **Create**. --  --## Give the experiment permission to your target resource -When you create a chaos experiment, Chaos Studio creates a system-assigned managed identity that executes faults against your target resources. This identity must be given [appropriate permissions](chaos-studio-fault-providers.md) to the target resource for the experiment to run successfully. You can use these steps for any resource and target type by modifying the role assignment in step 3 to match the [appropriate role for that resource and target type.](chaos-studio-fault-providers.md). --1. Go to your Azure Cosmos DB account and select **Access control (IAM)**. --  -1. Select **Add** > **Add role assignment**. --  -1. Search for **Cosmos DB Operator** and select the role. Select **Next**. --  -1. Choose **Select members** and search for your experiment name. Select your experiment and choose **Select**. If there are multiple experiments in the same tenant with the same name, your experiment name is truncated with random characters added. --  -1. Select **Review + assign** > **Review + assign**. --## Run your experiment -You're now ready to run your experiment. To see the effect, we recommend that you open your Azure Cosmos DB account overview and go to **Replicate data globally** in a separate browser tab. Refreshing periodically during the experiment shows the region swap. --1. In the **Experiments** view, select your experiment. Select **Start** > **OK**. -1. When **Status** changes to *Running*, select **Details** for the latest run under **History** to see details for the running experiment. --## Next steps -Now that you've run an Azure Cosmos DB service-direct experiment, you're ready to: -- [Create an experiment that uses agent-based faults](chaos-studio-tutorial-agent-based-portal.md)-- [Manage your experiment](chaos-studio-run-experiment.md) |
| chaos-studio | Chaos Studio Versions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/chaos-studio-versions.md | - Title: Azure Chaos Studio compatibility -description: Understand the compatibility of Azure Chaos Studio with operating systems and tools. --- Previously updated : 01/26/2024------# Azure Chaos Studio version compatibility --The following reference shows relevant version support and compatibility for features within Chaos Studio. --## Operating systems supported by the agent --The Chaos Studio agent is tested for compatibility with the following operating systems on Azure virtual machines. This testing involves deploying an Azure virtual machine with the specified SKU, installing the agent as a virtual machine extension, and validating the output of the available agent-based faults. --| Operating system | Chaos agent compatibility | Notes | -|::|::|::| -| Windows Server 2019 | Γ£ô | | -| Windows Server 2016 | Γ£ô | | -| Windows Server 2012 R2 | Γ£ô | | -| Azure Linux (Mariner) | Γ£ô | Installing `stress-ng` [manually](https://github.com/ColinIanKing/stress-ng) required for CPU Pressure, Physical Memory Pressure, Disk I/O Pressure, and Stress-ng faults | -| Red Hat Enterprise Linux 8 | Γ£ô | Currently tested up to 8.9 | -| openSUSE Leap 15.2 | Γ£ô | | -| Debian 10 Buster | Γ£ô | Installation of `unzip` utility required | -| Oracle Linux 8.3 | Γ£ô | | -| Ubuntu Server 20.04/22.04 LTS | Γ£ô | | --The agent isn't currently tested against custom Linux distributions or hardened Linux distributions (for example, FIPS or SELinux). --If an operating system isn't currently listed, you may still attempt to install, use, and troubleshoot the virtual machine extension, agent, and agent-based capabilities, but Chaos Studio cannot guarantee behavior or support for an unlisted operating system. --To request validation and support on more operating systems or versions, use the [Chaos Studio Feedback Community](https://aka.ms/ChaosStudioFeedback). --## Chaos Mesh compatibility --Faults within Azure Kubernetes Service resources currently integrate with the open-source project [Chaos Mesh](https://chaos-mesh.org/), which is part of the [Cloud Native Computing Foundation](https://www.cncf.io/projects/chaosmesh/). Review [Create a chaos experiment that uses a Chaos Mesh fault to kill AKS pods with the Azure portal](chaos-studio-tutorial-aks-portal.md) for more details on using Azure Chaos Studio with Chaos Mesh. --Find Chaos Mesh's support policy and release dates here: [Supported Releases](https://chaos-mesh.org/supported-releases/). --Chaos Studio currently tests with the following version combinations. --| Chaos Studio fault version | Kubernetes version | Chaos Mesh version | Notes | -|::|::|::|::| -| 2.1 | 1.27 | 2.6.3 | | -| 2.1 | 1.25.11 | 2.5.1 | | --The *Chaos Studio fault version* column refers to the individual fault version for each AKS Chaos Mesh fault used in the experiment JSON, for example `urn:csci:microsoft:azureKubernetesServiceChaosMesh:podChaos/2.1`. If a past version of the corresponding Chaos Studio fault remains available from the Chaos Studio API (for example, `...podChaos/1.0`), it is within support. --## Browser compatibility --Review the Azure portal documentation on [Supported devices](../azure-portal/azure-portal-supported-browsers-devices.md) for more information on browser support. |
| chaos-studio | Experiment Examples | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/experiment-examples.md | - Title: Azure CLI & Azure portal example experiments -description: See real examples of creating various chaos experiments in the Azure portal and CLI. --- Previously updated : 05/07/2024-------# Example Experiments --This article provides examples for creating experiments from your command line (CLI) and Azure portal parameter examples for various experiments. You can copy and paste the following commands into the CLI or Azure portal, and edit them for your specific resources. --Here's an example of where you would copy and paste the Azure portal parameter into: --[](images/azure-portal-parameter-examples.png#lightbox) --To save one of the "experiment.json" examples shown below, simply type *nano experiment.json* into your cloud shell, copy and paste any of the below experiment examples, save it (ctrl+o), exit nano (ctrl+x) and run the following command: - ```AzCLI -az rest --method put --uri https://management.azure.com/subscriptions/6b052e15-03d3-4f17-b2e1-be7f07588291/resourceGroups/exampleRG/providers/Microsoft.Chaos/experiments/exampleExperiment?api-version=2024-01-01 -``` -> [!NOTE] -> This is the generic command you would use to create any experiment from the Azure CLI --> [!NOTE] -> Make sure your experiment has permission to operate on **ALL** resources within the experiment. These examples exclusively use **System-assigned managed identity**, but we also support User-assigned managed identity. For more information, see [Experiment permissions](chaos-studio-permissions-security.md). These experiments will **NOT** run without granting the experiment permission to run on the target resources. -><br> -><br> ->View all available role assignments [here](chaos-studio-fault-providers.md) to determine which permissions are required for your target resources. -----Azure Kubernetes Service (AKS) - Network Delay --**Experiment Description** This experiment delays network communication by 200ms ---### [Azure CLI Experiment.JSON](#tab/azure-CLI) -```AzCLI -{ --"identity": { - "type": "SystemAssigned", - }, - "tags": {}, - "location": "westus", - "properties": { - "selectors": [ - { - "type": "List", - "targets": [ - { - "id": "/subscriptions/123hdq8-123d-89d7-5670-123123/resourceGroups/aks_network_delay_experiment/providers/Microsoft.ContainerService/managedClusters/nikhilAKScluster/providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh", - "type": "ChaosTarget" - } - ], - "id": "Selector1" - } - ], - "steps": [ - { - "name": "AKS network latency", - "branches": [ - { - "name": "AKS network latency", - "actions": [ - { - "type": "continuous", - "selectorId": "Selector1", - "duration": "PT5M", - "parameters": [ - { - "key": "jsonSpec", - "value": "{\"action\":\"delay\",\"mode\":\"all\",\"selector\":{\"namespaces\":[\"default\"]},\"delay\":{\"latency\":\"200ms\",\"correlation\":\"100\",\"jitter\":\"0ms\"}}" - } - ], - "name": "urn:csci:microsoft:azureKubernetesServiceChaosMesh:networkChaos/2.1" - } - ] - } - ] - } - ] - } -} --``` --### [Azure portal parameters](#tab/azure-portal) --```Azure portal -{"action":"delay","mode":"all","selector":{"namespaces":["default"]},"delay":{"latency":"200ms","correlation":"100","jitter":"0ms"}} -``` - -Azure Kubernetes Service (AKS) - Pod Failure --**Experiment Description** This experiment takes down all pods in the cluster for 10 minutes. --### [Azure CLI Experiment.JSON](#tab/azure-CLI) -```AzCLI -{ --"identity": { - "type": "SystemAssigned", - }, - "tags": {}, - "location": "westus", - "properties": { - "selectors": [ - { - "type": "List", - "targets": [ - { - "id": "/subscriptions/123hdq8-123d-89d7-5670-123123/resourceGroups/aks_pod_fail_experiment/providers/Microsoft.ContainerService/managedClusters/nikhilAKScluster/providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh", - "type": "ChaosTarget" - } - ], - "id": "Selector1" - } - ], - "steps": [ - { - "name": "AKS pod kill", - "branches": [ - { - "name": "AKS pod kill", - "actions": [ - { - "type": "continuous", - "selectorId": "Selector1", - "duration": "PT5M", - "parameters": [ - { - "key": "jsonSpec", - "value": "{\"action\":\"pod-failure\",\"mode\":\"all\",\"duration\":\"600s\",\"selector\":{\"namespaces\":[\"autoinstrumentationdemo\"]}}}" - } - ], - "name": "urn:csci:microsoft:azureKubernetesServiceChaosMesh:podChaos/2.1" - } - ] - } - ] - } - ] - } -} --``` ---### [Azure portal parameters](#tab/azure-portal) --```Azure portal -{"action":"pod-failure","mode":"all","duration":"600s","selector":{"namespaces":["autoinstrumentationdemo"]}} -``` --Azure Kubernetes Service (AKS) - Memory Stress --**Experiment Description** This experiment stresses the memory of 4 AKS pods to 95% for 10 minutes. --### [Azure CLI](#tab/azure-CLI) -```AzCLI -{ --"identity": { - "type": "SystemAssigned", - }, - "tags": {}, - "location": "westus", - "properties": { - "selectors": [ - { - "type": "List", - "targets": [ - { - "id": "/subscriptions/123hdq8-123d-89d7-5670-123123/resourceGroups/aks_memory_stress_experiment/providers/Microsoft.ContainerService/managedClusters/nikhilAKScluster/providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh", - "type": "ChaosTarget" - } - ], - "id": "Selector1" - } - ], - "steps": [ - { - "name": "AKS memory stress", - "branches": [ - { - "name": "AKS memory stress", - "actions": [ - { - "type": "continuous", - "selectorId": "Selector1", - "duration": "PT10M", - "parameters": [ - { - "key": "jsonSpec", - "value": "{\"mode\":\"all\",\"selector\":{\"namespaces\":[\"autoinstrumentationdemo\"]},\"stressors\":{\"memory\":{\"workers\":4,\"size\":\"95%\"}}" - } - ], - "name": "urn:csci:microsoft:azureKubernetesServiceChaosMesh:stressChaos/2.1" - } - ] - } - ] - } - ] - } -} --``` ---### [Azure portal parameters](#tab/azure-portal) --```Azure portal -{"mode":"all","selector":{"namespaces":["autoinstrumentationdemo"]},"stressors":{"memory":{"workers":4,"size":"95%"}} -``` ---Azure Kubernetes Service (AKS) - CPU Stress --**Experiment Description** This experiment stresses the CPU of four pods in the AKS cluster to 95%. --### [Azure CLI](#tab/azure-CLI) -```AzCLI -{ - "identity": { - "type": "SystemAssigned" - }, - "tags": {}, - "location": "westus", - "properties": { - "selectors": [ - { - "type": "List", - "targets": [ - { - "id": "/subscriptions/123hdq8-123d-89d7-5670-123123/resourceGroups/aks_memory_stress_experiment/providers/Microsoft.ContainerService/managedClusters/nikhilAKScluster/providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh", - "type": "ChaosTarget" - } - ], - "id": "Selector1" - } - ], - "steps": [ - { - "name": "AKS CPU stress", - "branches": [ - { - "name": "AKS CPU stress", - "actions": [ - { - "type": "continuous", - "selectorId": "Selector1", - "duration": "PT10M", - "parameters": [ - { - "key": "jsonSpec", - "value": "{\"mode\":\"all\",\"selector\":{\"namespaces\":[\"autoinstrumentationdemo\"]},\"stressors\":{\"cpu\":{\"workers\":4,\"load\":95}}}" - } - ], - "name": "urn:csci:microsoft:azureKubernetesServiceChaosMesh:stressChaos/2.1" - } - ] - } - ] - } - ] - } -} -``` --### [Azure portal parameters](#tab/azure-portal) --```Azure portal -{"mode":"all","selector":{"namespaces":["autoinstrumentationdemo"]},"stressors":{"cpu":{"workers":4,"load":95}}} -``` --Azure Kubernetes Service (AKS) - Network Emulation --**Experiment Description** This experiment applies a network emulation to all pods in the specified namespace, adding a latency of 100ms and a packet loss of 0.1% for 5 minutes. ---### [Azure CLI Experiment.JSON](#tab/azure-CLI) -```AzCLI -{ - "identity": { - "type": "SystemAssigned" - }, - "tags": {}, - "location": "westus", - "properties": { - "selectors": [ - { - "type": "List", - "targets": [ - { - "id": "/subscriptions/123hdq8-123d-89d7-5670-123123/resourceGroups/aks_network_emulation_experiment/providers/Microsoft.ContainerService/managedClusters/nikhilAKScluster/providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh", - "type": "ChaosTarget" - } - ], - "id": "Selector1" - } - ], - "steps": [ - { - "name": "AKS network emulation", - "branches": [ - { - "name": "AKS network emulation", - "actions": [ - { - "type": "continuous", - "selectorId": "Selector1", - "duration": "PT5M", - "parameters": [ - { - "key": "jsonSpec", - "value": "{\"action\":\"netem\",\"mode\":\"all\",\"selector\":{\"namespaces\":[\"default\"]},\"netem\":{\"latency\":\"100ms\",\"loss\":\"0.1\",\"correlation\":\"25\"}}" - } - ], - "name": "urn:csci:microsoft:azureKubernetesServiceChaosMesh:networkChaos/2.1" - } - ] - } - ] - } - ] - } -} --``` --### [Azure portal parameters](#tab/azure-portal) --```Azure portal -{"action":"netem","mode":"all","selector":{"namespaces":["default"]},"netem":{"latency":"100ms","loss":"0.1","correlation":"25"}} -``` --Azure Kubernetes Service (AKS) - Network Partition --**Experiment Description** This experiment partitions the network for all pods in the specified namespace, simulating a network split in the 'to' direction for 5 minutes. ---### [Azure CLI Experiment.JSON](#tab/azure-CLI) -```AzCLI -{ - "identity": { - "type": "SystemAssigned" - }, - "tags": {}, - "location": "westus", - "properties": { - "selectors": [ - { - "type": "List", - "targets": [ - { - "id": "/subscriptions/123hdq8-123d-89d7-5670-123123/resourceGroups/aks_partition_experiment/providers/Microsoft.ContainerService/managedClusters/nikhilAKScluster/providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh", - "type": "ChaosTarget" - } - ], - "id": "Selector1" - } - ], - "steps": [ - { - "name": "AKS network partition", - "branches": [ - { - "name": "AKS network partition", - "actions": [ - { - "type": "continuous", - "selectorId": "Selector1", - "duration": "PT5M", - "parameters": [ - { - "key": "jsonSpec", - "value": "{\"action\":\"partition\",\"mode\":\"all\",\"selector\":{\"namespaces\":[\"default\"]},\"partition\":{\"direction\":\"to\"}}" - } - ], - "name": "urn:csci:microsoft:azureKubernetesServiceChaosMesh:networkChaos/2.1" - } - ] - } - ] - } - ] - } -} --``` --### [Azure portal parameters](#tab/azure-portal) --```Azure portal -{"action":"partition","mode":"all","selector":{"namespaces":["default"]},"partition":{"direction":"to"}} -``` --Azure Kubernetes Service (AKS) - Network Bandwidth Limitation --**Experiment Description** This experiment limits the network bandwidth for all pods in the specified namespace to 1mbps, with additional parameters for limit, buffer, peak rate, and burst for 5 minutes. ---### [Azure CLI Experiment.JSON](#tab/azure-CLI) -```AzCLI -{ - "identity": { - "type": "SystemAssigned" - }, - "tags": {}, - "location": "westus", - "properties": { - "selectors": [ - { - "type": "List", - "targets": [ - { - "id": "/subscriptions/123hdq8-123d-89d7-5670-123123/resourceGroups/aks_bandwidth_experiment/providers/Microsoft.ContainerService/managedClusters/nikhilAKScluster/providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh", - "type": "ChaosTarget" - } - ], - "id": "Selector1" - } - ], - "steps": [ - { - "name": "AKS network bandwidth", - "branches": [ - { - "name": "AKS network bandwidth", - "actions": [ - { - "type": "continuous", - "selectorId": "Selector1", - "duration": "PT5M", - "parameters": [ - { - "key": "jsonSpec", - "value": "{\"action\":\"bandwidth\",\"mode\":\"all\",\"selector\":{\"namespaces\":[\"default\"]},\"bandwidth\":{\"rate\":\"1mbps\",\"limit\":\"50mb\",\"buffer\":\"10kb\",\"peakrate\":\"1mbps\",\"minburst\":\"0\"}}" - } - ], - "name": "urn:csci:microsoft:azureKubernetesServiceChaosMesh:networkChaos/2.1" - } - ] - } - ] - } - ] - } -} --``` --### [Azure portal parameters](#tab/azure-portal) --```Azure portal -{"action":"bandwidth","mode":"all","selector":{"namespaces":["default"]},"bandwidth":{"rate":"1mbps","limit":"50mb","buffer":"10kb","peakrate":"1mbps","minburst":"0"}} -``` --Azure Kubernetes Service (AKS) - Network Packet Re-order --**Experiment Description** This experiment reorders network packets for all pods in the specified namespace, with a gap of 5 packets and a reorder percentage of 25% for 5 minutes. ---### [Azure CLI Experiment.JSON](#tab/azure-CLI) -```AzCLI -{ - "identity": { - "type": "SystemAssigned" - }, - "tags": {}, - "location": "westus", - "properties": { - "selectors": [ - { - "type": "List", - "targets": [ - { - "id": "/subscriptions/123hdq8-123d-89d7-5670-123123/resourceGroups/aks_reorder_experiment/providers/Microsoft.ContainerService/managedClusters/nikhilAKScluster/providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh", - "type": "ChaosTarget" - } - ], - "id": "Selector1" - } - ], - "steps": [ - { - "name": "AKS network reorder", - "branches": [ - { - "name": "AKS network reorder", - "actions": [ - { - "type": "continuous", - "selectorId": "Selector1", - "duration": "PT5M", - "parameters": [ - { - "key": "jsonSpec", - "value": "{\"action\":\"reorder\",\"mode\":\"all\",\"selector\":{\"namespaces\":[\"default\"]},\"reorder\":{\"gap\":\"5\",\"reorder\":\"25\",\"correlation\":\"50\"}}" - } - ], - "name": "urn:csci:microsoft:azureKubernetesServiceChaosMesh:networkChaos/2.1" - } - ] - } - ] - } - ] - } -} --``` --### [Azure portal parameters](#tab/azure-portal) --```Azure portal -{"action":"reorder","mode":"all","selector":{"namespaces":["default"]},"reorder":{"gap":"5","reorder":"25","correlation":"50"}} -``` --Azure Kubernetes Service (AKS) - Network Packet Loss --**Experiment Description** This experiment simulates a packet loss of 10% for all pods in the specified namespace for 5 minutes. ---### [Azure CLI Experiment.JSON](#tab/azure-CLI) -```AzCLI -{ - "identity": { - "type": "SystemAssigned" - }, - "tags": {}, - "location": "westus", - "properties": { - "selectors": [ - { - "type": "List", - "targets": [ - { - "id": "/subscriptions/123hdq8-123d-89d7-5670-123123/resourceGroups/aks_loss_experiment/providers/Microsoft.ContainerService/managedClusters/nikhilAKScluster/providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh", - "type": "ChaosTarget" - } - ], - "id": "Selector1" - } - ], - "steps": [ - { - "name": "AKS network loss", - "branches": [ - { - "name": "AKS network loss", - "actions": [ - { - "type": "continuous", - "selectorId": "Selector1", - "duration": "PT5M", - "parameters": [ - { - "key": "jsonSpec", - "value": "{\"action\":\"loss\",\"mode\":\"all\",\"selector\":{\"namespaces\":[\"default\"]},\"loss\":{\"loss\":\"10\",\"correlation\":\"25\"}}" - } - ], - "name": "urn:csci:microsoft:azureKubernetesServiceChaosMesh:networkChaos/2.1" - } - ] - } - ] - } - ] - } -} --``` --### [Azure portal parameters](#tab/azure-portal) --```Azure portal -{"action":"loss","mode":"all","selector":{"namespaces":["default"]},"loss":{"loss":"10","correlation":"25"}} -``` --Azure Kubernetes Service (AKS) - Network Packet Duplication --**Experiment Description** This experiment duplicates 50% of the network packets for all pods in the specified namespace for 5 minutes. ---### [Azure CLI Experiment.JSON](#tab/azure-CLI) -```AzCLI -{ - "identity": { - "type": "SystemAssigned" - }, - "tags": {}, - "location": "westus", - "properties": { - "selectors": [ - { - "type": "List", - "targets": [ - { - "id": "/subscriptions/123hdq8-123d-89d7-5670-123123/resourceGroups/aks_duplicate_experiment/providers/Microsoft.ContainerService/managedClusters/nikhilAKScluster/providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh", - "type": "ChaosTarget" - } - ], - "id": "Selector1" - } - ], - "steps": [ - { - "name": "AKS network duplicate", - "branches": [ - { - "name": "AKS network duplicate", - "actions": [ - { - "type": "continuous", - "selectorId": "Selector1", - "duration": "PT5M", - "parameters": [ - { - "key": "jsonSpec", - "value": "{\"action\":\"duplicate\",\"mode\":\"all\",\"selector\":{\"namespaces\":[\"default\"]},\"duplicate\":{\"duplicate\":\"50\",\"correlation\":\"50\"}}" - } - ], - "name": "urn:csci:microsoft:azureKubernetesServiceChaosMesh:networkChaos/2.1" - } - ] - } - ] - } - ] - } -} --``` --### [Azure portal parameters](#tab/azure-portal) --```Azure portal -{"action":"duplicate","mode":"all","selector":{"namespaces":["default"]},"duplicate":{"duplicate":"50","correlation":"50"}} -``` --Azure Kubernetes Service (AKS) - Network Packet Corruption --**Experiment Description** This experiment corrupts 50% of the network packets for all pods in the specified namespace for 5 minutes. ---### [Azure CLI Experiment.JSON](#tab/azure-CLI) -```AzCLI -{ - "identity": { - "type": "SystemAssigned" - }, - "tags": {}, - "location": "westus", - "properties": { - "selectors": [ - { - "type": "List", - "targets": [ - { - "id": "/subscriptions/123hdq8-123d-89d7-5670-123123/resourceGroups/aks_corrupt_experiment/providers/Microsoft.ContainerService/managedClusters/nikhilAKScluster/providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh", - "type": "ChaosTarget" - } - ], - "id": "Selector1" - } - ], - "steps": [ - { - "name": "AKS network corrupt", - "branches": [ - { - "name": "AKS network corrupt", - "actions": [ - { - "type": "continuous", - "selectorId": "Selector1", - "duration": "PT5M", - "parameters": [ - { - "key": "jsonSpec", - "value": "{\"action\":\"corrupt\",\"mode\":\"all\",\"selector\":{\"namespaces\":[\"default\"]},\"corrupt\":{\"corrupt\":\"50\",\"correlation\":\"50\"}}" - } - ], - "name": "urn:csci:microsoft:azureKubernetesServiceChaosMesh:networkChaos/2.1" - } - ] - } - ] - } - ] - } -} --``` --### [Azure portal parameters](#tab/azure-portal) --```Azure portal -{"action":"corrupt","mode":"all","selector":{"namespaces":["default"]},"corrupt":{"corrupt":"50","correlation":"50"}} -``` --Azure Load Test - Start/Stop Load Test (With Delay) --**Experiment Description** This experiment starts an existing Azure load test, then waits for 10 minutes using the "delay" action before stopping the load test. ---### [Azure CLI Experiment.JSON](#tab/azure-CLI) -```AzCLI -{ --"identity": { - "type": "SystemAssigned", - }, - "tags": {}, - "location": "eastus", - "properties": { - "selectors": [ - { - "type": "List", - "targets": [ - { - "id": "/subscriptions/123hdq8-123d-89d7-5670-123123/resourceGroups/nikhilLoadTest/providers/microsoft.loadtestservice/loadtests/Nikhil-Demo-Load-Test/providers/Microsoft.Chaos/targets/microsoft-azureloadtest", - "type": "ChaosTarget" - } - ], - "id": "66e5124c-12db-4f7e-8549-7299c5828bff" - }, - { - "type": "List", - "targets": [ - { - "id": "/subscriptions/123hdq8-123d-89d7-5670-123123/resourceGroups/builddemo/providers/microsoft.loadtestservice/loadtests/Nikhil-Demo-Load-Test/providers/Microsoft.Chaos/targets/microsoft-azureloadtest", - "type": "ChaosTarget" - } - ], - "id": "9dc23b43-81ca-42c3-beae-3fe8ac80c30b" - } - ], - "steps": [ - { - "name": "Step 1 - Start Load Test", - "branches": [ - { - "name": "Branch 1", - "actions": [ - { - "selectorId": "66e5124c-12db-4f7e-8549-7299c5828bff", - "type": "discrete", - "parameters": [ - { - "key": "testId", - "value": "ae24e6z9-d88d-4752-8552-c73e8a9adebc" - } - ], - "name": "urn:csci:microsoft:azureLoadTest:start/1.0" - }, - { - "type": "delay", - "duration": "PT10M", - "name": "urn:csci:microsoft:chaosStudio:TimedDelay/1.0" - } - ] - } - ] - }, - { - "name": "Step 2 - End Load test", - "branches": [ - { - "name": "Branch 1", - "actions": [ - { - "selectorId": "9dc23b43-81ca-42c3-beae-3fe8ac80c30b", - "type": "discrete", - "parameters": [ - { - "key": "testId", - "value": "ae24e6z9-d88d-4752-8552-c73e8a9adebc" - } - ], - "name": "urn:csci:microsoft:azureLoadTest:stop/1.0" - } - ] - } - ] - } - ] - } -} -} --``` --### [Azure portal parameters](#tab/azure-portal) --```Azure portal -ae24e6z9-d88d-4752-8552-c73e8a9adebc -``` |
| chaos-studio | Sample Policy Targets | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/sample-policy-targets.md | - Title: Azure Policy samples for adding resources to Chaos Studio -description: Sample Azure policies to add resources to Azure Chaos Studio by using targets and capabilities. --- Previously updated : 11/11/2021------# Azure Policy samples for adding resources to Azure Chaos Studio --This article includes sample [Azure Policy](../governance/policy/overview.md) definitions that create [targets and capabilities](chaos-studio-targets-capabilities.md) for a specific resource type. You can automatically add resources to Azure Chaos Studio. First, you [deploy these samples as custom policy definitions](../governance/policy/tutorials/create-and-manage.md). Then you [assign the policy](../governance/policy/assign-policy-portal.md) to a scope. --In these samples, we add service-direct targets and capabilities for each [supported resource type](chaos-studio-fault-providers.md) by using [targets and capabilities](chaos-studio-targets-capabilities.md). --> [!NOTE] -> Each of these policies differs slightly, and you should consult the documentation of the Resource (e.g. Compute, Storage, etc.) you are using in addition to these below sample definitions to ensure you are setting everything ocrrectly for your specific scenario ---> [!NOTE] -> Make sure the subscription you are using for the automated Azure policy deployment has the correct [RBAC permissions](../governance/policy/overview.md) to do this. --## Azure Cache for Redis policy definition --```json -{ - "displayName": "Deploy Chaos Target and Capability for Azure Cache for Redis", - "policyType": "Custom", - "mode": "Indexed", - "metadata": { - "category": "Chaos Studio" - }, - "description": "Deploys the target and capabilities for an Azure Cache for Redis instance for onboarding to Azure Chaos Studio." - "parameters": { - "effect": { - "type": "String", - "metadata": { - "displayName": "Effect", - "description": "Enable or disable the execution of the policy" - }, - "allowedValues": [ - "DeployIfNotExists", - "Disabled" - ], - "defaultValue": "DeployIfNotExists" - } - }, - "policyRule": { - "if": { - "field": "type", - "equals": "Microsoft.Cache/Redis" - }, - "then": { - "effect": "[parameters('effect')]", - "details": { - "type": "Microsoft.Chaos/targets", - "name": "Microsoft-AzureCacheForRedis", - "roleDefinitionIds": [ - "/providers/Microsoft.Authorization/roleDefinitions/b24988ac-6180-42a0-ab88-20f7382dd24c" - ], - "deployment": { - "properties": { - "mode": "incremental", - "template": { - "$schema": "http://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "resourceName": { - "type": "string" - }, - "location": { - "type": "string" - } - }, - "variables": {}, - "resources": [ - { - "type": "Microsoft.Cache/Redis/providers/targets", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-AzureCacheForRedis')]", - "location": "[parameters('location')]", - "properties": {} - }, - { - "type": "Microsoft.Cache/Redis/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-AzureCacheForRedis/Reboot-1.0')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.Cache/Redis', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-AzureCacheForRedis')]" - ], - "properties": {} - } - ], - "outputs": {} - }, - "parameters": { - "resourceName": { - "value": "[field('name')]" - }, - "location": { - "value": "[field('location')]" - } - } - } - } - } - } - } -} -``` --## Azure Cosmos DB policy definition --```json -{ - "displayName": "Deploy Chaos Target and Capability for Cosmos DB", - "policyType": "Custom", - "mode": "Indexed", - "description": "Deploys the target and capabilities for a Cosmos DB for onboarding to Azure Chaos Studio.", - "metadata": { - "category": "Chaos Studio" - }, - "parameters": { - "effect": { - "type": "String", - "metadata": { - "displayName": "Effect", - "description": "Enable or disable the execution of the policy" - }, - "allowedValues": [ - "DeployIfNotExists", - "Disabled" - ], - "defaultValue": "DeployIfNotExists" - } - }, - "policyRule": { - "if": { - "field": "type", - "equals": "Microsoft.DocumentDB/databaseAccounts" - }, - "then": { - "effect": "[parameters('effect')]", - "details": { - "type": "Microsoft.Chaos/targets", - "name": "Microsoft-CosmosDB", - "roleDefinitionIds": [ - "/providers/Microsoft.Authorization/roleDefinitions/b24988ac-6180-42a0-ab88-20f7382dd24c" - ], - "deployment": { - "properties": { - "mode": "incremental", - "template": { - "$schema": "http://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "resourceName": { - "type": "string" - }, - "location": { - "type": "string" - } - }, - "variables": {}, - "resources": [ - { - "type": "Microsoft.DocumentDB/databaseAccounts/providers/targets", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-CosmosDB')]", - "location": "[parameters('location')]", - "properties": {} - }, - { - "type": "Microsoft.DocumentDB/databaseAccounts/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-CosmosDB/Failover-1.0')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.DocumentDB/databaseAccounts', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-CosmosDB')]" - ], - "properties": {} - } - ], - "outputs": {} - }, - "parameters": { - "resourceName": { - "value": "[field('name')]" - }, - "location": { - "value": "[field('location')]" - } - } - } - } - } - } - } -} -``` --## Azure Kubernetes Service policy definition --```json -{ - "displayName": "Deploy Chaos Target and Capabilities for Azure Kubernetes Service", - "policyType": "Custom", - "mode": "Indexed", - "description": "Deploys the target and capabilities for an AKS cluster for onboarding to Azure Chaos Studio.", - "metadata": { - "category": "Chaos Studio" - }, - "parameters": { - "effect": { - "type": "String", - "metadata": { - "displayName": "Effect", - "description": "Enable or disable the execution of the policy" - }, - "allowedValues": [ - "DeployIfNotExists", - "Disabled" - ], - "defaultValue": "DeployIfNotExists" - } - }, - "policyRule": { - "if": { - "field": "type", - "equals": "Microsoft.ContainerService/managedClusters" - }, - "then": { - "effect": "[parameters('effect')]", - "details": { - "type": "Microsoft.Chaos/targets", - "name": "Microsoft-AzureKubernetesServiceChaosMesh", - "roleDefinitionIds": [ - "/providers/Microsoft.Authorization/roleDefinitions/b24988ac-6180-42a0-ab88-20f7382dd24c" - ], - "deployment": { - "properties": { - "mode": "incremental", - "template": { - "$schema": "http://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "resourceName": { - "type": "string" - }, - "location": { - "type": "string" - } - }, - "variables": {}, - "resources": [ - { - "type": "Microsoft.ContainerService/managedClusters/providers/targets", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-AzureKubernetesServiceChaosMesh')]", - "location": "[parameters('location')]", - "properties": {} - }, - { - "type": "Microsoft.ContainerService/managedClusters/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-AzureKubernetesServiceChaosMesh/NetworkChaos-2.1')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.ContainerService/managedClusters', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh')]" - ], - "properties": {} - }, - { - "type": "Microsoft.ContainerService/managedClusters/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-AzureKubernetesServiceChaosMesh/PodChaos-2.1')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.ContainerService/managedClusters', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh')]" - ], - "properties": {} - }, - { - "type": "Microsoft.ContainerService/managedClusters/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-AzureKubernetesServiceChaosMesh/StressChaos-2.1')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.ContainerService/managedClusters', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh')]" - ], - "properties": {} - }, - { - "type": "Microsoft.ContainerService/managedClusters/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-AzureKubernetesServiceChaosMesh/IOChaos-2.1')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.ContainerService/managedClusters', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh')]" - ], - "properties": {} - }, - { - "type": "Microsoft.ContainerService/managedClusters/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-AzureKubernetesServiceChaosMesh/TimeChaos-2.1')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.ContainerService/managedClusters', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh')]" - ], - "properties": {} - }, - { - "type": "Microsoft.ContainerService/managedClusters/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-AzureKubernetesServiceChaosMesh/KernelChaos-2.1')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.ContainerService/managedClusters', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh')]" - ], - "properties": {} - }, - { - "type": "Microsoft.ContainerService/managedClusters/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-AzureKubernetesServiceChaosMesh/DNSChaos-2.1')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.ContainerService/managedClusters', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh')]" - ], - "properties": {} - }, - { - "type": "Microsoft.ContainerService/managedClusters/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-AzureKubernetesServiceChaosMesh/HTTPChaos-2.1')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.ContainerService/managedClusters', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh')]" - ], - "properties": {} - } - ], - "outputs": {} - }, - "parameters": { - "resourceName": { - "value": "[field('name')]" - }, - "location": { - "value": "[field('location')]" - } - } - } - } - } - } - } -} -``` --## Azure network security group policy definition --```json -{ - "displayName": "Deploy Chaos Target and Capability for Network Security Groups", - "policyType": "Custom", - "mode": "Indexed", - "description": "Deploys the target and capabilities for a network security group for onboarding to Azure Chaos Studio.", - "metadata": { - "category": "Chaos Studio" - }, - "parameters": { - "effect": { - "type": "String", - "metadata": { - "displayName": "Effect", - "description": "Enable or disable the execution of the policy" - }, - "allowedValues": [ - "DeployIfNotExists", - "Disabled" - ], - "defaultValue": "DeployIfNotExists" - } - }, - "policyRule": { - "if": { - "field": "type", - "equals": "Microsoft.Network/networkSecurityGroups" - }, - "then": { - "effect": "[parameters('effect')]", - "details": { - "type": "Microsoft.Chaos/targets", - "name": "Microsoft-NetworkSecurityGroup", - "roleDefinitionIds": [ - "/providers/Microsoft.Authorization/roleDefinitions/b24988ac-6180-42a0-ab88-20f7382dd24c" - ], - "deployment": { - "properties": { - "mode": "incremental", - "template": { - "$schema": "http://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "resourceName": { - "type": "string" - }, - "location": { - "type": "string" - } - }, - "variables": {}, - "resources": [ - { - "type": "Microsoft.Network/networkSecurityGroups/providers/targets", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-NetworkSecurityGroup')]", - "location": "[parameters('location')]", - "properties": {} - }, - { - "type": "Microsoft.Network/networkSecurityGroups/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-NetworkSecurityGroup/SecurityRule-1.0')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.Network/networkSecurityGroups', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-NetworkSecurityGroup')]" - ], - "properties": {} - } - ], - "outputs": {} - }, - "parameters": { - "resourceName": { - "value": "[field('name')]" - }, - "location": { - "value": "[field('location')]" - } - } - } - } - } - } - } -} -``` --## Azure Virtual Machines policy definition --```json -{ - "displayName": "Deploy Chaos Target and Capability for Virtual Machines (service-direct)", - "policyType": "Custom", - "mode": "Indexed", - "description": "Deploys the target and capabilities for a virtual machine for onboarding to Azure Chaos Studio (service-direct faults).", - "metadata": { - "category": "Chaos Studio" - }, - "parameters": { - "effect": { - "type": "String", - "metadata": { - "displayName": "Effect", - "description": "Enable or disable the execution of the policy" - }, - "allowedValues": [ - "DeployIfNotExists", - "Disabled" - ], - "defaultValue": "DeployIfNotExists" - } - }, - "policyRule": { - "if": { - "field": "type", - "equals": "Microsoft.Compute/virtualMachines" - }, - "then": { - "effect": "[parameters('effect')]", - "details": { - "type": "Microsoft.Chaos/targets", - "name": "Microsoft-VirtualMachine", - "roleDefinitionIds": [ - "/providers/Microsoft.Authorization/roleDefinitions/b24988ac-6180-42a0-ab88-20f7382dd24c" - ], - "deployment": { - "properties": { - "mode": "incremental", - "template": { - "$schema": "http://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "resourceName": { - "type": "string" - }, - "location": { - "type": "string" - } - }, - "variables": {}, - "resources": [ - { - "type": "Microsoft.Compute/virtualMachines/providers/targets", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-VirtualMachine')]", - "location": "[parameters('location')]", - "properties": {} - }, - { - "type": "Microsoft.Compute/virtualMachines/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-VirtualMachine/Shutdown-1.0')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.Compute/virtualMachines', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-VirtualMachine')]" - ], - "properties": {} - } - ], - "outputs": {} - }, - "parameters": { - "resourceName": { - "value": "[field('name')]" - }, - "location": { - "value": "[field('location')]" - } - } - } - } - } - } - } -} -``` --## Azure Virtual Machine Scale Sets policy definition --```json -{ - "displayName": "Deploy Chaos Target and Capability for Virtual Machine Scale Sets (service-direct)", - "policyType": "Custom", - "mode": "Indexed", - "description": "Deploys the target and capabilities for virtual machine scale sets for onboarding to Azure Chaos Studio (service-direct faults).", - "metadata": { - "category": "Chaos Studio" - }, - "parameters": { - "effect": { - "type": "String", - "metadata": { - "displayName": "Effect", - "description": "Enable or disable the execution of the policy" - }, - "allowedValues": [ - "DeployIfNotExists", - "Disabled" - ], - "defaultValue": "DeployIfNotExists" - } - }, - "policyRule": { - "if": { - "field": "type", - "equals": "Microsoft.Compute/virtualMachineScaleSets" - }, - "then": { - "effect": "[parameters('effect')]", - "details": { - "type": "Microsoft.Chaos/targets", - "name": "Microsoft-VirtualMachineScaleSet", - "roleDefinitionIds": [ - "/providers/Microsoft.Authorization/roleDefinitions/b24988ac-6180-42a0-ab88-20f7382dd24c" - ], - "deployment": { - "properties": { - "mode": "incremental", - "template": { - "$schema": "http://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "resourceName": { - "type": "string" - }, - "location": { - "type": "string" - } - }, - "variables": {}, - "resources": [ - { - "type": "Microsoft.Compute/virtualMachineScaleSets/providers/targets", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-VirtualMachineScaleSet')]", - "location": "[parameters('location')]", - "properties": {} - }, - { - "type": "Microsoft.Compute/virtualMachineScaleSets/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-VirtualMachineScaleSet/Shutdown-1.0')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.Compute/virtualMachineScaleSets', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-VirtualMachineScaleSet')]" - ], - "properties": {} - } - ], - "outputs": {} - }, - "parameters": { - "resourceName": { - "value": "[field('name')]" - }, - "location": { - "value": "[field('location')]" - } - } - } - } - } - } - } -} -``` --## Troubleshooting issues related to Azure Policy/RBAC -Please visit [Troubleshoot errors with using Azure Policy](../governance/policy/troubleshoot/general.md) to do this. ---## Next steps --* [Learn more about Chaos Studio](chaos-studio-overview.md) -* [Learn more about targets and capabilities](chaos-studio-targets-capabilities.md) |
| chaos-studio | Sample Template Experiment | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/sample-template-experiment.md | - Title: Azure Resource Manager template samples for chaos experiments -description: Sample Azure Resource Manager templates to create Azure Chaos Studio experiments. --- Previously updated : 11/10/2021-------# ARM template samples for experiments in Azure Chaos Studio --This article includes sample [Azure Resource Manager templates (ARM templates)](../azure-resource-manager/templates/syntax.md) to create a [chaos experiment](chaos-studio-chaos-experiments.md) in Azure Chaos Studio. Each sample includes a template file and a parameters file with sample values to provide to the template. --## Create an experiment (sample) --In this sample, we create a chaos experiment with a single target resource and a single CPU pressure fault. You can modify the experiment by referencing our [REST API](/rest/api/chaosstudio/experiments/create-or-update) and [fault library](chaos-studio-fault-library.md). --## Deploying templates --Once you've reviewed the template and parameter files, learn how to deploy them into your Azure subscription with the [Deploy resources with ARM templates and Azure portal](../azure-resource-manager/templates/deploy-portal.md) article. --### Template file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "experimentName": { - "type": "string", - "defaultValue": "simple-experiment", - "metadata": { - "description": "A name for the experiment." - } - }, - "location": { - "type": "string", - "defaultValue": "[resourceGroup().location]", - "metadata": { - "description": "A region where the experiment will be deployed." - } - }, - "chaosTargetResourceId": { - "type": "string", - "metadata": { - "description": "Resource ID of the chaos target. This is the full resource ID of the resource being targeted plus the target proxy resource." - } - } - }, - "functions": [], - "variables": {}, - "resources": [ - { - "type": "Microsoft.Chaos/experiments", - "apiVersion": "2024-01-01", - "name": "[parameters('experimentName')]", - "location": "[parameters('location')]", - "identity": { - "type": "SystemAssigned" - }, - "properties": { - "selectors": [ - { - "id": "Selector1", - "type": "List", - "targets": [ - { - "type": "ChaosTarget", - "id": "[parameters('chaosTargetResourceId')]" - } - ] - } - ], - "steps": [ - { - "name": "Step1", - "branches": [ - { - "name": "Branch1", - "actions": [ - { - "duration": "PT10M", - "name": "urn:csci:microsoft:agent:cpuPressure/1.0", - "parameters": [ - { - "key": "pressureLevel", - "value": "95" - } - ], - "selectorId": "Selector1", - "type": "continuous" - } - ] - } - ] - } - ] - } - } - ], - "outputs": {} -} -``` --### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "experimentName": { - "value": "my-first-experiment" - }, - "location": { - "value": "eastus" - }, - "chaosTargetResourceId": { - "value": "/subscriptions/<subscription-id>/resourceGroups/<rg-name>/providers/Microsoft.DocumentDB/databaseAccounts/<account-name>/providers/Microsoft.Chaos/targets/microsoft-cosmosdb" - } - } -} -``` --## Next steps --* [Learn more about Chaos Studio](chaos-studio-overview.md) -* [Learn more about chaos experiments](chaos-studio-chaos-experiments.md) |
| chaos-studio | Sample Template Targets | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/sample-template-targets.md | - Title: Resource Manager template samples for targets and capabilities in Chaos Studio -description: Sample Azure Resource Manager (ARM) templates to add resources to Azure Chaos Studio by using targets and capabilities. --- Previously updated : 11/10/2021-------# Azure Resource Manager template samples for targets and capabilities in Azure Chaos Studio --This article includes sample [Azure Resource Manager templates (ARM templates)](../azure-resource-manager/templates/syntax.md) to create [targets and capabilities](chaos-studio-targets-capabilities.md) to add a resource to Azure Chaos Studio. Each sample includes a template file and a parameters file with sample values to provide to the template. --## Add service-direct target and capabilities (single capability) --In this sample, we add an Azure Cosmos DB instance by using [targets and capabilities](chaos-studio-targets-capabilities.md). To modify the template for any service-direct target and capabilities, see the [fault library](chaos-studio-fault-library.md). --## Deploying templates --Once you've reviewed the template and parameter files, learn how to deploy them into your Azure subscription with the [Deploy resources with ARM templates and Azure portal](../azure-resource-manager/templates/deploy-portal.md) article. --### Template file --```json -{ - "$schema": "http://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "resourceName": { - "type": "string", - "metadata": { - "description": "The name of the resource being enabled." - } - }, - "resourceGroup": { - "type": "string", - "metadata": { - "description": "The name of the resource group where the resource being enabled is located." - } - }, - "location": { - "type": "string", - "defaultValue": "[resourceGroup().location]", - "metadata": { - "description": "Location" - } - } - }, - "variables": {}, - "resources": [ - { - "type": "Microsoft.DocumentDB/databaseAccounts/providers/targets", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-CosmosDB')]", - "location": "[parameters('location')]", - "properties": {} - }, - { - "type": "Microsoft.DocumentDB/databaseAccounts/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-CosmosDB/Failover-1.0')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.DocumentDB/databaseAccounts', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-CosmosDB')]" - ], - "properties": {} - } - ], - "outputs": {} -} -``` --### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "resourceName": { - "value": "my-cosmos-db" - }, - "resourceGroup": { - "value": "my-rg" - } - } -} -``` --## Add service-direct target and capabilities (multiple capabilities) --In this sample, we add an Azure Kubernetes Service cluster by using [targets and capabilities](chaos-studio-targets-capabilities.md). --### Template file --```json -{ - "$schema": "http://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "resourceName": { - "type": "string", - "metadata": { - "description": "The name of the resource being enabled." - } - }, - "resourceGroup": { - "type": "string", - "metadata": { - "description": "The name of the resource group where the resource being enabled is located." - } - }, - "location": { - "type": "string", - "defaultValue": "[resourceGroup().location]", - "metadata": { - "description": "Location" - } - } - }, - "variables": {}, - "resources": [ - { - "type": "Microsoft.ContainerService/managedClusters/providers/targets", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-AzureKubernetesServiceChaosMesh')]", - "location": "[parameters('location')]", - "properties": {} - }, - { - "type": "Microsoft.ContainerService/managedClusters/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-AzureKubernetesServiceChaosMesh/NetworkChaos-2.1')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.ContainerService/managedClusters', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh')]" - ], - "properties": {} - }, - { - "type": "Microsoft.ContainerService/managedClusters/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-AzureKubernetesServiceChaosMesh/PodChaos-2.1')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.ContainerService/managedClusters', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh')]" - ], - "properties": {} - }, - { - "type": "Microsoft.ContainerService/managedClusters/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-AzureKubernetesServiceChaosMesh/StressChaos-2.1')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.ContainerService/managedClusters', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh')]" - ], - "properties": {} - }, - { - "type": "Microsoft.ContainerService/managedClusters/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-AzureKubernetesServiceChaosMesh/IOChaos-2.1')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.ContainerService/managedClusters', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh')]" - ], - "properties": {} - }, - { - "type": "Microsoft.ContainerService/managedClusters/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-AzureKubernetesServiceChaosMesh/TimeChaos-2.1')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.ContainerService/managedClusters', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh')]" - ], - "properties": {} - }, - { - "type": "Microsoft.ContainerService/managedClusters/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-AzureKubernetesServiceChaosMesh/KernelChaos-2.1')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.ContainerService/managedClusters', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh')]" - ], - "properties": {} - }, - { - "type": "Microsoft.ContainerService/managedClusters/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-AzureKubernetesServiceChaosMesh/DNSChaos-2.1')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.ContainerService/managedClusters', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh')]" - ], - "properties": {} - }, - { - "type": "Microsoft.ContainerService/managedClusters/providers/targets/capabilities", - "apiVersion": "2023-11-01", - "name": "[concat(parameters('resourceName'), '/', 'Microsoft.Chaos/Microsoft-AzureKubernetesServiceChaosMesh/HTTPChaos-2.1')]", - "location": "[parameters('location')]", - "dependsOn": [ - "[concat(resourceId('Microsoft.ContainerService/managedClusters', parameters('resourceName')), '/', 'providers/Microsoft.Chaos/targets/Microsoft-AzureKubernetesServiceChaosMesh')]" - ], - "properties": {} - } - ], - "outputs": {} -} -``` --### Parameter file --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "resourceName": { - "value": "my-aks-cluster" - }, - "resourceGroup": { - "value": "my-rg" - } - } -} -``` --## Next steps --* [Learn more about Chaos Studio](chaos-studio-overview.md) -* [Learn more about targets and capabilities](chaos-studio-targets-capabilities.md) |
| chaos-studio | Troubleshooting | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/troubleshooting.md | - Title: Troubleshoot common Azure Chaos Studio problems -description: Learn to troubleshoot common problems when you use Azure Chaos Studio. ----- Previously updated : 11/10/2021----# Troubleshoot issues with Azure Chaos Studio --As you use Azure Chaos Studio, you might occasionally encounter some problems. This article explains common problems and troubleshooting steps. --## General troubleshooting tips --The following sources are useful when you troubleshoot problems with Chaos Studio: -- **Activity log**: The [Azure activity log](../azure-monitor/essentials/activity-log.md) has a record of all create, update, and delete operations in a subscription. These records include Chaos Studio operations like enabling a target or capabilities, installing the agent, and creating or running an experiment. Failures in the activity log indicate that a user action essential to using Chaos Studio might have failed to complete. Most service-direct faults also inject faults by executing an Azure Resource Manager operation, so the activity log also has the record of faults that were injected during an experiment for some service-direct faults.-- **Experiment details**: Experiment execution details show the status and errors of an individual experiment run. Opening a specific fault in experiment details shows the resources that failed and the error messages for a failure. Learn more about how to [access experiment details](chaos-studio-run-experiment.md#view-experiment-history-and-details).-- **Agent logs**: If you're using an agent-based fault, you might need to RDP or SSH in to the virtual machine (VM) to understand why the agent failed to run a fault. The instructions for accessing agent logs depend on the operating system:- * **Chaos Windows agent**: Agent logs are in the Windows Event Log in the Application category with the source `AzureChaosAgent`. The agent adds fault activity and regular health check (ability to authenticate to and communicate with the Chaos Studio agent service) events to this log. - * **Chaos Linux agent**: The Linux agent uses systemd to manage the agent process as a Linux service. To view the systemd journal for the agent (the events logged by the agent service), run the command `journalctl -u azure-chaos-agent`. -- **VM extension status**: If you're using an agent-based fault, verify that the VM extension is installed and healthy. In the Azure portal, go to your VM and go to **Extensions** or **Extensions + applications**. Select the `ChaosAgent` extension and look for the following fields:- * **Status** should show *Provisioning succeeded*. Any other status indicates that the agent failed to install. Verify that you meet all [system requirements](chaos-studio-limitations.md#limitations). Try to reinstall the agent. - * **Handler status** should show *Ready*. Any other status indicates that the agent installed but can't connect to Chaos Studio. Verify that you meet all [network requirements](chaos-studio-limitations.md#limitations) and that the user-assigned managed identity was added to the VM. Try to reboot. --## Problems when you add a resource --You might encounter the following problems when you add a resource. --### Resources don't show up in the targets list in the Azure portal -If you don't see the resources you want to enable in the Chaos Studio targets list, it might be because of any of the following problems: -* The resources aren't in [a supported region for Chaos Studio](https://azure.microsoft.com/global-infrastructure/services/?products=chaos-studio). -* The resources aren't of [a supported resource type in Chaos Studio](chaos-studio-fault-providers.md). -* The resources are in a subscription or resource group that's filtered out in the filters for the target list. Change the subscription and resource group filters to see your resources. --### Target or capability enablement fails or doesn't show correctly in the target list -If you see an error when you enable targets or capabilities, try the following steps: -1. Verify that you have appropriate permissions to the resources you're adding. Enabling a target or capabilities requires Microsoft.Chaos/\* permission at the scope of the resource. Built-in roles such as Contributor have wildcard read and write permission, which includes permission to all Microsoft.Chaos operations. -1. Wait a few minutes for the target and capability list to update. The Azure portal uses Azure Resource Graph to gather information on adding targets and capabilities. It can take up to five minutes for the update to propagate. -1. If the resource still shows *Not enabled*, try the following steps: - 1. Attempt to enable the resource again. - 2. If resource enablement still fails, go to the activity log and find the failed target create operation to see detailed error information. -1. If the resource shows *Enabled* but adding capabilities failed, try the following steps: - 1. Select **Manage actions** on the resource in the targets list. Check any capabilities that weren't checked and select **Save**. - 1. If capability enablement still fails, go to the activity log and find the failed target create operation to see detailed error information. --## Prerequisite problems --Some problems are caused by missing prerequisites. --### Agent-based faults fail on a virtual machine -Agent-based faults might fail for various reasons related to missing prerequisites: -* On Linux VMs, the [CPU Pressure](chaos-studio-fault-library.md#cpu-pressure), [Physical Memory Pressure](chaos-studio-fault-library.md#physical-memory-pressure), [Disk I/O pressure](chaos-studio-fault-library.md#linux-disk-io-pressure), and [Arbitrary Stress-ng Stress](chaos-studio-fault-library.md#arbitrary-stress-ng-stressor) faults all require that the [stress-ng utility](https://wiki.ubuntu.com/Kernel/Reference/stress-ng) is installed on your VM. For more information on how to install stress-ng, see the fault prerequisite sections. -* On either Linux or Windows VMs, the user-assigned managed identity provided during agent-based target enablement must also be added to the VM. -* On either Linux or Windows VMs, the system-assigned managed identity for the experiment must be granted the Reader role on the VM. (Seemingly elevated roles like Virtual Machine Contributor don't include the \*/Read operation that's necessary for the Chaos Studio agent to read the microsoft-agent target proxy resource on the VM.) --### Chaos agent won't install on virtual machine scale sets --Installing the Chaos agent on virtual machine scale sets might fail without showing an error if the virtual machine scale set upgrade policy is set to **Manual**. To check the virtual machine scale set upgrade policy: --1. Sign in to the Azure portal. -1. Select **Virtual Machine Scale Set**. -1. On the left pane, select **Upgrade policy**. -1. Check the **Upgrade mode** to see if it's set to **Manual - Existing instances must be manually upgraded**. --If the upgrade policy is set to **Manual**, you must upgrade your Azure Virtual Machine Scale Sets instances so that the Chaos agent installation can finish. --#### Upgrade instances from the Azure portal --You can upgrade your Virtual Machine Scale Sets instances from the Azure portal: --1. Sign in to the Azure portal. -1. Select **Virtual Machine Scale Set**. -1. On the left pane, select **Instances**. -1. Select all instances and select **Upgrade**. --#### Upgrade instances with the Azure CLI --You can upgrade your Virtual Machine Scale Sets instances with the Azure CLI: --- From the Azure CLI, use `az vmss update-instances` to manually upgrade your instances:-- ```azurecli - az vmss update-instances --resource-group myResourceGroup --name myScaleSet --instance-ids {instanceIds} - ``` --For more information, see [Bring VMs up to date with the latest scale set model](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-upgrade-policy). --### AKS Chaos Mesh faults fail -Azure Kubernetes Service (AKS) Chaos Mesh faults might fail for various reasons related to missing prerequisites: -* Chaos Mesh must first be installed on the AKS cluster before you use the AKS Chaos Mesh faults. For instructions, see the [Chaos Mesh faults on AKS tutorial](chaos-studio-tutorial-aks-portal.md#set-up-chaos-mesh-on-your-aks-cluster). -* Chaos Mesh must be version 2.0.4 or greater. You can get the Chaos Mesh version by connecting to your AKS cluster and running `helm version chaos-mesh`. -* Chaos Mesh must be installed with the namespace `chaos-testing`. Other namespace names for Chaos Mesh aren't supported. -* The AKS Cluster Admin role must be assigned to the system-assigned managed identity for the chaos experiment. --## Problems when you create or design an experiment --You might encounter problems when you create or design an experiment. --### When I add a fault, my resource doesn't show in the Target Resources list -When you add a fault, if you don't see the resource you want to target with a fault in the **Target Resources** list, it might be because of any of the following issues: -* The **Subscription** filter is set to exclude the subscription in which your target is deployed. Select the subscription filter and modify the selected subscriptions. -* The resource hasn't been added yet. Go to the **Targets** view and enable the target. Then close the **Add Fault** pane and reopen it to see an updated target list. -* The resource hasn't been enabled for the target type of that fault yet. See the [fault library](chaos-studio-fault-library.md) to see which target type is used for the fault. Then go to the **Targets** view and enable that target type. The type is either agent-based for microsoft-agent faults or service-direct for all other target types. Then close the **Add Fault** pane and reopen it to see an updated target list. -* The resource doesn't have the capability for that fault enabled yet. See the [fault library](chaos-studio-fault-library.md) to see the capability name for the fault. Then go to the **Targets** view and select **Manage actions** on the target resource. Select the checkbox for the capability that corresponds to the fault you're trying to run and select **Save**. Then close the **Add Fault** pane and reopen it to see an updated target list. -* The resource was recently added and hasn't appeared in Resource Graph yet. The **Target Resources** list is queried from Resource Graph. After a new target is enabled, it can take up to five minutes for the update to propagate to Resource Graph. Wait a few minutes, and then reopen the **Add Fault** pane. --### When I create an experiment, I get the error "The microsoft:agent provider requires a managed identity" --This error happens when the agent hasn't been deployed to your VM. For installation instructions, see [Create and run an experiment that uses agent-based faults](chaos-studio-tutorial-agent-based-portal.md). --### When I create an experiment, I get the error "The content media type 'null' is not supported. Only 'application/json' is supported" --You might encounter this error if you're creating your experiment by using an Azure Resource Manager template or the Chaos Studio REST API. The error indicates that there's malformed JSON in your experiment definition. Check to see if you have any syntax errors, such as mismatched braces or brackets ({} and \[\]). To check, use a JSON linter like Visual Studio Code. --## Problems when you run an experiment --You might encounter problems when you run an experiment. --### The execution status of my experiment after starting is "Failed" --From the **Experiments** list in the Azure portal, select the experiment name to see the **Experiment Overview**. In the **History** section, select **Details** next to the failed experiment run to see detailed error information. -- --Alternatively, use the REST API to obtain the experiment's execution details. Learn more in the [REST API sample article](chaos-studio-samples-rest-api.md). --```azurecli -az rest --method post --url "https://management.azure.com/{experimentId}/executions/{executionDetailsId}/getExecutionDetails?api-version={apiVersion}" -``` --### My agent-based fault failed with the error "Verify that the target is correctly added and proper read permissions are provided to the experiment msi" --This error might happen if you added the agent by using the Azure portal, which has a known issue. Enabling an agent-based target doesn't assign the user-assigned managed identity to the VM or virtual machine scale set. --To resolve this problem, go to the VM or virtual machine scale set in the Azure portal and go to **Identity**. Open the **User assigned** tab and add your user-assigned identity to the VM. After you're finished, you might need to reboot the VM for the agent to connect. --### My agent-based fault failed with the error "Agent is already performing another task" --This error will happen if you try to run multiple agent faults at the same time. Today the agent only supports running a single agent-fault at a time, and will fail if you define an experiment that runs multiple agent faults at the same time. --### The experiment didn't start or failed immediately --After starting an experiment, you might see an error message like: `The long-running operation has failed. InternalServerError. The target resource(s) could not be resolved. Error Code: OperationFailedException`. Usually, this indicates that the experiment's identity doesn't have the necessary permissions. --To resolve this error, ensure that the experiment's system-assigned or user-assigned managed identity has permission to all resources in the experiment. Learn more about permissions here: [Permissions and security in Azure Chaos Studio](chaos-studio-permissions-security.md). For example, if the experiment targets a virtual machine, navigate to the virtual machine's identity page and assign the "Virtual Machine Contributor" role to the experiment's managed identity. --## Problems when setting up a managed identity --### When I try to add a system-assigned/user-assigned managed identity to my existing experiment, it fails to save. --If you are trying to add a user-assigned or system-assigned managed identity to an experiment that **already** has a managed identity assigned to it, the experiment fails to deploy. You need to delete the existing user-assigned or system-assigned managed identity on the desired experiment **first** before adding your desired managed identity. --### When I run an experiment configured to automatically create and assign a custom role, I get the error "The target resource(s) could not be resolved. ErrorCode: AccessDenied. Target Resource(s):" --When the "Custom role permissions" checkbox is selected for an experiment, Chaos Studio creates and assigns a custom role with the necessary permissions to the experiment's identity. However, this is subject to the following role assignment and role definition limits: -* Each Azure subscription has a limit of 4000 role assignments. -* Each Microsoft Entra tenant has a limit of 5000 role definitions (or 2000 role definitions for Azure in China). --When one of these limits has been reached, this error will occur. To work around this, grant permissions to the experiment identity manually instead. |
| chaos-studio | Tutorial Schedule | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/chaos-studio/tutorial-schedule.md | - Title: Schedule a recurring experiment run with Chaos Studio -description: Set up a logic app that schedules a chaos experiment in Azure Chaos Studio to run periodically. --- Previously updated : 11/12/2021-------# Tutorial: Schedule a recurring experiment with Azure Chaos Studio --Azure Chaos Studio lets you run chaos experiments that intentionally fail part of your application or service to verify that it's resilient against those failures. It can be useful to run these chaos experiments periodically to ensure that your application's resilience hasn't regressed or to meet compliance requirements. In this tutorial, you use a [logic app](../logic-apps/logic-apps-overview.md) to trigger an experiment to run once a day. --In this tutorial, you learn how to: --> [!div class="checklist"] -> * Create a logic app. -> * Configure the logic app to trigger a chaos experiment to start once a day. -> * Test that the logic app is configured correctly. --## Prerequisites --- An Azure account with an active subscription. [Create an account for free](https://azure.microsoft.com/free/?WT.mc_id=A261C142F).-- A chaos experiment. [Create a chaos experiment by using the quickstart](chaos-studio-quickstart-azure-portal.md).-- All resources targeted in the chaos experiment must be [added to Chaos Studio](chaos-studio-targets-capabilities.md).--## Create a logic app -A logic app is an automated workflow that can execute based on a schedule. The logic app used in this tutorial starts a chaos experiment by using a recurrence schedule. --1. Sign in to the [Azure portal](https://portal.azure.com) with your Azure account credentials. On the Azure home page, select **Create a resource**. --1. On the Azure Marketplace menu, select **Integration** > **Logic App**. --  --1. On the **Create Logic App** pane, provide the information described here about the logic app that you want to create. --  -- | Property | Value | Description | - |-|-|-| - | **Subscription** | <*Azure-subscription-name*> | Your Azure subscription name. This example uses **Azure Chaos Studio Demo**. | - | **Resource group** | chaosstudiodemo | The name for the [Azure resource group](../azure-resource-manager/management/overview.md), which is used to organize related resources. This example creates a new resource group named **chaosstudiodemo**. | - | **Type** | Consumption | The [logic app resource type](../logic-apps/single-tenant-overview-compare.md). Set to **Consumption**. | - | **Name** | scheduleExperiment | Your logic app's name, which can contain only letters, numbers, hyphens, underscores, parentheses, and periods. This example uses **scheduleExperiment**. | - | **Location** | East US | The region where to store your logic app information. This example uses **East US**. | - | **Enable log analytics** | No | Set up diagnostic logging for the logic app. Set to **No**. | --1. When you're done, select **Review + create**. After Azure validates the information about your logic app, select **Create**. --1. After Azure deploys your app, select **Go to resource**. -- Azure opens the Logic Apps template selection pane, which shows an introduction video, commonly used triggers, and logic app template patterns. --## Add the Recurrence trigger -Next, add the Recurrence [trigger](../logic-apps/logic-apps-overview.md#logic-app-concepts), which runs the workflow based on a specified schedule. Every logic app must start with a trigger, which fires when a specific event happens or when new data meets a specific condition. --1. Scroll down past the video and common triggers sections to the **Templates** section and select **Blank Logic App**. --  --1. In the Logic Apps Designer search box, enter **recurrence** and select the trigger named **Recurrence**. --  --1. On the **Recurrence** shape, select the **ellipses** (**...**) button, and then select **Rename**. Rename the trigger with the description **Start chaos experiment every morning**. --  --1. Inside the trigger, change these properties as described and shown here. --  -- | Property | Required | Value | Description | - |-|-|-|-| - | **Interval** | Yes | 1 | The number of intervals to wait between checks | - | **Frequency** | Yes | Day | The unit of time to use for the recurrence | --1. Under **Interval** and **Frequency**, open the **Add new parameter** list. Select these properties to add to the trigger: -- * **At these hours** - * **At these minutes** --  --1. Now set the values for the properties as shown and described here. --  -- | Property | Value | Description | - |-|-|-| - | **At these hours** | 8 | This setting is available only when you set the **Frequency** to **Week** or **Day**. For this recurrence, select the hours of the day. This example runs at the **8**-hour mark. | - | **At these minutes** | 00 | This setting is available only when you set the **Frequency** to **Week** or **Day**. For this recurrence, select the minutes of the day. This example runs once at the zero-hour mark. | -- This trigger fires every weekday at 8:00 AM. The **Preview** box shows the recurrence schedule. For more information, see [Schedule tasks and workflows](../connectors/connectors-native-recurrence.md) and [Workflow actions and triggers](../logic-apps/logic-apps-workflow-actions-triggers.md#recurrence-trigger). --1. Save your logic app. On the designer toolbar, select **Save**. --## Add a run chaos experiment action -Now that you have a trigger, add an [action](../logic-apps/logic-apps-overview.md#logic-app-concepts) that starts the experiment. This tutorial uses the **Invoke resource operation** action to start the experiment. --1. In the Logic App Designer, under the Recurrence trigger, select **New step**. --1. Under **Choose an operation**, enter **Invoke resource operation**. Select the option under **Actions** named **Invoke resource operation**. --  --1. Set the correct **Tenant** where your experiment is stored and select **Sign in**. --1. Sign in to your Azure account for that tenant. --1. Now set the values for the action properties as shown and described here. --  -- | Property | Value | Description | - |-|-|-| - | **Subscription** | <*Azure-subscription-name*> | The name of the Azure subscription where your chaos experiment is deployed. This example uses **Azure Chaos Studio Demo**. | - | **Resource Group** | <*Resource-group-name*> | The name for the resource group where your chaos experiment is deployed. This example uses **chaosstudiodemo**. | - | **Resource Provider** | `Microsoft.Chaos` | The Chaos Studio resource provider. | - | **Short Resource Id** | `experiments/`<*Resource-group-name*> | The name of your chaos experiment preceded by **experiments/**. | - | **Client Api Version** | `2023-11-01` | The Chaos Studio REST API version. | - | **Action name** | `start` | The name of the Chaos Studio experiment action. Always **start**. | --1. Save your logic app. On the designer toolbar, select **Save**. --## Test the logic app -Now, test the logic app to make sure it successfully starts your experiment. --1. Close the Logic Apps Designer. --1. On the logic app overview, select **Run Trigger** > **Run**. --  --1. Go to your chaos experiment in the Azure portal and verify that **Status** is set to **Running**. --  --## Clean up resources --If you're not going to continue to use this application, delete the logic app with the following steps: --1. On the logic app overview, select **Delete**. -1. Enter the logic app name and select **Delete**. --## Next steps --Now that you've set a schedule for your experiment, you can: -> [!div class="nextstepaction"] -> [Run and manage your experiment](chaos-studio-run-experiment.md) |
| cloud-services | Cloud Services Diagnostics Powershell | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cloud-services/cloud-services-diagnostics-powershell.md | Remove-AzureServiceDiagnosticsExtension -ServiceName "MyService" -Role "WebRole" ## Next Steps * For more information on using Azure diagnostics and other techniques to troubleshoot problems, see [Enabling Diagnostics in Azure Cloud Services and Virtual Machines](cloud-services-dotnet-diagnostics.md).-* The [Diagnostics Configuration Schema](../azure-monitor/agents/diagnostics-extension-schema-windows.md) explains the various xml configurations options for the diagnostics extension. +* The [Diagnostics Configuration Schema](/azure/azure-monitor/agents/diagnostics-extension-schema-windows) explains the various xml configurations options for the diagnostics extension. * To learn how to enable the diagnostics extension for Virtual Machines, see [Create a Windows Virtual machine with monitoring and diagnostics using Azure Resource Manager Template](/azure/virtual-machines/extensions/diagnostics-template) |
| cloud-services | Cloud Services Dotnet Diagnostics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cloud-services/cloud-services-dotnet-diagnostics.md | -See [Azure Diagnostics Overview](../azure-monitor/agents/diagnostics-extension-overview.md) for a background on Azure Diagnostics. +See [Azure Diagnostics Overview](/azure/azure-monitor/agents/diagnostics-extension-overview) for a background on Azure Diagnostics. ## How to Enable Diagnostics in a Worker Role This walkthrough describes how to implement an Azure worker role that emits telemetry data using the .NET EventSource class. Azure Diagnostics is used to collect the telemetry data and store it in an Azure storage account. When you create a worker role, Visual Studio automatically enables Diagnostics 1.0 as part of the solution in Azure Software Development Kits (SDKs) for .NET 2.4 and earlier. The following instructions describe the process for creating the worker role, disabling Diagnostics 1.0 from the solution, and deploying Diagnostics 1.2 or 1.3 to your worker role. In the Visual Studio **Server Explorer**, navigate to the wadexample storage acc  ## Configuration File Schema-The Diagnostics configuration file defines values that are used to initialize diagnostic configuration settings when the diagnostics agent starts. See the [latest schema reference](../azure-monitor/agents/diagnostics-extension-versions.md) for valid values and examples. +The Diagnostics configuration file defines values that are used to initialize diagnostic configuration settings when the diagnostics agent starts. See the [latest schema reference](/azure/azure-monitor/agents/diagnostics-extension-versions) for valid values and examples. ## Troubleshooting-If you have trouble, see [Troubleshooting Azure Diagnostics](../azure-monitor/agents/diagnostics-extension-troubleshooting.md) for help with common problems. +If you have trouble, see [Troubleshooting Azure Diagnostics](/azure/azure-monitor/agents/diagnostics-extension-troubleshooting) for help with common problems. ## Next Steps-[See a list of related Azure virtual-machine diagnostic articles](../azure-monitor/agents/diagnostics-extension-overview.md) to change the data you collect, troubleshoot problems, or learn more about diagnostics in general. +[See a list of related Azure virtual-machine diagnostic articles](/azure/azure-monitor/agents/diagnostics-extension-overview) to change the data you collect, troubleshoot problems, or learn more about diagnostics in general. [EventSource Class]: /dotnet/api/system.diagnostics.tracing.eventsource |
| cloud-services | Cloud Services How To Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cloud-services/cloud-services-how-to-monitor.md | Most likely you have two **.cscfg** files, one named **ServiceConfiguration.clou ## Use Application Insights -When you publish the Cloud Service from Visual Studio, you have the option to send the diagnostic data to Application Insights. You can create the Application Insights Azure resource at that time or send the data to an existing Azure resource. Application Insights can monitor your cloud service for availability, performance, failures, and usage. Custom charts can be added to Application Insights so that you can see the data that matters the most. Role instance data can be collected by using the Application Insights SDK in your cloud service project. For more information on how to integrate Application Insights, see [Application Insights with Cloud Services](../azure-monitor/app/azure-web-apps-net-core.md). +When you publish the Cloud Service from Visual Studio, you have the option to send the diagnostic data to Application Insights. You can create the Application Insights Azure resource at that time or send the data to an existing Azure resource. Application Insights can monitor your cloud service for availability, performance, failures, and usage. Custom charts can be added to Application Insights so that you can see the data that matters the most. Role instance data can be collected by using the Application Insights SDK in your cloud service project. For more information on how to integrate Application Insights, see [Application Insights with Cloud Services](/azure/azure-monitor/app/azure-web-apps-net-core). While you can use Application Insights to display the performance counters (and the other settings) you specified through the Microsoft Azure Diagnostics extension, you only get a richer experience by integrating the Application Insights SDK into your worker and web roles. ## Next steps -- [Learn about Application Insights with Cloud Services](../azure-monitor/app/azure-web-apps-net-core.md)+- [Learn about Application Insights with Cloud Services](/azure/azure-monitor/app/azure-web-apps-net-core) - [Set up performance counters](diagnostics-performance-counters.md) |
| cloud-services | Cloud Services Performance Testing Visual Studio Profiler | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cloud-services/cloud-services-performance-testing-visual-studio-profiler.md | Congratulations! You got started with the profiler. ## Next Steps Instrumenting Azure binaries in the emulator isn't supported in the Visual Studio profiler, but if you want to test memory allocation, you can choose that option when profiling. You can also choose concurrency profiling, which helps you determine whether threads are wasting time competing for locks, or tier interaction profiling, which helps you track down performance problems when interacting between tiers of an application, most frequently between the data tier and a worker role. You can view the database queries that your app generates and use the profiling data to improve your use of the database. For information about tier interaction profiling, see the blog post [Walkthrough: Using the Tier Interaction Profiler in Visual Studio Team System 2010][3]. -[1]: ../azure-monitor/app/profiler.md +[1]: /azure/azure-monitor/app/profiler [2]: /previous-versions/azure/hh411542(v=azure.100) [3]: /archive/blogs/habibh/walkthrough-using-the-tier-interaction-profiler-in-visual-studio-team-system-2010 [4]: ./media/cloud-services-performance-testing-visual-studio-profiler/ProfilingLocally09.png |
| cloud-services | Diagnostics Performance Counters | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cloud-services/diagnostics-performance-counters.md | A performance counter can be added to your cloud service for either Azure Diagno ### Application Insights -Azure Application Insights for Cloud Services allows you specify what performance counters you want to collect. After you [add Application Insights to your project](../azure-monitor/app/azure-web-apps-net-core.md), a config file named **ApplicationInsights.config** is added to your Visual Studio project. This config file defines what type of information Application Insights collects and sends to Azure. +Azure Application Insights for Cloud Services allows you specify what performance counters you want to collect. After you [add Application Insights to your project](/azure/azure-monitor/app/azure-web-apps-net-core), a config file named **ApplicationInsights.config** is added to your Visual Studio project. This config file defines what type of information Application Insights collects and sends to Azure. Open the **ApplicationInsights.config** file and find the **ApplicationInsights** > **TelemetryModules** element. Each `<Add>` child-element defines a type of telemetry to collect, along with its configuration. The performance counter telemetry module type is `Microsoft.ApplicationInsights.Extensibility.PerfCounterCollector.PerformanceCollectorModule, Microsoft.AI.PerfCounterCollector`. If this element is already defined, don't add it a second time. Each performance counter to collect is defined under a node named `<Counters>`. Here's an example that collects drive performance counters: Application Insights automatically collects the following performance counters: * \Process(??APP_WIN32_PROC??)\IO Data Bytes/sec * \Processor(_Total)\% Processor Time -For more information, see [System performance counters in Application Insights](../azure-monitor/app/performance-counters.md) and [Application Insights for Azure Cloud Services](../azure-monitor/app/azure-web-apps-net-core.md). +For more information, see [System performance counters in Application Insights](/azure/azure-monitor/app/performance-counters) and [Application Insights for Azure Cloud Services](/azure/azure-monitor/app/azure-web-apps-net-core). ### Azure Diagnostics The Azure Diagnostics extension for Cloud Services allows you specify what perfo The performance counters you want to collect are defined in the **diagnostics.wadcfgx** file. Open this file in Visual Studio and find the **DiagnosticsConfiguration** > **PublicConfig** > **WadCfg** > **DiagnosticMonitorConfiguration** > **PerformanceCounters** element. Add a new **PerformanceCounterConfiguration** element as a child. This element has two attributes: `counterSpecifier` and `sampleRate`. The `counterSpecifier` attribute defines which system performance counter set (outlined in the previous section) to collect. The `sampleRate` value indicates how often that value is polled. As a whole, all performance counters are transferred to Azure according to the parent `PerformanceCounters` element's `scheduledTransferPeriod` attribute value. -For more information about the `PerformanceCounters` schema element, see the [Azure Diagnostics Schema](../azure-monitor/agents/diagnostics-extension-schema-windows.md#performancecounters-element). +For more information about the `PerformanceCounters` schema element, see the [Azure Diagnostics Schema](/azure/azure-monitor/agents/diagnostics-extension-schema-windows#performancecounters-element). The period defined by the `sampleRate` attribute uses the XML duration data type to indicate how often the performance counter is polled. In the following example, the rate is set to `PT3M`, which means `[P]eriod[T]ime[3][M]inutes`: every three minutes. As previously stated, the performance counters you want to collect are defined i ## Next steps -- [Application Insights for Azure Cloud Services](../azure-monitor/app/azure-web-apps-net-core.md)-- [System performance counters in Application Insights](../azure-monitor/app/performance-counters.md)+- [Application Insights for Azure Cloud Services](/azure/azure-monitor/app/azure-web-apps-net-core) +- [System performance counters in Application Insights](/azure/azure-monitor/app/performance-counters) - [Specifying a Counter Path](/windows/win32/perfctrs/specifying-a-counter-path)-- [Azure Diagnostics Schema - Performance Counters](../azure-monitor/agents/diagnostics-extension-schema-windows.md#performancecounters-element)+- [Azure Diagnostics Schema - Performance Counters](/azure/azure-monitor/agents/diagnostics-extension-schema-windows#performancecounters-element) |
| cloud-services | Resource Health For Cloud Services | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cloud-services/resource-health-for-cloud-services.md | -[Azure Resource Health](../service-health/resource-health-overview.md) for cloud services helps you diagnose and get support for service problems that affect your Cloud Service deployment, Roles & Role Instances. It reports on the current and past health of your cloud services at Deployment, Role & Role Instance level. +[Azure Resource Health](/azure/service-health/resource-health-overview) for cloud services helps you diagnose and get support for service problems that affect your Cloud Service deployment, Roles & Role Instances. It reports on the current and past health of your cloud services at Deployment, Role & Role Instance level. Azure status reports on problems that affect a broad set of Azure customers. Resource Health gives you a personalized dashboard of the health of your resources. Resource Health shows all the times that your resources were unavailable because of Azure service problems. This data makes it easy for you to see if a Service Level Agreement (SLA) was violated. |
| communication-services | Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/advanced-messaging/logs.md | -> The following refers to logs enabled through [Azure Monitor](../../../azure-monitor/overview.md) (see also [FAQ](../../../azure-monitor/overview.md#frequently-asked-questions)). To enable these logs for your Communications Services, see: [Enable logging in Diagnostic Settings](../analytics/enable-logging.md) +> The following refers to logs enabled through [Azure Monitor](/azure/azure-monitor/overview) (see also [FAQ](/azure/azure-monitor/overview#frequently-asked-questions)). To enable these logs for your Communications Services, see: [Enable logging in Diagnostic Settings](../analytics/enable-logging.md) ## ACSAdvancedMessagingOperations |
| communication-services | Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/advanced-messaging/metrics.md | -Azure Communication Services currently provides metrics for all Communication Services primitives. You can use [Azure Monitor metrics explorer](../../../azure-monitor/essentials/analyze-metrics.md) to: +Azure Communication Services currently provides metrics for all Communication Services primitives. You can use [Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics) to: - Plot your own charts. - Investigate abnormalities in your metric values. Primitives in Communication Services emit metrics for API requests. To find thes All API request metrics contain three dimensions that you can use to filter your metrics data. These dimensions can be aggregated together by using the `Count` aggregation type. They support all standard Azure Aggregation time series, including `Sum`, `Average`, `Min`, and `Max`. -For more information on supported aggregation types and time series aggregations, see [Azure Monitor Metrics aggregation and display explained](./../../../azure-monitor/essentials/metrics-aggregation-explained.md). +For more information on supported aggregation types and time series aggregations, see [Azure Monitor Metrics aggregation and display explained](/azure/azure-monitor/essentials/metrics-aggregation-explained). - **Operation**: All operations or routes that can be called on the Azure Communication Services Advanced Messaging gateway. - **Status Code**: The status code response sent after the request. |
| communication-services | Advisor Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/advisor-overview.md | -[Azure Advisor](../../advisor/advisor-overview.md) is a personalized cloud consultant that helps you follow best practices to optimize your Azure deployments. Azure Communication Services is onboarded to Azure Advisor and will post recommendations for ways to optimize your communication resources. You can view these recommendations in the [Azure portal](https://portal.azure.com) in the [Advisor blade](https://portal.azure.com/#blade/Microsoft_Azure_Expert/AdvisorMenuBlade/overview). Recommendations are stored in your [Azure Activity Log](../../azure-monitor/essentials/platform-logs-overview.md), and you can configure alerts for these recommendations via [ARM templates](../../advisor/advisor-alerts-arm.md) or the [portal](../../advisor/advisor-alerts-portal.md). +[Azure Advisor](/azure/advisor/advisor-overview) is a personalized cloud consultant that helps you follow best practices to optimize your Azure deployments. Azure Communication Services is onboarded to Azure Advisor and will post recommendations for ways to optimize your communication resources. You can view these recommendations in the [Azure portal](https://portal.azure.com) in the [Advisor blade](https://portal.azure.com/#blade/Microsoft_Azure_Expert/AdvisorMenuBlade/overview). Recommendations are stored in your [Azure Activity Log](/azure/azure-monitor/essentials/platform-logs-overview), and you can configure alerts for these recommendations via [ARM templates](/azure/advisor/advisor-alerts-arm) or the [portal](/azure/advisor/advisor-alerts-portal). ## Install the latest SDKs |
| communication-services | Chat Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/chat-metrics.md | -Azure Communication Services currently provides metrics for all Communication Services primitives. You can use [Azure Metrics Explorer](../../../azure-monitor\essentials\metrics-getting-started.md) to: +Azure Communication Services currently provides metrics for all Communication Services primitives. You can use [Azure Metrics Explorer](/azure/azure-monitor/essentials/metrics-getting-started) to: - Plot your own charts. - Investigate abnormalities in your metric values. Primitives in Communication Services emit metrics for API requests. To find thes All API request metrics contain three dimensions that you can use to filter your metrics data. These dimensions can be aggregated together by using the `Count` aggregation type. They support all standard Azure Aggregation time series, including `Sum`, `Average`, `Min`, and `Max`. -For more information on supported aggregation types and time series aggregations, see [Advanced features of Azure Metrics Explorer](../../../azure-monitor/essentials/metrics-charts.md#aggregation). +For more information on supported aggregation types and time series aggregations, see [Advanced features of Azure Metrics Explorer](/azure/azure-monitor/essentials/metrics-charts#aggregation). - **Operation**: All operations or routes that can be called on the Communication Services Chat gateway. - **Status Code**: The status code response sent after the request. If a request is made to an operation that isn't recognized, you receive a "Bad R ## Next steps -Learn more about [Data Platform Metrics](../../../azure-monitor/essentials/data-platform-metrics.md). +Learn more about [Data Platform Metrics](/azure/azure-monitor/essentials/data-platform-metrics). |
| communication-services | Enable Logging | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/enable-logging.md | -Communications Services provides monitoring and analytics features via [Azure Monitor Logs overview](../../../azure-monitor/logs/data-platform-logs.md) and [Azure Monitor Metrics](../../../azure-monitor/essentials/data-platform-metrics.md). Each Azure resource requires its own diagnostic setting, which defines the following criteria: +Communications Services provides monitoring and analytics features via [Azure Monitor Logs overview](/azure/azure-monitor/logs/data-platform-logs) and [Azure Monitor Metrics](/azure/azure-monitor/essentials/data-platform-metrics). Each Azure resource requires its own diagnostic setting, which defines the following criteria: - Categories of logs and metric data sent to the destinations defined in the setting. The available categories will vary for different resource types. - One or more destinations to send the logs. Current destinations include Log Analytics workspace, Event Hubs, and Azure Storage. - A single diagnostic setting can define no more than one of each of the destinations. If you want to send data to more than one of a particular destination type (for example, two different Log Analytics workspaces), then create multiple settings. Each resource can have up to five diagnostic settings. -The following are instructions for configuring your Azure Monitor resource to start creating logs and metrics for your Communications Services. For detailed documentation about using Diagnostic Settings across all Azure resources, see: [Diagnostic Settings](../../../azure-monitor/essentials/diagnostic-settings.md). +The following are instructions for configuring your Azure Monitor resource to start creating logs and metrics for your Communications Services. For detailed documentation about using Diagnostic Settings across all Azure resources, see: [Diagnostic Settings](/azure/azure-monitor/essentials/diagnostic-settings). These instructions apply to the following Communications Services logs: Click on the "Add diagnostic setting" link (note the various logs and metrics so ## Adding a Diagnostic Setting -You'll then be prompted to choose a name for your Diagnostic Setting, which is useful if you have many Azure resources you are monitoring. You'll also be prompted to select the log and metric data sources you wish to monitor as either logs or metrics. See [Azure Monitor data platform](../../../azure-monitor/data-platform.md) for more detail on the difference. +You'll then be prompted to choose a name for your Diagnostic Setting, which is useful if you have many Azure resources you are monitoring. You'll also be prompted to select the log and metric data sources you wish to monitor as either logs or metrics. See [Azure Monitor data platform](/azure/azure-monitor/data-platform) for more detail on the difference. :::image type="content" source="media\enable-logging\diagnostic-setting-categories-details-acs.png" alt-text="Adding a Diagnostic Setting"::: ## Choose Destinations -You'll also be prompted to select a destination to store the logs. Platform logs and metrics can be sent to the destinations in the following table, which is also included in Azure Monitor documentation in deeper detail: [Create diagnostic settings to send platform logs and metrics to different destinations.](../../../azure-monitor/essentials/diagnostic-settings.md?tabs=CMD) +You'll also be prompted to select a destination to store the logs. Platform logs and metrics can be sent to the destinations in the following table, which is also included in Azure Monitor documentation in deeper detail: [Create diagnostic settings to send platform logs and metrics to different destinations.](/azure/azure-monitor/essentials/diagnostic-settings?tabs=CMD) | Destination | Description | |:|:|-| [Log Analytics workspace](../../../azure-monitor/logs/log-analytics-workspace-overview.md) | Sending logs and metrics to a Log Analytics workspace allows you to analyze them with other monitoring data collected by Azure Monitor using powerful log queries and also to use other Azure Monitor features such as alerts and visualizations. <br><br> If you don't have a Log Analytics workspace to send your data to, you must [create one before you proceed.](../../../azure-monitor/logs/quick-create-workspace.md) | +| [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-workspace-overview) | Sending logs and metrics to a Log Analytics workspace allows you to analyze them with other monitoring data collected by Azure Monitor using powerful log queries and also to use other Azure Monitor features such as alerts and visualizations. <br><br> If you don't have a Log Analytics workspace to send your data to, you must [create one before you proceed.](/azure/azure-monitor/logs/quick-create-workspace) | | [Event Hubs](../../../event-hubs/index.yml) | Sending logs and metrics to Event Hubs allows you to stream data to external systems such as third-party SIEMs and other log analytics solutions. | | [Azure storage account](../../../storage/blobs/index.yml) | Archiving logs and metrics to an Azure storage account is useful for audit, static analysis, or backup. Compared to Azure Monitor Logs and a Log Analytics workspace, Azure storage is less expensive and logs can be kept there indefinitely. | They're all viable and flexible options that can adapt to your specific storage ## Log Analytics Workspace for additional analytics features -By choosing to send your logs to a [Log Analytics workspace](../../../azure-monitor/logs/log-analytics-overview.md) destination, you enable more features within Azure Monitor generally and for your Communications Services. Log Analytics is a tool within Azure portal used to create, edit, and run [queries](../../../azure-monitor/logs/queries.md) with data in your Azure Monitor logs and metrics and [Workbooks](../../../azure-monitor/visualize/workbooks-overview.md), [alerts](../../../azure-monitor/alerts/alerts-log.md), [notification actions](../../../azure-monitor/alerts/action-groups.md), [REST API access](/rest/api/loganalytics/), and many others. If you don't have a Log Analytics workspace, you must [create one before you proceed.](../../../azure-monitor/logs/quick-create-workspace.md) +By choosing to send your logs to a [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-overview) destination, you enable more features within Azure Monitor generally and for your Communications Services. Log Analytics is a tool within Azure portal used to create, edit, and run [queries](/azure/azure-monitor/logs/queries) with data in your Azure Monitor logs and metrics and [Workbooks](/azure/azure-monitor/visualize/workbooks-overview), [alerts](/azure/azure-monitor/alerts/alerts-log), [notification actions](/azure/azure-monitor/alerts/action-groups), [REST API access](/rest/api/loganalytics/), and many others. If you don't have a Log Analytics workspace, you must [create one before you proceed.](/azure/azure-monitor/logs/quick-create-workspace) -For your Communications Services logs, we've provided a useful [default query pack](../../../azure-monitor/logs/query-packs.md#default-query-pack) to provide an initial set of insights to quickly analyze and understand your data. These query packs are described here: [Log Analytics for Communications Services](query-call-logs.md). +For your Communications Services logs, we've provided a useful [default query pack](/azure/azure-monitor/logs/query-packs#default-query-pack) to provide an initial set of insights to quickly analyze and understand your data. These query packs are described here: [Log Analytics for Communications Services](query-call-logs.md). ## Next Steps -- If you don't have a Log Analytics workspace to send your data to, you must create one before you proceed. See: [Create a Log Analytics workspace](../../../azure-monitor/logs/quick-create-workspace.md)+- If you don't have a Log Analytics workspace to send your data to, you must create one before you proceed. See: [Create a Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace) -- You may start a Diagnostic Setting to use certain capabilities by enabling collection for all logs, however you should monitor costs associated with logs from Diagnostic Settings, see: [Controlling costs](../../../azure-monitor/essentials/diagnostic-settings.md#controlling-costs)+- You may start a Diagnostic Setting to use certain capabilities by enabling collection for all logs, however you should monitor costs associated with logs from Diagnostic Settings, see: [Controlling costs](/azure/azure-monitor/essentials/diagnostic-settings#controlling-costs) |
| communication-services | Call Automation Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/insights/call-automation-insights.md | -Within your Communications Resource, we've provided an **Insights Preview** feature that displays many data visualizations conveying insights from the Azure Monitor logs and metrics monitored for your Communications Services. The visualizations within Insights are made possible via [Azure Monitor Workbooks](../../../../azure-monitor/visualize/workbooks-overview.md). In order to take advantage of Workbooks, follow the instructions outlined in [Enable Azure Monitor in Diagnostic Settings](../enable-logging.md). To enable Workbooks, you need to send your logs to a [Log Analytics workspace](../../../../azure-monitor/logs/log-analytics-overview.md) destination. +Within your Communications Resource, we've provided an **Insights Preview** feature that displays many data visualizations conveying insights from the Azure Monitor logs and metrics monitored for your Communications Services. The visualizations within Insights are made possible via [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview). In order to take advantage of Workbooks, follow the instructions outlined in [Enable Azure Monitor in Diagnostic Settings](../enable-logging.md). To enable Workbooks, you need to send your logs to a [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-overview) destination. :::image type="content" source="..\media\workbooks\insights-overview-2.png" alt-text="Screenshot of Communication Services Insights dashboard."::: ## Prerequisites - In order to take advantage of Workbooks, follow the instructions outlined in [Enable Azure Monitor in Diagnostic Settings](../enable-logging.md). You need to enable `Operational Call Automation Logs`.-- To use Workbooks, you need to send your logs to a [Log Analytics workspace](../../../../azure-monitor/logs/log-analytics-overview.md) destination. +- To use Workbooks, you need to send your logs to a [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-overview) destination. ## Accessing Azure Insights for Communication Services The **Call Automation** tab displays data about calls placed or answered using C ## More information about workbooks -For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](../../../../azure-monitor/visualize/workbooks-overview.md) documentation. +For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview) documentation. ## Editing dashboards Editing these dashboards doesn't modify the **Insights** tab, but rather creates :::image type="content" source="..\media\workbooks\workbooks-tab.png" alt-text="Screenshot of the workbooks tab."::: -For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](../../../../azure-monitor/visualize/workbooks-overview.md) documentation. +For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview) documentation. |
| communication-services | Call Recording Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/insights/call-recording-insights.md | -Within your Communications Resource, we've provided an **Insights Preview** feature that displays many data visualizations conveying insights from the Azure Monitor logs and metrics monitored for your Communications Services. The visualizations within Insights are made possible via [Azure Monitor Workbooks](../../../../azure-monitor/visualize/workbooks-overview.md). In order to take advantage of Workbooks, follow the instructions outlined in [Enable Azure Monitor in Diagnostic Settings](../enable-logging.md). To enable Workbooks, you need to send your logs to a [Log Analytics workspace](../../../../azure-monitor/logs/log-analytics-overview.md) destination. +Within your Communications Resource, we've provided an **Insights Preview** feature that displays many data visualizations conveying insights from the Azure Monitor logs and metrics monitored for your Communications Services. The visualizations within Insights are made possible via [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview). In order to take advantage of Workbooks, follow the instructions outlined in [Enable Azure Monitor in Diagnostic Settings](../enable-logging.md). To enable Workbooks, you need to send your logs to a [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-overview) destination. :::image type="content" source="..\media\workbooks\insights-overview-2.png" alt-text="Screenshot of Communication Services Insights dashboard."::: ## Prerequisites - In order to take advantage of Workbooks, follow the instructions outlined in [Enable Azure Monitor in Diagnostic Settings](../enable-logging.md). You need to enable `Call Recording Summary Logs`.-- To use Workbooks, you need to send your logs to a [Log Analytics workspace](../../../../azure-monitor/logs/log-analytics-overview.md) destination. +- To use Workbooks, you need to send your logs to a [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-overview) destination. ## Accessing Azure Insights for Communication Services The **Recording** tab displays data relevant to total recordings, recording form ## More information about workbooks -For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](../../../../azure-monitor/visualize/workbooks-overview.md) documentation. +For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview) documentation. ## Editing dashboards Editing these dashboards doesn't modify the **Insights** tab, but rather creates :::image type="content" source="..\media\workbooks\workbooks-tab.png" alt-text="Screenshot of the workbooks tab."::: -For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](../../../../azure-monitor/visualize/workbooks-overview.md) documentation. +For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview) documentation. |
| communication-services | Chat Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/insights/chat-insights.md | -Within your Communications Resource, we've provided an **Insights Preview** feature that displays many data visualizations conveying insights from the Azure Monitor logs and metrics monitored for your Communications Services. The visualizations within Insights are made possible via [Azure Monitor Workbooks](../../../../azure-monitor/visualize/workbooks-overview.md). In order to take advantage of Workbooks, follow the instructions outlined in [Enable Azure Monitor in Diagnostic Settings](../enable-logging.md). To enable Workbooks, you need to send your logs to a [Log Analytics workspace](../../../../azure-monitor/logs/log-analytics-overview.md) destination. +Within your Communications Resource, we've provided an **Insights Preview** feature that displays many data visualizations conveying insights from the Azure Monitor logs and metrics monitored for your Communications Services. The visualizations within Insights are made possible via [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview). In order to take advantage of Workbooks, follow the instructions outlined in [Enable Azure Monitor in Diagnostic Settings](../enable-logging.md). To enable Workbooks, you need to send your logs to a [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-overview) destination. :::image type="content" source="..\media\workbooks\insights-overview-2.png" alt-text="Screenshot of Communication Services Insights dashboard."::: ## Prerequisites - In order to take advantage of Workbooks, follow the instructions outlined in [Enable Azure Monitor in Diagnostic Settings](../enable-logging.md). You need to enable `Operational Chat Logs`, `Operational Authentication Logs`.-- To use Workbooks, you need to send your logs to a [Log Analytics workspace](../../../../azure-monitor/logs/log-analytics-overview.md) destination. +- To use Workbooks, you need to send your logs to a [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-overview) destination. ## Accessing Azure Insights for Communication Services The **Chat** tab displays the data for all chat-related operations and their res ## More information about workbooks -For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](../../../../azure-monitor/visualize/workbooks-overview.md) documentation. +For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview) documentation. ## Editing dashboards Editing these dashboards doesn't modify the **Insights** tab, but rather creates :::image type="content" source="..\media\workbooks\workbooks-tab.png" alt-text="Screenshot of the workbooks tab."::: -For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](../../../../azure-monitor/visualize/workbooks-overview.md) documentation. +For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview) documentation. |
| communication-services | Email Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/insights/email-insights.md | -Within your Communications Resource, we've provided an **Insights Preview** feature that displays many data visualizations conveying insights from the Azure Monitor logs and metrics monitored for your Communications Services. The visualizations within Insights are made possible via [Azure Monitor Workbooks](../../../../azure-monitor/visualize/workbooks-overview.md). In order to take advantage of Workbooks, follow the instructions outlined in [Enable Azure Monitor in Diagnostic Settings](../enable-logging.md). To enable Workbooks, you need to send your logs to a [Log Analytics workspace](../../../../azure-monitor/logs/log-analytics-overview.md) destination. +Within your Communications Resource, we've provided an **Insights Preview** feature that displays many data visualizations conveying insights from the Azure Monitor logs and metrics monitored for your Communications Services. The visualizations within Insights are made possible via [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview). In order to take advantage of Workbooks, follow the instructions outlined in [Enable Azure Monitor in Diagnostic Settings](../enable-logging.md). To enable Workbooks, you need to send your logs to a [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-overview) destination. :::image type="content" source="..\media\workbooks\insights-overview-2.png" alt-text="Screenshot of Communication Services Insights dashboard."::: ## Prerequisites - In order to take advantage of Workbooks, follow the instructions outlined in [Enable Azure Monitor in Diagnostic Settings](../enable-logging.md). You need to enable `Email Service Send Mail Logs`, `Email Service Delivery Status Update Logs` , `Email Service User Engagement Logs.`-- To use Workbooks, you need to send your logs to a [Log Analytics workspace](../../../../azure-monitor/logs/log-analytics-overview.md) destination. +- To use Workbooks, you need to send your logs to a [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-overview) destination. ## Accessing Azure Insights for Communication Services Email failure rate represents the different types of unsuccessful email deliveri ## More information about workbooks -For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](../../../../azure-monitor/visualize/workbooks-overview.md) documentation. +For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview) documentation. ## Editing dashboards Editing these dashboards doesn't modify the **Insights** tab, but rather creates :::image type="content" source="../media/workbooks/workbooks-tab.png" alt-text="Screenshot of the workbooks tab."::: -For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](../../../../azure-monitor/visualize/workbooks-overview.md) documentation. +For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview) documentation. |
| communication-services | Rooms Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/insights/rooms-insights.md | -Within your Communications Resource, we've provided a **Rooms Insights** feature that displays many data visualizations conveying insights from the Azure Monitor logs and metrics monitored for Rooms. The visualizations within Insights are made possible via [Azure Monitor Workbooks](../../../../azure-monitor/visualize/workbooks-overview.md). In order to take advantage of Workbooks, follow the instructions outlined in [Enable Azure Monitor in Diagnostic Settings](../enable-logging.md). To enable Workbooks, you need to send your logs to a [Log Analytics workspace](../../../../azure-monitor/logs/log-analytics-overview.md) destination. +Within your Communications Resource, we've provided a **Rooms Insights** feature that displays many data visualizations conveying insights from the Azure Monitor logs and metrics monitored for Rooms. The visualizations within Insights are made possible via [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview). In order to take advantage of Workbooks, follow the instructions outlined in [Enable Azure Monitor in Diagnostic Settings](../enable-logging.md). To enable Workbooks, you need to send your logs to a [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-overview) destination. :::image type="content" source="..\media\workbooks\rooms-insights\rooms-insights-overview.png" alt-text="Screenshot of Rooms Communication Services Insights dashboard."::: ## Prerequisites - In order to take advantage of Workbooks, follow the instructions outlined in [Enable Azure Monitor in Diagnostic Settings](../enable-logging.md). You need to enable `Operational Rooms Logs`-- To use Workbooks, you need to send your logs to a [Log Analytics workspace](../../../../azure-monitor/logs/log-analytics-overview.md) destination. +- To use Workbooks, you need to send your logs to a [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-overview) destination. ## Accessing Rooms Insights for Communication Services The **Rooms** tab displays Rooms API success Rate, Rooms API Volume by Operation ## More information about workbooks -For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](../../../../azure-monitor/visualize/workbooks-overview.md) documentation. +For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview) documentation. ## Editing dashboards The **Rooms Insights** dashboards provided with your **Communication Service** r :::image type="content" source="..\media\workbooks\rooms-insights\rooms-insights-edit.png" alt-text="Screenshot of Rooms insights editing process." lightbox="..\media\workbooks\rooms-insights\rooms-insights-edit.png"::: -Editing these dashboards doesn't modify the **Insights** tab, but rather creates a separate workbook that can be accessed on your resourceÆs Workbooks tab: +Editing these dashboards doesn't modify the **Insights** tab, but rather creates a separate workbook that can be accessed on your resource∩┐╜s Workbooks tab: :::image type="content" source="..\media\workbooks\workbooks-tab.png" alt-text="Screenshot of the workbooks tab."::: -For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](../../../../azure-monitor/visualize/workbooks-overview.md) documentation. +For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview) documentation. |
| communication-services | Sms Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/insights/sms-insights.md | The SMS Insights dashboard in your communication resource shows data visualizati ## Prerequisites - In order to take advantage of Workbooks, follow the instructions outlined in [Enable Azure Monitor in Diagnostic Settings](../enable-logging.md). You need to enable `SMS Operational Logs`-- To use Workbooks, you need to send your logs to a [Log Analytics workspace](../../../../azure-monitor/logs/log-analytics-overview.md) destination. +- To use Workbooks, you need to send your logs to a [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-overview) destination. ## Accessing Azure Insights for Communication Services Editing these dashboards doesn't modify the **Insights** tab, but rather creates :::image type="content" source="..\media\workbooks\workbooks-tab.png" alt-text="Screenshot of the workbooks tab."::: -For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](../../../../azure-monitor/visualize/workbooks-overview.md) documentation. +For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview) documentation. |
| communication-services | Voice And Video Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/insights/voice-and-video-insights.md | -Within your Communications Resource, we've provided an **Insights Preview** feature that displays many data visualizations conveying insights from the Azure Monitor logs and metrics monitored for your Communications Services. The visualizations within Insights are made possible via [Azure Monitor Workbooks](../../../../azure-monitor/visualize/workbooks-overview.md). In order to take advantage of Workbooks, follow the instructions outlined in [Enable Azure Monitor in Diagnostic Settings](../enable-logging.md). To enable Workbooks, you need to send your logs to a [Log Analytics workspace](../../../../azure-monitor/logs/log-analytics-overview.md) destination. +Within your Communications Resource, we've provided an **Insights Preview** feature that displays many data visualizations conveying insights from the Azure Monitor logs and metrics monitored for your Communications Services. The visualizations within Insights are made possible via [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview). In order to take advantage of Workbooks, follow the instructions outlined in [Enable Azure Monitor in Diagnostic Settings](../enable-logging.md). To enable Workbooks, you need to send your logs to a [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-overview) destination. :::image type="content" source="..\media\workbooks\insights-overview-2.png" alt-text="Screenshot of Communication Services Insights dashboard."::: ## Prerequisites - In order to take advantage of Workbooks, follow the instructions outlined in [Enable Azure Monitor in Diagnostic Settings](../enable-logging.md). You need to enable `Operational Authentication Logs`, `Call Summary Logs`, `Call Diagnostic Logs`.-- To use Workbooks, you need to send your logs to a [Log Analytics workspace](../../../../azure-monitor/logs/log-analytics-overview.md) destination. +- To use Workbooks, you need to send your logs to a [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-overview) destination. ## Accessing Azure Insights for Communication Services And clicking on a participant displays a list of the outgoing streams for that p ## More information about workbooks -For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](../../../../azure-monitor/visualize/workbooks-overview.md) documentation. +For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview) documentation. ## Editing dashboards Editing these dashboards doesn't modify the **Insights** tab, but rather creates :::image type="content" source="..\media\workbooks\workbooks-tab.png" alt-text="Screenshot of the workbooks tab."::: -For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](../../../../azure-monitor/visualize/workbooks-overview.md) documentation. +For an in-depth description of workbooks, refer to the [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview) documentation. |
| communication-services | Call Automation Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/logs/call-automation-logs.md | Azure Communication Services offers logging capabilities that you can use to mon ## Prerequisites -Azure Communication Services provides monitoring and analytics features via [Azure Monitor Logs](../../../../azure-monitor/logs/data-platform-logs.md) and [Azure Monitor Metrics](../../../../azure-monitor/essentials/data-platform-metrics.md). Each Azure resource requires its own diagnostic setting, which defines the following criteria: +Azure Communication Services provides monitoring and analytics features via [Azure Monitor Logs](/azure/azure-monitor/logs/data-platform-logs) and [Azure Monitor Metrics](/azure/azure-monitor/essentials/data-platform-metrics). Each Azure resource requires its own diagnostic setting, which defines the following criteria: * Categories of log and metric data sent to the destinations that the setting defines. The available categories vary by resource type. * One or more destinations to send the logs. Current destinations include Log Analytics workspace, Azure Event Hubs, and Azure Storage. |
| communication-services | Call Automation Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/logs/call-automation-metrics.md | Primitives in Communication Services emit metrics for API requests. To find thes All API request metrics contain three dimensions that you can use to filter your metrics data. These dimensions can be aggregated together by using the `Count` aggregation type. They support all standard Azure Aggregation time series, including `Sum`, `Average`, `Min`, and `Max`. -For more information on supported aggregation types and time series aggregations, see [Advanced features of Azure Metrics Explorer](../../../../azure-monitor/essentials/metrics-charts.md#aggregation). +For more information on supported aggregation types and time series aggregations, see [Advanced features of Azure Metrics Explorer](/azure/azure-monitor/essentials/metrics-charts#aggregation). - **Operation**: All operations or routes that can be called on the Communication Services Chat gateway. - **Status Code**: The status code response sent after the request. The following operations are available on Call Automation API request metrics. ## Next steps -Learn more about [Data Platform Metrics](../../../../azure-monitor/essentials/data-platform-metrics.md). +Learn more about [Data Platform Metrics](/azure/azure-monitor/essentials/data-platform-metrics). |
| communication-services | Chat Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/logs/chat-logs.md | -> The following refers to logs enabled through [Azure Monitor](../../../../azure-monitor/overview.md) (see also [FAQ](../../../../azure-monitor/overview.md#frequently-asked-questions)). To enable these logs for your Communications Services, see: [Enable logging in Diagnostic Settings](../enable-logging.md) +> The following refers to logs enabled through [Azure Monitor](/azure/azure-monitor/overview) (see also [FAQ](/azure/azure-monitor/overview#frequently-asked-questions)). To enable these logs for your Communications Services, see: [Enable logging in Diagnostic Settings](../enable-logging.md) ## Resource log categories |
| communication-services | Closed Captions Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/logs/closed-captions-logs.md | -The content in this article refers to logs enabled through [Azure Monitor](../../../../azure-monitor/overview.md) (see also [FAQ](../../../../azure-monitor/overview.md#frequently-asked-questions)). To enable these logs for Communication Services, see [Enable logging in diagnostic settings](../enable-logging.md). +The content in this article refers to logs enabled through [Azure Monitor](/azure/azure-monitor/overview) (see also [FAQ](/azure/azure-monitor/overview#frequently-asked-questions)). To enable these logs for Communication Services, see [Enable logging in diagnostic settings](../enable-logging.md). ## Usage log schema |
| communication-services | Email Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/logs/email-logs.md | Azure Communication Services offers logging capabilities that you can use to mon ## Prerequisites -Azure Communications Services provides monitoring and analytics features via [Azure Monitor Logs overview](../../../../azure-monitor/logs/data-platform-logs.md) and [Azure Monitor Metrics](../../../../azure-monitor/essentials/data-platform-metrics.md). Each Azure resource requires its own diagnostic setting, which defines the following criteria: +Azure Communications Services provides monitoring and analytics features via [Azure Monitor Logs overview](/azure/azure-monitor/logs/data-platform-logs) and [Azure Monitor Metrics](/azure/azure-monitor/essentials/data-platform-metrics). Each Azure resource requires its own diagnostic setting, which defines the following criteria: * Categories of logs and metric data sent to the destinations defined in the setting. The available categories will vary for different resource types. * One or more destinations to send the logs. Current destinations include Log Analytics workspace, Event Hubs, and Azure Storage. * A single diagnostic setting can define no more than one of each of the destinations. If you want to send data to more than one of a particular destination type (for example, two different Log Analytics workspaces), then create multiple settings. Each resource can have up to five diagnostic settings. |
| communication-services | End Of Call Survey Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/logs/end-of-call-survey-logs.md | -Azure Communications Services provides monitoring and analytics features via [Azure Monitor Logs overview](../../../../azure-monitor/logs/data-platform-logs.md) and [Azure Monitor Metrics](../../../../azure-monitor/essentials/data-platform-metrics.md). Each Azure resource requires its own diagnostic setting, which defines the following criteria: +Azure Communications Services provides monitoring and analytics features via [Azure Monitor Logs overview](/azure/azure-monitor/logs/data-platform-logs) and [Azure Monitor Metrics](/azure/azure-monitor/essentials/data-platform-metrics). Each Azure resource requires its own diagnostic setting, which defines the following criteria: * Categories of logs and metric data sent to the destinations defined in the setting. The available categories will vary for different resource types. * One or more destinations to send the logs. Current destinations include Log Analytics workspace, Event Hubs, and Azure Storage. * A single diagnostic setting can define no more than one of each of the destinations. If you want to send data to more than one of a particular destination type (for example, two different Log Analytics workspaces), then create multiple settings. Each resource can have up to five diagnostic settings. |
| communication-services | Recording Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/logs/recording-logs.md | -The content in this article refers to logs enabled through [Azure Monitor](../../../../azure-monitor/overview.md) (see also [FAQ](../../../../azure-monitor/overview.md#frequently-asked-questions)). To enable these logs for Communication Services, see [Enable logging in diagnostic settings](../enable-logging.md). +The content in this article refers to logs enabled through [Azure Monitor](/azure/azure-monitor/overview) (see also [FAQ](/azure/azure-monitor/overview#frequently-asked-questions)). To enable these logs for Communication Services, see [Enable logging in diagnostic settings](../enable-logging.md). ## Resource log categories Communication Services offers the following types of logs that you can enable: A recording file is generated at the end of a call or meeting. Either a user or an app (bot) can start and stop the recording. The recording can also end because of a system failure. -Summary logs are published after a recording is ready to be downloaded. The logs are published within the standard latency time for Azure Monitor resource logs. See [Log data ingestion time in Azure Monitor](../../../../azure-monitor/logs/data-ingestion-time.md#azure-metrics-resource-logs-activity-log). +Summary logs are published after a recording is ready to be downloaded. The logs are published within the standard latency time for Azure Monitor resource logs. See [Log data ingestion time in Azure Monitor](/azure/azure-monitor/logs/data-ingestion-time#azure-metrics-resource-logs-activity-log). ### Usage log schema |
| communication-services | Rooms Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/logs/rooms-logs.md | -> The following refers to logs enabled through [Azure Monitor](../../../../azure-monitor/overview.md) (see also [FAQ](../../../../azure-monitor/overview.md#frequently-asked-questions)). To enable these logs for your Communications Services, see: [Enable logging in Diagnostic Settings](../enable-logging.md) +> The following refers to logs enabled through [Azure Monitor](/azure/azure-monitor/overview) (see also [FAQ](/azure/azure-monitor/overview#frequently-asked-questions)). To enable these logs for your Communications Services, see: [Enable logging in Diagnostic Settings](../enable-logging.md) ## Pre-requisites -Azure Communications Services provides monitoring and analytics features via [Azure Monitor Logs overview](../../../../azure-monitor/logs/data-platform-logs.md) and [Azure Monitor Metrics](../../../../azure-monitor/essentials/data-platform-metrics.md). Each Azure resource requires its own diagnostic setting, which defines the following criteria: +Azure Communications Services provides monitoring and analytics features via [Azure Monitor Logs overview](/azure/azure-monitor/logs/data-platform-logs) and [Azure Monitor Metrics](/azure/azure-monitor/essentials/data-platform-metrics). Each Azure resource requires its own diagnostic setting, which defines the following criteria: * Categories of logs and metric data sent to the destinations defined in the setting. The available categories will vary for different resource types. * One or more destinations to send the logs. Current destinations include Log Analytics workspace, Event Hubs, and Azure Storage. * A single diagnostic setting can define no more than one of each of the destinations. If you want to send data to more than one of a particular destination type (for example, two different Log Analytics workspaces), then create multiple settings. Each resource can have up to five diagnostic settings. Communication Services offers the following types of logs that you can enable: ] ``` - (See also [FAQ](../../../../azure-monitor/overview.md#frequently-asked-questions)). + (See also [FAQ](/azure/azure-monitor/overview#frequently-asked-questions)). |
| communication-services | Router Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/logs/router-logs.md | -The content in this article refers to logs enabled through [Azure Monitor](../../../../azure-monitor/overview.md) (see also [FAQ](../../../../azure-monitor/overview.md#frequently-asked-questions)). To enable these logs for Communication Services, see [Enable logging in diagnostic settings](../enable-logging.md). +The content in this article refers to logs enabled through [Azure Monitor](/azure/azure-monitor/overview) (see also [FAQ](/azure/azure-monitor/overview#frequently-asked-questions)). To enable these logs for Communication Services, see [Enable logging in diagnostic settings](../enable-logging.md). ## Resource log categories |
| communication-services | Sms Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/logs/sms-logs.md | -> The following refers to logs enabled through [Azure Monitor](../../../../azure-monitor/overview.md) (see also [FAQ](../../../../azure-monitor/overview.md#frequently-asked-questions)). To enable these logs for your Communications Services, see: [Enable logging in Diagnostic Settings](../enable-logging.md) +> The following refers to logs enabled through [Azure Monitor](/azure/azure-monitor/overview) (see also [FAQ](/azure/azure-monitor/overview#frequently-asked-questions)). To enable these logs for your Communications Services, see: [Enable logging in Diagnostic Settings](../enable-logging.md) ## Pre-requisites -Azure Communications Services provides monitoring and analytics features via [Azure Monitor Logs overview](../../../../azure-monitor/logs/data-platform-logs.md) and [Azure Monitor Metrics](../../../../azure-monitor/essentials/data-platform-metrics.md). Each Azure resource requires its own diagnostic setting, which defines the following criteria: +Azure Communications Services provides monitoring and analytics features via [Azure Monitor Logs overview](/azure/azure-monitor/logs/data-platform-logs) and [Azure Monitor Metrics](/azure/azure-monitor/essentials/data-platform-metrics). Each Azure resource requires its own diagnostic setting, which defines the following criteria: * Categories of logs and metric data sent to the destinations defined in the setting. The available categories will vary for different resource types. * One or more destinations to send the logs. Current destinations include Log Analytics workspace, Event Hubs, and Azure Storage. * A single diagnostic setting can define no more than one of each of the destinations. If you want to send data to more than one of a particular destination type (for example, two different Log Analytics workspaces), then create multiple settings. Each resource can have up to five diagnostic settings. Communication Services offers the following types of logs that you can enable: ``` - (see also [FAQ](../../../../azure-monitor/overview.md#frequently-asked-questions)). + (see also [FAQ](/azure/azure-monitor/overview#frequently-asked-questions)). |
| communication-services | Voice And Video Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/logs/voice-and-video-logs.md | -The content in this article refers to logs enabled through [Azure Monitor](../../../../azure-monitor/overview.md) (see also [FAQ](../../../../azure-monitor/overview.md#frequently-asked-questions)). To enable these logs for Communication Services, see [Enable logging in diagnostic settings](../enable-logging.md). +The content in this article refers to logs enabled through [Azure Monitor](/azure/azure-monitor/overview) (see also [FAQ](/azure/azure-monitor/overview#frequently-asked-questions)). To enable these logs for Communication Services, see [Enable logging in diagnostic settings](../enable-logging.md). ## Data concepts |
| communication-services | Query Call Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/query-call-logs.md | -Before you can take advantage of [Log Analytics](../../../azure-monitor/logs/log-analytics-overview.md) for your Communications Services logs, you must first follow the steps outlined in [Enable logging in Diagnostic Settings](enable-logging.md). Once you've enabled your logs and a [Log Analytics Workspace](../../../azure-monitor/logs/workspace-design.md), you will have access to many helpful [default query packs](../../../azure-monitor/logs/query-packs.md#default-query-pack) that will help you quickly visualize and understand the data available in your logs, which are described below. Through Log Analytics, you also get access to more Communications Services Insights via Azure Monitor Workbooks, the ability to create our own queries and Workbooks, [Log Analytics APIs overview](../../../azure-monitor/logs/api/overview.md) to any query. +Before you can take advantage of [Log Analytics](/azure/azure-monitor/logs/log-analytics-overview) for your Communications Services logs, you must first follow the steps outlined in [Enable logging in Diagnostic Settings](enable-logging.md). Once you've enabled your logs and a [Log Analytics Workspace](/azure/azure-monitor/logs/workspace-design), you will have access to many helpful [default query packs](/azure/azure-monitor/logs/query-packs#default-query-pack) that will help you quickly visualize and understand the data available in your logs, which are described below. Through Log Analytics, you also get access to more Communications Services Insights via Azure Monitor Workbooks, the ability to create our own queries and Workbooks, [Log Analytics APIs overview](/azure/azure-monitor/logs/api/overview) to any query. ### Access You can access the queries by starting on your Communications Services resource page, and then clicking on "Logs" in the left navigation within the Monitor section: :::image type="content" source="media\log-analytics\access-log-analytics.png" alt-text="Log Analytics navigation"::: -From there, you're presented with a modal screen that contains all of the [default query packs](../../../azure-monitor/logs/query-packs.md#default-query-pack) available for your Communications Services, with list of Query Packs available to navigate to the left. +From there, you're presented with a modal screen that contains all of the [default query packs](/azure/azure-monitor/logs/query-packs#default-query-pack) available for your Communications Services, with list of Query Packs available to navigate to the left. :::image type="content" source="media\log-analytics\log-analytics-modal-resource.png" alt-text="log analytics queries modal" lightbox="media\log-analytics\log-analytics-modal-resource.png"::: -If you close the modal screen, you can still navigate to the various query packs, directly access data in the form of tables based on the schema of the logs and metrics you've enabled in your Diagnostic Setting. Here, you can create your own queries from the data using [KQL (Kusto)](/azure/data-explorer/kusto/query/). Learn more about using, editing, and creating queries by reading more about: [Log Analytics Queries](../../../azure-monitor/logs/queries.md) +If you close the modal screen, you can still navigate to the various query packs, directly access data in the form of tables based on the schema of the logs and metrics you've enabled in your Diagnostic Setting. Here, you can create your own queries from the data using [KQL (Kusto)](/azure/data-explorer/kusto/query/). Learn more about using, editing, and creating queries by reading more about: [Log Analytics Queries](/azure/azure-monitor/logs/queries) :::image type="content" source="media\log-analytics\log-analytics-queries-resource.png" alt-text="Log Analytics queries in resource" lightbox="media\log-analytics\log-analytics-queries-resource.png"::: :::image type="content" source="media\log-analytics\log-analytics-tables-resource.png" alt-text="Log Analytics tables in resource" lightbox="media\log-analytics\log-analytics-tables-resource.png"::: ## Default query packs for call summary and call diagnostic logs-The following are descriptions of each query in the [default query pack](../../../azure-monitor/logs/query-packs.md#default-query-pack), for the [Call Summary and Call Diagnostic logs](logs/voice-and-video-logs.md) including code samples and example outputs for each query available: +The following are descriptions of each query in the [default query pack](/azure/azure-monitor/logs/query-packs#default-query-pack), for the [Call Summary and Call Diagnostic logs](logs/voice-and-video-logs.md) including code samples and example outputs for each query available: ### Call Overview Queries #### Number of participants per call |
| communication-services | Rooms Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/rooms-metrics.md | -Azure Communication Services currently provides metrics for all Communication Services primitives. You can use [Azure Monitor metrics explorer](../../../azure-monitor\essentials\analyze-metrics.md) to: +Azure Communication Services currently provides metrics for all Communication Services primitives. You can use [Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics) to: - Plot your own charts. - Investigate abnormalities in your metric values. Primitives in Communication Services emit metrics for API requests. To find thes All API request metrics contain three dimensions that you can use to filter your metrics data. These dimensions can be aggregated together by using the `Count` aggregation type. They support all standard Azure Aggregation time series, including `Sum`, `Average`, `Min`, and `Max`. -For more information on supported aggregation types and time series aggregations, see [Advanced features of Azure Metrics Explorer](../../../azure-monitor/essentials/metrics-charts.md#aggregation). +For more information on supported aggregation types and time series aggregations, see [Advanced features of Azure Metrics Explorer](/azure/azure-monitor/essentials/metrics-charts#aggregation). - **Operation**: All operations or routes that can be called on the Communication Services Chat gateway. - **Status Code**: The status code response sent after the request. The following operations are available on Rooms API request metrics. ## Next steps -Learn more about [Data Platform Metrics](../../../azure-monitor/essentials/data-platform-metrics.md). +Learn more about [Data Platform Metrics](/azure/azure-monitor/essentials/data-platform-metrics). |
| communication-services | Sms Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/analytics/sms-metrics.md | -Azure Communication Services currently provides metrics for all Communication Services primitives. You can use [Azure Monitor metrics explorer](../../../azure-monitor\essentials\analyze-metrics.md) to: +Azure Communication Services currently provides metrics for all Communication Services primitives. You can use [Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics) to: - Plot your own charts. - Investigate abnormalities in your metric values. Primitives in Communication Services emit metrics for API requests. To find thes All API request metrics contain three dimensions that you can use to filter your metrics data. These dimensions can be aggregated together by using the `Count` aggregation type. They support all standard Azure Aggregation time series, including `Sum`, `Average`, `Min`, and `Max`. -For more information on supported aggregation types and time series aggregations, see [Advanced features of Azure Metrics Explorer](../../../azure-monitor/essentials/metrics-charts.md#aggregation). +For more information on supported aggregation types and time series aggregations, see [Advanced features of Azure Metrics Explorer](/azure/azure-monitor/essentials/metrics-charts#aggregation). - **Operation**: All operations or routes that can be called on the Azure Communication Services Chat gateway. - **Status Code**: The status code response sent after the request. |
| communication-services | Email Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/email-metrics.md | -Azure Communication Services currently provides metrics for all Azure communication services' primitives. [Azure Metrics Explorer](../../azure-monitor/essentials/metrics-getting-started.md) can be used to plot your own charts, investigate abnormalities in your metric values, and understand your API traffic by using the metrics data that email requests emit. +Azure Communication Services currently provides metrics for all Azure communication services' primitives. [Azure Metrics Explorer](/azure/azure-monitor/essentials/metrics-getting-started) can be used to plot your own charts, investigate abnormalities in your metric values, and understand your API traffic by using the metrics data that email requests emit. ## Where to find metrics Primitives in Azure Communication Services emit metrics for API requests. These All API request metrics contain three dimensions that you can use to filter your metrics data. These dimensions can be aggregated together using the `Count` aggregation type and support all standard Azure Aggregation time series including `Sum`, `Average`, `Min`, and `Max`. -More information about supported aggregation types and time series aggregations, see [Advanced features of Azure Metrics Explorer](../../azure-monitor/essentials/metrics-charts.md#aggregation). +More information about supported aggregation types and time series aggregations, see [Advanced features of Azure Metrics Explorer](/azure/azure-monitor/essentials/metrics-charts#aggregation). - **Operation** - All operations or routes that can be called on the Azure Communication Services Chat gateway. - **Status Code** - The status code response sent after the request. The `Email Service User Engagement` metric is supported with HTML type emails an ## Next steps -- Learn more about [Data Platform Metrics](../../azure-monitor/essentials/data-platform-metrics.md)+- Learn more about [Data Platform Metrics](/azure/azure-monitor/essentials/data-platform-metrics) |
| communication-services | Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/metrics.md | -Azure Communication Services currently provides metrics for all Azure communication services' primitives. [Azure Metrics Explorer](../../azure-monitor/essentials/metrics-getting-started.md) can be used to plot your own charts, investigate abnormalities in your metric values, and understand your API traffic by using the metrics data that email requests emit. +Azure Communication Services currently provides metrics for all Azure communication services' primitives. [Azure Metrics Explorer](/azure/azure-monitor/essentials/metrics-getting-started) can be used to plot your own charts, investigate abnormalities in your metric values, and understand your API traffic by using the metrics data that email requests emit. ## Where to find metrics Primitives in Azure Communication Services emit metrics for API requests. These All API request metrics contain three dimensions that you can use to filter your metrics data. These dimensions can be aggregated together using the `Count` aggregation type and support all standard Azure Aggregation time series including `Sum`, `Average`, `Min`, and `Max`. -More information on supported aggregation types and time series aggregations can be found [Advanced features of Azure Metrics Explorer](../../azure-monitor/essentials/metrics-charts.md#aggregation) +More information on supported aggregation types and time series aggregations can be found [Advanced features of Azure Metrics Explorer](/azure/azure-monitor/essentials/metrics-charts#aggregation) - **Operation** - All operations or routes that can be called on the Azure Communication Services Chat gateway. - **Status Code** - The status code response sent after the request. The following operations are available on SMS API request metrics: ## Next steps -- Learn more about [Data Platform Metrics](../../azure-monitor/essentials/data-platform-metrics.md)+- Learn more about [Data Platform Metrics](/azure/azure-monitor/essentials/data-platform-metrics) |
| communication-services | Notifications | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/notifications.md | When you don't see push notifications on your device, there are three places whe The first place where a notification can be dropped (Azure Notification Hubs didn't accept the notifications from Azure Communication Services) is covered below. For the other two places, see [Diagnose dropped notifications in Azure Notification Hubs](../../notification-hubs/notification-hubs-push-notification-fixer.md). -One way to see if your Communication Services resource sends notifications to Azure Notification Hubs is by looking at the `incoming messages` metric from the linked [Azure Notification Hub metrics](../../azure-monitor/essentials/metrics-supported.md#microsoftnotificationhubsnamespacesnotificationhubs). +One way to see if your Communication Services resource sends notifications to Azure Notification Hubs is by looking at the `incoming messages` metric from the linked [Azure Notification Hub metrics](/azure/azure-monitor/essentials/metrics-supported#microsoftnotificationhubsnamespacesnotificationhubs). The following are some common misconfigurations that might be the cause why Azure Notification Hub doesn't accept the notifications from your Communication Services resource. |
| communication-services | Privacy | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/privacy.md | Email message content is ephemerally stored for processing in the resource's ``` ## Azure Monitor and Log Analytics -Azure Communication Services feed into Azure Monitor logging data for understanding operational health and utilization of the service. Some of these logs include Communication Service identities and phone numbers as field data. To delete any potentially personal data, [use these procedures for Azure Monitor](../../azure-monitor/logs/personal-data-mgmt.md). You may also want to configure [the default retention period for Azure Monitor](../../azure-monitor/logs/data-retention-configure.md). +Azure Communication Services feed into Azure Monitor logging data for understanding operational health and utilization of the service. Some of these logs include Communication Service identities and phone numbers as field data. To delete any potentially personal data, [use these procedures for Azure Monitor](/azure/azure-monitor/logs/personal-data-mgmt). You may also want to configure [the default retention period for Azure Monitor](/azure/azure-monitor/logs/data-retention-configure). ## Additional resources |
| communication-services | Room Concept | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/rooms/room-concept.md | The *Open Room* concept is now deprecated. Going forward, *Invite Only* rooms ar - Learn how to [manage a room call](../../quickstarts/rooms/manage-rooms-call.md). - Review the [Network requirements for media and signaling](../voice-video-calling/network-requirements.md). - Analyze your Rooms data, see: [Rooms Logs](../Analytics/logs/rooms-logs.md).-- Learn how to use the Log Analytics workspace, see: [Log Analytics Tutorial](../../../azure-monitor/logs/log-analytics-tutorial.md).-- Create your own queries in Log Analytics, see: [Get Started Queries](../../../azure-monitor/logs/get-started-queries.md).+- Learn how to use the Log Analytics workspace, see: [Log Analytics Tutorial](/azure/azure-monitor/logs/log-analytics-tutorial). +- Create your own queries in Log Analytics, see: [Get Started Queries](/azure/azure-monitor/logs/get-started-queries). |
| communication-services | Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/router/metrics.md | Primitives in Azure Communication Services emit metrics for API requests. These All API request metrics contain four dimensions that you can use to filter your metrics data. These dimensions can be aggregated together using the `Count` aggregation. -More information on supported aggregation types and time series aggregations can be found [Advanced features of Azure Metrics Explorer](../../../azure-monitor/essentials/metrics-charts.md#aggregation). +More information on supported aggregation types and time series aggregations can be found [Advanced features of Azure Metrics Explorer](/azure/azure-monitor/essentials/metrics-charts#aggregation). - **Operation** - All operations or routes that can be called on the Azure Communication Services gateway. The following operations are available on Job Router API request metrics: ## Next steps -- Learn more about [Data Platform Metrics](../../../azure-monitor/essentials/data-platform-metrics.md).+- Learn more about [Data Platform Metrics](/azure/azure-monitor/essentials/data-platform-metrics). |
| communication-services | Call Diagnostics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/voice-video-calling/call-diagnostics.md | analyze new call data. Since Call Diagnostics is an application layer on top of data for your Azure Communications Service Resource, you can query these call data and-[build workbook reports on top of your data.](../../../azure-monitor/logs/data-platform-logs.md#built-in-insights-and-custom-dashboards-workbooks-and-reports) +[build workbook reports on top of your data.](/azure/azure-monitor/logs/data-platform-logs#built-in-insights-and-custom-dashboards-workbooks-and-reports) You can access Call Diagnostics from any Azure Communication Services Resource in your Azure portal. When you open your Azure Communications quality](https://learn.microsoft.com/azure/communication-services/concepts/voice - **How do I set up Call Diagnostics?** - Follow instructions to add diagnostic settings for your resource here [Enable logs via Diagnostic Settings in Azure Monitor.](../analytics/enable-logging.md) We recommend you initially collect all logs and then determine which logs you want to retain and for how long after you have an understanding of the capabilities in Azure Monitor. When adding your diagnostic setting you are prompted to [select logs](../analytics/enable-logging.md#adding-a-diagnostic-setting), select "**allLogs**" to collect all logs. - - Your data volume, retention, and Call Diagnostics query usage in Log Analytics within Azure Monitor is billed through existing Azure data meters. We recommend you monitor your data usage and retention policies for cost considerations as needed. See: [Controlling costs.](../../../azure-monitor/essentials/diagnostic-settings.md#controlling-costs) + - Your data volume, retention, and Call Diagnostics query usage in Log Analytics within Azure Monitor is billed through existing Azure data meters. We recommend you monitor your data usage and retention policies for cost considerations as needed. See: [Controlling costs.](/azure/azure-monitor/essentials/diagnostic-settings#controlling-costs) - If you have multiple Azure Communications Services Resource IDs you must enable these settings for each resource ID and query call details for participants within their respective Azure Communications Services Resource ID. quality](https://learn.microsoft.com/azure/communication-services/concepts/voice - Continue to learn other quality best practices, see: [Best practices: Azure Communication Services calling SDKs](../best-practices.md) -- Learn how to use the Log Analytics workspace, see: [Log Analytics Tutorial](../../../../articles/azure-monitor/logs/log-analytics-tutorial.md)+- Learn how to use the Log Analytics workspace, see: [Log Analytics Tutorial](/azure/azure-monitor/logs/log-analytics-tutorial) -- Create your own queries in Log Analytics, see: [Get Started Queries](../../../../articles/azure-monitor/logs/get-started-queries.md)+- Create your own queries in Log Analytics, see: [Get Started Queries](/azure/azure-monitor/logs/get-started-queries) - Explore known call issues, see: [Known issues in the SDKs and APIs](../known-issues.md) |
| communication-services | End Of Call Survey Concept | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/voice-video-calling/end-of-call-survey-concept.md | You cannot access your survey and it will not be stored unless you have enabled - Analyze your survey data, see: [End of Call Survey Logs](../analytics/logs/end-of-call-survey-logs.md) -- Learn how to use the Log Analytics workspace, see: [Log Analytics Tutorial](../../../azure-monitor/logs/log-analytics-tutorial.md)+- Learn how to use the Log Analytics workspace, see: [Log Analytics Tutorial](/azure/azure-monitor/logs/log-analytics-tutorial) -- Create your own queries in Log Analytics, see: [Get Started Queries](../../../azure-monitor/logs/get-started-queries.md)+- Create your own queries in Log Analytics, see: [Get Started Queries](/azure/azure-monitor/logs/get-started-queries) |
| communication-services | Manage Call Quality | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/concepts/voice-video-calling/manage-call-quality.md | to ensure you collecting available logs and metrics. These call data aren't stor Review this documentation to start collecting call logs: [Enable logs via Diagnostic Settings in Azure Monitor.](../analytics/enable-logging.md) - We recommend you choose the category group "allLogs" and choose the destination detail of ΓÇ£Send to Log Analytics workspace" in order to view and analyze the data in Azure Monitor.-- If you don't have a Log Analytics workspace to send your data to, you'll need to [create one.](../../../azure-monitor/logs/quick-create-workspace.md)-- We recommend you monitor your data usage and retention policies for cost considerations as needed. See: [Controlling costs.](../../../azure-monitor/essentials/diagnostic-settings.md#controlling-costs)+- If you don't have a Log Analytics workspace to send your data to, you'll need to [create one.](/azure/azure-monitor/logs/quick-create-workspace) +- We recommend you monitor your data usage and retention policies for cost considerations as needed. See: [Controlling costs.](/azure/azure-monitor/essentials/diagnostic-settings#controlling-costs) ### Diagnose calls with Call Diagnostics Once you begin storing log data in your log analytics workspace, you can visuali Once you have enabled logs, you can view call insights in your Azure Resource using visualization examples: [Voice and video Insights](../analytics/insights/voice-and-video-insights.md) -- You can modify the existing workbooks or even create your own: [Azure Workbooks](../../../azure-monitor/visualize/workbooks-overview.md)+- You can modify the existing workbooks or even create your own: [Azure Workbooks](/azure/azure-monitor/visualize/workbooks-overview) - For examples of deeper suggested analysis see our [Query call logs](../analytics/query-call-logs.md) New Issue ┬╖ Azure/Communication (github.com) or New Issue ┬╖ Azure/azure-sdk-fo - If you don't have access to your customerΓÇÖs Azure portal to view data tied to their Azure Resource ID you can request to query their workspaces to improve quality on their behalf. - - [Create a log query across multiple workspaces and apps in Azure Monitor](../../../azure-monitor/logs/cross-workspace-query.md) + - [Create a log query across multiple workspaces and apps in Azure Monitor](/azure/azure-monitor/logs/cross-workspace-query) ## Next steps New Issue ┬╖ Azure/Communication (github.com) or New Issue ┬╖ Azure/azure-sdk-fo - Continue to learn other best practices: [Best practices: Azure Communication Services calling SDKs](../best-practices.md) - Explore known issues: [Known issues in the SDKs and APIs](../known-issues.md) - Learn how to debug calls: [Call Diagnostics](call-diagnostics.md)-- Learn how to use the Log Analytics workspace: [Log Analytics Tutorial](../../../../articles/azure-monitor/logs/log-analytics-tutorial.md)-- Create your own queries in Log Analytics: [Get Started Queries](../../../../articles/azure-monitor/logs/get-started-queries.md)+- Learn how to use the Log Analytics workspace: [Log Analytics Tutorial](/azure/azure-monitor/logs/log-analytics-tutorial) +- Create your own queries in Log Analytics: [Get Started Queries](/azure/azure-monitor/logs/get-started-queries) <!-- Comment this out - add to the toc.yml file at row 583. |
| communication-services | Closed Captions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/how-tos/ui-library-sdk/closed-captions.md | Captions are seamlessly integrated within the `CallingUILibrary`. :::image type="content" source="./includes/closed-captions/mobile-ui-closed-captions.png" alt-text="Screenshot that shows the experience of closed captions integration in the UI Library."::: > [!NOTE]-> Live translated captions in meetings are only available as part of [**Teams Premium**](https://learn.microsoft.com/MicrosoftTeams/teams-add-on-licensing/licensing-enhance-teams#meetings), an add-on license that provides additional features to make Teams meetings more personalized, intelligent, and secure. To get access to Teams Premium, contact your IT admin. More details you can find it [here](../calling-sdk/closed-captions-teams-interop-how-to.md). +> Live translated captions in meetings are only available as part of [**Teams Premium**](/MicrosoftTeams/teams-add-on-licensing/licensing-enhance-teams#meetings), an add-on license that provides additional features to make Teams meetings more personalized, intelligent, and secure. To get access to Teams Premium, contact your IT admin. More details you can find it [here](../calling-sdk/closed-captions-teams-interop-how-to.md). ## Supported languages |
| communication-services | Message Analysis With Azure Openai Quickstart | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/quickstarts/advanced-messaging/message-analysis/message-analysis-with-azure-openai-quickstart.md | If you want to clean up and remove a Communication Services subscription, you ca - [Message Analysis Transparency FAQ](../../../concepts/advanced-messaging/message-analysis/message-analysis-transparency-faq.md) - [Microsoft AI principles](https://www.microsoft.com/ai/responsible-ai) - [Microsoft responsible AI resources](https://www.microsoft.com/ai/responsible-ai-resources)-- [Microsoft Azure Learning courses on responsible AI](https://learn.microsoft.com/training/paths/responsible-ai-business-principles)+- [Microsoft Azure Learning courses on responsible AI](/training/paths/responsible-ai-business-principles) |
| communication-services | Telemetry Application Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/quickstarts/telemetry-application-insights.md | -The Azure OpenTelemetry Exporter is an SDK within [Azure Monitor](../../azure-monitor/index.yml). It allows you to export tracing data using OpenTelemetry and send the data to [Application Insights](../../azure-monitor/app/app-insights-overview.md). OpenTelemetry provides a standardized way for applications and frameworks to collect telemetry information. +The Azure OpenTelemetry Exporter is an SDK within [Azure Monitor](/azure/azure-monitor/). It allows you to export tracing data using OpenTelemetry and send the data to [Application Insights](/azure/azure-monitor/app/app-insights-overview). OpenTelemetry provides a standardized way for applications and frameworks to collect telemetry information. Azure Application Insights is a feature of Azure Monitor which is used to monitor live applications. It displays telemetry data about your application in a Microsoft Azure resource. The telemetry model is standardized so that it is possible to create platform and language-independent monitoring. |
| communication-services | Calling Widget Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/tutorials/calling-widget/calling-widget-overview.md | If you want to try out the experience without following either of the tutorials, A complete start to finish tutorial built using [React](https://react.dev/) that teaches you to create a Calling widget using [Fluent UI](https://developer.microsoft.com/en-us/fluentui#/) and the UI Library. - [Get started with Azure Communication Services UI library calling to Teams Call Queue and Auto Attendant](./calling-widget-tutorial.md) -]](../media/calling-widget/sample-app-splash-widget-open.png#lightbox) + #### Build it - Cross-platform: JavaScript A complete start to finish tutorial built using [React](https://react.dev/) that We also include JavaScript bundles that you can use to integrate our `CallComposite` Calling experiences into your application that is not built in react. This tutorial uses our precompiled JavaScript bundles to integrate the `CallComposite` into your web page. - [Get started with Azure Communication Services UI library JavaScript bundles calling to Teams Call Queue and Auto Attendant](./calling-widget-js-tutorial.md) -[].](../media/calling-widget/js-bundle-splash.png#lightbox) + ## Next steps |
| communication-services | End Of Call Survey Tutorial | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communication-services/tutorials/end-of-call-survey-tutorial.md | This tutorial shows you how to use the Azure Communication Services End of Call - An Azure account with an active subscription. [Create an account for free](https://azure.microsoft.com/free/?WT.mc_id=A261C142F). - An active Communication Services resource. [Create a Communication Services resource](../quickstarts/create-communication-resource.md). Survey results are tied to single Communication Services resources. - An active Log Analytics Workspace, also known as Azure Monitor Logs. See [End of Call Survey Logs](../concepts/analytics/logs/end-of-call-survey-logs.md).-- To conduct a survey with custom questions using free form text, you need an [App Insight resource](../../azure-monitor/app/create-workspace-resource.md#create-a-workspace-based-resource).+- To conduct a survey with custom questions using free form text, you need an [App Insight resource](/azure/azure-monitor/app/create-workspace-resource#create-a-workspace-based-resource). ::: zone pivot="platform-web" [!INCLUDE [End of Call Survey for Web](./includes/end-of-call-survey-web.md)] This tutorial shows you how to use the Azure Communication Services End of Call You need to enable a Log Analytics Workspace to both store the log data of your surveys and access survey results. To enable these logs for your Communications Service, see: [End of Call Survey Logs](../concepts/analytics/logs/end-of-call-survey-logs.md). -- You can also integrate your Log Analytics workspace with Power BI, see: [Integrate Log Analytics with Power BI](../../../articles/azure-monitor/logs/log-powerbi.md).+- You can also integrate your Log Analytics workspace with Power BI, see: [Integrate Log Analytics with Power BI](/azure/azure-monitor/logs/log-powerbi). ## Best practices Here are our recommended survey flows and suggested question prompts for consideration. Your development can use our recommendation or use customized question prompts and flows for your visual interface. If a survey participant responded to Question 1 with a score at or below the cut - Learn more about the End of Call Survey, see: [End of Call Survey overview](../concepts/voice-video-calling/end-of-call-survey-concept.md) -- Learn how to use the Log Analytics workspace, see: [Log Analytics Tutorial](../../../articles/azure-monitor/logs/log-analytics-tutorial.md)+- Learn how to use the Log Analytics workspace, see: [Log Analytics Tutorial](/azure/azure-monitor/logs/log-analytics-tutorial) -- Create your own queries in Log Analytics, see: [Get Started Queries](../../../articles/azure-monitor/logs/get-started-queries.md)+- Create your own queries in Log Analytics, see: [Get Started Queries](/azure/azure-monitor/logs/get-started-queries) |
| communications-gateway | Monitor Azure Communications Gateway | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communications-gateway/monitor-azure-communications-gateway.md | If you notice any concerning resource health indicators or metrics, you can [rai ## What is Azure Monitor? -Azure Communications Gateway creates monitoring data using [Azure Monitor](../azure-monitor/overview.md), which is a full stack monitoring service in Azure. Azure Monitor provides a complete set of features to monitor your Azure resources. It can also monitor resources in other clouds and on-premises. +Azure Communications Gateway creates monitoring data using [Azure Monitor](/azure/azure-monitor/overview), which is a full stack monitoring service in Azure. Azure Monitor provides a complete set of features to monitor your Azure resources. It can also monitor resources in other clouds and on-premises. -Start with the article [Monitoring Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md), which describes the following concepts: +Start with the article [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource), which describes the following concepts: - What is Azure Monitor? - Costs associated with monitoring Start with the article [Monitoring Azure resources with Azure Monitor](../azure- The following sections build on this article by describing the specific data gathered for Azure Communications Gateway. These sections also provide examples for configuring data collection and analyzing this data with Azure tools. > [!TIP]-> To understand costs associated with Azure Monitor, see [Azure Monitor cost and usage](../azure-monitor/cost-usage.md). +> To understand costs associated with Azure Monitor, see [Azure Monitor cost and usage](/azure/azure-monitor/cost-usage). ## Azure Monitor data for Azure Communications Gateway Azure Communications Gateway collects metrics. See [Monitoring Azure Communications Gateway data reference](monitoring-azure-communications-gateway-data-reference.md) for detailed information on the metrics created by Azure Communications Gateway. Azure Communications Gateway doesn't collect logs. - For clarification on the different types of metrics available in Azure Monitor, see [Monitoring data from Azure resources](../azure-monitor/essentials/monitor-azure-resource.md#monitoring-data-from-azure-resources). + For clarification on the different types of metrics available in Azure Monitor, see [Monitoring data from Azure resources](/azure/azure-monitor/essentials/monitor-azure-resource#monitoring-data-from-azure-resources). ## Analyzing, filtering and splitting metrics in Azure Monitor -You can analyze metrics for Azure Communications Gateway, along with metrics from other Azure services, by opening **Metrics** from the **Azure Monitor** menu. See [Analyze metrics with Azure Monitor metrics explorer](../azure-monitor/essentials/analyze-metrics.md) for details on using this tool. +You can analyze metrics for Azure Communications Gateway, along with metrics from other Azure services, by opening **Metrics** from the **Azure Monitor** menu. See [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics) for details on using this tool. Azure Communications Gateway metrics support the **Region** dimension, allowing you to filter any metric by the Service Locations defined in your Azure Communications Gateway resource. Connectivity metrics also support the **OPTIONS or INVITE** dimension. You can also split a metric by these dimensions to visualize how different segments of the metric compare with each other. -For more information on filtering and splitting, see [Advanced features of Azure Monitor](../azure-monitor/essentials/metrics-charts.md). +For more information on filtering and splitting, see [Advanced features of Azure Monitor](/azure/azure-monitor/essentials/metrics-charts). ## Alerts in Azure Monitor Resource Health reports one of the following statuses for each resource. - *Unavailable*: there's a significant problem with your resource or with the Azure platform. For Azure Communications Gateway, this status usually means that calls can't be handled. - *Unknown*: Resource Health hasn't received information about the resource for more than 10 minutes. -For more information, see [Resource Health overview](../service-health/resource-health-overview.md). +For more information, see [Resource Health overview](/azure/service-health/resource-health-overview). ## Using Azure Resource Health To access Resource Health for Azure Communications Gateway: 1. Select your Communications Gateway resource. 1. In the menu in the left pane, select **Resource health**. -You can also [configure Resource Health alerts in the Azure portal](../service-health/resource-health-alert-monitor-guide.md). These alerts can notify you in near real-time when these resources have a change in their health status. +You can also [configure Resource Health alerts in the Azure portal](/azure/service-health/resource-health-alert-monitor-guide). These alerts can notify you in near real-time when these resources have a change in their health status. ## Next steps - See [Monitoring Azure Communications Gateway data reference](monitoring-azure-communications-gateway-data-reference.md) for a reference of the metrics, logs, and other important values created by Azure Communications Gateway.-- See [Monitoring Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md) for an overview of monitoring Azure resources.-- See [Resource Health overview](../service-health/resource-health-overview.md) for an overview of Resource Health.+- See [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) for an overview of monitoring Azure resources. +- See [Resource Health overview](/azure/service-health/resource-health-overview) for an overview of Resource Health. |
| communications-gateway | Monitoring Azure Communications Gateway Data Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/communications-gateway/monitoring-azure-communications-gateway-data-reference.md | Azure Communications Gateway has the following dimensions associated with its me ## Next steps - See [Monitoring Azure Communications Gateway](monitor-azure-communications-gateway.md) for a description of monitoring Azure Communications Gateway.-- See [Monitoring Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md) for details on monitoring Azure resources.+- See [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) for details on monitoring Azure resources. |
| confidential-computing | Confidential Vm Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/confidential-computing/confidential-vm-overview.md | Confidential VMs support the following VM sizes: ### OS support Confidential VMs support the following OS options: -| Linux | Windows Client | Windows Server | -||--|-| -| **Ubuntu** | **Windows 11** | **Windows Server Datacenter** | -| 20.04 <span class="pill purple">LTS</span> (AMD SEV-SNP Only) | 22H2 Pro | 2019 Server Core | -| 22.04 <span class="pill purple">LTS</span> | 22H2 Pro <span class="pill red">ZH-CN</span> | | -| | 22H2 Pro N | 2022 Server Core | -| **RHEL** | 22H2 Enterprise | 2022 Azure Edition | -| 9.3 <span class="pill purple">(AMD SEV-SNP Only)</span> | 22H2 Enterprise N | 2022 Azure Edition Core | -| [9.3 <span class="pill purple">Preview (Intel TDX Only)](https://aka.ms/tdx-rhel-93-preview)</span> | 22H2 Enterprise Multi-session | | -| | | | -| **SUSE (Tech Preview)** | | | -| [15 SP5 <span class="pill purple">(Intel TDX, AMD SEV-SNP)](https://aka.ms/cvm-sles-preview)</span> | | | -| [15 SP5 for SAP <span class="pill purple">(Intel TDX, AMD SEV-SNP)](https://aka.ms/cvm-sles-preview)</span> | | | +| Linux | Windows Client | Windows Server | +|-|-|-- | +| **Ubuntu** | **Windows 11**| **Windows Server Datacenter** | +| 20.04 LTS (AMD SEV-SNP Only) | 21H2, 21H2 Pro, 21H2 Enterprise, 21H2 Enterprise N, 21H2 Enterprise Multi-session | 2019 Server Core | +| 22.04 LTS | 22H2, 22H2 Pro, 22H2 Enterprise, 22H2 Enterprise N, 22H2 Enterprise Multi-session | 2019 Datacenter | +| | 23H2, 23H2 Pro, 23H2 Enterprise, 23H2 Enterprise N, 23H2 Enterprise Multi-session | 2022 Server Core| +| **RHEL** | **Windows 10** | 2022 Azure Edition| +| 9.4 (AMD SEV-SNP Only) | 22H2, 22H2 Pro, 22H2 Enterprise, 22H2 Enterprise N, 22H2 Enterprise Multi-session | 2022 Azure Edition Core| +| [9.3 <span class="pill purple">Preview (Intel TDX Only)](https://aka.ms/tdx-rhel-93-preview)</span>| | 2022 Datacenter | +| **SUSE (Tech Preview)** | | | +| [15 SP5 <span class="pill purple">(Intel TDX, AMD SEV-SNP)](https://aka.ms/cvm-sles-preview)</span>| | | +| [15 SP5 for SAP <span class="pill purple">(Intel TDX, AMD SEV-SNP)](https://aka.ms/cvm-sles-preview)</span> | | | ### Regions |
| connectors | Connectors Azure Monitor Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/connectors/connectors-azure-monitor-logs.md | Both of the following actions can run a log query against a Log Analytics worksp - An Azure account and subscription. If you don't have an Azure subscription, [sign up for a free Azure account](https://azure.microsoft.com/free/?WT.mc_id=A261C142F). -- The [Log Analytics workspace](../azure-monitor/logs/quick-create-workspace.md) or [Application Insights resource](../azure-monitor/app/app-insights-overview.md) that you want to connect.+- The [Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace) or [Application Insights resource](/azure/azure-monitor/app/app-insights-overview) that you want to connect. - The [Standard or Consumption logic app workflow](../logic-apps/logic-apps-overview.md#resource-environment-differences) from where you want to access your Log Analytics workspace or Application Insights resource. To use an Azure Monitor Logs action, start your workflow with any trigger. This guide uses the [**Recurrence** trigger](connectors-native-recurrence.md). Both of the following actions can run a log query against a Log Analytics worksp ## Next steps -- Learn more about [log queries in Azure Monitor](../azure-monitor/logs/log-query-overview.md)-- Learn more about [queries for Log Analytics](../azure-monitor/logs/get-started-queries.md)+- Learn more about [log queries in Azure Monitor](/azure/azure-monitor/logs/log-query-overview) +- Learn more about [queries for Log Analytics](/azure/azure-monitor/logs/get-started-queries) |
| container-apps | Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/container-apps/alerts.md | +- [Metric alerts](/azure/azure-monitor/alerts/alerts-metric-overview) based on Azure Monitor metric data +- [Log alerts](/azure/azure-monitor/alerts/alerts-unified-log) based on Azure Monitor Log Analytics data -You can create alert rules from metric charts in the metric explorer and from queries in Log Analytics. You can also define and manage alerts from the **Monitor>Alerts** page. To learn more about alerts, refer to [Overview of alerts in Microsoft Azure](../azure-monitor/alerts/alerts-overview.md). +You can create alert rules from metric charts in the metric explorer and from queries in Log Analytics. You can also define and manage alerts from the **Monitor>Alerts** page. To learn more about alerts, refer to [Overview of alerts in Microsoft Azure](/azure/azure-monitor/alerts/alerts-overview). The **Alerts** page in the **Monitoring** section on your container app page displays all of your app's alerts. You can filter the list by alert type, resource, time and severity. You can also modify and create new alert rules from this page. To add more conditions to your alert rule: 1. Select **Add condition** in the **Condition** section. 1. Select from the metrics listed in the **Select a signal** pane. :::image type="content" source="media/observability/metrics-alert-select-a-signal.png" alt-text="Screenshot of the metric explorer alert rule editor showing the Select a signal pane.":::-1. Configure the settings for your alert condition. For more information about configuring alerts, see [Manage metric alerts](../azure-monitor/alerts/alerts-metric.md). +1. Configure the settings for your alert condition. For more information about configuring alerts, see [Manage metric alerts](/azure/azure-monitor/alerts/alerts-metric). You can receive individual alerts for specific revisions or replicas by enabling alert splitting and selecting **Revision** or **Replica** from the **Dimension name** list. Example of selecting a dimension to split an alert. :::image type="content" source="media/observability/metrics-alert-split-by-dimension.png" alt-text="Screenshot of the metrics explorer alert rule editor. This example shows the Split by dimensions options in the Configure signal logic pane."::: - To learn more about configuring alerts, visit [Create a metric alert for an Azure resource](../azure-monitor/alerts/tutorial-metric-alert.md) + To learn more about configuring alerts, visit [Create a metric alert for an Azure resource](/azure/azure-monitor/alerts/tutorial-metric-alert) ## Create log alert rules -You can create log alerts from queries in Log Analytics. When you create an alert rule from a query, the query is run at set intervals triggering alerts when the log data matches the alert rule conditions. To learn more about creating log alert rules, see [Manage log alerts](../azure-monitor/alerts/alerts-log.md). +You can create log alerts from queries in Log Analytics. When you create an alert rule from a query, the query is run at set intervals triggering alerts when the log data matches the alert rule conditions. To learn more about creating log alert rules, see [Manage log alerts](/azure/azure-monitor/alerts/alerts-log). To create an alert rule: |
| container-apps | Azure Arc Create Container App | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/container-apps/azure-arc-create-container-app.md | The application logs for all the apps hosted in your Kubernetes cluster are logg * **Log_s** contains application logs for a given Container Apps extension * **AppName_s** contains the Container App app name. In addition to logs you write via your application code, the *Log_s* column also contains logs on container startup and shutdown. -You can learn more about log queries in [getting started with Kusto](../azure-monitor/logs/get-started-queries.md). +You can learn more about log queries in [getting started with Kusto](/azure/azure-monitor/logs/get-started-queries). ## Next steps |
| container-apps | Azure Arc Enable Cluster | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/container-apps/azure-arc-enable-cluster.md | The following steps help you get started understanding the service, but for prod ## Create a Log Analytics workspace -A [Log Analytics workspace](../azure-monitor/logs/quick-create-workspace.md) provides access to logs for Container Apps applications running in the Azure Arc-enabled Kubernetes cluster. A Log Analytics workspace is optional, but recommended. +A [Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace) provides access to logs for Container Apps applications running in the Azure Arc-enabled Kubernetes cluster. A Log Analytics workspace is optional, but recommended. 1. Create a Log Analytics workspace. |
| container-apps | Azure Arc Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/container-apps/azure-arc-overview.md | All applications deployed with Azure Container Apps on Azure Arc-enabled Kuberne Logs for both system components and your applications are written to standard output. -Both log types can be collected for analysis using standard Kubernetes tools. You can also configure the application environment cluster extension with a [Log Analytics workspace](../azure-monitor/logs/log-analytics-overview.md), and it sends all logs to that workspace. +Both log types can be collected for analysis using standard Kubernetes tools. You can also configure the application environment cluster extension with a [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-overview), and it sends all logs to that workspace. By default, logs from system components are sent to the Azure team. Application logs aren't sent. You can prevent these logs from being transferred by setting `logProcessor.enabled=false` as an extension configuration setting. This configuration setting disables forwarding of application to your Log Analytics workspace. Disabling the log processor might affect the time needed for any support cases, and you'll be asked to collect logs from standard output through some other means. |
| container-apps | Azure Resource Manager Api Spec | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/container-apps/azure-resource-manager-api-spec.md | The following example ARM template snippet deploys a Container Apps environment. { "location": "East US", "properties": {- "daprAIConnectionString": "InstrumentationKey=00000000-0000-0000-0000-000000000000;IngestionEndpoint=https://northcentralus-0.in.applicationinsights.azure.com/", "appLogsConfiguration": { "logAnalyticsConfiguration": { "customerId": "string", |
| container-apps | Log Monitoring | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/container-apps/log-monitoring.md | ContainerAppSystemLogs_CL | take 100 ``` -For more information regarding Log Analytics and log queries, see the [Log Analytics tutorial](../azure-monitor/logs/log-analytics-tutorial.md). +For more information regarding Log Analytics and log queries, see the [Log Analytics tutorial](/azure/azure-monitor/logs/log-analytics-tutorial). ### Azure CLI/PowerShell |
| container-apps | Log Options | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/container-apps/log-options.md | To create a new *diagnostic setting*: - **Send to a partner solution**: Select from Azure partner solutions. 1. Select **Save**. -For more information about Diagnostic settings, see [Diagnostic settings in Azure Monitor](../azure-monitor/essentials/diagnostic-settings.md). +For more information about Diagnostic settings, see [Diagnostic settings in Azure Monitor](/azure/azure-monitor/essentials/diagnostic-settings). ## Configure options using the Azure CLI |
| container-apps | Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/container-apps/metrics.md | From this view, you can pin one or more charts to your dashboard or select a cha The Azure Monitor metrics explorer lets you create charts from metric data to help you analyze your container app's resource and network usage over time. You can pin charts to a dashboard or in a shared workbook. -1. Open the metrics explorer in the Azure portal by selecting **Metrics** from the sidebar menu on your container app's page. To learn more about metrics explorer, see [Analyze metrics with Azure Monitor metrics explorer](../azure-monitor/essentials/analyze-metrics.md). +1. Open the metrics explorer in the Azure portal by selecting **Metrics** from the sidebar menu on your container app's page. To learn more about metrics explorer, see [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics). 1. Create a chart by selecting **Metric**. You can modify the chart by changing aggregation, adding more metrics, changing time ranges and intervals, adding filters, and applying splitting. :::image type="content" source="media/observability/metrics-main-page.png" alt-text="Screenshot of the metrics explorer from the container app resource page."::: |
| container-apps | Observability | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/container-apps/observability.md | These features include: |[Azure Monitor alerts](alerts.md) | Create and manage alerts to notify you of events and conditions based on metric and log data.| >[!NOTE]-> While not a built-in feature, [Azure Monitor Application Insights](../azure-monitor/app/app-insights-overview.md) is a powerful tool to monitor your web and background applications. Although Container Apps doesn't support the Application Insights auto-instrumentation agent, you can instrument your application code using Application Insights SDKs. +> While not a built-in feature, [Azure Monitor Application Insights](/azure/azure-monitor/app/app-insights-overview) is a powerful tool to monitor your web and background applications. Although Container Apps doesn't support the Application Insights auto-instrumentation agent, you can instrument your application code using Application Insights SDKs. ## Application lifecycle observability |
| container-apps | Tutorial Java Quarkus Connect Managed Identity Postgresql Database | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/container-apps/tutorial-java-quarkus-connect-managed-identity-postgresql-database.md | description: Secure Azure Database for PostgreSQL connectivity with managed iden ms.devlang: java -+ Last updated 06/04/2024 |
| container-registry | Monitor Container Registry | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/container-registry/monitor-container-registry.md | For more information about the resource types for Container Registry, see [Azure ## Monitoring data -Azure Container Registry collects the same kinds of monitoring data as other Azure resources that are described in [Monitoring data from Azure resources](../azure-monitor/essentials/monitor-azure-resource.md#monitoring-data). +Azure Container Registry collects the same kinds of monitoring data as other Azure resources that are described in [Monitoring data from Azure resources](/azure/azure-monitor/essentials/monitor-azure-resource#monitoring-data). See [Monitoring Azure Container Registry data reference](monitor-service-reference.md) for detailed information on the metrics and logs created by Azure Container Registry. Platform metrics and the Activity log are collected and stored automatically, bu Resource Logs aren't collected and stored until you create a diagnostic setting and route them to one or more locations. -See [Create diagnostic setting to collect platform logs and metrics in Azure](../azure-monitor/essentials/diagnostic-settings.md) for the detailed process for creating a diagnostic setting using the Azure portal, CLI, or PowerShell. When you create a diagnostic setting, you specify which categories of logs to collect. The categories for Azure Container Registry are listed in [Azure Container Registry monitoring data reference](monitor-service-reference.md#resource-logs). +See [Create diagnostic setting to collect platform logs and metrics in Azure](/azure/azure-monitor/essentials/diagnostic-settings) for the detailed process for creating a diagnostic setting using the Azure portal, CLI, or PowerShell. When you create a diagnostic setting, you specify which categories of logs to collect. The categories for Azure Container Registry are listed in [Azure Container Registry monitoring data reference](monitor-service-reference.md#resource-logs). > [!TIP] > You can also create registry diagnostic settings by navigating to your registry in the portal. In the menu, select **Diagnostic settings** under **Monitoring**. For a list of available metrics for Container Registry, see [Azure Container Reg ## Analyzing metrics -You can analyze metrics for an Azure container registry with metrics from other Azure services using metrics explorer by opening **Metrics** from the **Azure Monitor** menu. See [Analyze metrics with Azure Monitor metrics explorer](../azure-monitor/essentials/analyze-metrics.md) for details on using this tool. +You can analyze metrics for an Azure container registry with metrics from other Azure services using metrics explorer by opening **Metrics** from the **Azure Monitor** menu. See [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics) for details on using this tool. > [!TIP] > You can also go to the metrics explorer by navigating to your registry in the portal. In the menu, select **Metrics** under **Monitoring**. You can use the Azure Monitor REST API to get information programmatically about Data in Azure Monitor Logs is stored in tables where each table has its own set of unique properties. -All resource logs in Azure Monitor have the same fields followed by service-specific fields. The common schema is outlined in [Azure Monitor resource log schema](../azure-monitor/essentials/resource-logs-schema.md#top-level-common-schema). The schema for Azure Container Registry resource logs is found in the [Azure Container Registry Data Reference](monitor-service-reference.md#schemas). +All resource logs in Azure Monitor have the same fields followed by service-specific fields. The common schema is outlined in [Azure Monitor resource log schema](/azure/azure-monitor/essentials/resource-logs-schema#top-level-common-schema). The schema for Azure Container Registry resource logs is found in the [Azure Container Registry Data Reference](monitor-service-reference.md#schemas). -The [Activity log](../azure-monitor/essentials/activity-log.md) is a platform log in Azure that provides insight into subscription-level events. You can view it independently or route it to Azure Monitor Logs, where you can do much more complex queries using Log Analytics. +The [Activity log](/azure/azure-monitor/essentials/activity-log) is a platform log in Azure that provides insight into subscription-level events. You can view it independently or route it to Azure Monitor Logs, where you can do much more complex queries using Log Analytics. For a list of the types of resource logs collected for Azure Container Registry, see [Monitoring Azure Container Registry data reference](monitor-service-reference.md#resource-logs). |
| copilot | Manage Access | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/copilot/manage-access.md | + - copilot-learning-hub |
| cost-management-billing | Cost Mgt Best Practices | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cost-management-billing/costs/cost-mgt-best-practices.md | After you've deployed your infrastructure in Azure, it's important to make sure Azure Advisor is a service that, among other things, identifies virtual machines with low utilization from a CPU or network usage standpoint. From there, you can decide to either shut down or resize the machine based on the estimated cost to continue running the machines. Advisor also provides recommendations for reserved instance purchases. The recommendations are based on your last 30 days of virtual machine usage. When acted on, the recommendations can help you reduce your spending. -For more information, see [Azure Advisor](../../advisor/advisor-overview.md). +For more information, see [Azure Advisor](/azure/advisor/advisor-overview). ### Size your VMs properly |
| cost-management-billing | Tutorial Acm Create Budgets | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cost-management-billing/costs/tutorial-acm-create-budgets.md | Budget cost evaluations are based on actual cost. They don't include amortizatio ## Trigger an action group -When you create or edit a budget for a subscription or resource group scope, you can configure it to call an action group. The action group can perform various actions when your budget threshold is met. You can receive mobile push notifications when your budget threshold is met by enabling [Azure app push notifications](../../azure-monitor/alerts/action-groups.md#create-an-action-group-in-the-azure-portal) while configuring the action group. +When you create or edit a budget for a subscription or resource group scope, you can configure it to call an action group. The action group can perform various actions when your budget threshold is met. You can receive mobile push notifications when your budget threshold is met by enabling [Azure app push notifications](/azure/azure-monitor/alerts/action-groups#create-an-action-group-in-the-azure-portal) while configuring the action group. -Action groups are currently only supported for subscription and resource group scopes. For more information about creating action groups, see [action groups](../../azure-monitor/alerts/action-groups.md). +Action groups are currently only supported for subscription and resource group scopes. For more information about creating action groups, see [action groups](/azure/azure-monitor/alerts/action-groups). For more information about using budget-based automation with action groups, see [Manage costs with budgets](../manage/cost-management-budget-scenario.md). To create or update action groups, select **Manage action group** while you're c Next, select **Add action group** and create the action group. -You can integrate budgets with action groups, regardless of whether the common alert schema is enabled or disabled in those groups. For more information on how to enable common alert schema, see [How do I enable the common alert schema?](../../azure-monitor/alerts/alerts-common-schema.md#enable-the-common-alert-schema) +You can integrate budgets with action groups, regardless of whether the common alert schema is enabled or disabled in those groups. For more information on how to enable common alert schema, see [How do I enable the common alert schema?](/azure/azure-monitor/alerts/alerts-common-schema#enable-the-common-alert-schema) ## Budgets in the Azure mobile app You can view budgets for your subscriptions and resource groups from the **Cost 1. Find the **Cost Management** card and tap **More**. 1. Budgets load below the **Current cost** card. They're sorted by descending order of usage. -To receive mobile push notifications when your budget threshold is met, you can configure action groups. When setting up budget alerts, make sure to select an action group that has [Azure app push notifications](../../azure-monitor/alerts/action-groups.md#create-an-action-group-in-the-azure-portal) enabled. +To receive mobile push notifications when your budget threshold is met, you can configure action groups. When setting up budget alerts, make sure to select an action group that has [Azure app push notifications](/azure/azure-monitor/alerts/action-groups#create-an-action-group-in-the-azure-portal) enabled. > [!NOTE] > Currently, the Azure mobile app only supports the subscription and resource group scopes for budgets. |
| cost-management-billing | Tutorial Acm Opt Recommendations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cost-management-billing/costs/tutorial-acm-opt-recommendations.md | The **Impact** category, along with the **Potential yearly savings**, are design High impact recommendations include: - [Buy an Azure savings plan to save money on a variety of compute services](../savings-plan/buy-savings-plan.md)-- [Buy reserved virtual machine instances to save money over pay-as-you-go costs](../../advisor/advisor-reference-cost-recommendations.md#buy-virtual-machine-reserved-instances-to-save-money-over-pay-as-you-go-costs)-- [Optimize virtual machine spend by resizing or shutting down underutilized instances](../../advisor/advisor-cost-recommendations.md#optimize-virtual-machine-vm-or-virtual-machine-scale-set-vmss-spend-by-resizing-or-shutting-down-underutilized-instances)-- [Use Standard Storage to store Managed Disks snapshots](../../advisor/advisor-reference-cost-recommendations.md#use-standard-storage-to-store-managed-disks-snapshots)+- [Buy reserved virtual machine instances to save money over pay-as-you-go costs](/azure/advisor/advisor-reference-cost-recommendations#buy-virtual-machine-reserved-instances-to-save-money-over-pay-as-you-go-costs) +- [Optimize virtual machine spend by resizing or shutting down underutilized instances](/azure/advisor/advisor-cost-recommendations#optimize-virtual-machine-vm-or-virtual-machine-scale-set-vmss-spend-by-resizing-or-shutting-down-underutilized-instances) +- [Use Standard Storage to store Managed Disks snapshots](/azure/advisor/advisor-reference-cost-recommendations#use-standard-storage-to-store-managed-disks-snapshots) Medium impact recommendations include:-- [Reduce costs by eliminating un-provisioned ExpressRoute circuits](../../advisor/advisor-reference-cost-recommendations.md#delete-expressroute-circuits-in-the-provider-status-of-not-provisioned)-- [Reduce costs by deleting or reconfiguring idle virtual network gateways](../../advisor/advisor-reference-cost-recommendations.md#repurpose-or-delete-idle-virtual-network-gateways)+- [Reduce costs by eliminating un-provisioned ExpressRoute circuits](/azure/advisor/advisor-reference-cost-recommendations#delete-expressroute-circuits-in-the-provider-status-of-not-provisioned) +- [Reduce costs by deleting or reconfiguring idle virtual network gateways](/azure/advisor/advisor-reference-cost-recommendations#repurpose-or-delete-idle-virtual-network-gateways) ## Act on a recommendation Azure Advisor monitors your virtual machine usage for seven days and then identifies underutilized virtual machines. Virtual machines whose CPU utilization is five percent or less and network usage is seven MB or less for four or more days are considered low-utilization virtual machines. -The 5% or less CPU utilization setting is the default, but you can adjust the settings. For more information about adjusting the setting, see the [Configure the average CPU utilization rule or the low usage virtual machine recommendation](../../advisor/advisor-get-started.md#configure-recommendations). +The 5% or less CPU utilization setting is the default, but you can adjust the settings. For more information about adjusting the setting, see the [Configure the average CPU utilization rule or the low usage virtual machine recommendation](/azure/advisor/advisor-get-started#configure-recommendations). Although some scenarios can result in low utilization by design, you can often save money by changing the size of your virtual machines to less expensive sizes. Your actual savings might vary if you choose a resize action. Let's walk through an example of resizing a virtual machine. |
| cost-management-billing | Add Change Subscription Administrator | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cost-management-billing/manage/add-change-subscription-administrator.md | This article describes how to add or change the administrator role for a user us This article applies to a Microsoft Online Service Program (pay-as-you-go) account or a Visual Studio account. If you have a Microsoft Customer Agreement (Azure plan) account, see [Understand Microsoft Customer Agreement administrative roles in Azure](understand-mca-roles.md). If you have an Azure Enterprise Agreement, see [Manage Azure Enterprise Agreement roles](understand-ea-roles.md). -Microsoft recommends that you manage access to resources using Azure RBAC. However, if you are still using the classic deployment model and managing the classic resources by using [Azure Service Management PowerShell Module](/powershell/azure/servicemanagement/install-azure-ps), you'll need to use a classic administrator. --> [!TIP] -> If you only use the Azure portal to manage the classic resources, you don't need to use the classic administrator. --For more information, see [Azure Resource Manager vs. classic deployment](../../azure-resource-manager/management/deployment-models.md) and [Azure classic subscription administrators](../../role-based-access-control/classic-administrators.md). +Microsoft recommends that you manage access to resources using Azure RBAC. Classic administrative roles are retried. For more information, see [Prepare for Azure classic administrator roles retirement](classic-administrator-retire.md). ## Determine account billing administrator |
| cost-management-billing | Billing Subscription Transfer | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cost-management-billing/manage/billing-subscription-transfer.md | If you want to keep your billing ownership but change subscription type, see [Sw If you're an Enterprise Agreement (EA) customer, your enterprise administrator can transfer billing ownership of your subscriptions between accounts. -Only the billing administrator of an account can transfer ownership of a subscription. +Only the account administrator of an account can transfer ownership of a subscription. When you send or accept a transfer request, you agree to terms and conditions. For more information, see [Transfer terms and conditions](subscription-transfer.md#transfer-terms-and-conditions). Visual Studio and Microsoft Cloud Partner Program subscriptions have monthly rec If you've accepted the billing ownership of an Azure subscription, we recommend you review these next steps: -1. Review and update the Service Admin, Co-Admins, and Azure role assignments. To learn more, see [Add or change Azure subscription administrators](add-change-subscription-administrator.md) and [Assign Azure roles using the Azure portal](../../role-based-access-control/role-assignments-portal.yml). +1. Review and update Azure role assignments. To learn more, see [Add or change Azure subscription administrators](add-change-subscription-administrator.md) and [Assign Azure roles using the Azure portal](../../role-based-access-control/role-assignments-portal.yml). 1. Update credentials associated with this subscription's services including: 1. Management certificates that grant the user admin rights to subscription resources. For more information, see [Create and upload a management certificate for Azure](../../cloud-services/cloud-services-certs-create.md) 1. Access keys for services like Storage. For more information, see [About Azure storage accounts](../../storage/common/storage-account-create.md) If you have questions or need help, [create a support request](https://go.micro ## Next steps -- Review and update the Service Admin, Co-Admins, and Azure role assignments. To learn more, see [Add or change Azure subscription administrators](add-change-subscription-administrator.md) and [Assign Azure roles using the Azure portal](../../role-based-access-control/role-assignments-portal.yml).+- Review and update Azure role assignments. To learn more, see [Add or change Azure subscription administrators](add-change-subscription-administrator.md) and [Assign Azure roles using the Azure portal](../../role-based-access-control/role-assignments-portal.yml). |
| cost-management-billing | Cancel Azure Subscription | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cost-management-billing/manage/cancel-azure-subscription.md | The following table describes the permission required to cancel a subscription. |Subscription type |Who can cancel | |||-|Subscriptions created when you sign up for Azure through the Azure website. For example, when you sign up for an [Azure Free Account](https://azure.microsoft.com/offers/ms-azr-0044p/), [account with pay-as-you-go rates](https://azure.microsoft.com/offers/ms-azr-0003p/) or as a [Visual studio subscriber](https://azure.microsoft.com/pricing/member-offers/credit-for-visual-studio-subscribers/). | Service administrator and subscription owner | +|Subscriptions created when you sign up for Azure through the Azure website. For example, when you sign up for an [Azure Free Account](https://azure.microsoft.com/offers/ms-azr-0044p/), [account with pay-as-you-go rates](https://azure.microsoft.com/offers/ms-azr-0003p/) or as a [Visual studio subscriber](https://azure.microsoft.com/pricing/member-offers/credit-for-visual-studio-subscribers/). | Subscription owner | |[Microsoft Enterprise Agreement](https://azure.microsoft.com/pricing/enterprise-agreement/) and [Enterprise Dev/Test](https://azure.microsoft.com/offers/ms-azr-0148p/) | Subscription owner | |[Azure plan](https://azure.microsoft.com/offers/ms-azr-0017g/) and [Azure plan for DevTest](https://azure.microsoft.com/offers/ms-azr-0148g/) | Subscription owners | -An account administrator without the service administrator or subscription owner role canΓÇÖt cancel an Azure subscription. For more information, see [Azure classic subscription administrators](../../role-based-access-control/classic-administrators.md). +An account administrator without the subscription owner role canΓÇÖt cancel an Azure subscription. For more information, see [Azure classic subscription administrators](../../role-based-access-control/classic-administrators.md). ## Cancel a subscription in the Azure portal |
| cost-management-billing | Classic Administrator Retire | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cost-management-billing/manage/classic-administrator-retire.md | -Azure classic administrator roles retire on August 31, 2024. +Azure classic administrator roles retired on August 31, 2024. If your organization has any active Co-Administrator or Service Administrator roles, you need to transition them to Azure role-based access control (RBAC) roles by then. [Azure Service manager and all Azure classic resources](https://azure.microsoft.com/updates/cloud-services-retirement-announcement/) also retire on that date. ## Required action -To avoid potential disruptions in service, transition any classic administrator roles that still need access to your subscription to Azure RBAC roles by August 31, 2024. For more information, see [Prepare for Co-Administrators retirement](https://aka.ms/ClassicAdmins). +To avoid potential disruptions in service, transition any classic administrator roles that still need access to your subscription to Azure RBAC roles. For more information, see [Prepare for Co-Administrators retirement](https://aka.ms/ClassicAdmins). -On August 31, 2024 and later: +After August 31, 2024: - When you create an Azure subscription, the classic Service Administrator role isn't assigned to the subscription. Instead, the user creating the subscription is assigned the Azure RBAC [Owner](../../role-based-access-control/built-in-roles.md#owner) role. - During the [Azure subscription Change Directory operation](/entr#owner) role. |
| cost-management-billing | Cost Management Budget Scenario | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cost-management-billing/manage/cost-management-budget-scenario.md | -Budgets are commonly used as part of cost control. Budgets can be scoped in Azure. For instance, you could narrow your budget view based on subscription, resource groups, or a collection of resources. Besides using the budgets API to send email notifications when a budget threshold is reached, you can also use [Azure Monitor action groups](../../azure-monitor/alerts/action-groups.md). Action groups trigger a coordinated set of actions in response to a budget event. +Budgets are commonly used as part of cost control. Budgets can be scoped in Azure. For instance, you could narrow your budget view based on subscription, resource groups, or a collection of resources. Besides using the budgets API to send email notifications when a budget threshold is reached, you can also use [Azure Monitor action groups](/azure/azure-monitor/alerts/action-groups). Action groups trigger a coordinated set of actions in response to a budget event. A typical budget scenario for a customer running a noncritical workload is to manage spending against a budget and achieve predictable costs when reviewing the monthly invoice. This scenario requires some cost-based orchestration of resources that are part of the Azure environment. In this scenario, a monthly budget of $1,000 for the subscription is set. Also, notification thresholds are set to trigger a few orchestrations. This scenario starts with an 80% cost threshold, which stops all virtual machines (VM) in the resource group **Optional**. Then, at the 100% cost threshold, all VM instances are stopped. |
| cost-management-billing | Grant Access To Create Subscription | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cost-management-billing/manage/grant-access-to-create-subscription.md | To [create subscriptions under an enrollment account](programmatically-create-su az role assignment create --role Owner --assignee-object-id <userObjectId> --scope /providers/Microsoft.Billing/enrollmentAccounts/<enrollmentAccountObjectId> ``` - Once a user becomes an Azure RBAC Owner for your enrollment account, they can [programmatically create subscriptions](programmatically-create-subscription-enterprise-agreement.md) under it. A subscription created by a delegated user still has the original Account Owner as Service Admin, but it also has the delegated user as an Azure RBAC Owner by default. + Once a user becomes an Azure RBAC Owner for your enrollment account, they can [programmatically create subscriptions](programmatically-create-subscription-enterprise-agreement.md) under it. When a delegated user creates a subscription, they get the Azure RBAC [Owner](../../role-based-access-control/built-in-roles.md#owner) role for the subscription. |
| cost-management-billing | Manage Billing Access | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cost-management-billing/manage/manage-billing-access.md | -The article applies to customers with Microsoft Online Service program accounts. If you're an Azure customer with an Enterprise Agreement (EA) and are the Enterprise Administrator, you can give permissions to the Department Administrators and Account Owners in the Azure portal. For more information, see [Understand Azure Enterprise Agreement administrative roles in Azure](understand-ea-roles.md). If you're a Microsoft Customer Agreement customer, see, [Understand Microsoft Customer Agreement administrative roles in Azure](understand-mca-roles.md). +The article applies to customers with Microsoft Online Service Program (MOSP) accounts. If you're an Azure customer with an Enterprise Agreement (EA) and are the Enterprise Administrator, you can give permissions to the Department Administrators and Account Owners in the Azure portal. For more information, see [Understand Azure Enterprise Agreement administrative roles in Azure](understand-ea-roles.md). If you're a Microsoft Customer Agreement customer, see, [Understand Microsoft Customer Agreement administrative roles in Azure](understand-mca-roles.md). ## Account administrators for Microsoft Online Service program accounts -An Account Administrator is the only owner for a Microsoft Online Service Program billing account. The role is assigned to a person who signed up for Azure. Account Administrators are authorized to perform various billing tasks like create subscriptions, view invoices or change the billing for a subscription. +By default, the Account Administrator is the only owner for an MOSP billing account. When a user creates an MOSP subscription, they get the Account Administrator role for the subscription. They also get the Azure Role-based access control (RBAC) Owner role for it. The role is assigned to a person who signed up for Azure. Account Administrators are authorized to perform various billing tasks like create subscriptions, view invoices or change the billing for a subscription. ## Give others access to view billing information Account administrator can grant others access to Azure billing information by assigning one of the following roles on a subscription in their account. -- Service Administrator-- Coadministrator - Owner - Contributor - Reader |
| cost-management-billing | Mca Request Billing Ownership | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cost-management-billing/manage/mca-request-billing-ownership.md | Use the following troubleshooting information if you're having trouble transferr It's possible that the original billing account owner who created an Azure account and an Azure subscription leaves your organization. If that situation happens, then their user identity is no longer in the organization's Microsoft Entra ID. Then the Azure subscription doesn't have a billing owner. This situation prevents anyone from performing billing operations to the account, including viewing and paying bills. The subscription could go into a past-due state. Eventually, the subscription could get disabled because of nonpayment. Ultimately, the subscription could get deleted, affecting every service that runs on the subscription. -When a subscription no longer has a valid billing account owner, Azure sends an email to other Billing account owners, Service Administrators (if any), Co-Administrators (if any), and Subscription Owners informing them of the situation and provides them with a link to accept billing ownership of the subscription. Any one of the users can select the link to accept billing ownership. For more information about billing roles, see [Billing Roles](understand-mca-roles.md) and [Azure roles, Microsoft Entra roles, and classic subscription administrator roles](../../role-based-access-control/rbac-and-directory-admin-roles.md). +When a subscription no longer has a valid billing account owner, Azure sends an email to other Billing account owner and Subscription Owners informing them of the situation and provides them with a link to accept billing ownership of the subscription. Any one of the users can select the link to accept billing ownership. For more information about billing roles, see [Billing Roles](understand-mca-roles.md) and [Azure roles, Microsoft Entra roles, and classic subscription administrator roles](../../role-based-access-control/rbac-and-directory-admin-roles.md). Here's an example of what the email looks like. :::image type="content" source="./media/mca-request-billing-ownership/orphaned-subscription-email.png" alt-text="Screenshot showing an example email to accept billing ownership." lightbox="./media/mca-request-billing-ownership/orphaned-subscription-email.png" ::: -Additionally, Azure shows a banner in the subscription's details window in the Azure portal to Billing owners, Service Administrators, Co-Administrators, and Subscription Owners. Select the link in the banner to accept billing ownership. +Additionally, Azure shows a banner in the subscription's details window in the Azure portal to Billing owners and Subscription Owners. Select the link in the banner to accept billing ownership. :::image type="content" source="./media/mca-request-billing-ownership/orphaned-subscription-example.png" alt-text="Screenshot showing an example of a subscription without a valid billing owner." lightbox="./media/mca-request-billing-ownership/orphaned-subscription-example.png" ::: |
| cost-management-billing | Reserved Instance Purchase Recommendations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cost-management-billing/reservations/reserved-instance-purchase-recommendations.md | Last updated 08/14/2023 # Reservation recommendations -Azure reserved instance (RI) purchase recommendations are provided through Azure Consumption [Reservation Recommendation API](/rest/api/consumption/reservationrecommendations), [Azure Advisor](../../advisor/advisor-reference-cost-recommendations.md#reserved-instances), and through the reservation purchase experience in the Azure portal. +Azure reserved instance (RI) purchase recommendations are provided through Azure Consumption [Reservation Recommendation API](/rest/api/consumption/reservationrecommendations), [Azure Advisor](/azure/advisor/advisor-reference-cost-recommendations#reserved-instances), and through the reservation purchase experience in the Azure portal. The savings that are presented as part of reservation recommendations are the savings that are calculated in addition to your negotiated, or discounted (if applicable) prices. |
| cost-management-billing | Troubleshoot Savings Plan Utilization | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cost-management-billing/savings-plan/troubleshoot-savings-plan-utilization.md | Only usage from eligible Azure resources may receive cost savings through Azure There are numerous reasons that an Azure saving plan may be underutilized. Examples are listed below. In some cases, broadening the savings plan benefit scope can result in greater utilization. - **Custom hourly commitment too large** - it is important to follow purchase recommendations provided through Azure Advisor, the savings plan purchase experience in Azure portal, and through the Savings plan benefit recommendations API. Purchasing an amount greater than the recommended value may result in underutilization, and negatively impact your cost savings goals. To learn more, see [Azure savings plans recommendations](purchase-recommendations.md). - **Recent changes in resource usage** - your savings plan-eligible usage may have recently decreased. Reasons for these changes include:- - ***VM rightsizing*** - To learn more, see [VM shutdown recommendations](../../advisor/advisor-cost-recommendations.md#shutdown-recommendations) - - ***VM shutdowns*** - To learn more, see [Resize SKU recommendations](../../advisor/advisor-cost-recommendations.md#resize-sku-recommendations) + - ***VM rightsizing*** - To learn more, see [VM shutdown recommendations](/azure/advisor/advisor-cost-recommendations#shutdown-recommendations) + - ***VM shutdowns*** - To learn more, see [Resize SKU recommendations](/azure/advisor/advisor-cost-recommendations#resize-sku-recommendations) - ***switch to non-eligible products*** - To learn which products are savings plan-eligible, compare your usage to the list of saving plan-eligible products in your price sheet. See instructions to [Download your savings plan price sheet](download-savings-plan-price-sheet.md) - **Recent savings plan/reservation purchase** - Savings plans and Azure reservations can provide cost savings benefits to some of the same types of products. A recently purchased/re-scoped reservation may be providing benefits to usage that was previously covered by your savings plan. Please review, and consider adjusting, the benefit scope(s) of any recently purchased savings plan(s) or reservations(s). - **Narrow benefit scope** - Your savings plan's scope may be excluding more usage than you intend. To learn more, see [Savings plan scopes](scope-savings-plan.md). |
| cost-management-billing | Analyze Unexpected Charges | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cost-management-billing/understand/analyze-unexpected-charges.md | Continue reading the following sections for more techniques to determine who own ### Analyze the audit logs for the resource -If you have permission to view a resource, you should be able to access its audit logs. Review the logs to find the user who was responsible for the most recent changes to a resource. To learn more, see [View and retrieve Azure Activity log events](../../azure-monitor/essentials/activity-log-insights.md#view-the-activity-log). +If you have permission to view a resource, you should be able to access its audit logs. Review the logs to find the user who was responsible for the most recent changes to a resource. To learn more, see [View and retrieve Azure Activity log events](/azure/azure-monitor/essentials/activity-log-insights#view-the-activity-log). ### Analyze user permissions to the resource's parent scope |
| cost-management-billing | Plan Manage Costs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/cost-management-billing/understand/plan-manage-costs.md | For more cost-cutting features for your development and test environments, check ### Turn on and review Azure Advisor recommendations -[Azure Advisor](../../advisor/advisor-overview.md) helps you reduce costs by identifying resources with low usage. Search for **Advisor** in the Azure portal: +[Azure Advisor](/azure/advisor/advisor-overview) helps you reduce costs by identifying resources with low usage. Search for **Advisor** in the Azure portal: :::image type="content" border="true" source="./media/plan-manage-costs/advisor-button.png" alt-text="Screenshot of Azure Advisor button in the Azure portal."::: |
| data-factory | Diagnostic Logs And Metrics For Workflow Orchestration Manager | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/data-factory/diagnostic-logs-and-metrics-for-workflow-orchestration-manager.md | Similarly, you can create custom queries according to your needs by using any ta For more information, see: -- [Log Analytics tutorial](../azure-monitor/logs/log-analytics-tutorial.md)+- [Log Analytics tutorial](/azure/azure-monitor/logs/log-analytics-tutorial) - [Kusto Query Language (KQL) overview - Azure Data Explorer | Microsoft Learn](/azure/data-explorer/kusto/query/) ## Monitor metrics |
| data-factory | How To Configure Shir For Log Analytics Collection | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/data-factory/how-to-configure-shir-for-log-analytics-collection.md | Centralize the events and the performance counter data to your Log Analytics wor ### Instrumenting on-premises virtual machines -The article [Install Log Analytics agent on Windows computers](../azure-monitor/agents/agent-windows.md) describes how to install the client on a virtual machine typically hosted on-premises. This can be either a physical server or a virtual machine hosted on a customer managed hypervisor. As mentioned in the prerequisite section, when installing the Log Analytics agent, you'll have to provide the Log Analytics workspace ID and Workspace Key to finalize the connection. +The article [Install Log Analytics agent on Windows computers](/azure/azure-monitor/agents/agent-windows) describes how to install the client on a virtual machine typically hosted on-premises. This can be either a physical server or a virtual machine hosted on a customer managed hypervisor. As mentioned in the prerequisite section, when installing the Log Analytics agent, you'll have to provide the Log Analytics workspace ID and Workspace Key to finalize the connection. ### Instrument Azure virtual machines -The recommended approach to instrument an Azure virtual machine based SHIR is to use virtual machine insights as described in the article [Enable VM insights overview](../azure-monitor/vm/vminsights-enable-overview.md). There are multiple ways to configure the Log Analytics agent when the SHIR is hosted in an Azure virtual machine. All the options are described in the article [Log Analytics agent overview](../azure-monitor/agents/log-analytics-agent.md#installation-options). +The recommended approach to instrument an Azure virtual machine based SHIR is to use virtual machine insights as described in the article [Enable VM insights overview](/azure/azure-monitor/vm/vminsights-enable-overview). There are multiple ways to configure the Log Analytics agent when the SHIR is hosted in an Azure virtual machine. All the options are described in the article [Log Analytics agent overview](/azure/azure-monitor/agents/log-analytics-agent#installation-options). ## Configure event log and performance counter capture This step will highlight how to configure both Event viewer logs and performance ### Select event viewer journals -First you must collect event viewer journals relevant to the SHIR as described in the article [Collect Windows event log data sources with Log Analytics agent in Azure Monitor](../azure-monitor/agents/data-sources-windows-events.md). +First you must collect event viewer journals relevant to the SHIR as described in the article [Collect Windows event log data sources with Log Analytics agent in Azure Monitor](/azure/azure-monitor/agents/data-sources-windows-events). It's important to note that when choosing the event logs using the interface, it's normal that you won't see all journals that can possibly exist on a machine. So, the two journals that we need for SHIR monitoring won't show up in this list. If you type the journal name exactly as it appears on the local virtual machine, it will be captured and sent to your Log analytics workspace. |
| data-factory | Monitor Ssis | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/data-factory/monitor-ssis.md | To lift & shift your SSIS workloads, you can [provision SSIS IR in ADF](./tutori Once provisioned, you can [check SSIS IR operational status using Azure PowerShell or on the **Monitor** hub of ADF portal](./monitor-integration-runtime.md#azure-ssis-integration-runtime). With Project Deployment Model, SSIS package execution logs are stored in SSISDB internal tables or views, so you can query, analyze, and visually present them using designated tools like SSMS. With Package Deployment Model, SSIS package execution logs can be stored in file system or Azure Files as CSV files that you still need to parse and process using other designated tools before you can query, analyze, and visually present them. -Now with [Azure Monitor](../azure-monitor/data-platform.md) integration, you can query, analyze, and visually present all metrics and logs generated from SSIS IR operations and SSIS package executions on Azure portal. Additionally, you can also raise alerts on them. +Now with [Azure Monitor](/azure/azure-monitor/data-platform) integration, you can query, analyze, and visually present all metrics and logs generated from SSIS IR operations and SSIS package executions on Azure portal. Additionally, you can also raise alerts on them. To send all metrics and logs generated from SSIS IR operations and SSIS package ## SSIS operational metrics -SSIS operational [metrics](../azure-monitor/essentials/data-platform-metrics.md) are performance counters or numerical values that describe the status of SSIS IR start and stop operations, as well as SSIS package executions at a particular point in time. They're part of [Azure Monitor metrics](monitor-data-factory-reference.md#metrics). +SSIS operational [metrics](/azure/azure-monitor/essentials/data-platform-metrics) are performance counters or numerical values that describe the status of SSIS IR start and stop operations, as well as SSIS package executions at a particular point in time. They're part of [Azure Monitor metrics](monitor-data-factory-reference.md#metrics). -When you configure diagnostic settings and workspace for your ADF on Azure Monitor, selecting the _AllMetrics_ check box will make SSIS operational metrics available for [interactive analysis using Azure metrics explorer](../azure-monitor/essentials/analyze-metrics.md), [presentation on Azure dashboard](../azure-monitor/app/tutorial-app-dashboards.md), and [near-real time alerts](../azure-monitor/alerts/alerts-metric.md). +When you configure diagnostic settings and workspace for your ADF on Azure Monitor, selecting the _AllMetrics_ check box will make SSIS operational metrics available for [interactive analysis using Azure metrics explorer](/azure/azure-monitor/essentials/analyze-metrics), [presentation on Azure dashboard](/azure/azure-monitor/app/tutorial-app-dashboards), and [near-real time alerts](/azure/azure-monitor/alerts/alerts-metric). :::image type="content" source="media/data-factory-monitor-oms/monitor-oms-image2.png" alt-text="Name your settings and select a log-analytics workspace"::: To raise alerts on SSIS operational metrics from Azure portal, [select the **Ale ## SSIS operational logs -SSIS operational [logs](../azure-monitor/logs/data-platform-logs.md) are events generated by SSIS IR operations and SSIS package executions that provide enough context on any identified issues and are useful for root cause analysis. +SSIS operational [logs](/azure/azure-monitor/logs/data-platform-logs) are events generated by SSIS IR operations and SSIS package executions that provide enough context on any identified issues and are useful for root cause analysis. -When you configure diagnostic settings and workspace for your ADF on Azure Monitor, you can select the relevant SSIS operational logs and send them to Log Analytics that's based on Azure Data Explorer. In there, they'll be made available for [analysis using rich query language](../azure-monitor/logs/log-query-overview.md), [presentation on Azure dashboard](../azure-monitor/app/overview-dashboard.md#create-custom-kpi-dashboards-using-application-insights), and [near-real time alerts](../azure-monitor/alerts/alerts-log.md). +When you configure diagnostic settings and workspace for your ADF on Azure Monitor, you can select the relevant SSIS operational logs and send them to Log Analytics that's based on Azure Data Explorer. In there, they'll be made available for [analysis using rich query language](/azure/azure-monitor/logs/log-query-overview), [presentation on Azure dashboard](/azure/azure-monitor/app/overview-dashboard#create-custom-kpi-dashboards-using-application-insights), and [near-real time alerts](/azure/azure-monitor/alerts/alerts-log). :::image type="content" source="media/data-factory-monitor-oms/monitor-oms-image2.png" alt-text="Name your settings and select a log-analytics workspace"::: You can query the following patterns to detect the unavailability of your SSIS I * There are missing `Heartbeat` records in many one-minute periods when your SSIS IR is still running. * There are `Heartbeat` records with the **ResultType** property set to `Unhealthy` in many one-minute periods when your SSIS IR is still running. -You can turn the above queries into [alerts](../azure-monitor/alerts/alerts-unified-log.md) and go to your [SSIS IR monitoring page](monitor-integration-runtime.md#monitor-the-azure-ssis-integration-runtime-in-azure-portal) to confirm when you receive those alerts. +You can turn the above queries into [alerts](/azure/azure-monitor/alerts/alerts-unified-log) and go to your [SSIS IR monitoring page](monitor-integration-runtime.md#monitor-the-azure-ssis-integration-runtime-in-azure-portal) to confirm when you receive those alerts. When querying SSIS package execution logs on Logs Analytics, you can join them using **OperationId**/**ExecutionId**/**CorrelationId** properties. **OperationId**/**ExecutionId** are always set to `1` for all operations/executions related to packages **not** stored in SSISDB/invoked via T-SQL. |
| databox-online | Azure Stack Edge Gpu Enable Azure Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/databox-online/azure-stack-edge-gpu-enable-azure-monitor.md | Monitoring containers on your Azure Stack Edge Pro GPU device is critical, speci This article describes the steps required to enable Azure Monitor on your device and gather container logs in Log Analytics workspace. The Azure Monitor metrics store is currently not supported with your Azure Stack Edge Pro GPU device. > [!NOTE]-> If Azure Arc is enabled on the Kubernetes cluster on your device, follow the steps in [Azure Monitor Container Insights for Azure Arc-enabled Kubernetes clusters](../azure-monitor/containers/container-insights-enable-arc-enabled-clusters.md?toc=%2fazure%2fazure-arc%2fkubernetes%2ftoc.json) to set up container monitoring. +> If Azure Arc is enabled on the Kubernetes cluster on your device, follow the steps in [Azure Monitor Container Insights for Azure Arc-enabled Kubernetes clusters](/azure/azure-monitor/containers/container-insights-enable-arc-enabled-clusters?toc=%2fazure%2fazure-arc%2fkubernetes%2ftoc.json) to set up container monitoring. ## Prerequisites Take the following steps to create a log analytics workspace. A log analytics wo  -For more information, see the detailed steps in [Create a Log Analytics workspace via Azure portal](../azure-monitor/logs/quick-create-workspace.md). +For more information, see the detailed steps in [Create a Log Analytics workspace via Azure portal](/azure/azure-monitor/logs/quick-create-workspace). For more information, see the detailed steps in [Create a Log Analytics workspac Take the following steps to enable Container Insights on your workspace. -1. Follow the detailed steps in [Add the Azure Monitor Containers solution](../azure-monitor/containers/container-insights-hybrid-setup.md#add-the-azure-monitor-containers-solution). Use the following template file `containerSolution.json`: +1. Follow the detailed steps in [Add the Azure Monitor Containers solution](/azure/azure-monitor/containers/container-insights-hybrid-setup#add-the-azure-monitor-containers-solution). Use the following template file `containerSolution.json`: ```yml { |
| databox-online | Azure Stack Edge Gpu Kubernetes Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/databox-online/azure-stack-edge-gpu-kubernetes-overview.md | The Kubernetes cluster on your Azure Stack Edge device allows Kubernetes role-b You can also monitor the health of your cluster and resources via the Kubernetes dashboard. Container logs are also available. For more information, see [Use the Kubernetes dashboard to monitor the Kubernetes cluster health on your Azure Stack Edge device](azure-stack-edge-gpu-monitor-kubernetes-dashboard.md). -Azure Monitor is also available as an add-on to collect health data from containers, nodes, and controllers. For more information, see [Azure Monitor overview](../azure-monitor/overview.md) +Azure Monitor is also available as an add-on to collect health data from containers, nodes, and controllers. For more information, see [Azure Monitor overview](/azure/azure-monitor/overview) ## Edge container registry |
| databox-online | Azure Stack Edge Gpu Manage Device Event Alert Notifications | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/databox-online/azure-stack-edge-gpu-manage-device-event-alert-notifications.md | This article describes how to create alert processing rules in the Azure portal. An alert processing rule can add action groups to alert notifications. Use alert notification preferences, like email or SMS messages, to notify users when alerts are triggered. -For more information about alert processing rules, see [Alert processing rules](../azure-monitor/alerts/alerts-processing-rules.md?tabs=portal). For more information about action groups, see [Create and manage action groups in the Azure portal](../azure-monitor/alerts/action-groups.md). +For more information about alert processing rules, see [Alert processing rules](/azure/azure-monitor/alerts/alerts-processing-rules?tabs=portal). For more information about action groups, see [Create and manage action groups in the Azure portal](/azure/azure-monitor/alerts/action-groups). ## Create an alert processing rule Use the following steps in the Azure portal to create an alert processing rule for your Azure Stack Edge device. > [!NOTE]-> These steps create an alert processing rule. The alert processing rule adds action groups to alert notifications. For details about creating an alert processing rule to suppress notifications, see [Alert processing rules](../azure-monitor/alerts/alerts-action-rules.md?tabs=portal). +> These steps create an alert processing rule. The alert processing rule adds action groups to alert notifications. For details about creating an alert processing rule to suppress notifications, see [Alert processing rules](/azure/azure-monitor/alerts/alerts-action-rules?tabs=portal). 1. Go to the Azure Stack Edge device in the [Azure portal](https://portal.azure.com), and select the **Alerts** menu item (under **Monitoring**). Then select **Alert processing rules**. Use the following steps in the Azure portal to create an alert processing rule f 1. On the **Add filters** pane, under **Filters**, add each filter you want to apply. For each filter, select the **Filter** type, **Operator**, and **Value**. - For a list of filter options, see [Filter criteria](../azure-monitor/alerts/alerts-processing-rules.md?tabs=portal#scope-and-filters-for-alert-processing-rules). + For a list of filter options, see [Filter criteria](/azure/azure-monitor/alerts/alerts-processing-rules?tabs=portal#scope-and-filters-for-alert-processing-rules). The filters in the following example apply to all alerts at Severity levels 2, 3, and 4 that the Monitor service raises for Azure Stack Edge resources. Use the following steps in the Azure portal to create an alert processing rule f Select an option to **+ Select action group** for an existing group or **+ Create action group** to create a new one. - To create a new action group, select **+ Create action group** and follow the steps in [Alert processing rules](../azure-monitor/alerts/alerts-processing-rules.md#add-action-groups-to-all-alert-types). + To create a new action group, select **+ Create action group** and follow the steps in [Alert processing rules](/azure/azure-monitor/alerts/alerts-processing-rules#add-action-groups-to-all-alert-types). >[!NOTE]- >Select the **Suppress notifications** option if you don't want to invoke notifications for alerts. For more information, see [Alert processing rules](../azure-monitor/alerts/alerts-processing-rules.md?tabs=portal#suppress-notifications-during-planned-maintenance). + >Select the **Suppress notifications** option if you don't want to invoke notifications for alerts. For more information, see [Alert processing rules](/azure/azure-monitor/alerts/alerts-processing-rules?tabs=portal#suppress-notifications-during-planned-maintenance). [](media/azure-stack-edge-gpu-manage-device-event-alert-notifications/azure-stack-edge-action-rule-setting-options-08.png#lightbox) The email notification looks similar to the following example. ## Next steps - [View device alerts](azure-stack-edge-alerts.md).-- [Work with alert metrics](../azure-monitor/alerts/alerts-metric.md).+- [Work with alert metrics](/azure/azure-monitor/alerts/alerts-metric). - [Set up Azure Monitor](azure-stack-edge-gpu-enable-azure-monitor.md). |
| databox-online | Azure Stack Edge Gpu Monitor Virtual Machine Activity | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/databox-online/azure-stack-edge-gpu-monitor-virtual-machine-activity.md | To view activity logs for the virtual machines on your Azure Stack Edge Pro GPU <!--Reshoot to remove pointer. May be able to replace drop-down only.--> -On any **Activity log** pane in Azure, you can filter and sort activities, select columns to display, drill down to details for a specific activity, and get **Quick Insights** into errors, failed deployments, alerts, service health, and security changes over the last 24 hours. For more information about the logs and the filtering options, see [View activity logs](../azure-monitor/essentials/activity-log.md). +On any **Activity log** pane in Azure, you can filter and sort activities, select columns to display, drill down to details for a specific activity, and get **Quick Insights** into errors, failed deployments, alerts, service health, and security changes over the last 24 hours. For more information about the logs and the filtering options, see [View activity logs](/azure/azure-monitor/essentials/activity-log). ## Next steps |
| databox-online | Azure Stack Edge Gpu System Requirements | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/databox-online/azure-stack-edge-gpu-system-requirements.md | Add the following URL patterns for Azure Monitor if you're using the containeriz | https://\*.oms.opinsights.azure.com | 443 | Operations Management Suite (OMS) onboarding | | https://\*.dc.services.visualstudio.com | 443 | Agent telemetry that uses Azure Public Cloud Application Insights | -For more information, see [Network firewall requirements for monitoring container insights](../azure-monitor/containers/container-insights-onboard.md#network-firewall-requirements). +For more information, see [Network firewall requirements for monitoring container insights](/azure/azure-monitor/containers/container-insights-onboard#network-firewall-requirements). ### URL patterns for gateway for Azure Government |
| databox-online | Azure Stack Edge Pro 2 System Requirements | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/databox-online/azure-stack-edge-pro-2-system-requirements.md | Add the following URL patterns for Azure Monitor if you're using the containeriz | https://\*.oms.opinsights.azure.com | 443 | Operations Management Suite (OMS) onboarding | | https://\*.dc.services.visualstudio.com | 443 | Agent telemetry that uses Azure Public Cloud Application Insights | -For more information, see [Network firewall requirements for monitoring container insights](../azure-monitor/containers/container-insights-onboard.md#network-firewall-requirements). +For more information, see [Network firewall requirements for monitoring container insights](/azure/azure-monitor/containers/container-insights-onboard#network-firewall-requirements). ### URL patterns for gateway for Azure Government |
| ddos-protection | Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/ddos-protection/alerts.md | You can select any of the available Azure DDoS Protection metrics to alert you w 1. Select **Review + create** and then select **Create**. > [!NOTE]-> Review the [Action groups](../azure-monitor/alerts/action-groups.md) documentation for more information on creating action groups. +> Review the [Action groups](/azure/azure-monitor/alerts/action-groups) documentation for more information on creating action groups. ### Continue configuring alerts through portal Within a few minutes of attack detection, you should receive an email from Azure :::image type="content" source="./media/ddos-alerts/ddos-alert.png" alt-text="Screenshot of a DDoS attack Alert after a DDoS attack." lightbox="./media/ddos-alerts/ddos-alert.png"::: -You can also learn more about [configuring webhooks](../azure-monitor/alerts/alerts-webhooks.md?toc=%2fazure%2fvirtual-network%2ftoc.json) and [logic apps](../logic-apps/logic-apps-overview.md?toc=%2fazure%2fvirtual-network%2ftoc.json) for creating alerts. +You can also learn more about [configuring webhooks](/azure/azure-monitor/alerts/alerts-webhooks?toc=%2fazure%2fvirtual-network%2ftoc.json) and [logic apps](../logic-apps/logic-apps-overview.md?toc=%2fazure%2fvirtual-network%2ftoc.json) for creating alerts. ## Clean up resources You can keep your resources for the next tutorial. If no longer needed, delete the alerts. |
| ddos-protection | Ddos Configure Log Analytics Workspace | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/ddos-protection/ddos-configure-log-analytics-workspace.md | In order to use diagnostic logging, you'll first need a Log Analytics workspace 1. Select **Save**. -For more information, see [Log Analytics workspace overview](../azure-monitor/logs/log-analytics-workspace-overview.md). +For more information, see [Log Analytics workspace overview](/azure/azure-monitor/logs/log-analytics-workspace-overview). ## Next steps |
| ddos-protection | Ddos Protection Features | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/ddos-protection/ddos-protection-features.md | The complexity of attacks (for example, multi-vector DDoS attacks) and the appli ## DDoS Protection telemetry, monitoring, and alerting -Azure DDoS Protection exposes rich telemetry via [Azure Monitor](../azure-monitor/overview.md). You can configure alerts for any of the Azure Monitor metrics that DDoS Protection uses. You can integrate logging with Splunk (Azure Event Hubs), Azure Monitor logs, and Azure Storage for advanced analysis via the Azure Monitor Diagnostics interface. +Azure DDoS Protection exposes rich telemetry via [Azure Monitor](/azure/azure-monitor/overview). You can configure alerts for any of the Azure Monitor metrics that DDoS Protection uses. You can integrate logging with Splunk (Azure Event Hubs), Azure Monitor logs, and Azure Storage for advanced analysis via the Azure Monitor Diagnostics interface. ### Azure DDoS Protection mitigation policies |
| ddos-protection | Ddos Response Strategy | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/ddos-protection/ddos-response-strategy.md | ItΓÇÖs imperative to understand the scope of your risk from a DDoS attack on an It's essential that you understand the normal behavior of an application and prepare to act if the application isn't behaving as expected during a DDoS attack. Have monitors configured for your business-critical applications that mimic client behavior, and notify you when relevant anomalies are detected. Refer to [monitoring and diagnostics best practices](/azure/architecture/best-practices/monitoring#monitoring-and-diagnostics-scenarios) to gain insights on the health of your application. -[Azure Application Insights](../azure-monitor/app/app-insights-overview.md) is an extensible application performance management (APM) service for web developers on multiple platforms. Use Application Insights to monitor your live web application. It automatically detects performance anomalies. It includes analytics tools to help you diagnose issues and to understand what users do with your app. It's designed to help you continuously improve performance and usability. +[Azure Application Insights](/azure/azure-monitor/app/app-insights-overview) is an extensible application performance management (APM) service for web developers on multiple platforms. Use Application Insights to monitor your live web application. It automatically detects performance anomalies. It includes analytics tools to help you diagnose issues and to understand what users do with your app. It's designed to help you continuously improve performance and usability. ## Customer DDoS response team |
| ddos-protection | Monitor Ddos Protection Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/ddos-protection/monitor-ddos-protection-reference.md | The metric names present different packet types, and bytes vs. packets, with a b > [!NOTE] > While multiple options for **Aggregation** are displayed on Azure portal, only the aggregation types listed in the table below are supported for each metric. We apologize for this confusion and we are working to resolve it.-The following [Azure Monitor metrics](../azure-monitor/essentials/metrics-supported.md#microsoftnetworkpublicipaddresses) are available for Azure DDoS Protection. These metrics are also exportable via diagnostic settings, see [View and configure DDoS diagnostic logging](diagnostic-logging.md). +The following [Azure Monitor metrics](/azure/azure-monitor/essentials/metrics-supported#microsoftnetworkpublicipaddresses) are available for Azure DDoS Protection. These metrics are also exportable via diagnostic settings, see [View and configure DDoS diagnostic logging](diagnostic-logging.md). | Metric | Metric Display Name | Unit | Aggregation Type | Description | | | | | | | |
| defender-for-iot | How To Region Move | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/defender-for-iot/device-builders/how-to-region-move.md | You can move a Microsoft Defender for IoT "iotsecuritysolutions" resource to a d In this section, you'll prepare to move the resource for the move by finding the resource and confirming it is in a region you wish to move from. -Before transitioning the resource to the new region, we recommended using [log analytics](../../azure-monitor/logs/quick-create-workspace.md) to store alerts, and raw events. +Before transitioning the resource to the new region, we recommended using [log analytics](/azure/azure-monitor/logs/quick-create-workspace) to store alerts, and raw events. **To find the resource you want to move**: |
| defender-for-iot | Tutorial Investigate Security Recommendations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/defender-for-iot/device-builders/tutorial-investigate-security-recommendations.md | Open each aggregated recommendation to display the detailed recommendation descr :::image type="content" source="media/how-to-configure-agent-based-solution/recommendation-alert.png" alt-text="Screenshot showing how to view a recommendation in the log analytics workspace."::: -For more information on querying data from Log Analytics, see [Get started with log queries in Azure Monitor](../../azure-monitor/logs/get-started-queries.md). +For more information on querying data from Log Analytics, see [Get started with log queries in Azure Monitor](/azure/azure-monitor/logs/get-started-queries). ## Clean up resources |
| defender-for-iot | Iot Solution | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/defender-for-iot/organizations/iot-solution.md | After you've connected a subscription to Microsoft Sentinel, you'll be able to v > [!NOTE] > The **Logs** page in Microsoft Sentinel is based on Azure Monitor's Log Analytics. >-> For more information, see [Log queries overview](../../azure-monitor/logs/log-query-overview.md) in the Azure Monitor documentation and the [Write your first KQL query](/training/modules/write-first-query-kusto-query-language/) Learn module. +> For more information, see [Log queries overview](/azure/azure-monitor/logs/log-query-overview) in the Azure Monitor documentation and the [Write your first KQL query](/training/modules/write-first-query-kusto-query-language/) Learn module. > ### Understand alert timestamps |
| defender-for-iot | Whats New | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/defender-for-iot/organizations/whats-new.md | For more information, see [Manage your device inventory from the Azure portal](h ### Use Azure Monitor workbooks with Microsoft Defender for IoT (Public preview) -[Azure Monitor workbooks](../../azure-monitor/visualize/workbooks-overview.md) provide graphs and dashboards that visually reflect your data, and are now available directly in Microsoft Defender for IoT with data from [Azure Resource Graph](../../governance/resource-graph/index.yml). +[Azure Monitor workbooks](/azure/azure-monitor/visualize/workbooks-overview) provide graphs and dashboards that visually reflect your data, and are now available directly in Microsoft Defender for IoT with data from [Azure Resource Graph](../../governance/resource-graph/index.yml). In the Azure portal, use the new Defender for IoT **Workbooks** page to view workbooks created by Microsoft and provided out-of-the-box, or create custom workbooks of your own. |
| defender-for-iot | Workbooks | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/defender-for-iot/organizations/workbooks.md | Learn more about viewing dashboards and reports on the sensor console: Learn more about Azure Monitor workbooks and Azure Resource Graph: - [Azure Resource Graph documentation](../../governance/resource-graph/index.yml)-- [Azure Monitor workbook documentation](../../azure-monitor/visualize/workbooks-overview.md)+- [Azure Monitor workbook documentation](/azure/azure-monitor/visualize/workbooks-overview) - [Kusto Query Language (KQL) documentation](/azure/data-explorer/kusto/query/) |
| dev-box | Monitor Dev Box Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/dev-box/monitor-dev-box-reference.md | The following table lists the properties of resource logs in a Microsoft Dev Box | **resultType** | **OperationResult** | Indicates whether the operation failed or succeeded. | | **correlationId** | **CorrelationId** | The unique correlation ID for the operation that can be shared with the app team to support further investigation. | -For a list of all Azure Monitor log categories and links to associated schemas, see [Common and service-specific schemas for Azure resource logs](../azure-monitor/essentials/resource-logs-schema.md). +For a list of all Azure Monitor log categories and links to associated schemas, see [Common and service-specific schemas for Azure resource logs](/azure/azure-monitor/essentials/resource-logs-schema). ## Azure Monitor Logs tables A dev center uses Kusto tables from Azure Monitor Logs. You can query these tabl ## Related content - [Monitor Dev Box](monitor-dev-box.md)-- [Monitor Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md)+- [Monitor Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) |
| dev-box | Monitor Dev Box | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/dev-box/monitor-dev-box.md | To use a storage account to store the logs, follow these steps: To use Log Analytics for the logs, follow these steps: >[!NOTE] ->A log analytics workspace is required to complete these steps. Refer to: **[Create a Log Analytics workspace in the Azure portal](../azure-monitor/logs/quick-create-workspace.md)** for more information. +>A log analytics workspace is required to complete these steps. Refer to: **[Create a Log Analytics workspace in the Azure portal](/azure/azure-monitor/logs/quick-create-workspace)** for more information. 1. For **Diagnostic setting name**, enter a name for your diagnostic log settings. The following example shows how to enable diagnostic logs via the Azure PowerShe ## Analyzing Logs This section describes existing tables for DevCenter diagnostic logs and how to query them. -All resource logs in Azure Monitor have the same fields followed by service-specific fields. The common schema is outlined in [Common and service-specific schemas for Azure resource logs](../azure-monitor/essentials/resource-logs-schema.md#top-level-common-schema). +All resource logs in Azure Monitor have the same fields followed by service-specific fields. The common schema is outlined in [Common and service-specific schemas for Azure resource logs](/azure/azure-monitor/essentials/resource-logs-schema#top-level-common-schema). DevCenter stores data in the following tables. These examples are just a small sample of the rich queries that can be performed ## Related content - [Monitor Dev Box](monitor-dev-box.md)-- [Azure Diagnostic logs](../azure-monitor/essentials/platform-logs-overview.md)-- [Azure Monitor logs](../azure-monitor/logs/log-query-overview.md)+- [Azure Diagnostic logs](/azure/azure-monitor/essentials/platform-logs-overview) +- [Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview) |
| devtest-labs | Activity Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/devtest-labs/activity-logs.md | This article explains how to view activity logs for a lab in Azure DevTest Labs :::image type="content" source="./media/activity-logs/change-history.png" alt-text="Stop VM event - Change history"::: 1. Select the change in the change history list to see more details about the change. -For more information about activity logs, see [Azure Activity Log](../azure-monitor/essentials/activity-log.md). +For more information about activity logs, see [Azure Activity Log](/azure/azure-monitor/essentials/activity-log). ## Next steps - To learn about setting **alerts** on activity logs, see [Create alerts](create-alerts.md).-- To learn more about activity logs, see [Azure Activity Log](../azure-monitor/essentials/activity-log.md).+- To learn more about activity logs, see [Azure Activity Log](/azure/azure-monitor/essentials/activity-log). |
| devtest-labs | Create Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/devtest-labs/create-alerts.md | In this example, you create an alert for all administrative operations on a lab ## Related content -- To learn more about creating action groups using different action types, see [Create and manage action groups in the Azure portal](../azure-monitor/alerts/action-groups.md).-- To learn more about activity logs, see [Azure Activity Log](../azure-monitor/essentials/activity-log.md).-- To learn about setting alerts on activity logs, see [Alerts on activity log](../azure-monitor/alerts/activity-log-alerts.md).+- To learn more about creating action groups using different action types, see [Create and manage action groups in the Azure portal](/azure/azure-monitor/alerts/action-groups). +- To learn more about activity logs, see [Azure Activity Log](/azure/azure-monitor/essentials/activity-log). +- To learn about setting alerts on activity logs, see [Alerts on activity log](/azure/azure-monitor/alerts/activity-log-alerts). |
| devtest-labs | Troubleshoot Vm Deployment Failures | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/devtest-labs/troubleshoot-vm-deployment-failures.md | This article guides you through possible causes and troubleshooting steps for de VM deployment errors are captured in activity logs. In the Azure portal, you can find lab VM activity logs under **Audit logs** or **Virtual machine diagnostics** on the resource menu on the lab's VM page. (This page appears after you select the VM from the **My virtual machines** list). -Sometimes, the deployment error occurs before VM deployment begins. An example is when the subscription limit for a resource that was created with the VM is exceeded. In this case, the error details are captured in the lab-level activity logs. In the Azure portal, activity logs are located at the bottom of the **Configuration and policies** settings section. For more information about activity logs in Azure, see [View activity logs to audit actions on resources](../azure-monitor/essentials/activity-log.md). +Sometimes, the deployment error occurs before VM deployment begins. An example is when the subscription limit for a resource that was created with the VM is exceeded. In this case, the error details are captured in the lab-level activity logs. In the Azure portal, activity logs are located at the bottom of the **Configuration and policies** settings section. For more information about activity logs in Azure, see [View activity logs to audit actions on resources](/azure/azure-monitor/essentials/activity-log). ## Resolve "Parent resource not found" |
| devtest | How To Manage Monitor Devtest | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/devtest/offer/how-to-manage-monitor-devtest.md | When managing from an operational expense perspective, you only pay for what you ## Monitoring through a different lens -[Azure Monitor](../../azure-monitor/overview.md) helps maximize availability and performance for your applications and services. Deliver comprehensive solutions for collecting, analyzing, and acting on data from your cloud and on-premises environments. Understand how your applications are performing. Azure Monitor proactively identifies issues affecting your applications and the resources they depend on. +[Azure Monitor](/azure/azure-monitor/overview) helps maximize availability and performance for your applications and services. Deliver comprehensive solutions for collecting, analyzing, and acting on data from your cloud and on-premises environments. Understand how your applications are performing. Azure Monitor proactively identifies issues affecting your applications and the resources they depend on. Within Azure, use monitoring to accelerate time to market and ensure performance data in your production services. You can aggregate and analyze metrics, logs, and traces. Through monitoring, you can also fire alerts and send notifications or call automated solutions. Load and duress analysis provide another data in preproduction so you can contin As you perform load and duress testing with your application or service, the method for scaling up or out depends on your workloads. You can learn more about scaling your apps in Azure: - [Scale up an app in Azure App Service](../../app-service/manage-scale-up.md) -- [Get started with Autoscale in Azure](../../azure-monitor/platform/autoscale-get-started.md?toc=/azure/app-service/toc.json) +- [Get started with Autoscale in Azure](/azure/azure-monitor/platform/autoscale-get-started?toc=/azure/app-service/toc.json) -Enable monitoring for your application with [Application Insights](../../azure-monitor/app/app-insights-overview.md) to collect detailed information including page views, application requests, and exceptions. +Enable monitoring for your application with [Application Insights](/azure/azure-monitor/app/app-insights-overview) to collect detailed information including page views, application requests, and exceptions. ## Azure Automation |
| digital-twins | Concepts High Availability Disaster Recovery | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/digital-twins/concepts-high-availability-disaster-recovery.md | If it's important for you to keep all data within certain geographical areas, ch ## Monitor service health -As Azure Digital Twins instances are failed over and recovered, you can monitor the process using the [Azure Service Health](../service-health/service-health-overview.md) tool. Service Health tracks the health of your Azure services across different regions and subscriptions, and shares service-impacting communications about outages and downtimes. +As Azure Digital Twins instances are failed over and recovered, you can monitor the process using the [Azure Service Health](/azure/service-health/service-health-overview) tool. Service Health tracks the health of your Azure services across different regions and subscriptions, and shares service-impacting communications about outages and downtimes. During a failover event, Service Health can provide an indication of when your service is down, and when it's back up. |
| digital-twins | How To Create Routes | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/digital-twins/how-to-create-routes.md | When you implement or update a filter, the change may take a few minutes to be r Routing metrics such as count, latency, and failure rate can be viewed in the [Azure portal](https://portal.azure.com/). -For information about viewing and managing metrics with Azure Monitor, see [Get started with metrics explorer](../azure-monitor/essentials/metrics-getting-started.md). For a full list of routing metrics available for Azure Digital Twins, see [Azure Digital Twins routing metrics](how-to-monitor.md#routing-metrics). +For information about viewing and managing metrics with Azure Monitor, see [Get started with metrics explorer](/azure/azure-monitor/essentials/metrics-getting-started). For a full list of routing metrics available for Azure Digital Twins, see [Azure Digital Twins routing metrics](how-to-monitor.md#routing-metrics). ## Next steps |
| digital-twins | How To Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/digital-twins/how-to-monitor.md | -Azure Digital Twins integrates with [Azure Monitor](../azure-monitor/overview.md) to provide metrics and diagnostic information that you can use to monitor your Azure Digital Twins resources. **Metrics** are enabled by default, and give you information about the state of Azure Digital Twins resources in your Azure subscription. **Alerts** can proactively notify you when certain conditions are found in your metrics data. You can also collect **diagnostic logs** for your service instance to monitor its performance, access, and other data. +Azure Digital Twins integrates with [Azure Monitor](/azure/azure-monitor/overview) to provide metrics and diagnostic information that you can use to monitor your Azure Digital Twins resources. **Metrics** are enabled by default, and give you information about the state of Azure Digital Twins resources in your Azure subscription. **Alerts** can proactively notify you when certain conditions are found in your metrics data. You can also collect **diagnostic logs** for your service instance to monitor its performance, access, and other data. These monitoring features can help you assess the overall health of the Azure Digital Twins service and the resources connected to it. You can use them to understand what is happening in your Azure Digital Twins instance, and analyze root causes on issues without needing to contact Azure support. They can be accessed from the [Azure portal](https://portal.azure.com), grouped ## Metrics and alerts -For general information about viewing Azure resource **metrics**, see [Get started with metrics explorer](../azure-monitor/essentials/metrics-getting-started.md) in the Azure Monitor documentation. For general information about configuring **alerts** for Azure metrics, see [Create a new alert rule](../azure-monitor/alerts/alerts-create-new-alert-rule.md?tabs=metric). +For general information about viewing Azure resource **metrics**, see [Get started with metrics explorer](/azure/azure-monitor/essentials/metrics-getting-started) in the Azure Monitor documentation. For general information about configuring **alerts** for Azure metrics, see [Create a new alert rule](/azure/azure-monitor/alerts/alerts-create-new-alert-rule?tabs=metric). The rest of this section describes the metrics tracked by each Azure Digital Twins instance, and how each metric relates to the overall status of your instance. The rest of this section describes the metrics tracked by each Azure Digital Twi You can configure these metrics to track when you're approaching a [published service limit](reference-service-limits.md#functional-limits) for some aspect of your solution. -To set up tracking, use the [alerts](../azure-monitor/alerts/alerts-overview.md) feature in Azure Monitor. You can define thresholds for these metrics so that you receive an alert when a metric reaches a certain percentage of its published limit. +To set up tracking, use the [alerts](/azure/azure-monitor/alerts/alerts-overview) feature in Azure Monitor. You can define thresholds for these metrics so that you receive an alert when a metric reaches a certain percentage of its published limit. | Metric | Metric display name | Unit | Aggregation type| Description | Dimensions | | | | | | | | Dimensions help identify more details about the metrics. Some of the routing met ## Diagnostics logs -For general information about Azure **diagnostics settings**, including how to enable them, see [Diagnostic settings in Azure Monitor](../azure-monitor/essentials/diagnostic-settings.md). For information about querying diagnostic logs using **Log Analytics**, see [Overview of Log Analytics in Azure Monitor](../azure-monitor/logs/log-analytics-overview.md). +For general information about Azure **diagnostics settings**, including how to enable them, see [Diagnostic settings in Azure Monitor](/azure/azure-monitor/essentials/diagnostic-settings). For information about querying diagnostic logs using **Log Analytics**, see [Overview of Log Analytics in Azure Monitor](/azure/azure-monitor/logs/log-analytics-overview). The rest of this section describes the diagnostic log categories that Azure Digital Twins can collect, and their schemas. Here's an example JSON body for an `ADTEventRoutesOperation` that of `Microsoft. ## Next steps -Read more about Azure Monitor and its capabilities in the [Azure Monitor documentation](../azure-monitor/overview.md). +Read more about Azure Monitor and its capabilities in the [Azure Monitor documentation](/azure/azure-monitor/overview). |
| digital-twins | Reference Service Limits | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/digital-twins/reference-service-limits.md | When a limit is reached, any requests beyond it are throttled by the service, wh To manage the throttling, here are some recommendations for working with limits. * Use retry logic. The [Azure Digital Twins SDKs](concepts-apis-sdks.md) implement retry logic for failed requests, so if you're working with a provided SDK, this functionality is already built-in. Otherwise, consider implementing retry logic in your own application. The service sends back a `Retry-After` header in the failure response, which you can use to determine how long to wait before retrying.-* Use thresholds and notifications to warn about approaching limits. Some of the service limits for Azure Digital Twins have corresponding [metrics](../azure-monitor/essentials/data-platform-metrics.md) that can be used to track usage in these areas. To configure thresholds and set up an alert on any metric when a threshold is approached, see the instructions in [Create a new alert rule](../azure-monitor/alerts/alerts-create-new-alert-rule.md?tabs=metric). To set up notifications for other limits where metrics aren't provided, consider implementing this logic in your own application code. +* Use thresholds and notifications to warn about approaching limits. Some of the service limits for Azure Digital Twins have corresponding [metrics](/azure/azure-monitor/essentials/data-platform-metrics) that can be used to track usage in these areas. To configure thresholds and set up an alert on any metric when a threshold is approached, see the instructions in [Create a new alert rule](/azure/azure-monitor/alerts/alerts-create-new-alert-rule?tabs=metric). To set up notifications for other limits where metrics aren't provided, consider implementing this logic in your own application code. * Deploy at scale across multiple instances. Avoid having a single point of failure. Instead of one large graph for your entire deployment, consider sectioning out subsets of twins logically (like by region or tenant) across multiple instances. * For modeling recommendations to help you operate within the functional limits, see [Modeling tools and best practices](concepts-models.md#modeling-tools-and-best-practices). |
| digital-twins | Troubleshoot Performance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/digital-twins/troubleshoot-performance.md | If you're experiencing delays or other performance issues when working with Azur ## Isolate the source of the delay -Determine whether the delay is coming from Azure Digital Twins or another service in your solution. To investigate this delay, you can use the **API Latency** metric in [Azure Monitor](../azure-monitor/essentials/quick-monitor-azure-resource.md) through the Azure portal. For more about Azure Monitor metrics for Azure Digital Twins, see [Azure Digital Twins metrics and alerts](how-to-monitor.md#metrics-and-alerts). +Determine whether the delay is coming from Azure Digital Twins or another service in your solution. To investigate this delay, you can use the **API Latency** metric in [Azure Monitor](/azure/azure-monitor/essentials/quick-monitor-azure-resource) through the Azure portal. For more about Azure Monitor metrics for Azure Digital Twins, see [Azure Digital Twins metrics and alerts](how-to-monitor.md#metrics-and-alerts). ## Check regions If your solution uses Azure Digital Twins in combination with other Azure servic ## Check logs -Azure Digital Twins can collect logs for your service instance to help monitor its performance, among other data. Logs can be sent to [Log Analytics](../azure-monitor/logs/log-analytics-overview.md) or your custom storage mechanism. To enable logging in your instance, use the instructions in [Diagnostic settings in Azure Monitor](../azure-monitor/essentials/diagnostic-settings.md). You can analyze the timestamps on the logs to measure latencies, evaluate if they're consistent, and understand their source. +Azure Digital Twins can collect logs for your service instance to help monitor its performance, among other data. Logs can be sent to [Log Analytics](/azure/azure-monitor/logs/log-analytics-overview) or your custom storage mechanism. To enable logging in your instance, use the instructions in [Diagnostic settings in Azure Monitor](/azure/azure-monitor/essentials/diagnostic-settings). You can analyze the timestamps on the logs to measure latencies, evaluate if they're consistent, and understand their source. ## Check API frequency |
| digital-twins | Troubleshoot Resource Health | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/digital-twins/troubleshoot-resource-health.md | -[Azure Service Health](../service-health/index.yml) is a suite of experiences that can help you diagnose and get support for service problems that affect your Azure resources. It contains resource health, service health, and status information, and reports on both current and past health information. +[Azure Service Health](/azure/service-health/) is a suite of experiences that can help you diagnose and get support for service problems that affect your Azure resources. It contains resource health, service health, and status information, and reports on both current and past health information. ## Use Azure Resource Health -[Azure Resource Health](../service-health/resource-health-overview.md) can help you monitor whether your Azure Digital Twins instance is up and running. You can also use it to learn whether a regional outage is impacting the health of your instance. +[Azure Resource Health](/azure/service-health/resource-health-overview) can help you monitor whether your Azure Digital Twins instance is up and running. You can also use it to learn whether a regional outage is impacting the health of your instance. To check the health of your instance, follow these steps: To check the health of your instance, follow these steps: :::image type="content" source="media/troubleshoot-resource-health/resource-health.png" alt-text="Screenshot showing the 'Resource health' page. There is a 'Health history' section showing a daily report from the last nine days."::: -In the image above, this instance is showing as **Available**, and has been for the past nine days. To learn more about the Available status and the other status types that may appear, see [Resource Health overview](../service-health/resource-health-overview.md). +In the image above, this instance is showing as **Available**, and has been for the past nine days. To learn more about the Available status and the other status types that may appear, see [Resource Health overview](/azure/service-health/resource-health-overview). -You can also learn more about the different checks that go into resource health for different types of Azure resources in [Resource types and health checks in Azure resource health](../service-health/resource-health-checks-resource-types.md). +You can also learn more about the different checks that go into resource health for different types of Azure resources in [Resource types and health checks in Azure resource health](/azure/service-health/resource-health-checks-resource-types). ## Use Azure Service Health -[Azure Service Health](../service-health/service-health-overview.md) can help you check the health of the entire Azure Digital Twins service in a certain region, and be aware of events like ongoing service issues and upcoming planned maintenance. +[Azure Service Health](/azure/service-health/service-health-overview) can help you check the health of the entire Azure Digital Twins service in a certain region, and be aware of events like ongoing service issues and upcoming planned maintenance. To check service health, sign in to the [Azure portal](https://portal.azure.com) and navigate to the **Service Health** service. You can find it by typing "service health" into the portal search bar. You can then filter service issues by subscription, region, and service. -For more information on using Azure Service Health, see [Service Health overview](../service-health/service-health-overview.md). +For more information on using Azure Service Health, see [Service Health overview](/azure/service-health/service-health-overview). ## Use Azure status -The [Azure status](../service-health/azure-status-overview.md) page provides a global view of the health of Azure services and regions. While Azure Service Health and Azure Resource Health are personalized to your specific resource, Azure status has a larger scope and can be useful to understand incidents with wide-ranging impact. +The [Azure status](/azure/service-health/azure-status-overview) page provides a global view of the health of Azure services and regions. While Azure Service Health and Azure Resource Health are personalized to your specific resource, Azure status has a larger scope and can be useful to understand incidents with wide-ranging impact. To check Azure status, navigate to the [Azure status](https://azure.status.microsoft/status/) page. The page displays a table of Azure services along with health indicators per region. You can view Azure Digital Twins by searching for its table entry on the page. -For more information on using the Azure status page, see [Azure status overview](../service-health/azure-status-overview.md). +For more information on using the Azure status page, see [Azure status overview](/azure/service-health/azure-status-overview). ## Next steps |
| dns | Dns Alerts Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/dns/dns-alerts-metrics.md | Azure DNS is a hosting service for DNS domains that provides name resolution usi ## Azure DNS metrics -Azure DNS provides metrics for you to monitor specific aspects of your DNS zones. With the metrics in Azure DNS, you can configure alerting based on conditions that are met. The metrics provided use the [Azure Monitor service](../azure-monitor/index.yml) to display the data. For more information on the Metrics Explorer experience and charting, see [Azure Monitor Metrics Explorer](../azure-monitor/essentials/metrics-charts.md). +Azure DNS provides metrics for you to monitor specific aspects of your DNS zones. With the metrics in Azure DNS, you can configure alerting based on conditions that are met. The metrics provided use the [Azure Monitor service](/azure/azure-monitor/) to display the data. For more information on the Metrics Explorer experience and charting, see [Azure Monitor Metrics Explorer](/azure/azure-monitor/essentials/metrics-charts). Azure DNS provides the following metrics to Azure Monitor for your DNS zones: Azure DNS provides the following metrics to Azure Monitor for your DNS zones: - RecordSetCount - RecordSetCapacityUtilization -For more information, see [metrics definition](../azure-monitor/essentials/metrics-supported.md#microsoftnetworkdnszones). +For more information, see [metrics definition](/azure/azure-monitor/essentials/metrics-supported#microsoftnetworkdnszones). > [!NOTE] > At this time, these metrics are only available for Public DNS zones hosted in Azure DNS. If you have Private Zones hosted in Azure DNS, these metrics won't provide data for those zones. In addition, the metrics and alerting feature is only supported in Azure Public cloud. Support for sovereign clouds will follow at a later time. To view this metric, select **Metrics** explorer experience from the **Monitor** ## Alerts in Azure DNS -Azure Monitor has alerting that you can configure for each available metric value. For more information, see [Azure Monitor alerts](../azure-monitor/alerts/alerts-metric.md). +Azure Monitor has alerting that you can configure for each available metric value. For more information, see [Azure Monitor alerts](/azure/azure-monitor/alerts/alerts-metric). 1. To configure alerting for Azure DNS zones, select **Alerts** from *Monitor* page in the Azure portal. Then select **+ New alert rule**. Azure Monitor has alerting that you can configure for each available metric valu :::image type="content" source="./media/dns-alerts-metrics/configure-signal-logic.png" alt-text="Screenshot of configure signal logic page."::: -1. To send a notification or invoke an action triggered by the alert, click the **Add action groups**. On the *Add action groups* page, select **+ Create action group**. For more information, see [Action Group](../azure-monitor/alerts/action-groups.md). +1. To send a notification or invoke an action triggered by the alert, click the **Add action groups**. On the *Add action groups* page, select **+ Create action group**. For more information, see [Action Group](/azure/azure-monitor/alerts/action-groups). 1. Enter an *Alert rule name* then select **Create alert rule** to save your configuration. :::image type="content" source="./media/dns-alerts-metrics/create-alert-rule.png" alt-text="Screenshot of create alert rule page."::: -For more information on how to configure alerting for Azure Monitor metrics, see [Create, view, and manage alerts using Azure Monitor](../azure-monitor/alerts/alerts-metric.md). +For more information on how to configure alerting for Azure Monitor metrics, see [Create, view, and manage alerts using Azure Monitor](/azure/azure-monitor/alerts/alerts-metric). ## Next steps |
| dns | Dns Private Resolver Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/dns/dns-private-resolver-overview.md | Outbound endpoints have the following limitations: - IPv6 enabled subnets aren't supported. - DNS private resolver doesn't support Azure ExpressRoute FastPath.-- DNS private resolver inbound endpoint provisioning isn't compatible with [Azure Lighthouse](../lighthouse/overview.md).+- DNS private resolver isn't compatible with [Azure Lighthouse](../lighthouse/overview.md). - To see if Azure Lighthouse is in use, search for **Service providers** in the Azure portal and select **Service provider offers**. ## Next steps |
| dns | Private Resolver Reliability | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/dns/private-resolver-reliability.md | In the event of a regional outage, use the same design as that described in [Set All instances of Azure DNS Private Resolver run as Active-Active within the same region. -The service health is onboarded to [Azure Resource Health](../service-health/resource-health-overview.md), so you'll be able to check for health notifications when you subscribe to them. For more information, see [Create activity log alerts on service notifications using the Azure portal](../service-health/alerts-activity-log-service-notifications-portal.md). +The service health is onboarded to [Azure Resource Health](/azure/service-health/resource-health-overview), so you'll be able to check for health notifications when you subscribe to them. For more information, see [Create activity log alerts on service notifications using the Azure portal](/azure/service-health/alerts-activity-log-service-notifications-portal). Also see the [SLA for Azure DNS](https://azure.microsoft.com/support/legal/sla/dns/v1_1/). |
| energy-data-services | How To Integrate Airflow Logs With Azure Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/energy-data-services/how-to-integrate-airflow-logs-with-azure-monitor.md | In this article, you'll learn how to start collecting Airflow Logs for your Micr * An existing **Log Analytics Workspace**. - This workspace will be used to query the Airflow logs using the Kusto Query Language (KQL) query editor in the Log Analytics Workspace. Useful Resource: [Create a log analytics workspace in Azure portal](../azure-monitor/logs/quick-create-workspace.md). + This workspace will be used to query the Airflow logs using the Kusto Query Language (KQL) query editor in the Log Analytics Workspace. Useful Resource: [Create a log analytics workspace in Azure portal](/azure/azure-monitor/logs/quick-create-workspace). To access logs via any of the above two options, you need to create a Diagnostic | Part | Description | |-|-| | Name | This is the name of the diagnostic log. Ensure a unique name is set for each log. |-| Categories | Category of logs to send to each of the destinations. The set of categories will vary for each Azure service. Visit: [Supported Resource Log Categories](../azure-monitor/essentials/resource-logs-categories.md) | +| Categories | Category of logs to send to each of the destinations. The set of categories will vary for each Azure service. Visit: [Supported Resource Log Categories](/azure/azure-monitor/essentials/resource-logs-categories) | | Destinations | One or more destinations to send the logs. All Azure services share the same set of possible destinations. Each diagnostic setting can define one or more destinations but no more than one destination of a particular type. It should be a storage account, an Event Hubs namespace or an event hub. | Follow the following steps to set up Diagnostic Settings: We have added document to help you [troubleshoot](../energy-data-services/troubl Now that you're collecting resource logs, create a log query alert to be proactively notified when interesting data is identified in your log data. > [!div class="nextstepaction"]-> [Create a log query alert for an Azure resource](../azure-monitor/alerts/tutorial-log-alert.md) +> [Create a log query alert for an Azure resource](/azure/azure-monitor/alerts/tutorial-log-alert) |
| energy-data-services | How To Integrate Elastic Logs With Azure Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/energy-data-services/how-to-integrate-elastic-logs-with-azure-monitor.md | In this article, you'll learn how to start collecting Elasticsearch logs for you ## Prerequisites -- You need to have a Log Analytics workspace. It will be used to query the Elasticsearch logs dataset using the Kusto Query Language (KQL) query editor in the Log Analytics workspace. [Create a log Analytics workspace in Azure portal](../azure-monitor/logs/quick-create-workspace.md).+- You need to have a Log Analytics workspace. It will be used to query the Elasticsearch logs dataset using the Kusto Query Language (KQL) query editor in the Log Analytics workspace. [Create a log Analytics workspace in Azure portal](/azure/azure-monitor/logs/quick-create-workspace). - You need to have a storage account. It will be used to store JSON dumps of Elasticsearch & Elasticsearch Operator logs. The storage account doesnΓÇÖt have to be in the same subscription as your Log Analytics workspace. Each diagnostic setting has three basic parts: | Part | Description | |-|-| | Name | This is the name of the diagnostic log. Ensure a unique name is set for each log. |-| Categories | Category of logs to send to each of the destinations. The set of categories will vary for each Azure service. Visit: [Supported Resource Log Categories](../azure-monitor/essentials/resource-logs-categories.md) | +| Categories | Category of logs to send to each of the destinations. The set of categories will vary for each Azure service. Visit: [Supported Resource Log Categories](/azure/azure-monitor/essentials/resource-logs-categories) | | Destinations | One or more destinations to send the logs. All Azure services share the same set of possible destinations. Each diagnostic setting can define one or more destinations but no more than one destination of a particular type. It should be a storage account, an Event Hubs namespace or an event hub. | We support two destinations for your Elasticsearch logs from Azure Data Manager for Energy instance: The editor in Log Analytics workspace support Kusto (KQL) queries through which After collecting resource logs as explained in this article, there are more capabilities you can explore. * Create a log query alert to be proactively notified when interesting data is identified in your log data.- [Create a log query alert for an Azure resource](../azure-monitor/alerts/tutorial-log-alert.md) + [Create a log query alert for an Azure resource](/azure/azure-monitor/alerts/tutorial-log-alert) * Start collecting logs from other sources such as Airflow in your Azure Data Manager for Energy instance. [How to Integrate Airflow logs with Azure Monitor](how-to-integrate-airflow-logs-with-azure-monitor.md) |
| energy-data-services | How To Integrate Osdu Service Logs With Azure Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/energy-data-services/how-to-integrate-osdu-service-logs-with-azure-monitor.md | Azure Data Manager for Energy supports exporting OSDU Service Logs to Azure Moni ## Prerequisites * An existing **Log Analytics Workspace**.- This workspace is used to query OSDU service logs using the Kusto Query Language (KQL) query editor in the Log Analytics workspace. Useful Resource: [Create a log analytics workspace in Azure portal](../azure-monitor/logs/quick-create-workspace.md). + This workspace is used to query OSDU service logs using the Kusto Query Language (KQL) query editor in the Log Analytics workspace. Useful Resource: [Create a log analytics workspace in Azure portal](/azure/azure-monitor/logs/quick-create-workspace). * An existing **storage account**: It's used to store JSON dumps of OSDU service logs. The storage account doesnΓÇÖt have to be in the same subscription as your Log Analytics workspace. You can archive OSDU service logs to storage accounts and take advantage of Azur Now that you're collecting OSDU service logs, create a log query alert to be proactively notified when interesting data is identified in your log data. > [!div class="nextstepaction"]-> [Create a log query alert for an Azure resource](../azure-monitor/alerts/tutorial-log-alert.md) +> [Create a log query alert for an Azure resource](/azure/azure-monitor/alerts/tutorial-log-alert) |
| energy-data-services | How To Manage Audit Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/energy-data-services/how-to-manage-audit-logs.md | To enable audit logs in diagnostic logging, select your Azure Data Manager for E > [!NOTE] > It might take up to 15 minutes for the first Logs to show in Log Analytics. -For information on how to work with diagnostic logs, see [Azure Resource Log documentation.](../azure-monitor/essentials/platform-logs-overview.md) +For information on how to work with diagnostic logs, see [Azure Resource Log documentation.](/azure/azure-monitor/essentials/platform-logs-overview) ## Audit log details The audit logs for Azure Data Manager for Energy service returns the following fields. |
| event-grid | Communication Services Chat Events | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/event-grid/communication-services-chat-events.md | Azure Communication Services emits chat events only when Azure Communication Ser ## Event types -Azure Communication Services emits chat events on two different levels: **User-level** and **Thread-level**. User-level events pertain to a specific user on the chat thread and are delivered once per user. Thread-level events pertain to the entire chat thread and are delivered once per thread. For example: if there are 10 users in a thread, there will be one thread-level event and 10 user-level events, one for each user, when a message is received in a thread. +Azure Communication Services emits chat events on two different levels: **User-level** and **Thread-level**. User-level events are specific to each user in the chat thread and are delivered once per user, excluding the event sender. Thread-level events pertain to the entire chat thread and are delivered once per thread. For instance, when a message is received in a thread with 10 users, there will be one thread-level event and 9 user-level events, one for each user, except for the sender. Azure Communication Services emits the following chat event types: |
| event-grid | Event Schema Health Resources | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/event-grid/event-schema-health-resources.md | Health Resources offers two event types for consumption: | Event type | Description | | - | -- |-| `Microsoft.ResourceNotifications.HealthResources.AvailabilityStatusChanged` | Raised when the availability status of a single instance VM, a virtual machine scale set, or a VM in a virtual machine scale set changes. <p>This information provides insight into all the times your single instance VMs, VMs in virtual machine scale sets, or virtual machine scale sets themselves have been unavailable because of Azure service issues. For more information on the various health statuses, see [Azure Resource Health overview - Azure Service Health](../service-health/resource-health-overview.md#health-status). </p>| -| `Microsoft.ResourceNotifications.HealthResources.ResourceAnnotated` | Raised when the health of a VM, a virtual machine scale set, or a VM in a virtual machine scale set, is impacted by availability impacting disruptions. The platform emits context as to why the disruption has occurred to assist you in responding appropriately. <p>This information helps you to infer the availability state of your resources by providing crucial information on the reasons and causes for changes in availability. Using this data, you can take faster and more targeted mitigation measures. For more information on the various annotations emitted, see [Resource Health virtual machine Health Annotations](../service-health/resource-health-vm-annotation.md). </p>| +| `Microsoft.ResourceNotifications.HealthResources.AvailabilityStatusChanged` | Raised when the availability status of a single instance VM, a virtual machine scale set, or a VM in a virtual machine scale set changes. <p>This information provides insight into all the times your single instance VMs, VMs in virtual machine scale sets, or virtual machine scale sets themselves have been unavailable because of Azure service issues. For more information on the various health statuses, see [Azure Resource Health overview - Azure Service Health](/azure/service-health/resource-health-overview#health-status). </p>| +| `Microsoft.ResourceNotifications.HealthResources.ResourceAnnotated` | Raised when the health of a VM, a virtual machine scale set, or a VM in a virtual machine scale set, is impacted by availability impacting disruptions. The platform emits context as to why the disruption has occurred to assist you in responding appropriately. <p>This information helps you to infer the availability state of your resources by providing crucial information on the reasons and causes for changes in availability. Using this data, you can take faster and more targeted mitigation measures. For more information on the various annotations emitted, see [Resource Health virtual machine Health Annotations](/azure/service-health/resource-health-vm-annotation). </p>| ## Role-based access control Currently, these events are exclusively emitted at the Azure subscription scope. It implies that the entity creating the event subscription for this topic type receives notifications throughout this Azure subscription. For security reasons, it's imperative to restrict the ability to create event subscriptions on this topic to principals with read access over the entire Azure subscription. To access data via this system topic, in addition to the generic permissions required by Event Grid, the following Azure Resource Notifications specific permission is necessary: `Microsoft.ResourceNotifications/systemTopics/subscribeToHealthResources/action`. For the `ResourceAnnotated` event, the `properties` object has the following pro | `targetResourceId` | String | The base resource for which the annotation information is being emitted. | | `targetResourceType` | String | The type of the base resource. | | `occurredTime` | String | Timestamp when the annotation was emitted by the Azure platform in response to availability-influencing event. |-| `annotationName` | String | The name of the annotation. For the list of annotations and the corresponding descriptions, see [Resource Health virtual machine Health Annotations - Azure Service Health](../service-health/resource-health-vm-annotation.md). | +| `annotationName` | String | The name of the annotation. For the list of annotations and the corresponding descriptions, see [Resource Health virtual machine Health Annotations - Azure Service Health](/azure/service-health/resource-health-vm-annotation). | | `reason` | String | Brief statement on why resource availability has changed or was influenced. | | `summary` | String | Detailed statement on the activity and cause for resource availability to change or be influenced. | | `context` | String | Determines whether resource availability was influenced due to Azure or user caused activity. | |
| event-grid | Handle Health Resources Events Using Azure Monitor Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/event-grid/handle-health-resources-events-using-azure-monitor-alerts.md | - 1. [Optional] Select the **action group**. See [Create an action group in the Azure portal](../azure-monitor/alerts/action-groups.md). + 1. [Optional] Select the **action group**. See [Create an action group in the Azure portal](/azure/azure-monitor/alerts/action-groups). 1. Enter a **description** for the alert. 1. Select **Confirm Selection**. 1. Now, on the **Create Event Subscription** page, select **Create** to create the event subscription. For detailed steps, see [subscribe to events through portal](subscribe-through-portal.md). In Azure monitor alerts, the Event Grid alerts appear as shown in the following :::image type="content" source="./media/handle-health-resources-events-using-azure-monitor-alerts/resource-annotated-alert.png" alt-text="Screenshot that shows the sample Resource Annotated alert in Azure Monitor."::: ## Event Filters-The event filter enables users to receive alerts for a specific resource group, specific transitions (when the availability state changes), or specific annotations (see [Resource Health virtual machine Health Annotations](../service-health/resource-health-vm-annotation.md) for the full list of annotations). Users can use this feature to customize their alerts based on their specific monitoring needs. +The event filter enables users to receive alerts for a specific resource group, specific transitions (when the availability state changes), or specific annotations (see [Resource Health virtual machine Health Annotations](/azure/service-health/resource-health-vm-annotation) for the full list of annotations). Users can use this feature to customize their alerts based on their specific monitoring needs. 1. Select the **Filters** tab to provide subject filtering and advanced filtering. For example, to filter for events from resources in a specific resource group, follow these steps: Here's a sample `AvailabilityStatusChanged` event. Notice that the `type` is set See the following articles: -- [Azure Monitor alerts](../azure-monitor/alerts/alerts-overview.md)-- [Manage Azure Monitor alert rules](../azure-monitor/alerts/alerts-manage-alert-rules.md)+- [Azure Monitor alerts](/azure/azure-monitor/alerts/alerts-overview) +- [Manage Azure Monitor alert rules](/azure/azure-monitor/alerts/alerts-manage-alert-rules) - [Pull delivery overview](pull-delivery-overview.md) - [Push delivery overview](push-delivery-overview.md) - [Concepts](concepts.md) |
| event-grid | Handle Key Vault Events Using Azure Monitor Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/event-grid/handle-key-vault-events-using-azure-monitor-alerts.md | When creating an event subscription, follow these steps: 1. Select **Configure an endpoint** link. 1. On the **Select Monitor Alert Configuration** page, follow these steps. 1. Select the alert **severity**.- 1. Select the **action group** (optional), see [Create an action group in the Azure portal](../azure-monitor/alerts/action-groups.md). + 1. Select the **action group** (optional), see [Create an action group in the Azure portal](/azure/azure-monitor/alerts/action-groups). 1. Enter a **description** for the alert. 1. Select **Confirm Selection**. You can manage the subscription directly in the source (for example, Key Vault r ## Fire alert instances Now, Key Vault events appear as alerts and you can view them in alerts page. See this article to learn how to-[manage alert instances](../azure-monitor/alerts/alerts-manage-alert-instances.md). +[manage alert instances](/azure/azure-monitor/alerts/alerts-manage-alert-instances). ## Next steps See the following articles: -- [Azure Monitor alerts](../azure-monitor/alerts/alerts-overview.md)-- [Manage Azure Monitor alert rules](../azure-monitor/alerts/alerts-manage-alert-rules.md)+- [Azure Monitor alerts](/azure/azure-monitor/alerts/alerts-overview) +- [Manage Azure Monitor alert rules](/azure/azure-monitor/alerts/alerts-manage-alert-rules) - [Pull delivery overview](pull-delivery-overview.md) - [Push delivery overview](push-delivery-overview.md) - [Concepts](concepts.md) |
| event-grid | Handler Azure Monitor Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/event-grid/handler-azure-monitor-alerts.md | This article describes how Azure Event Grid delivers Azure Key Vault events as A ## Overview -[Azure Monitor alerts](../azure-monitor/alerts/alerts-overview.md) help you detect and address issues before users notice them by proactively notifying you when Azure Monitor data indicates there might be a problem with your infrastructure or application. +[Azure Monitor alerts](/azure/azure-monitor/alerts/alerts-overview) help you detect and address issues before users notice them by proactively notifying you when Azure Monitor data indicates there might be a problem with your infrastructure or application. Azure Monitor alerts as a destination in Event Grid event subscriptions allow you to receive notification of critical events via Short Message Service (SMS), email, push notification, and more. You can use the low latency event delivery of Event Grid with the direct notification system of Azure Monitor alerts. ## Azure Monitor alerts -Azure Monitor alerts have three resources: [alert rules](../azure-monitor/alerts/alerts-overview.md), [alert processing rules](../azure-monitor/alerts/alerts-processing-rules.md), and [action groups](../azure-monitor/alerts/action-groups.md). Each of these resources is its own independent resource and can be mixed and matched with each other. +Azure Monitor alerts have three resources: [alert rules](/azure/azure-monitor/alerts/alerts-overview), [alert processing rules](/azure/azure-monitor/alerts/alerts-processing-rules), and [action groups](/azure/azure-monitor/alerts/action-groups). Each of these resources is its own independent resource and can be mixed and matched with each other. - **Alert rules**: defines a resource scope and conditions on the resourcesΓÇÖ telemetry. If conditions are met, it fires an alert. - **Alert processing rules**: modify the fired alerts as they're being fired. You can use these rules to add or suppress action groups, apply filters, or have the rule processed on a predefined schedule. |
| event-grid | Monitor Event Delivery | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/event-grid/monitor-event-delivery.md | Last updated 03/17/2021 This article describes how to use the portal to see metrics for Event Grid topics and subscriptions, and create alerts on them. > [!IMPORTANT]-> For a list of metrics supported Azure Event Grid, see [Metrics](../azure-monitor/essentials/metrics-supported.md#microsofteventgriddomains). +> For a list of metrics supported Azure Event Grid, see [Metrics](/azure/azure-monitor/essentials/metrics-supported#microsofteventgriddomains). ## View custom topic metrics If you've published a custom topic, you can view the metrics for it. :::image type="content" source="./media/monitor-event-delivery/system-topic-metrics-page.png" alt-text="System Topic - Metrics page"::: > [!IMPORTANT]- > For a list of metrics supported Azure Event Grid, see [Metrics](../azure-monitor/essentials/metrics-supported.md#microsofteventgriddomains). + > For a list of metrics supported Azure Event Grid, see [Metrics](/azure/azure-monitor/essentials/metrics-supported#microsofteventgriddomains). ## Next steps See the following articles: |
| event-grid | Monitor Namespaces | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/event-grid/monitor-namespaces.md | Last updated 01/17/2024 When you have critical applications and business processes relying on Azure resources, you want to monitor those resources for their availability, performance, and operation. This article describes the monitoring data generated by Azure Event Grid namespaces and how to analyze and alert on this data with Azure Monitor. ## What is Azure Monitor?-Azure Event Grid creates monitoring data using [Azure Monitor](../azure-monitor/overview.md), which is a full stack monitoring service in Azure. Azure Monitor provides a complete set of features to monitor your Azure resources. It can also monitor resources in other clouds and on-premises. +Azure Event Grid creates monitoring data using [Azure Monitor](/azure/azure-monitor/overview), which is a full stack monitoring service in Azure. Azure Monitor provides a complete set of features to monitor your Azure resources. It can also monitor resources in other clouds and on-premises. -Start with the article [Monitoring Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md), which describes the following concepts: +Start with the article [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource), which describes the following concepts: - What is Azure Monitor? - Costs associated with monitoring Start with the article [Monitoring Azure resources with Azure Monitor](../azure- The following sections build on this article by describing the specific data gathered for Azure Event Grid namespaces. These sections also provide examples for configuring data collection and analyzing this data with Azure tools. > [!TIP]-> To understand costs associated with Azure Monitor, see [Azure Monitor cost and usage](../azure-monitor/cost-usage.md). To understand the time it takes for your data to appear in Azure Monitor, see [Log data ingestion time](../azure-monitor/logs/data-ingestion-time.md). +> To understand costs associated with Azure Monitor, see [Azure Monitor cost and usage](/azure/azure-monitor/cost-usage). To understand the time it takes for your data to appear in Azure Monitor, see [Log data ingestion time](/azure/azure-monitor/logs/data-ingestion-time). ## Monitoring data from Event Grid namespaces-Azure Event Grid collects the same kinds of monitoring data as other Azure resources that are described in [Monitoring data from Azure resources](../azure-monitor/essentials/monitor-azure-resource.md#monitoring-data). +Azure Event Grid collects the same kinds of monitoring data as other Azure resources that are described in [Monitoring data from Azure resources](/azure/azure-monitor/essentials/monitor-azure-resource#monitoring-data). See the following monitoring data reference articles for a detailed reference of the logs and metrics created by Azure Event Grid. See the following monitoring data reference articles for a detailed reference of ## Collection and routing Platform metrics and the activity log are collected and stored automatically, but can be routed to other locations by using a diagnostic setting. Resource Logs aren't collected and stored until you create a diagnostic setting and route them to one or more locations. -See [Create diagnostic setting to collect platform logs and metrics in Azure](../azure-monitor/essentials/diagnostic-settings.md) for the detailed process for creating a diagnostic setting using the Azure portal, CLI, or PowerShell. When you create a diagnostic setting, you specify which categories of logs to collect. +See [Create diagnostic setting to collect platform logs and metrics in Azure](/azure/azure-monitor/essentials/diagnostic-settings) for the detailed process for creating a diagnostic setting using the Azure portal, CLI, or PowerShell. When you create a diagnostic setting, you specify which categories of logs to collect. The categories for Azure Event Grid's MQTT broker are listed in [Monitor data reference for Azure Event GridΓÇÖs MQTT broker feature](monitor-mqtt-delivery-reference.md#resource-logs). If you use **Log Analytics** to store the diagnostic logging information, the in The metrics and logs you can collect are discussed in the following sections. ## Analyze metrics-You can analyze metrics for Azure Event Grid namespaces by selecting **Metrics** from the **Azure Monitor** section on the home page for your Event Grid namespace. See [Analyze metrics with Azure Monitor metrics explorer](../azure-monitor/essentials/analyze-metrics.md) for details on using this tool. +You can analyze metrics for Azure Event Grid namespaces by selecting **Metrics** from the **Azure Monitor** section on the home page for your Event Grid namespace. See [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics) for details on using this tool. See the following monitoring data reference articles for metrics created by Azure Event Grid. See the following monitoring data reference articles for metrics created by Azur :::image type="content" source="./media/monitor-namespaces/metrics.png" alt-text="Screenshot that shows the Metrics Explorer with Event Grid namespace selected."::: -For reference, you can see a list of [all resource metrics supported in Azure Monitor](../azure-monitor/essentials/metrics-supported.md). +For reference, you can see a list of [all resource metrics supported in Azure Monitor](/azure/azure-monitor/essentials/metrics-supported). > [!TIP] > Azure Monitor metrics data is available for 90 days. However, when creating charts only 30 days can be visualized. For example, if you want to visualize a 90 day period, you must break it into three charts of 30 days within the 90 day period. ### Filter and split-For metrics that support dimensions, you can apply filters using a dimension value. You can also split a metric by dimension to visualize how different segments of the metric compare with each other. For more information of filtering and splitting, see [Advanced features of Azure Monitor](../azure-monitor/essentials/metrics-charts.md). +For metrics that support dimensions, you can apply filters using a dimension value. You can also split a metric by dimension to visualize how different segments of the metric compare with each other. For more information of filtering and splitting, see [Advanced features of Azure Monitor](/azure/azure-monitor/essentials/metrics-charts). :::image type="content" source="./media/monitor-namespaces/metrics-filter-split.png" alt-text="Screenshot that shows filtering and splitting metrics."::: See the following monitoring data reference articles for a detailed reference of ### Sample Kusto queries > [!IMPORTANT]-> When you select **Logs** on the left menu of the Azure Event Grid namespace page in the Azure portal, Log Analytics is opened with the query scope set to the current Azure Event Grid namespace. This means that log queries will only include data from that resource. If you want to run a query that includes data from other workspaces or data from other Azure services, select **Logs** from the **Azure Monitor** menu. See [Log query scope and time range in Azure Monitor Log Analytics](../azure-monitor/logs/scope.md) for details. +> When you select **Logs** on the left menu of the Azure Event Grid namespace page in the Azure portal, Log Analytics is opened with the query scope set to the current Azure Event Grid namespace. This means that log queries will only include data from that resource. If you want to run a query that includes data from other workspaces or data from other Azure services, select **Logs** from the **Azure Monitor** menu. See [Log query scope and time range in Azure Monitor Log Analytics](/azure/azure-monitor/logs/scope) for details. Following are sample queries that you can use to help you monitor your Azure Event Grid namespaces: You can analyze the collected runtime audit logs using the following sample quer ## Alerts-You can access alerts for Azure Event Grid by selecting **Alerts** from the **Azure Monitor** section on the home page for your Event Grid namespace. See [Create, view, and manage metric alerts using Azure Monitor](../azure-monitor/alerts/alerts-metric.md) for details on creating alerts. +You can access alerts for Azure Event Grid by selecting **Alerts** from the **Azure Monitor** section on the home page for your Event Grid namespace. See [Create, view, and manage metric alerts using Azure Monitor](/azure/azure-monitor/alerts/alerts-metric) for details on creating alerts. ## Next steps |
| event-grid | Set Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/event-grid/set-alerts.md | You can also create alerts by using the **Metrics** page. The steps are similar. > [!NOTE]-> This article doesn't cover all the different steps and combinations that you can use to create an alert. For an overview of alerts, see [Alerts overview](../azure-monitor/alerts/alerts-metric.md). +> This article doesn't cover all the different steps and combinations that you can use to create an alert. For an overview of alerts, see [Alerts overview](/azure/azure-monitor/alerts/alerts-metric). ## Next steps |
| event-grid | Troubleshoot Issues | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/event-grid/troubleshoot-issues.md | az eventgrid event-subscription create --name <event-grid-subscription-name> \ --delivery-attribute-mapping Diagnostic-Id dynamic traceparent ``` -Azure Functions supports [distributed tracing with Azure Monitor](../azure-monitor/app/azure-functions-supported-features.md), which includes built-in tracing of executions and bindings, performance monitoring, and more. +Azure Functions supports [distributed tracing with Azure Monitor](/azure/azure-monitor/app/azure-functions-supported-features), which includes built-in tracing of executions and bindings, performance monitoring, and more. [Microsoft.Azure.WebJobs.Extensions.EventGrid](https://www.nuget.org/packages/Microsoft.Azure.WebJobs.Extensions.EventGrid/) package version 3.1.0 or later enables correlation for CloudEvents between producer calls and Functions Event Grid trigger executions. For more information, see [Distributed tracing with Azure Functions and Event Grid triggers](https://devblogs.microsoft.com/azure-sdk/distributed-tracing-with-azure-functions-event-grid-triggers/). |
| event-hubs | Configure Customer Managed Key | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/event-hubs/configure-customer-managed-key.md | Conditions for enabling Geo-DR and Encryption with User-Assigned Identities: 2. It is not possible to enable Encryption on an already paired primary, even if the secondary has a User-Assigned identity associated with the namespace. ## Set up diagnostic logs -Setting diagnostic logs for BYOK enabled namespaces gives you the required information about the operations. These logs can be enabled and later stream to an event hub or analyzed through log analytics or streamed to storage to perform customized analytics. To learn more about diagnostic logs, see [Overview of Azure Diagnostic logs](../azure-monitor/essentials/platform-logs-overview.md). For the schema, see [Monitor data reference](monitor-event-hubs-reference.md#customer-managed-key-user-logs-schema). +Setting diagnostic logs for BYOK enabled namespaces gives you the required information about the operations. These logs can be enabled and later stream to an event hub or analyzed through log analytics or streamed to storage to perform customized analytics. To learn more about diagnostic logs, see [Overview of Azure Diagnostic logs](/azure/azure-monitor/essentials/platform-logs-overview). For the schema, see [Monitor data reference](monitor-event-hubs-reference.md#customer-managed-key-user-logs-schema). ## Next steps See the following articles: |
| event-hubs | Event Hubs Federation Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/event-hubs/event-hubs-federation-overview.md | For building log projections, Azure Functions supports output bindings for Azure Functions can run under a [Azure managed identity](../active-directory/managed-identities-azure-resources/overview.md) and with that, it can hold the configuration values for credentials in tightly access-controlled storage inside of [Azure Key Vault](/azure/key-vault/general/overview). -Azure Functions furthermore allows the replication tasks to directly integrate with Azure virtual networks and [service endpoints](../virtual-network/virtual-network-service-endpoints-overview.md) for all Azure messaging services, and it is readily integrated with [Azure Monitor](../azure-monitor/overview.md). +Azure Functions furthermore allows the replication tasks to directly integrate with Azure virtual networks and [service endpoints](../virtual-network/virtual-network-service-endpoints-overview.md) for all Azure messaging services, and it is readily integrated with [Azure Monitor](/azure/azure-monitor/overview). With the Azure Functions consumption plan, the prebuilt triggers can even scale down to zero while no messages are available for replication, which means you incur no costs for keeping the configuration ready to scale back up; the key downside of using the consumption plan is that the latency for replication tasks "waking up" from this state is significantly higher than with the hosting plans where the infrastructure is kept running. |
| event-hubs | Monitor Event Hubs Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/event-hubs/monitor-event-hubs-reference.md | -Azure Event Hubs creates monitoring data using [Azure Monitor](../azure-monitor/overview.md), which is a full stack monitoring service in Azure. Azure Monitor provides a complete set of features to monitor your Azure resources. It can also monitor resources in other clouds and on-premises. +Azure Event Hubs creates monitoring data using [Azure Monitor](/azure/azure-monitor/overview), which is a full stack monitoring service in Azure. Azure Monitor provides a complete set of features to monitor your Azure resources. It can also monitor resources in other clouds and on-premises. -Azure Event Hubs collects the same kinds of monitoring data as other Azure resources that are described in [Monitoring data from Azure resources](../azure-monitor/essentials/monitor-azure-resource.md#monitoring-data). +Azure Event Hubs collects the same kinds of monitoring data as other Azure resources that are described in [Monitoring data from Azure resources](/azure/azure-monitor/essentials/monitor-azure-resource#monitoring-data). [!INCLUDE [horz-monitor-ref-metrics-intro](~/reusable-content/ce-skilling/azure/includes/azure-monitor/horizontals/horz-monitor-ref-metrics-intro.md)] Adding dimensions to your metrics is optional. If you don't add dimensions, metr ### Event Hubs resource logs -Azure Event Hubs now has the capability to dispatch logs to either of two destination tables: Azure Diagnostic or [Resource specific tables](~/articles/azure-monitor/essentials/resource-logs.md) in Log Analytics. You could use the toggle available on Azure portal to choose destination tables. +Azure Event Hubs now has the capability to dispatch logs to either of two destination tables: Azure Diagnostic or [Resource specific tables](/azure/azure-monitor/essentials/resource-logs) in Log Analytics. You could use the toggle available on Azure portal to choose destination tables. :::image type="content" source="media/monitor-event-hubs-reference/destination-table-toggle.png" alt-text="Screenshot of dialog box to set destination table." lightbox="media/monitor-event-hubs-reference/destination-table-toggle.png"::: |
| event-hubs | Monitor Event Hubs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/event-hubs/monitor-event-hubs.md | Azure Monitor documentation describes the following concepts: The following sections describe the specific data gathered for Azure Event Hubs. These sections also provide examples for configuring data collection and analyzing this data with Azure tools. > [!TIP]-> To understand costs associated with Azure Monitor, see [Azure Monitor cost and usage](../azure-monitor/cost-usage.md). To understand the time it takes for your data to appear in Azure Monitor, see [Log data ingestion time](../azure-monitor/logs/data-ingestion-time.md). +> To understand costs associated with Azure Monitor, see [Azure Monitor cost and usage](/azure/azure-monitor/cost-usage). To understand the time it takes for your data to appear in Azure Monitor, see [Log data ingestion time](/azure/azure-monitor/logs/data-ingestion-time). [!INCLUDE [horz-monitor-resource-types](~/reusable-content/ce-skilling/azure/includes/azure-monitor/horizontals/horz-monitor-resource-types.md)] For more information about the resource types for Event Hubs, see [Azure Event Hubs monitoring data reference](monitor-event-hubs-reference.md). For a list of available metrics for Event Hubs, see [Azure Event Hubs monitoring ### Analyze metrics -You can analyze metrics for Azure Event Hubs, along with metrics from other Azure services, by selecting **Metrics** from the **Azure Monitor** section on the home page for your Event Hubs namespace. See [Analyze metrics with Azure Monitor metrics explorer](../azure-monitor/essentials/analyze-metrics.md) for details on using this tool. For a list of the platform metrics collected, see [Monitoring Azure Event Hubs data reference metrics](monitor-event-hubs-reference.md#metrics). +You can analyze metrics for Azure Event Hubs, along with metrics from other Azure services, by selecting **Metrics** from the **Azure Monitor** section on the home page for your Event Hubs namespace. See [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics) for details on using this tool. For a list of the platform metrics collected, see [Monitoring Azure Event Hubs data reference metrics](monitor-event-hubs-reference.md#metrics). :::image type="content" source="./media/monitor-event-hubs/metrics.png" alt-text="Screenshot showing the Metrics Explorer for an Event Hubs namespace." lightbox="./media/monitor-event-hubs/metrics.png"::: -For reference, you can see a list of [all resource metrics supported in Azure Monitor](../azure-monitor/essentials/metrics-supported.md). +For reference, you can see a list of [all resource metrics supported in Azure Monitor](/azure/azure-monitor/essentials/metrics-supported). > [!TIP] > Azure Monitor metrics data is available for 90 days. However, when creating charts only 30 days can be visualized. For example, if you want to visualize a 90 day period, you must break it into three charts of 30 days within the 90 day period. ### Filter and split -For metrics that support dimensions, you can apply filters using a dimension value. For example, add a filter with `EntityName` set to the name of an event hub. You can also split a metric by dimension to visualize how different segments of the metric compare with each other. For more information of filtering and splitting, see [Advanced features of Azure Monitor](../azure-monitor/essentials/metrics-charts.md). +For metrics that support dimensions, you can apply filters using a dimension value. For example, add a filter with `EntityName` set to the name of an event hub. You can also split a metric by dimension to visualize how different segments of the metric compare with each other. For more information of filtering and splitting, see [Advanced features of Azure Monitor](/azure/azure-monitor/essentials/metrics-charts). :::image type="content" source="./media/monitor-event-hubs/metrics-filter-split.png" alt-text="Screenshot showing the Metrics Explorer for an Event Hubs namespace with a filter." lightbox="./media/monitor-event-hubs/metrics-filter-split.png"::: For the available resource log categories, their associated Log Analytics tables Using Azure Monitor Log Analytics requires you to create a diagnostic configuration and enable **Send information to Log Analytics**. For more information, see the [Metrics](#azure-monitor-platform-metrics) section. Data in Azure Monitor Logs is stored in tables, with each table having its own set of unique properties. Azure Event Hubs has the capability to dispatch logs to either of two destination tables: Azure Diagnostic or Resource specific tables in Log Analytics. For a detailed reference of the logs and metrics, see [Azure Event Hubs monitoring data reference](monitor-event-hubs-reference.md). > [!IMPORTANT]-> When you select **Logs** from the Azure Event Hubs menu, Log Analytics is opened with the query scope set to the current workspace. This means that log queries will only include data from that resource. If you want to run a query that includes data from other databases or data from other Azure services, select **Logs** from the **Azure Monitor** menu. See [Log query scope and time range in Azure Monitor Log Analytics](../azure-monitor/logs/scope.md) for details. +> When you select **Logs** from the Azure Event Hubs menu, Log Analytics is opened with the query scope set to the current workspace. This means that log queries will only include data from that resource. If you want to run a query that includes data from other databases or data from other Azure services, select **Logs** from the **Azure Monitor** menu. See [Log query scope and time range in Azure Monitor Log Analytics](/azure/azure-monitor/logs/scope) for details. ### Use runtime logs AZMSApplicationMetricLogs [!INCLUDE [horz-monitor-alerts](~/reusable-content/ce-skilling/azure/includes/azure-monitor/horizontals/horz-monitor-alerts.md)] -You can access alerts for Azure Event Hubs by selecting **Alerts** from the **Azure Monitor** section on the home page for your Event Hubs namespace. See [Create, view, and manage metric alerts using Azure Monitor](../azure-monitor/alerts/alerts-metric.md) for details on creating alerts. +You can access alerts for Azure Event Hubs by selecting **Alerts** from the **Azure Monitor** section on the home page for your Event Hubs namespace. See [Create, view, and manage metric alerts using Azure Monitor](/azure/azure-monitor/alerts/alerts-metric) for details on creating alerts. ### Event Hubs alert rules |
| event-hubs | Resource Governance With App Groups | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/event-hubs/resource-governance-with-app-groups.md | The following ARM template shows how to update an existing namespace (`contosona Azure Event Hubs supports [Application Metric Logs](monitor-event-hubs-reference.md#application-metrics-logs) functionality to observe usual throughput within your system and accordingly decide on the threshold value for application group. You can follow these steps to decide on a threshold value: -1. Turn on [diagnostic settings](../azure-monitor/essentials/diagnostic-settings.md) in Event Hubs with **Application Metric logs** as selected category and choose **Log Analytics** as destination. +1. Turn on [diagnostic settings](/azure/azure-monitor/essentials/diagnostic-settings) in Event Hubs with **Application Metric logs** as selected category and choose **Log Analytics** as destination. 2. Create an empty application group without any throttling policy. 3. Continue sending messages/events to event hub at usual throughput. 4. Go to **Log Analytics workspace** and query for the right activity name (based on the (resource-governance-overview.md#throttling-policythreshold-limits)) in **AzureDiagnostics** table. The following sample query is set to track threshold value for incoming messages: |
| expressroute | Design Architecture For Resiliency | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/expressroute/design-architecture-for-resiliency.md | As a baseline, we recommend configuring [Network Insights](expressroute-network- #### Configure service health alerts for ExpressRoute circuit maintenance notifications -ExpressRoute uses [Azure Service Health](../service-health/overview.md) to notify you of planned and upcoming [ExpressRoute circuit maintenance](maintenance-alerts.md). With Service Health, you can view planned and past maintenance in the Azure portal along with configuring alerts and notifications that best suit your needs. In Service Health, you can see Planned & Past maintenance. You can also set alerts within Service Health to be notified of upcoming maintenance. +ExpressRoute uses [Azure Service Health](/azure/service-health/overview) to notify you of planned and upcoming [ExpressRoute circuit maintenance](maintenance-alerts.md). With Service Health, you can view planned and past maintenance in the Azure portal along with configuring alerts and notifications that best suit your needs. In Service Health, you can see Planned & Past maintenance. You can also set alerts within Service Health to be notified of upcoming maintenance. #### Configure connection monitor for ExpressRoute |
| expressroute | Expressroute About Virtual Network Gateways | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/expressroute/expressroute-about-virtual-network-gateways.md | Each virtual network can have only one virtual network gateway per gateway type. [!INCLUDE [expressroute-gwsku-include](../../includes/expressroute-gwsku-include.md)] -If you want to upgrade your gateway to a higher capacity gateway SKU, you can use the `Resize-AzVirtualNetworkGateway` PowerShell cmdlet or perform the upgrade directly in the ExpressRoute virtual network gateway configuration page in the Azure portal. The following upgrades are supported: +If you want to upgrade your gateway to a higher capacity gateway SKU, you can use the Seamless Gateway Migration tool in either Azure portal or PowerShell. The following upgrades are supported: -- Standard to High Performance-- Standard to Ultra Performance-- High Performance to Ultra Performance-- ErGw1Az to ErGw2Az-- ErGw1Az to ErGw3Az-- ErGw2Az to ErGw3Az-- Default to Standard+- Non-Az enabled SKU on Basic IP to Non Az enabled SKU on Standard IP. +- Non-Az enabled SKU on Basic IP to Az-enabled SKU on Standard IP. +- Non-Az enabled SKU on Standard IP to Az-enabled SKU on Standard IP. -Additionally, you can downgrade the virtual network gateway SKU. The following downgrades are supported: -- High Performance to Standard-- ErGw2Az to ErGw1Az+For more information, see [Migrate to an availability zone-enabled gateway](expressroute-howto-gateway-migration-powershell.md). For all other downgrade scenarios, you need to delete and recreate the gateway. Recreating a gateway incurs downtime. -## Virtual network gateway limitations and performance --### <a name="gatewayfeaturesupport"></a>Feature support by gateway SKU --The following table shows the features supported across each gateway types and max number of ExpressRoute circuit connections supported by each gateway SKU. --| Gateway SKU | VPN Gateway and ExpressRoute coexistence | FastPath | Max Number of Circuit Connections | -|--|--|--|--| -| **Standard SKU/ERGw1Az** | Yes | No | 4 | -| **High Perf SKU/ERGw2Az** | Yes | No | 8 | -| **Ultra Performance SKU/ErGw3Az** | Yes | Yes | 16 | -| **ErGwScale (Preview)** | Yes | Yes - minimum 10 of scale units | 4 - minimum 1 of scale unit<br>8 - minimum of 2 scale units<br>16 - minimum of 10 scale units | -->[!NOTE] -> The maximum number of ExpressRoute circuits from the same peering location that can connect to the same virtual network is 4 for all gateways. -> --### <a name="aggthroughput"></a>Estimated performances by gateway SKU -- ## <a name="gwsub"></a>Gateway subnet Before you create an ExpressRoute gateway, you must create a gateway subnet. The gateway subnet contains the IP addresses that the virtual network gateway VMs and services use. When you create your virtual network gateway, gateway VMs are deployed to the gateway subnet and configured with the required ExpressRoute gateway settings. Never deploy anything else into the gateway subnet. The gateway subnet must be named 'GatewaySubnet' to work properly. Naming the gateway subnet 'GatewaySubnet' lets Azure know to deploy the virtual network gateway VMs and services into this subnet. Add-AzVirtualNetworkSubnetConfig -Name 'GatewaySubnet' -AddressPrefix 10.0.3.0/2 [!INCLUDE [vpn-gateway-no-nsg](../../includes/vpn-gateway-no-nsg-include.md)] +## Virtual network gateway limitations and performance ++### <a name="gatewayfeaturesupport"></a>Feature support by gateway SKU ++The following table shows the features supported across each gateway types and max number of ExpressRoute circuit connections supported by each gateway SKU. ++| Gateway SKU | VPN Gateway and ExpressRoute coexistence | FastPath | Max Number of Circuit Connections | +|--|--|--|--| +| **Standard SKU/ERGw1Az** | Yes | No | 4 | +| **High Perf SKU/ERGw2Az** | Yes | No | 8 | +| **Ultra Performance SKU/ErGw3Az** | Yes | Yes | 16 | +| **ErGwScale (Preview)** | Yes | Yes - minimum 10 of scale units | 4 - minimum 1 of scale unit<br>8 - minimum of 2 scale units<br>16 - minimum of 10 scale units | ++>[!NOTE] +> The maximum number of ExpressRoute circuits from the same peering location that can connect to the same virtual network is 4 for all gateways. +> ++### <a name="aggthroughput"></a>Estimated performances by gateway SKU ++ ### <a name="zrgw"></a>Zone-redundant gateway SKUs You can also deploy ExpressRoute gateways in Azure Availability Zones. This configuration physically and logically separates them into different Availability Zones, protecting your on-premises network connectivity to Azure from zone-level failures. Zone-redundant gateways use specific new gateway SKUs for ExpressRoute gateway. * ErGw1AZ * ErGw2AZ * ErGw3AZ+* ErGwScale (Preview) The new gateway SKUs also support other deployment options to best match your needs. When creating a virtual network gateway using the new gateway SKUs, you can deploy the gateway in a specific zone. This type of gateway is referred to as a zonal gateway. When you deploy a zonal gateway, all the instances of the gateway are deployed in the same Availability Zone. To learn about migrating an ExpressRoute gateway, see [Gateway migration](gateway-migration.md). -## VNet to VNet and VNet to Virtual WAN connectivity --By default, VNet to VNet and VNet to Virtual WAN connectivity is disabled through an ExpressRoute circuit for all gateway SKUs. To enable this connectivity, you must configure the ExpressRoute virtual network gateway to allow this traffic. For more information, see guidance about [virtual network connectivity over ExpressRoute](virtual-network-connectivity-guidance.md). To enabled this traffic, see [Enable VNet to VNet or VNet to Virtual WAN connectivity through ExpressRoute](expressroute-howto-add-gateway-portal-resource-manager.md#enable-or-disable-vnet-to-vnet-or-vnet-to-virtual-wan-traffic-through-expressroute). --## <a name="fastpath"></a>FastPath --ExpressRoute virtual network gateway is designed to exchange network routes and route network traffic. FastPath is designed to improve the data path performance between your on-premises network and your virtual network. When enabled, FastPath sends network traffic directly to virtual machines in the virtual network, bypassing the gateway. --For more information about FastPath, including limitations and requirements, see [About FastPath](about-fastpath.md). --## Connectivity to private endpoints --The ExpressRoute virtual network gateway facilitates connectivity to private endpoints deployed in the same virtual network as the virtual network gateway and across virtual network peers. --> [!IMPORTANT] -> * Throughput and control plane capacity may be half compared to connectivity to non-private-endpoint resources. -> * During a maintenance period, you may experience intermittent connectivity issues to private endpoint resources. -> * Customers need to ensure their on-premises configuration, including router & firewall settings are correctly setup to ensure that packets for the IP 5-tuple transits via a single next hop (Microsoft Enterprise Edge router - MSEE) unless there is a maintenance event. If a customer's on-premises firewall or router configuration is causing the same IP 5-tuple to frequently switch next hops, then the customer will experience connectivity issues. --### Private endpoint connectivity and planned maintenance events --Private endpoint connectivity is stateful. When a connection to a private endpoint gets established over ExpressRoute private peering, inbound and outbound connections get routed through one of the backend instances of the gateway infrastructure. During a maintenance event, backend instances of the virtual network gateway infrastructure are rebooted one at a time, which could lead to intermittent connectivity issues. --To avoid or minimize connectivity issues with private endpoints during maintenance activities, we recommend setting the TCP time-out value to fall between 15-30 seconds on your on-premises applications. Test and configure the optimal value based on your application requirements. --## Route Server --The creation or deletion of an Azure Route Server from a virtual network that has a Virtual Network Gateway (either ExpressRoute or VPN) might cause downtime until the operation is completed. --## <a name="resources"></a>REST APIs and PowerShell cmdlets --For more technical resources and specific syntax requirements when using REST APIs and PowerShell cmdlets for virtual network gateway configurations, see the following pages: --| **Classic** | **Resource Manager** | -| | | -| [PowerShell](/powershell/module/servicemanagement/azure) |[PowerShell](/powershell/module/az.network#networking) | -| [REST API](/previous-versions/azure/reference/jj154113(v=azure.100)) |[REST API](/rest/api/virtual-network/) | --## VNet-to-VNet connectivity --By default, connectivity between virtual networks is enabled when you link multiple virtual networks to the same ExpressRoute circuit. Microsoft recommends not using your ExpressRoute circuit for communication between virtual networks. Instead, we recommend you to use [virtual network peering](../virtual-network/virtual-network-peering-overview.md). For more information about why VNet-to-VNet connectivity isn't recommended over ExpressRoute, see [connectivity between virtual networks over ExpressRoute](virtual-network-connectivity-guidance.md). --### Virtual network peering --A virtual network with an ExpressRoute gateway can have virtual network peering with up to 500 other virtual networks. Virtual network peering without an ExpressRoute gateway might have a higher peering limitation. - ## ExpressRoute scalable gateway (Preview) The ErGwScale virtual network gateway SKU enables you to achieve 40-Gbps connectivity to VMs and Private Endpoints in the virtual network. This SKU allows you to set a minimum and maximum scale unit for the virtual network gateway infrastructure, which auto scales based on the active bandwidth or flow count. You can also set a fixed scale unit to maintain a constant connectivity at a desired bandwidth value. ErGwScale supports both zonal and zonal-redundant deployments in Azure availabil ErGwScale is available in preview in the following regions: * Australia East+* Brazil South * Canada Central * East US * East Asia ErGwScale is available in preview in the following regions: * Sweden Central * UAE North * UK South+* West US 2 * West US 3 ### Autoscaling vs. fixed scale unit ErGwScale is free of charge during public preview. For information about Express | 20 | 20 | 2,000,000 | 140,000 | 30,000 | 2,000,000 | | 40 | 40 | 4,000,000 | 280,000 | 50,000 | 4,000,000 | -<sup>1</sup> Maximum VM connections scales differently beyond 10 scale units. The first 10 scale units will provide capacity for 2,000 VMs per scale unit. Scale units 11 and above will provide 1,000 additional VM capacity per scale unit. +<sup>1</sup> Maximum VM connections scale differently beyond 10 scale units. The first 10 scale units provide capacity for 2,000 VMs per scale unit. Scale units 11 and above provides 1,000 more VM capacity per scale unit. ++## VNet to VNet and VNet to Virtual WAN connectivity ++By default, VNet to VNet and VNet to Virtual WAN connectivity is disabled through an ExpressRoute circuit for all gateway SKUs. To enable this connectivity, you must configure the ExpressRoute virtual network gateway to allow this traffic. For more information, see guidance about [virtual network connectivity over ExpressRoute](virtual-network-connectivity-guidance.md). To enable this traffic, see [Enable VNet to VNet or VNet to Virtual WAN connectivity through ExpressRoute](expressroute-howto-add-gateway-portal-resource-manager.md#enable-or-disable-vnet-to-vnet-or-vnet-to-virtual-wan-traffic-through-expressroute). ++## <a name="fastpath"></a>FastPath ++ExpressRoute virtual network gateway is designed to exchange network routes and route network traffic. FastPath is designed to improve the data path performance between your on-premises network and your virtual network. When enabled, FastPath sends network traffic directly to virtual machines in the virtual network, bypassing the gateway. ++For more information about FastPath, including limitations, and requirements, see [About FastPath](about-fastpath.md). ++## Connectivity to private endpoints ++The ExpressRoute virtual network gateway facilitates connectivity to private endpoints deployed in the same virtual network as the virtual network gateway and across virtual network peers. ++> [!IMPORTANT] +> * The throughput and control plane capacity for connectivity to private endpoint resources may be reduced by half compared to connectivity to non-private-endpoint resources. +> * During a maintenance period, you may experience intermittent connectivity issues to private endpoint resources. +> * You need to ensure their on-premises configuration, including router & firewall settings, are correctly set up to ensure that packets for the IP 5-tuple transits uses a single next hop (Microsoft Enterprise Edge router - MSEE) unless there is a maintenance event. If your on-premises firewall or router configuration is causing the same IP 5-tuple to frequently switch next hops, then you will experience connectivity issues. ++### Private endpoint connectivity and planned maintenance events ++Private endpoint connectivity is stateful. When a connection to a private endpoint gets established over ExpressRoute private peering, inbound, and outbound connections get routed through one of the backend instances of the gateway infrastructure. During a maintenance event, backend instances of the virtual network gateway infrastructure are rebooted one at a time, which could lead to intermittent connectivity issues. ++To avoid or minimize connectivity issues with private endpoints during maintenance activities, we recommend setting the TCP time-out value to fall between 15-30 seconds on your on-premises applications. Test and configure the optimal value based on your application requirements. ++## <a name="resources"></a>REST APIs and PowerShell cmdlets ++For more technical resources and specific syntax requirements when using REST APIs and PowerShell cmdlets for virtual network gateway configurations, see the following pages: ++| **Classic** | **Resource Manager** | +| | | +| [PowerShell](/powershell/module/servicemanagement/azure) |[PowerShell](/powershell/module/az.network#networking) | +| [REST API](/previous-versions/azure/reference/jj154113(v=azure.100)) |[REST API](/rest/api/virtual-network/) | ++## VNet-to-VNet connectivity ++By default, connectivity between virtual networks is enabled when you link multiple virtual networks to the same ExpressRoute circuit. Microsoft recommends not using your ExpressRoute circuit for communication between virtual networks. Instead, we recommend you to use [virtual network peering](../virtual-network/virtual-network-peering-overview.md). For more information about why VNet-to-VNet connectivity isn't recommended over ExpressRoute, see [connectivity between virtual networks over ExpressRoute](virtual-network-connectivity-guidance.md). ++### Virtual network peering ++A virtual network with an ExpressRoute gateway can have virtual network peering with up to 500 other virtual networks. Virtual network peering without an ExpressRoute gateway might have a higher peering limitation. ## Next steps |
| expressroute | How To Configure Connection Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/expressroute/how-to-configure-connection-monitor.md | Create a workspace in the subscription that has the VNets link to the ExpressRou 1. Sign in to the [Azure portal](https://portal.azure.com). From the subscription that has the virtual networks connected to your ExpressRoute circuit, select **+ Create a resource**. Search for *Log Analytics Workspace*, then select **Create**. >[!NOTE]- >You can create a new workspace, or use an existing workspace. If you want to use an existing workspace, you must make sure that the workspace has been migrated to the new query language. [More information...](../azure-monitor/logs/log-query-overview.md) + >You can create a new workspace, or use an existing workspace. If you want to use an existing workspace, you must make sure that the workspace has been migrated to the new query language. [More information...](/azure/azure-monitor/logs/log-query-overview) > :::image type="content" source="./media/how-to-configure-connection-monitor/search-log-analytics.png" alt-text="Screenshot of searching for Log Analytics in create a resource."::: It's recommended that you install the Log Analytics agent on at least two server 1. Select the appropriate operating system for the steps to install the Log Analytics agent on your servers. - * [Windows](../azure-monitor/agents/agent-windows.md#install-the-agent) - * [Linux](../azure-monitor/agents/agent-linux.md) + * [Windows](/azure/azure-monitor/agents/agent-windows#install-the-agent) + * [Linux](/azure/azure-monitor/agents/agent-linux) -1. When complete, the Microsoft Monitoring Agent appears in the Control Panel. You can review your configuration, and [verify the agent connectivity](../azure-monitor/agents/agent-windows.md#verify-agent-connectivity-to-azure-monitor) to Azure Monitor logs. +1. When complete, the Microsoft Monitoring Agent appears in the Control Panel. You can review your configuration, and [verify the agent connectivity](/azure/azure-monitor/agents/agent-windows#verify-agent-connectivity-to-azure-monitor) to Azure Monitor logs. 1. Repeat steps 1 and 2 for the other on-premises machines that you wish to use for monitoring. |
| expressroute | Maintenance Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/expressroute/maintenance-alerts.md | -ExpressRoute uses Azure Service Health to notify you of planned and upcoming ExpressRoute circuit maintenance. With Service Health, you can view planned and past maintenance in the Azure portal along with configuring alerts and notifications that best suits your needs. To learn more about Azure Service Health refer to [What is Azure Service Health?](../service-health/overview.md) +ExpressRoute uses Azure Service Health to notify you of planned and upcoming ExpressRoute circuit maintenance. With Service Health, you can view planned and past maintenance in the Azure portal along with configuring alerts and notifications that best suits your needs. To learn more about Azure Service Health refer to [What is Azure Service Health?](/azure/service-health/overview) > [!NOTE] > * During a maintenance activity or in case of unplanned events impacting one of the connection, Microsoft will prefer to use AS path prepending to drain traffic over to the healthy connection. You will need to ensure the traffic is able to route over the healthy path when path prepend is configure from Microsoft and required route advertisements are configured appropriately to avoid any service disruption. ExpressRoute uses Azure Service Health to notify you of planned and upcoming Exp | | Service(s) | *ExpressRoute \ ExpressRoute Circuits* | | | Region(s) | Select a region or leave as *Global* for health events for all regions. | | Event type | Select *Planned maintenance*. |- | **Actions** | Action group name | The *Action Group* determines the notification type and defines the audience that the notification is sent to. For assistance in creating and managing the Action Group, refer to [Create and manage action groups](../azure-monitor/alerts/action-groups.md) in the Azure portal. | + | **Actions** | Action group name | The *Action Group* determines the notification type and defines the audience that the notification is sent to. For assistance in creating and managing the Action Group, refer to [Create and manage action groups](/azure/azure-monitor/alerts/action-groups) in the Azure portal. | | **Alert rule details** | Alert rule name | Enter a *name* to identify your alert rule. | | | Description | Provide a description for what this alert rule does. | | | Save alert rule to resource group | Select a *resource group* to create this alert rule in. | |
| expressroute | Monitor Expressroute Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/expressroute/monitor-expressroute-reference.md | The following table lists the operations related to ExpressRoute that might be c | Create or update ExpressRoute circuit | An ExpressRoute circuit was created or updated. | | Deletes ExpressRoute circuit | An ExpressRoute circuit was deleted.| -For more information on the schema of Activity Log entries, see [Activity Log schema](../azure-monitor/essentials/activity-log-schema.md). +For more information on the schema of Activity Log entries, see [Activity Log schema](/azure/azure-monitor/essentials/activity-log-schema). ## Schemas -For detailed description of the top-level diagnostic logs schema, see [Supported services, schemas, and categories for Azure Diagnostic Logs](../azure-monitor/essentials/resource-logs-schema.md). +For detailed description of the top-level diagnostic logs schema, see [Supported services, schemas, and categories for Azure Diagnostic Logs](/azure/azure-monitor/essentials/resource-logs-schema). When you review any metrics through Log Analytics, the output contains the following columns: |
| expressroute | Monitor Expressroute | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/expressroute/monitor-expressroute.md | For more information about the resource types for ExpressRoute, see [Azure Expre Resource Logs aren't collected and stored until you create a diagnostic setting and route them to one or more locations. -See [Create diagnostic setting to collect platform logs and metrics in Azure](../azure-monitor/essentials/diagnostic-settings.md) for the detailed process for creating a diagnostic setting using the Azure portal, CLI, or PowerShell. When you create a diagnostic setting, you specify which categories of logs to collect. The categories for *Azure ExpressRoute* are listed in [Azure ExpressRoute monitoring data reference](monitor-expressroute-reference.md#resource-logs). +See [Create diagnostic setting to collect platform logs and metrics in Azure](/azure/azure-monitor/essentials/diagnostic-settings) for the detailed process for creating a diagnostic setting using the Azure portal, CLI, or PowerShell. When you create a diagnostic setting, you specify which categories of logs to collect. The categories for *Azure ExpressRoute* are listed in [Azure ExpressRoute monitoring data reference](monitor-expressroute-reference.md#resource-logs). > [!IMPORTANT] > Enabling these settings requires additional Azure services (storage account, event hub, or Log Analytics), which may increase your cost. To calculate an estimated cost, visit the [Azure pricing calculator](https://azure.microsoft.com/pricing/calculator). For a list of available metrics for ExpressRoute, see [Azure ExpressRoute monito ## Analyzing metrics -You can analyze metrics for *Azure ExpressRoute* with metrics from other Azure services using metrics explorer by opening **Metrics** from the **Azure Monitor** menu. See [Analyze metrics with Azure Monitor metrics explorer](../azure-monitor/essentials/analyze-metrics.md) for details on using this tool. +You can analyze metrics for *Azure ExpressRoute* with metrics from other Azure services using metrics explorer by opening **Metrics** from the **Azure Monitor** menu. See [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics) for details on using this tool. :::image type="content" source="./media/expressroute-monitoring-metrics-alerts/metrics-page.png" alt-text="Screenshot of the metrics dashboard for ExpressRoute."::: -For reference, you can see a list of [all resource metrics supported in Azure Monitor](../azure-monitor/essentials/metrics-supported.md). +For reference, you can see a list of [all resource metrics supported in Azure Monitor](/azure/azure-monitor/essentials/metrics-supported). - To view **ExpressRoute** metrics, filter by Resource Type *ExpressRoute circuits*. - To view **Global Reach** metrics, filter by Resource Type *ExpressRoute circuits* and select an ExpressRoute circuit resource that has Global Reach enabled. For the ExpressRoute metrics, see [Azure ExpressRoute monitoring data reference] ### Aggregation Types -Metrics explorer supports sum, maximum, minimum, average and count as [aggregation types](../azure-monitor/essentials/metrics-charts.md#aggregation). You should use the recommended Aggregation type when reviewing the insights for each ExpressRoute metric. +Metrics explorer supports sum, maximum, minimum, average and count as [aggregation types](/azure/azure-monitor/essentials/metrics-charts#aggregation). You should use the recommended Aggregation type when reviewing the insights for each ExpressRoute metric. - Sum: The sum of all values captured during the aggregation interval. - Count: The number of measurements captured during the aggregation interval. You can also view ExpressRoute metrics by going to your ExpressRoute circuit res Data in Azure Monitor Logs is stored in tables where each table has its own set of unique properties. -All resource logs in Azure Monitor have the same fields followed by service-specific fields. The common schema is outlined in [Azure Monitor resource log schema](../azure-monitor/essentials/resource-logs-schema.md#top-level-common-schema). The schema for ExpressRoute resource logs is found in the [Azure ExpressRoute Data Reference](monitor-expressroute-reference.md#schemas). +All resource logs in Azure Monitor have the same fields followed by service-specific fields. The common schema is outlined in [Azure Monitor resource log schema](/azure/azure-monitor/essentials/resource-logs-schema#top-level-common-schema). The schema for ExpressRoute resource logs is found in the [Azure ExpressRoute Data Reference](monitor-expressroute-reference.md#schemas). -The [Activity log](../azure-monitor/essentials/activity-log.md) is a platform logging that provides insight into subscription-level events. You can view it independently or route it to Azure Monitor Logs, where you can do much more complex queries using Log Analytics. +The [Activity log](/azure/azure-monitor/essentials/activity-log) is a platform logging that provides insight into subscription-level events. You can view it independently or route it to Azure Monitor Logs, where you can do much more complex queries using Log Analytics. ExpressRoute stores data in the following tables. To view these tables, navigate to your ExpressRoute circuit resource and select ### Sample Kusto queries -These queries work with the [new language](../azure-monitor/logs/log-query-overview.md). +These queries work with the [new language](/azure/azure-monitor/logs/log-query-overview). - Query for Border Gateway Protocol (BGP) route table learned over the last 12 hours. |
| expressroute | Traffic Collector | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/expressroute/traffic-collector.md | -ExpressRoute Traffic Collector enables sampling of network flows sent over your ExpressRoute circuits. Flow logs get sent to a [Log Analytics workspace](../azure-monitor/logs/log-analytics-overview.md) where you can create your own log queries for further analysis. You can also export the data to any visualization tool or SIEM (Security Information and Event Management) of your choice. Flow logs can be enabled for both private peering and Microsoft peering with ExpressRoute Traffic Collector. +ExpressRoute Traffic Collector enables sampling of network flows sent over your ExpressRoute circuits. Flow logs get sent to a [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-overview) where you can create your own log queries for further analysis. You can also export the data to any visualization tool or SIEM (Security Information and Event Management) of your choice. Flow logs can be enabled for both private peering and Microsoft peering with ExpressRoute Traffic Collector. :::image type="content" source="./media/traffic-collector/main-diagram.png" alt-text="Diagram of ExpressRoute traffic collector in an Azure environment."::: Note: If your desired region is not yet supported, you can deploy ExpressRoute T ## Pricing -| Zone | Gateway per hour | Data processed per GB | +| Zone | Collector Instance Uptime | Data processed per GB | | - | - | | | Zone 1 | $0.60/hour | $0.10/GB | | Zone 2 | $0.80/hour | $0.20/GB | |
| firewall | Diagnostic Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/firewall/diagnostic-logs.md | - Title: Azure Firewall Diagnostic logs (legacy) -description: Diagnostic logs are the original Azure Firewall log queries that output log data in an unstructured or free-form text format. ---- Previously updated : 12/04/2023----# Azure Firewall diagnostic logs (legacy) --Diagnostic logs are the original Azure Firewall log queries that output log data in an unstructured or free-form text format. --The following log categories are supported in Diagnostic logs: --- Azure Firewall application rule -- Azure Firewall network rule -- Azure Firewall DNS proxy--## Application rule log --The Application rule log is saved to a storage account, streamed to Event hubs and/or sent to Azure Monitor logs only if you've enabled it for each Azure Firewall. Each new connection that matches one of your configured application rules results in a log for the accepted/denied connection. The data is logged in JSON format, as shown in the following examples: -- ``` - Category: application rule logs. - Time: log timestamp. - Properties: currently contains the full message. - note: this field will be parsed to specific fields in the future, while maintaining backward compatibility with the existing properties field. - ``` -- ```json - { - "category": "AzureFirewallApplicationRule", - "time": "2018-04-16T23:45:04.8295030Z", - "resourceId": "/SUBSCRIPTIONS/{subscriptionId}/RESOURCEGROUPS/{resourceGroupName}/PROVIDERS/MICROSOFT.NETWORK/AZUREFIREWALLS/{resourceName}", - "operationName": "AzureFirewallApplicationRuleLog", - "properties": { - "msg": "HTTPS request from 10.1.0.5:55640 to mydestination.com:443. Action: Allow. Rule Collection: collection1000. Rule: rule1002" - } - } - ``` -- ```json - { - "category": "AzureFirewallApplicationRule", - "time": "2018-04-16T23:45:04.8295030Z", - "resourceId": "/SUBSCRIPTIONS/{subscriptionId}/RESOURCEGROUPS/{resourceGroupName}/PROVIDERS/MICROSOFT.NETWORK/AZUREFIREWALLS/{resourceName}", - "operationName": "AzureFirewallApplicationRuleLog", - "properties": { - "msg": "HTTPS request from 10.11.2.4:53344 to www.bing.com:443. Action: Allow. Rule Collection: ExampleRuleCollection. Rule: ExampleRule. Web Category: SearchEnginesAndPortals" - } - } - ``` --## Network rule log --The Network rule log is saved to a storage account, streamed to Event hubs and/or sent to Azure Monitor logs only if you've enabled it for each Azure Firewall. Each new connection that matches one of your configured network rules results in a log for the accepted/denied connection. The data is logged in JSON format, as shown in the following example: -- ``` - Category: network rule logs. - Time: log timestamp. - Properties: currently contains the full message. - note: this field will be parsed to specific fields in the future, while maintaining backward compatibility with the existing properties field. - ``` -- ```json - { - "category": "AzureFirewallNetworkRule", - "time": "2018-06-14T23:44:11.0590400Z", - "resourceId": "/SUBSCRIPTIONS/{subscriptionId}/RESOURCEGROUPS/{resourceGroupName}/PROVIDERS/MICROSOFT.NETWORK/AZUREFIREWALLS/{resourceName}", - "operationName": "AzureFirewallNetworkRuleLog", - "properties": { - "msg": "TCP request from 111.35.136.173:12518 to 13.78.143.217:2323. Action: Deny" - } - } -- ``` --## DNS proxy log --The DNS proxy log is saved to a storage account, streamed to Event hubs, and/or sent to Azure Monitor logs only if youΓÇÖve enabled it for each Azure Firewall. This log tracks DNS messages to a DNS server configured using DNS proxy. The data is logged in JSON format, as shown in the following examples: --- ``` - Category: DNS proxy logs. - Time: log timestamp. - Properties: currently contains the full message. - note: this field will be parsed to specific fields in the future, while maintaining backward compatibility with the existing properties field. - ``` -- Success: - ```json - { - "category": "AzureFirewallDnsProxy", - "time": "2020-09-02T19:12:33.751Z", - "resourceId": "/SUBSCRIPTIONS/{subscriptionId}/RESOURCEGROUPS/{resourceGroupName}/PROVIDERS/MICROSOFT.NETWORK/AZUREFIREWALLS/{resourceName}", - "operationName": "AzureFirewallDnsProxyLog", - "properties": { - "msg": "DNS Request: 11.5.0.7:48197 ΓÇô 15676 AAA IN md-l1l1pg5lcmkq.blob.core.windows.net. udp 55 false 512 NOERROR - 0 2.000301956s" - } - } - ``` -- Failed: -- ```json - { - "category": "AzureFirewallDnsProxy", - "time": "2020-09-02T19:12:33.751Z", - "resourceId": "/SUBSCRIPTIONS/{subscriptionId}/RESOURCEGROUPS/{resourceGroupName}/PROVIDERS/MICROSOFT.NETWORK/AZUREFIREWALLS/{resourceName}", - "operationName": "AzureFirewallDnsProxyLog", - "properties": { - "msg": " Error: 2 time.windows.com.reddog.microsoft.com. A: read udp 10.0.1.5:49126->168.63.129.160:53: i/o timeoutΓÇ¥ - } - } - ``` -- msg format: -- `[clientΓÇÖs IP address]:[clientΓÇÖs port] ΓÇô [query ID] [type of the request] [class of the request] [name of the request] [protocol used] [request size in bytes] [EDNS0 DO (DNSSEC OK) bit set in the query] [EDNS0 buffer size advertised in the query] [response CODE] [response flags] [response size] [response duration]` --## Storage --You have three options for storing your logs: --* **Storage account**: Storage accounts are best used for logs when logs are stored for a longer duration and reviewed when needed. -* **Event hubs**: Event hubs are a great option for integrating with other security information and event management (SEIM) tools to get alerts on your resources. -* **Azure Monitor logs**: Azure Monitor logs is best used for general real-time monitoring of your application or looking at trends. --## Enable diagnostic logs --To learn how to enable the diagnostic logging using the Azure portal, see [Monitor Azure Firewall logs (legacy) and metrics](firewall-diagnostics.md). --## Next steps --- [Azure Firewall metrics and alerts](metrics.md) |
| firewall | Enable Top Ten And Flow Trace | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/firewall/enable-top-ten-and-flow-trace.md | - Title: Enable Top flows and Flow trace logs in Azure Firewall -description: Learn how to enable the Top flows and Flow trace logs in Azure Firewall. ----- Previously updated : 06/14/2024----# Enable Top flows and Flow trace logs in Azure Firewall --Azure Firewall has two new diagnostics logs you can use to help monitor your firewall: --- Top flows-- Flow trace--## Top flows --The Top flows log (known in the industry as Fat Flows), shows the top connections that are contributing to the highest throughput through the firewall. --> [!TIP] -> Activate Top flows logs only when troubleshooting a specific issue to avoid excessive CPU usage of Azure Firewall. -> --The flow rate is defined as the data transmission rate (in Megabits per second units). In other words, it's a measure of the amount of digital data that can be transmitted over a network in a period of time through the firewall. The Top Flows protocol runs periodically every three minutes. The minimum threshold to be considered a Top Flow is 1 Mbps. --### Prerequisites --- Enable [structured logs](firewall-structured-logs.md#enable-structured-logs)-- Use the Azure Resource Specific Table format in [Diagnostic Settings](firewall-diagnostics.md#enable-diagnostic-logging-through-the-azure-portal).--### Enable the log --Enable the log using the following Azure PowerShell commands: --```azurepowershell -Set-AzContext -SubscriptionName <SubscriptionName> -$firewall = Get-AzFirewall -ResourceGroupName <ResourceGroupName> -Name <FirewallName> -$firewall.EnableFatFlowLogging = $true -Set-AzFirewall -AzureFirewall $firewall -``` --### Disable the log --To disable the logs, use the same previous Azure PowerShell command and set the value to *False*. --For example: --```azurepowershell -Set-AzContext -SubscriptionName <SubscriptionName> -$firewall = Get-AzFirewall -ResourceGroupName <ResourceGroupName> -Name <FirewallName> -$firewall.EnableFatFlowLogging = $false -Set-AzFirewall -AzureFirewall $firewall -``` --### Verify the update --There are a few ways to verify the update was successful, but you can navigate to firewall **Overview** and select **JSON view** on the top right corner. HereΓÇÖs an example: ---### Create a diagnostic setting and enable Resource Specific Table --1. In the Diagnostic settings tab, select **Add diagnostic setting**. -2. Type a Diagnostic setting name. -3. Select **Azure Firewall Fat Flow Log** under **Categories** and any other logs you want to be supported in the firewall. -4. In Destination details, select **Send to Log Analytics** workspace. - 1. Choose your desired Subscription and preconfigured Log Analytics workspace. - 1. Enable **Resource specific**. - :::image type="content" source="media/enable-top-ten-and-flow-trace/log-destination-details.png" alt-text="Screenshot showing log destination details."::: --### View and analyze Azure Firewall logs --1. On a firewall resource, navigate to **Logs** under the **Monitoring** tab. -2. Select **Queries**, then load **Azure Firewall Top Flow Logs** by hovering over the option and selecting **Load to editor**. -3. When the query loads, select **Run**. -- :::image type="content" source="media/enable-top-ten-and-flow-trace/top-ten-flow-log.png" alt-text="Screenshot showing the Top flow log." lightbox="media/enable-top-ten-and-flow-trace/top-ten-flow-log.png"::: --## Flow trace --Currently, the firewall logs show traffic through the firewall in the first attempt of a TCP connection, known as the *SYN* packet. However, this doesn't show the full journey of the packet in the TCP handshake. As a result, it's difficult to troubleshoot if a packet is dropped, or asymmetric routing occurred. ---> [!TIP] -> To avoid excessive disk usage caused by Flow trace logs in Azure Firewall with many short-lived connections, activate the logs only when troubleshooting a specific issue for diagnostic purposes. --The following additional properties can be added: -- SYN-ACK-- ACK flag that indicates acknowledgment of SYN packet. -- FIN-- Finished flag of the original packet flow. No more data is transmitted in the TCP flow. -- FIN-ACK-- ACK flag that indicates acknowledgment of FIN packet. --- RST-- The Reset the flag indicates the original sender doesn't receive more data. --- INVALID (flows)-- Indicates packet canΓÇÖt be identified or don't have any state. -- For example: - - A TCP packet lands on a Virtual Machine Scale Sets instance, which doesn't have any prior history for this packet - - Bad CheckSum packets - - Connection Tracking table entry is full and new connections can't be accepted - - Overly delayed ACK packets --Flow Trace logs, such as SYN-ACK and ACK, are exclusively logged for network traffic. In addition, SYN packets aren't logged by default. However, you can access the initial SYN packets within the network rule logs. --### Prerequisites --- Enable [structured logs](firewall-structured-logs.md#enable-structured-logs).-- Use the Azure Resource Specific Table format in [Diagnostic Settings](firewall-diagnostics.md#enable-diagnostic-logging-through-the-azure-portal).--### Enable the log --Enable the log using the following Azure PowerShell commands or navigate in the portal and search for **Enable TCP Connection Logging**: --```azurepowershell -Connect-AzAccount -Select-AzSubscription -Subscription <subscription_id> or <subscription_name> -Register-AzProviderFeature -FeatureName AFWEnableTcpConnectionLogging -ProviderNamespace Microsoft.Network -Register-AzResourceProvider -ProviderNamespace Microsoft.Network -``` --It can take several minutes for this to take effect. Once the feature is registered, consider performing an update on Azure Firewall for the change to take effect immediately. --To check the status of the AzResourceProvider registration, you can run the Azure PowerShell command: --`Get-AzProviderFeature -FeatureName "AFWEnableTcpConnectionLogging" -ProviderNamespace "Microsoft.Network"` --### Disable the log --To disable the log, you can unregister it using the following command or select unregister in the previous portal example. - -`Unregister-AzProviderFeature -FeatureName AFWEnableTcpConnectionLogging -ProviderNamespace Microsoft.Network` ---### Create a diagnostic setting and enable Resource Specific Table --1. In the Diagnostic settings tab, select **Add diagnostic setting**. -2. Type a Diagnostic setting name. -3. Select **Azure Firewall Flow Trace Log** under **Categories** and any other logs you want to be supported in the firewall. -4. In Destination details, select **Send to Log Analytics** workspace. - 1. Choose your desired Subscription and preconfigured Log Analytics workspace. - 1. Enable **Resource specific**. - :::image type="content" source="media/enable-top-ten-and-flow-trace/log-destination-details.png" alt-text="Screenshot showing log destination details."::: --### View and analyze Azure Firewall Flow trace logs --1. On a firewall resource, navigate to **Logs** under the **Monitoring** tab. -2. Select **Queries**, then load **Azure Firewall flow trace logs** by hovering over the option and selecting **Load to editor**. -3. When the query loads, select **Run**. -- :::image type="content" source="media/enable-top-ten-and-flow-trace/trace-flow-logs.png" alt-text="Screenshot showing the Trace flow log." lightbox="media/enable-top-ten-and-flow-trace/trace-flow-logs.png"::: ---## Next steps --- [Azure Structured Firewall Logs](firewall-structured-logs.md) |
| firewall | Firewall Diagnostics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/firewall/firewall-diagnostics.md | - Title: Monitor Azure Firewall logs and metrics -description: In this article, you learn how to enable and manage Azure Firewall logs and metrics. ----- Previously updated : 06/07/2023--#Customer intent: As an administrator, I want monitor Azure Firewall logs and metrics so that I can track firewall activity. --# Monitor Azure Firewall logs (legacy) and metrics --> [!TIP] -> For an improved method to work with firewall logs, see [Azure Structured Firewall Logs](firewall-structured-logs.md). --You can monitor Azure Firewall using firewall logs. You can also use activity logs to audit operations on Azure Firewall resources. Using metrics, you can view performance counters in the portal. --You can access some of these logs through the portal. Logs can be sent to [Azure Monitor logs](/previous-versions/azure/azure-monitor/insights/azure-networking-analytics), Storage, and Event Hubs and analyzed in Azure Monitor logs or by different tools such as Excel and Power BI. ----## Prerequisites --Before starting, you should read [Azure Firewall logs and metrics](logs-and-metrics.md) for an overview of the diagnostics logs and metrics available for Azure Firewall. --## Enable diagnostic logging through the Azure portal --It can take a few minutes for the data to appear in your logs after you complete this procedure to turn on diagnostic logging. If you don't see anything at first, check again in a few more minutes. --1. In the Azure portal, open your firewall resource group and select the firewall. -2. Under **Monitoring**, select **Diagnostic settings**. -- For Azure Firewall, three service-specific legacy logs are available: -- * Azure Firewall Application Rule (Legacy Azure Diagnostics) - * Azure Firewall Network Rule (Legacy Azure Diagnostics) - * Azure Firewall Dns Proxy (Legacy Azure Diagnostics) ---3. Select **Add diagnostic setting**. The **Diagnostics settings** page provides the settings for the diagnostic logs. -5. Type a name for the diagnostic setting. -6. Under **Logs**, select **Azure Firewall Application Rule (Legacy Azure Diagnostics)**, **Azure Firewall Network Rule (Legacy Azure Diagnostics)**, and **Azure Firewall Dns Proxy (Legacy Azure Diagnostics)** to collect the logs. -7. Select **Send to Log Analytics** to configure your workspace. -8. Select your subscription. -1. For the **Destination table**, select **Azure diagnostics**. -1. Select **Save**. -- :::image type="content" source=".\media\firewall-diagnostics\diagnostic-setting-legacy.png" alt-text="Screenshot of Firewall Diagnostic setting."::: --## Enable diagnostic logging by using PowerShell --Activity logging is automatically enabled for every Resource Manager resource. Diagnostic logging must be enabled to start collecting the data available through those logs. --To enable diagnostic logging with PowerShell, use the following steps: --1. Note your Log Analytics Workspace resource ID, where the log data is stored. This value is of the form: -- `/subscriptions/<subscriptionId>/resourceGroups/<resource group name>/providers/microsoft.operationalinsights/workspaces/<workspace name>` -- You can use any workspace in your subscription. You can use the Azure portal to find this information. The information is located in the resource **Properties** page. --2. Note the resource ID for the firewall. This value is of the form: -- `/subscriptions/<subscriptionId>/resourceGroups/<resource group name>/providers/Microsoft.Network/azureFirewalls/<Firewall name>` -- You can use the portal to find this information. --3. Enable diagnostic logging for all logs and metrics by using the following PowerShell cmdlet: -- ```azurepowershell - $diagSettings = @{ - Name = 'toLogAnalytics' - ResourceId = '/subscriptions/<subscriptionId>/resourceGroups/<resource group name>/providers/Microsoft.Network/azureFirewalls/<Firewall name>' - WorkspaceId = '/subscriptions/<subscriptionId>/resourceGroups/<resource group name>/providers/microsoft.operationalinsights/workspaces/<workspace name>' - } - New-AzDiagnosticSetting @diagSettings - ``` --## Enable diagnostic logging by using the Azure CLI --Activity logging is automatically enabled for every Resource Manager resource. Diagnostic logging must be enabled to start collecting the data available through those logs. --To enable diagnostic logging with Azure CLI, use the following steps: --1. Note your Log Analytics Workspace resource ID, where the log data is stored. This value is of the form: -- `/subscriptions/<subscriptionId>/resourceGroups/<resource group name>/providers/microsoft.operationalinsights/workspaces/<workspace name>` -- You can use any workspace in your subscription. You can use the Azure portal to find this information. The information is located in the resource **Properties** page. --2. Note the resource ID for the firewall. This value is of the form: -- `/subscriptions/<subscriptionId>/resourceGroups/<resource group name>/providers/Microsoft.Network/azureFirewalls/<Firewall name>` -- You can use the portal to find this information. --3. Enable diagnostic logging for all logs and metrics by using the following Azure CLI command: -- ```azurecli - az monitor diagnostic-settings create -n 'toLogAnalytics' - --resource '/subscriptions/<subscriptionId>/resourceGroups/<resource group name>/providers/Microsoft.Network/azureFirewalls/<Firewall name>' - --workspace '/subscriptions/<subscriptionId>/resourceGroups/<resource group name>/providers/microsoft.operationalinsights/workspaces/<workspace name>' - --logs "[{\"category\":\"AzureFirewallApplicationRule\",\"Enabled\":true}, {\"category\":\"AzureFirewallNetworkRule\",\"Enabled\":true}, {\"category\":\"AzureFirewallDnsProxy\",\"Enabled\":true}]" - --metrics "[{\"category\": \"AllMetrics\",\"enabled\": true}]" - ``` --## View and analyze the activity log --You can view and analyze activity log data by using any of the following methods: --* **Azure tools**: Retrieve information from the activity log through Azure PowerShell, the Azure CLI, the Azure REST API, or the Azure portal. Step-by-step instructions for each method are detailed in the [Activity operations with Resource Manager](../azure-monitor/essentials/activity-log.md) article. -* **Power BI**: If you don't already have a [Power BI](https://powerbi.microsoft.com/pricing) account, you can try it for free. By using the [Azure Activity Logs content pack for Power BI](https://powerbi.microsoft.com/en-us/documentation/powerbi-content-pack-azure-audit-logs/), you can analyze your data with preconfigured dashboards that you can use as is or customize. -* **Microsoft Sentinel**: You can connect Azure Firewall logs to Microsoft Sentinel, enabling you to view log data in workbooks, use it to create custom alerts, and incorporate it to improve your investigation. The Azure Firewall data connector in Microsoft Sentinel is currently in public preview. For more information, see [Connect data from Azure Firewall](../sentinel/data-connectors/azure-firewall.md). -- See the following video by Mohit Kumar for an overview: - > [!VIDEO https://www.microsoft.com/videoplayer/embed/RWI4nn] ---## View and analyze the network and application rule logs --[Azure Firewall Workbook](firewall-workbook.md) provides a flexible canvas for Azure Firewall data analysis. You can use it to create rich visual reports within the Azure portal. You can tap into multiple Firewalls deployed across Azure, and combine them into unified interactive experiences. --You can also connect to your storage account and retrieve the JSON log entries for access and performance logs. After you download the JSON files, you can convert them to CSV and view them in Excel, Power BI, or any other data-visualization tool. --> [!TIP] -> If you are familiar with Visual Studio and basic concepts of changing values for constants and variables in C#, you can use the [log converter tools](https://github.com/Azure-Samples/networking-dotnet-log-converter) available from GitHub. --## View metrics -Browse to an Azure Firewall. Under **Monitoring**, select **Metrics**. To view the available values, select the **METRIC** drop-down list. --## Next steps --Now that you've configured your firewall to collect logs, you can explore Azure Monitor logs to view your data. --- [Monitor logs using Azure Firewall Workbook](firewall-workbook.md)-- [Networking monitoring solutions in Azure Monitor logs](/previous-versions/azure/azure-monitor/insights/azure-networking-analytics)-- [Learn more about Azure network security](../networking/security/index.yml)- |
| firewall | Firewall Preview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/firewall/firewall-preview.md | For more information, see [Azure Firewall Explicit proxy (preview)](explicit-pro With the Azure Firewall Resource Health check, you can now diagnose and get support for service problems that affect your Azure Firewall resource. Resource Health allows IT teams to receive proactive notifications on potential health degradations, and recommended mitigation actions per each health event type. The resource health is also available in a dedicated page in the Azure portal resource page. Starting in August 2023, this preview is automatically enabled on all firewalls and no action is required to enable this functionality.-For more information, see [Resource Health overview](../service-health/resource-health-overview.md). +For more information, see [Resource Health overview](/azure/service-health/resource-health-overview). ### Autolearn SNAT routes (preview) |
| firewall | Firewall Structured Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/firewall/firewall-structured-logs.md | - Title: Azure Structured Firewall Logs -description: Learn about Azure Structured Firewall Logs ---- Previously updated : 06/14/2024----# Azure Structured Firewall Logs --Structured logs are a type of log data that are organized in a specific format. They use a predefined schema to structure log data in a way that makes it easy to search, filter, and analyze. Unlike unstructured logs, which consist of free-form text, structured logs have a consistent format that machines can parse and analyze. --Azure Firewall's structured logs provide a more detailed view of firewall events. They include information such as source and destination IP addresses, protocols, port numbers, and action taken by the firewall. They also include more metadata, such as the time of the event and the name of the Azure Firewall instance. --Currently, the following diagnostic log categories are available for Azure Firewall: -- Application rule log-- Network rule log-- DNS proxy log--These log categories use [Azure diagnostics mode](../azure-monitor/essentials/resource-logs.md#azure-diagnostics-mode). In this mode, all data from any diagnostic setting is collected in the [AzureDiagnostics](/azure/azure-monitor/reference/tables/azurediagnostics) table. --With structured logs, you're able to choose to use [Resource Specific Tables](../azure-monitor/essentials/resource-logs.md#resource-specific) instead of the existing [AzureDiagnostics](/azure/azure-monitor/reference/tables/azurediagnostics) table. In case both sets of logs are required, at least two diagnostic settings need to be created per firewall. --## Resource specific mode --In **Resource specific** mode, individual tables in the selected workspace are created for each category selected in the diagnostic setting. This method is recommended since it: -- May reduce overall logging costs by up to 80%.-- makes it much easier to work with the data in log queries-- makes it easier to discover schemas and their structure-- improves performance across both ingestion latency and query times-- allows you to grant Azure RBAC rights on a specific table--New resource specific tables are now available in Diagnostic setting that allows you to utilize the following categories: --- [Network rule log](/azure/azure-monitor/reference/tables/azfwnetworkrule) - Contains all Network Rule log data. Each match between data plane and network rule creates a log entry with the data plane packet and the matched rule's attributes.-- [NAT rule log](/azure/azure-monitor/reference/tables/azfwnatrule) - Contains all DNAT (Destination Network Address Translation) events log data. Each match between data plane and DNAT rule creates a log entry with the data plane packet and the matched rule's attributes.-- [Application rule log](/azure/azure-monitor/reference/tables/azfwapplicationrule) - Contains all Application rule log data. Each match between data plane and Application rule creates a log entry with the data plane packet and the matched rule's attributes.-- [Threat Intelligence log](/azure/azure-monitor/reference/tables/azfwthreatintel) - Contains all Threat Intelligence events.-- [IDPS log](/azure/azure-monitor/reference/tables/azfwidpssignature) - Contains all data plane packets that were matched with one or more IDPS signatures.-- [DNS proxy log](/azure/azure-monitor/reference/tables/azfwdnsquery) - Contains all DNS Proxy events log data.-- [Internal FQDN resolve failure log](/azure/azure-monitor/reference/tables/azfwinternalfqdnresolutionfailure) - Contains all internal Firewall FQDN resolution requests that resulted in failure.-- [Application rule aggregation log](/azure/azure-monitor/reference/tables/azfwapplicationruleaggregation) - Contains aggregated Application rule log data for Policy Analytics.-- [Network rule aggregation log](/azure/azure-monitor/reference/tables/azfwnetworkruleaggregation) - Contains aggregated Network rule log data for Policy Analytics.-- [NAT rule aggregation log](/azure/azure-monitor/reference/tables/azfwnatruleaggregation) - Contains aggregated NAT rule log data for Policy Analytics.-- [Top flow log](/azure/azure-monitor/reference/tables/azfwfatflow) - The Top Flows (Fat Flows) log shows the top connections that are contributing to the highest throughput through the firewall.-- [Flow trace](/azure/azure-monitor/reference/tables/azfwflowtrace) - Contains flow information, flags, and the time period when the flows were recorded. You can see full flow information such as SYN, SYN-ACK, FIN, FIN-ACK, RST, INVALID (flows).--## Enable structured logs --To enable Azure Firewall structured logs, you must first configure a Log Analytics workspace in your Azure subscription. This workspace is used to store the structured logs generated by Azure Firewall. --Once you configure the Log Analytics workspace, you can enable structured logs in Azure Firewall by navigating to the Firewall's **Diagnostic settings** page in the Azure portal. From there, you must select the **Resource specific** destination table and select the type of events you want to log. --> [!NOTE] -> There's no requirement to enable this feature with a feature flag or Azure PowerShell commands. ---## Structured log queries --A list of predefined queries is available in the Azure portal. This list has a predefined KQL (Kusto Query Language) log query for each category and joined query showing the entire Azure firewall logging events in single view. ---## Azure Firewall Workbook --[Azure Firewall Workbook](firewall-workbook.md) provides a flexible canvas for Azure Firewall data analysis. You can use it to create rich visual reports within the Azure portal. You can tap into multiple firewalls deployed across Azure and combine them into unified interactive experiences. --To deploy the new workbook that uses Azure Firewall Structured Logs, see [Azure Monitor Workbook for Azure Firewall](https://github.com/Azure/Azure-Network-Security/tree/master/Azure%20Firewall/Workbook%20-%20Azure%20Firewall%20Monitor%20Workbook). --## Next steps --- For more information, see [Exploring the New Resource Specific Structured Logging in Azure Firewall](https://techcommunity.microsoft.com/t5/azure-network-security-blog/exploring-the-new-resource-specific-structured-logging-in-azure/ba-p/3620530).---- To learn more about Azure Firewall logs and metrics, see [Azure Firewall logs and metrics](logs-and-metrics.md) |
| firewall | Logs And Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/firewall/logs-and-metrics.md | - Title: Overview of Azure Firewall logs and metrics -description: You can monitor Azure Firewall using firewall logs. You can also use activity logs to audit operations on Azure Firewall resources. ---- Previously updated : 12/04/2023-----# Azure Firewall logs and metrics overview --You can use Azure Firewall logs and metrics to monitor your traffic and operations within the firewall. These logs and metrics serve several essential purposes, including: --- **Traffic Analysis**: Use logs to examine and analyze the traffic passing through the firewall. This includes examining permitted and denied traffic, inspecting source and destination IP addresses, URLs, port numbers, protocols, and more. These insights are essential for understanding traffic patterns, identifying potential security threats, and troubleshooting connectivity issues. --- **Performance and Health Metrics**: Azure Firewall metrics provide performance and health metrics, such as data processed, throughput, rule hit count, and latency. Monitor these metrics to assess the overall health of your firewall, identify performance bottlenecks, and detect any anomalies. --- **Audit Trail**: Activity logs enable auditing of operations related to firewall resources, capturing actions like creating, updating, or deleting firewall rules and policies. Reviewing activity logs helps maintain a historical record of configuration changes and ensures compliance with security and auditing requirements.--## Viewing and storage --Logs and metrics can be accessed through the Azure portal, with multiple options for storage and analysis: --- **Log Analytics Workspace (powered by Azure Monitor)**: Centralize your Azure Firewall logs and metrics in a Log Analytics workspace for advanced analysis, customized dashboard creation, and setting up alerts based on specific metric thresholds. --- **Storage Account**: Store logs in an Azure Storage account for long-term retention and integration with external log analysis tools. --- **Event Hub**: Stream Azure Firewall logs to Azure Event Hub for real-time processing, analysis, or integration with third-party SIEM solutions. --- **Partner Solutions**: Send Azure Firewall logs to third-party partner solutions for further analysis and correlation with other security data. --Log and metric configuration settings for Azure Firewall is typically done through the Azure portal. This allows you to specify the destination for logs and metrics and to set up retention and alerting configurations tailored to your organization's monitoring and security requirements. --## Structured logs --Monitor Azure Firewall using Structured Logs, which use a predefined schema to structure log data for easy searching, filtering, and analysis. These logs include information such as source and destination IP addresses, protocols, port numbers, and firewall actions. Prioritize setting up Structured Logs as your main log type using Resource Specific Tables instead of the existing AzureDiagnostics table. To enable these logs and explore log categories, see [Azure Structured Firewall Logs](firewall-structured-logs.md). --## Legacy Azure Diagnostics logs --Legacy Azure Diagnostic logs are the original Azure Firewall log queries that output log data in an unstructured or free-form text format. The Azure Firewall legacy log categories use [Azure diagnostics mode](../azure-monitor/essentials/resource-logs.md#azure-diagnostics-mode), collecting entire data in the [AzureDiagnostics table](/azure/azure-monitor/reference/tables/azurediagnostics). In case both Structured and Diagnostic logs are required, at least two diagnostic settings need to be created per firewall. To enable these logs and explore log categories, see [Azure Firewall diagnostic logs](diagnostic-logs.md). --## Metrics --Metrics in Azure Monitor are numerical values describing aspects of a system at a particular time. Collected every minute, metrics are useful for alerting due to their frequent sampling. Configure alerts quickly with relatively simple logic. For available metrics and configuring alerts for Azure Firewall, see [Azure Firewall metrics and alerts](metrics.md). --## Activity logs --Activity log entries are collected by default and can be viewed in the Azure portal. Use Azure activity logs (formerly known as operational logs and audit logs) to view all operations submitted to your Azure subscription. ---## Next steps --- To learn more about metrics in Azure Monitor, see [Metrics in Azure Monitor](../azure-monitor/essentials/data-platform-metrics.md). |
| firewall | Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/firewall/metrics.md | - Title: Azure Firewall metrics and alerts -description: Metrics in Azure Monitor are numerical values that describe some aspect of a system at a particular time. ---- Previously updated : 12/04/2023----# Azure Firewall metrics and alerts --Metrics in Azure Monitor are numerical values that describe some aspect of a system at a particular time. Metrics are collected every minute, and are useful for alerting because they can be sampled frequently. An alert can be fired quickly with relatively simple logic. --## Firewall metrics --The following metrics are available for Azure Firewall: --- **Application rules hit count** - The number of times an application rule has been hit.-- Unit: count --- **Network rules hit count** - The number of times a network rule has been hit.-- Unit: count --- **Data processed** - Sum of data traversing the firewall in a given time window.-- Unit: bytes --- **Throughput** - Rate of data traversing the firewall per second.-- Unit: bits per second --- **Firewall health state** - Indicates the health of the firewall based on SNAT port availability.-- Unit: percent -- This metric has two dimensions: - - Status: Possible values are *Healthy*, *Degraded*, *Unhealthy*. - - Reason: Indicates the reason for the corresponding status of the firewall. -- If SNAT ports are used > 95%, they're considered exhausted and the health is 50% with status=**Degraded** and reason=**SNAT port**. The firewall keeps processing traffic and existing connections aren't affected. However, new connections may not be established intermittently. -- If SNAT ports are used < 95%, then firewall is considered healthy and health is shown as 100%. -- If no SNAT ports usage is reported, health is shown as 0%. --- **SNAT port utilization** - The percentage of SNAT ports that have been utilized by the firewall.-- Unit: percent -- When you add more public IP addresses to your firewall, more SNAT ports are available, reducing the SNAT ports utilization. Additionally, when the firewall scales out for different reasons (for example, CPU or throughput) additional SNAT ports also become available. So effectively, a given percentage of SNAT ports utilization may go down without you adding any public IP addresses, just because the service scaled out. You can directly control the number of public IP addresses available to increase the ports available on your firewall. But, you can't directly control firewall scaling. -- If your firewall is running into SNAT port exhaustion, you should add at least five public IP address. This increases the number of SNAT ports available. For more information, see [Azure Firewall features](features.md#multiple-public-ip-addresses). --- **AZFW Latency Probe** - Estimates Azure Firewall average latency.-- Unit: ms -- This metric measures the overall or average latency of Azure Firewall in milliseconds. Administrators can use this metric for the following purposes: -- - Diagnose if Azure Firewall is the cause of latency in the network -- - Monitor and alert if there are any latency or performance issues, so IT teams can proactively engage. -- - There may be various reasons that can cause high latency in Azure Firewall. For example, high CPU utilization, high throughput, or a possible networking issue. -- This metric doesn't measure end-to-end latency of a given network path. In other words, this latency health probe doesn't measure how much latency Azure Firewall adds. -- - When the latency metric isn't functioning as expected, a value of 0 appears in the metrics dashboard. - - As a reference, the average expected latency for a firewall is approximately 1 ms. This may vary depending on deployment size and environment. - - The latency probe is based on Microsoft's Ping Mesh technology. So, intermittent spikes in the latency metric are to be expected. These spikes are normal and don't signal an issue with the Azure Firewall. They're part of the standard host networking setup that supports the system. - - As a result, if you experience consistent high latency that last longer than typical spikes, consider filing a Support ticket for assistance. -- :::image type="content" source="media/metrics/latency-probe.png" alt-text="Screenshot showing the Azure Firewall Latency Probe metric."::: --## Alert on Azure Firewall metrics --Metrics provide critical signals to track your resource health. So, itΓÇÖs important to monitor metrics for your resource and watch out for any anomalies. But what if the Azure Firewall metrics stop flowing? It could indicate a potential configuration issue or something more ominous like an outage. Missing metrics can happen because of publishing default routes that block Azure Firewall from uploading metrics, or the number of healthy instances going down to zero. In this section, you'll learn how to configure metrics to a log analytics workspace and to alert on missing metrics. --### Configure metrics to a log analytics workspace --The first step is to configure metrics availability to the log analytics workspace using diagnostics settings in the firewall. --Browse to the Azure Firewall resource page to configure diagnostic settings as shown in the following screenshot. This pushes firewall metrics to the configured workspace. -->[!Note] -> The diagnostics settings for metrics must be a separate configuration than logs. Firewall logs can be configured to use Azure Diagnostics or Resource Specific. However, Firewall metrics must always use Azure Diagnostics. ---### Create alert to track receiving firewall metrics without any failures --Browse to the workspace configured in the metrics diagnostics settings. Check if metrics are available using the following query: --``` -AzureMetrics --| where MetricName contains "FirewallHealth" -| where ResourceId contains "/SUBSCRIPTIONS/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX/RESOURCEGROUPS/PARALLELIPGROUPRG/PROVIDERS/MICROSOFT.NETWORK/AZUREFIREWALLS/HUBVNET-FIREWALL" -| where TimeGenerated > ago(30m) -``` --Next, create an alert for missing metrics over a time period of 60 minutes. Browse to the Alert page in the log analytics workspace to setup new alerts on missing metrics. ---## Next steps --- [Azure Firewall diagnostic logs (legacy)](diagnostic-logs.md)- |
| firewall | Monitor Firewall Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/firewall/monitor-firewall-reference.md | + + Title: Monitoring data reference for Azure Firewall +description: This article contains important reference material you need when you monitor Azure Firewall by using Azure Monitor. Last updated : 08/08/2024+++++++# Azure Firewall monitoring data reference +++See [Monitor Azure Firewall](monitor-firewall.md) for details on the data you can collect for Azure Firewall and how to use it. +++### Supported metrics for Microsoft.Network/azureFirewalls ++The following table lists the metrics available for the Microsoft.Network/azureFirewalls resource type. ++++### Firewall health state ++In the preceding table, the *Firewall health state* metric has two dimensions: ++- Status: Possible values are *Healthy*, *Degraded*, *Unhealthy*. +- Reason: Indicates the reason for the corresponding status of the firewall. ++If SNAT ports are used more than 95%, they're considered exhausted and the health is 50% with status=*Degraded* and reason=*SNAT port*. The firewall keeps processing traffic and existing connections aren't affected. However, new connections might not be established intermittently. ++If SNAT ports are used less than 95%, then firewall is considered healthy and health is shown as 100%. ++If no SNAT ports usage is reported, health is shown as 0%. ++#### SNAT port utilization ++For the *SNAT port utilization* metric, when you add more public IP addresses to your firewall, more SNAT ports are available, reducing the SNAT ports utilization. Additionally, when the firewall scales out for different reasons (for example, CPU or throughput) more SNAT ports also become available. ++Effectively, a given percentage of SNAT ports utilization might go down without you adding any public IP addresses, just because the service scaled out. You can directly control the number of public IP addresses available to increase the ports available on your firewall. But, you can't directly control firewall scaling. ++If your firewall is running into SNAT port exhaustion, you should add at least five public IP address. This increases the number of SNAT ports available. For more information, see [Azure Firewall features](features.md#multiple-public-ip-addresses). ++#### AZFW Latency Probe ++The *AZFW Latency Probe* metric measures the overall or average latency of Azure Firewall in milliseconds. Administrators can use this metric for the following purposes: ++- Diagnose if Azure Firewall is the cause of latency in the network +- Monitor and alert if there are any latency or performance issues, so IT teams can proactively engage. +- There might be various reasons that can cause high latency in Azure Firewall. For example, high CPU utilization, high throughput, or a possible networking issue. ++ This metric doesn't measure end-to-end latency of a given network path. In other words, this latency health probe doesn't measure how much latency Azure Firewall adds. ++- When the latency metric isn't functioning as expected, a value of 0 appears in the metrics dashboard. +- As a reference, the average expected latency for a firewall is approximately 1 ms. This value might vary depending on deployment size and environment. +- The latency probe is based on Microsoft's Ping Mesh technology. So, intermittent spikes in the latency metric are to be expected. These spikes are normal and don't signal an issue with the Azure Firewall. They're part of the standard host networking setup that supports the system. ++ As a result, if you experience consistent high latency that last longer than typical spikes, consider filing a Support ticket for assistance. ++ :::image type="content" source="media/metrics/latency-probe.png" alt-text="Screenshot showing the Azure Firewall Latency Probe metric."::: ++++- Protocol +- Reason +- Status +++### Supported resource logs for Microsoft.Network/azureFirewalls +++Azure Firewall has two new diagnostics logs you can use to help monitor your firewall: ++- Top flows +- Flow trace ++## Top flows ++The top flows log is known in the industry as *fat flow log* and in the preceding table as *Azure Firewall Fat Flow Log*. The top flows log shows the top connections that are contributing to the highest throughput through the firewall. ++> [!TIP] +> Activate Top flows logs only when troubleshooting a specific issue to avoid excessive CPU usage of Azure Firewall. +> ++The flow rate is defined as the data transmission rate in megabits per second units. It's a measure of the amount of digital data that can be transmitted over a network in a period of time through the firewall. The Top Flows protocol runs periodically every three minutes. The minimum threshold to be considered a Top Flow is 1 Mbps. ++Enable the Top flows log using the following Azure PowerShell commands: ++```powershell +Set-AzContext -SubscriptionName <SubscriptionName> +$firewall = Get-AzFirewall -ResourceGroupName <ResourceGroupName> -Name <FirewallName> +$firewall.EnableFatFlowLogging = $true +Set-AzFirewall -AzureFirewall $firewall +``` ++To disable the logs, use the same previous Azure PowerShell command and set the value to *False*. ++For example: ++```powershell +Set-AzContext -SubscriptionName <SubscriptionName> +$firewall = Get-AzFirewall -ResourceGroupName <ResourceGroupName> -Name <FirewallName> +$firewall.EnableFatFlowLogging = $false +Set-AzFirewall -AzureFirewall $firewall +``` ++There are a few ways to verify the update was successful, but you can navigate to firewall **Overview** and select **JSON view** on the top right corner. HereΓÇÖs an example: +++To create a diagnostic setting and enable Resource Specific Table, see [Create diagnostic settings in Azure Monitor](/azure/azure-monitor/essentials/create-diagnostic-settings). ++The firewall logs show traffic through the firewall in the first attempt of a TCP connection, known as the *SYN* packet. However, such an entry doesn't show the full journey of the packet in the TCP handshake. As a result, it's difficult to troubleshoot if a packet is dropped, or asymmetric routing occurred. The Azure Firewall Flow Trace Log addresses this concern. ++> [!TIP] +> To avoid excessive disk usage caused by Flow trace logs in Azure Firewall with many short-lived connections, activate the logs only when troubleshooting a specific issue for diagnostic purposes. ++The following properties can be added: ++- SYN-ACK: ACK flag that indicates acknowledgment of SYN packet. +- FIN: Finished flag of the original packet flow. No more data is transmitted in the TCP flow. +- FIN-ACK: ACK flag that indicates acknowledgment of FIN packet. +- RST: The Reset the flag indicates the original sender doesn't receive more data. +- INVALID (flows): Indicates packet canΓÇÖt be identified or don't have any state. ++ For example: ++ - A TCP packet lands on a Virtual Machine Scale Sets instance, which doesn't have any prior history for this packet + - Bad CheckSum packets + - Connection Tracking table entry is full and new connections can't be accepted + - Overly delayed ACK packets ++Enable the Flow trace log using the following Azure PowerShell commands or navigate in the portal and search for **Enable TCP Connection Logging**: ++```powershell +Connect-AzAccount +Select-AzSubscription -Subscription <subscription_id> or <subscription_name> +Register-AzProviderFeature -FeatureName AFWEnableTcpConnectionLogging -ProviderNamespace Microsoft.Network +Register-AzResourceProvider -ProviderNamespace Microsoft.Network +``` ++It can take several minutes for this change to take effect. Once the feature is registered, consider performing an update on Azure Firewall for the change to take effect immediately. ++To check the status of the AzResourceProvider registration, you can run the Azure PowerShell command: ++```powershell +Get-AzProviderFeature -FeatureName "AFWEnableTcpConnectionLogging" -ProviderNamespace "Microsoft.Network" +``` ++To disable the log, you can unregister it using the following command or select unregister in the previous portal example. ++```powershell +Unregister-AzProviderFeature -FeatureName AFWEnableTcpConnectionLogging -ProviderNamespace Microsoft.Network +``` ++To create a diagnostic setting and enable Resource Specific Table, see [Create diagnostic settings in Azure Monitor](/azure/azure-monitor/essentials/create-diagnostic-settings). +++### Azure Firewall Microsoft.Network/azureFirewalls ++- [AZFWNetworkRule](/azure/azure-monitor/reference/tables/azfwnetworkrule#columns) +- [AZFWFatFlow](/azure/azure-monitor/reference/tables/azfwfatflow#columns) +- [AZFWFlowTrace](/azure/azure-monitor/reference/tables/azfwflowtrace#columns) +- [AZFWApplicationRule](/azure/azure-monitor/reference/tables/azfwapplicationrule#columns) +- [AZFWThreatIntel](/azure/azure-monitor/reference/tables/azfwthreatintel#columns) +- [AZFWNatRule](/azure/azure-monitor/reference/tables/azfwnatrule#columns) +- [AZFWIdpsSignature](/azure/azure-monitor/reference/tables/azfwidpssignature#columns) +- [AZFWDnsQuery](/azure/azure-monitor/reference/tables/azfwdnsquery#columns) +- [AZFWInternalFqdnResolutionFailure](/azure/azure-monitor/reference/tables/azfwinternalfqdnresolutionfailure#columns) +- [AZFWNetworkRuleAggregation](/azure/azure-monitor/reference/tables/azfwnetworkruleaggregation#columns) +- [AZFWApplicationRuleAggregation](/azure/azure-monitor/reference/tables/azfwapplicationruleaggregation#columns) +- [AZFWNatRuleAggregation](/azure/azure-monitor/reference/tables/azfwnatruleaggregation#columns) +- [AzureActivity](/azure/azure-monitor/reference/tables/azureactivity#columns) +- [AzureMetrics](/azure/azure-monitor/reference/tables/azuremetrics#columns) +- [AzureDiagnostics](/azure/azure-monitor/reference/tables/azurediagnostics#columns) +++- [Networking resource provider operations](/azure/role-based-access-control/resource-provider-operations#microsoftnetwork) ++## Related content ++- See [Monitor Azure Firewall](monitor-firewall.md) for a description of monitoring Azure Firewall. +- See [Monitor Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) for details on monitoring Azure resources. |
| firewall | Monitor Firewall | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/firewall/monitor-firewall.md | + + Title: Monitor Azure Firewall +description: You can monitor Azure Firewall using firewall logs. You can also use activity logs to audit operations on Azure Firewall resources. Last updated : 08/08/2024+++++++# Monitor Azure Firewall +++You can use Azure Firewall logs and metrics to monitor your traffic and operations within the firewall. These logs and metrics serve several essential purposes, including: ++- **Traffic Analysis**: Use logs to examine and analyze the traffic passing through the firewall. This analysis includes examining permitted and denied traffic, inspecting source and destination IP addresses, URLs, port numbers, protocols, and more. These insights are essential for understanding traffic patterns, identifying potential security threats, and troubleshooting connectivity issues. ++- **Performance and Health Metrics**: Azure Firewall metrics provide performance and health metrics, such as data processed, throughput, rule hit count, and latency. Monitor these metrics to assess the overall health of your firewall, identify performance bottlenecks, and detect any anomalies. ++- **Audit Trail**: Activity logs enable auditing of operations related to firewall resources, capturing actions like creating, updating, or deleting firewall rules and policies. Reviewing activity logs helps maintain a historical record of configuration changes and ensures compliance with security and auditing requirements. +++For more information about the resource types for Azure Firewall, see [Azure Firewall monitoring data reference](monitor-firewall-reference.md). ++++For a list of available metrics for Azure Firewall, see [Azure Firewall monitoring data reference](monitor-firewall-reference.md#metrics). +++For the available resource log categories, their associated Log Analytics tables, and the log schemas for Azure Firewall, see [Azure Firewall monitoring data reference](monitor-firewall-reference.md#resource-logs). ++[Azure Firewall Workbook](firewall-workbook.md) provides a flexible canvas for Azure Firewall data analysis. You can use it to create rich visual reports within the Azure portal. You can tap into multiple Firewalls deployed across Azure, and combine them into unified interactive experiences. ++You can also connect to your storage account and retrieve the JSON log entries for access and performance logs. After you download the JSON files, you can convert them to CSV and view them in Excel, Power BI, or any other data-visualization tool. ++> [!TIP] +> If you are familiar with Visual Studio and basic concepts of changing values for constants and variables in C#, you can use the [log converter tools](https://github.com/Azure-Samples/networking-dotnet-log-converter) available from GitHub. +++## Structured Azure Firewall logs ++Structured logs are a type of log data that are organized in a specific format. They use a predefined schema to structure log data in a way that makes it easy to search, filter, and analyze. Unlike unstructured logs, which consist of free-form text, structured logs have a consistent format that machines can parse and analyze. ++Azure Firewall's structured logs provide a more detailed view of firewall events. They include information such as source and destination IP addresses, protocols, port numbers, and action taken by the firewall. They also include more metadata, such as the time of the event and the name of the Azure Firewall instance. ++Currently, the following diagnostic log categories are available for Azure Firewall: ++- Application rule log +- Network rule log +- DNS proxy log ++These log categories use [Azure diagnostics mode](/azure/azure-monitor/essentials/resource-logs#azure-diagnostics-mode). In this mode, all data from any diagnostic setting is collected in the [AzureDiagnostics](/azure/azure-monitor/reference/tables/azurediagnostics) table. ++With structured logs, you're able to choose to use [Resource Specific Tables](/azure/azure-monitor/essentials/resource-logs#resource-specific) instead of the existing [AzureDiagnostics](/azure/azure-monitor/reference/tables/azurediagnostics) table. In case both sets of logs are required, at least two diagnostic settings need to be created per firewall. ++### Resource specific mode ++In **Resource specific** mode, individual tables in the selected workspace are created for each category selected in the diagnostic setting. This method is recommended since it: ++- might reduce overall logging costs by up to 80%. +- makes it much easier to work with the data in log queries. +- makes it easier to discover schemas and their structure. +- improves performance across both ingestion latency and query times. +- allows you to grant Azure RBAC rights on a specific table. ++New resource specific tables are now available in Diagnostic setting that allows you to utilize the following categories: ++- [Network rule log](/azure/azure-monitor/reference/tables/azfwnetworkrule) - Contains all Network Rule log data. Each match between data plane and network rule creates a log entry with the data plane packet and the matched rule's attributes. +- [NAT rule log](/azure/azure-monitor/reference/tables/azfwnatrule) - Contains all DNAT (Destination Network Address Translation) events log data. Each match between data plane and DNAT rule creates a log entry with the data plane packet and the matched rule's attributes. +- [Application rule log](/azure/azure-monitor/reference/tables/azfwapplicationrule) - Contains all Application rule log data. Each match between data plane and Application rule creates a log entry with the data plane packet and the matched rule's attributes. +- [Threat Intelligence log](/azure/azure-monitor/reference/tables/azfwthreatintel) - Contains all Threat Intelligence events. +- [IDPS log](/azure/azure-monitor/reference/tables/azfwidpssignature) - Contains all data plane packets that were matched with one or more IDPS signatures. +- [DNS proxy log](/azure/azure-monitor/reference/tables/azfwdnsquery) - Contains all DNS Proxy events log data. +- [Internal FQDN resolve failure log](/azure/azure-monitor/reference/tables/azfwinternalfqdnresolutionfailure) - Contains all internal Firewall FQDN resolution requests that resulted in failure. +- [Application rule aggregation log](/azure/azure-monitor/reference/tables/azfwapplicationruleaggregation) - Contains aggregated Application rule log data for Policy Analytics. +- [Network rule aggregation log](/azure/azure-monitor/reference/tables/azfwnetworkruleaggregation) - Contains aggregated Network rule log data for Policy Analytics. +- [NAT rule aggregation log](/azure/azure-monitor/reference/tables/azfwnatruleaggregation) - Contains aggregated NAT rule log data for Policy Analytics. +- [Top flow log](/azure/azure-monitor/reference/tables/azfwfatflow) - The Top Flows (Fat Flows) log shows the top connections that are contributing to the highest throughput through the firewall. +- [Flow trace](/azure/azure-monitor/reference/tables/azfwflowtrace) - Contains flow information, flags, and the time period when the flows were recorded. You can see full flow information such as SYN, SYN-ACK, FIN, FIN-ACK, RST, INVALID (flows). ++### Enable structured logs ++To enable Azure Firewall structured logs, you must first configure a Log Analytics workspace in your Azure subscription. This workspace is used to store the structured logs generated by Azure Firewall. ++Once you configure the Log Analytics workspace, you can enable structured logs in Azure Firewall by navigating to the Firewall's **Diagnostic settings** page in the Azure portal. From there, you must select the **Resource specific** destination table and select the type of events you want to log. ++> [!NOTE] +> There's no requirement to enable this feature with a feature flag or Azure PowerShell commands. +++### Structured log queries ++A list of predefined queries is available in the Azure portal. This list has a predefined KQL (Kusto Query Language) log query for each category and joined query showing the entire Azure firewall logging events in single view. +++### Azure Firewall Workbook ++[Azure Firewall Workbook](firewall-workbook.md) provides a flexible canvas for Azure Firewall data analysis. You can use it to create rich visual reports within the Azure portal. You can tap into multiple firewalls deployed across Azure and combine them into unified interactive experiences. ++To deploy the new workbook that uses Azure Firewall Structured Logs, see [Azure Monitor Workbook for Azure Firewall](https://github.com/Azure/Azure-Network-Security/tree/master/Azure%20Firewall/Workbook%20-%20Azure%20Firewall%20Monitor%20Workbook). ++## Legacy Azure Diagnostics logs ++Legacy Azure Diagnostic logs are the original Azure Firewall log queries that output log data in an unstructured or free-form text format. The Azure Firewall legacy log categories use [Azure diagnostics mode](/azure/azure-monitor/essentials/resource-logs#azure-diagnostics-mode), collecting entire data in the [AzureDiagnostics table](/azure/azure-monitor/reference/tables/azurediagnostics). In case both Structured and Diagnostic logs are required, at least two diagnostic settings need to be created per firewall. ++The following log categories are supported in Diagnostic logs: ++- Azure Firewall application rule +- Azure Firewall network rule +- Azure Firewall DNS proxy ++To learn how to enable the diagnostic logging using the Azure portal, see [Enable structured logs](#enable-structured-logs). ++### Application rule log ++The Application rule log is saved to a storage account, streamed to Event hubs and/or sent to Azure Monitor logs only if you enable it for each Azure Firewall. Each new connection that matches one of your configured application rules results in a log for the accepted/denied connection. The data is logged in JSON format, as shown in the following examples: ++ ```console + Category: application rule logs. + Time: log timestamp. + Properties: currently contains the full message. + note: this field will be parsed to specific fields in the future, while maintaining backward compatibility with the existing properties field. + ``` ++ ```json + { + "category": "AzureFirewallApplicationRule", + "time": "2018-04-16T23:45:04.8295030Z", + "resourceId": "/SUBSCRIPTIONS/{subscriptionId}/RESOURCEGROUPS/{resourceGroupName}/PROVIDERS/MICROSOFT.NETWORK/AZUREFIREWALLS/{resourceName}", + "operationName": "AzureFirewallApplicationRuleLog", + "properties": { + "msg": "HTTPS request from 10.1.0.5:55640 to mydestination.com:443. Action: Allow. Rule Collection: collection1000. Rule: rule1002" + } + } + ``` ++ ```json + { + "category": "AzureFirewallApplicationRule", + "time": "2018-04-16T23:45:04.8295030Z", + "resourceId": "/SUBSCRIPTIONS/{subscriptionId}/RESOURCEGROUPS/{resourceGroupName}/PROVIDERS/MICROSOFT.NETWORK/AZUREFIREWALLS/{resourceName}", + "operationName": "AzureFirewallApplicationRuleLog", + "properties": { + "msg": "HTTPS request from 10.11.2.4:53344 to www.bing.com:443. Action: Allow. Rule Collection: ExampleRuleCollection. Rule: ExampleRule. Web Category: SearchEnginesAndPortals" + } + } + ``` ++### Network rule log ++The Network rule log is saved to a storage account, streamed to Event hubs and/or sent to Azure Monitor logs only if you enable it for each Azure Firewall. Each new connection that matches one of your configured network rules results in a log for the accepted/denied connection. The data is logged in JSON format, as shown in the following example: ++ ```console + Category: network rule logs. + Time: log timestamp. + Properties: currently contains the full message. + note: this field will be parsed to specific fields in the future, while maintaining backward compatibility with the existing properties field. + ``` ++ ```json + { + "category": "AzureFirewallNetworkRule", + "time": "2018-06-14T23:44:11.0590400Z", + "resourceId": "/SUBSCRIPTIONS/{subscriptionId}/RESOURCEGROUPS/{resourceGroupName}/PROVIDERS/MICROSOFT.NETWORK/AZUREFIREWALLS/{resourceName}", + "operationName": "AzureFirewallNetworkRuleLog", + "properties": { + "msg": "TCP request from 111.35.136.173:12518 to 13.78.143.217:2323. Action: Deny" + } + } ++ ``` ++### DNS proxy log ++The DNS proxy log is saved to a storage account, streamed to Event hubs, and/or sent to Azure Monitor logs only if you enable it for each Azure Firewall. This log tracks DNS messages to a DNS server configured using DNS proxy. The data is logged in JSON format, as shown in the following examples: ++ ```console + Category: DNS proxy logs. + Time: log timestamp. + Properties: currently contains the full message. + note: this field will be parsed to specific fields in the future, while maintaining backward compatibility with the existing properties field. + ``` ++ Success: ++ ```json + { + "category": "AzureFirewallDnsProxy", + "time": "2020-09-02T19:12:33.751Z", + "resourceId": "/SUBSCRIPTIONS/{subscriptionId}/RESOURCEGROUPS/{resourceGroupName}/PROVIDERS/MICROSOFT.NETWORK/AZUREFIREWALLS/{resourceName}", + "operationName": "AzureFirewallDnsProxyLog", + "properties": { + "msg": "DNS Request: 11.5.0.7:48197 ΓÇô 15676 AAA IN md-l1l1pg5lcmkq.blob.core.windows.net. udp 55 false 512 NOERROR - 0 2.000301956s" + } + } + ``` ++ Failed: ++ ```json + { + "category": "AzureFirewallDnsProxy", + "time": "2020-09-02T19:12:33.751Z", + "resourceId": "/SUBSCRIPTIONS/{subscriptionId}/RESOURCEGROUPS/{resourceGroupName}/PROVIDERS/MICROSOFT.NETWORK/AZUREFIREWALLS/{resourceName}", + "operationName": "AzureFirewallDnsProxyLog", + "properties": { + "msg": " Error: 2 time.windows.com.reddog.microsoft.com. A: read udp 10.0.1.5:49126->168.63.129.160:53: i/o timeoutΓÇ¥ + } + } + ``` ++ Message format: ++ ```console + [clientΓÇÖs IP address]:[clientΓÇÖs port] ΓÇô [query ID] [type of the request] [class of the request] [name of the request] [protocol used] [request size in bytes] [EDNS0 DO (DNSSEC OK) bit set in the query] [EDNS0 buffer size advertised in the query] [response CODE] [response flags] [response size] [response duration] + ``` ++++++## Alert on Azure Firewall metrics ++Metrics provide critical signals to track your resource health. So, itΓÇÖs important to monitor metrics for your resource and watch out for any anomalies. But what if the Azure Firewall metrics stop flowing? It could indicate a potential configuration issue or something more ominous like an outage. Missing metrics can happen because of publishing default routes that block Azure Firewall from uploading metrics, or the number of healthy instances going down to zero. In this section, you learn how to configure metrics to a log analytics workspace and to alert on missing metrics. ++### Configure metrics to a log analytics workspace ++The first step is to configure metrics availability to the log analytics workspace using diagnostics settings in the firewall. ++ To configure diagnostic settings as shown in the following screenshot, browse to the Azure Firewall resource page. This pushes firewall metrics to the configured workspace. ++> [!NOTE] +> The diagnostics settings for metrics must be a separate configuration than logs. Firewall logs can be configured to use Azure Diagnostics or Resource Specific. However, Firewall metrics must always use Azure Diagnostics. +++### Create alert to track receiving firewall metrics without any failures ++Browse to the workspace configured in the metrics diagnostics settings. Check if metrics are available using the following query: ++```kusto +AzureMetrics +| where MetricName contains "FirewallHealth" +| where ResourceId contains "/SUBSCRIPTIONS/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX/RESOURCEGROUPS/PARALLELIPGROUPRG/PROVIDERS/MICROSOFT.NETWORK/AZUREFIREWALLS/HUBVNET-FIREWALL" +| where TimeGenerated > ago(30m) +``` ++Next, create an alert for missing metrics over a time period of 60 minutes. To set up new alerts on missing metrics, browse to the Alert page in the log analytics workspace. +++### Azure Firewall alert rules ++You can set alerts for any metric, log entry, or activity log entry listed in the [Azure Firewall monitoring data reference](monitor-firewall-reference.md). +++## Related content ++- See [Azure Firewall monitoring data reference](monitor-firewall-reference.md) for a reference of the metrics, logs, and other important values created for Azure Firewall. +- See [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) for general details on monitoring Azure resources. |
| frontdoor | Front Door Diagnostics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/frontdoor/front-door-diagnostics.md | zone_pivot_groups: front-door-tiers Azure Front Door provides several features to help you monitor your application, track requests, and debug your Front Door configuration. -Logs and metrics get stored and managed by [Azure Monitor](../azure-monitor/overview.md). +Logs and metrics get stored and managed by [Azure Monitor](/azure/azure-monitor/overview). ::: zone pivot="front-door-standard-premium" Logs and metrics get stored and managed by [Azure Monitor](../azure-monitor/over ## Metrics -Azure Front Door measures and sends its metrics in 60-second intervals. The metrics can take up to 3 minutes to get processed by Azure Monitor, and they might not appear until processing is completed. Metrics can also be displayed in charts or grids, and are accessible through the Azure portal, Azure PowerShell, the Azure CLI, and the Azure Monitor APIs. For more information, seeΓÇ»[Azure Monitor metrics](../azure-monitor/essentials/data-platform-metrics.md). +Azure Front Door measures and sends its metrics in 60-second intervals. The metrics can take up to 3 minutes to get processed by Azure Monitor, and they might not appear until processing is completed. Metrics can also be displayed in charts or grids, and are accessible through the Azure portal, Azure PowerShell, the Azure CLI, and the Azure Monitor APIs. For more information, seeΓÇ»[Azure Monitor metrics](/azure/azure-monitor/essentials/data-platform-metrics). The metrics listed in the following table are recorded and stored free of charge for a limited period of time. For an extra cost, you can store for a longer period of time. Access activity logs in your Front Door or all the logs of your Azure resources Diagnostic logs provide rich information about operations and errors that are important for auditing and troubleshooting. Diagnostic logs differ from activity logs. -Activity logs provide insights into the operations done on Azure resources. Diagnostic logs provide insight into operations that your resource has done. For more information, see [Azure Monitor diagnostic logs](../azure-monitor/essentials/platform-logs-overview.md). +Activity logs provide insights into the operations done on Azure resources. Diagnostic logs provide insight into operations that your resource has done. For more information, see [Azure Monitor diagnostic logs](/azure/azure-monitor/essentials/platform-logs-overview). :::image type="content" source="./media/front-door-diagnostics/diagnostic-log.png" alt-text="Diagnostic logs"::: |
| frontdoor | How To Monitor Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/frontdoor/standard-premium/how-to-monitor-metrics.md | -You can also configure alerts for each metric such as a threshold for 4XXErrorRate or 5XXErrorRate. When the error rate exceeds the threshold, it triggers an alert as configured. For more information, see [Create, view, and manage metric alerts using Azure Monitor](../../azure-monitor/alerts/alerts-metric.md). +You can also configure alerts for each metric such as a threshold for 4XXErrorRate or 5XXErrorRate. When the error rate exceeds the threshold, it triggers an alert as configured. For more information, see [Create, view, and manage metric alerts using Azure Monitor](/azure/azure-monitor/alerts/alerts-metric). ## Access metrics in the Azure portal You can also configure alerts for each metric such as a threshold for 4XXErrorRa 1. Select **New alert rule** for metrics listed in Metrics section. -Alert is charged based on Azure Monitor. For more information about alerts, see [Azure Monitor alerts](../../azure-monitor/alerts/alerts-overview.md). +Alert is charged based on Azure Monitor. For more information about alerts, see [Azure Monitor alerts](/azure/azure-monitor/alerts/alerts-overview). ## Next steps |
| governance | Index | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/blueprints/samples/azure-security-benchmark-foundation/index.md | management jump boxes. This blueprint deploys several Azure services to provide a secure, monitored, enterprise-ready foundation. This environment is composed of: -- [Azure Monitor Logs](../../../../azure-monitor/logs/data-platform-logs.md)+- [Azure Monitor Logs](/azure/azure-monitor/logs/data-platform-logs) and an Azure storage account to ensure resource logs, activity logs, metrics, and networks traffic flows are stored in a central location for easy querying, analytics, archival, and alerting. - [Azure Security Center](../../../../security-center/security-center-introduction.md) |
| governance | Index | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/blueprints/samples/caf-foundation/index.md | This implementation incorporates several Azure services used to provide a secure - An [Azure Key Vault](/azure/key-vault/general/overview) instance used to host secrets used for the VMs deployed in the shared services environment-- Deploy [Log Analytics](../../../../azure-monitor/overview.md) is deployed to ensure all actions+- Deploy [Log Analytics](/azure/azure-monitor/overview) is deployed to ensure all actions and services log to a central location from the moment you start your secure deployment in to [Storage Accounts](../../../../storage/common/storage-introduction.md) for diagnostic logging - Deploy [Microsoft Defender for Cloud](../../../../security-center/security-center-introduction.md) (standard |
| governance | Index | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/blueprints/samples/caf-migrate-landing-zone/index.md | This environment is composed of several Azure services used to provide a secure, enterprise-ready governance. This environment is composed of: - An [Azure Key Vault](/azure/key-vault/general/overview) instance used to host secrets used for the Certificates, Keys, and Secrets deployed in the shared services environment-- Deploy [Log Analytics](../../../../azure-monitor/overview.md) is deployed to ensure all actions and services log to a central location from the moment you start your migration+- Deploy [Log Analytics](/azure/azure-monitor/overview) is deployed to ensure all actions and services log to a central location from the moment you start your migration - Deploy [Azure Virtual Network](../../../../virtual-network/virtual-networks-overview.md) providing an isolated network and subnets for your virtual machine. - Deploy [Azure Migrate Project](../../../../migrate/migrate-services-overview.md) for discovery and assessment. We're adding the tools for Server assessment, Server migration, Database assessment, and Database migration. |
| governance | Canada Federal Pbmm | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/blueprints/samples/canada-federal-pbmm.md | The following table provides a list of the blueprint artifact parameters: |Artifact name|Artifact type|Parameter name|Description| |-|-|-|-|-|\[Preview\]: Deploy Log Analytics Agent for Linux VMs |Policy assignment |Log Analytics workspace for Linux VMs |For more information, see [Create a Log Analytics workspace in the Azure portal](../../../azure-monitor/logs/quick-create-workspace.md). | +|\[Preview\]: Deploy Log Analytics Agent for Linux VMs |Policy assignment |Log Analytics workspace for Linux VMs |For more information, see [Create a Log Analytics workspace in the Azure portal](/azure/azure-monitor/logs/quick-create-workspace). | |\[Preview\]: Deploy Log Analytics Agent for Linux VMs |Policy assignment |Optional: List of VM images that have supported Linux OS to add to scope |An empty array may be used to indicate no optional parameters: `[]` | |\[Preview\]: Deploy Log Analytics Agent for Windows VMs |Policy assignment |Optional: List of VM images that have supported Windows OS to add to scope |An empty array may be used to indicate no optional parameters: `[]` |-|\[Preview\]: Deploy Log Analytics Agent for Windows VMs |Policy assignment |Log Analytics workspace for Windows VMs |For more information, see [Create a Log Analytics workspace in the Azure portal](../../../azure-monitor/logs/quick-create-workspace.md). | +|\[Preview\]: Deploy Log Analytics Agent for Windows VMs |Policy assignment |Log Analytics workspace for Windows VMs |For more information, see [Create a Log Analytics workspace in the Azure portal](/azure/azure-monitor/logs/quick-create-workspace). | |\[Preview\]: Audit Canada Federal PBMM controls and deploy specific VM Extensions to support audit requirements |Policy assignment |Log Analytics workspace ID that VMs should be configured for |This is the ID (GUID) of the Log Analytics workspace that the VMs should be configured for. |-|\[Preview\]: Audit Canada Federal PBMM controls and deploy specific VM Extensions to support audit requirements |Policy assignment |List of resource types that should have diagnostic logs enabled |List of resource types to audit if diagnostic log setting isn't enabled. Acceptable values can be found at [Azure Monitor diagnostic logs schemas](../../../azure-monitor/essentials/resource-logs-schema.md#service-specific-schemas). | +|\[Preview\]: Audit Canada Federal PBMM controls and deploy specific VM Extensions to support audit requirements |Policy assignment |List of resource types that should have diagnostic logs enabled |List of resource types to audit if diagnostic log setting isn't enabled. Acceptable values can be found at [Azure Monitor diagnostic logs schemas](/azure/azure-monitor/essentials/resource-logs-schema#service-specific-schemas). | |\[Preview\]: Audit Canada Federal PBMM controls and deploy specific VM Extensions to support audit requirements |Policy assignment |Administrators group |Group. Example: `Administrator; myUser1; myUser2` | |\[Preview\]: Audit Canada Federal PBMM controls and deploy specific VM Extensions to support audit requirements |Policy assignment |List of users that should be included in Windows VM Administrators group |A semicolon-separated list of members that should be included in the Administrators local group. Example: `Administrator; myUser1; myUser2` | |Deploy Advanced Threat Protection on Storage Accounts |Policy assignment |Effect |Information about policy effects can be found at [Understand Azure Policy Effects](../../policy/concepts/effects.md). | |
| governance | Deploy | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/blueprints/samples/ism-protected/deploy.md | The following table provides a list of the blueprint artifact parameters: |Artifact name|Artifact type|Parameter name|Description| |-|-|-|-| |\[Preview\]: Audit Australian Government ISM PROTECTED controls and deploy specific VM Extensions to support audit requirements|Policy assignment|Log Analytics workspace ID that VMs should be configured for|This is the ID (GUID) of the Log Analytics workspace that the VMs should be configured for.|-|\[Preview\]: Audit Australian Government ISM PROTECTED controls and deploy specific VM Extensions to support audit requirements|Policy assignment|List of resource types that should have diagnostic logs enabled|List of resource types to audit if diagnostic log setting is not enabled. Acceptable values can be found at [Azure Monitor resource logs categories](../../../../azure-monitor/essentials/resource-logs-categories.md#supported-log-categories-per-resource-type).| +|\[Preview\]: Audit Australian Government ISM PROTECTED controls and deploy specific VM Extensions to support audit requirements|Policy assignment|List of resource types that should have diagnostic logs enabled|List of resource types to audit if diagnostic log setting is not enabled. Acceptable values can be found at [Azure Monitor resource logs categories](/azure/azure-monitor/essentials/resource-logs-categories#supported-log-categories-per-resource-type).| |\[Preview\]: Audit Australian Government ISM PROTECTED controls and deploy specific VM Extensions to support audit requirements|Policy assignment|List of users that should be excluded from Windows VM Administrators group|A semicolon-separated list of members that should be excluded in the Administrators local group. Ex: Administrator; myUser1; myUser2| |\[Preview\]: Audit Australian Government ISM PROTECTED controls and deploy specific VM Extensions to support audit requirements|Policy assignment|List of users that should be included in Windows VM Administrators group|A semicolon-separated list of members that should be included in the Administrators local group. Ex: Administrator; myUser1; myUser2| |\[Preview\]: Deploy Log Analytics Agent for Linux VM Scale Sets (VMSS)|Policy assignment|Log Analytics workspace for Linux VM Scale Sets (VMSS)|If this workspace is outside of the scope of the assignment you must manually grant 'Log Analytics Contributor' permissions (or similar) to the policy assignment's principal ID.| The following table provides a list of the blueprint artifact parameters: |\[Preview\]: Audit Australian Government ISM PROTECTED controls and deploy specific VM Extensions to support audit requirements|Policy assignment|Function App should only be accessible over HTTPS v2 |Information about policy effects can be found at [Understand Azure Policy Effects](../../../policy/concepts/effects.md).| |\[Preview\]: Audit Australian Government ISM PROTECTED controls and deploy specific VM Extensions to support audit requirements|Policy assignment|Vulnerabilities should be remediated by a Vulnerability Assessment solution |Information about policy effects can be found at [Understand Azure Policy Effects](../../../policy/concepts/effects.md).| |\[Preview\]: Audit Australian Government ISM PROTECTED controls and deploy specific VM Extensions to support audit requirements|Policy assignment|Azure subscriptions should have a log profile for Activity Log |Information about policy effects can be found at [Understand Azure Policy Effects](../../../policy/concepts/effects.md).|-|\[Preview\]: Audit Australian Government ISM PROTECTED controls and deploy specific VM Extensions to support audit requirements|Policy assignment|List of resource types that should have diagnostic logs enabled|List of resource types to audit if diagnostic log setting is not enabled. Acceptable values can be found at [Azure Monitor resource logs categories](../../../../azure-monitor/essentials/resource-logs-categories.md#supported-log-categories-per-resource-type).| +|\[Preview\]: Audit Australian Government ISM PROTECTED controls and deploy specific VM Extensions to support audit requirements|Policy assignment|List of resource types that should have diagnostic logs enabled|List of resource types to audit if diagnostic log setting is not enabled. Acceptable values can be found at [Azure Monitor resource logs categories](/azure/azure-monitor/essentials/resource-logs-categories#supported-log-categories-per-resource-type).| |\[Preview\]: Audit Australian Government ISM PROTECTED controls and deploy specific VM Extensions to support audit requirements|Policy assignment|System updates should be installed on your machines|Information about policy effects can be found at [Understand Azure Policy Effects](../../../policy/concepts/effects.md).| |\[Preview\]: Audit Australian Government ISM PROTECTED controls and deploy specific VM Extensions to support audit requirements|Policy assignment|Latest TLS version should be used for App Service|Information about policy effects can be found at [Understand Azure Policy Effects](../../../policy/concepts/effects.md).| |\[Preview\]: Audit Australian Government ISM PROTECTED controls and deploy specific VM Extensions to support audit requirements|Policy assignment|MFA should be enabled accounts with write permissions on your subscription|Information about policy effects can be found at [Understand Azure Policy Effects](../../../policy/concepts/effects.md).| |
| governance | Iso 27001 2013 | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/blueprints/samples/iso-27001-2013.md | The following table provides a list of the blueprint artifact parameters: |\[Preview\]: Deploy Log Analytics Agent for Windows VMs|Policy assignment|Optional: List of VM images that have supported Windows OS to add to scope|An empty array may be used to indicate no optional parameters: \[\]| |Allowed storage account SKUs|Policy assignment|List of allowed storage SKUs|The list of SKUs that can be specified for storage accounts.| |Allowed virtual machine SKUs|Policy assignment|List of allowed virtual machine SKUs|The list of SKUs that can be specified for virtual machines.|-|Blueprint initiative for ISO 27001|Policy assignment|List of resource types that should have diagnostic logs enabled|List of resource types to audit if diagnostic log setting is not enabled. Acceptable values can be found at [Azure Monitor diagnostic logs schemas](../../../azure-monitor/essentials/resource-logs-schema.md#service-specific-schemas).| +|Blueprint initiative for ISO 27001|Policy assignment|List of resource types that should have diagnostic logs enabled|List of resource types to audit if diagnostic log setting is not enabled. Acceptable values can be found at [Azure Monitor diagnostic logs schemas](/azure/azure-monitor/essentials/resource-logs-schema#service-specific-schemas).| ## Next steps |
| governance | Deploy | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/blueprints/samples/iso27001-shared/deploy.md | The following table provides a list of the blueprint artifact parameters: |Allowed resource types|Policy assignment|Allowed resource types|List of resource types allowed to be deployed. This list is composed of all the resource types deployed in Shared Services.| |Allowed storage account SKUs|Policy assignment|Allowed storage SKUs|List of diagnostic logs storage account SKUs allowed. Default value is _["Standard_LRS"]_.| |Allowed virtual machine SKUs|Policy assignment|List of virtual machine SKUs allowed to be deployed. Default value is _["Standard_DS1_v2", "Standard_DS2_v2"]_.|-|Blueprint initiative for ISO 27001|Policy assignment|Resource types to audit diagnostic logs|List of resource types to audit if diagnostic log setting is not enabled. Acceptable values can be found at [Azure Monitor diagnostic logs schemas](../../../../azure-monitor/essentials/resource-logs-schema.md#service-specific-schemas).| +|Blueprint initiative for ISO 27001|Policy assignment|Resource types to audit diagnostic logs|List of resource types to audit if diagnostic log setting is not enabled. Acceptable values can be found at [Azure Monitor diagnostic logs schemas](/azure/azure-monitor/essentials/resource-logs-schema#service-specific-schemas).| |Log Analytics resource group|Resource group|Name|**Locked** - Concatenates the **Organization name** with `-sharedsvsc-log-rg` to make the resource group unique.| |Log Analytics resource group|Resource group|Location|**Locked** - Uses the blueprint parameter.| |Log Analytics template|Resource Manager template|Service tier|Sets the tier of the Log Analytics workspace. Default value is _PerNode_.| |
| governance | Index | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/blueprints/samples/iso27001-shared/index.md | composed of: [Azure Policy](../../../policy/overview.md) definitions, and other security-related rights - SysOps role has the necessary rights to define [Azure Policy](../../../policy/overview.md) definitions within the subscription, manage- [Log Analytics](../../../../azure-monitor/overview.md) for the entire environment, among other + [Log Analytics](/azure/azure-monitor/overview) for the entire environment, among other operational rights-- [Log Analytics](../../../../azure-monitor/overview.md) is deployed as the first Azure service to+- [Log Analytics](/azure/azure-monitor/overview) is deployed as the first Azure service to ensure all actions and services log to a central location from the moment you start your secure deployment - A virtual network supporting subnets for connectivity back to an on-premises datacenter, an |
| governance | Deploy | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/blueprints/samples/swift-2020/deploy.md | The following table provides a list of the blueprint artifact parameters: |Artifact name|Artifact type|Parameter name|Description| |-|-|-|-|-|\[Preview\]: Audit SWIFT CSP-CSCF v2020 controls and deploy specific VM Extensions to support audit requirements|Policy assignment|List of resource types that should have diagnostic logs enabled|List of resource types to audit if diagnostic log setting is not enabled. Acceptable values can be found at [Azure Monitor resource logs categories](../../../../azure-monitor/essentials/resource-logs-categories.md#supported-log-categories-per-resource-type).| +|\[Preview\]: Audit SWIFT CSP-CSCF v2020 controls and deploy specific VM Extensions to support audit requirements|Policy assignment|List of resource types that should have diagnostic logs enabled|List of resource types to audit if diagnostic log setting is not enabled. Acceptable values can be found at [Azure Monitor resource logs categories](/azure/azure-monitor/essentials/resource-logs-categories#supported-log-categories-per-resource-type).| |\[Preview\]: Audit SWIFT CSP-CSCF v2020 controls and deploy specific VM Extensions to support audit requirements|Policy assignment|Connected workspace IDs|A semicolon-separated list of the workspace IDs that the Log Analytics agent should be connected to| |\[Preview\]: Audit SWIFT CSP-CSCF v2020 controls and deploy specific VM Extensions to support audit requirements|Policy assignment|List of users that should be included in Windows VM Administrators group|A semicolon-separated list of members that should be included in the Administrators local group. Ex: Administrator; myUser1; myUser2| |\[Preview\]: Audit SWIFT CSP-CSCF v2020 controls and deploy specific VM Extensions to support audit requirements|Policy assignment|Domain Name (FQDN) |The fully qualified domain name (FQDN) that the Windows VMs should be joined to| |
| governance | Ukofficial Uknhs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/blueprints/samples/ukofficial-uknhs.md | The following table provides a list of the blueprint artifact parameters: |Artifact name|Artifact type|Parameter name|Description| |-|-|-|-|-|Blueprint initiative for UK OFFICIAL or UK NHS|Policy assignment |Resource types to audit diagnostic logs (Policy: Blueprint initiative for UK OFFICIAL or UK NHS) |List of resource types to audit if diagnostic log setting is note enabled. For acceptable values, see [Supported services, schemas, and categories for Azure Diagnostic Logs](../../../azure-monitor/essentials/resource-logs-schema.md). | -|\[Preview\]: Deploy Log Analytics Agent for Linux VMs |Policy assignment |Optional: List of VM images that have supported Linux OS to add to scope (Policy: \[Preview\]: Deploy Log Analytics Agent for Linux VMs) |(Optional) Default value is _none_. For more information, see [Create a Log Analytics workspace in the Azure portal](../../../azure-monitor/logs/quick-create-workspace.md). | -|\[Preview\]: Deploy Log Analytics Agent for Windows VMs |Policy assignment |Optional: List of VM images that have supported Windows OS to add to scope (Policy: \[Preview\]: Deploy Log Analytics Agent for Windows VMs) |(Optional) Default value is _none_. For more information, see [Create a Log Analytics workspace in the Azure portal](../../../azure-monitor/logs/quick-create-workspace.md). | +|Blueprint initiative for UK OFFICIAL or UK NHS|Policy assignment |Resource types to audit diagnostic logs (Policy: Blueprint initiative for UK OFFICIAL or UK NHS) |List of resource types to audit if diagnostic log setting is note enabled. For acceptable values, see [Supported services, schemas, and categories for Azure Diagnostic Logs](/azure/azure-monitor/essentials/resource-logs-schema). | +|\[Preview\]: Deploy Log Analytics Agent for Linux VMs |Policy assignment |Optional: List of VM images that have supported Linux OS to add to scope (Policy: \[Preview\]: Deploy Log Analytics Agent for Linux VMs) |(Optional) Default value is _none_. For more information, see [Create a Log Analytics workspace in the Azure portal](/azure/azure-monitor/logs/quick-create-workspace). | +|\[Preview\]: Deploy Log Analytics Agent for Windows VMs |Policy assignment |Optional: List of VM images that have supported Windows OS to add to scope (Policy: \[Preview\]: Deploy Log Analytics Agent for Windows VMs) |(Optional) Default value is _none_. For more information, see [Create a Log Analytics workspace in the Azure portal](/azure/azure-monitor/logs/quick-create-workspace). | ## Next steps |
| governance | Azure Management | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/management-groups/azure-management.md | content on the main Azure services intended to address them. Monitoring is the act of collecting and analyzing data to audit the performance, health, and availability of your resources. An effective monitoring strategy helps you understand the operation of components and to increase your uptime with notifications. Read an overview of Monitoring that-covers the different services used at [Monitoring Azure applications and resources](../../azure-monitor/overview.md). +covers the different services used at [Monitoring Azure applications and resources](/azure/azure-monitor/overview). ## Configure |
| governance | Manage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/management-groups/manage.md | az account management-group update --name 'Contoso' --parent ContosoIT ## Audit management groups by using activity logs -Management groups are supported in [Azure Monitor activity logs](../../azure-monitor/essentials/platform-logs-overview.md). You can query all +Management groups are supported in [Azure Monitor activity logs](/azure/azure-monitor/essentials/platform-logs-overview). You can query all events that happen to a management group in the same central location as other Azure resources. For example, you can see all role assignments or policy assignment changes made to a particular management group. |
| governance | Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/management-groups/overview.md | Owner role for the subscription, you can move it to any management group where y ## Auditing management groups by using activity logs -Management groups are supported in [Azure Monitor activity logs](../../azure-monitor/essentials/platform-logs-overview.md). You can query all +Management groups are supported in [Azure Monitor activity logs](/azure/azure-monitor/essentials/platform-logs-overview). You can query all events that happen to a management group in the same central location as other Azure resources. For example, you can see all role assignments or policy assignment changes made to a particular management group. |
| governance | Assignment Structure | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/policy/concepts/assignment-structure.md | One override can be used to replace the effect of many policies by specifying mu ## Enforcement mode -The `enforcementMode` property provides customers the ability to test the outcome of a policy on existing resources without initiating the policy effect or triggering entries in the [Azure Activity log](../../../azure-monitor/essentials/platform-logs-overview.md). +The `enforcementMode` property provides customers the ability to test the outcome of a policy on existing resources without initiating the policy effect or triggering entries in the [Azure Activity log](/azure/azure-monitor/essentials/platform-logs-overview). This scenario is commonly referred to as _What If_ and aligns to safe deployment practices. `enforcementMode` is different from the [Disabled](./effects.md#disabled) effect, as that effect prevents resource evaluation from happening at all. |
| governance | Evaluate Impact | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/policy/concepts/evaluate-impact.md | security and compliance organizations to ensure there are no gaps in coverage. Implementing and assigning your policy definition isn't the final step. Continuously monitor the [compliance](../how-to/get-compliance-data.md) level of resources to your new policy definition and setup appropriate-[Azure Monitor alerts and notifications](../../../azure-monitor/alerts/alerts-overview.md) for +[Azure Monitor alerts and notifications](/azure/azure-monitor/alerts/alerts-overview) for when non-compliant devices are identified. It's also recommended to evaluate the policy definition and related assignments on a scheduled basis to validate the policy definition is meeting business policy and compliance needs. Policies should be removed if no longer needed. Policies also need to update from time to time as the underlying Azure resources evolve and add new properties and |
| governance | Policy For Kubernetes | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/policy/concepts/policy-for-kubernetes.md | messages, see As a Kubernetes controller/container, both the _azure-policy_ and _gatekeeper_ pods keep logs in the Kubernetes cluster. In general, _azure-policy_ logs can be used to troubleshoot issues with policy ingestion onto the cluster and compliance reporting. The _gatekeeper-controller-manager_ pod logs can be used to troubleshoot runtime denies. The _gatekeeper-audit_ pod logs can be used to troubleshoot audits of existing resources. The logs can be exposed in the **Insights** page of the Kubernetes cluster. For more information, see-[Monitor your Kubernetes cluster performance with Azure Monitor for containers](../../../azure-monitor/containers/container-insights-analyze.md). +[Monitor your Kubernetes cluster performance with Azure Monitor for containers](/azure/azure-monitor/containers/container-insights-analyze). To view the add-on logs, use `kubectl`: |
| governance | Get Compliance Data | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/policy/how-to/get-compliance-data.md | Trent Baker ## Azure Monitor logs -If you have a [Log Analytics workspace](../../../azure-monitor/logs/log-query-overview.md) with +If you have a [Log Analytics workspace](/azure/azure-monitor/logs/log-query-overview) with `AzureActivity` from the-[Activity Log Analytics solution](../../../azure-monitor/essentials/activity-log.md) tied to your +[Activity Log Analytics solution](/azure/azure-monitor/essentials/activity-log) tied to your subscription, you can also view non-compliance results from the evaluation of new and updated resources using simple Kusto queries and the `AzureActivity` table. With details in Azure Monitor logs, alerts can be configured to watch for non-compliance. |
| governance | Migrate From Automanage Best Practices | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/policy/how-to/migrate-from-automanage-best-practices.md | next steps: [01]: ../overview.md [02]: ../../../backup/backup-azure-arm-userestapi-createorupdatepolicy.md [03]: /azure/virtual-machines/extensions/iaas-antimalware-windows-[04]: https://learn.microsoft.com/windows-server/manage/windows-admin-center/azure/manage-vm +[04]: /windows-server/manage/windows-admin-center/azure/manage-vm [05]: ../../../update-manager/migration-overview.md [06]: https://ms.portal.azure.com/ [07]: ../concepts/definition-structure-basics.md |
| governance | General | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/policy/troubleshoot/general.md | If you still have an issue with your duplicated and customized built-in policy d #### Issue -A resource that you expect Azure Policy to act on isn't being acted on, and there's no entry in the [Azure Activity log](../../../azure-monitor/data-sources.md#azure-resources). +A resource that you expect Azure Policy to act on isn't being acted on, and there's no entry in the [Azure Activity log](/azure/azure-monitor/data-sources#azure-resources). #### Cause A policy assignment to the scope of your new or updated resource meets the crite #### Resolution -The error message from a deny policy assignment includes the policy definition and policy assignment IDs. If the error information in the message is missed, it's also available in the [Activity log](../../../azure-monitor/essentials/activity-log-insights.md#view-the-activity-log). Use this information to get more details to understand the resource restrictions and adjust the resource properties in your request to match allowed values. +The error message from a deny policy assignment includes the policy definition and policy assignment IDs. If the error information in the message is missed, it's also available in the [Activity log](/azure/azure-monitor/essentials/activity-log-insights#view-the-activity-log). Use this information to get more details to understand the resource restrictions and adjust the resource properties in your request to match allowed values. ### Scenario: Definition targets multiple resource types |
| governance | Modify Virtual Machine Identity | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/policy/tutorials/modify-virtual-machine-identity.md | -Existing virtual machines and virtual machines scale sets that need to use the [Azure Monitoring Agent](../../../azure-monitor/agents/agents-overview.md) must be updated to use a user assigned managed identity. This article shows the steps needed to assign a custom definition that adds a user assigned identity to those resources at scale via Azure Policy. +Existing virtual machines and virtual machines scale sets that need to use the [Azure Monitoring Agent](/azure/azure-monitor/agents/agents-overview) must be updated to use a user assigned managed identity. This article shows the steps needed to assign a custom definition that adds a user assigned identity to those resources at scale via Azure Policy. > [!NOTE] > The definition template MUST be assigned with [enforcement mode disabled (DoNotEnforce)](../concepts/assignment-structure.md#enforcement-mode) to prevent failures on newly created resources. To remediate the existing resources, follow these steps: - Review [Understanding policy effects](../concepts/effects.md). - Learn how to [remediate noncompliant resources](../how-to/remediate-resources.md). - Learn more on [enforcement mode](../concepts/assignment-structure.md#enforcement-mode)-- Learn more on [installing Azure Monitor Agent using Azure Policy](../../../azure-monitor/agents/azure-monitor-agent-manage.md)+- Learn more on [installing Azure Monitor Agent using Azure Policy](/azure/azure-monitor/agents/azure-monitor-agent-manage) |
| governance | Alerts Query Quickstart | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/resource-graph/alerts-query-quickstart.md | For more information about the query language or how to explore resources, go to - [Troubleshoot Azure Resource Graph alerts](./troubleshoot/alerts.md) - [Understanding the Azure Resource Graph query language](./concepts/query-language.md) - [Explore your Azure resources with Resource Graph](./concepts/explore-resources.md)-- [Overview of Log Analytics in Azure Monitor](../../azure-monitor/logs/log-analytics-overview.md)-- [Collect events and performance counters from virtual machines with Azure Monitor Agent](../..//azure-monitor/agents/data-collection-rule-azure-monitor-agent.md)-- [Role assignments for Azure Data Explorer clusters](../../azure-monitor/alerts/alerts-create-log-alert-rule.md#configure-alert-rule-details)+- [Overview of Log Analytics in Azure Monitor](/azure/azure-monitor/logs/log-analytics-overview) +- [Collect events and performance counters from virtual machines with Azure Monitor Agent](/azure/azure-monitor/agents/data-collection-rule-azure-monitor-agent) +- [Role assignments for Azure Data Explorer clusters](/azure/azure-monitor/alerts/alerts-create-log-alert-rule#configure-alert-rule-details) |
| governance | Get Resource Changes | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/resource-graph/changes/get-resource-changes.md | When a resource is created, updated, or deleted, a new change resource (`Microso "tags.key1": { "newValue": "NewTagValue", "previousValue": "null",- "changeCategory": "User", - "propertyChangeType": "Insert" } } } |
| governance | Resource Graph Changes | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/governance/resource-graph/changes/resource-graph-changes.md | You can compose and join tables to project change data any way you want. ## Data retention -Changes are queryable for 14 days. For longer retention, you can [integrate your Resource Graph query with Azure Logic Apps](../tutorials/logic-app-calling-arg.md) and manually export query results to any of the Azure data stores like [Log Analytics](../../../azure-monitor/logs/log-analytics-overview.md) for your desired retention. +Changes are queryable for 14 days. For longer retention, you can [integrate your Resource Graph query with Azure Logic Apps](../tutorials/logic-app-calling-arg.md) and manually export query results to any of the Azure data stores like [Log Analytics](/azure/azure-monitor/logs/log-analytics-overview) for your desired retention. ## Cost You can use Azure Resource Graph Change Analysis at no extra cost. ## Change Analysis in Azure Resource Graph vs. Azure Monitor -The Change Analysis experience is in the process of moving from [Azure Monitor](../../../azure-monitor/change/change-analysis.md) to Azure Resource Graph. During this transition, you might see two options for Change Analysis when you search for it in the Azure portal: +The Change Analysis experience is in the process of moving from [Azure Monitor](/azure/azure-monitor/change/change-analysis) to Azure Resource Graph. During this transition, you might see two options for Change Analysis when you search for it in the Azure portal: :::image type="content" source="./media/transitional-overview/change-analysis-portal-search.png" alt-text="Screenshot of the search results for Change Analysis in the Azure portal."::: |
| hdinsight-aks | Monitor With Prometheus Grafana | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/hdinsight-aks/monitor-with-prometheus-grafana.md | Last updated 11/07/2023 Cluster and service Monitoring is integral part of any organization. Azure HDInsight on AKS comes with integrated monitoring experience with Azure services. In this article, we use managed Prometheus service with Azure Grafana dashboards for monitoring. -[Azure Managed Prometheus](../azure-monitor/essentials/prometheus-metrics-overview.md) is a service that monitors your cloud environments. The monitoring is to maintain their availability and performance and workload metrics. It collects data generated by resources in your Azure instances and from other monitoring tools. The data is used to provide analysis across multiple sources. +[Azure Managed Prometheus](/azure/azure-monitor/essentials/prometheus-metrics-overview) is a service that monitors your cloud environments. The monitoring is to maintain their availability and performance and workload metrics. It collects data generated by resources in your Azure instances and from other monitoring tools. The data is used to provide analysis across multiple sources. [Azure Managed Grafana](../managed-grafan) is a data visualization platform built on top of the Grafana software by Grafana Labs. It's built as a fully managed Azure service operated and supported by Microsoft. Grafana helps you bring together metrics, logs, and traces into a single user interface. With its extensive support for data sources and graphing capabilities, you can view and analyze your application and infrastructure telemetry data in real-time. This article covers the details of enabling the monitoring feature in HDInsight ## Prerequisites -* An Azure Managed Prometheus workspace. You can think of this workspace as a unique Azure Monitor logs environment with its own data repository, data sources, and solutions. For the instructions, see [Create an Azure Managed Prometheus workspace](../azure-monitor/essentials/azure-monitor-workspace-manage.md). +* An Azure Managed Prometheus workspace. You can think of this workspace as a unique Azure Monitor logs environment with its own data repository, data sources, and solutions. For the instructions, see [Create an Azure Managed Prometheus workspace](/azure/azure-monitor/essentials/azure-monitor-workspace-manage). * Azure Managed Grafana workspace. For the instructions, see [Create an Azure Managed Grafana workspace](../managed-grafan). * An [HDInsight on AKS cluster](./quickstart-create-cluster.md). Currently, you can use Azure Managed Prometheus with the following HDInsight on AKS cluster types: * Apache SparkΓäó |
| hdinsight | Cluster Availability Monitor Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/hdinsight/cluster-availability-monitor-logs.md | HDInsight clusters include Azure Monitor logs integration, which provides querya Azure Monitor logs enable data generated by multiple resources, such as HDInsight clusters, to be collected and aggregated in one place to achieve a unified monitoring experience. -As a prerequisite, you'll need a Log Analytics Workspace to store the collected data. If you haven't already created one, you can follow instructions here: [Create a Log Analytics Workspace](../azure-monitor/logs/quick-create-workspace.md). +As a prerequisite, you'll need a Log Analytics Workspace to store the collected data. If you haven't already created one, you can follow instructions here: [Create a Log Analytics Workspace](/azure/azure-monitor/logs/quick-create-workspace). ## Enable HDInsight Azure Monitor logs integration Since this query only returns unavailable nodes as results, if the number of res In the **Evaluated based on** section, set the **period** and **frequency** based on how often you want to check for unavailable nodes. -For the purpose of this alert, you want to make sure **Period=Frequency.** More information about period, frequency, and other alert parameters can be found [here](../azure-monitor/alerts/alerts-unified-log.md#alert-logic-definition). +For the purpose of this alert, you want to make sure **Period=Frequency.** More information about period, frequency, and other alert parameters can be found [here](/azure/azure-monitor/alerts/alerts-unified-log#alert-logic-definition). Select **Done** when you're finished configuring the signal logic. If you don't already have an existing action group, click **Create New** under t This will open **Add action group**. Choose an **Action group name**, **Short name**, **Subscription**, and **Resource group.** Under the **Actions** section, choose an **Action Name** and select **Email/SMS/Push/Voice** as the **Action Type.** > [!NOTE]-> There are several other actions an alert can trigger besides an Email/SMS/Push/Voice, such as an Azure Function, LogicApp, Webhook, ITSM, and Automation Runbook. [Learn More.](../azure-monitor/alerts/action-groups.md) +> There are several other actions an alert can trigger besides an Email/SMS/Push/Voice, such as an Azure Function, LogicApp, Webhook, ITSM, and Automation Runbook. [Learn More.](/azure/azure-monitor/alerts/action-groups) This will open **Email/SMS/Push/Voice**. Choose a **Name** for the recipient, **check** the **Email** box, and type an email address to which you want the alert sent. Select **OK** in **Email/SMS/Push/Voice**, then in **Add action group** to finish configuring your action group. |
| hdinsight | Cluster Management Best Practices | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/hdinsight/cluster-management-best-practices.md | Learn best practices for managing HDInsight clusters. | Manual scaling | [Scale Azure HDInsight clusters](./hdinsight-scaling-best-practices.md) | | Monitoring with Ambari| [Monitor cluster performance in Azure HDInsight](./hdinsight-key-scenarios-to-monitor.md) | | Monitoring with Azure Monitor logs | [Use Azure Monitor logs to monitor HDInsight clusters](./hdinsight-hadoop-oms-log-analytics-tutorial.md) |-| Service issues, planned maintenance, health & security advisories | [Subscribe to subscription specific service health alerts](../service-health/alerts-activity-log-service-notifications-portal.md) | +| Service issues, planned maintenance, health & security advisories | [Subscribe to subscription specific service health alerts](/azure/service-health/alerts-activity-log-service-notifications-portal) | ## How do I check on deleted HDInsight clusters? |
| hdinsight | Apache Hadoop On Premises Migration Best Practices Security Devops | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/hdinsight/hadoop/apache-hadoop-on-premises-migration-best-practices-security-devops.md | For more information, see the following articles: For more information, see the article: -[Azure Monitor Overview](../../azure-monitor/overview.md) +[Azure Monitor Overview](/azure/azure-monitor/overview) ## Upgrade clusters |
| hdinsight | Hdinsight Administer Use Portal Linux | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/hdinsight/hdinsight-administer-use-portal-linux.md | Select your cluster name from the [**HDInsight clusters**](#showClusters) page. | Item| Description | |||- |Resource health|See [Azure resource health overview](../service-health/resource-health-overview.md).| + |Resource health|See [Azure resource health overview](/azure/service-health/resource-health-overview).| |New support request|Allows you to create a support ticket with Microsoft support.| ## <a name="properties"></a> Cluster Properties |
| hdinsight | Hdinsight Go Sdk Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/hdinsight/hdinsight-go-sdk-overview.md | extClient.Authorizer, _ = credentials.Authorizer() ### Enable OMS monitoring > [!NOTE] -> To enable OMS Monitoring, you must have an existing Log Analytics workspace. If you have not already created one, you can learn how to do that here: [Create a Log Analytics workspace in the Azure portal](../azure-monitor/logs/quick-create-workspace.md). +> To enable OMS Monitoring, you must have an existing Log Analytics workspace. If you have not already created one, you can learn how to do that here: [Create a Log Analytics workspace in the Azure portal](/azure/azure-monitor/logs/quick-create-workspace). To enable OMS Monitoring on your cluster: |
| hdinsight | Hdinsight Hadoop Oms Log Analytics Tutorial | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/hdinsight/hdinsight-hadoop-oms-log-analytics-tutorial.md | Last updated 09/06/2024 Learn how to enable Azure Monitor logs to monitor Hadoop cluster operations in HDInsight. And how to add an HDInsight monitoring solution. -[Azure Monitor logs](../azure-monitor/logs/log-query-overview.md) is an Azure Monitor service that monitors your cloud and on-premises environments. The monitoring is to maintain their availability and performance. It collects data generated by resources in your cloud, on-premises environments and from other monitoring tools. The data is used to provide analysis across multiple sources. +[Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview) is an Azure Monitor service that monitors your cloud and on-premises environments. The monitoring is to maintain their availability and performance. It collects data generated by resources in your cloud, on-premises environments and from other monitoring tools. The data is used to provide analysis across multiple sources. [!INCLUDE [azure-monitor-log-analytics-rebrand](~/reusable-content/ce-skilling/azure/includes/azure-monitor-log-analytics-rebrand.md)] If you don't have an Azure subscription, [create a free account](https://azure.m ## Prerequisites -* A Log Analytics workspace. You can think of this workspace as a unique Azure Monitor logs environment with its own data repository, data sources, and solutions. For the instructions, see [Create a Log Analytics workspace](../azure-monitor/logs/quick-create-workspace.md). +* A Log Analytics workspace. You can think of this workspace as a unique Azure Monitor logs environment with its own data repository, data sources, and solutions. For the instructions, see [Create a Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace). * An Azure HDInsight cluster. Currently, you can use Azure Monitor logs with the following HDInsight cluster types: Screenshot of Spark Workbook ## Configuring performance counters -Azure monitor supports collecting and analyzing performance metrics for the nodes in your cluster. For more information, see [Linux performance data sources in Azure Monitor](../azure-monitor/agents/data-sources-performance-counters.md#linux-performance-counters). +Azure monitor supports collecting and analyzing performance metrics for the nodes in your cluster. For more information, see [Linux performance data sources in Azure Monitor](/azure/azure-monitor/agents/data-sources-performance-counters#linux-performance-counters). ## Cluster auditing For the log table mappings from the classic Azure Monitor integration to the new ## Prerequisites -* A Log Analytics workspace. You can think of this workspace as a unique Azure Monitor logs environment with its own data repository, data sources, and solutions. For the instructions, see [Create a Log Analytics workspace](../azure-monitor/vm/monitor-virtual-machine.md). +* A Log Analytics workspace. You can think of this workspace as a unique Azure Monitor logs environment with its own data repository, data sources, and solutions. For the instructions, see [Create a Log Analytics workspace](/azure/azure-monitor/vm/monitor-virtual-machine). * If you intend to use Azure Monitor integration on a cluster behind a firewall, complete the [Prerequisites for clusters behind a firewall](#oms-with-firewall). |
| hdinsight | Hdinsight Hadoop Oms Log Analytics Use Queries | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/hdinsight/hdinsight-hadoop-oms-log-analytics-use-queries.md | The first step to create an alert is to arrive at a query based on which the ale :::image type="content" source="media/hdinsight-hadoop-oms-log-analytics-use-queries/hdinsight-log-analytics-edit-alert.png" alt-text="HDInsight Azure Monitor logs alert delete edit."::: -For more information, see [Create, view, and manage metric alerts using Azure Monitor](../azure-monitor/alerts/alerts-metric.md). +For more information, see [Create, view, and manage metric alerts using Azure Monitor](/azure/azure-monitor/alerts/alerts-metric). ## See also -* [Get started with log queries in Azure Monitor](../azure-monitor/logs/get-started-queries.md) +* [Get started with log queries in Azure Monitor](/azure/azure-monitor/logs/get-started-queries) * [Create custom views by using View Designer in Azure Monitor](/previous-versions/azure/azure-monitor/visualize/view-designer) |
| hdinsight | Hdinsight Restrict Outbound Traffic | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/hdinsight/hdinsight-restrict-outbound-traffic.md | Once you've completed the logging setup, if you're using Log Analytics, you can AzureDiagnostics | where msg_s contains "Deny" | where TimeGenerated >= ago(1h) ``` -Integrating Azure Firewall with Azure Monitor logs is useful when first getting an application working. Especially when you aren't aware of all of the application dependencies. You can learn more about Azure Monitor logs from [Analyze log data in Azure Monitor](../azure-monitor/logs/log-query-overview.md) +Integrating Azure Firewall with Azure Monitor logs is useful when first getting an application working. Especially when you aren't aware of all of the application dependencies. You can learn more about Azure Monitor logs from [Analyze log data in Azure Monitor](/azure/azure-monitor/logs/log-query-overview) To learn about the scale limits of Azure Firewall and request increases, see [this](../azure-resource-manager/management/azure-subscription-service-limits.md#azure-firewall-limits) document or refer to the [FAQs](../firewall/firewall-faq.yml). |
| hdinsight | Apache Kafka Log Analytics Operations Management | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/hdinsight/kafka/apache-kafka-log-analytics-operations-management.md | Apache Kafka logs in the cluster are located at `/var/log/kafka`. Kafka logs are The steps to enable Azure Monitor logs for HDInsight are the same for all HDInsight clusters. Use the following links to understand how to create and configure the required -1. Create a Log Analytics workspace. For more information, see the [Logs in Azure Monitor](../../azure-monitor/logs/data-platform-logs.md) document. +1. Create a Log Analytics workspace. For more information, see the [Logs in Azure Monitor](/azure/azure-monitor/logs/data-platform-logs) document. 2. Create a Kafka on HDInsight cluster. For more information, see the [Start with Apache Kafka on HDInsight](apache-kafka-get-started.md) document. The steps to enable Azure Monitor logs for HDInsight are the same for all HDInsi ## Next steps -For more information on Azure Monitor, see [Azure Monitor overview](../../azure-monitor/overview.md), and [Query Azure Monitor logs to monitor HDInsight clusters](../hdinsight-hadoop-oms-log-analytics-use-queries.md). +For more information on Azure Monitor, see [Azure Monitor overview](/azure/azure-monitor/overview), and [Query Azure Monitor logs to monitor HDInsight clusters](../hdinsight-hadoop-oms-log-analytics-use-queries.md). For more information on working with Apache Kafka, see the following documents: |
| hdinsight | Log Analytics Migration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/hdinsight/log-analytics-migration.md | The following sections describe how customers can use the new Azure Monitor inte ## Activate a new Azure Monitor integration > [!NOTE]-> You must have a Log Analytics workspace created in a subscription you have access to before doing enabling the new integration. For more information about how to create a Log Analytics workspace, see [Create a Log Analytics workspace in the Azure portal](../azure-monitor/logs/quick-create-workspace.md). +> You must have a Log Analytics workspace created in a subscription you have access to before doing enabling the new integration. For more information about how to create a Log Analytics workspace, see [Create a Log Analytics workspace in the Azure portal](/azure/azure-monitor/logs/quick-create-workspace). Activate the new integration by going to your cluster's portal page and scrolling down the menu on the left until you reach the **Monitoring** section. In the **Monitoring** section, select **Monitor integration**. Then, select **Enable** and you can choose the Log Analytics workspace that you want your logs to be sent to. Select **Save** once you have chosen your workspace. You can enter your own queries in the Logs query editor. Queries used on the old #### Insights -Insights are cluster-specific visualization dashboards made using [Azure Workbooks](../azure-monitor/visualize/workbooks-overview.md). These dashboards give you detailed graphs and visualizations of how your cluster is running. The dashboards have sections for each cluster type, YARN, system metrics, and component logs. You can access your cluster's dashboard by visiting your cluster's page in the portal, scrolling down to the **Monitoring** section, and selecting the **Insights** pane. The dashboard loads automatically if you've enabled the new integration. Allow a few seconds for the graphs to load as they query the logs. +Insights are cluster-specific visualization dashboards made using [Azure Workbooks](/azure/azure-monitor/visualize/workbooks-overview). These dashboards give you detailed graphs and visualizations of how your cluster is running. The dashboards have sections for each cluster type, YARN, system metrics, and component logs. You can access your cluster's dashboard by visiting your cluster's page in the portal, scrolling down to the **Monitoring** section, and selecting the **Insights** pane. The dashboard loads automatically if you've enabled the new integration. Allow a few seconds for the graphs to load as they query the logs. :::image type="content" source="./media/log-analytics-migration/visualization-dashboard.png" lightbox="./media/log-analytics-migration/visualization-dashboard.png" alt-text="Screenshot that shows the visualization dashboard."::: You can create your own Azure workbooks with custom graphs and visualizations. I #### Alerts -You can add custom alerts to your clusters and workspaces in the Log query editor. Go to the Logs query editor by selecting the **Logs** pane from either your cluster or workspace portal. Run a query and then select **New Alert Rule** as shown in the following screenshot. For more information, read about [configuring alerts](../azure-monitor/alerts/alerts-log.md). +You can add custom alerts to your clusters and workspaces in the Log query editor. Go to the Logs query editor by selecting the **Logs** pane from either your cluster or workspace portal. Run a query and then select **New Alert Rule** as shown in the following screenshot. For more information, read about [configuring alerts](/azure/azure-monitor/alerts/alerts-log). :::image type="content" source="./media/log-analytics-migration/new-rule-alert.png" alt-text="Screenshot that shows the new rule alert." border="false"::: |
| hdinsight | Selective Logging Analysis Azure Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/hdinsight/selective-logging-analysis-azure-logs.md | Last updated 09/06/2024 # Use selective logging with a script action in Azure HDInsight -[Azure Monitor Logs](../azure-monitor/logs/log-query-overview.md) is an Azure Monitor service that monitors your cloud and on-premises environments. The monitoring helps maintain their availability and performance. +[Azure Monitor Logs](/azure/azure-monitor/logs/log-query-overview) is an Azure Monitor service that monitors your cloud and on-premises environments. The monitoring helps maintain their availability and performance. Azure Monitor Logs collects data generated by resources in your cloud, resources in on-premises environments, and other monitoring tools. It uses the data to provide analysis across multiple sources. To get the analysis, you enable the selective logging feature by using a script action for HDInsight in the Azure portal. Selective logging allows you to enable or disable all the tables, or enable sele ## Prerequisites -* A Log Analytics workspace. You can think of this workspace as a unique Azure Monitor Logs environment with its own data repository, data sources, and solutions. For instructions, see [Create a Log Analytics workspace](../azure-monitor/vm/monitor-virtual-machine.md). +* A Log Analytics workspace. You can think of this workspace as a unique Azure Monitor Logs environment with its own data repository, data sources, and solutions. For instructions, see [Create a Log Analytics workspace](/azure/azure-monitor/vm/monitor-virtual-machine). * An Azure HDInsight cluster. Currently, you can use the selective logging feature with the following HDInsight cluster types: * Hadoop * HBase |
| hdinsight | Selective Logging Analysis | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/hdinsight/selective-logging-analysis.md | Last updated 09/06/2024 # Use selective logging with a script action for Azure Monitor Agent (AMA) in Azure HDInsight -[Azure Monitor Logs](../azure-monitor/logs/log-query-overview.md) is an Azure Monitor service that monitors your cloud and on-premises environments. The monitoring helps maintain their availability and performance. +[Azure Monitor Logs](/azure/azure-monitor/logs/log-query-overview) is an Azure Monitor service that monitors your cloud and on-premises environments. The monitoring helps maintain their availability and performance. Azure Monitor Logs collects data generated by resources in your cloud, resources in on-premises environments, and other monitoring tools. It uses the data to provide analysis across multiple sources. To get the analysis, you enable the selective logging feature by using a script action for HDInsight in the Azure portal. Selective logging allows you to enable or disable all the tables, or enable sele ## Prerequisites -* A Log Analytics workspace. You can think of this workspace as a unique Azure Monitor Logs environment with its own data repository, data sources, and solutions. For instructions, see [Create a Log Analytics workspace](../azure-monitor/vm/monitor-virtual-machine.md). +* A Log Analytics workspace. You can think of this workspace as a unique Azure Monitor Logs environment with its own data repository, data sources, and solutions. For instructions, see [Create a Log Analytics workspace](/azure/azure-monitor/vm/monitor-virtual-machine). * An Azure HDInsight cluster. Currently, you can use the selective logging feature with the following HDInsight cluster types: * Hadoop * HBase |
| hdinsight | Apache Spark Analyze Application Insight Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/hdinsight/spark/apache-spark-analyze-application-insight-logs.md | Last updated 06/15/2024 Learn how to use [Apache Spark](https://spark.apache.org/) on HDInsight to analyze Application Insight telemetry data. -[Visual Studio Application Insights](../../azure-monitor/app/app-insights-overview.md) is an analytics service that monitors your web applications. Telemetry data generated by Application Insights can be exported to Azure Storage. Once the data is in Azure Storage, HDInsight can be used to analyze it. +[Visual Studio Application Insights](/azure/azure-monitor/app/app-insights-overview) is an analytics service that monitors your web applications. Telemetry data generated by Application Insights can be exported to Azure Storage. Once the data is in Azure Storage, HDInsight can be used to analyze it. ## Prerequisites Learn how to use [Apache Spark](https://spark.apache.org/) on HDInsight to analy The following resources were used in developing and testing this document: -* Application Insights telemetry data was generated using a [Node.js web app configured to use Application Insights](../../azure-monitor/app/nodejs.md). +* Application Insights telemetry data was generated using a [Node.js web app configured to use Application Insights](/azure/azure-monitor/app/nodejs). * A Linux-based Spark on HDInsight cluster version 3.5 was used to analyze the data. |
| healthcare-apis | Enable Diagnostic Logging | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/healthcare-apis/azure-api-for-fhir/enable-diagnostic-logging.md | Last updated 06/03/2022 [!INCLUDE [retirement banner](../includes/healthcare-apis-azure-api-fhir-retirement.md)] -In this article, you'll learn how to enable diagnostic logging in Azure API for FHIR and be able to review some sample queries for these logs. Access to diagnostic logs is essential for any healthcare service where compliance with regulatory requirements (such as HIPAA) is a must. The feature in Azure API for FHIR that enables diagnostic logs is the [**Diagnostic settings**](../../azure-monitor/essentials/diagnostic-settings.md) in the Azure portal. +In this article, you'll learn how to enable diagnostic logging in Azure API for FHIR and be able to review some sample queries for these logs. Access to diagnostic logs is essential for any healthcare service where compliance with regulatory requirements (such as HIPAA) is a must. The feature in Azure API for FHIR that enables diagnostic logs is the [**Diagnostic settings**](/azure/azure-monitor/essentials/diagnostic-settings) in the Azure portal. ## View and Download FHIR Metrics Data The screenshot below shows RUs used for a sample environment with few activities 2. **Stream to event hub** for ingestion by a third-party service or custom analytic solution. You'll need to create an event hub namespace and event hub policy before you can configure this step. 3. **Stream to the Log Analytics** workspace in Azure Monitor. You'll need to create your Logs Analytics Workspace before you can select this option. -6. Select **AuditLogs** and/or **AllMetrics**. The metrics include service name, availability, data size, total latency, total requests, total errors and timestamp. You can find more detail on [supported metrics](../../azure-monitor/essentials/metrics-supported.md#microsofthealthcareapisservices). +6. Select **AuditLogs** and/or **AllMetrics**. The metrics include service name, availability, data size, total latency, total requests, total errors and timestamp. You can find more detail on [supported metrics](/azure/azure-monitor/essentials/metrics-supported#microsofthealthcareapisservices). :::image type="content" source="media/diagnostic-logging/fhir-diagnostic-setting.png" alt-text="Azure FHIR Diagnostic Settings. Select AuditLogs and/or AllMetrics." lightbox="media/diagnostic-logging/fhir-diagnostic-setting.png"::: The screenshot below shows RUs used for a sample environment with few activities > [!Note] > It might take up to 15 minutes for the first Logs to show in Log Analytics. Also, if Azure API for FHIR is moved from one resource group or subscription to another, update the setting once the move is complete. -For more information on how to work with diagnostic logs, please refer to the [Azure Resource Log documentation](../../azure-monitor/essentials/platform-logs-overview.md) +For more information on how to work with diagnostic logs, please refer to the [Azure Resource Log documentation](/azure/azure-monitor/essentials/platform-logs-overview) ## Audit log details At this time, the Azure API for FHIR service returns the following fields in the audit log: |
| healthcare-apis | Monitor Deidentification Service Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/healthcare-apis/deidentification/monitor-deidentification-service-reference.md | + + Title: Monitoring data reference for the De-identification service (preview) in Azure Health Data Services +description: This article contains important reference material you need when you monitor the De-identification service (preview) in Azure Health Data Services. Last updated : 09/05/2024+++++++++# Azure Health Data Services de-identification service (preview) monitoring data reference ++See [Monitor the de-identification service (preview)](monitor-deidentification-service.md) for details on the data you can collect for the de-identification service and how to use it. +++### Supported resource logs for Microsoft.HealthDataAIServices/deidServices +++### Azure Health Data Services de-identification service (preview) +Microsoft.HealthDataAIServices/deidServices +- [AHDSDeidAuditLogs](/azure/azure-monitor/reference/tables/ahdsdeidauditlogs#columns) ++- [Microsoft.HealthDataAIServices/deidServices resource provider operations](/azure/role-based-access-control/resource-provider-operations#microsofthealthdataaiservices) ++## Related content ++- See [Monitor the Azure Health Data Services de-identification service](monitor-deidentification-service.md) for a description of monitoring the Azure Health Data Services de-identification service (preview). +- See [Monitor Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) for details on monitoring Azure resources. |
| healthcare-apis | Monitor Deidentification Service | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/healthcare-apis/deidentification/monitor-deidentification-service.md | + + Title: Monitor the De-identification service (preview) in Azure Health Data Services +description: Start here to learn how to monitor De-identification service (preview) in Azure Health Data Services. Last updated : 09/05/2024+++++++++# Monitor the Azure Health Data Services de-identification service (preview) ++For more information about the resource types for the de-identification service, see [the de-identification service monitoring data reference](monitor-deidentification-service-reference.md). +++++For the available resource log categories, their associated Log Analytics tables, and the log schemas for the de-identification service, see [the de-identification service monitoring data reference](monitor-deidentification-service-reference.md#resource-logs). ++++++- To list the 10 most common operations performed on your resource over the last three days: ++ ```kusto + AHDSDeidAuditLogs + | where TimeGenerated > ago(3d) + | summarize count() by OperationName + | top 10 by count_ desc + ``` ++- To list recent unauthenticated requests: ++ ```kusto + AHDSDeidAuditLogs + | where TimeGenerated > ago(3d) and StatusCode == 401 + | top 10 by count_ desc + ``` +++### De-identification service (preview) alert rules ++The following table lists some suggested alert rules for the de-identification service (preview). These alerts are just examples. You can set alerts for any metric, log entry, or activity log entry listed in the [de-identification service monitoring data reference](monitor-deidentification-service-reference.md). ++| Alert type | Condition | Description | +|:|:|:| +| Log | AHDSDeidAuditLogs<br>\| where StatusCode == 429 | De-identification service is throttled. | +| Log | AHDSDeidAuditLogs<br>\| where StatusCode >= 500 | De-identification service is failing. | ++<!-- ### Advisor recommendations --> ++## Related content ++- See [the de-identification service monitoring data reference](monitor-deidentification-service-reference.md) for a reference of the metrics, logs, and other important values created for the de-identification service. +- See [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) for general details on monitoring Azure resources. |
| healthcare-apis | Configure Customer Managed Keys | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/healthcare-apis/dicom/configure-customer-managed-keys.md | For the DICOM service to operate properly, it must always have access to the key - The DICOM service system-assigned managed identity loses access to the key vault. -In any scenario where the DICOM service can't access the key, API requests return with `500` errors and the data is inaccessible until access to the key is restored. The [Azure Resource health](../../service-health/overview.md) view for the DICOM service helps you diagnose key access issues. +In any scenario where the DICOM service can't access the key, API requests return with `500` errors and the data is inaccessible until access to the key is restored. The [Azure Resource health](/azure/service-health/overview) view for the DICOM service helps you diagnose key access issues. If key access is lost for more than 30 minutes, make sure you update the DICOM service to refresh the key access. For more information, see [Update the DICOM service with the encryption key](#update-the-dicom-service-with-the-encryption-key). If you don't also update the DICOM service, it continues to be unavailable even when key access is restored. |
| healthcare-apis | Dicom Data Lake | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/healthcare-apis/dicom/dicom-data-lake.md | To learn more about access tiers, including cost tradeoffs and best practices, s ## Health check The DICOM service writes a small file to the data lake every 30 seconds, following the [Data Contract](#data-contracts) to ensure it maintains access. Making any changes to files stored under the `healthCheck` subdirectory might result in incorrect status of the health check.-If there's an issue with access, status and details are displayed by [Azure Resource Health](../../service-health/overview.md). Azure Resource Health specifies if any action is required to restore access, for example reinstating a role to the DICOM service's identity. +If there's an issue with access, status and details are displayed by [Azure Resource Health](/azure/service-health/overview). Azure Resource Health specifies if any action is required to restore access, for example reinstating a role to the DICOM service's identity. ## Limitations |
| healthcare-apis | Enable Diagnostic Logging | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/healthcare-apis/dicom/enable-diagnostic-logging.md | -In this article, you'll learn how to enable diagnostic logging in DICOM® service and be able to review some sample queries for these logs. Access to diagnostic logs is essential for any healthcare service where compliance with regulatory requirements is required. The feature in DICOM service that enables diagnostic logs is the [Diagnostic settings](../../azure-monitor/essentials/diagnostic-settings.md) in the Azure portal. +In this article, you'll learn how to enable diagnostic logging in DICOM® service and be able to review some sample queries for these logs. Access to diagnostic logs is essential for any healthcare service where compliance with regulatory requirements is required. The feature in DICOM service that enables diagnostic logs is the [Diagnostic settings](/azure/azure-monitor/essentials/diagnostic-settings) in the Azure portal. ## Enable logs In this article, you'll learn how to enable diagnostic logging in DICOM® ser 5. Select the **Category** and **Destination** details for accessing the diagnostic logs: - * **Send to Log Analytics workspace** in the Azure Monitor. You need to create your Logs Analytics workspace before you can select this option. For more information about the platform logs, see [Overview of Azure platform logs](../../azure-monitor/essentials/platform-logs-overview.md). + * **Send to Log Analytics workspace** in the Azure Monitor. You need to create your Logs Analytics workspace before you can select this option. For more information about the platform logs, see [Overview of Azure platform logs](/azure/azure-monitor/essentials/platform-logs-overview). * **Archive to a storage account** for auditing or manual inspection. The storage account you want to use needs to already be created. * **Stream to an event hub** for ingestion by a third-party service or custom analytic solution. You need to create an event hub namespace and event hub policy before you can configure this step. * **Send to partner solution** that you're working with as a partner organization in Azure. For information about potential partner integrations, see [Azure partner solutions documentation](../../partner-solutions/overview.md) - For information about supported metrics, see [Supported metrics with Azure Monitor](.././../azure-monitor/essentials/metrics-supported.md). + For information about supported metrics, see [Supported metrics with Azure Monitor](/azure/azure-monitor/essentials/metrics-supported). 6. Select **Save**. > [!Note] > It might take up to 15 minutes for the first Logs to appear in Log Analytics. Also, if the DICOM service is moved from one resource group or subscription to another, update the settings once the move is complete. - For information on how to work with diagnostic logs, see [Azure Resource Log documentation](../../azure-monitor/essentials/platform-logs-overview.md) + For information on how to work with diagnostic logs, see [Azure Resource Log documentation](/azure/azure-monitor/essentials/platform-logs-overview) ## Log details The log schema used differs based on the destination. Log Analytics has a schema that differs from other destinations. Each log type has a different schema. MicrosoftHealthcareApisAuditLogs ## Next steps -Having access to diagnostic logs is essential for monitoring a service and providing compliance reports. The DICOM service allows you to do these actions through diagnostic logs. For more information, see [Azure Activity Log event schema](.././../azure-monitor/essentials/activity-log-schema.md) +Having access to diagnostic logs is essential for monitoring a service and providing compliance reports. The DICOM service allows you to do these actions through diagnostic logs. For more information, see [Azure Activity Log event schema](/azure/azure-monitor/essentials/activity-log-schema) |
| healthcare-apis | Events Enable Diagnostic Settings | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/healthcare-apis/events/events-enable-diagnostic-settings.md | In this article, learn how to enable the events diagnostic settings for Azure Ev |Description|Resource| |--|--| |Learn how to enable the Event Grid system topics diagnostic logging and metrics export feature.|[Enable diagnostic logs for Event Grid system topics](../../event-grid/enable-diagnostic-logs-topic.md#enable-diagnostic-logs-for-event-grid-system-topics)|-|View a list of currently captured Event Grid system topics diagnostic logs.|[Event Grid system topic diagnostic logs](../../azure-monitor/essentials/resource-logs-categories.md#microsofteventgridsystemtopics)| -|View a list of currently captured Event Grid system topics metrics.|[Event Grid system topic metrics](../../azure-monitor/essentials/metrics-supported.md#microsofteventgridsystemtopics)| -|More information about how to work with diagnostics logs.|[Azure Resource Log documentation](../../azure-monitor/essentials/platform-logs-overview.md)| +|View a list of currently captured Event Grid system topics diagnostic logs.|[Event Grid system topic diagnostic logs](/azure/azure-monitor/essentials/resource-logs-categories#microsofteventgridsystemtopics)| +|View a list of currently captured Event Grid system topics metrics.|[Event Grid system topic metrics](/azure/azure-monitor/essentials/metrics-supported#microsofteventgridsystemtopics)| +|More information about how to work with diagnostics logs.|[Azure Resource Log documentation](/azure/azure-monitor/essentials/platform-logs-overview)| > [!NOTE] > It might take up to 15 minutes for the first events diagnostic logs and metrics to display in the destination of your choice. |
| healthcare-apis | Events Use Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/healthcare-apis/events/events-use-metrics.md | -> To learn more about Azure Monitor and metrics, see [Azure Monitor Metrics overview](../../azure-monitor/essentials/data-platform-metrics.md). +> To learn more about Azure Monitor and metrics, see [Azure Monitor Metrics overview](/azure/azure-monitor/essentials/data-platform-metrics). > [!NOTE] > For the purposes of this article, an [Azure Event Hubs](../../event-hubs/event-hubs-about.md) was used as the events message endpoint. |
| healthcare-apis | Fhir Service Resource Manager Template | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/healthcare-apis/fhir/fhir-service-resource-manager-template.md | Last updated 06/06/2022 # Deploy a FHIR service within Azure Health Data Services - using ARM template -In this article, you'll learn how to deploy FHIR service within the Azure Health Data Services (hereby called FHIR service) using the Azure Resource Manager template (ARM template). We provide you two options using PowerShell or using CLI. +In this article, you'll learn how to deploy FHIR® service within the Azure Health Data Services using the Azure Resource Manager template (ARM template). We provide two options: using PowerShell or using CLI. An [ARM template](../../azure-resource-manager/templates/overview.md) is a JSON file that defines the infrastructure and configuration for your project. The template uses declarative syntax. In declarative syntax, you describe your intended deployment without writing the sequence of programming commands to create the deployment. The template used in this article is from [Azure Quickstart Templates](https://a The template defines three Azure resources: - Microsoft.HealthcareApis/workspaces-- Microsoft.HealthcareApis/workspaces/fhirservices +- Microsoft.HealthcareApis/workspaces/fhirservices - Microsoft.Storage/storageAccounts > [!NOTE]-> Local RBAC is deprecated. Access Policies configuration associated with Local RBAC in ARM template are deprecated. Existing customers using Local RBAC need to migrate to Azure RBAC by November 2024. For questions, please [contact us](https://portal.azure.com/#blade/Microsoft_Azure_Support/HelpAndSupportBlade/overview). +> Local RBAC is deprecated. Access Policies configuration associated with Local RBAC in ARM templates are deprecated. Existing customers using Local RBAC need to migrate to Azure RBAC by November 2024. For questions, please [contact us](https://portal.azure.com/#blade/Microsoft_Azure_Support/HelpAndSupportBlade/overview). You can deploy the FHIR service resource by **removing** the workspaces resource, the storage resource, and the `dependsOn` property in the ΓÇ£Microsoft.HealthcareApis/workspaces/fhirservicesΓÇ¥ resource. You can deploy the FHIR service resource by **removing** the workspaces resource You can deploy the ARM template using two options: PowerShell or CLI. -The sample code provided below uses the template in the ΓÇ£templatesΓÇ¥ subfolder of the subfolder ΓÇ£srcΓÇ¥. You may want to change the location path to reference the template file properly. +The following sample code uses the template in the ΓÇ£templatesΓÇ¥ subfolder of the subfolder ΓÇ£srcΓÇ¥. You may want to change the location path to reference the template file properly. -The deployment process takes a few minutes to complete. Take a note of the names for the FHIR service and the resource group, which you'll use later. +The deployment process takes a few minutes to complete. Take a note of the names for the FHIR service and the resource group, which you use later. # [PowerShell](#tab/PowerShell) ### Deploy the template: using PowerShell -Run the code in PowerShell locally, in Visual Studio Code, or in Azure Cloud Shell, to deploy the FHIR service. +To deploy the FHIR service, run the code in PowerShell locally, in Visual Studio Code, or in Azure Cloud Shell. If you haven't logged in to Azure, use "Connect-AzAccount" to log in. Once you've logged in, use "Get-AzContext" to verify the subscription and tenant you want to use. You can change the subscription and tenant if needed. -You can create a new resource group, or use an existing one by skipping the step or commenting out the line starting with ΓÇ£New-AzResourceGroupΓÇ¥. +You can create a new resource group, or use an existing one by skipping the step, or commenting out the line starting with ΓÇ£New-AzResourceGroupΓÇ¥. ```powershell-interactive ### variables New-AzResourceGroupDeployment -ResourceGroupName $resourcegroupname -TemplateFil ### Deploy the template: using CLI -Run the code locally, in Visual Studio Code or in Azure Cloud Shell, to deploy the FHIR service. +To deploy the FHIR service, run the code in PowerShell locally, in Visual Studio Code, or in Azure Cloud Shell. If you havenΓÇÖt logged in to Azure, use "az login" to log in. Once you've logged in, use "az account show --output table" to verify the subscription and tenant you want to use. You can change the subscription and tenant if needed. -You can create a new resource group, or use an existing one by skipping the step or commenting out the line starting with "az group create". +You can create a new resource group, or use an existing one by skipping the step, or commenting out the line starting with "az group create". ```azurecli-interactive ### variables az deployment group create --resource-group $resourcegroupname --template-file ' ## Review the deployed resources -You can verify that the FHIR service is up and running by opening the browser and navigating to `https://<yourfhir servic>.azurehealthcareapis.com/metadata`. If the capability statement is displayed or downloaded automatically, your deployment is successful. +You can verify that the FHIR service is up and running by opening a browser and navigating to `https://<yourfhir servic>.azurehealthcareapis.com/metadata`. If the capability statement is displayed or downloaded automatically, your deployment is successful. ## Clean up the resources -When the resource is no longer needed, run the code below to delete the resource group. +When the resource is no longer needed, run the following code to delete the resource group. # [PowerShell](#tab/PowerShell) ```powershell-interactive In this quickstart guide, you've deployed the FHIR service within Azure Health D >[!div class="nextstepaction"] >[Supported FHIR Features](fhir-features-supported.md) -FHIR® is a registered trademark of [HL7](https://hl7.org/fhir/) and is used with the permission of HL7. |
| healthcare-apis | Fhir Versioning Policy And History Management | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/healthcare-apis/fhir/fhir-versioning-policy-and-history-management.md | -The versioning policy in the Azure Health Data Services FHIR service is a configuration, which determines how history is stored for every resource type with the option for resource specific configuration. This policy is directly related to the concept of managing history for FHIR resources. +The versioning policy in the Azure Health Data Services FHIR® service is a configuration which determines how history is stored for every resource type, with the option for resource specific configuration. This policy is directly related to the concept of managing history for FHIR resources. ## History in FHIR -History in FHIR gives you the ability to see all previous versions of a resource. History in FHIR can be queried at the resource level, type level, or system level. The HL7 FHIR documentation has more information about the [history interaction](https://www.hl7.org/fhir/http.html#history). History is useful in scenarios where you want to see the evolution of a resource in FHIR or if you want to see the information of a resource at a specific point in time. +History in FHIR gives you the ability to see all previous versions of a resource. History in FHIR can be queried at the resource level, type level, or system level. The HL7 FHIR documentation has more information about the [history interaction](https://www.hl7.org/fhir/http.html#history). History is useful when you want to see the evolution of a resource in FHIR, or if you want to see a resource's information at a specific point in time. -All past versions of a resource are considered obsolete and the current version of a resource should be used for normal business workflow operations. However, it can be useful to see the state of a resource as a point in time when a past decision was made. +All past versions of a resource are considered obsolete, and the current version of a resource should be used for normal business workflow operations. However, it can be useful to see the state of a resource as a point in time when a past decision was made. ## Versioning policy -Versioning policy in the FHIR service lets you decide how history is stored either at a FHIR service level or at a specific resource level. +Versioning policy in the FHIR service lets you decide how history is stored, either at a FHIR service level or at a specific resource level. There are three different levels for versioning policy: There are three different levels for versioning policy: - `version-update`: History is stored for operation on resources. Resource version is incremented. Updates require a valid `If-Match` header. For more information, see [VersionedUpdateExample.http](https://github.com/microsoft/fhir-server/blob/main/docs/rest/VersionedUpdateExample.http). - `no-version`: History isn't created for resources. Resource version is incremented. -Versioning policy available to configure at as a system-wide setting and also to override at a resource level. The system-wide setting is used for all resources in your FHIR service, unless a specific resource level versioning policy has been added. +Versioning policy is available to configure as a system-wide setting, and also to override at a resource level. The system-wide setting is used for all resources in your FHIR service, unless a specific resource level versioning policy has been added. ### Versioning policy comparison Versioning policy available to configure at as a system-wide setting and also to ## Configuring versioning policy -To configure versioning policy, select the **Versioning Policy Configuration** blade inside your FHIR service. +To configure versioning policy, select **Versioning Policy Configuration** inside your FHIR service. :::image type="content" source="media/versioning-policy/fhir-service-versioning-policy-configuration.png" alt-text="Screenshot of the Azure portal Versioning Policy Configuration." lightbox="media/versioning-policy/fhir-service-versioning-policy-configuration.png"::: -After you've browsed to Versioning Policy Configuration, you'll be able to configure the setting at both system level and the resource level (as an override of the system level). The system level configuration (annotated as 1) will apply to every resource in your FHIR service unless a resource specific override (annotated at 2) has been configured. +After you've browsed to Versioning Policy Configuration, you'll be able to configure the setting at both system level and the resource level (as an override of the system level). The system level configuration (annotated as 1) applies to every resource in your FHIR service unless a resource specific override (annotated as 2) has been configured. :::image type="content" source="media/versioning-policy/system-level-versus-resource-level.png" alt-text="Screenshot of Azure portal versioning policy configuration showing system level vs resource level configuration." lightbox="media/versioning-policy/system-level-versus-resource-level.png"::: -When configuring resource level configuration, you'll be able to select the FHIR resource type (annotated as 1) and the specific versioning policy for this specific resource (annotated as 2). Make sure to select the **Add** button (annotated as 3) to queue up this setting for saving. +When configuring resource level configuration, you're able to select the FHIR resource type (annotated as 1) and the specific versioning policy for this specific resource (annotated as 2). Make sure to select the **Add** button (annotated as 3) to queue up this setting for saving. :::image type="content" source="media/versioning-policy/resource-versioning.jpg" alt-text="Screenshot of Azure portal versioning policy configuration showing resource level configuration." lightbox="media/versioning-policy/resource-versioning.jpg"::: When configuring resource level configuration, you'll be able to select the FHIR ## History management -History in FHIR is important for end users to see how a resource has changed over time. It's also useful in coordination with audit logs to see the state of a resource before and after a user modified it. In general, it's recommended to keep history for a resource unless you know that the history isn't needed. Frequent updates of resources can result in a large amount of data storage, which can be undesired in FHIR services with a large amount of data. +History in FHIR is important for end users to see how a resource has changed over time. It's also useful in coordination with audit logs to see the state of a resource before and after a user modified it. In general, it's recommended to keep history for a resource unless you know that the history isn't needed. Frequent resource updates can result in a large amount of data storage, which can be undesirable in FHIR services with a large amount of data. -Changing the versioning policy either at a system level or resource level won't remove the existing history for any resources in your FHIR service. If you're looking to reduce the history data size in your FHIR service, you must use the [$purge-history](purge-history.md) operation. +Changing the versioning policy, either at a system level or resource level, won't remove the existing history for any resources in your FHIR service. If you're looking to reduce the history data size in your FHIR service, you must use the [$purge-history](purge-history.md) operation. > [!NOTE] -> The query parameter _summary=count and _count=0 can be added to _history endpoint to get count of all versioned resources. This count includes soft deleted resources. +> The query parameter _summary=count and _count=0 can be added to _history endpoint to get a count of all versioned resources. This count includes soft deleted resources. ## Next steps In this article, you learned how to purge the history for resources in the FHIR >[!div class="nextstepaction"] >[Purge history operation](purge-history.md) -FHIR® is a registered trademark of [HL7](https://hl7.org/fhir/) and is used with the permission of HL7. - |
| healthcare-apis | Get Started With Fhir | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/healthcare-apis/fhir/get-started-with-fhir.md | As a prerequisite, you need an Azure subscription and permissions to create Azur ## Create a workspace in your Azure subscription -You can create a workspace from the [Azure portal](../healthcare-apis-quickstart.md), or using PowerShell, Azure CLI, and REST API. You can find scripts from the [Azure Health Data Services samples](https://github.com/microsoft/healthcare-apis-samples/tree/main/src/scripts). +Create a workspace from the [Azure portal](../healthcare-apis-quickstart.md), or using PowerShell, Azure CLI, and REST API. You can find scripts from the [Azure Health Data Services samples](https://github.com/microsoft/healthcare-apis-samples/tree/main/src/scripts). > [!NOTE] > There are limits to the number of workspaces and the number of FHIR service instances you can create in each Azure subscription. Optionally, you can create a [DICOM service](../dicom/deploy-dicom-services-in-a ## Access the FHIR service -The FHIR service is secured by Microsoft Entra ID that can't be disabled. To access the service API, you must create a client application also referred to as a service principal in Microsoft Entra ID and grant it with the right permissions. +The FHIR service is secured by Microsoft Entra ID that can't be disabled. To access the service API, you must create a client application (also referred to as a service principal) in Microsoft Entra ID, and grant it the right permissions. ### Register a client application You can grant access permissions or assign roles in the [Azure portal](../config ### Perform create, read, update, and delete (CRUD) transactions -You can perform Create, Read (search), Update, and Delete (CRUD) transactions against the FHIR service in your applications or by using tools such as Postman, REST Client, and cURL. Because the FHIR service is secured by default, you need to obtain an access token and include it in your transaction request. +You can perform Create, Read (search), Update, and Delete - CRUD - transactions against the FHIR service in your applications or by using tools such as Postman, REST Client, and cURL. Because the FHIR service is secured by default, you need to obtain an access token and include it in your transaction request. #### Get an access token You can find more details on interoperability and patient access, search, profil ### Export data -Optionally, you can export ($export) data to [Azure Storage](../data-transformation/export-data.md) and use it in your analytics or machine-learning projects. You can export the data "as-is" or [deID](../data-transformation/de-identified-export.md) in `ndjson` format. +Optionally, you can export ($export) data to [Azure Storage](../data-transformation/export-data.md) and use it in your analytics or machine-learning projects. You can export the data "as-is" or [de-identified](../data-transformation/de-identified-export.md) in `ndjson` format. ### Convert data |
| healthcare-apis | How To Do Custom Search | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/healthcare-apis/fhir/how-to-do-custom-search.md | -The FHIR specification defines a set of search parameters that apply to all resources. Additionally, FHIR defines many search parameters that are specific to certain resources. There are scenarios, however, where you might want to search against an element in a resource that isnΓÇÖt defined by the FHIR specification as a standard search parameter. This article describes how you can define your own custom [search parameters](https://www.hl7.org/fhir/searchparameter.html) for use in the FHIR service in Azure Health Data Services. +The FHIR® specification defines a set of search parameters that apply to all resources. Additionally, FHIR defines many search parameters that are specific to certain resources. However, you might also want to search against an element in a resource that isnΓÇÖt defined by the FHIR specification as a standard search parameter. This article describes how you can define your own custom [search parameters](https://www.hl7.org/fhir/searchparameter.html) for use in the FHIR service in Azure Health Data Services. > [!NOTE]-> Each time you create, update, or delete a search parameter, youΓÇÖll need to run a [reindex job](how-to-run-a-reindex.md) to enable the search parameter for live production. Below we will outline how you can test search parameters before reindexing the entire FHIR service database. +> Each time you create, update, or delete a search parameter, youΓÇÖll need to run a [reindex job](how-to-run-a-reindex.md) to enable the search parameter for live production. We will outline how you can test search parameters before reindexing the entire FHIR service database following. ## Create new search parameter To create a new search parameter, you need to `POST` a `SearchParameter` resourc POST {{FHIR_URL}}/SearchParameter ``` -The examples below demonstrate creating new custom search parameter +The following examples demonstrate creating a new custom search parameter. -### Create new search parameter per definition in Implementation Guide +### Create new search parameter per definition in the Implementation Guide -The code example below shows how to add the [US Core Race search parameter](http://hl7.org/fhir/us/core/STU3.1.1/SearchParameter-us-core-race.html) to the `Patient` resource type in your FHIR service database. +The following code example shows how to add the [US Core Race search parameter](http://hl7.org/fhir/us/core/STU3.1.1/SearchParameter-us-core-race.html) to the `Patient` resource type in your FHIR service database. ```rest The code example below shows how to add the [US Core Race search parameter](http ``` ### Create new search parameter for resource attributes with reference type -The code example shows how to create a custom search parameter to search MedicationDispense resources based on the location where they were dispensed. This is an example of adding custom search parameter for a Reference type. +The following code example shows how to create a custom search parameter to search MedicationDispense resources based on the location where they were dispensed. This is an example of adding a custom search parameter for a Reference type. ```rest { The code example shows how to create a custom search parameter to search Medicat > [!NOTE] > The new search parameter will appear in the capability statement of the FHIR service after you `POST` the search parameter to the database **and** reindex your database. Viewing the `SearchParameter` in the capability statement is the only way to tell if a search parameter is supported in your FHIR service. If you cannot find the `SearchParameter` in the capability statement, then you still need to reindex your database to activate the search parameter. You can `POST` multiple search parameters before triggering a reindex operation. -Important elements of a `SearchParameter` resource: +Important elements of a `SearchParameter` resource are: * `url`: A unique key to describe the search parameter. Organizations such as HL7 use a standard URL format for the search parameters that they define, as shown above in the US Core Race search parameter. -* `code`: The value stored in the **code** element is the name used for the search parameter when it's included in an API call. For the example above with the "US Core Race" extension, you would search with `GET {{FHIR_URL}}/Patient?race=<code>` where `<code>` is in the value set from the specified coding system. This call would retrieve all patients of a certain race. +* `code`: The value stored in the **code** element is the name used for the search parameter when it's included in an API call. For the preceding example with the "US Core Race" extension, you would search with `GET {{FHIR_URL}}/Patient?race=<code>` where `<code>` is in the value set from the specified coding system. This call would retrieve all patients of a certain race. -* `base`: Describes which resource type(s) the search parameter applies to. If the search parameter applies to all resources, you can use `Resource`; otherwise, you can list all the relevant resource types. +* `base`: Describes which resource types the search parameter applies to. If the search parameter applies to all resources, you can use `Resource`; otherwise, you can list all the relevant resource types. -* `target`: Describes which resource type(s) the search parameter matches to. +* `target`: Describes which resource types the search parameter matches to. * `type`: Describes the data type for the search parameter. Type is limited by the support for data types in the FHIR service. This means that you canΓÇÖt define a search parameter of type Special or define a [composite search parameter](overview-of-search.md) unless it's a supported combination. Important elements of a `SearchParameter` resource: ## Test new search parameters -While you canΓÇÖt use the new search parameters in production until you run a reindex job, there are a few ways to test your custom search parameters before reindexing the entire database. +While you canΓÇÖt use the new search parameters in production until you run a reindex job, there are ways to test your custom search parameters before reindexing the entire database. -First, you can test a new search parameter to see what values will be returned. By running the command below against a specific resource instance (by supplying the resource ID), you get back a list of value pairs with the search parameter name and the value stored in the corresponding element. This list includes all of the search parameters for the resource. You can scroll through to find the search parameter you created. Running this command won't change any behavior in your FHIR service. +First, you can test a new search parameter to see what values are returned. By running the following command against a specific resource instance (by supplying the resource ID), you get back a list of value pairs with the search parameter name and the value stored in the corresponding element. This list includes all of the search parameters for the resource. You can scroll through to find the search parameter you created. Running this command won't change any behavior in your FHIR service. ```rest GET https://{{FHIR_URL}}/{{RESOURCE}}/{{RESOURCE_ID}}/$reindex The result looks like this: ...} ``` -Once you see that your search parameter is displaying as expected, you can reindex a single resource to test searching with your new search parameter. To reindex a single resource: +Once you see that your search parameter is displaying as expected, you can reindex a single resource to test searching with your new search parameter. To reindex a single resource, use the following. ```rest POST https://{{FHIR_URL}/{{RESOURCE}}/{{RESOURCE_ID}}/$reindex Continuing with our example, you could index one patient to enable `SearchParame POST {{FHIR_URL}}/Patient/{{PATIENT_ID}}/$reindex ``` -And then do a test search +And then do test searches: + 1. For the patient by race: ```rest GET {{FHIR_URL}}/Patient?race=2028-9 x-ms-use-partial-indices: true ```-1. For Location (reference type): +2. For Location (reference type) + ```rest {{fhirurl}}/MedicationDispense?location=<locationid referenced in MedicationDispense Resource> x-ms-use-partial-indices: true ```-After you've tested your new search parameter and confirmed that it's working as expected, run or schedule your reindex job so the new search parameter(s) can be used in live production. ++After you've tested your new search parameter and confirmed that it's working as expected, run or schedule your reindex job so the new search parameters can be used in live production. See [Running a reindex job](../fhir/how-to-run-a-reindex.md) for information on how to reindex your FHIR service database. ## Update a search parameter -To update a search parameter, use `PUT` to create a new version of the search parameter. You must include the search parameter ID in the `id` field in the body of the `PUT` request as well as the `PUT` request string. +To update a search parameter, use `PUT` to create a new version of the search parameter. You must include the search parameter ID in the `id` field in the body of the `PUT` request and the `PUT` request string. > [!NOTE]-> If you don't know the ID for your search parameter, you can search for it using `GET {{FHIR_URL}}/SearchParameter`. This will return all custom as well as standard search parameters, and you can scroll through the list to find the search parameter you need. You could also limit the search by name. As shown in the example request below, the name of the custom `SearchParameter` resource instance is `USCoreRace`. You could search for this `SearchParameter` resource by name using `GET {{FHIR_URL}}/SearchParameter?name=USCoreRace`. +> If you don't know the ID for your search parameter, you can search for it using `GET {{FHIR_URL}}/SearchParameter`. This will return all custom and standard search parameters. You can scroll through the list to find the search parameter you need. You could also limit the search by name. As shown in the following example request, the name of the custom `SearchParameter` resource instance is `USCoreRace`. You could search for this `SearchParameter` resource by name using `GET {{FHIR_URL}}/SearchParameter?name=USCoreRace`. ```rest PUT {{FHIR_URL}}/SearchParameter/{{SearchParameter_ID}} The result of the above request will be an updated `SearchParameter` resource. > [!Warning] > Be careful when updating search parameters. Changing an existing search parameter could have impacts on the expected behavior. We recommend running a reindex job immediately. -- ## Delete a search parameter -If you need to delete a search parameter, use the following: +If you need to delete a search parameter, use the following. ```rest DELETE {{FHIR_URL}}/SearchParameter/{{SearchParameter_ID}} DELETE {{FHIR_URL}}/SearchParameter/{{SearchParameter_ID}} > [!Warning] > Be careful when deleting search parameters. Deleting an existing search parameter could have impacts on the expected behavior. We recommend running a reindex job immediately. -- ## Next steps In this article, youΓÇÖve learned how to create a custom search parameter. Next you can learn how to reindex your FHIR service database. For more information, see >[!div class="nextstepaction"] >[How to run a reindex job](how-to-run-a-reindex.md) -FHIR® is a registered trademark of [HL7](https://hl7.org/fhir/) and is used with the permission of HL7. |
| healthcare-apis | How To Run A Reindex | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/healthcare-apis/fhir/how-to-run-a-reindex.md | -There are scenarios where you may have search parameters in the FHIR service in Azure Health Data Services that haven't yet been indexed. This scenario is relevant when you define your own custom search parameters. Until the search parameter is indexed, it can't be used in live production. This article covers how to run a reindex job to index any custom search parameters that haven't yet been indexed in your FHIR service database. +There are scenarios where you may have search parameters in the FHIR® service in Azure Health Data Services that have yet to be indexed. This scenario is relevant when you define your own custom search parameters. Until a search parameter is indexed, it can't be used in live production. This article covers how to run a reindex job to index any custom search parameters in your FHIR service database. > [!Warning] > It's important that you read this entire article before getting started. A reindex job can be very performance intensive. This article discusses options for how to throttle and control a reindex job. ## How to run a reindex job -Reindex job can be executed against entire FHIR service database and against specific custom search parameter. +A reindex job can be executed against an entire FHIR service database, and against specific custom search parameters. -### Run reindex job on entire FHIR service database -To run reindex job, use the following `POST` call with the JSON formatted `Parameters` resource in the request body: +### Run a reindex job on entire FHIR service database +To run a reindex job, use the following `POST` call with the JSON formatted `Parameters` resource in the request body. ```json POST {{FHIR_URL}}/$reindex content-type: application/fhir+json } ``` -Leave the `"parameter": []` field blank (as shown) if you don't need to tweak the resources allocated to the reindex job. +Leave the `"parameter": []` field blank (as shown) if you don't need to adjust the resources allocated to the reindex job. If the request is successful, you receive a **201 Created** status code in addition to a `Parameters` resource in the response. Content-Location: https://{{FHIR URL}}/_operations/reindex/560c7c61-2c70-4c54-b8 ] } ```-### Run reindex job against specific custom search parameter -To run reindex job against specific custom search parameter, use the following `POST` call with the JSON formatted `Parameters` resource in the request body: ++### Run a reindex job against a specific custom search parameter +To run a reindex job against a specific custom search parameter, use the following `POST` call with the JSON formatted `Parameters` resource in the request body. ```json POST {{FHIR_URL}}/$reindex content-type: application/fhir+json } ``` > [!NOTE]-> To check the status of a reindex job or to cancel the job, you'll need the reindex ID. This is the `"id"` carried in the `"parameter"` value returned in the response. In the example above, the ID for the reindex job would be `560c7c61-2c70-4c54-b86d-c53a9d29495e`. +> To check the status of, or cancel a reindex job, you need the reindex ID. This is the `"id"` carried in the `"parameter"` value of the response. In the preceding example, the ID for the reindex job would be `560c7c61-2c70-4c54-b86d-c53a9d29495e`. ## How to check the status of a reindex job -Once youΓÇÖve started a reindex job, you can check the status of the job using the following call: +Once you start a reindex job, you can check the status of the job using the following call. `GET {{FHIR_URL}}/_operations/reindex/{{reindexJobId}}` -An example response: +Here's an example response. ```json { An example response: } ``` -The following information is shown in the above response: +The following information is shown in the preceding response: * `totalResourcesToReindex`: Includes the total number of resources that are being reindexed in this job. The following information is shown in the above response: * `resources`: Lists all the resource types impacted by the reindex job. -* 'resourceReindexProgressByResource (CountReindexed of Count)': Provides reindexed count of the total count, per resource type. In cases where reindexing for a specific resource type is queued, only Count is provided. +* 'resourceReindexProgressByResource (CountReindexed of Count)': Provides a reindexed count of the total count, per resource type. In cases where reindexing for a specific resource type is queued, only Count is provided. * 'searchParams': Lists url of the search parameters impacted by the reindex job. ## Delete a reindex job -If you need to cancel a reindex job, use a `DELETE` call and specify the reindex job ID: +If you need to cancel a reindex job, use a `DELETE` call and specify the reindex job ID. `DELETE {{FHIR URL}}/_operations/reindex/{{reindexJobId}}` ## Performance considerations -A reindex job can be quite performance intensive. The FHIR service offers some throttling controls to help you manage how a reindex job run on your database. +A reindex job can be quite performance intensive. The FHIR service offers throttling controls to help manage how a reindex job runs on your database. > [!NOTE] > It is not uncommon on large datasets for a reindex job to run for days. Below is a table outlining the available parameters, defaults, and recommended r | **Parameter** | **Description** | **Default** | **Available Range** | | | - | | - | | `QueryDelayIntervalInMilliseconds` | The delay between each batch of resources being kicked off during the reindex job. A smaller number speeds up the job while a larger number slows it down. | 500 MS (.5 seconds) | 50 to 500000 |-| `MaximumResourcesPerQuery` | The maximum number of resources included in the batch of resources to be reindexed. | 100 | 1-5000 | +| `MaximumResourcesPerQuery` | The maximum number of resources included in the batch to be reindexed. | 100 | 1-5000 | | `MaximumConcurrency` | The number of batches done at a time. | 1 | 1-10 | -If you want to use any of the parameters above, you can pass them into the `Parameters` resource when you send the initial `POST` request to start a reindex job. +If you want to use any of the preceding parameters, you can pass them into the `Parameters` resource when you send the initial `POST` request to start a reindex job. ```json In this article, you've learned how to perform a reindex job in your FHIR servic >[!div class="nextstepaction"] >[Defining custom search parameters](how-to-do-custom-search.md) -FHIR® is a registered trademark of [HL7](https://hl7.org/fhir/) and is used with the permission of HL7. |
| healthcare-apis | Import Data | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/healthcare-apis/fhir/import-data.md | -You can use the `import` operation to ingest FHIR data into the FHIR server with high throughput. +You can use the `import` operation to ingest FHIR® data into the FHIR server with high throughput. ## Import operation modes The `import` operation supports two modes: initial and incremental. Each mode has different features and use cases. -#### Initial mode +### Initial mode - Intended for loading FHIR resources into an empty FHIR server. - Supports only `create` operations and (when enabled) blocks API writes to the FHIR server. -#### Incremental mode +### Incremental mode - Optimized for loading data into the FHIR server periodically and doesn't block writes through the API. The `import` operation supports two modes: initial and incremental. Each mode ha - Allows you to ingest soft-deleted resources. This capability is beneficial when you migrate from Azure API for FHIR to the FHIR service in Azure Health Data Services. -This table shows the difference between import modes. +The following table shows the difference between import modes. |Areas|Initial mode |Incremental mode |-|:- |:-|:--| +|- |-|--| |Capability|Initial load of data into FHIR service|Continuous ingestion of data into FHIR service (Incremental or Near Real Time).| |Concurrent API calls|Blocks concurrent write operations|Data can be ingested concurrently while executing API CRUD operations on the FHIR server.| |Ingestion of versioned resources|Not supported|Enables ingestion of multiple versions of FHIR resources in single batch while maintaining resource history.| This table shows the difference between import modes. ## Performance considerations -To achieve the best performance with the `import` operation, consider these factors: +To achieve the best performance with the `import` operation, consider the following factors. -- **Use large files for import**. The optimal NDJSON file size for import is >=50MB (or >=20K resources, no upper limit). Consider combining smaller files together.+- **Use large files for import**. The optimal NDJSON file size for import is >=50 MB (or >=20 K resources, no upper limit). Consider combining smaller files together. -- **Import FHIR resource files as a single batch**. For optimal performance, import all the FHIR resource files that you want to ingest in the FHIR server in one `import` operation. Importing all the files in one operation reduces the overhead of creating and managing multiple import jobs. For optimal performance total size of files in single import should be large (>=100GB or >=100M resources, no upper limit).+- **Import FHIR resource files as a single batch**. For optimal performance, import all the FHIR resource files that you want to ingest in the FHIR server in one `import` operation. Importing all the files in one operation reduces the overhead of creating and managing multiple import jobs. Optimally, the total size of files in a single import should be large (>=100 GB or >=100M resources, no upper limit). -- **Limit the number of parallel import jobs**. You can run multiple `import` jobs at the same time, but running multiple jobs might affect the overall throughput of the `import` operation. +- **Limit the number of parallel import jobs**. You can run multiple `import` jobs at the same time, but might affect the overall throughput of the `import` operation. ## Perform the import operation Content-Type:application/fhir+json #### Body +The following tables describe the body parameters and inputs. + | Parameter name | Description | Cardinality | Accepted values | | -- | -- | -- | -- | | `inputFormat`| String that represents the name of the data source format. Only FHIR NDJSON files are supported. | 1..1 | `application/fhir+ndjson` | | `mode`| Import mode value. | 1..1 | For an initial-mode import, use the `InitialLoad` mode value. For incremental-mode import, use the `IncrementalLoad` mode value. If you don't provide a mode value, the `IncrementalLoad` mode value is used by default. |-| `allowNegativeVersions`| Allows FHIR server assigning negative versions for resource records with explicit lastUpdated value and no version specified when input does not fit in contiguous space of positive versions existing in the store. | 0..1 | To enable this feature pass true. By default it is false. | +| `allowNegativeVersions`| Allows FHIR server assigning negative versions for resource records with explicit lastUpdated value and no version specified when input doesn't fit in contiguous space of positive versions existing in the store. | 0..1 | To enable this feature, pass true. By default it's false. | | `input`| Details of the input files. | 1..* | A JSON array with the three parts described in the following table. | Registration of the `import` operation is implemented as an idempotent call. The To check the import status, make the REST call with the `GET` method to the `callback` link returned in the previous step. -Interpret the response by using this table: +Interpret the response by using this table. | Response code | Response body |Description | | -- | -- |-- | The following table describes the important fields in the response body: Incremental-mode import supports ingestion of soft-deleted resources. You need to use the extension to ingest soft-deleted resources in the FHIR service. -Add the extension to the resource to inform the FHIR service that the resource was soft-deleted: +Add the extension to the resource to inform the FHIR service that the resource was soft-deleted. ```ndjson {"resourceType": "Patient", "id": "example10", "meta": { "lastUpdated": "2023-10-27T04:00:00.000Z", "versionId": 4, "extension": [ { "url": "http://azurehealthcareapis.com/data-extensions/deleted-state", "valueString": "soft-deleted" } ] } } ``` -After the `import` operation finishes successfully, perform a history search on the resource to validate soft-deleted resources. If you know the ID of the deleted resource, use the URL pattern in this example: +After the `import` operation finishes successfully, perform a history search on the resource to validate soft-deleted resources. If you know the ID of the deleted resource, use the URL pattern in the following example. ```json <FHIR_URL>/<resource-type>/<resource-id>/_history ``` -If you don't know the ID of the resource, do a history search on the resource type: +If you don't know the ID of the resource, do a history search on the resource type. ```json <FHIR_URL>/<resource-type>/_history If you don't know the ID of the resource, do a history search on the resource ty Here are the error messages that occur if the `import` operation fails, along with recommended actions to resolve the problems. -#### 200 OK, but there's an error with the URL in the response +### 200 OK, but there's an error with the URL in the response -The `import` operation succeeds and returns `200 OK`. However, `error.url` is present in the response body. Files present at the `error.url` location contain JSON fragments similar to this example: +The `import` operation succeeds and returns `200 OK`. However, `error.url` is present in the response body. Files present at the `error.url` location contain JSON fragments similar to the following example. ```json { Cause: NDJSON files contain resources with conditional references that `import` Solution: Replace the conditional references to normal references in the NDJSON files. -#### 400 Bad Request +### 400 Bad Request The `import` operation fails and returns `400 Bad Request`. The response body contains diagnostic content The `import` operation fails and returns `400 Bad Request`. The response body co Solution: Verify that the link to the Azure storage is correct. Check the network and firewall settings to make sure that the FHIR server can access the storage. If your service is in a virtual network, ensure that the storage is in the same virtual network or in a virtual network peered with the FHIR service's virtual network. **SearchParameter resources cannot be processed by import**-Solution: The import operation returns a HTTP 400 error when a search parameter resource is ingested via the import process. This change is intended to prevent search parameters from being placed in an invalid state when ingested with an import operation. +Solution: The import operation returns an HTTP 400 error when a search parameter resource is ingested via the import process. This change is intended to prevent search parameters from being placed in an invalid state when ingested with an import operation. -#### 403 Forbidden +### 403 Forbidden -The `import` operation fails and returns `403 Forbidden`. The response body contains diagnostic content +The `import` operation fails and returns `403 Forbidden`. The response body contains diagnostic content. **import operation failed for reason: Server failed to authenticate the request. Make sure the value of Authorization header is formed correctly including the signature.** Cause: The FHIR service uses a managed identity for source storage authentication. This error indicates a missing or incorrect role assignment. Solution: Assign the **Storage Blob Data Contributor** role to the FHIR server. For more information, see [Assign Azure roles](../../role-based-access-control/role-assignments-portal.yml?tabs=current). -#### 500 Internal Server Error +### 500 Internal Server Error The `import` operation fails and returns `500 Internal Server Error`. The response body contains diagnostic content The `import` operation fails and returns `500 Internal Server Error`. The respon Cause: You reached the storage limit of the FHIR service. Solution: Reduce the size of your data or consider Azure API for FHIR, which has a higher storage limit. -#### 423 Locked +### 423 Locked **Behavior:** The `import` operation fails and returns `423 Locked`. The response body includes this content: Solution: Reduce the size of your data or consider Azure API for FHIR, which has ] } ```-**Cause:** The FHIR Service is configured with Initial import mode which will blocked other operations. +**Cause:** The FHIR Service is configured with Initial import mode which blocked other operations. -**Solution:** Switch the FHIR service's Initial import mode off, or select Incremental mode. +**Solution:** Switch off the FHIR service's Initial import mode, or select Incremental mode. ## Limitations - The maximum number of files allowed for each `import` operation is 10,000.-- The number of files ingested in the FHIR server with same lastUpdated field value upto milliseconds can't exceed beyond 10,000.-- Import operation is not supported for SearchParameter resource type.+- The number of files ingested in the FHIR server with same lastUpdated field value upto milliseconds can't exceed 10,000. +- Import operation isn't supported for SearchParameter resource type. - The import operation doesn't support conditional references in resources. ## Next steps |
| healthcare-apis | Configure Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/healthcare-apis/iot/configure-metrics.md | The screenshot shows an example of a line chart that monitors the **Number of In To keep your MedTech service metrics settings and view the metrics again later, pin them as a tile on an Azure dashboard. For steps, see [Create a dashboard in the Azure portal](../../azure-portal/azure-portal-dashboards.md). -To learn more about advanced metrics display and sharing options, see [Analyze metrics with Azure Monitor metrics explorer](../../azure-monitor/essentials/analyze-metrics.md). +To learn more about advanced metrics display and sharing options, see [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics). ## Next steps |
| healthcare-apis | How To Enable Diagnostic Settings | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/healthcare-apis/iot/how-to-enable-diagnostic-settings.md | In this article, learn how to enable diagnostic settings for the MedTech service 3. Under **Metrics**, select the **AllMetrics** option. > [!Note]- > To view a complete list of MedTech service metrics associated with **AllMetrics**, see [Supported metrics with Azure Monitor](../../azure-monitor/essentials/metrics-supported.md#microsofthealthcareapisworkspacesiotconnectors). + > To view a complete list of MedTech service metrics associated with **AllMetrics**, see [Supported metrics with Azure Monitor](/azure/azure-monitor/essentials/metrics-supported#microsofthealthcareapisworkspacesiotconnectors). 4. Under **Destination details**, select the destination or destinations you want to use for your exported MedTech service logs and metrics. In this example, we've selected an Azure Log Analytics workspace named *la-azuredocsdemo*. You'll select a destination of your own choosing. In this article, learn how to enable diagnostic settings for the MedTech service |Destination|Description| |--|--|- |[Azure Log Analytics workspace](../../azure-monitor/logs/log-analytics-workspace-overview.md)|Metrics are converted to log form. Sending the metrics to the Azure Monitor Logs store (which is searchable via Log Analytics) enables you to integrate them into queries, alerts, and visualizations with existing log data.| + |[Azure Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-workspace-overview)|Metrics are converted to log form. Sending the metrics to the Azure Monitor Logs store (which is searchable via Log Analytics) enables you to integrate them into queries, alerts, and visualizations with existing log data.| |[Azure storage account](../../storage/index.yml)|Archiving logs and metrics to an Azure storage account is useful for audit, static analysis, or backup. Compared to Azure Monitor Logs and a Log Analytics workspace, Azure storage is less expensive, and logs can be kept there indefinitely.| |[Azure event hub](../../event-hubs/index.yml)|Sending logs and metrics to an event hub allows you to stream data to external systems such as third-party Security Information and Event Managements (SIEMs) and other Log Analytics solutions.| |Azure Monitor partner integrations|Specialized integrations between Azure Monitor and other non-Microsoft monitoring platforms. Useful when you're already using one of the partners.| In this article, learn how to enable diagnostic settings for the MedTech service :::image type="content" source="media/how-to-enable-diagnostic-settings/view-and-edit-diagnostic-settings.png" alt-text="Screenshot of Diagnostic settings options." lightbox="media/how-to-enable-diagnostic-settings/view-and-edit-diagnostic-settings.png"::: > [!TIP]- > To learn about how to work with diagnostic settings, see [Diagnostic settings in Azure Monitor](../../azure-monitor/essentials/diagnostic-settings.md?tabs=portal). + > To learn about how to work with diagnostic settings, see [Diagnostic settings in Azure Monitor](/azure/azure-monitor/essentials/diagnostic-settings?tabs=portal). > - > To learn about how to work with diagnostic logs, see [Overview of Azure platform logs](../../azure-monitor/essentials/platform-logs-overview.md). + > To learn about how to work with diagnostic logs, see [Overview of Azure platform logs](/azure/azure-monitor/essentials/platform-logs-overview). ## Use the Azure Log Analytics workspace to view the MedTech service logs If you choose to include your Log Analytics workspace as a destination option fo > [!WARNING] > The above custom query is not saved and will have to be recreated if you leave your Log Analytics workspace without saving the custom query. >-> To learn how to save a custom query in Log Analytics, see [Save a query in Azure Monitor Log Analytics](../../azure-monitor/logs/save-query.md) +> To learn how to save a custom query in Log Analytics, see [Save a query in Azure Monitor Log Analytics](/azure/azure-monitor/logs/save-query) > [!TIP]-> To learn how to use the Log Analytics workspace, see [Azure Log Analytics workspace](../../azure-monitor/logs/log-analytics-workspace-overview.md). +> To learn how to use the Log Analytics workspace, see [Azure Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-workspace-overview). > > For assistance troubleshooting MedTech service errors, see [Troubleshoot errors using the MedTech service logs](troubleshoot-errors-logs.md). The MedTech service comes with predefined queries that can be used anytime in yo > [!WARNING] > Any changes that you've made to the predefined queries are not saved and will have to be recreated if you leave your Log Analytics workspace without saving custom changes you've made to the predefined queries. >-> To learn how to save a query in Log Analytics, see [Save a query in Azure Monitor Log Analytics](../../azure-monitor/logs/save-query.md) +> To learn how to save a query in Log Analytics, see [Save a query in Azure Monitor Log Analytics](/azure/azure-monitor/logs/save-query) > [!TIP]-> To learn how to use the Log Analytics workspace, see [Azure Log Analytics workspace](../../azure-monitor/logs/log-analytics-workspace-overview.md). +> To learn how to use the Log Analytics workspace, see [Azure Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-workspace-overview). > > For assistance troubleshooting MedTech service errors, see [Troubleshoot errors using the MedTech service logs](troubleshoot-errors-logs.md). |
| healthcare-apis | How To Use Monitoring And Health Checks Tabs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/healthcare-apis/iot/how-to-use-monitoring-and-health-checks-tabs.md | In this article, learn how to use the MedTech service monitoring and health chec :::image type="content" source="media\how-to-use-monitoring-and-health-checks-tabs\pin-metrics-to-dashboard.png" alt-text="Screenshot the MedTech service monitoring tile with red box around the pin icon." lightbox="media\how-to-use-monitoring-and-health-checks-tabs\pin-metrics-to-dashboard.png"::: > [!TIP]- > To learn more about advanced metrics display and sharing options, see [Analyze metrics with Azure Monitor metrics explorer](../../azure-monitor/essentials/analyze-metrics.md). + > To learn more about advanced metrics display and sharing options, see [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics). ## Available metrics for the MedTech service |
| healthcare-apis | Logging | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/healthcare-apis/logging.md | Here's an example of the AuditLog: [Enable diagnostic settings for the MedTech service](./../healthcare-apis/iot/how-to-enable-diagnostic-settings.md) -[Use Azure Monitor logs](../azure-monitor/essentials/platform-logs-overview.md). +[Use Azure Monitor logs](/azure/azure-monitor/essentials/platform-logs-overview). -[Supported metrics with Azure Monitor](../azure-monitor/essentials/metrics-supported.md) +[Supported metrics with Azure Monitor](/azure/azure-monitor/essentials/metrics-supported) |
| healthcare-apis | Workspace Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/healthcare-apis/workspace-overview.md | Some features are configured at the workspace level and apply to all child servi ### Application monitoring -Azure Monitor helps you maximize the availability and performance of your applications and services. It delivers a comprehensive solution for collecting, analyzing, and acting on telemetry from your cloud and on-premises environments. This information provides you insights to how your applications are performing and lets you proactively identify and resolve issues affecting them and the resources they depend on. For information about Azure Monitor, see [Azure Monitor overview](../azure-monitor/index.yml) documentation. +Azure Monitor helps you maximize the availability and performance of your applications and services. It delivers a comprehensive solution for collecting, analyzing, and acting on telemetry from your cloud and on-premises environments. This information provides you insights to how your applications are performing and lets you proactively identify and resolve issues affecting them and the resources they depend on. For information about Azure Monitor, see [Azure Monitor overview](/azure/azure-monitor/) documentation. ### Azure role-based access control |
| hpc-cache | Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/hpc-cache/metrics.md | The cache's **Overview** page shows graphs for some basic cache statistics - cac  -These charts are part of Azure's built-in monitoring and analytics tools. Learn more about these capabilities from the [Azure Monitor documentation](../azure-monitor/essentials/monitor-azure-resource.md). +These charts are part of Azure's built-in monitoring and analytics tools. Learn more about these capabilities from the [Azure Monitor documentation](/azure/azure-monitor/essentials/monitor-azure-resource). ## Metrics page These values can be useful when debugging connection issues between clients and ## Next steps -* Learn more about [Azure metrics and statistics tools](../azure-monitor/index.yml) +* Learn more about [Azure metrics and statistics tools](/azure/azure-monitor/) * [Manage the cache](hpc-cache-manage.md) |
| internet-peering | Walkthrough Device Maintenance Notification | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/internet-peering/walkthrough-device-maintenance-notification.md | Service Health supports forwarding rules, so you can set up your own alerts when Azure Peering Service notifications are forwarded to you based on your alert rule whenever maintenance events start, and whenever they're resolved. -For more information on the notification platform of Service Health, see [Create activity log alerts on service notifications using the Azure portal](../service-health/alerts-activity-log-service-notifications-portal.md). +For more information on the notification platform of Service Health, see [Create activity log alerts on service notifications using the Azure portal](/azure/service-health/alerts-activity-log-service-notifications-portal). ## Receive notifications for legacy peerings |
| iot-central | Howto Configure Rules | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-central/core/howto-configure-rules.md | If you have one or more webhooks created and saved before **3 April 2020**, dele ## Create an Azure Monitor group action -This section describes how to use [Azure Monitor](../../azure-monitor/overview.md) *action groups* to attach multiple actions to an IoT Central rule. You can attach an action group to multiple rules. An [action group](../../azure-monitor/alerts/action-groups.md) is a collection of notification preferences defined by the owner of an Azure subscription. +This section describes how to use [Azure Monitor](/azure/azure-monitor/overview) *action groups* to attach multiple actions to an IoT Central rule. You can attach an action group to multiple rules. An [action group](/azure/azure-monitor/alerts/action-groups) is a collection of notification preferences defined by the owner of an Azure subscription. -You can [create and manage action groups in the Azure portal](../../azure-monitor/alerts/action-groups.md) or with an [Azure Resource Manager template](../../azure-monitor/alerts/action-groups-create-resource-manager-template.md). +You can [create and manage action groups in the Azure portal](/azure/azure-monitor/alerts/action-groups) or with an [Azure Resource Manager template](/azure/azure-monitor/alerts/action-groups-create-resource-manager-template). An action group can: |
| iot-central | Howto Manage And Monitor Iot Central | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-central/core/howto-manage-and-monitor-iot-central.md | You can use the set of metrics provided by IoT Central to assess the health of d > [!NOTE] > IoT Central applications also have an internal [audit log](howto-use-audit-logs.md) to track activity within the application. -Metrics are enabled by default for your IoT Central application and you access them from the [Azure portal](https://portal.azure.com/). The [Azure Monitor data platform exposes these metrics](../../azure-monitor/essentials/data-platform-metrics.md) and provides several ways for you to interact with them. For example, you can use charts in the Azure portal, a REST API, or queries in PowerShell or the Azure CLI. +Metrics are enabled by default for your IoT Central application and you access them from the [Azure portal](https://portal.azure.com/). The [Azure Monitor data platform exposes these metrics](/azure/azure-monitor/essentials/data-platform-metrics) and provides several ways for you to interact with them. For example, you can use charts in the Azure portal, a REST API, or queries in PowerShell or the Azure CLI. [Azure role based access control](../../role-based-access-control/overview.md) manages access to metrics in the Azure portal. Use the Azure portal to add users to the IoT Central application/resource group/subscription to grant them access. You must add a user in the portal even they're already added to the IoT Central application. Use [Azure built-in roles](../../role-based-access-control/built-in-roles.md) for finer grained access control. ### View metrics in the Azure portal -The following example **Metrics** page shows a plot of the number of devices connected to your IoT Central application. For a list of the metrics that are currently available for IoT Central, see [Supported metrics with Azure Monitor](../../azure-monitor/essentials/metrics-supported.md#microsoftiotcentraliotapps). +The following example **Metrics** page shows a plot of the number of devices connected to your IoT Central application. For a list of the metrics that are currently available for IoT Central, see [Supported metrics with Azure Monitor](/azure/azure-monitor/essentials/metrics-supported#microsoftiotcentraliotapps). To view IoT Central metrics in the portal: To view IoT Central metrics in the portal: ### Export logs and metrics -Use the **Diagnostics settings** page to configure exporting metrics and logs to different destinations. To learn more, see [Diagnostic settings in Azure Monitor](../../azure-monitor/essentials/diagnostic-settings.md). +Use the **Diagnostics settings** page to configure exporting metrics and logs to different destinations. To learn more, see [Diagnostic settings in Azure Monitor](/azure/azure-monitor/essentials/diagnostic-settings). ### Analyze logs and metrics -Use the **Workbooks** page to analyze logs and create visual reports. To learn more, see [Azure Workbooks](../../azure-monitor/visualize/workbooks-overview.md). +Use the **Workbooks** page to analyze logs and create visual reports. To learn more, see [Azure Workbooks](/azure/azure-monitor/visualize/workbooks-overview). ### Metrics and invoices |
| iot-central | Howto Use Audit Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-central/core/howto-use-audit-logs.md | The built-in **App Administrator** role has access to the audit logs by default. You can export the audit log records to various destinations for long-term storage, detailed analysis, or integration with other logs. For more information, see [Export IoT data](howto-export-to-event-hubs.md). -To send audit logs to [Log Analytics in Azure Monitor](../../azure-monitor/logs/log-analytics-overview.md), use IoT Central data export to send the audit logs to Event Hubs, and then use an Azure Function to add the audit log data to Log Analytics. +To send audit logs to [Log Analytics in Azure Monitor](/azure/azure-monitor/logs/log-analytics-overview), use IoT Central data export to send the audit logs to Event Hubs, and then use an Azure Function to add the audit log data to Log Analytics. ## Next steps |
| iot-dps | Monitor Iot Dps | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-dps/monitor-iot-dps.md | To learn more about viewing metrics and setting up alerts on your DPS instance, ### Analyzing metrics -You can analyze metrics for DPS with metrics from other Azure services using metrics explorer by opening **Metrics** from the **Azure Monitor** menu. See [Analyze metrics with Azure Monitor metrics explorer](../azure-monitor/essentials/analyze-metrics.md) for details on using this tool. +You can analyze metrics for DPS with metrics from other Azure services using metrics explorer by opening **Metrics** from the **Azure Monitor** menu. See [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics) for details on using this tool. In Azure portal, you can select **Metrics** under **Monitoring** on the left-pane of your DPS instance to open metrics explorer scoped, by default, to the platform metrics emitted by your instance: :::image type="content" source="media/monitor-iot-dps/metrics-portal.png" alt-text="Screenshot showing the metrics explorer page for a DPS instance." border="true"::: -For a list of the platform metrics collected for DPS, see [Metrics](monitor-iot-dps-reference.md#metrics). For reference, you can see a list of [all resource metrics supported in Azure Monitor](../azure-monitor/essentials/metrics-supported.md). +For a list of the platform metrics collected for DPS, see [Metrics](monitor-iot-dps-reference.md#metrics). For reference, you can see a list of [all resource metrics supported in Azure Monitor](/azure/azure-monitor/essentials/metrics-supported). [!INCLUDE [horz-monitor-resource-logs](~/reusable-content/ce-skilling/azure/includes/azure-monitor/horizontals/horz-monitor-resource-logs.md)] In Azure portal, you can select **Logs** under **Monitoring** on the left-pane o :::image type="content" source="media/monitor-iot-dps/logs-portal.png" alt-text="Screenshot shows the Logs page for a DPS instance."::: > [!IMPORTANT]-> When you select **Logs** from the DPS menu, Log Analytics is opened with the query scope set to the current DPS instance. This means that log queries will only include data from that resource. If you want to run a query that includes data from other DPS instances or data from other Azure services, select **Logs** from the **Azure Monitor** menu. See [Log query scope and time range in Azure Monitor Log Analytics](../azure-monitor/logs/scope.md) for details. +> When you select **Logs** from the DPS menu, Log Analytics is opened with the query scope set to the current DPS instance. This means that log queries will only include data from that resource. If you want to run a query that includes data from other DPS instances or data from other Azure services, select **Logs** from the **Azure Monitor** menu. See [Log query scope and time range in Azure Monitor Log Analytics](/azure/azure-monitor/logs/scope) for details. Run queries against the **AzureDiagnostics** table to see the resource logs collected for the diagnostic settings you created for your DPS instance. Run queries against the **AzureDiagnostics** table to see the resource logs coll AzureDiagnostics ``` -All resource logs in Azure Monitor have the same fields followed by service-specific fields. The common schema is outlined in [Azure Monitor resource log schema](../azure-monitor/essentials/resource-logs-schema.md) The schema for DPS resource logs is found in [Resource logs in the Monitoring Azure IoT Hub Device Provisioning Service data reference](monitor-iot-dps-reference.md#resource-logs). +All resource logs in Azure Monitor have the same fields followed by service-specific fields. The common schema is outlined in [Azure Monitor resource log schema](/azure/azure-monitor/essentials/resource-logs-schema) The schema for DPS resource logs is found in [Resource logs in the Monitoring Azure IoT Hub Device Provisioning Service data reference](monitor-iot-dps-reference.md#resource-logs). ### Using Log Analytics to view and resolve errors |
| iot-edge | How To Add Custom Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-edge/how-to-add-custom-metrics.md | InsightsMetrics | where Name == 'replace-with-custom-metric-name' ``` -Once you have confirmed ingestion, you can either create a new workbook or augment an existing workbook. Use [workbooks docs](../azure-monitor/visualize/workbooks-overview.md) and queries from the curated [IoT Edge workbooks](how-to-explore-curated-visualizations.md) as a guide. +Once you have confirmed ingestion, you can either create a new workbook or augment an existing workbook. Use [workbooks docs](/azure/azure-monitor/visualize/workbooks-overview) and queries from the curated [IoT Edge workbooks](how-to-explore-curated-visualizations.md) as a guide. -When happy with the results, you can [share the workbook](../azure-monitor/visualize/workbooks-overview.md#access-control) with your team or [deploy them programmatically](../azure-monitor/visualize/workbooks-automate.md) as part of your organization's resource deployments. +When happy with the results, you can [share the workbook](/azure/azure-monitor/visualize/workbooks-overview#access-control) with your team or [deploy them programmatically](/azure/azure-monitor/visualize/workbooks-automate) as part of your organization's resource deployments. ## Next steps |
| iot-edge | How To Collect And Transport Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-edge/how-to-collect-and-transport-metrics.md | All configuration for the metrics-collector is done using environment variables. |-|-| | `ResourceId` | Resource ID of the IoT hub that the device communicates with. For more information, see the [Resource ID](#resource-id) section. <br><br> **Required** <br><br> Default value: *none* | | `UploadTarget` | Controls whether metrics are sent directly to Azure Monitor over HTTPS or to IoT Hub as D2C messages. For more information, see [upload target](#upload-target). <br><br>Can be either **AzureMonitor** or **IoTMessage** <br><br> **Not required** <br><br> Default value: *AzureMonitor* |-| `LogAnalyticsWorkspaceId` | [Log Analytics workspace ID](../azure-monitor/agents/agent-windows.md#workspace-id-and-key). <br><br>**Required** only if *UploadTarget* is *AzureMonitor* <br><br>Default value: *none* | -| `LogAnalyticsSharedKey` | [Log Analytics workspace key](../azure-monitor/agents/agent-windows.md#workspace-id-and-key). <br><br>**Required** only if *UploadTarget* is *AzureMonitor* <br><br> Default value: *none* | +| `LogAnalyticsWorkspaceId` | [Log Analytics workspace ID](/azure/azure-monitor/agents/agent-windows#workspace-id-and-key). <br><br>**Required** only if *UploadTarget* is *AzureMonitor* <br><br>Default value: *none* | +| `LogAnalyticsSharedKey` | [Log Analytics workspace key](/azure/azure-monitor/agents/agent-windows#workspace-id-and-key). <br><br>**Required** only if *UploadTarget* is *AzureMonitor* <br><br> Default value: *none* | | `ScrapeFrequencyInSecs` | Recurring time interval in seconds at which to collect and transport metrics.<br><br> Example: *600* <br><br> **Not required** <br><br> Default value: *300* | | `MetricsEndpointsCSV` | Comma-separated list of endpoints to collect Prometheus metrics from. All module endpoints to collect metrics from must appear in this list.<br><br> Example: *http://edgeAgent:9600/metrics, http://edgeHub:9600/metrics, http://MetricsSpewer:9417/metrics* <br><br> **Not required** <br><br> Default value: *http://edgeHub:9600/metrics, http://edgeAgent:9600/metrics* | | `AllowedMetrics` | List of metrics to collect, all other metrics are ignored. Set to an empty string to disable. For more information, see [allow and disallow lists](#allow-and-disallow-lists). <br><br>Example: *metricToScrape{quantile=0.99}[endpoint=http://MetricsSpewer:9417/metrics]*<br><br> **Not required** <br><br> Default value: *empty* | All configuration for the metrics-collector is done using environment variables. |-|-| | `ResourceId` | Resource ID of the IoT Central application that the device communicates with. For more information, see the [Resource ID](#resource-id) section. <br><br> **Required** <br><br> Default value: *none* | | `UploadTarget` | Controls whether metrics are sent directly to Azure Monitor over HTTPS or to IoT Central as D2C messages. For more information, see [upload target](#upload-target). <br><br>Can be either **AzureMonitor** or **IoTMessage** <br><br> **Not required** <br><br> Default value: *AzureMonitor* |-| `LogAnalyticsWorkspaceId` | [Log Analytics workspace ID](../azure-monitor/agents/agent-windows.md#workspace-id-and-key). <br><br>**Required** only if *UploadTarget* is *AzureMonitor* <br><br>Default value: *none* | -| `LogAnalyticsSharedKey` | [Log Analytics workspace key](../azure-monitor/agents/agent-windows.md#workspace-id-and-key). <br><br>**Required** only if *UploadTarget* is *AzureMonitor* <br><br> Default value: *none* | +| `LogAnalyticsWorkspaceId` | [Log Analytics workspace ID](/azure/azure-monitor/agents/agent-windows#workspace-id-and-key). <br><br>**Required** only if *UploadTarget* is *AzureMonitor* <br><br>Default value: *none* | +| `LogAnalyticsSharedKey` | [Log Analytics workspace key](/azure/azure-monitor/agents/agent-windows#workspace-id-and-key). <br><br>**Required** only if *UploadTarget* is *AzureMonitor* <br><br> Default value: *none* | | `ScrapeFrequencyInSecs` | Recurring time interval in seconds at which to collect and transport metrics.<br><br> Example: *600* <br><br> **Not required** <br><br> Default value: *300* | | `MetricsEndpointsCSV` | Comma-separated list of endpoints to collect Prometheus metrics from. All module endpoints to collect metrics from must appear in this list.<br><br> Example: *http://edgeAgent:9600/metrics, http://edgeHub:9600/metrics, http://MetricsSpewer:9417/metrics* <br><br> **Not required** <br><br> Default value: *http://edgeHub:9600/metrics, http://edgeAgent:9600/metrics* | | `AllowedMetrics` | List of metrics to collect, all other metrics are ignored. Set to an empty string to disable. For more information, see [allow and disallow lists](#allow-and-disallow-lists). <br><br>Example: *metricToScrape{quantile=0.99}[endpoint=http://MetricsSpewer:9417/metrics]*<br><br> **Not required** <br><br> Default value: *empty* | |
| iot-edge | How To Create Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-edge/how-to-create-alerts.md | -Use [Azure Monitor Log alerts](../azure-monitor/alerts/alerts-unified-log.md) to monitor IoT Edge devices at scale. As highlighted in the [solution architecture](how-to-collect-and-transport-metrics.md#architecture), Azure Monitor Log Analytics is used as the metrics database. This integration unlocks powerful and flexible alerting capabilities using resource-centric log alerts. +Use [Azure Monitor Log alerts](/azure/azure-monitor/alerts/alerts-unified-log) to monitor IoT Edge devices at scale. As highlighted in the [solution architecture](how-to-collect-and-transport-metrics.md#architecture), Azure Monitor Log Analytics is used as the metrics database. This integration unlocks powerful and flexible alerting capabilities using resource-centric log alerts. > [!IMPORTANT] > This feature is currently only available for IoT Hub and not for IoT Central. ## Create an alert rule -You can [create a log alert rule](../azure-monitor/alerts/alerts-log.md) for monitoring a broad range of conditions across your device fleet. +You can [create a log alert rule](/azure/azure-monitor/alerts/alerts-log) for monitoring a broad range of conditions across your device fleet. Sample [KQL](/azure/data-explorer/kusto/query/) alert queries are provided under the IoT Hub resource. Queries that operate on metrics data from edge devices are prefixed with *IoT Edge:* in their title. Use these examples as-is or modify them as needed to create a query for your exact need. All the example alert rule queries aggregate values by device ID. This grouping ### Choose notification preferences -Configure your notification preferences in an [action group](../azure-monitor/alerts/action-groups.md) and associate it with an alert rule when creating an alert rule. +Configure your notification preferences in an [action group](/azure/azure-monitor/alerts/action-groups) and associate it with an alert rule when creating an alert rule. ## Select alert rule scope |
| iot-edge | How To Explore Curated Visualizations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-edge/how-to-explore-curated-visualizations.md | Select a severity row to see alerts details. The **Alert rule** link takes you t ## Customize workbooks -[Azure Monitor workbooks](../azure-monitor/visualize/workbooks-overview.md) are very customizable. You can edit the public templates to suit your requirements. All the visualizations are driven by resource-centric [Kusto Query Language](/azure/data-explorer/kusto/query/) queries on the [InsightsMetrics](/azure/azure-monitor/reference/tables/insightsmetrics) table. +[Azure Monitor workbooks](/azure/azure-monitor/visualize/workbooks-overview) are very customizable. You can edit the public templates to suit your requirements. All the visualizations are driven by resource-centric [Kusto Query Language](/azure/data-explorer/kusto/query/) queries on the [InsightsMetrics](/azure/azure-monitor/reference/tables/insightsmetrics) table. To begin customizing a workbook, first enter editing mode. Select the **Edit** button in the menu bar of the workbook. Curated workbooks make extensive use of workbook groups. You may need to select **Edit** on several nested groups before being able to view a visualization query. -Save your changes as a new workbook. You can [share](../azure-monitor/visualize/workbooks-overview.md#access-control) the saved workbook with your team or [deploy them programmatically](../azure-monitor/visualize/workbooks-automate.md) as part of your organization's resource deployments. +Save your changes as a new workbook. You can [share](/azure/azure-monitor/visualize/workbooks-overview#access-control) the saved workbook with your team or [deploy them programmatically](/azure/azure-monitor/visualize/workbooks-automate) as part of your organization's resource deployments. ## Next steps |
| iot-edge | How To Observability | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-edge/how-to-observability.md | The La Ni├▒a service uses [OpenTelemetry](https://opentelemetry.io) to produce a IoT Edge modules `Temperature Sensor` and `Filter` export the logs and tracing data via OTLP (OpenTelemetry Protocol) to the [OpenTelemetryCollector](https://opentelemetry.io/docs/collector/) module, running on the same edge device. The `OpenTelemetryCollector` module, in its turn, exports logs and traces to Azure Monitor Application Insights service. -The Azure .NET Function sends the tracing data to Application Insights with [Azure Monitor Open Telemetry direct exporter](../azure-monitor/app/opentelemetry-enable.md). It also sends correlated logs directly to Application Insights with a configured ILogger instance. +The Azure .NET Function sends the tracing data to Application Insights with [Azure Monitor Open Telemetry direct exporter](/azure/azure-monitor/app/opentelemetry-enable). It also sends correlated logs directly to Application Insights with a configured ILogger instance. -The Java backend function uses [OpenTelemetry auto-instrumentation Java agent](../azure-monitor/app/opentelemetry-enable.md?tabs=java) to produce and export tracing data and correlated logs to the Application Insights instance. +The Java backend function uses [OpenTelemetry auto-instrumentation Java agent](/azure/azure-monitor/app/opentelemetry-enable?tabs=java) to produce and export tracing data and correlated logs to the Application Insights instance. By default, IoT Edge modules on the devices of the La Ni├▒a service are configured to not produce any tracing data and the [logging level](/aspnet/core/fundamentals/logging) is set to `Information`. The amount of produced tracing data is regulated by a [ratio based sampler](https://github.com/open-telemetry/opentelemetry-dotnet/blob/main/src/OpenTelemetry/Trace/Sampler/TraceIdRatioBasedSampler.cs). The sampler is configured with a desired [probability](https://github.com/open-telemetry/opentelemetry-dotnet/blob/bdcf942825915666dfe87618282d72f061f7567e/src/OpenTelemetry/Trace/TraceIdRatioBasedSampler.cs#L35) of a given activity to be included in a trace. By default, the probability is set to 0. With that in place, the devices don't flood the Azure Monitor with the detailed observability data if it's not requested. |
| iot-edge | How To Troubleshoot Monitoring And Faq | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-edge/how-to-troubleshoot-monitoring-and-faq.md | You could use [built-in log pull features](how-to-retrieve-iot-edge-logs.md). A ## Why can't I see device metrics in the metrics page in Azure portal? -Azure Monitor's [native metrics](../azure-monitor/essentials/data-platform-metrics.md) technology doesn't yet support Prometheus data format directly. Log-based metrics are currently better suited for IoT Edge metrics because of: +Azure Monitor's [native metrics](/azure/azure-monitor/essentials/data-platform-metrics) technology doesn't yet support Prometheus data format directly. Log-based metrics are currently better suited for IoT Edge metrics because of: * Native support for Prometheus metrics format via the standard *InsightsMetrics* table. * Advanced data processing via [KQL](/azure/data-explorer/kusto/query/) for visualizations and alerts. |
| iot-hub-device-update | Monitor Device Update Iot Hub | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-hub-device-update/monitor-device-update-iot-hub.md | Last updated 9/08/2022 When you have critical applications and business processes relying on Azure resources, you want to monitor those resources for their availability, performance, and operation. -This article describes the monitoring data generated by Device Update for IoT Hub (DU). Device Update uses [Azure Monitor](../azure-monitor/overview.md). If you are unfamiliar with the features of Azure Monitor common to all Azure services that use it, read [Monitoring Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md). +This article describes the monitoring data generated by Device Update for IoT Hub (DU). Device Update uses [Azure Monitor](/azure/azure-monitor/overview). If you are unfamiliar with the features of Azure Monitor common to all Azure services that use it, read [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource). ## Activity log Collection and Routing In Azure portal, you can select **Activity Logs** in the Device Update account m To create a diagnostic setting to send it to a destination of your choice (Log Analytics workspace, storage account, Event Hub, etc.), select **Export Activity Logs** followed by **Add diagnostic setting** and scope it to the logs and platform metrics emitted by your account. -See [Create diagnostic setting to collect platform logs and metrics in Azure](../azure-monitor/essentials/diagnostic-settings.md) for the detailed process for creating a diagnostic setting using the Azure portal, CLI, or PowerShell. When you create a diagnostic setting, you specify which categories of logs to collect. +See [Create diagnostic setting to collect platform logs and metrics in Azure](/azure/azure-monitor/essentials/diagnostic-settings) for the detailed process for creating a diagnostic setting using the Azure portal, CLI, or PowerShell. When you create a diagnostic setting, you specify which categories of logs to collect. ## Analyzing logs To route data to Azure Monitor Logs, you must create a diagnostic setting to sen In Azure portal, you can select **Logs** under **Monitoring** on the left-pane of your Device Update account to perform Log Analytics queries scoped, by default, to the logs and metrics collected in Azure Monitor Logs for your account. -All resource logs in Azure Monitor have the same fields followed by service-specific fields. The common schema is outlined in [Azure Monitor resource log schema](../azure-monitor/essentials/resource-logs-schema.md). +All resource logs in Azure Monitor have the same fields followed by service-specific fields. The common schema is outlined in [Azure Monitor resource log schema](/azure/azure-monitor/essentials/resource-logs-schema). -The [Activity log](../azure-monitor/essentials/activity-log.md) is a type of platform log in Azure that provides insight into subscription-level events. You can view it independently or route it to Azure Monitor Logs, where you can do much more complex queries using Log Analytics. +The [Activity log](/azure/azure-monitor/essentials/activity-log) is a type of platform log in Azure that provides insight into subscription-level events. You can view it independently or route it to Azure Monitor Logs, where you can do much more complex queries using Log Analytics. ## Alerts -Azure Monitor alerts proactively notify you when important conditions are found in your monitoring data. They allow you to identify and address issues in your system before your customers notice them. You can set alerts on [logs](../azure-monitor/alerts/alerts-unified-log.md) and the [activity log](../azure-monitor/alerts/activity-log-alerts.md). Different types of alerts have benefits and drawbacks. +Azure Monitor alerts proactively notify you when important conditions are found in your monitoring data. They allow you to identify and address issues in your system before your customers notice them. You can set alerts on [logs](/azure/azure-monitor/alerts/alerts-unified-log) and the [activity log](/azure/azure-monitor/alerts/activity-log-alerts). Different types of alerts have benefits and drawbacks. ## Next steps -- See [Monitoring Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md) for details on monitoring Azure resources.+- See [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) for details on monitoring Azure resources. |
| iot-hub | Device Twins Dotnet | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-hub/device-twins-dotnet.md | - Title: Get started with Azure IoT Hub device twins (.NET)- -description: How to use Azure IoT Hub device twins and the Azure IoT SDKs for .NET to create and simulate devices, add tags to device twins, and execute IoT Hub queries. ----- Previously updated : 02/17/2023----# Get started with device twins (.NET) ---This article shows you how to: --* Use a simulated device app to report its connectivity channel as a reported property on the device twin. --* Query devices from your back-end app using filters on the tags and properties previously created. --In this article, you create two .NET console apps: --* **AddTagsAndQuery**: a back-end app that adds tags and queries device twins. --* **ReportConnectivity**: a simulated device app that connects to your IoT hub and reports its connectivity condition. --> [!NOTE] -> See [Azure IoT SDKs](iot-hub-devguide-sdks.md) for more information about the SDK tools available to build both device and back-end apps. --## Prerequisites --* Visual Studio. --* An IoT hub in your Azure subscription. If you don't have a hub yet, you can follow the steps in [Create an IoT hub](create-hub.md). --* A device registered in your IoT hub. If you don't have a device in your IoT hub, follow the steps in [Register a device](create-connect-device.md#register-a-device). --* Make sure that port 8883 is open in your firewall. The device sample in this article uses MQTT protocol, which communicates over port 8883. This port may be blocked in some corporate and educational network environments. For more information and ways to work around this issue, see [Connecting to IoT Hub (MQTT)](../iot/iot-mqtt-connect-to-iot-hub.md#connecting-to-iot-hub). --## Get the IoT hub connection string ----## Create a device app that updates reported properties --In this section, you create a .NET console app that connects to your hub as **myDeviceId**, and then updates its reported properties to confirm that it's connected using a cellular network. --1. Open Visual Studio and select **Create new project**. --1. Choose **Console App (.NET Framework)**, then select **Next**. --1. In **Configure your new project**, name the project **ReportConnectivity**, then select **Next**. --1. In Solution Explorer, right-click the **ReportConnectivity** project, and then select **Manage NuGet Packages**. --1. Keep the default .NET Framework, then select **Create** to create the project. --1. Select **Browse** and search for and choose **Microsoft.Azure.Devices.Client**. Select **Install**. -- This step downloads, installs, and adds a reference to the [Azure IoT device SDK](https://www.nuget.org/packages/Microsoft.Azure.Devices.Client/) NuGet package and its dependencies. --1. Add the following `using` statements at the top of the **Program.cs** file: -- ```csharp - using Microsoft.Azure.Devices.Client; - using Microsoft.Azure.Devices.Shared; - using Newtonsoft.Json; - ``` --1. Add the following fields to the **Program** class. Replace `{device connection string}` with the device connection string you saw when you registered a device in the IoT Hub: -- ```csharp - static string DeviceConnectionString = "HostName=<yourIotHubName>.azure-devices.net;DeviceId=<yourIotDeviceName>;SharedAccessKey=<yourIotDeviceAccessKey>"; - static DeviceClient Client = null; - ``` --1. Add the following method to the **Program** class: -- ```csharp - public static async void InitClient() - { - try - { - Console.WriteLine("Connecting to hub"); - Client = DeviceClient.CreateFromConnectionString(DeviceConnectionString, - TransportType.Mqtt); - Console.WriteLine("Retrieving twin"); - await Client.GetTwinAsync(); - } - catch (Exception ex) - { - Console.WriteLine(); - Console.WriteLine("Error in sample: {0}", ex.Message); - } - } - ``` -- The **Client** object exposes all the methods you require to interact with device twins from the device. The code shown above initializes the **Client** object, and then retrieves the device twin for **myDeviceId**. --1. Add the following method to the **Program** class: -- ```csharp - public static async void ReportConnectivity() - { - try - { - Console.WriteLine("Sending connectivity data as reported property"); -- TwinCollection reportedProperties, connectivity; - reportedProperties = new TwinCollection(); - connectivity = new TwinCollection(); - connectivity["type"] = "cellular"; - reportedProperties["connectivity"] = connectivity; - await Client.UpdateReportedPropertiesAsync(reportedProperties); - } - catch (Exception ex) - { - Console.WriteLine(); - Console.WriteLine("Error in sample: {0}", ex.Message); - } - } - ``` -- The code above updates the reported property of **myDeviceId** with the connectivity information. --1. Finally, add the following lines to the **Main** method: -- ```csharp - try - { - InitClient(); - ReportConnectivity(); - } - catch (Exception ex) - { - Console.WriteLine(); - Console.WriteLine("Error in sample: {0}", ex.Message); - } - Console.WriteLine("Press Enter to exit."); - Console.ReadLine(); - ``` --1. In Solution Explorer, right-click on your solution, and select **Set StartUp Projects**. --1. In **Common Properties** > **Startup Project**, select **Multiple startup projects**. For **ReportConnectivity**, select **Start** as the **Action**. Select **OK** to save your changes. --1. Run this app by right-clicking the **ReportConnectivity** project and selecting **Debug**, then **Start new instance**. You should see the app getting the twin information, and then sending connectivity as a ***reported property***. --  -- After the device reported its connectivity information, it should appear in both queries. --1. Right-click the **AddTagsAndQuery** project and select **Debug** > **Start new instance** to run the queries again. This time, **myDeviceId** should appear in both query results. --  --## Create a service app that updates desired properties and queries twins --In this section, you create a .NET console app, using C#, that adds location metadata to the device twin associated with **myDeviceId**. The app queries IoT hub for devices located in the US and then queries devices that report a cellular network connection. --1. In Visual Studio, select **File > New > Project**. In **Create a new project**, select **Console App (.NET Framework)**, and then select **Next**. --1. In **Configure your new project**, name the project **AddTagsAndQuery**, the select **Next**. -- :::image type="content" source="./media/device-twins-dotnet/config-addtagsandquery-app.png" alt-text="Screenshot of how to create a new Visual Studio project." lightbox="./media/device-twins-dotnet/config-addtagsandquery-app.png"::: --1. Accept the default version of the .NET Framework, then select **Create** to create the project. --1. In Solution Explorer, right-click the **AddTagsAndQuery** project, and then select **Manage NuGet Packages**. --1. Select **Browse** and search for and select **Microsoft.Azure.Devices**. Select **Install**. --  -- This step downloads, installs, and adds a reference to the [Azure IoT service SDK](https://www.nuget.org/packages/Microsoft.Azure.Devices/) NuGet package and its dependencies. --1. Add the following `using` statements at the top of the **Program.cs** file: -- ```csharp - using Microsoft.Azure.Devices; - ``` --1. Add the following fields to the **Program** class. Replace `{iot hub connection string}` with the IoT Hub connection string that you copied in [Get the IoT hub connection string](#get-the-iot-hub-connection-string). -- ```csharp - static RegistryManager registryManager; - static string connectionString = "{iot hub connection string}"; - ``` --1. Add the following method to the **Program** class: -- ```csharp - public static async Task AddTagsAndQuery() - { - var twin = await registryManager.GetTwinAsync("myDeviceId"); - var patch = - @"{ - tags: { - location: { - region: 'US', - plant: 'Redmond43' - } - } - }"; - await registryManager.UpdateTwinAsync(twin.DeviceId, patch, twin.ETag); -- var query = registryManager.CreateQuery( - "SELECT * FROM devices WHERE tags.location.plant = 'Redmond43'", 100); - var twinsInRedmond43 = await query.GetNextAsTwinAsync(); - Console.WriteLine("Devices in Redmond43: {0}", - string.Join(", ", twinsInRedmond43.Select(t => t.DeviceId))); -- query = registryManager.CreateQuery("SELECT * FROM devices WHERE tags.location.plant = 'Redmond43' AND properties.reported.connectivity.type = 'cellular'", 100); - var twinsInRedmond43UsingCellular = await query.GetNextAsTwinAsync(); - Console.WriteLine("Devices in Redmond43 using cellular network: {0}", - string.Join(", ", twinsInRedmond43UsingCellular.Select(t => t.DeviceId))); - } - ``` -- The **RegistryManager** class exposes all the methods required to interact with device twins from the service. The previous code first initializes the **registryManager** object, then retrieves the device twin for **myDeviceId**, and finally updates its tags with the desired location information. -- After updating, it executes two queries: the first selects only the device twins of devices located in the **Redmond43** plant, and the second refines the query to select only the devices that are also connected through cellular network. -- The previous code, when it creates the **query** object, specifies a maximum number of returned documents. The **query** object contains a **HasMoreResults** boolean property that you can use to invoke the **GetNextAsTwinAsync** methods multiple times to retrieve all results. A method called **GetNextAsJson** is available for results that are not device twins, for example, results of aggregation queries. --1. Finally, add the following lines to the **Main** method: -- ```csharp - registryManager = RegistryManager.CreateFromConnectionString(connectionString); - AddTagsAndQuery().Wait(); - Console.WriteLine("Press Enter to exit."); - Console.ReadLine(); - ``` --1. Run this application by right-clicking on the **AddTagsAndQuery** project and selecting **Debug**, followed by **Start new instance**. You should see one device in the results for the query asking for all devices located in **Redmond43** and none for the query that restricts the results to devices that use a cellular network. --  --In this article, you: --* Added device metadata as tags from a back-end app -* Reported device connectivity information in the device twin -* Queried the device twin information, using SQL-like IoT Hub query language --## Next steps --To learn how to: --* Send telemetry from devices, see [Quickstart: Send telemetry from an IoT Plug and Play device to Azure IoT Hub](../iot/tutorial-send-telemetry-iot-hub.md?toc=/azure/iot-hub/toc.json&bc=/azure/iot-hub/breadcrumb/toc.json&pivots=programming-language-csharp). --* Configure devices using device twin's desired properties, see [Tutorial: Configure your devices from a back-end service](tutorial-device-twins.md). --* Control devices interactively, such as turning on a fan from a user-controlled app, see [Quickstart: Control a device connected to an IoT hub](quickstart-control-device.md?pivots=programming-language-csharp). |
| iot-hub | Device Twins Java | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-hub/device-twins-java.md | - Title: Get started with Azure IoT Hub device twins (Java)- -description: How to use Azure IoT Hub device twins and the Azure IoT SDKs for Java to create and simulate devices, add tags to device twins, and execute IoT Hub queries. ----- Previously updated : 02/17/2023----# Get started with device twins (Java) ---This article shows you how to: --* Use a simulated device app to report its connectivity channel as a reported property on the device twin. --* Query devices from your back-end app using filters on the tags and properties previously created. --In this article, you create two Java console apps: --* **add-tags-query**: a back-end app that adds tags and queries device twins. -* **simulated-device**: a simulated device app that connects to your IoT hub and reports its connectivity condition. --> [!NOTE] -> See [Azure IoT SDKs](iot-hub-devguide-sdks.md) for more information about the SDK tools available to build both device and back-end apps. --## Prerequisites --* An IoT hub in your Azure subscription. If you don't have a hub yet, you can follow the steps in [Create an IoT hub](create-hub.md). --* A device registered in your IoT hub. If you don't have a device in your IoT hub, follow the steps in [Register a device](create-connect-device.md#register-a-device). --* [Java SE Development Kit 8](/java/azure/jdk/). Make sure you select **Java 8** under **Long-term support** to get to downloads for JDK 8. --* [Maven 3](https://maven.apache.org/download.cgi) --* Make sure that port 8883 is open in your firewall. The device sample in this article uses MQTT protocol, which communicates over port 8883. This port may be blocked in some corporate and educational network environments. For more information and ways to work around this issue, see [Connecting to IoT Hub (MQTT)](../iot/iot-mqtt-connect-to-iot-hub.md#connecting-to-iot-hub). --## Get the IoT hub connection string ----## Create a device app that updates reported properties --In this section, you create a Java console app that connects to your hub as **myDeviceId**, and then updates its device twin's reported properties to confirm that it's connected using a cellular network. --1. In the **iot-java-twin-getstarted** folder, create a Maven project named **simulated-device** using the following command at your command prompt: -- ```cmd/sh - mvn archetype:generate -DgroupId=com.mycompany.app -DartifactId=simulated-device -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false - ``` --1. At your command prompt, navigate to the **simulated-device** folder. --1. Using a text editor, open the **pom.xml** file in the **simulated-device** folder and add the following dependencies to the **dependencies** node. This dependency enables you to use the **iot-device-client** package in your app to communicate with your IoT hub. -- ```xml - <dependency> - <groupId>com.microsoft.azure.sdk.iot</groupId> - <artifactId>iot-device-client</artifactId> - <version>1.17.5</version> - </dependency> - ``` -- > [!NOTE] - > You can check for the latest version of **iot-device-client** using [Maven search](https://search.maven.org/#search%7Cga%7C1%7Ca%3A%22iot-device-client%22%20g%3A%22com.microsoft.azure.sdk.iot%22). --1. Add the following dependency to the **dependencies** node. This dependency configures a NOP for the Apache [SLF4J](https://www.slf4j.org/) logging facade, which is used by the device client SDK to implement logging. This configuration is optional, but, if you omit it, you may see a warning in the console when you run the app. For more information about logging in the device client SDK, see [Logging](https://github.com/Azure/azure-iot-sdk-jav#logging) in the *Samples for the Azure IoT device SDK for Java* readme file. -- ```xml - <dependency> - <groupId>org.slf4j</groupId> - <artifactId>slf4j-nop</artifactId> - <version>1.7.28</version> - </dependency> - ``` --1. Add the following **build** node after the **dependencies** node. This configuration instructs Maven to use Java 1.8 to build the app: -- ```xml - <build> - <plugins> - <plugin> - <groupId>org.apache.maven.plugins</groupId> - <artifactId>maven-compiler-plugin</artifactId> - <version>3.3</version> - <configuration> - <source>1.8</source> - <target>1.8</target> - </configuration> - </plugin> - </plugins> - </build> - ``` --1. Save and close the **pom.xml** file. --1. Using a text editor, open the **simulated-device\src\main\java\com\mycompany\app\App.java** file. --1. Add the following **import** statements to the file: -- ```java - import com.microsoft.azure.sdk.iot.device.*; - import com.microsoft.azure.sdk.iot.device.DeviceTwin.*; -- import java.io.IOException; - import java.net.URISyntaxException; - import java.util.Scanner; - ``` --1. Add the following class-level variables to the **App** class. Replace `{yourdeviceconnectionstring}` with the device connection string you saw when you registered a device in the IoT Hub: -- ```java - private static String connString = "{yourdeviceconnectionstring}"; - private static IotHubClientProtocol protocol = IotHubClientProtocol.MQTT; - private static String deviceId = "myDeviceId"; - ``` -- This sample app uses the **protocol** variable when it instantiates a **DeviceClient** object. --1. Add the following method to the **App** class to print information about twin updates: -- ```java - protected static class DeviceTwinStatusCallBack implements IotHubEventCallback { - @Override - public void execute(IotHubStatusCode status, Object context) { - System.out.println("IoT Hub responded to device twin operation with status " + status.name()); - } - } - ``` --1. Replace the code in the **main** method with the following code to: -- * Create a device client to communicate with IoT Hub. -- * Create a **Device** object to store the device twin properties. -- ```java - DeviceClient client = new DeviceClient(connString, protocol); -- // Create a Device object to store the device twin properties - Device dataCollector = new Device() { - // Print details when a property value changes - @Override - public void PropertyCall(String propertyKey, Object propertyValue, Object context) { - System.out.println(propertyKey + " changed to " + propertyValue); - } - }; - ``` --1. Add the following code to the **main** method to create a **connectivityType** reported property and send it to IoT Hub: -- ```java - try { - // Open the DeviceClient and start the device twin services. - client.open(); - client.startDeviceTwin(new DeviceTwinStatusCallBack(), null, dataCollector, null); -- // Create a reported property and send it to your IoT hub. - dataCollector.setReportedProp(new Property("connectivityType", "cellular")); - client.sendReportedProperties(dataCollector.getReportedProp()); - } - catch (Exception e) { - System.out.println("On exception, shutting down \n" + " Cause: " + e.getCause() + " \n" + e.getMessage()); - dataCollector.clean(); - client.closeNow(); - System.out.println("Shutting down..."); - } - ``` --1. Add the following code to the end of the **main** method. Waiting for the **Enter** key allows time for IoT Hub to report the status of the device twin operations. -- ```java - System.out.println("Press any key to exit..."); -- Scanner scanner = new Scanner(System.in); - scanner.nextLine(); -- dataCollector.clean(); - client.close(); - ``` --1. Modify the signature of the **main** method to include the exceptions as follows: -- ```java - public static void main(String[] args) throws URISyntaxException, IOException - ``` --1. Save and close the **simulated-device\src\main\java\com\mycompany\app\App.java** file. --1. Build the **simulated-device** app and correct any errors. At your command prompt, navigate to the **simulated-device** folder and run the following command: -- ```cmd/sh - mvn clean package -DskipTests - ``` --## Create a service app that updates desired properties and queries twins --In this section, you create a Java app that adds location metadata as a tag to the device twin in IoT Hub associated with **myDeviceId**. The app queries IoT hub for devices located in the US and then queries devices that report a cellular network connection. --1. On your development machine, create an empty folder named **iot-java-twin-getstarted**. --1. In the **iot-java-twin-getstarted** folder, create a Maven project named **add-tags-query** using the following command at your command prompt: -- ```cmd/sh - mvn archetype:generate -DgroupId=com.mycompany.app -DartifactId=add-tags-query -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false - ``` --1. At your command prompt, navigate to the **add-tags-query** folder. --1. Using a text editor, open the **pom.xml** file in the **add-tags-query** folder and add the following dependency to the **dependencies** node. This dependency enables you to use the **iot-service-client** package in your app to communicate with your IoT hub: -- ```xml - <dependency> - <groupId>com.microsoft.azure.sdk.iot</groupId> - <artifactId>iot-service-client</artifactId> - <version>1.17.1</version> - <type>jar</type> - </dependency> - ``` -- > [!NOTE] - > You can check for the latest version of **iot-service-client** using [Maven search](https://search.maven.org/#search%7Cga%7C1%7Ca%3A%22iot-service-client%22%20g%3A%22com.microsoft.azure.sdk.iot%22). --1. Add the following **build** node after the **dependencies** node. This configuration instructs Maven to use Java 1.8 to build the app. -- ```xml - <build> - <plugins> - <plugin> - <groupId>org.apache.maven.plugins</groupId> - <artifactId>maven-compiler-plugin</artifactId> - <version>3.3</version> - <configuration> - <source>1.8</source> - <target>1.8</target> - </configuration> - </plugin> - </plugins> - </build> - ``` --1. Save and close the **pom.xml** file. --1. Using a text editor, open the **add-tags-query\src\main\java\com\mycompany\app\App.java** file. --1. Add the following **import** statements to the file: -- ```java - import com.microsoft.azure.sdk.iot.service.devicetwin.*; - import com.microsoft.azure.sdk.iot.service.exceptions.IotHubException; -- import java.io.IOException; - import java.util.HashSet; - import java.util.Set; - ``` --1. Add the following class-level variables to the **App** class. Replace `{youriothubconnectionstring}` with the IoT hub connection string you copied in [Get the IoT hub connection string](#get-the-iot-hub-connection-string). -- ```java - public static final String iotHubConnectionString = "{youriothubconnectionstring}"; - public static final String deviceId = "myDeviceId"; -- public static final String region = "US"; - public static final String plant = "Redmond43"; - ``` --1. Update the **main** method signature to include the following `throws` clause: -- ```java - public static void main( String[] args ) throws IOException - ``` --1. Replace the code in the **main** method with the following code to create the **DeviceTwin** and **DeviceTwinDevice** objects. The **DeviceTwin** object handles the communication with your IoT hub. The **DeviceTwinDevice** object represents the device twin with its properties and tags: -- ```java - // Get the DeviceTwin and DeviceTwinDevice objects - DeviceTwin twinClient = DeviceTwin.createFromConnectionString(iotHubConnectionString); - DeviceTwinDevice device = new DeviceTwinDevice(deviceId); - ``` --1. Add the following `try/catch` block to the **main** method: -- ```java - try { - // Code goes here - } catch (IotHubException e) { - System.out.println(e.getMessage()); - } catch (IOException e) { - System.out.println(e.getMessage()); - } - ``` --1. To update the **region** and **plant** device twin tags in your device twin, add the following code in the `try` block: -- ```java - // Get the device twin from IoT Hub - System.out.println("Device twin before update:"); - twinClient.getTwin(device); - System.out.println(device); -- // Update device twin tags if they are different - // from the existing values - String currentTags = device.tagsToString(); - if ((!currentTags.contains("region=" + region) && !currentTags.contains("plant=" + plant))) { - // Create the tags and attach them to the DeviceTwinDevice object - Set<Pair> tags = new HashSet<Pair>(); - tags.add(new Pair("region", region)); - tags.add(new Pair("plant", plant)); - device.setTags(tags); -- // Update the device twin in IoT Hub - System.out.println("Updating device twin"); - twinClient.updateTwin(device); - } -- // Retrieve the device twin with the tag values from IoT Hub - System.out.println("Device twin after update:"); - twinClient.getTwin(device); - System.out.println(device); - ``` --1. To query the device twins in IoT hub, add the following code to the `try` block after the code you added in the previous step. The code runs two queries. Each query returns a maximum of 100 devices. -- ```java - // Query the device twins in IoT Hub - System.out.println("Devices in Redmond:"); -- // Construct the query - SqlQuery sqlQuery = SqlQuery.createSqlQuery("*", SqlQuery.FromType.DEVICES, "tags.plant='Redmond43'", null); -- // Run the query, returning a maximum of 100 devices - Query twinQuery = twinClient.queryTwin(sqlQuery.getQuery(), 100); - while (twinClient.hasNextDeviceTwin(twinQuery)) { - DeviceTwinDevice d = twinClient.getNextDeviceTwin(twinQuery); - System.out.println(d.getDeviceId()); - } -- System.out.println("Devices in Redmond using a cellular network:"); -- // Construct the query - sqlQuery = SqlQuery.createSqlQuery("*", SqlQuery.FromType.DEVICES, "tags.plant='Redmond43' AND properties.reported.connectivityType = 'cellular'", null); -- // Run the query, returning a maximum of 100 devices - twinQuery = twinClient.queryTwin(sqlQuery.getQuery(), 3); - while (twinClient.hasNextDeviceTwin(twinQuery)) { - DeviceTwinDevice d = twinClient.getNextDeviceTwin(twinQuery); - System.out.println(d.getDeviceId()); - } - ``` --1. Save and close the **add-tags-query\src\main\java\com\mycompany\app\App.java** file --1. Build the **add-tags-query** app and correct any errors. At your command prompt, navigate to the **add-tags-query** folder and run the following command: -- ```cmd/sh - mvn clean package -DskipTests - ``` --## Run the apps --You are now ready to run the console apps. --1. At a command prompt in the **add-tags-query** folder, run the following command to run the **add-tags-query** service app: -- ```cmd/sh - mvn exec:java -Dexec.mainClass="com.mycompany.app.App" - ``` --  -- You can see the **plant** and **region** tags added to the device twin. The first query returns your device, but the second does not. --2. At a command prompt in the **simulated-device** folder, run the following command to add the **connectivityType** reported property to the device twin: -- ```cmd/sh - mvn exec:java -Dexec.mainClass="com.mycompany.app.App" - ``` --  --3. At a command prompt in the **add-tags-query** folder, run the following command to run the **add-tags-query** service app a second time: -- ```cmd/sh - mvn exec:java -Dexec.mainClass="com.mycompany.app.App" - ``` --  -- Now that your device has sent the **connectivityType** property to IoT Hub, the second query returns your device. --In this article, you: --* Added device metadata as tags from a back-end app -* Reported device connectivity information in the device twin -* Queried the device twin information, using SQL-like IoT Hub query language --## Next steps --To learn how to: --* Send telemetry from devices, see [Quickstart: Send telemetry from an IoT Plug and Play device to Azure IoT Hub](../iot/tutorial-send-telemetry-iot-hub.md?toc=/azure/iot-hub/toc.json&bc=/azure/iot-hub/breadcrumb/toc.json&pivots=programming-language-java) --* Configure devices using device twin's desired properties, see [Tutorial: Configure your devices from a back-end service](tutorial-device-twins.md) --* Control devices interactively, such as turning on a fan from a user-controlled app, see [Quickstart: Control a device connected to an IoT hub](quickstart-control-device.md?pivots=programming-language-java) |
| iot-hub | Device Twins Node | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-hub/device-twins-node.md | - Title: Get started with Azure IoT Hub device twins (Node.js)- -description: How to use Azure IoT Hub device twins and the Azure IoT SDKs for Node.js to create and simulate devices, add tags to device twins, and execute IoT Hub queries. ----- Previously updated : 02/17/2023----# Get started with device twins (Node.js) ---This article shows you how to: --* Use a simulated device app to report its connectivity channel as a reported property on the device twin. --* Query devices from your back-end app using filters on the tags and properties previously created. --In this article, you create two Node.js console apps: --* **AddTagsAndQuery.js**: a back-end app that adds tags and queries device twins. --* **TwinSimulatedDevice.js**: a simulated device app that connects to your IoT hub and reports its connectivity condition. --> [!NOTE] -> See [Azure IoT SDKs](iot-hub-devguide-sdks.md) for more information about the SDK tools available to build both device and back-end apps. --## Prerequisites --To complete this article, you need: --* An IoT hub in your Azure subscription. If you don't have a hub yet, you can follow the steps in [Create an IoT hub](create-hub.md). --* A device registered in your IoT hub. If you don't have a device in your IoT hub, follow the steps in [Register a device](create-connect-device.md#register-a-device). --* Node.js version 10.0.x or later. --* Make sure that port 8883 is open in your firewall. The device sample in this article uses MQTT protocol, which communicates over port 8883. This port may be blocked in some corporate and educational network environments. For more information and ways to work around this issue, see [Connecting to IoT Hub (MQTT)](../iot/iot-mqtt-connect-to-iot-hub.md#connecting-to-iot-hub). --## Get the IoT hub connection string ----## Create a device app that updates reported properties --In this section, you create a Node.js console app that connects to your hub as **myDeviceId**, and then updates its device twin's reported properties to confirm that it's connected using a cellular network. --1. Create a new empty folder called **reportconnectivity**. In the **reportconnectivity** folder, create a new package.json file using the following command at your command prompt. The `--yes` parameter accepts all the defaults. -- ```cmd/sh - npm init --yes - ``` --2. At your command prompt in the **reportconnectivity** folder, run the following command to install the **azure-iot-device**, and **azure-iot-device-mqtt** packages: -- ```cmd/sh - npm install azure-iot-device azure-iot-device-mqtt --save - ``` --3. Using a text editor, create a new **ReportConnectivity.js** file in the **reportconnectivity** folder. --4. Add the following code to the **ReportConnectivity.js** file. Replace `{device connection string}` with the device connection string you saw when you registered a device in the IoT Hub: -- ```javascript - 'use strict'; - var Client = require('azure-iot-device').Client; - var Protocol = require('azure-iot-device-mqtt').Mqtt; -- var connectionString = '{device connection string}'; - var client = Client.fromConnectionString(connectionString, Protocol); -- client.open(function(err) { - if (err) { - console.error('could not open IotHub client'); - } else { - console.log('client opened'); -- client.getTwin(function(err, twin) { - if (err) { - console.error('could not get twin'); - } else { - var patch = { - connectivity: { - type: 'cellular' - } - }; -- twin.properties.reported.update(patch, function(err) { - if (err) { - console.error('could not update twin'); - } else { - console.log('twin state reported'); - process.exit(); - } - }); - } - }); - } - }); - ``` -- The **Client** object exposes all the methods you require to interact with device twins from the device. The previous code, after it initializes the **Client** object, retrieves the device twin for **myDeviceId** and updates its reported property with the connectivity information. --5. Run the device app -- ```cmd/sh - node ReportConnectivity.js - ``` -- You should see the message `twin state reported`. --6. Now that the device reported its connectivity information, it should appear in both queries. Go back in the **addtagsandqueryapp** folder and run the queries again: -- ```cmd/sh - node AddTagsAndQuery.js - ``` -- This time **myDeviceId** should appear in both query results. --  --## Create a service app that updates desired properties and queries twins --In this section, you create a Node.js console app that adds location metadata to the device twin associated with **myDeviceId**. The app queries IoT hub for devices located in the US and then queries devices that report a cellular network connection. --1. Create a new empty folder called **addtagsandqueryapp**. In the **addtagsandqueryapp** folder, create a new package.json file using the following command at your command prompt. The `--yes` parameter accepts all the defaults. -- ```cmd/sh - npm init --yes - ``` --2. At your command prompt in the **addtagsandqueryapp** folder, run the following command to install the **azure-iothub** package: -- ```cmd/sh - npm install azure-iothub --save - ``` --3. Using a text editor, create a new **AddTagsAndQuery.js** file in the **addtagsandqueryapp** folder. --4. Add the following code to the **AddTagsAndQuery.js** file. Replace `{iot hub connection string}` with the IoT Hub connection string you copied in [Get the IoT hub connection string](#get-the-iot-hub-connection-string). -- ``` javascript - 'use strict'; - var iothub = require('azure-iothub'); - var connectionString = '{iot hub connection string}'; - var registry = iothub.Registry.fromConnectionString(connectionString); -- registry.getTwin('myDeviceId', function(err, twin){ - if (err) { - console.error(err.constructor.name + ': ' + err.message); - } else { - var patch = { - tags: { - location: { - region: 'US', - plant: 'Redmond43' - } - } - }; -- twin.update(patch, function(err) { - if (err) { - console.error('Could not update twin: ' + err.constructor.name + ': ' + err.message); - } else { - console.log(twin.deviceId + ' twin updated successfully'); - queryTwins(); - } - }); - } - }); - ``` -- The **Registry** object exposes all the methods required to interact with device twins from the service. The previous code first initializes the **Registry** object, then retrieves the device twin for **myDeviceId**, and finally updates its tags with the desired location information. -- After updating the tags it calls the **queryTwins** function. --5. Add the following code at the end of **AddTagsAndQuery.js** to implement the **queryTwins** function: -- ```javascript - var queryTwins = function() { - var query = registry.createQuery("SELECT * FROM devices WHERE tags.location.plant = 'Redmond43'", 100); - query.nextAsTwin(function(err, results) { - if (err) { - console.error('Failed to fetch the results: ' + err.message); - } else { - console.log("Devices in Redmond43: " + results.map(function(twin) {return twin.deviceId}).join(',')); - } - }); -- query = registry.createQuery("SELECT * FROM devices WHERE tags.location.plant = 'Redmond43' AND properties.reported.connectivity.type = 'cellular'", 100); - query.nextAsTwin(function(err, results) { - if (err) { - console.error('Failed to fetch the results: ' + err.message); - } else { - console.log("Devices in Redmond43 using cellular network: " + results.map(function(twin) {return twin.deviceId}).join(',')); - } - }); - }; - ``` -- The previous code executes two queries: the first selects only the device twins of devices located in the **Redmond43** plant, and the second refines the query to select only the devices that are also connected through cellular network. -- When the code creates the **query** object, it specifies the maximum number of returned documents in the second parameter. The **query** object contains a **hasMoreResults** boolean property that you can use to invoke the **nextAsTwin** methods multiple times to retrieve all results. A method called **next** is available for results that are not device twins, for example, the results of aggregation queries. --6. Run the application with: -- ```cmd/sh - node AddTagsAndQuery.js - ``` -- You should see one device in the results for the query asking for all devices located in **Redmond43** and none for the query that restricts the results to devices that use a cellular network. --  --In this article, you: --* Added device metadata as tags from a back-end app -* Reported device connectivity information in the device twin -* Queried the device twin information, using SQL-like IoT Hub query language --## Next steps --To learn how to: --* Send telemetry from devices, see [Quickstart: Send telemetry from an IoT Plug and Play device to Azure IoT Hub](../iot/tutorial-send-telemetry-iot-hub.md?toc=/azure/iot-hub/toc.json&bc=/azure/iot-hub/breadcrumb/toc.json&pivots=programming-language-nodejs) --* Configure devices using device twin's desired properties, see [Tutorial: Configure your devices from a back-end service](tutorial-device-twins.md) --* Control devices interactively, such as turning on a fan from a user-controlled app, see [Quickstart: Control a device connected to an IoT hub](quickstart-control-device.md?pivots=programming-language-nodejs) |
| iot-hub | Device Twins Python | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-hub/device-twins-python.md | - Title: Get started with Azure IoT Hub device twins (Python)- -description: How to use Azure IoT Hub device twins and the Azure IoT SDKs for Python to create and simulate devices, add tags to device twins, and execute IoT Hub queries. ----- Previously updated : 02/17/2023----# Get started with device twins (Python) ---This article shows you how to: --* Use a simulated device app to report its connectivity channel as a reported property on the device twin. --* Query devices from your back-end app using filters on the tags and properties previously created. --In this article, you create two Python console apps: --* **AddTagsAndQuery.py**: a back-end app that adds tags and queries device twins. --* **ReportConnectivity.py**: a simulated device app that connects to your IoT hub and reports its connectivity condition. --> [!NOTE] -> For more information about the SDK tools available to build both device and back-end apps, see [Azure IoT SDKs](iot-hub-devguide-sdks.md). --## Prerequisites --* An active Azure account. (If you don't have an account, you can create a [free account](https://azure.microsoft.com/pricing/free-trial/) in just a couple of minutes.) --* An IoT hub in your Azure subscription. If you don't have a hub yet, you can follow the steps in [Create an IoT hub](create-hub.md). --* A device registered in your IoT hub. If you don't have a device in your IoT hub, follow the steps in [Register a device](create-connect-device.md#register-a-device). --* [Python version 3.7 or later](https://www.python.org/downloads/) is recommended. Make sure to use the 32-bit or 64-bit installation as required by your setup. When prompted during the installation, make sure to add Python to your platform-specific environment variable. --* Make sure that port 8883 is open in your firewall. The device sample in this article uses MQTT protocol, which communicates over port 8883. This port may be blocked in some corporate and educational network environments. For more information and ways to work around this issue, see [Connecting to IoT Hub (MQTT)](../iot/iot-mqtt-connect-to-iot-hub.md#connecting-to-iot-hub). --## Get the IoT hub connection string ----## Create a service app that updates desired properties and queries twins --In this section, you create a Python console app that adds location metadata to the device twin associated with your **{Device ID}**. The app queries IoT hub for devices located in the US and then queries devices that report a cellular network connection. --1. In your working directory, open a command prompt and install the **Azure IoT Hub Service SDK for Python**. -- ```cmd/sh - pip install azure-iot-hub - ``` --2. Using a text editor, create a new **AddTagsAndQuery.py** file. --3. Add the following code to import the required modules from the service SDK: -- ```python - import sys - from time import sleep - from azure.iot.hub import IoTHubRegistryManager - from azure.iot.hub.models import Twin, TwinProperties, QuerySpecification, QueryResult - ``` --4. Add the following code. Replace `[IoTHub Connection String]` with the IoT hub connection string you copied in [Get the IoT hub connection string](#get-the-iot-hub-connection-string). Replace `[Device Id]` with the device ID (the name) from your registered device in the IoT hub. - - ```python - IOTHUB_CONNECTION_STRING = "[IoTHub Connection String]" - DEVICE_ID = "[Device Id]" - ``` --5. Add the following code to the **AddTagsAndQuery.py** file: -- ```python - def iothub_service_sample_run(): - try: - iothub_registry_manager = IoTHubRegistryManager(IOTHUB_CONNECTION_STRING) -- new_tags = { - 'location' : { - 'region' : 'US', - 'plant' : 'Redmond43' - } - } -- twin = iothub_registry_manager.get_twin(DEVICE_ID) - twin_patch = Twin(tags=new_tags, properties= TwinProperties(desired={'power_level' : 1})) - twin = iothub_registry_manager.update_twin(DEVICE_ID, twin_patch, twin.etag) -- # Add a delay to account for any latency before executing the query - sleep(1) -- query_spec = QuerySpecification(query="SELECT * FROM devices WHERE tags.location.plant = 'Redmond43'") - query_result = iothub_registry_manager.query_iot_hub(query_spec, None, 100) - print("Devices in Redmond43 plant: {}".format(', '.join([twin.device_id for twin in query_result.items]))) -- print() -- query_spec = QuerySpecification(query="SELECT * FROM devices WHERE tags.location.plant = 'Redmond43' AND properties.reported.connectivity = 'cellular'") - query_result = iothub_registry_manager.query_iot_hub(query_spec, None, 100) - print("Devices in Redmond43 plant using cellular network: {}".format(', '.join([twin.device_id for twin in query_result.items]))) -- except Exception as ex: - print("Unexpected error {0}".format(ex)) - return - except KeyboardInterrupt: - print("IoT Hub Device Twin service sample stopped") - ``` -- The **IoTHubRegistryManager** object exposes all the methods required to interact with device twins from the service. The code first initializes the **IoTHubRegistryManager** object, then updates the device twin for **DEVICE_ID**, and finally runs two queries. The first selects only the device twins of devices located in the **Redmond43** plant, and the second refines the query to select only the devices that are also connected through a cellular network. --6. Add the following code at the end of **AddTagsAndQuery.py** to implement the **iothub_service_sample_run** function: -- ```python - if __name__ == '__main__': - print("Starting the Python IoT Hub Device Twin service sample...") - print() -- iothub_service_sample_run() - ``` --7. Run the application with: -- ```cmd/sh - python AddTagsAndQuery.py - ``` -- You should see one device in the results for the query asking for all devices located in **Redmond43** and none for the query that restricts the results to devices that use a cellular network. In the next section, you'll create a device app that will use a cellular network and you'll rerun this query to see how it changes. --  --## Create a device app that updates reported properties --In this section, you create a Python console app that connects to your hub as your **{Device ID}** and then updates its device twin's reported properties to confirm that it's connected using a cellular network. --1. From a command prompt in your working directory, install the **Azure IoT Hub Device SDK for Python**: -- ```cmd/sh - pip install azure-iot-device - ``` --2. Using a text editor, create a new **ReportConnectivity.py** file. --3. Add the following code to import the required modules from the device SDK: -- ```python - import time - from azure.iot.device import IoTHubModuleClient - ``` --4. Add the following code. Replace the `[IoTHub Device Connection String]` placeholder value with the device connection string you saw when you registered a device in the IoT Hub: -- ```python - CONNECTION_STRING = "[IoTHub Device Connection String]" - ``` --5. Add the following code to the **ReportConnectivity.py** file to instantiate a client and implement the device twins functionality: -- ```python - def create_client(): - # Instantiate client - client = IoTHubModuleClient.create_from_connection_string(CONNECTION_STRING) -- # Define behavior for receiving twin desired property patches - def twin_patch_handler(twin_patch): - print("Twin patch received:") - print(twin_patch) -- try: - # Set handlers on the client - client.on_twin_desired_properties_patch_received = twin_patch_handler - except: - # Clean up in the event of failure - client.shutdown() -- return client - ``` --6. Add the following code at the end of **ReportConnectivity.py** to run the application: -- ```python - def main(): - print ( "Starting the Python IoT Hub Device Twin device sample..." ) - client = create_client() - print ( "IoTHubModuleClient waiting for commands, press Ctrl-C to exit" ) -- try: - # Update reported properties with cellular information - print ( "Sending data as reported property..." ) - reported_patch = {"connectivity": "cellular"} - client.patch_twin_reported_properties(reported_patch) - print ( "Reported properties updated" ) -- # Wait for program exit - while True: - time.sleep(1000000) - except KeyboardInterrupt: - print ("IoT Hub Device Twin device sample stopped") - finally: - # Graceful exit - print("Shutting down IoT Hub Client") - client.shutdown() -- if __name__ == '__main__': - main() - ``` --7. Run the device app: -- ```cmd/sh - python ReportConnectivity.py - ``` -- You should see confirmation the device twin reported properties were updated. --  --8. Now that the device reported its connectivity information, it should appear in both queries. Go back and run the queries again: -- ```cmd/sh - python AddTagsAndQuery.py - ``` -- This time your **{Device ID}** should appear in both query results. --  -- In your device app, you'll see confirmation that the desired properties twin patch sent by the service app was received. --  --In this article, you: --* Added device metadata as tags from a back-end app -* Reported device connectivity information in the device twin -* Queried the device twin information using the IoT Hub query language --## Next steps --To learn how to: --* Send telemetry from devices, see [Quickstart: Send telemetry from an IoT Plug and Play device to Azure IoT Hub](../iot/tutorial-send-telemetry-iot-hub.md?pivots=programming-language-python) article. --* Configure devices using device twin's desired properties, see [Tutorial: Configure your devices from a back-end service](tutorial-device-twins.md). --* Control devices interactively, such as turning on a fan from a user-controlled app, see [Quickstart: Control a device connected to an IoT hub](./quickstart-control-device.md?pivots=programming-language-python). |
| iot-hub | How To Device Twins | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-hub/how-to-device-twins.md | + + Title: Get started with Azure IoT Hub device twins ++description: How to use the Azure IoT SDKs to create device and backend service application code for device twins. +++++ms.devlang: csharp + Last updated : 09/10/2024+zone_pivot_groups: iot-hub-howto-c2d-1 ++++# Get started with device twins ++Use the Azure IoT Hub device SDK and service SDK to develop applications that handle common device twin tasks. Device twins are JSON documents that store device state information including metadata, configurations, and conditions. IoT Hub persists a device twin for each device that connects to it. ++You can use device twins to: ++* Store device metadata from your solution back end +* Report current state information such as available capabilities and conditions, for example, the connectivity method used, from your device app +* Synchronize the state of long-running workflows, such as firmware and configuration updates, between a device app and a back-end app +* Query your device metadata, configuration, or state ++For more information about device twins, including when to use device twins, see [Understand and use device twins in IoT Hub](iot-hub-devguide-device-twins.md). +++This article shows you how to develop two types of applications: ++* Device apps can handle requests to update desired properties and respond with changes to reported properties. +* Service apps can update device twin tags, set new desired properties, and query devices based on device twin values. ++> [!NOTE] +> This article is meant to complement [Azure IoT SDKs](iot-hub-devguide-sdks.md) samples that are referenced from within this article. You can use SDK tools to build both device and back-end applications. ++## Prerequisites ++* **An IoT hub**. Some SDK calls require the IoT Hub primary connection string, so make a note of the connection string. ++* **A registered device**. Some SDK calls require the device primary connection string, so make a note of the connection string. ++* **IoT Hub service connection string** ++ In this article, you create a back-end service that adds desired properties to a device twin and then queries the identity registry to find all devices with reported properties that have been updated accordingly. Your service needs the **service connect** permission to modify desired properties of a device twin, and it needs the **registry read** permission to query the identity registry. There is no default shared access policy that contains only these two permissions, so you need to create one. ++ To create a shared access policy that grants **service connect** and **registry read** permissions and get a connection string for this policy, follow these steps: ++ 1. In the Azure portal, select **Resource groups**. Select the resource group where your hub is located, and then select your hub from the list of resources. ++ 1. On the left-side pane of your hub, select **Shared access policies**. ++ 1. From the top menu above the list of policies, select **Add shared policy access policy**. ++ 1. In the **Add shared access policy** pane on the right, enter a descriptive name for your policy, such as "serviceAndRegistryRead". Under **Permissions**, select **Registry Read** and **Service Connect**, and then select **Add**. ++ 1. Select your new policy from the list of policies. ++ 1. Select the copy icon for the **Primary connection string** and save the value. ++ For more information about IoT Hub shared access policies and permissions, see [Control access to IoT Hub with shared access signatures](/azure/iot-hub/authenticate-authorize-sas). ++* If your application uses the MQTT protocol, make sure that **port 8883** is open in your firewall. The MQTT protocol communicates over port 8883. This port may be blocked in some corporate and educational network environments. For more information and ways to work around this issue, see [Connecting to IoT Hub (MQTT)](../iot/iot-mqtt-connect-to-iot-hub.md#connecting-to-iot-hub). ++* Language SDK requirements: + * **.NET SDK** - Requires Visual Studio. + * **Python SDK** - [Python version 3.7 or later](https://www.python.org/downloads/) is recommended. Make sure to use the 32-bit or 64-bit installation as required by your setup. When prompted during the installation, make sure to add Python to your platform-specific environment variable. + * **Java** - Requires [Java SE Development Kit 8](/azure/developer/java/fundamentals/). Make sure you select **Java 8** under **Long-term support** to navigate to downloads for JDK 8. + * **Node.js** - Requires Node.js version 10.0.x or later. ++++++++++++ |
| iot-hub | Iot Hub Azure Service Health Integration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-hub/iot-hub-azure-service-health-integration.md | -Azure IoT Hub integrates with [Azure Service Health](../service-health/overview.md) to enable service-level health monitoring of the IoT Hub service and individual IoT hubs. You can also set up alerts to be notified when the status of the IoT Hub service or an IoT hub (instance) changes. Azure Service Health is a combination of three smaller +Azure IoT Hub integrates with [Azure Service Health](/azure/service-health/overview) to enable service-level health monitoring of the IoT Hub service and individual IoT hubs. You can also set up alerts to be notified when the status of the IoT Hub service or an IoT hub (instance) changes. Azure Service Health is a combination of three smaller Azure Service Health helps you monitor service-level events like outages and upgrades that may affect the availability of the IoT Hub service and your individual IoT hubs. IoT Hub also integrates with Azure Monitor to provide IoT Hub platform metrics and IoT Hub resource logs that you can use to monitor operational errors and conditions that occur on a specific IoT hub. To learn more, see [Monitor IoT Hub](monitor-iot-hub.md). To see status and status history of your IoT hub using the portal, follow these :::image type="content" source="media/iot-hub-azure-service-health-integration/iot-hub-resource-health.png" alt-text="Screenshot of the 'Resource health' page in an IoT hub" lightbox="media/iot-hub-azure-service-health-integration/iot-hub-resource-health.png"::: -To learn more about Azure Resource Health and how to interpret health data, see [Resource Health overview](../service-health/resource-health-overview.md) in the Azure Service Health documentation. +To learn more about Azure Resource Health and how to interpret health data, see [Resource Health overview](/azure/service-health/resource-health-overview) in the Azure Service Health documentation. -You can also select **Add resource health alert** to configure alerts to trigger when the health status of your IoT hub changes. To learn more, see [Configure alerts for service health events](../service-health/alerts-activity-log-service-notifications-portal.md) and related topics in the Azure Service Health documentation. +You can also select **Add resource health alert** to configure alerts to trigger when the health status of your IoT hub changes. To learn more, see [Configure alerts for service health events](/azure/service-health/alerts-activity-log-service-notifications-portal) and related topics in the Azure Service Health documentation. ## Check all IoT hubs' health with Azure Service Health With Azure Service Health, you can check the health status of all IoT hubs in yo You see a list all IoT hubs in your subscription. -To learn more about Azure Service Health and how to interpret health data, see [Service Health overview](../service-health/service-health-overview.md) in the Azure Service Health documentation. +To learn more about Azure Service Health and how to interpret health data, see [Service Health overview](/azure/service-health/service-health-overview) in the Azure Service Health documentation. -To learn how to set up alerts with Azure Service Health, see [Configure alerts for service health events](../service-health/alerts-activity-log-service-notifications-portal.md) and related topics in the Azure Service Health documentation. +To learn how to set up alerts with Azure Service Health, see [Configure alerts for service health events](/azure/service-health/alerts-activity-log-service-notifications-portal) and related topics in the Azure Service Health documentation. ## Check health of the IoT Hub service by region on Azure status page -To check the status of IoT Hub and other services by region worldwide, view the [Azure status page](https://azure.status.microsoft/status). For more information about the Azure status page, see [Azure status overview](../service-health/azure-status-overview.md) in the Azure Service Health documentation. +To check the status of IoT Hub and other services by region worldwide, view the [Azure status page](https://azure.status.microsoft/status). For more information about the Azure status page, see [Azure status overview](/azure/service-health/azure-status-overview) in the Azure Service Health documentation. ## Next steps -* See [Azure Service Health service](../service-health/overview.md) for details on Azure Service Health, Azure Resource Health, and Azure status page. +* See [Azure Service Health service](/azure/service-health/overview) for details on Azure Service Health, Azure Resource Health, and Azure status page. * See [Monitor Azure IoT Hub](monitor-iot-hub.md) for a description of monitoring Azure IoT Hub. |
| iot-hub | Iot Hub Distributed Tracing | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-hub/iot-hub-distributed-tracing.md | -Use distributed tracing (preview) in IoT Hub to monitor IoT messages as they pass through Azure services. IoT Hub is one of the first Azure services to support distributed tracing. As more Azure services support distributed tracing, you're able to trace Internet of Things (IoT) messages throughout the Azure services involved in your solution. For more information about the feature, see [What is distributed tracing?](../azure-monitor/app/distributed-trace-data.md). +Use distributed tracing (preview) in IoT Hub to monitor IoT messages as they pass through Azure services. IoT Hub is one of the first Azure services to support distributed tracing. As more Azure services support distributed tracing, you're able to trace Internet of Things (IoT) messages throughout the Azure services involved in your solution. For more information about the feature, see [What is distributed tracing?](/azure/azure-monitor/app/distributed-trace-data). When you enable distributed tracing for IoT Hub, you can: To update the distributed tracing sampling configuration for multiple devices, u To see all the traces logged by an IoT hub, query the log store that you selected in diagnostic settings. This section shows how to query by using Log Analytics. -If you set up [Log Analytics with resource logs](../azure-monitor/essentials/resource-logs.md#send-to-azure-storage), query by looking for logs in the `DistributedTracing` category. For example, this query shows all the logged traces: +If you set up [Log Analytics with resource logs](/azure/azure-monitor/essentials/resource-logs#send-to-azure-storage), query by looking for logs in the `DistributedTracing` category. For example, this query shows all the logged traces: ```Kusto // All distributed traces |
| iot-hub | Monitor Device Connection State | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-hub/monitor-device-connection-state.md | For more information, see [Message expiration (time to live)](./iot-hub-devguide ## Other monitoring options -A more complex implementation could include the information from [Azure Monitor](../azure-monitor/index.yml) and [Azure Resource Health](../service-health/resource-health-overview.md) to identify devices that are trying to connect or communicate but failing. Azure Monitor dashboards are helpful for seeing the aggregate health of your devices, while Event Grid and heartbeat patterns make it easier to respond to individual device outages. +A more complex implementation could include the information from [Azure Monitor](/azure/azure-monitor/) and [Azure Resource Health](/azure/service-health/resource-health-overview) to identify devices that are trying to connect or communicate but failing. Azure Monitor dashboards are helpful for seeing the aggregate health of your devices, while Event Grid and heartbeat patterns make it easier to respond to individual device outages. To learn more about using these services with IoT Hub, see [Monitor IoT Hub](monitor-iot-hub.md) and [Check IoT Hub resource health](iot-hub-azure-service-health-integration.md). For more specific information about using Azure Monitor or Event Grid to monitor device connectivity, see [Monitor, diagnose, and troubleshoot device connectivity](iot-hub-troubleshoot-connectivity.md). |
| iot-hub | Monitor Iot Hub | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-hub/monitor-iot-hub.md | When routing IoT Hub platform metrics to other locations: - These platform metrics aren't exportable by using diagnostic settings: *Connected devices* and *Total devices*. -- Multi-dimensional metrics, for example some [routing metrics](monitor-iot-hub-reference.md#routing-metrics), are currently exported as flattened single dimensional metrics aggregated across dimension values. For more information, see [Exporting platform metrics to other locations](../azure-monitor/essentials/metrics-supported.md#exporting-platform-metrics-to-other-locations).+- Multi-dimensional metrics, for example some [routing metrics](monitor-iot-hub-reference.md#routing-metrics), are currently exported as flattened single dimensional metrics aggregated across dimension values. For more information, see [Exporting platform metrics to other locations](/azure/azure-monitor/essentials/metrics-supported#exporting-platform-metrics-to-other-locations). [!INCLUDE [horz-monitor-platform-metrics](~/reusable-content/ce-skilling/azure/includes/azure-monitor/horizontals/horz-monitor-platform-metrics.md)] To learn more about routing logs to a destination, see [Collection and routing]( ### Analyzing logs -Data in Azure Monitor Logs is stored in tables where each table has its own set of unique properties. The data in these tables are associated with a Log Analytics workspace and can be queried in Log Analytics. To learn more about Azure Monitor Logs, see [Azure Monitor Logs overview](../azure-monitor/logs/data-platform-logs.md) in the Azure Monitor documentation. +Data in Azure Monitor Logs is stored in tables where each table has its own set of unique properties. The data in these tables are associated with a Log Analytics workspace and can be queried in Log Analytics. To learn more about Azure Monitor Logs, see [Azure Monitor Logs overview](/azure/azure-monitor/logs/data-platform-logs) in the Azure Monitor documentation. To route data to Azure Monitor Logs, you must create a diagnostic setting to send resource logs or platform metrics to a Log Analytics workspace. To learn more, see [Collection and routing](#collection-and-routing). When routing IoT Hub platform metrics to Azure Monitor Logs: - The following platform metrics aren't exportable by using diagnostic settings: *Connected devices* and *Total devices*. -- Multi-dimensional metrics, for example some [routing metrics](monitor-iot-hub-reference.md#routing-metrics), are currently exported as flattened single dimensional metrics aggregated across dimension values. For more detail, see [Exporting platform metrics to other locations](../azure-monitor/essentials/metrics-supported.md#exporting-platform-metrics-to-other-locations).+- Multi-dimensional metrics, for example some [routing metrics](monitor-iot-hub-reference.md#routing-metrics), are currently exported as flattened single dimensional metrics aggregated across dimension values. For more detail, see [Exporting platform metrics to other locations](/azure/azure-monitor/essentials/metrics-supported#exporting-platform-metrics-to-other-locations). -For common queries with IoT Hub, see [Sample Kusto queries](#sample-kusto-queries). For more information on using Log Analytics queries, see [Overview of log queries in Azure Monitor](../azure-monitor/logs/log-query-overview.md). +For common queries with IoT Hub, see [Sample Kusto queries](#sample-kusto-queries). For more information on using Log Analytics queries, see [Overview of log queries in Azure Monitor](/azure/azure-monitor/logs/log-query-overview). ### SDK version in IoT Hub logs The [*Connected devices (preview)*](monitor-iot-hub-reference.md#device-metrics) You can use metric alert rules to monitor for device disconnect anomalies at-scale. That is, use alerts to determine when a significant number of devices unexpectedly disconnect. When this situation is detected, you can look at logs to help troubleshoot the issue. To monitor per-device disconnects and disconnects for critical devices in near real time, however, you must use Event Grid. -To learn more about alerts with IoT Hub, see [Alerts in Monitor IoT Hub](monitor-iot-hub.md#alerts). For a walk-through of creating alerts in IoT Hub, see the [Use metrics and logs tutorial](tutorial-use-metrics-and-diags.md). For a more detailed overview of alerts, see [Overview of alerts in Microsoft Azure](../azure-monitor/alerts/alerts-overview.md) in the Azure Monitor documentation. +To learn more about alerts with IoT Hub, see [Alerts in Monitor IoT Hub](monitor-iot-hub.md#alerts). For a walk-through of creating alerts in IoT Hub, see the [Use metrics and logs tutorial](tutorial-use-metrics-and-diags.md). For a more detailed overview of alerts, see [Overview of alerts in Microsoft Azure](/azure/azure-monitor/alerts/alerts-overview) in the Azure Monitor documentation. [!INCLUDE [horz-monitor-advisor-recommendations](~/reusable-content/ce-skilling/azure/includes/azure-monitor/horizontals/horz-monitor-advisor-recommendations.md)] |
| iot-operations | Howto Configure Observability Manual | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-operations/configure-observability-monitoring/howto-configure-observability-manual.md | To set up Prometheus metrics collection for the new Arc-enabled cluster, follow ## Install Container Insights Container Insights monitors the performance of container workloads deployed to the cloud. It gives you performance visibility by collecting memory and processor metrics from controllers, nodes, and containers that are available in Kubernetes through the Metrics API. After you enable monitoring from Kubernetes clusters, metrics and container logs are automatically collected through a containerized version of the Log Analytics agent for Linux. Metrics are sent to the metrics database in Azure Monitor. Log data is sent to your Log Analytics workspace. -To monitor container workload performance, complete the steps to [enable container insights](../../azure-monitor/containers/kubernetes-monitoring-enable.md). +To monitor container workload performance, complete the steps to [enable container insights](/azure/azure-monitor/containers/kubernetes-monitoring-enable). ## Install Grafana Azure Managed Grafana is a data visualization platform built on top of the Grafana software by Grafana Labs. Azure Managed Grafana is a fully managed Azure service operated and supported by Microsoft. Grafana helps you bring together metrics, logs and traces into a single user interface. With its extensive support for data sources and graphing capabilities, you can view and analyze your application and infrastructure telemetry data in real-time. To install Azure Managed Grafana, complete the following steps: 1. Use the Azure portal to [create an Azure Managed Grafana instance](../../managed-grafan). -1. Configure an [Azure Monitor managed service for Prometheus as a data source for Azure Managed Grafana](../../azure-monitor/essentials/prometheus-grafana.md). +1. Configure an [Azure Monitor managed service for Prometheus as a data source for Azure Managed Grafana](/azure/azure-monitor/essentials/prometheus-grafana). 1. Configure the dashboards by following the steps in [Deploy dashboards to Grafana](howto-configure-observability.md#deploy-dashboards-to-grafana). |
| iot-operations | Howto Configure Observability | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot-operations/configure-observability-monitoring/howto-configure-observability.md | Complete the following steps to install the Azure IoT Operations curated Grafana ## Related content -- [Azure Monitor overview](../../azure-monitor/overview.md)+- [Azure Monitor overview](/azure/azure-monitor/overview) - [How to Deploy observability resources manually](howto-configure-observability-manual.md) |
| iot | Iot Overview Solution Management | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/iot/iot-overview-solution-management.md | While there are tools specifically for [monitoring devices](iot-overview-device- | IoT Central | [Use audit logs to track activity in your IoT Central application](../iot-central/core/howto-use-audit-logs.md) </br> [Use Azure Monitor to monitor your IoT Central application](../iot-central/core/howto-manage-and-monitor-iot-central.md#monitor-application-health) | | Azure Digital Twins | [Use Azure Monitor to monitor Azure Digital Twins resources](../digital-twins/how-to-monitor.md) | -To learn more about the Azure Monitor service, see [Azure Monitor overview](../azure-monitor/overview.md). +To learn more about the Azure Monitor service, see [Azure Monitor overview](/azure/azure-monitor/overview). ## Azure portal |
| lab-services | Reliability In Azure Lab Services | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/lab-services/reliability-in-azure-lab-services.md | Azure Lab Services does not provide regional failover support. If you want to pr ### Outage detection, notification, and management -Azure Lab Services does not provide any service-specific signals about an outage, but is dependent on Azure communications that inform customers about outages. For more information on service health, see [Resource health overview](../service-health/resource-health-overview.md). +Azure Lab Services does not provide any service-specific signals about an outage, but is dependent on Azure communications that inform customers about outages. For more information on service health, see [Resource health overview](/azure/service-health/resource-health-overview). ## Next steps |
| lighthouse | Cross Tenant Management Experience | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/lighthouse/concepts/cross-tenant-management-experience.md | Most Azure tasks and services can be used with delegated resources across manage - Create migration projects in the customer tenant and migrate VMs -[Azure Monitor](../../azure-monitor/index.yml): +[Azure Monitor](/azure/azure-monitor/): - View alerts for delegated subscriptions, with the ability to view and refresh alerts across all subscriptions - View activity log details for delegated subscriptions-- [Log analytics](../../azure-monitor/logs/workspace-design.md#multiple-tenant-strategies): Query data from remote workspaces in multiple tenants (note that automation accounts used to access data from workspaces in customer tenants must be created in the same tenant)-- Create, view, and manage [alerts](../../azure-monitor/alerts/alerts-create-new-alert-rule.md) in customer tenants+- [Log analytics](/azure/azure-monitor/logs/workspace-design#multiple-tenant-strategies): Query data from remote workspaces in multiple tenants (note that automation accounts used to access data from workspaces in customer tenants must be created in the same tenant) +- Create, view, and manage [alerts](/azure/azure-monitor/alerts/alerts-create-new-alert-rule) in customer tenants - Create alerts in customer tenants that trigger automation, such as Azure Automation runbooks or Azure Functions, in the managing tenant through webhooks-- Create [diagnostic settings](../..//azure-monitor/essentials/diagnostic-settings.md) in workspaces created in customer tenants, to send resource logs to workspaces in the managing tenant+- Create [diagnostic settings](/azure/azure-monitor/essentials/diagnostic-settings) in workspaces created in customer tenants, to send resource logs to workspaces in the managing tenant - For SAP workloads, [monitor SAP Solutions metrics with an aggregated view across customer tenants](https://techcommunity.microsoft.com/t5/running-sap-applications-on-the/using-azure-lighthouse-and-azure-monitor-for-sap-solutions-to/ba-p/1537293) - For Azure AD B2C, [route sign-in and auditing logs](../../active-directory-b2c/azure-monitor.md) to different monitoring solutions Most Azure tasks and services can be used with delegated resources across manage - See the tenant ID in returned query results, allowing you to identify whether a subscription belongs to a managed tenant -[Azure Service Health](../../service-health/index.yml): +[Azure Service Health](/azure/service-health/): - Monitor the health of customer resources with Azure Resource Health - Track the health of the Azure services used by your customers |
| lighthouse | Enterprise | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/lighthouse/concepts/enterprise.md | Either way, be sure to [follow the principle of least privilege when defining wh Azure Lighthouse only provides logical links between a managing tenant and managed tenants, rather than physically moving data or resources. Furthermore, the access always goes in only one direction, from the managing tenant to the managed tenants. Users and groups in the managing tenant should use multifactor authentication when performing management operations on managed tenant resources. -Enterprises with internal or external governance and compliance guardrails can use [Azure Activity logs](../../azure-monitor/essentials/activity-log.md) to meet their transparency requirements. When enterprise tenants have established managing and managed tenant relationships, users in each tenant can view logged activity to see actions taken by users in the managing tenant. +Enterprises with internal or external governance and compliance guardrails can use [Azure Activity logs](/azure/azure-monitor/essentials/activity-log) to meet their transparency requirements. When enterprise tenants have established managing and managed tenant relationships, users in each tenant can view logged activity to see actions taken by users in the managing tenant. ## Onboarding considerations |
| lighthouse | Manage Hybrid Infrastructure Arc | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/lighthouse/how-to/manage-hybrid-infrastructure-arc.md | If your customer has created a service principal account to onboard Kubernetes c You can deploy [configurations and Helm charts](../../azure-arc/kubernetes/tutorial-use-gitops-flux2.md) using [GitOps for connected clusters](../../azure-arc/kubernetes/conceptual-gitops-flux2.md). -You can also [monitor connected clusters](../..//azure-monitor/containers/container-insights-enable-arc-enabled-clusters.md) with Azure Monitor, use tagging to organize clusters, and [use Azure Policy for Kubernetes](/azure/governance/policy/concepts/policy-for-kubernetes?toc=%2Fazure%2Fazure-arc%2Fkubernetes%2Ftoc.json&bc=%2Fazure%2Fazure-arc%2Fkubernetes%2Fbreadcrumb%2Ftoc.json) to manage and report on compliance state. +You can also [monitor connected clusters](/azure/azure-monitor/containers/container-insights-enable-arc-enabled-clusters) with Azure Monitor, use tagging to organize clusters, and [use Azure Policy for Kubernetes](/azure/governance/policy/concepts/policy-for-kubernetes?toc=%2Fazure%2Fazure-arc%2Fkubernetes%2Ftoc.json&bc=%2Fazure%2Fazure-arc%2Fkubernetes%2Fbreadcrumb%2Ftoc.json) to manage and report on compliance state. ## Next steps |
| lighthouse | Manage Sentinel Workspaces | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/lighthouse/how-to/manage-sentinel-workspaces.md | You can also deploy workbooks directly in an individual managed tenant for scena ## Run Log Analytics and hunting queries across Microsoft Sentinel workspaces -Create and save Log Analytics queries for threat detection centrally in the managing tenant, including [hunting queries](../../sentinel/extend-sentinel-across-workspaces-tenants.md#hunt-across-multiple-workspaces). These queries can be run across all of your customers' Microsoft Sentinel workspaces by using the Union operator and the [workspace() expression](../../azure-monitor/logs/workspace-expression.md). +Create and save Log Analytics queries for threat detection centrally in the managing tenant, including [hunting queries](../../sentinel/extend-sentinel-across-workspaces-tenants.md#hunt-across-multiple-workspaces). These queries can be run across all of your customers' Microsoft Sentinel workspaces by using the Union operator and the [workspace() expression](/azure/azure-monitor/logs/workspace-expression). For more information, see [Query multiple workspace](../../sentinel/extend-sentinel-across-workspaces-tenants.md#query-multiple-workspaces). |
| lighthouse | Monitor At Scale | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/lighthouse/how-to/monitor-at-scale.md | -This topic shows you how to use [Azure Monitor Logs](../../azure-monitor/logs/data-platform-logs.md) in a scalable way across the customer tenants you're managing. Though we refer to service providers and customers in this topic, this guidance also applies to [enterprises using Azure Lighthouse to manage multiple tenants](../concepts/enterprise.md). +This topic shows you how to use [Azure Monitor Logs](/azure/azure-monitor/logs/data-platform-logs) in a scalable way across the customer tenants you're managing. Though we refer to service providers and customers in this topic, this guidance also applies to [enterprises using Azure Lighthouse to manage multiple tenants](../concepts/enterprise.md). > [!NOTE]-> Be sure that users in your managing tenants have been granted the [necessary roles for managing Log Analytics workspaces](../../azure-monitor/logs/manage-access.md#azure-rbac) on your delegated customer subscriptions. +> Be sure that users in your managing tenants have been granted the [necessary roles for managing Log Analytics workspaces](/azure/azure-monitor/logs/manage-access#azure-rbac) on your delegated customer subscriptions. ## Create Log Analytics workspaces In order to collect data, you'll need to create Log Analytics workspaces. These Log Analytics workspaces are unique environments for data collected by Azure Monitor. Each workspace has its own data repository and configuration, and data sources and solutions are configured to store their data in a particular workspace. -We recommend creating these workspaces directly in the customer tenants. This way their data remains in their tenants rather than being exported into yours. Creating the workspaces in the customer tenants allows centralized monitoring of any resources or services supported by Log Analytics, giving you more flexibility on what types of data you monitor. Workspaces created in customer tenants are required in order to collect information from [diagnostic settings](../..//azure-monitor/essentials/diagnostic-settings.md). +We recommend creating these workspaces directly in the customer tenants. This way their data remains in their tenants rather than being exported into yours. Creating the workspaces in the customer tenants allows centralized monitoring of any resources or services supported by Log Analytics, giving you more flexibility on what types of data you monitor. Workspaces created in customer tenants are required in order to collect information from [diagnostic settings](/azure/azure-monitor/essentials/diagnostic-settings). > [!TIP] > Any automation account used to access data from a Log Analytics workspace must be created in the same tenant as the workspace. -You can create a Log Analytics workspace by using the [Azure portal](../../azure-monitor/logs/quick-create-workspace.md), by using [Azure Resource Manager templates](../../azure-monitor/logs/resource-manager-workspace.md), or by using [Azure PowerShell](../../azure-monitor/logs/powershell-workspace-configuration.md). +You can create a Log Analytics workspace by using the [Azure portal](/azure/azure-monitor/logs/quick-create-workspace), by using [Azure Resource Manager templates](/azure/azure-monitor/logs/resource-manager-workspace), or by using [Azure PowerShell](/azure/azure-monitor/logs/powershell-workspace-configuration). > [!IMPORTANT] > If all workspaces are created in customer tenants, the Microsoft.Insights resource providers must also be [registered](../../azure-resource-manager/management/resource-providers-and-types.md#register-resource-provider) on a subscription in the managing tenant. If your managing tenant doesn't have an existing Azure subscription, you can register the resource provider manually by using the following PowerShell commands: When you've determined which policies to deploy, you can [deploy them to your de ## Analyze the gathered data -After you've deployed your policies, data will be logged in the Log Analytics workspaces you've created in each customer tenant. To gain insights across all managed customers, you can use tools such as [Azure Monitor Workbooks](../../azure-monitor/visualize/workbooks-overview.md) to gather and analyze information from multiple data sources. +After you've deployed your policies, data will be logged in the Log Analytics workspaces you've created in each customer tenant. To gain insights across all managed customers, you can use tools such as [Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview) to gather and analyze information from multiple data sources. ## Query data across customer workspaces -You can run [log queries](../../azure-monitor/logs/log-query-overview.md) to retrieve data across Log Analytics workspaces in different customer tenants by creating a union that includes multiple workspaces. By including the TenantID column, you can see which results belong to which tenants. +You can run [log queries](/azure/azure-monitor/logs/log-query-overview) to retrieve data across Log Analytics workspaces in different customer tenants by creating a union that includes multiple workspaces. By including the TenantID column, you can see which results belong to which tenants. The following example query creates a union on the AzureDiagnostics table across workspaces in two separate customer tenants. The results show the Category, ResourceGroup, and TenantID columns. workspace("WS-customer-tenant-2").AzureDiagnostics | project Category, ResourceGroup, TenantId ``` -For more examples of queries across multiple Log Analytics workspaces, see [Create a log query across multiple workspaces and apps in Azure Monitor](../../azure-monitor/logs/cross-workspace-query.md). +For more examples of queries across multiple Log Analytics workspaces, see [Create a log query across multiple workspaces and apps in Azure Monitor](/azure/azure-monitor/logs/cross-workspace-query). > [!IMPORTANT] > If you use an automation account used to query data from a Log Analytics workspace, that automation account must be created in the same tenant as the workspace. ## View alerts across customers -You can view [alerts](../../azure-monitor/alerts/alerts-overview.md) for delegated subscriptions in the customer tenants that you manage. +You can view [alerts](/azure/azure-monitor/alerts/alerts-overview) for delegated subscriptions in the customer tenants that you manage. -From your managing tenant, you can [create, view, and manage activity log alerts](../../azure-monitor/alerts/alerts-activity-log.md) in the Azure portal or through APIs and management tools. +From your managing tenant, you can [create, view, and manage activity log alerts](/azure/azure-monitor/alerts/alerts-activity-log) in the Azure portal or through APIs and management tools. To refresh alerts automatically across multiple customers, use an [Azure Resource Graph](../../governance/resource-graph/overview.md) query to filter for alerts. You can pin the query to your dashboard and select all of the appropriate customers and subscriptions. For example, the query below will display severity 0 and 1 alerts, refreshing every 60 minutes. |
| lighthouse | Monitor Delegation Changes | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/lighthouse/how-to/monitor-delegation-changes.md | ms.devlang: azurecli As a service provider, you may want to be aware when customer subscriptions or resource groups are delegated to your tenant through [Azure Lighthouse](../overview.md), or when previously delegated resources are removed. -In the managing tenant, the [Azure activity log](../../azure-monitor/essentials/activity-log.md) tracks delegation activity at the tenant level. This logged activity includes any added or removed delegations from customer tenants. +In the managing tenant, the [Azure activity log](/azure/azure-monitor/essentials/activity-log) tracks delegation activity at the tenant level. This logged activity includes any added or removed delegations from customer tenants. This topic explains the permissions needed to monitor delegation activity to your tenant across all of your customers. It also includes a sample script that shows one method for querying and reporting on this data. When querying this data, keep in mind: - If multiple resource groups are delegated in a single deployment, separate entries will be returned for each resource group. - Changes made to a previous delegation (such as updating the permission structure) will be logged as an added delegation. - As noted above, an account must have the Monitoring Reader Azure built-in role at root scope (/) in order to access this tenant-level data.-- You can use this data in your own workflows and reporting. For example, you can use the [HTTP Data Collector API (preview)](../../azure-monitor/logs/data-collector-api.md) to log data to Azure Monitor from a REST API client, then use [action groups](../../azure-monitor/alerts/action-groups.md) to create notifications or alerts.+- You can use this data in your own workflows and reporting. For example, you can use the [HTTP Data Collector API (preview)](/azure/azure-monitor/logs/data-collector-api) to log data to Azure Monitor from a REST API client, then use [action groups](/azure/azure-monitor/alerts/action-groups) to create notifications or alerts. ```azurepowershell-interactive # Log in first with Connect-AzAccount if you're not using Cloud Shell else { ## Next steps - Learn how to [onboard customers to Azure Lighthouse](onboard-customer.md).-- Learn about [Azure Monitor](../../azure-monitor/index.yml) and the [Azure activity log](../../azure-monitor/essentials/activity-log.md).+- Learn about [Azure Monitor](/azure/azure-monitor/) and the [Azure activity log](/azure/azure-monitor/essentials/activity-log). - Review the [Activity Logs by Domain](https://github.com/Azure/Azure-Lighthouse-samples/tree/master/templates/workbook-activitylogs-by-domain) sample workbook to learn how to display Azure Activity logs across subscriptions with an option to filter them by domain name. |
| lighthouse | View Service Provider Activity | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/lighthouse/how-to/view-service-provider-activity.md | -Customers who have delegated subscriptions to service providers through [Azure Lighthouse](../overview.md) can [view Azure Activity log](../../azure-monitor/essentials/activity-log.md) data to see all actions taken. This data provides full visibility for actions that service providers take on delegated customer resources. The activity log also shows operations from users within the customer's own Microsoft Entra tenant. +Customers who have delegated subscriptions to service providers through [Azure Lighthouse](../overview.md) can [view Azure Activity log](/azure/azure-monitor/essentials/activity-log) data to see all actions taken. This data provides full visibility for actions that service providers take on delegated customer resources. The activity log also shows operations from users within the customer's own Microsoft Entra tenant. ## View activity log data -[View the activity log](../../azure-monitor/essentials/activity-log-insights.md#view-the-activity-log) from the **Monitor** menu in the Azure portal. Use the filters if you want to show results from a specific subscription. +[View the activity log](/azure/azure-monitor/essentials/activity-log-insights#view-the-activity-log) from the **Monitor** menu in the Azure portal. Use the filters if you want to show results from a specific subscription. -You can also [view and retrieve activity log events](../../azure-monitor/essentials/activity-log.md#other-methods-to-retrieve-activity-log-events) programmatically. +You can also [view and retrieve activity log events](/azure/azure-monitor/essentials/activity-log#other-methods-to-retrieve-activity-log-events) programmatically. > [!NOTE] > Users in a service provider's tenant can view activity log results for a delegated subscription if they were granted the [Reader](../../role-based-access-control/built-in-roles.md#reader) role (or another built-in role which includes Reader access) when that subscription was onboarded to Azure Lighthouse. In the activity log, you'll see the name of the operation and its status, along > [!NOTE] > Users from the service provider appear in the activity log, but these users and their role assignments aren't shown in **Access Control (IAM)** or when retrieving role assignment info via APIs. -Logged activity is available in the Azure portal for the past 90 days. You can also [store this data for a longer period](../../azure-monitor/essentials/activity-log-insights.md#retention-period) if needed. +Logged activity is available in the Azure portal for the past 90 days. You can also [store this data for a longer period](/azure/azure-monitor/essentials/activity-log-insights#retention-period) if needed. ## Set alerts for critical operations -To stay aware of critical operations that service providers (or users in the customer's own tenant) are performing, we recommend creating [activity log alerts](../../azure-monitor/alerts/alerts-types.md#activity-log-alerts). For example, you may want to track all administrative actions for a subscription, or be notified when any virtual machine in a particular resource group is deleted. When you create alerts, they'll include actions performed by users both in the customer's tenant and in any managing tenants. +To stay aware of critical operations that service providers (or users in the customer's own tenant) are performing, we recommend creating [activity log alerts](/azure/azure-monitor/alerts/alerts-types#activity-log-alerts). For example, you may want to track all administrative actions for a subscription, or be notified when any virtual machine in a particular resource group is deleted. When you create alerts, they'll include actions performed by users both in the customer's tenant and in any managing tenants. -For more information, see [Create, view, and manage activity log alerts](../../azure-monitor/alerts/alerts-activity-log.md). +For more information, see [Create, view, and manage activity log alerts](/azure/azure-monitor/alerts/alerts-activity-log). ## Create log queries Log queries can help you analyze your logged activity or focus on specific items. For example, an audit might require you to report on all administrative-level actions performed on a subscription. You can create a query to filter on only these actions and sort the results by user, date, or another value. -For more information, see [Log queries in Azure Monitor](../../azure-monitor/logs/log-query-overview.md). +For more information, see [Log queries in Azure Monitor](/azure/azure-monitor/logs/log-query-overview). ## View user activity across domains Results can be filtered by domain name. You can also apply additional filters su ## Next steps - Learn how to [audit and restrict delegations](view-manage-service-providers.md#audit-and-restrict-delegations-in-your-environment).-- Learn more about [Azure Monitor](../../azure-monitor/index.yml).+- Learn more about [Azure Monitor](/azure/azure-monitor/). - Learn how to [view and manage service provider offers](view-manage-service-providers.md) in the Azure portal. |
| load-balancer | Load Balancer Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/load-balancer/load-balancer-insights.md | For Standard Load Balancers, your backend pool resources are color-coded with He ## Metrics dashboard -From the Insights page of your Load Balancer, you can select More Detailed Metrics to view a preconfigured [Azure Monitor Workbook](../azure-monitor/visualize/workbooks-overview.md) containing metrics visuals relevant to specific aspects of your Load Balancer. This dashboard shows the Load Balancer status and links to relevant documentation at the top of the Overview tab. +From the Insights page of your Load Balancer, you can select More Detailed Metrics to view a preconfigured [Azure Monitor Workbook](/azure/azure-monitor/visualize/workbooks-overview) containing metrics visuals relevant to specific aspects of your Load Balancer. This dashboard shows the Load Balancer status and links to relevant documentation at the top of the Overview tab. You can navigate through the available tabs each of which contain visuals relevant to a specific aspect of your Load Balancer. Explicit guidance for each is available in the dashboard at the bottom of each tab. The Metric Definitions tab contains all the information shown in the [Multi-dime * Review the dashboard and provide feedback using the below link if there's anything that can be improved * [Review the metrics documentation to ensure you understand how each metric is calculated](./load-balancer-standard-diagnostics.md#multi-dimensional-metrics) * [Create Connection Monitors for your Load Balancer](../network-watcher/connection-monitor.md)-* [Create your own workbooks](../azure-monitor/visualize/workbooks-overview.md), you can take inspiration by clicking on the edit button in your detailed metrics dashboard +* [Create your own workbooks](/azure/azure-monitor/visualize/workbooks-overview), you can take inspiration by clicking on the edit button in your detailed metrics dashboard |
| load-balancer | Load Balancer Monitor Alert Health Event Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/load-balancer/load-balancer-monitor-alert-health-event-logs.md | In this article, you learn how to monitor and alert with Azure Load Balancer hea - An Azure subscription. If you don't have an Azure subscription, create a [free account](https://azure.microsoft.com/free/). - An Azure Load Balancer resource. To learn how to create a Load Balancer resource, see [Quickstart: Create a public Standard Load Balancer](./quickstart-load-balancer-standard-public-portal.md).-- An Azure Monitor Log Analytics workspace. To learn how to create a Log Analytics workspace, see [Quickstart: Create a Log Analytics workspace](../azure-monitor/logs/quick-create-workspace.md).+- An Azure Monitor Log Analytics workspace. To learn how to create a Log Analytics workspace, see [Quickstart: Create a Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace). ## Configuring diagnostic settings to collect LoadBalancerHealthEvent logs In this section, you learn configure diagnostic settings to collect LoadBalancerHealthEvent logs and store the logs in a log analytics workspace. > [!IMPORTANT]-> We recommend sending your logs to a Log Analytics workspace, which will enable you to control access, log data retention and archive settings, and more. To learn more about configuring Log Analytics workspaces, see [Log Analytics workspace overview - Azure Monitor](../azure-monitor/logs/log-analytics-workspace-overview.md). +> We recommend sending your logs to a Log Analytics workspace, which will enable you to control access, log data retention and archive settings, and more. To learn more about configuring Log Analytics workspaces, see [Log Analytics workspace overview - Azure Monitor](/azure/azure-monitor/logs/log-analytics-workspace-overview). 1. In the Azure portal, navigate to your load balancer resource. 1. From your load balancer resource's **Overview** page, choose **Monitoring** > **Diagnostic settings**. |
| load-balancer | Load Balancer Monitor Metrics Cli | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/load-balancer/load-balancer-monitor-metrics-cli.md | az monitor metrics list --resource <resource_id> --metric DipAvailability --filt ## Next steps * [Review the metric definitions to better understand how each is generated](./load-balancer-standard-diagnostics.md#multi-dimensional-metrics) * [Create Connection Monitors for your Load Balancer](./load-balancer-standard-diagnostics.md)-* [Create your own workbooks](../azure-monitor/visualize/workbooks-overview.md), you can take inspiration by clicking on the edit button in your detailed metrics dashboard +* [Create your own workbooks](/azure/azure-monitor/visualize/workbooks-overview), you can take inspiration by clicking on the edit button in your detailed metrics dashboard |
| load-balancer | Load Balancer Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/load-balancer/load-balancer-overview.md | Key scenarios that you can accomplish using Azure Standard Load Balancer include - Enable support for **[load-balancing](./virtual-network-ipv4-ipv6-dual-stack-standard-load-balancer-powershell.md)** of **[IPv6](../virtual-network/ip-services/ipv6-overview.md)**. -- Standard load balancer provides multi-dimensional metrics through [Azure Monitor](../azure-monitor/overview.md). These metrics can be filtered, grouped, and broken out for a given dimension. They provide current and historic insights into performance and health of your service. [Insights for Azure Load Balancer](./load-balancer-insights.md) offers a preconfigured dashboard with useful visualizations for these metrics. Resource Health is also supported. Review **[Standard load balancer diagnostics](load-balancer-standard-diagnostics.md)** for more details.+- Standard load balancer provides multi-dimensional metrics through [Azure Monitor](/azure/azure-monitor/overview). These metrics can be filtered, grouped, and broken out for a given dimension. They provide current and historic insights into performance and health of your service. [Insights for Azure Load Balancer](./load-balancer-insights.md) offers a preconfigured dashboard with useful visualizations for these metrics. Resource Health is also supported. Review **[Standard load balancer diagnostics](load-balancer-standard-diagnostics.md)** for more details. - Load balance services on **[multiple ports, multiple IP addresses, or both](./load-balancer-multivip-overview.md)**. |
| load-balancer | Load Balancer Standard Diagnostics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/load-balancer/load-balancer-standard-diagnostics.md | -* **Multi-dimensional metrics and alerts**: Provides multi-dimensional diagnostic capabilities through [Azure Monitor](../azure-monitor/overview.md) for standard load balancer configurations. You can monitor, manage, and troubleshoot your standard load balancer resources. +* **Multi-dimensional metrics and alerts**: Provides multi-dimensional diagnostic capabilities through [Azure Monitor](/azure/azure-monitor/overview) for standard load balancer configurations. You can monitor, manage, and troubleshoot your standard load balancer resources. * **Resource health**: The Resource Health status of your load balancer is available in the **Resource health** page under **Monitor**. This automatic check informs you of the current availability of your load balancer resource. To view the metrics for your standard load balancer resources: ### Retrieve multi-dimensional metrics programmatically via APIs -For API guidance for retrieving multi-dimensional metric definitions and values, see [Azure Monitoring REST API walkthrough](../azure-monitor/essentials/rest-api-walkthrough.md#retrieve-metric-definitions). These metrics can be written to a storage account by adding a [diagnostic setting](../azure-monitor/essentials/diagnostic-settings.md) for the 'All Metrics' category. +For API guidance for retrieving multi-dimensional metric definitions and values, see [Azure Monitoring REST API walkthrough](/azure/azure-monitor/essentials/rest-api-walkthrough#retrieve-metric-definitions). These metrics can be written to a storage account by adding a [diagnostic setting](/azure/azure-monitor/essentials/diagnostic-settings) for the 'All Metrics' category. ### <a name = "DiagnosticScenarios"></a>Common diagnostic scenarios and recommended views To view the health of your public standard load balancer resources: *Figure: Resource health status* -A generic description of a resource health status is available in the [resource health documentation](../service-health/resource-health-overview.md). +A generic description of a resource health status is available in the [resource health documentation](/azure/service-health/resource-health-overview). ### Resource health alerts |
| load-balancer | Monitor Load Balancer | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/load-balancer/monitor-load-balancer.md | For more information about the resource types for Load Balancer, see [Azure Load [!INCLUDE [horz-monitor-platform-metrics](~/reusable-content/ce-skilling/azure/includes/azure-monitor/horizontals/horz-monitor-platform-metrics.md)] -You can analyze metrics for Load Balancer with metrics from other Azure services using metrics explorer by opening **Metrics** from the **Azure Monitor** menu. See [Analyze metrics with Azure Monitor metrics explorer](../azure-monitor/essentials/analyze-metrics.md) for details on using this tool. +You can analyze metrics for Load Balancer with metrics from other Azure services using metrics explorer by opening **Metrics** from the **Azure Monitor** menu. See [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics) for details on using this tool. For a list of available metrics for Load Balancer, see [Azure Load Balancer monitoring data reference](monitor-load-balancer-reference.md#metrics). For the available resource log categories, their associated Log Analytics tables Resource logs aren't collected and stored until you create a diagnostic setting and route them to one or more locations. You can create a diagnostic setting with the Azure portal, Azure PowerShell, or the Azure CLI. -To use the Azure portal and for general guidance, see [Create diagnostic setting to collect platform logs and metrics in Azure](../azure-monitor/essentials/diagnostic-settings.md). To use PowerShell or the Azure CLI, see the following sections. +To use the Azure portal and for general guidance, see [Create diagnostic setting to collect platform logs and metrics in Azure](/azure/azure-monitor/essentials/diagnostic-settings). To use PowerShell or the Azure CLI, see the following sections. When you create a diagnostic setting, you specify which categories of logs to collect. The category for Load Balancer is **AllMetrics**. |
| logic-apps | Biztalk Server To Azure Integration Services Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/logic-apps/biztalk-server-to-azure-integration-services-overview.md | Beyond the previously described services, Microsoft also offers the following co | Azure Event Hubs | Build dynamic data pipelines and immediately respond to business challenges by streaming millions of events per second from any source with this fully managed, real-time data ingestion service that's simple, trusted, and scalable. <br><br>API Management performs custom logging using Event Hubs, which is one of the best solutions when implementing a decoupled tracking solution in Azure. For more information, see [Azure Event Hubs](../event-hubs/event-hubs-about.md). | | Azure SQL Database | At some point, you might need to create custom logging strategies or custom configurations to support your integration solutions. While SQL Server is commonly used on premises for this purpose, Azure SQL Database might offer a viable solution when migrating on-premises SQL Server databases to the cloud. For more information, see [Azure SQL Database](/azure/azure-sql/azure-sql-iaas-vs-paas-what-is-overview). | | Azure App Configuration | Centrally manage application settings and feature flags. Modern programs, especially those running in a cloud, generally have many distributed components by nature. Spreading configuration settings across these components can lead to hard-to-troubleshoot errors during application deployment. With App Configuration, you can store all the settings for your application and secure their accesses in one place. For more information, see [Azure App Configuration](../azure-app-configuration/overview.md). |-| Azure Monitor | Application Insights, which is part of Azure Monitor, provides application performance management and monitoring for live apps. Store application telemetry and monitor the overall health of your integration platform. You also have the capability to set thresholds and get alerts when performance exceeds configured thresholds. For more information, see [Application Insights](../azure-monitor/app/app-insights-overview.md). | +| Azure Monitor | Application Insights, which is part of Azure Monitor, provides application performance management and monitoring for live apps. Store application telemetry and monitor the overall health of your integration platform. You also have the capability to set thresholds and get alerts when performance exceeds configured thresholds. For more information, see [Application Insights](/azure/azure-monitor/app/app-insights-overview). | | Azure Automation | Automate your Azure management tasks and orchestrate actions across external systems within Azure. Built on PowerShell workflow so you can use this language's many capabilities. For more information, see [Azure Automation](../automation/overview.md). | ## Supported developer experiences In on-premises architectures, SSIS was a popular option for managing the loading #### Azure Integration Services -- [Azure Monitor](../azure-monitor/overview.md)+- [Azure Monitor](/azure/azure-monitor/overview) - To monitor Azure resources, you can use this service and the [Log Analytics](../azure-monitor/logs/log-analytics-workspace-overview.md) capability as a comprehensive solution for collecting, analyzing, and acting on telemetry data from your cloud and on-premises environments. + To monitor Azure resources, you can use this service and the [Log Analytics](/azure/azure-monitor/logs/log-analytics-workspace-overview) capability as a comprehensive solution for collecting, analyzing, and acting on telemetry data from your cloud and on-premises environments. - In [Azure Logic Apps](./logic-apps-overview.md), the following options are available: - For Consumption logic app workflows, you can install the Logic Apps Management Solution (Preview) in the Azure portal and set up Azure Monitor logs to collect diagnostic data. After you set up your logic app to send that data to an Azure Log Analytics workspace, telemetry flows to where the Logic Apps Management Solution can provide health visualizations. For more information, see [Set up Azure Monitor logs and collect diagnostics data for Azure Logic Apps](./monitor-workflows-collect-diagnostic-data.md). With diagnostics enabled, you can also use Azure Monitor to send alerts based on different signal types such as when a trigger or a run fails. For more information, see [Monitor run status, review trigger history, and set up alerts for Azure Logic Apps](./monitor-logic-apps.md?tabs=consumption#set-up-monitoring-alerts). - - For Standard logic app workflows, you can enable Application Insights at logic app resource creation to send diagnostic logging and traces from your logic app's workflows. In Application Insights, you can view an [application map](../azure-monitor/app/app-map.md) to better understand the performance and health characteristics of your interfaces. Application Insights also includes [availability capabilities](../azure-monitor/app/availability-overview.md) for you to configure synthetic tests that proactively call endpoints and then evaluate the response for specific HTTP status codes or payload. Based upon your configured criteria, you can send notifications to stakeholders or call a webhook for additional orchestration capabilities. + - For Standard logic app workflows, you can enable Application Insights at logic app resource creation to send diagnostic logging and traces from your logic app's workflows. In Application Insights, you can view an [application map](/azure/azure-monitor/app/app-map) to better understand the performance and health characteristics of your interfaces. Application Insights also includes [availability capabilities](/azure/azure-monitor/app/availability-overview) for you to configure synthetic tests that proactively call endpoints and then evaluate the response for specific HTTP status codes or payload. Based upon your configured criteria, you can send notifications to stakeholders or call a webhook for additional orchestration capabilities. - [Serverless 360](https://www.serverless360.com/) is an external solution from [Kovai](https://www.kovai.co/) that provides monitoring and management through mapping Azure services, such as Azure Logic Apps, Azure Service Bus, Azure API Management, and Azure Functions. You can reprocess messages by using dead letter queues in Azure Service Bus, enable self-healing to address intermittent service disruptions, and set up proactive monitoring through synthetic transactions. |
| logic-apps | Sap | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/logic-apps/connectors/sap.md | You can [export all of your gateway's configuration and service logs](/data-inte ### Capture ETW events -As an optional advanced logging task, you can directly capture ETW events, and then [consume the data in Azure Diagnostics in Event Hubs](../../azure-monitor/agents/diagnostics-extension-stream-event-hubs.md) or [collect your data to Azure Monitor Logs](../../azure-monitor/agents/diagnostics-extension-logs.md). For more information, review the [best practices for collecting and storing data](/azure/architecture/best-practices/monitoring#collecting-and-storing-data). +As an optional advanced logging task, you can directly capture ETW events, and then [consume the data in Azure Diagnostics in Event Hubs](/azure/azure-monitor/agents/diagnostics-extension-stream-event-hubs) or [collect your data to Azure Monitor Logs](/azure/azure-monitor/agents/diagnostics-extension-logs). For more information, review the [best practices for collecting and storing data](/azure/architecture/best-practices/monitoring#collecting-and-storing-data). To work with the resulting ETL files, you can use [PerfView](https://github.com/Microsoft/perfview/blob/main/README.md), or you can write your own program. The following walkthrough uses PerfView: You can control this tracing capability at the application level by adding the f ## Send SAP telemetry for on-premises data gateway to Azure Application Insights -With the August 2021 update for the on-premises data gateway, SAP connector operations can send telemetry data from the SAP NCo client library and traces from the Microsoft SAP Adapter to [Application Insights](../../azure-monitor/app/app-insights-overview.md), which is a capability in Azure Monitor. This telemetry primarily includes the following data: +With the August 2021 update for the on-premises data gateway, SAP connector operations can send telemetry data from the SAP NCo client library and traces from the Microsoft SAP Adapter to [Application Insights](/azure/azure-monitor/app/app-insights-overview), which is a capability in Azure Monitor. This telemetry primarily includes the following data: * Metrics and traces based on SAP NCo metrics and monitors. Before you can send SAP telemetry for your gateway installation to Application I * [Create an Application Insights resource (classic)](/previous-versions/azure/azure-monitor/app/create-new-resource) -* [Workspace-based Application Insights resources](../../azure-monitor/app/create-workspace-resource.md) +* [Workspace-based Application Insights resources](/azure/azure-monitor/app/create-workspace-resource) To enable sending SAP telemetry to Application insights, follow these steps: To enable sending SAP telemetry to Application insights, follow these steps: 1. In your on-premises data gateway installation directory, check that the **Microsoft.ApplicationInsights.dll** file has the same version number as the **Microsoft.ApplicationInsights.EventSourceListener.dll** file that you added. The gateway currently uses version 2.14.0. -1. In the **ApplicationInsights.config** file, add your [Application Insights instrumentation key](../../azure-monitor/app/sdk-connection-string.md) by uncommenting the line with the `<InstrumentationKey></InstrumentationKey>` element. Replace the placeholder, *your-Application-Insights-instrumentation-key*, with your key, for example: +1. In the **ApplicationInsights.config** file, add your [Application Insights instrumentation key](/azure/azure-monitor/app/sdk-connection-string) by uncommenting the line with the `<InstrumentationKey></InstrumentationKey>` element. Replace the placeholder, *your-Application-Insights-instrumentation-key*, with your key, for example: ```xml <?xml version="1.0" encoding="utf-8"?> To enable sending SAP telemetry to Application insights, follow these steps: * `Level` values: [EventLevel Enum](/dotnet/api/system.diagnostics.tracing.eventlevel) - * [EventSource tracking](../../azure-monitor/app/configuration-with-applicationinsights-config.md#eventsource-tracking) + * [EventSource tracking](/azure/azure-monitor/app/configuration-with-applicationinsights-config#eventsource-tracking) - * [EventSource events](../../azure-monitor/app/asp-net-trace-logs.md#use-eventsource-events) + * [EventSource events](/azure/azure-monitor/app/asp-net-trace-logs#use-eventsource-events) 1. After you apply your changes, restart the on-premises data gateway service. |
| logic-apps | Create Monitoring Tracking Queries | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/logic-apps/create-monitoring-tracking-queries.md | Last updated 01/04/2024 > This article applies only to Consumption logic apps. For information about monitoring Standard logic apps, review > [Enable or open Application Insights after deployment for Standard logic apps](create-single-tenant-workflows-azure-portal.md#enable-open-application-insights). -You can view the underlying queries that produce the results from [Azure Monitor logs](../azure-monitor/logs/log-query-overview.md) and create queries that filter the results based your specific criteria. For example, you can find messages based on a specific interchange control number. Queries use the [Kusto query language](/azure/data-explorer/kusto/query/), which you can edit if you want to view different results. For more information, see [Azure Monitor log queries](/azure/data-explorer/kusto/query/). +You can view the underlying queries that produce the results from [Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview) and create queries that filter the results based your specific criteria. For example, you can find messages based on a specific interchange control number. Queries use the [Kusto query language](/azure/data-explorer/kusto/query/), which you can edit if you want to view different results. For more information, see [Azure Monitor log queries](/azure/data-explorer/kusto/query/). ## Prerequisites * An Azure account and subscription. If you don't have a subscription, [sign up for a free Azure account](https://azure.microsoft.com/free/?WT.mc_id=A261C142F). -* A Log Analytics workspace. If you don't have a Log Analytics workspace, learn [how to create a Log Analytics workspace](../azure-monitor/logs/quick-create-workspace.md). +* A Log Analytics workspace. If you don't have a Log Analytics workspace, learn [how to create a Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace). * A logic app that's set up with Azure Monitor logging and sends that information to a Log Analytics workspace. Learn [how to set up Azure Monitor logs for your logic app](../logic-apps/monitor-logic-apps.md). To view or edit the query that produces the results in your workspace summary, f ## Create your own query -To find or filter results based on specific properties or values, you can create your own query by starting from an empty query or use an existing query. For more information, see [Get started with log queries in Azure Monitor](../azure-monitor/logs/get-started-queries.md). +To find or filter results based on specific properties or values, you can create your own query by starting from an empty query or use an existing query. For more information, see [Get started with log queries in Azure Monitor](/azure/azure-monitor/logs/get-started-queries). 1. In the [Azure portal](https://portal.azure.com), find and select your Log Analytics workspace. |
| logic-apps | Create Replication Tasks Azure Resources | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/logic-apps/create-replication-tasks-azure-resources.md | To learn how you can build your own automated workflows so that you can integrat ## Monitor replication tasks -To check the performance and health of your replication task, or underlying logic app workflow, you can use [Application Insights](../azure-monitor/app/app-insights-overview.md), which is a capability in Azure Monitor. The [Application Insights Application Map](../azure-monitor/app/app-map.md) is a useful visual tool that you can use to monitor replication tasks. This map is automatically generated from the captured monitoring information so that you can explore the performance and reliability of the replication task source and target transfers. For immediate diagnostic insights and low latency visualization of log details, you can work with the [Live Metrics](../azure-monitor/app/live-stream.md) portal tool, also a capability in Azure Monitor. +To check the performance and health of your replication task, or underlying logic app workflow, you can use [Application Insights](/azure/azure-monitor/app/app-insights-overview), which is a capability in Azure Monitor. The [Application Insights Application Map](/azure/azure-monitor/app/app-map) is a useful visual tool that you can use to monitor replication tasks. This map is automatically generated from the captured monitoring information so that you can explore the performance and reliability of the replication task source and target transfers. For immediate diagnostic insights and low latency visualization of log details, you can work with the [Live Metrics](/azure/azure-monitor/app/live-stream) portal tool, also a capability in Azure Monitor. <a name="edit-task"></a> |
| logic-apps | Create Single Tenant Workflows Azure Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/logic-apps/create-single-tenant-workflows-azure-portal.md | To create and manage a Standard logic app workflow using other tools, see [Creat * To deploy your Standard logic app resource to an [App Service Environment v3 (ASEv3) - Windows plan only](../app-service/environment/overview.md), you have to create this environment resource first. You can then select this environment as the deployment location when you create your logic app. For more information, see [Resources types and environments](single-tenant-overview-compare.md#resource-environment-differences) and [Create an App Service Environment](../app-service/environment/creation.md). -* If you enable [Application Insights](../azure-monitor/app/app-insights-overview.md) on your logic app, you can optionally enable diagnostics logging and tracing. You can do so either when you create your logic app or after deployment. You need to have an Application Insights instance, but you can [create this resource in advance](../azure-monitor/app/create-workspace-resource.md), when you create your logic app, or after deployment. +* If you enable [Application Insights](/azure/azure-monitor/app/app-insights-overview) on your logic app, you can optionally enable diagnostics logging and tracing. You can do so either when you create your logic app or after deployment. You need to have an Application Insights instance, but you can [create this resource in advance](/azure/azure-monitor/app/create-workspace-resource), when you create your logic app, or after deployment. ## Best practices and recommendations More workflows in your logic app raise the risk of longer load times, which nega | **On** | Your logic app workflows can privately and securely communicate with endpoints in the virtual network. | | **Off** | Your logic app workflows can't communicate with endpoints in the virtual network. | -1. If your creation and deployment settings support using [Application Insights](../azure-monitor/app/app-insights-overview.md), you can optionally enable diagnostics logging and tracing for your logic app workflows by following these steps: +1. If your creation and deployment settings support using [Application Insights](/azure/azure-monitor/app/app-insights-overview), you can optionally enable diagnostics logging and tracing for your logic app workflows by following these steps: 1. On the **Monitoring** tab, under **Application Insights**, set **Enable Application Insights** to **Yes**. To debug a stateless workflow more easily, you can enable the run history for th ## Enable or open Application Insights after deployment -During workflow run, your logic app emits telemetry along with other events. You can use this telemetry to get better visibility into how well your workflow runs and how the Logic Apps runtime works in various ways. You can monitor your workflow by using [Application Insights](../azure-monitor/app/app-insights-overview.md), which provides near real-time telemetry (live metrics). This capability can help you investigate failures and performance problems more easily when you use this data to diagnose issues, set up alerts, and build charts. +During workflow run, your logic app emits telemetry along with other events. You can use this telemetry to get better visibility into how well your workflow runs and how the Logic Apps runtime works in various ways. You can monitor your workflow by using [Application Insights](/azure/azure-monitor/app/app-insights-overview), which provides near real-time telemetry (live metrics). This capability can help you investigate failures and performance problems more easily when you use this data to diagnose issues, set up alerts, and build charts. -If your logic app's creation and deployment settings support using [Application Insights](../azure-monitor/app/app-insights-overview.md), you can optionally enable diagnostics logging and tracing for your logic app workflow. You can do so either when you create your logic app resource in the Azure portal or after deployment. You need to have an Application Insights instance, but you can create this resource either [in advance](../azure-monitor/app/create-workspace-resource.md), when you create your logic app, or after deployment. You can also optionally [enable enhanced telemetry in Application Insights for Standard workflows](enable-enhanced-telemetry-standard-workflows.md). +If your logic app's creation and deployment settings support using [Application Insights](/azure/azure-monitor/app/app-insights-overview), you can optionally enable diagnostics logging and tracing for your logic app workflow. You can do so either when you create your logic app resource in the Azure portal or after deployment. You need to have an Application Insights instance, but you can create this resource either [in advance](/azure/azure-monitor/app/create-workspace-resource), when you create your logic app, or after deployment. You can also optionally [enable enhanced telemetry in Application Insights for Standard workflows](enable-enhanced-telemetry-standard-workflows.md). ### Enable Application Insights on a deployed logic app |
| logic-apps | Create Single Tenant Workflows Visual Studio Code | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/logic-apps/create-single-tenant-workflows-visual-studio-code.md | As you progress, you'll complete these high-level tasks: 1. To locally run webhook-based triggers and actions, such as the [built-in HTTP Webhook trigger](../connectors/connectors-native-webhook.md), in Visual Studio Code, you need to [set up forwarding for the callback URL](#webhook-setup). -1. If you create your logic app resources with settings that support using [Application Insights](../azure-monitor/app/app-insights-overview.md), you can optionally enable diagnostics logging and tracing for your logic app resource. You can do so either when you create your logic app or after deployment. You need to have an Application Insights instance, but you can create this resource either [in advance](../azure-monitor/app/create-workspace-resource.md), when you create your logic app, or after deployment. +1. If you create your logic app resources with settings that support using [Application Insights](/azure/azure-monitor/app/app-insights-overview), you can optionally enable diagnostics logging and tracing for your logic app resource. You can do so either when you create your logic app or after deployment. You need to have an Application Insights instance, but you can create this resource either [in advance](/azure/azure-monitor/app/create-workspace-resource), when you create your logic app, or after deployment. 1. Install or use a tool that can send HTTP requests to test your solution, for example: Deployment for the Standard logic app resource requires a hosting plan and prici  - 1. If your logic app's creation and deployment settings support using [Application Insights](../azure-monitor/app/app-insights-overview.md), you can optionally enable diagnostics logging and tracing for your logic app. You can do so either when you deploy your logic app from Visual Studio Code or after deployment. You need to have an Application Insights instance, but you can create this resource either [in advance](../azure-monitor/app/create-workspace-resource.md), when you deploy your logic app, or after deployment. + 1. If your logic app's creation and deployment settings support using [Application Insights](/azure/azure-monitor/app/app-insights-overview), you can optionally enable diagnostics logging and tracing for your logic app. You can do so either when you deploy your logic app from Visual Studio Code or after deployment. You need to have an Application Insights instance, but you can create this resource either [in advance](/azure/azure-monitor/app/create-workspace-resource), when you deploy your logic app, or after deployment. To enable logging and tracing now, follow these steps: After you deploy a **Logic App (Standard)** resource from Visual Studio Code to ## Enable or open Application Insights after deployment -During workflow execution, your logic app emits telemetry along with other events. You can use this telemetry to get better visibility into how well your workflow runs and how the Logic Apps runtime works in various ways. You can monitor your workflow by using [Application Insights](../azure-monitor/app/app-insights-overview.md), which provides near real-time telemetry (live metrics). This capability can help you investigate failures and performance problems more easily when you use this data to diagnose issues, set up alerts, and build charts. +During workflow execution, your logic app emits telemetry along with other events. You can use this telemetry to get better visibility into how well your workflow runs and how the Logic Apps runtime works in various ways. You can monitor your workflow by using [Application Insights](/azure/azure-monitor/app/app-insights-overview), which provides near real-time telemetry (live metrics). This capability can help you investigate failures and performance problems more easily when you use this data to diagnose issues, set up alerts, and build charts. -If your logic app's creation and deployment settings support using [Application Insights](../azure-monitor/app/app-insights-overview.md), you can optionally enable diagnostics logging and tracing for your logic app. You can do so either when you deploy your logic app from Visual Studio Code or after deployment. You need to have an Application Insights instance, but you can create this resource either [in advance](../azure-monitor/app/create-workspace-resource.md), when you deploy your logic app, or after deployment. +If your logic app's creation and deployment settings support using [Application Insights](/azure/azure-monitor/app/app-insights-overview), you can optionally enable diagnostics logging and tracing for your logic app. You can do so either when you deploy your logic app from Visual Studio Code or after deployment. You need to have an Application Insights instance, but you can create this resource either [in advance](/azure/azure-monitor/app/create-workspace-resource), when you deploy your logic app, or after deployment. To enable Application Insights on a deployed logic app or to review Application Insights data when already enabled, follow these steps: |
| logic-apps | Enable Enhanced Telemetry Standard Workflows | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/logic-apps/enable-enhanced-telemetry-standard-workflows.md | This how-to guide shows how to turn on enhanced telemetry collection in Applicat - An Azure account and subscription. If you don't have a subscription, [sign up for a free Azure account](https://azure.microsoft.com/free/?WT.mc_id=A261C142F). -- An [Application Insights](../azure-monitor/app/app-insights-overview.md) instance. You create this resource [in advance](../azure-monitor/app/create-workspace-resource.md), when you create your Standard logic app, or after logic app deployment.+- An [Application Insights](/azure/azure-monitor/app/app-insights-overview) instance. You create this resource [in advance](/azure/azure-monitor/app/create-workspace-resource), when you create your Standard logic app, or after logic app deployment. - A Standard logic app and workflow, either in the Azure portal or in Visual Studio Code. With the telemetry enhancements in Application Insights, you also get workflow i When you enable multidimensional metrics in the Metrics dashboard, you can target a subset of the overall events captured in Application Insights and filter events based on a specific workflow. -1. On your Application Insights resource, [enable multidimensional metrics](../azure-monitor/app/get-metric.md#enable-multidimensional-metrics). +1. On your Application Insights resource, [enable multidimensional metrics](/azure/azure-monitor/app/get-metric#enable-multidimensional-metrics). 1. In Application Insights, [open the Metrics dashboard](#open-metrics-dashboard). With Application Insights enhanced telemetry enabled, you can view near real-tim :::image type="content" source="media/enable-enhanced-telemetry-standard-workflows/live-metrics.png" alt-text="Screenshot shows Azure portal and Application Insights menu with selected item named Live metrics." lightbox="media/enable-enhanced-telemetry-standard-workflows/live-metrics.png"::: -For more information, see [Live Metrics: Monitor and diagnose with 1-second latency](../azure-monitor/app/live-stream.md). +For more information, see [Live Metrics: Monitor and diagnose with 1-second latency](/azure/azure-monitor/app/live-stream). > [!NOTE] > |
| logic-apps | Error Exception Handling | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/logic-apps/error-exception-handling.md | To perform different exception handling patterns, you can use the expressions pr The previous patterns are useful ways to handle errors and exceptions that happen within a run. However, you can also identify and respond to errors that happen independently from the run. To evaluate run statuses, you can monitor the logs and metrics for your runs, or publish them into any monitoring tool that you prefer. -For example, [Azure Monitor](../azure-monitor/overview.md) provides a streamlined way to send all workflow events, including all run and action statuses, to a destination. You can [set up alerts for specific metrics and thresholds in Azure Monitor](monitor-logic-apps.md#set-up-monitoring-alerts). You can also send workflow events to a [Log Analytics workspace](../azure-monitor/logs/data-platform-logs.md) or [Azure storage account](../storage/blobs/storage-blobs-overview.md). Or, you can stream all events through [Azure Event Hubs](../event-hubs/event-hubs-about.md) into [Azure Stream Analytics](https://azure.microsoft.com/services/stream-analytics/). In Stream Analytics, you can write live queries based on any anomalies, averages, or failures from the diagnostic logs. You can use Stream Analytics to send information to other data sources, such as queues, topics, SQL, Azure Cosmos DB, or Power BI. +For example, [Azure Monitor](/azure/azure-monitor/overview) provides a streamlined way to send all workflow events, including all run and action statuses, to a destination. You can [set up alerts for specific metrics and thresholds in Azure Monitor](monitor-logic-apps.md#set-up-monitoring-alerts). You can also send workflow events to a [Log Analytics workspace](/azure/azure-monitor/logs/data-platform-logs) or [Azure storage account](../storage/blobs/storage-blobs-overview.md). Or, you can stream all events through [Azure Event Hubs](../event-hubs/event-hubs-about.md) into [Azure Stream Analytics](https://azure.microsoft.com/services/stream-analytics/). In Stream Analytics, you can write live queries based on any anomalies, averages, or failures from the diagnostic logs. You can use Stream Analytics to send information to other data sources, such as queues, topics, SQL, Azure Cosmos DB, or Power BI. For more information, review [Set up Azure Monitor logs and collect diagnostics data for Azure Logic Apps](monitor-workflows-collect-diagnostic-data.md). |
| logic-apps | Healthy Unhealthy Resource | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/logic-apps/healthy-unhealthy-resource.md | When you monitor your Azure Logic Apps resources in [Microsoft Azure Security Ce * Existing logic apps with [diagnostic logging enabled](#enable-diagnostic-logging). -* A Log Analytics workspace, which is required to enable logging for your logic app. If you don't have a workspace, first [create your workspace](../azure-monitor/logs/quick-create-workspace.md). +* A Log Analytics workspace, which is required to enable logging for your logic app. If you don't have a workspace, first [create your workspace](/azure/azure-monitor/logs/quick-create-workspace). ## Enable diagnostic logging |
| logic-apps | Logic Apps Limits And Config | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/logic-apps/logic-apps-limits-and-config.md | Single-tenant Azure Logic Apps dynamically scales to effectively handle increasi > For a Standard logic app in an App Service Environment v3, dynamic scaling isn't available. > You must set scaling rules on the associated App Service Plan. As a commonly used scaling rule, > you can use the CPU metric, and scale your App Service Plan to keep the virtual CPU between 50-70%. -> For more information, see [Get started with autoscale in Azure](../azure-monitor/autoscale/autoscale-get-started.md). +> For more information, see [Get started with autoscale in Azure](/azure/azure-monitor/autoscale/autoscale-get-started). - Trigger |
| logic-apps | Monitor B2b Messages Log Analytics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/logic-apps/monitor-b2b-messages-log-analytics.md | Last updated 01/04/2024 > This article applies only to Consumption logic apps. For information about monitoring Standard logic apps, review > [Enable or open Application Insights after deployment for Standard logic apps](create-single-tenant-workflows-azure-portal.md#enable-open-application-insights). -After you set up B2B communication between trading partners in your integration account, those partners can exchange messages by using protocols such as AS2, X12, and EDIFACT. To check that this communication works the way you expect, you can set up [Azure Monitor logs](../azure-monitor/logs/data-platform-logs.md) for your integration account. [Azure Monitor](../azure-monitor/overview.md) helps you monitor your cloud and on-premises environments so that you can more easily maintain their availability and performance. By using Azure Monitor logs, you can record and store data about runtime data and events, such as trigger events, run events, and action events in a [Log Analytics workspace](../azure-monitor/essentials/resource-logs.md#send-to-log-analytics-workspace). For messages, logging also collects information such as: +After you set up B2B communication between trading partners in your integration account, those partners can exchange messages by using protocols such as AS2, X12, and EDIFACT. To check that this communication works the way you expect, you can set up [Azure Monitor logs](/azure/azure-monitor/logs/data-platform-logs) for your integration account. [Azure Monitor](/azure/azure-monitor/overview) helps you monitor your cloud and on-premises environments so that you can more easily maintain their availability and performance. By using Azure Monitor logs, you can record and store data about runtime data and events, such as trigger events, run events, and action events in a [Log Analytics workspace](/azure/azure-monitor/essentials/resource-logs#send-to-log-analytics-workspace). For messages, logging also collects information such as: * Message count and status * Acknowledgments status * Correlations between messages and acknowledgments * Detailed error descriptions for failures -Azure Monitor lets you create [log queries](../azure-monitor/logs/log-query-overview.md) to help you find and review this information. You can also [use this diagnostics data with other Azure services](monitor-workflows-collect-diagnostic-data.md#other-destinations), such as Azure Storage and Azure Event Hubs. +Azure Monitor lets you create [log queries](/azure/azure-monitor/logs/log-query-overview) to help you find and review this information. You can also [use this diagnostics data with other Azure services](monitor-workflows-collect-diagnostic-data.md#other-destinations), such as Azure Storage and Azure Event Hubs. To set up logging for your integration account, [install the Logic Apps B2B solution](#install-b2b-solution) in the Azure portal. This solution provides aggregated information for B2B message events. Then, to enable logging and creating queries for this information, set up [Azure Monitor logs](#set-up-resource-logs). This article shows how to enable Azure Monitor logging for your integration acco ## Prerequisites -* A Log Analytics workspace. If you don't have a Log Analytics workspace, learn [how to create a Log Analytics workspace](../azure-monitor/logs/quick-create-workspace.md). +* A Log Analytics workspace. If you don't have a Log Analytics workspace, learn [how to create a Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace). * A logic app that's set up with Azure Monitor logging and sends that information to a Log Analytics workspace. Learn [how to set up Azure Monitor logs for your logic app](../logic-apps/monitor-logic-apps.md). After your logic app runs, you can view the status and data about those messages * To search results with prebuilt queries, select **Favorites**. - * Learn [how to build queries by adding filters](../logic-apps/create-monitoring-tracking-queries.md). Or learn more about [how to find data with log searches in Azure Monitor logs](../azure-monitor/logs/log-query-overview.md). + * Learn [how to build queries by adding filters](../logic-apps/create-monitoring-tracking-queries.md). Or learn more about [how to find data with log searches in Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview). * To change query in the search box, update the query with the columns and values that you want to use as filters. --> |
| logic-apps | Monitor Workflows Collect Diagnostic Data | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/logic-apps/monitor-workflows-collect-diagnostic-data.md | Last updated 01/10/2024 [!INCLUDE [logic-apps-sku-consumption-standard](../../includes/logic-apps-sku-consumption-standard.md)] -To get richer data for debugging and diagnosing your workflows in Azure Logic Apps, you can log workflow runtime data and events, such as trigger events, run events, and action events, that you can send to a [Log Analytics workspace](../azure-monitor/essentials/resource-logs.md#send-to-log-analytics-workspace), Azure [storage account](../storage/common/storage-account-overview.md), Azure [event hub](../event-hubs/event-hubs-features.md#namespace), another partner destination, or all these destinations when you set up and use [Azure Monitor Logs](../azure-monitor/logs/data-platform-logs.md). +To get richer data for debugging and diagnosing your workflows in Azure Logic Apps, you can log workflow runtime data and events, such as trigger events, run events, and action events, that you can send to a [Log Analytics workspace](/azure/azure-monitor/essentials/resource-logs#send-to-log-analytics-workspace), Azure [storage account](../storage/common/storage-account-overview.md), Azure [event hub](../event-hubs/event-hubs-features.md#namespace), another partner destination, or all these destinations when you set up and use [Azure Monitor Logs](/azure/azure-monitor/logs/data-platform-logs). > [!NOTE] > This how-to guide shows how to complete the following tasks, based on whether yo * The destination resource for where you want to send diagnostic data: - * A [Log Analytics workspace](../azure-monitor/logs/quick-create-workspace.md) + * A [Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace) * An [Azure storage account](../storage/common/storage-account-create.md) For a Standard logic app, you can continue with [Add a diagnostic setting](#add- |-|| | **Send to Log Analytics workspace** | Select the Azure subscription for your Log Analytics workspace and the workspace. | | **Archive to a storage account** | Select the Azure subscription for your Azure storage account and the storage account. For more information, see [Send diagnostic data to Azure Storage and Azure Event Hubs](#other-destinations). |- | **Stream to an event hub** | Select the Azure subscription for your event hub namespace, event hub, and event hub policy name. For more information, see [Send diagnostic data to Azure Storage and Azure Event Hubs](#other-destinations) and [Azure Monitor partner integrations](../azure-monitor/partners.md). | + | **Stream to an event hub** | Select the Azure subscription for your event hub namespace, event hub, and event hub policy name. For more information, see [Send diagnostic data to Azure Storage and Azure Event Hubs](#other-destinations) and [Azure Monitor partner integrations](/azure/azure-monitor/partners). | | **Send to partner solution** | Select your Azure subscription and the destination. For more information, see [Azure Native ISV Services overview](../partner-solutions/overview.md). | The following example selects a Log Analytics workspace as the destination: For a Standard logic app, you can continue with [Add a diagnostic setting](#add- |-|| | **Send to Log Analytics workspace** | Select the Azure subscription for your Log Analytics workspace and the workspace. | | **Archive to a storage account** | Select the Azure subscription for your Azure storage account and the storage account. For more information, see [Send diagnostic data to Azure Storage and Azure Event Hubs](#other-destinations). |- | **Stream to an event hub** | Select the Azure subscription for your event hub namespace, event hub, and event hub policy name. For more information, see [Send diagnostic data to Azure Storage and Azure Event Hubs](#other-destinations) and [Azure Monitor partner integrations](../azure-monitor/partners.md). | + | **Stream to an event hub** | Select the Azure subscription for your event hub namespace, event hub, and event hub policy name. For more information, see [Send diagnostic data to Azure Storage and Azure Event Hubs](#other-destinations) and [Azure Monitor partner integrations](/azure/azure-monitor/partners). | | **Send to partner solution** | Select your Azure subscription and the destination. For more information, see [Azure Native ISV Services overview](../partner-solutions/overview.md). | The following example selects a Log Analytics workspace as the destination: In your Log Analytics workspace's query pane, you can enter your own queries to Along with Azure Monitor Logs, you can send the collected data to other destinations, for example: -* [Archive Azure resource logs to storage account](../azure-monitor/essentials/resource-logs.md#send-to-azure-storage) -* [Stream Azure platform logs to Azure Event Hubs](../azure-monitor/essentials/resource-logs.md#send-to-azure-event-hubs) +* [Archive Azure resource logs to storage account](/azure/azure-monitor/essentials/resource-logs#send-to-azure-storage) +* [Stream Azure platform logs to Azure Event Hubs](/azure/azure-monitor/essentials/resource-logs#send-to-azure-event-hubs) -You can then get real-time monitoring by using telemetry and analytics from other services, such as [Azure Stream Analytics](../stream-analytics/stream-analytics-introduction.md) and [Power BI](../azure-monitor/logs/log-powerbi.md), for example: +You can then get real-time monitoring by using telemetry and analytics from other services, such as [Azure Stream Analytics](../stream-analytics/stream-analytics-introduction.md) and [Power BI](/azure/azure-monitor/logs/log-powerbi), for example: * [Stream data from Event Hubs to Stream Analytics](../stream-analytics/stream-analytics-define-inputs.md) * [Analyze streaming data with Stream Analytics and create a real-time analytics dashboard in Power BI](../stream-analytics/stream-analytics-power-bi-dashboard.md) |
| logic-apps | Single Tenant Overview Compare | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/logic-apps/single-tenant-overview-compare.md | The single-tenant model and **Standard** logic app include many current and new * Directly publish or deploy logic apps and their workflows from Visual Studio Code to various hosting environments such as Azure and Azure Arc enabled Logic Apps. -* Enable diagnostics logging and tracing capabilities for your logic app by using [Application Insights](../azure-monitor/app/app-insights-overview.md) when supported by your Azure subscription and logic app settings. +* Enable diagnostics logging and tracing capabilities for your logic app by using [Application Insights](/azure/azure-monitor/app/app-insights-overview) when supported by your Azure subscription and logic app settings. * Access networking capabilities, such as connect and integrate privately with Azure virtual networks, similar to Azure Functions when you create and deploy your logic apps using the [Azure Functions Premium plan](../azure-functions/functions-premium-plan.md). For more information, review the following documentation: |
| logic-apps | View Workflow Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/logic-apps/view-workflow-metrics.md | This guide shows how you can check the health and performance for both Consumpti :::image type="content" source="./media/view-workflow-metrics/view-metrics-consumption.png" alt-text="Screenshot showing Azure portal, Consumption logic app resource menu with Metrics selected, and the Metric list opened."::: - For more information about Consumption workflow metrics, see [Supported metrics with Azure Monitor - Microsoft.Logic/workflows](../azure-monitor/essentials/metrics-supported.md#microsoftlogicworkflows). + For more information about Consumption workflow metrics, see [Supported metrics with Azure Monitor - Microsoft.Logic/workflows](/azure/azure-monitor/essentials/metrics-supported#microsoftlogicworkflows). 1. From the **Metric** list, select the metric that you want to review. From the **Aggregation** list, select the option for how you want to group the metric's values: **Count**, **Avg**, **Min**, **Max**, or **Sum**. |
| logic-apps | View Workflow Status Run History | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/logic-apps/view-workflow-status-run-history.md | To monitor and review the workflow run status for Standard workflows, see the fo - [Review workflow run history](create-single-tenant-workflows-azure-portal.md#review-run-history). - [Enable or open Application Insights after deployment](create-single-tenant-workflows-azure-portal.md#enable-open-application-insights). -For real-time event monitoring and richer debugging, you can set up diagnostics logging for your logic app workflow by using [Azure Monitor logs](../azure-monitor/overview.md). This Azure service helps you monitor your cloud and on-premises environments so that you can more easily maintain their availability and performance. You can then find and view events, such as trigger events, run events, and action events. By storing this information in [Azure Monitor logs](../azure-monitor/logs/data-platform-logs.md), you can create [log queries](../azure-monitor/logs/log-query-overview.md) that help you find and analyze this information. You can also use this diagnostic data with other Azure services, such as Azure Storage and Azure Event Hubs. For more information, see [Monitor logic apps by using Azure Monitor](monitor-workflows-collect-diagnostic-data.md). +For real-time event monitoring and richer debugging, you can set up diagnostics logging for your logic app workflow by using [Azure Monitor logs](/azure/azure-monitor/overview). This Azure service helps you monitor your cloud and on-premises environments so that you can more easily maintain their availability and performance. You can then find and view events, such as trigger events, run events, and action events. By storing this information in [Azure Monitor logs](/azure/azure-monitor/logs/data-platform-logs), you can create [log queries](/azure/azure-monitor/logs/log-query-overview) that help you find and analyze this information. You can also use this diagnostic data with other Azure services, such as Azure Storage and Azure Event Hubs. For more information, see [Monitor logic apps by using Azure Monitor](monitor-workflows-collect-diagnostic-data.md). <a name="review-trigger-history"></a> The resubmit capability is available for all actions except for non-sequential a ## Set up monitoring alerts -To get alerts based on specific metrics or exceeded thresholds for your logic app, set up [alerts in Azure Monitor](../azure-monitor/alerts/alerts-overview.md). For more information, review [Metrics in Azure](../azure-monitor/data-platform.md). +To get alerts based on specific metrics or exceeded thresholds for your logic app, set up [alerts in Azure Monitor](/azure/azure-monitor/alerts/alerts-overview). For more information, review [Metrics in Azure](/azure/azure-monitor/data-platform). -To set up alerts without using [Azure Monitor](../azure-monitor/logs/log-query-overview.md), follow these steps, which apply to both Consumption and Standard logic app resources: +To set up alerts without using [Azure Monitor](/azure/azure-monitor/logs/log-query-overview), follow these steps, which apply to both Consumption and Standard logic app resources: 1. On your logic app menu, under **Monitoring**, select **Alerts**. On the toolbar, select **Create** > **Alert rule**. To set up alerts without using [Azure Monitor](../azure-monitor/logs/log-query-o 1. When you're ready, select **Review + Create**. -For general information, see [Create an alert rule from a specific resource - Azure Monitor](../azure-monitor/alerts/alerts-create-new-alert-rule.md#create-or-edit-an-alert-rule-in-the-azure-portal). +For general information, see [Create an alert rule from a specific resource - Azure Monitor](/azure/azure-monitor/alerts/alerts-create-new-alert-rule#create-or-edit-an-alert-rule-in-the-azure-portal). ## Next steps |
| managed-ccf | How To Enable Azure Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/managed-ccf/how-to-enable-azure-monitor.md | The logs from your TypeScript and JavaScript application can be viewed in Azure ## Create the Log Analytics workspace -1. Follow the instructions at [Create a workspace](../azure-monitor/logs/quick-create-workspace.md) to create a workspace. +1. Follow the instructions at [Create a workspace](/azure/azure-monitor/logs/quick-create-workspace) to create a workspace. 2. After the workspace is created, make a note of the Resource ID from the properties page. :::image type="content" source="media/how-to/log-analytics-workspace-properties.png" alt-text="Screenshot that shows the properties of a Log Analytics workspace screen."::: 1. Navigate to the Managed CCF resource and make a note of the Resource ID from the properties page. |
| managed-grafana | How To Connect Azure Monitor Workspace | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/managed-grafana/how-to-connect-azure-monitor-workspace.md | In this guide, learn how to connect an Azure Monitor workspace to Grafana direct - An Azure account with an active subscription. [Create an account for free](https://azure.microsoft.com/free). - An Azure Managed Grafana instance in the Standard tier. [Create a new instance](quickstart-managed-grafana-portal.md) if you don't have one.-- An [Azure Monitor workspace with Prometheus data](../azure-monitor/containers/monitor-kubernetes.md).+- An [Azure Monitor workspace with Prometheus data](/azure/azure-monitor/containers/monitor-kubernetes). ## Add a new role assignment To build a brand new dashboard with Prometheus metrics: For more information about editing a dashboard, read [Edit a dashboard panel](./how-to-create-dashboard.md#edit-a-dashboard-panel). > [!TIP]-> If you're unable to get Prometheus data in your dashboard, check if your Azure Monitor workspace is collecting Prometheus data. Go to [Troubleshoot collection of Prometheus metrics in Azure Monitor](../azure-monitor/containers/prometheus-metrics-troubleshoot.md) for more information. +> If you're unable to get Prometheus data in your dashboard, check if your Azure Monitor workspace is collecting Prometheus data. Go to [Troubleshoot collection of Prometheus metrics in Azure Monitor](/azure/azure-monitor/containers/prometheus-metrics-troubleshoot) for more information. ## Remove an Azure Monitor workspace Optionally also remove the role assignment that was previously added in the Azur 1. In the Azure Monitor workspace resource, select **Access control (IAM)** > **Role assignments**. 1. Under **Monitoring Data Reader**, select the row with the name of your Azure Managed Grafana resource and select **Remove** > **OK**. -To learn more about Azure Monitor managed service for Prometheus, read the [Azure Monitor managed service for Prometheus guide](../azure-monitor/essentials/prometheus-metrics-overview.md). +To learn more about Azure Monitor managed service for Prometheus, read the [Azure Monitor managed service for Prometheus guide](/azure/azure-monitor/essentials/prometheus-metrics-overview). ## Next steps |
| managed-grafana | How To Monitor Managed Grafana Workspace | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/managed-grafana/how-to-monitor-managed-grafana-workspace.md | You can create up to five different diagnostic settings to send different logs t | Log Analytics workspace | Send data to a Log Analytics workspace | Select the **subscription** containing an existing Log Analytics workspace, then select the **Log Analytics workspace** | | Storage account | Archive data to a storage account | Select the **subscription** containing an existing storage account, then select the **storage account**. Only storage accounts in the same region as the Grafana instance are displayed in the dropdown menu. | | Event hub | Stream to an event hub | Select a **subscription** and an existing Azure Event Hubs **namespace**. Optionally also choose an existing **event hub**. Lastly, choose an **event hub policy** from the list. Only event hubs in the same region as the Grafana instance are displayed in the dropdown menu. |- | Partner solution | Send to a partner solution | Select a **subscription** and a **destination**. For more information about available destinations, go to [partner destinations](../azure-monitor/partners.md). | + | Partner solution | Send to a partner solution | Select a **subscription** and a **destination**. For more information about available destinations, go to [partner destinations](/azure/azure-monitor/partners). | :::image type="content" source="media//monitoring-logs/monitoring-settings.png" alt-text="Screenshot of the Azure platform. Diagnostic settings configuration."::: |
| managed-grafana | How To Permissions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/managed-grafana/how-to-permissions.md | To edit permissions for a specific resource, follow these steps. 1. Select **Next**, then **Review + assign** to confirm the assignment of the new permission. -For more information about how to use Managed Grafana with Azure Monitor, go to [Monitor your Azure services in Grafana](../azure-monitor/visualize/grafana-plugin.md). +For more information about how to use Managed Grafana with Azure Monitor, go to [Monitor your Azure services in Grafana](/azure/azure-monitor/visualize/grafana-plugin). ### [Azure CLI](#tab/azure-cli) |
| managed-grafana | How To Set Up Private Access | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/managed-grafana/how-to-set-up-private-access.md | In this guide, you'll learn how to disable public access to your Azure Managed G Public access is enabled by default when you create an Azure Grafana workspace. Disabling public access prevents all traffic from accessing the resource unless you go through a private endpoint. > [!NOTE]-> When private access is enabled, pinging charts using the [*Pin to Grafana*](../azure-monitor/visualize/grafana-plugin.md#pin-charts-from-the-azure-portal-to-azure-managed-grafana) feature will no longer work as the Azure portal can't access an Azure Managed Grafana workspace on a private IP address. +> When private access is enabled, pinging charts using the [*Pin to Grafana*](/azure/azure-monitor/visualize/grafana-plugin#pin-charts-from-the-azure-portal-to-azure-managed-grafana) feature will no longer work as the Azure portal can't access an Azure Managed Grafana workspace on a private IP address. ### [Portal](#tab/azure-portal) |
| managed-grafana | How To Use Azure Monitor Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/managed-grafana/how-to-use-azure-monitor-alerts.md | Both Azure Monitor and Grafana provide alerting functions. Grafana provides an alerting function for a number of [supported data sources](https://grafana.com/docs/grafana/latest/alerting/fundamentals/data-source-alerting/#data-sources-and-grafana-alerting). Alert rules are processed in your Azure Managed Grafana workspace and they share the same compute resources and query throttling limits with dashboard rendering. For more information about these limits, refer to [performance considerations and limitations](https://grafana.com/docs/grafana/latest/alerting/set-up/performance-limitations/#performance-considerations-and-limitations). -Azure Monitor has its own [alert system](../azure-monitor/alerts/alerts-overview.md). It offers many advantages: +Azure Monitor has its own [alert system](/azure/azure-monitor/alerts/alerts-overview). It offers many advantages: * Scalability: Azure Monitor alerts are evaluated in the Azure Monitor platform that's been architected to autoscale to your needs.-* Compliance: Azure Monitor alerts and [action groups](../azure-monitor/alerts/action-groups.md) are governed by Azure's compliance standards on privacy, including unsubscribe support. +* Compliance: Azure Monitor alerts and [action groups](/azure/azure-monitor/alerts/action-groups) are governed by Azure's compliance standards on privacy, including unsubscribe support. * Customized notifications and actions: Azure Monitor alerts use action groups to send notifications by email, SMS, voice, and push notifications. These events can be configured to trigger further actions implemented in Functions, Logic apps, webhook, and other supported action types. * Consistent resource management: Azure Monitor alerts are managed as Azure resources. They can be created, updated and viewed using Azure APIs and tools, such as ARM templates, Azure CLI or SDKs. Define alert rules in Azure Monitor based on the type of alerts: | Alert Type | Description | |--|--|-| Managed service for Prometheus | Use [Prometheus rule groups](../azure-monitor/essentials/prometheus-rule-groups.md). A set of [predefined Prometheus alert rules](../azure-monitor/containers/container-insights-metric-alerts.md) and [recording rules](../azure-monitor/essentials/prometheus-metrics-scrape-default.md#recording-rules) for AKS is available. | -| Other metrics, logs, health | Create new [alert rules](../azure-monitor/alerts/alerts-create-new-alert-rule.md). | +| Managed service for Prometheus | Use [Prometheus rule groups](/azure/azure-monitor/essentials/prometheus-rule-groups). A set of [predefined Prometheus alert rules](/azure/azure-monitor/containers/container-insights-metric-alerts) and [recording rules](/azure/azure-monitor/essentials/prometheus-metrics-scrape-default#recording-rules) for AKS is available. | +| Other metrics, logs, health | Create new [alert rules](/azure/azure-monitor/alerts/alerts-create-new-alert-rule). | You can view alert state and conditions using the Azure Alert Consumption dashboard in your Azure Managed Grafana workspace. |
| managed-grafana | Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/managed-grafana/overview.md | Azure Managed Grafana is a data visualization platform built on top of the Grafa Azure Managed Grafana is optimized for the Azure environment. It works seamlessly with many Azure services and provides the following integration features: -* Built-in support for [Azure Monitor](../azure-monitor/index.yml) and [Azure Data Explorer](/azure/data-explorer/) +* Built-in support for [Azure Monitor](/azure/azure-monitor/) and [Azure Data Explorer](/azure/data-explorer/) * User authentication and access control using Microsoft Entra identities * Direct import of existing charts from the Azure portal |
| managed-grafana | Quickstart Managed Grafana Cli | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/managed-grafana/quickstart-managed-grafana-cli.md | Now let's check if you can access your new Managed Grafana instance. :::image type="content" source="media/quickstart-portal/grafana-ui.png" alt-text="Screenshot of a Managed Grafana instance."::: -You can now start interacting with the Grafana application to configure data sources, create dashboards, reports and alerts. Suggested read: [Monitor Azure services and applications using Grafana](../azure-monitor/visualize/grafana-plugin.md). +You can now start interacting with the Grafana application to configure data sources, create dashboards, reports and alerts. Suggested read: [Monitor Azure services and applications using Grafana](/azure/azure-monitor/visualize/grafana-plugin). ## Clean up resources |
| managed-grafana | Quickstart Managed Grafana Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/managed-grafana/quickstart-managed-grafana-portal.md | In this quickstart, you get started with Azure Managed Grafana by creating an Az :::image type="content" source="media/quickstart-portal/grafana-ui.png" alt-text="Screenshot of an Azure Managed Grafana instance."::: -You can now start interacting with the Grafana application to configure data sources, create dashboards, reports and alerts. Suggested read: [Monitor Azure services and applications using Grafana](../azure-monitor/visualize/grafana-plugin.md). +You can now start interacting with the Grafana application to configure data sources, create dashboards, reports and alerts. Suggested read: [Monitor Azure services and applications using Grafana](/azure/azure-monitor/visualize/grafana-plugin). ## Clean up resources |
| migrate | Common Questions Discovery Dependency Analysis | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/migrate/common-questions-discovery-dependency-analysis.md | The differences between agentless visualization and agent-based visualization ar **Requirement** | **Agentless** | **Agent-based** | | Support | Generally available for VMware VMs, Hyper-V VMs, bare-metal servers, and servers running on other public clouds like AWS, GCP etc. | In General Availability (GA).-Agent | No need to install agents on machines you want to cross-check. | Agents to be installed on each on-premises machine that you want to analyze: The [Microsoft Monitoring agent (MMA)](../azure-monitor/agents/agent-windows.md), and the [Dependency agent](../azure-monitor/vm/vminsights-dependency-agent-maintenance.md). +Agent | No need to install agents on machines you want to cross-check. | Agents to be installed on each on-premises machine that you want to analyze: The [Microsoft Monitoring agent (MMA)](/azure/azure-monitor/agents/agent-windows), and the [Dependency agent](/azure/azure-monitor/vm/vminsights-dependency-agent-maintenance). Prerequisites | [Review](concepts-dependency-visualization.md#agentless-analysis) the prerequisites and deployment requirements. | [Review](concepts-dependency-visualization.md#agent-based-analysis) the prerequisites and deployment requirements.-Log Analytics | Not required. | Azure Migrate uses the [Service Map](../azure-monitor/vm/service-map.md) solution in [Azure Monitor logs](../azure-monitor/logs/log-query-overview.md) for dependency visualization. [Learn more](concepts-dependency-visualization.md#agent-based-analysis). +Log Analytics | Not required. | Azure Migrate uses the [Service Map](/azure/azure-monitor/vm/service-map) solution in [Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview) for dependency visualization. [Learn more](concepts-dependency-visualization.md#agent-based-analysis). How it works | Captures TCP connection data on machines enabled for dependency visualization. After discovery, it gathers data at intervals of five minutes. | Service Map agents installed on a machine gather data about TCP processes and inbound/outbound connections for each process. Data | Source machine server name, process, application name.<br/><br/> Destination machine server name, process, application name, and port. | Source machine server name, process, application name.<br/><br/> Destination machine server name, process, application name, and port.<br/><br/> Number of connections, latency, and data transfer information are gathered and available for Log Analytics queries. Visualization | Dependency map of single server can be viewed over a duration of one hour to 30 days. | Dependency map of a single server.<br/><br/> Map can be viewed over an hour only.<br/><br/> Dependency map of a group of servers.<br/><br/> Add and remove servers in a group from the map view. No. Learn more about [Azure Migrate pricing](https://azure.microsoft.com/pricing To use agent-based dependency visualization, download and install agents on each on-premises machine that you want to evaluate: -- [Microsoft Monitoring Agent (MMA)](../azure-monitor/agents/agent-windows.md)-- [Dependency agent](../azure-monitor/vm/vminsights-dependency-agent-maintenance.md)+- [Microsoft Monitoring Agent (MMA)](/azure/azure-monitor/agents/agent-windows) +- [Dependency agent](/azure/azure-monitor/vm/vminsights-dependency-agent-maintenance) - If you've machines that don't have internet connectivity, download and install the Log Analytics gateway on them. You need these agents only if you use agent-based dependency visualization. No, the dependency visualization report in agent-based visualization can't be ex For agent-based dependency visualization: -- Use a [script to install the Dependency agent](../azure-monitor/vm/vminsights-dependency-agent-maintenance.md#install-or-upgrade-dependency-agent).-- For MMA, [use the command line or automation](../azure-monitor/agents/log-analytics-agent.md#installation-options), or use a [script](https://www.powershellgallery.com/).+- Use a [script to install the Dependency agent](/azure/azure-monitor/vm/vminsights-dependency-agent-maintenance#install-or-upgrade-dependency-agent). +- For MMA, [use the command line or automation](/azure/azure-monitor/agents/log-analytics-agent#installation-options), or use a [script](https://www.powershellgallery.com/). - In addition to scripts, you can use deployment tools like Microsoft Configuration Manager and Intigua to deploy the agents. ## What operating systems does MMA support? -- View the list of [Windows operating systems that MMA supports](../azure-monitor/agents/log-analytics-agent.md#installation-options).-- View the list of [Linux operating systems that MMA supports](../azure-monitor/agents/log-analytics-agent.md#installation-options).+- View the list of [Windows operating systems that MMA supports](/azure/azure-monitor/agents/log-analytics-agent#installation-options). +- View the list of [Linux operating systems that MMA supports](/azure/azure-monitor/agents/log-analytics-agent#installation-options). ## Can I visualize dependencies for more than one hour? |
| migrate | Concepts Dependency Visualization | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/migrate/concepts-dependency-visualization.md | After discovery of dependency data begins, polling begins: ## Agent-based analysis -For agent-based analysis, Azure Migrate: Discovery and assessment uses the [Service Map](/previous-versions/azure/azure-monitor/vm/service-map) solution in Azure Monitor. You install the [Microsoft Monitoring Agent/Log Analytics agent](../azure-monitor/agents/log-analytics-agent.md) and the [Dependency agent](../azure-monitor/vm/vminsights-dependency-agent-maintenance.md), on each server you want to analyze. +For agent-based analysis, Azure Migrate: Discovery and assessment uses the [Service Map](/previous-versions/azure/azure-monitor/vm/service-map) solution in Azure Monitor. You install the [Microsoft Monitoring Agent/Log Analytics agent](/azure/azure-monitor/agents/log-analytics-agent) and the [Dependency agent](/azure/azure-monitor/vm/vminsights-dependency-agent-maintenance), on each server you want to analyze. ### Dependency data The differences between agentless visualization and agent-based visualization ar | | **Support** | Generally Available for VMware VMs, Hyper-V VMs, Physical servers, or servers running on other public clouds like AWS and GCP. | In general availability (GA). **Agent** | No agents needed on servers you want to analyze. | Agents required on each on-premises server that you want to analyze.-**Log Analytics** | Not required. | Azure Migrate uses the [Service Map](/previous-versions/azure/azure-monitor/vm/service-map) solution in [Azure Monitor logs](../azure-monitor/logs/log-query-overview.md) for dependency analysis.<br/><br/> You associate a Log Analytics workspace with a project. The workspace must reside in the East US, Southeast Asia, or West Europe regions. The workspace must be in a region in which [Service Map is supported](https://azure.microsoft.com/global-infrastructure/services/?products=monitor®ions=all). You can monitor Azure VMs in any region. The VMs themselves aren't limited to the regions supported by the Log Analytics workspace. +**Log Analytics** | Not required. | Azure Migrate uses the [Service Map](/previous-versions/azure/azure-monitor/vm/service-map) solution in [Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview) for dependency analysis.<br/><br/> You associate a Log Analytics workspace with a project. The workspace must reside in the East US, Southeast Asia, or West Europe regions. The workspace must be in a region in which [Service Map is supported](https://azure.microsoft.com/global-infrastructure/services/?products=monitor®ions=all). You can monitor Azure VMs in any region. The VMs themselves aren't limited to the regions supported by the Log Analytics workspace. **Process** | Captures TCP connection data. After discovery, it gathers data at intervals of five minutes. | Service Map agents installed on a server gather data about TCP processes, and inbound/outbound connections for each process. **Data** | Source server name, process, application name.<br/><br/> Destination server name, process, application name, and port. | Source server name, process, application name.<br/><br/> Destination server name, process, application name, and port.<br/><br/> Number of connections, latency, and data transfer information are gathered and available for Log Analytics queries. **Visualization** | Dependency map of single server can be viewed over a duration of one hour to 30 days. | Dependency map of a single server.<br/><br/> Dependency map of a group of servers.<br/><br/> Map can be viewed over an hour only.<br/><br/> Add and remove servers in a group from the map view. |
| migrate | Create Manage Projects | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/migrate/create-manage-projects.md | Note that: - If you've already deleted the project, select **Resource Groups** in the left pane of the Azure portal and find the workspace. -2. [Follow the instructions](../azure-monitor/logs/delete-workspace.md) to delete the workspace. +2. [Follow the instructions](/azure/azure-monitor/logs/delete-workspace) to delete the workspace. ## Next steps |
| migrate | How To Create Group Machine Dependencies | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/migrate/how-to-create-group-machine-dependencies.md | This article describes how to set up agent-based dependency analysis in Azure Mi - [Servers in VMware environment](how-to-set-up-appliance-vmware.md) - [Servers in Hyper-V environment](how-to-set-up-appliance-hyper-v.md) - [Physical servers](how-to-set-up-appliance-physical.md)-- To use dependency visualization, you associate a [Log Analytics workspace](../azure-monitor/logs/manage-access.md) with an Azure Migrate project:+- To use dependency visualization, you associate a [Log Analytics workspace](/azure/azure-monitor/logs/manage-access) with an Azure Migrate project: - You can attach a workspace only after setting up the Azure Migrate appliance, and discovering servers in the Azure Migrate project. - Make sure you have a workspace in the subscription that contains the Azure Migrate project. - The workspace must reside in the East US, Southeast Asia, or West Europe regions. Workspaces in other regions can't be associated with a project. This article describes how to set up agent-based dependency analysis in Azure Mi  > [!Note]-> [Learn how](../azure-monitor/logs/private-link-security.md) to configure the OMS workspace for private endpoint connectivity. +> [Learn how](/azure/azure-monitor/logs/private-link-security) to configure the OMS workspace for private endpoint connectivity. ## Download and install the VM agents To install the agent on a Windows server: 5. Click **Add** to add a new Log Analytics workspace. Paste in the workspace ID and key that you copied from the portal. Click **Next**. You can install the agent from the command line or using an automated method such as Configuration Manager or Intigua.-- [Learn more](../azure-monitor/agents/log-analytics-agent.md#installation-options) about using these methods to install the MMA agent.+- [Learn more](/azure/azure-monitor/agents/log-analytics-agent#installation-options) about using these methods to install the MMA agent. - The MMA agent can also be installed using this [script](https://github.com/brianbar-MSFT/Install-MMA).-- [Learn more](../azure-monitor/agents/agents-overview.md#supported-operating-systems) about the Windows operating systems supported by MMA.+- [Learn more](/azure/azure-monitor/agents/agents-overview#supported-operating-systems) about the Windows operating systems supported by MMA. ### Install MMA on a Linux server To install the MMA on a Linux server: `sudo sh ./omsagent-<version>.universal.x64.sh --install -w <workspace id> -s <workspace key>` -[Learn more](../azure-monitor/agents/agents-overview.md#supported-operating-systems) about the list of Linux operating systems support by MMA. +[Learn more](/azure/azure-monitor/agents/agents-overview#supported-operating-systems) about the list of Linux operating systems support by MMA. ## Install the Dependency agent To install the MMA on a Linux server: `sh InstallDependencyAgent-Linux64.bin` -- [Learn more](../azure-monitor/vm/vminsights-dependency-agent-maintenance.md#install-or-upgrade-dependency-agent) about how you can use scripts to install the Dependency agent.-- [Learn more](../azure-monitor/vm/vminsights-enable-overview.md#supported-operating-systems) about the operating systems supported by the Dependency agent.+- [Learn more](/azure/azure-monitor/vm/vminsights-dependency-agent-maintenance#install-or-upgrade-dependency-agent) about how you can use scripts to install the Dependency agent. +- [Learn more](/azure/azure-monitor/vm/vminsights-enable-overview#supported-operating-systems) about the operating systems supported by the Dependency agent. ## Create a group using dependency visualization After creating the group, we recommend that you install agents on all the server You can query dependency data captured by Service Map in the Log Analytics workspace associated with the Azure Migrate project. Log Analytics is used to write and run Azure Monitor log queries. - [Learn how to](/previous-versions/azure/azure-monitor/vm/service-map#log-analytics-records) search for Service Map data in Log Analytics.-- [Get an overview](../azure-monitor/logs/get-started-queries.md) of writing log queries in [Log Analytics](../azure-monitor/logs/log-analytics-tutorial.md).+- [Get an overview](/azure/azure-monitor/logs/get-started-queries) of writing log queries in [Log Analytics](/azure/azure-monitor/logs/log-analytics-tutorial). Run a query for dependency data as follows: |
| migrate | How To Delete Project | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/migrate/how-to-delete-project.md | Before you delete a project: - The workspace isn't automatically deleted. Delete it manually. - Verify what a workspace is used for before you delete it. The same Log Analytics workspace can be used for multiple scenarios. - Before you delete the project, you can find a link to the workspace in **Azure Migrate - Servers** > **Azure Migrate - Server Assessment**, under **OMS Workspace**.- - To delete a workspace after deleting a project, find the workspace in the relevant resource group, and follow [these instructions](../azure-monitor/logs/delete-workspace.md). + - To delete a workspace after deleting a project, find the workspace in the relevant resource group, and follow [these instructions](/azure/azure-monitor/logs/delete-workspace). ## Delete a project |
| migrate | How To Use Azure Migrate With Private Endpoints | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/migrate/how-to-use-azure-migrate-with-private-endpoints.md | You must have Contributor + User Access Administrator or Owner permissions on th | | **Discovery and assessment** | Perform an agentless, at-scale discovery and assessment of your servers running on any platform. Examples include hypervisor platforms such as [VMware vSphere](./tutorial-discover-vmware.md) or [Microsoft Hyper-V](./tutorial-discover-hyper-v.md), public clouds such as [AWS](./tutorial-discover-aws.md) or [GCP](./tutorial-discover-gcp.md), or even [bare metal servers](./tutorial-discover-physical.md). | Azure Migrate: Discovery and assessment <br/> **Software inventory** | Discover apps, roles, and features running on VMware VMs. | Azure Migrate: Discovery and assessment-**Dependency visualization** | Use the dependency analysis capability to identify and understand dependencies across servers. <br/> [Agentless dependency visualization](./how-to-create-group-machine-dependencies-agentless.md) is supported natively with Azure Migrate private link support. <br/>[Agent-based dependency visualization](./how-to-create-group-machine-dependencies.md) requires internet connectivity. Learn how to use [private endpoints for agent-based dependency visualization](../azure-monitor/logs/private-link-security.md). | Azure Migrate: Discovery and assessment | +**Dependency visualization** | Use the dependency analysis capability to identify and understand dependencies across servers. <br/> [Agentless dependency visualization](./how-to-create-group-machine-dependencies-agentless.md) is supported natively with Azure Migrate private link support. <br/>[Agent-based dependency visualization](./how-to-create-group-machine-dependencies.md) requires internet connectivity. Learn how to use [private endpoints for agent-based dependency visualization](/azure/azure-monitor/logs/private-link-security). | Azure Migrate: Discovery and assessment | **Migration** | Perform [agentless VMware migrations](./tutorial-migrate-vmware.md), [agentless Hyper-V migrations](./tutorial-migrate-hyper-v.md), or use the agent-based approach to migrate your [VMware VMs](./tutorial-migrate-vmware-agent.md), [Hyper-V VMs](./tutorial-migrate-physical-virtual-machines.md), [physical servers](./tutorial-migrate-physical-virtual-machines.md), [VMs running on AWS](./tutorial-migrate-aws-virtual-machines.md), [VMs running on GCP](./tutorial-migrate-gcp-virtual-machines.md), or VMs running on a different virtualization provider. | Migration and modernization #### Other integrated tools |
| migrate | Migrate Support Matrix Hyper V | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/migrate/migrate-support-matrix-hyper-v.md | Requirement | Details | Before deployment | You should have a project in place with the Azure Migrate: Discovery and assessment tool added to the project.<br/><br/> You deploy dependency visualization after setting up an Azure Migrate appliance to discover your on-premises servers.<br/><br/> [Learn how](create-manage-projects.md) to create a project for the first time.<br/> [Learn how](how-to-assess.md) to add the Azure Migrate: Discovery and assessment tool to an existing project.<br/> Learn how to set up the appliance for discovery and assessment of [servers on Hyper-V](how-to-set-up-appliance-hyper-v.md). Azure Government | Dependency visualization isn't available in Azure Government.-Log Analytics | Azure Migrate and Modernize uses the [Service Map](/previous-versions/azure/azure-monitor/vm/service-map) solution in [Azure Monitor logs](../azure-monitor/logs/log-query-overview.md) for dependency visualization.<br/><br/> You associate a new or existing Log Analytics workspace with a project. You can't modify the workspace for a project after you add the workspace. <br/><br/> The workspace must be in the same subscription as the project.<br/><br/> The workspace must reside in the East US, Southeast Asia, or West Europe regions. Workspaces in other regions can't be associated with a project.<br/><br/> The workspace must be in a region in which [Service Map is supported](https://azure.microsoft.com/global-infrastructure/services/?products=monitor®ions=all). You can monitor Azure VMs in any region. The VMs themselves aren't limited to the regions supported by the Log Analytics workspace.<br/><br/> In Log Analytics, the workspace associated with Azure Migrate and Modernize is tagged with the Migration Project key and the project name. -Required agents | On each server you want to analyze, install the following agents:<br/><br/> [Microsoft Monitoring agent (MMA)](../azure-monitor/agents/agent-windows.md)<br/> [Dependency agent](../azure-monitor/vm/vminsights-dependency-agent-maintenance.md)<br/><br/> If on-premises servers aren't connected to the internet, you need to download and install the Log Analytics gateway on them.<br/><br/> Learn more about installing the [Dependency agent](how-to-create-group-machine-dependencies.md#install-the-dependency-agent) and [MMA](how-to-create-group-machine-dependencies.md#install-the-mma). +Log Analytics | Azure Migrate and Modernize uses the [Service Map](/previous-versions/azure/azure-monitor/vm/service-map) solution in [Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview) for dependency visualization.<br/><br/> You associate a new or existing Log Analytics workspace with a project. You can't modify the workspace for a project after you add the workspace. <br/><br/> The workspace must be in the same subscription as the project.<br/><br/> The workspace must reside in the East US, Southeast Asia, or West Europe regions. Workspaces in other regions can't be associated with a project.<br/><br/> The workspace must be in a region in which [Service Map is supported](https://azure.microsoft.com/global-infrastructure/services/?products=monitor®ions=all). You can monitor Azure VMs in any region. The VMs themselves aren't limited to the regions supported by the Log Analytics workspace.<br/><br/> In Log Analytics, the workspace associated with Azure Migrate and Modernize is tagged with the Migration Project key and the project name. +Required agents | On each server you want to analyze, install the following agents:<br/><br/> [Microsoft Monitoring agent (MMA)](/azure/azure-monitor/agents/agent-windows)<br/> [Dependency agent](/azure/azure-monitor/vm/vminsights-dependency-agent-maintenance)<br/><br/> If on-premises servers aren't connected to the internet, you need to download and install the Log Analytics gateway on them.<br/><br/> Learn more about installing the [Dependency agent](how-to-create-group-machine-dependencies.md#install-the-dependency-agent) and [MMA](how-to-create-group-machine-dependencies.md#install-the-mma). Log Analytics workspace | The workspace must be in the same subscription as the project.<br/><br/> Azure Migrate and Modernize supports workspaces residing in the East US, Southeast Asia, and West Europe regions.<br/><br/> The workspace must be in a region in which [Service Map is supported](https://azure.microsoft.com/global-infrastructure/services/?products=monitor®ions=all). You can monitor Azure VMs in any region. The VMs themselves aren't limited to the regions supported by the Log Analytics workspace.<br/><br/> You can't modify the workspace for a project after you add the workspace. Costs | The Service Map solution doesn't incur any charges for the first 180 days. The count starts from the day that you associate the Log Analytics workspace with the project.<br/><br/> After 180 days, standard Log Analytics charges apply.<br/><br/> Using any solution other than Service Map in the associated Log Analytics workspace incurs [standard charges](https://azure.microsoft.com/pricing/details/log-analytics/) for Log Analytics.<br/><br/> When the project is deleted, the workspace isn't deleted along with it. After you delete the project, Service Map usage isn't free. Each node is charged according to the paid tier of the Log Analytics workspace.<br/><br/>If you have projects that you created before Azure Migrate general availability (GA on February 28, 2018), you might incur other Service Map charges. To ensure payment after 180 days only, we recommend that you create a new project. Workspaces that were created before GA are still chargeable.-Management | When you register agents to the workspace, you use the ID and key provided by the project.<br/><br/> You can use the Log Analytics workspace outside Azure Migrate and Modernize.<br/><br/> If you delete the associated project, the workspace isn't deleted automatically. [Delete it manually](../azure-monitor/logs/manage-access.md).<br/><br/> Don't delete the workspace created by Azure Migrate and Modernize unless you delete the project. If you do, the dependency visualization functionality doesn't work as expected. +Management | When you register agents to the workspace, you use the ID and key provided by the project.<br/><br/> You can use the Log Analytics workspace outside Azure Migrate and Modernize.<br/><br/> If you delete the associated project, the workspace isn't deleted automatically. [Delete it manually](/azure/azure-monitor/logs/manage-access).<br/><br/> Don't delete the workspace created by Azure Migrate and Modernize unless you delete the project. If you do, the dependency visualization functionality doesn't work as expected. Internet connectivity | If servers aren't connected to the internet, you need to install the Log Analytics gateway on them. Azure Government | Agent-based dependency analysis isn't supported. |
| migrate | Migrate Support Matrix Physical | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/migrate/migrate-support-matrix-physical.md | Requirement | Details | Before deployment | You should have a project in place with the Azure Migrate: Discovery and assessment tool added to the project.<br/><br/> You deploy dependency visualization after setting up an Azure Migrate appliance to discover your on-premises servers.<br/><br/> [Learn how](create-manage-projects.md) to create a project for the first time.<br/> [Learn how](how-to-assess.md) to add an assessment tool to an existing project.<br/> Learn how to set up the Azure Migrate appliance for assessment of [Hyper-V](how-to-set-up-appliance-hyper-v.md), [VMware](how-to-set-up-appliance-vmware.md), or physical servers. Azure Government | Dependency visualization isn't available in Azure Government.-Log Analytics | Azure Migrate and Modernize uses the [Service Map](/previous-versions/azure/azure-monitor/vm/service-map) solution in [Azure Monitor logs](../azure-monitor/logs/log-query-overview.md) for dependency visualization.<br/><br/> You associate a new or existing Log Analytics workspace with a project. You can't modify the workspace for a project after you add the workspace. <br/><br/> The workspace must be in the same subscription as the project.<br/><br/> The workspace must reside in the East US, Southeast Asia, or West Europe regions. Workspaces in other regions can't be associated with a project.<br /> The workspace must be in a region in which [Service Map is supported](https://azure.microsoft.com/global-infrastructure/services/?products=monitor®ions=all). You can monitor Azure VMs in any region. The VMs themselves aren't limited to the regions supported by the Log Analytics workspace.<br/><br/> In Log Analytics, the workspace associated with Azure Migrate and Modernize is tagged with the Migration Project key and the project name. -Required agents | On each server that you want to analyze, install the following agents:<br/>- [Microsoft Monitoring agent (MMA)](../azure-monitor/agents/agent-windows.md)<br/> - [Dependency agent](../azure-monitor/vm/vminsights-dependency-agent-maintenance.md)<br/><br/> If on-premises servers aren't connected to the internet, you need to download and install the Log Analytics gateway on them.<br/><br/> Learn more about installing the [Dependency agent](how-to-create-group-machine-dependencies.md#install-the-dependency-agent) and [MMA](how-to-create-group-machine-dependencies.md#install-the-mma). +Log Analytics | Azure Migrate and Modernize uses the [Service Map](/previous-versions/azure/azure-monitor/vm/service-map) solution in [Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview) for dependency visualization.<br/><br/> You associate a new or existing Log Analytics workspace with a project. You can't modify the workspace for a project after you add the workspace. <br/><br/> The workspace must be in the same subscription as the project.<br/><br/> The workspace must reside in the East US, Southeast Asia, or West Europe regions. Workspaces in other regions can't be associated with a project.<br /> The workspace must be in a region in which [Service Map is supported](https://azure.microsoft.com/global-infrastructure/services/?products=monitor®ions=all). You can monitor Azure VMs in any region. The VMs themselves aren't limited to the regions supported by the Log Analytics workspace.<br/><br/> In Log Analytics, the workspace associated with Azure Migrate and Modernize is tagged with the Migration Project key and the project name. +Required agents | On each server that you want to analyze, install the following agents:<br/>- [Microsoft Monitoring agent (MMA)](/azure/azure-monitor/agents/agent-windows)<br/> - [Dependency agent](/azure/azure-monitor/vm/vminsights-dependency-agent-maintenance)<br/><br/> If on-premises servers aren't connected to the internet, you need to download and install the Log Analytics gateway on them.<br/><br/> Learn more about installing the [Dependency agent](how-to-create-group-machine-dependencies.md#install-the-dependency-agent) and [MMA](how-to-create-group-machine-dependencies.md#install-the-mma). Log Analytics workspace | The workspace must be in the same subscription as a project.<br/><br/> Azure Migrate and Modernize supports workspaces residing in the East US, Southeast Asia, and West Europe regions.<br/><br/> The workspace must be in a region in which [Service Map is supported](https://azure.microsoft.com/global-infrastructure/services/?products=monitor®ions=all). You can monitor Azure VMs in any region. The VMs themselves aren't limited to the regions supported by the Log Analytics workspace.<br/><br/> You can't modify the workspace for a project after you add the workspace. Costs | The Service Map solution doesn't incur any charges for the first 180 days. The count starts from the day that you associate the Log Analytics workspace with the project.<br/><br/> After 180 days, standard Log Analytics charges apply.<br/><br/> Using any solution other than Service Map in the associated Log Analytics workspace incurs [standard charges](https://azure.microsoft.com/pricing/details/log-analytics/) for Log Analytics.<br/><br/> When the project is deleted, the workspace isn't automatically deleted. After you delete the project, Service Map usage isn't free. Each node is charged according to the paid tier of the Log Analytics workspace.<br/><br/>If you have projects that you created before Azure Migrate general availability (GA on February 28, 2018), you might incur other Service Map charges. To ensure that you're charged only after 180 days, we recommend that you create a new project. Workspaces that were created before GA are still chargeable.-Management | When you register agents to the workspace, use the ID and key provided by the project.<br/><br/> You can use the Log Analytics workspace outside Azure Migrate and Modernize.<br/><br/> If you delete the associated project, the workspace isn't deleted automatically. [Delete it manually](../azure-monitor/logs/manage-access.md).<br/><br/> Don't delete the workspace created by Azure Migrate and Modernize unless you delete the project. If you do, the dependency visualization functionality doesn't work as expected. +Management | When you register agents to the workspace, use the ID and key provided by the project.<br/><br/> You can use the Log Analytics workspace outside Azure Migrate and Modernize.<br/><br/> If you delete the associated project, the workspace isn't deleted automatically. [Delete it manually](/azure/azure-monitor/logs/manage-access).<br/><br/> Don't delete the workspace created by Azure Migrate and Modernize unless you delete the project. If you do, the dependency visualization functionality doesn't work as expected. Internet connectivity | If servers aren't connected to the internet, install the Log Analytics gateway on the servers. Azure Government | Agent-based dependency analysis isn't supported. |
| migrate | Migrate V1 | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/migrate/migrate-v1.md | To use dependency visualization, you associate a Log Analytics workspace with a ### Download and install VM agents -After you configure a workspace, you download and install agents on each on-premises machine that you want to evaluate. In addition, if you have machines with no internet connectivity, you need to download and install [Log Analytics gateway](../azure-monitor/agents/gateway.md) on them. +After you configure a workspace, you download and install agents on each on-premises machine that you want to evaluate. In addition, if you have machines with no internet connectivity, you need to download and install [Log Analytics gateway](/azure/azure-monitor/agents/gateway) on them. 1. In **Overview**, click **Manage** > **Machines**, and select the required machine. 2. In the **Dependencies** column, click **Install agents**. To install the agent on a Windows machine: 4. In **Agent Setup Options**, select **Azure Log Analytics** > **Next**. 5. Click **Add** to add a new Log Analytics workspace. Paste in the workspace ID and key that you copied from the portal. Click **Next**. -You can install the agent from the command line or using an automated method such as Configuration Manager. [Learn more](../azure-monitor/agents/log-analytics-agent.md#installation-options) about using these methods to install the MMA agent. +You can install the agent from the command line or using an automated method such as Configuration Manager. [Learn more](/azure/azure-monitor/agents/log-analytics-agent#installation-options) about using these methods to install the MMA agent. #### Install the MMA agent on a Linux machine To install the agent on a Linux machine: `sudo sh ./omsagent-<version>.universal.x64.sh --install -w <workspace id> -s <workspace key>` -[Learn more](../azure-monitor/agents/agents-overview.md#supported-operating-systems) about the list of Linux operating systems support by MMA. +[Learn more](/azure/azure-monitor/agents/agents-overview#supported-operating-systems) about the list of Linux operating systems support by MMA. ### Install the MMA agent on a machine monitored by Operations Manager For machines monitored by System Center Operations Manager 2012 R2 or later, the `sh InstallDependencyAgent-Linux64.bin` - - Learn more about the [Dependency agent support](../azure-monitor/vm/vminsights-enable-overview.md#supported-operating-systems) for the Windows and Linux operating systems. - - [Learn more](../azure-monitor/vm/vminsights-dependency-agent-maintenance.md#install-or-upgrade-dependency-agent) about how you can use scripts to install the Dependency agent. + - Learn more about the [Dependency agent support](/azure/azure-monitor/vm/vminsights-enable-overview#supported-operating-systems) for the Windows and Linux operating systems. + - [Learn more](/azure/azure-monitor/vm/vminsights-dependency-agent-maintenance#install-or-upgrade-dependency-agent) about how you can use scripts to install the Dependency agent. >[!NOTE] > The Azure Monitor for VMs article referenced to provide an overview of the system prerequisites and methods to deploy the Dependency agent are also applicable to the Service Map solution. To run the Kusto queries: 4. Write your query to gather dependency data using Azure Monitor logs. Find sample queries in the next section. 5. Run your query by clicking on Run. -[Learn more](../azure-monitor/logs/log-analytics-tutorial.md) about how to write Kusto queries. +[Learn more](/azure/azure-monitor/logs/log-analytics-tutorial) about how to write Kusto queries. ### Sample Azure Monitor logs queries |
| migrate | Troubleshoot Dependencies | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/migrate/troubleshoot-dependencies.md | For Linux VMs, make sure that the installation commands for MMA and the dependen ## Supported operating systems for agent-based dependency analysis -- **MMS agent**: The supported [Windows](../azure-monitor/agents/agents-overview.md#supported-operating-systems) and [Linux](../azure-monitor/agents/agents-overview.md#supported-operating-systems) operating systems.-- **Dependency agent**: The supported [Windows and Linux](../azure-monitor/vm/vminsights-enable-overview.md#supported-operating-systems) operating systems.+- **MMS agent**: The supported [Windows](/azure/azure-monitor/agents/agents-overview#supported-operating-systems) and [Linux](/azure/azure-monitor/agents/agents-overview#supported-operating-systems) operating systems. +- **Dependency agent**: The supported [Windows and Linux](/azure/azure-monitor/vm/vminsights-enable-overview#supported-operating-systems) operating systems. ## Visualize dependencies for >1 hour with agent-based dependency analysis |
| migrate | Migrate Support Matrix Vmware | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/migrate/vmware/migrate-support-matrix-vmware.md | Requirement | Details | Before deployment | You should have a project in place with the Azure Migrate: Discovery and assessment tool added to the project.<br /><br />You deploy dependency visualization after setting up an Azure Migrate appliance to discover your on-premises servers.<br /><br />Learn how to [create a project for the first time](../create-manage-projects.md).<br /> Learn how to [add a discovery and assessment tool to an existing project](../how-to-assess.md).<br /> Learn how to set up the Azure Migrate appliance for assessment of [Hyper-V](../how-to-set-up-appliance-hyper-v.md), [VMware](how-to-set-up-appliance-vmware.md), or physical servers. Supported servers | Supported for all servers in your on-premises environment.-Log Analytics | Azure Migrate and Modernize uses the [Service Map](/previous-versions/azure/azure-monitor/vm/service-map) solution in [Azure Monitor logs](../../azure-monitor/logs/log-query-overview.md) for dependency visualization.<br /><br /> You associate a new or existing Log Analytics workspace with a project. You can't modify the workspace for a project after you add the workspace. <br /><br /> The workspace must be in the same subscription as the project.<br /><br /> The workspace must be located in the East US, Southeast Asia, or West Europe regions. Workspaces in other regions can't be associated with a project.<br /><br /> The workspace must be in a [region in which Service Map is supported](https://azure.microsoft.com/global-infrastructure/services/?products=monitor®ions=all). You can monitor Azure VMs in any region. The VMs themselves aren't limited to the regions supported by the Log Analytics workspace.<br /><br /> In Log Analytics, the workspace associated with Azure Migrate is tagged with the project key and project name. -Required agents | On each server that you want to analyze, install the following agents:<br />- Azure Monitor agent (AMA)<br />- [Dependency agent](../../azure-monitor/vm/vminsights-dependency-agent-maintenance.md)<br /><br /> If on-premises servers aren't connected to the internet, download and install the Log Analytics gateway on them.<br /><br /> Learn more about installing the [Dependency agent](../how-to-create-group-machine-dependencies.md#install-the-dependency-agent) and the Azure Monitor agent. +Log Analytics | Azure Migrate and Modernize uses the [Service Map](/previous-versions/azure/azure-monitor/vm/service-map) solution in [Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview) for dependency visualization.<br /><br /> You associate a new or existing Log Analytics workspace with a project. You can't modify the workspace for a project after you add the workspace. <br /><br /> The workspace must be in the same subscription as the project.<br /><br /> The workspace must be located in the East US, Southeast Asia, or West Europe regions. Workspaces in other regions can't be associated with a project.<br /><br /> The workspace must be in a [region in which Service Map is supported](https://azure.microsoft.com/global-infrastructure/services/?products=monitor®ions=all). You can monitor Azure VMs in any region. The VMs themselves aren't limited to the regions supported by the Log Analytics workspace.<br /><br /> In Log Analytics, the workspace associated with Azure Migrate is tagged with the project key and project name. +Required agents | On each server that you want to analyze, install the following agents:<br />- Azure Monitor agent (AMA)<br />- [Dependency agent](/azure/azure-monitor/vm/vminsights-dependency-agent-maintenance)<br /><br /> If on-premises servers aren't connected to the internet, download and install the Log Analytics gateway on them.<br /><br /> Learn more about installing the [Dependency agent](../how-to-create-group-machine-dependencies.md#install-the-dependency-agent) and the Azure Monitor agent. Log Analytics workspace | The workspace must be in the same subscription as the project.<br /><br /> Azure Migrate supports workspaces that are located in the East US, Southeast Asia, and West Europe regions.<br /><br /> The workspace must be in a region in which [Service Map is supported](https://azure.microsoft.com/global-infrastructure/services/?products=monitor®ions=all). You can monitor Azure VMs in any region. The VMs themselves aren't limited to the regions supported by the Log Analytics workspace.<br /><br /> You can't modify the workspace for a project after you add the workspace. Cost | The Service Map solution doesn't incur any charges for the first 180 days. The count starts from the day you associate the Log Analytics workspace with the project.<br /><br /> After 180 days, standard Log Analytics charges apply.<br /><br /> Using any solution other than Service Map in the associated Log Analytics workspace incurs [standard charges](https://azure.microsoft.com/pricing/details/log-analytics/) for Log Analytics.<br /><br /> When the project is deleted, the workspace isn't automatically deleted. After you delete the project, Service Map usage isn't free. Each node is charged according to the paid tier of the Log Analytics workspace.<br /><br />If you have projects that you created before Azure Migrate general availability (GA on February 28, 2018), you might incur other Service Map charges. To ensure that you're charged only after 180 days, we recommend that you create a new project. Workspaces that were created before GA are still chargeable.-Management | When you register agents to the workspace, use the ID and key provided by the project.<br /><br /> You can use the Log Analytics workspace outside Azure Migrate and Modernize.<br /><br /> If you delete the associated project, the workspace isn't deleted automatically. [Delete it manually](../../azure-monitor/logs/manage-access.md).<br /><br /> Don't delete the workspace created by Azure Migrate and Modernize unless you delete the project. If you do, the dependency visualization functionality doesn't work as expected. +Management | When you register agents to the workspace, use the ID and key provided by the project.<br /><br /> You can use the Log Analytics workspace outside Azure Migrate and Modernize.<br /><br /> If you delete the associated project, the workspace isn't deleted automatically. [Delete it manually](/azure/azure-monitor/logs/manage-access).<br /><br /> Don't delete the workspace created by Azure Migrate and Modernize unless you delete the project. If you do, the dependency visualization functionality doesn't work as expected. Internet connectivity | If servers aren't connected to the internet, install the Log Analytics gateway on the servers. Azure Government | Agent-based dependency analysis isn't supported. |
| nat-gateway | Nat Gateway Design | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/nat-gateway/nat-gateway-design.md | The NAT gateway supersedes any outbound configuration from a load-balancing rule For guides on how to enable VNet flow logs, see [Manage virtual network flow logs](../network-watcher/vnet-flow-logs-portal.md). -It is recommended to access the log data on [Log Analytics workspaces](../azure-monitor/logs/log-analytics-overview.md) where you can also query and filter the data for outbound traffic. To learn more about using Log Analytics, see [Log Analytics tutorial](../azure-monitor/logs/log-analytics-tutorial.md). +It is recommended to access the log data on [Log Analytics workspaces](/azure/azure-monitor/logs/log-analytics-overview) where you can also query and filter the data for outbound traffic. To learn more about using Log Analytics, see [Log Analytics tutorial](/azure/azure-monitor/logs/log-analytics-tutorial). For more details on the VNet flow log schema, see [Traffic analytics schema and data aggregation](../network-watcher/traffic-analytics-schema.md). |
| nat-gateway | Nat Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/nat-gateway/nat-metrics.md | Possible reasons for a drop in data path availability include: Alerts can be configured in Azure Monitor for all NAT gateway metrics. These alerts proactively notify you when important conditions are found in your monitoring data. They allow you to identify and address potential issues with NAT gateway. -For more information about how metric alerts work, see [Azure Monitor Metric Alerts](../azure-monitor/alerts/alerts-metric-overview.md). The following guidance describes how to configure some common and recommended types of alerts for your NAT gateway. +For more information about how metric alerts work, see [Azure Monitor Metric Alerts](/azure/azure-monitor/alerts/alerts-metric-overview). The following guidance describes how to configure some common and recommended types of alerts for your NAT gateway. ### Alerts for datapath availability degradation Refer to [troubleshooting metrics charts](/azure/azure-monitor/essentials/metric * Learn about [Azure NAT Gateway](nat-overview.md) * Learn about [NAT gateway resource](nat-gateway-resource.md)-* Learn about [Azure Monitor](../azure-monitor/overview.md) +* Learn about [Azure Monitor](/azure/azure-monitor/overview) * Learn about [troubleshooting NAT gateway resources](troubleshoot-nat.md). * Learn about [troubleshooting NAT gateway connectivity](/azure/nat-gateway/troubleshoot-nat-connectivity) |
| nat-gateway | Resource Health | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/nat-gateway/resource-health.md | This article provides guidance on how to use Azure Resource Health to monitor an ## Resource health status -[Azure Resource Health](../service-health/overview.md) provides information about the health of your NAT gateway resource. You can use resource health and Azure monitor notifications to keep you informed on the availability and health status of your NAT gateway resource. Resource health can help you quickly assess whether an issue is due to a problem in your Azure infrastructure or because of an Azure platform event. The resource health of your NAT gateway is evaluated by measuring the data-path availability of your NAT gateway endpoint. +[Azure Resource Health](/azure/service-health/overview) provides information about the health of your NAT gateway resource. You can use resource health and Azure monitor notifications to keep you informed on the availability and health status of your NAT gateway resource. Resource health can help you quickly assess whether an issue is due to a problem in your Azure infrastructure or because of an Azure platform event. The resource health of your NAT gateway is evaluated by measuring the data-path availability of your NAT gateway endpoint. You can view the status of your NAT gatewayΓÇÖs health status on the **Resource Health** page, found under **Support + troubleshooting** for your NAT gateway resource. The health of your NAT gateway resource is displayed as one of the following sta | Unavailable | Your NAT gateway resource isn't healthy. The metric for the data-path availability reports less than 25% for the past 15 minutes. You experience significant performance effect or unavailability of your NAT gateway resource for outbound connectivity. There might be user or platform events causing unavailability. | | Unknown | Health status for your NAT gateway resource isn't updated or received information for data-path availability for more than 5 minutes. This state should be transient and reflects the correct status as soon as data is received. | -For more information about Azure Resource Health, see [Resource Health overview](../service-health/resource-health-overview.md). +For more information about Azure Resource Health, see [Resource Health overview](/azure/service-health/resource-health-overview). To view the health of your NAT gateway resource: For more information on how to set up these resource health alerts, see: - Learn about [Azure NAT Gateway](./nat-overview.md) - Learn about [metrics and alerts for NAT gateway](./nat-metrics.md) - Learn about [troubleshooting NAT gateway resources](./troubleshoot-nat.md)-- Learn about [Azure resource health](../service-health/resource-health-overview.md)+- Learn about [Azure resource health](/azure/service-health/resource-health-overview) |
| nat-gateway | Troubleshoot Nat | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/nat-gateway/troubleshoot-nat.md | To analyze outbound traffic from NAT gateway, use virtual network (VNet) flow lo * For guides on how to enable VNet flow logs, see [Manage virtual network flow logs](../network-watcher/vnet-flow-logs-portal.md). -* It is recommended to access the log data on [Log Analytics workspaces](../azure-monitor/logs/log-analytics-overview.md) where you can also query and filter the data for outbound traffic. To learn more about using Log Analytics, see [Log Analytics tutorial](../azure-monitor/logs/log-analytics-tutorial.md). +* It is recommended to access the log data on [Log Analytics workspaces](/azure/azure-monitor/logs/log-analytics-overview) where you can also query and filter the data for outbound traffic. To learn more about using Log Analytics, see [Log Analytics tutorial](/azure/azure-monitor/logs/log-analytics-tutorial). * For more details on the VNet flow log schema, see [Traffic analytics schema and data aggregation](../network-watcher/traffic-analytics-schema.md). |
| network-watcher | Azure Monitor Agent With Connection Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/network-watcher/azure-monitor-agent-with-connection-monitor.md | Azure Monitor agent provides the following benefits: * Effective cost savings with efficient data collection * Ease of troubleshooting, with simpler data collection management for the Log Analytics agent -For more information, see [Azure Monitor agent](../azure-monitor/agents/agents-overview.md). +For more information, see [Azure Monitor agent](/azure/azure-monitor/agents/agents-overview). To start using connection monitor for monitoring, follow these steps: To make connection monitor recognize your on-premises machines as sources for mo This agent doesn't deliver any other functionality, and it doesn't replace Azure Monitor agent. The Azure Connected Machine agent simply enables you to manage the Windows and Linux machines that are hosted outside of Azure on your corporate network or other cloud providers. -* [Install Azure Monitor agent](../azure-monitor/agents/agents-overview.md) to enable the Network Watcher extension. +* [Install Azure Monitor agent](/azure/azure-monitor/agents/agents-overview) to enable the Network Watcher extension. The agent collects monitoring logs and data from the hybrid sources and delivers them to Azure Monitor. |
| network-watcher | Connection Monitor Create Using Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/network-watcher/connection-monitor-create-using-portal.md | In the Azure portal, to create alerts for a connection monitor, specify values f - **Condition name**: The alert is created on the `Test Result(preview)` metric. When the connection monitor test fails, the alert rule will fire. -- **Action group name**: You can enter your email directly, or you can create alerts via action groups. If you enter your email directly, an action group with the name **NPM Email ActionGroup** is created. The email ID is added to that action group. If you choose to use action groups, you need to select a previously created action group. To learn how to create an action group, see [Create action groups in the Azure portal](../azure-monitor/alerts/action-groups.md). After the alert is created, you can [manage your alerts](../azure-monitor/alerts/alerts-metric.md#view-and-manage-with-azure-portal).+- **Action group name**: You can enter your email directly, or you can create alerts via action groups. If you enter your email directly, an action group with the name **NPM Email ActionGroup** is created. The email ID is added to that action group. If you choose to use action groups, you need to select a previously created action group. To learn how to create an action group, see [Create action groups in the Azure portal](/azure/azure-monitor/alerts/action-groups). After the alert is created, you can [manage your alerts](/azure/azure-monitor/alerts/alerts-metric#view-and-manage-with-azure-portal). - **Alert rule name**: The name of the connection monitor. |
| network-watcher | Connection Monitor Install Azure Monitor Agent | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/network-watcher/connection-monitor-install-azure-monitor-agent.md | -Azure Monitor Agent is implemented as an Azure virtual machine (VM) extension. You can install Azure Monitor Agent using any of the methods described in [Azure Monitor Agent overview](../azure-monitor/agents/agents-overview.md?toc=/azure/network-watcher/toc.json). +Azure Monitor Agent is implemented as an Azure virtual machine (VM) extension. You can install Azure Monitor Agent using any of the methods described in [Azure Monitor Agent overview](/azure/azure-monitor/agents/agents-overview?toc=/azure/network-watcher/toc.json). -This article covers installing Azure Monitor Agent on Azure Arc-enabled servers using PowerShell or the Azure CLI. For more information, see [Manage Azure Monitor Agent](../azure-monitor/agents/azure-monitor-agent-manage.md?tabs=ARMAgentPowerShell%2CPowerShellWindows%2CPowerShellWindowsArc%2CCLIWindows%2CCLIWindowsArc). +This article covers installing Azure Monitor Agent on Azure Arc-enabled servers using PowerShell or the Azure CLI. For more information, see [Manage Azure Monitor Agent](/azure/azure-monitor/agents/azure-monitor-agent-manage?tabs=ARMAgentPowerShell%2CPowerShellWindows%2CPowerShellWindowsArc%2CCLIWindows%2CCLIWindowsArc). ## Use PowerShell |
| network-watcher | Connection Monitor Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/network-watcher/connection-monitor-overview.md | If you wish to escape the installation process for enabling the Network Watcher To make Connection monitor recognize your on-premises machines as sources for monitoring, install the Log Analytics agent on the machines. Then, enable the [Network Performance Monitor solution](../network-watcher/connection-monitor-overview.md#enable-the-network-performance-monitor-solution-for-on-premises-machines). These agents are linked to Log Analytics workspaces, so you need to set up the workspace ID and primary key before the agents can start monitoring. -To install the Log Analytics agent for Windows machines, see [Install Log Analytics agent on Windows](../azure-monitor/agents/agent-windows.md). +To install the Log Analytics agent for Windows machines, see [Install Log Analytics agent on Windows](/azure/azure-monitor/agents/agent-windows). If the path includes firewalls or network virtual appliances (NVAs), make sure that the destination is reachable. To open the port: The script creates the registry keys that are required by the solution. It also creates Windows Firewall rules to allow agents to create TCP connections with each other. The registry keys that are created by the script specify whether to log the debug logs and the path for the logs file. The script also defines the agent TCP port that's used for communication. The values for these keys are automatically set by the script. Don't manually change these keys. By default, the port that's opened is 8084. You can use a custom port by providing the parameter portNumber to the script. Use the same port on all the computers where the script is run. -For more information, see the "Network requirements" section of [Log Analytics agent overview](../azure-monitor/agents/log-analytics-agent.md#network-requirements). +For more information, see the "Network requirements" section of [Log Analytics agent overview](/azure/azure-monitor/agents/log-analytics-agent#network-requirements). The script configures only Windows Firewall locally. If you have a network firewall, make sure that it allows traffic destined for the TCP port that's used by Network Performance Monitor. |
| network-watcher | Connection Monitor Virtual Machine Scale Set | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/network-watcher/connection-monitor-virtual-machine-scale-set.md | In the Azure portal, to create alerts for a connection monitor, specify values f * **Condition name**: The alert is created on the `Test Result(preview)` metric. When the result of the connection monitor test is a failing result, the alert rule will fire. -* **Action group name**: You can enter your email directly or you can create alerts via action groups. If you enter your email directly, an action group with the name **NPM Email ActionGroup** is created. The email ID is added to that action group. If you choose to use action groups, you need to select a previously created action group. To learn how to create an action group, see [Create action groups in the Azure portal](../azure-monitor/alerts/action-groups.md). After the alert is created, you can [manage your alerts](../azure-monitor/alerts/alerts-metric.md#view-and-manage-with-azure-portal). +* **Action group name**: You can enter your email directly or you can create alerts via action groups. If you enter your email directly, an action group with the name **NPM Email ActionGroup** is created. The email ID is added to that action group. If you choose to use action groups, you need to select a previously created action group. To learn how to create an action group, see [Create action groups in the Azure portal](/azure/azure-monitor/alerts/action-groups). After the alert is created, you can [manage your alerts](/azure/azure-monitor/alerts/alerts-metric#view-and-manage-with-azure-portal). * **Alert rule name**: The name of the connection monitor. |
| network-watcher | Flow Logs Read | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/network-watcher/flow-logs-read.md | The results of this value are shown in the following example: ## Related content - [Traffic analytics overview](./traffic-analytics.md)-- [Log Analytics tutorial](../azure-monitor/logs/log-analytics-tutorial.md?toc=/azure/network-watcher/toc.json&bc=/azure/network-watcher/breadcrumb/toc.json)+- [Log Analytics tutorial](/azure/azure-monitor/logs/log-analytics-tutorial?toc=/azure/network-watcher/toc.json&bc=/azure/network-watcher/breadcrumb/toc.json) - [Azure Blob storage bindings for Azure Functions overview](../azure-functions/functions-bindings-storage-blob.md?toc=/azure/network-watcher/toc.json&bc=/azure/network-watcher/breadcrumb/toc.json) |
| network-watcher | Network Insights Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/network-watcher/network-insights-overview.md | -Azure Monitor Network Insights provides a comprehensive and visual representation through [topology](network-insights-topology.md), [health](../service-health/resource-health-checks-resource-types.md) and [metrics](/azure/azure-monitor/reference/supported-metrics/metrics-index) for all deployed network resources, without requiring any configuration. It also provides access to network monitoring capabilities like [Connection monitor](../network-watcher/connection-monitor-overview.md), [NSG flow logs](../network-watcher/nsg-flow-logs-overview.md), [VNet flow logs](vnet-flow-logs-overview.md), and [Traffic analytics](../network-watcher/traffic-analytics.md). Additionally, it provides access to Network Watcher [diagnostic tools](../network-watcher/network-watcher-overview.md#network-diagnostic-tools). +Azure Monitor Network Insights provides a comprehensive and visual representation through [topology](network-insights-topology.md), [health](/azure/service-health/resource-health-checks-resource-types) and [metrics](/azure/azure-monitor/reference/supported-metrics/metrics-index) for all deployed network resources, without requiring any configuration. It also provides access to network monitoring capabilities like [Connection monitor](../network-watcher/connection-monitor-overview.md), [NSG flow logs](../network-watcher/nsg-flow-logs-overview.md), [VNet flow logs](vnet-flow-logs-overview.md), and [Traffic analytics](../network-watcher/traffic-analytics.md). Additionally, it provides access to Network Watcher [diagnostic tools](../network-watcher/network-watcher-overview.md#network-diagnostic-tools). Azure Monitor Network Insights is structured around these key components of monitoring: Resources that have been onboarded are: ## Related content - To learn more about network monitoring, see [What is Azure Network Watcher?](../network-watcher/network-watcher-overview.md)-- To learn about the scenarios workbooks are designed to support and how to create reports and customize existing reports, see [Create interactive reports with Azure Monitor workbooks](../azure-monitor/visualize/workbooks-overview.md).+- To learn about the scenarios workbooks are designed to support and how to create reports and customize existing reports, see [Create interactive reports with Azure Monitor workbooks](/azure/azure-monitor/visualize/workbooks-overview). |
| network-watcher | Network Insights Troubleshooting | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/network-watcher/network-insights-troubleshooting.md | Last updated 09/29/2023 # Troubleshoot network insights -For general troubleshooting guidance, see [Troubleshooting workbook-based insights](../azure-monitor/insights/troubleshoot-workbooks.md). +For general troubleshooting guidance, see [Troubleshooting workbook-based insights](/azure/azure-monitor/insights/troubleshoot-workbooks). This article helps you diagnose and troubleshoot some common problems you might encounter when you use Azure Monitor network insights. |
| network-watcher | Network Watcher Alert Triggered Packet Capture | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/network-watcher/network-watcher-alert-triggered-packet-capture.md | You can configure alerts to notify individuals when a specific metric crosses a ### Create the alert rule -Go to an existing virtual machine and [add an alert rule](../azure-monitor/alerts/alerts-classic-portal.md). On the **Create an Alert rule** page, take the following steps: +Go to an existing virtual machine and [add an alert rule](/azure/azure-monitor/alerts/alerts-classic-portal). On the **Create an Alert rule** page, take the following steps: 1. On the **Select a signal** pane, search for the name of the signal and select it. In this example, **Network Out Total** is the selected signal. It denotes the number of bytes out on all network interfaces by the virtual machine. |
| network-watcher | Nsg Flow Logs Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/network-watcher/nsg-flow-logs-portal.md | Create a flow log for your network security group. This NSG flow log is saved in :::image type="content" source="./media/nsg-flow-logs-portal/create-nsg-flow-log-analytics.png" alt-text="Screenshot that shows how to enable traffic analytics for a new flow log in the Azure portal."::: > [!NOTE]- > To create and select a Log Analytics workspace other than the default one, see [Create a Log Analytics workspace](../azure-monitor/logs/quick-create-workspace.md?toc=/azure/network-watcher/toc.json) + > To create and select a Log Analytics workspace other than the default one, see [Create a Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace?toc=/azure/network-watcher/toc.json) 1. Select **Review + create**. |
| network-watcher | Required Rbac Permissions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/network-watcher/required-rbac-permissions.md | Since traffic analytics is enabled as part of the Flow log resource, the followi > | Microsoft.Insights/dataCollectionEndpoints/write <sup>1</sup> | Create or update a data collection endpoint | > | Microsoft.Insights/dataCollectionEndpoints/delete <sup>1</sup> | Delete a data collection endpoint | -<sup>1</sup> Only required when using traffic analytics to analyze virtual network flow logs. For more information, see [Data collection rules in Azure Monitor](../azure-monitor/essentials/data-collection-rule-overview.md?toc=/azure/network-watcher/toc.json) and [Data collection endpoints in Azure Monitor](../azure-monitor/essentials/data-collection-endpoint-overview.md?toc=/azure/network-watcher/toc.json). +<sup>1</sup> Only required when using traffic analytics to analyze virtual network flow logs. For more information, see [Data collection rules in Azure Monitor](/azure/azure-monitor/essentials/data-collection-rule-overview?toc=/azure/network-watcher/toc.json) and [Data collection endpoints in Azure Monitor](/azure/azure-monitor/essentials/data-collection-endpoint-overview?toc=/azure/network-watcher/toc.json). > [!CAUTION] > Data collection rule and data collection endpoint resources are created and managed by traffic analytics. If you perform any operation on these resources, traffic analytics may not function as expected. |
| network-watcher | Traffic Analytics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/network-watcher/traffic-analytics.md | To use traffic analytics, you need the following components: - **Network Watcher**: A regional service that you can use to monitor and diagnose conditions at a network-scenario level in Azure. You can use Network Watcher to turn network security group flow logs on and off. For more information, see [What is Azure Network Watcher?](network-watcher-monitoring-overview.md) -- **Log Analytics**: A tool in the Azure portal that you use to work with Azure Monitor Logs data. Azure Monitor Logs is an Azure service that collects monitoring data and stores the data in a central repository. This data can include events, performance data, or custom data that's provided through the Azure API. After this data is collected, it's available for alerting, analysis, and export. Monitoring applications such as network performance monitor and traffic analytics use Azure Monitor Logs as a foundation. For more information, see [Azure Monitor Logs](../azure-monitor/logs/log-query-overview.md?toc=/azure/network-watcher/toc.json). Log Analytics provides a way to edit and run queries on logs. You can also use this tool to analyze query results. For more information, see [Overview of Log Analytics in Azure Monitor](../azure-monitor/logs/log-analytics-overview.md?toc=/azure/network-watcher/toc.json).+- **Log Analytics**: A tool in the Azure portal that you use to work with Azure Monitor Logs data. Azure Monitor Logs is an Azure service that collects monitoring data and stores the data in a central repository. This data can include events, performance data, or custom data that's provided through the Azure API. After this data is collected, it's available for alerting, analysis, and export. Monitoring applications such as network performance monitor and traffic analytics use Azure Monitor Logs as a foundation. For more information, see [Azure Monitor Logs](/azure/azure-monitor/logs/log-query-overview?toc=/azure/network-watcher/toc.json). Log Analytics provides a way to edit and run queries on logs. You can also use this tool to analyze query results. For more information, see [Overview of Log Analytics in Azure Monitor](/azure/azure-monitor/logs/log-analytics-overview?toc=/azure/network-watcher/toc.json). -- **Log Analytics workspace**: The environment that stores Azure Monitor log data that pertains to an Azure account. For more information about Log Analytics workspaces, see [Overview of Log Analytics workspace](../azure-monitor/logs/log-analytics-workspace-overview.md?toc=/azure/network-watcher/toc.json).+- **Log Analytics workspace**: The environment that stores Azure Monitor log data that pertains to an Azure account. For more information about Log Analytics workspaces, see [Overview of Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-workspace-overview?toc=/azure/network-watcher/toc.json). - Additionally, you need a network security group enabled for flow logging if you're using traffic analytics to analyze [network security group flow logs](nsg-flow-logs-overview.md) or a virtual network enabled for flow logging if you're using traffic analytics to analyze [virtual network flow logs](vnet-flow-logs-overview.md): Traffic analytics requires the following prerequisites: - A Network Watcher enabled subscription. For more information, see [Enable or disable Azure Network Watcher](network-watcher-create.md). - Network security group flow logs enabled for the network security groups you want to monitor or virtual network flow logs enabled for the virtual network you want to monitor. For more information, see [Create a network security group flow log](nsg-flow-logs-portal.md#create-a-flow-log) or [Create a virtual network flow log](vnet-flow-logs-portal.md#create-a-flow-log).-- An Azure Log Analytics workspace with read and write access. For more information, see [Create a Log Analytics workspace](../azure-monitor/logs/quick-create-workspace.md?toc=/azure/network-watcher/toc.json).+- An Azure Log Analytics workspace with read and write access. For more information, see [Create a Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace?toc=/azure/network-watcher/toc.json). - One of the following [Azure built-in roles](../role-based-access-control/built-in-roles.md) needs to be assigned to your account: Traffic analytics requires the following prerequisites: <sup>1</sup> Network contributor doesn't cover `Microsoft.OperationalInsights/workspaces/*` actions. - <sup>2</sup> Only required when using traffic analytics to analyze virtual network flow logs. For more information, see [Data collection rules in Azure Monitor](../azure-monitor/essentials/data-collection-rule-overview.md?toc=/azure/network-watcher/toc.json) and [Data collection endpoints in Azure Monitor](../azure-monitor/essentials/data-collection-endpoint-overview.md?toc=/azure/network-watcher/toc.json). + <sup>2</sup> Only required when using traffic analytics to analyze virtual network flow logs. For more information, see [Data collection rules in Azure Monitor](/azure/azure-monitor/essentials/data-collection-rule-overview?toc=/azure/network-watcher/toc.json) and [Data collection endpoints in Azure Monitor](/azure/azure-monitor/essentials/data-collection-endpoint-overview?toc=/azure/network-watcher/toc.json). To learn how to check roles assigned to a user for a subscription, see [List Azure role assignments using the Azure portal](../role-based-access-control/role-assignments-list-portal.yml?toc=/azure/network-watcher/toc.json). If you can't see the role assignments, contact the respective subscription admin. |
| network-watcher | Vnet Flow Logs Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/network-watcher/vnet-flow-logs-portal.md | Create a flow log for your virtual network, subnet, or network interface. This f :::image type="content" source="./media/vnet-flow-logs-portal/create-vnet-flow-log-analytics.png" alt-text="Screenshot that shows how to enable traffic analytics for a new flow log in the Azure portal."::: > [!NOTE]- > To create and select a Log Analytics workspace other than the default one, see [Create a Log Analytics workspace](../azure-monitor/logs/quick-create-workspace.md?toc=/azure/network-watcher/toc.json) + > To create and select a Log Analytics workspace other than the default one, see [Create a Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace?toc=/azure/network-watcher/toc.json) 1. Select **Review + create**. |
| networking | Networking Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/networking/fundamentals/networking-overview.md | For more information about Traffic Manager, see [What is Azure Traffic Manager?] ### <a name="azuremonitor"></a>Azure Monitor -[Azure Monitor](../../azure-monitor/overview.md?toc=%2fazure%2fnetworking%2ftoc.json) maximizes the availability and performance of your applications by delivering a comprehensive solution for collecting, analyzing, and acting on telemetry from your cloud and on-premises environments. It helps you understand how your applications are performing and proactively identifies issues affecting them and the resources they depend on. +[Azure Monitor](/azure/azure-monitor/overview?toc=%2fazure%2fnetworking%2ftoc.json) maximizes the availability and performance of your applications by delivering a comprehensive solution for collecting, analyzing, and acting on telemetry from your cloud and on-premises environments. It helps you understand how your applications are performing and proactively identifies issues affecting them and the resources they depend on. ## <a name="delivery"></a>Load balancing and content delivery |
| notification-hubs | Notification Hubs Diagnostic Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/notification-hubs/notification-hubs-diagnostic-logs.md | The new settings take effect in about 10 minutes. The logs are displayed in the ## Related content To learn more about configuring diagnostics settings, see:-* [Overview of Azure diagnostics logs](../azure-monitor/essentials/platform-logs-overview.md). +* [Overview of Azure diagnostics logs](/azure/azure-monitor/essentials/platform-logs-overview). To learn more about Azure Notification Hubs, see: * [What is Azure Notification Hubs?](notification-hubs-push-notification-overview.md) |
| openshift | Howto Remotewrite Prometheus | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/openshift/howto-remotewrite-prometheus.md | In some scenarios, you might want to centralize data from self-managed Prometheu To send data from a Prometheus server by using remote write, you need: -- An [Azure Monitor workspace](../azure-monitor/essentials/azure-monitor-workspace-overview.md). If you don't already have a workspace, you must [create a new workspace](../azure-monitor/essentials/azure-monitor-workspace-manage.md#create-an-azure-monitor-workspace).+- An [Azure Monitor workspace](/azure/azure-monitor/essentials/azure-monitor-workspace-overview). If you don't already have a workspace, you must [create a new workspace](/azure/azure-monitor/essentials/azure-monitor-workspace-manage#create-an-azure-monitor-workspace). ## Register an application with Microsoft Entra ID You can use community Grafana dashboards to visualize the captured metrics, or y 1. Create an [Azure Managed Grafana workspace](../managed-grafan). -1. [Link the Azure Managed Grafana workspace](../azure-monitor/essentials/azure-monitor-workspace-manage.md?tabs=azure-portal#link-a-grafana-workspace) to your Azure Monitor workspace. +1. [Link the Azure Managed Grafana workspace](/azure/azure-monitor/essentials/azure-monitor-workspace-manage?tabs=azure-portal#link-a-grafana-workspace) to your Azure Monitor workspace. 1. [Import](../managed-grafan?tabs=azure-portal#import-a-grafana-dashboard) the community Grafana dashboard [Openshift/K8 Cluster Overview](https://grafana.com/grafana/dashboards/3870-openshift-k8-cluster-overview/) (ID 3870) to the Grafana workspace. To access the dashboard, in your Azure Managed Grafana workspace, go to **Home** ## Troubleshoot -For troubleshooting information, see [Azure Monitor managed service for Prometheus remote write](../azure-monitor/containers/prometheus-remote-write-troubleshooting.md#ingestion-quotas-and-limits). +For troubleshooting information, see [Azure Monitor managed service for Prometheus remote write](/azure/azure-monitor/containers/prometheus-remote-write-troubleshooting#ingestion-quotas-and-limits). ## Related content -- [Learn more about Azure Monitor managed service for Prometheus](../azure-monitor/essentials/prometheus-metrics-overview.md)+- [Learn more about Azure Monitor managed service for Prometheus](/azure/azure-monitor/essentials/prometheus-metrics-overview) |
| openshift | Howto Restrict Egress | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/openshift/howto-restrict-egress.md | For additional information on remote health monitoring and telemetry, see the [R ### Azure Monitor container insights -ARO clusters can be monitored using the Azure Monitor container insights extension. Review the pre-requisites and instructions for [enabling the extension](../azure-monitor/containers/container-insights-enable-arc-enabled-clusters.md). +ARO clusters can be monitored using the Azure Monitor container insights extension. Review the pre-requisites and instructions for [enabling the extension](/azure/azure-monitor/containers/container-insights-enable-arc-enabled-clusters). |
| operational-excellence | Relocation Log Analytics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/operational-excellence/relocation-log-analytics.md | If you want to relocate your Log Analytics workspace to a region that supports a - To export the workspace configuration to a template that can be deployed to another region, you need the [Log Analytics Contributor](../role-based-access-control/built-in-roles.md#log-analytics-contributor) or [Monitoring Contributor](../role-based-access-control/built-in-roles.md#monitoring-contributor) role, or higher. - Identify all the resources that are currently associated with your workspace, including:- - *Connected agents*: Enter **Logs** in your workspace and query a [heartbeat](../azure-monitor/insights/solution-agenthealth.md#azure-monitor-log-records) table to list connected agents. + - *Connected agents*: Enter **Logs** in your workspace and query a [heartbeat](/azure/azure-monitor/insights/solution-agenthealth#azure-monitor-log-records) table to list connected agents. ```kusto Heartbeat | summarize by Computer, Category, OSType, _ResourceId If you want to relocate your Log Analytics workspace to a region that supports a ``` - *Installed solutions*: Select **Legacy solutions** on the workspace navigation pane for a list of installed solutions.- - *Data collector API*: Data arriving through a [Data Collector API](../azure-monitor/logs/data-collector-api.md) is stored in custom log tables. For a list of custom log tables, select **Logs** on the workspace navigation pane, and then select **Custom log** on the schema pane. + - *Data collector API*: Data arriving through a [Data Collector API](/azure/azure-monitor/logs/data-collector-api) is stored in custom log tables. For a list of custom log tables, select **Logs** on the workspace navigation pane, and then select **Custom log** on the schema pane. - *Linked services*: Workspaces might have linked services to dependent resources such as an Azure Automation account, a storage account, or a dedicated cluster. Remove linked services from your workspace. Reconfigure them manually in the target workspace.- - *Alerts*: To list alerts, select **Alerts** on your workspace navigation pane, and then select **Manage alert rules** on the toolbar. Alerts in workspaces created after June 1, 2019, or in workspaces that were [upgraded from the Log Analytics Alert API to the scheduledQueryRules API](../azure-monitor/alerts/alerts-log-api-switch.md) can be included in the template. + - *Alerts*: To list alerts, select **Alerts** on your workspace navigation pane, and then select **Manage alert rules** on the toolbar. Alerts in workspaces created after June 1, 2019, or in workspaces that were [upgraded from the Log Analytics Alert API to the scheduledQueryRules API](/azure/azure-monitor/alerts/alerts-log-api-switch) can be included in the template. - You can [check if the scheduledQueryRules API is used for alerts in your workspace](../azure-monitor/alerts/alerts-log-api-switch.md#check-switching-status-of-workspace). Alternatively, you can configure alerts manually in the target workspace. + You can [check if the scheduledQueryRules API is used for alerts in your workspace](/azure/azure-monitor/alerts/alerts-log-api-switch#check-switching-status-of-workspace). Alternatively, you can configure alerts manually in the target workspace. - *Query packs*: A workspace can be associated with multiple query packs. To identify query packs in your workspace, select **Logs** on the workspace navigation pane, select **queries** on the left pane, and then select the ellipsis to the right of the search box. A dialog with the selected query packs opens on the right. If your query packs are in the same resource group as the workspace that you're moving, you can include it with this migration. - Verify that your Azure subscription allows you to create Log Analytics workspaces in the target region. The following procedures show how to prepare the workspace and resources for the | summarize max(TimeGenerated) by Type ``` -After data sources are connected to the target workspace, ingested data is stored in the target workspace. Older data stays in the original workspace and is subject to the retention policy. You can perform a [cross-workspace query](../azure-monitor/logs/cross-workspace-query.md). If both workspaces were assigned the same name, use a qualified name (*subscriptionName/resourceGroup/componentName*) in the workspace reference. +After data sources are connected to the target workspace, ingested data is stored in the target workspace. Older data stays in the original workspace and is subject to the retention policy. You can perform a [cross-workspace query](/azure/azure-monitor/logs/cross-workspace-query). If both workspaces were assigned the same name, use a qualified name (*subscriptionName/resourceGroup/componentName*) in the workspace reference. Here's an example for a query across two workspaces that have the same name: If you want to discard the source workspace, delete the exported resources or th ## Clean up -While new data is being ingested to your new workspace, older data in the original workspace remains available for query and is subject to the retention policy defined in the workspace. We recommend that you keep the original workspace for as long as you need older data to [query across](../azure-monitor/logs/cross-workspace-query.md) workspaces. +While new data is being ingested to your new workspace, older data in the original workspace remains available for query and is subject to the retention policy defined in the workspace. We recommend that you keep the original workspace for as long as you need older data to [query across](/azure/azure-monitor/logs/cross-workspace-query) workspaces. If you no longer need access to older data in the original workspace: |
| operational-excellence | Relocation Storage Account | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/operational-excellence/relocation-storage-account.md | The following table lists these features along with guidance for adding them to | **Lifecycle management policies** | [Manage the Azure Blob storage lifecycle](../storage/blobs/storage-lifecycle-management-concepts.md) | | **Static websites** | [Host a static website in Azure Storage](../storage/blobs/storage-blob-static-website-how-to.md) | | **Event subscriptions** | [Reacting to Blob storage events](../storage/blobs/storage-blob-event-overview.md) |-| **Alerts** | [Create, view, and manage activity log alerts by using Azure Monitor](../azure-monitor/alerts/alerts-activity-log.md) | +| **Alerts** | [Create, view, and manage activity log alerts by using Azure Monitor](/azure/azure-monitor/alerts/alerts-activity-log) | | **Content Delivery Network (CDN)** | [Use Azure CDN to access blobs with custom domains over HTTPS](../storage/blobs/storage-https-custom-domain-cdn.md) | > [!NOTE] |
| operator-nexus | Concepts Observability | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/operator-nexus/concepts-observability.md | These logs and metrics are used to observe the state of the platform. You can se Operator Nexus observability allows you to collect the same kind of data as other Azure resources. The data collected from each of your instances can be viewed in your LAW. - You can learn about monitoring Azure resources [here](../azure-monitor/essentials/monitor-azure-resource.md#monitoring-data). + You can learn about monitoring Azure resources [here](/azure/azure-monitor/essentials/monitor-azure-resource#monitoring-data). ### Collection and Routing You can also collect data from the tenant layers created for running Containeriz * Collection of logs from Kubernetes clusters and the applications deployed on top. You'll need to enable the collection of the logs from the tenant Kubernetes clusters and Virtual Machines.-You should follow the steps to deploy the [Azure monitoring agents](../azure-monitor/agents/agents-overview.md#install-the-agent-and-configure-data-collection). The data would be collected in your Azure LAW. +You should follow the steps to deploy the [Azure monitoring agents](/azure/azure-monitor/agents/agents-overview#install-the-agent-and-configure-data-collection). The data would be collected in your Azure LAW. ### Operator Nexus Logs storage Data in Azure Monitor Logs is stored in tables where each table has its own set of unique properties. -All resource logs in Azure Monitor have the same fields followed by service-specific fields; see the [common schema](../azure-monitor/essentials/resource-logs-schema.md#top-level-common-schema). +All resource logs in Azure Monitor have the same fields followed by service-specific fields; see the [common schema](/azure/azure-monitor/essentials/resource-logs-schema#top-level-common-schema). The logs from Operator Nexus platform are stored in the following tables: The 'InsightMetrics' table in the Logs section contains the metrics collected fr Figure: Azure Monitor Metrics Selection -See **[Analyze metrics with Azure Monitor metrics explorer](../azure-monitor/essentials/analyze-metrics.md)** for details on using this tool. +See **[Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics)** for details on using this tool. #### Workbooks You can use the sample Azure Resource Manager alarm templates for [Operator Nexu ## Log Analytic Workspace -A [Log Analytics Workspace (LAW)](../azure-monitor/logs/log-analytics-workspace-overview.md) is a unique environment to log data from Azure Monitor and other Azure services. Each workspace has its own data repository and configuration but may combine data from multiple services. Each workspace consists of multiple data tables. +A [Log Analytics Workspace (LAW)](/azure/azure-monitor/logs/log-analytics-workspace-overview) is a unique environment to log data from Azure Monitor and other Azure services. Each workspace has its own data repository and configuration but may combine data from multiple services. Each workspace consists of multiple data tables. A single LAW can be created to collect all relevant data or multiple workspaces based on operator requirements. |
| operator-nexus | Howto Monitor Naks Cluster | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/operator-nexus/howto-monitor-naks-cluster.md | Each Nexus Kubernetes cluster consists of multiple layers: Figure: Sample Nexus Kubernetes cluster -On an instance, Nexus Kubernetes clusters are delivered with an _optional_ [Container Insights](../azure-monitor/containers/container-insights-overview.md) observability solution. +On an instance, Nexus Kubernetes clusters are delivered with an _optional_ [Container Insights](/azure/azure-monitor/containers/container-insights-overview) observability solution. Container Insights captures the logs and metrics from Nexus Kubernetes clusters and workloads. It's solely your discretion whether to enable this tooling or deploy your own telemetry stack. Install latest version of the ## Monitor Nexus Kubernetes cluster – VM layer -This how-to guide provides steps and utility scripts to [Arc connect](../azure-arc/servers/overview.md) the Nexus Kubernetes cluster Virtual Machines to Azure and enable monitoring agents for the collection of System logs from these VMs using [Azure Monitoring Agent](../azure-monitor/agents/agents-overview.md). +This how-to guide provides steps and utility scripts to [Arc connect](../azure-arc/servers/overview.md) the Nexus Kubernetes cluster Virtual Machines to Azure and enable monitoring agents for the collection of System logs from these VMs using [Azure Monitoring Agent](/azure/azure-monitor/agents/agents-overview). The instructions further capture details on how to set up log data collection into a Log Analytics workspace. The following resources provide you with support: Assign the service principal to the Azure resource group that has the machines t | Role | Needed to | |-|-- | | [Azure Connected Machine Resource Administrator](../role-based-access-control/built-in-roles.md#azure-connected-machine-resource-administrator)  or [Contributor](../role-based-access-control/built-in-roles.md#contributor) | Connect Arc-enabled Nexus Kubernetes cluster VM server in the resource group and install the Azure Monitoring Agent (AMA)|-| [Monitoring Contributor](../role-based-access-control/built-in-roles.md#user-access-administrator) or [Contributor](../role-based-access-control/built-in-roles.md#contributor) | Create a [Data Collection Rule (DCR)](../azure-monitor/agents/data-collection-rule-azure-monitor-agent.md) in the resource group and associate Arc-enabled servers to it | +| [Monitoring Contributor](../role-based-access-control/built-in-roles.md#user-access-administrator) or [Contributor](../role-based-access-control/built-in-roles.md#contributor) | Create a [Data Collection Rule (DCR)](/azure/azure-monitor/agents/data-collection-rule-azure-monitor-agent) in the resource group and associate Arc-enabled servers to it | | [User Access Administrator](../role-based-access-control/built-in-roles.md#user-access-administrator), and [Resource Policy Contributor](../role-based-access-control/built-in-roles.md#resource-policy-contributor) or [Contributor](../role-based-access-control/built-in-roles.md#contributor) | Needed if you want to use Azure policy assignment(s) to ensure that a DCR is associated with [Arc-enabled machines](https://ms.portal.azure.com/#view/Microsoft_Azure_Policy/PolicyDetailBlade/definitionId/%2Fproviders%2FMicrosoft.Authorization%2FpolicyDefinitions%2Fd5c37ce1-5f52-4523-b949-f19bf945b73a) | | [Kubernetes Extension Contributor](../role-based-access-control/built-in-roles.md#kubernetes-extension-contributor) | Needed to deploy the K8s extension for Container Insights | For convenience, you can modify the template file, `arc-connect.env`, to set the Associate the Arc-enabled servers with a DCR to enable the collection of log data into a Log Analytics workspace. You can create the DCR via the Azure portal or CLI.-Information on creating a DCR to collect data from the VMs is available [here](../azure-monitor/agents/data-collection-rule-azure-monitor-agent.md). +Information on creating a DCR to collect data from the VMs is available [here](/azure/azure-monitor/agents/data-collection-rule-azure-monitor-agent). The included **`dcr.sh`** script creates a DCR, in the specified resource group, that will configure log collection. In the Azure portal, select the `Assign` button from the [policy definition](htt For convenience, the provided **`assign.sh`** script assigns the built-in policy to the specified resource group and DCR created with the **`dcr.sh`** script. 1. Ensure proper [environment setup](#environment-setup) and role [prerequisites](#prerequisites-vm) for the service principal to do policy and role assignments.-2. Create the DCR, in the resource group, using **`dcr.sh`** script as described in [Adding a Data Collection Rule](../azure-monitor/essentials/data-collection-endpoint-overview.md?tabs=portal#create-a-data-collection-endpoint) section. +2. Create the DCR, in the resource group, using **`dcr.sh`** script as described in [Adding a Data Collection Rule](/azure/azure-monitor/essentials/data-collection-endpoint-overview?tabs=portal#create-a-data-collection-endpoint) section. 3. Run the **`assign.sh`** script. It creates the policy assignment and necessary role assignments. ```bash After you configure a policy, there may be some delay to observe the logs in Azu There are certain prerequisites the operator should ensure to configure the monitoring tools on Nexus Kubernetes Clusters. -Container Insights stores its data in a [Log Analytics workspace](../azure-monitor/logs/log-analytics-workspace-overview.md). +Container Insights stores its data in a [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-workspace-overview). Log data flows into the workspace whose Resource ID you provided during the initial scripts covered in the ["Add a data collection rule (DCR)"](#add-a-data-collection-rule-dcr) section. Else, data funnels into a default workspace in the Resource group associated with your subscription (based on Azure location). Container Insights and view data in the applicable Log Analytics workspace requi For example, the "Contributor" role assignment. See the instructions for [assigning required roles](../role-based-access-control/role-assignments-steps.md#step-5-assign-role): -- [Log Analytics Contributor](../azure-monitor/logs/manage-access.md?tabs=portal#azure-rbac) role: necessary permissions to enable container monitoring on a CNF (provisioned) cluster.-- [Log Analytics Reader](../azure-monitor/logs/manage-access.md?tabs=portal#azure-rbac) role: non-members of the Log Analytics Contributor role, receive permissions to view data in the Log Analytics workspace once you enable container monitoring.+- [Log Analytics Contributor](/azure/azure-monitor/logs/manage-access?tabs=portal#azure-rbac) role: necessary permissions to enable container monitoring on a CNF (provisioned) cluster. +- [Log Analytics Reader](/azure/azure-monitor/logs/manage-access?tabs=portal#azure-rbac) role: non-members of the Log Analytics Contributor role, receive permissions to view data in the Log Analytics workspace once you enable container monitoring. #### Install the cluster extension Look for a Provisioning State of "Succeeded" for the extension. The "k8s-extensi #### Customize logs & metrics collection -Container Insights provides end-users functionality to fine-tune the collection of logs and metrics from Nexus Kubernetes Clusters--[Configure Container insights agent data collection](../azure-monitor/containers/container-insights-data-collection-configmap.md). +Container Insights provides end-users functionality to fine-tune the collection of logs and metrics from Nexus Kubernetes Clusters--[Configure Container insights agent data collection](/azure/azure-monitor/containers/container-insights-data-collection-configmap). ## Extra resources -- Review [workbooks documentation](../azure-monitor/visualize/workbooks-overview.md) and then you may use Operator Nexus telemetry sample Operator Nexus workbooks.-- Review [Azure Monitor Alerts](../azure-monitor/alerts/alerts-overview.md), how to create [Azure Monitor Alert rules](../azure-monitor/alerts/alerts-create-new-alert-rule.md?tabs=metric), and use sample Operator Nexus Alert templates.+- Review [workbooks documentation](/azure/azure-monitor/visualize/workbooks-overview) and then you may use Operator Nexus telemetry sample Operator Nexus workbooks. +- Review [Azure Monitor Alerts](/azure/azure-monitor/alerts/alerts-overview), how to create [Azure Monitor Alert rules](/azure/azure-monitor/alerts/alerts-create-new-alert-rule?tabs=metric), and use sample Operator Nexus Alert templates. |
| operator-nexus | Howto Monitor Virtualized Network Functions Virtual Machines | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/operator-nexus/howto-monitor-virtualized-network-functions-virtual-machines.md | Some common reasons for errors: ## Azure monitor agent The Azure Monitor Agent is implemented as an [Azure VM extension](/azure/virtual-machines/extensions/overview) -ver Arc connected Machines. It also lists the options to create [associations with Data Collection Rules](../azure-monitor/agents/data-collection-rule-azure-monitor-agent.md) that define which data the agent should collect. Installing, upgrading, or uninstalling the Azure Monitor Agent won't require you to restart your server. +ver Arc connected Machines. It also lists the options to create [associations with Data Collection Rules](/azure/azure-monitor/agents/data-collection-rule-azure-monitor-agent) that define which data the agent should collect. Installing, upgrading, or uninstalling the Azure Monitor Agent won't require you to restart your server. Ensure that you configure collection of logs and metrics using the Data Collection Rule. az connectedmachine extension create --name AzureMonitorLinuxAgent --publisher M To collect data from virtual machines by using Azure Monitor Agent, you'll need to: -1. Create [Data Collection Rules (DCRs)](../azure-monitor/essentials/data-collection-rule-overview.md)that define which data Azure Monitor Agent sends to which destinations. +1. Create [Data Collection Rules (DCRs)](/azure/azure-monitor/essentials/data-collection-rule-overview)that define which data Azure Monitor Agent sends to which destinations. 2. Associate the Data Collection Rule to specific Virtual Machines. #### Data Collection Rule via Portal -The steps to create a DCR and associate it to a Log Analytics Workspace can be found [here](../azure-monitor/agents/data-collection-rule-azure-monitor-agent.md?tabs=portal). +The steps to create a DCR and associate it to a Log Analytics Workspace can be found [here](/azure/azure-monitor/agents/data-collection-rule-azure-monitor-agent?tabs=portal). Lastly verify if you're getting the logs in the Log Analytics Workspace specified. az monitor data-collection rule association create --name \<name-for-dcr-associa ## Additional resources -- Review [workbooks documentation](../azure-monitor/visualize/workbooks-overview.md) and then you may use Operator Nexus telemetry [sample Operator Nexus workbooks](https://github.com/microsoft/AzureMonitorCommunity/tree/master/Azure%20Services/Azure%20Operator%20Nexus).-- Review [Azure Monitor Alerts](../azure-monitor/alerts/alerts-overview.md), how to create [Azure Monitor Alert rules](../azure-monitor/alerts/alerts-create-new-alert-rule.md?tabs=metric), and use [sample Operator Nexus Alert templates](https://github.com/microsoft/AzureMonitorCommunity/tree/master/Azure%20Services/Azure%20Operator%20Nexus).+- Review [workbooks documentation](/azure/azure-monitor/visualize/workbooks-overview) and then you may use Operator Nexus telemetry [sample Operator Nexus workbooks](https://github.com/microsoft/AzureMonitorCommunity/tree/master/Azure%20Services/Azure%20Operator%20Nexus). +- Review [Azure Monitor Alerts](/azure/azure-monitor/alerts/alerts-overview), how to create [Azure Monitor Alert rules](/azure/azure-monitor/alerts/alerts-create-new-alert-rule?tabs=metric), and use [sample Operator Nexus Alert templates](https://github.com/microsoft/AzureMonitorCommunity/tree/master/Azure%20Services/Azure%20Operator%20Nexus). |
| operator-nexus | List Logs Available | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/operator-nexus/list-logs-available.md | -Logs emitted by Nexus Resources provide insight in the detailed operations of Nexus Resources and are useful for monitoring their health and availability. The logs are categorized into different categories based on the type of resource emitting the logs. These logs can be streamed to specific targets by creating [Diagnostic Settings](../azure-monitor/essentials/diagnostic-settings.md) in Azure Monitor. +Logs emitted by Nexus Resources provide insight in the detailed operations of Nexus Resources and are useful for monitoring their health and availability. The logs are categorized into different categories based on the type of resource emitting the logs. These logs can be streamed to specific targets by creating [Diagnostic Settings](/azure/azure-monitor/essentials/diagnostic-settings) in Azure Monitor. ## Nexus Cluster |
| operator-nexus | Reference Limits And Quotas | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/operator-nexus/reference-limits-and-quotas.md | The table here briefly mentions other Azure resources that are necessary. Howeve | Load Balancers (Standard) | [Load Balancer Limits](../azure-resource-manager/management/azure-subscription-service-limits.md#load-balancer) | | Public IP Address (Standard) | [Public IP Address Limits](../azure-resource-manager/management/azure-subscription-service-limits.md#publicip-address) | | Azure Monitor Metrics | [Azure Monitor Limits](../azure-resource-manager/management/azure-subscription-service-limits.md#azure-monitor-limits) |-| Log Analytics Workspace | [Log Analytics Workspace Limits](../azure-monitor/service-limits.md#log-analytics-workspaces) | +| Log Analytics Workspace | [Log Analytics Workspace Limits](/azure/azure-monitor/service-limits#log-analytics-workspaces) | |
| orbital | Geospatial Reference Architecture | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/orbital/geospatial-reference-architecture.md | When Analysis Ready Datasets are made available through APIs that enable search Although not shown in the diagrams above, Azure Monitor, Log Analytics and Key Vault would also be part of a broader solution. -- [Azure Monitor](../azure-monitor/overview.md) collects data on environments and Azure resources. This diagnostic information is helpful for maintaining availability and performance. Two data platforms make up Monitor:- - [Azure Monitor Logs](../azure-monitor/logs/log-analytics-overview.md) records and stores log and performance data. - - [Azure Monitor Metrics](../azure-monitor/essentials/metrics-getting-started.md) collects numerical values at regular intervals. -- [Azure Log Analytics](../azure-monitor/logs/log-analytics-overview.md) is an Azure portal tool that runs queries on Monitor log data. Log Analytics also provides features for charting and statistically analyzing query results.+- [Azure Monitor](/azure/azure-monitor/overview) collects data on environments and Azure resources. This diagnostic information is helpful for maintaining availability and performance. Two data platforms make up Monitor: + - [Azure Monitor Logs](/azure/azure-monitor/logs/log-analytics-overview) records and stores log and performance data. + - [Azure Monitor Metrics](/azure/azure-monitor/essentials/metrics-getting-started) collects numerical values at regular intervals. +- [Azure Log Analytics](/azure/azure-monitor/logs/log-analytics-overview) is an Azure portal tool that runs queries on Monitor log data. Log Analytics also provides features for charting and statistically analyzing query results. - [Key Vault](/azure/key-vault/general/basic-concepts) stores and controls access to secrets such as tokens, passwords, and API keys. Key Vault also creates and controls encryption keys and manages security certificates. ## Alternatives |
| orbital | Organize Stac Data | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/orbital/organize-stac-data.md | The following Azure services are used in this architecture. - [Container Registry](../container-registry/container-registry-intro.md) to store and manage your container images and related artifacts. - [Virtual Machine](/azure/virtual-machines/overview) (VM) gives you the flexibility of virtualization for a wide range of computing solutions. In a fully secured deployment, a user connects to a VM via Azure Bastion (described in the next item below) to perform a range of operations like copying files to storage accounts, running Azure CLI commands, and interacting with other services. - [Azure Bastion](../bastion/bastion-overview.md) enables you to securely and seamlessly RDP & SSH to your VMs in Azure virtual network, without the need of public IP on the VM, directly from the Azure portal, and without the need of any other client/agent or any piece of software.-- [Application Insights](../azure-monitor/app/app-insights-overview.md) provides extensible application performance management and monitoring for live web apps.-- [Log Analytics](../azure-monitor/logs/log-analytics-overview.md) is a tool to edit and run log queries from data collected by Azure Monitor logs and interactively analyze the results.+- [Application Insights](/azure/azure-monitor/app/app-insights-overview) provides extensible application performance management and monitoring for live web apps. +- [Log Analytics](/azure/azure-monitor/logs/log-analytics-overview) is a tool to edit and run log queries from data collected by Azure Monitor logs and interactively analyze the results. The following Geospatial libraries are also used: |
| partner-solutions | Create | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/partner-solutions/datadog/create.md | The Microsoft Entra admin center gives you access to three activity logs: To send subscription level logs to Datadog, select **Send subscription activity logs**. If this option is left unchecked, none of the subscription level logs are sent to Datadog. -To send Azure resource logs to Datadog, select **Send Azure resource logs for all defined resources**. The types of Azure resource logs are listed in [Azure Monitor Resource Log categories](../../azure-monitor/essentials/resource-logs-categories.md). To filter the set of Azure resources sending logs to Datadog, use Azure resource tags. +To send Azure resource logs to Datadog, select **Send Azure resource logs for all defined resources**. The types of Azure resource logs are listed in [Azure Monitor Resource Log categories](/azure/azure-monitor/essentials/resource-logs-categories). To filter the set of Azure resources sending logs to Datadog, use Azure resource tags. You can request your IT Administrator to route Microsoft Entra logs to Datadog. For more information, see [Microsoft Entra activity logs in Azure Monitor](../../active-directory/reports-monitoring/concept-activity-logs-azure-monitor.md). |
| partner-solutions | Link To Existing Organization | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/partner-solutions/datadog/link-to-existing-organization.md | There are two types of logs that can be emitted from Azure to Datadog. To send subscription level logs to Datadog, select **Send subscription activity logs**. If this option is left unchecked, none of the subscription level logs are sent to Datadog. -To send Azure resource logs to Datadog, select **Send Azure resource logs for all defined resources**. The types of Azure resource logs are listed in [Azure Monitor Resource Log categories](../../azure-monitor/essentials/resource-logs-categories.md). To filter the set of Azure resources sending logs to Datadog, use Azure resource tags. +To send Azure resource logs to Datadog, select **Send Azure resource logs for all defined resources**. The types of Azure resource logs are listed in [Azure Monitor Resource Log categories](/azure/azure-monitor/essentials/resource-logs-categories). To filter the set of Azure resources sending logs to Datadog, use Azure resource tags. The logs sent to Datadog are charged by Azure. For more information, see the [pricing of platform logs](https://azure.microsoft.com/pricing/details/monitor/) sent to Azure Marketplace partners. |
| partner-solutions | Manage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/partner-solutions/datadog/manage.md | You can filter the list of resources by resource type, subscription, resource gr The column **Logs to Datadog** indicates whether the resource is sending logs to Datadog. If the resource isn't sending logs, this field indicates why logs aren't being sent to Datadog. The reasons could be: - Resource doesn't support sending logs. Only resources types with monitoring log categories can be configured to send logs to Datadog.-- Limit of five diagnostic settings reached. Each Azure resource can have a maximum of five diagnostic settings. For more information, see [diagnostic settings](../../azure-monitor/essentials/diagnostic-settings.md).+- Limit of five diagnostic settings reached. Each Azure resource can have a maximum of five diagnostic settings. For more information, see [diagnostic settings](/azure/azure-monitor/essentials/diagnostic-settings). - Error. The resource is configured to send logs to Datadog, but is blocked by an error. - Logs not configured. Only Azure resources that have the appropriate resource tags are configured to send logs to Datadog. - Region not supported. The Azure resource is in a region that doesn't currently support sending logs to Datadog. |
| partner-solutions | Prerequisites | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/partner-solutions/datadog/prerequisites.md | This article describes how to set up your environment before deploying your firs To set up the Datadog - An Azure Native ISV Service, you must have **Owner** access on the Azure subscription. [Confirm that you have the appropriate access](../../role-based-access-control/check-access.md) before starting the setup. ## Add enterprise application- -To use the Security Assertion Markup Language (SAML) single sign-on (SSO) feature within the Datadog resource, you must set up an enterprise application. To add an enterprise application, you need one of these roles: Global Administrator, Cloud Application Administrator, Application Administrator, or owner of the service principal. ++To use the Security Assertion Markup Language (SAML) single sign-on (SSO) feature within the Datadog resource, you must set up an enterprise application. To add an enterprise application, you need one of these roles: Cloud Application Administrator, Application Administrator, or owner of the service principal. Use the following steps to set up the enterprise application: |
| partner-solutions | Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/partner-solutions/datadog/troubleshoot.md | To set up the Azure Datadog integration, you must have **Owner** access on the A :::image type="content" source="media/troubleshoot/diagnostic-setting.png" alt-text="Datadog diagnostic setting on the Azure resource" border="true"::: -- Resource doesn't support sending logs. Only resource types with monitoring log categories can be configured to send logs. For more information, see [supported categories](../../azure-monitor/essentials/resource-logs-categories.md).+- Resource doesn't support sending logs. Only resource types with monitoring log categories can be configured to send logs. For more information, see [supported categories](/azure/azure-monitor/essentials/resource-logs-categories). -- Limit of five diagnostic settings reached. Each Azure resource can have a maximum of five diagnostic settings. For more information, see [diagnostic settings](../../azure-monitor/essentials/diagnostic-settings.md?tabs=portal).+- Limit of five diagnostic settings reached. Each Azure resource can have a maximum of five diagnostic settings. For more information, see [diagnostic settings](/azure/azure-monitor/essentials/diagnostic-settings?tabs=portal). - Export of Metrics data isn't supported currently by the partner solutions under Azure Monitor diagnostic settings. |
| partner-solutions | Dynatrace Create | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/partner-solutions/dynatrace/dynatrace-create.md | Use the Azure portal to find Azure Native Dynatrace Service application. - **Send Azure resource logs for all defined sources** - Azure resource logs provide insight into operations that were taken on an Azure resource at the [data plane](../../azure-resource-manager/management/control-plane-and-data-plane.md). For example, getting a secret from a Key Vault is a data plane operation. Or, making a request to a database is also a data plane operation. The content of resource logs varies by the Azure service and resource type. - - **Send Microsoft Entra logs** – Microsoft Entra logs allow you to route the audit, sign-in, and provisioning logs to Dynatrace. The details are listed in [Microsoft Entra activity logs in Azure Monitor](../../active-directory/reports-monitoring/concept-activity-logs-azure-monitor.md). The global administrator or security administrator for your Microsoft Entra tenant can enable Microsoft Entra logs. + - **Send Microsoft Entra logs** – Microsoft Entra logs allow you to route the audit, sign-in, and provisioning logs to Dynatrace. The details are listed in [Microsoft Entra activity logs in Azure Monitor](../../active-directory/reports-monitoring/concept-activity-logs-azure-monitor.md). The administrator or security administrator for your Microsoft Entra tenant can enable Microsoft Entra logs. 1. To send subscription level logs to Dynatrace, select **Send subscription activity logs**. If this option is left unchecked, none of the subscription level logs are sent to Dynatrace. -1. To send Azure resource logs to Dynatrace, select **Send Azure resource logs for all defined resources**. The types of Azure resource logs are listed in [Azure Monitor Resource Log categories](../../azure-monitor/essentials/resource-logs-categories.md). +1. To send Azure resource logs to Dynatrace, select **Send Azure resource logs for all defined resources**. The types of Azure resource logs are listed in [Azure Monitor Resource Log categories](/azure/azure-monitor/essentials/resource-logs-categories). When the checkbox for Azure resource logs is selected, by default, logs are forwarded for all resources. To filter the set of Azure resources sending logs to Dynatrace, use inclusion and exclusion rules and set the Azure resource tags: |
| partner-solutions | Dynatrace How To Configure Prereqs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/partner-solutions/dynatrace/dynatrace-how-to-configure-prereqs.md | To set up Dynatrace for Azure, you must have **Owner** or **Contributor** access ## Add enterprise application -To use the Security Assertion Markup Language (SAML) based single sign-on (SSO) feature within the Dynatrace resource, you must set up an enterprise application. To add an enterprise application, you need one of these roles: Global administrator, Cloud Application Administrator, or Application Administrator. +To use the Security Assertion Markup Language (SAML) based single sign-on (SSO) feature within the Dynatrace resource, you must set up an enterprise application. To add an enterprise application, you need one of these roles: Cloud Application Administrator, or Application Administrator. 1. Go to Azure portal. Select **Microsoft Entra ID,** then **Enterprise App** and then **New Application**. |
| partner-solutions | Dynatrace How To Manage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/partner-solutions/dynatrace/dynatrace-how-to-manage.md | You can filter the list of resources by resource type, resource group name, regi The column **Logs to Dynatrace** indicates whether the resource is sending logs to Dynatrace. If the resource isn't sending logs, this field indicates why logs aren't being sent. The reasons could be: -- _Resource doesn't support sending logs_ - Only resource types with monitoring log categories can be configured to send logs. See [supported categories](../../azure-monitor/essentials/resource-logs-categories.md).+- _Resource doesn't support sending logs_ - Only resource types with monitoring log categories can be configured to send logs. See [supported categories](/azure/azure-monitor/essentials/resource-logs-categories). - _Limit of five diagnostic settings reached_ - Each Azure resource can have a maximum of five diagnostic settings. For more information, see [diagnostic settings](/cli/azure/monitor/diagnostic-settings). - _Error_ - The resource is configured to send logs to Dynatrace, but is blocked by an error. - _Logs not configured_ - Only Azure resources that have the appropriate resource tags are configured to send logs to Dynatrace. |
| partner-solutions | Dynatrace Link To Existing | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/partner-solutions/dynatrace/dynatrace-link-to-existing.md | Select **Next: Metrics and logs** to configure metrics and logs. - **Azure resource logs** - These logs provide insight into operations that were taken on an Azure resource at the [data plane](../../azure-resource-manager/management/control-plane-and-data-plane.md). For example, getting a secret from a Key Vault is a data plane operation. Or, making a request to a database is also a data plane operation. The content of resource logs varies by the Azure service and resource type. -1. To send Azure resource logs to Dynatrace, select **Send Azure resource logs for all defined resources**. The types of Azure resource logs are listed in [Azure Monitor Resource Log categories](../../azure-monitor/essentials/resource-logs-categories.md). +1. To send Azure resource logs to Dynatrace, select **Send Azure resource logs for all defined resources**. The types of Azure resource logs are listed in [Azure Monitor Resource Log categories](/azure/azure-monitor/essentials/resource-logs-categories). When the checkbox for Azure resource logs is selected, by default, logs are forwarded for all resources. To filter the set of Azure resources sending logs to Dynatrace, use inclusion and exclusion rules and set the Azure resource tags: |
| partner-solutions | Dynatrace Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/partner-solutions/dynatrace/dynatrace-troubleshoot.md | If those options don't solve the problem, contact [Dynatrace support](https://s - To set up the Azure Native Dynatrace Service, you must have **Owner** or **Contributor** access on the Azure subscription. Ensure you have the appropriate access before starting the setup. -- Create fails because Last Name is empty. The issue happens when the user info in Microsoft Entra ID is incomplete and doesn't contain Last Name. Contact your Azure tenant's global administrator to rectify the issue and try again.+- Create fails because Last Name is empty. The issue happens when the user info in Microsoft Entra ID is incomplete and doesn't contain Last Name. Contact your Azure tenant's administrator to rectify the issue and try again. ## Logs not being emitted or limit reached issue -- Resource doesn't support sending logs. Only resource types with monitoring log categories can be configured to send logs. For more information, see [supported categories](../../azure-monitor/essentials/resource-logs-categories.md).+- Resource doesn't support sending logs. Only resource types with monitoring log categories can be configured to send logs. For more information, see [supported categories](/azure/azure-monitor/essentials/resource-logs-categories). -- Limit of five diagnostic settings reached. This displays the message of Limit reached against the resource. Each Azure resource can have a maximum of five diagnostic settings. For more information, see [diagnostic settings](../../azure-monitor/essentials/diagnostic-settings.md?tabs=portal) You can go ahead and remove the other destinations to make sure each resource is sending data to at max five destinations.+- Limit of five diagnostic settings reached. This displays the message of Limit reached against the resource. Each Azure resource can have a maximum of five diagnostic settings. For more information, see [diagnostic settings](/azure/azure-monitor/essentials/diagnostic-settings?tabs=portal) You can go ahead and remove the other destinations to make sure each resource is sending data to at max five destinations. - Export of Metrics data isn't supported currently by the partner solutions under Azure Monitor diagnostic settings. |
| partner-solutions | Create | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/partner-solutions/elastic/create.md | After you've selected the offer for Elastic, you're ready to set up the applicat **Subscription logs** provide insights into the operations on each Azure resource in the subscription from the [management plane](../../azure-resource-manager/management/control-plane-and-data-plane.md). The logs also provide updates on Service Health events. Use the activity log to determine what, who, and when for any write operations (PUT, POST, DELETE) on the resources in your subscription. There's a single activity log for each Azure subscription. - **Azure resource logs** provide insights into operations that happen within the [data plane](../../azure-resource-manager/management/control-plane-and-data-plane.md). For example, getting a secret from a key vault or making a request to a database are data plane activities. The content of resource logs varies by the Azure service and resource type. The types of Azure resource logs are listed in [Azure Monitor Resource Log categories](../../azure-monitor/essentials/resource-logs-categories.md). + **Azure resource logs** provide insights into operations that happen within the [data plane](../../azure-resource-manager/management/control-plane-and-data-plane.md). For example, getting a secret from a key vault or making a request to a database are data plane activities. The content of resource logs varies by the Azure service and resource type. The types of Azure resource logs are listed in [Azure Monitor Resource Log categories](/azure/azure-monitor/essentials/resource-logs-categories). To filter the Azure resources that send logs to Elastic, use resource tags. The tag rules for sending logs are: |
| partner-solutions | Manage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/partner-solutions/elastic/manage.md | You can filter the list by resource type, resource group name, location, and whe The **Logs to Elastic** column indicates whether the resource is sending Logs to Elastic. If the resource isn't sending logs, this field specifies why logs aren't being sent. The reasons could be: - Resource doesn't support sending logs. Only Azure resource logs for all resources types and log categories defined here can be configured to send logs to Elastic-- Limit of five diagnostic settings reached. Each Azure resource can have a maximum of five [diagnostic settings](../../azure-monitor/essentials/diagnostic-settings.md).+- Limit of five diagnostic settings reached. Each Azure resource can have a maximum of five [diagnostic settings](/azure/azure-monitor/essentials/diagnostic-settings). - An error is blocking the logs from being sent to Elastic. - Logs aren't configured for the resource. Only resources that have the appropriate resource tags are sent to Elastic. You specified the tag rules in the log configuration. - Region isn't supported. The Azure resource is in a region that doesn't currently send logs to Elastic. |
| partner-solutions | Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/partner-solutions/elastic/troubleshoot.md | Only users who have *Owner* or *Contributor* access on the Azure subscription ca ## Logs not being emitted to Elastic -- Only resources listed in [Azure Monitor resource log categories](../../azure-monitor/essentials/resource-logs-categories.md) emit logs to Elastic. To verify whether the resource is emitting logs to Elastic:+- Only resources listed in [Azure Monitor resource log categories](/azure/azure-monitor/essentials/resource-logs-categories) emit logs to Elastic. To verify whether the resource is emitting logs to Elastic: - 1. Navigate to [Azure diagnostic setting](../../azure-monitor/essentials/diagnostic-settings.md) for the resource. + 1. Navigate to [Azure diagnostic setting](/azure/azure-monitor/essentials/diagnostic-settings) for the resource. 1. Verify that there's a diagnostic setting option available. :::image type="content" source="media/troubleshoot/check-diagnostic-setting.png" alt-text="Screenshot of verify diagnostic setting."::: -- Resource doesn't support sending logs. Only resource types with monitoring log categories can be configured to send logs. For more information, see [supported categories](../../azure-monitor/essentials/resource-logs-categories.md).+- Resource doesn't support sending logs. Only resource types with monitoring log categories can be configured to send logs. For more information, see [supported categories](/azure/azure-monitor/essentials/resource-logs-categories). -- Limit of five diagnostic settings reached. Each Azure resource can have a maximum of five diagnostic settings. For more information, see [diagnostic settings](../../azure-monitor/essentials/diagnostic-settings.md?tabs=portal)+- Limit of five diagnostic settings reached. Each Azure resource can have a maximum of five diagnostic settings. For more information, see [diagnostic settings](/azure/azure-monitor/essentials/diagnostic-settings?tabs=portal) - Export of Metrics data isn't supported currently by the partner solutions under Azure Monitor diagnostic settings. |
| partner-solutions | Create | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/partner-solutions/logzio/create.md | There are two types of logs that can be sent from Azure to Logz.io: Subscription level logs can be sent to Logz.io by checking the box titled **Send subscription level logs**. If this box isn't checked, none of the subscription level logs are sent to Logz.io. -Azure resource logs can be sent to Logz.io by checking the box titled **Send Azure resource logs for all defined resources**. The types of Azure resource logs are listed in [Azure Monitor Resource Log categories](../../azure-monitor/essentials/resource-logs-categories.md). To filter the specific set of Azure resources sending logs to Logz.io, you can use Azure resource tags. +Azure resource logs can be sent to Logz.io by checking the box titled **Send Azure resource logs for all defined resources**. The types of Azure resource logs are listed in [Azure Monitor Resource Log categories](/azure/azure-monitor/essentials/resource-logs-categories). To filter the specific set of Azure resources sending logs to Logz.io, you can use Azure resource tags. Tag rules for sending logs are as follows: |
| partner-solutions | Manage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/partner-solutions/logzio/manage.md | The following are descriptions of columns shown on the **Monitored resources** s - **Resource group**: Show resource group name for the Azure resource. - **Region**: Shows region or location of the Azure resource. - **Logs to Logz**: Indicates whether the resource is sending Logs to Logz.io. If the resource isn't sending logs, this field indicates the appropriate reason why logs aren't being sent to Logz.io. The reasons could be:- - Resource doesn't support sending logs: Only Azure resource logs for all resources types and [log categories defined here](../../azure-monitor/essentials/resource-logs-categories.md) can be configured to send logs to Logz.io. - - Limit of five diagnostic settings reached: Each Azure resource can have a maximum of five diagnostic settings. For more information, see [Create diagnostic settings to send platform logs and metrics to different destinations](../../azure-monitor/essentials/diagnostic-settings.md). + - Resource doesn't support sending logs: Only Azure resource logs for all resources types and [log categories defined here](/azure/azure-monitor/essentials/resource-logs-categories) can be configured to send logs to Logz.io. + - Limit of five diagnostic settings reached: Each Azure resource can have a maximum of five diagnostic settings. For more information, see [Create diagnostic settings to send platform logs and metrics to different destinations](/azure/azure-monitor/essentials/diagnostic-settings). - Error: An error is blocking the logs from being sent to Logz.io. - Logs not configured: Only resources that have the appropriate resource tags can send logs to Logz.io. See [configure logs](./create.md#configure-logs). - Region not supported: The Azure resource is in a region that doesn't currently send logs to Logz.io. |
| partner-solutions | Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/partner-solutions/logzio/troubleshoot.md | Use the following patterns to add new values: ### Logs not being sent to Logz.io -- Only resources listed in [Azure Monitor resource log categories](../../azure-monitor/essentials/resource-logs-categories.md) send logs to Logz.io. To verify whether a resource is sending logs to Logz.io:+- Only resources listed in [Azure Monitor resource log categories](/azure/azure-monitor/essentials/resource-logs-categories) send logs to Logz.io. To verify whether a resource is sending logs to Logz.io: - 1. Go to [Azure diagnostic setting](../../azure-monitor/essentials/diagnostic-settings.md) for the specific resource. + 1. Go to [Azure diagnostic setting](/azure/azure-monitor/essentials/diagnostic-settings) for the specific resource. 1. Verify that there's a Logz.io diagnostic setting. :::image type="content" source="media/troubleshoot/diagnostics.png" alt-text="Screenshot of the Azure monitoring diagnostic settings for Logz.io."::: -- Limit of five diagnostic settings reached. Each Azure resource can have a maximum of five diagnostic settings. For more information, see [diagnostic settings](../../azure-monitor/essentials/diagnostic-settings.md?tabs=portal).+- Limit of five diagnostic settings reached. Each Azure resource can have a maximum of five diagnostic settings. For more information, see [diagnostic settings](/azure/azure-monitor/essentials/diagnostic-settings?tabs=portal). - Export of Metrics data isn't supported currently by the partner solutions under Azure Monitor diagnostic settings. |
| partner-solutions | New Relic How To Manage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/partner-solutions/new-relic/new-relic-how-to-manage.md | You can filter the list of resources by resource type, resource group name, regi The column **Logs to New Relic** indicates whether the resource is sending logs to New Relic. If the resource isn't sending logs, the reasons could be: -- **Resource does not support sending logs**: Only resource types with monitoring log categories can be configured to send logs. See [Supported categories](../../azure-monitor/essentials/resource-logs-categories.md).+- **Resource does not support sending logs**: Only resource types with monitoring log categories can be configured to send logs. See [Supported categories](/azure/azure-monitor/essentials/resource-logs-categories). - **Limit of five diagnostic settings reached**: Each Azure resource can have a maximum of five diagnostic settings. For more information, see [Diagnostic settings](/cli/azure/monitor/diagnostic-settings). - **Error**: The resource is configured to send logs to New Relic but an error blocked it. - **Logs not configured**: Only Azure resources that have the appropriate resource tags are configured to send logs to New Relic. |
| partner-solutions | New Relic Link To Existing | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/partner-solutions/new-relic/new-relic-link-to-existing.md | When you use Azure Native New Relic Service in the Azure portal for linking, and | **Region** | Select the Azure region where the New Relic resource should be created.| | **New Relic account** | The Azure portal displays a list of existing accounts that can be linked. Select the desired account from the available options.| -1. After you select an account from New Relic, the New Relic billing details appear for your reference. The user who is performing the linking action should have global administrator permissions on the New Relic account that's being linked. +1. After you select an account from New Relic, the New Relic billing details appear for your reference. The user who is performing the linking action should have administrator permissions on the New Relic account that's being linked. :::image type="content" source="media/new-relic-link-to-existing/new-relic-form.png" alt-text="Screenshot that shows the Basics tab and New Relic account details in a red box."::: When you use Azure Native New Relic Service in the Azure portal for linking, and > Linking requires: > > - The account and the New Relic resource reside in the same Azure region- > - The user who is linking the account and resource must have Global administrator permissions on the New Relic account being linked + > - The user who is linking the account and resource must have administrator permissions on the New Relic account being linked > > If the account that you want to link to does not appear in the dropdown list, verify that these conditions are satisfied. Your next step is to configure metrics and logs on the **Metrics + Logs** tab. W :::image type="content" source="media/new-relic-link-to-existing/new-relic-metrics.png" alt-text="Screenshot that shows the tab for metrics and logs, with actions to complete."::: -1. To send Azure resource logs to New Relic, select **Send Azure resource logs for all defined resources**. The types of Azure resource logs are listed in [Azure Monitor resource log categories](../../azure-monitor/essentials/resource-logs-categories.md). +1. To send Azure resource logs to New Relic, select **Send Azure resource logs for all defined resources**. The types of Azure resource logs are listed in [Azure Monitor resource log categories](/azure/azure-monitor/essentials/resource-logs-categories). 1. When the checkbox for Azure resource logs is selected, logs are forwarded for all resources by default. To filter the set of Azure resources that are sending logs to New Relic, use inclusion and exclusion rules and set the Azure resource tags: |
| partner-solutions | New Relic Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/partner-solutions/new-relic/new-relic-troubleshoot.md | To register the resource provider from a command line, enter `az provider regist ## Logs aren't being sent to New Relic -Only resource types in [supported categories](../../azure-monitor/essentials/resource-logs-categories.md) send logs to New Relic through the integration. To check whether the resource is set up to send logs to New Relic, go to the [Azure diagnostic settings](/azure/azure-monitor/platform/diagnostic-settings) for that resource. Then, verify that there's a New Relic diagnostic setting. +Only resource types in [supported categories](/azure/azure-monitor/essentials/resource-logs-categories) send logs to New Relic through the integration. To check whether the resource is set up to send logs to New Relic, go to the [Azure diagnostic settings](/azure/azure-monitor/platform/diagnostic-settings) for that resource. Then, verify that there's a New Relic diagnostic setting. ## You can't install or uninstall an extension on a virtual machine |
| partner-solutions | Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/partner-solutions/split-experimentation/troubleshoot.md | -## Getting support --To log a support request about a Split Experimentation Workspace, send an email to <exp_preview@microsoft.com>. +> [!NOTE] +> To log an issue about a Split Experimentation Workspace resource in Azure App Configuration, [open a support ticket](https://azure.microsoft.com/support/create-ticket/). Support for this capability is managed by Microsoft. ## Known issues When creating metrics, creating experiments, or getting experiment results, data - Example error message: - An unknown error occurred. -- There is an unknown server error. [Contact support](#getting-support).+- There is an unknown server error. [Open a support ticket](https://azure.microsoft.com/support/create-ticket/). ## Related content |
| private-5g-core | Azure Private 5G Core Release Notes 2404 | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/private-5g-core/azure-private-5g-core-release-notes-2404.md | ISSU is supported for deployments on a 2-node cluster. Software upgrades can be This feature allows you to monitor the health of your control plane resource using Azure Resource Health. Azure Resource Health is a service that processes and displays health signals from your resource and displays the health in the Azure portal. This service gives you a personalized dashboard showing all the times your resource was unavailable or in a degraded state, along with recommended actions to take to restore health. -For more information, on using Azure Resource Health to monitor the health of your deployment, see [Resource Health overview](../service-health/resource-health-overview.md). +For more information, on using Azure Resource Health to monitor the health of your deployment, see [Resource Health overview](/azure/service-health/resource-health-overview). ### NAS Encryption |
| private-5g-core | Modify Packet Core | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/private-5g-core/modify-packet-core.md | In this step, you'll navigate to the **Packet Core Control Plane** resource repr - Select **Resource Health** under the **Help** section on the left side. - Check that the resource is healthy and there are no unexpected alerts. - If there are any unexpected alerts, follow the recommended steps listed to recover the system.- - To learn more about health and the status types that may appear, see [Resource Health overview](../service-health/resource-health-overview.md). + - To learn more about health and the status types that may appear, see [Resource Health overview](/azure/service-health/resource-health-overview). 1. Select **Modify packet core**. :::image type="content" source="media/modify-packet-core/modify-packet-core-configuration.png" alt-text="Screenshot of the Azure portal showing the Modify packet core option."::: This change requires a manual packet core reinstall to take effect. See [Next st - Check that the resource is healthy and there are no unexpected alerts. - If there are any unexpected alerts, follow the recommended steps listed to recover the system.- - To learn more about health and the status types that may appear, see [Resource Health overview](../service-health/resource-health-overview.md). + - To learn more about health and the status types that may appear, see [Resource Health overview](/azure/service-health/resource-health-overview). ## Remove data network resource |
| private-5g-core | Monitor Private 5G Core Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/private-5g-core/monitor-private-5g-core-alerts.md | Alerts help track important events in your network by sending a notification con :::image type="content" source="media/packet-core-alerts-signal-list.png" alt-text="Screenshot of Azure portal showing alert signal selection menu." lightbox="media/packet-core-alerts-signal-list.png"::: -1. Select the signal you want the alert to be based on and follow the rest of the create instructions. For more information on alert options and setting actions groups used for notification, please refer to [the Azure Monitor alerts create and edit documentation](../azure-monitor/alerts/alerts-create-new-alert-rule.md?tabs=metric). +1. Select the signal you want the alert to be based on and follow the rest of the create instructions. For more information on alert options and setting actions groups used for notification, please refer to [the Azure Monitor alerts create and edit documentation](/azure/azure-monitor/alerts/alerts-create-new-alert-rule?tabs=metric). 1. Once you've reached the end of the create instructions, select **Review + create** to create your alert. 1. Verify that your alert rule was created by navigating to the alerts page for your packet core (see steps 1 and 2) and finding it in the list of alert rules on the page. ## Next steps-- [Learn more about Azure Monitor alerts](../azure-monitor/alerts/alerts-overview.md).+- [Learn more about Azure Monitor alerts](/azure/azure-monitor/alerts/alerts-overview). |
| private-5g-core | Private 5G Core Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/private-5g-core/private-5g-core-overview.md | For more information on using Azure Monitor to analyze metrics in your deploymen Azure Private 5G Core is integrated with Azure Resource Health, which reports on the health of your control plane resources and allows you to diagnose and get support for service issues. -For more information on using Azure Resource Health to monitor the health of your deployment, see [Resource Health overview](../service-health/resource-health-overview.md). +For more information on using Azure Resource Health to monitor the health of your deployment, see [Resource Health overview](/azure/service-health/resource-health-overview). Azure Private 5G Core can be configured to integrate with Azure Monitor Event Hubs, allowing you to monitor UE usage. |
| private-5g-core | Reinstall Packet Core | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/private-5g-core/reinstall-packet-core.md | Reconfigure your deployment using the information you gathered in [Back up deplo - Check that the resource is healthy and there are no unexpected alerts. - If there are any unexpected alerts, follow the recommended steps listed to recover the system.- - To learn more about health and the status types that may appear, see [Resource Health overview](../service-health/resource-health-overview.md). + - To learn more about health and the status types that may appear, see [Resource Health overview](/azure/service-health/resource-health-overview). 1. Use [Azure Monitor platform metrics](monitor-private-5g-core-with-platform-metrics.md) or the [packet core dashboards](packet-core-dashboards.md) to confirm your packet core instance is operating normally after the reinstall. ## Next steps |
| private-5g-core | Upgrade Packet Core Arm Template | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/private-5g-core/upgrade-packet-core-arm-template.md | To use Azure Resource Health to confirm the packet core instance is healthy: 1. Select **Resource Health** under the **Help** section on the left side. 1. Check that the resource is healthy and there are no unexpected alerts. 1. If there are any unexpected alerts, follow the recommended steps listed to recover the system.-1. To learn more about health and the status types that may appear, see [Resource Health overview](../service-health/resource-health-overview.md). +1. To learn more about health and the status types that may appear, see [Resource Health overview](/azure/service-health/resource-health-overview). ## Upgrade the packet core instance |
| private-5g-core | Upgrade Packet Core Azure Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/private-5g-core/upgrade-packet-core-azure-portal.md | In addition, consider the following points for pre- and post-upgrade steps you m - Select **Resource Health** under the **Help** section on the left side. - Check that the resource is healthy and there are no unexpected alerts. - If there are any unexpected alerts, follow the recommended steps listed to recover the system.- - To learn more about health and the status types that may appear, see [Resource Health overview](../service-health/resource-health-overview.md). + - To learn more about health and the status types that may appear, see [Resource Health overview](/azure/service-health/resource-health-overview). 1. Use [Azure Monitor platform metrics](monitor-private-5g-core-with-platform-metrics.md) or the [packet core dashboards](packet-core-dashboards.md) to confirm your packet core instance is operating normally. ## Upgrade the packet core instance |
| private-5g-core | Whats New | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/private-5g-core/whats-new.md | ISSU is supported for deployments on a 2-node cluster. Software upgrades can be This feature allows you to monitor the health of your control plane resource using Azure Resource Health. Azure Resource Health is a service that processes and displays health signals from your resource and displays the health in the Azure portal. This service gives you a personalized dashboard showing all the times your resource was unavailable or in a degraded state, along with recommended actions to take to restore health. -For more information, on using Azure Resource Health to monitor the health of your deployment, see [Resource Health overview](../service-health/resource-health-overview.md). +For more information, on using Azure Resource Health to monitor the health of your deployment, see [Resource Health overview](/azure/service-health/resource-health-overview). ### NAS Encryption |
| private-link | Availability | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/private-link/availability.md | The following tables list the Private Link services and the regions where they'r |:-|:--|:-|:--| |Azure Synapse Analytics| All public regions <br/> All Government regions | Supported for Proxy [connection policy](/azure/azure-sql/database/connectivity-architecture#connection-policy) |GA <br/> [Learn how to create a private endpoint for Azure Synapse Analytics.](/azure/azure-sql/database/private-endpoint-overview)| |Azure Event Hubs | All public regions<br/>All Government regions | | GA <br/> [Learn how to create a private endpoint for Azure Event Hubs.](../event-hubs/private-link-service.md) |-| Azure Monitor <br/>(Log Analytics & Application Insights) | All public regions | | GA <br/> [Learn how to create a private endpoint for Azure Monitor.](../azure-monitor/logs/private-link-security.md) | +| Azure Monitor <br/>(Log Analytics & Application Insights) | All public regions | | GA <br/> [Learn how to create a private endpoint for Azure Monitor.](/azure/azure-monitor/logs/private-link-security) | |Azure Data Factory | All public regions<br/> All Government regions<br/>All China regions | Credentials need to be stored in an Azure key vault| GA <br/> [Learn how to create a private endpoint for Azure Data Factory.](../data-factory/data-factory-private-link.md) | |Azure HDInsight | All public regions<br/>All Government regions | | GA <br/> [Learn how to create a private endpoint for Azure HDInsight.](../hdinsight/hdinsight-private-link.md) | | Azure Data Explorer | All public regions | | GA </br> [Learn how to create a private endpoint for Azure Data Explorer.](/azure/data-explorer/security-network-private-endpoint) | |
| private-link | Troubleshoot Private Endpoint Connectivity | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/private-link/troubleshoot-private-endpoint-connectivity.md | Review these steps to make sure all the usual configurations are as expected to :::image type="content" source="./media/private-endpoint-tsg/vnet-dns-configuration.png" alt-text="Screenshot of virtual network and DNS configuration."::: -1. Use [Azure Monitor](../azure-monitor/overview.md) to see if data is flowing. +1. Use [Azure Monitor](/azure/azure-monitor/overview) to see if data is flowing. a. On the private endpoint resource, select **Metrics**. |
| private-link | Troubleshoot Private Link Connectivity | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/private-link/troubleshoot-private-link-connectivity.md | If you experience connectivity problems with your private link setup, review the - You can also review the load balancer metric through Azure Monitor to see if data is flowing through the load balancer. -1. Use [Azure Monitor](../azure-monitor/overview.md) to see if data is flowing. +1. Use [Azure Monitor](/azure/azure-monitor/overview) to see if data is flowing. a. On the private link service resource, select **Metrics**. |
| private-link | Tutorial Inspect Traffic Azure Firewall | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/private-link/tutorial-inspect-traffic-azure-firewall.md | If you don't have an Azure subscription, create a [free account](https://azure.m - An Azure account with an active subscription. -- A Log Analytics workspace. For more information about the creation of a log analytics workspace, see [Create a Log Analytics workspace in the Azure portal](../azure-monitor/logs/quick-create-workspace.md).+- A Log Analytics workspace. For more information about the creation of a log analytics workspace, see [Create a Log Analytics workspace in the Azure portal](/azure/azure-monitor/logs/quick-create-workspace). ## Sign in to the Azure portal |
| quotas | How To Guide Monitoring Alerting | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/quotas/how-to-guide-monitoring-alerting.md | You can create alerts for quotas and manage them. ### Prerequisites -Users must have the necessary [permissions to create alerts](../azure-monitor/alerts/alerts-overview.md#azure-role-based-access-control-for-alerts). +Users must have the necessary [permissions to create alerts](/azure/azure-monitor/alerts/alerts-overview#azure-role-based-access-control-for-alerts). The [managed identity](/entra/identity/managed-identities-azure-resources/how-manage-user-assigned-managed-identities?pivots=identity-mi-methods-azp) must have the **Reader** role (or another role that includes read access) on the subscription. The simplest way to create a quota alert is to use the Azure portal. Follow thes :::image type="content" source="media/monitoring-alerting/my-quotas-create-rule-navigation-inline.png" alt-text="Screenshot showing how to select Quotas to navigate to create Alert rule screen." lightbox="media/monitoring-alerting/my-quotas-create-rule-navigation-expanded.png"::: -1. When the **Create usage alert rule** page appears, populate the fields with data as shown in the table. Make sure you have the [permissions to create alerts](../azure-monitor/alerts/alerts-overview.md#azure-role-based-access-control-for-alerts). +1. When the **Create usage alert rule** page appears, populate the fields with data as shown in the table. Make sure you have the [permissions to create alerts](/azure/azure-monitor/alerts/alerts-overview#azure-role-based-access-control-for-alerts). :::image type="content" source="media/monitoring-alerting/quota-details-create-rule-inline.png" alt-text="Screenshot showing create Alert rule screen with required fields." lightbox="media/monitoring-alerting/quota-details-create-rule-expanded.png"::: The simplest way to create a quota alert is to use the Azure portal. Follow thes | Alert Rule Name | Alert rule name must be **distinct** and can't be duplicated, even across different resource groups | | Alert me when the usage % reaches | **Adjust** the slider to select your desired usage percentage for **triggering** alerts. For example, at the default 80%, you receive an alert when your quota reaches 80% capacity.| | Severity | Select the **severity** of the alert when the **ruleΓÇÖs condition** is met.|- | [Frequency of evaluation](../azure-monitor/alerts/alerts-overview.md#stateful-alerts) | Choose how **often** the alert rule should **run**, by selecting 5, 10, or 15 minutes. If the frequency is smaller than the aggregation granularity, frequency of evaluation results in sliding window evaluation. | + | [Frequency of evaluation](/azure/azure-monitor/alerts/alerts-overview#stateful-alerts) | Choose how **often** the alert rule should **run**, by selecting 5, 10, or 15 minutes. If the frequency is smaller than the aggregation granularity, frequency of evaluation results in sliding window evaluation. | | [Resource Group](../azure-resource-manager/management/manage-resource-groups-portal.md) | Resource Group is a collection of resources that share the same lifecycles, permissions, and policies. Select a resource group similar to other quotas in your subscription, or create a new resource group. | | [Managed identity](../active-directory/managed-identities-azure-resources/how-manage-user-assigned-managed-identities.md?pivots=identity-mi-methods-azp) | Select from the dropdown, or **Create New**. Managed Identity should have **read permissions** for the selected Subscription (to read Usage data from ARG). | | Notify me by | There are three notifications methods and you can check one or all three check boxes, depending on your notification preference. |- | [Use an existing action group](../azure-monitor/alerts/action-groups.md) | Check the box to use an existing action group. An action group **invokes** a defined set of **notifications** and actions when an alert is triggered. You can create Action Group to automatically Increase the Quota whenever possible. | - | [Dimensions](../azure-monitor/alerts/alerts-types.md#monitor-the-same-condition-on-multiple-resources-using-splitting-by-dimensions-1) | Here are the options for selecting **multiple Quotas** and **regions** within a single alert rule. Adding dimensions is a cost-effective approach compared to creating a new alert for each quota or region.| + | [Use an existing action group](/azure/azure-monitor/alerts/action-groups) | Check the box to use an existing action group. An action group **invokes** a defined set of **notifications** and actions when an alert is triggered. You can create Action Group to automatically Increase the Quota whenever possible. | + | [Dimensions](/azure/azure-monitor/alerts/alerts-types#monitor-the-same-condition-on-multiple-resources-using-splitting-by-dimensions-1) | Here are the options for selecting **multiple Quotas** and **regions** within a single alert rule. Adding dimensions is a cost-effective approach compared to creating a new alert for each quota or region.| > [!TIP] > Within the same subscription, we advise using the same **Resource Group** and **Managed identity** values for all alert rules. For a sample request body, see the [API documentation](/rest/api/monitor/schedul ### Create alerts using Azure Resource Graph query -You can use the **Azure Monitor Alerts** pane to [create alerts using a query](../azure-monitor/alerts/alerts-create-new-alert-rule.md?tabs=log). Resource Graph Explorer lets you run and test queries before using them to create an alert. To learn more, see the [Configure Azure alerts](/training/modules/configure-azure-alerts/) training module. +You can use the **Azure Monitor Alerts** pane to [create alerts using a query](/azure/azure-monitor/alerts/alerts-create-new-alert-rule?tabs=log). Resource Graph Explorer lets you run and test queries before using them to create an alert. To learn more, see the [Configure Azure alerts](/training/modules/configure-azure-alerts/) training module. -For quota alerts, make sure the **Scope** is your Subscription and the **Signal type** is the customer query log. Add a sample query for quota usages. Follow the remaining steps as described in the [Create or edit an alert rule](../azure-monitor/alerts/alerts-create-new-alert-rule.md?tabs=log). +For quota alerts, make sure the **Scope** is your Subscription and the **Signal type** is the customer query log. Add a sample query for quota usages. Follow the remaining steps as described in the [Create or edit an alert rule](/azure/azure-monitor/alerts/alerts-create-new-alert-rule?tabs=log). The following example shows a query that creates quota alerts. You can use functions to call the Quota API and request for more quota. Use `Tes ## Query using Resource Graph Explorer -Using [Azure Resource Graph](../governance/resource-graph/overview.md), alerts can be [managed programatically](../azure-monitor/alerts/alerts-manage-alert-instances.md#manage-your-alerts-programmatically). This allows you to query your alert instances and analyze your alerts to identify patterns and trends. +Using [Azure Resource Graph](../governance/resource-graph/overview.md), alerts can be [managed programatically](/azure/azure-monitor/alerts/alerts-manage-alert-instances#manage-your-alerts-programmatically). This allows you to query your alert instances and analyze your alerts to identify patterns and trends. The **QuotaResources** table in [Azure Resource Graph](../governance/resource-graph/overview.md) explorer provides usage and limit/quota data for a given resource, region, and/or subscription. You can also query usage and quota data across multiple subscriptions with Azure Resource Graph queries. |
| quotas | Monitoring Alerting | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/quotas/monitoring-alerting.md | Quota alerts in Azure are notifications triggered when the usage of a specific A For more information, see [Create alerts for quotas](how-to-guide-monitoring-alerting.md). > [!NOTE]-> [General Role based access control](../azure-monitor/alerts/alerts-overview.md#azure-role-based-access-control-for-alerts) applies while creating alerts. +> [General Role based access control](/azure/azure-monitor/alerts/alerts-overview#azure-role-based-access-control-for-alerts) applies while creating alerts. ## Next steps - Learn [how to create quota alerts](how-to-guide-monitoring-alerting.md).-- Learn more about [alerts](../azure-monitor/alerts/alerts-overview.md)+- Learn more about [alerts](/azure/azure-monitor/alerts/alerts-overview) - Learn about [Azure Resource Graph](../governance/resource-graph/overview.md) |
| reliability | Availability Zones Service Support | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/reliability/availability-zones-service-support.md | Azure offerings are grouped into three categories that reflect their _regional_ | [Azure IoT Hub](../iot-hub/iot-hub-ha-dr.md) |  | | [Azure Kubernetes Service (AKS)](/azure/aks/availability-zones) |   | | [Azure Logic Apps](../logic-apps/logic-apps-overview.md) |  |-| [Azure Monitor](../azure-monitor/logs/availability-zones.md) |  | -| [Azure Monitor: Application Insights](../azure-monitor/logs/availability-zones.md) |  | +| [Azure Monitor](/azure/azure-monitor/logs/availability-zones) |  | +| [Azure Monitor: Application Insights](/azure/azure-monitor/logs/availability-zones) |  | | [Azure Monitor: Log Analytics](./migrate-monitor-log-analytics.md) |  | | [Azure NAT Gateway](../nat-gateway/nat-availability-zones.md) |  | | [Azure Network Watcher](../network-watcher/frequently-asked-questions.yml) |  | |
| reliability | Migrate Monitor Log Analytics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/reliability/migrate-monitor-log-analytics.md | There are no downtime requirements. ### Step 1: Determine the current cluster for your workspace -To determine the current workspace link status for your workspace, use [CLI, PowerShell, or REST](../azure-monitor/logs/logs-dedicated-clusters.md#check-workspace-link-status) to retrieve the [cluster details](../azure-monitor/logs/logs-dedicated-clusters.md#check-cluster-provisioning-status). If the cluster uses an availability zone, then it has a property called `isAvailabilityZonesEnabled` with a value of `true`. Once a cluster is created, this property cannot be altered. +To determine the current workspace link status for your workspace, use [CLI, PowerShell, or REST](/azure/azure-monitor/logs/logs-dedicated-clusters#check-workspace-link-status) to retrieve the [cluster details](/azure/azure-monitor/logs/logs-dedicated-clusters#check-cluster-provisioning-status). If the cluster uses an availability zone, then it has a property called `isAvailabilityZonesEnabled` with a value of `true`. Once a cluster is created, this property cannot be altered. ### Step 2: Create a dedicated cluster with availability zone support -Move your workspace to an availability zone by [creating a new dedicated cluster](../azure-monitor/logs/logs-dedicated-clusters.md#create-a-dedicated-cluster) in a region that supports availability zones. The cluster is automatically enabled for availability zones. Then [link your workspace to the new cluster](../azure-monitor/logs/logs-dedicated-clusters.md#link-a-workspace-to-a-cluster). +Move your workspace to an availability zone by [creating a new dedicated cluster](/azure/azure-monitor/logs/logs-dedicated-clusters#create-a-dedicated-cluster) in a region that supports availability zones. The cluster is automatically enabled for availability zones. Then [link your workspace to the new cluster](/azure/azure-monitor/logs/logs-dedicated-clusters#link-a-workspace-to-a-cluster). > [!IMPORTANT] > Availability zone is defined on the cluster at creation time and canΓÇÖt be modified. Transitioning to a new cluster can be a gradual process. Don't remove the previo Any queries against your workspace queries both clusters as required to provide you with a single, unified result set. As a result, all Azure Monitor features that rely on the workspace, such as workbooks and dashboards, continue to receive the full, unified result set based on data from both clusters. ## Billing-[Dedicated clusters](../azure-monitor/logs/logs-dedicated-clusters.md#create-a-dedicated-cluster) require a commitment tier starting at 100 GB per day. +[Dedicated clusters](/azure/azure-monitor/logs/logs-dedicated-clusters#create-a-dedicated-cluster) require a commitment tier starting at 100 GB per day. The new cluster isnΓÇÖt billed during its first day to avoid double billing during configuration. Only the data ingested before the migration completes would still be billed on the date of migration. Learn more about: - [Relocate Log Analytics workspaces to another region](../operational-excellence/relocation-log-analytics.md) -- [Azure Monitor Logs Dedicated Clusters](../azure-monitor/logs/logs-dedicated-clusters.md)+- [Azure Monitor Logs Dedicated Clusters](/azure/azure-monitor/logs/logs-dedicated-clusters) - [Azure Services that support Availability Zones](availability-zones-service-support.md) |
| reliability | Overview Reliability Guidance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/reliability/overview-reliability-guidance.md | For a more detailed overview of reliability principles in Azure, see [Reliabilit |Azure Logic Apps|[Protect logic apps from region failures with zone redundancy and availability zones](../logic-apps/set-up-zone-redundancy-availability-zones.md?toc=/azure/reliability/toc.json&bc=/azure/reliability/breadcrumb/toc.json)| [Business continuity and disaster recovery for Azure Logic Apps](../logic-apps/business-continuity-disaster-recovery-guidance.md?toc=/azure/reliability/toc.json&bc=/azure/reliability/breadcrumb/toc.json) | |Azure Media Services||[High Availability with Media Services and Video on Demand (VOD)](/azure/media-services/latest/architecture-high-availability-encoding-concept) | |Azure Migrate|| [Does Azure Migrate offer Backup and Disaster Recovery?](../migrate/resources-faq.md?toc=/azure/reliability/toc.json&bc=/azure/reliability/breadcrumb/toc.json#does-azure-migrate-offer-backup-and-disaster-recovery) |-|Azure Monitor-Log Analytics |[Enhance data and service resilience in Azure Monitor Logs with availability zones](../azure-monitor/logs/availability-zones.md?toc=/azure/reliability/toc.json&bc=/azure/reliability/breadcrumb/toc.json?toc=/azure/reliability/toc.json&bc=/azure/reliability/breadcrumb/toc.json)| [Enable data export](../azure-monitor/logs/logs-data-export.md?toc=/azure/reliability/toc.json&bc=/azure/reliability/breadcrumb/toc.json#enable-data-export) | +|Azure Monitor-Log Analytics |[Enhance data and service resilience in Azure Monitor Logs with availability zones](/azure/azure-monitor/logs/availability-zones?toc=/azure/reliability/toc.json&bc=/azure/reliability/breadcrumb/toc.json?toc=/azure/reliability/toc.json&bc=/azure/reliability/breadcrumb/toc.json)| [Enable data export](/azure/azure-monitor/logs/logs-data-export?toc=/azure/reliability/toc.json&bc=/azure/reliability/breadcrumb/toc.json#enable-data-export) | |Azure Network Watcher|[Service availability and redundancy](../network-watcher/frequently-asked-questions.yml?bc=%2fazure%2freliability%2fbreadcrumb%2ftoc.json&toc=%2fazure%2freliability%2ftoc.json#service-availability-and-redundancy)|| |Azure Notification Hubs|[Reliability Azure Notification Hubs](reliability-notification-hubs.md)|[Reliability Azure Notification Hubs](reliability-notification-hubs.md)| |Azure Operator Nexus|[Reliability in Azure Operator Nexus](reliability-operator-nexus.md)|[Reliability in Azure Operator Nexus](reliability-operator-nexus.md)| |
| reliability | Reliability App Service | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/reliability/reliability-app-service.md | To prepare for availability zone failure, you should over-provision capacity of ### Zone down experience -Traffic is routed to all of your available App Service instances. In the case when a zone goes down, the App Service platform will detect lost instances and automatically attempt to find new replacement instances and spread traffic as needed. If you have [autoscale](../app-service/manage-scale-up.md) configured, and if it decides more instances are needed, autoscale will also issue a request to App Service to add more instances. Note that [autoscale behavior is independent of App Service platform behavior](../azure-monitor/autoscale/autoscale-overview.md) and that your autoscale instance count specification doesn't need to be a multiple of three. +Traffic is routed to all of your available App Service instances. In the case when a zone goes down, the App Service platform will detect lost instances and automatically attempt to find new replacement instances and spread traffic as needed. If you have [autoscale](../app-service/manage-scale-up.md) configured, and if it decides more instances are needed, autoscale will also issue a request to App Service to add more instances. Note that [autoscale behavior is independent of App Service platform behavior](/azure/azure-monitor/autoscale/autoscale-overview) and that your autoscale instance count specification doesn't need to be a multiple of three. >[!NOTE] >There's no guarantee that requests for additional instances in a zone-down scenario will succeed. The back filling of lost instances occurs on a best-effort basis. The recommended solution is to create and configure your App Service plans to account for losing a zone as described in the next section. To avoid the limitations of backup and restore methods, configure your CI/CD pip #### Outage detection, notification, and management -- It's recommended that you set up monitoring and alerts for your web apps to for timely notifications during a disaster. For more information, see [Application Insights availability tests](../azure-monitor/app/availability-overview.md).+- It's recommended that you set up monitoring and alerts for your web apps to for timely notifications during a disaster. For more information, see [Application Insights availability tests](/azure/azure-monitor/app/availability-overview). - To manage your application resources in Azure, use an infrastructure-as-Code (IaC) mechanism. In a complex deployment across multiple regions, to manage the regions independently and to keep the configuration synchronized across regions in a reliable manner requires a predictable, testable, and repeatable process. Consider an IaC tool such as [Azure Resource Manager templates](../azure-resource-manager/management/overview.md) or [Terraform](/azure/developer/terraform/overview). |
| reliability | Reliability Functions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/reliability/reliability-functions.md | Title: Reliability in Azure Functions -description: Find out about reliability in Azure Functions +description: Find out about reliability support in Azure Functions, including intra-regional resiliency and cross-region recovery and business continuity. Previously updated : 11/14/2023 Last updated : 09/10/2024 #Customer intent: I want to understand reliability support in Azure Functions so that I can respond to and/or avoid failures in order to minimize downtime and data loss. Last updated 11/14/2023 This article describes reliability support in [Azure Functions](../azure-functions/functions-overview.md), and covers both intra-regional resiliency with [availability zones](#availability-zone-support) and [cross-region recovery and business continuity](#cross-region-disaster-recovery-and-business-continuity). For a more detailed overview of reliability principles in Azure, see [Azure reliability](/azure/architecture/framework/resiliency/overview). -Availability zone support for Azure Functions is available on both Premium (Elastic Premium) and Dedicated (App Service) plans. This article focuses on zone redundancy support for Premium plans. For zone redundancy on Dedicated plans, see [Migrate App Service to availability zone support](migrate-app-service.md). +Availability zone support for Azure Functions is available on both Premium (Elastic Premium) and Dedicated (App Service) plans. This article focuses on zone redundancy support for Premium plans. For zone redundancy on Dedicated plans, see [Migrate App Service to availability zone support](migrate-app-service.md). ## Availability zone support There are currently two ways to deploy a zone-redundant Premium plan and functio # [Azure portal](#tab/azure-portal) -1. Open the Azure portal and navigate to the **Create Function App** page. Information on creating a function app in the portal can be found [here](../azure-functions/functions-create-function-app-portal.md#create-a-function-app). +1. In the Azure portal, go to the **Create Function App** page. For more information about creating a function app in the portal, see [Create a function app](../azure-functions/functions-create-function-app-portal.md#create-a-function-app). -1. In the **Basics** page, fill out the fields for your function app. Pay special attention to the fields in the table below (also highlighted in the screenshot below), which have specific requirements for zone redundancy. +1. Select **Functions Premium** and then select the **Select** button. This article describes how to create a zone redundant app in a Premium plan. Zone redundancy isn't currently available in Consumption plans. For information on zone redundancy on app service plans, see [Reliability in Azure App Service](../reliability/migrate-app-service.md). - | Setting | Suggested value | Notes for Zone Redundancy | - | | - | -- | - | **Region** | Preferred region | The subscription under which this new function app is created. You must pick a region that is availability zone enabled from the [list above](#prerequisites). | --  +1. On the **Create Function App (Functions Premium)** page, on the **Basics** tab, enter the settings for your function app. Pay special attention to the settings in the following table (also highlighted in the following screenshot), which have specific requirements for zone redundancy. -1. In the **Hosting** page, fill out the fields for your function app hosting plan. Pay special attention to the fields in the table below (also highlighted in the screenshot below), which have specific requirements for zone redundancy. -- | Setting | Suggested value | Notes for Zone Redundancy | + | Setting | Suggested value | Notes for zone redundancy | | | - | -- |- | **Storage Account** | A [zone-redundant storage account](../azure-functions/storage-considerations.md#storage-account-requirements) | As mentioned above in the [prerequisites](#prerequisites) section, we strongly recommend using a zone-redundant storage account for your zone redundant function app. | - | **Plan Type** | Functions Premium | This article details how to create a zone redundant app in a Premium plan. Zone redundancy isn't currently available in Consumption plans. Information on zone redundancy on app service plans can be found [in this article](../reliability/migrate-app-service.md). | - | **Zone Redundancy** | Enabled | This field populates the flag that determines if your app is zone redundant or not. You won't be able to select `Enabled` unless you have chosen a region supporting zone redundancy, as mentioned in step 2. | + | **Region** | Your preferred supported region | The region under which the new function app is created. You must pick a region that supports availability zones. See the [region availability list](#regional-availability). | + | **Pricing plan** | One of the Elastic Premium plans. For more information, see [Available instance SKUs](../azure-functions/functions-premium-plan.md#available-instance-skus). | This article describes how to create a zone redundant app in a Premium plan. Zone redundancy isn't currently available in Consumption plans. For information on zone redundancy on App Service plans, see [Reliability in Azure App Service](../reliability/migrate-app-service.md). | + | **Zone redundancy** | Enabled | This setting specifies whether your app is zone redundant. You won't be able to select `Enabled` unless you have chosen a region that supports zone redundancy, as described previously. | + + :::image type="content" source="../azure-functions/media/functions-az-redundancy\azure-functions-basics-az.png" alt-text="Screenshot of the Basics tab of the function app create page."::: + -  +1. On the **Storage** tab, enter the settings for your function app storage account. Pay special attention to the setting in the following table, which has specific requirements for zone redundancy. -1. For the rest of the function app creation process, create your function app as normal. There are no fields in the rest of the creation process that affect zone redundancy. + | Setting | Suggested value | Notes for zone redundancy | + | | - | -- | + | **Storage account** | A [zone-redundant storage account](../azure-functions/storage-considerations.md#storage-account-requirements) | As described in the [prerequisites](#prerequisites) section, we strongly recommend using a zone-redundant storage account for your zone-redundant function app. | + +1. For the rest of the function app creation process, create your function app as normal. There are no settings in the rest of the creation process that affect zone redundancy. # [ARM template](#tab/arm-template) You can use an [ARM template](../azure-resource-manager/templates/quickstart-create-templates-use-visual-studio-code.md) to deploy to a zone-redundant Premium plan. To learn how to deploy function apps to a Premium plan, see [Automate resource deployment in Azure Functions](../azure-functions/functions-infrastructure-as-code.md?pivots=premium-plan). -The only properties to be aware of while creating a zone-redundant hosting plan are the new `zoneRedundant` property and the plan's instance count (`capacity`) fields. The `zoneRedundant` property must be set to `true` and the `capacity` property should be set based on the workload requirement, but not less than `3`. Choosing the right capacity varies based on several factors and high availability/fault tolerance strategies. A good rule of thumb is to ensure sufficient instances for the application such that losing one zone of instances leaves sufficient capacity to handle expected load. +The only properties to be aware of while creating a zone-redundant hosting plan are the `zoneRedundant` property and the plan's instance count (`capacity`) fields. The `zoneRedundant` property must be set to `true` and the `capacity` property should be set based on the workload requirement, but not less than `3`. Choosing the right capacity varies based on several factors and high availability / fault tolerance strategies. A good rule of thumb is to specify sufficient instances for the application to ensure that losing one zone instance leaves sufficient capacity to handle expected load. > [!IMPORTANT]-> Azure Functions apps hosted on an elastic premium, zone-redundant plan must have a minimum [always ready instance](../azure-functions/functions-premium-plan.md#always-ready-instances) count of 3. This make sure that a zone-redundant function app always has enough instances to satisfy at least one worker per zone. +> Azure Functions apps hosted on an Elastic Premium, zone-redundant plan must have a minimum [always ready instance](../azure-functions/functions-premium-plan.md#always-ready-instances) count of 3. This minimum ensures that a zone-redundant function app always has enough instances to satisfy at least one worker per zone. -Below is an ARM template snippet for a zone-redundant, Premium plan showing the `zoneRedundant` field and the `capacity` specification. +Following is an ARM template snippet for a zone-redundant, Premium plan. It shows the `zoneRedundant` field and the `capacity` specification. ```json "resources": [ For disaster recovery for Durable Functions, see [Disaster recovery and geo-dist ### Multi-region disaster recovery -Because there is no built-in redundancy available, functions run in a function app in a specific Azure region. To avoid loss of execution during outages, you can redundantly deploy the same functions to function apps in multiple regions. To learn more about multi-region deployments, see the guidance in [Highly available multi-region web application](/azure/architecture/reference-architectures/app-service-web-app/multi-region). +Because there is no built-in redundancy available, functions run in a function app in a specific Azure region. To avoid loss of execution during outages, you can redundantly deploy the same functions to function apps in multiple regions. To learn more about multi-region deployments, see the guidance in [Highly available multi-region web application](/azure/architecture/reference-architectures/app-service-web-app/multi-region). When you run the same function code in multiple regions, there are two patterns to consider, [active-active](#active-active-pattern-for-http-trigger-functions) and [active-passive](#active-passive-pattern-for-non-https-trigger-functions). Consider an example topology using an Azure Event Hubs trigger. In this case, th  -Before failover, publishers sending to the shared alias route to the primary event hub. The primary function app is listening exclusively to the primary event hub. The secondary function app is passive and idle. As soon as failover is initiated, publishers sending to the shared alias are routed to the secondary event hub. The secondary function app now becomes active and starts triggering automatically. Effective failover to a secondary region can be driven entirely from the event hub, with the functions becoming active only when the respective event hub is active. +Before failover, publishers sending to the shared alias route to the primary event hub. The primary function app is listening exclusively to the primary event hub. The secondary function app is passive and idle. As soon as failover is initiated, publishers sending to the shared alias are routed to the secondary event hub. The secondary function app now becomes active and starts triggering automatically. Effective failover to a secondary region can be driven entirely from the event hub, with the functions becoming active only when the respective event hub is active. Read more on information and considerations for failover with [Service Bus](../service-bus-messaging/service-bus-geo-dr.md) and [Event Hubs](../event-hubs/event-hubs-geo-dr.md). |
| reliability | Reliability Hdinsight On Aks | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/reliability/reliability-hdinsight-on-aks.md | Azure HDInsight on AKS currently doesn't support cross-region failover. Improvin - Use Azure monitoring tools on HDInsight on AKS to detect abnormal behavior in the cluster and set corresponding alert notifications. You can enable Log Analytics in various ways and use managed Prometheus service with Azure Grafana dashboards for monitoring. For more information, see [Azure Monitor integration](../hdinsight-aks/concept-azure-monitor-integration.md). -- Subscribe to Azure health alerts to be notified about service issues, planned maintenance, health and security advisories for a subscription, service, or region. Health notifications that include the issue cause and resolute ETA help you to better execute failover and failbacks. For more information, see [Manage service health](../hdinsight-aks/service-health.md) and [Azure Service Health documentation](../service-health/index.yml).+- Subscribe to Azure health alerts to be notified about service issues, planned maintenance, health and security advisories for a subscription, service, or region. Health notifications that include the issue cause and resolute ETA help you to better execute failover and failbacks. For more information, see [Manage service health](../hdinsight-aks/service-health.md) and [Azure Service Health documentation](/azure/service-health/). ### Single-region disaster recovery |
| reliability | Reliability Hdinsight | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/reliability/reliability-hdinsight.md | When you create your multi region disaster recovery plan, consider the following - Use Azure monitoring tools on HDInsight to detect abnormal behavior in the cluster and set corresponding alert notifications. You can deploy the pre-configured HDInsight cluster-specific management solutions that collect important performance metrics of the specific cluster type. For more information, see [Azure Monitoring for HDInsight](../hdinsight/hdinsight-hadoop-oms-log-analytics-tutorial.md). -- Subscribe to Azure health alerts to be notified about service issues, planned maintenance, health and security advisories for a subscription, service, or region. Health notifications that include the issue cause and resolute ETA help you to better execute failover and failbacks. For more information, see [Azure Service Health documentation](../service-health/index.yml).+- Subscribe to Azure health alerts to be notified about service issues, planned maintenance, health and security advisories for a subscription, service, or region. Health notifications that include the issue cause and resolute ETA help you to better execute failover and failbacks. For more information, see [Azure Service Health documentation](/azure/service-health/). ### Disaster recovery in single-region geography |
| reliability | Reliability Virtual Machine Scale Sets | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/reliability/reliability-virtual-machine-scale-sets.md | For more information on how to use scale sets appropriately, see [When to use Vi #### :::image type="icon" source="../reliability/media/icon-recommendation-high.svg"::: **Configure Virtual Machine Scale Sets Autoscale to Automatic** -[Autoscale is a built-in feature of Azure Monitor](../azure-monitor/autoscale/autoscale-overview.md) that helps the performance and cost-effectiveness of your resources by adding and removing scale set VMs based on demand. In addition, you can choose to scale your resources manually to a specific instance count or in accordance with metrics thresholds. You can also schedule instance counts that scale during designated time windows. +[Autoscale is a built-in feature of Azure Monitor](/azure/azure-monitor/autoscale/autoscale-overview) that helps the performance and cost-effectiveness of your resources by adding and removing scale set VMs based on demand. In addition, you can choose to scale your resources manually to a specific instance count or in accordance with metrics thresholds. You can also schedule instance counts that scale during designated time windows. To learn how to enable automatic OS image upgrades, see [Azure Virtual Machine Scale Set automatic OS image upgrades](/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-automatic-upgrade). |
| remote-rendering | Commercial Ready | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/remote-rendering/tutorials/unity/commercial-ready/commercial-ready.md | Azure Application Insights helps you understand how people use your Azure Remote For more information, visit: -* [Usage Analysis with Application Insights](../../../../azure-monitor/app/usage.md) +* [Usage Analysis with Application Insights](/azure/azure-monitor/app/usage) ## Fast startup time strategies |
| role-based-access-control | Built In Roles | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/role-based-access-control/built-in-roles.md | The following table provides a brief description of each built-in role. Click th > | <a name='azure-service-bus-data-receiver'></a>[Azure Service Bus Data Receiver](./built-in-roles/integration.md#azure-service-bus-data-receiver) | Allows for receive access to Azure Service Bus resources. | 4f6d3b9b-027b-4f4c-9142-0e5a2a2247e0 | > | <a name='azure-service-bus-data-sender'></a>[Azure Service Bus Data Sender](./built-in-roles/integration.md#azure-service-bus-data-sender) | Allows for send access to Azure Service Bus resources. | 69a216fc-b8fb-44d8-bc22-1f3c2cd27a39 | > | <a name='biztalk-contributor'></a>[BizTalk Contributor](./built-in-roles/integration.md#biztalk-contributor) | Lets you manage BizTalk services, but not access to them. | 5e3c6656-6cfa-4708-81fe-0de47ac73342 |+> | <a name='deid-batch-data-owner'></a>[DeID Batch Data Owner](./built-in-roles/integration.md#deid-batch-data-owner) | Create and manage DeID batch jobs. This role is in preview and subject to change. | 8a90fa6b-6997-4a07-8a95-30633a7c97b9 | +> | <a name='deid-batch-data-reader'></a>[DeID Batch Data Reader](./built-in-roles/integration.md#deid-batch-data-reader) | Read DeID batch jobs. This role is in preview and subject to change. | b73a14ee-91f5-41b7-bd81-920e12466be9 | +> | <a name='deid-data-owner'></a>[DeID Data Owner](./built-in-roles/integration.md#deid-data-owner) | Full access to DeID data. This role is in preview and subject to change | 78e4b983-1a0b-472e-8b7d-8d770f7c5890 | +> | <a name='deid-realtime-data-user'></a>[DeID Realtime Data User](./built-in-roles/integration.md#deid-realtime-data-user) | Execute requests against DeID realtime endpoint. This role is in preview and subject to change. | bb6577c4-ea0a-40b2-8962-ea18cb8ecd4e | > | <a name='eventgrid-contributor'></a>[EventGrid Contributor](./built-in-roles/integration.md#eventgrid-contributor) | Lets you manage EventGrid operations. | 1e241071-0855-49ea-94dc-649edcd759de | > | <a name='eventgrid-data-sender'></a>[EventGrid Data Sender](./built-in-roles/integration.md#eventgrid-data-sender) | Allows send access to event grid events. | d5a91429-5739-47e2-a06b-3470a27159e7 | > | <a name='eventgrid-eventsubscription-contributor'></a>[EventGrid EventSubscription Contributor](./built-in-roles/integration.md#eventgrid-eventsubscription-contributor) | Lets you manage EventGrid event subscription operations. | 428e0ff0-5e57-4d9c-a221-2c70d0e0a443 | |
| role-based-access-control | Integration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/role-based-access-control/built-in-roles/integration.md | Lets you manage BizTalk services, but not access to them. } ``` +## DeID Batch Data Owner ++Create and manage DeID batch jobs. This role is in preview and subject to change. ++[Learn more](/azure/healthcare-apis/deidentification/manage-access-rbac) ++> [!div class="mx-tableFixed"] +> | Actions | Description | +> | | | +> | *none* | | +> | **NotActions** | | +> | *none* | | +> | **DataActions** | | +> | [Microsoft.HealthDataAIServices](../permissions/integration.md#microsofthealthdataaiservices)/DeidServices/Batch/write | Creates batches | +> | [Microsoft.HealthDataAIServices](../permissions/integration.md#microsofthealthdataaiservices)/DeidServices/Batch/delete | Deletes a batch | +> | [Microsoft.HealthDataAIServices](../permissions/integration.md#microsofthealthdataaiservices)/DeidServices/Batch/read | Reads a batch | +> | **NotDataActions** | | +> | *none* | | ++```json +{ + "assignableScopes": [ + "/" + ], + "description": "Create and manage DeID batch jobs. This role is in preview and subject to change.", + "id": "/providers/Microsoft.Authorization/roleDefinitions/8a90fa6b-6997-4a07-8a95-30633a7c97b9", + "name": "8a90fa6b-6997-4a07-8a95-30633a7c97b9", + "permissions": [ + { + "actions": [], + "notActions": [], + "dataActions": [ + "Microsoft.HealthDataAIServices/DeidServices/Batch/write", + "Microsoft.HealthDataAIServices/DeidServices/Batch/delete", + "Microsoft.HealthDataAIServices/DeidServices/Batch/read" + ], + "notDataActions": [] + } + ], + "roleName": "DeID Batch Data Owner", + "roleType": "BuiltInRole", + "type": "Microsoft.Authorization/roleDefinitions" +} +``` ++## DeID Batch Data Reader ++Read DeID batch jobs. This role is in preview and subject to change. ++[Learn more](/azure/healthcare-apis/deidentification/manage-access-rbac) ++> [!div class="mx-tableFixed"] +> | Actions | Description | +> | | | +> | *none* | | +> | **NotActions** | | +> | *none* | | +> | **DataActions** | | +> | [Microsoft.HealthDataAIServices](../permissions/integration.md#microsofthealthdataaiservices)/DeidServices/Batch/read | Reads a batch | +> | **NotDataActions** | | +> | [Microsoft.HealthDataAIServices](../permissions/integration.md#microsofthealthdataaiservices)/DeidServices/Batch/write | Creates batches | +> | [Microsoft.HealthDataAIServices](../permissions/integration.md#microsofthealthdataaiservices)/DeidServices/Batch/delete | Deletes a batch | ++```json +{ + "assignableScopes": [ + "/" + ], + "description": "Read DeID batch jobs. This role is in preview and subject to change.", + "id": "/providers/Microsoft.Authorization/roleDefinitions/b73a14ee-91f5-41b7-bd81-920e12466be9", + "name": "b73a14ee-91f5-41b7-bd81-920e12466be9", + "permissions": [ + { + "actions": [], + "notActions": [], + "dataActions": [ + "Microsoft.HealthDataAIServices/DeidServices/Batch/read" + ], + "notDataActions": [ + "Microsoft.HealthDataAIServices/DeidServices/Batch/write", + "Microsoft.HealthDataAIServices/DeidServices/Batch/delete" + ] + } + ], + "roleName": "DeID Batch Data Reader", + "roleType": "BuiltInRole", + "type": "Microsoft.Authorization/roleDefinitions" +} +``` ++## DeID Data Owner ++Full access to DeID data. This role is in preview and subject to change ++[Learn more](/azure/healthcare-apis/deidentification/manage-access-rbac) ++> [!div class="mx-tableFixed"] +> | Actions | Description | +> | | | +> | *none* | | +> | **NotActions** | | +> | *none* | | +> | **DataActions** | | +> | [Microsoft.HealthDataAIServices](../permissions/integration.md#microsofthealthdataaiservices)/DeidServices/* | | +> | **NotDataActions** | | +> | *none* | | ++```json +{ + "assignableScopes": [ + "/" + ], + "description": "Full access to DeID data. This role is in preview and subject to change", + "id": "/providers/Microsoft.Authorization/roleDefinitions/78e4b983-1a0b-472e-8b7d-8d770f7c5890", + "name": "78e4b983-1a0b-472e-8b7d-8d770f7c5890", + "permissions": [ + { + "actions": [], + "notActions": [], + "dataActions": [ + "Microsoft.HealthDataAIServices/DeidServices/*" + ], + "notDataActions": [] + } + ], + "roleName": "DeID Data Owner", + "roleType": "BuiltInRole", + "type": "Microsoft.Authorization/roleDefinitions" +} +``` ++## DeID Realtime Data User ++Execute requests against DeID realtime endpoint. This role is in preview and subject to change. ++[Learn more](/azure/healthcare-apis/deidentification/manage-access-rbac) ++> [!div class="mx-tableFixed"] +> | Actions | Description | +> | | | +> | *none* | | +> | **NotActions** | | +> | *none* | | +> | **DataActions** | | +> | [Microsoft.HealthDataAIServices](../permissions/integration.md#microsofthealthdataaiservices)/DeidServices/Realtime/action | Allows access to the realtime endpoint | +> | **NotDataActions** | | +> | *none* | | ++```json +{ + "assignableScopes": [ + "/" + ], + "description": "Execute requests against DeID realtime endpoint. This role is in preview and subject to change.", + "id": "/providers/Microsoft.Authorization/roleDefinitions/bb6577c4-ea0a-40b2-8962-ea18cb8ecd4e", + "name": "bb6577c4-ea0a-40b2-8962-ea18cb8ecd4e", + "permissions": [ + { + "actions": [], + "notActions": [], + "dataActions": [ + "Microsoft.HealthDataAIServices/DeidServices/Realtime/action" + ], + "notDataActions": [] + } + ], + "roleName": "DeID Realtime Data User", + "roleType": "BuiltInRole", + "type": "Microsoft.Authorization/roleDefinitions" +} +``` + ## EventGrid Contributor Lets you manage EventGrid operations. |
| role-based-access-control | Change History Report | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/role-based-access-control/change-history-report.md | ms.devlang: azurecli # View activity logs for Azure RBAC changes -Sometimes you need information about Azure role-based access control (Azure RBAC) changes, such as for auditing or troubleshooting purposes. Anytime someone makes changes to role assignments or role definitions within your subscriptions, the changes get logged in [Azure Activity Log](../azure-monitor/essentials/platform-logs-overview.md). You can view the activity logs to see all the Azure RBAC changes for the past 90 days. +Sometimes you need information about Azure role-based access control (Azure RBAC) changes, such as for auditing or troubleshooting purposes. Anytime someone makes changes to role assignments or role definitions within your subscriptions, the changes get logged in [Azure Activity Log](/azure/azure-monitor/essentials/platform-logs-overview). You can view the activity logs to see all the Azure RBAC changes for the past 90 days. ## Operations that are logged The activity log in the portal has several filters. Here are the Azure RBAC-rela | Event category | <ul><li>Administrative</li></ul> | | Operation | <ul><li>Create role assignment</li><li>Delete role assignment</li><li>Create or update custom role definition</li><li>Delete custom role definition</li></ul> | -For more information about activity logs, see [Azure Activity log](../azure-monitor/essentials/activity-log.md). +For more information about activity logs, see [Azure Activity log](/azure/azure-monitor/essentials/activity-log). ## Interpret a log entry The following shows an example of the filtered log output when creating a role a ## Azure Monitor logs -[Azure Monitor logs](../azure-monitor/logs/log-query-overview.md) is another tool you can use to collect and analyze Azure RBAC changes for all your Azure resources. Azure Monitor logs has the following benefits: +[Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview) is another tool you can use to collect and analyze Azure RBAC changes for all your Azure resources. Azure Monitor logs has the following benefits: - Write complex queries and logic - Integrate with alerts, Power BI, and other tools The following shows an example of the filtered log output when creating a role a Here are the basic steps to get started: -1. [Create a Log Analytics workspace](../azure-monitor/logs/quick-create-workspace.md). +1. [Create a Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace). -1. [Configure the Activity](../azure-monitor/essentials/activity-log.md) for your workspace. +1. [Configure the Activity](/azure/azure-monitor/essentials/activity-log) for your workspace. -1. [View the activity logs Insights](../azure-monitor/essentials/activity-log.md). A quick way to navigate to the Activity Log Overview page is to click the **Logs** option. +1. [View the activity logs Insights](/azure/azure-monitor/essentials/activity-log). A quick way to navigate to the Activity Log Overview page is to click the **Logs** option.  -1. Optionally use the [Azure Monitor Log Analytics](../azure-monitor/logs/log-analytics-tutorial.md) to query and view the logs. For more information, see [Get started with log queries in Azure Monitor](../azure-monitor/logs/get-started-queries.md). +1. Optionally use the [Azure Monitor Log Analytics](/azure/azure-monitor/logs/log-analytics-tutorial) to query and view the logs. For more information, see [Get started with log queries in Azure Monitor](/azure/azure-monitor/logs/get-started-queries). Here's a query that returns new role assignments organized by target resource provider: AzureActivity ## Next steps * [Alert on privileged Azure role assignments](role-assignments-alert.md)-* [View activity logs to monitor actions on resources](../azure-monitor/essentials/activity-log.md) -* [Monitor subscription activity with the Azure Activity log](../azure-monitor/essentials/platform-logs-overview.md) +* [View activity logs to monitor actions on resources](/azure/azure-monitor/essentials/activity-log) +* [Monitor subscription activity with the Azure Activity log](/azure/azure-monitor/essentials/platform-logs-overview) |
| role-based-access-control | Integration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/role-based-access-control/permissions/integration.md | Azure service: [Azure API for FHIR](/azure/healthcare-apis/azure-api-for-fhir/) > | Microsoft.HealthcareApis/workspaces/fhirservices/resources/editProfileDefinitions/action | Allows user to perform Create Update Delete operations on profile resources. | > | Microsoft.HealthcareApis/workspaces/fhirservices/resources/searchParameter/action | Allows running of $status operation for Search Parameters | +## Microsoft.HealthDataAIServices ++Azure service: [Azure Health Data Services](/azure/healthcare-apis/healthcare-apis-overview) ++> [!div class="mx-tableFixed"] +> | Action | Description | +> | | | +> | Microsoft.HealthDataAIServices/register/action | Register the subscription for Microsoft.HealthDataAIServices | +> | Microsoft.HealthDataAIServices/unregister/action | Unregister the subscription for Microsoft.HealthDataAIServices | +> | Microsoft.HealthDataAIServices/DeidServices/read | List DeidService resources by subscription ID | +> | Microsoft.HealthDataAIServices/DeidServices/read | List DeidService resources by resource group | +> | Microsoft.HealthDataAIServices/DeidServices/read | Get a DeidService | +> | Microsoft.HealthDataAIServices/DeidServices/write | Create a DeidService | +> | Microsoft.HealthDataAIServices/DeidServices/delete | Delete a DeidService | +> | Microsoft.HealthDataAIServices/DeidServices/write | Update a DeidService | +> | Microsoft.HealthDataAIServices/locations/operationStatuses/read | read operationStatuses | +> | Microsoft.HealthDataAIServices/locations/operationStatuses/write | write operationStatuses | +> | Microsoft.HealthDataAIServices/Operations/read | read Operations | +> | **DataAction** | **Description** | +> | Microsoft.HealthDataAIServices/DeidServices/Realtime/action | Allows access to the realtime endpoint | +> | Microsoft.HealthDataAIServices/DeidServices/Batch/write | Creates batches | +> | Microsoft.HealthDataAIServices/DeidServices/Batch/delete | Deletes a batch | +> | Microsoft.HealthDataAIServices/DeidServices/Batch/read | Reads a batch | +> | Microsoft.HealthDataAIServices/DeidServices/PrivateEndpointConnectionProxies/delete | Deletes private endpoint connection proxies | +> | Microsoft.HealthDataAIServices/DeidServices/PrivateEndpointConnectionProxies/read | Reads private endpoint connection proxies | +> | Microsoft.HealthDataAIServices/DeidServices/PrivateEndpointConnectionProxies/write | Writes private endpoint connection proxies | +> | Microsoft.HealthDataAIServices/DeidServices/PrivateEndpointConnectionProxies/validate/action | Validates private endpoint connection proxies | +> | Microsoft.HealthDataAIServices/DeidServices/PrivateEndpointConnectionProxies/validate/action | Validates private endpoint connection proxies | +> | Microsoft.HealthDataAIServices/DeidServices/PrivateEndpointConnections/read | Reads private endpoint connections | +> | Microsoft.HealthDataAIServices/DeidServices/PrivateEndpointConnections/write | Writes private endpoint connections | +> | Microsoft.HealthDataAIServices/DeidServices/PrivateEndpointConnections/delete | Deletes private endpoint connections | +> | Microsoft.HealthDataAIServices/DeidServices/PrivateLinkResources/read | Reads private link resources | + ## Microsoft.Logic Automate the access and use of data across clouds without writing code. |
| role-based-access-control | Resource Provider Operations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/role-based-access-control/resource-provider-operations.md | Click the resource provider name in the following list to see the list of permis > | [Microsoft.EventGrid](./permissions/integration.md#microsofteventgrid) | Get reliable event delivery at massive scale. | [Event Grid](/azure/event-grid/) | > | [Microsoft.EventHub](./permissions/integration.md#microsofteventhub) | Receive telemetry from millions of devices. | [Event Hubs](/azure/event-hubs/) | > | [Microsoft.HealthcareApis](./permissions/integration.md#microsofthealthcareapis) | | [Azure API for FHIR](/azure/healthcare-apis/azure-api-for-fhir/) |+> | [Microsoft.HealthDataAIServices](./permissions/integration.md#microsofthealthdataaiservices) | | [Azure Health Data Services](/azure/healthcare-apis/healthcare-apis-overview) | > | [Microsoft.Logic](./permissions/integration.md#microsoftlogic) | Automate the access and use of data across clouds without writing code. | [Logic Apps](/azure/logic-apps/) | > | [Microsoft.NotificationHubs](./permissions/integration.md#microsoftnotificationhubs) | Send push notifications to any platform from any back end. | [Notification Hubs](/azure/notification-hubs/) | > | [Microsoft.Relay](./permissions/integration.md#microsoftrelay) | Expose services that run in your corporate network to the public cloud. | [Azure Relay](/azure/azure-relay/relay-what-is-it) | |
| role-based-access-control | Role Assignments Alert | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/role-based-access-control/role-assignments-alert.md | To create an alert rule, you must have: - Access to an Azure subscription - Permission to create resource groups and resources within the subscription-- [Log Analytics configured](../azure-monitor/logs/quick-create-workspace.md) so it has access to the AzureActivity table+- [Log Analytics configured](/azure/azure-monitor/logs/quick-create-workspace) so it has access to the AzureActivity table ## Estimate costs before using Azure Monitor To get notified of privileged role assignments, you create an alert rule in Azur An action group defines the actions and notifications that are executed when the alert is triggered. - When you create an action group, you must specify the resource group to put the action group within. Then, select the notifications (Email/SMS message/Push/Voice action) to invoke when the alert rule triggers. You can skip the **Actions** and **Tag** tabs. For more information, see [Create and manage action groups in the Azure portal](../azure-monitor/alerts/action-groups.md). + When you create an action group, you must specify the resource group to put the action group within. Then, select the notifications (Email/SMS message/Push/Voice action) to invoke when the alert rule triggers. You can skip the **Actions** and **Tag** tabs. For more information, see [Create and manage action groups in the Azure portal](/azure/azure-monitor/alerts/action-groups). 1. On the **Details** tab, select the resource group to save the alert rule. Follow these steps to delete the role assignment alert rule and stop additional ## Next steps -- [Create, view, and manage activity log alerts by using Azure Monitor](../azure-monitor/alerts/alerts-activity-log.md)+- [Create, view, and manage activity log alerts by using Azure Monitor](/azure/azure-monitor/alerts/alerts-activity-log) - [View activity logs for Azure RBAC changes](change-history-report.md) |
| route-server | Monitor Route Server | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/route-server/monitor-route-server.md | To view Azure Route Server metrics, follow these steps: ## Aggregation types -Metrics explorer supports Sum, Count, Average, Minimum, and Maximum as [aggregation types](../azure-monitor/essentials/metrics-charts.md#aggregation). You should use the recommended Aggregation type when reviewing the insights for each Route Server metric. +Metrics explorer supports Sum, Count, Average, Minimum, and Maximum as [aggregation types](/azure/azure-monitor/essentials/metrics-charts#aggregation). You should use the recommended Aggregation type when reviewing the insights for each Route Server metric. - Sum: The sum of all values captured during the aggregation interval. - Count: The number of measurements captured during the aggregation interval. |
| route-server | Route Server Faq | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/route-server/route-server-faq.md | Title: Azure Route Server frequently asked questions (FAQ) -description: Find answers to frequently asked questions about Azure Route Server. +description: In this article, you find answers to the most frequently asked questions about Azure Route Server. Previously updated : 08/27/2024 Last updated : 09/11/2024 # Azure Route Server frequently asked questions (FAQ) No. Azure Route Server only exchanges BGP routes with your network virtual appli Azure Route Server supports only Border Gateway (BGP) Protocol. Your network virtual appliance (NVA) must support multi-hop external BGP because you need to deploy the Route Server in a dedicated subnet in your virtual network. When you configure the BGP on your NVA, the ASN you choose must be different from the Route Server ASN. -### Does Azure Route Server preserve the BGP AS Path of the route it receives? +### Does Azure Route Server preserve the BGP AS path of the route it receives? -Yes, Azure Route Server propagates the route with the BGP AS Path intact. +Yes, Azure Route Server propagates the route with the BGP AS path intact. ++### If AS path prepend is configured on an NVA towards the route server, will the ExpressRoute circuit pass the AS path prepend information to on-premises? ++When ExpressRoute advertises routes to on-premises, it removes the private BGP ASN information. On-premises receives the prefix with [AS 12076](../expressroute/expressroute-routing.md#autonomous-system-numbers-asn). ### Does Azure Route Server preserve the BGP communities of the route it receives? Yes. If a VNet peering is created between your hub VNet and spoke VNet, Azure Ro ### How is the 1000 route limit calculated on a BGP peering session between an NVA and Azure Route Server? -Today, Route Server can accept a maximum of 1000 routes from a single BGP peer. When processing BGP route updates, this limit is calculated as the number of current routes learnt from a BGP peer plus the number of routes coming in the BGP route update. For example, if an NVA initially advertises 501 routes to Route Server and later re-advertises these 501 routes in a BGP route update, Route Server will calculate this as 1002 routes and tear down the BGP session. +Currently, Route Server can accept a maximum of 1000 routes from a single BGP peer. When processing BGP route updates, this limit is calculated as the number of current routes learnt from a BGP peer plus the number of routes coming in the BGP route update. For example, if an NVA initially advertises 501 routes to Route Server and later re-advertises these 501 routes in a BGP route update, the route server calculates this as 1002 routes and tear down the BGP session. ### What Autonomous System Numbers (ASNs) can I use? |
| sap | About Azure Monitor Sap Solutions | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sap/monitor/about-azure-monitor-sap-solutions.md | -When you have critical SAP applications and business processes that rely on Azure resources, you might want to monitor those resources for availability, performance, and operation. Azure Monitor for SAP solutions is an Azure-native monitoring product for SAP landscapes that run on Azure. It uses specific parts of the [Azure Monitor](../../azure-monitor/overview.md) infrastructure. +When you have critical SAP applications and business processes that rely on Azure resources, you might want to monitor those resources for availability, performance, and operation. Azure Monitor for SAP solutions is an Azure-native monitoring product for SAP landscapes that run on Azure. It uses specific parts of the [Azure Monitor](/azure/azure-monitor/overview) infrastructure. You can use Azure Monitor for SAP solutions with both [SAP on Azure virtual machines (VMs)](/azure/virtual-machines/workloads/sap/hana-get-started) and [SAP on Azure Large Instances](/azure/virtual-machines/workloads/sap/hana-overview-architecture). You can use Azure Monitor for SAP solutions to collect data from Azure infrastru To monitor components of an SAP landscape, add the corresponding [provider](providers.md). These components include Azure VMs, high-availability (HA) clusters, SAP HANA databases, and SAP NetWeaver. For more information, see [Quickstart: Deploy Azure Monitor for SAP solutions in Azure portal](quickstart-portal.md). -Azure Monitor for SAP solutions uses the [Azure Monitor](../../azure-monitor/overview.md) capabilities of [Log Analytics](../../azure-monitor/logs/log-analytics-overview.md) and [workbooks](../../azure-monitor/visualize/workbooks-overview.md). With it, you can: +Azure Monitor for SAP solutions uses the [Azure Monitor](/azure/azure-monitor/overview) capabilities of [Log Analytics](/azure/azure-monitor/logs/log-analytics-overview) and [workbooks](/azure/azure-monitor/visualize/workbooks-overview). With it, you can: -- Create [custom visualizations](../../azure-monitor/visualize/workbooks-overview.md) by editing the default that Azure Monitor for SAP solutions provides.-- Write [custom queries](../../azure-monitor/logs/log-analytics-tutorial.md).-- Create [custom alerts](../../azure-monitor/alerts/alerts-log.md) by using Log Analytics workspaces.-- Take advantage of the [flexible retention period](../../azure-monitor/logs/data-retention-configure.md) in Azure Monitor Logs and Log Analytics.+- Create [custom visualizations](/azure/azure-monitor/visualize/workbooks-overview) by editing the default that Azure Monitor for SAP solutions provides. +- Write [custom queries](/azure/azure-monitor/logs/log-analytics-tutorial). +- Create [custom alerts](/azure/azure-monitor/alerts/alerts-log) by using Log Analytics workspaces. +- Take advantage of the [flexible retention period](/azure/azure-monitor/logs/data-retention-configure) in Azure Monitor Logs and Log Analytics. - Connect monitoring data with your ticketing system. ## What data is collected? The key components of the architecture are: - The managed resource group, which is deployed automatically as part of the Azure Monitor for SAP solutions resource's deployment. Inside the managed resource group, resources like these help collect data: - An [Azure Functions resource](../../azure-functions/functions-overview.md) hosts the monitoring code. This logic collects data from the source systems and transfers the data to the monitoring framework. - An [Azure Key Vault resource](/azure/key-vault/general/basic-concepts) holds the SAP HANA database credentials and stores information about providers.- - A [Log Analytics workspace](../../azure-monitor/logs/log-analytics-workspace-overview.md) is the destination for storing data. Optionally, you can choose to use an existing workspace in the same subscription as your Azure Monitor for SAP solutions resource at deployment. + - A [Log Analytics workspace](/azure/azure-monitor/logs/log-analytics-workspace-overview) is the destination for storing data. Optionally, you can choose to use an existing workspace in the same subscription as your Azure Monitor for SAP solutions resource at deployment. - A [storage account](../../storage/common/storage-account-overview.md) is associated with the Azure Functions resource. It's used to manage triggers and executions of logging functions. -[Azure Monitor workbooks](../../azure-monitor/visualize/workbooks-overview.md) provide customizable visualization of the data in Log Analytics. To automatically refresh your workbooks or visualizations, pin the items to the Azure dashboard. The maximum refresh frequency is every 30 minutes. +[Azure Monitor workbooks](/azure/azure-monitor/visualize/workbooks-overview) provide customizable visualization of the data in Log Analytics. To automatically refresh your workbooks or visualizations, pin the items to the Azure dashboard. The maximum refresh frequency is every 30 minutes. -You can also use Kusto Query Language (KQL) to [run log queries](../../azure-monitor/logs/log-query-overview.md) against the raw tables inside the Log Analytics workspace. +You can also use Kusto Query Language (KQL) to [run log queries](/azure/azure-monitor/logs/log-query-overview) against the raw tables inside the Log Analytics workspace. ## How do you analyze logs? Azure Monitor for SAP solutions doesn't support resource logs or activity logs. ## How do you make Kusto queries? -When you select **Logs** from the **Azure Monitor for SAP solutions** menu, Log Analytics opens with the query scope set to the current instance of Azure Monitor for SAP solutions. Log queries include only data from that resource. To run a query that includes data from other accounts or data from other Azure services, select **Logs** from the **Azure Monitor** menu. For more information, see [Log query scope and time range in Azure Monitor Log Analytics](../../azure-monitor/logs/scope.md). +When you select **Logs** from the **Azure Monitor for SAP solutions** menu, Log Analytics opens with the query scope set to the current instance of Azure Monitor for SAP solutions. Log queries include only data from that resource. To run a query that includes data from other accounts or data from other Azure services, select **Logs** from the **Azure Monitor** menu. For more information, see [Log query scope and time range in Azure Monitor Log Analytics](/azure/azure-monitor/logs/scope). You can use Kusto queries to help you monitor your Azure Monitor for SAP solutions resources. The following sample query gives you data from a custom log for a specified time range. You can view the list of custom tables by expanding the **Custom Logs** section. You can specify the time range and the number of rows. In this example, you get five rows of data for your selected time range: |
| sap | Data Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sap/monitor/data-reference.md | For more information, see [sys.sysprocesses (Transact-SQL)](/sql/relational-data ## Next steps - For more information on using Azure Monitor for SAP solutions, see [Monitor SAP on Azure](about-azure-monitor-sap-solutions.md).-- For more information on Azure Monitor, see [Monitoring Azure resources with Azure Monitor](../../azure-monitor/essentials/monitor-azure-resource.md).+- For more information on Azure Monitor, see [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource). |
| sap | Get Alerts Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sap/monitor/get-alerts-portal.md | In this how-to guide, you learn how to configure alerts in Azure Monitor for SAP 1. Select **Create rule** to configure an alert of your choice. 1. For **Alert threshold**, enter your alert threshold. 1. For **Provider instance**, select a provider instance.-1. For **Action group**, select or create an [action group](../../azure-monitor/alerts/action-groups.md) to configure the notification setting. You can edit frequency and severity information according to your requirements. +1. For **Action group**, select or create an [action group](/azure/azure-monitor/alerts/action-groups) to configure the notification setting. You can edit frequency and severity information according to your requirements. 1. Select **Enable alert rule** to create the alert rule. |
| sap | Sap On Azure Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sap/sap-on-azure-overview.md | For more information, see the [SAP on Azure deployment automation framework](aut ## Azure Monitor for SAP solutions -Azure Monitor for SAP solutions is an Azure-native monitoring product for SAP landscapes that run on Azure, which uses specific parts of the [Azure Monitor](../azure-monitor/overview.md) infrastructure. +Azure Monitor for SAP solutions is an Azure-native monitoring product for SAP landscapes that run on Azure, which uses specific parts of the [Azure Monitor](/azure/azure-monitor/overview) infrastructure. For more information, see the [Azure Monitor for SAP solutions](monitor/about-azure-monitor-sap-solutions.md) documentation. |
| sap | Deployment Checklist | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sap/workloads/deployment-checklist.md | Here are some common methods: During the go-live phase, be sure to follow the playbooks you developed during earlier phases. Execute the steps that you tested and practiced. Don't accept last-minute changes in configurations and processes. Also complete these steps: -- Verify that Azure portal monitoring and other monitoring tools are working. Use Azure tools such as [Azure Monitor](../../azure-monitor/overview.md) for infrastructure monitoring. [Azure Monitor for SAP](../monitor/about-azure-monitor-sap-solutions.md) for a combination of OS and application KPIs, allowing you to integrate all in one dashboard for visibility during and after go-live. +- Verify that Azure portal monitoring and other monitoring tools are working. Use Azure tools such as [Azure Monitor](/azure/azure-monitor/overview) for infrastructure monitoring. [Azure Monitor for SAP](../monitor/about-azure-monitor-sap-solutions.md) for a combination of OS and application KPIs, allowing you to integrate all in one dashboard for visibility during and after go-live. For operating system key performance indicators: - [SAP note 1286256 - How-to: Using Windows LogMan tool to collect performance data on Windows Platforms](https://launchpad.support.sap.com/#/notes/1286256) - On Linux ensure sysstat tool is installed and capturing details at regular intervals |
| security | Secure Deploy | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/security/develop/secure-deploy.md | Azure services that assist with application monitoring are: #### Application Insights -[Application Insights](../../azure-monitor/app/app-insights-overview.md) is an extensible Application Performance Management (APM) service for web developers on multiple platforms. Use it to monitor your live web application. Application Insights automatically detects performance anomalies. It includes powerful analytics tools to help you diagnose issues and understand what users actually do with your app. It's designed to help you continuously improve performance and usability. +[Application Insights](/azure/azure-monitor/app/app-insights-overview) is an extensible Application Performance Management (APM) service for web developers on multiple platforms. Use it to monitor your live web application. Application Insights automatically detects performance anomalies. It includes powerful analytics tools to help you diagnose issues and understand what users actually do with your app. It's designed to help you continuously improve performance and usability. #### Microsoft Defender for Cloud |
| security | Database Security Checklist | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/security/fundamentals/database-security-checklist.md | We recommend that you read the [Azure Database Security Best Practices](/azure/a |<br> Database Access | <ul><li>[Authentication](/azure/azure-sql/database/logins-create-manage) (Microsoft Entra authentication) AD authentication uses identities managed by Microsoft Entra ID.</li><li>[Authorization](/azure/azure-sql/database/logins-create-manage) grant users the least privileges necessary.</li></ul> | |<br>Application Access| <ul><li>[Row level Security](/sql/relational-databases/security/row-level-security) (Using Security Policy, at the same time restricting row-level access based on a user's identity,role, or execution context).</li><li>[Dynamic Data Masking](/azure/azure-sql/database/dynamic-data-masking-overview) (Using Permission & Policy, limits sensitive data exposure by masking it to non-privileged users)</li></ul>| |**Proactive Monitoring**|| -| <br>Tracking & Detecting| <ul><li>[Auditing](/azure/azure-sql/database/auditing-overview) tracks database events and writes them to an Audit log/ Activity log in your [Azure Storage account](../../storage/common/storage-account-create.md).</li><li>Track Azure Database health using [Azure Monitor Activity Logs](../../azure-monitor/essentials/platform-logs-overview.md).</li><li>[Threat Detection](/azure/azure-sql/database/threat-detection-configure) detects anomalous database activities indicating potential security threats to the database. </li></ul> | +| <br>Tracking & Detecting| <ul><li>[Auditing](/azure/azure-sql/database/auditing-overview) tracks database events and writes them to an Audit log/ Activity log in your [Azure Storage account](../../storage/common/storage-account-create.md).</li><li>Track Azure Database health using [Azure Monitor Activity Logs](/azure/azure-monitor/essentials/platform-logs-overview).</li><li>[Threat Detection](/azure/azure-sql/database/threat-detection-configure) detects anomalous database activities indicating potential security threats to the database. </li></ul> | |<br>Microsoft Defender for Cloud| <ul><li>[Data Monitoring](../../security-center/security-center-remediate-recommendations.md) Use Microsoft Defender for Cloud as a centralized security monitoring solution for SQL and other Azure services.</li></ul>| ## Conclusion |
| security | End To End | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/security/fundamentals/end-to-end.md | The [Microsoft cloud security benchmark](/security/benchmark/azure/introduction) | Service | Description | ||--| | [Microsoft Sentinel](../../sentinel/hunting.md) | Powerful search and query tools to hunt for security threats across your organization's data sources. |-| [Azure Monitor logs and metrics](../../azure-monitor/overview.md) | Delivers a comprehensive solution for collecting, analyzing, and acting on telemetry from your cloud and on-premises environments. Azure Monitor [collects and aggregates data](../../azure-monitor/data-platform.md#observability-data-in-azure-monitor) from a variety of sources into a common data platform where it can be used for analysis, visualization, and alerting. | +| [Azure Monitor logs and metrics](/azure/azure-monitor/overview) | Delivers a comprehensive solution for collecting, analyzing, and acting on telemetry from your cloud and on-premises environments. Azure Monitor [collects and aggregates data](/azure/azure-monitor/data-platform#observability-data-in-azure-monitor) from a variety of sources into a common data platform where it can be used for analysis, visualization, and alerting. | | **Identity & Access Management** | | | [Azure AD reports and monitoring](../../active-directory/reports-monitoring/index.yml) | [Microsoft Entra reports](../../active-directory/reports-monitoring/overview-reports.md) provide a comprehensive view of activity in your environment. | | | [Microsoft Entra monitoring](../../active-directory/reports-monitoring/overview-monitoring.md) lets you route your Microsoft Entra activity logs to different endpoints.| |
| security | Iaas | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/security/fundamentals/iaas.md | To monitor the security posture of your [Windows](../../security-center/security Defender for Cloud can actively monitor for threats, and potential threats are exposed in security alerts. Correlated threats are aggregated in a single view called a security incident. -Defender for Cloud stores data in [Azure Monitor logs](../../azure-monitor/logs/log-query-overview.md). Azure Monitor logs provides a query language and analytics engine that gives you insights into the operation of your applications and resources. Data is also collected from [Azure Monitor](../../batch/monitoring-overview.md), management solutions, and agents installed on virtual machines in the cloud or on-premises. This shared functionality helps you form a complete picture of your environment. +Defender for Cloud stores data in [Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview). Azure Monitor logs provides a query language and analytics engine that gives you insights into the operation of your applications and resources. Data is also collected from [Azure Monitor](../../batch/monitoring-overview.md), management solutions, and agents installed on virtual machines in the cloud or on-premises. This shared functionality helps you form a complete picture of your environment. Organizations that don't enforce strong security for their VMs remain unaware of potential attempts by unauthorized users to circumvent security controls. ## Monitor VM performance Resource abuse can be a problem when VM processes consume more resources than they should. Performance issues with a VM can lead to service disruption, which violates the security principle of availability. This is particularly important for VMs that are hosting IIS or other web servers, because high CPU or memory usage might indicate a denial of service (DoS) attack. ItΓÇÖs imperative to monitor VM access not only reactively while an issue is occurring, but also proactively against baseline performance as measured during normal operation. -We recommend that you use [Azure Monitor](../../azure-monitor/data-platform.md) to gain visibility into your resourceΓÇÖs health. Azure Monitor features: +We recommend that you use [Azure Monitor](/azure/azure-monitor/data-platform) to gain visibility into your resourceΓÇÖs health. Azure Monitor features: -- [Resource diagnostic log files](../../azure-monitor/essentials/platform-logs-overview.md): Monitors your VM resources and identifies potential issues that might compromise performance and availability.-- [Azure Diagnostics extension](../../azure-monitor/agents/diagnostics-extension-overview.md): Provides monitoring and diagnostics capabilities on Windows VMs. You can enable these capabilities by including the extension as part of the [Azure Resource Manager template](/azure/virtual-machines/extensions/diagnostics-template).+- [Resource diagnostic log files](/azure/azure-monitor/essentials/platform-logs-overview): Monitors your VM resources and identifies potential issues that might compromise performance and availability. +- [Azure Diagnostics extension](/azure/azure-monitor/agents/diagnostics-extension-overview): Provides monitoring and diagnostics capabilities on Windows VMs. You can enable these capabilities by including the extension as part of the [Azure Resource Manager template](/azure/virtual-machines/extensions/diagnostics-template). Organizations that don't monitor VM performance canΓÇÖt determine whether certain changes in performance patterns are normal or abnormal. A VM thatΓÇÖs consuming more resources than normal might indicate an attack from an external resource or a compromised process running in the VM. |
| security | Log Audit | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/security/fundamentals/log-audit.md | Cloud applications are complex with many moving parts. Logging data can provide - Automate actions that would otherwise require manual intervention Azure logs are categorized into the following types:-* **Control/management logs** provide information about Azure Resource Manager CREATE, UPDATE, and DELETE operations. For more information, see [Azure activity logs](../../azure-monitor/essentials/platform-logs-overview.md). +* **Control/management logs** provide information about Azure Resource Manager CREATE, UPDATE, and DELETE operations. For more information, see [Azure activity logs](/azure/azure-monitor/essentials/platform-logs-overview). -* **Data plane logs** provide information about events raised as part of Azure resource usage. Examples of this type of log are the Windows event system, security, and application logs in a virtual machine (VM) and the [diagnostics logs](../../azure-monitor/essentials/platform-logs-overview.md) that are configured through Azure Monitor. +* **Data plane logs** provide information about events raised as part of Azure resource usage. Examples of this type of log are the Windows event system, security, and application logs in a virtual machine (VM) and the [diagnostics logs](/azure/azure-monitor/essentials/platform-logs-overview) that are configured through Azure Monitor. * **Processed events** provide information about analyzed events/alerts that have been processed on your behalf. Examples of this type are [Microsoft Defender for Cloud alerts](../../security-center/security-center-managing-and-responding-alerts.md) where [Microsoft Defender for Cloud](../../security-center/security-center-introduction.md) has processed and analyzed your subscription and provides concise security alerts. The following table lists the most important types of logs available in Azure: | Log category | Log type | Usage | Integration | | | -- | | -- |-|[Activity logs](../../azure-monitor/essentials/platform-logs-overview.md)|Control-plane events on Azure Resource Manager resources| Provides insight into the operations that were performed on resources in your subscription.| REST API, [Azure Monitor](../../azure-monitor/essentials/platform-logs-overview.md)| -|[Azure Resource logs](../../azure-monitor/essentials/platform-logs-overview.md)|Frequent data about the operation of Azure Resource Manager resources in subscription| Provides insight into operations that your resource itself performed.| Azure Monitor| +|[Activity logs](/azure/azure-monitor/essentials/platform-logs-overview)|Control-plane events on Azure Resource Manager resources| Provides insight into the operations that were performed on resources in your subscription.| REST API, [Azure Monitor](/azure/azure-monitor/essentials/platform-logs-overview)| +|[Azure Resource logs](/azure/azure-monitor/essentials/platform-logs-overview)|Frequent data about the operation of Azure Resource Manager resources in subscription| Provides insight into operations that your resource itself performed.| Azure Monitor| |[Microsoft Entra ID reporting](../../active-directory/reports-monitoring/overview-reports.md)|Logs and reports | Reports user sign-in activities and system activity information about users and group management.|[Microsoft Graph](/graph/overview)|-|[Virtual machines and cloud services](../../azure-monitor/vm/monitor-virtual-machine.md)|Windows Event Log service and Linux Syslog| Captures system data and logging data on the virtual machines and transfers that data into a storage account of your choice.| Windows (using [Azure Diagnostics](../../azure-monitor/agents/diagnostics-extension-overview.md)] storage) and Linux in Azure Monitor| +|[Virtual machines and cloud services](/azure/azure-monitor/vm/monitor-virtual-machine)|Windows Event Log service and Linux Syslog| Captures system data and logging data on the virtual machines and transfers that data into a storage account of your choice.| Windows (using [Azure Diagnostics](/azure/azure-monitor/agents/diagnostics-extension-overview)] storage) and Linux in Azure Monitor| |[Azure Storage Analytics](/rest/api/storageservices/fileservices/storage-analytics)|Storage logging, provides metrics data for a storage account|Provides insight into trace requests, analyzes usage trends, and diagnoses issues with your storage account.| REST API or the [client library](/dotnet/api/overview/azure/storage)| |[Network security group (NSG) flow logs](../../network-watcher/network-watcher-nsg-flow-logging-overview.md)|JSON format, shows outbound and inbound flows on a per-rule basis|Displays information about ingress and egress IP traffic through a Network Security Group.|[Azure Network Watcher](../../network-watcher/network-watcher-monitoring-overview.md)|-|[Application insight](../../azure-monitor/app/app-insights-overview.md)|Logs, exceptions, and custom diagnostics| Provides an application performance monitoring (APM) service for web developers on multiple platforms.| REST API, [Power BI](https://powerbi.microsoft.com/documentation/powerbi-azure-and-power-bi/)| +|[Application insight](/azure/azure-monitor/app/app-insights-overview)|Logs, exceptions, and custom diagnostics| Provides an application performance monitoring (APM) service for web developers on multiple platforms.| REST API, [Power BI](https://powerbi.microsoft.com/documentation/powerbi-azure-and-power-bi/)| |[Process data / security alerts](../../security-center/security-center-introduction.md)| Microsoft Defender for Cloud alerts, Azure Monitor logs alerts| Provides security information and alerts.| REST APIs, JSON| ## Log integration with on-premises SIEM systems |
| security | Network Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/security/fundamentals/network-overview.md | Learn more: Logging at a network level is a key function for any network security scenario. In Azure, you can log information obtained for NSGs to get network level logging information. With NSG logging, you get information from: -* [Activity logs](../../azure-monitor/essentials/platform-logs-overview.md). Use these logs to view all operations submitted to your Azure subscriptions. These logs are enabled by default, and can be used within the Azure portal. They were previously known as audit or operational logs. +* [Activity logs](/azure/azure-monitor/essentials/platform-logs-overview). Use these logs to view all operations submitted to your Azure subscriptions. These logs are enabled by default, and can be used within the Azure portal. They were previously known as audit or operational logs. * Event logs. These logs provide information about what NSG rules were applied. * Counter logs. These logs let you know how many times each NSG rule was applied to deny or allow traffic. |
| security | Operational Best Practices | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/security/fundamentals/operational-best-practices.md | The secure score, which is based on Center for Internet Security (CIS) controls, **Detail**: Most organizations with a SIEM use it as a central clearinghouse for security alerts that require an analyst response. Processed events produced by Defender for Cloud are published to the Azure Activity Log, one of the logs available through Azure Monitor. Azure Monitor offers a consolidated pipeline for routing any of your monitoring data into a SIEM tool. See [Stream alerts to a SIEM, SOAR, or IT Service Management solution](../../security-center/export-to-siem.md) for instructions. If youΓÇÖre using Microsoft Sentinel, see [Connect Microsoft Defender for Cloud](../../sentinel/connect-azure-security-center.md). **Best practice**: Integrate Azure logs with your SIEM. -**Detail**: Use [Azure Monitor to gather and export data](../../azure-monitor/overview.md#integrate). This practice is critical for enabling security incident investigation, and online log retention is limited. If youΓÇÖre using Microsoft Sentinel, see [Connect data sources](../../sentinel/connect-data-sources.md). +**Detail**: Use [Azure Monitor to gather and export data](/azure/azure-monitor/overview#integrate). This practice is critical for enabling security incident investigation, and online log retention is limited. If youΓÇÖre using Microsoft Sentinel, see [Connect data sources](../../sentinel/connect-data-sources.md). **Best practice**: Speed up your investigation and hunting processes and reduce false positives by integrating Endpoint Detection and Response (EDR) capabilities into your attack investigation. **Detail**: [Enable the Microsoft Defender for Endpoint integration](../../security-center/security-center-wdatp.md#enable-the-microsoft-defender-for-endpoint-integration) via your Defender for Cloud security policy. Consider using Microsoft Sentinel for threat hunting and incident response. You can use [Azure Resource Manager](../../azure-resource-manager/templates/synt [Apache JMeter](https://jmeter.apache.org/) is a free, popular open source tool with a strong community backing. **Best practice**: Monitor application performance. -**Detail**: [Azure Application Insights](../../azure-monitor/app/app-insights-overview.md) is an extensible application performance management (APM) service for web developers on multiple platforms. Use Application Insights to monitor your live web application. It automatically detects performance anomalies. It includes analytics tools to help you diagnose issues and to understand what users actually do with your app. It's designed to help you continuously improve performance and usability. +**Detail**: [Azure Application Insights](/azure/azure-monitor/app/app-insights-overview) is an extensible application performance management (APM) service for web developers on multiple platforms. Use Application Insights to monitor your live web application. It automatically detects performance anomalies. It includes analytics tools to help you diagnose issues and to understand what users actually do with your app. It's designed to help you continuously improve performance and usability. ## Mitigate and protect against DDoS Distributed denial of service (DDoS) is a type of attack that tries to exhaust application resources. The goal is to affect the applicationΓÇÖs availability and its ability to handle legitimate requests. These attacks are becoming more sophisticated and larger in size and impact. They can be targeted at any endpoint that is publicly reachable through the internet. |
| security | Operational Checklist | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/security/fundamentals/operational-checklist.md | This checklist is intended to help enterprises think through various operational | [<br>Data Protection & Storage](../../storage/blobs/security-recommendations.md)|<ul><li>Use Management Plane Security to secure your Storage Account using [Azure role-based access control (Azure RBAC)](../../role-based-access-control/role-assignments-portal.yml).</li><li>Data Plane Security to Securing Access to your Data using [Shared Access Signatures (SAS)](../../storage/common/storage-sas-overview.md) and Stored Access Policies.</li><li>Use Transport-Level Encryption ΓÇô Using HTTPS and the encryption used by [SMB (Server message block protocols) 3.0](/windows/win32/fileio/microsoft-smb-protocol-and-cifs-protocol-overview) for [Azure File Shares](../../storage/files/storage-dotnet-how-to-use-files.md).</li><li>Use [Client-side encryption](../../storage/common/storage-client-side-encryption.md) to secure data that you send to storage accounts when you require sole control of encryption keys. </li><li>Use [Storage Service Encryption (SSE)](../../storage/common/storage-service-encryption.md) to automatically encrypt data in Azure Storage, and [Azure Disk Encryption for Linux VMs](/azure/virtual-machines/linux/disk-encryption-overview) and [Azure Disk Encryption for Windows VMs](/azure/virtual-machines/linux/disk-encryption-overview) to encrypt virtual machine disk files for the OS and data disks.</li><li>Use Azure [Storage Analytics](/rest/api/storageservices/storage-analytics) to monitor authorization type; like with Blob Storage, you can see if users have used a Shared Access Signature or the storage account keys.</li><li>Use [Cross-Origin Resource Sharing (CORS)](/rest/api/storageservices/cross-origin-resource-sharing--cors--support-for-the-azure-storage-services) to access storage resources from different domains.</li></ul> | |[<br>Security Policies & Recommendations](/azure/defender-for-cloud/defender-for-cloud-planning-and-operations-guide#security-policies-and-recommendations)|<ul><li>Use [Microsoft Defender for Cloud](/azure/defender-for-cloud/integration-defender-for-endpoint) to deploy endpoint solutions.</li><li>Add a [web application firewall (WAF)](../../web-application-firewall/ag/ag-overview.md) to secure web applications.</li><li>Use [Azure Firewall](../../firewall/overview.md) to increase your security protections. </li><li>Apply security contact details for your Azure subscription. The [Microsoft Security Response Center (MSRC)](https://technet.microsoft.com/security/dn528958.aspx) contacts you if it discovers that your customer data has been accessed by an unlawful or unauthorized party.</li></ul> | | [<br>Identity & Access Management](identity-management-best-practices.md)|<ul><li>[Synchronize your on-premises directory with your cloud directory using Microsoft Entra ID](../../active-directory/hybrid/whatis-hybrid-identity.md).</li><li>Use [single sign-on](../../active-directory/manage-apps/what-is-single-sign-on.md) to enable users to access their SaaS applications based on their organizational account in Azure AD.</li><li>Use the [Password Reset Registration Activity](../../active-directory/authentication/howto-sspr-reporting.md) report to monitor the users that are registering.</li><li>Enable [multi-factor authentication (MFA)](../../active-directory/authentication/concept-mfa-howitworks.md) for users.</li><li>Developers to use secure identity capabilities for apps like [Microsoft Security Development Lifecycle (SDL)](https://www.microsoft.com/download/details.aspx?id=12379).</li><li>Actively monitor for suspicious activities by using Microsoft Entra ID P1 or P2 anomaly reports and [Microsoft Entra ID Protection capability](../../active-directory/identity-protection/overview-identity-protection.md).</li></ul> |-|[<br>Ongoing Security Monitoring](/azure/defender-for-cloud/defender-for-cloud-introduction)|<ul><li>Use Malware Assessment Solution [Azure Monitor logs](../../azure-monitor/logs/log-query-overview.md) to report on the status of antimalware protection in your infrastructure.</li><li>Use [Update Management](../../automation/update-management/overview.md) to determine the overall exposure to potential security problems, and whether or how critical these updates are for your environment.</li><li>The [Microsoft Entra admin center](https://entra.microsoft.com) provides visibility into the integrity and security of your organization's directory. | +|[<br>Ongoing Security Monitoring](/azure/defender-for-cloud/defender-for-cloud-introduction)|<ul><li>Use Malware Assessment Solution [Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview) to report on the status of antimalware protection in your infrastructure.</li><li>Use [Update Management](../../automation/update-management/overview.md) to determine the overall exposure to potential security problems, and whether or how critical these updates are for your environment.</li><li>The [Microsoft Entra admin center](https://entra.microsoft.com) provides visibility into the integrity and security of your organization's directory. | | [<br>Microsoft Defender for Cloud detection capabilities](../../security-center/security-center-alerts-overview.md#detect-threats)|<ul><li>Use [Cloud Security Posture Management (CSPM)](/azure/defender-for-cloud/concept-cloud-security-posture-management) for hardening guidance that helps you efficiently and effectively improve your security.</li><li>Use [alerts](/azure/defender-for-cloud/alerts-overview) to be notified when threats are identified in your cloud, hybrid, or on-premises environment. </li><li>Use [security policies, initiatives, and recommendations](/azure/defender-for-cloud/security-policy-concept) to improve your security posture.</li></ul> | ## Conclusion |
| security | Operational Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/security/fundamentals/operational-overview.md | -[Microsoft Azure Monitor logs](../../azure-monitor/overview.md) is a cloud-based IT management solution that helps you manage and protect your on-premises and cloud infrastructure. Its core functionality is provided by the following services that run in Azure. Azure includes multiple services that help you manage and protect your on-premises and cloud infrastructure. Each service provides a specific management function. You can combine services to achieve different management scenarios. +[Microsoft Azure Monitor logs](/azure/azure-monitor/overview) is a cloud-based IT management solution that helps you manage and protect your on-premises and cloud infrastructure. Its core functionality is provided by the following services that run in Azure. Azure includes multiple services that help you manage and protect your on-premises and cloud infrastructure. Each service provides a specific management function. You can combine services to achieve different management scenarios. ### Azure Monitor -[Azure Monitor](../../azure-monitor/overview.md) collects data from managed sources into central data stores. This data can include events, performance data, or custom data provided through the API. After the data is collected, it's available for alerting, analysis, and export. +[Azure Monitor](/azure/azure-monitor/overview) collects data from managed sources into central data stores. This data can include events, performance data, or custom data provided through the API. After the data is collected, it's available for alerting, analysis, and export. You can consolidate data from a variety of sources and combine data from your Azure services with your existing on-premises environment. Azure Monitor logs also clearly separates the collection of the data from the action taken on that data, so that all actions are available to all kinds of data. Defender for Cloud assesses the configuration of your resources to identify secu >[!Note] >To learn more about roles and allowed actions in Defender for Cloud, see [Permissions in Microsoft Defender for Cloud](../../security-center/security-center-permissions.md). -Defender for Cloud uses the Microsoft Monitoring Agent. This is the same agent that the Azure Monitor service uses. Data collected from this agent is stored in either an existing Log Analytics [workspace](../../azure-monitor/logs/manage-access.md) associated with your Azure subscription or a new workspace, taking into account the geolocation of the VM. +Defender for Cloud uses the Microsoft Monitoring Agent. This is the same agent that the Azure Monitor service uses. Data collected from this agent is stored in either an existing Log Analytics [workspace](/azure/azure-monitor/logs/manage-access) associated with your Azure subscription or a new workspace, taking into account the geolocation of the VM. ## Azure Monitor Performance issues in your cloud app can affect your business. With multiple interconnected components and frequent releases, degradations can happen at any time. And if youΓÇÖre developing an app, your users usually discover issues that you didnΓÇÖt find in testing. You should know about these issues immediately, and you should have tools for diagnosing and fixing the problems. -[Azure Monitor](../../azure-monitor/overview.md) is basic tool for monitoring services running on Azure. It gives you infrastructure-level data about the throughput of a service and the surrounding environment. If you're managing your apps all in Azure and deciding whether to scale up or down resources, Azure Monitor is the place to start. +[Azure Monitor](/azure/azure-monitor/overview) is basic tool for monitoring services running on Azure. It gives you infrastructure-level data about the throughput of a service and the surrounding environment. If you're managing your apps all in Azure and deciding whether to scale up or down resources, Azure Monitor is the place to start. You can also use monitoring data to gain deep insights about your application. That knowledge can help you to improve application performance or maintainability, or automate actions that would otherwise require manual intervention. Azure Monitor includes the following components. ### Azure Activity Log -The [Azure Activity Log](../../azure-monitor/essentials/platform-logs-overview.md) provides insight into the operations that were performed on resources in your subscription. It was previously known as ΓÇ£Audit LogΓÇ¥ or ΓÇ£Operational Log,ΓÇ¥ because it reports control-plane events for your subscriptions. +The [Azure Activity Log](/azure/azure-monitor/essentials/platform-logs-overview) provides insight into the operations that were performed on resources in your subscription. It was previously known as ΓÇ£Audit LogΓÇ¥ or ΓÇ£Operational Log,ΓÇ¥ because it reports control-plane events for your subscriptions. ### Azure diagnostic logs -[Azure diagnostic logs](../../azure-monitor/essentials/platform-logs-overview.md) are emitted by a resource and provide rich, frequent data about the operation of that resource. The content of these logs varies by resource type. +[Azure diagnostic logs](/azure/azure-monitor/essentials/platform-logs-overview) are emitted by a resource and provide rich, frequent data about the operation of that resource. The content of these logs varies by resource type. Windows event system logs are one category of diagnostic logs for VMs. Blob, table, and queue logs are categories of diagnostic logs for storage accounts. -Diagnostic logs differ from the [Activity Log](../../azure-monitor/essentials/platform-logs-overview.md). The Activity log provides insight into the operations that were performed on resources in your subscription. Diagnostic logs provide insight into operations that your resource performed itself. +Diagnostic logs differ from the [Activity Log](/azure/azure-monitor/essentials/platform-logs-overview). The Activity log provides insight into the operations that were performed on resources in your subscription. Diagnostic logs provide insight into operations that your resource performed itself. ### Metrics -Azure Monitor provides telemetry that gives you visibility into the performance and health of your workloads on Azure. The most important type of Azure telemetry data is the [metrics](../../azure-monitor/data-platform.md) (also called performance counters) emitted by most Azure resources. Azure Monitor provides several ways to configure and consume these metrics for monitoring and troubleshooting. +Azure Monitor provides telemetry that gives you visibility into the performance and health of your workloads on Azure. The most important type of Azure telemetry data is the [metrics](/azure/azure-monitor/data-platform) (also called performance counters) emitted by most Azure resources. Azure Monitor provides several ways to configure and consume these metrics for monitoring and troubleshooting. ### Azure Diagnostics -Azure Diagnostics enables the collection of diagnostic data on a deployed application. You can use the Diagnostics extension from various sources. Currently supported are [Azure cloud service roles](/visualstudio/azure/vs-azure-tools-configure-roles-for-cloud-service), [Azure virtual machines](/visualstudio/azure/vs-azure-tools-configure-roles-for-cloud-service) running Microsoft Windows, and [Azure Service Fabric](../../azure-monitor/agents/diagnostics-extension-overview.md). +Azure Diagnostics enables the collection of diagnostic data on a deployed application. You can use the Diagnostics extension from various sources. Currently supported are [Azure cloud service roles](/visualstudio/azure/vs-azure-tools-configure-roles-for-cloud-service), [Azure virtual machines](/visualstudio/azure/vs-azure-tools-configure-roles-for-cloud-service) running Microsoft Windows, and [Azure Service Fabric](/azure/azure-monitor/agents/diagnostics-extension-overview). ## Azure Network Watcher To learn about the Security and Audit solution, see the following articles: - [Security and compliance](https://azure.microsoft.com/overview/trusted-cloud/) - [Microsoft Defender for Cloud](../../security-center/security-center-introduction.md)-- [Azure Monitor](../../azure-monitor/overview.md)+- [Azure Monitor](/azure/azure-monitor/overview) |
| security | Operational Security | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/security/fundamentals/operational-security.md | AzureΓÇÖs infrastructure is designed from the facility to applications for hosti Azure Operational Security refers to the services, controls, and features available to users for protecting their data, applications,and other assets in Microsoft Azure. Azure Operational Security is built on a framework that incorporates the knowledge gained through various capabilities that are unique to Microsoft, including the Microsoft Security Development Lifecycle (SDL), the Microsoft Security Response Center program, and deep awareness of the cybersecurity threat landscape. This white paper outlines MicrosoftΓÇÖs approach to Azure Operational Security within the Microsoft Azure cloud platform and covers following -1. [Azure Monitor](../../azure-monitor/index.yml) +1. [Azure Monitor](/azure/azure-monitor/) 2. [Microsoft Defender for Cloud](../../security-center/security-center-introduction.md) -3. [Azure Monitor](../../azure-monitor/overview.md) +3. [Azure Monitor](/azure/azure-monitor/overview) 4. [Azure Network watcher](../../network-watcher/network-watcher-monitoring-overview.md) Protected data in Azure Backup is stored in a backup vault located in a particul  -A good example of a solution that uses multiple services to provide additional functionality is the [Update Management solution](../../automation/update-management/overview.md). This solution uses the [Azure Monitor logs](../../azure-monitor/logs/log-query-overview.md) agent for Windows and Linux to collect information about required updates on each agent. It writes this data to the Azure Monitor logs repository where you can analyze it with an included dashboard. +A good example of a solution that uses multiple services to provide additional functionality is the [Update Management solution](../../automation/update-management/overview.md). This solution uses the [Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview) agent for Windows and Linux to collect information about required updates on each agent. It writes this data to the Azure Monitor logs repository where you can analyze it with an included dashboard. When you create a deployment, runbooks in [Azure Automation](../../automation/automation-intro.md) are used to install required updates. You manage this entire process in the portal and donΓÇÖt need to worry about the underlying details. These logs are emitted by a resource and provide rich, frequent data about the o For example, Windows event system logs are one category of Diagnostic Log for VMs and blob, table, and queue logs are categories of Diagnostic Logs for storage accounts. -Diagnostics Logs differ from the [Activity Log (formerly known as Audit Log or Operational Log)](../../azure-monitor/essentials/platform-logs-overview.md). The Activity log provides insight into the operations that were performed on resources in your subscription. Diagnostics logs provide insight into operations that your resource performed itself. +Diagnostics Logs differ from the [Activity Log (formerly known as Audit Log or Operational Log)](/azure/azure-monitor/essentials/platform-logs-overview). The Activity log provides insight into the operations that were performed on resources in your subscription. Diagnostics logs provide insight into operations that your resource performed itself. ### Metrics -Azure Monitor enables you to consume telemetry to gain visibility into the performance and health of your workloads on Azure. The most important type of Azure telemetry data is the metrics (also called performance counters) emitted by most Azure resources. Azure Monitor provides several ways to configure and consume these [metrics](../../azure-monitor/data-platform.md) for monitoring and troubleshooting. Metrics are a valuable source of telemetry and enable you to do the following tasks: +Azure Monitor enables you to consume telemetry to gain visibility into the performance and health of your workloads on Azure. The most important type of Azure telemetry data is the metrics (also called performance counters) emitted by most Azure resources. Azure Monitor provides several ways to configure and consume these [metrics](/azure/azure-monitor/data-platform) for monitoring and troubleshooting. Metrics are a valuable source of telemetry and enable you to do the following tasks: - **Track the performance** of your resource (such as a VM, website, or logic app) by plotting its metrics on a portal chart and pinning that chart to a dashboard. Azure Monitor enables you to consume telemetry to gain visibility into the perfo ### Azure Diagnostics -It is the capability within Azure that enables the collection of diagnostic data on a deployed application. You can use the diagnostics extension from various different sources. Currently supported are [Azure Cloud Service Web and Worker Roles](/visualstudio/azure/vs-azure-tools-configure-roles-for-cloud-service), [Azure Virtual Machines](/azure/virtual-machines/windows/overview) running Microsoft Windows,and [Service Fabric](../../azure-monitor/agents/diagnostics-extension-overview.md). Other Azure services have their own separate diagnostics. +It is the capability within Azure that enables the collection of diagnostic data on a deployed application. You can use the diagnostics extension from various different sources. Currently supported are [Azure Cloud Service Web and Worker Roles](/visualstudio/azure/vs-azure-tools-configure-roles-for-cloud-service), [Azure Virtual Machines](/azure/virtual-machines/windows/overview) running Microsoft Windows,and [Service Fabric](/azure/azure-monitor/agents/diagnostics-extension-overview). Other Azure services have their own separate diagnostics. ## Azure Network Watcher |
| security | Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/security/fundamentals/overview.md | Azure Resource Manager template-based deployments help improve the security of s ### Application Insights -[Application Insights](../../azure-monitor/app/app-insights-overview.md) is an extensible Application Performance Management (APM) service for web developers. With Application Insights, you can monitor your live web applications and automatically detect performance anomalies. It includes powerful analytics tools to help you diagnose issues and to understand what users actually do with your apps. It monitors your application all the time it's running, both during testing and after you've published or deployed it. +[Application Insights](/azure/azure-monitor/app/app-insights-overview) is an extensible Application Performance Management (APM) service for web developers. With Application Insights, you can monitor your live web applications and automatically detect performance anomalies. It includes powerful analytics tools to help you diagnose issues and to understand what users actually do with your apps. It monitors your application all the time it's running, both during testing and after you've published or deployed it. Application Insights creates charts and tables that show you, for example, what times of day you get most users, how responsive the app is, and how well it is served by any external services that it depends on. If there are crashes, failures or performance issues, you can search through the ### Azure Monitor -[Azure Monitor](/azure/monitoring-and-diagnostics/) offers visualization, query, routing, alerting, auto scale, and automation on data both from the Azure subscription ([Activity Log](../../azure-monitor/essentials/platform-logs-overview.md)) and each individual Azure resource ([Resource Logs](../../azure-monitor/essentials/platform-logs-overview.md)). You can use Azure Monitor to alert you on security-related events that are generated in Azure logs. +[Azure Monitor](/azure/monitoring-and-diagnostics/) offers visualization, query, routing, alerting, auto scale, and automation on data both from the Azure subscription ([Activity Log](/azure/azure-monitor/essentials/platform-logs-overview)) and each individual Azure resource ([Resource Logs](/azure/azure-monitor/essentials/platform-logs-overview)). You can use Azure Monitor to alert you on security-related events that are generated in Azure logs. ### Azure Monitor logs -[Azure Monitor logs](../../azure-monitor/logs/log-query-overview.md) ΓÇô Provides an IT management solution for both on-premises and third-party cloud-based infrastructure (such as AWS) in addition to Azure resources. Data from Azure Monitor can be routed directly to Azure Monitor logs so you can see metrics and logs for your entire environment in one place. +[Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview) ΓÇô Provides an IT management solution for both on-premises and third-party cloud-based infrastructure (such as AWS) in addition to Azure resources. Data from Azure Monitor can be routed directly to Azure Monitor logs so you can see metrics and logs for your entire environment in one place. -Azure Monitor logs can be a useful tool in forensic and other security analysis, as the tool enables you to quickly search through large amounts of security-related entries with a flexible query approach. In addition, on-premises [firewall and proxy logs can be exported into Azure and made available for analysis using Azure Monitor logs.](../../azure-monitor/agents/agent-windows.md) +Azure Monitor logs can be a useful tool in forensic and other security analysis, as the tool enables you to quickly search through large amounts of security-related entries with a flexible query approach. In addition, on-premises [firewall and proxy logs can be exported into Azure and made available for analysis using Azure Monitor logs.](/azure/azure-monitor/agents/agent-windows) ### Azure Advisor -[Azure Advisor](../../advisor/advisor-overview.md) is a personalized cloud consultant that helps you to optimize your Azure deployments. It analyzes your resource configuration and usage telemetry. It then recommends solutions to help improve the [performance](../../advisor/advisor-performance-recommendations.md), [security](../../advisor/advisor-security-recommendations.md), and [reliability](../../advisor/advisor-high-availability-recommendations.md) of your resources while looking for opportunities to [reduce your overall Azure spend](../../advisor/advisor-cost-recommendations.md). Azure Advisor provides security recommendations, which can significantly improve your overall security posture for solutions you deploy in Azure. These recommendations are drawn from security analysis performed by [Microsoft Defender for Cloud.](../../security-center/security-center-introduction.md) +[Azure Advisor](/azure/advisor/advisor-overview) is a personalized cloud consultant that helps you to optimize your Azure deployments. It analyzes your resource configuration and usage telemetry. It then recommends solutions to help improve the [performance](/azure/advisor/advisor-performance-recommendations), [security](/azure/advisor/advisor-security-recommendations), and [reliability](/azure/advisor/advisor-high-availability-recommendations) of your resources while looking for opportunities to [reduce your overall Azure spend](/azure/advisor/advisor-cost-recommendations). Azure Advisor provides security recommendations, which can significantly improve your overall security posture for solutions you deploy in Azure. These recommendations are drawn from security analysis performed by [Microsoft Defender for Cloud.](../../security-center/security-center-introduction.md) ## Applications |
| security | Paas Deployments | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/security/fundamentals/paas-deployments.md | Web applications are increasingly targets of malicious attacks that exploit comm ## Monitor the performance of your applications Monitoring is the act of collecting and analyzing data to determine the performance, health, and availability of your application. An effective monitoring strategy helps you understand the detailed operation of the components of your application. It helps you increase your uptime by notifying you of critical issues so that you can resolve them before they become problems. It also helps you detect anomalies that might be security related. -Use [Azure Application Insights](../../azure-monitor/app/app-insights-overview.md) to monitor availability, performance, and usage of your application, whether it's hosted in the cloud or on-premises. By using Application Insights, you can quickly identify and diagnose errors in your application without waiting for a user to report them. With the information that you collect, you can make informed choices on your application's maintenance and improvements. +Use [Azure Application Insights](/azure/azure-monitor/app/app-insights-overview) to monitor availability, performance, and usage of your application, whether it's hosted in the cloud or on-premises. By using Application Insights, you can quickly identify and diagnose errors in your application without waiting for a user to report them. With the information that you collect, you can make informed choices on your application's maintenance and improvements. Application Insights has extensive tools for interacting with the data that it collects. Application Insights stores its data in a common repository. It can take advantage of shared functionality such as alerts, dashboards, and deep analysis with the Kusto query language. |
| security | Services Technologies | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/security/fundamentals/services-technologies.md | Over time, this list will change and grow, just as Azure does. Make sure to chec |[Microsoft Defender for Cloud](/azure/defender-for-cloud/defender-for-cloud-introduction)| A cloud workload protection solution that provides security management and advanced threat protection across hybrid cloud workloads.| |[Microsoft Sentinel](../../sentinel/overview.md)| A scalable, cloud-native solution that delivers intelligent security analytics and threat intelligence across the enterprise.| |[Azure Key Vault](/azure/key-vault/general/overview)| A secure secrets store for the passwords, connection strings, and other information you need to keep your apps working. |-|[Azure Monitor logs](../../azure-monitor/logs/log-query-overview.md)|A monitoring service that collects telemetry and other data, and provides a query language and analytics engine to deliver operational insights for your apps and resources. Can be used alone or with other services such as Defender for Cloud. | +|[Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview)|A monitoring service that collects telemetry and other data, and provides a query language and analytics engine to deliver operational insights for your apps and resources. Can be used alone or with other services such as Defender for Cloud. | |[Azure Dev/Test Labs](../../devtest-labs/devtest-lab-overview.md)|A service that helps developers and testers quickly create environments in Azure while minimizing waste and controlling cost. | <!|[Azure Disk Encryption](/azure/azure-security-disk-encryption-overview)| THIS WILL GO TO THE NEW OVERVIEW TOPIC MEGHAN STEWART IS WRITING|> |
| security | Technical Capabilities | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/security/fundamentals/technical-capabilities.md | Azure Operational Security is built on a framework that incorporates the knowled ### Microsoft Azure Monitor -[Azure Monitor](../../azure-monitor/index.yml) is the IT management solution for the hybrid cloud. Used alone or to extend your existing System Center deployment, Azure Monitor logs gives you the maximum flexibility and control for cloud-based management of your infrastructure. +[Azure Monitor](/azure/azure-monitor/) is the IT management solution for the hybrid cloud. Used alone or to extend your existing System Center deployment, Azure Monitor logs gives you the maximum flexibility and control for cloud-based management of your infrastructure.  Defender for Cloud automatically collects, analyzes, and integrates log data fro ### Azure monitor -[Azure Monitor](../../azure-monitor/overview.md) provides pointers to information on specific types of resources. It offers visualization, query, routing, alerting, auto scale, and automation on data both from the Azure infrastructure (Activity Log) and each individual Azure resource (Diagnostic Logs). +[Azure Monitor](/azure/azure-monitor/overview) provides pointers to information on specific types of resources. It offers visualization, query, routing, alerting, auto scale, and automation on data both from the Azure infrastructure (Activity Log) and each individual Azure resource (Diagnostic Logs). Cloud applications are complex with many moving parts. Monitoring provides data to ensure that your application stays up and running in a healthy state. It also helps you to stave off potential problems or troubleshoot past ones. Auditing your network security is vital for detecting network vulnerabilities an ### Application Insights -[Application Insights](../../azure-monitor/app/app-insights-overview.md) is an extensible Application Performance Management (APM) service for web developers on multiple platforms. Use it to monitor your live web application. It will automatically detect performance anomalies. It includes powerful analytics tools to help you diagnose issues and to understand what users do with your app. It's designed to help you continuously improve performance and usability. It works for apps on a wide variety of platforms including .NET, Node.js and Java EE, hosted on-premises or in the cloud. It integrates with your DevOps process, and has connection points to a various development tools. +[Application Insights](/azure/azure-monitor/app/app-insights-overview) is an extensible Application Performance Management (APM) service for web developers on multiple platforms. Use it to monitor your live web application. It will automatically detect performance anomalies. It includes powerful analytics tools to help you diagnose issues and to understand what users do with your app. It's designed to help you continuously improve performance and usability. It works for apps on a wide variety of platforms including .NET, Node.js and Java EE, hosted on-premises or in the cloud. It integrates with your DevOps process, and has connection points to a various development tools. It monitors: |
| security | Threat Detection | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/security/fundamentals/threat-detection.md | PIM helps you: ## Azure Monitor logs -[Azure Monitor logs](../../azure-monitor/logs/data-platform-logs.md) is a Microsoft cloud-based IT management solution that helps you manage and protect your on-premises and cloud infrastructure. Because Azure Monitor logs is implemented as a cloud-based service, you can have it up and running quickly with minimal investment in infrastructure services. New security features are delivered automatically, saving ongoing maintenance and upgrade costs. +[Azure Monitor logs](/azure/azure-monitor/logs/data-platform-logs) is a Microsoft cloud-based IT management solution that helps you manage and protect your on-premises and cloud infrastructure. Because Azure Monitor logs is implemented as a cloud-based service, you can have it up and running quickly with minimal investment in infrastructure services. New security features are delivered automatically, saving ongoing maintenance and upgrade costs. ### Holistic security and compliance posture PIM helps you: Azure Monitor logs help you quickly and easily understand the overall security posture of any environment, all within the context of IT Operations, including software update assessment, antimalware assessment, and configuration baselines. Security log data is readily accessible to streamline the security and compliance audit processes. ### Insight and analytics-At the center of [Azure Monitor logs](../../azure-monitor/logs/log-query-overview.md) is the repository, which is hosted by Azure. +At the center of [Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview) is the repository, which is hosted by Azure.  You collect data into the repository from connected sources by configuring data Data sources and solutions each create separate record types with their own set of properties, but you can still analyze them together in queries to the repository. You can use the same tools and methods to work with a variety of data that's collected by various sources. Most of your interaction with Azure Monitor logs is through the Azure portal, which runs in any browser and provides you with access to configuration settings and multiple tools to analyze and act on collected data. From the portal, you can use:-* [Log searches](../../azure-monitor/logs/log-query-overview.md) where you construct queries to analyze collected data. -* [Dashboards](../../azure-monitor/visualize/tutorial-logs-dashboards.md), which you can customize with graphical views of your most valuable searches. +* [Log searches](/azure/azure-monitor/logs/log-query-overview) where you construct queries to analyze collected data. +* [Dashboards](/azure/azure-monitor/visualize/tutorial-logs-dashboards), which you can customize with graphical views of your most valuable searches. * [Solutions](/previous-versions/azure/azure-monitor/insights/solutions), which provide additional functionality and analysis tools. Solutions add functionality to Azure Monitor logs. They primarily run in the cloud and provide analysis of data that's collected in the log analytics repository. Solutions might also define new record types to be collected that can be analyzed with log searches or by using an additional user interface that the solution provides in the log analytics dashboard. |
| sentinel | Ama Migrate | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/ama-migrate.md | This article describes the migration process to the Azure Monitor Agent (AMA) wh > The Log Analytics agent will be [retired on **31 August, 2024**](https://azure.microsoft.com/updates/were-retiring-the-log-analytics-agent-in-azure-monitor-on-31-august-2024/). If you are using the Log Analytics agent in your Microsoft Sentinel deployment, we recommend that you start planning your migration to the AMA. ## Prerequisites-Start with the [Azure Monitor documentation](../azure-monitor/agents/azure-monitor-agent-migration.md) which provides an agent comparison and general information for this migration process. +Start with the [Azure Monitor documentation](/azure/azure-monitor/agents/azure-monitor-agent-migration) which provides an agent comparison and general information for this migration process. This article provides specific details and differences for Microsoft Sentinel. Each organization will have different metrics of success and internal migration **Include the following steps in your migration process**: -1. Make sure that you've reviewed necessary prerequisites and other considerations as [documented here](../azure-monitor/agents/azure-monitor-agent-migration.md#before-you-begin) in the Azure Monitor documentation. +1. Make sure that you've reviewed necessary prerequisites and other considerations as [documented here](/azure/azure-monitor/agents/azure-monitor-agent-migration#before-you-begin) in the Azure Monitor documentation. 1. Run a proof of concept to test how the AMA sends data to Microsoft Sentinel, ideally in a development or sandbox environment. Each organization will have different metrics of success and internal migration 5. Check your Microsoft Sentinel workspace to make sure that all your data streams have been replaced using the new AMA-based connectors. -6. Uninstall the legacy agent. For more information, see [Manage the Azure Log Analytics agent ](../azure-monitor/agents/agent-manage.md#uninstall-agent). +6. Uninstall the legacy agent. For more information, see [Manage the Azure Log Analytics agent ](/azure/azure-monitor/agents/agent-manage#uninstall-agent). ## FAQs-The following FAQs address issues specific to AMA migration with Microsoft Sentinel. For more information, see [Frequently asked questions for Azure Monitor Agent](../azure-monitor/agents/agents-overview.md#frequently-asked-questions) in the Azure Monitor documentation. +The following FAQs address issues specific to AMA migration with Microsoft Sentinel. For more information, see [Frequently asked questions for Azure Monitor Agent](/azure/azure-monitor/agents/agents-overview#frequently-asked-questions) in the Azure Monitor documentation. ## What happens if I run both MMA/OMS and AMA in parallel in my Microsoft Sentinel deployment? Both the AMA and MMA/OMS agents can co-exist on the same machine. If they both send data, from the same data source to a Microsoft Sentinel workspace, at the same time, from a single host, duplicate events and double ingestion charges will occur. -For your production rollout, we recommend that you configure either an MM#frequently-asked-questions). +For your production rollout, we recommend that you configure either an MMA/OMS agent or the AMA for each data source. To address any issues for duplication, see the relevant FAQs in the [Azure Monitor documentation](/azure/azure-monitor/agents/agents-overview#frequently-asked-questions). ## The AMA doesnΓÇÖt yet have the features my Microsoft Sentinel deployment needs to work. Should I migrate yet? The legacy Log Analytics agent will be retired on 31 August 2024. While you can run the MMA and AMA simultaneously, you may want to migrate each c For more information, see: -- [Overview of the Azure Monitor agents](../azure-monitor/agents/agents-overview.md)-- [Migrate from Log Analytics agents](../azure-monitor/agents/azure-monitor-agent-migration.md)+- [Overview of the Azure Monitor agents](/azure/azure-monitor/agents/agents-overview) +- [Migrate from Log Analytics agents](/azure/azure-monitor/agents/azure-monitor-agent-migration) - [Windows Security Events via AMA](data-connectors/windows-security-events-via-ama.md) - [Security events via Legacy Agent (Windows)](data-connectors/security-events-via-legacy-agent.md) - [Windows agent-based connections](connect-services-windows-based.md) |
| sentinel | Audit Sentinel Data | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/audit-sentinel-data.md | Microsoft Sentinel provides access to: ## Auditing with Azure Activity logs -Microsoft Sentinel's audit logs are maintained in the [Azure Activity Logs](../azure-monitor/essentials/platform-logs-overview.md), where the **AzureActivity** table includes all actions taken in your Microsoft Sentinel workspace. +Microsoft Sentinel's audit logs are maintained in the [Azure Activity Logs](/azure/azure-monitor/essentials/platform-logs-overview), where the **AzureActivity** table includes all actions taken in your Microsoft Sentinel workspace. You can use the **AzureActivity** table when auditing activity in your SOC environment with Microsoft Sentinel. AzureActivity ### Microsoft Sentinel data included in Azure Activity logs -Microsoft Sentinel's audit logs are maintained in the [Azure Activity Logs](../azure-monitor/essentials/platform-logs-overview.md), and include the following types of information: +Microsoft Sentinel's audit logs are maintained in the [Azure Activity Logs](/azure/azure-monitor/essentials/platform-logs-overview), and include the following types of information: |Operation |Information types | ||| For example, the following table lists selected operations found in Azure Activi |Update settings |Microsoft.SecurityInsights/settings| -For more information, see [Azure Activity Log event schema](../azure-monitor/essentials/activity-log-schema.md). +For more information, see [Azure Activity Log event schema](/azure/azure-monitor/essentials/activity-log-schema). ## Auditing with LAQueryLogs LAQueryLogs data includes information such as: 1. The **LAQueryLogs** table isn't enabled by default in your Log Analytics workspace. To use **LAQueryLogs** data when auditing in Microsoft Sentinel, first enable the **LAQueryLogs** in your Log Analytics workspace's **Diagnostics settings** area. - For more information, see [Audit queries in Azure Monitor logs](../azure-monitor/logs/query-audit.md). + For more information, see [Audit queries in Azure Monitor logs](/azure/azure-monitor/logs/query-audit). 1. Then, query the data using KQL, like you would any other table. |
| sentinel | Automate Incident Handling With Automation Rules | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/automate-incident-handling-with-automation-rules.md | You can [create and manage automation rules](create-manage-use-automation-rules. When you create an automation rule from here, the **Create new automation rule** panel populates all the fields with values from the incident. It names the rule the same name as the incident, applies it to the analytics rule that generated the incident, and uses all the available entities in the incident as conditions of the rule. It also suggests a suppression (closing) action by default, and suggests an expiration date for the rule. You can add or remove conditions and actions, and change the expiration date, as you wish. -### Export and import automation rules (Preview) +### Export and import automation rules Export your automation rules to Azure Resource Manager (ARM) template files, and import rules from these files, as part of managing and controlling your Microsoft Sentinel deployments as code. The export action creates a JSON file in your browser's downloads location, that you can then rename, move, and otherwise handle like any other file. |
| sentinel | Basic Logs Use Cases | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/basic-logs-use-cases.md | A new and growing source of log data is Internet of Things (IoT)-connected devic ## Next steps -- [Select a table plan based on data usage in a Log Analytics workspace](../azure-monitor/logs/logs-table-plans.md)-- [Set up a table with the Auxiliary plan in your Log Analytics workspace (Preview)](../azure-monitor/logs/create-custom-table-auxiliary.md)-- [Manage data retention in a Log Analytics workspace](../azure-monitor/logs/data-retention-configure.md)+- [Select a table plan based on data usage in a Log Analytics workspace](/azure/azure-monitor/logs/logs-table-plans) +- [Set up a table with the Auxiliary plan in your Log Analytics workspace (Preview)](/azure/azure-monitor/logs/create-custom-table-auxiliary) +- [Manage data retention in a Log Analytics workspace](/azure/azure-monitor/logs/data-retention-configure) - [Start an investigation by searching for events in large datasets (preview)](investigate-large-datasets.md) |
| sentinel | Best Practices Data | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/best-practices-data.md | Standard configuration for data collection may not work well for your organizati |||| |**Requires log filtering** | Use Logstash <br><br>Use Azure Functions <br><br> Use LogicApps <br><br> Use custom code (.NET, Python) | While filtering can lead to cost savings, and ingests only the required data, some Microsoft Sentinel features aren't supported, such as [UEBA](identify-threats-with-entity-behavior-analytics.md), [entity pages](entity-pages.md), [machine learning](bring-your-own-ml.md), and [fusion](fusion.md). <br><br>When configuring log filtering, make updates in resources such as threat hunting queries and analytics rules | |**Agent cannot be installed** |Use Windows Event Forwarding, supported with the [Azure Monitor Agent](connect-windows-security-events.md#connector-options) | Using Windows Event forwarding lowers load-balancing events per second from the Windows Event Collector, from 10,000 events to 500-1000 events.|-|**Servers do not connect to the internet** | Use the [Log Analytics gateway](../azure-monitor/agents/gateway.md) | Configuring a proxy to your agent requires extra firewall rules to allow the Gateway to work. | +|**Servers do not connect to the internet** | Use the [Log Analytics gateway](/azure/azure-monitor/agents/gateway) | Configuring a proxy to your agent requires extra firewall rules to allow the Gateway to work. | |**Requires tagging and enrichment at ingestion** |Use Logstash to inject a ResourceID <br><br>Use an ARM template to inject the ResourceID into on-premises machines <br><br>Ingest the resource ID into separate workspaces | Log Analytics doesn't support RBAC for custom tables <br><br>Microsoft Sentinel doesnΓÇÖt support row-level RBAC <br><br>**Tip**: You may want to adopt cross workspace design and functionality for Microsoft Sentinel. | |**Requires splitting operation and security logs** | Use the [Microsoft Monitor Agent or Azure Monitor Agent](connect-windows-security-events.md) multi-home functionality | Multi-home functionality requires more deployment overhead for the agent. | |**Requires custom logs** | Collect files from specific folder paths <br><br>Use API ingestion <br><br>Use PowerShell <br><br>Use Logstash | You may have issues filtering your logs. <br><br>Custom methods aren't supported. <br><br>Custom connectors may require developer skills. | Standard configuration for data collection may not work well for your organizati |||| |**Requires log filtering** | Use Syslog-NG <br><br>Use Rsyslog <br><br>Use FluentD configuration for the agent <br><br> Use the Azure Monitor Agent/Microsoft Monitoring Agent <br><br> Use Logstash | Some Linux distributions might not be supported by the agent. <br> <br>Using Syslog or FluentD requires developer knowledge. <br><br>For more information, see [Connect to Windows servers to collect security events](connect-windows-security-events.md) and [Resources for creating Microsoft Sentinel custom connectors](create-custom-connector.md). | |**Agent cannot be installed** | Use a Syslog forwarder, such as (syslog-ng or rsyslog. | |-|**Servers do not connect to the internet** | Use the [Log Analytics gateway](../azure-monitor/agents/gateway.md) | Configuring a proxy to your agent requires extra firewall rules to allow the Gateway to work. | +|**Servers do not connect to the internet** | Use the [Log Analytics gateway](/azure/azure-monitor/agents/gateway) | Configuring a proxy to your agent requires extra firewall rules to allow the Gateway to work. | |**Requires tagging and enrichment at ingestion** | Use Logstash for enrichment, or custom methods, such as API or Event Hubs. | You may have extra effort required for filtering. | |**Requires splitting operation and security logs** | Use the [Azure Monitor Agent](connect-windows-security-events.md) with the multi-homing configuration. | | |**Requires custom logs** | Create a custom collector using the Microsoft Monitoring (Log Analytics) agent. | | If you need to collect Microsoft Office data, outside of the standard connector |||| |**Filter logs from other platforms** | Use Logstash <br><br>Use the Azure Monitor Agent / Microsoft Monitoring (Log Analytics) agent | Custom collection has extra ingestion costs. <br><br>You may have a challenge of collecting all Windows events vs only security events. | |**Agent cannot be used** | Use Windows Event Forwarding | You may need to load balance efforts across your resources. |-|**Servers are in air-gapped network** | Use the [Log Analytics gateway](../azure-monitor/agents/gateway.md) | Configuring a proxy to your agent requires firewall rules to allow the Gateway to work. | +|**Servers are in air-gapped network** | Use the [Log Analytics gateway](/azure/azure-monitor/agents/gateway) | Configuring a proxy to your agent requires firewall rules to allow the Gateway to work. | |**RBAC, tagging, and enrichment at ingestion** | Create custom collection via Logstash or the Log Analytics API. | RBAC isn't supported for custom tables <br><br>Row-level RBAC isn't supported for any tables. | |
| sentinel | Billing Monitor Costs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/billing-monitor-costs.md | To define a daily volume cap, select **Usage and estimated costs** in the left n The **Usage and estimated costs** screen also shows your ingested data volume trend in the past 31 days, and the total retained data volume. -For more information, see [Set daily cap on Log Analytics workspace](../azure-monitor/logs/daily-cap.md). +For more information, see [Set daily cap on Log Analytics workspace](/azure/azure-monitor/logs/daily-cap). ## Next steps For more information, see [Set daily cap on Log Analytics workspace](../azure-mo - Learn more about managing costs with [cost analysis](../cost-management-billing/costs/quick-acm-cost-analysis.md?WT.mc_id=costmanagementcontent_docsacmhorizontal_-inproduct-learn). - Learn about how to [prevent unexpected costs](../cost-management-billing/understand/analyze-unexpected-charges.md?WT.mc_id=costmanagementcontent_docsacmhorizontal_-inproduct-learn). - Take the [Cost Management](/training/paths/control-spending-manage-bills?WT.mc_id=costmanagementcontent_docsacmhorizontal_-inproduct-learn) guided learning course.-- For more tips on reducing Log Analytics data volume, see [Azure Monitor best practices - Cost management](../azure-monitor/best-practices-cost.md).+- For more tips on reducing Log Analytics data volume, see [Azure Monitor best practices - Cost management](/azure/azure-monitor/best-practices-cost). |
| sentinel | Billing Reduce Costs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/billing-reduce-costs.md | When hunting or investigating threats in Microsoft Sentinel, you might need to a ## Select low-cost log types for high-volume, low-value data -While standard analytics logs are most appropriate for continuous, real-time threat detection, two other log types—[basic logs and auxiliary logs](../azure-monitor/logs/basic-logs-configure.md)—are more suited for ad-hoc querying and search of verbose, high-volume, low-value logs that aren't frequently needed or accessed on demand. Enable basic log data ingestion at a significantly reduced cost, or auxiliary log data ingestion (now in Preview) at an even lower cost, for eligible data tables. For more information, see [Microsoft Sentinel Pricing](https://azure.microsoft.com/pricing/details/microsoft-sentinel/). +While standard analytics logs are most appropriate for continuous, real-time threat detection, two other log types—[basic logs and auxiliary logs](/azure/azure-monitor/logs/basic-logs-configure)—are more suited for ad-hoc querying and search of verbose, high-volume, low-value logs that aren't frequently needed or accessed on demand. Enable basic log data ingestion at a significantly reduced cost, or auxiliary log data ingestion (now in Preview) at an even lower cost, for eligible data tables. For more information, see [Microsoft Sentinel Pricing](https://azure.microsoft.com/pricing/details/microsoft-sentinel/). - [Log retention plans in Microsoft Sentinel](log-plans.md) - [Log sources to use for Auxiliary Logs ingestion](basic-logs-use-cases.md) If you ingest at least 500 GB into your Microsoft Sentinel workspace or workspac You can add multiple Microsoft Sentinel workspaces to a Log Analytics dedicated cluster. There are a couple of advantages to using a Log Analytics dedicated cluster for Microsoft Sentinel: -- Cross-workspace queries run faster if all the workspaces involved in the query are in the dedicated cluster. It's still best to have as few workspaces as possible in your environment, and a dedicated cluster still retains the [100 workspace limit](../azure-monitor/logs/cross-workspace-query.md) for inclusion in a single cross-workspace query.+- Cross-workspace queries run faster if all the workspaces involved in the query are in the dedicated cluster. It's still best to have as few workspaces as possible in your environment, and a dedicated cluster still retains the [100 workspace limit](/azure/azure-monitor/logs/cross-workspace-query) for inclusion in a single cross-workspace query. - All workspaces in the dedicated cluster can share the Log Analytics Commitment Tier set on the cluster. Not having to commit to separate Log Analytics Commitment Tiers for each workspace can allow for cost savings and efficiencies. By enabling a dedicated cluster, you commit to a minimum Log Analytics Commitment Tier of 500-GB ingestion per day. Here are some other considerations for moving to a dedicated cluster for cost op - Moving a cluster to another resource group or subscription isn't currently supported. - A workspace link to a cluster fails if the workspace is linked to another cluster. -For more information about dedicated clusters, see [Log Analytics dedicated clusters](../azure-monitor/logs/cost-logs.md#dedicated-clusters). +For more information about dedicated clusters, see [Log Analytics dedicated clusters](/azure/azure-monitor/logs/cost-logs#dedicated-clusters). ## Reduce data retention costs with long-term retention Microsoft Sentinel retains data by default in interactive form for the first 90 Microsoft Sentinel security data might lose some of its value after a few months. Security operations center (SOC) users might not need to access older data as frequently as newer data, but still might need to access the data for sporadic investigations or audit purposes. -To help you reduce Microsoft Sentinel data retention costs, Azure Monitor now offers long-term retention. Data that ages out of its interactive retention state can still be retained for up to twelve years, at a much-reduced cost, and with limitations on its usage. For more information, see [Manage data retention in a Log Analytics workspace](../azure-monitor/logs/data-retention-configure.md). +To help you reduce Microsoft Sentinel data retention costs, Azure Monitor now offers long-term retention. Data that ages out of its interactive retention state can still be retained for up to twelve years, at a much-reduced cost, and with limitations on its usage. For more information, see [Manage data retention in a Log Analytics workspace](/azure/azure-monitor/logs/data-retention-configure). You can reduce costs even further by enrolling tables that contain secondary security data in the **Auxiliary logs** plan (now in Preview). This plan allows you to store high-volume, low-value logs at a low price, with a lower-cost 30-day interactive retention period at the beginning to allow for summarization and basic querying. To learn more about the Auxiliary logs plan and other plans, see [Log retention plans in Microsoft Sentinel](log-plans.md). While the auxiliary logs plan remains in Preview, you also have the option of enrolling these tables in the **Basic logs** plan. Basic logs offers similar functionality to auxiliary logs, but with less of a cost savings. You can reduce costs even further by enrolling tables that contain secondary sec The [Windows Security Events connector](connect-windows-security-events.md?tabs=LAA) enables you to stream security events from any computer running Windows Server that's connected to your Microsoft Sentinel workspace, including physical, virtual, or on-premises servers, or in any cloud. This connector includes support for the Azure Monitor agent, which uses data collection rules to define the data to collect from each agent. -Data collection rules enable you to manage collection settings at scale, while still allowing unique, scoped configurations for subsets of machines. For more information, see [Configure data collection for the Azure Monitor agent](../azure-monitor/agents/azure-monitor-agent-data-collection.md). +Data collection rules enable you to manage collection settings at scale, while still allowing unique, scoped configurations for subsets of machines. For more information, see [Configure data collection for the Azure Monitor agent](/azure/azure-monitor/agents/azure-monitor-agent-data-collection). Besides for the predefined sets of events that you can select to ingest, such as All events, Minimal, or Common, data collection rules enable you to build custom filters and select specific events to ingest. The Azure Monitor Agent uses these rules to filter the data at the source, and then ingest only the events you selected, while leaving everything else behind. Selecting specific events to ingest can help you optimize your costs and save more. Besides for the predefined sets of events that you can select to ingest, such as - Learn more about managing costs with [cost analysis](../cost-management-billing/costs/quick-acm-cost-analysis.md?WT.mc_id=costmanagementcontent_docsacmhorizontal_-inproduct-learn). - Learn about how to [prevent unexpected costs](../cost-management-billing/understand/analyze-unexpected-charges.md?WT.mc_id=costmanagementcontent_docsacmhorizontal_-inproduct-learn). - Take the [Cost Management](/training/paths/control-spending-manage-bills?WT.mc_id=costmanagementcontent_docsacmhorizontal_-inproduct-learn) guided learning course.-- For more tips on reducing Log Analytics data volume, see [Azure Monitor best practices - Cost management](../azure-monitor/best-practices-cost.md).+- For more tips on reducing Log Analytics data volume, see [Azure Monitor best practices - Cost management](/azure/azure-monitor/best-practices-cost). |
| sentinel | Billing | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/billing.md | These two log types are best suited for use in playbook automation, ad-hoc query - [Log retention plans in Microsoft Sentinel](log-plans.md) - [Log sources to use for Auxiliary Logs ingestion](basic-logs-use-cases.md) -To learn more about the difference between **interactive retention** and **long-term retention** (formerly known as archive), see [Manage data retention in a Log Analytics workspace](../azure-monitor/logs/data-retention-archive.md). +To learn more about the difference between **interactive retention** and **long-term retention** (formerly known as archive), see [Manage data retention in a Log Analytics workspace](/azure/azure-monitor/logs/data-retention-archive). > [!IMPORTANT] > If you're billed at classic pay-as-you-go rate, this table shows how Microsoft S # [Free data meters](#tab/free-data-meters/simplified) -This table shows how Microsoft Sentinel and Log Analytics no charge costs appear in the **Service name** and **Meter** columns of your Azure bill for free data services when billing is at a simplified pricing tier. For more information, see [View Data Allocation Benefits](../azure-monitor/cost-usage.md#view-data-allocation-benefits). +This table shows how Microsoft Sentinel and Log Analytics no charge costs appear in the **Service name** and **Meter** columns of your Azure bill for free data services when billing is at a simplified pricing tier. For more information, see [View Data Allocation Benefits](/azure/azure-monitor/cost-usage#view-data-allocation-benefits). | Cost description | Service name | Meter | |--|--|--| This table shows how Microsoft Sentinel and Log Analytics no charge costs appear # [Free data meters](#tab/free-data-meters/classic) -This table shows how Microsoft Sentinel and Log Analytics no charge costs appear in the **Service name** and **Meter** columns of your Azure bill for free data services when billing is at a classic pricing tier. For more information, see [View Data Allocation Benefits](../azure-monitor/cost-usage.md#view-data-allocation-benefits). +This table shows how Microsoft Sentinel and Log Analytics no charge costs appear in the **Service name** and **Meter** columns of your Azure bill for free data services when billing is at a classic pricing tier. For more information, see [View Data Allocation Benefits](/azure/azure-monitor/cost-usage#view-data-allocation-benefits). | Cost description | Service name | Meter | |--|--|--| Any other services you use might have associated costs. After you enable Microsoft Sentinel on a Log Analytics workspace, consider these configuration options: - Retain all data ingested into the workspace at no charge for the first 90 days. Retention beyond 90 days is charged per the standard [Log Analytics retention prices](https://azure.microsoft.com/pricing/details/monitor/).-- Specify different retention settings for individual data types. Learn about [retention by data type](../azure-monitor/logs/data-retention-configure.md#configure-table-level-retention). -- Enable long-term retention for your data so you have access to historical logs. Long-term retention is a low-cost retention state for the preservation of data for such things as regulatory compliance. It's charged based on the volume of data stored and scanned. Learn how to [configure interactive and long-term data retention policies in Azure Monitor Logs](../azure-monitor/logs/data-retention-configure.md). +- Specify different retention settings for individual data types. Learn about [retention by data type](/azure/azure-monitor/logs/data-retention-configure#configure-table-level-retention). +- Enable long-term retention for your data so you have access to historical logs. Long-term retention is a low-cost retention state for the preservation of data for such things as regulatory compliance. It's charged based on the volume of data stored and scanned. Learn how to [configure interactive and long-term data retention policies in Azure Monitor Logs](/azure/azure-monitor/logs/data-retention-configure). - Enroll tables that contain secondary security data in the **Auxiliary logs** plan. This plan allows you to store high-volume, low-value logs at a low price, with a lower-cost 30-day interactive retention period at the beginning to allow for summarization and basic querying. To learn more about the Auxiliary logs plan and other plans, see [Log retention plans in Microsoft Sentinel](log-plans.md). ## Other CEF ingestion costs The following data sources are free with Microsoft Sentinel: Although alerts are free, the raw logs for some Microsoft Defender XDR, Defender for Endpoint/Identity/Office 365/Cloud Apps, Microsoft Entra ID, and Azure Information Protection (AIP) data types are paid. -The following table lists the data sources in Microsoft Sentinel and Log Analytics that aren't charged. For more information, see [excluded tables](../azure-monitor/logs/cost-logs.md#excluded-tables). +The following table lists the data sources in Microsoft Sentinel and Log Analytics that aren't charged. For more information, see [excluded tables](/azure/azure-monitor/logs/cost-logs#excluded-tables). | Microsoft Sentinel data connector | Free data type | | - | | Learn more about how to [connect data sources](connect-data-sources.md), includi - Learn more about managing costs with [cost analysis](../cost-management-billing/costs/quick-acm-cost-analysis.md?WT.mc_id=costmanagementcontent_docsacmhorizontal_-inproduct-learn). - Learn about how to [prevent unexpected costs](../cost-management-billing/understand/analyze-unexpected-charges.md?WT.mc_id=costmanagementcontent_docsacmhorizontal_-inproduct-learn). - Take the [Cost Management](/training/paths/control-spending-manage-bills?WT.mc_id=costmanagementcontent_docsacmhorizontal_-inproduct-learn) guided learning course.-- For more tips on reducing Log Analytics data volume, see [Azure Monitor best practices - Cost management](../azure-monitor/best-practices-cost.md).+- For more tips on reducing Log Analytics data volume, see [Azure Monitor best practices - Cost management](/azure/azure-monitor/best-practices-cost). ## Next steps |
| sentinel | Cef Syslog Ama Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/cef-syslog-ama-overview.md | Last updated 07/12/2024 # Syslog and Common Event Format (CEF) via AMA connectors for Microsoft Sentinel -The Syslog via AMA and Common Event Format (CEF) via AMA data connectors for Microsoft Sentinel filter and ingest Syslog messages, including messages in Common Event Format (CEF), from Linux machines and from network and security devices and appliances. These connectors install the Azure Monitor Agent (AMA) on any Linux machine from which you want to collect Syslog and/or CEF messages. This machine could be the originator of the messages, or it could be a forwarder that collects messages from other machines, such as network or security devices and appliances. The connector sends the agents instructions based on [Data Collection Rules (DCRs)](../azure-monitor/essentials/data-collection-rule-overview.md) that you define. DCRs specify the systems to monitor and the types of logs or messages to collect. They define filters to apply to the messages before they're ingested, for better performance and more efficient querying and analysis. +The Syslog via AMA and Common Event Format (CEF) via AMA data connectors for Microsoft Sentinel filter and ingest Syslog messages, including messages in Common Event Format (CEF), from Linux machines and from network and security devices and appliances. These connectors install the Azure Monitor Agent (AMA) on any Linux machine from which you want to collect Syslog and/or CEF messages. This machine could be the originator of the messages, or it could be a forwarder that collects messages from other machines, such as network or security devices and appliances. The connector sends the agents instructions based on [Data Collection Rules (DCRs)](/azure/azure-monitor/essentials/data-collection-rule-overview) that you define. DCRs specify the systems to monitor and the types of logs or messages to collect. They define filters to apply to the messages before they're ingested, for better performance and more efficient querying and analysis. Syslog and CEF are two common formats for logging data from different devices and applications. They help system administrators and security analysts to monitor and troubleshoot the network and identify potential threats or incidents. To avoid this scenario, use one of these methods: To see an example of how to arrange a DCR to ingest both Syslog and CEF messages from the same agent, go to [Syslog and CEF streams in the same DCR](connect-cef-syslog-ama.md?tabs=api#syslog-and-cef-streams-in-the-same-dcr). -- **If changing the facility for the source appliance isn't applicable**: After you create the DCR, add ingestion time transformation to filter out CEF messages from the Syslog stream to avoid duplication. See [Tutorial: Edit a data collection rule (DCR)](../azure-monitor/essentials/data-collection-rule-edit.md). Add KQL transformation similar to the following example:+- **If changing the facility for the source appliance isn't applicable**: After you create the DCR, add ingestion time transformation to filter out CEF messages from the Syslog stream to avoid duplication. See [Tutorial: Edit a data collection rule (DCR)](/azure/azure-monitor/essentials/data-collection-rule-edit). Add KQL transformation similar to the following example: ```json "transformKql": " source\n | where ProcessName !contains \"CEF\"\n" |
| sentinel | Configure Data Retention Archive | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/configure-data-retention-archive.md | In the previous deployment step, you enabled the User and Entity Behavior Analyt Retention policies define when to remove data, or mark it for long-term retention, in a Log Analytics workspace. Long-term retention lets you keep older, less used data in your workspace at a reduced cost. To set up data retention plans, consult [Log retention plans in Microsoft Sentinel](log-plans.md), and use one or both of these methods, depending on your use case: -- [Configure interactive and long-term data retention for one or more tables](../azure-monitor/logs/data-retention-configure.md) (one table at a time)+- [Configure interactive and long-term data retention for one or more tables](/azure/azure-monitor/logs/data-retention-configure) (one table at a time) - [Configure data retention for multiple tables](https://github.com/Azure/Azure-Sentinel/tree/master/Tools/Archive-Log-Tool) at once ## Next steps |
| sentinel | Configure Data Retention | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/configure-data-retention.md | No resources were created but you might want to restore the data retention setti ## Next steps > [!div class="nextstepaction"]-> [Configure interactive and long-term data retention policies in Azure Monitor Logs](../azure-monitor/logs/data-retention-configure.md) +> [Configure interactive and long-term data retention policies in Azure Monitor Logs](/azure/azure-monitor/logs/data-retention-configure) |
| sentinel | Configure Data Transformation | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/configure-data-transformation.md | Before you start configuring DCRs for data transformation: - **Learn more about data transformation and DCRs in Azure Monitor and Microsoft Sentinel**. For more information, see: - - [Data collection rules in Azure Monitor](../azure-monitor/essentials/data-collection-rule-overview.md) - - [Logs ingestion API in Azure Monitor Logs (Preview)](../azure-monitor/logs/logs-ingestion-api-overview.md) - - [Transformations in Azure Monitor Logs (preview)](../azure-monitor/essentials/data-collection-transformations.md) + - [Data collection rules in Azure Monitor](/azure/azure-monitor/essentials/data-collection-rule-overview) + - [Logs ingestion API in Azure Monitor Logs (Preview)](/azure/azure-monitor/logs/logs-ingestion-api-overview) + - [Transformations in Azure Monitor Logs (preview)](/azure/azure-monitor/essentials/data-collection-transformations) - [Data transformation in Microsoft Sentinel (preview)](data-transformation.md) - **Verify data connector support**. Make sure that your data connectors are supported for data transformation. Before you start configuring DCRs for data transformation: | If you are ingesting | Ingestion-time transformation is... | Use this DCR type | | -- | - | -- |-| **Custom data** through <br>the [**Log Ingestion API**](../azure-monitor/logs/logs-ingestion-api-overview.md) | <li>Required<li>Included in the DCR that defines the data model | Standard DCR | +| **Custom data** through <br>the [**Log Ingestion API**](/azure/azure-monitor/logs/logs-ingestion-api-overview) | <li>Required<li>Included in the DCR that defines the data model | Standard DCR | | **Built-in data types** <br>(Syslog, CommonSecurityLog, WindowsEvent, SecurityEvent) <br>using the legacy **Log Analytics Agent (MMA)** | <li>Optional<li>If desired, added to the DCR attached to the Workspace where this data is being ingested | Workspace transformation DCR | | **Built-in data types** <br>from most other sources | <li>Optional<li>If desired, added to the DCR attached to the Workspace where this data is being ingested | Workspace transformation DCR | Before you start configuring DCRs for data transformation: Use the following procedures from the Log Analytics and Azure Monitor documentation to configure your data transformation DCRs: -[Direct ingestion through the Log Ingestion API](../azure-monitor/logs/logs-ingestion-api-overview.md): -- Walk through a tutorial for [ingesting logs using the Azure portal](../azure-monitor/logs/tutorial-logs-ingestion-portal.md).-- Walk through a tutorial for [ingesting logs using Azure Resource Manager (ARM) templates and REST API](../azure-monitor/logs/tutorial-logs-ingestion-api.md).+[Direct ingestion through the Log Ingestion API](/azure/azure-monitor/logs/logs-ingestion-api-overview): +- Walk through a tutorial for [ingesting logs using the Azure portal](/azure/azure-monitor/logs/tutorial-logs-ingestion-portal). +- Walk through a tutorial for [ingesting logs using Azure Resource Manager (ARM) templates and REST API](/azure/azure-monitor/logs/tutorial-logs-ingestion-api). -[Workspace transformations](../azure-monitor/essentials/data-collection-transformations-workspace.md): -- Walk through a tutorial for [configuring workspace transformation using the Azure portal](../azure-monitor/logs/tutorial-workspace-transformations-portal.md).-- Walk through a tutorial for [configuring workspace transformation using Azure Resource Manager (ARM) templates and REST API](../azure-monitor/logs/tutorial-workspace-transformations-api.md).- +[Workspace transformations](/azure/azure-monitor/essentials/data-collection-transformations-workspace): +- Walk through a tutorial for [configuring workspace transformation using the Azure portal](/azure/azure-monitor/logs/tutorial-workspace-transformations-portal). +- Walk through a tutorial for [configuring workspace transformation using Azure Resource Manager (ARM) templates and REST API](/azure/azure-monitor/logs/tutorial-workspace-transformations-api).- -[More on data collection rules](../azure-monitor/essentials/data-collection-rule-overview.md): -- [Structure of a data collection rule in Azure Monitor (preview)](../azure-monitor/essentials/data-collection-rule-structure.md)-- [Data collection transformations in Azure Monitor (preview)](../azure-monitor/essentials/data-collection-transformations.md)+[More on data collection rules](/azure/azure-monitor/essentials/data-collection-rule-overview): +- [Structure of a data collection rule in Azure Monitor (preview)](/azure/azure-monitor/essentials/data-collection-rule-structure) +- [Data collection transformations in Azure Monitor (preview)](/azure/azure-monitor/essentials/data-collection-transformations) When you're done, come back to Microsoft Sentinel to verify that your data is being ingested based on your newly configured transformation. It may take up to 60 minutes for the data transformation configurations to apply. Use one of the following methods: After you've verified that your data is properly ingested to the new table, you can delete the legacy table, as well as your legacy, custom data connector. -- Continue using the custom table created by your custom data connector. You might use this option if you have a lot of custom security content created for your existing table. In such cases, see [Migrate from Data Collector API and custom fields-enabled tables to DCR-based custom logs](../azure-monitor/logs/custom-logs-migrate.md) in the Azure Monitor documentation.+- Continue using the custom table created by your custom data connector. You might use this option if you have a lot of custom security content created for your existing table. In such cases, see [Migrate from Data Collector API and custom fields-enabled tables to DCR-based custom logs](/azure/azure-monitor/logs/custom-logs-migrate) in the Azure Monitor documentation. ## Next steps For more information about data transformation and DCRs, see: - [Custom data ingestion and transformation in Microsoft Sentinel (preview)](data-transformation.md)-- [Data collection transformations in Azure Monitor Logs (preview)](../azure-monitor/essentials/data-collection-transformations.md)-- [Logs ingestion API in Azure Monitor Logs (Preview)](../azure-monitor/logs/logs-ingestion-api-overview.md)-- [Structure of a data collection rule in Azure Monitor (preview)](../azure-monitor/essentials/data-collection-rule-structure.md)-- [Configure data collection for the Azure Monitor agent](../azure-monitor/agents/azure-monitor-agent-data-collection.md)+- [Data collection transformations in Azure Monitor Logs (preview)](/azure/azure-monitor/essentials/data-collection-transformations) +- [Logs ingestion API in Azure Monitor Logs (Preview)](/azure/azure-monitor/logs/logs-ingestion-api-overview) +- [Structure of a data collection rule in Azure Monitor (preview)](/azure/azure-monitor/essentials/data-collection-rule-structure) +- [Configure data collection for the Azure Monitor agent](/azure/azure-monitor/agents/azure-monitor-agent-data-collection) |
| sentinel | Connect Azure Functions Template | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/connect-azure-functions-template.md | Make sure that you have the following permissions and credentials before using A - You must have read and write permissions on the Microsoft Sentinel workspace. -- You must have read permissions to shared keys for the workspace. [Learn more about workspace keys](../azure-monitor/agents/agent-windows.md#workspace-id-and-key).+- You must have read permissions to shared keys for the workspace. [Learn more about workspace keys](/azure/azure-monitor/agents/agent-windows#workspace-id-and-key). - You must have read and write permissions on Azure Functions to create a Function App. [Learn more about Azure Functions](../azure-functions/index.yml). |
| sentinel | Connect Azure Stack | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/connect-azure-stack.md | Add the **Azure Monitor, Update, and Configuration Management** virtual machine 1. After the extension installation completes, its status shows as **Provisioning Succeeded**. It might take up to one hour for the virtual machine to appear in the Microsoft Sentinel portal. -For more information on installing and configuring the agent for Windows, see [Connect Windows computers](../azure-monitor/agents/agent-windows.md#install-the-agent). +For more information on installing and configuring the agent for Windows, see [Connect Windows computers](/azure/azure-monitor/agents/agent-windows#install-the-agent). -For Linux troubleshooting of agent issues, see [Troubleshoot Azure Log Analytics Linux Agent](../azure-monitor/agents/agent-linux-troubleshoot.md). +For Linux troubleshooting of agent issues, see [Troubleshoot Azure Log Analytics Linux Agent](/azure/azure-monitor/agents/agent-linux-troubleshoot). In the Microsoft Sentinel portal on Azure, under **Virtual Machines**, you have an overview of all VMs and computers along with their status. |
| sentinel | Connect Azure Virtual Desktop | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/connect-azure-virtual-desktop.md | Azure Virtual Desktop data in Microsoft Sentinel includes the following types: |Data |Description | |||-|**Windows event logs** | Windows event logs from the Azure Virtual Desktop environment are streamed into a Microsoft Sentinel-enabled Log Analytics workspace in the same manner as Windows event logs from other Windows machines, outside of the Azure Virtual Desktop environment. <br><br>Install the Log Analytics agent onto your Windows machine and configure the Windows event logs to be sent to the Log Analytics workspace.<br><br>For more information, see:<br>- [Install Log Analytics agent on Windows computers](../azure-monitor/agents/agent-windows.md)<br>- [Collect Windows event log data sources with Log Analytics agent](../azure-monitor/agents/data-sources-windows-events.md)<br>- [Connect Windows security events](connect-windows-security-events.md) | +|**Windows event logs** | Windows event logs from the Azure Virtual Desktop environment are streamed into a Microsoft Sentinel-enabled Log Analytics workspace in the same manner as Windows event logs from other Windows machines, outside of the Azure Virtual Desktop environment. <br><br>Install the Log Analytics agent onto your Windows machine and configure the Windows event logs to be sent to the Log Analytics workspace.<br><br>For more information, see:<br>- [Install Log Analytics agent on Windows computers](/azure/azure-monitor/agents/agent-windows)<br>- [Collect Windows event log data sources with Log Analytics agent](/azure/azure-monitor/agents/data-sources-windows-events)<br>- [Connect Windows security events](connect-windows-security-events.md) | |**Microsoft Defender for Endpoint alerts** | To configure Defender for Endpoint for Azure Virtual Desktop, use the same procedure as you would for any other Windows endpoint. <br><br>For more information, see: <br>- [Set up Microsoft Defender for Endpoint deployment](/windows/security/threat-protection/microsoft-defender-atp/production-deployment)<br>- [Connect data from Microsoft Defender XDR to Microsoft Sentinel](connect-microsoft-365-defender.md) | |**Azure Virtual Desktop diagnostics** | Azure Virtual Desktop diagnostics is a feature of the Azure Virtual Desktop PaaS service, which logs information whenever someone assigned Azure Virtual Desktop role uses the service. <br><br>Each log contains information about which Azure Virtual Desktop role was involved in the activity, any error messages that appear during the session, tenant information, and user information. <br><br>The diagnostics feature creates activity logs for both user and administrative actions. <br><br>For more information, see [Use Log Analytics for the diagnostics feature in Azure Virtual Desktop](../virtual-desktop/virtual-desktop-fall-2019/diagnostics-log-analytics-2019.md). | |
| sentinel | Connect Cef Syslog Ama | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/connect-cef-syslog-ama.md | -> Container Insights now supports the automatic collection of Syslog events from Linux nodes in your AKS clusters. To learn more, see [Syslog collection with Container Insights](../azure-monitor/containers/container-insights-syslog.md). +> Container Insights now supports the automatic collection of Syslog events from Linux nodes in your AKS clusters. To learn more, see [Syslog collection with Container Insights](/azure/azure-monitor/containers/container-insights-syslog). ## Prerequisites If you're collecting messages from a log forwarder, the following prerequisites - You must have a designated Linux VM as a log forwarder to collect logs. - [Create a Linux VM in the Azure portal](/azure/virtual-machines/linux/quick-create-portal).- - [Supported Linux operating systems for Azure Monitor Agent](../azure-monitor/agents/agents-overview.md#linux). + - [Supported Linux operating systems for Azure Monitor Agent](/azure/azure-monitor/agents/agents-overview#linux). - If your log forwarder *isn't* an Azure virtual machine, it must have the Azure Arc [Connected Machine agent](../azure-arc/servers/overview.md) installed on it. If you're collecting messages from a log forwarder, the following prerequisites - The log forwarder must have either the `syslog-ng` or `rsyslog` daemon enabled. -- For space requirements for your log forwarder, refer to the [Azure Monitor Agent Performance Benchmark](../azure-monitor/agents/azure-monitor-agent-performance.md). You can also review [this blog post](https://techcommunity.microsoft.com/t5/microsoft-sentinel-blog/designs-for-accomplishing-microsoft-sentinel-scalable-ingestion/ba-p/3741516), which includes designs for scalable ingestion.+- For space requirements for your log forwarder, refer to the [Azure Monitor Agent Performance Benchmark](/azure/azure-monitor/agents/azure-monitor-agent-performance). You can also review [this blog post](https://techcommunity.microsoft.com/t5/microsoft-sentinel-blog/designs-for-accomplishing-microsoft-sentinel-scalable-ingestion/ba-p/3741516), which includes designs for scalable ingestion. - Your log sources, security devices, and appliances, must be configured to send their log messages to the log forwarder's syslog daemon instead of to their local syslog daemon. After you complete all the tabs, review what you entered and create the data col ### Install the Azure Monitor Agent Follow the appropriate instructions from the Azure Monitor documentation to install the Azure Monitor Agent on your log forwarder. Remember to use the instructions for Linux, not for Windows.-- [Install the AMA using PowerShell](../azure-monitor/agents/azure-monitor-agent-manage.md?tabs=azure-powershell)-- [Install the AMA using the Azure CLI](../azure-monitor/agents/azure-monitor-agent-manage.md?tabs=azure-cli)-- [Install the AMA using an Azure Resource Manager template](../azure-monitor/agents/azure-monitor-agent-manage.md?tabs=azure-resource-manager)+- [Install the AMA using PowerShell](/azure/azure-monitor/agents/azure-monitor-agent-manage?tabs=azure-powershell) +- [Install the AMA using the Azure CLI](/azure/azure-monitor/agents/azure-monitor-agent-manage?tabs=azure-cli) +- [Install the AMA using an Azure Resource Manager template](/azure/azure-monitor/agents/azure-monitor-agent-manage?tabs=azure-resource-manager) -You can create Data Collection Rules (DCRs) using the [Azure Monitor Logs Ingestion API](/rest/api/monitor/data-collection-rules). For more information, see [Data collection rules in Azure Monitor](../azure-monitor/essentials/data-collection-rule-overview.md). +You can create Data Collection Rules (DCRs) using the [Azure Monitor Logs Ingestion API](/rest/api/monitor/data-collection-rules). For more information, see [Data collection rules in Azure Monitor](/azure/azure-monitor/essentials/data-collection-rule-overview). ### Create the data collection rule If you're using a log forwarder, configure the syslog daemon to listen for messa If you're using Python 3, and it's not set as the default command on the machine, substitute `python3` for `python` in the pasted command. See [Log forwarder prerequisites](#log-forwarder-prerequisites). > [!NOTE] - > To avoid [Full Disk scenarios](../azure-monitor/agents/azure-monitor-agent-troubleshoot-linux-vm-rsyslog.md) where the agent can't function, we recommend that you set the `syslog-ng` or `rsyslog` configuration not to store unneeded logs. A Full Disk scenario disrupts the function of the installed AMA. + > To avoid [Full Disk scenarios](/azure/azure-monitor/agents/azure-monitor-agent-troubleshoot-linux-vm-rsyslog) where the agent can't function, we recommend that you set the `syslog-ng` or `rsyslog` configuration not to store unneeded logs. A Full Disk scenario disrupts the function of the installed AMA. > For more information, see [RSyslog](https://www.rsyslog.com/doc/master/configuration/actions.html) or [Syslog-ng](https://syslog-ng.github.io/). ## Configure the security device or appliance Verify that logs messages from your linux machine or security devices and applia ## Related content - [Syslog and Common Event Format (CEF) via AMA connectors for Microsoft Sentinel](cef-syslog-ama-overview.md)-- [Data collection rules in Azure Monitor](../azure-monitor/essentials/data-collection-rule-overview.md)+- [Data collection rules in Azure Monitor](/azure/azure-monitor/essentials/data-collection-rule-overview) - [CEF via AMA data connector - Configure specific appliance or device for Microsoft Sentinel data ingestion](unified-connector-cef-device.md) - [Syslog via AMA data connector - Configure specific appliance or device for the Microsoft Sentinel data ingestion](unified-connector-syslog-device.md) |
| sentinel | Connect Common Event Format | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/connect-common-event-format.md | -Learn how to [collect Syslog with the AMA](../azure-monitor/agents/data-collection-syslog.md), including how to configure Syslog and create a DCR. +Learn how to [collect Syslog with the AMA](/azure/azure-monitor/agents/data-collection-syslog), including how to configure Syslog and create a DCR. > [!IMPORTANT] > A Microsoft Sentinel workspace is required in order to ingest CEF data into Log - You must have read and write permissions on this workspace. -- You must have read permissions to the shared keys for the workspace. [Learn more about workspace keys](../azure-monitor/agents/agent-windows.md).+- You must have read permissions to the shared keys for the workspace. [Learn more about workspace keys](/azure/azure-monitor/agents/agent-windows). ## Designate a log forwarder and install the Log Analytics agent |
| sentinel | Connect Custom Logs Ama | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/connect-custom-logs-ama.md | Many applications log data to text files instead of standard logging services li For more information about the applications for which Microsoft Sentinel has solutions to support log collection, see [Custom Logs via AMA data connector - Configure data ingestion to Microsoft Sentinel from specific applications](unified-connector-custom-device.md). -For more general information about ingesting custom logs from text files, see [Collect logs from a text file with Azure Monitor Agent](../azure-monitor/agents/data-collection-log-text.md). +For more general information about ingesting custom logs from text files, see [Collect logs from a text file with Azure Monitor Agent](/azure/azure-monitor/agents/data-collection-log-text). > [!IMPORTANT] > - The **Custom Logs via AMA** data connector is currently in PREVIEW. See the [Supplemental Terms of Use for Microsoft Azure Previews](https://azure.microsoft.com/support/legal/preview-supplemental-terms/) for additional legal terms that apply to Azure features that are in beta, preview, or otherwise not yet released into general availability. Certain custom applications are hosted on closed appliances that necessitate sen - You must have a designated Linux VM as a log forwarder to collect logs. - [Create a Linux VM in the Azure portal](/azure/virtual-machines/linux/quick-create-portal).- - [Supported Linux operating systems for Azure Monitor Agent](../azure-monitor/agents/agents-overview.md#linux). + - [Supported Linux operating systems for Azure Monitor Agent](/azure/azure-monitor/agents/agents-overview#linux). - If your log forwarder *isn't* an Azure virtual machine, it must have the Azure Arc [Connected Machine agent](../azure-arc/servers/overview.md) installed on it. Certain custom applications are hosted on closed appliances that necessitate sen - The log forwarder must have either the `syslog-ng` or `rsyslog` daemon enabled. -- For space requirements for your log forwarder, refer to the [Azure Monitor Agent Performance Benchmark](../azure-monitor/agents/azure-monitor-agent-performance.md). You can also review [this blog post](https://techcommunity.microsoft.com/t5/microsoft-sentinel-blog/designs-for-accomplishing-microsoft-sentinel-scalable-ingestion/ba-p/3741516), which includes designs for scalable ingestion.+- For space requirements for your log forwarder, refer to the [Azure Monitor Agent Performance Benchmark](/azure/azure-monitor/agents/azure-monitor-agent-performance). You can also review [this blog post](https://techcommunity.microsoft.com/t5/microsoft-sentinel-blog/designs-for-accomplishing-microsoft-sentinel-scalable-ingestion/ba-p/3741516), which includes designs for scalable ingestion. - Your log sources, security devices, and appliances must be configured to send their log messages to the log forwarder's syslog daemon instead of to their local syslog daemon. After you complete all the tabs, review what you entered and create the data col ### Install the Azure Monitor Agent Follow the appropriate instructions from the Azure Monitor documentation to install the Azure Monitor Agent on the machine hosting your application, or on your log forwarder. Use the instructions for Windows or for Linux, as appropriate.-- [Install the AMA using PowerShell](../azure-monitor/agents/azure-monitor-agent-manage.md?tabs=azure-powershell)-- [Install the AMA using the Azure CLI](../azure-monitor/agents/azure-monitor-agent-manage.md?tabs=azure-cli)-- [Install the AMA using an Azure Resource Manager template](../azure-monitor/agents/azure-monitor-agent-manage.md?tabs=azure-resource-manager)+- [Install the AMA using PowerShell](/azure/azure-monitor/agents/azure-monitor-agent-manage?tabs=azure-powershell) +- [Install the AMA using the Azure CLI](/azure/azure-monitor/agents/azure-monitor-agent-manage?tabs=azure-cli) +- [Install the AMA using an Azure Resource Manager template](/azure/azure-monitor/agents/azure-monitor-agent-manage?tabs=azure-resource-manager) -Create Data Collection Rules (DCRs) using the [Azure Monitor Logs Ingestion API](/rest/api/monitor/data-collection-rules). For more information, see [Data collection rules in Azure Monitor](../azure-monitor/essentials/data-collection-rule-overview.md). +Create Data Collection Rules (DCRs) using the [Azure Monitor Logs Ingestion API](/rest/api/monitor/data-collection-rules). For more information, see [Data collection rules in Azure Monitor](/azure/azure-monitor/essentials/data-collection-rule-overview). ### Create the data collection rule If you're collecting logs from an appliance using a log forwarder, configure the If you're using Python 3, and it's not set as the default command on the machine, substitute `python3` for `python` in the pasted command. See [Log forwarder prerequisites](#log-forwarder-prerequisites). > [!NOTE] - > To avoid [Full Disk scenarios](../azure-monitor/agents/azure-monitor-agent-troubleshoot-linux-vm-rsyslog.md) where the agent can't function, we recommend that you set the `syslog-ng` or `rsyslog` configuration not to store unneeded logs. A Full Disk scenario disrupts the function of the installed AMA. + > To avoid [Full Disk scenarios](/azure/azure-monitor/agents/azure-monitor-agent-troubleshoot-linux-vm-rsyslog) where the agent can't function, we recommend that you set the `syslog-ng` or `rsyslog` configuration not to store unneeded logs. A Full Disk scenario disrupts the function of the installed AMA. > For more information, see [RSyslog](https://www.rsyslog.com/doc/master/configuration/actions.html) or [Syslog-ng](https://syslog-ng.github.io/). ## Configure the security device or appliance Contact the solution provider for more information or where information is unava ## Related content -- [Data collection rules in Azure Monitor](../azure-monitor/essentials/data-collection-rule-overview.md)-- [Collect logs from a text file with Azure Monitor Agent](../azure-monitor/agents/data-collection-log-text.md)+- [Data collection rules in Azure Monitor](/azure/azure-monitor/essentials/data-collection-rule-overview) +- [Collect logs from a text file with Azure Monitor Agent](/azure/azure-monitor/agents/data-collection-log-text) |
| sentinel | Connect Custom Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/connect-custom-logs.md | For more information about supported data connectors that collect custom log for > [!IMPORTANT] > **The Log Analytics agent will be [retired on 31 August, 2024](https://azure.microsoft.com/updates/were-retiring-the-log-analytics-agent-in-azure-monitor-on-31-august-2024/).** If you are using the Log Analytics agent in your Microsoft Sentinel deployment, we recommend that you complete your migration to the **Azure Monitor Agent (AMA)**. For more information, see [AMA migration for Microsoft Sentinel](ama-migrate.md). -Learn all about [custom logs in the Azure Monitor documentation](../azure-monitor/agents/data-sources-custom-logs.md). +Learn all about [custom logs in the Azure Monitor documentation](/azure/azure-monitor/agents/data-sources-custom-logs). [!INCLUDE [reference-to-feature-availability](includes/reference-to-feature-availability.md)] |
| sentinel | Connect Dns Ama | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/connect-dns-ama.md | Before you begin, verify that you have: - A defined Microsoft Sentinel workspace. - Windows Server 2012 R2 with auditing hotfix and later. - A Windows DNS Server. -- To collect events from any system that isn't an Azure virtual machine, ensure that [Azure Arc](../azure-monitor/agents/azure-monitor-agent-manage.md) is installed. Install and enable Azure Arc before you enable the Azure Monitor Agent-based connector. This requirement includes:+- To collect events from any system that isn't an Azure virtual machine, ensure that [Azure Arc](/azure/azure-monitor/agents/azure-monitor-agent-manage) is installed. Install and enable Azure Arc before you enable the Azure Monitor Agent-based connector. This requirement includes: - Windows servers installed on physical machines - Windows servers installed on on-premises virtual machines - Windows servers installed on virtual machines in non-Azure clouds |
| sentinel | Connect Log Forwarder | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/connect-log-forwarder.md | If you don't have access to that page, copy the link from the text below (copyin > > If you plan to use this log forwarder machine to forward [Syslog messages](connect-syslog.md) as well as CEF, then in order to avoid the duplication of events to the Syslog and CommonSecurityLog tables: >- > 1. On each source machine that sends logs to the forwarder in CEF format, you must edit the Syslog configuration file to remove the facilities that are being used to send CEF messages. This way, the facilities that are sent in CEF won't also be sent in Syslog. See [Configure Syslog on Linux agent](../azure-monitor/agents/data-sources-syslog.md#configure-syslog-on-linux-agent) for detailed instructions on how to do this. + > 1. On each source machine that sends logs to the forwarder in CEF format, you must edit the Syslog configuration file to remove the facilities that are being used to send CEF messages. This way, the facilities that are sent in CEF won't also be sent in Syslog. See [Configure Syslog on Linux agent](/azure/azure-monitor/agents/data-sources-syslog#configure-syslog-on-linux-agent) for detailed instructions on how to do this. > > 1. You must run the following command on those machines to disable the synchronization of the agent with the Syslog configuration in Microsoft Sentinel. This ensures that the configuration change you made in the previous step does not get overwritten.<br> > `sudo su omsagent -c 'python /opt/microsoft/omsconfig/Scripts/OMS_MetaConfigHelper.py --disable'` |
| sentinel | Connect Logstash Data Connection Rules | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/connect-logstash-data-connection-rules.md | The Logstash engine is composed of three components: The Microsoft Sentinel output plugin for Logstash sends JSON-formatted data to your Log Analytics workspace, using the Log Analytics Log Ingestion API. The data is ingested into custom logs or standard table. -- Learn more about the [Logs ingestion API](../azure-monitor/logs/logs-ingestion-api-overview.md).+- Learn more about the [Logs ingestion API](/azure/azure-monitor/logs/logs-ingestion-api-overview). ## Deploy the Microsoft Sentinel output plugin in Logstash In this section, you create resources to use for your DCR, in one of these scena #### Create DCR resources for ingestion into a custom table -To ingest the data to a custom table, follow these steps (based on the [Send data to Azure Monitor Logs using REST API (Azure portal) tutorial](../azure-monitor/logs/tutorial-logs-ingestion-portal.md)): +To ingest the data to a custom table, follow these steps (based on the [Send data to Azure Monitor Logs using REST API (Azure portal) tutorial](/azure/azure-monitor/logs/tutorial-logs-ingestion-portal)): -1. Review the [prerequisites](../azure-monitor/logs/tutorial-logs-ingestion-portal.md#prerequisites). -1. [Configure the application](../azure-monitor/logs/tutorial-logs-ingestion-portal.md#create-azure-ad-application). -1. [Add a custom log table](../azure-monitor/logs/tutorial-logs-ingestion-portal.md#create-new-table-in-log-analytics-workspace). -1. [Parse and filter sample data](../azure-monitor/logs/tutorial-logs-ingestion-portal.md#parse-and-filter-sample-data) using [the sample file you created in the previous section](#create-a-sample-file). -1. [Collect information from the DCR](../azure-monitor/logs/tutorial-logs-ingestion-portal.md#collect-information-from-the-dcr). -1. [Assign permissions to the DCR](../azure-monitor/logs/tutorial-logs-ingestion-portal.md#assign-permissions-to-the-dcr). +1. Review the [prerequisites](/azure/azure-monitor/logs/tutorial-logs-ingestion-portal#prerequisites). +1. [Configure the application](/azure/azure-monitor/logs/tutorial-logs-ingestion-portal#create-azure-ad-application). +1. [Add a custom log table](/azure/azure-monitor/logs/tutorial-logs-ingestion-portal#create-new-table-in-log-analytics-workspace). +1. [Parse and filter sample data](/azure/azure-monitor/logs/tutorial-logs-ingestion-portal#parse-and-filter-sample-data) using [the sample file you created in the previous section](#create-a-sample-file). +1. [Collect information from the DCR](/azure/azure-monitor/logs/tutorial-logs-ingestion-portal#collect-information-from-the-dcr). +1. [Assign permissions to the DCR](/azure/azure-monitor/logs/tutorial-logs-ingestion-portal#assign-permissions-to-the-dcr). Skip the Send sample data step. -If you come across any issues, see the [troubleshooting steps](../azure-monitor/logs/tutorial-logs-ingestion-code.md#troubleshooting). +If you come across any issues, see the [troubleshooting steps](/azure/azure-monitor/logs/tutorial-logs-ingestion-code#troubleshooting). #### Create DCR resources for ingestion into a standard table -To ingest the data to a standard table like Syslog or CommonSecurityLog, you use a process based on the [Send data to Azure Monitor Logs using REST API (Resource Manager templates) tutorial](../azure-monitor/logs/tutorial-logs-ingestion-api.md). While the tutorial explains how to ingest data into a custom table, you can easily adjust the process to ingest data into a standard table. The steps below indicate relevant changes in the steps. +To ingest the data to a standard table like Syslog or CommonSecurityLog, you use a process based on the [Send data to Azure Monitor Logs using REST API (Resource Manager templates) tutorial](/azure/azure-monitor/logs/tutorial-logs-ingestion-api). While the tutorial explains how to ingest data into a custom table, you can easily adjust the process to ingest data into a standard table. The steps below indicate relevant changes in the steps. -1. Review the [prerequisites](../azure-monitor/logs/tutorial-logs-ingestion-api.md#prerequisites). -1. [Collect workspace details](../azure-monitor/logs/tutorial-logs-ingestion-api.md#collect-workspace-details). -1. [Configure an application](../azure-monitor/logs/tutorial-logs-ingestion-api.md#create-azure-ad-application). +1. Review the [prerequisites](/azure/azure-monitor/logs/tutorial-logs-ingestion-api#prerequisites). +1. [Collect workspace details](/azure/azure-monitor/logs/tutorial-logs-ingestion-api#collect-workspace-details). +1. [Configure an application](/azure/azure-monitor/logs/tutorial-logs-ingestion-api#create-azure-ad-application). Skip the Create new table in Log Analytics workspace step. This step isn't relevant when ingesting data into a standard table, because the table is already defined in Log Analytics. -1. [Create the DCR](../azure-monitor/logs/tutorial-logs-ingestion-api.md#create-data-collection-rule). In this step: +1. [Create the DCR](/azure/azure-monitor/logs/tutorial-logs-ingestion-api#create-data-collection-rule). In this step: - Provide [the sample file you created in the previous section](#create-a-sample-file). - Use the sample file you created to define the `streamDeclarations` property. Each of the fields in the sample file should have a corresponding column with the same name and the appropriate type (see the [example](#example-dcr-that-ingests-data-into-the-syslog-table) below). - Configure the value of the `outputStream` property with the name of the standard table instead of the custom table. Unlike custom tables, standard table names don't have the `_CL` suffix. - The prefix of the table name should be `Microsoft-` instead of `Custom-`. In our example, the `outputStream` property value is `Microsoft-Syslog`. -1. [Assign permissions to a DCR](../azure-monitor/logs/tutorial-logs-ingestion-api.md#assign-permissions-to-a-dcr). +1. [Assign permissions to a DCR](/azure/azure-monitor/logs/tutorial-logs-ingestion-api#assign-permissions-to-a-dcr). Skip the Send sample data step. -If you come across any issues, see the [troubleshooting steps](../azure-monitor/logs/tutorial-logs-ingestion-code.md#troubleshooting). +If you come across any issues, see the [troubleshooting steps](/azure/azure-monitor/logs/tutorial-logs-ingestion-code#troubleshooting). ##### Example: DCR that ingests data into the Syslog table The following table lists the firewall requirements for scenarios where Azure vi - Ingestion into standard tables is limited only to [standard tables supported for custom logs ingestion](data-transformation.md#data-transformation-support-for-custom-data-connectors). - The columns of the input stream in the `streamDeclarations` property must start with a letter. If you start a column with other characters (for example `@` or `_`), the operation fails. - The `TimeGenerated` datetime field is required. You must include this field in the KQL transform.-- For additional possible issues, review the [troubleshooting section](../azure-monitor/logs/tutorial-logs-ingestion-code.md#troubleshooting) in the tutorial. +- For additional possible issues, review the [troubleshooting section](/azure/azure-monitor/logs/tutorial-logs-ingestion-code#troubleshooting) in the tutorial. ## Next steps |
| sentinel | Connect Logstash | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/connect-logstash.md | The Logstash engine is comprised of three components: The Microsoft Sentinel output plugin for Logstash sends JSON-formatted data to your Log Analytics workspace, using the Log Analytics HTTP Data Collector REST API. The data is ingested into custom logs. - Learn more about the [Log Analytics REST API](/rest/api/loganalytics/create-request).-- Learn more about [custom logs](../azure-monitor/agents/data-sources-custom-logs.md).+- Learn more about [custom logs](/azure/azure-monitor/agents/data-sources-custom-logs). ## Deploy the Microsoft Sentinel output plugin in Logstash |
| sentinel | Connect Rest Api Template | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/connect-rest-api-template.md | -API integrations built by third-party vendors pull data from their products' data sources and connect to Microsoft Sentinel's [Azure Monitor Data Collector API](../azure-monitor/logs/data-collector-api.md) to push the data into custom log tables in your Microsoft Sentinel workspace. +API integrations built by third-party vendors pull data from their products' data sources and connect to Microsoft Sentinel's [Azure Monitor Data Collector API](/azure/azure-monitor/logs/data-collector-api) to push the data into custom log tables in your Microsoft Sentinel workspace. For the most part, you can find all the information you need to configure these data sources to connect to Microsoft Sentinel in each vendor's documentation. Data will be stored in the geographic location of the workspace on which you are - You must have read and write permissions on the Microsoft Sentinel workspace. -- You must have read permissions to shared keys for the workspace. [Learn more about workspace keys](../azure-monitor/agents/agent-windows.md).+- You must have read permissions to shared keys for the workspace. [Learn more about workspace keys](/azure/azure-monitor/agents/agent-windows). - Install the product's solution from the **Content Hub** in Microsoft Sentinel. For more information, see [Discover and manage Microsoft Sentinel out-of-the-box content](sentinel-solutions-deploy.md). ## Configure and connect your data source |
| sentinel | Connect Services Diagnostic Setting Based | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/connect-services-diagnostic-setting-based.md | To ingest data into Microsoft Sentinel: 1. Select **Save** at the top of the screen. -For more information, see also [Create diagnostic settings to send Azure Monitor platform logs and metrics to different destinations](../azure-monitor/essentials/diagnostic-settings.md) in the Azure Monitor documentation. +For more information, see also [Create diagnostic settings to send Azure Monitor platform logs and metrics to different destinations](/azure/azure-monitor/essentials/diagnostic-settings) in the Azure Monitor documentation. ## Azure Policy managed diagnostic settings-based connectors Connectors of this type use Azure Policy to apply a single diagnostic settings c With this type of data connector, the connectivity status indicators (a color stripe in the data connectors gallery and connection icons next to the data type names) will show as *connected* (green) only if data has been ingested at some point in the past 14 days. Once 14 days have passed with no data ingestion, the connector will show as being disconnected. The moment more data comes through, the *connected* status will return. -You can find and query the data for each resource type using the table name that appears in the section for the resource's connector in the [Data connectors reference](data-connectors-reference.md) page. For more information, see [Create diagnostic settings to send Azure Monitor platform logs and metrics to different destinations](../azure-monitor/essentials/diagnostic-settings.md?tabs=CMD) in the Azure Monitor documentation. +You can find and query the data for each resource type using the table name that appears in the section for the resource's connector in the [Data connectors reference](data-connectors-reference.md) page. For more information, see [Create diagnostic settings to send Azure Monitor platform logs and metrics to different destinations](/azure/azure-monitor/essentials/diagnostic-settings?tabs=CMD) in the Azure Monitor documentation. ## Next steps |
| sentinel | Connect Services Windows Based | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/connect-services-windows-based.md | Some connectors based on the Azure Monitor Agent (AMA) are currently in **PREVIE The Azure Monitor Agent is currently supported only for Windows Security Events, Windows Forwarded Events, and Windows DNS Events. -The [Azure Monitor agent](../azure-monitor/agents/azure-monitor-agent-overview.md) uses **Data collection rules (DCRs)** to define the data to collect from each agent. Data collection rules offer you two distinct advantages: +The [Azure Monitor agent](/azure/azure-monitor/agents/azure-monitor-agent-overview) uses **Data collection rules (DCRs)** to define the data to collect from each agent. Data collection rules offer you two distinct advantages: -- **Manage collection settings at scale** while still allowing unique, scoped configurations for subsets of machines. They are independent of the workspace and independent of the virtual machine, which means they can be defined once and reused across machines and environments. See [Configure data collection for the Azure Monitor agent](../azure-monitor/agents/azure-monitor-agent-data-collection.md).+- **Manage collection settings at scale** while still allowing unique, scoped configurations for subsets of machines. They are independent of the workspace and independent of the virtual machine, which means they can be defined once and reused across machines and environments. See [Configure data collection for the Azure Monitor agent](/azure/azure-monitor/agents/azure-monitor-agent-data-collection). - **Build custom filters** to choose the exact events you want to ingest. The Azure Monitor Agent uses these rules to filter the data *at the source* and ingest only the events you want, while leaving everything else behind. This can save you a lot of money in data ingestion costs! See below how to create data collection rules. - You must have read and write permissions on the Microsoft Sentinel workspace. -- To collect events from any system that is not an Azure virtual machine, the system must have [**Azure Arc**](../azure-monitor/agents/azure-monitor-agent-manage.md) installed and enabled *before* you enable the Azure Monitor Agent-based connector.+- To collect events from any system that is not an Azure virtual machine, the system must have [**Azure Arc**](/azure/azure-monitor/agents/azure-monitor-agent-manage) installed and enabled *before* you enable the Azure Monitor Agent-based connector. This includes: See below how to create data collection rules. 1. In the **Resources** tab, select **+Add resource(s)** to add machines to which the Data Collection Rule will apply. The **Select a scope** dialog will open, and you will see a list of available subscriptions. Expand a subscription to see its resource groups, and expand a resource group to see the available machines. You will see Azure virtual machines and Azure Arc-enabled servers in the list. You can mark the check boxes of subscriptions or resource groups to select all the machines they contain, or you can select individual machines. Select **Apply** when you've chosen all your machines. At the end of this process, the Azure Monitor Agent will be installed on any selected machines that don't already have it installed. -1. On the **Collect** tab, choose the events you would like to collect: select **All events** or **Custom** to specify other logs or to filter events using [XPath queries](../azure-monitor/agents/data-collection-windows-events.md#filter-events-using-xpath-queries) (see note below). Enter expressions in the box that evaluate to specific XML criteria for events to collect, then select **Add**. You can enter up to 20 expressions in a single box, and up to 100 boxes in a rule. +1. On the **Collect** tab, choose the events you would like to collect: select **All events** or **Custom** to specify other logs or to filter events using [XPath queries](/azure/azure-monitor/agents/data-collection-windows-events#filter-events-using-xpath-queries) (see note below). Enter expressions in the box that evaluate to specific XML criteria for events to collect, then select **Add**. You can enter up to 20 expressions in a single box, and up to 100 boxes in a rule. - Learn more about [data collection rules](../azure-monitor/essentials/data-collection-rule-overview.md) from the Azure Monitor documentation. + Learn more about [data collection rules](/azure/azure-monitor/essentials/data-collection-rule-overview) from the Azure Monitor documentation. > [!NOTE] > PUT https://management.azure.com/subscriptions/{subscriptionId}/resourceGroups/m } ``` -See this [complete description of data collection rules](../azure-monitor/essentials/data-collection-rule-overview.md) from the Azure Monitor documentation. +See this [complete description of data collection rules](/azure/azure-monitor/essentials/data-collection-rule-overview) from the Azure Monitor documentation. ## Log Analytics Agent (Legacy) The Log Analytics agent will be [retired on **31 August, 2024**](https://azure.m To allow Windows systems without the necessary internet connectivity to still stream events to Microsoft Sentinel, download and install the **Log Analytics Gateway** on a separate machine, using the **Download Log Analytics Gateway** link on the **Agents Management** page, to act as a proxy. You still need to install the Log Analytics agent on each Windows system whose events you want to collect. -For more information on this scenario, see the [**Log Analytics gateway** documentation](../azure-monitor/agents/gateway.md). +For more information on this scenario, see the [**Log Analytics gateway** documentation](/azure/azure-monitor/agents/gateway). -For additional installation options and further details, see the [**Log Analytics agent** documentation](../azure-monitor/agents/agent-windows.md). +For additional installation options and further details, see the [**Log Analytics agent** documentation](/azure/azure-monitor/agents/agent-windows). ### Determine the logs to send |
| sentinel | Connect Syslog | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/connect-syslog.md | Last updated 06/18/2024 This article describes how to connect your data sources to Microsoft Sentinel using Syslog. For more information about supported connectors for this method, see [Data connectors reference](data-connectors-reference.md). -Learn how to [collect Syslog with the Azure Monitor Agent](../azure-monitor/agents/data-collection-syslog.md), including how to configure Syslog and create a DCR. +Learn how to [collect Syslog with the Azure Monitor Agent](/azure/azure-monitor/agents/data-collection-syslog), including how to configure Syslog and create a DCR. > [!IMPORTANT] > The Log Analytics agent will be [retired on **31 August, 2024**](https://azure.microsoft.com/updates/were-retiring-the-log-analytics-agent-in-azure-monitor-on-31-august-2024/). If you are using the Log Analytics agent in your Microsoft Sentinel deployment, we recommend that you start planning your migration to the AMA. For more information, see [AMA migration for Microsoft Sentinel](ama-migrate.md). Learn how to [collect Syslog with the Azure Monitor Agent](../azure-monitor/agen When the Log Analytics agent is installed on your VM or appliance, the installation script configures the local Syslog daemon to forward messages to the agent on UDP port 25224. After receiving the messages, the agent sends them to your Log Analytics workspace over HTTPS, where they are ingested into the Syslog table in **Microsoft Sentinel > Logs**. -For more information, see [Syslog data sources in Azure Monitor](../azure-monitor/agents/data-sources-syslog.md). +For more information, see [Syslog data sources in Azure Monitor](/azure/azure-monitor/agents/data-sources-syslog). :::image type="content" source="media/connect-syslog/syslog-diagram.png" alt-text="This diagram shows the data flow from syslog sources to the Microsoft Sentinel workspace, where the Log Analytics agent is installed directly on the data source device."::: You can use your existing [CEF log forwarder machine](connect-log-forwarder.md) Having already set up [data collection from your CEF sources](connect-common-event-format.md), and having configured the Log Analytics agent: -1. On each machine that sends logs in CEF format, you must edit the Syslog configuration file to remove the facilities that are being used to send CEF messages. This way, the facilities that are sent in CEF won't also be sent in Syslog. See [Configure Syslog on Linux agent](../azure-monitor/agents/data-sources-syslog.md#configure-syslog-on-linux-agent) for detailed instructions on how to do this. +1. On each machine that sends logs in CEF format, you must edit the Syslog configuration file to remove the facilities that are being used to send CEF messages. This way, the facilities that are sent in CEF won't also be sent in Syslog. See [Configure Syslog on Linux agent](/azure/azure-monitor/agents/data-sources-syslog#configure-syslog-on-linux-agent) for detailed instructions on how to do this. 1. You must run the following command on those machines to disable the synchronization of the agent with the Syslog configuration in Microsoft Sentinel. This ensures that the configuration change you made in the previous step does not get overwritten. For more information, see [Advanced Security Information Model (ASIM) parsers](n (Some connectors using the Syslog mechanism might store their data in tables other than `Syslog`. Consult your connector's section in the [Microsoft Sentinel data connectors reference](data-connectors-reference.md) page.) -1. You can use the query parameters described in [Using functions in Azure Monitor log queries](../azure-monitor/logs/functions.md) to parse your Syslog messages. You can then save the query as a new Log Analytics function and use it as a new data type. +1. You can use the query parameters described in [Using functions in Azure Monitor log queries](/azure/azure-monitor/logs/functions) to parse your Syslog messages. You can then save the query as a new Log Analytics function and use it as a new data type. ### Configure the Syslog connector for anomalous SSH login detection |
| sentinel | Create Codeless Connector | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/create-codeless-connector.md | Before building a connector, understand your data source and how Microsoft Senti 1. Data Collection Endpoint (DCE) - A DCE is a requirement for a DCR. Only one DCE is created per log analytics workspace DCR deployment. Every DCR deployed for a Microsoft Sentinel workspace uses the same DCE. For more information on how to create one or whether you need a new one, see [Data collection endpoints in Azure Monitor](../azure-monitor/essentials/data-collection-endpoint-overview.md). + A DCE is a requirement for a DCR. Only one DCE is created per log analytics workspace DCR deployment. Every DCR deployed for a Microsoft Sentinel workspace uses the same DCE. For more information on how to create one or whether you need a new one, see [Data collection endpoints in Azure Monitor](/azure/azure-monitor/essentials/data-collection-endpoint-overview). 1. Schema of the output table(s). If your data source doesn't conform to the schema of a standard table, you have - Create a custom table for all the data - Create a custom table for some data and split conforming data out to a standard table -Use the Log Analytics UI for a straight forward method to create a custom table together with a DCR. If you create the custom table using the [Tables API](/rest/api/loganalytics/tables/create-or-update) or another programmatic method, add the `_CL` suffix manually to the table name. For more information, see [Create a custom table](../azure-monitor/logs/create-custom-table.md#create-a-custom-table). +Use the Log Analytics UI for a straight forward method to create a custom table together with a DCR. If you create the custom table using the [Tables API](/rest/api/loganalytics/tables/create-or-update) or another programmatic method, add the `_CL` suffix manually to the table name. For more information, see [Create a custom table](/azure/azure-monitor/logs/create-custom-table#create-a-custom-table). For more information on splitting your data to more than one table, see the [example data](#example-data) and the [example custom table](#example-custom-table) created for that data. Data collection rules (DCRs) define the data collection process in Azure Monitor - When the CCP data connector is deployed, the DCR is created if it doesn't already exist. Reference the latest information on DCRs in these articles:-- [Data collection rules overview](../azure-monitor/essentials/data-collection-rule-overview.md)-- [Structure of a data collections rule](../azure-monitor//essentials/data-collection-rule-structure.md)+- [Data collection rules overview](/azure/azure-monitor/essentials/data-collection-rule-overview) +- [Structure of a data collections rule](/azure/azure-monitor/essentials/data-collection-rule-structure) -For a tutorial demonstrating the creation of a DCE, including using sample data to create the custom table and DCR, see [Tutorial: Send data to Azure Monitor Logs with Logs ingestion API (Azure portal)](../azure-monitor/logs/tutorial-logs-ingestion-portal.md). Use the process in this tutorial to verify data is ingested correctly to your table with your DCR. +For a tutorial demonstrating the creation of a DCE, including using sample data to create the custom table and DCR, see [Tutorial: Send data to Azure Monitor Logs with Logs ingestion API (Azure portal)](/azure/azure-monitor/logs/tutorial-logs-ingestion-portal). Use the process in this tutorial to verify data is ingested correctly to your table with your DCR. To understand how to create a complex DCR with multiple data flows, see the [DCR example section](#example-data-collection-rule). The following DCR defines a single stream `Custom-ExampleConnectorInput` using t 1. The first dataflow directs `eventType` = **Alert** to the custom `ExampleConnectorAlerts_CL` table. 1. the second dataflow directs `eventType` = **File** to the normalized standard table,`ASimFileEventLogs`. -For more information on the structure of this example, see [Structure of a data collection rule](../azure-monitor/essentials/data-collection-rule-structure.md). +For more information on the structure of this example, see [Structure of a data collection rule](/azure/azure-monitor/essentials/data-collection-rule-structure). To create this DCR in a test environment, follow the [Data Collection Rules API](/rest/api/monitor/data-collection-rules/create). Elements of the example in `{{double curly braces}}` indicate variables that require values for ease of use with an [API testing tool](#testing-apis). When you create this resource in the ARM template, the variables expressed here are exchanged for parameters. |
| sentinel | Create Custom Connector | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/create-custom-connector.md | For more information, see [Create a codeless connector for Microsoft Sentinel](c If your data source delivers events in files, we recommend that you use the Azure Monitor Log Analytics agent to create your custom connector. -- For more information, see [Collecting custom logs in Azure Monitor](../azure-monitor/agents/data-sources-custom-logs.md).+- For more information, see [Collecting custom logs in Azure Monitor](/azure/azure-monitor/agents/data-sources-custom-logs). -- For an example of this method, see [Collecting custom JSON data sources with the Log Analytics agent for Linux in Azure Monitor](../azure-monitor/agents/data-sources-json.md).+- For an example of this method, see [Collecting custom JSON data sources with the Log Analytics agent for Linux in Azure Monitor](/azure/azure-monitor/agents/data-sources-json). ## Connect with Logstash You can stream events to Microsoft Sentinel by using the Log Analytics Data Coll While calling a RESTful endpoint directly requires more programming, it also provides more flexibility. -For more information, see the [Log Analytics Data collector API](../azure-monitor/logs/data-collector-api.md), especially the following examples: +For more information, see the [Log Analytics Data collector API](/azure/azure-monitor/logs/data-collector-api), especially the following examples: -- [C#](../azure-monitor/logs/data-collector-api.md#sample-requests)-- [Python](../azure-monitor/logs/data-collector-api.md#sample-requests)+- [C#](/azure/azure-monitor/logs/data-collector-api#sample-requests) +- [Python](/azure/azure-monitor/logs/data-collector-api#sample-requests) ## Connect with Azure Functions For examples of this method, see: - [Connect your Okta Single Sign-On to Microsoft Sentinel with Azure Function](./data-connectors/okta-single-sign-on-using-azure-function.md) - [Connect your Proofpoint TAP to Microsoft Sentinel with Azure Function](./data-connectors/proofpoint-tap-using-azure-functions.md) - [Connect your Qualys VM to Microsoft Sentinel with Azure Function](data-connectors/qualys-vulnerability-management-using-azure-functions.md)-- [Ingesting XML, CSV, or other formats of data](../azure-monitor/logs/create-pipeline-datacollector-api.md#ingesting-xml-csv-or-other-formats-of-data)+- [Ingesting XML, CSV, or other formats of data](/azure/azure-monitor/logs/create-pipeline-datacollector-api#ingesting-xml-csv-or-other-formats-of-data) - [Monitoring Zoom with Microsoft Sentinel](https://techcommunity.microsoft.com/t5/azure-sentinel/monitoring-zoom-with-azure-sentinel/ba-p/1341516) (blog) - [Deploy a Function App for getting Office 365 Management API data into Microsoft Sentinel](https://github.com/Azure/Azure-Sentinel/tree/master/DataConnectors/O365%20Data) (Microsoft Sentinel GitHub community) |
| sentinel | Create Manage Use Automation Rules | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/create-manage-use-automation-rules.md | This article explains how to create and use automation rules in Microsoft Sentin In this article you'll learn how to define the triggers and conditions that determine when your automation rule runs, the various actions that you can have the rule perform, and the remaining features and functionalities. -> [!IMPORTANT] -> -> Noted features of automation rules are currently in **PREVIEW**. See the [Supplemental Terms of Use for Microsoft Azure Previews](https://azure.microsoft.com/support/legal/preview-supplemental-terms/) for additional legal terms that apply to Azure features that are in beta, preview, or otherwise not yet released into general availability. -> -> [!INCLUDE [unified-soc-preview-without-alert](includes/unified-soc-preview-without-alert.md)] ## Design your automation rule |
| sentinel | Customer Managed Keys | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/customer-managed-keys.md | appliesto: # Set up Microsoft Sentinel customer-managed key -This article provides background information and steps to configure a [customer-managed key (CMK)](../azure-monitor/logs/customer-managed-keys.md) for Microsoft Sentinel. All the data stored in Microsoft Sentinel is already encrypted by Microsoft in all relevant storage resources. CMK provides an extra layer of protection with an encryption key created and owned by you and stored in your [Azure Key Vault](/azure/key-vault/general/overview). +This article provides background information and steps to configure a [customer-managed key (CMK)](/azure/azure-monitor/logs/customer-managed-keys) for Microsoft Sentinel. All the data stored in Microsoft Sentinel is already encrypted by Microsoft in all relevant storage resources. CMK provides an extra layer of protection with an encryption key created and owned by you and stored in your [Azure Key Vault](/azure/key-vault/general/overview). ## Prerequisites -1. Configure a Log Analytics dedicated cluster with at least a 100 GB/day commitment tier. When multiple workspaces are linked to the same dedicated cluster, they share the same customer-managed key. Learn about [Log Analytics Dedicated Cluster Pricing](../azure-monitor/logs/logs-dedicated-clusters.md#cluster-pricing-model). -1. Configure CMK on the dedicated cluster and link your workspace to that cluster. Learn about the [CMK provisioning steps in Azure Monitor](../azure-monitor/logs/customer-managed-keys.md?tabs=portal#customer-managed-key-provisioning-steps). +1. Configure a Log Analytics dedicated cluster with at least a 100 GB/day commitment tier. When multiple workspaces are linked to the same dedicated cluster, they share the same customer-managed key. Learn about [Log Analytics Dedicated Cluster Pricing](/azure/azure-monitor/logs/logs-dedicated-clusters#cluster-pricing-model). +1. Configure CMK on the dedicated cluster and link your workspace to that cluster. Learn about the [CMK provisioning steps in Azure Monitor](/azure/azure-monitor/logs/customer-managed-keys?tabs=portal#customer-managed-key-provisioning-steps). ## Considerations This article provides background information and steps to configure a [customer- - Microsoft Sentinel supports System Assigned Identities in CMK configuration. Therefore, the dedicated Log Analytics cluster's identity should be of **System Assigned** type. We recommend that you use the identity that's automatically assigned to the Log Analytics cluster when it's created. -- Changing the customer-managed key to another key (with another URI) currently *isn't supported*. You should change the key by [rotating it](../azure-monitor/logs/customer-managed-keys.md#key-rotation).+- Changing the customer-managed key to another key (with another URI) currently *isn't supported*. You should change the key by [rotating it](/azure/azure-monitor/logs/customer-managed-keys#key-rotation). - Before you make any CMK changes to a production workspace or to a Log Analytics cluster, contact the [Microsoft Sentinel Product Group](mailto:onboardrecoeng@microsoft.com). - CMK enabled workspaces don't support [search jobs](investigate-large-datasets.md). This article provides background information and steps to configure a [customer- The Microsoft Sentinel solution uses a dedicated Log Analytics cluser for log collection and features. As part of the Microsoft Sentinel CMK configuration, you must configure the CMK settings on the related Log Analytics dedicated cluster. Data saved by Microsoft Sentinel in storage resources other than Log Analytics is also encrypted using the customer-managed key configured for the dedicated Log Analytics cluster. For more information, see:-- [Azure Monitor customer-managed keys (CMK)](../azure-monitor/logs/customer-managed-keys.md).+- [Azure Monitor customer-managed keys (CMK)](/azure/azure-monitor/logs/customer-managed-keys). - [Azure Key Vault](/azure/key-vault/general/overview).-- [Log Analytics dedicated clusters](../azure-monitor/logs/logs-dedicated-clusters.md).+- [Log Analytics dedicated clusters](/azure/azure-monitor/logs/logs-dedicated-clusters). > [!NOTE] > If you enable CMK on Microsoft Sentinel, any Public Preview features that don't support CMK aren't enabled. To provision CMK, follow these steps: As mentioned in the [prerequisites](#prerequisites), to onboard a Log Analytics workspace with CMK to Microsoft Sentinel, this workspace must first be linked to a dedicated Log Analytics cluster on which CMK is enabled. Microsoft Sentinel will use the same key used by the dedicated cluster.-Follow the instructions in [Azure Monitor customer-managed key configuration](../azure-monitor/logs/customer-managed-keys.md) in order to create a CMK workspace that is used as the Microsoft Sentinel workspace in the following steps. +Follow the instructions in [Azure Monitor customer-managed key configuration](/azure/azure-monitor/logs/customer-managed-keys) in order to create a CMK workspace that is used as the Microsoft Sentinel workspace in the following steps. ### Step 2: Register the Azure Cosmos DB Resource Provider If access is restored after revocation, Microsoft Sentinel restores access to th Access to the data can be revoked by disabling the customer-managed key in the key vault, or deleting the access policy to the key, for both the dedicated Log Analytics cluster and Azure Cosmos DB. Revoking access by removing the key from the dedicated Log Analytics cluster, or by removing the identity associated with the dedicated Log Analytics cluster isn't supported. -To understand more about how key revocation works in Azure Monitor, see [Azure Monitor CMK revocation](../azure-monitor/logs/customer-managed-keys.md#key-revocation). +To understand more about how key revocation works in Azure Monitor, see [Azure Monitor CMK revocation](/azure/azure-monitor/logs/customer-managed-keys#key-revocation). ## Customer-managed key rotation In Azure Key Vault, perform key rotation by creating a new version of the key: Disable the previous version of the key after 24 hours, or after the Azure Key Vault audit logs no longer show any activity that uses the previous version. -After rotating a key, you must explicitly update the dedicated Log Analytics cluster resource in Log Analytics with the new Azure Key Vault key version. For more information, see [Azure Monitor CMK rotation](../azure-monitor/logs/customer-managed-keys.md#key-rotation). +After rotating a key, you must explicitly update the dedicated Log Analytics cluster resource in Log Analytics with the new Azure Key Vault key version. For more information, see [Azure Monitor CMK rotation](/azure/azure-monitor/logs/customer-managed-keys#key-rotation). ## Replacing a customer-managed key |
| sentinel | Cisco Web Security Appliance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/data-connectors/cisco-web-security-appliance.md | This is autogenerated content. For changes, contact the solution provider. | Connector attribute | Description | | | | | **Log Analytics table(s)** | Syslog (CiscoWSAEvent)<br/> |-| **Data collection rules support** | [Workspace transform DCR](../../azure-monitor/logs/tutorial-workspace-transformations-portal.md) | +| **Data collection rules support** | [Workspace transform DCR](/azure/azure-monitor/logs/tutorial-workspace-transformations-portal) | | **Supported by** | [Microsoft Corporation](https://support.microsoft.com) | ## Query samples |
| sentinel | Common Event Format Cef | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/data-connectors/common-event-format-cef.md | This is autogenerated content. For changes, contact the solution provider. | Connector attribute | Description | | | | | **Log Analytics table(s)** | CommonSecurityLog<br/> |-| **Data collection rules support** | [Workspace transform DCR](../../azure-monitor/logs/tutorial-workspace-transformations-portal.md) | +| **Data collection rules support** | [Workspace transform DCR](/azure/azure-monitor/logs/tutorial-workspace-transformations-portal) | | **Supported by** | [Microsoft Corporation](https://support.microsoft.com) | |
| sentinel | Microsoft Sysmon For Linux | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/data-connectors/microsoft-sysmon-for-linux.md | This is autogenerated content. For changes, contact the solution provider. | Connector attribute | Description | | | | | **Log Analytics table(s)** | Syslog (Sysmon)<br/> |-| **Data collection rules support** | [Workspace transform DCR](../../azure-monitor/logs/tutorial-workspace-transformations-portal.md) | +| **Data collection rules support** | [Workspace transform DCR](/azure/azure-monitor/logs/tutorial-workspace-transformations-portal) | | **Supported by** | [Microsoft Corporation](https://support.microsoft.com) | ## Query samples |
| sentinel | Syslog | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/data-connectors/syslog.md | -> Container Insights now supports the automatic collection of Syslog events from Linux nodes in your AKS clusters. To learn more, see [Syslog collection with Container Insights](../../azure-monitor/containers/container-insights-syslog.md). +> Container Insights now supports the automatic collection of Syslog events from Linux nodes in your AKS clusters. To learn more, see [Syslog collection with Container Insights](/azure/azure-monitor/containers/container-insights-syslog). This is autogenerated content. For changes, contact the solution provider. |
| sentinel | Data Transformation | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/data-transformation.md | Last updated 02/27/2022 Azure Monitor's Log Analytics serves as the platform behind the Microsoft Sentinel workspace. All logs ingested into Microsoft Sentinel are stored in Log Analytics by default. From Microsoft Sentinel, you can access the stored logs and run Kusto Query Language (KQL) queries to detect threats and monitor your network activity. -Log Analytics' custom data ingestion process gives you a high level of control over the data that gets ingested. It uses [**data collection rules (DCRs)**](../azure-monitor/essentials/data-collection-rule-overview.md) to collect your data and manipulate it even before it's stored in your workspace. This allows you to filter and enrich standard tables and to create highly customizable tables for storing data from sources that produce unique log formats. +Log Analytics' custom data ingestion process gives you a high level of control over the data that gets ingested. It uses [**data collection rules (DCRs)**](/azure/azure-monitor/essentials/data-collection-rule-overview) to collect your data and manipulate it even before it's stored in your workspace. This allows you to filter and enrich standard tables and to create highly customizable tables for storing data from sources that produce unique log formats. Microsoft Sentinel gives you two tools to control this process: -- The [**Logs ingestion API**](../azure-monitor/logs/logs-ingestion-api-overview.md) allows you to send custom-format logs from any data source to your Log Analytics workspace, and store those logs either in certain specific standard tables, or in custom-formatted tables that you create. You have full control over the creation of these custom tables, down to specifying the column names and types. You create [**Data collection rules (DCRs)**](../azure-monitor/essentials/data-collection-rule-overview.md) to define, configure, and apply transformations to these data flows.+- The [**Logs ingestion API**](/azure/azure-monitor/logs/logs-ingestion-api-overview) allows you to send custom-format logs from any data source to your Log Analytics workspace, and store those logs either in certain specific standard tables, or in custom-formatted tables that you create. You have full control over the creation of these custom tables, down to specifying the column names and types. You create [**Data collection rules (DCRs)**](/azure/azure-monitor/essentials/data-collection-rule-overview) to define, configure, and apply transformations to these data flows. -- [**Data collection transformation**](../azure-monitor/essentials/data-collection-transformations.md) uses DCRs to apply basic KQL queries to incoming standard logs (and certain types of custom logs) before they're stored in your workspace. These transformations can filter out irrelevant data, enrich existing data with analytics or external data, or mask sensitive or personal information.+- [**Data collection transformation**](/azure/azure-monitor/essentials/data-collection-transformations) uses DCRs to apply basic KQL queries to incoming standard logs (and certain types of custom logs) before they're stored in your workspace. These transformations can filter out irrelevant data, enrich existing data with analytics or external data, or mask sensitive or personal information. These two tools will be explained in more detail below. In Log Analytics, data collection rules (DCRs) determine the data flow for diffe Support for DCRs in Microsoft Sentinel includes: -- *Standard DCRs*, currently supported only for AMA-based connectors and workflows using the new [Logs ingestion API](../azure-monitor/logs/logs-ingestion-api-overview.md). +- *Standard DCRs*, currently supported only for AMA-based connectors and workflows using the new [Logs ingestion API](/azure/azure-monitor/logs/logs-ingestion-api-overview). Each connector or log source workflow can have its own dedicated *standard DCR*, though multiple connectors or sources can share a common *standard DCR* as well. - *Workspace transformation DCRs*, for workflows that don't currently support standard DCRs. - A single *workspace transformation DCR* serves all the supported workflows in a workspace that aren't served by standard DCRs. A workspace can have only one *workspace transformation DCR*, but that DCR contains separate transformations for each input stream. Also, *workspace transformation DCR*s are supported only for a [specific set of tables](../azure-monitor/logs/tables-feature-support.md). + A single *workspace transformation DCR* serves all the supported workflows in a workspace that aren't served by standard DCRs. A workspace can have only one *workspace transformation DCR*, but that DCR contains separate transformations for each input stream. Also, *workspace transformation DCR*s are supported only for a [specific set of tables](/azure/azure-monitor/logs/tables-feature-support). Microsoft Sentinel's support for ingestion-time transformation depends on the type of data connector you're using. For more in-depth information on custom logs, ingestion-time transformation, and data collection rules, see the articles linked in the [Next steps](#next-steps) section at the end of this article. The following table describes DCR support for Microsoft Sentinel data connector | Data connector type | DCR support | | - | -- |-| **Direct ingestion via [Logs ingestion API](../azure-monitor/logs/logs-ingestion-api-overview.md)** | Standard DCRs | +| **Direct ingestion via [Logs ingestion API](/azure/azure-monitor/logs/logs-ingestion-api-overview)** | Standard DCRs | | [**AMA standard logs**](connect-services-windows-based.md), such as: <li>[Windows Security Events via AMA](./data-connectors/windows-security-events-via-ama.md)<li>[Windows Forwarded Events](./data-connectors/windows-forwarded-events.md)<li>[CEF data](connect-cef-ama.md)<li>[Syslog data](connect-cef-syslog.md) | Standard DCRs | | [**MMA standard logs**](connect-services-windows-based.md), such as <li>[Syslog data](connect-syslog.md)<li>[CommonSecurityLog](connect-azure-windows-microsoft-services.md) | Workspace transformation DCRs |-| [**Diagnostic settings-based connections**](connect-services-diagnostic-setting-based.md) | Workspace transformation DCRs, based on the [supported output tables](../azure-monitor/logs/tables-feature-support.md) for specific data connectors | -| **Built-in, service-to-service data connectors**, such as:<li>[Microsoft Office 365](connect-services-api-based.md)<li>[Microsoft Entra ID](connect-azure-active-directory.md)<li>[Amazon S3](connect-aws.md) | Workspace transformation DCRs, based on the [supported output tables](../azure-monitor/logs/tables-feature-support.md) for specific data connectors | +| [**Diagnostic settings-based connections**](connect-services-diagnostic-setting-based.md) | Workspace transformation DCRs, based on the [supported output tables](/azure/azure-monitor/logs/tables-feature-support) for specific data connectors | +| **Built-in, service-to-service data connectors**, such as:<li>[Microsoft Office 365](connect-services-api-based.md)<li>[Microsoft Entra ID](connect-azure-active-directory.md)<li>[Amazon S3](connect-aws.md) | Workspace transformation DCRs, based on the [supported output tables](/azure/azure-monitor/logs/tables-feature-support) for specific data connectors | | **Built-in, API-based data connector**, such as: <li>[Codeless data connectors](create-codeless-connector.md) | Standard DCRs | | **Built-in, API-based data connectors**, such as: <li>[Legacy codeless data connectors](create-codeless-connector-legacy.md)<li>[Azure Functions-based data connectors](connect-azure-functions-template.md) | Not currently supported | Only the following tables are currently supported for custom log ingestion: - [**ASimNetworkSessionLogs**](/azure/azure-monitor/reference/tables/asimnetworksessionlogs) - [**ASimWebSessionLogs**](/azure/azure-monitor/reference/tables/asimwebsessionlogs) -For more information, see [Tables that support ingestion-time transformations](../azure-monitor/logs/tables-feature-support.md). +For more information, see [Tables that support ingestion-time transformations](/azure/azure-monitor/logs/tables-feature-support). ## Limitations Ingestion-time data transformation currently has the following known issues for - It make take up to 60 minutes for the data transformation configurations to apply. -- KQL syntax: Not all operators are supported. For more information, see [**KQL limitations** and **Supported KQL features**](../azure-monitor/essentials/data-collection-transformations-structure.md#kql-limitations) in the Azure Monitor documentation.+- KQL syntax: Not all operators are supported. For more information, see [**KQL limitations** and **Supported KQL features**](/azure/azure-monitor/essentials/data-collection-transformations-structure#kql-limitations) in the Azure Monitor documentation. - You can only send logs from one specific data source to one workspace. To send data from a single data source to multiple workspaces (destinations) with a standard DCR, please create one DCR per workspace. Learn more about Microsoft Sentinel data connector types. For more information, For more in-depth information on ingestion-time transformation, the Custom Logs API, and data collection rules, see the following articles in the Azure Monitor documentation: -- [Data collection transformations in Azure Monitor Logs](../azure-monitor/essentials/data-collection-transformations.md)-- [Logs ingestion API in Azure Monitor Logs](../azure-monitor/logs/logs-ingestion-api-overview.md)-- [Data collection rules in Azure Monitor](../azure-monitor/essentials/data-collection-rule-overview.md)+- [Data collection transformations in Azure Monitor Logs](/azure/azure-monitor/essentials/data-collection-transformations) +- [Logs ingestion API in Azure Monitor Logs](/azure/azure-monitor/logs/logs-ingestion-api-overview) +- [Data collection rules in Azure Monitor](/azure/azure-monitor/essentials/data-collection-rule-overview) |
| sentinel | Deploy Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/deploy-overview.md | The fine tune and review phase is typically performed by a SOC engineer or relat |✅ **Add data to watchlists** |Check that your watchlists are up to date. If any changes have occurred in your environment, such as new users or use cases, [update your watchlists accordingly](watchlists-manage.md). | |✅ **Review commitment tiers** | [Review the commitment tiers](billing.md#analytics-logs) you initially set up, and verify that these tiers reflect your current configuration. | |✅ **Keep track of ingestion costs** |To keep track of ingestion costs, use one of these workbooks:<br>- The [**Workspace Usage Report** workbook](billing-monitor-costs.md#deploy-a-workbook-to-visualize-data-ingestion) provides your workspace's data consumption, cost, and usage statistics. The workbook gives the workspace's data ingestion status and amount of free and billable data. You can use the workbook logic to monitor data ingestion and costs, and to build custom views and rule-based alerts.<br>- The **Microsoft Sentinel Cost** workbook gives a more focused view of Microsoft Sentinel costs, including ingestion and retention data, ingestion data for eligible data sources, Logic Apps billing information, and more. |-|✅ **Fine-tune Data Collection Rules (DCRs)** |- Check that your [DCRs](../azure-monitor/essentials/data-collection-rule-overview.md) reflect your data ingestion needs and use cases.<br>- If needed, [implement ingestion-time transformation](data-transformation.md#filtering) to filter out irrelevant data even before it's first stored in your workspace. | +|✅ **Fine-tune Data Collection Rules (DCRs)** |- Check that your [DCRs](/azure/azure-monitor/essentials/data-collection-rule-overview) reflect your data ingestion needs and use cases.<br>- If needed, [implement ingestion-time transformation](data-transformation.md#filtering) to filter out irrelevant data even before it's first stored in your workspace. | |✅ **Check analytics rules against MITRE framework** |[Check your MITRE coverage in the Microsoft Sentinel MITRE page](mitre-coverage.md): View the detections already active in your workspace, and those available for you to configure, to understand your organization's security coverage, based on the tactics and techniques from the MITRE ATT&CK┬« framework. | |✅ **Hunt for suspicious activity** |Make sure that your SOC has a process in place for [proactive threat hunting](hunts.md). Hunting is a process where security analysts seek out undetected threats and malicious behaviors. By creating a hypothesis, searching through data, and validating that hypothesis, they determine what to act on. Actions can include creating new detections, new threat intelligence, or spinning up a new incident. | |
| sentinel | Deploy Dynamics 365 Finance Operations Solution | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/dynamics-365/deploy-dynamics-365-finance-operations-solution.md | Before you begin, verify that: - You have a defined Microsoft Sentinel workspace and have read and write permissions to the workspace. - [Microsoft Dynamics 365 Finance version 10.0.33 or above](/dynamics365/finance/get-started/whats-new-changed-changed-10-0-33) is enabled and you have administrative access to the monitored environments. - You can create an [Azure Function App](../../azure-functions/functions-overview.md) with the `Microsoft.Web/Sites`, `Microsoft.Web/ServerFarms`, `Microsoft.Insights/Components`, andΓÇ»`Microsoft.Storage/StorageAccounts` permissions.-- You can create [Data Collection Rules/Endpoints](../../azure-monitor/essentials/data-collection-rule-overview.md) with the permissions:+- You can create [Data Collection Rules/Endpoints](/azure/azure-monitor/essentials/data-collection-rule-overview) with the permissions: - `Microsoft.Insights/DataCollectionEndpoints`, and `Microsoft.Insights/DataCollectionRules`. - Assign the Monitoring Metrics Publisher role to the Azure Function. |
| sentinel | Enable Monitoring | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/enable-monitoring.md | Monitor the health and audit the integrity of supported Microsoft Sentinel resou To get health data from the [*SentinelHealth*](health-table-reference.md) data table, or to get auditing information from the [*SentinelAudit*](audit-table-reference.md) data table, you must first turn on the Microsoft Sentinel auditing and health monitoring feature for your workspace. This article instructs you how to turn on these features. -To implement the health and audit feature using API (Bicep/AZURE RESOURCE MANAGER (ARM)/REST), review the [Diagnostic Settings operations](/rest/api/monitor/diagnostic-settings). To configure the retention time for your audit and health events, see [Manage data retention in a Log Analytics workspace](../azure-monitor/logs/data-retention-configure.md). +To implement the health and audit feature using API (Bicep/AZURE RESOURCE MANAGER (ARM)/REST), review the [Diagnostic Settings operations](/rest/api/monitor/diagnostic-settings). To configure the retention time for your audit and health events, see [Manage data retention in a Log Analytics workspace](/azure/azure-monitor/logs/data-retention-configure). > [!IMPORTANT] > |
| sentinel | Enroll Simplified Pricing Tier | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/enroll-simplified-pricing-tier.md | The following sample template sets Microsoft Sentinel to the classic pricing tie } ``` -See [Deploying the sample templates](../azure-monitor/resource-manager-samples.md) to learn more about using Resource Manager templates. +See [Deploying the sample templates](/azure/azure-monitor/resource-manager-samples) to learn more about using Resource Manager templates. To reference how to implement this template in Terraform or Bicep start [here](/azure/templates/microsoft.operationalinsights/2020-08-01/workspaces). To reference how to implement this template in Terraform or Bicep start [here](/ ## Simplified pricing tiers for dedicated clusters In classic pricing tiers, Microsoft Sentinel was always billed as a secondary meter at the workspace level. The meter for Microsoft Sentinel could differ from the overall meter of the workspace. -With simplified pricing tiers, the same Commitment tier and billing mode used by the cluster is set for the Microsoft Sentinel workspace. Microsoft Sentinel usage is billed at the effective per GB price of that tier meter, and all usage is counted towards the total allocation for the dedicated cluster. This allocation is either at the cluster level or proportionately at the workspace level depending on the billing mode of the cluster. For more information, see [Cost details - Dedicated cluster](../azure-monitor/logs/cost-logs.md#dedicated-clusters). +With simplified pricing tiers, the same Commitment tier and billing mode used by the cluster is set for the Microsoft Sentinel workspace. Microsoft Sentinel usage is billed at the effective per GB price of that tier meter, and all usage is counted towards the total allocation for the dedicated cluster. This allocation is either at the cluster level or proportionately at the workspace level depending on the billing mode of the cluster. For more information, see [Cost details - Dedicated cluster](/azure/azure-monitor/logs/cost-logs#dedicated-clusters). ### Dedicated cluster billing examples Compare the following cluster scenarios to better understand simplified pricing when adding Microsoft Sentinel enabled workspaces to a dedicated cluster. It's possible your Microsoft account team negotiated a discounted price for Log ## Learn more -- For more tips on reducing Log Analytics data volume, see [Azure Monitor best practices - Cost management](../azure-monitor/best-practices-cost.md).+- For more tips on reducing Log Analytics data volume, see [Azure Monitor best practices - Cost management](/azure/azure-monitor/best-practices-cost). - Learn [how to optimize your cloud investment with Microsoft Cost Management](../cost-management-billing/costs/cost-mgt-best-practices.md?WT.mc_id=costmanagementcontent_docsacmhorizontal_-inproduct-learn). - Learn more about managing costs with [cost analysis](../cost-management-billing/costs/quick-acm-cost-analysis.md?WT.mc_id=costmanagementcontent_docsacmhorizontal_-inproduct-learn). - Learn about how to [prevent unexpected costs](../cost-management-billing/understand/analyze-unexpected-charges.md?WT.mc_id=costmanagementcontent_docsacmhorizontal_-inproduct-learn). |
| sentinel | Extend Sentinel Across Workspaces Tenants | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/extend-sentinel-across-workspaces-tenants.md | -When you onboard Microsoft Sentinel, your first step is to select your Log Analytics workspace. While you can get the full benefit of the Microsoft Sentinel experience with a single workspace, in some cases, you might want to extend your workspace to query and analyze your data across workspaces and tenants. For more information, see [Design a Log Analytics workspace architecture](../azure-monitor/logs/workspace-design.md) and [Prepare for multiple workspaces and tenants in Microsoft Sentinel](prepare-multiple-workspaces.md). +When you onboard Microsoft Sentinel, your first step is to select your Log Analytics workspace. While you can get the full benefit of the Microsoft Sentinel experience with a single workspace, in some cases, you might want to extend your workspace to query and analyze your data across workspaces and tenants. For more information, see [Design a Log Analytics workspace architecture](/azure/azure-monitor/logs/workspace-design) and [Prepare for multiple workspaces and tenants in Microsoft Sentinel](prepare-multiple-workspaces.md). ## Manage incidents on multiple workspaces Microsoft Sentinel supports a [multiple workspace incident view](./multiple-work ## Query multiple workspaces -You can query [multiple workspaces](../azure-monitor/logs/cross-workspace-query.md), allowing you to search and correlate data from multiple workspaces in a single query. +You can query [multiple workspaces](/azure/azure-monitor/logs/cross-workspace-query), allowing you to search and correlate data from multiple workspaces in a single query. -- Use the [`workspace( )` expression](../azure-monitor/logs/workspace-expression.md), with the workspace identifier as the argument, to refer to a table in a different workspace.+- Use the [`workspace( )` expression](/azure/azure-monitor/logs/workspace-expression), with the workspace identifier as the argument, to refer to a table in a different workspace. - - See [important information](../azure-monitor/logs/workspace-expression.md#syntax) about the use of identifier formats to ensure proper performance. + - See [important information](/azure/azure-monitor/logs/workspace-expression#syntax) about the use of identifier formats to ensure proper performance. - Use the [union operator](/azure/data-explorer/kusto/query/unionoperator?pivots=azuremonitor) alongside the `workspace( )` expression to apply a query across tables in multiple workspaces. -- You can use saved [functions](../azure-monitor/logs/functions.md) to simplify cross-workspace queries. For example, you can shorten a long reference to the *SecurityEvent* table in Customer A's workspace by saving the expression +- You can use saved [functions](/azure/azure-monitor/logs/functions) to simplify cross-workspace queries. For example, you can shorten a long reference to the *SecurityEvent* table in Customer A's workspace by saving the expression ```kusto workspace("/subscriptions/<customerA_subscriptionId>/resourcegroups/<resourceGroupName>/providers/microsoft.OperationalInsights/workspaces/<workspaceName>").SecurityEvent |
| sentinel | Forward Syslog Monitor Agent | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/forward-syslog-monitor-agent.md | -> Container Insights now supports the automatic collection of Syslog events from Linux nodes in your AKS clusters. To learn more, see [Syslog collection with Container Insights](../azure-monitor/containers/container-insights-syslog.md). +> Container Insights now supports the automatic collection of Syslog events from Linux nodes in your AKS clusters. To learn more, see [Syslog collection with Container Insights](/azure/azure-monitor/containers/container-insights-syslog). Configure your Linux-based device to send data to a Linux VM. Azure Monitor Agent on the VM forwards the Syslog data to the Log Analytics workspace. Then use Microsoft Sentinel or Azure Monitor to monitor the device from the data stored in the Log Analytics workspace. To complete the steps in this tutorial, you must have the following resources an |[Monitoring Contributor ](../role-based-access-control/built-in-roles.md) |- Subscription </br>- Resource group </br>- Existing data collection rule | To create or edit data collection rules | - A Log Analytics workspace. - A Linux server that's running an operating system that supports Azure Monitor Agent.- - [Supported Linux operating systems for Azure Monitor Agent](../azure-monitor/agents/agents-overview.md#linux). + - [Supported Linux operating systems for Azure Monitor Agent](/azure/azure-monitor/agents/agents-overview#linux). - [Create a Linux VM in the Azure portal](/azure/virtual-machines/linux/quick-create-portal) or [add an on-premises Linux server to Azure Arc](../azure-arc/servers/learn/quick-enable-hybrid-vm.md). - A Linux-based device that generates event log data like a firewall network device. ## Configure Azure Monitor Agent to collect Syslog data -See the step-by-step instructions in [Collect Syslog events with Azure Monitor Agent](../azure-monitor/agents/data-collection-syslog.md). +See the step-by-step instructions in [Collect Syslog events with Azure Monitor Agent](/azure/azure-monitor/agents/data-collection-syslog). ## Verify that Azure Monitor Agent is running sudo wget -O Forwarder_AMA_installer.py https://raw.githubusercontent.com/Azure/ This script can make changes for both rsyslog.d and syslog-ng. > [!NOTE]-> To avoid [Full Disk scenarios](../azure-monitor/agents/azure-monitor-agent-troubleshoot-linux-vm-rsyslog.md) where the agent can't function, we recommend that you set the `syslog-ng` or `rsyslog` configuration not to store unneeded logs. A Full Disk scenario disrupts the function of the installed Azure Monitor Agent. +> To avoid [Full Disk scenarios](/azure/azure-monitor/agents/azure-monitor-agent-troubleshoot-linux-vm-rsyslog) where the agent can't function, we recommend that you set the `syslog-ng` or `rsyslog` configuration not to store unneeded logs. A Full Disk scenario disrupts the function of the installed Azure Monitor Agent. > Read more about [rsyslog](https://www.rsyslog.com/doc/master/configuration/actions.html) or [syslog-ng](https://www.syslog-ng.com/technical-documents). ## Verify Syslog data is forwarded to your Log Analytics workspace Evaluate whether you need the resources like the VM that you created. Resources ## Related content -- [Data collection rules in Azure Monitor](../azure-monitor/essentials/data-collection-rule-overview.md)-- [Collect Syslog events with Azure Monitor Agent](../azure-monitor/agents/data-collection-syslog.md)+- [Data collection rules in Azure Monitor](/azure/azure-monitor/essentials/data-collection-rule-overview) +- [Collect Syslog events with Azure Monitor Agent](/azure/azure-monitor/agents/data-collection-syslog) |
| sentinel | Health Audit | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/health-audit.md | To start collecting health and audit data, you need to [enable health and audit |**Run queries** on the *SentinelHealth* and *SentinelAudit* data tables from the Microsoft Sentinel **Logs** page. | <li> [Data connectors](monitor-data-connector-health.md#run-queries-to-detect-health-drifts) <li> [Automation rules and playbooks](monitor-automation-health.md#get-the-complete-automation-picture) (join query with Azure Logic Apps diagnostics)<li> [Analytics rules](monitor-analytics-rule-integrity.md#run-queries-to-detect-health-and-integrity-issues) | |**Use the auditing and health monitoring workbooks** provided in Microsoft Sentinel. | <li> [Data connectors](monitor-data-connector-health.md#use-the-health-monitoring-workbook) <li> [Automation rules and playbooks](monitor-automation-health.md#use-the-health-monitoring-workbook) <li> [Analytics rules](monitor-analytics-rule-integrity.md#use-the-auditing-and-health-monitoring-workbook) | |**Use Microsoft Sentinel's execution management tools** to monitor and optimize scheduled analytics rules' execution | <li> [Monitor and optimize the execution of your scheduled analytics rules](monitor-optimize-analytics-rule-execution.md) |-|**Export the data into various destinations**, like your Log Analytics workspace, archiving to a storage account, and more. | <li> [Diagnostic settings in Azure Monitor](../azure-monitor/essentials/diagnostic-settings.md) | +|**Export the data into various destinations**, like your Log Analytics workspace, archiving to a storage account, and more. | <li> [Diagnostic settings in Azure Monitor](/azure/azure-monitor/essentials/diagnostic-settings) | ## Related content |
| sentinel | Hunting | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/hunting.md | Use queries before, during, and after a compromise to take the following actions View the query's results, and select **New alert rule** > **Create Microsoft Sentinel alert**. Use the **Analytics rule wizard** to create a new rule based on your query. For more information, see [Create custom analytics rules to detect threats](detect-threats-custom.md). -You can also create hunting and livestream queries over data stored in Azure Data Explorer. For more information, see details of [constructing cross-resource queries](../azure-monitor/logs/azure-monitor-data-explorer-proxy.md) in the Azure Monitor documentation. +You can also create hunting and livestream queries over data stored in Azure Data Explorer. For more information, see details of [constructing cross-resource queries](/azure/azure-monitor/logs/azure-monitor-data-explorer-proxy) in the Azure Monitor documentation. To find more queries and data sources, go to the **Content hub** in Microsoft Sentinel or refer to community resources like [Microsoft Sentinel GitHub repository](https://github.com/Azure/Azure-Sentinel/tree/master/Hunting%20Queries). For more information, see: Hunting queries are built in [Kusto Query Language (KQL)](/azure/data-explorer/kusto/query/), a powerful query language with IntelliSense language that gives you the power and flexibility you need to take hunting to the next level. -It's the same language used by the queries in your analytics rules and elsewhere in Microsoft Sentinel. For more information, see [Query Language Reference](../azure-monitor/logs/get-started-queries.md). +It's the same language used by the queries in your analytics rules and elsewhere in Microsoft Sentinel. For more information, see [Query Language Reference](/azure/azure-monitor/logs/get-started-queries). The following operators are especially helpful in Microsoft Sentinel hunting queries: The following operators are especially helpful in Microsoft Sentinel hunting que - **find** - Find rows that match a predicate across a set of tables. -- **adx()** - This function performs cross-resource queries of Azure Data Explorer data sources from the Microsoft Sentinel hunting experience and Log Analytics. For more information, see [Cross-resource query Azure Data Explorer by using Azure Monitor](../azure-monitor/logs/azure-monitor-data-explorer-proxy.md).+- **adx()** - This function performs cross-resource queries of Azure Data Explorer data sources from the Microsoft Sentinel hunting experience and Log Analytics. For more information, see [Cross-resource query Azure Data Explorer by using Azure Monitor](/azure/azure-monitor/logs/azure-monitor-data-explorer-proxy). ## Related articles |
| sentinel | Import Export Automation Rules | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/import-export-automation-rules.md | The file includes all the parameters defined in the automation rule. Rules of an This article shows you how to export and import automation rules. -> [!IMPORTANT] -> -> - Exporting and importing rules is in **PREVIEW**. See the [Supplemental Terms of Use for Microsoft Azure Previews](https://azure.microsoft.com/support/legal/preview-supplemental-terms/) for additional legal terms that apply to Azure features that are in beta, preview, or otherwise not yet released into general availability. -> -> - [!INCLUDE [unified-soc-preview](includes/unified-soc-preview-without-alert.md)] ## Export rules |
| sentinel | Ingestion Delay | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/ingestion-delay.md | For more information, see: - [Customize alert details in Azure Sentinel](customize-alert-details.md) - [Manage template versions for your scheduled analytics rules in Azure Sentinel](manage-analytics-rule-templates.md) - [Use the health monitoring workbook](monitor-data-connector-health.md)-- [Log data ingestion time in Azure Monitor](../azure-monitor/logs/data-ingestion-time.md)+- [Log data ingestion time in Azure Monitor](/azure/azure-monitor/logs/data-ingestion-time) |
| sentinel | Investigate Large Datasets | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/investigate-large-datasets.md | The following image shows example search criteria for a search job. Use search to find events in any of the following log types: -- [Analytics logs](../azure-monitor/logs/data-platform-logs.md)-- [Basic logs](../azure-monitor/logs/data-platform-logs.md)-- [Auxiliary logs](../azure-monitor/logs/data-platform-logs.md)+- [Analytics logs](/azure/azure-monitor/logs/data-platform-logs) +- [Basic logs](/azure/azure-monitor/logs/data-platform-logs) +- [Auxiliary logs](/azure/azure-monitor/logs/data-platform-logs) -You can also search analytics or basic log data stored in [long-term retention](../azure-monitor/logs/data-retention-configure.md#interactive-long-term-and-total-retention). +You can also search analytics or basic log data stored in [long-term retention](/azure/azure-monitor/logs/data-retention-configure#interactive-long-term-and-total-retention). ### Limitations of a search job Search jobs aren't currently supported for the following workspaces: - Customer-managed key enabled workspaces - Workspaces in the China East 2 region -To learn more, see [Search job in Azure Monitor](../azure-monitor/logs/search-jobs.md) in the Azure Monitor documentation. +To learn more, see [Search job in Azure Monitor](/azure/azure-monitor/logs/search-jobs) in the Azure Monitor documentation. ## Restore historical data from archived logs Before you start to restore an archived log table, be aware of the following lim - Restore up to four archived tables per workspace per week. - Limited to two concurrent restore jobs per workspace. -To learn more, see [Restore logs in Azure Monitor](../azure-monitor/logs/restore.md). +To learn more, see [Restore logs in Azure Monitor](/azure/azure-monitor/logs/restore). ## Bookmark search results or restored data rows |
| sentinel | Kusto Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/kusto-overview.md | This article introduces the basics of Kusto Query Language, covering some of the ## Background - Why Kusto Query Language? -Microsoft Sentinel is built on top of the Azure Monitor service and it uses Azure MonitorΓÇÖs [Log Analytics](../azure-monitor/logs/log-analytics-overview.md) workspaces to store all of its data. This data includes any of the following: +Microsoft Sentinel is built on top of the Azure Monitor service and it uses Azure MonitorΓÇÖs [Log Analytics](/azure/azure-monitor/logs/log-analytics-overview) workspaces to store all of its data. This data includes any of the following: - data ingested from external sources into predefined tables using Microsoft Sentinel data connectors. - data ingested from external sources into user-defined custom tables, using custom-created data connectors as well as some types of out-of-the-box connectors. - data created by Microsoft Sentinel itself, resulting from the analyses it creates and performs - for example, alerts, incidents, and UEBA-related information. |
| sentinel | Kusto Resources | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/kusto-resources.md | Microsoft Sentinel uses Azure Monitor's Log Analytics environment and the Kusto ### Azure Monitor documentation - [Tutorial: Use Kusto queries](/azure/data-explorer/kusto/query/tutorial?pivots=azuremonitor)-- [Get started with KQL queries](../azure-monitor/logs/get-started-queries.md)+- [Get started with KQL queries](/azure/azure-monitor/logs/get-started-queries) - [Query best practices](/azure/data-explorer/kusto/query/best-practices) ### Reference guides |
| sentinel | Livestream | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/livestream.md | You can create a livestream session from an existing hunting query, or create yo - If you started livestream from a query, review the query and make any changes you want to make. - If you started livestream from scratch, create your query. - Livestream supports **cross-resource queries** of data in Azure Data Explorer. [**Learn more about cross-resource queries**](../azure-monitor/logs/azure-monitor-data-explorer-proxy.md). + Livestream supports **cross-resource queries** of data in Azure Data Explorer. [**Learn more about cross-resource queries**](/azure/azure-monitor/logs/azure-monitor-data-explorer-proxy). 1. Select **Play** from the command bar. |
| sentinel | Log Plans | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/log-plans.md | This category encompasses logs whose individual security value is limited but ar - **Large-scale searches**. Data can be ingested and searched in the background at petabyte scale, while being stored efficiently with minimal processing. -- **Summarization via summary rules**. Summarize high-volume logs into aggregate information and store the results as primary security data. To learn more about summary rules, see [Aggregate Microsoft Sentinel data with summary rules](../azure-monitor/logs/summary-rules.md).+- **Summarization via summary rules**. Summarize high-volume logs into aggregate information and store the results as primary security data. To learn more about summary rules, see [Aggregate Microsoft Sentinel data with summary rules](/azure/azure-monitor/logs/summary-rules). Some examples of secondary data log sources are cloud storage access logs, NetFlow logs, TLS/SSL certificate logs, firewall logs, proxy logs, and IoT logs. To learn more about how each of these sources brings value to security detections without being needed all the time, see [Log sources to use for Auxiliary Logs ingestion](basic-logs-use-cases.md). Microsoft Sentinel provides two different log storage plans, or types, to accomm - The **long-term retention** state preserves older data in its original tables for up to 12 years, at **extremely low cost**, regardless of the plan. -To learn more about retention states, see [Manage data retention in a Log Analytics workspace](../azure-monitor/logs/data-retention-configure.md). +To learn more about retention states, see [Manage data retention in a Log Analytics workspace](/azure/azure-monitor/logs/data-retention-configure). The following diagram summarizes and compares these two log management plans. When the interactive retention period ends, data goes into the **long-term reten ### Auxiliary logs plan -The **Auxiliary logs** plan keeps data in the **interactive retention** state for **30 days**. In the Auxiliary plan, this state has very low retention costs as compared to the Analytics plan. However, the query capabilities are limited: queries are charged per gigabyte of data scanned and are limited to a single table, and performance is significantly lower. While this data remains in the interactive retention state, you can run [summary rules](../azure-monitor/logs/summary-rules.md) on this data to create tables of aggregate, summary data in the Analytics logs plan, so that you have the full query capabilities on this aggregate data. +The **Auxiliary logs** plan keeps data in the **interactive retention** state for **30 days**. In the Auxiliary plan, this state has very low retention costs as compared to the Analytics plan. However, the query capabilities are limited: queries are charged per gigabyte of data scanned and are limited to a single table, and performance is significantly lower. While this data remains in the interactive retention state, you can run [summary rules](/azure/azure-monitor/logs/summary-rules) on this data to create tables of aggregate, summary data in the Analytics logs plan, so that you have the full query capabilities on this aggregate data. When the interactive retention period ends, data goes into the **long-term retention** state, remaining in its original table. Long-term retention in the auxiliary logs plan is similar to long-term retention in the analytics logs plan, except that the only option to access the data is with a [**search job**](investigate-large-datasets.md). [Restore](restore.md) is not supported for the auxiliary logs plan. ### Basic logs plan -A third plan, known as **Basic logs**, provides similar functionality to the auxiliary logs plan, but at a higher interactive retention cost (though not as high as the analytics logs plan). While the auxiliary logs plan remains in preview, basic logs can be an option for long-term, low-cost retention if your organization doesn't use preview features. To learn more about the basic logs plan, see [Table plans](../azure-monitor/logs/data-platform-logs.md#table-plans) in the Azure Monitor documentation. +A third plan, known as **Basic logs**, provides similar functionality to the auxiliary logs plan, but at a higher interactive retention cost (though not as high as the analytics logs plan). While the auxiliary logs plan remains in preview, basic logs can be an option for long-term, low-cost retention if your organization doesn't use preview features. To learn more about the basic logs plan, see [Table plans](/azure/azure-monitor/logs/data-platform-logs#table-plans) in the Azure Monitor documentation. ## Related content -- For a more in-depth comparison of log data plans, and more general information about log types, see [Azure Monitor Logs overview | Table plans](../azure-monitor/logs/data-platform-logs.md#table-plans).+- For a more in-depth comparison of log data plans, and more general information about log types, see [Azure Monitor Logs overview | Table plans](/azure/azure-monitor/logs/data-platform-logs#table-plans). -- To set up a table in the Auxiliary logs plan, see [Set up a table with the Auxiliary plan in your Log Analytics workspace (Preview)](../azure-monitor/logs/create-custom-table-auxiliary.md).+- To set up a table in the Auxiliary logs plan, see [Set up a table with the Auxiliary plan in your Log Analytics workspace (Preview)](/azure/azure-monitor/logs/create-custom-table-auxiliary). -- To understand more about retention periods—which exist across plans—see [Manage data retention in a Log Analytics workspace](../azure-monitor/logs/data-retention-configure.md).+- To understand more about retention periods—which exist across plans—see [Manage data retention in a Log Analytics workspace](/azure/azure-monitor/logs/data-retention-configure). |
| sentinel | Migration Arcsight Detection Rules | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/migration-arcsight-detection-rules.md | Learn more about analytics rules: - [**Create custom analytics rules to detect threats**](detect-threats-custom.md). Use [alert grouping](detect-threats-custom.md#alert-grouping) to reduce alert fatigue by grouping alerts that occur within a given timeframe. - [**Map data fields to entities in Microsoft Sentinel**](map-data-fields-to-entities.md) to enable SOC engineers to define entities as part of the evidence to track during an investigation. Entity mapping also makes it possible for SOC analysts to take advantage of an intuitive [investigation graph](investigate-cases.md#use-the-investigation-graph-to-deep-dive) that can help reduce time and effort. - [**Investigate incidents with UEBA data**](investigate-with-ueba.md), as an example of how to use evidence to surface events, alerts, and any bookmarks associated with a particular incident in the incident preview pane.-- [**Kusto Query Language (KQL)**](/azure/data-explorer/kusto/query/), which you can use to send read-only requests to your [Log Analytics](../azure-monitor/logs/log-analytics-tutorial.md) database to process data and return results. KQL is also used across other Microsoft services, such as [Microsoft Defender for Endpoint](https://www.microsoft.com/microsoft-365/security/endpoint-defender) and [Application Insights](../azure-monitor/app/app-insights-overview.md).+- [**Kusto Query Language (KQL)**](/azure/data-explorer/kusto/query/), which you can use to send read-only requests to your [Log Analytics](/azure/azure-monitor/logs/log-analytics-tutorial) database to process data and return results. KQL is also used across other Microsoft services, such as [Microsoft Defender for Endpoint](https://www.microsoft.com/microsoft-365/security/endpoint-defender) and [Application Insights](/azure/azure-monitor/app/app-insights-overview). ## Compare rule terminology |
| sentinel | Migration Convert Dashboards | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/migration-convert-dashboards.md | To convert your dashboard, complete the following tasks in Azure Workbooks and M ### 1. Identify data sources -Azure Workbooks are compatible with a large number of data sources. For more information, see [Azure Workbooks data sources](../azure-monitor/visualize/workbooks-data-sources.md). In most cases, use the Azure Monitor logs data source and Kusto Query Language (KQL) queries to visualize the underlying logs in your Microsoft Sentinel workspace. +Azure Workbooks are compatible with a large number of data sources. For more information, see [Azure Workbooks data sources](/azure/azure-monitor/visualize/workbooks-data-sources). In most cases, use the Azure Monitor logs data source and Kusto Query Language (KQL) queries to visualize the underlying logs in your Microsoft Sentinel workspace. ### 2. Construct or review KQL queries Before finalizing your KQL queries, always review and tune the queries to improv For more information, see the following resources: - [KQL query best practices](/azure/data-explorer/kusto/query/best-practices)-- [Optimize queries in Azure Monitor Logs](../azure-monitor/logs/query-optimization.md)+- [Optimize queries in Azure Monitor Logs](/azure/azure-monitor/logs/query-optimization) - [Optimizing KQL performance (webinar)](https://youtu.be/jN1Cz0JcLYU) ### 3. Create or update the workbook Create a workbook, update the workbook, or clone an existing workbook so that yo For more information, see the following articles: - [Visualize and monitor your data by using workbooks in Microsoft Sentinel](monitor-your-data.md)-- [Add groups in Azure Workbooks](../azure-monitor/visualize/workbooks-create-workbook.md#add-groups)+- [Add groups in Azure Workbooks](/azure/azure-monitor/visualize/workbooks-create-workbook#add-groups) ### 4. Create or update workbook parameters or user inputs By the time you arrive at this stage, you identified the required parameters for Workbooks allow you to control how your parameter controls are presented to consumers. For example, you select whether the controls are presented as a text box vs. drop down, or single- vs. multi-select. You can also select which values to use, from text, JSON, KQL, or Azure Resource Graph, and more. -Review the [supported workbook parameters](../azure-monitor/visualize/workbooks-parameters.md). You can reference these parameter values in other parts of workbooks either via bindings or value expansions. +Review the [supported workbook parameters](/azure/azure-monitor/visualize/workbooks-parameters). You can reference these parameter values in other parts of workbooks either via bindings or value expansions. ### 5. Create or update visualizations Workbooks provide a rich set of capabilities for visualizing your data. Review these detailed examples of each visualization type. -- [Text](../azure-monitor/visualize/workbooks-text-visualizations.md)-- [Charts](../azure-monitor/visualize/workbooks-chart-visualizations.md)-- [Grids](../azure-monitor/visualize/workbooks-grid-visualizations.md)-- [Tiles](../azure-monitor/visualize/workbooks-tile-visualizations.md)-- [Trees](../azure-monitor/visualize/workbooks-tree-visualizations.md)-- [Graphs](../azure-monitor/visualize/workbooks-graph-visualizations.md)-- [Map](../azure-monitor/visualize/workbooks-map-visualizations.md)-- [Honey comb](../azure-monitor/visualize/workbooks-honey-comb.md)-- [Composite bar](../azure-monitor/visualize/workbooks-composite-bar.md)+- [Text](/azure/azure-monitor/visualize/workbooks-text-visualizations) +- [Charts](/azure/azure-monitor/visualize/workbooks-chart-visualizations) +- [Grids](/azure/azure-monitor/visualize/workbooks-grid-visualizations) +- [Tiles](/azure/azure-monitor/visualize/workbooks-tile-visualizations) +- [Trees](/azure/azure-monitor/visualize/workbooks-tree-visualizations) +- [Graphs](/azure/azure-monitor/visualize/workbooks-graph-visualizations) +- [Map](/azure/azure-monitor/visualize/workbooks-map-visualizations) +- [Honey comb](/azure/azure-monitor/visualize/workbooks-honey-comb) +- [Composite bar](/azure/azure-monitor/visualize/workbooks-composite-bar) ### 6. Preview and save the workbook |
| sentinel | Migration Export Ingest | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/migration-export-ingest.md | To ingest your historical data into Azure Data Explorer (ADX) (option 1 in the [ To ingest your historical data into Microsoft Sentinel Basic Logs (option 2 in the [diagram above](#export-data-from-the-legacy-siem)): 1. If you don't have an existing Log Analytics workspace, create a new workspace and [install Microsoft Sentinel](quickstart-onboard.md#enable-microsoft-sentinel-).-1. [Create an App registration to authenticate against the API](../azure-monitor/logs/tutorial-logs-ingestion-portal.md#create-azure-ad-application). -1. [Create a custom log table](../azure-monitor/logs/tutorial-logs-ingestion-portal.md#create-new-table-in-log-analytics-workspace) to store the data, and provide a data sample. In this step, you can also define a transformation before the data is ingested. -1. [Collect information from the data collection rule](../azure-monitor/logs/tutorial-logs-ingestion-portal.md#collect-information-from-the-dcr) and assign permissions to the rule. -1. [Change the table from Analytics to Basic Logs](../azure-monitor/logs/logs-table-plans.md). +1. [Create an App registration to authenticate against the API](/azure/azure-monitor/logs/tutorial-logs-ingestion-portal#create-azure-ad-application). +1. [Create a custom log table](/azure/azure-monitor/logs/tutorial-logs-ingestion-portal#create-new-table-in-log-analytics-workspace) to store the data, and provide a data sample. In this step, you can also define a transformation before the data is ingested. +1. [Collect information from the data collection rule](/azure/azure-monitor/logs/tutorial-logs-ingestion-portal#collect-information-from-the-dcr) and assign permissions to the rule. +1. [Change the table from Analytics to Basic Logs](/azure/azure-monitor/logs/logs-table-plans). 1. Run the [Custom Log Ingestion script](https://github.com/Azure/Azure-Sentinel/tree/master/Tools/CustomLogsIngestion-DCE-DCR). The script asks for the following details: - Path to the log files to ingest - Microsoft Entra tenant ID |
| sentinel | Migration Ingestion Target Platform | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/migration-ingestion-target-platform.md | This article compares target platforms in terms of performance, cost, usability > [!NOTE] > The considerations in this table only apply to historical log migration, and don't apply in other scenarios, such as long-term retention. -| |[Basic Logs/Archive](../azure-monitor/logs/logs-table-plans.md) |[Azure Data Explorer (ADX)](/azure/data-explorer/data-explorer-overview) |[Azure Blob Storage](../storage/blobs/storage-blobs-overview.md) |[ADX + Azure Blob Storage](../azure-monitor/logs/azure-data-explorer-query-storage.md) | +| |[Basic Logs/Archive](/azure/azure-monitor/logs/logs-table-plans) |[Azure Data Explorer (ADX)](/azure/data-explorer/data-explorer-overview) |[Azure Blob Storage](../storage/blobs/storage-blobs-overview.md) |[ADX + Azure Blob Storage](/azure/azure-monitor/logs/azure-data-explorer-query-storage) | ||||||-|**Capabilities**: |ΓÇó Apply most of the existing Azure Monitor Logs experiences at a lower cost.<br>ΓÇó Basic Logs are retained for eight days, and are then automatically transferred to the archive (according to the original retention period).<br>ΓÇó Use [search jobs](../azure-monitor/logs/search-jobs.md) to search across petabytes of data and find specific events.<br>ΓÇó For deep investigations on a specific time range, [restore data from the archive](../azure-monitor/logs/restore.md). The data is then available in the hot cache for further analytics. |ΓÇó Both ADX and Microsoft Sentinel use the Kusto Query Language (KQL), allowing you to query, aggregate, or correlate data in both platforms. For example, you can run a KQL query from Microsoft Sentinel to [join data stored in ADX with data stored in Log Analytics](../azure-monitor/logs/azure-monitor-data-explorer-proxy.md).<br>ΓÇó With ADX, you have substantial control over the cluster size and configuration. For example, you can create a larger cluster to achieve higher ingestion throughput, or create a smaller cluster to control your costs. |ΓÇó Blob storage is optimized for storing massive amounts of unstructured data.<br>ΓÇó Offers competitive costs.<br>ΓÇó Suitable for a scenario where your organization doesn't prioritize accessibility or performance, such as when there the organization must align with compliance or audit requirements. |ΓÇó Data is stored in a blob storage, which is low in costs.<br>ΓÇó You use ADX to query the data in KQL, allowing you to easily access the data. [Learn how to query Azure Monitor data with ADX](../azure-monitor/logs/azure-data-explorer-query-storage.md) | -|**Usability**: |**Great**<br><br>The archive and search options are simple to use and accessible from the Microsoft Sentinel portal. However, the data isn't immediately available for queries. You need to perform a search to retrieve the data, which might take some time, depending on the amount of data being scanned and returned. |**Good**<br><br>Fairly easy to use in the context of Microsoft Sentinel. For example, you can use an Azure workbook to visualize data spread across both Microsoft Sentinel and ADX. You can also query ADX data from the Microsoft Sentinel portal using the [ADX proxy](../azure-monitor/logs/azure-monitor-data-explorer-proxy.md). |**Poor**<br><br>With historical data migrations, you might have to deal with millions of files, and exploring the data becomes a challenge. |**Fair**<br><br>While using the `externaldata` operator is very challenging with large numbers of blobs to reference, using external ADX tables eliminates this issue. The external table definition understands the blob storage folder structure, and allows you to transparently query the data contained in many different blobs and folders. | +|**Capabilities**: |ΓÇó Apply most of the existing Azure Monitor Logs experiences at a lower cost.<br>ΓÇó Basic Logs are retained for eight days, and are then automatically transferred to the archive (according to the original retention period).<br>ΓÇó Use [search jobs](/azure/azure-monitor/logs/search-jobs) to search across petabytes of data and find specific events.<br>ΓÇó For deep investigations on a specific time range, [restore data from the archive](/azure/azure-monitor/logs/restore). The data is then available in the hot cache for further analytics. |ΓÇó Both ADX and Microsoft Sentinel use the Kusto Query Language (KQL), allowing you to query, aggregate, or correlate data in both platforms. For example, you can run a KQL query from Microsoft Sentinel to [join data stored in ADX with data stored in Log Analytics](/azure/azure-monitor/logs/azure-monitor-data-explorer-proxy).<br>ΓÇó With ADX, you have substantial control over the cluster size and configuration. For example, you can create a larger cluster to achieve higher ingestion throughput, or create a smaller cluster to control your costs. |ΓÇó Blob storage is optimized for storing massive amounts of unstructured data.<br>ΓÇó Offers competitive costs.<br>ΓÇó Suitable for a scenario where your organization doesn't prioritize accessibility or performance, such as when there the organization must align with compliance or audit requirements. |ΓÇó Data is stored in a blob storage, which is low in costs.<br>ΓÇó You use ADX to query the data in KQL, allowing you to easily access the data. [Learn how to query Azure Monitor data with ADX](/azure/azure-monitor/logs/azure-data-explorer-query-storage) | +|**Usability**: |**Great**<br><br>The archive and search options are simple to use and accessible from the Microsoft Sentinel portal. However, the data isn't immediately available for queries. You need to perform a search to retrieve the data, which might take some time, depending on the amount of data being scanned and returned. |**Good**<br><br>Fairly easy to use in the context of Microsoft Sentinel. For example, you can use an Azure workbook to visualize data spread across both Microsoft Sentinel and ADX. You can also query ADX data from the Microsoft Sentinel portal using the [ADX proxy](/azure/azure-monitor/logs/azure-monitor-data-explorer-proxy). |**Poor**<br><br>With historical data migrations, you might have to deal with millions of files, and exploring the data becomes a challenge. |**Fair**<br><br>While using the `externaldata` operator is very challenging with large numbers of blobs to reference, using external ADX tables eliminates this issue. The external table definition understands the blob storage folder structure, and allows you to transparently query the data contained in many different blobs and folders. | |**Management overhead**: |**Fully managed**<br><br>The search and archive options are fully managed and don't add management overhead. |**High**<br><br>ADX is external to Microsoft Sentinel, which requires monitoring and maintenance. |**Low**<br><br>While this platform requires little maintenance, selecting this platform adds monitoring and configuration tasks, such as setting up lifecycle management. |**Medium**<br><br>With this option, you maintain and monitor ADX and Azure Blob Storage, both of which are external components to Microsoft Sentinel. While ADX can be shut down at times, consider the extra management overhead with this option. |-|**Performance**: |**Medium**<br><br>You typically interact with basic logs within the archive using [search jobs](../azure-monitor/logs/search-jobs.md), which are suitable when you want to maintain access to the data, but don't need immediate access to the data. |**High to low**<br><br>ΓÇó The query performance of an ADX cluster depends on the number of nodes in the cluster, the cluster virtual machine SKU, data partitioning, and more.<br>ΓÇó As you add nodes to the cluster, the performance improves, with added cost.<br>ΓÇó If you use ADX, we recommend that you configure your cluster size to balance performance and cost. This configuration depends on your organization's needs, including how fast your migration needs to complete, how often the data is accessed, and the expected response time. |**Low**<br><br>Offers two performance tiers: Premium or Standard. Although both tiers are an option for long-term storage, Standard is more cost-efficient. Learn about [performance and scalability limits](../storage/common/scalability-targets-standard-account.md). |**Low**<br><br>Because the data resides in the Blob Storage, the performance is limited by that platform. | +|**Performance**: |**Medium**<br><br>You typically interact with basic logs within the archive using [search jobs](/azure/azure-monitor/logs/search-jobs), which are suitable when you want to maintain access to the data, but don't need immediate access to the data. |**High to low**<br><br>ΓÇó The query performance of an ADX cluster depends on the number of nodes in the cluster, the cluster virtual machine SKU, data partitioning, and more.<br>ΓÇó As you add nodes to the cluster, the performance improves, with added cost.<br>ΓÇó If you use ADX, we recommend that you configure your cluster size to balance performance and cost. This configuration depends on your organization's needs, including how fast your migration needs to complete, how often the data is accessed, and the expected response time. |**Low**<br><br>Offers two performance tiers: Premium or Standard. Although both tiers are an option for long-term storage, Standard is more cost-efficient. Learn about [performance and scalability limits](../storage/common/scalability-targets-standard-account.md). |**Low**<br><br>Because the data resides in the Blob Storage, the performance is limited by that platform. | |**Cost**: |**High**<br><br>The cost is composed of two components:<br>ΓÇó **Ingestion cost**. Every GB of data ingested into Basic Logs is subject to Microsoft Sentinel and Azure Monitor Logs ingestion costs, which sum up to approximately $1/GB. See the [pricing details](https://azure.microsoft.com/pricing/details/microsoft-sentinel/).<br>ΓÇó **Archival cost**. The cost for data in the archive tier sums up to approximately $0.02/GB per month. See the [pricing details](https://azure.microsoft.com/pricing/details/monitor/).<br>In addition to these two cost components, if you need frequent access to the data, extra costs apply when you access data via search jobs. |**High to low**<br><br>ΓÇó Because ADX is a cluster of virtual machines, you're charged based on compute, storage and networking usage, plus an ADX markup (see the [pricing details](https://azure.microsoft.com/pricing/details/data-explorer/). Therefore, the more nodes you add to your cluster and the more data you store, the higher the cost will be.<br>ΓÇó ADX also offers autoscaling capabilities to adapt to workload on demand. ADX can also benefit from Reserved Instance pricing. You can run your own cost calculations in the [Azure Pricing Calculator](https://azure.microsoft.com/pricing/calculator/). |**Low**<br><br>With optimal setup, Azure Blob Storage has the lowest costs. For greater efficiency and cost savings, [Azure Storage lifecycle management](../storage/blobs/lifecycle-management-overview.md) can be used to automatically place older blobs into cheaper storage tiers. |**Low**<br><br>ADX only acts as a proxy in this case, so the cluster can be small. In addition, the cluster can be shut down when you don't need access to the data and only start it when data access is needed.. | |**How to access data**: |[Search jobs](search-jobs.md) |Direct KQL queries |[externaldata](/azure/data-explorer/kusto/query/externaldata-operator) |Modified KQL queries | |**Scenario**: |**Occasional access**<br><br>Relevant in scenarios where you donΓÇÖt need to run heavy analytics or trigger analytics rules, and you only need to access the data occasionally. |**Frequent access**<br><br>Relevant in scenarios where you need to access the data frequently, and need to control how the cluster is sized and configured. |**Compliance/audit**<br><br>ΓÇó Optimal for storing massive amounts of unstructured data.<br>ΓÇó Relevant in scenarios where you don't need quick access to the data or high performance, such as for compliance or audit purposes. |**Occasional access**<br><br>Relevant in scenarios where you want to benefit from the low cost of Azure Blob Storage, and maintain relatively quick access to the data. | |
| sentinel | Migration Ingestion Tool | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/migration-ingestion-tool.md | This article describes a set of different tools used to transfer your historical ## Azure Monitor Basic Logs/Archive -Before you ingest data to Azure Monitor Basic Logs or Archive, for lower ingestion prices, ensure that the table you're writing to is [configured as Basic Logs](../azure-monitor/logs/logs-table-plans.md). Review the [Azure Monitor custom log ingestion tool](#azure-monitor-custom-log-ingestion-tool) and the [direct API](#direct-api) method for Azure Monitor Basic Logs. +Before you ingest data to Azure Monitor Basic Logs or Archive, for lower ingestion prices, ensure that the table you're writing to is [configured as Basic Logs](/azure/azure-monitor/logs/logs-table-plans). Review the [Azure Monitor custom log ingestion tool](#azure-monitor-custom-log-ingestion-tool) and the [direct API](#direct-api) method for Azure Monitor Basic Logs. ### Azure Monitor custom log ingestion tool The [custom log ingestion tool](https://github.com/Azure/Azure-Sentinel/tree/mas ### Direct API -With this option, you [ingest your custom logs into Azure Monitor Logs](../azure-monitor/logs/tutorial-logs-ingestion-portal.md). You ingest the logs with a PowerShell script that uses a REST API. Alternatively, you can use any other programming language to perform the ingestion, and you can use other Azure services to abstract the compute layer, such as Azure Functions or Azure Logic Apps. +With this option, you [ingest your custom logs into Azure Monitor Logs](/azure/azure-monitor/logs/tutorial-logs-ingestion-portal). You ingest the logs with a PowerShell script that uses a REST API. Alternatively, you can use any other programming language to perform the ingestion, and you can use other Azure services to abstract the compute layer, such as Azure Functions or Azure Logic Apps. ## Azure Data Explorer |
| sentinel | Migration Qradar Detection Rules | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/migration-qradar-detection-rules.md | Learn more about analytics rules: - [**Create custom analytics rules to detect threats**](detect-threats-custom.md). Use [alert grouping](detect-threats-custom.md#alert-grouping) to reduce alert fatigue by grouping alerts that occur within a given timeframe. - [**Map data fields to entities in Microsoft Sentinel**](map-data-fields-to-entities.md) to enable SOC engineers to define entities as part of the evidence to track during an investigation. Entity mapping also makes it possible for SOC analysts to take advantage of an intuitive [investigation graph (investigate-cases.md#use-the-investigation-graph-to-deep-dive) that can help reduce time and effort. - [**Investigate incidents with UEBA data**](investigate-with-ueba.md), as an example of how to use evidence to surface events, alerts, and any bookmarks associated with a particular incident in the incident preview pane.-- [**Kusto Query Language (KQL)**](/azure/data-explorer/kusto/query/), which you can use to send read-only requests to your [Log Analytics](../azure-monitor/logs/log-analytics-tutorial.md) database to process data and return results. KQL is also used across other Microsoft services, such as [Microsoft Defender for Endpoint](https://www.microsoft.com/microsoft-365/security/endpoint-defender) and [Application Insights](../azure-monitor/app/app-insights-overview.md).+- [**Kusto Query Language (KQL)**](/azure/data-explorer/kusto/query/), which you can use to send read-only requests to your [Log Analytics](/azure/azure-monitor/logs/log-analytics-tutorial) database to process data and return results. KQL is also used across other Microsoft services, such as [Microsoft Defender for Endpoint](https://www.microsoft.com/microsoft-365/security/endpoint-defender) and [Application Insights](/azure/azure-monitor/app/app-insights-overview). ## Compare rule terminology |
| sentinel | Migration Splunk Detection Rules | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/migration-splunk-detection-rules.md | Last updated 03/11/2024 This article describes how to identify, compare, and migrate your Splunk detection rules to Microsoft Sentinel built-in rules. -If you want to migrate your Splunk Observability deployment, learn more about how to [migrate from Splunk to Azure Monitor Logs](../azure-monitor/logs/migrate-splunk-to-azure-monitor-logs.md). +If you want to migrate your Splunk Observability deployment, learn more about how to [migrate from Splunk to Azure Monitor Logs](/azure/azure-monitor/logs/migrate-splunk-to-azure-monitor-logs). ## Identify and migrate rules Learn more about analytics rules: - [**Create custom analytics rules to detect threats**](detect-threats-custom.md). Use [alert grouping](detect-threats-custom.md#alert-grouping) to reduce alert fatigue by grouping alerts that occur within a given timeframe. - [**Map data fields to entities in Microsoft Sentinel**](map-data-fields-to-entities.md) to enable SOC engineers to define entities as part of the evidence to track during an investigation. Entity mapping also makes it possible for SOC analysts to take advantage of an intuitive [investigation graph] (investigate-cases.md#use-the-investigation-graph-to-deep-dive) that can help reduce time and effort. - [**Investigate incidents with UEBA data**](investigate-with-ueba.md), as an example of how to use evidence to surface events, alerts, and any bookmarks associated with a particular incident in the incident preview pane.-- [**Kusto Query Language (KQL)**](/azure/data-explorer/kusto/query/), which you can use to send read-only requests to your [Log Analytics](../azure-monitor/logs/log-analytics-tutorial.md) database to process data and return results. KQL is also used across other Microsoft services, such as [Microsoft Defender for Endpoint](https://www.microsoft.com/microsoft-365/security/endpoint-defender) and [Application Insights](../azure-monitor/app/app-insights-overview.md).+- [**Kusto Query Language (KQL)**](/azure/data-explorer/kusto/query/), which you can use to send read-only requests to your [Log Analytics](/azure/azure-monitor/logs/log-analytics-tutorial) database to process data and return results. KQL is also used across other Microsoft services, such as [Microsoft Defender for Endpoint](https://www.microsoft.com/microsoft-365/security/endpoint-defender) and [Application Insights](/azure/azure-monitor/app/app-insights-overview). ## Compare rule terminology |
| sentinel | Migration Track | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/migration-track.md | The **ArchiveRetention** value is calculated by subtracting the **TotalRetention If you prefer to make changes in the UI, select **Update Retention in UI** to open the relevant page. -Learn about [data lifecycle management](../azure-monitor/logs/data-retention-configure.md). +Learn about [data lifecycle management](/azure/azure-monitor/logs/data-retention-configure). ## Enable migration tips and instructions |
| sentinel | Migration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/migration.md | In this guide, you learn how to migrate your legacy SIEM to Microsoft Sentinel. |Track migration with a workbook |[Track your Microsoft Sentinel migration with a workbook](migration-track.md) | |Use the SIEM Migration experience | [SIEM Migration (Preview)](siem-migration.md) | |Migrate from ArcSight |ΓÇó [Migrate detection rules](migration-arcsight-detection-rules.md)<br>ΓÇó [Migrate SOAR automation](migration-arcsight-automation.md)<br>ΓÇó [Export historical data](migration-arcsight-historical-data.md) |-|Migrate from Splunk |ΓÇó [Migrate detection rules](migration-splunk-detection-rules.md)<br>ΓÇó [Migrate SOAR automation](migration-splunk-automation.md)<br>ΓÇó [Export historical data](migration-splunk-historical-data.md)<br><br>If you want to migrate your Splunk Observability deployment, learn more about how to [migrate from Splunk to Azure Monitor Logs](../azure-monitor/logs/migrate-splunk-to-azure-monitor-logs.md). | +|Migrate from Splunk |ΓÇó [Migrate detection rules](migration-splunk-detection-rules.md)<br>ΓÇó [Migrate SOAR automation](migration-splunk-automation.md)<br>ΓÇó [Export historical data](migration-splunk-historical-data.md)<br><br>If you want to migrate your Splunk Observability deployment, learn more about how to [migrate from Splunk to Azure Monitor Logs](/azure/azure-monitor/logs/migrate-splunk-to-azure-monitor-logs). | |Migrate from QRadar |ΓÇó [Migrate detection rules](migration-qradar-detection-rules.md)<br>ΓÇó [Migrate SOAR automation](migration-qradar-automation.md)<br>ΓÇó [Export historical data](migration-qradar-historical-data.md) | |Ingest historical data |ΓÇó [Select a target Azure platform to host the exported historical data](migration-ingestion-target-platform.md)<br>ΓÇó [Select a data ingestion tool](migration-ingestion-tool.md)<br>ΓÇó [Ingest historical data into your target platform](migration-export-ingest.md) | |Convert dashboards to workbooks |[Convert dashboards to Azure Workbooks](migration-convert-dashboards.md) | |
| sentinel | Monitor Data Connector Health | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/monitor-data-connector-health.md | lastestStatus ### Configure alerts and automated actions for health issues -While you can use the Microsoft Sentinel [analytics rules](automate-incident-handling-with-automation-rules.md) to configure automation in Microsoft Sentinel logs, if you want to be notified and take immediate action for health drifts in your data connectors, we recommend that you use [Azure Monitor alert rules](../azure-monitor/alerts/alerts-overview.md). +While you can use the Microsoft Sentinel [analytics rules](automate-incident-handling-with-automation-rules.md) to configure automation in Microsoft Sentinel logs, if you want to be notified and take immediate action for health drifts in your data connectors, we recommend that you use [Azure Monitor alert rules](/azure/azure-monitor/alerts/alerts-overview). For example: For example: 1. For the rule actions, select an existing action group or create a new one as needed to configure push notifications or other automated actions such as triggering a Logic App, Webhook, or Azure Function in your system. -For more information, see [Azure Monitor alerts overview](../azure-monitor/alerts/alerts-overview.md) and [Azure Monitor alerts log](../azure-monitor/alerts/alerts-log.md). +For more information, see [Azure Monitor alerts overview](/azure/azure-monitor/alerts/alerts-overview) and [Azure Monitor alerts log](/azure/azure-monitor/alerts/alerts-log). ## Next steps |
| sentinel | Monitor Your Data | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/monitor-your-data.md | Use a template installed from the content hub to create a workbook. For more information, see: -- [Create interactive reports with Azure Monitor Workbooks](../azure-monitor/visualize/workbooks-overview.md)-- [Tutorial: Visual data in Log Analytics](../azure-monitor/visualize/tutorial-logs-dashboards.md)+- [Create interactive reports with Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview) +- [Tutorial: Visual data in Log Analytics](/azure/azure-monitor/visualize/tutorial-logs-dashboards) ## Create new workbook Create a workbook from scratch in Microsoft Sentinel. 1. Select **Add workbook**. -1. To edit the workbook, select **Edit**, and then add text, queries, and parameters as necessary. For more information on how to customize the workbook, see how to [Create interactive reports with Azure Monitor Workbooks](../azure-monitor/visualize/workbooks-overview.md). +1. To edit the workbook, select **Edit**, and then add text, queries, and parameters as necessary. For more information on how to customize the workbook, see how to [Create interactive reports with Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview). [  ](media/monitor-your-data/create-workbook.png#lightbox) Create a workbook from scratch in Microsoft Sentinel. ## Create new tiles for your workbooks -To add a custom tile to a Microsoft Sentinel workbook, first create the tile in Log Analytics. For more information, see [Visual data in Log Analytics](../azure-monitor/visualize/tutorial-logs-dashboards.md). +To add a custom tile to a Microsoft Sentinel workbook, first create the tile in Log Analytics. For more information, see [Visual data in Log Analytics](/azure/azure-monitor/visualize/tutorial-logs-dashboards). Once you create a tile, select **Pin** and then select the workbook where you want the tile to appear. |
| sentinel | Mssp Protect Intellectual Property | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/mssp-protect-intellectual-property.md | Exporting your workbook to Power BI: - **Makes the workbook visualizations easier to share**. You can send the customer a link to the Power BI dashboard, where they can view the reported data, without requiring Azure access permissions. - **Enables scheduling**. Configure Power BI to send emails periodically that contain a snapshot of the dashboard for that time. -For more information, see [Import Azure Monitor log data into Power BI](../azure-monitor/logs/log-powerbi.md). +For more information, see [Import Azure Monitor log data into Power BI](/azure/azure-monitor/logs/log-powerbi). ### Playbooks |
| sentinel | Normalization About Schemas | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/normalization-about-schemas.md | The allowed values for a device ID type are: | **VectraId** | A Vectra AI assigned resource ID.| | **Other** | An ID type not listed above.| -For example, the Azure Monitor [VM Insights solution](../azure-monitor/vm/vminsights-log-query.md) provides network sessions information in the `VMConnection`. The table provides an Azure Resource ID in the `_ResourceId` field and a VM insights specific device ID in the `Machine` field. Use the following mapping to represent those IDs: +For example, the Azure Monitor [VM Insights solution](/azure/azure-monitor/vm/vminsights-log-query) provides network sessions information in the `VMConnection`. The table provides an Azure Resource ID in the `_ResourceId` field and a VM insights specific device ID in the `Machine` field. Use the following mapping to represent those IDs: | Field | Map to | | -- | -- | |
| sentinel | Normalization Common Fields | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/normalization-common-fields.md | The following fields are generated by Log Analytics, in most cases, for each rec > [!NOTE]-> Log Analytics also adds other fields that are less relevant to security use cases. For more information, see [Standard columns in Azure Monitor Logs](../azure-monitor/logs/log-standard-columns.md). +> Log Analytics also adds other fields that are less relevant to security use cases. For more information, see [Standard columns in Azure Monitor Logs](/azure/azure-monitor/logs/log-standard-columns). > ## Common ASIM fields |
| sentinel | Normalization Develop Parsers | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/normalization-develop-parsers.md | To avoid duplicate events and excessive processing, make sure each function star ## Deploy parsers -Deploy parsers manually by copying them to the Azure Monitor Log page and saving the query as a function. This method is useful for testing. For more information, see [Create a function](../azure-monitor/logs/functions.md). +Deploy parsers manually by copying them to the Azure Monitor Log page and saving the query as a function. This method is useful for testing. For more information, see [Create a function](/azure/azure-monitor/logs/functions). To deploy a large number of parsers, we recommend using parser ARM templates, as follows: |
| sentinel | Normalization Ingest Time | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/normalization-ingest-time.md | Learn more about writing parsers in [Developing ASIM parsers](normalization-deve ## Implementing ingest time normalization -To normalize data at ingest, you will need to use a [Data Collection Rule (DCR)](../azure-monitor/essentials/data-collection-rule-overview.md). The procedure for implementing the DCR depends on the method used to ingest the data. For more information, refer to the article [Transform or customize data at ingestion time in Microsoft Sentinel](configure-data-transformation.md). +To normalize data at ingest, you will need to use a [Data Collection Rule (DCR)](/azure/azure-monitor/essentials/data-collection-rule-overview). The procedure for implementing the DCR depends on the method used to ingest the data. For more information, refer to the article [Transform or customize data at ingestion time in Microsoft Sentinel](configure-data-transformation.md). -A [KQL](kusto-overview.md) transformation query is the core of a DCR. The KQL version used in DCRs is slightly different than the version used elsewhere in Microsoft Sentinel to accommodate for requirements of pipeline event processing. Therefore, you will need to modify any query-time parser to use it in a DCR. For more information on the differences, and how to convert a query-time parser to an ingest-time parser, read about the [DCR KQL limitations](../azure-monitor/essentials/data-collection-transformations-structure.md#kql-limitations). +A [KQL](kusto-overview.md) transformation query is the core of a DCR. The KQL version used in DCRs is slightly different than the version used elsewhere in Microsoft Sentinel to accommodate for requirements of pipeline event processing. Therefore, you will need to modify any query-time parser to use it in a DCR. For more information on the differences, and how to convert a query-time parser to an ingest-time parser, read about the [DCR KQL limitations](/azure/azure-monitor/essentials/data-collection-transformations-structure#kql-limitations). ## <a name="next-steps"></a>Next steps |
| sentinel | Normalization Manage Parsers | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/normalization-manage-parsers.md | Microsoft Sentinel users cannot edit built-in unifying parsers. Instead, use the To add a custom parser, insert a line to the custom unifying parser to reference the new, custom parser. -Make sure to add both a filtering custom parser and a parameter-less custom parser. To learn more about how to edit parsers, refer to the document [Functions in Azure Monitor log queries](../azure-monitor/logs/functions.md#edit-a-function). +Make sure to add both a filtering custom parser and a parameter-less custom parser. To learn more about how to edit parsers, refer to the document [Functions in Azure Monitor log queries](/azure/azure-monitor/logs/functions#edit-a-function). The syntax of the line to add is different for each schema: |
| sentinel | Normalization Parsers List | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/normalization-parsers-list.md | ASIM Network Session parsers are available in every workspace. Microsoft Sentine | **AppGate SDP** | IP connection logs collected using Syslog. | `_Im_NetworkSession_AppGateSDPVxx` | | **AWS VPC logs** | Collected using the AWS S3 connector. | `_Im_NetworkSession_AWSVPCVxx` | | **Azure Firewall logs** | |`_Im_NetworkSession_AzureFirewallVxx`|-| **Azure Monitor VMConnection** | Collected as part of the Azure Monitor [VM Insights solution](../azure-monitor/vm/vminsights-overview.md). | `_Im_NetworkSession_VMConnectionVxx` | -| **Azure Network Security Groups (NSG) logs** | Collected as part of the Azure Monitor [VM Insights solution](../azure-monitor/vm/vminsights-overview.md). | `_Im_NetworkSession_AzureNSGVxx` | +| **Azure Monitor VMConnection** | Collected as part of the Azure Monitor [VM Insights solution](/azure/azure-monitor/vm/vminsights-overview). | `_Im_NetworkSession_VMConnectionVxx` | +| **Azure Network Security Groups (NSG) logs** | Collected as part of the Azure Monitor [VM Insights solution](/azure/azure-monitor/vm/vminsights-overview). | `_Im_NetworkSession_AzureNSGVxx` | | **Checkpoint Firewall-1** | Collected using CEF. | `_Im_NetworkSession_CheckPointFirewallVxx` | | **Cisco ASA** | Collected using the CEF connector. | `_Im_NetworkSession_CiscoASAVxx` | | **Cisco Meraki** | Collected using the Cisco Meraki API connector. | `_Im_NetworkSession_CiscoMerakiVxx` | |
| sentinel | Ops Guide | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/ops-guide.md | Schedule the following activities daily. |**Explore hunting queries and bookmarks**|Explore results for all built-in queries, and update existing hunting queries and bookmarks. Manually generate new incidents or update old incidents if applicable. For more information, see:</br></br>- [Automatically create incidents from Microsoft security alerts](create-incidents-from-alerts.md)</br>- [Hunt for threats with Microsoft Sentinel](hunting.md)</br>- [Keep track of data during hunting with Microsoft Sentinel](bookmarks.md)| |**Analytic rules**|Review and enable new analytics rules as applicable, including both newly released or newly available rules from recently connected data connectors.| |**Data connectors**| Review the status, date, and time of the last log received from each data connector to ensure that data is flowing. Check for new connectors, and review ingestion to ensure set limits aren't exceeded. For more information, see [Data collection best practices](best-practices-data.md) and [Connect data sources](connect-data-sources.md).|-|**Log Analytics Agent**| Verify that servers and workstations are actively connected to the workspace, and troubleshoot and remediate any failed connections. For more information, see [Log Analytics Agent overview](../azure-monitor/agents/log-analytics-agent.md).| +|**Log Analytics Agent**| Verify that servers and workstations are actively connected to the workspace, and troubleshoot and remediate any failed connections. For more information, see [Log Analytics Agent overview](/azure/azure-monitor/agents/log-analytics-agent).| |**Playbook failures**| Verify playbook run statuses and troubleshoot any failures. For more information, see [Tutorial: Respond to threats by using playbooks with automation rules in Microsoft Sentinel](tutorial-respond-threats-playbook.md).| ## Weekly tasks |
| sentinel | Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/overview.md | Use Microsoft Sentinel to alleviate the stress of increasingly sophisticated att [!INCLUDE [unified-soc-preview](includes/unified-soc-preview.md)] -Microsoft Sentinel inherits the Azure Monitor [tamper-proofing and immutability](../azure-monitor/logs/data-security.md#tamper-proofing-and-immutability) practices. While Azure Monitor is an append-only data platform, it includes provisions to delete data for compliance purposes +Microsoft Sentinel inherits the Azure Monitor [tamper-proofing and immutability](/azure/azure-monitor/logs/data-security#tamper-proofing-and-immutability) practices. While Azure Monitor is an append-only data platform, it includes provisions to delete data for compliance purposes [!INCLUDE [azure-lighthouse-supported-service](../../includes/azure-lighthouse-supported-service-no-note.md)] |
| sentinel | Powerbi | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/powerbi.md | Refresh your Power BI report on a schedule, so updated data always appears in th For more information, see: -- [Azure Monitor service limits](../azure-monitor/service-limits.md)-- [Import Azure Monitor log data into Power BI](../azure-monitor/logs/log-powerbi.md)+- [Azure Monitor service limits](/azure/azure-monitor/service-limits) +- [Import Azure Monitor log data into Power BI](/azure/azure-monitor/logs/log-powerbi) - [Power Query M formula language](/powerquery-m/) |
| sentinel | Prepare Multiple Workspaces | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/prepare-multiple-workspaces.md | This table lists some of these scenarios and, when possible, suggests how you mi | **Data ownership** | The boundaries of data ownership, for example by subsidiaries or affiliated companies, are better delineated using separate workspaces. | | | **Multiple Azure tenants** | Microsoft Sentinel supports data collection from Microsoft and Azure SaaS resources only within its own Microsoft Entra tenant boundary. Therefore, each Microsoft Entra tenant requires a separate workspace. | | | **Granular data access control** | An organization might need to allow different groups, within or outside the organization, to access some of the data collected by Microsoft Sentinel. For example:<br><ul><li>Resource owners' access to data pertaining to their resources</li><li>Regional or subsidiary SOCs' access to data relevant to their parts of the organization</li></ul> | Use [resource Azure RBAC](resource-context-rbac.md) or [table level Azure RBAC](https://techcommunity.microsoft.com/t5/azure-sentinel/table-level-rbac-in-azure-sentinel/ba-p/965043) |-| **Granular retention settings** | Historically, multiple workspaces were the only way to set different retention periods for different data types. This is no longer needed in many cases, thanks to the introduction of table level retention settings. | Use [table level retention settings](https://techcommunity.microsoft.com/t5/azure-sentinel/new-per-data-type-retention-is-now-available-for-azure-sentinel/ba-p/917316) or automate [data deletion](../azure-monitor/logs/personal-data-mgmt.md#exporting-and-deleting-personal-data) | +| **Granular retention settings** | Historically, multiple workspaces were the only way to set different retention periods for different data types. This is no longer needed in many cases, thanks to the introduction of table level retention settings. | Use [table level retention settings](https://techcommunity.microsoft.com/t5/azure-sentinel/new-per-data-type-retention-is-now-available-for-azure-sentinel/ba-p/917316) or automate [data deletion](/azure/azure-monitor/logs/personal-data-mgmt#exporting-and-deleting-personal-data) | | **Split billing** | By placing workspaces in separate subscriptions, they can be billed to different parties. | Usage reporting and cross-charging | | **Legacy architecture** | The use of multiple workspaces might stem from a historical design that took into consideration limitations or best practices which don't hold true anymore. It might also be an arbitrary design choice that can be modified to better accommodate Microsoft Sentinel.<br><br>Examples include:<br><ul><li>Using a per-subscription default workspace when deploying Microsoft Defender for Cloud</li><li>The need for granular access control or retention settings, the solutions for which are relatively new</li></ul> | Re-architect workspaces | |
| sentinel | Prerequisites | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/prerequisites.md | Before deploying Microsoft Sentinel, make sure that your Azure tenant meets the For more information about other roles and permissions supported for Microsoft Sentinel, see [Permissions in Microsoft Sentinel](roles.md). -- A [Log Analytics workspace](../azure-monitor/logs/quick-create-workspace.md) is required to house the data that Microsoft Sentinel ingests and analyzes for detections, analytics, and other features. For more information, see [Design a Log Analytics workspace architecture](/azure/azure-monitor/logs/workspace-design?toc=/azure/sentinel/TOC.json&bc=/azure/sentinel/breadcrumb/toc.json).+- A [Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace) is required to house the data that Microsoft Sentinel ingests and analyzes for detections, analytics, and other features. For more information, see [Design a Log Analytics workspace architecture](/azure/azure-monitor/logs/workspace-design?toc=/azure/sentinel/TOC.json&bc=/azure/sentinel/breadcrumb/toc.json). - The Log Analytics workspace must not have a resource lock applied, and the workspace pricing tier must be pay-as-you-go or a commitment tier. Log Analytics legacy pricing tiers and resource locks aren't supported when enabling Microsoft Sentinel. For more information about pricing tiers, see [Simplified pricing tiers for Microsoft Sentinel](enroll-simplified-pricing-tier.md#prerequisites). |
| sentinel | Prioritize Data Connectors | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/prioritize-data-connectors.md | Check which data connectors are relevant to your environment, in the following o For the custom and partner connectors, we recommend that you start by setting up [CEF/Syslog](connect-cef-syslog-options.md) connectors, with the highest priority first, as well as any Linux-based devices. -If your data ingestion becomes too expensive, too quickly, stop or filter the logs forwarded using the [Azure Monitor Agent](../azure-monitor/agents/azure-monitor-agent-overview.md). +If your data ingestion becomes too expensive, too quickly, stop or filter the logs forwarded using the [Azure Monitor Agent](/azure/azure-monitor/agents/azure-monitor-agent-overview). > [!TIP] > Custom data connectors enable you to ingest data into Microsoft Sentinel from data sources not currently supported by built-in functionality, such as via agent, Logstash, or API. For more information, see [Resources for creating Microsoft Sentinel custom connectors](create-custom-connector.md). |
| sentinel | Quickstart Onboard | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/quickstart-onboard.md | To onboard to Microsoft Sentinel by using the API, see the latest supported vers - **Active Azure Subscription**. If you don't have one, create a [free account](https://azure.microsoft.com/free/?WT.mc_id=A261C142F) before you begin. -- **Log Analytics workspace**. Learn how to [create a Log Analytics workspace](../azure-monitor/logs/quick-create-workspace.md). For more information about Log Analytics workspaces, see [Designing your Azure Monitor Logs deployment](../azure-monitor/logs/workspace-design.md).+- **Log Analytics workspace**. Learn how to [create a Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace). For more information about Log Analytics workspaces, see [Designing your Azure Monitor Logs deployment](/azure/azure-monitor/logs/workspace-design). - You may have a default of [30 days retention](../azure-monitor/logs/cost-logs.md#legacy-pricing-tiers) in the Log Analytics workspace used for Microsoft Sentinel. To make sure that you can use all Microsoft Sentinel functionality and features, raise the retention to 90 days. [Configure data retention and archive policies in Azure Monitor Logs](../azure-monitor/logs/data-retention-configure.md). + You may have a default of [30 days retention](/azure/azure-monitor/logs/cost-logs#legacy-pricing-tiers) in the Log Analytics workspace used for Microsoft Sentinel. To make sure that you can use all Microsoft Sentinel functionality and features, raise the retention to 90 days. [Configure data retention and archive policies in Azure Monitor Logs](/azure/azure-monitor/logs/data-retention-configure). - **Permissions**: |
| sentinel | Resource Context Rbac | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/resource-context-rbac.md | When users have access to Microsoft Sentinel data via the resources they can acc - **Via Azure Monitor**. Use this method when you want to create queries that span multiple resources and/or resource groups. When navigating to logs and workbooks in Azure Monitor, define your scope to one or more specific resource groups or resources. -Enable resource-context RBAC in Azure Monitor. For more information, see [Manage access to log data and workspaces in Azure Monitor](../azure-monitor/logs/manage-access.md). +Enable resource-context RBAC in Azure Monitor. For more information, see [Manage access to log data and workspaces in Azure Monitor](/azure/azure-monitor/logs/manage-access). > [!NOTE] > If your data is not an Azure resource, such as Syslog, CEF, or Microsoft Entra ID data, or data collected by a custom collector, you'll need to manually configure the resource ID that's used to identify the data and enable access. For more information, see [Explicitly configure resource-context RBAC for non-Azure resources](#explicitly-configure-resource-context-rbac-for-non-azure-resources). >-> Additionally, [functions](../azure-monitor/logs/functions.md) and saved searches are not supported in resource-centric contexts. Therefore, Microsoft Sentinel features such as parsing and [normalization](normalization.md) are not supported for resource-context RBAC in Microsoft Sentinel. +> Additionally, [functions](/azure/azure-monitor/logs/functions) and saved searches are not supported in resource-centric contexts. Therefore, Microsoft Sentinel features such as parsing and [normalization](normalization.md) are not supported for resource-context RBAC in Microsoft Sentinel. > ## Scenarios for resource-context RBAC Use the following steps if you want to configure resource-context RBAC, but your **To explicitly configure resource-context RBAC**: -1. Make sure that you've [enabled resource-context RBAC](../azure-monitor/logs/manage-access.md) in Azure Monitor. +1. Make sure that you've [enabled resource-context RBAC](/azure/azure-monitor/logs/manage-access) in Azure Monitor. 1. [Create a resource group](../azure-resource-manager/management/manage-resource-groups-portal.md) for each team of users who needs to access your resources without the entire Microsoft Sentinel environment. - Assign [log reader permissions](../azure-monitor/logs/manage-access.md#resource-permissions) for each of the team members. + Assign [log reader permissions](/azure/azure-monitor/logs/manage-access#resource-permissions) for each of the team members. 1. Assign resources to the resource team groups you created, and tag events with the relevant resource IDs. For example, the following code shows a sample Logstash configuration file: > ### Resource IDs with the Log Analytics API collection -When collecting using the [Log Analytics data collector API](../azure-monitor/logs/data-collector-api.md), you can assign to events with a resource ID using the HTTP [*x-ms-AzureResourceId*](../azure-monitor/logs/data-collector-api.md#request-headers) request header. +When collecting using the [Log Analytics data collector API](/azure/azure-monitor/logs/data-collector-api), you can assign to events with a resource ID using the HTTP [*x-ms-AzureResourceId*](/azure/azure-monitor/logs/data-collector-api#request-headers) request header. If you are using resource-context RBAC and want the events collected by API to be available to specific users, use the resource ID of the resource group you [created for your users](#explicitly-configure-resource-context-rbac-for-non-azure-resources). The following list describes scenarios where other solutions for data access may ||| |**A subsidiary has a SOC team that requires a full Microsoft Sentinel experience**. | In this case, use a multi-workspace architecture to separate your data permissions. <br><br>For more information, see: <ul><li>[Extend Microsoft Sentinel across workspaces and tenants](extend-sentinel-across-workspaces-tenants.md)<li>> [Work with incidents in many workspaces at once](multiple-workspace-view.md) | |**You want to provide access to a specific type of event**. | For example, provide a Windows administrator with access to Windows Security events in all systems. <br><br>In such cases, use [table-level RBAC](https://techcommunity.microsoft.com/t5/azure-sentinel/table-level-rbac-in-azure-sentinel/ba-p/965043) to define permissions for each table. |-| **Limit access to a more granular level, either not based on the resource, or to only a subset of the fields in an event** | For example, you might want to limit access to Office 365 logs based on a user's subsidiary. <br><br>In this case, provide access to data using built-in integration with [Power BI dashboards and reports](../azure-monitor/logs/log-powerbi.md). | +| **Limit access to a more granular level, either not based on the resource, or to only a subset of the fields in an event** | For example, you might want to limit access to Office 365 logs based on a user's subsidiary. <br><br>In this case, provide access to data using built-in integration with [Power BI dashboards and reports](/azure/azure-monitor/logs/log-powerbi). | | **Limit access by management group** | Place Microsoft Sentinel under a separate management group that's dedicated to security, ensuring that only minimal permissions are inherited to group members. Within your security team, assign permissions to different groups according to each group function. Since all teams have access to the entire workspace, they'll have access to the full Microsoft Sentinel experience, restricted only by the Microsoft Sentinel roles they're assigned. For more information, see [Permissions in Microsoft Sentinel](roles.md). | |
| sentinel | Restore | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/restore.md | -Before you restore data in an archived log, see [Start an investigation by searching large datasets (preview)](investigate-large-datasets.md) and [Restore in Azure Monitor](../azure-monitor/logs/restore.md). +Before you restore data in an archived log, see [Start an investigation by searching large datasets (preview)](investigate-large-datasets.md) and [Restore in Azure Monitor](/azure/azure-monitor/logs/restore). [!INCLUDE [unified-soc-preview](includes/unified-soc-preview.md)] |
| sentinel | Roles | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/roles.md | Review the [role recommendations](#role-and-permissions-recommendations) for whi - **Log Analytics RBAC**. You can use the Log Analytics advanced Azure RBAC across the data in your Microsoft Sentinel workspace. This includes both data type-based Azure RBAC and resource-context Azure RBAC. To learn more: - - [Manage log data and workspaces in Azure Monitor](../azure-monitor/logs/manage-access.md#azure-rbac) + - [Manage log data and workspaces in Azure Monitor](/azure/azure-monitor/logs/manage-access#azure-rbac) - [Resource-context RBAC for Microsoft Sentinel](resource-context-rbac.md) - [Table-level RBAC](https://techcommunity.microsoft.com/t5/azure-sentinel/table-level-rbac-in-azure-sentinel/ba-p/965043) |
| sentinel | Collect Sap Hana Audit Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/sap/collect-sap-hana-audit-logs.md | For more information, see [Ingest syslog and CEF messages to Microsoft Sentinel 4. Install an agent on your machine and confirm that your machine is connected. For more information, see: - [Azure Monitor Agent](/azure/azure-monitor/agents/azure-monitor-agent-manage?tabs=azure-portal)- - [Log Analytics Agent](../../azure-monitor/agents/agent-linux.md) (legacy) + - [Log Analytics Agent](/azure/azure-monitor/agents/agent-linux) (legacy) 5. Configure your agent to collect Syslog data. For more information, see: |
| sentinel | Cross Workspace | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/sap/cross-workspace.md | Creating separate workspaces for the SAP and SOC data has these benefits: - Microsoft Sentinel can trigger alerts that include both SOC and SAP data, and it can run those alerts on the SOC workspace. > [!NOTE]- > For larger SAP landscapes, running queries that are made by the SOC on data from the SAP workspace can affect performance. The SAP data must travel to the SOC workspace when it's being queried. For improved performance and cost optimizations, consider having both the SOC and SAP workspaces on the same [dedicated cluster](../../azure-monitor/logs/logs-dedicated-clusters.md?tabs=cli#cluster-pricing-model). + > For larger SAP landscapes, running queries that are made by the SOC on data from the SAP workspace can affect performance. The SAP data must travel to the SOC workspace when it's being queried. For improved performance and cost optimizations, consider having both the SOC and SAP workspaces on the same [dedicated cluster](/azure/azure-monitor/logs/logs-dedicated-clusters?tabs=cli#cluster-pricing-model). - The SAP team has its own Log Analytics workspace enabled for Microsoft Sentinel that includes all features except detections that include both SOC and SAP data. - Flexibility. The SAP team can focus on the control of internal threats in its landscape, and the SOC can focus on external threats. |
| sentinel | Sap Solution Log Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/sap/sap-solution-log-reference.md | This article describes the functions, logs, and tables available as part of the ## Functions available from the SAP solution -This section describes the [functions](../../azure-monitor/logs/functions.md) that are available in your workspace after you've deployed the Microsoft Sentinel solution for SAP® applications. Find these functions in the Microsoft Sentinel **Logs** page to use in your KQL queries, listed under **Workspace functions**. +This section describes the [functions](/azure/azure-monitor/logs/functions) that are available in your workspace after you've deployed the Microsoft Sentinel solution for SAP® applications. Find these functions in the Microsoft Sentinel **Logs** page to use in your KQL queries, listed under **Workspace functions**. Users are *strongly encouraged* to use the functions as the subjects of their analysis whenever possible, instead of the underlying logs or tables. These functions are intended to serve as the principal user interface to the data. They form the basis for all the built-in analytics rules and workbooks available to you out of the box. This allows for changes to be made to the data infrastructure beneath the functions, without breaking user-created content. |
| sentinel | Search Jobs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/search-jobs.md | +- For more information on search job concepts and limitations, see [Start an investigation by searching large datasets](investigate-large-datasets.md) and [Search jobs in Azure Monitor](/azure/azure-monitor/logs/search-jobs). - Search jobs across certain data sets might incur extra charges. For more information, see [Microsoft Sentinel pricing page](billing.md). To learn more, see the following articles. - [Hunt with bookmarks](bookmarks.md) - [Restore archived logs](restore.md)-- [Configure data retention and archive policies in Azure Monitor Logs (Preview)](../azure-monitor/logs/data-retention-configure.md)+- [Configure data retention and archive policies in Azure Monitor Logs (Preview)](/azure/azure-monitor/logs/data-retention-configure) |
| sentinel | Sentinel Service Limits | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/sentinel-service-limits.md | The following limit applies to multiple workspaces in Microsoft Sentinel. Limits |Description | Limit |Dependency| -|--|--| | Incident view | 100 concurrently displayed workspaces | |-| Log query | 100 Sentinel workspaces | [Log Analytics](../azure-monitor/logs/cross-workspace-query.md#limitations) | +| Log query | 100 Sentinel workspaces | [Log Analytics](/azure/azure-monitor/logs/cross-workspace-query#limitations) | | Analytics rules | 20 Sentinel workspaces per query | | ## Notebook limits The following limits apply to watchlists in Microsoft Sentinel. The limits are r ## Workbook limits -Workbook limits for Sentinel are the same result limits found in Azure Monitor. For more information, see [Workbooks result limits](../azure-monitor/visualize/workbooks-limits.md). +Workbook limits for Sentinel are the same result limits found in Azure Monitor. For more information, see [Workbooks result limits](/azure/azure-monitor/visualize/workbooks-limits). ## Workspace manager limits The following limits apply to workspace manager in Microsoft Sentinel. ## Next steps - [Azure subscription and service limits, quotas, and constraints](../azure-resource-manager/management/azure-subscription-service-limits.md)-- [Azure Monitor service limits](../azure-monitor/service-limits.md)+- [Azure Monitor service limits](/azure/azure-monitor/service-limits) |
| sentinel | Skill Up Resources | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/skill-up-resources.md | If you want to _retain data_ for more than two years or _reduce the retention co Want more in-depth information? View the ["Improving the breadth and coverage of threat hunting with ADX support, more entity types, and updated MITRE integration"](https://www.youtube.com/watch?v=5coYjlw2Qqs&ab_channel=MicrosoftSecurityCommunity) webinar. -If you prefer another long-term retention solution, see [Export from Microsoft Sentinel / Log Analytics workspace to Azure Storage and Event Hubs](/cli/azure/monitor/log-analytics/workspace/data-export) or [Move logs to long-term storage by using Azure Logic Apps](../azure-monitor/logs/logs-export-logic-app.md). The advantage of using Logic Apps is that it can export historical data. +If you prefer another long-term retention solution, see [Export from Microsoft Sentinel / Log Analytics workspace to Azure Storage and Event Hubs](/cli/azure/monitor/log-analytics/workspace/data-export) or [Move logs to long-term storage by using Azure Logic Apps](/azure/azure-monitor/logs/logs-export-logic-app). The advantage of using Logic Apps is that it can export historical data. -Finally, you can set fine-grained retention periods by using [table-level retention settings](https://techcommunity.microsoft.com/t5/core-infrastructure-and-security/azure-log-analytics-data-retention-by-type-in-real-life/ba-p/1416287). For more information, see [Configure data retention and archive policies in Azure Monitor Logs (Preview)](../azure-monitor/logs/data-retention-configure.md). +Finally, you can set fine-grained retention periods by using [table-level retention settings](https://techcommunity.microsoft.com/t5/core-infrastructure-and-security/azure-log-analytics-data-retention-by-type-in-real-life/ba-p/1416287). For more information, see [Configure data retention and archive policies in Azure Monitor Logs (Preview)](/azure/azure-monitor/logs/data-retention-configure). #### Log security -- Use [resource role-based access control (RBAC)](https://techcommunity.microsoft.com/t5/azure-sentinel/controlling-access-to-azure-sentinel-data-resource-rbac/ba-p/1301463) or [table-level RBAC](../azure-monitor/logs/manage-access.md) to enable multiple teams to use a single workspace.+- Use [resource role-based access control (RBAC)](https://techcommunity.microsoft.com/t5/azure-sentinel/controlling-access-to-azure-sentinel-data-resource-rbac/ba-p/1301463) or [table-level RBAC](/azure/azure-monitor/logs/manage-access) to enable multiple teams to use a single workspace. -- If needed, [delete customer content from your workspaces](../azure-monitor/logs/personal-data-mgmt.md).+- If needed, [delete customer content from your workspaces](/azure/azure-monitor/logs/personal-data-mgmt). - Learn how to [audit workspace queries and Microsoft Sentinel use by using alerts workbooks and queries](https://techcommunity.microsoft.com/t5/microsoft-sentinel-blog/auditing-microsoft-sentinel-activities/ba-p/1718328). -- Use [private links](../azure-monitor/logs/private-link-security.md) to ensure that logs never leave your private network.+- Use [private links](/azure/azure-monitor/logs/private-link-security) to ensure that logs never leave your private network. #### Dedicated cluster -Use a [dedicated workspace cluster](../azure-monitor/logs/logs-dedicated-clusters.md) if your projected data ingestion is about or more than 500 GB per day. With a dedicated cluster, you can secure resources for your Microsoft Sentinel data, which enables better query performance for large data sets. +Use a [dedicated workspace cluster](/azure/azure-monitor/logs/logs-dedicated-clusters) if your projected data ingestion is about or more than 500 GB per day. With a dedicated cluster, you can secure resources for your Microsoft Sentinel data, which enables better query performance for large data sets. ### Module 6: Enrichment: Threat intelligence, watchlists, and more View the "Use watchlists to manage alerts, reduce alert fatigue, and improve SOC Microsoft Sentinel supports two new features for data ingestion and transformation. These features, provided by Log Analytics, act on your data even before it's stored in your workspace. The features are: -- [**Logs ingestion API**](../azure-monitor/logs/logs-ingestion-api-overview.md): Use it to send custom-format logs from any data source to your Log Analytics workspace and then store those logs either in certain specific standard tables, or in custom-formatted tables that you create. You can perform the actual ingestion of these logs by using direct API calls. You can use Azure Monitor [data collection rules](../azure-monitor/essentials/data-collection-rule-overview.md) to define and configure these workflows.+- [**Logs ingestion API**](/azure/azure-monitor/logs/logs-ingestion-api-overview): Use it to send custom-format logs from any data source to your Log Analytics workspace and then store those logs either in certain specific standard tables, or in custom-formatted tables that you create. You can perform the actual ingestion of these logs by using direct API calls. You can use Azure Monitor [data collection rules](/azure/azure-monitor/essentials/data-collection-rule-overview) to define and configure these workflows. -- [**Workspace data transformations for standard logs**](../azure-monitor/essentials/data-collection-transformations-workspace.md): It uses [data collection rules](../azure-monitor/essentials/data-collection-rule-overview.md) to filter out irrelevant data, to enrich or tag your data, or to hide sensitive or personal information. You can configure data transformation at ingestion time for the following types of built-in data connectors:+- [**Workspace data transformations for standard logs**](/azure/azure-monitor/essentials/data-collection-transformations-workspace): It uses [data collection rules](/azure/azure-monitor/essentials/data-collection-rule-overview) to filter out irrelevant data, to enrich or tag your data, or to hide sensitive or personal information. You can configure data transformation at ingestion time for the following types of built-in data connectors: - Azure Monitor agent (AMA)-based data connectors (based on the new Azure Monitor agent) - Microsoft Monitoring agent (MMA)-based data connectors (based on the legacy Azure Monitor Logs Agent) - Data connectors that use diagnostics settings The next section on writing rules explains how to use KQL in the specific contex As you learn KQL, you might also find the following references useful: - [The KQL Cheat Sheet](https://www.mbsecure.nl/blog/2019/12/kql-cheat-sheet)-- [Query optimization best practices](../azure-monitor/logs/query-optimization.md)+- [Query optimization best practices](/azure/azure-monitor/logs/query-optimization) ### Module 11: Analytics Find dozens of useful playbooks in the [*Playbooks* folder](https://github.com/A As the nerve center of your SOC, Microsoft Sentinel is required for visualizing the information it collects and produces. Use workbooks to visualize data in Microsoft Sentinel. -- To learn how to create workbooks, read the [Azure Workbooks documentation](../azure-monitor/visualize/workbooks-overview.md) or watch Billy York's [Workbooks training](https://www.youtube.com/watch?v=iGiPpD_-10M&ab_channel=FestiveTechCalendar) (and [accompanying text](https://www.cloudsma.com/2019/12/azure-advent-calendar-azure-monitor-workbooks/)).+- To learn how to create workbooks, read the [Azure Workbooks documentation](/azure/azure-monitor/visualize/workbooks-overview) or watch Billy York's [Workbooks training](https://www.youtube.com/watch?v=iGiPpD_-10M&ab_channel=FestiveTechCalendar) (and [accompanying text](https://www.cloudsma.com/2019/12/azure-advent-calendar-azure-monitor-workbooks/)). - The mentioned resources aren't Microsoft Sentinel-specific. They apply to workbooks in general. To learn more about workbooks in Microsoft Sentinel, view the webinar: [YouTube](https://www.youtube.com/watch?v=7eYNaYSsk1A&list=PLmAptfqzxVEUD7-w180kVApknWHJCXf0j&ab_channel=MicrosoftSecurityCommunity), [MP4](https://onedrive.live.com/?authkey=%21ALoa5KFEhBq2DyQ&cid=66C31D2DBF8E0F71&id=66C31D2DBF8E0F71%21373&parId=66C31D2DBF8E0F71%21372&o=OneUp), or [presentation](https://onedrive.live.com/view.aspx?resid=66C31D2DBF8E0F71!374&ithint=file%2cpptx&authkey=!AD5hvwtCTeHvQLQ). Read the [documentation](monitor-your-data.md). You'll find dozens of workbooks in the [*Workbooks* folder](https://github.com/A Workbooks can serve for reporting. For more advanced reporting capabilities, such as reports scheduling and distribution or pivot tables, you might want to use: -- Power BI, which natively [integrates with Azure Monitor Logs and Microsoft Sentinel](../azure-monitor/logs/log-powerbi.md).+- Power BI, which natively [integrates with Azure Monitor Logs and Microsoft Sentinel](/azure/azure-monitor/logs/log-powerbi). -- Excel, which can use [Azure Monitor Logs and Microsoft Sentinel as the data source](../azure-monitor/logs/log-excel.md), and view the ["Integrate Azure Monitor Logs and Excel with Azure Monitor"](https://www.youtube.com/watch?v=Rx7rJhjzTZA) video.+- Excel, which can use [Azure Monitor Logs and Microsoft Sentinel as the data source](/azure/azure-monitor/logs/log-excel), and view the ["Integrate Azure Monitor Logs and Excel with Azure Monitor"](https://www.youtube.com/watch?v=Rx7rJhjzTZA) video. - Jupyter notebooks, a topic that's covered later in the hunting module, are also a great visualization tool. Part of operating a SIEM is making sure that it works smoothly and is an evolvin - The Microsoft Sentinel Health data table provides insights on health drifts, such as latest failure events per connector, or connectors with changes from success to failure states, which you can use to create alerts and other automated actions. For more information, see [Monitor the health of your data connectors](monitor-data-connector-health.md). View the ["Data Connectors Health Monitoring Workbook"](https://www.youtube.com/watch?v=T6Vyo7gZYds&ab_channel=MicrosoftSecurityCommunity) video. And [get notifications on anomalies](https://techcommunity.microsoft.com/t5/microsoft-sentinel-blog/data-connector-health-push-notification-alerts/ba-p/1996442). -- Monitor agents by using the [agents' health solution](../azure-monitor/insights/solution-agenthealth.md) (Windows only) and the [Heartbeat table](/azure/azure-monitor/reference/tables/heartbeat) (Linux and Windows).+- Monitor agents by using the [agents' health solution](/azure/azure-monitor/insights/solution-agenthealth) (Windows only) and the [Heartbeat table](/azure/azure-monitor/reference/tables/heartbeat) (Linux and Windows). - Monitor your Log Analytics workspace: [YouTube](https://www.youtube.com/watch?v=DmDU9QP_JlI&ab_channel=MicrosoftSecurityCommunity), [MP4](https://onedrive.live.com/?cid=66c31d2dbf8e0f71&id=66C31D2DBF8E0F71%21792&ithint=video%2Cmp4&authkey=%21ALgHojpWDidvFyo), or [presentation](https://onedrive.live.com/?cid=66c31d2dbf8e0f71&id=66C31D2DBF8E0F71%21794&ithint=file%2Cpdf&authkey=%21AAva%2Do6Ru1fjJ78), including query execution and ingestion health. |
| sentinel | Summary Rules | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/summary-rules.md | Use [summary rules](/azure/azure-monitor/logs/summary-rules) in Microsoft Sentin Access summary rule results via Kusto Query Language (KQL) across detection, investigation, hunting, and reporting activities. Use summary rule results for longer in historical investigations, hunting, and compliance activities. -Summary rule results are stored in separate tables under the **Analytics** data plan, and charged accordingly. For more information on data plans and storage costs, see [Select a table plan based on usage patterns in a Log Analytics workspace](../azure-monitor/logs/basic-logs-configure.md) +Summary rule results are stored in separate tables under the **Analytics** data plan, and charged accordingly. For more information on data plans and storage costs, see [Select a table plan based on usage patterns in a Log Analytics workspace](/azure/azure-monitor/logs/basic-logs-configure) > [!IMPORTANT] > Summary rules are currently in PREVIEW. See the [Supplemental Terms of Use for Microsoft Azure Previews](https://azure.microsoft.com/support/legal/preview-supplemental-terms/) for additional legal terms that apply to Azure features that are in beta, preview, or otherwise not yet released into general availability. |
| sentinel | Troubleshoot Analytics Rules | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/troubleshoot-analytics-rules.md | Another kind of permanent failure occurs due to an **improperly built query** th To re-enable the rule, you must address the issues in the query that cause it to use too many resources. See the following articles for best practices to optimize your Kusto queries: - [Query best practices - Azure Data Explorer](/azure/data-explorer/kusto/query/best-practices)-- [Optimize log queries in Azure Monitor](../azure-monitor/logs/query-optimization.md)+- [Optimize log queries in Azure Monitor](/azure/azure-monitor/logs/query-optimization) Also see [Useful resources for working with Kusto Query Language in Microsoft Sentinel](kusto-resources.md) for further assistance. |
| sentinel | Troubleshooting Cef Syslog | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/troubleshooting-cef-syslog.md | The Syslog server, either rsyslog or syslog-ng, forwards any data defined in the Make sure to add details about the facilities and severity log levels that you want to be ingested into Microsoft Sentinel. The configuration process may take about 20 minutes. -For more information, see [Deployment script explained](./connect-log-forwarder.md#deployment-script-explained). and [Configure Syslog in the Azure portal](../azure-monitor/agents/data-sources-syslog.md). +For more information, see [Deployment script explained](./connect-log-forwarder.md#deployment-script-explained). and [Configure Syslog in the Azure portal](/azure/azure-monitor/agents/data-sources-syslog). **For example, for an rsyslog server**, run the following command to display the current settings for your Syslog forwarding, and review any changes to the configuration file: In such cases, continue troubleshooting by verifying the following: - Make sure that you can see data packets flowing on port 25226 -- Make sure that your virtual machine has an outbound connection to port 443 via TCP, or can connect to the [Log Analytics endpoints](../azure-monitor/agents/log-analytics-agent.md#network-requirements)+- Make sure that your virtual machine has an outbound connection to port 443 via TCP, or can connect to the [Log Analytics endpoints](/azure/azure-monitor/agents/log-analytics-agent#network-requirements) -- Make sure that you have access to required URLs from your CEF collector through your firewall policy. For more information, see [Log Analytics agent firewall requirements](../azure-monitor/agents/log-analytics-agent.md#firewall-requirements).+- Make sure that you have access to required URLs from your CEF collector through your firewall policy. For more information, see [Log Analytics agent firewall requirements](/azure/azure-monitor/agents/log-analytics-agent#firewall-requirements). Run the following command to determine if the agent is communicating successfully with Azure, or if the OMS agent is blocked from connecting to the Log Analytics workspace. In such cases, continue troubleshooting by verifying the following: - Make sure that you can see data packets flowing on port 25224 -- Make sure that your virtual machine has an outbound connection to port 443 via TCP, or can connect to the [Log Analytics endpoints](../azure-monitor/agents/log-analytics-agent.md#network-requirements)+- Make sure that your virtual machine has an outbound connection to port 443 via TCP, or can connect to the [Log Analytics endpoints](/azure/azure-monitor/agents/log-analytics-agent#network-requirements) -- Make sure that you have access to required URLs from your Syslog or CEF collector through your firewall policy. For more information, see [Log Analytics agent firewall requirements](../azure-monitor/agents/log-analytics-agent.md#firewall-requirements).+- Make sure that you have access to required URLs from your Syslog or CEF collector through your firewall policy. For more information, see [Log Analytics agent firewall requirements](/azure/azure-monitor/agents/log-analytics-agent#firewall-requirements). - Make sure that your Azure Virtual Machine is shown as connected in your workspace's list of virtual machines. |
| sentinel | Understand Threat Intelligence | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/understand-threat-intelligence.md | Microsoft provides access to its threat intelligence through the Defender Threat Workbooks provide powerful interactive dashboards that give you insights into all aspects of Microsoft Sentinel, and threat intelligence is no exception. Use the built-in **Threat Intelligence** workbook to visualize key information about your threat intelligence. You can easily customize the workbook according to your business needs. Create new dashboards by combining many data sources to help you visualize your data in unique ways. -Because Microsoft Sentinel workbooks are based on Azure Monitor workbooks, extensive documentation and many more templates are already available. For more information, see [Create interactive reports with Azure Monitor workbooks](../azure-monitor/visualize/workbooks-overview.md). +Because Microsoft Sentinel workbooks are based on Azure Monitor workbooks, extensive documentation and many more templates are already available. For more information, see [Create interactive reports with Azure Monitor workbooks](/azure/azure-monitor/visualize/workbooks-overview). There's also a rich resource for [Azure Monitor workbooks on GitHub](https://github.com/microsoft/Application-Insights-Workbooks), where you can download more templates and contribute your own templates. |
| sentinel | Unified Connector Custom Device | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/unified-connector-custom-device.md | Follow these steps to ingest log messages from VMware vCenter: - Replace the `{TABLE_NAME}` and `{LOCAL_PATH_FILE}` placeholders in the [DCR template](connect-custom-logs-ama.md?tabs=arm#create-the-data-collection-rule) with the values in steps 1 and 2. Replace the other placeholders as directed. - - dataCollectionEndpointId should be populated with your DCE. If you don't have one, define a new one. See [Create a data collection endpoint](../azure-monitor/essentials/data-collection-endpoint-overview.md#create-a-data-collection-endpoint) for the instructions. + - dataCollectionEndpointId should be populated with your DCE. If you don't have one, define a new one. See [Create a data collection endpoint](/azure/azure-monitor/essentials/data-collection-endpoint-overview#create-a-data-collection-endpoint) for the instructions. 1. Configure the machine where the Azure Monitor Agent is installed to open the syslog ports, and configure the syslog daemon there to accept messages from external sources. For detailed instructions and a script to automate this configuration, see [Configure the log forwarder to accept logs](connect-custom-logs-ama.md#configure-the-log-forwarder-to-accept-logs). |
| sentinel | Watchlists | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/watchlists.md | Before you create a watchlist, be aware of the following limitations: - When you create a watchlist, the watchlist name and alias must each be between 3 and 64 characters. The first and last characters must be alphanumeric. But you can include whitespaces, hyphens, and underscores in between the first and last characters. - The use of watchlists should be limited to reference data, as they aren't designed for large data volumes.-- The **total number of active watchlist items** across all watchlists in a single workspace is currently limited to **10 million**. Deleted watchlist items don't count against this total. If you require the ability to reference large data volumes, consider ingesting them using [custom logs](../azure-monitor/agents/data-sources-custom-logs.md) instead.+- The **total number of active watchlist items** across all watchlists in a single workspace is currently limited to **10 million**. Deleted watchlist items don't count against this total. If you require the ability to reference large data volumes, consider ingesting them using [custom logs](/azure/azure-monitor/agents/data-sources-custom-logs) instead. - Watchlists are refreshed in your workspace every 12 days, updating the `TimeGenerated` field. - Using Lighthouse to manage watchlists across different workspaces is not supported at this time. - Local file uploads are currently limited to files of up to 3.8 MB in size. |
| sentinel | Whats New | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/whats-new.md | The listed features were released in the last three months. For information abou ## September 2024 +- [Import/export of automation rules now generally available (GA)](#importexport-of-automation-rules-now-generally-available-ga) - [Google Cloud Platform data connectors are now generally available (GA)](#google-cloud-platform-data-connectors-are-now-generally-available-ga) - [Microsoft Sentinel now generally available (GA) in Azure Israel Central](#microsoft-sentinel-now-generally-available-ga-in-azure-israel-central) +### Import/export of automation rules now generally available (GA) ++The ability to export automation rules to Azure Resource Manager (ARM) templates in JSON format, and to import them from ARM templates, is now generally available after a [short preview period](#export-and-import-automation-rules-preview). ++Learn more about [exporting and importing automation rules](import-export-automation-rules.md). + ### Google Cloud Platform data connectors are now generally available (GA) Microsoft Sentinel's [Google Cloud Platform (GCP) data connectors](connect-google-cloud-platform.md), based on our [Codeless Connector Platform (CCP)](create-codeless-connector.md), are now **generally available**. WIth these connectors, you can ingest logs from your GCP environment using the GCP [Pub/Sub capability](https://cloud.google.com/pubsub/docs/overview): The new **Auxiliary logs** retention plan for Log Analytics tables allows you to To learn more about Auxiliary logs and compare with Analytics logs, see [Log retention plans in Microsoft Sentinel](log-plans.md). -For more in-depth information about the different log management plans, see [**Table plans**](../azure-monitor/logs/data-platform-logs.md#table-plans) in the [Azure Monitor Logs overview](../azure-monitor/logs/data-platform-logs.md) article from the Azure Monitor documentation. +For more in-depth information about the different log management plans, see [**Table plans**](/azure/azure-monitor/logs/data-platform-logs#table-plans) in the [Azure Monitor Logs overview](/azure/azure-monitor/logs/data-platform-logs) article from the Azure Monitor documentation. ### Create summary rules in Microsoft Sentinel for large sets of data (Preview) |
| sentinel | Windows Security Event Id Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/windows-security-event-id-reference.md | When ingesting security events from Windows devices using the [Windows Security - **Minimal** - A small set of events that might indicate potential threats. This set does not contain a full audit trail. It covers only events that might indicate a successful breach, and other important events that have very low rates of occurrence. For example, it contains successful and failed user logons (event IDs 4624, 4625), but it doesn't contain sign-out information (4634) which, while important for auditing, is not meaningful for breach detection and has relatively high volume. Most of the data volume of this set consists of sign-in events and process creation events (event ID 4688). -- **Custom** - A set of events determined by you, the user, and defined in a data collection rule using XPath queries. [Learn more about data collection rules](../azure-monitor/agents/data-collection-windows-events.md#filter-events-using-xpath-queries).+- **Custom** - A set of events determined by you, the user, and defined in a data collection rule using XPath queries. [Learn more about data collection rules](/azure/azure-monitor/agents/data-collection-windows-events#filter-events-using-xpath-queries). ## Event ID reference |
| sentinel | Work With Threat Indicators | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/sentinel/work-with-threat-indicators.md | Here's how to find the threat intelligence workbook provided in Microsoft Sentin Workbooks provide powerful interactive dashboards that give you insights into all aspects of Microsoft Sentinel. You can do many tasks with workbooks, and the provided templates are a great starting point. Customize the templates or create new dashboards by combining many data sources so that you can visualize your data in unique ways. -Microsoft Sentinel workbooks are based on Azure Monitor workbooks, so extensive documentation and many more templates are available. For more information, see [Create interactive reports with Azure Monitor workbooks](../azure-monitor/visualize/workbooks-overview.md). +Microsoft Sentinel workbooks are based on Azure Monitor workbooks, so extensive documentation and many more templates are available. For more information, see [Create interactive reports with Azure Monitor workbooks](/azure/azure-monitor/visualize/workbooks-overview). There's also a rich resource for [Azure Monitor workbooks on GitHub](https://github.com/microsoft/Application-Insights-Workbooks), where you can download more templates and contribute your own templates. |
| service-bus-messaging | Automate Update Messaging Units | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-bus-messaging/automate-update-messaging-units.md | Last updated 05/16/2022 # Automatically update messaging units of an Azure Service Bus namespace -Autoscale allows you to have the right amount of resources running to handle the load on your application. It allows you to add resources to handle increases in load and also save money by removing resources that are sitting idle. See [Overview of autoscale in Microsoft Azure](../azure-monitor/autoscale/autoscale-overview.md) to learn more about the Autoscale feature of Azure Monitor. +Autoscale allows you to have the right amount of resources running to handle the load on your application. It allows you to add resources to handle increases in load and also save money by removing resources that are sitting idle. See [Overview of autoscale in Microsoft Azure](/azure/azure-monitor/autoscale/autoscale-overview) to learn more about the Autoscale feature of Azure Monitor. Service Bus Premium Messaging provides resource isolation at the CPU and memory level so that each customer workload runs in isolation. This resource container is called a **messaging unit**. To learn more about messaging units, see [Service Bus Premium Messaging](service-bus-premium-messaging.md). The previous section shows you how to add a default condition for the autoscale :::image type="content" source="./media/automate-update-messaging-units/repeat-specific-days-2.png" alt-text="scale to specific messaging units - repeat specific days"::: - To learn more about how autoscale settings work, especially how it picks a profile or condition and evaluates multiple rules, see [Understand Autoscale settings](../azure-monitor/autoscale/autoscale-understanding-settings.md). + To learn more about how autoscale settings work, especially how it picks a profile or condition and evaluates multiple rules, see [Understand Autoscale settings](/azure/azure-monitor/autoscale/autoscale-understanding-settings). > [!NOTE] > - The metrics you review to make decisions on autoscaling may be 5-10 minutes old. When you are dealing with spiky workloads, we recommend that you have shorter durations for scaling up and longer durations for scaling down (> 10 minutes) to ensure that there are enough messaging units to process spiky workloads. |
| service-bus-messaging | Monitor Service Bus Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-bus-messaging/monitor-service-bus-reference.md | The following *resource metrics* are available only with the **premium** tier. | CPU usage per namespace | The percentage CPU usage of the namespace. | | Memory size usage per namespace | The percentage memory usage of the namespace. | -The important metrics to monitor for any outages for a premium tier namespace are: **CPU usage per namespace** and **memory size per namespace**. [Set up alerts](../azure-monitor/alerts/alerts-metric.md) for these metrics using Azure Monitor. +The important metrics to monitor for any outages for a premium tier namespace are: **CPU usage per namespace** and **memory size per namespace**. [Set up alerts](/azure/azure-monitor/alerts/alerts-metric) for these metrics using Azure Monitor. The other metric you could monitor is: **throttled requests**. It shouldn't be an issue though as long as the namespace stays within its memory, CPU, and brokered connections limits. For more information, see [Throttling in Azure Service Bus Premium tier](service-bus-throttling.md#throttling-in-premium-tier) This section lists the types of resource logs you can collect for Azure Service - Virtual network and IP filtering logs - Runtime Audit logs -Azure Service Bus now has the capability to dispatch logs to either of two destination tables - Azure Diagnostic or [Resource specific tables](~/articles/azure-monitor/essentials/resource-logs.md) in Log Analytics. You could use the toggle available on Azure portal to choose destination tables. +Azure Service Bus now has the capability to dispatch logs to either of two destination tables - Azure Diagnostic or [Resource specific tables](/azure/azure-monitor/essentials/resource-logs) in Log Analytics. You could use the toggle available on Azure portal to choose destination tables. :::image type="content" source="media/monitor-service-bus-reference/destination-table-toggle.png" alt-text="Screenshot of dialog box to set destination table." lightbox="media/monitor-service-bus-reference/destination-table-toggle.png"::: |
| service-bus-messaging | Monitor Service Bus | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-bus-messaging/monitor-service-bus.md | -> To understand costs associated with Azure Monitor, see [Azure Monitor cost and usage](../azure-monitor/cost-usage.md). To understand the time it takes for your data to appear in Azure Monitor, see [Log data ingestion time](../azure-monitor/logs/data-ingestion-time.md). +> To understand costs associated with Azure Monitor, see [Azure Monitor cost and usage](/azure/azure-monitor/cost-usage). To understand the time it takes for your data to appear in Azure Monitor, see [Log data ingestion time](/azure/azure-monitor/logs/data-ingestion-time). [!INCLUDE [horz-monitor-insights](~/reusable-content/ce-skilling/azure/includes/azure-monitor/horizontals/horz-monitor-insights.md)] The diagnostic logging information is stored in tables named **AzureDiagnostics* For a list of available metrics for Service Bus, see [Azure Service Bus monitoring data reference](monitor-service-bus-reference.md#metrics). -You can analyze metrics for Azure Service Bus, along with metrics from other Azure services, by selecting **Metrics** from the **Monitoring** section on the home page for your Service Bus namespace. See [Analyze metrics with Azure Monitor metrics explorer](../azure-monitor/essentials/analyze-metrics.md) for details on using this tool. For a list of the platform metrics collected, see [Monitoring Azure Service Bus data reference metrics](monitor-service-bus-reference.md#metrics). +You can analyze metrics for Azure Service Bus, along with metrics from other Azure services, by selecting **Metrics** from the **Monitoring** section on the home page for your Service Bus namespace. See [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics) for details on using this tool. For a list of the platform metrics collected, see [Monitoring Azure Service Bus data reference metrics](monitor-service-bus-reference.md#metrics). :::image type="content" source="./media/monitor-service-bus/metrics.png" alt-text="Screenshot shows Metrics Explorer with Service Bus namespace selected."::: |
| service-bus-messaging | Service Bus End To End Tracing | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-bus-messaging/service-bus-end-to-end-tracing.md | The `ServiceBusProcessor` class of [Azure Messaging Service Bus client for .NET] [Microsoft Application Insights](https://azure.microsoft.com/services/application-insights/) provides rich performance monitoring capabilities including automagical request and dependency tracking. Depending on your project type, install Application Insights SDK:-- [ASP.NET](../azure-monitor/app/asp-net.md) - install version 2.5-beta2 or higher-- [ASP.NET Core](../azure-monitor/app/asp-net-core.md) - install version 2.2.0-beta2 or higher.-These links provide details on installing SDK, creating resources, and configuring SDK (if needed). For non-ASP.NET applications, refer to [Azure Application Insights for Console Applications](../azure-monitor/app/console.md) article. +- [ASP.NET](/azure/azure-monitor/app/asp-net) - install version 2.5-beta2 or higher +- [ASP.NET Core](/azure/azure-monitor/app/asp-net-core) - install version 2.2.0-beta2 or higher. +These links provide details on installing SDK, creating resources, and configuring SDK (if needed). For non-ASP.NET applications, refer to [Azure Application Insights for Console Applications](/azure/azure-monitor/app/console) article. If you use [`ProcessMessageAsync` of `ServiceBusProcessor`](/dotnet/api/azure.messaging.servicebus.servicebusprocessor.processmessageasync) (message handler pattern) to process messages, the message processing is also instrumented. All Service Bus calls done by your service are automatically tracked and correlated with other telemetry items. Otherwise refer to the following example for manual message processing tracking. async Task ProcessAsync(ProcessMessageEventArgs args) In this example, request telemetry is reported for each processed message, having a timestamp, duration, and result (success). The telemetry also has a set of correlation properties. Nested traces and exceptions reported during message processing are also stamped with correlation properties representing them as 'children' of the `RequestTelemetry`. -In case you make calls to supported external components during message processing, they're also automatically tracked and correlated. Refer to [Track custom operations with Application Insights .NET SDK](../azure-monitor/app/custom-operations-tracking.md) for manual tracking and correlation. +In case you make calls to supported external components during message processing, they're also automatically tracked and correlated. Refer to [Track custom operations with Application Insights .NET SDK](/azure/azure-monitor/app/custom-operations-tracking) for manual tracking and correlation. If you're running any external code in addition to the Application Insights SDK, expect to see longer **duration** when viewing Application Insights logs. The instrumentation allows tracking all calls to the Service Bus messaging servi [Microsoft Application Insights](https://azure.microsoft.com/services/application-insights/) provides rich performance monitoring capabilities including automagical request and dependency tracking. Depending on your project type, install Application Insights SDK:-- [ASP.NET](../azure-monitor/app/asp-net.md) - install version 2.5-beta2 or higher-- [ASP.NET Core](../azure-monitor/app/asp-net-core.md) - install version 2.2.0-beta2 or higher.-These links provide details on installing SDK, creating resources, and configuring SDK (if needed). For non-ASP.NET applications, refer to [Azure Application Insights for Console Applications](../azure-monitor/app/console.md) article. +- [ASP.NET](/azure/azure-monitor/app/asp-net) - install version 2.5-beta2 or higher +- [ASP.NET Core](/azure/azure-monitor/app/asp-net-core) - install version 2.2.0-beta2 or higher. +These links provide details on installing SDK, creating resources, and configuring SDK (if needed). For non-ASP.NET applications, refer to [Azure Application Insights for Console Applications](/azure/azure-monitor/app/console) article. If you use [message handler pattern](/dotnet/api/microsoft.azure.servicebus.queueclient.registermessagehandler) to process messages, you're done: all Service Bus calls done by your service are automatically tracked and correlated with other telemetry items. Otherwise refer to the following example for manual message processing tracking. async Task ProcessAsync(Message message) In this example, `RequestTelemetry` is reported for each processed message, having a timestamp, duration, and result (success). The telemetry also has a set of correlation properties. Nested traces and exceptions reported during message processing are also stamped with correlation properties representing them as 'children' of the `RequestTelemetry`. -In case you make calls to supported external components during message processing, they're also automatically tracked and correlated. Refer to [Track custom operations with Application Insights .NET SDK](../azure-monitor/app/custom-operations-tracking.md) for manual tracking and correlation. +In case you make calls to supported external components during message processing, they're also automatically tracked and correlated. Refer to [Track custom operations with Application Insights .NET SDK](/azure/azure-monitor/app/custom-operations-tracking) for manual tracking and correlation. If you're running any external code in addition to the Application Insights SDK, expect to see longer **duration** when viewing Application Insights logs. In presence of multiple `DiagnosticSource` listeners for the same source, it's e ## Next steps -* [Application Insights Correlation](../azure-monitor/app/distributed-tracing-telemetry-correlation.md) -* [Application Insights Monitor Dependencies](../azure-monitor/app/asp-net-dependencies.md) to see if REST, SQL, or other external resources are slowing you down. -* [Track custom operations with Application Insights .NET SDK](../azure-monitor/app/custom-operations-tracking.md) +* [Application Insights Correlation](/azure/azure-monitor/app/distributed-tracing-telemetry-correlation) +* [Application Insights Monitor Dependencies](/azure/azure-monitor/app/asp-net-dependencies) to see if REST, SQL, or other external resources are slowing you down. +* [Track custom operations with Application Insights .NET SDK](/azure/azure-monitor/app/custom-operations-tracking) |
| service-bus-messaging | Service Bus Federation Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-bus-messaging/service-bus-federation-overview.md | Implementing the patterns above requires a scalable and reliable execution envir Azure Functions can run under a [Azure managed identity](../active-directory/managed-identities-azure-resources/overview.md) such that the replication tasks can integrate with the role-based access control rules of the source and target services without you having to manage secrets along the replication path. For replication sources and targets that require explicit credentials, Azure Functions can hold the configuration values for those credentials in tightly access-controlled storage inside of [Azure Key Vault](/azure/key-vault/general/overview). -Azure Functions furthermore allows the replication tasks to directly integrate with Azure virtual networks and [service endpoints](../virtual-network/virtual-network-service-endpoints-overview.md) for all Azure messaging services, and it's readily integrated with [Azure Monitor](../azure-monitor/overview.md). +Azure Functions furthermore allows the replication tasks to directly integrate with Azure virtual networks and [service endpoints](../virtual-network/virtual-network-service-endpoints-overview.md) for all Azure messaging services, and it's readily integrated with [Azure Monitor](/azure/azure-monitor/overview). Most importantly, Azure Functions has prebuilt, scalable triggers and output bindings for [Azure Event Hubs](../azure-functions/functions-bindings-service-bus.md), [Azure IoT Hub](../azure-functions/functions-bindings-event-iot.md), [Azure Service Bus](../azure-functions/functions-bindings-service-bus.md), [Azure Event Grid](../azure-functions/functions-bindings-event-grid.md), and [Azure Queue Storage](../azure-functions/functions-bindings-storage-queue.md), custom extensions for [RabbitMQ](https://github.com/azure/azure-functions-rabbitmq-extension), and [Apache Kafka](https://github.com/azure/azure-functions-kafka-extension). Most triggers will dynamically adapt to the throughput needs by scaling the number of concurrently executing instances up and down based on documented metrics. |
| service-bus-messaging | Service Bus Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-bus-messaging/service-bus-insights.md | On the **Service Bus Overview - Azure Monitor** page, select **Edit** to make mo ## Troubleshooting -For troubleshooting guidance, refer to the dedicated workbook-based insights [troubleshooting article](../azure-monitor/insights/troubleshoot-workbooks.md). +For troubleshooting guidance, refer to the dedicated workbook-based insights [troubleshooting article](/azure/azure-monitor/insights/troubleshoot-workbooks). ## Next steps -* Configure [metric alerts](../azure-monitor/alerts/alerts-metric.md) and [service health notifications](../service-health/alerts-activity-log-service-notifications-portal.md) to set up automated alerting to aid in detecting issues. +* Configure [metric alerts](/azure/azure-monitor/alerts/alerts-metric) and [service health notifications](/azure/service-health/alerts-activity-log-service-notifications-portal) to set up automated alerting to aid in detecting issues. -* Learn the scenarios workbooks are designed to support, how to author new and customize existing reports, and more by reviewing [Create interactive reports with Azure Monitor workbooks](../azure-monitor/visualize/workbooks-overview.md). +* Learn the scenarios workbooks are designed to support, how to author new and customize existing reports, and more by reviewing [Create interactive reports with Azure Monitor workbooks](/azure/azure-monitor/visualize/workbooks-overview). |
| service-bus-messaging | Service Bus Outages Disasters | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-bus-messaging/service-bus-outages-disasters.md | When you use availability zones, **both metadata and data (messages)** are repli When you create a namespace, the support for availability zones (if available in the selected region) is automatically enabled for the namespace. There's no extra cost for using this feature and you can't disable or enable this feature after namespace creation. > [!NOTE]-> Previously it was required to set the property `zoneRedundant` to `true` to enable availability zones, however this behavior has changed to enable availability zones by default. Existing namespaces are being migrated to availability zones as well, and the property `zoneRedundant` is being deprecated. The property `zoneRedundant` might still show as `false`, even when availability zones has been enabled. +> Previously it was required to set the property `zoneRedundant` to `true` to enable availability zones, however this behavior has changed to enable availability zones by default. Existing namespaces are being migrated to availability zones where possible, and the property `zoneRedundant` is being deprecated. The property `zoneRedundant` might still show as `false`, even when availability zones has been enabled. +> Existing namespaces that are being migrated: +> - Currently does not have availability zones enabled. +> - The [region supports availability zones](/azure/reliability/availability-zones-service-support). +> - The region has sufficient availability zone capacity. ## Protection against disasters - standard tier |
| service-connector | Concept Permission | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/concept-permission.md | Service Connector creates connections between Azure services using an [on-behalf ### Azure Cosmos DB +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + > [!div class="mx-tableFixed"] > | Action | Description | > | | | |
| service-connector | How To Integrate App Configuration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/how-to-integrate-app-configuration.md | Refer to the steps and code below to connect to Azure App Configuration using a ### Connection string +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + > [!div class="mx-tdBreakAll"] > | Default environment variable name | Description | Sample value | > | | | | |
| service-connector | How To Integrate Confluent Kafka | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/how-to-integrate-confluent-kafka.md | Use the connection details below to connect compute services to Kafka. For each ### Secret / Connection String +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + #### SpringBoot client type | Default environment variable name | Description | Example value | |
| service-connector | How To Integrate Cosmos Cassandra | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/how-to-integrate-cosmos-cassandra.md | Refer to the steps and code below to connect to Azure Cosmos DB for Cassandra us ### Connection String +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + #### SpringBoot client type | Default environment variable name | Description | Example value | |
| service-connector | How To Integrate Cosmos Db | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/how-to-integrate-cosmos-db.md | Refer to the steps and code below to connect to Azure Cosmos DB for MongoDB usin ### Connection string +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + #### SpringBoot client type | Default environment variable name | Description | Example value | |
| service-connector | How To Integrate Cosmos Gremlin | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/how-to-integrate-cosmos-gremlin.md | Refer to the steps and code below to connect to Azure Cosmos DB for Gremlin usin ### Connection string +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + | Default environment variable name | Description | Example value | |--|--|| | AZURE_COSMOS_HOSTNAME | Your Gremlin Unique Resource Identifier (UFI) | `<Azure-Cosmos-DB-account>.gremlin.cosmos.azure.com` | |
| service-connector | How To Integrate Cosmos Sql | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/how-to-integrate-cosmos-sql.md | Refer to the steps and code below to connect to Azure Cosmos DB for NoSQL using ### Connection string +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + #### SpringBoot client type | Default environment variable name | Description | Example value | |
| service-connector | How To Integrate Cosmos Table | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/how-to-integrate-cosmos-table.md | Refer to the steps and code below to connect to Azure Cosmos DB for Table using |--|-|-| | AZURE_COSMOS_CONNECTIONSTRING | Azure Cosmos DB for Table connection string | `DefaultEndpointsProtocol=https;AccountName=<account-name>;AccountKey=<account-key>;TableEndpoint=https://<table-name>.table.cosmos.azure.com:443/; ` | +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + #### Sample code Refer to the steps and code below to connect to Azure Cosmos DB for Table using a connection string. |
| service-connector | How To Integrate Event Hubs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/how-to-integrate-event-hubs.md | Refer to the steps and code below to connect to Azure Event Hubs using a user-as ### Connection string +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + #### SpringBoot client type > [!div class="mx-tdBreakAll"] |
| service-connector | How To Integrate Mysql | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/how-to-integrate-mysql.md | Refer to the steps and code below to connect to Azure Database for MySQL using a ### Connection String +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + #### [.NET](#tab/dotnet) | Default environment variable name | Description | Example value | |
| service-connector | How To Integrate Postgres | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/how-to-integrate-postgres.md | Refer to the steps and code below to connect to Azure Database for PostgreSQL us ### Connection String +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + #### [.NET](#tab/dotnet) | Default environment variable name | Description | Example value | |
| service-connector | How To Integrate Redis Cache | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/how-to-integrate-redis-cache.md | Use the environment variable names and application properties listed below to co ### Connection String +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + #### [.NET](#tab/dotnet) | Default environment variable name | Description | Example value | |
| service-connector | How To Integrate Service Bus | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/how-to-integrate-service-bus.md | Refer to the steps and code below to connect to Service Bus using a user-assigne ### Connection string +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + #### SpringBoot client type > [!div class="mx-tdBreakAll"] |
| service-connector | How To Integrate Signalr | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/how-to-integrate-signalr.md | Refer to the steps and code below to connect to Azure SignalR Service using a us ### Connection string +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + | Default environment variable name | Description | Example value | | | | | | AZURE_SIGNALR_CONNECTIONSTRING | SignalR Service connection string | `Endpoint=https://<SignalR-name>.service.signalr.net;AccessKey=<access-key>;Version=1.0;` | |
| service-connector | How To Integrate Sql Database | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/how-to-integrate-sql-database.md | Refer to the steps and code below to connect to Azure SQL Database using a user- ### Connection String +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + #### [.NET](#tab/sql-secret-dotnet) > [!div class="mx-tdBreakAll"] |
| service-connector | How To Integrate Storage Blob | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/how-to-integrate-storage-blob.md | Refer to the steps and code below to connect to Azure Blob Storage using a user- ### Connection string +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + For default environment variables and sample code of other authentication type, please choose from beginning of the documentation. #### SpringBoot client type |
| service-connector | How To Integrate Storage File | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/how-to-integrate-storage-file.md | Use the connection details below to connect compute services to Azure File Stora ### Connection string +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + #### SpringBoot client type | Application properties | Description | Example value | |
| service-connector | How To Integrate Storage Queue | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/how-to-integrate-storage-queue.md | Refer to the steps and code below to connect to Azure Queue Storage using a user ### Connection string +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + #### SpringBoot client type | Application properties | Description | Example value | |
| service-connector | How To Integrate Storage Table | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/how-to-integrate-storage-table.md | Refer to the steps and code below to connect to Azure Table Storage using a user ### Connection string +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + | Default environment variable name | Description | Example value | |-||-| | AZURE_STORAGETABLE_CONNECTIONSTRING | Table Storage connection string | `DefaultEndpointsProtocol=https;AccountName=<account-name>;AccountKey=<account-key>;EndpointSuffix=core.windows.net` | |
| service-connector | How To Integrate Web Pubsub | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/how-to-integrate-web-pubsub.md | Refer to the steps and code below to connect to Azure Web PubSub using a user-as ### Connection string +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + > [!div class="mx-tdBreakAll"] > > | Default environment variable name | Description | Sample value | |
| service-connector | Quickstart Cli Aks Connection | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/quickstart-cli-aks-connection.md | This quickstart shows you how to connect Azure Kubernetes Service (AKS) to other ## Create a service connection -### [Using an access key](#tab/Using-access-key) --Run the following Azure CLI command to create a service connection to an Azure Blob Storage with an access key, providing the following information. --```azurecli -az aks connection create storage-blob --secret -``` --Provide the following information as prompted: --* **Source compute service resource group name:** the resource group name of the AKS cluster. -* **AKS cluster name:** the name of your AKS cluster that connects to the target service. -* **Target service resource group name:** the resource group name of the Blob Storage. -* **Storage account name:** the account name of your Blob Storage. --> [!NOTE] -> If you don't have a Blob Storage, you can run `az aks connection create storage-blob --new --secret` to provision a new one and directly get connected to your aks cluster. - ### [Using a workload identity](#tab/Using-Managed-Identity) > [!IMPORTANT] az aks connection create storage-blob \ > [!NOTE] > If you don't have a Blob Storage, you can run `az aks connection create storage-blob --new --workload-identity <user-identity-resource-id>"` to provision a new one and get connected to your function app straightaway. +### [Using an access key](#tab/Using-access-key) ++> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. ++Run the following Azure CLI command to create a service connection to an Azure Blob Storage with an access key, providing the following information. ++```azurecli +az aks connection create storage-blob --secret +``` ++Provide the following information as prompted: ++* **Source compute service resource group name:** the resource group name of the AKS cluster. +* **AKS cluster name:** the name of your AKS cluster that connects to the target service. +* **Target service resource group name:** the resource group name of the Blob Storage. +* **Storage account name:** the account name of your Blob Storage. ++> [!NOTE] +> If you don't have a Blob Storage, you can run `az aks connection create storage-blob --new --secret` to provision a new one and connect it to your AKS cluster. + ## View connections |
| service-connector | Quickstart Cli App Service Connection | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/quickstart-cli-app-service-connection.md | az webapp connection create storage-blob #### [Using an access key](#tab/Using-access-key) +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + Use the Azure CLI [az webapp connection create](/cli/azure/webapp/connection/create) command to create a service connection to an Azure Blob Storage with an access key, providing the following information: - **Source compute service resource group name:** the resource group name of the App Service. |
| service-connector | Quickstart Cli Container Apps | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/quickstart-cli-container-apps.md | Create a connection using a managed identity or an access key. ### [Access key](#tab/using-access-key) +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + 1. Run the `az containerapp connection create` command to create a service connection between Container Apps and Azure Blob Storage using an access key. ```azurecli |
| service-connector | Quickstart Cli Functions Connection | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/quickstart-cli-functions-connection.md | az functionapp connection create storage-blob --system-identity #### [Using an access key](#tab/Using-access-key) +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + Use the Azure CLI [az functionapp connection create](/cli/azure/functionapp/connection/create) command to create a service connection to an Azure Blob Storage with an access key, providing the following information: - **Source compute service resource group name:** the resource group name of the Function App. |
| service-connector | Quickstart Cli Spring Cloud Connection | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/quickstart-cli-spring-cloud-connection.md | Create a connection from Azure Spring Apps using a managed identity or an access ### [Access key](#tab/Using-access-key) +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + 1. Run the `az spring connection create` command to create a service connection between Azure Spring Apps and an Azure Blob Storage using an access key. ```azurecli |
| service-connector | Quickstart Portal Aks Connection | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/quickstart-portal-aks-connection.md | Sign in to the Azure portal at [https://portal.azure.com/](https://portal.azure. ### [Workload identity](#tab/UMI) Select **Workload identity** to authenticate through [Microsoft Entra workload identity](/entra/workload-id/workload-identities-overview) to one or more instances of an Azure service. Then select a user-assigned managed identity to enable workload identity.-- ### [Connection string](#tab/CS) - - Select **Connection string** to generate or configure one or multiple key-value pairs with pure secrets or tokens. ### [Service principal](#tab/SP) Select **Service principal** to use a service principal that defines the access policy and permissions for the user/application. + ### [Connection string](#tab/CS) + + > [!WARNING] + > Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. ++ Select **Connection string** to generate or configure one or multiple key-value pairs with pure secrets or tokens. + 1. Select **Next: Networking** to configure the network access to your target service and select **Configure firewall rules to enable access to your target service**. |
| service-connector | Quickstart Portal App Service Connection | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/quickstart-portal-app-service-connection.md | Sign in to the Azure portal at [https://portal.azure.com/](https://portal.azure. Select **User-assigned managed identity** to authenticate through a standalone identity assigned to one or more instances of an Azure service. - ### [Connection string](#tab/CS) -- Select **Connection string** to generate or configure one or multiple key-value pairs with pure secrets or tokens. - ### [Service principal](#tab/SP) Select **Service principal** to use a service principal that defines the access policy and permissions for the user/application in Microsoft Entra ID. + ### [Connection string](#tab/CS) + + > [!WARNING] + > Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + + Select **Connection string** to generate or configure one or multiple key-value pairs with pure secrets or tokens. + + + 1. Select **Next: Networking** to configure the network access to your target service and select **Configure firewall rules to enable access to your target service**. 1. Select **Next: Review + Create** to review the provided information. Then select **Create** to create the service connection. This operation might take a minute to complete. > [!NOTE]-> You need enough permissions to create connection successfully, for more details, see [Permission requirements](./concept-permission.md). +> You need enough permissions to create a connection successfully, for more details, see [Permission requirements](./concept-permission.md). ## View service connections in App Service |
| service-connector | Quickstart Portal Container Apps | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/quickstart-portal-container-apps.md | Use Service Connector to create a new service connection in Container Apps. For more information, go to [create a user-assigned managed identity](../active-directory/managed-identities-azure-resources/how-manage-user-assigned-managed-identities.md?pivots=identity-mi-methods-azp). - ### [Connection string](#tab/CS) -- Select **Connection string** to generate or configure one or multiple key-value pairs with pure secrets or tokens. - ### [Service principal](#tab/SP) 1. Select **Service principal** to use a service principal that defines the access policy and permissions for the user/application in Microsoft Entra ID. 1. Select a service principal from the list and enter a **secret** + ### [Connection string](#tab/CS) ++ > [!WARNING] + > Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. ++ Select **Connection string** to generate or configure one or multiple key-value pairs with pure secrets or tokens. + 1. Select **Next: Networking** to select the network configuration and select **Configure firewall rules to enable access to target service** so that your container can reach the Blob Storage. |
| service-connector | Tutorial Connect Web App App Configuration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/tutorial-connect-web-app-app-configuration.md | Start by creating your Azure resources. Follow these steps to create an App Service and deploy the sample app. Make sure you have the Subscription Contributor or Owner role. - ### [SMI](#tab/smi) + ### [System-assigned managed identity (Recommended)](#tab/smi) Create an app service and deploy the sample app that uses system-assigned managed identity to interact with App Config. Start by creating your Azure resources. | Resource group name | You'll use this resource group to organize all the Azure resources needed to complete this tutorial. | *service-connector-tutorial-rg* | | App service name | The app service name is used as the name of the resource in Azure and to form the fully qualified domain name for your app, in the form of the server endpoint `https://<app-service-name>.azurewebsites.com`. This name must be unique across all Azure and the only allowed characters are `A`-`Z`, `0`-`9`, and `-`. | *webapp-appconfig-smi* | - ### [UMI](#tab/umi) + ### [User-assigned managed identity](#tab/umi) Create an app service and deploy the sample app that uses user-assigned managed identity to interact with App Config. Start by creating your Azure resources. ### [Connection string](#tab/connectionstring) + > [!WARNING] + > Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + Create an app service and deploy the sample app that uses connection string to interact with App Config. ```azurecli Start by creating your Azure resources. ### [Connection string](#tab/connectionstring) + > [!WARNING] + > Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + Import the test configuration file to Azure App Configuration using a connection string. 1. Cd into the folder `ServiceConnectorSample` |
| service-connector | Tutorial Java Spring Confluent Kafka | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/tutorial-java-spring-confluent-kafka.md | Learn how to access Apache Kafka on Confluent Cloud for a Spring Boot applicatio > * Build and deploy the Spring Boot app > * Connect Apache Kafka on Confluent Cloud to Azure Spring Apps using Service Connector +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + ## Prerequisites * An Azure account with an active subscription. [Create an account for free](https://azure.microsoft.com/free/). |
| service-connector | Tutorial Java Spring Mysql | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/tutorial-java-spring-mysql.md | In this tutorial, you'll complete the following tasks using the Azure portal or > * Build and deploy apps to Azure Spring Apps > * Integrate Azure Spring Apps with Azure Database for MySQL with Service Connector ++> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + ## Prerequisites * [Install JDK 8 or JDK 11](/azure/developer/java/fundamentals/java-jdk-install) |
| service-connector | Tutorial Portal Key Vault | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/tutorial-portal-key-vault.md | Now you can create a service connection to another target service and directly s ### [Connection string](#tab/connectionstring) + > [!IMPORTANT] + > Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + Select **Next: Authentication** to select the authentication type and select **Connection string** to use an access key to connect your storage account. | Setting | Suggested value | Description | |
| service-connector | Tutorial Python Aks Keyvault Csi Driver | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/tutorial-python-aks-keyvault-csi-driver.md | Learn how to connect to Azure Key Vault using CSI driver in an Azure Kubernetes > [!IMPORTANT] > Service Connect within AKS is currently in preview. See the [Supplemental Terms of Use for Microsoft Azure Previews](https://azure.microsoft.com/support/legal/preview-supplemental-terms/) for legal terms that apply to Azure features that are in beta, preview, or otherwise not yet released into general availability. +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + ## Prerequisites * An Azure account with an active subscription. [Create an account for free](https://azure.microsoft.com/free/). |
| service-connector | Tutorial Python Aks Openai Connection String | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/tutorial-python-aks-openai-connection-string.md | In this tutorial, you learn how to create a pod in an Azure Kubernetes (AKS) clu > * Deploy the application to a pod in the AKS cluster and test the connection. > * Clean up resources. +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. See the [tutorial using a managed identity](tutorial-python-aks-openai-workload-identity.md). + ## Prerequisites * An Azure account with an active subscription. [Create an account for free](https://azure.microsoft.com/free/). |
| service-connector | Tutorial Python Aks Sql Database Connection String | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/tutorial-python-aks-sql-database-connection-string.md | In this tutorial, you learn how to connect an application deployed to AKS, to an > * Update your application code > * Clean up Azure resources. +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. See the [tutorial using a managed identity](tutorial-python-aks-storage-workload-identity.md). + ## Prerequisites * An Azure account with an active subscription. [Create an account for free](https://azure.microsoft.com/free/). |
| service-connector | Tutorial Python Functions Storage Blob As Input | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/tutorial-python-functions-storage-blob-as-input.md | An overview of the function project components in this tutorial: | Local Project Auth Type | Connection String | | Cloud Function Auth Type | System-Assigned Managed Identity | +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + ## Prerequisites - Install [Visual Studio Code](https://code.visualstudio.com) on one of the [supported platforms](https://code.visualstudio.com/docs/supporting/requirements#_platforms). |
| service-connector | Tutorial Python Functions Storage Queue As Trigger | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/tutorial-python-functions-storage-queue-as-trigger.md | An overview of the function project components in this tutorial: | Local Project Auth Type | Connection String | | Cloud Function Auth Type | Connection String | +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + ## Prerequisites - Install [Visual Studio Code](https://code.visualstudio.com) on one of the [supported platforms](https://code.visualstudio.com/docs/supporting/requirements#_platforms). |
| service-connector | Tutorial Python Functions Storage Table As Output | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-connector/tutorial-python-functions-storage-table-as-output.md | An overview of the function project components in this tutorial: | Local Project Auth Type | Connection String | | Cloud Function Auth Type | Connection String | +> [!WARNING] +> Microsoft recommends that you use the most secure authentication flow available. The authentication flow described in this procedure requires a very high degree of trust in the application, and carries risks that are not present in other flows. You should only use this flow when other more secure flows, such as managed identities, aren't viable. + ## Prerequisites - Install [Visual Studio Code](https://code.visualstudio.com) on one of the [supported platforms](https://code.visualstudio.com/docs/supporting/requirements#_platforms). |
| service-health | Admin Access Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/admin-access-reference.md | - Title: Roles with tenant admin access -description: This article defines the tenant roles with access to tenant scope view. - Previously updated : 06/10/2022---# Roles with tenant admin access --This document defines all of the roles with tenant admin access, which grant permission to the tenant scope view. --For descriptions of each role, see [Microsoft Entra built-in roles](../active-directory/roles/permissions-reference.md). --|**Role** | -|| -| Application Administrator | -| Authentication Administrator | -| Authentication Policy Administrator | -| Azure Information Protection Administrator | -| B2C IEF Keyset Administrator | -| B2C IEF Policy Administrator | -| Billing Administrator | -| Cloud App Security Administrator | -| Cloud Application Administrator | -| Cloud Device Administrator | -| Compliance Administrator | -| Compliance Data Administrator | -| Conditional Access Administrator | -| Customer LockBox Access Approver | -| Desktop Analytics Administrator | -| Directory Reviewer | -| Domain Name Administrator | -| Dynamics 365 Administrator | -| Exchange Administrator | -| Exchange Recipient Administrator | -| External ID User Flow Administrator | -| External ID User Flow Attribute Administrator | -| External Identity Provider Administrator | -| Global Administrator | -| Global Reader | -| Groups Administrator | -| Helpdesk Administrator | -| Hybrid Identity Administrator | -| Identity Governance Administrator | -| Insights Administrator | -| Intune Administrator | -| Kaizala Administrator | -| Knowledge Administrator | -| License Administrator | -| Message Center Privacy Reader | -| Message Center Reader | -| Network Administrator | -| Office Apps Administrator | -| Password Administrator | -| Power BI Administrator | -| Power Platform Administrator | -| Privileged Authentication Administrator | -| Privileged Role Administrator | -| Reports Reader | -| Search Administrator | -| Security Administrator | -| Security Operator | -| Security Reader | -| Service Support Administrator | -| SharePoint Administrator | -| Skype for Business Administrator | -| Teams Administrator | -| Teams Communications Administrator | -| Teams Communications Support Engineer | -| Teams Communications Support Specialist | -| Teams Devices Administrator | -| User Administrator | |
| service-health | Alerts Activity Log Service Notifications Arm | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/alerts-activity-log-service-notifications-arm.md | - Title: Receive activity log alerts on Azure service notifications using Resource Manager template -description: Get notified via SMS, email, or webhook when Azure service occurs using a Resource Manager template. Previously updated : 05/13/2022-----# Quickstart: Create activity log alerts on service notifications using an ARM template --This article shows you how to set up activity log alerts for service health notifications by using an Azure Resource Manager template (ARM template). ---Service health notifications are stored in the [Azure activity log](../azure-monitor/essentials/platform-logs-overview.md). Given the possibly large volume of information stored in the activity log, there is a separate user interface to make it easier to view and set up alerts on service health notifications. --You can receive an alert when Azure sends service health notifications to your Azure subscription. You can configure the alert based on: --- The class of service health notification (Service issues, Planned maintenance, Health advisories).-- The subscription affected.-- The service(s) affected.-- The region(s) affected.--> [!NOTE] -> Service health notifications does not send an alert regarding resource health events. --You also can configure who the alert should be sent to: --- Select an existing action group.-- Create a new action group (that can be used for future alerts).--To learn more about action groups, see [Create and manage action groups](../azure-monitor/alerts/action-groups.md). --## Prerequisites --- If you don't have an Azure subscription, create a [free account](https://azure.microsoft.com/free/?WT.mc_id=A261C142F) before you begin.-- To run the commands from your local computer, install Azure CLI or the Azure PowerShell modules. For more information, see [Install the Azure CLI](/cli/azure/install-azure-cli) and [Install Azure PowerShell](/powershell/azure/install-azure-powershell).--## Review the template --The following template creates an action group with an email target and enables all service health notifications for the target subscription. Save this template as *CreateServiceHealthAlert.json*. --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "actionGroups_name": { - "type": "string", - "defaultValue": "SubHealth" - }, - "activityLogAlerts_name": { - "type": "string", - "defaultValue": "ServiceHealthActivityLogAlert" - }, - "emailAddress": { - "type": "string" - } - }, - "variables": { - "alertScope": "[format('/subscriptions/{0}', subscription().subscriptionId)]" - }, - "resources": [ - { - "type": "microsoft.insights/actionGroups", - "apiVersion": "2019-06-01", - "name": "[parameters('actionGroups_name')]", - "location": "Global", - "properties": { - "groupShortName": "[parameters('actionGroups_name')]", - "enabled": true, - "emailReceivers": [ - { - "name": "[parameters('actionGroups_name')]", - "emailAddress": "[parameters('emailAddress')]" - } - ], - "smsReceivers": [], - "webhookReceivers": [] - } - }, - { - "type": "microsoft.insights/activityLogAlerts", - "apiVersion": "2017-04-01", - "name": "[parameters('activityLogAlerts_name')]", - "location": "Global", - "properties": { - "scopes": [ - "[variables('alertScope')]" - ], - "condition": { - "allOf": [ - { - "field": "category", - "equals": "ServiceHealth" - }, - { - "field": "properties.incidentType", - "equals": "Incident" - } - ] - }, - "actions": { - "actionGroups": [ - { - "actionGroupId": "[resourceId('microsoft.insights/actionGroups', parameters('actionGroups_name'))]", - "webhookProperties": {} - } - ] - }, - "enabled": true - }, - "dependsOn": [ - "[resourceId('microsoft.insights/actionGroups', parameters('actionGroups_name'))]" - ] - } - ] -} -``` --The template defines two resources: --- [Microsoft.Insights/actionGroups](/azure/templates/microsoft.insights/actiongroups)-- [Microsoft.Insights/activityLogAlerts](/azure/templates/microsoft.insights/activityLogAlerts)--## Deploy the template --Deploy the template using any standard method for [deploying an ARM template](../azure-resource-manager/templates/deploy-portal.md) such as the following examples using CLI and PowerShell. Replace the sample values for **Resource Group** and **emailAddress** with appropriate values for your environment. --# [CLI](#tab/CLI) --```azurecli -az login -az deployment group create --name CreateServiceHealthAlert --resource-group my-resource-group --template-file CreateServiceHealthAlert.json --parameters emailAddress='user@contoso.com' -``` --# [PowerShell](#tab/PowerShell) --```powershell -Connect-AzAccount -Select-AzSubscription -SubscriptionName my-subscription -New-AzResourceGroupDeployment -Name CreateServiceHealthAlert -ResourceGroupName my-resource-group -TemplateFile CreateServiceHealthAlert.json -emailAddress user@contoso.com -``` ----## Validate the deployment --Verify that the workspace has been created using one of the following commands. Replace the sample values for **Resource Group** with the value you used above. --# [CLI](#tab/CLI) --```azurecli -az monitor activity-log alert show --resource-group my-resource-group --name ServiceHealthActivityLogAlert -``` --# [PowerShell](#tab/PowerShell) --```powershell -Get-AzActivityLogAlert -ResourceGroupName my-resource-group -Name ServiceHealthActivityLogAlert -``` ----## Clean up resources --If you plan to continue working with subsequent quickstarts and tutorials, you might want to leave these resources in place. When no longer needed, delete the resource group, which deletes the alert rule and the related resources. To delete the resource group by using Azure CLI or Azure PowerShell --# [CLI](#tab/CLI) --```azurecli -az group delete --name my-resource-group -``` --# [PowerShell](#tab/PowerShell) --```powershell -Remove-AzResourceGroup -Name my-resource-group -``` ----## Next steps --- Learn about [best practices for setting up Azure Service Health alerts](https://www.microsoft.com/en-us/videoplayer/embed/RE2OtUa).-- Learn how to [setup mobile push notifications for Azure Service Health](https://www.microsoft.com/en-us/videoplayer/embed/RE2OtUw).-- Learn how to [configure webhook notifications for existing problem management systems](service-health-alert-webhook-guide.md).-- Learn about [service health notifications](service-notifications.md).-- Learn about [notification rate limiting](../azure-monitor/alerts/alerts-rate-limiting.md).-- Review the [activity log alert webhook schema](../azure-monitor/alerts/activity-log-alerts-webhook.md).-- Get an [overview of activity log alerts](../azure-monitor/alerts/alerts-overview.md), and learn how to receive alerts.-- Learn more about [action groups](../azure-monitor/alerts/action-groups.md). |
| service-health | Alerts Activity Log Service Notifications Bicep | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/alerts-activity-log-service-notifications-bicep.md | - Title: Receive activity log alerts on Azure service notifications using Bicep -description: Get notified via SMS, email, or webhook when Azure service occurs using a Bicep file. Previously updated : 05/13/2022-----# Quickstart: Create activity log alerts on service notifications using a Bicep file --This article shows you how to set up activity log alerts for service health notifications by using a Bicep file. ---Service health notifications are stored in the [Azure activity log](../azure-monitor/essentials/platform-logs-overview.md). Given the possibly large volume of information stored in the activity log, there is a separate user interface to make it easier to view and set up alerts on service health notifications. --You can receive an alert when Azure sends service health notifications to your Azure subscription. You can configure the alert based on: --- The class of service health notification (Service issues, Planned maintenance, Health advisories).-- The subscription affected.-- The service(s) affected.-- The region(s) affected.--> [!NOTE] -> Service health notifications does not send an alert regarding resource health events. --You also can configure who the alert should be sent to: --- Select an existing action group.-- Create a new action group (that can be used for future alerts).--To learn more about action groups, see [Create and manage action groups](../azure-monitor/alerts/action-groups.md). --## Prerequisites --- If you don't have an Azure subscription, create a [free account](https://azure.microsoft.com/free/?WT.mc_id=A261C142F) before you begin.-- To run the commands from your local computer, install Azure CLI or the Azure PowerShell modules. For more information, see [Install the Azure CLI](/cli/azure/install-azure-cli) and [Install Azure PowerShell](/powershell/azure/install-azure-powershell).--## Review the Bicep file --The following Bicep file creates an action group with an email target and enables all service health notifications for the target subscription. Save this Bicep as *CreateServiceHealthAlert.bicep*. --```bicep -param actionGroups_name string = 'SubHealth' -param activityLogAlerts_name string = 'ServiceHealthActivityLogAlert' -param emailAddress string --var alertScope = '/subscriptions/${subscription().subscriptionId}' --resource actionGroups_name_resource 'microsoft.insights/actionGroups@2019-06-01' = { - name: actionGroups_name - location: 'Global' - properties: { - groupShortName: actionGroups_name - enabled: true - emailReceivers: [ - { - name: actionGroups_name - emailAddress: emailAddress - } - ] - smsReceivers: [] - webhookReceivers: [] - } -} --resource activityLogAlerts_name_resource 'microsoft.insights/activityLogAlerts@2017-04-01' = { - name: activityLogAlerts_name - location: 'Global' - properties: { - scopes: [ - alertScope - ] - condition: { - allOf: [ - { - field: 'category' - equals: 'ServiceHealth' - } - { - field: 'properties.incidentType' - equals: 'Incident' - } - ] - } - actions: { - actionGroups: [ - { - actionGroupId: actionGroups_name_resource.id - webhookProperties: {} - } - ] - } - enabled: true - } -} --``` --The Bicep file defines two resources: --- [Microsoft.Insights/actionGroups](/azure/templates/microsoft.insights/actiongroups)-- [Microsoft.Insights/activityLogAlerts](/azure/templates/microsoft.insights/activityLogAlerts)--## Deploy the Bicep file --Deploy the Bicep file using Azure CLI and Azure PowerShell. Replace the sample values for **Resource Group** and **emailAddress** with appropriate values for your environment. --# [CLI](#tab/CLI) --```azurecli -az login -az deployment group create --name CreateServiceHealthAlert --resource-group my-resource-group --template-file CreateServiceHealthAlert.bicep --parameters emailAddress='user@contoso.com' -``` --# [PowerShell](#tab/PowerShell) --```powershell -Connect-AzAccount -Select-AzSubscription -SubscriptionName my-subscription -New-AzResourceGroupDeployment -Name CreateServiceHealthAlert -ResourceGroupName my-resource-group -TemplateFile CreateServiceHealthAlert.bicep -emailAddress user@contoso.com -``` ----## Validate the deployment --Verify that the workspace has been created using one of the following commands. Replace the sample values for **Resource Group** with the value you used above. --# [CLI](#tab/CLI) --```azurecli -az monitor activity-log alert show --resource-group my-resource-group --name ServiceHealthActivityLogAlert -``` --# [PowerShell](#tab/PowerShell) --```powershell -Get-AzActivityLogAlert -ResourceGroupName my-resource-group -Name ServiceHealthActivityLogAlert -``` ----## Clean up resources --If you plan to continue working with subsequent quickstarts and tutorials, you might want to leave these resources in place. When no longer needed, delete the resource group, which deletes the alert rule and the related resources. To delete the resource group by using Azure CLI or Azure PowerShell --# [CLI](#tab/CLI) --```azurecli -az group delete --name my-resource-group -``` --# [PowerShell](#tab/PowerShell) --```powershell -Remove-AzResourceGroup -Name my-resource-group -``` ----## Next steps --- Learn about [best practices for setting up Azure Service Health alerts](https://www.microsoft.com/en-us/videoplayer/embed/RE2OtUa).-- Learn how to [setup mobile push notifications for Azure Service Health](https://www.microsoft.com/en-us/videoplayer/embed/RE2OtUw).-- Learn how to [configure webhook notifications for existing problem management systems](service-health-alert-webhook-guide.md).-- Learn about [service health notifications](service-notifications.md).-- Learn about [notification rate limiting](../azure-monitor/alerts/alerts-rate-limiting.md).-- Review the [activity log alert webhook schema](../azure-monitor/alerts/activity-log-alerts-webhook.md).-- Get an [overview of activity log alerts](../azure-monitor/alerts/alerts-overview.md), and learn how to receive alerts.-- Learn more about [action groups](../azure-monitor/alerts/action-groups.md). |
| service-health | Alerts Activity Log Service Notifications Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/alerts-activity-log-service-notifications-portal.md | - Title: Receive activity log alerts on Azure service notifications using Azure portal -description: Learn how to use the Azure portal to set up activity log alerts for service health notifications by using the Azure portal. - Previously updated : 07/31/2024---# Create activity log alerts on service notifications using the Azure portal --This article shows you how to use the Azure portal to set up activity log alerts for service health notifications by using the Azure portal. --Service health notifications are stored in the [Azure activity log](../azure-monitor/essentials/platform-logs-overview.md). Given the large volume of information stored in the activity log, there is a separate user interface to make it easier to view and set up alerts on service health notifications. --You can receive an alert when Azure sends service health notifications to your Azure subscription. You can configure the alert based on: --- The class of service health notification (Service issues, Planned maintenance, Health advisories, Security advisories).-- The subscription affected.-- The service(s) affected.-- The region(s) affected.--> [!NOTE] -> Service health notifications do not send alerts for resource health events. --You also can configure who the alert should be sent to: --- Select an existing action group.-- Create a new action group (that can be used for future alerts).-> [!NOTE] -> Service Health Alerts are only supported in public clouds within the global region. For Action Groups to properly function in response to a Service Health Alert the region of the action group must be set as "Global". --To learn more about action groups, see [Create and manage action groups](../azure-monitor/alerts/action-groups.md). --For information on how to configure service health notification alerts by using Azure Resource Manager templates, see [Resource Manager templates](../azure-monitor/alerts/alerts-activity-log.md). --## Create a Service Health alert using the Azure portal -1. In the [portal](https://portal.azure.com), select **Service Health**. --  --1. In the **Alerts** section, select **Health alerts**. --  --1. Select **Add service health alert**. --  --1. The **Create an alert rule wizard** opens to the **Conditions** tab, with the **Scope** tab already populated. Follow the steps for Service Health alerts, starting from the **Conditions** tab, in the [create a new alert rule wizard](../azure-monitor/alerts/alerts-create-activity-log-alert-rule.md?tabs=activity-log). ---Learn how to [Configure webhook notifications for existing problem management systems](service-health-alert-webhook-guide.md). For information on the webhook schema for activity log alerts, see [Webhooks for Azure activity log alerts](../azure-monitor/alerts/activity-log-alerts-webhook.md). ---## Next steps -- Learn about [best practices for setting up Azure Service Health alerts](https://www.microsoft.com/en-us/videoplayer/embed/RE2OtUa).-- Learn how to [setup mobile push notifications for Azure Service Health](https://www.microsoft.com/en-us/videoplayer/embed/RE2OtUw).-- Learn how to [configure webhook notifications for existing problem management systems](service-health-alert-webhook-guide.md).-- Learn about [service health notifications](service-notifications.md).-- Learn about [notification rate limiting](../azure-monitor/alerts/alerts-rate-limiting.md).-- Review the [activity log alert webhook schema](../azure-monitor/alerts/activity-log-alerts-webhook.md).-- Get an [overview of activity log alerts](../azure-monitor/alerts/alerts-overview.md), and learn how to receive alerts.-- Learn more about [action groups](../azure-monitor/alerts/action-groups.md). |
| service-health | Azure Status Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/azure-status-overview.md | - Title: Azure status overview | Microsoft Docs -description: A global view into the health of Azure services - Previously updated : 05/26/2022---# Azure status overview --[Azure status](https://azure.status.microsoft/) provides you with a global view of the health of Azure services and regions. With Azure status, you can get information on service availability. Azure status is available to everyone to view all services that report their service health, as well as incidents with wide-ranging impact. If you're a current Azure user, however, we strongly encourage you to use the personalized experience in [Azure Service Health](https://aka.ms/azureservicehealth). Azure Service Health includes all outages, upcoming planned maintenance activities, and service advisories. ---This experience was updated on July 25, 2022. For more information, see [What's New in Azure Service Health](whats-new.md#azure-service-health-portal-experience-update) --## Azure status updates --The Azure status page gets updated in real time as the health of Azure services change. If you leave the Azure status page open, you can control the rate at which the page refreshes with new data. At the top, you can see the last time the page was updated. ---## Azure status banner --The status banner on the Azure Status page highlights active incidents affecting Azure services. ---## Current Impact tab --Azure status page shows the current impact of an active event on the entirety of Azure. Use [Azure Service Health](service-health-overview.md) to see view other issues that may be impacting your services. ---## Azure status history --While the Azure status page always shows the latest health information, you can view older events using the Azure status history page. The history page contains all RCAs for incidents that occurred on November 20th, 2019 or later. RCAs prior to November 20th, 2019 are not available. From this point forward, the history page will show RCAs up to five years old. ---## RSS Feed --Azure status also provides [an RSS feed](https://azure.status.microsoft/status/feed/) of changes to the health of Azure services that you can subscribe to. --## When does Azure publish communications to the Status page? - -Most of our service issue communications are provided as targeted notifications sent directly to impacted customers & partners. These are delivered through [Azure Service Health](https://azure.microsoft.com/features/service-health/) in the Azure portal and trigger any [Azure Service Health alerts](./alerts-activity-log-service-notifications-portal.md?toc=%2fazure%2fservice-health%2ftoc.json) that have been configured. The public Status page is only used to communicate about service issues under three specific scenarios: --- **Scenario 1 - Broad impact involving multiple regions, zones, or services** - A service issue has broad/significant customer impact across multiple services for a full region or multiple regions. We notify you in this case because customer-configured resilience like high availability and/or disaster recovery may not be sufficient to avoid impact.-- **Scenario 2 - Azure portal / Service Health not accessible** - A service issue impedes you from accessing the Azure portal or Azure Service Health and thus impacted our standard outage communications path described earlier. -- **Scenario 3 - Service Impact, but not sure who exactly is affected yet** - The service issue has broad/significant customer impact but we aren't yet able to confirm which customers, regions, or services are affected. In this case, we aren't able to send targeted communications, so we provide public updates.- -## When does Azure publish RCAs to the Status History page? --While the [Azure status page](https://azure.status.microsoft/status) always shows the latest health information, you can view older events using the [Azure status history page](https://azure.status.microsoft/status/history/). The history page contains all RCAs (Root Cause Analyses) for incidents that occurred on November 20, 2019 or later and will - from that date forward - provide a 5-year RCA history. RCAs prior to November 20, 2019 aren't available. - -After June 1st 2022, the [Azure status history page](https://azure.status.microsoft/status/history/) will only be used to provide RCAs for scenario 1 above. We're committed to publishing RCAs publicly for service issues that had the broadest impact, such as those with both a multi-service and multi-region impact. We publish to ensure that all customers and the industry at large can learn from our retrospectives on these issues, and understand what steps we're taking to make such issues less likely and/or less impactful in future. - -For scenarios 2 and 3 above - We may communicate publicly on the Status page during impact to work around when our standard, targeted communications aren't able to reach all impacted customers. After the issue is mitigated, we'll conduct a thorough impact analysis to determine exactly which customer subscriptions were impacted. In such scenarios, we'll provide the relevant PIR only to affected customers via [Azure Service Health](https://azure.microsoft.com/features/service-health/) in the Azure portal. ---## Next Steps --* Learn how you can get a more personalized view into Azure health with [Service Health](./service-health-overview.md). -* Learn how you can get a more granular view into the health of your specific Azure resources with [Resource Health](./resource-health-overview.md). |
| service-health | Impacted Resources Outage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/impacted-resources-outage.md | - Title: Resource impact from Azure outages -description: This article details where to find information from Azure Service Health about how Azure outages might affect your resources. - Previously updated : 12/16/2022---# Resource impact from Azure outages --[Azure Service Health](https://azure.microsoft.com/get-started/azure-portal/service-health/) helps customers view any health events that affect their subscriptions and tenants. In the Azure portal, the **Service Issues** pane in **Service Health** shows any ongoing problems in Azure services that are affecting your resources. You can understand when each problem began, and what services and regions are impacted. --Previously, the **Potential Impact** tab on the **Service Issues** pane appeared in the incident details section. It showed any resources under a subscription that an outage might affect, along with a signal from [Azure Resource Health](../service-health/resource-health-overview.md) to help you evaluate impact. --In support of the experience of viewing impacted resources, Service Health has enabled a new feature to: --- Replace the **Potential Impact** tab with an **Impacted Resources** tab on the **Service Issues** pane.-- Display resources that are confirmed to be impacted by an outage.-- Display resources that are not confirmed to be impacted by an outage but could be impacted because they fall under a service or region that's confirmed to be impacted.-- Provide the status of both confirmed and potential impacted resources to show their availability.--This article details what Service Health communicates and where you can view information about your impacted resources. -->[!Note] ->This feature will be rolled out in phases. Initially, only selected subscription-level customers will get the experience. The rollout will gradually expand to 100 percent of subscription and tenant-level users. --## View impacted resources --In the Azure portal, the **Impacted Resources** tab under **Service Health** > **Service Issues** displays resources that are or might be impacted by an outage. Service Health provides the below information to users whose resources are impacted by an outage: --|Column |Description | -||| -|**Resource Name**|Name of the resource. This name is a clickable link that goes to the Resource Health page for the resource. If no Resource Health signal is available for the resource, this name is text only.| -|**Resource Health**|Health status of the resource: <br><br>**Available**: Your resource is healthy, but a service event might have impacted it at a previous point in time. <br><br>**Degraded** or **Unavailable**: A customer-initiated action or a platform-initiated action might have caused this status. It means your resource was impacted but might now be healthy, pending a status update. <br><br>:::image type="content" source="./media/impacted-resource-outage/rh-cropped.PNG" alt-text="Screenshot of health statuses for a resource.":::| -|**Impact Type**|Indication of whether the resource is or might be impacted: <br><br>**Confirmed**: The resource is confirmed to be impacted by an outage. Check the **Summary** section for any action items that you can take to remediate the problem. <br><br>**Potential**: The resource is not confirmed to be impacted, but it could potentially be impacted because it's under a service or region that an outage is affecting. Check the **Resource Health** column to make sure that everything is working as planned.| -|**Resource Type**|Type of impacted resource (for example, virtual machine).| -|**Resource Group**|Resource group that contains the impacted resource.| -|**Location**|Location that contains the impacted resource.| -|**Subscription ID**|Unique ID for the subscription that contains the impacted resource.| -|**Subscription Name**|Subscription name for the subscription that contains the impacted resource.| --The following is an example of outage **Impacted Resources** from the subscription and tenant scope. --->[!Note] ->Not all resources in subscription scope will show a Resource Health status. The status appears only on resources for which a Resource Health signal is available. The status of resources for which a Resource Health signal is not available appears as **N/A**, and the corresponding **Resource Name** value is text instead of a clickable link. --->[!Note] ->Resource Health status, tenant name, and tenant ID are not included at the tenant level scope. The corresponding **Resource Name** value is text only instead of a clickable link. --## Filter results --You can adjust the results by using these filters: --- **Impact type**: Select **Confirmed** or **Potential**.-- **Subscription ID**: Show all subscription IDs that the user can access.-- **Status**: Focus on Resource Health status by selecting **Available**, **Unavailable**, **Degraded**, **Unknown**, or **N/A**.--## Export to CSV --To export the list of impacted resources to an Excel file, select the **Export to CSV** option. --## Access impacted resources programmatically via an API --You can get information about outage-impacted resources programmatically by using the Events API. For details on how to access this data, see the [API documentation](/rest/api/resourcehealth/2022-10-01/impacted-resources). --## Next steps -- [Introduction to the Azure Service Health dashboard](service-health-overview.md)-- [Introduction to Azure Resource Health](resource-health-overview.md)-- [Frequently asked questions about Azure Resource Health](resource-health-faq.yml) |
| service-health | Impacted Resources Planned Maintenance | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/impacted-resources-planned-maintenance.md | - Title: Resource impact from Azure planned maintenance events -description: This article details where to find information from Azure Service Health about how Azure Planned Maintenance impact your resources. - Previously updated : 9/29/2023---# Resource impact from Azure planned maintenance --In support of the experience for viewing Impacted Resources, Service Health has enabled a new feature to: --- Display resources that are impacted by a planned maintenance event.-- Provide impacted resources information for planned maintenance via the Service Health Portal. --This article details what is communicated to users and where they can view information about their impacted resources. -->[!Note] ->This feature will be rolled out in phases. Initially, impacted resources will only be shown for **SQL resources with advance customer notifications and rebootful updates for compute resources.** Planned maintenance impacted resources coverage will be expanded to other resource types and scenarios in the future. --## Viewing Impacted Resources for Planned Maintenance Events on the Service Health Portal --In the Azure portal, the **Impacted Resources** tab under **Service Health** > **Planned Maintenance** displays resources that are affected by a planned maintenance event. The following example of the Impacted Resources tab shows a planned maintenance event with impacted resources. ---Service Health provides the information below on resources impacted by a planned maintenance event: --|Fields |Description | -||| -|**Resource Name**|Name of the resource impacted by the planned maintenance event| -|**Resource Type**|Type of resource impacted by the planned maintenance event| -|**Resource Group**|Resource group which contains the impacted resource| -|**Region**|Region which contains the impacted resource| -|**Subscription ID**|Unique ID for the subscription that contains the impacted resource| -|**Action(*)**|Link to the apply update page during Self-Service window (only for rebootful updates on compute resources)| -|**Self-serve Maintenance Due Date(*)**|Due date for Self-Service window during which the update can be applied by the user (only for rebootful updates on compute resources)| -->[!Note] ->Fields with an asterisk * are optional fields that are available depending on the resource type. ----## Filters --Customers can filter on the results using the below filters -- Region-- Subscription ID: All Subscription IDs the user has access to -- Resource Type: All Resource types under the users subscriptions---## Export to CSV --The list of impacted resources can be exported to an excel file by clicking on this option. ---## Next steps -- [Introduction to the Azure Service Health dashboard](service-health-overview.md)-- [Introduction to Azure Resource Health](resource-health-overview.md)-- [Frequently asked questions about Azure Resource Health](resource-health-faq.yml) |
| service-health | Impacted Resources Security | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/impacted-resources-security.md | - Title: Resource impact from Azure security incidents -description: This article details where to find information from Azure Service Health about how Azure security incidents impact your resources. - Previously updated : 3/3/2023---# Resource impact from Azure security incidents --In support of the experience of viewing impacted resources, Service Health has enabled a new feature to: --- Display resources impacted by a security incident-- Enabling role-based access control (RBAC) for viewing security incident impacted resource information--This article details what is communicated to users and where they can view information about their impacted resources. -->[!Note] ->This feature will be rolled out in phases. The rollout will gradually expand to 100 percent of subscription and tenant customers. --## Role Based Access (RBAC) For Security Incident Resource Impact --[Azure role-based access control (Azure RBAC)](../role-based-access-control/overview.md) helps you manage who has access to Azure resources, what they can do with those resources, and what areas they have access to. Given the sensitive nature of security incidents, role-based access is leveraged to limit the audience of their impacted resource information. Along with resource information, Service Health provides the below information to users whose resources are impacted by a security incident: --Users authorized with the following roles can view security impacted resource information: --**Subscription level** -- Subscription Owner-- Subscription Admin-- Custom Roles with Microsoft.ResourceHealth/events/fetchEventDetails/action permissions or Microsoft.ResourceHealth/events/action permissions--**Tenant level** -- Security Admin/Security Reader-- Global Admin/Tenant Admin-- Custom Roles with Microsoft.ResourceHealth/events/fetchEventDetails/action permissions or Microsoft.ResourceHealth/events/action permissions--## Viewing Impacted Resources for Security Incidents on the Service Health Portal --In the Azure portal, the **Impacted Resources** tab under **Service Health** > **Security Advisories** displays resources that are impacted by a security incident. Along with resource information, Service Health provides the below information to users whose resources are impacted by a security incident: --|Column |Description | -||| -|**Subscription ID**|Unique ID for the subscription that contains the impacted resource| -|**Subscription Name**|Subscription name for the subscription that contains the impacted resource| -|**Tenant Name**|Tenant name for the tenant that contains the impacted resource| -|**Tenant ID**|Unique ID for the tenant that contains the impacted resource| --The following examples show a security incident with impacted resources from the subscription and tenant scope. --**Subscription** ---**Tenant** ----## Accessing Impacted Resources programmatically via an API --Impacted resource information for security incidents can be retrieved programmatically using the Events API. To access the list of resources impacted by a security incident, users authorized with the above-mentioned roles can use the endpoints below. For details on how to access this data, see the [API documentation](/rest/api/resourcehealth/2022-10-01/security-advisory-impacted-resources). --**Subscription** --```HTTP -https://management.azure.com/subscriptions/(ΓÇ£Subscription IDΓÇ¥)/providers/microsoft.resourcehealth/events/("Tracking ID")/listSecurityAdvisoryImpactedResources?api-version=2022-10-01 -``` --**Tenant** --```HTTP -https://management.azure.com/providers/microsoft.resourcehealth/events/("Tracking ID")/listSecurityAdvisoryImpactedResources?api-version=2022-10-01 -``` --## Next steps -- [Introduction to the Azure Service Health dashboard](service-health-overview.md)-- [Introduction to Azure Resource Health](resource-health-overview.md)-- [Frequently asked questions about Azure Resource Health](resource-health-faq.yml) |
| service-health | Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/overview.md | - Title: What is Azure Service Health? -description: Personalized information about how your Azure apps are affected by current and future Azure service problems and maintenance. - Previously updated : 07/15/2024--# What is Azure Service Health? --Azure offers a suite of experiences to keep you informed about the health of your cloud resources. This information includes current and upcoming issues such as service impacting events, planned maintenance, and other changes that may affect your availability. --Azure Service Health is a combination of three separate smaller services. --[Azure status](azure-status-overview.md) informs you of service outages in Azure on the **[Azure Status page](https://azure.status.microsoft)**. The page is a global view of the health of all Azure services across all Azure regions. The status page is a good reference for incidents with widespread impact, but we strongly recommend that current Azure users leverage Azure service health to stay informed about Azure incidents and maintenance. --[Service health](service-health-overview.md) provides a personalized view of the health of the Azure services and regions you're using. This is the best place to look for service impacting communications about outages, planned maintenance activities, and other health advisories because the authenticated Service Health experience knows which services and resources you currently use. The best way to use Service Health is to set up Service Health alerts to notify you via your preferred communication channels when service issues, planned maintenance, or other changes may affect the Azure services and regions you use. --[Resource health](resource-health-overview.md) provides information about the health of your individual cloud resources such as a specific virtual machine instance. Using Azure Monitor, you can also configure alerts to notify you of availability changes to your cloud resources. Resource Health along with Azure Monitor notifications will help you stay better informed about the availability of your resources minute by minute and quickly assess whether an issue is due to a problem on your side or related to an Azure platform event. --Together, these experiences provide you with a comprehensive view into the health of Azure, at the granularity that is most relevant to you. --**Watch an overview of the Azure Status page, Azure Service Health, and Azure Resource Health** -->[!VIDEO https://www.microsoft.com/en-us/videoplayer/embed/RE2OgX6] - |
| service-health | Resource Graph Samples | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/resource-graph-samples.md | - Title: Azure Resource Graph sample queries for Azure Service Health -description: Sample Azure Resource Graph queries for Azure Service Health showing use of resource types and tables to access Azure Service Health related resources and properties. Previously updated : 07/07/2022----# Azure Resource Graph sample queries for Azure Service Health --This page is a collection of [Azure Resource Graph](../governance/resource-graph/overview.md) sample queries for Azure Service Health. --## Azure Service Health ----## Resource health ---## Next steps --- Learn more about the [query language](../governance/resource-graph/concepts/query-language.md).-- Learn more about how to [explore resources](../governance/resource-graph/concepts/explore-resources.md). |
| service-health | Resource Health Alert Arm Template Guide | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/resource-health-alert-arm-template-guide.md | - Title: Template to create Resource Health alerts -description: Create alerts programmatically that notify you when your Azure resources become unavailable. - Previously updated : 9/4/2018 ----# Configure resource health alerts using Resource Manager templates --This article will show you how to create Resource Health Activity Log Alerts programmatically using Azure Resource Manager templates and Azure PowerShell. --Azure Resource Health keeps you informed about the current and historical health status of your Azure resources. Azure Resource Health alerts can notify you in near real-time when these resources have a change in their health status. Creating Resource Health alerts programmatically allow for users to create and customize alerts in bulk. ---## Prerequisites --To follow the instructions on this page, you'll need to set up a few things in advance: --1. You need to install the [Azure PowerShell module](/powershell/azure/install-azure-powershell) -2. You need to [create or reuse an Action Group](../azure-monitor/alerts/action-groups.md) configured to notify you --## Instructions -1. Using PowerShell, log in to Azure using your account, and select the subscription you want to interact with -- ```azurepowershell - Login-AzAccount - Select-AzSubscription -Subscription <subscriptionId> - ``` -- > You can use `Get-AzSubscription` to list the subscriptions you have access to. --2. Find and save the full Azure Resource Manager ID for your Action Group -- ```azurepowershell - (Get-AzActionGroup -ResourceGroupName <resourceGroup> -Name <actionGroup>).Id - ``` --3. Create and save a Resource Manager template for Resource Health alerts as `resourcehealthalert.json` ([see details below](#resource-manager-template-options-for-resource-health-alerts)) --4. Create a new Azure Resource Manager deployment using this template -- ```azurepowershell - New-AzResourceGroupDeployment -Name ExampleDeployment -ResourceGroupName <resourceGroup> -TemplateFile <path\to\resourcehealthalert.json> - ``` --5. You'll be prompted to type in the Alert Name and Action Group Resource ID you copied earlier: -- ```azurepowershell - Supply values for the following parameters: - (Type !? for Help.) - activityLogAlertName: <Alert Name> - actionGroupResourceId: /subscriptions/<subscriptionId>/resourceGroups/<resourceGroup>/providers/microsoft.insights/actionGroups/<actionGroup> - ``` --6. If everything worked successfully, you'll get a confirmation in PowerShell -- ```output - DeploymentName : ExampleDeployment - ResourceGroupName : <resourceGroup> - ProvisioningState : Succeeded - Timestamp : 11/8/2017 2:32:00 AM - Mode : Incremental - TemplateLink : - Parameters : - Name Type Value - =============== ========= ========== - activityLogAlertName String <Alert Name> - activityLogAlertEnabled Bool True - actionGroupResourceId String /... -- Outputs : - DeploymentDebugLogLevel : - ``` --Note that if you are planning on fully automating this process, you simply need to edit the Resource Manager template to not prompt for the values in Step 5. --## Resource Manager template options for Resource Health alerts --You can use this base template as a starting point for creating Resource Health alerts. This template will work as written, and will sign you up to receive alerts for all newly activated resource health events across all resources in a subscription. --> At the bottom of this article we have also included a more complex alert template which should increase the signal to noise ratio for Resource Health alerts as compared to this template. --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "activityLogAlertName": { - "type": "string", - "metadata": { - "description": "Unique name (within the Resource Group) for the Activity log alert." - } - }, - "actionGroupResourceId": { - "type": "string", - "metadata": { - "description": "Resource Id for the Action group." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/activityLogAlerts", - "apiVersion": "2017-04-01", - "name": "[parameters('activityLogAlertName')]", - "location": "Global", - "properties": { - "enabled": true, - "scopes": [ - "[subscription().id]" - ], - "condition": { - "allOf": [ - { - "field": "category", - "equals": "ResourceHealth" - }, - { - "field": "status", - "equals": "Active" - } - ] - }, - "actions": { - "actionGroups": - [ - { - "actionGroupId": "[parameters('actionGroupResourceId')]" - } - ] - } - } - } - ] -} -``` --However, a broad alert like this one is generally not recommended. Learn how we can scope down this alert to focus on the events we care about below. --### Adjusting the alert scope --Resource Health alerts can be configured to monitor events at three different scopes: -- * Subscription Level - * Resource Group Level - * Resource Level --The alert template is configured at the subscription level, but if you would like to configure your alert to only notify you about certain resources, or resources within a certain resource group, you simply need to modify the `scopes` section in the above template. --For a resource group level scope, the scopes section should look like: -```json -"scopes": [ - "/subscriptions/<subscription id>/resourcegroups/<resource group>" -], -``` --And for a resource level scope, the scope section should look like: --```json -"scopes": [ - "/subscriptions/<subscription id>/resourcegroups/<resource group>/providers/<resource>" -], -``` --For example: `"/subscriptions/d37urb3e-ed41-4670-9c19-02a1d2808ff9/resourcegroups/myRG/providers/microsoft.compute/virtualmachines/myVm"` --> You can go to the Azure Portal and look at the URL when viewing your Azure resource to get this string. --### Adjusting the resource types which alert you --Alerts at the subscription or resource group level may have different kinds of resources. If you want to limit alerts to only come from a certain subset of resource types, you can define that in the `condition` section of the template like so: --```json -"condition": { - "allOf": [ - ..., - { - "anyOf": [ - { - "field": "resourceType", - "equals": "MICROSOFT.COMPUTE/VIRTUALMACHINES", - "containsAny": null - }, - { - "field": "resourceType", - "equals": "MICROSOFT.STORAGE/STORAGEACCOUNTS", - "containsAny": null - }, - ... - ] - } - ] -}, -``` --Here we use the `anyOf` wrapper to allow the resource health alert to match any of the conditions we specify, allowing for alerts that target specific resource types. --### Adjusting the Resource Health events that alert you -When resources undergo a health event, they can go through a series of stages that represents the state of the health event: `Active`, `In Progress`, `Updated`, and `Resolved`. --You may only want to be notified when a resource becomes unhealthy, in which case you want to configure your alert to only notify when the `status` is `Active`. However if you want to also be notified on the other stages, you can add those details like so: --```json -"condition": { - "allOf": [ - ..., - { - "anyOf": [ - { - "field": "status", - "equals": "Active" - }, - { - "field": "status", - "equals": "In Progress" - }, - { - "field": "status", - "equals": "Resolved" - }, - { - "field": "status", - "equals": "Updated" - } - ] - } - ] -} -``` --If you want to be notified for all four stages of health events, you can remove this condition all together, and the alert will notify you irrespective of the `status` property. --> [!NOTE] -> Each "anyOf" section should contain just one field type values. --### Adjusting the Resource Health alerts to avoid "Unknown" events --Azure Resource Health can report to you the latest health of your resources by constantly monitoring them using test runners. The relevant reported health statuses are: "Available", "Unavailable", and "Degraded". However, in situations where the runner and the Azure resource are unable to communicate, an "Unknown" health status is reported for the resource, and that is considered an "Active" health event. --However, when a resource reports "Unknown", it's likely that its health status has not changed since the last accurate report. If you would like to eliminate alerts on "Unknown" events, you can specify that logic in the template: --```json -"condition": { - "allOf": [ - ..., - { - "anyOf": [ - { - "field": "properties.currentHealthStatus", - "equals": "Available", - "containsAny": null - }, - { - "field": "properties.currentHealthStatus", - "equals": "Unavailable", - "containsAny": null - }, - { - "field": "properties.currentHealthStatus", - "equals": "Degraded", - "containsAny": null - } - ] - }, - { - "anyOf": [ - { - "field": "properties.previousHealthStatus", - "equals": "Available", - "containsAny": null - }, - { - "field": "properties.previousHealthStatus", - "equals": "Unavailable", - "containsAny": null - }, - { - "field": "properties.previousHealthStatus", - "equals": "Degraded", - "containsAny": null - } - ] - }, - ] -}, -``` --In this example, we are only notifying on events where the current and previous health status does not have "Unknown". This change may be a useful addition if your alerts are sent directly to your mobile phone or email. --Note that it is possible for the currentHealthStatus and previousHealthStatus properties to be null in some events. For example, when an Updated event occurs it's likely that the health status of the resource has not changed since the last report, only that additional event information is available (e.g. cause). Therefore, using the clause above may result in some alerts not being triggered, because the properties.currentHealthStatus and properties.previousHealthStatus values will be set to null. --### Adjusting the alert to avoid User Initiated events --Resource Health events can be triggered by platform initiated and user initiated events. It may make sense to only send a notification when the health event is caused by the Azure platform. --It's easy to configure your alert to filter for only these kinds of events: --```json -"condition": { - "allOf": [ - ..., - { - "field": "properties.cause", - "equals": "PlatformInitiated", - "containsAny": null - } - ] -} -``` -Note that it is possible for the cause field to be null in some events. That is, a health transition takes place (e.g. available to unavailable) and the event is logged immediately to prevent notification delays. Therefore, using the clause above may result in an alert not being triggered, because the properties.cause property value will be set to null. --## Complete Resource Health alert template --Using the different adjustments described in the previous section, here is a sample template that is configured to maximize the signal to noise ratio. Bear in mind the caveats noted above where the currentHealthStatus, previousHealthStatus, and cause property values may be null in some events. --```json -{ - "$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#", - "contentVersion": "1.0.0.0", - "parameters": { - "activityLogAlertName": { - "type": "string", - "metadata": { - "description": "Unique name (within the Resource Group) for the Activity log alert." - } - }, - "actionGroupResourceId": { - "type": "string", - "metadata": { - "description": "Resource Id for the Action group." - } - } - }, - "resources": [ - { - "type": "Microsoft.Insights/activityLogAlerts", - "apiVersion": "2017-04-01", - "name": "[parameters('activityLogAlertName')]", - "location": "Global", - "properties": { - "enabled": true, - "scopes": [ - "[subscription().id]" - ], - "condition": { - "allOf": [ - { - "field": "category", - "equals": "ResourceHealth", - "containsAny": null - }, - { - "anyOf": [ - { - "field": "properties.currentHealthStatus", - "equals": "Available", - "containsAny": null - }, - { - "field": "properties.currentHealthStatus", - "equals": "Unavailable", - "containsAny": null - }, - { - "field": "properties.currentHealthStatus", - "equals": "Degraded", - "containsAny": null - } - ] - }, - { - "anyOf": [ - { - "field": "properties.previousHealthStatus", - "equals": "Available", - "containsAny": null - }, - { - "field": "properties.previousHealthStatus", - "equals": "Unavailable", - "containsAny": null - }, - { - "field": "properties.previousHealthStatus", - "equals": "Degraded", - "containsAny": null - } - ] - }, - { - "anyOf": [ - { - "field": "properties.cause", - "equals": "PlatformInitiated", - "containsAny": null - } - ] - }, - { - "anyOf": [ - { - "field": "status", - "equals": "Active", - "containsAny": null - }, - { - "field": "status", - "equals": "Resolved", - "containsAny": null - }, - { - "field": "status", - "equals": "In Progress", - "containsAny": null - }, - { - "field": "status", - "equals": "Updated", - "containsAny": null - } - ] - } - ] - }, - "actions": { - "actionGroups": [ - { - "actionGroupId": "[parameters('actionGroupResourceId')]" - } - ] - } - } - } - ] -} -``` --However, you'll know best what configurations are effective for you, so use the tools taught to you in this documentation to make your own customization. --## Next steps --Learn more about Resource Health: -- [Azure Resource Health overview](Resource-health-overview.md)-- [Resource types and health checks available through Azure Resource Health](resource-health-checks-resource-types.md)---Create Service Health Alerts: -- [Configure Alerts for Service Health](./alerts-activity-log-service-notifications-portal.md) -- [Azure Activity Log event schema](../azure-monitor/essentials/activity-log-schema.md) |
| service-health | Resource Health Alert Monitor Guide | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/resource-health-alert-monitor-guide.md | - Title: Create Resource Health Alerts using Azure portal -description: Create alert using Azure portal that notifies you when your Azure resources become unavailable. - Previously updated : 6/23/2020----# Create Resource Health alerts in the Azure portal --This article shows you how to set up activity log alerts for resource health notifications in the Azure portal. --Azure Resource Health keeps you informed about the current and historical health status of your Azure resources. Azure Resource Health alerts can notify you when these resources have a change in their health status. Creating Resource Health alerts programmatically allow for users to create and customize alerts in bulk. --Resource health notifications are stored in the [Azure activity log](../azure-monitor/essentials/platform-logs-overview.md) Given the possibly large volume of information stored in the activity log, there is a separate user interface to make it easier to view and set up alerts on resource health notifications. -You can receive an alert when Azure resource sends resource health notifications to your Azure subscription. You can configure the alert based on: --* The subscription affected. -* The resource(s) type(s) affected. -* The resource group(s) affected. -* The resource(s) affected. -* The event status(s) of the resource(s) affected. -* The resource(s) affected statuses. -* The reason(s) type(s) of the resource(s) affected. --You also can configure who the alert should be sent to: --* Select an existing action group. -* a new action group (that can be used for future alerts). --To learn more about action groups, see [Azure Monitor action groups](../azure-monitor/alerts/action-groups.md). --For information on how to configure resource health notification alerts by using Azure Resource Manager templates, see [Resource Manager templates](./resource-health-alert-arm-template-guide.md). --## Create a Resource Health alert rule in the Azure portal --1. In the Azure [portal](https://portal.azure.com/), select **Service Health**. --  -1. In the **Resource Health** section, select **Resource Health**. -1. Select **Add resource health alert**. -1. The **Create an alert rule** wizard opens to the **Conditions** tab, with the **Scope** tab already populated. Follow the steps for Resource Health alerts, starting from the **Conditions** tab, in the [new alert rule wizard](../azure-monitor/alerts/alerts-create-activity-log-alert-rule.md). --## Next steps --Learn more about Resource Health: --* [Azure Resource Health overview](Resource-health-overview.md) -* [Resource types and health checks available through Azure Resource Health](resource-health-checks-resource-types.md) --Create Service Health Alerts: --* [Configure Alerts for Service Health](./alerts-activity-log-service-notifications-portal.md) -* [Azure Activity Log event schema](../azure-monitor/essentials/activity-log-schema.md) -* [Configure resource health alerts using Resource Manager templates](./resource-health-alert-arm-template-guide.md) |
| service-health | Resource Health Checks Resource Types | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/resource-health-checks-resource-types.md | - Title: Supported Resource Types through Azure Resource Health | Microsoft Docs -description: Supported Resource Types through Azure Resource health - Previously updated : 01/23/2023---# Resource types and health checks in Azure resource health -Below is a complete list of all the checks executed through resource health by resource types. --## Microsoft.AnalysisServices/servers -|Executed Checks| -|| -| - Is the server up and running?<br> - Has the server run out of memory?<br> - Is the server starting up?<br> - Is the server recovering?| --## Microsoft.ApiManagement/service -|Executed Checks| -|| -| - Is the Api Management service up and running?| --## Microsoft.AppPlatform/Spring -|Executed Checks| -|| -| - Is the Azure Spring Cloud instance available?| --## Microsoft.Batch/batchAccounts -|Executed Checks| -|| -| - Is the Batch account up and running?<br> - Has the pool quota been exceeded for this batch account?| --## Microsoft.Cache/Redis -|Executed Checks| -|| -| - Are all the Cache nodes up and running?<br> - Can the Cache be reached from within the datacenter?<br> - Has the Cache reached the maximum number of connections?<br> - Has the cache exhausted its available memory? <br> - Is the Cache experiencing a high number of page faults?<br> - Is the Cache under heavy load?| --## Microsoft.CDN/profile -|Executed Checks| -|| -| - Is the supplemental portal accessible for CDN configuration operations?<br> - Are there ongoing delivery issues with the CDN endpoints?<br> - Can users change the configuration of their CDN resources?<br> - Are configuration changes propagating at the expected rate?<br> - Can users manage the CDN configuration using the Azure portal, PowerShell, or the API?| --## Microsoft.classiccompute/virtualmachines -|Executed Checks| -|| -| - Is the server hosting this virtual machine up and running?<br> - Is the virtual machine container provisioned and powered up?<br> - Is there network connectivity between the host and the storage account?<br> - Is there ongoing planned maintenance?<br> - Are there heartbeats between Guest and host agent *(if Guest extension is installed)*?| --## Microsoft.classiccompute/domainnames -|Executed Checks| -|| -| - Is production slot deployment healthy across all role instances?<br> - Is the role healthy across all its VM instances?<br> - What is the health status of each VM within a role of a cloud service?<br> - Was the VM status change due to platform or customer initiated operation?<br> - Has the booting of the guest OS completed?<br> - Is there ongoing planned maintenance?<br> - Is the host hardware degraded and predicted to fail soon?<br> - [Learn More](../cloud-services/resource-health-for-cloud-services.md) about Executed Checks| --## Microsoft.cognitiveservices/accounts -|Executed Checks| -|| -| - Can the account be reached from within the datacenter?<br> - Is the Azure AI services resource provider available?<br> - Is the Cognitive Service available in the appropriate region?<br> - Can read operations be performed on the storage account holding the resource metadata?<br> - Has the API call quota been reached?<br> - Has the API call read-limit been reached?| --## Microsoft.compute/hostgroups/hosts -|Executed Checks| -|| -| - Is the host up and running?<br> - Is the host hardware degraded?<br> - Is the host deallocated?<br> - Has the host hardware service healed to different hardware?| --## Microsoft.compute/virtualmachines -|Executed Checks| -|| -| - Is the server hosting this virtual machine up and running?<br> - Is the virtual machine container provisioned and powered up?<br> - Is there network connectivity between the host and the storage account?<br> - Is there ongoing planned maintenance?<br> - Are there heartbeats between Guest and host agent *(if Guest extension is installed)*?| --## Microsoft.compute/virtualmachinescalesets -|Executed Checks| -|| -| - Is the server hosting this virtual machine up and running?<br> - Is the virtual machine container provisioned and powered up?<br> - Is there network connectivity between the host and the storage account?<br> - Is there ongoing planned maintenance?<br> - Are there heartbeats between Guest and host agent *(if Guest extension is installed)*?| ---## Microsoft.ContainerService/managedClusters -|Executed Checks| -|| -| - Is the cluster up and running?<br> - Are core services available on the cluster?<br> - Are all cluster nodes ready?<br> - Is the service principal current and valid?| --## Microsoft.datafactory/factories -|Executed Checks| -|| -| - Have there been pipeline run failures?<br> - Is the cluster hosting the Data Factory healthy?| --## Microsoft.datalakeanalytics/accounts -|Executed Checks| -|| -| - Have users experienced problems submitting or listing their Data Lake Analytics jobs?<br> - Are Data Lake Analytics jobs unable to complete due to system errors?| ---## Microsoft.datalakestore/accounts -|Executed Checks| -|| -| - Have users experienced problems uploading data to Data Lake Store?<br> - Have users experienced problems downloading data from Data Lake Store?| --## Microsoft.datamigration/services -|Executed Checks| -|| -| - Has the database migration service failed to provision?<br> - Has the database migration service stopped due to inactivity or user request?| --## Microsoft.DataShare/accounts -|Executed Checks| -|| -| - Is the Data Share account up and running?<br> - Is the cluster hosting the Data Share available?| --## Microsoft.DBforMariaDB/servers -|Executed Checks| -|| -| - Is the server unavailable due to maintenance?<br> - Is the server unavailable due to reconfiguration?| --## Microsoft.DBforMySQL/servers -|Executed Checks| -|| -| - Is the server unavailable due to maintenance?<br> - Is the server unavailable due to reconfiguration?| --## Microsoft.DBforPostgreSQL/servers -|Executed Checks| -|| -| - Is the server unavailable due to maintenance?<br> - Is the server unavailable due to reconfiguration?| --## Microsoft.devices/iothubs -|Executed Checks| -|| -| - Is the IoT hub up and running?| --## Microsoft.DigitalTwins/DigitalTwinsInstances -|Executed Checks| -|| -| - Is the Azure Digital Twins instance up and running?| --## Microsoft.documentdb/databaseAccounts -|Executed Checks| -|| -| - Have there been any database or collection requests not served due to an Azure Cosmos DB service unavailability?<br> - Have there been any document requests not served due to an Azure Cosmos DB service unavailability?| --## Microsoft.eventhub/namespaces -|Executed Checks| -|| -| - Is the Event Hubs namespace experiencing user generated errors?<br> - Is the Event Hubs namespace currently being upgraded?| --## Microsoft.hdinsight/clusters -|Executed Checks| -|| -| - Are core services available on the HDInsight cluster?<br> - Can the HDInsight cluster access the key for BYOK encryption at rest?| --## Microsoft.HealthcareApis/workspaces/dicomservices -|Executed Checks| -|| -| - Is the DICOM service up and running?<br> - Can the DICOM service access the customer-managed encryption key?<br> - Can the DICOM service access the connected data lake?| --## Microsoft.HybridCompute/machines -|Executed Checks| -|| -| - Is the agent on your server connected to Azure and sending heartbeats?| --## Microsoft.IoTCentral/IoTApps -|Executed Checks| -|| -| - Is the IoT Central Application available?| --## Microsoft.Insights/scheduledQueryRules -|Executed Checks| -|| -|- Is this log search alert rule currently disabled?<br> - Does this rule runs less frequently than every 15 minutes?<br> - Is there a semantic, syntax, or validation error in the query?<br> - Is the response size is too large?<br> - Is the query consuming too many resources?<br> - Can the target Log Analytics/Application Insights workspace for this alert rule be found?<br> - Is the alert rule query failing because of throttling (Error 429)?<br> - Does the query have the correct permissions?<br> - Are there NSP validations issues for the query?<br> - Does the query evaluation fail due to exceeding the limit of fired (non- resolved) alerts per day?<br> - Did the alert evaluation fail due to exceeding the allowed limit of dimension combinations values that meet the threshold?| --## Microsoft.KeyVault/vaults -|Executed Checks| -|| -| - Are requests to key vault failing due to Azure KeyVault platform issues?<br> - Are requests to key vault being throttled due to too many requests made by customer?| --## Microsoft.Kusto/clusters -|Executed Checks| -|| -| - Is the cluster experiencing low ingestion success rates?<br> - Is the cluster experiencing high ingestion latency?<br> - Is the cluster experiencing a high number of query failures?| --## Microsoft.MachineLearning/webServices -|Executed Checks| -|| -| - Is the web service up and running?| --## Microsoft.Media/mediaservices -|Executed Checks| -|| -| - Is the media service up and running?| --## Microsoft.network/applicationgateways -|Executed Checks| -|| -| - Is performance of the Application Gateway degraded?<br> - Is the Application Gateway available?| --## Microsoft.network/azureFirewalls -|Executed Checks| -|| -| - Are there enough remaining available ports to perform Source NAT?<br> - Are there enough remaining available connections?| --## Microsoft.network/bastionhosts -|Executed Checks| -|| -| - Is the Bastion Host up and running?| --## Microsoft.network/connections -|Executed Checks| -|| -| - Is the VPN tunnel connected?<br> - Are there configuration conflicts in the connection?<br> - Are the pre-shared keys properly configured?<br> - Is the VPN on-premises device reachable?<br> - Are there mismatches in the IPSec/IKE security policy?<br> - Is the S2S VPN connection properly provisioned or in a failed state?<br> - Is the VNET-to-VNET connection properly provisioned or in a failed state?| --## Microsoft.network/expressroutecircuits -|Executed Checks| -|| -| - Is the ExpressRoute circuit healthy?| --## Microsoft.Network/expressRouteGateways (ExpressRoute Gateways in Virtual WAN) -|Executed Checks| -|| -| - Is the ExpressRoute Gateway up and running?| --## Microsoft.network/frontdoors -|Executed Checks| -|| -| - Are Front Door backends responding with errors to health probes?<br> - Are configuration changes delayed?| --## Microsoft.network/LoadBalancers -|Executed Checks| -|| -| - Are the load balancing endpoints available?| ---## Microsoft.network/natGateways -|Executed Checks| -|| -| - Are the NAT gateway endpoints available?| --## Microsoft.network/trafficmanagerprofiles -|Executed Checks| -|| -| - Are there any issues impacting the Traffic Manager profile?| --## Microsoft.Network/virtualHubs -|Executed Checks| -|| -| - Is the virtual hub router up and running?| --## Microsoft.network/virtualNetworkGateways -|Executed Checks| -|| -| - Is the VPN gateway reachable from the internet?<br> - Is the VPN Gateway in standby mode?<br> - Is the VPN service running on the gateway?| --## Microsoft.network/vpnGateways (VPN Gateways in Virtual WAN) -|Executed Checks| -|| -| - Is the VPN gateway reachable from the internet?<br> - Is the VPN Gateway in standby mode?<br> - Is the VPN service running on the gateway?| --## Microsoft.NotificationHubs/namespace -|Executed Checks| -|| -| - Can runtime operations like registration, installation, or send be performed on the namespace?| --## Microsoft.operationalinsights/workspaces -|Executed Checks| -|| -| - Are there ingestion delays in the workspace?| --## Microsoft.PowerBIDedicated/Capacities -|Executed Checks| -|| -| - Is the capacity resource up and running?<br> - Are all the workloads up and running? --## Microsoft.search/searchServices -|Executed Checks| -|| -| - Can diagnostics operations be performed on the cluster?| --## Microsoft.ServiceBus/namespaces -|Executed Checks| -|| -| - Are customers experiencing user generated Service Bus errors?<br> - Are users experiencing an increase in transient errors due to a Service Bus namespace upgrade?| --## Microsoft.ServiceFabric/clusters -|Executed Checks| -|| -| - Is the Service Fabric cluster up and running?<br> - Can the Service Fabric cluster be managed through Azure Resource Manager?| --## Microsoft.SQL/managedInstances/databases -|Executed Checks| -|| -| - Is the database up and running?| --## Microsoft.SQL/servers/databases -|Executed Checks| -|| -| - When there are many logins, have more than a quarter of the login attempts failed for system reasons?<br> - Have more that one login attempt failed for system reasons (in two of the last three minutes)?| --## Microsoft.Storage/storageAccounts -|Executed Checks| -|| -| - Are requests to read data from the Storage account failing due to Azure Storage platform issues?<br> - Are requests to write data to the Storage account failing due to Azure Storage platform issues?<br> - Is the Storage cluster where the Storage account resides unavailable?| --## Microsoft.StreamAnalytics/streamingjobs -|Executed Checks| -|| -| - Are all the hosts where the job is executing up and running?<br> - Was the job unable to start?<br> - Are there ongoing runtime upgrades?<br> - Is the job in an expected state (for example running or stopped by customer)?<br> - Has the job encountered out of memory exceptions?<br> - Are there ongoing scheduled compute updates?<br> - Is the Execution Manager (control plan) available?| --## Microsoft.web/serverFarms -|Executed Checks| -|| -| - Is the host server up and running?<br> - Is Internet Information Services running?<br> - Is the Load balancer running?<br> - Can the App Service Plan be reached from within the datacenter?<br> - Is the storage account hosting the sites content for the serverFarm available?| --## Microsoft.web/sites -|Executed Checks| -|| -| - Is the host server up and running?<br> - Is Internet Information server running?<br> - Is the Load balancer running?<br> - Can the Web App be reached from within the datacenter?<br> - Is the storage account hosting the site content available?| --## Microsoft.RecoveryServices/vaults --| Executed Checks | -| | -| - Are any Backup operations on Backup Items configured in this vault failing due to causes beyond user control?<br>- Are any Restore operations on Backup Items configured in this vault failing due to causes beyond user control?| --## Microsoft.VoiceServices/communicationsgateway --| Executed Checks | -| | -| - Are traffic-carrying instances running?<br>- Can the service handle calls?| --## Next Steps -- See [Introduction to Azure Service Health dashboard](service-health-overview.md) and [Introduction to Azure Resource Health](resource-health-overview.md) to understand more about them.-- [Frequently asked questions about Azure Resource Health](resource-health-faq.yml)-- Set up alerts so you are notified of health issues. For more information, see [Configure Alerts for service health events](./alerts-activity-log-service-notifications-portal.md). |
| service-health | Resource Health Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/resource-health-overview.md | - Title: Azure Resource Health overview -description: Learn how Azure Resource Health helps you diagnose and get support for service problems that affect your Azure resources. - Previously updated : 02/14/2023---# Resource Health overview - -Azure Resource Health helps you diagnose and get support for service problems that affect your Azure resources. It reports on the current and past health of your resources. --[Azure status](https://azure.status.microsoft) reports on service problems that affect a broad set of Azure customers. Resource Health gives you a personalized dashboard of the health of your resources. Resource Health shows all the times that your resources have been unavailable because of Azure service problems. This data makes it easy for you to see if an SLA was violated. --## Resource definition and health assessment --A *resource* is a specific instance of an Azure service, such as a virtual machine, web app, or SQL Database. Resource Health relies on signals from different Azure services to assess whether a resource is healthy. If a resource is unhealthy, Resource Health analyzes additional information to determine the source of the problem. It also reports on actions that Microsoft is taking to fix the problem and identifies things that you can do to address it. --For more information on how health is assessed, see the list of resource types and health checks at [Azure Resource Health](resource-health-checks-resource-types.md). --## Health status --The health of a resource is displayed as one of the following statuses. --### Available --*Available* means that there are no events detected that affect the health of the resource. In cases where the resource recovered from unplanned downtime during the last 24 hours, you'll see a "Recently resolved" notification. -- --### Unavailable --*Unavailable* means that the service detected an ongoing platform or non-platform event that affects the health of the resource. --#### Platform events --Platform events are triggered by multiple components of the Azure infrastructure. They include both scheduled actions (for example, planned maintenance) and unexpected incidents (for example, an unplanned host reboot or degraded host hardware that is predicted to fail after a specified time window). --Resource Health provides additional details about the event and the recovery process. It also enables you to contact Microsoft Support even if you don't have an active support agreement. -- --#### Non-platform events --Non-platform events are triggered by user actions. Examples include stopping a virtual machine or reaching the maximum number of connections to Azure Cache for Redis. -- --### Unknown --*Unknown* means that Resource Health hasn't received information about the resource for more than 10 minutes. This commonly occurs when virtual machines have been deallocated. Although this status isn't a definitive indication of the state of the resource, it can be an important data point for troubleshooting. --If the resource is running as expected, the status of the resource will change to *Available* after a few minutes. --If you experience problems with the resource, the *Unknown* health status might mean that an event in the platform is affecting the resource. -- --### Degraded --*Degraded* means that your resource detected a loss in performance, although it's still available for use. --Different resources have their own criteria for when they report that they are degraded. -- --For Virtual Machine Scale Sets, visit [Resource health state is "Degraded" in Azure Virtual Machine Scale Set](/troubleshoot/azure/virtual-machine-scale-sets/resource-health-degraded-state) page for more information. --### Health not supported --The message *Health not supported* or *RP has no information about the resource, or you don't have read/write access for that resource* means that your resource is not supported for the health metrics. --To know which resources support health metrics, refer to [Supported Resource Types](resource-health-checks-resource-types.md) page. --## Resource health events sent to the activity log --A resource health event is recorded in the activity log when: -- An annotation, for example "ResourceDegraded" or "AccountClientThrottling", is submitted for a resource.-- A resource transitioned to or from Unhealthy.-- A resource was Unhealthy for more than 15 minutes.--The following resource health transitions aren't recorded in the activity log: -- A transition to Unknown state.-- A transition from Unknown state if:- - This is the first transition. - - If the state prior to Unknown is the same as the new state after. (For example, if the resource transitioned from Healthy to Unknown and back to Healthy). - - For compute resources: VMs that transition from Healthy to Unhealthy, and back to Healthy, when the Unhealthy time is less than 35 seconds. --## History information --> [!NOTE] -> You can list current service health events in subscription and query data up to 1 year using the QueryStartTime parameter of [Events - List By Subscription Id](/rest/api/resourcehealth/2022-05-01/events/list-by-subscription-id) REST API but currently there is no QueryStartTime parameter under [Events - List By Single Resource](/rest/api/resourcehealth/2022-05-01/events/list-by-single-resource) REST API so you cannot query data up to 1 year while listing current service health events for given resource. - -You can access up to 30 days of history in the **Health history** section of Resource Health from Azure portal. -- --## Root cause information --If Azure has further information about the root cause of a platform-initiated unavailability, that information may be posted in resource health up to 72 hours after the initial unavailability. This information is only available for virtual machines at this time. --## Get started --To open Resource Health for one resource: --1. Sign in to the Azure portal. -2. Browse to your resource. -3. On the resource menu in the left pane, select **Resource health**. -4. From the health history grid, you can either download a PDF or click the "Share/Manage" RCA button. -- ---You can also access Resource Health by selecting **All services** and typing **resource health** in the filter text box. In the **Help + support** pane, select [Resource health](https://portal.azure.com/#blade/Microsoft_Azure_Monitoring/AzureMonitoringBrowseBlade/resourceHealth). -- --## Next steps --Check out these references to learn more about Resource Health: -- [Resource types and health checks in Azure Resource Health](resource-health-checks-resource-types.md)-- [Resource Health virtual machine Health Annotations](resource-health-vm-annotation.md)-- [Frequently asked questions about Azure Resource Health](resource-health-faq.yml) |
| service-health | Resource Health Vm Annotation | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/resource-health-vm-annotation.md | - Title: Resource Health virtual machine Health Annotations -description: Messages, meanings and troubleshooting for virtual machines resource health statuses. - Previously updated : 05/07/2024----# Resource Health virtual machine Health Annotations --Virtual Machine (VM) health annotations inform any ongoing activity that influences the availability of VMs (see [Resource types and health checks](resource-health-checks-resource-types.md)). Annotations carry metadata that help rationalize the exact impact to availability. --Here are more details on important attributes recently added to help understand below annotations you might observe in [Resource Health](resource-health-overview.md), [Azure Resource Graph](/azure/governance/resource-graph/overview) and [Event Grid System](/azure/event-grid/event-schema-health-resources?tabs=event-grid-event-schema) topics: --- **Context**: Informs whether VM availability was influenced due to Azure or user orchestrated activity. It can assume values of _Platform Initiated | Customer Initiated | VM Initiated | Unknown_-- **Category**: Informs whether VM availability was influenced due to planned or unplanned activity and is only applicable to ΓÇÿPlatform-InitiatedΓÇÖ events. It can assume values of _Planned | Unplanned | Not Applicable | Unknown_-- **ImpactType**: Informs the type of impact to VM availability. It can assume values of:-- - *Downtime Reboot or Downtime Freeze*: Informs when VM is Unavailable due to Azure orchestrated activity (for example, VirtualMachineStorageOffline, LiveMigrationSucceeded etc.). The reboot or freeze distinction can help you discern the type of downtime impact faced. - - *Degraded*: Informs when Azure predicts a HW failure on the host server or detects potential degradation in performance. (for example, VirtualMachinePossiblyDegradedDueToHardwareFailure) - - *Informational*: Informs when an authorized user or process triggers a control plane operation (for example, VirtualMachineDeallocationInitiated, VirtualMachineRestarted). This category also captures cases of platform actions due to customer defined thresholds or conditions. (for example, VirtualMachinePreempted) -->[!Note] -> A VMs availability impact start and end time is **only** applicable to degraded annotations, and does not apply to downtime or informational annotations. --The below table summarizes all the annotations that the platform emits today: ---| Annotation | Description | Attributes | -||-|-| -| PossiblyDegradedDueToHardwareFailureWithRedeployDeadline | The Physical Host on which your Virtual Machine is running has potentially degraded. Live Migration, if applicable, will be attempted as best effort to safely migrate your Virtual Machine. We strongly recommend redeploying your Virtual Machine before the specified redeployment deadline to avoid unexpected disruptions. | <ul><li>**Context**: Platform Initiated<li>**Category**: Unplanned<li>**ImpactType**: Degraded | -| VirtualMachineRestarted | The Virtual Machine is undergoing a reboot as requested by a restart action triggered by an authorized user or process from within the Virtual Machine. No other action is required at this time. For more information, see [understanding Virtual Machine reboots in Azure](/troubleshoot/azure/virtual-machines/understand-vm-reboot). | <ul><li>**Context**: Customer Initiated<li>**Category**: Not Applicable<li>**ImpactType**: Informational | -| VirtualMachineCrashed | The Virtual Machine is undergoing a reboot due to a guest OS crash. The local data remains unaffected during this process. No other action is required at this time. For more information, see [understanding Virtual Machine crashes in Azure](/troubleshoot/azure/virtual-machines/understand-vm-reboot#vm-crashes). | <ul><li>**Context**: VM Initiated<li>**Category**: Not Applicable<li>**ImpactType**: Downtime Reboot | -| VirtualMachineStorageOffline | The Virtual Machine is either currently undergoing a reboot or experiencing an application freeze due to a temporary loss of access to disk. No other action is required at this time, while the platform is working on reestablishing disk connectivity. | <ul><li>**Context**: Platform Initiated<li>**Category**: Unplanned<li>**ImpactType**: Downtime Reboot | -| VirtualMachineFailedToSecureBoot | Applicable to Azure Confidential Compute Virtual Machines when guest activity such as unsigned booting components leads to a guest OS issue preventing the Virtual Machine from booting securely. You can attempt to retry deployment after ensuring OS boot components are signed by trusted publishers. For more information, see [Secure Boot](/windows-hardware/design/device-experiences/oem-secure-boot). | <ul><li> **Context**: Customer Initiated<li>**Category**: Not Applicable<li>**ImpactType**: Informational | -| LiveMigrationSucceeded | The Virtual Machine was briefly paused as a Live Migration operation was successfully performed on your Virtual Machine. This operation was carried out either as a repair action, for allocation optimization or as part of routine maintenance workflows. No other action is required at this time. For more information, see [Live Migration](/azure/virtual-machines/maintenance-and-updates#live-migration). | <ul><li> **Context**: Platform Initiated<li>**Category**: Unplanned<li>**ImpactType**: Downtime Freeze | -| LiveMigrationFailure | A Live Migration operation was attempted on your Virtual Machine as either a repair action, for allocation optimization or as part of routine maintenance workflows. This operation, however, couldn't be successfully completed and may have resulted in a brief pause of your Virtual Machine. No other action is required at this time. <br/> Also note that [M Series](/azure/virtual-machines/m-series), [L Series](/azure/virtual-machines/lasv3-series) VM SKUs aren't applicable for Live Migration. For more information, see [Live Migration](/azure/virtual-machines/maintenance-and-updates#live-migration). | <ul><li> **Context**: Platform Initiated<li>**Category**: Unplanned<li>**ImpactType**: Downtime Freeze | -| VirtualMachineAllocated | The Virtual Machine is in the process of being set up as requested by an authorized user or process. No other action is required at this time. | <ul><li>**Context**: Customer Initiated<li>**Category**: Not Applicable<li>**ImpactType**: Informational | -| VirtualMachineDeallocationInitiated | The Virtual Machine is in the process of being stopped and deallocated as requested by an authorized user or process. No other action is required at this time. | <ul><li>**Context**: Customer Initiated<li>**Category**: Not Applicable<li>**ImpactType**: Informational | -| VirtualMachineHostCrashed | The Virtual Machine has unexpectedly crashed due to the underlying host server experiencing a software failure or due to a failed hardware component. While the Virtual Machine is rebooting, the local data remains unaffected. You may attempt to redeploy the Virtual Machine to a different host server if you continue to experience issues. | <ul><li> **Context**: Platform Initiated<li>**Category**: Unplanned<li>**ImpactType**: Downtime Reboot | -| VirtualMachineMigrationInitiatedForPlannedMaintenance | The Virtual Machine is being migrated to a different host server as part of routine maintenance workflows orchestrated by the platform. No other action is required at this time. For more information, see [Planned Maintenance](/azure/virtual-machines/maintenance-and-updates). | <ul><li>**Context**: Platform Initiated<li>**Category**: Planned<li>**ImpactType**: Downtime Reboot | -| VirtualMachineRebootInitiatedForPlannedMaintenance | The Virtual Machine is undergoing a reboot as part of routine maintenance workflows orchestrated by the platform. No other action is required at this time. For more information, see [Maintenance and updates](/azure/virtual-machines/maintenance-and-updates). | <ul><li> **Context**: Platform Initiated<li>**Category**: Planned<li>**ImpactType**: Downtime Reboot | -| VirtualMachineHostRebootedForRepair | The Virtual Machine is undergoing a reboot due to the underlying host server experiencing unexpected failures. While the Virtual Machine is rebooting, the local data remains unaffected. For more information, see [understanding Virtual Machine reboots in Azure](/troubleshoot/azure/virtual-machines/understand-vm-reboot). | <ul><li> **Context**: Platform Initiated<li>**Category**: Unplanned<li>**ImpactType**: Downtime Reboot | -| VirtualMachineMigrationInitiatedForRepair | The Virtual Machine is being migrated to a different host server due to the underlying host server experiencing unexpected failures. Since the Virtual Machine is being migrated to a new host server, the local data won't persist. For more information, see [Service Healing](https://azure.microsoft.com/blog/service-healing-auto-recovery-of-virtual-machines/). | <ul><li>**Context**: Platform Initiated<li>**Category**: Unplanned<li>**ImpactType**: Downtime Reboot | -| VirtualMachinePlannedFreezeStarted | This virtual machine is undergoing freeze impact due to a routine update. This update is necessary to ensure the underlying platform is up to date with the latest improvements. No action is required at this time. | <ul><li> **Context**: Platform Initiated <li>**Category**: Planned<li>**ImpactType**: Informational | -| VirtualMachinePlannedFreezeSucceeded | This virtual machine has successfully undergone a routine update that resulted in freeze impact. This update is necessary to ensure the underlying platform is up to date with the latest improvements. No action is required at this time. | <ul><li>**Context**: Platform Initiated <li>**Category**: Planned<li>**ImpactType**: Downtime Freeze | -| VirtualMachinePlannedFreezeFailed | This virtual machine underwent a routine update that may have resulted in freeze impact. However this update failed to successfully complete. The platform will automatically coordinate recovery actions, as necessary. This update was to ensure the underlying platform is up to date with the latest improvements. No action is required at this time. | <ul><li> **Context**: Platform Initiated <li>**Category**: Planned<li>**ImpactType**: Downtime Freeze | -| VirtualMachineRedeployInitiatedByControlPlaneDueToPlannedMaintenance | The Virtual Machine is being migrated to a different host server as part of routine maintenance workflows triggered by an authorized user or process. Since the Virtual Machine is being migrated to a new host server, the local data won't persist. For more information, see [Maintenance and updates](/azure/virtual-machines/maintenance-and-updates). | <ul><li> **Context**: Customer Initiated <li>**Category**: Not Applicable <li> **ImpactType**: Informational | -| VirtualMachineMigrationScheduledForDegradedHardware | The Physical Host in which your Virtual Machine is running has potentially degraded. Live Migration, if applicable, will be attempted as a best effort to safely migrate your Virtual Machine to a healthy host server. <br/> We strongly advise you to redeploy your Virtual Machine to avoid unexpected disruptions by the redeploy deadline specified. For more information, see [Advancing failure prediction and mitigation](https://azure.microsoft.com/blog/advancing-failure-prediction-and-mitigation-introducing-narya/). | <ul><li> **Context**: Platform Initiated <li>**Category**: Unplanned <li>**ImpactType**: Degraded | -| VirtualMachinePossiblyDegradedDueToHardwareFailure | The Physical Host in which your Virtual Machine is running has potentially degraded or experienced an error. Live Migration will be attempted to safely migrate your Virtual Machine to a healthy host server. <br/> We strongly advise you to redeploy your Virtual Machine to avoid unexpected failures by the redeploy deadline specified. For more information, see [Advancing failure prediction and mitigation](https://azure.microsoft.com/blog/advancing-failure-prediction-and-mitigation-introducing-narya/). | <ul><li> **Context**: Platform Initiated <li>**Category**: Unplanned<li>**ImpactType**: Degraded | -| VirtualMachineScheduledForServiceHealing | The Physical Host in which your Virtual Machine is running has potentially degraded. Live Migration, if applicable, will be attempted as a best effort to safely migrate your Virtual Machine to a healthy host server. <br/> We strongly advise you to redeploy your Virtual Machine to avoid unexpected disruptions by the redeploy deadline specified. For more information, see [Advancing failure prediction and mitigation](https://azure.microsoft.com/blog/advancing-failure-prediction-and-mitigation-introducing-narya/). | <ul><li>**Context**: Platform Initiated <li>**Category**: Unplanned<li>**ImpactType**: Degraded | -| VirtualMachinePreempted | If you're running a Spot/Low Priority Virtual Machine, it has been preempted either due to capacity recall by the platform or due to billing-based eviction where cost exceeded user defined thresholds. No other action is required at this time. For more information, see [Spot Virtual Machines](/azure/virtual-machines/spot-vms). | <ul><li> **Context**: Platform Initiated <li>**Category**: Unplanned<li>**ImpactType**: Informational | -| VirtualMachineRebootInitiatedByControlPlane | The Virtual Machine is undergoing a reboot as requested by an authorized user or process from within the Virtual machine. No other action is required at this time. | <ul><li> **Context**: Customer Initiated <li>**Category**: Not Applicable<li>**ImpactType**: Informational | -| VirtualMachineRedeployInitiatedByControlPlane | The Virtual Machine is being migrated to a different host server as requested by an authorized user or process from within the Virtual machine. No other action is required at this time. Since the Virtual Machine is being migrated to a new host server, the local data won't persist. | <ul><li> **Context**: Customer Initiated <li>**Category**: Not Applicable <li>**ImpactType**: Informational | -| VirtualMachineSizeChanged | The Virtual Machine is being resized as requested by an authorized user or process. No other action is required at this time. | <ul><li> **Context**: Customer Initiated <li>**Category**: Not Applicable<li>**ImpactType**: Informational | -|VirtualMachineConfigurationUpdated | The Virtual Machine configuration is being updated as requested by an authorized user or process. No other action is required at this time. | <ul><li> **Context**: Customer Initiated <li>**Category**: Not Applicable<li>**ImpactType**: Informational | -| VirtualMachineStartInitiatedByControlPlane |The Virtual Machine is starting as requested by an authorized user or process. No other action is required at this time. | <ul><li> **Context**: Customer Initiated<li>**Category**: Not Applicable<li>**ImpactType**: Informational | -| VirtualMachineStopInitiatedByControlPlane | The Virtual Machine is stopping as requested by an authorized user or process. No other action is required at this time. | <ul><li> **Context**: Customer Initiated<li>**Category**: Not Applicable<li>**ImpactType**: Informational | -| VirtualMachineStoppedInternally | The Virtual Machine is stopping as requested by an authorized user or process, or due to a guest activity from within the Virtual Machine. No other action is required at this time. | <ul><li> **Context**: Customer Initiated <li>**Category**: Not Applicable<li>**ImpactType**: Informational | -| VirtualMachineProvisioningTimedOut | The Virtual Machine provisioning has failed due to Guest OS issues or incorrect user run scripts. You can attempt to either re-create this Virtual Machine or if this Virtual Machine is part of a virtual machine scale set, you can try reimaging it. | <ul><li> **Context**: Platform Initiated <li> **Category**: Unplanned <li> **ImpactType**: Informational | -| AccelnetUnhealthy | Applicable if Accelerated Networking is enabled for your Virtual Machine ΓÇô We have detected that the Accelerated Networking feature isn't functioning as expected. You can attempt to redeploy your Virtual Machine to potentially mitigate the issue. | <ul><li> **Context**: Platform Initiated <li>**Category**: Unplanned <li> **ImpactType**: Degraded | - |
| service-health | Security Advisories Elevated Access | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/security-advisories-elevated-access.md | - Title: Elevated access for viewing Security Advisories -description: This article details an upcoming change that requires users to obtain elevated access roles in order to view Security Advisory details - Previously updated : 10/10/2023--# Elevated access for viewing Security Advisories --This article details an upcoming change that requires users to obtain elevated access roles in order to view Security Advisory details on Azure Service Health. --## What are Security Advisories? --Azure customers use [Service Health](service-health-overview.md) to stay informed about security events that are impacting their critical and noncritical business applications. Security event notifications are displayed on Azure Service Health within the Security Advisories blade. Important security advisory details are displayed in three tabs: Summary, Impacted Resources, and Issue Updates. ----## Who can view Security Advisories? -Security Advisories are displayed to users at the subscription or tenant level. Users with the subscription reader role or higher; can view Security Advisory details on the Summary and Issue update tabs. Users with tenant roles [listed here](admin-access-reference.md) can also access tenant level security advisory details on the Summary and Issue update tabs. --## What are Impacted Resources within Security Advisories? --In 2023, the Impacted resources tab was introduced for Security Advisory events. Since details displayed in this tab are sensitive, role based access (RBAC) is required for customers viewing security impacted resources via UI or API. [Review this article](impacted-resources-security.md) for more information on the current RBAC requirements for accessing security impacted resources. --->[!Note] -> The above screenshots reflect the RBAC experience for the Security Advisories as of today. --## What is changing in Security Advisories? --In the future, accessing Security Advisories will require elevated access across the Summary, Impacted Resources, and Issue Updates tabs. Users who have subscription reader access, or tenant roles at tenant scope, will not be able to view security advisory details until they get the required roles. --### 1. On the Service Health portal -A banner will be displayed to the users until April 2024 on the Summary and Issue Updates tabs prompting customers to get the right roles to view these tabs in future. ---After April 2024, an error message on the Summary and Issue Updates tabs will be displayed to users who do not have the following required roles: --**Subscription level** -- Subscription Owner-- Subscription Admin-- Custom Roles with Microsoft.ResourceHealth/events/fetchEventDetails/action permissions or Microsoft.ResourceHealth/events/action permissions--**Tenant level** -- Security Admin/Security Reader-- Global Admin/Tenant Admin-- Custom Roles with Microsoft.ResourceHealth/events/fetchEventDetails/action permissions or Microsoft.ResourceHealth/events/action permissions--### 2. Service Health API Changes --Events API users will need to update their code to use the new **ARM endpoint (/fetchEventDetails)** to receive Security Advisories notification details. If users have the above-mentioned roles, they can view event details for a specific event with the new endpoint. The existing endpoint **(/events)** that returns all Service Health event types impacting a subscription or tenant, will no longer return sensitive security notification details. This update will be made to API version 2023-10-01-preview and future versions. --The new and existing endpoints listed below will return the security notification details for a specific event. --#### New API Endpoint Details --- To access the new endpoint below, users need to be authorized with the above-mentioned roles. -- This endpoint will return the event object with all available properties for a specific event. -- This is like the impacted resources endpoint below.-- Available since API version 2022-10-01--**Example** --```HTTP -https://management.azure.com/subscriptions/227b734f-e14f-4de6-b7fc-3190c21e69f6/providers/microsoft.ResourceHealth/events/{trackingId}/fetchEventDetails?api-version=2023-10-01-preview -``` -Operation: POST --#### Impacted Resources for Security Advisories -- Customers authorized with the above-mentioned roles can use the following endpoints to access the list of resources impacted by a Security Incident-- Available since API version 2022-05-01- -**Subscription** -```HTTP -https://management.azure.com/subscriptions/4970d23e-ed41-4670-9c19-02a1d2808ff9/providers/microsoft.resourcehealth/events/{trackingId}/listSecurityAdvisoryImpactedResources?api-version=2023-10-01-preview -``` -Operation: POST --**Tenant** -```HTTP -https://management.azure.com/providers/microsoft.resourcehealth/events/{trackingId}/listSecurityAdvisoryImpactedResources?api-version=2023-10-01-preview -``` -Operation: POST ---#### Existing Events API Endpoint --**Security Advisories Subscription List Events** --With API version 2023-10-01-preview (and future API versions), the existing Events API endpoint which returns the list of events(including security events with eventType: ΓÇ£SecurityΓÇ¥) will be restricted to pass only nonsensitive properties listed below for security events. --```HTTP -https://management.azure.com/subscriptions/227b734f-e14f-4de6-b7fc-3190c21e69f6/providers/microsoft.ResourceHealth/events?api-version=2023-10-01-preview&$filter= "eventType eq SecurityAdvisory" -``` -Operation: GET --The following in the events object response will be populated for security Advisories events using this endpoint: -- Id-- name-- type-- nextLink-- properties--Only the following will be populated in the properties object: -- eventType-- eventSource-- status-- title-- platformInitiated-- level-- eventLevel-- isHIR-- priority-- subscriptionId-- lastUpdateTime-- impact--The impactedService property will be populated for the impact object, but only the following properties in the impactedServiceRegion object in the impact object will be populated: -- impactedService-- impactedSubscriptions-- impactedTenants-- impactedRegion-- status------## Next steps -- [Stay informed about Azure security events](stay-informed-security.md)-- [Introduction to Azure Resource Health](resource-health-overview.md)-- [Frequently asked questions about Azure Resource Health](resource-health-faq.yml) |
| service-health | Service Health Alert Webhook Guide | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/service-health-alert-webhook-guide.md | - Title: Send Azure Service Health notifications via webhooks -description: Send personalized notifications about service health events to your existing problem management system. -- Previously updated : 3/27/2018----# Use a webhook to configure health notifications for problem management systems --This article shows you how to configure Azure Service Health alerts to send data through webhooks to your existing notification system. --You can configure Service Health alerts to notify you by text message or email when an Azure service incident affects you. --But you might already have an existing external notification system in place that you prefer to use. This article identifies the most important parts of the webhook payload. And it describes how to create custom alerts to notify you when relevant service issues occur. --If you want to use a preconfigured integration, see: -* [Configure alerts with ServiceNow](service-health-alert-webhook-servicenow.md) -* [Configure alerts with PagerDuty](service-health-alert-webhook-pagerduty.md) -* [Configure alerts with OpsGenie](service-health-alert-webhook-opsgenie.md) --**Watch an introductory video:** -->[!VIDEO https://www.microsoft.com/en-us/videoplayer/embed/RE2OtUV] --## Configure a custom notification by using the Service Health webhook payload -To set up your own custom webhook integration, you need to parse the JSON payload that's sent via Service Health notification. --See [an example](../azure-monitor/alerts/activity-log-alerts-webhook.md) `ServiceHealth` webhook payload. --You can confirm that it's a service health alert by looking at `context.eventSource == "ServiceHealth"`. The following properties are the most relevant: -- **data.context.activityLog.status**-- **data.context.activityLog.level**-- **data.context.activityLog.subscriptionId**-- **data.context.activityLog.properties.title**-- **data.context.activityLog.properties.impactStartTime**-- **data.context.activityLog.properties.communication**-- **data.context.activityLog.properties.impactedServices**-- **data.context.activityLog.properties.trackingId**--## Create a link to the Service Health dashboard for an incident -You can create a direct link to your Service Health dashboard on a desktop or mobile device by generating a specialized URL. Use the *trackingId* and the first three and last three digits of your *subscriptionId* in this format: --https<i></i>://app.azure.com/h/*<trackingId>*/*<first three and last three digits of subscriptionId>* --For example, if your *subscriptionId* is bba14129-e895-429b-8809-278e836ecdb3 and your *trackingId* is 0DET-URB, your Service Health URL is: --https<i></i>://app.azure.com/h/0DET-URB/bbadb3 --## Use the level to detect the severity of the issue -From lowest to highest severity, the **level** property in the payload can be *Informational*, *Warning*, *Error*, or *Critical*. --## Parse the impacted services to determine the incident scope -Service Health alerts can inform you about issues across multiple regions and services. To get complete details, you need to parse the value of `impactedServices`. --The content that's inside is an escaped [JSON](https://json.org/) string that, when unescaped, contains another JSON object that can be parsed regularly. For example: --```json -{"data.context.activityLog.properties.impactedServices": "[{\"ImpactedRegions\":[{\"RegionName\":\"Australia East\"},{\"RegionName\":\"Australia Southeast\"}],\"ServiceName\":\"Alerts & Metrics\"},{\"ImpactedRegions\":[{\"RegionName\":\"Australia Southeast\"}],\"ServiceName\":\"App Service\"}]"} -``` --becomes: --```json -[ - { - "ImpactedRegions":[ - { - "RegionName":"Australia East" - }, - { - "RegionName":"Australia Southeast" - } - ], - "ServiceName":"Alerts & Metrics" - }, - { - "ImpactedRegions":[ - { - "RegionName":"Australia Southeast" - } - ], - "ServiceName":"App Service" - } -] -``` --This example shows problems for: -- "Alerts & Metrics" in Australia East and Australia Southeast.-- "App Service" in Australia Southeast.--## Test your webhook integration via an HTTP POST request --Follow these steps: --1. Create the service health payload that you want to send. See an example service health webhook payload at [Webhooks for Azure activity log alerts](../azure-monitor/alerts/activity-log-alerts-webhook.md). --1. Create an HTTP POST request as follows: -- ``` - POST https://your.webhook.endpoint -- HEADERS Content-Type: application/json -- BODY <service health payload> - ``` - You should receive a "2XX - Successful" response. --1. Go to [PagerDuty](https://www.pagerduty.com/) to confirm that your integration was set up successfully. --## Next steps -- Review the [activity log alert webhook schema](../azure-monitor/alerts/activity-log-alerts-webhook.md). -- Learn about [service health notifications](./service-notifications.md).-- Learn more about [action groups](../azure-monitor/alerts/action-groups.md). |
| service-health | Service Health Alert Webhook Opsgenie | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/service-health-alert-webhook-opsgenie.md | - Title: Send Azure service health alerts with OpsGenie using webhooks -description: Get personalized notifications about service health events to your OpsGenie instance. - Previously updated : 06/10/2019-- -# Send Azure service health alerts with OpsGenie using webhooks --This article shows you how to set up Azure service health alerts with OpsGenie using a webhook. By using [OpsGenie](https://www.opsgenie.com/)'s Azure Service Health Integration, you can forward Azure Service Health alerts to OpsGenie. OpsGenie can determine the right people to notify based on on-call schedules, using email, text messages (SMS), phone calls, iOS & Android push notifications, and escalating alerts until the alert is acknowledged or closed. --## Creating a service health integration URL in OpsGenie -1. Make sure you have signed up for and are signed into your [OpsGenie](https://www.opsgenie.com/) account. --1. Navigate to the **Integrations** section in OpsGenie. --  --1. Select the **Azure Service Health** integration button. --  --1. **Name** your alert and specify the **Assigned to Team** field. --1. Fill out the other fields like **Recipients**, **Enabled**, and **Suppress Notifications**. --1. Copy and save the **Integration URL**, which should already contain your `apiKey` appended to the end. --  --1. Select **Save Integration** --## Create an alert using OpsGenie in the Azure portal -### For a new action group: -1. Follow steps 1 through 8 in [Create an alert on a service health notification for a new action group by using the Azure portal](./alerts-activity-log-service-notifications-portal.md). --1. Define in the list of **Actions**: -- a. **Action Type:** *Webhook* -- b. **Details:** The OpsGenie **Integration URL** you previously saved. -- c. **Name:** Webhook's name, alias, or identifier. --1. Select **Save** when done to create the alert. --### For an existing action group: -1. In the [Azure portal](https://portal.azure.com/), select **Monitor**. --1. In the **Settings** section, select **Action groups**. --1. Find and select the action group you want to edit. --1. Add to the list of **Actions**: -- a. **Action Type:** *Webhook* -- b. **Details:** The OpsGenie **Integration URL** you previously saved. -- c. **Name:** Webhook's name, alias, or identifier. --1. Select **Save** when done to update the action group. --## Testing your webhook integration via an HTTP POST request -1. Create the service health payload you want to send. You can find an example service health webhook payload at [Webhooks for Azure activity log alerts](../azure-monitor/alerts/activity-log-alerts-webhook.md). --1. Create an HTTP POST request as follows: -- ``` - POST https://api.opsgenie.com/v1/json/azureservicehealth?apiKey=<APIKEY> -- HEADERS Content-Type: application/json -- BODY <service health payload> - ``` -1. You should receive a `200 OK` response with the message of status "successful." --1. Go to [OpsGenie](https://www.opsgenie.com/) to confirm that your integration was set up successfully. --## Next steps -- Learn how to [configure webhook notifications for existing problem management systems](service-health-alert-webhook-guide.md).-- Review the [activity log alert webhook schema](../azure-monitor/alerts/activity-log-alerts-webhook.md). -- Learn about [service health notifications](./service-notifications.md).-- Learn more about [action groups](../azure-monitor/alerts/action-groups.md). |
| service-health | Service Health Alert Webhook Pagerduty | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/service-health-alert-webhook-pagerduty.md | - Title: Send Azure service health alerts with PagerDuty -description: Get personalized notifications about service health events to your PagerDuty instance. - Previously updated : 06/10/2019---# Send Azure service health alerts with PagerDuty using webhooks --This article shows you how to set up Azure service health notifications through PagerDuty using a webhook. By using [PagerDuty](https://www.pagerduty.com/)'s custom Microsoft Azure integration type, you can effortlessly add Service Health alerts to your new or existing PagerDuty services. --## Creating a service health integration URL in PagerDuty -1. Make sure you have signed up for and are signed into your [PagerDuty](https://www.pagerduty.com/) account. --1. Navigate to the **Services** section in PagerDuty. --  --1. Select **Add New Service** or open an existing service you have set up. --1. In the **Integration Settings**, select the following: -- a. **Integration Type**: Microsoft Azure -- b. **Integration Name**: \<Name\> --  --1. Fill out any other required fields and select **Add**. --1. Open this new integration and copy and save the **Integration URL**. --  --## Create an alert using PagerDuty in the Azure portal -### For a new action group: -1. Follow steps 1 through 8 in [Create an alert on a service health notification for a new action group by using the Azure portal](./alerts-activity-log-service-notifications-portal.md). --1. Define in the list of **Actions**: -- a. **Action Type:** *Webhook* -- b. **Details:** The PagerDuty **Integration URL** you previously saved. -- c. **Name:** Webhook's name, alias, or identifier. --1. Select **Save** when done to create the alert. --### For an existing action group: -1. In the [Azure portal](https://portal.azure.com/), select **Monitor**. --1. In the **Settings** section, select **Action groups**. --1. Find and select the action group you want to edit. --1. Add to the list of **Actions**: -- a. **Action Type:** *Webhook* -- b. **Details:** The PagerDuty **Integration URL** you previously saved. -- c. **Name:** Webhook's name, alias, or identifier. --1. Select **Save** when done to update the action group. --## Testing your webhook integration via an HTTP POST request -1. Create the service health payload you want to send. You can find an example service health webhook payload at [Webhooks for Azure activity log alerts](../azure-monitor/alerts/activity-log-alerts-webhook.md). --1. Create an HTTP POST request as follows: -- ``` - POST https://events.pagerduty.com/integration/<IntegrationKey>/enqueue -- HEADERS Content-Type: application/json -- BODY <service health payload> - ``` -1. You should receive a `202 Accepted` with a message containing your "event ID." --1. Go to [PagerDuty](https://www.pagerduty.com/) to confirm that your integration was set up successfully. --## Next steps -- Learn how to [configure webhook notifications for existing problem management systems](service-health-alert-webhook-guide.md).-- Review the [activity log alert webhook schema](../azure-monitor/alerts/activity-log-alerts-webhook.md). -- Learn about [service health notifications](./service-notifications.md).-- Learn more about [action groups](../azure-monitor/alerts/action-groups.md). |
| service-health | Service Health Alert Webhook Servicenow | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/service-health-alert-webhook-servicenow.md | - Title: Send Azure service health alerts with ServiceNow -description: Get personalized notifications about service health events to your ServiceNow instance. - Previously updated : 06/10/2019---# Send Azure service health alerts with ServiceNow using webhooks --This article shows you how to integrate Azure service health alerts with ServiceNow using a webhook. After setting up webhook integration with your ServiceNow instance, you get alerts through your existing notification infrastructure when Azure service issues affect you. Every time an Azure Service Health alert fires, it calls a webhook through the ServiceNow Scripted REST API. --## Creating a scripted REST API in ServiceNow --1. Make sure you have signed up for and are signed into your [ServiceNow](https://www.servicenow.com/) account. --1. Navigate to the **System Web Services** section in ServiceNow and select **Scripted REST APIs**. --  --1. Select **New** to create a new Scripted REST service. - -  --1. Add a **Name** to your REST API and set the **API ID** to `azureservicehealth`. --1. Select **Submit**. --  --1. Select the REST API you created, and under the **Resources** tab select **New**. --  --1. **Name** your new resource `event` and change the **HTTP method** to `POST`. --1. In the **Script** section, add the following JavaScript code: -- >[!NOTE] - >You need to update the `<secret>`,`<group>`, and `<email>` value in the script below. - >* `<secret>` should be a random string, like a GUID - >* `<group>` should be the ServiceNow group you want to assign the incident to - >* `<email>` should be the specific person you want to assign the incident to (optional) - > -- ```javascript - (function process( /*RESTAPIRequest*/ request, /*RESTAPIResponse*/ response) { - var apiKey = request.queryParams['apiKey']; - var secret = '<secret>'; - if (apiKey == secret) { - var event = request.body.data; - var responseBody = {}; - if (event.data.context.activityLog.operationName == 'Microsoft.ServiceHealth/incident/action') { - var inc = new GlideRecord('incident'); - var incidentExists = false; - inc.addQuery('number', event.data.context.activityLog.properties.trackingId); - inc.query(); - if (inc.hasNext()) { - incidentExists = true; - inc.next(); - } else { - inc.initialize(); - } - var short_description = "Azure Service Health"; - if (event.data.context.activityLog.properties.incidentType == "Incident") { - short_description += " - Service Issue - "; - } else if (event.data.context.activityLog.properties.incidentType == "Maintenance") { - short_description += " - Planned Maintenance - "; - } else if (event.data.context.activityLog.properties.incidentType == "Informational" || event.data.context.activityLog.properties.incidentType == "ActionRequired") { - short_description += " - Health Advisory - "; - } - short_description += event.data.context.activityLog.properties.title; - inc.short_description = short_description; - inc.description = event.data.context.activityLog.properties.communication; - inc.work_notes = "Impacted subscription: " + event.data.context.activityLog.subscriptionId; - if (incidentExists) { - if (event.data.context.activityLog.properties.stage == 'Active') { - inc.state = 2; - } else if (event.data.context.activityLog.properties.stage == 'Resolved') { - inc.state = 6; - } else if (event.data.context.activityLog.properties.stage == 'Closed') { - inc.state = 7; - } - inc.update(); - responseBody.message = "Incident updated."; - } else { - inc.number = event.data.context.activityLog.properties.trackingId; - inc.state = 1; - inc.impact = 2; - inc.urgency = 2; - inc.priority = 2; - inc.assigned_to = '<email>'; - inc.assignment_group.setDisplayValue('<group>'); - var subscriptionId = event.data.context.activityLog.subscriptionId; - var comments = "Azure portal Link: https://app.azure.com/h"; - comments += "/" + event.data.context.activityLog.properties.trackingId; - comments += "/" + subscriptionId.substring(0, 3) + subscriptionId.slice(-3); - var impactedServices = JSON.parse(event.data.context.activityLog.properties.impactedServices); - var impactedServicesFormatted = ""; - for (var i = 0; i < impactedServices.length; i++) { - impactedServicesFormatted += impactedServices[i].ServiceName + ": "; - for (var j = 0; j < impactedServices[i].ImpactedRegions.length; j++) { - if (j != 0) { - impactedServicesFormatted += ", "; - } - impactedServicesFormatted += impactedServices[i].ImpactedRegions[j].RegionName; - } -- impactedServicesFormatted += "\n"; -- } - comments += "\n\nImpacted - inc.comments = comments; - inc.insert(); - responseBody.message = "Incident created."; - } - } else { - responseBody.message = "Hello from the other side!"; - } - response.setBody(responseBody); - } else { - var unauthorized = new sn_ws_err.ServiceError(); - unauthorized.setStatus(401); - unauthorized.setMessage('Invalid apiKey'); - response.setError(unauthorized); - } - })(request, response); - ``` --1. In the security tab, uncheck **Requires authentication** and select **Submit**. The `<secret>` you set protects this API instead. --  --1. Back at the Scripted REST APIs section, you should find the **Base API Path** for your new REST API: --  --1. Your full Integration URL looks like: -- ```http - https://<yourInstanceName>.service-now.com/<baseApiPath>?apiKey=<secret> - ``` --## Create an alert using ServiceNow in the Azure portal -### For a new action group: -1. Follow steps 1 through 8 in [this article](./alerts-activity-log-service-notifications-portal.md) to create an alert with a new action group. --1. Define in the list of **Actions**: -- a. **Action Type:** *Webhook* -- b. **Details:** The ServiceNow **Integration URL** you previously saved. -- c. **Name:** Webhook's name, alias, or identifier. --1. Select **Save** when done to create the alert. --### For an existing action group: -1. In the [Azure portal](https://portal.azure.com/), select **Monitor**. --1. In the **Settings** section, select **Action groups**. --1. Find and select the action group you want to edit. --1. Add to the list of **Actions**: -- a. **Action Type:** *Webhook* -- b. **Details:** The ServiceNow **Integration URL** you previously saved. -- c. **Name:** Webhook's name, alias, or identifier. --1. Select **Save** when done to update the action group. --## Testing your webhook integration via an HTTP POST request -1. Create the service health payload you want to send. You can find an example service health webhook payload at [Webhooks for Azure activity log alerts](../azure-monitor/alerts/activity-log-alerts-webhook.md). --1. Create an HTTP POST request as follows: -- ``` - POST https://<yourInstanceName>.service-now.com/<baseApiPath>?apiKey=<secret> -- HEADERS Content-Type: application/json -- BODY <service health payload> - ``` -1. You should receive a `200 OK` response with the message "Incident created." --1. Go to [ServiceNow](https://www.servicenow.com/) to confirm that your integration was set up successfully. --## Next steps -- Learn how to [configure webhook notifications for existing problem management systems](service-health-alert-webhook-guide.md).-- Review the [activity log alert webhook schema](../azure-monitor/alerts/activity-log-alerts-webhook.md). -- Learn about [service health notifications](./service-notifications.md).-- Learn more about [action groups](../azure-monitor/alerts/action-groups.md). |
| service-health | Service Health Notifications Properties | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/service-health-notifications-properties.md | - Title: What are Azure service health notifications? -description: Service health notifications allow you to view service health messages published by Microsoft Azure. - Previously updated : 4/12/2018----# Use the Azure portal to view service health notifications --Service health notifications are published by Azure, and contain information about the resources under your subscription. These notifications are a sub-class of activity log events, and can also be found in the activity log. Service health notifications can be informational or actionable, depending on the class. --There are various classes of service health notifications: --- **Action required:** Azure might notice something unusual happen on your account, and work with you to remedy this. Azure sends you a notification, either detailing the actions you need to take or how to contact Azure engineering or support. -- **Incident:** An event that impacts service is currently affecting one or more of the resources in your subscription. -- **Maintenance:** A planned maintenance activity that might impact one or more of the resources under your subscription. -- **Information:** Potential optimizations that might help improve your resource use. -- **Security:** Urgent security-related information regarding your solutions that run on Azure.--Each service health notification includes details on the scope and impact to your resources. Details include: --Property name | Description | ---channels | One of the following values: **Admin** or **Operation**. -correlationId | Usually a GUID in the string format. Events that belong to the same action usually share the same correlationId. -eventDataId | The unique identifier of an event. -eventName | The title of an event. -level | The level of an event -resourceProviderName | The name of the resource provider for the impacted resource. -resourceType| The type of resource of the impacted resource. -subStatus | Usually the HTTP status code of the corresponding REST call, but can also include other strings describing a substatus. For example: OK (HTTP Status Code: 200), Created (HTTP Status Code: 201), Accepted (HTTP Status Code: 202), No Content (HTTP Status Code: 204), Bad Request (HTTP Status Code: 400), Not Found (HTTP Status Code: 404), Conflict (HTTP Status Code: 409), Internal Server Error (HTTP Status Code: 500), Service Unavailable (HTTP Status Code: 503), and Gateway Timeout (HTTP Status Code: 504). -eventTimestamp | Timestamp when the event was generated by the Azure service processing the request corresponding to the event. -submissionTimestamp | Timestamp when the event became available for querying. -subscriptionId | The Azure subscription in which this event was logged. -status | String describing the status of the operation. Values are: **Active**, and **Resolved**. -operationName | The name of the operation. -category | This property is always **ServiceHealth**. -resourceId | The Resource ID of the impacted resource. -Properties.title | The localized title for this communication. English is the default. -Properties.communication | The localized details of the communication with HTML markup. English is the default. -Properties.incidentType | One of the following values: **ActionRequired**, **Informational**, **Incident**, **Maintenance**, or **Security**. -Properties.trackingId | The incident with which this event is associated. Use this to correlate the events related to an incident. -Properties.impactedServices | An escaped JSON blob that describes the services and regions impacted by the incident. The property includes a list of services, each of which has a **ServiceName**, and a list of impacted regions, each of which has a **RegionName**. -Properties.defaultLanguageTitle | The communication in English. -Properties.defaultLanguageContent | The communication in English as either HTML markup or plain text. -Properties.stage | The possible values for **Incident**, and **Security** are **Active,** **Resolved** or **RCA**. For **ActionRequired** or **Informational** the only value is **Active.** For **Maintenance** they are: **Active**, **Planned**, **InProgress**, **Canceled**, **Rescheduled**, **Resolved**, or **Complete**. -Properties.communicationId | The communication with which this event is associated. --### Details on service health level information --**Action Required** (properties.incidentType == ActionRequired) -- Informational - Administrator action is required to prevent impact to existing services.- -**Maintenance** (properties.incidentType == Maintenance) -- Warning - Emergency maintenance-- Informational - Standard planned maintenance--**Information** (properties.incidentType == Informational) -- Informational - Administrator may be required to prevent impact to existing services.--**Security** (properties.incidentType == Security) -- Warning - Security advisory that affects existing services and may require administrator action.-- Informational - Security advisory that affects existing services.--**Service Issues** (properties.incidentType == Incident) -- Error - Widespread issues accessing multiple services across multiple regions are impacting a broad set of customers.-- Warning - Issues accessing specific services and/or specific regions are impacting a subset of customers.-- Informational - Issues impacting management operations and/or latency, not impacting service availability. |
| service-health | Service Health Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/service-health-overview.md | - Title: Service Health portal classic experience overview | Microsoft Docs -description: Learn how the Service Health portal provides you with a customizable dashboard which tracks the health of your Azure services in the regions where you use them. - Previously updated : 07/31/2024----# Service Health portal classic experience overview --The [Service Health portal](https://portal.azure.com/#view/Microsoft_Azure_Health/AzureHealthBrowseBlade/~/serviceIssues) is part of the [Service Health service](overview.md). The portal provides you with a customizable dashboard which tracks the health of your Azure services in the regions where you use them. In this dashboard, you can track active events like ongoing service issues, upcoming planned maintenance, or relevant health advisories. When events become inactive, they get placed in your health history for up to 90 days. Finally, you can use the Service Health dashboard to create and manage service health alerts which proactively notify you when service issues are affecting you. --This article goes through the classic portal experience. The portal is in process of updating to a new user interface. Some users will see the experience below. Others will see the [updated service Health portal experience](service-health-portal-update.md). --## Service Health Events --The [Service Health portal](https://portal.azure.com/#view/Microsoft_Azure_Health/AzureHealthBrowseBlade/~/serviceIssues) tracks four types of health events that may impact your resources: --1. **Service issues** - Problems in the Azure services that affect you right now. -2. **Planned maintenance** - Upcoming maintenance that can affect the availability of your services in the future. -3. **Health advisories** - Changes in Azure services that require your attention. Examples include deprecation of Azure features or upgrade requirements (e.g upgrade to a supported PHP framework). -4. **Security advisories** - Security related notifications or violations that may affect the availability of your Azure services. --> [!NOTE] -> To view Service Health events, users must be [granted the Reader role](../role-based-access-control/role-assignments-portal.yml) on a subscription. --## Get started with Service Health portal --To launch your Service Health dashboard, select the Service Health tile on your portal dashboard. If you have previously removed the tile or you're using custom dashboard, search for Service Health service in "More services" (bottom left on your dashboard). -- --## See current issues which impact your services --The **Service issues** view shows any ongoing problems in Azure services that are impacting your resources. You can understand when the issue began, and what services and regions are impacted. You can also read the most recent update to understand what Azure is doing to resolve the issue. --[](./media/service-health-overview/azure-service-health-overview-2.png#lightbox) --Choose the **Potential impact** tab to see the specific list of resources you own that might be impacted by the issue. You can download a CSV list of these resources to share with your team. --[](./media/service-health-overview/azure-service-health-overview-4.png#lightbox) --## See emerging issues which may impact your services --There are situations when widespread service issues may be posted to the [Azure Status page](https://azure.status.microsoft) before targeted communications can be sent to impacted customers. To ensure that Azure Service Health provides a comprehensive view of issues that may affect you, active Azure Status page issues are surfaced in Service Health as *emerging issues*. When an event is active on the Azure Status page, an emerging issues banner will be present in Service Health. Click the banner to see the full details of the issue. -- --## Get links and downloadable explanations --You can get a link for the issue to use in your problem management system. You can download PDF and sometimes CSV files to share with people who don't have access to the Azure portal. --[](./media/service-health-overview/azure-service-health-overview-3.png#lightbox) --## Get support from Microsoft --Contact support if your resource is left in a bad state even after the issue is resolved. Use the support links on the right of the page. --## Pin a personalized health map to your dashboard --Filter Service Health to show your business-critical subscriptions, regions, and resource types. Save the filter and pin a personalized health world map to your portal dashboard. --[](./media/service-health-overview/azure-service-health-overview-6a.png#lightbox) -- --## Configure service health alerts --Service Health integrates with Azure Monitor to alert you via emails, text messages, and webhook notifications when your business-critical resources are impacted. Set up an activity log alert for the appropriate service health event. Route that alert to the appropriate people in your organization using Action Groups. For more information, see [Configure Alerts for Service Health](./alerts-activity-log-service-notifications-portal.md) -->[!VIDEO https://www.microsoft.com/en-us/videoplayer/embed/RE2OaXt] --## Next steps --Set up alerts so you are notified of health issues. For more information, see [Best practices for setting up Azure Service Health Alerts](https://www.youtube.com/watch?v=k5d5ca8K6tc&list=PLLasX02E8BPBBSqygdRvlTnHfp1POwE8K&index=6&t=0s). |
| service-health | Service Health Portal Update | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/service-health-portal-update.md | - Title: Azure Service Health portal update -description: We're updating the Azure Service Health portal experience to let users engage with service events and manage actions to maintain the business continuity of impacted applications. - Previously updated : 06/10/2022---# Azure Service Health portal update --We're updating the Azure Service Health portal experience. The new experience lets users engage with service events and manage actions to maintain the business continuity of impacted applications. --The new experience will be rolled out in phases. Some users will see the updated experience, while others will still see the [classic Service Health portal experience](service-health-overview.md). In the new experience, you can select \*\*Switch to Classic\*\* to switch back to the old experience. ---## Highlights of the new experience --##### Health Alerts Blade -The Health Alerts blade has been updated for better usability. Users can search for and sort their alert rule by name. Users can also group their alert rules by subscription and status. ---In the new updated Health Alerts experience, users can click on their alert rule for additional details and see their alert firing history. --->[!Note] ->The classic experience for the Health Alerts blade will be retired. Users will not be able to switch back from the new experience once it is rolled out. --##### Tenant Level View - Users with [tenant admin access](admin-access-reference.md#roles-with-tenant-admin-access), can now view events at the tenant scope. The Service Issues, Health Advisories, Security Advisories, and Health History blades are updated to show events both at tenant and subscription levels. ---##### Filtering and Sorting -Users can filter on the scope (tenant or subscription) within the blades. The scope column indicates when an event is at the tenant or subscription level. Classic view does not support tenant-level events. Tenant-level events are only available in the new user interface. ---##### Enhanced Map -The Service Issues blade shows an enhanced version of the map with all the user services across the world. This version helps you find services that might be impacted by an outage easily. --##### Issues Details -The issues details look and feel has been updated, for better readability. --##### Removal of Personalized Dashboard -Users can no longer pin a personalized map to the dashboard. This feature has been deprecated in the new experience. --## Coming Soon --The following user interface(s) will be updated to the new experience. --> [!div class="checklist"] -> * Planned Maintenance |
| service-health | Service Notifications | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/service-notifications.md | - Title: View service health notifications by using the Azure portal -description: View your service health notifications in the Azure portal. Service health notifications are published by the Azure infrastructure into the Azure activity log. - Previously updated : 6/27/2019--# View service health notifications by using the Azure portal --Service health notifications are published by the Azure infrastructure into the [Azure activity log](../azure-monitor/essentials/platform-logs-overview.md). The notifications contain information about the resources under your subscription. Given the possibly large volume of information stored in the activity log, there is a separate user interface to make it easier to view and set up alerts on service health notifications. --Service health notifications can be informational or actionable, depending on the class. --For more information on the various classes of service health notifications, see [Service health notifications properties](service-health-notifications-properties.md). --## View your service health notifications in the Azure portal --1. In the [Azure portal](https://portal.azure.com), select **Monitor**. -- Azure Monitor brings together all your monitoring settings and data into one consolidated view. It first opens to the **Activity log** section. --1. Select **Service health**. --1. Select **+Create/Add activity log alert**, and set up an alert to ensure you are notified for future service notifications. For more information, see [Create activity log alerts on service notifications](./alerts-activity-log-service-notifications-portal.md). --## Next steps --* Learn more about [activity log alerts](/azure/azure-monitor/alerts/alerts-types). |
| service-health | Stay Informed Security | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/stay-informed-security.md | - Title: Stay informed about Azure security issues -description: This article shows you where Azure customers receive Azure security notifications and three steps you can follow to ensure security alerts reach the right people in your organization. - Previously updated : 10/27/2022--# Stay informed about Azure security issues --With the increased adoption of cloud computing, customers rely increasingly on Azure to run their workload for critical and non-critical business applications. It is important for you as Azure customers to stay informed about Azure security issues or privacy breaches and take the right action to protect your environment. --This article shows you where Azure customers receive Azure security notifications and three steps you can follow to ensure security alerts reach the right people in your organization. ---## View and manage Azure security notifications ---### Security issues affecting your Azure subscription workloads --You receive security-related notifications affecting your Azure **subscription** workloads in two ways: --**Security Advisory in [Azure Service Health](https://azure.microsoft.com/get-started/azure-portal/service-health/)** --Service Health notifications are published by Azure and contain information about the resources under your subscription. You can review these security advisories in the Service Health experience in the Azure portal and get notified about security advisories via your preferred channel by setting up Service Health alerts for this type of notification. You can create [Activity Log alerts](../service-health/alerts-activity-log-service-notifications-portal.md) on Service Health notifications by using the Azure Portal. -->[!Note] ->Depending on your requirements, you can configure various alerts to use the same [action group](../azure-monitor/alerts/action-groups.md) or different action groups. Action group types include sending a voice call, SMS, or email. You can also trigger various types of automated actions. --**Email Notification** --We communicate security-related information affecting your Azure subscription workloads via Email and/or Azure Service Health Notifications. We send notifications to subscription admins or owners. -->[!Note] ->You should ensure that there is a **contactable email address** as the [subscription administrator or subscription owner](../cost-management-billing/manage/add-change-subscription-administrator.md). This email address is used for security issues that would have impact at the subscription level. --### Security issues affecting your Azure tenant workloads --We communicate security-related information affecting your Azure **tenant** workloads via Email and/or Azure Service Health Notifications. We send notifications to Global Admin(s), Technical Contacts, and Security Admin(s). --> [!Note] -> You should ensure that there are **contactable email addresses** entered for your organization's [Global Admin(s)](../active-directory/roles/permissions-reference.md), [Technical Contact(s)](../active-directory/fundamentals/active-directory-properties-area.md), and [Security Admin(s)](/azure/defender-for-cloud/permissions). These email addresses are used for security issues that would have impact at the tenant level. --As of June 2024, we've enhanced the visibility of our Azure Service Health security communications. Typically, notifications are issued at the level for which they are architected. If a service is architected at the subscription level, we send communications at the subscription level. If the service is architected at the tenant level (such as Entra), we send communications at the tenant level. However, when Microsoft determines a security event is particularly impactful AND architected at the subscription level, we will also proactively issue additional communications at the tenant level to guarantee the broadest possible awareness.  --## Three steps to help you stay informed about Azure security issues --**1. Check Contact on Subscription Admin Owner Role** --Ensure that there is a **contactable email address** as the [subscription administrator or subscription owner](../cost-management-billing/manage/add-change-subscription-administrator.md). This email address is used for security issues that would have impact at the subscription level. --**2. Check Contacts for Tenant Global Admin, Technical Contact, and Security Admin Roles** --Ensure that there are **contactable email addresses** entered for your [Global Admin(s)](../active-directory/roles/permissions-reference.md), [Technical contact(s)](../active-directory/fundamentals/active-directory-properties-area.md), and [security admin(s)](/azure/defender-for-cloud/permissions). These email addresses are used for security issues that would have an impact at the tenant level. --**3. Create Azure Service Health Alerts for Subscription Notifications** --Create **Azure Service Health** alerts for security events so that your organization can be alerted for any security event that Microsoft identifies. This is the same channel you would configure to be alerted of outages, or maintenance information on the platform: [Create Activity Log Alerts on Service Notifications using the Azure portal](../service-health/alerts-activity-log-service-notifications-portal.md). --Depending on your requirements, you can configure various alerts to use the same [action group](../azure-monitor/alerts/action-groups.md) or different action groups. Action group types include sending a voice call, SMS, or email. You can also trigger various types of automated actions. --There's an important difference between Service Health security advisories and [Microsoft Defender for Cloud](/azure/defender-for-cloud/defender-for-cloud-introduction) security notifications. Security advisories in Service Health provide notifications dealing with platform vulnerabilities and security and privacy breaches at the subscription and tenant level. Security notifications in Microsoft Defender for Cloud communicate vulnerabilities that pertain to affected individual Azure resources. --More information about the Azure Service Health notifications can be found at: [What are Azure service health notifications? - Azure Service Health | Microsoft Learn](../service-health/service-health-notifications-properties.md) |
| service-health | Whats New | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/service-health/whats-new.md | - Title: What's new in Azure Service Health service -description: What's New in Azure Service Health service - Previously updated : 12/19/2022---# What's new in Azure Service Health service --This article lists recent changes in the Azure Service Health service. --## Azure Status page location changed -On July 25, 2022 the Azure status page location changed to [azure.status.microsoft](https://azure.status.microsoft) from status.azure.com. Starting February 2023, you will be automatically redirected to this new page. The current page will be discontinued soon after. --## User interface changes in Azure Status page -The following changes were made on July 25, 2022: --For more information on the Azure Status page, visit [Azure status overview](azure-status-overview.md) --## Azure Service Health Portal experience update -On June 6, 2022, the Azure Service Health portal experience was updated. For more information, see [Azure Service Health portal update](service-health-portal-update.md) |
| site-recovery | Encryption Feature Deprecation | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/site-recovery/encryption-feature-deprecation.md | Title: Deprecation of Azure Site Recovery data encryption feature description: Get details about the Azure Site Recovery data encryption feature. - - Previously updated : 03/02/2023+ Last updated : 09/06/2024 |
| site-recovery | File Server Disaster Recovery | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/site-recovery/file-server-disaster-recovery.md | Title: Protect a file server by using Azure Site Recovery description: This article describes how to protect a file server by using Azure Site Recovery - - Previously updated : 07/31/2019+ Last updated : 09/06/2024 |
| site-recovery | Hyper V Exclude Disk | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/site-recovery/hyper-v-exclude-disk.md | Title: Exclude Hyper-V VM disks from disaster recovery to Azure with Azure Site Recovery description: How to exclude Hyper-V VM disks from replication to Azure with Azure Site Recovery. - -+ Previously updated : 12/14/2023 Last updated : 09/06/2024 # Exclude disks from replication |
| site-recovery | Hyper V Vmm Network Mapping | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/site-recovery/hyper-v-vmm-network-mapping.md | Title: About Hyper-V (with VMM) network mapping with Site Recovery description: Describes how to set up network mapping for disaster recovery of Hyper-V VMs (managed in VMM clouds) to Azure, with Azure Site Recovery. - Previously updated : 01/10/2024+ Last updated : 09/06/2024 |
| site-recovery | Monitor Log Analytics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/site-recovery/monitor-log-analytics.md | -This article describes how to monitor machines replicated by Azure [Site Recovery](site-recovery-overview.md), using [Azure Monitor Logs](../azure-monitor/logs/data-platform-logs.md), and [Log Analytics](../azure-monitor/logs/log-query-overview.md). +This article describes how to monitor machines replicated by Azure [Site Recovery](site-recovery-overview.md), using [Azure Monitor Logs](/azure/azure-monitor/logs/data-platform-logs), and [Log Analytics](/azure/azure-monitor/logs/log-query-overview). Azure Monitor Logs provide a log data platform that collects activity and resource logs, along with other monitoring data. Within Azure Monitor Logs, you use Log Analytics to write and test log queries and interactively analyze log data. You can visualize and query log results, and configure alerts to take actions based on monitored data. Using Azure Monitor Logs with Site Recovery is supported for **Azure to Azure** Here's what you need: - At least one machine is protected in a Recovery Services vault.-- A Log Analytics workspace to store Site Recovery logs. [Learn about](../azure-monitor/logs/quick-create-workspace.md) setting up a workspace.-- A basic understanding of how to write, run, and analyze log queries in Log Analytics. [Learn more](../azure-monitor/logs/log-analytics-tutorial.md).+- A Log Analytics workspace to store Site Recovery logs. [Learn about](/azure/azure-monitor/logs/quick-create-workspace) setting up a workspace. +- A basic understanding of how to write, run, and analyze log queries in Log Analytics. [Learn more](/azure/azure-monitor/logs/log-analytics-tutorial). We recommend that you review [common monitoring questions](monitoring-common-questions.md) before you start. You can capture the data churn rate information and source data upload rate info 1. Go to the Log Analytics workspace and select **Advanced Settings**. 2. Select **Connected Sources** page and further select **Windows Servers**. 3. Download the Windows Agent (64-bit) on the Process Server. -4. [Obtain the workspace ID and key](../azure-monitor/agents/agent-windows.md#workspace-id-and-key) -5. [Configure agent to use TLS 1.2](../azure-monitor/agents/agent-windows.md#configure-agent-to-use-tls-12) -6. [Complete the agent installation](../azure-monitor/agents/agent-windows.md#install-the-agent) by providing the obtained workspace ID and key. +4. [Obtain the workspace ID and key](/azure/azure-monitor/agents/agent-windows#workspace-id-and-key) +5. [Configure agent to use TLS 1.2](/azure/azure-monitor/agents/agent-windows#configure-agent-to-use-tls-12) +6. [Complete the agent installation](/azure/azure-monitor/agents/agent-windows#install-the-agent) by providing the obtained workspace ID and key. 7. Once the installation is complete, go to Log Analytics workspace and select **Legacy agents management**. Go to the **Data** page and select **Windows Performance Counters**. 8. Select **'+'** to add the following two counters with a sample interval of 300 seconds: You can capture the data churn rate information and source data upload rate info ## Query the logs - examples -You retrieve data from logs using log queries written with the [Kusto query language](../azure-monitor/logs/get-started-queries.md). This section provides a few examples of common queries you might use for Site Recovery monitoring. +You retrieve data from logs using log queries written with the [Kusto query language](/azure/azure-monitor/logs/get-started-queries). This section provides a few examples of common queries you might use for Site Recovery monitoring. > [!NOTE] > Some of the examples use **replicationProviderName_s** set to **A2A**. This retrieves Azure virtual machines that are replicated to a secondary Azure region using Site Recovery. In these examples, you can replace **A2A** with **InMageRcm**, if you want to retrieve on-premises VMware virtual machines or physical servers that are replicated to Azure using Site Recovery. AzureDiagnosticsΓÇ» ## Set up alerts - examples -You can set up Site Recovery alerts based on Azure Monitor data. [Learn more](../azure-monitor/alerts/alerts-log.md#create-a-new-log-alert-rule-in-the-azure-portal) about setting up log alerts. +You can set up Site Recovery alerts based on Azure Monitor data. [Learn more](/azure/azure-monitor/alerts/alerts-log#create-a-new-log-alert-rule-in-the-azure-portal) about setting up log alerts. > [!NOTE] > Some of the examples use **replicationProviderName_s** set to **A2A**. This sets alerts for Azure virtual machines that are replicated to a secondary Azure region. In these examples, you can replace **A2A** with **InMageRcm** if you want to set alerts for on-premises VMware virtual machines or physical servers replicated to Azure. |
| site-recovery | Monitor Site Recovery Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/site-recovery/monitor-site-recovery-reference.md | To understand the fields of each Site Recovery table in Log Analytics, review th > [!TIP] > Expand this table for better readability. -| Category | Category Display Name | Log Table | [Supports basic log plan](../azure-monitor/logs/data-platform-logs.md#table-plans) | [Supports ingestion-time transformation](../azure-monitor/essentials/data-collection-transformations.md) | Example queries | Costs to export | +| Category | Category Display Name | Log Table | [Supports basic log plan](/azure/azure-monitor/logs/data-platform-logs#table-plans) | [Supports ingestion-time transformation](/azure/azure-monitor/essentials/data-collection-transformations) | Example queries | Costs to export | | | | | | | | | | *ASRReplicatedItems* | Azure Site Recovery Replicated Item Details | [ASRReplicatedItems](/azure/azure-monitor/reference/tables/asrreplicateditems) <br> This table contains details of Azure Site Recovery replicated items, such as associated vault, policy, replication health, failover readiness. etc. Data is pushed once a day to this table for all replicated items, to provide the latest information for each item. | No | No | [Queries](/azure/azure-monitor/reference/queries/asrreplicateditems) | Yes | | *AzureSiteRecoveryJobs* | Azure Site Recovery Jobs | [ASRJobs](/azure/azure-monitor/reference/tables/asrjobs) <br> This table contains records of Azure Site Recovery jobs such as failover, test failover, reprotection etc., with key details for monitoring and diagnostics, such as the replicated item information, duration, status, description, and so on. Whenever an Azure Site Recovery job is completed (that is, succeeded or failed), a corresponding record for the job is sent to this table. You can view history of Azure Site Recovery jobs by querying this table over a larger time range, provided your workspace has the required retention configured. | No | No | [Queries](/azure/azure-monitor/reference/queries/asrjobs) | No | |
| site-recovery | Report Site Recovery | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/site-recovery/report-site-recovery.md | Azure Site Recovery provides a reporting solution for Backup and Disaster Recove - Identifying key trends at different levels of detail. -Like [Azure Backup](../backup/configure-reports.md), Azure Site Recovery offers a reporting solution that uses [Azure Monitor logs](../azure-monitor/logs/log-analytics-tutorial.md) and [Azure workbooks](../azure-monitor/visualize/workbooks-overview.md). These resources help you gain insights on your estate that are protected with Site Recovery. +Like [Azure Backup](../backup/configure-reports.md), Azure Site Recovery offers a reporting solution that uses [Azure Monitor logs](/azure/azure-monitor/logs/log-analytics-tutorial) and [Azure workbooks](/azure/azure-monitor/visualize/workbooks-overview). These resources help you gain insights on your estate that are protected with Site Recovery. This article shows how to set up and view Azure Site Recovery reports. To start using Azure Site Recovery reports, follow these steps: Set up one or more Log Analytics workspaces to store your Backup reporting data. The location and subscription of this Log Analytics workspace, can be different from where your vaults are located or subscribed. -To set up a Log Analytics workspace, [follow these steps](../azure-monitor/logs/quick-create-workspace.md). The data in a Log Analytics workspace is kept for 30 days by default. If you want to see data for a longer time span, change the retention period of the Log Analytics workspace. To change the retention period, see [Configure data retention and archive policies in Azure Monitor Logs](../azure-monitor/logs/data-retention-configure.md). +To set up a Log Analytics workspace, [follow these steps](/azure/azure-monitor/logs/quick-create-workspace). The data in a Log Analytics workspace is kept for 30 days by default. If you want to see data for a longer time span, change the retention period of the Log Analytics workspace. To change the retention period, see [Configure data retention and archive policies in Azure Monitor Logs](/azure/azure-monitor/logs/data-retention-configure). ### Configure diagnostics settings for your vaults |
| site-recovery | Site Recovery Citrix Xenapp And Xendesktop | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/site-recovery/site-recovery-citrix-xenapp-and-xendesktop.md | Title: Set up Citrix XenDesktop/XenApp disaster recovery with Azure Site Recovery description: This article describes how to set up disaster recovery fo Citrix XenDesktop and XenApp deployments using Azure Site Recovery. - Previously updated : 11/27/2018 Last updated : 09/06/2024 # End of support for disaster recovery of Citrix workloads -As of March 2020, Citrix has announced deprecation and end-of-support for public cloud hosted workloads. Therefore, we do not recommend using Site Recovery for protecting Citrix workloads. +As of March 2020, Citrix announced the deprecation and end-of-support for public cloud hosted workloads. Therefore, we don't recommend using Site Recovery for protecting Citrix workloads. |
| site-recovery | Site Recovery Monitor And Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/site-recovery/site-recovery-monitor-and-troubleshoot.md | To configure email notifications for built-in Azure Monitor alerts for Azure Sit ### Configure notifications to non-email channels -With Azure Monitor action groups, you can route alerts to other notification channels like webhooks, logic apps, functions, etc. [Learn more about supported action groups in Azure Monitor](../azure-monitor/alerts/action-groups.md). +With Azure Monitor action groups, you can route alerts to other notification channels like webhooks, logic apps, functions, etc. [Learn more about supported action groups in Azure Monitor](/azure/azure-monitor/alerts/action-groups). ### Configure notifications through programmatic interfaces |
| site-recovery | Site Recovery Sharepoint | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/site-recovery/site-recovery-sharepoint.md | Title: Disaster recovery for a multi-tier SharePoint app using Azure Site Recovery description: This article describes how to set up disaster recovery for a multi-tier SharePoint application using Azure Site Recovery capabilities. - - Previously updated : 6/27/2019+ Last updated : 09/10/2024 This article describes in detail how to protect a SharePoint application using Microsoft SharePoint is a powerful application that can help a group or department organize, collaborate, and share information. SharePoint can provide intranet portals, document and file management, collaboration, social networks, extranets, websites, enterprise search, and business intelligence. It also has system integration, process integration, and workflow automation capabilities. Typically, organizations consider it as a Tier-1 application sensitive to downtime and data loss. -Today, Microsoft SharePoint does not provide any out-of-the-box disaster recovery capabilities. Regardless of the type and scale of a disaster, recovery involves the use of a standby data center that you can recover the farm to. Standby data centers are required for scenarios where local redundant systems and backups cannot recover from the outage at the primary data center. +Today, Microsoft SharePoint does not provide any out-of-the-box disaster recovery capabilities. Regardless of the type and scale of a disaster, recovery involves the use of a standby data center that you can recover the farm to. Standby data centers are required for scenarios where local redundant systems and backups can't recover from the outage at the primary data center. A good disaster recovery solution should allow modeling of recovery plans around the complex application architectures such as SharePoint. It should also have the ability to add customized steps to handle application mappings between various tiers and hence providing a single-click failover with a lower RTO in the event of a disaster. -This article describes in detail how to protect a SharePoint application using [Azure Site Recovery](site-recovery-overview.md). This article will cover best practices for replicating a three tier SharePoint application to Azure, how you can do a disaster recovery drill, and how you can failover the application to Azure. +This article describes in detail how to protect a SharePoint application using [Azure Site Recovery](site-recovery-overview.md). This article covers the best practices for replicating a three tier SharePoint application to Azure, how you can do a disaster recovery drill, and how you can fail over the application to Azure. -You can watch the below video about recovering a multi-tier application to Azure. ## Prerequisites Before you start, make sure you understand the following: ## SharePoint architecture -SharePoint can be deployed on one or more servers using tiered topologies and server roles to implement a farm design that meets specific goals and objectives. A typical large, high-demand SharePoint server farm that supports a high number of concurrent users and a large number of content items use service grouping as part of their scalability strategy. This approach involves running services on dedicated servers, grouping these services together, and then scaling out the servers as a group. The following topology illustrates the service and server grouping for a three tier SharePoint server farm. Please refer to SharePoint documentation and product line architectures for detailed guidance on different SharePoint topologies. You can find more details about SharePoint 2013 deployment in [this document](/SharePoint/sharepoint-server). +SharePoint can be deployed on one or more servers using tiered topologies and server roles to implement a farm design that meets specific goals and objectives. A typical large, high-demand SharePoint server farm that supports a high number of concurrent users and a large number of content items use service grouping as part of their scalability strategy. This approach involves running services on dedicated servers, grouping these services together, and then scaling out the servers as a group. The following topology illustrates the service and server grouping for a three tier SharePoint server farm. Refer to SharePoint documentation and product line architectures for detailed guidance on different SharePoint topologies. You can find more details about SharePoint 2013 deployment in [this document](/SharePoint/sharepoint-server). SharePoint can be deployed on one or more servers using tiered topologies and se ## Site Recovery support -Site Recovery is application-agnostic and should work with any version of SharePoint running on a supported machine. For creating this article, VMware virtual machines with Windows Server 2012 R2 Enterprise were used. SharePoint 2013 Enterprise edition and SQL server 2014 Enterprise edition were used. +Site Recovery is application-agnostic and should work with any version of SharePoint running on a supported machine. For this article, VMware virtual machines with Windows Server 2012 R2 Enterprise was used. SharePoint 2013 Enterprise edition and SQL server 2014 Enterprise edition were used. ### Source and target Site Recovery is application-agnostic and should work with any version of ShareP ### Things to keep in mind -If you are using a shared disk-based cluster as any tier in your application then you will not be able to use Site Recovery replication to replicate those virtual machines. You can use native replication provided by the application and then use a [recovery plan](site-recovery-create-recovery-plans.md) to failover all tiers. +If you're using a shared disk-based cluster as any tier in your application, then you wn't be able to use Site Recovery replication to replicate those virtual machines. You can use native replication provided by the application and then use a [recovery plan](site-recovery-create-recovery-plans.md) to fail over all tiers. ## Replicating virtual machines Follow [this guidance](./vmware-azure-tutorial.md) to start replicating the virtual machine to Azure. -* Once the replication is complete, make sure you go to each virtual machine of each tier and select same availability set in 'Replicated item > Settings > Properties > Compute and Network'. For example, if your web tier has 3 VMs, ensure all the 3 VMs are configured to be part of same availability set in Azure. +* Once the replication is complete, make sure you go to each virtual machine of each tier and select same availability set in **Replicated item**> **Settings** > **Properties** > **Compute and Network**. For example, if your web tier has 3 virtual machines, ensure all the 3 virtual machines are configured to be part of the same availability set in Azure.  Follow [this guidance](./vmware-azure-tutorial.md) to start replicating the virt ### Network properties -* For the App and Web tier VMs, configure network settings in Azure portal so that the VMs get attached to the right DR network after failover. +* For the App and Web tier virtual machines, configure network settings in Azure portal so that the virtual machines get attached to the right DR network after failover.  -* If you are using a static IP, then specify the IP that you want the virtual machine to take in the **Target IP** field +* If you're using a static IP, then specify the IP that you want the virtual machine to take in the **Target IP** field  In the Traffic Manager profile, [create the primary and recovery endpoints](../t Host a test page on a specific port (for example, 800) in the SharePoint web tier in order for Traffic Manager to automatically detect availability post failover. This is a workaround in case you cannot enable anonymous authentication on any of your SharePoint sites. -[Configure the Traffic Manager profile](../traffic-manager/traffic-manager-configure-priority-routing-method.md) with the below settings. +[Configure the Traffic Manager profile](../traffic-manager/traffic-manager-configure-priority-routing-method.md) with the following settings: * Routing method - 'Priority' * DNS time to live (TTL) - '30 seconds' Host a test page on a specific port (for example, 800) in the SharePoint web tie ## Creating a recovery plan -A recovery plan allows sequencing the failover of various tiers in a multi-tier application, hence, maintaining application consistency. Follow the below steps while creating a recovery plan for a multi-tier web application. [Learn more about creating a recovery plan](site-recovery-runbook-automation.md#customize-the-recovery-plan). +A recovery plan allows sequencing the failover of various tiers in a multi-tier application, hence, maintaining application consistency. Follow the given steps while creating a recovery plan for a multi-tier web application. [Learn more about creating a recovery plan](site-recovery-runbook-automation.md#customize-the-recovery-plan). ### Adding virtual machines to failover groups -1. Create a recovery plan by adding the App and Web tier VMs. -2. Click on 'Customize' to group the VMs. By default, all VMs are part of 'Group 1'. +1. Create a recovery plan by adding the App and Web tier virtual machines. +2. Click on 'Customize' to group the virtual machines. By default, all virtual machines are part of 'Group 1'.  -3. Create another Group (Group 2) and move the Web tier VMs into the new group. Your App tier VMs should be part of 'Group 1' and Web tier VMs should be part of 'Group 2'. This is to ensure that the App tier VMs boot up first followed by Web tier VMs. +3. Create another Group (Group 2) and move the Web tier virtual machines into the new group. Your App tier virtual machines should be part of 'Group 1' and Web tier virtual machines should be part of 'Group 2'. This is to ensure that the App tier virtual machines boot up first followed by Web tier virtual machines. ### Adding scripts to the recovery plan -You can deploy the most commonly used Azure Site Recovery scripts into your Automation account clicking the 'Deploy to Azure' button below. When you are using any published script, ensure you follow the guidance in the script. +You can deploy the most commonly used Azure Site Recovery scripts into your Automation account clicking the 'Deploy to Azure' button. When you're using any published script, ensure you follow the guidance in the script. [](https://aka.ms/asr-automationrunbooks-deploy) -1. Add a pre-action script to 'Group 1' to failover SQL Availability group. Use the 'ASR-SQL-FailoverAG' script published in the sample scripts. Ensure you follow the guidance in the script and make the required changes in the script appropriately. +1. Add a pre action script to 'Group 1' to failover SQL Availability group. Use the `ASR-SQL-FailoverAG` script published in the sample scripts. Ensure you follow the guidance in the script and make the required changes in the script appropriately.   -2. Add a post action script to attach a load balancer on the failed over virtual machines of Web tier (Group 2). Use the 'ASR-AddSingleLoadBalancer' script published in the sample scripts. Ensure you follow the guidance in the script and make the required changes in the script appropriately. +2. Add a post action script to attach a load balancer on the failed over virtual machines of Web tier (Group 2). Use the `ASR-AddSingleLoadBalancer` script published in the sample scripts. Ensure you follow the guidance in the script and make the required changes in the script appropriately.  You can deploy the most commonly used Azure Site Recovery scripts into your Auto 3. Add a manual step to update the DNS records to point to the new farm in Azure. - * For internet facing sites, no DNS updates are required post failover. Follow the steps described in the 'Networking guidance' section to configure Traffic Manager. If the Traffic Manager profile has been set up as described in the previous section, add a script to open dummy port (800 in the example) on the Azure VM. + * For internet facing sites, no DNS updates are required post failover. Follow the steps described in the 'Networking guidance' section to configure Traffic Manager. If the Traffic Manager profile has been set up as described in the previous section, add a script to open dummy port (800 in the example) on the Azure virtual machine. - * For internal facing sites, add a manual step to update the DNS record to point to the new Web tier VMΓÇÖs load balancer IP. + * For internal facing sites, add a manual step to update the DNS record to point to the new Web tier virtual machineΓÇÖs load balancer IP. 4. Add a manual step to restore search application from a backup or start a new search service. -5. For restoring Search service application from a backup, follow below steps. +5. For restoring Search service application from a backup, follow these steps: * This method assumes that a backup of the Search Service Application was performed before the catastrophic event and that the backup is available at the DR site. * This can easily be achieved by scheduling the backup (for example, once daily) and using a copy procedure to place the backup at the DR site. Copy procedures could include scripted programs such as AzCopy (Azure Copy) or setting up DFSR (Distributed File Services Replication). You can deploy the most commonly used Azure Site Recovery scripts into your Auto * Search is restored. Keep in mind that the restore expects to find the same topology (same number of servers) and same hard drive letters assigned to those servers. For more information, see ['Restore Search service application in SharePoint 2013'](/SharePoint/administration/restore-a-search-service-application) document. -6. For starting with a new Search service application, follow below steps. +6. For starting with a new Search service application, follow these steps: - * This method assumes that a backup of the ΓÇ£Search AdministrationΓÇ¥ database is available at the DR site. - * Since the other Search Service Application databases are not replicated, they need to be re-created. To do so, navigate to Central Administration and delete the Search Service Application. On any servers which host the Search Index, delete the index files. - * Re-create the Search Service Application and this re-creates the databases. It is recommended to have a prepared script that re-creates this service application since it is not possible to perform all actions via the GUI. For example, setting the index drive location and configuring the search topology are only possible by using SharePoint PowerShell cmdlets. Use the Windows PowerShell cmdlet Restore-SPEnterpriseSearchServiceApplication and specify the log-shipped and replicated Search Administration database, Search_Service__DB. This cmdlet gives the search configuration, schema, managed properties, rules, and sources and creates a default set of the other components. + * This method assumes that a backup of the *Search Administration* database is available at the DR site. + * Since the other Search Service Application databases aren't replicated, they need to be re-created. To do so, navigate to Central Administration and delete the Search Service Application. On any servers which host the Search Index, delete the index files. + * Re-create the Search Service Application and this re-creates the databases. It is recommended to have a prepared script that re-creates this service application since it's not possible to perform all actions via the GUI. For example, setting the index drive location and configuring the search topology are only possible by using SharePoint PowerShell cmdlets. Use the Windows PowerShell cmdlet Restore-SPEnterpriseSearchServiceApplication and specify the log-shipped and replicated Search Administration database, Search_Service__DB. This cmdlet gives the search configuration, schema, managed properties, rules, and sources and creates a default set of the other components. * Once the Search Service Application has be re-created, you must start a full crawl for each content source to restore the Search Service. You lose some analytics information from the on-premises farm, such as search recommendations. -7. Once all the steps are completed, save the recovery plan and the final recovery plan will look like following. +7. Once all the steps are completed, save the recovery plan and the final recovery plan looks like following:  ## Doing a test failover+ Follow [this guidance](site-recovery-test-failover-to-azure.md) to do a test failover. 1. Go to Azure portal and select your Recovery Service vault.-2. Click on the recovery plan created for SharePoint application. -3. Click on 'Test Failover'. +2. Select the recovery plan created for SharePoint application. +3. Select **Test Failover**. 4. Select recovery point and Azure virtual network to start the test failover process. 5. Once the secondary environment is up, you can perform your validations. 6. Once the validations are complete, you can click 'Cleanup test failover' on the recovery plan and the test failover environment is cleaned. |
| site-recovery | Vmware Azure Exclude Disk | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/site-recovery/vmware-azure-exclude-disk.md | Title: Exclude VMware VM disks from disaster recovery to Azure with Azure Site Recovery description: How to exclude VMware VM disks from replication to Azure with Azure Site Recovery. - -+ Previously updated : 05/27/2021 Last updated : 09/06/2024 |
| site-recovery | Vmware Azure Install Linux Master Target | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/site-recovery/vmware-azure-install-linux-master-target.md | Title: Install a master target server for Linux VM failback with Azure Site Reco description: Learn how to set up a Linux master target server for failback to an on-premises site during disaster recovery of VMware VMs to Azure using Azure Site Recovery. - -+ Previously updated : 03/07/2024 Last updated : 09/06/2024 |
| site-recovery | Vmware Azure Multi Tenant Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/site-recovery/vmware-azure-multi-tenant-overview.md | |
| site-recovery | Vmware Azure Set Up Process Server Azure | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/site-recovery/vmware-azure-set-up-process-server-azure.md | Title: Set up a process server VMware/physical failback in Azure Site Recovery description: This article describes how to set up a process server in Azure, to failback Azure VMs to VMware. - -+ Previously updated : 05/27/2021 Last updated : 09/06/2024 # Set up a process server in Azure for failback |
| site-recovery | Vmware Azure Set Up Process Server Scale | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/site-recovery/vmware-azure-set-up-process-server-scale.md | Title: Set up a scale-out process server during disaster recovery of VMware VMs and physical servers with Azure Site Recovery | Microsoft Docs' description: This article describes how to set up scale-out process server during disaster recovery of VMware VMs and physical servers. - -+ Previously updated : 05/27/2021 Last updated : 09/11/2024 -# Scale with additional process servers +# Scale with extra process servers -By default, when you're replicating VMware VMs or physical servers to Azure using [Site Recovery](site-recovery-overview.md), a process server is installed on the configuration server machine, and is used to coordinate data transfer between Site Recovery and your on-premises infrastructure. To increase capacity and scale out your replication deployment, you can add additional standalone process servers. This article describes how to setup a scale-out process server. +By default, when you're replicating VMware VMs or physical servers to Azure using [Site Recovery](site-recovery-overview.md), a process server is installed on the configuration server machine, and is used to coordinate data transfer between Site Recovery and your on-premises infrastructure. To increase capacity and scale out your replication deployment, you can add an extra standalone process servers. This article describes how to set up a scale-out process server. ## Before you start ### Capacity planning -Make sure you've performed [capacity planning](site-recovery-plan-capacity-vmware.md) for VMware replication. This helps you to identify how and when you should deploy additional process servers. +Ensure to perform [capacity planning](site-recovery-plan-capacity-vmware.md) for VMware replication. This helps you to identify how and when you should deploy extra process servers. -From 9.24 version, guidance is added during selection of process server for new replications. Process server will be marked Healthy, Warning and Critical based on certain criteria. To understand different scenarios that can influence state of process server, review the [process server alerts](vmware-physical-azure-monitor-process-server.md#process-server-alerts). +From 9.24 version, guidance is added during selection of process server for new replications. Process server is marked *Healthy*, *Warning*, and *Critical* based on certain criteria. To understand different scenarios that can influence state of process server, review the [process server alerts](vmware-physical-azure-monitor-process-server.md#process-server-alerts). > [!NOTE] > Use of a cloned Process Server component is not supported. Follow the steps in this article for each PS scale-out. ### Sizing requirements -Verify the sizing requirements summarized in the table. In general, if you have to scale your deployment to more than 200 source machines, or you have a total daily churn rate of more than 2 TB, you need additional process servers to handle the traffic volume. +Verify the sizing requirements summarized in the table. In general, if you have to scale your deployment to more than 200 source machines, or you have a total daily churn rate of more than 2 TB, you need extra process servers to handle the traffic volume. | **Additional process server** | **Cache disk size** | **Data change rate** | **Protected machines** | | | | | | |
| site-recovery | Vmware Azure Troubleshoot Vcenter Discovery Failures | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/site-recovery/vmware-azure-troubleshoot-vcenter-discovery-failures.md | description: This article describes how to troubleshooting VMware vCenter discov -+ Previously updated : 05/27/2021 Last updated : 09/06/2024 # Troubleshoot vCenter Server discovery failures |
| spring-apps | Application Observability | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/basic-standard/application-observability.md | This article uses the well-known [PetClinic](https://github.com/azure-samples/sp Log Analytics and Application Insights are deeply integrated with Azure Spring Apps. You can use Log Analytics to diagnose your application with various log queries and use Application Insights to investigate production issues. For more information, see the following articles: -- [Overview of Log Analytics in Azure Monitor](../../azure-monitor/logs/log-analytics-overview.md)-- [Azure Monitor Insights overview](../../azure-monitor/insights/insights-overview.md)+- [Overview of Log Analytics in Azure Monitor](/azure/azure-monitor/logs/log-analytics-overview) +- [Azure Monitor Insights overview](/azure/azure-monitor/insights/insights-overview) ## Prerequisites If you encounter production issues, you need to do a root cause analysis. Findin This section explains how to use Log Analytics to query the application logs and use Application Insights to investigate request failures. For more information, see the following articles: -- [Log Analytics tutorial](../../azure-monitor/logs/log-analytics-tutorial.md)-- [Application Map: Triage distributed applications](../../azure-monitor/app/app-map.md)+- [Log Analytics tutorial](/azure/azure-monitor/logs/log-analytics-tutorial) +- [Application Map: Triage distributed applications](/azure/azure-monitor/app/app-map) ### Log queries |
| spring-apps | Quickstart Logs Metrics Tracing | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/basic-standard/quickstart-logs-metrics-tracing.md | zone_pivot_groups: programming-languages-spring-apps ::: zone pivot="programming-language-csharp" -With the built-in monitoring capability in Azure Spring Apps, you can debug and monitor complex issues. Azure Spring Apps integrates Steeltoe [distributed tracing](https://docs.steeltoe.io/api/v3/tracing/) with Azure's [Application Insights](../../azure-monitor/app/app-insights-overview.md). This integration provides powerful logs, metrics, and distributed tracing capability from the Azure portal. +With the built-in monitoring capability in Azure Spring Apps, you can debug and monitor complex issues. Azure Spring Apps integrates Steeltoe [distributed tracing](https://docs.steeltoe.io/api/v3/tracing/) with Azure's [Application Insights](/azure/azure-monitor/app/app-insights-overview). This integration provides powerful logs, metrics, and distributed tracing capability from the Azure portal. The following procedures explain how to use Log Streaming, Log Analytics, Metrics, and Distributed Tracing with the sample app that you deployed in the preceding quickstarts. Executing ObjectResult, writing value of type 'System.Collections.Generic.KeyVal 1. Edit the query to remove the Where clauses that limit the display to warning and error logs. -1. Select **Run**. You're shown logs. For more information, see [Get started with log queries in Azure Monitor](../../azure-monitor/logs/get-started-queries.md). +1. Select **Run**. You're shown logs. For more information, see [Get started with log queries in Azure Monitor](/azure/azure-monitor/logs/get-started-queries). :::image type="content" source="media/quickstart-logs-metrics-tracing/logs-query-steeltoe.png" alt-text="Screenshot of the Azure portal that shows the Logs Analytics query result." lightbox="media/quickstart-logs-metrics-tracing/logs-query-steeltoe.png"::: Executing ObjectResult, writing value of type 'System.Collections.Generic.KeyVal ::: zone pivot="programming-language-java" -With the built-in monitoring capability in Azure Spring Apps, you can debug and monitor complex issues. Azure Spring Apps integrates [Spring Cloud Sleuth](https://spring.io/projects/spring-cloud-sleuth) with Azure's [Application Insights](../../azure-monitor/app/app-insights-overview.md). This integration provides powerful logs, metrics, and distributed tracing capability from the Azure portal. The following procedures explain how to use Log Streaming, Log Analytics, Metrics, and Distributed tracing with deployed PetClinic apps. +With the built-in monitoring capability in Azure Spring Apps, you can debug and monitor complex issues. Azure Spring Apps integrates [Spring Cloud Sleuth](https://spring.io/projects/spring-cloud-sleuth) with Azure's [Application Insights](/azure/azure-monitor/app/app-insights-overview). This integration provides powerful logs, metrics, and distributed tracing capability from the Azure portal. The following procedures explain how to use Log Streaming, Log Analytics, Metrics, and Distributed tracing with deployed PetClinic apps. ## Prerequisites Use the following steps to get the logs using the Azure Toolkit for IntelliJ: :::image type="content" source="media/quickstart-logs-metrics-tracing/logs-entry.png" alt-text="Screenshot of the Azure portal that shows the Queries page with Run highlighted." lightbox="media/quickstart-logs-metrics-tracing/logs-entry.png"::: -1. Then you're shown filtered logs. For more information, see [Get started with log queries in Azure Monitor](../../azure-monitor/logs/get-started-queries.md). +1. Then you're shown filtered logs. For more information, see [Get started with log queries in Azure Monitor](/azure/azure-monitor/logs/get-started-queries). :::image type="content" source="media/quickstart-logs-metrics-tracing/logs-query.png" alt-text="Screenshot of the Azure portal that shows the query result of filtered logs." lightbox="media/quickstart-logs-metrics-tracing/logs-query.png"::: |
| spring-apps | Quickstart Setup Log Analytics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/basic-standard/quickstart-setup-log-analytics.md | Complete the previous quickstart in this series: [Provision an Azure Spring Apps ## Create a Log Analytics workspace -To create a workspace, follow the steps in [Create a Log Analytics workspace](../../azure-monitor/logs/quick-create-workspace.md). +To create a workspace, follow the steps in [Create a Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace). ## Set up Log Analytics for a new service In the wizard for creating an Azure Spring Apps service instance, you can config 1. Fill out the form on the **Diagnostic setting** page: - **Diagnostic setting name**: Set a unique name for the configuration.- - **Logs** > **Categories**: Select **ApplicationConsole** and **SystemLogs**. For more information on log categories and contents, see [Diagnostic settings in Azure Monitor](../../azure-monitor/essentials/diagnostic-settings.md). + - **Logs** > **Categories**: Select **ApplicationConsole** and **SystemLogs**. For more information on log categories and contents, see [Diagnostic settings in Azure Monitor](/azure/azure-monitor/essentials/diagnostic-settings). - **Destination details**: Select **Send to Log Analytics workspace** and specify the Log Analytics workspace that you created previously. :::image type="content" source="media/quickstart-setup-log-analytics/diagnostic-settings-edit-form.png" alt-text="Screenshot that shows an example of set-up diagnostic settings." lightbox="media/quickstart-setup-log-analytics/diagnostic-settings-edit-form.png"::: Setting up for a new service isn't applicable when you're using the Azure CLI. --query id --output tsv ``` -1. Configure the diagnostic settings. For more information on log categories and contents, see [Diagnostic settings in Azure Monitor](../../azure-monitor/essentials/diagnostic-settings.md). +1. Configure the diagnostic settings. For more information on log categories and contents, see [Diagnostic settings in Azure Monitor](/azure/azure-monitor/essentials/diagnostic-settings). ```azurecli az monitor diagnostic-settings create \ |
| spring-apps | Quickstart Analyze Logs And Metrics Standard Consumption | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/consumption-dedicated/quickstart-analyze-logs-and-metrics-standard-consumption.md | Azure Spring Apps provides the metrics described in the following table: The Azure Monitor metrics explorer enables you to create charts from metric data to help you analyze your Azure Spring Apps resource and network usage over time. You can pin charts to a dashboard or in a shared workbook. -1. Open the metrics explorer in the Azure portal by selecting **Metrics** in the navigation pane on the overview page of your Azure Spring Apps instance. To learn more about metrics explorer, see [Analyze metrics with Azure Monitor metrics explorer](../../azure-monitor/essentials/analyze-metrics.md). +1. Open the metrics explorer in the Azure portal by selecting **Metrics** in the navigation pane on the overview page of your Azure Spring Apps instance. To learn more about metrics explorer, see [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics). 1. Create a chart by selecting a metric in the **Metric** dropdown menu. You can modify the chart by changing the aggregation, adding more metrics, changing time ranges and intervals, adding filters, and applying splitting. |
| spring-apps | Concept Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/enterprise/concept-metrics.md | The following table applies to the Tanzu Spring Cloud Gateway in Enterprise plan ## Next steps * [Quickstart: Monitoring Azure Spring Apps apps with logs, metrics, and tracing](../basic-standard/quickstart-logs-metrics-tracing.md)-* [Analyze metrics with Azure Monitor metrics explorer](../../azure-monitor/essentials/analyze-metrics.md) +* [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics) * [Analyze logs and metrics with diagnostics settings](./diagnostic-services.md) * [Tutorial: Monitor Spring app resources using alerts and action groups](./tutorial-alerts-action-groups.md) * [Quotas and Service Plans for Azure Spring Apps](./quotas.md) |
| spring-apps | Diagnostic Services | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/enterprise/diagnostic-services.md | Choose the log category and metric category you want to monitor. For a complete list of metrics, see the [User metrics options](./concept-metrics.md#user-metrics-options) section of [Metrics for Azure Spring Apps](concept-metrics.md). -To get started, enable one of these services to receive the data. To learn about configuring Log Analytics, see [Get started with Log Analytics in Azure Monitor](../../azure-monitor/logs/log-analytics-tutorial.md). +To get started, enable one of these services to receive the data. To learn about configuring Log Analytics, see [Get started with Log Analytics in Azure Monitor](/azure/azure-monitor/logs/log-analytics-tutorial). ## Configure diagnostics settings To learn more about sending diagnostics information to a storage account, see [S 1. To review application logs, search for an event hub called **insights-logs-applicationconsole**. 1. To review application metrics, search for an event hub called **insights-metrics-pt1m**. -To learn more about sending diagnostics information to an event hub, see [Streaming Azure Diagnostics data in the hot path by using Event Hubs](../../azure-monitor/agents/diagnostics-extension-stream-event-hubs.md). +To learn more about sending diagnostics information to an event hub, see [Streaming Azure Diagnostics data in the hot path by using Event Hubs](/azure/azure-monitor/agents/diagnostics-extension-stream-event-hubs). ## Analyze the logs -Azure Log Analytics is running with a Kusto engine so you can query your logs for analysis. For a quick introduction to querying logs by using Kusto, review the [Log Analytics tutorial](../../azure-monitor/logs/log-analytics-tutorial.md). +Azure Log Analytics is running with a Kusto engine so you can query your logs for analysis. For a quick introduction to querying logs by using Kusto, review the [Log Analytics tutorial](/azure/azure-monitor/logs/log-analytics-tutorial). Application logs provide critical information and verbose logs about your application's health, performance, and more. In the next sections are some simple queries to help you understand your application's current and past states. AppPlatformSystemLogs  ### Learn more about querying application logs -Azure Monitor provides extensive support for querying application logs by using Log Analytics. To learn more about this service, see [Get started with log queries in Azure Monitor](../../azure-monitor/logs/get-started-queries.md). For more information about building queries to analyze your application logs, see [Overview of log queries in Azure Monitor](../../azure-monitor/logs/log-query-overview.md). +Azure Monitor provides extensive support for querying application logs by using Log Analytics. To learn more about this service, see [Get started with log queries in Azure Monitor](/azure/azure-monitor/logs/get-started-queries). For more information about building queries to analyze your application logs, see [Overview of log queries in Azure Monitor](/azure/azure-monitor/logs/log-query-overview). ### Convenient entry points in Azure portal |
| spring-apps | Faq | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/enterprise/faq.md | For the quickest way to get started with Azure Spring Apps, follow the instructi ### Where can I view my Spring application logs and metrics? -Find metrics in the App Overview tab and the [Azure Monitor](../../azure-monitor/essentials/data-platform-metrics.md#metrics-explorer) tab. +Find metrics in the App Overview tab and the [Azure Monitor](/azure/azure-monitor/essentials/data-platform-metrics#metrics-explorer) tab. -Azure Spring Apps supports exporting Spring application logs and metrics to Azure Storage, Event Hubs, and [Log Analytics](../../azure-monitor/logs/data-platform-logs.md). The table name in Log Analytics is *AppPlatformLogsforSpring*. To learn how to enable it, see [Diagnostic services](diagnostic-services.md). +Azure Spring Apps supports exporting Spring application logs and metrics to Azure Storage, Event Hubs, and [Log Analytics](/azure/azure-monitor/logs/data-platform-logs). The table name in Log Analytics is *AppPlatformLogsforSpring*. To learn how to enable it, see [Diagnostic services](diagnostic-services.md). ### Does Azure Spring Apps support distributed tracing? |
| spring-apps | How To Application Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/enterprise/how-to-application-insights.md | az spring app-insights update \ This section applies to the Enterprise plan only, and provides instructions that supplement the previous section. -The Azure Spring Apps Enterprise plan uses buildpack bindings to integrate [Azure Application Insights](../../azure-monitor/app/app-insights-overview.md) with the type `ApplicationInsights`. For more information, see [How to configure APM integration and CA certificates](how-to-enterprise-configure-apm-integration-and-ca-certificates.md). +The Azure Spring Apps Enterprise plan uses buildpack bindings to integrate [Azure Application Insights](/azure/azure-monitor/app/app-insights-overview) with the type `ApplicationInsights`. For more information, see [How to configure APM integration and CA certificates](how-to-enterprise-configure-apm-integration-and-ca-certificates.md). To create an Application Insights buildpack binding, use the following command: When data is stored in Application Insights, it contains the history of Azure Sp * [Analyze logs and metrics](diagnostic-services.md) * [Stream logs in real time](./how-to-log-streaming.md)-* [Application Map](../../azure-monitor/app/app-map.md) -* [Live Metrics](../../azure-monitor/app/live-stream.md) -* [Metrics](../../azure-monitor/essentials/tutorial-metrics.md) -* [Logs](../../azure-monitor/logs/data-platform-logs.md) +* [Application Map](/azure/azure-monitor/app/app-map) +* [Live Metrics](/azure/azure-monitor/app/live-stream) +* [Metrics](/azure/azure-monitor/essentials/tutorial-metrics) +* [Logs](/azure/azure-monitor/logs/data-platform-logs) |
| spring-apps | How To Circuit Breaker Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/enterprise/how-to-circuit-breaker-metrics.md | Use the following steps to build and deploy the sample applications. > [!NOTE] > If you don't enable Application Insights, you can enable the Java In-Process agent. For more information, see the [Manage Application Insights using the Azure portal](./how-to-application-insights.md#manage-application-insights-using-the-azure-portal) section of [Use Application Insights Java In-Process Agent in Azure Spring Apps](./how-to-application-insights.md). -1. Enable dimension collection for resilience4j metrics. For more information, see the [Custom metrics dimensions and preaggregation](../../azure-monitor/app/pre-aggregated-metrics-log-metrics.md#custom-metrics-dimensions-and-preaggregation) section of [Log-based and preaggregated metrics in Application Insights](../../azure-monitor/app/pre-aggregated-metrics-log-metrics.md). +1. Enable dimension collection for resilience4j metrics. For more information, see the [Custom metrics dimensions and preaggregation](/azure/azure-monitor/app/pre-aggregated-metrics-log-metrics#custom-metrics-dimensions-and-preaggregation) section of [Log-based and preaggregated metrics in Application Insights](/azure/azure-monitor/app/pre-aggregated-metrics-log-metrics). 1. Select **Metrics** in the navigation pane. The **Metrics** page provides dropdown menus and options to define the charts in this procedure. For all charts, set **Metric Namespace** to **azure.applicationinsights**. Use the following steps to build and deploy the sample applications. > [!NOTE] > If there's no default Application Insights available, you can enable the Java In-Process agent. For more information, see the [Manage Application Insights using the Azure portal](./how-to-application-insights.md#manage-application-insights-using-the-azure-portal) section of [Use Application Insights Java In-Process Agent in Azure Spring Apps](./how-to-application-insights.md). -1. Enable dimension collection for resilience4j metrics. For more information, see the [Custom metrics dimensions and preaggregation](../../azure-monitor/app/pre-aggregated-metrics-log-metrics.md#custom-metrics-dimensions-and-preaggregation) section of [Log-based and preaggregated metrics in Application Insights](../../azure-monitor/app/pre-aggregated-metrics-log-metrics.md). +1. Enable dimension collection for resilience4j metrics. For more information, see the [Custom metrics dimensions and preaggregation](/azure/azure-monitor/app/pre-aggregated-metrics-log-metrics#custom-metrics-dimensions-and-preaggregation) section of [Log-based and preaggregated metrics in Application Insights](/azure/azure-monitor/app/pre-aggregated-metrics-log-metrics). 1. Select **Metrics** in the navigation pane. The **Metrics** page provides dropdown menus and options to define the charts in this procedure. For all charts, set **Metric Namespace** to **azure.applicationinsights**. |
| spring-apps | How To Configure Enterprise Spring Cloud Gateway | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/enterprise/how-to-configure-enterprise-spring-cloud-gateway.md | To monitor VMware Spring Cloud Gateway, you can configure APM. The following tab For other supported environment variables, see the following sources: -- [Application Insights overview](../../azure-monitor/app/app-insights-overview.md?tabs=net)+- [Application Insights overview](/azure/azure-monitor/app/app-insights-overview?tabs=net) - [Dynatrace environment variables](https://www.dynatrace.com/support/help/setup-and-configuration/setup-on-cloud-platforms/microsoft-azure-services/azure-integrations/azure-spring#envvar) - [New Relic environment variables](https://docs.newrelic.com/docs/apm/agents/java-agent/configuration/java-agent-configuration-config-file/#Environment_Variables) - [AppDynamics environment variables](https://docs.appdynamics.com/appd/24.x/24.3/en/application-monitoring/install-app-server-agents/java-agent/monitor-azure-spring-cloud-with-java-agent#id-.MonitorAzureSpringCloudwithJavaAgentv24.3-ConfigureUsingtheEnvironmentVariablesorSystemProperties) |
| spring-apps | How To Configure Ingress | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/enterprise/how-to-configure-ingress.md | This article shows you how to set and update an application's ingress settings i The Azure Spring Apps service uses an underlying ingress controller to handle application traffic management. The following ingress settings are supported for customization. -| Name | Ingress setting | Default value | Valid range | Description | -|-|||-|--| -| `ingress-read-timeout` | `proxy-read-timeout` | 300 | \[1,1800\] | The timeout in seconds for reading a response from a proxied server. | -| `ingress-send-timeout` | `proxy-send-timeout` | 60 | \[1,1800\] | The timeout in seconds for transmitting a request to the proxied server. | -| `session-affinity` | `affinity` | None | Session, None | The type of the affinity that will make the request come to the same pod replica that was responding to the previous request. Set `session-affinity` to Cookie to enable session affinity. In the portal only, you must choose the enable session affinity box. | -| `session-max-age` | `session-cookie-max-age` | 0 | \[0, 604800\] | The time in seconds until the cookie expires, corresponding to the `Max-Age` cookie directive. If you set `session-max-age` to 0, the expiration period is equal to the browser session period. | -| `backend-protocol` | `backend-protocol` | Default | Default, GRPC | Sets the backend protocol to indicate how NGINX should communicate with the backend service. Default means HTTP/HTTPS/WebSocket. The `backend-protocol` setting only applies to client-to-app traffic. For app-to-app traffic within the same service instance, choose any protocol for app-to-app traffic without modifying the `backend-protocol` setting. The protocol doesn't restrict your choice of protocol for app-to-app traffic within the same service instance. | +| Name | Ingress setting | Default value | Valid range | Description | +||--||-|--| +| `ingress-read-timeout` | `proxy-read-timeout` | 300 | \[1,1800\] | The timeout in seconds for reading a response from a proxied server. | +| `ingress-send-timeout` | `proxy-send-timeout` | 60 | \[1,1800\] | The timeout in seconds for transmitting a request to the proxied server. | +| `session-affinity` | `affinity` | None | `Session`, `None` | The type of the affinity that makes the request come to the same pod replica that was responding to the previous request. Set `session-affinity` to Cookie to enable session affinity. In the portal only, you must choose the enable session affinity box. | +| `session-max-age` | `session-cookie-max-age` | 0 | \[0, 604800\] | The time in seconds until the cookie expires, corresponding to the `Max-Age` cookie directive. If you set `session-max-age` to 0, the expiration period is equal to the browser session period. | +| `backend-protocol` | `backend-protocol` | Default | Default, `GRPC` | Sets the backend protocol to indicate how NGINX should communicate with the backend service. Default means HTTP/HTTPS/WebSocket. The `backend-protocol` setting only applies to client-to-app traffic. For app-to-app traffic within the same service instance, choose any protocol for app-to-app traffic without modifying the `backend-protocol` setting. The protocol doesn't restrict your choice of protocol for app-to-app traffic within the same service instance. | +| `client-auth` | `client-auth` | 0 selected | - | Select the certificates with the public key you uploaded in the TLS/SSL settings. Ingress concatenates these certificates into one and then uses it for client authentication. | ## Prerequisites Use the following Azure CLI command to set the ingress configuration when you cr az spring app create \ --resource-group <resource-group-name> \ --service <service-name> \- --name <service-name> \ + --name <app-name> \ --ingress-read-timeout 300 \ --ingress-send-timeout 60 \ --session-affinity Cookie \ --session-max-age 1800 \ --backend-protocol Default \+ --client-auth-certs <cert-id> ``` +> [!NOTE] +> The `cert-id` value is in the format `/subscriptions/<your-sub-id>/resourceGroups/<resource-group-name>/providers/Microsoft.AppPlatform/Spring/<service-name>/certificates/<cert-name>`. To get the `cert-id` value, use the following command: `az spring certificate show --service <service-instance-name> --resource-group <resource-group-name> --name <certificate-name> --query id` + This command creates an app with the following settings: - Ingress read timeout: 300 seconds This command creates an app with the following settings: - Session affinity: Cookie - Session cookie max age: 1800 seconds - Backend protocol: Default+- Client Auth: cert-name ## Update the ingress settings for an existing app Use the following command to update the ingress settings for an existing app. az spring app update \ --resource-group <resource-group-name> \ --service <service-name> \- --name <service-name> \ + --name <app-name> \ --ingress-read-timeout 600 \ --ingress-send-timeout 600 \ --session-affinity None \ --session-max-age 0 \ --backend-protocol GRPC \+ --client-auth-certs '' ``` This command updates the app with the following settings: This command updates the app with the following settings: - Session affinity: None - Session cookie max age: 0 - Backend protocol: GRPC+- Client Auth: 0 selected This command updates the app with the following settings: - How do you enable WebSocket? - WebSocket is enabled by default if you set the backend protocol to *Default*. The WebSocket connection limit is 20000. When you reach that limit, the connection will fail. + WebSocket is enabled by default if you set the backend protocol to *Default*. The WebSocket connection limit is 20000. When you reach that limit, the connection fails. You can also use RSocket based on WebSocket. - What is the difference between ingress config and ingress settings? - Ingress config can still be used in the Azure CLI and SDK, and that setting will apply to all apps within the service instance. Once an app has been configured by ingress settings, the Ingress config won't affect it. We don't recommend that new scripts use ingress config since we plan to stop supporting it in the future. + Ingress config can still be used in the Azure CLI and SDK, and that setting applies to all apps within the service instance. After ingress settings configure an app, the Ingress config can't affect it. We don't recommend that new scripts use ingress config since we plan to stop supporting it in the future. - When ingress settings are used together with App Gateway/APIM, what happens when you set the timeout in both Azure Spring Apps ingress and the App Gateway/APIM? |
| spring-apps | How To Configure Palo Alto | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/enterprise/how-to-configure-palo-alto.md | crl.microsoft.com, crl3.digicert.com ``` -Name the third file *AzureMonitorAddresses.csv*. This file should contain all addresses and IP ranges to be made available for metrics and monitoring via Azure Monitor, if you're using Azure monitor. The values in the following example are for demonstration purposes only. For up-to-date values, see [IP addresses used by Azure Monitor](../../azure-monitor/ip-addresses.md). +Name the third file *AzureMonitorAddresses.csv*. This file should contain all addresses and IP ranges to be made available for metrics and monitoring via Azure Monitor, if you're using Azure monitor. The values in the following example are for demonstration purposes only. For up-to-date values, see [IP addresses used by Azure Monitor](/azure/azure-monitor/ip-addresses). ```CSV name,type,address,tag |
| spring-apps | How To Enterprise Configure Apm Integration And Ca Certificates | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/enterprise/how-to-enterprise-configure-apm-integration-and-ca-certificates.md | This section lists the supported languages and required environment variables fo Environment variables required for buildpack binding: - `connection-string` - For other supported environment variables, see [Application Insights Overview](../../azure-monitor/app/app-insights-overview.md?tabs=java). + For other supported environment variables, see [Application Insights Overview](/azure/azure-monitor/app/app-insights-overview?tabs=java). - **DynaTrace** |
| spring-apps | How To Migrate Standard Tier To Enterprise Tier | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/enterprise/how-to-migrate-standard-tier-to-enterprise-tier.md | Use the following steps to provision an Azure Spring Apps service instance: - Choose an existing Application Insights instance or create a new Application Insights instance. - Enter a **Sampling rate** in the range of 0-100, or use the default value 10. - You can also enable Application Insights after you provision the Azure Spring Apps instance. For more information about Application Insights pricing, see the [Application Insights billing](../../azure-monitor/logs/cost-logs.md#application-insights-billing) section of [Azure Monitor Logs cost calculations and options](../../azure-monitor/logs/cost-logs.md). + You can also enable Application Insights after you provision the Azure Spring Apps instance. For more information about Application Insights pricing, see the [Application Insights billing](/azure/azure-monitor/logs/cost-logs#application-insights-billing) section of [Azure Monitor Logs cost calculations and options](/azure/azure-monitor/logs/cost-logs). > [!NOTE] > You'll pay for the usage of Application Insights when integrated with Azure Spring Apps. Use the following steps to build locally: ## Use Application Insights -The Azure Spring Apps Enterprise plan uses buildpack bindings to integrate [Application Insights](../../azure-monitor/app/app-insights-overview.md) with the type `ApplicationInsights` instead of In-Process Agent. For more information, see [How to configure APM integration and CA certificates](how-to-enterprise-configure-apm-integration-and-ca-certificates.md). +The Azure Spring Apps Enterprise plan uses buildpack bindings to integrate [Application Insights](/azure/azure-monitor/app/app-insights-overview) with the type `ApplicationInsights` instead of In-Process Agent. For more information, see [How to configure APM integration and CA certificates](how-to-enterprise-configure-apm-integration-and-ca-certificates.md). The following table lists the APM providers available the plans. |
| spring-apps | How To Setup Autoscale | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/enterprise/how-to-setup-autoscale.md | If you're on the Basic plan and constrained by one or more of these limits, you ## Next steps -* [Overview of autoscale in Microsoft Azure](../../azure-monitor/autoscale/autoscale-overview.md) +* [Overview of autoscale in Microsoft Azure](/azure/azure-monitor/autoscale/autoscale-overview) * [Azure CLI Monitoring autoscale](/cli/azure/monitor/autoscale) |
| spring-apps | How To Start Stop Service | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/enterprise/how-to-start-stop-service.md | The following list describes some common actions you can take to recover from th ## Next steps - [Monitor app lifecycle events using Azure Activity log and Azure Service Health](./monitor-app-lifecycle-events.md)-- [Azure Monitor cost and usage](../../azure-monitor/cost-usage.md)+- [Azure Monitor cost and usage](/azure/azure-monitor/cost-usage) |
| spring-apps | How To Troubleshoot Enterprise Spring Cloud Gateway | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/enterprise/how-to-troubleshoot-enterprise-spring-cloud-gateway.md | Use the following steps to adjust the log levels: ## Setup alert rules -You can create alert rules based on logs and metrics. For more information, see [Create or edit a metric alert rule](../../azure-monitor/alerts/alerts-create-metric-alert-rule.yml). +You can create alert rules based on logs and metrics. For more information, see [Create or edit a metric alert rule](/azure/azure-monitor/alerts/alerts-create-metric-alert-rule). Use the following steps to directly create alert rules from the Azure portal for Azure Spring Apps: |
| spring-apps | Monitor App Lifecycle Events | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/enterprise/monitor-app-lifecycle-events.md | Azure Spring Apps provides built-in tools to monitor the status and health of yo ## Monitor app lifecycle events triggered by users in Azure Activity logs -[Azure Activity logs](../../azure-monitor/essentials/activity-log.md) contain resource events emitted by operations taken on the resources in your subscription. The following details for application lifecycle events (such as start, stop, and restart) are added into Azure Activity Logs: +[Azure Activity logs](/azure/azure-monitor/essentials/activity-log) contain resource events emitted by operations taken on the resources in your subscription. The following details for application lifecycle events (such as start, stop, and restart) are added into Azure Activity Logs: - The time the operation occurred. - The status of the operation. To see the affected instances when you restart your app, navigate to your Azure ## Monitor app lifecycle events in Azure Service Health -[Azure Resource Health](../../service-health/resource-health-overview.md) helps you diagnose and get support for issues that may affect the availability of your service. These issues include service incidents, planned maintenance periods, and regional outages. Application restarting events are added into Azure Service Health. They include both unexpected incidents (for example, an unplanned app crash) and scheduled actions (for example, planned maintenance). +[Azure Resource Health](/azure/service-health/resource-health-overview) helps you diagnose and get support for issues that may affect the availability of your service. These issues include service incidents, planned maintenance periods, and regional outages. Application restarting events are added into Azure Service Health. They include both unexpected incidents (for example, an unplanned app crash) and scheduled actions (for example, planned maintenance). ### Monitor unplanned app lifecycle events |
| spring-apps | Structured App Log | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/enterprise/structured-app-log.md | AppPlatformLogsforSpring ## Next steps -* To learn more about the Log Query, see [Get started with log queries in Azure Monitor](../../azure-monitor/logs/get-started-queries.md) +* To learn more about the Log Query, see [Get started with log queries in Azure Monitor](/azure/azure-monitor/logs/get-started-queries) |
| spring-apps | Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/enterprise/troubleshoot.md | When you're debugging application crashes, start by checking the running status > "required memory 2728741K is greater than 2000M available for allocation" -To learn more about Azure Log Analytics, see [Get started with Log Analytics in Azure Monitor](../../azure-monitor/logs/log-analytics-tutorial.md). +To learn more about Azure Log Analytics, see [Get started with Log Analytics in Azure Monitor](/azure/azure-monitor/logs/log-analytics-tutorial). ### My application experiences high CPU usage or high memory usage For more information, see [Metrics for Azure Spring Apps](./concept-metrics.md). If all instances are up and running, go to Azure Log Analytics to query your application logs and review your code logic. This review helps you see whether any of them might affect scale partitioning. For more information, see [Analyze logs and metrics with diagnostics settings](diagnostic-services.md). -To learn more about Azure Log Analytics, see [Get started with Log Analytics in Azure Monitor](../../azure-monitor/logs/log-analytics-tutorial.md). Query the logs by using the [Kusto query language](/azure/kusto/query/). +To learn more about Azure Log Analytics, see [Get started with Log Analytics in Azure Monitor](/azure/azure-monitor/logs/log-analytics-tutorial). Query the logs by using the [Kusto query language](/azure/kusto/query/). ### Checklist for deploying your Spring application to Azure Spring Apps If you're migrating an existing Spring Cloud-based solution to Azure, be sure to You can also check the *Service Registry* client logs in Azure Log Analytics. For more information, see [Analyze logs and metrics with diagnostics settings](diagnostic-services.md) -To learn more about Azure Log Analytics, see [Get started with Log Analytics in Azure Monitor](../../azure-monitor/logs/log-analytics-tutorial.md). Query the logs by using the [Kusto query language](/azure/kusto/query/). +To learn more about Azure Log Analytics, see [Get started with Log Analytics in Azure Monitor](/azure/azure-monitor/logs/log-analytics-tutorial). Query the logs by using the [Kusto query language](/azure/kusto/query/). ### I want to inspect my application's environment variables Check to see whether the `spring-boot-actuator` dependency is enabled in your ap </dependency> ``` -If your application logs can be archived to a storage account but not sent to Azure Log Analytics, check to see whether you set up your workspace correctly. For more information, see [Create a Log Analytics workspace](../../azure-monitor/logs/quick-create-workspace.md). Also, be aware that the Basic plan doesn't provide a service-level agreement (SLA). For more information, see [Service Level Agreements (SLA) for Online Services](https://azure.microsoft.com/support/legal/sla/log-analytics/v1_3/). +If your application logs can be archived to a storage account but not sent to Azure Log Analytics, check to see whether you set up your workspace correctly. For more information, see [Create a Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace). Also, be aware that the Basic plan doesn't provide a service-level agreement (SLA). For more information, see [Service Level Agreements (SLA) for Online Services](https://azure.microsoft.com/support/legal/sla/log-analytics/v1_3/). ## Enterprise plan |
| spring-apps | Tutorial Alerts Action Groups | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/enterprise/tutorial-alerts-action-groups.md | Use the following steps configure an alert: In this article, you learned how to set up alerts and action groups for an application in Azure Spring Apps. To learn more about action groups, see: > [!div class="nextstepaction"]-> [Action groups](../../azure-monitor/alerts/action-groups.md) +> [Action groups](/azure/azure-monitor/alerts/action-groups) |
| spring-apps | Vnet Customer Responsibilities | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/spring-apps/enterprise/vnet-customer-responsibilities.md | Azure Firewall provides the FQDN tag `AzureKubernetesService` to simplify the fo ## Azure Spring Apps optional FQDN for Application Insights -You need to open some outgoing ports in your server's firewall to allow the Application Insights SDK or the Application Insights Agent to send data to the portal. For more information, see the [Outgoing ports](../../azure-monitor/ip-addresses.md#outgoing-ports) section of [IP addresses used by Azure Monitor](../../azure-monitor/ip-addresses.md). +You need to open some outgoing ports in your server's firewall to allow the Application Insights SDK or the Application Insights Agent to send data to the portal. For more information, see the [Outgoing ports](/azure/azure-monitor/ip-addresses#outgoing-ports) section of [IP addresses used by Azure Monitor](/azure/azure-monitor/ip-addresses). ## Next steps |
| static-web-apps | Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/static-web-apps/monitor.md | -Enable [Application Insights](../azure-monitor/app/app-insights-overview.md) to monitor API requests, failures, and tracing information. +Enable [Application Insights](/azure/azure-monitor/app/app-insights-overview) to monitor API requests, failures, and tracing information. > [!IMPORTANT] > Application Insights has an [independent pricing model](https://azure.microsoft.com/pricing/details/monitor) from Azure Static Web Apps. Use the following steps to add Application Insights monitoring to your static we Once you create the Application Insights instance, it creates an associated application setting in the Azure Static Web Apps instance used to link the services together. > [!NOTE]-> If you want to track how the different features of your web app are used end-to-end client side, you can insert trace calls in your JavaScript code. For more information, see [Application Insights for webpages](../azure-monitor/app/javascript.md?tabs=snippet). +> If you want to track how the different features of your web app are used end-to-end client side, you can insert trace calls in your JavaScript code. For more information, see [Application Insights for webpages](/azure/azure-monitor/app/javascript?tabs=snippet). ## Access data Once you create the Application Insights instance, it creates an associated appl The following table highlights a few locations in the portal you can use to inspect aspects of your application's API endpoints. > [!NOTE]-> For more information on Application Insights usage, see the [App insights overview](../azure-monitor/app/app-insights-overview.md). +> For more information on Application Insights usage, see the [App insights overview](/azure/azure-monitor/app/app-insights-overview). | Type | Menu location | Description | | | | |-| [Failures](../azure-monitor/app/asp-net-exceptions.md) | _Investigate > Failures_ | Review failed requests. | -| [Server requests](../azure-monitor/app/tutorial-performance.md) | _Investigate > Performance_ | Review individual API requests. | -| [Logs](../azure-monitor/app/search-and-transaction-diagnostics.md?tabs=transaction-search) | _Monitoring > Logs_ | Interact with an editor to query transaction logs. | -| [Metrics](../azure-monitor/essentials/app-insights-metrics.md) | _Monitoring > Metrics_ | Interact with a designer to create custom charts using various metrics. | +| [Failures](/azure/azure-monitor/app/asp-net-exceptions) | _Investigate > Failures_ | Review failed requests. | +| [Server requests](/azure/azure-monitor/app/tutorial-performance) | _Investigate > Performance_ | Review individual API requests. | +| [Logs](/azure/azure-monitor/app/search-and-transaction-diagnostics?tabs=transaction-search) | _Monitoring > Logs_ | Interact with an editor to query transaction logs. | +| [Metrics](/azure/azure-monitor/essentials/app-insights-metrics) | _Monitoring > Metrics_ | Interact with a designer to create custom charts using various metrics. | ### Traces |
| static-web-apps | Troubleshooting | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/static-web-apps/troubleshooting.md | There are three folder locations specified in the workflow. Ensure these setting ## Review server errors -Use [Application Insights](../azure-monitor/app/app-insights-overview.md) to find runtime error messages. If you don't already have an instance created, refer to [Monitoring Azure Static Web Apps](monitor.md). Application Insights logs the full error message and stack trace generated by each error. +Use [Application Insights](/azure/azure-monitor/app/app-insights-overview) to find runtime error messages. If you don't already have an instance created, refer to [Monitoring Azure Static Web Apps](monitor.md). Application Insights logs the full error message and stack trace generated by each error. > [!NOTE] > You can only view error messages that are generated after Application Insights is installed. |
| storage-actions | Storage Tasks Monitor Data Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage-actions/storage-tasks/storage-tasks-monitor-data-reference.md | For more information on the schema of Activity Log entries, see [Activity Log s ## See Also - See [Monitoring Azure Storage Actions](monitor-storage-tasks.md) for a description of monitoring Azure Storage Actions.-- See [Monitoring Azure resources with Azure Monitor](../../azure-monitor/essentials/monitor-azure-resource.md) for details on monitoring Azure resources.+- See [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) for details on monitoring Azure resources. |
| storage-mover | Log Monitoring | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage-mover/log-monitoring.md | After your Storage Mover diagnostic setting has been saved, it will be reflected ## Analyzing logs -All resource logs in Azure Monitor have the same fields, and are followed by service-specific fields. The common schema is outlined in [Azure Monitor resource log schema](../azure-monitor/essentials/resource-logs-schema.md). +All resource logs in Azure Monitor have the same fields, and are followed by service-specific fields. The common schema is outlined in [Azure Monitor resource log schema](/azure/azure-monitor/essentials/resource-logs-schema). Storage Mover generates two tables, StorageMoverCopyLogsFailed and StorageMoverJobRunLogs. The schema for **StorageMoverCopyLogsFailed** is found in the [Azure Storage Copy log data reference](/azure/azure-monitor/reference/tables/StorageMoverCopyLogsFailed), and the schema for **StorageMoverJobRunLogs** is found in the [Azure Storage Job run log data reference](/azure/azure-monitor/reference/tables/StorageMoverJobRunLogs). After the **Welcome** window is closed within the main content pane, the **New Q ### Sample Kusto queries -After you send logs to Log Analytics, you can access those logs by using Azure Monitor log queries. For more information, see the [Log Analytics tutorial](../azure-monitor/logs/log-analytics-tutorial.md). +After you send logs to Log Analytics, you can access those logs by using Azure Monitor log queries. For more information, see the [Log Analytics tutorial](/azure/azure-monitor/logs/log-analytics-tutorial). -The following sample queries provided can be entered in the **Log search** bar to help you monitor your migration. These queries work with the [new language](../azure-monitor/logs/log-query-overview.md). +The following sample queries provided can be entered in the **Log search** bar to help you monitor your migration. These queries work with the [new language](/azure/azure-monitor/logs/log-query-overview). - To list all the files that failed to copy from a specific job run within the last 30 days. The following sample queries provided can be entered in the **Log search** bar t Get started with any of these guides. -- [Log Analytics workspaces](../azure-monitor/logs/log-analytics-workspace-overview.md)-- [Azure Monitor Logs overview](../azure-monitor/logs/data-platform-logs.md)-- [Diagnostic settings in Azure Monitor](../azure-monitor/essentials/diagnostic-settings.md?tabs=portal)+- [Log Analytics workspaces](/azure/azure-monitor/logs/log-analytics-workspace-overview) +- [Azure Monitor Logs overview](/azure/azure-monitor/logs/data-platform-logs) +- [Diagnostic settings in Azure Monitor](/azure/azure-monitor/essentials/diagnostic-settings?tabs=portal) - [Azure Storage Mover support bundle overview](troubleshooting.md) - [Troubleshooting Storage Mover job run error codes](status-code.md) |
| storage | Anonymous Read Access Prevent | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/blobs/anonymous-read-access-prevent.md | To understand how disallowing anonymous access may affect client applications, w ### Monitor anonymous requests with Metrics Explorer -To track anonymous requests to a storage account, use Azure Metrics Explorer in the Azure portal. For more information about Metrics Explorer, see [Analyze metrics with Azure Monitor metrics explorer](../../azure-monitor/essentials/analyze-metrics.md). +To track anonymous requests to a storage account, use Azure Metrics Explorer in the Azure portal. For more information about Metrics Explorer, see [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics). Follow these steps to create a metric that tracks anonymous requests: After you have configured the metric, anonymous requests will begin to appear on :::image type="content" source="media/anonymous-read-access-prevent/metric-anonymous-blob-requests.png" alt-text="Screenshot showing aggregated anonymous requests against Blob storage"::: -You can also configure an alert rule to notify you when a certain number of anonymous requests are made against your storage account. For more information, see [Create, view, and manage metric alerts using Azure Monitor](../../azure-monitor/alerts/alerts-metric.md). +You can also configure an alert rule to notify you when a certain number of anonymous requests are made against your storage account. For more information, see [Create, view, and manage metric alerts using Azure Monitor](/azure/azure-monitor/alerts/alerts-metric). ### Analyze logs to identify containers receiving anonymous requests Azure Storage logs capture details about requests made against the storage accou To log requests to your Azure Storage account in order to evaluate anonymous requests, you can use Azure Storage logging in Azure Monitor. For more information, see [Monitor Azure Storage](./monitor-blob-storage.md). -Azure Storage logging in Azure Monitor supports using log queries to analyze log data. To query logs, you can use an Azure Log Analytics workspace. To learn more about log queries, see [Tutorial: Get started with Log Analytics queries](../../azure-monitor/logs/log-analytics-tutorial.md). +Azure Storage logging in Azure Monitor supports using log queries to analyze log data. To query logs, you can use an Azure Log Analytics workspace. To learn more about log queries, see [Tutorial: Get started with Log Analytics queries](/azure/azure-monitor/logs/log-analytics-tutorial). #### Create a diagnostic setting in the Azure portal -To log Azure Storage data with Azure Monitor and analyze it with Azure Log Analytics, you must first create a diagnostic setting that indicates what types of requests and for which storage services you want to log data. After you configure logging for your storage account, the logs are available in the Log Analytics workspace. To create a workspace, see [Create a Log Analytics workspace in the Azure portal](../../azure-monitor/logs/quick-create-workspace.md). +To log Azure Storage data with Azure Monitor and analyze it with Azure Log Analytics, you must first create a diagnostic setting that indicates what types of requests and for which storage services you want to log data. After you configure logging for your storage account, the logs are available in the Log Analytics workspace. To create a workspace, see [Create a Log Analytics workspace in the Azure portal](/azure/azure-monitor/logs/quick-create-workspace). To learn how to create a diagnostic setting in the Azure portal, see [Create diagnostic settings in Azure Monitor](/azure/azure-monitor/essentials/create-diagnostic-settings). StorageBlobLogs | project TimeGenerated, AccountName, AuthenticationType, Uri ``` -You can also configure an alert rule based on this query to notify you about anonymous requests. For more information, see [Create, view, and manage log alerts using Azure Monitor](../../azure-monitor/alerts/alerts-log.md). +You can also configure an alert rule based on this query to notify you about anonymous requests. For more information, see [Create, view, and manage log alerts using Azure Monitor](/azure/azure-monitor/alerts/alerts-log). ### Responses to anonymous requests |
| storage | Archive Cost Estimation | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/blobs/archive-cost-estimation.md | description: Learn how to calculate the cost of storing and maintaining data in Previously updated : 07/31/2024 Last updated : 9/10/2024 The following chart shows the impact on monthly spending given various read perc ## Sample prices -This article uses the following fictitious prices. --> [!IMPORTANT] -> These prices are meant only as examples, and should not be used to calculate your costs. --| Price factor | Archive | Cold | Cool | -|--|--|--|--| -| Price of write operations (per 10,000) | $0.11 | $0.18 | $0.10 | -| Price of a single write operation (cost / 10,000) | $0.000011 | $0.000018 | $0.00001 | -| Data prices (pay-as-you-go) | $0.0020 | $0.0045 | $0.0115 | -| Price of read operations (per 10,000) | $5.50 | $0.10 | $0.01 | -| Price of a single read operation (cost / 10,000) | $0.00055 | $0.00001 | $0.000001 | -| Price of high priority read operations (per 10,000) | $50.00 | N/A | N/A | -| Price of data retrieval (per GB) | $0.02 | $0.03 | $0.01 | -| Price of high priority data retrieval (per GB) | $0.10 | N/A | N/A | --For official prices, see [Azure Blob Storage pricing](https://azure.microsoft.com/pricing/details/storage/blobs/) or [Azure Data Lake Storage pricing](https://azure.microsoft.com/pricing/details/storage/data-lake/). --For more information about how to choose the correct pricing page, see [Understand the full billing model for Azure Blob Storage](../common/storage-plan-manage-costs.md). ## Next steps |
| storage | Azcopy Cost Estimation | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/blobs/azcopy-cost-estimation.md | The following table calculates the number of write operations required to upload | Calculation | Value | |--|-| | Number of MiB in 5 GiB | 5,120 |-| PutBlock operations per blob (5,120 MiB / 8 MiB block) | 640 | +| PutBlock operations per blob (5,120 MiB / 8-MiB block) | 640 | | PutBlockList operations per blob | 1 | | **Total write operations (1,000 * 641)** | **641,000** | The following table calculates the number of write operations required to upload | Calculation | Value | |-|--| | Number of MiB in 5 GiB | 5,120 |-| Path - Update (append) operations per blob (5,120 MiB / 4 MiB block) | 1,280 | +| Path - Update (append) operations per blob (5,120 MiB / 4-MiB block) | 1,280 | | Path - Update (flush) operations per blob | 1 | | **Total write operations (1,000 * 1,281)** | **1,281,00** | The following table calculates the number of write operations required to upload | Calculation | Value | |-|| | Number of MiB in 5 GiB | 5,120 |-| Path - Update operations per blob (5,120 MiB / 4 MiB block) | 1,280 | -| Total read operations (1000* 1,280) | **1,280,000** | +| Path - Update operations per blob (5,120 MiB / 4-MiB block) | 1,280 | +| Total read operations (1000 * 1,280) | **1,280,000** | Using the [Sample prices](#sample-prices) that appear in this article, the following table calculates the cost to download these blobs. The following table contains all of the estimates presented in this article. All ## Sample prices -The following table includes sample (fictitious) prices for each request to the Blob Service endpoint (`blob.core.windows.net`). For official prices, see [Azure Blob Storage pricing](https://azure.microsoft.com/pricing/details/storage/blobs/). --| Price factor | Hot | Cool | Cold | Archive | -|--||||| -| Price of write transactions (per 10,000) | $0.055 | $0.10 | $0.18 | $0.10 | -| Price of read transactions (per 10,000) | $0.0044 | $0.01 | $0.10 | $5.50 | -| Price of data retrieval (per GiB) | Free | $0.01 | $0.03 | $0.022 | -| List and container operations (per 10,000) | $0.055 | $0.050 | $0.065 | $0.055 | -| All other operations (per 10,000) | $0.0044 | $0.0044 | $0.0052 | $0.0044 | --The following table includes sample prices (fictitious) prices for each request to the Data Lake Storage endpoint (`dfs.core.windows.net`). For official prices, see [Azure Data Lake Storage pricing](https://azure.microsoft.com/pricing/details/storage/data-lake/). --| Price factor | Hot | Cool | Cold | Archive | -|||||| -| Price of write transactions (every 4 MiB, per 10,000) | $0.0720 | $0.13 | $0.234 | $0.143 | -| Price of read transactions (every 4 MiB, per 10,000) | $0.0057 | $0.013 | $0.13 | $7.15 | -| Price of data retrieval (per GiB) | Free | $0.01 | $0.03 | $0.022 | -| Iterative Read operations (per 10,000) | $0.0715 | $0.0715 | $0.0845 | $0.0715 | --## Operations used by AzCopy commands --The following table shows the operations that are used by each AzCopy command. To map each operation to a price, see [Map each REST operation to a price](map-rest-apis-transaction-categories.md). --### Commands that target the Blob Service Endpoint --| Command | Scenario | Operations | -||-|--| -| [azcopy bench](../common/storage-ref-azcopy-bench.md?toc=/azure/storage/blobs/toc.json) | Upload | [Put Block](/rest/api/storageservices/put-block-list) and [Put Block List](/rest/api/storageservices/put-block-list). Possibly [Put Blob](/rest/api/storageservices/put-blob) based on object size.| -| [azcopy bench](../common/storage-ref-azcopy-bench.md?toc=/azure/storage/blobs/toc.json) | Download |[List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), and [Get Blob](/rest/api/storageservices/get-blob) | -| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Upload | [Put Block](/rest/api/storageservices/put-block-list), [Put Block List](/rest/api/storageservices/put-block-list), and [Get Blob Properties](/rest/api/storageservices/get-blob-properties). Possibly [Put Blob](/rest/api/storageservices/put-blob) based on object size. | -| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Download | [List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), and [Get Blob](/rest/api/storageservices/get-blob) | -| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Perform a dry run | [List Blobs](/rest/api/storageservices/list-blobs) | -| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Copy from Amazon S3|[Put Blob from URL](/rest/api/storageservices/put-blob-from-url). Based on object size, could also be [Put Block From URL](/rest/api/storageservices/put-block-from-url) and [Put Block List](/rest/api/storageservices/put-block-list). | -| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Copy from Google Cloud Storage |[Put Blob from URL](/rest/api/storageservices/put-blob-from-url). Based on object size, could also be [Put Block From URL](/rest/api/storageservices/put-block-from-url) and [Put Block List](/rest/api/storageservices/put-block-list). | -| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Copy to another container |[List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), and [Put Blob From URL](/rest/api/storageservices/put-blob-from-url). Based on object size, could also be [Put Block From URL](/rest/api/storageservices/put-block-from-url) and [Put Block List](/rest/api/storageservices/put-block-list). | -| [azcopy sync](../common/storage-ref-azcopy-sync.md?toc=/azure/storage/blobs/toc.json) | Update local with changes to container |[List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), and [Get Blob](/rest/api/storageservices/get-blob) | -| [azcopy sync](../common/storage-ref-azcopy-sync.md?toc=/azure/storage/blobs/toc.json) | Update container with changes to local file system |[List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), [Put Block](/rest/api/storageservices/put-block-list), and [Put Block List](/rest/api/storageservices/put-block-list). Possibly [Put Blob](/rest/api/storageservices/put-blob) based on object size. | -| [azcopy sync](../common/storage-ref-azcopy-sync.md?toc=/azure/storage/blobs/toc.json) | Synchronize containers |[List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), and [Put Blob From URL](/rest/api/storageservices/put-blob-from-url). Based on object size, could also be [Put Block From URL](/rest/api/storageservices/put-block-from-url) and [Put Block List](/rest/api/storageservices/put-block-list). | -| [azcopy set-properties](../common/storage-ref-azcopy-set-properties.md?toc=/azure/storage/blobs/toc.json) | Set blob tier |[Set Blob Tier](/rest/api/storageservices/set-blob-tier) and [List Blobs](/rest/api/storageservices/list-blobs) (if targeting a virtual directory) | -| [azcopy set-properties](../common/storage-ref-azcopy-set-properties.md?toc=/azure/storage/blobs/toc.json) | Set metadata |[Set Blob Metadata](/rest/api/storageservices/set-blob-metadata) and [List Blobs](/rest/api/storageservices/list-blobs) (if targeting a virtual directory) | -| [azcopy set-properties](../common/storage-ref-azcopy-set-properties.md?toc=/azure/storage/blobs/toc.json) | Set blob tags |[Set Blob Tags](/rest/api/storageservices/set-blob-tags) and [List Blobs](/rest/api/storageservices/list-blobs) (if targeting a virtual directory) | -| [azcopy list](../common/storage-ref-azcopy-list.md?toc=/azure/storage/blobs/toc.json) | List blobs in a container|[List Blobs](/rest/api/storageservices/list-blobs) | -| [azcopy make](../common/storage-ref-azcopy-make.md?toc=/azure/storage/blobs/toc.json) | Create a container |[Create Container](/rest/api/storageservices/create-container) | -| [azcopy remove](../common/storage-ref-azcopy-remove.md?toc=/azure/storage/blobs/toc.json) | Delete a container |[Delete Container](/rest/api/storageservices/delete-container) | -| [azcopy remove](../common/storage-ref-azcopy-remove.md?toc=/azure/storage/blobs/toc.json) | Delete a blob |[Get Blob Properties](/rest/api/storageservices/get-blob-properties). [List Blobs](/rest/api/storageservices/list-blobs) (if targeting a virtual directory), and [Delete Blob](/rest/api/storageservices/delete-blob) | --### Commands that target the Data Lake Storage endpoint --| Command | Scenario | Operations | -||-|--| -| [azcopy bench](../common/storage-ref-azcopy-bench.md?toc=/azure/storage/blobs/toc.json) | Upload | [Path - Update](/rest/api/storageservices/datalakestoragegen2/path/update) (Append), and [Path - Update](/rest/api/storageservices/datalakestoragegen2/path/update) (Flush) | -| [azcopy bench](../common/storage-ref-azcopy-bench.md?toc=/azure/storage/blobs/toc.json) | Download | [List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), and [Path - Read](/rest/api/storageservices/datalakestoragegen2/path/read)| -| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Upload | [Path - Update](/rest/api/storageservices/datalakestoragegen2/path/update), and [Get Blob Properties](/rest/api/storageservices/get-blob-properties) | -| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Download |[List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), and [Path - Read](/rest/api/storageservices/datalakestoragegen2/path/read) | -| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Perform a dry run | [List Blobs](/rest/api/storageservices/list-blobs) | -| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Copy from Amazon S3| Not supported | -| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Copy from Google Cloud Storage | Not supported | -| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Copy to another container | [List Blobs](/rest/api/storageservices/list-blobs), and [Copy Blob](/rest/api/storageservices/copy-blob). if --preserve-permissions-true, then [Path - Get Properties](/rest/api/storageservices/datalakestoragegen2/path/get-properties) (Get Access Control List) and [Path - Update](/rest/api/storageservices/datalakestoragegen2/path/update) (Set access control) otherwise, [Get Blob Properties](/rest/api/storageservices/get-blob-properties). | -| [azcopy sync](../common/storage-ref-azcopy-sync.md?toc=/azure/storage/blobs/toc.json) | Update local with changes to container | [List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), and [Get Blob](/rest/api/storageservices/get-blob) | -| [azcopy sync](../common/storage-ref-azcopy-sync.md?toc=/azure/storage/blobs/toc.json) | Update container with changes to local file system | [List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), [Path - Update](/rest/api/storageservices/datalakestoragegen2/path/update) (Append), and [Path - Update](/rest/api/storageservices/datalakestoragegen2/path/update) (Flush)| -| [azcopy sync](../common/storage-ref-azcopy-sync.md?toc=/azure/storage/blobs/toc.json) | Synchronize containers | [List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), and [Copy Blob](/rest/api/storageservices/copy-blob) | -| [azcopy set-properties](../common/storage-ref-azcopy-set-properties.md?toc=/azure/storage/blobs/toc.json) | Set blob tier | Not supported | -| [azcopy set-properties](../common/storage-ref-azcopy-set-properties.md?toc=/azure/storage/blobs/toc.json) | Set metadata | Not supported | -| [azcopy set-properties](../common/storage-ref-azcopy-set-properties.md?toc=/azure/storage/blobs/toc.json) | Set blob tags | Not supported | -| [azcopy list](../common/storage-ref-azcopy-list.md?toc=/azure/storage/blobs/toc.json) | List blobs in a container| [List Blobs](/rest/api/storageservices/list-blobs)| -| [azcopy make](../common/storage-ref-azcopy-make.md?toc=/azure/storage/blobs/toc.json) | Create a container | [Filesystem - Create](/rest/api/storageservices/datalakestoragegen2/filesystem/create) | -| [azcopy remove](../common/storage-ref-azcopy-remove.md?toc=/azure/storage/blobs/toc.json) | Delete a container | [Filesystem - Delete](/rest/api/storageservices/datalakestoragegen2/filesystem/delete) | -| [azcopy remove](../common/storage-ref-azcopy-remove.md?toc=/azure/storage/blobs/toc.json) | Delete a blob | [Filesystem - Delete](/rest/api/storageservices/datalakestoragegen2/filesystem/delete) | ## See also - [Plan and manage costs for Azure Blob Storage](../common/storage-plan-manage-costs.md)+- [Map each AzCopy command to a REST operation](../common/storage-reference-azcopy-map-commands-to-rest-operations.md?toc=/azure/storage/blobs/toc.json&bc=/azure/storage/blobs/breadcrumb/toc.json) - [Map each REST operation to a price](map-rest-apis-transaction-categories.md) - [Get started with AzCopy](../common/storage-use-azcopy-v10.md) |
| storage | Blob Storage Estimate Costs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/blobs/blob-storage-estimate-costs.md | + + Title: Estimate the cost of using Azure Blob Storage +description: Learn how to estimate the cost of using Azure Blob Storage. ++++ Last updated : 09/10/2024+++++# Estimate the cost of using Azure Blob Storage ++This article helps you estimate the cost to store, upload, download, and work with data in Azure Blob Storage. ++All calculations are based on a fictitious price. You can find each price in the [sample prices](#sample-prices) section at the end of this article. ++> [!IMPORTANT] +> These prices are meant only as examples, and shouldn't be used to calculate your costs. For official prices, see the [Azure Blob Storage pricing](https://azure.microsoft.com/pricing/details/storage/blobs/) or [Azure Data Lake Storage pricing](https://azure.microsoft.com/pricing/details/storage/data-lake/) pages. For more information about how to choose the correct pricing page, see [Understand the full billing model for Azure Blob Storage](../common/storage-plan-manage-costs.md). ++## The cost to store data ++You can calculate your storage costs by multiplying the <u>size of your data</u> in GB by the <u>storage price of the chosen access tier</u>. For example (assuming [sample pricing](#sample-prices)), if you plan to store 10 TB of blobs in the cool access tier, the capacity cost is $0.0115 * 10 * 1024 = **$117.78** per month. ++Depending on how much storage space you require, it might make sense to [reserve capacity](../blobs/storage-blob-reserved-capacity.md) at a discount. You can reserve capacity in increments of 100 TB and 1 PB for a 1-year or 3-year commitment duration. Reserved capacity is available only for data stored in the hot, cool, and archive access tiers. ++Using the [Sample prices](#sample-prices) that appear in this article, the following table compares the pay-as-you-go and reserved capacity cost of storing 100 TB (102,400 GB) of data. ++| Calculation | Hot | Cool | Archive | +|--|--||| +| Monthly price for 100 TB of storage | $2,130 | $963 | $205 | +| Monthly price for 100 TB of storage (one-year reserved) | $1,747 | $966 | $183 | +| Monthly price for 100 TB of storage (three-year reserved) | $1,406 | $872 | $168 | ++To calculate the point at which reserved capacity begins to make sense, divide the cost of reserved capacity by the pay-as-you-go rate. For example, if the cost of 1-year reserved capacity for cool tier storage is $966 and the pay-as-you-go rate is $0.0115, then the calculation is $966 / $0.0115 = 84,000 GB (roughly **82 TB**). If you plan to store at least 82 TB of data in the cool tier for the entirety of the reservation period, then reserved capacity begins to make sense. The following table calculates break even point in TB for each access tier. ++| Calculation | Hot | Cool | Archive | +||-||| +| Monthly price per GB of Data storage (pay-as-you-go) | $0.0208 | $0.0115 | $0.002 | +| Price for 100 TB of reserved storage | $1,747 | $966 | $183 | +| Break even for 1-year reserved capacity | 82 TB<sup>1 | 82 TB | 89 TB | +| Break even for 3-year reserved capacity | 66 TB<sup>1 | 74 TB | 82 TB | ++<sup>1</sup>The hot tier has multiple pay-as-you-go rates. The price of the first 50 TB and the price of the second 50 TB are factored into this calculation.<br /> ++To learn more about reserved capacity, see [Optimize costs for Blob Storage with reserved capacity](storage-blob-reserved-capacity.md). ++For general information about storage costs, see [Data storage and index meters](../common/storage-plan-manage-costs.md#data-storage-and-index-meters). ++## The cost to transfer data ++When you transfer data, you're billed for _write_ and _read_ operations. Some client applications use additional operations to transfer data such as operations to list blobs or get properties. The [AzCopy](../common/storage-use-azcopy-s3.md) utility is optimized to data transfer efficiently and can serve as a canonical example on which to base your cost estimates. ++See [Estimate the cost of using AzCopy to transfer blobs](azcopy-cost-estimation.md). ++#### The cost to upload ++When you upload data, your client divides that data into blocks and uploads each block individually. Each block that is upload is billed as a _write_ operation. A final write operation is needed to assemble blocks into a blob that is stored in the account. The number of write operations required to upload a blob depends on the size of each block. **8 MiB** is the default block size for uploads to the Blob Service endpoint (`blob.core.windows.net`) and that size is configurable. **4 MiB** is the block size for uploads to the Data Lake Storage endpoint (`dfs.core.windows.net`) and that size isn't configurable. A smaller block size performs better because blocks can upload in parallel. However, the cost is higher because more write operations are required to upload a blob. ++Using the [Sample prices](#sample-prices) that appear in this article, and assuming an **8-MiB** block size, the following table estimates the cost to upload **1000** blobs that are each **5 MiB** in size to the hot tier. ++| Price factor | Value | +|-|-| +| Number of MiB in 5 GiB | 5,120 | +| Write operations per blob (5,120 MiB / 8-MiB block) | 640 | +| Write operation to commit the blocks | 1 | +| **Total write operations (1,000 * 641)** | 641,000 | +| Price of a single write operation (price / 10,000) | $0.0000055 | +| **Cost of write operations (641,000 * operation price)** | **$3.5255** | +| **Total cost (write + properties)** | **$3.5250055** | ++For more detailed examples, see [Estimate the cost to upload](azcopy-cost-estimation.md#the-cost-to-upload). ++#### The cost to download ++The number of operations required to download a blob depends on which endpoint you use. If you download a blob from the Blob Service endpoint, you're billed the cost of a single _read_ operation. If you download a blob from the Data Lake Storage endpoint, you're billed for cost of multiple read operations because blobs must be downloaded in 4-MiB blocks. If you download blobs from the cool or cold tier, you're also charged a data retrieval per GiB downloaded from the cool, cold, or archive tier. ++Using the [Sample prices](#sample-prices) that appear in this article, the following table estimates the cost to download **1,000** blobs that are **5 GiB** each in size from the cool tier by using the Blob Storage endpoint. ++| Price factor | Value | +||| +| Price of a single read operation (price / 10,000) | $0.000001 | +| **Cost of read operations (1000 * operation price)** | **$0.001** | +| Price of data retrieval (per GiB) | $0.01 | +| **Cost of data retrieval (5 * operation price)** | **$0.05** | +| **Total cost (read + retrieval)** | **$0.051** | ++Utilities such as AzCopy also use list operations and operations to obtain blob properties. As a proportion of the overall bill, these charges are relatively small. For examples, see [Estimate the cost to download](azcopy-cost-estimation.md#the-cost-to-download). ++#### The cost to copy between containers ++If you copy a blob to another container in the same account, then you're billed the cost of a single _write_ operation that is based on the destination tier. If the destination container is in another account, then you're also billed the cost of data retrieval and the cost of a read operation that is based on the source tier. If the destination account is in another region, then the cost of network egress is added to your bill. ++Using the [Sample prices](#sample-prices) that appear in this article, the following table estimates the cost to copy **1,000** blobs that are **5 GiB** each in size between two containers in the hot tier. ++| Price factor | Value | +|-|--| +| Price of a single write operation (price / 10,000) | $0.0000055 | +| **Cost to write (1000 * operation price)** | **$0.0055** | +| Price of a single read operation (price / 10,000) | $0.00000044 | +| **Cost of read operations (1,000 * operation price)** | **$0.00044** | +| **Total cost (previous section + retrieval + read)** | **$0.0068** | ++For a complete example, see [Estimate the cost to copy between containers](azcopy-cost-estimation.md#the-cost-to-copy-between-containers). ++## The cost to rename a blob ++The cost to rename blobs depends on the file structure of your account and the number of blobs that you're renaming. ++If the account has a flat namespace, there's no dedicated operation to rename a blob. Instead, your client tool copies the blob to a new blob, and then delete the source blob. Delete operations are free. Therefore, when you rename a blob, you're billed for the cost of single _write_ operation. If the account has a hierarchical namespace, then there's a dedicated operation to rename a blob and it's billed as an _iterative write_ operation. ++The cost of a write operation against the Blob Service endpoint is lower than the cost of an iterative write operation against the Data Lake Storage endpoint. Therefore, the cost to rename blobs one-by-one, it costs less in accounts that have a flat namespace. ++Using the [Sample prices](#sample-prices) that appear in this article, the following table calculates the cost to rename 1,000 blobs. ++| Price factor | Hot | Cool | Cold | +||-||| +| Price of a single write operation to the Blob Service endpoint (price / 10,000) | $0.0000055 | $0.00001 | $0.000018 | +| **Cost to rename blob virtual directories (1000 * operation price)** | **$0.0055** | **$0.01** | **$.018** | +| Price of a single iterative write operation to the Data Lake Storage endpoint (price / 100) | $0.000715 | $0.000715 | $0.000715 | +| **Cost to rename Data Lake Storage directories (1000 * operation price)** | **$0.715** | **$0.715** | **$0.715** | ++Based on these calculations, the cost to rename 1,000 blobs in the hot tier differs by **70** cents. ++## The cost to rename a directory ++If the account has a flat namespace, then blobs are organized into _virtual directories_ that mimic a folder structure. A virtual directory forms part of the name of the blob and is indicated by the delimiter character. Because a virtual directory is a part of the blob name, it doesn't actually exist as an independent object. There's no way to rename a virtual directory without renaming all of the blobs that contain that virtual directory in the name. To effectively rename each blob, client applications have to copy a blob, and then delete the source blob. ++If the account has a hierarchical namespace, directories aren't virtual. They're concrete, independent objects that you can operate on directly. Therefore, renaming a blob is far more efficient because client applications can rename a blob in a single operation. ++Using the [Sample prices](#sample-prices) that appear in this article, the following table calculates the cost to rename 1,000 directories that each contain 1,000 blobs. ++| Price factor | Hot | Cool | Cold | +||||| +| Price of a single write operation to the Blob Service endpoint (price / 10,000) | $0.0000055 | $0.00001 | $0.000018 | +| **Cost to rename blob virtual directories (1000 * (1000 * operation price))** | **$5.50** | **$10.00** | **$18.00** | +| Price of a single iterative write operation to the Data Lake Storage endpoint (price / 100) | $0.000715 | $0.000715 | $0.000715 | +| **Cost to rename Data Lake Storage directories (1000 * operation price)** | **$0.715** | **$0.715** | **0.715** | ++Based on these calculations, the cost to rename 1,000 directories in the hot tier that each contain 1,000 blobs differs by almost **$5.00**. For directories in the cold tier, the difference is over **$17**. ++## Example: Upload, download, and change access tiers ++This example shows four months of spending based uploads, downloads, and the impact of moving objects between tiers. ++### Parameters ++At the beginning of each month, 1,000 files are uploaded to the hot access tier. Each file is 5 GB in size. During the month, half of these files read by client workloads. After 30 days, a [lifecycle management policy](lifecycle-management-overview.md) moves the other half to the cool access tier to save on storage costs. ++In March, client applications read 10% of the data that is stored in the cool access tier. A lifecycle management policy is configured to move those blobs back to the hot tier after they're read. ++Twenty days into April, clients once again read 10% of the data that is stored in the cool access tier. However, those blobs were stored in the cool tier for less than 30 days. Because the lifecycle management policy moves those blobs back to the hot tier before the minimum 30 days elapses, an early penalty is assessed. The early deletion penalty is the cost of cool storage for 10 days. ++### Calculations ++Using the [Sample prices](#sample-prices) that appear in this article, the following table demonstrates four months of spending. ++> [!NOTE] +> These calculations provide an approximate estimate given sample pricing. If blobs were uploaded in batches, then some portion of the storage costs would be prorated as they would not incur storage costs for the entire month. See [Data storage and index meters](../common/storage-plan-manage-costs.md#data-storage-and-index-meters). ++| Cost factor | January | February | March | April | +|-|--||-|--| +| **Cost to write 1000 blobs to the hot tier**<sup>1 | **$3.53** | **$3.53** | **$3.53** | **$3.53** | +| Number of blobs in the hot tier after monthly ingest | 1000 | 2000 | 2100 | 2155 | +| Number of blobs to move to the cool tier | 0 | 1000 | 1050 | 1078 | +| **Cost to set blobs to the cool tier (billed as a write operation)** | **$0.00** | **$0.01** | **$0.0105** | **$0.010775** | +| Number of blobs in the cool tier | 0 | 1000 | 1050 | 1078 | +| Total size of blobs in the cool tier (GB) | 0 | 5000 | 5250 | 5388 | +| Number of blobs read from the cool tier then moved back to the hot tier | 0 | 100 | 105 | 108 | +| **Cost to read blobs from the cool tier** | **$0.00** | **$0.0001** | **$0.000105** | **$0.00010775** | +| **Cost to move blobs back to the hot tier** | **$0.00** | **$0.0001** | **$0.000105** | **$0.00010775** | +| Number of blobs that remain in the cool tier | 0 | 900 | 945 | 970 | +| Total size of blobs that remain in the cool tier (GB) | 0 | 4500 | 4725 | 4849 | +| **Cost to store blobs in the cool tier** | **$0.00** | **$51.75** | **$54.34** | **$55.76** | +| **Early deletion penalty** | **$0.00** | **$0.00** | **$0.00** | **$0.41** | +| Number of blobs that remain in the hot tier | 1000 | 1100 | 1155 | 1185 | +| Total size of blobs that remain in the hot tier (GB) | 5000 | 5500 | 5775 | 5926 | +| **Cost to store blobs in hot tier** | **$104.00** | **$114.40** | **$120.12** | **$123.27** | +| Number of blobs read from the hot tier | 500 | 550 | 578 | 593 | +| **Cost to read blobs from the hot tier** | **$0.00022** | **$0.000242** | **$0.0002541** | **$0.00026076** | +| **Monthly total** | **$107.53** | **$169.69** | **$178.00** | **$182.98** | ++<sup>1</sup>The number of operations required to complete each monthly upload is **641,000**. The formula to calculate that number is 1000 blobs * 5 GB / 8-MiB block + the write operation that is required to assemble all of the blocks into a blob.<br /> ++## Sample prices +++## See also ++- [Plan and manage costs for Azure Blob Storage](../common/storage-plan-manage-costs.md) +- [Map each REST operation to a price](map-rest-apis-transaction-categories.md) +- [Get started with AzCopy](../common/storage-use-azcopy-v10.md) |
| storage | Blob Storage Monitoring Scenarios | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/blobs/blob-storage-monitoring-scenarios.md | To examine the blobs associated with this used capacity, you can use Storage Exp If you partition your customer's data by container, then can monitor how much capacity is used by each customer. You can use Azure Storage blob inventory to take an inventory of blobs with size information. Then, you can aggregate the size and count at the container level. For an example, see [Calculate blob count and total size per container using Azure Storage inventory](calculate-blob-count-size.yml). -You can also evaluate traffic at the container level by querying logs. To learn more about writing Log Analytic queries, see [Log Analytics](../../azure-monitor/logs/log-analytics-tutorial.md). To learn more about the storage logs schema, see [Azure Blob Storage monitoring data reference](monitor-blob-storage-reference.md#resource-logs-preview). +You can also evaluate traffic at the container level by querying logs. To learn more about writing Log Analytic queries, see [Log Analytics](/azure/azure-monitor/logs/log-analytics-tutorial). To learn more about the storage logs schema, see [Azure Blob Storage monitoring data reference](monitor-blob-storage-reference.md#resource-logs-preview). Here's a query to get the number of read transactions and the number of bytes read on each container. The section shows you how to identify the "when", "who", "what" and "how" inform ### Auditing control plane operations -Resource Manager operations are captured in the [Azure activity log](../../azure-monitor/essentials/activity-log.md). To view the activity log, open your storage account in the Azure portal, and then select **Activity log**. +Resource Manager operations are captured in the [Azure activity log](/azure/azure-monitor/essentials/activity-log). To view the activity log, open your storage account in the Azure portal, and then select **Activity log**. > [!div class="mx-imgBorder"] >  You can find the friendly name of that security principal by taking the value of ### Auditing data plane operations -Data plane operations are captured in [Azure resource logs for Storage](monitor-blob-storage.md#analyzing-logs). You can [configure Diagnostic setting](../../azure-monitor/platform/diagnostic-settings.md) to export logs to Log Analytics workspace for a native query experience. +Data plane operations are captured in [Azure resource logs for Storage](monitor-blob-storage.md#analyzing-logs). You can [configure Diagnostic setting](/azure/azure-monitor/platform/diagnostic-settings) to export logs to Log Analytics workspace for a native query experience. Here's a Log Analytics query that retrieves the "when", "who", "what", and "how" information in a list of log entries. You can export logs to Log Analytics for rich native query capabilities. When yo With Azure Synapse, you can create server-less SQL pool to query log data when you need. This could save costs significantly. -1. Export logs to storage account. For more information, see [Creating a diagnostic setting](../../azure-monitor/platform/diagnostic-settings.md). +1. Export logs to storage account. For more information, see [Creating a diagnostic setting](/azure/azure-monitor/platform/diagnostic-settings). 2. Create and configure a Synapse workspace. For more information, see [Quickstart: Create a Synapse workspace](../../synapse-analytics/quickstart-create-workspace.md). With Azure Synapse, you can create server-less SQL pool to query log data when y - [Monitoring Azure Blob Storage](monitor-blob-storage.md). - [Azure Blob Storage monitoring data reference](monitor-blob-storage-reference.md) - [Tutorial: Use Kusto queries in Azure Data Explorer and Azure Monitor](/azure/data-explorer/kusto/query/tutorial?pivots=azuredataexplorer).-- [Get started with log queries in Azure Monitor](../../azure-monitor/logs/get-started-queries.md).+- [Get started with log queries in Azure Monitor](/azure/azure-monitor/logs/get-started-queries). |
| storage | Monitor Blob Storage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/blobs/monitor-blob-storage.md | All other failed anonymous requests aren't logged. For a full list of the logged [!INCLUDE [horz-monitor-kusto-queries](~/reusable-content/ce-skilling/azure/includes/azure-monitor/horizontals/horz-monitor-kusto-queries.md)] -Here are some queries that you can enter in the **Log search** bar to help you monitor your Blob storage. These queries work with the [new language](../../azure-monitor/logs/log-query-overview.md). +Here are some queries that you can enter in the **Log search** bar to help you monitor your Blob storage. These queries work with the [new language](/azure/azure-monitor/logs/log-query-overview). - To list the 10 most common errors over the last three days. |
| storage | Security Recommendations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/blobs/security-recommendations.md | Microsoft Defender for Cloud periodically analyzes the security state of your Az | Recommendation | Comments | Defender for Cloud | |-|-|--| | Track how requests are authorized | Enable logging for Azure Storage to track how requests to the service are authorized. The logs indicate whether a request was made anonymously, by using an OAuth 2.0 token, by using Shared Key, or by using a shared access signature (SAS). For more information, see [Monitoring Azure Blob Storage with Azure Monitor](monitor-blob-storage.md) or [Azure Storage analytics logging with Classic Monitoring](../common/storage-analytics-logging.md). | - |-| Set up alerts in Azure Monitor | Configure log alerts to evaluate resources logs at a set frequency and fire an alert based on the results. For more information, see [Log alerts in Azure Monitor](../../azure-monitor/alerts/alerts-unified-log.md). | - | +| Set up alerts in Azure Monitor | Configure log alerts to evaluate resources logs at a set frequency and fire an alert based on the results. For more information, see [Log alerts in Azure Monitor](/azure/azure-monitor/alerts/alerts-unified-log). | - | ## Next steps |
| storage | Sas Expiration Policy | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/common/sas-expiration-policy.md | The SAS expiration period appears in the console output. ## Query logs for policy violations -To log the use of a SAS that is valid over a longer interval than the SAS expiration policy recommends, first create a diagnostic setting that sends logs to an Azure Log Analytics workspace. For more information, see [Send logs to Azure Log Analytics](../../azure-monitor/platform/diagnostic-settings.md). +To log the use of a SAS that is valid over a longer interval than the SAS expiration policy recommends, first create a diagnostic setting that sends logs to an Azure Log Analytics workspace. For more information, see [Send logs to Azure Log Analytics](/azure/azure-monitor/platform/diagnostic-settings). Next, use an Azure Monitor log query to monitor whether policy has been violated. Create a new query in your Log Analytics workspace, add the following query text, and press **Run**. |
| storage | Security Restrict Copy Operations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/common/security-restrict-copy-operations.md | Azure Storage logs capture details in Azure Monitor about requests made against ### Create a diagnostic setting in the Azure portal -To log Azure Storage data with Azure Monitor and analyze it with Azure Log Analytics, you must first create a diagnostic setting that indicates what types of requests and for which storage services you want to log data. After you configure logging for your storage account, the logs are available in the Log Analytics workspace. To create a workspace, see [Create a Log Analytics workspace in the Azure portal](../../azure-monitor/logs/quick-create-workspace.md). +To log Azure Storage data with Azure Monitor and analyze it with Azure Log Analytics, you must first create a diagnostic setting that indicates what types of requests and for which storage services you want to log data. After you configure logging for your storage account, the logs are available in the Log Analytics workspace. To create a workspace, see [Create a Log Analytics workspace in the Azure portal](/azure/azure-monitor/logs/quick-create-workspace). To learn how to create a diagnostic setting in the Azure portal, see [Create diagnostic settings in Azure Monitor](/azure/azure-monitor/essentials/create-diagnostic-settings). The results of the query should look similar to the following: The URI is the full path to the source object being copied, which includes the storage account name, the container name and the file name. From the list of URIs, determine whether the copy operations would be blocked if a specific **AllowedCopyScope** setting was applied. -You can also configure an alert rule based on this query to notify you about Copy Blob requests for the account. For more information, see [Create, view, and manage log alerts using Azure Monitor](../../azure-monitor/alerts/alerts-log.md). +You can also configure an alert rule based on this query to notify you about Copy Blob requests for the account. For more information, see [Create, view, and manage log alerts using Azure Monitor](/azure/azure-monitor/alerts/alerts-log). ## Restrict the Permitted scope for copy operations (preview) |
| storage | Shared Key Authorization Prevent | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/common/shared-key-authorization-prevent.md | A SAS may be authorized with either Shared Key or Microsoft Entra ID. For more i ### Determine the number and frequency of requests authorized with Shared Key -To track how requests to a storage account are being authorized, use Azure Metrics Explorer in the Azure portal. For more information about Metrics Explorer, see [Analyze metrics with Azure Monitor metrics explorer](../../azure-monitor/essentials/analyze-metrics.md). +To track how requests to a storage account are being authorized, use Azure Metrics Explorer in the Azure portal. For more information about Metrics Explorer, see [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics). Follow these steps to create a metric that tracks requests made with Shared Key or SAS: After you have configured the metric, requests to your storage account will begi :::image type="content" source="media/shared-key-authorization-prevent/metric-shared-key-requests.png" alt-text="Screenshot showing aggregated requests authorized with Shared Key." lightbox="media/shared-key-authorization-prevent/metric-shared-key-requests.png"::: -You can also configure an alert rule to notify you when a certain number of requests that are authorized with Shared Key are made against your storage account. For more information, see [Create, view, and manage metric alerts using Azure Monitor](../../azure-monitor/alerts/alerts-metric.md). +You can also configure an alert rule to notify you when a certain number of requests that are authorized with Shared Key are made against your storage account. For more information, see [Create, view, and manage metric alerts using Azure Monitor](/azure/azure-monitor/alerts/alerts-metric). ### Analyze logs to identify clients that are authorizing requests with Shared Key or SAS Azure Storage logs capture details about requests made against the storage accou To log requests to your Azure Storage account in order to evaluate how they are authorized, you can use Azure Storage logging in Azure Monitor. For more information, see [Monitor Azure Storage](../blobs/monitor-blob-storage.md). -Azure Storage logging in Azure Monitor supports using log queries to analyze log data. To query logs, you can use an Azure Log Analytics workspace. To learn more about log queries, see [Tutorial: Get started with Log Analytics queries](../../azure-monitor/logs/log-analytics-tutorial.md). +Azure Storage logging in Azure Monitor supports using log queries to analyze log data. To query logs, you can use an Azure Log Analytics workspace. To learn more about log queries, see [Tutorial: Get started with Log Analytics queries](/azure/azure-monitor/logs/log-analytics-tutorial). #### Create a diagnostic setting in the Azure portal -To log Azure Storage data with Azure Monitor and analyze it with Azure Log Analytics, you must first create a diagnostic setting that indicates what types of requests and for which storage services you want to log data. After you configure logging for your storage account, the logs are available in the Log Analytics workspace. To create a workspace, see [Create a Log Analytics workspace in the Azure portal](../../azure-monitor/logs/quick-create-workspace.md). +To log Azure Storage data with Azure Monitor and analyze it with Azure Log Analytics, you must first create a diagnostic setting that indicates what types of requests and for which storage services you want to log data. After you configure logging for your storage account, the logs are available in the Log Analytics workspace. To create a workspace, see [Create a Log Analytics workspace in the Azure portal](/azure/azure-monitor/logs/quick-create-workspace). To learn how to create a diagnostic setting in the Azure portal, see [Create diagnostic settings in Azure Monitor](/azure/azure-monitor/essentials/create-diagnostic-settings). StorageBlobLogs | top 10 by count_ desc ``` -You can also configure an alert rule based on this query to notify you about requests authorized with Shared Key or SAS. For more information, see [Create, view, and manage log alerts using Azure Monitor](../../azure-monitor/alerts/alerts-log.md). +You can also configure an alert rule based on this query to notify you about requests authorized with Shared Key or SAS. For more information, see [Create, view, and manage log alerts using Azure Monitor](/azure/azure-monitor/alerts/alerts-log). ## Remediate authorization via Shared Key |
| storage | Storage Insights Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/common/storage-insights-overview.md | In this example, we are working with the storage account capacity workbook and d ## Troubleshooting -For general troubleshooting guidance, refer to the dedicated workbook-based insights [troubleshooting article](../../azure-monitor/insights/troubleshoot-workbooks.md). +For general troubleshooting guidance, refer to the dedicated workbook-based insights [troubleshooting article](/azure/azure-monitor/insights/troubleshoot-workbooks). This section will help you with the diagnosis and troubleshooting of some of the common issues you may encounter when using Storage insights. Use the list below to locate the information relevant to your specific issue. Each workbook is saved in the storage account that you saved it in. Try to find ## Next steps -- Configure [metric alerts](../../azure-monitor/alerts/alerts-metric.md) and [service health notifications](../../service-health/alerts-activity-log-service-notifications-portal.md) to set up automated alerting to aid in detecting issues.+- Configure [metric alerts](/azure/azure-monitor/alerts/alerts-metric) and [service health notifications](/azure/service-health/alerts-activity-log-service-notifications-portal) to set up automated alerting to aid in detecting issues. -- Learn the scenarios workbooks are designed to support, how to author new and customize existing reports, and more by reviewing [Create interactive reports with Azure Monitor workbooks](../../azure-monitor/visualize/workbooks-overview.md).+- Learn the scenarios workbooks are designed to support, how to author new and customize existing reports, and more by reviewing [Create interactive reports with Azure Monitor workbooks](/azure/azure-monitor/visualize/workbooks-overview). |
| storage | Storage Metrics Migration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/common/storage-metrics-migration.md | To transition to metrics in Azure Monitor, we recommend the following approach. > [!NOTE] > Metrics in Azure Monitor are enabled by default, so there is nothing you need to do to begin capturing metrics. You must however, create charts or dashboards to view those metrics. -1. If you've created alert rules that are based on classic storage metrics, then [create alert rules](../../azure-monitor/alerts/alerts-overview.md) that are based on metrics in Azure Monitor. +1. If you've created alert rules that are based on classic storage metrics, then [create alert rules](/azure/azure-monitor/alerts/alerts-overview) that are based on metrics in Azure Monitor. <a id="key-differences-between-classic-metrics-and-metrics-in-azure-monitor"></a> As far as metrics support, classic metrics provide **capacity** metrics only for If the activity in your account does not trigger a metric, classic metrics will show a value of zero (0) for that metric. Metrics in Azure Monitor will omit the data entirely, which leads to cleaner reports. For example, with classic metrics, if no server timeout errors are reported, then the `ServerTimeoutError` value in the metrics table is set to 0. Azure Monitor doesn't return any data when you query the value of metric `Transactions` with dimension `ResponseType` equal to `ServerTimeoutError`. -To learn more about metrics in Azure Monitor, see [Metrics in Azure Monitor](../../azure-monitor/essentials/data-platform-metrics.md). +To learn more about metrics in Azure Monitor, see [Metrics in Azure Monitor](/azure/azure-monitor/essentials/data-platform-metrics). <a id="metrics-mapping-between-old-metrics-and-new-metrics"></a> To learn more about metrics in Azure Monitor, see [Metrics in Azure Monitor](../ ## Next steps -- [Azure Monitor](../../azure-monitor/overview.md)+- [Azure Monitor](/azure/azure-monitor/overview) |
| storage | Storage Network Security | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/common/storage-network-security.md | Resources of some services can access your storage account for selected operatio | Azure File Sync | `Microsoft.StorageSync` | Transform your on-premises file server to a cache for Azure file shares. This capability allows multiple-site sync, fast disaster recovery, and cloud-side backup. [Learn more](../file-sync/file-sync-planning.md). | | Azure HDInsight | `Microsoft.HDInsight` | Provision the initial contents of the default file system for a new HDInsight cluster. [Learn more](../../hdinsight/hdinsight-hadoop-use-blob-storage.md). | | Azure Import/Export | `Microsoft.ImportExport` | Import data to Azure Storage or export data from Azure Storage. [Learn more](../../import-export/storage-import-export-service.md). |-| Azure Monitor | `Microsoft.Insights` | Write monitoring data to a secured storage account, including resource logs, Microsoft Entra sign-in and audit logs, and Microsoft Intune logs. [Learn more](../../azure-monitor/roles-permissions-security.md). | +| Azure Monitor | `Microsoft.Insights` | Write monitoring data to a secured storage account, including resource logs, Microsoft Entra sign-in and audit logs, and Microsoft Intune logs. [Learn more](/azure/azure-monitor/roles-permissions-security). | | Azure networking services | `Microsoft.Network` | Store and analyze network traffic logs, including through the Azure Network Watcher and Azure Traffic Manager services. [Learn more](../../network-watcher/network-watcher-nsg-flow-logging-overview.md). | | Azure Site Recovery | `Microsoft.SiteRecovery` | Enable replication for disaster recovery of Azure IaaS virtual machines when you're using firewall-enabled cache, source, or target storage accounts. [Learn more](../../site-recovery/azure-to-azure-tutorial-enable-replication.md). | |
| storage | Storage Plan Manage Costs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/common/storage-plan-manage-costs.md | -This article helps you plan and manage costs for Azure Blob Storage. First, estimate costs by using the Azure pricing calculator. After you create your storage account, optimize the account so that you pay only for what you need. Use cost management features to set budgets and monitor costs. You can also review forecasted costs, and monitor spending trends to identify areas where you might want to act. +This article helps you plan and manage costs for Azure Blob Storage. -Keep in mind that costs for Blob Storage are only a portion of the monthly costs in your Azure bill. Although this article explains how to estimate and manage costs for Blob Storage, you're billed for all Azure services and resources used for your Azure subscription, including the third-party services. After you're familiar with managing costs for Blob Storage, you can apply similar methods to manage costs for all the Azure services used in your subscription. --## Estimate costs --Use the [Azure pricing calculator](https://azure.microsoft.com/pricing/calculator/) to estimate costs before you create and begin transferring data to an Azure Storage account. --1. On the [Azure pricing calculator](https://azure.microsoft.com/pricing/calculator/) page, choose the **Storage Accounts** tile. --2. Scroll down the page and locate the **Storage Accounts** section of your estimate. +First, become familiar with each billing meter and how to find the price of each meter. Then, you can estimate your cost by using the Azure pricing calculator. Use cost management features to set budgets and monitor costs. You can also review forecasted costs, and monitor spending trends to identify areas where you might want to act. -3. Choose options from the drop-down lists. -- As you modify the value of these drop-down lists, the cost estimate changes. That estimate appears in the upper corner as well as the bottom of the estimate. --  -- As you change the value of the **Type** drop-down list, other options that appear on this worksheet change as well. Use the links in the **More Info** section to learn more about what each option means and how these options affect the price of storage-related operations. --4. Modify the remaining options to see their effect on your estimate. --### Supportive tools and guides --The following resources can also help you forecast the cost of using Azure Blob Storage: --- [Estimating Pricing for Azure Block Blob Deployments](https://azure.github.io/Storage/docs/application-and-user-data/code-samples/estimate-block-blob/)--- [Estimate the cost of archiving data](../blobs/archive-cost-estimation.md)--- [Estimate the cost of using AzCopy to transfer blobs](../blobs/azcopy-cost-estimation.md)--- [Map each REST operation to a price](../blobs/map-rest-apis-transaction-categories.md)+Keep in mind that costs for Blob Storage are only a portion of the monthly costs in your Azure bill. Although this article explains how to estimate and manage costs for Blob Storage, you're billed for all Azure services and resources used for your Azure subscription, including the third-party services. After you're familiar with managing costs for Blob Storage, you can apply similar methods to manage costs for all the Azure services used in your subscription. ## Understand the full billing model for Azure Blob Storage -Azure Blob Storage runs on Azure infrastructure that accrues costs when you deploy new resources. It's important to understand that there could be other additional infrastructure costs that might accrue. +Azure Blob Storage runs on Azure infrastructure that accrues costs when you deploy new resources. It's important to understand that there could be other additional infrastructure costs that might accrue. ### How you're charged for Azure Blob Storage -When you create or use Blob Storage resources, you'll be charged for the following meters: +When you create or use Blob Storage resources, you're charged for the following meters: | Meter | Unit | |||-| Data storage | Per GB / per month| +| Data storage | Per GB / per month | +| Index | Per GB / per month<sup>1 | | Operations | Per transaction |-| Data transfer | Per GB | -| Metadata | Per GB / per month<sup>1 | -| Blob index tags | Per tag<sup>2 | -| Change feed | Per logged change<sup>2 | -| Encryption scopes | Per month<sup>2 | +| Data transfer | Per GB<sup>2 | +| Data retrieval | Per GB<sup>3 | +| Blob index tags | Per tag<sup>4 | +| Change feed | Per logged change<sup>4 | +| SSH File Transfer Protocol (SFTP) | Per hour<sup>4 | +| Blob inventory | Per million objects scanned<sup>4 | +| Encryption scopes | Per month<sup>4 | | Query acceleration | Per GB scanned & Per GB returned |+| Point-in-time restore Data Processed | Per MB restored | <sup>1</sup> Applies only to accounts that have a hierarchical namespace.<br />-<sup>2</sup> Applies only if you enable the feature.<br /> +<sup>2</sup> Applies only when copying data to another region.<br /> +<sup>3</sup> Applies only to the cool, cold, and archive tiers.<br /> +<sup>4</sup> Applies only if you enable the feature.<br /> -Data traffic might also incur networking costs. See the [Bandwidth pricing](https://azure.microsoft.com/pricing/details/data-transfers/). +At the end of your billing cycle, the charges for each meter are summed. Your bill or invoice shows a section for all Azure Blob Storage costs. There's a separate line item for each meter. -At the end of your billing cycle, the charges for each meter are summed. Your bill or invoice shows a section for all Azure Blob Storage costs. There's a separate line item for each meter. +#### Data storage and index meters -Data storage and metadata are billed per GB on a monthly basis. For data and metadata stored for less than a month, you can estimate the impact on your monthly bill by calculating the cost of each GB per day. You can use a similar approach to estimating the cost of encryption scopes that are in use for less than a month. The number of days in any given month varies. Therefore, to obtain the best approximation of your costs in a given month, make sure to divide the monthly cost by the number of days that occur in that month. +Data storage and metadata are billed per GB on a monthly basis. Most metadata is stored as part of the blob and includes properties and key-value pairs. The metadata that is associated with blobs in the archive tier is stored separately in the cold tier. That way, users can list the blob and its properties, metadata, and index tags. Because the size of metadata doesn't exceed 8 KB in size, its cost is relatively insignificant as a percent of total storage capacity. -#### Storage units +Blob index tags are stored as a sub resource in the hot tier, and have their own billing meter. The **Index** meter applies only to accounts that have a hierarchical namespace as a means to bill for the space required to facilitate a hierarchical file structure including the access control lists (ACLs) associated with objects in that structure. Data associated with the index is always stored in the hot tier. -Azure Blob Storage uses the following base-2 units of measurement to represent storage capacity: KiB, MiB, GiB, TiB, PiB. Line items on your bill that contain GB as a unit of measurement (For example, per GB / per month) are calculated by Azure Blob Storage as binary GB (GiB). For example, a line item on your bill that shows **1** for **Data Stored (GB/month)** corresponds to 1 GiB per month of usage. The following table describes each base-2 unit: +For data and metadata stored for less than a month, you can estimate the impact on your monthly bill by calculating the cost of each GB per day. The number of days in any given month varies. Therefore, to obtain the best approximation of your costs in a given month, make sure to divide the monthly cost by the number of days that occur in that month. ++Azure Blob Storage uses the following base-2 units of measurement to represent storage capacity: KiB, MiB, GiB, TiB, PiB. While the line items in your bill contain GB as a unit of measurement, those units are calculated by Azure Blob Storage as binary GB (GiB). For example, a line item on your bill that shows **1** for **Data Stored (GB/month)** corresponds to 1 GiB per month of usage. The following table describes each base-2 unit: | Acronym | Unit | Definition | |||--| | KiB | kibibyte | 1,024 bytes | | MiB | mebibyte | 1,024 KiB (1,048,576 bytes) |-| GiB | gibibyte | 1024 MiB (1,073,741,824 bytes) | -| TiB | tebibyte | 1024 GiB (1,099,511,627,776 bytes) | +| GiB | gibibyte | 1,024 MiB (1,073,741,824 bytes) | +| TiB | tebibyte | 1,024 GiB (1,099,511,627,776 bytes) | ++For more information about how to calculate the cost of storage, see [The cost to store data](../blobs/blob-storage-estimate-costs.md#the-cost-to-store-data). ++#### Operations meters ++Each request made by a client arrives to the service in the form of a REST operation. You can monitor your resource logs to see which operations are executing against your data. ++The pricing pages don't list a price for each individual operation but instead lists the price of an operation _type_. To determine the price of an operation, you must first determine how that operation is classified in terms of its type. To trace a _logged operation_ to a _REST operation_ and then to an operation _type_, see [Map each REST operation to a price](../blobs/map-rest-apis-transaction-categories.md). ++The price that appears beside an operation type isn't the price you pay for each operation. In most cases, it's the price of `10,000` operations. To obtain the price of an individual operation, divide the price by `10,000`. For example, if the price for write operations is `$0.055`, then the price of an individual operation is `$.0555` / `10,000` = `$0.0000055`. You can estimate the cost to upload a file by multiplying the number write operations required to complete the upload by the cost of an individual transaction. To learn more, see [Estimate the cost of using Azure Blob Storage](../blobs/blob-storage-estimate-costs.md). ++#### Data transfer meter ++Any data that leaves the Azure region incurs data transfer and network bandwidth charges. These charges commonly appear in scenarios where an account is configured for geo-redundant storage or when an object replication policy is configured to copy data to an account in another region. However, these charges also apply to data that is downloaded to an on-premises client. The price of network bandwidth doesn't appear in the Azure Storage pricing pages. To find the price of network bandwidth, see [Bandwidth pricing](https://azure.microsoft.com/pricing/details/data-transfers/). -### Finding the unit price for each meter +#### Feature-related meters ++There's no cost to enable Blob Storage features. There are only three features that incur a passive charge after you enable them (SFTP support, encryption scopes, and blob index tags). For all other features, you're billed for the storage space that is occupied by the output of a feature and the operations executed as a result of using the feature. For example, if you enable versioning, your bill reflects the cost to store versions and the cost to perform operations to list or retrieve versions. Some features have added meters. For a complete list, see the [How you're charged for Azure Blob Storage](#how-youre-charged-for-azure-blob-storage) section of this article. ++You can prorate time-based meters if you use those features for less than a month. For example, Encryption scopes are billed on a monthly basis. Encryption scopes in place for less than a month, you can estimate the impact on your monthly bill by calculating the cost of each day. The number of days in any given month varies. Therefore, to obtain the best approximation of your costs in a given month, make sure to divide the monthly cost by the number of days that occur in that month. ++## Find the unit price for each meter To find unit prices, open the correct pricing page and select the appropriate file structure. Then, apply the appropriate redundancy, region, and currency filters. Prices for each meter appear in a table. Prices differ based on other settings in your account such as data redundancy options, access tier and performance tier. The correct pricing page and file structure matter mostly to the cost of reading and writing data as the cost to store data is essentially unchanged by those selections. To accurately estimate the cost of reading and writing data, start by determining which [Storage account endpoint](storage-account-overview.md#storage-account-endpoints) clients, applications, and workloads will use to read and write data. -#### Pricing requests to the blob service endpoint +### Requests to the blob service endpoint The format of the blob service endpoint is `https://<storage-account>.blob.core.windows.net` and is the most common endpoint used by tools and applications that interact with Blob Storage. Requests can originate from any of these sources: -- Hadoop workloads that use the [WASB](https://hadoop.apache.org/docs/current/hadoop-azure/https://docsupdatetracker.net/index.html) driver- - Clients that use [Blob Storage REST APIs](/rest/api/storageservices/blob-service-rest-api) or Blob Storage APIs from an Azure Storage client library - Transfers to [Network File System (NFS) 3.0](../blobs/network-file-system-protocol-support.md) mounted containers - Transfers made by using the [SSH File Transfer Protocol (SFTP)](../blobs/secure-file-transfer-protocol-support.md) +- Hadoop workloads that use the [WASB](https://hadoop.apache.org/docs/current/hadoop-azure/https://docsupdatetracker.net/index.html) driver + The correct pricing page for these requests is the [Block blob pricing](https://azure.microsoft.com/pricing/details/storage/blobs/) page. Requests to this endpoint can also occur in accounts that have a hierarchical namespace. In fact, to use NFS 3.0 and SFTP protocols, you must first enable the hierarchical namespace feature of the account. -If your account has the hierarchical namespace feature enabled, make sure that the **File Structure** drop-down list is set to **Hierarchical Namespace (NFS v3.0, SFTP Protocol)**. Otherwise, make sure that it is set to **Flat Namespace**. +If your account has the hierarchical namespace feature enabled, make sure that the **File Structure** drop-down list is set to **Hierarchical Namespace (NFS v3.0, SFTP Protocol)**. Otherwise, make sure that it's set to **Flat Namespace**. -#### Pricing requests to the Data Lake Storage endpoint +### Requests to the Data Lake Storage endpoint The format of the Data Lake Storage endpoint is `https://<storage-account>.dfs.core.windows.net` and is most common endpoint used by analytic workloads and applications. This endpoint is typically used with accounts that have a hierarchical namespace but not always. Requests can originate from any of these sources: The correct pricing page for these requests is the [Azure Data Lake Storage pricing](https://azure.microsoft.com/pricing/details/storage/data-lake/) page. -If your account does not have the hierarchical namespace feature enabled, but you expect clients, workloads, or applications to make requests over the Data Lake Storage endpoint of your account, then set the **File Structure** drop-down list to **Flat Namespace**. Otherwise, make sure that it is set to **Hierarchical Namespace**. --#### Find the price of each operation +If your account doesn't have the hierarchical namespace feature enabled, but you expect clients, workloads, or applications to make requests over the Data Lake Storage endpoint of your account, then set the **File Structure** drop-down list to **Flat Namespace**. Otherwise, make sure that it's set to **Hierarchical Namespace**. -Each request made by tools such as AzCopy or Azure Storage Explorer arrives to the service in the form of a REST operation. This is also true for a custom application that leverages an Azure Storage Client library. +## Estimate costs -To determine the price of each operation, you must first determine how that operation is classified in terms of its _type_. That's because the pricing pages list prices only by operation type and not by each individual operation. To see how each operation maps to an operation type, see [Map each REST operation to a price](../blobs/map-rest-apis-transaction-categories.md). +Use the [Azure pricing calculator](https://azure.microsoft.com/pricing/calculator/) to estimate costs before you create and begin transferring data to an Azure Storage account. -### Using Azure Prepayment with Azure Blob Storage +1. On the [Azure pricing calculator](https://azure.microsoft.com/pricing/calculator/) page, choose the **Storage Accounts** tile. -You can pay for Azure Blob Storage charges with your Azure Prepayment (previously called monetary commitment) credit. However, you can't use Azure Prepayment credit to pay for charges for third party products and services including those from the Azure Marketplace. +2. Scroll down the page and locate the **Storage Accounts** section of your estimate. -## Optimize costs +3. Choose options from the drop-down lists. -Consider using these options to reduce costs. + As you modify the value of these drop-down lists, the cost estimate changes. That estimate appears in the upper corner as well as the bottom of the estimate. -- Analyze existing containers and blobs+  -- Reserve storage capacity+ As you change the value of the **Type** drop-down list, other options that appear on this worksheet change as well. Use the links in the **More Info** section to learn more about what each option means and how these options affect the price of storage-related operations. -- Organize data into access tiers+4. Modify the remaining options to see their effect on your estimate. -- Automatically move data between access tiers+ > [!TIP] + > See these in-depth guides to help you predict and forecast costs: + > + > - [Estimating Pricing for Azure Block Blob Deployments](https://azure.github.io/Storage/docs/application-and-user-data/code-samples/estimate-block-blob/) + > - [Estimate the cost of archiving data](../blobs/archive-cost-estimation.md) + > - [Estimate the cost of using AzCopy to transfer blobs](../blobs/azcopy-cost-estimation.md) -This section covers each option in more detail. +### Using Azure Prepayment with Azure Blob Storage -#### Analyze existing containers and blobs +You can pay for Azure Blob Storage charges with your Azure Prepayment (previously called monetary commitment) credit. However, you can't use Azure Prepayment credit to pay for charges for third party products and services including those from the Azure Marketplace. -If you've been using Blob Storage for some time, you should periodically review the contents of your containers to identify opportunities to reduce your costs. By understanding how your blobs are stored, organized, and used in production, you can better optimize the tradeoffs between availability, performance, and cost of those blobs. +## Optimize costs -See any of these articles to itemize and analyze your existing containers and blobs: +If you've been using Blob Storage for some time, you should periodically review the contents of your containers to identify opportunities to reduce your costs. By understanding how your blobs are stored, organized, and used in production, you can better optimize the tradeoffs between availability, performance, and cost of those blobs. See any of these articles to itemize and analyze your existing containers and blobs: - [Tutorial: Analyze blob inventory reports](../blobs/storage-blob-inventory-report-analytics.md)- - [Tutorial: Calculate container statistics by using Databricks](../blobs/storage-blob-calculate-container-statistics-databricks.md)- - [Calculate blob count and total size per container using Azure Storage inventory](../blobs/calculate-blob-count-size.yml) -#### Reserve storage capacity +If you can model future capacity requirements, you can save money with Azure Storage reserved capacity. Azure Storage reserved capacity is available for most access tiers and offers you a discount on capacity for block blobs and for Azure Data Lake Storage data in standard storage accounts when you commit to a reservation for either one year or three years. A reservation provides a fixed amount of storage capacity for the term of the reservation. Azure Storage reserved capacity can significantly reduce your capacity costs for block blobs and Azure Data Lake Storage data. To learn more, see [Optimize costs for Blob Storage with reserved capacity](../blobs/storage-blob-reserved-capacity.md). -You can save money on storage costs for blob data with Azure Storage reserved capacity. Azure Storage reserved capacity offers you a discount on capacity for block blobs and for Azure Data Lake Storage data in standard storage accounts when you commit to a reservation for either one year or three years. A reservation provides a fixed amount of storage capacity for the term of the reservation. Azure Storage reserved capacity can significantly reduce your capacity costs for block blobs and Azure Data Lake Storage data. --To learn more, see [Optimize costs for Blob Storage with reserved capacity](../blobs/storage-blob-reserved-capacity.md). --#### Organize data into access tiers --You can reduce costs by placing blob data into the most cost effective access tiers. Choose from three tiers that are designed to optimize your costs around data use. For example, the *hot* tier has a higher storage cost but lower access cost. Therefore, if you plan to access data frequently, the hot tier might be the most cost-efficient choice. If you plan to access data less frequently, the *cold* or *archive* tier might make the most sense because it raises the cost of accessing data while reducing the cost of storing data. --See any of these articles: +You can also reduce costs by placing blob data into the most cost effective access tiers. Choose from three tiers that are designed to optimize your costs around data use. For example, the _hot_ tier has a higher storage cost but lower access cost. Therefore, if you plan to access data frequently, the hot tier might be the most cost-efficient choice. If you plan to access data less frequently, the _cold_ or _archive_ tier might make the most sense because it raises the cost of accessing data while reducing the cost of storing data. See any of these articles: - [Access tiers for blob data](../blobs/access-tiers-overview.md?tabs=azure-portal)- - [Best practices for using blob access tiers](../blobs/access-tiers-best-practices.md)- - [Estimate the cost of archiving data](../blobs/archive-cost-estimation.md) -#### Automatically move data between access tiers --Use lifecycle management policies to periodically move data between tiers to save the most money. These policies can move data to by using rules that you specify. For example, you might create a rule that moves blobs to the archive tier if that blob hasn't been modified in 90 days. By creating policies that adjust the access tier of your data, you can design the least expensive storage options for your needs. --To learn more, see [Manage the Azure Blob Storage lifecycle](../blobs/lifecycle-management-overview.md?tabs=azure-portal) +Use lifecycle management policies to periodically move data between tiers to save the most money. These policies can move data to by using rules that you specify. For example, you might create a rule that moves blobs to the archive tier if that blob hasn't been modified in 90 days. By creating policies that adjust the access tier of your data, you can design the least expensive storage options for your needs. To learn more, see [Manage the Azure Blob Storage lifecycle](../blobs/lifecycle-management-overview.md?tabs=azure-portal). ## Create budgets -You can create [budgets](../../cost-management-billing/costs/tutorial-acm-create-budgets.md?WT.mc_id=costmanagementcontent_docsacmhorizontal_-inproduct-learn) to manage costs and create alerts that automatically notify stakeholders of spending anomalies and overspending risks. Alerts are based on spending compared to budget and cost thresholds. Budgets and alerts are created for Azure subscriptions and resource groups, so they're useful as part of an overall cost monitoring strategy. However, they might have limited functionality to manage individual Azure service costs like the cost of Azure Storage because they are designed to track costs at a higher level. +You can create [budgets](../../cost-management-billing/costs/tutorial-acm-create-budgets.md?WT.mc_id=costmanagementcontent_docsacmhorizontal_-inproduct-learn) to manage costs and create alerts that automatically notify stakeholders of spending anomalies and overspending risks. Alerts are based on spending compared to budget and cost thresholds. Budgets and alerts are created for Azure subscriptions and resource groups, so they're useful as part of an overall cost monitoring strategy. However, they might have limited functionality to manage individual Azure service costs like the cost of Azure Storage because they're designed to track costs at a higher level. ## Monitor costs Some actions, such as changing the default access tier of your account, can lead |-|--|-| | Access tiers | Changing the default access tier setting | If your account contains a large number of blobs for which the access tier is inferred, then a change to this setting can incur a significant cost. <br><br>A change to the default access tier setting of a storage account applies to all blobs in the account for which an access tier hasn't been explicitly set. For example, if you toggle the default access tier setting from hot to cool in a general-purpose v2 account, then you're charged for write operations (per 10,000) for all blobs for which the access tier is inferred. You're charged for both read operations (per 10,000) and data retrieval (per GB) if you toggle from cool to hot in a general-purpose v2 account. <br><br>For more information, see [Default account access tier setting](../blobs/access-tiers-overview.md#default-account-access-tier-setting). | | Access tiers | Rehydrating from archive | High priority rehydration from archive can lead to higher than normal bills. Microsoft recommends reserving high-priority rehydration for use in emergency data restoration situations. <br><br>For more information, see [Rehydration priority](../blobs/archive-rehydrate-overview.md#rehydration-priority).|+| Access tiers | Deleting, overwriting, or moving a blob to another tier | Tools or applications that use the [Copy Blob](/rest/api/storageservices/copy-blob) operation to update a blob will overwrite the blob. Blobs are subject to an early deletion penalty if they're deleted, overwritten, or moved to a different tier before the minimum number of days required by the tier have transpired. | | Data protection | Enabling blob soft delete | Overwriting blobs can lead to blob snapshots. Unlike the case where a blob is deleted, the creation of these snapshots isn't logged. This can lead to unexpected storage costs. Consider whether data that is frequently overwritten should be placed in an account that doesn't have soft delete enabled.<br><br>For more information, see [How overwrites are handled when soft delete is enabled](../blobs/soft-delete-blob-overview.md#how-overwrites-are-handled-when-soft-delete-is-enabled).| | Data protection | Enabling blob versioning | Every write operation on a blob creates a new version. As is the case with enabling blob soft delete, consider whether data that is frequently overwritten should be placed in an account that doesn't have versioning enabled. <br><br>For more information, see [Versioning on write operations](../blobs/versioning-overview.md#versioning-on-write-operations). |-| Monitoring | Enabling Storage Analytics logs (classic logs)| Storage analytics logs can accumulate in your account over time if the retention policy is not set. Make sure to set the retention policy to avoid log buildup which can lead to unexpected capacity charges.<br><br>For more information, see [Modify log data retention period](manage-storage-analytics-logs.md#modify-log-data-retention-period) | -| Protocols | Enabling SSH File Transfer Protocol (SFTP) support| Enabling the SFTP endpoint incurs an hourly cost. To avoid passive charges, consider enabling SFTP only when you are actively using it to transfer data.<br><br> For guidance about how to enable and then disable SFTP support, see [Connect to Azure Blob Storage by using the SSH File Transfer Protocol (SFTP)](../blobs/secure-file-transfer-protocol-support-how-to.md). | +| Monitoring | Enabling Storage Analytics logs (classic logs)| Storage analytics logs can accumulate in your account over time if the retention policy isn't set. Make sure to set the retention policy to avoid log buildup which can lead to unexpected capacity charges.<br><br>For more information, see [Modify log data retention period](manage-storage-analytics-logs.md#modify-log-data-retention-period) | +| Protocols | Enabling SSH File Transfer Protocol (SFTP) support| Enabling the SFTP endpoint incurs an hourly cost. To avoid passive charges, consider enabling SFTP only when you're actively using it to transfer data.<br><br> For guidance about how to enable and then disable SFTP support, see [Connect to Azure Blob Storage by using the SSH File Transfer Protocol (SFTP)](../blobs/secure-file-transfer-protocol-support-how-to.md). | ## Frequently asked questions (FAQ) See [Managing costs FAQ](../blobs/storage-blob-faq.yml#managing-costs). - Learn more on how pricing works with Azure Storage. See [Azure Storage Overview pricing](https://azure.microsoft.com/pricing/details/storage/). - Understanding how your blobs and containers are stored, organized, and used in production so that you better optimize the tradeoffs between cost and performance. See [Tutorial: Analyze blob inventory reports](../blobs/storage-blob-inventory-report-analytics.md). - [Optimize costs for Blob Storage with reserved capacity](../blobs/storage-blob-reserved-capacity.md).-- Learn [how to optimize your cloud investment with Azure Cost Management](../../cost-management-billing/costs/cost-mgt-best-practices.md?WT.mc_id=costmanagementcontent_docsacmhorizontal_-inproduct-learn).+- Learn [how to optimize your cloud investment with Microsoft Cost Management](../../cost-management-billing/costs/cost-mgt-best-practices.md?WT.mc_id=costmanagementcontent_docsacmhorizontal_-inproduct-learn). - Learn more about managing costs with [cost analysis](../../cost-management-billing/costs/quick-acm-cost-analysis.md?WT.mc_id=costmanagementcontent_docsacmhorizontal_-inproduct-learn). - Learn about how to [prevent unexpected costs](../../cost-management-billing/cost-management-billing-overview.md?WT.mc_id=costmanagementcontent_docsacmhorizontal_-inproduct-learn). - Take the [Cost Management](/training/paths/control-spending-manage-bills?WT.mc_id=costmanagementcontent_docsacmhorizontal_-inproduct-learn) guided learning course. |
| storage | Storage Reference Azcopy Map Commands To Rest Operations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/common/storage-reference-azcopy-map-commands-to-rest-operations.md | + + Title: Map of AzCopy commands to REST operations (Azure Blob Storage) +description: Find the REST operations used by each AzCopy v10 command. +++ Last updated : 09/10/2024+++++# Map of AzCopy v10 commands to Azure Blob Storage REST operations ++When you run a command that operates on data in your storage account, AzCopy translates that command to a REST operation. This article maps AzCopy commands to Azure Blob Storage REST operations. ++## Command mapping ++The following table shows the operations that are used by each AzCopy command. To determine the price of each operation, see [Map each REST operation to a price](../blobs/map-rest-apis-transaction-categories.md). ++### Commands that target the Blob Service Endpoint ++| Command | Scenario | Operations | +||-|--| +| [azcopy bench](../common/storage-ref-azcopy-bench.md?toc=/azure/storage/blobs/toc.json) | Upload | [Put Block](/rest/api/storageservices/put-block-list) and [Put Block List](/rest/api/storageservices/put-block-list). Possibly [Put Blob](/rest/api/storageservices/put-blob) based on object size.| +| [azcopy bench](../common/storage-ref-azcopy-bench.md?toc=/azure/storage/blobs/toc.json) | Download |[List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), and [Get Blob](/rest/api/storageservices/get-blob) | +| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Upload | [Put Block](/rest/api/storageservices/put-block-list), [Put Block List](/rest/api/storageservices/put-block-list), and [Get Blob Properties](/rest/api/storageservices/get-blob-properties). Possibly [Put Blob](/rest/api/storageservices/put-blob) based on object size. | +| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Download | [List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), and [Get Blob](/rest/api/storageservices/get-blob) | +| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Perform a dry run | [List Blobs](/rest/api/storageservices/list-blobs) | +| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Copy from Amazon S3|[Put Blob from URL](/rest/api/storageservices/put-blob-from-url). Based on object size, could also be [Put Block From URL](/rest/api/storageservices/put-block-from-url) and [Put Block List](/rest/api/storageservices/put-block-list). | +| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Copy from Google Cloud Storage |[Put Blob from URL](/rest/api/storageservices/put-blob-from-url). Based on object size, could also be [Put Block From URL](/rest/api/storageservices/put-block-from-url) and [Put Block List](/rest/api/storageservices/put-block-list). | +| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Copy to another container |[List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), and [Put Blob From URL](/rest/api/storageservices/put-blob-from-url). Based on object size, could also be [Put Block From URL](/rest/api/storageservices/put-block-from-url) and [Put Block List](/rest/api/storageservices/put-block-list). | +| [azcopy sync](../common/storage-ref-azcopy-sync.md?toc=/azure/storage/blobs/toc.json) | Update local with changes to container |[List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), and [Get Blob](/rest/api/storageservices/get-blob) | +| [azcopy sync](../common/storage-ref-azcopy-sync.md?toc=/azure/storage/blobs/toc.json) | Update container with changes to local file system |[List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), [Put Block](/rest/api/storageservices/put-block-list), and [Put Block List](/rest/api/storageservices/put-block-list). Possibly [Put Blob](/rest/api/storageservices/put-blob) based on object size. | +| [azcopy sync](../common/storage-ref-azcopy-sync.md?toc=/azure/storage/blobs/toc.json) | Synchronize containers |[List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), and [Put Blob From URL](/rest/api/storageservices/put-blob-from-url). Based on object size, could also be [Put Block From URL](/rest/api/storageservices/put-block-from-url) and [Put Block List](/rest/api/storageservices/put-block-list). | +| [azcopy set-properties](../common/storage-ref-azcopy-set-properties.md?toc=/azure/storage/blobs/toc.json) | Set blob tier |[Set Blob Tier](/rest/api/storageservices/set-blob-tier) and [List Blobs](/rest/api/storageservices/list-blobs) (if targeting a virtual directory) | +| [azcopy set-properties](../common/storage-ref-azcopy-set-properties.md?toc=/azure/storage/blobs/toc.json) | Set metadata |[Set Blob Metadata](/rest/api/storageservices/set-blob-metadata) and [List Blobs](/rest/api/storageservices/list-blobs) (if targeting a virtual directory) | +| [azcopy set-properties](../common/storage-ref-azcopy-set-properties.md?toc=/azure/storage/blobs/toc.json) | Set blob tags |[Set Blob Tags](/rest/api/storageservices/set-blob-tags) and [List Blobs](/rest/api/storageservices/list-blobs) (if targeting a virtual directory) | +| [azcopy list](../common/storage-ref-azcopy-list.md?toc=/azure/storage/blobs/toc.json) | List blobs in a container|[List Blobs](/rest/api/storageservices/list-blobs) | +| [azcopy make](../common/storage-ref-azcopy-make.md?toc=/azure/storage/blobs/toc.json) | Create a container |[Create Container](/rest/api/storageservices/create-container) | +| [azcopy remove](../common/storage-ref-azcopy-remove.md?toc=/azure/storage/blobs/toc.json) | Delete a container |[Delete Container](/rest/api/storageservices/delete-container) | +| [azcopy remove](../common/storage-ref-azcopy-remove.md?toc=/azure/storage/blobs/toc.json) | Delete a blob |[Get Blob Properties](/rest/api/storageservices/get-blob-properties). [List Blobs](/rest/api/storageservices/list-blobs) (if targeting a virtual directory), and [Delete Blob](/rest/api/storageservices/delete-blob) | ++### Commands that target the Data Lake Storage endpoint ++| Command | Scenario | Operations | +||-|--| +| [azcopy bench](../common/storage-ref-azcopy-bench.md?toc=/azure/storage/blobs/toc.json) | Upload | [Path - Update](/rest/api/storageservices/datalakestoragegen2/path/update) (Append), and [Path - Update](/rest/api/storageservices/datalakestoragegen2/path/update) (Flush) | +| [azcopy bench](../common/storage-ref-azcopy-bench.md?toc=/azure/storage/blobs/toc.json) | Download | [List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), and [Path - Read](/rest/api/storageservices/datalakestoragegen2/path/read)| +| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Upload | [Path - Update](/rest/api/storageservices/datalakestoragegen2/path/update), and [Get Blob Properties](/rest/api/storageservices/get-blob-properties) | +| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Download |[List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), and [Path - Read](/rest/api/storageservices/datalakestoragegen2/path/read) | +| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Perform a dry run | [List Blobs](/rest/api/storageservices/list-blobs) | +| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Copy from Amazon S3| Not supported | +| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Copy from Google Cloud Storage | Not supported | +| [azcopy copy](../common/storage-ref-azcopy-copy.md?toc=/azure/storage/blobs/toc.json) | Copy to another container | [List Blobs](/rest/api/storageservices/list-blobs), and [Copy Blob](/rest/api/storageservices/copy-blob). if --preserve-permissions-true, then [Path - Get Properties](/rest/api/storageservices/datalakestoragegen2/path/get-properties) (Get Access Control List) and [Path - Update](/rest/api/storageservices/datalakestoragegen2/path/update) (Set access control) otherwise, [Get Blob Properties](/rest/api/storageservices/get-blob-properties). | +| [azcopy sync](../common/storage-ref-azcopy-sync.md?toc=/azure/storage/blobs/toc.json) | Update local with changes to container | [List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), and [Get Blob](/rest/api/storageservices/get-blob) | +| [azcopy sync](../common/storage-ref-azcopy-sync.md?toc=/azure/storage/blobs/toc.json) | Update container with changes to local file system | [List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), [Path - Update](/rest/api/storageservices/datalakestoragegen2/path/update) (Append), and [Path - Update](/rest/api/storageservices/datalakestoragegen2/path/update) (Flush)| +| [azcopy sync](../common/storage-ref-azcopy-sync.md?toc=/azure/storage/blobs/toc.json) | Synchronize containers | [List Blobs](/rest/api/storageservices/list-blobs), [Get Blob Properties](/rest/api/storageservices/get-blob-properties), and [Copy Blob](/rest/api/storageservices/copy-blob) | +| [azcopy set-properties](../common/storage-ref-azcopy-set-properties.md?toc=/azure/storage/blobs/toc.json) | Set blob tier | Not supported | +| [azcopy set-properties](../common/storage-ref-azcopy-set-properties.md?toc=/azure/storage/blobs/toc.json) | Set metadata | Not supported | +| [azcopy set-properties](../common/storage-ref-azcopy-set-properties.md?toc=/azure/storage/blobs/toc.json) | Set blob tags | Not supported | +| [azcopy list](../common/storage-ref-azcopy-list.md?toc=/azure/storage/blobs/toc.json) | List blobs in a container| [List Blobs](/rest/api/storageservices/list-blobs)| +| [azcopy make](../common/storage-ref-azcopy-make.md?toc=/azure/storage/blobs/toc.json) | Create a container | [Filesystem - Create](/rest/api/storageservices/datalakestoragegen2/filesystem/create) | +| [azcopy remove](../common/storage-ref-azcopy-remove.md?toc=/azure/storage/blobs/toc.json) | Delete a container | [Filesystem - Delete](/rest/api/storageservices/datalakestoragegen2/filesystem/delete) | +| [azcopy remove](../common/storage-ref-azcopy-remove.md?toc=/azure/storage/blobs/toc.json) | Delete a blob | [Filesystem - Delete](/rest/api/storageservices/datalakestoragegen2/filesystem/delete) | ++## See also ++- [Get started with AzCopy](storage-use-azcopy-v10.md) +- [Optimize the performance of AzCopy v10 with Azure Storage](storage-use-azcopy-optimize.md) +- [Troubleshoot AzCopy V10 issues in Azure Storage by using log files](storage-use-azcopy-configure.md) |
| storage | Transport Layer Security Configure Minimum Version | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/common/transport-layer-security-configure-minimum-version.md | When you enforce a minimum TLS version for your storage account, you risk reject To log requests to your Azure Storage account and determine the TLS version used by the client, you can use Azure Storage logging in Azure Monitor. For more information, see [Monitor Azure Storage](../blobs/monitor-blob-storage.md). -Azure Storage logging in Azure Monitor supports using log queries to analyze log data. To query logs, you can use an Azure Log Analytics workspace. To learn more about log queries, see [Tutorial: Get started with Log Analytics queries](../../azure-monitor/logs/log-analytics-tutorial.md). +Azure Storage logging in Azure Monitor supports using log queries to analyze log data. To query logs, you can use an Azure Log Analytics workspace. To learn more about log queries, see [Tutorial: Get started with Log Analytics queries](/azure/azure-monitor/logs/log-analytics-tutorial). To log Azure Storage data with Azure Monitor and analyze it with Azure Log Analytics, you must first create a diagnostic setting that indicates what types of requests and for which storage services you want to log data. To create a diagnostic setting in the Azure portal, follow these steps: -1. Create a new Log Analytics workspace in the subscription that contains your Azure Storage account. After you configure logging for your storage account, the logs will be available in the Log Analytics workspace. For more information, see [Create a Log Analytics workspace in the Azure portal](../../azure-monitor/logs/quick-create-workspace.md). +1. Create a new Log Analytics workspace in the subscription that contains your Azure Storage account. After you configure logging for your storage account, the logs will be available in the Log Analytics workspace. For more information, see [Create a Log Analytics workspace in the Azure portal](/azure/azure-monitor/logs/quick-create-workspace). 1. Navigate to your storage account in the Azure portal. 1. In the Monitoring section, select **Diagnostic settings**. 1. Select the Azure Storage service for which you want to log requests. For example, choose **Blob** to log requests to Blob storage. To log Azure Storage data with Azure Monitor and analyze it with Azure Log Analy :::image type="content" source="media/transport-layer-security-configure-minimum-version/create-diagnostic-setting-logs.png" alt-text="Screenshot showing how to create a diagnostic setting for logging requests"::: -After you create the diagnostic setting, requests to the storage account are subsequently logged according to that setting. For more information, see [Create diagnostic setting to collect resource logs and metrics in Azure](../../azure-monitor/essentials/diagnostic-settings.md). +After you create the diagnostic setting, requests to the storage account are subsequently logged according to that setting. For more information, see [Create diagnostic setting to collect resource logs and metrics in Azure](/azure/azure-monitor/essentials/diagnostic-settings). For a reference of fields available in Azure Storage logs in Azure Monitor, see [Resource logs](../blobs/monitor-blob-storage-reference.md#resource-logs). |
| storage | Elastic San Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/elastic-san/elastic-san-metrics.md | Available log categories: ## Next steps -- [Azure Monitor Metrics overview](../../azure-monitor/essentials/data-platform-metrics.md)-- [Azure Monitor Metrics aggregation and display explained](../../azure-monitor/essentials/metrics-aggregation-explained.md)+- [Azure Monitor Metrics overview](/azure/azure-monitor/essentials/data-platform-metrics) +- [Azure Monitor Metrics aggregation and display explained](/azure/azure-monitor/essentials/metrics-aggregation-explained) |
| storage | File Sync Monitor Cloud Tiering | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/file-sync/file-sync-monitor-cloud-tiering.md | To be more specific on what you want your graphs to display, consider using **Ad For details on the different types of metrics for Azure File Sync and how to use them, see [Monitor Azure File Sync](file-sync-monitoring.md). -For details on how to use metrics, see [Analyze metrics with Azure Monitor metrics explorer](../../azure-monitor/essentials/analyze-metrics.md). +For details on how to use metrics, see [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics). To change your cloud tiering policy, see [Choose cloud tiering policies](file-sync-choose-cloud-tiering-policies.md). |
| storage | File Sync Monitoring | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/file-sync/file-sync-monitoring.md | This article describes how to monitor your Azure File Sync deployment by using A ## Azure Monitor -Use [Azure Monitor](../../azure-monitor/overview.md) to view metrics and to configure alerts for sync, cloud tiering, and server connectivity. +Use [Azure Monitor](/azure/azure-monitor/overview) to view metrics and to configure alerts for sync, cloud tiering, and server connectivity. ### Metrics The following metrics for Azure File Sync are available in Azure Monitor: ### Alerts -Alerts proactively notify you when important conditions are found in your monitoring data. To learn more about configuring alerts in Azure Monitor, see [Overview of alerts in Microsoft Azure](../../azure-monitor/alerts/alerts-overview.md). +Alerts proactively notify you when important conditions are found in your monitoring data. To learn more about configuring alerts in Azure Monitor, see [Overview of alerts in Microsoft Azure](/azure/azure-monitor/alerts/alerts-overview). **How to create alerts for Azure File Sync** |
| storage | Storage Files Monitoring | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/files/storage-files-monitoring.md | Requests made by the Azure Files service itself, such as log creation or deletio [!INCLUDE [horz-monitor-kusto-queries](~/reusable-content/ce-skilling/azure/includes/azure-monitor/horizontals/horz-monitor-kusto-queries.md)] -Here are some queries that you can enter in the **Log search** bar to help you monitor your Azure file shares. These queries work with the [new language](../../azure-monitor/logs/log-query-overview.md). +Here are some queries that you can enter in the **Log search** bar to help you monitor your Azure file shares. These queries work with the [new language](/azure/azure-monitor/logs/log-query-overview). - View SMB errors over the last week. |
| storage | Monitor Queue Storage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/queues/monitor-queue-storage.md | Requests made by the Queue Storage service itself, such as log creation or delet <!-- ### Sample Kusto queries. Required section. If you have sample Kusto queries for your service, add them after the include. --> [!INCLUDE [horz-monitor-kusto-queries](~/reusable-content/ce-skilling/azure/includes/azure-monitor/horizontals/horz-monitor-kusto-queries.md)] <!-- Add sample Kusto queries for your service here. -->-Here are some queries that you can enter in the **Log search** bar to help you monitor your Queue Storage. These queries work with the [new language](../../azure-monitor/logs/log-query-overview.md). For more information, see [Log Analytics tutorial](/azure/azure-monitor/logs/log-analytics-tutorial). +Here are some queries that you can enter in the **Log search** bar to help you monitor your Queue Storage. These queries work with the [new language](/azure/azure-monitor/logs/log-query-overview). For more information, see [Log Analytics tutorial](/azure/azure-monitor/logs/log-analytics-tutorial). - To list the 10 most common errors over the last three days. |
| storage | Queues Storage Monitoring Scenarios | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/queues/queues-storage-monitoring-scenarios.md | The section shows you how to identify the "when", "who", "what" and "how" inform ### Auditing control plane operations -Resource Manager operations are captured in the [Azure activity log](../../azure-monitor/essentials/activity-log.md). To view the activity log, open your storage account in the Azure portal, and then select **Activity log**. +Resource Manager operations are captured in the [Azure activity log](/azure/azure-monitor/essentials/activity-log). To view the activity log, open your storage account in the Azure portal, and then select **Activity log**. > [!div class="mx-imgBorder"] >  You can find the friendly name of that security principal by taking the value of ### Auditing data plane operations -Data plane operations are captured in [Azure resource logs for Storage](monitor-queue-storage.md#analyzing-logs). You can [configure Diagnostic setting](../../azure-monitor/platform/diagnostic-settings.md) to export logs to Log Analytics workspace for a native query experience. +Data plane operations are captured in [Azure resource logs for Storage](monitor-queue-storage.md#analyzing-logs). You can [configure Diagnostic setting](/azure/azure-monitor/platform/diagnostic-settings) to export logs to Log Analytics workspace for a native query experience. Here's a Log Analytics query that retrieves the "when", "who", "what", and "how" information in a list of log entries. You can export logs to Log Analytics for rich native query capabilities. When yo With Azure Synapse, you can create server-less SQL pool to query log data when you need. This could save costs significantly. -1. Export logs to storage account. See [Creating a diagnostic setting](../../azure-monitor/platform/diagnostic-settings.md). +1. Export logs to storage account. See [Creating a diagnostic setting](/azure/azure-monitor/platform/diagnostic-settings). 2. Create and configure a Synapse workspace. See [Quickstart: Create a Synapse workspace](../../synapse-analytics/quickstart-create-workspace.md). With Azure Synapse, you can create server-less SQL pool to query log data when y - [Monitoring Azure Queue Storage](monitor-queue-storage.md). - [Azure Queue Storage monitoring data reference](monitor-queue-storage-reference.md) - [Tutorial: Use Kusto queries in Azure Data Explorer and Azure Monitor](/azure/data-explorer/kusto/query/tutorial?pivots=azuredataexplorer).-- [Get started with log queries in Azure Monitor](../../azure-monitor/logs/get-started-queries.md).+- [Get started with log queries in Azure Monitor](/azure/azure-monitor/logs/get-started-queries). |
| storage | Commvault Solution Guide | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/solution-integration/validated-partners/backup-archive-disaster-recovery/commvault/commvault-solution-guide.md | It is advisable to monitor both your Azure resources and Commvault's ability to #### Azure portal -Azure provides a robust monitoring solution in the form of [Azure Monitor](../../../../../azure-monitor/essentials/monitor-azure-resource.md). You can [configure Azure Monitor](../../../../blobs/monitor-blob-storage.md) to track Azure Storage capacity, transactions, availability, authentication, and more. You can find the full reference of metrics that are collected [here](../../../../blobs/monitor-blob-storage-reference.md). A few useful metrics to track are BlobCapacity - to make sure you remain below the maximum [storage account capacity limit](../../../../common/scalability-targets-standard-account.md), Ingress and Egress - to track the amount of data being written to and read from your Azure Storage account, and SuccessE2ELatency - to track the roundtrip time for requests to and from Azure Storage and your MediaAgent. +Azure provides a robust monitoring solution in the form of [Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource). You can [configure Azure Monitor](../../../../blobs/monitor-blob-storage.md) to track Azure Storage capacity, transactions, availability, authentication, and more. You can find the full reference of metrics that are collected [here](../../../../blobs/monitor-blob-storage-reference.md). A few useful metrics to track are BlobCapacity - to make sure you remain below the maximum [storage account capacity limit](../../../../common/scalability-targets-standard-account.md), Ingress and Egress - to track the amount of data being written to and read from your Azure Storage account, and SuccessE2ELatency - to track the roundtrip time for requests to and from Azure Storage and your MediaAgent. -You can also [create log alerts](../../../../../service-health/alerts-activity-log-service-notifications-portal.md) to track Azure Storage service health and view the [Azure status dashboard](https://azure.status.microsoft/status) at any time. +You can also [create log alerts](/azure/service-health/alerts-activity-log-service-notifications-portal) to track Azure Storage service health and view the [Azure status dashboard](https://azure.status.microsoft/status) at any time. #### Commvault Command Center |
| storage | Datadobi Solution Guide | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/solution-integration/validated-partners/backup-archive-disaster-recovery/datadobi/datadobi-solution-guide.md | This section provides a brief guide for how to add Azure Storage to an on-premis #### Azure portal -Azure provides a robust monitoring solution in the form of [Azure Monitor](../../../../../azure-monitor/essentials/monitor-azure-resource.md). You can [configure Azure Monitor](../../../../blobs/monitor-blob-storage.md) to track Azure Storage capacity, transactions, availability, authentication, and more. You can find the full reference of metrics that are collected [here](../../../../blobs/monitor-blob-storage-reference.md). A few useful metrics to track are BlobCapacity - to make sure you remain below the maximum [storage account capacity limit](../../../../common/scalability-targets-standard-account.md), Ingress and Egress - to track the amount of data being written to and read from your Azure Storage account, and SuccessE2ELatency - to track the roundtrip time for requests to and from Azure Storage and your MediaAgent. +Azure provides a robust monitoring solution in the form of [Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource). You can [configure Azure Monitor](../../../../blobs/monitor-blob-storage.md) to track Azure Storage capacity, transactions, availability, authentication, and more. You can find the full reference of metrics that are collected [here](../../../../blobs/monitor-blob-storage-reference.md). A few useful metrics to track are BlobCapacity - to make sure you remain below the maximum [storage account capacity limit](../../../../common/scalability-targets-standard-account.md), Ingress and Egress - to track the amount of data being written to and read from your Azure Storage account, and SuccessE2ELatency - to track the roundtrip time for requests to and from Azure Storage and your MediaAgent. -You can also [create log alerts](../../../../../service-health/alerts-activity-log-service-notifications-portal.md) to track Azure Storage service health and view the [Azure status dashboard](https://azure.status.microsoft/status) at any time. +You can also [create log alerts](/azure/service-health/alerts-activity-log-service-notifications-portal) to track Azure Storage service health and view the [Azure status dashboard](https://azure.status.microsoft/status) at any time. #### DobiSync documentation |
| storage | Monitor Table Storage | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/storage/tables/monitor-table-storage.md | Requests made by the Table Storage service itself, such as log creation or delet [!INCLUDE [horz-monitor-kusto-queries](~/reusable-content/ce-skilling/azure/includes/azure-monitor/horizontals/horz-monitor-kusto-queries.md)] -Here are some queries that you can enter in the **Log search** bar to help you monitor your Table Storage. These queries work with the [new language](../../azure-monitor/logs/log-query-overview.md). For more information, see [Log Analytics tutorial](/azure/azure-monitor/logs/log-analytics-tutorial). +Here are some queries that you can enter in the **Log search** bar to help you monitor your Table Storage. These queries work with the [new language](/azure/azure-monitor/logs/log-query-overview). For more information, see [Log Analytics tutorial](/azure/azure-monitor/logs/log-analytics-tutorial). * To list the 10 most common errors over the last three days. |
| stream-analytics | Automation Powershell | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/stream-analytics/automation-powershell.md | This article anticipates the need to interact with Stream Analytics on the follo For Stream Analytics resource management, you can use the [REST API](/rest/api/streamanalytics/), the [.NET SDK](/dotnet/api/microsoft.azure.management.streamanalytics), or one of the CLI libraries ([Azure CLI](/cli/azure/stream-analytics) or [PowerShell](/powershell/module/az.streamanalytics)). -For metrics and logs, everything in Azure is centralized under [Azure Monitor](../azure-monitor/overview.md), with a similar choice of API surfaces. Logs and metrics are always 1 to 3 minutes behind when you're querying the APIs. So setting *N* at 5 usually means the job runs 6 to 8 minutes in reality. +For metrics and logs, everything in Azure is centralized under [Azure Monitor](/azure/azure-monitor/overview), with a similar choice of API surfaces. Logs and metrics are always 1 to 3 minutes behind when you're querying the APIs. So setting *N* at 5 usually means the job runs 6 to 8 minutes in reality. Another consideration is that metrics are always emitted. When the job is stopped, the API returns empty records. You have to clean up the output of your API calls to focus on relevant values. In PowerShell, use the [Az PowerShell](/powershell/azure/new-azureps-module-az) - [Get-AzStreamAnalyticsJob](/powershell/module/az.streamanalytics/get-azstreamanalyticsjob) for the current job status - [Start-AzStreamAnalyticsJob](/powershell/module/az.streamanalytics/start-azstreamanalyticsjob) or [Stop-AzStreamAnalyticsJob](/powershell/module/az.streamanalytics/stop-azstreamanalyticsjob)-- [Get-AzMetric](/powershell/module/az.monitor/get-azmetric) with `InputEventsSourcesBacklogged` (from [Stream Analytics metrics](../azure-monitor/essentials/metrics-supported.md#microsoftstreamanalyticsstreamingjobs))+- [Get-AzMetric](/powershell/module/az.monitor/get-azmetric) with `InputEventsSourcesBacklogged` (from [Stream Analytics metrics](/azure/azure-monitor/essentials/metrics-supported#microsoftstreamanalyticsstreamingjobs)) - [Get-AzActivityLog](/powershell/module/az.monitor/get-azactivitylog) for event names that begin with `Stop Job` ### Hosting service Next, set up **Alert logic** as follows: - Threshold value: **0** - Frequency of evaluation: **5 minutes** -From there, reuse or create a new [action group](../azure-monitor/alerts/action-groups.md?WT.mc_id=Portal-Microsoft_Azure_Monitoring). Then complete the configuration. +From there, reuse or create a new [action group](/azure/azure-monitor/alerts/action-groups?WT.mc_id=Portal-Microsoft_Azure_Monitoring). Then complete the configuration. To check that you set up the alert properly, you can add `throw "Testing the alert"` anywhere in the PowerShell script and then wait 5 minutes to receive an email. You can check that everything is wired properly in **Test pane**. After that, you need to publish the job (by selecting **Publish**) so that you can link the runbook to a schedule. Creating and linking the schedule is a straightforward process. Now is a good time to remember that there are [workarounds](../automation/shared-resources/schedules.md#schedule-runbooks-to-run-more-frequently) to achieve schedule intervals under 1 hour. -Finally, you can set up an alert. The first step is to enable logs by using the [diagnostic settings](../azure-monitor/essentials/create-diagnostic-settings.md?tabs=cli) of the Automation account. The second step is to capture errors by using a query like you did for Functions. +Finally, you can set up an alert. The first step is to enable logs by using the [diagnostic settings](/azure/azure-monitor/essentials/create-diagnostic-settings?tabs=cli) of the Automation account. The second step is to capture errors by using a query like you did for Functions. ## Outcome |
| stream-analytics | Cicd Autoscale | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/stream-analytics/cicd-autoscale.md | If you have a working Stream Analytics project on the local machine, follow thes  - To learn more about defining autoscale rules, see [Understand autoscale settings](../azure-monitor/autoscale/autoscale-understanding-settings.md). + To learn more about defining autoscale rules, see [Understand autoscale settings](/azure/azure-monitor/autoscale/autoscale-understanding-settings). 5. Deploy to Azure. |
| stream-analytics | Monitor Azure Stream Analytics Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/stream-analytics/monitor-azure-stream-analytics-reference.md | The following table lists the metrics available for the Microsoft.StreamAnalytic ## Related content -- [Monitor Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md)+- [Monitor Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) - [Monitor Azure Stream Analytics](monitor-azure-stream-analytics.md) - [Dimensions for Azure Stream Analytics metrics](monitor-azure-stream-analytics-reference.md#metric-dimensions) - [Understand and adjust streaming units](stream-analytics-streaming-unit-consumption.md) |
| stream-analytics | Monitor Azure Stream Analytics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/stream-analytics/monitor-azure-stream-analytics.md | For detailed instructions on how to set up an alert for Azure Stream Analytics, ## Related content -- See [Monitoring Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md) for general details on monitoring Azure resources.+- See [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) for general details on monitoring Azure resources. - See [Azure Stream Analytics monitoring data reference](monitor-azure-stream-analytics-reference.md) for a reference of the metrics, logs, and other important values created for Azure Stream Analytics. - See the following Azure Stream Analytics monitoring and troubleshooting articles: - [Monitor jobs using Azure portal](stream-analytics-monitoring.md) |
| stream-analytics | Stream Analytics Autoscale | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/stream-analytics/stream-analytics-autoscale.md | The two types of scaling supported by Stream Analytics are _manual scale_ and _c _Manual scale_ allows you to maintain and adjust a fixed number of streaming units for your job. -_Custom autoscale_ allows you to specify the minimum and maximum number of streaming units for your job to dynamically adjust based on your rule definitions. Custom autoscale examines the preconfigured set of rules. Then it determines to add SUs to handle increases in load or to reduce the number of SUs when computing resources are sitting idle. For more information about autoscale in Azure Monitor, see [Overview of autoscale in Microsoft Azure](../azure-monitor/autoscale/autoscale-overview.md). +_Custom autoscale_ allows you to specify the minimum and maximum number of streaming units for your job to dynamically adjust based on your rule definitions. Custom autoscale examines the preconfigured set of rules. Then it determines to add SUs to handle increases in load or to reduce the number of SUs when computing resources are sitting idle. For more information about autoscale in Azure Monitor, see [Overview of autoscale in Microsoft Azure](/azure/azure-monitor/autoscale/autoscale-overview). > [!NOTE] > Although you can use manual scale regardless of the job's state, custom autoscale can only be enabled when the job is in the `running` state. The previous section shows you how to add a default condition for the autoscale 1. If you select **Specify start/end dates**, select the **Timezone**, **Start date and time**, and **End date and time** for the condition to be in effect. 2. If you select **Repeat specific days**, select the days of the week, timezone, start time, and end time when the condition should apply. -To learn more about how autoscale settings work, especially how it picks a profile or condition and evaluates multiple rules, see [Understand Autoscale settings](../azure-monitor/autoscale/autoscale-understanding-settings.md). +To learn more about how autoscale settings work, especially how it picks a profile or condition and evaluates multiple rules, see [Understand Autoscale settings](/azure/azure-monitor/autoscale/autoscale-understanding-settings). ## Next steps |
| stream-analytics | Stream Analytics Job Diagnostic Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/stream-analytics/stream-analytics-job-diagnostic-logs.md | It's highly recommended to enable resource logs for all jobs as it will greatly Stream Analytics offers two types of logs: -* [Activity logs](../azure-monitor/essentials/platform-logs-overview.md) (always on), which give insights into operations performed on jobs. +* [Activity logs](/azure/azure-monitor/essentials/platform-logs-overview) (always on), which give insights into operations performed on jobs. -* [Resource logs](../azure-monitor/essentials/platform-logs-overview.md) (configurable), which provide richer insights into everything that happens with a job. Resource logs start when the job is created and end when the job is deleted. They cover events when the job is updated and while itΓÇÖs running. +* [Resource logs](/azure/azure-monitor/essentials/platform-logs-overview) (configurable), which provide richer insights into everything that happens with a job. Resource logs start when the job is created and end when the job is deleted. They cover events when the job is updated and while itΓÇÖs running. > [!NOTE] > You can use services like Azure Storage, Azure Event Hubs, and Azure Monitor logs to analyze nonconforming data. You are charged based on the pricing model for those services. |
| stream-analytics | Stream Analytics Monitoring | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/stream-analytics/stream-analytics-monitoring.md | You can also specify the time range to view the metrics you're interested in. :::image type="content" source="./media/stream-analytics-monitoring/08-stream-analytics-monitoring.png" alt-text="Diagram that shows the Stream Analytics monitor page with time range." lightbox="./media/stream-analytics-monitoring/08-stream-analytics-monitoring.png"::: -For details, see [How to Customize Monitoring](../azure-monitor/data-platform.md). +For details, see [How to Customize Monitoring](/azure/azure-monitor/data-platform). |
| stream-analytics | Stream Analytics Troubleshoot Output | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/stream-analytics/stream-analytics-troubleshoot-output.md | This article describes common issues with Azure Stream Analytics output connecti * If the **Input Events** value is greater than zero, the job can read the input data. If the **Input Events** value isn't greater than zero, there's an issue with the job's input. See [Troubleshoot input connections](stream-analytics-troubleshoot-input.md) for more information. If your job has reference data input, apply splitting by logical name when looking at **Input Events** metric. If there are no input events from your reference data alone, then it likely means that this input source has not be configured properly to fetch the right reference dataset. * If the **Data Conversion Errors** value is greater than zero and climbing, see [Azure Stream Analytics data errors](data-errors.md) for detailed information about data conversion errors.- * If the **Runtime Errors** value is greater than zero, your job receives data but generates errors while processing the query. To find the errors, go to the [audit logs](../azure-monitor/essentials/activity-log.md), and then filter on the **Failed** status. + * If the **Runtime Errors** value is greater than zero, your job receives data but generates errors while processing the query. To find the errors, go to the [audit logs](/azure/azure-monitor/essentials/activity-log), and then filter on the **Failed** status. * If the **Input Events** value is greater than zero and the **Output Events** value equals zero, one of the following statements is true: * The query processing resulted in zero output events. * Events or fields might be malformed, resulting in a zero output after the query processing. |
| stream-analytics | Stream Analytics Troubleshoot Query | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/stream-analytics/stream-analytics-troubleshoot-query.md | This article describes common issues with developing Azure Stream Analytics quer 5. Ensure event ordering policies are configured as expected. Go to **Settings** and select [**Event Ordering**](./stream-analytics-time-handling.md). The policy is *not* applied when you use the **Test** button to test the query. This result is one difference between testing in-browser versus running the job in production. 6. Debug by using activity and resource logs:- - Use [Activity Logs](../azure-monitor/essentials/activity-log.md), and filter to identify and debug errors. + - Use [Activity Logs](/azure/azure-monitor/essentials/activity-log), and filter to identify and debug errors. - Use [job resource logs](stream-analytics-job-diagnostic-logs.md) to identify and debug errors. ## Resource utilization is high |
| synapse-analytics | Implementation Success Evaluate Data Integration Design | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/synapse-analytics/guidance/implementation-success-evaluate-data-integration-design.md | As you review the data integration design, consider the following recommendation For operational excellence, evaluate the following points. - **Environment:** When planning your environments, segregate them by development/test, user acceptance testing (UAT), and production. Use the folder organizational options to organize your pipelines and datasets by business/ETL jobs to support better maintainability. Use [annotations](https://azure.microsoft.com/resources/videos/azure-friday-enhanced-monitoring-capabilities-and-tagsannotations-in-azure-data-factory/) to tag your pipelines so you can easily monitor them. Create reusable pipelines by using parameters, and iteration and conditional activities.-- **Monitoring and alerting:** Synapse workspaces include the [Monitor Hub](../get-started-monitor.md), which has rich monitoring information of each and every pipeline run. It also integrates with [Log Analytics](../../azure-monitor/logs/log-analytics-overview.md) for further log analysis and alerting. You should implement these features to provide proactive error notifications. Also, use *Upon Failure* paths to implement customized [error handling](https://techcommunity.microsoft.com/t5/azure-data-factory/understanding-pipeline-failures-and-error-handling/ba-p/1630459).+- **Monitoring and alerting:** Synapse workspaces include the [Monitor Hub](../get-started-monitor.md), which has rich monitoring information of each and every pipeline run. It also integrates with [Log Analytics](/azure/azure-monitor/logs/log-analytics-overview) for further log analysis and alerting. You should implement these features to provide proactive error notifications. Also, use *Upon Failure* paths to implement customized [error handling](https://techcommunity.microsoft.com/t5/azure-data-factory/understanding-pipeline-failures-and-error-handling/ba-p/1630459). - **Automated deployment and testing:** Azure Synapse pipelines are built into Synapse workspace, so you can take advantage of workspace automation and deployment. Use [ARM templates](../quickstart-deployment-template-workspaces.md) to minimize manual activities when creating Synapse workspaces. Also, [integrate Synapse workspaces with Azure DevOps](../cicd/continuous-integration-delivery.md#set-up-a-release-pipeline-in-azure-devops) to build code versioning and automate publication. ### Performance efficiency |
| synapse-analytics | Implementation Success Perform Monitoring Review | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/synapse-analytics/guidance/implementation-success-perform-monitoring-review.md | Monitoring is a key part of the operationalization of any Azure solution. This a Using your solution requirements and other data collected during the [assessment stage](implementation-success-assess-environment.md) and [solution development](implementation-success-evaluate-solution-development-environment-design.md), build a list of important behaviors and activities that need to be monitored in your production environment. As you build this list, identify the groups of users that will need access to monitoring information and build the procedures they can follow to respond to monitoring results. -You can use [Azure Monitor](../../azure-monitor/overview.md) to provide base-level infrastructure metrics, alerts, and logs for most Azure services. Azure diagnostic logs are emitted by a resource to provide rich, frequent data about the operation of that resource. Azure Synapse can write diagnostic logs in Azure Monitor. +You can use [Azure Monitor](/azure/azure-monitor/overview) to provide base-level infrastructure metrics, alerts, and logs for most Azure services. Azure diagnostic logs are emitted by a resource to provide rich, frequent data about the operation of that resource. Azure Synapse can write diagnostic logs in Azure Monitor. For more information, see [Use Azure Monitor with your Azure Synapse Analytics workspace](../monitor-synapse-analytics.md). You can monitor a dedicated SQL pool by using Azure Monitor, alerting, dynamic m - **Alerts:** You can set up alerts that send you an email or call a webhook when a certain metric reaches a predefined threshold. For example, you can receive an alert email when the database size grows too large. For more information, see [Alerts](../monitor-synapse-analytics.md#alerts). - **DMVs:** You can use [DMVs](../sql-data-warehouse/sql-data-warehouse-manage-monitor.md) to monitor workloads to help investigate query executions in SQL pools.-- **Log Analytics:** [Log Analytics](../../azure-monitor/logs/log-analytics-tutorial.md) is a tool in the Azure portal that you can use to edit and run log queries from data collected by Azure Monitor. For more information, see [Monitor workload - Azure portal](../sql-data-warehouse/sql-data-warehouse-monitor-workload-portal.md).+- **Log Analytics:** [Log Analytics](/azure/azure-monitor/logs/log-analytics-tutorial) is a tool in the Azure portal that you can use to edit and run log queries from data collected by Azure Monitor. For more information, see [Monitor workload - Azure portal](../sql-data-warehouse/sql-data-warehouse-monitor-workload-portal.md). ## Monitor serverless SQL pools |
| synapse-analytics | Implementation Success Perform Operational Readiness Review | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/synapse-analytics/guidance/implementation-success-perform-operational-readiness-review.md | Set and document expectations for monitoring readiness with your business. These - Details of proactive health checks. - Any mechanisms that are in place that automate actions in response to incidents, for example, raising tickets automatically. -Consider using [Azure Monitor](../../azure-monitor/overview.md) to collect, analyze, and act on telemetry data from your Azure and on-premises environments. Azure Monitor helps you maximize performance and availability of your applications by proactively identify problems in seconds. +Consider using [Azure Monitor](/azure/azure-monitor/overview) to collect, analyze, and act on telemetry data from your Azure and on-premises environments. Azure Monitor helps you maximize performance and availability of your applications by proactively identify problems in seconds. List all the important metrics to monitor for each service in your solution along with their acceptable thresholds. For example, you can [view metrics](../monitor-synapse-analytics-reference.md#supported-metrics-for-microsoftsynapseworkspacessqlpools) to monitor for a dedicated SQL pool. Consider using [Azure Service Health](https://azure.microsoft.com/features/service-health/) to notify you about Azure service incidents and planned maintenance. That way, you can take action to mitigate downtime. You can set up customizable cloud alerts and use a personalized dashboard to analyze health issues, monitor the impact to your cloud resources, get guidance and support, and share details and updates. -Lastly, ensure proper notifications are set up to notify appropriate people when incidents occur. Incidents could be proactive, such as when a certain metric exceeds a threshold, or reactive, such as a failure of a component or service. For more information, see [Overview of alerts in Microsoft Azure](../../azure-monitor/alerts/alerts-overview.md). +Lastly, ensure proper notifications are set up to notify appropriate people when incidents occur. Incidents could be proactive, such as when a certain metric exceeds a threshold, or reactive, such as a failure of a component or service. For more information, see [Overview of alerts in Microsoft Azure](/azure/azure-monitor/alerts/alerts-overview). ### High availability |
| synapse-analytics | How To Analyze Complex Schema | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/synapse-analytics/how-to-analyze-complex-schema.md | Data engineers need to understand how to efficiently process complex data types ## What are arrays and nested structures? -The following object comes from [Application Insights](../azure-monitor/app/app-insights-overview.md). In this object, there are nested structures and arrays that contain nested structures. +The following object comes from [Application Insights](/azure/azure-monitor/app/app-insights-overview). In this object, there are nested structures and arrays that contain nested structures. ```json { |
| synapse-analytics | 3 Security Access Operations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/synapse-analytics/migration-guides/oracle/3-security-access-operations.md | The Azure portal can also provide recommendations for performance enhancements, :::image type="content" source="../media/3-security-access-operations/azure-portal-recommendations.png" border="true" alt-text="Screenshot of Azure portal recommendations for performance enhancements." lightbox="../media/3-security-access-operations/azure-portal-recommendations-lrg.png"::: -The portal supports integration with other Azure monitoring services, such as Operations Management Suite (OMS) and [Azure Monitor](../../../azure-monitor/overview.md), to provide an integrated monitoring experience of the data warehouse and the entire Azure analytics platform. For more information, see [Azure Synapse operations and management options](../../sql-data-warehouse/sql-data-warehouse-how-to-manage-and-monitor-workload-importance.md). +The portal supports integration with other Azure monitoring services, such as Operations Management Suite (OMS) and [Azure Monitor](/azure/azure-monitor/overview), to provide an integrated monitoring experience of the data warehouse and the entire Azure analytics platform. For more information, see [Azure Synapse operations and management options](../../sql-data-warehouse/sql-data-warehouse-how-to-manage-and-monitor-workload-importance.md). ### High availability (HA) and disaster recovery (DR) |
| synapse-analytics | Monitor Synapse Analytics Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/synapse-analytics/monitor-synapse-analytics-reference.md | Microsoft.Synapse/workspaces | spark.synapse.logAnalytics.keyVault.name | - | The Key Vault name for the Log Analytics ID and key. | | spark.synapse.logAnalytics.keyVault.key.workspaceId | SparkLogAnalyticsWorkspaceId | The Key Vault secret name for the Log Analytics workspace ID. | | spark.synapse.logAnalytics.keyVault.key.secret | SparkLogAnalyticsSecret | The Key Vault secret name for the Log Analytics workspace |-| spark.synapse.logAnalytics.uriSuffix | ods.opinsights.azure.com | The destination Log Analytics workspace [URI suffix](../azure-monitor/logs/data-collector-api.md#request-uri). If your workspace isn't in Azure global, you need to update the URI suffix according to the respective cloud. | +| spark.synapse.logAnalytics.uriSuffix | ods.opinsights.azure.com | The destination Log Analytics workspace [URI suffix](/azure/azure-monitor/logs/data-collector-api#request-uri). If your workspace isn't in Azure global, you need to update the URI suffix according to the respective cloud. | | spark.synapse.logAnalytics.filter.eventName.match | - | Optional. The comma-separated spark event names, you can specify which events to collect. For example: `SparkListenerJobStart,SparkListenerJobEnd` | | spark.synapse.logAnalytics.filter.loggerName.match | - | Optional. The comma-separated log4j logger names, you can specify which logs to collect. For example: `org.apache.spark.SparkContext,org.example.Logger` | | spark.synapse.logAnalytics.filter.metricName.match | - | Optional. The comma-separated spark metric name suffixes, you can specify which metrics to collect. For example: `jvm.heap.used`| |
| synapse-analytics | Apache Spark Azure Log Analytics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/synapse-analytics/spark/apache-spark-azure-log-analytics.md | -In this tutorial, you learn how to enable the Synapse Studio connector that's built in to Log Analytics. You can then collect and send Apache Spark application metrics and logs to your [Log Analytics workspace](../../azure-monitor/logs/quick-create-workspace.md). Finally, you can use an Azure Monitor workbook to visualize the metrics and logs. +In this tutorial, you learn how to enable the Synapse Studio connector that's built in to Log Analytics. You can then collect and send Apache Spark application metrics and logs to your [Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace). Finally, you can use an Azure Monitor workbook to visualize the metrics and logs. ## Configure workspace information Follow these steps to configure the necessary information in Synapse Studio. ### Step 1: Create a Log Analytics workspace Consult one of the following resources to create this workspace:-- [Create a workspace in the Azure portal.](../../azure-monitor/logs/quick-create-workspace.md)-- [Create a workspace with Azure CLI.](../../azure-monitor/logs/resource-manager-workspace.md)-- [Create and configure a workspace in Azure Monitor by using PowerShell.](../../azure-monitor/logs/powershell-workspace-configuration.md)+- [Create a workspace in the Azure portal.](/azure/azure-monitor/logs/quick-create-workspace) +- [Create a workspace with Azure CLI.](/azure/azure-monitor/logs/resource-manager-workspace) +- [Create and configure a workspace in Azure Monitor by using PowerShell.](/azure/azure-monitor/logs/powershell-workspace-configuration) ### Step 2: Prepare an Apache Spark configuration file SparkMetrics_CL ## Create and manage alerts -Users can query to evaluate metrics and logs at a set frequency, and fire an alert based on the results. For more information, see [Create, view, and manage log alerts by using Azure Monitor](../../azure-monitor/alerts/alerts-log.md). +Users can query to evaluate metrics and logs at a set frequency, and fire an alert based on the results. For more information, see [Create, view, and manage log alerts by using Azure Monitor](/azure/azure-monitor/alerts/alerts-log). ## Synapse workspace with data exfiltration protection enabled After the Synapse workspace is created with [data exfiltration protection](../security/workspace-data-exfiltration-protection.md) enabled. -When you want to enable this feature, you need to create managed private endpoint connection requests to [Azure Monitor private link scopes (A M P L S)](../../azure-monitor/logs/private-link-security.md) in the workspaceΓÇÖs approved Microsoft Entra tenants. +When you want to enable this feature, you need to create managed private endpoint connection requests to [Azure Monitor private link scopes (A M P L S)](/azure/azure-monitor/logs/private-link-security) in the workspaceΓÇÖs approved Microsoft Entra tenants. You can follow below steps to create a managed private endpoint connection to Azure Monitor private link scopes (A M P L S): -1. If there is no existing A M P L S, you can follow [Azure Monitor Private Link connection setup](../../azure-monitor/logs/private-link-security.md) to create one. +1. If there is no existing A M P L S, you can follow [Azure Monitor Private Link connection setup](/azure/azure-monitor/logs/private-link-security) to create one. 2. Navigate to your A M P L S in Azure portal, on the **Azure Monitor Resources** page, click **Add** to add connection to your Azure Log Analytics workspace. 3. Navigate to **Synapse Studio > Manage > Managed private endpoints**, click **New** button, select **Azure Monitor Private Link Scopes**, and **continue**. > [!div class="mx-imgBorder"] You can follow below steps to create a managed private endpoint connection to Az 6. Navigate to your A M P L S in Azure portal again, on the **Private Endpoint connections** page, select the connection provisioned and **Approve**. > [!NOTE] -> - The A M P L S object has a number of limits you should consider when planning your Private Link setup. See [A M P L S limits](../../azure-monitor/logs/private-link-security.md) for a deeper review of these limits. +> - The A M P L S object has a number of limits you should consider when planning your Private Link setup. See [A M P L S limits](/azure/azure-monitor/logs/private-link-security) for a deeper review of these limits. > - Check if you have [right permission](../security/synapse-workspace-access-control-overview.md) to create managed private endpoint. ## Next steps |
| synapse-analytics | Apache Spark Development Using Notebooks | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/synapse-analytics/spark/apache-spark-development-using-notebooks.md | The following sections describe the operations for developing notebooks: * [Undo or redo a cell operation](#undo-redo-cell-operation) * [Comment on a code cell](#code-cell-commenting) * [Move a cell](#move-a-cell)+* [Copy a cell](#copy-a-cell) * [Delete a cell](#delete-a-cell) * [Collapse cell input](#collapse-a-cell-input) * [Collapse cell output](#collapse-a-cell-output) To move a cell, select the left side of the cell and drag the cell to the desire  +### <a name = "move-a-cell"></a>Copy a cell ++To copy a cell, create a new cell, select all the text in your original cell, copy the text, and paste the text into the new cell. When your cell is in edit mode, traditional keyboard shortcuts to select all text are limited to the cell. ++>[!TIP] +>Synapse notebooks also provide [snippits](#code-snippets) of commonly used code patterns. + ### <a name = "delete-a-cell"></a>Delete a cell To delete a cell, select the **Delete** button to the right of the cell. |
| synapse-analytics | Synapse File Mount Api | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/synapse-analytics/spark/synapse-file-mount-api.md | You can create a linked service for Data Lake Storage Gen2 or Blob Storage. Curr  -+ **Create a linked service by using a managed identity** ++ **Create a linked service using a system-assigned managed identity**  |
| synapse-analytics | Gen2 Migration Schedule | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/synapse-analytics/sql-data-warehouse/gen2-migration-schedule.md | For more information, see [Upgrade to Gen2](upgrade-to-latest-generation.md). - [Upgrade steps](upgrade-to-latest-generation.md) - [Maintenance windows](maintenance-scheduling.md)-- [Resource health monitor](../../service-health/resource-health-overview.md?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json)+- [Resource health monitor](/azure/service-health/resource-health-overview?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json) - [Review Before you begin a migration](upgrade-to-latest-generation.md#before-you-begin) - [Upgrade in-place and upgrade from a restore point](upgrade-to-latest-generation.md) - [Create a user-defined restore point](sql-data-warehouse-restore-points.md) |
| synapse-analytics | Maintenance Scheduling | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/synapse-analytics/sql-data-warehouse/maintenance-scheduling.md | Service Health offers a personalized view of the Azure services and regions you To set up a service health alert for planned maintenance, navigate to the Azure Portal and access the **Service Health** section. Select the **Alerts** tab and create a new alert by specifying the service type as **Azure Synapse Analytics or (and) SQL Data Warehouse**, based on your pool type. Choose **Maintenance** as the event type, define the scope and notification settings according to your preferences, and save the alert configuration. For detailed instructions, refer to the following resources: -- [Service Health alerts](https://learn.microsoft.com/azure/service-health/service-health-overview).-- [How to create a service health alert](https://learn.microsoft.com/azure/service-health/alerts-activity-log-service-notifications-portal#create-a-service-health-alert-using-the-azure-portal).+- [Service Health alerts](/azure/service-health/service-health-overview). +- [How to create a service health alert](/azure/service-health/alerts-activity-log-service-notifications-portal#create-a-service-health-alert-using-the-azure-portal). Remarks: As part of the configurations you need to set the condition details to be match the service which you are using. There are various factors that could lead to the cancellation of scheduled maint ## Next steps -- [Learn more](../../azure-monitor/alerts/alerts-metric.md?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json) about creating, viewing, and managing alerts by using Azure Monitor.-- [Learn more](../..//azure-monitor/alerts/alerts-log-webhook.md?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json) about webhook actions for log alert rules.-- [Learn more](../..//azure-monitor/alerts/action-groups.md?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json) Creating and managing Action Groups.-- [Learn more](../../service-health/service-health-overview.md?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json) about Azure Service Health.+- [Learn more](/azure/azure-monitor/alerts/alerts-metric?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json) about creating, viewing, and managing alerts by using Azure Monitor. +- [Learn more](/azure/azure-monitor/alerts/alerts-log-webhook?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json) about webhook actions for log alert rules. +- [Learn more](/azure/azure-monitor/alerts/action-groups?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json) Creating and managing Action Groups. +- [Learn more](/azure/service-health/service-health-overview?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json) about Azure Service Health. |
| synapse-analytics | Release Notes 10 0 10106 0 | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/synapse-analytics/sql-data-warehouse/release-notes-10-0-10106-0.md | For tooling improvements, make sure you have the correct version installed speci |**Advanced Advisors**|Advanced tuning for Synapse SQL in Azure Synapse just got simpler with additional data warehouse recommendations and metrics. There are additional advanced performance recommendations through Azure Advisor at your disposal, including:<br/><br/>1. Adaptive cache ΓÇô Be advised when to scale to optimize cache utilization.<br/>2. Table distribution ΓÇô Determine when to replicate tables to reduce data movement and increase workload performance.<br/>3. Tempdb ΓÇô Understand when to scale and configure resource classes to reduce tempdb contention.<br/><br/>There is a deeper integration of data warehouse metrics with [Azure Monitor](https://azure.microsoft.com/blog/enhanced-capabilities-to-monitor-manage-and-integrate-sql-data-warehouse-in-the-azure-portal/) including an enhanced customizable monitoring chart for near real-time metrics in the overview blade. You no longer must leave the data warehouse overview blade to access Azure Monitor metrics when monitoring usage, or validating and applying data warehouse recommendations. In addition, there are new metrics available, such as tempdb and adaptive cache utilization to complement your performance recommendations.| |**Advanced tuning with integrated advisors**|Advanced tuning for Azure Synapse just got simpler with additional data warehouse recommendations and metrics and a redesign of the portal overview blade that provides an integrated experience with Azure Advisor and Azure Monitor.| |**Accelerated Database Recovery (ADR)**|Azure Synapse Accelerated Database Recovery (ADR) is now in Public Preview. ADR is a new SQL Server Engine that greatly improves database availability, especially in the presence of long running transactions, by completely redesigning the current recovery process from the ground up. The primary benefits of ADR are fast and consistent database recovery and instantaneous transaction rollback.|-|**Azure Monitor resource logs**|Azure Synapse now enables enhanced insights into analytical workloads by integrating directly with Azure Monitor resource logs. This new capability enables developers to analyze workload behavior over an extended time period and make informed decisions on query optimization or capacity management. We have now introduced an external logging process through [Azure Monitor resource logs](../../azure-monitor/data-platform.md?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json#logs) that provide additional insights into your data warehouse workload. With a single click of a button, you are now able to configure resource logs for historical query performance troubleshooting capabilities using [Log Analytics](../../azure-monitor/logs/log-query-overview.md?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json). Azure Monitor resource logs support customizable retention periods by saving the logs to a storage account for auditing purposes, the capability to stream logs to event hubs near real-time telemetry insights, and the ability to analyze logs using Log Analytics with log queries. Resource logs consist of telemetry views of your data warehouse equivalent to the most commonly used performance troubleshooting DMVs for SQL Analytics in Azure Synapse. For this initial release, we have enabled views for the following system dynamic management views:<br/><br/>• [sys.dm_pdw_exec_requests](/sql/relational-databases/system-dynamic-management-views/sys-dm-pdw-exec-requests-transact-sql?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json&view=azure-sqldw-latest&preserve-view=true)<br/>• [sys.dm_pdw_request_steps](/sql/relational-databases/system-dynamic-management-views/sys-dm-pdw-request-steps-transact-sql?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json&view=azure-sqldw-latest&preserve-view=true)<br/>• [sys.dm_pdw_dms_workers](/sql/relational-databases/system-dynamic-management-views/sys-dm-pdw-dms-workers-transact-sql?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json&view=azure-sqldw-latest&preserve-view=true)<br/>• [sys.dm_pdw_waits](/sql/relational-databases/system-dynamic-management-views/sys-dm-pdw-waits-transact-sql?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json&view=azure-sqldw-latest&preserve-view=true)<br/>• [sys.dm_pdw_sql_requests](/sql/relational-databases/system-dynamic-management-views/sys-dm-pdw-sql-requests-transact-sql?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json&view=azure-sqldw-latest&preserve-view=true)| +|**Azure Monitor resource logs**|Azure Synapse now enables enhanced insights into analytical workloads by integrating directly with Azure Monitor resource logs. This new capability enables developers to analyze workload behavior over an extended time period and make informed decisions on query optimization or capacity management. We have now introduced an external logging process through [Azure Monitor resource logs](/azure/azure-monitor/data-platform?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json#logs) that provide additional insights into your data warehouse workload. With a single click of a button, you are now able to configure resource logs for historical query performance troubleshooting capabilities using [Log Analytics](/azure/azure-monitor/logs/log-query-overview?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json). Azure Monitor resource logs support customizable retention periods by saving the logs to a storage account for auditing purposes, the capability to stream logs to event hubs near real-time telemetry insights, and the ability to analyze logs using Log Analytics with log queries. Resource logs consist of telemetry views of your data warehouse equivalent to the most commonly used performance troubleshooting DMVs for SQL Analytics in Azure Synapse. For this initial release, we have enabled views for the following system dynamic management views:<br/><br/>• [sys.dm_pdw_exec_requests](/sql/relational-databases/system-dynamic-management-views/sys-dm-pdw-exec-requests-transact-sql?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json&view=azure-sqldw-latest&preserve-view=true)<br/>• [sys.dm_pdw_request_steps](/sql/relational-databases/system-dynamic-management-views/sys-dm-pdw-request-steps-transact-sql?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json&view=azure-sqldw-latest&preserve-view=true)<br/>• [sys.dm_pdw_dms_workers](/sql/relational-databases/system-dynamic-management-views/sys-dm-pdw-dms-workers-transact-sql?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json&view=azure-sqldw-latest&preserve-view=true)<br/>• [sys.dm_pdw_waits](/sql/relational-databases/system-dynamic-management-views/sys-dm-pdw-waits-transact-sql?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json&view=azure-sqldw-latest&preserve-view=true)<br/>• [sys.dm_pdw_sql_requests](/sql/relational-databases/system-dynamic-management-views/sys-dm-pdw-sql-requests-transact-sql?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json&view=azure-sqldw-latest&preserve-view=true)| |**Columnstore memory management**|As the number of compressed column store row groups increases, the memory required to manage the internal column segment metadata for those rowgroups increases. As a result, query performance and queries executed against some of the Columnstore Dynamic Management Views (DMVs) can degrade. Improvements have made in this release to optimize the size of the internal metadata for these cases, leading to improved experience and performance for such queries.| |**Azure Data Lake Storage Gen2 integration (GA)**|Synapse Analytics now has native integration with Azure Data Lake Storage Gen2. Customers can now load data using external tables from ABFS into dedicated SQL pool(formerly SQL DW). This functionality enables customers to integrate with their data lakes in Data Lake Storage Gen2.| |**Notable Bugs**|CETAS to Parquet failures in small resource classes on Data warehouses of DW2000 and more - This fix correctly identifies a null reference in the Create External Table As to Parquet code path.<br/><br/>Identity column value might lose in some CTAS operation - The value of an identify column may not be preserved when CTASed to another table. Reported in a [blog](https://blog.westmonroepartners.com/azure-sql-dw-identity-column-bugs/).<br/><br/>Internal failure in some cases when a session is terminated while a query is still running - This fix triggers an InvalidOperationException if a session is terminated when the query is still running.<br/><br/>(Deployed in November 2018) Customers were experiencing a suboptimal performance when attempting to load multiple small files from ADLS (Gen1) using Polybase. - System performance was bottlenecked during AAD security token validation. Performance problems were mitigated by enabling caching of security tokens. | |
| synapse-analytics | Sql Data Warehouse Concept Recommendations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/synapse-analytics/sql-data-warehouse/sql-data-warehouse-concept-recommendations.md | -Dedicated SQL pool provides recommendations to ensure your data warehouse workload is consistently optimized for performance. Recommendations are tightly integrated with [Azure Advisor](../../advisor/advisor-performance-recommendations.md?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json) to provide you with best practices directly within the [Azure portal](https://aka.ms/Azureadvisor). Dedicated SQL pool collects telemetry and surfaces recommendations for your active workload on a daily cadence. The supported recommendation scenarios are outlined below along with how to apply recommended actions. +Dedicated SQL pool provides recommendations to ensure your data warehouse workload is consistently optimized for performance. Recommendations are tightly integrated with [Azure Advisor](/azure/advisor/advisor-performance-recommendations?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json) to provide you with best practices directly within the [Azure portal](https://aka.ms/Azureadvisor). Dedicated SQL pool collects telemetry and surfaces recommendations for your active workload on a daily cadence. The supported recommendation scenarios are outlined below along with how to apply recommended actions. You can [check your recommendations](https://aka.ms/Azureadvisor) today! |
| synapse-analytics | Sql Data Warehouse Concept Resource Utilization Query Activity | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/synapse-analytics/sql-data-warehouse/sql-data-warehouse-concept-resource-utilization-query-activity.md | To view the list of DMVs that apply to Synapse SQL, review [dedicated SQL pool D ## Metrics and diagnostics logging -Both metrics and logs can be exported to Azure Monitor, specifically the [Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json) component and can be programmatically accessed through [log queries](../../azure-monitor/logs/log-analytics-tutorial.md?bc=%2fazure%2fsynapse-analytics%2fsql-data-warehouse%2fbreadcrumb%2ftoc.json&toc=%2fazure%2fsynapse-analytics%2fsql-data-warehouse%2ftoc.json). The log latency for Synapse SQL is about 10-15 minutes. +Both metrics and logs can be exported to Azure Monitor, specifically the [Azure Monitor logs](/azure/azure-monitor/logs/log-query-overview?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json) component and can be programmatically accessed through [log queries](/azure/azure-monitor/logs/log-analytics-tutorial?bc=%2fazure%2fsynapse-analytics%2fsql-data-warehouse%2fbreadcrumb%2ftoc.json&toc=%2fazure%2fsynapse-analytics%2fsql-data-warehouse%2ftoc.json). The log latency for Synapse SQL is about 10-15 minutes. ## Related content |
| synapse-analytics | Sql Data Warehouse Monitor Workload Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/synapse-analytics/sql-data-warehouse/sql-data-warehouse-monitor-workload-portal.md | In the Azure portal, navigate to the page for Log Analytics workspaces, or use t :::image type="content" source="./media/sql-data-warehouse-monitor-workload-portal/add_analytics_workspace_2.png" alt-text="Screenshot shows the Log Analytics workspace where you can enter values."::: -For more information on workspaces, see [Create a Log Analytics workspace](../../azure-monitor/logs/quick-create-workspace.md). +For more information on workspaces, see [Create a Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace). ## Turn on Resource logs For details on the capabilities of log queries using Kusto, see [Kusto Query Lan ## Sample log queries -Set the [scope of your queries](../../azure-monitor/logs/scope.md) to the Log Analytics workspace resource. +Set the [scope of your queries](/azure/azure-monitor/logs/scope) to the Log Analytics workspace resource. ```Kusto //List all queries |
| synapse-analytics | Sql Data Warehouse Troubleshoot Connectivity | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/synapse-analytics/sql-data-warehouse/sql-data-warehouse-troubleshoot-connectivity.md | The status of your dedicated SQL pool (formerly SQL DW) will be shown here. If t  -For more information, see [Resource Health](../../service-health/resource-health-overview.md). +For more information, see [Resource Health](/azure/service-health/resource-health-overview). ## Check for paused or scaling operation |
| synapse-analytics | Sql Data Warehouse Workload Management Portal Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/synapse-analytics/sql-data-warehouse/sql-data-warehouse-workload-management-portal-monitor.md | -For details on how to configure the Azure Metrics Explorer see the [Analyze metrics with Azure Monitor metrics explorer](../../azure-monitor/essentials/analyze-metrics.md?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json) article. See the [Resource utilization](sql-data-warehouse-concept-resource-utilization-query-activity.md#resource-utilization) section in Azure Synapse Analytics Monitoring documentation for details on how to monitor system resource consumption. +For details on how to configure the Azure Metrics Explorer see the [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json) article. See the [Resource utilization](sql-data-warehouse-concept-resource-utilization-query-activity.md#resource-utilization) section in Azure Synapse Analytics Monitoring documentation for details on how to monitor system resource consumption. There are two different categories of workload group metrics provided for monitoring workload management: resource allocation and query activity. These metrics can be split and filtered by workload group. The metrics can be split and filtered based on if they're system defined (resource class workload groups) or user-defined (created by user with [CREATE WORKLOAD GROUP](/sql/t-sql/statements/create-workload-group-transact-sql?toc=/azure/synapse-analytics/sql-data-warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json&view=azure-sqldw-latest&preserve-view=true) syntax). ## Workload management metric definitions |
| synapse-analytics | Query History Storage Analysis | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/synapse-analytics/sql/query-history-storage-analysis.md | Known Limitation: - [Azure Data Explorer](/azure/data-explorer/) - [Azure Data Factory](../../data-factory/index.yml)+ - [Log Analytics in Azure Monitor](/azure/azure-monitor/logs/log-analytics-overview) - [Azure Synapse SQL architecture](overview-architecture.md) - [Get Started with Azure Synapse Analytics](../get-started.md) |
| time-series-insights | How To Monitor Tsi Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/time-series-insights/how-to-monitor-tsi-reference.md | Learn about the data and resources collected by Azure Monitor from your Azure Ti ## Metrics -This section lists all the automatically collected platform metrics collected for Azure Time Series Insights. For a list of all Azure Monitor support metrics (including Azure Time Series Insights), see [Azure Monitor supported metrics](../azure-monitor/essentials/metrics-supported.md). -The resource provider for these metrics is [Microsoft.TimeSeriesInsights/environments/eventsources](../azure-monitor/essentials/metrics-supported.md#microsofttimeseriesinsightsenvironmentseventsources) and [Microsoft.TimeSeriesInsights/environments](../azure-monitor/essentials/metrics-supported.md#microsofttimeseriesinsightsenvironments). +This section lists all the automatically collected platform metrics collected for Azure Time Series Insights. For a list of all Azure Monitor support metrics (including Azure Time Series Insights), see [Azure Monitor supported metrics](/azure/azure-monitor/essentials/metrics-supported). +The resource provider for these metrics is [Microsoft.TimeSeriesInsights/environments/eventsources](/azure/azure-monitor/essentials/metrics-supported#microsofttimeseriesinsightsenvironmentseventsources) and [Microsoft.TimeSeriesInsights/environments](/azure/azure-monitor/essentials/metrics-supported#microsofttimeseriesinsightsenvironments). ### Ingress |
| time-series-insights | How To Monitor Tsi | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/time-series-insights/how-to-monitor-tsi.md | The **Overview** page in the Azure portal for each Time Series Insights environm ## What is Azure Monitor -Time Series Insights creates monitoring data using [Azure Monitor](../azure-monitor/overview.md), which is a full stack monitoring service in Azure that provides a complete set of features to monitor your Azure resources in addition to resources in other clouds and on-premises. +Time Series Insights creates monitoring data using [Azure Monitor](/azure/azure-monitor/overview), which is a full stack monitoring service in Azure that provides a complete set of features to monitor your Azure resources in addition to resources in other clouds and on-premises. -Start with the article [Monitoring Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md), which describes the following concepts: +Start with the article [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource), which describes the following concepts: - What is Azure Monitor? - Costs associated with monitoring Start with the article [Monitoring Azure resources with Azure Monitor](../azure- The following sections build on this article by describing the specific data gathered for Azure Time Series Insights. These sections also provide examples for configuring data collection and analyzing this data with Azure tools. > [!TIP]-> To understand costs associated with Azure Monitor, see [Azure Monitor cost and usage](../azure-monitor/cost-usage.md). To understand the time it takes for your data to appear in Azure Monitor, see [Log data ingestion time](../azure-monitor/logs/data-ingestion-time.md). +> To understand costs associated with Azure Monitor, see [Azure Monitor cost and usage](/azure/azure-monitor/cost-usage). To understand the time it takes for your data to appear in Azure Monitor, see [Log data ingestion time](/azure/azure-monitor/logs/data-ingestion-time). ## Monitoring data from Azure Time Series Insights -Azure Time Series Insights collects the same kinds of monitoring data as other Azure resources that are described in [Monitoring data from Azure resources](../azure-monitor/essentials/monitor-azure-resource.md#monitoring-data). +Azure Time Series Insights collects the same kinds of monitoring data as other Azure resources that are described in [Monitoring data from Azure resources](/azure/azure-monitor/essentials/monitor-azure-resource#monitoring-data). See [Azure Time Series Insights monitoring data reference](how-to-monitor-tsi-reference.md) for a detailed reference of the logs and metrics that you can collect. See [Azure Time Series Insights monitoring data reference](how-to-monitor-tsi-re Platform metrics are collected and stored automatically, but can be routed to other locations by using a diagnostic setting. Resource Logs are not collected and stored until you create a diagnostic setting and route them to one or more locations.-See [Create diagnostic setting to collect platform logs and metrics in Azure](../azure-monitor/essentials/diagnostic-settings.md) for the detailed process for creating a diagnostic setting using the Azure portal, CLI, or PowerShell. When you create a diagnostic setting, you specify which categories of logs to collect. +See [Create diagnostic setting to collect platform logs and metrics in Azure](/azure/azure-monitor/essentials/diagnostic-settings) for the detailed process for creating a diagnostic setting using the Azure portal, CLI, or PowerShell. When you create a diagnostic setting, you specify which categories of logs to collect. You can collect logs from the following categories for Azure Time Series Insights: You can collect logs from the following categories for Azure Time Series Insight ## Analyzing metrics -You can analyze metrics for Azure Time Series Insights, along with metrics from other Azure services, by opening Metrics from the Azure Monitor menu. See [Analyze metrics with Azure Monitor metrics explorer](../azure-monitor/essentials/analyze-metrics.md) for details on using this tool. +You can analyze metrics for Azure Time Series Insights, along with metrics from other Azure services, by opening Metrics from the Azure Monitor menu. See [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics) for details on using this tool. For a list of the platform metrics collected, see [Monitoring Azure Time Series Insights data reference](how-to-monitor-tsi-reference.md#metrics) You can access resource logs either as a blob in a storage account, as event dat Data in Azure Monitor Logs is stored in tables which each table having its own set of unique properties. -All resource logs in Azure Monitor have the same fields followed by service-specific fields. The common schema is outlined in [Azure Monitor resource log schema](../azure-monitor/essentials/resource-logs-schema.md#top-level-common-schema). For a list of the types of resource logs collected for Azure Time Series Insights, see [Azure Time Series Insights monitoring data reference](how-to-monitor-tsi-reference.md#resource-logs). +All resource logs in Azure Monitor have the same fields followed by service-specific fields. The common schema is outlined in [Azure Monitor resource log schema](/azure/azure-monitor/essentials/resource-logs-schema#top-level-common-schema). For a list of the types of resource logs collected for Azure Time Series Insights, see [Azure Time Series Insights monitoring data reference](how-to-monitor-tsi-reference.md#resource-logs). Azure Time Series Insights stores data in the following tables. Following are queries that you can use to help you monitor your Azure Time Serie ## Alerts -Azure Monitor alerts proactively notify you when important conditions are found in your monitoring data. They allow you to identify and address issues in your system before your customers notice them. You can set alerts on [metrics](../azure-monitor/alerts/alerts-metric-overview.md), [logs](../azure-monitor/alerts/alerts-unified-log.md), and the [activity log](../azure-monitor/alerts/activity-log-alerts.md). Different types of alerts have benefits and drawbacks. +Azure Monitor alerts proactively notify you when important conditions are found in your monitoring data. They allow you to identify and address issues in your system before your customers notice them. You can set alerts on [metrics](/azure/azure-monitor/alerts/alerts-metric-overview), [logs](/azure/azure-monitor/alerts/alerts-unified-log), and the [activity log](/azure/azure-monitor/alerts/activity-log-alerts). Different types of alerts have benefits and drawbacks. When creating an alert rule based on platform metrics, be aware that for Time Series Insights platform metrics that are collected in units of count, some aggregations may not be available or usable. ## Next Steps * See [Azure Time Series Insights monitoring data reference](how-to-monitor-tsi-reference.md) for a reference of the logs and metrics created by Azure Time Series Insights.-* See [Monitoring Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md) for details on monitoring Azure resources. +* See [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) for details on monitoring Azure resources. |
| time-series-insights | How To Plan Your Environment | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/time-series-insights/how-to-plan-your-environment.md | For more information and to understand how events will be flattened and stored, ## Next steps -* Review [Azure Advisor](../advisor/advisor-overview.md) to plan out your business recovery configuration options. -* Review [Azure Advisor](../advisor/advisor-overview.md) to plan out your business recovery configuration options. +* Review [Azure Advisor](/azure/advisor/advisor-overview) to plan out your business recovery configuration options. +* Review [Azure Advisor](/azure/advisor/advisor-overview) to plan out your business recovery configuration options. * Read more about [data ingestion](./concepts-ingestion-overview.md) in Azure Time Series Insights Gen2. * Review the article on [data storage](./concepts-storage.md) in Azure Time Series Insights Gen2. * Learn about [data modeling](./concepts-model-overview.md) in Azure Time Series Insights Gen2. |
| traffic-manager | Traffic Manager Faqs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/traffic-manager/traffic-manager-FAQs.md | Azure Resource Manager requires all resource groups to specify a location, which The current monitoring status of each endpoint, in addition to the overall profile, is displayed in the Azure portal. This information also is available via the Traffic Monitor [REST API](/rest/api/trafficmanager/), [PowerShell cmdlets](/powershell/module/az.trafficmanager), and [cross-platform Azure CLI](/cli/azure/install-classic-cli). -You can also use Azure Monitor to track the health of your endpoints and see a visual representation of them. For more about using Azure Monitor, see the [Azure Monitoring documentation](../azure-monitor/data-platform.md). +You can also use Azure Monitor to track the health of your endpoints and see a visual representation of them. For more about using Azure Monitor, see the [Azure Monitoring documentation](/azure/azure-monitor/data-platform). ### Can I monitor HTTPS endpoints? The number of Traffic Manager health checks reaching your endpoint depends on th ### How can I get notified if one of my endpoints goes down? -One of the metrics provided by Traffic Manager is the health status of endpoints in a profile. You can see this as an aggregate of all endpoints inside a profile (for example, 75% of your endpoints are healthy), or, at a per endpoint level. Traffic Manager metrics are exposed through Azure Monitor and you can use its [alerting capabilities](../azure-monitor/alerts/alerts-metric.md) to get notifications when there's a change in the health status of your endpoint. For more information, see [Traffic Manager metrics and alerts](traffic-manager-metrics-alerts.md). +One of the metrics provided by Traffic Manager is the health status of endpoints in a profile. You can see this as an aggregate of all endpoints inside a profile (for example, 75% of your endpoints are healthy), or, at a per endpoint level. Traffic Manager metrics are exposed through Azure Monitor and you can use its [alerting capabilities](/azure/azure-monitor/alerts/alerts-metric) to get notifications when there's a change in the health status of your endpoint. For more information, see [Traffic Manager metrics and alerts](traffic-manager-metrics-alerts.md). ## Traffic Manager nested profiles |
| traffic-manager | Traffic Manager Diagnostic Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/traffic-manager/traffic-manager-diagnostic-logs.md | To access log files follow the following steps. ## Traffic Manager log schema All resource logs available through Azure Monitor share a common top-level schema, with flexibility for each service to emit unique properties for their own events. -For top-level resource logs schema, see [Supported services, schemas, and categories for Azure Resource Logs](../azure-monitor/essentials/resource-logs-schema.md). +For top-level resource logs schema, see [Supported services, schemas, and categories for Azure Resource Logs](/azure/azure-monitor/essentials/resource-logs-schema). The following table includes logs schema specific to the Azure Traffic Manager profile resource. |
| traffic-manager | Traffic Manager Metrics Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/traffic-manager/traffic-manager-metrics-alerts.md | Traffic Manager provides you with DNS-based load balancing that includes multipl Traffic Manager provides the following metrics on a per profile basis that customers can use to understand their usage of Traffic manager and the status of their endpoints under that profile. ### Queries by endpoint returned-Use [this metric](../azure-monitor/essentials/metrics-supported.md) to view the number of queries that a Traffic Manager profile processes over a specified period. You can also view the same information at an endpoint level granularity that helps you understand how many times an endpoint was returned in the query responses from Traffic Manager. +Use [this metric](/azure/azure-monitor/essentials/metrics-supported) to view the number of queries that a Traffic Manager profile processes over a specified period. You can also view the same information at an endpoint level granularity that helps you understand how many times an endpoint was returned in the query responses from Traffic Manager. In the following example, Figure 1 displays all the query responses that the Traffic Manager profile returns. Figure 2 displays the same information, however, it is split by endpoints. As a *Figure 2: Split view with query volume shown per endpoint returned* ## Endpoint status by endpoint-Use [this metric](../azure-monitor/essentials/metrics-supported.md#microsoftnetworktrafficmanagerprofiles) to understand the health status of the endpoints in the profile. It takes two values: +Use [this metric](/azure/azure-monitor/essentials/metrics-supported#microsoftnetworktrafficmanagerprofiles) to understand the health status of the endpoints in the profile. It takes two values: - use **1** if the endpoint is up. - use **0** if the endpoint is down. This metric can be shown either as an aggregate value representing the status of *Figure 4: Split view of endpoint status metrics* -You can consume these metrics through [Azure Monitor service](../azure-monitor/essentials/metrics-supported.md)ΓÇÖs portal, [REST API](/rest/api/monitor/), [Azure CLI](/cli/azure/monitor), and [Azure PowerShell](/powershell/module/az.applicationinsights), or through the metrics section of Traffic ManagerΓÇÖs portal experience. +You can consume these metrics through [Azure Monitor service](/azure/azure-monitor/essentials/metrics-supported)ΓÇÖs portal, [REST API](/rest/api/monitor/), [Azure CLI](/cli/azure/monitor), and [Azure PowerShell](/powershell/module/az.applicationinsights), or through the metrics section of Traffic ManagerΓÇÖs portal experience. ## Alerts on Traffic Manager metrics-In addition to processing and displaying metrics from Traffic Manager, Azure Monitor enables customers to configure and receive alerts associated with these metrics. You can choose what conditions need to be met in these metrics for an alert to occur, how often those conditions need to be monitored, and how the alerts should be sent to you. For more information, see [Azure Monitor alerts documentation](../azure-monitor/alerts/alerts-metric.md). +In addition to processing and displaying metrics from Traffic Manager, Azure Monitor enables customers to configure and receive alerts associated with these metrics. You can choose what conditions need to be met in these metrics for an alert to occur, how often those conditions need to be monitored, and how the alerts should be sent to you. For more information, see [Azure Monitor alerts documentation](/azure/azure-monitor/alerts/alerts-metric). Alert monitoring is important to ensure the system notifies when probes are down. Overly sensitive monitoring can be a distraction. Traffic Manager deploys multiple probes to increase resiliency. The threshold for probe statuses should be less than 0.5. If the average for **up** status falls below 0.5 (meaning less than 50% of probes are up) there should be an alert for an endpoint failure. The following configuration is an example of an alert setup. For more information about probes and monitoring, see [Traffic Manager endpoint monitoring](traffic-manager-monitoring.md). ## Next steps-- Learn more about [Azure Monitor service](../azure-monitor/essentials/metrics-supported.md)-- Learn how to [create a chart in Azure Monitor](../azure-monitor/essentials/analyze-metrics.md#create-a-metric-chart)+- Learn more about [Azure Monitor service](/azure/azure-monitor/essentials/metrics-supported) +- Learn how to [create a chart in Azure Monitor](/azure/azure-monitor/essentials/analyze-metrics#create-a-metric-chart) |
| trusted-signing | How To Device Guard Signing Service Migration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/trusted-signing/how-to-device-guard-signing-service-migration.md | This guide outlines the steps needed to migrate to Trusted Signing. **Read the e > [!IMPORTANT] -> Migration isn't possible without creating a Trusted Signing account, Private Trust identity validation, and Private Trust CI policy signing certificate profile using these steps: [Quickstart: Set up Trusted Signing | Microsoft Learn](https://learn.microsoft.com/azure/trusted-signing/quickstart?tabs=registerrp-portal%2Caccount-portal%2Ccertificateprofile-portal%2Cdeleteresources-portal). +> Migration isn't possible without creating a Trusted Signing account, Private Trust identity validation, and Private Trust CI policy signing certificate profile using these steps: [Quickstart: Set up Trusted Signing](/azure/trusted-signing/quickstart?tabs=registerrp-portal%2Caccount-portal%2Ccertificateprofile-portal%2Cdeleteresources-portal). ## Scenario 1: Signed CI Policy Migration and Deployment Sample: ConvertFrom-CIPolicy -XmlFilePath <xmlCIPolicyFilePath> -BinaryFilePath <binaryCIPolicyFilePath> ```-4. Sign the generated policy .bin file with Trusted Signing using the following instructions: [Sign a CI policy | Microsoft Learn](https://learn.microsoft.com/azure/trusted-signing/how-to-sign-ci-policy). -5. Deploy this signed policy .bin file. For more information, refer to [Deploy Windows Defender Application Control polices](https://docs.microsoft.com/windows/security/threat-protection/windows-defender-application-control/deploy-windows-defender-application-control-policies-using-group-policy). +4. Sign the generated policy .bin file with Trusted Signing using the following instructions: [Sign a CI policy](/azure/trusted-signing/how-to-sign-ci-policy). +5. Deploy this signed policy .bin file. For more information, refer to [Deploy Windows Defender Application Control polices](/windows/security/threat-protection/windows-defender-application-control/deploy-windows-defender-application-control-policies-using-group-policy). 6. Reboot the machine and confirm the Code Integrity event 3099 shows that the policy is activated. - Open Event Viewer (Select Start, type Event Viewer) → Applications and Services Logs → Microsoft → Windows → CodeIntegrity → Operational - Filter by event ID 3099 >[!NOTE] > If you don't see event 3099, DON'T proceed to step 7. Restart from No.1 and make sure your CI policy file is well formed and successfully signed. -> - Well formed: Compare the xml with the [default CI policy xml](https://learn.microsoft.com/windows/security/application-security/application-control/windows-defender-application-control/design/example-wdac-base-policies) to verify the format. -> - Successfully signed: To verify, use SignTool; refer to this [link](https://docs.microsoft.com/windows/win32/seccrypto/using-signtool-to-verify-a-file-signature). +> - Well formed: Compare the xml with the [default CI policy xml](/windows/security/application-security/application-control/windows-defender-application-control/design/example-wdac-base-policies) to verify the format. +> - Successfully signed: To verify, use SignTool; refer to this [link](/windows/win32/seccrypto/using-signtool-to-verify-a-file-signature). 7. Run the command to delete this CI policy:ΓÇ»`del SiPolicy.p7b`ΓÇ»from both folders:ΓÇ»C:\Windows\System32\CodeIntegrity and S:\EFI\Microsoft\Boot. 1. If there's no S: drive, run the command: ΓÇ» ConvertFrom-CIPolicy -XmlFilePath <xmlCIPolicyFilePath> -BinaryFilePath <binaryC ### Step 1: Determine your new EKUs 1. Since Trusted Signing is a new service it has different EKUs than DGSSv2. Therefore, you need to get the new EKUs added to your policy. You need to get your EKU from the Trusted Signing account to add to your CI policyΓÇÖs EKU section. The two ways to do so are: - 1. Using the steps in [Sign a CI policy | Microsoft Learn](https://learn.microsoft.com/azure/trusted-signing/how-to-sign-ci-policy) run the command Get-AzCodeSigningCustomerEkuto get the customer EKU. + 1. Using the steps in [Sign a CI policy](/azure/trusted-signing/how-to-sign-ci-policy) run the command Get-AzCodeSigningCustomerEkuto get the customer EKU. 2. Within your Trusted Signing account, select ΓÇ£Certificate ProfilesΓÇ¥, then select your Private Trust certificate profile. You'll see information on the profile like the screenshot below. The ΓÇÿEnhanced key usageΓÇÖ listed is your customer EKU. :::image type="content" source="media/trusted-signing-select-eku.png" alt-text="Screenshot that shows eku." lightbox="media/trusted-signing-select-eku.png"::: private string CalculateEkuValue(string CustomerEku) ### Step 2: Deploy and test the new CI policy -1. Now that you have your two EKUs, it is time to edit your CI policy. If you have an existing CI policy, you can proceed to the next section. To create a new one go to: [Policy creation for common WDAC usage scenarios - Windows Security | Microsoft Learn](https://learn.microsoft.com/windows/security/application-security/application-control/windows-defender-application-control/design/common-wdac-use-cases). +1. Now that you have your two EKUs, it is time to edit your CI policy. If you have an existing CI policy, you can proceed to the next section. To create a new one go to: [Policy creation for common WDAC usage scenarios - Windows Security](/windows/security/application-security/application-control/windows-defender-application-control/design/common-wdac-use-cases). 2. Add the new EKU in the EKU section of your policy, using the two EKU values from Step 1. ``` <EKU ID="ID_EKU_ACS" FriendlyName="ACS EKU -Customer EKU" Value="function EKU"/> Sample: ConvertFrom-CIPolicy -XmlFilePath <xmlCIPolicyFilePath> -BinaryFilePath <binaryCIPolicyFilePath> ``` -5. If you would like to sign this policy, following these instructions [Sign a CI policy | Microsoft Learn](https://learn.microsoft.com/azure/trusted-signing/how-to-sign-ci-policy)to sign the policy using Trusted Signing. +5. If you would like to sign this policy, following these instructions [Sign a CI policy](/azure/trusted-signing/how-to-sign-ci-policy)to sign the policy using Trusted Signing. -6. Deploy this signed policy .bin file; refer to this [link](https://docs.microsoft.com/windows/security/threat-protection/windows-defender-application-control/windows-defender-application-control-deployment-guide) for instructions. +6. Deploy this signed policy .bin file; refer to this [link](/windows/security/threat-protection/windows-defender-application-control/windows-defender-application-control-deployment-guide) for instructions. 7. Reboot the machine and confirm that Code Integrity event 3099 is showing, which means the new CI policy is activated. > [!NOTE] > If you don't see event 3099, DON'T proceed to step 8. Restart from No.1 and make sure your CI policy file is well formed and successfully signed. 1. Well formed: Compare the xml with the default CI policy xml to verify the format. - 2. Successfully signed: To verify, use SignTool; refer to this [link](https://docs.microsoft.com/windows/win32/seccrypto/using-signtool-to-verify-a-file-signature). + 2. Successfully signed: To verify, use SignTool; refer to this [link](/windows/win32/seccrypto/using-signtool-to-verify-a-file-signature). 8. Reboot the machine again to ensure a successful boot. 9. Reboot the machine twice more, to ensure the CI policy is properly enabled, before moving on or deploying this change to other machines. ConvertFrom-CIPolicy -XmlFilePath <xmlCIPolicyFilePath> -BinaryFilePath <binaryC 1. Verify that any files signed with Trusted Signing still behave as expected. 2. Sign a catalog file with Trusted Signing and make sure it can run on your test machine with the Trusted Signing (new) CI policy. 1. To sign catalog files with Trusted Signing, refer to the steps in: - 1. [Quickstart: Set up Trusted Signing | Microsoft Learn](https://learn.microsoft.com/azure/trusted-signing/quickstart?tabs=registerrp-portal%2Caccount-portal%2Ccertificateprofile-portal%2Cdeleteresources-portal) to set up a Private Trust certificate profile. - 2. [Set up signing integrations to use Trusted Signing | Microsoft Learn](https://learn.microsoft.com/azure/trusted-signing/how-to-signing-integrations) to sign the files using Private Trust in the Trusted Signing service. + 1. [Quickstart: Set up Trusted Signing](/azure/trusted-signing/quickstart?tabs=registerrp-portal%2Caccount-portal%2Ccertificateprofile-portal%2Cdeleteresources-portal) to set up a Private Trust certificate profile. + 2. [Set up signing integrations to use Trusted Signing](/azure/trusted-signing/how-to-signing-integrations) to sign the files using Private Trust in the Trusted Signing service. - 2. To sign MSIX packages with Trusted Signing, refer to instructions on how to sign MSIX packages with [MSIX Packaging Tool](https://learn.microsoft.com/windows/msix/packaging-tool/tool-overview) or SignTool - directly through Trusted Signing. + 2. To sign MSIX packages with Trusted Signing, refer to instructions on how to sign MSIX packages with [MSIX Packaging Tool](/windows/msix/packaging-tool/tool-overview) or SignTool - directly through Trusted Signing. 1. To sign with Trusted Signing in the MSIX Packaging Tool you need to join the MSIX Insiders program. 3. After confirming the CI policy is activated on this machine and all scenarios work as expected, repeat steps on the rest of the desired machines in your environment. If isolation is desired, deploy a new CI policy by following steps outlined in S ## Related content -- [Understand Windows Defender Application Control (WDAC) policy rules and file rules](https://docs.microsoft.com/windows/security/threat-protection/windows-defender-application-control/select-types-of-rules-to-create).-- [Deploy catalog files to support Windows Defender Application Control (Windows 10) - Windows security](https://docs.microsoft.com/windows/security/threat-protection/windows-defender-application-control/deploy-catalog-files-to-support-windows-defender-application-control#:~:text=%20Deploy%20catalog%20files%20to%20support%20Windows%20Defender,signing%20certificate%20to%20a%20Windows%20Defender...%20More%20).-- [Example Windows Defender Application Control (WDAC) base policies (Windows 10) - Windows security | Microsoft Docs](https://docs.microsoft.com/windows/security/threat-protection/windows-defender-application-control/example-wdac-base-policies)-- [Use multiple Windows Defender Application Control Policies (Windows 10)](https://docs.microsoft.com/windows/security/threat-protection/windows-defender-application-control/deploy-multiple-windows-defender-application-control-policies#deploying-multiple-policies-locally)+- [Understand Windows Defender Application Control (WDAC) policy rules and file rules](/windows/security/threat-protection/windows-defender-application-control/select-types-of-rules-to-create). +- [Deploy catalog files to support Windows Defender Application Control (Windows 10) - Windows security](/windows/security/threat-protection/windows-defender-application-control/deploy-catalog-files-to-support-windows-defender-application-control#:~:text=%20Deploy%20catalog%20files%20to%20support%20Windows%20Defender,signing%20certificate%20to%20a%20Windows%20Defender...%20More%20). +- [Example Windows Defender Application Control (WDAC) base policies (Windows 10) - Windows security | Microsoft Docs](/windows/security/threat-protection/windows-defender-application-control/example-wdac-base-policies) +- [Use multiple Windows Defender Application Control Policies (Windows 10)](/windows/security/threat-protection/windows-defender-application-control/deploy-multiple-windows-defender-application-control-policies#deploying-multiple-policies-locally) |
| trusted-signing | How To Signing Integrations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/trusted-signing/how-to-signing-integrations.md | To sign by using Trusted Signing, you need to provide the details of your Truste ### Authentication -This Task performs authentication using [DefaultAzureCredential](https://learn.microsoft.com/dotnet/api/azure.identity.defaultazurecredential?view=azure-dotnet), which attempts a series of authentication methods in order. If one method fails, it attempts the next one until authentication is successful. +This Task performs authentication using [DefaultAzureCredential](/dotnet/api/azure.identity.defaultazurecredential), which attempts a series of authentication methods in order. If one method fails, it attempts the next one until authentication is successful. Each authentication method can be disabled individually to avoid unnecessary attempts. -For example, when authenticating with [EnvironmentCredential](https://learn.microsoft.com/dotnet/api/azure.identity.environmentcredential?view=azure-dotnet) specifically, disable the other credentials with the following inputs: +For example, when authenticating with [EnvironmentCredential](/dotnet/api/azure.identity.environmentcredential) specifically, disable the other credentials with the following inputs: ExcludeEnvironmentCredential: false ExcludeManagedIdentityCredential: true ExcludeAzureCliCredential: true ExcludeAzurePowershellCredential: true ExcludeInteractiveBrowserCredential: true -Similarly, if using for example an [AzureCliCredential](https://learn.microsoft.com/dotnet/api/azure.identity.azureclicredential?view=azure-dotnet) , then we want to skip over attempting to authenticate with the several methods that come before it in order. +Similarly, if using for example an [AzureCliCredential](/dotnet/api/azure.identity.azureclicredential) , then we want to skip over attempting to authenticate with the several methods that come before it in order. ### Use SignTool to sign a file |
| update-manager | Deploy Updates | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/update-manager/deploy-updates.md | To install one-time updates on a single VM: 1. On the **Install one-time updates** page, the selected machine appears. Choose the machine, select **Next**, and follow the procedure from step 4 listed in **From Overview pane** of [Install updates on a single VM](#install-updates-on-a-single-vm). - A notification informs you when the activity starts, and another tells you when it's finished. After it's successfully finished, you can view the installation operation results in **History**. You can view the status of the operation at any time from the [Azure activity log](../azure-monitor/essentials/activity-log.md). + A notification informs you when the activity starts, and another tells you when it's finished. After it's successfully finished, you can view the installation operation results in **History**. You can view the status of the operation at any time from the [Azure activity log](/azure/azure-monitor/essentials/activity-log). # [From a selected VM](#tab/singlevm-deploy-home) You can schedule updates. - -A notification informs you when the activity starts, and another tells you when it's finished. After it's successfully finished, you can view the installation operation results in **History**. You can view the status of the operation at any time from the [Azure activity log](../azure-monitor/essentials/activity-log.md). +A notification informs you when the activity starts, and another tells you when it's finished. After it's successfully finished, you can view the installation operation results in **History**. You can view the status of the operation at any time from the [Azure activity log](/azure/azure-monitor/essentials/activity-log). ## View update history for a single VM |
| update-manager | Manage Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/update-manager/manage-alerts.md | To enable alerts (Preview) with Azure Update Manager through Azure portal, follo :::image type="content" source="./media/manage-alerts/advance-alert-rule-configuration-inline.png" alt-text="Screenshot that shows how to configure advanced alert rule." lightbox="./media/manage-alerts/advance-alert-rule-configuration-expanded.png"::: -1. Select **Review + create** to create alert. For more information, see [Create Azure Monitor alert rules](../azure-monitor/alerts/alerts-create-log-alert-rule.md#configure-alert-rule-conditions). +1. Select **Review + create** to create alert. For more information, see [Create Azure Monitor alert rules](/azure/azure-monitor/alerts/alerts-create-log-alert-rule#configure-alert-rule-conditions). - To identify alerts & alert rules created for Azure Update Manager, provide unique **Alert rule name** in the **Details** tab. :::image type="content" source="./media/manage-alerts/unique-alert-name-inline.png" alt-text="Screenshot that shows how to create unique alert name." lightbox="./media/manage-alerts/unique-alert-name-expanded.png"::: |
| update-manager | Manage Multiple Machines | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/update-manager/manage-multiple-machines.md | For assessed machines that are reporting updates available, select one or more o :::image type="content" source="./media/manage-multiple-machines/update-center-install-updates-now-multi-selection-inline.png" alt-text="Screenshot that shows installing one-time updates for machines on the Updates (Preview) page." lightbox="./media/manage-multiple-machines/update-center-install-updates-now-multi-selection-expanded.png"::: - A notification confirms when an activity starts and another tells you when it's finished. After it's successfully finished, the installation operation results are available to view. You can use the **Update history** tab, when you select the machine from the **Machines** page. You can also select the **History** page. You're redirected to this page automatically after you begin the update deployment. You can view the status of the operation at any time from the [Azure activity log](../azure-monitor/essentials/activity-log.md). + A notification confirms when an activity starts and another tells you when it's finished. After it's successfully finished, the installation operation results are available to view. You can use the **Update history** tab, when you select the machine from the **Machines** page. You can also select the **History** page. You're redirected to this page automatically after you begin the update deployment. You can view the status of the operation at any time from the [Azure activity log](/azure/azure-monitor/essentials/activity-log). ### Set up a recurring update deployment |
| update-manager | Manage Workbooks | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/update-manager/manage-workbooks.md | This article describes how to create and edit a workbook and make customized rep 1. Sign in to the [Azure portal](https://portal.azure.com) and go to **Azure Update Manager**. 1. Under **Monitoring**, selectΓÇ»**Update reports** to view the **Update Manager | Update reports | Gallery** page. 1. Select **Quick start** tile > **Empty**. Alternatively, you can select **New** to create a workbook.-1. Select **Add** to select any [elements](../azure-monitor/visualize/workbooks-create-workbook.md#create-a-new-azure-workbook) to add to the workbook. +1. Select **Add** to select any [elements](/azure/azure-monitor/visualize/workbooks-create-workbook#create-a-new-azure-workbook) to add to the workbook. :::image type="content" source="./media/manage-workbooks/create-workbook-elements.png" alt-text="Screenshot that shows how to create a workbook by using elements."::: |
| update-manager | Migration Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/update-manager/migration-overview.md | -This article provides guidance to move virtual machines from Automation Update Management to Azure Update Manager. +This article provides guidance to move virtual machines from Automation Update Management to Azure Update Manager. -Azure Update Manager provides a SaaS solution to manage and govern software updates to Windows and Linux machines across Azure, on-premises, and multicloud environments. It's an evolution of [Azure Automation Update management solution](../automation/update-management/overview.md) with new features and functionality, for assessment and deployment of software updates on a single machine or on multiple machines at scale. +Azure Update Manager provides a SaaS solution to manage and govern software updates to Windows and Linux machines across Azure, on-premises, and multicloud environments. It's an evolution of [Azure Automation Update management solution](../automation/update-management/overview.md) with new features and functionality, for assessment and deployment of software updates on a single machine or on multiple machines at scale. > [!Note]-> - On 31 August 2024, both Azure Automation Update Management and the Log Analytics agent it uses [will be retired](https://azure.microsoft.com/updates/were-retiring-the-log-analytics-agent-in-azure-monitor-on-31-august-2024/). Therefore, if you are using the Azure Automation Update Management solution, we recommend that you move to Azure Update Manager for your software update needs. Follow guidance in this document to move your machines and schedules from Automation Update Management to Azure Update Manager. For more information, see the [FAQs on retirement](https://aka.ms/aum-migration-faqs) You can [sign up](https://aka.ms/AUMLive) for monthly live sessions on migration including Q&A sessions. -> - If you are using Azure Automation Update Management Solution, we recommend that you don't remove MMA agents from the machines without completing the migration to Azure Update Manager for the machine's patch management needs. If you remove the MMA agent from the machine without moving to Azure Update Manager, it will break the patching workflows for that machine. +> - On 31 August 2024, both Azure Automation Update Management and the Log Analytics agent it uses [will be retired](https://azure.microsoft.com/updates/were-retiring-the-log-analytics-agent-in-azure-monitor-on-31-august-2024/). Therefore, if you are using the Azure Automation Update Management solution, we recommend that you move to Azure Update Manager for your software update needs. Follow guidance in this document to move your machines and schedules from Automation Update Management to Azure Update Manager. For more information, see the [FAQs on retirement](https://aka.ms/aum-migration-faqs) You can [sign up](https://aka.ms/AUMLive) for monthly live sessions on migration including Q&A sessions. +> - If you are using Azure Automation Update Management Solution, we recommend that you don't remove MMA agents from the machines without completing the migration to Azure Update Manager for the machine's patch management needs. If you remove the MMA agent from the machine without moving to Azure Update Manager, it will break the patching workflows for that machine. -For the Azure Update Manager, both AMA and MMA aren't a requirement to manage software update workflows as it relies on the Microsoft Azure VM Agent for Azure VMs and Azure connected machine agent for Arc-enabled servers. When you perform an update operation for the first time on a machine, an extension is pushed to the machine, and it interacts with the agents to assess missing updates and install updates. +For the Azure Update Manager, both AMA and MMA aren't a requirement to manage software update workflows as it relies on the Microsoft Azure VM Agent for Azure VMs and Azure connected machine agent for Arc-enabled servers. When you perform an update operation for the first time on a machine, an extension is pushed to the machine, and it interacts with the agents to assess missing updates and install updates. -We provide three methods to move from Automation Update Management to Azure Update Manager which are explained in detail: -- [Portal migration tool](migration-using-portal.md)-- [Migration runbook scripts](migration-using-runbook-scripts.md)-- [Manual migration](migration-manual.md)+We provide three methods to move from Automation Update Management to Azure Update Manager which are explained in detail: +- [Portal migration tool](migration-using-portal.md) +- [Migration runbook scripts](migration-using-runbook-scripts.md) +- [Manual migration](migration-manual.md) ## Next steps |
| update-manager | Migration Troubleshoot | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/update-manager/migration-troubleshoot.md | Encountering a warning as - unable to acquire token `organizations` with error ` ### Cause -This is part of one of the documented [issues](https://github.com/Azure/azure-powershell/issues/25005) with Az.Accounts 3.0.0 module. [Learn more](https://learn.microsoft.com/answers/questions/1342970/warning-unable-to-acquire-token-for-tenant-organiz) +This is part of one of the documented [issues](https://github.com/Azure/azure-powershell/issues/25005) with Az.Accounts 3.0.0 module. [Learn more](/answers/questions/1342970/warning-unable-to-acquire-token-for-tenant-organiz) ### Resolution |
| update-manager | Support Matrix | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/update-manager/support-matrix.md | description: This article provides a summary of supported regions and operating Previously updated : 08/01/2024 Last updated : 08/23/2024 Following is the list of supported images and no other marketplace images releas #### Supported Windows OS versions -| **Publisher**| **Offer** | **SKU**| **Unsupported image(s)** | -|-|-|--| | -|microsoftwindowsserver | windows server | * | windowsserver 2008| +| **Publisher**| **Offer** | **Plan**|**Unsupported image(s)** | +|-|-|--| | +| | cis-windows-server-2012-r2-v2-2-1-l2 | cis-ws2012-r2-l2 || +| | cis-windows-server-2016-v1-0-0-l1 | cis--l1 || +| | cis-windows-server-2016-v1-0-0-l2 | cis-ws2016-l2 || +| | cis-windows-server-2019-v1-0-0-l1 | cis-ws2019-l1 || +| | cis-windows-server-2019-v1-0-0-l2 | cis-ws2019-l2 || +| | cis-windows-server-2022-l1| cis-windows-server-2022-l1 </br> cis-windows-server-2022-l1-gen2 | | +| | cis-windows-server-2022-l2 | cis-windows-server-2022-l2 </br> cis-windows-server-2022-l2-gen2 | | +| | cis-windows-server| cis-windows-server2016-l1-gen1 </br> cis-windows-server2019-l1-gen1 </br> cis-windows-server2019-l1-gen2 </br> cis-windows-server2019-l2-gen1 </br> cis-windows-server2022-l1-gen2 </br> cis-windows-server2022-l2-gen2 </br> cis-windows-server2022-l1-gen1 | | +| | hpc2019-windows-server-2019| hpc2019-windows-server-2019|| +| | sql2016sp2-ws2016 | standard| +| | sql2017-ws2016 | enterprise | +| | sql2017-ws2016 | standard| +| | sql2019-ws2019 | enterprise | +| | sql2019-ws2019 | sqldev| +| | sql2019-ws2019 | standard | +| | sql2019-ws2019 | standard-gen2| +|cognosys | sql-server-2016-sp2-std-win2016-debug-utilities |sql-server-2016-sp2-std-win2016-debug-utilities| +|filemagellc| filemage-gateway-vm-win |filemage-gateway-vm-win-001 </br> filemage-gateway-vm-win-002 | +|github | github-enterprise| github-enterprise|| +|matillion | matillion | matillion-etl-for-snowflake|| +|microsoft-ads| windows-data-science-vm| windows2016 </br> windows2016byol|| +|microsoft-dsvm | ubuntu-1804| 1804-gen2 || +|microsoft-dvsm | dsvm-windows </br> dsvm-win-2019 </br> dsvm-win-2022 | * </br> * </br> * | +|microsoftazuresiterecovery | process-server | windows-2012-r2-datacenter | |microsoftbiztalkserver | biztalk-server | *| |microsoftdynamicsax | dynamics | * | |microsoftpowerbi |* |* | |microsoftsharepoint | microsoftsharepointserver | *|+|microsoftsqlserver | sql2016sp1-ws2016 | standard | |microsoftvisualstudio | Visualstudio* | *-ws2012r2 </br> *-ws2016-ws2019 </br> *-ws2022 |+|microsoftwindowsserver | windows server | windowsserver 2008| | |microsoftwindowsserver | windows-cvm | * |-|microsoftwindowsserver | windowsserverdotnet | *| |microsoftwindowsserver | windowsserver-gen2preview | *|+|microsoftwindowsserver | windowsserverdotnet | *| |microsoftwindowsserver | windowsserverupgrade | * | |microsoftwindowsserverhpcpack | windowsserverhpcpack | * |-|microsoftsqlserver | sql2016sp1-ws2016 | standard | -| | sql2016sp2-ws2016 | standard| -| | sql2017-ws2016 | standard| -| | sql2017-ws2016 | enterprise | -| | sql2019-ws2019 | enterprise | -| | sql2019-ws2019 | sqldev| -| | sql2019-ws2019 | standard | -| | sql2019-ws2019 | standard-gen2| -|microsoftazuresiterecovery | process-server | windows-2012-r2-datacenter | -|microsoft-dvsm | dsvm-windows </br> dsvm-win-2019 </br> dsvm-win-2022 | * </br> * </br> * | +|netapp |netapp-oncommand-cloud-manager| occm-byol|| + #### Supported Linux OS versions -| **Publisher**| **Offer** | **SKU**| **Unsupported image(s)** | -|-|-|--|-| -|canonical | * | *|| -|microsoftsqlserver | * | * | **Offers**: sql2019-sles* </br> sql2019-rhel7 </br> sql2017-rhel 7 </br></br> Example </br> Publisher: </br> microsoftsqlserver </br> Offer: sql2019-sles12sp5 </br> sku:webARM </br></br> Publisher: microsoftsqlserver </br> Offer: sql2019-rhel7 </br> sku: web-ARM | -|microsoftsqlserver | * | *|**Offers**: sql2019-sles*</br> sql2019-rhel7 </br> sql2017-rhel7 | -|microsoftcblmariner | cbl-mariner | cbl-mariner-1 </br> 1-gen2 </br> cbl-mariner-2 </br> cbl-mariner-2-gen2. | | -|microsoft-aks | aks |aks-engine-ubuntu-1804-202112 | | -|microsoft-dsvm |aml-workstation | ubuntu-20, ubuntu-20-gen2 | | -|microsoft-dsvm | aml-workstation | ubuntu | -|| ubuntu-hpc | 1804, 2004-preview-ndv5, 2004, 2204, 2204-preview-ndv5 | -|| ubuntu-2004 | 2004, 2004-gen2 | -|redhat | rhel| 7*,8*,9* | | -|redhat | rhel-ha | 8* | 81_gen2 | -|redhat | rhel-raw | 7*,8*,9* | | -|redhat | rhel-sap | 7*| | -|redhat | sap-apps | 7*, 8* | -|redhat | rhel-sap* | 9_0 | -|redhat | rhel-sap-ha| 7*, 8* | | -|redhat | rhel-sap-apps | 90sapapps-gen2 | -|redhat | rhel-sap-ha | 90sapha-gen2 | -|redhat | rhel-byos | rhel-lvm88, rhel-lvm88-gent2, rhel-lvm92, rhel-lvm92-gen2 | -|| rhel-ha | 9_2, 9_2-gen2 | -|| rhel-sap-apps | 9_0, 90sapapps-gen2, 9_2, 92sapapps-gen2 | -|| rhel-sap-ha | 9_2, 92sapha-gen2 | -|suse | opensuse-leap-15-* | gen* | -|suse | sles-12-sp5-* | gen* | -|suse | sles-sap-12-sp5* |gen* | -|suse | sles-sap-15-* | gen* | **Offer**: sles-sap-15-\*-byos </br></br> **Sku**: gen\* </br> Example </br> Publisher: suse </br> Offer: sles-sap-15-sp3-byos </br> sku: gen1-ARM | -|suse | sles-12-sp5 | gen1, gen2 | -|suse | sles-15-sp2 | gen1, gen2 | -| |sle-hpc-15-sp4 | gen1, gen2 | -| | sles| 12-sp4-gen2 | -| | sles-15-sp1-sapcal | gen1, gen2 | -| | sles-15-sp2-basic | gen2 | -| | sles-15-sp2-hpc | gen2 | -| | sles-15-sp3-sapcal | gen1, gen2 | -| | sles-15-sp4 | gen1, gen2 | -| | sles-byos | 12-sp4, 12-sp4-gen2 | -| | sles-sap | 12-sp4, 12-sp4-gen2 | -| | sles-sap-byos | 12-sp4, 12-sp4-gen2, gen2-12-sp4 | -| | sles-sapcal | 12-sp3 | -| | sles-standard | 12-sp4-gen2 | -|| sle-hpc-15-sp4-byos | gen1, gen2 | -|| sle-hpc-15-sp5-byos | gen1, gen 2 | -|| sle-hpc-15-sp5 | gen1, gen 2 | -|| sles-15-sp4-byos | gen1, gen2 | -|| sles-15-sp4-chost-byos | gen1, gen 2| -|| sles-15-sp4-hardened-byos | gen1, gen2 | -|| sles-15-sp5-basic | gen1, gen2 | -|| sles-15-sp5-byos | gen1, gen2| -|| sles-15-sp5-chost-byos | gen1, gen2 | -|| sles-15-sp5-hardened-byos | gen1, gen2 | -|| sles-15-sp5-sapcal | gen1, gen2 | -|| sles-15-sp5 | gen1, gen2 | -|| sles-sap-15-sp4-byos | gen1, gen2 | -|| sles-sap-15-sp4-hardened-byos | gen1, gen2 | -|| sles-sap-15-sp5-byos | gen1, gen2 | -|| sles-sap-15-sp5-hardened-byos| gen1, gen2 | -|oracle | oracle-linux | 7*, ol7*, ol8*, ol9*, ol9-lvm*, 8, 8-ci, 81, 81-ci, 81-gen2 | -| | oracle-database | oracle_db_21 | -| | oracle-database-19-3 | oracle-database-19-0904 | -|microsoftcblmariner| cbl-mariner | cbl-mariner-1,1-gen2, cbl-mariner-2, cbl-mariner-2-gen2 | -| openlogic | centos | 7.2, 7.3, 7.4, 7.5, 7.6, 7_8, 7_9, 7_9-gen2 | -| |centos-hpc | 7.1, 7.3, 7.4 | -| |centos-lvm | 7-lvm, 8-lvm | +| **Publisher**| **Offer** | **Plan**|**Unsupported image(s)** | +|-|-|--| | +| |ad-dc-2016 | ad-dc-2016| +| |ad-dc-2019| ad-dc-2019 | +| |ad-dc-2022 | ad-dc-2022 || +| |almalinux-hpc | 8_6-hpc, 8_6-hpc-gen2 | +| |aviatrix-companion-gateway-v9 | aviatrix-companion-gateway-v9| +| |aviatrix-companion-gateway-v10 | aviatrix-companion-gateway-v10,</br> aviatrix-companion-gateway-v10u| +| |aviatrix-companion-gateway-v12 | aviatrix-companion-gateway-v12| +| |aviatrix-companion-gateway-v13 | aviatrix-companion-gateway-v13,</br> aviatrix-companion-gateway-v13u| +| |aviatrix-companion-gateway-v14 | aviatrix-companion-gateway-v14,</br> aviatrix-companion-gateway-v14u | +| |aviatrix-companion-gateway-v16 | aviatrix-companion-gateway-v16| +| |aviatrix-copilot |avx-cplt-byol-01, avx-cplt-byol-02 | | |centos-ci | 7-ci |+| |centos-hpc | 7.1, 7.3, 7.4 | | |centos-lvm | 7-lvm-gen2 |-|almalinux | almalinux </br> | 8-gen1, 8-gen2, 9-gen1, 9-gen2| -||almalinux-x86_64 | 8-gen1, 8-gen2, 9-gen1, 9-gen2 -||almalinux-hpc | 8_6-hpc, 8_6-hpc-gen2 | -| aviatrix-systems | aviatrix-bundle-payg | aviatrix-enterprise-bundle-byol| -|| aviatrix-copilot |avx-cplt-byol-01, avx-cplt-byol-02 | -|| aviatrix-companion-gateway-v9 | aviatrix-companion-gateway-v9| -|| aviatrix-companion-gateway-v10 | aviatrix-companion-gateway-v10,</br> aviatrix-companion-gateway-v10u| -|| aviatrix-companion-gateway-v12 | aviatrix-companion-gateway-v12| -|| aviatrix-companion-gateway-v13 | aviatrix-companion-gateway-v13,</br> aviatrix-companion-gateway-v13u| -|| aviatrix-companion-gateway-v14 | aviatrix-companion-gateway-v14,</br> aviatrix-companion-gateway-v14u | -|| aviatrix-companion-gateway-v16 | aviatrix-companion-gateway-v16| -| cncf-upstream | capi | ubuntu-1804-gen1, ubuntu-2004-gen1, ubuntu-2204-gen1 | -| credativ | debian | 9, 9-backports | -| debian | debian-10 | 10, 10-gen2,</br> 10-backports, </br> 10-backports-gen2 | -|| debian-10-daily | 10, 10-gen2,</br> 10-backports,</br> 10-backports-gen2| -|| debian-11 | 11, 11-gen2,</br> 11-backports, </br> 11-backports-gen2 | -|| debian-11-daily | 11, 11-gen2,</br> 11-backports, </br> 11-backports-gen2 | +| |centos-lvm | 7-lvm, 8-lvm | +| |cis-oracle-linux-8-l1 | cis-oracle8-l1|| +| |cis-rhel | cis-redhat7-l1-gen1 </br> cis-redhat8-l1-gen1 </br> cis-redhat8-l2-gen1 </br> cis-redhat9-l1-gen1 </br> cis-redhat9-l1-gen2| | +| |cis-rhel-7-l2 | cis-rhel7-l2 | | +| |cis-rhel-8-l1 | | | | +| |cis-rhel-8-l2 | cis-rhel8-l2 | | +| |cis-rhel9-l1 | cis-rhel9-l1 </br> cis-rhel9-l1-gen2 || +| |cis-ubuntu | cis-ubuntu1804-l1 </br> cis-ubuntulinux2004-l1-gen1 </br> cis-ubuntulinux2204-l1-gen1 </br> cis-ubuntulinux2204-l1-gen2 || +| |cis-ubuntu-linux-1804-l1| cis-ubuntu1804-l1|| +| |cis-ubuntu-linux-2004-l1 | cis-ubuntu2004-l1 </br> cis-ubuntu-linux-2204-l1-gen2|| +| |cis-ubuntu-linux-2004-l1| cis-ubuntu2004-l1|| +| |cis-ubuntu-linux-2204-l1 | cis-ubuntu-linux-2204-l1 </br> cis-ubuntu-linux-2204-l1-gen2 | | +| |debian-10-daily | 10, 10-gen2,</br> 10-backports,</br> 10-backports-gen2| +| |debian-11 | 11, 11-gen2,</br> 11-backports, </br> 11-backports-gen2 | +| |debian-11-daily | 11, 11-gen2,</br> 11-backports, </br> 11-backports-gen2 | +| |dns-ubuntu-2004 | dns-ubuntu-2004| +| |oracle-database | oracle_db_21 | +| |oracle-database-19-3 | oracle-database-19-0904 | +| |rhel-ha | 9_2, 9_2-gen2 | +| |rhel-sap-apps | 9_0, 90sapapps-gen2, 9_2, 92sapapps-gen2 | +| |rhel-sap-ha | 9_2, 92sapha-gen2 | +| |servercore-2019| servercore-2019| +| |sftp-2016 | sftp-2016| +| |sle-hpc-15-sp4 | gen1, gen2 | +| |sle-hpc-15-sp4-byos | gen1, gen2 | +| |sle-hpc-15-sp5 | gen1, gen 2 | +| |sle-hpc-15-sp5-byos | gen1, gen 2 | +| |sles-15-sp1-sapcal | gen1, gen2 | +| |sles-15-sp2-basic | gen2 | +| |sles-15-sp2-hpc | gen2 | +| |sles-15-sp3-sapcal | gen1, gen2 | +| |sles-15-sp4 | gen1, gen2 | +| |sles-15-sp4-byos | gen1, gen2 | +| |sles-15-sp4-chost-byos | gen1, gen 2| +| |sles-15-sp4-hardened-byos | gen1, gen2 | +| |sles-15-sp5 | gen1, gen2 | +| |sles-15-sp5-basic | gen1, gen2 | +| |sles-15-sp5-byos | gen1, gen2| +| |sles-15-sp5-hardened-byos | gen1, gen2 | +| |sles-15-sp5-sapcal | gen1, gen2 | +| |sles-byos | 12-sp4, 12-sp4-gen2 | +| |sles-sap | 12-sp4, 12-sp4-gen2 | +| |sles-sap-15-sp4-byos | gen1, gen2 | +| |sles-sap-15-sp4-hardened-byos | gen1, gen2 | +| |sles-sap-15-sp5-byos | gen1, gen2 | +| |sles-sap-15-sp5-hardened-byos| gen1, gen2 | +| |sles-sap-byos | 12-sp4, 12-sp4-gen2, gen2-12-sp4 | +| |sles-sapcal | 12-sp3 | +| |sles-standard | 12-sp4-gen2 | +| |sles| 12-sp4-gen2 | +| |squid-ubuntu-2004 | squid-ubuntu-2004| +| |ubuntu-2004 | 2004, 2004-gen2 | +| |ubuntu-hpc | 1804, 2004-preview-ndv5, 2004, 2204, 2204-preview-ndv5 | +| sles-15-sp5-chost-byos | gen1, gen2 | +|almalinux |almalinux </br> | 8-gen1, 8-gen2, 9-gen1, 9-gen2| +|almalinux|almalinux-x86_64 | 8-gen1, 8-gen2, 8_7-gen2, 9-gen1, 9-gen2 +|aviatrix-systems |aviatrix-bundle-payg | aviatrix-enterprise-bundle-byol| +|belindaczsro1588885355210 |belvmsrv01 |belvmsrv003|| +|canonical | * | *|| +|cloud-infrastructure-services |rds-farm-2019| rds-farm-2019| +|cloudera |cloudera-centos-os| 7_5|| +|cncf-upstream | capi | ubuntu-1804-gen1, ubuntu-2004-gen1, ubuntu-2204-gen1 | +|credativ | debian | 9, 9-backports | +|debian | debian-10 | 10, 10-gen2,</br> 10-backports, </br> 10-backports-gen2 | +|esri |arcgis-enterprise-107| byol-1071|| +|esri |pro-byol| pro-byol-29|| +|esri|arcgis-enterprise | byol-108 </br> byol-109 </br> byol-111 </br> byol-1081 </br> byol-1091| +|esri|arcgis-enterprise-106| byol-1061|| +|microsoft-aks |aks |aks-engine-ubuntu-1804-202112 | | +|microsoft-dsvm |aml-workstation | ubuntu-20, ubuntu-20-gen2 | | +|microsoft-dsvm |aml-workstation | ubuntu | +|microsoftcblmariner |cbl-mariner | cbl-mariner-1 </br> 1-gen2 </br> cbl-mariner-2 </br> cbl-mariner-2-gen2. | | +|microsoftcblmariner|cbl-mariner | cbl-mariner-1,1-gen2, cbl-mariner-2, cbl-mariner-2-gen2 | +|microsoftsqlserver | * | * | |**Offers**: sql2019-sles* </br> sql2019-rhel7 </br> sql2017-rhel 7 </br></br> Example </br> Publisher: </br> microsoftsqlserver </br> Offer: sql2019-sles12sp5 </br> sku:webARM </br></br> Publisher: microsoftsqlserver </br> Offer: sql2019-rhel7 </br> sku: web-ARM | +|microsoftsqlserver | * | *||**Offers**: sql2019-sles*</br> sql2019-rhel7 </br> sql2017-rhel7 | +|nginxinc|nginx-plus-ent-v1 | nginx-plus-ent-centos7 | +|ntegralinc1586961136942|ntg_oracle_8_7| ntg_oracle_8_7| +|openlogic | centos | 7.2, 7.3, 7.4, 7.5, 7.6, 7_8, 7_9, 7_9-gen2 | +|oracle |oracle-linux | 7*, ol7*, ol8*, ol9*, ol9-lvm*, 8, 8-ci, 81, 81-ci, 81-gen2 | +|procomputers |almalinux-8-7| almalinux-8-7|| +|procomputers |rhel-8-2 | rhel-8-2|| +|redhat | rhel | 8.1|| +|redhat | rhel | 89-gen2 | +|redhat | rhel-sap | 7.4| | +|redhat | rhel-sap | 7.7 | +|redHat |rhel | 8_9|| +|redhat |rhel-byos | rhel-lvm79 </br> rhel-lvm79-gen2 </br> rhel-lvm8 </br> rhel-lvm82-gen2 </br> rhel-lvm83 </br> rhel-lvm84 </br> rhel-lvm84-gen2 </br> rhel-lvm85-gen2 </br> rhel-lvm86 </br> rhel-lvm86-gen2 </br> rhel-lvm87-gen2 </br> rhel-raw76 </br> | +|redhat |rhel-byos |rhel-lvm88 </br> rhel-lvm88-gent2 </br> rhel-lvm92 </br>rhel-lvm92-gen2 || | +|redhat |rhel-ha | 8* | 81_gen2 | +|redhat |rhel-raw | 7*,8*,9* | | +|redhat |rhel-sap | 7*| | +|redhat |rhel-sap-apps | 90sapapps-gen2 | +|redhat |rhel-sap-ha | 90sapha-gen2 | +|redhat |rhel-sap-ha| 7*, 8* | | +|redhat |rhel-sap* | 9_0 | +|redhat |rhel| 7*,8*,9* | | +|redhat |sap-apps | 7*, 8* | +|southrivertech1586314123192 | tn-ent-payg| Tnentpayg|| +|southrivertech1586314123192 | tn-sftp-payg | Tnsftppayg || +|suse |opensuse-leap-15-* | gen* | +|suse |sles-12-sp5 | gen1, gen2 | +|suse |sles-12-sp5-* | gen* | +|suse |sles-15-sp2 | gen1, gen2 | +|suse |sles-15-sp5 | gen2 || +|suse |sles-sap-12-sp5* |gen* | +|suse |sles-sap-15-* | gen* </br> **Offer**: sles-sap-15-\*-byos </br></br> **Sku**: gen\* </br> Example </br> Publisher: suse </br> Offer: sles-sap-15-sp3-byos </br> sku: gen1-ARM | +|suse |sles-sap-15-sp2-byos | gen2|| +|talend |talend_re_image | tlnd_re| +|thorntechnologiesllc | sftpgateway | Sftpgateway| +|veeam |office365backup | veeamoffice365backup || +|veeam |veeam-backup-replication| veeam-backup-replication-v11|| +|zscaler | zscaler-private-access | zpa-con-azure || + ### Custom images |
| update-manager | Whats New | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/update-manager/whats-new.md | Last updated 07/24/2024 ## August 2024 +### Support for 35 CIS images added along with 59 other images ++Azure Update Manager now supports CIS images along with 59 other popular images. For more information, see the [latest list of supported images](support-matrix.md#supported-operating-systems). ++ ### Pre and Post events General Availability: Azure Update Manager now supports creating and managing pre and post events on scheduled maintenance configurations. [Learn more](pre-post-scripts-overview.md). |
| virtual-desktop | Autoscale Diagnostics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/autoscale-diagnostics.md | -Currently, you can either send diagnostic logs for Autoscale to an Azure Storage account or consume logs with Microsoft Azure Event Hubs. If you're using an Azure Storage account, make sure it's in the same region as your scaling plan. Learn more about diagnostic settings at [Create diagnostic settings](../azure-monitor/essentials/diagnostic-settings.md). For more information about resource log data ingestion time, see [Log data ingestion time in Azure Monitor](../azure-monitor/logs/data-ingestion-time.md). +Currently, you can either send diagnostic logs for Autoscale to an Azure Storage account or consume logs with Microsoft Azure Event Hubs. If you're using an Azure Storage account, make sure it's in the same region as your scaling plan. Learn more about diagnostic settings at [Create diagnostic settings](/azure/azure-monitor/essentials/diagnostic-settings). For more information about resource log data ingestion time, see [Log data ingestion time in Azure Monitor](/azure/azure-monitor/logs/data-ingestion-time). > [!TIP] > For pooled host pools, we recommend you use Autoscale diagnostic data integrated with Insights in Azure Virtual Desktop, which providing a more comprehensive view of your Autoscale operations. For more information, see [Monitor Autoscale operations with Insights in Azure Virtual Desktop](autoscale-monitor-operations-insights.md). To enable diagnostics for your scaling plan: 1. Select **Save**. > [!NOTE]-> If you select **Archive to a storage account**, you'll need to [Migrate from diagnostic settings storage retention to Azure Storage lifecycle management](../azure-monitor/essentials/migrate-to-azure-storage-lifecycle-policy.md). +> If you select **Archive to a storage account**, you'll need to [Migrate from diagnostic settings storage retention to Azure Storage lifecycle management](/azure/azure-monitor/essentials/migrate-to-azure-storage-lifecycle-policy). ## Find Autoscale diagnostic logs in Azure Storage |
| virtual-desktop | Autoscale Monitor Operations Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/autoscale-monitor-operations-insights.md | Before you can monitor Autoscale operations with Insights, you need: | Configure diagnostic settings | [Desktop Virtualization Contributor](rbac.md#desktop-virtualization-contributor) | Assigned on the resource group or subscription for your host pools, workspaces, and session hosts. | | View and query data | [Desktop Virtualization Reader](../role-based-access-control/built-in-roles.md#desktop-virtualization-reader)<br /><br />[Log Analytics Reader](../role-based-access-control/built-in-roles.md#log-analytics-reader) | - Desktop Virtualization Reader assigned on the resource group or subscription where the host pools, workspaces, and session hosts are.<br /><br />- Log Analytics Reader assigned on any Log Analytics workspace used for Azure Virtual Desktop Insights.<sup>1</sup>| - <sup>1. You can also create a custom role to reduce the scope of assignment on the Log Analytics workspace. For more information, see [Manage access to Log Analytics workspaces](../azure-monitor/logs/manage-access.md).</sup> + <sup>1. You can also create a custom role to reduce the scope of assignment on the Log Analytics workspace. For more information, see [Manage access to Log Analytics workspaces](/azure/azure-monitor/logs/manage-access).</sup> ## Configure diagnostic settings and verify Insights workbook configuration After you configured your diagnostic settings and verified your Insights workboo ## Queries for Autoscale data in Log Analytics -For additional information about Autoscale operations, you can use run queries against the data in Log Analytics. The data is written to the `WVDAutoscaleEvaluationPooled` table. The following sections contain the schema and some example queries. To learn how to run queries in Log Analytics, see [Log Analytics tutorial](../azure-monitor/logs/log-analytics-tutorial.md). +For additional information about Autoscale operations, you can use run queries against the data in Log Analytics. The data is written to the `WVDAutoscaleEvaluationPooled` table. The following sections contain the schema and some example queries. To learn how to run queries in Log Analytics, see [Log Analytics tutorial](/azure/azure-monitor/logs/log-analytics-tutorial). ### WVDAutoscaleEvaluationPooled Schema WVDAutoscaleEvaluationPooled ## Related content -For more information about the time for log data to become available after collection, see [Log data ingestion time in Azure Monitor](../azure-monitor/logs/data-ingestion-time.md). +For more information about the time for log data to become available after collection, see [Log data ingestion time in Azure Monitor](/azure/azure-monitor/logs/data-ingestion-time). |
| virtual-desktop | Configure Rdp Shortpath | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/configure-rdp-shortpath.md | The possible values are: For any other value, the connection isn't using UDP and is connected using TCP instead. -The following query lets you review connection information. You can run this query in the [Log Analytics query editor](../azure-monitor/logs/log-analytics-tutorial.md#write-a-query). When you run this query, replace `user@contoso.com` with the UPN of the user you want to look up: +The following query lets you review connection information. You can run this query in the [Log Analytics query editor](/azure/azure-monitor/logs/log-analytics-tutorial#write-a-query). When you run this query, replace `user@contoso.com` with the UPN of the user you want to look up: ```kusto let Events = WVDConnections | where UserName == "user@contoso.com" ; |
| virtual-desktop | Connection Quality Monitoring | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/connection-quality-monitoring.md | ->Normal storage charges for Log Analytics will apply. Learn more at [Azure Monitor Logs pricing details](../azure-monitor/logs/cost-logs.md). +>Normal storage charges for Log Analytics will apply. Learn more at [Azure Monitor Logs pricing details](/azure/azure-monitor/logs/cost-logs). ## Configure diagnostics settings To check and modify your diagnostics settings in the Azure portal: ## Sample queries for Azure Log Analytics: network data -In this section, we have a list of queries that will help you review connection quality information. You can run queries in the [Log Analytics query editor](../azure-monitor/logs/log-analytics-tutorial.md#write-a-query). +In this section, we have a list of queries that will help you review connection quality information. You can run queries in the [Log Analytics query editor](/azure/azure-monitor/logs/log-analytics-tutorial#write-a-query). >[!NOTE] >For each example, replace the *userupn* variable with the UPN of the user you want to look up. |
| virtual-desktop | Diagnostics Log Analytics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/diagnostics-log-analytics.md | -Azure Virtual Desktop uses [Azure Monitor](../azure-monitor/overview.md) for monitoring and alerts like many other Azure services. This lets admins identify issues through a single interface. The service creates activity logs for both user and administrative actions. Each activity log falls under the following categories: +Azure Virtual Desktop uses [Azure Monitor](/azure/azure-monitor/overview) for monitoring and alerts like many other Azure services. This lets admins identify issues through a single interface. The service creates activity logs for both user and administrative actions. Each activity log falls under the following categories: | Category | Description | |--|--| Connections that don't reach Azure Virtual Desktop won't show up in diagnostics Azure Monitor lets you analyze Azure Virtual Desktop data and review virtual machine (VM) performance counters, all within the same tool. This article will tell you more about how to enable diagnostics for your Azure Virtual Desktop environment. >[!NOTE]->To learn how to monitor your VMs in Azure, see [Monitoring Azure virtual machines with Azure Monitor](../azure-monitor/vm/monitor-vm-azure.md). Also, make sure to review the [Azure Virtual Desktop Insights glossary](./insights-glossary.md) for a better understanding of your user experience on the session host. +>To learn how to monitor your VMs in Azure, see [Monitoring Azure virtual machines with Azure Monitor](/azure/azure-monitor/vm/monitor-vm-azure). Also, make sure to review the [Azure Virtual Desktop Insights glossary](./insights-glossary.md) for a better understanding of your user experience on the session host. ## Prerequisites Before you can use Azure Virtual Desktop with Log Analytics, you need: -- A Log Analytics workspace. For more information, see [Create a Log Analytics workspace in Azure portal](../azure-monitor/logs/quick-create-workspace.md) or [Create a Log Analytics workspace with PowerShell](../azure-monitor/logs/powershell-workspace-configuration.md). After you've created your workspace, follow the instructions in [Connect Windows computers to Azure Monitor](../azure-monitor/agents/agent-windows.md#workspace-id-and-key) to get the following information:+- A Log Analytics workspace. For more information, see [Create a Log Analytics workspace in Azure portal](/azure/azure-monitor/logs/quick-create-workspace) or [Create a Log Analytics workspace with PowerShell](/azure/azure-monitor/logs/powershell-workspace-configuration). After you've created your workspace, follow the instructions in [Connect Windows computers to Azure Monitor](/azure/azure-monitor/agents/agent-windows#workspace-id-and-key) to get the following information: - The workspace ID - The primary key of your workspace Before you can use Azure Virtual Desktop with Log Analytics, you need: - Access to specific URLs from your session hosts for diagnostics to work. For more information, see [Required URLs for Azure Virtual Desktop](safe-url-list.md) where you'll see entries for **Diagnostic output**. -- Make sure to review permission management for Azure Monitor to enable data access for those who monitor and maintain your Azure Virtual Desktop environment. For more information, see [Get started with roles, permissions, and security with Azure Monitor](../azure-monitor/roles-permissions-security.md).+- Make sure to review permission management for Azure Monitor to enable data access for those who monitor and maintain your Azure Virtual Desktop environment. For more information, see [Get started with roles, permissions, and security with Azure Monitor](/azure/azure-monitor/roles-permissions-security). ## Push diagnostics data to your workspace To set up Log Analytics for a new object: The options shown in the Diagnostic Settings page will vary depending on what kind of object you're editing. - For example, when you're enabling diagnostics for an application group, you'll see options to configure checkpoints, errors, and management. For workspaces, these categories configure a feed to track when users subscribe to the list of apps. To learn more about diagnostic settings see [Create diagnostic setting to collect resource logs and metrics in Azure](../azure-monitor/essentials/diagnostic-settings.md). + For example, when you're enabling diagnostics for an application group, you'll see options to configure checkpoints, errors, and management. For workspaces, these categories configure a feed to track when users subscribe to the list of apps. To learn more about diagnostic settings see [Create diagnostic setting to collect resource logs and metrics in Azure](/azure/azure-monitor/essentials/diagnostic-settings). >[!IMPORTANT] >Remember to enable diagnostics for each Azure Resource Manager object that you want to monitor. Data will be available for activities after diagnostics has been enabled. It might take a few hours after first set-up. To set up Log Analytics for a new object: 6. Select **Save**. >[!NOTE]->Log Analytics gives you the option to stream data to [Event Hubs](../event-hubs/event-hubs-about.md) or archive it in a storage account. To learn more about this feature, see [Stream Azure monitoring data to an event hub](../azure-monitor/essentials/stream-monitoring-data-event-hubs.md) and [Archive Azure resource logs to storage account](../azure-monitor/essentials/resource-logs.md#send-to-azure-storage). +>Log Analytics gives you the option to stream data to [Event Hubs](../event-hubs/event-hubs-about.md) or archive it in a storage account. To learn more about this feature, see [Stream Azure monitoring data to an event hub](/azure/azure-monitor/essentials/stream-monitoring-data-event-hubs) and [Archive Azure resource logs to storage account](/azure/azure-monitor/essentials/resource-logs#send-to-azure-storage). ## How to access Log Analytics Access example queries through the Azure Monitor Log Analytics UI: 1. Select **Azure Virtual Desktop** to review available queries. 1. Select **Run** to run the selected query. -Learn more about the sample query interface in [Saved queries in Azure Monitor Log Analytics](../azure-monitor/logs/queries.md). +Learn more about the sample query interface in [Saved queries in Azure Monitor Log Analytics](/azure/azure-monitor/logs/queries). -The following query list lets you review connection information or issues for a single user. You can run these queries in the [Log Analytics query editor](../azure-monitor/logs/log-analytics-tutorial.md#write-a-query). For each query, replace `userupn` with the UPN of the user you want to look up. +The following query list lets you review connection information or issues for a single user. You can run these queries in the [Log Analytics query editor](/azure/azure-monitor/logs/log-analytics-tutorial#write-a-query). For each query, replace `userupn` with the UPN of the user you want to look up. To find all connections for a single user: |
| virtual-desktop | Insights Costs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/insights-costs.md | These are the default Windows Events for Azure Virtual Desktop Insights: Windows Events sends events whenever the environment meets the terms of the event. Machines in healthy states will send fewer events than machines in unhealthy states. Since event count is unpredictable, we use a range of 1,000 to 10,000 events per VM per day based on examples from healthy environments for this estimate. For example, if we estimate each event record size in this example to be 1,500 bytes, this comes out to roughly 2 to 15 megabytes of event data per day for the specified environment. -To learn more about configuring Windows event log data collection with the Azure Monitor Agent, see [How to collect events and performance counters from virtual machines with Azure Monitor Agent](../azure-monitor/agents/data-collection-rule-azure-monitor-agent.md). +To learn more about configuring Windows event log data collection with the Azure Monitor Agent, see [How to collect events and performance counters from virtual machines with Azure Monitor Agent](/azure/azure-monitor/agents/data-collection-rule-azure-monitor-agent). -To learn more about Windows events, see [Windows event records properties](../azure-monitor/agents/data-sources-windows-events.md). +To learn more about Windows events, see [Windows event records properties](/azure/azure-monitor/agents/data-sources-windows-events). ## Estimating diagnostics ingestion To learn more about the activity log categories, see [Azure Virtual Desktop diag ## Measure and manage your performance counter data -Your true monitoring costs will depend on your environment size, usage, and health. To understand how to measure data ingestion in your Log Analytics workspace, see [Analyze usage in Log Analytics workspace](../azure-monitor/logs/analyze-usage.md). +Your true monitoring costs will depend on your environment size, usage, and health. To understand how to measure data ingestion in your Log Analytics workspace, see [Analyze usage in Log Analytics workspace](/azure/azure-monitor/logs/analyze-usage). The performance counters the session hosts use is among the largest source of ingested data for Azure Virtual Desktop Insights. This query will show all performance counters you've enabled in the environment, not just the default ones for Azure Virtual Desktop Insights. This information can help you understand which areas to target to reduce costs. Using the default Pay-as-you-go model for [Log Analytics pricing](https://azure. This section will explain how to measure and manage data ingestion to reduce costs. -To learn about managing rights and permissions to the workbook, see [Access control](../azure-monitor/visualize/workbooks-overview.md#access-control). +To learn about managing rights and permissions to the workbook, see [Access control](/azure/azure-monitor/visualize/workbooks-overview#access-control). >[!NOTE] >Removing data points will impact their corresponding visuals in Azure Virtual Desktop Insights. To learn about managing rights and permissions to the workbook, see [Access cont Here are some suggestions to optimize your Log Analytics settings to manage data ingestion: - Use a designated Log Analytics workspace for your Azure Virtual Desktop resources to ensure that Log Analytics only collects performance counters and events for the virtual machines in your Azure Virtual Desktop deployment.-- Adjust your Log Analytics storage settings to manage costs. You can reduce the retention period, evaluate whether a fixed storage pricing tier would be more cost-effective, or set boundaries on how much data you can ingest to limit impact of an unhealthy deployment. To learn more, see [Azure Monitor Logs pricing details](../azure-monitor/logs/cost-logs.md).+- Adjust your Log Analytics storage settings to manage costs. You can reduce the retention period, evaluate whether a fixed storage pricing tier would be more cost-effective, or set boundaries on how much data you can ingest to limit impact of an unhealthy deployment. To learn more, see [Azure Monitor Logs pricing details](/azure/azure-monitor/logs/cost-logs). ### Remove excess data Our default configuration is the only set of data we recommend for Azure Virtual ### Measure and manage your performance counter data -Your true monitoring costs will depend on your environment size, usage, and health. To understand how to measure data ingestion in your Log Analytics workspace, see [Analyze usage in Log Analytics workspace](../azure-monitor/logs/analyze-usage.md). +Your true monitoring costs will depend on your environment size, usage, and health. To understand how to measure data ingestion in your Log Analytics workspace, see [Analyze usage in Log Analytics workspace](/azure/azure-monitor/logs/analyze-usage). The performance counters the session hosts use will probably be your largest source of ingested data for Azure Virtual Desktop Insights. The following custom query template for a Log Analytics workspace can track frequency and megabytes ingested per performance counter over the last day: Perf This query will show all performance counters you have enabled on the environment, not just the default ones for Azure Virtual Desktop Insights. This information can help you understand which areas to target to reduce costs, like reducing a counterΓÇÖs frequency or removing it altogether. -You can also reduce costs by removing performance counters. To learn how to remove performance counters or edit existing counters to reduce their frequency, see [Configuring performance counters](../azure-monitor/agents/data-sources-performance-counters.md#configure-performance-counters). +You can also reduce costs by removing performance counters. To learn how to remove performance counters or edit existing counters to reduce their frequency, see [Configuring performance counters](/azure/azure-monitor/agents/data-sources-performance-counters#configure-performance-counters). ### Manage Windows Event Logs -Windows Events are unlikely to cause a spike in data ingestion when all hosts are healthy. An unhealthy host can increase the number of events sent to the log, but the information can be critical to fixing the host's issues. We recommend keeping them. To learn more about how to manage Windows Event Logs, see [Configuring Windows Event logs](../azure-monitor/agents/data-sources-windows-events.md#configure-windows-event-logs). +Windows Events are unlikely to cause a spike in data ingestion when all hosts are healthy. An unhealthy host can increase the number of events sent to the log, but the information can be critical to fixing the host's issues. We recommend keeping them. To learn more about how to manage Windows Event Logs, see [Configuring Windows Event logs](/azure/azure-monitor/agents/data-sources-windows-events#configure-windows-event-logs). ### Manage diagnostics Learn more about Azure Virtual Desktop Insights at these articles: - [Use Azure Virtual Desktop Insights to monitor your deployment](insights.md). - Use the [glossary](insights-glossary.md) to learn more about terms and concepts. - If you encounter a problem, check out our [troubleshooting guide](troubleshoot-insights.md) for help.-- Check out [Azure Monitor cost and usage](../azure-monitor/cost-usage.md) to learn more about managing your monitoring costs.+- Check out [Azure Monitor cost and usage](/azure/azure-monitor/cost-usage) to learn more about managing your monitoring costs. |
| virtual-desktop | Insights Glossary | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/insights-glossary.md | This article lists and briefly describes key terms and concepts related to Azure ## Alerts -Any active Azure Monitor alerts that you've configured on the subscription and classified as [severity 0](#severity-0-alerts) will appear in the Overview page. To learn how to set up alerts, see [Azure Monitor Log Alerts](../azure-monitor/alerts/alerts-log.md). +Any active Azure Monitor alerts that you've configured on the subscription and classified as [severity 0](#severity-0-alerts) will appear in the Overview page. To learn how to set up alerts, see [Azure Monitor Log Alerts](/azure/azure-monitor/alerts/alerts-log). ## Available sessions The following table lists the required Windows Event Logs for Azure Virtual Desk - If you encounter a problem, check out our [troubleshooting guide](troubleshoot-insights.md) for help and known issues. -You can also set up Azure Advisor to help you figure out how to resolve or prevent common issues. Learn more at [Introduction to Azure Advisor](../advisor/advisor-overview.md). +You can also set up Azure Advisor to help you figure out how to resolve or prevent common issues. Learn more at [Introduction to Azure Advisor](/azure/advisor/advisor-overview). If you need help or have any questions, check out our community resources: |
| virtual-desktop | Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/insights.md | ->[The Log Analytics Agent is currently being deprecated](https://azure.microsoft.com/updates/were-retiring-the-log-analytics-agent-in-azure-monitor-on-31-august-2024/). If you use the Log Analytics Agent, you'll eventually need to migrate to the [Azure Monitor Agent](../azure-monitor/agents/agents-overview.md) by August 31, 2024. +>[The Log Analytics Agent is currently being deprecated](https://azure.microsoft.com/updates/were-retiring-the-log-analytics-agent-in-azure-monitor-on-31-august-2024/). If you use the Log Analytics Agent, you'll eventually need to migrate to the [Azure Monitor Agent](/azure/azure-monitor/agents/agents-overview) by August 31, 2024. ## Prerequisites Before you start using Azure Virtual Desktop Insights, you'll need to set up the - [Desktop Virtualization Reader](../role-based-access-control/built-in-roles.md#desktop-virtualization-reader) assigned on the resource group or subscription where the host pools, workspaces and session hosts are. - [Log Analytics Reader](../role-based-access-control/built-in-roles.md#log-analytics-reader) assigned on any Log Analytics workspace used with Azure Virtual Desktop Insights. - You can also create a custom role to reduce the scope of assignment on the Log Analytics workspace. For more information, see [Manage access to Log Analytics workspaces](../azure-monitor/logs/manage-access.md). + You can also create a custom role to reduce the scope of assignment on the Log Analytics workspace. For more information, see [Manage access to Log Analytics workspaces](/azure/azure-monitor/logs/manage-access). > [!NOTE] > Read access only lets admins view data. They'll need different permissions to manage resources in the Azure Virtual Desktop portal. ## Log Analytics settings -To start using Azure Virtual Desktop Insights, you'll need at least one Log Analytics workspace. Use a designated Log Analytics workspace for your Azure Virtual Desktop session hosts to ensure that performance counters and events are only collected from session hosts in your Azure Virtual Desktop deployment. If you already have a workspace set up, skip ahead to [Set up the configuration workbook](#set-up-the-configuration-workbook). To set one up, see [Create a Log Analytics workspace in the Azure portal](../azure-monitor/logs/quick-create-workspace.md). +To start using Azure Virtual Desktop Insights, you'll need at least one Log Analytics workspace. Use a designated Log Analytics workspace for your Azure Virtual Desktop session hosts to ensure that performance counters and events are only collected from session hosts in your Azure Virtual Desktop deployment. If you already have a workspace set up, skip ahead to [Set up the configuration workbook](#set-up-the-configuration-workbook). To set one up, see [Create a Log Analytics workspace in the Azure portal](/azure/azure-monitor/logs/quick-create-workspace). >[!NOTE] >Standard data storage charges for Log Analytics will apply. To start, we recommend you choose the pay-as-you-go model and adjust as you scale your deployment and take in more data. To learn more, see [Azure Monitor pricing](https://azure.microsoft.com/pricing/details/monitor/). You can use either the Azure Monitor Agent or the Log Analytics agent to collect # [Azure Monitor Agent](#tab/monitor) -To collect information on your Azure Virtual Desktop session hosts, you must configure a [Data Collection Rule (DCR)](../azure-monitor/essentials/data-collection-rule-overview.md) to collect performance data and Windows Event Logs, associate the session hosts with the DCR, install the Azure Monitor Agent on all session hosts in host pools you're collecting data from, and ensure the session hosts are sending data to a Log Analytics workspace. +To collect information on your Azure Virtual Desktop session hosts, you must configure a [Data Collection Rule (DCR)](/azure/azure-monitor/essentials/data-collection-rule-overview) to collect performance data and Windows Event Logs, associate the session hosts with the DCR, install the Azure Monitor Agent on all session hosts in host pools you're collecting data from, and ensure the session hosts are sending data to a Log Analytics workspace. The Log Analytics workspace you send session host data to doesn't have to be the same one you send diagnostic data to. To set up your remaining session hosts using the configuration workbook: 1. Select **Add extension** to deploy the Azure Monitor Agent to all the session hosts in the host pool. -1. Select **Add system managed identity** to configure the required [managed identity](../azure-monitor/agents/azure-monitor-agent-manage.md#prerequisites). +1. Select **Add system managed identity** to configure the required [managed identity](/azure/azure-monitor/agents/azure-monitor-agent-manage#prerequisites). 1. Once the agent has installed and the managed identity has been added, refresh the configuration workbook. >[!NOTE]->For larger host pools (over 1,000 session hosts) or if you encounter deployment issues, we recommend you [install the Azure Monitor Agent](../azure-monitor/agents/azure-monitor-agent-manage.md#installation-options) when you create a session host by using an Azure Resource Manager template. +>For larger host pools (over 1,000 session hosts) or if you encounter deployment issues, we recommend you [install the Azure Monitor Agent](/azure/azure-monitor/agents/azure-monitor-agent-manage#installation-options) when you create a session host by using an Azure Resource Manager template. # [Log Analytics agent](#tab/analytics) To set up your remaining session hosts using the configuration workbook: You'll need to enable specific performance counters to collect performance information from your session hosts and send it to the Log Analytics workspace. -If you already have performance counters enabled and want to remove them, follow the instructions in [Configuring performance counters](../azure-monitor/agents/data-sources-performance-counters.md). You can add and remove performance counters in the same location. +If you already have performance counters enabled and want to remove them, follow the instructions in [Configuring performance counters](/azure/azure-monitor/agents/data-sources-performance-counters). You can add and remove performance counters in the same location. To set up performance counters using the configuration workbook: To set up performance counters using the configuration workbook: You'll also need to enable specific Windows Event Logs to collect errors, warnings, and information from the session hosts and send them to the Log Analytics workspace. -If you've already enabled Windows Event Logs and want to remove them, follow the instructions in [Configuring Windows Event Logs](../azure-monitor/agents/data-sources-windows-events.md#configure-windows-event-logs). You can add and remove Windows Event Logs in the same location. +If you've already enabled Windows Event Logs and want to remove them, follow the instructions in [Configuring Windows Event Logs](/azure/azure-monitor/agents/data-sources-windows-events#configure-windows-event-logs). You can add and remove Windows Event Logs in the same location. To set up Windows Event Logs using the configuration workbook: To set up Windows Event Logs using the configuration workbook: ## Optional: configure alerts -Azure Virtual Desktop Insights allows you to monitor Azure Monitor alerts happening within your selected subscription in the context of your Azure Virtual Desktop data. Azure Monitor alerts are an optional feature on your Azure subscriptions, and you need to set them up separately from Azure Virtual Desktop Insights. You can use the Azure Monitor alerts framework to set custom alerts on Azure Virtual Desktop events, diagnostics, and resources. To learn more about Azure Monitor alerts, see [Azure Monitor Log Alerts](../azure-monitor/alerts/alerts-log.md). +Azure Virtual Desktop Insights allows you to monitor Azure Monitor alerts happening within your selected subscription in the context of your Azure Virtual Desktop data. Azure Monitor alerts are an optional feature on your Azure subscriptions, and you need to set them up separately from Azure Virtual Desktop Insights. You can use the Azure Monitor alerts framework to set custom alerts on Azure Virtual Desktop events, diagnostics, and resources. To learn more about Azure Monitor alerts, see [Azure Monitor Log Alerts](/azure/azure-monitor/alerts/alerts-log). ## Diagnostic and usage data |
| virtual-desktop | Security Recommendations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/security-recommendations.md | Enabling [Conditional Access](../active-directory/conditional-access/overview.md Enabling audit log collection lets you view user and admin activity related to Azure Virtual Desktop. Some examples of key audit logs are: -- [Azure Activity Log](../azure-monitor/essentials/activity-log.md)+- [Azure Activity Log](/azure/azure-monitor/essentials/activity-log) - [Microsoft Entra Activity Log](../active-directory/reports-monitoring/concept-activity-logs-azure-monitor.md) - [Microsoft Entra ID](../active-directory/fundamentals/active-directory-whatis.md)-- [Session hosts](../azure-monitor/agents/agent-windows.md)+- [Session hosts](/azure/azure-monitor/agents/agent-windows) - [Key Vault logs](/azure/key-vault/general/logging) ### Use RemoteApp When choosing a deployment model, you can either provide remote users access to ### Monitor usage with Azure Monitor -Monitor your Azure Virtual Desktop service's usage and availability with [Azure Monitor](https://azure.microsoft.com/services/monitor/). Consider creating [service health alerts](../service-health/alerts-activity-log-service-notifications-portal.md) for the Azure Virtual Desktop service to receive notifications whenever there's a service impacting event. +Monitor your Azure Virtual Desktop service's usage and availability with [Azure Monitor](https://azure.microsoft.com/services/monitor/). Consider creating [service health alerts](/azure/service-health/alerts-activity-log-service-notifications-portal) for the Azure Virtual Desktop service to receive notifications whenever there's a service impacting event. ### Encrypt your session hosts |
| virtual-desktop | Set Up Service Alerts | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/set-up-service-alerts.md | -To learn more about Azure Service Health, see the [Azure Health Documentation](../service-health/index.yml). +To learn more about Azure Service Health, see the [Azure Health Documentation](/azure/service-health/). ## Create service alerts To configure service alerts: 1. Sign in to the [Azure portal](https://portal.azure.com/). 2. Select **Service Health.**-3. Follow the instructions in [Create activity log alerts on service notifications](../service-health/alerts-activity-log-service-notifications-portal.md?toc=%2fazure%2fservice-health%2ftoc.json) to set up your alerts and notifications. +3. Follow the instructions in [Create activity log alerts on service notifications](/azure/service-health/alerts-activity-log-service-notifications-portal?toc=%2fazure%2fservice-health%2ftoc.json) to set up your alerts and notifications. ## Next steps |
| virtual-desktop | Troubleshoot Agent | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/troubleshoot-agent.md | If the issue continues, create a support case and include detailed information a - To troubleshoot issues when using PowerShell with Azure Virtual Desktop, see [Azure Virtual Desktop PowerShell](troubleshoot-powershell.md). - To learn more about the service, see [Azure Virtual Desktop environment](environment-setup.md). - To go through a troubleshoot tutorial, see [Tutorial: Troubleshoot Resource Manager template deployments](../azure-resource-manager/templates/template-tutorial-troubleshoot.md).-- To learn about auditing actions, see [Audit operations with Resource Manager](../azure-monitor/essentials/activity-log.md).+- To learn about auditing actions, see [Audit operations with Resource Manager](/azure/azure-monitor/essentials/activity-log). - To learn about actions to determine the errors during deployment, see [View deployment operations](../azure-resource-manager/templates/deployment-history.md). |
| virtual-desktop | Troubleshoot Connection Quality | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/troubleshoot-connection-quality.md | To reduce round trip time: - Check if something is interfering with your network bandwidth. If your network's available bandwidth is too low, you may need to change your network settings to improve connection quality. Make sure your configured settings follow our [network guidelines](/windows-server/remote/remote-desktop-services/network-guidance). -- Check your compute resources by looking at CPU utilization and available memory on your VM. You can view your compute resources by following the instructions in [Configuring performance counters](../azure-monitor/agents/data-sources-performance-counters.md#configure-performance-counters) to set up a performance counter to track certain information. For example, you can use the Processor Information(_Total)\\% Processor Time counter to track CPU utilization, or the Memory(\*)\\Available Mbytes counter for available memory. Both of these counters are enabled by default in Azure Virtual Desktop Insights. If both counters show that CPU usage is too high or available memory is too low, your VM size or storage may be too small to support your users' workloads, and you'll need to upgrade to a larger size.+- Check your compute resources by looking at CPU utilization and available memory on your VM. You can view your compute resources by following the instructions in [Configuring performance counters](/azure/azure-monitor/agents/data-sources-performance-counters#configure-performance-counters) to set up a performance counter to track certain information. For example, you can use the Processor Information(_Total)\\% Processor Time counter to track CPU utilization, or the Memory(\*)\\Available Mbytes counter for available memory. Both of these counters are enabled by default in Azure Virtual Desktop Insights. If both counters show that CPU usage is too high or available memory is too low, your VM size or storage may be too small to support your users' workloads, and you'll need to upgrade to a larger size. ## Optimize VM latency by reviewing Azure network round-trip latency statistics |
| virtual-desktop | Troubleshoot Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/troubleshoot-insights.md | ->[The Log Analytics Agent is currently being deprecated](https://azure.microsoft.com/updates/were-retiring-the-log-analytics-agent-in-azure-monitor-on-31-august-2024/). If you use the Log Analytics Agent for Azure Virtual Desktop support, you'll eventually need to migrate to the [Azure Monitor Agent](../azure-monitor/agents/agents-overview.md) by August 31, 2024. +>[The Log Analytics Agent is currently being deprecated](https://azure.microsoft.com/updates/were-retiring-the-log-analytics-agent-in-azure-monitor-on-31-august-2024/). If you use the Log Analytics Agent for Azure Virtual Desktop support, you'll eventually need to migrate to the [Azure Monitor Agent](/azure/azure-monitor/agents/agents-overview) by August 31, 2024. # [Azure Monitor Agent](#tab/monitor) This article presents known issues and solutions for common problems in Azure Vi If the configuration workbook isn't working properly to automate setup, you can use these resources to set up your environment manually: - To manually enable diagnostics or access the Log Analytics workspace, see [Send Azure Virtual Desktop diagnostics to Log Analytics](diagnostics-log-analytics.md).-- To install the Azure Monitor Agent extension on a session host manually, see [Azure Monitor Agent virtual machine extension for Windows](../azure-monitor/agents/azure-monitor-agent-manage.md#installation-options).-- To set up a new Log Analytics workspace, see [Create a Log Analytics workspace in the Azure portal](../azure-monitor/logs/quick-create-workspace.md).-- To validate the Data Collection Rules in use, see [View data collection rules](../azure-monitor/essentials/data-collection-rule-view.md).+- To install the Azure Monitor Agent extension on a session host manually, see [Azure Monitor Agent virtual machine extension for Windows](/azure/azure-monitor/agents/azure-monitor-agent-manage#installation-options). +- To set up a new Log Analytics workspace, see [Create a Log Analytics workspace in the Azure portal](/azure/azure-monitor/logs/quick-create-workspace). +- To validate the Data Collection Rules in use, see [View data collection rules](/azure/azure-monitor/essentials/data-collection-rule-view). ## My data isn't displaying properly If your data isn't displaying properly, check the following common solutions: - Read-access to the Azure resource groups that hold your Azure Virtual Desktop resources - Read-access to the subscription's resource groups that hold your Azure Virtual Desktop session hosts - Read-access to whichever Log Analytics workspaces you're using-- You may need to open outgoing ports in your server's firewall to allow Azure Monitor to send data to the portal. To learn how to do this, see [Firewall requirements](../azure-monitor/agents/azure-monitor-agent-data-collection-endpoint.md#firewall-requirements).-- If you're not seeing data from recent activity, you may need to wait for 15 minutes and refresh the feed. Azure Monitor has a 15-minute latency period for populating log data. To learn more, see [Log data ingestion time in Azure Monitor](../azure-monitor/logs/data-ingestion-time.md).+- You may need to open outgoing ports in your server's firewall to allow Azure Monitor to send data to the portal. To learn how to do this, see [Firewall requirements](/azure/azure-monitor/agents/azure-monitor-agent-data-collection-endpoint#firewall-requirements). +- If you're not seeing data from recent activity, you may need to wait for 15 minutes and refresh the feed. Azure Monitor has a 15-minute latency period for populating log data. To learn more, see [Log data ingestion time in Azure Monitor](/azure/azure-monitor/logs/data-ingestion-time). If you're not missing any information but your data still isn't displaying properly, there may be an issue in the query or the data sources. For more information, see [known issues and limitations](#known-issues-and-limitations). If the configuration workbook isn't working properly to automate setup, you can - To manually enable diagnostics or access the Log Analytics workspace, see [Send Azure Virtual Desktop diagnostics to Log Analytics](diagnostics-log-analytics.md). - To install the Log Analytics extension on a session host manually, see [Log Analytics virtual machine extension for Windows](/azure/virtual-machines/extensions/oms-windows).-- To set up a new Log Analytics workspace, see [Create a Log Analytics workspace in the Azure portal](../azure-monitor/logs/quick-create-workspace.md).-- To add, remove, or edit performance counters, see [Configuring performance counters](../azure-monitor/agents/data-sources-performance-counters.md).-- To configure Windows Event Logs for a Log Analytics workspace, see [Collect Windows event log data sources with Log Analytics agent](../azure-monitor/agents/data-sources-windows-events.md).+- To set up a new Log Analytics workspace, see [Create a Log Analytics workspace in the Azure portal](/azure/azure-monitor/logs/quick-create-workspace). +- To add, remove, or edit performance counters, see [Configuring performance counters](/azure/azure-monitor/agents/data-sources-performance-counters). +- To configure Windows Event Logs for a Log Analytics workspace, see [Collect Windows event log data sources with Log Analytics agent](/azure/azure-monitor/agents/data-sources-windows-events). ## My data isn't displaying properly If your data isn't displaying properly, check the following common solutions: - Read-access to the subscription's resource groups that hold your Azure Virtual Desktop session hosts - Read-access to whichever Log Analytics workspaces you're using - You may need to open outgoing ports in your server's firewall to allow Azure Monitor and Log Analytics to send data to the portal. To learn how to do this, see the following articles:- - [Azure Monitor Outgoing ports](../azure-monitor/ip-addresses.md) - - [Log Analytics Firewall Requirements](../azure-monitor/agents/log-analytics-agent.md#firewall-requirements). -- Not seeing data from recent activity? You may want to wait for 15 minutes and refresh the feed. Azure Monitor has a 15-minute latency period for populating log data. To learn more, see [Log data ingestion time in Azure Monitor](../azure-monitor/logs/data-ingestion-time.md).+ - [Azure Monitor Outgoing ports](/azure/azure-monitor/ip-addresses) + - [Log Analytics Firewall Requirements](/azure/azure-monitor/agents/log-analytics-agent#firewall-requirements). +- Not seeing data from recent activity? You may want to wait for 15 minutes and refresh the feed. Azure Monitor has a 15-minute latency period for populating log data. To learn more, see [Log data ingestion time in Azure Monitor](/azure/azure-monitor/logs/data-ingestion-time). If you're not missing any information but your data still isn't displaying properly, there may be an issue in the query or the data sources. For more information, see [known issues and limitations](#known-issues-and-limitations). If you're not missing any information but your data still isn't displaying prope Azure Virtual Desktop Insights uses Azure Monitor Workbooks. Workbooks lets you save a copy of the Azure Virtual Desktop workbook template and make your own customizations. -By design, custom Workbook templates will not automatically adopt updates from the products group. For more information, see [Troubleshooting workbook-based insights](../azure-monitor/insights/troubleshoot-workbooks.md) and the [Workbooks overview](../azure-monitor/visualize/workbooks-overview.md). +By design, custom Workbook templates will not automatically adopt updates from the products group. For more information, see [Troubleshooting workbook-based insights](/azure/azure-monitor/insights/troubleshoot-workbooks) and the [Workbooks overview](/azure/azure-monitor/visualize/workbooks-overview). ## I can't interpret the data If this article doesn't have the data point you need to resolve an issue, you ca If you want to monitor more Performance counters or Windows Event Logs, you can enable them to send diagnostics info to your Log Analytics workspace and monitor them in **Host Diagnostics: Host browser**. -- To add performance counters, see [Configuring performance counters](../azure-monitor/agents/data-sources-performance-counters.md#configure-performance-counters)-- To add Windows Events, see [Configuring Windows Event Logs](../azure-monitor/agents/data-sources-windows-events.md#configure-windows-event-logs)+- To add performance counters, see [Configuring performance counters](/azure/azure-monitor/agents/data-sources-performance-counters#configure-performance-counters) +- To add Windows Events, see [Configuring Windows Event Logs](/azure/azure-monitor/agents/data-sources-windows-events#configure-windows-event-logs) Can't find a data point to help diagnose an issue? Send us feedback! |
| virtual-desktop | Troubleshoot Powershell | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/troubleshoot-powershell.md | New-AzWvdApplicationGroup_CreateExpanded: ActivityId: e5fe6c1d-5f2c-4db9-817d-e4 - To troubleshoot issues with Azure Virtual Desktop client connections, see [Azure Virtual Desktop service connections](troubleshoot-service-connection.md). - To troubleshoot issues with Remote Desktop clients, see [Troubleshoot the Remote Desktop client](troubleshoot-client-windows.md) - To learn more about the service, see [Azure Virtual Desktop environment](environment-setup.md).-- To learn about auditing actions, see [Audit operations with Resource Manager](../azure-monitor/essentials/activity-log.md).+- To learn about auditing actions, see [Audit operations with Resource Manager](/azure/azure-monitor/essentials/activity-log). - To learn about actions to determine the errors during deployment, see [View deployment operations](../azure-resource-manager/templates/deployment-history.md). |
| virtual-desktop | Troubleshoot Set Up Issues | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/troubleshoot-set-up-issues.md | When you re-register the resource provider, you won't see any specific UI feedba Follow these instructions to troubleshoot unsuccessful deployments of Azure Resource Manager templates and PowerShell DSC. 1. Review errors in the deployment using [View deployment operations with Azure Resource Manager](../azure-resource-manager/templates/deployment-history.md).-2. If there are no errors in the deployment, review errors in the activity log using [View activity logs to audit actions on resources](../azure-monitor/essentials/activity-log.md). +2. If there are no errors in the deployment, review errors in the activity log using [View activity logs to audit actions on resources](/azure/azure-monitor/essentials/activity-log). 3. Once the error is identified, use the error message and the resources in [Troubleshoot common Azure deployment errors with Azure Resource Manager](../azure-resource-manager/templates/common-deployment-errors.md) to address the issue. 4. Delete any resources created during the previous deployment and retry deploying the template again. the VM.\\\" - To troubleshoot issues when using PowerShell with Azure Virtual Desktop, see [Azure Virtual Desktop PowerShell](troubleshoot-powershell.md). - To learn more about the service, see [Azure Virtual Desktop environment](environment-setup.md). - To go through a troubleshoot tutorial, see [Tutorial: Troubleshoot Resource Manager template deployments](../azure-resource-manager/templates/template-tutorial-troubleshoot.md).-- To learn about auditing actions, see [Audit operations with Resource Manager](../azure-monitor/essentials/activity-log.md).+- To learn about auditing actions, see [Audit operations with Resource Manager](/azure/azure-monitor/essentials/activity-log). - To learn about actions to determine the errors during deployment, see [View deployment operations](../azure-resource-manager/templates/deployment-history.md). |
| virtual-desktop | Troubleshoot Set Up Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/troubleshoot-set-up-overview.md | Use the following table to identify and resolve issues you may encounter when se - To troubleshoot issues when using PowerShell with Azure Virtual Desktop, see [Azure Virtual Desktop PowerShell](troubleshoot-powershell.md). - To learn more about the service, see [Azure Virtual Desktop environment](environment-setup.md). - To go through a troubleshoot tutorial, see [Tutorial: Troubleshoot Resource Manager template deployments](../azure-resource-manager/templates/template-tutorial-troubleshoot.md).-- To learn about auditing actions, see [Audit operations with Resource Manager](../azure-monitor/essentials/activity-log.md).+- To learn about auditing actions, see [Audit operations with Resource Manager](/azure/azure-monitor/essentials/activity-log). - To learn about actions to determine errors during deployment, see [View deployment operations](../azure-resource-manager/templates/deployment-history.md). |
| virtual-desktop | Troubleshoot Vm Configuration | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/troubleshoot-vm-configuration.md | Golden images must not include the Azure Virtual Desktop agent. You can install - To troubleshoot issues when using PowerShell with Azure Virtual Desktop, see [Azure Virtual Desktop PowerShell](troubleshoot-powershell.md). - To learn more about the service, see [Azure Virtual Desktop environment](environment-setup.md). - To go through a troubleshoot tutorial, see [Tutorial: Troubleshoot Resource Manager template deployments](../azure-resource-manager/templates/template-tutorial-troubleshoot.md).-- To learn about auditing actions, see [Audit operations with Resource Manager](../azure-monitor/essentials/activity-log.md).+- To learn about auditing actions, see [Audit operations with Resource Manager](/azure/azure-monitor/essentials/activity-log). - To learn about actions to determine the errors during deployment, see [View deployment operations](../azure-resource-manager/templates/deployment-history.md). |
| virtual-desktop | Deploy Diagnostics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/virtual-desktop-fall-2019/deploy-diagnostics.md | Here's how to manually configure the recommended performance counters: - Processor Information(\*)\\Processor Time - User Input Delay per Session(\*)\\Max Input Delay -Learn more about the performance counters at [Windows and Linux performance data sources in Azure Monitor](../../azure-monitor/agents/data-sources-performance-counters.md). +Learn more about the performance counters at [Windows and Linux performance data sources in Azure Monitor](/azure/azure-monitor/agents/data-sources-performance-counters). >[!NOTE] >Any additional counters you configure won't show up in the diagnostics tool itself. To make it appear in the diagnostics tool, you need to configure the tool's config file. Instructions for how to do this with advanced administration will be available in GitHub at a later date. To set the Redirect URI: Before you make the diagnostics tool available to your users, make sure they have the following permissions: -- Users need read access for log analytics. For more information, see [Get started with roles, permissions, and security with Azure Monitor](../../azure-monitor/roles-permissions-security.md).+- Users need read access for log analytics. For more information, see [Get started with roles, permissions, and security with Azure Monitor](/azure/azure-monitor/roles-permissions-security). - Users also need read access for the Azure Virtual Desktop tenant (RDS Reader role). For more information, see [Delegated access in Azure Virtual Desktop](delegated-access-virtual-desktop-2019.md). You also need to give your users the following information: |
| virtual-desktop | Diagnostics Log Analytics 2019 | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/virtual-desktop-fall-2019/diagnostics-log-analytics-2019.md | We recommend you use Log Analytics to analyze diagnostics data in the Azure clie ## Before you get started -Before you can use Log Analytics with the diagnostics feature, you'll need to [create a workspace](../../azure-monitor/logs/quick-create-workspace.md). +Before you can use Log Analytics with the diagnostics feature, you'll need to [create a workspace](/azure/azure-monitor/logs/quick-create-workspace). -After you've created your workspace, follow the instructions in [Connect Windows computers to Azure Monitor](../../azure-monitor/agents/agent-windows.md#workspace-id-and-key) to get the following information: +After you've created your workspace, follow the instructions in [Connect Windows computers to Azure Monitor](/azure/azure-monitor/agents/agent-windows#workspace-id-and-key) to get the following information: - The workspace ID - The primary key of your workspace |
| virtual-desktop | Set Up Service Alerts 2019 | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/virtual-desktop-fall-2019/set-up-service-alerts-2019.md | In this tutorial, you'll learn how to: > [!div class="checklist"] > * Create and configure service alerts. -To learn more about Azure Service Health, see the [Azure Health Documentation](../../service-health/index.yml). +To learn more about Azure Service Health, see the [Azure Health Documentation](/azure/service-health/). ## Prerequisites To configure service alerts: 1. Sign in to the [Azure portal](https://portal.azure.com/). 2. Select **Service Health.**-3. Use the instructions in [Create activity log alerts on service notifications](../../service-health/alerts-activity-log-service-notifications-portal.md?toc=%2fazure%2fservice-health%2ftoc.json) to set up your alerts and notifications. +3. Use the instructions in [Create activity log alerts on service notifications](/azure/service-health/alerts-activity-log-service-notifications-portal?toc=%2fazure%2fservice-health%2ftoc.json) to set up your alerts and notifications. ## Next steps |
| virtual-desktop | Troubleshoot Powershell 2019 | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/virtual-desktop-fall-2019/troubleshoot-powershell-2019.md | Using the force command will let you delete the session host even if it has assi - To troubleshoot issues with Remote Desktop clients, see [Troubleshoot the Remote Desktop client](../troubleshoot-client-windows.md) - To learn more about the service, see [Azure Virtual Desktop environment](environment-setup-2019.md). - To go through a troubleshoot tutorial, see [Tutorial: Troubleshoot Resource Manager template deployments](../../azure-resource-manager/templates/template-tutorial-troubleshoot.md).-- To learn about auditing actions, see [Audit operations with Resource Manager](../../azure-monitor/essentials/activity-log.md).+- To learn about auditing actions, see [Audit operations with Resource Manager](/azure/azure-monitor/essentials/activity-log). - To learn about actions to determine the errors during deployment, see [View deployment operations](../../azure-resource-manager/templates/deployment-history.md). |
| virtual-desktop | Troubleshoot Set Up Issues 2019 | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/virtual-desktop-fall-2019/troubleshoot-set-up-issues-2019.md | If your operation template goes over the quota limit, you can do one of the foll Follow these instructions to troubleshoot unsuccessful deployments of Azure Resource Manager templates and PowerShell DSC. 1. Review errors in the deployment using [View deployment operations with Azure Resource Manager](../../azure-resource-manager/templates/deployment-history.md).-2. If there are no errors in the deployment, review errors in the activity log using [View activity logs to audit actions on resources](../../azure-monitor/essentials/activity-log.md). +2. If there are no errors in the deployment, review errors in the activity log using [View activity logs to audit actions on resources](/azure/azure-monitor/essentials/activity-log). 3. Once the error is identified, use the error message and the resources in [Troubleshoot common Azure deployment errors with Azure Resource Manager](../../azure-resource-manager/templates/common-deployment-errors.md) to address the issue. 4. Delete any resources created during the previous deployment and retry deploying the template again. If you're running the GitHub Azure Resource Manager template, provide values for - To troubleshoot issues when using PowerShell with Azure Virtual Desktop, see [Azure Virtual Desktop PowerShell](troubleshoot-powershell-2019.md). - To learn more about the service, see [Azure Virtual Desktop environment](environment-setup-2019.md). - To go through a troubleshoot tutorial, see [Tutorial: Troubleshoot Resource Manager template deployments](../../azure-resource-manager/templates/template-tutorial-troubleshoot.md).-- To learn about auditing actions, see [Audit operations with Resource Manager](../../azure-monitor/essentials/activity-log.md).+- To learn about auditing actions, see [Audit operations with Resource Manager](/azure/azure-monitor/essentials/activity-log). - To learn about actions to determine the errors during deployment, see [View deployment operations](../../azure-resource-manager/templates/deployment-history.md). |
| virtual-desktop | Troubleshoot Set Up Overview 2019 | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/virtual-desktop-fall-2019/troubleshoot-set-up-overview-2019.md | Use the following table to identify and resolve issues you may encounter when se - To troubleshoot issues when using PowerShell with Azure Virtual Desktop, see [Azure Virtual Desktop PowerShell](troubleshoot-powershell-2019.md). - To learn more about the service, see [Azure Virtual Desktop environment](environment-setup-2019.md). - To go through a troubleshoot tutorial, see [Tutorial: Troubleshoot Resource Manager template deployments](../../azure-resource-manager/templates/template-tutorial-troubleshoot.md).-- To learn about auditing actions, see [Audit operations with Resource Manager](../../azure-monitor/essentials/activity-log.md).+- To learn about auditing actions, see [Audit operations with Resource Manager](/azure/azure-monitor/essentials/activity-log). - To learn about actions to determine errors during deployment, see [View deployment operations](../../azure-resource-manager/templates/deployment-history.md). |
| virtual-desktop | Troubleshoot Vm Configuration 2019 | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/virtual-desktop-fall-2019/troubleshoot-vm-configuration-2019.md | To learn more about this policy, see [Allow log on through Remote Desktop Servic - To troubleshoot issues when using PowerShell with Azure Virtual Desktop, see [Azure Virtual Desktop PowerShell](troubleshoot-powershell-2019.md). - To learn more about the service, see [Azure Virtual Desktop environment](environment-setup-2019.md). - To go through a troubleshoot tutorial, see [Tutorial: Troubleshoot Resource Manager template deployments](../../azure-resource-manager/templates/template-tutorial-troubleshoot.md).-- To learn about auditing actions, see [Audit operations with Resource Manager](../../azure-monitor/essentials/activity-log.md).+- To learn about auditing actions, see [Audit operations with Resource Manager](/azure/azure-monitor/essentials/activity-log). - To learn about actions to determine the errors during deployment, see [View deployment operations](../../azure-resource-manager/templates/deployment-history.md). |
| virtual-desktop | Whats New Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/whats-new-insights.md | In this release, we've made the following changes: In this release, we've made the following change: -- We added support for [category groups](../azure-monitor/essentials/diagnostic-settings.md#resource-logs) for resource logs.+- We added support for [category groups](/azure/azure-monitor/essentials/diagnostic-settings#resource-logs) for resource logs. ## Version 1.1.8 |
| virtual-desktop | Whats New | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-desktop/whats-new.md | Make sure to check back here often to keep up with new updates. > [!TIP] > See [What's new in documentation](whats-new-documentation.md), where we highlight new and updated articles for Azure Virtual Desktop. +## August 2024 ++Here's what changed in August 2024: ++### Configure the session lock behavior for Azure Virtual Desktop is now available ++You can choose whether the session is disconnected or the remote lock screen is shown when a remote session is locked, either by the user or by policy. When the session lock behavior is set to disconnect, a dialog is shown to let users know they were disconnected. Users can choose the **Reconnect** option from the dialog when they're ready to connect again. ++For more information, see [Configure the session lock behavior for Azure Virtual Desktop](configure-session-lock-behavior.md). ++### Configuring the clipboard transfer direction in Azure Virtual Desktop is now available ++Clipboard redirection in Azure Virtual Desktop allows users to copy and paste content between the user's local device and the remote session in either direction. You might want to limit the direction of the clipboard for users, to help prevent data exfiltration or malicious files being copied to a session host. You can configure whether users can use the clipboard from session host to client, or client to session host, and the types of data that can be copied. ++For more information see [Configure the clipboard transfer direction in Azure Virtual Desktop](clipboard-transfer-direction-data-types.md). ++### Microsoft Purview forensic evidence is now compatible with Azure Virtual Desktop ++Forensic evidence is an opt-in add-on feature in Insider Risk Management that gives security teams visual insights into potential insider data security incidents, with user privacy built in. Microsoft Purview Insider Risk Management correlates various signals to identify potential malicious or inadvertent insider risks, such as IP theft, data leakage and security violations. Insider risk management enables customers to create policies to manage security and compliance.  ++For more information see [Learn about insider risk management forensic evidence](purview-forensic-evidence.md). ++### Support for FIDO devices and passkeys on macOS and iOS is now available ++Windows App and the Remote Desktop app now support FIDO devices and passkeys for Microsoft Entra ID sign in on macOS and iOS. ++For more information see [Azure Virtual Desktop identities and authentication](authentication.md). ++### New Microsoft Teams can be installed on an image using custom image templates ++New Teams has replaced classic Teams when using [custom image templates](custom-image-templates.md). When updating an existing template, classic Teams is replaced by new Teams. No action is required. When reusing an existing template which references classic Teams, it's updated to new Teams by Microsoft. ++For more information see [End of availability for classic Teams client](/microsoftteams/teams-classic-client-end-of-availability). + ## July 2024 Here's what changed in July 2024: For more information about what's new in FSLogix, see the [FSLogix Release Notes Azure Virtual Desktop Insights is a dashboard built on Azure Monitor workbooks that helps you understand your Azure Virtual Desktop environments. Azure Virtual Desktop Insights support for the Azure Monitor agent is now generally available. For more information, see [Use Azure Virtual Desktop Insights to monitor your deployment](insights.md?tabs=monitor). -The Log Analytics agent for Azure Monitor is deprecating on August 31, 2024. We recommend you migrate monitoring your virtual machines (VMs) and servers to Azure Monitor Agent before that date. For more information about how to migrate, see [Migrate to Azure Monitor Agent from Log Analytics agent](../azure-monitor/agents/azure-monitor-agent-migration.md). +The Log Analytics agent for Azure Monitor is deprecating on August 31, 2024. We recommend you migrate monitoring your virtual machines (VMs) and servers to Azure Monitor Agent before that date. For more information about how to migrate, see [Migrate to Azure Monitor Agent from Log Analytics agent](/azure/azure-monitor/agents/azure-monitor-agent-migration). ### Custom Image Template feature is now generally available Here's what changed in August 2020: - We fixed an issue in the Teams Desktop client (version 1.3.00.21759) where the client only showed the UTC time zone in the chat, channels, and calendar. The updated client now shows the remote session's time zone instead. -- Azure Advisor is now a part of Azure Virtual Desktop. When you access Azure Virtual Desktop through the Azure portal, you can see recommendations for optimizing your Azure Virtual Desktop environment. Learn more at [Introduction to Azure Advisor](../advisor/advisor-overview.md).+- Azure Advisor is now a part of Azure Virtual Desktop. When you access Azure Virtual Desktop through the Azure portal, you can see recommendations for optimizing your Azure Virtual Desktop environment. Learn more at [Introduction to Azure Advisor](/azure/advisor/advisor-overview). - Azure CLI now supports Azure Virtual Desktop (`az desktopvirtualization`) to help you automate your Azure Virtual Desktop deployments. Check out [desktopvirtualization](/cli/azure/desktopvirtualization) for a list of extension commands. |
| virtual-network-manager | Concept Event Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-network-manager/concept-event-logs.md | Within the `AppliedConnectivityConfigurations` attribute are several nested attr ## Accessing logs Depending on how you consume event logs, you need to set up a Log Analytics workspace or a storage account for storing your log events. -- Learn to [create a Log Analytics workspace](../azure-monitor/logs/quick-create-workspace.md).+- Learn to [create a Log Analytics workspace](/azure/azure-monitor/logs/quick-create-workspace). - Learn to [create a storage account](../storage/common/storage-account-create.md). When setting up a Log Analytics workspace or a storage account, you need to select a region. If youΓÇÖre using a storage account, it needs to be in the same region of the virtual network manager youΓÇÖre accessing logs from. If youΓÇÖre using a Log Analytics workspace, it can be in any region. |
| virtual-network-manager | How To Configure Event Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-network-manager/how-to-configure-event-logs.md | In this article, you learn how to monitor Azure Virtual Network Manager for virt ## Prerequisites - An Azure account with an active subscription. [Create an account for free](https://azure.microsoft.com/free/?WT.mc_id=A261C142F). - A deployed instance of [Azure Virtual Network Manager](./create-virtual-network-manager-portal.md) in your subscription, with managed virtual networks.-- You deployed either a [Log Analytics workspace](../azure-monitor/essentials/tutorial-resource-logs.md#create-a-log-analytics-workspace) or a [storage account](../storage/common/storage-account-create.md) to store event logs and observe data related to Azure Virtual Network Manager.+- You deployed either a [Log Analytics workspace](/azure/azure-monitor/essentials/tutorial-resource-logs#create-a-log-analytics-workspace) or a [storage account](../storage/common/storage-account-create.md) to store event logs and observe data related to Azure Virtual Network Manager. ## Configure Diagnostic Settings Depending on how you consume event logs, you need to set up a Log Analytics work > At least one virtual network must be added or removed from a network group in order to generate logs for the Network Group Membership Change schema. A log will generate for this event a couple minutes after network group membership change occurs. ### Configure event logs with Log Analytics -Log analytics is one option for storing event logs. In this task, you configure your Azure Virtual Network Manager Instance to use a Log Analytics workspace. This task assumes you have already deployed a Log Analytics workspace. If you haven't, see [Create a Log Analytics workspace](../azure-monitor/essentials/tutorial-resource-logs.md#create-a-log-analytics-workspace). +Log analytics is one option for storing event logs. In this task, you configure your Azure Virtual Network Manager Instance to use a Log Analytics workspace. This task assumes you have already deployed a Log Analytics workspace. If you haven't, see [Create a Log Analytics workspace](/azure/azure-monitor/essentials/tutorial-resource-logs#create-a-log-analytics-workspace). 1. Navigate to the network manager you want to obtain the logs of. 1. Under the **Monitoring** in the left pane, select the **Diagnostic settings**. In this task, you access the event logs for your Azure Virtual Network Manager i ## Next steps - Learn about [Security admin rules](concept-security-admins.md)-- Learn how to [Use queries in Azure Monitor Log Analytics](../azure-monitor/logs/queries.md)+- Learn how to [Use queries in Azure Monitor Log Analytics](/azure/azure-monitor/logs/queries) - Learn how to block network traffic with a [SecurityAdmin configuration](how-to-block-network-traffic-portal.md). |
| virtual-network-manager | Query Azure Resource Graph | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-network-manager/query-azure-resource-graph.md | To get started with querying your virtual network manager data in ARG, follow th 1. Enter your Kusto queries in the query editor and select **Run Query**. -You can download the output of these queries as CSV from the **Resource Graph Explorer**. You can also use these queries in custom automation using any automation clients supported by ARG, such as [PowerShell](../governance/resource-graph/first-query-powershell.md), [CLI](../governance/resource-graph/first-query-azurecli.md), or [SDK](../governance/resource-graph/first-query-python.md). You can also create [custom workbooks](../azure-monitor/visualize/workbooks-overview.md) in the Azure portal using ARG as a data source. +You can download the output of these queries as CSV from the **Resource Graph Explorer**. You can also use these queries in custom automation using any automation clients supported by ARG, such as [PowerShell](../governance/resource-graph/first-query-powershell.md), [CLI](../governance/resource-graph/first-query-azurecli.md), or [SDK](../governance/resource-graph/first-query-python.md). You can also create [custom workbooks](/azure/azure-monitor/visualize/workbooks-overview) in the Azure portal using ARG as a data source. > [!NOTE] > ARG allows you to query the resources for which you have the appropriate RBAC rights. |
| virtual-network | Kubernetes Network Policies | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-network/kubernetes-network-policies.md | The metrics can be scraped through Azure Monitor for containers or through Prome ### Set up for Azure Monitor -The first step is to enable Azure Monitor for containers for your Kubernetes cluster. Steps can be found in [Azure Monitor for containers Overview](../azure-monitor/containers/container-insights-overview.md). Once you have Azure Monitor for containers enabled, configure the [Azure Monitor for containers ConfigMap](https://aka.ms/container-azm-ms-agentconfig) to enable Network Policy Manager integration and collection of Prometheus Network Policy Manager metrics. +The first step is to enable Azure Monitor for containers for your Kubernetes cluster. Steps can be found in [Azure Monitor for containers Overview](/azure/azure-monitor/containers/container-insights-overview). Once you have Azure Monitor for containers enabled, configure the [Azure Monitor for containers ConfigMap](https://aka.ms/container-azm-ms-agentconfig) to enable Network Policy Manager integration and collection of Prometheus Network Policy Manager metrics. Azure Monitor for containers ConfigMap has an ```integrations``` section with settings to collect Network Policy Manager metrics. integrations: |- Advanced metrics are optional, and turning them on automatically turns on basic metrics collection. Advanced metrics currently include only `Network Policy Manager_ipset_counts`. -Learn more about [Azure Monitor for containers collection settings in config map](../azure-monitor/containers/container-insights-data-collection-configmap.md). +Learn more about [Azure Monitor for containers collection settings in config map](/azure/azure-monitor/containers/container-insights-data-collection-configmap). ### Visualization options for Azure Monitor Besides viewing the workbook, you can also directly query the Prometheus metrics | where Name contains "npm_" ``` -You can also query log analytics directly for the metrics. For more information, see [Getting Started with Log Analytics Queries](../azure-monitor/containers/container-insights-log-query.md). +You can also query log analytics directly for the metrics. For more information, see [Getting Started with Log Analytics Queries](/azure/azure-monitor/containers/container-insights-log-query). #### Viewing in Grafana dashboard |
| virtual-network | Manage Network Security Group | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-network/manage-network-security-group.md | Under **Help**, you can view **Effective security rules**. For more information, To learn more about the common Azure settings listed, see the following articles: -- [Activity log](../azure-monitor/essentials/platform-logs-overview.md)+- [Activity log](/azure/azure-monitor/essentials/platform-logs-overview) - [Access control (IAM)](../role-based-access-control/overview.md) Get-AzNetworkSecurityGroup -Name myNSG -ResourceGroupName myResourceGroup To learn more about the common Azure settings listed, see the following articles: -- [Activity log](../azure-monitor/essentials/platform-logs-overview.md)+- [Activity log](/azure/azure-monitor/essentials/platform-logs-overview) - [Access control (IAM)](../role-based-access-control/overview.md) az network nsg show --resource-group myResourceGroup --name myNSG To learn more about the common Azure settings listed, see the following articles: -- [Activity log](../azure-monitor/essentials/platform-logs-overview.md)+- [Activity log](/azure/azure-monitor/essentials/platform-logs-overview) - [Access control (IAM)](../role-based-access-control/overview.md) |
| virtual-network | Virtual Machine Network Throughput | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-network/virtual-machine-network-throughput.md | Today, the Azure networking stack supports 1M total flows (500k inbound and 500k Once this limit is hit, other connections are dropped. Connection establishment and termination rates can also affect network performance as connection establishment and termination shares CPU with packet processing routines. We recommend that you benchmark workloads against expected traffic patterns and scale out workloads appropriately to match your performance needs. -Metrics are available in [Azure Monitor](../azure-monitor/essentials/metrics-supported.md#microsoftcomputevirtualmachines) to track the number of network flows and the flow creation rate on your VM or Virtual Machine Scale Sets instances. +Metrics are available in [Azure Monitor](/azure/azure-monitor/essentials/metrics-supported#microsoftcomputevirtualmachines) to track the number of network flows and the flow creation rate on your VM or Virtual Machine Scale Sets instances. :::image type="content" source="./media/virtual-machine-network-throughput/azure-monitor-flow-metrics.png" alt-text="A screenshot shows the Metrics page of Azure Monitor with a line chart and totals for inbound and outbound flows."::: |
| virtual-network | Virtual Network Encryption Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-network/virtual-network-encryption-overview.md | Virtual network encryption has the following requirements: | Storage intensive workloads | LSv3 | **[LSv3-series](/azure/virtual-machines/lsv3-series)** | | Memory intensive workloads | M-series | **[Mv2-series](/azure/virtual-machines/mv2-series)** </br> **[Msv2 and Mdsv2-series Medium Memory](/azure/virtual-machines/msv2-mdsv2-series)** </br> **[Msv3 and Mdsv3 Medium Memory Series](/azure/virtual-machines/msv3-mdsv3-medium-series)** | -- Accelerated Networking must be enabled on the network interface of the virtual machine. For more information about Accelerated Networking, see ΓÇ»[What is Accelerated Networking?](/azure/virtual-network/accelerated-networking-overview).+- Accelerated Networking must be enabled on the network interface of the virtual machine. For more information about Accelerated Networking, see ΓÇ»[What is Accelerated Networking?](/azure/virtual-network/accelerated-networking-overview) - Encryption is only applied to traffic between virtual machines in a virtual network. Traffic is encrypted from a private IP address to a private IP address. Virtual network encryption has the following requirements: ## Availability -Azure Virtual Network encryption is generally available in all Azure public regions. +Azure Virtual Network encryption is generally available in all Azure public regions and is currently in public preview in Azure Government and Microsoft Azure operated by 21Vianet. ## Limitations |
| virtual-network | Virtual Network Nsg Manage Log | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-network/virtual-network-nsg-manage-log.md | When you enable logging for an NSG, you can gather the following types of resour Resource logs are only available for NSGs deployed through the Azure Resource Manager deployment model. You can't enable resource logging for NSGs deployed through the classic deployment model. For more information, see [Understand deployment models](../azure-resource-manager/management/deployment-models.md). -Resource logging is enabled separately for *each* NSG for which to collect diagnostic data. If you're interested in *activity*, or *operational*, logs instead, see [Overview of Azure platform logs](../azure-monitor/essentials/platform-logs-overview.md). If you're interested in IP traffic flowing through NSGs, see [Flow logs for network security groups](../network-watcher/network-watcher-nsg-flow-logging-overview.md). +Resource logging is enabled separately for *each* NSG for which to collect diagnostic data. If you're interested in *activity*, or *operational*, logs instead, see [Overview of Azure platform logs](/azure/azure-monitor/essentials/platform-logs-overview). If you're interested in IP traffic flowing through NSGs, see [Flow logs for network security groups](../network-watcher/network-watcher-nsg-flow-logging-overview.md). ## Enable logging New-AzDiagnosticSetting ` -WorkspaceId $Oms.ResourceId ``` -If you want to log to a different [destination](#log-destinations) than a Log Analytics workspace, use an appropriate parameter in the command. For more information, see [Azure resource logs](../azure-monitor/essentials/resource-logs.md). +If you want to log to a different [destination](#log-destinations) than a Log Analytics workspace, use an appropriate parameter in the command. For more information, see [Azure resource logs](/azure/azure-monitor/essentials/resource-logs). For more information about settings, see [New-AzDiagnosticSetting](/powershell/module/az.monitor/new-azdiagnosticsetting). az monitor diagnostic-settings create \ --resource-group myWorkspaces ``` -If you don't have an existing workspace, create one using the [Azure portal](../azure-monitor/logs/quick-create-workspace.md) or [Azure PowerShell](/powershell/module/az.operationalinsights/new-azoperationalinsightsworkspace). There are two categories of logging for which you can enable logs. +If you don't have an existing workspace, create one using the [Azure portal](/azure/azure-monitor/logs/quick-create-workspace) or [Azure PowerShell](/powershell/module/az.operationalinsights/new-azoperationalinsightsworkspace). There are two categories of logging for which you can enable logs. -If you only want to log data for one category or the other, remove the category you don't want to log data for in the previous command. If you want to log to a different [destination](#log-destinations) than a Log Analytics workspace, use an appropriate parameter. For more information, see [Azure resource logs](../azure-monitor/essentials/resource-logs.md). +If you only want to log data for one category or the other, remove the category you don't want to log data for in the previous command. If you want to log to a different [destination](#log-destinations) than a Log Analytics workspace, use an appropriate parameter. For more information, see [Azure resource logs](/azure/azure-monitor/essentials/resource-logs). View and analyze logs. For more information, see [View and analyze logs](#view-and-analyze-logs). View and analyze logs. For more information, see [View and analyze logs](#view-a You can send diagnostics data to the following options: -- [Log Analytics workspace](../azure-monitor/essentials/resource-logs.md#send-to-log-analytics-workspace)-- [Azure Event Hubs](../azure-monitor/essentials/resource-logs.md#send-to-azure-event-hubs)-- [Azure Storage](../azure-monitor/essentials/resource-logs.md#send-to-azure-storage)-- [Azure Monitor partner integrations](../azure-monitor/essentials/resource-logs.md#azure-monitor-partner-integrations)+- [Log Analytics workspace](/azure/azure-monitor/essentials/resource-logs#send-to-log-analytics-workspace) +- [Azure Event Hubs](/azure/azure-monitor/essentials/resource-logs#send-to-azure-event-hubs) +- [Azure Storage](/azure/azure-monitor/essentials/resource-logs#send-to-azure-storage) +- [Azure Monitor partner integrations](/azure/azure-monitor/essentials/resource-logs#azure-monitor-partner-integrations) ## Log categories The rule counter log contains information about each rule applied to resources. If you send diagnostics data to: -- **Azure Monitor logs**: You can use the [network security group analytics](../azure-monitor/insights/azure-networking-analytics.md?toc=%2fazure%2fvirtual-network%2ftoc.json) solution for enhanced insights. The solution provides visualizations for NSG rules that allow or deny traffic, per MAC address, of the network interface in a virtual machine.+- **Azure Monitor logs**: You can use the [network security group analytics](/azure/azure-monitor/insights/azure-networking-analytics?toc=%2fazure%2fvirtual-network%2ftoc.json) solution for enhanced insights. The solution provides visualizations for NSG rules that allow or deny traffic, per MAC address, of the network interface in a virtual machine. - **Azure Storage account**: Data is written to a *PT1H.json* file. You can find the: - Event log that is in the following path: *insights-logs-networksecuritygroupevent/resourceId=/SUBSCRIPTIONS/[ID]/RESOURCEGROUPS/[RESOURCE-GROUP-NAME-FOR-NSG]/PROVIDERS/MICROSOFT.NETWORK/NETWORKSECURITYGROUPS/[NSG NAME]/y=[YEAR]/m=[MONTH/d=[DAY]/h=[HOUR]/m=[MINUTE]* - Rule counter log that is in the following path: *insights-logs-networksecuritygrouprulecounter/resourceId=/SUBSCRIPTIONS/[ID]/RESOURCEGROUPS/[RESOURCE-GROUP-NAME-FOR-NSG]/PROVIDERS/MICROSOFT.NETWORK/NETWORKSECURITYGROUPS/[NSG NAME]/y=[YEAR]/m=[MONTH/d=[DAY]/h=[HOUR]/m=[MINUTE]* -To learn how to view resource log data, see [Azure platform logs overview](../azure-monitor/essentials/platform-logs-overview.md). +To learn how to view resource log data, see [Azure platform logs overview](/azure/azure-monitor/essentials/platform-logs-overview). ## Next steps -- For more information about Activity logging, see [Overview of Azure platform logs](../azure-monitor/essentials/platform-logs-overview.md).+- For more information about Activity logging, see [Overview of Azure platform logs](/azure/azure-monitor/essentials/platform-logs-overview). Activity logging is enabled by default for NSGs created through either Azure deployment model. To determine which operations were completed on NSGs in the activity log, look for entries that contain the following resource types: |
| virtual-wan | Azure Monitor Insights | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-wan/azure-monitor-insights.md | You can select **View detailed metrics** to access the detailed **Metrics** page ## Next steps -* To learn more, see [Metrics in Azure Monitor](../azure-monitor/essentials/data-platform-metrics.md). +* To learn more, see [Metrics in Azure Monitor](/azure/azure-monitor/essentials/data-platform-metrics). * For a full description of all the Virtual WAN metrics, see [Monitoring Virtual WAN data reference](monitor-virtual-wan-reference.md). * For additional Virtual WAN monitoring information, see [Monitoring Azure Virtual WAN](monitor-virtual-wan.md) |
| virtual-wan | Cross Tenant Vnet | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-wan/cross-tenant-vnet.md | In this article, you learn how to: The steps for this configuration use a combination of the Azure portal and PowerShell. However, the feature itself is available in PowerShell and the Azure CLI only. >[!NOTE]-> You can manage cross-tenant virtual network connections only through PowerShell or the Azure CLI. You *cannot* manage cross-tenant virtual network connections in the Azure portal. +> You can manage cross-tenant virtual network connections only through PowerShell or the Azure CLI installed on your local machine. Because Azure Portal does not support cross-tenant operations, you can't manage cross-tenant virtual network connections through Azure portal or Azure portal CloudShell (both PowerShell and CLI). ## Before you begin |
| virtual-wan | Monitor Virtual Wan Reference | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-wan/monitor-virtual-wan-reference.md | For Azure Firewall, a [workbook](../firewall/firewall-workbook.md) is provided t ## <a name="activity-logs"></a>Activity logs -[**Activity log**](../azure-monitor/essentials/activity-log.md) entries are collected by default and can be viewed in the Azure portal. You can use Azure activity logs (formerly known as *operational logs* and *audit logs*) to view all operations submitted to your Azure subscription. +[**Activity log**](/azure/azure-monitor/essentials/activity-log) entries are collected by default and can be viewed in the Azure portal. You can use Azure activity logs (formerly known as *operational logs* and *audit logs*) to view all operations submitted to your Azure subscription. You can view activity logs independently or route it to Azure Monitor Logs, where you can do much more complex queries using Log Analytics. -For more information on the schema of Activity Log entries, see [Activity Log schema](../azure-monitor/essentials/activity-log-schema.md). +For more information on the schema of Activity Log entries, see [Activity Log schema](/azure/azure-monitor/essentials/activity-log-schema). ## <a name="schemas"></a>Schemas -For detailed description of the top-level diagnostic logs schema, see [Supported services, schemas, and categories for Azure Diagnostic Logs](../azure-monitor/essentials/resource-logs-schema.md). +For detailed description of the top-level diagnostic logs schema, see [Supported services, schemas, and categories for Azure Diagnostic Logs](/azure/azure-monitor/essentials/resource-logs-schema). When reviewing any metrics through Log Analytics, the output contains the following columns: For every Azure Virtual WAN you secure and convert to a Secured Hub, an explicit * To learn how to monitor Azure Firewall logs and metrics, see [Tutorial: Monitor Azure Firewall logs](../firewall/firewall-diagnostics.md). * For more information about Virtual WAN monitoring, see [Monitoring Azure Virtual WAN](monitor-virtual-wan.md).-* To learn more about metrics in Azure Monitor, see [Metrics in Azure Monitor](../azure-monitor/essentials/data-platform-metrics.md). +* To learn more about metrics in Azure Monitor, see [Metrics in Azure Monitor](/azure/azure-monitor/essentials/data-platform-metrics). |
| virtual-wan | Monitor Virtual Wan | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-wan/monitor-virtual-wan.md | Last updated 02/15/2024 When you have critical applications and business processes relying on Azure resources, you want to monitor those resources for their availability and performance. -This article describes the monitoring data generated by Azure Virtual WAN. Virtual WAN uses [Azure Monitor](../azure-monitor/overview.md). If you're unfamiliar with the features of Azure Monitor common to all Azure services that use it, read [Monitoring Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md). +This article describes the monitoring data generated by Azure Virtual WAN. Virtual WAN uses [Azure Monitor](/azure/azure-monitor/overview). If you're unfamiliar with the features of Azure Monitor common to all Azure services that use it, read [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource). ## Prerequisites $MetricInformation.Data Data in Azure Monitor Logs is stored in tables where each table has its own set of unique properties. Resource Logs aren't collected and stored until you create a diagnostic setting and route them to one or more locations. -For a list of supported logs in Virtual WAN, see [Monitoring Virtual WAN data reference logs](monitor-virtual-wan-reference.md#diagnostic). All resource logs in Azure Monitor have the same fields followed by service-specific fields. The common schema is outlined in [Azure Monitor resource log schema](../azure-monitor/essentials/resource-logs-schema.md). +For a list of supported logs in Virtual WAN, see [Monitoring Virtual WAN data reference logs](monitor-virtual-wan-reference.md#diagnostic). All resource logs in Azure Monitor have the same fields followed by service-specific fields. The common schema is outlined in [Azure Monitor resource log schema](/azure/azure-monitor/essentials/resource-logs-schema). ### <a name="create-diagnostic"></a>Create diagnostic setting to view logs The following steps help you create, edit, and view diagnostic settings: ## Alerts -Azure Monitor alerts proactively notify you when important conditions are found in your monitoring data. They allow you to identify and address issues in your system before your customers notice them. You can set alerts on [metrics](../azure-monitor/alerts/alerts-types.md#metric-alerts), [logs](../azure-monitor/alerts/alerts-types.md#log-alerts), and the [activity log](../azure-monitor/alerts/alerts-types.md#activity-log-alerts). Different types of alerts have benefits and drawbacks. +Azure Monitor alerts proactively notify you when important conditions are found in your monitoring data. They allow you to identify and address issues in your system before your customers notice them. You can set alerts on [metrics](/azure/azure-monitor/alerts/alerts-types#metric-alerts), [logs](/azure/azure-monitor/alerts/alerts-types#log-alerts), and the [activity log](/azure/azure-monitor/alerts/alerts-types#activity-log-alerts). Different types of alerts have benefits and drawbacks. To see a list of monitoring best practices when configuring alerts, see [Monitoring - best practices](monitoring-best-practices.md). Virtual WAN uses Network Insights to provide users and operators with the abilit ## Next steps * See [Monitoring Virtual WAN - Data reference](monitor-virtual-wan-reference.md) for a data reference of the metrics, logs, and other important values created by Virtual WAN.-* See [Monitoring Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md) for details on monitoring Azure resources. -* See [Analyze metrics with Azure Monitor metrics explorer](../azure-monitor/essentials/analyze-metrics.md) for more details on **Azure Monitor Metrics**. -* See [All resource metrics supported in Azure Monitor](../azure-monitor/essentials/metrics-supported.md) for a list of all supported metrics. -* See [Create diagnostic settings in Azure Monitor](../azure-monitor/essentials/diagnostic-settings.md) for more information and troubleshooting for creating diagnostic settings via Azure portal, CLI, PowerShell, etc. +* See [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) for details on monitoring Azure resources. +* See [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics) for more details on **Azure Monitor Metrics**. +* See [All resource metrics supported in Azure Monitor](/azure/azure-monitor/essentials/metrics-supported) for a list of all supported metrics. +* See [Create diagnostic settings in Azure Monitor](/azure/azure-monitor/essentials/diagnostic-settings) for more information and troubleshooting for creating diagnostic settings via Azure portal, CLI, PowerShell, etc. |
| virtual-wan | Monitoring Best Practices | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-wan/monitoring-best-practices.md | Last updated 01/12/2024 This article provides configuration best practices for monitoring Virtual WAN and the different components that can be deployed with it. The recommendations presented in this article are mostly based on existing Azure Monitor metrics and logs generated by Azure Virtual WAN. For a list of metrics and logs collected for Virtual WAN, see the [Monitoring Virtual WAN data reference](monitor-virtual-wan-reference.md). -Most of the recommendations in this article suggest creating Azure Monitor alerts. Azure Monitor alerts are meant to proactively notify you when there is an important event in the monitoring data to help you address the root cause quicker and ultimately reduce downtime. To learn how to create a metric alert, see [Tutorial: Create a metric alert for an Azure resource](../azure-monitor/alerts/tutorial-metric-alert.md). To learn how to create a log query alert, see [Tutorial: Create a log query alert for an Azure resource](../azure-monitor/alerts/tutorial-log-alert.md). +Most of the recommendations in this article suggest creating Azure Monitor alerts. Azure Monitor alerts are meant to proactively notify you when there is an important event in the monitoring data to help you address the root cause quicker and ultimately reduce downtime. To learn how to create a metric alert, see [Tutorial: Create a metric alert for an Azure resource](/azure/azure-monitor/alerts/tutorial-metric-alert). To learn how to create a log query alert, see [Tutorial: Create a log query alert for an Azure resource](/azure/azure-monitor/alerts/tutorial-log-alert). ## Virtual WAN gateways This section of the article focuses on metric-based alerts. Azure Firewall offer ## Resource Health Alerts -You can also configure [Resource Health Alerts](../service-health/resource-health-alert-monitor-guide.md) via Service Health for the below resources. This ensures you are informed of the availability of your Virtual WAN environment, and this allows you to troubleshoot if networking issues are due to your Azure resources entering an unhealthy state, as opposed to issues from your on-premises environment. It is recommended to configure alerts when the resource status becomes degraded or unavailable. If the resource status does become degraded/unavailable, you can analyze if there are any recent spikes in the amount of traffic processed by these resources, the routes advertised to these resources, or the number of branch/VNet connections created. Please see [Azure Virtual WAN limits](../azure-resource-manager/management/azure-subscription-service-limits.md#virtual-wan-limits) for additional info on limits supported in Virtual WAN. +You can also configure [Resource Health Alerts](/azure/service-health/resource-health-alert-monitor-guide) via Service Health for the below resources. This ensures you are informed of the availability of your Virtual WAN environment, and this allows you to troubleshoot if networking issues are due to your Azure resources entering an unhealthy state, as opposed to issues from your on-premises environment. It is recommended to configure alerts when the resource status becomes degraded or unavailable. If the resource status does become degraded/unavailable, you can analyze if there are any recent spikes in the amount of traffic processed by these resources, the routes advertised to these resources, or the number of branch/VNet connections created. Please see [Azure Virtual WAN limits](../azure-resource-manager/management/azure-subscription-service-limits.md#virtual-wan-limits) for additional info on limits supported in Virtual WAN. * Microsoft.Network/vpnGateways * Microsoft.Network/expressRouteGateways You can also configure [Resource Health Alerts](../service-health/resource-healt ## Next steps * See [Monitoring Virtual WAN data reference](monitor-virtual-wan-reference.md) for a data reference of the metrics, logs, and other important values created by Virtual WAN.-* See [Monitoring Azure resources with Azure Monitor](../azure-monitor/essentials/monitor-azure-resource.md) for details on monitoring Azure resources. -* See [Analyze metrics with Azure Monitor metrics explorer](../azure-monitor/essentials/analyze-metrics.md) for more details about **Azure Monitor Metrics**. -* See [All resource metrics supported in Azure Monitor](../azure-monitor/essentials/metrics-supported.md) for a list of all supported metrics. -* See [Create diagnostic settings in Azure Monitor](../azure-monitor/essentials/diagnostic-settings.md) for more information and troubleshooting when creating diagnostic settings via the Azure portal, CLI, PowerShell, etc. +* See [Monitoring Azure resources with Azure Monitor](/azure/azure-monitor/essentials/monitor-azure-resource) for details on monitoring Azure resources. +* See [Analyze metrics with Azure Monitor metrics explorer](/azure/azure-monitor/essentials/analyze-metrics) for more details about **Azure Monitor Metrics**. +* See [All resource metrics supported in Azure Monitor](/azure/azure-monitor/essentials/metrics-supported) for a list of all supported metrics. +* See [Create diagnostic settings in Azure Monitor](/azure/azure-monitor/essentials/diagnostic-settings) for more information and troubleshooting when creating diagnostic settings via the Azure portal, CLI, PowerShell, etc. |
| virtual-wan | Virtual Wan Faq | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/virtual-wan/virtual-wan-faq.md | Also, be sure to plan for downtime in case you decide to scale up or down on the ### For User VPN (point-to-site) is Microsoft registered app in Entra Id Authentication supported? -Yes, [Microsoft-registered app](https://learn.microsoft.com/azure/vpn-gateway/point-to-site-entra-gateway) is supported on Virtual WAN. You can [migrate your User VPN from manually registered app](https://learn.microsoft.com/azure/vpn-gateway/point-to-site-entra-gateway-update) to Microsoft-registered app for a more secure connectivity. +Yes, [Microsoft-registered app](/azure/vpn-gateway/point-to-site-entra-gateway) is supported on Virtual WAN. You can [migrate your User VPN from manually registered app](/azure/vpn-gateway/point-to-site-entra-gateway-update) to Microsoft-registered app for a more secure connectivity. ### What are Virtual WAN gateway scale units? |
| vpn-gateway | Azure Vpn Client Optional Configurations | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/vpn-gateway/azure-vpn-client-optional-configurations.md | description: Learn how to configure optional configuration settings for the Azur Previously updated : 05/15/2024 Last updated : 09/06/2024 The steps in this article assume that you have configured your P2S gateway and h ## Working with VPN client profile configuration files -The steps in this article require you to modify and import the Azure VPN Client profile configuration file. To work with VPN client profile configuration files (xml files), use the following steps: +The steps in this article require you to modify and import the Azure VPN Client profile configuration file. The following profile configuration files are generated, depending on the authentication types configured for your P2S VPN gateway. ++* **azurevpnconfig.xml**: This file is generated when only one authentication type is selected. +* **azurevpnconfig_aad.xml**: This file is generated for Microsoft Entra ID authentication when there are multiple authentication types selected. +* **azurevpnconfig_cert.xml**: This file is generated for Certificate authentication when there are multiple authentication types selected. ++To work with VPN client profile configuration files (xml files), use the following steps: 1. Locate the profile configuration file and open it using the editor of your choice. 1. Using the examples in the following sections, modify the file as necessary, then save your changes. 1. Import the file to configure the Azure VPN client. You can import the file for the Azure VPN Client using these methods: - * **Azure VPN Client interface**: Open the Azure VPN Client and click **+** and then **Import**. Locate the modified xml file, configure any additional settings in the Azure VPN Client interface (if necessary), then click **Save**. + * **Azure VPN Client interface**: Open the Azure VPN Client and click **+** and then **Import**. Locate the modified .xml file, configure any additional settings in the Azure VPN Client interface (if necessary), then click **Save**. - * **Command-line prompt**: Place the downloaded *azurevpnconfig.xml* file in the *%userprofile%\AppData\Local\Packages\Microsoft.AzureVpn_8wekyb3d8bbwe\LocalState* folder, then run the following command: `azurevpn -i azurevpnconfig.xml`. To force the import, use the **-f** switch. + * **Command-line prompt**: Place the appropriate downloaded configuration xml file in the *%userprofile%\AppData\Local\Packages\Microsoft.AzureVpn_8wekyb3d8bbwe\LocalState* folder, then run the command that corresponds to the configuration file name. For example, `azurevpn -i azurevpnconfig_aad.xml`. To force the import, use the **-f** switch. ## DNS |
| vpn-gateway | Monitor Vpn Gateway | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/vpn-gateway/monitor-vpn-gateway.md | For more information about the resource types for VPN Gateway, see [Azure VPN Ga [!INCLUDE [horz-monitor-data-storage](~/reusable-content/ce-skilling/azure/includes/azure-monitor/horizontals/horz-monitor-data-storage.md)] -See [Create diagnostic setting to collect platform logs and metrics in Azure](../azure-monitor/essentials/diagnostic-settings.md) for the detailed process for creating a diagnostic setting using the Azure portal, CLI, or PowerShell. When you create a diagnostic setting, you specify which categories of logs to collect. The categories for VPN Gateway are listed in [VPN Gateway monitoring data reference](monitor-vpn-gateway-reference.md). +See [Create diagnostic setting to collect platform logs and metrics in Azure](/azure/azure-monitor/essentials/diagnostic-settings) for the detailed process for creating a diagnostic setting using the Azure portal, CLI, or PowerShell. When you create a diagnostic setting, you specify which categories of logs to collect. The categories for VPN Gateway are listed in [VPN Gateway monitoring data reference](monitor-vpn-gateway-reference.md). > [!IMPORTANT] > Enabling these settings requires additional Azure services (storage account, event hub, or Log Analytics), which might increase your cost. To calculate an estimated cost, visit the [Azure pricing calculator](https://azure.microsoft.com/pricing/calculator). |
| vpn-gateway | Point To Site Certificate Client Linux Azure Vpn Client | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/vpn-gateway/point-to-site-certificate-client-linux-azure-vpn-client.md | The basic workflow is as follows: 1. Generate and install client certificates. 1. Locate the VPN client profile configuration package that you generated in the [Configure server settings for P2S VPN Gateway connections - certificate authentication](vpn-gateway-howto-point-to-site-resource-manager-portal.md#profile-files) article.-1. Download and configure Azure VPN Client for Linux. +1. Download and configure the Azure VPN Client for Linux. 1. Connect to Azure. ## Generate certificates openssl x509 -req -days 365 -in "${USERNAME}Req.pem" -CA caCert.pem -CAkey caKey ## View VPN client profile configuration files -When you generate a VPN client profile configuration package, all the necessary configuration settings for VPN clients are contained in a VPN client profile configuration zip file. The VPN client profile configuration files are specific to the P2S VPN gateway configuration for the virtual network. If there are any changes to the P2S VPN configuration after you generate the files, such as changes to the VPN protocol type or authentication type, you need to generate new VPN client profile configuration files and apply the new configuration to all of the VPN clients that you want to connect. +When you generate and download a VPN client profile configuration package, all the necessary configuration settings for VPN clients are contained in a VPN client profile configuration zip file. The VPN client profile configuration files are specific to the P2S VPN gateway configuration for the virtual network. If there are any changes to the P2S VPN configuration after you generate the files, such as changes to the VPN protocol type or authentication type, you need to generate new VPN client profile configuration files and apply the new configuration to all of the VPN clients that you want to connect. -Locate and unzip the VPN client profile configuration package you generated (listed in the [Prequisites](#prerequisites)). For P2S **Certificate authentication** and with an **OpenVPN** tunnel type, you'll see the **AzureVPN** folder. In the AzureVPN folder, locate the **azurevpnconfig.xml** file. This file contains the settings you use to configure the VPN client profile. +Locate and unzip the VPN client profile configuration package you generated and downloaded (listed in the [Prequisites](#prerequisites)). Open the **AzureVPN** folder. In this folder, you'll see either the **azurevpnconfig_cert.xml** file or the **azurevpnconfig.xml** file, depending on whether your P2S configuration includes multiple authentication types. The .xml file contains the settings you use to configure the VPN client profile. -If you don't see the **azurevpnconfig.xml** file, verify the following items: --* Verify that your VPN gateway is configured to use the OpenVPN tunnel type. -* Verify your P2S configuration is set for certificate authentication. -* If you're using Microsoft Entra ID authentication, you might not have an AzureVPN folder. See the [Microsoft Entra ID](point-to-site-entra-gateway.md) configuration article instead. +If you don't see either file, or you don't have an **AzureVPN** folder, verify that your VPN gateway is configured to use the OpenVPN tunnel type and that certificate authentication is selected. ## Download the Azure VPN Client For more information about the repository, see [Linux Software Repository for Mi 1. On the bottom left of the page of the Linux VPN client, select **Import**. :::image type="content" source="./media/azure-vpn-client-certificate-linux/import.png" alt-text="Screenshot of Azure VPN Client for Linux with Import." lightbox="./media/azure-vpn-client-certificate-linux/import.png":::-1. In the window, navigate to the **azurevpnconfig.xml** file, select it, then select **Open**. +1. In the window, navigate to either the **azurevpnconfig.xml** or **azurevpnconfig_cert.xml** file, select it, then select **Open**. 1. To add **Client Certificate Public Data**, use the file picker and locate the related **.pem** files. :::image type="content" source="./media/azure-vpn-client-certificate-linux/client-certificate-data.png" alt-text="Screenshot of Azure VPN Client for Linux with client certificate data selected." lightbox="./media/azure-vpn-client-certificate-linux/client-certificate-data.png"::: |
| vpn-gateway | Point To Site Entra Vpn Client Linux | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/vpn-gateway/point-to-site-entra-vpn-client-linux.md | In this section, you configure the Azure VPN client for Linux. * If your P2S gateway configuration was previously configured to use the older, manually registered App ID versions, your P2S configuration doesn't support the Linux VPN client. See [About the Microsoft-registered App ID for Azure VPN Client](point-to-site-entra-gateway.md). -* For Microsoft Entra ID authentication, use the **azurevpnconfig_aad.xml** file. The file is located in the **AzureVPN** folder of the VPN client profile configuration package. +* For Microsoft Entra ID authentication, use the **azurevpnconfig_aad.xml** or **azurevpnconfig.xml** file that's located in the **AzureVPN** folder of the VPN client profile configuration package. The file name depends on whether your P2S configuration includes multiple authentication types. 1. On the Azure VPN Client page, select **Import**. |
| vpn-gateway | Point To Site Entra Vpn Client Mac | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/vpn-gateway/point-to-site-entra-vpn-client-mac.md | This article continues on from the [Configure a P2S VPN gateway for Microsoft En ## <a name="generate"></a>Extract client profile configuration files -To configure your Azure VPN Client profile, you download a VPN client profile configuration package from the Azure P2S gateway. This package contains the necessary settings to configure the VPN client. - If you used the P2S server configuration steps as mentioned in the [Prerequisites](#prerequisites) section, you've already generated and downloaded the VPN client profile configuration package that contains the VPN profile configuration files. If you need to generate configuration files, see [Download the VPN client profile configuration package](point-to-site-entra-gateway.md#download). -After you obtain the VPN client profile configuration package, extract the files. +When you generate and download a VPN client profile configuration package, all the necessary configuration settings for VPN clients are contained in a VPN client profile configuration zip file. The VPN client profile configuration files are specific to the P2S VPN gateway configuration for the virtual network. If there are any changes to the P2S VPN configuration after you generate the files, such as changes to the VPN protocol type or authentication type, you need to generate new VPN client profile configuration files and apply the new configuration to all of the VPN clients that you want to connect. ++Locate and unzip the VPN client profile configuration package you generated and downloaded (listed in the [Prequisites](#prerequisites)). Open the **AzureVPN** folder. In this folder, you'll see either the **azurevpnconfig_aad.xml** file or the **azurevpnconfig.xml** file, depending on whether your P2S configuration includes multiple authentication types. The .xml file contains the settings you use to configure the VPN client profile. ## Import VPN client profile configuration files |
| vpn-gateway | Point To Site Entra Vpn Client Windows | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/vpn-gateway/point-to-site-entra-vpn-client-windows.md | This article continues on from the [Configure a P2S VPN gateway for Microsoft En ## <a name="generate"></a>Extract client profile configuration files -To configure your Azure VPN Client profile, you must first download the VPN client profile configuration package from the Azure P2S gateway. This package is specific to the configured VPN gateway and contains the necessary settings to configure the VPN client. +To configure your Azure VPN Client profile, you must first download the VPN client profile configuration package from the Azure P2S gateway. This package is specific to the configured VPN gateway and contains the necessary settings to configure the VPN client. If you used the P2S server configuration steps as mentioned in the [Prerequisites](#prerequisites) section, you've already generated and downloaded the VPN client profile configuration package that contains the VPN profile configuration files. If you need to generate configuration files, see [Download the VPN client profile configuration package](point-to-site-entra-gateway.md#download). -If you used the P2S server configuration steps as mentioned in the [Prerequisites](#prerequisites) section, you've already generated and downloaded the VPN client profile configuration package that contains the VPN profile configuration files. If you need to generate configuration files, see [Download the VPN client profile configuration package](point-to-site-entra-gateway.md#download). --After you obtain the VPN client profile configuration package, extract the zip file. The file contains the following folders: --* **AzureVPN**: The AzureVPN folder contains the **Azurevpnconfig.xml** file that is used to configure the Azure VPN Client. -* **Generic**: The generic folder contains the public server certificate and the VpnSettings.xml file. The VpnSettings.xml file contains information needed to configure a generic client. +After you obtain the VPN client profile configuration package, extract the zip file. The zip file contains the **AzureVPN** folder. The **AzureVPN** folder contains the **azurevpnconfig_aad.xml** file or the **azurevpnconfig.xml** file, depending on whether your P2S configuration includes multiple authentication types. If you don't see **azurevpnconfig_aad.xml** or **azurevpnconfig.xml**, or you don't have an **AzureVPN** folder, verify that your VPN gateway is configured to use the OpenVPN tunnel type and that Azure Active Directory (Microsoft Entra ID) authentication is selected. ## <a name="import"></a>Import client profile configuration settings > [!NOTE] > [!INCLUDE [Entra VPN client note](../../includes/vpn-gateway-entra-vpn-client-note.md)] -When your P2S configuration specifies Microsoft Entra ID authentication, the VPN client profile configuration settings are contained in the **azurevpnconfig.xml** file. This file is located in the **AzureVPN** folder of the VPN client profile configuration package. - 1. On the page, select **Import**. :::image type="content" source="./media/point-to-site-entra-vpn-client-windows/import.png" alt-text="Screenshot that shows the Add button selected and the Import action highlighted in the lower left-side of the window." lightbox="./media/point-to-site-entra-vpn-client-windows/import.png"::: -1. Browse to the Azure VPN Client profile configuration folder that you extracted. In the AzureVPN folder, select **azurevpnconfig.xml**. With the file selected, select **Open**. +1. Browse to the Azure VPN Client profile configuration folder that you extracted. Open the **AzureVPN** folder and select the client profile configuration file (azurevpnconfig_aad.xml or azurevpnconfig.xml). Select **Open** to import the file. 1. Change the name of the Connection name (optional). In this example, you'll notice that the Audience value shown is the new Azure Public value associated to the Microsoft-registered Azure VPN Client App ID. The value in this field must match the value that your P2S VPN gateway is configured to use. |
| vpn-gateway | Point To Site Vpn Client Certificate Windows Azure Vpn Client | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/vpn-gateway/point-to-site-vpn-client-certificate-windows-azure-vpn-client.md | This article assumes that you've already performed the following prerequisites: To connect to Azure, each connecting client computer requires the following items: * The Azure VPN Client software must be installed on each client computer.-* The Azure VPN Client profile must be configured using the downloaded **azurevpnconfig.xml** configuration file. +* The Azure VPN Client profile is configured using the settings contained in the downloaded **azurevpnconfig.xml** or **azurevpnconfig_cert.xml** configuration file. * The client computer must have a client certificate that's installed locally. ## Generate and install client certificates Each computer needs a client certificate in order to authenticate. If the client The VPN client profile configuration package contains specific folders. The files within the folders contain the settings needed to configure the VPN client profile on the client computer. The files and the settings they contain are specific to the VPN gateway and the type of authentication and tunnel your VPN gateway is configured to use. -Locate and unzip the VPN client profile configuration package you generated. For Certificate authentication and OpenVPN, you'll see the **AzureVPN** folder. Locate the **azurevpnconfig.xml** file. This file contains the settings you use to configure the VPN client profile. +Locate and unzip the VPN client profile configuration package you generated. For Certificate authentication and OpenVPN, you'll see the **AzureVPN** folder. In this folder, you'll see either the **azurevpnconfig_cert.xml** file or the **azurevpnconfig.xml** file, depending on whether your P2S configuration includes multiple authentication types. The .xml file contains the settings you use to configure the VPN client profile. -If you don't see the file, verify the following items: --* Verify that your VPN gateway is configured to use the OpenVPN tunnel type. -* If you're using Microsoft Entra authentication, you might not have an AzureVPN folder. See the [Microsoft Entra ID](point-to-site-entra-vpn-client-windows.md) configuration article instead. +If you don't see either file, or you don't have an **AzureVPN** folder, verify that your VPN gateway is configured to use the OpenVPN tunnel type and that certificate authentication is selected. ## Download the Azure VPN Client If you don't see the file, verify the following items: 1. Select **+** on the bottom left of the page, then select **Import**. -1. In the window, navigate to the **azurevpnconfig.xml** file. Select the file, then select **Open**. +1. In the window, navigate to the **azurevpnconfig.xml** or **azurevpnconfig_cert.xml** file. Select the file, then select **Open**. 1. On the client profile page, notice that many of the settings are already specified. The preconfigured settings are contained in the VPN client profile package that you imported. Even though most of the settings are already specified, you need to configure settings specific to the client computer. |
| vpn-gateway | Troubleshoot Vpn With Azure Diagnostics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/vpn-gateway/troubleshoot-vpn-with-azure-diagnostics.md | For all VPN Gateway logs, see [Azure VPN Gateway monitoring data reference](moni <a name="setup"></a> -To set up diagnostic log events from Azure VPN Gateway using Azure Log Analytics, see [Create diagnostic settings in Azure Monitor](../azure-monitor/essentials/create-diagnostic-settings.md). +To set up diagnostic log events from Azure VPN Gateway using Azure Log Analytics, see [Create diagnostic settings in Azure Monitor](/azure/azure-monitor/essentials/create-diagnostic-settings). ## <a name="GatewayDiagnosticLog"></a>GatewayDiagnosticLog |
| vpn-gateway | Vpn Gateway Howto Point To Site Resource Manager Portal | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/vpn-gateway/vpn-gateway-howto-point-to-site-resource-manager-portal.md | |
| web-application-firewall | Waf Front Door Monitor | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/web-application-firewall/afds/waf-front-door-monitor.md | zone_pivot_groups: front-door-tiers Azure Web Application Firewall on Azure Front Door provides extensive logging and telemetry to help you understand how your web application firewall (WAF) is performing and the actions it takes. -The Azure Front Door WAF log is integrated with [Azure Monitor](../../azure-monitor/overview.md). Azure Monitor enables you to track diagnostic information, including WAF alerts and logs. You can configure WAF monitoring within the Azure Front Door resource in the Azure portal under the **Diagnostics** tab, through infrastructure as code approaches, or by using Azure Monitor directly. +The Azure Front Door WAF log is integrated with [Azure Monitor](/azure/azure-monitor/overview). Azure Monitor enables you to track diagnostic information, including WAF alerts and logs. You can configure WAF monitoring within the Azure Front Door resource in the Azure portal under the **Diagnostics** tab, through infrastructure as code approaches, or by using Azure Monitor directly. ## Metrics The following filters are provided as part of this metric: ## Logs and diagnostics -The Azure Front Door WAF provides detailed reporting on each request and each threat that it detects. Logging is integrated with Azure's diagnostics logs and alerts by using [Azure Monitor logs](../../azure-monitor/insights/azure-networking-analytics.md). +The Azure Front Door WAF provides detailed reporting on each request and each threat that it detects. Logging is integrated with Azure's diagnostics logs and alerts by using [Azure Monitor logs](/azure/azure-monitor/insights/azure-networking-analytics). Logs aren't enabled by default. You must explicitly enable logs. You can configure logs in the Azure portal by using the **Diagnostic settings** tab. |
| web-application-firewall | Ag Overview | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/web-application-firewall/ag/ag-overview.md | This section describes the core benefits that WAF on Application Gateway provide ### Monitoring -* Monitor attacks against your web applications by using a real-time WAF log. The log is integrated with [Azure Monitor](../../azure-monitor/overview.md) to track WAF alerts and easily monitor trends. +* Monitor attacks against your web applications by using a real-time WAF log. The log is integrated with [Azure Monitor](/azure/azure-monitor/overview) to track WAF alerts and easily monitor trends. * The Application Gateway WAF is integrated with Microsoft Defender for Cloud. Defender for Cloud provides a central view of the security state of all your Azure, hybrid, and multicloud resources. It's important to monitor the health of your application gateway. You can suppor #### Azure Monitor -Application Gateway logs are integrated with [Azure Monitor](../../azure-monitor/overview.md). This allows you to track diagnostic information, including WAF alerts and logs. You can access this capability on the **Diagnostics** tab in the Application Gateway resource in the portal or directly through Azure Monitor. To learn more about enabling logs, see [Application Gateway diagnostics](../../application-gateway/application-gateway-diagnostics.md). +Application Gateway logs are integrated with [Azure Monitor](/azure/azure-monitor/overview). This allows you to track diagnostic information, including WAF alerts and logs. You can access this capability on the **Diagnostics** tab in the Application Gateway resource in the portal or directly through Azure Monitor. To learn more about enabling logs, see [Application Gateway diagnostics](../../application-gateway/application-gateway-diagnostics.md). #### Microsoft Defender for Cloud |
| web-application-firewall | Application Gateway Waf Metrics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/web-application-firewall/ag/application-gateway-waf-metrics.md | Azure Web Application Firewall (WAF) monitoring and logging are provided through ## Azure Monitor -WAF with Application Gateway log is integrated with [Azure Monitor](../../azure-monitor/overview.md). Azure Monitor allows you to track diagnostic information including WAF alerts and logs. You can configure WAF monitoring within the Application Gateway resource in the portal under the **Diagnostics** tab or through the Azure Monitor service directly. +WAF with Application Gateway log is integrated with [Azure Monitor](/azure/azure-monitor/overview). Azure Monitor allows you to track diagnostic information including WAF alerts and logs. You can configure WAF monitoring within the Application Gateway resource in the portal under the **Diagnostics** tab or through the Azure Monitor service directly. ## Logs and diagnostics For metrics supported by Application Gateway V1 SKU, see [Application Gateway v1 1. Select **New alert rule** for metrics listed in Metrics section. -Alert will be charged based on Azure Monitor. For more information about alerts, see [Azure Monitor alerts](../../azure-monitor/alerts/alerts-overview.md). +Alert will be charged based on Azure Monitor. For more information about alerts, see [Azure Monitor alerts](/azure/azure-monitor/alerts/alerts-overview). ## Next steps |
| web-application-firewall | Log Analytics | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/web-application-firewall/ag/log-analytics.md | -Once your Application Gateway WAF is operational, you can enable logs to inspect what is happening with each request. Firewall logs give insight to what the WAF is evaluating, matching, and blocking. With Azure Monitor Log Analytics, you can examine the data inside the firewall logs to give even more insights. For more information about creating a Log Analytics workspace, see [Create a Log Analytics workspace in the Azure portal](../../azure-monitor/logs/quick-create-workspace.md). For more information about log queries, see [Overview of log queries in Azure Monitor](../../azure-monitor/logs/log-query-overview.md). +Once your Application Gateway WAF is operational, you can enable logs to inspect what is happening with each request. Firewall logs give insight to what the WAF is evaluating, matching, and blocking. With Azure Monitor Log Analytics, you can examine the data inside the firewall logs to give even more insights. For more information about creating a Log Analytics workspace, see [Create a Log Analytics workspace in the Azure portal](/azure/azure-monitor/logs/quick-create-workspace). For more information about log queries, see [Overview of log queries in Azure Monitor](/azure/azure-monitor/logs/log-query-overview). ## Import WAF logs |
| web-application-firewall | Web Application Firewall Logs | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/web-application-firewall/ag/web-application-firewall-logs.md | You can monitor Web Application Firewall resources using logs. You can save perf You can use different types of logs in Azure to manage and troubleshoot application gateways. You can access some of these logs through the portal. All logs can be extracted from Azure Blob storage and viewed in different tools, such as [Azure Monitor logs](/previous-versions/azure/azure-monitor/insights/azure-networking-analytics), Excel, and Power BI. You can learn more about the different types of logs from the following list: -* **Activity log**: You can use [Azure activity logs](../../azure-monitor/essentials/activity-log.md) to view all operations that are submitted to your Azure subscription, and their status. Activity log entries are collected by default, and you can view them in the Azure portal. +* **Activity log**: You can use [Azure activity logs](/azure/azure-monitor/essentials/activity-log) to view all operations that are submitted to your Azure subscription, and their status. Activity log entries are collected by default, and you can view them in the Azure portal. * **Access Resource log**: You can use this log to view Application Gateway access patterns and analyze important information. This includes the caller's IP, requested URL, response latency, return code, and bytes in and out. This log contains individual records for each request and associates that request to the unique Application Gateway that processed the request. Unique Application Gateway instances can be identified by the property instanceId. * **Performance Resource log**: You can use this log to view how Application Gateway instances are performing. This log captures performance information for each instance, including total requests served, throughput in bytes, total requests served, failed request count, and healthy and unhealthy back-end instance count. A performance log is collected every 60 seconds. The Performance log is available only for the v1 SKU. For the v2 SKU, use [Metrics](../../application-gateway/application-gateway-metrics.md) for performance data. * **Firewall Resource log**: You can use this log to view the requests that are logged through either detection or prevention mode of an application gateway that is configured with the web application firewall. Activity logging is automatically enabled for every Resource Manager resource. Y ## Activity log -Azure generates the activity log by default. The logs are preserved for 90 days in the Azure event logs store. Learn more about these logs by reading the [View events and activity log](../../azure-monitor/essentials/activity-log.md) article. +Azure generates the activity log by default. The logs are preserved for 90 days in the Azure event logs store. Learn more about these logs by reading the [View events and activity log](/azure/azure-monitor/essentials/activity-log) article. ## Access log The firewall log is generated only if you have enabled it for each application g You can view and analyze activity log data by using any of the following methods: -* **Azure tools**: Retrieve information from the activity log through Azure PowerShell, the Azure CLI, the Azure REST API, or the Azure portal. Step-by-step instructions for each method are detailed in the [Activity operations with Resource Manager](../../azure-monitor/essentials/activity-log.md) article. +* **Azure tools**: Retrieve information from the activity log through Azure PowerShell, the Azure CLI, the Azure REST API, or the Azure portal. Step-by-step instructions for each method are detailed in the [Activity operations with Resource Manager](/azure/azure-monitor/essentials/activity-log) article. * **Power BI**: If you don't already have a [Power BI](https://powerbi.microsoft.com/pricing) account, you can try it for free. By using the [Power BI template apps](/power-bi/service-template-apps-overview), you can analyze your data. ## View and analyze the access, performance, and firewall logs |
| web-application-firewall | Waf New Threat Detection | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/web-application-firewall/waf-new-threat-detection.md | You can configure Analytic Rules in Sentinel for various web application attacks ## Next steps - [Learn more about Microsoft Sentinel](../sentinel/overview.md)-- [Learn more about Azure Monitor Workbooks](../azure-monitor/visualize/workbooks-overview.md)+- [Learn more about Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview) |
| web-application-firewall | Waf Sentinel | https://github.com/MicrosoftDocs/azure-docs/commits/main/articles/web-application-firewall/waf-sentinel.md | The automation section of these rules can help you automatically respond to the ## Next steps - [Learn more about Microsoft Sentinel](../sentinel/overview.md)-- [Learn more about Azure Monitor Workbooks](../azure-monitor/visualize/workbooks-overview.md)+- [Learn more about Azure Monitor Workbooks](/azure/azure-monitor/visualize/workbooks-overview) |